TW202246309A - Synthetic degrader system for targeted protein degradation - Google Patents
Synthetic degrader system for targeted protein degradationInfo
- Publication number
- TW202246309A TW202246309ATW111104424ATW111104424ATW202246309ATW 202246309 ATW202246309 ATW 202246309ATW 111104424 ATW111104424 ATW 111104424ATW 111104424 ATW111104424 ATW 111104424ATW 202246309 ATW202246309 ATW 202246309A
- Authority
- TW
- Taiwan
- Prior art keywords
- sequence
- binding element
- fusion protein
- patent application
- composition
- Prior art date
Links
- 230000017854proteolysisEffects0.000titledescription3
- 239000001064degraderSubstances0.000titledescription2
- 230000027455bindingEffects0.000claimsabstractdescription437
- 230000015556catabolic processEffects0.000claimsabstractdescription233
- 238000006731degradation reactionMethods0.000claimsabstractdescription233
- 108090000623proteins and genesProteins0.000claimsabstractdescription229
- 108020001507fusion proteinsProteins0.000claimsabstractdescription206
- 102000037865fusion proteinsHuman genes0.000claimsabstractdescription206
- 102000004169proteins and genesHuman genes0.000claimsabstractdescription198
- 102000006275Ubiquitin-Protein LigasesHuman genes0.000claimsabstractdescription155
- 108010083111Ubiquitin-Protein LigasesProteins0.000claimsabstractdescription155
- 239000000203mixtureSubstances0.000claimsabstractdescription135
- 208000037265diseases, disorders, signs and symptomsDiseases0.000claimsabstractdescription92
- 201000010099diseaseDiseases0.000claimsabstractdescription79
- 239000003999initiatorSubstances0.000claimsabstractdescription69
- 208000035475disorderDiseases0.000claimsabstractdescription13
- 210000004027cellAnatomy0.000claimsdescription247
- 108090000765processed proteins & peptidesProteins0.000claimsdescription185
- 102000004196processed proteins & peptidesHuman genes0.000claimsdescription179
- 229920001184polypeptidePolymers0.000claimsdescription174
- 239000013598vectorSubstances0.000claimsdescription156
- 150000003384small moleculesChemical class0.000claimsdescription107
- 150000007523nucleic acidsChemical class0.000claimsdescription94
- 108091028043Nucleic acid sequenceProteins0.000claimsdescription66
- 238000000034methodMethods0.000claimsdescription65
- 239000012634fragmentSubstances0.000claimsdescription63
- 108010019670Chimeric Antigen ReceptorsProteins0.000claimsdescription56
- 210000001744T-lymphocyteAnatomy0.000claimsdescription52
- 230000001939inductive effectEffects0.000claimsdescription45
- 102000040945Transcription factorHuman genes0.000claimsdescription41
- 108091023040Transcription factorProteins0.000claimsdescription41
- 206010028980NeoplasmDiseases0.000claimsdescription31
- 239000000427antigenSubstances0.000claimsdescription31
- 102000036639antigensHuman genes0.000claimsdescription31
- 108091007433antigensProteins0.000claimsdescription31
- 102100026245E3 ubiquitin-protein ligase RNF43Human genes0.000claimsdescription30
- 101000692702Homo sapiens E3 ubiquitin-protein ligase RNF43Proteins0.000claimsdescription30
- 241000282414Homo sapiensSpecies0.000claimsdescription29
- 230000003834intracellular effectEffects0.000claimsdescription29
- 102000039446nucleic acidsHuman genes0.000claimsdescription28
- 108020004707nucleic acidsProteins0.000claimsdescription28
- 230000001105regulatory effectEffects0.000claimsdescription27
- 150000001413amino acidsChemical group0.000claimsdescription26
- 201000011510cancerDiseases0.000claimsdescription25
- -1XNRF3Proteins0.000claimsdescription24
- 239000000833heterodimerSubstances0.000claimsdescription24
- 239000008194pharmaceutical compositionSubstances0.000claimsdescription24
- 102100022409E3 ubiquitin-protein ligase LNXHuman genes0.000claimsdescription22
- 101000620132Homo sapiens E3 ubiquitin-protein ligase LNXProteins0.000claimsdescription22
- 108700010039chimeric receptorProteins0.000claimsdescription21
- 230000014509gene expressionEffects0.000claimsdescription21
- 239000013603viral vectorSubstances0.000claimsdescription21
- 238000006471dimerization reactionMethods0.000claimsdescription19
- 108091027981Response elementProteins0.000claimsdescription18
- 102100021820E3 ubiquitin-protein ligase RNF4Human genes0.000claimsdescription17
- 101001107086Homo sapiens E3 ubiquitin-protein ligase RNF4Proteins0.000claimsdescription17
- 210000000130stem cellAnatomy0.000claimsdescription16
- 230000015572biosynthetic processEffects0.000claimsdescription15
- 230000004069differentiationEffects0.000claimsdescription15
- 210000004962mammalian cellAnatomy0.000claimsdescription15
- 108010047041Complementarity Determining RegionsProteins0.000claimsdescription14
- 229950002891danoprevirDrugs0.000claimsdescription14
- 239000003937drug carrierSubstances0.000claimsdescription13
- 210000003958hematopoietic stem cellAnatomy0.000claimsdescription13
- 229920000642polymerPolymers0.000claimsdescription13
- 210000003705ribosomeAnatomy0.000claimsdescription13
- 239000013604expression vectorSubstances0.000claimsdescription12
- 239000003814drugSubstances0.000claimsdescription11
- 210000005260human cellAnatomy0.000claimsdescription11
- 238000000926separation methodMethods0.000claimsdescription11
- 230000017105transpositionEffects0.000claimsdescription11
- 210000004970cd4 cellAnatomy0.000claimsdescription10
- 102100034214E3 ubiquitin-protein ligase RNF128Human genes0.000claimsdescription9
- 101000851370Homo sapiens Tumor necrosis factor receptor superfamily member 9Proteins0.000claimsdescription9
- 102100024784Suppressor of cytokine signaling 2Human genes0.000claimsdescription9
- 102100036856Tumor necrosis factor receptor superfamily member 9Human genes0.000claimsdescription9
- 239000013612plasmidSubstances0.000claimsdescription9
- 102100031918E3 ubiquitin-protein ligase NEDD4Human genes0.000claimsdescription8
- 102000001301EGF receptorHuman genes0.000claimsdescription8
- 108060006698EGF receptorProteins0.000claimsdescription8
- 208000016621Hearing diseaseDiseases0.000claimsdescription8
- 101000636713Homo sapiens E3 ubiquitin-protein ligase NEDD4Proteins0.000claimsdescription8
- 208000029462Immunodeficiency diseaseDiseases0.000claimsdescription8
- 241000700605VirusesSpecies0.000claimsdescription8
- 230000034431double-strand break repair via homologous recombinationEffects0.000claimsdescription8
- 210000002865immune cellAnatomy0.000claimsdescription8
- 208000015181infectious diseaseDiseases0.000claimsdescription8
- 125000006850spacer groupChemical group0.000claimsdescription8
- 102000004127CytokinesHuman genes0.000claimsdescription7
- 108090000695CytokinesProteins0.000claimsdescription7
- 241000702421DependoparvovirusSpecies0.000claimsdescription7
- 102100023196E3 ubiquitin-protein ligase MARCHF8Human genes0.000claimsdescription7
- 108020004684Internal Ribosome Entry SitesProteins0.000claimsdescription7
- 102000003714TNF receptor-associated factor 6Human genes0.000claimsdescription7
- 108090000009TNF receptor-associated factor 6Proteins0.000claimsdescription7
- 101710165473Tumor necrosis factor receptor superfamily member 4Proteins0.000claimsdescription7
- 102100022153Tumor necrosis factor receptor superfamily member 4Human genes0.000claimsdescription7
- 102000003675cytokine receptorsHuman genes0.000claimsdescription7
- 108010057085cytokine receptorsProteins0.000claimsdescription7
- 210000003527eukaryotic cellAnatomy0.000claimsdescription7
- 210000004698lymphocyteAnatomy0.000claimsdescription7
- OUYCCCASQSFEME-QMMMGPOBSA-NL-tyrosineChemical compoundOC(=O)[C@@H](N)CC1=CC=C(O)C=C1OUYCCCASQSFEME-QMMMGPOBSA-N0.000claimsdescription6
- 210000000653nervous systemAnatomy0.000claimsdescription6
- 102100038576F-box/WD repeat-containing protein 1AHuman genes0.000claimsdescription5
- 101001030691Homo sapiens F-box/WD repeat-containing protein 1AProteins0.000claimsdescription5
- 208000026350Inborn Genetic diseaseDiseases0.000claimsdescription5
- 102100035987Leucine-rich alpha-2-glycoproteinHuman genes0.000claimsdescription5
- 241000700584SimplexvirusSpecies0.000claimsdescription5
- 241000700618Vaccinia virusSpecies0.000claimsdescription5
- 208000016361genetic diseaseDiseases0.000claimsdescription5
- 208000027866inflammatory diseaseDiseases0.000claimsdescription5
- 208000017169kidney diseaseDiseases0.000claimsdescription5
- 230000002829reductive effectEffects0.000claimsdescription5
- 208000024891symptomDiseases0.000claimsdescription5
- OUYCCCASQSFEME-UHFFFAOYSA-NtyrosineNatural productsOC(=O)C(N)CC1=CC=C(O)C=C1OUYCCCASQSFEME-UHFFFAOYSA-N0.000claimsdescription5
- 208000023275Autoimmune diseaseDiseases0.000claimsdescription4
- 208000035473Communicable diseaseDiseases0.000claimsdescription4
- 101000608935Homo sapiens LeukosialinProteins0.000claimsdescription4
- 102100039564LeukosialinHuman genes0.000claimsdescription4
- 241000713880Spleen focus-forming virusSpecies0.000claimsdescription4
- 210000004369bloodAnatomy0.000claimsdescription4
- 239000008280bloodSubstances0.000claimsdescription4
- 210000004204blood vesselAnatomy0.000claimsdescription4
- 230000000977initiatory effectEffects0.000claimsdescription4
- 208000023589ischemic diseaseDiseases0.000claimsdescription4
- 230000002062proliferating effectEffects0.000claimsdescription4
- 230000002103transcriptional effectEffects0.000claimsdescription4
- 108010067306FibronectinsProteins0.000claimsdescription3
- 240000007019Oxalis corniculataSpecies0.000claimsdescription3
- 210000000988bone and boneAnatomy0.000claimsdescription3
- 241001529453unidentified herpesvirusSpecies0.000claimsdescription3
- 102000006395GlobulinsHuman genes0.000claimsdescription2
- 108010044091GlobulinsProteins0.000claimsdescription2
- 241000700721Hepatitis B virusSpecies0.000claimsdescription2
- 101001033280Homo sapiens Cytokine receptor common subunit betaProteins0.000claimsdescription2
- 108010065805Interleukin-12Proteins0.000claimsdescription2
- 108010038453Interleukin-2 ReceptorsProteins0.000claimsdescription2
- 102000010789Interleukin-2 ReceptorsHuman genes0.000claimsdescription2
- 241000125945ProtoparvovirusSpecies0.000claimsdescription2
- 108010017324STAT3 Transcription FactorProteins0.000claimsdescription2
- 102000055647human CSF2RBHuman genes0.000claimsdescription2
- 239000002502liposomeSubstances0.000claimsdescription2
- 239000000693micelleSubstances0.000claimsdescription2
- 239000002105nanoparticleSubstances0.000claimsdescription2
- 230000013819transposition, DNA-mediatedEffects0.000claimsdescription2
- 101150030061Eloc geneProteins0.000claims2
- 102100037114Elongin-CHuman genes0.000claims2
- 101710105178F-box/WD repeat-containing protein 7Proteins0.000claims2
- 102100028138F-box/WD repeat-containing protein 7Human genes0.000claims2
- 101000978729Homo sapiens E3 ubiquitin-protein ligase MARCHF8Proteins0.000claims2
- 101000711673Homo sapiens E3 ubiquitin-protein ligase RNF128Proteins0.000claims2
- 101000783723Homo sapiens Leucine-rich alpha-2-glycoproteinProteins0.000claims2
- 101000642268Homo sapiens Speckle-type POZ proteinProteins0.000claims2
- 101000687808Homo sapiens Suppressor of cytokine signaling 2Proteins0.000claims2
- 102100036422Speckle-type POZ proteinHuman genes0.000claims2
- ZVTDLPBHTSMEJZ-UPZRXNBOSA-NdanoprevirChemical compoundO=C([C@@]12C[C@H]1\C=C/CCCCC[C@H](C(N1C[C@@H](C[C@H]1C(=O)N2)OC(=O)N1CC2=C(F)C=CC=C2C1)=O)NC(=O)OC(C)(C)C)NS(=O)(=O)C1CC1ZVTDLPBHTSMEJZ-UPZRXNBOSA-N0.000claims2
- 208000019423liver diseaseDiseases0.000claims2
- 102000016359FibronectinsHuman genes0.000claims1
- 102000004495STAT3 Transcription FactorHuman genes0.000claims1
- 230000003111delayed effectEffects0.000claims1
- 238000001727in vivoMethods0.000abstractdescription9
- 238000011282treatmentMethods0.000abstractdescription5
- 230000002265preventionEffects0.000abstractdescription2
- 102000040430polynucleotideHuman genes0.000description328
- 108091033319polynucleotideProteins0.000description328
- 239000002157polynucleotideSubstances0.000description328
- 235000018102proteinsNutrition0.000description159
- 235000001014amino acidNutrition0.000description31
- 230000003993interactionEffects0.000description30
- 229940024606amino acidDrugs0.000description22
- 125000003275alpha amino acid groupChemical group0.000description21
- 230000001225therapeutic effectEffects0.000description21
- 108091008874T cell receptorsProteins0.000description18
- 102000016266T-Cell Antigen ReceptorsHuman genes0.000description18
- 210000000234capsidAnatomy0.000description17
- 230000006870functionEffects0.000description17
- 239000002773nucleotideSubstances0.000description17
- 125000003729nucleotide groupChemical group0.000description17
- 230000011664signalingEffects0.000description17
- 102000035160transmembrane proteinsHuman genes0.000description17
- 108091005703transmembrane proteinsProteins0.000description17
- 238000006467substitution reactionMethods0.000description16
- 108010003751ElonginProteins0.000description15
- 102000004662ElonginHuman genes0.000description15
- 230000001086cytosolic effectEffects0.000description14
- 230000004048modificationEffects0.000description14
- 238000012986modificationMethods0.000description14
- 108020004414DNAProteins0.000description13
- DHMQDGOQFOQNFH-UHFFFAOYSA-NGlycineChemical compoundNCC(O)=ODHMQDGOQFOQNFH-UHFFFAOYSA-N0.000description13
- 239000000546pharmaceutical excipientSubstances0.000description13
- 238000002659cell therapyMethods0.000description12
- ZVTDLPBHTSMEJZ-JSZLBQEHSA-NdanoprevirChemical compoundO=C([C@@]12C[C@H]1\C=C/CCCCC[C@@H](C(N1C[C@@H](C[C@H]1C(=O)N2)OC(=O)N1CC2=C(F)C=CC=C2C1)=O)NC(=O)OC(C)(C)C)NS(=O)(=O)C1CC1ZVTDLPBHTSMEJZ-JSZLBQEHSA-N0.000description12
- 108020004999messenger RNAProteins0.000description12
- 102000005962receptorsHuman genes0.000description12
- 108020003175receptorsProteins0.000description12
- 102000004190EnzymesHuman genes0.000description11
- 108090000790EnzymesProteins0.000description11
- 102000027257transmembrane receptorsHuman genes0.000description11
- 108091008578transmembrane receptorsProteins0.000description11
- 230000034512ubiquitinationEffects0.000description11
- 238000010798ubiquitinationMethods0.000description11
- 230000000735allogeneic effectEffects0.000description10
- 150000001875compoundsChemical class0.000description10
- 238000010586diagramMethods0.000description10
- 230000000694effectsEffects0.000description10
- 238000001415gene therapyMethods0.000description10
- 230000004068intracellular signalingEffects0.000description10
- 238000004519manufacturing processMethods0.000description10
- 230000001737promoting effectEffects0.000description10
- 230000003612virological effectEffects0.000description10
- 102000006108VHLHuman genes0.000description9
- 101150046474Vhl geneProteins0.000description9
- 125000000539amino acid groupChemical group0.000description9
- 238000004806packaging method and processMethods0.000description9
- 239000000651prodrugSubstances0.000description9
- 229940002612prodrugDrugs0.000description9
- 239000000126substanceSubstances0.000description9
- 230000008685targetingEffects0.000description9
- 238000013518transcriptionMethods0.000description9
- 230000035897transcriptionEffects0.000description9
- 108010021625Immunoglobulin FragmentsProteins0.000description8
- 102000008394Immunoglobulin FragmentsHuman genes0.000description8
- 102000044159UbiquitinHuman genes0.000description8
- 108090000848UbiquitinProteins0.000description8
- 230000001413cellular effectEffects0.000description8
- 230000000139costimulatory effectEffects0.000description8
- 230000004927fusionEffects0.000description8
- 150000003839saltsChemical class0.000description8
- 108091032973(ribonucleotides)n+mProteins0.000description7
- 102000053602DNAHuman genes0.000description7
- 101710162557E3 ubiquitin-protein ligase RNF128Proteins0.000description7
- 101710137422Suppressor of cytokine signaling 2Proteins0.000description7
- 239000002299complementary DNASubstances0.000description7
- 239000012141concentrateSubstances0.000description7
- 238000013461designMethods0.000description7
- 239000000539dimerSubstances0.000description7
- 229940079593drugDrugs0.000description7
- 239000012729immediate-release (IR) formulationSubstances0.000description7
- 210000003292kidney cellAnatomy0.000description7
- 102000037979non-receptor tyrosine kinasesHuman genes0.000description7
- 108091008046non-receptor tyrosine kinasesProteins0.000description7
- 239000003381stabilizerSubstances0.000description7
- 230000004936stimulating effectEffects0.000description7
- MTCFGRXMJLQNBG-REOHCLBHSA-N(2S)-2-Amino-3-hydroxypropansäureChemical compoundOC[C@H](N)C(O)=OMTCFGRXMJLQNBG-REOHCLBHSA-N0.000description6
- 108700022150Designed Ankyrin Repeat ProteinsProteins0.000description6
- 101001103039Homo sapiens Inactive tyrosine-protein kinase transmembrane receptor ROR1Proteins0.000description6
- 101001103036Homo sapiens Nuclear receptor ROR-alphaProteins0.000description6
- 102000053646Inducible T-Cell Co-StimulatorHuman genes0.000description6
- 108700013161Inducible T-Cell Co-StimulatorProteins0.000description6
- AGPKZVBTJJNPAG-WHFBIAKZSA-NL-isoleucineChemical compoundCC[C@H](C)[C@H](N)C(O)=OAGPKZVBTJJNPAG-WHFBIAKZSA-N0.000description6
- 102000003960LigasesHuman genes0.000description6
- 108090000364LigasesProteins0.000description6
- 102100039614Nuclear receptor ROR-alphaHuman genes0.000description6
- 208000000453Skin NeoplasmsDiseases0.000description6
- KZSNJWFQEVHDMF-UHFFFAOYSA-NValineNatural productsCC(C)C(N)C(O)=OKZSNJWFQEVHDMF-UHFFFAOYSA-N0.000description6
- 102000035181adaptor proteinsHuman genes0.000description6
- 108091005764adaptor proteinsProteins0.000description6
- OIRDTQYFTABQOQ-KQYNXXCUSA-NadenosineChemical compoundC1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1OOIRDTQYFTABQOQ-KQYNXXCUSA-N0.000description6
- 210000000349chromosomeAnatomy0.000description6
- 239000002552dosage formSubstances0.000description6
- 230000007246mechanismEffects0.000description6
- 210000001778pluripotent stem cellAnatomy0.000description6
- 108020001580protein domainsProteins0.000description6
- 201000000849skin cancerDiseases0.000description6
- 210000002536stromal cellAnatomy0.000description6
- 208000032791BCR-ABL1 positive chronic myelogenous leukemiaDiseases0.000description5
- 208000010833Chronic myeloid leukaemiaDiseases0.000description5
- 101710168833E3 ubiquitin-protein ligase MARCHF8Proteins0.000description5
- WHUUTDBJXJRKMK-UHFFFAOYSA-NGlutamic acidNatural productsOC(=O)C(N)CCC(O)=OWHUUTDBJXJRKMK-UHFFFAOYSA-N0.000description5
- 239000004471GlycineSubstances0.000description5
- 101000899111Homo sapiens Hemoglobin subunit betaProteins0.000description5
- WHUUTDBJXJRKMK-VKHMYHEASA-NL-glutamic acidChemical compoundOC(=O)[C@@H](N)CCC(O)=OWHUUTDBJXJRKMK-VKHMYHEASA-N0.000description5
- COLNVLDHVKWLRT-QMMMGPOBSA-NL-phenylalanineChemical compoundOC(=O)[C@@H](N)CC1=CC=CC=C1COLNVLDHVKWLRT-QMMMGPOBSA-N0.000description5
- AYFVYJQAPQTCCC-GBXIJSLDSA-NL-threonineChemical compoundC[C@@H](O)[C@H](N)C(O)=OAYFVYJQAPQTCCC-GBXIJSLDSA-N0.000description5
- 208000033761Myelogenous Chronic BCR-ABL Positive LeukemiaDiseases0.000description5
- 101710163270NucleaseProteins0.000description5
- 239000002253acidSubstances0.000description5
- 239000002585baseSubstances0.000description5
- 210000000170cell membraneAnatomy0.000description5
- 230000033077cellular processEffects0.000description5
- 230000005754cellular signalingEffects0.000description5
- 238000013270controlled releaseMethods0.000description5
- 238000010362genome editingMethods0.000description5
- 230000004481post-translational protein modificationEffects0.000description5
- 238000000746purificationMethods0.000description5
- 238000012216screeningMethods0.000description5
- 210000001519tissueAnatomy0.000description5
- 241000701044Human gammaherpesvirus 4Species0.000description4
- 108060003951ImmunoglobulinProteins0.000description4
- XUJNEKJLAYXESH-REOHCLBHSA-NL-CysteineChemical compoundSC[C@H](N)C(O)=OXUJNEKJLAYXESH-REOHCLBHSA-N0.000description4
- HNDVDQJCIGZPNO-YFKPBYRVSA-NL-histidineChemical compoundOC(=O)[C@@H](N)CC1=CN=CN1HNDVDQJCIGZPNO-YFKPBYRVSA-N0.000description4
- ROHFNLRQFUQHCH-YFKPBYRVSA-NL-leucineChemical compoundCC(C)C[C@H](N)C(O)=OROHFNLRQFUQHCH-YFKPBYRVSA-N0.000description4
- KDXKERNSBIXSRK-YFKPBYRVSA-NL-lysineChemical compoundNCCCC[C@H](N)C(O)=OKDXKERNSBIXSRK-YFKPBYRVSA-N0.000description4
- 206010058467Lung neoplasm malignantDiseases0.000description4
- 206010025323LymphomasDiseases0.000description4
- KDXKERNSBIXSRK-UHFFFAOYSA-NLysineNatural productsNCCCCC(N)C(O)=OKDXKERNSBIXSRK-UHFFFAOYSA-N0.000description4
- 208000015914Non-Hodgkin lymphomasDiseases0.000description4
- 108010076504Protein Sorting SignalsProteins0.000description4
- 102000000369SOCS box domainsHuman genes0.000description4
- 108050008939SOCS box domainsProteins0.000description4
- 101710137414Suppressor of cytokine signaling 4Proteins0.000description4
- 101710137416Suppressor of cytokine signaling 6Proteins0.000description4
- IQFYYKKMVGJFEH-XLPZGREQSA-NThymidineChemical compoundO=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1IQFYYKKMVGJFEH-XLPZGREQSA-N0.000description4
- 239000013543active substanceSubstances0.000description4
- 230000008901benefitEffects0.000description4
- 239000011230binding agentSubstances0.000description4
- 210000003162effector t lymphocyteAnatomy0.000description4
- 238000005516engineering processMethods0.000description4
- HNDVDQJCIGZPNO-UHFFFAOYSA-NhistidineNatural productsOC(=O)C(N)CC1=CN=CN1HNDVDQJCIGZPNO-UHFFFAOYSA-N0.000description4
- 102000018358immunoglobulinHuman genes0.000description4
- 230000010354integrationEffects0.000description4
- 208000032839leukemiaDiseases0.000description4
- 201000005202lung cancerDiseases0.000description4
- 208000020816lung neoplasmDiseases0.000description4
- 230000001404mediated effectEffects0.000description4
- 239000012528membraneSubstances0.000description4
- 102000027426receptor tyrosine kinasesHuman genes0.000description4
- 108091008598receptor tyrosine kinasesProteins0.000description4
- 230000004044responseEffects0.000description4
- 108091006024signal transducing proteinsProteins0.000description4
- 102000034285signal transducing proteinsHuman genes0.000description4
- 206010062261spinal cord neoplasmDiseases0.000description4
- 208000024893Acute lymphoblastic leukemiaDiseases0.000description3
- 208000014697Acute lymphocytic leukaemiaDiseases0.000description3
- 208000031261Acute myeloid leukaemiaDiseases0.000description3
- 239000004475ArginineSubstances0.000description3
- 208000010839B-cell chronic lymphocytic leukemiaDiseases0.000description3
- 206010006187Breast cancerDiseases0.000description3
- 108091007381CBL proteinsProteins0.000description3
- 102000017420CD3 protein, epsilon/gamma/delta subunitHuman genes0.000description3
- 108050005493CD3 protein, epsilon/gamma/delta subunitProteins0.000description3
- 108010069682CSK Tyrosine-Protein KinaseProteins0.000description3
- OYPRJOBELJOOCE-UHFFFAOYSA-NCalciumChemical compound[Ca]OYPRJOBELJOOCE-UHFFFAOYSA-N0.000description3
- 206010008342Cervix carcinomaDiseases0.000description3
- 102000036364Cullin Ring E3 LigasesHuman genes0.000description3
- 108091007045Cullin Ring E3 LigasesProteins0.000description3
- 102100035813E3 ubiquitin-protein ligase CBLHuman genes0.000description3
- 102100035273E3 ubiquitin-protein ligase CBL-BHuman genes0.000description3
- 102100034968E3 ubiquitin-protein ligase ZNRF3Human genes0.000description3
- 101710175573E3 ubiquitin-protein ligase ZNRF3Proteins0.000description3
- NYHBQMYGNKIUIF-UUOKFMHZSA-NGuanosineChemical compoundC1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1ONYHBQMYGNKIUIF-UUOKFMHZSA-N0.000description3
- 102100029360Hematopoietic cell signal transducerHuman genes0.000description3
- 101000903742Homo sapiens Basic leucine zipper transcriptional factor ATF-likeProteins0.000description3
- 101000737265Homo sapiens E3 ubiquitin-protein ligase CBL-BProteins0.000description3
- 101000990188Homo sapiens Hematopoietic cell signal transducerProteins0.000description3
- 101000679555Homo sapiens TOX high mobility group box family member 2Proteins0.000description3
- 101000648265Homo sapiens Thymocyte selection-associated high mobility group box protein TOXProteins0.000description3
- 101001050288Homo sapiens Transcription factor JunProteins0.000description3
- 101000818543Homo sapiens Tyrosine-protein kinase ZAP-70Proteins0.000description3
- 101001135572Homo sapiens Tyrosine-protein phosphatase non-receptor type 2Proteins0.000description3
- ONIBWKKTOPOVIA-BYPYZUCNSA-NL-ProlineChemical compoundOC(=O)[C@@H]1CCCN1ONIBWKKTOPOVIA-BYPYZUCNSA-N0.000description3
- 150000008575L-amino acidsChemical class0.000description3
- DCXYFEDJOCDNAF-REOHCLBHSA-NL-asparagineChemical compoundOC(=O)[C@@H](N)CC(N)=ODCXYFEDJOCDNAF-REOHCLBHSA-N0.000description3
- CKLJMWTZIZZHCS-REOHCLBHSA-NL-aspartic acidChemical compoundOC(=O)[C@@H](N)CC(O)=OCKLJMWTZIZZHCS-REOHCLBHSA-N0.000description3
- ZDXPYRJPNDTMRX-VKHMYHEASA-NL-glutamineChemical compoundOC(=O)[C@@H](N)CCC(N)=OZDXPYRJPNDTMRX-VKHMYHEASA-N0.000description3
- QIVBCDIJIAJPQS-VIFPVBQESA-NL-tryptophaneChemical compoundC1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1QIVBCDIJIAJPQS-VIFPVBQESA-N0.000description3
- KZSNJWFQEVHDMF-BYPYZUCNSA-NL-valineChemical compoundCC(C)[C@H](N)C(O)=OKZSNJWFQEVHDMF-BYPYZUCNSA-N0.000description3
- GUBGYTABKSRVRQ-QKKXKWKRSA-NLactoseNatural productsOC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1OGUBGYTABKSRVRQ-QKKXKWKRSA-N0.000description3
- 241000713666LentivirusSpecies0.000description3
- 101710083711Leucine-rich alpha-2-glycoproteinProteins0.000description3
- 102000004232Mitogen-Activated Protein Kinase KinasesHuman genes0.000description3
- 108090000744Mitogen-Activated Protein Kinase KinasesProteins0.000description3
- 241000699666Mus <mouse, genus>Species0.000description3
- 108091008638NR4AProteins0.000description3
- 102100022679Nuclear receptor subfamily 4 group A member 1Human genes0.000description3
- MUBZPKHOEPUJKR-UHFFFAOYSA-NOxalic acidChemical compoundOC(=O)C(O)=OMUBZPKHOEPUJKR-UHFFFAOYSA-N0.000description3
- 229910019142PO4Inorganic materials0.000description3
- 206010035226Plasma cell myelomaDiseases0.000description3
- 102100037935Polyubiquitin-CHuman genes0.000description3
- 208000006664Precursor Cell Lymphoblastic Leukemia-LymphomaDiseases0.000description3
- ONIBWKKTOPOVIA-UHFFFAOYSA-NProlineNatural productsOC(=O)C1CCCN1ONIBWKKTOPOVIA-UHFFFAOYSA-N0.000description3
- 229920002472StarchPolymers0.000description3
- 102100022611TOX high mobility group box family member 2Human genes0.000description3
- AYFVYJQAPQTCCC-UHFFFAOYSA-NThreonineNatural productsCC(O)C(N)C(O)=OAYFVYJQAPQTCCC-UHFFFAOYSA-N0.000description3
- 239000004473ThreonineSubstances0.000description3
- 102100028788Thymocyte selection-associated high mobility group box protein TOXHuman genes0.000description3
- QIVBCDIJIAJPQS-UHFFFAOYSA-NTryptophanNatural productsC1=CC=C2C(CC(N)C(O)=O)=CNC2=C1QIVBCDIJIAJPQS-UHFFFAOYSA-N0.000description3
- 102100031167Tyrosine-protein kinase CSKHuman genes0.000description3
- 102100021125Tyrosine-protein kinase ZAP-70Human genes0.000description3
- 102100033141Tyrosine-protein phosphatase non-receptor type 2Human genes0.000description3
- 208000006105Uterine Cervical NeoplasmsDiseases0.000description3
- 108010035430X-Box Binding Protein 1Proteins0.000description3
- ODKSFYDXXFIFQN-UHFFFAOYSA-NarginineNatural productsOC(=O)C(N)CCCNC(N)=NODKSFYDXXFIFQN-UHFFFAOYSA-N0.000description3
- 210000003719b-lymphocyteAnatomy0.000description3
- 210000004556brainAnatomy0.000description3
- 229910052791calciumInorganic materials0.000description3
- 239000011575calciumSubstances0.000description3
- 238000004364calculation methodMethods0.000description3
- 230000024245cell differentiationEffects0.000description3
- 201000010881cervical cancerDiseases0.000description3
- 239000003153chemical reaction reagentSubstances0.000description3
- 239000003795chemical substances by applicationSubstances0.000description3
- KRKNYBCHXYNGOX-UHFFFAOYSA-Ncitric acidChemical compoundOC(=O)CC(O)(C(O)=O)CC(O)=OKRKNYBCHXYNGOX-UHFFFAOYSA-N0.000description3
- 238000010367cloningMethods0.000description3
- 230000001276controlling effectEffects0.000description3
- XUJNEKJLAYXESH-UHFFFAOYSA-NcysteineNatural productsSCC(N)C(O)=OXUJNEKJLAYXESH-UHFFFAOYSA-N0.000description3
- 235000018417cysteineNutrition0.000description3
- 238000004090dissolutionMethods0.000description3
- 238000013265extended releaseMethods0.000description3
- 125000000524functional groupChemical group0.000description3
- 201000011243gastrointestinal stromal tumorDiseases0.000description3
- 235000013922glutamic acidNutrition0.000description3
- 239000004220glutamic acidSubstances0.000description3
- 239000004615ingredientSubstances0.000description3
- 108010051920interferon regulatory factor-4Proteins0.000description3
- AGPKZVBTJJNPAG-UHFFFAOYSA-NisoleucineNatural productsCCC(C)C(N)C(O)=OAGPKZVBTJJNPAG-UHFFFAOYSA-N0.000description3
- 229960000310isoleucineDrugs0.000description3
- 201000007270liver cancerDiseases0.000description3
- 208000014018liver neoplasmDiseases0.000description3
- 210000005265lung cellAnatomy0.000description3
- 210000002540macrophageAnatomy0.000description3
- 239000003550markerSubstances0.000description3
- 201000001441melanomaDiseases0.000description3
- 210000003071memory t lymphocyteAnatomy0.000description3
- 230000002503metabolic effectEffects0.000description3
- 150000007522mineralic acidsChemical class0.000description3
- 239000000178monomerSubstances0.000description3
- 210000000663muscle cellAnatomy0.000description3
- 210000000107myocyteAnatomy0.000description3
- 210000000581natural killer T-cellAnatomy0.000description3
- 210000000822natural killer cellAnatomy0.000description3
- 231100000252nontoxicToxicity0.000description3
- 230000003000nontoxic effectEffects0.000description3
- 235000015097nutrientsNutrition0.000description3
- COLNVLDHVKWLRT-UHFFFAOYSA-NphenylalanineNatural productsOC(=O)C(N)CC1=CC=CC=C1COLNVLDHVKWLRT-UHFFFAOYSA-N0.000description3
- NBIIXXVUZAFLBC-UHFFFAOYSA-KphosphateChemical compound[O-]P([O-])([O-])=ONBIIXXVUZAFLBC-UHFFFAOYSA-K0.000description3
- 239000010452phosphateSubstances0.000description3
- 230000026731phosphorylationEffects0.000description3
- 238000006366phosphorylation reactionMethods0.000description3
- 229920001223polyethylene glycolPolymers0.000description3
- 125000002924primary amino groupChemical group[H]N([H])*0.000description3
- 230000004853protein functionEffects0.000description3
- 230000004850protein–protein interactionEffects0.000description3
- 210000003289regulatory T cellAnatomy0.000description3
- 230000010076replicationEffects0.000description3
- 238000002864sequence alignmentMethods0.000description3
- 210000004927skin cellAnatomy0.000description3
- 229940126586small molecule drugDrugs0.000description3
- 239000008107starchSubstances0.000description3
- 235000019698starchNutrition0.000description3
- 239000000758substrateSubstances0.000description3
- 238000002560therapeutic procedureMethods0.000description3
- 230000032258transportEffects0.000description3
- 210000004881tumor cellAnatomy0.000description3
- 241000701161unidentified adenovirusSpecies0.000description3
- 241000701447unidentified baculovirusSpecies0.000description3
- 239000004474valineSubstances0.000description3
- 239000003981vehicleSubstances0.000description3
- 1020000015561-Phosphatidylinositol 4-KinaseHuman genes0.000description2
- 1080100291901-Phosphatidylinositol 4-KinaseProteins0.000description2
- 1021000262051-phosphatidylinositol 4,5-bisphosphate phosphodiesterase gamma-1Human genes0.000description2
- 208000030507AIDSDiseases0.000description2
- 206010061424Anal cancerDiseases0.000description2
- 208000007860Anus NeoplasmsDiseases0.000description2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-NAscorbic acidChemical compoundOC[C@H](O)[C@H]1OC(=O)C(O)=C1OCIWBSHSKHKDKBQ-JLAZNSOCSA-N0.000description2
- DCXYFEDJOCDNAF-UHFFFAOYSA-NAsparagineNatural productsOC(=O)C(N)CC(N)=ODCXYFEDJOCDNAF-UHFFFAOYSA-N0.000description2
- 102100022970Basic leucine zipper transcriptional factor ATF-likeHuman genes0.000description2
- 206010005003Bladder cancerDiseases0.000description2
- 206010005949Bone cancerDiseases0.000description2
- 208000018084Bone neoplasmDiseases0.000description2
- 208000003174Brain NeoplasmsDiseases0.000description2
- 208000026310Breast neoplasmDiseases0.000description2
- 239000002126C01EB10 - AdenosineSubstances0.000description2
- 210000005236CD8+ effector T cellAnatomy0.000description2
- 108091033409CRISPRProteins0.000description2
- VTYYLEPIZMXCLO-UHFFFAOYSA-LCalcium carbonateChemical compound[Ca+2].[O-]C([O-])=OVTYYLEPIZMXCLO-UHFFFAOYSA-L0.000description2
- 101710167800Capsid assembly scaffolding proteinProteins0.000description2
- 241000282693CercopithecidaeSpecies0.000description2
- 108091033380Coding strandProteins0.000description2
- 108020004705CodonProteins0.000description2
- 206010009944Colon cancerDiseases0.000description2
- 208000001333Colorectal NeoplasmsDiseases0.000description2
- 102100033772Complement C4-AHuman genes0.000description2
- 201000003883Cystic fibrosisDiseases0.000description2
- 150000008574D-amino acidsChemical class0.000description2
- 230000004568DNA-bindingEffects0.000description2
- 239000006144Dulbecco’s modified Eagle's mediumSubstances0.000description2
- 206010014733Endometrial cancerDiseases0.000description2
- 206010014759Endometrial neoplasmDiseases0.000description2
- 208000000461Esophageal NeoplasmsDiseases0.000description2
- 208000006168Ewing SarcomaDiseases0.000description2
- 108091008794FGF receptorsProteins0.000description2
- 102000044168Fibroblast Growth Factor ReceptorHuman genes0.000description2
- 102100037362FibronectinHuman genes0.000description2
- 102100028122Forkhead box protein P1Human genes0.000description2
- 101710088095Forkhead box protein P1Proteins0.000description2
- VZCYOOQTPOCHFL-OWOJBTEDSA-NFumaric acidChemical compoundOC(=O)\C=C\C(O)=OVZCYOOQTPOCHFL-OWOJBTEDSA-N0.000description2
- 102000003688G-Protein-Coupled ReceptorsHuman genes0.000description2
- 108090000045G-Protein-Coupled ReceptorsProteins0.000description2
- 208000022072Gallbladder NeoplasmsDiseases0.000description2
- 206010051066Gastrointestinal stromal tumourDiseases0.000description2
- AEMRFAOFKBGASW-UHFFFAOYSA-NGlycolic acidChemical compoundOCC(O)=OAEMRFAOFKBGASW-UHFFFAOYSA-N0.000description2
- 208000031220HemophiliaDiseases0.000description2
- 208000009292Hemophilia ADiseases0.000description2
- 208000009889Herpes SimplexDiseases0.000description2
- 208000017604Hodgkin diseaseDiseases0.000description2
- 208000021519Hodgkin lymphomaDiseases0.000description2
- 208000010747Hodgkins lymphomaDiseases0.000description2
- 101000691599Homo sapiens 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase gamma-1Proteins0.000description2
- 101000710884Homo sapiens Complement C4-AProteins0.000description2
- 101001047640Homo sapiens Linker for activation of T-cells family member 1Proteins0.000description2
- 101001109700Homo sapiens Nuclear receptor subfamily 4 group A member 1Proteins0.000description2
- 101001109698Homo sapiens Nuclear receptor subfamily 4 group A member 2Proteins0.000description2
- 101001109689Homo sapiens Nuclear receptor subfamily 4 group A member 3Proteins0.000description2
- 101001012157Homo sapiens Receptor tyrosine-protein kinase erbB-2Proteins0.000description2
- 206010056305Hypopharyngeal neoplasmDiseases0.000description2
- 102100039688Insulin-like growth factor 1 receptorHuman genes0.000description2
- 101710184277Insulin-like growth factor 1 receptorProteins0.000description2
- 102100030126Interferon regulatory factor 4Human genes0.000description2
- 208000007766Kaposi sarcomaDiseases0.000description2
- 208000008839Kidney NeoplasmsDiseases0.000description2
- QNAYBMKLOCPYGJ-REOHCLBHSA-NL-alanineChemical compoundC[C@H](N)C(O)=OQNAYBMKLOCPYGJ-REOHCLBHSA-N0.000description2
- FFEARJCKVFRZRR-BYPYZUCNSA-NL-methionineChemical compoundCSCC[C@H](N)C(O)=OFFEARJCKVFRZRR-BYPYZUCNSA-N0.000description2
- ROHFNLRQFUQHCH-UHFFFAOYSA-NLeucineNatural productsCC(C)CC(N)C(O)=OROHFNLRQFUQHCH-UHFFFAOYSA-N0.000description2
- 108010064548Lymphocyte Function-Associated Antigen-1Proteins0.000description2
- 208000031422Lymphocytic Chronic B-Cell LeukemiaDiseases0.000description2
- 239000004472LysineSubstances0.000description2
- 102000043136MAP kinase familyHuman genes0.000description2
- 108091054455MAP kinase familyProteins0.000description2
- 208000004059Male Breast NeoplasmsDiseases0.000description2
- 241000124008MammaliaSpecies0.000description2
- 241001465754MetazoaSpecies0.000description2
- AFVFQIVMOAPDHO-UHFFFAOYSA-NMethanesulfonic acidChemical compoundCS(O)(=O)=OAFVFQIVMOAPDHO-UHFFFAOYSA-N0.000description2
- 102100025751Mothers against decapentaplegic homolog 2Human genes0.000description2
- 101710143123Mothers against decapentaplegic homolog 2Proteins0.000description2
- 102100025748Mothers against decapentaplegic homolog 3Human genes0.000description2
- 101710143111Mothers against decapentaplegic homolog 3Proteins0.000description2
- 208000034578Multiple myelomasDiseases0.000description2
- 101100268066Mus musculus Zap70 geneProteins0.000description2
- 241000699670Mus sp.Species0.000description2
- 201000003793Myelodysplastic syndromeDiseases0.000description2
- 206010028729Nasal cavity cancerDiseases0.000description2
- 206010029260NeuroblastomaDiseases0.000description2
- 102100022676Nuclear receptor subfamily 4 group A member 2Human genes0.000description2
- 102100022673Nuclear receptor subfamily 4 group A member 3Human genes0.000description2
- 206010030155Oesophageal carcinomaDiseases0.000description2
- 241000283973Oryctolagus cuniculusSpecies0.000description2
- 206010033128Ovarian cancerDiseases0.000description2
- 206010061535Ovarian neoplasmDiseases0.000description2
- 108091007960PI3KsProteins0.000description2
- 108010011536PTEN PhosphohydrolaseProteins0.000description2
- 102000014160PTEN PhosphohydrolaseHuman genes0.000description2
- 206010061902Pancreatic neoplasmDiseases0.000description2
- 206010034299Penile cancerDiseases0.000description2
- 102000035195PeptidasesHuman genes0.000description2
- 108091005804PeptidasesProteins0.000description2
- 208000007913Pituitary NeoplasmsDiseases0.000description2
- 102100030264PleckstrinHuman genes0.000description2
- 102220556195Polyubiquitin-C_K63R_mutationHuman genes0.000description2
- 101710130420Probable capsid assembly scaffolding proteinProteins0.000description2
- 206010060862Prostate cancerDiseases0.000description2
- 208000000236Prostatic NeoplasmsDiseases0.000description2
- 239000004365ProteaseSubstances0.000description2
- KAESVJOAVNADME-UHFFFAOYSA-NPyrroleChemical compoundC=1C=CNC=1KAESVJOAVNADME-UHFFFAOYSA-N0.000description2
- 241000700159RattusSpecies0.000description2
- 102100030086Receptor tyrosine-protein kinase erbB-2Human genes0.000description2
- 108010091086RecombinasesProteins0.000description2
- 102000018120RecombinasesHuman genes0.000description2
- 206010038389Renal cancerDiseases0.000description2
- 201000000582RetinoblastomaDiseases0.000description2
- 208000004337Salivary Gland NeoplasmsDiseases0.000description2
- 206010061934Salivary gland cancerDiseases0.000description2
- 206010039491SarcomaDiseases0.000description2
- 101710204410Scaffold proteinProteins0.000description2
- MTCFGRXMJLQNBG-UHFFFAOYSA-NSerineNatural productsOCC(N)C(O)=OMTCFGRXMJLQNBG-UHFFFAOYSA-N0.000description2
- 108010003723Single-Domain AntibodiesProteins0.000description2
- 108020004682Single-Stranded DNAProteins0.000description2
- FAPWRFPIFSIZLT-UHFFFAOYSA-MSodium chlorideChemical compound[Na+].[Cl-]FAPWRFPIFSIZLT-UHFFFAOYSA-M0.000description2
- 208000021712Soft tissue sarcomaDiseases0.000description2
- 208000005718Stomach NeoplasmsDiseases0.000description2
- 108700027336Suppressor of Cytokine Signaling 1Proteins0.000description2
- 108700027337Suppressor of Cytokine Signaling 3Proteins0.000description2
- 102100024779Suppressor of cytokine signaling 1Human genes0.000description2
- 102100024283Suppressor of cytokine signaling 3Human genes0.000description2
- 102100030524Suppressor of cytokine signaling 4Human genes0.000description2
- 101710137415Suppressor of cytokine signaling 5Proteins0.000description2
- 102100030523Suppressor of cytokine signaling 5Human genes0.000description2
- 102100030530Suppressor of cytokine signaling 6Human genes0.000description2
- 102100030529Suppressor of cytokine signaling 7Human genes0.000description2
- 101710137344Suppressor of cytokine signaling 7Proteins0.000description2
- 208000024313Testicular NeoplasmsDiseases0.000description2
- 206010057644Testis cancerDiseases0.000description2
- 208000000728Thymus NeoplasmsDiseases0.000description2
- 208000024770Thyroid neoplasmDiseases0.000description2
- 102100023132Transcription factor JunHuman genes0.000description2
- 108020004566Transfer RNAProteins0.000description2
- 108010020764TransposasesProteins0.000description2
- 102000008579TransposasesHuman genes0.000description2
- 102100033019Tyrosine-protein phosphatase non-receptor type 11Human genes0.000description2
- 101710116241Tyrosine-protein phosphatase non-receptor type 11Proteins0.000description2
- 102100021657Tyrosine-protein phosphatase non-receptor type 6Human genes0.000description2
- 101710128901Tyrosine-protein phosphatase non-receptor type 6Proteins0.000description2
- ISAKRJDGNUQOIC-UHFFFAOYSA-NUracilChemical compoundO=C1C=CNC(=O)N1ISAKRJDGNUQOIC-UHFFFAOYSA-N0.000description2
- DRTQHJPVMGBUCF-XVFCMESISA-NUridineChemical compoundO[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1DRTQHJPVMGBUCF-XVFCMESISA-N0.000description2
- 208000007097Urinary Bladder NeoplasmsDiseases0.000description2
- 108091008605VEGF receptorsProteins0.000description2
- 206010046865Vaccinia virus infectionDiseases0.000description2
- 102000009484Vascular Endothelial Growth Factor ReceptorsHuman genes0.000description2
- 206010047741Vulval cancerDiseases0.000description2
- 208000004354Vulvar NeoplasmsDiseases0.000description2
- 208000008383Wilms tumorDiseases0.000description2
- 102100038151X-box-binding protein 1Human genes0.000description2
- 108010017070Zinc Finger NucleasesProteins0.000description2
- 230000002378acidificating effectEffects0.000description2
- 230000009471actionEffects0.000description2
- 230000004913activationEffects0.000description2
- 229960005305adenosineDrugs0.000description2
- 210000001789adipocyteAnatomy0.000description2
- 201000005188adrenal gland cancerDiseases0.000description2
- 208000024447adrenal gland neoplasmDiseases0.000description2
- 208000014619adult acute lymphoblastic leukemiaDiseases0.000description2
- 235000004279alanineNutrition0.000description2
- PYMYPHUHKUWMLA-LMVFSUKVSA-Naldehydo-D-riboseChemical compoundOC[C@@H](O)[C@@H](O)[C@@H](O)C=OPYMYPHUHKUWMLA-LMVFSUKVSA-N0.000description2
- 239000003242anti bacterial agentSubstances0.000description2
- 230000005809anti-tumor immunityEffects0.000description2
- 229940088710antibiotic agentDrugs0.000description2
- 201000011165anus cancerDiseases0.000description2
- 238000013459approachMethods0.000description2
- 125000003118aryl groupChemical group0.000description2
- 235000009582asparagineNutrition0.000description2
- 229960001230asparagineDrugs0.000description2
- 235000003704aspartic acidNutrition0.000description2
- 210000000270basal cellAnatomy0.000description2
- WPYMKLBDIGXBTP-UHFFFAOYSA-Nbenzoic acidChemical compoundOC(=O)C1=CC=CC=C1WPYMKLBDIGXBTP-UHFFFAOYSA-N0.000description2
- 125000003236benzoyl groupChemical group[H]C1=C([H])C([H])=C(C([H])=C1[H])C(*)=O0.000description2
- OQFSQFPPLPISGP-UHFFFAOYSA-Nbeta-carboxyaspartic acidNatural productsOC(=O)C(N)C(C(O)=O)C(O)=OOQFSQFPPLPISGP-UHFFFAOYSA-N0.000description2
- 230000031018biological processes and functionsEffects0.000description2
- 230000033228biological regulationEffects0.000description2
- 210000001185bone marrowAnatomy0.000description2
- 239000001506calcium phosphateSubstances0.000description2
- 238000004422calculation algorithmMethods0.000description2
- 125000003178carboxy groupChemical group[H]OC(*)=O0.000description2
- 208000002458carcinoid tumorDiseases0.000description2
- 210000004413cardiac myocyteAnatomy0.000description2
- 239000000969carrierSubstances0.000description2
- 210000003169central nervous systemAnatomy0.000description2
- 208000011654childhood malignant neoplasmDiseases0.000description2
- 208000006990cholangiocarcinomaDiseases0.000description2
- 210000001612chondrocyteAnatomy0.000description2
- 208000032852chronic lymphocytic leukemiaDiseases0.000description2
- 201000010902chronic myelomonocytic leukemiaDiseases0.000description2
- 238000003776cleavage reactionMethods0.000description2
- 239000002131composite materialSubstances0.000description2
- CVSVTCORWBXHQV-UHFFFAOYSA-NcreatineChemical compoundNC(=[NH2+])N(C)CC([O-])=OCVSVTCORWBXHQV-UHFFFAOYSA-N0.000description2
- 208000030381cutaneous melanomaDiseases0.000description2
- OPTASPLRGRRNAP-UHFFFAOYSA-NcytosineChemical compoundNC=1C=CNC(=O)N=1OPTASPLRGRRNAP-UHFFFAOYSA-N0.000description2
- 238000012217deletionMethods0.000description2
- 230000037430deletionEffects0.000description2
- 210000004443dendritic cellAnatomy0.000description2
- 230000001419dependent effectEffects0.000description2
- 206010012601diabetes mellitusDiseases0.000description2
- 239000007884disintegrantSubstances0.000description2
- 239000000890drug combinationSubstances0.000description2
- 210000002919epithelial cellAnatomy0.000description2
- 201000004101esophageal cancerDiseases0.000description2
- 230000007717exclusionEffects0.000description2
- 208000024519eye neoplasmDiseases0.000description2
- 201000010175gallbladder cancerDiseases0.000description2
- 206010017758gastric cancerDiseases0.000description2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-NglutamineNatural productsOC(=O)C(N)CCC(N)=OZDXPYRJPNDTMRX-UHFFFAOYSA-N0.000description2
- OBMNJSNZOWALQB-NCQNOWPTSA-NgrazoprevirChemical compoundO=C([C@@H]1C[C@@H]2CN1C(=O)[C@@H](NC(=O)O[C@@H]1C[C@H]1CCCCCC1=NC3=CC=C(C=C3N=C1O2)OC)C(C)(C)C)N[C@]1(C(=O)NS(=O)(=O)C2CC2)C[C@H]1C=COBMNJSNZOWALQB-NCQNOWPTSA-N0.000description2
- 229960002914grazoprevirDrugs0.000description2
- UYTPUPDQBNUYGX-UHFFFAOYSA-NguanineChemical compoundO=C1NC(N)=NC2=C1N=CN2UYTPUPDQBNUYGX-UHFFFAOYSA-N0.000description2
- 229940093915gynecological organic acidDrugs0.000description2
- 201000010536head and neck cancerDiseases0.000description2
- 208000014829head and neck neoplasmDiseases0.000description2
- 208000019622heart diseaseDiseases0.000description2
- 210000003494hepatocyteAnatomy0.000description2
- 230000028993immune responseEffects0.000description2
- 230000002401inhibitory effectEffects0.000description2
- 210000004964innate lymphoid cellAnatomy0.000description2
- NOESYZHRGYRDHS-UHFFFAOYSA-NinsulinChemical compoundN1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1NOESYZHRGYRDHS-UHFFFAOYSA-N0.000description2
- 210000003734kidneyAnatomy0.000description2
- 201000010982kidney cancerDiseases0.000description2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-Nlactic acidChemical compoundCC(O)C(O)=OJVTAAEKCZFNVCJ-UHFFFAOYSA-N0.000description2
- 206010023841laryngeal neoplasmDiseases0.000description2
- 210000000265leukocyteAnatomy0.000description2
- 230000021633leukocyte mediated immunityEffects0.000description2
- 150000002632lipidsChemical class0.000description2
- 210000005229liver cellAnatomy0.000description2
- 230000004807localizationEffects0.000description2
- 239000000314lubricantSubstances0.000description2
- 230000002132lysosomal effectEffects0.000description2
- HQKMJHAJHXVSDF-UHFFFAOYSA-Lmagnesium stearateChemical compound[Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=OHQKMJHAJHXVSDF-UHFFFAOYSA-L0.000description2
- 201000003175male breast cancerDiseases0.000description2
- 208000010907male breast carcinomaDiseases0.000description2
- 208000006178malignant mesotheliomaDiseases0.000description2
- 208000015486malignant pancreatic neoplasmDiseases0.000description2
- 210000000716merkel cellAnatomy0.000description2
- 230000004060metabolic processEffects0.000description2
- 229930182817methionineNatural products0.000description2
- 239000007758minimum essential mediumSubstances0.000description2
- 238000012544monitoring processMethods0.000description2
- 230000035772mutationEffects0.000description2
- 210000003928nasal cavityAnatomy0.000description2
- 201000008026nephroblastomaDiseases0.000description2
- 230000000955neuroendocrineEffects0.000description2
- 201000011519neuroendocrine tumorDiseases0.000description2
- 210000004498neuroglial cellAnatomy0.000description2
- 210000002569neuronAnatomy0.000description2
- 201000008106ocular cancerDiseases0.000description2
- 201000002575ocular melanomaDiseases0.000description2
- 238000011275oncology therapyMethods0.000description2
- 150000007524organic acidsChemical class0.000description2
- 235000005985organic acidsNutrition0.000description2
- 201000008968osteosarcomaDiseases0.000description2
- 210000001672ovaryAnatomy0.000description2
- 201000002528pancreatic cancerDiseases0.000description2
- 208000008443pancreatic carcinomaDiseases0.000description2
- 208000021010pancreatic neuroendocrine tumorDiseases0.000description2
- 150000003904phospholipidsChemical class0.000description2
- DCWXELXMIBXGTH-UHFFFAOYSA-NphosphotyrosineChemical compoundOC(=O)C(N)CC1=CC=C(OP(O)(O)=O)C=C1DCWXELXMIBXGTH-UHFFFAOYSA-N0.000description2
- 208000010916pituitary tumorDiseases0.000description2
- 239000013600plasmid vectorSubstances0.000description2
- 108010026735platelet protein P47Proteins0.000description2
- 230000008488polyadenylationEffects0.000description2
- 230000001323posttranslational effectEffects0.000description2
- 238000001556precipitationMethods0.000description2
- 230000008569processEffects0.000description2
- 239000000047productSubstances0.000description2
- 210000001236prokaryotic cellAnatomy0.000description2
- 108091008597receptor serine/threonine kinasesProteins0.000description2
- 230000007115recruitmentEffects0.000description2
- 230000009467reductionEffects0.000description2
- 230000008672reprogrammingEffects0.000description2
- 238000011160researchMethods0.000description2
- 201000009410rhabdomyosarcomaDiseases0.000description2
- 229920002477rna polymerPolymers0.000description2
- 102200012888rs121918644Human genes0.000description2
- YGSDEFSMJLZEOE-UHFFFAOYSA-Nsalicylic acidChemical compoundOC(=O)C1=CC=CC=C1OYGSDEFSMJLZEOE-UHFFFAOYSA-N0.000description2
- 230000007017scissionEffects0.000description2
- 208000037968sinus cancerDiseases0.000description2
- 210000002363skeletal muscle cellAnatomy0.000description2
- 210000000329smooth muscle myocyteAnatomy0.000description2
- 230000009870specific bindingEffects0.000description2
- 201000011549stomach cancerDiseases0.000description2
- 238000013268sustained releaseMethods0.000description2
- 239000012730sustained-release formSubstances0.000description2
- 201000003120testicular cancerDiseases0.000description2
- RWQNBRDOKXIBIV-UHFFFAOYSA-NthymineChemical compoundCC1=CNC(=O)NC1=ORWQNBRDOKXIBIV-UHFFFAOYSA-N0.000description2
- 201000009377thymus cancerDiseases0.000description2
- 201000002510thyroid cancerDiseases0.000description2
- VZCYOOQTPOCHFL-UHFFFAOYSA-Ntrans-butenedioic acidNatural productsOC(=O)C=CC(O)=OVZCYOOQTPOCHFL-UHFFFAOYSA-N0.000description2
- 230000005030transcription terminationEffects0.000description2
- 238000010361transductionMethods0.000description2
- 230000026683transductionEffects0.000description2
- 230000009466transformationEffects0.000description2
- 238000013519translationMethods0.000description2
- 238000000108ultra-filtrationMethods0.000description2
- 210000003932urinary bladderAnatomy0.000description2
- 201000005112urinary bladder cancerDiseases0.000description2
- 208000037965uterine sarcomaDiseases0.000description2
- 208000007089vacciniaDiseases0.000description2
- 206010046885vaginal cancerDiseases0.000description2
- 208000013139vaginal neoplasmDiseases0.000description2
- 229940124676vascular endothelial growth factor receptorDrugs0.000description2
- 201000005102vulva cancerDiseases0.000description2
- XLYOFNOQVPJJNP-UHFFFAOYSA-NwaterSubstancesOXLYOFNOQVPJJNP-UHFFFAOYSA-N0.000description2
- 210000005253yeast cellAnatomy0.000description2
- ZXSBHXZKWRIEIA-JTQLQIEISA-N(2s)-3-(4-acetylphenyl)-2-azaniumylpropanoateChemical compoundCC(=O)C1=CC=C(C[C@H](N)C(O)=O)C=C1ZXSBHXZKWRIEIA-JTQLQIEISA-N0.000description1
- BJEPYKJPYRNKOW-REOHCLBHSA-N(S)-malic acidChemical compoundOC(=O)[C@@H](O)CC(O)=OBJEPYKJPYRNKOW-REOHCLBHSA-N0.000description1
- UWYVPFMHMJIBHE-OWOJBTEDSA-N(e)-2-hydroxybut-2-enedioic acidChemical compoundOC(=O)\C=C(\O)C(O)=OUWYVPFMHMJIBHE-OWOJBTEDSA-N0.000description1
- HKWJHKSHEWVOSS-OMDJCSNQSA-N1,2-dihexadecanoyl-sn-glycero-3-phospho-(1D-myo-inositol-3,4-bisphosphate)Chemical compoundCCCCCCCCCCCCCCCC(=O)OC[C@@H](OC(=O)CCCCCCCCCCCCCCC)COP(O)(=O)O[C@H]1[C@H](O)[C@@H](O)[C@H](OP(O)(O)=O)[C@@H](OP(O)(O)=O)[C@H]1OHKWJHKSHEWVOSS-OMDJCSNQSA-N0.000description1
- 1021000383691-acyl-sn-glycerol-3-phosphate acyltransferase betaHuman genes0.000description1
- UHDGCWIWMRVCDJ-UHFFFAOYSA-N1-beta-D-Xylofuranosyl-NH-CytosineNatural productsO=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1UHDGCWIWMRVCDJ-UHFFFAOYSA-N0.000description1
- YKBGVTZYEHREMT-KVQBGUIXSA-N2'-deoxyguanosineChemical compoundC1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1YKBGVTZYEHREMT-KVQBGUIXSA-N0.000description1
- CKTSBUTUHBMZGZ-SHYZEUOFSA-N2'‐deoxycytidineChemical compoundO=C1N=C(N)C=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1CKTSBUTUHBMZGZ-SHYZEUOFSA-N0.000description1
- LBLYYCQCTBFVLH-UHFFFAOYSA-N2-Methylbenzenesulfonic acidChemical compoundCC1=CC=CC=C1S(O)(=O)=OLBLYYCQCTBFVLH-UHFFFAOYSA-N0.000description1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acidChemical compoundOCC[NH+]1CCN(CCS([O-])(=O)=O)CC1JKMHFZQWWAIEOD-UHFFFAOYSA-N0.000description1
- ASJSAQIRZKANQN-CRCLSJGQSA-N2-deoxy-D-riboseChemical compoundOC[C@@H](O)[C@@H](O)CC=OASJSAQIRZKANQN-CRCLSJGQSA-N0.000description1
- WLJVXDMOQOGPHL-PPJXEINESA-N2-phenylacetic acidChemical compoundO[14C](=O)CC1=CC=CC=C1WLJVXDMOQOGPHL-PPJXEINESA-N0.000description1
- 1250000040803-carboxypropanoyl groupChemical groupO=C([*])C([H])([H])C([H])([H])C(O[H])=O0.000description1
- ZXIATBNUWJBBGT-JXOAFFINSA-N5-methoxyuridineChemical compoundO=C1NC(=O)C(OC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1ZXIATBNUWJBBGT-JXOAFFINSA-N0.000description1
- 102100031585ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1Human genes0.000description1
- 102000017918ADRB3Human genes0.000description1
- 108060003355ADRB3Proteins0.000description1
- 102100024645ATP-binding cassette sub-family C member 8Human genes0.000description1
- 241000251468ActinopterygiiSpecies0.000description1
- 229930024421AdenineNatural products0.000description1
- GFFGJBXGBJISGV-UHFFFAOYSA-NAdenineChemical compoundNC1=NC=NC2=C1N=CN2GFFGJBXGBJISGV-UHFFFAOYSA-N0.000description1
- 102100031786AdiponectinHuman genes0.000description1
- GUBGYTABKSRVRQ-XLOQQCSPSA-NAlpha-LactoseChemical compoundO[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1OGUBGYTABKSRVRQ-XLOQQCSPSA-N0.000description1
- 102100032360Alstrom syndrome protein 1Human genes0.000description1
- 102100034604Angiopoietin-like protein 8Human genes0.000description1
- 241000269350AnuraSpecies0.000description1
- 102100021569Apoptosis regulator Bcl-2Human genes0.000description1
- 108091023037AptamerProteins0.000description1
- 108010036221Aquaporin 2Proteins0.000description1
- 102000011899Aquaporin 2Human genes0.000description1
- 239000000592Artificial CellSubstances0.000description1
- BSYNRYMUTXBXSQ-UHFFFAOYSA-NAspirinChemical compoundCC(=O)OC1=CC=CC=C1C(O)=OBSYNRYMUTXBXSQ-UHFFFAOYSA-N0.000description1
- 206010003571AstrocytomaDiseases0.000description1
- 208000003950B-cell lymphomaDiseases0.000description1
- 102100021568B-cell scaffold protein with ankyrin repeatsHuman genes0.000description1
- 238000011725BALB/c mouseMethods0.000description1
- 241000894006BacteriaSpecies0.000description1
- 239000005711Benzoic acidSubstances0.000description1
- DWRXFEITVBNRMK-UHFFFAOYSA-NBeta-D-1-ArabinofuranosylthymineNatural productsO=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1DWRXFEITVBNRMK-UHFFFAOYSA-N0.000description1
- 102100035687Bile salt-activated lipaseHuman genes0.000description1
- 102100028237Breast cancer anti-estrogen resistance protein 1Human genes0.000description1
- 208000011691Burkitt lymphomasDiseases0.000description1
- 102100035875C-C chemokine receptor type 5Human genes0.000description1
- 101710149870C-C chemokine receptor type 5Proteins0.000description1
- 229930182476C-glycosideNatural products0.000description1
- 150000000700C-glycosidesChemical class0.000description1
- 102000002110C2 domainsHuman genes0.000description1
- 108050009459C2 domainsProteins0.000description1
- 102100024263CD160 antigenHuman genes0.000description1
- 102100038078CD276 antigenHuman genes0.000description1
- 101710185679CD276 antigenProteins0.000description1
- 101150013553CD40 geneProteins0.000description1
- 102100029348CDGSH iron-sulfur domain-containing protein 2Human genes0.000description1
- 102100025465Calpain-10Human genes0.000description1
- 241000282465CanisSpecies0.000description1
- 241000282472Canis lupus familiarisSpecies0.000description1
- 241000283707CapraSpecies0.000description1
- 102000014914Carrier ProteinsHuman genes0.000description1
- 108700004991Cas12aProteins0.000description1
- 102100032230Caveolae-associated protein 1Human genes0.000description1
- 102100035888Caveolin-1Human genes0.000description1
- 241000700198CaviaSpecies0.000description1
- 108091007741Chimeric antigen receptor T cellsProteins0.000description1
- 241000282552Chlorocebus aethiopsSpecies0.000description1
- 102100023335Chymotrypsin-like elastase family member 2AHuman genes0.000description1
- 108020004638Circular DNAProteins0.000description1
- 102100036045ColipaseHuman genes0.000description1
- 102100032768Complement receptor type 2Human genes0.000description1
- 108010051219Cre recombinaseProteins0.000description1
- 241000699800CricetinaeSpecies0.000description1
- 241000699802Cricetulus griseusSpecies0.000description1
- 108010031504Crk Associated Substrate ProteinProteins0.000description1
- MIKUYHXYGGJMLM-GIMIYPNGSA-NCrotonosideNatural productsC1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1OMIKUYHXYGGJMLM-GIMIYPNGSA-N0.000description1
- 101710151559Crystal proteinProteins0.000description1
- 108010024986Cyclin-Dependent Kinase 2Proteins0.000description1
- 102100032857Cyclin-dependent kinase 1Human genes0.000description1
- 101710106279Cyclin-dependent kinase 1Proteins0.000description1
- 102100036239Cyclin-dependent kinase 2Human genes0.000description1
- 108090000266Cyclin-dependent kinasesProteins0.000description1
- 102000003903Cyclin-dependent kinasesHuman genes0.000description1
- UHDGCWIWMRVCDJ-PSQAKQOGSA-NCytidineNatural productsO=C1N=C(N)C=CN1[C@@H]1[C@@H](O)[C@@H](O)[C@H](CO)O1UHDGCWIWMRVCDJ-PSQAKQOGSA-N0.000description1
- 102100032218Cytokine-inducible SH2-containing proteinHuman genes0.000description1
- 101710132484Cytokine-inducible SH2-containing proteinProteins0.000description1
- 102100036943Cytoplasmic protein NCK1Human genes0.000description1
- 102100039498Cytotoxic T-lymphocyte protein 4Human genes0.000description1
- NYHBQMYGNKIUIF-UHFFFAOYSA-ND-guanosineNatural productsC1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1ONYHBQMYGNKIUIF-UHFFFAOYSA-N0.000description1
- 102100024395DCC-interacting protein 13-alphaHuman genes0.000description1
- 102100029581DDB1- and CUL4-associated factor 17Human genes0.000description1
- 230000006820DNA synthesisEffects0.000description1
- 241000252212Danio rerioSpecies0.000description1
- CKTSBUTUHBMZGZ-UHFFFAOYSA-NDeoxycytidineNatural productsO=C1N=C(N)C=CN1C1OC(CO)C(O)C1CKTSBUTUHBMZGZ-UHFFFAOYSA-N0.000description1
- 102100031149Deoxyribonuclease gammaHuman genes0.000description1
- 102100030012Deoxyribonuclease-1Human genes0.000description1
- 229920002307DextranPolymers0.000description1
- FEWJPZIEWOKRBE-JCYAYHJZSA-NDextrotartaric acidChemical compoundOC(=O)[C@H](O)[C@@H](O)C(O)=OFEWJPZIEWOKRBE-JCYAYHJZSA-N0.000description1
- 235000019739DicalciumphosphateNutrition0.000description1
- 101100520033Dictyostelium discoideum pikC geneProteins0.000description1
- 101100520034Dictyostelium discoideum pikE geneProteins0.000description1
- 108700019745Disks Large Homolog 4Proteins0.000description1
- 102100022264Disks large homolog 4Human genes0.000description1
- 102100035347DmX-like protein 2Human genes0.000description1
- 102100031681DnaJ homolog subfamily C member 3Human genes0.000description1
- 241000255581Drosophila <fruit fly, genus>Species0.000description1
- 101100015729Drosophila melanogaster drk geneProteins0.000description1
- 101100136092Drosophila melanogaster peng geneProteins0.000description1
- 102100033363Dual specificity tyrosine-phosphorylation-regulated kinase 1BHuman genes0.000description1
- 241000196324EmbryophytaSpecies0.000description1
- 108010042407EndonucleasesProteins0.000description1
- 102000004533EndonucleasesHuman genes0.000description1
- 101800003838Epidermal growth factorProteins0.000description1
- 241000283086EquidaeSpecies0.000description1
- 241000206602EukaryotaSpecies0.000description1
- 102100034174Eukaryotic translation initiation factor 2-alpha kinase 3Human genes0.000description1
- 102000010834Extracellular Matrix ProteinsHuman genes0.000description1
- 108010037362Extracellular Matrix ProteinsProteins0.000description1
- 108010046276FLP recombinaseProteins0.000description1
- 102100035261FYN-binding protein 1Human genes0.000description1
- 108091011190FYN-binding protein 1Proteins0.000description1
- 241000282326Felis catusSpecies0.000description1
- 102000002090Fibronectin type IIIHuman genes0.000description1
- 108050009401Fibronectin type IIIProteins0.000description1
- 102100027581Forkhead box protein P3Human genes0.000description1
- 102100022086GRB2-related adapter protein 2Human genes0.000description1
- 201000003741Gastrointestinal carcinomaDiseases0.000description1
- 108700028146Genetic Enhancer ElementsProteins0.000description1
- 241000699694GerbillinaeSpecies0.000description1
- 208000032612Glial tumorDiseases0.000description1
- 206010018338GliomaDiseases0.000description1
- 102100040890Glucagon receptorHuman genes0.000description1
- WQZGKKKJIJFFOK-GASJEMHNSA-NGlucoseNatural productsOC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1OWQZGKKKJIJFFOK-GASJEMHNSA-N0.000description1
- 101710155270Glycerate 2-kinaseProteins0.000description1
- 108010051975Glycogen Synthase Kinase 3 betaProteins0.000description1
- 102100039262Glycogen [starch] synthase, muscleHuman genes0.000description1
- 102100022975Glycogen synthase kinase-3 alphaHuman genes0.000description1
- 102100038104Glycogen synthase kinase-3 betaHuman genes0.000description1
- 102000009465Growth Factor ReceptorsHuman genes0.000description1
- 108010009202Growth Factor ReceptorsProteins0.000description1
- 102100033067Growth factor receptor-bound protein 2Human genes0.000description1
- 108091009389Growth factor receptor-bound protein 2Proteins0.000description1
- 239000007995HEPES bufferSubstances0.000description1
- 101150003775HNF1A geneProteins0.000description1
- 241000711549Hepacivirus CSpecies0.000description1
- 239000004705High-molecular-weight polyethyleneSubstances0.000description1
- 101000605571Homo sapiens 1-acyl-sn-glycerol-3-phosphate acyltransferase betaProteins0.000description1
- 101000777636Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1Proteins0.000description1
- 101000760570Homo sapiens ATP-binding cassette sub-family C member 8Proteins0.000description1
- 101000775469Homo sapiens AdiponectinProteins0.000description1
- 101000797795Homo sapiens Alstrom syndrome protein 1Proteins0.000description1
- 101000924544Homo sapiens Angiopoietin-like protein 8Proteins0.000description1
- 101000971171Homo sapiens Apoptosis regulator Bcl-2Proteins0.000description1
- 101000971155Homo sapiens B-cell scaffold protein with ankyrin repeatsProteins0.000description1
- 101000715643Homo sapiens Bile salt-activated lipaseProteins0.000description1
- 101000761938Homo sapiens CD160 antigenProteins0.000description1
- 101000989662Homo sapiens CDGSH iron-sulfur domain-containing protein 2Proteins0.000description1
- 101100275686Homo sapiens CR2 geneProteins0.000description1
- 101000984149Homo sapiens Calpain-10Proteins0.000description1
- 101000869049Homo sapiens Caveolae-associated protein 1Proteins0.000description1
- 101000715467Homo sapiens Caveolin-1Proteins0.000description1
- 101000897353Homo sapiens Cell division cycle protein 123 homologProteins0.000description1
- 101000907955Homo sapiens Chymotrypsin-like elastase family member 2AProteins0.000description1
- 101000876022Homo sapiens ColipaseProteins0.000description1
- 101000710883Homo sapiens Complement C4-BProteins0.000description1
- 101001024707Homo sapiens Cytoplasmic protein NCK1Proteins0.000description1
- 101000889276Homo sapiens Cytotoxic T-lymphocyte protein 4Proteins0.000description1
- 101001053277Homo sapiens DCC-interacting protein 13-alphaProteins0.000description1
- 101000917433Homo sapiens DDB1- and CUL4-associated factor 17Proteins0.000description1
- 101000845618Homo sapiens Deoxyribonuclease gammaProteins0.000description1
- 101000863721Homo sapiens Deoxyribonuclease-1Proteins0.000description1
- 101000804534Homo sapiens DmX-like protein 2Proteins0.000description1
- 101000845898Homo sapiens DnaJ homolog subfamily C member 3Proteins0.000description1
- 101000926738Homo sapiens Dual specificity tyrosine-phosphorylation-regulated kinase 1BProteins0.000description1
- 101000926508Homo sapiens Eukaryotic translation initiation factor 2-alpha kinase 3Proteins0.000description1
- 101000861452Homo sapiens Forkhead box protein P3Proteins0.000description1
- 101000900690Homo sapiens GRB2-related adapter protein 2Proteins0.000description1
- 101001040075Homo sapiens Glucagon receptorProteins0.000description1
- 101001036130Homo sapiens Glycogen [starch] synthase, muscleProteins0.000description1
- 101000903717Homo sapiens Glycogen synthase kinase-3 alphaProteins0.000description1
- 101000971538Homo sapiens Killer cell lectin-like receptor subfamily F member 1Proteins0.000description1
- 101000917824Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-bProteins0.000description1
- 101001137987Homo sapiens Lymphocyte activation gene 3 proteinProteins0.000description1
- 101001109503Homo sapiens NKG2-C type II integral membrane proteinProteins0.000description1
- 101000812677Homo sapiens Nucleotide pyrophosphataseProteins0.000description1
- 101001120056Homo sapiens Phosphatidylinositol 3-kinase regulatory subunit alphaProteins0.000description1
- 101001120097Homo sapiens Phosphatidylinositol 3-kinase regulatory subunit betaProteins0.000description1
- 101000946275Homo sapiens Protein CLEC16AProteins0.000description1
- 101000702132Homo sapiens Protein spinster homolog 1Proteins0.000description1
- 101000798015Homo sapiens RAC-beta serine/threonine-protein kinaseProteins0.000description1
- 101000688582Homo sapiens SH3 domain-containing kinase-binding protein 1Proteins0.000description1
- 101000633784Homo sapiens SLAM family member 7Proteins0.000description1
- 101000898985Homo sapiens SeipinProteins0.000description1
- 101001059454Homo sapiens Serine/threonine-protein kinase MARK2Proteins0.000description1
- 101000831007Homo sapiens T-cell immunoreceptor with Ig and ITIM domainsProteins0.000description1
- 101000737828Homo sapiens Threonylcarbamoyladenosine tRNA methylthiotransferaseProteins0.000description1
- 101000795169Homo sapiens Tumor necrosis factor receptor superfamily member 13CProteins0.000description1
- 101000801234Homo sapiens Tumor necrosis factor receptor superfamily member 18Proteins0.000description1
- 101000851376Homo sapiens Tumor necrosis factor receptor superfamily member 8Proteins0.000description1
- 101000984551Homo sapiens Tyrosine-protein kinase BlkProteins0.000description1
- 101000641003Homo sapiens Tyrosine-tRNA ligase, cytoplasmicProteins0.000description1
- 101000807859Homo sapiens Vasopressin V2 receptorProteins0.000description1
- 101000857276Homo sapiens Zinc finger protein GLIS3Proteins0.000description1
- 208000019758HypergammaglobulinemiaDiseases0.000description1
- 206010020751HypersensitivityDiseases0.000description1
- 206010021143HypoxiaDiseases0.000description1
- 108010042653IgA receptorProteins0.000description1
- 108010067060Immunoglobulin Variable RegionProteins0.000description1
- 102000017727Immunoglobulin Variable RegionHuman genes0.000description1
- 102100023915InsulinHuman genes0.000description1
- 108090001061InsulinProteins0.000description1
- 108010038498Interleukin-7 ReceptorsProteins0.000description1
- 102000010782Interleukin-7 ReceptorsHuman genes0.000description1
- 102100021458Killer cell lectin-like receptor subfamily F member 1Human genes0.000description1
- AHLPHDHHMVZTML-BYPYZUCNSA-NL-OrnithineChemical compoundNCCC[C@H](N)C(O)=OAHLPHDHHMVZTML-BYPYZUCNSA-N0.000description1
- 125000000998L-alanino groupChemical group[H]N([*])[C@](C([H])([H])[H])([H])C(=O)O[H]0.000description1
- ODKSFYDXXFIFQN-BYPYZUCNSA-PL-argininium(2+)Chemical compoundNC(=[NH2+])NCCC[C@H]([NH3+])C(O)=OODKSFYDXXFIFQN-BYPYZUCNSA-P0.000description1
- FFFHZYDWPBMWHY-VKHMYHEASA-NL-homocysteineChemical compoundOC(=O)[C@@H](N)CCSFFFHZYDWPBMWHY-VKHMYHEASA-N0.000description1
- FBOZXECLQNJBKD-ZDUSSCGKSA-NL-methotrexateChemical compoundC=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1FBOZXECLQNJBKD-ZDUSSCGKSA-N0.000description1
- 102000017578LAG3Human genes0.000description1
- 102100029205Low affinity immunoglobulin gamma Fc region receptor II-bHuman genes0.000description1
- FYYHWMGAXLPEAU-UHFFFAOYSA-NMagnesiumChemical compound[Mg]FYYHWMGAXLPEAU-UHFFFAOYSA-N0.000description1
- 208000032271Malignant tumor of penisDiseases0.000description1
- 208000000172MedulloblastomaDiseases0.000description1
- 210000002361Megakaryocyte Progenitor CellAnatomy0.000description1
- 108010061593Member 14 Tumor Necrosis Factor ReceptorsProteins0.000description1
- 108010052285Membrane ProteinsProteins0.000description1
- 229920000168Microcrystalline cellulosePolymers0.000description1
- 108010058682Mitochondrial ProteinsProteins0.000description1
- 102000006404Mitochondrial ProteinsHuman genes0.000description1
- 102100028192Mitogen-activated protein kinase kinase kinase kinase 2Human genes0.000description1
- 101710144533Mitogen-activated protein kinase kinase kinase kinase 2Proteins0.000description1
- 229920000881Modified starchPolymers0.000description1
- 102100025725Mothers against decapentaplegic homolog 4Human genes0.000description1
- 101710143112Mothers against decapentaplegic homolog 4Proteins0.000description1
- 241000711408Murine respirovirusSpecies0.000description1
- 101100275687Mus musculus Cr2 geneProteins0.000description1
- 101100405118Mus musculus Nr4a1 geneProteins0.000description1
- 208000033776Myeloid Acute LeukemiaDiseases0.000description1
- 102000010168Myeloid Differentiation Factor 88Human genes0.000description1
- 108010077432Myeloid Differentiation Factor 88Proteins0.000description1
- 102100022683NKG2-C type II integral membrane proteinHuman genes0.000description1
- 208000002454Nasopharyngeal CarcinomaDiseases0.000description1
- 208000001894Nasopharyngeal NeoplasmsDiseases0.000description1
- 206010061306Nasopharyngeal cancerDiseases0.000description1
- 108010077854Natural Killer Cell ReceptorsProteins0.000description1
- 102000010648Natural Killer Cell ReceptorsHuman genes0.000description1
- 241000244206NematodaSpecies0.000description1
- 229930193140NeomycinNatural products0.000description1
- 102000014736NotchHuman genes0.000description1
- 102100039306Nucleotide pyrophosphataseHuman genes0.000description1
- AHLPHDHHMVZTML-UHFFFAOYSA-NOrn-delta-NH2Natural productsNCCCC(N)C(O)=OAHLPHDHHMVZTML-UHFFFAOYSA-N0.000description1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-NOrnithineNatural productsOC(=O)C(C)CCCNUTJLXEIPEHZYQJ-UHFFFAOYSA-N0.000description1
- 102000000470PDZ domainsHuman genes0.000description1
- 108050008994PDZ domainsProteins0.000description1
- 102000038030PI3KsHuman genes0.000description1
- 241001494479PecoraSpecies0.000description1
- 208000002471Penile NeoplasmsDiseases0.000description1
- 108091093037Peptide nucleic acidProteins0.000description1
- 102100026169Phosphatidylinositol 3-kinase regulatory subunit alphaHuman genes0.000description1
- 108090000430Phosphatidylinositol 3-kinasesProteins0.000description1
- 102000003993Phosphatidylinositol 3-kinasesHuman genes0.000description1
- 108010056751Phospholipase C gammaProteins0.000description1
- 102000004422Phospholipase C gammaHuman genes0.000description1
- 108700019535Phosphoprotein PhosphatasesProteins0.000description1
- 102000045595Phosphoprotein PhosphatasesHuman genes0.000description1
- 102000004160Phosphoric Monoester HydrolasesHuman genes0.000description1
- 108090000608Phosphoric Monoester HydrolasesProteins0.000description1
- 108091000080PhosphotransferaseProteins0.000description1
- 239000004952PolyamideSubstances0.000description1
- 239000002202Polyethylene glycolSubstances0.000description1
- 239000004372Polyvinyl alcoholSubstances0.000description1
- 241000288906PrimatesSpecies0.000description1
- 102100033237Pro-epidermal growth factorHuman genes0.000description1
- 101710089372Programmed cell death protein 1Proteins0.000description1
- 102100040678Programmed cell death protein 1Human genes0.000description1
- 102100034014Prolyl 3-hydroxylase 3Human genes0.000description1
- OFOBLEOULBTSOW-UHFFFAOYSA-NPropanedioic acidNatural productsOC(=O)CC(O)=OOFOBLEOULBTSOW-UHFFFAOYSA-N0.000description1
- 102100034718Protein CLEC16AHuman genes0.000description1
- 102000004022Protein-Tyrosine KinasesHuman genes0.000description1
- 108090000412Protein-Tyrosine KinasesProteins0.000description1
- KDCGOANMDULRCW-UHFFFAOYSA-NPurineNatural productsN1=CNC2=NC=NC2=C1KDCGOANMDULRCW-UHFFFAOYSA-N0.000description1
- CZPWVGJYEJSRLH-UHFFFAOYSA-NPyrimidineChemical compoundC1=CN=CN=C1CZPWVGJYEJSRLH-UHFFFAOYSA-N0.000description1
- 102100032315RAC-beta serine/threonine-protein kinaseHuman genes0.000description1
- 241000700157Rattus norvegicusSpecies0.000description1
- 102100025234Receptor of activated protein C kinase 1Human genes0.000description1
- 108010044157Receptors for Activated C KinaseProteins0.000description1
- 108091028664RibonucleotideProteins0.000description1
- 241000283984RodentiaSpecies0.000description1
- 102100024244SH3 domain-containing kinase-binding protein 1Human genes0.000description1
- 102100029198SLAM family member 7Human genes0.000description1
- 240000004808Saccharomyces cerevisiaeSpecies0.000description1
- 102100021463SeipinHuman genes0.000description1
- 102100028904Serine/threonine-protein kinase MARK2Human genes0.000description1
- 102100024040Signal transducer and activator of transcription 3Human genes0.000description1
- 108010074687Signaling Lymphocytic Activation Molecule Family Member 1Proteins0.000description1
- 102000008115Signaling Lymphocytic Activation Molecule Family Member 1Human genes0.000description1
- 108010052160Site-specific recombinaseProteins0.000description1
- DBMJMQXJHONAFJ-UHFFFAOYSA-MSodium laurylsulphateChemical compound[Na+].CCCCCCCCCCCCOS([O-])(=O)=ODBMJMQXJHONAFJ-UHFFFAOYSA-M0.000description1
- 235000021355Stearic acidNutrition0.000description1
- 241000282887SuidaeSpecies0.000description1
- 241000282898Sus scrofaSpecies0.000description1
- 230000006052T cell proliferationEffects0.000description1
- 102100024834T-cell immunoreceptor with Ig and ITIM domainsHuman genes0.000description1
- 238000010459TALENMethods0.000description1
- 108091005735TGF-beta receptorsProteins0.000description1
- FEWJPZIEWOKRBE-UHFFFAOYSA-NTartaric acidNatural products[H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=OFEWJPZIEWOKRBE-UHFFFAOYSA-N0.000description1
- 239000004098TetracyclineSubstances0.000description1
- RYYWUUFWQRZTIU-UHFFFAOYSA-NThiophosphoric acidChemical classOP(O)(S)=ORYYWUUFWQRZTIU-UHFFFAOYSA-N0.000description1
- 108091036066Three prime untranslated regionProteins0.000description1
- 102100035310Threonylcarbamoyladenosine tRNA methylthiotransferaseHuman genes0.000description1
- 108010043645Transcription Activator-Like Effector NucleasesProteins0.000description1
- 102000004338TransferrinHuman genes0.000description1
- 108090000901TransferrinProteins0.000description1
- 102000016715Transforming Growth Factor beta ReceptorsHuman genes0.000description1
- 108060008683Tumor Necrosis Factor ReceptorProteins0.000description1
- 102100029690Tumor necrosis factor receptor superfamily member 13CHuman genes0.000description1
- 102100028785Tumor necrosis factor receptor superfamily member 14Human genes0.000description1
- 102100033728Tumor necrosis factor receptor superfamily member 18Human genes0.000description1
- 102100040245Tumor necrosis factor receptor superfamily member 5Human genes0.000description1
- 102100036857Tumor necrosis factor receptor superfamily member 8Human genes0.000description1
- 102100027053Tyrosine-protein kinase BlkHuman genes0.000description1
- 102100034298Tyrosine-tRNA ligase, cytoplasmicHuman genes0.000description1
- 101150058395US22 geneProteins0.000description1
- 102000003431Ubiquitin-Conjugating EnzymeHuman genes0.000description1
- 108060008747Ubiquitin-Conjugating EnzymeProteins0.000description1
- 108091023045Untranslated RegionProteins0.000description1
- 244000000188Vaccinium ovalifoliumSpecies0.000description1
- 102100037108Vasopressin V2 receptorHuman genes0.000description1
- 108020005202Viral DNAProteins0.000description1
- 208000033559Waldenström macroglobulinemiaDiseases0.000description1
- 210000001766X chromosomeAnatomy0.000description1
- 101100405120Xenopus laevis nr4a1 geneProteins0.000description1
- 210000002593Y chromosomeAnatomy0.000description1
- 101001038499Yarrowia lipolytica (strain CLIB 122 / E 150) Lysine acetyltransferaseProteins0.000description1
- HCHKCACWOHOZIP-UHFFFAOYSA-NZincChemical compound[Zn]HCHKCACWOHOZIP-UHFFFAOYSA-N0.000description1
- 102100025879Zinc finger protein GLIS3Human genes0.000description1
- ZSZXYWFCIKKZBT-ZVDPZPSOSA-N[(2r)-3-[[(2s,3s,5r,6s)-2,6-dihydroxy-3,4,5-triphosphonooxycyclohexyl]oxy-hydroxyphosphoryl]oxy-2-hexadecanoyloxypropyl] hexadecanoateChemical compoundCCCCCCCCCCCCCCCC(=O)OC[C@@H](OC(=O)CCCCCCCCCCCCCCC)COP(O)(=O)OC1[C@H](O)[C@H](OP(O)(O)=O)C(OP(O)(O)=O)[C@H](OP(O)(O)=O)[C@H]1OZSZXYWFCIKKZBT-ZVDPZPSOSA-N0.000description1
- 125000002777acetyl groupChemical group[H]C([H])([H])C(*)=O0.000description1
- 230000021736acetylationEffects0.000description1
- 238000006640acetylation reactionMethods0.000description1
- 239000002535acidifierSubstances0.000description1
- 101150063416add geneProteins0.000description1
- 229960000643adenineDrugs0.000description1
- 230000001464adherent effectEffects0.000description1
- 210000000577adipose tissueAnatomy0.000description1
- 239000002671adjuvantSubstances0.000description1
- 210000004504adult stem cellAnatomy0.000description1
- 150000001298alcoholsChemical class0.000description1
- 239000000783alginic acidSubstances0.000description1
- 235000010443alginic acidNutrition0.000description1
- 229920000615alginic acidPolymers0.000description1
- 229960001126alginic acidDrugs0.000description1
- 150000004781alginic acidsChemical class0.000description1
- 229910052783alkali metalInorganic materials0.000description1
- 150000001340alkali metalsChemical class0.000description1
- 125000004453alkoxycarbonyl groupChemical group0.000description1
- 230000029936alkylationEffects0.000description1
- 238000005804alkylation reactionMethods0.000description1
- BJEPYKJPYRNKOW-UHFFFAOYSA-Nalpha-hydroxysuccinic acidNatural productsOC(=O)C(O)CC(O)=OBJEPYKJPYRNKOW-UHFFFAOYSA-N0.000description1
- 150000001412aminesChemical class0.000description1
- BFNBIHQBYMNNAN-UHFFFAOYSA-Nammonium sulfateChemical compoundN.N.OS(O)(=O)=OBFNBIHQBYMNNAN-UHFFFAOYSA-N0.000description1
- 229910052921ammonium sulfateInorganic materials0.000description1
- 235000011130ammonium sulphateNutrition0.000description1
- 229960000723ampicillinDrugs0.000description1
- AVKUERGKIZMTKX-NJBDSQKTSA-NampicillinChemical compoundC1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1AVKUERGKIZMTKX-NJBDSQKTSA-N0.000description1
- 230000000259anti-tumor effectEffects0.000description1
- 230000000890antigenic effectEffects0.000description1
- PYMYPHUHKUWMLA-UHFFFAOYSA-NarabinoseNatural productsOCC(O)C(O)C(O)C=OPYMYPHUHKUWMLA-UHFFFAOYSA-N0.000description1
- 235000010323ascorbic acidNutrition0.000description1
- 239000011668ascorbic acidSubstances0.000description1
- 229960005070ascorbic acidDrugs0.000description1
- 238000011914asymmetric synthesisMethods0.000description1
- 230000005784autoimmunityEffects0.000description1
- 230000001580bacterial effectEffects0.000description1
- 210000003651basophilAnatomy0.000description1
- 230000009286beneficial effectEffects0.000description1
- 235000010233benzoic acidNutrition0.000description1
- 229960004365benzoic acidDrugs0.000description1
- SRBFZHDQGSBBOR-UHFFFAOYSA-Nbeta-D-Pyranose-LyxoseNatural productsOC1COC(O)C(O)C1OSRBFZHDQGSBBOR-UHFFFAOYSA-N0.000description1
- IQFYYKKMVGJFEH-UHFFFAOYSA-Nbeta-L-thymidineNatural productsO=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1IQFYYKKMVGJFEH-UHFFFAOYSA-N0.000description1
- DRTQHJPVMGBUCF-PSQAKQOGSA-Nbeta-L-uridineNatural productsO[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1DRTQHJPVMGBUCF-PSQAKQOGSA-N0.000description1
- 108091008324binding proteinsProteins0.000description1
- 230000004071biological effectEffects0.000description1
- 210000000601blood cellAnatomy0.000description1
- 210000001772blood plateletAnatomy0.000description1
- 238000006664bond formation reactionMethods0.000description1
- 210000002449bone cellAnatomy0.000description1
- 108010006025bovine growth hormoneProteins0.000description1
- 210000000481breastAnatomy0.000description1
- 239000000872bufferSubstances0.000description1
- 125000004063butyryl groupChemical groupO=C([*])C([H])([H])C([H])([H])C([H])([H])[H]0.000description1
- 210000004899c-terminal regionAnatomy0.000description1
- 229910000019calcium carbonateInorganic materials0.000description1
- 229910000389calcium phosphateInorganic materials0.000description1
- 235000011010calcium phosphatesNutrition0.000description1
- 125000003917carbamoyl groupChemical group[H]N([H])C(*)=O0.000description1
- 150000007942carboxylatesChemical class0.000description1
- 150000001735carboxylic acidsChemical class0.000description1
- 210000000845cartilageAnatomy0.000description1
- 230000003197catalytic effectEffects0.000description1
- 230000020411cell activationEffects0.000description1
- 230000003915cell functionEffects0.000description1
- 230000010261cell growthEffects0.000description1
- 238000005119centrifugationMethods0.000description1
- 210000003679cervix uteriAnatomy0.000description1
- 230000008859changeEffects0.000description1
- 230000007073chemical hydrolysisEffects0.000description1
- 201000002797childhood leukemiaDiseases0.000description1
- 210000004978chinese hamster ovary cellAnatomy0.000description1
- 238000004587chromatography analysisMethods0.000description1
- 230000001684chronic effectEffects0.000description1
- 235000015165citric acidNutrition0.000description1
- 239000013599cloning vectorSubstances0.000description1
- 201000003970colon lymphomaDiseases0.000description1
- 201000002660colon sarcomaDiseases0.000description1
- 208000029742colonic neoplasmDiseases0.000description1
- 230000000295complement effectEffects0.000description1
- 210000002808connective tissueAnatomy0.000description1
- 239000000356contaminantSubstances0.000description1
- 229960003624creatineDrugs0.000description1
- 239000006046creatineSubstances0.000description1
- 238000009295crossflow filtrationMethods0.000description1
- 238000012258culturingMethods0.000description1
- UHDGCWIWMRVCDJ-ZAKLUEHWSA-NcytidineChemical compoundO=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O1UHDGCWIWMRVCDJ-ZAKLUEHWSA-N0.000description1
- 229940104302cytosineDrugs0.000description1
- 210000001151cytotoxic T lymphocyteAnatomy0.000description1
- 230000003013cytotoxicityEffects0.000description1
- 231100000135cytotoxicityToxicity0.000description1
- 230000007812deficiencyEffects0.000description1
- 230000000593degrading effectEffects0.000description1
- 238000002298density-gradient ultracentrifugationMethods0.000description1
- 239000005549deoxyribonucleosideSubstances0.000description1
- 239000005547deoxyribonucleotideSubstances0.000description1
- 125000002637deoxyribonucleotide groupChemical group0.000description1
- 238000011026diafiltrationMethods0.000description1
- NEFBYIFKOOEVPA-UHFFFAOYSA-Kdicalcium phosphateChemical compound[Ca+2].[Ca+2].[O-]P([O-])([O-])=ONEFBYIFKOOEVPA-UHFFFAOYSA-K0.000description1
- 229910000390dicalcium phosphateInorganic materials0.000description1
- 229940038472dicalcium phosphateDrugs0.000description1
- 150000001991dicarboxylic acidsChemical class0.000description1
- 210000002249digestive systemAnatomy0.000description1
- 239000003085diluting agentSubstances0.000description1
- 101150069842dlg4 geneProteins0.000description1
- 238000010573double replacement reactionMethods0.000description1
- 238000011143downstream manufacturingMethods0.000description1
- 230000004064dysfunctionEffects0.000description1
- 239000012636effectorSubstances0.000description1
- 239000003995emulsifying agentSubstances0.000description1
- 230000007613environmental effectEffects0.000description1
- 230000002255enzymatic effectEffects0.000description1
- 230000007071enzymatic hydrolysisEffects0.000description1
- 238000006047enzymatic hydrolysis reactionMethods0.000description1
- 210000003979eosinophilAnatomy0.000description1
- 229940116977epidermal growth factorDrugs0.000description1
- 210000003743erythrocyteAnatomy0.000description1
- 210000003238esophagusAnatomy0.000description1
- AFAXGSQYZLGZPG-UHFFFAOYSA-Nethanedisulfonic acidChemical compoundOS(=O)(=O)CCS(O)(=O)=OAFAXGSQYZLGZPG-UHFFFAOYSA-N0.000description1
- 125000003754ethoxycarbonyl groupChemical groupC(=O)(OCC)*0.000description1
- 210000002744extracellular matrixAnatomy0.000description1
- 238000000605extractionMethods0.000description1
- 102000018823fas ReceptorHuman genes0.000description1
- 108010052621fas ReceptorProteins0.000description1
- 239000003925fatSubstances0.000description1
- 230000004129fatty acid metabolismEffects0.000description1
- 210000004700fetal bloodAnatomy0.000description1
- 239000000945fillerSubstances0.000description1
- 239000000796flavoring agentSubstances0.000description1
- 239000012530fluidSubstances0.000description1
- 102000034287fluorescent proteinsHuman genes0.000description1
- 108091006047fluorescent proteinsProteins0.000description1
- 235000013355food flavoring agentNutrition0.000description1
- 235000003599food sweetenerNutrition0.000description1
- 238000009472formulationMethods0.000description1
- 239000001530fumaric acidSubstances0.000description1
- 230000002496gastric effectEffects0.000description1
- 210000004051gastric juiceAnatomy0.000description1
- 210000001035gastrointestinal tractAnatomy0.000description1
- 208000005017glioblastomaDiseases0.000description1
- 239000008103glucoseSubstances0.000description1
- 229960002989glutamic acidDrugs0.000description1
- 230000034659glycolysisEffects0.000description1
- 230000013595glycosylationEffects0.000description1
- 238000006206glycosylation reactionMethods0.000description1
- 101150098203grb2 geneProteins0.000description1
- 230000012010growthEffects0.000description1
- 239000003102growth factorSubstances0.000description1
- 239000001963growth mediumSubstances0.000description1
- 229940029575guanosineDrugs0.000description1
- 210000002443helper t lymphocyteAnatomy0.000description1
- 210000003630histaminocyteAnatomy0.000description1
- 230000006801homologous recombinationEffects0.000description1
- 238000002744homologous recombinationMethods0.000description1
- 229940088597hormoneDrugs0.000description1
- 239000005556hormoneSubstances0.000description1
- 238000009396hybridizationMethods0.000description1
- 238000006460hydrolysis reactionMethods0.000description1
- 230000002209hydrophobic effectEffects0.000description1
- 125000001165hydrophobic groupChemical group0.000description1
- 125000004356hydroxy functional groupChemical groupO*0.000description1
- 230000005847immunogenicityEffects0.000description1
- 230000008676importEffects0.000description1
- 230000006872improvementEffects0.000description1
- 238000000338in vitroMethods0.000description1
- 238000010348incorporationMethods0.000description1
- 210000004263induced pluripotent stem cellAnatomy0.000description1
- 239000003112inhibitorSubstances0.000description1
- 108091008042inhibitory receptorsProteins0.000description1
- 150000002484inorganic compoundsChemical class0.000description1
- 229910010272inorganic materialInorganic materials0.000description1
- 238000003780insertionMethods0.000description1
- 230000037431insertionEffects0.000description1
- 229940125396insulinDrugs0.000description1
- 102000006495integrinsHuman genes0.000description1
- 108010044426integrinsProteins0.000description1
- 201000002313intestinal cancerDiseases0.000description1
- 230000007794irritationEffects0.000description1
- 238000002372labellingMethods0.000description1
- 239000004310lactic acidSubstances0.000description1
- 235000014655lactic acidNutrition0.000description1
- 239000008101lactoseSubstances0.000description1
- 239000003446ligandSubstances0.000description1
- 230000029226lipidationEffects0.000description1
- 210000004185liverAnatomy0.000description1
- 244000144972livestockSpecies0.000description1
- 210000004072lungAnatomy0.000description1
- 230000001926lymphatic effectEffects0.000description1
- 210000004324lymphatic systemAnatomy0.000description1
- 125000003588lysine groupChemical group[H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O0.000description1
- 230000006674lysosomal degradationEffects0.000description1
- 229920002521macromoleculePolymers0.000description1
- 229910052749magnesiumInorganic materials0.000description1
- 239000011777magnesiumSubstances0.000description1
- 235000019359magnesium stearateNutrition0.000description1
- VZCYOOQTPOCHFL-UPHRSURJSA-Nmaleic acidChemical compoundOC(=O)\C=C/C(O)=OVZCYOOQTPOCHFL-UPHRSURJSA-N0.000description1
- 239000011976maleic acidSubstances0.000description1
- 239000001630malic acidSubstances0.000description1
- 235000011090malic acidNutrition0.000description1
- 239000000463materialSubstances0.000description1
- 239000002609mediumSubstances0.000description1
- 210000002901mesenchymal stem cellAnatomy0.000description1
- 229940098779methanesulfonic acidDrugs0.000description1
- 229960000485methotrexateDrugs0.000description1
- 238000001471micro-filtrationMethods0.000description1
- 230000000813microbial effectEffects0.000description1
- 235000019813microcrystalline celluloseNutrition0.000description1
- 239000008108microcrystalline celluloseSubstances0.000description1
- 229940016286microcrystalline celluloseDrugs0.000description1
- 238000001823molecular biology techniqueMethods0.000description1
- 238000010369molecular cloningMethods0.000description1
- 239000002062molecular scaffoldSubstances0.000description1
- 210000002890mucosal invariant T lymphocyteAnatomy0.000description1
- 238000002887multiple sequence alignmentMethods0.000description1
- 210000003205muscleAnatomy0.000description1
- 210000001167myeloblastAnatomy0.000description1
- 201000000050myeloid neoplasmDiseases0.000description1
- 201000011216nasopharynx carcinomaDiseases0.000description1
- 229960004927neomycinDrugs0.000description1
- 210000000440neutrophilAnatomy0.000description1
- QIQXTHQIDYTFRH-UHFFFAOYSA-Noctadecanoic acidChemical compoundCCCCCCCCCCCCCCCCCC(O)=OQIQXTHQIDYTFRH-UHFFFAOYSA-N0.000description1
- OQCDKBAXFALNLD-UHFFFAOYSA-Noctadecanoic acidNatural productsCCCCCCCC(C)CCCCCCCCC(O)=OOQCDKBAXFALNLD-UHFFFAOYSA-N0.000description1
- 239000006186oral dosage formSubstances0.000description1
- 229960003104ornithineDrugs0.000description1
- 210000000963osteoblastAnatomy0.000description1
- 235000006408oxalic acidNutrition0.000description1
- 230000003647oxidationEffects0.000description1
- 238000007254oxidation reactionMethods0.000description1
- 230000010627oxidative phosphorylationEffects0.000description1
- WLJNZVDCPSBLRP-UHFFFAOYSA-Npamoic acidChemical compoundC1=CC=C2C(CC=3C4=CC=CC=C4C=C(C=3O)C(=O)O)=C(O)C(C(O)=O)=CC2=C1WLJNZVDCPSBLRP-UHFFFAOYSA-N0.000description1
- 210000000496pancreasAnatomy0.000description1
- 238000004091panningMethods0.000description1
- FJKROLUGYXJWQN-UHFFFAOYSA-Npapa-hydroxy-benzoic acidNatural productsOC(=O)C1=CC=C(O)C=C1FJKROLUGYXJWQN-UHFFFAOYSA-N0.000description1
- 239000002245particleSubstances0.000description1
- 230000037361pathwayEffects0.000description1
- 208000030940penile carcinomaDiseases0.000description1
- 201000008174penis carcinomaDiseases0.000description1
- 238000010647peptide synthesis reactionMethods0.000description1
- 239000002304perfumeSubstances0.000description1
- 230000002688persistenceEffects0.000description1
- 230000002085persistent effectEffects0.000description1
- 229940124531pharmaceutical excipientDrugs0.000description1
- 239000012071phaseSubstances0.000description1
- 238000005191phase separationMethods0.000description1
- 150000003915phosphatidylinositol 4,5-bisphosphatesChemical class0.000description1
- 150000003906phosphoinositidesChemical class0.000description1
- 150000003013phosphoric acid derivativesChemical class0.000description1
- 102000020233phosphotransferaseHuman genes0.000description1
- 210000004180plasmocyteAnatomy0.000description1
- 239000004033plasticSubstances0.000description1
- 229920003023plasticPolymers0.000description1
- 230000004983pleiotropic effectEffects0.000description1
- 229920002647polyamidePolymers0.000description1
- 229920005862polyolPolymers0.000description1
- 150000003077polyolsChemical class0.000description1
- 229920002451polyvinyl alcoholPolymers0.000description1
- 230000001124posttranscriptional effectEffects0.000description1
- 238000002360preparation methodMethods0.000description1
- 239000003755preservative agentSubstances0.000description1
- 238000012545processingMethods0.000description1
- 125000001501propionyl groupChemical groupO=C([*])C([H])([H])C([H])([H])[H]0.000description1
- 210000002307prostateAnatomy0.000description1
- 235000019419proteasesNutrition0.000description1
- 230000006916protein interactionEffects0.000description1
- 230000012743protein taggingEffects0.000description1
- 230000004063proteosomal degradationEffects0.000description1
- IGFXRKMLLMBKSA-UHFFFAOYSA-NpurineChemical compoundN1=C[N]C2=NC=NC2=C1IGFXRKMLLMBKSA-UHFFFAOYSA-N0.000description1
- 238000012797qualificationMethods0.000description1
- 238000003908quality control methodMethods0.000description1
- 150000003242quaternary ammonium saltsChemical class0.000description1
- 230000033300receptor internalizationEffects0.000description1
- 238000010188recombinant methodMethods0.000description1
- 210000000664rectumAnatomy0.000description1
- 230000025218regulation of catabolic processEffects0.000description1
- 239000002342ribonucleosideSubstances0.000description1
- 239000002336ribonucleotideSubstances0.000description1
- 125000002652ribonucleotide groupChemical group0.000description1
- 229960004889salicylic acidDrugs0.000description1
- 230000003248secreting effectEffects0.000description1
- 230000010305self ubiquitinationEffects0.000description1
- 230000001953sensory effectEffects0.000description1
- 210000000717sertoli cellAnatomy0.000description1
- 239000013605shuttle vectorSubstances0.000description1
- 150000004760silicatesChemical class0.000description1
- 238000001542size-exclusion chromatographyMethods0.000description1
- 201000002314small intestine cancerDiseases0.000description1
- 239000011780sodium chlorideSubstances0.000description1
- 239000001509sodium citrateSubstances0.000description1
- NLJMYIDDQXHKNR-UHFFFAOYSA-Ksodium citrateChemical compoundO.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=ONLJMYIDDQXHKNR-UHFFFAOYSA-K0.000description1
- 235000019333sodium laurylsulphateNutrition0.000description1
- 238000010532solid phase synthesis reactionMethods0.000description1
- 210000001082somatic cellAnatomy0.000description1
- 108010087686src-Family KinasesProteins0.000description1
- 102000009076src-Family KinasesHuman genes0.000description1
- 239000008117stearic acidSubstances0.000description1
- 210000002784stomachAnatomy0.000description1
- 125000003107substituted aryl groupChemical group0.000description1
- 229940124530sulfonamideDrugs0.000description1
- 150000003456sulfonamidesChemical class0.000description1
- 150000003467sulfuric acid derivativesChemical class0.000description1
- 239000013589supplementSubstances0.000description1
- 239000000375suspending agentSubstances0.000description1
- 238000004114suspension cultureMethods0.000description1
- 239000003765sweetening agentSubstances0.000description1
- 239000000454talcSubstances0.000description1
- 229910052623talcInorganic materials0.000description1
- 235000012222talcNutrition0.000description1
- 235000002906tartaric acidNutrition0.000description1
- 239000011975tartaric acidSubstances0.000description1
- 238000012360testing methodMethods0.000description1
- 229960002180tetracyclineDrugs0.000description1
- 229930101283tetracyclineNatural products0.000description1
- 235000019364tetracyclineNutrition0.000description1
- 150000003522tetracyclinesChemical class0.000description1
- 229940124597therapeutic agentDrugs0.000description1
- 150000007970thio estersChemical class0.000description1
- 125000003396thiol groupChemical group[H]S*0.000description1
- 150000003573thiolsChemical class0.000description1
- 229940104230thymidineDrugs0.000description1
- 229940113082thymineDrugs0.000description1
- 210000001541thymus glandAnatomy0.000description1
- 231100000419toxicityToxicity0.000description1
- 230000001988toxicityEffects0.000description1
- 239000003053toxinSubstances0.000description1
- 231100000765toxinToxicity0.000description1
- 108700012359toxinsProteins0.000description1
- 239000011573trace mineralSubstances0.000description1
- 235000013619trace mineralNutrition0.000description1
- 238000001890transfectionMethods0.000description1
- 238000012546transferMethods0.000description1
- 239000012581transferrinSubstances0.000description1
- 238000000844transformationMethods0.000description1
- 230000014621translational initiationEffects0.000description1
- QORWJWZARLRLPR-UHFFFAOYSA-Htricalcium bis(phosphate)Chemical compound[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=OQORWJWZARLRLPR-UHFFFAOYSA-H0.000description1
- 239000013638trimerSubstances0.000description1
- 230000005909tumor killingEffects0.000description1
- 102000003298tumor necrosis factor receptorHuman genes0.000description1
- 108010087967type I signal peptidaseProteins0.000description1
- 241001430294unidentified retrovirusSpecies0.000description1
- 229940035893uracilDrugs0.000description1
- DRTQHJPVMGBUCF-UHFFFAOYSA-Nuracil arabinosideNatural productsOC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1DRTQHJPVMGBUCF-UHFFFAOYSA-N0.000description1
- 229940045145uridineDrugs0.000description1
- VBEQCZHXXJYVRD-GACYYNSASA-NuroantheloneChemical compoundC([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1VBEQCZHXXJYVRD-GACYYNSASA-N0.000description1
- 210000004291uterusAnatomy0.000description1
- 229960005486vaccineDrugs0.000description1
- 235000015112vegetable and seed oilNutrition0.000description1
- 239000008158vegetable oilSubstances0.000description1
- 210000002845virionAnatomy0.000description1
- 238000011179visual inspectionMethods0.000description1
- 239000001993waxSubstances0.000description1
- 239000000080wetting agentSubstances0.000description1
- 239000011701zincSubstances0.000description1
- 229910052725zincInorganic materials0.000description1
Images















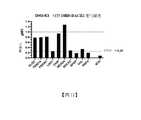






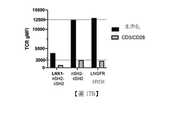



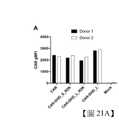











Classifications
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
- C12N9/104—Aminoacyltransferases (2.3.2)
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y203/00—Acyltransferases (2.3)
- C12Y203/02—Aminoacyltransferases (2.3.2)
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70521—CD28, CD152
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/80—Fusion polypeptide containing a DNA binding domain, e.g. Lacl or Tet-repressor
- C07K2319/81—Fusion polypeptide containing a DNA binding domain, e.g. Lacl or Tet-repressor containing a Zn-finger domain for DNA binding
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Cell Biology (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
Description
Translated fromChinese相關申請案的交叉引用:本申請要求2021年2月2日提交的美國臨時專利申請案US 63/144,895及2021年9月26日提交的美國臨時專利申請案US 63/248,516的優先權以及2022年2月2日提交的國際專利申請號PCT/US22/14998 的優先權。這些申請案的全部內容通過引用併入本文。CROSS REFERENCE TO RELATED APPLICATIONS: This application claims priority to U.S. Provisional Patent Applications US 63/144,895, filed February 2, 2021, and U.S. Provisional Patent Applications US 63/248,516, filed September 26, 2021, and 2022 Priority of International Patent Application No. PCT/US22/14998 filed February 2, 2009. The entire contents of these applications are incorporated herein by reference.
序列表的併入:在此提交的序列表為文字文件,文件名為“016-TNP023TW_SeqList_v2”,創建於2022年2月2日,大小為52,267 KB,在此通過引用併入本文。Incorporation of sequence listing: The sequence listing submitted here is a text file named "016-TNP023TW_SeqList_v2", created on February 2, 2022, with a size of 52,267 KB, which is incorporated herein by reference.
本揭示係關於一種用於目標性降解相關分子的合成降解系統。降解系統包括融合到結合元件的降解引發劑,其中結合元件用於將降解引發劑集中到相關分子以啟動降解。The present disclosure relates to a synthetic degradation system for targeted degradation of related molecules. The degradation system includes a degradation initiator fused to a binding element for concentrating the degradation initiator to the relevant molecule to initiate degradation.
蛋白質降解是一個重要的細胞過程,它提供了蛋白質品質控制機制和對大量細胞信號的快速反應。在細胞內,蛋白質功能的適當協調和同步是由其在空間和時間順序上的降解控制的。為了開發有效和安全的下一代細胞和基因療法,越來越需要能夠精確控制蛋白質穩定性和半衰期以調節細胞過程的技術。Protein degradation is an important cellular process that provides a mechanism for protein quality control and a rapid response to a multitude of cellular signals. In cells, proper coordination and synchronization of protein functions is governed by their spatially and temporally sequential degradation. To develop effective and safe next-generation cell and gene therapies, technologies that enable precise control of protein stability and half-life to regulate cellular processes are increasingly required.
本揭示提供了一種融合蛋白,其包括結合元件和降解引發劑,其中該結合元件選擇性地結合目標分子,並且其中該降解引發劑包括分離或衍生自E3連接酶的序列。在一些實施例中,(a)E3連接酶包括LNX1、RNF4、RNF43、RNF128、XNRF3、MARCH8、LRG1、NEDD4、SOCS2、CHIP、SPOP、FBXW7、FBXW1A、ELOC、TRAF6、VHL或其任何功能片段;或(b) E3連接酶包括LNX1、RNF4、RNF43或其任何功能片段;或(c) E3連接酶包括LNX1或其任何功能片段;或(d) E3連接酶包括RNF4或其任何功能片段;或(e)E3連接酶包括RNF43或其任何功能片段;或(f) 分離或衍生自E3連接酶的序列,包括表 10 的序列、其功能片段;或與表10的序列或其功能片段具有至少70%、75%、80%、85%、90%、95%、97%或99%的同源性的序列;或(g)分離或衍生自E3連接酶的序列包括 SEQ ID NO:74-114 的E3連接酶的序列;或(h)分離或衍生自E3連接酶的序列包括 SEQ ID NO:159-163 中的任一個;或 (i) 包括表 14 的基序的 E3 連接酶。在一些實施例中,融合蛋白進一步包括DAP10序列,任選地包括標籤或SEQ ID NO:157的序列。在一些實施例中,融合蛋白進一步包括CD8跨膜結構域,任選地,包括SEQ ID NO:158的序列。在一些實施例中,在能夠表達融合蛋白的細胞中,目標分子是內源分子。在一些實施例中,目標分子是天然存在的分子。在一些實施例中,結合元件包括DNA序列、RNA序列、氨基酸序列或其任何組合。在一些實施例中,結合元件的序列與目標分子的序列形成核酸雙鏈體。在一些實施例中,通過結合元件的DNA或RNA序列與目標分子的DNA或RNA序列雜交,結合元件的序列與目標分子的序列形成核酸雙鏈體。在一些實施例中,結合元件選擇性地結合到目標分子的表位。在一些實施例中,結合元件包括抗體或其功能片段、抗體模擬物、纖維連接蛋白結構域、蛋白質支架或適配子。在一些實施例中,目標分子包括序列列表文件“016-TNP023PCT_SeqList_v2”中的序列,該文件創建於2022年2月2日並且大小為52,267 KB,其整體通過引用併入本文,或包括編碼目標分子的核酸序列。The present disclosure provides a fusion protein comprising a binding element and a degradation initiator, wherein the binding element selectively binds a target molecule, and wherein the degradation initiator comprises a sequence isolated or derived from an E3 ligase. In some embodiments, (a) the E3 ligase comprises LNX1, RNF4, RNF43, RNF128, XNRF3, MARCH8, LRG1, NEDD4, SOCS2, CHIP, SPOP, FBXW7, FBXW1A, ELOC, TRAF6, VHL, or any functional fragment thereof; or (b) the E3 ligase comprises LNX1, RNF4, RNF43 or any functional fragment thereof; or (c) the E3 ligase comprises LNX1 or any functional fragment thereof; or (d) the E3 ligase comprises RNF4 or any functional fragment thereof; or (e) E3 ligase comprises RNF43 or any functional fragment thereof; Or (f) is isolated or is derived from the sequence of E3 ligase, comprises the sequence of Table 10, its functional fragment; A sequence of 70%, 75%, 80%, 85%, 90%, 95%, 97% or 99% homology; or (g) a sequence isolated or derived from an E3 ligase comprising SEQ ID NO: 74- or (h) a sequence isolated or derived from an E3 ligase comprising any one of SEQ ID NO: 159-163; or (i) an E3 ligase comprising a motif of Table 14. In some embodiments, the fusion protein further includes a DAP10 sequence, optionally including a tag or the sequence of SEQ ID NO:157. In some embodiments, the fusion protein further comprises a CD8 transmembrane domain, optionally comprising the sequence of SEQ ID NO:158. In some embodiments, the molecule of interest is an endogenous molecule in the cell capable of expressing the fusion protein. In some embodiments, the molecule of interest is a naturally occurring molecule. In some embodiments, a binding element includes a DNA sequence, RNA sequence, amino acid sequence, or any combination thereof. In some embodiments, the sequence of the binding element forms a nucleic acid duplex with the sequence of the target molecule. In some embodiments, the sequence of the binding element forms a nucleic acid duplex with the sequence of the target molecule by hybridization of the DNA or RNA sequence of the binding element to the DNA or RNA sequence of the target molecule. In some embodiments, a binding element selectively binds to an epitope of a molecule of interest. In some embodiments, binding elements include antibodies or functional fragments thereof, antibody mimetics, fibronectin domains, protein scaffolds, or aptamers. In some embodiments, the target molecule comprises a sequence in the sequence listing file "016-TNP023PCT_SeqList_v2", which was created on February 2, 2022 and is 52,267 KB in size, which is hereby incorporated by reference in its entirety, or includes the sequence encoding the target molecule nucleic acid sequence.
在本揭示的融合蛋白的一些實施例中,融合蛋白或結合元件包括二聚化結構域。在一些實施例中,二聚化結構域包括設計的異二聚體(DHD)多肽。在一些實施例中,目標分子或編碼目標分子的序列被修飾(a)以包括能夠與融合蛋白的二聚化結構域形成異二聚體的結合元件;或(b)可操作地連接到能夠與融合蛋白的二聚化結構域形成異二聚體的結合元件。在一些實施例中,結合元件包括二聚化結構域。在一些實施例中,二聚化結構域包括設計的異二聚體(DHD)多肽。在一些實施例中,融合蛋白的結合元件是第一結合元件並且目標分子的結合元件是第二結合元件,並且(a)其中第一結合元件或第二結合元件包括單螺旋;或(b)其中第一結合元件或第二結合元件包括至少雙螺旋;或 (c)其中第一結合元件或第二結合元件包括3、4、5、6、7或8個螺旋;或(d) 第一結合元件包括單螺旋並且第二結合元件包括三個螺旋;或 (e) 第一結合元件包括三個螺旋並且第二結合元件包括單螺旋。在一些實施例中,(a)第一結合元件包括DHD-A並且第二結合元件包括DHD-B;或(b)第一結合元件包括DHD-B並且第二結合元件包括DHD-A。在一些實施例中,DHD-B 包括 DHD37-short-B-KtoR 序列 (SEQ ID NO:16)。在一些實施例中,第一結合元件或第二結合元件包括非螺旋元件。在一些實施例中,異二聚體包括非螺旋元件。在一些實施例中,非螺旋元件包括小分子。In some embodiments of the fusion proteins of the disclosure, the fusion protein or binding element includes a dimerization domain. In some embodiments, the dimerization domain comprises a designed heterodimer (DHD) polypeptide. In some embodiments, the molecule of interest or the sequence encoding the molecule of interest is modified (a) to include a binding element capable of forming a heterodimer with the dimerization domain of the fusion protein; or (b) operably linked to a Binding element that forms a heterodimer with the dimerization domain of a fusion protein. In some embodiments, a binding element includes a dimerization domain. In some embodiments, the dimerization domain comprises a designed heterodimer (DHD) polypeptide. In some embodiments, the binding element of the fusion protein is a first binding element and the binding element of the target molecule is a second binding element, and (a) wherein the first binding element or the second binding element comprises a single helix; or (b) wherein the first binding element or the second binding element comprises at least a double helix; or (c) wherein the first binding element or the second binding element comprises 3, 4, 5, 6, 7 or 8 helices; or (d) the first The binding element comprises a single helix and the second binding element comprises three helices; or (e) the first binding element comprises three helices and the second binding element comprises a single helix. In some embodiments, (a) the first binding element comprises DHD-A and the second binding element comprises DHD-B; or (b) the first binding element comprises DHD-B and the second binding element comprises DHD-A. In some embodiments, DHD-B comprises the sequence DHD37-short-B-KtoR (SEQ ID NO: 16). In some embodiments, the first binding element or the second binding element comprises a non-helical element. In some embodiments, the heterodimer includes non-helical elements. In some embodiments, non-helical elements include small molecules.
本揭示提供了一種組合物,其包括:(a)包括第一結合元件的第一融合蛋白;(b) 包括第二結合元件的第二融合蛋白;The present disclosure provides a composition comprising: (a) a first fusion protein comprising a first binding element; (b) a second fusion protein comprising a second binding element;
其中,(1)第一融合蛋白進一步包括降解引發劑或其功能變體,第二融合蛋白進一步包括目標分子;或(2)第一融合蛋白進一步包括目標分子,第二融合蛋白進一步包括降解引發劑或其功能變體。Wherein, (1) the first fusion protein further includes a degradation initiator or a functional variant thereof, and the second fusion protein further includes a target molecule; or (2) the first fusion protein further includes a target molecule, and the second fusion protein further includes a degradation trigger agents or their functional variants.
在本揭示的組合物的一些實施例中,第一結合元件和第二結合元件能夠形成異二聚體。在一些實施例中,第一結合元件或第二結合元件包括單螺旋。在一些實施例中,第一結合元件或第二結合元件包括至少雙螺旋。在一些實施例中,第一結合元件或第二結合元件包括3、4、5、6、7或8個螺旋。在一些實施例中,(a)第一結合元件包括單螺旋並且第二結合元件包括三個螺旋,或(b)第一結合元件包括三個螺旋並且第二結合元件包括單螺旋。在一些實施例中,(a)第一結合元件包括DHD-A並且第二結合元件包括DHD-B;或(b)第一結合元件包括DHD-B並且第二結合元件包括DHD-A。在一些實施例中,第一結合元件或第二結合元件包括非螺旋元件。在一些實施例中,異二聚體包括非螺旋元件。在一些實施例中,非螺旋元件包括小分子。In some embodiments of the compositions of the present disclosure, the first binding element and the second binding element are capable of forming a heterodimer. In some embodiments, the first binding element or the second binding element comprises a single helix. In some embodiments, the first binding element or the second binding element comprises at least a double helix. In some embodiments, the first binding element or the second binding element comprises 3, 4, 5, 6, 7 or 8 helices. In some embodiments, (a) the first binding element comprises a single helix and the second binding element comprises three helices, or (b) the first binding element comprises three helices and the second binding element comprises a single helix. In some embodiments, (a) the first binding element comprises DHD-A and the second binding element comprises DHD-B; or (b) the first binding element comprises DHD-B and the second binding element comprises DHD-A. In some embodiments, the first binding element or the second binding element comprises a non-helical element. In some embodiments, the heterodimer includes non-helical elements. In some embodiments, non-helical elements include small molecules.
在本揭示的組合物的一些實施例中,第一結合元件包含DHD37-short-B-KtoR的序列(SEQ ID NO:16)。在一些實施例中,第一結合元件進一步包含從E3連接酶分離或衍生的序列。在一些實施例中,(a)E3連接酶包含LNX1、RNF4、RNF43、RNF128、XNRF3、MARCH8、LRG1、NEDD4、SOCS2、CHIP、SPOP、FBXW7、FBXW1A、ELOC、TRAF6、VHL或其任何功能片段;或(b)E3連接酶包含LNX1、RNF4、RNF43或其任何功能片段;或(c)E3連接酶包含LNX1或其任何功能片段;或(d)E3連接酶包含RNF4或其任何功能片段;或(e) E3連接酶包含RNF43或其任何功能片段;或(f)從E3連接酶分離或衍生的序列,包含表10的序列、其功能片段或與表10的序列或其功能片段具有至少70%、75%、80%、85%、90%、95%、97%或99%同源性的序列;或(g)從E3連接酶分離或衍生的序列,包含SEQ ID NO:74-114的E3連接酶序列;(h) 分離或衍生自 E3 連接酶的序列包含 SEQ ID NO:159-163 中的任一個;或 (i) 包含表 14 的基序的 E3 連接酶。在一些實施例中,第一融合蛋白進一步包含DAP10序列,任選包含一標籤序列或SEQ ID NO:157的序列。在一些實施例中,該第一融合蛋白進一步包含CD8跨膜結構域,任選地,包含SEQ ID NO:158的序列。在一些實施例中,第一結合元件包含SEQ ID NO:174的序列。In some embodiments of the compositions of the present disclosure, the first binding element comprises the sequence of DHD37-short-B-KtoR (SEQ ID NO: 16). In some embodiments, the first binding element further comprises a sequence isolated or derived from an E3 ligase. In some embodiments, (a) the E3 ligase comprises LNX1, RNF4, RNF43, RNF128, XNRF3, MARCH8, LRG1, NEDD4, SOCS2, CHIP, SPOP, FBXW7, FBXW1A, ELOC, TRAF6, VHL, or any functional fragment thereof; or (b) the E3 ligase comprises LNX1, RNF4, RNF43 or any functional fragment thereof; or (c) the E3 ligase comprises LNX1 or any functional fragment thereof; or (d) the E3 ligase comprises RNF4 or any functional fragment thereof; or (e) an E3 ligase comprising RNF43 or any functional fragment thereof; or (f) a sequence isolated or derived from an E3 ligase comprising a sequence of Table 10, a functional fragment thereof, or at least 70% of a sequence of Table 10 or a functional fragment thereof %, 75%, 80%, 85%, 90%, 95%, 97% or 99% homologous sequence; or (g) a sequence isolated or derived from E3 ligase comprising SEQ ID NO: 74-114 (h) the sequence isolated or derived from the E3 ligase comprises any one of SEQ ID NO: 159-163; or (i) the E3 ligase comprising the motif of Table 14. In some embodiments, the first fusion protein further comprises a DAP10 sequence, optionally comprising a tag sequence or the sequence of SEQ ID NO:157. In some embodiments, the first fusion protein further comprises a CD8 transmembrane domain, optionally comprising the sequence of SEQ ID NO:158. In some embodiments, the first binding element comprises the sequence of SEQ ID NO:174.
在本揭示的組合物的一些實施例中,第一結合元件包含SEQ ID NO:1-73或121-125中任一個的序列。In some embodiments of the compositions of the present disclosure, the first binding element comprises the sequence of any one of SEQ ID NOs: 1-73 or 121-125.
在本揭示的組合物的一些實施例中,第二結合元件包含DHD37-short-B-KtoR的序列(SEQ ID NO:16)。在一些實施例中,第一結合元件還包含從E3連接酶分離或衍生的序列。在一些實施例中,(a)E3連接酶包含LNX1、RNF4、RNF43、RNF128、XNRF3、MARCH8、LRG1、NEDD4、SOCS2、CHIP、SPOP、FBXW7、FBXW1A、ELOC、TRAF6、VHL或其任何功能片段;或(b)E3連接酶包含LNX1、RNF4、RNF43或其任何功能片段;或(c) E3連接酶包含LNX1或其任何功能片段;或(d) E3連接酶包含RNF4或其任何功能片段;或(e) E3連接酶包含RNF43或其任何功能片段;或(f)從E3連接酶分離或衍生的序列,包含表10的序列、其功能片段或與表10的序列或其功能片段具有至少70%、75%、80%、85%、90%、95%、97%或99%同源性的序列;或(g)從E3連接酶分離或衍生的序列,包含SEQ ID NO:74-114的E3連接酶序列;或(h)從E3連接酶分離或衍生的序列,包含SEQ ID NO:159-163中的任一個;或(i) 包含表 14 基序的 E3 連接酶。在一些實施例中,第二融合蛋白進一步包含 DAP10 序列,任選地包含標籤或 SEQ ID NO:157 的序列。在一些實施例中,第二融合蛋白進一步包含CD8跨膜結構域,任選地,包含SEQ ID NO:158的序列。在一些實施例中,第一結合元件包含SEQ ID NO:174的序列。In some embodiments of the compositions of the present disclosure, the second binding element comprises the sequence of DHD37-short-B-KtoR (SEQ ID NO: 16). In some embodiments, the first binding element further comprises a sequence isolated or derived from an E3 ligase. In some embodiments, (a) the E3 ligase comprises LNX1, RNF4, RNF43, RNF128, XNRF3, MARCH8, LRG1, NEDD4, SOCS2, CHIP, SPOP, FBXW7, FBXW1A, ELOC, TRAF6, VHL, or any functional fragment thereof; or (b) the E3 ligase comprises LNX1, RNF4, RNF43 or any functional fragment thereof; or (c) the E3 ligase comprises LNX1 or any functional fragment thereof; or (d) the E3 ligase comprises RNF4 or any functional fragment thereof; or (e) the E3 ligase comprises RNF43 or any functional fragment thereof; or (f) a sequence isolated or derived from the E3 ligase comprising the sequence of Table 10, a functional fragment thereof, or at least 70% of the sequence of Table 10 or a functional fragment thereof %, 75%, 80%, 85%, 90%, 95%, 97% or 99% homologous sequence; or (g) a sequence isolated or derived from E3 ligase comprising SEQ ID NO: 74-114 or (h) a sequence isolated or derived from an E3 ligase comprising any one of SEQ ID NO: 159-163; or (i) an E3 ligase comprising a motif of Table 14. In some embodiments, the second fusion protein further comprises a DAP10 sequence, optionally comprising a tag or the sequence of SEQ ID NO:157. In some embodiments, the second fusion protein further comprises a CD8 transmembrane domain, optionally comprising the sequence of SEQ ID NO:158. In some embodiments, the first binding element comprises the sequence of SEQ ID NO:174.
在本揭示的組合物的一些實施例中,第二結合元件包含SEQ ID NO:1-73或121-125中任一個的序列。In some embodiments of the compositions of the present disclosure, the second binding element comprises the sequence of any one of SEQ ID NOs: 1-73 or 121-125.
在本揭示的組合物的一些實施例中,一個小分子介導異二聚體的形成。在一些實施例中,第一結合元件或第二結合元件結合小分子。在一些實施例中,第一結合元件及第二結合元件結合小分子。在一些實施例中,第一結合元件和第二結合元件不直接彼此結合。在一些實施例中,小分子增加異二聚體的形成。在一些實施例中,小分子減少異二聚體的形成。在一些實施例中,第一小分子和第二小分子調控異二聚體的形成,並且其中第二小分子通過與第一小分子競爭以結合第一結合元件或第二結合元件來減少與第一小分子形成異二聚體。在一些實施例中,(a)第一結合元件包含NS3a序列並且第二結合元件包含DNCR2序列或GNCR1序列;或(b)第一結合元件包含DNCR2序列或GNCR1序列並且第二結合元件包含NS3a序列。在一些實施例中,該小分子包括達諾瑞韋或其類似物。在一些實施例中,第一小分子或第二小分子包括達諾瑞韋或其類似物。在一些實施例中,小分子包含格拉唑瑞韋或其類似物。在一些實施例中,第一小分子或第二小分子包括格拉唑瑞韋或其類似物。In some embodiments of the compositions of the present disclosure, a small molecule mediates the formation of the heterodimer. In some embodiments, the first binding element or the second binding element binds the small molecule. In some embodiments, the first binding element and the second binding element bind the small molecule. In some embodiments, the first binding element and the second binding element are not directly bound to each other. In some embodiments, small molecules increase heterodimer formation. In some embodiments, small molecules reduce heterodimer formation. In some embodiments, the first small molecule and the second small molecule regulate the formation of a heterodimer, and wherein the second small molecule reduces the interaction with the first binding element or the second binding element by competing with the first small molecule for binding to the first binding element or the second binding element. The first small molecule forms a heterodimer. In some embodiments, (a) the first binding element comprises an NS3a sequence and the second binding element comprises a DNCR2 sequence or a GNCR1 sequence; or (b) the first binding element comprises a DNCR2 sequence or a GNCR1 sequence and the second binding element comprises an NS3a sequence . In some embodiments, the small molecule comprises danoprevir or an analog thereof. In some embodiments, the first small molecule or the second small molecule comprises danoprevir or an analog thereof. In some embodiments, the small molecule comprises glazoprevir or an analog thereof. In some embodiments, the first small molecule or the second small molecule includes glazoprevir or an analog thereof.
在本揭示的組合物的一些實施例中,包括包含第一融合蛋白和第二融合蛋白的那些組合物,目標分子包括合成分子或外源分子。在一些實施例中,合成分子或外源分子包含蛋白質。在一些實施例中,合成分子或外源分子包含嵌合蛋白、嵌合受體或嵌合抗原受體。在一些實施例中,嵌合受體包含細胞外結構域,該細胞外結構域包含抗原感應結構域、跨膜結構域和胞內結構域。在一些實施例中,抗原感應結構域包含以下中的一個或多個:(a)重鏈可變區的一組三個互補決定區(CDR);(b)重鏈可變區的一組三個互補決定區(CDR)和輕鏈可變區的一組三個互補決定區(CDR);(c) 基於纖維連接蛋白的支架;其中抗原感應結構域特異性結合目標抗原。在一些實施例中,抗原感應區包含一種或多種從哺乳動物序列分離或衍生的序列。在一些實施例中,抗原感應區包含一種或多種從人序列分離或衍生的序列。在一些實施例中,抗原感應區包含人源化或完全人源抗體。在一些實施例中,抗原傳感區包含單鏈可變片段(scFv)。In some embodiments of the compositions of the present disclosure, including those comprising a first fusion protein and a second fusion protein, the target molecule comprises a synthetic molecule or an exogenous molecule. In some embodiments, the synthetic or exogenous molecule comprises a protein. In some embodiments, the synthetic or exogenous molecule comprises a chimeric protein, chimeric receptor or chimeric antigen receptor. In some embodiments, the chimeric receptor comprises an extracellular domain comprising an antigen sensing domain, a transmembrane domain and an intracellular domain. In some embodiments, the antigen sensing domain comprises one or more of: (a) a set of three complementarity determining regions (CDRs) of the heavy chain variable region; (b) a set of three complementarity determining regions (CDRs) of the heavy chain variable region Three complementarity-determining regions (CDRs) and a set of three complementarity-determining regions (CDRs) for the light chain variable region; (c) a fibronectin-based scaffold; where the antigen-sensing domain specifically binds the target antigen. In some embodiments, the antigen sensing region comprises one or more sequences isolated or derived from mammalian sequences. In some embodiments, the antigen sensing region comprises one or more sequences isolated or derived from human sequences. In some embodiments, the antigen sensing region comprises humanized or fully human antibodies. In some embodiments, the antigen sensing region comprises a single chain variable fragment (scFv).
在本揭示的組合物的一些實施例中,胞外結構域進一步包含鉸鏈區、間隔序列或安全開關中的一種或多種。在一些實施例中,鉸鏈區包含從CD4(分化簇4)多肽、CD8(分化簇8)多肽或CD28(分化簇28)多肽分離或衍生的序列。在一些實施例中,鉸鏈區包含從人類序列分離或衍生的序列。在一些實施例中,鉸鏈區和間隔區是相同的區域。在一些實施例中,鉸鏈區和間隔區是不同的區域。In some embodiments of the compositions of the present disclosure, the extracellular domain further comprises one or more of a hinge region, a spacer sequence, or a safety switch. In some embodiments, the hinge region comprises a sequence isolated or derived from a CD4 (cluster of differentiation 4) polypeptide, a CD8 (cluster of differentiation 8) polypeptide, or a CD28 (cluster of differentiation 28) polypeptide. In some embodiments, the hinge region comprises a sequence isolated or derived from a human sequence. In some embodiments, the hinge region and the spacer region are the same region. In some embodiments, the hinge region and the spacer region are different regions.
在本揭示的組合物的一些實施例中,間隔序列包含從CD4多肽、CD8多肽、CD28多肽分離或衍生的序列。在一些實施例中,間隔序列包含從人類序列分離或衍生的序列。In some embodiments of the compositions of the present disclosure, the spacer sequence comprises a sequence isolated or derived from a CD4 polypeptide, a CD8 polypeptide, a CD28 polypeptide. In some embodiments, the spacer sequence comprises a sequence isolated or derived from a human sequence.
在本揭示的組合物的一些實施例中,安全開關包含分離或衍生自表皮生長因子受體(EGFR)多肽的序列。在一些實施例中,安全開關包含截短的EGFR(EGFRt)多肽。在一些實施例中,安全開關包括從人類序列分離或衍生的序列。In some embodiments of the compositions of the present disclosure, the safety switch comprises a sequence isolated or derived from an epidermal growth factor receptor (EGFR) polypeptide. In some embodiments, the safety switch comprises a truncated EGFR (EGFRt) polypeptide. In some embodiments, the safety switch comprises a sequence isolated or derived from a human sequence.
在本揭示的組合物的一些實施例中,跨膜結構域包含從CD4多肽、CD8多肽、CD28多肽分離或衍生的序列。在一些實施例中,跨膜結構域包含從人類序列分離或衍生的序列。In some embodiments of the compositions of the present disclosure, the transmembrane domain comprises a sequence isolated or derived from a CD4 polypeptide, a CD8 polypeptide, a CD28 polypeptide. In some embodiments, the transmembrane domain comprises a sequence isolated or derived from a human sequence.
在本揭示的組合物的一些實施例中,胞內結構域包含一個或多個共刺激結構域。在一些實施例中,一個或多個共刺激結構域包含從CD3ζ(分化簇3zeta)多肽分離或衍生的序列。在一些實施例中,一個或多個共刺激結構域包含從CD28多肽、4-1BB (分化簇137)多肽、ICOS (誘導性T細胞共刺激物)多肽、OX40多肽分離或衍生的序列,或 CD27 (分化簇 27) 多肽。在一些實施例中,一個或多個共刺激結構域包含(a)第一共刺激結構域,其包含從CD28多肽、4-1BB多肽或ICOS多肽分離或衍生的序列;(b) 包含從 4-1BB 多肽、OX40 多肽或 CD27 多肽分離或衍生的序列的第二共刺激結構域。在一些實施例中,一個或多個共刺激結構域包含從人類序列分離或衍生的序列。In some embodiments of the compositions of the present disclosure, the intracellular domain comprises one or more co-stimulatory domains. In some embodiments, the one or more co-stimulatory domains comprise a sequence isolated or derived from a CD3ζ (cluster of differentiation 3zeta) polypeptide. In some embodiments, the one or more co-stimulatory domains comprise a sequence isolated or derived from a CD28 polypeptide, a 4-1BB (cluster of differentiation 137) polypeptide, an ICOS (inducible T cell co-stimulator) polypeptide, an OX40 polypeptide, or CD27 (cluster of differentiation 27) polypeptide. In some embodiments, the one or more co-stimulatory domains comprise (a) a first co-stimulatory domain comprising a sequence isolated or derived from a CD28 polypeptide, a 4-1BB polypeptide or an ICOS polypeptide; (b) comprising a sequence derived from 4 - a second co-stimulatory domain of an isolated or derived sequence of a 1BB polypeptide, OX40 polypeptide or CD27 polypeptide. In some embodiments, one or more co-stimulatory domains comprise sequences isolated or derived from human sequences.
在本揭示的組合物的一些實施例中,嵌合受體包含進一步包含誘導型細胞因子結構域的胞內結構域。在一些實施例中,誘導型細胞因子結構域包含能夠誘導IL-12細胞因子表達的活化T細胞核因子(NFAT)多肽。In some embodiments of the compositions of the present disclosure, the chimeric receptor comprises an intracellular domain further comprising an inducible cytokine domain. In some embodiments, the inducible cytokine domain comprises a nuclear factor of activated T cell (NFAT) polypeptide capable of inducing expression of the IL-12 cytokine.
在本揭示的組合物的一些實施例中,嵌合受體包含胞內結構域,進一步包含細胞因子受體的胞內結構域。在一些實施例中,細胞因子受體的胞內結構域包含IL-2受體β(IL-2Rβ)鏈片段。在一些實施例中,嵌合受體包含胞內結構域,所述胞內結構域還包含信號轉導和轉錄啟動因子(STAT3/5)結合基序。In some embodiments of the compositions of the present disclosure, the chimeric receptor comprises an intracellular domain, further comprising an intracellular domain of a cytokine receptor. In some embodiments, the intracellular domain of the cytokine receptor comprises an IL-2 receptor beta (IL-2Rβ) chain fragment. In some embodiments, the chimeric receptor comprises an intracellular domain that further comprises a Signal Transducer and Initiator of Transcription (STAT3/5) binding motif.
在本揭示的組合物的一些實施例中,所述嵌合受體包含胞內結構域,所述胞內結構域還包含至少一個基於免疫受體酪氨酸的啟動基序(ITAM)序列。In some embodiments of the compositions of the present disclosure, the chimeric receptor comprises an intracellular domain further comprising at least one immunoreceptor tyrosine-based initiation motif (ITAM) sequence.
本揭示還提供一種核酸序列,包括:具有編碼:(a)本揭示的融合蛋白;或(b)(a)的一個或多個元件。在一些實施例中,融合蛋白包含結合元件和降解引發劑,其中結合元件選擇性地結合目標分子,並且其中降解引發劑包含分離或衍生自E3連接酶的序列。在一些實施例中,在能夠表達融合蛋白的細胞中,目標分子是內源分子。在一些實施例中,目標分子是天然存在的分子。The disclosure also provides a nucleic acid sequence, comprising: encoding: (a) the fusion protein of the disclosure; or (b) one or more elements of (a). In some embodiments, the fusion protein comprises a binding element and a degradation initiator, wherein the binding element selectively binds a target molecule, and wherein the degradation initiator comprises a sequence isolated or derived from an E3 ligase. In some embodiments, the molecule of interest is an endogenous molecule in the cell capable of expressing the fusion protein. In some embodiments, the molecule of interest is a naturally occurring molecule.
本揭示還提供一種核酸序列,包括:具有編碼:(a)本揭示的第一融合蛋白;(b) 本揭示的第二融合蛋白;(c) (a) 的一個或多個元件;(d) (b)的一個或多個元件的核酸序列。The present disclosure also provides a nucleic acid sequence, comprising: encoding: (a) the first fusion protein of the present disclosure; (b) the second fusion protein of the present disclosure; (c) one or more elements of (a); (d ) the nucleic acid sequence of one or more elements of (b).
本揭示還提供一種核酸序列,包括:編碼本揭示的第一融合蛋白和本揭示的第二融合蛋白的核酸序列。The disclosure also provides a nucleic acid sequence, including: a nucleic acid sequence encoding the first fusion protein disclosed herein and the second fusion protein disclosed herein.
在本揭示的核酸序列的一些實施例中,核酸序列還包括非編碼序列、非轉譯區、調節元件、分離元件、多順反子元件或轉譯後元件中的一個或多個。In some embodiments of the nucleic acid sequences of the disclosure, the nucleic acid sequence further includes one or more of non-coding sequences, untranslated regions, regulatory elements, segregating elements, polycistronic elements, or post-translational elements.
在本揭示的核酸序列的一些實施例中,該核酸序列進一步包含至少一種能夠驅動該核酸序列在哺乳動物細胞中表現的啟動子。在一些實施例中,核酸序列還包含至少一種能夠驅動核酸序列在人類細胞中表現的啟動子。在一些實施例中,至少一種啟動子包括組成型啟動子。在一些實施例中,組成型啟動子包含分離或衍生自MND啟動子、hPGK啟動子、CMV啟動子、CAG啟動子、SFFV啟動子、EF1α啟動子、UBC啟動子和CD43啟動子中的一種或多種的序列。在一些實施例中,所述至少一種啟動子包含誘導型啟動子。在一些實施例中,誘導型啟動子包含從YB_TATA啟動子、人類β球蛋白(huBG)啟動子、minIL2啟動子、minimalCMV (minCMV)啟動子和TRE3G啟動子中的一種或多種分離或衍生的序列。在一些實施例中,誘導型啟動子包含最小序列。在一些實施例中,誘導型啟動子還包含轉錄因子特異性識別序列。在一些實施例中,轉錄因子特異性識別序列包含轉錄因子特異性反應元件。在一些實施例中,轉錄因子反應元件包含從NFAT序列分離或衍生的序列。在一些實施例中,轉錄因子特異性識別序列包含轉錄因子特異性反應元件的至少一個重複序列。在一些實施例中,轉錄因子特異性識別序列包含轉錄因子特異性反應元件的至少2、3、4、5、6、7、8、9或10個重複序列。In some embodiments of the nucleic acid sequences disclosed herein, the nucleic acid sequences further comprise at least one promoter capable of driving expression of the nucleic acid sequences in mammalian cells. In some embodiments, the nucleic acid sequence further comprises at least one promoter capable of driving expression of the nucleic acid sequence in human cells. In some embodiments, at least one promoter includes a constitutive promoter. In some embodiments, the constitutive promoter comprises one of MND promoter, hPGK promoter, CMV promoter, CAG promoter, SFFV promoter, EF1α promoter, UBC promoter and CD43 promoter isolated or derived from or Various sequences. In some embodiments, the at least one promoter comprises an inducible promoter. In some embodiments, the inducible promoter comprises a sequence isolated or derived from one or more of the YB_TATA promoter, the human beta globin (huBG) promoter, the minIL2 promoter, the minimalCMV (minCMV) promoter, and the TRE3G promoter . In some embodiments, an inducible promoter comprises minimal sequence. In some embodiments, the inducible promoter further comprises a transcription factor specific recognition sequence. In some embodiments, the transcription factor specific recognition sequence comprises a transcription factor specific response element. In some embodiments, the transcription factor response element comprises a sequence isolated or derived from an NFAT sequence. In some embodiments, the transcription factor-specific recognition sequence comprises at least one repeat of a transcription factor-specific response element. In some embodiments, the transcription factor-specific recognition sequence comprises at least 2, 3, 4, 5, 6, 7, 8, 9, or 10 repeats of a transcription factor-specific response element.
在本揭示的核酸序列的一些實施例中,(a)第一啟動子驅動第一融合蛋白的表達;或(b)第二啟動子驅動第二融合蛋白的表達。在一些實施例中,第一啟動子和第二啟動子是相同的。在一些實施例中,第一啟動子和第二啟動子不相同。In some embodiments of the nucleic acid sequences of the disclosure, (a) the first promoter drives expression of the first fusion protein; or (b) the second promoter drives expression of the second fusion protein. In some embodiments, the first promoter and the second promoter are the same. In some embodiments, the first promoter and the second promoter are not the same.
在本揭示的核酸序列的一些實施例中,分離元件包括核醣體跳躍序列。在一些實施例中,分離元件包含至少兩個核醣體跳躍序列。在一些實施例中,核醣體跳躍序列包含P2a序列或T2a序列。在一些實施例中,核醣體跳躍序列包含T2a-RFP-P2a序列、P2a-T2a序列或T2a-P2a序列。In some embodiments of the nucleic acid sequences of the disclosure, the separation element comprises a ribosomal skipping sequence. In some embodiments, the separation element comprises at least two ribosomal skipping sequences. In some embodiments, the ribosomal skipping sequence comprises a P2a sequence or a T2a sequence. In some embodiments, the ribosomal skipping sequence comprises a T2a-RFP-P2a sequence, a P2a-T2a sequence, or a T2a-P2a sequence.
在本揭示的核酸序列的一些實施例中,多順反子元件包含內部核醣體進入位點(IRES)序列。In some embodiments of the nucleic acid sequences of the disclosure, the polycistronic element comprises an internal ribosome entry site (IRES) sequence.
本揭示提供一種載體,其包括:本揭示的核酸序列的載體。The present disclosure provides a vector, which includes: the vector of the nucleic acid sequence disclosed herein.
本揭示提供了包含編碼本揭示的第一融合蛋白的核酸序列的第一載體和包含編碼本揭示的第二融合蛋白的核酸序列的第二載體。The present disclosure provides a first vector comprising a nucleic acid sequence encoding a first fusion protein of the present disclosure and a second vector comprising a nucleic acid sequence encoding a second fusion protein of the present disclosure.
在本揭示的載體的一些實施例中,該載體是能夠在哺乳動物細胞中表達核酸的表現載體。在一些實施例中,哺乳動物細胞是人類細胞。在一些實施例中,載體包含質粒。In some embodiments of the disclosed vectors, the vector is an expression vector capable of expressing a nucleic acid in a mammalian cell. In some embodiments, the mammalian cells are human cells. In some embodiments, vectors comprise plasmids.
在本揭示的載體的一些實施例中,該載體包括能夠將核酸引入哺乳動物細胞的遞送載體。在一些實施例中,哺乳動物細胞是人類細胞。在一些實施例中,遞送載體包括病毒載體、非病毒載體、脂質體、膠束、聚合體和奈米顆粒中的一種或多種。在一些實施例中,病毒載體包含從病毒或病毒載體分離或衍生的序列。在一些實施例中,病毒載體包含從腺病毒載體、慢病毒載體、杆狀病毒載體、愛潑斯坦-巴爾病毒載體、巴氏病毒(細小病毒)載體、痘苗病毒載體、單純皰疹病毒載體、腺相關病毒(AAV)載體和乙型肝炎病毒載體中的一個或多個分離或衍生的序列。在一些實施例中,載體包括從轉位元系統分離或衍生的序列。在一些實施例中,該載體包含分離或衍生自piggyBAC轉座系統、睡美人轉座系統、Tc1/mariner轉座系統、Tol2轉座系統、helraiser轉座系統和Tn7轉座系統中的一種或多種的序列。In some embodiments of the vectors of the present disclosure, the vector comprises a delivery vehicle capable of introducing nucleic acid into a mammalian cell. In some embodiments, the mammalian cells are human cells. In some embodiments, delivery vehicles include one or more of viral vectors, non-viral vectors, liposomes, micelles, polymers, and nanoparticles. In some embodiments, a viral vector comprises sequences isolated or derived from a virus or viral vector. In some embodiments, the viral vector comprises an adenoviral vector, a lentiviral vector, a baculoviral vector, an Epstein-Barr virus vector, a Babeicavirus (parvovirus) vector, a vaccinia virus vector, a herpes simplex virus vector, One or more isolated or derived sequences from adeno-associated virus (AAV) vectors and hepatitis B virus vectors. In some embodiments, vectors include sequences isolated or derived from transposon systems. In some embodiments, the vector comprises one or more of the piggyBAC transposition system, Sleeping Beauty transposition system, Tc1/mariner transposition system, Tol2 transposition system, helraiser transposition system and Tn7 transposition system isolated or derived from the sequence of.
在本揭示的載體的一些實施例中,該載體包含一個或多個介導同源定向修復的序列In some embodiments of the disclosed vectors, the vector comprises one or more sequences that mediate homology-directed repair
本揭示提供一種細胞,其包括:包含本揭示的融合蛋白的細胞。在一些實施例中,融合蛋白包含結合元件和降解引發劑,其中結合元件選擇性地結合目標分子,並且其中降解引發劑包含分離或衍生自E3連接酶的序列。在一些實施例中,在能夠表達融合蛋白的細胞中,目標分子是內源分子。在一些實施例中,目標分子是天然存在的分子。The present disclosure provides a cell comprising: a cell comprising the fusion protein of the present disclosure. In some embodiments, the fusion protein comprises a binding element and a degradation initiator, wherein the binding element selectively binds a target molecule, and wherein the degradation initiator comprises a sequence isolated or derived from an E3 ligase. In some embodiments, the molecule of interest is an endogenous molecule in the cell capable of expressing the fusion protein. In some embodiments, the molecule of interest is a naturally occurring molecule.
本揭示提供了一種包括本揭示的組合物的細胞。在一些實施例中,組合物包含第一融合蛋白和第二融合蛋白。The disclosure provides a cell comprising a composition of the disclosure. In some embodiments, the composition comprises a first fusion protein and a second fusion protein.
本揭示提供了一種包括本揭示的核酸序列的細胞。The disclosure provides a cell comprising the nucleic acid sequence of the disclosure.
本揭示提供一種包括本揭示的載體的細胞。在一些實施例中,細胞穩定地表達本揭示的融合蛋白。在一些實施例中,融合蛋白包含結合元件和降解引發劑,其中結合元件選擇性地結合目標分子,並且其中降解引發劑包含分離或衍生自E3連接酶的序列。在一些實施例中,在能夠表達融合蛋白的細胞中,目標分子是內源分子。在一些實施例中,目標分子是天然存在的分子。The disclosure provides a cell comprising a vector of the disclosure. In some embodiments, cells stably express fusion proteins of the disclosure. In some embodiments, the fusion protein comprises a binding element and a degradation initiator, wherein the binding element selectively binds a target molecule, and wherein the degradation initiator comprises a sequence isolated or derived from an E3 ligase. In some embodiments, the molecule of interest is an endogenous molecule in the cell capable of expressing the fusion protein. In some embodiments, the molecule of interest is a naturally occurring molecule.
本揭示提供一 種包含本揭示的載體的細胞。在一些實施例中,細胞穩定地表現本揭示的第一融合蛋白或第二融合蛋白。The disclosure provides a cell comprising a vector of the disclosure. In some embodiments, the cell stably expresses the first fusion protein or the second fusion protein of the present disclosure.
在本揭示的細胞的一些實施例中,所述細胞是真核細胞。在一些實施例中,細胞是哺乳動物細胞。在一些實施例中,細胞是人類細胞。在一些實施例中,細胞是乾細胞。在一些實施例中,幹細胞是造血細胞。在一些實施例中,幹細胞是間充質細胞。在一些實施例中,細胞是免疫細胞。在一些實施例中,免疫細胞是T細胞、自然殺手(NK)細胞或先天性淋巴細胞(ILC)。In some embodiments of the cells of the present disclosure, the cells are eukaryotic cells. In some embodiments, the cells are mammalian cells. In some embodiments, the cells are human cells. In some embodiments, the cells are stem cells. In some embodiments, the stem cells are hematopoietic cells. In some embodiments, the stem cells are mesenchymal cells. In some embodiments, the cells are immune cells. In some embodiments, the immune cells are T cells, natural killer (NK) cells, or innate lymphoid cells (ILCs).
本揭示提供了一種組合物,其包含(a)本揭示的融合蛋白;或(b) 本揭示中任何一項的組合物;或 (c) 本揭示中任一種的核酸序列;或 (d) 本揭示中任一種的載體;或 (e) 本揭示中任一種的細胞。The disclosure provides a composition comprising (a) the fusion protein disclosed herein; or (b) the composition of any one of the disclosures; or (c) the nucleic acid sequence of any one of the disclosures; or (d) A vector of any of the disclosures; or (e) a cell of any of the disclosures.
本揭示提供了一種藥物組合物,其包含本揭示的組合物和藥學上可接受的載體。The present disclosure provides a pharmaceutical composition, which comprises the composition of the present disclosure and a pharmaceutically acceptable carrier.
本揭示提供了本揭示任一種的融合蛋白;本揭示任一種的組合物的用途;本揭示任一種的核酸序列;本揭示任一種的載體;本揭示任一種的細胞;或本揭示的藥物組合物,用於製備用於治療一疾病或一病症的一藥物。This disclosure provides any fusion protein of this disclosure; the use of any composition of this disclosure; any nucleic acid sequence of this disclosure; any vector of this disclosure; any cell of this disclosure; or the drug combination of this disclosure A substance for the preparation of a medicament for treating a disease or a condition.
本揭示提供了本揭示任一種的融合蛋白;本揭示任一種的組合物的用途;本揭示任一種的核酸序列;本揭示任一種的載體;本揭示任一種的細胞;或本揭示的藥物組合物,用於治療疾病或病症。This disclosure provides any fusion protein of this disclosure; the use of any composition of this disclosure; any nucleic acid sequence of this disclosure; any vector of this disclosure; any cell of this disclosure; or the drug combination of this disclosure substances for the treatment of diseases or conditions.
在本揭示的用途的一些實施例中,該疾病或病症包括一種或多種自身免疫疾病或病症;發炎性疾病或病症;免疫缺陷疾病或失調;缺血性疾病或病症;血液疾病或病症;骨骼疾病或病症;神經系統疾病或病症;心臟疾病或病症;血管疾病或病症;代謝性疾病或病症;皮膚疾病或皮膚病症;消化系統疾病或病症;線粒體疾病或病症;肌肉疾病或病症;肝病或病症;腎臟疾病或病症;聽力疾病或障礙;眼科疾病或病症;和增殖性疾病或病症。In some embodiments of the disclosed uses, the disease or condition comprises one or more of an autoimmune disease or condition; an inflammatory disease or condition; an immunodeficiency disease or disorder; an ischemic disease or condition; diseases or conditions of the nervous system; diseases or conditions of the heart; diseases or conditions of the blood vessels; diseases or conditions of the metabolic system; diseases or conditions of the digestive system; diseases or conditions of the kidney disease or disorder; hearing disease or disorder; ophthalmic disease or disorder; and proliferative disease or disorder.
在本揭示的用途的一些實施例中,這種疾病包括癌症。在一些實施例中,癌症包括選自下列一種或多種的成人急性淋巴細胞白血病(ALL)、成人急性髓系白血病(AML)、腎上腺癌、肛門癌、基底細胞和鱗狀細胞皮膚癌、膽管癌、膀胱癌、骨癌、成人腦和脊髓腫瘤、兒童腦和脊髓腫瘤、乳腺癌、男性乳腺癌、青少年癌症、兒童癌症、年輕人癌症、原發性不明癌症、子宮頸癌、慢性淋巴細胞白血病(CLL)、慢性粒細胞白血病 (CML)、慢性粒單核細胞白血病 (CMML)、結直腸癌、子宮內膜癌、食道癌、尤因腫瘤家族、眼癌(眼部黑色素瘤)、膽囊癌、胃腸道神經內分泌(類癌)腫瘤、胃腸道間質瘤(GIST)、頭頸部癌症、霍奇金淋巴瘤、卡波西肉瘤、腎癌、喉癌和下嚥癌、白血病、兒童白血病、肝癌、肺癌、類肺癌、淋巴瘤、皮膚淋巴瘤、惡性間皮瘤、黑色素瘤皮膚癌、默克爾細胞皮膚癌、多發性骨髓瘤、骨髓增生異常綜合症、鼻腔和鼻竇癌、鼻咽癌、神經母細胞瘤、非霍奇金淋巴瘤、兒童非霍奇金淋巴瘤、口腔(口腔)和口咽(咽喉)癌、骨肉瘤、卵巢癌、胰腺癌、胰腺神經內分泌腫瘤(NET)、陰莖癌、垂體瘤、前列腺癌、視網膜母細胞瘤、橫紋肌肉瘤、唾液腺癌、皮膚癌、小腸癌、軟組織肉瘤、胃癌、睾丸癌、胸腺癌、甲狀腺癌、子宮肉瘤、陰道癌、外陰癌、Waldenstrom 巨球蛋白血症和腎母細胞瘤。In some embodiments of the disclosed uses, the disease comprises cancer. In some embodiments, the cancer comprises adult acute lymphoblastic leukemia (ALL), adult acute myeloid leukemia (AML), adrenal cancer, anal cancer, basal cell and squamous cell skin cancer, cholangiocarcinoma selected from one or more of the following , bladder cancer, bone cancer, adult brain and spinal cord tumors, childhood brain and spinal cord tumors, breast cancer, male breast cancer, adolescent cancer, childhood cancer, young adult cancer, cancer of unknown primary, cervical cancer, chronic lymphocytic leukemia (CLL), chronic myeloid leukemia (CML), chronic myelomonocytic leukemia (CMML), colorectal cancer, endometrial cancer, esophageal cancer, Ewing tumor family, eye cancer (ocular melanoma), gallbladder cancer , neuroendocrine (carcinoid) tumors of the gastrointestinal tract, gastrointestinal stromal tumors (GIST), head and neck cancers, Hodgkin's lymphoma, Kaposi's sarcoma, renal cancer, laryngeal and hypopharyngeal cancers, leukemia, childhood leukemia, Liver cancer, lung cancer, lung cancer, lymphoma, cutaneous lymphoma, malignant mesothelioma, melanoma skin cancer, Merkel cell skin cancer, multiple myeloma, myelodysplastic syndrome, nasal cavity and sinus cancer, nasopharyngeal cancer, Neuroblastoma, Non-Hodgkin's Lymphoma, Pediatric Non-Hodgkin's Lymphoma, Oral (mouth) and Oropharyngeal (Throat) Cancers, Osteosarcoma, Ovarian Cancer, Pancreatic Cancer, Pancreatic Neuroendocrine Tumors (NET), Penis Carcinoma, pituitary tumor, prostate cancer, retinoblastoma, rhabdomyosarcoma, salivary gland cancer, skin cancer, small bowel cancer, soft tissue sarcoma, gastric cancer, testicular cancer, thymus cancer, thyroid cancer, uterine sarcoma, vaginal cancer, vulvar cancer, Waldenstrom's giant Gammaglobulinemia and Wilms tumor.
在本揭示的用途的一些實施例中,疾病或病症包括感染或由傳染病引起的疾病或病症。In some embodiments of the disclosed uses, the disease or condition comprises an infection or a disease or condition caused by an infectious disease.
在本揭示的用途的一些實施例中,該疾病或病症包括遺傳疾病或病症。In some embodiments of the disclosed uses, the disease or condition comprises a genetic disease or condition.
本揭示進一步提供一種治療疾病或病症的方法,包括向受試者施用一有效劑量的本揭示的任一種的融合蛋白、本揭示任一種的組合物、本揭示任一種的核酸序列、本揭示任一種的載體、本揭示任一種的細胞、或本揭示的藥物組合物,其中該疾病或病症的體徵或症狀的嚴重程度減少,從而治療疾病或病症。The present disclosure further provides a method for treating a disease or condition, comprising administering to a subject an effective dose of any fusion protein disclosed herein, any composition disclosed herein, any nucleic acid sequence disclosed herein, any nucleic acid sequence disclosed herein, any A vector of any of the disclosures, a cell of any of the disclosures, or a pharmaceutical composition of the disclosures, wherein the severity of the signs or symptoms of the disease or disorder is reduced, thereby treating the disease or disorder.
本揭示提供了一種治療疾病或病症的方法,包括向受試者施用一有效劑量的本揭示任一種融合蛋白、本揭示任一種組合物、本揭示的任何一種核酸序列、本揭示任何一種載體、本揭示任何一種細胞或藥物組合物,用以延遲或抑制疾病或病症的體徵或症狀的出現或復發,從而預防疾病或病症。The disclosure provides a method for treating a disease or condition, comprising administering to a subject an effective dose of any fusion protein of the disclosure, any composition of the disclosure, any nucleic acid sequence of the disclosure, any carrier of the disclosure, Any cell or pharmaceutical composition disclosed herein is used to delay or inhibit the appearance or recurrence of signs or symptoms of a disease or disorder, thereby preventing the disease or disorder.
在本揭示的方法的一些實施例中,所述疾病或病症包括一種或多種自身免疫性疾病或病症;炎症性疾病或病症;免疫缺陷疾病或病症;缺血性疾病或病症;血液疾病或病症;骨病或病症;神經系統疾病或病症;心髒病或病症;血管疾病或病症;代謝疾病或病症;皮膚病或病症;消化系統疾病或病症;線粒體疾病或病症;肌肉疾病或病症;肝臟疾病或病症;腎臟疾病或病症;聽力疾病或障礙;眼科疾病或病症;和增殖性疾病或病症。In some embodiments of the methods of the present disclosure, the disease or disorder comprises one or more of an autoimmune disease or disorder; an inflammatory disease or disorder; an immunodeficiency disease or disorder; an ischemic disease or disorder; Diseases or conditions of the nervous system; Diseases or conditions of the nervous system; Diseases or conditions of the nervous system; Diseases or conditions of the blood vessels; renal disease or disorder; hearing disease or disorder; ophthalmic disease or disorder; and proliferative disease or disorder.
在本揭示的方法的一些實施例中,這種疾病包括癌症。在一些實施例中,這種癌症包括選自下列一種或多種的成人急性淋巴細胞白血病(ALL)、成人急性髓系白血病(AML)、腎上腺癌、肛門癌、基底細胞和鱗狀細胞皮膚癌、膽管癌、膀胱癌、骨癌、成人腦和脊髓腫瘤、兒童腦和脊髓腫瘤、乳腺癌、男性乳腺癌、青少年癌症、兒童癌症、年輕人癌症、原發性不明癌症、子宮頸癌、慢性淋巴細胞白血病(CLL)、慢性粒細胞白血病 (CML)、慢性粒單核細胞白血病 (CMML)、結直腸癌、子宮內膜癌、食道癌、尤因腫瘤家族、眼癌(眼部黑色素瘤)、膽囊癌、胃腸道神經內分泌(類癌)腫瘤、胃腸道間質瘤(GIST)、頭頸部癌症、霍奇金淋巴瘤、卡波西肉瘤、腎癌、喉癌和下嚥癌、白血病、兒童白血病、肝癌、肺癌、類肺癌、淋巴瘤、皮膚淋巴瘤、惡性間皮瘤、黑色素瘤皮膚癌、默克爾細胞皮膚癌、多發性骨髓瘤、骨髓增生異常綜合症、鼻腔和鼻竇癌、鼻咽癌、神經母細胞瘤、非霍奇金淋巴瘤、兒童非霍奇金淋巴瘤、口腔(口腔)和口咽(咽喉)癌、骨肉瘤、卵巢癌、胰腺癌、胰腺神經內分泌腫瘤(NET)、陰莖癌、垂體瘤、前列腺癌、視網膜母細胞瘤、橫紋肌肉瘤、唾液腺癌、皮膚癌、小腸癌、軟組織肉瘤、胃癌、睾丸癌、胸腺癌、甲狀腺癌、子宮肉瘤、陰道癌、外陰癌、Waldenstrom 巨球蛋白血症和腎母細胞瘤。In some embodiments of the disclosed methods, the disease comprises cancer. In some embodiments, the cancer includes adult acute lymphoblastic leukemia (ALL), adult acute myeloid leukemia (AML), adrenal cancer, anal cancer, basal cell and squamous cell skin cancer selected from one or more of the following, Cholangiocarcinoma, bladder cancer, bone cancer, adult brain and spinal cord tumors, childhood brain and spinal cord tumors, breast cancer, male breast cancer, adolescent cancer, childhood cancer, young adult cancer, cancer of unknown primary, cervical cancer, chronic lymphatic Cellular leukemia (CLL), chronic myeloid leukemia (CML), chronic myelomonocytic leukemia (CMML), colorectal cancer, endometrial cancer, esophageal cancer, Ewing tumor family, eye cancer (ocular melanoma), Gallbladder cancer, Gastrointestinal neuroendocrine (carcinoid) tumors, Gastrointestinal stromal tumor (GIST), Head and neck cancers, Hodgkin lymphoma, Kaposi's sarcoma, Kidney cancer, Laryngeal and hypopharyngeal cancers, Leukemia, Children Leukemia, liver cancer, lung cancer, lung cancer, lymphoma, cutaneous lymphoma, malignant mesothelioma, melanoma skin cancer, Merkel cell skin cancer, multiple myeloma, myelodysplastic syndrome, nasal cavity and sinus cancer, nasopharynx Carcinoma, Neuroblastoma, Non-Hodgkin's Lymphoma, Pediatric Non-Hodgkin's Lymphoma, Oral (Mouth) and Oropharyngeal (Throat) Cancers, Osteosarcoma, Ovarian Cancer, Pancreatic Cancer, Pancreatic Neuroendocrine Tumors (NET) , penile cancer, pituitary tumor, prostate cancer, retinoblastoma, rhabdomyosarcoma, salivary gland cancer, skin cancer, small intestine cancer, soft tissue sarcoma, stomach cancer, testicular cancer, thymus cancer, thyroid cancer, uterine sarcoma, vaginal cancer, vulvar cancer, Waldenstrom's macroglobulinemia and Wilms tumor.
在本揭示的方法的一些實施例中,疾病或病症包括感染或由傳染病引起的疾病或病症。In some embodiments of the methods of the present disclosure, the disease or condition comprises an infection or a disease or condition caused by an infectious disease.
在本揭示的方法的一些實施例中,疾病或病症包括遺傳疾病或病症。In some embodiments of the methods of the present disclosure, the disease or condition comprises a genetic disease or condition.
本揭示提供了一種多核苷酸組,包括:(a)編碼包含第一結合元件的第一融合蛋白的第一多核苷酸;以及(b) 編碼包含第二結合元件的第二融合蛋白的第二多核苷酸;其中:(i)第一融合蛋白或第二融合蛋白進一步包含降解引發劑或其功能變體;及(ii)第一融合蛋白或第二融合蛋白中的另一個進一步包含感興趣的目標分子;(iii)第一結合元件和第二結合元件的相互作用介導降解引發劑集中到感興趣的目標分子以引發降解。The disclosure provides a set of polynucleotides comprising: (a) a first polynucleotide encoding a first fusion protein comprising a first binding element; and (b) a second fusion protein encoding a second binding element A second polynucleotide; wherein: (i) the first fusion protein or the second fusion protein further comprises a degradation initiator or a functional variant thereof; and (ii) the other of the first fusion protein or the second fusion protein further comprising a target molecule of interest; (iii) the interaction of the first binding element and the second binding element mediates the concentration of the degradation initiator to the target molecule of interest to initiate degradation.
在本揭示的多核苷酸組的一些實施例中,第一和第二結合元件包含一對異二聚體蛋白。在一些實施例中,該對異二聚體蛋白包含具有一個或兩個亞基的二聚體,所述亞基由單螺旋亞基組成。在一些實施例中,該對異二聚體蛋白質包含具有一個或兩個亞基的二聚體,所述亞基由雙螺旋亞基組成。在一些實施例中,該對異二聚體蛋白包含具有一個或兩個亞基的二聚體,所述亞基由多螺旋亞基組成。在一些實施例中,該對異二聚體蛋白包含三螺旋亞基和單螺旋亞基。在一些實施例中,該對異二聚體蛋白質包含非螺旋亞基。在一些實施例中,第一或第二結合元件選自:DHD37-short-A (SEQ ID NO:11) 和DHD37-short-B (SEQ ID NO:13)、DHD37-short-B -Ntrunc (SEQ ID NO:15),或 DHD37-short-B-KtoR (SEQ ID NO:16)所組成的群組中。In some embodiments of the disclosed set of polynucleotides, the first and second binding elements comprise a pair of heterodimeric proteins. In some embodiments, the pair of heterodimeric proteins comprises a dimer having one or two subunits consisting of single helical subunits. In some embodiments, the pair of heterodimeric proteins comprises a dimer having one or two subunits consisting of double helical subunits. In some embodiments, the pair of heterodimeric proteins comprises a dimer with one or two subunits consisting of multihelical subunits. In some embodiments, the pair of heterodimeric proteins comprises a triple helical subunit and a single helical subunit. In some embodiments, the pair of heterodimeric proteins comprises non-helical subunits. In some embodiments, the first or second binding element is selected from: DHD37-short-A (SEQ ID NO: 11) and DHD37-short-B (SEQ ID NO: 13), DHD37-short-B-Ntrunc ( SEQ ID NO: 15), or the group consisting of DHD37-short-B-KtoR (SEQ ID NO: 16).
在本揭示的多核苷酸組的一些實施例中,選擇第一結合元件和第二結合元件,以便通過小分子的存在來介導第一結合元件和第二結合元件的相互作用。In some embodiments of the disclosed set of polynucleotides, the first binding element and the second binding element are selected such that the interaction of the first binding element and the second binding element is mediated by the presence of the small molecule.
在本揭示的多核苷酸組的一些實施例中,如上述之多核苷酸組,其中:(a)第一結合元件或第二結合元件包含NS3a;(b)該第一結合元件或第二結合元件中的另一個選自DNCR2和GNCR1所組成的群組中;以及(c)其中選擇該第一結合元件和第二結合元件,使得該第一結合元件和第二結合元件的相互作用通過小分子的存在來調節。在一些實施例中,小分子調節第一結合元件和第二結合元件的結合。在一些實施例中,小分子破壞第一結合元件和第二結合元件的結合。在一些實施例中,第二小分子通過與第一小分子競爭而破壞第一結合元件和第二結合元件的結合。在一些實施例中,細胞中第一結合元件和第二結合元件的相互作用相對於向細胞施用小分子是可滴定的。在一些實施例中,小分子選自:達諾瑞韋和格拉唑瑞韋及其類似物。In some embodiments of the set of polynucleotides disclosed herein, the set of polynucleotides described above, wherein: (a) the first binding element or the second binding element comprises NS3a; (b) the first binding element or the second binding element Another one of the binding elements is selected from the group consisting of DNCR2 and GNCR1; and (c) wherein the first binding element and the second binding element are selected such that the interaction of the first binding element and the second binding element is achieved by The presence of small molecules to regulate. In some embodiments, the small molecule modulates the binding of the first binding element and the second binding element. In some embodiments, the small molecule disrupts the binding of the first binding element and the second binding element. In some embodiments, the second small molecule disrupts the binding of the first binding element and the second binding element by competing with the first small molecule. In some embodiments, the interaction of the first binding member and the second binding member in the cell is titratable relative to administration of the small molecule to the cell. In some embodiments, the small molecule is selected from: danoprevir and glazoprevir and analogs thereof.
在本揭示的多核苷酸組的一些實施例中,感興趣的分子包括合成分子或外源分子。In some embodiments of the disclosed polynucleotide sets, the molecules of interest include synthetic molecules or exogenous molecules.
在本揭示的多核苷酸組的一些實施例中,合成分子或外源分子包含蛋白質。In some embodiments of the sets of polynucleotides disclosed herein, the synthetic or exogenous molecules comprise proteins.
在本揭示的多核苷酸組的一些實施例中,第一多核苷酸和第二多核苷酸在單一載體上。In some embodiments of the set of polynucleotides of the present disclosure, the first polynucleotide and the second polynucleotide are on a single vector.
在本揭示的多核苷酸組的一些實施例中,該多核苷酸組包含至少兩個載體,該載體包括:(a) 包含第一多核苷酸的第一載體;(b)包含第二多核苷酸的第二載體。In some embodiments of the set of polynucleotides disclosed herein, the set of polynucleotides comprises at least two vectors comprising: (a) a first vector comprising a first polynucleotide; (b) a second vector comprising A secondary vector for the polynucleotide.
在本揭示的多核苷酸組的一些實施例中,多核苷酸組被整合到一載體骨架中。在一些實施例中,載體骨架選自腺病毒載體、慢病毒載體、桿狀病毒載體、Epstein Barr病毒載體、多空病毒載體、牛痘病毒載體、單純皰疹病毒載體、腺相關病毒(AAV)載體和轉座子載體的骨架所組成的群組中。在一些實施例中,該載體骨架包含同源定向修復載體。In some embodiments of the set of polynucleotides disclosed herein, the set of polynucleotides is incorporated into a vector backbone. In some embodiments, the vector backbone is selected from adenoviral vectors, lentiviral vectors, baculoviral vectors, Epstein Barr viral vectors, polyvacuum viral vectors, vaccinia viral vectors, herpes simplex viral vectors, adeno-associated viral (AAV) vectors and the backbone of the transposon vector. In some embodiments, the vector backbone comprises a homology directed repair vector.
在本揭示的多核苷酸組的一些實施例中,多核苷酸組被整合到染色體中。In some embodiments of the set of polynucleotides disclosed herein, the set of polynucleotides is integrated into a chromosome.
在本揭示的多核苷酸組的一些實施例中,編碼第一融合蛋白或第二融合蛋白的第一多核苷酸及/或第二多核苷酸可操作地連接到包含一個或多個啟動子序列的多核苷酸成分。In some embodiments of the disclosed set of polynucleotides, the first polynucleotide encoding the first fusion protein or the second fusion protein and/or the second polynucleotide is operably linked to a polynucleotide comprising one or more The polynucleotide component of the promoter sequence.
在本揭示的多核苷酸組的一些實施例中,(a)編碼包含降解引發劑或其功能變體的第一融合蛋白或第二融合蛋白的第一多核苷酸或第二多核苷酸可操作地連接至編碼包括誘導型啟動子序列的多核苷酸成分;以及(b)編碼包含感興趣的分子的第一融合蛋白或第二融合蛋白的第一多核苷酸或第二多核苷酸可操作地連接至編碼包括組成型啟動子序列的多核苷酸成分。In some embodiments of the set of polynucleotides of the present disclosure, (a) a first polynucleotide or a second polynucleoside encoding a first fusion protein or a second fusion protein comprising a degradation initiator or a functional variant thereof The acid is operably linked to a polynucleotide component encoding a sequence comprising an inducible promoter; and (b) a first polynucleotide or a second polynucleotide encoding a first fusion protein or a second fusion protein comprising a molecule of interest Nucleotides are operably linked to elements encoding polynucleotides that include constitutive promoter sequences.
在本揭示的多核苷酸組的一些實施例中,(a)編碼包含降解引發劑或其功能變體的第一融合蛋白或第二融合蛋白的第一多核苷酸或第二多核苷酸與編碼第一誘導型啟動子序列的多核苷酸成分操作性連接;以及(b)編碼包含感興趣分子的第一融合蛋白或第二融合蛋白的第一多核苷酸或第二多核苷酸可操作地連接至編碼第二誘導型啟動子序列的多核苷酸成分。In some embodiments of the set of polynucleotides of the present disclosure, (a) a first polynucleotide or a second polynucleoside encoding a first fusion protein or a second fusion protein comprising a degradation initiator or a functional variant thereof Acid is operably linked to a polynucleotide component encoding a first inducible promoter sequence; and (b) a first polynucleotide or a second polynucleotide encoding a first fusion protein or a second fusion protein comprising a molecule of interest The nucleotide is operably linked to the polynucleotide component encoding the second inducible promoter sequence.
在本揭示的多核苷酸組的一些實施例中,編碼第一融合蛋白的第一多核苷酸和編碼第二融合蛋白的第二多核苷酸包含一組兩個或更多多核苷酸成分。In some embodiments of the set of polynucleotides of the present disclosure, the first polynucleotide encoding the first fusion protein and the second polynucleotide encoding the second fusion protein comprise a set of two or more polynucleotides Element.
本揭示提供一種多核苷酸組,其中編碼第一融合蛋白的第一多核苷酸和編碼第二融合蛋白的第二多核苷酸包含單一個多核苷酸組分。在一些實施例中,編碼第一融合蛋白的多核苷酸組分和編碼第二融合蛋白的多核苷酸由包含防止第一融合蛋白和第二融合蛋白融合的多核苷酸序列的分離元件分開。在一些實施例中,分離元件包含多核苷酸序列,該多核苷酸序列包含核醣體跳躍序列。在一些實施例中,分離元件包括含有至少兩個核醣體跳躍序列的多核苷酸序列。在一些實施例中,核醣體跳躍序列包括含有P2a及/或T2a的多核苷酸序列。在一些實施例中,分離元件包含選自由以下群組組成的多核苷酸序列:P2a、T2a、T2a-RFP-P2a、P2a-T2a、T2a-P2a和IRES。在一些實施例中,分離元件包括含有第二組成型啟動子的多核苷酸序列。The present disclosure provides a set of polynucleotides wherein a first polynucleotide encoding a first fusion protein and a second polynucleotide encoding a second fusion protein comprise a single polynucleotide component. In some embodiments, the polynucleotide component encoding the first fusion protein and the polynucleotide encoding the second fusion protein are separated by a separation element comprising a polynucleotide sequence that prevents fusion of the first fusion protein and the second fusion protein. In some embodiments, the separation element comprises a polynucleotide sequence comprising a ribosomal skipping sequence. In some embodiments, the separation element comprises a polynucleotide sequence comprising at least two ribosomal skipping sequences. In some embodiments, the ribosomal skipping sequence comprises a polynucleotide sequence comprising P2a and/or T2a. In some embodiments, the isolated element comprises a polynucleotide sequence selected from the group consisting of: P2a, T2a, T2a-RFP-P2a, P2a-T2a, T2a-P2a, and IRES. In some embodiments, the isolated element comprises a polynucleotide sequence comprising a second constitutive promoter.
在本揭示的多核苷酸組的一些實施例中,組成型啟動子序列選自由下列組成的群組:MND、hPGK、CMV、CAG、SFFV、EF1α、UBC和CD43。In some embodiments of the disclosed polynucleotide sets, the constitutive promoter sequence is selected from the group consisting of: MND, hPGK, CMV, CAG, SFFV, EF1α, UBC, and CD43.
在本揭示的多核苷酸組的一些實施例中,誘導型啟動子序列包括選自由下列組成的群組中的最小啟動子序列:YB_TATA、人類β球蛋白(huBG)、minIL2、minimalCMV (minCMV)和TRE3G。In some embodiments of the disclosed polynucleotide sets, the inducible promoter sequence comprises a minimal promoter sequence selected from the group consisting of: YB_TATA, human beta globin (huBG), minIL2, minimalCMV (minCMV) and TRE3G.
在本揭示的多核苷酸組的一些實施例中,誘導型啟動子序列包含轉錄因子特異性識別序列,該識別序列包含轉錄因子特異性反應元件。在一些實施例中,轉錄因子特異性反應元件包括選自由下列組成的群組中的多核苷酸:NFAT-AP1。在一些實施例中,轉錄因子反應元件是重複片段的。在一些實施例中,轉錄因子特異性反應元件具有2、3、4、5、6、7、8、9、10或更多個重複片段。In some embodiments of the disclosed set of polynucleotides, the inducible promoter sequence comprises a transcription factor specific recognition sequence comprising a transcription factor specific response element. In some embodiments, the transcription factor specific response element comprises a polynucleotide selected from the group consisting of: NFAT-AP1. In some embodiments, the transcription factor response elements are repeats. In some embodiments, the transcription factor specific response element has 2, 3, 4, 5, 6, 7, 8, 9, 10 or more repeats.
本揭示提供一種多核苷酸組,其包括編碼融合蛋白的單一個多核苷酸組分,該融合蛋白包括:(a) 對目標分子上的天然基序特異的結合元件;以及(b)降解引發劑;並且其中融合蛋白與該目標分子的結合調節降解引發劑重新集合到該目標分子以啟動降解。在一些實施例中,感興趣的分子包括內源分子。在一些實施例中,內源分子包含蛋白質。在一些實施例中,融合蛋白與感興趣的分子的結合包括構象特異性相互作用。在一些實施例中,融合蛋白與感興趣的分子的結合對應於分子上的特定修飾。在一些實施例中,對分子的特定修飾包括轉譯後修飾。在一些實施例中,轉譯後修飾包括磷酸化。在一些實施例中,結合元件包含對蛋白質-蛋白質相互作用結構域特異的結構域。在一些實施例中,結合元件包含單鏈可變片段(scFVf)。在一些實施例中,結合元件包含單體可變抗體結構域。在一些實施例中,結合元件包含設計的錨蛋白重複蛋白結構域(DARPin)。在一些實施例中,結合元件包含可變淋巴細胞受體(VLR)結構域。The present disclosure provides a set of polynucleotides comprising a single polynucleotide component encoding a fusion protein comprising: (a) a binding element specific for a native motif on a molecule of interest; and (b) a degradation trigger agent; and wherein binding of the fusion protein to the target molecule modulates reassembly of the degradation initiator to the target molecule to initiate degradation. In some embodiments, molecules of interest include endogenous molecules. In some embodiments, endogenous molecules comprise proteins. In some embodiments, binding of the fusion protein to the molecule of interest involves conformation-specific interactions. In some embodiments, the binding of the fusion protein to the molecule of interest corresponds to specific modifications on the molecule. In some embodiments, specific modifications to molecules include post-translational modifications. In some embodiments, post-translational modifications include phosphorylation. In some embodiments, the binding element comprises a domain specific for a protein-protein interaction domain. In some embodiments, the binding element comprises a single chain variable fragment (scFVf). In some embodiments, the binding element comprises a monomeric variable antibody domain. In some embodiments, the binding element comprises a designed ankyrin repeat protein domain (DARPin). In some embodiments, the binding element comprises a variable lymphocyte receptor (VLR) domain.
在本揭示的多核苷酸組的一些實施例中,降解引發劑包含E3泛素連接酶結構域或其任何功能變體。In some embodiments of the disclosed polynucleotide sets, the degradation initiator comprises an E3 ubiquitin ligase domain or any functional variant thereof.
本揭示進一步提供一種包括本揭示的多核苷酸組的細胞。在一些實施例中,細胞是原核細胞。在一些實施例中,細胞是酵母細胞。在一些實施例中,細胞是哺乳動物細胞。在一些實施例中,細胞是人類細胞。在一些實施例中,細胞是體內的人類細胞。在一些實施例中,細胞是離體的人類細胞。在一些實施例中,細胞是幹細胞。在一些實施例中,細胞是多能幹細胞。在一些實施例中,細胞是多能幹細胞。在一些實施例中,細胞是造血幹細胞。在一些實施例中,細胞是間充質基質細胞。在一些實施例中,細胞是間充質細胞。在一些實施例中,細胞是選擇用於細胞療法的自體細胞或者是選擇用於細胞療法的自體細胞的後代。在一些實施例中,細胞是選擇用於細胞療法的同種異體細胞或者是選擇用於細胞療法的同種異體細胞的後代。The disclosure further provides a cell comprising the set of polynucleotides of the disclosure. In some embodiments, the cells are prokaryotic cells. In some embodiments, the cells are yeast cells. In some embodiments, the cells are mammalian cells. In some embodiments, the cells are human cells. In some embodiments, the cells are human cells in vivo. In some embodiments, the cells are ex vivo human cells. In some embodiments, the cells are stem cells. In some embodiments, the cells are pluripotent stem cells. In some embodiments, the cells are pluripotent stem cells. In some embodiments, the cells are hematopoietic stem cells. In some embodiments, the cells are mesenchymal stromal cells. In some embodiments, the cells are mesenchymal cells. In some embodiments, the cells are autologous cells selected for cell therapy or progeny of autologous cells selected for cell therapy. In some embodiments, the cells are allogeneic cells selected for cell therapy or progeny of allogeneic cells selected for cell therapy.
本揭示提供一種實現幹細胞分化的方法,包括使用本揭示的多核苷酸組的多肽組修飾幹細胞。在一些實施例中,細胞是癌細胞。在一些實施例中,細胞是來自被診斷患有癌症的人類受試者的非癌細胞。在一些實施例中,細胞是免疫細胞。在一些實施例中,細胞選自白細胞、淋巴細胞、T細胞、調節性T細胞、效應T細胞、CD4+效應T細胞、CD8+效應T細胞、記憶T細胞、自身反應性T細胞、衰竭T細胞、自然殺手 T 細胞、B 細胞、樹突狀細胞和巨噬細胞。在一些實施例中,細胞選自心肌細胞、肺細胞、肌細胞、上皮細胞、胰腺細胞、皮膚細胞、CNS細胞、神經元、肌細胞、骨骼肌細胞、平滑肌細胞、肝細胞、腎細胞和膠質細胞。The present disclosure provides a method of achieving differentiation of stem cells comprising modifying the stem cells using the polypeptide set of the polynucleotide set of the present disclosure. In some embodiments, the cells are cancer cells. In some embodiments, the cells are non-cancerous cells from a human subject diagnosed with cancer. In some embodiments, the cells are immune cells. In some embodiments, the cells are selected from the group consisting of leukocytes, lymphocytes, T cells, regulatory T cells, effector T cells, CD4+ effector T cells, CD8+ effector T cells, memory T cells, autoreactive T cells, exhausted T cells, Natural killer T cells, B cells, dendritic cells and macrophages. In some embodiments, the cells are selected from cardiomyocytes, lung cells, myocytes, epithelial cells, pancreatic cells, skin cells, CNS cells, neurons, myocytes, skeletal muscle cells, smooth muscle cells, liver cells, kidney cells, and glia cell.
本揭示提供了一種經遺傳修飾以表現CAR的細胞,其包含本揭示的多核苷酸組。在一些實施例中,細胞是T細胞、自然殺手(NK)細胞、自然殺手T(NKT)細胞或ILC細胞。The disclosure provides a cell genetically modified to express a CAR comprising the set of polynucleotides of the disclosure. In some embodiments, the cells are T cells, natural killer (NK) cells, natural killer T (NKT) cells, or ILC cells.
本揭示提供了一種包含本揭示的多核苷酸組的病毒殼體。在一些實施例中,病毒殼體選自腺病毒、慢病毒、杆狀病毒、愛潑斯坦-巴爾病毒、巴氏病毒、痘苗病毒、皰疹病毒、單純皰疹病毒和腺相關病毒的殼體。The disclosure provides a capsid comprising the set of polynucleotides of the disclosure. In some embodiments, the viral capsid is selected from capsids of adenovirus, lentivirus, baculovirus, Epstein-Barr virus, Barr virus, vaccinia virus, herpes virus, herpes simplex virus, and adeno-associated virus .
本揭示提供了一種產生本揭示的病毒殼體的細胞。在一些實施例中,病毒殼體選自腺病毒、慢病毒、杆狀病毒、愛潑斯坦-巴爾病毒、巴氏病毒、痘苗病毒、皰疹病毒、單純皰疹病毒和腺相關病毒的殼體。The disclosure provides a cell that produces capsids of the disclosure. In some embodiments, the viral capsid is selected from capsids of adenovirus, lentivirus, baculovirus, Epstein-Barr virus, Barr virus, vaccinia virus, herpes virus, herpes simplex virus, and adeno-associated virus .
本揭示提供一種組合物,包括本揭示的多核苷酸組。The present disclosure provides a composition comprising the set of polynucleotides of the present disclosure.
本揭示提供一種用途,包括本揭示的組合物,包括包含本揭示的多核苷酸組的組合物,用於治療需要CAR治療的受試者。The present disclosure provides a use comprising a composition of the present disclosure, including a composition comprising a polynucleotide set of the present disclosure, for treating a subject in need of CAR therapy.
本揭示提供一種包含本揭示的多核苷酸組的試劑盒。The disclosure provides a kit comprising the set of polynucleotides of the disclosure.
本揭示還提供一種製備工程化細胞的方法,包括將本揭示的任何一組多核苷酸的多核苷酸引入細胞。在一些實施例中,多肽在細胞中表達。在一些實施例中,該方法還包括在需要細胞的受試者中施用細胞。在一些實施例中,該方法還包括向受試者施用小分子。The present disclosure also provides a method of making an engineered cell comprising introducing a polynucleotide of any set of polynucleotides of the present disclosure into the cell. In some embodiments, the polypeptide is expressed in a cell. In some embodiments, the method further comprises administering the cells to the subject in need thereof. In some embodiments, the method further comprises administering the small molecule to the subject.
本揭示還提供了一種在有需要的受試者中控制T細胞介導的免疫反應的方法,包括向受試者施用一有效劑量的本揭示的細胞。The present disclosure also provides a method of controlling a T cell-mediated immune response in a subject in need thereof, comprising administering to the subject an effective dose of the cells of the present disclosure.
本揭示還提供一種在有需要的受試者中提供抗腫瘤免疫的方法,該方法包括向受試者施用一有效劑量的本揭示的細胞。在一些實施例中,細胞是T細胞。在一些實施例中,細胞是自體T細胞。在一些實施例中,細胞是同種異體T細胞。在一些實施例中,該方法還包括向受試者施用小分子。The present disclosure also provides a method of providing anti-tumor immunity in a subject in need thereof, the method comprising administering to the subject an effective dose of the cells of the present disclosure. In some embodiments, the cells are T cells. In some embodiments, the cells are autologous T cells. In some embodiments, the cells are allogeneic T cells. In some embodiments, the method further comprises administering the small molecule to the subject.
本揭示還提供一種在有需要的受試者中治療癌症的方法,包括向受試者施用一有效劑量的本揭示的細胞。在一些實施例中,細胞是T細胞。在一些實施例中,細胞是自體T細胞。在一些實施例中,細胞是同種異體T細胞。在一些實施例中,該方法還包括向受試者施用小分子。The present disclosure also provides a method of treating cancer in a subject in need thereof, comprising administering to the subject an effective dose of the cells of the present disclosure. In some embodiments, the cells are T cells. In some embodiments, the cells are autologous T cells. In some embodiments, the cells are allogeneic T cells. In some embodiments, the method further comprises administering the small molecule to the subject.
本揭示還提供一種基因治療方法,其中包括:(a) 一多核苷酸組,包括一降解引發劑,可操作地連接到小分子調節啟動子;以及(b) 治療分子;該方法包括向有需要的受試者施用一治療有效劑量的本揭示的多核苷酸組。在一些實施例中,該方法還包括向受試者施用小分子。在一些實施例中,該方法進一步包括調整小分子的劑量以調整受試者中治療分子的含量。在一些實施例中,該方法進一步包括(a) 監測受試者中治療分子的產生;以及(b)調整小分子的劑量以將受試者中治療分子的含量調整至所需含量。在一些實施例中,受試者患有選自於下列組成的群組的病症:癌症、囊性纖維化、心髒病、糖尿病、血友病和AIDS。The present disclosure also provides a gene therapy method comprising: (a) a set of polynucleotides, including a degradation initiator, operably linked to a small molecule regulated promoter; and (b) a therapeutic molecule; the method comprising adding A subject in need thereof is administered a therapeutically effective dose of a panel of polynucleotides of the present disclosure. In some embodiments, the method further comprises administering the small molecule to the subject. In some embodiments, the method further comprises adjusting the dose of the small molecule to adjust the amount of the therapeutic molecule in the subject. In some embodiments, the method further comprises (a) monitoring production of the therapeutic molecule in the subject; and (b) adjusting the dose of the small molecule to adjust the level of the therapeutic molecule in the subject to a desired level. In some embodiments, the subject has a condition selected from the group consisting of cancer, cystic fibrosis, heart disease, diabetes, hemophilia, and AIDS.
本揭示還提供一種本揭示的多核苷酸組用於製造用於治療有需要的受試者癌症的藥物的用途。The present disclosure also provides a use of the polynucleotide set of the present disclosure for the manufacture of a medicament for treating cancer in a subject in need thereof.
核酸和相關術語Nucleic Acids and Related Terms
在一些實施例中,本文所用術語“核酸”、“核酸分子”、“核苷酸”、“核苷酸序列”、“多核苷酸”及其語法變體可以互換使用,並指核糖核苷(腺苷、鳥苷、尿苷或胞苷;“RNA分子”)或去氧核糖核苷的磷酸酯聚合形式(去氧腺苷、去氧鳥苷、去氧胸苷或去氧胞苷;“DNA分子”)或其任何磷酸酯類似物,如單鏈或雙鏈螺旋的硫代磷酸酯和硫酯。單鏈核酸序列是指單鏈DNA(ssDNA)或單鏈RNA(ssRNA)。雙鏈DNA-DNA、DNA-RNA和RNA-RNA螺旋是可能的。In some embodiments, the terms "nucleic acid", "nucleic acid molecule", "nucleotide", "nucleotide sequence", "polynucleotide" and grammatical variants thereof are used interchangeably herein and refer to ribonucleoside (adenosine, guanosine, uridine, or cytidine; "RNA molecule") or the phosphate polymerized form of deoxyribonucleosides (deoxyadenosine, deoxyguanosine, deoxythymidine, or deoxycytidine; "DNA molecule") or any of its phosphate analogues, such as single-stranded or double-stranded helical phosphorothioates and thioesters. Single-stranded nucleic acid sequence refers to single-stranded DNA (ssDNA) or single-stranded RNA (ssRNA). Double-stranded DNA-DNA, DNA-RNA and RNA-RNA helices are possible.
在一些實施例中,本文所用術語“核酸”,特別是DNA或RNA分子,可以僅指分子的一級和二級結構,並且不將其限制為任何特定的三級形式。因此,該術語包括尤其存在於線性或環狀 DNA 分子(例如限制性片段)、質粒、超螺旋 DNA 和染色體中的雙鏈 DNA。在討論特定雙鏈DNA分子的結構時,按照正常慣例,沿著DNA的非轉錄鏈(即,具有與信使RNA或mRNA同源的序列的鏈),從左到右沿5’到3’方向書寫序列。除非另有說明,否則所有核酸和核苷酸序列均以 5' 到 3' 方向從左到右書寫。In some embodiments, the term "nucleic acid" as used herein, particularly a DNA or RNA molecule, may refer only to the primary and secondary structure of the molecule, and does not limit it to any particular tertiary form. Thus, the term includes double-stranded DNA found inter alia in linear or circular DNA molecules (such as restriction fragments), plasmids, supercoiled DNA, and chromosomes. When discussing the structure of a particular double-stranded DNA molecule, it is normal convention to follow the 5' to 3' direction from left to right along the non-transcribed strand of DNA (that is, the strand with sequence homology to messenger RNA or mRNA) Write the sequence. Unless otherwise indicated, all nucleic acids and nucleotide sequences are written left to right in 5' to 3' orientation.
IUPAC-IUB 生化命名委員會推薦的眾所周知的單字母符號表示核苷酸。因此,“A”代表腺嘌呤,“C”代表胞嘧啶,“G”代表鳥糞嘌呤,“T”代表胸腺嘧啶,“U”代表尿嘧啶。Nucleotides are denoted by the well-known single-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Thus, "A" stands for adenine, "C" for cytosine, "G" for guanine, "T" for thymine, and "U" for uracil.
在一些實施例中,本文所用術語“多核苷酸”是指任何長度或類型的核苷酸的聚合物,包括核糖核苷酸、脫氧核糖核苷酸、其類似物或它們的混合物。該術語是指分子的一級結構。因此,該術語包括三鏈、雙鍊和單鏈脫氧核糖核酸(“DNA”)和核糖核酸(“RNA”)。其還包括修飾的,例如通過烷基化及/或通過加帽修飾的和未修飾的多核苷酸形式。更具體地說,“多核苷酸”包括多去氧核糖核苷酸(含2-去氧-D-核糖)和多核糖核苷酸(含D-核糖),包括mRNA,無論是剪接的還是未剪接的,作為嘌呤或嘧啶鹼基的N-或C-糖苷的任何其他類型的多核苷酸,以及包含核苷酸骨架的其他聚合物,例如,聚醯胺(例如,肽核酸“PNA”)和多嗎啉聚合物,以及其他合成序列特異性核酸聚合物,前提是這些聚合物包含允許鹼基配對和堿基堆疊的構型中的鹼基,如脫氧核糖核酸和核糖核酸中的鹼基。In some embodiments, the term "polynucleotide" as used herein refers to a polymer of nucleotides of any length or type, including ribonucleotides, deoxyribonucleotides, analogs thereof, or mixtures thereof. The term refers to the primary structure of a molecule. Accordingly, the term includes triple-, double-, and single-stranded deoxyribonucleic acid ("DNA") and ribonucleic acid ("RNA"). It also includes modified, for example by alkylation and/or by capping, and unmodified polynucleotide forms. More specifically, "polynucleotide" includes polydeoxyribonucleotides (containing 2-deoxy-D-ribose) and polyribonucleotides (containing D-ribose), including mRNA, whether spliced or Unspliced, any other type of polynucleotide that is an N- or C-glycoside of a purine or pyrimidine base, and other polymers containing a nucleotide backbone, for example, polyamide (e.g., peptide nucleic acid "PNA" ) and polymorpholine polymers, and other synthetic sequence-specific nucleic acid polymers, provided that these polymers contain bases in configurations that allow base pairing and base stacking, such as those in deoxyribonucleic acid and ribonucleic acid base.
在一些實施例中,本揭示的載體包含本揭示的核酸序列和(多個)骨架序列。In some embodiments, a vector of the disclosure comprises a nucleic acid sequence and a backbone sequence(s) of the disclosure.
在一些實施例中,多核苷酸包括DNA,例如插入載體中的DNA。在其他實施例,多核苷酸包括mRNA。在一些實施例,mRNA是合成的mRNA。在一些實施例中,合成的mRNA包括至少一種非天然核鹼基。在一些實施例中,某一類的所有核鹼基已被非天然核鹼基替換(例如,多核苷酸中的所有尿苷都可以被非天然核鹼基替換,例如5-甲氧基尿苷)。In some embodiments, a polynucleotide comprises DNA, eg, inserted into a vector. In other embodiments, the polynucleotide comprises mRNA. In some embodiments, the mRNA is synthetic mRNA. In some embodiments, the synthetic mRNA includes at least one non-natural nucleobase. In some embodiments, all nucleobases of a class have been replaced with non-natural nucleobases (e.g., all uridines in a polynucleotide may be replaced with non-natural nucleobases, such as 5-methoxyuridine ).
在一些實施例中,本文所用術語“表現”是指由啟動子驅動的特定核苷酸序列的轉錄及/或轉譯。In some embodiments, the term "expression" as used herein refers to the transcription and/or translation of a specific nucleotide sequence driven by a promoter.
在一些實施例中,本文所用術語“表現載體”是指設計用於在細胞中表達多肽的質粒、病毒或其他核酸。載體或構建體用於將基因引入宿主細胞,由此載體將與細胞中的聚合酶相互作用以表現載體/構建體中編碼的蛋白質。表現載體可以存在於染色體外的細胞中或可以整合到染色體中。表現載體可以包括使載體適合在原核生物、真核生物或優選兩者中複製和整合的附加序列(例如,穿梭載體)。本揭示的多核苷酸可以作為表現載體的組成提供。In some embodiments, the term "expression vector" as used herein refers to a plasmid, virus or other nucleic acid designed to express a polypeptide in a cell. A vector or construct is used to introduce a gene into a host cell whereby the vector will interact with the polymerase in the cell to express the protein encoded in the vector/construct. Expression vectors can be present in the cell extrachromosomally or can be integrated into the chromosome. Expression vectors may include additional sequences that render the vector suitable for replication and integration in prokaryotes, eukaryotes, or preferably both (eg, shuttle vectors). The polynucleotides of the present disclosure may be provided as components of expression vectors.
在一些實施例中,本文所用術語“克隆載體”是指設計用於產生多核苷酸複製的質粒、病毒或其他核酸。克隆載體可以包含轉錄和轉譯起始序列、轉錄和轉譯終止序列以及多腺苷酸化信號。此類構建體通常將包括 5' LTR、tRNA 結合位點、包裝信號、第二鏈 DNA 合成的起點和3' LTR 或其一部分。本揭示的多核苷酸可作為克隆載體的組成提供,其可用於產生本揭示的多核苷酸。In some embodiments, the term "cloning vector" as used herein refers to a plasmid, virus or other nucleic acid designed to produce copies of a polynucleotide. Cloning vectors can contain transcriptional and translational initiation sequences, transcriptional and translational termination sequences, and polyadenylation signals. Such constructs will typically include a 5' LTR, a tRNA binding site, a packaging signal, the origin of second-strand DNA synthesis, and a 3' LTR or a portion thereof. The polynucleotides of the disclosure can be provided as components of cloning vectors, which can be used to generate the polynucleotides of the disclosure.
在一些實施例中,本文所用術語“啟動子”是指指示基因轉錄起始位置和轉錄將繼續的方向的核苷酸序列。In some embodiments, the term "promoter" as used herein refers to a nucleotide sequence that indicates where transcription of a gene begins and the direction in which transcription will continue.
在一些實施例中,本文所用術語“編碼”是指多核苷酸(如基因、cDNA或mRNA)中的特定核苷酸序列作為範本,用於在具有規定核苷酸序列(如rRNA、tRNA和mRNA)或規定氨基酸序列的生物過程中合成其他聚合物和大分子的能力。因此,如果一個基因、cDNA或RNA的mRNA轉錄和轉譯在細胞或其他生物系統中產生蛋白質,則該基因、cDNA或RNA編碼該蛋白質。編碼鏈(其核苷酸序列與mRNA序列相同,通常在序列列表中提供)和非編碼鏈(用作基因或cDNA轉錄的範本)都可以稱為編碼該基因或cDNA的蛋白質或其他產物。In some embodiments, the term "encoding" as used herein refers to a specific nucleotide sequence in a polynucleotide (such as a gene, cDNA or mRNA) as a template for use in a specific nucleotide sequence (such as rRNA, tRNA and mRNA) or the ability to synthesize other polymers and macromolecules in biological processes that specify amino acid sequences. Thus, a gene, cDNA or RNA encodes a protein if mRNA transcription and translation of that gene, cDNA or RNA produces the protein in a cell or other biological system. Both the coding strand (which has the same nucleotide sequence as the mRNA sequence and is usually given in a sequence listing) and the noncoding strand (used as a template for gene or cDNA transcription) can be referred to as encoding the protein or other product of that gene or cDNA.
除非另有說明,“編碼氨基酸序列”的核苷酸序列(包括“編碼”本揭示內容的嵌合多肽的多核苷酸)包括所有核苷酸序列,它們是彼此的簡併形式並且編碼相同的氨基酸序列。Unless otherwise stated, a nucleotide sequence "encoding an amino acid sequence" (including a polynucleotide "encoding" a chimeric polypeptide of the disclosure) includes all nucleotide sequences that are degenerate forms of each other and that encode the same amino acid sequence.
多肽及相關術語Peptides and related terms
氨基酸可通過其常見的三個字母符號或IUPAC-IUB生物化學命名委員會推薦的一個字母符號來表示。氨基酸殘基縮寫如下,其中括弧中顯示縮寫:丙氨酸(Ala;A)、天冬醯胺(Asn;N)、天冬氨酸(Asp;D)、精氨酸(Arg;R)、半胱氨酸(Cys;C)、谷氨酸(Glu;E)、穀氨醯胺(Gln;Q)、甘氨酸(Gly;G)、組氨酸(His;H)、異亮氨酸(Ile;I)、亮氨酸(Leu;L)、賴氨酸(Lys;K)、蛋氨酸(Met;M)、苯丙氨酸(Phe;F),脯氨酸(Pro;P)、絲氨酸(Ser;S)、蘇氨酸(Thr;T)、色氨酸(Trp;W)、酪氨酸(Tyr;Y)和纈氨酸(Val;V)。Amino acids may be referred to by their common three-letter symbols or by the one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Amino acid residues are abbreviated as follows, where the abbreviation is shown in parentheses: alanine (Ala; A), asparagine (Asn; N), aspartic acid (Asp; D), arginine (Arg; R), Cysteine (Cys; C), Glutamic acid (Glu; E), Glutamine (Gln; Q), Glycine (Gly; G), Histidine (His; H), Isoleucine ( Ile; I), Leucine (Leu; L), Lysine (Lys; K), Methionine (Met; M), Phenylalanine (Phe; F), Proline (Pro; P), Serine (Ser; S), threonine (Thr; T), tryptophan (Trp; W), tyrosine (Tyr; Y) and valine (Val; V).
氨基酸序列以氨基到羧基的方向從左到右寫入。Amino acid sequences are written left to right in amino to carboxyl orientation.
在一些實施例中,本文所用術語“多肽”是指氨基酸亞基的序列。在一些實施例中,“肽”可包含至多50個氨基酸。在一些實施例中,“肽”可包含約5、10、15、20、25、30、35、40、45或50個氨基酸。本文所用術語“多肽”可以指任何長度、大小、結構或功能的蛋白質、多肽和肽。本文所用 術語“多肽”、“肽”和“蛋白質”可以互換使用。In some embodiments, the term "polypeptide" as used herein refers to a sequence of amino acid subunits. In some embodiments, a "peptide" may comprise up to 50 amino acids. In some embodiments, a "peptide" may comprise about 5, 10, 15, 20, 25, 30, 35, 40, 45, or 50 amino acids. The term "polypeptide" as used herein may refer to proteins, polypeptides and peptides of any length, size, structure or function. As used herein, the terms "polypeptide", "peptide" and "protein" are used interchangeably.
在一些實施例中,本揭示的多肽包含天然或合成產生或修飾的氨基酸,例如,二硫鍵形成、糖基化、脂質化、乙醯化、磷酸化或任何其他操作或修飾,例如與標記組分結合。在一些實施例中,本揭示的多肽包含一個或多個氨基酸殘基是相應天然氨基酸(包括例如合成氨基酸,例如同型半胱氨酸、鳥氨酸、對乙醯苯丙氨酸、D-氨基酸和肌酸)的人工化學類似物,以及本領域已知的其他修飾。在一些實施例中,本揭示的多肽包括基因產物、同源物、直向同源物、旁系同源物、片段和前述的其他等價物、變體和類似物。在一些實施例中,本揭示的多肽包含單個多肽或可以是多分子復合物,例如二聚體、三聚體或四聚體。在一些實施例中,本揭示的多肽包括單鍊或多鏈多肽。在一些實施例中,本揭示的多肽包含二硫鍵,其可存在於多鏈多肽中。In some embodiments, polypeptides of the present disclosure comprise amino acids that are naturally or synthetically produced or modified, e.g., disulfide bond formation, glycosylation, lipidation, acetylation, phosphorylation, or any other manipulation or modification, e.g., with labeling Combination of components. In some embodiments, a polypeptide of the present disclosure comprises one or more amino acid residues that are the corresponding natural amino acids (including, for example, synthetic amino acids, such as homocysteine, ornithine, p-acetylphenylalanine, D-amino acid and creatine), and other modifications known in the art. In some embodiments, polypeptides of the present disclosure include gene products, homologues, orthologs, paralogs, fragments, and other equivalents, variants, and analogs of the foregoing. In some embodiments, polypeptides of the present disclosure comprise a single polypeptide or may be a multimolecular complex, such as a dimer, trimer, or tetramer. In some embodiments, polypeptides of the present disclosure include single-chain or multi-chain polypeptides. In some embodiments, polypeptides of the present disclosure comprise disulfide bonds, which may be present in multi-chain polypeptides.
在一些實施例中,本揭示的多肽包括L-氨基酸+甘氨酸、D-氨基酸+甘氨酸(其在體內對L-氨基酸特異性蛋白酶具有抗性)或D-和L-氨基酸+甘氨酸的組合。本揭示的多肽可以是化學合成的或重組表達的。In some embodiments, polypeptides of the present disclosure include L-amino acids+glycine, D-amino acids+glycine (which are resistant to L-amino acid-specific proteases in vivo), or a combination of D- and L-amino acids+glycine. The polypeptides of the present disclosure can be chemically synthesized or expressed recombinantly.
本揭示的多肽可以包括在N末端、C末端、多肽內部或其組合處的額外殘基;這些額外的殘基不包括在確定本揭示的多肽相對於參考多肽的百分比同一性中。這樣的殘基可以是適合預期用途的任何殘基,包括但不限於標籤。A polypeptide of the disclosure may include additional residues at the N-terminus, C-terminus, internal to the polypeptide, or a combination thereof; these additional residues are not included in determining the percent identity of a polypeptide of the disclosure relative to a reference polypeptide. Such residues may be any suitable for the intended use, including but not limited to tags.
在一些實施例中,本文所用術語“標籤”是指可檢測部分,包括但不限於熒光蛋白、抗體表位標籤、純化標籤、組氨酸標籤或連接子。在一些實施例中,本揭示的標記的治療劑或本揭示的標記的配體包含適用於純化目的的可檢測部分,以驅動多肽的定位,以及向多肽添加功能性。In some embodiments, the term "tag" as used herein refers to a detectable moiety including, but not limited to, a fluorescent protein, an antibody epitope tag, a purification tag, a histidine tag, or a linker. In some embodiments, a labeled therapeutic agent of the disclosure or a labeled ligand of the disclosure comprises a detectable moiety suitable for purification purposes, to drive localization of the polypeptide, and to add functionality to the polypeptide.
在一些實施例中,本文所用術語“嵌合多肽”是指包含衍生自第一來源的第一氨基酸序列的任何多肽,該第一氨基酸序列與衍生自第二來源的第二氨基酸序列可操作地共價或非共價連接,其中第一來源和第二來源不相同(兩個不同的來源)。不相同的第一來源和第二來源可以包括兩種不同的生物實體,或來自同一生物實體的兩種不同蛋白質,或生物實體和非生物實體。本揭示的嵌合蛋白可以包括衍生自至少2種不同生物來源的蛋白。生物來源可以包括任何非合成產生的核酸或氨基酸序列(例如基因組或cDNA序列、質粒或病毒載體、天然病毒體或任何上述的突變體或類似物)。合成來源可以包括化學產生的而不是由生物系統產生的蛋白質或核酸序列(例如氨基酸序列的固相合成)。本揭示的嵌合蛋白可包括源自至少兩種不同合成來源的蛋白質或源自至少一種生物來源和至少一種合成來源的蛋白質。本揭示的嵌合蛋白可以包括源自第一來源的第一氨基酸序列,共價或非共價連接至源自任何來源的核酸或源自任何來源的有機或無機小分子。嵌合蛋白可以包括在第一氨基酸序列和第二氨基酸序列之間或在第一氨基酸序列和核酸之間、或在第一氨基酸序列和有機或無機小分子之間的連接子分子。In some embodiments, the term "chimeric polypeptide" as used herein refers to any polypeptide comprising a first amino acid sequence derived from a first source operably with a second amino acid sequence derived from a second source. Covalently or non-covalently linked, where the first source and the second source are not the same (two different sources). The non-identical first and second sources may comprise two different biological entities, or two different proteins from the same biological entity, or a biological entity and a non-biological entity. Chimeric proteins of the present disclosure can include proteins derived from at least 2 different biological sources. A biological source can include any non-synthetically produced nucleic acid or amino acid sequence (eg, a genomic or cDNA sequence, a plasmid or viral vector, a natural virion, or a mutant or analog of any of the foregoing). Synthetic sources can include protein or nucleic acid sequences that are produced chemically rather than by biological systems (eg, solid-phase synthesis of amino acid sequences). Chimeric proteins of the present disclosure can include proteins derived from at least two different synthetic sources or proteins derived from at least one biological source and at least one synthetic source. A chimeric protein of the present disclosure may comprise a first amino acid sequence derived from a first source, covalently or non-covalently linked to a nucleic acid derived from any source or to a small organic or inorganic molecule derived from any source. A chimeric protein may include a linker molecule between a first amino acid sequence and a second amino acid sequence or between a first amino acid sequence and a nucleic acid, or between a first amino acid sequence and a small organic or inorganic molecule.
在一些實施例中,本文所用術語多肽的“片段”或“截短的多肽”可以指比參考序列短的多肽的氨基酸序列。在一些實施例中,參考序列包含或由天然存在的序列組成。與參考序列相比,該片段可包含N-末端或C-末端缺失(任選地稱為截短)。或者或另外,與參考序列相比,該片段可在多肽的任何一個或多個氨基酸位置包含內部缺失。本揭示的多肽可以作為參考多肽的片段或截短形式提供。此外,本揭示的多肽的所有可能的片段和截短的變體都涵蓋在本揭示提供的實施例中。In some embodiments, the term "fragment" of a polypeptide or "truncated polypeptide" as used herein may refer to an amino acid sequence of a polypeptide that is shorter than a reference sequence. In some embodiments, the reference sequence comprises or consists of a naturally occurring sequence. This fragment may contain N-terminal or C-terminal deletions (optionally referred to as truncations) compared to the reference sequence. Alternatively or additionally, the fragment may comprise an internal deletion at any one or more amino acid positions of the polypeptide compared to the reference sequence. Polypeptides of the disclosure may be provided as fragments or truncated forms of a reference polypeptide. Furthermore, all possible fragments and truncated variants of the polypeptides of the disclosure are encompassed by the examples provided in the disclosure.
在一些實施例中,本文所用術語“功能片段”是指保留多肽功能的多肽片段。因此,在一些實施例中,諸如酶的生物活性肽的功能片段保留催化生物作用的能力,因為該功能片段包含酶的催化結構域。本揭示的多肽可以作為參考多肽的片段或截短形式提供。此外,本揭示的多肽的所有可能的片段和截短的變體都涵蓋在本揭示提供的實施例中。在一些實施例中,即使與全長多肽相比,功能片段的活性或功能片段的功效被修飾,本揭示的功能片段仍保留多肽的功能。在一些實施例中,即使與全長多肽相比,功能片段的活性或功能片段的功效降低,本揭示的功能片段仍保留多肽的功能。In some embodiments, the term "functional fragment" as used herein refers to a fragment of a polypeptide that retains the function of the polypeptide. Thus, in some embodiments, a functional fragment such as a biologically active peptide of an enzyme retains the ability to catalyze a biological action because the functional fragment comprises the catalytic domain of the enzyme. Polypeptides of the disclosure may be provided as fragments or truncated forms of a reference polypeptide. Furthermore, all possible fragments and truncated variants of the polypeptides of the disclosure are encompassed by the examples provided in the disclosure. In some embodiments, the functional fragments of the disclosure retain the function of the polypeptide even though the activity of the functional fragment or the efficacy of the functional fragment is modified compared to the full-length polypeptide. In some embodiments, the functional fragments of the present disclosure retain the function of the polypeptide even though the activity of the functional fragment or the efficacy of the functional fragment is reduced compared to the full-length polypeptide.
在一些實施例中,本文所用術語“功能變體”是指多肽、片段或一類多肽的成員的修飾形式,其保持多肽的功能。在一些實施例中,即使與未修飾的多肽相比,功能變體的活性或功能變體的功效被修飾,本揭示的功能變體仍保留多肽的功能。在一些實施例中,即使與未修飾的多肽相比,功能變體的活性或功能變體的功效降低,本揭示的功能變體仍保留多肽的功能。In some embodiments, the term "functional variant" as used herein refers to a modified form of a polypeptide, fragment, or member of a class of polypeptides that retains the function of the polypeptide. In some embodiments, the functional variants of the disclosure retain the function of the polypeptide even though the activity of the functional variant or the efficacy of the functional variant is modified compared to the unmodified polypeptide. In some embodiments, the functional variants of the disclosure retain the function of the polypeptide even though the activity of the functional variant or the efficacy of the functional variant is reduced compared to the unmodified polypeptide.
在一些實施例中,本文所用術語“氨基酸取代”是指用另一個氨基酸殘基取代存在於親本或參考序列(例如野生型序列)中的氨基酸殘基。氨基酸可以被取代,例如,通過化學肽合成或通過本領域已知的重組方法。例如,用替代氨基酸殘基取代氨基酸殘基是通過用編碼第二氨基酸的密碼子取代編碼第一個氨基酸的密碼子來進行的。本揭示的各種多肽組成可以具有氨基酸取代。In some embodiments, the term "amino acid substitution" as used herein refers to the substitution of an amino acid residue present in a parental or reference sequence (eg, a wild-type sequence) with another amino acid residue. Amino acids may be substituted, for example, by chemical peptide synthesis or by recombinant methods known in the art. For example, substitution of an amino acid residue with a substitute amino acid residue is performed by substituting a codon encoding a first amino acid with a codon encoding a second amino acid. Various polypeptide compositions of the present disclosure may have amino acid substitutions.
在一些實施例中,本文所用術語“保守氨基酸取代”是其中一個氨基酸殘基被具有化學相似側鏈的氨基酸殘基取代。本領域已經定義了具有相似側鏈的氨基酸殘基家族,包括酸性側鏈(例如,天冬氨酸、谷氨酸)、鹼性側鏈(例如,賴氨酸、精氨酸、組氨酸)、不帶電荷的極性側鏈(例如,甘氨酸、天冬醯胺、穀氨醯胺、絲氨酸、蘇氨酸、酪氨酸、半胱氨酸)、非極性側鏈(例如丙氨酸、纈氨酸、亮氨酸、異亮氨酸、脯氨酸、苯丙氨酸、蛋氨酸、色氨酸)、β-支鏈側鏈(例如蘇氨酸、纈氨酸、異亮氨酸)和芳香側鏈(例如酪氨酸、苯丙氨酸、色氨酸、組氨酸)。因此,如果多肽中的一個氨基酸被來自同一側鏈家族的另一個氨基酸取代,則該取代被認為是保守的。在另一個方面,一串氨基酸可以被保守地替換為側鏈家族成員的順序及/或組成不同的化學相似串。本揭示的各種多肽組分可以提供有保守氨基酸取代。In some embodiments, the term "conservative amino acid substitution" as used herein is one in which an amino acid residue is replaced with an amino acid residue having a chemically similar side chain. Families of amino acid residues with similar side chains have been defined in the art, including acidic side chains (e.g., aspartic acid, glutamic acid), basic side chains (e.g., lysine, arginine, histidine ), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, Valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g. threonine, valine, isoleucine) and aromatic side chains (e.g. tyrosine, phenylalanine, tryptophan, histidine). Thus, if an amino acid in a polypeptide is substituted with another amino acid from the same side chain family, the substitution is considered conservative. In another aspect, a string of amino acids can be conservatively substituted with chemically similar strings that differ in the order and/or composition of side chain family members. Various polypeptide components of the disclosure may be provided with conservative amino acid substitutions.
在一些實施例中,本文所用術語“非保守氨基酸取代”可指(i)具有正電荷側鏈的殘基(例如Arg、His或Lys)被取代或被負電荷殘基(例如Glu或Asp)取代,(ii)親水殘基(例如Ser或Thr)被取代或被疏水殘基(例如Ala、Leu、Ile、Phe或Val)取代的那些替換,(iii)半胱氨酸或脯氨酸被任何其他殘基取代,或被任何其他殘基取代,或(iv)具有大量疏水或芳香側鏈(例如,Val、His、Ile或Trp)的殘基被具有較小側鏈(例如,Ala或Ser)或無側鏈(例如,Gly)的殘基取代,或被具有較小側鏈(例如,Ala或Ser)或無側鏈(例如,Gly)的殘基取代。本揭示的各種多肽成分可提供非保守氨基酸取代物。上述一種非保守取代物改變蛋白質功能特性的可能性也與取代物相對於蛋白質功能重要區域的位置相關:因此,一些非保守取代物對生物特性的影響很小或沒有影響。本揭示的各種多肽組分可以具有不顯著改變改變的組分的功能的非保守氨基酸取代。In some embodiments, the term "non-conservative amino acid substitution" as used herein may refer to (i) a residue with a positively charged side chain (such as Arg, His, or Lys) being replaced or a negatively charged residue (such as Glu or Asp) Substitutions, (ii) those in which a hydrophilic residue (such as Ser or Thr) is substituted or replaced by a hydrophobic residue (such as Ala, Leu, Ile, Phe, or Val), (iii) cysteine or proline is replaced by Any other residue is substituted, or substituted by any other residue, or (iv) a residue with a large number of hydrophobic or aromatic side chains (e.g., Val, His, Ile, or Trp) is replaced by a residue with a smaller side chain (e.g., Ala or Ser) or no side chain (e.g., Gly), or by a residue with a smaller side chain (e.g., Ala or Ser) or no side chain (e.g., Gly). Various polypeptide components of the disclosure may provide non-conservative amino acid substitutions. The likelihood that one of the above non-conservative substitutions will alter the functional properties of the protein is also related to the position of the substitution relative to regions important for protein function: thus, some non-conservative substitutions will have little or no effect on the biological properties. Various polypeptide components of the disclosure can have non-conservative amino acid substitutions that do not significantly alter the function of the altered component.
在一些實施例中,本文所用術語“跨膜元件”或“跨膜結構域”可以指細胞外元件和細胞內元件之間的多肽元件。一部分跨膜元件存在於細胞膜內。本揭示的嵌合抗原受體(CAR)包括跨膜元件。In some embodiments, the term "transmembrane element" or "transmembrane domain" as used herein may refer to a polypeptide element between an extracellular element and an intracellular element. A portion of transmembrane elements reside within the cell membrane. The chimeric antigen receptors (CARs) of the present disclosure include transmembrane elements.
在一些實施例中,本文所用術語“細胞內元件”或“細胞內結構域”可以指位於細胞質膜的細胞質側並將信號傳遞到真核細胞中的多肽元件。本揭示的CAR包括細胞內元件。在一些實施例中,細胞是真核細胞。In some embodiments, the term "intracellular element" or "intracellular domain" as used herein may refer to a polypeptide element that is located on the cytoplasmic side of the plasma membrane of a cell and transmits signals into eukaryotic cells. The CARs of the present disclosure include intracellular elements. In some embodiments, the cells are eukaryotic cells.
在一些實施例中,本文所用術語“細胞內信號元件”或“細胞內信號結構域”是指細胞內元件的一部分,其轉導效應器功能信號並隨後引導細胞執行特定功能。在一些實施例中,細胞是真核細胞。In some embodiments, the term "intracellular signaling element" or "intracellular signaling domain" as used herein refers to a portion of an intracellular element that transduces effector function signals and subsequently directs the cell to perform a specific function. In some embodiments, the cells are eukaryotic cells.
在一些實施例中,本文所用術語“細胞外元件”或“細胞外元件”可以指位於細胞的細胞質膜外的多肽元件。在表達CAR的細胞中,細胞外元件可以包括CAR的抗原結合元件。在一些實施例中,細胞是真核細胞。In some embodiments, the term "extracellular element" or "extracellular element" as used herein may refer to a polypeptide element located outside the plasma membrane of a cell. In a CAR-expressing cell, the extracellular element can include the antigen-binding element of the CAR. In some embodiments, the cells are eukaryotic cells.
序列同一性和相關術語Sequence Identity and Related Terms
在一些實施例中,如果兩個或多個序列彼此 100% 相同,則稱它們是“相同的”。In some embodiments, two or more sequences are said to be "identical" if they are 100% identical to each other.
在一些實施例中,“同源性”是指聚合分子之間,例如多肽分子或多核苷酸分子之間的整體單體保守性。沒有任何附加限定“相同”,例如,蛋白質 A 與蛋白質 B 相同,意味著序列是 100% 相同的(100% 序列同一性)。將兩個序列描述為“70% 相同”等價於將它們描述為具有“70% 序列同源性”。In some embodiments, "homology" refers to overall monomeric conservation between polymeric molecules, such as between polypeptide molecules or polynucleotide molecules. Without any additional qualification "identical", for example, protein A is identical to protein B, meaning that the sequences are 100% identical (100% sequence identity). Describing two sequences as "70% identical" is equivalent to describing them as having "70% sequence identity".
在一些實施例中,當第一個序列中的一個位置被與第二個序列中相應位置相同的氨基酸佔據時,則分子在該位置是相同的。兩個序列之間的同一性百分比是序列共用的相同位置數量的函數,考慮到間隙的數量和每個間隙的長度,需要引入該長度以實現兩個序列的最佳比對。序列的比較和兩個序列之間的一致性百分比的確定可以使用數學演算法來完成。In some embodiments, when a position in the first sequence is occupied by the same amino acid as the corresponding position in the second sequence, then the molecules are identical at that position. The percent identity between two sequences is a function of the number of identical positions shared by the sequences, taking into account the number of gaps and the length of each gap that needs to be introduced for optimal alignment of the two sequences. The comparison of sequences and the determination of percent identity between two sequences can be accomplished using a mathematical algorithm.
在某些方面,第一氨基酸(或核酸)序列與第二氨基酸(或核酸)序列的百分比同一性(%ID)計算為%ID = 100(Y/Z),其中 Y 是 在第一序列和第二序列的比對中(通過目視檢查或特定的序列比對程式進行比對),被評分為相同匹配的氨基酸(或核鹼基)殘基的數量,Z 是第二序列中的殘基總數。如果第一序列的長度長於第二序列,則第一序列與第二序列的同一性百分比將高於第二序列與第一序列的同一性百分比。In certain aspects, the percent identity (%ID) of a first amino acid (or nucleic acid) sequence to a second amino acid (or nucleic acid) sequence is calculated as %ID = 100 (Y/Z), where Y is the difference between the first sequence and The number of amino acid (or nucleobase) residues scored as identical matches in an alignment of the second sequence (by visual inspection or by a specific sequence alignment program), where Z is the residue in the second sequence total. If the first sequence is longer than the second sequence, the percent identity of the first sequence to the second sequence will be higher than the percent identity of the second sequence to the first sequence.
在一些實施例中,例如,為了最佳比對目的,可以通過比對兩個序列來計算兩個多肽序列的百分比同一性。例如,可以在第一多肽序列和第二多肽序列中的一個或兩個中引入空位以進行最佳比對,並且為了比較的目的可以忽略不同的序列。在某些方面中,出於比較目的而比對的序列的長度是參考序列長度的至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%或100%。然後比較相應氨基酸位置的氨基酸。In some embodiments, the percent identity of two polypeptide sequences can be calculated by aligning the two sequences, eg, for optimal alignment purposes. For example, gaps can be introduced in one or both of the first and second polypeptide sequences for optimal alignment, and differing sequences can be ignored for comparison purposes. In certain aspects, the length of the sequences aligned for comparison purposes is at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 90% of the length of the reference sequence. At least 95% or 100%. The amino acids at corresponding amino acid positions are then compared.
在一些實施例中,用於計算百分比序列同一性的序列比對的生成不限於僅由一級序列數據驅動的二元序列-序列比較。還應瞭解的是,可以通過將序列資料與來自異構源的資料(例如結構資料(例如,晶體蛋白質結構)、功能資料(例如,突變位置)或系統發育資料)整合來生成序列比對。整合異質數據以生成多序列比對的合適程式是 T-Coffee,可在 www.tcoffee.org 獲得,或者可從例如歐洲生物資訊學研究所 (EBI) 網站 ebi.ac.uk/Tools/psa獲得。還應理解,用於計算百分比序列同一性的最終比對可以自動或手動進行管理。In some embodiments, the generation of sequence alignments for calculating percent sequence identity is not limited to binary sequence-sequence comparisons driven only by primary sequence data. It should also be appreciated that sequence alignments can be generated by integrating sequence data with data from heterogeneous sources such as structural data (eg, crystal protein structures), functional data (eg, mutation positions), or phylogenetic data. A suitable program for integrating heterogeneous data to generate multiple sequence alignments is T-Coffee, available at www.tcoffee.org, or from, for example, the European Bioinformatics Institute (EBI) website ebi.ac.uk/Tools/psa . It is also understood that the final alignment used to calculate percent sequence identity can be managed automatically or manually.
合適的軟件程式可從各種來源獲得,用於蛋白質和核苷酸序列的比對。一種確定序列同一性百分比的合適程式是 bl2seq,它是 BLAST 程式套件的一部分,可從美國政府的國家生物技術資訊中心BLAST網站 (blast.ncbi.nlm.nih.gov) 獲得。B12seq 使用 BLASTN 或 BLASTP 演算法在兩個序列之間進行比較。BLASTN用於比較核酸序列,而BLASTP用於比較氨基酸序列。其他合適的程式是,例如,Needle、Stretcher、Water 或 Matcher,它們是 EMBOSS 生物資訊學程式套件的一部分,也可從 EBI 獲得。可以使用本領域已知的方法進行序列比對,例如 MAFFT、Clustal (ClustalW、Clustal X 或 Clustal Omega)、MUSCLE 等。與多核苷酸或多肽參考序列比對的單個多核苷酸或多肽靶序列內的不同區域可以各自具有它們自己的百分比序列同一性。需注意的是,百分比序列同一性值四捨五入到最接近的十分之一。例如,從 80.11 到 80.14 的值向下舍入為 80.1,而從 80.15 到 80.19 的值向上舍入為 80.2。還應注意的是,長度值將始終為整數。Suitable software programs are available from various sources for the alignment of protein and nucleotide sequences. One suitable program for determining percent sequence identity is bl2seq, which is part of the BLAST suite of programs available from the US Government's National Center for Biotechnology Information BLAST website (blast.ncbi.nlm.nih.gov). B12seq uses the BLASTN or BLASTP algorithms to make a comparison between two sequences. BLASTN is used to compare nucleic acid sequences, while BLASTP is used to compare amino acid sequences. Other suitable programs are, for example, Needle, Stretcher, Water or Matcher, which are part of the EMBOSS suite of bioinformatics programs, also available from EBI. Sequence alignments can be performed using methods known in the art, such as MAFFT, Clustal (ClustalW, Clustal X, or Clustal Omega), MUSCLE, and the like. Different regions within a single polynucleotide or polypeptide target sequence aligned to a polynucleotide or polypeptide reference sequence may each have their own percent sequence identity. Note that percent sequence identity values are rounded to the nearest tenth. For example, values from 80.11 to 80.14 are rounded down to 80.1, and values from 80.15 to 80.19 are rounded up to 80.2. It should also be noted that the length value will always be an integer.
在一些實施例中,本文所用術語“相似性”是指聚合物分子之間的整體相關性,例如多核苷酸分子之間和/或多肽分子之間的相關性。聚合物分子彼此的相似性百分比的計算可以以與同一性百分比的計算相同的方式進行,除了相似性百分比的計算考慮到本領域所理解的保守取代。應當理解,相似性百分比取決於所使用的比較量表,例如是否比較氨基酸,例如根據它們的進化接近度、電荷、體積、柔韌性、極性、疏水性、芳香性、等電點、抗原性或它們的組合。In some embodiments, the term "similarity" as used herein refers to the overall relatedness between polymer molecules, eg, between polynucleotide molecules and/or between polypeptide molecules. Calculations of percent similarity of polymer molecules to one another can be performed in the same manner as percent identity calculations, except that percent similarity calculations take into account conservative substitutions as understood in the art. It will be appreciated that the percent similarity depends on the comparison scale used, e.g. whether amino acids are compared e.g. according to their evolutionary proximity, charge, volume, flexibility, polarity, hydrophobicity, aromaticity, isoelectric point, antigenicity or their combination.
在一些實施例中,本文所用術語“連接”可以指第一部分與第二部分在C-末端或N-末端的融合。在一些實施例中,本文所用術語“連接”可以指將整個第一部分(或第二部分)插入第二部分(或分別為第一部分)中的任何兩個點,例如氨基酸。在一些方面,第一部分通過肽鍵或連接子與第二部分連接。第一部分可以通過磷酸二酯鍵或連接子與第二部分連接。連接子可以是肽、多肽、核苷酸、核苷酸鍊或任何化學部分。In some embodiments, the term "linked" as used herein may refer to the fusion of a first moiety to a second moiety at the C-terminus or N-terminus. In some embodiments, the term "linking" as used herein may refer to the insertion of the entire first part (or the second part) at any two points, such as amino acids, in the second part (or the first part, respectively). In some aspects, the first moiety is linked to the second moiety by a peptide bond or a linker. The first part can be linked to the second part by a phosphodiester bond or a linker. Linkers can be peptides, polypeptides, nucleotides, chains of nucleotides, or any chemical moiety.
在一些實施例中,本文所用術語“可操作地連接”可以指在序列內功能連接的兩個或更多個元件。在一些實施例中,兩個元件可以在折疊蛋白中功能性連接,其相對於線性序列不連續。在一些實施例中,兩個元件可以在功能上連接,遵循來自多順反子序列的表達。在一些實施例中,兩個元件可以在功能上連接,因為一個元件可以直接或間接地誘導或抑制另一個元件的表現或功能。In some embodiments, the term "operably linked" as used herein may refer to two or more elements that are functionally linked within a sequence. In some embodiments, two elements can be functionally linked in a folded protein that is discontinuous with respect to a linear sequence. In some embodiments, two elements may be functionally linked, following expression from a polycistronic sequence. In some embodiments, two elements can be functionally linked in that one element can directly or indirectly induce or inhibit the expression or function of the other element.
在一些實施例中,本文所用術語非天然存在的”可以指自然界中不存在的多肽或多核苷酸序列。在一些實施例中,非天然存在的序列在自然界中不存在,因為該序列相對於天然存在的序列發生了改變。在一些實施例中,非天然存在的序列在自然界中不存在,因為它是自然界中不一起存在的兩個天然存在的序列的組合(例如,嵌合多肽)。在一些實施例中,非天然存在的多肽是嵌合多肽。在一些實施例中,多肽或多核苷酸不是天然存在的,因為該序列包含自然界中不能發現的部分(例如,片段),即新序列。本文所述的任何多核苷酸可以作為非天然存在的序列提供,例如,具有相對於天然序列改變的序列或作為以自然界不存在的方式與其他多核苷酸連接的多核苷酸提供。本文所述的任何多肽可以作為非天然存在的序列提供,例如,具有相對於天然序列改變的序列或作為以自然界不存在的方式與其他多肽連接的多肽提供。In some embodiments, the term "non-naturally occurring" as used herein may refer to a polypeptide or polynucleotide sequence that does not occur in nature. In some embodiments, a non-naturally occurring sequence does not occur in nature because the sequence is relative to A naturally occurring sequence is altered. In some embodiments, a non-naturally occurring sequence does not occur in nature because it is a combination of two naturally occurring sequences that do not occur together in nature (eg, a chimeric polypeptide). In some embodiments, the non-naturally occurring polypeptide is a chimeric polypeptide. In some embodiments, the polypeptide or polynucleotide is not naturally occurring because the sequence contains portions (e.g., fragments) that cannot be found in nature, i.e., novel Sequence. Any polynucleotide described herein may be provided as a non-naturally occurring sequence, for example, having a sequence altered relative to a native sequence or provided as a polynucleotide linked to other polynucleotides in a manner that does not occur in nature. Any of the polypeptides described may be provided as a non-naturally occurring sequence, eg, having a sequence altered relative to a native sequence or as a polypeptide linked to other polypeptides in a manner not found in nature.
抗體及相關術語Antibodies and related terms
在一些實施例中,本文所用術語“抗體”可以指各種抗體結構,包括但不限於單克隆抗體、多克隆抗體和抗體片段,只要它們表現出所需的抗原結合活性即可。In some embodiments, the term "antibody" as used herein may refer to various antibody structures, including but not limited to monoclonal antibodies, polyclonal antibodies, and antibody fragments, so long as they exhibit the desired antigen-binding activity.
在一些實施例中,本文所用術語“抗體片段”可以指除了完整抗體之外的分子,其包括結合完整抗體所結合的抗原的完整抗體的一部分。抗體片段的實例包括但不限於Fab、Fab'、F(ab')2和Fv片段、scFv抗體片段、線性抗體、單域抗體如sdAb(VL或VH)、駱駝VHH 域,以及由抗體片段形成的多特異性抗體。例如,本揭示中的感興趣基因可以包括抗體片段。In some embodiments, the term "antibody fragment" as used herein may refer to a molecule other than an intact antibody, which includes a portion of an intact antibody that binds the antigen to which the intact antibody binds. Examples of antibody fragments include, but are not limited to, Fab, Fab', F(ab')2 and Fv fragments, scFv antibody fragments, linear antibodies, single domain antibodies such as sdAb (VL or VH), camelid VHH domains, and antibodies formed from antibody fragments multispecific antibodies. For example, a gene of interest in the present disclosure can include an antibody fragment.
在一些實施例中,本文所用術語“單鏈抗體”(scFv)可以指包括通過柔性肽連接子連接的重鏈(VH)和輕鏈(VL)可變區的抗體片段。In some embodiments, the term "single chain antibody" (scFv) as used herein may refer to an antibody fragment comprising heavy (VH) and light (VL) chain variable regions linked by a flexible peptide linker.
在一些實施例中,本文所用術語“抗原結合分子”可以指特異性結合抗原決定簇的分子。本揭示的感興趣的基因可以例如包括抗原結合分子。In some embodiments, the term "antigen-binding molecule" as used herein may refer to a molecule that specifically binds an antigenic determinant. A gene of interest of the present disclosure may, for example, include an antigen binding molecule.
在一些實施例中,本文所用術語“抗原”可以指引起免疫反應的分子。In some embodiments, the term "antigen" as used herein may refer to a molecule that elicits an immune response.
在一些實施例中,本文所用術語“嵌合抗原受體”或“CAR”可以指包括抗原識別部分和細胞活化元件的融合蛋白。本揭示的多核苷酸可以包括產生CAR的目的基因。In some embodiments, the term "chimeric antigen receptor" or "CAR" as used herein may refer to a fusion protein comprising an antigen recognition portion and a cell activation element. A polynucleotide of the present disclosure may include a gene of interest for the production of a CAR.
在一些實施例中,本文所用術語“CAR T細胞”或“CAR T淋巴細胞”可以指具有產生CAR多肽的能力的T細胞。例如,能夠表達CAR的細胞是含有用於在細胞中表達CAR的核酸序列的T細胞。本揭示的細胞可以是CAR T細胞。In some embodiments, the term "CAR T cell" or "CAR T lymphocyte" as used herein may refer to a T cell having the ability to produce a CAR polypeptide. For example, a cell capable of expressing a CAR is a T cell that contains a nucleic acid sequence for expressing a CAR in the cell. The cells of the present disclosure may be CAR T cells.
在一些實施例中,本文所用術語“共刺激元件”或“共刺激信號結構域”或“共刺激多肽”可以指共刺激多肽的細胞內部分。在一些實施例中,與缺乏共刺激結構域的CAR相比,當在T細胞中表達時,包含共刺激結構域的CAR表現出增加或增強的T細胞擴增、功能、持久性和抗腫瘤活性。通過併入來自一種或多種T細胞共刺激分子(例如CD28或4-1BB)的細胞內信號結構域,可以在本揭示的CAR中提供共刺激結構域。In some embodiments, the term "costimulatory element" or "costimulatory signaling domain" or "costimulatory polypeptide" as used herein may refer to the intracellular portion of a costimulatory polypeptide. In some embodiments, a CAR comprising a co-stimulatory domain exhibits increased or enhanced T cell expansion, function, persistence, and anti-tumor activity when expressed in a T cell compared to a CAR lacking a co-stimulatory domain active. Costimulatory domains can be provided in CARs of the present disclosure by incorporating intracellular signaling domains from one or more T cell costimulatory molecules (eg, CD28 or 4-1BB).
在一些實施例中,共刺激多肽可以包含從以下一種或多種分離或衍生的序列:TNF受體蛋白、免疫球蛋白樣蛋白、細胞因子受體、整合素、信號淋巴細胞活化分子(SLAM蛋白)和活化自然殺手細胞受體。在一些實施例中,共刺激多肽可以包含從CD27、CD28、4-1BB (CD137)、OX40、GITR、CD30、CD40、ICOS、BAFFR、HVEM、淋巴細胞功能相關抗原1 (LFA-1)、CD2、CD7、LIGHT、NKG2C、SLAMF7、NKp80、CD160、B7-H3 和MyD88中的一種或多種分離或衍生的序列。In some embodiments, costimulatory polypeptides may comprise sequences isolated or derived from one or more of: TNF receptor proteins, immunoglobulin-like proteins, cytokine receptors, integrins, signaling lymphocyte activation molecules (SLAM proteins) and activation of natural killer cell receptors. In some embodiments, the co-stimulatory polypeptide may comprise a protein selected from CD27, CD28, 4-1BB (CD137), OX40, GITR, CD30, CD40, ICOS, BAFFR, HVEM, lymphocyte function-associated antigen 1 (LFA-1), CD2 , CD7, LIGHT, NKG2C, SLAMF7, NKp80, CD160, B7-H3 and MyD88 one or more isolated or derived sequences.
治療有效及相關技術Effective treatment and related technologies
在一些實施例中,本文所用術語“治療有效”可以指對接受者提供有益效果,例如,提供受試者臨床症狀的一些減輕、緩解或減少或受試者臨床狀態的改善。治療效果不必是完全的或治癒性的,只要為受試者提供一些益處即可。In some embodiments, the term "therapeutically effective" as used herein may refer to providing a beneficial effect to a recipient, for example, providing some relief, relief or reduction of a subject's clinical symptoms or an improvement in a subject's clinical state. The therapeutic effect need not be complete or curative, just provide some benefit to the subject.
在一些實施例中,本文所用術語“治療有效劑量”可以指足以賦予接受者治療有效益處的劑量。例如,本揭示的融合蛋白、核酸、載體、細胞、組合物或藥物組合物可以治療有效劑量施用。已施用本揭示的融合蛋白、核酸、載體、細胞、組合物或藥物組合物的受試者隨後可施用治療有效量的本揭示小分子,以誘導或破壞本揭示融合蛋白的二聚體形成,以實現所需的細胞結果。In some embodiments, the term "therapeutically effective dose" as used herein may refer to a dose sufficient to confer a therapeutically effective benefit in a recipient. For example, a fusion protein, nucleic acid, vector, cell, composition or pharmaceutical composition of the present disclosure can be administered in a therapeutically effective dose. A subject who has been administered a fusion protein, nucleic acid, vector, cell, composition or pharmaceutical composition of the disclosure may then be administered a therapeutically effective amount of a small molecule of the disclosure to induce or disrupt dimer formation of the fusion protein of the disclosure, to achieve the desired cellular outcome.
細胞術語cell term
在一些實施例中,本文所用術語“幹細胞”可以指未分化或部分分化的細胞,其可以分化成各種類型的細胞並無限增殖以產生更多相同的幹細胞。In some embodiments, the term "stem cell" as used herein may refer to an undifferentiated or partially differentiated cell that can differentiate into various types of cells and immortalize to produce more of the same stem cell.
在一些實施例中,本文所用術語“多能幹細胞”(PSC)可能是指能夠無限期維持未分化狀態的細胞,並且可以分化為身體的大多數細胞(如果不是所有細胞的話)。In some embodiments, the term "pluripotent stem cell" (PSC) as used herein may refer to a cell that is capable of maintaining an undifferentiated state indefinitely and that can differentiate into most, if not all, cells of the body.
在一些實施例中,本文所用術語“誘導多能幹細胞”(iPS或iPSC)可以指可以直接從體細胞產生的多能幹細胞。這包括但不限於來自成人的特化細胞,例如皮膚或血細胞。In some embodiments, the term "induced pluripotent stem cells" (iPS or iPSCs) as used herein may refer to pluripotent stem cells that can be generated directly from somatic cells. This includes, but is not limited to, specialized cells from adults, such as skin or blood cells.
在一些實施例中,本文所用術語“多能”可以指可以發育成多於一種細胞類型但比多能細胞更受限制的細胞。例如,成體幹細胞和臍帶血幹細胞可以被認為是多能的。In some embodiments, the term "pluripotent" as used herein may refer to cells that can develop into more than one cell type but are more restricted than pluripotent cells. For example, adult stem cells and cord blood stem cells can be considered multipotent.
在一些實施例中,本文所用術語“造血細胞”可以指由造血幹細胞產生的細胞。這包括但不限於骨髓系祖細胞、淋巴系祖細胞、巨核細胞、紅細胞、肥大細胞、成髓細胞、嗜鹼性粒細胞、中性粒細胞、嗜酸性粒細胞、巨噬細胞、血小板、單核細胞、自然殺手細胞、T淋巴細胞、B淋巴細胞和漿細胞 .In some embodiments, the term "hematopoietic cell" as used herein may refer to a cell derived from a hematopoietic stem cell. These include, but are not limited to, myeloid progenitors, lymphoid progenitors, megakaryocytes, erythrocytes, mast cells, myeloblasts, basophils, neutrophils, eosinophils, macrophages, platelets, Nuclear cells, natural killer cells, T lymphocytes, B lymphocytes and plasma cells .
在一些實施例中,本文所用術語“T-淋巴細胞”或“T-細胞”可以指通常在胸腺中發育的造血細胞。T淋巴細胞或T細胞包括但不限於自然殺手T細胞、調節T細胞、輔助T細胞、細胞毒性T細胞、記憶T細胞、γδT細胞和粘膜不變T細胞。In some embodiments, the term "T-lymphocyte" or "T-cell" as used herein may refer to a hematopoietic cell that normally develops in the thymus. T lymphocytes or T cells include, but are not limited to, natural killer T cells, regulatory T cells, helper T cells, cytotoxic T cells, memory T cells, γδ T cells, and mucosal invariant T cells.
在一些實施例中,本文所用術語“間充質”可以指一種動物組織,其包括嵌入網狀蛋白質和流體中的鬆散細胞,即細胞外基質。間充質直接產生身體的大部分結締組織,包括骨骼、軟骨、淋巴系統和循環系統。In some embodiments, the term "mesenchymal" as used herein may refer to an animal tissue comprising loose cells embedded in a network of proteins and fluid, ie, an extracellular matrix. Mesenchyme directly produces most of the body's connective tissue, including bone, cartilage, lymphatic system, and circulatory system.
在一些實施例中,本文所用術語“間充質細胞”可以指來源於間充質組織的細胞。在一些情況下,本揭示的細胞可以是間充質細胞。In some embodiments, the term "mesenchymal cells" as used herein may refer to cells derived from mesenchymal tissue. In some cases, cells of the present disclosure can be mesenchymal cells.
在一些實施例中,本文所用術語“間充質基質細胞”(MSC)可以指從骨髓、脂肪和其他組織來源中分離的紡錘形塑膠貼壁細胞,具有體外多能分化能力。例如,間充質基質細胞可以分化為成骨細胞(骨細胞)、軟骨細胞(軟骨細胞)、肌細胞(肌肉細胞)和脂肪細胞(產生骨髓脂肪組織的脂肪細胞)。在科學文獻中建議使用術語間充質基質細胞來代替術語“間充質乾細胞”。在一些情況下,本揭示的細胞可以是間充質基質細胞。In some embodiments, the term "mesenchymal stromal cells" (MSCs) as used herein may refer to spindle-shaped plastic adherent cells isolated from bone marrow, adipose, and other tissue sources, having pluripotent differentiation capacity in vitro. For example, mesenchymal stromal cells can differentiate into osteoblasts (bone cells), chondrocytes (chondrocytes), myocytes (muscle cells), and adipocytes (fat cells that give rise to the fatty tissue of the bone marrow). The use of the term mesenchymal stromal cells has been suggested in the scientific literature instead of the term "mesenchymal stem cells". In some cases, the cells of the present disclosure can be mesenchymal stromal cells.
在本揭示的一些實施例中,“自體細胞”是從可以作為治療對其施用的同一個體獲得的細胞(該細胞對於受試者而言是自體的)。本揭示的自體細胞包括但不限於造血細胞和幹細胞,例如造血幹細胞。In some embodiments of the present disclosure, an "autologous cell" is a cell obtained from the same individual to which it can be administered as therapy (the cell is autologous to the subject). Autologous cells of the present disclosure include, but are not limited to, hematopoietic cells and stem cells, eg, hematopoietic stem cells.
在本揭示的一些實施例中,同種異體細胞是從不是作為治療的細胞的預期接受者的個體獲得的細胞(該細胞對於受試者是同種異體的)。本揭示的同種異體細胞可以選自與本揭示的方法的主題相關的免疫學相容的供體。本揭示內容的同種異體細胞可以被修飾以產生“通用”同種異體細胞,適用於向任何受試者施用而沒有非預期的免疫原性。本揭示的同種異體細胞包括但不限於造血細胞和幹細胞,例如造血幹細胞。In some embodiments of the present disclosure, allogeneic cells are cells obtained from an individual who is not the intended recipient of the treated cells (the cells are allogeneic to the subject). The allogeneic cells of the present disclosure can be selected from immunologically compatible donors relevant to the subject matter of the methods of the present disclosure. The allogeneic cells of the disclosure can be modified to generate "universal" allogeneic cells, suitable for administration to any subject without unintended immunogenicity. Allogeneic cells of the present disclosure include, but are not limited to, hematopoietic cells and stem cells, eg, hematopoietic stem cells.
在一些實施例中,本文所用術語“轉染”或“轉化”或“轉導”可指將外源核酸轉移或引入細胞或宿主細胞的過程。“轉染的”或“轉化的”或“轉導的”細胞是已經用外源核酸或細胞後代轉染、轉化或轉導的細胞。In some embodiments, the term "transfection" or "transformation" or "transduction" as used herein may refer to the process of transferring or introducing exogenous nucleic acid into a cell or host cell. A "transfected" or "transformed" or "transduced" cell is a cell that has been transfected, transformed or transduced with exogenous nucleic acid or progeny of the cell.
在一些實施例中,本文所用術語“細胞療法”可以指將一個或多個細胞遞送到受體中以用於治療目的。In some embodiments, the term "cell therapy" as used herein may refer to the delivery of one or more cells into a recipient for therapeutic purposes.
小分子術語Small Molecule Terminology
在一些實施例中,本文所用術語“類似物”可以指本文所述的化合物或化合物類別的成員的化學修飾形式,其保持化合物或類別的結合特性。例如,達諾瑞韋的類似物將包括化學修飾形式的達諾瑞韋,其保留如本文所述結合DNCR2和NS3a的能力。In some embodiments, the term "analog" as used herein may refer to a chemically modified form of a compound or member of a class of compounds described herein that retains the binding properties of the compound or class. For example, an analog of danoprevir would include a chemically modified form of danoprevir that retains the ability to bind DNCR2 and NS3a as described herein.
在一些實施例中,本文所用術語“前藥”可以包括任何共價結合的載體,當這種前藥施用於患者時,它們在體內釋放本揭示的小分子。本揭示的前藥可以通過修飾存在於化合物中的官能基團以使得修飾在常規操作或體內裂解為母體化合物的方式來製備。例如,體內轉化可能是某些代謝過程的結果,例如羧酸酯、磷酸酯或硫酸酯的化學或酶水解,或敏感官能團的還原或氧化。本揭示範圍內的前藥包括其中羥基、氨基或巰基與任何基團結合的化合物,當本揭示的前藥施用於哺乳動物受試者時,其分別裂解形成遊離羥基、遊離氨基或遊離巰基。可通過代謝裂解在體內快速轉化的官能團形成一類與本揭示化合物的羧基反應的基團。它們包括但不限於烷醯基(例如乙醯基、丙醯基、丁醯基等)、未取代和取代芳醯基(例如苯甲醯基和取代苯甲醯基)、烷氧羰基(例如乙氧羰基)、三烷基(例如三甲基和三乙基)、由二羧酸形成的單酯(例如琥珀醯)等基團。本揭示的小分子可以作為前藥施用。本揭示的小分子可以作為前藥施用於受試者。可以施用治療有效量的本揭示的這種前藥。前藥可以與本揭示的多核苷酸、基因治療載體或細胞的施用同時施用,或在本揭示的多核苷酸、基因治療載體或細胞的施用之後施用。In some embodiments, the term "prodrug" as used herein may include any covalently bound carrier that releases the disclosed small molecule in vivo when such prodrug is administered to a patient. Prodrugs of the present disclosure can be prepared by modifying functional groups present on the compounds in such a way that the modifications are cleaved to the parent compound during routine manipulation or in vivo. For example, in vivo transformations may be the result of certain metabolic processes, such as chemical or enzymatic hydrolysis of carboxylate, phosphate, or sulfate esters, or reduction or oxidation of sensitive functional groups. Prodrugs within the scope of the present disclosure include compounds wherein a hydroxy, amino or thiol group is bonded to any group that, when the prodrugs of the present disclosure are administered to a mammalian subject, cleaves to form a free hydroxy, free amino or free thiol, respectively. Functional groups that can be rapidly transformed in vivo by metabolic cleavage form a class of groups reactive with the carboxyl group of the disclosed compounds. They include, but are not limited to, alkylyl groups (such as acetyl, propionyl, butyryl, etc.), unsubstituted and substituted aryl groups (such as benzoyl and substituted benzoyl), alkoxycarbonyl groups (such as ethoxy carbonyl), trialkyl groups such as trimethyl and triethyl, monoesters formed from dicarboxylic acids such as succinyl, etc. Small molecules of the present disclosure can be administered as prodrugs. Small molecules of the present disclosure can be administered to a subject as prodrugs. A therapeutically effective amount of such prodrugs of the present disclosure may be administered. Prodrugs can be administered concurrently with or subsequent to administration of the polynucleotides, gene therapy vectors or cells of the present disclosure.
配方及相關技術Formula and related technology
在一些實施例中,本文所用術語“藥學上可接受的”是指在合理醫學判斷範圍內,適合與人類和動物組織接觸使用的化合物、材料、組合物和/或劑型,無過度毒性、刺激性、過敏反應或與合理的效益/風險比相稱的其他問題或併發症。例如,本揭示的小分子、多核苷酸、多肽、基因治療載體或細胞可以作為組合物的一部分與其他藥學上可接受的成分,包括藥學上可接受的載體一起施用。In some embodiments, the term "pharmaceutically acceptable" as used herein refers to a compound, material, composition and/or dosage form suitable for use in contact with human and animal tissues within the scope of reasonable medical judgment, without excessive toxicity, irritation sex, allergic reactions, or other problems or complications commensurate with a reasonable benefit/risk ratio. For example, the small molecules, polynucleotides, polypeptides, gene therapy vectors or cells of the disclosure can be administered as part of a composition with other pharmaceutically acceptable ingredients, including a pharmaceutically acceptable carrier.
在一些實施例中,本文所用術語“藥學上可接受的鹽”可以指本揭示的小分子的衍生物,其中指定的化合物被轉化為其酸或鹼鹽。此類藥學上可接受的鹽包括但不限於鹼性殘基如胺的無機或有機酸鹽;酸性殘基如羧酸的鹼金屬鹽或有機鹽諸如此類。藥學上可接受的鹽包括例如由無毒無機或有機酸形成的母體化合物的常規無毒鹽或季銨鹽。例如,此類常規無毒鹽包括源自無機酸的鹽,例如鹽酸、氫溴酸、硫酸、氨基磺酸、磷酸、硝酸等;以及由有機酸製備的鹽,例如乙酸、丙酸、琥珀酸、乙醇酸、硬脂酸、乳酸、蘋果酸、酒石酸、檸檬酸、抗壞血酸、帕莫酸、馬來酸、羥基馬來酸、苯乙酸、谷氨酸、苯甲酸、水楊酸、磺胺酸、2-乙醯氧基苯甲酸、富馬酸、甲苯磺酸、甲烷磺酸、乙烷二磺酸、草酸、異硫醚等。例如,本揭示的小分子可作為藥學上可接受的鹽提供。In some embodiments, the term "pharmaceutically acceptable salt" as used herein may refer to a derivative of a small molecule of the present disclosure, wherein the specified compound is converted to its acid or base salt. Such pharmaceutically acceptable salts include, but are not limited to, inorganic or organic acid salts of basic residues such as amines; alkali metal or organic salts of acidic residues such as carboxylic acids, and the like. Pharmaceutically acceptable salts include, for example, conventional non-toxic or quaternary ammonium salts of the parent compound formed from non-toxic inorganic or organic acids. Such conventional nontoxic salts include, for example, those derived from inorganic acids, such as hydrochloric, hydrobromic, sulfuric, sulfamic, phosphoric, nitric, and the like; and those prepared from organic acids, such as acetic, propionic, succinic, Glycolic acid, stearic acid, lactic acid, malic acid, tartaric acid, citric acid, ascorbic acid, pamoic acid, maleic acid, hydroxymaleic acid, phenylacetic acid, glutamic acid, benzoic acid, salicylic acid, sulfonamide, 2 -Acetyloxybenzoic acid, fumaric acid, toluenesulfonic acid, methanesulfonic acid, ethanedisulfonic acid, oxalic acid, isosulfide, etc. For example, small molecules of the present disclosure can be provided as pharmaceutically acceptable salts.
在一些實施例中,本文所用術語“控制釋放”可以指可以在延長的時間段內(即,在超過1小時的時間段內)釋放一種或多種活性藥劑的劑型的部分或全部。控制釋放(CR)的特性也可稱為緩釋(SR)、延長釋放(PR)或延伸釋放(ER)。當與本文討論的溶出曲線結合使用時,本文所用術語“控制釋放”是指根據本揭示的劑型中在超過1小時的時間內釋放活性劑的部分。例如,本揭示的小分子可在控制釋放組合物中施用。In some embodiments, the term "controlled release" as used herein may refer to part or all of a dosage form that releases one or more active agents over an extended period of time (ie, over a period of more than 1 hour). The controlled release (CR) profile may also be referred to as sustained release (SR), extended release (PR) or extended release (ER). When used in conjunction with the dissolution profiles discussed herein, the term "controlled release" as used herein refers to the portion of a dosage form according to the present disclosure that releases the active agent over a period of more than 1 hour. For example, small molecules of the present disclosure can be administered in controlled release compositions.
在一些實施例中,本文所用術語“立即釋放”可以指與胃液接觸後基本上立即釋放活性劑並且導致在約1小時內基本上完全溶解的劑型的部分或全部。立即釋放(IR)的特性也可以稱為速釋(IR)。當與本文討論的溶出曲線結合使用時,術語“立即釋放”是指根據本揭示的劑型在少於1小時的時間段內遞送活性劑的那部分。本揭示內容的小分子可以一立即釋放組合物施用。In some embodiments, the term "immediate release" as used herein may refer to part or all of a dosage form that releases the active agent substantially immediately upon contact with gastric juices and results in substantially complete dissolution within about 1 hour. Immediate release (IR) properties may also be referred to as immediate release (IR). When used in conjunction with the dissolution profiles discussed herein, the term "immediate release" refers to that portion of the dosage form according to the present disclosure that delivers the active agent over a period of less than 1 hour. The small molecules of the present disclosure can be administered as an immediate release composition.
在一些實施例中,本文所用術語“賦形劑”可以指在體內沒有活性的藥理學惰性成分。例如參見 Hancock、B. C.、Moss、G. P.、&;戈德法布,D. J. (2020),藥用輔料手冊,倫敦:製藥出版社,其全部公開內容通過引用併入本文。本揭示的小分子可以與藥學上可接受的載體、稀釋劑、佐劑、賦形劑或載體混合,例如防腐劑、填充劑、聚合物、崩解劑、助流劑、潤濕劑、乳化劑、助懸劑、甜味劑、調味劑、芳香劑、潤滑劑、酸化劑和分配劑,取決於給藥方式和劑型的性質。此類成分,包括可用於配製口服劑型的藥學上可接受的載體和賦形劑。藥學上可接受的載體包括水、乙醇、多元醇、植物油、脂肪、蠟聚合物,包括凝膠形成和非凝膠形成聚合物,以及它們的合適混合物。賦形劑的例子包括澱粉、預膠化澱粉、微晶纖維素、乳糖、牛奶糖、檸檬酸鈉、碳酸鈣、磷酸二鈣和有色澱粉混合物。崩解劑的例子包括澱粉、藻酸和某些複合矽酸鹽。潤滑劑的例子包括硬脂酸鎂、十二烷基硫酸鈉、滑石粉以及高分子量聚乙二醇。例如,本揭示的小分子、多核苷酸、多肽、基因治療載體或細胞可以在包括藥學上可接受的賦形劑的組合物中提供和施用。In some embodiments, the term "excipient" as used herein may refer to a pharmacologically inert ingredient that has no activity in vivo. See, eg, Hancock, B. C., Moss, G. P., & Goldfarb, D. J. (2020), Handbook of Pharmaceutical Excipients, London: Pharmaceutical Press, the entire disclosure of which is incorporated herein by reference. Small molecules of the present disclosure may be mixed with pharmaceutically acceptable carriers, diluents, adjuvants, excipients or vehicles, such as preservatives, fillers, polymers, disintegrants, glidants, wetting agents, emulsifying Agents, suspending agents, sweetening agents, flavoring agents, perfuming agents, lubricants, acidifying agents and distributing agents, depending on the mode of administration and the nature of the dosage form. Such ingredients include pharmaceutically acceptable carriers and excipients useful for formulating oral dosage forms. Pharmaceutically acceptable carriers include water, alcohols, polyols, vegetable oils, fats, waxes, polymers, including gel-forming and non-gel-forming polymers, and suitable mixtures thereof. Examples of excipients include starch, pregelatinized starch, microcrystalline cellulose, lactose, milk sugar, sodium citrate, calcium carbonate, dicalcium phosphate, and colored starch mixtures. Examples of disintegrants include starch, alginic acid, and certain complex silicates. Examples of lubricants include magnesium stearate, sodium lauryl sulfate, talc, and high molecular weight polyethylene glycols. For example, the small molecules, polynucleotides, polypeptides, gene therapy vectors or cells of the present disclosure can be provided and administered in compositions comprising pharmaceutically acceptable excipients.
一般術語general terms
如在整個本文中使用的術語“受試者”包括任何哺乳動物,包括但不限於人類。在一些實施例中,受試者是人。在一些實施例中,受試者是新生兒、嬰兒、蹣跚學步的兒童、兒童、青少年、成人、老年人、百歲老人。在一些實施例中,受試者俱有至少1、2或3條X染色體。在一些實施例中,受試者俱有至少1條或2條Y染色體。在一些實施例中,受試者被診斷患有本揭示的疾病或病症,或以其他方式需要本揭示的治療。在一些實施例中,受試者處於發展本揭示的疾病或病症的風險中,或者需要預防本揭示的疾病或病症的風險。The term "subject" as used throughout this document includes any mammal, including but not limited to a human. In some embodiments, the subject is a human. In some embodiments, the subject is a neonate, infant, toddler, child, adolescent, adult, elderly, centenarian. In some embodiments, the subject has at least 1, 2 or 3 X chromosomes. In some embodiments, the subject has at least 1 or 2 Y chromosomes. In some embodiments, the subject is diagnosed with a disease or condition disclosed herein, or is otherwise in need of a treatment disclosed herein. In some embodiments, the subject is at risk of developing, or in need of prevention of, a disease or disorder of the present disclosure.
在一些實施例中,受試者是非人類靈長類動物。在一些實施例中,受試者是哺乳動物,包括但不限於家畜、馬、狗、貓、豬、兔、豚鼠、囓齒動物、大鼠、沙鼠和小鼠 。在一些實施例中,受試者是非靈長類哺乳動物並且受試者是基因修飾的。In some embodiments, the subject is a non-human primate. In some embodiments, the subject is a mammal, including but not limited to livestock, horses, dogs, cats, pigs, rabbits, guinea pigs, rodents, rats, gerbils, and mice. In some embodiments, the subject is a non-primate mammal and the subject is genetically modified.
“一”、“一個”和“該”包括它們的複數形式,除非上下文另有明確規定。"A", "an" and "the" include plural forms unless the context clearly dictates otherwise.
除非另有明確說明,否則“和”可與“或”互換使用。"And" is used interchangeably with "or" unless expressly stated otherwise.
“及/或”將被視為對兩個指定特徵或元件中的每一個的具體公開,具有或不具有另一個。因此,在諸如“A及/或B”之類的術語中使用的“及/或”包括“A和B”、“A或B”、“A”(單獨)和“B”(單獨)。同樣,在諸如“A、B及/或C”之類的術語中使用的“及/或”,旨在涵蓋以下每個方面:A、B和C;A、B或C;A或C;A或B;B或C;A和C;A和B;B和C;A(單獨);B(單獨);和C(單獨)。"And/or" is to be considered as specific disclosure of each of the two specified features or elements, with or without the other. Thus, "and/or" used in terms such as "A and/or B" includes "A and B", "A or B", "A" (alone) and "B" (alone). Likewise, the use of "and/or" in terms such as "A, B and/or C" is intended to cover each of the following: A, B and C; A, B or C; A or C; A or B; B or C; A and C; A and B; B and C; A (alone); B (alone); and C (alone).
在一些實施例中,本文所用術語“大約”是指大概、大致、周圍或在其區域內。當“約”與數值範圍一起使用時,它可以通過將邊界延伸到所列數值之上和之下來修改該範圍。In some embodiments, the term "about" as used herein means roughly, roughly, around, or within the region thereof. When "about" is used in conjunction with a numerical range, it modifies that range by extending the boundaries above and below the numerical values set forth.
在一些實施例中,數字範圍包括定義範圍的數字。在陳述了值的範圍的情況下,還具體公開了在該範圍的所述上限和下限之間的每個中間整數值及其每個分數,以及這些值之間的每個子範圍。任何範圍的上限和下限都可以獨立地包含在或不包含在該範圍內,並且其中一個、不包含或不包含這兩個限制的每個範圍也包含在本揭示的範圍內。因此,範圍被理解為範圍內所有值的簡寫,包括列舉的端點。例如,1至10的範圍被理解為包括任何數字、數字的組合或來自由1、2、3、4、5、6、7、8、9和10組成的組的子範圍。In some embodiments, numerical ranges include numbers defining the range. Where a range of values is stated, each intervening integer value and each fraction thereof between the stated upper and lower limits of that range, and each subrange between such values, is also specifically disclosed. The upper and lower limits of any range may independently be included or excluded from that range, and every range where either, neither, or both limits are included is also encompassed within the disclosure. Accordingly, range is understood to be shorthand for all values within the range, including the enumerated endpoints. For example, a range of 1 to 10 is understood to include any number, combination of numbers, or subrange from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10.
在明確說明值的情況下,應當理解的是,與所述值大致相同數量或量的值也在本揭示的範圍內。在公開了組合的情況下,該組合的元件的每個子組合也被具體公開並且在本揭示的範圍內。相反的,在單獨公開不同元素或元素組的情況下,也公開了它們的組合。在公開的任何要素被公開為具有多個替代方案的情況下,在此還公開了其中每個替代方案單獨或與其他替代方案的任何組合被排除在外的該公開內容的示例;一項公開內容的一個以上要素可以具有此類排除,並且在此公開具有此類排除的要素的所有組合。Where a value is explicitly stated, it is to be understood that approximately the same number or amount of the stated value is also within the scope of the disclosure. Where a combination is disclosed, each subcombination of the elements of that combination is also specifically disclosed and is within the scope of the disclosure. Conversely, where different elements or groups of elements are disclosed individually, their combinations are also disclosed. Where any element of the disclosure is disclosed as having multiple alternatives, examples of the disclosure are also disclosed herein in which each alternative is excluded alone or in any combination with other alternatives; a disclosure More than one element of may have such exclusion, and all combinations of elements with such exclusion are disclosed herein.
除非上下文另有要求,否則在整個說明書和權利要求書中,詞語“包括”、“包括”等應以包容性的意義來解釋,而不是排他性或窮舉性的意義;也就是說,在“包括但不限於”的意義上。Unless the context requires otherwise, throughout the specification and claims, the words "comprise", "comprise", etc. are to be interpreted in an inclusive sense rather than an exclusive or exhaustive sense; that is, in the " including but not limited to ".
單數或複數詞也分別包括複數和單數。因此,例如,在說明書描述感興趣基因的情況下,本揭示內容包括具有單個感興趣基因或多個感興趣基因的多核苷酸。Words that are singular or plural also include plural and singular respectively. Thus, for example, where the specification describes a gene of interest, the disclosure includes polynucleotides having a single gene of interest or a plurality of genes of interest.
“以上”和“以下”以及類似含義的詞語指的是整個本文,而不是本文的任何特定部分。"Above" and "below" and words of similar import refer to the text as a whole and not to any particular parts of the text.
“組”包括一個或多個元件或對象的集合。A "group" includes a collection of one or more elements or objects.
單位、前置代號和符號在其國際單位制(SI)接受形式中表示。Units, prefixes and symbols are indicated in their International System of Units (SI) accepted form.
本文包括標題以供參考和幫助定義各個部分。這些標題並非旨在限制關於標題所描述的概念的範圍。這樣的概念可以在整個本文說明書中具有適用性。This article includes headings for reference and to help define the various sections. These headings are not intended to limit the scope of the concepts described with respect to the headings. Such concepts may have applicability throughout the specification herein.
儘管為了清楚和理解的目的通過說明和示例的方式對本揭示進行了一些詳細的描述,但是對於本領域技術人員來說顯然可以實施某些改變和修改。對“本揭示”等的提及旨在作為對本揭示的多種實施例或方面的任何一種的提及,而不是將本揭示限制為單個實施例或目的。正如在本揭示中所使用的術語“方面”和“實施例”可以互換。在本揭示的“某些”、“一些”或“其他”方面或實施例的上下文中討論的特徵可以在本揭示的任何實施例中找到,然而,在這些實施例中,該特徵可以被視為這些突出顯示的實施例中的優選特徵。Although the disclosure has been described in some detail by way of illustration and example for purposes of clarity and understanding, it will be apparent that certain changes and modifications will be practiced by those skilled in the art. References to "the present disclosure" and the like are intended as references to any of various embodiments or aspects of the disclosure and not to limit the disclosure to a single embodiment or object. As used in this disclosure, the terms "aspect" and "embodiment" are interchangeable. A feature discussed in the context of "some", "some" or "other" aspects or embodiments of the disclosure may be found in any embodiments of the disclosure, however, in those embodiments the feature may be considered are preferred features in these highlighted embodiments.
描述和示例不應被解釋為將本揭示的範圍限制於本文描述的實施例和示例,而是包括落入本揭示的真實範圍和精神內的所有修改和替代。The descriptions and examples should not be construed to limit the scope of the disclosure to the embodiments and examples described herein, but include all modifications and substitutions falling within the true scope and spirit of the disclosure.
用於定向降解的合成降解系統Synthetic degradation system for directed degradation
本揭示提供了一種用於目標分子降解的合成降解系統。該系統通常包括編碼與結合元件融合的降解引發劑的多核苷酸,其中結合元件將降解引發劑集中到感興趣的分子以引發降解。The present disclosure provides a synthetic degradation system for the degradation of target molecules. The system typically includes a polynucleotide encoding a degradation initiator fused to a binding element, wherein the binding element concentrates the degradation initiator to the molecule of interest to initiate degradation.
在一些實施例中,該系統包括多核苷酸組,該多核苷酸組包括第一多核苷酸和第二多核苷酸,其中第一多核苷酸或第二多核苷酸編碼融合到第一結合元件的降解引發劑,而第一多核苷酸或第二多核苷酸中的另一個編碼融合到第二結合元件的合成或外源的目標分子。例如,第一多核苷酸可以編碼與第一結合元件融合的降解引發劑,第二多核苷酸可以編碼合成的或外源的目標分子,其中第一結合元件和第二結合元件的相互作用調控降解引發劑集中到目標分子以引發降解。第一和第二多核苷酸可以作為單個多核苷酸或作為一組兩個或更多個多核苷酸提供。In some embodiments, the system comprises a set of polynucleotides comprising a first polynucleotide and a second polynucleotide, wherein the first polynucleotide or the second polynucleotide encodes a fusion The degradation initiator to the first binding element, and the other of the first polynucleotide or the second polynucleotide encodes a synthetic or exogenous target molecule fused to the second binding element. For example, a first polynucleotide can encode a degradation initiator fused to a first binding element, and a second polynucleotide can encode a synthetic or exogenous target molecule, wherein the interaction of the first binding element and the second binding element Action Modulated Degradation Initiators concentrate to target molecules to initiate degradation. The first and second polynucleotides may be provided as a single polynucleotide or as a set of two or more polynucleotides.
在一些實施例中,該系統包括多核苷酸組,該組包括編碼降解引發劑的多核苷酸,該多核苷酸融合到對內源性目標分子上的天然基序具有特異性的結合元件上。例如,結合域可以識別和結合目標分子上的特定區域或目標分子上的特定修飾。結合元件與分子上的天然基序的相互作用將降解引發劑集中到分子以引發降解。In some embodiments, the system comprises a set of polynucleotides comprising a polynucleotide encoding an initiator of degradation fused to a binding element specific for a native motif on an endogenous target molecule . For example, a binding domain can recognize and bind to a specific region on a target molecule or a specific modification on a target molecule. The interaction of the binding element with the native motif on the molecule concentrates the degradation initiator to the molecule to initiate degradation.
在一些實施例中,一對設計的異二聚體 (DHD) 蛋白可用作結合元件,其中一個 DHD 結合元件與降解引發劑融合,而第二個 DHD 結合元件與合成或外源的目標分子融合。DHD結合元件的二聚化使降解引發劑接近目標分子,從而促進目標分子的降解。In some embodiments, a pair of designer heterodimeric (DHD) proteins can be used as binding elements, where one DHD binding element is fused to a degradation initiator and the second DHD binding element is fused to a synthetic or exogenous target molecule fusion. Dimerization of the DHD-binding element brings the degradation initiator closer to the target molecule, thereby promoting the degradation of the target molecule.
在一些實施例中,一對小分子調節的多肽可用作結合元件,其中一個結合元件融合至降解引發劑,而第二個多肽融合至合成或外源的目標蛋白質分子。可以選擇第一和第二小分子調節的多肽,以便通過小分子的存在來調節第一和第二多肽的相互作用。例如,第一和第二小分子調節多肽可以與小分子一起組裝形成二聚複合物。二聚複合物的形成使降解引發劑接近目標分子,從而促進目標分子的降解。In some embodiments, a pair of small molecule regulated polypeptides can be used as binding elements, where one binding element is fused to a degradation initiator and the second polypeptide is fused to a synthetic or exogenous protein molecule of interest. The polypeptides modulated by the first and second small molecules can be selected such that the interaction of the first and second polypeptides is modulated by the presence of the small molecules. For example, first and second small molecule modulatory polypeptides can assemble with the small molecule to form a dimeric complex. The formation of the dimerization complex brings the degradation initiator close to the target molecule, thereby promoting the degradation of the target molecule.
在一些實施例中,該系統包括多核苷酸組,該多核苷酸組包括編碼降解引發劑的多核苷酸,該降解引發劑融合到特定於內源性目標分子上的天然基序的結合元件。例如,結合元件可以識別並結合目標分子上的特定區域或目標分子上的特定修飾。結合元件與分子上的天然基序的相互作用有效地將降解引發劑集中到感興趣的分子以引發降解。In some embodiments, the system comprises a set of polynucleotides comprising polynucleotides encoding a degradation initiator fused to a binding element specific for a native motif on an endogenous target molecule . For example, a binding element can recognize and bind to a specific region on a target molecule or a specific modification on a target molecule. The interaction of the binding element with the native motif on the molecule effectively concentrates the degradation initiator to the molecule of interest to initiate degradation.
在一些實施例中,本揭示提供了一種合成降解系統,用於靶向降解合成的或外源的感興趣的蛋白質。該系統通常包括編碼與結合元件融合的E3泛素連接酶(“E3連接酶”)結構域(或其功能變體)的多核苷酸,其中結合元件用於將E3連接酶結構域集中到感興趣的蛋白質中,以通過細胞泛素途徑進行靶向降解。In some embodiments, the present disclosure provides a synthetic degradation system for targeted degradation of a synthetic or exogenous protein of interest. The system typically includes a polynucleotide encoding an E3 ubiquitin ligase ("E3 ligase") domain (or functional variant thereof) fused to a binding element for centralizing the E3 ligase domain to a sensory protein of interest for targeted degradation through the cellular ubiquitin pathway.
在一些實施例中,一對設計的異二聚體 (DHD) 蛋白作為結合元件,其中一個DHD結合元件與E3連接酶結構域(或其功能變體)融合,第二個DHD結合元件與合成的或外源的目標蛋白靶標融合。DHD 結合元件的二聚化使修飾的 E3 連接酶與目標蛋白接近,從而促進目標蛋白的泛素化和隨後的降解。In some embodiments, a pair of designed heterodimeric (DHD) proteins are used as binding elements, wherein one DHD binding element is fused to an E3 ligase domain (or a functional variant thereof) and the second DHD binding element is fused to a synthetic target fusion with native or exogenous protein of interest. Dimerization of the DHD-binding element brings the modified E3 ligase into proximity with the target protein, thereby promoting the ubiquitination and subsequent degradation of the target protein.
在一些實施例中,一對小分子調節多肽作為結合元件,其中一種結合元件與E3連接酶結構域(或其功能變體)融合,而第二種多肽與合成的或外源的目標蛋白靶標融合。可以選擇第一和第二小分子調節的多肽,以便通過小分子的存在來調節第一和第二多肽的相互作用。例如,第一和第二小分子調節多肽可與小分子一起組裝形成二聚複合物。二聚複合物的形成使E3連接酶與目標蛋白接近,從而促進目標蛋白的降解。In some embodiments, a pair of small molecule regulatory polypeptides serve as binding elements, one of which is fused to an E3 ligase domain (or a functional variant thereof) and the second polypeptide is fused to a synthetic or exogenous protein-of-interest target fusion. The polypeptides modulated by the first and second small molecules can be selected such that the interaction of the first and second polypeptides is modulated by the presence of the small molecules. For example, first and second small molecule modulatory polypeptides can assemble with the small molecule to form a dimeric complex. The formation of the dimeric complex brings the E3 ligase into proximity with the target protein, thereby promoting the degradation of the target protein.
在一些實施例中,該系統包括多核苷酸組,該多核苷酸組包括編碼E3連接酶結構域(或其功能變體)的多核苷酸,該多核苷酸與特定於感興趣的內源性蛋白質上的天然基序的結合元件融合。例如,結合元件可以識別和結合感興趣的蛋白質上的特定區域或感興趣的蛋白質上的特定轉譯後修飾。結合元件與蛋白質上的天然基序的相互作用有效地將 E3 連接酶結構域集中到蛋白質以進行靶向降解。In some embodiments, the system comprises a set of polynucleotides comprising a polynucleotide encoding an E3 ligase domain (or a functional variant thereof) that is specific for an endogenous enzyme of interest. Binding elements fused to native motifs on sex proteins. For example, a binding element can recognize and bind a specific region on a protein of interest or a specific post-translational modification on a protein of interest. The interaction of the binding element with native motifs on the protein effectively centers the E3 ligase domain to the protein for targeted degradation.
本揭示的合成降解系統可用於在各種合成生物學應用例如治療應用中調節一系列目標分子(例如蛋白質)的活性。The synthetic degradation systems of the present disclosure can be used to modulate the activity of a range of target molecules (eg, proteins) in various synthetic biology applications, such as therapeutic applications.
在一些實施例中,本揭示的合成降解系統可用於細胞治療應用以對細胞群進行編程以執行及/或調節治療功能。In some embodiments, the synthetic degradation systems of the present disclosure can be used in cell therapy applications to program cell populations to perform and/or modulate therapeutic functions.
一方面,本揭示的合成降解系統可用於調節(降解)用於癌症治療的T細胞受體(TCR)和/或嵌合抗原受體(CAR)細胞。更具體地,本揭示的合成降解系統可用於降解CAR和/或TCR,並抑制可能導致在許多現有T細胞療法中觀察到的不希望的衰竭表型的過度CAR/TCR信號傳導。In one aspect, the synthetic degradation systems of the present disclosure can be used to modulate (degrade) T cell receptor (TCR) and/or chimeric antigen receptor (CAR) cells for cancer therapy. More specifically, the disclosed synthetic degradation systems can be used to degrade CARs and/or TCRs and inhibit excessive CAR/TCR signaling that may lead to the undesirable exhaustion phenotype observed in many existing T cell therapies.
在一個實施例中,本揭示的合成降解系統可用于基因治療應用。In one embodiment, the synthetic degradation systems of the present disclosure can be used in gene therapy applications.
結合元件binding element
本揭示提供一種結合元件,其被設計為將融合的降解引發劑集中到感興趣的分子以進行靶向降解。在一些實施例中,結合元件被設計為特異性和/或選擇性地結合到目標為降解的目標分子。在一些實施例中,可基於目標為降解的目標分子選擇結合元件。The present disclosure provides a binding element designed to focus a fused degradation initiator to a molecule of interest for targeted degradation. In some embodiments, binding elements are designed to specifically and/or selectively bind to target molecules targeted for degradation. In some embodiments, binding elements can be selected based on target molecules targeted for degradation.
可以使用從頭設計策略來設計用於靶向降解感興趣的蛋白質的結合元件或一對結合元件。在一些實施例中,可以設計結合元件用於特定蛋白質靶標的靶向降解。在一些實施例中,可以設計結合元件用於多種蛋白質的靶向降解。例如,可以設計對存在於多種蛋白質(例如,蛋白質家族)中的保守基序特異的結合元件。A de novo design strategy can be used to design a binding element or pair of binding elements for targeted degradation of a protein of interest. In some embodiments, binding elements can be designed for targeted degradation of specific protein targets. In some embodiments, binding elements can be designed for targeted degradation of various proteins. For example, binding elements can be designed that are specific to conserved motifs present in multiple proteins (eg, protein families).
在一些實施例中,基於文庫的結合子淘選方法可用於鑑定對感興趣的蛋白質特異的重組結合元件。例如,重組結合元件可以是基於天然或設計的蛋白質支架的免疫球蛋白衍生物或非免疫球蛋白結合劑。可以使用的免疫球蛋白衍生的結合形式的例子包括但不限於單鏈可變片段(scFv)和奈米抗體。可以使用的非免疫球蛋白結合劑形式的例子包括但不限於單體、設計的錨蛋白重複蛋白結構域(DARPins)和可變淋巴細胞受體(VLR)結構域。In some embodiments, library-based binder panning methods can be used to identify recombinant binding elements specific for a protein of interest. For example, recombinant binding elements may be immunoglobulin derivatives or non-immunoglobulin binding agents based on natural or engineered protein scaffolds. Examples of immunoglobulin-derived conjugate formats that may be used include, but are not limited to, single chain variable fragments (scFv) and Nanobodies. Examples of non-immunoglobulin binder formats that may be used include, but are not limited to, monomers, designed ankyrin repeat protein domains (DARPins), and variable lymphocyte receptor (VLR) domains.
設計的異二聚體 (DHD)Designed heterodimers (DHD)
一對設計的異二聚體 (DHD) 蛋白可用作結合元件,以將融合的降解引發劑集中到感興趣的合成或外源分子。例如,一個DHD結合元件可與降解引發劑融合,結合對的第二個DHD結合元件可與感興趣的合成或外源分子融合。一對 DHD 結合元件的二聚化使降解引發劑接近目標分子以進行靶向降解。A pair of designed heterodimeric (DHD) proteins can be used as binding elements to focus a fused degradation initiator to a synthetic or exogenous molecule of interest. For example, one DHD binding element can be fused to a degradation initiator, and the second DHD binding element of the binding pair can be fused to a synthetic or exogenous molecule of interest. Dimerization of a pair of DHD-binding elements brings the degradation initiator close to the target molecule for targeted degradation.
例如,可以使用從頭Rosetta蛋白質設計套裝軟體和先前發佈的方法(Chen、Z. 等人,自然期刊,(2019) doi:10.1038/s41586-018-0802- y,其全部內容通過引用的方式併入本文)來設計一對設計的DHD結合元件。表 1 提供了二聚化結構域的氨基酸序列,包括設計的 DHD 序列。For example, the de novo Rosetta protein design suite and previously published methods (Chen, Z. et al., Nature, (2019) doi:10.1038/s41586-018-0802-y, the entire contents of which are incorporated by reference paper) to design a pair of designed DHD binding elements. Table 1 provides the amino acid sequence of the dimerization domain, including the designed DHD sequence.
例如,DHD結合對可包括三螺旋蛋白束結合元件和單螺旋蛋白質結合元件,即3+1異二聚體結合對。圖1中顯示了3+1異二聚體結合對的實施例。For example, a DHD binding pair can include a triple helix protein bundle binding element and a single helix protein binding element, ie a 3+1 heterodimeric binding pair. An example of a 3+1 heterodimeric binding pair is shown in FIG. 1 .
圖1是3+1異二聚體結合元件對的示意圖100。在這個實施例中,結合對包括一個三螺旋蛋白束 DHD-A 和一個單螺旋蛋白 DHD-B。一個結合元件(例如,“A”)可以融合到感興趣的分子(例如,蛋白質;未圖示),並且結合對的第二個結合元件(例如,“B”)可以融合到降解引發劑 (例如,E3 連接酶結構域;未圖示)以提供“僅蛋白質”二聚化系統,用於靶向降解感興趣的分子。Figure 1 is a schematic diagram 100 of a pair of 3+1 heterodimeric binding elements. In this example, the binding pair includes a triple helix protein bundle DHD-A and a single helix protein DHD-B. One binding element (e.g., "A") can be fused to a molecule of interest (e.g., protein; not shown), and the second binding element of the binding pair (e.g., "B") can be fused to a degradation initiator ( For example, the E3 ligase domain; not shown) to provide a "protein-only" dimerization system for targeted degradation of molecules of interest.
一對具有替代拓撲的 DHD 結合元件也可以作為結合元件。替代拓撲包括但不限於具有一個或兩個亞基的二聚體,所述亞基由單螺旋亞基、雙螺旋亞基、多螺旋亞基或具有非螺旋拓撲的亞基組成。A pair of DHD binding elements with alternative topologies can also serve as binding elements. Alternative topologies include, but are not limited to, dimers with one or two subunits consisting of single helical subunits, double helical subunits, multihelical subunits, or subunits with non-helical topologies.
例如,一對結合元件可以包括 SYNZIP。SYNZIP 是合成異二聚體結合捲曲螺旋,其形成一組不同的相互作用連接(Thompson、K.E.、ACS Synth. Biol. (2012) 1:118-129,其通過引用整體併入本文)。For example, a pair of binding elements can include SYNZIP. SYNZIP is a synthetic heterodimer-binding coiled-coil that forms a diverse set of interacting junctions (Thompson, K.E., ACS Synth. Biol. (2012) 1:118-129, which is hereby incorporated by reference in its entirety).
例如,一對結合元件可以包括雙螺旋結合捲曲螺旋(Ghosh、I. 等人,J. Am. Chem. Soc. (2000) 122:5658-5659,其通過引用整體併入本文)。For example, a pair of binding elements can comprise a duplex binding coiled coil (Ghosh, I. et al., J. Am. Chem. Soc. (2000) 122:5658-5659, which is hereby incorporated by reference in its entirety).
在一些實施例中,設計的結合元件序列中的表面賴氨酸殘基可以突變為精氨酸以防止結合元件的自泛素化而不改變結合元件的結構和功能。可以改變設計的結合元件的表面殘基以改變電荷和其他可能影響表現水準的特性(例如表 1 中的“表面殘基”變體)。設計的結合元件的核心突變可用於改變給定異二聚體的結合親和力(例如DHD37-short-B-Y8A;SEQ ID NO:14)。In some embodiments, surface lysine residues in the designed binding element sequence can be mutated to arginine to prevent self-ubiquitination of the binding element without altering the structure and function of the binding element. The surface residues of a designed binding element can be altered to alter charge and other properties that may affect performance levels (e.g. "surface residue" variants in Table 1). Core mutations of designed binding elements can be used to alter the binding affinity of a given heterodimer (eg DHD37-short-B-Y8A; SEQ ID NO: 14).
小分子調控多肽Small Molecule Modulatory Peptides
在一些實施例中,一對小分子調節的多肽可作為結合元件以將融合的降解引發劑集中到感興趣的分子。小分子調節多肽的使用擴展了降解系統的功能,並提供了用於調節目標分子降解的外在控制機制(即化學控制機制)。In some embodiments, a pair of small molecule regulated polypeptides can serve as binding elements to focus the fused degradation initiator to the molecule of interest. The use of small molecule regulatory peptides extends the functionality of the degradation system and provides an extrinsic control mechanism (ie, chemical control mechanism) for modulating the degradation of target molecules.
例如,第一小分子調節多肽可以融合到降解引發劑,第二小分子調節多肽可以融合到合成的或外源的目標分子。可以選擇第一和第二小分子調節多肽,使得第一和第二小分子調節多肽形成二聚複合物的相互作用由小分子的存在調節。在某些情況下,小分子可以介導二聚複合物的組合。在其他情況下,小分子可能介導二聚複合物的分解。在其他情況下,第一小分子可以介導二聚複合物的組合,而第二小分子可以置換第一小分子並由此調節二聚複合物的分解。For example, a first small molecule modulating polypeptide can be fused to a degradation initiator and a second small molecule modulating polypeptide can be fused to a synthetic or exogenous target molecule. The first and second small molecule modulating polypeptides can be selected such that the interaction of the first and second small molecule modulating polypeptides to form the dimeric complex is mediated by the presence of the small molecule. In some cases, small molecules can mediate the assembly of dimeric complexes. In other cases, small molecules may mediate the disassembly of dimeric complexes. In other cases, a first small molecule can mediate the assembly of the dimeric complex, while a second small molecule can displace the first small molecule and thereby regulate the disassembly of the dimeric complex.
圖2顯示一對小分子調節的多肽結合元件的實施例的示意圖200。一個結合元件(例如“A”)可與感興趣的分子(例如蛋白質;未圖示)融合,第二個結合元件(例如“B”)可與降解引發劑(例如E3連接酶結構域;未圖示)融合,以提供小分子調節的二聚系統,用於目標分子的靶向降解。Figure 2 shows a schematic diagram 200 of an embodiment of a pair of small molecule-regulated polypeptide binding elements. One binding element (e.g., "A") can be fused to a molecule of interest (e.g., a protein; not shown), and a second binding element (e.g., "B") can be fused to a degradation initiator (e.g., an E3 ligase domain; not shown). Schematic) fusion to provide a small-molecule-regulated dimerization system for targeted degradation of target molecules.
例如,一對小分子調節的結合元件可包括作為第一結合元件的丙型肝炎病毒蛋白酶NS3a/4a蛋白(以下稱為NS3a)或其功能變體,以及作為第二結合元件的“讀取器”蛋白。例如,可以選擇閱讀器蛋白以識別 NS3a 蛋白的特定藥物結合狀態。NS3a 蛋白和NS3a 閱讀器蛋白已在 Baker 等人於 2020 年 6 月 11 日公開的名稱為“控制蛋白質功能和相互作用的試劑和方法”的國際專利公開號 WO2020117778 中進行了描述,其全文通過引用併入本文。For example, a pair of small molecule-regulated binding elements may include the hepatitis C virus protease NS3a/4a protein (hereafter referred to as NS3a) or a functional variant thereof as a first binding element, and a "reader" as a second binding element. "protein. For example, a reader protein can be selected to recognize a specific drug-bound state of the NS3a protein. NS3a proteins and NS3a reader proteins have been described in International Patent Publication No. WO2020117778, Baker et al., published June 11, 2020, entitled "Reagents and Methods for Controlling Protein Function and Interactions," which is incorporated by reference in its entirety Incorporated into this article.
NS3a 可以整合多種藥物輸入,並使用不同的工程閱讀器蛋白作為結合元件將藥物輸入轉化為不同的輸出。達諾瑞韋/NS3a複合物閱讀器、達諾瑞韋/NS3a複合物閱讀器和ANR/NS3a複合物閱讀器的NS3a蛋白質和多效性反應輸出已在Foight,G.W.等人的《自然生物技術》(2019)37:1209–1216中描述;Cunningham Bryant,D.等人,《美國化學學會雜誌》(2019)141:3352-3355;和Kügler,J.等人,《生物化學雜誌》(2012)287:39224–39232,其全文通過引用併入本文。NS3a can integrate multiple drug inputs and convert drug inputs into different outputs using different engineered reader proteins as binding elements. The NS3a protein and pleiotropic response outputs of the danoprevir/NS3a complex reader, danoprevir/NS3a complex reader, and ANR/NS3a complex reader have been described in Nature Biotechnology by Foight, G.W. et al. (2019) 37:1209–1216; Cunningham Bryant, D. et al., J. American Chemical Society (2019) 141:3352-3355; and Kügler, J. et al., J. Biochemistry (2012 ) 287:39224–39232, which is hereby incorporated by reference in its entirety.
NS3a 和閱讀器結合夥伴之間的相互作用可能受到小分子藥物的控制。可以選擇閱讀器來識別和結合特定的 NS3a/藥物複合物。Interactions between NS3a and reader binding partners may be controlled by small molecule drugs. Readers can be selected to recognize and bind specific NS3a/drug complexes.
在一些實施例中,為二聚體選擇的閱讀器是達諾瑞韋/NS3複合閱讀器(DNCR)多肽(或其功能變體),設計用於在小分子藥物達諾瑞韋存在的情況下識別和結合NS3a,從而提供藥物誘導的轉錄系統。在一些實施例中,DNCR多肽為DNCR2。參閱Foight,G.W.等人,《自然生物技術》,(2019)37:1209–1216。In some embodiments, the reader selected for the dimer is a danoprevir/NS3 composite reader (DNCR) polypeptide (or a functional variant thereof), designed for use in the presence of the small molecule drug danoprevir Down recognition and binding of NS3a, thus providing a drug-induced transcription system. In some embodiments, the DNCR polypeptide is DNCR2. See Foight, G.W. et al., Nature Biotechnology, (2019) 37:1209–1216.
在一些實施例中,為結合元件對選擇的閱讀器是grazoprevir/NS3複合閱讀器(GNCR)多肽(或其功能變體),設計用於在小分子藥物grazoprevir存在的情況下識別和結合NS3a,從而提供藥物誘導的轉錄系統。在一些實施例中,GNCR蛋白質為GNCR1。參閱Foight,G.W.等人,《自然生物技術》(2019)37:1209–1216。In some embodiments, the reader selected for the pair of binding elements is a grazoprevir/NS3 composite reader (GNCR) polypeptide (or a functional variant thereof) designed to recognize and bind NS3a in the presence of the small molecule drug grazoprevir, A drug-induced transcription system is thereby provided. In some embodiments, the GNCR protein is GNCR1. See Foight, G.W. et al., Nature Biotechnology (2019) 37:1209–1216.
原生基序目標特異性結合元件native motif target-specific binding element
可以使用融合到與分子上的天然基序相互作用的結合元件的降解引發劑對內源性感興趣分子進行降解。Endogenous molecules of interest can be degraded using degradation initiators fused to binding elements that interact with native motifs on the molecule.
在一個實施例中,可以設計結合元件以以構象特異性方式結合目標分子。In one example, binding elements can be designed to bind target molecules in a conformation-specific manner.
在一個實施例中,可以設計結合元件以對應分子上的特定修飾結合分子。例如,可以設計結合元件以對應蛋白質的轉譯後修飾結合目標蛋白質及/或蛋白質複合物。在一個實施例中,可以設計結合元件以結合目標蛋白的特定磷酸化狀態。In one example, binding elements can be designed to correspond to specific modifications of the binding molecule on the molecule. For example, binding elements can be designed to bind a protein and/or protein complex of interest in response to a post-translational modification of the protein. In one example, binding elements can be designed to bind a specific phosphorylation state of a protein of interest.
圖3顯示使用對目標分子上的天然基序(“A”)特異的結合元件(“B”)調節內源性目的分子的實施例的示意圖300。可以使用對目標分子上的天然基序A特異的結合元件B來調節內源目標分子,包括構象特異性結合或對應於分子上的特定修飾的結合。Figure 3 shows a schematic diagram 300 of an embodiment of the modulation of an endogenous molecule of interest using a binding element ("B") specific to a native motif ("A") on the molecule of interest. An endogenous target molecule can be modulated using a binding element B specific for a native motif A on the target molecule, including conformation-specific binding or binding corresponding to a specific modification on the molecule.
蛋白質的靶向降解Targeted degradation of proteins
本揭示提供了一種用於靶向降解感興趣的蛋白質的合成降解系統。該系統通常包括編碼與結合元件融合的E3連接酶結構域(或其功能變體)的多核苷酸,其中該結合元件用於將E3連接酶結構域集中到感興趣的蛋白質以啟動降解。The present disclosure provides a synthetic degradation system for targeted degradation of a protein of interest. The system typically comprises a polynucleotide encoding an E3 ligase domain (or a functional variant thereof) fused to a binding element for targeting the E3 ligase domain to a protein of interest to initiate degradation.
E3 泛素連接酶E3 ubiquitin ligase
E3 連接酶控制基質特異性和泛素化拓撲。例如,在細胞泛素蛋白酶體系統中,E3 連接酶蛋白集中已加載泛素的 E2 泛素結合酶,識別蛋白質基質,並協助或直接催化泛素從 E2 轉移到蛋白質基質,從而靶向蛋白質進行降解。E3連接酶結構域和/或其變體可以基於靶向降解的預期蛋白質來選擇。例如,可以選擇一種E3連接酶和/或一組E3連接酶來調節靶向跨膜蛋白的穩定性和/或半衰期。在另一個例子中,可以選擇一種E3連接酶和/或一組E3連接酶來調節細胞質蛋白(例如,轉錄因子)的穩定性和/或半衰期。E3 ligases control substrate specificity and ubiquitination topology. For example, in the cellular ubiquitin-proteasome system, E3 ligase proteins concentrate ubiquitin-loaded E2 ubiquitin-conjugating enzymes, recognize protein substrates, and assist or directly catalyze the transfer of ubiquitin from E2 to protein substrates, thereby targeting proteins for degradation. E3 ligase domains and/or variants thereof can be selected based on the desired protein targeted for degradation. For example, an E3 ligase and/or group of E3 ligases can be selected to modulate the stability and/or half-life of a targeted transmembrane protein. In another example, an E3 ligase and/or a group of E3 ligases can be selected to modulate the stability and/or half-life of a cytoplasmic protein (eg, a transcription factor).
可以使用篩選組策略來鑑定用於有效降解目標蛋白的功能性E3連接酶(及其功能變體)。例如,篩選組可包括編碼 E3-連接酶結構域或與結合元件(例如,DHD-B 或 DHD-A 結合元件)融合的泛素變體的構建體。用於鑑定功能性 E3 連接酶降解目標蛋白的篩選組示例如表 2 所示。在此示例中,E3 連接酶結構域和泛素變體組包括幾個已公開的泛素和E3 連接酶結構域:3xUb、LNX1、NEDD4、VHL、SPOP、SOCS2、Elongin C、CHIP、FBW1A、FBXW7 和RFN4(Zhu、L. 等人,Elife (2017) doi:10.7554/eLife.26403;Hatakeyama、E.、等人,Cancer Res. (2005) doi:10.1158/0008-5472.CAN-05-1581;Lim、S. 等人,Proc. Natl. Acad. Sci. U. S. A. (2020) doi:10.1073/pnas;1920251117;Ibrahim、A.F.M. 等人,Mol. Cell (2020) doi:10.1016/j.molcel.2020.04.032;以及 Deng、W. 等人,Nat. Commun. (2020) doi:10.1038/s41467- 019-14160-8;通過引用將其全文併入本文)。E3 連接酶結構域和泛素變體組還包括幾個新設計,其中包含以下結構域:RNF43、RNF128、ZNRF3、MARCH8、TRAF6 和串聯泛素突變體(K48R 和K63R)。該介面包括細胞質和膜相關的 DHD-E3 降解劑設計。A screening panel strategy can be used to identify functional E3 ligases (and functional variants thereof) for efficient degradation of a protein of interest. For example, a screening panel may include constructs encoding E3-ligase domains or ubiquitin variants fused to binding elements (eg, DHD-B or DHD-A binding elements). Examples of screening panels used to identify proteins of interest for degradation by functional E3 ligases are shown in Table 2. In this example, the set of E3 ligase domains and ubiquitin variants includes several published ubiquitin and E3 ligase domains: 3xUb, LNX1, NEDD4, VHL, SPOP, SOCS2, Elongin C, CHIP, FBW1A, FBXW7 and RFN4 (Zhu, L. et al., Elife (2017) doi: 10.7554/eLife.26403; Hatakeyama, E., et al., Cancer Res. (2005) doi: 10.1158/0008-5472.CAN-05-1581 ; Lim, S. et al, Proc. Natl. Acad. Sci. U. S. A. (2020) doi: 10.1073/pnas; 1920251117; Ibrahim, A.F.M. et al., Mol. Cell (2020) doi: 10.1016/j.molcel.2020.04. 032; and Deng, W. et al., Nat. Commun. (2020) doi: 10.1038/s41467-019-14160-8; incorporated herein by reference in its entirety). The E3 ligase domain and ubiquitin variant panel also includes several new designs containing the following domains: RNF43, RNF128, ZNRF3, MARCH8, TRAF6 and tandem ubiquitin mutants (K48R and K63R). This interface includes the design of cytoplasmic and membrane-associated DHD-E3 degraders.
篩選策略可以使用,例如,細胞與DHD-E3連接酶構建體或DHD-泛素變體構建體與融合到相應DHD結合元件配偶體的模型目標蛋白組合的共轉導。例如,為了篩選用於有效降解跨膜蛋白的DHD-E3連接酶構建體或DHD-泛素變體構建體,可以使用與相應的DHD結合元件配偶體融合的跨膜受體結構域。在一個實例中,與 DHD-A 結合元件融合的 ROR1 特異性嵌合抗原受體可用作模型目標蛋白以篩選跨膜蛋白的降解。Screening strategies can use, for example, cotransduction of cells with a DHD-E3 ligase construct or a DHD-ubiquitin variant construct in combination with a model protein of interest fused to the corresponding DHD binding element partner. For example, to screen for DHD-E3 ligase constructs or DHD-ubiquitin variant constructs for efficient degradation of transmembrane proteins, transmembrane receptor domains fused to the corresponding DHD binding element partners can be used. In one example, a ROR1-specific chimeric antigen receptor fused to a DHD-A binding element can be used as a model target protein to screen for degradation of transmembrane proteins.
類似地,為了篩選 DHD-E3 連接酶構建體或 DHD-泛素變體構建體以有效降解細胞質蛋白,可以使用融合到相應 DHD 結合元件的模型轉錄因子結構域。在一個示例中,融合到DHD-B結合元件的標記有FLAG的轉錄因子BACH2可作為篩選細胞質蛋白質降解的模型目標蛋白。Similarly, to screen DHD-E3 ligase constructs or DHD-ubiquitin variant constructs for efficient degradation of cytoplasmic proteins, model transcription factor domains fused to corresponding DHD-binding elements can be used. In one example, the FLAG-tagged transcription factor BACH2 fused to a DHD-B binding element serves as a model target protein for screening cytoplasmic protein degradation.
可用於篩選結合元件-E3連接酶構建體或結合元件-泛素變體構建體以有效降解跨膜蛋白或細胞質蛋白的模型目標蛋白融合構建體的示例顯示在表3中。Examples of model target protein fusion constructs that can be used to screen binding element-E3 ligase constructs or binding element-ubiquitin variant constructs for efficient degradation of transmembrane or cytoplasmic proteins are shown in Table 3.
多核苷酸polynucleotide
降解系統通常包括編碼與結合元件融合的E3泛素連接酶(“E3連接酶”)結構域(或其功能變體)的多核苷酸,其中該結合元件用於將E3連接酶結構域集中至目標蛋白質以用於靶向降解。The degradation system typically comprises a polynucleotide encoding an E3 ubiquitin ligase ("E3 ligase") domain (or functional variant thereof) fused to a binding element for funneling the E3 ligase domain to Target protein for targeted degradation.
異二聚體結合元件heterodimer binding element
在不同實施例中,降解系統可包括多核苷酸組,其包括第一多核苷酸和第二多核苷酸,其中,第一或第二多核苷酸編碼與第一結合元件融合的E3連接酶結構域,而第一或第二多核苷酸中的另一個編碼與相應的第二結合元件融合的合成的或外源的目標蛋白。In various embodiments, the degradation system may comprise a set of polynucleotides comprising a first polynucleotide and a second polynucleotide, wherein the first or second polynucleotide encodes a polynucleotide fused to the first binding element. E3 ligase domain, and the other of the first or second polynucleotides encodes a synthetic or exogenous protein of interest fused to a corresponding second binding element.
在一些實施例中,多核苷酸組包括多核苷酸成分,其可以包括:In some embodiments, a polynucleotide set includes a polynucleotide composition, which may include:
(i)編碼第一融合蛋白的第一多核苷酸,所述第一融合蛋白包括第一結合元件和E3連接酶結構域;(i) a first polynucleotide encoding a first fusion protein comprising a first binding element and an E3 ligase domain;
(ii) 編碼第二融合蛋白的第二多核苷酸,所述第二融合蛋白包括第二結合元件和合成的或外源的目標蛋白;(ii) a second polynucleotide encoding a second fusion protein comprising a second binding element and a synthetic or exogenous protein of interest;
(iii)與第一和/或第二多核苷酸可操作地連接的一個或多個啟動子序列;(iii) one or more promoter sequences operably linked to the first and/or second polynucleotide;
(iv)任選的包括分離元件,其包括防止第一融合蛋白和第二融合蛋白融合的多核苷酸序列;以及(iv) optionally including a separation element comprising a polynucleotide sequence that prevents fusion of the first fusion protein and the second fusion protein; and
(v) 一種或多種任選的調節序列。(v) one or more optional regulatory sequences.
其中第一和第二多核苷酸、啟動子序列和任選的分離元件和調節元件被配置用於目標蛋白的表現和調節降解。wherein the first and second polynucleotides, the promoter sequence, and optionally separate and regulatory elements are configured for expression and regulated degradation of the protein of interest.
編碼第一和第二融合蛋白、啟動子序列和任選的分離元件和調節序列的多核苷酸可以配置在載體骨架中,用於表現和調節目標蛋白的降解。Polynucleotides encoding the first and second fusion proteins, the promoter sequence and optionally separate elements and regulatory sequences can be configured in a vector backbone for expression and regulation of degradation of the protein of interest.
在不同的實施例中,編碼融合蛋白的多核苷酸成分可以包括編碼分離融合蛋白的分離元件的多核苷酸序列。In various embodiments, the polynucleotide component encoding the fusion protein can include polynucleotide sequences encoding separate elements of the fusion protein.
在一些實施例中,分離元件可以包括選自P2a和T2a的核醣體跳躍序列。In some embodiments, the separation element may comprise a ribosomal skipping sequence selected from P2a and T2a.
在一些實施例中,分離元件可以包括多核苷酸序列,該多核苷酸序列包括至少兩個選自T2a-RFP-P2a、P2a-T2a和T2a-P2a的核醣體跳躍序列。In some embodiments, the separation element can comprise a polynucleotide sequence comprising at least two ribosomal skipping sequences selected from T2a-RFP-P2a, P2a-T2a, and T2a-P2a.
在一些實施例中,分離元件可以包括內部核醣體進入位點(IRES)。In some embodiments, the separation element can include an internal ribosome entry site (IRES).
在一些實施例中,分離元件可以包括第二啟動子序列。In some embodiments, the isolated element can include a second promoter sequence.
在一些實施例中,包括第一和第二多核苷酸的多核苷酸成分編碼一個或多個與第一和/或第二多核苷酸可操作連接的組成型啟動子序列。In some embodiments, the polynucleotide component comprising the first and second polynucleotides encodes one or more constitutive promoter sequences operably linked to the first and/or second polynucleotides.
在一些實施例中,包括第一和第二多核苷酸的多核苷酸成分編碼一個或多個可操作地連接到第一和/或第二多核苷酸的誘導型啟動子序列。In some embodiments, the polynucleotide component comprising the first and second polynucleotides encodes one or more inducible promoter sequences operably linked to the first and/or second polynucleotides.
在一些實施例中,編碼包括E3連接酶結構域的第一融合蛋白的第一多核苷酸也編碼誘導型啟動子,並且編碼包括目標蛋白的第二融合蛋白的第二多核苷酸編碼不同的誘導型啟動子。In some embodiments, the first polynucleotide encoding the first fusion protein comprising the E3 ligase domain also encodes an inducible promoter, and the second polynucleotide encoding the second fusion protein comprising the protein of interest encodes different inducible promoters.
在一些實施例中,編碼包含E3連接酶結構域的第一融合蛋白的多核苷酸編碼誘導型啟動子序列,並且編碼包含目標蛋白的第二融合蛋白的多核苷酸編碼組成型啟動子序列。In some embodiments, the polynucleotide encoding the first fusion protein comprising the E3 ligase domain encodes an inducible promoter sequence and the polynucleotide encoding the second fusion protein comprising the protein of interest encodes a constitutive promoter sequence.
在不同的實施例中,組成型啟動子序列可以包括組成型啟動子序列,該組成型啟動子序列選自下列所組成的群組中:MND (SEQ ID NO:144)、hPGK (SEQ ID NO:145)、CMV (SEQ ID NO:146)、CAG (SEQ ID NO:147) )、SFFV (SEQ ID NO:148)、EF1alpha (SEQ ID NO:149)、UBC (SEQ ID NO:150) 和CD43 (SEQ ID NO:151) (參見表 8)。In various embodiments, the constitutive promoter sequence may comprise a constitutive promoter sequence selected from the group consisting of: MND (SEQ ID NO: 144), hPGK (SEQ ID NO : 145), CMV (SEQ ID NO: 146), CAG (SEQ ID NO: 147) ), SFFV (SEQ ID NO: 148), EF1alpha (SEQ ID NO: 149), UBC (SEQ ID NO: 150) and CD43 (SEQ ID NO: 151) (see Table 8).
在一些實施例中,誘導型啟動子序列可以包括最小啟動子序列,例如最小核心啟動子。在一些實施例中,最小啟動子序列選自下列所組成的群組中:YB_TATA (SEQ ID NO: 152)、人類β球蛋白 (huBG) (SEQ ID NO: 153)、minIL2 (SEQ ID NO: 154)、minimalCMV ( minCMV) (SEQ ID NO: 155),和TRE3G (SEQ ID NO: 156) (參見表 9)。In some embodiments, an inducible promoter sequence can include a minimal promoter sequence, such as a minimal core promoter. In some embodiments, the minimal promoter sequence is selected from the group consisting of: YB_TATA (SEQ ID NO: 152), human beta globulin (huBG) (SEQ ID NO: 153), minIL2 (SEQ ID NO: 154), minimalCMV ( minCMV) (SEQ ID NO: 155), and TRE3G (SEQ ID NO: 156) (see Table 9).
在一些實施例中,誘導型啟動子序列包括轉錄因子特異性識別序列。In some embodiments, the inducible promoter sequence includes a transcription factor specific recognition sequence.
在一些實施例中,轉錄因子特異性識別序列可以包括重複2、3、4、5、6、7、8、9、10或更多次的反應元件。In some embodiments, a transcription factor-specific recognition sequence can include a response element repeated 2, 3, 4, 5, 6, 7, 8, 9, 10 or more times.
在一些實施例中,轉錄因子特異性識別序列可以包括選擇以反應細胞內在刺激的反應元件。In some embodiments, a transcription factor-specific recognition sequence can include a response element selected to respond to a cell-intrinsic stimulus.
在一些實施例中,轉錄因子特異性識別序列可以包括鈣反應性NFAT-AP1反應元件(Hooijberg,E.,等人,血液期刊,(2000) 96:459-466,其通過引用整體併入本文)。In some embodiments, the transcription factor-specific recognition sequence may include a calcium-responsive NFAT-AP1 response element (Hooijberg, E., et al., Blood Journal, (2000) 96:459-466, which is incorporated herein by reference in its entirety ).
在某些實施例中,誘導型啟動子序列包括最小CMV(minCMV)啟動子序列和重複4次的NFAT-AP1反應元件(SEQ ID NO:143)(參見表7)。In certain embodiments, the inducible promoter sequence includes a minimal CMV (minCMV) promoter sequence and a NFAT-AP1 response element (SEQ ID NO: 143) repeated 4 times (see Table 7).
在一些實施例中,轉錄因子特異性識別序列包括選擇以反應環境刺激的反應元件。In some embodiments, transcription factor-specific recognition sequences include response elements selected to respond to environmental stimuli.
在一些實施例中,第一和/或第二多核苷酸可以編碼一個或多個選自由polyA、endo組成的組的任選調節序列。In some embodiments, the first and/or second polynucleotide may encode one or more optional regulatory sequences selected from the group consisting of polyA, endo.
在一些實施例中,編碼第一和/或第二融合蛋白的多核苷酸進一步包括蛋白質標籤序列(例如,FLAG-標籤序列)。In some embodiments, the polynucleotide encoding the first and/or second fusion protein further includes a protein tag sequence (eg, FLAG-tag sequence).
在一些實施例中,編碼E3連接酶結構域和第一結合元件的第一或第二多核苷酸進一步包括分隔E3連接酶結構域和結合元件的柔性連接子序列。在一個實例中,柔性連接子是甘氨酸-絲氨酸連接子。In some embodiments, the first or second polynucleotide encoding the E3 ligase domain and the first binding element further comprises a flexible linker sequence separating the E3 ligase domain and the binding element. In one example, the flexible linker is a glycine-serine linker.
在一些實施例中,編碼感興趣的蛋白質和第二結合元件的第一或第二多核苷酸進一步包括將感興趣的蛋白質和結合元件分開的柔性連接子序列。在一個實施例中,柔性連接子是甘氨酸-絲氨酸連接子。In some embodiments, the first or second polynucleotide encoding the protein of interest and the second binding element further comprises a flexible linker sequence separating the protein of interest and the binding element. In one embodiment, the flexible linker is a glycine-serine linker.
在一些實施例中,第一或第二多核苷酸編碼DHD-A結合元件,並且第一或第二多核苷酸中的另一個編碼DHD-B結合元件,其中DHD結合對選自下列所組成的群組中:DHD37-short-A (SEQ ID NO: 11) 和DHD37-short-B (SEQ ID NO: 13)、DHD37-short-B-Ntrunc (SEQ ID NO: 13) NO: 15),或 DHD37-short-B-KtoR (SEQ ID NO: 16)。In some embodiments, the first or second polynucleotide encodes a DHD-A binding element and the other of the first or second polynucleotide encodes a DHD-B binding element, wherein the DHD binding pair is selected from In the group formed: DHD37-short-A (SEQ ID NO: 11) and DHD37-short-B (SEQ ID NO: 13), DHD37-short-B-Ntrunc (SEQ ID NO: 13) NO: 15 ), or DHD37-short-B-KtoR (SEQ ID NO: 16).
在一些實施例中,第一或第二多核苷酸編碼結合元件,該結合元件選自下列所組成的群組中:Synzip1 (SEQ ID NO: 66)、Synzip2 (SEQ ID NO: 67)、Synzip3 (SEQ ID NO: 68)、Synzip4 (SEQ ID NO: 69) 、Synzip5 (SEQ ID NO: 70)、Synzip6 (SEQ ID NO: 71)、Coil-coil-CZ-A (SEQ ID NO: 72) 或 Coil-coil-NZ-B (SEQ ID NO: 73)。In some embodiments, the first or second polynucleotide encodes a binding element selected from the group consisting of Synzip1 (SEQ ID NO: 66), Synzip2 (SEQ ID NO: 67), Synzip3 (SEQ ID NO: 68), Synzip4 (SEQ ID NO: 69), Synzip5 (SEQ ID NO: 70), Synzip6 (SEQ ID NO: 71), Coil-coil-CZ-A (SEQ ID NO: 72) or Coil-coil-NZ-B (SEQ ID NO: 73).
在不同的實施例中,第一或第二多核苷酸編碼包含結合元件和E3連接酶結構域的融合蛋白,其可以包括:RNF43198-783-DHD37-short-B (SEQ ID NO: 74)、RNF43198-364-DHD37-short-B (SEQ ID NO: 75)、RNF43195-325-DHD37-short-B (SEQ ID NO: 76)、RNF43198-317-DHD37-short-B (SEQ ID NO: 77)、RNF128208-428-DHD37-short-B (SEQ ID NO: 78)、RNF128208-333-DHD37-short-B (SEQ ID NO: 79)、RNF128208-325-DHD37-short-B (SEQ ID NO: 80)、DHD37-short-B-3xUb (SEQ ID NO: 81)、DHD37-short-B-3xUbK48R(SEQ ID NO: 82)、DHD37-short-B-3xUbK63R(SEQ ID NO: 83)、ZNRF3219-936-DHD37-short-B (SEQ ID NO: 84)、ZNRF3219-528-DHD37-short-B (SEQ ID NO: 85)、ZNRF3219-345-DHD37-short-B (SEQ ID NO: 86)、DHD37-short-B-MARCH81-154-KLRG137-60(SEQ ID NO: 87)、DHD37-short-B-MARCH81-228(SEQ ID NO: 88)、MARCH81-228-DHD37-short-B (SEQ ID NO: 89)、LNX11-171-DHD37-short-B (SEQ ID NO: 90)、DHD37-short-B-VHL152-213(SEQ ID NO: 91)、DHD37-short-B-NEDD4921-1303(SEQ ID NO: 92)、DHD37-short-B-SPOP167-374(SEQ ID NO: 93)、DHD37-short-B-SOCS2143-198(SEQ ID NO: 94)、DHD37-short-B-CHIP128-303(SEQ ID NO: 95)、FBXW71-293-DHD37-short-B (SEQ ID NO: 96)、ELOC1-87-DHD37-short-B (SEQ ID NO: 97)、FBW1A1-261-DHD37-short-B (SEQ ID NO: 98)、DHD37-short-B-RNF471-190(SEQ ID NO: 99)、TRAF649-237-DHD37-short-B (SEQ ID NO: 100)、LNX11-171-DHD37-short-A (SEQ ID NO: 101)、DHD37-short-A-VHL152-213(SEQ ID NO: 102)、DHD37-short-A-NEDD4921-1303(SEQ ID NO: 103)、DHD37-short-A-SPOP167-374(SEQ ID NO: 104)、DHD37-short-A-SOCS2143-198(SEQ ID NO: 105)、DHD37-short-A-CHIP128-303(SEQ ID NO: 106)、FBXW71-293-DHD37-short-A (SEQ ID NO: 107)、ELOC1-87-DHD37-short-A (SEQ ID NO: 108)、FBW1A1-261-DHD37-short-A (SEQ ID NO: 109)、DHD37-short-A-RNF471-190(SEQ ID NO: 110)、Synzip2-RNF4 (SEQ ID NO: 111)、Synzip4-RNF4 (SEQ ID NO: 112)、Synzip6-RNF4 (SEQ ID NO;113)、Coil-coil-NZ-RNF4 (SEQ ID NO: 114)、RNF43198-317-DHD37-short-B-KtoR (SEQ ID NO: 121)、RNF43198-317-DHD37-short-B-endo-var1 (SEQ ID NO: 122)、RNF43198-317-DHD37-short-B-endo-var2 (SEQ ID NO: 123)、RNF43198-317-DHD37-short-B-endo-var3 (SEQ ID NO: 124)、或RNF43198-317-KtoR-DHD37-short-B-endo-var1 (SEQ ID NO: 125)。見表 2 和表 4。In various embodiments, the first or second polynucleotide encodes a fusion protein comprising a binding element and an E3 ligase domain, which may comprise:RNF43198-783 -DHD37-short-B (SEQ ID NO: 74 ), RNF43198-364 -DHD37-short-B (SEQ ID NO: 75), RNF43195-325 -DHD37-short-B (SEQ ID NO: 76), RNF43198-317 -DHD37-short-B (SEQ ID NO: 76) ID NO: 77), RNF128208-428 -DHD37-short-B (SEQ ID NO: 78), RNF128208-333 -DHD37-short-B (SEQ ID NO: 79), RNF128208-325 -DHD37-short -B (SEQ ID NO: 80), DHD37-short-B-3xUb (SEQ ID NO: 81), DHD37-short-B-3xUbK48R (SEQ ID NO: 82), DHD37-short-B-3xUbK63R ( SEQ ID NO: 83), ZNRF3219-936 -DHD37-short-B (SEQ ID NO: 84), ZNRF3219-528-DHD37-short-B (SEQ ID NO: 85), ZNRF3219-345 -DHD37-short -B (SEQ ID NO: 86), DHD37-short-B-MARCH81-154 -KLRG137-60 (SEQ ID NO: 87), DHD37-short-B-MARCH81-228 (SEQ ID NO: 88) , MARCH81-228 -DHD37-short-B (SEQ ID NO: 89), LNX11-171 -DHD37-short-B (SEQ ID NO: 90), DHD37-short-B-VHL152-213 (SEQ ID NO: 91), DHD37-short-B-NEDD4 921-1303 (SEQ ID NO: 92), DHD37-short-B-SPOP167-374 (SEQ ID NO: 93), DHD37-short-B-SOCS2143- 198 (SEQ ID NO: 94), DHD37-short-B-CHIP128-303 ( SEQ ID NO: 95), FBXW71-293 -DHD37-short-B (SEQ ID NO: 96), ELOC1-87 -DHD37-short-B (SEQ ID NO: 97), FBW1A1-261- DHD37- short-B (SEQ ID NO: 98), DHD37-short-B-RNF471-190 (SEQ ID NO: 99), TRAF649-237 -DHD37-short-B (SEQ ID NO: 100), LNX11- 171 -DHD37-short-A (SEQ ID NO: 101), DHD37-short-A-VHL152-213 (SEQ ID NO: 102), DHD37-short-A-NEDD4 921-1303 (SEQ ID NO: 103) , DHD37-short-A-SPOP167-374 (SEQ ID NO: 104), DHD37-short-A-SOCS2143-198 (SEQ ID NO: 105), DHD37-short-A-CHIP128-303 (SEQ ID NO: 106), FBXW71-293 -DHD37-short-A (SEQ ID NO: 107), ELOC1-87 -DHD37-short-A (SEQ ID NO: 108), FBW1A1-261 -DHD37-short-A A (SEQ ID NO: 109), DHD37-short-A-RNF471-190 (SEQ ID NO: 110), Synzip2-RNF4 (SEQ ID NO: 111), Synzip4-RNF4 (SEQ ID NO: 112), Synzip6 - RNF4 (SEQ ID NO: 113), Coil-coil-NZ-RNF4 (SEQ ID NO: 114), RNF43198-317 - DHD37-short-B-KtoR (SEQ ID NO: 121), RNF43198-317 - DHD37-short-B-endo-var1 (SEQ ID NO: 122), RNF43198-317 -DHD37-short-B-endo-var2 (SEQ ID NO: 123), RNF43198-317 -DHD37-short-B- endo-var3 (SEQ ID NO: 124), or RNF43198-317 -KtoR-DHD37-short-B-endo-var1 (SEQ ID NO: 125). See Table 2 and Table 4.
在不同的實施例中,第一或第二多核苷酸編碼包含結合元件和感興趣的目標蛋白的融合蛋白。In various embodiments, the first or second polynucleotide encodes a fusion protein comprising a binding element and a target protein of interest.
在一些實施例中,第一或第二多核苷酸編碼包含結合元件和ROR1-CAR蛋白的融合蛋白,其可以包括:ROR1-CAR-DHD37-short-A (SEQ ID NO: 115)、ROR1 CAR-Synzip1 (SEQ ID NO: 116)、ROR1 CAR-Synzip3 (SEQ ID NO: 117)、ROR1 CAR-Synzip5 (SEQ ID NO: 118),或 ROR1 CAR-線圈序列-CZ (SEQ ID NO: 119)。見表 2。In some embodiments, the first or second polynucleotide encodes a fusion protein comprising a binding element and a ROR1-CAR protein, which may include: ROR1-CAR-DHD37-short-A (SEQ ID NO: 115), ROR1 CAR-Synzip1 (SEQ ID NO: 116), ROR1 CAR-Synzip3 (SEQ ID NO: 117), ROR1 CAR-Synzip5 (SEQ ID NO: 118), or ROR1 CAR-coil sequence-CZ (SEQ ID NO: 119) . See Table 2.
在某些實施例中,第一或第二多核苷酸編碼融合蛋白,包括DHD多肽和BACH2多肽(SEQ ID NO:120)。見表 2。In certain embodiments, the first or second polynucleotide encodes a fusion protein comprising a DHD polypeptide and a BACH2 polypeptide (SEQ ID NO: 120). See Table 2.
小分子調控多核苷酸Small Molecule Regulatory Polynucleotides
一對小分子調節的多肽可用作結合元件以將融合的E3連接酶結構域(或其功能變體)集中到感興趣的蛋白質。A pair of small molecule regulated polypeptides can be used as binding elements to focus a fused E3 ligase domain (or a functional variant thereof) to a protein of interest.
例如,降解系統可以包括多核苷酸組,該多核苷酸組包括第一多核苷酸和第二多核苷酸,第一或第二多核苷酸編碼與第一小分子調節多肽融合的E3連接酶結構域,並且第一或第二多核苷酸中的另一個編碼與相應的第二小分子調節多肽融合的合成的或外源的目標蛋白。For example, a degradation system can include a set of polynucleotides comprising a first polynucleotide and a second polynucleotide, either the first or second polynucleotide encoding a protein fused to a first small molecule modulating polypeptide. E3 ligase domain, and the other of the first or second polynucleotides encodes a synthetic or exogenous protein of interest fused to a corresponding second small molecule regulatory polypeptide.
在不同的實施例中,第一或第二多核苷酸可以編碼包括NS3a(或其功能變體)的結合元件,並且第一或第二多核苷酸中的另一個可以編碼選自由DNCR2(或其修飾物)和GNCR1所組成的群組中的結合元件( 或其修飾物)。In various embodiments, the first or second polynucleotide may encode a binding element comprising NS3a (or a functional variant thereof), and the other of the first or second polynucleotide may encode a binding element selected from the group consisting of DNCR2. (or its modification) and the binding element (or its modification) in the group consisting of GNCR1.
在一些實施例中,第一或第二多核苷酸編碼結合元件,該結合元件可包括NS3a多肽,其包括:NS3a。In some embodiments, the first or second polynucleotide encodes a binding element, which may comprise a NS3a polypeptide, comprising: NS3a.
在某些實施例中,第一或第二多核苷酸編碼包含ROR1-CAR和NS3a結合元件(SEQ ID NO: 126)的ROR1-CAR-NS3a融合蛋白。見表 5。In certain embodiments, the first or second polynucleotide encodes a ROR1-CAR-NS3a fusion protein comprising a ROR1-CAR and NS3a binding element (SEQ ID NO: 126). See Table 5.
在一些實施例中,第一或第二多核苷酸編碼可包括DNCR2多肽的結合元件,所述DNCR2多肽包括:DNCR2。In some embodiments, the first or second polynucleotide encodes a binding element that may comprise a DNCR2 polypeptide comprising: DNCR2.
在一些實施例中,第一或第二多核苷酸編碼結合元件,該結合元件可包括GNCR1多肽,其包括:GNCR1。In some embodiments, the first or second polynucleotide encodes a binding element which may comprise a GNCR1 polypeptide comprising: GNCR1.
在一些實施例中,第一或第二多核苷酸編碼包含DNCR2多肽和E3連接酶結構域的融合蛋白,其可以包括:RNF43198-317-DNCR (SEQ ID NO: 127)、DNCR-RNF471-190(SEQ ID NO: 128)、LNX11-171-DNCR (SEQ ID NO: 129)、RNF43198-317-DNCR-endo (SEQ ID NO: 130)、RNF43198-317-DNCR-KtoR (SEQ ID NO: 131)、或 RNF43198-317-DNCR-KtoR-endo (SEQ ID NO: 132)。見表 5。In some embodiments, the first or second polynucleotide encodes a fusion protein comprising a DNCR2 polypeptide and an E3 ligase domain, which may include: RNF43198-317- DNCR (SEQ ID NO: 127), DNCR-RNF471-190 (SEQ ID NO: 128), LNX11-171- DNCR (SEQ ID NO: 129), RNF43198-317 -DNCR-endo (SEQ ID NO: 130), RNF43198-317 -DNCR-KtoR ( SEQ ID NO: 131), or RNF43198-317 -DNCR-KtoR-endo (SEQ ID NO: 132). See Table 5.
天然基序多肽native motif peptide
在不同的實施例中,編碼融合蛋白的多核苷酸包括對內源性目標蛋白上的天然基序具有特異性的結合元件和E3連接酶結構域(或其功能變體)。In various embodiments, a polynucleotide encoding a fusion protein includes a binding element specific for a native motif on an endogenous protein of interest and an E3 ligase domain (or a functional variant thereof).
在一些實施例中,該多核苷酸可以編碼結合元件,該結合元件包括對跨膜蛋白和/或蛋白複合物的區域具有特異性的結構域。In some embodiments, the polynucleotide can encode a binding element comprising a domain specific for a region of a transmembrane protein and/or protein complex.
在一實施例中,結合元件包括靶向跨膜蛋白和/或蛋白複合物的胞內結構域的結構域。In one embodiment, the binding element comprises a domain targeting the transmembrane protein and/or the intracellular domain of the protein complex.
在一實施例中,結合元件包括靶向跨膜蛋白和/或蛋白複合物的跨膜結構域的結構域。In one embodiment, the binding element comprises a domain targeting the transmembrane domain of a transmembrane protein and/or protein complex.
在一實施例中,跨膜蛋白是一種 T 細胞受體 (TCR) 複合物。In one embodiment, the transmembrane protein is a T cell receptor (TCR) complex.
在一實施例中,該多核苷酸可以編碼結合元件,該結合元件包括對選自TMCD3z的TCR複合物的跨膜結構域特異的結構域。In one embodiment, the polynucleotide may encode a binding element comprising a domain specific for a transmembrane domain of a TCR complex selected fromTMCD3z .
在一些實施例中,該多核苷酸可以編碼結合元件,該結合元件包括對內源性目的蛋白質上的蛋白質-蛋白質相互作用結構域特異的結構域。蛋白質-蛋白質相互作用結構域的實例包括但不限於pleckstrin同源性(PH)結構域、Src同源性2結構域(SH2)和Src同源性3結構域(SH3)。In some embodiments, the polynucleotide can encode a binding element comprising a domain specific for a protein-protein interaction domain on an endogenous protein of interest. Examples of protein-protein interaction domains include, but are not limited to, pleckstrin homology (PH) domains,
在一些實施例中,多核苷酸可以編碼結合元件,該結合元件包括作為單鏈可變片段(scFV)的結構域,其識別並結合感興趣的蛋白質的特定區域。In some embodiments, a polynucleotide may encode a binding element comprising a domain as a single-chain variable fragment (scFV) that recognizes and binds a specific region of a protein of interest.
在一些實施例中,多核苷酸可以編碼結合元件,包括識別和結合感興趣蛋白質的特定區域的單個單體可變抗體結構域或“奈米抗體”。In some embodiments, a polynucleotide may encode a binding element, comprising a single monomeric variable antibody domain or "nanobody" that recognizes and binds a specific region of a protein of interest.
在一些實施例中,該多核苷酸可以編碼結合元件,該結合元件包括識別並結合感興趣蛋白質的特定區域的單體。單體是使用纖維連接蛋白 III 型結構域 (FN3) 作為分子支架構建的合成結合蛋白。In some embodiments, the polynucleotide can encode a binding element comprising a monomer that recognizes and binds a specific region of a protein of interest. Monomer is a synthetic binding protein constructed using the fibronectin type III domain (FN3) as a molecular scaffold.
在一些實施例中,該多核苷酸可以編碼結合元件,包括設計的錨蛋白重複蛋白結構域(DARPin),該結構域識別並結合感興趣的蛋白質的特定區域。In some embodiments, the polynucleotide can encode a binding element, including a designed ankyrin repeat protein domain (DARPin), that recognizes and binds a specific region of a protein of interest.
在一些實施例中,該多核苷酸可以編碼結合元件,該結合元件包括識別和結合感興趣蛋白質的特定區域的可變淋巴細胞受體(VLR)結構域。In some embodiments, the polynucleotide can encode a binding element comprising a variable lymphocyte receptor (VLR) domain that recognizes and binds a specific region of a protein of interest.
在一些實施例中,該多核苷酸編碼包含結合元件和E3連接酶結構域的融合蛋白,其可以包括:TMCD3z-RNF43226-317(v1) (SEQ ID NO: 133)、TMCD3z-K54R-RNF43226-317(v2) (SEQ ID NO: 134)、TMCD3z-RNF43236-317(v3) (SEQ ID NO: 135)、TMCD3z-K54R-RNF43236-317(v4) (SEQ ID NO: 136)、ZAP70nSH2-cSH2-RNF471-190(SEQ ID NO;137)、ZAP70cSH2-RNF471-190(SEQ ID NO: 138)、LNX11-171-ZAP70nSH2-cSH2(SEQ ID NO: 139)、LNX11-171-ZAP70cSH2(SEQ ID NO: 140)、NCK1SH3.1-RNF471-19(SEQ ID NO: 141)、或LNX11-171-NCK1SH3.1(SEQ ID NO: 142)。參閱表6。In some embodiments, the polynucleotide encodes a fusion protein comprising a binding element and an E3 ligase domain, which may include: TMCD3z -RNF43226-317 (v1) (SEQ ID NO: 133), TMCD3z-K54 R-RNF43226-317 (v2) (SEQ ID NO: 134), TMCD3z -RNF43236-317 (v3) (SEQ ID NO: 135), TMCD3z-K54R- RNF43236-317 (v4) (SEQ ID NO: 136), ZAP70nSH2-cSH2- RNF471-190 (SEQ ID NO; 137), ZAP70cSH2 -RNF471-190 (SEQ ID NO: 138), LNX11-171 -ZAP70nSH2-cSH2 (SEQ ID NO : 139), LNX11-171- ZAP70cSH2 (SEQ ID NO: 140), NCK1SH3.1 -RNF471-19 (SEQ ID NO: 141), or LNX11-171 -NCK1SH3.1 (SEQ ID NO : 142). See Table 6.
目標蛋白質target protein
本揭示的合成降解系統可用於調節一系列目標分子的活性。可以基於降解的目標蛋白質來選擇降解系統中使用的結合元件和降解引發劑(例如,E3連接酶結構域)的組合。目標蛋白質可以是合成蛋白質或外源蛋白質。目標蛋白質可以是內源性蛋白質和/或蛋白質複合物。The synthetic degradation systems disclosed herein can be used to modulate the activity of a range of target molecules. The combination of binding elements and degradation initiators (eg, E3 ligase domains) used in the degradation system can be selected based on the target protein for degradation. The target protein can be a synthetic protein or an exogenous protein. The protein of interest can be an endogenous protein and/or protein complex.
本揭示的降解系統可用於提供對感興趣的目標蛋白質的組成性調節。The degradation systems of the present disclosure can be used to provide constitutive regulation of a target protein of interest.
本揭示的降解系統可以用於以上下文相關的方式提供對感興趣的目標蛋白質的動態調節。例如,降解系統可以是誘導型系統,其可以在細胞過程中的一個點“關閉”,其中需要目標蛋白質的功能,並在細胞過程中的另一個點“打開”,其中不需要目標蛋白質的功能。The degradation systems of the present disclosure can be used to provide dynamic regulation of a target protein of interest in a context-sensitive manner. For example, a degradation system can be an inducible system that can be "turned off" at one point in the cellular process, where the function of the target protein is required, and "turned on" at another point in the cellular process, where the function of the target protein is not required .
本揭示的降解系統可用於同時調節多種蛋白質。例如,靶向降解系統可以使用降解引發劑和識別和結合存在於多種蛋白質(例如,蛋白質家族成員)中的保守結構域的單一個結合元件。例如,結合元件可以是具有混雜目標屬性的設計結合元件。The degradation systems of the present disclosure can be used to regulate multiple proteins simultaneously. For example, a targeted degradation system can use a degradation initiator and a single binding element that recognizes and binds a conserved domain present in multiple proteins (eg, protein family members). For example, a binding element may be a design binding element with mixed target properties.
可靶向降解的蛋白質包括但不限於代謝酶,例如參與糖酵解、氧化磷酸化和脂肪酸代謝的酶;參與細胞信號傳導過程的酶;轉錄因子;支架和銜接蛋白;以及線粒體蛋白。Proteins that can be targeted for degradation include, but are not limited to, metabolic enzymes such as those involved in glycolysis, oxidative phosphorylation, and fatty acid metabolism; enzymes involved in cellular signaling processes; transcription factors; scaffold and adapter proteins; and mitochondrial proteins.
蛋白質中的某個結構域和/或基序可用於靶向蛋白質以進行降解。A domain and/or motif in a protein can be used to target the protein for degradation.
對蛋白質和/或蛋白質結構域的某種轉錄後修飾可用於靶向蛋白質以進行降解。Certain post-transcriptional modifications to proteins and/or protein domains can be used to target proteins for degradation.
跨膜受體transmembrane receptor
本揭示的降解系統可用於整合(內在)膜蛋白例如跨膜受體的靶向降解。可靶向降解的跨膜受體的例子包括但不限於嵌合抗原受體 (CAR)、T 細胞受體 (TCR)、受體酪氨酸激酶 (RTK)、Notch、Notch 樣受體、生長因子家族受體 、受體絲氨酸/蘇氨酸激酶、G 蛋白偶聯受體 (GPCR)、抑制性受體如 PD-1、TIGIT、LAG3、TGFβ、FAS 和細胞因子受體。The degradation systems of the present disclosure can be used for the targeted degradation of integral (intrinsic) membrane proteins such as transmembrane receptors. Examples of transmembrane receptors that can be targeted for degradation include, but are not limited to, chimeric antigen receptors (CARs), T cell receptors (TCRs), receptor tyrosine kinases (RTKs), Notch, Notch-like receptors, growth Factor family receptors, receptor serine/threonine kinases, G protein-coupled receptors (GPCRs), inhibitory receptors such as PD-1, TIGIT, LAG3, TGFβ, FAS, and cytokine receptors.
可靶向降解的受體酪氨酸激酶 (RTK) 的實例包括但不限於表皮生長因子受體 (EGFR)、ErbB、ERBB2 (HER2)、成纖維細胞生長因子受體 (FGFR)、胰島素類生長因子 1 受體 (IGF1R) 和血管內皮生長因子受體 (VEGFR)。Examples of receptor tyrosine kinases (RTKs) that can be targeted for degradation include, but are not limited to, epidermal growth factor receptor (EGFR), ErbB, ERBB2 (HER2), fibroblast growth factor receptor (FGFR), insulin-
在一些實施例中,靶向降解的跨膜蛋白是T細胞受體(TCR)。In some embodiments, the transmembrane protein targeted for degradation is T cell receptor (TCR).
在一些實施例中,靶向降解的跨膜蛋白是嵌合抗原受體(CAR)。在一個例子中,靶向降解的 CAR 蛋白是 ROR1 特異性嵌合抗原受體蛋白 (ROR1-CAR)。In some embodiments, the transmembrane protein targeted for degradation is a chimeric antigen receptor (CAR). In one example, the CAR protein targeted for degradation is the ROR1-specific chimeric antigen receptor protein (ROR1-CAR).
在一些實施例中,細胞因子受體 IL-7R 可能成為降解的目標。組成型 IL-7 受體信號轉導已顯示可促進 T 細胞增殖和持久殺傷腫瘤細胞(Shum 等人,(20017)和Peng(2017),通過引用將其整體併入本文)。In some embodiments, the cytokine receptor IL-7R may be targeted for degradation. Constitutive IL-7 receptor signaling has been shown to promote T cell proliferation and persistent killing of tumor cells (Shum et al., (20017) and Peng (2017), which are hereby incorporated by reference in their entireties).
轉錄因子transcription factor
本揭示的降解系統可用於轉錄因子的靶向降解。可靶向降解的轉錄因子 (TF) 的例子包括但不限於調節 T 細胞受體信號傳導、T 細胞耗竭、T 細胞記憶形成、T 細胞分化的 TF;調節幹細胞分化和/或幹細胞的TF;bzip 系列中的 TF;TOX、TOX2、NR4A1、NR4A2、NR4A3、IRF4、BATF、XBP1、c-Jun、Fos、AP1、Bach2、Tcf1/Tcf7、FoxP1 和FoxP3。The degradation systems of the present disclosure can be used for targeted degradation of transcription factors. Examples of transcription factors (TFs) that can be targeted for degradation include, but are not limited to, TFs that regulate T cell receptor signaling, T cell exhaustion, T cell memory formation, T cell differentiation; TFs that regulate stem cell differentiation and/or stem cells; bzip TFs in series; TOX, TOX2, NR4A1, NR4A2, NR4A3, IRF4, BATF, XBP1, c-Jun, Fos, AP1, Bach2, Tcf1/Tcf7, FoxP1 and FoxP3.
在一些實施例中,NR4A 轉錄因子家族 NR4A1 (Nur77)、NR4A2 和NR4A3 可以使用識別和結合所有三個家族成員的結合元件靶向降解。NR4A 轉錄因子家族已被證明在 T 細胞耗竭和剔除(或降低)三種 NR4A 轉錄因子的表達中發揮作用,有望減輕耗竭和提高 T 細胞功效(Chen 等人,2019,其全部內容通過引用併入本文)。In some embodiments, the NR4A family of transcription factors NR4A1 (Nur77), NR4A2, and NR4A3 can be targeted for degradation using binding elements that recognize and bind all three family members. The NR4A transcription factor family has been shown to play a role in T cell exhaustion and knockout (or reduced) expression of three NR4A transcription factors is expected to alleviate exhaustion and improve T cell efficacy (Chen et al., 2019, the entire contents of which are incorporated herein by reference ).
在一些實施例中,轉錄因子 TOX 和/或 TOX2 可以以上下文相關的方式(即動態調節)進行降解。TOX 和TOX2 已被證明在 T 細胞耗竭中起作用,但由於它們在 T 細胞記憶形成中的重要作用而不能被完全剔除(Sekine 等人,(2020),Seo 等人,(2019),和Bordon (2019),其全部內容通過引用併入本文)。In some embodiments, the transcription factors TOX and/or TOX2 can be degraded in a context-dependent manner (i.e., dynamically regulated). TOX and TOX2 have been shown to play a role in T cell exhaustion, but cannot be completely knocked out due to their important roles in T cell memory formation (Sekine et al., (2020), Seo et al., (2019), and Bordon et al. (2019), the entire contents of which are incorporated herein by reference).
在一些實施例中,轉錄因子 IRF4 可能成為降解的目標。IRF4(Man 等人,(2017),其全部內容以引用的方式併入本文)。In some embodiments, the transcription factor IRF4 may be targeted for degradation. IRF4 (Man et al., (2017), which is hereby incorporated by reference in its entirety).
在一些實施例中,轉錄因子 BATF 可能成為降解的目標。BATF (Kurachi等人,(2014),其全部內容以引用的方式併入本文中)。In some embodiments, the transcription factor BATF may be targeted for degradation. BATF (Kurachi et al., (2014), the entire contents of which are incorporated herein by reference).
在一些實施例中,轉錄因子 XBP1 可能成為降解的目標。XBP1(Song 等人,(2018);美國癌症研究協會,通過引用將其整體併入本文)。In some embodiments, the transcription factor XBP1 may be targeted for degradation. XBP1 (Song et al., (2018); American Association for Cancer Research, which is hereby incorporated by reference in its entirety).
在一些實施例中,轉錄因子 c-Jun 可能成為降解的目標。c-Jun(Lynn 等人,(2019 年),通過引用將其全部內容併入本文)In some embodiments, the transcription factor c-Jun may be targeted for degradation. c-Jun (Lynn et al., (2019), which is incorporated by reference in its entirety)
在一些實施例中,轉錄因子 Bach2 可能成為降解的目標。Bach2 (Utzschneider等人,(2020);Sidwell等人,(2020);Roychoudhuri等人,(2016);以及 Richer等人,(2016),通過引用整體併入本文)。In some embodiments, the transcription factor Bach2 may be targeted for degradation. Bach2 (Utzschneider et al., (2020); Sidwell et al., (2020); Roychoudhuri et al., (2016); and Richer et al., (2016), incorporated herein by reference in their entirety).
細胞質酶和酶調節劑Cytoplasmic enzymes and enzyme regulators
用於降解的蛋白質可能是細胞質酶或酶活性的調節劑。可靶向降解的細胞質酶和/或其調節劑的實例包括但不限於非受體酪氨酸激酶(nRTK)、非受體絲氨酸/蘇氨酸激酶、磷酸肌醇激酶、磷酸酶和E3泛素連接酶。Proteins used for degradation may be cytoplasmic enzymes or regulators of enzymatic activity. Examples of cytoplasmic enzymes and/or their modulators that can be targeted for degradation include, but are not limited to, non-receptor tyrosine kinases (nRTKs), non-receptor serine/threonine kinases, phosphoinositide kinases, phosphatases, and E3 ubiquitin kinases. prime ligase.
可靶向降解的非受體酪氨酸激酶包括但不限於Src家族酪氨酸激酶,例如Lck、Src、Fyn、Yes、Fgr、Hck、Blk和Lyn;Tec 家族酪氨酸激酶,例如 Tec、Itk、Btk、Rlk 和Bmx;C-末端 Src 激酶 (CSK) 和Zap70。Non-receptor tyrosine kinases that can be targeted for degradation include, but are not limited to, Src family tyrosine kinases such as Lck, Src, Fyn, Yes, Fgr, Hck, Blk, and Lyn; Tec family tyrosine kinases such as Tec, Itk, Btk, Rlk, and Bmx; C-terminal Src kinase (CSK) and Zap70.
在一些實施例中,非受體酪氨酸激酶 Lck 可能成為降解的目標。Lck 已被證明對於啟動近端 T 細胞信號傳導至關重要(Salmond 等人,(2009),其通過引用整體併入本文)。In some embodiments, the non-receptor tyrosine kinase Lck may be targeted for degradation. Lck has been shown to be critical for initiating proximal T cell signaling (Salmond et al., (2009), which is hereby incorporated by reference in its entirety).
在一些實施例中,非受體酪氨酸激酶 Fyn 可能成為降解的目標。Fyn 已被證明對於啟動近端 T 細胞信號傳導和CAR T 細胞信號傳導至關重要(Salmond 等人,(2009),Salter 等人,(2018),Bommhardt 等人,(2019),Suryadevara等人,(2019) 和Hartl等人,(2020),通過引用將其全部併入本文)。In some embodiments, the non-receptor tyrosine kinase Fyn may be targeted for degradation. Fyn has been shown to be critical for initiating proximal T cell signaling and CAR T cell signaling (Salmond et al., (2009), Salter et al., (2018), Bommhardt et al., (2019), Suryadevara et al., (2019) and Hartl et al., (2020), which are incorporated by reference in their entirety).
在一些實施例中,非受體酪氨酸激酶 Itk 可能成為降解的目標。(Andreotti等人,(2010) 和Andreotti等人,(2018),通過引用將其全部併入本文)。In some embodiments, the non-receptor tyrosine kinase Itk may be targeted for degradation. (Andreotti et al., (2010) and Andreotti et al., (2018), which are hereby incorporated by reference in their entirety).
在一些實施例中,非受體酪氨酸激酶 CSK 可能成為降解的目標。(Okada,(2012),其全部內容以引用的方式併入本文)。In some embodiments, the non-receptor tyrosine kinase CSK may be targeted for degradation. (Okada, (2012), the entire contents of which are incorporated herein by reference).
在一些實施例中,非受體酪氨酸激酶 Zap70 可能成為降解的目標。(Yokosuka等人,(2005) 和Wang等人,(2010)),通過引用將其全部併入本文)。In some embodiments, the non-receptor tyrosine kinase Zap70 may be targeted for degradation. (Yokosuka et al., (2005) and Wang et al., (2010)), which are hereby incorporated by reference in their entirety).
可靶向降解的非受體絲氨酸/蘇氨酸激酶包括但不限於絲裂原活化蛋白激酶 (MAPK)、MAPK 激酶 (MAPKK)、MAPKK 激酶 (MAPKKK)、鈣依賴性激酶、細胞週期蛋白依賴性激酶 CDK1 和CDK2 等激酶。Non-receptor serine/threonine kinases that can be targeted for degradation include, but are not limited to, mitogen-activated protein kinase (MAPK), MAPK kinase (MAPKK), MAPKK kinase (MAPKKK), calcium-dependent kinase, cyclin-dependent Kinases such as CDK1 and CDK2.
可靶向降解的磷酸肌醇激酶包括但不限於磷酸肌醇 3-激酶(PI3K 或 PIK3)、PI3Ka p85、PI3Ka p110 和磷酸肌醇 5-激酶(PI5K 或 PIK5)。Phosphoinositide kinases that can be targeted for degradation include, but are not limited to, phosphoinositide 3-kinase (PI3K or PIK3), PI3Ka p85, PI3Ka p110, and phosphoinositide 5-kinase (PI5K or PIK5).
可作為降解目標的磷酸酶包括但不限於 PTEN、SHP1、SHP2 和PTPN2/TCPTP。Phosphatases that can be targeted for degradation include, but are not limited to, PTEN, SHP1, SHP2, and PTPN2/TCPTP.
在一些實施例中,磷酸酶 PTEN 可能成為降解的目標。(Newton 和Turka,(2012);Lin 等人,(2021);Amaria 等人,(2016);Cheng 等人,(2019);和Locke 等人,(2013),其全部內容以引用的方式併入本文)。In some embodiments, the phosphatase PTEN may be targeted for degradation. (Newton and Turka, (2012); Lin et al., (2021); Amaria et al., (2016); Cheng et al., (2019); and Locke et al., (2013), the entire contents of which are incorporated by reference. into this article).
在一些實施例中,磷酸酶 SHP1 可能成為降解的目標。(Johnson 等人,(2013);和Brockdorff 等人,(1999),其全部內容通過引用併入本文)。In some embodiments, the phosphatase SHP1 may be targeted for degradation. (Johnson et al., (2013); and Brockdorff et al., (1999), the entire contents of which are incorporated herein by reference).
在一些實施例中,磷酸酶 SHP2 可能成為降解的目標。(Yokosuka 等人,(2012);和Strazza 等人,(2021),其全部內容通過引用併入本文)。In some embodiments, the phosphatase SHP2 may be targeted for degradation. (Yokosuka et al., (2012); and Strazza et al., (2021), the entire contents of which are incorporated herein by reference).
在一些實施例中,磷酸酶 PTPN2/TCPTP 可能成為降解的目標。PTPN2/TCPTP(LaFleur 等人,(2019);和Wiede 等人,(2020),通過引用將其整體併入本文)。In some embodiments, the phosphatase PTPN2/TCPTP may be targeted for degradation. PTPN2/TCPTP (LaFleur et al., (2019); and Wiede et al., (2020), which are hereby incorporated by reference in their entirety).
可靶向降解的 E3 泛素連接酶蛋白和/或 E3 泛素連接酶複合物的組分包括但不限於 von Hippel-Lindau 蛋白 (VHL)、細胞因子誘導的 SH2 蛋白 (CISH)、Cbl-b、c-Cbl,細胞因子信號 (SOCS) 1、SOCS2、SOCS3、SOCS4、SOCS5、SOCS6、SOCS7、Elongin B、Elongin C 和 Elongin BC 異二聚體的抑制因子。E3 ubiquitin ligase proteins and/or components of E3 ubiquitin ligase complexes that can be targeted for degradation include, but are not limited to, von Hippel-Lindau protein (VHL), cytokine-induced SH2 protein (CISH), Cbl-b , c-Cbl, inhibitor of cytokine signaling (SOCS) 1, SOCS2, SOCS3, SOCS4, SOCS5, SOCS6, SOCS7, Elongin B, Elongin C, and Elongin BC heterodimers.
在一些實施例中,E3 泛素連接酶複合蛋白 VHL 可能成為降解的目標。VHL 已被證明可調節調節 T 細胞分化和功能的缺氧誘導因子(Cardote 等人,(20177);Stebbins 等人,(1999);Velixa 等人,(2021);和 McNamee 等人,(2013),通過引用將其全部併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein VHL may be targeted for degradation. VHL has been shown to regulate hypoxia-inducible factors that regulate T cell differentiation and function (Cardote et al., (20177); Stebbins et al., (1999); Velixa et al., (2021); and McNamee et al., (2013) , which is incorporated herein by reference in its entirety).
在一些實施例中,E3 泛素連接酶複合蛋白 CISH 可能成為降解的目標。CISH 已顯示通過靶向 PLCγ(和可能的其他目標)下調 T 細胞信號傳導。T 細胞中 CISH 的缺失會增加 T 細胞活性和細胞毒性(Palmer 等人,(2015);Palmer 等人,(2014);和 Guittard 等人,(2018),其通過引用整體併入本文 )。In some embodiments, the E3 ubiquitin ligase complex protein CISH may be targeted for degradation. CISH has been shown to downregulate T cell signaling by targeting PLCγ (and possibly other targets). Loss of CISH in T cells increases T cell activity and cytotoxicity (Palmer et al., (2015); Palmer et al., (2014); and Guittard et al., (2018), which are hereby incorporated by reference in their entirety).
在一些實施例中,E3 泛素連接酶複合蛋白 Cbl-b 和/或 c-Cbl 可能成為降解的目標。Cbl-b 和 c-Cbl(Nguyen 等人,(2021);Lutz-Nicoladoni 等人,(2015);和 Tang 等人,(2019),通過引用將其整體併入本文)。In some embodiments, the E3 ubiquitin ligase complex proteins Cbl-b and/or c-Cbl may be targeted for degradation. Cbl-b and c-Cbl (Nguyen et al., (2021); Lutz-Nicoladoni et al., (2015); and Tang et al., (2019), which are hereby incorporated by reference in their entirety).
在一些實施例中,E3 泛素連接酶複合蛋白 SOCS1 可能成為降解的目標。SOCS1 (Takahashi等人,(2011);Takahashi等人,(2017);和 Tamiya等人,(2011),通過引用將其全部併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein SOCS1 may be targeted for degradation. SOCS1 (Takahashi et al., (2011); Takahashi et al., (2017); and Tamiya et al., (2011), which are incorporated herein by reference in their entirety).
在一些實施例中,E3 泛素連接酶複合蛋白 SOCS2 可能成為降解的目標。SOCS2 (Tannahill等人,(2005);Greenhalgh等人,(2005);和 Knosp等人,(2011),通過引用將其全部併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein SOCS2 may be targeted for degradation. SOCS2 (Tannahill et al., (2005); Greenhalgh et al., (2005); and Knosp et al., (2011), all of which are incorporated herein by reference).
在一些實施例中,E3 泛素連接酶複合蛋白 SOCS3 可能成為降解的目標。(Croker等人,(2003);和 Chen等人,(2006),通過引用將其全部併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein SOCS3 may be targeted for degradation. (Croker et al., (2003); and Chen et al., (2006), which are incorporated herein by reference in their entirety).
在一些實施例中,E3 泛素連接酶複合蛋白 SOCS4 可能成為降解的目標。(Bullock等人,(2007),其全部內容以引用的方式併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein SOCS4 may be targeted for degradation. (Bullock et al., (2007), the entire contents of which are incorporated herein by reference).
在一些實施例中,E3 泛素連接酶複合蛋白 SOCS5 可能成為降解的目標。(Zhang等人,(2009),其全部內容以引用的方式併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein SOCS5 may be targeted for degradation. (Zhang et al., (2009), the entire contents of which are incorporated herein by reference).
在一些實施例中,E3 泛素連接酶複合蛋白 SOCS6 可能成為降解的目標。(Choi等人,(2010),其全部內容以引用的方式併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein SOCS6 may be targeted for degradation. (Choi et al., (2010), the entire contents of which are incorporated herein by reference).
在一些實施例中,E3 泛素連接酶複合蛋白 SOCS7 可能成為降解的目標。(Bondar 等人(2018 年),其全文以引用方式併入本文)。In some embodiments, the E3 ubiquitin ligase complex protein SOCS7 may be targeted for degradation. (Bondar et al. (2018), which is incorporated by reference in its entirety).
在一些實施例中,E3 泛素連接酶複合蛋白 Elongin B、elongin C 和/或 Elongin BC 異二聚體可作為降解的目標。已顯示 Elongin B、Elongin C 和 Elongin BC 異二聚體在調節 Cullin-Ring 泛素連接酶中起關鍵作用(Okumura 等人,(2012),其通過引用整體併入本文)。In some embodiments, E3 ubiquitin ligase complex proteins Elongin B, elongin C and/or Elongin BC heterodimers can be targeted for degradation. Elongin B, Elongin C, and Elongin BC heterodimers have been shown to play key roles in regulating Cullin-Ring ubiquitin ligases (Okumura et al., (2012), which is hereby incorporated by reference in its entirety).
信號蛋白signal protein
靶向降解的蛋白質可以是信號蛋白。可靶向降解的信號蛋白的實例包括但不限於CIN85、PLCγ1、PLCγ2、Smad2、Smad3和Smad4。The protein targeted for degradation may be a signaling protein. Examples of signaling proteins that can be targeted for degradation include, but are not limited to, CIN85, PLCγ1, PLCγ2, Smad2, Smad3, and Smad4.
在一些實施例中,信號蛋白 PLCγ1 可能成為降解的目標。(Su 等人,(2016);Bilal 和 Houtman (2015);和 Braiman 等人,(2006),通過引用將其全部併入本文)。In some embodiments, the signaling protein PLCγ1 may be targeted for degradation. (Su et al., (2016); Bilal and Houtman (2015); and Braiman et al., (2006), all of which are incorporated herein by reference).
在一些實施例中,信號蛋白 Smad2 和/或 Smad3 可能成為降解的目標。(Yang 等人,(1999);Takimoto 等人,(2010);Malhotra 和 Kang(2013);和 Kashiwagi 等人,(2015),其全部內容通過引用併入本文)。In some embodiments, the signaling proteins Smad2 and/or Smad3 may be targeted for degradation. (Yang et al., (1999); Takimoto et al., (2010); Malhotra and Kang (2013); and Kashiwagi et al., (2015), the entire contents of which are incorporated herein by reference).
支架和銜接蛋白Scaffolds and adapter proteins
靶向降解的蛋白質可以是支架蛋白或銜接蛋白。可靶向降解的支架和銜接蛋白的例子包括但不限於SLP76、LAT、Grb2、GADS、Ste5p、KDS、HOP、PSD95、Cullin-Skp1、RACK1 和 ADAP。Proteins targeted for degradation can be scaffold proteins or adapter proteins. Examples of scaffolds and adapter proteins that can be targeted for degradation include, but are not limited to, SLP76, LAT, Grb2, GADS, Ste5p, KDS, HOP, PSD95, Cullin-Skpl, RACK1, and ADAP.
在一些實施例中,銜接蛋白 LAT 可能成為降解的目標。(Zhang等人,(1998);Williamson等人,(2011);和 Liu等人,(1999),通過引用將其全部併入本文)。In some embodiments, the adapter protein LAT may be targeted for degradation. (Zhang et al., (1998); Williamson et al., (2011); and Liu et al., (1999), all of which are incorporated herein by reference).
在一些實施例中,銜接蛋白 SLP76 可能成為降解的目標。(Yokosuka等人,(2005),其全文以引用的方式併入本文)。In some embodiments, the adapter protein SLP76 may be targeted for degradation. (Yokosuka et al., (2005), which is hereby incorporated by reference in its entirety).
在一些實施例中,銜接蛋白 Grb2 可能成為降解的目標。(Zhang 等人,(2000);Gong 等人,(2001);以及 Bilal 和 Houtman (2015),通過引用將其全部併入本文)。In some embodiments, the adapter protein Grb2 may be targeted for degradation. (Zhang et al., (2000); Gong et al., (2001); and Bilal and Houtman (2015), all of which are incorporated herein by reference).
在一些實施例中,銜接蛋白 Gads 可能成為降解的目標。(Liu 等人,(1999);Zhang 等人,(2000);和 Yoder 等人,(2001),通過引用將其全部併入本文)。In some embodiments, adapter protein Gads may be targeted for degradation. (Liu et al., (1999); Zhang et al., (2000); and Yoder et al., (2001), all of which are incorporated herein by reference).
蛋白質結構域作為靶標protein domains as targets
蛋白質的功能和/或結構域可用於靶向蛋白質以進行降解。可用於靶向蛋白質進行降解的蛋白質結構域的實例包括但不限於信號結構域、調節結構域、脂質膜結合結構域、磷脂結合結構域和DNA結合結構域。可以靶向的調節和信號結構域的具體例子包括但不限於 Src 同源性 2 (SH2)、src 同源性 3 (SH3)、pleckstrin 同源性 (PH)、dbl 同源性 (DH)、DHPH、Bcl-2 同源性 (BH)、PDZ 結構域、PDZ 結合和 C2 結構域。可以靶向的脂質膜結合結構域的具體例子包括但不限於DHPH、PH和C2。可靶向的磷脂結合結構域的具體實例包括但不限於PH、DHPH、C2、PI(3,4,5)P3結合、PI(3,4)P2結合和PI(4,5) P2。可以靶向的 DNA 結合結構域的具體例子包括但不限於鋅手指 (ZF)、TALE、Cas9 和 Cas12a。Functional and/or structural domains of proteins can be used to target proteins for degradation. Examples of protein domains that can be used to target proteins for degradation include, but are not limited to, signaling domains, regulatory domains, lipid membrane binding domains, phospholipid binding domains, and DNA binding domains. Specific examples of regulatory and signaling domains that can be targeted include, but are not limited to, Src homology 2 (SH2), src homology 3 (SH3), pleckstrin homology (PH), dbl homology (DH), DHPH, Bcl-2 homology (BH), PDZ domain, PDZ binding and C2 domain. Specific examples of lipid membrane binding domains that can be targeted include, but are not limited to, DHPH, PH, and C2. Specific examples of targetable phospholipid binding domains include, but are not limited to, PH, DHPH, C2, PI(3,4,5)P3 binding, PI(3,4)P2 binding, and PI(4,5)P2. Specific examples of DNA binding domains that can be targeted include, but are not limited to, zinc fingers (ZFs), TALEs, Cas9, and Cas12a.
SOCS-盒子圖案SOCS-box pattern
SOCS-box基序可用於靶向含有SOCS-box的蛋白質以進行降解。含有 SOCS-box 的蛋白質的例子包括但不限於細胞因子抑制因子 (SOC) 家族蛋白、VHL 和 CISH。SOCS-box motifs can be used to target SOCS-box containing proteins for degradation. Examples of SOCS-box-containing proteins include, but are not limited to, suppressor of cytokines (SOC) family proteins, VHL, and CISH.
嵌合抗原受體chimeric antigen receptor
感興趣的目標蛋白可能包括嵌合抗原受體 (CAR)。CAR可以是融合蛋白,包括細胞外抗原結合/識別元件、將受體錨定到細胞膜的跨膜元件和至少一種細胞內元件。這些CAR元件在本領域中是已知的,例如,如2014年8月28日公開的專利申請US20140242701中所述,名稱為“嵌合抗原受體”,其通過引用整體併入本文。CAR可以是從多核苷酸表達的重組多肽,該多核苷酸至少包括細胞外抗原結合元件、跨膜元件和細胞內信號元件,該細胞內信號元件包括衍生自刺激分子的功能性信號元件。Target proteins of interest may include chimeric antigen receptors (CARs). A CAR may be a fusion protein comprising an extracellular antigen binding/recognition element, a transmembrane element that anchors the receptor to the cell membrane, and at least one intracellular element. These CAR elements are known in the art, for example, as described in patent application US20140242701 published on August 28, 2014, entitled "Chimeric Antigen Receptor", which is incorporated herein by reference in its entirety. A CAR may be a recombinant polypeptide expressed from a polynucleotide comprising at least an extracellular antigen binding element, a transmembrane element, and an intracellular signaling element, including a functional signaling element derived from a stimulatory molecule.
刺激分子例如可以是與T細胞受體複合物相關的zeta鏈。Stimulatory molecules can be, for example, zeta chains associated with T cell receptor complexes.
細胞質信號元件可以,例如,包括一種或多種源自至少一種共刺激分子的功能性信號元件。A cytoplasmic signaling element may, for example, comprise one or more functional signaling elements derived from at least one co-stimulatory molecule.
共刺激分子可以例如選自4-1BB(即CD137)、CD27和/或CD28。Costimulatory molecules may eg be selected from 4-1BB (ie CD137), CD27 and/or CD28.
CAR可以是嵌合融合蛋白,其包括細胞外抗原識別元件、跨膜元件和細胞內信號元件,所述細胞內信號元件包括源自刺激分子的功能性信號元件。A CAR may be a chimeric fusion protein that includes an extracellular antigen recognition element, a transmembrane element, and an intracellular signaling element, including a functional signaling element derived from a stimulatory molecule.
CAR可以包括嵌合融合蛋白,該嵌合融合蛋白包括細胞外抗原識別元件、跨膜元件和細胞內信號元件,包括源自共刺激分子的功能性信號元件和源自刺激分子的功能性信號元件。A CAR may comprise a chimeric fusion protein comprising an extracellular antigen recognition element, a transmembrane element, and an intracellular signaling element, including a functional signaling element derived from a co-stimulatory molecule and a functional signaling element derived from a stimulatory molecule .
CAR可以是嵌合融合蛋白,包括細胞外抗原識別元件、跨膜元件和細胞內信號元件,細胞內信號元件包括兩個衍生自一個或多個共刺激分子的功能信號元件和衍生自刺激分子的功能信號元件。CAR can be a chimeric fusion protein, including an extracellular antigen recognition element, a transmembrane element, and an intracellular signaling element. The intracellular signaling element includes two functional signaling elements derived from one or more co-stimulatory molecules and a stimulatory molecule. Functional signal element.
CAR可包括嵌合融合蛋白,包括細胞外抗原識別元件、跨膜元件和細胞內信號元件,細胞內信號元件包括至少兩個衍生自一個或多個共刺激分子的功能信號元件和衍生自刺激分子的功能信號元件。A CAR may comprise a chimeric fusion protein comprising an extracellular antigen recognition element, a transmembrane element, and an intracellular signaling element comprising at least two functional signaling elements derived from one or more co-stimulatory molecules and one derived from a stimulatory molecule. The functional signal element.
CAR可在CAR融合蛋白的氨基末端(N-端)包含可選的先導序列。CAR還可包括細胞外抗原識別元件N端的前導序列,其中前導序列在CAR的細胞處理和定位到細胞膜期間任選地從抗原識別元件(例如,單鏈抗體)上切割。The CAR may contain an optional leader sequence at the amino terminus (N-terminus) of the CAR fusion protein. The CAR may also include a leader sequence at the N-terminus of the extracellular antigen recognition element, wherein the leader sequence is optionally cleaved from the antigen recognition element (eg, single-chain antibody) during cellular processing and localization of the CAR to the cell membrane.
降解系統的選擇Choice of degradation system
結合元件和降解系統中使用的降解引發劑(例如,E3連接酶結構域)的組合可以基於降解的目標蛋白進行選擇。The combination of binding elements and degradation initiators (eg, E3 ligase domains) used in the degradation system can be selected based on the target protein being degraded.
在一些實施例中,一對 DHD 結合元件用於合成或外源跨膜蛋白的靶向降解。圖4A是使用3+1 DHD對作為用於靶向降解跨膜蛋白的結合元件的實施例示意圖400。以降解為目標的跨膜蛋白 (“TMP”) 與結合元件對 (DHD-B) 的一個夥伴融合,E3 連接酶結構域與結合元件對 (DHD-A) 的第二個結合元件夥伴融合。DHD-A 和 DHD-B 結合夥伴的相互作用使 E3 連接酶結構域與目標蛋白接近,從而促進跨膜蛋白的泛素化。跨膜蛋白的泛素化促進隨後的受體內化、內體運輸和跨膜蛋白的溶酶體降解。In some embodiments, a pair of DHD binding elements are used for targeted degradation of synthetic or exogenous transmembrane proteins. FIG. 4A is a schematic diagram 400 of an example of using 3+1 DHD pairs as binding elements for targeted degradation of transmembrane proteins. The degradation-targeted transmembrane protein ("TMP") is fused to one partner of the binding element pair (DHD-B) and the E3 ligase domain is fused to the second binding element partner of the binding element pair (DHD-A). The interaction of DHD-A and DHD-B binding partners brings the E3 ligase domain into proximity with the target protein, thereby promoting the ubiquitination of transmembrane proteins. Ubiquitination of transmembrane proteins facilitates subsequent receptor internalization, endosomal trafficking, and lysosomal degradation of transmembrane proteins.
在一些實施例中,一對 DHD 結合元件用於靶向降解合成或外源細胞質蛋白,例如轉錄因子。圖4B是使用3+1 DHD對作為結合元件用於細胞質蛋白的靶向降解的實施例的示意圖410。靶向降解的細胞質蛋白(“目標”)與結合元件對(DHD-B)的一個夥伴融合,E3連接酶結構域與結合元件對(DHD-A)的第二個結合元件夥伴融合。融合蛋白的 DHD-A 和 DHD-B 靶向結構域的相互作用使 E3 連接酶結構域與目標蛋白接近,從而促進細胞質蛋白靶標的泛素化。靶蛋白的多泛素化(“Ub”)在與 DHD-E3 連接酶相互作用時被誘導並促進下游蛋白酶體降解。In some embodiments, a pair of DHD binding elements is used to target degradation of synthetic or exogenous cytoplasmic proteins, such as transcription factors. Figure 4B is a schematic diagram 410 of an example of using 3+1 DHD pairs as binding elements for targeted degradation of cytoplasmic proteins. Cytoplasmic proteins targeted for degradation ("targets") are fused to one partner of the binding element pair (DHD-B), and the E3 ligase domain is fused to the second binding element partner of the binding element pair (DHD-A). The interaction of the DHD-A and DHD-B targeting domains of the fusion protein brings the E3 ligase domain into proximity with the target protein, thereby promoting the ubiquitination of the cytoplasmic protein target. Polyubiquitination ("Ub") of target proteins is induced upon interaction with DHD-E3 ligase and promotes downstream proteasomal degradation.
在一些實施例中,小分子調控降解系統用於跨膜受體的靶向降解。在一個實例中,跨膜受體是嵌合受體,例如CAR。圖5是用於降解嵌合受體的小分子調節的降解系統的實施例的示意圖500。在這個例子中,靶向降解的嵌合受體融合到 NS3a 多肽上,而 E3 連接酶結構域融合到 DNCR2 多肽上。在小分子達諾瑞韋存在下,DNCR2和NS3a多肽與小分子達諾瑞韋一起組裝形成二聚複合物。二聚複合物的形成使 E3 連接酶與靶向嵌合受體接近,從而促進泛素化 (“Ub”) 和隨後的靶向受體降解。In some embodiments, small molecule regulated degradation systems are used for targeted degradation of transmembrane receptors. In one example, the transmembrane receptor is a chimeric receptor, such as a CAR. 5 is a schematic diagram 500 of an embodiment of a small molecule-mediated degradation system for degrading a chimeric receptor. In this example, a chimeric receptor targeting degradation is fused to the NS3a polypeptide and an E3 ligase domain is fused to the DNCR2 polypeptide. In the presence of the small molecule danoprevir, DNCR2 and NS3a polypeptides assembled with the small molecule danoprevir to form a dimeric complex. Formation of the dimeric complex brings the E3 ligase into proximity with the targeted chimeric receptor, thereby promoting ubiquitination (“Ub”) and subsequent degradation of the targeted receptor.
在一些實施例中,結合元件可以靶向內源性目的蛋白質上的天然基序。在一個實例中,結合元件可以是與感興趣的跨膜蛋白的細胞內區域上的天然基序相互作用的蛋白質結構域。在又一個例子中,結合元件可以是與感興趣的跨膜蛋白的跨膜結構域上的天然基序相互作用的蛋白質結構域。結合元件和目標蛋白質上的天然基序的相互作用使 E3 連接酶與目標蛋白質接近,從而促進目標蛋白質的泛素化和隨後的降解。In some embodiments, a binding element can target a native motif on an endogenous protein of interest. In one example, the binding element can be a protein domain that interacts with a native motif on the intracellular region of the transmembrane protein of interest. In yet another example, a binding element can be a protein domain that interacts with a native motif on the transmembrane domain of a transmembrane protein of interest. The interaction of the binding element and native motifs on the target protein brings the E3 ligase into proximity with the target protein, thereby promoting the ubiquitination and subsequent degradation of the target protein.
圖6A是圖示跨膜受體結構域作為用於嵌合跨膜受體的靶向降解的結合元件的示意圖600。在此示例中,E3 連接酶結構域與受體靶向跨膜結構域融合,該跨膜結構域旨在結合嵌合受體上的天然跨膜基序。受體靶向跨膜結構域和嵌合受體的相互作用使E3連接酶結構域與靶向受體接近,從而促進嵌合受體的泛素化。嵌合受體的泛素化促進隨後的溶酶體運輸和受體降解。Figure 6A is a schematic diagram 600 illustrating transmembrane receptor domains as binding elements for targeted degradation of chimeric transmembrane receptors. In this example, an E3 ligase domain is fused to a receptor-targeting transmembrane domain designed to bind a native transmembrane motif on a chimeric receptor. The interaction of the receptor-targeting transmembrane domain and the chimeric receptor brings the E3 ligase domain into proximity with the targeted receptor, thereby promoting ubiquitination of the chimeric receptor. Ubiquitination of chimeric receptors promotes subsequent lysosomal trafficking and receptor degradation.
在一些實施例中,結合元件可以是與感興趣的蛋白質上的特定翻譯後修飾相互作用的蛋白質結構域。例如,結合元件可以與靶蛋白的轉譯後磷酸化區域相互作用。In some embodiments, a binding element can be a protein domain that interacts with a specific post-translational modification on a protein of interest. For example, a binding element can interact with a post-translationally phosphorylated region of a target protein.
在一實施例中,本揭示的合成降解系統使用磷酸酪氨酸結合結構域(PYBD)作為結合元件以將E3連接酶結構域募集到跨膜受體以進行降解。圖6B是圖示磷酸酪氨酸結合結構域(PYBD)作為用於靶向降解轉譯後磷酸化(“P”)跨膜受體的結合物的示意圖610。PYBD結構域與跨膜受體磷酸化區域的相互作用使E3連接酶結構域接近靶受體,從而促進嵌合受體的泛素化。受體的泛素化促進隨後的溶酶體運輸和受體降解。In one embodiment, the synthetic degradation system of the present disclosure uses a phosphotyrosine binding domain (PYBD) as a binding element to recruit an E3 ligase domain to a transmembrane receptor for degradation. Figure 6B is a schematic diagram 610 illustrating phosphotyrosine binding domains (PYBDs) as binders for targeting degradation of post-translational phosphorylated ("P") transmembrane receptors. Interaction of the PYBD domain with the phosphorylated domain of the transmembrane receptor brings the E3 ligase domain close to the target receptor, thereby promoting ubiquitination of the chimeric receptor. Ubiquitination of receptors facilitates subsequent lysosomal trafficking and receptor degradation.
在一個具體實例中,結合元件可用於靶向內源性T細胞受體(TCR)複合物。例如,編碼 CD3𝜁 跨膜結構域 (TMCD3z) 的構建體可用於將 E3 連接酶結構域(例如 RNF43)靶向 TCR 複合物,其中CD3𝜁跨膜結構域(TMCD3z)用於識別和破壞TCR複合物,E3連接酶結構域用於促進受體降解,從而提供兩種調節TCR複合物活性的機制。In one specific example, binding elements can be used to target the endogenous T cell receptor (TCR) complex. For example, a construct encoding the CD3𝜁 transmembrane domain (TMCD3z ), which is used to recognize and disrupt the TCR complex, can be used to target an E3 ligase domain (such asRNF43 ) to the TCR complex The E3 ligase domain serves to facilitate receptor degradation, thus providing two mechanisms for modulating the activity of the TCR complex.
載體和載體配置Carriers and Carrier Configurations
本揭示的多核苷酸可以作為載體的一部分提供。合適載體的例子包括表達載體、病毒載體和質粒載體。表達載體可以包括質粒、噬菌粒、病毒及其衍生物。在一些方面,本揭示的多核苷酸可以作為同源定向修復載體的一部分提供。The polynucleotides of the disclosure can be provided as part of a vector. Examples of suitable vectors include expression vectors, viral vectors and plasmid vectors. Expression vectors may include plasmids, phagemids, viruses and derivatives thereof. In some aspects, polynucleotides of the disclosure can be provided as part of a homology directed repair vector.
在一些方面,病毒載體可以包括編碼基因編輯多肽的多核苷酸,例如用於實施基因編輯技術的多肽。此類基因編輯技術的示例包括 RNA/DNA 引導的核酸內切酶(例如,CRISPR(成簇的規則間隔的短回文重複序列))、TALEN(轉錄啟動因子樣效應核酸酶)、ZFN(鋅手指核酸酶)、重組酶、大範圍核酸酶或病毒整合 .In some aspects, a viral vector can include a polynucleotide encoding a gene editing polypeptide, such as a polypeptide useful in practicing gene editing techniques. Examples of such gene editing technologies include RNA/DNA-guided endonucleases (e.g., CRISPR (clustered regularly interspaced short palindromic repeats)), TALENs (transcriptional finger nuclease), recombinase, meganuclease or viral integration .
在一些方面,本揭示的多核苷酸可以作為同源定向修復(HDR)載體的一部分提供。同源定向修復機制可用於將多核苷酸組整合到染色體中。可用於將多核苷酸組整合到染色體中的機制的實例包括序列特異性核酸酶,例如轉座酶、CRISPR/Cas9、ZF核酸酶、TALE核酸酶、重組酶和本領域已知的其他同源重組靶向載體。In some aspects, polynucleotides of the disclosure can be provided as part of a homology directed repair (HDR) vector. Homology-directed repair mechanisms can be used to integrate sets of polynucleotides into chromosomes. Examples of mechanisms that can be used to integrate sets of polynucleotides into chromosomes include sequence-specific nucleases such as transposases, CRISPR/Cas9, ZF nucleases, TALE nucleases, recombinases, and other homologs known in the art Recombinant targeting vector.
載體成分通常包括但不限於以下一種或多種:信號序列、複製起點、一種或多種標記基因、增強子元件、啟動子和轉錄終止序列。用於真核宿主細胞的載體還可以編碼信號序列或在感興趣的成熟蛋白質或多肽的N末端具有特定切割位點的其他多肽。選擇的信號序列優選地是被宿主細胞識別和加工(即,被信號肽酶切割)的信號序列。在哺乳動物細胞表達中,可以使用哺乳動物信號序列以及病毒分泌前導序列。用於真核宿主細胞的表達載體通常還包含終止轉錄和穩定mRNA所必需的序列。此類序列通常可從真核或病毒 DNA 或 cDNA 的 5' 和偶爾 3' 非翻譯區獲得。一種有用的轉錄終止成分是牛生長激素多腺苷酸化區。Vector components typically include, but are not limited to, one or more of the following: a signal sequence, an origin of replication, one or more marker genes, an enhancer element, a promoter, and a transcription termination sequence. Vectors for use in eukaryotic host cells may also encode signal sequences or other polypeptides with specific cleavage sites at the N-terminus of the mature protein or polypeptide of interest. The signal sequence selected is preferably one that is recognized and processed (ie, cleaved by a signal peptidase) by the host cell. In mammalian cell expression, mammalian signal sequences as well as viral secretory leaders can be used. Expression vectors for use in eukaryotic host cells also typically contain sequences necessary to terminate transcription and stabilize the mRNA. Such sequences are usually available from the 5' and occasionally 3' untranslated regions of eukaryotic or viral DNA or cDNA. One useful transcription termination element is the bovine growth hormone polyadenylation region.
表達和克隆載體可以包含選擇基因,也稱為選擇標記。典型的選擇基因編碼的蛋白質(a)賦予對抗生素或其他毒素的抗性,例如氨芐青黴素、新黴素、甲氨蝶呤或四環素,(b)在相關的情況下補充營養缺陷型缺陷,或(c)提供從復雜培養基中無法獲得的關鍵營養素 。Expression and cloning vectors can contain a selectable gene, also called a selectable marker. Typical selection genes encode proteins that (a) confer resistance to antibiotics or other toxins, such as ampicillin, neomycin, methotrexate, or tetracycline, (b) complement auxotrophic deficiencies where relevant, or (c) Provides key nutrients not available from complex media.
本揭示的多核苷酸在一些情況下可以作為單個載體的一部分提供。本揭示的多核苷酸可以作為一組至少兩個載體的一部分提供;包括第一多核苷酸的第一載體和包括第二多核苷酸的第二載體。The polynucleotides of the disclosure can in some cases be provided as part of a single vector. The polynucleotides of the present disclosure may be provided as part of a set of at least two vectors; a first vector comprising the first polynucleotide and a second vector comprising the second polynucleotide.
適用於本揭示的多核苷酸的載體的實例包括腺病毒載體、慢病毒載體、桿狀病毒載體、Epstein Barr病毒載體、多空病毒載體、牛痘病毒載體、單純皰疹病毒載體、腺相關病毒(AAV)載體和轉座子載體 . 本揭示的多核苷酸可以作為同源定向修復載體的一部分提供。Examples of vectors suitable for use with polynucleotides of the present disclosure include adenoviral vectors, lentiviral vectors, baculoviral vectors, Epstein Barr viral vectors, polyvacuum viral vectors, vaccinia viral vectors, herpes simplex viral vectors, adeno-associated virus ( AAV) vectors and transposon vectors. The polynucleotides of the disclosure can be provided as part of a homology directed repair vector.
本揭示提供了一種多核苷酸組,其包括以下作為一個或多個載體的一部分: (i)編碼包含第一結合元件的第一融合蛋白的第一多核苷酸;和 (ii) 編碼包含相應第二結合元件的第二融合蛋白的第二多核苷酸;其中: (iii)第一或第二融合蛋白還包括降解引發劑;和 (iv)第一種或第二種融合蛋白中的另一個還包括目標分子;以及 (v) 第一和第二元素的相互作用有效地將降解引發劑集中到感興趣的分子以進行靶向降解。The disclosure provides a set of polynucleotides comprising, as part of one or more vectors: (i) a first polynucleotide encoding a first fusion protein comprising a first binding element; and (ii) a second polynucleotide encoding a second fusion protein comprising a corresponding second binding element; wherein: (iii) the first or second fusion protein also includes a degradation initiator; and (iv) the other of the first or second fusion protein also includes a target molecule; and (v) The interaction of the first and second elements effectively concentrates the degradation initiator to the molecule of interest for targeted degradation.
在一些實施例中,本揭示提供了一種多核苷酸組,其包括以下作為一個或多個載體的一部分: (i)編碼包含第一結合元件的第一融合蛋白的第一多核苷酸,和 (ii) 編碼包含相應的第二結合元件的第二融合蛋白的第二多核苷酸,其中: (iii)第一或第二融合蛋白進一步包括E3連接酶結構域(或其功能變體);和 (iv)第一或第二融合蛋白中的另一個還包括感興趣的目的蛋白;以及 (v) 第一和第二結合元件的相互作用有效地將 E3 連接酶集中到感興趣的蛋白質以進行靶向降解。In some embodiments, the present disclosure provides a set of polynucleotides comprising, as part of one or more vectors: (i) a first polynucleotide encoding a first fusion protein comprising a first binding element, and (ii) a second polynucleotide encoding a second fusion protein comprising a corresponding second binding element, wherein: (iii) the first or second fusion protein further comprises an E3 ligase domain (or a functional variant thereof); and (iv) the other of the first or second fusion protein also includes a protein of interest; and (v) The interaction of the first and second binding elements efficiently focuses the E3 ligase to the protein of interest for targeted degradation.
在一些實施例中,本揭示提供了一種多核苷酸組,其包括以下作為一個或多個載體的一部分: (i)編碼包含第一結合元件和E3連接酶結構域(或其功能變體)的第一融合蛋白的第一多核苷酸,和 (ii)編碼第二融合蛋白的第二多核苷酸,所述第二融合蛋白包括相應的第二結合元件和合成的或外源的目的蛋白,其中第一和第二結合元件的相互作用有效地將E3連接酶結構域集中到目標蛋白用於靶向降解. 在一些實施例中,本揭示提供了包括以下作為一個或多個載體的一部分的多核苷酸組: (i)編碼包含DHD結合元件和E3連接酶結構域(或其功能變體)的第一融合蛋白的第一多核苷酸;以及 (ii)編碼第二融合蛋白的第二多核苷酸,所述第二融合蛋白包括相應的第二DHD結合元件和合成的或外源的目的蛋白,其中第一和第二結合元件的相互作用有效地將E3連接酶結構域集中到目標蛋白用於靶向降解。In some embodiments, the present disclosure provides a set of polynucleotides comprising, as part of one or more vectors: (i) a first polynucleotide encoding a first fusion protein comprising a first binding element and an E3 ligase domain (or a functional variant thereof), and (ii) a second polynucleotide encoding a second fusion protein comprising a corresponding second binding element and a synthetic or exogenous protein of interest, wherein the interaction of the first and second binding elements Efficiently concentrates the E3 ligase domain to the target protein for targeted degradation. In some embodiments, the present disclosure provides sets of polynucleotides comprising, as part of one or more vectors: (i) a first polynucleotide encoding a first fusion protein comprising a DHD binding element and an E3 ligase domain (or a functional variant thereof); and (ii) a second polynucleotide encoding a second fusion protein comprising a corresponding second DHD binding element and a synthetic or exogenous protein of interest, wherein the interaction of the first and second binding elements Acts effectively to focus the E3 ligase domain to the target protein for targeted degradation.
在一些實施例中,本揭示提供了多核苷酸組,其包括以下作為一個或多個載體的一部分: (i)編碼第一融合蛋白的第一多核苷酸,該第一融合蛋白包括結合元件,該結合元件包含閱讀蛋白和E3連接酶結構域(或其功能變體);以及 (ii)編碼包含NS3a結合元件和合成或外源目標蛋白的第二融合蛋白的第二多核苷酸,其中第一和第二結合元件的相互作用由小分子的存在調節,從而將 E3 連接酶結構域集中到感興趣的蛋白質上以進行靶向降解。In some embodiments, the present disclosure provides sets of polynucleotides comprising, as part of one or more vectors: (i) a first polynucleotide encoding a first fusion protein comprising a binding element comprising a reader protein and an E3 ligase domain (or a functional variant thereof); and (ii) a second polynucleotide encoding a second fusion protein comprising an NS3a binding element and a synthetic or exogenous protein of interest, wherein the interaction of the first and second binding elements is regulated by the presence of a small molecule, thereby linking the E3 Enzyme domains focus on proteins of interest for targeted degradation.
在一些實施例中,本揭示提供了編碼融合蛋白的多核苷酸組,其包括以下作為單個載體的一部分: (i) 降解引發劑;以及 (ii)對內源性目標分子上的天然基序特異的結合域,其中融合蛋白與目標分子的結合調節降解引發劑集中到目標分子以進行靶向降解。In some embodiments, the present disclosure provides sets of polynucleotides encoding fusion proteins comprising the following as part of a single vector: (i) degradation initiators; and (ii) A binding domain specific for a native motif on an endogenous target molecule, wherein binding of the fusion protein to the target molecule modulates the concentration of the degradation initiator to the target molecule for targeted degradation.
在一些實施例中,本揭示提供了編碼融合蛋白的多核苷酸組,其包括以下作為單個載體的一部分: (i) E3 連接酶結構域;以及 (ii)對內源性目標蛋白上的天然基序特異的結合域,其中融合蛋白與目標蛋白的結合調節E3連接酶集中到目標蛋白以進行靶向降解。In some embodiments, the present disclosure provides sets of polynucleotides encoding fusion proteins comprising the following as part of a single vector: (i) E3 ligase domain; and (ii) A binding domain specific to a native motif on an endogenous target protein, wherein binding of the fusion protein to the target protein regulates the recruitment of the E3 ligase to the target protein for targeted degradation.
單一載體配置single carrier configuration
圖7A顯示用於在單個載體上編碼誘導型多核苷酸成分和組成型多核苷酸成分的單一載體配置700的示意圖。在該示例中,載體被配置為表達編碼第一融合蛋白的誘導型多核苷酸組分710,該第一融合蛋白包括與第一結合元件融合的E3連接酶結構域,以及編碼第二融合蛋白的組成型多核苷酸組分715,該第二融合蛋白包括與第二結合元件融合的目標蛋白。例如,第一和第二結合元件可以是DHD多肽。誘導型啟動子組件由一個最小啟動子組成,該啟動子具有一個或多個 5' 反應元件重複序列,這些重複序列被特定轉錄因子識別並結合以反應刺激。誘導型啟動子成分還可以包括任選的調節序列,例如polyA序列。組成型多核苷酸成分還可以包括任選的調節序列,例如polyA序列。Figure 7A shows a schematic diagram of a single vector configuration 700 for encoding an inducible polynucleotide component and a constitutive polynucleotide component on a single vector. In this example, the vector is configured to express an inducible polynucleotide component 710 encoding a first fusion protein comprising an E3 ligase domain fused to a first binding element and encoding a second fusion protein The constitutive polynucleotide component 715 of the second fusion protein includes a protein of interest fused to a second binding element. For example, the first and second binding elements can be DHD polypeptides. The inducible promoter component consists of a minimal promoter with one or more 5' response element repeats that are recognized and bound by specific transcription factors in response to stimuli. An inducible promoter component may also include optional regulatory sequences, such as a polyA sequence. A constitutive polynucleotide component may also include optional regulatory sequences, such as polyA sequences.
在一些實施例中,載體進一步包括轉導標記。In some embodiments, the vector further includes a transduction marker.
兩載體配置Two carrier configuration
在一些實施例中,包括第一多核苷酸和第二多核苷酸的多核苷酸組整合在兩個載體上,其中: (i)第一載體可以包括編碼第一融合蛋白的第一多核苷酸;以及 (ii)第二載體可以包括編碼第二融合蛋白的第二多核苷酸。In some embodiments, the set of polynucleotides comprising the first polynucleotide and the second polynucleotide are integrated on two vectors, wherein: (i) the first vector may comprise a first polynucleotide encoding a first fusion protein; and (ii) The second vector may include a second polynucleotide encoding a second fusion protein.
在一些實施例中,第一載體被配置為表達編碼第一融合蛋白的誘導型多核苷酸成分,該第一融合蛋白包括與第一結合元件融合的降解引發劑,並且第二載體被配置為表達編碼第二融合蛋白的組成型多核苷酸成分,該第二融合蛋白包括目標分子和 第二結合元件。In some embodiments, the first vector is configured to express an inducible polynucleotide component encoding a first fusion protein comprising a degradation initiator fused to the first binding element, and the second vector is configured to A constitutive polynucleotide component encoding a second fusion protein comprising the molecule of interest and the second binding element is expressed.
在一些實施例中,第一載體被配置為表達編碼第一融合蛋白的誘導型多核苷酸成分,包括與第一結合元件融合的E3連接酶結構域(或其功能變體),第二載體被配置為表達編碼第二融合蛋白的組成型多核苷酸成分,第二融合蛋白包括感興趣的目標蛋白和第二結合元件。In some embodiments, the first vector is configured to express an inducible polynucleotide component encoding a first fusion protein comprising an E3 ligase domain (or a functional variant thereof) fused to the first binding element, the second vector configured to express a constitutive polynucleotide component encoding a second fusion protein comprising a protein of interest and a second binding element.
圖7B顯示用於編碼誘導型多核苷酸成分和組成型多核苷酸成分的兩載體系統720的示意圖。在該實例中,第一載體725包括用於表達包括與第一結合元件融合的E3連接酶結構域的第一融合蛋白的誘導型多核苷酸成分710,第二載體730包括編碼包括目標蛋白和第二結合元件的第二融合蛋白的組成型多核苷酸成分715。Figure 7B shows a schematic diagram of a two-vector system 720 for encoding an inducible polynucleotide component and a constitutive polynucleotide component. In this example, a first vector 725 includes an inducible polynucleotide component 710 for expressing a first fusion protein comprising an E3 ligase domain fused to a first binding element, and a second vector 730 includes an inducible polynucleotide component 710 encoding a protein comprising the protein of interest and The constitutive polynucleotide component 715 of the second fusion protein of the second binding element.
包括多個載體的組合物Compositions comprising multiple carriers
本揭示的多核苷酸組可以作為載體的一部分提供。在一些實施例中,多核苷酸組的第一和第二多核苷酸成分可以作為單個載體的一部分提供。The set of polynucleotides of the disclosure can be provided as part of a vector. In some embodiments, the first and second polynucleotide components of a set of polynucleotides can be provided as part of a single vector.
本揭示提供了一種組合物,其包括單一個載體,該載體包括:The present disclosure provides a composition comprising a single carrier comprising:
(i)編碼第一結合元件的第一多核苷酸成分;以及(i) a first polynucleotide component encoding a first binding element; and
(ii)編碼第二結合元件的第二多核苷酸成分。(ii) a second polynucleotide component encoding a second binding element.
其中,第一或第二多核苷酸成分進一步編碼降解引發劑,並且第一或第二多核苷酸成分中的另一個進一步編碼感興趣的分子,並且第一和第二結合元件的相互作用調解降解引發劑集中到感興趣的分子以進行靶向降解。wherein the first or second polynucleotide component further encodes a degradation initiator, and the other of the first or second polynucleotide component further encodes a molecule of interest, and the interaction of the first and second binding elements Action-mediated degradation initiators focus on molecules of interest for targeted degradation.
在一些實施例中,本揭示提供了一種組合物,該組合物包括單一載體,該載體包括:In some embodiments, the present disclosure provides a composition comprising a single carrier comprising:
(i)編碼第一結合元件的第一多核苷酸組分;以及(i) a first polynucleotide component encoding a first binding element; and
(ii)編碼第二結合元件的第二多核苷酸組分。(ii) a second polynucleotide component encoding a second binding element.
其中,第一或第二多核苷酸組分中的任一個進一步編碼E3連接酶結構域(或其功能變體),並且第一或第二多核苷酸組分中的另一個進一步編碼感興趣的蛋白質,並且第一和第二結合元件的相互作用調節E3連接酶集合到感興趣的蛋白質以進行靶向降解。Wherein, any one of the first or second polynucleotide components further encodes an E3 ligase domain (or a functional variant thereof), and the other of the first or second polynucleotide components further encodes The protein of interest, and the interaction of the first and second binding elements regulates the recruitment of E3 ligases to the protein of interest for targeted degradation.
在一些方面,組合物可用於治療需要治療的受試者。本揭示提供了一種藥物組合物,其包括:In some aspects, compositions are useful for treating a subject in need thereof. The disclosure provides a pharmaceutical composition comprising:
一單一載體,包含編碼第一結合元件的第一多核苷酸成分和編碼第二結合元件的第二多核苷酸成分,其中,第一或第二多核苷酸成分中的任一個進一步編碼降解引發劑,並且第一或第二多核苷酸成分中的另一個進一步編碼感興趣的分子;以及A single vector comprising a first polynucleotide component encoding a first binding element and a second polynucleotide component encoding a second binding element, wherein either the first or the second polynucleotide component is further encodes a degradation initiator, and the other of the first or second polynucleotide components further encodes a molecule of interest; and
一藥學上可接受的載體、賦形劑和/或穩定劑。A pharmaceutically acceptable carrier, excipient and/or stabilizer.
在一些方面,本揭示提供了一種藥物組合物,其包括:In some aspects, the present disclosure provides a pharmaceutical composition comprising:
(i)一單一載體,其包含編碼第一結合元件的第一多核苷酸成分和編碼第二結合元件的第二多核苷酸成分,其中第一或第二多核苷酸成分中的任一個進一步編碼E3連接酶結構域,並且第一或第二多核苷酸成分中的另一個進一步編碼感興趣的蛋白質;以及(i) a single vector comprising a first polynucleotide component encoding a first binding element and a second polynucleotide component encoding a second binding element, wherein the first or second polynucleotide component Either further encodes an E3 ligase domain, and the other of the first or second polynucleotide components further encodes a protein of interest; and
(ii) 藥學上可接受的載體、賦形劑和/或穩定劑。(ii) Pharmaceutically acceptable carriers, excipients and/or stabilizers.
在一些實施例中,多核苷酸組的第一和第二多核苷酸成分可以作為一組至少兩個載體的一部分提供,其中,例如,第一載體包括第一多核苷酸成分,第二載體包括第二多核苷酸成分。In some embodiments, the first and second polynucleotide components of the set of polynucleotides may be provided as part of a set of at least two vectors, wherein, for example, the first vector comprises the first polynucleotide component, the second polynucleotide component Secondary vectors include a second polynucleotide component.
本揭示提供了一種組合物,其包括:The present disclosure provides a composition comprising:
(i) 包含編碼第一結合元件的第一多核苷酸成分的第一載體;以及(i) a first vector comprising a first polynucleotide component encoding a first binding element; and
(ii) 包含編碼第二結合元件的第二多核苷酸成分的第二載體。(ii) a second vector comprising a second polynucleotide component encoding a second binding element.
其中,第一或第二多核苷酸成分中的任一個進一步編碼降解引發劑,並且第一或第二多核苷酸成分中的另一個進一步編碼感興趣的分子,並且第一和第二結合元件的相互作用調節降解引發劑集中到感興趣的分子以進行靶向降解。Wherein, any one of the first or second polynucleotide components further encodes a degradation initiator, and the other of the first or second polynucleotide components further encodes a molecule of interest, and the first and second The interaction of the binding elements regulates the concentration of the degradation initiator to the molecule of interest for targeted degradation.
在一些目的中,該組合物可用於治療需要治療的受試者。本揭示提供了一種藥物組合物,其包括:For some purposes, the compositions are useful for treating a subject in need thereof. The disclosure provides a pharmaceutical composition comprising:
(i) 包含編碼第一結合元件的第一多核苷酸成分的第一載體;以及(i) a first vector comprising a first polynucleotide component encoding a first binding element; and
(ii) 包含編碼第二結合元件的第二多核苷酸成分的第二載體。其中第一或第二多核苷酸成分中的任一個進一步編碼降解引發劑,並且第一或第二多核苷酸成分中的另一個進一步編碼感興趣的分子;以及(ii) a second vector comprising a second polynucleotide component encoding a second binding element. wherein either of the first or second polynucleotide components further encodes a degradation initiator, and the other of the first or second polynucleotide components further encodes a molecule of interest; and
(iii) 藥學上可接受的載體、賦形劑和/或穩定劑。(iii) Pharmaceutically acceptable carriers, excipients and/or stabilizers.
在一些方面,本揭示提供了一種藥物組合物,其包括:In some aspects, the present disclosure provides a pharmaceutical composition comprising:
(i) 包含編碼第一結合元件的第一多核苷酸成分的第一載體;以及(i) a first vector comprising a first polynucleotide component encoding a first binding element; and
(ii) 包含編碼第二結合元件的第二多核苷酸成分的第二載體,其中第一或第二多核苷酸成分中的任一個進一步編碼E3連接酶(或其功能變體),並且第一或第二多核苷酸成分中的另一個進一步編碼感興趣的蛋白質;以及(ii) a second vector comprising a second polynucleotide component encoding a second binding element, wherein either of the first or second polynucleotide components further encodes an E3 ligase (or a functional variant thereof), and the other of the first or second polynucleotide components further encodes a protein of interest; and
(iii) 藥學上可接受的載體、賦形劑和/或穩定劑。(iii) Pharmaceutically acceptable carriers, excipients and/or stabilizers.
本揭示提供了一種組合物,其包括單一載體,該單一載體包括編碼融合蛋白的多核苷酸,該融合蛋白包括降解引發劑和結合元件作為單一載體的一部分,其中結合元件對感興趣的內源分子上的天然基序是特異性的。The present disclosure provides a composition comprising a single vector comprising a polynucleotide encoding a fusion protein comprising a degradation trigger and a binding element as part of a single vector, wherein the binding element is specific to an endogenous The native motif on the molecule is specific.
在一些方面,該組合物可用於治療需要治療的受試者。本揭示提供了一種藥物組合物,其包括:In some aspects, the compositions are useful for treating a subject in need thereof. The disclosure provides a pharmaceutical composition comprising:
(i) 包含編碼融合蛋白的多核苷酸的載體,該融合蛋白包含降解引發劑和結合元件,其中結合元件對內源性目的分子上的天然基序是特異性的;以及(i) a vector comprising a polynucleotide encoding a fusion protein comprising a degradation initiator and a binding element, wherein the binding element is specific for a native motif on an endogenous molecule of interest; and
(ii) 藥學上可接受的載體、賦形劑和/或穩定劑。(ii) Pharmaceutically acceptable carriers, excipients and/or stabilizers.
在一些實施例中,本揭示提供了一種組合物,該組合物包括編碼融合蛋白的多核苷酸,該融合蛋白包括E3連接酶結構域和結合元件作為單一個載體的一部分,其中結合元件對內源性目的蛋白質上的天然基序是特異性的。In some embodiments, the present disclosure provides a composition comprising a polynucleotide encoding a fusion protein comprising an E3 ligase domain and a binding element as part of a single vector, wherein the binding element pairs within The native motif on the derived protein of interest is specific.
在一些方面,該組合物可用於治療需要治療的受試者。本揭示提供了一種藥物組合物,其包括:In some aspects, the compositions are useful for treating a subject in need thereof. The disclosure provides a pharmaceutical composition comprising:
(i)包含編碼融合蛋白的多核苷酸的載體,該融合蛋白包含E3連接酶結構域和結合元件,其中結合元件對內源蛋白質上的天然基序是特異性的;以及(i) a vector comprising a polynucleotide encoding a fusion protein comprising an E3 ligase domain and a binding element, wherein the binding element is specific for a native motif on the endogenous protein; and
(ii) 藥學上可接受的載體、賦形劑和/或穩定劑。(ii) Pharmaceutically acceptable carriers, excipients and/or stabilizers.
細胞cell
本揭示的表現載體可以在宿主細胞中表達。例如,宿主細胞可以是原核細胞,例如細菌細胞;或真核細胞,例如酵母細胞、植物細胞或哺乳動物細胞。適用於本揭示的哺乳動物細胞的實施例包括人、小鼠、大鼠、豬、兔、綿羊和山羊細胞。在某些情況下,細胞是合成細胞。The expression vectors of the present disclosure can be expressed in host cells. For example, a host cell can be a prokaryotic cell, such as a bacterial cell; or a eukaryotic cell, such as a yeast cell, a plant cell, or a mammalian cell. Examples of mammalian cells suitable for use in the present disclosure include human, mouse, rat, pig, rabbit, sheep, and goat cells. In some cases, the cells are synthetic cells.
例如,宿主細胞可以選自心肌細胞、肺細胞、肌肉細胞、上皮細胞、胰腺細胞、皮膚細胞、CNS細胞、神經元、肌細胞、骨骼肌細胞、平滑肌細胞 、肝細胞、腎細胞和神經膠質細胞。For example, host cells may be selected from cardiomyocytes, lung cells, muscle cells, epithelial cells, pancreatic cells, skin cells, CNS cells, neurons, muscle cells, skeletal muscle cells, smooth muscle cells, liver cells, kidney cells, and glial cells .
在一些實施例中,宿主細胞是離體的人類細胞。在一些實施例中,宿主細胞是體內的人類細胞。In some embodiments, the host cell is an ex vivo human cell. In some embodiments, the host cell is a human cell in vivo.
在一些實施例中,宿主細胞是幹細胞,例如多能幹細胞或造血幹細胞。In some embodiments, the host cell is a stem cell, such as a pluripotent stem cell or a hematopoietic stem cell.
在一些實施例中,宿主細胞是多能細胞或間充質細胞或間充質基質細胞(MSC)。In some embodiments, the host cell is a pluripotent cell or a mesenchymal cell or a mesenchymal stromal cell (MSC).
在一些實施例中,宿主細胞是乾細胞並且本揭示的多核苷酸用於控制由多能細胞例如多能幹細胞產生的細胞產物的分化。例如,包括誘導型 E3 連接酶融合蛋白的降解系統可用於控制驅動分化的蛋白質的穩定性(例如,半衰期)。In some embodiments, the host cell is a stem cell and the polynucleotides of the disclosure are used to control the differentiation of cellular products produced by pluripotent cells, eg, pluripotent stem cells. For example, degradation systems that include inducible E3 ligase fusion proteins can be used to control the stability (e.g., half-life) of proteins that drive differentiation.
在一些實施例中,宿主細胞不是多能性的,並且本揭示的多核苷酸用於控制細胞的重編程以調節多能性。例如,包括誘導型 E3 連接酶融合蛋白的降解系統可用於控制驅動重編程的蛋白質的穩定性(例如,半衰期)。In some embodiments, the host cell is not pluripotent, and the polynucleotides of the disclosure are used to control reprogramming of the cell to regulate pluripotency. For example, degradation systems including inducible E3 ligase fusion proteins can be used to control the stability (e.g., half-life) of proteins driving reprogramming.
在一些實施例中,宿主細胞是有機體的一部分。除了本文其他地方描述的治療實施例外,細胞可以是模型生物體的一部分。例如,降解系統可用於控制蛋白質的穩定性,調節細胞過程並產生用於科學研究的特徵,例如疾病特徵或生物增強。合適的模式生物的例子包括酵母、果蠅、線蟲、青蛙、小鼠和魚(例如斑馬魚)。例如,感興趣的蛋白質可以是功能失調的多肽,或與生物體的基因相互作用或調節或幹擾代謝過程的多肽。在一個實施例中,降解系統是誘導型的,並且可以施用誘導刺激來調節或滴定E3連接酶融合蛋白的表達,從而產生所研究的特徵的變化。In some embodiments, a host cell is part of an organism. In addition to the therapeutic embodiments described elsewhere herein, cells can be part of a model organism. For example, degradation systems can be used to control protein stability, regulate cellular processes and generate signatures for scientific research, such as disease signatures or biological enhancement. Examples of suitable model organisms include yeast, Drosophila, nematodes, frogs, mice and fish (eg zebrafish). For example, a protein of interest may be a dysfunctional polypeptide, or a polypeptide that interacts with an organism's genes or regulates or interferes with metabolic processes. In one embodiment, the degradation system is inducible, and an inducing stimulus can be administered to modulate or titrate the expression of the E3 ligase fusion protein to produce a change in the characteristic of interest.
在一些實施例中,宿主細胞是來自被診斷患有癌症的人類受試者的癌細胞和/或非癌細胞。In some embodiments, the host cell is a cancer cell and/or a non-cancer cell from a human subject diagnosed with cancer.
在一些實施例中,宿主細胞是選自白細胞、淋巴細胞、T細胞、調節性T細胞、效應T細胞、CD4+效應T細胞、CD8+效應T細胞、記憶T細胞、自身反應性T細胞、衰竭T細胞的免疫細胞、自然殺手 T 細胞、B 細胞、樹突狀細胞和巨噬細胞所組成的群組。In some embodiments, the host cell is selected from leukocytes, lymphocytes, T cells, regulatory T cells, effector T cells, CD4+ effector T cells, CD8+ effector T cells, memory T cells, autoreactive T cells, exhausted T cells group of immune cells, natural killer T cells, B cells, dendritic cells, and macrophages.
宿主細胞可以用本揭示的一種或多種多核苷酸或載體轉化並在營養培養基中培養。可以配製營養培養基以誘導啟動子、選擇轉化體或擴增感興趣的基因。該細胞是哺乳動物細胞或細胞系。非限制性示例包括:非洲綠猴腎細胞(VERO-76、ATCC CRL-1587);小倉鼠腎細胞(BHK,ATCC CCL 10);BALB/c 小鼠骨髓瘤系 (NSO/I, ECACC No: 85110503);水牛大鼠肝細胞(BRL 3A,ATCC CRL 1442);犬腎細胞(MDCK、ATCC CCL 34);中國倉鼠卵巢(CHO)細胞或細胞系CHO-K1細胞系(參見例如ATCC目錄號CCL-61™和Lewis, N.E.等人(2013) ,國家生物期刊,31:759-765);中國倉鼠卵巢細胞 +/-DHFR (參見例如 Urlaub, G. 和 Chasin, L.A. (1980) Proc. Natl. Acad. Sci. 77:4216-4220);FS4 細胞;HEK 293 細胞;HT-1080 細胞(ATCC® CCL-121™);人宮頸癌細胞(HeLa、ATCC CCL-2);人胚胎腎細胞系(293 或 293 細胞亞克隆以在懸浮培養中生長,Graham 等人,J. Gen Virol. 36:59 (1977));人肝癌線(Hep G2);人肝細胞(Hep G2,HB 8065);人肺細胞(W138、ATCC CCL 75);人視網膜母細胞(PER.C6,CruCell,Leiden,荷蘭);猴腎細胞(CV1 ATCC CCL 70);SV40 轉化的猴腎 CV1 系 (COS-7, ATCC CRL 1651);小鼠支持細胞 (TM4, Mather, Biol. Reprod. 23:243-251 (1980));小鼠乳腺腫瘤(MMT 060562,ATCC CCL51);MRC 5 細胞; TRI 細胞(Mather 等人,Annals N. Y. Acad. Sci. 383:44-68 (1982));和工程化的 T 細胞和工程化的自然殺手細胞。Host cells can be transformed with one or more polynucleotides or vectors of the present disclosure and cultured in a nutrient medium. Nutrient media can be formulated to induce promoters, select for transformants, or amplify a gene of interest. The cell is a mammalian cell or cell line. Non-limiting examples include: African green monkey kidney cells (VERO-76, ATCC CRL-1587); baby hamster kidney cells (BHK, ATCC CCL 10); BALB/c mouse myeloma line (NSO/I, ECACC No: 85110503); buffalo rat hepatocytes (BRL 3A, ATCC CRL 1442); canine kidney cells (MDCK, ATCC CCL 34); Chinese hamster ovary (CHO) cells or cell line CHO-K1 cell line (see for example ATCC catalog number CCL -61™ and Lewis, N.E. et al. (2013), National Journal of Biology, 31:759-765); Chinese hamster ovary cells +/-DHFR (see e.g. Urlaub, G. and Chasin, L.A. (1980) Proc. Natl. Acad. Sci. 77:4216-4220); FS4 cells; HEK 293 cells; HT-1080 cells (ATCC® CCL-121™); human cervical cancer cells (HeLa, ATCC CCL-2); human embryonic kidney cell line ( 293 or subcloning of 293 cells for growth in suspension culture, Graham et al., J. Gen Virol. 36:59 (1977)); human liver cancer line (Hep G2); human hepatocytes (Hep G2, HB 8065); human Lung cells (W138, ATCC CCL 75); human retinoblastocytes (PER.C6, CruCell, Leiden, Netherlands); monkey kidney cells (CV1 ATCC CCL 70); SV40 transformed monkey kidney CV1 line (COS-7, ATCC CRL 1651); mouse Sertoli cells (TM4, Mather, Biol. Reprod. 23:243-251 (1980)); mouse mammary tumor (MMT 060562, ATCC CCL51); MRC 5 cells; TRI cells (Mather et al., Annals N. Y. Acad. Sci. 383:44-68 (1982)); and Engineered T cells and engineered natural killer cells.
包含宿主細胞的組合物Compositions comprising host cells
可以在宿主細胞中提供本揭示的多核苷酸組。可以將細胞瞬時或穩定地工程化以摻入本揭示的多核苷酸組。The set of polynucleotides of the disclosure can be provided in a host cell. Cells can be transiently or stably engineered to incorporate the disclosed set of polynucleotides.
本揭示提供了一種組合物,其包括包含多核苷酸組的細胞,所述多核苷酸組包括編碼第一結合元件的第一多核苷酸成分和編碼第二結合元件的第二多核苷酸成分,其中第一或第二多核苷酸成分中的任一個進一步編碼降解引發劑,並且第一或第二多核苷酸成分中的另一個進一步編碼感興趣的分子,並且第一和第二結合元件的相互作用調節降解引發劑集中到感興趣的分子以進行靶向降解。The present disclosure provides a composition comprising a cell comprising a set of polynucleotides comprising a first polynucleotide component encoding a first binding element and a second polynucleotide encoding a second binding element An acid component, wherein any one of the first or second polynucleotide components further encodes a degradation initiator, and the other of the first or second polynucleotide components further encodes a molecule of interest, and the first and The interaction of the second binding element regulates the concentration of the degradation initiator to the molecule of interest for targeted degradation.
在一些實施例中,本揭示提供了一種組合物,其包括包含多核苷酸組的細胞,所述多核苷酸組包括編碼第一結合元件的第一多核苷酸組分和編碼第二結合元件的第二多核苷酸組分,其中第一或第二多核苷酸組分中的任一個進一步編碼E3連接酶結構域(或其功能變體),並且第一或第二多核苷酸組分中的另一個進一步編碼感興趣的蛋白質,且第一和第二結合元件的相互作用調節E3連接酶集中到感興趣的蛋白質以進行靶向降解。In some embodiments, the present disclosure provides a composition comprising a cell comprising a set of polynucleotides comprising a first polynucleotide component encoding a first binding element and a second binding element encoding The second polynucleotide component of the element, wherein any one of the first or second polynucleotide components further encodes an E3 ligase domain (or a functional variant thereof), and the first or second polynucleotide Another of the nucleotide components further encodes a protein of interest, and the interaction of the first and second binding elements regulates the concentration of the E3 ligase to the protein of interest for targeted degradation.
本揭示提供了一種組合物,其包括細胞,所述細胞包括編碼融合蛋白的多核苷酸,所述融合蛋白包括降解引發劑和結合元件,其中結合元件對感興趣的內源分子上的天然基序是特異性的。The present disclosure provides a composition comprising a cell comprising a polynucleotide encoding a fusion protein comprising a degradation initiator and a binding element, wherein the binding element binds to a naturally occurring gene on an endogenous molecule of interest. sequence is specific.
在一些實施例中,本揭示提供了包含細胞的組合物,所述細胞包含編碼融合蛋白的多核苷酸,所述融合蛋白包括E3連接酶(或其功能變體)和結合元件,其中結合元件對內源性目的蛋白質上的天然基序是特異性的。In some embodiments, the present disclosure provides compositions comprising a cell comprising a polynucleotide encoding a fusion protein comprising an E3 ligase (or a functional variant thereof) and a binding element, wherein the binding element Specific for a native motif on an endogenous protein of interest.
在一些目的,包含細胞的組合物可用於治療需要治療的受試者。本揭示提供了一種藥物組合物,其包括:For some purposes, compositions comprising cells may be used to treat a subject in need thereof. The disclosure provides a pharmaceutical composition comprising:
(i) 已被修飾以表達多核苷酸組的細胞;以及(i) cells that have been modified to express the set of polynucleotides; and
(ii) 藥學上可接受的載體、賦形劑或穩定劑。(ii) A pharmaceutically acceptable carrier, excipient or stabilizer.
細胞可以包括本揭示的多核苷酸,其表達提供治療益處的目標基因。感興趣的基因的表達可以賦予細胞攻擊腫瘤細胞的能力。感興趣的基因可以是嵌合抗原受體(CAR),例如靶向腫瘤細胞的嵌合抗原受體。感興趣的基因可以表達與鉸鏈相連的單鏈抗體片段,該鉸鏈與跨膜區相連。跨膜區可以連接到細胞內信號結構域。跨膜區可以連接到共刺激結構域。A cell may include a polynucleotide of the disclosure expressing a gene of interest that provides a therapeutic benefit. Expression of a gene of interest can confer on the cell the ability to attack tumor cells. The gene of interest may be a chimeric antigen receptor (CAR), such as a chimeric antigen receptor targeted to tumor cells. The gene of interest can express a single-chain antibody fragment attached to the hinge that connects to the transmembrane region. The transmembrane region can be linked to an intracellular signaling domain. The transmembrane region can be linked to a co-stimulatory domain.
組合物的細胞可以是例如T細胞。組合物的細胞可以是例如CAR-T細胞。The cells of the composition can be, for example, T cells. The cells of the composition can be, for example, CAR-T cells.
在一些實施例中,本揭示提供了一種細胞組合物,其包括用於減少、改善或抑制免疫細胞群體(例如表達CAR的免疫細胞)中的衰竭和/或功能障礙的手段。在一些方面,該方法包括在多核苷酸組中將CAR表達為感興趣的基因並調節CAR的降解,從而抑制可能導致在許多現有T細胞療法中觀察到的不良衰竭表型的過度CAR信號傳導。In some embodiments, the present disclosure provides a cellular composition comprising means for reducing, ameliorating or inhibiting exhaustion and/or dysfunction in a population of immune cells (eg, CAR-expressing immune cells). In some aspects, the method includes expressing a CAR as a gene of interest in a polynucleotide panel and modulating the degradation of the CAR, thereby inhibiting excessive CAR signaling that can lead to the undesirable exhaustion phenotype observed in many existing T cell therapies .
製造小分子的方法Methods of making small molecules
本揭示的小分子可以使用已知技術合成。達諾瑞韋((2R,6S,12Z,13aS,14aR,16aS)-14a-[(環丙基磺醯基)氨甲醯基]-6-({[(2-甲基-2-丙基)氧基]羰基}氨基)-5,16-二氧基-1,2,3,5,6,7,8,9,10,11,13a,14,14a,15,16,16a-十六烷基氫環丙烷[e]吡咯[1,2-a][1,4]重氮環戊烷-2-基-4-氟-1,3-二氫-2H-異吲哚-2-羧酸酯)可使用已知技術合成。例如,參閱Carreira、Erick Moran、Hisashi Yamamoto和N.K.Yee。“不對稱合成的工業應用”在綜合手冊9中,阿姆斯特丹:Elsevier,2012年,第9.19.6節,達諾瑞韋,其公開內容通過引用併入本文。Small molecules of the present disclosure can be synthesized using known techniques. Danprevir ((2R, 6S, 12Z, 13aS, 14aR, 16aS)-14a-[(cyclopropylsulfonyl)carbamoyl]-6-({[(2-methyl-2-propane yl)oxy]carbonyl}amino)-5,16-dioxy-1,2,3,5,6,7,8,9,10,11,13a,14,14a,15,16,16a- Hexadecylhydrocyclopropane[e]pyrrole[1,2-a][1,4]diazocyclopentane-2-yl-4-fluoro-1,3-dihydro-2H-isoindole- 2-carboxylates) can be synthesized using known techniques. See, for example, Carreira, Erick Moran, Hisashi Yamamoto, and N.K. Yee. "Industrial Applications of Asymmetric Synthesis" In General Handbook 9, Amsterdam: Elsevier, 2012, section 9.19.6, danoprevir, the disclosure of which is incorporated herein by reference.
製作多核苷酸making polynucleotides
本揭示提供了生產本揭示的多核苷酸的方法,例如本揭示的DNA載體及其亞組分,以及包裝載體和本揭示的質粒。標準分子生物學技術可用於組裝本揭示的多核苷酸。多核苷酸可以化學合成。The disclosure provides methods of producing polynucleotides of the disclosure, such as DNA vectors of the disclosure and subcomponents thereof, as well as packaging vectors and plasmids of the disclosure. Standard molecular biology techniques can be used to assemble the polynucleotides of the disclosure. Polynucleotides can be chemically synthesized.
製作包覆的病毒殼體Making Encapsulated Viral Capsids
本揭示內容包括製備含有本揭示內容的多核苷酸的病毒殼體的方法。通常,本揭示的病毒殼體可以通過向細胞供應本揭示的包裝多核苷酸來產生。例如,包裝多核苷酸可以作為質粒提供給包裝細胞。可以培養包裝細胞以產生含有本揭示的多核苷酸的病毒殼體。較佳地,包裝的病毒殼體是不能複制的。The disclosure includes methods of making capsids comprising polynucleotides of the disclosure. Typically, capsids of the present disclosure can be produced by supplying cells with packaging polynucleotides of the present disclosure. For example, packaging polynucleotides can be provided to packaging cells as plasmids. Packaging cells can be cultured to produce capsids containing polynucleotides of the disclosure. Preferably, the packaged viral capsids are replication incompetent.
多種市售試劑盒適用於生產本揭示內容的包裝病毒殼體。示例包括:MISSION® 慢病毒包裝混合物(可從 Millipore Sigma 獲得);LV-Max 慢病毒包裝混合物(可從 ThermoFisher Scientific 獲得)。A variety of commercially available kits are suitable for producing packaged viral capsids of the disclosure. Examples include: MISSION® Lentiviral Packaging Mix (available from Millipore Sigma); LV-Max Lentiviral Packaging Mix (available from ThermoFisher Scientific).
可以純化包裝細胞產生的病毒殼體以用於下游方法,例如遞送至細胞以用於基於細胞的療法,或遞送至受試者以用於基因療法方法。純化可包括從宿主細胞或培養基中去除污染物的處理。純化步驟可以包括基於質粒的物理和/或化學特徵的步驟。化學特性可以包括例如親水性-疏水性。物理特性可以包括例如尺寸。基於細微性的純化策略的例子包括密度梯度超速離心、超濾、沉澱、兩相萃取系統和尺寸排阻色譜。在一些情況下,沉澱可以與離心一起使用,例如,使用聚乙二醇、硫酸銨或磷酸鈣。在某些情況下,可以使用具有 PEG、葡聚醣或聚乙烯醇的水性兩相分離系統。在某些情況下,使用基於膜的切向流過濾技術;例子包括超濾、滲濾和微濾。在其他實施例中,色譜方法可用於純化病毒衣殼。在其他實施例中,免疫親和方法可用於使用對相關衣殼具有特異性的單克隆抗體來捕獲衣殼。參見 Morenweiser, R.,“病毒載體和疫苗的下游加工”,基因治療,(2005) 12, S103-S110 (2005),其全部公開內容通過引用併入本文。Capsids produced by packaging cells can be purified for use in downstream methods, such as delivery to cells for cell-based therapy, or delivery to a subject for gene therapy approaches. Purification can include treatments to remove contaminants from host cells or culture media. Purification steps may include steps based on the physical and/or chemical characteristics of the plasmid. Chemical properties may include, for example, hydrophilicity-hydrophobicity. Physical characteristics may include, for example, size. Examples of nuance-based purification strategies include density gradient ultracentrifugation, ultrafiltration, precipitation, two-phase extraction systems, and size exclusion chromatography. In some cases, precipitation can be used with centrifugation, for example, using polyethylene glycol, ammonium sulfate, or calcium phosphate. In some cases, aqueous two-phase separation systems with PEG, dextran, or polyvinyl alcohol can be used. In some cases, membrane-based tangential flow filtration techniques are used; examples include ultrafiltration, diafiltration, and microfiltration. In other embodiments, chromatographic methods can be used to purify viral capsids. In other embodiments, immunoaffinity methods can be used to capture capsids using monoclonal antibodies specific for the relevant capsids. See Morenweiser, R., "Downstream Processing of Viral Vectors and Vaccines", Gene Therapy, (2005) 12, S103-S110 (2005), the entire disclosure of which is incorporated herein by reference.
合適的病毒殼體的例子包括但不限於腺病毒、逆轉錄病毒、慢病毒、仙台病毒、桿狀病毒、愛潑斯坦巴爾病毒、乳多空病毒、牛痘病毒、單純皰疹病毒和腺相關病毒(AAV)。Examples of suitable capsids include, but are not limited to, adenovirus, retrovirus, lentivirus, Sendai virus, baculovirus, Epstein-Barr virus, papovavirus, vaccinia virus, herpes simplex virus, and adeno-associated virus (AAV).
製作細胞making cells
本揭示提供了製造修飾細胞以表現感興趣基因的方法。The present disclosure provides methods for making cells modified to express a gene of interest.
在一些實施例中,本揭示提供了一種製備治療細胞的方法,該治療細胞表達用於治療需要細胞療法的受試者的多核苷酸組。在一目的中,本揭示提供了一種產生或製備治療細胞的方法,該治療細胞從整合到單個載體中的多核苷酸組表達感興趣的基因。在一目的中,本揭示提供了一種產生或製備治療細胞的方法,該治療細胞從整合到兩個(或更多)載體中的多核苷酸組表現感興趣的基因。In some embodiments, the present disclosure provides a method of making therapeutic cells expressing a set of polynucleotides for treating a subject in need of cell therapy. In one object, the present disclosure provides a method of producing or preparing a therapeutic cell expressing a gene of interest from a set of polynucleotides integrated into a single vector. In one object, the present disclosure provides a method of producing or preparing a therapeutic cell expressing a gene of interest from a set of polynucleotides integrated into two (or more) vectors.
在一些實施例中,本揭示的多核苷酸在宿主細胞中作為染色體外多核苷酸維持。在一些實施例中,本揭示的多核苷酸存在於宿主細胞中的載體(例如,表達載體)中。在一些實施例中,本揭示的多核苷酸或其子集或亞組分被整合到宿主細胞的染色體中。In some embodiments, polynucleotides of the present disclosure are maintained in host cells as extrachromosomal polynucleotides. In some embodiments, a polynucleotide of the disclosure is present in a vector (eg, an expression vector) in a host cell. In some embodiments, polynucleotides of the disclosure, or a subset or subcomponent thereof, are integrated into the chromosome of the host cell.
可以使用各種方法將本揭示的一些實施例的表達載體引入細胞以產生本揭示的細胞。例如,參見Green等人的《分子克隆:實驗室手冊》,紐約冷泉港:冷泉港實驗室出版社(2014)。Various methods can be used to introduce expression vectors of some embodiments of the present disclosure into cells to produce cells of the present disclosure. See, eg, Molecular Cloning: A Laboratory Manual by Green et al., Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press (2014).
將核酸改變引入目的基因的方法是本領域眾所周知的。示例包括靶向同源重組(如“Hit and run”、“雙重替換”)、位點特異性重組酶(如Cre重組酶和Flp重組酶)、PB轉座酶(如Sleeping Beauty、piggyBac、To12 或 Frog Prince)、通過工程核酸酶(如巨核酸酶、鋅手指核酸酶(ZFNs))編輯基因組,使用重組腺相關病毒(rAAV)平臺編輯基因組。用於將核酸改變引入感興趣的基因的試劑可以使用可公開獲得的資源來設計或從 Transposagen、Addgene 和 Sangamo Biosciences 商業獲得。本揭示的載體可以利用這些方法將本揭示的多核苷酸整合到宿主基因組中。本揭示的多核苷酸和載體可以包括編碼多肽的多核苷酸,這些多肽是實施這些用於將本揭示的多核苷酸整合到宿主基因組中的方法所需的。Methods for introducing nucleic acid changes into a gene of interest are well known in the art. Examples include targeted homologous recombination (e.g. "Hit and run", "double replacement"), site-specific recombinases (e.g. Cre recombinase and Flp recombinase), PB transposases (e.g. Sleeping Beauty, piggyBac, To12 or Frog Prince), genome editing by engineered nucleases (e.g., meganucleases, zinc finger nucleases (ZFNs)), genome editing using recombinant adeno-associated virus (rAAV) platforms. Reagents for introducing nucleic acid changes into a gene of interest can be designed using publicly available resources or obtained commercially from Transposagen, Addgene, and Sangamo Biosciences. The vectors of the present disclosure can utilize these methods to integrate the polynucleotides of the present disclosure into the host genome. The polynucleotides and vectors of the disclosure may include polynucleotides encoding polypeptides required for carrying out the methods for integrating the polynucleotides of the disclosure into the host genome.
適用於將多核苷酸整合到宿主細胞基因組中的各種方法是本領域已知的,包括隨機整合或特定地點整合(例如“著陸墊”方法);參見,例如,Zhao, M. el al. (2018) ,微生物 生物技術,102:6105-6117;李,J.S. 等人,(2015)科學期刊,5:8572;和 Gaidukov, L. 等人,(2018) 核酸期刊,46:4072-4086。本揭示的載體可以利用這些方法將本揭示的多核苷酸整合到宿主基因組中。本揭示的載體可以包括編碼多肽的多核苷酸,這些多肽是實施這些用於將本揭示的多核苷酸整合到宿主基因組中的方法所需的。Various methods suitable for integrating polynucleotides into the host cell genome are known in the art, including random integration or site-specific integration (e.g., the "landing pad" approach); see, e.g., Zhao, M. el al. ( 2018), Microbial Biotechnology, 102:6105-6117; Li, J.S. et al., (2015) Journal of Science, 5:8572; and Gaidukov, L. et al., (2018) Journal of Nucleic Acids, 46:4072-4086. The vectors of the present disclosure can utilize these methods to integrate the polynucleotides of the present disclosure into the host genome. Vectors of the present disclosure may include polynucleotides encoding polypeptides required to perform the methods for integrating polynucleotides of the present disclosure into the genome of a host.
適用於培養本揭示宿主細胞的市售培養基的示例包括Ham的F10(Sigma)、Minimum Essential培養基((MEM),(Sigma)、RP MI-1640(Sigma))和Dulbecco的改良Eagle培養基((DMEM),Sigma)。Examples of commercially available media suitable for culturing the host cells of the present disclosure include Ham's F10 (Sigma), Minimum Essential Medium ((MEM), (Sigma), RP MI-1640 (Sigma)) and Dulbecco's Modified Eagle Medium ((DMEM ), Sigma).
培養基可根據需要補充激素和/或其他生長因子(如胰島素、轉鐵蛋白或表皮生長因子)、鹽(如氯化鈉、鈣、鎂和磷酸鹽)、緩衝液(如 HEPES)、核苷酸(如腺苷和胸苷)、抗生素(如 GENTAMYCIN™ 藥物)、微量元素(定義為通常以微摩爾範圍的最終濃度存在的無機化合物)和葡萄糖或等效能源。也可以以本領域技術人員已知的適當濃度包括任何其他必要的補充劑。培養條件,例如溫度、pH等,對於普通技術人員將是顯而易見的。Media can be supplemented as needed with hormones and/or other growth factors (such as insulin, transferrin, or epidermal growth factor), salts (such as sodium chloride, calcium, magnesium, and phosphate), buffers (such as HEPES), nucleotides (such as adenosine and thymidine), antibiotics (such as the GENTAMYCIN™ drug), trace elements (defined as inorganic compounds usually present in final concentrations in the micromolar range), and glucose or an equivalent energy source. Any other necessary supplements may also be included at appropriate concentrations known to those skilled in the art. Culture conditions, such as temperature, pH, etc., will be apparent to those of ordinary skill.
細胞治療方法Cell Therapy
本揭示提供了治療需要細胞療法的受試者的方法。該方法包括以下步驟:The present disclosure provides methods of treating a subject in need of cell therapy. The method includes the following steps:
(i) 向受試者施用有效劑量的藥物組合物,該藥物組合物包括編碼多核苷酸組的治療細胞,該多核苷酸組包括從誘導型啟動子和感興趣的治療性分子表達的降解引發劑;以及(i) administering to a subject an effective dose of a pharmaceutical composition comprising a therapeutic cell encoding a set of polynucleotides comprising degradation from an inducible promoter and expression of a therapeutic molecule of interest Initiator; and
(ii) 向受試者施用治療有效劑量的誘導刺激。(ii) administering to the subject a therapeutically effective dose of the inducing stimulus.
在一些實施例中,該方法包括以下步驟:In some embodiments, the method includes the steps of:
(i) 向受試者施用有效量的藥物組合物,該藥物組合物包括編碼多核苷酸組的治療細胞,該多核苷酸組包括從誘導型啟動子和感興趣的治療分子表達的E3連接酶(或其功能變體);以及(i) administering to the subject an effective amount of a pharmaceutical composition comprising a therapeutic cell encoding a set of polynucleotides comprising an E3 linkage expressed from an inducible promoter and a therapeutic molecule of interest an enzyme (or a functional variant thereof); and
(ii) 向受試者施用治療有效劑量的誘導刺激。(ii) administering to the subject a therapeutically effective dose of the inducing stimulus.
在一個方面,本揭示提供了一種用於在有需要的受試者中治療癌症例如腫瘤的方法。可以使用本揭示的藥物組合物治療的癌症的實例包括但不限於黑素瘤、淋巴瘤、肉瘤和結腸癌、腎癌、胃癌、膀胱癌、腦癌(例如,神經膠質瘤、成膠質細胞瘤、星形細胞瘤、髓母細胞瘤)、前列腺、膀胱、直腸、食道、胰腺、肝、肺、乳腺、子宮、子宮頸、卵巢、血液(例如,急性髓細胞白血病、急性淋巴細胞白血病、慢性髓細胞白血病、慢性淋巴細胞白血病、伯基特淋巴瘤、EBV- 誘導的 B 細胞淋巴瘤)。In one aspect, the present disclosure provides a method for treating cancer, eg, a tumor, in a subject in need thereof. Examples of cancers that may be treated using the pharmaceutical compositions of the present disclosure include, but are not limited to, melanoma, lymphoma, sarcoma, and cancer of the colon, kidney, stomach, bladder, brain (e.g., glioma, glioblastoma , astrocytoma, medulloblastoma), prostate, bladder, rectum, esophagus, pancreas, liver, lung, breast, uterus, cervix, ovary, blood (eg, acute myeloid leukemia, acute lymphoblastic leukemia, chronic myeloid leukemia, chronic lymphocytic leukemia, Burkitt lymphoma, EBV-induced B-cell lymphoma).
在一個目的中,本揭示提供了一種在有需要的受試者中控製或調節T細胞介導的免疫反應的方法。In one object, the present disclosure provides a method of controlling or modulating a T cell mediated immune response in a subject in need thereof.
在一個目的中,本揭示提供了一種刺激T細胞調節的對受試者的目標細胞群或組織的免疫反應的方法。In one object, the present disclosure provides a method of stimulating a T cell modulated immune response to a target cell population or tissue in a subject.
在一個目的中,本揭示提供了一種在受試者中提供抗腫瘤免疫的方法。In one object, the present disclosure provides a method of providing anti-tumor immunity in a subject.
在一個目的中,本揭示提供了一種防止受試者在CAR T細胞癌症治療期間T細胞耗盡的方法。In one object, the present disclosure provides a method of preventing T cell exhaustion in a subject during CAR T cell cancer therapy.
基因治療方法gene therapy method
本揭示提供了將本揭示的多核苷酸組遞送至受試者的方法。本揭示的多核苷酸組可以被遞送到受試者的細胞中。該方法可以包括向受試者施用藥學有效劑量的多核苷酸組。施用可通過包含一種或多種本揭示的多核苷酸的病毒顆粒的施用。施用可通過包含本揭示的一種或多種多核苷酸的藥物組合物的給藥。The present disclosure provides methods of delivering the set of polynucleotides of the present disclosure to a subject. A set of polynucleotides of the present disclosure can be delivered into cells of a subject. The method can comprise administering to the subject a pharmaceutically effective amount of the set of polynucleotides. Administration can be by administration of viral particles comprising one or more polynucleotides of the present disclosure. Administration can be by administration of a pharmaceutical composition comprising one or more polynucleotides of the present disclosure.
在一些實施例中,該方法包括以下步驟:In some embodiments, the method includes the steps of:
(i)向受試者施用有效劑量的藥物組合物,該藥物組合物包括編碼從小分子調節的啟動子和感興趣的治療分子表達的降解引發劑(例如,E3連接酶結構域)的多核苷酸組;(i) administering to the subject an effective dose of a pharmaceutical composition comprising a polynucleoside encoding a degradation initiator (e.g., an E3 ligase domain) expressed from a small molecule-regulated promoter and a therapeutic molecule of interest Acid group;
(ii) 向受試者施用治療有效劑量的小分子調節劑;(ii) administering to the subject a therapeutically effective dose of the small molecule modulator;
(iii) 監測受試者中治療分子的含量;以及(iii) monitoring the level of the therapeutic molecule in the subject; and
(iv)任選地,調整小分子調節劑的劑量以將受試者中治療性分子的含量調整至所需含量。(iv) Optionally, adjusting the dose of the small molecule modulator to adjust the level of the therapeutic molecule in the subject to the desired level.
受試者可以是哺乳動物受試者。受試者可以是人類受試者。The subject can be a mammalian subject. A subject can be a human subject.
可選擇用於基因治療的病症的例子包括但不限於癌症、囊性纖維化、心髒病、糖尿病、血友病和AIDS。Examples of conditions that may be selected for gene therapy include, but are not limited to, cancer, cystic fibrosis, heart disease, diabetes, hemophilia, and AIDS.
試劑盒Reagent test kit
本揭示提供了試劑盒或製品,包括本揭示的多核苷酸和用於將多核苷酸遞送至細胞的製劑。多核苷酸可以作為本揭示的載體的一部分提供。在一些實施例中,試劑盒或製品還包括使用該組多核苷酸轉化細胞以表達感興趣的基因以產生感興趣的多肽和/或調節感興趣的基因的說明書。The disclosure provides kits or articles of manufacture comprising the polynucleotides of the disclosure and formulations for delivering the polynucleotides to cells. A polynucleotide can be provided as part of a vector of the present disclosure. In some embodiments, the kit or article of manufacture further includes instructions for using the set of polynucleotides to transform cells to express a gene of interest to produce a polypeptide of interest and/or to modulate a gene of interest.
本揭示提供了包括藥物組合物的試劑盒或製品,該藥物組合物包括編碼本揭示的多核苷酸組的治療細胞。試劑盒或製品還可包括用於將藥物組合物施用於受試者的說明書。The present disclosure provides kits or articles of manufacture comprising pharmaceutical compositions comprising therapeutic cells encoding the set of polynucleotides of the present disclosure. The kit or article of manufacture may also include instructions for administering the pharmaceutical composition to a subject.
在一些情況下,試劑盒或製品還可以包括本揭示的小分子調節劑。In some cases, a kit or article of manufacture may also include a small molecule modulator of the disclosure.
表surface
表 A-序列
表B
表 1、二聚結構域(結合元件)的氨基酸序列,包括設計的異二聚體 (DHD) 的序列。
表 2、設計降解物的氨基酸序列:結合元件-E3 連接酶構建體。甘氨酸-絲氨酸柔性連接子加底線。DHD 和其他結合元件的序列以粗體顯示,可以用表 1 中的任何結合元件序列替換。圖中和正文中使用的簡寫名稱在括號中。
表3、用於降解篩選的目標蛋白的氨基酸序列。可選標籤和甘氨酸-絲氨酸柔性連接子加底線。DHD和其他結合元件的序列以粗體顯示,可以用表1中的任何結合元件序列替換。圖和正文中使用的簡寫名稱在括弧中。
表4、最佳化的 RNF43-DHD-B 構建體的氨基酸序列表現出增強的目標降解。內吞基序的序列用加底線表示,DHD 的序列用粗體表示。一些圖表和正文中使用的簡寫名稱在括號中。
表5、DNCR-E3 和 CAR-NS3a 構建體的氨基酸序列。內吞基序和甘氨酸-絲氨酸柔性連接子以加底線表示,DNCR 和 NS3a 的序列用粗體表示。
表 6、TMCD3z-、SH2ZAP70-、SH3NCK1-E3 融合構建體的氨基酸序列。甘氨酸-絲氨酸柔性連接子加底線表示,跨膜結構域、SH2結構域 和 SH3 結構域的序列用粗體表示。
表7、NFAT-AP1 啟動子的 DNA 序列。最小的 CMV 啟動子加底線,4 個重複的 NFAT-AP1 結合位點的序列以粗體顯示。
表 9、 組成型啟動子的 DNA 序列。
表 10、用於組合篩選成分的氨基酸序列。
表 11、CAR-DHD 構建體,DHD 的氨基酸序列
表 12、DHD-e3 序列
表 13、目標分子
表 14、E3 連接酶基序Table 14. E3 ligase motifs
E3連接酶 基序 APC/C (DBOX) .R..L..[LIVM]. APC/C (KEN) .KEN. APC/C (ABBA) [FIVL].[ILMVP][FHY].[DE].{0,3}[DEST] APCC_TPR_1 .[ILM]R$ CBL (PTK) [DN].Y[ST]..P CBL (MET) DYR COP1 [DE][DE].{2,3}VP[DE] CRL4_CDT2_1 [NQ]{0,1}..[ILMV][ST][DEN][FY][FY].{2,3}[KR]{2,3}[^DE] CRL4_CDT2_2 [NQ]{0,1}..[ILMV]T[DEN][HMFY][FMY].{2,3}[KR]{2,3}[^DE] Kelch_KEAP1_1 [DNS].[DES][TNS]GE Kelch_KEAP1_2 QD.DLGV Kelch_actinfilin [AP]P[MV][IM]V Kelch_KLHL3 E.EE.E[AV]DQH MDM2_SWIB F[^P]{3}W[^P]{2,3}[VIL] Nend_Nbox_1 ^M{0,1}[FYLIW][^P] Nend_UBRbox_1 ^M{0,1}[RK][^P]. Nend_UBRbox_2 ^M{0,1}([ED]). Nend_UBRbox_3 ^M{0,1}([NQ]). Nend_UBRbox_4 ^M{0,1}(C). ODPH_VHL_1 [IL]A(P).{6,8}[FLIVM].[FLIVM] SCF_COI1_1 ..[RK][RK].SL..F[FLM].[RK]R[HRK].[RK]. SCF_FBW7_1 [LIVMP].{0,2}(T)P..([ST]) SCF_FBW7_2 [LIVMP].{0,2}(T)P..E SCF_SKP2-CKS1_1 ..[DE].(T)P.K SCF_TIR1_1 .[VLIA][VLI]GWPP[VLI]...R. SCF-TRCP1 D(S)G.{2,3}([ST]) SIAH .P.A.V.P[^P] SPOP [AVP].[ST][ST][ST]E3 ligase motif APC/C (DBOX) .R..L..[LIVM].APC/C (KEN) .KEN.APC/C (ABBA) [FIVL].[ILMVP][FHY].[DE ].{0,3}[DEST] APCC_TPR_1 .[ILM]R$ CBL (PTK) [DN].Y [ST]..P CBL (MET) DY R COP1 [DE][DE].{2, 3}VP[DE] CRL4_CDT2_1 [NQ]{0,1}..[ILMV][ST][DEN][FY][FY].{2,3}[KR]{2,3}[^DE] CRL4_CDT2_2 [NQ]{0,1}..[ILMV]T[DEN][HMFY][FMY].{2,3}[KR]{2,3}[^DE] Kelch_KEAP1_1 [DNS].[DES] [TNS]GE Kelch_KEAP1_2 QD.DLGV Kelch_actinfilin [AP]P[MV][IM]V Kelch_KLHL3 E.EE.E[AV]DQH MDM2_SWIB F[^P]{3}W[^P]{2,3}[ VIL] Nend_Nbox_1 ^M{0,1}[FYLIW][^P] Nend_UBRbox_1 ^M{0,1}[RK][^P]. Nend_UBRbox_2 ^M{0,1}([ED]). Nend_UBRbox_3 ^M {0,1}([NQ]).Nend_UBRbox_4 ^M{0,1}(C).ODPH_VHL_1 [IL]A(P ).{6,8}[FLIVM].[FLIVM] SCF_COI1_1 ..[RK] [RK].SL..F[FLM].[RK]R[HRK].[RK]. SCF_FBW7_1 [LIVMP].{0,2}(T )P..([ST ]) SCF_FBW7_2 [LIVMP]. {0,2}(T )P..E SCF_SKP2-CKS1_1 ..[DE].(T )PK SCF_TIR1_1 .[VLIA][VLI]GWPP[VLI]...R. SCF-TRCP1 D(S )G .{2,3}([ST ]) SIAH .PAVP[^P] SPOP [AVP].[ST][ST][ST]
對於表 14 的 E3 連接酶,基序模式使用以下命名法:“.”指定任何氨基酸類型,“[X]”指定該位置允許的氨基酸類型,“^X”在開頭 模式的指定序列以氨基酸類型 X 開始,'[^X]' 表示該位置可以具有除類型 X 之外的任何氨基酸,數字指定為以下 'X{x,y}',其中 x 和 y 指定該位置所需的“X”氨基酸類型的最小和最大數量。“$”符號表示蛋白質鏈的C末端。粗體顯示了已知翻譯後修飾(例如,磷酸化和脯氨酸羥基化)的一級脫輔基內的保守殘基位置(來自UniProt61的PTM資料)。For the E3 ligases in Table 14, the motif patterns use the following nomenclature: "." designates any amino acid type, "[X]" designates the amino acid types allowed at that position, and "^X" starts with the amino acid type in the specified sequence of the pattern. X, '[^X]' indicates that the position can have any amino acid except type X, and the numbers are specified as follows 'X{x,y}', where x and y specify the 'X' amino acids required for the position The minimum and maximum number of types. The "$" symbol indicates the C-terminus of the protein chain. Bold shows conserved residue positions within the primary apogroup of known post-translational modifications (eg, phosphorylation and proline hydroxylation) (PTM data from UniProt61).
實施例Example
DHD-A 和 DHD-B 結合元件對DHD-A and DHD-B binding element pair
為了評估參考表 1 描述的設計的 DHD-A 和 DHD-B 結合元件對,根據標準方案進行酶聯免疫吸附測定 (ELISA)。簡而言之,96 孔 Maxisorp 板(Nunc-Immuno,Sigma-Aldrich)在 4°C 下塗上 NeutrAvidin(10 μg/ml)過夜,隨後在 20°C 下用 BSA(2% w/v)封閉 1 小時。將兩(2)nM生物素化MBP-DHD-B捕獲在塗有中和素的孔上30分鐘,然後添加在ELISA緩衝液(PBS,pH 7.4,0.05%吐溫-20,0.2%BSA)中稀釋的標記有FLAG的DHD-A 30分鐘。然後使用辣根過氧化物酶 (HRP) 綴合的抗 FLAG M2 單克隆抗體 (Sigma Aldrich) 和 TMB 底物檢測結合的 DHD-A 蛋白。為了分析,使用 Graphpad Prism 軟體將曲線擬合到具有希爾係數的單點特異性結合模型。To evaluate pairs of DHD-A and DHD-B binding elements with reference to the design described in Table 1, an enzyme-linked immunosorbent assay (ELISA) was performed according to a standard protocol. Briefly, 96-well Maxisorp plates (Nunc-Immuno, Sigma-Aldrich) were coated with NeutrAvidin (10 μg/ml) overnight at 4°C and subsequently blocked with BSA (2% w/v) at 20°C1 Hour. Two (2) nM biotinylated MBP-DHD-B were captured on neutralin-coated wells for 30 min, then added in ELISA buffer (PBS, pH 7.4, 0.05% Tween-20, 0.2% BSA) FLAG-labeled DHD-A diluted in medium for 30 minutes. Bound DHD-A protein was then detected using horseradish peroxidase (HRP)-conjugated anti-FLAG M2 monoclonal antibody (Sigma Aldrich) and TMB substrate. For analysis, the Graphpad Prism software was used to fit curves to a single-site specific binding model with Hill coefficients.
圖8A是顯示來自DHD-A(SEQ ID NO:11)和DHD-B(SEQ ID NO:13)結合元件的DHD-A:DHD-B相互作用的競爭性結合ELISA測定的Kd測定的示意圖。圖8B是顯示來自結合元件DHD-A(SEQ ID NO:11)和DHD-B-Ntrunc(SEQ ID NO:15)的DHD-A:DHD-B相互作用的競爭性結合ELISA測定的Kd測定的示意圖。將結合的 DHD-B 競爭性抑制劑的濃度與 DHD-B 競爭性抑制劑的總濃度作成圖示。構建結合曲線並使用Graphpad Prism軟體通過非線性曲線擬合確定Kd值。數據表明,設計的結合元件與納摩爾範圍內的 Kd 具有高親和力。Figure 8A is a schematic diagram showing the Kd determination of a competitive binding ELISA assay of DHD-A:DHD-B interaction from DHD-A (SEQ ID NO: 11) and DHD-B (SEQ ID NO: 13) binding elements. Figure 8B is a Kd assay showing a competitive binding ELISA assay of DHD-A:DHD-B interaction from binding elements DHD-A (SEQ ID NO: 11) and DHD-B-Ntrunc (SEQ ID NO: 15). schematic diagram. The concentration of bound DHD-B competitive inhibitor is plotted against the total concentration of DHD-B competitive inhibitor. Binding curves were constructed and Kd values were determined by nonlinear curve fitting using Graphpad Prism software. The data demonstrate that the designed binding elements have high affinity with Kd in the nanomolar range.
預期融合到E3連接酶結構域後結合元件的自動泛素化,DHD-B蛋白(SEQ ID NO:13)中的賴氨酸(K)殘基被改變為精氨酸(R),以生成DHD37-short-B-KtoR(SEQ ID NO:16)。圖9是顯示在與DHD-A (SEQ ID NO: 11)的直接結合ELISA測定中比較DHD-B (SEQ ID NO: 13)和DHD37-short-B-KtoR (SEQ ID NO: 16)的示意圖 。根據添加的DHD-A濃度繪製450 nm處的ELISA吸光度。使用Graphpad Prism軟體通過非線性曲線模擬構建結合曲線。數據顯示,結合元件的親和力在賴氨酸到精氨酸的突變後基本上沒有改變。通常,設計序列中的表面賴氨酸殘基可以突變為精氨酸,而不會改變結構和功能(除了防止自泛素化的預期效果)。In anticipation of autoubiquitination of the binding element upon fusion to the E3 ligase domain, the lysine (K) residue in the DHD-B protein (SEQ ID NO:13) was changed to arginine (R) to generate DHD37-short-B-KtoR (SEQ ID NO: 16). Figure 9 is a schematic diagram showing the comparison of DHD-B (SEQ ID NO: 13) and DHD37-short-B-KtoR (SEQ ID NO: 16) in a direct binding ELISA assay with DHD-A (SEQ ID NO: 11) . ELISA absorbance at 450 nm was plotted against the added DHD-A concentration. Binding curves were constructed by nonlinear curve simulation using Graphpad Prism software. The data show that the affinity of the binding element is essentially unchanged following the lysine to arginine mutation. Often, surface lysine residues in the designed sequence can be mutated to arginine without altering structure and function (except for the expected effect of preventing autoubiquitination).
E3 連接酶篩選和表現構建體的評估E3 ligase screening and evaluation of expression constructs
使用 T 細胞的慢病毒轉導和流式細胞術分析評估了可用於生成用於靶向蛋白質降解的表達構建體的功能性 E3 連接酶結構域和泛素變體(參考上文表 2 所述)。Functional E3 ligase domain and ubiquitin variants that could be used to generate expression constructs for targeted protein degradation were evaluated using lentiviral transduction of T cells and flow cytometric analysis (see Table 2 above ).
Jurkat、SupT1、A549 和 Jeko1 T 細胞系獲自美國典型培養物保藏中心 (Manassas VA)。SupT1 和 Jeko1 細胞維持在含有 10% 熱滅活胎牛血清 (Gibco) 的 Glutamax (Gibco) 的 RPMI 1640 培養基中。對於慢病毒轉導,在轉導前 4-16 小時用新鮮培養基餵養 SupT1 和 Jurkat 細胞,然後在完全培養基 + LentiBOOST 中以製造商推薦的濃度 (Sirion Biotech) 與慢病毒一起孵育。在轉染後 18 小時,通過添加 1 體積的新鮮培養基稀釋慢病毒和 LentiBOOST。Jurkat, SupT1, A549, and Jeko1 T cell lines were obtained from the American Type Culture Collection (Manassas VA). SupT1 and Jeko1 cells were maintained in RPMI 1640 medium in Glutamax (Gibco) containing 10% heat-inactivated fetal bovine serum (Gibco). For lentiviral transduction, SupT1 and Jurkat cells were fed with fresh medium 4-16 hours prior to transduction and then incubated with lentivirus in complete medium + LentiBOOST at the manufacturer's recommended concentration (Sirion Biotech). 18 hours after transfection, dilute lentivirus and LentiBOOST by adding 1 volume of fresh medium.
從 Bloodworks (Seattle WA) 或 Stemcell (Vancouver BC) 獲得預選、冷凍保存的原代人 CD4 和 CD8 T 細胞,或來自正常供體的混合 CD4/CD8+ T 細胞。人類T細胞在補充有免疫細胞血清置換(Thermo-Fisher)、2mM L-穀氨醯胺(Gibco)、2mM穀氨醯胺(Gibco)、200IU/ml IL-2(培養系統)、120 IU/ml IL-7(培養系統)和20 IU/ml IL-15(培養系統)的OpTmizer培養基(Thermo-Fisher)中培養。Obtain preselected, cryopreserved primary human CD4 and CD8 T cells from Bloodworks (Seattle WA) or Stemcell (Vancouver BC), or pooled CD4/CD8+ T cells from normal donors. Human T cells were supplemented with immune cell serum exchange (Thermo-Fisher), 2mM L-glutamine (Gibco), 2mM glutamine (Gibco), 200IU/ml IL-2 (culture system), 120 IU/ ml IL-7 (culture system) and 20 IU/ml IL-15 (culture system) in OpTmizer medium (Thermo-Fisher).
對於慢病毒轉導,用 1:100 稀釋的 T 細胞 TransAct (Miltenyi) 刺激 T 細胞 30 小時。然後將病毒添加到 T 細胞中 18-24 小時。在某些情況下,在刺激 24 小時後將病毒添加到 T 細胞中,並在刺激 30 小時後添加第二種慢病毒。然後通過添加 7 體積不含 TransAct 的新鮮培養基終止刺激和病毒感染,並在分析前將細胞再培養 3-7 天。對於達諾瑞韋誘導的結合元件二聚化,在分析之前,用500 nM的達諾瑞韋(RG7227,產品編號A4024)或等量的二甲基亞碸處理細胞18-24小時。為了刺激表達E3連接酶結構域和SH2或SH3結構域融合構建的細胞中的CD3/CD28,在分析之前,將T細胞與1:100稀釋的T細胞TransAct孵育4小時。對於CD3啟動,在4°C條件下,在24孔培養板上預塗PBS中的單克隆CD3激動劑抗體(OKT3)過夜。用PBS清洗培養皿,在收集流式細胞術和免疫印跡之前,將~2x106轉導細胞在培養皿的每個孔中培養1-2小時。For lentiviral transduction, T cells were stimulated for 30 h with a 1:100 dilution of T cell TransAct (Miltenyi). Viruses are then added to T cells for 18-24 hours. In some cases, virus was added to T cells 24 hours after stimulation and a second lentivirus was added 30 hours after stimulation. Stimulation and virus infection were then terminated by adding 7 volumes of fresh medium without TransAct, and cells were cultured for an additional 3-7 days before analysis. For danoprevir-induced dimerization of binding elements, cells were treated with 500 nM danoprevir (RG7227, Product No. A4024) or an equivalent amount of dimethylsulfoxide for 18-24 hours prior to analysis. To stimulate CD3/CD28 in cells expressing E3 ligase domain and SH2 or SH3 domain fusion constructs, T cells were incubated with a 1:100 dilution of T Cell TransAct for 4 hours prior to analysis. For CD3 priming, precoat a 24-well plate with monoclonal CD3 agonist antibody (OKT3) in PBS overnight at 4°C. The dishes were washed with PBS and ~2x106 transduced cells were incubated in each well of the dish for 1–2 hr before collection for flow cytometry and immunoblotting.
流式細胞術在Ze5細胞儀(Biorad)上進行。為了確定細胞表面標記物的表達,將1x105-2x105個總細胞轉移到V底96孔培養皿(康寧)中。細胞用流式細胞儀染色緩衝液 (eBioscience) 洗滌兩次,然後在冰上用總體積為 50 µL 的流式細胞儀染色緩衝液中的相關試劑染色 30 分鐘。染色後,用流式細胞儀染色緩衝液洗滌細胞兩次,固定在 FluoroFix 緩衝液(Biolegend)中,並在黑暗中保持在 4oC 直到分析。對於涉及細胞內BACH2染色的實驗,如上所述對細胞進行表面染色,然後根據FoxP3轉錄因子染色緩衝液集製造商的協議(eBioscience,#00-5523-00)對細胞進行固定、滲透和標記。與人類 Ig Fc 連接的純化重組 ROR1 胞外域是在內部生產的,並與 Alexa 647 染料結合用於檢測。在一級抗體染色過程中,以1:8000稀釋度加入eFluor 780可固定活性染料(eBioscience)。使用 FlowJo 10 (Tree Star) 分析流式細胞術數據。使用的抗體列表如表 8 所示。
篩選一組設計的 DHD-E3/Ub 構建體(見表 2)以有效降解 ROR1 特異性 CAR(ROR1 CAR-DHD-A,SEQ ID NO: 115),見表 3,它被作為降解膜蛋白的模型目標。篩選的膜相關 DHD-E3 連接酶組如下:RNF43-v1 (SEQ ID NO: 74)、RNF43-v2 (SEQ ID NO: 77)、RNF43-v3 (SEQ ID NO: 76)、ZNRF3-v1 (SEQ ID NO: 84)、ZNRF3-v2 (SEQ ID NO: 84) NO: 85)、ZNRF3-v3 (SEQ ID NO: 86)、MARCH8-v1 (SEQ ID NO: 87)、MARCH8-v2 (SEQ ID NO: 88)、MARCH8-v3 (SEQ ID NO: 89)、RNF128 -v1 (SEQ ID NO: 78)、RNF128-v2 (SEQ ID NO: 79)、RNF128-v3 (SEQ ID NO: 80)。篩選的細胞質 DHD-E3 連接酶組如下:ELOC (SEQ ID NO: 97)、FBW1A (SEQ ID NO: 98)、FBXW7 (SEQ ID NO: 96)、LNX1 (SEQ ID NO: 90)、CHIP (SEQ ID NO: 95)、NEDD4 (SEQ ID NO: : 92)、SOCS2 (SEQ ID NO: 94)、SPOP (SEQ ID NO: 93)、VHL (SEQ ID NO: 91)、RNF4 (SEQ ID NO: 99)、TRAF6 (SEQ ID NO: 100)、3xUb ( SEQ ID NO: 81)、3xUbK48R (SEQ ID NO: 82) 以及3xUbK63R (SEQ ID NO: 83)。簡言之,SupT1 細胞與表現組中每個成員的慢病毒和 ROR1 CAR-DHD-A(黑條)或缺乏二聚化結構域的對照 CAR(結合元件;白條)共轉導,並且細胞用 ROR1-ECD-Fc Alexa Fluor 647 結合物染色,通過流式細胞術檢測 CAR-DHD 的表面表現。每個構建體的 gMFI 比率通過用在僅用 CAR 構建體轉導的細胞中測量的 gMFI 進行標準化來計算。功能構造被確定為具有低於 0.25 截止值的標準化 gMFI。A panel of designed DHD-E3/Ub constructs (see Table 2) were screened to efficiently degrade a ROR1-specific CAR (ROR1 CAR-DHD-A, SEQ ID NO: 115), see Table 3, which was proposed as a target for degrading membrane proteins. model target. The set of membrane-associated DHD-E3 ligases screened was as follows: RNF43-v1 (SEQ ID NO: 74), RNF43-v2 (SEQ ID NO: 77), RNF43-v3 (SEQ ID NO: 76), ZNRF3-v1 (SEQ ID NO: 76), ID NO: 84), ZNRF3-v2 (SEQ ID NO: 84) NO: 85), ZNRF3-v3 (SEQ ID NO: 86), MARCH8-v1 (SEQ ID NO: 87), MARCH8-v2 (SEQ ID NO : 88), MARCH8-v3 (SEQ ID NO: 89), RNF128-v1 (SEQ ID NO: 78), RNF128-v2 (SEQ ID NO: 79), RNF128-v3 (SEQ ID NO: 80). The set of cytoplasmic DHD-E3 ligases screened was as follows: ELOC (SEQ ID NO: 97), FBW1A (SEQ ID NO: 98), FBXW7 (SEQ ID NO: 96), LNX1 (SEQ ID NO: 90), CHIP (SEQ ID NO: 95), NEDD4 (SEQ ID NO: 92), SOCS2 (SEQ ID NO: 94), SPOP (SEQ ID NO: 93), VHL (SEQ ID NO: 91), RNF4 (SEQ ID NO: 99 ), TRAF6 (SEQ ID NO: 100), 3xUb (SEQ ID NO: 81), 3xUbK48R (SEQ ID NO: 82) and 3xUbK63R (SEQ ID NO: 83). Briefly, SupT1 cells were co-transduced with lentivirus for each member of the expressed panel and the ROR1 CAR-DHD-A (black bars) or a control CAR lacking the dimerization domain (binding element; white bars), and cells were treated with ROR1-ECD-Fc Alexa Fluor 647 conjugate staining, and the surface expression of CAR-DHD detected by flow cytometry. The gMFI ratio for each construct was calculated by normalizing with the gMFI measured in cells transduced with the CAR construct only. Functional constructs were determined as normalized gMFI with a cutoff below 0.25.
圖10A和圖10B是分別顯示膜相關DHD-E3連接酶和細胞質DHD-E3連接酶的標準化gMFI的示意圖。新的E3連接酶設計用星號 (*) 表示。我們鑑定了能夠降解CAR靶標的膜相關DHD-E3設計(圖10A)和細胞質DHD-E3設計(圖10B)。表現出最大降解活性的設計是:RNF43、RNF4、LNX1、TRAF6 和泛素 K48R 突變體 (3xUbK48R) 的三串聯線性鏈。當 CAR-DHD 與這些合成降解劑共表達時,CAR-DHD 表達的幾何平均螢光強度 (gMFI) 降低到對照 CAR 的 10-20% 左右。10A and 10B are schematic diagrams showing normalized gMFI of membrane-associated DHD-E3 ligase and cytoplasmic DHD-E3 ligase, respectively. New E3 ligase designs are indicated with an asterisk (*). We identified a membrane-associated DHD-E3 design (Fig. 10A) and a cytoplasmic DHD-E3 design (Fig. 10B) capable of degrading CAR targets. The design exhibiting the greatest degradative activity was: a triple tandem linear chain of RNF43, RNF4, LNX1, TRAF6 and a ubiquitin K48R mutant (3xUbK48R ). When CAR-DHD was co-expressed with these synthetic degraders, the geometric mean fluorescence intensity (gMFI) of CAR-DHD expression was reduced to about 10-20% of that of control CAR.
篩選細胞質DHD-E3構建體組(SEQ ID NO,參見上文參考圖10)的3xFLAG標記的DHD-B-BACH2作為細胞質蛋白的模型靶標的有效降解。簡言之,SupT1 細胞與表達 DHD-B-BACH2 (SEQ ID NO: 120) (參見表 3) 的慢病毒和小組的每個成員共轉導,然後用抗 FLAG Brilliant Violet 421 抗體結合物染色,通過細胞內流式細胞術檢測 DHD-BACH2 的異位表現。通過對用野生型BACH2構建體轉導的細胞中測得的gMFI進行歸一化,計算每個構建體的gMFI比率。功能性構建體被確定為在0.25臨界點附近或以下具有標準化的gMFI。The panel of cytoplasmic DHD-E3 constructs (SEQ ID NO, see above with reference to Figure 10) was screened for efficient degradation of 3xFLAG-tagged DHD-B-BACH2 as a model target of cytoplasmic proteins. Briefly, SupT1 cells were co-transduced with lentivirus expressing DHD-B-BACH2 (SEQ ID NO: 120) (see Table 3) and each member of the panel, then stained with anti-FLAG Brilliant Violet 421 antibody conjugate, Ectopic expression of DHD-BACH2 was detected by intracellular flow cytometry. The gMFI ratio for each construct was calculated by normalizing to the gMFI measured in cells transduced with the wild-type BACH2 construct. Functional constructs were identified as having a normalized gMFI around or below the 0.25 cut-off point.
圖11是曲線圖,顯示了為降解3xFLAG標記的DHD-B-BACH2而篩選的細胞質DHD-E3連接酶的標準化gMFI。FLAG標記的BACH2水準的細胞內流式細胞術分析表明,當LNX1、SOCS2、SPOP、VHL和RNF4 E3域的DHD-B融合與DHD-BACH2共表現時,外源表現的BACH2有效降解至陰性對照的10-20%。Figure 11 is a graph showing the normalized gMFI of cytoplasmic DHD-E3 ligases screened for degradation of 3xFLAG-tagged DHD-B-BACH2. Intracellular flow cytometric analysis of FLAG-tagged BACH2 levels demonstrates efficient degradation of exogenously expressed BACH2 to negative controls when DHD-B fusions of LNX1, SOCS2, SPOP, VHL, and RNF4 E3 domains are co-expressed with DHD-BACH2 10-20% of that.
現在參考圖10A、圖10B和圖11,這兩個篩選實驗的結果使我們能夠確定DHD-E3候選結構,以最佳化膜受體和細胞質目標蛋白的降解。Referring now to Figure 10A, Figure 10B and Figure 11, the results of these two screening experiments allowed us to identify DHD-E3 candidate structures for optimal degradation of membrane receptors and cytoplasmic target proteins.
由於 DHD 亞基含有賴氨酸殘基,這些殘基是自動泛素化的潛在位點,我們假設結合域可以用其賴氨酸耗盡的變體 DHD-KtoR (SEQ ID NO: 16) 替換,以穩定結合元件-E3 融合併改善蛋白質靶標的降解。除了賴氨酸到精氨酸的誘變(即,賴氨酸 (K) 到精氨酸 (R);KtoR),探索了使用 C 末端內吞基序來增強 CAR 降解。內吞基序(用“endo”表示)包含一個雙亮氨酸基序 [D/E]xxxLL 和一個 C末端纈氨酸殘基,可實現有效的內質網輸出(Kozik, P.等人,Traffic (2010) doi :10.1111/j.1600-0854.2010.01056.x,其全部內容通過引用併入本文)。表 4 顯示了優化的 RNF43-DHD-B 構建體的氨基酸序列,其表現出增強的目標降解。Since the DHD subunit contains lysine residues that are potential sites for autoubiquitination, we hypothesized that the binding domain could be replaced with its lysine-depleted variant DHD-KtoR (SEQ ID NO: 16) , to stabilize binding element-E3 fusions and improve degradation of protein targets. In addition to lysine to arginine mutagenesis (i.e., lysine (K) to arginine (R); KtoR), the use of a C-terminal endocytic motif was explored to enhance CAR degradation. The endocytic motif (indicated by "endo") contains a double leucine motif [D/E]xxxLL and a C-terminal valine residue, enabling efficient endoplasmic reticulum export (Kozik, P. et al. , Traffic (2010) doi:10.1111/j.1600-0854.2010.01056.x, the entire contents of which are incorporated herein by reference). Table 4 shows the amino acid sequence of the optimized RNF43-DHD-B construct that exhibits enhanced target degradation.
為了檢驗這些假設,將原代 CD4+ T細胞與表現CAR-DHD 和 RNF43-DHD、RNF43-DHD-endo (SEQ ID NO: 122) 或 RNF43-DHD-KtoR 變體 (SEQ ID NO : 121)共轉導 (見表 4)。將CD4+T細胞與CAR-DHD單獨轉導以及CD4+T細胞與CAR對照和RNF43 DHD-KtoR共轉導作為對照。未轉導的 CD4+ T 細胞用作背景 CAR 表現水準對照。使用 CAR 表面染色和流式細胞術評估轉導和非轉導細胞中的 CAR 表現水準。To test these hypotheses, primary CD4+ T cells were co-transfected with CAR-DHD-expressing and RNF43-DHD, RNF43-DHD-endo (SEQ ID NO: 122) or RNF43-DHD-KtoR variants (SEQ ID NO: 121) guide (see Table 4). CD4+ T cells were transduced with CAR-DHD alone and CD4+ T cells were co-transduced with CAR control and RNF43 DHD-KtoR as controls. Untransduced CD4+ T cells were used as a background CAR expression level control. The level of CAR expression in transduced and nontransduced cells was assessed using CAR surface staining and flow cytometry.
圖12是顯示轉導和對照CD4+T細胞中的CAR表面染色和幾何平均螢光強度(gMFI)水平的示意圖。圖A是顯示用於每個 CD4+ T 細胞轉導的“CAR”和“E3”表現構建體的表格(即,第1行:僅CAR-DHD;第2行:CAR-DHD+RNF43-DHD;第3行:CAR-DHD+RNF43 DHD endo;第4行:CAR-DHD+RNF43 DHD KtoR;第5行:CAR control+RNF43 DHD KtoR,以及第6行:非轉導細胞(-,-)。圖 B 是疊加直方圖,顯示每個 CD4+ T 細胞轉導和非轉導細胞的 CAR 表面染色水準。圖C 是顯示每個 CD4+ T 細胞轉導和非轉導細胞的 CAR gMFI 的直方圖。圖B和圖C中顯示的直方圖與圖A中顯示的相應表達構建體(CAR 和 E3)對齊。流式細胞術分析表明,CAR-DHD + RNF43-DHD-KtoR 轉導細胞中的 CAR 表面表達降低到與非轉導對照細胞相同的水準 (-,-)。數據還表明,賴氨酸耗盡的變體 RNF43-DHD-KtoR 不影響 CAR 對照的表面表現(第 5 行:CAR控制 + RNF43-DHD-KtoR)。與 RNF43-DHD-KtoR 變體類似,含有內吞基序的構建體 RNF43-DHD-endo 誘導 CAR-DHD 降解至在非轉導對照中觀察到的背景水準。我們還觀察到與其他兩個內吞基序相似的降解量(數據未顯示)。gMFI 測量證實,當 RNF43-DHD-KtoR 或 RNF43-DHD-endo 與 CAR-DHD 構建體共同轉導時,模擬對照中的 CAR 表現降低至接近背景水準。這兩種最佳化方法的結果表明,通過最大限度地減少自身泛素化和通過使用內吞基序增強 CAR 內吞作用來增加 DHD-E3 連接酶的細胞池,可以進一步促進 CAR 降解。Figure 12 is a graph showing CAR surface staining and geometric mean fluorescent intensity (gMFI) levels in transduced and control CD4+ T cells. Panel A is a table showing the "CAR" and "E3" expressing constructs used for each CD4+ T cell transduction (i.e., row 1: CAR-DHD only; row 2: CAR-DHD+RNF43-DHD; Row 3: CAR-DHD+RNF43 DHD endo; Row 4: CAR-DHD+RNF43 DHD KtoR; Row 5: CAR control+RNF43 DHD KtoR, and Row 6: non-transduced cells (-,-). Panel B is an overlay of histograms showing CAR surface staining levels for each CD4+ T cell transduced and non-transduced cells. Panel C is a histogram showing CAR gMFI for each CD4+ T cell transduced and nontransduced cells. The histograms shown in panels B and C are aligned with the corresponding expression constructs (CAR and E3) shown in panel A. Flow cytometry analysis indicated that CAR surface expression in CAR-DHD + RNF43-DHD-KtoR transduced cells decreased to the same level as non-transduced control cells (-,-). The data also showed that the lysine-depleted variant RNF43-DHD-KtoR did not affect the surface expression of the CAR control (row 5: CAR control + RNF43 -DHD-KtoR). Similar to the RNF43-DHD-KtoR variant, the construct RNF43-DHD-endo containing the endocytic motif induced degradation of CAR-DHD to background levels observed in non-transduced controls. We also observed to similar amounts of degradation as the other two endocytic motifs (data not shown). gMFI measurements confirmed that when RNF43-DHD-KtoR or RNF43-DHD-endo were co-transduced with CAR-DHD constructs, CAR expression was reduced to near background levels.The results of these two optimization methods show that the cellular pool of DHD-E3 ligase is increased by minimizing autoubiquitination and enhancing CAR endocytosis by using endocytic motifs , can further promote the degradation of CAR.
小分子集中多肽Small molecule concentrated peptide
DHD 降解系統不需要添加小分子來控制結合元件對的二聚化。然而,在我們的篩選中發現的功能性E3連接酶結構域可以通過使用“化學誘導二聚體”(CID)代替DHD進行小分子控制。上文參考圖5描述了小分子控制的異二聚體系統的示例。表5顯示了DNCR-E3和CAR-NS3a結構的氨基酸序列,用於評估小分子集中結合元件在降解系統中的使用情況。The DHD degradation system does not require the addition of small molecules to control dimerization of binding element pairs. However, the functional E3 ligase domain discovered in our screen could be manipulated by small molecules by using "chemically induced dimer" (CID) instead of DHD. An example of a small molecule controlled heterodimer system is described above with reference to FIG. 5 . Table 5 shows the amino acid sequences of the DNCR-E3 and CAR-NS3a constructs used to evaluate the use of small molecule focused binding elements in degradation systems.
為了評估小分子結合元素在降解系統中的使用,編碼 CAR-NS3a (SEQ ID NO: 126) 和 DNCR2-E3 連接酶的慢病毒構建體,包括 E3 連接酶結構域 RNF43、DNCR2-RNF4 (SEQ ID NO: 128) 和 LNX1-DNCR2 (SEQ ID NO: 129) (參見表 5 ) 被生成,並被評估其促進 CAR 回應於達諾瑞韋降解的能力。簡言之,SUP-T1 細胞與表達 CAR-NS3a 和每種 DNCR-E3 連接酶的慢病毒共轉導。在添加達諾瑞韋 24 小時後,通過流式細胞儀測量表面 CAR 表現的 gMFI。僅用 CAR-NS3a 轉導的 SUP-T1 細胞用作對照。功能性構建體的 gMFI 值低於僅用 CAR-NS3a 轉導的細胞的 10%。To assess the use of small molecule binding elements in degradation systems, lentiviral constructs encoding CAR-NS3a (SEQ ID NO: 126) and DNCR2-E3 ligase, including the E3 ligase domain RNF43, DNCR2-RNF4 (SEQ ID NO: 128) and LNX1-DNCR2 (SEQ ID NO: 129) (see Table 5) were generated and evaluated for their ability to promote CAR degradation in response to danoprevir. Briefly, SUP-T1 cells were co-transduced with lentivirus expressing CAR-NS3a and each DNCR-E3 ligase. The gMFI of surface CAR expression was measured by flow cytometry 24 hours after addition of danoprevir. SUP-T1 cells transduced with CAR-NS3a only were used as controls. Functional constructs had gMFI values lower than 10% of cells transduced with CAR-NS3a alone.
圖13是顯示在500nM達諾瑞韋存在下CAR-NS3a與LNX1-DNCR2、DNCR2-RNF4和RNF43-DNCR2的可誘導降解的示意圖。CAR 表面表現的流式細胞術分析表明,當細胞用 RNF43-DNCR2 和 DNCR2-RNF4 轉導時,加入達諾瑞韋後 CAR-NS3a 降解至原始 CAR 水平的 10% 以下。Figure 13 is a schematic diagram showing the inducible degradation of CAR-NS3a with LNX1-DNCR2, DNCR2-RNF4 and RNF43-DNCR2 in the presence of 500 nM danoprevir. Flow cytometry analysis of CAR surface expression showed that when cells were transduced with RNF43-DNCR2 and DNCR2-RNF4, CAR-NS3a was degraded to less than 10% of the original CAR level upon addition of danoprevir.
我們通過在單個慢病毒構建物中引入賴氨酸-精氨酸突變(KtoR)和內吞基序(endo),進一步優化了設計,該慢病毒構建物由P2A自切割肽連接的轉導標記物CAR-NS3a和RNF43-DNCR2-KtoR-endo(SEQ ID NO:132)變體。編碼 RNF43-DNCR2 的單個慢病毒構建體作為對照。圖14是編碼通過P2A自切割肽連接的CAR-NS3a和RNF43-DNCR2(i)和RNF43-DNCR2-KtoR-endo(ii)的單載體構建體的示意圖。We further optimized the design by introducing a lysine-arginine mutation (KtoR) and an endocytic motif (endo) in a single lentiviral construct tagged with a P2A self-cleaving peptide-linked transduction CAR-NS3a and RNF43-DNCR2-KtoR-endo (SEQ ID NO: 132) variants. A single lentiviral construct encoding RNF43-DNCR2 served as a control. Figure 14 is a schematic diagram of a single vector construct encoding CAR-NS3a linked by a P2A self-cleaving peptide and RNF43-DNCR2 (i) and RNF43-DNCR2-KtoR-endo (ii).
用表達對照RNF43-DNCR2對照構建體(i)或DNCR2 KtoR endo(ii)構建體的慢病毒轉染SUP-T1細胞,與500 nM的達諾瑞韋一起孵育。在添加達諾瑞韋 24 小時後,通過流式細胞儀測量表面 CAR 表現的 gMFI。SUP-T1 cells were transfected with lentivirus expressing control RNF43-DNCR2 control construct (i) or DNCR2 KtoR endo (ii) construct and incubated with 500 nM of danoprevir. The gMFI of surface CAR expression was measured by flow cytometry 24 hours after addition of danoprevir.
圖15是顯示用表達對照RNF43-DNCR陰性對照(i)或RNF43-DNCR-KtoR-endo(ii)構建體的慢病毒轉導的SUP-T1細胞中的CAR表面染色和gMFI水平的示意圖。圖A 是顯示對照 (i) DNCR-KtoR endo (ii) 以及每個實驗條件下是否添加達諾瑞韋 (Dano) 的表格。圖B是疊加直方圖,顯示每個 SUP-T1 細胞轉導和非轉導細胞 (-,-) 的 CAR 表面染色水平。圖C是顯示每個 SUP-T1 細胞轉導和非轉導細胞 (NTD) 的 CAR的gMFI 的直方圖。圖B 中顯示的直方圖與圖A 中顯示的相應表現結構(i 和 ii)對齊。轉導細胞的流式細胞術分析顯示,添加 500 nM 達諾瑞韋可將用構建體 (i) 轉導的細胞的 CAR gMFI 降低至低於陰性對照的約 10%。正如單一慢病毒格式所預期的那樣,DNCR2-E3的表達水準可能受到限制,因此觀察到藥物治療後的CAR降解僅為原始水準的約32%。使用 RNF43-DNCR2-KtoR 變體後,CAR 降解水平大幅降低了四倍,約為原始水平的 8%。數據表明,這些優化的設計在需要對目標降解進行外部控制的應用中可能是有用的。Figure 15 is a schematic diagram showing CAR surface staining and gMFI levels in SUP-T1 cells transduced with lentiviruses expressing control RNF43-DNCR negative control (i) or RNF43-DNCR-KtoR-endo (ii) constructs. Panel A is a table showing the control (i) DNCR-KtoR endo (ii) with and without the addition of danoprevir (Dano) for each experimental condition. Panel B is an overlay of histograms showing the level of CAR surface staining for each SUP-T1 cell transduced and non-transduced (-,-). Panel C is a histogram showing the gMFI of CAR for each SUP-T1 cell transduced and non-transduced cell (NTD). The histogram shown in panel B aligns with the corresponding representational structures (i and ii) shown in panel A. Flow cytometry analysis of transduced cells showed that addition of 500 nM danoprevir reduced the CAR gMFI of cells transduced with construct (i) to approximately 10% below the negative control. As expected from a single lentiviral format, the level of expression of DNCR2-E3 may be limited, so the observed CAR degradation after drug treatment was only ~32% of the original level. With the RNF43-DNCR2-KtoR variant, the level of CAR degradation was substantially reduced by four-fold, approximately 8% of the original level. The data suggest that these optimized designs may be useful in applications that require external control over targeted degradation.
用於集中 E3 連接酶的天然基序結合元件Native motif-binding elements for concentrating E3 ligases
除了使用 DHD 和小分子集中的多肽結合元件外,還可以使用將 E3 連接酶集中到內源性目標蛋白質結構域來控制我們系統中的降解,包括對應轉譯後修飾的結構域(如參考上文所述的圖6A和圖6B)。我們生成序列來測試我們識別的 E3 連接酶結構域與其他蛋白質識別模組,包括靶向 TCR 的跨膜結構域和靶向磷酸化位點的蛋白質結合劑。TMCD3z-、SH2ZAP70-、SH3NCK1-E3 融合構建體的氨基酸序列見表 6。In addition to using DHD and small-molecule-focused peptide-binding elements, it is also possible to control degradation in our system using the focus of E3 ligases to endogenous target protein domains, including domains corresponding to post-translational modifications (as referenced above described in Figure 6A and Figure 6B). We generated sequences to test our identified E3 ligase domains against other protein recognition modules, including transmembrane domains targeting TCRs and protein binders targeting phosphorylation sites. The amino acid sequences of TMCD3z-, SH2ZAP70-, SH3NCK1-E3 fusion constructs are shown in Table 6.
為了靶向內源性 TCR 複合物,生成了編碼 CD3𝜁 跨膜結構域 (TMCD3z) 和 RNF43 的 E3 連接酶結構域的構建體。用表達這些 TMCD3z-RNF43 融合蛋白的慢病毒轉導 Jurkat 細胞,並通過流式細胞術測量 TCR 複合物的表面表現。To target the endogenous TCR complex, constructs encoding the CD3𝜁 transmembrane domain (TMCD3z) and the E3 ligase domain of RNF43 were generated. Jurkat cells were transduced with lentiviruses expressing these TMCD3z-RNF43 fusion proteins, and the surface expression of TCR complexes was measured by flow cytometry.
圖16是示意圖,分別顯示用TMCD3z-RNF43構建體、GFP對照轉導的細胞和使用抗TCRα/β抗體(BV421)的非轉導細胞的TCR染色和gMFI水平的疊加直方圖 。在該示例中,顯示了 TMCD3z-RNF43 構建體的四個版本的數據:v1 (SEQ ID NO: 133)、v2 (SEQ ID NO: 134)、v3 (SEQ ID NO: 135) 和 v4 (SEQ ID NO: : 136)。流式細胞儀分析顯示,內源性 TCR 蛋白的 gMFI 降解為 10-20% 的非轉導對照細胞。此外,使用來自 ZAP70 的 SH2 結構域和來自 NCK1 的 SH3 結構域,已知它們分別與 CD3𝜁 和 TCR-CD3𝜀 相互作用,在活化的 TCR 複合物中也進行了測試。用表達磷酸反應域和E3連接酶域融合結構的慢病毒轉導Jurkat細胞,並用與重組人源化CD3和CD28激動劑(TransAct-1)結合的聚合物奈米基質刺激4小時。通過流式細胞術測量 TCR 複合物的表面表現。測試的構建體是:LNX1-nSH2-cSH2 (SEQ ID NO: 139)、nSH2-cSH2 和 LNGFR (參見表 6)。Figure 16 is a schematic diagram showing overlaid histograms of TCR staining and gMFI levels for cells transduced with TMCD3z-RNF43 construct, GFP control, and non-transduced cells using anti-TCRα/β antibody (BV421), respectively. In this example, data are shown for four versions of the TMCD3z-RNF43 construct: v1 (SEQ ID NO: 133), v2 (SEQ ID NO: 134), v3 (SEQ ID NO: 135) and v4 (SEQ ID NO: : 136). Flow cytometry analysis revealed that gMFI degraded endogenous TCR proteins in 10-20% of non-transduced control cells. Furthermore, using the SH2 domain from ZAP70 and the SH3 domain from NCK1, which are known to interact with CD3𝜁 and TCR-CD3𝜀, respectively, were also tested in activated TCR complexes. Jurkat cells were transduced with a lentivirus expressing a fusion construct of a phosphoresponse domain and an E3 ligase domain, and stimulated for 4 hours with a polymer nanomatrix conjugated to a recombinant humanized CD3 and CD28 agonist (TransAct-1). Surface representation of TCR complexes was measured by flow cytometry. Constructs tested were: LNX1-nSH2-cSH2 (SEQ ID NO: 139), nSH2-cSH2 and LNGFR (see Table 6).
圖17A是疊加直方圖,其顯示了使用抗TCRα/β抗體在表達LNX1-nSH2-cSH2、nSH2-cSH2和LNGFR對照細胞的細胞上的內源性TCR染色水平。圖17B是顯示表達LNX1-nSH2-cSH2、nSH2-cSH2和LNGFR的細胞中的gMFI值的條形圖。流式細胞儀分析顯示,在表達具有串聯 SH2 結構域 (nSH2-cSH2) 的 E3 融合蛋白的未刺激細胞中,內源性 TCR 蛋白的水平下調了約 70%。用與人源化重組CD3和CD28激動劑抗體結合的聚合物奈米基質刺激4小時後,內源性TCR水準進一步下調至約5%,並保持在比未轉導細胞或表達串聯SH2結構域的細胞中觀察到的水準低約3倍的水準。這些結果表明,這些融合構建體可用於在 CAR-T 應用(例如,CAR-T 細胞療法)中有效調節 TCR 信號傳導。Figure 17A is an overlay of histograms showing the level of endogenous TCR staining on cells expressing LNX1-nSH2-cSH2, nSH2-cSH2, and LNGFR control cells using anti-TCRα/β antibodies. Figure 17B is a bar graph showing gMFI values in cells expressing LNX1-nSH2-cSH2, nSH2-cSH2 and LNGFR. Flow cytometric analysis revealed that levels of endogenous TCR proteins were downregulated by approximately 70% in unstimulated cells expressing an E3 fusion protein with a tandem SH2 domain (nSH2-cSH2). After 4 hours of stimulation with polymer nanomatrixes conjugated to humanized recombinant CD3 and CD28 agonist antibodies, endogenous TCR levels were further downregulated to approximately 5% and remained at a higher level than in untransduced cells or cells expressing tandem SH2 domains The levels observed in the cells were approximately 3-fold lower. These results suggest that these fusion constructs can be used to efficiently modulate TCR signaling in CAR-T applications such as CAR-T cell therapy.
原代 T 細胞中的 CAR 調節CAR Regulation in Primary T Cells
為了證實我們設計的 DHD-E3 連接酶能夠調節原代 T 細胞中的 CAR 活性,將 CD4+/CD8+ 原代細胞的 1:1 混合物與表達 ROR1 CAR-DHD(SEQ ID NO: 115)的慢病毒共轉導( 指定為“CAR-DHD”)和 RNF43-DHD-KtoR(SEQ ID NO:121)(指定為“DHD-E3R”)或 LNX1-DHD-KtoR(指定為“DHD-E3L”)如下:未轉導(模擬 -T),單獨用 CAR 或 CAR-DHD 轉導,或用 CAR-DHD 和 DHD-E3R 或 DHD-ESL 或 GFP 對照雙重轉導。測定細胞的細胞因子分泌、免疫細胞殺傷和標誌物表現。To confirm that our designed DHD-E3 ligase can regulate CAR activity in primary T cells, a 1:1 mixture of CD4+/CD8+ primary cells was co-infected with lentivirus expressing ROR1 CAR-DHD (SEQ ID NO: 115). Transductions (designated "CAR-DHD") and RNF43-DHD-KtoR (SEQ ID NO: 121) (designated "DHD-E3R") or LNX1-DHD-KtoR (designated "DHD-E3L") were as follows: Not transduced (mock-T), transduced with CAR or CAR-DHD alone, or double transduced with CAR-DHD and DHD-E3R or DHD-ESL or GFP control. Cytokine secretion, immune cell killing, and marker expression of cells were measured.
為了測試 DHD-E3集中調節急性 CAR 活化的能力,我們挑戰了非轉導 (Mock-T)、單轉導或雙轉導 T 細胞對抗共培養 Jeko1 目標細胞或 ROR1 剔除 Jeko1 細胞。細胞以 1:4 Jeko1細胞或缺乏CAR目標抗原的對照 Jeko1 細胞(即 Jeko1-KO)的效應物與靶標比率共培養。共培養 24 小時後,從培養的 T 細胞中收集上清液,以 300xg 離心 5 分鐘以去除細胞和碎片,然後在 -80°C 下冷凍直至分析。使用定制的 V-plex 人類促炎試劑盒(人 IFNγ、IL2、TNFα;Meso Scale Discovery (MSD),Rockville,MD)測量細胞因子白細胞介素 2 (IL2) 和干擾素-γ (IFNγ) 的分泌。對於細胞因子檢測,上清液用 MDS 校準稀釋劑 1:5 稀釋,並根據製造商的說明進行分析。To test the ability of DHD-E3 to centrally regulate acute CAR activation, we challenged non-transduced (Mock-T), single-transduced or double-transduced T cells against co-cultured Jeko1 target cells or ROR1 knockout Jeko1 cells. Cells were co-cultured at an effector-to-target ratio of 1:4 Jeko1 cells or control Jeko1 cells lacking the CAR target antigen (i.e., Jeko1-KO). After 24 h of co-culture, supernatants from cultured T cells were collected, centrifuged at 300xg for 5 min to remove cells and debris, and then frozen at -80°C until analysis. Secretion of the cytokines interleukin 2 (IL2) and interferon-gamma (IFNγ) was measured using a custom V-plex human pro-inflammatory kit (human IFNγ, IL2, TNFα; Meso Scale Discovery (MSD), Rockville, MD) . For cytokine assays, supernatants were diluted 1:5 with MDS calibration diluent and analyzed according to the manufacturer's instructions.
圖18是兩個示意圖,分別顯示了共培養24小時後上清液中存在的IL-2和IFNγ的濃度。資料顯示,與僅用CAR-DHD或不含DHD的CAR轉導的細胞相比,DHD-E3構建體的共表達調節了CAR-T細胞抗原驅動細胞因子產生的顯著減少。Figure 18 is two graphs showing the concentrations of IL-2 and IFNγ present in the supernatant after 24 hours of co-cultivation, respectively. The data showed that co-expression of the DHD-E3 construct modulated a significant reduction in CAR-T cell antigen-driven cytokine production compared to cells transduced with CAR-DHD alone or CAR without DHD.
為了檢測CAR調節的細胞溶解活性,測量了T細胞:Jeko-1共培養物中的目標細胞數隨時間的變化。簡言之,CAR T細胞以1:1或1:5效應細胞與目標細胞的比率與NucLight Red(NLR)-ROR1+目標細胞或NLR-ROR1-JeKo1 KO目標細胞或康寧 96 孔板中的 A549 Nuclight Red (NLR) 目標細胞進行接種。將板在 Incucyte 系統 (Sartorius;基礎生物科學,Ann Arbor, MI) 中培養 72 小時。與單獨的腫瘤細胞相比,通過 Incucyte 測量隨時間推移對總 NLR+ 細胞/孔的腫瘤細胞 (JeKo1) 傷害進行了測定。To examine CAR-mediated cytolytic activity, the number of target cells in T cell:Jeko-1 co-cultures was measured over time. Briefly, CAR T cells were mixed with NucLight Red (NLR)-ROR1+ target cells or NLR-ROR1-JeKo1 KO target cells or A549 Nuclight in Corning 96-well plates at a ratio of 1:1 or 1:5 effector cells to target cells Red (NLR) target cells were seeded. Plates were incubated for 72 hours in the Incucyte system (Sartorius; Basic Biosciences, Ann Arbor, MI). Tumor cell (JeKo1) injury to total NLR+ cells/well was determined over time by Incucyte measurements compared to tumor cells alone.
圖19是顯示以1:4的效應物與靶標比率共培養的T細胞殺死Jeko1目標細胞的示意圖。數據顯示,DHD-E3 構建體的共表達有效地阻斷了 CAR 抗原驅動的靶細胞殺傷,結果接近於在對照 Mock T 共培養物中觀察到的結果。這些結果表明 DHD-E3 融合蛋白的表達有效地阻斷了急性 CAR 活性。Figure 19 is a schematic diagram showing the killing of Jeko1 target cells by T cells co-cultured at an effector to target ratio of 1:4. The data showed that co-expression of the DHD-E3 construct effectively blocked CAR antigen-driven killing of target cells, with results close to those observed in control Mock T co-cultures. These results suggest that expression of DHD-E3 fusion protein effectively blocks acute CAR activity.
我們接下來試圖確定 CAR 表達的內在控制是否可以防止慢性 CAR 信號傳導引起的衰竭。為了檢測慢性信號誘導的體外耗竭,將T細胞與A549肺腺癌細胞系(目標細胞)在恒定抗原暴露條件下以1:3的效應靶比共培養7天,然後通過流式細胞術檢測T細胞耗竭的表面標誌物(CD39、PD-1和Lag3)。We next sought to determine whether intrinsic control of CAR expression could prevent exhaustion caused by chronic CAR signaling. To examine chronic signaling-induced exhaustion in vitro, T cells were co-cultured with the A549 lung adenocarcinoma cell line (target cells) at an effector-to-target ratio of 1:3 under constant antigen exposure for 7 days, and then T cells were detected by flow cytometry. Surface markers of cellular depletion (CD39, PD-1 and Lag3).
圖20是一組示意圖,顯示了gMFI在與A549靶細胞共培養的單轉導或雙轉導CAR-T細胞上的CD39、PD-1和Lag3耗竭標誌物的表面表現。數據顯示,與 CAR、CAR-DHD 或 CAR-DHD + eGFP 培養物相比,CAR-DHD 和 DHD-E3 構建體的共表達降低了衰竭標記 CD39、PD1 和 Lag3 的表現。這些結果表明,DHD-E3融合的模組化表達調控來自成對CAR-DHD結構的急性和慢性信號。Figure 20 is a set of schematic diagrams showing the surface expression of CD39, PD-1 and Lag3 depletion markers by gMFI on single or double transduced CAR-T cells co-cultured with A549 target cells. The data showed that co-expression of the CAR-DHD and DHD-E3 constructs reduced the expression of the exhaustion markers CD39, PD1 and Lag3 compared to CAR, CAR-DHD or CAR-DHD + eGFP cultures. These results suggest that modular expression of DHD-E3 fusions regulates both acute and chronic signals from paired CAR-DHD constructs.
由於 CAR 的調節降解是由集中到 CAR 的配對 E3 融合物的表現觸發的,因此可以通過將工程化 E3 模組置於反應細胞內在或環境刺激的誘導型啟動子的控制下來產生動態調節模式 。在一個實施例中,DHD-E3 模組的表現置於鈣反應 NFAT 驅動的啟動子下(參見表 7)。在這個例子中,通過 CAR 信號啟動 T 細胞將誘導鈣通量和調節性 DHD-E3 模組的表現,從而降低 CAR 表現並終止信號傳導。由於 T 細胞耗竭被認為是限制嵌合抗原受體 (CAR) T 細胞抗癌功效的主要因素,我們假設,這種由我們設計的E3連接酶融合調節的內在CAR降解系統將使 CAR 信號傳導暫時停止,並使耗盡的細胞恢復其抗腫瘤功能並分化為記憶狀態。Since regulated degradation of the CAR is triggered by the expression of paired E3 fusions that converge to the CAR, dynamic regulatory patterns can be generated by placing engineered E3 modules under the control of inducible promoters that respond to cell-intrinsic or environmental stimuli. In one embodiment, expression of the DHD-E3 module is placed under a calcium-responsive NFAT-driven promoter (see Table 7). In this example, priming T cells with CAR signaling would induce calcium flux and expression of the regulatory DHD-E3 module, thereby reducing CAR expression and terminating signaling. Since T cell depletion is considered a major factor limiting the anticancer efficacy of chimeric antigen receptor (CAR) T cells, we hypothesized that this intrinsic CAR degradation system regulated by our engineered E3 ligase fusion would render CAR signaling transiently stops, and allows the exhausted cells to resume their antitumor functions and differentiate into a memory state.
圖1為示出3+1異二聚體結合元件對的示意圖。Figure 1 is a schematic diagram showing a pair of 3+1 heterodimeric binding elements.
圖2為示出一對小分子調節的多肽結合組件的示例示意圖。Figure 2 is an exemplary schematic diagram showing a pair of small molecule-mediated polypeptide binding modules.
圖3為使用特定於靶標上天然基序(“A”)的結合元件(“B”)調節內源性蛋白質靶標的示意圖。Figure 3 is a schematic illustration of the modulation of an endogenous protein target using a binding element ("B") specific to a native motif ("A") on the target.
圖4A示出使用3+1 DHD對作為靶向降解跨膜蛋白的結合元件的示意圖。Figure 4A shows a schematic diagram of the use of 3+1 DHD pairs as binding elements for targeted degradation of transmembrane proteins.
圖4B示出使用3+1 DHD對作為用於靶向降解細胞質蛋白的結合元件的示意圖。Figure 4B shows a schematic of the use of 3+1 DHD pairs as binding elements for targeted degradation of cytoplasmic proteins.
圖5示出使用小分子調節的降解系統降解嵌合受體的示意圖。Figure 5 shows a schematic diagram of the degradation of chimeric receptors using a small molecule-mediated degradation system.
圖6A示出使用跨膜受體結構域作為結合元件來靶向降解嵌合跨膜受體的示意圖。Figure 6A shows a schematic diagram of the targeted degradation of chimeric transmembrane receptors using transmembrane receptor domains as binding elements.
圖6B示出使用磷酸酪氨酸結合結構域(PYBD)作為靶向降解轉譯後磷酸化(“P”)跨膜受體的結合劑的示意圖。Figure 6B shows a schematic of the use of phosphotyrosine binding domains (PYBDs) as binders targeting degradation of post-translationally phosphorylated ("P") transmembrane receptors.
圖7A示出用於在單個載體上編碼誘導型多核苷酸組分和組成型多核苷酸組分的單向正向構型的示意圖。Figure 7A shows a schematic diagram of a unidirectional forward configuration for encoding an inducible polynucleotide component and a constitutive polynucleotide component on a single vector.
圖7B是說明用於編碼誘導型多核苷酸組分和組成型多核苷酸組分的雙載體系統的示意圖。Figure 7B is a schematic diagram illustrating a two-vector system for encoding an inducible polynucleotide component and a constitutive polynucleotide component.
圖8A是顯示來自二聚化結構域 DHD-A (SEQ ID NO:11) 和DHD-B (SEQ ID NO:13) 的 DHD-A:DHD-B 相互作用的競爭性結合 ELISA 測定的 Kd 測定的示意圖。Figure 8A is a Kd assay showing a competitive binding ELISA assay of DHD-A:DHD-B interaction from dimerization domains DHD-A (SEQ ID NO: 11) and DHD-B (SEQ ID NO: 13) schematic diagram.
圖8B顯示來自 DHD-A:DHD-B 相互作用的競爭性結合 ELISA 測定對二聚化結構域 DHD-A (SEQ ID NO:11) 和DHD-B-Ntrunc (SEQ ID NO:15) 的 Kd 測定的示意圖。Figure 8B shows the Kd for dimerization domains DHD-A (SEQ ID NO: 11) and DHD-B-Ntrunc (SEQ ID NO: 15) from a competitive binding ELISA assay of DHD-A:DHD-B interaction Schematic diagram of the assay.
圖9顯示了在與 DHD-A (SEQ ID NO:11)的直接結合 ELISA 測定中 DHD-B (SEQ ID NO:13) 和DHD37-short-B-KtoR (SEQ ID NO:16) 的比較示意圖。Figure 9 shows a schematic comparison of DHD-B (SEQ ID NO: 13) and DHD37-short-B-KtoR (SEQ ID NO: 16) in a direct binding ELISA assay with DHD-A (SEQ ID NO: 11) .
圖 10A 和圖10B分別顯示膜相關DHD-E3連接酶和細胞質DHD-E3連接酶的標準化gMFI的示意圖。Figure 10A and Figure 10B show schematic diagrams of normalized gMFI of membrane-associated DHD-E3 ligase and cytoplasmic DHD-E3 ligase, respectively.
圖11是顯示針對3xFLAG標記的DHD-B-BACH2的降解篩選的細胞質DHD-E3連接酶的標準化gMFI的示意圖。Figure 11 is a schematic diagram showing normalized gMFI of cytoplasmic DHD-E3 ligases screened for degradation of 3xFLAG-tagged DHD-B-BACH2.
圖12顯示轉導組和對照組的CD4+ T 細胞中 CAR 表面染色和幾何平均螢光強度 (gMFI) 水準的示意圖。Figure 12 shows a schematic diagram of CAR surface staining and geometric mean fluorescence intensity (gMFI) levels in CD4+ T cells from transduced and control groups.
圖13顯示在 500 nM 達諾瑞韋存在下 CAR-NS3a 與 LNX1-DNCR2、DNCR2-RNF4 和RNF43-DNCR2 的誘導降解示意圖。Figure 13 shows a schematic diagram of the induced degradation of CAR-NS3a and LNX1-DNCR2, DNCR2-RNF4 and RNF43-DNCR2 in the presence of 500 nM danoprevir.
圖14顯示編碼CAR-NS3a和RNF43-DNCR2(i)和RNF43-DNCR2-KtoR-endo (ii) 由 P2A 自切割肽連接的單載體構建體示意圖。Figure 14 shows a schematic diagram of a single vector construct encoding CAR-NS3a and RNF43-DNCR2 (i) and RNF43-DNCR2-KtoR-endo (ii) connected by a P2A self-cleaving peptide.
圖15顯示SUP-T1細胞中CAR表面染色和gMFI水準的面板示意圖,SUP-T1細胞由表達對照RNF43-DNCR陰性對照(i)或RNF43-DNCR-KtoR-endo(ii)建構體的慢病毒轉導。Figure 15. Schematic panel showing CAR surface staining and gMFI levels in SUP-T1 cells transfected with lentiviruses expressing control RNF43-DNCR negative control (i) or RNF43-DNCR-KtoR-endo (ii) constructs guide.
圖16是兩個示意圖,分別顯示了用TMCD3z-RNF43構建物轉導的細胞、GFP對照和使用抗TCRα/β抗體(BV421)的未轉導細胞的TCR染色和gMFI水準的重疊長條示意圖。Figure 16 is two graphs showing overlaid bars of TCR staining and gMFI levels of cells transduced with TMCD3z-RNF43 construct, GFP control, and non-transduced cells using anti-TCRα/β antibody (BV421), respectively.
圖17A是顯示使用抗TCRα/β抗體在表達LNX1-nSH2-cSH2、nSH2-cSH2和LNGFR對照細胞的細胞上的內源性TCR染色水準的疊加直方圖。Figure 17A is an overlay histogram showing the level of endogenous TCR staining on cells expressing LNX1-nSH2-cSH2, nSH2-cSH2, and LNGFR control cells using anti-TCRα/β antibodies.
圖17B顯示表達LNX1-nSH2-cSH2、nSH2-cSH2和LNGFR的細胞中的gMFI值的橫條示意圖。Figure 17B shows a bar graph of gMFI values in cells expressing LNX1-nSH2-cSH2, nSH2-cSH2, and LNGFR.
圖18是顯示在共培養24小時後上清液中分別存在的IL-2和IFNγ濃度的兩個示意圖。Figure 18 is two graphs showing the concentrations of IL-2 and IFNγ, respectively, present in the supernatant after 24 hours of co-cultivation.
圖19是顯示以1:4的效應物與靶標比率共培養的T細胞殺死Jeko1目標細胞的示意圖。Figure 19 is a schematic diagram showing the killing of Jeko1 target cells by T cells co-cultured at an effector to target ratio of 1:4.
圖20是一組曲線圖,顯示了與A549目標細胞共培養的單個或雙轉導CAR-T細胞上CD39、PD-1和Lag3耗盡標記物表面表達的gMFI。Figure 20 is a set of graphs showing gMFI surface expressed CD39, PD-1 and Lag3 depletion markers on single or double transduced CAR-T cells co-cultured with A549 target cells.
圖21A至圖21C是顯示向CAR添加DHD不改變CAR的表面表現或功能的一系列示意圖。如圖所示,標籤“CAR”是沒有任何DHD的CAR,標籤“CAR-DHD_S_R2K”是與SEQ ID NO:170融合的CAR,標籤“CAR-DHD_L_R2K”是與SEQ ID NO:172融合的CAR,並且標籤“CAR-DHD_L”是與 SEQ ID NO:173 融合的 CAR。(A) 未修改的 CAR 和CAR-DHD 結構中 CAR 表面表現的比較。篩選一組設計的 Her2 CAR-DHD 構建體的 Her2 CAR 表面表現。用僅表現Her2 CAR或一組Her2 CAR-DHD構建體或未表現(類比T)的慢病毒轉導原代T細胞,並用Her2 Alexa-Fluor 647結合物染色細胞,通過流式細胞術檢測CAR-DHD的表面表現。通過比較構建體之間的轉導標記陽性 Her2 CAR gMFI 進行表面表現的測量。(B)未經修飾的 CAR 和CAR-DHD 構建體中的腫瘤細胞攻擊後的細胞因子釋放。CAR T 細胞與 A549 細胞以 1:1 的效應物與目標物的比例共培養。共培養 24 小時後測量上清液中 IL2(右 Y 軸)和乾擾素-γ(左 Y 軸)的濃度。(C) 在未修飾的 CAR 和CAR-DHD 結構中測量 T 細胞的細胞毒性。CAR T 細胞在 96 孔板中以 1:1 的效應物與目標物的比例與用對 Her2 目標物呈陽性的 NucLight Red (NLR) 細胞標記的 A549 共培養。將孔板在孵育細胞 (Sartorius) 中培養 72 小時。與單獨的腫瘤細胞相比,腫瘤細胞殺手通過 Incucyte 測量隨時間變化的總 NLR+ 細胞/孔來確定。21A-21C are a series of schematic diagrams showing that adding DHD to CAR does not change the surface appearance or function of CAR. As shown in the figure, the label "CAR" is a CAR without any DHD, the label "CAR-DHD_S_R2K" is a CAR fused with SEQ ID NO: 170, and the label "CAR-DHD_L_R2K" is a CAR fused with SEQ ID NO: 172, And the label "CAR-DHD_L" is a CAR fused with SEQ ID NO:173. (A) Comparison of CAR surface representation in unmodified CAR and CAR-DHD constructs. Screening of a panel of designed Her2 CAR-DHD constructs for Her2 CAR surface expression. Primary T cells were transduced with lentivirus expressing only Her2 CAR or a set of Her2 CAR-DHD constructs or not (analog T), and cells were stained with Her2 Alexa-Fluor 647 conjugate, and CAR- Surface manifestations of DHD. Measurement of surface expression was performed by comparing transduced marker-positive Her2 CAR gMFI between constructs. (B) Cytokine release after challenge with tumor cells in unmodified CAR and CAR-DHD constructs. CAR T cells were co-cultured with A549 cells at a 1:1 ratio of effector to target. The concentrations of IL2 (right Y-axis) and interferon-γ (left Y-axis) in supernatants were measured after 24 h of co-culture. (C) Measurement of T cell cytotoxicity in unmodified CAR and CAR-DHD constructs. CAR T cells were co-cultured at a 1:1 effector-to-target ratio in 96-well plates with A549 labeled with NucLight Red (NLR) cells positive for Her2 targets. Plates were incubated in incubation cells (Sartorius) for 72 hours. Tumor cell killer was determined by Incucyte measuring total NLR+ cells/well over time compared to tumor cells alone.
圖22A至圖22B是一系列示意圖,顯示設計的降解劑有助於蛋白質目標物的有效降解。(A) 篩選了一組設計的 DHD-E3/Ub 結構,以有效降解 Her2 特異性 CAR,作為降解膜蛋白的模型靶標。原代 T 細胞與表現組中每個成員的慢病毒和Her2 CAR-DHD 共轉導,細胞用 Her2-Alexa Fluor 647 偶聯物染色,以通過流式細胞術檢測 CAR-DHD 的表面表現。每個構建體的 gMFI 比率通過用在僅用 CAR 構建體轉導的細胞中測量的 gMFI 進行標準化來計算。如圖所示,從左到右,設計的 DHD-E3/Ub 構建體(表 10 中提供的序列):F43 原生 RNF43 1X DHD-B;DAP10-V5 CD8TMD LNX1 2X DHD-B;DAP10-V5 CD8TMD LNX1 3X DHD-B;DAP10-V5 CD8TMD LNX1 4X DHD-B;DAP10-V5 CD8TMD LNX1 KtoR 2X DHD-B;DAP10-V5 CD8TMD LNX1 KtoR 2X DHD-B;DAP10-V5 CD8TMD LNX1 KtoR 3X DHD-B;DAP10-V5 CD8TMD LNX1 KtoR 4X DHD-B;LNX1 1X DHD-B;LNX1 2X DHD-B;LNX1 3X DHD-B;LNX1 KtoR 1X DHD-B;LNX1 KtoR 2X DHD-B;LNX1 KtoR 3X DHD-B;DAP10-V5 CD8TMD RNF4 KtoR 1X DHD-B;DAP10-V5 CD8TMD RNF4 KtoR 2X DHD-B;DAP10-V5 CD8TMD RNF4 3X DHD-B;DAP10-V5 CD8TMD RNF4 4X DHD-B;DAP10-V5 CD8TMD RNF4 1X DHD-B;DAP10-V5 CD8TMD RNF4 2X DHD-B;DAP10-V5 CD8TMD RNF4 3X DHD-B;DAP10-V5 CD8TMD RNF4 4X DHD-B;RNF4 2X DHD-B;RNF4 3X DHD-B;RNF4 4X DHD-B;RNF4 2X DHD-B;RNF4 3X DHD-B;RNF4 4X DHD-B;DAP10-V5 RNF43 1X DHD-B;DAP10-V5 RNF43 2X DHD-B;DAP10-V5 RNF43 3X DHD-B;DAP10-V5 RNF43 4X DHD-B。(B)在兩個正常供體的原代T細胞中,功能性結構被確定為具有低於0.25臨界值的標準化gMFI。條形圖顯示單轉導(僅限 CAR-DHD)和雙轉導(+ DHD-E3)細胞中的 CAR gMFI。如該圖所示,術語“1X”、“2X”、“3X”和“4X”是指包含 G4S 連接物的重複數(其中單個或“1X”重複具有序列“GGGGS” )(見表 10)。如該圖所示,術語“K2R”可與術語“KtoR”互換,並不表示所示任何降解物序列的第二個位置的氨基酸取代。如該圖所示,標籤“DHD37B”是指“DHD37-short-B-KtoR”(SEQ ID NO:16)。22A-22B are a series of schematic diagrams showing that designed degraders facilitate efficient degradation of protein targets. (A) A panel of designed DHD-E3/Ub constructs were screened to efficiently degrade Her2-specific CARs as model targets for degrading membrane proteins. Primary T cells were co-transduced with lentivirus and Her2 CAR-DHD for each member of the expression panel, and cells were stained with Her2-Alexa Fluor 647 conjugate to detect surface expression of CAR-DHD by flow cytometry. The gMFI ratio for each construct was calculated by normalizing with the gMFI measured in cells transduced with the CAR construct only. As shown, left to right, designed DHD-E3/Ub constructs (sequences provided in Table 10): F43 native RNF43 1X DHD-B; DAP10-V5 CD8TMD LNX1 2X DHD-B; DAP10-V5 CD8TMD DAP10-V5 CD8TMD LNX1 4X DHD-B; DAP10-V5 CD8TMD LNX1 KtoR 2X DHD-B; DAP10-V5 CD8TMD LNX1 KtoR 2X DHD-B; DAP10-V5 CD8TMD LNX1 KtoR 3X DHD-B; DAP10 -V5 CD8TMD LNX1 KtoR 4X DHD-B; LNX1 1X DHD-B; LNX1 2X DHD-B; LNX1 3X DHD-B; LNX1 KtoR 1X DHD-B; LNX1 KtoR 2X DHD-B; -V5 CD8TMD RNF4 KtoR 1X DHD-B; DAP10-V5 CD8TMD RNF4 KtoR 2X DHD-B; DAP10-V5 CD8TMD RNF4 3X DHD-B; DAP10-V5 CD8TMD RNF4 4X DHD-B; DAP10-V5 CD8TMD RNF4 1X DHD-B ;DAP10-V5 CD8TMD RNF4 2X DHD-B; DAP10-V5 CD8TMD RNF4 3X DHD-B; DAP10-V5 CD8TMD RNF4 4X DHD-B; RNF4 2X DHD-B; RNF4 3X DHD-B; 2X DHD-B; RNF4 3X DHD-B; RNF4 4X DHD-B; DAP10-V5 RNF43 1X DHD-B; DAP10-V5 RNF43 2X DHD-B; DAP10-V5 RNF43 3X DHD-B; -B. (B) In primary T cells from two normal donors, functional structure was determined with a normalized gMFI below the 0.25 cutoff. Bar graph showing CAR gMFI in single-transduced (CAR-DHD only) and double-transduced (+DHD-E3) cells. As shown in this figure, the terms "1X", "2X", "3X" and "4X" refer to the number of repeats containing the G4S linker (where a single or "1X" repeat has the sequence "GGGGS") (see Table 10) . As shown in this figure, the term "K2R" is interchangeable with the term "KtoR" and does not indicate an amino acid substitution at the second position of any degradant sequence shown. As shown in the figure, the label "DHD37B" refers to "DHD37-short-B-KtoR" (SEQ ID NO: 16).
圖23是證明RtoK突變增加CAR的下調的示意圖。CAR-DHD 和CAR-DHD RtoK 構建體中 CAR 表面表達的比較。將原代T細胞與表達具有一系列降解活性的DHD-e3構建體和Her2 CAR-DHD或具有RtoK突變的Her2 CAR-DHD的慢病毒共轉導,並用Her2 Alexa-Fluor 647結合物染色細胞,通過流式細胞術檢測CAR-DHD的表面表現。每個構建體的 gMFI 比率通過用僅用 CAR 構建體轉導的細胞中測量的 gMFI 進行標準化來計算,並使用 Wilcoxon 配對符號秩檢驗評估 RtoK 突變的影響。如該圖所示,術語“R2K”可與術語“RtoK”互換,並不表示所示任何降解物序列的第二個位置的氨基酸取代。Figure 23 is a schematic diagram demonstrating that RtoK mutations increase CAR downregulation. Comparison of CAR surface expression in CAR-DHD and CAR-DHD RtoK constructs. Primary T cells were co-transduced with lentiviruses expressing DHD-e3 constructs with a range of degradative activities and Her2 CAR-DHD or Her2 CAR-DHD with RtoK mutation, and cells were stained with Her2 Alexa-Fluor 647 conjugate, The surface expression of CAR-DHD was detected by flow cytometry. The gMFI ratio for each construct was calculated by normalizing to the gMFI measured in cells transduced with the CAR construct only, and the effect of the RtoK mutation was assessed using the Wilcoxon paired signed-rank test. As shown in this figure, the term "R2K" is interchangeable with the term "RtoK" and does not indicate an amino acid substitution at the second position of any degradant sequence shown.
圖24A至圖24C是一系列示意圖,顯示線圈-線圈結構域的C末端融合能夠維持CAR活性,並通過成對的線圈-線圈結構域-E3融合實現有針對性的調節。A) 用 Jeko1 靶細胞攻擊的 CART 細胞的細胞溶解活性,顯示對照 T 細胞、(模擬)、親本 CAR 和CAR 構建體融合到指定的線圈-線圈結構域。B) CAR 構建體的細胞因子分泌。C) 通過與所示線圈-線圈-E3 融合的共轉導調節表面 CAR 表現。Figures 24A-24C are a series of schematic diagrams showing that C-terminal fusions of coil-coil domains can maintain CAR activity and enable targeted modulation by paired coil-coil domain-E3 fusions. A) Cytolytic activity of CART cells challenged with Jeko1 target cells showing control T cells, (mock), parental CAR, and CAR constructs fused to the indicated coil-coil domains. B) Cytokine secretion by CAR constructs. C) Modulation of surface CAR expression by co-transduction of Coil-Coil-E3 fusions as indicated.
圖25A至圖25C是一系列示意圖,表示在腫瘤細胞共培養模型中,用 DHD-e3 構建體調節 CAR-DHD 可提高存活率並阻止啟動/耗盡標誌物的獲得。A) 實驗設計:用編碼 CAR-DHD 的單個慢病毒構建體(僅 CAR)轉導 T 細胞,編碼 2 種不同的 CAR-DHD 設計(CAR_DHD_L 和CAR_DHD_S),或與 CAR-DHD 和DHD-E3 構建體共同轉導。CAR T細胞與A549腺癌細胞重複培養4天,然後進行流式細胞術分析。B) CD39、PD1 和Lag3 耗盡/活化標記在 CAR 轉導細胞上的表現模式。C) 與輸入細胞相比,共培養後在指定的轉導條件下為CAR+的CD3+細胞的百分比。如本圖所示,標籤“DHD\U S”為序號171,標籤“DHD\U L”為序號173。Figures 25A-25C are a series of schematic diagrams showing that modulation of CAR-DHD with a DHD-e3 construct improves survival and prevents the acquisition of priming/depletion markers in a tumor cell co-culture model. A) Experimental design: T cells were transduced with a single lentiviral construct encoding CAR-DHD (CAR only), encoding 2 different CAR-DHD designs (CAR_DHD_L and CAR_DHD_S), or with CAR-DHD and DHD-E3 constructs co-transduction. CAR T cells were cultured repeatedly with A549 adenocarcinoma cells for 4 days, followed by flow cytometry analysis. B) Expression patterns of CD39, PD1, and Lag3 depletion/activation markers on CAR-transduced cells. C) Percentage of CD3+ cells that were CAR+ under the indicated transduction conditions after co-culture compared to input cells. As shown in this figure, the label "DHD\U S" is the serial number 171, and the label "DHD\U L" is the serial number 173.
序列表<110> 歐特佩斯生物股份有限公司<120> 用於靶向蛋白質降解的合成降解系統<130> TP220208-TW<140> 111104424<141> 2022-02-07<150> US 6314895<151> 2021-02-02<150> US 63248516<151> 2021-09-26<160> <170> PatentIn version 3.5>sp|Q96NG5|ZN558_人類鋅手指蛋白 558 OS=Homo sapiens OX=9606GN=ZNF558 PE=1 SV=1MAAVILPSTAAPSSLFPASQQKGHTQGGELVNELLTSWLRGLVTFEDVAVEFTQEEWALLDPAQRTLYRDVMLENCRNLASLGCRVNKPSLISQLEQDKKVVTEERGILPSTCPDLETLLKAKWLTPKKNVFRKEQSKGVKTERSHRGVKLNECNQCFKVFSTKSNLTQHKRIHTGEKPYDCSQCGKSFSSRSYLTIHKRIHNGEKPYECNHCGKAFSDPSSLRLHLRIHTGEKPYECNQCFHVFRTSCNLKSHKRIHTGENHHECNQCGKAFSTRSSLTGHNSIHTGEKPYECHDCGKTFRKSSYLTQHVRTHTGEKPYECNECGKSFSSSFSLTVHKRIHTGEKPYECSDCGKAFNNLSAVKKHLRTHTGEKPYECNHCGKSFTSNSYLSVHKRIHNRWI>sp|Q96NG5-2|ZN558_人類鋅手指蛋白異構體 2 558 OS=Homosapiens OX=9606 GN=ZNF558MLENCRNLASLGCRVNKPSLISQLEQDKKVVTEERGILPSTCPDLETLLKAKWLTPKKNVFRKEQSKGVKTERSHRGVKLNECNQCFKVFSTKSNLTQHKRIHTGEKPYDCSQCGKSFSSRSYLTIHKRIHNGEKPYECNHCGKAFSDPSSLRLHLRIHTGEKPYECNQCFHVFRTSCNLKSHKRIHTGENHHECNQCGKAFSTRSSLTGHNSIHTGEKPYECHDCGKTFRKSSYLTQHVRTHTGEKPYECNECGKSFSSSFSLTVHKRIHTGEKPYECSDCGKAFNNLSAVKKHLRTHTGEKPYECNHCGKSFTSNSYLSVHKRIHNRWI>sp|Q6ZN19|ZN841_人類鋅手指蛋白 841 OS=Homo sapiens OX=9606GN=ZNF841 PE=1 SV=1MLEGHESYDTENFYFREIRKNLQEVDFQWKDGEINYKEGPMTHKNNLTGQRVRHSQGDVENKHMENQLILRFQSGLGELQKFQTAEKIYGCNQIERTVNNCFLASPLQRIFPGVQTNISRKYGNDFLQLSLPTQDEKTHIREKPYIGNECGKAFRVSSSLINHQMIHTTEKPYRCNESGKAFHRGSLLTVHQIVHTRGKPYQCDVCGRIFRQNSDLVNHRRSHTGDKPYICNECGKSFSKSSHLAVHQRIHTGEKPYKCNRCGKCFSQSSSLATHQTVHTGDKPYKCNECGKTFKRNSSLTAHHIIHAGKKPYTCDVCGKVFYQNSQLVRHQIIHTGETPYKCNECGKVFFQRSRLAGHRRIHTGEKPYKCNECGKVFSQHSHLAVHQRVHTGEKPYKCNECGKAFNWGSLLTVHQRIHTGEKPYKCNVCGKVFNYGGYLSVHMRCHTGEKPLHCNKCGMVFTYYSCLARHQRMHTGEKPYKCNVCGKVFIDSGNLSIHRRSHTGEKPFQCNECGKVFSYYSCLARHRKIHTGEKPYKCNDCGKAYTQRSSLTKHLVIHTGENPYHCNEFGEAFIQSSKLARYHRNPTGEKPHKCSECGRTFSHKTSLVYHQRRHTGEMPYKCIECGKVFNSTTTLARHRRIHTGEKPYKCNECGKVFRYRSGLARHWSIHTGEKPYKCNECGKAFRVRSILLNHQMMHTGEKPYKCNECGKAFIERSNLVYHQRNHTGEKPYKCMECGKAFGRRSCLTKHQRIHSSEKPYKCNECGKSYISRSGLTKHQIKHAGENLTTKLNVERPLDVVLTSGIPK>sp|Q6ZN19-2|ZN841_人類鋅手指蛋白異構體 841 OS=Homosapiens OX=9606 GN=ZNF841MLEGHESYDTENFYFREIRKNLQEVDFQWKDGEINYKEGPMTHKNNLTGQRVRHSQGDVENKHMENQLILRFQSGLGELQKFQTAEKIYGCNQIERTVNNCFLASPLQRIFPGVQTNISRKYGNDFLQLSLPTQDEKTHIREKPYIGNECGKAFRVSSSLINHQMIHTTEKPYRCNESGKAFHRGSLLTVHQIVHTRGKPYQCDVCGRIFRQNSDLVNHRRSHTGDKPYICNECGKSFSKSSHLAVHQRIHTGEKPYKCNRCGKCFSQSSSLATHQTVHTGDKPYKCNECGKTFKRNSSLTAHHIIHAGKKPYTCDVCGKVFYQNSQLVRHQIIHTGETPYKCNECGKVFRYRSGLARHWSIHTGEKPYKCNECGKAFRVRSILLNHQMMHTGEKPYKCNECGKAFIERSNLVYHQRNHTGEKPYKCMECGKAFGRRSCLTKHQRIHSSEKPYKCNECGKSYISRSGLTKHQIKHAGENLTTKLNVERPLDVVLTSGIPK>sp|Q6ZN19-3|ZN841_人類鋅手指蛋白異構體 3 841 OS=Homosapiens OX=9606 GN=ZNF841MALPQGSLTFRDVAVEFSQEEWKCLDPVQKALYRDVMLENYRNLGFLGLCLPDLNIISMLEQGKEPWTVVSQVKIARNPNCGECMKGVITGISPKCVIKELPPIQNSNTGEKFQAVMLEGHESYDTENFYFREIRKNLQEVDFQWKDGEINYKEGPMTHKNNLTGQRVRHSQGDVENKHMENQLILRFQSGLGELQKFQTAEKIYGCNQIERTVNNCFLASPLQRIFPGVQTNISRKYGNDFLQLSLPTQDEKTHIREKPYIGNECGKAFRVSSSLINHQMIHTTEKPYRCNESGKAFHRGSLLTVHQIVHTRGKPYQCDVCGRIFRQNSDLVNHRRSHTGDKPYICNECGKSFSKSSHLAVHQRIHTGEKPYKCNRCGKCFSQSSSLATHQTVHTGDKPYKCNECGKTFKRNSSLTAHHIIHAGKKPYTCDVCGKVFYQNSQLVRHQIIHTGETPYKCNECGKVFFQRSRLAGHRRIHTGEKPYKCNECGKVFSQHSHLAVHQRVHTGEKPYKCNECGKAFNWGSLLTVHQRIHTGEKPYKCNVCGKVFNYGGYLSVHMRCHTGEKPLHCNKCGMVFTYYSCLARHQRMHTGEKPYKCNVCGKVFIDSGNLSIHRRSHTGEKPFQCNECGKVFSYYSCLARHRKIHTGEKPYKCNDCGKAYTQRSSLTKHLVIHTGENPYHCNEFGEAFIQSSKLARYHRNPTGEKPHKCSECGRTFSHKTSLVYHQRRHTGEMPYKCIECGKVFNSTTTLARHRRIHTGEKPYKCNECGKVFRYRSGLARHWSIHTGEKPYKCNECGKAFRVRSILLNHQMMHTGEKPYKCNECGKAFIERSNLVYHQRNHTGEKPYKCMECGKAFGRRSCLTKHQRIHSSEKPYKCNECGKSYISRSGLTKHQIKHAGENLTTKLNVERPLDVVLTSGIPK>sp|Q9UI25|YP002_人類推定的未表徵蛋白質 PRO0461 OS=Homosapiens OX=9606 GN=PRO0461 PE=5 SV=1MEEMSYGENSGTHVGSFSCSPQPSQQMKVLFVGNSFLLTPVLHRQPHLQPCNFGPEVVAPQRL>sp|Q86XN6|ZN761_HUMAN Zinc finger protein 761 OS=Homo sapiens OX=9606GN=ZNF761 PE=1 SV=3MAFSQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCTMKEFLSTAQGNREVFHAGTLQIHESHHNGDFCYQDVDKDIHDYEFQWQEDERNGHEAPMTKIKKLTGITERYDQSHARNKPIKDQLGSSFHSHLPEMHIFQTEEKIDNQVVKSVHDASLVSTAQRISCRPKTHISNNHGNNFWNSSLLTQKQEVHMREKSFQCNESGKAFNYSSLLRKHQIIHLADKYKCDVCGKLFNQKRNLACHRRCHTGENPYKCNECGKTFSQTSSLTCHRRLHTGEKPYKCEECDKAFHFKSILERHRIIHTEEKPYKCNECGKTFRQKSILTRHHRLHTGEKPYKCNECGKTFSHKSSLTCHHRLHTGEKPYKCNECGKTFSHKSSLTCHRRLHTGEKPYKCEECDKAYSFRSNFEIHRKIHTEDNAYKCNECGKTFSRTSSLTCHRRRHTGEQPYKCEECDKAFRFKSNLERHRRIHTGEKPYKCNECGKTFSRKSYLTCHHRLHTGEKAYKCNECGKTFSWKSSLTCHRRLHSGEKPYKCKECGKTFNQQLTLKRHRRLHSGENPYKCEDSDKAYSFKSNLEIHQKIHTEENPYKCNECGKTFSRTSSLTCHRRLHTGEKPYKCEECDKAFRVKSNLEGHRRIHTGEKPYKCNECGKTFSRKSYFICHHRLHTGEKPYKCNECGKNFSQKSSLICHHRLHTGEKPYKCNECGKTFSQKSNLTCHRRLHTGEKQV>sp|A8MUZ8|Z705G_人類推定的鋅手指蛋白 705G OS=Homo sapiensOX=9606 GN=ZNF705G PE=2 SV=2MHSLKKLTFEDVAIDFTQEEWAMMDTSKRKLYRDVMLENISHLVSLGYQISKSYIILQLEQGKELWREGRVFLQDQNPNRESALKKTHMISMHPITRKDASTSMTMENSLILEDPFECNDSGEDCTRSSTITQCLLTHSGKKPYVSKQCGKSLRNLLSTEPHKQIHTKGKSYQCNLCEKAYTNCFHLRRHKMTHTGERPYACHLCRKAFTQCSHLRRHEKTHTGQRPYKCHQYGKVFIQSFNLQRHERTHLGKKCYECDKSGKAFSQSSGFRGNKIIHTGEKPHACLLCGKAFSLSSNLR>sp|Q08ER8|ZN543_人類鋅手指蛋白 543 OS=Homo sapiens OX=9606GN=ZNF543 PE=1 SV=3MAASAQVSVTFEDVAVTFTQEEWGQLDAAQRTLYQEVMLETCGLLMSLGCPLFKPELIYQLDHRQELWMATKDLSQSSYPGDNTKPKTTEPTFSHLALPEEVLLQEQLTQGASKNSQLGQSKDQDGPSEMQEVHLKIGIGPQRGKLLEKMSSERDGLGSDDGVCTKITQKQVSTEGDLYECDSHGPVTDALIREEKNSYKCEECGKVFKKNALLVQHERIHTQVKPYECTECGKTFSKSTHLLQHLIIHTGEKPYKCMECGKAFNRRSHLTRHQRIHSGEKPYKCSECGKAFTHRSTFVLHHRSHTGEKPFVCKECGKAFRDRPGFIRHYIIHTGEKPYECIECGKAFNRRSYLTWHQQIHTGVKPFECNECGKAFCESADLIQHYIIHTGEKPYKCMECGKAFNRRSHLKQHQRIHTGEKPYECSECGKAFTHCSTFVLHKRTHTGEKPYECKECGKAFSDRADLIRHFSIHTGEKPYECVECGKAFNRSSHLTRHQQIHTGEKPYECIQCGKAFCRSANLIRHSIIHTGEKPYECSECGKAFNRGSSLTHHQRIHTGRNPTIVTDVGRPFMTAQTSVNIQELLLGKEFLNITTEENLW>sp|Q9GZX5|ZN350_人類鋅手指蛋白 350 OS=Homo sapiens OX=9606GN=ZNF350 PE=1 SV=3MIQAQESITLEDVAVDFTWEEWQLLGAAQKDLYRDVMLENYSNLVAVGYQASKPDALFKLEQGEQLWTIEDGIHSGACSDIWKVDHVLERLQSESLVNRRKPCHEHDAFENIVHCSKSQFLLGQNHDIFDLRGKSLKSNLTLVNQSKGYEIKNSVEFTGNGDSFLHANHERLHTAIKFPASQKLISTKSQFISPKHQKTRKLEKHHVCSECGKAFIKKSWLTDHQVMHTGEKPHRCSLCEKAFSRKFMLTEHQRTHTGEKPYECPECGKAFLKKSRLNIHQKTHTGEKPYICSECGKGFIQKGNLIVHQRIHTGEKPYICNECGKGFIQKTCLIAHQRFHTGKTPFVCSECGKSCSQKSGLIKHQRIHTGEKPFECSECGKAFSTKQKLIVHQRTHTGERPYGCNECGKAFAYMSCLVKHKRIHTREKQEAAKVENPPAERHSSLHTSDVMQEKNSANGATTQVPSVAPQTSLNISGLLANRNVVLVGQPVVRCAASGDNRGFAQDRNLVNAVNVVVPSVINYVLFYVTENP>sp|Q9GZP7|VN1R1_人類犁鼻 1 型受體 1 OS=Homo sapiensOX=9606 GN=VN1R1 PE=2 SV=1MVGDTLKLLSPLMTRYFFLLFYSTDSSDLNENQHPLDFDEMAFGKVKSGISFLIQTGVGILGNSFLLCFYNLILFTGHKLRPTDLILSQLALANSMVLFFKGIPQTMAAFGLKYLLNDTGCKFVFYYHRVGTRVSLSTICLLNGFQAIKLNPSICRWMEIKIRSPRFIDFCCLLCWAPHVLMNASVLLLVNGPLNSKNSSAKNNYGYCSYKASKRFSSLHAVLYFSPDFMSLGFMVWASGSMVFFLYRHKQQVQHNHSNRLSCRPSQEARATHTIMVLVSSFFVFYSVHSFLTIWTTVVANPGQWIVTNSVLVASCFPARSPFVLIMSDTHISQFCFACRTRKTLFPNLVVMP>sp|Q3MJ13|WDR72_人類 WD 含有重複序列的蛋白質 72 OS=Homo sapiensOX=9606 GN=WDR72 PE=2 SV=2MRTSLQAVALWGQKAPPHSITAIMITDDQRTIVTGSQEGQLCLWNLSHELKISAKELLFGHSASVTCLARARDFSKQPYIVSAAENGEMCVWNVTNGQCMEKATLPYRHTAICYYHCSFRMTGEGWLLCCGEYQDVLIIDAKTLAVVHSFRSSQFPDWINCMCIVHSMRIQEDSLLVVSVAGELKVWDLSSSINSIQEKQDVYEKESKFLESLNCQTIRFCTYTERLLLVVFSKCWKVYDYCDFSLLLTEVSRNGQFFAGGEVIAAHRILIWTEDGHSYIYQLLNSGLSKSIYPADGRVLKETIYPHLLCSTSVQENKEQSRPFVMGYMNERKEPFYKVLFSGEVSGRITLWHIPDVPVSKFDGSPREIPVTATWTLQDNFDKHDTMSQSIIDYFSGLKDGAGTAVVTSSEYIPSLDKLICGCEDGTIIITQALNAAKARLLEGGSLVKDSPPHKVLKGHHQSVTSLLYPHGLSSKLDQSWMLSGDLDSCVILWDIFTEEILHKFFLEAGPVTSLLMSPEKFKLRGEQIICCVCGDHSVALLHLEGKSCLLHARKHLFPVRMIKWHPVENFLIVGCADDSVYIWEIETGTLERHETGERARIILNCCDDSQLVKSVLPIASETLKHKSIEQRSSSPYQLGPLPCPGLQVESSCKVTDAKFCPRPFNVLPVKTKWSNVGFHILLFDLENLVELLLPTPLSDVDSSSSFYGGEVLRRAKSTVEKKTLTLRKSKTACGPLSAEALAKPITESLAQGDNTIKFSEENDGIKRQKKMKISKKMQPKPSRKVDASLTIDTAKLFLSCLLPWGVDKDLDYLCIKHLNILKLQGPISLGISLNEDNFSLMLPGWDLCNSGMIKDYSGVNLFSRKVLDLSDKYTATLPNQVGIPRGLENNCDSLRESDTIVYLLSRLFLVNKLVNMPLELACRVGSSFRMESIHNKMRGAGNDILNMSSFYSCLRNGKNESHVPEADLSLLKLISCWRDQSVQVTEAIQAVLLAEVQQHMKSLGKIPVNSQPVSMAENGNCEMKQMLPKLEWTEELELQCVRNTLPLQTPVSPVKHDSNSNSANFQDVEDMPDRCALEESESPGEPRHHSWIAKVCPCKVS>sp|Q9NY84|VNN3_人類血管非炎症分子 3OS=Homosapiens OX=9606 GN=VNN3 PE=1 SV=3MIISHFPKCVAVFALLALSVGALDTFIAAVYEHAVILPNRTETPVSKEEALLLMNKNIDVLEKAVKLAAKQGAHIIVTPEDGIYGWIFTRESIYPYLEDIPDPGVNWIPCRDPWRFGNTPVQQRLSCLAKDNSIYVVANIGDKKPCNASDSQCPPDGRYQYNTDVVFDSQGKLLARYHKYNLFAPEIQFDFPKDSELVTFDTPFGKFGIFTCFDIFSHDPAVVVVDEFQLTAFSTPQHGTTRCPSSRLFPSIQHGPRPWESIYLLQIPTTPACT>sp|Q9NY84-3|VNN3_血管非炎症分子 3 的人類異構體 2OS=Homo sapiens OX=9606 GN=VNN3MIISHFPKCVAVFALLALSVGALDTFIAAVYEHAVILPNRTETPVSKEEALLLMNKNIDVLEKAVKLAAKQGAHIIVTPEDGIYGWIFTRESIYPYLEDIPDPGVNWIPCRDPWRNH>sp|Q9NY84-4|VNN3_血管非炎症分子 3 的人類異構體 3OS=Homo sapiens OX=9606 GN=VNN3MIISHFPKCVAVFALLALSVGALDTFIAAVYEHAVILPNRTETPVSKEEALLLMNKNIDVLEKAVKLAAKQGAHIIVTPEDGIYGWIFTRESIYPYLEDIPDPGVNWIPCRDPWRKSKKMNEPVSKELCYHCHSECNQYGQWKLYRT>sp|Q9NY84-5|VNN3_血管非炎症分子 3 的人類異構體 4OS=Homo sapiens OX=9606 GN=VNN3MIISHFPKCVAVFALLALSVGALDTFIAAVYEHAVILPNRTETPVSKEEALLLMNKNIDVLEKAVKLAAKQGAHIIVTPEDGIYGWIFTRESIYPYLEDIPDPGVNWIPCRDPWRFGNTPVQQRLSCLAKDNSIYVVANIGDKKPCNASDSQCPPDGRYQYNTDVVFDSQGKLLARYHKGVESTPQKQSRCTTMTWKQRVVSCCYQN>sp|Q9NY84-6|VNN3_血管非炎症分子 3 的人類異構體 5OS=Homo sapiens OX=9606 GN=VNN3MIISHFPKCVAVFALLALSVGALDTFIAAVYEHAVILPNRTETPVSKEEALLLMNKNIDVLEKAVKLAAKQGAHIIVTPEDGIYGWIFTRESIYPYLEDIPDPGVNWIPCRDPWSTIFLHLKFSLISPRIQNL>sp|Q9NY84-7|VNN3_血管非炎症分子 3 的人類異構體 6OS=Homo sapiens OX=9606 GN=VNN3MIISHFPKCVAVFALLALSVGALDTFIAAVYEHAVILPNRTETPVSKEEALLLMNKNIDVLEKAVKLAAKQGAHIIVTPEDGIYGWIFTRESIYPYLEDIPDPGVNWIPCRDPWREWNLRPRSSQGVPL>sp|Q9NY84-8|VNN3_血管非炎症分子 3 的人類異構體 7OS=Homo sapiens OX=9606 GN=VNN3MIISHFPKCVAVFALLALSVGALDTFIAAVYEHAVILPNRTETPVSKEEALLLMNKNIDVLEKAVKLAAKQVLPFYTCKGDLQFGQRVFGIHDKLFCPTCFEQGAHIIVTPEDGIYGWIFTRESIYPYLEDIPDPGVNWIPCRDPWREWNLRPRSSQGVPL>sp|B1APH4|ZN487_人類推定的鋅手指蛋白 487 OS=Homo sapiensOX=9606 GN=ZNF487 PE=5 SV=3MASRPRPRTPSRGPSDLRFRGEAGLRRVFLKKAGGSVSFSDVAVGFTQEEWQHLDSAQRTPYRDMMLENYSLLLSVGYCITKPEVVCKLEHGQVLWILEEESPSQSHLDCCIDDDLMEKRQENQDQHLQKVDFVNNKTLTMDRNGVLGKTFSLDTNPILSRKIRGNCDSSGMNLNNISELIISNRSSFVRNPAECNVRGKFLLCMKRENPYARGKPLEYDGNGKAVSQNEDLFRHQYIQTLKQCFEYNHRGYTEERNPMNALNVGKLLDIGHALQYIKEHTRDKTYECNECGKNFCEKSNLHVHQRTHTGEKPYGCNECQKAFGDRSALKVHQRIHTGEKPYELHQRTHTGEKPYACSECGKTFYQKSSLTTHQRTHTREQPYEYNESFYQNPNFTKCQRDNIEETLVNILKAQKPSPSWTRSIAETTQVGGSVSLKDVTVDFTQEEW>sp|B1APH4-2|ZN487_推定鋅手指蛋白的人類異構體 2 487OS=Homo sapiens OX=9606 GN=ZNF487MMLENYSLLLSVGYCITKPEVVCKLEHGQVLWILEEESPSQSHLDCCIDDDLMEKRQENQDQHLQKVDFVNNKTLTMDRNGVLGKTFSLDTNPILSRKIRGNCDSSGMNLNNISELIISNRSSFVRNPAECNVRGKFLLCMKRENPYARGKPLEYDGNGKAVSQNEDLFRHQYIQTLKQCFEYNQCGKAFHEEAACSTHKRVCSWETL>sp|Q9HBT8|Z286A_人類鋅手指蛋白 286A OS=Homo sapiens OX=9606GN=ZNF286A PE=1 SV=1METDLAEMPEKGALSSQDSPHFQEKSTEEGEVAALRLTARSQETVTFKDVAMDFTPEEWGKLDPAQRDVMLENYRNLVSLWLPVSKPESYNLENGKEPLKLERKAPKSSYSDMETRPQSKDSTSVQDFSKAESCKVAIIDRLTRNSVYDSNLEAALECENWLENQQGNQERHLREMFTHMNSLSEETDHKHDVYWKSFNQKSVLITEDRVPKGSYAFHTLEKSLKQKSNLMKKQRTYKEKKPHKCNDCGELFTYHSVLIRHQRVHTGEKPYTCNECGKSFSHRANLTKHQRTHTRILFECSECKKTFTESSSLATHQRIHVGERPYECNECGKGFNRSTHLVQHQLIHTGVKPYECNECDKAFIHSSALIKHQRTHTGEKPYKCQECGKAFSHCSSLTKHQRVHTGEKPYECSECGKTFSQSTHLVQHQRIHTGEKPYECNECGKTFSRSSNFAKHQRIHIGKKPYKCSECGKAFIHSSALIQHQRTHTGEKPFRCNECGKSFKCSSSLIRHQRVHTEEQP>sp|Q9HBT8-2|Z286A_人類鋅手指蛋白異構體 2 286A OS=Homosapiens OX=9606 GN=ZNF286AMGALSSQDSPHFQEKSTEEGEVAALRLTARSQETVTFKDVAMDFTPEEWGKLDPAQRDVMLENYRNLVSLWLPVSKPESYNLENGKEPLKLERKAPKSSYSDMETRPQSKDSTSVQDFSKAESCKVAIIDRLTRNSVYDSNLEAALECENWLENQQGNQERHLREMFTHMNSLSEETDHKHDVYWKSFNQKSVLITEDRVPKGSYAFHTLEKSLKQKSNLMKKQRTYKEKKPHKCNDCGELFTYHSVLIRHQRVHTGEKPYTCNECGKSFSHRANLTKHQRTHTRILFECSECKKTFTESSSLATHQRIHVGERPYECNECGKGFNRSTHLVQHQLIHTGVKPYECNECDKAFIHSSALIKHQRTHTGEKPYKCQECGKAFSHCSSLTKHQRVHTGEKPYECSECGKTFSQSTHLVQHQRIHTGEKPYECNECGKTFSRSSNFAKHQRIHIGKKPYKCSECGKAFIHSSALIQHQRTHTGEKPFRCNECGKSFKCSSSLIRHQRVHTEEQP>sp|Q76KX8|ZN534_人類鋅手指蛋白 534 OS=Homo sapiens OX=9606GN=ZNF534 PE=1 SV=1MALTQGQLSFSDVAIEFSQEEWKCLDPGQKALYRDVMLENYRNLVSLGEDNVRPEACICSGICLPDLSVTSMLEQKRDPWTLQSEVKIINNPDGRECIKGVNTEKSSKLGSSAGNKSLKNQHGLTLQLHLTEWQPFQAVRNIYGCKHVEKSISDNSSVSPVQISFFSVKTHIFNNYRNDFLFSTLLPQEQKVHIREKPYGCNEHGKVFRVSSSLTNRQVIHIADKTYKCSDCGEIFSSNSNFAQHQRIHTGEKPYKYNECGKVFNQNSHLAQHQKIHTGQKPYNNKECGKVFSHHAYLAQHRKIHTGEKPYKCSECGKAFSVCSSLTAHLVIHTGEKPYDCKECGKVFRHKSSLTTHQTVHTGERPYKCNECGKGFSRIAFLARHRKVHTGEKPYKCNECGKVFIGNSRLARHRKIHTGGRRYKCNECGKAFRTCSDLTAHLLIHTGEKPYECIDCGKVFRHKSSLTYHCRIHTGEKPYKCNECGKVFSQNSNLQRHRKIHTGEKLYKCNECGKVFRQNSHLAQHRDIHTGEKPYSCNECGKVFRRNSHLVRHRNVHTGEKPYSCNECGKVFSRNSHLARHRNIHTGEKPHSCNECGKVFSRNSHLARHRKIHTGEKLYKCNECSKVFSRNSRLAQHRNIHTGVKPYSCNECGKVFSKNSILVQHCSIHTREKP>sp|Q76KX8-2|ZN534_人類鋅手指蛋白異構體 2 534 OS=Homosapiens OX=9606 GN=ZNF534MALTQGQLSFSDVAIEFSQEEWKCLDPGQKALYRDVMLENYRNLVSLGICLPDLSVTSMLEQKRDPWTLQSEVKIINNPDGRECIKGVNTEKSSKLGSSAGNKSLKNQHGLTLQLHLTEWQPFQAVRNIYGCKHVEKSISDNSSVSPVQISFFSVKTHIFNNYRNDFLFSTLLPQEQKVHIREKPYGCNEHGKVFRVSSSLTNRQVIHIADKTYKCSDCGEIFSSNSNFAQHQRIHTGEKPYKYNECGKVFNQNSHLAQHQKIHTGQKPYNNKECGKVFSHHAYLAQHRKIHTGEKPYKCSECGKAFSVCSSLTAHLVIHTGEKPYDCKECGKVFRHKSSLTTHQTVHTGERPYKCNECGKGFSRIAFLARHRKVHTGEKPYKCNECGKVFIGNSRLARHRKIHTGGRRYKCNECGKAFRTCSDLTAHLLIHTGEKPYECIDCGKVFRHKSSLTYHCRIHTGEKPYKCNECGKVFSQNSNLQRHRKIHTGEKLYKCNECGKVFRQNSHLAQHRDIHTGEKPYSCNECGKVFRRNSHLVRHRNVHTGEKPYSCNECGKVFSRNSHLARHRNIHTGEKPHSCNECGKVFSRNSHLARHRKIHTGEKLYKCNECSKVFSRNSRLAQHRNIHTGVKPYSCNECGKVFSKNSILVQHCSIHTREKP>sp|Q96E35|ZMY19_人類鋅手指MYND 結構域蛋白 19OS=Homo sapiens OX=9606 GN=ZMYND19 PE=1 SV=1MTDFKLGIVRLGRVAGKTKYTLIDEQDIPLVESYSFEARMEVDADGNGAKIFAYAFDKNRGRGSGRLLHELLWERHRGGVAPGFQVVHLNAVTVDNRLDNLQLVPWGWRPKAEETSSKQREQSLYWLAIQQLPTDPIEEQFPVLNVTRYYNANGDVVEEEENSCTYYECHYPPCTVIEKQLREFNICGRCQVARYCGSQCQQKDWPAHKKHCRERKRPFQHELEPER>sp|P38606|VATA_人V型質子ATP?催化亞基 A OS=Homosapiens OX=9606 GN=ATP6V1A PE=1 SV=2MDFSKLPKILDEDKESTFGYVHGVSGPVVTACDMAGAAMYELVRVGHSELVGEIIRLEGDMATIQVYEETSGVSVGDPVLRTGKPLSVELGPGIMGAIFDGIQRPLSDISSQTQSIYIPRGVNVSALSRDIKWDFTPCKNLRVGSHITGGDIYGIVSENSLIKHKIMLPPRNRGTVTYIAPPGNYDTSDVVLELEFEGVKEKFTMVQVWPVRQVRPVTEKLPANHPLLTGQRVLDALFPCVQGGTTAIPGAFGCGKTVISQSLSKYSNSDVIIYVGCGERGNEMSEVLRDFPELTMEVDGKVESIMKRTALVANTSNMPVAAREASIYTGITLSEYFRDMGYHVSMMADSTSRWAEALREISGRLAEMPADSGYPAYLGARLASFYERAGRVKCLGNPEREGSVSIVGAVSPPGGDFSDPVTSATLGIVQVFWGLDKKLAQRKHFPSVNWLISYSKYMRALDEYYDKHFTEFVPLRTKAKEILQEEEDLAEIVQLVGKASLAETDKITLEVAKLIKDDFLQQNGYTPYDRFCPFYKTVGMLSNMIAFYDMARRAVETTAQSDNKITWSIIREHMGDILYKLSSMKFKDPLKDGEAKIKSDYAQLLEDMQNAFRSLED>sp|P38606-2|VATA_V型質子ATP?催化的人類異構體2亞基 A OS=Homo sapiens OX=9606 GN=ATP6V1AMAGAAMYELVRVGHSELVGEIIRLEGDMATIQVYEETSGVSVGDPVLRTGKPLSVELGPGIMGAIFDGIQRPLSDISSQTQSIYIPRGVNVSALSRDIKWDFTPCKNLRVGSHITGGDIYGIVSENSLIKHKIMLPPRNRGTVTYIAPPGNYDTSDVVLELEFEGVKEKFTMVQVWPVRQVRPVTEKLPANHPLLTGQRVLDALFPCVQGGTTAIPGAFGCGKTVISQSLSKYSNSDVIIYVGCGERGNEMSEVLRDFPELTMEVDGKVESIMKRTALVANTSNMPVAAREASIYTGITLSEYFRDMGYHVSMMADSTSRWAEALREISGRLAEMPADSGYPAYLGARLASFYERAGRVKCLGNPEREGSVSIVGAVSPPGGDFSDPVTSATLGIVQVFWGLDKKLAQRKHFPSVNWLISYSKYMRALDEYYDKHFTEFVPLRTKAKEILQEEEDLAEIVQLVGKASLAETDKITLEVAKLIKDDFLQQNGYTPYDRFCPFYKTVGMLSNMIAFYDMARRAVETTAQSDNKITWSIIREHMGDILYKLSSMKFKDPLKDGEAKIKSDYAQLLEDMQNAFRSLED>sp|Q9BZH6|WDR11_人類WD 含有重複序列的蛋白質 11 OS=Homo sapiensOX=9606 GN=WDR11 PE=1 SV=1MLPYTVNFKVSARTLTGALNAHNKAAVDWGWQGLIAYGCHSLVVVIDSITAQTLQVLEKHKADVVKVKWARENYHHNIGSPYCLRLASADVNGKIIVWDVAAGVAQCEIQEHAKPIQDVQWLWNQDASRDLLLAIHPPNYIVLWNADTGTKLWKKSYADNILSFSFDPFDPSHLTLLTSEGIVFISDFSPSKPPSGPGKKVYISSPHSSPAHNKLATATGAKKALNKVKILITQEKPSAEFITLNDCLQLAYLPSKRNHMLLLYPREILILDLEVNQTVGVIAIERTGVPFLQVIPCFQRDGLFCLHENGCITLRVRRSYNNIFTTSNEEPDPDPVQELTYDLRSQCDAIRVTKTVRPFSMVCCPVNENAAALVVSDGRVMIWELKSAVCNRNSRNSSSGVSPLYSPVSFCGIPVGVLQNKLPDLSLDNMIGQSAIAGEEHPRGSILREVHLKFLLTGLLSGLPAPQFAIRMCPPLTTKNIKMYQPLLAVGTSNGSVLVYHLTSGLLHKELSIHSCEVKGIEWTSLTSFLSFATSTPNNMGLVRNELQLVDLPTGRSIAFRGERGNDESAIEMIKVSHLKQYLAVVFRDKPLELWDVRTCTLLREMSKNFPTITALEWSPSHNLKSLRKKQLATREAMARQTVVSDTELSIVESSVISLLQEAESKSELSQNISAREHFVFTDIDGQVYHLTVEGNSVKDSARIPPDGSMGSITCIAWKGDTLVLGDMDGNLNFWDLKGRVSRGIPTHRSWVRKIRFAPGKGNQKLIAMYNDGAEVWDTKEVQMVSSLRSGRNVTFRILDVDWCTSDKVILASDDGCIRVLEMSMKSACFRMDEQELTEPVWCPYLLVPRASLALKAFLLHQPWNGQYSLDISHVDYPENEEIKNLLQEQLNSLSNDIKKLLLDPEFTLLQRCLLVSRLYGDESELHFWTVAAHYLHSLSQEKSASTTAPKEAAPRDKLSNPLDICYDVLCENAYFQKFQLERVNLQEVKRSTYDHTRKCTDQLLLLGQTDRAVQLLLETSADNQHYYCDSLKACLVTTVTSSGPSQSTIKLVATNMIANGKLAEGVQLLCLIDKAADACRYLQTYGEWNRAAWLAKVRLNPEECADVLRRWVDHLCSPQVNQKSKALLVLLSLGCFFSVAETLHSMRYFDRAALFVEACLKYGAFEVTEDTEKLITAIYADYARSLKNLGFKQGAVLFASKAGAAGKDLLNELESPKEEPIEE>sp|Q6ZS52|YF013_HUMAN Putative uncharacterized protein FLJ45825 OS=Homosapiens OX=9606 PE=5 SV=1MHQTHAIQRLEVLPSFSNESPTSRETSESWTNQDDIFYAYASMSPGAEHRGTTQLLRFQLAPIKKLEGSLQTHFLLSSLHPRMTFPGRAGGGEAGSRPPRRPWAGILILQLPSTRGGRRSGHGAVRSWGPWKVVAEQPVGGTDPPAHGGRGRPSPNENT>sp|A8MVM7|YD021_HUMAN Putative uncharacterized protein ENSP00000382790OS=Homo sapiens OX=9606 PE=5 SV=3MDKIRHTEADIFKNGSKRMIATVPLRHSIRDRKPSLHFLHSLASSSSLIYRNALLHKSYKLHLQKNKSQKEKHRHSKMKIAYKDTPRNRLSRNAKKCLEDNKLVPISEVSLDPIISSNPLLRWWATSASNDSLLEELNNRFEQITNAWVQVSGDEAENCIHKKREHIENDHFKVASPLETCLLELEVSPVKMLFQKKYDLNELCTWFMQTTETQSLSLVRKANARNPLEVINTRGIKLGTKYSDFNASPFRKHFKKFALSSPSKSAEKLHILHKVANSPLLNVKSNLAIARLKRTEFKRLHHERWKREGKLHNHGTVDWNSKRRNLRFFCQNQFLNKTEGETNADIPLQGKSIVDNQCVLPPEIRGDLQQRVVMPDFKIHASFENKFKSEAKENGTNCSQKDFQKGPRLENVCPNSWRSKTLKDCRIFLRKLNCLEHRNTFKLNTIIYSPESTDSGNTHQTHMEESKRFTLRSHSARQNSFKKQSKEIENANTNNPSADEFADHLGNSKLSKCVNFDKNPDSFEVLSNLNKRKRPPWKITEMSTKRHKRQSCNSGQMANYFSKSLVSKIFGQPNFLAPSMKLVKLGAAKCTSALPHLLICPGFHTNKNIYSRDIEIIFKIYYFNNVDVISFCIW>sp|Q9BRH9|ZN251_HUMAN Zinc finger protein 251 OS=Homo sapiens OX=9606GN=ZNF251 PE=1 SV=4MAATFQLPGHQEMPLTFQDVAVYFSQAEGRQLGPQQRALYRDVMLENYGNVASLGFPVPKPELISQLEQGKELWVLNLLGAEEPDILKSCQKDSEVGTKKELSILNQKFSEEVKTPEFVSRRLLRDNAQAAEFREAWGREGKLKERVGNSAGQSLNKPNIHKRVLTEATVGRERSLGERTQECSAFDRNLNLDQNVVRLQRNKTGERVFKCDICSKTFKYNSDLSRHQRSHTGEKPYECGRCGRAFTHSSNLVLHHHIHTGNKPFKCDECGKTFGLNSHLRLHRRIHTGEKPFGCGECGKAFSRSSTLIQHRIIHTGEKPYKCNECGRGFSQSPQLTQHQRIHTGEKPHECSHCGKAFSRSSSLIQHERIHTGEKPHKCNQCGKAFSQSSSLFLHHRVHTGEKPYVCNECGRAFGFNSHLTEHVRIHTGEKPYVCNECGKAFRRSSTLVQHRRVHTGEKPYQCVECGKAFSQSSQLTLHQRVHTGEKPYDCGDCGKAFSRRSTLIQHQKVHSGETRKCRKHGPAFVHGSSLTADGQIPTGEKHGRAFNHGANLILRWTVHTGEKSFGCNEYGKAFSPTSRPTEDQIMHAGEKPYKCQECGNAFSGKSTLIQHQVTHTGQKPCHCSVYGKAFSQSSQLTPPQQTRVGEKPALNDGSKRYFIHIKKIFQERHF>sp|Q7Z3T8|ZFY16_HUMAN Zinc finger FYVE domain-containing protein 16OS=Homo sapiens OX=9606 GN=ZFYVE16 PE=1 SV=3MDSYFKAAVSDLDKLLDDFEQNPDEQDYLQDVQNAYDSNHCSVSSELASSQRTSLLPKDQECVNSCASSETSYGTNESSLNEKTLKGLTSIQNEKNVTGLDLLSSVDGGTSDEIQPLYMGRCSKPICDLISDMGNLVHATNSEEDIKKLLPDDFKSNADSLIGLDLSSVSDTPCVSSTDHDSDTVREQQNDISSELQNREIGGIKELGIKVDTTLSDSYNYSGTENLKDKKIFNQLESIVDFNMSSALTRQSSKMFHAKDKLQHKSQPCGLLKDVGLVKEEVDVAVITAAECLKEEGKTSALTCSLPKNEDLCLNDSNSRDENFKLPDFSFQEDKTVIKQSAQEDSKSLDLKDNDVIQDSSSALHVSSKDVPSSLSCLPASGSMCGSLIESKARGDFLPQHEHKDNIQDAVTIHEEIQNSVVLGGEPFKENDLLKQEKCKSILLQSLIEGMEDRKIDPDQTVIRAESLDGGDTSSTVVESQEGLSGTHVPESSDCCEGFINTFSSNDMDGQDLDYFNIDEGAKSGPLISDAELDAFLTEQYLQTTNIKSFEENVNDSKSQMNQIDMKGLDDGNINNIYFNAEAGAIGESHGINIICEIVDKQNTIENGLSLGEKSTIPVQQGLPTSKSEITNQLSVSDINSQSVGGARPKQLFSLPSRTRSSKDLNKPDVPDTIESEPSTADTVVPITCAIDSTADPQVSFNSNYIDIESNSEGGSSFVTANEDSVPENTCKEGLVLGQKQPTWVPDSEAPNCMNCQVKFTFTKRRHHCRACGKVFCGVCCNRKCKLQYLEKEARVCVVCYETISKAQAFERMMSPTGSNLKSNHSDECTTVQPPQENQTSSIPSPATLPVSALKQPGVEGLCSKEQKRVWFADGILPNGEVADTTKLSSGSKRCSEDFSPLSPDVPMTVNTVDHSHSTTVEKPNNETGDITRNEIIQSPISQVPSVEKLSMNTGNEGLPTSGSFTLDDDVFAETEEPSSPTGVLVNSNLPIASISDYRLLCDINKYVCNKISLLPNDEDSLPPLLVASGEKGSVPVVEEHPSHEQIILLLEGESFHPVTFVLNANLLVNVKFIFYSSDKYWYFSTNGLHGLGQAEIIILLLCLPNEDTIPKDIFRLFITIYKDALKGKYIENLDNITFTESFLSSKDHGGFLFITPTFQKLDDLSLPSNPFLCGILIQKLEIPWAKVFPMRLMLRLGAEYKAYPAPLTSIRGRKPLFGEIGHTIMNLLVDLRNYQYTLHNIDQLLIHMEMGKSCIKIPRKKYSDVMKVLNSSNEHVISIGASFSTEADSHLVCIQNDGIYETQANSATGHPRKVTGASFVVFNGALKTSSGFLAKSSIVEDGLMVQITPETMNGLRLALREQKDFKITCGKVDAVDLREYVDICWVDAEEKGNKGVISSVDGISLQGFPSEKIKLEADFETDEKIVKCTEVFYFLKDQDLSILSTSYQFAKEIAMACSAALCPHLKTLKSNGMNKIGLRVSIDTDMVEFQAGSEGQLLPQHYLNDLDSALIPVIHGGTSNSSLPLEIELVFFIIEHLF>sp|Q7Z3T8-3|ZFY16_HUMAN Isoform 2 of Zinc finger FYVE domain-containingprotein 16 OS=Homo sapiens OX=9606 GN=ZFYVE16MDSYFKAAVSDLDKLLDDFEQNPDEQDYLQDVQNAYDSNHCSVSSELASSQRTSLLPKDQECVNSCASSETSYGTNESSLNEKTLKGLTSIQNEKNVTGLDLLSSVDGGTSDEIQPLYMGRCSKPICDLISDMGNLVHATNSEEDIKKLLPDDFKSNADSLIGLDLSSVSDTPCVSSTDHDSDTVREQQNDISSELQNREIGGIKELGIKVDTTLSDSYNYSGTENLKDKKIFNQLESIVDFNMSSALTRQSSKMFHAKDKLQHKSQPCGLLKDVGLVKEEVDVAVITAAECLKEEGKTSALTCSLPKNEDLCLNDSNSRDENFKLPDFSFQEDKTVIKQSAQEDSKSLDLKDNDVIQDSSSALHVSSKDVPSSLSCLPASGSMCGSLIESKARGDFLPQHEHKDNIQDAVTIHEEIQNSVVLGGEPFKENDLLKQEKCKSILLQSLIEGMEDRKIDPDQTVIRAESLDGGDTSSTVVESQEGLSGTHVPESSDCCEGFINTFSSNDMDGQDLDYFNIDEGAKSGPLISDAELDAFLTEQYLQTTNIKSFEENVNDSKSQMNQIDMKGLDDGNINNIYFNAEAGAIGESHGINIICEIVDKQNTIENGLSLGEKSTIPVQQGLPTSKSEITNQLSVSDINSQSVGGARPKQLFSLPSRTRSSKDLNKPDVPDTIESEPSTADTVVPITCAIDSTADPQVSFNSNYIDIESNSEGGSSFVTANEDSVPENTCKEGLVLGQKQPTWVPDSEAPNCMNCQVKFTFTKRRHHCRACGKVFCGVCCNRKCKLQYLEKEARVCVVCYETISKGEC>sp|Q96DA0|ZG16B_HUMAN Zymogen granule protein 16 homolog B OS=Homosapiens OX=9606 GN=ZG16B PE=1 SV=3MGAQGAQESIKAMWRVPGTTRRPVTGESPGMHRPEAMLLLLTLALLGGPTWAGKMYGPGGGKYFSTTEDYDHEITGLRVSVGLLLVKSVQVKLGDSWDVKLGALGGNTQEVTLQPGEYITKVFVAFQAFLRGMVMYTSKDRYFYFGKLDGQISSAYPSQEGQVLVGIYGQYQLLGIKSIGFEWNYPLEEPTTEPPVNLTYSANSPVGR>sp|Q9UI54|YT001_HUMAN Putative uncharacterized protein PRO0628 OS=Homosapiens OX=9606 GN=PRO0628 PE=5 SV=1MESPKCLYSRITVNTAFGTKFSHISFIILFKVFLFPRITISKKTKLVTLSNYLNK>sp|Q8IYP9|ZDH23_HUMAN Palmitoyltransferase ZDHHC23 OS=Homo sapiensOX=9606 GN=ZDHHC23 PE=1 SV=3MTQKGSMKPVKKKKTEEPELEPLCCCEYIDRNGEKNHVATCLCDCQDLDEGCDRWITCKSLQPETCERIMDTISDRLRIPWLRGAKKVNISIIPPLVLLPVFLHVASWHFLLGVVVLTSLPVLALWYYYLTHRRKEQTLFFLSLGLFSLGYMYYVFLQEVVPKGRVGPVQLAVLTCGLFLILLALHRAKKNPGYLSNPASGDRSLSSSQLECLSRKGQEKTKGFPGADMSGSLNNRTTKDDPKGSSKMPAGSPTKAKEDWCAKCQLVRPARAWHCRICGICVRRMDHHCVWINSCVGESNHQAFILALLIFLLTSVYGITLTLDTICRDRSVFTALFYCPGVYANYSSALSFTCVWYSVIITAGMAYIFLIQLINISYNVTEREVQQALRQKTGRRLLCGLIVDTGLLG>sp|Q68DK2|ZFY26_HUMAN Zinc finger FYVE domain-containing protein 26OS=Homo sapiens OX=9606 GN=ZFYVE26 PE=1 SV=3MNHPFGKEEAASQKQLFGFFCECLRRGEWELAQACVPQLQEGQGDIPKRVEDILQALVVCPNLLRCGQDINPQRVAWVWLLVLEKWLAREKKLLPVVFRRKLEFLLLSEDLQGDIPENILEELYETLTQGAVGHVPDGNPRRESWTPRLSSEAVSVLWDLLRQSPQPAQALLELLLEEDDGTGLCHWPLQNALVDLIRKALRALQGPDSVPPGVVDAIYGALRTLRCPAEPLGVELHLLCEELLEACRTEGSPLREERLLSCLLHKASRGLLSLYGHTYAEKVTEKPPRATASGKVSPDHLDPERAMLALFSNPNPAEAWKVAYFYCLSNNKHFLEQILVTALTLLKEEDFPNLGCLLDREFRPLSCLLVLLGWTHCQSLESAKRLLQTLHRTQGPGCDELLRDACDGLWAHLEVLEWCIQQSSNPIPKRDLLYHLHGGDSHSVLYTLHHLTNLPALREEDVLKLLQKVPAKDPQQEPDAVDAPVPEHLSQCQNLTLYQGFCAMKYAIYALCVNSHQHSQCQDCKDSLSEDLASATEPANDSLSSPGAANLFSTYLARCQQYLCSIPDSLCLELLENIFSLLLITSADLHPEPHLPEDYAEDDDIEGKSPSGLRSPSESPQHIAHPERKSERGSLGVPKTLAYTMPSHVKAEPKDSYPGPHRHSFLDLKHFTSGISGFLADEFAIGAFLRLLQEQLDEISSRSPPEKPKQESQSCSGSRDGLQSRLHRLSKVVSEAQWRHKVVTSNHRSEEQPSRRYQPATRHPSLRRGRRTRRSQADGRDRGSNPSLESTSSELSTSTSEGSLSAMSGRNELHSRLHPHPQSSLIPMMFSPPESLLASCILRGNFAEAHQVLFTFNLKSSPSSGELMFMERYQEVIQELAQVEHKIENQNSDAGSSTIRRTGSGRSTLQAIGSAAAAGMVFYSISDVTDKLLNTSGDPIPMLQEDFWISTALVEPTAPLREVLEDLSPPAMAAFDLACSQCQLWKTCKQLLETAERRLNSSLERRGRRIDHVLLNADGIRGFPVVLQQISKSLNYLLMSASQTKSESVEEKGGGPPRCSITELLQMCWPSLSEDCVASHTTLSQQLDQVLQSLREALELPEPRTPPLSSLVEQAAQKAPEAEAHPVQIQTQLLQKNLGKQTPSGSRQMDYLGTFFSYCSTLAAVLLQSLSSEPDHVEVKVGNPFVLLQQSSSQLVSHLLFERQVPPERLAALLAQENLSLSVPQVIVSCCCEPLALCSSRQSQQTSSLLTRLGTLAQLHASHCLDDLPLSTPSSPRTTENPTLERKPYSSPRDSSLPALTSSALAFLKSRSKLLATVACLGASPRLKVSKPSLSWKELRGRREVPLAAEQVARECERLLEQFPLFEAFLLAAWEPLRGSLQQGQSLAVNLCGWASLSTVLLGLHSPIALDVLSEAFEESLVARDWSRALQLTEVYGRDVDDLSSIKDAVLSCAVACDKEGWQYLFPVKDASLRSRLALQFVDRWPLESCLEILAYCISDTAVQEGLKCELQRKLAELQVYQKILGLQSPPVWCDWQTLRSCCVEDPSTVMNMILEAQEYELCEEWGCLYPIPREHLISLHQKHLLHLLERRDHDKALQLLRRIPDPTMCLEVTEQSLDQHTSLATSHFLANYLTTHFYGQLTAVRHREIQALYVGSKILLTLPEQHRASYSHLSSNPLFMLEQLLMNMKVDWATVAVQTLQQLLVGQEIGFTMDEVDSLLSRYAEKALDFPYPQREKRSDSVIHLQEIVHQAADPETLPRSPSAEFSPAAPPGISSIHSPSLRERSFPPTQPSQEFVPPATPPARHQWVPDETESICMVCCREHFTMFNRRHHCRRCGRLVCSSCSTKKMVVEGCRENPARVCDQCYSYCNKDVPEEPSEKPEALDSSKSESPPYSFVVRVPKADEVEWILDLKEEENELVRSEFYYEQAPSASLCIAILNLHRDSIACGHQLIEHCCRLSKGLTNPEVDAGLLTDIMKQLLFSAKMMFVKAGQSQDLALCDSYISKVDVLNILVAAAYRHVPSLDQILQPAAVTRLRNQLLEAEYYQLGVEVSTKTGLDTTGAWHAWGMACLKAGNLTAAREKFSRCLKPPFDLNQLNHGSRLVQDVVEYLESTVRPFVSLQDDDYFATLRELEATLRTQSLSLAVIPEGKIMNNTYYQECLFYLHNYSTNLAIISFYVRHSCLREALLHLLNKESPPEVFIEGIFQPSYKSGKLHTLENLLESIDPTLESWGKYLIAACQHLQKKNYYHILYELQQFMKDQVRAAMTCIRFFSHKAKSYTELGEKLSWLLKAKDHLKIYLQETSRSSGRKKTTFFRKKMTAADVSRHMNTLQLQMEVTRFLHRCESAGTSQITTLPLPTLFGNNHMKMDVACKVMLGGKNVEDGFGIAFRVLQDFQLDAAMTYCRAARQLVEKEKYSEIQQLLKCVSESGMAAKSDGDTILLNCLEAFKRIPPQELEGLIQAIHNDDNKVRAYLICCKLRSAYLIAVKQEHSRATALVQQVQQAAKSSGDAVVQDICAQWLLTSHPRGAHGPGSRK>sp|Q68DK2-2|ZFY26_HUMAN Isoform 2 of Zinc finger FYVE domain-containingprotein 26 OS=Homo sapiens OX=9606 GN=ZFYVE26MNHPFGKEEAASQKQLFGFFCECLRRGEWELAQACVPQLQEGQGDIPKRVEDILQALVVCPNLLRCGQDINPQRVAWVWLLVLEKWLAREKKLLPVVFRRKLEFLLLSEDLQGDIPENILEELYETLTQGAVGHVPDGNPRRESWTPRLSSEAVSVLWDLLRQSPQPAQALLELLLEEDDGTGLCHWPLQNALVDLIRKALRTLRCPAEPLGVELHLLCEELLEACRTEGSPLREERLLSCLLHKASRGLLSLYGHTYAEKVTEKPPRATASGKVSPDHLDPERAMLALFSNPNPAEAWKVAYFYCLSNNKHFLEQILVTALTLLKEEDFPNLGCLLDREFRPLSCLLVLLGWTHCQSLESAKRLLQTLHRTQGPGCDELLRDACDGLWAHLEVLEWCIQQSSNPIPKRDLLYHLHGGDSHSVLYTLHHLTNLPALREEDVLKLLQKVPAKDPQQEPDAVDAPVPEHLSQCQNLTLYQGFCAMKYAIYALCVNSHQHSQCQDCKDSLSEDLASATEPANDSLSSPGAANLFSTYLARCQQYLCSIPDSLCLELLENIFSLLLITSADLHPEPHLPEDYAEDDDIEGKSPSGLRSPSESPQHIAHPERKSERGSLGVPKTLAYTMPSHVKAEPKDSYPGPHRHSFLDLKHFTSGISGFLADEFAIGAFLRLLQEQLDEISSRSPPEKPKQESQSCSGSRDGLQSRLHRLSKVVSEAQWRHKVVTSNHRSEEQPSRRYQPATRHPSLRRGRRTRRSQADGRDRGSNPSLESTSSELSTSTSEGSLSAMSGRNELHSRLHPHPQSSLIPMMFSPPESLLASCILRGNFAEAHQVLFTFNLKSSPSSGELMFMERYQEVIQELAQVEHKIENQNSDAGSSTIRRTGSGRSTLQAIGSAAAAGMVFYSISDVTDKLLNTSGDPIPMLQEDFWISTALVEPTAPLREVLEDLSPPAMAAFDLACSQCQLWKTCKQLLETAERRLNSSLERRGRRIDHVLLNADGIRGFPVVLQQISKSLNYLLMSASQTKSESVEEKGGGPPRCSITELLQMCWPSLSEDCVASHTTLSQQLDQVLQSLREALELPEPRTPPLSSLVEQAAQKAPEAEAHPVQIQTQLLQKNLGKQTPSGSRQMDYLGTFFSYCSTLAAVLLQSLSSEPDHVEVKVGNPFVLLQQSSSQLVSHLLFERQVPPERLAALLAQENLSLSVPQVIVSCCCEPLALCSSRQSQQTSSLLTRLGTLAQLHASHCLDDLPLSTPSSPRTTENPTLERKPYSSPRDSSLPALTSSALAFLKSRSKLLATVACLGASPRLKVSKPSLSWKELRGRREVPLAAEQVARECERLLEQFPLFEAFLLAAWEPLRGSLQQGQSLAVNLCGWASLSTVLLGLHSPIALDVLSEAFEESLVARDWSRALQLTEVYGRDVDDLSSIKDAVLSCAVACDKEGWQYLFPVKDASLRSRLALQFVDRWPLESCLEILAYCISDTAVQEGLKCELQRKLAELQVYQKILGLQSPPVWCDWQTLRSCCVEDPSTVMNMILEAQEYELCEEWGCLYPIPREHLISLHQKHLLHLLERRDHDKALQLLRRIPDPTMCLEVTEQSLDQHTSLATSHFLANYLTTHFYGQLTAVRHREIQALYVGSKILLTLPEQHRASYSHLSSNPLFMLEQLLMNMKVDWATVAVQTLQQLLVGQEIGFTMDEVDSLLSRYAEKALDFPYPQREKRSDSVIHLQEIVHQAADPETLPRSPSAEFSPAAPPGISSIHSPSLRERSFPPTQPSQEFVPPATPPARHQWVPDETESICMVCCREHFTMFNRRHHCRRCGRLVCSSCSTKKMVVEGCRENPARVCDQCYSYCNKDVPEEPSEKPEALDSSKSESPPYSFVVRVPKADEVEWILDLKEEENELVRSEFYYEQAPSASLCIAILNLHRDSIACGHQLIEHCCRLSKGLTNPEVDAGLLTDIMKQLLFSAKMMFVKAGQSQDLALCDSYISKVDVLNILVAAAYRHVPSLDQILQPAAVTRLRNQLLEAEYYQLGVEVSTKTGLDTTGAWHAWGMACLKAGNLTAAREKFSRCLKPPFDLNQLNHGSRLVQDVVEYLESTVRPFVSLQDDDYFATLRELEATLRTQSLSLAVIPEGKIMNNTYYQECLFYLHNYSTNLAIISFYVRHSCLREALLHLLNKESPPEVFIEGIFQPSYKSGKLHTLENLLESIDPTLESWGKYLIAACQHLQKKNYYHILYELQQFMKDQVRAAMTCIRFFSHKAKSYTELGEKLSWLLKAKDHLKIYLQETSRSSGRKKTTFFRKKMTAADVSRHMNTLQLQMEVTRFLHRCESAGTSQITTLPLPTLFGNNHMKMDVACKVMLGGKNVEDGFGIAFRVLQDFQLDAAMTYCRAARQLVEKEKYSEIQQLLKCVSESGMAAKSDGDTILLNCLEAFKRIPPQELEGLIQAIHNDDNKVRAYLICCKLRSAYLIAVKQEHSRATALVQQVQQAAKSSGDAVVQDICAQWLLTSHPRGAHGPGSRK>sp|Q68DK2-4|ZFY26_HUMAN Isoform 4 of Zinc finger FYVE domain-containingprotein 26 OS=Homo sapiens OX=9606 GN=ZFYVE26MNHPFGKEEAASQKQLFGFFCECLRRGEWELAQACVPQLQEGQGDIPKRVEDILQALVVCPNLLRCGQDINPQRVAWVWLLVLEKWLAREKKLLPVVFRRKLEFLLLSEDLQGDIPENILEELYETLTQGAVGHVPDGNPRRESWTPRLSSEAVSVLWDLLRQSPQPAQALLELLLEEDDGTGLCHWPLQNALVDLIRKALRALQGPDSVPPGVVDAIYGALRTLRCPAEPLGVELHLLCEELLEACRTEGSPLREERLLSCLLHKASRGLLSLYGHTYAEKVTEKPPRATASGKVSPDHLDPERAMLALFSNPNPAEAWKVAYFYCLSNNKHFLEQILVTALTLLKEEDFPNLGCLLDREFRPLSCLLVLLGWTHCQSLESAKRLLQTLHRTQGPGCDELLRDACDGLWAHLEVLEWCIQQSSNPIPKRDLLYHLHGGDSHSVLYTLHHLTNLPALREEDVLKLLQKVPAKDPQQEPDAVDAPVPEHLSQCQNLTLYQGFCAMKYAIYALCVNSHQHSQCQDCKDSLSEDLASATEPANDSLSSPGAANLFSTYLARCQQYLCSIPDSLCLELLENIFSLLLITSADLHPEPHLPEDYAEDDDIEGKSPSGLRSPSESPQHIAHPERKSERGSLGVPKTLAYTMPSHVKAEPKDSYPGPHRHSFLDLKHFTSGISGFLADEFAIGAFLRLLQEQLDEISSRSPPEKPKQESQSCSGSRDGLQSRLHRLSKVVSEAQWRHKVVTSNHRSEEQPSRRYQPATRHPSLRRGRRTRRSQAGNLKSSFPCTRQVV>sp|Q68DK2-3|ZFY26_HUMAN Isoform 3 of Zinc finger FYVE domain-containingprotein 26 OS=Homo sapiens OX=9606 GN=ZFYVE26MAISPSLLPLSSPPDGIPQFNRRHHCRRCGRLVCSSCSTKKMVVEGCRENPARVCDQCYSYCNKDVPEEPSEKPEALDSSKSESPPYSFVVRVPKADEVEWILDLKEEENELVRSEFYYEQAPSASLCIAILNLHRDSIACGHQLIEHCCRLSKGLTNPEVDAGLLTDIMKQLLFSAKMMFVKAGQSQDLALCDSYISKVDVLNILVAAAYRHVPSLDQILQPAAVTRLRNQLLEAEYYQLGVEVSTKTGLDTTGAWHAWGMACLKAGNLTAAREKFSRCLKPPFDLNQLNHGSRLVQDVVEYLESTVRPFVSLQDDDYFATLRELEATLRTQSLSLAVIPEGKIMNNTYYQECLFYLHNYSTNLAIISFYVRHSCLREALLHLLNKESPPEVFIEGIFQPSYKSGKLHTLENLLESIDPTLESWGKYLIAACQHLQKKNYYHILYELQQFMKDQVRAAMTCIRFFSHKAKSYTELGEKLSWLLKAKDHLKIYLQETSRSSGRKKTTFFRKKMTAADVSRHMNTLQLQMEVTRFLHRCESAGTSQITTLPLPTLFGNNHMKMDVACKVMLGGKNVEDGFGIAFRVLQDFQLDAAMTYCRAARQLVEKEKYSEIQQLLKCVSESGMAAKSDGDTILLNCLEAFKRIPPQELEGLIQAIHNDDNKIVPILAALRDRVHTEERGRSPSTLC>sp|Q68DK2-5|ZFY26_HUMAN Isoform 5 of Zinc finger FYVE domain-containingprotein 26 OS=Homo sapiens OX=9606 GN=ZFYVE26MNHPFGKEEAASQKQLFGFFCECLRRGEWELAQACVPQLQEGQGDIPKRVEDILQALVVCPNLLRCGQDINPQRVAWVWLLVLEKWLAREKKLLPVVFRRKLEFLLLSEDLQGDIPENILEELYETLTQGAVGHVPDGNPRRESWTPRLSSEAVSVLWDLLRQSPQPAQALLELLLEEDDGTGLCHWPLQNALVDLIRKALRALQGPDSVPPGVVDAIYGALRTLRCPAEPLGVELHLLCEELLEACRTEGSPLREERLLSCLLHKASRGLLSLYGHTYAEKVTEKPPRATASGKVSPDHLDPERAMLALFSNPNPAEAWKVAYFYCLSNNKHFLEQILVTALTLLKEEDFPNLGCLLDREFRPLSCLLVLLGWTHCQSLESAKRLLQTLHRTQGPGCDELLRDACDGLWAHLEVLEWCIQQSSNPIPKRDLLYHLHGGDSHSVLYTLHHLTNLPALREEDVLKLLQKVPAKDPQQEPDAVDAPVPEHLSQCQNLTLYQGFCAMKYAIYALCVNSHQHSQCQDCKDSLSEDLASATEPANDSLSSPGAANLFSTYLARCQQYLCSIPDSLCLELLENIFSLLLITSADLHPEPHLPEDYAEDDDIEGKSPSGLRSPSESPQHIAHPERKSERGSLGVPKTLAYTMPSHVKAEPKDSYPGPHRHSFLDLKHFTSGISGFLADEFAIGAFLRLLQEQLDEISSRSPPEKPKQESQSCSGSRDGLQSRLHRLSKVVSEAQWRHKVVTSNHRSEEQPSRRYQPATRHPSLRRGRRTRRSQADGRDRGSNPSLESTSSELSTSTSEGSLSAMSGRNELHSRLHPHPQSSLIPMMFSPPESLLASCILRGNFAEAHQVLFTFNLKSSPSSGELMFMERYQEVIQELAQVEHKIENQNSDAGSSTIRRTGSGRSTLQAIGSAAAAGMVFYSISDVTDKLLNTSGDPIPMLQEDFWISTALVEPTAPLREVLEDLSPPAMAAFDLACSQCQLWKTCKQLLETAERRLNSSLERRGRRIDHVLLNADGIRGFPVVLQQISKSLNYLLMSASQTKSESVEEKGGGPPRCSITELLQMCWPSLSEDCVASHTTLSQQLDQVLQSLREALELPEPRTPPLSSLVEQAAQKAPEAEAHPVQIQTQLLQKNLGKQTPSGSRQMDYLGTFFSYCSTLAAVLLQSLSSEPDHVEVKVGNPFVLLQQSSSQLVSHLLFERQVPPERLAALLAQENLSLSVPQVIVSCCCEPLALCSSRQSQQTSSLLTRLGTLAQLHASHCLDDLPLSTPSSPRTTENPTLERKPYSSPRDSSLPALTSSALAFLKSRSKLLATVACLGASPRLKVSKPSLSWKELRGRREVPLAAEQVARECERLLEQFPLFEAFLLAAWEPLRGSLQQGQSLAVNLCGWASLSTVLLGLHSPIALDVLSEAFEESLVARDWSRALQLTEVYGRDVDDLSSIKDAVLSCAVACDKEGWQYLFPVKDASLRSRLALQFVDRWPLESCLEILAYCISDTAVQEGLKCELQRKLAELQVYQKILGLQSPPVWCDWQTLRSCCVEDPSTVMNMILEAQEYELCEEWGCLYPIPREHLISLHQKHLLHLLERRDHDKALQLLRRIPDPTMCLEVTEQSLDQHTSLATSHFLANYLTTHFYGQLTAVRHREIQALYVGSKILLTLPEQHRASYSHLSSNPLFMLEQLLMNMKVDWATVAVQTLQQLLVGQEIGFTMDEVDSLLSRYAEKALDFPYPQREKRSDSVIHLQEIVHQAADPETLPRSPSAEFSPAAPPGISSIHSPSLRERSFPPTQPSQEFVPPATPPARHQWVPDETESICMVCCREHFTMFNRRHHCRRCGRLVCSSCSTKKMVVEGCRENPARVCDQCYSYCNKDVPEEPSEKPEALDSSKSESPPYSFVVRVPKADEVEWILDLKEEENELVRSEFYYEQAPSASLCIAILNLHRDSIACGHQLIEHCCRLSKGLTNPEVDAGLLTDIMKQLLFSAKMMFVKAGQSQDLALCDSYISKVDVLNILVAAAYRHVPSLDQILQPAAVTRLRNQLLEAEYYQLGVEVSTKTGLDTTGAWHAWGMACLKAGNLTAAREKFSRCLKPPFDLNQLNHGSRLVQDVVEYLESTVRPFVSLQDDDYFATLRELEATLRTQSLSLAVIPEGKIMNNTYYQECLFYLHNYSTNLAIISFYVRHSCLREALLHLLNKESPPEVFIEGIFQPSYKSGKLHTLENLLESIDPTLESWGKYLIAACQHLQKKNYYHILYELQQFMKDQVRAAMTCIRFFSHKAKSYTELGEKLSWLLKAKDHLKIYLQETSRSSGRKKTTFFRKKMTAADVSRHMNTLQLQMEVTRFLHRCESAGTSQITTLPLPTLFGNNHMKMDVACKVMLGGKNVEDGFGIAFRVLQDFQLDAAMTYCRAARQLVEKEKYSEIQQLLKCVSESGMAAKSDGDTILLNCLEAFKRIPPQELEGLIQAIHNDDNKVSGIVSKRW>sp|Q9UFB7|ZBT47_HUMAN Zinc finger and BTB domain-containing protein 47OS=Homo sapiens OX=9606 GN=ZBTB47 PE=1 SV=3MGRLNEQRLFQPDLCDVDLVLVPQRSVFPAHKGVLAAYSQFFHSLFTQNKQLQRVELSLEALAPGGLQQILNFIYTSKLLVNAANVHEVLSAASLLQMADIAASCQELLDARSLGPPGPGTVALAQPAASCTPAAPPYYCDIKQEADTPGLPKIYAREGPDPYSVRVEDGAGTAGGTVPATIGPAQPFFKEEKEGGVEEAGGPPASLCKLEGGEELEEELGGSGTYSRREQSQIIVEVNLNNQTLHVSTGPEGKPGAGPSPATVVLGREDGLQRHSDEEEEDDEEEEEEEEEEEGGGSGREEEEEEEGGSQGEEEEEEEDGHSEQEEEEEEEEEEGPSEQDQESSEEEEGEEGEAGGKQGPRGSRSSRADPPPHSHMATRSRENARRRGTPEPEEAGRRGGKRPKPPPGVASASARGPPATDGLGAKVKLEEKQHHPCQKCPRVFNNRWYLEKHMNVTHSRMQICDQCGKRFLLESELLLHRQTDCERNIQCVTCGKAFKKLWSLHEHNKIVHGYAEKKFSCEICEKKFYTMAHVRKHMVAHTKDMPFTCETCGKSFKRSMSLKVHSLQHSGEKPFRCENCNERFQYKYQLRSHMSIHIGHKQFMCQWCGKDFNMKQYFDEHMKTHTGEKPYICEICGKSFTSRPNMKRHRRTHTGEKPYPCDVCGQRFRFSNMLKAHKEKCFRVSHTLAGDGVPAAPGLPPTQPQAHALPLLPGLPQTLPPPPHLPPPPPLFPTTASPGGRMNANN>sp|Q9UFB7-2|ZBT47_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 47 OS=Homo sapiens OX=9606 GN=ZBTB47MGRLNEQRLFQPDLCDVDLVLVPQRSVFPAHKGVLAAYSQFFHSLFTQNKQLQRVELSLEALAPGGLQQILNFIYTSKLLVNAANVHEVLSAASLLQMADIAASCQELLDARSLGPPGPGTVALAQPAASCTPAAPPYYCDIKQEADTPGLPKIYAREGPDPYSVRVEDGAGTAGGTVPATIGPAQPFFKEEKEGGVEEAGGPPASLCKLEGGEELEEELGGSGTYSRREQSQIIVEVNLNNQTLHVSTGPEGKPGAGPSPATVVLGREDGLQRHSDEEEEDDEEEEEEEEEEEGGGSGREEEEEEEGGSQGEEEEEEEDGHSEQEEEEEEKQHHPCQKCPRVFNNRWYLEKHMNVTHSRMQICDQCGKRFLLESELLLHRQTDCERNIQCVTCGKAFKKLWSLHEHNKIVHGYAEKKFSCEICEKKFYTMAHVRKHMVAHTKDMPFTCETCGKSFKRSMSLKVHSLQHSGEKPFRCENCNERFQYKYQLRSHMSIHIGHKQFMCQWCGKDFNMKQYFDEHMKTHTGEKPYICEICGKSFTSRPNMKRHRRTHTGEKPYPCDVCGQRFRFSNMLKAHKEKCFRVSHTLAGDGVPAAPGLPPTQPQAHALPLLPGLPQTLPPPPHLPPPPPLFPTTASPGGRMNANN>sp|O15062|ZBTB5_HUMAN Zinc finger and BTB domain-containing protein 5OS=Homo sapiens OX=9606 GN=ZBTB5 PE=1 SV=1MDFPGHFEQIFQQLNYQRLHGQLCDCVIVVGNRHFKAHRSVLAACSTHFRALFSVAEGDQTMNMIQLDSEVVTAEAFAALIDMMYTSTLMLGESNVMDVLLAASHLHLNSVVKACKHYLTTRTLPMSPPSERVQEQSARMQRSFMLQQLGLSIVSSALNSSQNGEEQPAPMSSSMRSNLDQRTPFPMRRLHKRKQSAEERARQRLRPSIDESAISDVTPENGPSGVHSREEFFSPDSLKIVDNPKADGMTDNQEDSAIMFDQSFGTQEDAQVPSQSDNSAGNMAQLSMASRATQVETSFDQEAAPEKSSFQCENPEVGLGEKEHMRVVVKSEPLSSPEPQDEVSDVTSQAEGSESVEVEGVVVSAEKIDLSPESSDRSFSDPQSSTDRVGDIHILEVTNNLEHKSTFSISNFLNKSRGNNFTANQNNDDNIPNTTSDCRLESEAPYLLSPEAGPAGGPSSAPGSHVENPFSEPADSHFVRPMQEVMGLPCVQTSGYQGGEQFGMDFSRSGLGLHSSFSRVMIGSPRGGASNFPYYRRIAPKMPVVTSVRSSQIPENSTSSQLMMNGATSSFENGHPSQPGPPQLTRASADVLSKCKKALSEHNVLVVEGARKYACKICCKTFLTLTDCKKHIRVHTGEKPYACLKCGKRFSQSSHLYKHSKTTCLRWQSSNLPSTLL>sp|Q9C0B5|ZDHC5_HUMAN Palmitoyltransferase ZDHHC5 OS=Homo sapiensOX=9606 GN=ZDHHC5 PE=1 SV=2MPAESGKRFKPSKYVPVSAAAIFLVGATTLFFAFTCPGLSLYVSPAVPIYNAIMFLFVLANFSMATFMDPGIFPRAEEDEDKEDDFRAPLYKTVEIKGIQVRMKWCATCRFYRPPRCSHCSVCDNCVEEFDHHCPWVNNCIGRRNYRYFFLFLLSLTAHIMGVFGFGLLYVLYHIEELSGVRTAVTMAVMCVAGLFFIPVAGLTGFHVVLVARGRTTNEQVTGKFRGGVNPFTNGCCNNVSRVLCSSPAPRYLGRPKKEKTIVIRPPFLRPEVSDGQITVKIMDNGIQGELRRTKSKGSLEITESQSADAEPPPPPKPDLSRYTGLRTHLGLATNEDSSLLAKDSPPTPTMYKYRPGYSSSSTSAAMPHSSSAKLSRGDSLKEPTSIAESSRHPSYRSEPSLEPESFRSPTFGKSFHFDPLSSGSRSSSLKSAQGTGFELGQLQSIRSEGTTSTSYKSLANQTRNGSLSYDSLLTPSDSPDFESVQAGPEPDPPLGYTSPFLSARLAQQREAERHPRLVPTGPTHREPSPVRYDNLSRHIVASLQEREKLLRQSPPLPGREEEPGLGDSGIQSTPGSGHAPRTSSSSDDSKRSPLGKTPLGRPAVPRFGKPDGLRGRGVGSPEPGPTAPYLGRSMSYSSQKAQPGVSETEEVALQPLLTPKDEVQLKTTYSKSNGQPKSLGSASPGPGQPPLSSPTRGGVKKVSGVGGTTYEISV>sp|Q9C0B5-2|ZDHC5_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC5 OS=Homosapiens OX=9606 GN=ZDHHC5MFLFVLANFSMATFMDPGIFPRAEEDEDKEDDFRAPLYKTVEIKGIQVRMKWCATCRFYRPPRCSHCSVCDNCVEEFDHHCPWVNNCIGRRNYRYFFLFLLSLTAHIMGVFGFGLLYVLYHIEELSGVRTAVTMAVMCVAGLFFIPVAGLTGFHVVLVARGRTTNEQVTGKFRGGVNPFTNGCCNNVSRVLCSSPAPRYLGRPKKEKTIVIRPPFLRPEVSDGQITVKIMDNGIQGELRRTKSKGSLEITESQSADAEPPPPPKPDLSRYTGLRTHLGLATNEDSSLLAKDSPPTPTMYKYRPGYSSSSTSAAMPHSSSAKLSRGDSLKEPTSIAESSRHPSYRSEPSLEPESFRSPTFGKSFHFDPLSSGSRSSSLKSAQGTGFELGQLQSIRSEGTTSTSYKSLANQTRNGSLSYDSLLTPSDSPDFESVQAGPEPDPPLGYTSPFLSARLAQQREAERHPRLVPTGPTHREPSPVRYDNLSRHIVASLQEREKLLRQSPPLPGREEEPGLGDSGIQSTPGSGHAPRTSSSSDDSKRSPLGKTPLGRPAVPRFGKPDGLRGRGVGSPEPGPTAPYLGRSMSYSSQKAQPGVSETEEVALQPLLTPKDEVQLKTTYSKSNGQPKSLGSASPGPGQPPLSSPTRGGVKKVSGVGGTTYEISV>sp|Q96M85|YV008_HUMAN Putative uncharacterized protein FLJ32756 OS=Homosapiens OX=9606 PE=2 SV=1MSHSRRAAPTQDQCHTPGFPTSRETSGSIWQARICGSLQALDTWRTHIPRKSPAPTQASQICLLLPESPWRNPTPRGFLKPLINWDAILYFKEKRNIQVTTQAHPQNQASCSSQEVATPGLVPQAAAPKVYERSHDNLNAEAQGLAGAQVSKPQNPITRLCSLKEQSILKIFTKQSI>sp|Q32M78|ZN699_HUMAN Zinc finger protein 699 OS=Homo sapiens OX=9606GN=ZNF699 PE=1 SV=1MEEERKTAELQKNRIQDSVVFEDVAVDFTQEEWALLDLAQRNLYRDVMLENFQNLASLGYPLHTPHLISQWEQEEDLQTVKRELIQGIFMGEHREGFETQLKTNESVASQDICGEKISNEQKIVRFKRNDSWFSSLHENQESCGIDYQNKSHERHLRNHMVENIYECYEENQDGQTFSQVPNLDSLKRNTEVKSCECHECGKAFVDHSSLKSHIRSHTGSKPYQCKECGKAFHFLACFKKHMKTPTEEKPYECKECTKAFSCSSFFRAHMKIHIGKTNYECKECGKGFSCSSSLTEHKRIHSGDKPYECKECGKAFSCSSSLSKHKRIHSGDKPYECKECGKAFSSSSHLIIHIRIHTGEKPYECKECGKAFSESSKLTVHGRTHTGEKPYKCKECGKAYNCPSSLSIHMRKHTGEKPYECLECGKAFYLPTSLNTHVKNQSREKPYECKECGKAFSCPSSFRAHVRDHTGKIQYECKECGKTFSRSSSLTEHLRTHSGEKPYECKECGKAFISSSHLTVHIRTHTGEKPYECKKCGKAFIYPSALRIHMRTHTGEKPYECKECGKAFRHSSYLTVHARMHTGEKPFECLECGKAFSCPSSFRRHVRSHTGEKPYECKECGKAFVCPAYFRRHVKTHTRENI>sp|Q5VIY5|ZN468_HUMAN Zinc finger protein 468 OS=Homo sapiens OX=9606GN=ZNF468 PE=2 SV=1MALPQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCMLKTLSSTGQGNTEVIHTGTLHRQASHHIGEFCFHEIEKDIHGFEFQWKEDETNGHAAPMTEIKELAGSTGQHDQRHAGNKRIKDQLGSSFHLHLPEPHIFQSEGKIGNQVEKSINNASSVSTSQRICCRPKTHISNKYGNNSLHSSLLTQKWEVHMREKSFECIQSFKSFNCSSLLKKHQIIHLEEKQCKCDVCGKVFNQKRYLACHRRCHTGEKPYKCNECGKTFGHNSSLFIHKALHTGEKPYECEECDKVFSRKSHLERHKRIHTGEKPYKCKVCDEAFAYNSYLAKHTILHTGEKPYTCNECGKVFNRLSTLARHHRLHTGEKPYKCEECDKVFSRKSHLERHRRIHSGEKPYKCEECCKVFSRKSNLERHRRIHTGEKPYKCKVCDKAFQRDSHLAQHQRVHTGEKPYKCNECGKTFGQTSSLIIHRRLHTGEKPYKCNECGKTFSQMSSLVYHHRLHSGEKP>sp|Q5VIY5-2|ZN468_HUMAN Isoform 2 of Zinc finger protein 468 OS=Homosapiens OX=9606 GN=ZNF468MLKTLSSTGQGNTEVIHTGTLHRQASHHIGEFCFHEIEKDIHGFEFQWKEDETNGHAAPMTEIKELAGSTGQHDQRHAGNKRIKDQLGSSFHLHLPEPHIFQSEGKIGNQVEKSINNASSVSTSQRICCRPKTHISNKYGNNSLHSSLLTQKWEVHMREKSFECIQSFKSFNCSSLLKKHQIIHLEEKQCKCDVCGKVFNQKRYLACHRRCHTGEKPYKCNECGKTFGHNSSLFIHKALHTGEKPYECEECDKVFSRKSHLERHKRIHTGEKPYKCKVCDEAFAYNSYLAKHTILHTGEKPYTCNECGKVFNRLSTLARHHRLHTGEKPYKCEECDKVFSRKSHLERHRRIHSGEKPYKCEECCKVFSRKSNLERHRRIHTGEKPYKCKVCDKAFQRDSHLAQHQRVHTGEKPYKCNECGKTFGQTSSLIIHRRLHTGEKPYKCNECGKTFSQMSSLVYHHRLHSGEKP>sp|Q9NTW7|ZF64B_HUMAN Zinc finger protein 64 OS=Homo sapiens OX=9606GN=ZFP64 PE=1 SV=3MNASSEGESFAGSVQIPGGTTVLVELTPDIHICGICKQQFNNLDAFVAHKQSGCQLTGTSAAAPSTVQFVSEETVPATQTQTTTRTITSETQTITVSAPEFVFEHGYQTYLPTESNENQTATVISLPAKSRTKKPTTPPAQKRLNCCYPGCQFKTAYGMKDMERHLKIHTGDKPHKCEVCGKCFSRKDKLKTHMRCHTGVKPYKCKTCDYAAADSSSLNKHLRIHSDERPFKCQICPYASRNSSQLTVHLRSHTASELDDDVPKANCLSTESTDTPKAPVITLPSEAREQMATLGERTFNCCYPGCHFKTVHGMKDLDRHLRIHTGDKPHKCEFCDKCFSRKDNLTMHMRCHTSVKPHKCHLCDYAAVDSSSLKKHLRIHSDERPYKCQLCPYASRNSSQLTVHLRSHTGDTPFQCWLCSAKFKISSDLKRHMIVHSGEKPFKCEFCDVRCTMKANLKSHIRIKHTFKCLHCAFQGRDRADLLEHSRLHQADHPEKCPECSYSCSSAAALRVHSRVHCKDRPFKCDFCSFDTKRPSSLAKHVDKVHRDEAKTENRAPLGKEGLREGSSQHVAKIVTQRAFRCETCGASFVRDDSLRCHKKQHSDQSENKNSDLVTFPPESGASGQLSTLVSVGQLEAPLEPSQDL>sp|Q9NTW7-2|ZF64B_HUMAN Isoform 4 of Zinc finger protein 64 OS=Homosapiens OX=9606 GN=ZFP64MSRRKQAKPQHLNSEEPRPARRECAEVAPQVAGEPASELDDDVPKANCLSTESTDTPKAPVITLPSEAREQMATLGERTFNCCYPGCHFKTVHGMKDLDRHLRIHTGDKPHKCEFCDKCFSRKDNLTMHMRCHTSVKPHKCHLCDYAAVDSSSLKKHLRIHSDERPYKCQLCPYASRNSSQLTVHLRSHTGDTPFQCWLCSAKFKISSDLKRHMIVHSGEKPFKCEFCDVRCTMKANLKSHIRIKHTFKCLHCAFQGRDRADLLEHSRLHQADHPEKCPECSYSCSSAAALRVHSRVHCKDRPFKCDFCSFDTKRPSSLAKHVDKVHRDEAKTENRAPLGKEGLREGSSQHVAKIVTQRAFRCETCGASFVRDDSLRCHKKQHSDQSENKNSDLVTFPPESGASGQLSTLVSVGQLEAPLEPSQDL>sp|Q9NTW7-3|ZF64B_HUMAN Isoform 5 of Zinc finger protein 64 OS=Homosapiens OX=9606 GN=ZFP64MNASSEGESFAGSVQIPGGTTVLVELTPDIHICGICKQQFNNLDAFVAHKQSGCQLTGTSAAAPSTVQFVSEETVPATQTQTTTRTITSETQTITVSAPEFVFEHGYQTYLPTESNENQTATVISLPAKSRTKKPTTPPAQKRLNCCYPGCQFKTAYGMKDMERHLKIHTGDKPHKCEVCGKCFSRKDKLKTHMRCHTGVKPYKCKTCDYAAADSSSLNKHLRIHSDERPFKCQICPYASRNSSQLTVHLRSHTASELDDDVPKANCLSTESTDTPKAPVITLPSEAREQMATLGERTFNCCYPGCHFKTVHGMKDLDRHLRIHTGDKPHKCEFCDKCFSRKDNLTMHMRCHTSVKPHKCHLCDYAAVDSSSLKKHLRIHSDERPYKCQLCPYASRNSSQLTVHLRSHTGCCYVA>sp|Q9NTW7-4|ZF64B_HUMAN Isoform 6 of Zinc finger protein 64 OS=Homosapiens OX=9606 GN=ZFP64MNASSEGESFAGSVQSGTTVLVELTPDIHICGICKQQFNNLDAFVAHKQSGCQLTGTSAAAPSTVQFVSEETVPATQTQTTTRTITSETQTITVSAPEFVFEHGYQTYLPTESNENQTATVISLPAKSRTKKPTTPPAQKRLNCCYPGCQFKTAYGMKDMERHLKIHTGDKPHKCEVCGKCFSRKDKLKTHMRCHTGVKPYKCKTCDYAAADSSSLNKHLRIHSDERPFKCQICPYASRNSSQLTVHLRSHTGDAPFQCWLCSAKFKISSDLKRHMRVHSGEKPFKCEFCNVRCTMKGNLKSHIRIKHSGNNFKCPHCDFLGDSKATLRKHSRVHQSEHPEKCSECSYSCSSKAALRIHERIHCTDRPFKCNYCSFDTKQPSNLSKHMKKFHGDMVKTEALERKDTGRQSSRQVAKLDAKKSFHCDICDASFMREDSLRSHKRQHSEYSESKNSDVTVLQFQIDPSKQPATPLTVGHLQVPLQPSQVPQFSEGRVKIIVGHQVPQANTIVQAAAAAVNIVPPALVAQNPEELPGNSRLQILRQVSLIAPPQSSRCPSEAGAMTQPAVLLTTHEQTDGATLHQTLIPTASGGPQEGSGNQTFITSSGITCTDFEGLNALIQEGTAEVTVVSDGGQNIAVATTAPPVFSSSSQQELPKQTYSIIQGAAHPALLCPADSIPD>sp|Q9NTW7-5|ZF64B_HUMAN Isoform 1 of Zinc finger protein 64 OS=Homosapiens OX=9606 GN=ZFP64MNASSEGESFAGSVQIPGGTTVLVELTPDIHICGICKQQFNNLDAFVAHKQSGCQLTGTSAAAPSTVQFVSEETVPATQTQTTTRTITSETQTITVSAPEFVFEHGYQTYLPTESNENQTATVISLPAKSRTKKPTTPPAQKRLNCCYPGCQFKTAYGMKDMERHLKIHTGDKPHKCEVCGKCFSRKDKLKTHMRCHTGVKPYKCKTCDYAAADSSSLNKHLRIHSDERPFKCQICPYASRNSSQLTVHLRSHTGDAPFQCWLCSAKFKISSDLKRHMRVHSGEKPFKCEFCNVRCTMKGNLKSHIRIKHSGNNFKCPHCDFLGDSKATLRKHSRVHQSEHPEKCSECSYSCSSKAALRIHERIHCTDRPFKCNYCSFDTKQPSNLSKHMKKFHGDMVKTEALERKDTGRQSSRQVAKLDAKKSFHCDICDASFMREDSLRSHKRQHSEYSESKNSDVTVLQFQIDPSKQPATPLTVGHLQVPLQPSQVPQFSEGRVKIIVGHQVPQANTIVQAAAAAVNIVPPALVAQNPEELPGNSRLQILRQVSLIAPPQSSRCPSEAGAMTQPAVLLTTHEQTDGATLHQTLIPTASGGPQEGSGNQTFITSSGITCTDFEGLNALIQEGTAEVTVVSDGGQNIAVATTAPPVFSSSSQQELPKQTYSIIQGAAHPALLCPADSIPD>sp|Q9NTW7-6|ZF64B_HUMAN Isoform 2 of Zinc finger protein 64 OS=Homosapiens OX=9606 GN=ZFP64MNASSEGESFAGSVQIPGGTTVLVELTPDIHICGICKQQFNNLDAFVAHKQSGCQLTGTSAAAPSTVQFVSEETVPATQTQTTTRTITSETQTITGCQFKTAYGMKDMERHLKIHTGDKPHKCEVCGKCFSRKDKLKTHMRCHTGVKPYKCKTCDYAAADSSSLNKHLRIHSDERPFKCQICPYASRNSSQLTVHLRSHTGDAPFQCWLCSAKFKISSDLKRHMRVHSGEKPFKCEFCNVRCTMKGNLKSHIRIKHSGNNFKCPHCDFLGDSKATLRKHSRVHQSEHPEKCSECSYSCSSKAALRIHERIHCTDRPFKCNYCSFDTKQPSNLSKHMKKFHGDMVKTEALERKDTGRQSSRQVAKLDAKKSFHCDICDASFMREDSLRSHKRQHSEYSESKNSDVTVLQFQIDPSKQPATPLTVGHLQVPLQPSQVPQFSEGRVKIIVGHQVPQANTIVQAAAAAVNIVPPALVAQNPEELPGNSRLQILRQVSLIAPPQSSRCPSEAGAMTQPAVLLTTHEQTDGATLHQTLIPTASGGPQEGSGNQTFITSSGITCTDFEGLNALIQEGTAEVTVVSDGGQNIAVATTAPPVFSSSSQQELPKQTYSIIQGAAHPALLCPADSIPD>sp|Q3ZCX4|ZN568_HUMAN Zinc finger protein 568 OS=Homo sapiens OX=9606GN=ZNF568 PE=2 SV=2MTSQSSVISNSCVTMERLSHMMERKAWCSQESALSEEEEDTTRPLETVTFKDVAVDLTQEEWEQMKPAQRNLYRDVMLENYSNLVTVGCQVTKPDVIFKLEQEEEPWVMEEEMFGRHCPEVWEVDEQIKKQQETLVRKVTSISKKILIKEKVIECKKVAKIFPLSSDIVTSRQSFYDCDSLDKGLEHNLDLLRYEKGCVREKQSNEFGKPFYHCASYVVTPFKCNQCGQDFSHKFDLIRHERIHAGEKPYECKECGKAFSRKENLITHQKIHTGEKPYKCNECGKAFIQMSNLIRHHRIHTGEKPYACKDCWKAFSQKSNLIEHERIHTGEKPYECKECGKSFSQKQNLIEHEKIHTGEKPYACNECGRAFSRMSSVTLHMRSHTGEKPYKCNKCGKAFSQCSVFIIHMRSHTGEKPYVCSECGKAFSQSSSLTVHMRNHTAEKPYECKECGKAFSRKENLITHQKIHTGEKPYECSECGKAFIQMSNLIRHQRIHTGEKPYACTVCGKAFSQKSNLTEHEKIHTGEKPYHCNQCGKAFSQRQNLLEHEKIHTGEKPFKCNECGKAFSRISSLTLHVRSHTGEKPYECNKCGKAFSQCSLLIIHMRSHTGEKPFECNECGKAFSQRASLSIHKRGHTGERHQVY>sp|Q3ZCX4-2|ZN568_HUMAN Isoform 2 of Zinc finger protein 568 OS=Homosapiens OX=9606 GN=ZNF568MKPAQRNLYRDVMLENYSNLVTVGCQVTKPDVIFKLEQEEEPWVMEEEMFGRHCPEVWEVDEQIKKQQETLVRKVTSISKKILIKEKVIECKKVAKIFPLSSDIVTSRQSFYDCDSLDKGLEHNLDLLRYEKGCVREKQSNEFGKPFYHCASYVVTPFKCNQCGQDFSHKFDLIRHERIHAGEKPYECKECGKAFSRKENLITHQKIHTGEKPYKCNECGKAFIQMSNLIRHHRIHTGEKPYACKDCWKAFSQKSNLIEHERIHTGEKPYECKECGKSFSQKQNLIEHEKIHTGEKPYACNECGRAFSRMSSVTLHMRSHTGEKPYKCNKCGKAFSQCSVFIIHMRSHTGEKPYVCSECGKAFSQSSSLTVHMRNHTAEKPYECKECGKAFSRKENLITHQKIHTGEKPYECSECGKAFIQMSNLIRHQRIHTGEKPYACTVCGKAFSQKSNLTEHEKIHTGEKPYHCNQCGKAFSQRQNLLEHEKIHTGEKPFKCNECGKAFSRISSLTLHVRSHTGEKPYECNKCGKAFSQCSLLIIHMRSHTGEKPFECNECGKAFSQRASLSIHKRGHTGERHQVY>sp|Q3ZCX4-3|ZN568_HUMAN Isoform 3 of Zinc finger protein 568 OS=Homosapiens OX=9606 GN=ZNF568MKPAQRNLYRDVMLENYSNLVTVGCQVTKPDVIFKLEQEEEPWVMEEEMFGRHCPEPRRGENCCASEVMAEGLKFKDVVIYFSQKEWECLHSAQKDLYRDVMLENYGNLVLLGLSDTKPNVISLLEQKKEPWMVKRKETKEWCPDWEFGRETKNLSPKENIYEIRSPQQEKARVIREIRCQVERQQGHQEGHFRPAVIPFTSMQCTAHREYQWLHTGEKSCECRKCKNAFRYQSCPIQHEIIHNKEKEPECGECRKIFNSGSDLIKHQTLHESKKHSENNKCAFNHDSGITQPQSINTGEKPHKCKECGKAFRSSSQISQHQRMHLGEKPYKCRECGKAFPSTAQLNLHQRIHTDEKYYESKACGKAFTRPSHLFRHQRIHTGEKPHKCKECGKAFRYDTQLSLHQIIHTGERRYECRECGKVYSCASQLSLHQRIHTGEKPHECKECGKAFISDSHLIRHQSVHTGEKPCKCKECGKSFRRGSELTRHQRAHTGEKPYECKECEKAFTCSTELVRHQKVHTGERPHKCKECGKAFIRRSELTHHERSHTGEKPYECKECGKPFGGGSELS>sp|Q99536|VAT1_HUMAN Synaptic vesicle membrane protein VAT-1 homologOS=Homo sapiens OX=9606 GN=VAT1 PE=1 SV=2MSDEREVAEAATGEDASSPPPKTEAASDPQHPAASEGAAAAAASPPLLRCLVLTGFGGYDKVKLQSRPAAPPAPGPGQLTLRLRACGLNFADLMARQGLYDRLPPLPVTPGMEGAGVVIAVGEGVSDRKAGDRVMVLNRSGMWQEEVTVPSVQTFLIPEAMTFEEAAALLVNYITAYMVLFDFGNLQPGHSVLVHMAAGGVGMAAVQLCRTVENVTVFGTASASKHEALKENGVTHPIDYHTTDYVDEIKKISPKGVDIVMDPLGGSDTAKGYNLLKPMGKVVTYGMANLLTGPKRNLMALARTWWNQFSVTALQLLQANRAVCGFHLGYLDGEVELVSGVVARLLALYNQGHIKPHIDSVWPFEKVADAMKQMQEKKNVGKVLLVPGPEKEN>sp|Q99536-2|VAT1_HUMAN Isoform 2 of Synaptic vesicle membrane proteinVAT-1 homolog OS=Homo sapiens OX=9606 GN=VAT1MVLNRSGMWQEEVTVPSVQTFLIPEAMTFEEAAALLVNYITAYMVLFDFGNLQPGHSVLVHMAAGGVGMAAVQLCRTVENVTVFGTASASKHEALKENGVTHPIDYHTTDYVDEIKKISPKGVDIVMDPLGGSDTAKGYNLLKPMGKVVTYGMANLLTGPKRNLMALARTWWNQFSVTALQLLQANRAVCGFHLGYLDGEVELVSGVVARLLALYNQGHIKPHIDSVWPFEKVADAMKQMQEKKNVGKVLLVPGPEKEN>sp|Q99536-3|VAT1_HUMAN Isoform 3 of Synaptic vesicle membrane proteinVAT-1 homolog OS=Homo sapiens OX=9606 GN=VAT1MSDEREVAEAATGEDASSPPPKTEAASDPQHPAASEGAAAAAASPPLLRCLVLTGFGGYDKAGDRVMVLNRSGMWQEEVTVPSVQTFLIPEAMTFEEAAALLVNYITAYMVLFDFGNLQPGHSVLVHMAAGGVGMAAVQLCRTVENVTVFGTASASKHEALKENGVTHPIDYHTTDYVDEIKKISPKGVDIVMDPLGGSDTAKGYNLLKPMGKVVTYGMANLLTGPKRNLMALARTWWNQFSVTALQLLQANRAVCGFHLGYLDGEVELVSGVVARLLALYNQGHIKPHIDSVWPFEKVADAMKQMQEKKNVGKVLLVPGPEKEN>sp|Q5BKZ1|ZN326_HUMAN DBIRD complex subunit ZNF326 OS=Homo sapiensOX=9606 GN=ZNF326 PE=1 SV=2MDFEDDYTHSACRNTYQGFNGMDRDYGPGSYGGMDRDYGHGSYGGQRSMDSYLNQSYGMDNHSGGGGGSRFGPYESYDSRSSLGGRDLYRSGYGFNEPEQSRFGGSYGGRFESSYRNSLDSFGGRNQGGSSWEAPYSRSKLRPGFMEDRGRENYSSYSSFSSPHMKPAPVGSRGRGTPAYPESTFGSRNYDAFGGPSTGRGRGRGHMGDFGSIHRPGIVVDYQNKSTNVTVAAARGIKRKMMQPFNKPSGTFIKKPKLAKPMEKISLSKSPTKTDPKNEEEEKRRIEARREKQRRRREKNSEKYGDGYRMAFTCSFCKFRTFEEKDIELHLESSSHQETLDHIQKQTKFDKVVMEFLHECMVNKFKKTSIRKQQTNNQTEVVKIIEKDVMEGVTVDDHMMKVETVHCSACSVYIPALHSSVQQHLKSPDHIKGKQAYKEQIKRESVLTATSILNNPIVKARYERFVKGENPFEIQDHSQDQQIEGDEEDEEKIDEPIEEEEDEDEEEEAEEVGEVEEVEEVEEVREGGIEGEGNIQGVGEGGEVGVVGEVEGVGEVEEVEELEEETAKEEPADFPVEQPEEN>sp|Q5BKZ1-2|ZN326_HUMAN Isoform 2 of DBIRD complex subunit ZNF326OS=Homo sapiens OX=9606 GN=ZNF326MDFEDDYTHSACRNTYQGFNGMDRDYGPGSYGGMDRDYGHGSYGGQRSMDSYLNQSYGMDNHSGGGGGSR>sp|Q5BKZ1-3|ZN326_HUMAN Isoform 3 of DBIRD complex subunit ZNF326OS=Homo sapiens OX=9606 GN=ZNF326MGDFGSIHRPGIVVDYQNKSTNVTVAAARGIKRKMMQPFNKPSGTFIKKPKLAKPMEKISLSKSPTKTDPKNEEEEKRRIEARREKQRRRREKNSEKYGDGYRMAFTCSFCKFRTFEEKDIELHLESSSHQETLDHIQKQTKFDKVVMEFLHECMVNKFKKTSIRKQQTNNQTEVVKIIEKDVMEGVTVDDHMMKVETVHCSACSVYIPALHSSVQQHLKSPDHIKGKQAYKEQIKRESVLTATSILNNPIVKARYERFVKGENPFEIQDHSQDQQIEGDEEDEEKIDEPIEEEEDEDEEEEAEEVGEVEEVEEVEEVREGGIEGEGNIQGVGEGGEVGVVGEVEGVGEVEEVEELEEETAKEEPADFPVEQPEEN>sp|Q9H0M5|ZN700_HUMAN Zinc finger protein 700 OS=Homo sapiens OX=9606GN=ZNF700 PE=2 SV=1MPCCSHRSCREDPGTSESREMDPVAFEDVAVNFTQEEWTLLDISQKNLFREVMLETFRNLTSIGKKWSDQNIEYEYQNPRRSFRSLIEEKVNEIKEDSHCGETFTQVPDDRLNFQEKKASPEVKSCDSFVCAEVGIGNSSFNMSIRGDTGHKAYEYQEYGPKPYKCQQPKNKKAFRYRPSIRTQERDHTGEKPYACKVCGKTFIFHSSIRRHMVMHSGDGTYKCKFCGKAFHSFSLYLIHERTHTGEKPYECKQCGKSFTYSATLQIHERTHTGEKPYECSKCDKAFHSSSSYHRHERSHMGEKPYQCKECGKAFAYTSSLRRHERTHSGKKPYECKQYGEGLSYLISFQTHIRMNSGERPYKCKICGKGFYSAKSFQTHEKTHTGEKRYKCKQCGKAFNLSSSFRYHERIHTGEKPYECKQCGKAFRSASQLRVHGGTHTGEKPYECKECGKAFRSTSHLRVHGRTHTGEKPYECKECGKAFRYVKHLQIHERTEKHIRMPSGERPYKCSICEKGFYSAKSFQTHEKTHTGEKPYECNQCGKAFRCCNSLRYHERTHTGEKPYECKQCGKAFRSASHLRMHERTHTGEKPYECKQCGKAFSCASNLRKHGRTHTGEKPYECKQCGKAFRSASNLQMHERTHTGEKPYECKECEKAFCKFSSFQIHERKHRGEKPYECKHCGNGFTSAKILQIHARTHIGEKHYECKECGKAFNYFSSLHIHARTHMGEKPYECKDCGKAFS>sp|Q02386|ZNF45_HUMAN Zinc finger protein 45 OS=Homo sapiens OX=9606GN=ZNF45 PE=1 SV=2MTKSKEAVTFKDVAVVFSEEELQLLDLAQRKLYRDVMLENFRNVVSVGHQSTPDGLPQLEREEKLWMMKMATQRDNSSGAKNLKEMETLQEVGLRYLPHEELFCSQIWQQITRELIKYQDSVVNIQRTGCQLEKRDDLHYKDEGFSNQSSHLQVHRVHTGEKPYKGEHCVKSFSWSSHLQINQRAHAGEKPYKCEKCDNAFRRFSSLQAHQRVHSRAKSYTNDASYRSFSQRSHLPHHQRVPTGENPYKYEECGRNVGKSSHCQAPLIVHTGEKPYKCEECGVGFSQRSYLQVHLKVHTGKKPYKCEECGKSFSWRSRLQAHERIHTGEKPYKCNACGKSFSYSSHLNIHCRIHTGEKPYKCEECGKGFSVGSHLQAHQISHTGEKPYKCEECGKGFCRASNLLDHQRGHTGEKPYQCDACGKGFSRSSDFNIHFRVHTGEKPYKCEECGKGFSQASNLLAHQRGHTGEKPYKCGTCGKGFSRSSDLNVHCRIHTGEKPYKCERCGKAFSQFSSLQVHQRVHTGEKPYQCAECGKGFSVGSQLQAHQRCHTGEKPYQCEECGKGFCRASNFLAHRGVHTGEKPYRCDVCGKRFRQRSYLQAHQRVHTGERPYKCEECGKVFSWSSYLQAHQRVHTGEKPYKCEECGKGFSWSSSLIIHQRVHADDEGDKDFPSSEDSHRKTR>sp|P17031|ZNF26_HUMAN Zinc finger protein 26 OS=Homo sapiens OX=9606GN=ZNF26 PE=1 SV=3MATSFRTASCWGLLSFKDISMEFTWDEWQLLDSTQKYLYRDVILENYHNLISVGYHGTKPDLIFKLEQGEDPWIINAKISRQSCPDGWEEWYQNNQDELESIERSYACSVLGRLNLSKTHDSSRQRLYNTRGKSLTQNSAPSRSYLRKNPDKFHGYEEPYFLKHQRAHSIEKNCVCSECGKAFRCKSQLIVHLRIHTGERPYECSKCERAFSAKSNLNAHQRVHTGEKPYSCSECEKVFSFRSQLIVHQEIHTGGKPYGCSECGKAYSWKSQLLLHQRSHTGVKPYECSECGKAFSLKSPFVVHQRTHTGVKPHKCSECGKAFRSKSYLLVHIRMHTGEKPYQCSDCGKAFNMKTQLIVHQGVHTGNNPYQCGECGKAFGRKEQLTAHLRAHAGEKPYGCSECGKAFSSKSYLVIHRRTHTGERPYECSLCERAFCGKSQLIIHQRTHSTEKPYECNECEKAYPRKASLQIHQKTHSGEKPFKCSECGKAFTQKSSLSEHQRVHTGEKPWKCSECGKSFCWNSGLRIHRKTHK>sp|P17038|ZNF43_HUMAN Zinc finger protein 43 OS=Homo sapiens OX=9606GN=ZNF43 PE=2 SV=4MGPLTFMDVAIEFCLEEWQCLDIAQQNLYRNVMLENYRNLVFLGIAVSKPDLITCLEQEKEPWEPMRRHEMVAKPPVMCSHFTQDFWPEQHIKDPFQKATLRRYKNCEHKNVHLKKDHKSVDECKVHRGGYNGFNQCLPATQSKIFLFDKCVKAFHKFSNSNRHKISHTEKKLFKCKECGKSFCMLPHLAQHKIIHTRVNFCKCEKCGKAFNCPSIITKHKRINTGEKPYTCEECGKVFNWSSRLTTHKKNYTRYKLYKCEECGKAFNKSSILTTHKIIRTGEKFYKCKECAKAFNQSSNLTEHKKIHPGEKPYKCEECGKAFNWPSTLTKHKRIHTGEKPYTCEECGKAFNQFSNLTTHKRIHTAEKFYKCTECGEAFSRSSNLTKHKKIHTEKKPYKCEECGKAFKWSSKLTEHKLTHTGEKPYKCEECGKAFNWPSTLTKHNRIHTGEKPYKCEVCGKAFNQFSNLTTHKRIHTAEKPYKCEECGKAFSRSSNLTKHKKIHIEKKPYKCEECGKAFKWSSKLTEHKITHTGEKPYKCEECGKAFNHFSILTKHKRIHTGEKPYKCEECGKAFTQSSNLTTHKKIHTGEKFYKCEECGKAFTQSSNLTTHKKIHTGGKPYKCEECGKAFNQFSTLTKHKIIHTEEKPYKCEECGKAFKWSSTLTKHKIIHTGEKPYKCEECGKAFKLSSTLSTHKIIHTGEKPYKCEKCGKAFNRSSNLIEHKKIHTGEQPYKCEECGKAFNYSSHLNTHKRIHTKEQPYKCKECGKAFNQYSNLTTHNKIHTGEKLYKPEDVTVILTTPQTFSNIK>sp|P17038-2|ZNF43_HUMAN Isoform 2 of Zinc finger protein 43 OS=Homosapiens OX=9606 GN=ZNF43MDVAIEFCLEEWQCLDIAQQNLYRNVMLENYRNLVFLGIAVSKPDLITCLEQEKEPWEPMRRHEMVAKPPVMCSHFTQDFWPEQHIKDPFQKATLRRYKNCEHKNVHLKKDHKSVDECKVHRGGYNGFNQCLPATQSKIFLFDKCVKAFHKFSNSNRHKISHTEKKLFKCKECGKSFCMLPHLAQHKIIHTRVNFCKCEKCGKAFNCPSIITKHKRINTGEKPYTCEECGKVFNWSSRLTTHKKNYTRYKLYKCEECGKAFNKSSILTTHKIIRTGEKFYKCKECAKAFNQSSNLTEHKKIHPGEKPYKCEECGKAFNWPSTLTKHKRIHTGEKPYTCEECGKAFNQFSNLTTHKRIHTAEKFYKCTECGEAFSRSSNLTKHKKIHTEKKPYKCEECGKAFKWSSKLTEHKLTHTGEKPYKCEECGKAFNWPSTLTKHNRIHTGEKPYKCEVCGKAFNQFSNLTTHKRIHTAEKPYKCEECGKAFSRSSNLTKHKKIHIEKKPYKCEECGKAFKWSSKLTEHKITHTGEKPYKCEECGKAFNHFSILTKHKRIHTGEKPYKCEECGKAFTQSSNLTTHKKIHTGEKFYKCEECGKAFTQSSNLTTHKKIHTGGKPYKCEECGKAFNQFSTLTKHKIIHTEEKPYKCEECGKAFKWSSTLTKHKIIHTGEKPYKCEECGKAFKLSSTLSTHKIIHTGEKPYKCEKCGKAFNRSSNLIEHKKIHTGEQPYKCEECGKAFNYSSHLNTHKRIHTKEQPYKCKECGKAFNQYSNLTTHNKIHTGEKLYKPEDVTVILTTPQTFSNIK>sp|Q96MX3|ZNF48_HUMAN Zinc finger protein 48 OS=Homo sapiens OX=9606GN=ZNF48 PE=1 SV=2MERAVEPWGPDLHRPEEREPQRGARTGLGSENVISQPNEFEHTPQEDDLGFKEEDLAPDHEVGNASLKPEGIQNWDDLWVQREGLGKPQPRDRGPRLLGEPRWGQASSDRAAVCGECGKSFRQMSDLVKHQRTHTGEKPYKCGVCGKGFGDSSARIKHQRTHSGEKPYRARPPAQGPPKIPRSRIPAGERPTICGECGKSFRQSSDLVKHQRTHTGEKPYKCGICGKGFGDSSARIKHQRTHRGEQPPRPVVPRRQPSRAATAATQGPKAQDKPYICTDCGKRFVLSCSLLSHQRSHLGPKPFGCDVCGKEFARGSDLVKHLRVHTGEKPYLCPECGKGFADSSARVKHLRTHSGERPHACPECDRTFSLSSTLLRHRLTHMEPQDFSFPGYPLPALIPSPPPPPLGTSPPLTPRSPSHSGEPFGLPGLEPEPGGPQAGEPPPPLAGDKPHKCPECGKGFRRSSDLVKHHRVHTGEKPYLCPECGKGFADSSARVKHLRTHRGERARPPPPSTLLRPHNPPGPVPMAPRPRVRAQPSGPSQPHVCGFCGKEFPRSSDLVKHRRTHTGEKPYKCAECGKGFGDSSARIKHQRGHLVLTPFGIGDGRARPLKQEAATGLE>sp|Q96K83|ZN521_HUMAN Zinc finger protein 521 OS=Homo sapiens OX=9606GN=ZNF521 PE=1 SV=1MSRRKQAKPRSLKDPNCKLEDKTEDGEALDCKKRPEDGEELEDEAVHSCDSCLQVFESLSDITEHKINQCQLTDGVDVEDDPTCSWPASSPSSKDQTSPSHGEGCDFGEEEGGPGLPYPCQFCDKSFSRLSYLKHHEQSHSDKLPFKCTYCSRLFKHKRSRDRHIKLHTGDKKYHCSECDAAFSRSDHLKIHLKTHTSNKPYKCAICRRGFLSSSSLHGHMQVHERNKDGSQSGSRMEDWKMKDTQKCSQCEEGFDFPEDLQKHIAECHPECSPNEDRAALQCVYCHELFVEETSLMNHMEQVHSGEKKNSCSICSESFHTVEELYSHMDSHQQPESCNHSNSPSLVTVGYTSVSSTTPDSNLSVDSSTMVEAAPPIPKSRGRKRAAQQTPDMTGPSSKQAKVTYSCIYCNKQLFSSLAVLQIHLKTMHLDKPEQAHICQYCLEVLPSLYNLNEHLKQVHEAQDPGLIVSAMPAIVYQCNFCSEVVNDLNTLQEHIRCSHGFANPAAKDSNAFFCPHCYMGFLTDSSLEEHIRQVHCDLSGSRFGSPVLGTPKEPVVEVYSCSYCTNSPIFNSVLKLNKHIKENHKNIPLALNYIHNGKKSRALSPLSPVAIEQTSLKMMQAVGGAPARPTGEYICNQCGAKYTSLDSFQTHLKTHLDTVLPKLTCPQCNKEFPNQESLLKHVTIHFMITSTYYICESCDKQFTSVDDLQKHLLDMHTFVFFRCTLCQEVFDSKVSIQLHLAVKHSNEKKVYRCTSCNWDFRNETDLQLHVKHNHLENQGKVHKCIFCGESFGTEVELQCHITTHSKKYNCKFCSKAFHAIILLEKHLREKHCVFETKTPNCGTNGASEQVQKEEVELQTLLTNSQESHNSHDGSEEDVDTSEPMYGCDICGAAYTMETLLQNHQLRDHNIRPGESAIVKKKAELIKGNYKCNVCSRTFFSENGLREHMQTHLGPVKHYMCPICGERFPSLLTLTEHKVTHSKSLDTGNCRICKMPLQSEEEFLEHCQMHPDLRNSLTGFRCVVCMQTVTSTLELKIHGTFHMQKTGNGSAVQTTGRGQHVQKLYKCASCLKEFRSKQDLVKLDINGLPYGLCAGCVNLSKSASPGINVPPGTNRPGLGQNENLSAIEGKGKVGGLKTRCSSCNVKFESESELQNHIQTIHRELVPDSNSTQLKTPQVSPMPRISPSQSDEKKTYQCIKCQMVFYNEWDIQVHVANHMIDEGLNHECKLCSQTFDSPAKLQCHLIEHSFEGMGGTFKCPVCFTVFVQANKLQQHIFSAHGQEDKIYDCTQCPQKFFFQTELQNHTMTQHSS>sp|A8MVS1|Z705F_HUMAN Zinc finger protein 705F OS=Homo sapiens OX=9606GN=ZNF705F PE=3 SV=1MHSLEKVTFEDVAIDFTQEEWDMMDTSKRKLYRDVMLENISHLVSLGYQISKSYIILQLEQGKELWREGRVFLQDQNPDRESALKKKHMISMHPIIRKDASTSMTMSKTLILEDPFEYNDSGEDCTHSSTITQCLLTHSRKKPYVSKQCGKSLRNLLSPKPRKQIHTKGKSYQCNLCEKAYTNCFYLRRHKMTHTGERPYACHLCGKAFTQCSHLRRHEKTHTGERPYKCHQCGKAFIQSFNLRRHERTHLGQKCYECDKSGKAFSQSSGFRGNKIIHIGEKPHACLLCGKAFSLSSDLR>sp|P17035|ZNF28_HUMAN Zinc finger protein 28 OS=Homo sapiens OX=9606GN=ZNF28 PE=1 SV=5MALPQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCMMKTFFSTGQGNTEAFHTGTLQRQASHHIGDFCFQKIEKDIHGFQFQWKEDETNDHAAPMTEIKELTGSTGQHDQRHAGNKHIKDQLGLSFHSHLPELHIFQPEGKIGNQVEKSINNASSVSTSQRICCRPKTHISNKYGNNSLHSSLLTQKRNVHMREKSFQCIESGKSFNCSSLLKKHQITHLEEKQCKCDVYGKVFNQKRYLACHRRSHIDEKPYKCNECGKIFGHNTSLFLHKALHTADKPYECEECDKVFSRKSHLETHKIIYTGGKPYKCKVCDKAFTCNSYLAKHTIIHTGEKPYKCNECGKVFNRLSTLARHRRLHTGEKPYECEECEKVFSRKSHLERHKRIHTGEKPYKCKVCDKAFAYNSYLAKHSIIHTGEKPYKCNECGKVFNQQSTLARHHRLHTAEKPYKCEECDKVFRCKSHLERHRRIHTGEKPYKCKVCDKAFRSDSCLTEHQRVHTGEKPYMCNECGKVFSTKANLACHHKLHTAEKPYKCEECEKVFSRKSHMERHRRIHTGEKPYKCKVCDKAFRRDSHLAQHQRVHTGEKPYKCNECGKTFRQTSSLIIHRRLHTGEKPYKCNECGKTFSQMSSLVYHHRLHSGEKPYKCNECGKVFNQQAHLAQHQRVHTGEKPYKCNECGKTFSQMSNLVYHHRLHSGEKP>sp|P17035-2|ZNF28_HUMAN Isoform 2 of Zinc finger protein 28 OS=Homosapiens OX=9606 GN=ZNF28MMKTFFSTGQGNTEAFHTGTLQRQASHHIGDFCFQKIEKDIHGFQFQWKEDETNDHAAPMTEIKELTGSTGQHDQRHAGNKHIKDQLGLSFHSHLPELHIFQPEGKIGNQVEKSINNASSVSTSQRICCRPKTHISNKYGNNSLHSSLLTQKRNVHMREKSFQCIESGKSFNCSSLLKKHQITHLEEKQCKCDVYGKVFNQKRYLACHRRSHIDEKPYKCNECGKIFGHNTSLFLHKALHTADKPYECEECDKVFSRKSHLETHKIIYTGGKPYKCKVCDKAFTCNSYLAKHTIIHTGEKPYKCNECGKVFNRLSTLARHRRLHTGEKPYECEECEKVFSRKSHLERHKRIHTGEKPYKCKVCDKAFAYNSYLAKHSIIHTGEKPYKCNECGKVFNQQSTLARHHRLHTAEKPYKCEECDKVFRCKSHLERHRRIHTGEKPYKCKVCDKAFRSDSCLTEHQRVHTGEKPYMCNECGKVFSTKANLACHHKLHTAEKPYKCEECEKVFSRKSHMERHRRIHTGEKPYKCKVCDKAFRRDSHLAQHQRVHTGEKPYKCNECGKTFRQTSSLIIHRRLHTGEKPYKCNECGKTFSQMSSLVYHHRLHSGEKPYKCNECGKVFNQQAHLAQHQRVHTGEKPYKCNECGKTFSQMSNLVYHHRLHSGEKP>sp|O00488|ZN593_HUMAN Zinc finger protein 593 OS=Homo sapiens OX=9606GN=ZNF593 PE=1 SV=2MGRSRRTGAHRAHSLARQMKAKRRRPDLDEIHRELRPQGSARPQPDPNAEFDPDLPGGGLHRCLACARYFIDSTNLKTHFRSKDHKKRLKQLSVEPYSQEEAERAAGMGSYVPPRRLAVPTEVSTEVPEMDTST>sp|P58317|ZN121_HUMAN Zinc finger protein 121 OS=Homo sapiens OX=9606GN=ZNF121 PE=1 SV=2MAEIHNGGELCDFMENGEIFSEHSCLNAHMGTENTGDTYDCDEYGENFPMLHNSAPAGETLSVLNQCRKAFSLPPNVHQRTWIGDKSFEYSDCEEAFVDQSHLQANRITHNGETLYEQKQCGRAFTYSTSHAVSVKMHTVEKPYECKECGKFFRYSSYLNSHMRTHTGEKPYECKECGKCFTVSSHLVEHVRIHTGEKPYQCKECGRAFAGRSGLTKHVRIHTGEKPYECNECGKAYNRFYLLTEHFKTHTEEKPFECKVCGKSFRSSSCLKNHFRIHTGIKPYKCKECGKAFTVSSSLHNHVKIHTGEKPYECKDCGKAFATSSQLIEHIRTHTGEKPYICKECGKTFRASSHLQKHVRIHTGEKPYICNECGKAYNRFYLLTKHLKTH>sp|Q96MR9|ZN560_HUMAN Zinc finger protein 560 OS=Homo sapiens OX=9606GN=ZNF560 PE=2 SV=2MAYCLTNCYQYSVTFEDTAVDFTQEEWILLDPVQRNLYRDVMLENYENVAKVGFQLFKPSVISWLEEEELRTLQQGVLQDWAIKHQTSVSALQQEFWKIQTSNGIQMDLVTFDSVAVEFTQEEWTLLDPAQRNLYSDVMLENYKNLSSVGYQLFKPSLISWLEEEEELSTLPRVLQEWKMCLKTKGPALWQDNFCLKTLNGIQLARNQNGEELYDCKQCEDVFCKHPCLKTNMSTQNRGNTSECIQYAKDLLSLYNKTSTIRKVSVFSKHGKSFRLILNVQVQRKCTQDKSFEGTDYGKAFIYQSYLEAHRKTQSGEKLNEWKQCGEAFTHSTSHAVNVETHIIKNPYECKECGKDFRYPTHLNNHMQTHIGIKPYKCKHCGKTFTVPSGFLEHVRTHTGEKPYGCKECGKAFGTSAGLIEHIRCHAREKTFKCDHCGKAFISYPSLFGHLRVHNGEKPYEHKEYGKAFGTSSGVIEDRRSNTGQKRFDCDQCGKVFVSFSSLFAHLRTHTGEKPFKCYKCGKPFTSSACLRIHMRTHTEERLYQCKKCGKAFTKCSYLTKHLRTHAGEKPYECMKCGKAFTERSYLTKHLRRHSGEKPYECKKCGKAFTERSDLTKHLRRHTGDKPYEYKDCGKAFVVSSSLVDHLRTHTGYKPYKCNACEKAYSRSCVLTQHLKTHAAEKTSECNACGNSFRNSMCFHDRLKTLTKIKPYKCKDCGKAFTCHSDLTNHVRIHTGEKPYKCKECGKAFRTSSGRIQHLRTHMGEKPFECDQCGKAFASFSARIAHLKTH>sp|Q3KQV3|ZN792_HUMAN Zinc finger protein 792 OS=Homo sapiens OX=9606GN=ZNF792 PE=1 SV=2MAAAALRDPAQGCVTFEDVTIYFSQEEWVLLDEAQRLLYCDVMLENFALIASLGLISFRSHIVSQLEMGKEPWVPDSVDMTSAMARGAYGRPGSDFCHGTEGKDLPSEHNVSVEGVAQDRSPEATLCPQKTCPCDICGLRLKDILHLAEHQTTHPRQKPFVCEAYVKGSEFSANLPRKQVQQNVHNPIRTEEGQASPVKTCRDHTSDQLSTCREGGKDFVATAGFLQCEVTPSDGEPHEATEGVVDFHIALRHNKCCESGDAFNNKSTLVQHQRIHSRERPYECSKCGIFFTYAADLTQHQKVHNRGKPYECCECGKFFSQHSSLVKHRRVHTGESPHVCGDCGKFFSRSSNLIQHKRVHTGEKPYECSDCGKFFSQRSNLIHHKRVHTGRSAHECSECGKSFNCNSSLIKHWRVHTGERPYKCNECGKFFSHIASLIQHQIVHTGERPHGCGECGKAFSRSSDLMKHQRVHTGERPYECNECGKLFSQSSSLNSHRRLHTGERPYQCSECGKFFNQSSSLNNHRRLHTGERPYECSECGKTFRQRSNLRQHLKVHKPDRPYECSECGKAFNQRPTLIRHQKIHIRERSMENVLLPCSQHTPEISSENRPYQGAVNYKLKLVHPSTHPGEVP>sp|Q8N184|ZN567_HUMAN Zinc finger protein 567 OS=Homo sapiens OX=9606GN=ZNF567 PE=1 SV=3MAQGSVSFNDVTVDFTQEEWQHLDHAQKTLYMDVMLENYCHLISVGCHMTKPDVILKLERGEEPWTSFAGHTCLEENWKAEDFLVKFKEHQEKYSRSVVSINHKKLVKEKSKIYEKTFTLGKNPVNSKNLPPEYDTHGRILKNVSELIISNLNPARKRLSEYNGYGKSLLSTKQETTHPEVKSHNQSARAFSHNEVLMQYQKTETPAQSFGYNDCEKSFLQRGGLITHSRPYKGENPSVYNKKRRATNIEKKHTCNECGKSFCRKSVLILHQGIHSEEKPYQCHQCGNAFRRKSYLIDHQRTHTGEKPFVCNECGKSFRLKTALTDHQRTHTGEKSYECLQCRNAFRLKSHLIRHQRTHTGEKPYECNDCGKSFRQKTTLSLHQRIHTGEKPYICKECGKSFHQKANLTVHQRTHTGEKPYICNECGKSFSQKTTLALHEKTHNEEKPYICSECGKSFRQKTTLVAHQRTHTGEKSYECPHCGKAFRMKSYLIDHHRTHTGEKPYECNECGKSFSQKTNLNLHQRIHTGEKPYVCNECGKSFRQKATLTVHQKIHTGQKSYECPQCGKAFSRKSYLIHHQRTHTGEKPYKCSECGKCFRQKTNLIVHQRTHTGEKPYVCNECGKSFSYKRNLIVHQRTHKGENIEMQ>sp|Q8N184-1|ZN567_HUMAN Isoform 1 of Zinc finger protein 567 OS=Homosapiens OX=9606 GN=ZNF567MDVMLENYCHLISVGCHMTKPDVILKLERGEEPWTSFAGHTCLEENWKAEDFLVKFKEHQEKYSRSVVSINHKKLVKEKSKIYEKTFTLGKNPVNSKNLPPEYDTHGRILKNVSELIISNLNPARKRLSEYNGYGKSLLSTKQETTHPEVKSHNQSARAFSHNEVLMQYQKTETPAQSFGYNDCEKSFLQRGGLITHSRPYKGENPSVYNKKRRATNIEKKHTCNECGKSFCRKSVLILHQGIHSEEKPYQCHQCGNAFRRKSYLIDHQRTHTGEKPFVCNECGKSFRLKTALTDHQRTHTGEKSYECLQCRNAFRLKSHLIRHQRTHTGEKPYECNDCGKSFRQKTTLSLHQRIHTGEKPYICKECGKSFHQKANLTVHQRTHTGEKPYICNECGKSFSQKTTLALHEKTHNEEKPYICSECGKSFRQKTTLVAHQRTHTGEKSYECPHCGKAFRMKSYLIDHHRTHTGEKPYECNECGKSFSQKTNLNLHQRIHTGEKPYVCNECGKSFRQKATLTVHQKIHTGQKSYECPQCGKAFSRKSYLIHHQRTHTGEKPYKCSECGKCFRQKTNLIVHQRTHTGEKPYVCNECGKSFSYKRNLIVHQRTHKGENIEMQ>sp|Q8N184-2|ZN567_HUMAN Isoform 2 of Zinc finger protein 567 OS=Homosapiens OX=9606 GN=ZNF567MAQGSVSFNDVTVDFTQEEWQHLDHAQKTLYMDVMLENYCHLISVGCHMTKPDVILKLERGEEPWTSFAGHTCLEENWKAEDFLVKFKEHQEKYSRSVVSINHKKLVKEKSKIYEKTFTLGKNPVNSKNLPPEYDTHGRILKNVSELIISNLNPARKRLSEYNGYGKSLLSTKQETTHPEVKSHNQSARAFSHNEVLMQYQKTETPAQSFGYNDCEKSFLQRGGLITHSRPYKGENPSVYNKKRRATNIEKKHTCNECGKSFCRKSVLILHQGIHSEEKPYQCHQCGNAFRRKSYLIDHQRTHTGEKPFVCNECGKSFRLKTALTDHQRTHTGEKSYECLQCRNAFRLKSHLIRHQRTHTGEKPYECNDCGKSFRQKTTLSLHQRIHTGEKPYICKECGKSFHQKANLTVHQRTHTGEKPYICNECGKSFSQKTTLALHEKTHNEEKPYICSECGKSFRQKTTLVAHQRTHTGEKSYECPHCGKAFRMKSYLIDHHRTHTGEKPYECNECGKSFSQKTNLNLHQRIHTGEKPYVCNECGKSFRQKATLTVHQKIHTGQKSYECPQCGKAFSRKSYLIHHQRTHKGENIEMQ>sp|Q8N814|YG045_HUMAN Putative uncharacterized protein FLJ40140 OS=Homosapiens OX=9606 PE=5 SV=1MGWVIPEWPGAQSCPTAAQVAQPVPFMCNAPASPINDKEKDKAGGRLPSGSEPRARAFCEAGADGEQGDPSPADTIKANQGHIPAAPGETGSVICWCDQSVAPPRPAGLSVSGRQSYLVGCFRWVLTFFFSVFYLTP>sp|Q9ULM3|YETS2_HUMAN YEATS domain-containing protein 2 OS=Homo sapiensOX=9606 GN=YEATS2 PE=1 SV=2MSGIKRTIKETDPDYEDVSVALPNKRHKAIENSARDAAVQKIETIIKEQFALEMKNKEHEIEVIDQRLIEARRMMDKLRACIVANYYASAGLLKVSEGSKTCDTMVFNHPAIKKFLESPSRSSSPANQRAETPSANHSESDSLSQHNDFLSDKDNNSNMDIEERLSNNMEQRPSRNTGRDTSRITGSHKTEQRNADLTDETSRLFVKKTIVVGNVSKYIPPDKREENDQSTHKWMVYVRGSRREPSINHFVKKVWFFLHPSYKPNDLVEVREPPFHLTRRGWGEFPVRVQVHFKDSQNKRIDIIHNLKLDRTYTGLQTLGAETVVDVELHRHSLGEDCIYPQSSESDISDAPPSLPLTIPAPVKASSPIKQSHEPVPDTSVEKGFPASTEAERHTPFYALPSSLERTPTKMTTSQKVTFCSHGNSAFQPIASSCKIVPQSQVPNPESPGKSFQPITMSCKIVSGSPISTPSPSPLPRTPTSTPVHVKQGTAGSVINNPYVIMDKQPGQVIGATTPSTGSPTNKISTASQVSQGTGSPVPKIHGSSFVTSTVKQEDSLFASMPPLCPIGSHPKVQSPKPITGGLGAFTKVIIKQEPGEAPHVPATGAASQSPLPQYVTVKGGHMIAVSPQKQVITPGEGIAQSAKVQPSKVVGVPVGSALPSTVKQAVAISGGQILVAKASSSVSKAVGPKQVVTQGVAKAIVSGGGGTIVAQPVQTLTKAQVTAAGPQKSGSQGSVMATLQLPATNLANLANLPPGTKLYLTTNSKNPSGKGKLLLIPQGAILRATNNANLQSGSAASGGSGAGGGGGGGGGGGSGSGGGGSTGGGGGTAGGGTQSTAGPGGISQHLTYTSYILKQTPQGTFLVGQPSPQTSGKQLTTGSVVQGTLGVSTSSAQGQQTLKVISGQKTTLFTQAAHGGQASLMKISDSTLKTVPATSQLSKPGTTMLRVAGGVITTATSPAVALSANGPAQQSEGMAPVSSSTVSSVTKTSGQQQVCVSQATVGTCKAATPTVVSATSLVPTPNPISGKATVSGLLKIHSSQSSPQQAVLTIPSQLKPLSVNTSGGVQTILMPVNKVVQSFSTSKPPAILPVAAPTPVVPSSAPAAVAKVKTEPETPGPSCLSQEGQTAVKTEESSELGNYVIKIDHLETIQQLLTAVVKKIPLITAKSEDASCFSAKSVEQYYGWNIGKRRAAEWQRAMTMRKVLQEILEKNPRFHHLTPLKTKHIAHWCRCHGYTPPDPESLRNDGDSIEDVLTQIDSEPECPSSFSSADNLCRKLEDLQQFQKREPENEEEVDILSLSEPVKINIKKEQEEKQEEVKFYLPPTPGSEFIGDVTQKIGITLQPVALHRNVYASVVEDMILKATEQLVNDILRQALAVGYQTASHNRIPKEITVSNIHQAICNIPFLDFLTNKHMGILNEDQ>sp|Q9NXF8|ZDHC7_HUMAN Palmitoyltransferase ZDHHC7 OS=Homo sapiensOX=9606 GN=ZDHHC7 PE=1 SV=2MQPSGHRLRDVEHHPLLAENDNYDSSSSSSSEADVADRVWFIRDGCGMICAVMTWLLVAYADFVVTFVMLLPSKDFWYSVVNGVIFNCLAVLALSSHLRTMLTDPGAVPKGNATKEYMESLQLKPGEVIYKCPKCCCIKPERAHHCSICKRCIRKMDHHCPWVNNCVGEKNQRFFVLFTMYIALSSVHALILCGFQFISCVRGQWTECSDFSPPITVILLIFLCLEGLLFFTFTAVMFGTQIHSICNDETEIERLKSEKPTWERRLRWEGMKSVFGGPPSLLWMNPFVGFRFRRLPTRPRKGGPEFSV>sp|Q9NXF8-2|ZDHC7_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC7 OS=Homosapiens OX=9606 GN=ZDHHC7MQPSGHRLRDVEHHPLLAENDNYDSSSSSSSEADVADRVWFIRDGCGMICAVMTWLLVAYADFVVTFVMLLPSKDFWYSVVNGVIFNCLAVLALSSHLRTMLTDPEKSSDCRPSACTVKTGLDPTLVGICGEGTESVQSLLLGAVPKGNATKEYMESLQLKPGEVIYKCPKCCCIKPERAHHCSICKRCIRKMDHHCPWVNNCVGEKNQRFFVLFTMYIALSSVHALILCGFQFISCVRGQWTECSDFSPPITVILLIFLCLEGLLFFTFTAVMFGTQIHSICNDETEIERLKSEKPTWERRLRWEGMKSVFGGPPSLLWMNPFVGFRFRRLPTRPRKGGPEFSV>sp|Q8WTX9|ZDHC1_HUMAN Palmitoyltransferase ZDHHC1 OS=Homo sapiensOX=9606 GN=ZDHHC1 PE=1 SV=1MYKMNICNKPSNKTAPEKSVWTAPAQPSGPSPELQGQRSRRNGWSWPPHPLQIVAWLLYLFFAVIGFGILVPLLPHHWVPAGYACMGAIFAGHLVVHLTAVSIDPADANVRDKSYAGPLPIFNRSQHAHVIEDLHCNLCNVDVSARSKHCSACNKCVCGFDHHCKWLNNCVGERNYRLFLHSVASALLGVLLLVLVATYVFVEFFVNPMRLRTNRHFEVLKNHTDVWFVFLPAAPVETQAPAILALAALLILLGLLSTALLGHLLCFHIYLMWHKLTTYEYIVQHRPPQEAKGVHRELESCPPKMRPIQEMEFYMRTFRHMRPEPPGQAGPAAVNAKHSRPASPDPTPGRRDCAGPPVQVEWDRKKPLPWRSPLLLLAMWGPQAPPCLCRKRGRGACIKCERLRPRIRRRGLGPPAAAPARRRIPRTPALCTPLALPAPTTRRRQSPWTRFQWRRRAWAAPLWPPRGAGADSPRWRGRRVRPPFS>sp|Q8NB50|ZFP62_HUMAN Zinc finger protein 62 homolog OS=Homo sapiensOX=9606 GN=ZFP62 PE=1 SV=3MSHLKTSTEDEEPTEEYENVGNAASKWPKVEDPMPESKVGDTCVWDSKVENQQKKPVENRMKEDKSSIREAISKAKSTANIKTEQEGEASEKSLHLSPQHITHQTMPIGQRGSEQGKRVENINGTSYPSLQQKTNAVKKLHKCDECGKSFKYNSRLVQHKIMHTGEKRYECDDCGGTFRSSSSLRVHKRIHTGEKPYKCEECGKAYMSYSSLINHKSTHSGEKNCKCDECGKSFNYSSVLDQHKRIHTGEKPYECGECGKAFRNSSGLRVHKRIHTGEKPYECDICGKTFSNSSGLRVHKRIHTGEKPYECDECGKAFITCRTLLNHKSIHFGDKPYKCDECEKSFNYSSLLIQHKVIHTGEKPYECDECGKAFRNSSGLIVHKRIHTGEKPYKCDVCGKAFSYSSGLAVHKSIHPGKKAHECKECGKSFSYNSLLLQHRTIHTGERPYVCDVCGKTFRNNAGLKVHRRLHTGEKPYKCDVCGKAYISRSSLKNHKGIHLGEKPYKCSYCEKSFNYSSALEQHKRIHTREKPFGCDECGKAFRNNSGLKVHKRIHTGERPYKCEECGKAYISLSSLINHKSVHPGEKPFKCDECEKAFITYRTLTNHKKVHLGEKPYKCDVCEKSFNYTSLLSQHRRVHTREKPYECDRCEKVFRNNSSLKVHKRIHTGERPYECDVCGKAYISHSSLINHKSTHPGRTPHTCDECGKAFFSSRTLISHKRVHLGEKPFKCVECGKSFSYSSLLSQHKRIHTGEKPYVCDRCGKAFRNSSGLTVHKRIHTGEKPYECDECGKAYISHSSLINHKSVHQGKQPYNCECGKSFNYRSVLDQHKRIHTGKKPYRCNECGKAFNIRSNLTKHKRTHTGEESLNVIYVGSYSGTSQKRTYEGGNALDGGRMRMPL>sp|Q8NB50-2|ZFP62_HUMAN Isoform 2 of Zinc finger protein 62 homologOS=Homo sapiens OX=9606 GN=ZFP62MSHLKTSTEDEEPTEEYENVGNAASKWPKVEDPMPESKVGDTCVWDSKVENQQKKPVENRMKEDKSSIREAISKAKSTANIKTEQEGEASEKSLHLSPQHITHQTMPIGQRGSEQGKRVENINGTSYPSLQQKTNAVKKLHKCDECGKSFKYNSRLVQHKIMHTGEKRYECDDCGGTFRSSSSLRVHKRIHTGEKPYKCEECGKAYMSYSSLINHKSTHSGEKNCKCDECGKSFNYSSVLDQHKRIHTGEKPYECGECGKAFRNSSGLRVHKRIHTGEKPYECDICGKTFSNSSGLRVHKRIHTGEKPYECDECGKAFITCRTLLNHKSIHFGDKPYKCDECGKAFRNNSGLKVHKRIHTGERPYKCEECGKAYISLSSLINHKSVHPGEKPFKCDECEKAFITYRTLTNHKKVHLGEKPYKCDVCEKSFNYTSLLSQHRRVHTREKPYECDRCEKVFRNNSSLKVHKRIHTGERPYECDVCGKAYISHSSLINHKSTHPGRTPHTCDECGKAFFSSRTLISHKRVHLGEKPFKCVECGKSFSYSSLLSQHKRIHTGEKPYVCDRCGKAFRNSSGLTVHKRIHTGEKPYECDECGKAYISHSSLINHKSVHQGKQPYNCECGKSFNYRSVLDQHKRIHTGKKPYRCNECGKAFNIRSNLTKHKRTHTGEESLNVIYVGSYSGTSQKRTYEGGNALDGGRMRMPL>sp|Q8NB50-3|ZFP62_HUMAN Isoform 3 of Zinc finger protein 62 homologOS=Homo sapiens OX=9606 GN=ZFP62MPESKVGDTCVWDSKVENQQKKPVENRMKEDKSSIREAISKAKSTANIKTEQEGEASEKSLHLSPQHITHQTMPIGQRGSEQGKRVENINGTSYPSLQQKTNAVKKLHKCDECGKSFKYNSRLVQHKIMHTGEKRYECDDCGGTFRSSSSLRVHKRIHTGEKPYKCEECGKAYMSYSSLINHKSTHSGEKNCKCDECGKSFNYSSVLDQHKRIHTGEKPYECGECGKAFRNSSGLRVHKRIHTGEKPYECDICGKTFSNSSGLRVHKRIHTGEKPYECDECGKAFITCRTLLNHKSIHFGDKPYKCDECEKSFNYSSLLIQHKVIHTGEKPYECDECGKAFRNSSGLIVHKRIHTGEKPYKCDVCGKAFSYSSGLAVHKSIHPGKKAHECKECGKSFSYNSLLLQHRTIHTGERPYVCDVCGKTFRNNAGLKVHRRLHTGEKPYKCDVCGKAYISRSSLKNHKGIHLGEKPYKCSYCEKSFNYSSALEQHKRIHTREKPFGCDECGKAFRNNSGLKVHKRIHTGERPYKCEECGKAYISLSSLINHKSVHPGEKPFKCDECEKAFITYRTLTNHKKVHLGEKPYKCDVCEKSFNYTSLLSQHRRVHTREKPYECDRCEKVFRNNSSLKVHKRIHTGERPYECDVCGKAYISHSSLINHKSTHPGRTPHTCDECGKAFFSSRTLISHKRVHLGEKPFKCVECGKSFSYSSLLSQHKRIHTGEKPYVCDRCGKAFRNSSGLTVHKRIHTGEKPYECDECGKAYISHSSLINHKSVHQGKQPYNCECGKSFNYRSVLDQHKRIHTGKKPYRCNECGKAFNIRSNLTKHKRTHTGEESLNVIYVGSYSGTSQKRTYEGGNALDGGRMRMPL>sp|O15156|ZBT7B_HUMAN Zinc finger and BTB domain-containing protein 7BOS=Homo sapiens OX=9606 GN=ZBTB7B PE=1 SV=2MGSPEDDLIGIPFPDHSSELLSCLNEQRQLGHLCDLTIRTQGLEYRTHRAVLAACSHYFKKLFTEGGGGAVMGAGGSGTATGGAGAGVCELDFVGPEALGALLEFAYTATLTTSSANMPAVLQAARLLEIPCVIAACMEILQGSGLEAPSPDEDDCERARQYLEAFATATASGVPNGEDSPPQVPLPPPPPPPPRPVARRSRKPRKAFLQTKGARANHLVPEVPTVPAHPLTYEEEEVAGRVGSSGGSGPGDSYSPPTGTASPPEGPQSYEPYEGEEEEEELVYPPAYGLAQGGGPPLSPEELGSDEDAIDPDLMAYLSSLHQDNLAPGLDSQDKLVRKRRSQMPQECPVCHKIIHGAGKLPRHMRTHTGEKPFACEVCGVRFTRNDKLKIHMRKHTGERPYSCPHCPARFLHSYDLKNHMHLHTGDRPYECHLCHKAFAKEDHLQRHLKGQNCLEVRTRRRRKDDAPPHYPPPSTAAASPAGLDLSNGHLDTFRLSLARFWEQSAPTGPPVSTPGPPDDDEEEGAPTTPQAEGAMESS>sp|O15156-2|ZBT7B_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 7B OS=Homo sapiens OX=9606 GN=ZBTB7BMLQPGPHPPSPQAAAPGEAWPGPSQAPWQSLEEKMGSPEDDLIGIPFPDHSSELLSCLNEQRQLGHLCDLTIRTQGLEYRTHRAVLAACSHYFKKLFTEGGGGAVMGAGGSGTATGGAGAGVCELDFVGPEALGALLEFAYTATLTTSSANMPAVLQAARLLEIPCVIAACMEILQGSGLEAPSPDEDDCERARQYLEAFATATASGVPNGEDSPPQVPLPPPPPPPPRPVARRSRKPRKAFLQTKGARANHLVPEVPTVPAHPLTYEEEEVAGRVGSSGGSGPGDSYSPPTGTASPPEGPQSYEPYEGEEEEEELVYPPAYGLAQGGGPPLSPEELGSDEDAIDPDLMAYLSSLHQDNLAPGLDSQDKLVRKRRSQMPQECPVCHKIIHGAGKLPRHMRTHTGEKPFACEVCGVRFTRNDKLKIHMRKHTGERPYSCPHCPARFLHSYDLKNHMHLHTGDRPYECHLCHKAFAKEDHLQRHLKGQNCLEVRTRRRRKDDAPPHYPPPSTAAASPAGLDLSNGHLDTFRLSLARFWEQSAPTGPPVSTPGPPDDDEEEGAPTTPQAEGAMESS>sp|Q15697|ZN174_HUMAN Zinc finger protein 174 OS=Homo sapiens OX=9606GN=ZNF174 PE=1 SV=1MAAKMEITLSSNTEASSKQERHIIAKLEEKRGPPLQKNCPDPELCRQSFRRFCYQEVSGPQEALSQLRQLCRQWLQPELHTKEQILELLVMEQFLTILPPEIQARVRHRCPMSSKEIVTLVEDFHRASKKPKQWVAVCMQGQKVLLEKTGSQLGEQELPDFQPQTPRRDLRESSPAEPSQAGAYDRLSPHHWEKSPLLQEPTPKLAGTEAPRMRSDNKENPQQEGAKGAKPCAVSAGRSKGNGLQNPEPRGANMSEPRLSRRQVSSPNAQKPFAHYQRHCRVEYISSPLKSHPLRELKKSKGGKRSLSNRLQHLGHQPTRSAKKPYKCDDCGKSFTWNSELKRHKRVHTGERPYTCGECGNCFGRQSTLKLHQRIHTGEKPYQCGQCGKSFRQSSNLHQHHRLHHGD>sp|Q15697-2|ZN174_HUMAN Isoform 2 of Zinc finger protein 174 OS=Homosapiens OX=9606 GN=ZNF174MAAKMEITLSSNTEASSKQERHIIAKLEEKRGPPLQKNCPDPELCRQSFRRFCYQEVSGPQEALSQLRQLCRQWLQPELHTKEQILELLVMEQFLTILPPEIQARVRHRCPMSSKEIVTLVEDFHRASKKPKQWVAVCMQGQKVLLEKTGSQLGEQELPDFQPQTPRRDLRESSPAEPSQAGAYDRLSPHHWEKSPLLQEPTPKLAGTELLIEKTDPNMATDELPCKLWLSFIA>sp|O15209|ZBT22_HUMAN Zinc finger and BTB domain-containing protein 22OS=Homo sapiens OX=9606 GN=ZBTB22 PE=1 SV=1MEPSPLSPSGAALPLPLSLAPPPLPLPAAAVVHVSFPEVTSALLESLNQQRLQGQLCDVSIRVQGREFRAHRAVLAASSPYFHDQVLLKGMTSISLPSVMDPGAFETVLASAYTGRLSMAAADIVNFLTVGSVLQMWHIVDKCTELLREGRASATTTITTAAATSVTVPGAGVPSGSGGTVAPATMGSARSHASSRASENQSPSSSNYFSPRESTDFSSSSQEAFAASAVGSGERRGGGPVFPAPVVGSGGATSGKLLLEADELCDDGGDGRGAVVPGAGLRRPTYTPPSIMPQKHWVYVKRGGNCPAPTPLVPQDPDLEEEEEEEDLVLTCEDDEDEELGGSSRVPVGGGPEATLSISDVRTLSEPPDKGEEQVNFCESSNDFGPYEGGGPVAGLDDSGGPTPSSYAPSHPPRPLLPLDMQGNQILVFPSSSSSSSSQAPGQPPGNQAEHGAVTVGGTSVGSLGVPGSVGGVPGGTGSGDGNKIFLCHCGKAFSHKSMRDRHVNMHLNLRPFDCPVCNKKFKMKHHLTEHMKTHTGLKPYECGVCAKKFMWRDSFMRHRGHCERRHRLGGVGAVPGPGTPTGPSLPSKRESPGVGGGSGDEASAATPPSSRRVWSPPRVHKVEMGFGGGGGAN>sp|O60315|ZEB2_HUMAN Zinc finger E-box-binding homeobox 2 OS=Homosapiens OX=9606 GN=ZEB2 PE=1 SV=1MKQPIMADGPRCKRRKQANPRRKNVVNYDNVVDTGSETDEEDKLHIAEDDGIANPLDQETSPASVPNHESSPHVSQALLPREEEEDEIREGGVEHPWHNNEILQASVDGPEEMKEDYDTMGPEATIQTAINNGTVKNANCTSDFEEYFAKRKLEERDGHAVSIEEYLQRSDTAIIYPEAPEELSRLGTPEANGQEENDLPPGTPDAFAQLLTCPYCDRGYKRLTSLKEHIKYRHEKNEENFSCPLCSYTFAYRTQLERHMVTHKPGTDQHQMLTQGAGNRKFKCTECGKAFKYKHHLKEHLRIHSGEKPYECPNCKKRFSHSGSYSSHISSKKCIGLISVNGRMRNNIKTGSSPNSVSSSPTNSAITQLRNKLENGKPLSMSEQTGLLKIKTEPLDFNDYKVLMATHGFSGTSPFMNGGLGATSPLGVHPSAQSPMQHLGVGMEAPLLGFPTMNSNLSEVQKVLQIVDNTVSRQKMDCKAEEISKLKGYHMKDPCSQPEEQGVTSPNIPPVGLPVVSHNGATKSIIDYTLEKVNEAKACLQSLTTDSRRQISNIKKEKLRTLIDLVTDDKMIENHNISTPFSCQFCKESFPGPIPLHQHERYLCKMNEEIKAVLQPHENIVPNKAGVFVDNKALLLSSVLSEKGMTSPINPYKDHMSVLKAYYAMNMEPNSDELLKISIAVGLPQEFVKEWFEQRKVYQYSNSRSPSLERSSKPLAPNSNPPTKDSLLPRSPVKPMDSITSPSIAELHNSVTNCDPPLRLTKPSHFTNIKPVEKLDHSRSNTPSPLNLSSTSSKNSHSSSYTPNSFSSEELQAEPLDLSLPKQMKEPKSIIATKNKTKASSISLDHNSVSSSSENSDEPLNLTFIKKEFSNSNNLDNKSTNPVFSMNPFSAKPLYTALPPQSAFPPATFMPPVQTSIPGLRPYPGLDQMSFLPHMAYTYPTGAATFADMQQRRKYQRKQGFQGELLDGAQDYMSGLDDMTDSDSCLSRKKIKKTESGMYACDLCDKTFQKSSSLLRHKYEHTGKRPHQCQICKKAFKHKHHLIEHSRLHSGEKPYQCDKCGKRFSHSGSYSQHMNHRYSYCKREAEEREAAEREAREKGHLEPTELLMNRAYLQSITPQGYSDSEERESMPRDGESEKEHEKEGEDGYGKLGRQDGDEEFEEEEEESENKSMDTDPETIRDEEETGDHSMDDSSEDGKMETKSDHEEDNMEDGM>sp|O60315-2|ZEB2_HUMAN Isoform 2 of Zinc finger E-box-binding homeobox 2OS=Homo sapiens OX=9606 GN=ZEB2MKQPIMADGPRCKRRKQANPRRKNVVNYDNVVDTGSETDEEDKLHIAEDDGIANPLDQETSPASVPNHESSPHVSQALLPREEEEDEIREGGVEHPWHNNEILQASVDGPVKNANCTSDFEEYFAKRKLEERDGHAVSIEEYLQRSDTAIIYPEAPEELSRLGTPEANGQEENDLPPGTPDAFAQLLTCPYCDRGYKRLTSLKEHIKYRHEKNEENFSCPLCSYTFAYRTQLERHMVTHKPGTDQHQMLTQGAGNRKFKCTECGKAFKYKHHLKEHLRIHSGEKPYECPNCKKRFSHSGSYSSHISSKKCIGLISVNGRMRNNIKTGSSPNSVSSSPTNSAITQLRNKLENGKPLSMSEQTGLLKIKTEPLDFNDYKVLMATHGFSGTSPFMNGGLGATSPLGVHPSAQSPMQHLGVGMEAPLLGFPTMNSNLSEVQKVLQIVDNTVSRQKMDCKAEEISKLKGYHMKDPCSQPEEQGVTSPNIPPVGLPVVSHNGATKSIIDYTLEKVNEAKACLQSLTTDSRRQISNIKKEKLRTLIDLVTDDKMIENHNISTPFSCQFCKESFPGPIPLHQHERYLCKMNEEIKAVLQPHENIVPNKAGVFVDNKALLLSSVLSEKGMTSPINPYKDHMSVLKAYYAMNMEPNSDELLKISIAVGLPQEFVKEWFEQRKVYQYSNSRSPSLERSSKPLAPNSNPPTKDSLLPRSPVKPMDSITSPSIAELHNSVTNCDPPLRLTKPSHFTNIKPVEKLDHSRSNTPSPLNLSSTSSKNSHSSSYTPNSFSSEELQAEPLDLSLPKQMKEPKSIIATKNKTKASSISLDHNSVSSSSENSDEPLNLTFIKKEFSNSNNLDNKSTNPVFSMNPFSAKPLYTALPPQSAFPPATFMPPVQTSIPGLRPYPGLDQMSFLPHMAYTYPTGAATFADMQQRRKYQRKQGFQGELLDGAQDYMSGLDDMTDSDSCLSRKKIKKTESGMYACDLCDKTFQKSSSLLRHKYEHTGKRPHQCQICKKAFKHKHHLIEHSRLHSGEKPYQCDKCGKRFSHSGSYSQHMNHRYSYCKREAEEREAAEREAREKGHLEPTELLMNRAYLQSITPQGYSDSEERESMPRDGESEKEHEKEGEDGYGKLGRQDGDEEFEEEEEESENKSMDTDPETIRDEEETGDHSMDDSSEDGKMETKSDHEEDNMEDGM>sp|Q9H5U6|ZCHC4_HUMAN rRNA N6-adenosine-methyltransferase ZCCHC4 OS=Homosapiens OX=9606 GN=ZCCHC4 PE=1 SV=3MAASRNGFEAVEAEGSAGCRGSSGMEVVLPLDPAVPAPLCPHGPTLLFVKVTQGKEETRRFYACSACRDRKDCNFFQWEDEKLSGARLAAREAHNRRCQPPLSRTQCVERYLKFIELPLTQRKFCQTCQQLLLPDDWGQHSEHQVLGNVSITQLRRPSQLLYPLENKKTNAQYLFADRSCQFLVDLLSALGFRRVLCVGTPRLHELIKLTASGDKKSNIKSLLLDIDFRYSQFYMEDSFCHYNMFNHHFFDGKTALEVCRAFLQEDKGEGIIMVTDPPFGGLVEPLAITFKKLIAMWKEGQSQDDSHKELPIFWIFPYFFESRICQFFPSFQMLDYQVDYDNHALYKHGKTGRKQSPVRIFTNIPPNKIILPTEEGYRFCSPCQRYVSLENQHCELCNSCTSKDGRKWNHCFLCKKCVKPSWIHCSICNHCAVPDHSCEGPKHGCFICGELDHKRSTCPNIATSKRANKAVRKQKQRKSNKMKMETTKGQSMNHTSATRRKKRRERAHQYLGS>sp|Q9H5U6-2|ZCHC4_HUMAN Isoform 2 of rRNA N6-adenosine-methyltransferaseZCCHC4 OS=Homo sapiens OX=9606 GN=ZCCHC4MAASRNGFEAVEAEGSAGCRGSSGMEVVLPLDPAVPAPLCPHGPTLLFVKVTQGKEETRRFYACSACRDRKDCNFFQWEDEKLSGARLAAREAHNRRCQPPLSRTQCVERYLKFIELPLTQRKFCQTCQQLLLPDDWGQHSEHQVLGNVSITQLRRPSQLLYPLENKKTNAQYLFADRSCQFLVDLLSALGFRRVLCVGTPRLHELIKLTASGDKKSNIKSLLLDIDFR>sp|Q9H5U6-3|ZCHC4_HUMAN Isoform 3 of rRNA N6-adenosine-methyltransferaseZCCHC4 OS=Homo sapiens OX=9606 GN=ZCCHC4MAASRNGFEAVEAEGSAGCRGSSGMEVVLPLDPAVPAPLCPHGPTLLFVKVTQGKEETRRFYACSACRDRKDCNFFQWEDEKLSGARLAAREAHNRRCQPPLSRTQCVERYLKFIELPLTQRKFCQTCQQLLLPDDWGQHSEHQVLGNVSITQLRRPSQLLYPLENKKTNAQYLFADRSCQFLVDLLSALGFRRVLCVGTPRLHELIKLTASGDKKSNIKSLLLDIDFRYSQFYMEDSFCHYNMFNHHFFDGKTALEVCRAFLQEDKGEGIIMVTDPPFGGLVEPLAITFKKLIAMWKEGQSQDDSHKELPIFWIFPYFFESRICQFFPSFQMLDYQVDYDNHALYKHGKTGRKQSPVRIFTNIPPNKIILPTEEGYRFCSPCQRYVSLENQHCELCNSCTSKDGRKWNHCFLCKKCVKPSWIHCSICNHCAVPDHSCEGPKHGCFICGELDHKRSTCPNIATSKRANKKQKQRKSNKMKMETTKGQSMNHTSATRRKKRRERAHQYLGS>sp|Q8N402|YV020_HUMAN Putative uncharacterized protein LOC388882 OS=Homosapiens OX=9606 PE=2 SV=1MGIHFSCIRGDLKKPSKKRVKREPYSTTMLQVTSLSPINEILRRYSLYTNQHWRHHGFWRKKIQPQEASEEPPAHKDRGGGERPVNARVVRVAPLRPGFALCGYAVQDISKEDTVYDICNEDAVDISDEDTVDISNEASVHDISNEAAVCDISNDAVNISNEAAVRDISNDAVDICNEAAVHDISNEDTIEDISYEDTVYDITNEDAVRYLCKKDATKEPLTLENDLIVESMSDDEDFAA>sp|Q9H0C1|ZMY12_HUMAN Zinc finger MYND domain-containing protein 12OS=Homo sapiens OX=9606 GN=ZMYND12 PE=1 SV=3MNVIYPLAVPKGRRLCCEVCEAPAERVCAACTVTYYCGVVHQKADWDSIHEKICQLLIPLRTSMPFYNSEEERQHGLQQLQQRQKYLIEFCYTIAQKYLFEGKHEDAVPAALQSLRFRVKLYGLSSVELVPAYLLLAEASLGLGRIVQAEEYLFQAQWTVLKSTDCSNATHSLLHRNLGLLYIAKKNYEEARYHLANDIYFASCAFGTEDIRTSGGYFHLANIFYDLKKLDLADTLYTKVSEIWHAYLNNHYQVLSQAHIQQMDLLGKLFENDTGLDEAQEAEAIRILTSILNIRESTSDKAPQKTIFVLKILVMFYYLMMNSSKAQEYGMRALSLAKEQQLDVHEQSTIQELLSLISTEDHPIT>sp|Q96C55|ZN524_HUMAN Zinc finger protein 524 OS=Homo sapiens OX=9606GN=ZNF524 PE=1 SV=1MDTPSPDPLPSPLPGEEEKPLALSPPVPRGRRGRRPGGATSSNRTLKASLPRKRGRPPKSGQEPPLVQVQGVTAPVGSSGGSDLLLIDDQGVPYTVSEGSAAGPEGSGPRKAPHFCPVCLRAFPYLSDLERHSISHSELKPHQCKVCGKTFKRSSHLRRHCNIHAGLRPFRCPLCPRRFREAGELAHHHRVHSGERPYQCPICRLRFTEANTLRRHAKRKHPEAMGVPLCAPDPGSEPPWDEEGIPATAGAEEEEETEGKGEPA>sp|Q96JG9|ZN469_HUMAN Zinc finger protein 469 OS=Homo sapiens OX=9606GN=ZNF469 PE=2 SV=3MPGERPRGAPPPTMTGDLQPRQVASSPGHPSQPPLEDNTPATRTTKGAREAGGQAQAMELPEAQPRQARDGELKPPSLRGQAPSSTPGKRGSPQTPPGRSPLQAPSRLAGRAEGSPPQRYILGIASSRTKPTLDETPENPQLEAAQLPEVDTPQGPGTGAPLRPGLPRTEAQPAAEELGFHRCFQEPPSSFTSTNYTSPSATPRPPAPGPPQSRGTSPLQPGSYPEYQASGADSWPPAAENSFPGANFGVPPAEPEPIPKGSRPGGSPRGVSFQFPFPALHGASTKPFPADVAGHAFTNGPLVFAFHQPQGAWPEEAVGTGPAYPLPTQPAPSPLPCYQGQPGGLNRHSDLSGALSSPGAAHSAPRPFSDSLHKSLTKILPERPPSAQDGLGSTRGPPSSLPQRHFPGQAYRASGVDTSPGPPDTELAAPGPPPARLPQLWDPTAAPYPTPPGGPLAATRSMFFNGQPSPGQRLCLPQSAPLPWPQVLPTARPSPHGMEMLSRLPFPAGGPEWQGGSQGALGTAGKTPGPREKLPAVRSSQGGSPALFTYNGMTDPGAQPLFFGVAQPQVSPHGTPSLPPPRVVGASPSESPLPSPATNTAGSTCSSLSPMSSSPANPSSEESQLPGPLGPSAFFHPPTHPQETGSPFPSPEPPHSLPTHYQPEPAKAFPFPADGLGAEGAFQCLEETPFPHEGPEVGRGGLQGFPRAPPPYPTHHFSLSSASLDQLDVLLTCRQCDRNYSSLAAFLAHRQFCGLLLARAKDGHQRSPGPPGLPSPPAAPRVPADAHAGLLSHAKTFLLAGDAQAEGKDDPLRTGFLPSLAATPFPLPASDLDMEDDAKLDSLITEALNGMEYQSDNPEIDSSFIDVFADEEPSGPRGPSSGHPLKSKAGVTPESKAPPPLPAATPDPQTPRPGDRGCPARGRPKTRSLGLAPTEADAPSQGRQQRRGKQLKLFRKDLDSGGAAEGSGSGGGGRASGLRPRRNDGLGERPPPRPRRPRTQAPGSRADPAPRVPRAAALPEETRSSRRRRLPPRKDPRKRKARGGAWGKELILKIVQQKNRLREYDFASESEEDEQPPPRGPGFRGRRGRGEKRKEVELTQGPREDEPQKPRKAARQEAGGDGAPANPEEPGGSRPGPGRSPQARGPSRSLETGAAAREGGPKCADRPSVAPKDPLQVPTNTETSEETRPSLDFPQEAKEPETAEESAPDSTEFTEALRSPPAACAGEMGASPGLLIPEQPPPSRHDTGTPKPSGSLANTAPHGSSPTPGVGSLLGGPGGTQAPVSHNSKDPPARQPGEFLAPVANPSSTACPKPSVLSSKISSFGCDPAGFNRDPLGVPVAKKGPQPYSSPHSELFLGPKDLAGCFLEELHPKPSARDAPPASSSCLCQDGEDAGSLEPQLPRSPPGTAETEPGRAASPPTLESSSLFPDLPVDRFDPPLYGSLSANRDSGLPFACADPPQKTVPSDPPYPSFLLLEEVSPMLPSHFPDLSGGKVLSKTCPPERTVVPGAAPSLPGKGSGCSVALMSHLSEDELEIQKLVTELESQLQRSKDTRGAPRELAEAESVGRVELGTGTEPPSQRRTCQATVPHEDTFSAADLTRVGESTAHREGAESAVATVEAVQGRPGGTWPCPASFHPGHAALLPCAQEDLVSGAPFSPRGANFHFQPVQKAGASKTGLCQAEGDSRPPQDVCLPEPSKQPGPQLDAGSLAKCSPDQELSFPKNKEAASSQESEDSLRLLPCEQRGGFLPEPGTADQPHRGAPAPEAFGSPAVHLAPDLAFQGDGAPPLDATWPFGASPSHAAQGHSAGRAGGHLHPTAGRPGFEGNEFAPAGASSLTAPRGREAWLVPVPSPACVSNTHPSRRSQDPALSPPIRQLQLPGPGVAKSKDGILGLQELTPAAQSPPRVNPSGLEGGTVEGGKVACGPAQGSPGGVQVTTLPAVAGHQLGLEADGHWGLLGQAEKTQGQGTANQLQPENGVSPGGTDNHASVNASPKTALTGPTEGAVLLEKCKGSRAAMSLQEEAEPTPSPPSPNRESLALALTAAHSRSGSEGRTPERASSPGLNKPLLATGDSPAPSVGDLAACAPSPTSAAHMPCSLGPLPREDPLTSPSRAQGGLGGQLPASPSCRDPPGPQQLLACSPAWAPLEEADGVQATTDTGAEDSPVAPPSLTTSPCDPKEALAGCLLQGEGSPLEDPSSWPPGSVSAVTCTHSGDTPKDSTLRIPEDSRKEKLWESPGRATSPPLAGAVSPSVAVRATGLSSTPTGDEAQAGRGLPGPDPQSRGAPPHTNPDRMPRGHSSYSPSNTARLGHREGQAVTAVPTEPPTLQGAGPDSPACLEGEMGTSSKEPEDPGTPETGRSGATKMPRVTCPSTGLGLGRTTAPSSTASDFQSDSPQSHRNASHQTPQGDPLGPQDLKQRSRGYKKKPASTENGQWKGQAPHGPVTCEVCAASFRSGPGLSRHKARKHRPHPGAPAEPSPAALPAQQPLEPLAQKCQPPRKKSHRVSGKERPNHSRGDPSHVTQPPPAQGSKEVLRAPGSPHSQQLHPPSPTEHEVDVKTPASKPRPDQAREDELHPKQAEKREGRRWRREPTVDSPSHSEGKSNKKRGKLRGRRLREESILPVSADVISDGRGSRPSPAMASYAASPSHCLSVEGGPEADGEQPPRLATLGPGVMEGAAETDQEALCAGETGAQKPPGDRMLCPGRMDGAALGEQPTGQKGASARGFWGPRETKALGVCKESGSEPAEDSSRAHSRSEEGVWEENTPPLGPLGFPETSSSPADSTTSSCLQGLPDNPDTQGGVQGPEGPTPDASGSSAKDPPSLFDDEVSFSQLFPPGGRLTRKRNPHVYGKRCEKPVLPLPTQPSFEEGGDPTLGPARLPTDLSDSSSLCLCHEDPWEDEDPAGLPESFLLDGFLNSRVPGIDPWAPGLSLWALEPSREAGAEKLPSHCPEDDRPEAIPELHMVPAAWRGLEMPAPADDSSSSLGDVSPEPPSLERERCDGGLPGNTHLLPLRATDFEVLSTKFEMQDLCFLGPFEDPVGLPGPSFLDFEGTASSQGPQSRRTEEAAGAGRAQGRGRPAKGRRASYKCKVCFQRFRSLGELDLHKLAHTPAPPPTCYMCVERRFGSRELLRGHLQERHAQSKAGPWACGMCLKEVADVWMYNEHLREHAVRFARRGQARRSLGDLPGGLEGSSAVAHLLNSITEPAPKHHRGKRSAGKAAGSPGDPWGQEGEAKKDSPGERAKPRARSTPSNPDGAATPDSASATALADAGSPGPPRTTPSPSPDPWAGGEPLLQATPVHEACKDPSRDCHHCGKRFPKPFKLQRHLAVHSPQRVYLCPRCPRVYPEHGELLAHLGGAHGLLERPELQHTPLYACELCATVMRIIKKSFACSSCNYTFAKKEQFDRHMNKHLRGGRQPFAFRGVRRPGAPGQKARALEGTLPSKRRRVAMPGSAPGPGEDRPPPRGSSPILSEGSLPALLHLCSEVAPSTTKGWPETLERPVDPVTHPIRGCELPSNHQECPPPSLSPFPAALADGRGDCALDGALERPENEASPGSPGPLLQQALPLGASLPRPGARGQDAEGKRAPLVFSGKRRAPGARGRCAPDHFQEDHLLQKEKEVSSSHMVSEGGPRGTFHKGSATKPAGCQSSSKDRSAASTPSKALKFPVHPRKAVGSLAPGELARGTENGMKPATPKAKPGPSSQGSGSPRPGTKTGGGSQPQPASGQLQSETATTPAKPSFPSRSPAPERLPARAQAKSCTKGPREAGEQGPHGSLGPKEKGESSTKRKKGQVPGPARSESVGSFGRAPSAPDKPPRTPRKQATPSRVLPTKPKPNSQNKPRPPPSEQRKAEPGHTQRKDRLGKAFPQGRPLLRPPKRGTAVHGAEPAEPHTHRTAEAQSDLLSQLFGQRLTGFKIPLKKDASE>sp|Q9H7M9|VISTA_HUMAN V-type immunoglobulin domain-containing suppressorof T-cell activation OS=Homo sapiens OX=9606 GN=VSIR PE=1 SV=3MGVPTALEAGSWRWGSLLFALFLAASLGPVAAFKVATPYSLYVCPEGQNVTLTCRLLGPVDKGHDVTFYKTWYRSSRGEVQTCSERRPIRNLTFQDLHLHHGGHQAANTSHDLAQRHGLESASDHHGNFSITMRNLTLLDSGLYCCLVVEIRHHHSEHRVHGAMELQVQTGKDAPSNCVVYPSSSQDSENITAAALATGACIVGILCLPLILLLVYKQRQAASNRRAQELVRMDSNIQGIENPGFEASPPAQGIPEAKVRHPLSYVAQRQPSESGRHLLSEPSTPLSPPGPGDVFFPSLDPVPDSPNFEVI>sp|Q7Z5K2|WAPL_HUMAN Wings apart-like protein homolog OS=Homo sapiensOX=9606 GN=WAPL PE=1 SV=1MTSRFGKTYSRKGGNGSSKFDEVFSNKRTTLSTKWGETTFMAKLGQKRPNFKPDIQEIPKKPKVEEESTGDPFGFDSDDESLPVSSKNLAQVKCSSYSESSEAAQLEEVTSVLEANSKISHVVVEDTVVSDKCFPLEDTLLGKEKSTNRIVEDDASISSCNKLITSDKVENFHEEHEKNSHHIHKNADDSTKKPNAETTVASEIKETNDTWNSQFGKRPESPSEISPIKGSVRTGLFEWDNDFEDIRSEDCILSLDSDPLLEMKDDDFKNRLENLNEAIEEDIVQSVLRPTNCRTYCRANKTKSSQGASNFDKLMDGTSQALAKANSESSKDGLNQAKKGGVSCGTSFRGTVGRTRDYTVLHPSCLSVCNVTIQDTMERSMDEFTASTPADLGEAGRLRKKADIATSKTTTRFRPSNTKSKKDVKLEFFGFEDHETGGDEGGSGSSNYKIKYFGFDDLSESEDDEDDDCQVERKTSKKRTKTAPSPSLQPPPESNDNSQDSQSGTNNAENLDFTEDLPGVPESVKKPINKQGDKSKENTRKIFSGPKRSPTKAVYNARHWNHPDSEELPGPPVVKPQSVTVRLSSKEPNQKDDGVFKAPAPPSKVIKTVTIPTQPYQDIVTALKCRREDKELYTVVQHVKHFNDVVEFGENQEFTDDIEYLLSGLKSTQPLNTRCLSVISLATKCAMPSFRMHLRAHGMVAMVFKTLDDSQHHQNLSLCTAALMYILSRDRLNMDLDRASLDLMIRLLELEQDASSAKLLNEKDMNKIKEKIRRLCETVHNKHLDLENITTGHLAMETLLSLTSKRAGDWFKEELRLLGGLDHIVDKVKECVDHLSRDEDEEKLVASLWGAERCLRVLESVTVHNPENQSYLIAYKDSQLIVSSAKALQHCEELIQQYNRAEDSICLADSKPLPHQNVTNHVGKAVEDCMRAIIGVLLNLTNDNEWGSTKTGEQDGLIGTALNCVLQVPKYLPQEQRFDIRVLGLGLLINLVEYSARNRHCLVNMETSCSFDSSICSGEGDDSLRIGGQVHAVQALVQLFLERERAAQLAESKTDELIKDAPTTQHDKSGEWQETSGEIQWVSTEKTDGTEEKHKKEEEDEELDLNKALQHAGKHMEDCIVASYTALLLGCLCQESPINVTTVREYLPEGDFSIMTEMLKKFLSFMNLTCAVGTTGQKSISRVIEYLEHC>sp|Q7Z5K2-2|WAPL_HUMAN Isoform 2 of Wings apart-like protein homologOS=Homo sapiens OX=9606 GN=WAPLMVQGPVQTPALTIHRRKRRRRRRRRPVAKAPARLRGEYETGVKMTSRFGKTYSRKGGNGSSKFDEVFSNKRTTLSTKWGETTFMAKLGQKRPNFKPDIQEIPKKPKVEEESTGDPFGFDSDDESLPVSSKNLAQVKCSSYSESSEAAQLEEVTSVLEANSKISHVVVEDTVVSDKCFPLEDTLLGKEKSTNRIVEDDASISSCNKLITSDKVENFHEEHEKNSHHIHKNADDSTKKPNAETTVASEIKETNDTWNSQFGKRPESPSEISPIKGSVRTGLFEWDNDFEDIRSEDCILSLDSDPLLEMKDDDFKNRLENLNEAIEEDIVQSVLRPTNCRTYCRANKTKSSQGASNFDKLMDGTSQALAKANSESSKDGLNQAKKGGVSCGTSFRGTVGRTRDYTVLHPSCLSVCNVTIQDTMERSMDEFTASTPADLGEAGRLRKKADIATSKTTTRFRPSNTKSKKDVKLEFFGFEDHETGGDEGGSGSSNYKIKYFGFDDLSESEDDEDDDCQVERKTSKKRTKTAPSPSLQPPPESNDNSQDSQSGTNNAEDLPGVPESVKKPINKQGDKSKENTRKIFSGPKRSPTKAVYNARHWNHPDSEELPGPPVVKPQSVTVRLSSKEPNQKDDGVFKAPAPPSKVIKTVTIPTQPYQDIVTALKCRREDKELYTVVQHVKHFNDVVEFGENQEFTDDIEYLLSGLKSTQPLNTRCLSVISLATKCAMPSFRMHLRAHGMVAMVFKTLDDSQHHQNLSLCTAALMYILSRDRLNMDLDRASLDLMIRLLELEQDASSAKLLNEKDMNKIKEKIRRLCETVHNKHLDLENITTGHLAMETLLSLTSKRAGDWFKEELRLLGGLDHIVDKVKECVDHLSRDEDEEKLVASLWGAERCLRVLESVTVHNPENQSYLIAYKDSQLIVSSAKALQHCEELIQQYNRAEDSICLADSKPLPHQNVTNHVGKAVEDCMRAIIGVLLNLTNDNEWGSTKTGEQDGLIGTALNCVLQVPKYLPQEQRFDIRVLGLGLLINLVEYSARNRHCLVNMETSCSFDSSICSGEGDDSLRIGGQVHAVQALVQLFLERERAAQLAESKTDELIKDAPTTQHDKSGEWQETSGEIQWVSTEKTDGTEEKHKKEEEDEELDLNKALQHAGKHMEDCIVASYTALLLGCLCQESPINVTTVREYLPEGDFSIMTEMLKKFLSFMNLTCAVGTTGQKSISRVIEYLEHC>sp|Q7Z5K2-3|WAPL_HUMAN Isoform 3 of Wings apart-like protein homologOS=Homo sapiens OX=9606 GN=WAPLMVQGPVQTPALTIHRRKRRRSCPPNRASYLPKAESLASLGSHLPALLSRARVPRPPAGRRERERRRRPVAKAPARLRGEYETGVKMTSRFGKTYSRKGGNGSSKFDEVFSNKRTTLSTKWGETTFMAKLGQKRPNFKPDIQEIPKKPKVEEESTGDPFGFDSDDESLPVSSKNLAQVKCSSYSESSEAAQLEEVTSVLEANSKISHVVVEDTVVSDKCFPLEDTLLGKEKSTNRIVEDDASISSCNKLITSDKVENFHEEHEKNSHHIHKNADDSTKKPNAETTVASEIKETNDTWNSQFGKRPESPSEISPIKGSVRTGLFEWDNDFEDIRSEDCILSLDSDPLLEMKDDDFKNRLENLNEAIEEDIVQSVLRPTNCRTYCRANKTKSSQGASNFDKLMDGTSQALAKANSESSKDGLNQAKKGGVSCGTSFRGTVGRTRDYTVLHPSCLSVCNVTIQDTMERSMDEFTASTPADLGEAGRLRKKADIATSKTTTRFRPSNTKSKKDVKLEFFGFEDHETGGDEGGSGSSNYKIKYFGFDDLSESEDDEDDDCQVERKTSKKRTKTAPSPSLQPPPESNDNSQDSQSGTNNAENLDFTEDLPGVPESVKKPINKQGDKSKENTRKIFSGPKRSPTKAVYNARHWNHPDSEELPGPPVVKPQSVTVRLSSKEPNQKDDGVFKAPAPPSKVIKTVTIPTQPYQDIVTALKCRREDKELYTVVQHVKHFNDVVEFGENQEFTDDIEYLLSGLKSTQPLNTRCLSVISLATKCAMPSFRMHLRAHGMVAMVFKTLDDSQHHQNLSLCTAALMYILSRDRLNMDLDRASLDLMIRLLELEQDASSAKLLNEKDMNKIKEKIRRLCETVHNKHLDLENITTGHLAMETLLSLTSKRAGDWFKEELRLLGGLDHIVDKVKECVDHLSRDEDEEKLVASLWGAERCLRVLESVTVHNPENQSYLIAYKDSQLIVSSAKALQHCEELIQQYNRAEDSICLADSKPLPHQNVTNHVGKAVEDCMRAIIGVLLNLTNDNEWGSTKTGEQDGLIGTALNCVLQVPKYLPQEQRFDIRVLGLGLLINLVEYSARNRHCLVNMETSCSFDSSICSGEGDDSLRIGGQVHAVQALVQLFLERERAAQLAESKTDELIKDAPTTQHDKSGEWQETSGEIQWVSTEKTDGTEEKHKKEEEDEELDLNKALQHAGKHMEDCIVASYTALLLGCLCQESPINVTTVREYLPEGDFSIMTEMLKKFLSFMNLTCAVGTTGQKSISRVIEYLEHC>sp|Q6UXN9|WDR82_HUMAN WD repeat-containing protein 82 OS=Homo sapiensOX=9606 GN=WDR82 PE=1 SV=1MKLTDSVLRSFRVAKVFRENSDKINCFDFSPNGETVISSSDDDSIVLYDCQEGKPKRTLYSKKYGVDLIRYTHAANTVVYSSNKIDDTIRYLSLHDNKYIRYFPGHSKRVVALSMSPVDDTFISGSLDKTIRLWDLRSPNCQGLMHLQGKPVCSFDPEGLIFAAGVNSEMVKLYDLRSFDKGPFATFKMQYDRTCEWTGLKFSNDGKLILISTNGSFIRLIDAFKGVVMHTFGGYANSKAVTLEASFTPDSQFIMIGSEDGKIHVWNGESGIKVAVLDGKHTGPITCLQFNPKFMTFASACSNMAFWLPTIDD>sp|Q6RFH5|WDR74_HUMAN WD repeat-containing protein 74 OS=Homo sapiensOX=9606 GN=WDR74 PE=1 SV=1MAAAAARWNHVWVGTETGILKGVNLQRKQAANFTAGGQPRREEAVSALCWGTGGETQMLVGCADRTVKHFSTEDGIFQGQRHCPGGEGMFRGLAQADGTLITCVDSGILRVWHDKDKDTSSDPLLELRVGPGVCRMRQDPAHPHVVATGGKENALKIWDLQGSEEPVFRAKNVRNDWLDLRVPIWDQDIQFLPGSQKLVTCTGYHQVRVYDPASPQRRPVLETTYGEYPLTAMTLTPGGNSVIVGNTHGQLAEIDLRQGRLLGCLKGLAGSVRGLQCHPSKPLLASCGLDRVLRIHRIQNPRGLEHKVYLKSQLNCLLLSGRDNWEDEPQEPQEPNKVPLEDTETDELWASLEAAAKRKLSGLEQPQGALQTRRRKKKRPGSTSP>sp|Q6RFH5-2|WDR74_HUMAN Isoform 2 of WD repeat-containing protein 74OS=Homo sapiens OX=9606 GN=WDR74MAAAAARWNHVWVGTETGILKGVNLQRKQAANFTAGGQPRREEAVSALCWGTGGETQMLVGCADRTVKHFSTEDGIFQGQRHCPGGEGMFRGLAQADGTLITCVDSGILRVWHDKDKDTSSDPLLELRVGPGVCRMRQDPAHPHVVATGGKENALKIWDLQGSEEPVFRAKNVRNDWLDLRVPIWDQDIQFLPGSQKLVTCTGYHQVRVYDPASPQRRPVLETTYGEYPLTAMTLTPGGNSVIVGNTHGQLAEIDLRQGRLLGCLKGLAGSVRGLQCHPSKPLLASCGLDRVLRIHRIQNPRGLEHKDEPQEPQEPNKVPLEDTETDELWASLEAAAKRKLSGLEQPQGALQTRRRKKKRPGSTSP>sp|O14980|XPO1_HUMAN Exportin-1 OS=Homo sapiens OX=9606 GN=XPO1 PE=1SV=1MPAIMTMLADHAARQLLDFSQKLDINLLDNVVNCLYHGEGAQQRMAQEVLTHLKEHPDAWTRVDTILEFSQNMNTKYYGLQILENVIKTRWKILPRNQCEGIKKYVVGLIIKTSSDPTCVEKEKVYIGKLNMILVQILKQEWPKHWPTFISDIVGASRTSESLCQNNMVILKLLSEEVFDFSSGQITQVKSKHLKDSMCNEFSQIFQLCQFVMENSQNAPLVHATLETLLRFLNWIPLGYIFETKLISTLIYKFLNVPMFRNVSLKCLTEIAGVSVSQYEEQFVTLFTLTMMQLKQMLPLNTNIRLAYSNGKDDEQNFIQNLSLFLCTFLKEHDQLIEKRLNLRETLMEALHYMLLVSEVEETEIFKICLEYWNHLAAELYRESPFSTSASPLLSGSQHFDVPPRRQLYLPMLFKVRLLMVSRMAKPEEVLVVENDQGEVVREFMKDTDSINLYKNMRETLVYLTHLDYVDTERIMTEKLHNQVNGTEWSWKNLNTLCWAIGSISGAMHEEDEKRFLVTVIKDLLGLCEQKRGKDNKAIIASNIMYIVGQYPRFLRAHWKFLKTVVNKLFEFMHETHDGVQDMACDTFIKIAQKCRRHFVQVQVGEVMPFIDEILNNINTIICDLQPQQVHTFYEAVGYMIGAQTDQTVQEHLIEKYMLLPNQVWDSIIQQATKNVDILKDPETVKQLGSILKTNVRACKAVGHPFVIQLGRIYLDMLNVYKCLSENISAAIQANGEMVTKQPLIRSMRTVKRETLKLISGWVSRSNDPQMVAENFVPPLLDAVLIDYQRNVPAAREPEVLSTMAIIVNKLGGHITAEIPQIFDAVFECTLNMINKDFEEYPEHRTNFFLLLQAVNSHCFPAFLAIPPTQFKLVLDSIIWAFKHTMRNVADTGLQILFTLLQNVAQEEAAAQSFYQTYFCDILQHIFSVVTDTSHTAGLTMHASILAYMFNLVEEGKISTSLNPGNPVNNQIFLQEYVANLLKSAFPHLQDAQVKLFVTGLFSLNQDIPAFKEHLRDFLVQIKEFAGEDTSDLFLEEREIALRQADEEKHKRQMSVPGIFNPHEIPEEMCD>sp|Q96EC8|YIPF6_HUMAN Protein YIPF6 OS=Homo sapiens OX=9606 GN=YIPF6PE=1 SV=2MAEAEESPGDPGTASPRPLFAGLSDISISQDIPVEGEITIPMRSRIREFDSSTLNESVRNTIMRDLKAVGKKFMHVLYPRKSNTLLRDWDLWGPLILCVTLALMLQRDSADSEKDGGPQFAEVFVIVWFGAVTITLNSKLLGGNISFFQSLCVLGYCILPLTVAMLICRLVLLADPGPVNFMVRLFVVIVMFAWSIVASTAFLADSQPPNRRALAVYPVFLFYFVISWMILTFTPQ>sp|Q96EC8-2|YIPF6_HUMAN Isoform 2 of Protein YIPF6 OS=Homo sapiensOX=9606 GN=YIPF6MAEAEESPGDPGTASPRPLMRDLKAVGKKFMHVLYPRKSNTLLRDWDLWGPLILCVTLALMLQRDSADSEKDGGPQFAEVFVIVWFGAVTITLNSKLLGGNISFFQSLCVLGYCILPLTVAMLICRLVLLADPGPVNFMVRLFVVIVMFAWSIVASTAFLADSQPPNRRALAVYPVFLFYFVISWMILTFTPQ>sp|Q0VFX4|YL016_HUMAN Putative uncharacterized protein LOC100128554OS=Homo sapiens OX=9606 PE=2 SV=1MLKKPSSLEQWEILGTSSGEFRCISRDCPGAGNNNREPSISTRGRTSSSKMVLPHPKVAEEAVGGPQSCKWLSCGLQGTGGGHLEGHPPRVSQESAPAGHTGISPSSSGVHLIQAKTAGWPQRVSSAEQCLLPIQHVPGADFLHVFTLRLHCGPARNAKLVEALFNSNSSC>sp|Q8NA96|YE027_HUMAN Putative uncharacterized protein FLJ35723 OS=Homosapiens OX=9606 PE=5 SV=2MPSSVPKTSIESLGSPSSLSSSQASEPLCPLKHPSHRPPASTLSPNLTSSTESLGYLSSLSSSQPPEPLRPLECPSHKPCGRSLPRRRNPGWVSWSDSMQADSETDAIICPMCKAPERSCPHTWWVPSSPRVIRGVGRCSDPNLGLSWRQEAARAWCHCTSSQYPFKHPNLPTHLPKASF>sp|Q8TF47|ZFP90_HUMAN Zinc finger protein 90 homolog OS=Homo sapiensOX=9606 GN=ZFP90 PE=1 SV=2MAPRPPTAAPQESVTFKDVSVDFTQEEWYHVDPAQRSLYRDVMLENYSHLVSLGYQVSKPEVIFKLEQGEEPWISEGEIQRPFYPDWKTRPEVKSSHLQQDVSEVSHCTHDLLHATLEDSWDVSSQLDRQQENWKRHLGSEASTQKKIITPQENFEQNKFGENSRLNTNLVTQLNIPARIRPSECETLGSNLGHNADLLNENNILAKKKPYKCDKCRKAFIHRSSLTKHEKTHKGEGAFPNGTDQGIYPGKKHHECTDCGKTFLWKTQLTEHQRIHTGEKPFECNVCGKAFRHSSSLGQHENAHTGEKPYQCSLCGKAFQRSSSLVQHQRIHTGEKPYRCNLCGRSFRHGTSLTQHEVTHSGEKPFQCKECGKAFSRCSSLVQHERTHTGEKPFECSICGRAFGQSPSLYKHMRIHKRGKPYQSSNYSIDFKHSTSLTQDESTLTEVKSYHCNDCGEDFSHITDFTDHQRIHTAENPYDCEQAFSQQAISHPGEKPYQCNVCGKAFKRSTSFIEHHRIHTGEKPYECNECGEAFSRRSSLTQHERTHTGEKPYECIDCGKAFSQSSSLIQHERTHTGEKPYECNECGRAFRKKTNLHDHQRIHTGEKPYSCKECGKNFSRSSALTKHQRIHTRNKL>sp|Q8TF47-3|ZFP90_HUMAN Isoform 2 of Zinc finger protein 90 homologOS=Homo sapiens OX=9606 GN=ZFP90MAPRPPTAAPQESVTFKDVSVDFTQEEWYHVDPAQRSLYRDVMLENYSHLVSLGYQVSKPEVIFKLEQGEEPWISEGEIQRPFYPGFVCLLPLSLPSGSKGERRQKLPRKNPE>sp|Q5D1E8|ZC12A_HUMAN Endoribonuclease ZC3H12A OS=Homo sapiens OX=9606GN=ZC3H12A PE=1 SV=1MSGPCGEKPVLEASPTMSLWEFEDSHSRQGTPRPGQELAAEEASALELQMKVDFFRKLGYSSTEIHSVLQKLGVQADTNTVLGELVKHGTATERERQTSPDPCPQLPLVPRGGGTPKAPNLEPPLPEEEKEGSDLRPVVIDGSNVAMSHGNKEVFSCRGILLAVNWFLERGHTDITVFVPSWRKEQPRPDVPITDQHILRELEKKKILVFTPSRRVGGKRVVCYDDRFIVKLAYESDGIVVSNDTYRDLQGERQEWKRFIEERLLMYSFVNDKFMPPDDPLGRHGPSLDNFLRKKPLTLEHRKQPCPYGRKCTYGIKCRFFHPERPSCPQRSVADELRANALLSPPRAPSKDKNGRRPSPSSQSSSLLTESEQCSLDGKKLGAQASPGSRQEGLTQTYAPSGRSLAPSGGSGSSFGPTDWLPQTLDSLPYVSQDCLDSGIGSLESQMSELWGVRGGGPGEPGPPRAPYTGYSPYGSELPATAAFSAFGRAMGAGHFSVPADYPPAPPAFPPREYWSEPYPLPPPTSVLQEPPVQSPGAGRSPWGRAGSLAKEQASVYTKLCGVFPPHLVEAVMGRFPQLLDPQQLAAEILSYKSQHPSE>sp|Q9UJW7|ZN229_HUMAN Zinc finger protein 229 OS=Homo sapiens OX=9606GN=ZNF229 PE=1 SV=3METLTSRHEKRALHSQASAISQDREEKIMSQEPLSFKDVAVVFTEEELELLDSTQRQLYQDVMQENFRNLLSVGERNPLGDKNGKDTEYIQDEELRFFSHKELSSCKIWEEVAGELPGSQDCRVNLQGKDFQFSEDAAPHQGWEGASTPCFPIENSLDSLQGDGLIGLENQQFPAWRAIRPIPIQGSWAKAFVNQLGDVQERCKNLDTEDTVYKCNWDDDSFCWISCHVDHRFPEIDKPCGCNKCRKDCIKNSVLHRINPGENGLKSNEYRNGFRDDADLPPHPRVPLKEKLCQYDEFSEGLRHSAHLNRHQRVPTGEKSVKSLERGRGVRQNTHIRNHPRAPVGDMPYRCDVCGKGFRYKSVLLIHQGVHTGRRPYKCEECGKAFGRSSNLLVHQRVHTGEKPYKCSECGKGFSYSSVLQVHQRLHTGEKPYTCSECGKGFCAKSALHKHQHIHPGEKPYSCGECGKGFSCSSHLSSHQKTHTGERPYQCDKCGKGFSHNSYLQAHQRVHMGQHLYKCNVCGKSFSYSSGLLMHQRLHTGEKPYKCECGKSFGRSSDLHIHQRVHTGEKPYKCSECGKGFRRNSDLHSHQRVHTGERPYVCDVCGKGFIYSSDLLIHQRVHTGEKPYKCAECGKGFSYSSGLLIHQRVHTGEKPYRCQECGKGFRCTSSLHKHQRVHTGKKPYTCDQCGKGFSYGSNLRTHQRLHTGEKPYTCCECGKGFRYGSGLLSHKRVHTGEKPYRCHVCGKGYSQSSHLQGHQRVHTGEKPYKCEECGKGFGRNSCLHVHQRVHTGEKPYTCGVCGKGFSYTSGLRNHQRVHLGENPYK>sp|Q9UJW7-2|ZN229_HUMAN Isoform 2 of Zinc finger protein 229 OS=Homosapiens OX=9606 GN=ZNF229METLTSRHEKRALHSQASAISQDREEKIMSQEPLSFKDVAVVFTEEELELLDSTQRQLYQDVMQENFRNLLSVGDKNGKDTEYIQDEELRFFSHKELSSCKIWEEVAGELPGSQDCRVNLQGKDFQFSEDAAPHQGWEGASTPCFPIENSLDSLQGDGLIGLENQQFPAWRAIRPIPIQGSWAKAFVNQLGDVQERCKNLDTEDTVYKCNWDDDSFCWISCHVDHRFPEIDKPCGCNKCRKDCIKNSVLHRINPGENGLKSNEYRNGFRDDADLPPHPRVPLKEKLCQYDEFSEGLRHSAHLNRHQRVPTGEKSVKSLERGRGVRQNTHIRNHPRAPVGDMPYRCDVCGKGFRYKSVLLIHQGVHTGRRPYKCEECGKAFGRSSNLLVHQRVHTGEKPYKCSECGKGFSYSSVLQVHQRLHTGEKPYTCSECGKGFCAKSALHKHQHIHPGEKPYSCGECGKGFSCSSHLSSHQKTHTGERPYQCDKCGKGFSHNSYLQAHQRVHMGQHLYKCNVCGKSFSYSSGLLMHQRLHTGEKPYKCECGKSFGRSSDLHIHQRVHTGEKPYKCSECGKGFRRNSDLHSHQRVHTGERPYVCDVCGKGFIYSSDLLIHQRVHTGEKPYKCAECGKGFSYSSGLLIHQRVHTGEKPYRCQECGKGFRCTSSLHKHQRVHTGKKPYTCDQCGKGFSYGSNLRTHQRLHTGEKPYTCCECGKGFRYGSGLLSHKRVHTGEKPYRCHVCGKGYSQSSHLQGHQRVHTGEKPYKCEECGKGFGRNSCLHVHQRVHTGEKPYTCGVCGKGFSYTSGLRNHQRVHLGENPYK>sp|Q6ZTC4|YT009_HUMAN Putative uncharacterized protein FLJ44790 OS=Homosapiens OX=9606 PE=2 SV=1MQLGEHTHPQKNPKSLAGCLLPNPHPQLQLRGKRAAGLLLRRNPWCHPQAPGGSSTWAPSLPPILAPQAYLNFAPPTLVPGGSPGTEAQPVAPANALGSRSKLNLTQPSCLSSGSHLPLPFPAGMCPHPANPTWALRKGAEVPQGPPLSHTRKALCLAASGVGALLLEVPRHPGWGQQSAAGFQQVFQEGAGTHFPSVRVQPGRGKLQGQR>sp|O75820|ZN189_HUMAN Zinc finger protein 189 OS=Homo sapiens OX=9606GN=ZNF189 PE=1 SV=2MASPSPPPESKGLLTFEDVAVFFTQEEWDYLDPAQRSLYKDVMMENYGNLVSLDVLNRDKDEEPTVKQEIEEIEEEVEPQGVIVTRIKSEIDQDPMGRETFELVGRLDKQRGIFLWEIPRESLTQEQRMFRENTNIIRKRPNSEEKCHKCEECGKGFVRKAHFIQHQRVHTGEKPFQCNECGKSFSRSSFVIEHQRIHTGERPYECNYCGKTFSVSSTLIRHQRIHTGERPYQCNQCKQSFSQRRSLVKHQRIHTGEKPHKCSDCGKAFSWKSHLIEHQRTHTGEKPYHCTKCKKSFSRNSLLVEHQRIHTGERPHKCGECGKAFRLSTYLIQHQKIHTGEKPFLCIECGKSFSRSSFLIEHQRIHTGERPYQCKECGKSFSQLCNLTRHQRIHTGDKPHKCEECGKAFSRSSGLIQHQRIHTREKTYPYNETKESFDPNCSLVIQQEVYPKEKSYKCDECGKTFSVSAHLVQHQRIHTGEKPYLCTVCGKSFSRSSFLIEHQRIHTGERPYLCRQCGKSFSQLCNLIRHQGVHTGNKPHKCDECGKAFSRNSGLIQHQRIHTGEKPYKCEKCDKSFSQQRSLVNHQKIHAEVKTQETHECDACGEAFNCRISLIQHQKLHTAWMQ>sp|O75820-2|ZN189_HUMAN Isoform 2 of Zinc finger protein 189 OS=Homosapiens OX=9606 GN=ZNF189MASPSPPPESKEEWDYLDPAQRSLYKDVMMENYGNLVSLDVLNRDKDEEPTVKQEIEEIEEEVEPQGVIVTRIKSEIDQDPMGRETFELVGRLDKQRGIFLWEIPRESLTQEQRMFRENTNIIRKRPNSEEKCHKCEECGKGFVRKAHFIQHQRVHTGEKPFQCNECGKSFSRSSFVIEHQRIHTGERPYECNYCGKTFSVSSTLIRHQRIHTGERPYQCNQCKQSFSQRRSLVKHQRIHTGEKPHKCSDCGKAFSWKSHLIEHQRTHTGEKPYHCTKCKKSFSRNSLLVEHQRIHTGERPHKCGECGKAFRLSTYLIQHQKIHTGEKPFLCIECGKSFSRSSFLIEHQRIHTGERPYQCKECGKSFSQLCNLTRHQRIHTGDKPHKCEECGKAFSRSSGLIQHQRIHTREKTYPYNETKESFDPNCSLVIQQEVYPKEKSYKCDECGKTFSVSAHLVQHQRIHTGEKPYLCTVCGKSFSRSSFLIEHQRIHTGERPYLCRQCGKSFSQLCNLIRHQGVHTGNKPHKCDECGKAFSRNSGLIQHQRIHTGEKPYKCEKCDKSFSQQRSLVNHQKIHAEVKTQETHECDACGEAFNCRISLIQHQKLHTAWMQ>sp|O75820-3|ZN189_HUMAN Isoform 3 of Zinc finger protein 189 OS=Homosapiens OX=9606 GN=ZNF189MGRETFELVGRLDKQRGIFLWEIPRESLTQEQRMFRENTNIIRKRPNSEEKCHKCEECGKGFVRKAHFIQHQRVHTGEKPFQCNECGKSFSRSSFVIEHQRIHTGERPYECNYCGKTFSVSSTLIRHQRIHTGERPYQCNQCKQSFSQRRSLVKHQRIHTGEKPHKCSDCGKAFSWKSHLIEHQRTHTGEKPYHCTKCKKSFSRNSLLVEHQRIHTGERPHKCGECGKAFRLSTYLIQHQKIHTGEKPFLCIECGKSFSRSSFLIEHQRIHTGERPYQCKECGKSFSQLCNLTRHQRIHTGDKPHKCEECGKAFSRSSGLIQHQRIHTREKTYPYNETKESFDPNCSLVIQQEVYPKEKSYKCDECGKTFSVSAHLVQHQRIHTGEKPYLCTVCGKSFSRSSFLIEHQRIHTGERPYLCRQCGKSFSQLCNLIRHQGVHTGNKPHKCDECGKAFSRNSGLIQHQRIHTGEKPYKCEKCDKSFSQQRSLVNHQKIHAEVKTQETHECDACGEAFNCRISLIQHQKLHTAWMQ>sp|O75820-4|ZN189_HUMAN Isoform 4 of Zinc finger protein 189 OS=Homosapiens OX=9606 GN=ZNF189MMENYGNLVSLDVLNRDKDEEPTVKQEIEEIEEEVEPQGVIVTRIKSEIDQDPMGRETFELVGRLDKQRGIFLWEIPRESLTQEQRMFRENTNIIRKRPNSEEKCHKCEECGKGFVRKAHFIQHQRVHTGEKPFQCNECGKSFSRSSFVIEHQRIHTGERPYECNYCGKTFSVSSTLIRHQRIHTGERPYQCNQCKQSFSQRRSLVKHQRIHTGEKPHKCSDCGKAFSWKSHLIEHQRTHTGEKPYHCTKCKKSFSRNSLLVEHQRIHTGERPHKCGECGKAFRLSTYLIQHQKIHTGEKPFLCIECGKSFSRSSFLIEHQRIHTGERPYQCKECGKSFSQLCNLTRHQRIHTGDKPHKCEECGKAFSRSSGLIQHQRIHTREKTYPYNETKESFDPNCSLVIQQEVYPKEKSYKCDECGKTFSVSAHLVQHQRIHTGEKPYLCTVCGKSFSRSSFLIEHQRIHTGERPYLCRQCGKSFSQLCNLIRHQGVHTGNKPHKCDECGKAFSRNSGLIQHQRIHTGEKPYKCEKCDKSFSQQRSLVNHQKIHAEVKTQETHECDACGEAFNCRISLIQHQKLHTAWMQ>sp|Q99676|ZN184_HUMAN Zinc finger protein 184 OS=Homo sapiens OX=9606GN=ZNF184 PE=1 SV=4MEDLSSPDSTLLQGGHNLLSSASFQEAVTFKDVIVDFTQEEWKQLDPGQRDLFRDVTLENYTHLVSIGLQVSKPDVISQLEQGTEPWIMEPSIPVGTCADWETRLENSVSAPEPDISEEELSPEVIVEKHKRDDSWSSNLLESWEYEGSLERQQANQQTLPKEIKVTEKTIPSWEKGPVNNEFGKSVNVSSNLVTQEPSPEETSTKRSIKQNSNPVKKEKSCKCNECGKAFSYCSALIRHQRTHTGEKPYKCNECEKAFSRSENLINHQRIHTGDKPYKCDQCGKGFIEGPSLTQHQRIHTGEKPYKCDECGKAFSQRTHLVQHQRIHTGEKPYTCNECGKAFSQRGHFMEHQKIHTGEKPFKCDECDKTFTRSTHLTQHQKIHTGEKTYKCNECGKAFNGPSTFIRHHMIHTGEKPYECNECGKAFSQHSNLTQHQKTHTGEKPYDCAECGKSFSYWSSLAQHLKIHTGEKPYKCNECGKAFSYCSSLTQHRRIHTREKPFECSECGKAFSYLSNLNQHQKTHTQEKAYECKECGKAFIRSSSLAKHERIHTGEKPYQCHECGKTFSYGSSLIQHRKIHTGERPYKCNECGRAFNQNIHLTQHKRIHTGAKPYECAECGKAFRHCSSLAQHQKTHTEEKPYQCNKCEKTFSQSSHLTQHQRIHTGEKPYKCNECDKAFSRSTHLTEHQNTHTGEKPYNCNECRKTFSQSTYLIQHQRIHSGEKPFGCNDCGKSFRYRSALNKHQRLHPGI>sp|Q15776|ZKSC8_HUMAN Zinc finger protein with KRAB and SCAN domains 8OS=Homo sapiens OX=9606 GN=ZKSCAN8 PE=1 SV=2MAEESRKPSAPSPPDQTPEEDLVIVKVEEDHGWDQESSLHESNPLGQEVFRLRFRQLRYQETLGPREALIQLRALCHQWLRPDLNTKEQILELLVLEQFLTILPEELQTLVKEHQLENGEEVVTLLEDLERQIDILGRPVSARVHGHRVLWEEVVHSASAPEPPNTQLQSEATQHKSPVPQESQERAMSTSQSPTRSQKGSSGDQEMTATLLTAGFQTLEKIEDMAVSLIREEWLLDPSQKDLCRDNRPENFRNMFSLGGETRSENRELASKQVISTGIQPHGETAAKCNGDVIRGLEHEEARDLLGRLERQRGNPTQERRHKCDECGKSFAQSSGLVRHWRIHTGEKPYQCNVCGKAFSYRSALLSHQDIHNKVKRYHCKECGKAFSQNTGLILHQRIHTGEKPYQCNQCGKAFSQSAGLILHQRIHSGERPYECNECGKAFSHSSHLIGHQRIHTGEKPYECDECGKTFRRSSHLIGHQRSHTGEKPYKCNECGRAFSQKSGLIEHQRIHTGERPYKCKECGKAFNGNTGLIQHLRIHTGEKPYQCNECGKAFIQRSSLIRHQRIHSGEKSESISV>sp|Q15776-2|ZKSC8_HUMAN Isoform 2 of Zinc finger protein with KRAB andSCAN domains 8 OS=Homo sapiens OX=9606 GN=ZKSCAN8MAEESRKPSAPSPPDQTPEEDLVIVKVEEDHGWDQESSLHESNPLGQEVFRLRFRQLRYQETLGPREALIQLRALCHQWLRPDLNTKEQILELLVLEQFLTILPEELQTLVKEHQLENGEEVVTLLEDLERQIDILGRPVSRRRSQLAYMDIGYSGRR>sp|Q8TCH9|YV004_HUMAN Putative uncharacterized protein FLJ23865 OS=Homosapiens OX=9606 PE=2 SV=1MPSTEGFGGLDRLVLPPPPQVLPLLSPARGRIQFSGRKSTGSWVTQMENLLLAQPLPDDCEILCGWRSLLHLTFLIGFAPHFPHWFCNHHCHQHPPSHLTEVLQSSGELAHQLAPSRCSMRAEGTHRG>sp|Q6ZQY7|YO026_HUMAN Putative uncharacterized protein FLJ46792 OS=Homosapiens OX=9606 PE=2 SV=1MISFHVIFLSLGRGKLFLPVNFCFLKLKNSQVRIPKDFTCNLHVLFRTVQGEDRNTMFRGHWSIYSRNFPLAVVPAYVTEDGKNTSHRASGQFCNALSQGEIPSSLQLVNSYALEPRTDMPCNFLT>sp|Q8TBZ8|ZN564_HUMAN Zinc finger protein 564 OS=Homo sapiens OX=9606GN=ZNF564 PE=1 SV=1MDSVASEDVAVNFTLEEWALLDPSQKKLYRDVMRETFRNLACVGKKWEDQSIEDWYKNQGRILRNHMEEGLSESKEYDQCGEAFSQILNLNLNKKIPTIVRPCECSLCGKVFMHHSSLSRHIRSHLGHKPYDYQEYGEKPYKCKQCGKAFSSCQSFRRHERTHTGEKPYACPECGKAFISLPSVRRHMIKHTGDGPYKCQECGKAFDRPSLFQIHERTHTGEKPYECQECAKAFISLPSFQRHMIRHTGDGPYKCQECGKAFDRPSLFRIHERTHTGEKPHECKQCGKAFISFTNFQSHMIRHTGDGPYKCKVCGRAFIFPSYVRKHERTHTGEKPYECNKCGKTFSSSSNVRTHERTHTGEKPYECKECGKAFISLPSVRRHMIKHTGDGPYKCQVCGRAFDCPSSFQIHERTHTGEKPYECQVCGKAFISLKRIRKHMILHTGDGPYKCQVCGKAFDCPSSVRTHERTHTGEKPYECKECGKAFNYASSIRIHERTHTGEKPYECKQCGKTFSYSSSFQRHERAHNGDKPYVKNVGKLSFITQPSNTCENE>sp|O60304|ZN500_HUMAN Zinc finger protein 500 OS=Homo sapiens OX=9606GN=ZNF500 PE=1 SV=2MATVPGLQPLPTLEQDLEQEEILIVKVEEDFCLEEEPSVETEDPSPETFRQLFRLFCYQEVAGPREALSRLWELCCRWLRPELRTKEQILELLVLEQFLTVLPGEIQARVREQQPESGEEAVVLVEGLQRKPRKHRQRGSELLSDDEVPLGIGGQFLKHQAEAQPEDLSLEEEARFSSQQPPAQLSHRPQRGPLLWPERGPPAPRHQEMASASPFLSAWSQVPVNLEDVAVYLSGEEPRCMDPAQRDAPLENEGPGIQLEDGGDGREDAPLRMEWYRVLSARCQGPGHPLPGQRPAPVRGLVRPDQPRGGPPPGRRASHGADKPYTCPECGKGFSKTSHLTKHQRTHTGERPYKCLVCGKGFSDRSNFSTHQRVHTGEKPYPCPECGKRFSQSSSLVIHRRTHSGERPYACTQCGKRFNNSSHFSAHRRTHTGEKPYTCPACGRGFRRGTDLHKHQRTHMGAGSLPTLQPVAPGGPGAKA>sp|O60304-2|ZN500_HUMAN Isoform 2 of Zinc finger protein 500 OS=Homosapiens OX=9606 GN=ZNF500MATVPGLQPLPTLEQDLEQEEILIVKVEEDFCLEEEPSVETEDPSPETFRQLFRLFCYQEVAGPREALSRLWELCCRWLRPELRTKEQILELLVLEQFLTVLPGEIQARVREQQPESGEEAVVLVEGLQRKPRKHRQRGSELLSDDEVPLGIGGQFLKHQAEAQPEDLSLEEEARFSSQQPPAQLSHRPQRGPLLWPERGPPAPRHQEMASASPFLSAWSQVPVNLEDVAVYLSGEEPRCMDPAQRDAPLENEGPGIQLEDGGDGREDAPLRMEWYRVLSARCQGPGHPLPGQRPAPVRGLVRPDQPRGGPPPGRRASHGADKPYTCPECGKGFSKTSHLTKHQRTHTGERPYKCLVCGKGFSDRSNFSTHQRVHTGEKPYPCPECGKRFSQSSSLVIHRRTHSGERPYACTQCGKRFNNSSHFSAHRRTHTGHILRSGCT>sp|Q8N8E2|ZN513_HUMAN Zinc finger protein 513 OS=Homo sapiens OX=9606GN=ZNF513 PE=1 SV=2MPRRKQSHPQPVKCEGVKVDTEDSLDEGPGALVLESDLLLGQDLEFEEEEEEEEGDGNSDQLMGFERDSEGDSLGARPGLPYGLSDDESGGGRALSAESEVEEPARGPGEARGERPGPACQLCGGPTGEGPCCGAGGPGGGPLLPPRLLYSCRLCTFVSHYSSHLKRHMQTHSGEKPFRCGRCPYASAQLVNLTRHTRTHTGEKPYRCPHCPFACSSLGNLRRHQRTHAGPPTPPCPTCGFRCCTPRPARPPSPTEQEGAVPRRPEDALLLPDLSLHVPPGGASFLPDCGQLRGEGEGLCGTGSEPLPELLFPWTCRGCGQELEEGEGSRLGAAMCGRCMRGEAGGGASGGPQGPSDKGFACSLCPFATHYPNHLARHMKTHSGEKPFRCARCPYASAHLDNLKRHQRVHTGEKPYKCPLCPYACGNLANLKRHGRIHSGDKPFRCSLCNYSCNQSMNLKRHMLRHTGEKPFRCATCAYTTGHWDNYKRHQKVHGHGGAGGPGLSASEGWAPPHSPPSVLSSRGPPALGTAGSRAVHTDSS>sp|Q8N8E2-2|ZN513_HUMAN Isoform 2 of Zinc finger protein 513 OS=Homosapiens OX=9606 GN=ZNF513MGFERDSEGDSLGARPGLPYGLSDDESGGGRALSAESEVEEPARGPGEARGERPGPACQLCGGPTGEGPCCGAGGPGGGPLLPPRLLYSCRLCTFVSHYSSHLKRHMQTHSGEKPFRCGRCPYASAQLVNLTRHTRTHTGEKPYRCPHCPFACSSLGNLRRHQRTHAGPPTPPCPTCGFRCCTPRPARPPSPTEQEGAVPRRPEDALLLPDLSLHVPPGGASFLPDCGQLRGEGEGLCGTGSEPLPELLFPWTCRGCGQELEEGEGSRLGAAMCGRCMRGEAGGGASGGPQGPSDKGFACSLCPFATHYPNHLARHMKTHSGEKPFRCARCPYASAHLDNLKRHQRVHTGEKPYKCPLCPYACGNLANLKRHGRIHSGDKPFRCSLCNYSCNQSMNLKRHMLRHTGEKPFRCATCAYTTGHWDNYKRHQKVHGHGGAGGPGLSASEGWAPPHSPPSVLSSRGPPALGTAGSRAVHTDSS>sp|Q8N8E2-3|ZN513_HUMAN Isoform 3 of Zinc finger protein 513 OS=Homosapiens OX=9606 GN=ZNF513MCGRCMRGEAGGGASGGPQGPSDKGFACSLCPFATHYPNHLARHMKTHSGEKPFRCARCPYASAHLDNLKRHQRVHTGEKPYKCPLCPYACGNLANLKRHGRIHSGDKPFRCSLCNYSCNQSMNLKRHMLRHTGEKPFRCATCAYTTGHWDNYKRHQKVHGHGGAGGPGLSASEGWAPPHSPPSVLSSRGPPALGTAGSRAVHTDSS>sp|Q92610|ZN592_HUMAN Zinc finger protein 592 OS=Homo sapiens OX=9606GN=ZNF592 PE=1 SV=2MGDMKTPDFDDLLAAFDIPDPTSLDAKEAIQTPSEENESPLKPPGICMDESVSLSHSGSAPDVPAVSVIVKNTSRQESFEAEKDHITPSLLHNGFRGSDLPPDPHNCGKFDSTFMNGDSARSFPGKLEPPKSEPLPTFNQFSPISSPEPEDPIKDNGFGIKPKHSDSYFPPPLGCGAVGGPVLEALAKFPVPELHMFDHFCKKEPKPEPLPLGSQQEHEQSGQNTVEPHKDPDATRFFGEALEFNSHPSNSIGESKGLARELGTCSSVPPRQRLKPAHSKLSSCVAALVALQAKRVASVTKEDQPGHTKDLSGPTKESSKGSPKMPKSPKSPRSPLEATRKSIKPSDSPRSICSDSSSKGSPSVAASSPPAIPKVRIKTIKTSSGEIKRTVTRILPDPDDPSKSPVGSPLGSAIAEAPSEMPGDEVPVEEHFPEAGTNSGSPQGARKGDESMTKASDSSSPSCSSGPRVPKGAAPGSQTGKKQQSTALQASTLAPANLLPKAVHLANLNLVPHSVAASVTAKSSVQRRSQPQLTQMSVPLVHQVKKAAPLIVEVFNKVLHSSNPVPLYAPNLSPPADSRIHVPASGYCCLECGDAFALEKSLSQHYGRRSVHIEVLCTLCSKTLLFFNKCSLLRHARDHKSKGLVMQCSQLLVKPISADQMFVSAPVNSTAPAAPAPSSSPKHGLTSGSASPPPPALPLYPDPVRLIRYSIKCLECHKQMRDYMVLAAHFQRTTEETEGLTCQVCQMLLPNQCSFCAHQRIHAHKSPYCCPECGVLCRSAYFQTHVKENCLHYARKVGYRCIHCGVVHLTLALLKSHIQERHCQVFHKCAFCPMAFKTASSTADHSATQHPTQPHRPSQLIYKCSCEMVFNKKRHIQQHFYQNVSKTQVGVFKCPECPLLFVQKPELMQHVKSTHGVPRNVDELSSLQSSADTSSSRPGSRVPTEPPATSVAARSSSLPSGRWGRPEAHRRVEARPRLRNTGWTCQECQEWVPDRESYVSHMKKSHGRTLKRYPCRQCEQSFHTPNSLRKHIRNNHDTVKKFYTCGYCTEDSPSFPRPSLLESHISLMHGIRNPDLSQTSKVKPPGGHSPQVNHLKRPVSGVGDAPGTSNGATVSSTKRHKSLFQCAKCSFATDSGLEFQSHIPQHQVDSSTAQCLLCGLCYTSASSLSRHLFIVHKVRDQEEEEEEEAAAAEMAVEVAEPEEGSGEEVPMETRENGLEECAGEPLSADPEARRLLGPAPEDDGGHNDHSQPQASQDQDSHTLSPQV>sp|O15014|ZN609_HUMAN Zinc finger protein 609 OS=Homo sapiens OX=9606GN=ZNF609 PE=1 SV=2MSLSSGASGGKGVDANPVETYDSGDEWDIGVGNLIIDLDADLEKDQQKLEMSGSKEVGIPAPNAVATLPDNIKFVTPVPGPQGKEGKSKSKRSKSGKDTSKPTPGTSLFTPSEGAASKKEVQGRSGDGANAGGLVAAIAPKGSEKAAKASRSVAGSKKEKENSSSKSKKERSEGVGTCSEKDPGVLQPVPLGGRGGQYDGSAGVDTGAVEPLGSIAIEPGAALNPLGTKPEPEEGENECRLLKKVKSEKMESPVSTPAVLPIHLLVPVVNNDISSPCEQIMVRTRSVGVNTCDVALATEPECLGPCEPGTSVNLEGIVWQETEDGMLVVNVTWRNKTYVGTLLDCTRHDWAPPRFCDSPTSDLEMRNGRGRGKRMRPNSNTPVNETATASDSKGTSNSSKTRAGANSKGRRGSQNSSEHRPPASSTSEDVKASPSSANKRKNKPLSDMELNSSSEDSKGSKRVRTNSMGSATGPLPGTKVEPTVLDRNCPSPVLIDCPHPNCNKKYKHINGLKYHQAHAHTDDDSKPEADGDSEYGEEPILHADLGSCNGASVSQKGSLSPARSATPKVRLVEPHSPSPSSKFSTKGLCKKKLSGEGDTDLGALSNDGSDDGPSVMDETSNDAFDSLERKCMEKEKCKKPSSLKPEKIPSKSLKSARPIAPAIPPQQIYTFQTATFTAASPGSSSGLTATVAQAMPNSPQLKPIQPKPTVMGEPFTVNPALTPAKDKKKKDKKKKESSKELESPLTPGKVCRAEEGKSPFRESSGDGMKMEGLLNGSSDPHQSRLASIKAEADKIYSFTDNAPSPSIGGSSRLENTTPTQPLTPLHVVTQNGAEASSVKTNSPAYSDISDAGEDGEGKVDSVKSKDAEQLVKEGAKKTLFPPQPQSKDSPYYQGFESYYSPSYAQSSPGALNPSSQAGVESQALKTKRDEEPESIEGKVKNDICEEKKPELSSSSQQPSVIQQRPNMYMQSLYYNQYAYVPPYGYSDQSYHTHLLSTNTAYRQQYEEQQKRQSLEQQQRGVDKKAEMGLKEREAALKEEWKQKPSIPPTLTKAPSLTDLVKSGPGKAKEPGADPAKSVIIPKLDDSSKLPGQAPEGLKVKLSDASHLSKEASEAKTGAECGRQAEMDPILWYRQEAEPRMWTYVYPAKYSDIKSEDERWKEERDRKLKEERSRSKDSVPKEDGKESTSSDCKLPTSEESRLGSKEPRPSVHVPVSSPLTQHQSYIPYMHGYSYSQSYDPNHPSYRSMPAVMMQNYPGSYLPSSYSFSPYGSKVSGGEDADKARASPSVTCKSSSESKALDILQQHASHYKSKSPTISDKTSQERDRGGCGVVGGGGSCSSVGGASGGERSVDRPRTSPSQRLMSTHHHHHHLGYSLLPAQYNLPYAAGLSSTAIVASQQGSTPSLYPPPRR>sp|O15014-2|ZN609_HUMAN Isoform 2 of Zinc finger protein 609 OS=Homosapiens OX=9606 GN=ZNF609MSLSSGASGGKGVDANPVETYDSGDEWDIGVGNLIIDLDADLEKDQQKLEMSGSKEVGIPAPNAVATLPDNIKFVTPVPGPQGKEGKSKSKRSKSGKDTSKPTPGTSLFTPSEGAASKKEVQGRSGDGANAGGLVAAIAPKGSEKAAKASRSVAGSKKEKENSSSKSKKERSEGVGTCSEKDPGVLQPVPLGGRGGQYDGSAGVDTGAVEPLGSIAIEPGAALNPLGTKPEPEEGENECRLLKKVKSEKQ>sp|Q9UM01|YLAT1_HUMAN Y+L amino acid transporter 1 OS=Homo sapiensOX=9606 GN=SLC7A7 PE=1 SV=2MVDSTEYEVASQPEVETSPLGDGASPGPEQVKLKKEISLLNGVCLIVGNMIGSGIFVSPKGVLIYSASFGLSLVIWAVGGLFSVFGALCYAELGTTIKKSGASYAYILEAFGGFLAFIRLWTSLLIIEPTSQAIIAITFANYMVQPLFPSCFAPYAASRLLAAACICLLTFINCAYVKWGTLVQDIFTYAKVLALIAVIVAGIVRLGQGASTHFENSFEGSSFAVGDIALALYSALFSYSGWDTLNYVTEEIKNPERNLPLSIGISMPIVTIIYILTNVAYYTVLDMRDILASDAVAVTFADQIFGIFNWIIPLSVALSCFGGLNASIVAASRLFFVGSREGHLPDAICMIHVERFTPVPSLLFNGIMALIYLCVEDIFQLINYYSFSYWFFVGLSIVGQLYLRWKEPDRPRPLKLSVFFPIVFCLCTIFLVAVPLYSDTINSLIGIAIALSGLPFYFLIIRVPEHKRPLYLRRIVGSATRYLQVLCMSVAAEMDLEDGGEMPKQRDPKSN>sp|Q07157|ZO1_HUMAN Tight junction protein ZO-1 OS=Homo sapiens OX=9606GN=TJP1 PE=1 SV=3MSARAAAAKSTAMEETAIWEQHTVTLHRAPGFGFGIAISGGRDNPHFQSGETSIVISDVLKGGPAEGQLQENDRVAMVNGVSMDNVEHAFAVQQLRKSGKNAKITIRRKKKVQIPVSRPDPEPVSDNEEDSYDEEIHDPRSGRSGVVNRRSEKIWPRDRSASRERSLSPRSDRRSVASSQPAKPTKVTLVKSRKNEEYGLRLASHIFVKEISQDSLAARDGNIQEGDVVLKINGTVTENMSLTDAKTLIERSKGKLKMVVQRDERATLLNVPDLSDSIHSANASERDDISEIQSLASDHSGRSHDRPPRRSRSRSPDQRSEPSDHSRHSPQQPSNGSLRSRDEERISKPGAVSTPVKHADDHTPKTVEEVTVERNEKQTPSLPEPKPVYAQVGQPDVDLPVSPSDGVLPNSTHEDGILRPSMKLVKFRKGDSVGLRLAGGNDVGIFVAGVLEDSPAAKEGLEEGDQILRVNNVDFTNIIREEAVLFLLDLPKGEEVTILAQKKKDVYRRIVESDVGDSFYIRTHFEYEKESPYGLSFNKGEVFRVVDTLYNGKLGSWLAIRIGKNHKEVERGIIPNKNRAEQLASVQYTLPKTAGGDRADFWRFRGLRSSKRNLRKSREDLSAQPVQTKFPAYERVVLREAGFLRPVTIFGPIADVAREKLAREEPDIYQIAKSEPRDAGTDQRSSGIIRLHTIKQIIDQDKHALLDVTPNAVDRLNYAQWYPIVVFLNPDSKQGVKTMRMRLCPESRKSARKLYERSHKLRKNNHHLFTTTINLNSMNDGWYGALKEAIQQQQNQLVWVSEGKADGATSDDLDLHDDRLSYLSAPGSEYSMYSTDSRHTSDYEDTDTEGGAYTDQELDETLNDEVGTPPESAITRSSEPVREDSSGMHHENQTYPPYSPQAQPQPIHRIDSPGFKPASQQKAEASSPVPYLSPETNPASSTSAVNHNVNLTNVRLEEPTPAPSTSYSPQADSLRTPSTEAAHIMLRDQEPSLSSHVDPTKVYRKDPYPEEMMRQNHVLKQPAVSHPGHRPDKEPNLTYEPQLPYVEKQASRDLEQPTYRYESSSYTDQFSRNYEHRLRYEDRVPMYEEQWSYYDDKQPYPSRPPFDNQHSQDLDSRQHPEESSERGYFPRFEEPAPLSYDSRPRYEQAPRASALRHEEQPAPGYDTHGRLRPEAQPHPSAGPKPAESKQYFEQYSRSYEQVPPQGFTSRAGHFEPLHGAAAVPPLIPSSQHKPEALPSNTKPLPPPPTQTEEEEDPAMKPQSVLTRVKMFENKRSASLETKKDVNDTGSFKPPEVASKPSGAPIIGPKPTSQNQFSEHDKTLYRIPEPQKPQLKPPEDIVRSNHYDPEEDEEYYRKQLSYFDRRSFENKPPAHIAASHLSEPAKPAHSQNQSNFSSYSSKGKPPEADGVDRSFGEKRYEPIQATPPPPPLPSQYAQPSQPVTSASLHIHSKGAHGEGNSVSLDFQNSLVSKPDPPPSQNKPATFRPPNREDTAQAAFYPQKSFPDKAPVNGTEQTQKTVTPAYNRFTPKPYTSSARPFERKFESPKFNHNLLPSETAHKPDLSSKTPTSPKTLVKSHSLAQPPEFDSGVETFSIHAEKPKYQINNISTVPKAIPVSPSAVEEDEDEDGHTVVATARGIFNSNGGVLSSIETGVSIIIPQGAIPEGVEQEIYFKVCRDNSILPPLDKEKGETLLSPLVMCGPHGLKFLKPVELRLPHCDPKTWQNKCLPGDPNYLVGANCVSVLIDHF>sp|Q07157-2|ZO1_HUMAN Isoform Short of Tight junction protein ZO-1OS=Homo sapiens OX=9606 GN=TJP1MSARAAAAKSTAMEETAIWEQHTVTLHRAPGFGFGIAISGGRDNPHFQSGETSIVISDVLKGGPAEGQLQENDRVAMVNGVSMDNVEHAFAVQQLRKSGKNAKITIRRKKKVQIPVSRPDPEPVSDNEEDSYDEEIHDPRSGRSGVVNRRSEKIWPRDRSASRERSLSPRSDRRSVASSQPAKPTKVTLVKSRKNEEYGLRLASHIFVKEISQDSLAARDGNIQEGDVVLKINGTVTENMSLTDAKTLIERSKGKLKMVVQRDERATLLNVPDLSDSIHSANASERDDISEIQSLASDHSGRSHDRPPRRSRSRSPDQRSEPSDHSRHSPQQPSNGSLRSRDEERISKPGAVSTPVKHADDHTPKTVEEVTVERNEKQTPSLPEPKPVYAQVGQPDVDLPVSPSDGVLPNSTHEDGILRPSMKLVKFRKGDSVGLRLAGGNDVGIFVAGVLEDSPAAKEGLEEGDQILRVNNVDFTNIIREEAVLFLLDLPKGEEVTILAQKKKDVYRRIVESDVGDSFYIRTHFEYEKESPYGLSFNKGEVFRVVDTLYNGKLGSWLAIRIGKNHKEVERGIIPNKNRAEQLASVQYTLPKTAGGDRADFWRFRGLRSSKRNLRKSREDLSAQPVQTKFPAYERVVLREAGFLRPVTIFGPIADVAREKLAREEPDIYQIAKSEPRDAGTDQRSSGIIRLHTIKQIIDQDKHALLDVTPNAVDRLNYAQWYPIVVFLNPDSKQGVKTMRMRLCPESRKSARKLYERSHKLRKNNHHLFTTTINLNSMNDGWYGALKEAIQQQQNQLVWVSEGKADGATSDDLDLHDDRLSYLSAPGSEYSMYSTDSRHTSDYEDTDTEGGAYTDQELDETLNDEVGTPPESAITRSSEPVREDSSGMHHENQTYPPYSPQAQPQPIHRIDSPGFKPASQQVYRKDPYPEEMMRQNHVLKQPAVSHPGHRPDKEPNLTYEPQLPYVEKQASRDLEQPTYRYESSSYTDQFSRNYEHRLRYEDRVPMYEEQWSYYDDKQPYPSRPPFDNQHSQDLDSRQHPEESSERGYFPRFEEPAPLSYDSRPRYEQAPRASALRHEEQPAPGYDTHGRLRPEAQPHPSAGPKPAESKQYFEQYSRSYEQVPPQGFTSRAGHFEPLHGAAAVPPLIPSSQHKPEALPSNTKPLPPPPTQTEEEEDPAMKPQSVLTRVKMFENKRSASLETKKDVNDTGSFKPPEVASKPSGAPIIGPKPTSQNQFSEHDKTLYRIPEPQKPQLKPPEDIVRSNHYDPEEDEEYYRKQLSYFDRRSFENKPPAHIAASHLSEPAKPAHSQNQSNFSSYSSKGKPPEADGVDRSFGEKRYEPIQATPPPPPLPSQYAQPSQPVTSASLHIHSKGAHGEGNSVSLDFQNSLVSKPDPPPSQNKPATFRPPNREDTAQAAFYPQKSFPDKAPVNGTEQTQKTVTPAYNRFTPKPYTSSARPFERKFESPKFNHNLLPSETAHKPDLSSKTPTSPKTLVKSHSLAQPPEFDSGVETFSIHAEKPKYQINNISTVPKAIPVSPSAVEEDEDEDGHTVVATARGIFNSNGGVLSSIETGVSIIIPQGAIPEGVEQEIYFKVCRDNSILPPLDKEKGETLLSPLVMCGPHGLKFLKPVELRLPHCDPKTWQNKCLPGDPNYLVGANCVSVLIDHF>sp|O43309|ZSC12_HUMAN Zinc finger and SCAN domain-containing protein 12OS=Homo sapiens OX=9606 GN=ZSCAN12 PE=1 SV=2MASTWAIQAHMDQDEPLEVKIEEEKYTTRQDWDLRKNNTHSREVFRQYFRQFCYQETSGPREALSRLRELCHQWLRPETHTKEQILELLVLEQFLTILPEELQAWVQEQHPESGEEVVTVLEDLERELDEPGEQVSVHTGEQEMFLQETVRLRKEGEPSMSLQSMKAQPKYESPELESQQEQVLDVETGNEYGNLKQEVSEEMEPHGKTSSKFENDMSKSARCGETREPEEITEEPSACSREDKQPTCDENGVSLTENSDHTEHQRICPGEESYGCDDCGKAFSQHSHLIEHQRIHTGDRPYKCEECGKAFRGRTVLIRHKIIHTGEKPYKCNECGKAFGRWSALNQHQRLHTGEKHYHCNDCGKAFSQKAGLFHHIKIHTRDKPYQCTQCNKSFSRRSILTQHQGVHTGAKPYECNECGKAFVYNSSLVSHQEIHHKEKCYQCKECGKSFSQSGLIQHQRIHTGEKPYKCDVCEKAFIQRTSLTEHQRIHTGERPYKCDKCGKAFTQRSVLTEHQRIHTGERPYKCDECGNAFRGITSLIQHQRIHTGEKPYQCDECGKAFRQRSDLSKHQRIHNRRGTYVCKECGKSFRQNSALTQHQTIHKGEKSVSV>sp|O43309-2|ZSC12_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 12 OS=Homo sapiens OX=9606 GN=ZSCAN12MASTWAIQAHMDQDEPLEVKIEEEKYTTRQDWDLRKNNTHSREVFRQYFRQFCYQETSGPREALSRLRELCHQWLRPETHTKEQILELLVLEQFLTILPEELQAWVQEQHPESGEEVVTVLEDLERELDEPGEQVSVHTGEQEMFLQETVRLRKEGEPSMSLQSMKAQPKYESPELESQQEQVLDVETGNEYGNLKQEVSEEMEPHGKTSSKFENDMSKSARCGETREPEEITEEPSACSREDKQPTCDENGVSLTENSDHTEHQRICPGEESYGCDDCGKAFSQHSHLIEHQRIHTGDRPYKCEECGKAFRGRTVLIRHKIIHTGEKPYKCNECGKAFGRWSALNQHQRLHTGEKHYHCNDCGKAFSQKAGLFHHIKIHTRDKPYQCTQCNKSFSRRSILTQHQGVHTGAKPYECNECGKAFVYNSSLVSHQEIHHKEKCYQCKECGKSFSQSGLIQHQRIHTGEKPYKCDVCEKAFIQRTSLTEHQRIHTGERPYKCDKCGKAFTQRSVLTEHQRIHTGERPYKCDECGNAFRGITSLIQHQRIHTGEKPYQCDECGKAFRQRKKTSYKEILLKNHSEPQAGVNLLLSSLIPEWQSCFRRDL>sp|Q6NSZ9|ZSC25_HUMAN Zinc finger and SCAN domain-containing protein 25OS=Homo sapiens OX=9606 GN=ZSCAN25 PE=1 SV=3MLKEHPEMAEAPQQQLGIPVVKLEKELPWGRGREDPSPETFRLRFRQFRYQEAAGPQEALRELQELCRRWLRPELHTKEQILELLVLEQFLTILPREFYAWIREHGPESGKALAAMVEDLTERALEAKAVPCHRQGEQEETALCRGAWEPGIQLGPVEVKPEWGMPPGEGVQGPDPGTEEQLSQDPGDETRAFQEQALPVLQAGPGLPAVNPRDQEMAAGFFTAGSQGLGPFKDMALAFPEEEWRHVTPAQIDCFGEYVEPQDCRVSPGGGSKEKEAKPPQEDLKGALVALTSERFGEASLQGPGLGRVCEQEPGGPAGSAPGLPPPQHGAIPLPDEVKTHSSFWKPFQCPECGKGFSRSSNLVRHQRTHEEKSYGCVECGKGFTLREYLMKHQRTHLGKRPYVCSECWKTFSQRHHLEVHQRSHTGEKPYKCGDCWKSFSRRQHLQVHRRTHTGEKPYTCECGKSFSRNANLAVHRRAHTGEKPYGCQVCGKRFSKGERLVRHQRIHTGEKPYHCPACGRSFNQRSILNRHQKTQHRQEPLVQ>sp|Q6NSZ9-2|ZSC25_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 25 OS=Homo sapiens OX=9606 GN=ZSCAN25MLKEHPEMAEAPQQQLGIPVVKLEKELPWGRGREDPSPETFRLRFRQFRYQEAAGPQEALRELQELCRRWLRPELHTKEQILELLVLEQFLTILPREFYAWIREHGPESGKALAAMVEDLTERALEAKAVPCHRQGEQEETALCRGAWEPGIQLGPVEVKPEWGMPPGEGVQGPDPGTEEQLSQDPGDETRAFQEQGGGSKEKEAKPPQEDLKGALVALTSERFGEASLQGPGLGRVCEQEPGGPAGSAPGLPPPQHGAIPLPDEVKTHSSFWKPFQCPECGKGFSRSSNLVRHQRTHEEKSYGCVECGKGFTLREYLMKHQRTHLGKRPYVCSECWKTFSQRHHLEVHQRSHTGEKPYKCGDCWKSFSRRQHLQVHRRTHTGEKPYTCECGKSFSRNANLAVHRRAHTGEKPYGCQVCGKRFSKGERLVRHQRIHTGEKPYHCPACGRSFNQRSILNRHQKTQHRQEPLVQ>sp|Q6NSZ9-3|ZSC25_HUMAN Isoform 3 of Zinc finger and SCAN domain-containing protein 25 OS=Homo sapiens OX=9606 GN=ZSCAN25MAAGFFTAGSQGLGPFKDMALAFPEEEWRHVTPAQIDCFGEYVEPQDCRVSPGGGSKEKEAKPPQEDLKGALVALTSERFGEASLQGPGLGRVCEQEPGGPAGSAPGLPPPQHGAIPLPDEVKTHSSFWKPFQCPECGKGFSRSSNLVRHQRTHEEKSYGCVECGKGFTLREYLMKHQRTHLGKRPYVCSECWKTFSQRHHLEVHQRSHTGEKPYKCGDCWKSFSRRQHLQVHRRTHTGEKPYTCECGKSFSRNANLAVHRRAHTGEKPYGCQVCGKRFSKGERLVRHQRIHTGEKPYHCPACGRSFNQRSILNRHQKTQHRQEPLVQ>sp|Q6NSZ9-4|ZSC25_HUMAN Isoform 4 of Zinc finger and SCAN domain-containing protein 25 OS=Homo sapiens OX=9606 GN=ZSCAN25MLKEHPEMAEAPQQQLGIPVVKLEKELPWGRGREDPSPETFRLRFRQFRYQEAAGPQEALRELQELCRRWLRPELHTKEQILELLVLEQFLTILPREFYAWIREHGPESGKALAAMVEDLTERALEAKAVGSMPQAGRAGGNSTLQRRLGARHPAGASGGQA>sp|Q9UHR6|ZNHI2_HUMAN Zinc finger HIT domain-containing protein 2OS=Homo sapiens OX=9606 GN=ZNHIT2 PE=1 SV=1MEPAGPCGFCPAGEVQPARYTCPRCNAPYCSLRCYRTHGTCAENFYRDQVLGELRGCSAPPSRLASALRRLRQQRETEDEPGEAGLSSGPAPGGLSGLWERLAPGEKAAFERLLSRGEAGRLLPPWRPWWWNRGAGPQLLEELDNAPGSDAAELELAPARTPPDSVKDASAAEPAAAERVLGDVPGACTPVVPTRIPAIVSLSRGPVSPLVRFQLPNVLFAYAHTLALYHGGDDALLSDFCATLLGVSGALGAQQVFASAEEALQAAAHVLEAGEHPPGPLGTRGAMHEVARILLGEGPTNQKGYTLAALGDLAQTLGRARKQAVAREERDHLYRARKKCQFLLAWTNENEAALTPLALDCARAHQAHAVVAEEVAALTGELERLWGGPVPPAPRTLIEELPS>sp|Q86W11|ZSC30_HUMAN Zinc finger and SCAN domain-containing protein 30OS=Homo sapiens OX=9606 GN=ZSCAN30 PE=1 SV=1MSGEATVLAYHAPEEQEGLLVVKVEEENYVLDQDFGLQENPWSQEVFRQKFRQFSYSDSTGPREALSRLRELCCQWLRPEVHSKEQILELLMLEQFLAILPEELQAWLREHRPENGEEAVTMLEELEKELEEPRQQDTTHGQEMFWQEMTSTGALKSLSLNSPVQPLENQCKTETQESQAFQERDGRMVAGKVLMAKQEIVECVASAAMISPGKLPGETHSQRIAEEALGGLDNSKKQKGNAAGNKISQLPSQDRHFSLATFNRRIPTEHSVLESHESEGSFSMNSNDITQQSVDTREKLYECFDCGKAFCQSSKLIRHQRIHTGERPYACKECGKAFSLSSDLVRHQRIHSGEKPYECCECGKAFRGSSELIRHRRIHTGEKPYECGECGKAFSRSSALIQHKKIHTGDKSYECIACGKAFGRSSILIEHQRIHTGEKPYECNECGKSFNQSSALTQHQRIHTGEKPYECSECRKTFRHRSGLMQHQRTHTRV>sp|Q86W11-3|ZSC30_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 30 OS=Homo sapiens OX=9606 GN=ZSCAN30MSGEATVLAYHAPEEQEGLLVVKVEEENYVLDQDFGLQENPWSQEVFRQKFRQFSYSDSTGPREALSRLRELCCQWLRPEVHSKEQILELLMLEQFLAILPEELQAWLREHRPENGEEAVTMLEELEKELEEPRQQDTTHGQEMFWQEMTSTGALKSLSLNSPVQPLENQCKTETQESQAFQERDGVSLCHPGWSAVVQPQLTAVALNPWVKVILLPQPPE>sp|Q9Y5A6|ZSC21_HUMAN Zinc finger and SCAN domain-containing protein 21OS=Homo sapiens OX=9606 GN=ZSCAN21 PE=1 SV=2MMTKVLGMAPVLGPRPPQEQVGPLMVKVEEKEEKGKYLPSLEMFRQRFRQFGYHDTPGPREALSQLRVLCCEWLRPEIHTKEQILELLVLEQFLTILPQELQAWVQEHCPESAEEAVTLLEDLERELDEPGHQVSTPPNEQKPVWEKISSSGTAKESPSSMQPQPLETSHKYESWGPLYIQESGEEQEFAQDPRKVRDCRLSTQHEESADEQKGSEAEGLKGDIISVIIANKPEASLERQCVNLENEKGTKPPLQEAGSKKGRESVPTKPTPGERRYICAECGKAFSNSSNLTKHRRTHTGEKPYVCTKCGKAFSHSSNLTLHYRTHLVDRPYDCKCGKAFGQSSDLLKHQRMHTEEAPYQCKDCGKAFSGKGSLIRHYRIHTGEKPYQCNECGKSFSQHAGLSSHQRLHTGEKPYKCKECGKAFNHSSNFNKHHRIHTGEKPYWCHHCGKTFCSKSNLSKHQRVHTGEGEAP>sp|Q9P2E3|ZNFX1_HUMAN NFX1-type zinc finger-containing protein 1 OS=Homosapiens OX=9606 GN=ZNFX1 PE=2 SV=2MEERRPHLDARPRNSHTNHRGPVDGELPPRARNQANNPPANALRGGASHPGRHPRANNHPAAYWQREERFRAMGRNPHQGRRNQEGHASDEARDQRHDQENDTRWRNGNQDCRNRRPPWSNDNFQQWRTPHQKPTEQPQQAKKLGYKFLESLLQKDPSEVVITLATSLGLKELLSHSSMKSNFLELICQVLRKACSSKMDRQSVLHVLGILKNSKFLKVCLPAYVVGMITEPIPDIRNQYPEHISNIISLLQDLVSVFPASSVQETSMLVSLLPTSLNALRASGVDIEEETEKNLEKVQTIIEHLQEKRREGTLRVDTYTLVQPEAEDHVESYRTMPIYPTYNEVHLDERPFLRPNIISGKYDSTAIYLDTHFRLLREDFVRPLREGILELLQSFEDQGLRKRKFDDIRIYFDTRIITPMCSSSGIVYKVQFDTKPLKFVRWQNSKRLLYGSLVCMSKDNFETFLFATVSNREQEDLCRGIVQLCFNEQSQQLLAEVQPSDSFLMVETTAYFEAYRHVLEGLQEVQEEDVPFQRNIVECNSHVKEPRYLLMGGRYDFTPLIENPSATGEFLRNVEGLRHPRINVLDPGQWPSKEALKLDDSQMEALQFALTRELAIIQGPPGTGKTYVGLKIVQALLTNESVWQISLQKFPILVVCYTNHALDQFLEGIYNCQKTSIVRVGGRSNSEILKQFTLRELRNKREFRRNLPMHLRRAYMSIMTQMKESEQELHEGAKTLECTMRGVLREQYLQKYISPQHWESLMNGPVQDSEWICFQHWKHSMMLEWLGLGVGSFTQSVSPAGPENTAQAEGDEEEEGEEESSLIEIAEEADLIQADRVIEEEEVVRPQRRKKEESGADQELAKMLLAMRLDHCGTGTAAGQEQATGEWQTQRNQKKKMKKRVKDELRKLNTMTAAEANEIEDVWQLDLSSRWQLYRLWLQLYQADTRRKILSYERQYRTSAERMAELRLQEDLHILKDAQVVGMTTTGAAKYRQILQKVEPRIVIVEEAAEVLEAHTIATLSKACQHLILIGDHQQLRPSANVYDLAKNFNLEVSLFERLVKVNIPFVRLNYQHRMCPEIARLLTPHIYQDLENHPSVLKYEKIKGVSSNLFFVEHNFPEQEIQEGKSHQNQHEAHFVVELCKYFLCQEYLPSQITILTTYTGQLFCLRKLMPAKTFAGVRVHVVDKYQGEENDIILLSLVRSNQEGKVGFLQISNRICVALSRAKKGMYCIGNMQMLAKVPLWSKIIHTLRENNQIGPMLRLCCQNHPETHTLVSKASDFQKVPEGGCSLPCEFRLGCGHVCTRACHPYDSSHKEFQCMKPCQKVICQEGHRCPLVCFQECQPCQVKVPKTIPRCGHEQMVPCSVPESDFCCQEPCSKSLRCGHRCSHPCGEDCVQLCSEMVTIKLKCGHSQPVKCGHVEGLLYGGLLVKCTTKCGTILDCGHPCPGSCHSCFEGRFHERCQQPCKRLLICSHKCQEPCIGECPPCQRTCQNRCVHSQCKKKCGELCSPCVEPCVWRCQHYQCTKLCSEPCNRPPCYVPCTKLLVCGHPCIGLCGEPCPKKCRICHMDEVTQIFFGFEDEPDARFVQLEDCSHIFEVQALDRYMNEQKDDEVAIRLKVCPICQVPIRKNLRYGTSIKQRLEEIEIIKEKIQGSAGEIATSQERLKALLERKSLLHQLLPEDFLMLKEKLAQKNLSVKDLGLVENYISFYDHLASLWDSLKKMHVLEEKRVRTRLEQVHEWLAKKRLSFTSQELSDLRSEIQRLTYLVNLLTRYKIAEKKVKDSIAVEVYSVQNILEKTCKFTQEDEQLVQEKMEALKATLPCSGLGISEEERVQIVSAIGYPRGHWFKCRNGHIYVIGDCGGAMERGTCPDCKEVIGGTNHTLERSNQLASEMDGAQHAAWSDTANNLMNFEEIQGMM>sp|Q9P2E3-2|ZNFX1_HUMAN Isoform 2 of NFX1-type zinc finger-containingprotein 1 OS=Homo sapiens OX=9606 GN=ZNFX1MEERRPHLDARPRNSHTNHRGPVDGELPPRARNQANNPPANALRGGASHPGRHPRANNHPAAYWQREERFRAMGRNPHQGRRNQEGHASDEARDQRHDQENDTRWRNGNQDCRNRRPPWSNDNFQQWRTPHQKPTEQPQQAKKLGYKFLESLLQKDPSEVVITLATSLGLKELLSHSSMKSNFLELICQVLRKACSSKMDRQSVLHVLGILKNSKFLKVCLPAYVVGMITEPIPDIRNQYPEHISNIISLLQDLVSVFPASSVQETSMLVSLLPTSLNALRASGVDIEEETEKNLEKVQTIIEHLQEKRREGTLRVDTYTLVQPEAEDHVESYRTMPIYPTYNEVHLDERPFLRPNIISGKYDSTAIYLDTHFRLLREDFVRPLREGILELLQSFEDQGLRKRKFDDIRIYFDTRIITPMCSSSGIVYKVQFDTKPLKFVRWQNSKRLLYGSLVCMSKDNFETFLFATVSNREQEDLCRGIVQLCFNEQSQQLLAEVQPSDSFLMVETTAYFEAYRHVLEGLQEVQEEDVPFQRNIVECNSHVKEPRYLLMGGRYDFTPLIENPSATGEFLRNVEGLRHPRINVLDPGQWPSKEALKLDDSQMEALQFALTRELAIIQGPPGTGKTYVGLKIVQALLTNESVWQISLQKFPILVVCYTNHALDQFLEGIYNCQKTSIVRVGGRSNSEILKQFTLRELRNKREFRRNLPMHLRRAYMSIMTQMKESEQELHEGAKTLECTMRGVLREQYLQKYISPQHWESLMNGPVQDSEWICFQHWKHSMMLEWLGLGVGSFTQSVSPAGPENTAQAEGDEEEEGEEESSLIEIAEEADLIQADRVIEEEEVVRPQRRKKEESGADQELAKMLLAMRLDHCGTGTAAGQEQATGEWQTVPCLVLMSADPAQP>sp|A0A0U1RRA0|ZNOS_HUMAN Putative transmembrane protein ZNF593OS OS=Homosapiens OX=9606 GN=ZNF593OS PE=5 SV=1MRFRRLTPGYFRVLQMQVAGELKAEPRSLLAGVVATVLAVLGLGGSCYAVWKMVGQRRVPRAP>sp|O14863|ZNT4_HUMAN Zinc transporter 4 OS=Homo sapiens OX=9606GN=SLC30A4 PE=1 SV=2MAGSGAWKRLKSMLRKDDAPLFLNDTSAFDFSDEAGDEGLSRFNKLRVVVADDGSEAPERPVNGAHPTLQADDDSLLDQDLPLTNSQLSLKVDSCDNCSKQREILKQRKVKARLTIAAVLYLLFMIGELVGGYIANSLAIMTDALHMLTDLSAIILTLLALWLSSKSPTKRFTFGFHRLEVLSAMISVLLVYILMGFLLYEAVQRTIHMNYEINGDIMLITAAVGVAVNVIMGFLLNQSGHRHSHSHSLPSNSPTRGSGCERNHGQDSLAVRAAFVHALGDLVQSVGVLIAAYIIRFKPEYKIADPICTYVFSLLVAFTTFRIIWDTVVIILEGVPSHLNVDYIKEALMKIEDVYSVEDLNIWSLTSGKSTAIVHIQLIPGSSSKWEEVQSKANHLLLNTFGMYRCTIQLQSYRQEVDRTCANCQSSSP>sp|Q9NX65|ZSC32_HUMAN Zinc finger and SCAN domain-containing protein 32OS=Homo sapiens OX=9606 GN=ZSCAN32 PE=1 SV=3MMAAVKSTEAHPSSNKDPTQGQKSALQGNSPDSEASRQRFRQFCYQEVTGPHEAFSKLWELCCQWLRPKTHSKEEILELLVLEQFLTILPEEIQTWVREQHPENGEEAVALVEDVQRAPGQQVLDSEKDLKVLMKEMAPLGATRESLRSQWKQEVQPEEPTFKGSQSSHQRPGEQSEAWLAPQAPRNLPQNTGLHDQETGAVVWTAGSQGPAMRDNRAVSLCQQEWMCPGPAQRALYRGATQRKDSHVSLATGVPWGYEETKTLLAILSSSQFYGKLQTCQQNSQIYRAMAEGLWEQGFLRTPEQCRTKFKSLQLSYRKVRRGRVPEPCIFYEEMNALSGSWASAPPMASDAVPGQEGSDIEAGELNHQNGEPTEVEDGTVDGADRDEKDFRNPGQEVRKLDLPVLFPNRLGFEFKNEIKKENLKWDDSEEVEINKALQRKSRGVYWHSELQKGLESEPTSRRQCRNSPGESEEKTPSQEKMSHQSFCARDKACTHILCGKNCSQSVHSPHKPALKLEKVSQCPECGKTFSRSSYLVRHQRIHTGEKPHKCSECGKGFSERSNLTAHLRTHTGERPYQCGQCGKSFNQSSSLIVHQRTHTGEKPYQCIVCGKRFNNSSQFSAHRRIHTGESPYKCAVCGKIFNNSSHFSAHRKTHTGEKPYRCSHCERGFTKNSALTRHQTVHMKAVLSSQEGRDAL>sp|Q9NX65-2|ZSC32_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 32 OS=Homo sapiens OX=9606 GN=ZSCAN32MRDNRAVSLCQQEWMCPGPAQRALYRGATQRKDSHVSLATGVPWGYEETKTLLAILSSSQFYGKLQTCQQNSQIYRAMAEGLWEQGFLRTPEQCRTKFKSLQLSYRKVRRGRVPEPCIFYEEMNALSGSWASAPPMASDAVPGQEGSDIEAGELNHQNGEPTEVEDGTVDGADRDEKDFRNPGQEVRKLDLPVLFPNRLGFEFKNEIKKENLKWDDSEEVEINKALQRKSRGVYWHSELQKGLESEPTSRRQCRNSPGESEEKTPSQEKMSHQSFCARDKACTHILCGKNCSQSVHSPHKPALKLEKVSQCPECGKTFSRSSYLVRHQRIHTGEKPHKCSECGKGFSERSNLTAHLRTHTGERPYQCGQCGKSFNQSSSLIVHQRTHTGEKPYQCIVCGKRFNNSSQFSAHRRIHTGESPYKCAVCGKIFNNSSHFSAHRKTHTGEKPYRCSHCERGFTKNSALTRHQTVHMKAVLSSQEGRDAL>sp|Q9NX65-3|ZSC32_HUMAN Isoform 3 of Zinc finger and SCAN domain-containing protein 32 OS=Homo sapiens OX=9606 GN=ZSCAN32MAEGLWEQGFLRTPEQCRTKFKSLQLSYRKVRRGRVPEPCIFYEEMNALSGSWASAPPMASDAVPGQEGSDIEAGELNHQNGEPTEVEDGTVDGADRDEKDFRNPGQEVRKLDLPVLFPNRLGFEFKNEIKKENLKWDDSEEVEINKALQRKSRGVYWHSELQKGLESEPTSRRQCRNSPGESEEKTPSQEKMSHQSFCARDKACTHILCGKNCSQSVHSPHKPALKLEKVSQCPECGKTFSRSSYLVRHQRIHTGEKPHKCSECGKGFSERSNLTAHLRTHTGERPYQCGQCGKSFNQSSSLIVHQRTHTGEKPYQCIVCGKRFNNSSQFSAHRRIHTGESPYKCAVCGKIFNNSSHFSAHRKTHTGEKPYRCSHCERGFTKNSALTRHQTVHMKAVLSSQEGRDAL>sp|Q6PML9|ZNT9_HUMAN Zinc transporter 9 OS=Homo sapiens OX=9606GN=SLC30A9 PE=1 SV=1MLPGLAAAAAHRCSWSSLCRLRLRCRAAACNPSDRQEWQNLVTFGSFSNMVPCSHPYIGTLSQVKLYSTNVQKEGQGSQTLRVEKVPSFETAEGIGTELKAPLKQEPLQVRVKAVLKKREYGSKYTQNNFITGVRAINEFCLKSSDLEQLRKIRRRSPHEDTESFTVYLRSDVEAKSLEVWGSPEALAREKKLRKEAEIEYRERLFRNQKILREYRDFLGNTKPRSRTASVFFKGPGKVVMVAICINGLNCFFKFLAWIYTGSASMFSEAIHSLSDTCNQGLLALGISKSVQTPDPSHPYGFSNMRYISSLISGVGIFMMGAGLSWYHGVMGLLHPQPIESLLWAYCILAGSLVSEGATLLVAVNELRRNARAKGMSFYKYVMESRDPSTNVILLEDTAAVLGVIIAATCMGLTSITGNPLYDSLGSLGVGTLLGMVSAFLIYTNTEALLGRSIQPEQVQRLTELLENDPSVRAIHDVKATDLGLGKVRFKAEVDFDGRVVTRSYLEKQDFDQMLQEIQEVKTPEELETFMLKHGENIIDTLGAEVDRLEKELKKRNPEVRHVDLEIL>sp|P0CG00|ZSA5D_HUMAN Putative zinc finger and SCAN domain-containingprotein 5D OS=Homo sapiens OX=9606 GN=ZSCAN5DP PE=5 SV=1MGQCRNWKWGLESFDFSINRRSSAPGQLESASQMRESWRHKAGRRMFSCPEESDPIQALRKLTELCHLWLRPDLHTKEQILDMLVMEQFMISMPQELQVLVKVNGVQSCKDLEDLLRNNRRPKKWSVVNFLGKEYLMQESDVEMAEIPASVRDDPRGVSSQRASSVNEMRPGEGQASQELQTLPRVPALSRRQEEDFLLPETTVMKSAPKALRPKPTLEKDLNVDREENTGLTSPEPQLPNGPSVVGAKEGKEPKKRASVENVDADTPSACVVEREASTHSGSRGDALNLRCPKRSKPDATSISQEGPQGGATPVGNSESPGKPEINSVYSPGPAGAVSHPNGQEAKELLPFACGVCNKRFTCNSKLAIHMRSHTGERPFQCNFCERCFTQLSDLRVHQRIHTGEKPYTCDICHKRFNRMFSLKCHKRSHTGEKPYKCKDCNQVFTYRKNLNEHKLIHSGEKPYKCPKCLRAFRRPETLKYHQKTHQETTAPRECEG>sp|B4DU55|ZN879_HUMAN Zinc finger protein 879 OS=Homo sapiens OX=9606GN=ZNF879 PE=2 SV=2MARRLLPAHVQESVTFRDVAVFFSQDEWLHLDSAQRALYREVMLENYSILVSLGILFSKPKVISQLEQGEDPWMVESGVPQGAHLGWESLFGTIVSKEENQEVMKKLIIDGTFDFKLEKTYINEDKLEKQQGKKNRLFSKVLVTIKKVYMKERSFKGVEFGKNLGLKSSLIRKPRIVSRGRRPRSQQYSVLFKQLGVNTVRKCYKCNICGKIFLHSSSLSKHQRIHTGEKLYKCKECRKAFSQSSSLTQHLRVHTGEKPYICSECGKAFSFTTSLIGHQRMHTGERPYKCKECGKTFKGSSSLNNHQRIHTGEKPYKCNECGRAFSQCSSLIQHHRIHTGEKPYECTQCGKAFTSISRLSRHHRIHTGEKPFHCNECGKVFSYHSALIIHQRIHTGEKPYACKECGKAFSQSSALIQHQRIHTGEKPYKCNECGKAFSWISRLNIHHRIHTGEKPYNCKECGKAFSSHSGVNTHRKIHTGEKPYKCNDCEKAFNQSSALIQHQRIHTGEKPYNCKVCGKAFRQSSSLMTHMRIHTGEKPYKCKECGKAFSQSSSLTNHQRTHN>sp|Q8NCK3|ZN485_HUMAN Zinc finger protein 485 OS=Homo sapiens OX=9606GN=ZNF485 PE=1 SV=1MAPRAQIQGPLTFGDVAVAFTRIEWRHLDAAQRALYRDVMLENYGNLVSVGLLSSKPKLITQLEQGAEPWTEVREAPSGTHAVEDYWFETKMSALKQSTSEASVLGERTKSVMMEKGLDWEGRSSTEKNYKCKECGKVFKYNSSFISHQRNHTSEKPHKCKECGIAFMNSSSLLNHHKVHAGKQPYRCIECGKFLKKHSTFINHQRIHSREKPHKCIECGKTFRKNSILLSHQRIHTGQKPYKCNDCGKAFAQNAALTRHERIHSGEKPFKCNKCGRAFRDNSTVLEHQKIHTGEKPYQCNECGKAFRKSSTLISHQRMHTGEKPYHCSKCGKSFRYSSSFAGHQKTHSGNKPYQCRDCGKAFTKSSTLTGHQRIHTGEKPYHCKKCGKAFRHSSGLVEHQRLHTGEKPYKCNECGKAFPRSSALKQHKKIHNKERAMKCS>sp|Q8NCK3-2|ZN485_HUMAN Isoform 2 of Zinc finger protein 485 OS=Homosapiens OX=9606 GN=ZNF485MSALKQSTSEASVLGERTKSVMMEKGLDWEGRSSTEKNYKCKECGKVFKYNSSFISHQRNHTSEKPHKCKECGIAFMNSSSLLNHHKVHAGKQPYRCIECGKFLKKHSTFINHQRIHSREKPHKCIECGKTFRKNSILLSHQRIHTGQKPYKCNDCGKAFAQNAALTRHERIHSGEKPFKCNKCGRAFRDNSTVLEHQKIHTGEKPYQCNECGKAFRKSSTLISHQRMHTGEKPYHCSKCGKSFRYSSSFAGHQKTHSGNKPYQCRDCGKAFTKSSTLTGHQRIHTGEKPYHCKKCGKAFRHSSGLVEHQRLHTGEKPYKCNECGKAFPRSSALKQHKKIHNKERAMKCS>sp|Q2M1K9|ZN423_HUMAN Zinc finger protein 423 OS=Homo sapiens OX=9606GN=ZNF423 PE=1 SV=1MHKKRVEEGEASDFSLAWDSSVTAAGGLEGEPECDQKTSRALEDRNSVTSQEERNEDDEDMEDESIYTCDHCQQDFESLADLTDHRAHRCPGDGDDDPQLSWVASSPSSKDVASPTQMIGDGCDLGLGEEEGGTGLPYPCQFCDKSFIRLSYLKRHEQIHSDKLPFKCTYCSRLFKHKRSRDRHIKLHTGDKKYHCHECEAAFSRSDHLKIHLKTHSSSKPFKCTVCKRGFSSTSSLQSHMQAHKKNKEHLAKSEKEAKKDDFMCDYCEDTFSQTEELEKHVLTRHPQLSEKADLQCIHCPEVFVDENTLLAHIHQAHANQKHKCPMCPEQFSSVEGVYCHLDSHRQPDSSNHSVSPDPVLGSVASMSSATPDSSASVERGSTPDSTLKPLRGQKKMRDDGQGWTKVVYSCPYCSKRDFNSLAVLEIHLKTIHADKPQQSHTCQICLDSMPTLYNLNEHVRKLHKNHAYPVMQFGNISAFHCNYCPEMFADINSLQEHIRVSHCGPNANPSDGNNAFFCNQCSMGFLTESSLTEHIQQAHCSVGSAKLESPVVQPTQSFMEVYSCPYCTNSPIFGSILKLTKHIKENHKNIPLAHSKKSKAEQSPVSSDVEVSSPKRQRLSASANSISNGEYPCNQCDLKFSNFESFQTHLKLHLELLLRKQACPQCKEDFDSQESLLQHLTVHYMTTSTHYVCESCDKQFSSVDDLQKHLLDMHTFVLYHCTLCQEVFDSKVSIQVHLAVKHSNEKKMYRCTACNWDFRKEADLQVHVKHSHLGNPAKAHKCIFCGETFSTEVELQCHITTHSKKYNCKFCSKAFHAIILLEKHLREKHCVFDAATENGTANGVPPMATKKAEPADLQGMLLKNPEAPNSHEASEDDVDASEPMYGCDICGAAYTMEVLLQNHRLRDHNIRPGEDDGSRKKAEFIKGSHKCNVCSRTFFSENGLREHLQTHRGPAKHYMCPICGERFPSLLTLTEHKVTHSKSLDTGTCRICKMPLQSEEEFIEHCQMHPDLRNSLTGFRCVVCMQTVTSTLELKIHGTFHMQKLAGSSAASSPNGQGLQKLYKCALCLKEFRSKQDLVKLDVNGLPYGLCAGCMARSANGQVGGLAPPEPADRPCAGLRCPECSVKFESAEDLESHMQVDHRDLTPETSGPRKGTQTSPVPRKKTYQCIKCQMTFENEREIQIHVANHMIEEGINHECKLCNQMFDSPAKLLCHLIEHSFEGMGGTFKCPVCFTVFVQANKLQQHIFAVHGQEDKIYDCSQCPQKFFFQTELQNHTMSQHAQ>sp|Q2M1K9-2|ZN423_HUMAN Isoform 2 of Zinc finger protein 423 OS=Homosapiens OX=9606 GN=ZNF423MEDESIYTCDHCQQDFESLADLTDHRAHRCPGDGDDDPQLSWVASSPSSKDVASPTQMIGDGCDLGLGEEEGGTGLPYPCQFCDKSFIRLSYLKRHEQIHSDKLPFKCTYCSRLFKHKRSRDRHIKLHTGDKKYHCHECEAAFSRSDHLKIHLKTHSSSKPFKCTVCKRGFSSTSSLQSHMQAHKKNKEHLAKSEKEAKKDDFMCDYCEDTFSQTEELEKHVLTRHPQLSEKADLQCIHCPEVFVDENTLLAHIHQAHANQKHKCPMCPEQFSSVEGVYCHLDSHRQPDSSNHSVSPDPVLGSVASMSSATPDSSASVERGSTPDSTLKPLRGQKKMRDDGQGWTKVVYSCPYCSKRDFNSLAVLEIHLKTIHADKPQQSHTCQICLDSMPTLYNLNEHVRKLHKNHAYPVMQFGNISAFHCNYCPEMFADINSLQEHIRVSHCGPNANPSDGNNAFFCNQCSMGFLTESSLTEHIQQAHCSVGSAKLESPVVQPTQSFMEVYSCPYCTNSPIFGSILKLTKHIKENHKNIPLAHSKKSKAEQSPVSSDVEVSSPKRQRLSASANSISNGEYPCNQCDLKFSNFESFQTHLKLHLELLLRKQACPQCKEDFDSQESLLQHLTVHYMTTSTHYVCESCDKQFSSVDDLQKHLLDMHTFVLYHCTLCQEVFDSKVSIQVHLAVKHSNEKKMYRCTACNWDFRKEADLQVHVKHSHLGNPAKAHKCIFCGETFSTEVELQCHITTHSKKYNCKFCSKAFHAIILLEKHLREKHCVFDAATENGTANGVPPMATKKAEPADLQGMLLKNPEAPNSHEASEDDVDASEPMYGCDICGAAYTMEVLLQNHRLRDHNIRPGEDDGSRKKAEFIKGSHKCNVCSRTFFSENGLREHLQTHRGPAKHYMCPICGERFPSLLTLTEHKVTHSKSLDTGTCRICKMPLQSEEEFIEHCQMHPDLRNSLTGFRCVVCMQTVTSTLELKIHGTFHMQKLAGSSAASSPNGQGLQKLYKCALCLKEFRSKQDLVKLDVNGLPYGLCAGCMARSANGQVGGLAPPEPADRPCAGLRCPECSVKFESAEDLESHMQVDHRDLTPETSGPRKGTQTSPVPRKKTYQCIKCQMTFENEREIQIHVANHMIEEGINHECKLCNQMFDSPAKLLCHLIEHSFEGMGGTFKCPVCFTVFVQANKLQQHIFAVHGQEDKIYDCSQCPQKFFFQTELQNHTMSQHAQ>sp|Q5T5D7|ZN684_HUMAN Zinc finger protein 684 OS=Homo sapiens OX=9606GN=ZNF684 PE=2 SV=1MISFQESVTFQDVAVDFTAEEWQLLDCAERTLYWDVMLENYRNLISVGCPITKTKVILKVEQGQEPWMVEGANPHESSPESDYPLVDEPGKHRESKDNFLKSVLLTFNKILTMERIHHYNMSTSLNPMRKKSYKSFEKCLPPNLDLLKYNRSYTVENAYECSECGKAFKKKFHFIRHEKNHTRKKPFECNDCGKAYSRKAHLATHQKIHNGERPFVCNDCGKAFMHKAQLVVHQRLHTGEKPYECSQCGKTFTWNSSFNQHVKSHTLEKSFECKECGKTFRYSSSLYKHSRFHTGEKPYQCIICGKAFGNTSVLVTHQRIHTGEKPYSCIECGKAFIKKSHLLRHQITHTGEKPYECNRCGKAFSQKSNLIVHQKIHT>sp|Q8WTZ3|YS049_HUMAN Zinc finger protein ENSP00000375192 OS=Homosapiens OX=9606 PE=2 SV=1MKNVANTVTISHILPHIKIIHTEEKPDKCEECNKVFNWSSTHTKYKRIHTEDKFYKYEECDKSFKNISTLITHKIIYVVEKFYKCEECGKVFFFFLKWSLTLSPKLECNGAISVHCNLRLLGSSDSLASTSQAAGIAGACHHAQLIFVFLVETGFHHFDQAGFELLTSSDPPALASQSAPKCWDYKHEPLSPVECGKVFNKLSNHTGEKLYKPKRHDSALENTLNFSKHKRNHSVKKP>sp|Q9NQZ8|ZNF71_HUMAN Endothelial zinc finger protein induced by tumornecrosis factor alpha OS=Homo sapiens OX=9606 GN=ZNF71 PE=1 SV=1MKELDPKNDISEDKLSVVGEATGGPTRNGARGPGSEGVWEPGSWPERPRGDAGAEWEPLGIPQGNKLLGGSVPACHELKAFANQGCVLVPPRLDDPTEKGACPPVRRGKNFSSTSDLSKPPMPCEEKKTYDCSECGKAFSRSSSLIKHQRIHTGEKPFECDTCGKHFIERSSLTIHQRVHTGEKPYACGDCGKAFSQRMNLTVHQRTHTGEKPYVCDVCGKAFRKTSSLTQHERIHTGEKPYACGDCGKAFSQNMHLIVHQRTHTGEKPYVCPECGRAFSQNMHLTEHQRTHTGEKPYACKECGKAFNKSSSLTLHQRNHTGEKPYVCGECGKAFSQSSYLIQHQRFHIGVKPFECSECGKAFSKNSSLTQHQRIHTGEKPYECYICKKHFTGRSSLIVHQIVHTGEKPYVCGECGKAFSQSAYLIEHQRIHTGEKPYRCGQCGKSFIKNSSLTVHQRIHTGEKPYRCGECGKTFSRNTNLTRHLRIHT>sp|Q96F44|TRI11_HUMAN E3 ubiquitin-protein ligase TRIM11 OS=Homo sapiensOX=9606 GN=TRIM11 PE=1 SV=2MAAPDLSTNLQEEATCAICLDYFTDPVMTDCGHNFCRECIRRCWGQPEGPYACPECRELSPQRNLRPNRPLAKMAEMARRLHPPSPVPQGVCPAHREPLAAFCGDELRLLCAACERSGEHWAHRVRPLQDAAEDLKAKLEKSLEHLRKQMQDALLFQAQADETCVLWQKMVESQRQNVLGEFERLRRLLAEEEQQLLQRLEEEELEVLPRLREGAAHLGQQSAHLAELIAELEGRCQLPALGLLQDIKDALRRVQDVKLQPPEVVPMELRTVCRVPGLVETLRRFRGDVTLDPDTANPELILSEDRRSVQRGDLRQALPDSPERFDPGPCVLGQERFTSGRHYWEVEVGDRTSWALGVCRENVNRKEKGELSAGNGFWILVFLGSYYNSSERALAPLRDPPRRVGIFLDYEAGHLSFYSATDGSLLFIFPEIPFSGTLRPLFSPLSSSPTPMTICRPKGGSGDTLAPQ>sp|Q96F44-2|TRI11_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM11OS=Homo sapiens OX=9606 GN=TRIM11MAAPDLSTNLQEEATCAICLDYFTDPVMTDCGHNFCRECIRRCWGQPEGPYACPECRELSPQRNLRPNRPLAKMAEMARRLHPPSPVPQGVCPAHREPLAAFCGDELRLLCAACERSGEHWAHRVRPLQDAAEDLKAKLEKSLEHLRKQMQDALLFQAQADETCVLWQKMVESQRQNVLGEFERLRRLLAEEEQQLLQRLEEEELEVLPRLREGAAHLGQQSAHLAELIAELEGRCQLPALGLLQDIKDALRRVQDVKLQPPEVVPMELRTVCRVPGLVETLRRFRGRCGGPRWGDDSRRGPAKDLGSQPRVLCPATASSKLTVSWWWVVGKTSSAHTSDISCVGIFTPNNSSTSGNELGIQGFHSALNRIASADTTGVSTDPTD>sp|Q96F44-3|TRI11_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM11OS=Homo sapiens OX=9606 GN=TRIM11MAAPDLSTNLQEEATCAICLDYFTDPVMTDCGHNFCRECIRRCWGQPEGPYACPECRELSPQRNLRPNRPLAKMAEMARRLHPPSPVPQGVCPAHREPLAAFCGDELRLLCAACERSGEHWAHRVRPLQDAAEDLKAKLEKSLEHLRKQMQDALLFQAQADETCVLWQMVESQRQNVLGEFERLRRLLAEEEQQLLQRLEEEELEVLPRLREGAAHLGQQSAHLAELIAELEGRCQLPALGLLQDIKDALRRVQDVKLQPPEVVPMELRTVCRVPGLVETLRRFRGDVTLDPDTANPELILSEDRRSVQRGDLRQALPDSPERFDPGPCVLGQERFTSGRHYWEVEVGDRTSWALGVCRENVNRKEKGELSAGNGFWILVFLGSYYNSSERALAPLRDPPRRVGIFLDYEAGHLSFYSATDGSLLFIFPEIPFSGTLRPLFSPLSSSPTPMTICRPKGGSGDTLAPQ>sp|Q8TBZ6|TM10A_HUMAN tRNA methyltransferase 10 homolog A OS=Homosapiens OX=9606 GN=TRMT10A PE=1 SV=1MSSEMLPAFIETSNVDKKQGINEDQEESQKPRLGEGCEPISKRQMKKLIKQKQWEEQRELRKQKRKEKRKRKKLERQCQMEPNSDGHDRKRVRRDVVHSTLRLIIDCSFDHLMVLKDIKKLHKQIQRCYAENRRALHPVQFYLTSHGGQLKKNMDENDKGWVNWKDIHIKPEHYSELIKKEDLIYLTSDSPNILKELDESKAYVIGGLVDHNHHKGLTYKQASDYGINHAQLPLGNFVKMNSRKVLAVNHVFEIILEYLETRDWQEAFFTILPQRKGAVPTDKACESASHDNQSVRMEEGGSDSDSSEEEYSRNELDSPHEEKQDKENHTESTVNSLPH>sp|Q9Y5R8|TPPC1_HUMAN Trafficking protein particle complex subunit 1OS=Homo sapiens OX=9606 GN=TRAPPC1 PE=1 SV=1MTVHNLYLFDRNGVCLHYSEWHRKKQAGIPKEEEYKLMYGMLFSIRSFVSKMSPLDMKDGFLAFQTSRYKLHYYETPTGIKVVMNTDLGVGPIRDVLHHIYSALYVELVVKNPLCPLGQTVQSELFRSRLDSYVRSLPFFSARAG>sp|Q9UL52|TM11E_HUMAN Transmembrane protease serine 11E OS=Homo sapiensOX=9606 GN=TMPRSS11E PE=1 SV=2MMYRPDVVRARKRVCWEPWVIGLVIFISLIVLAVCIGLTVHYVRYNQKKTYNYYSTLSFTTDKLYAEFGREASNNFTEMSQRLESMVKNAFYKSPLREEFVKSQVIKFSQQKHGVLAHMLLICRFHSTEDPETVDKIVQLVLHEKLQDAVGPPKVDPHSVKIKKINKTETDSYLNHCCGTRRSKTLGQSLRIVGGTEVEEGEWPWQASLQWDGSHRCGATLINATWLVSAAHCFTTYKNPARWTASFGVTIKPSKMKRGLRRIIVHEKYKHPSHDYDISLAELSSPVPYTNAVHRVCLPDASYEFQPGDVMFVTGFGALKNDGYSQNHLRQAQVTLIDATTCNEPQAYNDAITPRMLCAGSLEGKTDACQGDSGGPLVSSDARDIWYLAGIVSWGDECAKPNKPGVYTRVTALRDWITSKTGI>sp|P01374|TNFB_HUMAN Lymphotoxin-alpha OS=Homo sapiens OX=9606 GN=LTAPE=1 SV=2MTPPERLFLPRVCGTTLHLLLLGLLLVLLPGAQGLPGVGLTPSAAQTARQHPKMHLAHSTLKPAAHLIGDPSKQNSLLWRANTDRAFLQDGFSLSNNSLLVPTSGIYFVYSQVVFSGKAYSPKATSSPLYLAHEVQLFSSQYPFHVPLLSSQKMVYPGLQEPWLHSMYHGAAFQLTQGDQLSTHTDGIPHLVLSPSTVFFGAFAL>sp|Q99973|TEP1_HUMAN Telomerase protein component 1 OS=Homo sapiensOX=9606 GN=TEP1 PE=1 SV=2MEKLHGHVSAHPDILSLENRCLAMLPDLQPLEKLHQHVSTHSDILSLKNQCLATLPDLKTMEKPHGYVSAHPDILSLENQCLATLSDLKTMEKPHGHVSAHPDILSLENRCLATLSSLKSTVSASPLFQSLQISHMTQADLYRVNNSNCLLSEPPSWRAQHFSKGLDLSTCPIALKSISATETAQEATLGRWFDSEEKKGAETQMPSYSLSLGEEEEVEDLAVKLTSGDSESHPEPTDHVLQEKKMALLSLLCSTLVSEVNMNNTSDPTLAAIFEICRELALLEPEFILKASLYARQQLNVRNVANNILAIAAFLPACRPHLRRYFCAIVQLPSDWIQVAELYQSLAEGDKNKLVPLPACLRTAMTDKFAQFDEYQLAKYNPRKHRAKRHPRRPPRSPGMEPPFSHRCFPRYIGFLREEQRKFEKAGDTVSEKKNPPRFTLKKLVQRLHIHKPAQHVQALLGYRYPSNLQLFSRSRLPGPWDSSRAGKRMKLSRPETWERELSLRGNKASVWEELIENGKLPFMAMLRNLCNLLRVGISSRHHELILQRLQHAKSVIHSRQFPFRFLNAHDAIDALEAQLRNQALPFPSNITLMRRILTRNEKNRPRRRFLCHLSRQQLRMAMRIPVLYEQLKREKLRVHKARQWKYDGEMLNRYRQALETAVNLSVKHSLPLLPGRTVLVYLTDANADRLCPKSNPQGPPLNYALLLIGMMITRAEQVDVVLCGGDTLKTAVLKAEEGILKTAIKLQAQVQEFDENDGWSLNTFGKYLLSLAGQRVPVDRVILLGQSMDDGMINVAKQLYWQRVNSKCLFVGILLRRVQYLSTDLNPNDVTLSGCTDAILKFIAEHGASHLLEHVGQMDKIFKIPPPPGKTGVQSLRPLEEDTPSPLAPVSQQGWRSIRLFISSTFRDMHGERDLLLRSVLPALQARAAPHRISLHGIDLRWGVTEEETRRNRQLEVCLGEVENAQLFVGILGSRYGYIPPSYNLPDHPHFHWAQQYPSGRSVTEMEVMQFLNRNQRLQPSAQALIYFRDSSFLSSVPDAWKSDFVSESEEAARRISELKSYLSRQKGITCRRYPCEWGGVAAGRPYVGGLEEFGQLVLQDVWNMIQKLYLQPGALLEQPVSIPDDDLVQATFQQLQKPPSPARPRLLQDTVQRLMLPHGRLSLVTGQSGQGKTAFLASLVSALQAPDGAKVASLVFFHFSGARPDQGLALTLLRRLCTYLRGQLKEPGALPSTYRSLVWELQQRLLPKSAESLHPGQTQVLIIDGADRLVDQNGQLISDWIPKKLPRCVHLVLSVSSDAGLGETLEQSQGAHVLALGPLEASARARLVREELALYGKRLEESPFNNQMRLLLVKRESGRPLYLRLVTDHLRLFTLYEQVSERLRTLPATVPLLLQHILSTLEKEHGPDVLPQALTALEVTRSGLTVDQLHGVLSVWRTLPKGTKSWEEAVAAGNSGDPYPMGPFACLVQSLRSLLGEGPLERPGARLCLPDGPLRTAAKRCYGKRPGLEDTAHILIAAQLWKTCDADASGTFRSCPPEALGDLPYHLLQSGNRGLLSKFLTNLHVVAAHLELGLVSRLLEAHALYASSVPKEEQKLPEADVAVFRTFLRQQASILSQYPRLLPQQAANQPLDSPLCHQASLLSRRWHLQHTLRWLNKPRTMKNQQSSSLSLAVSSSPTAVAFSTNGQRAAVGTANGTVYLLDLRTWQEEKSVVSGCDGISACLFLSDDTLFLTAFDGLLELWDLQHGCRVLQTKAHQYQITGCCLSPDCRLLATVCLGGCLKLWDTVRGQLAFQHTYPKSLNCVAFHPEGQVIATGSWAGSISFFQVDGLKVTKDLGAPGASIRTLAFNVPGGVVAVGRLDSMVELWAWREGARLAAFPAHHGFVAAALFLHAGCQLLTAGEDGKVQVWSGSLGRPRGHLGSLSLSPALSVALSPDGDRVAVGYRADGIRIYKISSGSQGAQGQALDVAVSALAWLSPKVLVSGAEDGSLQGWALKECSLQSLWLLSRFQKPVLGLATSQELLASASEDFTVQLWPRQLLTRPHKAEDFPCGTELRGHEGPVSCCSFSTDGGSLATGGRDRSLLCWDVRTPKTPVLIHSFPACHRDWVTGCAWTKDNLLISCSSDGSVGLWDPESGQRLGQFLGHQSAVSAVAAVEEHVVSVSRDGTLKVWDHQGVELTSIPAHSGPISHCAAAMEPRAAGQPGSELLVVTVGLDGATRLWHPLLVCQTHTLLGHSGPVRAAAVSETSGLMLTASEDGSVRLWQVPKEADDTCIPRSSAAVTAVAWAPDGSMAVSGNQAGELILWQEAKAVATAQAPGHIGALIWSSAHTFFVLSADEKISEWQVKLRKGSAPGNLSLHLNRILQEDLGVLTSLDWAPDGHFLILAKADLKLLCMKPGDAPSEIWSSYTENPMILSTHKEYGIFVLQPKDPGVLSFLRQKESGEFEERLNFDINLENPSRTLISITQAKPESESSFLCASSDGILWNLAKCSPEGEWTTGNMWQKKANTPETQTPGTDPSTCRESDASMDSDASMDSEPTPHLKTRQRRKIHSGSVTALHVLPELLVTASKDRDVKLWERPSMQLLGLFRCEGSVSCLEPWLGANSTLQLAVGDVQGNVYFLNWE>sp|Q99973-2|TEP1_HUMAN Isoform 2 of Telomerase protein component 1OS=Homo sapiens OX=9606 GN=TEP1MEKLHGHVSAHPDILSLENRCLAMLPDLQPLEKLHQHVSTHSDILSLKNQCLATLPDLKTMEKPHGYVSAHPDILSLENQCLATLSDLKTMEKPHGHVSAHPDILSLENRCLATLSSLKSTVSASPLFQSLQISHMTQADLYRVNNSNCLLSEPPSWRAQHFSKGLDLSTCPIALKSISATETAQEATLGRWFDSEEKKGAETQMPSYSLSLGEEEEVEDLAVKLTSGDSESHPEPTDHVLQEKKMALLSLLCSTLVSEVNMNNTSDPTLAAIFEICRELALLEPEFILKASLYARQQLNVRNVANNILAIAAFLPACRPHLRRYFCAIVQLPSDWIQVAELYQSLAEGDKNKLVPLPACLRTAMTDKFAQFDEYQLAKYNPRKHRAKRHPRRPPRSPGMEPPFSHRCFPRYIGFLREEQRKFEKAGDTVSEKKNPPRFTLKKLVQRLHIHKPAQHVQALLGYRYPSNLQLFSRSRLPGPWDSSRAGKRMKLSRPETWERELSLRGNKASVWEELIENGKLPFMAMLRNLCNLLRVGISSRHHELILQRLQHAKSVIHSRQFPFRFLNAHDAIDALEAQLRNQALPFPSNITLMRRILTRNEKNRPRRRFLCHLSRQQLRMAMRIPVLYEQLKREKLRVHKARQWKYDGEMLNRYRQALETAVNLSVKHSLPLLPGRTVLVYLTDANADRLCPKSNPQGPPLNYALLLIGMMITRAEQVDVVLCGGDTLKTAVLKAEEGILKTAIKLQAQVQEFDENDGWSLNTFGKYLLSLAGQRVPVDRVILLGQSMDDGMINVAKQLYWQRVNSKCLFVGILLRRVQYLSTDLNPNDVTLSGCTDAILKFIAEHGASHLLEHVGQMDKIFKIPPPPGKTGVQSLRPLEEDTPSPLAPVSQQGWRSIRLFISSTFRDMHGERDLLLRSVLPALQARAAPHRISLHGIDLRWGVTEEETRRNRQLEVCLGEVENAQLFVGILGSRYGYIPPSYNLPDHPHFHWAQQYPSGRSVTEMEVMQFLNRNQRLQPSAQALIYFRDSSFLSSVPDAWKSDFVSESEEAARRISELKSYLSRQKGITCRRYPCEWGGVAAGRPYVGGLEEFGQLVLQDVWNMIQKLYLQPGALLEQPVSIPDDDLVQATFQQLQKPPSPARPRLLQDTVQRLMLPHGRLSLVTGQSGQGKTAFLASLVSALQAPDGAKVASLVFFHFSGARPDQGLALTLLRRLCTYLRGQLKEPGALPSTYRSLVWELQQRLLPKSAESLHPGQTQVLIIDGADRLVDQNGQLISDWIPKKLPRCVHLVLSVSSDAGLGETLEQSQGAHVLALGPLEASARARLVREELALYGKRLEESPFNNQMRLLLVKRESGRPLYLRLVTDHLRLFTLYEQVSERLRTLPATVPLLLQHILSTLEKEHGPDVLPQALTALEVTRSGLTVDQLHGVLSVWRTLPKGTKSWEEAVAAGNSGDPYPMGPFACLVQSLRSLLGEGPLERPGARLCLPDGPLRTAAKRCYGKRPGLEDTAHILIAAQLWKTCDADASGTFRSCPPEALGDLPYHLLQSGNRGLLSKFLTNLHVVAAHLELGLVSRLLEAHALYASSVPKEEQKLPEADVAVFRTFLRQQASILSQYPRLLPQQAANQPLDSPLCHQASLLSRRWHLQHTLRWLNKPRTMKNQQSSSLSLAVSSSPTAVAFSTNGQRAAVGTANGTVYLLDLRTWQEEKSVVSGCDGISACLFLSDDTLFLTAFDGLLELWDLQHGCRVLQTKAHQYQITGCCLSPDCRLLATVCLGGCLKLWDTVRGQLAFQHTYPKSLNCVAFHPEGQVIATGSWAGSISFFQVDGLKVTKDLGAPGASIRTLAFNVPGGVVAVGRLDSMVELWAWREGARLAAFPAHHGFVAAALFLHAGCQLLTAGEDGKVQVWSGSLGRPRGHLGSLSLSPALSVALSPDGDRVAVGYRADGIRIYKISSGSQGAQGQALDVAVSALAWLSPKVLVSGAEDGSLQGWALKECSLQSLWLLSRFQKPVLGLATSQELLASASEDFTVQLWPRQLLTRPHKAEDFPCGTELRGHEGPVSCCSFSTDGGSLATGGRDRSLLCWDVRTPKTPVLIHSFPACHRDWVTGCAWTKDNLLISCSSDGSVGLWDPESGQRLGQFLGHQSAVSAVAAVEEHVVSVSRDGTLKVWDHQGVELTSIPAHSGPISHCAAAMEPRAAGQPGSELLVVTVGLDGATRLWHPLLVCQTHTLLGHSGPVRAAAVSETSGLMLTASEDGSVRLWQVPKEADDTCIPRSSAAVTAVAWAPDGSMAVSGNQAGELILWQEAKAVATAQAPGHIGALIWSSAHTFFVLSADEKISEWQVKLRKGSAPGNLSLHLNRILQEDLGVLTSLDWAPDGHFLILAKADLKLLCMKPGDAPSEIWSSYTENPMILSTHKEYGIFVLQPKDPGVLSFLRQKESGEFEERLNFDINLENPSRTLISITQAKPESALMGSYGTWPNAAQKENGPQVTCGRKKANTPETQTPGTDPSTCRESDASMDSDASMDSEPTPHLKTRQRRKIHSGSVTALHVLPELLVTASKDRDVKLWERPSMQLLGLFRCEGSVSCLEPWLGANSTLQLAVGDVQGNVYFLNWE>sp|Q6UX40|TM107_HUMAN Transmembrane protein 107 OS=Homo sapiens OX=9606GN=TMEM107 PE=1 SV=1MGRVSGLVPSRFLTLLAHLVVVITLFWSRDSNIQACLPLTFTPEEYDKQDIQLVAALSVTLGLFAVELAGFLSGVSMFNSTQSLISIGAHCSASVALSFFIFERWECTTYWYIFVFCSALPAVTEMALFVTVFGLKKKPF>sp|Q6UX40-2|TM107_HUMAN Isoform 2 of Transmembrane protein 107 OS=Homosapiens OX=9606 GN=TMEM107MGRVSGLVPSRFLTLLAHLVVVITLFWSRVRPTAALNPSPFPSLSGPSPTLPPPSVLPSWVFLFPAAPRPALQPAPFSLLSAGWWPRSLSPWASLQWSWPVSSQESPCSTAPRASSVSFLPAHLSHTTHFYQDSLQPPDTIVSAVANPSSSKIFNDVLNPAVY>sp|Q6UX40-3|TM107_HUMAN Isoform 3 of Transmembrane protein 107 OS=Homosapiens OX=9606 GN=TMEM107MGRVSGLVPSRFLTLLAHLVVVITLFWSRDSNIQACLPLTFTPEEYDKQDIHPLPLCRLVAALSVTLGLFAVELAGFLSGVSMFNSTQSLISIGAHCSASVALSFFIFERWECTTYCALPAVTEMALFVTVFGLKKKPF>sp|Q6UX40-4|TM107_HUMAN Isoform 4 of Transmembrane protein 107 OS=Homosapiens OX=9606 GN=TMEM107MGRVSGLVPSRFLTLLAHLVVVITLFWSRDSNIQACLPLTFTPEEYDKQDIHPLPLCRLVAALSVTLGLFAVELAGFLSGVSMFNSTQSLISIGAHCSASVALSFFIFERWECTTYWYIFVFCSALPAVTEMALFVTVFGLKKKPF>sp|P67936|TPM4_HUMAN Tropomyosin alpha-4 chain OS=Homo sapiens OX=9606GN=TPM4 PE=1 SV=3MAGLNSLEAVKRKIQALQQQADEAEDRAQGLQRELDGERERREKAEGDVAALNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRAMKDEEKMEIQEMQLKEAKHIAEEADRKYEEVARKLVILEGELERAEERAEVSELKCGDLEEELKNVTNNLKSLEAASEKYSEKEDKYEEEIKLLSDKLKEAETRAEFAERTVAKLEKTIDDLEEKLAQAKEENVGLHQTLDQTLNELNCI>sp|P67936-2|TPM4_HUMAN Isoform 2 of Tropomyosin alpha-4 chain OS=Homosapiens OX=9606 GN=TPM4MEAIKKKMQMLKLDKENAIDRAEQAEADKKAAEDKCKQVEEELTHLQKKLKGTEDELDKYSEDLKDAQEKLELTEKKASDAEGDVAALNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRAMKDEEKMEIQEMQLKEAKHIAEEADRKYEEVARKLVILEGELERAEERAEVSELKCGDLEEELKNVTNNLKSLEAASEKYSEKEDKYEEEIKLLSDKLKEAETRAEFAERTVAKLEKTIDDLEEKLAQAKEENVGLHQTLDQTLNELNCI>sp|Q9BSN7|TM204_HUMAN Transmembrane protein 204 OS=Homo sapiens OX=9606GN=TMEM204 PE=2 SV=1MTVQRLVAAAVLVALVSLILNNVAAFTSNWVCQTLEDGRRRSVGLWRSCWLVDRTRGGPSPGARAGQVDAHDCEALGWGSEAAGFQESRGTVKLQFDMMRACNLVATAALTAGQLTFLLGLVGLPLLSPDAPCWEEAMAAAFQLASFVLVIGLVTFYRIGPYTNLSWSCYLNIGACLLATLAAAMLIWNILHKREDCMAPRVIVISRSLTARFRRGLDNDYVESPC>sp|Q7L0Y3|TM10C_HUMAN tRNA methyltransferase 10 homolog C OS=Homosapiens OX=9606 GN=TRMT10C PE=1 SV=2MAAFLKMSVSVNFFRPFTRFLVPFTLHRKRNNLTILQRYMSSKIPAVTYPKNESTPPSEELELDKWKTTMKSSVQEECVSTISSSKDEDPLAATREFIEMWRLLGREVPEHITEEELKTLMECVSNTAKKKYLKYLYTKEKVKKARQIKKEMKAAAREEAKNIKLLETTEEDKQKNFLFLRLWDRNMDIAMGWKGAQAMQFGQPLVFDMAYENYMKRKELQNTVSQLLESEGWNRRNVDPFHIYFCNLKIDGALHRELVKRYQEKWDKLLLTSTEKSHVDLFPKDSIIYLTADSPNVMTTFRHDKVYVIGSFVDKSMQPGTSLAKAKRLNLATECLPLDKYLQWEIGNKNLTLDQMIRILLCLKNNGNWQEALQFVPKRKHTGFLEISQHSQEFINRLKKAKT>sp|Q9BTD3|TM121_HUMAN Transmembrane protein 121 OS=Homo sapiens OX=9606GN=TMEM121 PE=1 SV=1MVLPPPDRRHVCLTTLVIMGSMAVMDAYLVEQNQGPRKIGVCIIVLVGDVCFLLVLRYVAVWVGAEVRTAKRGYAMILWFLYIFVLEIKLYFIFQNYKAARRGAADPVARKALTLLLSVCVPGLFLLLVALDRMEYVRTFRKREDLRGRLFWVALDLLDLLDMQASLWEPPRSGLPLWAEGLTFFYCYMLLLVLPCVALSEVSMQGEHIAPQKMMLYPVLSLATVNVVAVLARAANMALFRDSRVSAIFVGKNVVALATKACTFLEYRRQVRDFPPPALSLELQPPPPQRNSVPPPPPPLHGPPGRPHMSSPTRDPLDT>sp|Q9BRJ7|TIRR_HUMAN Tudor-interacting repair regulator protein OS=Homosapiens OX=9606 GN=NUDT16L1 PE=1 SV=1MSTAAVPELKQISRVEAMRLGPGWSHSCHAMLYAANPGQLFGRIPMRFSVLMQMRFDGLLGFPGGFVDRRFWSLEDGLNRVLGLGLGCLRLTEADYLSSHLTEGPHRVVAHLYARQLTLEQLHAVEISAVHSRDHGLEVLGLVRVPLYTQKDRVGGFPNFLSNAFVSTAKCQLLFALKVLNMMPEEKLVEALAAATEKQKKALEKLLPASS>sp|Q9BRJ7-2|TIRR_HUMAN Isoform 2 of Tudor-interacting repair regulatorprotein OS=Homo sapiens OX=9606 GN=NUDT16L1MSTAAVPELKQISRVEAMRLGPGWSHSCHAMLYAANPGQLFGRIPMRFSVLMQMRFDGLLGFPGGFVDRRFWSLEDGLNRVLGLGLGCLRLTEADYLSSHLTEGPHRVVAHLYARQLTLEQLHAVEISAVHSRDHGLEVGPPPGPRPPPRGLALAPWKAPMGNTSPEGPLAGLGRVSLSPAMGWGEGSGAGRPGKEGRGWGPALGLPQGCVTSALLPAIANPGSGGVGSVGRKGWGRSGDCLGSWET>sp|P16035|TIMP2_HUMAN Metalloproteinase inhibitor 2 OS=Homo sapiensOX=9606 GN=TIMP2 PE=1 SV=2MGAAARTLRLALGLLLLATLLRPADACSCSPVHPQQAFCNADVVIRAKAVSEKEVDSGNDIYGNPIKRIQYEIKQIKMFKGPEKDIEFIYTAPSSAVCGVSLDVGGKKEYLIAGKAEGDGKMHITLCDFIVPWDTLSTTQKKSLNHRYQMGCECKITRCPMIPCYISSPDECLWMDWVTEKNINGHQAKFFACIKRSDGSCAWYRGAAPPKQEFLDIEDP>sp|Q9Y5S1|TRPV2_HUMAN Transient receptor potential cation channelsubfamily V member 2 OS=Homo sapiens OX=9606 GN=TRPV2 PE=1 SV=1MTSPSSSPVFRLETLDGGQEDGSEADRGKLDFGSGLPPMESQFQGEDRKFAPQIRVNLNYRKGTGASQPDPNRFDRDRLFNAVSRGVPEDLAGLPEYLSKTSKYLTDSEYTEGSTGKTCLMKAVLNLKDGVNACILPLLQIDRDSGNPQPLVNAQCTDDYYRGHSALHIAIEKRSLQCVKLLVENGANVHARACGRFFQKGQGTCFYFGELPLSLAACTKQWDVVSYLLENPHQPASLQATDSQGNTVLHALVMISDNSAENIALVTSMYDGLLQAGARLCPTVQLEDIRNLQDLTPLKLAAKEGKIEIFRHILQREFSGLSHLSRKFTEWCYGPVRVSLYDLASVDSCEENSVLEIIAFHCKSPHRHRMVVLEPLNKLLQAKWDLLIPKFFLNFLCNLIYMFIFTAVAYHQPTLKKQAAPHLKAEVGNSMLLTGHILILLGGIYLLVGQLWYFWRRHVFIWISFIDSYFEILFLFQALLTVVSQVLCFLAIEWYLPLLVSALVLGWLNLLYYTRGFQHTGIYSVMIQKVILRDLLRFLLIYLVFLFGFAVALVSLSQEAWRPEAPTGPNATESVQPMEGQEDEGNGAQYRGILEASLELFKFTIGMGELAFQEQLHFRGMVLLLLLAYVLLTYILLLNMLIALMSETVNSVATDSWSIWKLQKAISVLEMENGYWWCRKKQRAGVMLTVGTKPDGSPDERWCFRVEEVNWASWEQTLPTLCEDPSGAGVPRTLENPVLASPPKEDEDGASEENYVPVQLLQSN>sp|A0A0C4DH27|TRGV8_HUMAN T cell receptor gamma variable 8 OS=Homosapiens OX=9606 GN=TRGV8 PE=1 SV=1MLLALALLLAFLPPASQKSSNLEGRTKSVTRPTGSSAVITCDLPVENAVYTHWYLHQEGKAPQRLLYYDSYNSRVVLESGISREKYHTYASTGKSLKFILENLIERDSGVYYCATWDR>sp|Q9BZD6|TMG4_HUMAN Transmembrane gamma-carboxyglutamic acid protein 4OS=Homo sapiens OX=9606 GN=PRRG4 PE=1 SV=1MFTLLVLLSQLPTVTLGFPHCARGPKASKHAGEEVFTSKEEANFFIHRRLLYNRFDLELFTPGNLERECNEELCNYEEAREIFVDEDKTIAFWQEYSAKGPTTKSDGNREKIDVMGLLTGLIAAGVFLVIFGLLGYYLCITKCNRLQHPCSSAVYERGRHTPSIIFRRPEEAALSPLPPSVEDAGLPSYEQAVALTRKHSVSPPPPYPGHTKGFRVFKKSMSLPSH>sp|Q7Z4N2|TRPM1_HUMAN Transient receptor potential cation channelsubfamily M member 1 OS=Homo sapiens OX=9606 GN=TRPM1 PE=1 SV=2MKDSNRCCCGQFTNQHIPPLPSATPSKNEEESKQVETQPEKWSVAKHTQSYPTDSYGVLEFQGGGYSNKAMYIRVSYDTKPDSLLHLMVKDWQLELPKLLISVHGGLQNFEMQPKLKQVFGKGLIKAAMTTGAWIFTGGVSTGVISHVGDALKDHSSKSRGRVCAIGIAPWGIVENKEDLVGKDVTRVYQTMSNPLSKLSVLNNSHTHFILADNGTLGKYGAEVKLRRLLEKHISLQKINTRLGQGVPLVGLVVEGGPNVVSIVLEYLQEEPPIPVVICDGSGRASDILSFAHKYCEEGGIINESLREQLLVTIQKTFNYNKAQSHQLFAIIMECMKKKELVTVFRMGSEGQQDIEMAILTALLKGTNVSAPDQLSLALAWNRVDIARSQIFVFGPHWPPLGSLAPPTDSKATEKEKKPPMATTKGGRGKGKGKKKGKVKEEVEEETDPRKIELLNWVNALEQAMLDALVLDRVDFVKLLIENGVNMQHFLTIPRLEELYNTRLGPPNTLHLLVRDVKKSNLPPDYHISLIDIGLVLEYLMGGAYRCNYTRKNFRTLYNNLFGPKRPKALKLLGMEDDEPPAKGKKKKKKKKEEEIDIDVDDPAVSRFQYPFHELMVWAVLMKRQKMAVFLWQRGEESMAKALVACKLYKAMAHESSESDLVDDISQDLDNNSKDFGQLALELLDQSYKHDEQIAMKLLTYELKNWSNSTCLKLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNPGLKVIMGILLPPTILFLEFRTYDDFSYQTSKENEDGKEKEEENTDANADAGSRKGDEENEHKKQRSIPIGTKICEFYNAPIVKFWFYTISYLGYLLLFNYVILVRMDGWPSLQEWIVISYIVSLALEKIREILMSEPGKLSQKIKVWLQEYWNITDLVAISTFMIGAILRLQNQPYMGYGRVIYCVDIIFWYIRVLDIFGVNKYLGPYVMMIGKMMIDMLYFVVIMLVVLMSFGVARQAILHPEEKPSWKLARNIFYMPYWMIYGEVFADQIDLYAMEINPPCGENLYDEEGKRLPPCIPGAWLTPALMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHDRPVLPPPMIILSHIYIIIMRLSGRCRKKREGDQEERDRGLKLFLSDEELKRLHEFEEQCVQEHFREKEDEQQSSSDERIRVTSERVENMSMRLEEINERETFMKTSLQTVDLRLAQLEELSNRMVNALENLAGIDRSDLIQARSRASSECEATYLLRQSSINSADGYSLYRYHFNGEELLFEDTSLSTSPGTGVRKKTCSFRIKEEKDVKTHLVPECQNSLHLSLGTSTSATPDGSHLAVDDLKNAEESKLGPDIGISKEDDERQTDSKKEETISPSLNKTDVIHGQDKSDVQNTQLTVETTNIEGTISYPLEETKITRYFPDETINACKTMKSRSFVYSRGRKLVGGVNQDVEYSSITDQQLTTEWQCQVQKITRSHSTDIPYIVSEAAVQAEHKEQFADMQDEHHVAEAIPRIPRLSLTITDRNGMENLLSVKPDQTLGFPSLRSKSLHGHPRNVKSIQGKLDRSGHASSVSSLVIVSGMTAEEKKVKKEKASTETEC>sp|Q7Z4N2-2|TRPM1_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily M member 1 OS=Homo sapiens OX=9606 GN=TRPM1MYIRVSYDTKPDSLLHLMVKDWQLELPKLLISVHGGLQNFEMQPKLKQVFGKGLIKAAMTTGAWIFTGGVSTGVISHVGDALKDHSSKSRGRVCAIGIAPWGIVENKEDLVGKDVTRVYQTMSNPLSKLSVLNNSHTHFILADNGTLGKYGAEVKLRRLLEKHISLQKINTRLGQGVPLVGLVVEGGPNVVSIVLEYLQEEPPIPVVICDGSGRASDILSFAHKYCEEGGIINESLREQLLVTIQKTFNYNKAQSHQLFAIIMECMKKKELVTVFRMGSEGQQDIEMAILTALLKGTNVSAPDQLSLALAWNRVDIARSQIFVFGPHWPPLGSLAPPTDSKATEKEKKPPMATTKGGRGKGKGKKKGKVKEEVEEETDPRKIELLNWVNALEQAMLDALVLDRVDFVKLLIENGVNMQHFLTIPRLEELYNTRLGPPNTLHLLVRDVKKSNLPPDYHISLIDIGLVLEYLMGGAYRCNYTRKNFRTLYNNLFGPKRPKALKLLGMEDDEPPAKGKKKKKKKKEEEIDIDVDDPAVSRFQYPFHELMVWAVLMKRQKMAVFLWQRGEESMAKALVACKLYKAMAHESSESDLVDDISQDLDNNSKDFGQLALELLDQSYKHDEQIAMKLLTYELKNWSNSTCLKLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNPGLKVIMGILLPPTILFLEFRTYDDFSYQTSKENEDGKEKEEENTDANADAGSRKGDEENEHKKQRSIPIGTKICEFYNAPIVKFWFYTISYLGYLLLFNYVILVRMDGWPSLQEWIVISYIVSLALEKIREILMSEPGKLSQKIKVWLQEYWNITDLVAISTFMIGAILRLQNQPYMGYGRVIYCVDIIFWYIRVLDIFGVNKYLGPYVMMIGKMMIDMLYFVVIMLVVLMSFGVARQAILHPEEKPSWKLARNIFYMPYWMIYGEVFADQIDLYAMEINPPCGENLYDEEGKRLPPCIPGAWLTPALMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHDRPVLPPPMIILSHIYIIIMRLSGRCRKKREGDQEERDRGLKLFLSDEELKRLHEFEEQCVQEHFREKEDEQQSSSDERIRVTSERVENMSMRLEEINERETFMKTSLQTVDLRLAQLEELSNRMVNALENLAGIDRSDLIQARSRASSECEATYLLRQSSINSADGYSLYRYHFNGEELLFEDTSLSTSPGTGVRKKTCSFRIKEEKDVKTHLVPECQNSLHLSLGTSTSATPDGSHLAVDDLKNAEESKLGPDIGISKEDDERQTDSKKEETISPSLNKTDVIHGQDKSDVQNTQLTVETTNIEGTISYPLEETKITRYFPDETINACKTMKSRSFVYSRGRKLVGGVNQDVEYSSITDQQLTTEWQCQVQKITRSHSTDIPYIVSEAAVQAEHKEQFADMQDEHHVAEAIPRIPRLSLTITDRNGMENLLSVKPDQTLGFPSLRSKSLHGHPRNVKSIQGKLDRSGHASSVSSLVIVSGMTAEEKKVKKEKASTETEC>sp|Q7Z4N2-3|TRPM1_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily M member 1 OS=Homo sapiens OX=9606 GN=TRPM1MKDSNRCCCGQFTNQHIPPLPSATPSKNEEESKQVETQPEKWSVAKHTQSYPTDSYGVLEFQGGGYSNKAMYIRVSYDTKPDSLLHLMVKDWQLELPKLLISVHGGLQNFEMQPKLKQVFGKGLIKAAMTTGAWIFTGGVSTGVISHVGDALKDHSSKSRGRVCAIGIAPWGIVENKEDLVGKDVTRVYQTMSNPLSKLSVLNNSHTHFILADNGTLGKYGAEVKLRRLLEKHISLQKINTRLGQGVPLVGLVVEGGPNVVSIVLEYLQEEPPIPVVICDGSGRASDILSFAHKIINESLREQLLVTIQKTFNYNKAQSHQLFAIIMECMKKKELVTVFRMGSEGQQDIEMAILTALLKGTNVSAPDQLSLALAWNRVDIARSQIFVFGPHWPPLGSLAPPTDSKATEKEKKPPMATTKGGRGKGKGKKKGKVKEEVEEETDPRKIELLNWVNALEQAMLDALVLDRVDFVKLLIENGVNMQHFLTIPRLEELYNTRLGPPNTLHLLVRDVKKSNLPPDYHISLIDIGLVLEYLMGGAYRCNYTRKNFRTLYNNLFGPKRPKALKLLGMEDDEPPAKGKKKKKKKKEEEIDIDVDDPAVSRFQYPFHELMVWAVLMKRQKMAVFLWQRGEESMAKALVACKLYKAMAHESSESDLVDDISQDLDNNSKDFGQLALELLDQSYKHDEQIAMKLLTYELKNWSNSTCLKLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNPGLKVIMGILLPPTILFLEFRTYDDFSYQTSKENEDGKEKEEENTDANADAGSRKGDEENEHKKQRSIPIGTKICEFYNAPIVKFWFYTISYLGYLLLFNYVILVRMDGWPSLQEWIVISYIVSLALEKIREILMSEPGKLSQKIKVWLQEYWNITDLVAISTFMIGAILRLQNQPYMGYGRVIYCVDIIFWYIRVLDIFGVNKYLGPYVMMIGKMMIDMLYFVVIMLVVLMSFGVARQAILHPEEKPSWKLARNIFYMPYWMIYGEVFADQIDLYAMEINPPCGENLYDEEGKRLPPCIPGAWLTPALMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHDRPVLPPPMIILSHIYIIIMRLSGRCRKKREGDQEERDRGLKLFLSDEELKRLHEFEEQCVQEHFREKEDEQQSSSDERIRVTSERVENMSMRLEEINERETFMKTSLQTVDLRLAQLEELSNRMVNALENLAGIDRSDLIQARSRASSECEATYLLRQSSINSADGYSLYRYHFNGEELLFEDTSLSTSPGTGVRKKTCSFRIKEEKDVKTHLVPECQNSLHLSLGTSTSATPDGSHLAVDDLKNAEESKLGPDIGISKEDDERQTDSKKEETISPSLNKTDVIHGQDKSDVQNTQLTVETTNIEGTISYPLEETKITRYFPDETINACKTMKSRSFVYSRGRKLVGGVNQDVEYSSITDQQLTTEWQCQVQKITRSHSTDIPYIVSEAAVQAEHKEQFADMQDEHHVAEAIPRIPRLSLTITDRNGMENLLSVKPDQTLGFPSLRSKSLHGHPRNVKSIQGKLDRSGHASSVSSLVIVSGMTAEEKKVKKEKASTETEC>sp|Q7Z4N2-4|TRPM1_HUMAN Isoform 4 of Transient receptor potential cationchannel subfamily M member 1 OS=Homo sapiens OX=9606 GN=TRPM1MKDSNRCCCGQFTNQHIPPLPSATPSKNEEESKQVETQPEKWSVAKHTQSYPTDSYGVLEFQGGGYSNKAMYIRVSYDTKPDSLLHLMVKDWQLELPKLLISVHGGLQNFEMQPKLKQVFGKGLIKAAMTTGAWIFTGGVSTGVISHVGDALKDHSSKSRGRVCAIGIAPWGIVENKEDLVGKDVTRVYQTMSNPLSKLSVLNNSHTHFILADNGTLGKYGAEVKLRRLLEKHISLQKINTRLGQGVPLVGLVVEGGPNVVSIVLEYLQEEPPIPVVICDGSGRASDILSFAHKYCEEGG>sp|Q7Z4N2-5|TRPM1_HUMAN Isoform 5 of Transient receptor potential cationchannel subfamily M member 1 OS=Homo sapiens OX=9606 GN=TRPM1MSSFKRGSLKSSTSGSQKGQKSWIEKTFCKRECIFVIPSMKDSNRCCCGQFTNQHIPPLPSATPSKNEEESKQVETQPEKWSVAKHTQSYPTDSYGVLEFQGGGYSNKAMYIRVSYDTKPDSLLHLMVKDWQLELPKLLISVHGGLQNFEMQPKLKQVFGKGLIKAAMTTGAWIFTGGVSTGVISHVGDALKDHSSKSRGRVCAIGIAPWGIVENKEDLVGKDVTRVYQTMSNPLSKLSVLNNSHTHFILADNGTLGKYGAEVKLRRLLEKHISLQKINTRLGQGVPLVGLVVEGGPNVVSIVLEYLQEEPPIPVVICDGSGRASDILSFAHKYCEEGGIINESLREQLLVTIQKTFNYNKAQSHQLFAIIMECMKKKELVTVFRMGSEGQQDIEMAILTALLKGTNVSAPDQLSLALAWNRVDIARSQIFVFGPHWPPLGSLAPPTDSKATEKEKKPPMATTKGGRGKGKGKKKGKVKEEVEEETDPRKIELLNWVNALEQAMLDALVLDRVDFVKLLIENGVNMQHFLTIPRLEELYNTRLGPPNTLHLLVRDVKKSNLPPDYHISLIDIGLVLEYLMGGAYRCNYTRKNFRTLYNNLFGPKRPKALKLLGMEDDEPPAKGKKKKKKKKEEEIDIDVDDPAVSRFQYPFHELMVWAVLMKRQKMAVFLWQRGEESMAKALVACKLYKAMAHESSESDLVDDISQDLDNNSKDFGQLALELLDQSYKHDEQIAMKLLTYELKNWSNSTCLKLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNPGLKVIMGILLPPTILFLEFRTYDDFSYQTSKENEDGKEKEEENTDANADAGSRKGDEENEHKKQRSIPIGTKICEFYNAPIVKFWFYTISYLGYLLLFNYVILVRMDGWPSLQEWIVISYIVSLALEKIREILMSEPGKLSQKIKVWLQEYWNITDLVAISTFMIGAILRLQNQPYMGYGRVIYCVDIIFWYIRVLDIFGVNKYLGPYVMMIGKMMIDMLYFVVIMLVVLMSFGVARQAILHPEEKPSWKLARNIFYMPYWMIYGEVFADQIDLYAMEINPPCGENLYDEEGKRLPPCIPGAWLTPALMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHDRPVLPPPMIILSHIYIIIMRLSGRCRKKREGDQEERDRGLKLFLSDEELKRLHEFEEQCVQEHFREKEDEQQSSSDERIRVTSERVENMSMRLEEINERETFMKTSLQTVDLRLAQLEELSNRMVNALENLAGIDRSDLIQARSRASSECEATYLLRQSSINSADGYSLYRYHFNGEELLFEDTSLSTSPGTGVRKKTCSFRIKEEKDVKTHLVPECQNSLHLSLGTSTSATPDGSHLAVDDLKNAEESKLGPDIGISKEDDERQTDSKKEETISPSLNKTDVIHGQDKSDVQNTQLTVETTNIEGTISYPLEETKITRYFPDETINACKTMKSRSFVYSRGRKLVGGVNQDVEYSSITDQQLTTEWQCQVQKITRSHSTDIPYIVSEAAVQAEHKEQFADMQDEHHVAEAIPRIPRLSLTITDRNGMENLLSVKPDQTLGFPSLRSKSLHGHPRNVKSIQGKLDRSGHASSVSSLVIVSGMTAEEKKVKKEKASTETEC>sp|Q7Z4N2-6|TRPM1_HUMAN Isoform 6 of Transient receptor potential cationchannel subfamily M member 1 OS=Homo sapiens OX=9606 GN=TRPM1MGQKSWIEKTFCKRECIFVIPSMKDSNRCCCGQFTNQHIPPLPSATPSKNEEESKQVETQPEKWSVAKHTQSYPTDSYGVLEFQGGGYSNKAMYIRVSYDTKPDSLLHLMVKDWQLELPKLLISVHGGLQNFEMQPKLKQVFGKGLIKAAMTTGAWIFTGGVSTGVISHVGDALKDHSSKSRGRVCAIGIAPWGIVENKEDLVGKDVTRVYQTMSNPLSKLSVLNNSHTHFILADNGTLGKYGAEVKLRRLLEKHISLQKINTRLGQGVPLVGLVVEGGPNVVSIVLEYLQEEPPIPVVICDGSGRASDILSFAHKYCEEGGIINESLREQLLVTIQKTFNYNKAQSHQLFAIIMECMKKKELVTVFRMGSEGQQDIEMAILTALLKGTNVSAPDQLSLALAWNRVDIARSQIFVFGPHWPPLGSLAPPTDSKATEKEKKPPMATTKGGRGKGKGKKKGKVKEEVEEETDPRKIELLNWVNALEQAMLDALVLDRVDFVKLLIENGVNMQHFLTIPRLEELYNTRLGPPNTLHLLVRDVKKSNLPPDYHISLIDIGLVLEYLMGGAYRCNYTRKNFRTLYNNLFGPKRPKALKLLGMEDDEPPAKGKKKKKKKKEEEIDIDVDDPAVSRFQYPFHELMVWAVLMKRQKMAVFLWQRGEESMAKALVACKLYKAMAHESSESDLVDDISQDLDNNSKDFGQLALELLDQSYKHDEQIAMKLLTYELKNWSNSTCLKLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNPGLKVIMGILLPPTILFLEFRTYDDFSYQTSKENEDGKEKEEENTDANADAGSRKGDEENEHKKQRSIPIGTKICEFYNAPIVKFWFYTISYLGYLLLFNYVILVRMDGWPSLQEWIVISYIVSLALEKIREILMSEPGKLSQKIKVWLQEYWNITDLVAISTFMIGAILRLQNQPYMGYGRVIYCVDIIFWYIRVLDIFGVNKYLGPYVMMIGKMMIDMLYFVVIMLVVLMSFGVARQAILHPEEKPSWKLARNIFYMPYWMIYGEVFADQIDLYAMEINPPCGENLYDEEGKRLPPCIPGAWLTPALMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHDRPVLPPPMIILSHIYIIIMRLSGRCRKKREGDQEERDRGLKLFLSDEELKRLHEFEEQCVQEHFREKEDEQQSSSDERIRVTSERVENMSMRLEEINERETFMKTSLQTVDLRLAQLEELSNRMVNALENLAGIDRSDLIQARSRASSECEATYLLRQSSINSADGYSLYRYHFNGEELLFEDTSLSTSPGTGVRKKTCSFRIKEEKDVKTHLVPECQNSLHLSLGTSTSATPDGSHLAVDDLKNAEESKLGPDIGISKEDDERQTDSKKEETISPSLNKTDVIHGQDKSDVQNTQLTVETTNIEGTISYPLEETKITRYFPDETINACKTMKSRSFVYSRGRKLVGGVNQDVEYSSITDQQLTTEWQCQVQKITRSHSTDIPYIVSEAAVQAEHKEQFADMQDEHHVAEAIPRIPRLSLTITDRNGMENLLSVKPDQTLGFPSLRSKSLHGHPRNVKSIQGKLDRSGHASSVSSLVIVSGMTAEEKKVKKEKASTETEC>sp|Q7Z4N2-7|TRPM1_HUMAN Isoform 7 of Transient receptor potential cationchannel subfamily M member 1 OS=Homo sapiens OX=9606 GN=TRPM1MKDSNRCCCGQFTNQHIPPLPSATPSKNEEESKQVETQPEKWSVAKHTQSYPTDSYGVLEFQGGGYSNKAMVRKAFRHGATRITAFIGGQSPSPKLQIPGLLHGCGSIFLDISLKNQEIYLCTWLLAMRLGNWTPL>sp|Q96H15|TIMD4_HUMAN T-cell immunoglobulin and mucin domain-containingprotein 4 OS=Homo sapiens OX=9606 GN=TIMD4 PE=1 SV=2MSKEPLILWLMIEFWWLYLTPVTSETVVTEVLGHRVTLPCLYSSWSHNSNSMCWGKDQCPYSGCKEALIRTDGMRVTSRKSAKYRLQGTIPRGDVSLTILNPSESDSGVYCCRIEVPGWFNDVKINVRLNLQRASTTTHRTATTTTRRTTTTSPTTTRQMTTTPAALPTTVVTTPDLTTGTPLQMTTIAVFTTANTCLSLTPSTLPEEATGLLTPEPSKEGPILTAESETVLPSDSWSSVESTSADTVLLTSKESKVWDLPSTSHVSMWKTSDSVSSPQPGASDTAVPEQNKTTKTGQMDGIPMSMKNEMPISQLLMIIAPSLGFVLFALFVAFLLRGKLMETYCSQKHTRLDYIGDSKNVLNDVQHGREDEDGLFTL>sp|Q96H15-2|TIMD4_HUMAN Isoform 2 of T-cell immunoglobulin and mucindomain-containing protein 4 OS=Homo sapiens OX=9606 GN=TIMD4MSKEPLILWLMIEFWWLYLTPVTSETVVTEVLGHRVTLPCLYSSWSHNSNSMCWGKDQCPYSGCKEALIRTDGMRVTSRKSAKYRLQGTIPRGDVSLTILNPSESDSGVYCCRIEVPGWFNDVKINVRLNLQRASTTTHRTATTTTRRTTTTSPTTTRQMTTTPAALPTTVVTTPDLTTGTPLQMTTIAVFTTANTCLSLTPSTLPEEATGLLTPEPSKEGPILTAESETVLPSDSWSSVESTSADTVLLTSKASDTAVPEQNKTTKTGQMDGIPMSMKNEMPISQLLMIIAPSLGFVLFALFVAFLLRGKLMETYCSQKHTRLDYIGDSKNVLNDVQHGREDEDGLFTL>sp|Q8TD43|TRPM4_HUMAN Transient receptor potential cation channelsubfamily M member 4 OS=Homo sapiens OX=9606 GN=TRPM4 PE=1 SV=1MVVPEKEQSWIPKIFKKKTCTTFIVDSTDPGGTLCQCGRPRTAHPAVAMEDAFGAAVVTVWDSDAHTTEKPTDAYGELDFTGAGRKHSNFLRLSDRTDPAAVYSLVTRTWGFRAPNLVVSVLGGSGGPVLQTWLQDLLRRGLVRAAQSTGAWIVTGGLHTGIGRHVGVAVRDHQMASTGGTKVVAMGVAPWGVVRNRDTLINPKGSFPARYRWRGDPEDGVQFPLDYNYSAFFLVDDGTHGCLGGENRFRLRLESYISQQKTGVGGTGIDIPVLLLLIDGDEKMLTRIENATQAQLPCLLVAGSGGAADCLAETLEDTLAPGSGGARQGEARDRIRRFFPKGDLEVLQAQVERIMTRKELLTVYSSEDGSEEFETIVLKALVKACGSSEASAYLDELRLAVAWNRVDIAQSELFRGDIQWRSFHLEASLMDALLNDRPEFVRLLISHGLSLGHFLTPMRLAQLYSAAPSNSLIRNLLDQASHSAGTKAPALKGGAAELRPPDVGHVLRMLLGKMCAPRYPSGGAWDPHPGQGFGESMYLLSDKATSPLSLDAGLGQAPWSDLLLWALLLNRAQMAMYFWEMGSNAVSSALGACLLLRVMARLEPDAEEAARRKDLAFKFEGMGVDLFGECYRSSEVRAARLLLRRCPLWGDATCLQLAMQADARAFFAQDGVQSLLTQKWWGDMASTTPIWALVLAFFCPPLIYTRLITFRKSEEEPTREELEFDMDSVINGEGPVGTADPAEKTPLGVPRQSGRPGCCGGRCGGRRCLRRWFHFWGAPVTIFMGNVVSYLLFLLLFSRVLLVDFQPAPPGSLELLLYFWAFTLLCEELRQGLSGGGGSLASGGPGPGHASLSQRLRLYLADSWNQCDLVALTCFLLGVGCRLTPGLYHLGRTVLCIDFMVFTVRLLHIFTVNKQLGPKIVIVSKMMKDVFFFLFFLGVWLVAYGVATEGLLRPRDSDFPSILRRVFYRPYLQIFGQIPQEDMDVALMEHSNCSSEPGFWAHPPGAQAGTCVSQYANWLVVLLLVIFLLVANILLVNLLIAMFSYTFGKVQGNSDLYWKAQRYRLIREFHSRPALAPPFIVISHLRLLLRQLCRRPRSPQPSSPALEHFRVYLSKEAERKLLTWESVHKENFLLARARDKRESDSERLKRTSQKVDLALKQLGHIREYEQRLKVLEREVQQCSRVLGWVAEALSRSALLPPGGPPPPDLPGSKD>sp|Q8TD43-2|TRPM4_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily M member 4 OS=Homo sapiens OX=9606 GN=TRPM4MASTGGTKVVAMGVAPWGVVRNRDTLINPKGSFPARYRWRGDPEDGVQFPLDYNYSAFFLVDDGTHGCLGGENRFRLRLESYISQQKTGVGGTGIDIPVLLLLIDGDEKMLTRIENATQAQLPCLLVAGSGGAADCLAETLEDTLAPGSGGARQGEARDRIRRFFPKGDLEVLQAQVERIMTRKELLTVYSSEDGSEEFETIVLKALVKACGSSEASAYLDELRLAVAWNRVDIAQSELFRGDIQWRSFHLEASLMDALLNDRPEFVRLLISHGLSLGHFLTPMRLAQLYSAAPSNSLIRNLLDQASHSAGTKAPALKGGAAELRPPDVGHVLRMLLGKMCAPRYPSGGAWDPHPGQGFGESMYLLSDKATSPLSLDAGLGQAPWSDLLLWALLLNRAQMAMYFWEMGSNAVSSALGACLLLRVMARLEPDAEEAARRKDLAFKFEGMGVDLFGECYRSSEVRAARLLLRRCPLWGDATCLQLAMQADARAFFAQDGVQSLLTQKWWGDMASTTPIWALVLAFFCPPLIYTRLITFRKSEEEPTREELEFDMDSVINGEGPVGTADPAEKTPLGVPRQSGRPGCCGGRCGGRRCLRRWFHFWGAPVTIFMGNVVSYLLFLLLFSRVLLVDFQPAPPGSLELLLYFWAFTLLCEELRQGLSGGGGSLASGGPGPGHASLSQRLRLYLADSWNQCDLVALTCFLLGVGCRLTPGLYHLGRTVLCIDFMVFTVRLLHIFTVNKQLGPKIVIVSKMMKDVFFFLFFLGVWLVAYGVATEGLLRPRDSDFPSILRRVFYRPYLQIFGQIPQEDMDVALMEHSNCSSEPGFWAHPPGAQAGTCVSQYANWLVVLLLVIFLLVANILLVNLLIAMFSYTFGKVQGNSDLYWKAQRYRLIREFHSRPALAPPFIVISHLRLLLRQLCRRPRSPQPSSPALEHFRVYLSKEAERKLLTWESVHKENFLLARARDKRESDSERLKRTSQKVDLALKQLGHIREYEQRLKVLEREVQQCSRVLGWVAEALSRSALLPPGGPPPPDLPGSKD>sp|Q8TD43-3|TRPM4_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily M member 4 OS=Homo sapiens OX=9606 GN=TRPM4MVVPEKEQSWIPKIFKKKTCTTFIVDSTDPGGTLCQCGRPRTAHPAVAMEDAFGAAVVTVWDSDAHTTEKPTDAYGELDFTGAGRKHSNFLRLSDRTDPAAVYSLVTRTWGFRAPNLVVSVLGGSGGPVLQTWLQDLLRRGLVRAAQSTGAWIVTGGLHTGIGRHVGVAVRDHQMASTGGTKVVAMGVAPWGVVRNRDTLINPKGSFPARYRWRGDPEDGVQFPLDYNYSAFFLVDDGTHGCLGGENRFRLRLESYISQQKTGVGGTGIDIPVLLLLIDGDEKMLTRIENATQAQLPCLLVAGSGGAADCLAETLEDTLAPGSGGARQGEARDRIRRFFPKGDLEVLQAQVERIMTRKELLTVYSSEDGSEEFETIVLKALVKACGSSEASAYLDELRLAVAWNRVDIAQSELFRGDIQWRSFHLEASLMDALLNDRPEFVRLLISHGLSLGHFLTPMRLAQLYSAAPSNSLIRNLLDQASHSAGTKAPALKGGAAELRPPDVGHVLRMLLGKMCAPRYPSGGAWDPHPGQGFGESMYLLSDKATSPLSLDAGLGQAPWSDLLLWALLLNRAQMAMYFWEMGSNAVSSALGACLLLRVMARLEPDAEEAARRKDLAFKFEGMGVDLFGECYRSSEVRAARLLLRRCPLWGDATCLQLAMQADARAFFAQDGVQSLLTQKWWGDMASTTPIWALVLAFFCPPLIYTRLITFRKSEEEPTREELEFDMDSVINGEGPVGLTPGLYHLGRTVLCIDFMVFTVRLLHIFTVNKQLGPKIVIVSKMMKDVFFFLFFLGVWLVAYGVATEGLLRPRDSDFPSILRRVFYRPYLQIFGQIPQEDMDVALMEHSNCSSEPGFWAHPPGAQAGTCVSQYANWLVVLLLVIFLLVANILLVNLLIAMFSYTFGKVQGNSDLYWKAQRYRLIREFHSRPALAPPFIVISHLRLLLRQLCRRPRSPQPSSPALEHFRVYLSKEAERKLLTWESVHKENFLLARARDKRESDSERLKRTSQKVDLALKQLGHIREYEQRLKVLEREVQQCSRVLGWVAEALSRSALLPPGGPPPPDLPGSKD>sp|Q9UBN4|TRPC4_HUMAN Short transient receptor potential channel 4OS=Homo sapiens OX=9606 GN=TRPC4 PE=1 SV=1MAQFYYKRNVNAPYRDRIPLRIVRAESELSPSEKAYLNAVEKGDYASVKKSLEEAEIYFKININCIDPLGRTALLIAIENENLELIELLLSFNVYVGDALLHAIRKEVVGAVELLLNHKKPSGEKQVPPILLDKQFSEFTPDITPIILAAHTNNYEIIKLLVQKGVSVPRPHEVRCNCVECVSSSDVDSLRHSRSRLNIYKALASPSLIALSSEDPFLTAFQLSWELQELSKVENEFKSEYEELSRQCKQFAKDLLDQTRSSRELEIILNYRDDNSLIEEQSGNDLARLKLAIKYRQKEFVAQPNCQQLLASRWYDEFPGWRRRHWAVKMVTCFIIGLLFPVFSVCYLIAPKSPLGLFIRKPFIKFICHTASYLTFLFLLLLASQHIDRSDLNRQGPPPTIVEWMILPWVLGFIWGEIKQMWDGGLQDYIHDWWNLMDFVMNSLYLATISLKIVAFVKYSALNPRESWDMWHPTLVAEALFAIANIFSSLRLISLFTANSHLGPLQISLGRMLLDILKFLFIYCLVLLAFANGLNQLYFYYEETKGLTCKGIRCEKQNNAFSTLFETLQSLFWSIFGLINLYVTNVKAQHEFTEFVGATMFGTYNVISLVVLLNMLIAMMNNSYQLIADHADIEWKFARTKLWMSYFEEGGTLPTPFNVIPSPKSLWYLIKWIWTHLCKKKMRRKPESFGTIGRRAADNLRRHHQYQEVMRNLVKRYVAAMIRDAKTEEGLTEENFKELKQDISSFRFEVLGLLRGSKLSTIQSANASKESSNSADSDEKSDSEGNSKDKKKNFSLFDLTTLIHPRSAAIASERHNISNGSALVVQEPPREKQRKVNFVTDIKNFGLFHRRSKQNAAEQNANQIFSVSEEVARQQAAGPLERNIQLESRGLASRGDLSIPGLSEQCVLVDHRERNTDTLGLQVGKRVCPFKSEKVVVEDTVPIIPKEKHAKEEDSSIDYDLNLPDTVTHEDYVTTRL>sp|Q9UBN4-2|TRPC4_HUMAN Isoform Beta of Short transient receptorpotential channel 4 OS=Homo sapiens OX=9606 GN=TRPC4MAQFYYKRNVNAPYRDRIPLRIVRAESELSPSEKAYLNAVEKGDYASVKKSLEEAEIYFKININCIDPLGRTALLIAIENENLELIELLLSFNVYVGDALLHAIRKEVVGAVELLLNHKKPSGEKQVPPILLDKQFSEFTPDITPIILAAHTNNYEIIKLLVQKGVSVPRPHEVRCNCVECVSSSDVDSLRHSRSRLNIYKALASPSLIALSSEDPFLTAFQLSWELQELSKVENEFKSEYEELSRQCKQFAKDLLDQTRSSRELEIILNYRDDNSLIEEQSGNDLARLKLAIKYRQKEFVAQPNCQQLLASRWYDEFPGWRRRHWAVKMVTCFIIGLLFPVFSVCYLIAPKSPLGLFIRKPFIKFICHTASYLTFLFLLLLASQHIDRSDLNRQGPPPTIVEWMILPWVLGFIWGEIKQMWDGGLQDYIHDWWNLMDFVMNSLYLATISLKIVAFVKYSALNPRESWDMWHPTLVAEALFAIANIFSSLRLISLFTANSHLGPLQISLGRMLLDILKFLFIYCLVLLAFANGLNQLYFYYEETKGLTCKGIRCEKQNNAFSTLFETLQSLFWSIFGLINLYVTNVKAQHEFTEFVGATMFGTYNVISLVVLLNMLIAMMNNSYQLIADHADIEWKFARTKLWMSYFEEGGTLPTPFNVIPSPKSLWYLIKWIWTHLCKKKMRRKPESFGTIGRRAADNLRRHHQYQEVMRNLVKRYVAAMIRDAKTEEGLTEENFKELKQDISSFRFEVLGLLRGSKLSTIQSANASKESSNSADSDEKSDSEEEVARQQAAGPLERNIQLESRGLASRGDLSIPGLSEQCVLVDHRERNTDTLGLQVGKRVCPFKSEKVVVEDTVPIIPKEKHAKEEDSSIDYDLNLPDTVTHEDYVTTRL>sp|Q9UBN4-3|TRPC4_HUMAN Isoform Delta of Short transient receptorpotential channel 4 OS=Homo sapiens OX=9606 GN=TRPC4MAQFYYKRNVNAPYRDRIPLRIVRAESELSPSEKAYLNAVEKGDYASVKKSLEEAEIYFKININCIDPLGRTALLIAIENENLELIELLLSFNVYVGDALLHAIRKEVVGAVELLLNHKKPSGEKQVPPILLDKQFSEFTPDITPIILAAHTNNYEIIKLLVQKGVSVPRPHEVRCNCVECVSSSDVDSLRHSRSRLNIYKALASPSLIALSSEDPFLTAFQLSWELQELSKVENEFKSEYEELSRQCKQFAKDLLDQTRSSRELEIILNYRDDNSLIEEQSGNDLARLKLAIKYRQKEFVAQPNCQQLLASRWYDEFPGWRRRHWAVKMVTCFIIGLLFPVFSVCYLIAPKSPLGLFIRKPFIKFICHTASYLTFLFLLLLASQHIDRSDLNRQGPPPTIVEWMILPWVLGFIWGEIKQMWDGGLQDYIHDWWNLMDFVMNSLYLATISLKIVAFVKYSALNPRESWDMWHPTLVAEALFAIANIFSSLRLISLFTANSHLGPLQISLGRMLLDILKFLFIYCLVLLAFANGLNQLYFYYEETKGLTCKGIRCEKQNNAFSTLFETLQSLFWSIFGLINLYVTNVKAQHEFTEFVGATMFGTYNVISLVVLLNMLIAMMNNSYQLIADHADIEWKFARTKLWMSYFEEGGTLPTPFNVIPSPKSLWYLIKWIWTHLCKKKMRRKPESFGTIGRRAADNLRRHHQYQEVMRNLVKRYVAAMIRDAKTEEVARQQAAGPLERNIQLESRGLASRGDLSIPGLSEQCVLVDHRERNTDTLGLQVGKRVCPFKSEKVVVEDTVPIIPKEKHAKEEDSSIDYDLNLPDTVTHEDYVTTRL>sp|Q9UBN4-4|TRPC4_HUMAN Isoform Gamma of Short transient receptorpotential channel 4 OS=Homo sapiens OX=9606 GN=TRPC4MAQFYYKRNVNAPYRDRIPLRIVRAESELSPSEKAYLNAVEKGDYASVKKSLEEAEIYFKININCIDPLGRTALLIAIENENLELIELLLSFNVYVGDALLHAIRKEVVGAVELLLNHKKPSGEKQVPPILLDKQFSEFTPDITPIILAAHTNNYEIIKLLVQKGVSVPRPHEVRCNCVECVSSSDVDSLRHSRSRLNIYKALASPSLIALSSEDPFLTAFQLSWELQELSKVENEFKSEYEELSRQCKQFAKDLLDQTRSSRELEIILNYRDDNSLIEEQSGNDLARLKLAIKYRQKEFVAQPNCQQLLASRWYDEFPGWRRRHWAVKMVTCFIIGLLFPVFSVCYLIAPKSPLGLFIRKPFIKFICHTASYLTFLFLLLLASQHIDRSDLNRQGPPPTIVEWMILPWVLGFIWGEIKQMWDGGLQDYIHDWWNLMDFVMNSLYLATISLKIVAFVKYSALNPRESWDMWHPTLVAEALFAIANIFSSLRLISLFTANSHLGPLQISLGRMLLDILKFLFIYCLVLLAFANGLNQLYFYYEETKGLTCKGIRCEKQNNAFSTLFETLQSLFWSIFGLINLYVTNVKAQHEFTEFVGATMFGTYNVISLVVLLNMLIAMMNNSYQLIARRAADNLRRHHQYQEVMRNLVKRYVAAMIRDAKTEEGLTEENFKELKQDISSFRFEVLGLLRGSKLSTIQSANASKESSNSADSDEKSDSEEEVARQQAAGPLERNIQLESRGLASRGDLSIPGLSEQCVLVDHRERNTDTLGLQVGKRVCPFKSEKVVVEDTVPIIPKEKHAKEEDSSIDYDLNLPDTVTHEDYVTTRL>sp|Q9UBN4-5|TRPC4_HUMAN Isoform Epsilon of Short transient receptorpotential channel 4 OS=Homo sapiens OX=9606 GN=TRPC4MAQFYYKRNVNAPYRDRIPLRIVRAESELSPSEKAYLNAVEKGDYASVKKSLEEAEIYFKININCIDPLGRTALLIAIENENLELIELLLSFNVYVGDALLHAIRKEVVGAVELLLNHKKPSGEKQVPPILLDKQFSEFTPDITPIILAAHTNNYEIIKLLVQKGVSVPRPHEVRCNCVECVSSSDVDSLRHSRSRLNIYKALASPSLIALSSEDPFLTAFQLSWELQELSKVENEFKSEYEELSRQCKQFAKDLLDQTRSSRELEIILNYRDDNSLIEEQSGNDLARLKLAIKYRQKEFVAQPNCQQLLASRWYDEFPGWRRRHWAVKMVTCFIIGLLFPVFSVCYLIAPKSPLGLFIRKPFIKFICHTASYLTFLFLLLLASQHIDRSDLNRQGPPPTIVEWMILPWVLGFIWGEIKQMWDGGLQDYIHDWWNLMDFVMNSLYLATISLKIVAFVKYSALNPRESWDMWHPTLVAEALFAIANIFSSLRLISLFTANSHLGPLQISLGRMLLDILKFLFIYCLVLLAFANGLNQLYFYYEETKGLTCKGIRCEKQNNAFSTLFETLQSLFWSIFGLINLYVTNVKAQHEFTEFVGATMFGTYNVISLVVLLNMLIAMMNNSYQLIADHADIEWKFARTKLWMSYFEEGGTLPTPFNVIPSPKSLWYLIKWIWTHLCKKKMRRKPESFGTIGVRTQHRRAADNLRRHHQYQEVMRNLVKRYVAAMIRDAKTEEGLTEENFKELKQDISSFRFEVLGLLRGSKLSTIQSANASKESSNSADSDEKSDSEGNSKDKKKNFSLFDLTTLIHPRSAAIASERHNISNGSALVVQEPPREKQRKVNFVTDIKNFGLFHRRSKQNAAEQNANQIFSVSEEVARQQAAGPLERNIQLESRGLASRGDLSIPGLSEQCVLVDHRERNTDTLGLQVGKRVCPFKSEKVVVEDTVPIIPKEKHAKEEDSSIDYDLNLPDTVTHEDYVTTRL>sp|Q9UBN4-6|TRPC4_HUMAN Isoform Zeta of Short transient receptorpotential channel 4 OS=Homo sapiens OX=9606 GN=TRPC4MAQFYYKRNVNAPYRDRIPLRIVRAESELSPSEKAYLNAVEKGDYASVKKSLEEAEIYFKININCIDPLGRTALLIAIENENLELIELLLSFNVYVGDALLHAIRKEVVGAVELLLNHKKPSGEKQFVAQPNCQQLLASRWYDEFPGWRRRHWAVKMVTCFIIGLLFPVFSVCYLIAPKSPLGLFIRKPFIKFICHTASYLTFLFLLLLASQHIDRSDLNRQGPPPTIVEWMILPWVLGFIWGEIKQMWDGGLQDYIHDWWNLMDFVMNSLYLATISLKIVAFVKYSALNPRESWDMWHPTLVAEALFAIANIFSSLRLISLFTANSHLGPLQISLGRMLLDILKFLFIYCLVLLAFANGLNQLYFYYEETKGLTCKGIRCEKQNNAFSTLFETLQSLFWSIFGLINLYVTNVKAQHEFTEFVGATMFGTYNVISLVVLLNMLIAMMNNSYQLIADHADIEWKFARTKLWMSYFEEGGTLPTPFNVIPSPKSLWYLIKWIWTHLCKKKMRRKPESFGTIGRRAADNLRRHHQYQEVMRNLVKRYVAAMIRDAKTEEGLTEENFKELKQDISSFRFEVLGLLRGSKLSTIQSANASKESSNSADSDEKSDSEGNSKDKKKNFSLFDLTTLIHPRSAAIASERHNISNGSALVVQEPPREKQRKVNFVTDIKNFGLFHRRSKQNAAEQNANQIFSVSEEVARQQAAGPLERNIQLESRGLASRGDLSIPGLSEQCVLVDHRERNTDTLGLQVGKRVCPFKSEKVVVEDTVPIIPKEKHAKEEDSSIDYDLNLPDTVTHEDYVTTRL>sp|Q9UBN4-7|TRPC4_HUMAN Isoform Eta of Short transient receptorpotential channel 4 OS=Homo sapiens OX=9606 GN=TRPC4MAQFYYKRNVNAPYRDRIPLRIVRAESELSPSEKAYLNAVEKGDYASVKKSLEEAEIYFKININCIDPLGRTALLIAIENENLELIELLLSFNVYVGDALLHAIRKEVVGAVELLLNHKKPSGEKQVPPILLDKQFSEFTPDITPIILAAHTNNYEIIKLLVQKGVSVPRPHEVRCNCVECVSSSDVDSLRHSRSRLNIYKALASPSLIALSSEDPFLTAFQLSWELQELSKVENEFKSEYEELSRQCKQFAKDLLDQTRSSRELEIILNYRDDNSLIEEQSGNDLARLKLAIKYRQKEASYGEKLNRCGMADFRTTSMIGGI>sp|Q9HCX4|TRPC7_HUMAN Short transient receptor potential channel 7OS=Homo sapiens OX=9606 GN=TRPC7 PE=1 SV=1MLRNSTFKNMQRRHTTLREKGRRQAIRGPAYMFNEKGTSLTPEEERFLDSAEYGNIPVVRKMLEESKTLNFNCVDYMGQNALQLAVGNEHLEVTELLLKKENLARVGDALLLAISKGYVRIVEAILNHPAFAQGQRLTLSPLEQELRDDDFYAYDEDGTRFSHDITPIILAAHCQEYEIVHILLLKGARIERPHDYFCKCNECTEKQRKDSFSHSRSRMNAYKGLASAAYLSLSSEDPVLTALELSNELARLANIETEFKNDYRKLSMQCKDFVVGVLDLCRDTEEVEAILNGDVNFQVWSDHHRPSLSRIKLAIKYEVKKFVAHPNCQQQLLTMWYENLSGLRQQSIAVKFLAVFGVSIGLPFLAIAYWIAPCSKLGRTLRSPFMKFVAHAVSFTIFLGLLVVNASDRFEGVKTLPNETFTDYPKQIFRVKTTQFSWTEMLIMKWVLGMIWSECKEIWEEGPREYVLHLWNLLDFGMLSIFVASFTARFMAFLKATEAQLYVDQHVQDDTLHNVSLPPEVAYFTYARDKWWPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVIFIMVFVAFMIGMFNLYSYYRGAKYNPAFTTVEESFKTLFWSIFGLSEVISVVLKYDHKFIENIGYVLYGVYNVTMVVVLLNMLIAMINNSYQEIEEDADVEWKFARAKLWLSYFDEGRTLPAPFNLVPSPKSFYYLIMRIKMCLIKLCKSKAKSCENDLEMGMLNSKFKKTRYQAGMRNSENLTANNTLSKPTRYQKIMKRLIKRYVLKAQVDRENDEVNEGELKEIKQDISSLRYELLEEKSQATGELADLIQQLSEKFGKNLNKDHLRVNKGKDI>sp|Q9HCX4-2|TRPC7_HUMAN Isoform 2 of Short transient receptor potentialchannel 7 OS=Homo sapiens OX=9606 GN=TRPC7MLRNSTFKNMQRRHTTLREKGRRQAIRGPAYMFNEKGTSLTPEEERFLDSAEYGNIPVVRKMLEESKTLNFNCVDYMGQNALQLAVGNEHLEVTELLLKKENLARVGDALLLAISKGYVRIVEAILNHPAFAQGQRLTLSPLEQELRDDDFYAYDEDGTRFSHDITPIILAAHCQEYEIVHILLLKGARIERPHDYFCKCNECTEKQRKDSFSHSRSRMNAYKGLASAAYLSLSSEDPVLTALELSNELARLANIETEFKLGRTLRSPFMKFVAHAVSFTIFLGLLVVNASDRFEGVKTLPNETFTDYPKQIFRVKTTQFSWTEMLIMKWVLGMIWSECKEIWEEGPREYVLHLWNLLDFGMLSIFVASFTARFMAFLKATEAQLYVDQHVQDDTLHNVSLPPEVAYFTYARDKWWPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVIFIMVFVAFMIGMFNLYSYYRGAKYNPAFTTVEESFKTLFWSIFGLSEVISVVLKYDHKFIENIGYVLYGVYNVTMVVVLLNMLIAMINNSYQEIEEDADVEWKFARAKLWLSYFDEGRTLPAPFNLVPSPKSFYYLIMRIKMCLIKLCKSKAKSCENDLEMGMLNSKFKKTRYQAGMRNSENLTANNTLSKPTRYQKIMKRLIKRYVLKAQVDRENDEVNEGELKEIKQDISSLRYELLEEKSQATGELADLIQQLSEKFGKNLNKDHLRVNKGKDI>sp|Q9HCX4-3|TRPC7_HUMAN Isoform 3 of Short transient receptor potentialchannel 7 OS=Homo sapiens OX=9606 GN=TRPC7MLRNSTFKNMQRRHTTLREKGRRQAIRGPAYMFNEKGTSLTPEEERFLDSAEYGNIPVVRKMLEESKTLNFNCVDYMGQNALQLAVGNEHLEVTELLLKKENLARVGDALLLAISKGYVRIVEAILNHPAFAQGQRLTLSPLEQELRDDDFYAYDEDGTRFSHDITPIILAAHCQEYEIVHILLLKGARIERPHDYFCKCNECTEKQRKDSFSHSRSRMNAYKGLASAAYLSLSSEDPVLTALELSNELARLANIETEFKFVAHPNCQQQLLTMWYENLSGLRQQSIAVKFLAVFGVSIGLPFLAIAYWIAPCSKLGRTLRSPFMKFVAHAVSFTIFLGLLVVNASDRFEGVKTLPNETFTDYPKQIFRVKTTQFSWTEMLIMKWVLGMIWSECKEIWEEGPREYVLHLWNLLDFGMLSIFVASFTARFMAFLKATEAQLYVDQHVQDDTLHNVSLPPEVAYFTYARDKWWPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVIFIMVFVAFMIGMFNLYSYYRGAKYNPAFTTVEESFKTLFWSIFGLSEVISVVLKYDHKFIENIGYVLYGVYNVTMVVVLLNMLIAMINNSYQEIEEDADVEWKFARAKLWLSYFDEGRTLPAPFNLVPSPKSFYYLIMRIKMCLIKLCKSKAKSCENDLEMGMLNSKFKKTRYQAGMRNSENLTANNTLSKPTRYQKIMKRLIKRYVLKAQVDRENDEVNEGELKEIKQDISSLRYELLEEKSQATGELADLIQQLSEKFGKNLNKDHLRVNKGKDI>sp|Q16831|UPP1_HUMAN Uridine phosphorylase 1 OS=Homo sapiens OX=9606GN=UPP1 PE=1 SV=1MAATGANAEKAESHNDCPVRLLNPNIAKMKEDILYHFNLTTSRHNFPALFGDVKFVCVGGSPSRMKAFIRCVGAELGLDCPGRDYPNICAGTDRYAMYKVGPVLSVSHGMGIPSISIMLHELIKLLYYARCSNVTIIRIGTSGGIGLEPGTVVITEQAVDTCFKAEFEQIVLGKRVIRKTDLNKKLVQELLLCSAELSEFTTVVGNTMCTLDFYEGQGRLDGALCSYTEKDKQAYLEAAYAAGVRNIEMESSVFAAMCSACGLQAAVVCVTLLNRLEGDQISSPRNVLSEYQQRPQRLVSYFIKKKLSKA>sp|Q16831-2|UPP1_HUMAN Isoform 2 of Uridine phosphorylase 1 OS=Homosapiens OX=9606 GN=UPP1MAATGANAEKAESHKSGARHCGHNRAGSGYLLQGRV>sp|Q6DKK2|TTC19_HUMAN Tetratricopeptide repeat protein 19, mitochondrialOS=Homo sapiens OX=9606 GN=TTC19 PE=1 SV=4MFRLLSWSLGRGFLRAAGRRCRGCSARLLPGLAGGPGPEVQVPPSRVAPHGRGPGLLPLLAALAWFSRPAAAEEEEQQGADGAAAEDGADEAEAEIIQLLKRAKLSIMKDEPEEAELILHDALRLAYQTDNKKAITYTYDLMANLAFIRGQLENAEQLFKATMSYLLGGGMKQEDNAIIEISLKLASIYAAQNRQEFAVAGYEFCISTLEEKIEREKELAEDIMSVEEKANTHLLLGMCLDACARYLLFSKQPSQAQRMYEKALQISEEIQGERHPQTIVLMSDLATTLDAQGRFDEAYIYMQRASDLARQINHPELHMVLSNLAAVLMHRERYTQAKEIYQEALKQAKLKKDEISVQHIREELAELSKKSRPLTNSVKL>sp|Q96NA8|TSNA1_HUMAN t-SNARE domain-containing protein 1 OS=Homosapiens OX=9606 GN=TSNARE1 PE=1 SV=2MSYGSIARGGGLGSRGPFGGPSRQGCQPLECARCWTEYGIRHFPCPSPESKLQNRCVGKDGEGDLGPAGTPIVPRARKRGPGVAPEGSRMPEPTSSPTIGPRKDSAAGPHGRMAGPSTTRAKKRKPNFCPQETEVLVSKVSKHHQLLFGTGLLKAEPTRRYRVWSRILQAVNALGYCRRDVVDLKHKWRDLRAVVRRKLGDLRKAAHGPSPGSGKPQALALTPVEQVVAKTFSCQALPSEGFSLEPPRATQVDPCNLQELFQEMSANVFRINSSVTSLERSLQSLGTPSDTQELRDSLHTAQQETNKTIAASASSVKQMAELLRSSCPQERLQQERPQLDRLKTQLSDAIQCYGVVQKKIAEKSRALLPMAQRGSKQSPQAPFAELADDEKVFNGSDNMWQGQEQALLPDITEEDLEAIRLREEAILQMESNLLDVNQIIKDLASMVSEQGEAVDSIEASLEAASSHAEAARQLLAGASRHQLQRHKIKCCFLSAGVTALLVIIIIIATSVRK>sp|Q96NA8-2|TSNA1_HUMAN Isoform 2 of t-SNARE domain-containing protein 1OS=Homo sapiens OX=9606 GN=TSNARE1MSYGSIARGGGLGSRGPFGGPSRQGCQPLECARCWTEYGIRHFPCPSPESKLQNRCVGKDGEGDLGPAGTPIVPRARKRGPGVAPEGSRMPEPTSSPTIGPRKDSAAGPHGRMAGPSTTRAKKRKPNFCPQETEVLVSKVSKHHQLLFGTGLLKAEPTRRYRVWSRILQAVNALGYCRRDVVDLKHKWRDLRAVVRRKLGDLRKAAHGPSPGSGKPQALALTPVEQVVAKTFSCQALPSEGFSLEPPRATQVDPCNLQELFQEMSANVFRINSSVTSLERSLQSLGTPSDTQELRDSLHTAQQETNKTIAASASSVKQMAELLRSSCPERLQQERPQLDRLKTQLSDAIQCYGVVQKKIAEKSRALLPMAQRGSKQSPQAPFAELADDEKVFNGSDNMWQGQEQALLPDITEEDLEAIRLREEAILQMESNLLDVNQIIKDLASMVSEQGEAVDSIEASLEAASSHAEAARQLLAGASRHQLQRHKIKCCFLSAGVTALLVIIIIIATSVRK>sp|Q8TAS1|UHMK1_HUMAN Serine/threonine-protein kinase Kist OS=Homosapiens OX=9606 GN=UHMK1 PE=1 SV=2MAGSGCAWGAEPPRFLEAFGRLWQVQSRLGSGSSASVYRVRCCGNPGSPPGALKQFLPPGTTGAAASAAEYGFRKERAALEQLQGHRNIVTLYGVFTIHFSPNVPSRCLLLELLDVSVSELLLYSSHQGCSMWMIQHCARDVLEALAFLHHEGYVHADLKPRNILWSAENECFKLIDFGLSFKEGNQDVKYIQTDGYRAPEAELQNCLAQAGLQSDTECTSAVDLWSLGIILLEMFSGMKLKHTVRSQEWKANSSAIIDHIFASKAVVNAAIPAYHLRDLIKSMLHDDPSRRIPAEMALCSPFFSIPFAPHIEDLVMLPTPVLRLLNVLDDDYLENEEEYEDVVEDVKEECQKYGPVVSLLVPKENPGRGQVFVEYANAGDSKAAQKLLTGRMFDGKFVVATFYPLSAYKRGYLYQTLL>sp|Q8TAS1-2|UHMK1_HUMAN Isoform 2 of Serine/threonine-protein kinaseKist OS=Homo sapiens OX=9606 GN=UHMK1MAGSGCAWGAEPPRFLEAFGRLWQVQSRLGSGSSASVYRVRCCGNPGSPPGALKQFLPPGTTGAAASAAEYGFRKERAALEQLQGHRNIVTLYGVFTIHFSPNVPSRCLLLELLDVSVSELLLYSSHQGCSMWMIQHCARDVLEALAFLHHEGYVHADLKPRNILWSAENECFKLIDFGLSFKEGNQDVKYIQTDGYRAPEAELQNCLAQAGLQSDTECTSAVDLWSLGIILLEMFSGMKLKHTVRSQEWKANSSAIIDHIFASKAVVNAAIPAYHLRDLIKSMLHDDPSRRIPAEMALCSPFFSIPFAPHIEDLVMLPTPVLRLLNVLDDDYLENEEEYEGLC>sp|Q8TAS1-3|UHMK1_HUMAN Isoform 3 of Serine/threonine-protein kinaseKist OS=Homo sapiens OX=9606 GN=UHMK1MFLTRPKVCVDLNRRVTLYGVFTIHFSPNVPSRCLLLELLDVSVSELLLYSSHQGCSMWMIQHCARDVLEALAFLHHEGYVHADLKPRNILWSAENECFKLIDFGLSFKEGNQDVKYIQTDGYRAPEAELQNCLAQAGLQSDTECTSAVDLWSLGIILLEMFSGMKLKHTVRSQEWKANSSAIIDHIFASKAVVNAAIPAYHLRDLIKSMLHDDPSRRIPAEMALCSPFFSIPFAPHIEDLVMLPTPVLRLLNVLDDDYLENEEEYEDVVEDVKEECQKYGPVVSLLVPKENPGRGQVFVEYANAGDSKAAQKLLTGRMFDGKFVVATFYPLSAYKRGYLYQTLL>sp|Q9UJK0|TSR3_HUMAN 18S rRNA aminocarboxypropyltransferase OS=Homosapiens OX=9606 GN=TSR3 PE=1 SV=1MGRRRAARGPGAEGGRPRHLPTRSLEAFAEEVGAALQASVEPGAADGEGGPGPAALPCTLAMWELGHCDPRRCTGRKLARLGLVRCLRLGHRFGGLVLSPVGKQYASPADRQLVAQSGVAVIDCSWARLDETPFGKMRGSHLRLLPYLVAANPVNYGRPYRLSCVEAFAATFCIVGFPDLAVILLRKFKWGKGFLDLNRQLLDKYAACGSPEEVLQAEQEFLANAKESPQEEEIDPFDVDSGREFGNPNRPVASTRLPSDTDDSDASEDPGPGAERGGASSSCCEEEQTQGRGAEARAPAEVWKGIKKRQRD>sp|Q9BZX2|UCK2_HUMAN Uridine-cytidine kinase 2 OS=Homo sapiens OX=9606GN=UCK2 PE=1 SV=1MAGDSEQTLQNHQQPNGGEPFLIGVSGGTASGKSSVCAKIVQLLGQNEVDYRQKQVVILSQDSFYRVLTSEQKAKALKGQFNFDHPDAFDNELILKTLKEITEGKTVQIPVYDFVSHSRKEETVTVYPADVVLFEGILAFYSQEVRDLFQMKLFVDTDADTRLSRRVLRDISERGRDLEQILSQYITFVKPAFEEFCLPTKKYADVIIPRGADNLVAINLIVQHIQDILNGGPSKRQTNGCLNGYTPSRKRQASESSSRPH>sp|Q9BZX2-2|UCK2_HUMAN Isoform 2 of Uridine-cytidine kinase 2 OS=Homosapiens OX=9606 GN=UCK2MKLFVDTDADTRLSRRVLRDISERGRDLEQILSQYITFVKPAFEEFCLPTKKYADVIIPRGADNLVAINLIVQHIQDILNGGPSKRQTNGCLNGYTPSRKRQASESSSRPH>sp|C9J7I0|UMAD1_HUMAN UBAP1-MVB12-associated (UMA)-domain containingprotein 1 OS=Homo sapiens OX=9606 GN=UMAD1 PE=1 SV=2MFHFFRKPPESKKPSVPETEADGFVLLGDTTDEQRMTARGKTSDIEANQPLETNKENSSSVTVSDPEMENKAGQTLENSSLMAELLSDVPFTLAPHVLAVQGTITDLPDHLLSYDGSENLSRFWYDFTLENSVLCDS>sp|Q6PKC3|TXD11_HUMAN Thioredoxin domain-containing protein 11 OS=Homosapiens OX=9606 GN=TXNDC11 PE=1 SV=2MSECGGRGGGSSSSEDAEDEGGGGGGPAGSDCLSSSPTLATASSAGRLRRGLRGAFLMARQRPELLCGAVALGCALLLALKFTCSRAKDVIIPAKPPVSFFSLRSPVLDLFQGQLDYAEYVRRDSEVVLLFFYAPWCGQSIAARAEIEQAASRLSDQVLFVAINCWWNQGKCRKQKHFFYFPVIYLYHRSFGPIEYKGPMSAVYIEKFVRRVMKPLLYIPSQSELLDFLSNYEPGVLGYFEFSGSPQPPGYLTFFTSALHSLKKALESTSSPRALVSFTGEWHLETKIYVLDYLGTVRFGVITNKHLAKLVSLVHSGSVYLHRHFNTSLVFPREVLNYTAENICKWALENQETLFRWLRPHGGKSLLLNNELKKGPALFLFIPFNPLAESHPLIDEITEVALEYNNCHGDQVVERLLQHLRRVDAPVLESLALEVPAQLPDPPTITASPCCNTVVLPQWHSFSRTHNVCELCVNQTSGGMKPSSVSVPQCSFFEMAAALDSFYLKEQTFYHVASDSIECSNFLTSYSPFSYYTACCRTISRGVSGFIDSEQGVFEAPTVAFSSLEKKCEVDAPSSVPHIEENRYLFPEVDMTSTNFTGLSCRTNKTLNIYLLDSNLFWLYAERLGAPSSTQVKEFAAIVDVKEESHYILDPKQALMKLTLESFIQNFSVLYSPLKRHLIGSGSAQFPSQHLITEVTTDTFWEVVLQKQDVLLLYYAPWCGFCPSLNHIFIQLARNLPMDTFTVARIDVSQNDLPWEFMVDRLPTVLFFPCNRKDLSVKYPEDVPITLPNLLRFILHHSDPASSPQNVANSPTKECLQSEAVLQRGHISHLEREIQKLRAEISSLQRAQVQVESQLSSARRDEHRLRQQQRALEEQHSLLHAHSEQLQALYEQKTRELQELARKLQELADASENLLTENTWLKILVATMERKLEGRDGAESLAAQREVHPKQPEPSATPQLPGSSPPPANVSATLVSERNKENRTD>sp|Q6PKC3-2|TXD11_HUMAN Isoform 2 of Thioredoxin domain-containingprotein 11 OS=Homo sapiens OX=9606 GN=TXNDC11MSECGGRGGGSSSSEDAEDEGGGGGGPAGSDCLSSSPTLATASSAGRLRRGLRGAFLMARQRPELLCGAVALGCALLLALKFTCSRAKDVIIPAKPPVSFFSLRSPVLDLFQGQLDYAEYVRRDSEVVLLFFYAPWCGQSIAARAEIEQAASRLSDQVLFVAINCWWNQGKCRKQKHFFYFPVIYLYHRSFGPIEYKGPMSAVYIEKFVRRVMKPLLYIPSQSELLDFLSNYEPGVLGYFEFSGSPQPPGYLTFFTSALHSLKKDYLGTVRFGVITNKHLAKLVSLVHSGSVYLHRHFNTSLVFPREVLNYTAENICKWALENQETLFRWLRPHGGKSLLLNNELKKGPALFLFIPFNPLAESHPLIDEITEVALEYNNCHGDQVVERLLQHLRRVDAPVLESLALEVPAQLPDPPTITASPCCNTVVLPQWHSFSRTHNVCELCVNQTSGGMKPSSVSVPQCSFFEMAAALDSFYLKEQTFYHVASDSIECSNFLTSYSPFSYYTACCRTISRGVSGFIDSEQGVFEAPTVAFSSLEKKCEVDAPSSVPHIEENRYLFPEVDMTSTNFTGLSCRTNKTLNIYLLDSNLFWLYAERLGAPSSTQVKEFAAIVDVKEESHYILDPKQALMKLTLESFIQNFSVLYSPLKRHLIGSGSAQFPSQHLITEVTTDTFWEVVLQKQDVLLLYYAPWCGFCPSLNHIFIQLARNLPMDTFTVARIDVSQNDLPWEFMVDRLPTVLFFPCNRKDLSVKYPEDVPITLPNLLRFILHHSDPASSPQNVANSPTKECLQSEAVLQRGHISHLEREIQKLRAEISSLQRAQVQVESQLSSARRDEHRLRQQQRALEEQHSLLHAHSEQLQALYEQKTRELQELARKLQELADASENLLTENTWLKILVATMERKLEGRDGAESLAAQREVHPKQPEPSATPQLPGSSPPPANVSATLVSERNKENRTD>sp|Q6PKC3-3|TXD11_HUMAN Isoform 3 of Thioredoxin domain-containingprotein 11 OS=Homo sapiens OX=9606 GN=TXNDC11MSECGGRGGGSSSSEDAEDEGGGGGGPAGSDCLSSSPTLATASSAGRLRRGLRGAFLMARQRPELLCGAVALGCALLLALKFTCSRAKDVIIPAKPPVSFFSLRSPVLDLFQGQLDYAEYVRRDSEVVLLFFYAPWCGQSIAARAEIEQAASRLSDQVLFVAINCWWNQGKCRKQKHFFYFPVIYLYHRSFGPIEYKGPMSAVYIEKFVRRVMKPLLYIPSQSELLDFLSNYEPGVLGYFEFSGSPQPPGYLTFFTSALHSLKKDGVSPCRPGWSAVA>sp|O75841|UPK1B_HUMAN Uroplakin-1b OS=Homo sapiens OX=9606 GN=UPK1B PE=1SV=5MAKDNSTVRCFQGLLIFGNVIIGCCGIALTAECIFFVSDQHSLYPLLEATDNDDIYGAAWIGIFVGICLFCLSVLGIVGIMKSSRKILLAYFILMFIVYAFEVASCITAATQQDFFTPNLFLKQMLERYQNNSPPNNDDQWKNNGVTKTWDRLMLQDNCCGVNGPSDWQKYTSAFRTENNDADYPWPRQCCVMNNLKEPLNLEACKLGVPGFYHNQGCYELISGPMNRHAWGVAWFGFAILCWTFWVLLGTMFYWSRIEY>sp|Q7Z7E8|UB2Q1_HUMAN Ubiquitin-conjugating enzyme E2 Q1 OS=Homo sapiensOX=9606 GN=UBE2Q1 PE=1 SV=1MQQPQPQGQQQPGPGQQLGGQGAAPGAGGGPGGGPGPGPCLRRELKLLESIFHRGHERFRIASACLDELSCEFLLAGAGGAGAGAAPGPHLPPRGSVPGDPVRIHCNITESYPAVPPIWSVESDDPNLAAVLERLVDIKKGNTLLLQHLKRIISDLCKLYNLPQHPDVEMLDQPLPAEQCTQEDVSSEDEDEEMPEDTEDLDHYEMKEEEPAEGKKSEDDGIGKENLAILEKIKKNQRQDYLNGAVSGSVQATDRLMKELRDIYRSQSFKGGNYAVELVNDSLYDWNVKLLKVDQDSALHNDLQILKEKEGADFILLNFSFKDNFPFDPPFVRVVSPVLSGGYVLGGGAICMELLTKQGWSSAYSIESVIMQISATLVKGKARVQFGANKSQYSLTRAQQSYKSLVQIHEKNGWYTPPKEDG>sp|Q7Z7E8-2|UB2Q1_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 Q1OS=Homo sapiens OX=9606 GN=UBE2Q1MLDQPLPAEQCTQEDVSSEDEDEEMPEDTEDLDHYEMKEEEPAEGKKSEDDGIGKENLAILEKIKKNQRQDYLNGAVSGSVQATDRLMKELRDIYRSQSFKGGNYAVELVNDSLYDWNVKLLKVDQDSALHNDLQILKEKEGADFILLNFSFKDNFPFDPPFVRVVSPVLSGGYVLGGGAICMELLTKQGWSSAYSIESVIMQISATLVKGKARVQFGANKSQYSLTRAQQSYKSLVQIHEKNGWYTPPKEDG>sp|Q70CQ4|UBP31_HUMAN Ubiquitin carboxyl-terminal hydrolase 31 OS=Homosapiens OX=9606 GN=USP31 PE=2 SV=2MSKVTAPGSGPPAAASGKEKRSFSKRLFRSGRAGGGGAGGPGASGPAAPSSPSSPSSARSVGSFMSRVLKTLSTLSHLSSEGAAPDRGGLRSCFPPGPAAAPTPPPCPPPPASPAPPACAAEPVPGVAGLRNHGNTCFMNATLQCLSNTELFAEYLALGQYRAGRPEPSPDPEQPAGRGAQGQGEVTEQLAHLVRALWTLEYTPQHSRDFKTIVSKNALQYRGNSQHDAQEFLLWLLDRVHEDLNHSVKQSGQPPLKPPSETDMMPEGPSFPVCSTFVQELFQAQYRSSLTCPHCQKQSNTFDPFLCISLPIPLPHTRPLYVTVVYQGKCSHCMRIGVAVPLSGTVARLREAVSMETKIPTDQIVLTEMYYDGFHRSFCDTDDLETVHESDCIFAFETPEIFRPEGILSQRGIHLNNNLNHLKFGLDYHRLSSPTQTAAKQGKMDSPTSRAGSDKIVLLVCNRACTGQQGKRFGLPFVLHLEKTIAWDLLQKEILEKMKYFLRPTVCIQVCPFSLRVVSVVGITYLLPQEEQPLCHPIVERALKSCGPGGTAHVKLVVEWDKETRDFLFVNTEDEYIPDAESVRLQRERHHQPQTCTLSQCFQLYTKEERLAPDDAWRCPHCKQLQQGSITLSLWTLPDVLIIHLKRFRQEGDRRMKLQNMVKFPLTGLDMTPHVVKRSQSSWSLPSHWSPWRRPYGLGRDPEDYIYDLYAVCNHHGTMQGGHYTAYCKNSVDGLWYCFDDSDVQQLSEDEVCTQTAYILFYQRRTAIPSWSANSSVAGSTSSSLCEHWVSRLPGSKPASVTSAASSRRTSLASLSESVEMTGERSEDDGGFSTRPFVRSVQRQSLSSRSSVTSPLAVNENCMRPSWSLSAKLQMRSNSPSRFSGDSPIHSSASTLEKIGEAADDKVSISCFGSLRNLSSSYQEPSDSHSRREHKAVGRAPLAVMEGVFKDESDTRRLNSSVVDTQSKHSAQGDRLPPLSGPFDNNNQIAYVDQSDSVDSSPVKEVKAPSHPGSLAKKPESTTKRSPSSKGTSEPEKSLRKGRPALASQESSLSSTSPSSPLPVKVSLKPSRSRSKADSSSRGSGRHSSPAPAQPKKESSPKSQDSVSSPSPQKQKSASALTYTASSTSAKKASGPATRSPFPPGKSRTSDHSLSREGSRQSLGSDRASATSTSKPNSPRVSQARAGEGRGAGKHVRSSSMASLRSPSTSIKSGLKRDSKSEDKGLSFFKSALRQKETRRSTDLGKTALLSKKAGGSSVKSVCKNTGDDEAERGHQPPASQQPNANTTGKEQLVTKDPASAKHSLLSARKSKSSQLDSGVPSSPGGRQSAEKSSKKLSSSMQTSARPSQKPQ>sp|Q70CQ4-2|UBP31_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 31 OS=Homo sapiens OX=9606 GN=USP31MSQRDGVCGSHEVAGAASPGADGGLSLAAYCKNSVDGLWYCFDDSDVQQLSEDEVCTQTAYILFYQRRTAIPSWSANSSVAGSTSSSLCEHWVSRLPGSKPASVTSAASSRRTSLASLSESVEMTGERSEDDGGFSTRPFVRSVQRQSLSSRSSVTSPLAVNENCMRPSWSLSAKLQMRSNSPSRFSGDSPIHSSASTLEKIGEAADDKVSISCFGSLRNLSSSYQEPSDSHSRREHKAVGRAPLAVMEGVFKDESDTRRLNSSVVDTQSKHSAQGDRLPPLSGPFDNNNQIAYVDQSDSVDSSPVKEVKAPSHPGSLAKKPESTTKRSPSSKGTSEPEKSLRKGRPALASQESSLSSTSPSSPLPVKVSLKPSRSRSKADSSSRGSGRHSSPAPAQTQFPSGEPGPSRGGQGGREARAELLHGQPALPQHKHQVWFEEGQQV>sp|O95847|UCP4_HUMAN Mitochondrial uncoupling protein 4 OS=Homo sapiensOX=9606 GN=SLC25A27 PE=2 SV=1MSVPEEEERLLPLTQRWPRASKFLLSGCAATVAELATFPLDLTKTRLQMQGEAALARLGDGARESAPYRGMVRTALGIIEEEGFLKLWQGVTPAIYRHVVYSGGRMVTYEHLREVVFGKSEDEHYPLWKSVIGGMMAGVIGQFLANPTDLVKVQMQMEGKRKLEGKPLRFRGVHHAFAKILAEGGIRGLWAGWVPNIQRAALVNMGDLTTYDTVKHYLVLNTPLEDNIMTHGLSSLCSGLVASILGTPADVIKSRIMNQPRDKQGRGLLYKSSTDCLIQAVQGEGFMSLYKGFLPSWLRMTPWSMVFWLTYEKIREMSGVSPF>sp|O95847-2|UCP4_HUMAN Isoform 2 of Mitochondrial uncoupling protein 4OS=Homo sapiens OX=9606 GN=SLC25A27MSVPEEEERLLPLTQRWPRASKFLLSGCAATVAELATFPLDLTKTRLQMQGEAALARLGDGARESAPYRGMVRTALGIIEEEGFLKLWQGVTPAIYRHVVYSGGRMVTYEHLREVVFGKSEDEHYPLWKSVIGGMMAGVIGQFLANPTDLVKVQMQMEGKRKLEGKPLRFRGVHHAFAKILAEGGIRGLWAGWVPNIQRAALVNMGDLTTYDTVKHYLVLNTPLEDNIMTHGLSSDLVGSHKAIQ>sp|Q9P2H5|UBP35_HUMAN Ubiquitin carboxyl-terminal hydrolase 35 OS=Homosapiens OX=9606 GN=USP35 PE=1 SV=3MDKILEAVVTSSYPVSVKQGLVRRVLEAARQPLEREQCLALLALGARLYVGGAEELPRRVGCQLLHVAGRHHPDVFAEFFSARRVLRLLQGGAGPPGPRALACVQLGLQLLPEGPAADEVFALLRREVLRTVCERPGPAACAQVARLLARHPRCVPDGPHRLLFCQQLVRCLGRFRCPAEGEEGAVEFLEQAQQVSGLLAQLWRAQPAAILPCLKELFAVISCAEEEPPSSALASVVQHLPLELMDGVVRNLSNDDSVTDSQMLTAISRMIDWVSWPLGKNIDKWIIALLKGLAAVKKFSILIEVSLTKIEKVFSKLLYPIVRGAALSVLKYMLLTFQHSHEAFHLLLPHIPPMVASLVKEDSNSGTSCLEQLAELVHCMVFRFPGFPDLYEPVMEAIKDLHVPNEDRIKQLLGQDAWTSQKSELAGFYPRLMAKSDTGKIGLINLGNTCYVNSILQALFMASDFRHCVLRLTENNSQPLMTKLQWLFGFLEHSQRPAISPENFLSASWTPWFSPGTQQDCSEYLKYLLDRLHEEEKTGTRICQKLKQSSSPSPPEEPPAPSSTSVEKMFGGKIVTRICCLCCLNVSSREEAFTDLSLAFPPPERCRRRRLGSVMRPTEDITARELPPPTSAQGPGRVGPRRQRKHCITEDTPPTSLYIEGLDSKEAGGQSSQEERIEREEEGKEERTEKEEVGEEEESTRGEGEREKEEEVEEEEEKVEKETEKEAEQEKEEDSLGAGTHPDAAIPSGERTCGSEGSRSVLDLVNYFLSPEKLTAENRYYCESCASLQDAEKVVELSQGPCYLILTLLRFSFDLRTMRRRKILDDVSIPLLLRLPLAGGRGQAYDLCSVVVHSGVSSESGHYYCYAREGAARPAASLGTADRPEPENQWYLFNDTRVSFSSFESVSNVTSFFPKDTAYVLFYRQRPREGPEAELGSSRVRTEPTLHKDLMEAISKDNILYLQEQEKEARSRAAYISALPTSPHWGRGFDEDKDEDEGSPGGCNPAGGNGGDFHRLVF>sp|Q9P2H5-2|UBP35_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 35 OS=Homo sapiens OX=9606 GN=USP35MIDWVSWPLGKNIDKWIIALLKGLAAVKKFSILIEVSLTKIEKVFSKLLYPIVRGAALSVLKYMLLTFQHSHEAFHLLLPHIPPMVASLVKEDSNSGTSCLEQLAELVHCMVFRFPGFPDLYEPVMEAIKDLHVPNEDRIKQLLGQDAWTSQKSELAGFYPRLMAKSDTGKIGLINLGNTCYVNSILQALFMASDFRHCVLRLTENNSQPLMTKLQWLFGFLEHSQRPAISPENFLSASWTPWFSPGTQQDCSEYLKYLLDRLHEEEKTGTRICQKLKQSSSPSPPEEPPAPSSTSVEKMFGGKIVTRICCLCCLNVSSREEAFTDLSLAFPPPERCRRRRLGSVMRPTEDITARELPPPTSAQGPGRVGPRRQRKHCITEDTPPTSLYIEGLDSKEAGGQSSQEERIEREEEGKEERTEKEEVGEEEESTRGEGEREKEEEVEEEEEKVEKETEKEAEQEKEEDSLGAGTHPDAAIPSGERTCGSEGSRSVLDLVNYFLSPEKLTAENRYYCESCASLQDAEKVVELSQGPCYLILTLLRFSFDLRTMRRRKILDDVSIPLLLRLPLAGGRGQAYDLCSVVVHSGVSSESGHYYCYAREGAARPAASLGTADRPEPENQWYLFNDTRVSFSSFESVSNVTSFFPKDTAYVLFYRQRPREGPEAELGSSRVRTEPTLHKDLMEAISKDNILYLQEQEKEARSRAAYISALPTSPHWGRGFDEDKDEDEGSPGGCNPAGGNGGDFHRLVF>sp|Q13107|UBP4_HUMAN Ubiquitin carboxyl-terminal hydrolase 4 OS=Homosapiens OX=9606 GN=USP4 PE=1 SV=3MAEGGGCRERPDAETQKSELGPLMRTTLQRGAQWYLIDSRWFKQWKKYVGFDSWDMYNVGEHNLFPGPIDNSGLFSDPESQTLKEHLIDELDYVLVPTEAWNKLLNWYGCVEGQQPIVRKVVEHGLFVKHCKVEVYLLELKLCENSDPTNVLSCHFSKADTIATIEKEMRKLFNIPAERETRLWNKYMSNTYEQLSKLDNTVQDAGLYQGQVLVIEPQNEDGTWPRQTLQSKSSTAPSRNFTTSPKSSASPYSSVSASLIANGDSTSTCGMHSSGVSRGGSGFSASYNCQEPPSSHIQPGLCGLGNLGNTCFMNSALQCLSNTAPLTDYFLKDEYEAEINRDNPLGMKGEIAEAYAELIKQMWSGRDAHVAPRMFKTQVGRFAPQFSGYQQQDSQELLAFLLDGLHEDLNRVKKKPYLELKDANGRPDAVVAKEAWENHRLRNDSVIVDTFHGLFKSTLVCPECAKVSVTFDPFCYLTLPLPLKKDRVMEVFLVPADPHCRPTQYRVTVPLMGAVSDLCEALSRLSGIAAENMVVADVYNHRFHKIFQMDEGLNHIMPRDDIFVYEVCSTSVDGSECVTLPVYFRERKSRPSSTSSASALYGQPLLLSVPKHKLTLESLYQAVCDRISRYVKQPLPDEFGSSPLEPGACNGSRNSCEGEDEEEMEHQEEGKEQLSETEGSGEDEPGNDPSETTQKKIKGQPCPKRLFTFSLVNSYGTADINSLAADGKLLKLNSRSTLAMDWDSETRRLYYDEQESEAYEKHVSMLQPQKKKKTTVALRDCIELFTTMETLGEHDPWYCPNCKKHQQATKKFDLWSLPKILVVHLKRFSYNRYWRDKLDTVVEFPIRGLNMSEFVCNLSARPYVYDLIAVSNHYGAMGVGHYTAYAKNKLNGKWYYFDDSNVSLASEDQIVTKAAYVLFYQRRDDEFYKTPSLSSSGSSDGGTRPSSSQQGFGDDEACSMDTN>sp|Q13107-2|UBP4_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 4 OS=Homo sapiens OX=9606 GN=USP4MAEGGGCRERPDAETQKSELGPLMRTTLQRGAQWYLIDSRWFKQWKKYVGFDSWDMYNVGEHNLFPGPIDNSGLFSDPESQTLKEHLIDELDYVLVPTEAWNKLLNWYGCVEGQQPIVRKVVEHGLFVKHCKVEVYLLELKLCENSDPTNVLSCHFSKADTIATIEKEMRKLFNIPAERETRLWNKYMSNTYEQLSKLDNTVQDAGLYQGQVLVIEPQNEDGTWPRQTLQSNGSGFSASYNCQEPPSSHIQPGLCGLGNLGNTCFMNSALQCLSNTAPLTDYFLKDEYEAEINRDNPLGMKGEIAEAYAELIKQMWSGRDAHVAPRMFKTQVGRFAPQFSGYQQQDSQELLAFLLDGLHEDLNRVKKKPYLELKDANGRPDAVVAKEAWENHRLRNDSVIVDTFHGLFKSTLVCPECAKVSVTFDPFCYLTLPLPLKKDRVMEVFLVPADPHCRPTQYRVTVPLMGAVSDLCEALSRLSGIAAENMVVADVYNHRFHKIFQMDEGLNHIMPRDDIFVYEVCSTSVDGSECVTLPVYFRERKSRPSSTSSASALYGQPLLLSVPKHKLTLESLYQAVCDRISRYVKQPLPDEFGSSPLEPGACNGSRNSCEGEDEEEMEHQEEGKEQLSETEGSGEDEPGNDPSETTQKKIKGQPCPKRLFTFSLVNSYGTADINSLAADGKLLKLNSRSTLAMDWDSETRRLYYDEQESEAYEKHVSMLQPQKKKKTTVALRDCIELFTTMETLGEHDPWYCPNCKKHQQATKKFDLWSLPKILVVHLKRFSYNRYWRDKLDTVVEFPIRGLNMSEFVCNLSARPYVYDLIAVSNHYGAMGVGHYTAYAKNKLNGKWYYFDDSNVSLASEDQIVTKAAYVLFYQRRDDEFYKTPSLSSSGSSDGGTRPSSSQQGFGDDEACSMDTN>sp|Q13107-3|UBP4_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 4 OS=Homo sapiens OX=9606 GN=USP4MAEGGGCRERPDAETQKSELGPLMRTTLQRGAQWYLIDSRWFKQWKKYVGFDSWDMYNVGEHNLFPGPIDNSGLFSDPESQTLKEHLIDELDYVLVPTEAWNKLLNWYGCVEGQQPIVRKVVEHGLFVKHCKVEVYLLELKLCENSDPTNVLSCHFSKADTIATIEKEMRKLFNIPAERETRLWNKYMSNTYEQLSKLDNTVQDAGLYQGQVLVIEPQNEDGTWPRQTLQSKVSFFLPRLECNGAILAHCNFCLPGSSNSPASASRVAPSHLANFFFFEMESHSVTKLECGGAVSAYSRVQVMLLPQPPEWLG>sp|Q70EL2|UBP45_HUMAN Ubiquitin carboxyl-terminal hydrolase 45 OS=Homosapiens OX=9606 GN=USP45 PE=1 SV=3MRVKDPTKALPEKAKRSKRPTVPHDEDSSDDIAVGLTCQHVSHAISVNHVKRAIAENLWSVCSECLKERRFYDGQLVLTSDIWLCLKCGFQGCGKNSESQHSLKHFKSSRTEPHCIIINLSTWIIWCYECDEKLSTHCNKKVLAQIVDFLQKHASKTQTSAFSRIMKLCEEKCETDEIQKGGKCRNLSVRGITNLGNTCFFNAVMQNLAQTYTLTDLMNEIKESSTKLKIFPSSDSQLDPLVVELSRPGPLTSALFLFLHSMKETEKGPLSPKVLFNQLCQKAPRFKDFQQQDSQELLHYLLDAVRTEETKRIQASILKAFNNPTTKTADDETRKKVKAYGKEGVKMNFIDRIFIGELTSTVMCEECANISTVKDPFIDISLPIIEERVSKPLLWGRMNKYRSLRETDHDRYSGNVTIENIHQPRAAKKHSSSKDKSQLIHDRKCIRKLSSGETVTYQKNENLEMNGDSLMFASLMNSESRLNESPTDDSEKEASHSESNVDADSEPSESESASKQTGLFRSSSGSGVQPDGPLYPLSAGKLLYTKETDSGDKEMAEAISELRLSSTVTGDQDFDRENQPLNISNNLCFLEGKHLRSYSPQNAFQTLSQSYITTSKECSIQSCLYQFTSMELLMGNNKLLCENCTKNKQKYQEETSFAEKKVEGVYTNARKQLLISAVPAVLILHLKRFHQAGLSLRKVNRHVDFPLMLDLAPFCSATCKNASVGDKVLYGLYGIVEHSGSMREGHYTAYVKVRTPSRKLSEHNTKKKNVPGLKAADNESAGQWVHVSDTYLQVVPESRALSAQAYLLFYERVL>sp|Q70EL2-2|UBP45_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 45 OS=Homo sapiens OX=9606 GN=USP45MRVKDPTKALPEKAKRSKRPTVPHDEDSSDDIAVGLTCQHVSHAISVNHVKRAIAENLWSVCSECLKERRFYDGQLVLTSDIWLCLKCGFQGCGKNSESQHSLKHFKSSRTEPHCIIINLSTWIIWCYECDEKLSTHCNKKVLAQIVDFLQKHASKTQTSAFSRIMKLCEEKCETDEIQKGGKCRNLSVRGITNLGNTCFFNAVMQNLAQTYTLTDLMNEIKESSTKLKIFPSSDSQLDPLVVELSRPGPLTSALFLFLHSMKETEKGPLSPKVLFNQLCQKRVHLHLI>sp|Q70EL2-3|UBP45_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 45 OS=Homo sapiens OX=9606 GN=USP45MRSKKVVQNSRFFLPQTLSWAPRFKDFQQQDSQELLHYLLDAVRTEETKISTVKDPFIDISLPIIEERVSKPLLWGRMNKYRSLRETDHDRYSGNVTIENIHQPRAAKKHSSSKDKSQLIHDRKCIRKLSSGETVTYQKNENLEMNGDSLMFASLMNSESRLNESPTDDSEKEASHSESNVDADSEPSESESASKQTGLFRSSSGSGVQPDGPLYPLSAGKLLYTKETDSGDKEMAEAISELRLSSTVTGDQDFDRENQPLNISNNLCFLEGKHLRSYSPQNAFQTLSQSYITTSKECSIQSCLYQFTSMELLMGNNKLLCENCTKNKQKYQEETSFAEKKVEGVYTNARKQLLISAVPAVLILHLKRFHQAGLSLRKVNRHVDFPLMLDLAPFCSATCKNASVGDKVLYGLYGIVEHSGSMREGHYTAYVKVRTPSRKLSEHNTKKKNVPGLKAADNESAGQWVHVSDTYLQVVPESRALSAQAYLLFYERVL>sp|P37288|V1AR_HUMAN Vasopressin V1a receptor OS=Homo sapiens OX=9606GN=AVPR1A PE=1 SV=1MRLSAGPDAGPSGNSSPWWPLATGAGNTSREAEALGEGNGPPRDVRNEELAKLEIAVLAVTFAVAVLGNSSVLLALHRTPRKTSRMHLFIRHLSLADLAVAFFQVLPQMCWDITYRFRGPDWLCRVVKHLQVFGMFASAYMLVVMTADRYIAVCHPLKTLQQPARRSRLMIAAAWVLSFVLSTPQYFVFSMIEVNNVTKARDCWATFIQPWGSRAYVTWMTGGIFVAPVVILGTCYGFICYNIWCNVRGKTASRQSKGAEQAGVAFQKGFLLAPCVSSVKSISRAKIRTVKMTFVIVTAYIVCWAPFFIIQMWSVWDPMSVWTESENPTITITALLGSLNSCCNPWIYMFFSGHLLQDCVQSFPCCQNMKEKFNKEDTDSMSRRQTFYSNNRSPTNSTGMWKDSPKSSKSIKFIPVST>sp|Q8N0U8|VKORL_HUMAN Vitamin K epoxide reductase complex subunit 1-likeprotein 1 OS=Homo sapiens OX=9606 GN=VKORC1L1 PE=1 SV=2MAAPVLLRVSVPRWERVARYAVCAAGILLSIYAYHVEREKERDPEHRALCDLGPWVKCSAALASRWGRGFGLLGSIFGKDGVLNQPNSVFGLIFYILQLLLGMTASAVAALILMTSSIMSVVGSLYLAYILYFVLKEFCIICIVTYVLNFLLLIINYKRLVYLNEAWKRQLQPKQD>sp|Q8N0U8-2|VKORL_HUMAN Isoform 2 of Vitamin K epoxide reductase complexsubunit 1-like protein 1 OS=Homo sapiens OX=9606 GN=VKORC1L1MAAPVLLRVSVPRWERVARYAVCAAGILLSIYAYHVEREKERDPEHRALCDLGPWVKCSAALASRHDSKRCGGFDPHDVLHHVGRGVPVPGLHSVLCAEGVLHHLHRHVRAELPSSHYQLQTTSLLERGLEAAAATQAGLTPDRLHPNSLKPLSIQFILQQVFIIIIIIIIHNRHFP>sp|P55060|XPO2_HUMAN Exportin-2 OS=Homo sapiens OX=9606 GN=CSE1L PE=1SV=3MELSDANLQTLTEYLKKTLDPDPAIRRPAEKFLESVEGNQNYPLLLLTLLEKSQDNVIKVCASVTFKNYIKRNWRIVEDEPNKICEADRVAIKANIVHLMLSSPEQIQKQLSDAISIIGREDFPQKWPDLLTEMVNRFQSGDFHVINGVLRTAHSLFKRYRHEFKSNELWTEIKLVLDAFALPLTNLFKATIELCSTHANDASALRILFSSLILISKLFYSLNFQDLPEFFEDNMETWMNNFHTLLTLDNKLLQTDDEEEAGLLELLKSQICDNAALYAQKYDEEFQRYLPRFVTAIWNLLVTTGQEVKYDLLVSNAIQFLASVCERPHYKNLFEDQNTLTSICEKVIVPNMEFRAADEEAFEDNSEEYIRRDLEGSDIDTRRRAACDLVRGLCKFFEGPVTGIFSGYVNSMLQEYAKNPSVNWKHKDAAIYLVTSLASKAQTQKHGITQANELVNLTEFFVNHILPDLKSANVNEFPVLKADGIKYIMIFRNQVPKEHLLVSIPLLINHLQAESIVVHTYAAHALERLFTMRGPNNATLFTAAEIAPFVEILLTNLFKALTLPGSSENEYIMKAIMRSFSLLQEAIIPYIPTLITQLTQKLLAVSKNPSKPHFNHYMFEAICLSIRITCKANPAAVVNFEEALFLVFTEILQNDVQEFIPYVFQVMSLLLETHKNDIPSSYMALFPHLLQPVLWERTGNIPALVRLLQAFLERGSNTIASAAADKIPGLLGVFQKLIASKANDHQGFYLLNSIIEHMPPESVDQYRKQIFILLFQRLQNSKTTKFIKSFLVFINLYCIKYGALALQEIFDGIQPKMFGMVLEKIIIPEIQKVSGNVEKKICAVGITKLLTECPPMMDTEYTKLWTPLLQSLIGLFELPEDDTIPDEEHFIDIEDTPGYQTAFSQLAFAGKKEHDPVGQMVNNPKIHLAQSLHKLSTACPGRVPSMVSTSLNAEALQYLQGYLQAASVTLL>sp|P55060-2|XPO2_HUMAN Isoform 2 of Exportin-2 OS=Homo sapiens OX=9606GN=CSE1LMELSDANLQTLTEYLKKTLDPDPAIRRPAEKFLESVEGNQNYPLLLLTLLEKSQDNVIKVCASVTFKNYIKRNWRIVEDEPNKICEADRVAIKANIVHLMLSSPEQIQKQLSDAISIIGREDFPQKWPDLLTEMVNRFQSGDFHVINGVLRTAHSLFKRYRHEFKSNELWTEIKLVLDAFALPLTNLFKVWNASW>sp|P55060-3|XPO2_HUMAN Isoform 3 of Exportin-2 OS=Homo sapiens OX=9606GN=CSE1LMELSDANLQTLTEYLKKTLDPDPAIRRPAEKFLESVEGNQNYPLLLLTLLEKSQDNVIKVCASVTFKNYIKRNWRIVEDEPNKICEADRVAIKANIVHLMLSSPEQIQKQLSDAISIIGREDFPQKWPDLLTEMVNRFQSGDFHVINGVLRTAHSLFKRYRHEFKSNELWTEIKLVLDAFALPLTNLFKATIELCSTHANDASALRILFSSLILISKLFYSLNFQDLPEFFEDNMETWMNNFHTLLTLDNKLLQTDDEEEAGLLELLKSQICDNAALYAQKYDEEFQRYLPRFVTAIWNLLVTTGQEVKYDLLVSNAIQFLASVCERPHYKNLFEDQNTLTSICEKVIVPNMEFRAADEEAFEDNSEEYIRRDLEGSDIDTRRRAACDLVRGLCKFFEGPVTGIFSGYVNSMLQEYAKNPSVNWKHKDAAIYLVTSLASKAQTQKHGITQANELVNLTEFFVNHILPDLKSANVNEFPVLKADGIKYIMIFRNQVPKEHLLVSIPLLINHLQAESIVVHTYAAHALERLFTMRGPNNATLFTAAEIAPFVEILLTNLFKALTLPGSSENEYIMKAIMRSFSLLQEAIIPYIPTLITQLTQKLLAVSKNPSKPHFNHYMFEAICLSIRITCKANPAAVVNFEEALFLVFTEILQNDVQEFIPYVFQVMSLLLETHKNDIPSSYMALFPHLLQPVLWERTGNIPALVRLLQAFLERGSNTIASAAADKIPGLLGVFQKLIASKANDHQGFYLLNSIIEHMPPESVDQYRKQIFILLFQRLQNSKTTKFIKSFLVFINLYCIKYGALALQEIFDGIQPKMFGMVLEKIIIPEIQKVSGNVEKKICAVGITKLLTECPPMMDTEYTKLWTPLLQSLIGLFELPEDDTIPDEEHFIDIEDTPGYQTAFSQLAFAGKKEHDPVGQMVNNPKIHLAQSLHKLSTACPGRTYF>sp|P55060-4|XPO2_HUMAN Isoform 4 of Exportin-2 OS=Homo sapiens OX=9606GN=CSE1LMELSDANLQTLTEYLKKTLDPDPAIRRPAEKFLESVEGNQNYPLLLLTLLEKSQDNVIKVCASVTFKNYIKRNWRIVEDEPNKICEADRVAIKANIVHLMLSSPEQIQKQLSDAISIIGREDFPQKWPDLLTEMVNRFQSGDFHVINGVLRTAHSLFKRYRHEFKSNELWTEIKLVLDAFALPLTNLFKATIELCSTHANDASALRILFSSLILISKLFYSLNFQDLPEFFEDNMETWMNNFHTLLTLDNKLLQTDLVSNAIQFLASVCERPHYKNLFEDQNTLTSICEKVIVPNMEFRAADEEAFEDNSEEYIRRDLEGSDIDTRRRAACDLVRGLCKFFEGPVTGIFSGYVNSMLQEYAKNPSVNWKHKDAAIYLVTSLASKAQTQKHGITQANELVNLTEFFVNHILPDLKSANVNEFPVLKADGIKYIMIFRNQVPKEHLLVSIPLLINHLQAESIVVHTYAAHALERLFTMRGPNNATLFTAAEIAPFVEILLTNLFKALTLPGSSENEYIMKAIMRSFSLLQEAIIPYIPTLITQLTQKLLAVSKNPSKPHFNHYMFEAICLSIRITCKANPAAVVNFEEALFLVFTEILQNDVQEFIPYVFQVMSLLLETHKNDIPSSYMALFPHLLQPVLWERTGNIPALVRLLQAFLERGSNTIASAAADKIPGLLGVFQKLIASKANDHQGFYLLNSIIEHMPPESVDQYRKQIFILLFQRLQNSKTTKFIKSFLVFINLYCIKYGALALQEIFDGIQPKMFGMVLEKIIIPEIQKVSGNVEKKICAVGITKLLTECPPMMDTEYTKLWTPLLQSLIGLFELPEDDTIPDEEHFIDIEDTPGYQTAFSQLAFAGKKEHDPVGQMVNNPKIHLAQSLHKLSTACPGRVPSMVSTSLNAEALQYLQGYLQAASVTLL>sp|O00401|WASL_HUMAN Neural Wiskott-Aldrich syndrome protein OS=Homosapiens OX=9606 GN=WASL PE=1 SV=2MSSVQQQPPPPRRVTNVGSLLLTPQENESLFTFLGKKCVTMSSAVVQLYAADRNCMWSKKCSGVACLVKDNPQRSYFLRIFDIKDGKLLWEQELYNNFVYNSPRGYFHTFAGDTCQVALNFANEEEAKKFRKAVTDLLGRRQRKSEKRRDPPNGPNLPMATVDIKNPEITTNRFYGPQVNNISHTKEKKKGKAKKKRLTKADIGTPSNFQHIGHVGWDPNTGFDLNNLDPELKNLFDMCGISEAQLKDRETSKVIYDFIEKTGGVEAVKNELRRQAPPPPPPSRGGPPPPPPPPHNSGPPPPPARGRGAPPPPPSRAPTAAPPPPPPSRPSVAVPPPPPNRMYPPPPPALPSSAPSGPPPPPPSVLGVGPVAPPPPPPPPPPPGPPPPPGLPSDGDHQVPTTAGNKAALLDQIREGAQLKKVEQNSRPVSCSGRDALLDQIRQGIQLKSVADGQESTPPTPAPTSGIVGALMEVMQKRSKAIHSSDEDEDEDDEEDFEDDDEWED>sp|Q9UHU1|YK039_HUMAN Putative uncharacterized protein PRO1716 OS=Homosapiens OX=9606 GN=PRO1716 PE=5 SV=1MLTALGQVNNIQKEFTIKKTKQADHNLVARIDEIQYVQGTINL>sp|Q9Y5A9|YTHD2_HUMAN YTH domain-containing family protein 2 OS=Homosapiens OX=9606 GN=YTHDF2 PE=1 SV=2MSASSLLEQRPKGQGNKVQNGSVHQKDGLNDDDFEPYLSPQARPNNAYTAMSDSYLPSYYSPSIGFSYSLGEAAWSTGGDTAMPYLTSYGQLSNGEPHFLPDAMFGQPGALGSTPFLGQHGFNFFPSGIDFSAWGNNSSQGQSTQSSGYSSNYAYAPSSLGGAMIDGQSAFANETLNKAPGMNTIDQGMAALKLGSTEVASNVPKVVGSAVGSGSITSNIVASNSLPPATIAPPKPASWADIASKPAKQQPKLKTKNGIAGSSLPPPPIKHNMDIGTWDNKGPVAKAPSQALVQNIGQPTQGSPQPVGQQANNSPPVAQASVGQQTQPLPPPPPQPAQLSVQQQAAQPTRWVAPRNRGSGFGHNGVDGNGVGQSQAGSGSTPSEPHPVLEKLRSINNYNPKDFDWNLKHGRVFIIKSYSEDDIHRSIKYNIWCSTEHGNKRLDAAYRSMNGKGPVYLLFSVNGSGHFCGVAEMKSAVDYNTCAGVWSQDKWKGRFDVRWIFVKDVPNSQLRHIRLENNENKPVTNSRDTQEVPLEKAKQVLKIIASYKHTTSIFDDFSHYEKRQEEEESVKKERQGRGK>sp|Q9Y5A9-2|YTHD2_HUMAN Isoform 2 of YTH domain-containing familyprotein 2 OS=Homo sapiens OX=9606 GN=YTHDF2MSDSYLPSYYSPSIGFSYSLGEAAWSTGGDTAMPYLTSYGQLSNGEPHFLPDAMFGQPGALGSTPFLGQHGFNFFPSGIDFSAWGNNSSQGQSTQSSGYSSNYAYAPSSLGGAMIDGQSAFANETLNKAPGMNTIDQGMAALKLGSTEVASNVPKVVGSAVGSGSITSNIVASNSLPPATIAPPKPASWADIASKPAKQQPKLKTKNGIAGSSLPPPPIKHNMDIGTWDNKGPVAKAPSQALVQNIGQPTQGSPQPVGQQANNSPPVAQASVGQQTQPLPPPPPQPAQLSVQQQAAQPTRWVAPRNRGSGFGHNGVDGNGVGQSQAGSGSTPSEPHPVLEKLRSINNYNPKDFDWNLKHGRVFIIKSYSEDDIHRSIKYNIWCSTEHGNKRLDAAYRSMNGKGPVYLLFSVNGSGHFCGVAEMKSAVDYNTCAGVWSQDKWKGRFDVRWIFVKDVPNSQLRHIRLENNENKPVTNSRDTQEVPLEKAKQVLKIIASYKHTTSIFDDFSHYEKRQEEEESVKKERQGRGK>sp|Q8WVZ1|ZDH19_HUMAN Palmitoyltransferase ZDHHC19 OS=Homo sapiensOX=9606 GN=ZDHHC19 PE=1 SV=2MTLLTDATPLVKEPHPLPLVPRPWFLPSLFAAFNVVLLVFFSGLFFAFPCRWLAQNGEWAFPVITGSLFVLTFFSLVSLNFSDPGILHQGSAEQGPLTVHVVWVNHGAFRLQWCPKCCFHRPPRTYHCPWCNICVEDFDHHCKWVNNCIGHRNFRFFMLLVLSLCLYSGAMLVTCLIFLVRTTHLPFSTDKAIAIVVAVSAAGLLVPLSLLLLIQALSVSSADRTYKGKCRHLQGYNPFDQGCASNWYLTICAPLGPKYMAEAVQLQRVVGPDWTSMPNLHPPMSPSALNPPAPTSGSLQSREGTPGAW>sp|Q8WVZ1-2|ZDH19_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC19OS=Homo sapiens OX=9606 GN=ZDHHC19MTLLTDATPLVKEPHPLPLVPRPWFLPSLFAAFNVVLLVFFSGLFFAFPCRWLAQNGEWAFPVITGSLFVLTFFSLVSLNFSDPGILHQGSAEQGPLTVHVVWVNHGAFRLQWCPKCCFHRPPRTYHCPWCNICVEDFDHHCKWVNNCIGHRNFRFFMLLVLSLCLYSGAMLVTCLIFLVRTTHLPFSTDKAIAIVVAVSAAGLLVPLSLLLLIQALSVSSADRTYKGK>sp|Q8WVZ1-3|ZDH19_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC19OS=Homo sapiens OX=9606 GN=ZDHHC19MTLLTDATPLVKEPHPLPLVPRPWFLPSLFAAFNVVLLVFFSGLFFAFPCRWLAQNGEWAFPVITGSLFVLTFFSLVSLNFSDPGILHQGSAEQGPLTVHVVWVNHGAFRLQWCPKCCFHRPPRTYHCPWCNICVEDFDHHCKWVNNCIGHRNFRFFMLLVLSLCLYSGAMLVTCLIFLVRTTHLPFSTDKAIAIVVAVSAAGLLVPLSLLLLIQALSVSSADRTYKGKCRHLQGYNPFDQGCASNWYLTICAPLGPKAAASWMRLASASCRAKPWAVCFPS>sp|Q92670|ZN75C_HUMAN Putative zinc finger protein 75C OS=Homo sapiensOX=9606 GN=ZNF75CP PE=5 SV=2MIMRELKADACLNSHMGAMWETNRSVKENSSQSKKYSTQIECLSPGSACRHFRSFHYHEATEPLEAINQLQKLCHQWLRPEIHSKKHILEMLVLEHFLTILPKGTQNWVQKHHPQLAKQALVLVERLQREPGGTKNEVTAHELGEEAVLLRGTTVAPGFKWKPAELEPMERILEHIQILALSEHKSTKDWKMAPKLIWPESQSLLTFEDMAVYFSEEEWQLLGPLEKTLYNDVMQDIYETAISLGKQRTGKIMGIEMASSFSKEEKKLTTCKQELPKLMDLHGKGHTGEKPFKCQDCGKIFRVSSDLIKHQRIHTEEKLYKCQQCDRRFRWSSGLNKHFMTHQGINPYRCSWYGKSISYDTNLQTHQRIHTGEKPFKCHECGKIFIHKSNLIKYQRTHTGEQPYTCSICRRNFSRQLSLLRHQKLH>sp|Q9C0D4|Z518B_HUMAN Zinc finger protein 518B OS=Homo sapiens OX=9606GN=ZNF518B PE=1 SV=2MKDIGQQLYTTHLNGGHNSLTMSPKQPDANGAPRPNRQEAQTLLYQGSEAEAAMMTIATCAKCKSVHKISLQDLQKGTGKDGMYVCFQCSLGAAPPNFHFVSNNSSATHVGNKTENFSSSVNSKFKVRNFKPGKYYCDKCRFSTKDPLQYKKHTLQHEEIKFICSHCSYISYTKGEFQRHLVKHTGIFPYQCEYCDYGAIRNDYIVKHTKRVHERAGAKRPVKAVAKLEPKRTGTSKQNPELLKASNPRTTFQNKWSDQLSGFSLHANKDKMHNIMLLPEPKEYQKDVVCIPNKMTLSEPNEVNLFENKNVEVEVLSPAKEPVQPGMPLTVVAPAELVVPANCLAQLIDVKVVNGTQQLVLKLFPLEENNCLEAGRDNGGNSERMVKEKGSNEQEKVLSAEKTKSLTVDGNVGKLVGIDSFQPSVQKQLKNVKWVRSYDFIMPNSSVHNNGKSFINSETIEDFQKKNNLYPHRTAFPSVALKGHSLASVFKNSVLRSLGAASNPFPYKAAVCFAESGRNLHSSSQQLLPFAASPATCSFSGEKGLLPVSENDLESTSKVNIPVKVVSSNRKQEDNQTEEHKAVSTVGQISSQHKSEYLHINITGEDRSQQPGDKPLELKNSERTNNTNDGPVISSVFSLSSGSENVPEGIKWNSSTSKIKSIELLRRKIAQLIESCGKPSSLASNSAHRRSVGQASKGTSKATSEGIQEINVSLTGLGHSTGTLQKPPNDGGITGNRQLTHQQIYPHFADGSNRKTKSRVARKAHVATPVLIPKGAVLRVLNSSENAHIIEATCEAPVSIPCSERQLIKPVPFCPVRQADSDLQPLRSERGPIDMSPNIETPLRPKLRKESAVCSTIHRKTGLLYGQQGSSELNKQGRLLSRSLSISRNKTKQVHLSRKKNKIQAEPSRCLKDPSIFQVARQLRLIAAKPDQLIKCPRRNQPVIVLNHPDVDSPEVTNVMKVINKYKGNVLKVVLSERTRCQLGIRRHHVRLTYQNAEEASQIKRQMMLKMKLKKVHKNNYQVVDSLPDDSSQCVFKCWFCGRLYEDQEEWMSHGQRHLIEATRDWDVLSSKGK>sp|P0CJ78|ZN865_HUMAN Zinc finger protein 865 OS=Homo sapiens OX=9606GN=ZNF865 PE=1 SV=1MEANPAGSGAGGGGSSGIGGEDGVHFQSYPFDFLEFLNHQRFEPMELYGEHAKAVAALPCAPGPPPQPPPQPPPPQYDYPPQSTFKPKAEVPSSSSSSSSSSSSSSSSSSSSSSSSSQAKKPDPPLPPAFGAPPPPLFDAAFPTPQWGIVDLSGHQHLFGNLKRGGPASGPGVTPGLGAPAGAPGPLPAPSQTPPGPPAAAACDPTKDDKGYFRRLKYLMERRFPCGVCQKSFKQSSHLVQHMLVHSGERPYECGVCGRTYNHVSSLIRHRRCHKDVPPAAGGPPQPGPHLPPLGLPAPAASAATAAAPSTVSSGPPATPVAPAPSADGSAAPAGVGVPPPATGGGDGPFACPLCWKVFKKPSHLHQHQIIHTGEKPFSCSVCSKSFNRRESLKRHVKTHSADLLRLPCGICGKAFRDASYLLKHQAAHAGAGAGGPRPVYPCDLCGKSYSAPQSLLRHKAAHAPPAAAAEAPKDGAASAPQPPPTFPPGPYLLPPDPPTTDSEKAAAAAAAVVYGAVPVPLLGAHPLLLGGAGTSGAGGSGASVPGKTFCCGICGRGFGRRETLKRHERIHTGEKPHQCPVCGKRFRESFHLSKHHVVHTRERPYKCELCGKVFGYPQSLTRHRQVHRLQLPCALAGAAGLPSTQGTPGACGPGASGTSAGPTDGLSYACSDCGEHFPDLFHVMSHKEVHMAEKPYGCDACGKTFGFIENLMWHKLVHQAAPERLLPPAPGGLQPPDGSSGTDAASVLDNGLAGEVGAAVAALAGVSGGEDAGGAAVAGAGGGASSGPERFSCATCGQSFKHFLGLVTHKYVHLVRRTLGCGLCGQSFAGAYDLLLHRRSHRQKRGFRCPVCGKRFWEAALLMRHQRCHTEQRPYRCGVCGRGFLRSWYLRQHRVVHTGERAFKCGVCAKRFAQSSSLAEHRRLHAVARPQRCSACGKTFRYRSNLLEHQRLHLGERAYRCEHCGKGFFYLSSVLRHQRAHEPPRPELRCPACLKAFKDPGYFRKHLAAHQGGRPFRCSSCGEGFANTYGLKKHRLAHKAENLGGPGAGAGTLAGKDA>sp|Q9H869|YYAP1_HUMAN YY1-associated protein 1 OS=Homo sapiens OX=9606GN=YY1AP1 PE=1 SV=2MEEEASRSAAATNPGSRLTRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-2|YYAP1_HUMAN Isoform 2 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNLLALGLKHFEGTEFLNPLISKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-3|YYAP1_HUMAN Isoform 3 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNLLALGLKHFEGTEFLNPLISKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-4|YYAP1_HUMAN Isoform 4 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-5|YYAP1_HUMAN Isoform 5 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNLLALGLKHFEGTEFLNPLISKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-6|YYAP1_HUMAN Isoform 6 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-7|YYAP1_HUMAN Isoform 7 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-8|YYAP1_HUMAN Isoform 8 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRLTRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q9H869-9|YYAP1_HUMAN Isoform 9 of YY1-associated protein 1 OS=Homosapiens OX=9606 GN=YY1AP1MAGVGRSGGPWGRTRGGRSGRLGVSLGALSSLPLEELPRPLCCRRCRRHFGFALRGETIPVSVAGSASSQFAPLALHLSLLLSRISASRLTRWPPPDKREGSAVDPGKRRSLAATPSSSLPCTLIALGLRHEKEANELMEDLFETFQDEMGFSNMEDDGPEEEERVAEPQANFNTPQALRFEELLANLLNEQHQIAKELFEQLKMKKPSAKQQKEVEKVKPQCKEVHQTLILDPAQRKRLQQQMQQHVQLLTQIHLLATCNPNLNPEASSTRICLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGAMQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKILFTKAEDNLLALGLKHFEGTEFLNPLISKYLLTCKTARQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCCEEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDQGLEKDNSELGSETRYPLLLPKGVVLKLKPVADRFPKKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPAQSTHSEAPPSKMVLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAMPPEARTSFPLSESQTLLSSAPVPKVMMPSPASSMFRKPYVRRRPSKRRGARAFRCIKPAPVIHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQSPQTIPIATLLVNPTSFPCPLNQPLVASSVSPLIVSGNSVNLPIPSTPEDKAHMNVDIACAVADGENAFQGLEPKLEPQELSPLSATVFPKVEHSPGPPPVDKQCQEGLSENSAYRWTVVKTEEGRQALEPLPQGIQESLNNSSPGDLEEVVKMEPEDATEEISGFL>sp|Q96N77|ZN641_HUMAN Zinc finger protein 641 OS=Homo sapiens OX=9606GN=ZNF641 PE=1 SV=2MQAEDRSQFGSAAEMLSEQTAALGTGWESMNVQLDGAEPQVERGSQEERPWRTVPGPLEHLCCDLEEEPQSLQEKAQSAPWVPAIPQEGNTGDWEMAAALLAAGSQGLVTIKDVSLCFSQEEWRSLDPSQTDFYGEYVMQENCGIVVSLRFPIPKLDMLSQLEGGEEQWVPDPQDLEERDILRVTYTGDGSEHEGDTPELEAEPPRMLSSVSEDTVLWNPEHDESWDSMPSSSRGMLLGPPFLQEDSFSNLLCSTEMDSLLRPHTCPQCGKQFVWGSHLARHQQTHTGERPYSCLKCEKTFGRRHHLIRHQKTHLHDKTSRCSECGKNFRCNSHLASHQRVHAEGKSCKGQEVGESPGTRKRQRAPPVPKCHVCTECGKSFGRRHHLVRHWLTHTGEKPFQCPRCEKSFGRKHHLDRHLLTHQGQSPRNSWDRGTSVF>sp|Q96N77-2|ZN641_HUMAN Isoform 2 of Zinc finger protein 641 OS=Homosapiens OX=9606 GN=ZNF641MLSEQTAALGTGWESMNVQLDGAEPQVERGSQEERPWRTVPGPLEHLCCDLEEEPQSLQEKAQSAPWVPAIPQEGNTGDWEMAAALLAAGSQGLVTIKDVSLCFSQEEWRSLDPSQTDFYGEYVMQENCGIVVSLRFPIPKLDMLSQLEGGEEQWVPDPQDLEERDILRVTYTGDGSEHEGDTPELEAEPPRMLSSVSEDTVLWNPEHDESWDSMPSSSRGMLLGPPFLQEDSFSNLLCSTEMDSLLRPHTCPQCGKQFVWGSHLARHQQTHTGERPYSCLKCEKTFGRRHHLIRHQKTHLHDKTSRCSECGKNFRCNSHLASHQRVHAEGKSCKGQEVGESPGTRKRQRAPPVPKCHVCTECGKSFGRRHHLVRHWLTHTGE>sp|Q96N77-3|ZN641_HUMAN Isoform 3 of Zinc finger protein 641 OS=Homosapiens OX=9606 GN=ZNF641MLSEQTAALGTGWESMNVQLDGAEPQVERGSQEERPWRTVPGPLEHLCCDLEEEPQSLQEKAQSAPWVPAIPQEGNTGDWEMAAALLAAGSQVSSASLGVSCGPITAAFVLLSHQPIDELAHMIINGFPIPKLDMLSQLEGGEEQWVPDPQDLEERDILRVTYTGDGSEHEGDTPELEAEPPRMLSSVSEDTVLWNPEHDESWDSMPSSSRGMLLGPPFLQEDSFSNLLCSTEMDSLLRPHTCPQCGKQFVWGSHLARHQQTHTGERPYSCLKCEKTFGRRHHLIRHQKTHLHDKTSRCSECGKNFRCNSHLASHQRVHAEGKSCKGQEVGESPGTRKRQRAPPVPKCHVCTECGKSFGRRHHLVRHWLTHTGEKPFQCPRCEKSFGRKHHLDRHLLTHQGQSPRNSWDRGTSVF>sp|Q96N77-4|ZN641_HUMAN Isoform 4 of Zinc finger protein 641 OS=Homosapiens OX=9606 GN=ZNF641MLSEQTAALGTGWESMNVQLDGAEPQVERGSQEERPWRTVPGPLEHLCCDLEEEPQSLQEKAQSAPWVPAIPQEGNTGDWEMAAALLAAGSQGLVTIKDVSLCFSQEEWRSLDPSQTDFYGEYVMQENCGIVVSLRFPIPKLDMLSQLEGGEEQWVPDPQDLEERDILRVTYTGDGSEHEGDTPELEAEPPRMLSSVSEDTVLWNPEHDESWDSMPSSSRGMLLGPPFLQEDSFSNLLCSTEMDSLLRPHTCPQCGKQFVWGSHLARHQQTHTGERPYSCLKCEKTFGRRHHLIRHQKTHLHDKTSRCSECGKNFRCNSHLASHQRVHAEGKSCKGQEVGESPGTRKRQRAPPVPKCHVCTECGKSFGRRHHLVRHWLTHTGEKPFQCPRCEKSFGRKHHLDRHLLTHQGQSPRNSWDRGTSVF>sp|P35916|VGFR3_HUMAN Vascular endothelial growth factor receptor 3OS=Homo sapiens OX=9606 GN=FLT4 PE=1 SV=3MQRGAALCLRLWLCLGLLDGLVSGYSMTPPTLNITEESHVIDTGDSLSISCRGQHPLEWAWPGAQEAPATGDKDSEDTGVVRDCEGTDARPYCKVLLLHEVHANDTGSYVCYYKYIKARIEGTTAASSYVFVRDFEQPFINKPDTLLVNRKDAMWVPCLVSIPGLNVTLRSQSSVLWPDGQEVVWDDRRGMLVSTPLLHDALYLQCETTWGDQDFLSNPFLVHITGNELYDIQLLPRKSLELLVGEKLVLNCTVWAEFNSGVTFDWDYPGKQAERGKWVPERRSQQTHTELSSILTIHNVSQHDLGSYVCKANNGIQRFRESTEVIVHENPFISVEWLKGPILEATAGDELVKLPVKLAAYPPPEFQWYKDGKALSGRHSPHALVLKEVTEASTGTYTLALWNSAAGLRRNISLELVVNVPPQIHEKEASSPSIYSRHSRQALTCTAYGVPLPLSIQWHWRPWTPCKMFAQRSLRRRQQQDLMPQCRDWRAVTTQDAVNPIESLDTWTEFVEGKNKTVSKLVIQNANVSAMYKCVVSNKVGQDERLIYFYVTTIPDGFTIESKPSEELLEGQPVLLSCQADSYKYEHLRWYRLNLSTLHDAHGNPLLLDCKNVHLFATPLAASLEEVAPGARHATLSLSIPRVAPEHEGHYVCEVQDRRSHDKHCHKKYLSVQALEAPRLTQNLTDLLVNVSDSLEMQCLVAGAHAPSIVWYKDERLLEEKSGVDLADSNQKLSIQRVREEDAGRYLCSVCNAKGCVNSSASVAVEGSEDKGSMEIVILVGTGVIAVFFWVLLLLIFCNMRRPAHADIKTGYLSIIMDPGEVPLEEQCEYLSYDASQWEFPRERLHLGRVLGYGAFGKVVEASAFGIHKGSSCDTVAVKMLKEGATASEHRALMSELKILIHIGNHLNVVNLLGACTKPQGPLMVIVEFCKYGNLSNFLRAKRDAFSPCAEKSPEQRGRFRAMVELARLDRRRPGSSDRVLFARFSKTEGGARRASPDQEAEDLWLSPLTMEDLVCYSFQVARGMEFLASRKCIHRDLAARNILLSESDVVKICDFGLARDIYKDPDYVRKGSARLPLKWMAPESIFDKVYTTQSDVWSFGVLLWEIFSLGASPYPGVQINEEFCQRLRDGTRMRAPELATPAIRRIMLNCWSGDPKARPAFSELVEILGDLLQGRGLQEEEEVCMAPRSSQSSEEGSFSQVSTMALHIAQADAEDSPPSLQRHSLAARYYNWVSFPGCLARGAETRGSSRMKTFEEFPMTPTTYKGSVDNQTDSGMVLASEEFEQIESRHRQESGFSCKGPGQNVAVTRAHPDSQGRRRRPERGARGGQVFYNSEYGELSEPSEEDHCSPSARVTFFTDNSY>sp|P35916-1|VGFR3_HUMAN Isoform 2 of Vascular endothelial growth factorreceptor 3 OS=Homo sapiens OX=9606 GN=FLT4MQRGAALCLRLWLCLGLLDGLVSGYSMTPPTLNITEESHVIDTGDSLSISCRGQHPLEWAWPGAQEAPATGDKDSEDTGVVRDCEGTDARPYCKVLLLHEVHANDTGSYVCYYKYIKARIEGTTAASSYVFVRDFEQPFINKPDTLLVNRKDAMWVPCLVSIPGLNVTLRSQSSVLWPDGQEVVWDDRRGMLVSTPLLHDALYLQCETTWGDQDFLSNPFLVHITGNELYDIQLLPRKSLELLVGEKLVLNCTVWAEFNSGVTFDWDYPGKQAERGKWVPERRSQQTHTELSSILTIHNVSQHDLGSYVCKANNGIQRFRESTEVIVHENPFISVEWLKGPILEATAGDELVKLPVKLAAYPPPEFQWYKDGKALSGRHSPHALVLKEVTEASTGTYTLALWNSAAGLRRNISLELVVNVPPQIHEKEASSPSIYSRHSRQALTCTAYGVPLPLSIQWHWRPWTPCKMFAQRSLRRRQQQDLMPQCRDWRAVTTQDAVNPIESLDTWTEFVEGKNKTVSKLVIQNANVSAMYKCVVSNKVGQDERLIYFYVTTIPDGFTIESKPSEELLEGQPVLLSCQADSYKYEHLRWYRLNLSTLHDAHGNPLLLDCKNVHLFATPLAASLEEVAPGARHATLSLSIPRVAPEHEGHYVCEVQDRRSHDKHCHKKYLSVQALEAPRLTQNLTDLLVNVSDSLEMQCLVAGAHAPSIVWYKDERLLEEKSGVDLADSNQKLSIQRVREEDAGRYLCSVCNAKGCVNSSASVAVEGSEDKGSMEIVILVGTGVIAVFFWVLLLLIFCNMRRPAHADIKTGYLSIIMDPGEVPLEEQCEYLSYDASQWEFPRERLHLGRVLGYGAFGKVVEASAFGIHKGSSCDTVAVKMLKEGATASEHRALMSELKILIHIGNHLNVVNLLGACTKPQGPLMVIVEFCKYGNLSNFLRAKRDAFSPCAEKSPEQRGRFRAMVELARLDRRRPGSSDRVLFARFSKTEGGARRASPDQEAEDLWLSPLTMEDLVCYSFQVARGMEFLASRKCIHRDLAARNILLSESDVVKICDFGLARDIYKDPDYVRKGSARLPLKWMAPESIFDKVYTTQSDVWSFGVLLWEIFSLGASPYPGVQINEEFCQRLRDGTRMRAPELATPAIRRIMLNCWSGDPKARPAFSELVEILGDLLQGRGLQEEEEVCMAPRSSQSSEEGSFSQVSTMALHIAQADAEDSPPSLQRHSLAARYYNWVSFPGCLARGAETRGSSRMKTFEEFPMTPTTYKGSVDNQTDSGMVLASEEFEQIESRHRQESGFR>sp|P35916-3|VGFR3_HUMAN Isoform 3 of Vascular endothelial growth factorreceptor 3 OS=Homo sapiens OX=9606 GN=FLT4MQRGAALCLRLWLCLGLLDGLVSGYSMTPPTLNITEESHVIDTGDSLSISCRGQHPLEWAWPGAQEAPATGDKDSEDTGVVRDCEGTDARPYCKVLLLHEVHANDTGSYVCYYKYIKARIEGTTAASSYVFVRDFEQPFINKPDTLLVNRKDAMWVPCLVSIPGLNVTLRSQSSVLWPDGQEVVWDDRRGMLVSTPLLHDALYLQCETTWGDQDFLSNPFLVHITGNELYDIQLLPRKSLELLVGEKLVLNCTVWAEFNSGVTFDWDYPGKQAERGKWVPERRSQQTHTELSSILTIHNVSQHDLGSYVCKANNGIQRFRESTEVIVHENPFISVEWLKGPILEATAGDELVKLPVKLAAYPPPEFQWYKDGKALSGRHSPHALVLKEVTEASTGTYTLALWNSAAGLRRNISLELVVNVPPQIHEKEASSPSIYSRHSRQALTCTAYGVPLPLSIQWHWRPWTPCKMFAQRSLRRRQQQDLMPQCRDWRAVTTQDAVNPIESLDTWTEFVEGKNKTVSKLVIQNANVSAMYKCVVSNKVGQDERLIYFYVTTIPDGFTIESKPSEELLEGQPVLLSCQADSYKYEHLRWYRLNLSTLHDAHGNPLLLDCKNVHLFATPLAASLEEVAPGARHATLSLSIPRVAPEHEGHYVCEVQDRRSHDKHCHKKYLSVQALEAPRLTQNLTDLLVNVSDSLEMQCLVAGAHAPSIVWYKDERLLEEKSGREGGPGEGQVRRPARPTIPNPGGPAPPPHPLQESTWRTPTRSCKGPGQNVAVTRAHPDSQGRRRRPERGARGGQVFYNSEYGELSEPSEEDHCSPSARVTFFTDNSY>sp|Q8NHE4|VA0E2_HUMAN V-type proton ATPase subunit e 2 OS=Homo sapiensOX=9606 GN=ATP6V0E2 PE=2 SV=1MTAHSFALPVIIFTTFWGLVGIAGPWFVPKGPNRGVIITMLVATAVCCYLFWLIAILAQLNPLFGPQLKNETIWYVRFLWE>sp|Q8NHE4-2|VA0E2_HUMAN Isoform 2 of V-type proton ATPase subunit e 2OS=Homo sapiens OX=9606 GN=ATP6V0E2MTAHSFALPVIIFTTFWGLVGIAGPWFVPKGPNRGVIITMLVATAVCCYLLCPALGMTVAPLSLTTPSSGPSPTQLCLVTSSLLLAPRDPDPQGLPGSWKSSQSSQPARALGSPGHSSGRGDVLLQYPHCSGVCPLSQGDAAGELVWVGSFPLQTGQMPGLSPS>sp|Q8NHE4-3|VA0E2_HUMAN Isoform 3 of V-type proton ATPase subunit e 2OS=Homo sapiens OX=9606 GN=ATP6V0E2MTAHSFALPVIIFTTFWGLVGIAGPWFVPKGPNRGVIITMLVATAVCCYLFWLIAILAQLNPLFGPQLKNETIWCPALGMTVAPLSLTTPSSGPSPTQLCLVTSSLLLAPRDPDPQGLPGSWKSSQSSQPARALGSPGHSSGRGDVLLQYPHCSGVCPLSQGDAAGELVWVGSFPLQTGQMPGLSPS>sp|Q8NHE4-4|VA0E2_HUMAN Isoform 4 of V-type proton ATPase subunit e 2OS=Homo sapiens OX=9606 GN=ATP6V0E2MRVRGPARLIASGARLLLRMLSALPGWGPAHLQRPLLGPASCLGILRPAMTAHSFALPVIIFTTFWGLVGIAGPWFVPKGPNRGVIITMLVATAVCCYLFWLIAILAQLNPLFGPQLKNETIWYVRFLWE>sp|O95231|VENTX_HUMAN Homeobox protein VENTX OS=Homo sapiens OX=9606GN=VENTX PE=1 SV=1MRLSSSPPRGPQQLSSFGSVDWLSQSSCSGPTHTPRPADFSLGSLPGPGQTSGAREPPQAVSIKEAAGSSNLPAPERTMAGLSKEPNTLRAPRVRTAFTMEQVRTLEGVFQHHQYLSPLERKRLAREMQLSEVQIKTWFQNRRMKHKRQMQDPQLHSPFSGSLHAPPAFYSTSSGLANGLQLLCPWAPLSGPQALMLPPGSFWGLCQVAQEALASAGASCCGQPLASHPPTPGRPSLGPALSTGPRGLCAMPQTGDAF>sp|A0A1B0GTU1|ZC11B_HUMAN Zinc finger CCCH domain-containing protein 11BOS=Homo sapiens OX=9606 GN=ZC3H11B PE=4 SV=1MPNQGEDCYFFFYSTCTKGDSCPFRHCEAALGNETVCTLWQEGRCFRRVCRFRHMEIDKKRSEIPCYWENQPTGCQKLNCVFHHNRGRYVDGLFLPPSKSVLPTVPESPEEEVKASQLSVQQNKLSVQSNTSPQLRSVMKVESSENVPSPKHPPVVINAADDDEDDDDQFSEEGDETKTPTLQPTPEVHNGLRVTSVRKPAVNIKQGECLHFGIKTLEEIKSKKMKEKSEEQGEGSSGVSSLLLHPEPVPGPEKENVRTVVRTVTLSTKQGEEPLVRLGLTETLGKRKFSTGGDSDPPLKRSLAQRLGKKVEAPETNTDETPKKAQVSKSLKERLGMSADPNNEDATDKVNKVGEIHVKTLEEMLLERASQKHGESQTKLKTEGPSKTDDSTSGARSSSTIRIKTFSEVLAEEEHRQQEAERQKSKKDTTCIKLKTDSEIKKTVVLPPIVASKGQSEEPAGKTKSMQEVHMKTVEEIKLEKALRVQQSSESSTSSPSQHEATPGARLLLRITKRTWRKEEKKLQEGNEVDFLSRVRMEATEASVETTGVDITKIQVKRCEIMRETRMQKQQEREKSVLTPLQGDVASCNTQVAEKPVLTAVPGITWHLTKQLPTKSSQKVEVETSGIADSLLNVKWSAQTLEKRGEAKPTVNVKQSVVKVVSSPKLAPKRKAVEMHPAVTAAVKPLSSSSVLQEPPAKKAAVDAVVLLDSEDKSVTVPEAENPRDSLVLPPTQSSSDSSPPEVSGPSSSQMSMKTRRLSSASTGKPPLSVEDDFEKLTWEISGGKLEAEIDLDPGKDEDDLPLEL>sp|P22309|UD11_HUMAN UDP-glucuronosyltransferase 1A1 OS=Homo sapiensOX=9606 GN=UGT1A1 PE=1 SV=1MAVESQGGRPLVLGLLLCVLGPVVSHAGKILLIPVDGSHWLSMLGAIQQLQQRGHEIVVLAPDASLYIRDGAFYTLKTYPVPFQREDVKESFVSLGHNVFENDSFLQRVIKTYKKIKKDSAMLLSGCSHLLHNKELMASLAESSFDVMLTDPFLPCSPIVAQYLSLPTVFFLHALPCSLEFEATQCPNPFSYVPRPLSSHSDHMTFLQRVKNMLIAFSQNFLCDVVYSPYATLASEFLQREVTVQDLLSSASVWLFRSDFVKDYPRPIMPNMVFVGGINCLHQNPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|P22309-2|UD11_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A1OS=Homo sapiens OX=9606 GN=UGT1A1MAVESQGGRPLVLGLLLCVLGPVVSHAGKILLIPVDGSHWLSMLGAIQQLQQRGHEIVVLAPDASLYIRDGAFYTLKTYPVPFQREDVKESFVSLGHNVFENDSFLQRVIKTYKKIKKDSAMLLSGCSHLLHNKELMASLAESSFDVMLTDPFLPCSPIVAQYLSLPTVFFLHALPCSLEFEATQCPNPFSYVPRPLSSHSDHMTFLQRVKNMLIAFSQNFLCDVVYSPYATLASEFLQREVTVQDLLSSASVWLFRSDFVKDYPRPIMPNMVFVGGINCLHQNPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|Q9Y484|WIPI4_HUMAN WD repeat domain phosphoinositide-interactingprotein 4 OS=Homo sapiens OX=9606 GN=WDR45 PE=1 SV=1MTQQPLRGVTSLRFNQDQSCFCCAMETGVRIYNVEPLMEKGHLDHEQVGSMGLVEMLHRSNLLALVGGGSSPKFSEISVLIWDDAREGKDSKEKLVLEFTFTKPVLSVRMRHDKIVIVLKNRIYVYSFPDNPRKLFEFDTRDNPKGLCDLCPSLEKQLLVFPGHKCGSLQLVDLASTKPGTSSAPFTINAHQSDIACVSLNQPGTVVASASQKGTLIRLFDTQSKEKLVELRRGTDPATLYCINFSHDSSFLCASSDKGTVHIFALKDTRLNRRSALARVGKVGPMIGQYVDSQWSLASFTVPAESACICAFGRNTSKNVNSVIAICVDGTFHKYVFTPDGNCNREAFDVYLDICDDDDF>sp|Q9Y484-2|WIPI4_HUMAN Isoform 2 of WD repeat domain phosphoinositide-interacting protein 4 OS=Homo sapiens OX=9606 GN=WDR45MTQQPLRGVTSLRFNQDQSCFCCAMETGVRIYNVEPLMEKGHLDHEQVGSMGLVEMLHRSNLLALVGGGSSPKFSEISVLIWDDAREGKDSKEKLVLEFTFTKPVLSVRMRHDKIVIVLKNRIYVYSFPDNPRKLFEFDTRDNPKAAHPTPHLHTLGLCDLCPSLEKQLLVFPGHKCGSLQLVDLASTKPGTSSAPFTINAHQSDIACVSLNQPGTVVASASQKGTLIRLFDTQSKEKLVELRRGTDPATLYCINFSHDSSFLCASSDKGTVHIFALKDTRLNRRSALARVGKVGPMIGQYVDSQWSLASFTVPAESACICAFGRNTSKNVNSVIAICVDGTFHKYVFTPDGNCNREAFDVYLDICDDDDF>sp|Q9Y484-3|WIPI4_HUMAN Isoform 3 of WD repeat domain phosphoinositide-interacting protein 4 OS=Homo sapiens OX=9606 GN=WDR45MTQQPLRGVTSLRFNQDQSCFCCAMETGVRIYNVEPLMEKGHLDHEQVGSMGLVEMLHRSNLLALVGGGSSPKFSEISAVLIWDDAREGKDSKEKLVLEFTFTKPVLSVRMRHDKIVIVLKNRIYVYSFPDNPRKLFEFDTRDNPKGLCDLCPSLEKQLLVFPGHKCGSLQLVDLASTKPGTSSAPFTINAHQSDIACVSLNQPGTVVASASQKGTLIRLFDTQSKEKLVELRRGTDPATLYCINFSHDSSFLCASSDKGTVHIFALKDTRLNRRSALARVGKVGPMIGQYVDSQWSLASFTVPAESACICAFGRNTSKNVNSVIAICVDGTFHKYVFTPDGNCNREAFDVYLDICDDDDF>sp|Q96S55|WRIP1_HUMAN ATPase WRNIP1 OS=Homo sapiens OX=9606 GN=WRNIP1PE=1 SV=2MEVSGPEDDPFLSQLHQVQCPVCQQMMPAAHINSHLDRCLLLHPAGHAEPAAGSHRAGERAKGPSPPGAKRRRLSESSALKQPATPTAAESSEGEGEEGDDGGETESRESYDAPPTPSGARLIPDFPVARSSSPGRKGSGKRPAAAAAAGSASPRSWDEAEAQEEEEAVGDGDGDGDADADGEDDPGHWDADAAEAATAFGASGGGRPHPRALAAEEIRQMLQGKPLADTMRPDTLQDYFGQSKAVGQDTLLRSLLETNEIPSLILWGPPGCGKTTLAHIIASNSKKHSIRFVTLSATNAKTNDVRDVIKQAQNEKSFFKRKTILFIDEIHRFNKSQQDTFLPHVECGTITLIGATTENPSFQVNAALLSRCRVIVLEKLPVEAMVTILMRAINSLGIHVLDSSRPTDPLSHSSNSSSEPAMFIEDKAVDTLAYLSDGDARAGLNGLQLAVLARLSSRKMFCKKSGQSYSPSRVLITENDVKEGLQRSHILYDRAGEEHYNCISALHKSMRGSDQNASLYWLARMLEGGEDPLYVARRLVRFASEDIGLADPSALTQAVAAYQGCHFIGMPECEVLLAQCVVYFARAPKSIEVYSAYNNVKACLRNHQGPLPPVPLHLRNAPTRLMKDLGYGKGYKYNPMYSEPVDQEYLPEELRGVDFFKQRRC>sp|Q96S55-2|WRIP1_HUMAN Isoform 2 of ATPase WRNIP1 OS=Homo sapiensOX=9606 GN=WRNIP1MEVSGPEDDPFLSQLHQVQCPVCQQMMPAAHINSHLDRCLLLHPAGHAEPAAGSHRAGERAKGPSPPGAKRRRLSESSALKQPATPTAAESSEGEGEEGDDGGETESRESYDAPPTPSGARLIPDFPVARSSSPGRKGSGKRPAAAAAAGSASPRSWDEAEAQEEEEAVGDGDGDGDADADGEDDPGHWDADAAEAATAFGASGGGRPHPRALAAEEIRQMLQGKPLADTMRPDTLQDYFGQSKAVGQDTLLRSLLETNEIPSLILWGPPGCGKTTLAHIIASNSKKHSIRFVTLSATNAKTNDVRDVIKQAQNEKSFFKRKTILFIDEIHRFNKSQQVNAALLSRCRVIVLEKLPVEAMVTILMRAINSLGIHVLDSSRPTDPLSHSSNSSSEPAMFIEDKAVDTLAYLSDGDARAGLNGLQLAVLARLSSRKMFCKKSGQSYSPSRVLITENDVKEGLQRSHILYDRAGEEHYNCISALHKSMRGSDQNASLYWLARMLEGGEDPLYVARRLVRFASEDIGLADPSALTQAVAAYQGCHFIGMPECEVLLAQCVVYFARAPKSIEVYSAYNNVKACLRNHQGPLPPVPLHLRNAPTRLMKDLGYGKGYKYNPMYSEPVDQEYLPEELRGVDFFKQRRC>sp|Q96S55-3|WRIP1_HUMAN Isoform 3 of ATPase WRNIP1 OS=Homo sapiensOX=9606 GN=WRNIP1MLQGKPLADTMRPDTLQDYFGQSKAVGQDTLLRSLLETNEIPSLILWGPPGCGKTTLAHIIASNSKKHSIRFVTLSATNAKTNDVRDVIKQAQNEKSFFKRKTILFIDEIHRFNKSQQDTFLPHVECGTITLIGATTENPSFQVNAALLSRCRVIVLEKLPVEAMVTILMRAINSLGIHVLDSSRPTDPLSHSSNSSSEPAMFIEDKAVDTLAYLSDGDARAGLNGLQLAVLARLSSRKMFCKKSGQSYSPSRVLITENDVKEGLQRSHILYDRAGEEHYNCISALHKSMRGSDQNASLYWLARMLEGGEDPLYVARRLVRFASEDIGLADPSALTQAVAAYQGCHFIGMPECEVLLAQCVVYFARAPKSIEVYSAYNNVKACLRNHQGPLPPVPLHLRNAPTRLMKDLGYGKGYKYNPMYSEPVDQEYLPEELRGVDFFKQRRC>sp|Q96S55-4|WRIP1_HUMAN Isoform 4 of ATPase WRNIP1 OS=Homo sapiensOX=9606 GN=WRNIP1MVTILMRAINSLGIHVLDSSRPTDPLSHSSNSSSEPAMFIEDKAVDTLAYLSDGDARAGLNGLQLAVLARLSSRKMFCKKSGQSYSPSRVLITENDVKEGLQRSHILYDRAGEEHYNCISALHKSMRGSDQNASLYWLARMLEGGEDPLYVARRLVRFASEDIGLADPSALTQAVAAYQGCHFIGMPECEVLLAQCVVYFARAPKSIEVYSAYNNVKACLRNHQGPLPPVPLHLRNAPTRLMKDLGYGKGYKYNPMYSEPVDQEYLPEELRGVDFFKQRRC>sp|Q9NYH9|UTP6_HUMAN U3 small nucleolar RNA-associated protein 6 homologOS=Homo sapiens OX=9606 GN=UTP6 PE=1 SV=2MAEIIQERIEDRLPELEQLERIGLFSHAEIKAIIKKASDLEYKIQRRTLFKEDFINYVQYEINLLELIQRRRTRIGYSFKKDEIENSIVHRVQGVFQRASAKWKDDVQLWLSYVAFCKKWATKTRLSKVFSAMLAIHSNKPALWIMAAKWEMEDRLSSESARQLFLRALRFHPECPKLYKEYFRMELMHAEKLRKEKEEFEKASMDVENPDYSEEILKGELAWIIYKNSVSIIKGAEFHVSLLSIAQLFDFAKDLQKEIYDDLQALHTDDPLTWDYVARRELEIESQTEEQPTTKQAKAVEVGRKEERCCAVYEEAVKTLPTEAMWKCYITFCLERFTKKSNSGFLRGKRLERTMTVFRKAHELKLLSECQYKQLSVSLLCYNFLREALEVAVAGTELFRDSGTMWQLKLQVLIESKSPDIAMLFEEAFVHLKPQVCLPLWISWAEWSEGAKSQEDTEAVFKKALLAVIGADSVTLKNKYLDWAYRSGGYKKARAVFKSLQESRPFSVDFFRKMIQFEKEQESCNMANIREYYERALREFGSADSDLWMDYMKEELNHPLGRPENCGQIYWRAMKMLQGESAEAFVAKHAMHQTGHL>sp|P63125|VPK25_HUMAN Endogenous retrovirus group K member 25 Proprotein OS=Homo sapiens OX=9606 GN=ERVK-25 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGVGTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPLYSPTSQKIMTKMGYIPGKGLGKNEDGIKIPVEAKINQKREGIGYPF>sp|Q8TAG5|VTM2A_HUMAN V-set and transmembrane domain-containing protein2A OS=Homo sapiens OX=9606 GN=VSTM2A PE=1 SV=3MMGIFLVYVGFVFFSVLYVQQGLSSQAKFTEFPRNVTATEGQNVEMSCAFQSGSASVYLEIQWWFLRGPEDLDPGAEGAGAQVELLPDRDPDSDGTKISTVKVQGNDISHKLQISKVRKKDEGLYECRVTDANYGELQEHKAQAYLKVNANSHARRMQAFEASPMWLQDMKPRKNVSAAIPSSIHGSANQRTHSTSSPQVVAKIPKQSPQSGARIATSHGLSVLLLVCGFVKGALL>sp|Q8TAG5-2|VTM2A_HUMAN Isoform 2 of V-set and transmembrane domain-containing protein 2A OS=Homo sapiens OX=9606 GN=VSTM2AMMGIFLVYVGFVFFSVLYVQQGLSSQAKFTEFPRNVTATEGQNVEMSCAFQSGSASVYLEIQWWFLRGPEDLDPGAEGAGAQVELLPDRDPDSDGTKISTVKVQGNDISHKLQISKVRKKDEGLYECRVTDANYGELQEHKAQAYLKVNANSHARRMQAFEASPMWLQDMKPRKNVSAAIPSSIHGSANQRTHSTSSPQVVAKIPKQSPQSGMETHFEPFILPLTNAPQKGQSYRVDRFMNGDF>sp|P56705|WNT4_HUMAN Protein Wnt-4 OS=Homo sapiens OX=9606 GN=WNT4 PE=1SV=4MSPRSCLRSLRLLVFAVFSAAASNWLYLAKLSSVGSISEEETCEKLKGLIQRQVQMCKRNLEVMDSVRRGAQLAIEECQYQFRNRRWNCSTLDSLPVFGKVVTQGTREAAFVYAISSAGVAFAVTRACSSGELEKCGCDRTVHGVSPQGFQWSGCSDNIAYGVAFSQSFVDVRERSKGASSSRALMNLHNNEAGRKAILTHMRVECKCHGVSGSCEVKTCWRAVPPFRQVGHALKEKFDGATEVEPRRVGSSRALVPRNAQFKPHTDEDLVYLEPSPDFCEQDMRSGVLGTRGRTCNKTSKAIDGCELLCCGRGFHTAQVELAERCSCKFHWCCFVKCRQCQRLVELHTCR>sp|P56705-2|WNT4_HUMAN Isoform 2 of Protein Wnt-4 OS=Homo sapiensOX=9606 GN=WNT4MCKRNLEVMDSVRRGAQLAIEECQYQFRNRRWNCSTLDSLPVFGKVVTQGTREAAFVYAISSAGVAFAVTRACSSGELEKCGCDRTVHGVSPQGFQWSGCSDNIAYGVAFSQSFVDVRERSKGASSSRALMNLHNNEAGRKAILTHMRVECKCHGVSGSCEVKTCWRAVPPFRQVGHALKEKFDGATEVEPRRVGSSRALVPRNAQFKPHTDEDLVYLEPSPDFCEQDMRSGVLGTRGRTCNKTSKAIDGCELLCCGRGFHTAQVELAERCSCKFHWCCFVKCRQCQRLVELHTCR>sp|O75083|WDR1_HUMAN WD repeat-containing protein 1 OS=Homo sapiensOX=9606 GN=WDR1 PE=1 SV=4MPYEIKKVFASLPQVERGVSKIIGGDPKGNNFLYTNGKCVILRNIDNPALADIYTEHAHQVVVAKYAPSGFYIASGDVSGKLRIWDTTQKEHLLKYEYQPFAGKIKDIAWTEDSKRIAVVGEGREKFGAVFLWDSGSSVGEITGHNKVINSVDIKQSRPYRLATGSDDNCAAFFEGPPFKFKFTIGDHSRFVNCVRFSPDGNRFATASADGQIYIYDGKTGEKVCALGGSKAHDGGIYAISWSPDSTHLLSASGDKTSKIWDVSVNSVVSTFPMGSTVLDQQLGCLWQKDHLLSVSLSGYINYLDRNNPSKPLHVIKGHSKSIQCLTVHKNGGKSYIYSGSHDGHINYWDSETGENDSFAGKGHTNQVSRMTVDESGQLISCSMDDTVRYTSLMLRDYSGQGVVKLDVQPKCVAVGPGGYAVVVCIGQIVLLKDQRKCFSIDNPGYEPEVVAVHPGGDTVAIGGVDGNVRLYSILGTTLKDEGKLLEAKGPVTDVAYSHDGAFLAVCDASKVVTVFSVADGYSENNVFYGHHAKIVCLAWSPDNEHFASGGMDMMVYVWTLSDPETRVKIQDAHRLHHVSSLAWLDEHTLVTTSHDASVKEWTITY>sp|O75083-3|WDR1_HUMAN Isoform 2 of WD repeat-containing protein 1OS=Homo sapiens OX=9606 GN=WDR1MPYEIKKVFASLPQVERGVSKIIGGDPKGNNFLYTNGKCVILRNIDDHSRFVNCVRFSPDGNRFATASADGQIYIYDGKTGEKVCALGGSKAHDGGIYAISWSPDSTHLLSASGDKTSKIWDVSVNSVVSTFPMGSTVLDQQLGCLWQKDHLLSVSLSGYINYLDRNNPSKPLHVIKGHSKSIQCLTVHKNGGKSYIYSGSHDGHINYWDSETGENDSFAGKGHTNQVSRMTVDESGQLISCSMDDTVRYTSLMLRDYSGQGVVKLDVQPKCVAVGPGGYAVVVCIGQIVLLKDQRKCFSIDNPGYEPEVVAVHPGGDTVAIGGVDGNVRLYSILGTTLKDEGKLLEAKGPVTDVAYSHDGAFLAVCDASKVVTVFSVADGYSENNVFYGHHAKIVCLAWSPDNEHFASGGMDMMVYVWTLSDPETRVKIQDAHRLHHVSSLAWLDEHTLVTTSHDASVKEWTITY>sp|Q6P2D8|XRRA1_HUMAN X-ray radiation resistance-associated protein 1OS=Homo sapiens OX=9606 GN=XRRA1 PE=2 SV=2MAFSGIYKLDDGKPYLNNCFPARNLLRVPEEGQGHWLVVQKGNLKKKPKGLVGAQAERRESLKATSFEFKGKKESRRENQVDLPGHILDQAFLLKHHCVRKPSDLCTINAKENDFKHFHSVIYINASENLLPLEAFHTFPALKELDLAFNGIKTIYVKYGDFKLLEFLDLSFNSLTVEAICDLGILPHLRVLLLTGNGLTSLPPNLAVAEQEASVTSLTSKRYILRFPALETLMLDDNRLSNPSCFASLAGLRRLKKLSLDENRIIRIPYLQQVQLYDESVDWNGGRGSPHKEPQFMLQSKPRMLEDSDEQLDYTVLPMKKDVDRTEVVFSSYPGFSTSETTKICSLPPIFEILPVKSLKARNQTLAPPFPELRYLSLAYNKIAKEDAVLPVALFPSLCEFVFHNNPLVAHTRGVPPLLKSFLQERLGIHLIRRKIVKPKHHVLMSRKESWKVKSEIPKVPKQPLVLHHPRMTTTKSPSKDMLEPEAELAEDLPTTKSTSVESEMPTENLEGHSPSCRTFVPLPPICSNSTVHSEETLSHLSDTTVRLSPERPSDEDSKSTESIFLTQVSELPSSVIHKDDLELKEKDQKKPPTAPREVKGTRRKLPTAFLPSKYHGYEELLTAKPDPAFIEPKGIQKNAQALQQMLKHPLLCHSSKPKLDTLQKPYVHKEKRAQRIPIPPPKKTRAQLLDDIFIRLRDPRNITEAPLGAVLHQWTERRLVNHKQYLEAKRLLKEFQARYRQLVSGSLRTVFGTTPLPMACPALSESQPKFGHFLEFMDEFCQEPTASDSQG>sp|Q6P2D8-2|XRRA1_HUMAN Isoform 2 of X-ray radiation resistance-associated protein 1 OS=Homo sapiens OX=9606 GN=XRRA1MAFSGIYKLDDGKPYLNNCFPARNLLRVPEEGQGHWLVVQKGNLKKKPKGLVGAQAERRESLKATSFEFKGKKESRRENQVDLPGHILDQAFLLKHHCVRKPSDLCTINAKENDFKHFHSVIYINASENLLPLEAFHTFPALKELDLAFNGIKTIYVKYGDFKLLEFLDLSFNSLTVEAICDLGILPHLRVLLLTGNGLTSLPPNLAVAEQEASVTSLTSKRYILRFPALETLMLDDNRLSNPSCFASLAGLRRLKKLSLDENRIIRIPYLQQVQLYDESVDWNGGRGSPHKEPQFMLQSKPRMLEDSDEQLDYTVLPMKKDVDRTGVPPLLKSFLQERLGIHLIRRKIVKPKHHVLMSRKESWKVKSEIPKVPKQPLVLHHPRMTTTKSPSKDMLEPEAELAEDLPTTKSTSVESEMPTENLEGHSPSCRTFVPLPPICSNSTVHSEETLSHLSDTTVRLSPERPSDEDSKSTESIFLTQVSELPSSVIHKDDLELKEKDQKKPPTAPREVKGTRRKLPTAFLPSKYHGYEELLTAKPDPAFIEPKGIQKNAQALQQMLKHPLLCHSSKPKLDTLQKPYVHKEKRVLSCTSGQNGGW>sp|Q6P2D8-3|XRRA1_HUMAN Isoform 3 of X-ray radiation resistance-associated protein 1 OS=Homo sapiens OX=9606 GN=XRRA1MAFSGIYKLDDGKPYLNNCFPARNLLRVPEEGQGHWLVVQKGNLKKKPKGLVGAQAERRESLKATSFEFKGKKESRRENQVDLPGHILDQAFLLKHHCVRKPSDLCTINAKENDFKHFHSVIYINASENLLPLEAFHTFPALKELDLAFNGIKTIYVKYGDFKLLEFLDLSFNSLTVEAICDLGILPHLRVLLLTGNGLTSLPPNLAVAEQEASVTSLTSKRYILRFPALETLMLDDNRLSNPSCFASLAGLRRLKKLSLDENRIIRIPYLQQVQLYDESVDWNGGRGSPHKEPQFMLQSKPRMLEDSDEQLDYTVLPMKKDVDRTTTKICSLPPIFEILPVKSLKARNQTLAPPFPELRYLSLAYNKIAKEDAVLPVALFPSLCEFVFHNNPLVAHTRGVPPLLKSFLQERLGIHLIRRKIVKPKHHVLMSRKESWKVKSEIPKVPKQPLVLHHPRMTTTKSPSKDMLEPEAELAEDLPTTKSTSVESEMPTENLEGHSPSCRTFVPLPPICSNSTVHSEETLSHLSDTTVRLSPERPSDEDSKSTESIFLTQVSELPSSVIHKDDLELKEKDQKKPPTAPREVKGTRRKLPTAFLPSKYHGYEELLTAKPDPAFIEPKGIQKNAQALQQMLKHPLLCHSSKPKLDTLQKPYVHKEKRAQRIPIPPPKKTRAQLLDDIFIRLRDPRNITEAPLGAVLHQWTERRLVNHKQYLEAKRLLKEFQARYRQLVSGSLRTVFGTTPLPMACPALSESQPKFGHFLEFMDEFCQEPTASDSQG>sp|Q6P2D8-4|XRRA1_HUMAN Isoform 4 of X-ray radiation resistance-associated protein 1 OS=Homo sapiens OX=9606 GN=XRRA1MAFSGIYKLDDGKPYLNNCFPARNLLRVPEEGQGHWLVVQKGNLKKKPKGLVGAQAERRESLKATSFEFKGKKESRRENQVDLPGHILDQAFLLKHHCVRKPSDLCTINAKENDFKHFHSVIYINASENLLPLEAFHTFPALKELDLAFNGIKTIYVKYGDFKLLEFLDLSFNSLTVEAICDLGILPHLRVLLLTGNGLTSLPPNLAVAEQEASVTSLTSKRYILRFPALETLMLDDNRLSNPSCFASLAGLRRLKKLSLDENRIIRIPYLQQVQLYDESVDWNGGRGSPHKEPQFMLQSKPRMLEDSDEQLDYTVLPMKKDVDRTIAKEDAVLPVALFPSLCEFVFHNNPLVAHTRGVPPLLKSFLQERLGIHLIRRKIVKPKHHVLMSRKESWKVKSEIPKVPKQPLVLHHPRMTTTKSPSKDMLEPEAELAEDLPTTKSTSVESEMPTENLEGHSPSCRTFVPLPPICSNSTVHSEETLSHLSDTTVRLSPERPSDEDSKSTESIFLTQVSELPSSVIHKDDLELKEKDQKKPPTAPREVKGTRRKLPTAFLPSKYHGYEELLTAKPDPAFIEPKGIQKNAQALQQMLKHPLLCHSSKPKLDTLQKPYVHKEKRAQRIPIPPPKKTRAQLLDDIFIRLRDPRNITEAPLGAVLHQWTERRLVNHKQYLEAKRLLKEFQARYRQLVSGSLRTVFGTTPLPMACPALSESQPKFGHFLEFMDEFCQEPTASDSQG>sp|Q6P2D8-5|XRRA1_HUMAN Isoform 5 of X-ray radiation resistance-associated protein 1 OS=Homo sapiens OX=9606 GN=XRRA1MLDDNRLSNPSCFASLAGLRRLKKLSLDENRIIRIPYLQQVQLYDESVDWNGGRGSPHKEPQFMLQSKPRMLEDSDEQLDYTVLPMKKDVDRTEVVFSSYPGFSTSEIAKEDAVLPVALFPSLCEFVFHNNPLVAHTRGVPPLLKSFLQERLGIHLIRRKIVKPKHHVLMSRKESWKVKSEIPKVPKQPLVLHHPRMTTTKSPSKDMLEPEAELAEDLPTTKSTSVESEMPTENLEGHSPSCRTFVPLPPICSNSTVHSEETLSHLSDTTVRLSPERPSDEDSKSTESIFLTQVSELPSSVIHKDDLELKEKDQKKPPTAPREVKGTRRKLPTAFLPSKYHGYEELLTAKPDPAFIEPKGIQKNAQALQQMLKHPLLCHSSKPKLDTLQKPYVHKEKRAQRIPIPPPKKTRAQLLDDIFIRLRDPRNITEAPLGAVLHQWTERRLVNHKQYLEAKRLLKEFQARYRQLVSGSLRTVFGTTPLPMACPALSESQPKFGHFLEFMDEFCQEPTASDSQG>sp|Q5JTN6|WDR38_HUMAN WD repeat-containing protein 38 OS=Homo sapiensOX=9606 GN=WDR38 PE=2 SV=1MNSGVPATLAVRRVKFFGQHGGEVNSSAFSPDGQMLLTGSEDGCVYGWETRSGQLLWRLGGHTGPVKFCRFSPDGHLFASASCDCTVRLWDVARAKCLRVLKGHQRSVETVSFSPDSRQLASGGWDKRVMLWDVQSGQMLRLLVGHRDSIQSSDFSPTVNCLATGSWDSTVHIWDLRMVTPAVSHQALEGHSANISCLCYSASGLLASGSWDKTIHIWKPTTSSLLIQLKGHVTWVKSIAFSPDELWLASAGYSRMVKVWDCNTGKCLETLKGVLDVAHTCAFTPDGKILVSGAADQTRRQISRTSKSPRDPQT>sp|Q9H0M0|WWP1_HUMAN NEDD4-like E3 ubiquitin-protein ligase WWP1 OS=Homosapiens OX=9606 GN=WWP1 PE=1 SV=1MATASPRSDTSNNHSGRLQLQVTVSSAKLKRKKNWFGTAIYTEVVVDGEITKTAKSSSSSNPKWDEQLTVNVTPQTTLEFQVWSHRTLKADALLGKATIDLKQALLIHNRKLERVKEQLKLSLENKNGIAQTGELTVVLDGLVIEQENITNCSSSPTIEIQENGDALHENGEPSARTTARLAVEGTNGIDNHVPTSTLVQNSCCSYVVNGDNTPSSPSQVAARPKNTPAPKPLASEPADDTVNGESSSFAPTDNASVTGTPVVSEENALSPNCTSTTVEDPPVQEILTSSENNECIPSTSAELESEARSILEPDTSNSRSSSAFEAAKSRQPDGCMDPVRQQSGNANTETLPSGWEQRKDPHGRTYYVDHNTRTTTWERPQPLPPGWERRVDDRRRVYYVDHNTRTTTWQRPTMESVRNFEQWQSQRNQLQGAMQQFNQRYLYSASMLAAENDPYGPLPPGWEKRVDSTDRVYFVNHNTKTTQWEDPRTQGLQNEEPLPEGWEIRYTREGVRYFVDHNTRTTTFKDPRNGKSSVTKGGPQIAYERGFRWKLAHFRYLCQSNALPSHVKINVSRQTLFEDSFQQIMALKPYDLRRRLYVIFRGEEGLDYGGLAREWFFLLSHEVLNPMYCLFEYAGKNNYCLQINPASTINPDHLSYFCFIGRFIAMALFHGKFIDTGFSLPFYKRMLSKKLTIKDLESIDTEFYNSLIWIRDNNIEECGLEMYFSVDMEILGKVTSHDLKLGGSNILVTEENKDEYIGLMTEWRFSRGVQEQTKAFLDGFNEVVPLQWLQYFDEKELEVMLCGMQEVDLADWQRNTVYRHYTRNSKQIIWFWQFVKETDNEVRMRLLQFVTGTCRLPLGGFAELMGSNGPQKFCIEKVGKDTWLPRSHTCFNRLDLPPYKSYEQLKEKLLFAIEETEGFGQE>sp|Q9H0M0-2|WWP1_HUMAN Isoform 2 of NEDD4-like E3 ubiquitin-proteinligase WWP1 OS=Homo sapiens OX=9606 GN=WWP1MATASPRSDTSNNHSGRLQLQVTVSSAKLKRKKNWFGTAIYTEVVVDGEITKTAKSSSSSNPKWDEQLTVNVTPQTTLEFQVWSHRTLKADALLGKATIDLKQALLIHNRKCWLLKARME>sp|Q9H0M0-3|WWP1_HUMAN Isoform 3 of NEDD4-like E3 ubiquitin-proteinligase WWP1 OS=Homo sapiens OX=9606 GN=WWP1MATASPRSDTSNNHSGRLQLQVTVSSAKLKRKKNWFGTAIYTEVVVDGEITKTAKSSSSSNPKWDEQLTVNVTPQTTLEFQVWSHRTLKADALLGKATIDLKQALLIHNRKFNGESSSFAPTDNASVTGTPVVSEENALSPNCTSTTVEDPPVQEILTSSENNECIPSTSAELESEARSILEPDTSNSRSSSAFEAAKSRQPDGCMDPVRQQSGNANTETLPSGWEQRKDPHGRTYYVDHNTRTTTWERPQPLPPGWERRVDDRRRVYYVDHNTRTTTWQRPTMESVRNFEQWQSQRNQLQGAMQQFNQRYLYSASMLAAENDPYGPLPPGWEKRVDSTDRVYFVNHNTKTTQWEDPRTQGLQNEEPLPEGWEIRYTREGVRYFVDHNTRTTTFKDPRNGKSSVTKGGPQIAYERGFRWKLAHFRYLCQSNALPSHVKINVSRQTLFEDSFQQIMALKPYDLRRRLYVIFRGEEGLDYGGLAREWFFLLSHEVLNPMYCLFEYAGKNNYCLQINPASTINPDHLSYFCFIGRFIAMALFHGKFIDTGFSLPFYKRMLSKKLTIKDLESIDTEFYNSLIWIRDNNIEECGLEMYFSVDMEILGKVTSHDLKLGGSNILVTEENKDEYIGLMTEWRFSRGVQEQTKAFLDGFNEVVPLQWLQYFDEKELEVMLCGMQEVDLADWQRNTVYRHYTRNSKQIIWFWQFVKETDNEVRMRLLQFVTGTCRLPLGGFAELMGSNGPQKFCIEKVGKDTWLPRSHTCFNRLDLPPYKSYEQLKEKLLFAIEETEGFGQE>sp|Q9H0M0-6|WWP1_HUMAN Isoform 6 of NEDD4-like E3 ubiquitin-proteinligase WWP1 OS=Homo sapiens OX=9606 GN=WWP1MATASPRSDTSNNHSGRLQLQVTVNGESSSFAPTDNASVTGTPVVSEENALSPNCTSTTVEDPPVQEILTSSENNECIPSTSAELESEARSILEPDTSNSRSSSAFEAAKSRQPDGCMDPVRQQSGNANTETLPSGWEQRKDPHGRTYYVDHNTRTTTWERPQPLPPGWERRVDDRRRVYYVDHNTRTTTWQRPTMESVRNFEQWQSQRNQLQGAMQQFNQRYLYSASMLAAENDPYGPLPPGWEKRVDSTDRVYFVNHNTKTTQWEDPRTQGLQNEEPLPEGWEIRYTREGVRYFVDHNTRTTTFKDPRNGKSSVTKGGPQIAYERGFRWKLAHFRYLCQSNALPSHVKINVSRQTLFEDSFQQIMALKPYDLRRRLYVIFRGEEGLDYGGLAREWFFLLSHEVLNPMYCLFEYAGKNNYCLQINPASTINPDHLSYFCFIGRFIAMALFHGKFIDTGFSLPFYKRMLSKKLTIKDLESIDTEFYNSLIWIRDNNIEECGLEMYFSVDMEILGKVTSHDLKLGGSNILVTEENKDEYIGLMTEWRFSRGVQEQTKAFLDGFNEVVPLQWLQYFDEKELEVMLCGMQEVDLADWQRNTVYRHYTRNSKQIIWFWQFVKETDNEVRMRLLQFVTGTCRLPLGGFAELMGSNGPQKFCIEKVGKDTWLPRSHTCFNRLDLPPYKSYEQLKEKLLFAIEETEGFGQE>sp|Q8NEZ2|VP37A_HUMAN Vacuolar protein sorting-associated protein 37AOS=Homo sapiens OX=9606 GN=VPS37A PE=1 SV=1MSWLFPLTKSASSSAAGSPGGLTSLQQQKQRLIESLRNSHSSIAEIQKDVEYRLPFTINNLTININILLPPQFPQEKPVISVYPPIRHHLMDKQGVYVTSPLVNNFTMHSDLGKIIQSLLDEFWKNPPVLAPTSTAFPYLYSNPSGMSPYASQGFPFLPPYPPQEANRSITSLSVADTVSSSTTSHTTAKPAAPSFGVLSNLPLPIPTVDASIPTSQNGFGYKMPDVPDAFPELSELSVSQLTDMNEQEEVLLEQFLTLPQLKQIITDKDDLVKSIEELARKNLLLEPSLEAKRQTVLDKYELLTQMKSTFEKKMQRQHELSESCSASALQARLKVAAHEAEEESDNIAEDFLEGKMEIDDFLSSFMEKRTICHCRRAKEEKLQQAIAMHSQFHAPL>sp|Q8NEZ2-2|VP37A_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 37A OS=Homo sapiens OX=9606 GN=VPS37AMSWLFPLTKSASSSAAGSPGGLTSLQQQKQRLIESLRNSHSRLLPPQFPQEKPVISVYPPIRHHLMDKQGVYVTSPLVNNFTMHSDLGKIIQSLLDEFWKNPPVLAPTSTAFPYLYSNPSGMSPYASQGFPFLPPYPPQEANRSITSLSVADTVSSSTTSHTTAKPAAPSFGVLSNLPLPIPTVDASIPTSQNGFGYKMPDVPDAFPELSELSVSQLTDMNEQEEVLLEQFLTLPQLKQIITDKDDLVKSIEELARKNLLLEPSLEAKRQTVLDKYELLTQMKSTFEKKMQRQHELSESCSASALQARLKVAAHEAEEESDNIAEDFLEGKMEIDDFLSSFMEKRTICHCRRAKEEKLQQAIAMHSQFHAPL>sp|Q8NEZ2-3|VP37A_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 37A OS=Homo sapiens OX=9606 GN=VPS37AMSWLFPLTKSASSSAAGSPGGLTSLQQQKQRLIESLRNSHSSIAEIQKDVEYRLPFTINNLTININILLPPQFPQEKPVISVYPPIRHHLMDKQGVYVTSPLVNNFTMHSDLGKIIQSLLDEFWKNPPVLAPTSTAFPYQLEIRWHHPHCLEISLARSSNSLGFSISSSISSTRSKQEYHFFICC>sp|O60281|ZN292_HUMAN Zinc finger protein 292 OS=Homo sapiens OX=9606GN=ZNF292 PE=1 SV=3MADEEAEQERLSCGEGGCVAELQRLGERLQELELQLRESRVPAVEAATDYCQQLCQTLLEYAEKWKTSEDPLPLLEVYTVAIQSYVKARPYLTSECENVALVLERLALSCVELLLCLPVELSDKQWEQFQTLVQVAHEKLMENGSCELHFLATLAQETGVWKNPVLCTILSQEPLDKDKVNEFLAFEGPILLDMRIKHLIKTNQLSQATALAKLCSDHPEIGIKGSFKQTYLVCLCTSSPNGKLIEEISEVDCKDALEMICNLESEGDEKSALVLCTAFLSRQLQQGDMYCAWELTLFWSKLQQRVEPSIQVYLERCRQLSLLTKTVYHIFFLIKVINSETEGAGLATCIELCVKALRLESTENTEVKISICKTISCLLPDDLEVKRACQLSEFLIEPTVDAYYAVEMLYNQPDQKYDEENLPIPNSLRCELLLVLKTQWPFDPEFWDWKTLKRQCLALMGEEASIVSSIDELNDSEVYEKVVDYQEESKETSMNGLSGGVGANSGLLKDIGDEKQKKREIKQLRERGFISARFRNWQAYMQYCVLCDKEFLGHRIVRHAQKHYKDGIYSCPICAKNFNSKETFVPHVTLHVKQSSKERLAAMKPLRRLGRPPKITTTNENQKTNTVAKQEQRPIKKNSLYSTDFIVFNDNDGSDDENDDKDKSYEPEVIPVQKPVPVNEFNCPVTFCKKGFKYFKNLIAHVKGHKDNEDAKRFLEMQSKKVICQYCRRHFVSVTHLNDHLQMHCGSKPYICIQMKCKAGFNSYAELLTHRKEHQVFRAKCMFPKCGRIFSEAYLLYDHEAQHYNTYTCKFTGCGKVYRSQGELEKHLDDHSTPPEKVLPPEAQLNSSGDSIQPSEVNQNTAENIEKERSMLPSENNIENSLLADRSDAWDKSKAESAVTKQDQISASELRQANGPLSNGLENPATTPLLQSSEVAVSIKVSLNQGIEDNFGKQENSTVEGSGEALVTDLHTPVEDTCNDLCHPGFQERKEQDCFNDAHVTQNSLVNSETLKIGDLTPQNLERQVNNLMTFSVQNQAAFQNNLPTSKFECGDNVKTSSNLYNLPLKTLESIAFVPPQSDLSNSLGTPSVPPKAPVQKFSCQVEGCTRTYNSSQSIGKHMKTAHPDQYAAFKMQRKSKKGQKANNLNTPNNGKFVYFLPSPVNSSNPFFTSQTKANGNPACSAQLQHVSPPIFPAHLASVSTPLLSSMESVINPNITSQDKNEQGGMLCSQMENLPSTALPAQMEDLTKTVLPLNIDSGSDPFLPLPAESSSMSLFPSPADSGTNSVFSQLENNTNHYSSQIEGNTNSSFLKGGNGENAVFPSQVNVANNFSSTNAQQSAPEKVKKDRGRGPNGKERKPKHNKRAKWPAIIRDGKFICSRCYRAFTNPRSLGGHLSKRSYCKPLDGAEIAQELLQSNGQPSLLASMILSTNAVNLQQPQQSTFNPEACFKDPSFLQLLAENRSPAFLPNTFPRSGVTNFNTSVSQEGSEIIKQALETAGIPSTFEGAEMLSHVSTGCVSDASQVNATVMPNPTVPPLLHTVCHPNTLLTNQNRTSNSKTSSIEECSSLPVFPTNDLLLKTVENGLCSSSFPNSGGPSQNFTSNSSRVSVISGPQNTRSSHLNKKGNSASKRRKKVAPPLIAPNASQNLVTSDLTTMGLIAKSVEIPTTNLHSNVIPTCEPQSLVENLTQKLNNVNNQLFMTDVKENFKTSLESHTVLAPLTLKTENGDSQMMALNSCTTSINSDLQISEDNVIQNFEKTLEIIKTAMNSQILEVKSGSQGAGETSQNAQINYNIQLPSVNTVQNNKLPDSSPFSSFISVMPTKSNIPQSEVSHKEDQIQEILEGLQKLKLENDLSTPASQCVLINTSVTLTPTPVKSTADITVIQPVSEMINIQFNDKVNKPFVCQNQGCNYSAMTKDALFKHYGKIHQYTPEMILEIKKNQLKFAPFKCVVPTCTKTFTRNSNLRAHCQLVHHFTTEEMVKLKIKRPYGRKSQSENVPASRSTQVKKQLAMTEENKKESQPALELRAETQNTHSNVAVIPEKQLVEKKSPDKTESSLQVITVTSEQCNTNALTNTQTKGRKIRRHKKEKEEKKRKKPVSQSLEFPTRYSPYRPYRCVHQGCFAAFTIQQNLILHYQAVHKSDLPAFSAEVEEESEAGKESEETETKQTLKEFRCQVSDCSRIFQAITGLIQHYMKLHEMTPEEIESMTASVDVGKFPCDQLECKSSFTTYLNYVVHLEADHGIGLRASKTEEDGVYKCDCEGCDRIYATRSNLLRHIFNKHNDKHKAHLIRPRRLTPGQENMSSKANQEKSKSKHRGTKHSRCGKEGIKMPKTKRKKKNNLENKNAKIVQIEENKPYSLKRGKHVYSIKARNDALSECTSRFVTQYPCMIKGCTSVVTSESNIIRHYKCHKLSKAFTSQHRNLLIVFKRCCNSQVKETSEQEGAKNDVKDSDTCVSESNDNSRTTATVSQKEVEKNEKDEMDELTELFITKLINEDSTSVETQANTSSNVSNDFQEDNLCQSERQKASNLKRVNKEKNVSQNKKRKVEKAEPASAAELSSVRKEEETAVAIQTIEEHPASFDWSSFKPMGFEVSFLKFLEESAVKQKKNTDKDHPNTGNKKGSHSNSRKNIDKTAVTSGNHVCPCKESETFVQFANPSQLQCSDNVKIVLDKNLKDCTELVLKQLQEMKPTVSLKKLEVHSNDPDMSVMKDISIGKATGRGQY>sp|O60281-2|ZN292_HUMAN Isoform 2 of Zinc finger protein 292 OS=Homosapiens OX=9606 GN=ZNF292MENGSCELHFLATLAQETGVWKNPVLCTILSQEPLDKDKAFEGPILLDMRIKHLIKTNQLSQATALAKLCSDHPEIGIKGSFKQTYLVCLCTSSPNGKLIEEISEVDCKDALEMICNLESEGDEKSALVLCTAFLSRQLQQGDMYCAWELTLFWSKLQQRVEPSIQVYLERCRQLSLLTKTVYHIFFLIKVINSETEGAGLATCIELCVKALRLESTENTEVKISICKTISCLLPDDLEVKRACQLSEFLIEPTVDAYYAVEMLYNQPDQKYDEENLPIPNSLRCELLLVLKTQWPFDPEFWDWKTLKRQCLALMGEEASIVSSIDELNDSEVYEKVVDYQEESKETSMNGLSGGVGANSGLLKDIGDEKQKKREIKQLRERGFISARFRNWQAYMQYCVLCDKEFLGHRIVRHAQKHYKDGIYSCPICAKNFNSKETFVPHVTLHVKQSSKERLAAMKPLRRLGRPPKITTTNENQKTNTVAKQEQRPIKKNSLYSTDFIVFNDNDGSDDENDDKDKSYEPEVIPVQKPVPVNEFNCPVTFCKKGFKYFKNLIAHVKGHKDNEDAKRFLEMQSKKVICQYCRRHFVSVTHLNDHLQMHCGSKPYICIQMKCKAGFNSYAELLTHRKEHQVFRAKCMFPKCGRIFSEAYLLYDHEAQHYNTYTCKFTGCGKVYRSQGELEKHLDDHSTPPEKVLPPEAQLNSSGDSIQPSEVNQNTAENIEKERSMLPSENNIENSLLADRSDAWDKSKAESAVTKQDQISASELRQANGPLSNGLENPATTPLLQSSEVAVSIKVSLNQGIEDNFGKQENSTVEGSGEALVTDLHTPVEDTCNDLCHPGFQERKEQDCFNDAHVTQNSLVNSETLKIGDLTPQNLERQVNNLMTFSVQNQAAFQNNLPTSKFECGDNVKTSSNLYNLPLKTLESIAFVPPQSDLSNSLGTPSVPPKAPVQKFSCQVEGCTRTYNSSQSIGKHMKTAHPDQYAAFKMQRKSKKGQKANNLNTPNNGKFVYFLPSPVNSSNPFFTSQTKANGNPACSAQLQHVSPPIFPAHLASVSTPLLSSMESVINPNITSQDKNEQGGMLCSQMENLPSTALPAQMEDLTKTVLPLNIDSGSDPFLPLPAESSSMSLFPSPADSGTNSVFSQLENNTNHYSSQIEGNTNSSFLKGGNGENAVFPSQVNVANNFSSTNAQQSAPEKVKKDRGRGPNGKERKPKHNKRAKWPAIIRDGKFICSRCYRAFTNPRSLGGHLSKRSYCKPLDGAEIAQELLQSNGQPSLLASMILSTNAVNLQQPQQSTFNPEACFKDPSFLQLLAENRSPAFLPNTFPRSGVTNFNTSVSQEGSEIIKQALETAGIPSTFEGAEMLSHVSTGCVSDASQVNATVMPNPTVPPLLHTVCHPNTLLTNQNRTSNSKTSSIEECSSLPVFPTNDLLLKTVENGLCSSSFPNSGGPSQNFTSNSSRVSVISGPQNTRSSHLNKKGNSASKRRKKVAPPLIAPNASQNLVTSDLTTMGLIAKSVEIPTTNLHSNVIPTCEPQSLVENLTQKLNNVNNQLFMTDVKENFKTSLESHTVLAPLTLKTENGDSQMMALNSCTTSINSDLQISEDNVIQNFEKTLEIIKTAMNSQILEVKSGSQGAGETSQNAQINYNIQLPSVNTVQNNKLPDSSPFSSFISVMPTKSNIPQSEVSHKEDQIQEILEGLQKLKLENDLSTPASQCVLINTSVTLTPTPVKSTADITVIQPVSEMINIQFNDKVNKPFVCQNQGCNYSAMTKDALFKHYGKIHQYTPEMILEIKKNQLKFAPFKCVVPTCTKTFTRNSNLRAHCQLVHHFTTEEMVKLKIKRPYGRKSQSENVPASRSTQVKKQLAMTEENKKESQPALELRAETQNTHSNVAVIPEKQLVEKKSPDKTESSLQVITVTSEQCNTNALTNTQTKGRKIRRHKKEKEEKKRKKPVSQSLEFPTRYSPYRPYRCVHQGCFAAFTIQQNLILHYQAVHKSDLPAFSAEVEEESEAGKESEETETKQTLKEFRCQVSDCSRIFQAITGLIQHYMKLHEMTPEEIESMTASVDVGKFPCDQLECKSSFTTYLNYVVHLEADHGIGLRASKTEEDGVYKCDCEGCDRIYATRSNLLRHIFNKHNDKHKAHLIRPRRLTPGQENMSSKANQEKSKSKHRGTKHSRCGKEGIKMPKTKRKKKNNLENKNAKIVQIEENKPYSLKRGKHVYSIKARNDALSECTSRFVTQYPCMIKGCTSVVTSESNIIRHYKCHKLSKAFTSQHRNLLIVFKRCCNSQVKETSEQEGAKNDVKDSDTCVSESNDNSRTTATVSQKEVEKNEKDEMDELTELFITKLINEDSTSVETQANTSSNVSNDFQEDNLCQSERQKASNLKRVNKEKNVSQNKKRKVEKAEPASAAELSSVRKEEETAVAIQTIEEHPASFDWSSFKPMGFEVSFLKFLEESAVKQKKNTDKDHPNTGNKKGSHSNSRKNIDKTAVTSGNHVCPCKESETFVQFANPSQLQCSDNVKIVLDKNLKDCTELVLKQLQEMKPTVSLKKLEVHSNDPDMSVMKDISIGKATGRGQY>sp|Q8N0Z9|VSI10_HUMAN V-set and immunoglobulin domain-containing protein10 OS=Homo sapiens OX=9606 GN=VSIG10 PE=2 SV=1MAAGGSAPEPRVLVCLGALLAGWVAVGLEAVVIGEVHENVTLHCGNISGLRGQVTWYRNNSEPVFLLSSNSSLRPAEPRFSLVDATSLHIESLSLGDEGIYTCQEILNVTQWFQVWLQVASGPYQIEVHIVATGTLPNGTLYAARGSQVDFSCNSSSRPPPVVEWWFQALNSSSESFGHNLTVNFFSLLLISPNLQGNYTCLALNQLSKRHRKVTTELLVYYPPPSAPQCWAQMASGSFMLQLTCRWDGGYPDPDFLWIEEPGGVIVGKSKLGVEMLSESQLSDGKKFKCVTSHIVGPESGASCMVQIRGPSLLSEPMKTCFTGGNVTLTCQVSGAYPPAKILWLRNLTQPEVIIQPSSRHLITQDGQNSTLTIHNCSQDLDEGYYICRADSPVGVREMEIWLSVKEPLNIGGIVGTIVSLLLLGLAIISGLLLHYSPVFCWKVGNTSRGQNMDDVMVLVDSEEEEEEEEEEEEDAAVGEQEGAREREELPKEIPKQDHIHRVTALVNGNIEQMGNGFQDLQDDSSEEQSDIVQEEDRPV>sp|Q8N0Z9-2|VSI10_HUMAN Isoform 2 of V-set and immunoglobulin domain-containing protein 10 OS=Homo sapiens OX=9606 GN=VSIG10MAAGGSAPEPRVLVCLGALLAGWVAVGLEAVVIGEVHENVTLHCGNISGLRGQVTWYRNNSEPVFLLSSNSSLRPAEPRFSLVDATSLHIESLSLGDEGIYTCQEILNVTQWFQVWLQVASGPYQIEVHIVATGTLPNGTLYAARGSQVDFSCNSSSRPPPVVEWWFQALNSSSESFGHNLTVNFFSLLLISPNLQGNYTCLALNQLSKRHRKVTTELLVYYPPPSAPQCWAQMASGSFMLQLTCRWDGGYPDPDFLWIEEPGGVIVGKSKLGVEMLSESQLSDGKKFKCVTSHIVGPESGASCMVQIRGPSLLSEPMKTCFTGGNVTLTCQVSGAYPPAKILWLRNLTQPEVIIQPSSRHLITQDGQNSTLTIHNCSQDLDEGYYICRADSPVGVREMEIWLSVKEPLNIGGIVGTIVSLLLLGLAIISGLLLHYSPVFCWKVGNTSRGQNMDDVMVLVDSEEEEEEEEEEDAAVGEQEGAREREELPKEIPKQDHIHRVTALVNGNIEQMGNGFQDLQDDSSEEQSDIVQEEDRPV>sp|Q4G0F5|VP26B_HUMAN Vacuolar protein sorting-associated protein 26BOS=Homo sapiens OX=9606 GN=VPS26B PE=1 SV=2MSFFGFGQSVEVEILLNDAESRKRAEHKTEDGKKEKYFLFYDGETVSGKVSLALKNPNKRLEHQGIKIEFIGQIELYYDRGNHHEFVSLVKDLARPGEITQSQAFDFEFTHVEKPYESYTGQNVKLRYFLRATISRRLNDVVKEMDIVVHTLSTYPELNSSIKMEVGIEDCLHIEFEYNKSKYHLKDVIVGKIYFLLVRIKIKHMEIDIIKRETTGTGPNVYHENDTIAKYEIMDGAPVRGESIPIRLFLAGYELTPTMRDINKKFSVRYYLNLVLIDEEERRYFKQQEVVLWRKGDIVRKSMSHQAAIASQRFEGTTSLGEVRTPSQLSDNNCRQ>sp|Q7Z5U6|WDR53_HUMAN WD repeat-containing protein 53 OS=Homo sapiensOX=9606 GN=WDR53 PE=2 SV=1MAVKWTGGHSSPVLCLNASKEGLLASGAEGGDLTAWGEDGTPLGHTRFQGADDVTSVLFSPSCPTKLYASHGETISVLDVRSLKDSLDHFHVNEEEINCLSLNQTENLLASADDSGAIKILDLENKKVIRSLKRHSNICSSVAFRPQRPQSLVSCGLDMQVMLWSLQKARPLWITNLQEDETEEMEGPQSPGQLLNPALAHSISVASCGNIFSCGAEDGKVRIFRVMGVKCEQELGFKGHTSGVSQVCFLPESYLLLTGGNDGKITLWDANSEVEKKQKSPTKRTHRKKPKRGTCTKQGGNTNASVTDEEEHGNILPKLNIEHGEKVNWLLGTKIKGHQNILVADQTSCISVYPLNEF>sp|Q9UIA9|XPO7_HUMAN Exportin-7 OS=Homo sapiens OX=9606 GN=XPO7 PE=1SV=3MADHVQSLAQLENLCKQLYETTDTTTRLQAEKALVEFTNSPDCLSKCQLLLERGSSSYSQLLAATCLTKLVSRTNNPLPLEQRIDIRNYVLNYLATRPKLATFVTQALIQLYARITKLGWFDCQKDDYVFRNAITDVTRFLQDSVEYCIIGVTILSQLTNEINQADTTHPLTKHRKIASSFRDSSLFDIFTLSCNLLKQASGKNLNLNDESQHGLLMQLLKLTHNCLNFDFIGTSTDESSDDLCTVQIPTSWRSAFLDSSTLQLFFDLYHSIPPSFSPLVLSCLVQIASVRRSLFNNAERAKFLSHLVDGVKRILENPQSLSDPNNYHEFCRLLARLKSNYQLGELVKVENYPEVIRLIANFTVTSLQHWEFAPNSVHYLLSLWQRLAASVPYVKATEPHMLETYTPEVTKAYITSRLESVHIILRDGLEDPLEDTGLVQQQLDQLSTIGRCEYEKTCALLVQLFDQSAQSYQELLQSASASPMDIAVQEGRLTWLVYIIGAVIGGRVSFASTDEQDAMDGELVCRVLQLMNLTDSRLAQAGNEKLELAMLSFFEQFRKIYIGDQVQKSSKLYRRLSEVLGLNDETMVLSVFIGKIITNLKYWGRCEPITSKTLQLLNDLSIGYSSVRKLVKLSAVQFMLNNHTSEHFSFLGINNQSNLTDMRCRTTFYTALGRLLMVDLGEDEDQYEQFMLPLTAAFEAVAQMFSTNSFNEQEAKRTLVGLVRDLRGIAFAFNAKTSFMMLFEWIYPSYMPILQRAIELWYHDPACTTPVLKLMAELVHNRSQRLQFDVSSPNGILLFRETSKMITMYGNRILTLGEVPKDQVYALKLKGISICFSMLKAALSGSYVNFGVFRLYGDDALDNALQTFIKLLLSIPHSDLLDYPKLSQSYYSLLEVLTQDHMNFIASLEPHVIMYILSSISEGLTALDTMVCTGCCSCLDHIVTYLFKQLSRSTKKRTTPLNQESDRFLHIMQQHPEMIQQMLSTVLNIIIFEDCRNQWSMSRPLLGLILLNEKYFSDLRNSIVNSQPPEKQQAMHLCFENLMEGIERNLLTKNRDRFTQNLSAFRREVNDSMKNSTYGVNSNDMMS>sp|Q96QU8|XPO6_HUMAN Exportin-6 OS=Homo sapiens OX=9606 GN=XPO6 PE=1SV=1MASEEASLRALESLMTEFFHDCTTNERKREIEELLNNFAQQIGAWRFCLYFLSSTRNDYVMMYSLTVFENLINKMWLGVPSQDKMEIRSCLPKLLLAHHKTLPYFIRNKLCKVIVDIGRQDWPMFYHDFFTNILQLIQSPVTTPLGLIMLKTTSEELACPREDLSVARKEELRKLLLDQVQTVLGLLTGILETVWDKHSVTAATPPPSPTSGESGDLLSNLLQSPSSAKLLNQPIPILDVESEYICSLALECLAHLFSWIPLSASITPSLLTTIFHFARFGCDIRARKMASVNGSSQNCVSGQERGRLGVLAMSCINELMSKNCVPMEFEEYLLRMFQQTFYLLQKITKDNNAHTVKSRLEELDESYIEKFTDFLRLFVSVHLRRIESYSQFPVVEFLTLLFKYTFHQPTHEGYFSCLDIWTLFLDYLTSKIKSRLGDKEAVLNRYEDALVLLLTEVLNRIQFRYNQAQLEELDDETLDDDQQTEWQRYLRQSLEVVAKVMELLPTHAFSTLFPVLQDNLEVYLGLQQFIVTSGSGHRLNITAENDCRRLHCSLRDLSSLLQAVGRLAEYFIGDVFAARFNDALTVVERLVKVTLYGSQIKLYNIETAVPSVLKPDLIDVHAQSLAALQAYSHWLAQYCSEVHRQNTQQFVTLISTTMDAITPLISTKVQDKLLLSACHLLVSLATTVRPVFLISIPAVQKVFNRITDASALRLVDKAQVLVCRALSNILLLPWPNLPENEQQWPVRSINHASLISALSRDYRNLKPSAVAPQRKMPLDDTKLIIHQTLSVLEDIVENISGESTKSRQICYQSLQESVQVSLALFPAFIHQSDVTDEMLSFFLTLFRGLRVQMGVPFTEQIIQTFLNMFTREQLAESILHEGSTGCRVVEKFLKILQVVVQEPGQVFKPFLPSIIALCMEQVYPIIAERPSPDVKAELFELLFRTLHHNWRYFFKSTVLASVQRGIAEEQMENEPQFSAIMQAFGQSFLQPDIHLFKQNLFYLETLNTKQKLYHKKIFRTAMLFQFVNVLLQVLVHKSHDLLQEEIGIAIYNMASVDFDGFFAAFLPEFLTSCDGVDANQKSVLGRNFKMDRDLPSFTQNVHRLVNDLRYYRLCNDSLPPGTVKL>sp|Q96QU8-2|XPO6_HUMAN Isoform 2 of Exportin-6 OS=Homo sapiens OX=9606GN=XPO6MTEFFHDCTTNERKREIEELLNNFAQQIGAWRFCLYFLSSTRNDYVMMYSLTVFENLINKMWLGVPSQDKMEIRSCLPKLLLAHHKTLPYFIRNKLCKVIVDIGRQDWPMFYHDFFTNILQLIQSPVTTPLGLIMLKTTSEELACPREDLSVARKEELRKLLLDQVQTVLGLLTGILETVWDKHSVTAATPPPSPTSGESGDLLSNLLQSPSSAKLLNQPIPILDVESEYICSLALECLAHLFSWIPLSASITPSLLTTIFHFARFGCDIRARKMASVNGSSQNCVSGQERGRLGVLAMSCINELMSKNCVPMEFEEYLLRMFQQTFYLLQKITKDNNAHTVKSRLEELDESYIEKFTDFLRLFVSVHLRRIESYSQFPVVEFLTLLFKYTFHQPTHEGYFSCLDIWTLFLDYLTSKIKSRLGDKEAVLNRYEDALVLLLTEVLNRIQFRYNQAQLEELDDETLDDDQQTEWQRYLRQSLEVVAKVMELLPTHAFSTLFPVLQDNLEVYLGLQQFIVTSGSGHRLNITAENDCRRLHCSLRDLSSLLQAVGRLAEYFIGDVFAARFNDALTVVERLVKVTLYGSQIKLYNIETAVPSVLKPDLIDVHAQSLAALQAYSHWLAQYCSEVHRQNTQQFVTLISTTMDAITPLISTKVQDKLLLSACHLLVSLATTVRPVFLISIPAVQKVFNRITDASALRLVDKAQVLVCRALSNILLLPWPNLPENEQQWPVRSINHASLISALSRDYRNLKPSAVAPQRKMPLDDTKLIIHQTLSVLEDIVENISGESTKSRQICYQSLQESVQVSLALFPAFIHQSDVTDEMLSFFLTLFRGLRVQMGVPFTEQIIQTFLNMFTREQLAESILHEGSTGCRVVEKFLKILQVVVQEPGQVFKPFLPSIIALCMEQVYPIIAERPSPDVKAELFELLFRTLHHNWRYFFKSTVLASVQRGIAEEQMENEPQFSAIMQAFGQSFLQPDIHLFKQNLFYLETLNTKQKLYHKKIFRTAMLFQFVNVLLQVLVHKSHDLLQEEIGIAIYNMASVDFDGFFAAFLPEFLTSCDGVDANQKSVLGRNFKMDRDLPSFTQNVHRLVNDLRYYRLCNDSLPPGTVKL>sp|Q6N043|Z280D_HUMAN Zinc finger protein 280D OS=Homo sapiens OX=9606GN=ZNF280D PE=1 SV=3MGDNPFQPKSNSKMAELFMECEEEELEPWQKKVKEVEDDDDDEPIFVGEISSSKPAISNILNRVNPSSYSRGLKNGALSRGITAAFKPTSQHYTNPTSNPVPASPINFHPESRSSDSSVIVQPFSKPGYITNSSRVVSNKSSELLFDLTQDTGLSHYQGGPTLSMAGMSESSFLSKRPSTSEVNNVNPKKPKPSESVSGANSSAVLPSVKSPSVTSSQAMLAKGTNTSSNQSKNGTPFPRACPKCNIHFNLLDPLKNHMKYCCPDMINNFLGLAKTEFSSTVNKNTTIDSEKGKLIMLVNDFYYGKHEGDVQEEQKTHTTFKCFSCLKILKNNIRFMNHMKHHLELEKQSSESWENHTTCQHCYRQFPTPFQLQCHIESTHTPHEFSTICKICELSFETEHVLLQHMKDNHKPGEMPYVCQVCNYRSSSFSDVETHFRTSHENTKNLLCPFCLKVIKIATPYMHHYMKHQKKGIHRCTKCRLQFLTCKEKMDHKTQHHRTFIKPKQLEGLPPGTKVTIRASVGPLQSGASPTPSISASASTLQLSPPRTKNITAKNPAKSNTSKPNTVKSNASKPNTSKPNGSKSKYKPKISNMQKKQSTLASSNKKSKVNTALRNLRYRRGIHKCIECCSEIKDFANHFPTYVHCSFCRYNTSCSKAYVNHMMSFHSNRPSKRFCIFKKHSENLRGITLVCLNCDFLSDVSGLDNMATHLSQHKTHTCQVVMQKVSVCIPTSEHLSELKKEAPAKEQEPVSKEIARPNMAERETETSNSESKQDKAASSKEKNGCNANSFEGSSTTKSEESITVSDKENETCLADQETGSKNIVSCDSNIGADKVEKKKQIQHVCQEMELKMCQSSENIILSDQIKDHNSSEARFSSKNIKDLRLASDNVSIDQFLRKRHEPESVSSDVSEQGSIHLEPLTPSEVLEYEATEILQKGSGDPSAKTDEVVSDQTDDIPGGNNPSTTEATVDLEDEKERS>sp|Q6N043-2|Z280D_HUMAN Isoform 2 of Zinc finger protein 280D OS=Homosapiens OX=9606 GN=ZNF280DMAELFMECEEEELEPWQKKVKEVEDDDDDEPIFVGEISSSKPAISNILNRVNPSSYSRGLKNGALSRGITAAFKPTSQHYTNPTSNPVPASPINFHPESRSSDSSVIVQPFSKPGYITNSSRVVSNKSSELLFDLTQDTGLSHYQGGPTLSMAGMSESSFLSKRPSTSEVNNVNPKKPKPSESVSGANSSAVLPSVKSPSVTSSQAMLAKGTNTSSNQSKNGTPFPRACPKCNIHFNLLDPLKNHMKYCCPDMINNFLGLAKTEFSSTVNKNTTIDSEKGKLIMLVNDFYYGKHEGDVQEEQKTHTTFKCFSCLKILKNNIRFMNHMKHHLELEKQSSESWENHTTCQHCYRQFPTPFQLQCHIESTHTPHEFSTICKICELSFETEHVLLQHMKDNHKPGEMPYVCQVCNYRSSSFSDVETHFRTSHENTKNLLCPFCLKVIKIATPYMHHYMKHQKKGIHRCTKCRLQFLTCKEKMDHKTQHHRTFIKPKQLEGLPPGTKVTIRASVGPLQSGASPTPSISASASTLQLSPPRTKNITAKNPAKSNTSKPNTVKSNASKPNTSKPNGSKSKYKPKISNMQKKQSTLASSNKKSKVNTALRNLRYRRGIHKCIECCSEIKDFANHFPTYVHCSFCRYNTSCSKAYVNHMMSFHSNRPSKRFCIFKKHSENLRGITLVCLNCDFLSDVSGLDNMATHLSQHKTHTCQVVMQKVSVCIPTSEHLSELKKEAPAKEQEPVSKEIARPNMAERETETSNSESKQDKAASSKEKNGCNANSFEGSSTTKSEESITVSDKENETCLADQETGSKNIVSCDSNIGADKVEKKKQIQHVCQEMELKMCQSSENIILSDQIKDHNSSEARFSSKNIKDLRLASDNVSIDQFLRKRHEPESVSSDVSEQGSIHLEPLTPSEVLEYEATEILQKGSGDPSAKTDEVVSDQTDDIPGGNNPSTTEATVDLEDEKERS>sp|Q6N043-3|Z280D_HUMAN Isoform 3 of Zinc finger protein 280D OS=Homosapiens OX=9606 GN=ZNF280DMGDNPFQPKSNSKMAELFMECEEEELEPWQKKVKEVEDDDDDEPIFVGEISSSKPAISNILNRVNPSSYSRGLKNGALSRGITAAFKPTSQHYTNPTSNPVPASPINFHPESRSSDSSVIVQPFSKPGYITNSSRVVSNKSSELLFDLTQDTGLSHYQGGPTLSMAGMSESSFLSKRPSTSEVNNVNPKKPKPSESVSGANSSAVLPSVKSPSVTSSQAMLAKGTNTSSNQSKNGTPFPRACPKCNIHFNLLDPLKNHMKYCCPDMINNFLGLAKTEFSSTVNKNTTIDSEKGKLIMLVNDFYYGKHEGDVQEEQKTHTTFKCFSCLKILKNNIRFMNHMKHHLELEKQSSESWENHTTCQHCYRQFPTPFQLQCHIESTHTPHEFSTICKICELSFETEHVLLQHMKDNHKPGEMPYVCQVCNYRSSSFSDVETHFRTSHENTKNLLCPFCLKVIKIATPYMHHYMKHQKKGIHRCTKCRLQFLTCKEKMDHKTQHHRTFIKPKQLEGLPPGTKVTIRASVGPLQSGASPTPSISASASTLQLSPPRTKNITAKNPAKSNTSKPNTVKSNASKPNTSIVGAFTNALSVVPK>sp|Q6N043-4|Z280D_HUMAN Isoform 4 of Zinc finger protein 280D OS=Homosapiens OX=9606 GN=ZNF280DMLVNDFYYGKHEGDVQEEQKTHTTFKCFSCLKILKNNIRFMNHMKHHLELEKQSSESWENHTTCQHCYRQFPTPFQLQCHIESTHTPHEFSTICKICELSFETEHVLLQHMKDNHKPGEMPYVCQVCNYRSSSFSDVETHFRTSHENTKNLLCPFCLKVIKIATPYMHHYMKHQKKGIHRCTKCRLQFLTCKEKMDHKTQHHRTFIKPKQLEGLPPGTKVTIRASVGPLQSGASPTPSISASASTLQLSPPRTKNITAKNPAKSNTSKPNTVKSNASKPNTSKPNGSKSKYKPKISNMQKKQSTLASSNKKSKVNTALRNLRYRRGIHKCIECCSEIKDFANHFPTYVHCSFCRYNTSCSKAYVNHMMSFHSNRPSKRFCIFKKHSENLRCVGGQIECDLPKLHKLVVEPRLTLGLLTPNF>sp|Q6N043-5|Z280D_HUMAN Isoform 5 of Zinc finger protein 280D OS=Homosapiens OX=9606 GN=ZNF280DMAERETETSNSESKQDKAASSKEKNGCNANSFEGSSTTKSEESITVSDKENETCLADQETGSKNIVSCDSNIGADKVEKKKQIQHVCQEMELKMCQSSENIILSDQIKDHNSSEARFSSKNIKDLRLASDNVSIDQFLRKRHEPESVSSDVSEQGSIHLEPLTPSEVLEYEATEILQKGSGDPSAKTDEVVSDQTDDIPGGNNPSTTEATVDLEDEKERS>sp|Q6N043-6|Z280D_HUMAN Isoform 6 of Zinc finger protein 280D OS=Homosapiens OX=9606 GN=ZNF280DMGDNPFQPKSNSKMAELFMECEEEELEPWQKKVKEVEDDDDDEPIFVGEISSSKPAISNILNRVNPSSYSRGLKNGALSRGITAAFKPTSQHYTNPTSNPVPASPINFHPESRSSDSSVIVQPFSKPVSVSKTIRPAQGSIGCCLSISTVPSYNSGLS>sp|Q9H9D4|ZN408_HUMAN Zinc finger protein 408 OS=Homo sapiens OX=9606GN=ZNF408 PE=1 SV=1MEEAEELLLEGKKALQLAREPRLGLDLGWNPSGEGCTQGLKDVPPEPTRDILALKSLPRGLALGPSLAKEQRLGVWCVGDPLQPGLLWGPLEEESASKEKGEGVKPRQEENLSLGPWGDVCACEQSSGWTSLVQRGRLESEGNVAPVRISERLHLQVYQLVLPGSELLLWPQPSSEGPSLTQPGLDKEAAVAVVTEVESAVQQEVASPGEDAAEPCIDPGSQSPSGIQAENMVSPGLKFPTQDRISKDSQPLGPLLQDGDVDEECPAQAQMPPELQSNSATQQDPDGSGASFSSSARGTQPHGYLAKKLHSPSDQCPPRAKTPEPGAQQSGFPTLSRSPPGPAGSSPKQGRRYRCGECGKAFLQLCHLKKHAFVHTGHKPFLCTECGKSYSSEESFKAHMLGHRGVRPFPCPQCDKAYGTQRDLKEHQVVHSGARPFACDQCGKAFARRPSLRLHRKTHQVPAAPAPCPCPVCGRPLANQGSLRNHMRLHTGEKPFLCPHCGRAFRQRGNLRGHLRLHTGERPYRCPHCADAFPQLPELRRHLISHTGEAHLCPVCGKALRDPHTLRAHERLHSGERPFPCPQCGRAYTLATKLRRHLKSHLEDKPYRCPTCGMGYTLPQSLRRHQLSHRPEAPCSPPSVPSAASEPTVVLLQAEPQLLDTHREEEVSPARDVVEVTISESQEKCFVVPEEPDAAPSLVLIHKDMGLGAWAEVVEVEMGT>sp|Q8NI36|WDR36_HUMAN WD repeat-containing protein 36 OS=Homo sapiensOX=9606 GN=WDR36 PE=1 SV=1MCCTEGSLRKRDSQRAPEAVLCLQLWQRTVPLDTLKGLGTCFPSGPELRGAGIAAAMERASERRTASALFAGFRALGLFSNDIPHVVRFSALKRRFYVTTCVGKSFHTYDVQKLSLVAVSNSVPQDICCMAADGRLVFAAYGNVFSAFARNKEIVHTFKGHKAEIHFLQPFGDHIISVDTDGILIIWHIYSEEEYLQLTFDKSVFKISAILHPSTYLNKILLGSEQGSLQLWNVKSNKLLYTFPGWKVGVTALQQAPAVDVVAIGLMSGQVIIHNIKFNETLMKFRQDWGPITSISFRTDGHPVMAAGSPCGHIGLWDLEDKKLINQMRNAHSTAIAGLTFLHREPLLVTNGADNALRIWIFDGPTGEGRLLRFRMGHSAPLTNIRYYGQNGQQILSASQDGTLQSFSTVHEKFNKSLGHGLINKKRVKRKGLQNTMSVRLPPITKFAAEEARESDWDGIIACHQGKLSCSTWNYQKSTIGAYFLKPKELKKDDITATAVDITSCGNFAVIGLSSGTVDVYNMQSGIHRGSFGKDQAHKGSVRGVAVDGLNQLTVTTGSEGLLKFWNFKNKILIHSVSLSSSPNIMLLHRDSGILGLALDDFSISVLDIETRKIVREFSGHQGQINDMAFSPDGRWLISAAMDCSIRTWDLPSGCLIDCFLLDSAPLNVSMSPTGDFLATSHVDHLGIYLWSNISLYSVVSLRPLPADYVPSIVMLPGTCQTQDVEVSEETVEPSDELIEYDSPEQLNEQLVTLSLLPESRWKNLLNLDVIKKKNKPKEPPKVPKSAPFFIPTIPGLVPRYAAPEQNNDPQQSKVVNLGVLAQKSDFCLKLEEGLVNNKYDTALNLLKESGPSGIETELRSLSPDCGGSIEVMQSFLKMIGMMLDRKRDFELAQAYLALFLKLHLKMLPSEPVLLEEITNLSSQVEENWTHLQSLFNQSMCILNYLKSALL>sp|P49754|VPS41_HUMAN Vacuolar protein sorting-associated protein 41homolog OS=Homo sapiens OX=9606 GN=VPS41 PE=1 SV=3MAEAEEQETGSLEESTDESEEEESEEEPKLKYERLSNGVTEILQKDAASCMTVHDKFLALGTHYGKVYLLDVQGNITQKFDVSPVKINQISLDESGEHMGVCSEDGKVQVFGLYSGEEFHETFDCPIKIIAVHPHFVRSSCKQFVTGGKKLLLFERSWMNRWKSAVLHEGEGNIRSVKWRGHLIAWANNMGVKIFDIISKQRITNVPRDDISLRPDMYPCSLCWKDNVTLIIGWGTSVKVCSVKERHASEMRDLPSRYVEIVSQFETEFYISGLAPLCDQLVVLSYVKEISEKTEREYCARPRLDIIQPLSETCEEISSDALTVRGFQENECRDYHLEYSEGESLFYIVSPRDVVVAKERDQDDHIDWLLEKKKYEEALMAAEISQKNIKRHKILDIGLAYINHLVERGDYDIAARKCQKILGKNAALWEYEVYKFKEIGQLKAISPYLPRGDPVLKPLIYEMILHEFLESDYEGFATLIREWPGDLYNNSVIVQAVRDHLKKDSQNKTLLKTLAELYTYDKNYGNALEIYLTLRHKDVFQLIHKHNLFSSIKDKIVLLMDFDSEKAVDMLLDNEDKISIKKVVEELEDRPELQHVYLHKLFKRDHHKGQRYHEKQISLYAEYDRPNLLPFLRDSTHCPLEKALEICQQRNFVEETVYLLSRMGNSRSALKMIMEELHDVDKAIEFAKEQDDGELWEDLILYSIDKPPFITGLLNNIGTHVDPILLIHRIKEGMEIPNLRDSLVKILQDYNLQILLREGCKKILVADSLSLLKKMHRTQMKGVLVDEENICESCLSPILPSDAAKPFSVVVFHCRHMFHKECLPMPSMNSAAQFCNICSAKNRGPGSAILEMKK>sp|P49754-2|VPS41_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 41 homolog OS=Homo sapiens OX=9606 GN=VPS41MAEAEEQETGSLEESTDESEEEESEEEPKLKYERLSNGVTEILQKDAASCMTVHDKFLALGTHYGKVYLLDVQGNITQKFDVSPVKINQISLDESGEHMGVCSEDGKVQVFGLYSGEEFHETFDCPIKIIAVHPHFVRSSCKQFVTGGKKLLLFERSWMNRWKSAVLHEGEGNIRSVKWRGHLIAWANNMGVKIFDIISKQRITNVPRDDISLRPDMYPCSLCWKDNVTLIIGWGTSVKVCSVKERHASEMRDLPSRYVEIVSQFETEFYISGLAPLCDQLVVLSYVKEISEKTEREYCARPRLDIIQPLSETCEEISSDALTVRGFQENECRDYHLEYSEGESLFYIVSPRDVVVAKERDQDDHIDWLLEKKKYEEALMAAEISQKNIKRHKILDIGLAYINHLVERGDYDIAARKCQKILGKNAALWEYEVYKFKEIGQLKAISPYLPRGDPVLKPLIYEMILHEFLESDYEGFATLIREWPGDLYNNSVIVQAVRDHLKKDSQNKTLLKTLAELYTYDKNYGNALEIYLTLRHKDVFQLIHKHNLFSSIKDKIVLLMDFDSEKAVDMLLDNEDKISIKKVVEELEDRPELQHVYLHKLFKRDHHKGQRYHEKQISLYAEYDRPNLLPFLRDSTHCPLEKALEICQQRNFVEETVYLLSRMGNSRSALKMIMEELHDVDKAIEFAKEQDDGELWEDLILYSIDKPPFITGLLNNIGTHVDPILLIHRIKEGMEIPNLRDSLVKILQDYNLQILLREGCKKILVADSLSLLKKMHRTQMKGVLVDEENICESCLSPILPSE>sp|P49754-3|VPS41_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 41 homolog OS=Homo sapiens OX=9606 GN=VPS41MAEAEEQETGSLEESTDESEEEESEEEPKLKYERLSNGVTEILQKDAASCMTVHDKFLALGTHYGKVYLLDVQGNITQKFDVVQVFGLYSGEEFHETFDCPIKIIAVHPHFVRSSCKQFVTGGKKLLLFERSWMNRWKSAVLHEGEGNIRSVKWRGHLIAWANNMGVKIFDIISKQRITNVPRDDISLRPDMYPCSLCWKDNVTLIIGWGTSVKVCSVKERHASEMRDLPSRYVEIVSQFETEFYISGLAPLCDQLVVLSYVKEISEKTEREYCARPRLDIIQPLSETCEEISSDALTVRGFQENECRDYHLEYSEGESLFYIVSPRDVVVAKERDQDDHIDWLLEKKKYEEALMAAEISQKNIKRHKILDIGLAYINHLVERGDYDIAARKCQKILGKNAALWEYEVYKFKEIGQLKAISPYLPRGDPVLKPLIYEMILHEFLESDYEGFATLIREWPGDLYNNSVIVQAVRDHLKKDSQNKTLLKTLAELYTYDKNYGNALEIYLTLRHKDVFQLIHKHNLFSSIKDKIVLLMDFDSEKAVDMLLDNEDKISIKKVVEELEDRPELQHVYLHKLFKRDHHKGQRYHEKQISLYAEYDRPNLLPFLRDSTHCPLEKALEICQQRNFVEETVYLLSRMGNSRSALKMIMEELHDVDKAIEFAKEQDDGELWEDLILYSIDKPPFITGLLNNIGTHVDPILLIHRIKEGMEIPNLRDSLVKILQDYNLQILLREGCKKILVADSLSLLKKMHRTQMKGVLVDEENICESCLSPILPSDAAKPFSVVVFHCRHMFHKECLPMPSMNSAAQFCNICSAKNRGPGSAILEMKK>sp|Q96MM3|ZFP42_HUMAN Zinc finger protein 42 homolog OS=Homo sapiensOX=9606 GN=ZFP42 PE=1 SV=2MSQQLKKRAKTRHQKGLGGRAPSGAKPRQGKSSQDLQAEIEPVSAVWALCDGYVCYEPGPQALGGDDFSDCYIECVIRGEFSQPILEEDSLFESLEYLKKGSEQQLSQKVFEASSLECSLEYMKKGVKKELPQKIVGENSLEYSEYMTGKKLPPGGIPGIDLSDPKQLAEFARKKPPINKEYDSLSAIACPQSGCTRKLRNRAALRKHLLIHGPRDHVCAECGKAFVESSKLKRHFLVHTGEKPFRCTFEGCGKRFSLDFNLRTHVRIHTGEKRFVCPFQGCNRRFIQSNNLKAHILTHANTNKNEQEGK>sp|Q8NEM1|ZN680_HUMAN Zinc finger protein 680 OS=Homo sapiens OX=9606GN=ZNF680 PE=1 SV=2MPGPPGSLEMGPLTFRDVAIEFSLEEWQCLDTAQRNLYRKVMFENYRNLVFLGIAVSKPHLITCLEQGKEPWNRKRQEMVAKPPVIYSHFTEDLWPEHSIKDSFQKVILRGYGKCGHENLQLRISCKSVDESKVFKEGYNELNQCLRTTQSKIFQCDKYVKVFHKFSNSNSHKKRNTGKKVFKCKECGKSFCMLSHLTQHIRIHTRENSYKCEECGKVLNWFSELIKHKGIHMGEKPYKCEECGKAFNQSSTLIKHKKIHIEEKPFKCEECGKAFSLFSILSKHKIIHTGDKPYKCDECHKAFNWFATLTNHKRIHTGEKPFKCEECGKDFNQFSNLTKHKKIHTGEKPYKCEECGKAFNQFANLTRHKKIHTGEKSYKCEECGKAFIQSSNLTEHMRIHTGEKPYKCEECGKAFNGCSSLTRHKRIHTRENTYKCEECGKGFTLFSTLTNHKVIHTGEKSYKCDECGNVFNWPATLANHKRIHAREKPYKCEECGKAFNRSSHLTRHKKIHTGEKLYKPEKCDNNFDNT>sp|Q8NEM1-2|ZN680_HUMAN Isoform 2 of Zinc finger protein 680 OS=Homosapiens OX=9606 GN=ZNF680MPGPPGSLEMGPLTFRDVAIEFSLEEWQCLDTAQRNLYRKVMFENYRNLVFLGIAVSKPHLITCLEQGKEPWNRKRQEMVAKPPESYCVAQADLELLVSSYLTALASLKMWDYRNNPLCQATM>sp|Q8NEZ3|WDR19_HUMAN WD repeat-containing protein 19 OS=Homo sapiensOX=9606 GN=WDR19 PE=1 SV=2MKRIFSLLEKTWLGAPIQFAWQKTSGNYLAVTGADYIVKIFDRHGQKRSEINLPGNCVAMDWDKDGDVLAVIAEKSSCIYLWDANTNKTSQLDNGMRDQMSFLLWSKVGSFLAVGTVKGNLLIYNHQTSRKIPVLGKHTKRITCGCWNAENLLALGGEDKMITVSNQEGDTIRQTQVRSEPSNMQFFLMKMDDRTSAAESMISVVLGKKTLFFLNLNEPDNPADLEFQQDFGNIVCYNWYGDGRIMIGFSCGHFVVISTHTGELGQEIFQARNHKDNLTSIAVSQTLNKVATCGDNCIKIQDLVDLKDMYVILNLDEENKGLGTLSWTDDGQLLALSTQRGSLHVFLTKLPILGDACSTRIAYLTSLLEVTVANPVEGELPITVSVDVEPNFVAVGLYHLAVGMNNRAWFYVLGENAVKKLKDMEYLGTVASICLHSDYAAALFEGKVQLHLIESEILDAQEERETRLFPAVDDKCRILCHALTSDFLIYGTDTGVVQYFYIEDWQFVNDYRHPVSVKKIFPDPNGTRLVFIDEKSDGFVYCPVNDATYEIPDFSPTIKGVLWENWPMDKGVFIAYDDDKVYTYVFHKDTIQGAKVILAGSTKVPFAHKPLLLYNGELTCQTQSGKVNNIYLSTHGFLSNLKDTGPDELRPMLAQNLMLKRFSDAWEMCRILNDEAAWNELARACLHHMEVEFAIRVYRRIGNVGIVMSLEQIKGIEDYNLLAGHLAMFTNDYNLAQDLYLASSCPIAALEMRRDLQHWDSALQLAKHLAPDQIPFISKEYAIQLEFAGDYVNALAHYEKGITGDNKEHDEACLAGVAQMSIRMGDIRRGVNQALKHPSRVLKRDCGAILENMKQFSEAAQLYEKGLYYDKAASVYIRSKNWAKVGDLLPHVSSPKIHLQYAKAKEADGRYKEAVVAYENAKQWQSVIRIYLDHLNNPEKAVNIVRETQSLDGAKMVARFFLQLGDYGSAIQFLVMSKCNNEAFTLAQQHNKMEIYADIIGSEDTTNEDYQSIALYFEGEKRYLQAGKFFLLCGQYSRALKHFLKCPSSEDNVAIEMAIETVGQAKDELLTNQLIDHLLGENDGMPKDAKYLFRLYMALKQYREAAQTAIIIAREEQSAGNYRNAHDVLFSMYAELKSQKIKIPSEMATNLMILHSYILVKIHVKNGDHMKGARMLIRVANNISKFPSHIVPILTSTVIECHRAGLKNSAFSFAAMLMRPEYRSKIDAKYKKKIEGMVRRPDISEIEEATTPCPFCKFLLPECELLCPGCKNSIPYCIATGRHMLKDDWTVCPHCDFPALYSELKIMLNTESTCPMCSERLNAAQLKKISDCTQYLRTEEEL>sp|Q8NEZ3-2|WDR19_HUMAN Isoform 2 of WD repeat-containing protein 19OS=Homo sapiens OX=9606 GN=WDR19MKRIFSLLEKTWLGAPIQFAWQKTSGNYLAVTGADYIVKIFDRHGQKRSEINLPGNCVAMDWDKDGDVLAVIAEKSSCIYLWDANTNKTSQLDNGMRDQMSFLLWSKVGSFLAVGTVKGNLLIYNHQTSRKIPVLGKHTKRITCGCWNAENLLALGGEDKMITVSNQEGDTIRQTQVRSEPSNMQFFLMKMDDRTSAAESMISVVLGKKTLFFLNLNEPDNPADLEFQQDFGNIVCYNWYGDGRIMIGFSCGHFVVISTHTGELGQEIFQARNHKDNLTSIAVSQTLNKVATCGDNCIKIQDLVDLKDMYVILNLDEENKGLGTLSWTDDGQLLALSTQRGSLHVFLTKLPILGDACSTRIAYLTSLLEVTVANPVEGELPITVSVDVEPNFVAVGLYHLAVGMNNRAWFYVLGENAVKKLKDMEYLGTVASICLHSDYAAALFEGKVQLHLKAKSWMLTKNVRLGFSQQWMISAVSYAMP>sp|Q9NQH7|XPP3_HUMAN Xaa-Pro aminopeptidase 3 OS=Homo sapiens OX=9606GN=XPNPEP3 PE=1 SV=1MPWLLSAPKLVPAVANVRGLSGCMLCSQRRYSLQPVPERRIPNRYLGQPSPFTHPHLLRPGEVTPGLSQVEYALRRHKLMSLIQKEAQGQSGTDQTVVVLSNPTYYMSNDIPYTFHQDNNFLYLCGFQEPDSILVLQSLPGKQLPSHKAILFVPRRDPSRELWDGPRSGTDGAIALTGVDEAYTLEEFQHLLPKMKAETNMVWYDWMRPSHAQLHSDYMQPLTEAKAKSKNKVRGVQQLIQRLRLIKSPAEIERMQIAGKLTSQAFIETMFTSKAPVEEAFLYAKFEFECRARGADILAYPPVVAGGNRSNTLHYVKNNQLIKDGEMVLLDGGCESSCYVSDITRTWPVNGRFTAPQAELYEAVLEIQRDCLALCFPGTSLENIYSMMLTLIGQKLKDLGIMKNIKENNAFKAARKYCPHHVGHYLGMDVHDTPDMPRSLPLQPGMVITIEPGIYIPEDDKDAPEKFRGLGVRIEDDVVVTQDSPLILSADCPKEMNDIEQICSQAS>sp|Q9NQH7-2|XPP3_HUMAN Isoform 2 of Xaa-Pro aminopeptidase 3 OS=Homosapiens OX=9606 GN=XPNPEP3MSLIQKEAQGQSGTDQTVVVLSNPTYYMSNDIPYTFHQDNNFLYLCGFQEPDSILVLQSLPGKQLPSHKAILFVPRRDPSRELWDGPRSGTDGAIALTGVDEAYTLEEFQHLLPKMKAETNMVWYDWMRPSHAQLHSDYMQPLTEAKAKSKNKVRGVQQLIQRLRLIKSPAEIERMQIAGKLTSQAFIETMFTSKAPVEEAFLYAKFEFECRARGADILAYPPVVAGGNRSNTLHYVKNNQLIKDGEMVLLDGGCESSCYVSDITRTWPVNGRFTAPQAELYEAVLEIQRDCLALCFPGTSLENIYSMMLTLIGQKLKDLGIMKNIKENNAFKAARKYCPHHVGHYLGMDVHDTPDMPRSLPLQPGMVITIEPGIYIPEDDKDAPEKFRGLGVRIEDDVVVTQDSPLILSADCPKEMNDIEQICSQAS>sp|Q9NQH7-3|XPP3_HUMAN Isoform 3 of Xaa-Pro aminopeptidase 3 OS=Homosapiens OX=9606 GN=XPNPEP3MPWLLSAPKLVPAVANVRGLSGCMLCSQRRYSLQPVPERRIPNRYLGQPSPFTHPHLLRPGEVTPGLSQVEYALRRHKLMSLIQKEAQGQSGTDQTVVVLSNPTYYMSNDIPYTFHQDNNFLYLCGFQEPDSILVLQSLPGKQLPSHKAILFVPRRDPSRELWDGPRSGTDGAIALTGVDEAYTLEEFQHLLPKMKAETNMVWYDWMRPSHAQLHSDYMQPLTEAKAKSKNKVRGVQQLIQRLRLIKSPAEIERMQIAGKLTSQRQGFSVLSRLVSNS>sp|Q9NQH7-4|XPP3_HUMAN Isoform 4 of Xaa-Pro aminopeptidase 3 OS=Homosapiens OX=9606 GN=XPNPEP3MLCSQRRYSLQPVPERRIPNRYLGQPSPFTHPHLLRPGEVTPGLSQVEYALRRHKLMSLIQKEAQGQSGTDQTVVVLSNPTYYMSNDIPYTFHQDNNFLYLCGFQEPDSILVLQSLPGKQLPSHKAILFVPRRDPSRELWDGPRSGTDGAIALTGVDEAYTLEEFQHLLPKMKAETNMVWYDWMRPSHAQLHSDYMQPLTEAKAKSKNKVRGVQQLIQRLRLIKSPAEIERMQIAGKLTSQAFIETMFTSKAPVEEAFLYAKFEFECRARGADILAYPPVVAGGNRSNTLHYVKNNQLIKDGEMVLLDGGCESSCYVSDITRTWPVNGRFTAPQAELYEAVLEIQRDCLALCFPGTSLENIYSMMLTLIGQKLKDLGIMKNIKENNAFKAARKYCPHHVGHYLGMDVHDTPDMPRSLPLQPGMVITIEPGIYIPEDDKDAPEKFRGLGVRIEDDVVVTQDSPLILSADCPKEMNDIEQICSQAS>sp|Q9NQH7-5|XPP3_HUMAN Isoform 5 of Xaa-Pro aminopeptidase 3 OS=Homosapiens OX=9606 GN=XPNPEP3MPWLLSAPKLVPAVANVRGLSGCMLCSQRRYSLQPVPERRIPNRYLGQPSPFTHPHLLRPGEVTPGLSQVEYALRRHKLMSLIQKEAQGQSGTDQTVVVLSNPTYYMSNDIPYTFHQDNNFLYLCGFQEPDSILVLQSLPGKQLPSHKAILFVPRRDPSRELWDGPRSGTDGAIALTGVDEAYTLEEFQHLLPKMKAETNMVWYDWMRPSHAQLHSDYMQPLTEAKAKSKNKVRGVQQLIQRLRLIKSPAEIERMQIAGKLTSQKSVLLARHGGSRLYSHHFGRPRLS>sp|P0DKX0|ZN728_HUMAN Zinc finger protein 728 OS=Homo sapiens OX=9606GN=ZNF728 PE=4 SV=1MGSLTFRDVAIQFSLEEWQCLDTAQQNLYRNVMLENYRNLVFLGIAAPKPDLIIFLEQGKEPWNMKRHELVKEPPVICSHFAQDLWPEQGREDSFQKVILRRYEKCGHENLQLKIGCTNVDECKVHKKGYNKLNQSLTTTQSKVFQCGKYANIFHKCSNSKRHKIRHTGKKLLKCKEYVRSFCMLSHLSQHKRIYTRENSYKSEEHGKAFNWSSALTYKRIHTGEKPCKCEECGKAFSKFSILTKHKVIHTGEKHYKCEECGKAFTRSSSLIEHKRSHAGEKPYKCEECGKAFSKASTLTAHKTIHAGEKPYKCEECGKAFNRSSNLMEHKRIHTGEKPCKCEECGKAFGNFSTLTKHKVIHTGEKPYKCEECGKAFSWPSSLTEHKRIHAGDKPYKCEECGKTFKWSSTLTKHKIIHTGEKPYKCEECGKAFTTFSSLTKHKVIHTGEKHYKCEECGKVFSWSSSLTTHKAIHAGEKLYKCEECGKAFKWSSNLMEHKRIHTGEKPYKCEECGKAFSKVANLTKHKVIHTGEKQYKCEECGKAFIWSSRLSEHKRIHTGEKPYKCEECGKAFSWVSVLNKHKKIHAGKKFYKCEECGKDFNQSSHLTTHKRIHTGGKTLQM>sp|Q9ULD5|ZN777_HUMAN Zinc finger protein 777 OS=Homo sapiens OX=9606GN=ZNF777 PE=1 SV=3MENQRSSPLSFPSVPQEETLRQAPAGLPRETLFQSRVLPPKEIPSLSPTIPRQGSLPQTSSAPKQETSGRMPHVLQKGPSLLCSAASEQETSLQGPLASQEGTQYPPPAAAEQEVSLLSHSPHHQEAPVHSPEAPEKDPLTLSPTVPETDMDPLLQSPVSQKDTPFQISSAVQKEQPLPTAEITRLAVWAAVQAVERKLEAQAMRLLTLEGRTGTNEKKIADCEKTAVEFANHLESKWVVLGTLLQEYGLLQRRLENMENLLKNRNFWILRLPPGSNGEVPKVPVTFDDVAVHFSEQEWGNLSEWQKELYKNVMRGNYESLVSMDYAISKPDLMSQMERGERPTMQEQEDSEEGETPTDPSAAHDGIVIKIEVQTNDEGSESLETPEPLMGQVEEHGFQDSELGDPCGEQPDLDMQEPENTLEESTEGSSEFSELKQMLVQQRNCTEGIVIKTEEQDEEEEEEEEDELPQHLQSLGQLSGRYEASMYQTPLPGEMSPEGEESPPPLQLGNPAVKRLAPSVHGERHLSENRGASSQQQRNRRGERPFTCMECGKSFRLKINLIIHQRNHIKEGPYECAECEISFRHKQQLTLHQRIHRVRGGCVSPERGPTFNPKHALKPRPKSPSSGSGGGGPKPYKCPECDSSFSHKSSLTKHQITHTGERPYTCPECKKSFRLHISLVIHQRVHAGKHEVSFICSLCGKSFSRPSHLLRHQRTHTGERPFKCPECEKSFSEKSKLTNHCRVHSRERPHACPECGKSFIRKHHLLEHRRIHTGERPYHCAECGKRFTQKHHLLEHQRAHTGERPYPCTHCAKCFRYKQSLKYHLRTHTGE>sp|Q9Y2L8|ZKSC5_HUMAN Zinc finger protein with KRAB and SCAN domains 5OS=Homo sapiens OX=9606 GN=ZKSCAN5 PE=1 SV=1MIMTESREVIDLDPPAETSQEQEDLFIVKVEEEDCTWMQEYNPPTFETFYQRFRHFQYHEASGPREALSQLRVLCCEWLRPELHTKEQILELLVLEQFLTILPEEFQPWVREHHPESGEEAVAVIENIQRELEERRQQIVACPDVLPRKMATPGAVQESCSPHPLTVDTQPEQAPQKPRLLEENALPVLQVPSLPLKDSQELTASLLSTGSQKLVKIEEVADVAVSFILEEWGHLDQSQKSLYRDDRKENYGSITSMGYESRDNMELIVKQISDDSESHWVAPEHTERSVPQDPDFAEVSDLKGMVQRWQVNPTVGKSRQNPSQKRDLDAITDISPKQSTHGERGHRCSDCGKFFLQASNFIQHRRIHTGEKPFKCGECGKSYNQRVHLTQHQRVHTGEKPYKCQVCGKAFRVSSHLVQHHSVHSGERPYGCNECGKNFGRHSHLIEHLKRHFREKSQRCSDKRSKNTKLSVKKKISEYSEADMELSGKTQRNVSQVQDFGEGCEFQGKLDRKQGIPMKEILGQPSSKRMNYSEVPYVHKKSSTGERPHKCNECGKSFIQSAHLIQHQRIHTGEKPFRCEECGKSYNQRVHLTQHQRVHTGEKPYTCPLCGKAFRVRSHLVQHQSVHSGERPFKCNECGKGFGRRSHLAGHLRLHSREKSHQCRECGEIFFQYVSLIEHQVLHMGQKNEKNGICEEAYSWNLTVIEDKKIELQEQPYQCDICGKAFGYSSDLIQHYRTHTAEKPYQCDICRENVGQCSHTKQHQKIYSSTKSHQCHECGRGFTLKSHLNQHQRIHTGEKPFQCKECGMNFSWSCSLFKHLRSHERTDPINTLSVEGSLL>sp|O95498|VNN2_HUMAN Vascular non-inflammatory molecule 2 OS=Homosapiens OX=9606 GN=VNN2 PE=1 SV=3MVTSSFPISVAVFALITLQVGTQDSFIAAVYEHAVILPNKTETPVSQEDALNLMNENIDILETAIKQAAEQGARIIVTPEDALYGWKFTRETVFPYLEDIPDPQVNWIPCQDPHRFGHTPVQARLSCLAKDNSIYVLANLGDKKPCNSRDSTCPPNGYFQYNTNVVYNTEGKLVARYHKYHLYSEPQFNVPEKPELVTFNTAFGRFGIFTCFDIFFYDPGVTLVKDFHVDTILFPTAWMNVLPLLTAIEFHSAWAMGMGVNLLVANTHHVSLNMTGSGIYAPNGPKVYHYDMKTELGKLLLSEVDSHPLSSLAYPTAVNWNAYATTIKPFPVQKNTFRGFISRDGFNFTELFENAGNLTVCQKELCCHLSYRMLQKEENEVYVLGAFTGLHGRRRREYWQVCTLLKCKTTNLTTCGRPVETASTRFEMFSLSGTFGTEYVFPEVLLTEIHLSPGKFEVLKDGRLVNKNGSSGPILTVSLFGRWYTKDSLYSSCGTSNSAITYLLIFILLMIIALQNIVML>sp|O95498-2|VNN2_HUMAN Isoform 2 of Vascular non-inflammatory molecule 2OS=Homo sapiens OX=9606 GN=VNN2MVTSSFPISVAVFALITLQVGTQDSFIAAVYEHAVILPNKTETPVSQEDALNLMNENIDILETAIKQAAEQGARIIVTPEDALYGWKFTRETVFPYLEDIPDPQVNWIPCQDPHRFGHTPVQARLSCLAKDNSIYVLANLGDKKPCNSRDSTCPPNGYFQYNTNVVYNTEGKLVARYHKVCTLLKCKTTNLTTCGRPVETASTRFEMFSLSGTFGTEYVFPEVLLTEIHLSPGKFEVLKDGRLVNKNGSSGPILTVSLFGRWYTKDSLYSSCGTSNSAITYLLIFILLMIIALQNIVML>sp|O95498-3|VNN2_HUMAN Isoform 3 of Vascular non-inflammatory molecule 2OS=Homo sapiens OX=9606 GN=VNN2MVTSSFPISVAVFALITLQVGTQDSFIAAVYEHAVILPNKTETPVSQEDALNLMNENIDILETAIKQAAEQGARIIVTPEDALYGWKFTRETVFPYLEDIPDPQVNWIPCQDPHRFGHTPVQARLSCLAKDNSIYVLANLGDKKPCNSRDSTCPPNGYFQYNTNVVYNTEGKLVARYHKETLQSVKRSFAVI>sp|O95498-4|VNN2_HUMAN Isoform 4 of Vascular non-inflammatory molecule 2OS=Homo sapiens OX=9606 GN=VNN2MVTSSFPISVAVFALITLQVGTQDSFIAAVYEHAVILPNKTETPVSQEDALNLMNENIDILETAIKQAAEQGARIIVTPEDALYGWKFTRETVFPYLEDIPDPQVNWIPCQDPHRFGHTPVQARLSCLAKDNSIYVLANLGDKKPCNSRDSTCPPNGYFQYNTNVVYNTEGKLVARYHKEVVFMHQMVPKCIIMT>sp|O95498-5|VNN2_HUMAN Isoform 5 of Vascular non-inflammatory molecule 2OS=Homo sapiens OX=9606 GN=VNN2MVTSSFPISVAVFALITLQVGTQDSFIAAVYEHAVILPNKTETPVSQEDALNLMNENIDILETAIKQAAEQGARIIVTPEDALYGWKFTRETVFPYLEDIPDPQVNWIPCQDPHRSAQC>sp|O95498-6|VNN2_HUMAN Isoform 6 of Vascular non-inflammatory molecule 2OS=Homo sapiens OX=9606 GN=VNN2MNENIDILETAIKQAAEQGARIIVTPEDALYGWKFTRETVFPYLEDIPDPQVNWIPCQDPHRFGHTPVQARLSCLAKDNSIYVLANLGDKKPCNSRDSTCPPNGYFQYNTNVVYNTEGKLVARYHKYHLYSEPQFNVPEKPELVTFNTAFGRFGIFTCFDIFFYDPGVTLVKDFHVDTILFPTAWMNVLPLLTAIEFHSAWAMGMGVNLLVANTHHVSLNMTGSGIYAPNGPKVYHYDMKTELGKLLLSEVDSHPLSSLAYPTAVNWNAYATTIKPFPVQKNTFRGFISRDGFNFTELFENAGNLTVCQKELCCHLSYRMLQKEENEVYVLGAFTGLHGRRRREYWQVCTLLKCKTTNLTTCGRPVETASTRFEMFSLSGTFGTEYVFPEVLLTEIHLSPGKFEVLKDGRLVNKNGSSGPILTVSLFGRWYTKDSLYSSCGTSNSAITYLLIFILLMIIALQNIVML>sp|P98170|XIAP_HUMAN E3 ubiquitin-protein ligase XIAP OS=Homo sapiensOX=9606 GN=XIAP PE=1 SV=2MTFNSFEGSKTCVPADINKEEEFVEEFNRLKTFANFPSGSPVSASTLARAGFLYTGEGDTVRCFSCHAAVDRWQYGDSAVGRHRKVSPNCRFINGFYLENSATQSTNSGIQNGQYKVENYLGSRDHFALDRPSETHADYLLRTGQVVDISDTIYPRNPAMYSEEARLKSFQNWPDYAHLTPRELASAGLYYTGIGDQVQCFCCGGKLKNWEPCDRAWSEHRRHFPNCFFVLGRNLNIRSESDAVSSDRNFPNSTNLPRNPSMADYEARIFTFGTWIYSVNKEQLARAGFYALGEGDKVKCFHCGGGLTDWKPSEDPWEQHAKWYPGCKYLLEQKGQEYINNIHLTHSLEECLVRTTEKTPSLTRRIDDTIFQNPMVQEAIRMGFSFKDIKKIMEEKIQISGSNYKSLEVLVADLVNAQKDSMQDESSQTSLQKEISTEEQLRRLQEEKLCKICMDRNIAIVFVPCGHLVTCKQCAEAVDKCPMCYTVITFKQKIFMS>sp|Q7L3S4|ZN771_HUMAN Zinc finger protein 771 OS=Homo sapiens OX=9606GN=ZNF771 PE=1 SV=1MPGEQQAEEEEEEEMQEEMVLLVKGEEDEGEEKYEVVKLKIPMDNKEVPGEAPAPSADPARPHACPDCGRAFARRSTLAKHARTHTGERPFGCTECGRRFSQKSALTKHGRTHTGERPYECPECDKRFSAASNLRQHRRRHTGEKPYACAHCGRRFAQSSNYAQHLRVHTGEKPYACPDCGRAFGGSSCLARHRRTHTGERPYACADCGTRFAQSSALAKHRRVHTGEKPHRCAVCGRRFGHRSNLAEHARTHTGERPYPCAECGRRFRLSSHFIRHRRAHMRRRLYICAGCGRDFKLPPGATAATATERCPECEGS>sp|Q68EA5|ZNF57_HUMAN Zinc finger protein 57 OS=Homo sapiens OX=9606GN=ZNF57 PE=1 SV=3MDSVVFEDVAVDFTLEEWALLDSAQRDLYRDVMLETFRNLASVDDGTQFKANGSVSLQDMYGQEKSKEQTIPNFTGNNSCAYTLEKNCEGYGTEDHHKNLRNHMVDRFCTHNEGNQYGEAIHQMPDLTLHKKVSAGEKPYECTKCRTVFTHLSSLKRHVKSHCGRKAPPGEECKQACICPSHLHSHGRTDTEEKPYKCQACGQTFQHPRYLSHHVKTHTAEKTYKCEQCRMAFNGFASFTRHVRTHTKDRPYKCQECGRAFIYPSTFQRHMTTHTGEKPYKCQHCGKAFTYPQAFQRHEKTHTGEKPYECKQCGKTFSWSETLRVHMRIHTGDKLYKCEHCGKAFTSSRSFQGHLRTHTGEKPYECKQCGKAFTWSSTFREHVRIHTQEQLYKCEQCGKAFTSSRSFRGHLRTHTGEKPYECKQCGKTFTWSSTFREHVRIHTQEQLHKCEHCGKAFTSSRAFQGHLRMHTGEKPYECKQCGKTFTWSSTLHNHVRMHTGEKPHKCKQCGMSFKWHSSFRNHLRMHTGQKSHECQSYSKAFSCQVILSKTSESTH>sp|Q9NUE0|ZDH18_HUMAN Palmitoyltransferase ZDHHC18 OS=Homo sapiensOX=9606 GN=ZDHHC18 PE=1 SV=2MKDCEYQQISPGAAPLPASPGARRPGPAASPTPGPGPAPPAAPAPPRWSSSGSGSGSGSGSLGRRPRRKWEVFPGRNRFYCGGRLMLAGHGGVFALTLLLILTTTGLFFVFDCPYLARKLTLAIPIIAAILFFFVMSCLLQTSFTDPGILPRATVCEAAALEKQIDNTGSSTYRPPPRTREVLINGQMVKLKYCFTCKMFRPPRTSHCSVCDNCVERFDHHCPWVGNCVGRRNYRFFYAFILSLSFLTAFIFACVVTHLTLRAQGSNFLSTLKETPASVLELVICFFSIWSILGLSGFHTYLVASNLTTNEDIKGSWSSKRGGEASVNPYSHKSIITNCCAVLCGPLPPSLIDRRGFVQSDTVLPSPIRSDEPACRAKPDASMVGGHP>sp|Q9NUE0-2|ZDH18_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC18OS=Homo sapiens OX=9606 GN=ZDHHC18MSCLLQTSFTDPGILPRATVCEAAALEKQIDNTGSSTYRPPPRTREVLINGQMVKLKYCFTCKMFRPPRTSHCSVCDNCVERFDHHCPWVGNCVGRRNYRFFYAFILSLSFLTAFIFACVVTHLTLRAQGSNFLSTLKETPASVLELVICFFSIWSILGLSGFHTYLVASNLTTNEDIKGSWSSKRGGEASVNPYSHKSIITNCCAVLCGPLPPSLIDRRGFVQSDTVLPSPIRSDEPACRAKPDASMVGGHP>sp|Q86SH2|ZAR1_HUMAN Zygote arrest protein 1 OS=Homo sapiens OX=9606GN=ZAR1 PE=1 SV=1MAALGDEVLDGYVFPACPPCSYRYPYPAATKGKGAAGGSWQQRGRGCLPASSPCSAGAASLSFPGCGRLTAAEYFDSYQRERLMALLAQVGPGLGPRARRAGSCDVAVQVSPRIDAAVQCSLGRRTLQRRARDPESPAGPGAEGTTGGGSFSQQPSRRGLEQGSPQNGAPRPMRFPRTVAVYSPLALRRLTAFLEGPGPAAGEQRSGASDGERGPPPARLQGPEEGEVWTKKAPRRPQSDDDGEAQAAVRASWEQPADGPELPPREAQEGEAAPRSALRSPGQPPSAGRARDGGDGREAAVAGEGPSPRSPELGKERLRFQFLEQKYGYYHCKDCNIRWESAYVWCVQGTNKVYFKQFCRTCQKSYNPYRVEDITCQSCKQTRCSCPVKLRHVDPKRPHRQDLCGRCKGKRLSCDSTFSFKYII>sp|Q9UJ78|ZMYM5_HUMAN Zinc finger MYM-type protein 5 OS=Homo sapiensOX=9606 GN=ZMYM5 PE=1 SV=4MEKCSVGGLELTEQTPALLGNMAMATSLMDIGDSFGHPACPLVSRSRNSPVEDDDDDDDVVFIESIQPPSISAPAIADQRNFIFASSKNEKPQGNYSVIPPSSRDLASQKGNISETIVIDDEEDIETNGGAEKKSSCFIEWGLPGTKNKTNDLDFSTSSLSRSKTKTGVRPFNPGRMNVAGDLFQNGEFATHHSPDSWISQSASFPSNQKQPGVDSLSPVALLRKQNFQPTAQQQLTKPAKITCANCKKPLQKGQTAYQRKGSAHLFCSTTCLSSFSHKRTQNTRSIICKKDASTKKANVILPVESSKSFQEFYSTSCLSPCENNWNLKKGVFNKSRCTICSKLAEIRHEVSVNNVTHKLCSNHCFNKYRLANGLIMNCCEHCGEYMPSKSTGNNILVIGGQQKRFCCQSCINEYKQMMETKSKKLTASENRKRNAFREENEKQLYGSSNTLLKKIEGIPEKKEKTSQLQLSVECGTDTLLIQENVNLPPSSTSTIADTFQEQLEEKNFEDSIVPVVLSADPGTWPRILNIKQRDTLVENVPPQVRNFNFPKDNTGRKFSETYYTRILPNGEKTTRSWLLYSTSKDSVFCLYCKLFGEGKNQLKNENGCKDWQHLSHILSKHEESEMHVNNSVKYSKLKSDLKKNKAIDAAEHRLYENEKNDGVLLLYT>sp|Q9UJ78-1|ZMYM5_HUMAN Isoform 1 of Zinc finger MYM-type protein 5OS=Homo sapiens OX=9606 GN=ZMYM5MEKCSVGGLELTEQTPALLGNMAMATSLMDIGDSFGHPACPLVSRSRNSPVEDDDDDDDVVFIESIQPPSISAPAIADQRNFIFASSKNEKPQGNYSVIPPSSRDLASQKGNISETIVIDDEEDIETNGGAEKKSSCFIEWGLPGTKNKTNDLDFSTSSLSRSKTKTGVRPFNPGRMNVAGDLFQNGEFATHHSPDSWISQSASFPSNQKQPGVDSLSPVALLRKQNFQPTAQQQLTKPAKITCANCKKPLQKGQTAYQRKGSAHLFCSTTCLSSFSHKRTQNTRSIICKKDASTKKANVILPVESSKSFQEFYSTSCLSPCENNWNLKKGVFNKSRCTICSKLAEVWIFIPKLLFRLTVIILTFKCYYVLFHLHNARVLDV>sp|Q9UJ78-2|ZMYM5_HUMAN Isoform 2 of Zinc finger MYM-type protein 5OS=Homo sapiens OX=9606 GN=ZMYM5MEKCSVGGLELTEQTPALLGNMAMATSLMDIGDSFGHPACPLVSRSRNSPVEDDDDDDDVVFIESIQPPSISAPAIADQRNFIFASSKNEKPQGNYSVIPPSSRDLASQKGNISETIVIDDEEDIETNGGAEKKSSCFIEWGLPGTKNKTNDLDFSTSSLSRSKTKTGVRPFNPGRMNVAGDLFQNGEFATHHSPEMHLQRRLMSFFQ>sp|Q9UJ78-3|ZMYM5_HUMAN Isoform 3 of Zinc finger MYM-type protein 5OS=Homo sapiens OX=9606 GN=ZMYM5MEKCSVGGLELTEQTPALLGNMAMATSLMDIGDSFGHPACPLVSRSRNSPVEDDDDDDDVVFIESIQPPSISAPAIADQRNFIFASSKNEKPQGNYSVIPPSSRDLASQKGNISETIVIDDEEDIETNGGAEKKSSCFIEWGLPGTKNKTNDLDFSTSSLSRSKVNAGMGNSGITTELTLKYIITNVTTLETGISSVNAGQDVNIIITYKTSL>sp|Q9UJ78-5|ZMYM5_HUMAN Isoform 5 of Zinc finger MYM-type protein 5OS=Homo sapiens OX=9606 GN=ZMYM5MNVAGDLFQNGEFATHHSPDSWISQSASFPSNQKQPGVDSLSPVALLRKQNFQPTAQQQLTKPAKITCANCKKPLQKGQTAYQRKGSAHLFCSTTCLSSFSHKRTQNTRSIICKKDASTKKANVILPVESSKSFQEFYSTSCLSPCENNWNLKKGVFNKSRCTICSKLAEIRHEVSVNNVTHKLCSNHCFNKYRLANGLIMNCCEHCGEYMPSKSTGNNILVIGGQQKRFCCQSCINEYKQMMETKSKKLTASENRKRNAFREENEKQLYGSSNTLLKKIEGIPEKKEKTSQLQLSVECGTDTLLIQENVNLPPSSTSTIADTFQEQLEEKNFEDSIVPVVLSADPGTWPRILNIKQRDTLVENVPPQVRNFNFPKDNTGRKFSETYYTRILPNGEKTTRSWLLYSTSKDSVFCLYCKLFGEGKNQLKNENGCKDWQHLSHILSKHEESEMHVNNSVKYSKLKSDLKKNKAIDAAEHRLYENEKNDGVLLLYT>sp|Q9H963|ZN702_HUMAN Putative zinc finger protein 702 OS=Homo sapiensOX=9606 GN=ZNF702P PE=5 SV=2MREKSFQCNESGKAFNCSSLLKKCQIIHLGEKKYKCDICGKVFNQKRYLAYHHRCHTGEKPYKCNQCGKTFSYKSSLVIHKAIHTGEKPHKCNECGKVFNQKAYLASHHRLHTGEKPYKCEECDKVFSR>sp|Q9C0F3|ZN436_HUMAN Zinc finger protein 436 OS=Homo sapiens OX=9606GN=ZNF436 PE=1 SV=2MAATLLMAGSQAPVTFEDMAMYLTREEWRPLDAAQRDLYRDVMQENYGNVVSLDFEIRSENEVNPKQEISEDVQFGTTSERPAENAEENPESEEGFESGDRSERQWGDLTAEEWVSYPLQPVTDLLVHKEVHTGIRYHICSHCGKAFSQISDLNRHQKTHTGDRPYKCYECGKGFSRSSHLIQHQRTHTGERPYDCNECGKSFGRSSHLIQHQTIHTGEKPHKCNECGKSFCRLSHLIQHQRTHSGEKPYECEECGKSFSRSSHLAQHQRTHTGEKPYECNECGRGFSERSDLIKHYRVHTGERPYKCDECGKNFSQNSDLVRHRRAHTGEKPYHCNECGENFSRISHLVQHQRTHTGEKPYECNACGKSFSRSSHLITHQKIHTGEKPYECNECWRSFGERSDLIKHQRTHTGEKPYECVQCGKGFTQSSNLITHQRVHTGEKPYECTECEKSFSRSSALIKHKRVHTD>sp|P17028|ZNF24_HUMAN Zinc finger protein 24 OS=Homo sapiens OX=9606GN=ZNF24 PE=1 SV=4MSAQSVEEDSILIIPTPDEEEKILRVKLEEDPDGEEGSSIPWNHLPDPEIFRQRFRQFGYQDSPGPREAVSQLRELCRLWLRPETHTKEQILELVVLEQFVAILPKELQTWVRDHHPENGEEAVTVLEDLESELDDPGQPVSLRRRKREVLVEDMVSQEEAQGLPSSELDAVENQLKWASWELHSLRHCDDDGRTENGALAPKQELPSALESHEVPGTLNMGVPQIFKYGETCFPKGRFERKRNPSRKKQHICDECGKHFSQGSALILHQRIHSGEKPYGCVECGKAFSRSSILVQHQRVHTGEKPYKCLECGKAFSQNSGLINHQRIHTGEKPYECVQCGKSYSQSSNLFRHQRRHNAEKLLNVVKV>sp|P17028-2|ZNF24_HUMAN Isoform 2 of Zinc finger protein 24 OS=Homosapiens OX=9606 GN=ZNF24MSAQSVEEDSILIIPTPDEEEKILRVKLEEDPDGEEGSSIPWNHLPDPEIFRQRFRQFGYQDSPGPREAVSQLRELCRLWLRPETHTKEQILELVVLEQFVAILPKELQTWVRDHHPENGEEAVTVLEDLESELDDPGQPVSLRRRKREVLVEDMVSQEEAQGLPSSELDAVENQLKWASWELHSLRHCVIIP>sp|Q17R98|ZN827_HUMAN Zinc finger protein 827 OS=Homo sapiens OX=9606GN=ZNF827 PE=1 SV=1MPRRKQEQPKRLPSHVSRQEEAEGELSEGEHWYGNSSETPSEASYGEVQENYKLSLEDRIQEQSTSPDTSLGSTTPSSHTLELVALDSEVLRDSLQCQDHLSPGVSSLCDDDPGSNKPLSSNLRRLLEAGSLKLDAAATANGRVESPVNVGSNLSFSPPSHHAQQLSVLARKLAEKQEQNDQYTPSNRFIWNQGKWLPNSTTTCSLSPDSAILKLKAAANAVLQDKSLTRTEETMRFESFSSPFSSQSASSTLAALSKKVSERSLTPGQEHPPPASSFLSLASMTSSAALLKEVAARAAGSLLAEKSSLLPEDPLPPPPSEKKPEKVTPPPPPPPPPPPPPPPQSLELLLLPVPKGRVSKPSNSASEEESGKPFQCPICGLVIKRKSYWKRHMVIHTGLKSHQCPLCPFRCARKDNLKSHMKVHQHQDRGETFQCQLCPFTSSRHFSLKLHMRCHQHFLRTEAKVKEEIPDPDVKGSPHLSDSACLGQQREGGGTELVGTMMTSNTPERTSQGGAGVSPLLVKEEPKEDNGLPTSFTLNAADRPANHTKLKDPSEYVANSASALFSQDISVKMASDFLMKLSAANQKEPMNLNFKVKEEPKEGESLSTTLPRSSYVFSPESEVSAPGVSEDALKPQEGKGSVLRRDVSVKAASELLMKLSAESYKETQMVKIKEEPMEVDIQDSHVSISPSRNVGYSTLIGREKTEPLQKMPEGRVPPERNLFSQDISVKMASELLFQLSEKVSKEHNHTKENTIRTTTSPFFSEDTFRQSPFTSNSKELLPSDSVLHGRISAPETEKIVLEAGNGLPSWKFNDQLFPCDVCGKVFGRQQTLSRHLSLHTEERKYKCHLCPYAAKCRANLNQHLTVHSVKLVSTDTEDIVSAVTSEGSDGKKHPYYYSCHVCGFETELNVQFVSHMSLHVDKEQWMFSICCTACDFVTMEEAEIKTHIGTKHTGEDRKTPSESNSPSSSSLSALSDSANSKDDSDGSQKNKGGNNLLVISVMPGSQPSLNSEEKPEKGFECVFCNFVCKTKNMFERHLQIHLITRMFECDVCHKFMKTPEQLLEHKKCHTVPTGGLNSGQW>sp|Q17R98-2|ZN827_HUMAN Isoform 2 of Zinc finger protein 827 OS=Homosapiens OX=9606 GN=ZNF827MPRRKQEQPKRLPSHVSRQEEAEGELSEGEHWYGNSSETPSEASYGEVQENYKLSLEDRIQEQSTSPDTSLGSTTPSSHTLELVALDSEVLRDSLQCQDHLSPGVSSLCDDDPGSNKPLSSNLRRLLEAGSLKLDAAATANGRVESPVNVGSNLSFSPPSHHAQQLSVLARKLAEKQEQNDQYTPSNRFIWNQGKWLPNSTTTCSLSPDSAILKLKAAANAVLQDKSLTRTEETMRFESFSSPFSSQSASSTLAALSKKVSERSLTPGQEHPPPASSFLSLASMTSSAALLKEVAARAAGSLLAEKSSLLPEDPLPPPPSEKKPEKVTPPPPPPPPPPPPPPPQSLELLLLPVPKGRVSKPSNSASEEESGKPFQCPICGLVIKRKSYWKRHMVIHTGLKSHQCPLCPFRCARKDNLKSHMKVHQHQDRGETFQCQLCPFTSSRHFSLKLHMRCHQHFLRTEAKVKEEIPDPDVKGSPHLSDSACLGQQREGGGTELVGTMMTSNTPERTSQGGAGVSPLLVKEEPKEDNGLPTSFTLNAADRPANHTKLKDPSEYVANSASALFSQDISVKMASDFLMKLSAANQKEPMNLNFKVKEEPKEGESLSTTLPRSSYVFSPESEVSAPGVSEDALKPQEGKGSVLRRDVSVKAASELLMKLSAESYKETQMVKIKEEPMEVDIQDSHVSISPSRNVGYSTLIGREKTEPLQKMPEGRVPPERNLFSQDISVKMASELLFQLSEKVSKEHNHTKENTIRTTTSPFFSEDTFRQSPFTSNSKELLPSDSVLHGRISAPETEKIVLEAGNGLPSWKFNDQLFPCDVCGKVFGRQQTLSRHLSLHTEERKYKCHLCPYAAKCRANLNQHLTVHSVKLVSTDTEDIVSAVTSEGSDGKKHPYYYSCHVCGFETELNVQFVSHMSLHVDKEQWMFSICCTACDFVTMEEAEIKTHIGTKHTGEDRKTPSESNSPSSSSLSALSDSANSKDDSDGSQKNKGGNNLLVISVMPGSQPSLNSEEKPEKGFECVFCNFVCKTKNMFERHLQIHLITRMFECDVCHKFMKTPEQLLEHKKCHTVPTGGLK>sp|Q17R98-3|ZN827_HUMAN Isoform 3 of Zinc finger protein 827 OS=Homosapiens OX=9606 GN=ZNF827MPRRKQEQPKRLPSHSEEESGKPFQCPICGLVIKRKSYWKRHMVIHTGLKSHQCPLCPFRCARKDNLKSHMKVHQHQDRGETFQCQLCPFTSSRHFSLKLHMRCHQHFLRTEAKVKEEIPDPDVKGSPHLSDSACLGQQREGGGTELVGTMMTSNTPERTSQGGAGVSPLLVKEEPKEDNGLPTSFTLNAADRPANHTKLKDPSEYVANSASALFSQDISVKMASDFLMKLSAANQKEPMNLNFKVKEEPKEGESLSTTLPRSSYVFSPESEVSAPGVSEDALKPQEGKGSVLRRDVSVKAASELLMKLSAESYKETQMVKIKEEPMEVDIQDSHVSISPSRNVGYSTLIGREKTEPLQKMPEGRVPPERNLFSQDISVKMASELLFQLSEKVSKEHNHTKENTIRTTTSPFFSEDTFRQSPFTSNSKELLPSDSVLHGRISAPETEKIVLEAGNGLPSWKFNDQLFPCDVCGKVFGRQQTLSRHLSLHTEERKYKCHLCPYAAKCRANLNQHLTVHSVKLVSTDTEDIVSAVTSEGSDGKKHPYYYSCHVCGFETELNVQFVSHMSLHVDKEQWMFSICCTACDFVTMEEAEIKTHIGTKHTGEDRKTPSESNSPSSSSLSALSDSANSKDDSDGSQKNKGGNNLLVISVMPGSQPSLNSEEKPEKGFECVFCNFVCKTKNMFERHLQIHLITRMFECDVCHKFMKTPEQLLEHKKCHTVPTGGLNSGQW>sp|Q96I27|ZN625_HUMAN Zinc finger protein 625 OS=Homo sapiens OX=9606GN=ZNF625 PE=1 SV=1MGERLLESKKDHQHGEILTQVPDDMLKKKTPRVKSCGEVSVGHASLNRHHRADTGHKPYEYQEYGQKPYKCTYCKKAFSDLPYFRTHEWAHTGGKPYDCEECGKSFISRSSIRRHRIMHSGDGPYKCNFCGKALMCLSLYLIHKRTHTGEKPYECKQCGKAFSHSGSLRIHERTHTGEKPYECSECGKAFHSSTCLHAHKITHTGEKPYECKQCGKAFVSFNSVRYHERTHTGEKPYECKQCGKAFRSASHLRTHGRTHTGEKPYECKQCGKAFGCASSVKIHERTHTGEKPCSSNTSKGQGEKIA>sp|Q96I27-2|ZN625_HUMAN Isoform 2 of Zinc finger protein 625 OS=Homosapiens OX=9606 GN=ZNF625MDSVVFEDVDVNFTQEEWALLDPSQKNLYRDVMQETFRNLASVGKKWKDQKIEDEYKNPRRNLRGLMGERLLESKKDHQHGEILTQVPDDMLKKKTPRVKSCGEVSVGHASLNRHHRADTGHKPYEYQEYGQKPYKCTYCKKAFSDLPYFRTHEWAHTGGKPYDCEECGKSFISRSSIRRHRIMHSGDGPYKCNFCGKALMCLSLYLIHKRTHTGEKPYECKQCGKAFSHSGSLRIHERTHTGEKPYECSECGKAFHSSTCLHAHKITHTGEKPYECKQCGKAFVSFNSVRYHERTHTGEKPYECKQCGKAFRSASHLRTHGRTHTGEKPYECKQCGKAFGCASSVKIHERTHTGEKPCSSNTSKGQGEKIA>sp|Q3SXZ3|ZN718_HUMAN Zinc finger protein 718 OS=Homo sapiens OX=9606GN=ZNF718 PE=2 SV=2MELLTFKDVAIEFSPEEWKCLDTSQQNLYRDVMLENYRNLVSLGVSISNPDLVTSLEQRKEPYNLKIHETAARPPAVCSHFTQNLWTVQGIEDSFHKLIPKGHEKRGHENLRKTCKSINECKVQKGGYNRINQCLLTTQKKTIQSNICVKVFHKFSNSNKDKIRYTGDKTFKCKECGKSFHVLSRLTQHKRIHTGENPYTCEECGKAFNWSSILTKHKRIHAREKFYKCEECGKGFTRSSHLTKHKRIHTGEKPYICEKCGKAFNQSSTLNLHKRIHSAQKYYKCEECGKAFKWSSSLNEHKRIHAGEKPFSCEECGNVFTTSSDFAKHKRIHTGEKPYKCEECGKSFNRSTTLTTHKRIHTGEKPYTCEECGKAFNWSSTLNVHKRIHSGKNPYKCEDCGKAFKVFANLHNHKKIHTGEKPYICKQCGKAFKQSSHLNKHKKIHTVDKPYKCKECGKAFKQYSNLPQHKRTHTGGKF>sp|Q3SXZ3-2|ZN718_HUMAN Isoform 2 of Zinc finger protein 718 OS=Homosapiens OX=9606 GN=ZNF718MLENYRNLVSLGVSISNPDLVTSLEQRKEPYNLKIHETAARPPAVCSHFTQNLWTVQGIEDSFHKLIPKGHEKRGHENLRKTCKSINECKVQKGGYNRINQCLLTTQKKTIQSNICVKVFHKFSNSNKDKIRYTGDKTFKCKECGKSFHVLSRLTQHKRIHTGENPYTCEECGKAFNWSSILTKHKRIHAREKFYKCEECGKGFTRSSHLTKHKRIHTGEKPYICEKCGKAFNQSSTLNLHKRIHSAQKYYKCEECGKAFKWSSSLNEHKRIHAGEKPFSCEECGNVFTTSSDFAKHKRIHTGEKPYKCEECGKSFNRSTTLTTHKRIHTGEKPYTCEECGKAFNWSSTLNVHKRIHSGKNPYKCEDCGKAFKVFANLHNHKKIHTGEKPYICKQCGKAFKQSSHLNKHKKIHTVDKPYKCKECGKAFKQYSNLPQHKRTHTGGKF>sp|Q9BRX5|PSF3_HUMAN DNA replication complex GINS protein PSF3 OS=Homosapiens OX=9606 GN=GINS3 PE=1 SV=1MSEAYFRVESGALGPEENFLSLDDILMSHEKLPVRTETAMPRLGAFFLERSAGAETDNAVPQGSKLELPLWLAKGLFDNKRRILSVELPKIYQEGWRTVFSADPNVVDLHKMGPHFYGFGSQLLHFDSPENADISQSLLQTFIGRFRRIMDSSQNAYNEDTSALVARLDEMERGLFQTGQKGLNDFQCWEKGQASQITASNLVQNYKKRKFTDMED>sp|Q9BRX5-2|PSF3_HUMAN Isoform 2 of DNA replication complex GINS proteinPSF3 OS=Homo sapiens OX=9606 GN=GINS3MSEAYFRVESGALGPEENFLSLDDILMSHEKLPVRTETAMPRLGAFFLERSAGAETDNAVPQTFIGRFRRIMDSSQNAYNEDTSALVARLDEMERGLFQTGQKGLNDFQCWEKGQASQITASNLVQNYKKRKFTDMED>sp|Q9BRX5-3|PSF3_HUMAN Isoform 3 of DNA replication complex GINS proteinPSF3 OS=Homo sapiens OX=9606 GN=GINS3MSEAYFRVESGALGPEENFLSLDDILMSHEKLPVRTETAMPRLGAFFLERSAGAETDNAVPQGFALLPRLECSGVIWLTAALTSQAPEILPPQPPMWLVLQGSKLELPLWLAKGLFDNKRRILSVELPKIYQEGWRTVFSADPNVVDLHKMGPHFYGFGSQLLHFDSPENADISQSLLQTFIGRFRRIMDSSQNAYNEDTSALVARLDEMERGLFQTGQKGLNDFQCWEKGQASQITASNLVQNYKKRKFTDMED>sp|P25105|PTAFR_HUMAN Platelet-activating factor receptor OS=Homosapiens OX=9606 GN=PTAFR PE=1 SV=1MEPHDSSHMDSEFRYTLFPIVYSIIFVLGVIANGYVLWVFARLYPCKKFNEIKIFMVNLTMADMLFLITLPLWIVYYQNQGNWILPKFLCNVAGCLFFINTYCSVAFLGVITYNRFQAVTRPIKTAQANTRKRGISLSLVIWVAIVGAASYFLILDSTNTVPDSAGSGNVTRCFEHYEKGSVPVLIIHIFIVFSFFLVFLIILFCNLVIIRTLLMQPVQQQRNAEVKRRALWMVCTVLAVFIICFVPHHVVQLPWTLAELGFQDSKFHQAINDAHQVTLCLLSTNCVLDPVIYCFLTKKFRKHLTEKFYSMRSSRKCSRATTDTVTEVVVPFNQIPGNSLKN>sp|P47914|RL29_HUMAN 60S ribosomal protein L29 OS=Homo sapiens OX=9606GN=RPL29 PE=1 SV=2MAKSKNHTTHNQSRKWHRNGIKKPRSQRYESLKGVDPKFLRNMRFAKKHNKKGLKKMQANNAKAMSARAEAIKALVKPKEVKPKIPKGVSRKLDRLAYIAHPKLGKRARARIAKGLRLCRPKAKAKAKAKDQTKAQAAAPASVPAQAPKRTQAPTKASE>sp|O95150|TNF15_HUMAN Tumor necrosis factor ligand superfamily member 15OS=Homo sapiens OX=9606 GN=TNFSF15 PE=1 SV=2MAEDLGLSFGETASVEMLPEHGSCRPKARSSSARWALTCCLVLLPFLAGLTTYLLVSQLRAQGEACVQFQALKGQEFAPSHQQVYAPLRADGDKPRAHLTVVRQTPTQHFKNQFPALHWEHELGLAFTKNRMNYTNKFLLIPESGDYFIYSQVTFRGMTSECSEIRQAGRPNKPDSITVVITKVTDSYPEPTQLLMGTKSVCEVGSNWFQPIYLGAMFSLQEGDKLMVNVSDISLVDYTKEDKTFFGAFLL>sp|O95150-2|TNF15_HUMAN Isoform 2 of Tumor necrosis factor ligandsuperfamily member 15 OS=Homo sapiens OX=9606 GN=TNFSF15MQLTKGRLHFSHPLSHTKHISPFVTDAPLRADGDKPRAHLTVVRQTPTQHFKNQFPALHWEHELGLAFTKNRMNYTNKFLLIPESGDYFIYSQVTFRGMTSECSEIRQAGRPNKPDSITVVITKVTDSYPEPTQLLMGTKSVCEVGSNWFQPIYLGAMFSLQEGDKLMVNVSDISLVDYTKEDKTFFGAFLL>sp|O95150-3|TNF15_HUMAN Isoform 3 of Tumor necrosis factor ligandsuperfamily member 15 OS=Homo sapiens OX=9606 GN=TNFSF15MRRFLSKVYSFPMRKLILFLVFPVVRQTPTQHFKNQFPALHWEHELGLAFTKNRMNYTNKFLLIPESGDYFIYSQVTFRGMTSECSEIRQAGRPNKPDSITVVITKVTDSYPEPTQLLMGTKSVCEVGSNWFQPIYLGAMFSLQEGDKLMVNVSDISLVDYTKEDKTFFGAFLL>sp|P48023|TNFL6_HUMAN Tumor necrosis factor ligand superfamily member 6OS=Homo sapiens OX=9606 GN=FASLG PE=1 SV=1MQQPFNYPYPQIYWVDSSASSPWAPPGTVLPCPTSVPRRPGQRRPPPPPPPPPLPPPPPPPPLPPLPLPPLKKRGNHSTGLCLLVMFFMVLVALVGLGLGMFQLFHLQKELAELRESTSQMHTASSLEKQIGHPSPPPEKKELRKVAHLTGKSNSRSMPLEWEDTYGIVLLSGVKYKKGGLVINETGLYFVYSKVYFRGQSCNNLPLSHKVYMRNSKYPQDLVMMEGKMMSYCTTGQMWARSSYLGAVFNLTSADHLYVNVSELSLVNFEESQTFFGLYKL>sp|P48023-2|TNFL6_HUMAN Isoform 2 of Tumor necrosis factor ligandsuperfamily member 6 OS=Homo sapiens OX=9606 GN=FASLGMQQPFNYPYPQIYWVDSSASSPWAPPGTVLPCPTSVPRRPGQRRPPPPPPPPPLPPPPPPPPLPPLPLPPLKKRGNHSTGLCLLVMFFMVLVALVGLGLGMFQLFHLQKELAELREATPVHPLKKRS>sp|P56180|TPTE_HUMAN Putative tyrosine-protein phosphatase TPTE OS=Homosapiens OX=9606 GN=TPTE PE=1 SV=3MNESPDPTDLAGVIIELGPNDSPQTSEFKGATEEAPAKESPHTSEFKGAARVSPISESVLARLSKFEVEDAENVASYDSKIKKIVHSIVSSFAFGLFGVFLVLLDVTLILADLIFTDSKLYIPLEYRSISLAIALFFLMDVLLRVFVERRQQYFSDLFNILDTAIIVILLLVDVVYIFFDIKLLRNIPRWTHLLRLLRLIILLRIFHLFHQKRQLEKLIRRRVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIKEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVVRIMIDDHNVPTLHQMVVFTKEVNEWMAQDLENIVAIHCKGGTDRTGTMVCAFLIASEICSTAKESLYYFGERRTDKTHSEKFQGVKTPSQKRYVAYFAQVKHLYNWNLPPRRILFIKHFIIYSIPRYVRDLKIQIEMEKKVVFSTISLGKCSVLDNITTDKILIDVFDGLPLYDDVKVQFFYSNLPTYYDNCSFYFWLHTSFIENNRLYLPKNELDNLHKQKARRIYPSDFAVEILFGEKMTSSDVVAGSD>sp|P56180-2|TPTE_HUMAN Isoform 2 of Putative tyrosine-proteinphosphatase TPTE OS=Homo sapiens OX=9606 GN=TPTEMNESPDPTDLAGVIIELGPNDSPQTSEFKGATEEAPAKESVLARLSKFEVEDAENVASYDSKIKKIVHSIVSSFAFGLFGVFLVLLDVTLILADLIFTDSKLYIPLEYRSISLAIALFFLMDVLLRVFVERRQQYFSDLFNILDTAIIVILLLVDVVYIFFDIKLLRNIPRWTHLLRLLRLIILLRIFHLFHQKRQLEKLIRRRVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIKEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVVRIMIDDHNVPTLHQMVVFTKEVNEWMAQDLENIVAIHCKGGTDRTGTMVCAFLIASEICSTAKESLYYFGERRTDKTHSEKFQGVKTPSQKRYVAYFAQVKHLYNWNLPPRRILFIKHFIIYSIPRYVRDLKIQIEMEKKVVFSTISLGKCSVLDNITTDKILIDVFDGLPLYDDVKVQFFYSNLPTYYDNCSFYFWLHTSFIENNRLYLPKNELDNLHKQKARRIYPSDFAVEILFGEKMTSSDVVAGSD>sp|P56180-3|TPTE_HUMAN Isoform 3 of Putative tyrosine-proteinphosphatase TPTE OS=Homo sapiens OX=9606 GN=TPTEMNESPDPTDLAGVIIELGPNDSPQTSEFKGATEEAPAKESSKIKKIVHSIVSSFAFGLFGVFLVLLDVTLILADLIFTDSKLYIPLEYRSISLAIALFFLMDVLLRVFVERRQQYFSDLFNILDTAIIVILLLVDVVYIFFDIKLLRNIPRWTHLLRLLRLIILLRIFHLFHQKRQLEKLIRRRVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIKEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVVRIMIDDHNVPTLHQMVVFTKEVNEWMAQDLENIVAIHCKGGTDRTGTMVCAFLIASEICSTAKESLYYFGERRTDKTHSEKFQGVKTPSQKRYVAYFAQVKHLYNWNLPPRRILFIKHFIIYSIPRYVRDLKIQIEMEKKVVFSTISLGKCSVLDNITTDKILIDVFDGLPLYDDVKVQFFYSNLPTYYDNCSFYFWLHTSFIENNRLYLPKNELDNLHKQKARRIYPSDFAVEILFGEKMTSSDVVAGSD>sp|P56180-4|TPTE_HUMAN Isoform 4 of Putative tyrosine-proteinphosphatase TPTE OS=Homo sapiens OX=9606 GN=TPTEMDVLLRVFVERRQQYFSDLFNILDTAIIVILLLVDVVYIFFDIKLLRNIPRWTHLLRLLRLIILLRIFHLFHQKRQLEKLIRRRVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIKEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVVRIMIDDHNVPTLHQMVVFTKEVNEWMAQDLENIVAIHCKGGTDRTGTMVCAFLIASEICSTAKESLYYFGERRTDKTHSEKFQGVKTPSQKRYVAYFAQVKHLYNWNLPPRRILFIKHFIIYSIPRYVRDLKIQIEMEKKVVFSTISLGKCSVLDNITTDKILIDVFDGLPLYDDVKVQFFYSNLPTYYDNCSFYFWLHTSFIENNRLYLPKNELDNLHKQKARRIYPSDFAVEILFGEKMTSSDVVAGSD>sp|P09493|TPM1_HUMAN Tropomyosin alpha-1 chain OS=Homo sapiens OX=9606GN=TPM1 PE=1 SV=2MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEDELVSLQKKLKGTEDELDKYSEALKDAQEKLELAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGKCAELEEELKTVTNNLKSLEAQAEKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEDELYAQKLKYKAISEELDHALNDMTSI>sp|P09493-2|TPM1_HUMAN Isoform 2 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MCRLRIFLRTASSEHLHERKLRETAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGQVRQLEEQLRIMDSDLESINAAEDKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEEKVAHAKEENLSMHQMLDQTLLELNNM>sp|P09493-3|TPM1_HUMAN Isoform 3 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEDELVSLQKKLKGTEDELDKYSEALKDAQEKLELAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGQVRQLEEQLRIMDQTLKALMAAEDKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEEKVAHAKEENLSMHQMLDQTLLELNNM>sp|P09493-4|TPM1_HUMAN Isoform 4 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEDELVSLQKKLKGTEDELDKYSEALKDAQEKLELAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGQVRQLEEQLRIMDQTLKALMAAEDKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEDELYAQKLKYKAISEELDHALNDMTSI>sp|P09493-5|TPM1_HUMAN Isoform 5 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MAGSSSLEAVRRKIRSLQEQADAAEERAGTLQRELDHERKLRETAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGKCAELEEELKTVTNNLKSLEAQAEKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEDQLYQQLEQNRRLTNELKLALNED>sp|P09493-6|TPM1_HUMAN Isoform 6 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEEDIAAKEKLLRVSEDERDRVLEELHKAEDSLLAAEEAAAKAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGKCAELEEELKTVTNNLKSLEAQAEKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEDELYAQKLKYKAISEELDHALNDMTSI>sp|P09493-7|TPM1_HUMAN Isoform 7 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEEDIAAKEKLLRVSEDERDRVLEELHKAEDSLLAAEEAAAKAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGKCAELEEELKTVTNNLKSLEAQAEKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEEKVAHAKEENLSMHQMLDQTLLELNNM>sp|P09493-8|TPM1_HUMAN Isoform 8 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEEDIAAKEKLLRVSEDERDRVLEELHKAEDSLLAAEEAAAKAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGQVRQLEEQLRIMDQTLKALMAAEDKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEEKVAHAKEENLSMHQMLDQTLLELNNM>sp|P09493-9|TPM1_HUMAN Isoform 9 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEDELVSLQKKLKGTEDELDKYSEALKDAQEKLELAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGKCAELEEELKTVTNNLKSLEAQAEKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEEKVAHAKEENLSMHQMLDQTLLELNNM>sp|P09493-10|TPM1_HUMAN Isoform 10 of Tropomyosin alpha-1 chain OS=Homosapiens OX=9606 GN=TPM1MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEDELVSLQKKLKGTEDELDKYSEALKDAQEKLELAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELSEGQVRQLEEQLRIMDQTLKALMAAEDKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKSIDDLEDELYAQKLKYKAISEELDHALNDMTSM>sp|P0DTU3|TRAR2_HUMAN T cell receptor alpha chain MC.7.G5 OS=Homosapiens OX=9606 GN=TRA PE=1 SV=1MACPGFLWALVISTCLEFSMAQTVTQSQPEMSVQEAETVTLSCTYDTSESDYYLFWYKQPPSRQMILVIRQEAYKQQNATENRFSVNFQKAAKSFSLKISDSQLGDAAMYFCAYRSAVNARLMFGDGTQLVVKPNIQNPDPAVYQLRDSKSSDKSVCLFTDFDSQTNVSQSKDSDVYITDKTVLDMRSMDFKSNSAVAWSNKSDFACANAFNNSIIPEDTFFPSPESSCDVKLVEKSFETDTNLNFQNLSVIGFRILLLKVAGFNLLMTLRLWSS>sp|A6NML5|TM212_HUMAN Transmembrane protein 212 OS=Homo sapiens OX=9606GN=TMEM212 PE=2 SV=2MKGLYQAAGRILVTLGILSVCSGVIAFFPVFSYKPWFTGWSVRIACPIWNGALAITTGVLLLLAYREWTQRYLGEATFTFVILSIMGCPLHFAIALESALLGPYCFYSFSGIAGTNYLGYAVTFPYPYAKFPLACVDPPHYEEYHLTLQALDLCLSFTLLCTSLTVFIKLSARLIQNGHINMQLPAGNPNPFSP>sp|Q96B77|TM186_HUMAN Transmembrane protein 186 OS=Homo sapiens OX=9606GN=TMEM186 PE=1 SV=1MAALLRAVRRFRGKAVWERPLHGLWCCSGQEDPKRWVGSSSPISKEKLPNAETEKFWMFYRFDAIRTFGFLSRLKLAQTALTVVALPPGYYLYSQGLLTLNTVCLMSGISGFALTMLCWMSYFLRRLVGILYLNESGTMLRVAHLNFWGWRQDTYCPMADVIPLTETKDRPQEMFVRIQRYSGKQTFYVTLRYGRILDRERFTQVFGVHQMLK>sp|O00300|TR11B_HUMAN Tumor necrosis factor receptor superfamily member11B OS=Homo sapiens OX=9606 GN=TNFRSF11B PE=1 SV=3MNNLLCCALVFLDISIKWTTQETFPPKYLHYDEETSHQLLCDKCPPGTYLKQHCTAKWKTVCAPCPDHYYTDSWHTSDECLYCSPVCKELQYVKQECNRTHNRVCECKEGRYLEIEFCLKHRSCPPGFGVVQAGTPERNTVCKRCPDGFFSNETSSKAPCRKHTNCSVFGLLLTQKGNATHDNICSGNSESTQKCGIDVTLCEEAFFRFAVPTKFTPNWLSVLVDNLPGTKVNAESVERIKRQHSSQEQTFQLLKLWKHQNKDQDIVKKIIQDIDLCENSVQRHIGHANLTFEQLRSLMESLPGKKVGAEDIEKTIKACKPSDQILKLLSLWRIKNGDQDTLKGLMHALKHSKTYHFPKTVTQSLKKTIRFLHSFTMYKLYQKLFLEMIGNQVQSVKISCL>sp|Q9NXH9|TRM1_HUMAN tRNA (guanine(26)-N(2))-dimethyltransferase OS=Homosapiens OX=9606 GN=TRMT1 PE=1 SV=1MQGSSLWLSLTFRSARVLSRARFFEWQSPGLPNTAAMENGTGPYGEERPREVQETTVTEGAAKIAFPSANEVFYNPVQEFNRDLTCAVITEFARIQLGAKGIQIKVPGEKDTQKVVVDLSEQEEEKVELKESENLASGDQPRTAAVGEICEEGLHVLEGLAASGLRSIRFALEVPGLRSVVANDASTRAVDLIRRNVQLNDVAHLVQPSQADARMLMYQHQRVSERFDVIDLDPYGSPATFLDAAVQAVSEGGLLCVTCTDMAVLAGNSGETCYSKYGAMALKSRACHEMALRIVLHSLDLRANCYQRFVVPLLSISADFYVRVFVRVFTGQAKVKASASKQALVFQCVGCGAFHLQRLGKASGVPSGRAKFSAACGPPVTPECEHCGQRHQLGGPMWAEPIHDLDFVGRVLEAVSANPGRFHTSERIRGVLSVITEELPDVPLYYTLDQLSSTIHCNTPSLLQLRSALLHADFRVSLSHACKNAVKTDAPASALWDIMRCWEKECPVKRERLSETSPAFRILSVEPRLQANFTIREDANPSSRQRGLKRFQANPEANWGPRPRARPGGKAADEAMEERRRLLQNKRKEPPEDVAQRAARLKTFPCKRFKEGTCQRGDQCCYSHSPPTPRVSADAAPDCPETSNQTPPGPGAAAGPGID>sp|Q9NXH9-2|TRM1_HUMAN Isoform 2 of tRNA (guanine(26)-N(2))-dimethyltransferase OS=Homo sapiens OX=9606 GN=TRMT1MQGSSLWLSLTFRSARVLSRARFFEWQSPGLPNTAAMENGTGPYGEERPREVQETTVTEGAAKIAFPSANEVFYNPVQEFNRDLTCAVITEFARIQLGAKGIQIKVPGEKDTQKVVVDLSEQEEEKVELKESENLASGDQPRTAAVGEICEEGLHVLEGLAASGLRSIRFALEVPGLRSVVANDASTRAVDLIRRNVQLNDVAHLVQPSQADARMLMYQHQRVSERFDVIDLDPYGSPATFLDAAVQAVSEGGLLCVTCTDMAVLAGNSGETCYSKYGAMALKSRACHEMALRIVLHSLDLRANCYQRFVVPLLSISADFYVRVFVRVFTGQAKVKASARAKFSAACGPPVTPECEHCGQRHQLGGPMWAEPIHDLDFVGRVLEAVSANPGRFHTSERIRGVLSVITEELPDVPLYYTLDQLSSTIHCNTPSLLQLRSALLHADFRVSLSHACKNAVKTDAPASALWDIMRCWEKECPVKRERLSETSPAFRILSVEPRLQANFTIREDANPSSRQRGLKRFQANPEANWGPRPRARPGGKAADEAMEERRRLLQNKRKEPPEDVAQRAARLKTFPCKRFKEGTCQRGDQCCYSHSPPTPRVSADAAPDCPETSNQTPPGPGAAAGPGID>sp|Q9UPQ4|TRI35_HUMAN E3 ubiquitin-protein ligase TRIM35 OS=Homo sapiensOX=9606 GN=TRIM35 PE=1 SV=2MERSPDVSPGPSRSFKEELLCAVCYDPFRDAVTLRCGHNFCRGCVSRCWEVQVSPTCPVCKDRASPADLRTNHTLNNLVEKLLREEAEGARWTSYRFSRVCRLHRGQLSLFCLEDKELLCCSCQADPRHQGHRVQPVKDTAHDFRAKCRNMEHALREKAKAFWAMRRSYEAIAKHNQVEAAWLEGRIRQEFDKLREFLRVEEQAILDAMAEETRQKQLLADEKMKQLTEETEVLAHEIERLQMEMKEDDVSFLMKHKSRKRRLFCTMEPEPVQPGMLIDVCKYLGSLQYRVWKKMLASVESVPFSFDPNTAAGWLSVSDDLTSVTNHGYRVQVENPERFSSAPCLLGSRVFSQGSHAWEVALGGLQSWRVGVVRVRQDSGAEGHSHSCYHDTRSGFWYVCRTQGVEGDHCVTSDPATSPLVLAIPRRLRVELECEEGELSFYDAERHCHLYTFHARFGEVRPYFYLGGARGAGPPEPLRICPLHISVKEELDG>sp|Q9UPQ4-2|TRI35_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM35OS=Homo sapiens OX=9606 GN=TRIM35MERSPDVSPGPSRSFKEELLCAVCYDPFRDAVTLRCGHNFCRGCVSRCWEVQVSPTCPVCKDRASPADLRTNHTLNNLVEKLLREEAEGARWTSYRFSRVCRLHRGQLSLFCLEDKELLCCSCQADPRHQGHRVQPVKDTAHDFRVRSLIAEERRNFLPTHQWIVTKTRLQTSSPNLQSRRQGQVQEHGACTAGEGQGLLGHAALLDAMAEETRQKQLLADEKMKQLTEETEVLAHEIERLQMEMKEDDVSFLMKHKSRKRRLFCTMEPEPVQPGMLIDVCKYLGSLQYRVWKKMLASVESVPFSFDPNTAAGWLSVSDDLTSVTNHGYRVQVENPERFSSAPCLLGSRVFSQGSHAWEVALGGLQSWRVGVVRVRQDSGAEGHSHSCYHDTRSGFWYVCRTQGVEGDHCVTSDPATSPLVLAIPRRLRVELECEEGELSFYDAERHCHLYTFHARFGEVRPYFYLGGARGAGPPEPLRICPLHISVKEELDG>sp|Q5T0D9|TPRGL_HUMAN Tumor protein p63-regulated gene 1-like proteinOS=Homo sapiens OX=9606 GN=TPRG1L PE=1 SV=1MLQLRDSVDSAGTSPTAVLAAGEEVGAGGGPGGGRPGAGTPLRQTLWPLSIHDPTRRARVKEYFVFRPGSIEQAVEEIRVVVRPVEDGEIQGVWLLTEVDHWNNEKERLVLVTEQSLLICKYDFISLQCQQVVRIALNAVDTISYGEFQFPPKSLNKREGFGIRIQWDKQSRPSFINRWNPWSTNVPYATFTEHPMAGADEKTASLCQLESFKALLIQAVKKAQKESPLPGQANGVLILERPLLIETYVGLMSFINNEAKLGYSMTRGKIGF>sp|Q5T0D9-2|TPRGL_HUMAN Isoform 2 of Tumor protein p63-regulated gene 1-like protein OS=Homo sapiens OX=9606 GN=TPRG1LMLQLRDSVDSAGTSPTAVLAAGEEVGAGGGPGGGRPGAGTPLRQTLWPLSIHDPTRRARVKEYFVFRPGSIEQAVEEIRVVVRPVEDGEIQGVWLLTEREGFGIRIQWDKQSRPSFINRWNPWSTNVPYATFTEHPMAGADEKTASLCQLESFKALLIQAVKKAQKESPLPGQANGVLILERPLLIETYVGLMSFINNEAKLGYSMTRGKIGF>sp|A0A5B9|TRBC2_HUMAN T cell receptor beta constant 2 OS=Homo sapiensOX=9606 GN=TRBC2 PE=1 SV=2DLKNVFPPKVAVFEPSEAEISHTQKATLVCLATGFYPDHVELSWWVNGKEVHSGVSTDPQPLKEQPALNDSRYCLSSRLRVSATFWQNPRNHFRCQVQFYGLSENDEWTQDRAKPVTQIVSAEAWGRADCGFTSESYQQGVLSATILYEILLGKATLYAVLVSALVLMAMVKRKDSRG>sp|A2RRL7|TM213_HUMAN Transmembrane protein 213 OS=Homo sapiens OX=9606GN=TMEM213 PE=3 SV=2MQRLPAATRATLILSLAFASLHSACSAEASSSNSSSLTAHHPDPGTLEQCLNVDFCPQAARCCRTGVDEYGWIAAAVGWSLWFLTLILLCVDKLMKLTPDEPKDLQA>sp|A2RRL7-2|TM213_HUMAN Isoform 2 of Transmembrane protein 213 OS=Homosapiens OX=9606 GN=TMEM213MQRLPAATRATLILSLAFASLHSACSADVDFCPQAARCCRTGVDEYGWIAAAVGWSLWFLTLILLCVDKLMKLTPDEPKDLQA>sp|A2RRL7-3|TM213_HUMAN Isoform 3 of Transmembrane protein 213 OS=Homosapiens OX=9606 GN=TMEM213MQRLPAATRATLILSLAFASLHSACSAASSSNSSSLTAHHPDPGTLEQCLNVDFCPQAARCCRTGVDEYGWIAAAVGWSLWFLTLILLCVDKLMKLTPDEPKDLQA>sp|A2RRL7-4|TM213_HUMAN Isoform 4 of Transmembrane protein 213 OS=Homosapiens OX=9606 GN=TMEM213MQRLPAATRATLILSLAFASLHSACSAEASSSNSSSLTAHHPDPGTLEQCLRSGYLANLRGEADQLWKFCTVLCFWESRRSSSRIALMREAEEWPGWRSSVELVG>sp|P20333|TNR1B_HUMAN Tumor necrosis factor receptor superfamily member1B OS=Homo sapiens OX=9606 GN=TNFRSF1B PE=1 SV=3MAPVAVWAALAVGLELWAAAHALPAQVAFTPYAPEPGSTCRLREYYDQTAQMCCSKCSPGQHAKVFCTKTSDTVCDSCEDSTYTQLWNWVPECLSCGSRCSSDQVETQACTREQNRICTCRPGWYCALSKQEGCRLCAPLRKCRPGFGVARPGTETSDVVCKPCAPGTFSNTTSSTDICRPHQICNVVAIPGNASMDAVCTSTSPTRSMAPGAVHLPQPVSTRSQHTQPTPEPSTAPSTSFLLPMGPSPPAEGSTGDFALPVGLIVGVTALGLLIIGVVNCVIMTQVKKKPLCLQREAKVPHLPADKARGTQGPEQQHLLITAPSSSSSSLESSASALDRRAPTRNQPQAPGVEASGAGEARASTGSSDSSPGGHGTQVNVTCIVNVCSSSDHSSQCSSQASSTMGDTDSSPSESPKDEQVPFSKEECAFRSQLETPETLLGSTEEKPLPLGVPDAGMKPS>sp|P20333-2|TNR1B_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 1B OS=Homo sapiens OX=9606 GN=TNFRSF1BMAPVAVWAALAVGLELWAAAHALPAQVAFTPYAPEPGSTCRLREYYDQTAQMCCSKCSPGQHAKVFCTKTSDTVCDSCEDSTYTQLWNWVPECLSCGSRCSSDQVETQACTREQNRICTCRPGWYCALSKQEGCRLCAPLRKCRPGFGVARPGTETSDVVCKPCAPGTFSNTTSSTDICRPHQICNVVAIPGNASMDAVCTSTSPTRSMAPGAVHLPQPVSTRSQHTQPTPEPSTAPSTSFLLPMGPSPPAEGSTGDFALPVASLACR>sp|Q02223|TNR17_HUMAN Tumor necrosis factor receptor superfamily member17 OS=Homo sapiens OX=9606 GN=TNFRSF17 PE=1 SV=2MLQMAGQCSQNEYFDSLLHACIPCQLRCSSNTPPLTCQRYCNASVTNSVKGTNAILWTCLGLSLIISLAVFVLMFLLRKINSEPLKDEFKNTGSGLLGMANIDLEKSRTGDEIILPRGLEYTVEECTCEDCIKSKPKVDSDHCFPLPAMEEGATILVTTKTNDYCKSLPAALSATEIEKSISAR>sp|Q02223-2|TNR17_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 17 OS=Homo sapiens OX=9606 GN=TNFRSF17MLQMAGQCSQNEYFDSLLHACIPCQLRCSSNTPPLTCQRYCNARSGLLGMANIDLEKSRTGDEIILPRGLEYTVEECTCEDCIKSKPKVDSDHCFPLPAMEEGATILVTTKTNDYCKSLPAALSATEIEKSISAR>sp|Q9Y4G6|TLN2_HUMAN Talin-2 OS=Homo sapiens OX=9606 GN=TLN2 PE=1 SV=4MVALSLKICVRHCNVVKTMQFEPSTAVYDACRVIRERVPEAQTGQASDYGLFLSDEDPRKGIWLEAGRTLDYYMLRNGDILEYKKKQRPQKIRMLDGSVKTVMVDDSKTVGELLVTICSRIGITNYEEYSLIQETIEEKKEEGTGTLKKDRTLLRDERKMEKLKAKLHTDDDLNWLDHSRTFREQGVDENETLLLRRKFFYSDQNVDSRDPVQLNLLYVQARDDILNGSHPVSFEKACEFGGFQAQIQFGPHVEHKHKPGFLDLKEFLPKEYIKQRGAEKRIFQEHKNCGEMSEIEAKVKYVKLARSLRTYGVSFFLVKEKMKGKNKLVPRLLGITKDSVMRVDEKTKEVLQEWPLTTVKRWAASPKSFTLDFGEYQESYYSVQTTEGEQISQLIAGYIDIILKKKQSKDRFGLEGDEESTMLEESVSPKKSTILQQQFNRTGKAEHGSVALPAVMRSGSSGPETFNVGSMPSPQQQVMVGQMHRGHMPPLTSAQQALMGTINTSMHAVQQAQDDLSELDSLPPLGQDMASRVWVQNKVDESKHEIHSQVDAITAGTASVVNLTAGDPADTDYTAVGCAITTISSNLTEMSKGVKLLAALMDDEVGSGEDLLRAARTLAGAVSDLLKAVQPTSGEPRQTVLTAAGSIGQASGDLLRQIGENETDERFQDVLMSLAKAVANAAAMLVLKAKNVAQVAEDTVLQNRVIAAATQCALSTSQLVACAKVVSPTISSPVCQEQLIEAGKLVDRSVENCVRACQAATTDSELLKQVSAAASVVSQALHDLLQHVRQFASRGEPIGRYDQATDTIMCVTESIFSSMGDAGEMVRQARVLAQATSDLVNAMRSDAEAEIDMENSKKLLAAAKLLADSTARMVEAAKGAAANPENEDQQQRLREAAEGLRVATNAAAQNAIKKKIVNRLEVAAKQAAAAATQTIAASQNAAVSNKNPAAQQQLVQSCKAVADHIPQLVQGVRGSQAQAEDLSAQLALIISSQNFLQPGSKMVSSAKAAVPTVSDQAAAMQLSQCAKNLATSLAELRTASQKAHEACGPMEIDSALNTVQTLKNELQDAKMAAVESQLKPLPGETLEKCAQDLGSTSKAVGSSMAQLLTCAAQGNEHYTGVAARETAQALKTLAQAARGVAASTTDPAAAHAMLDSARDVMEGSAMLIQEAKQALIAPGDAERQQRLAQVAKAVSHSLNNCVNCLPGQKDVDVALKSIGESSKKLLVDSLPPSTKPFQEAQSELNQAAADLNQSAGEVVHATRGQSGELAAASGKFSDDFDEFLDAGIEMAGQAQTKEDQIQVIGNLKNISMASSKLLLAAKSLSVDPGAPNAKNLLAAAARAVTESINQLITLCTQQAPGQKECDNALRELETVKGMLDNPNEPVSDLSYFDCIESVMENSKVLGESMAGISQNAKTGDLPAFGECVGIASKALCGLTEAAAQAAYLVGISDPNSQAGHQGLVDPIQFARANQAIQMACQNLVDPGSSPSQVLSAATIVAKHTSALCNACRIASSKTANPVAKRHFVQSAKEVANSTANLVKTIKALDGDFSEDNRNKCRIATAPLIEAVENLTAFASNPEFVSIPAQISSEGSQAQEPILVSAKTMLESSSYLIRTARSLAINPKDPPTWSVLAGHSHTVSDSIKSLITSIRDKAPGQRECDYSIDGINRCIRDIEQASLAAVSQSLATRDDISVEALQEQLTSVVQEIGHLIDPIATAARGEAAQLGHKVTQLASYFEPLILAAVGVASKILDHQQQMTVLDQTKTLAESALQMLYAAKEGGGNPKAQHTHDAITEAAQLMKEAVDDIMVTLNEAASEVGLVGGMVDAIAEAMSKLDEGTPPEPKGTFVDYQTTVVKYSKAIAVTAQEMMTKSVTNPEELGGLASQMTSDYGHLAFQGQMAAATAEPEEIGFQIRTRVQDLGHGCIFLVQKAGALQVCPTDSYTKRELIECARAVTEKVSLVLSALQAGNKGTQACITAATAVSGIIADLDTTIMFATAGTLNAENSETFADHRENILKTAKALVEDTKLLVSGAASTPDKLAQAAQSSAATITQLAEVVKLGAASLGSDDPETQVVLINAIKDVAKALSDLISATKGAASKPVDDPSMYQLKGAAKVMVTNVTSLLKTVKAVEDEATRGTRALEATIECIKQELTVFQSKDVPEKTSSPEESIRMTKGITMATAKAVAAGNSCRQEDVIATANLSRKAVSDMLTACKQASFHPDVSDEVRTRALRFGTECTLGYLDLLEHVLVILQKPTPEFKQQLAAFSKRVAGAVTELIQAAEAMKGTEWVDPEDPTVIAETELLGAAASIEAAAKKLEQLKPRAKPKQADETLDFEEQILEAAKSIAAATSALVKSASAAQRELVAQGKVGSIPANAADDGQWSQGLISAARMVAAATSSLCEAANASVQGHASEEKLISSAKQVAASTAQLLVACKVKADQDSEAMRRLQAAGNAVKRASDNLVRAAQKAAFGKADDDDVVVKTKFVGGIAQIIAAQEEMLKKERELEEARKKLAQIRQQQYKFLPTELREDEG>sp|O14669|TMG2_HUMAN Transmembrane gamma-carboxyglutamic acid protein 2OS=Homo sapiens OX=9606 GN=PRRG2 PE=1 SV=1MRGHPSLLLLYMALTTCLDTSPSEETDQEVFLGPPEAQSFLSSHTRIPRANHWDLELLTPGNLERECLEERCSWEEAREYFEDNTLTERFWESYIYNGKGGRGRVDVASLAVGLTGGILLIVLAGLGAFWYLRWRQHRGQQPCPQEAGLISPLSPLNPLGPPTPLPPPPPPPPGLPTYEQALAASGVHDAPPPPYTSLRRPH>sp|O75896|TUSC2_HUMAN Tumor suppressor candidate 2 OS=Homo sapiensOX=9606 GN=TUSC2 PE=1 SV=3MGASGSKARGLWPFASAAGGGGSEAAGAEQALVRPRGRAVPPFVFTRRGSMFYDEDGDLAHEFYEETIVTKNGQKRAKLRRVHKNLIPQGIVKLDHPRIHVDFPVILYEV>sp|Q5TGU0|TSPO2_HUMAN Translocator protein 2 OS=Homo sapiens OX=9606GN=TSPO2 PE=1 SV=1MRLQGAIFVLLPHLGPILVWLFTRDHMSGWCEGPRMLSWCPFYKVLLLVQTAIYSVVGYASYLVWKDLGGGLGWPLALPLGLYAVQLTISWTVLVLFFTVHNPGLALLHLLLLYGLVVSTALIWHPINKLAALLLLPYLAWLTVTSALTYHLWRDSLCPVHQPQPTEKSD>sp|Q5TGU0-2|TSPO2_HUMAN Isoform 2 of Translocator protein 2 OS=Homosapiens OX=9606 GN=TSPO2MRLQGAIFVLLPHLGPILVWLFTRDHMSGWCEGPRMLSWCPFYKVLLLVQTAIYSVVGPCCTCCCCMGWW>sp|Q9H892|TTC12_HUMAN Tetratricopeptide repeat protein 12 OS=Homosapiens OX=9606 GN=TTC12 PE=1 SV=2MDADKEKDLQKFLKNVDEISNLIQEMNSDDPVVQQKAVLETEKRLLLMEEDQEEDECRTTLNKTMISPPQTAMKSAEEINSEAFLASVEKDAKERAKRRRENKVLADALKEKGNEAFAEGNYETAILRYSEGLEKLKDMKVLYTNRAQAYMKLEDYEKALVDCEWALKCDEKCTKAYFHMGKANLALKNYSVSRECYKKILEINPKLQTQVKGYLNQVDLQEKADLQEKEAHELLDSGKNTAVTTKNLLETLSKPDQIPLFYAGGIEILTEMINECTEQTLFRMHNGFSIISDNEVIRRCFSTAGNDAVEEMVCVSVLKLWQAVCSRNEENQRVLVIHHDRARLLAALLSSKVLAIRQQSFALLLHLAQTESGRSLIINHLDLTRLLEALVSFLDFSDKEANTAMGLFTDLALEERFQVWFQANLPGVLPALTGVLKTDPKVSSSSALCQCIAIMGNLSAEPTTRRHMAACEEFGDGCLSLLARCEEDVDLFREVIYTLLGLMMNLCLQAPFVSEVWAVEVSRRCLSLLNSQDGGILTRAAGVLSRTLSSSLKIVEEALRAGVVKKMMKFLKTGGETASRYAIKILAICTNSYHEAREEVIRLDKKLSVMMKLLSSEDEVLVGNAALCLGNCMEVPNVASSLLKTDLLQVLLKLAGSDTQKTAVQVNAGIALGKLCTAEPRFAAQLRKLHGLEILNSTMKYISDS>sp|Q9H892-2|TTC12_HUMAN Isoform 2 of Tetratricopeptide repeat protein 12OS=Homo sapiens OX=9606 GN=TTC12MDADKEKDLQKFLKNVDEISNLIQEMNSDDPVVQQKAVLETEKRLLLMEEDQEEDECRTTLNKTMISPPQTAMKSAEEINSEAFLASVEKDAKERAKRRRENKVLADALKEKGNEAFAEGNYETAILRYSEGLEKLKDMKVLYTNRAQAYMKLEDYEKALVDCEWALKCDEKCTKAYFHMGKANLALKNYSVSRECYKKILEINPKLQTQVKGYLNQVDLQEKADLQEKEAHELLDSGKNTAVTTKNLLETLSKPDQIPLFYAGGIEILTEMINECTEQTLFRMHNGFSIISDNEVIRRCFSTAGNDAVEEMVCVSVLKLWQAVCSRNEENQRVLVIHHDRARLLAALLSSKVLAIRQQSFALLLHLAQTESGRSLIINHLDLTRLLEALVSFLDFSDKEANTAMGLFTDLALEERFQVWFQANLPGVLPALTGVLKTDPKVSSSSALCQCIAIMGNLSAEPTTRRHMAACEEFGDGCLSLLARCEEDVDLFREVIYTLLGLMMNLCLQAPFVSEVWAVEVSRRCLSLLNSQDGGILTRAAGVLSRTLSSSLKIVEEALRAGVVKKMMKFLKTGGETASRYAIKILAICTNSYHEAREEVIRLDKKLSVMMKLLSSEDEVLVGNAALCLGNCMEVPNVASSLLKTDLLQVLLKLAGSDTQKTAVQVNAGIALGKLCTAEPRVPAESSHLQFGRESAAPEALSPRRWEEMFHMLVFSLSSVDPPPPPPQTCYP>sp|Q5SRH9|TT39A_HUMAN Tetratricopeptide repeat protein 39A OS=Homosapiens OX=9606 GN=TTC39A PE=1 SV=1MGQKGHKDSLYPCGGTPESSLHEALDQCMTALDLFLTNQFSEALSYLKPRTKESMYHSLTYATILEMQAMMTFDPQDILLAGNMMKEAQMLCQRHRRKSSVTDSFSSLVNRPTLGQFTEEEIHAEVCYAECLLQRAALTFLQGSSHGGAVRPRALHDPSHACSCPPGPGRQHLFLLQDENMVSFIKGGIKVRNSYQTYKELDSLVQSSQYCKGENHPHFEGGVKLGVGAFNLTLSMLPTRILRLLEFVGFSGNKDYGLLQLEEGASGHSFRSVLCVMLLLCYHTFLTFVLGTGNVNIEEAEKLLKPYLNRYPKGAIFLFFAGRIEVIKGNIDAAIRRFEECCEAQQHWKQFHHMCYWELMWCFTYKGQWKMSYFYADLLSKENCWSKATYIYMKAAYLSMFGKEDHKPFGDDEVELFRAVPGLKLKIAGKSLPTEKFAIRKSRRYFSSNPISLPVPALEMMYIWNGYAVIGKQPKLTDGILEIITKAEEMLEKGPENEYSVDDECLVKLLKGLCLKYLGRVQEAEENFRSISANEKKIKYDHYLIPNALLELALLLMEQDRNEEAIKLLESAKQNYKNYSMESRTHFRIQAATLQAKSSLENSSRSMVSSVSL>sp|Q5SRH9-2|TT39A_HUMAN Isoform 2 of Tetratricopeptide repeat protein39A OS=Homo sapiens OX=9606 GN=TTC39AMKAAYLSMFGKEDHKPFGDDEVELFRAVPGLKLKIAGKSLPTEKFAIRKSRRYFSSNPISLPVPALEMMYIWNGYAVIGKQPKLTDGILEIITKAEEMLEKGPENEYSVDDECLVKLLKGLCLKYLGRVQEAEENFRSISANEKKIKYDHYLIPNALLELALLLMEQDRNEEAIKLLESAKQNYKNYSMESRTHFRIQAATLQAKSSLENSSRSMVSSVSL>sp|Q5SRH9-3|TT39A_HUMAN Isoform 3 of Tetratricopeptide repeat protein39A OS=Homo sapiens OX=9606 GN=TTC39AMDSSPSLPLIRTPESSLHEALDQCMTALDLFLTNQFSEALSYLKPRTKESMYHSLTYATILEMQAMMTFDPQDILLAGNMMKEAQMLCQRHRRKSSVTDSFSSLVNRPTLGQFTEEEIHAEVCYAECLLQRAALTFLQGSSHGGAVRPRALHDPSHACSCPPGPGRQHLFLLQDENMVSFIKGGIKVRNSYQTYKELDSLVQSSQYCKGENHPHFEGGVKLGVGAFNLTLSMLPTRILRLLEFVGFSGNKDYGLLQLEEGASGHSFRSVLCVMLLLCYHTFLTFVLGTGNVNIEEAEKLLKPYLNRYPKGAIFLFFAGRIEVIKGNIDAVSDGGPGRGWGSLGVSQTSRKSGTCDILRDRIDWGRGGGQERTNQRAGAGEALLAEQPGKTREEEAFVVPGILTGRYRTAALQWREVEGGA>sp|Q5SRH9-4|TT39A_HUMAN Isoform 4 of Tetratricopeptide repeat protein39A OS=Homo sapiens OX=9606 GN=TTC39AMAFLTTWKEAASGKSDRRTPESSLHEALDQCMTALDLFLTNQFSEALSYLKPRTKESMYHSLTYATILEMQAMMTFDPQDILLAGNMMKEAQMLCQRHRRKSSVTDSFSSLVNRPTLGQFTEEEIHAEVCYAECLLQRAALTFLQDENMVSFIKGGIKVRNSYQTYKELDSLVQSSQYCKGENHPHFEGGVKLGVGAFNLTLSMLPTRILRLLEFVGFSGNKDYGLLQLEEGASGHSFRSVLCVMLLLCYHTFLTFVLGTGNVNIEEAEKLLKPYLNRYPKGAIFLFFAGRIEVIKGNIDAAIRRFEECCEAQQHWKQFHHMCYWELMWCFTYKGQWKMSYFYADLLSKENCWSKATYIYMKAAYLSMFGKEDHKPFGDDEVELFRAVPGLKLKIAGKSLPTEKFAIRKSRRYFSSNPISLPVPALEMMYIWNGYAVIGKQPKLTDGILEIITKAEEMLEKGPENEYSVDDECLVKLLKGLCLKYLGRVQEAEENFRSISANEKKIKYDHYLIPNALLELALLLMEQDRNEEAIKLLESAKQNYKNYSMESRTHFRIQAATLQAKSSLENSSRSMVSSVSL>sp|Q5SRH9-5|TT39A_HUMAN Isoform 5 of Tetratricopeptide repeat protein39A OS=Homo sapiens OX=9606 GN=TTC39AMTSAGGAPGALPAGTPESSLHEALDQCMTALDLFLTNQFSEALSYLKPRTKESMYHSLTYATILEMQAMMTFDPQDILLAGNMMKEAQMLCQRHRRKSSVTDSFSSLVNRPTLGQFTEEEIHAEVCYAECLLQRAALTFLQDENMVSFIKGGIKVRNSYQTYKELDSLVQSSQYCKGENHPHFEGGVKLGVGAFNLTLSMLPTRILRLLEFVGFSGNKDYGLLQLEEGASGHSFRSVLCVMLLLCYHTFLTFVLGTGNVNIEEAEKLLKPYLNRYPKGAIFLFFAGRIEVIKGNIDAAIRRFEECCEAQQHWKQFHHMCYWELMWCFTYKGQWKMSYFYADLLSKENCWSKATYIYMKAAYLSMFGKEDHKPFGDDEVELFRAVPGLKLKIAGKSLPTEKFAIRKSRRYFSSNPISLPVPALEMMYIWNGYAVIGKQPKLTDGILEIITKAEEMLEKGPENEYSVDDECLVKLLKGLCLKYLGRVQEAEENFRSISANEKKIKYDHYLIPNALLELALLLMEQDRNEEAIKLLESAKQNYKNYSMESRTHFRIQAATLQAKSSLENSSRSMVSSVSL>sp|Q5SRH9-6|TT39A_HUMAN Isoform 6 of Tetratricopeptide repeat protein39A OS=Homo sapiens OX=9606 GN=TTC39AMGQKGHKDSLYPCGGTPESSLHEALDQCMTALDLFLTNQFSEALSYLKPRTKESMYHSLTYATILEMQAMMTFDPQDILLAGNMMKEAQMLCQRHRRKSSVTDSFSSLVNRPTLGQFTEEEIHAEVCYAECLLQRAALTFLQDENMVSFIKGGIKVRNSYQTYKELDSLVQSSQYCKGENHPHFEGGVKLGVGAFNLTLSMLPTRILRLLEFVGFSGNKDYGLLQLEEGASGHSFRSVLCVMLLLCYHTFLTFVLGTGNVNIEEAEKLLKPYLNRYPKGAIFLFFAGRIEVIKGNIDAAIRRFEECCEAQQHWKQFHHMCYWELMWCFTYKGQWKMSYFYADLLSKENCWSKATYIYMKAAYLSMFGKEDHKPFGDDEVELFRAVPGLKLKIAGKSLPTEKFAIRKSRRYFSSNPISLPVPALEMMYIWNGYAVIGKQPKLTDGILEIITKAEEMLEKGPENEYSVDDECLVKLLKGLCLKYLGRVQEAEENFRSISANEKKIKYDHYLIPNALLELALLLMEQDRNEEAIKLLESAKQNYKNYSMESRTHFRIQAATLQAKSSLENSSRSMVSSVSL>sp|Q3KQV9|UAP1L_HUMAN UDP-N-acetylhexosamine pyrophosphorylase-likeprotein 1 OS=Homo sapiens OX=9606 GN=UAP1L1 PE=1 SV=2MASEQDVRARLQRAGQEHLLRFWAELAPEPRAALLAELALLEPEALREHCRRAAEACARPHGPPPDLAARLRPLPPERVGRASRSDPETRRRWEEEGFRQISLNKVAVLLLAGGQGTRLGVTYPKGMYRVGLPSRKTLYQLQAERIRRVEQLAGERHGTRCTVPWYVMTSEFTLGPTAEFFREHNFFHLDPANVVMFEQRLLPAVTFDGKVILERKDKVAMAPDGNGGLYCALEDHKILEDMERRGVEFVHVYCVDNILVRLADPVFIGFCVLQGADCGAKVVEKAYPEEPVGVVCQVDGVPQVVEYSEISPETAQLRASDGSLLYNAGNICNHFFTRGFLKAVTREFEPLLKPHVAVKKVPYVDEEGNLVKPLKPNGIKMEKFVFDVFRFAKNFAALEVLREEEFSPLKNAEPADRDSPRTARQALLTQHYRWALRAGARFLDAHGAWLPELPSLPPNGDPPAICEISPLVSYSGEGLEVYLQGREFQSPLILDEDQAREPQLQES>sp|Q3KQV9-2|UAP1L_HUMAN Isoform 2 of UDP-N-acetylhexosaminepyrophosphorylase-like protein 1 OS=Homo sapiens OX=9606 GN=UAP1L1MGPGPSPNWTLDPEPRCRLWSEPRLPAGPGVLAAGSPRLPCRYVMTSEFTLGPTAEFFREHNFFHLDPANVVMFEQRLLPAVTFDGKVILERKDKVAMAPDGNGGLYCALEDHKILEDMERRGVEFVHVYCVDNILVRLADPVFIGFCVLQGADCGAKVVEKAYPEEPVGVVCQVDGVPQVVEYSEISPETAQLRASDGSLLYNAGNICNHFFTRGFLKAVTREFEPLLKPHVAVKKVPYVDEEGNLVKPLKPNGIKMEKFVFDVFRFAKNFAALEVLREEEFSPLKNAEPADRDSPRTARQALLTQHYRWALRAGARFLDAHGAWLPELPSLPPNGDPPAICEISPLVSYSGEGLEVYLQGREFQSPLILDEDQAREPQLQES>sp|P62328|TYB4_HUMAN Thymosin beta-4 OS=Homo sapiens OX=9606 GN=TMSB4XPE=1 SV=2MSDKPDMAEIEKFDKSKLKKTETQEKNPLPSKETIEQEKQAGES>sp|Q9NUW8|TYDP1_HUMAN Tyrosyl-DNA phosphodiesterase 1 OS=Homo sapiensOX=9606 GN=TDP1 PE=1 SV=2MSQEGDYGRWTISSSDESEEEKPKPDKPSTSSLLCARQGAANEPRYTCSEAQKAAHKRKISPVKFSNTDSVLPPKRQKSGSQEDLGWCLSSSDDELQPEMPQKQAEKVVIKKEKDISAPNDGTAQRTENHGAPACHRLKEEEDEYETSGEGQDIWDMLDKGNPFQFYLTRVSGVKPKYNSGALHIKDILSPLFGTLVSSAQFNYCFDVDWLVKQYPPEFRKKPILLVHGDKREAKAHLHAQAKPYENISLCQAKLDIAFGTHHTKMMLLLYEEGLRVVIHTSNLIHADWHQKTQGIWLSPLYPRIADGTHKSGESPTHFKADLISYLMAYNAPSLKEWIDVIHKHDLSETNVYLIGSTPGRFQGSQKDNWGHFRLKKLLKDHASSMPNAESWPVVGQFSSVGSLGADESKWLCSEFKESMLTLGKESKTPGKSSVPLYLIYPSVENVRTSLEGYPAGGSLPYSIQTAEKQNWLHSYFHKWSAETSGRSNAMPHIKTYMRPSPDFSKIAWFLVTSANLSKAAWGALEKNGTQLMIRSYELGVLFLPSAFGLDSFKVKQKFFAGSQEPMATFPVPYDLPPELYGSKDRPWIWNIPYVKAPDTHGNMWVPS>sp|Q9NUW8-2|TYDP1_HUMAN Isoform 2 of Tyrosyl-DNA phosphodiesterase 1OS=Homo sapiens OX=9606 GN=TDP1MVISERLRLTSMPRPSLTRTSLSARKMMLLLYEEGLRVVIHTSNLIHADWHQKTQGIWLSPLYPRIADGTHKSGESPTHFKADLISYLMAYNAPSLKEWIDVIHKHDLSETNVYLIGSTPGRFQGSQKDNWGHFRLKKLLKDHASSMPNAESWPVVGQFSSVGSLGADESKWLCSEFKESMLTLGKESKTPGKSSVPLYLIYPSVENVRTSLEGYPAGGSLPYSIQTAEKQNWLHSYFHKWSAETSGRSNAMPHIKTYMRPSPDFSKIAWFLVTSANLSKAAWGALEKNGTQLMIRSYELGVLFLPSAFGLDSFKVKQKFFAGSQEPMATFPVPYDLPPELYGSKDRPWIWNIPYVKAPDTHGNMWVPS>sp|Q96J42|TXD15_HUMAN Thioredoxin domain-containing protein 15 OS=Homosapiens OX=9606 GN=TXNDC15 PE=1 SV=1MVPAAGRRPPRVMRLLGWWQVLLWVLGLPVRGVEVAEESGRLWSEEQPAHPLQVGAVYLGEEELLHDPMGQDRAAEEANAVLGLDTQGDHMVMLSVIPGEAEDKVSSEPSGVTCGAGGAEDSRCNVRESLFSLDGAGAHFPDREEEYYTEPEVAESDAAPTEDSNNTESLKSPKVNCEERNITGLENFTLKILNMSQDLMDFLNPNGSDCTLVLFYTPWCRFSASLAPHFNSLPRAFPALHFLALDASQHSSLSTRFGTVAVPNILLFQGAKPMARFNHTDRTLETLKIFIFNQTGIEAKKNVVVTQADQIGPLPSTLIKSVDWLLVFSLFFLISFIMYATIRTESIRWLIPGQEQEHVE>sp|Q96J42-2|TXD15_HUMAN Isoform 2 of Thioredoxin domain-containingprotein 15 OS=Homo sapiens OX=9606 GN=TXNDC15MVPAAGRRPPRVMRLLGWWQVLLWVLGLPVRGVEVAEESGRLWSEELLHDPMGQDRAAEEANAVLGLDTQGDHMVMLSVIPGEAEDKVSSEPSGVTCGAGGAEDSRCNVRESLFSLDGAGAHFPDREEEYYTEPEVAESDAAPTEDSNNTESLKSPKVNCEERNITGLENFTLKILNMSQDLMDFLNPNGSDCTLVLFYTPWCRFSASLAPHFNSLPRAFPALHFLALDASQHSSLSTRFGTVAVPNILLFQGAKPMARFNHTDRTLETLKIFIFNQTGIEAKKNVVVTQADQIGPLPSTLIKSVDWLLVFSLFFLISFIMYATIRTESIRWLIPGQEQEHVE>sp|Q92995|UBP13_HUMAN Ubiquitin carboxyl-terminal hydrolase 13 OS=Homosapiens OX=9606 GN=USP13 PE=1 SV=2MQRRGALFGMPGGSGGRKMAAGDIGELLVPHMPTIRVPRSGDRVYKNECAFSYDSPNSEGGLYVCMNTFLAFGREHVERHFRKTGQSVYMHLKRHVREKVRGASGGALPKRRNSKIFLDLDTDDDLNSDDYEYEDEAKLVIFPDHYEIALPNIEELPALVTIACDAVLSSKSPYRKQDPDTWENELPVSKYANNLTQLDNGVRIPPSGWKCARCDLRENLWLNLTDGSVLCGKWFFDSSGGNGHALEHYRDMGYPLAVKLGTITPDGADVYSFQEEEPVLDPHLAKHLAHFGIDMLHMHGTENGLQDNDIKLRVSEWEVIQESGTKLKPMYGPGYTGLKNLGNSCYLSSVMQAIFSIPEFQRAYVGNLPRIFDYSPLDPTQDFNTQMTKLGHGLLSGQYSKPPVKSELIEQVMKEEHKPQQNGISPRMFKAFVSKSHPEFSSNRQQDAQEFFLHLVNLVERNRIGSENPSDVFRFLVEERIQCCQTRKVRYTERVDYLMQLPVAMEAATNKDELIAYELTRREAEANRRPLPELVRAKIPFSACLQAFSEPENVDDFWSSALQAKSAGVKTSRFASFPEYLVVQIKKFTFGLDWVPKKFDVSIDMPDLLDINHLRARGLQPGEEELPDISPPIVIPDDSKDRLMNQLIDPSDIDESSVMQLAEMGFPLEACRKAVYFTGNMGAEVAFNWIIVHMEEPDFAEPLTMPGYGGAASAGASVFGASGLDNQPPEEIVAIITSMGFQRNQAIQALRATNNNLERALDWIFSHPEFEEDSDFVIEMENNANANIISEAKPEGPRVKDGSGTYELFAFISHMGTSTMSGHYICHIKKEGRWVIYNDHKVCASERPPKDLGYMYFYRRIPS>sp|Q92995-2|UBP13_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 13 OS=Homo sapiens OX=9606 GN=USP13MNTFLAFGREHVERHFRKTGQSVYMHLKRHVREKVRGASGGALPKRRNSKIFLDLDTDDDLNSDDYEYEDEAKLVIFPDHYEIALPNIEELPALVTIACDAVLSSKSPYRKQDPDTWENELPVSKYANNLTQLDNGVRIPPSGWKCARCDLRENLWLNLTDGSVLCGKWFFDSSGGNGHALEHYRDMGYPLAVKLGTITPDGADVYSFQEEEPVLDPHLAKHLAHFGIDMLHMHGTENGLQDNDIKLRVSEWEVIQESGTKLKPMYGPGYTGLKNLGNSCYLSSVMQAIFSIPEFQRAYVGNLPRIFDYSPLDPTQDFNTQMTKLGHGLLSGQYSKPPVKSELIEQVMKEEHKPQQNGISPRMFKAFVSKSHPEFSSNRQQDAQEFFLHLVNLVERNRIGSENPSDVFRFLVEERIQCCQTRKVRYTERVDYLMQLPVAMEAATNKDELIAYELTRREAEANRRPLPELVRAKIPFSACLQAFSEPENVDDFWSSALQAKSAGVKTSRFASFPEYLVVQIKKFTFGLDWVPKKFDVSIDMPDLLDINHLRARGLQPGEEELPDISPPIVIPDDSKDRLMNQLIDPSDIDESSVMQLAEMGFPLEACRKAVYFTGNMGAEVAFNWIIVHMEEPDFAEPLTMPGYGGAASAGASVFGASGLDNQPPEEIVAIITSMGFQRNQAIQALRATNNNLERALDWIFSHPEFEEDSDFVIEMENNANANIISEAKPEGPRVKDGSGTYELFAFISHMGTSTMSGHYICHIKKEGRWVIYNDHKVCASERPPKDLGYMYFYRRIPS>sp|Q6IBS0|TWF2_HUMAN Twinfilin-2 OS=Homo sapiens OX=9606 GN=TWF2 PE=1SV=2MAHQTGIHATEELKEFFAKARAGSVRLIKVVIEDEQLVLGASQEPVGRWDQDYDRAVLPLLDAQQPCYLLYRLDSQNAQGFEWLFLAWSPDNSPVRLKMLYAATRATVKKEFGGGHIKDELFGTVKDDLSFAGYQKHLSSCAAPAPLTSAERELQQIRINEVKTEISVESKHQTLQGLAFPLQPEAQRALQQLKQKMVNYIQMKLDLERETIELVHTEPTDVAQLPSRVPRDAARYHFFLYKHTHEGDPLESVVFIYSMPGYKCSIKERMLYSSCKSRLLDSVEQDFHLEIAKKIEIGDGAELTAEFLYDEVHPKQHAFKQAFAKPKGPGGKRGHKRLIRGPGENGDDS>sp|P35504|UD15_HUMAN UDP-glucuronosyltransferase 1A5 OS=Homo sapiensOX=9606 GN=UGT1A5 PE=1 SV=1MATGLQVPLPQLATGLLLLLSVQPWAESGKVLVVPTDGSHWLSMREALRDLHARGHQVVVLTLEVNMYIKEENFFTLTTYAISWTQDEFDRLLLGHTQSFFETEHLLMKFSRRMAIMNNMSLIIHRSCVELLHNEALIRHLHATSFDVVLTDPFHLCAAVLAKYLSIPAVFFLRNIPCDLDFKGTQCPNPSSYIPRLLTTNSDHMTFLQRVKNMLYPLALSYLCHAVSAPYASLASELFQREVSVVDLVSHASVWLFRGDFVMDYPRPIMPNMVFIGGINCANGKPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|P35504-2|UD15_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A5OS=Homo sapiens OX=9606 GN=UGT1A5MATGLQVPLPQLATGLLLLLSVQPWAESGKVLVVPTDGSHWLSMREALRDLHARGHQVVVLTLEVNMYIKEENFFTLTTYAISWTQDEFDRLLLGHTQSFFETEHLLMKFSRRMAIMNNMSLIIHRSCVELLHNEALIRHLHATSFDVVLTDPFHLCAAVLAKYLSIPAVFFLRNIPCDLDFKGTQCPNPSSYIPRLLTTNSDHMTFLQRVKNMLYPLALSYLCHAVSAPYASLASELFQREVSVVDLVSHASVWLFRGDFVMDYPRPIMPNMVFIGGINCANGKPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|Q86T82|UBP37_HUMAN Ubiquitin carboxyl-terminal hydrolase 37 OS=Homosapiens OX=9606 GN=USP37 PE=1 SV=2MSPLKIHGPIRIRSMQTGITKWKEGSFEIVEKENKVSLVVHYNTGGIPRIFQLSHNIKNVVLRPSGAKQSRLMLTLQDNSFLSIDKVPSKDAEEMRLFLDAVHQNRLPAAMKPSQGSGSFGAILGSRTSQKETSRQLSYSDNQASAKRGSLETKDDIPFRKVLGNPGRGSIKTVAGSGIARTIPSLTSTSTPLRSGLLENRTEKRKRMISTGSELNEDYPKENDSSSNNKAMTDPSRKYLTSSREKQLSLKQSEENRTSGLLPLQSSSFYGSRAGSKEHSSGGTNLDRTNVSSQTPSAKRSLGFLPQPVPLSVKKLRCNQDYTGWNKPRVPLSSHQQQQLQGFSNLGNTCYMNAILQSLFSLQSFANDLLKQGIPWKKIPLNALIRRFAHLLVKKDICNSETKKDLLKKVKNAISATAERFSGYMQNDAHEFLSQCLDQLKEDMEKLNKTWKTEPVSGEENSPDISATRAYTCPVITNLEFEVQHSIICKACGEIIPKREQFNDLSIDLPRRKKPLPPRSIQDSLDLFFRAEELEYSCEKCGGKCALVRHKFNRLPRVLILHLKRYSFNVALSLNNKIGQQVIIPRYLTLSSHCTENTKPPFTLGWSAHMAISRPLKASQMVNSCITSPSTPSKKFTFKSKSSLALCLDSDSEDELKRSVALSQRLCEMLGNEQQQEDLEKDSKLCPIEPDKSELENSGFDRMSEEELLAAVLEISKRDASPSLSHEDDDKPTSSPDTGFAEDDIQEMPENPDTMETEKPKTITELDPASFTEITKDCDENKENKTPEGSQGEVDWLQQYDMEREREEQELQQALAQSLQEQEAWEQKEDDDLKRATELSLQEFNNSFVDALGSDEDSGNEDVFDMEYTEAEAEELKRNAETGNLPHSYRLISVVSHIGSTSSSGHYISDVYDIKKQAWFTYNDLEVSKIQEAAVQSDRDRSGYIFFYMHKEIFDELLETEKNSQSLSTEVGKTTRQAL>sp|Q86T82-2|UBP37_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 37 OS=Homo sapiens OX=9606 GN=USP37MLTLQDNSFLSIDKVPSKDAEEMRLFLDAVHQNRLPAAMKPSQGSGSFGAILGSRTSQKETSRQLSYSDNQASAKRGSLETKDDIPFRKVLGNPGRGSIKTVAGSGIARTIPSLTSTSTPLRSGLLENRTEKRKRMISTGSELNEDYPKENDSSSNNKAMTDPSRKYLTSSREKQLSLKQSEENRTSGLLPLQSSSFYGSRAGSKEHSSGGTNLDRTNVSSQTPSAKRSLGFLPQPVPLSVKKLRCNQDYTGWNKPRVPLSSHQQQQLQGFSNLGNTCYMNAILQSLFSLQSFANDLLKQGIPWKKIPLNALIRRFAHLLVKKDICNSETKKDLLKKVKNAISATAERFSGYMQNDAHEFLSQCLDQLKEDMEKLNKTWKTEPVSGEENSPDISATRAYTCPVITNLEFEVQHSIICKACGEIIPKREQFNDLSIDLPRRKKPLPPRSIQDSLDLFFRAEELEYSCEKCGGKCALVRHKFNRLPRVLILHLKRYSFNVALSLNNKIGQQVIIPRYLTLSSHCTENTKPPFTLGWSAHMAMKFTFKSKSSLALCLDSDSEDELKRSVALSQRLCEMLGNEQQQEDLEKDSKLCPIEPDKSELENSGFDRMSEEELLAAVLEISKRDASPSLSHEDDDKPTSSPDTGFAEDDIQEMPENPDTMETEKPKTITELDPASFTEITKDCDENKENKTPEGSQGEVDWLQQYDMEREREEQELQQALAQSLQEQEAWEQKEDDDLKRATELSLQEFNNSFVDALGSDEDSGNEDVFDMEYTEAEAEELKRNAETGNLPHSYRLISVVSHIGSTSSSGHYISDVYDIKKQAWFTYNDLEVSKIQEAAVQSDRDRSGYIFFYMHKEIFDELLETEKNSQSLSTEVGKTTRQAL>sp|Q9UMX0|UBQL1_HUMAN Ubiquilin-1 OS=Homo sapiens OX=9606 GN=UBQLN1 PE=1SV=2MAESGESGGPPGSQDSAAGAEGAGAPAAAASAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQDHSAQQTNTAGSNVTTSSTPNSNSTSGSATSNPFGLGGLGGLAGLSSLGLNTTNFSELQSQMQRQLLSNPEMMVQIMENPFVQSMLSNPDLMRQLIMANPQMQQLIQRNPEISHMLNNPDIMRQTLELARNPAMMQEMMRNQDRALSNLESIPGGYNALRRMYTDIQEPMLSAAQEQFGGNPFASLVSNTSSGEGSQPSRTENRDPLPNPWAPQTSQSSSASSGTASTVGGTTGSTASGTSGQSTTAPNLVPGVGASMFNTPGMQSLLQQITENPQLMQNMLSAPYMRSMMQSLSQNPDLAAQMMLNNPLFAGNPQLQEQMRQQLPTFLQQMQNPDTLSAMSNPRAMQALLQIQQGLQTLATEAPGLIPGFTPGLGALGSTGGSSGTNGSNATPSENTSPTAGTTEPGHQQFIQQMLQALAGVNPQLQNPEVRFQQQLEQLSAMGFLNREANLQALIATGGDINAAIERLLGSQPS>sp|Q9UMX0-2|UBQL1_HUMAN Isoform 2 of Ubiquilin-1 OS=Homo sapiens OX=9606GN=UBQLN1MAESGESGGPPGSQDSAAGAEGAGAPAAAASAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQDHSAQQTNTAGSNVTTSSTPNSNSTSGSATSNPFGLGGLGGLAGLSSLGLNTTNFSELQSQMQRQLLSNPEMMVQIMENPFVQSMLSNPDLMRQLIMANPQMQQLIQRNPEISHMLNNPDIMRQTLELARNPAMMQEMMRNQDRALSNLESIPGGYNALRRMYTDIQEPMLSAAQEQFGGNPFASLVSNTSSGEGSQPSRTENRDPLPNPWAPQTSQSSSASSGTASTVGGTTGSTASGTSGQSTTAPNLVPGVGASMFNTPGMQSLLQQITENPQLMQNMLSAPYMRSMMQSLSQNPDLAAQMQNPDTLSAMSNPRAMQALLQIQQGLQTLATEAPGLIPGFTPGLGALGSTGGSSGTNGSNATPSENTSPTAGTTEPGHQQFIQQMLQALAGVNPQLQNPEVRFQQQLEQLSAMGFLNREANLQALIATGGDINAAIERLLGSQPS>sp|Q9UMX0-3|UBQL1_HUMAN Isoform 3 of Ubiquilin-1 OS=Homo sapiens OX=9606GN=UBQLN1MAESGESGGPPGSQDSAAGAEGAGAPAAAASAEPKIMKVTVKTPKEKEEFAVPENSSVQQTLELARNPAMMQEMMRNQDRALSNLESIPGGYNALRRMYTDIQEPMLSAAQEQFGGNPFASLVSNTSSGEGSQPSRTENRDPLPNPWAPQTSQSSSASSGTASTVGGTTGSTASGTSGQSTTAPNLVPGVGASMFNTPGMQSLLQQITENPQLMQNMLSAPYMRSMMQSLSQNPDLAAQMMLNNPLFAGNPQLQEQMRQQLPTFLQQMQNPDTLSAMSNPRAMQALLQIQQGLQTLATEAPGLIPGFTPGLGALGSTGGSSGTNGSNATPSENTSPTAGTTEPGHQQFIQQMLQALAGVNPQLQNPEVRFQQQLEQLSAMGFLNREANLQALIATGGDINAAIERLLGSQPS>sp|Q9UMX0-4|UBQL1_HUMAN Isoform 4 of Ubiquilin-1 OS=Homo sapiens OX=9606GN=UBQLN1MAESGESGGPPGSQDSAAGAEGAGAPAAAASAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQDHSAQQTNTAGSNVTTSSTPNSNSTSGSATSNPFGLDVGTCQESSNDAGDDEEPGPSFEQPRKHPRGI>sp|P23763|VAMP1_HUMAN Vesicle-associated membrane protein 1 OS=Homosapiens OX=9606 GN=VAMP1 PE=1 SV=1MSAPAQPPAEGTEGTAPGGGPPGPPPNMTSNRRLQQTQAQVEEVVDIIRVNVDKVLERDQKLSELDDRADALQAGASQFESSAAKLKRKYWWKNCKMMIMLGAICAIIVVVIVIYFFT>sp|P23763-3|VAMP1_HUMAN Isoform 2 of Vesicle-associated membrane protein1 OS=Homo sapiens OX=9606 GN=VAMP1MSAPAQPPAEGTEGTAPGGGPPGPPPNMTSNRRLQQTQAQVEEVVDIIRVNVDKVLERDQKLSELDDRADALQAGASQFESSAAKLKRKYWWKNCKMMIMLGAICAIIVVVIVSKYR>sp|P23763-2|VAMP1_HUMAN Isoform 3 of Vesicle-associated membrane protein1 OS=Homo sapiens OX=9606 GN=VAMP1MSAPAQPPAEGTEGTAPGGGPPGPPPNMTSNRRLQQTQAQVEEVVDIIRVNVDKVLERDQKLSELDDRADALQAGASQFESSAAKLKRKYWWKNCKMMIMLGAICAIIVVVIVRRD>sp|Q5DID0|UROL1_HUMAN Uromodulin-like 1 OS=Homo sapiens OX=9606GN=UMODL1 PE=2 SV=2MLRTSGLALLALVSAVGPSQASGFTEKGLSLLGYQLCSHRVTHTVQKVEAVQTSYTSYVSCGGWIPWRRCPKMVYRTQYLVVEVPESRNVTDCCEGYEQLGLYCVLPLNQSGQFTSRPGACPAEGPEPSTSPCSLDIDCPGLEKCCPWSGGRYCMAPAPQAPERDPVGSWYNVTILVKMDFKELQQVDPRLLNHMRLLHSLVTSALQPMASTVHHLHSAPGNASTTVSRLLLGLPRPLPVADVSTLLGDIAKRVYEVISVQVQDVNECFYEELNACSGRELCANLEGSYWCVCHQEAPATSPRKLNLEWEDCPPVSDYVVLNVTSDSFQVSWRLNSTQNHTFHVRVYRGMELLRSARTQSQALAVAGLEAGVLYRVKTSYQGCGADVSTTLTIKTNAQVFEVTIKIVNHNLTEKLLNRSSVEYQDFSRQLLHEVESSFPPVVSDLYRSGKLRMQIVSLQAGSVVVRLKLTVQDPGFPMGISTLAPILQPLLASTVFQIDRQGTRVQDWDECVDSAEHDCSPAAWCINLEGSYTCQCRTTRDATPSRAGRACEGDLVSPMGGGLSAATGVTVPGLGTGTAALGLENFTLSPSPGYPQGTPAAGQAWTPEPSPRRGGSNVVGYDRNNTGKGVEQELQGNSIMEPPSWPSPTEDPTGHFLWHATRSTRETLLNPTWLRNEDSGPSGSVDLPLTSTLTALKTPACVPVSIGRIMVSNVTSTGFHLAWEADLAMDSTFQLTLTSMWSPAVVLETWNTSVTLSGLEPGVLHLVEIMAKACGKEGARAHLKVRTAARKLIGKVRIKNVRYSESFRNASSQEYRDFLELFFRMVRGSLPATMCQHMDAGGVRMEVVSVTNGSIVVEFHLLIIADVDVQEVSAAFLTAFQTVPLLEVIRGDTFIQDYDECERKEDDCVPGTSCRNTLGSFTCSCEGGAPDFPVEYSERPCEGDSPGNETWATSPERPLTTAGTKAAFVQGTSPTPQGLPQRLNLTGAVRVLCEIEKVVVAIQKRFLQQESIPESSLYLSHPSCNVSHSNGTHVLLEAGWSECGTLMQSNMTNTVVRTTLRNDLSQEGIIHHLKILSPIYCAFQNDLLTSSGFTLEWGVYTIIEDLHGAGNFVTEMQLFIGDSPIPQNYSVSASDDVRIEVGLYRQKSNLKVVLTECWATPSSNARDPITFSFINNSCPVPNTYTNVIENGNSNKAQFKLRIFSFINDSIVYLHCKLRVCMESPGATCKINCNNFRLLQNSETSATHQMSWGPLIRSEGEPPHAEAGLGAGYVVLIVVAIFVLVAGTATLLIVRYQRMNGRYNFKIQSNNFSYQVFYE>sp|Q5DID0-2|UROL1_HUMAN Isoform 2 of Uromodulin-like 1 OS=Homo sapiensOX=9606 GN=UMODL1MLRTSGLALLALVSAVGPSQASGFTEKGLSLLGYQLCSHRVTHTVQKVEAVQTSYTSYVSCGGWIPWRRCPKMVYRTQYLVVEVPESRNVTDCCEGYEQLGLYCVLPLNQSGQFTSRPGACPAEGPEPSTSPCSLDIDCPGLEKCCPWSGGRYCMAPAPQAPERDPVGSWYNVTILVKMDFKELQQVDPRLLNHMRLLHSLVTSALQPMASTVHHLHSAPGNASTTVSRLLLGLPRPLPVADVSTLLGDIAKRVYEVISVQVQDVNECFYEELNACSGRELCANLEGSYWCVCHQEAPATSPRKLNLEWEDCPPVSDYVVLNVTSDSFQVSWRLNSTQNHTFHVRVYRGMELLRSARTQSQALAVAGLEAGVLYRVKTSYQGCGADVSTTLTIKTNAQVFEVTIKIVNHNLTEKLLNRSSVEYQDFSRQLLHEVESSFPPVVSDLYRSGKLRMQIVSLQAGSVVVRLKLTVQDPGFPMGISTLAPILQPLLASTVFQIDRQGTRVQDWDECVDSAEHDCSPAAWCINLEGSYTCQCRTTRDATPSRAGRACEGDLVSPMGGGLSAATGVTVPGLGTGTAALGLENFTLSPSPGYPQGTPAAGQAWTPEPSPRRGGSNVVGYDRNNTGKGVEQEVPSTAPGLGMDQGSPSQVNPSQGSPSQGSLRQESTSQASPSQRSTSQGSPSQVNPSQRSTSHANSSQGSPSQGSPSQESPSQGSTSQASPSHRNTIGVIGTTSSPKATGSTHSFPPGATDGPLALPGQLQGNSIMEPPSWPSPTEDPTGHFLWHATRSTRETLLNPTWLRNEDSGPSGSVDLPLTSTLTALKTPACVPVSIGRIMVSNVTSTGFHLAWEADLAMDSTFQLTLTSMWSPAVVLETWNTSVTLSGLEPGVLHLVEIMAKACGKEGARAHLKVRTAARKLIGKVRIKNVRYSESFRNASSQEYRDFLELFFRMVRGSLPATMCQHMDAGGVRMEVVSVTNGSIVVEFHLLIIADVDVQEVSAAFLTAFQTVPLLEVIRGDTFIQDYDECERKEDDCVPGTSCRNTLGSFTCSCEGGAPDFPVEYSERPCEGDSPGNETWATSPERPLTTAGTKAAFVQGTSPTPQGLPQRLNLTGAVRVLCEIEKVVVAIQKRFLQQESIPESSLYLSHPSCNVSHSNGTHVLLEAGWSECGTLMQSNMTNTVVRTTLRNDLSQEGIIHHLKILSPIYCAFQNDLLTSSGFTLEWGVYTIIEDLHGAGNFVTEMQLFIGDSPIPQNYSVSASDDVRIEVGLYRQKSNLKVVLTECWATPSSNARDPITFSFINNSCPVPNTYTNVIENGNSNKAQFKLRIFSFINDSIVYLHCKLRVCMESPGATCKINCNNFRLLQNSETSATHQMSWGPLIRSEGEPPHAEAGLGAGYVVLIVVAIFVLVAGTATLLIVRYQRMNGRYNFKIQSNNFSYQVFYE>sp|Q5DID0-3|UROL1_HUMAN Isoform 3 of Uromodulin-like 1 OS=Homo sapiensOX=9606 GN=UMODL1MVYRTQYLVVEVPESRNVTDCCEGYEQLGLYCVLPLNQSGQFTSRPGACPAEGPEPSTSPCSLDIDCPGLEKCCPWSGGRYCMAPAPQAPERDPVGSWYNVTILVKMDFKELQQVDPRLLNHMRLLHSLVTSALQPMASTVHHLHSAPGNASTTVSRLLLGLPRPLPVADVSTLLGDIAKRVYEVISVQVQDVNECFYEELNACSGRELCANLEGSYWCVCHQEAPATSPRKLNLEWEDCPPVSDYVVLNVTSDSFQVSWRLNSTQNHTFHVRVYRGMELLRSARTQSQALAVAGLEAGVLYRVKTSYQGCGADVSTTLTIKTNAQVFEVTIKIVNHNLTEKLLNRSSVEYQDFSRQLLHEVESSFPPVVSDLYRSGKLRMQIVSLQAGSVVVRLKLTVQDPGFPMGISTLAPILQPLLASTVFQIDRQGTRVQDWDECVDSAEHDCSPAAWCINLEGSYTCQCRTTRDATPSRAGRACEGDLVSPMGGGLSAATGVTVPGLGTGTAALGLENFTLSPSPGYPQGTPAAGQAWTPEPSPRRGGSNVVGYDRNNTGKGVEQELQGNSIMEPPSWPSPTEDPTGHFLWHATRSTRETLLNPTWLRNEDSGPSGSVDLPLTSTLTALKTPACVPVSIGRIMVSNVTSTGFHLAWEADLAMDSTFQLTLTSMWSPAVVLETWNTSVTLSGLEPGVLHLVEIMAKACGKEGARAHLKVRTAARKLIGKVRIKNVRYSESFRNASSQEYRDFLELFFRMVRGSLPATMCQHMDAGGVRMEVVSVTNGSIVVEFHLLIIADVDVQEVSAAFLTAFQTVPLLEVIRGDTFIQDYDECERKEDDCVPGTSCRNTLGSFTCSCEGGAPDFPVEYSERPCEGDSPGNETWATSPERPLTTAGTKAAFVQGTSPTPQGLPQRLNLTGAVRVLCEIEKVVVAIQKRFLQQESIPESSLYLSHPSCNVSHSNGTHVLLEAGWSECGTLMQSNMTNTVVRTTLRNDLSQEGIIHHLKILSPIYCAFQNDLLTSSGFTLEWGVYTIIEDLHGAGNFVTEMQLFIGDSPIPQNYSVSASDDVRIEVGLYRQKSNLKVVLTECWATPSSNARDPITFSFINNSCPVPNTYTNVIENGNSNKAQFKLRIFSFINDSIVYLHCKLRVCMESPGATCKINCNNFRLLQNSETSATHQMSWGPLIRSEGEPPHAEAGLGAGYVVLIVVAIFVLVAGTATLLIVRYQRMNGRYNFKIQSNNFSYQVFYE>sp|Q5DID0-4|UROL1_HUMAN Isoform 4 of Uromodulin-like 1 OS=Homo sapiensOX=9606 GN=UMODL1MVYRTQYLVVEVPESRNVTDCCEGYEQLGLYCVLPLNQSGQFTSRPGACPAEGPEPSTSPCSLDIDCPGLEKCCPWSGGRYCMAPAPQAPERDPVGSWYNVTILVKMDFKELQQVDPRLLNHMRLLHSLVTSALQPMASTVHHLHSAPGNASTTVSRLLLGLPRPLPVADVSTLLGDIAKRVYEVISVQVQDVNECFYEELNACSGRELCANLEGSYWCVCHQEAPATSPRKLNLEWEDCPPVSDYVVLNVTSDSFQVSWRLNSTQNHTFHVRVYRGMELLRSARTQSQALAVAGLEAGVLYRVKTSYQGCGADVSTTLTIKTNAQVFEVTIKIVNHNLTEKLLNRSSVEYQDFSRQLLHEVESSFPPVVSDLYRSGKLRMQIVSLQAGSVVVRLKLTVQDPGFPMGISTLAPILQPLLASTVFQIDRQGTRVQDWDECVDSAEHDCSPAAWCINLEGSYTCQCRTTRDATPSRAGRACEGDLVSPMGGGLSAATGVTVPGLGTGTAALGLENFTLSPSPGYPQGTPAAGQAWTPEPSPRRGGSNVVGYDRNNTGKGVEQEVPSTAPGLGMDQGSPSQVNPSQGSPSQGSLRQESTSQASPSQRSTSQGSPSQVNPSQRSTSHANSSQGSPSQGSPSQESPSQGSTSQASPSHRNTIGVIGTTSSPKATGSTHSFPPGATDGPLALPGQLQGNSIMEPPSWPSPTEDPTGHFLWHATRSTRETLLNPTWLRNEDSGPSGSVDLPLTSTLTALKTPACVPVSIGRIMVSNVTSTGFHLAWEADLAMDSTFQLTLTSMWSPAVVLETWNTSVTLSGLEPGVLHLVEIMAKACGKEGARAHLKVRTAARKLIGKVRIKNVRYSESFRNASSQEYRDFLELFFRMVRGSLPATMCQHMDAGGVRMEVVSVTNGSIVVEFHLLIIADVDVQEVSAAFLTAFQTVPLLEVIRGDTFIQDYDECERKEDDCVPGTSCRNTLGSFTCSCEGGAPDFPVEYSERPCEGDSPGNETWATSPERPLTTAGTKAAFVQGTSPTPQGLPQRLNLTGAVRVLCEIEKVVVAIQKRFLQQESIPESSLYLSHPSCNVSHSNGTHVLLEAGWSECGTLMQSNMTNTVVRTTLRNDLSQEGIIHHLKILSPIYCAFQNDLLTSSGFTLEWGVYTIIEDLHGAGNFVTEMQLFIGDSPIPQNYSVSASDDVRIEVGLYRQKSNLKVVLTECWATPSSNARDPITFSFINNSCPVPNTYTNVIENGNSNKAQFKLRIFSFINDSIVYLHCKLRVCMESPGATCKINCNNFRLLQNSETSATHQMSWGPLIRSEGEPPHAEAGLGAGYVVLIVVAIFVLVAGTATLLIVRYQRMNGRYNFKIQSNNFSYQVFYE>sp|Q9UPY6|WASF3_HUMAN Wiskott-Aldrich syndrome protein family member 3OS=Homo sapiens OX=9606 GN=WASF3 PE=1 SV=2MPLVKRNIEPRHLCRGALPEGITSELECVTNSTLAAIIRQLSSLSKHAEDIFGELFNEANNFYIRANSLQDRIDRLAVKVTQLDSTVEEVSLQDINMKKAFKSSTVQDQQVVSKNSIPNPVADIYNQSDKPPPLNILTPYRDDKKDGLKFYTDPSYFFDLWKEKMLQDTEDKRKEKRRQKEQKRIDGTTREVKKVRKARNRRQEWNMMAYDKELRPDNRLSQSVYHGASSEGSLSPDTRSHASDVTDYSYPATPNHSLHPQPVTPSYAAGDVPPHGPASQAAEHEYRPPSASARHMALNRPQQPPPPPPPQAPEGSQASAPMAPADYGMLPAQIIEYYNPSGPPPPPPPPVIPSAQTAFVSPLQMPMQPPFPASASSTHAAPPHPPSTGLLVTAPPPPGPPPPPPGPPGPGSSLSSSPMHGPPVAEAKRQEPAQPPISDARSDLLAAIRMGIQLKKVQEQREQEAKREPVGNDVATILSRRIAVEYSDSDDDSEFDENDWSD>sp|Q9UPY6-2|WASF3_HUMAN Isoform 2 of Wiskott-Aldrich syndrome proteinfamily member 3 OS=Homo sapiens OX=9606 GN=WASF3MPLVKRNIEPRHLCRGALPEGITSELECVTNSTLAAIIRQLSSLSKHAEDIFGELFNEANNFYIRANSLQDRIDRLAVKVTQLDSTVEEVSLQDINMKKAFKSSTVQDQQVVSKNSIPNPVADIYNQSDKPPPLNILTPYRDDKKDGLKFYTDPSYFFDLWKEKMLQDTEDKRKEKRRQKREKHKLNPNRNQQVNVRKVRTRKEEWERRKMGIEFMSDAKKLEQAGSAKEDRVPSGSHASDVTDYSYPATPNHSLHPQPVTPSYAAGDVPPHGPASQAAEHEYRPPSASARHMALNRPQQPPPPPPPQAPEGSQASAPMAPADYGMLPAQIIEYYNPSGPPPPPPPPVIPSAQTAFVSPLQMPMQPPFPASASSTHAAPPHPPSTGLLVTAPPPPGPPPPPPGPPGPGSSLSSSPMHGPPVAEAKRQEPAQPPISDARSDLLAAIRMGIQLKKVQEQREQEAKREPVGNDVATILSRRIAVEYSDSDDDSEFDENDWSD>sp|Q9BRX9|WDR83_HUMAN WD repeat domain-containing protein 83 OS=Homosapiens OX=9606 GN=WDR83 PE=1 SV=1MAFPEPKPRPPELPQKRLKTLDCGQGAVRAVRFNVDGNYCLTCGSDKTLKLWNPLRGTLLRTYSGHGYEVLDAAGSFDNSSLCSGGGDKAVVLWDVASGQVVRKFRGHAGKVNTVQFNEEATVILSGSIDSSIRCWDCRSRRPEPVQTLDEARDGVSSVKVSDHEILAGSVDGRVRRYDLRMGQLFSDYVGSPITCTCFSRDGQCTLVSSLDSTLRLLDKDTGELLGEYKGHKNQEYKLDCCLSERDTHVVSCSEDGKVFFWDLVEGALALALPVGSGVVQSLAYHPTEPCLLTAMGGSVQCWREEAYEAEDGAG>sp|A8MTW9|YB043_HUMAN Putative uncharacterized protein ENSP00000380674OS=Homo sapiens OX=9606 PE=5 SV=2MRPLLCALAGLALLCAVGALADGREDRGSPGDTGERPAGPARGPGLEPARGTLQPRPRPPRKRWLLSPGAGAQQLEVVHLPGSTL>sp|Q5BJH7|YIF1B_HUMAN Protein YIF1B OS=Homo sapiens OX=9606 GN=YIF1BPE=1 SV=1MHPAGLAAAAAGTPRLRKWPSKRRIPVSQPGMADPHQLFDDTSSAQSRGYGAQRAPGGLSYPAASPTPHAAFLADPVSNMAMAYGSSLAAQGKELVDKNIDRFIPITKLKYYFAVDTMYVGRKLGLLFFPYLHQDWEVQYQQDTPVAPRFDVNAPDLYIPAMAFITYVLVAGLALGTQDRFSPDLLGLQASSALAWLTLEVLAILLSLYLVTVNTDLTTIDLVAFLGYKYVGMIGGVLMGLLFGKIGYYLVLGWCCVAIFVFMIRTLRLKILADAAAEGVPVRGARNQLRMYLTMAVAAAQPMLMYWLTFHLVR>sp|Q5BJH7-2|YIF1B_HUMAN Isoform 2 of Protein YIF1B OS=Homo sapiensOX=9606 GN=YIF1BMADPHQLFDDTSSAQSRGYGAQRAPGGLSYPAASPTPHAAFLADPVSNMAMAYGSSLAAQGKELVDKNIDRFIPITKLKYYFAVDTMYVGRKLGLLFFPYLHQDWEVQYQQDTPVAPRFDVNAPDLYIPAMAFITYVLVAGLALGTQDRFSPDLLGLQASSALAWLTLEVLAILLSLYLVTVNTDLTTIDLVAFLGYKYVGMIGGVLMGLLFGKIGYYLVLGWCCVAIFVFMIRTLRLKILADAAAEGVPVRGARNQLRMYLTMAVAAAQPMLMYWLTFHLVR>sp|Q5BJH7-3|YIF1B_HUMAN Isoform 3 of Protein YIF1B OS=Homo sapiensOX=9606 GN=YIF1BMHPAGLAAAAAGTPRLPSKRRIPVSQPGMADPHQLFDDTSSAQSRGYGAQRAPGGLSYPAASPTPHAAFLADPVSNMAMAYGSSLAAQGKELVDKNIDRFIPITKLKYYFAVDTMYVGRKLGLLFFPYLHQDWEVQYQQDTPVAPRFDVNAPDLYIPAMAFITYVLVAGLALGTQDRFSPDLLGLQASSALAWLTLEVLAILLSLYLVTVNTDLTTIDLVAFLGYKYVGMIGGVLMGLLFGKIGYYLVLGWCCVAIFVFMIRTLRLKILADAAAEGVPVRGARNQLRMYLTMAVAAAQPMLMYWLTFHLVR>sp|Q5BJH7-4|YIF1B_HUMAN Isoform 4 of Protein YIF1B OS=Homo sapiensOX=9606 GN=YIF1BMHPAGLAAAAAGTPRLPSKRRIPVSQPGMADPHQLFDDTSSAQSRGYGAQRAPGGLSYPAASPTPHAAFLADPVSNMAMAYGSSLAAQGKELVDKNIDRFIPITKLKYYFAVDTMYVGRKLGLLFFPYLHQDWEVQYQQDTPVAPRFDVNAPDLYIPAMAFITYVLVAGLALGTQDRFSPDLLGLQASSALAWLTLEVLAILLSLYLVTVNTDLTTIDLVAFLGYKYVGMIGGVLMGLLFGKIGYYLVLGWCCVAIFVFMFPLLPGAVAHACNPSTLGGRGGRITRSGRCG>sp|Q5BJH7-5|YIF1B_HUMAN Isoform 5 of Protein YIF1B OS=Homo sapiensOX=9606 GN=YIF1BMHPAGLAAAAAGTPRLPSKRRIPVSQPGMADPHQLFDDTSSAQSRGYGAQRAPGGLSYPAASPTPHAAFLADPVSNMAMAYGSSLAAQGKELVDKNIDRFIPITKLKYYFAVDTMYVGRKLGLLFFPYLHQDWEVQYQQDTPVAPRFDVNAPDLYIPAMAFITYVLVAGLALGTQDRFSPDLLGLQASSALAWLTLEVLAILLSLYLVTVNTDLTTIDLVAFLGYKYVGMIGGVLMGLLFGKIGYYLVLGWCCVAIFVFMFPLLPGAVAHACNPSTLGGRGGRITRSGDQDHPG>sp|Q5BJH7-6|YIF1B_HUMAN Isoform 6 of Protein YIF1B OS=Homo sapiensOX=9606 GN=YIF1BMPGSASKRRIPVSQPGMADPHQLFDDTSSAQSRGYGAQRAPGGLSYPAASPTPHAAFLADPVSNMAMAYGSSLAAQGKELVDKNIDRFIPITKLKYYFAVDTMYVGRKLGLLFFPYLHQDWEVQYQQDTPVAPRFDVNAPDLYIPAMAFITYVLVAGLALGTQDRFSPDLLGLQASSALAWLTLEVLAILLSLYLVTVNTDLTTIDLVAFLGYKYVGMIGGVLMGLLFGKIGYYLVLGWCCVAIFVFMIRTLRLKILADAAAEGVPVRGARNQLRMYLTMAVAAAQPMLMYWLTFHLVR>sp|Q8N393|ZN786_HUMAN Zinc finger protein 786 OS=Homo sapiens OX=9606GN=ZNF786 PE=1 SV=2MAEPPRLPLTFEDVAIYFSEQEWQDLEAWQKELYKHVMRSNYETLVSLDDGLPKPELISWIEHGGEPFRKWRESQKSGNIICSSVDMHFDPGFEEQLFWGSQQAMNSGKTKSHFQLDPESQCSFGSFVSFRPDQGITLGSPQRHDARAPPPLACGPSESTLKEGIPGPRNLDLPGLWDVPAWESTQHPWPVCGESCWENNHLVMHQRGHSKDRTRRAWEKFNKRAETQMPWSSPRVQRHFRCGVCGKSFRRKLCLLRHLAAHTGRGPFRNADGEMCFRHELTHPSHRLPQQGEKPAQCTPCGKRSLPVDSTQARRCQHSREGPASWREGRGASSSVHSGQKPGSRLPQEGNSHQEGDTEALQHGAEGPCSCSECGERSPMSARLASPCRAHTGEKPFQCAHCTKRFRLRRLLQVHQHAHGGERPFSCRKCGKGFAKQCKLTEHIRVHSGEKPFRCAKCGRNFRQRGQLLRHQRLHTDEKPFQCPECGLSFRLESMLRAHRLRHGGERPFSCSECGRGFTHQCKLREHLRVHSGERPFQCLKCDKRFRLKGILKAHQHTHSKERPFSCGECGKGFTRQSKLTEHLRVHSGERPFQCPECNRSFRLKGQLLSHQRLHTGERPFQCPECDKRYRVKADMKAHQLLHSGEMPFSCECGKGFVKHSKLIEHIRTHTGEKPFQCPKCDKSFRLKAQLLSHQGLHTGERPFHCPECDKNFRERGHMLRHQRIHRPERPFACGDCGKGFIYKSKLAEHIRVHTKSCPAPNELDIKKRLSQLFAMIEADWS>sp|Q8N393-2|ZN786_HUMAN Isoform 2 of Zinc finger protein 786 OS=Homosapiens OX=9606 GN=ZNF786MRSNYETLVSLDDGLPKPELISWIEHGGEPFRKWRESQKSGNIICSSVDMHFDPGFEEQLFWGSQQAMNSGKTKSHFQLDPESQCSFGSFVSFRPDQGITLGSPQRHDARAPPPLACGPSESTLKEGIPGPRNLDLPGLWDVPAWESTQHPWPVCGESCWENNHLVMHQRGHSKDRTRRAWEKFNKRAETQMPWSSPRVQRHFRCGVCGKSFRRKLCLLRHLAAHTGRGPFRNADGEMCFRHELTHPSHRLPQQGEKPAQCTPCGKRSLPVDSTQARRCQHSREGPASWREGRGASSSVHSGQKPGSRLPQEGNSHQEGDTEALQHGAEGPCSCSECGERSPMSARLASPCRAHTGEKPFQCAHCTKRFRLRRLLQVHQHAHGGERPFSCRKCGKGFAKQCKLTEHIRVHSGEKPFRCAKCGRNFRQRGQLLRHQRLHTDEKPFQCPECGLSFRLESMLRAHRLRHGGERPFSCSECGRGFTHQCKLREHLRVHSGERPFQCLKCDKRFRLKGILKAHQHTHSKERPFSCGECGKGFTRQSKLTEHLRVHSGERPFQCPECNRSFRLKGQLLSHQRLHTGERPFQCPECDKRYRVKADMKAHQLLHSGEMPFSCECGKGFVKHSKLIEHIRTHTGEKPFQCPKCDKSFRLKAQLLSHQGLHTGERPFHCPECDKNFRERGHMLRHQRIHRPERPFACGDCGKGFIYKSKLAEHIRVHTKSCPAPNELDIKKRLSQLFAMIEADWS>sp|Q9H0M4|ZCPW1_HUMAN Zinc finger CW-type PWWP domain protein 1 OS=Homosapiens OX=9606 GN=ZCWPW1 PE=1 SV=2MMTTLQNKEECGKGPKRIFAPPAQKSYSLLPCSPNSPKEETPGISSPETEARISLPKASLKKKEEKATMKNVPSREQEKKRKAQINKQAEKKEKEKSSLTNAEFEEIVQIVLQKSLQECLGMGSGLDFAETSCAQPVVSTQSDKEPGITASATDTDNANGEEVPHTQEISVSWEGEAAPEIRTSKLGQPDPAPSKKKSNRLTLSKRKKEAHEKVEKTQGGHEHRQEDRLKKTVQDHSQIRDQQKGEISGFGQCLVWVQCSFPNCGKWRRLCGNIDPSVLPDNWSCDQNTDVQYNRCDIPEETWTGLESDVAYASYIPGSIIWAKQYGYPWWPGMIESDPDLGEYFLFTSHLDSLPSKYHVTFFGETVSRAWIPVNMLKNFQELSLELSVMKKRRNDCSQKLGVALMMAQEAEQISIQERVNLFGFWSRFNGSNSNGERKDLQLSGLNSPGSCLEKKEKEEELEKEEGEKTDPILPIRKRVKIQTQKTKPRGLGGDAGTADGRGRTLQRKIMKRSLGRKSTAPPAPRMGRKEGQGNSDSDQPGPKKKFKAPQSKALAASFSEGKEVRTVPKNLGLSACKGACPSSAKEEPRHREPLTQEAGSVPLEDEASSDLDLEQLMEDVGRELGQSGELQHSNSDGEDFPVALFGK>sp|Q9H0M4-2|ZCPW1_HUMAN Isoform 2 of Zinc finger CW-type PWWP domainprotein 1 OS=Homo sapiens OX=9606 GN=ZCWPW1MMTTLQNKEECGKGPKRIFAPPAQKSYSLLPCSPNSPKEETPGISSPETEARISLPKASLKKKEEKATMKNVPSREQEKKRKAQINKQAEKKEKEKSSLTNAEFEEIVQIVLQKSLQECLGMGSGLDFAETSCAQPVVSTQSDKEPGITASATDTDNANGEEVPHTQEISVSWEGEAAPEIRTSKLGQPDPAPSKKKSNRLTLSKRKKEAQDEKVEKTQGGHEHRQEDRLKKTVQDHSQIRDQQKGEISGFGQCLVWVQCSFPNCGKWRRLCGNIDPSVLPDNWSCDQNTADVQYNRCDIPEETWTGLESDVAYASYIPGSIIWAKQYGYPWWPGMIESDPDLGEYFLFTSHLDSLPSKYHVTFFGETVSRAWIPVNMLKNFQELSLELSVMKKRRNDCSQKLGVALMMAQEAEQISIQERVNLFGFWSRFNGSNSNGERKDLQLSGLNSPGSCTQNGKERRPREFRF>sp|Q9H0M4-3|ZCPW1_HUMAN Isoform 3 of Zinc finger CW-type PWWP domainprotein 1 OS=Homo sapiens OX=9606 GN=ZCWPW1MGSGLDFAETSCAQPVVSTQSDKEPGITASATDTDNANGEEVPHTQEISVSWEGEAAPEIRTSKLGQPDPAPSKKKSNRLTLSKRKKEAQDEKVEKTQGGHEHRQEDRLKKTVQDHSQIRDQQKGEISGFGQCLVWVQCSFPNCGKWRRLCGNIDPSVLPDNWSCDQNTDVQYNRCDIPEETWTGLESDVAYASYIPGSIIWAKQYGYPWWPGMIESDPDLGEYFLFTSHLDSLPSKYHVTFFGETVSRAWIPVNMLKNFQELSLELSVMKKRRNDCSQKLGVALMMAQEAEQISIQERVNLFGFWSRFNGSNSNGERKDLQLSGLNSPGSCLEKKEKEEELEKEEGEKTALRKNLKLPRARPWQPAFQREKKLEQCQRTWAYQRVRGPAPHLRKKSPDTGNP>sp|Q9H0M4-4|ZCPW1_HUMAN Isoform 4 of Zinc finger CW-type PWWP domainprotein 1 OS=Homo sapiens OX=9606 GN=ZCWPW1MGSGLDFAETSCAQPVVSTQSDKEPGITASATDTDNANGEEVPHTQEISVSWEGEAAPEIRTSKLGQPDPAPSKKKSNRLTLSKRKKEAQDEKVEKTQGGHEHRQEDRLKKTVQDHSQIRDQQKGEISGFGQCLVWVQCSFPNCGKWRRLCGNIDPSVLPDNWSCDQNTDVQYNRCDIPEETWTGLESDVAYASYIPGSIIWAKQYGYPWWPGMIESDPDLGEYFLFTSHLDSLPSKYHVTFFGETVSRAWIPVNMLKNFQELSLELSVMKKRRNDCSQKLGVALMMAQEAEQISIQERVNLFGFWSRFNGSNSNGERKDLQLSGLNSPGSCLEKKEKEEELEKEEGEKTDPILPIRKRVKIQTQKTKPRGPKKKFKAPQSKALAASFSEGKEVRTVPKNLGLSACKGACPSSAKEEPRHREPLTQEAGSVPLEDEASSDLDLEQLMEDVGRELGQSGELQHSNSDGEDFPVALFGK>sp|Q9H0M4-5|ZCPW1_HUMAN Isoform 5 of Zinc finger CW-type PWWP domainprotein 1 OS=Homo sapiens OX=9606 GN=ZCWPW1MMTTLQNKEECGKGPKRIFAPPAQKSYSLLPCSPNSPKEETPGISSPETEARISLPKASLKKKEEKATMKNVPSREQEKKRKAQINKQAEKKEKEKSSLTNAEFEEIVQIVLQKSLQECLGMGSGLDFAETSCAQPVVSTQSDKEPGITASATDTDNANGEEVPHTQEISVSWEGEAAPEIRTSKLGQPDPAPSKKKSNRLTLSKRKKEAQDEKVEKTQGGHEHRQEDRLKKTVQDHSQIRDQQKGEISGFGQCLVWVQCSFPNCGKWRRLCGNIDPSVLPDNWSCDQNTDVQYNRCDIPEETWTGLESDVAYASYIPGSIIWAKQYGYPWWPGMIESDPDLGEYFLFTSHLDSLPSKYHVTFFGETVSRAWIPVNMLKNFQELSLELSVMKKRRNDCSQKLGVALMMAQEAEQISIQERVNLFGFWSRFNGSNSNGERKDLQLSGLNSPGSCLEKKEKEEELEKEEGEKTALRKNLKLPRARPWQPAFQREKKLEQCQRTWAYQRVRGPAPHLRKKSPDTGNP>sp|P16415|ZN823_HUMAN Zinc finger protein 823 OS=Homo sapiens OX=9606GN=ZNF823 PE=2 SV=2MDSVAFEDVAVNFTQEEWALLGPSQKSLYRNVMQETIRNLDCIEMKWEDQNIGDQCQNAKRNLRSHTCEIKDDSQCGETFGQIPDSIVNKNTPRVNPCDSGECGEVVLGHSSLNCNIRVDTGHKSCEHQEYGEKPYTHKQRGKAISHQHSFQTHERPPTGKKPFDCKECAKTFSSLGNLRRHMAAHHGDGPYKCKLCGKAFVWPSLFHLHERTHTGEKPYECKQCSKAFPFYSSYLRHERIHTGEKAYECKQCSKAFPDYSTYLRHERTHTGEKPYKCTQCGKAFSCYYYTRLHERTHTGEQPYACKQCGKTFYHHTSFRRHMIRHTGDGPHKCKICGKGFDCPSSVRNHETTHTGEKPYECKQCGKVLSHSSSFRSHMITHTGDGPQKCKICGKAFGCPSLFQRHERTHTGEKPYQCKQCGKAFSLAGSLRRHEATHTGVKPYKCQCGKAFSDLSSFQNHETTHTGEKPYECKECGKAFSCFKYLSQHKRTHTVEKPYECKTCRKAFSHFSNLKVHERIHSGEKPYECKECGKAFSWLTCLLRHERIHTGEKPYECLQCGKAFTRSRFLRGHEKTHTGEKLYECKECGKALSSLRSLHRHKRTHWKDTL>sp|P16415-2|ZN823_HUMAN Isoform 2 of Zinc finger protein 823 OS=Homosapiens OX=9606 GN=ZNF823MAAHHGDGPYKCKLCGKAFVWPSLFHLHERTHTGEKPYECKQCSKAFPFYSSYLRHERIHTGEKAYECKQCSKAFPDYSTYLRHERTHTGEKPYKCTQCGKAFSCYYYTRLHERTHTGEQPYACKQCGKTFYHHTSFRRHMIRHTGDGPHKCKICGKGFDCPSSVRNHETTHTGEKPYECKQCGKVLSHSSSFRSHMITHTGDGPQKCKICGKAFGCPSLFQRHERTHTGEKPYQCKQCGKAFSLAGSLRRHEATHTGVKPYKCQCGKAFSDLSSFQNHETTHTGEKPYECKECGKAFSCFKYLSQHKRTHTVEKPYECKTCRKAFSHFSNLKVHERIHSGEKPYECKECGKAFSWLTCLLRHERIHTGEKPYECLQCGKAFTRSRFLRGHEKTHTGEKLYECKECGKALSSLRSLHRHKRTHWKDTL>sp|Q96FA7|ZB6CL_HUMAN ZBED6 C-terminal-like protein OS=Homo sapiensOX=9606 GN=ZBED6CL PE=2 SV=1MVVREASAAQASLSQVLPQLRYLHIFLEQVHTHFQEQSVGERGAAIQLAEGLARQLCTDCQLNKLFYREEFVLATLLDPCFKGKIEAILPWGPTDIDHWKQVLVYKVKEIRVSEYSLNSPSPLQSPRGLCVDPTRVAKSSGVEGRSQGEPLQSSSHSGAFLLAQREKGLLESMGLLASERSGGSLSTKSHWASIIVKKYLWENETVGAQDDPLAYWEKKREAWPPSICLTPHRSLL>sp|P25311|ZA2G_HUMAN Zinc-alpha-2-glycoprotein OS=Homo sapiens OX=9606GN=AZGP1 PE=1 SV=2MVRMVPVLLSLLLLLGPAVPQENQDGRYSLTYIYTGLSKHVEDVPAFQALGSLNDLQFFRYNSKDRKSQPMGLWRQVEGMEDWKQDSQLQKAREDIFMETLKDIVEYYNDSNGSHVLQGRFGCEIENNRSSGAFWKYYYDGKDYIEFNKEIPAWVPFDPAAQITKQKWEAEPVYVQRAKAYLEEECPATLRKYLKYSKNILDRQDPPSVVVTSHQAPGEKKKLKCLAYDFYPGKIDVHWTRAGEVQEPELRGDVLHNGNGTYQSWVVVAVPPQDTAPYSCHVQHSSLAQPLVVPWEAS>sp|Q8N782|ZN525_HUMAN Zinc finger protein 525 OS=Homo sapiens OX=9606GN=ZNF525 PE=2 SV=2MSSLTYHHRLHTGEKPYKCEECDKAFRHNSALQRHRRIHTGEKPHKCNECGKTFSQKSYLACHRSIHTGKKPYECEECDKAFSFKSNLESHRITHTGEKPYKCNDCGKTFSHMSTLTCHRRLHTGEKPYKCEECDEAFRFKSSLERHRRIHNGEKLYKCNECGKTFSQELSLTCHCRLHSGEKPCKCGECDKAYSFK>sp|Q9Y462|ZN711_HUMAN Zinc finger protein 711 OS=Homo sapiens OX=9606GN=ZNF711 PE=1 SV=2MDSGGGSLGLHTPDSRMAHTMIMQDFVAGMAGTAHIDGDHIVVSVPEAVLVSDVVTDDGITLDHGLAAEVVHGPDIITETDVVTEGVIVPEAVLEADVAIEEDLEEDDGDHILTSELITETVRVPEQVFVADLVTGPNGHLEHVVQDCVSGVDSPTMVSEEVLVTNSDTETVIQAAGGVPGSTVTIKTEDDDDDDVKSTSEDYLMISLDDVGEKLEHMGNTPLKIGSDGSQEDAKEDGFGSEVIKVYIFKAEAEDDVEIGGTEIVTESEYTSGHSVAGVLDQSRMQREKMVYMAVKDSSQEEDDIRDERRVSRRYEDCQASGNTLDSALESRSSTAAQYLQICDGINTNKVLKQKAKKRRRGETRQWQTAVIIGPDGQPLTVYPCHICTKKFKSRGFLKRHMKNHPDHLMRKKYQCTDCDFTTNKKVSFHNHLESHKLINKVDKTHEFTEYTRRYREASPLSSNKLILRDKEPKMHKCKYCDYETAEQGLLNRHLLAVHSKNFPHVCVECGKGFRHPSELKKHMRTHTGEKPYQCQYCIFRCADQSNLKTHIKSKHGNNLPYKCEHCPQAFGDERELQRHLDLFQGHKTHQCPHCDHKSTNSSDLKRHIISVHTKDFPHKCEVCDKGFHRPSELKKHSDIHKGRKIHQCRHCDFKTSDPFILSGHILSVHTKDQPLKCKRCKRGFRQQNELKKHMKTHTGRKIYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEFCKKGFRRPSEKNQHIMRHHKEALM>sp|Q9Y462-2|ZN711_HUMAN Isoform 2 of Zinc finger protein 711 OS=Homosapiens OX=9606 GN=ZNF711MDSGGGSLGLHTPDSRMAHTMIMQDFVAGMAGTAHIDGDHIVVSVPEAVLVSDVVTDDGITLDHGLAAEVVHGPDIITETDVVTEGVIVPEAVLEADVAIEEDLEEDDGDHILTSELITETVRVPEQVFVADLVTGPNGHLEHVVQDCVSGVDSPTMVSEEVLVTNSDTETVIQAAGGVPGSTVTIKTEDDDDDDVKSTSEDYLMISLDDVGEKLEHMGNTPLKIGSDGSQEDAKEDGFGSEVIKVYIFKAEAEDDVEIGGTEIVTESEYTSGHSVAGVLDQSRMQREKMVYMAVKDSSQEEDDISCAEIADEVYMEVIVGEEEGTSLPEIQLEDSDVNKTVVPVVWAAAYGNTLDSALESRSSTAAQYLQICDGINTNKVLKQKAKKRRRGETRQWQTAVIIGPDGQPLTVYPCHICTKKFKSRGFLKRHMKNHPDHLMRKKYQCTDCDFTTNKKVSFHNHLESHKLINKVDKTHEFTEYTRRYREASPLSSNKLILRDKEPKMHKCKYCDYETAEQGLLNRHLLAVHSKNFPHVCVECGKGFRHPSELKKHMRTHTGEKPYQCQYCIFRCADQSNLKTHIKSKHGNNLPYKCEHCPQAFGDERELQRHLDLFQGHKTHQCPHCDHKSTNSSDLKRHIISVHTKDFPHKCEVCDKGFHRPSELKKHSDIHKGRKIHQCRHCDFKTSDPFILSGHILSVHTKDQPLKCKRCKRGFRQQNELKKHMKTHTGRKIYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEFCKKGFRRPSEKNQHIMRHHKEALM>sp|Q9Y462-3|ZN711_HUMAN Isoform 3 of Zinc finger protein 711 OS=Homosapiens OX=9606 GN=ZNF711MDSGGGSLGLHTPDSRMAHTMIMQDFVAGMAGTAHIDGDHIVVSVPEAVLVSDVVTDDGITLDHGLAAEVVHGPDIITETDVVTEGVIVPEAVLEADVAIEEDLEEDDGDHILTSELITETVRVPEQVFVADLVTGPNGHLEHVVQDCVSGVDSPTMVSEEVLVTNSDTETVIQAAGGVPGSTVTIKTEDDDDDDVKSTSEDYLMISLDDVGEKLEHMGNTPLKIGSDGSQEDAKEDGFGSEVIKVYIFKAEAEDDVEIGGTEIVTESEYTSGHSVAGVLDQSRMQREKMVYMAVKDSSQEEDDISCAEIADEVYMEVIVGEEEGTSLPEIQLEDSDVNKTVVPVVWAAAYGDERRVSRRYEDCQASGNTLDSALESRSSTAAQYLQICDGINTNKVLKQKAKKRRRGETRQWQTAVIIGPDGQPLTVYPCHICTKKFKSRGFLKRHMKNHPDHLMRKKYQCTDCDFTTNKKVSFHNHLESHKLINKVDKTHEFTEYTRRYREASPLSSNKLILRDKEPKMHKCKYCDYETAEQGLLNRHLLAVHSKNFPHVCVECGKGFRHPSELKKHMRTHTGEKPYQCQYCIFRCADQSNLKTHIKSKHGNNLPYKCEHCPQAFGDERELQRHLDLFQGHKTHQCPHCDHKSTNSSDLKRHIISVHTKDFPHKCEVCDKGFHRPSELKKHSDIHKGRKIHQCRHCDFKTSDPFILSGHILSVHTKDQPLKCKRCKRGFRQQNELKKHMKTHTGRKIYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEFCKKGFRRPSEKNQHIMRHHKEALM>sp|Q9UII5|ZN107_HUMAN Zinc finger protein 107 OS=Homo sapiens OX=9606GN=ZNF107 PE=1 SV=1MVAKPPVMSFHFAQDLWPEQNIKDSFQKVTLRRYGKCEYENLQLRKGCKHVDECTGHKGGHNTVNQCLTATPSKIFQCNKYVKVFDKFSNSNRYKRRHTGNKHFKCKECSKSFCVLSQLTQHRRIHTRVNSYKCEECGKAFNWFSTLTKHKRIHTGEKPYKCEECGKAFNQSSQLTRHKIIHTEEKPNKCEECGKAFKQASHLTIHKIIHTGEKPYKYEECGKVFSQSSHLTTQKILHTGENLYKCKECGKAFNLFSNLTNHKRIHAGEKPYKCKECGRAFNISSNLNKQEKIHTGGKLNKCEECDKAFNRSLKLTAHKKILMEEKPYKCEECGKVFNQFSTLTRHKIIHTGEKPYKCKECGKAFNQSSNLTEHKKIHTAEKSYKCEECGKAFNQHSNLINHRKIYSGEKPYKCEECGKAFNRSSTLTRHKKIHTGEKPYKCEECDRAFSQSSNLTEHKKIHTGEKPYKCEECGKAFNRFSTLTKHKRIHTGEKPYKCEECGKAFNQSYQLTRHKIVHTKEKLNKCEEFGKAFKQSSHRTIHKIIHTGEKPYKCEEHGKVFNQSSNLTTQKIIHTGENLYKFEEHGKAFNLFSNITNHKIIYTGEKPHKCEECGKAYNRFSNLTIHKRIHTGEKPYQCAECGKAFNCSSTLNRHKIIHTGEKPYKCKECGKAFNLSSTLTAHKKIHTGEKPYKCEECGKAFNQSSNLTTHKKIHTSEKPYKCEECGKSFNQFSSLNIHKIIHTGEKPYKCGDYGRAFNLSSNLTTHKKIHTGEKPYKCEYGKT>sp|Q96TA2|YMEL1_HUMAN ATP-dependent zinc metalloprotease YME1L1 OS=Homosapiens OX=9606 GN=YME1L1 PE=1 SV=2MFSLSSTVQPQVTVPLSHLINAFHTPKNTSVSLSGVSVSQNQHRDVVPEHEAPSSECMFSDFLTKLNIVSIGKGKIFEGYRSMFMEPAKRMKKSLDTTDNWHIRPEPFSLSIPPSLNLRDLGLSELKIGQIDQLVENLLPGFCKGKNISSHWHTSHVSAQSFFENKYGNLDIFSTLRSSCLYRHHSRALQSICSDLQYWPVFIQSRGFKTLKSRTRRLQSTSERLAETQNIAPSFVKGFLLRDRGSDVESLDKLMKTKNIPEAHQDAFKTGFAEGFLKAQALTQKTNDSLRRTRLILFVLLLFGIYGLLKNPFLSVRFRTTTGLDSAVDPVQMKNVTFEHVKGVEEAKQELQEVVEFLKNPQKFTILGGKLPKGILLVGPPGTGKTLLARAVAGEADVPFYYASGSEFDEMFVGVGASRIRNLFREAKANAPCVIFIDELDSVGGKRIESPMHPYSRQTINQLLAEMDGFKPNEGVIIIGATNFPEALDNALIRPGRFDMQVTVPRPDVKGRTEILKWYLNKIKFDQSVDPEIIARGTVGFSGAELENLVNQAALKAAVDGKEMVTMKELEFSKDKILMGPERRSVEIDNKNKTITAYHESGHAIIAYYTKDAMPINKATIMPRGPTLGHVSLLPENDRWNETRAQLLAQMDVSMGGRVAEELIFGTDHITTGASSDFDNATKIAKRMVTKFGMSEKLGVMTYSDTGKLSPETQSAIEQEIRILLRDSYERAKHILKTHAKEHKNLAEALLTYETLDAKEIQIVLEGKKLEVR>sp|Q96TA2-2|YMEL1_HUMAN Isoform 2 of ATP-dependent zinc metalloproteaseYME1L1 OS=Homo sapiens OX=9606 GN=YME1L1MFSLSSTVQPQVTVPLSHLINAFHTPKNTSVSLSGVSVSQNQHRDVVPEHEAPSSEPSLNLRDLGLSELKIGQIDQLVENLLPGFCKGKNISSHWHTSHVSAQSFFENKYGNLDIFSTLRSSCLYRHHSRALQSICSDLQYWPVFIQSRGFKTLKSRTRRLQSTSERLAETQNIAPSFVKGFLLRDRGSDVESLDKLMKTKNIPEAHQDAFKTGFAEGFLKAQALTQKTNDSLRRTRLILFVLLLFGIYGLLKNPFLSVRFRTTTGLDSAVDPVQMKNVTFEHVKGVEEAKQELQEVVEFLKNPQKFTILGGKLPKGILLVGPPGTGKTLLARAVAGEADVPFYYASGSEFDEMFVGVGASRIRNLFREAKANAPCVIFIDELDSVGGKRIESPMHPYSRQTINQLLAEMDGFKPNEGVIIIGATNFPEALDNALIRPGRFDMQVTVPRPDVKGRTEILKWYLNKIKFDQSVDPEIIARGTVGFSGAELENLVNQAALKAAVDGKEMVTMKELEFSKDKILMGPERRSVEIDNKNKTITAYHESGHAIIAYYTKDAMPINKATIMPRGPTLGHVSLLPENDRWNETRAQLLAQMDVSMGGRVAEELIFGTDHITTGASSDFDNATKIAKRMVTKFGMSEKLGVMTYSDTGKLSPETQSAIEQEIRILLRDSYERAKHILKTHAKEHKNLAEALLTYETLDAKEIQIVLEGKKLEVR>sp|Q96TA2-3|YMEL1_HUMAN Isoform 3 of ATP-dependent zinc metalloproteaseYME1L1 OS=Homo sapiens OX=9606 GN=YME1L1MFSLSSTVQPQVTVPLSHLINAFHTPKNTSVSLSGVSVSQNQHRDVVPEHEAPSSEPSLNLRDLGLSELKIGQIDQLVENLLPGFCKGKNISSHWHTSHVSAQSFFENKYVFIQSRGFKTLKSRTRRLQSTSERLAETQNIAPSFVKGFLLRDRGSDVESLDKLMKTKNIPEAHQDAFKTGFAEGFLKAQALTQKTNDSLRRTRLILFVLLLFGIYGLLKNPFLSVRFRTTTGLDSAVDPVQMKNVTFEHVKGVEEAKQELQEVVEFLKNPQKFTILGGKLPKGILLVGPPGTGKTLLARAVAGEADVPFYYASGSEFDEMFVGVGASRIRNLFREAKANAPCVIFIDELDSVGGKRIESPMHPYSRQTINQLLAEMDGFKPNEGVIIIGATNFPEALDNALIRPGRFDMQVTVPRPDVKGRTEILKWYLNKIKFDQSVDPEIIARGTVGFSGAELENLVNQAALKAAVDGKEMVTMKELEFSKDKILMGPERRSVEIDNKNKTITAYHESGHAIIAYYTKDAMPINKATIMPRGPTLGHVSLLPENDRWNETRAQLLAQMDVSMGGRVAEELIFGTDHITTGASSDFDNATKIAKRMVTKFGMSEKLGVMTYSDTGKLSPETQSAIEQEIRILLRDSYERAKHILKTHAKEHKNLAEALLTYETLDAKEIQIVLEGKKLEVR>sp|O75123|ZN623_HUMAN Zinc finger protein 623 OS=Homo sapiens OX=9606GN=ZNF623 PE=1 SV=3MILLSFVSDSNVGTGEKKVTEAWISEDENSHRTTSDRLTVMELPSPESEEVHEPRLGELLGNPEGQSLGSSPSQDRGCKQVTVTHWKIQTGETAQVCTKSGRNHILNSDLLLLQRELIEGEANPCDICGKTFTFNSDLVRHRISHAGEKPYTCDQCGKGFGQSSHLMEHQRIHTGERLYVCNVCGKDFIHYSGLIEHQRVHSGEKPFKCAQCGKAFCHSSDLIRHQRVHTRERPFECKECGKGFSQSSLLIRHQRIHTGERPYECNECGKSFIRSSSLIRHYQIHTEVKQYECKECGKAFRHRSDLIEHQRIHTGERPFECNECGKAFIRSSKLIQHQRIHTGERPYVCNECGKRFSQTSNFTQHQRIHTGEKLYECNECGKAFFLSSYLIRHQKIHTGERVYECKECGKAFLQKAHLTEHQKIHSGDRPFECKDCGKAFIQSSKLLLHQIIHTGEKPYVCSYCGKGFIQRSNFLQHQKIHTEEKLYECSQYGRDFNSTTNVKNNQRVHQEGLSLSKAPIHLGERSVDKGEHTGNL>sp|O75123-2|ZN623_HUMAN Isoform 2 of Zinc finger protein 623 OS=Homosapiens OX=9606 GN=ZNF623MELPSPESEEVHEPRLGELLGNPEGQSLGSSPSQDRGCKQVTVTHWKIQTGETAQVCTKSGRNHILNSDLLLLQRELIEGEANPCDICGKTFTFNSDLVRHRISHAGEKPYTCDQCGKGFGQSSHLMEHQRIHTGERLYVCNVCGKDFIHYSGLIEHQRVHSGEKPFKCAQCGKAFCHSSDLIRHQRVHTRERPFECKECGKGFSQSSLLIRHQRIHTGERPYECNECGKSFIRSSSLIRHYQIHTEVKQYECKECGKAFRHRSDLIEHQRIHTGERPFECNECGKAFIRSSKLIQHQRIHTGERPYVCNECGKRFSQTSNFTQHQRIHTGEKLYECNECGKAFFLSSYLIRHQKIHTGERVYECKECGKAFLQKAHLTEHQKIHSGDRPFECKDCGKAFIQSSKLLLHQIIHTGEKPYVCSYCGKGFIQRSNFLQHQKIHTEEKLYECSQYGRDFNSTTNVKNNQRVHQEGLSLSKAPIHLGERSVDKGEHTGNL>sp|Q7Z5H4|VN1R5_HUMAN Vomeronasal type-1 receptor 5 OS=Homo sapiensOX=9606 GN=VN1R5 PE=2 SV=2MLKLVIIENMAEIMLFSLDLLLFSTDILCFNFPSKMIKLPGFITIQIFFYPQASFGISANTILLLFHIFTFVFSHRSKSIDMIISHLSLIHILLLFTQAILVSLDFFGSQNTQDDLRYKVIVFLNKVMRGLSICTPCLLSVLQAIISPSIFSLAKLKHPSASHILGFFLFSWVLNMFIGVIFCCTLRLPPVKRGQSSVCHTALFLFAHELHPQETVFHTNDFEGCHLYRVHGPLKRLHGDYFIQTIRGYLSAFTQPACPRVSPVKRASQAILLLVSFVFTYWVDFTFSFSGGVTWINDSLLVWLQVIVANSYAAISPLMLIYADNQIFKTLQMLWFKYLSPPKLMLKFNRQCGSTKK>sp|Q96G27|WBP1_HUMAN WW domain-binding protein 1 OS=Homo sapiens OX=9606GN=WBP1 PE=1 SV=1MARASSGNGSEEAWGALRAPQQQLRELCPGVNNQPYLCESGHCCGETGCCTYYYELWWFWLLWTVLILFSCCCAFRHRRAKLRLQQQQRQREINLLAYHGACHGAGPFPTGSLLDLRFLSTFKPPAYEDVVHRPGTPPPPYTVAPGRPLTASSEQTCCSSSSSCPAHFEGTNVEGVSSHQSAPPHQEGEPGAGVTPASTPPSCRYRRLTGDSGIELCPCPASGEGEPVKEVRVSATLPDLEDYSPCALPPESVPQIFPMGLSSSEGDIP>sp|Q6ZVH6|YK004_HUMAN Putative uncharacterized protein FLJ42569 OS=Homosapiens OX=9606 PE=2 SV=1MGPWPRDWLGKGWRLGSCEARAGAKEVSVIRHGAPNPAQSHLHVQARAQVHSEDGHSLPPVVDGEDEVLSLLVFVQDSQECCRQAVQGRQGRGVTWGLGLPSYHLRTLLSPVCVPARDQRAPRKCCEAVLACPLVETLVTTLLTR>sp|Q6ZSR9|YJ005_HUMAN Uncharacterized protein FLJ45252 OS=Homo sapiensOX=9606 PE=2 SV=2MGTKGLPLYPDPSRVPGTKTQNNLESDYLARDGPSSNSSFHSSEEEGTDLEGDMLDCSGSRPLLMESEEEDESCRPPPGKLGGAVPFAPPEVSPEQAKTVQGGRKNQFQAFTQPATDGLSEPDVFAIAPFRSSRVPNDDMDIFSKAPFVSKSSMAPSQPEESDVFLRAPFTKKKSMEELTVIQCTSQELPAQTGLLSQTGDVPLPAGRERAVYTSVQAQYSTAGFVQQSNLLSHSVQAADHLDSISPRGSCLESGGHSNDRNKGPQLQKEAVSGPMAGKPFRPQSLSKYSRHYSPEDEPSPEAQPIAAYKIVSQTNKQSIAGSVSITSLSSRTTELPAADPFALAPFPSKSGKKP>sp|Q9UL59|ZN214_HUMAN Zinc finger protein 214 OS=Homo sapiens OX=9606GN=ZNF214 PE=2 SV=2MAVTFEDVTIIFTWEEWKFLDSSQKRLYREVMWENYTNVMSVENWNESYKSQEEKFRYLEYENFSYWQGWWNAGAQMYENQNYGETVQGTDSKDLTQQDRSQCQEWLILSTQVPGYGNYELTFESKSLRNLKYKNFMPWQSLETKTTQDYGREIYMSGSHGFQGGRYRLGISRKNLSMEKEQKLIVQHSYIPVEEALPQYVGVICQEDLLRDSMEEKYCGCNKCKGIYYWNSRCVFHKRNQPGENLCQCSICKACFSQRSDLYRHPRNHIGKKLYGCDEVDGNFHQSSGVHFHQRVHIGEVPYSCNACGKSFSQISSLHNHQRVHTEEKFYKIECDKDLSRNSLLHIHQRLHIGEKPFKCNQCGKSFNRSSVLHVHQRVHTGEKPYKCDECGKGFSQSSNLRIHQLVHTGEKSYKCEDCGKGFTQRSNLQIHQRVHTGEKPYKCDDCGKDFSHSSDLRIHQRVHTGEKPYTCPECGKGFSKSSKLHTHQRVHTGEKPYKCEECGKGFSQRSHLLIHQRVHTGEKPYKCHDCGKGFSHSSNLHIHQRVHTGEKPYQCAKCGKGFSHSSALRIHQRVHAGEKPYKCREYYKGFDHNSHLHNNHRRGNL>sp|Q5W0Z9|ZDH20_HUMAN Palmitoyltransferase ZDHHC20 OS=Homo sapiensOX=9606 GN=ZDHHC20 PE=1 SV=1MAPWTLWRCCQRVVGWVPVLFITFVVVWSYYAYVVELCVFTIFGNEENGKTVVYLVAFHLFFVMFVWSYWMTIFTSPASPSKEFYLSNSEKERYEKEFSQERQQEILRRAARALPIYTTSASKTIRYCEKCQLIKPDRAHHCSACDSCILKMDHHCPWVNNCVGFSNYKFFLLFLLYSLLYCLFVAATVLEYFIKFWTNELTDTRAKFHVLFLFFVSAMFFISVLSLFSYHCWLVGKNRTTIESFRAPTFSYGPDGNGFSLGCSKNWRQVFGDEKKYWLLPIFSSLGDGCSFPTRLVGMDPEQASVTNQNEYARSSGSNQPFPIKPLSESKNRLLDSESQWLENGAEEGIVKSGTNNHVTVAIEN>sp|Q5W0Z9-2|ZDH20_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC20OS=Homo sapiens OX=9606 GN=ZDHHC20MAPWTLWRCCQRVVGWVPVLFITFVVVWSYYAYVVELCVFTIFGNEENGKTVVYLVAFHLFFVMFVWSYWMTIFTSPASPSKEFYLSNSEKERYEKEFSQERQQEILRRAARALPIYTTSASKSLMQSTK>sp|Q5W0Z9-3|ZDH20_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC20OS=Homo sapiens OX=9606 GN=ZDHHC20MAPWTLWRCCQRVVGWVPVLFITFVVVWSYYAYVVELCVFTIFGNEENGKTVVYLVAFHLFFVMFVWSYWMTIFTSPASPSKEFYLSNSEKERYEKEFSQERQQEILRRAARALPIYTTSASKTIRYCEKCQLIKPDRAHHCSACDSCILKMDHHCPWVNNCVGFSNYKFFLLFLLYSLLYCLFVAATVLEYFIKFWTNELTDTRAKFHVLFLFFVSAMFFISVLSLFSYHCWLVGKNRTTIESFRAPTFSYGPDGNGFSLGCSKNWRQVFGDEKKYWLLPIFSSLGDGCSFPTRLVGMDPEQASVTNQNEYARSGSNQPFPIKPLSESKNRLLDSESQWLENGAEEGIVKSGV>sp|Q5W0Z9-4|ZDH20_HUMAN Isoform 4 of Palmitoyltransferase ZDHHC20OS=Homo sapiens OX=9606 GN=ZDHHC20MAPWTLWRCCQRVVGWVPVLFITFVVVWSYYAYVVELCVFTIFGNEENGKTVVYLVAFHLFFVMFVWSYWMTIFTSPASPSKEFYLSNSEKERYEKEFSQERQQEILRRAARALPIYTTSASKTIRYCEKCQLIKPDRAHHCSACDSCILKMDHHCPWVNNCVGFSNYKFFLLFLLYSLLYCLFVAATVLEYFIKFWTNELTDTRAKFHVLFLFFVSAMFFISVLSLFSYHCWLVGKNRTTIESFRAPTFSYGPDGNGFSLGCSKNWRQVFGDEKKYWLLPIFSSLGDGCSFPTRLVGMDPEQASVTNQNEYARRSKLQR>sp|Q7L2R6|ZN765_HUMAN Zinc finger protein 765 OS=Homo sapiens OX=9606GN=ZNF765 PE=1 SV=2MALPQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCMMKEFSSTAQGNREVFHAGTSQRHESHHNGDFCFQDIDKDIHDIEFQWQEDERNGHEALMTKIKKLTGSTERYDQNYAGNKPVKYQLGFSFHSHLPELHIFHTEEKIDNQVVKSIHDASLVSTAQRISCRPETHISNDYGNNFLNSSLFTQKQEVHMREKSFQCNDSGKAYNCSSLLRKHQLIHLGEKQYKCDICGKVFNSKRYVARHRRCHTGEKPYKCNECGKTFSQTYYLTCHRRLHTGEKPYKCEECDKAFHFKSKLQIHRRIHTGEKPYKCNECGKTFSQKSYLTCHRRLHTGEKPYKCNECGKTFSRKSHFTCHHRVHTGEKPYKCNECSKTFSHKSSLTYHRRLHTEEKPYKCNECGKTFNQQLTLNICRLHSGEKPYKCEECDKAYSFKSNLEIHQKIHTEENPYKCNECGKTFSRTSSLTYHHRLHTGQKPYKCEDCDEAFSFKSNLERHRRIYTGEKLHV>sp|Q7L2R6-2|ZN765_HUMAN Isoform 2 of Zinc finger protein 765 OS=Homosapiens OX=9606 GN=ZNF765MALPQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLELSGECPLAAPAS>sp|Q7L2R6-3|ZN765_HUMAN Isoform 3 of Zinc finger protein 765 OS=Homosapiens OX=9606 GN=ZNF765MALPQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLEFWSVIPAKVQWCHLRSLQPPLPRFKQFSCLSLPSTWDYRYLFQMHVEDVVVNRARQYRSDPHRDIAQTSKSSHWRILFP>sp|P21506|ZNF10_HUMAN Zinc finger protein 10 OS=Homo sapiens OX=9606GN=ZNF10 PE=1 SV=3MDAKSLTAWSRTLVTFKDVFVDFTREEWKLLDTAQQIVYRNVMLENYKNLVSLGYQLTKPDVILRLEKGEEPWLVEREIHQETHPDSETAFEIKSSVSSRSIFKDKQSCDIKMEGMARNDLWYLSLEEVWKCRDQLDKYQENPERHLRQVAFTQKKVLTQERVSESGKYGGNCLLPAQLVLREYFHKRDSHTKSLKHDLVLNGHQDSCASNSNECGQTFCQNIHLIQFARTHTGDKSYKCPDNDNSLTHGSSLGISKGIHREKPYECKECGKFFSWRSNLTRHQLIHTGEKPYECKECGKSFSRSSHLIGHQKTHTGEEPYECKECGKSFSWFSHLVTHQRTHTGDKLYTCNQCGKSFVHSSRLIRHQRTHTGEKPYECPECGKSFRQSTHLILHQRTHVRVRPYECNECGKSYSQRSHLVVHHRIHTGLKPFECKDCGKCFSRSSHLYSHQRTHTGEKPYECHDCGKSFSQSSALIVHQRIHTGEKPYECCQCGKAFIRKNDLIKHQRIHVGEETYKCNQCGIIFSQNSPFIVHQIAHTGEQFLTCNQCGTALVNTSNLIGYQTNHIRENAY>sp|Q96M66|YP010_HUMAN Putative uncharacterized protein FLJ32790 OS=Homosapiens OX=9606 PE=2 SV=2MAAKSTQDSLPRDTGEPSALPVQGRAEGRSSEGRKERTAECALRGKQASEPALRKRNFLPGPNSDTVRPAAETELVPCSLRHPRQDLCGEHPSFPVMQPSLETQAKPERDRAVLIPPKGPWPPAQGLAMRTHCPTGPPSKAYCRGGSSSTSRNQVASLAYRTQNTAASQPRQPGGRGKEDTAGYGSCSPRSLAV>sp|Q6ZTB9|ZN833_HUMAN Putative zinc finger protein 833 OS=Homo sapiensOX=9606 GN=ZNF833P PE=5 SV=1MVMHSEDEPYKCKFCGKAFDNLHLYLTHERTHTGEKPYECNKCGKAFSCSSSIRKHARIHTGEKPYICKQCGKAFRYSSSIRNHENTHTGEKPCECKQCGKAFSYSSYFRIHERIHTGEQVYKCKECGKTFTYPSAFHKHKSTHTSQKLYECKECGKAFDCFSSFHSHEGVHTGEKPYECRTWKSLQ>sp|Q96C28|ZN707_HUMAN Zinc finger protein 707 OS=Homo sapiens OX=9606GN=ZNF707 PE=1 SV=2MDMAQEPVTFRDVAIYFSREEWACLEPSQRALYRDVMLDNFSSVAALGFCSPRPDLVSRLEQWEEPWVEDRERPEFQAVQRGPRPGARKSADPKRPCDHPAWAHKKTHVRRERAREGSSFRKGFRLDTDDGQLPRAAPERTDAKPTAFPCQVLTQRCGRRPGRRERRKQRAVELSFICGTCGKALSCHSRLLAHQTVHTGTKAFECPECGQTFRWASNLQRHQKNHTREKPFCCEACGQAFSLKDRLAQHRKVHTEHRPYSCGDCGKAFKQKSNLLRHQLVHTGERPFYCADCGKAFRTKENLSHHQRVHSGEKPYTCAECGKSFRWPKGFSIHRRLHLTKRFYECGHCGKGFRHLGFFTRHQRTHRHGEV>sp|Q5VZL5|ZMYM4_HUMAN Zinc finger MYM-type protein 4 OS=Homo sapiensOX=9606 GN=ZMYM4 PE=1 SV=1MAEREVESGPRKRFEQKSGAVFDEIVENCGGIMDTEMSEDIDHNLTPTLDSMSYGMPNQTGSENSLLDEDDYFLNSGDLAGIPVVGSDNEDEQDFSSKDNLVSSIHTDDSLEVERRVTQHESDNENEIQIQNKLKKDFPKQFDQVSVFKSIRKDFSLVRENSKETFSGKEKNRDLTYEREKRLDKPHKDLDSRLKSSFFDKAANQVEETLHTHLPQTPETNFRDSSYPFANKESIGSELGNSFASNIRIKEEPLDDEYDKAMAPQQGLLDKIKDEPDNAQEYSHGQQQKTQEGELKISAVFSVSGSPLAPQLTTGFQPSLASSGMNKMLPSVPATAVRVSCSGCKKILQKGQTAYQRKGSTQLFCSTLCLTGYTVPPARPPPPLTKKTCSSCSKDILNPKDVISAQFENTTTSKDFCSQSCLSTYELKKKPIVTINTNSISTKCSMCQKNAVIRHEVNYQNVVHKLCSDACFSKFRSANNLTMNCCENCGGYCYSGSGQCHMLQIEGQSKKFCSSSCITAYKQKSAKITPCALCKSLRSSAEMIENTNSLGKTELFCSVNCLSAYRVKMVTSAGVQVQCNSCKTSAIPQYHLAMSDGSIRNFCSYSCVVAFQNLFNKPTGMNSSVVPLSQGQVIVSIPTGSTVSAGGGSTSAVSPTSISSSAAAGLQRLAAQSQHVGFARSVVKLKCQHCNRLFATKPELLDYKGKMFQFCGKNCSDEYKKINNVMAMCEYCKIEKIVKETVRFSGADKSFCSEGCKLLYKHDLAKRWGNHCKMCSYCLQTSPKLVQNNLGGKVEEFCCEECMSKYTVLFYQMAKCDACKRQGKLSESLKWRGEMKHFCNLLCILMFCNQQSVCDPPSQNNAANISMVQAASAGPPSLRKDSTPVIANVVSLASAPAAQPTVNSNSVLQGAVPTVTAKIIGDASTQTDALKLPPSQPPRLLKNKALLCKPITQTKATSCKPHTQNKECQTEDTPSQPQIIVVPVPVPVFVPIPLHLYTQYAPVPFGIPVPMPVPMLIPSSMDSEDKVTESIEDIKEKLPTHPFEADLLEMAEMIAEDEEKKTLSQGESQTSEHELFLDTKIFEKDQGSTYSGDLESEAVSTPHSWEEELNHYALKSNAVQEADSELKQFSKGETEQDLEADFPSDSFDPLNKGQGIQARSRTRRRHRDGFPQPRRRGRKKSIVAVEPRSLIQGAFQGCSVSGMTLKYMYGVNAWKNWVQWKNAKEEQGDLKCGGVEQASSSPRSDPLGSTQDHALSQESSEPGCRVRSIKLKEDILSCTFAELSLGLCQFIQEVRRPNGEKYDPDSILYLCLGIQQYLFENGRIDNIFTEPYSRFMIELTKLLKIWEPTILPNGYMFSRIEEEHLWECKQLGAYSPIVLLNTLLFFNTKYFQLKNVTEHLKLSFAHVMRRTRTLKYSTKMTYLRFFPPLQKQESEPDKLTVGKRKRNEDDEVPVGVEMAENTDNPLRCPVRLYEFYLSKCSESVKQRNDVFYLQPERSCVPNSPMWYSTFPIDPGTLDTMLTRILMVREVHEELAKAKSEDSDVELSD>sp|Q5VZL5-2|ZMYM4_HUMAN Isoform 2 of Zinc finger MYM-type protein 4OS=Homo sapiens OX=9606 GN=ZMYM4MAEREVESGPRKRFEQKSGAVFDEIVENCGGIMDTEMSEDIDHNLTPTLDSMSYGMPNQTGSENSLLDEDDYFLNSGDLAGIPVVGSDNEDEQDFSSKDNLVSSIHTDDSLEVERRVTQHESDNENEIQIQNKLKKDFPKQFDQVSVFKSIRKDFSLVRENSKETFSGKEKNRDLTYEREKRLDKPHKDLDSRLKSSFFDKAANQVEETLHTHLPQTPETNFRDSSYPFANKESIGSELGNSFASNIRIKEEPLDDEYDKAMAPQQGLLDKIKDEPDNAQEYSHGQQQKTQEGELKISAVFSVSGSPLAPQLTTGFQPSLASSGMNKMLPSVPATAVRVSCSGCKKILQKGQTAYQRKGSTQLFCSTLCLTGYTVPPARPPPPLTKKTCSSCSKDILNPKDVISAQFENTTTSKDFCSQSCLSTYELKKKPIVTINTNSISTKCSMCQKNAVIRHEVNYQNVVHKLCSDACFSKFRSANNLTMNCCENCGGYCYSGSGQCHMLQIEGQSKKFCSSSCITAYKQNLFNKPTGMNSSVVPLSQGQVIVSIPTGSTVSAGGGSTSAVSPTSISSSAAAGLQRLAAQSQHVGFARSVVKLKCQHCNRLFATKPELLDYKGKMFQFCGKNCSDEYKKINNVMAMCEYCKIEKIVKETVRFSGADKSFCSEGCKLLYKHDLAKRWGNHCKMCSYCLQTSPKLVQNNLGGKVEEFCCEECMSKYTVLFYQMAKCDACKRQGKLSESLKWRGEMKHFCNLLCILMFCNQQSVCDPPSQNNAANISMVQAASAGPPSLRKDSTPVIANVVSLASAPAAQPTVNSNSVLQGAVPTVTAKIIGDASTQTDALKLPPSQPPRLLKNKALLCKPITQTKATSCKPHTQNKECQTEDTPSQPQIIVVPVPVPVFVPIPLHLYTQYAPVPFGIPVPMPVPMLIPSSMDSEDKVTESIEDIKEKLPTHPFEADLLEMAEMIAEDEEKKTLSQGESQTSEHELFLDTKIFEKDQGSTYSGDLESEAVSTPHSWEEELNHYALKSNAVQEADSELKQFSKGETEQDLEADFPSDSFDPLNKGQGIQARSRTRRRHRDGFPQPRRRGRKKSIVAVEPRSLIQGAFQGCSVSGMTLKYMYGVNAWKNWVQWKNAKEEQGDLKCGGVEQASSSPRSDPLGSTQDHALSQESSEPGCRVRSIKLKEDILSCTFAELSLGLCQFIQEVRRPNGEKYDPDSILYLCLGIQQYLFENGRIDNIFTEPYSRFMIELTKLLKIWEPTILPNGYMFSRIEEEHLWECKQLGAYSPIVLLNTLLFFNTKYFQLKNVTEHLKLSFAHVMRRTRTLKYSTKMTYLRFFPPLQKQESEPDKLTVGKRKRNEDDEVPVGVEMAENTDNPLRCPVRLYEFYLSKCSESVKQRNDVFYLQPERSCVPNSPMWYSTFPIDPGTLDTMLTRILMVREVHEELAKAKSEDSDVELSD>sp|Q5VZL5-3|ZMYM4_HUMAN Isoform 3 of Zinc finger MYM-type protein 4OS=Homo sapiens OX=9606 GN=ZMYM4MNKMLPSVPATAVRVSCSGCKKILQKGQTAYQRKGSTQLFCSTLCLTGYTVPPARPPPPLTKKTCSSCSKDILNPKDVISAQFENTTTSKDFCSQSCLSTYELKKKPIVTINTNSISTKCSMCQKNAVIRHEVNYQNVVHKLCSDACFSKFRSANNLTMNCCENCGGYCYSGSGQCHMLQIEGQSKKFCSSSCITAYKQKSAKITPCALCKSLRSSAEMIENTNSLGKTELFCSVNCLSAYRVKMVTSAGVQVQCNSCKTSAIPQYHLAMSDGSIRNFCSYSCVVAFQNLFNKPTGMNSSVVPLSQGQVIVSIPTGSTVSAGGGSTSAVSPTSISSSAAAGLQRLAAQSQHVGFARSVVKLKCQHCNRLFATKPELLDYKGKMFQFCGKNCSDEYKKINNVMAMCEYCKIEKIVKETVRFSGADKSFCSEGCKLLYKHDLAKRWGNHCKMCSYCLQTSPKLVQNNLGGKVEEFCCEECMSKYTVLFYQMAKCDACKRQGKLSESLKWRGEMKHFCNLLCILMFCNQQSVCDPPSQNNAANISMVQAASAGPPSLRKDSTPVIANVVSLASAPAAQPTVNSNSVLQGAVPTVTAKIIGDASTQTDALKLPPSQPPRLLKNKALLCKPITQTKATSCKPHTQNKECQTEDTPSQPQIIVVPVPVPVFVPIPLHLYTQYAPVPFGIPVPMPVPMLIPSSMDSEDKVTESIEDIKEKLPTHPFEADLLEMAEMIAEDEEKKTLSQGESQTSEHELFLDTKIFEKDQGSTYSGDLESEAVSTPHSWEEELNHYALKSNAVQEADSELKQFSKGETEQDLEADFPSDSFDPLNKGQGIQARSRTRRRHRDGFPQPRRRGRKKSIVAVEPRSLIQGAFQGCSVSGMTLKYMYGVNAWKNWVQWKNAKEEQGDLKCGGVEQASSSPRSDPLGSTQDHALSQESSEPGCRVRSIKLKEDILSCTFAELSLGLCQFIQEVRRPNGEKYDPDSILYLCLGIQQYLFENGRIDNIFTEPYSRFMIELTKLLKIWEPTILPNGYMFSRIEEEHLWECKQLGAYSPIVLLNTLLFFNTKYFQLKNVTEHLKLSFAHVMRRTRTLKYSTKMTYLRFFPPLQKQESEPDKLTVGKRKRNEDDEVPVGVEMAENTDNPLRCPVRLYEFYLSKCSESVKQRNDVFYLQPERSCVPNSPMWYSTFPIDPGTLDTMLTRILMVREVHEELAKAKSEDSDVELSD>sp|Q5VZL5-4|ZMYM4_HUMAN Isoform 4 of Zinc finger MYM-type protein 4OS=Homo sapiens OX=9606 GN=ZMYM4MDTEMSEDIDHNLTPTLDSMSYGMPNQTGSENSLLDEDDYFLNSGDLAGIPVVGSDNEDEQDFSSKDNLVSSIHTDDSLEVERRVTQHESDNENEIQIQNKLKKDFPKQFDQVSVFKSIRKDFSLVRENSKETFSGKEKNRDLTYEREKRLDKPHKDLDSRLKSSFFDKAANQVEETLHTHLPQTPETNFRDSSYPFANKESIGSELGNSFASNIRIKEEPLDDEYDKAMAPQQGLLDKIKDEPDNAQEYSHGQQQKTQEGELKISAVFSVSGSPLAPQLTTGFQPSLASSGMNKMLPSVPATAVRVSCSGCKKILQKGQTAYQRKGSTQLFCSTLCLTGYTVPPARPPPPLTKKTCSSCSKDILNPKDVISAQFENTTTSKDFCSQSCLSTYELKKKPIVTINTNSISTKCSMCQKNAVIRHEVNYQNVVHKLCSDACFSKFRSANNLTMNCCENCGGYCYSGSGQCHMLQIEGQSKKFCSSSCITAYKQKSAKITPCALCKSLRSSAEMIENTNSLGKTELFCSVNCLSAYRVKMVTSAGVQVQCNSCKTSAIPQYHLAMSDGSIRNFCSYSCVVAFQNLFNKPTGMNSSVVPLSQGQVIVSIPTGSTVSAGGGSTSAVSPTSISSSAAAGLQRLAAQSQHVGFARSVVKLKCQHCNRLFATKPELLDYKGKMFQFCGKNCSDEYKKINNVMAMCEYCKIEKIVKETVRFSGADKSFCSEGCKLLYKHDLAKRWGNHCKMCSYCLQTSPKLVQNNLGGKVEEFCCEECMSKYTVLFYQMAKCDACKRQGKLSESLKWRGEMKHFCNLLCILMFCNQQSVCDPPSQNNAANISMVQAASAGPPSLRKDSTPVIANVVSLASAPAAQPTVNSNSVLQGAVPTVTAKIIGDASTQTDALKLPPSQPPRLLKNKALLCKPITQTKATSCKPHTQNKECQTEDTPSQPQIIVVPVPVPVFVPIPLHLYTQYAPVPFGIPVPMPVPMLIPSSMDSEDKVTESIEDIKEKLPTHPFEADLLEMAEMIAEDEEKKTLSQGESQTSEHELFLDTKIFEKDQGSTYSGDLESEAVSTPHSWEEELNHYALKSNAVQEADSELKQFSKGETEQDLEADFPSDSFDPLNKGQGIQARSRTRRRHRDGFPQPRRRGRKKSIVAVEPRSLIQGAFQGCSVSGMTLKYMYGVNAWKNWVQWKNAKEEQGDLKCGGVEQASSSPRSDPLGSTQDHALSQESSEPGCRVRSIKLKEDILSCTFAELSLGLCQFIQEVRRPNGEKYDPDSILYLCLGIQQYLFENGRIDNIFTEPYSRFMIELTKLLKIWEPTILPNGYMFSRIEEEHLWECKQLGAYSPIVLLNTLLFFNTKYFQLKNVTEHLKLSFAHVMRRTRTLKYSTKMTYLRFFPPLQKQESEPDKLTVGKRKRNEDDEVPVGVEMAENTDNPLRCPVRLYEFYLSKCSESVKQRNDVFYLQPERSCVPNSPMWYSTFPIDPGTLDTMLTRILMVREVHEELAKAKSEDSDVELSD>sp|Q6ZNG0|ZN620_HUMAN Zinc finger protein 620 OS=Homo sapiens OX=9606GN=ZNF620 PE=1 SV=1MFQTAWRQEPVTFEDVAVYFTQNEWASLDSVQRALYREVMLENYANVASLAFPFTTPVLVSQLEQGELPWGLDPWEPMGREALRGICPGDEARTEKEGLTPKDHVSKETESFRLMVGGLPGNVSQHLDFGSSLEQPQGHWIIKTKSKRRHFTDTSARHHEAYEVKNGEKFEKLGKNISVSTQLTTNQTNPSGQISYECGQCGRYFIQMADFHRHEKCHTGEKSFECKECGKYFRYNSLLIRHQIIHTGKKPFKCKECGKGLSSDTALIQHQRIHTGEKPYECKECGKAFSSSSVFLQHQRFHTGEKLYECNECWKTFSCSSSFTVHQRMHTGEKPYECKECGKRLSSNTALTQHQRIHTGEKPFECKECGKAFNQKITLIQHQRVHTGEKPYECKVCGKTFSWCGRFILHQKLHTQKTPVQA>sp|Q6ZNG0-2|ZN620_HUMAN Isoform 2 of Zinc finger protein 620 OS=Homosapiens OX=9606 GN=ZNF620MVGGLPGNVSQHLDFGSSLEQPQGHWIIKTKSKRRHFTDTSARHHEAYEVKNGEKFEKLGKNISVSTQLTTNQTNPSGQISYECGQCGRYFIQMADFHRHEKCHTGEKSFECKECGKYFRYNSLLIRHQIIHTGKKPFKCKECGKGLSSDTALIQHQRIHTGEKPYECKECGKAFSSSSVFLQHQRFHTGEKLYECNECWKTFSCSSSFTVHQRMHTGEKPYECKECGKRLSSNTALTQHQRIHTGEKPFECKECGKAFNQKITLIQHQRVHTGEKPYECKVCGKTFSWCGRFILHQKLHTQKTPVQA>sp|Q9ULD9|ZN608_HUMAN Zinc finger protein 608 OS=Homo sapiens OX=9606GN=ZNF608 PE=1 SV=4MSVNISTAGKGVDPNTVDTYDSGDDWEIGVGNLIIDLDADLEKDRQKFEMNNSTTTTSSSNSKDCGGPASSGAGATAALADGLKFASVQASAPQGNSHKETSKSKVKRSKTSKDANKSLPSAALYGIPEISSTGKRQEVQGRPGEATGMNSALGQSVSSGGSGNPNSNSTSTSTSAATAGAGSCGKSKEEKPGKSQSSRGAKRDKDAGKSRKDKHDLLQGHQNGSGSQAPSGGHLYGFGAKSNGGGASPFHCGGTGSGSVAAAGEVSKSAPDSGLMGNSMLVKKEEEEEESHRRIKKLKTEKVDPLFTVPAPPPPISSSLTPQILPSYFSPSSSNIAAPVEQLLVRTRSVGVNTCEVGVVTEPECLGPCEPGTSVNLEGIVWHETEEGVLVVNVTWRNKTYVGTLLDCTKHDWAPPRFCESPTSDLEMRGGRGRGKRARSAAAAPGSEASFTESRGLQNKNRGGANGKGRRGSLNASGRRTPPNCAAEDIKASPSSTNKRKNKPPMELDLNSSSEDNKPGKRVRTNSRSTPTTPQGKPETTFLDQGCSSPVLIDCPHPNCNKKYKHINGLRYHQAHAHLDPENKLEFEPDSEDKISDCEEGLSNVALECSEPSTSVSAYDQLKAPASPGAGNPPGTPKGKRELMSNGPGSIIGAKAGKNSGKKKGLNNELNNLPVISNMTAALDSCSAADGSLAAEMPKLEAEGLIDKKNLGDKEKGKKATNCKTDKNLSKLKSARPIAPAPAPTPPQLIAIPTATFTTTTTGTIPGLPSLTTTVVQATPKSPPLKPIQPKPTIMGEPITVNPALVSLKDKKKKEKRKLKDKEGKETGSPKMDAKLGKLEDSKGASKDLPGHFLKDHLNKNEGLANGLSESQESRMASIKAEADKVYTFTDNAPSPSIGSASRLECSTLVNGQAPMAPLHVLTQNGAESSAAKTSSPAYSDISDAADDGGSDSRSEGMRSKASSPSDIISSKDSVVKGHSSTTAQSSQLKESHSPYYHSYDPYYSPSYMHPGQVGAPAAGNSGSTQGMKIKKESEEDAEKKDKAEQLDSKKVDHNSASLQPQHQSVITQRHPALAQSLYYGQYAYGLYMDQKSLMATSPAYRQQYEKYYEDQRLAEQKMAQTGRGDCERKSELPLKELGKEETKQKNMPSATISKAPSTPEPNKNHSKLGPSVPNKTEETGKSQLLSNHQQQLQADSFKAKQMENHQLIKEAVEMKSVMDSMKQTGVDPTSRFKQDPDSRTWHHYVYQPKYLDQQKSEELDREKKLKEDSPRKTPNKESGVPSLPVSLTSIKEEPKEAKHPDSQSMEESKLKNDDRKTPVNWKDSRGTRVAVSSPMSQHQSYIQYLHAYPYPQMYDPSHPAYRAVSPVLMHSYPGAYLSPGFHYPVYGKMSGREETEKVNTSPSVNTKTTTESKALDLLQQHANQYRSKSPAPVEKATAEREREAERERDRHSPFGQRHLHTHHHTHVGMGYPLIPGQYDPFQGLTSAALVASQQVAAQASASGMFPGQRRE>sp|Q9ULD9-2|ZN608_HUMAN Isoform 2 of Zinc finger protein 608 OS=Homosapiens OX=9606 GN=ZNF608MRGGRGRGKRARSAAAAPGSEASFTESRGLQNKNRGGANGKGRRGSLNASGRRTPPNCAAEDIKASPSSTNKRKNKPPMELDLNSSSEDNKPGKRVRTNSRSTPTTPQGKPETTFLDQGCSSPVLIDCPHPNCNKKYKHINGLRYHQAHAHLDPENKLEFEPDSEDKISDCEEGLSNVALECSEPSTSVSAYDQLKAPASPGAGNPPGTPKGKRELMSNGPGSIIGAKAGKNSGKKKGLNNELNNLPVISNMTAALDSCSAADGSLAAEMPKLEAEGLIDKKNLGDKEKGKKATNCKTDKNLSKLKSARPIAPAPAPTPPQLIAIPTATFTTTTTGTIPGLPSLTTTVVQATPKSPPLKPIQPKPTIMGEPITVNPALVSLKDKKKKEKRKLKDKEGKETGSPKMDAKLGKLEDSKGASKDLPGHFLKDHLNKNEGLANGLSESQESRMASIKAEADKVYTFTDNAPSPSIGSASRLECSTLVNGQAPMAPLHVLTQNGAESSAAKTSSPAYSDISDAADDGGSDSRSEGMRSKASSPSDIISSKDSVVKGHSSTTAQSSQLKESHSPYYHSYDPYYSPSYMHPGQVGAPAAGNSGSTQGMKIKKESEEDAEKKDKAEQLDSKKVDHNSASLQPQHQSVITQRHPALAQSLYYGQYAYGLYMDQKSLMATSPAYRQQYEKYYEDQRLAEQKMAQTGRGDCERKSELPLKELGKEETKQKNMPSATISKAPSTPEPNKNHSKLGPSVPNKTEETGKSQLLSNHQQQLQADSFKAKQMENHQLIKEAVEMKSVMDSMKQTGVDPTSRFKQDPDSRTWHHYVYQPKYLDQQKSEELDREKKLKEDSPRKTPNKESGVPSLPVSLTSIKEEPKEAKHPDSQSMEESKLKNDDRKTPVNWKDSRGTRVAVSSPMSQHQSYIQYLHAYPYPQMYDPSHPAYRAVSPVLMHSYPGAYLSPGFHYPVYGKMSGREETEKVNTSPSVNTKTTTESKALDLLQQHANQYRSKSPAPVEKATAEREREAERERDRHSPFGQRHLHTHHHTHVGMGYPLIPGQYDPFQGLTSAALVASQQVAAQASASGMFPGQRRE>sp|Q96NL3|ZN599_HUMAN Zinc finger protein 599 OS=Homo sapiens OX=9606GN=ZNF599 PE=1 SV=1MAAPALALVSFEDVVVTFTGEEWGHLDLAQRTLYQEVMLETCRLLVSLGHPVPKPELIYLLEHGQELWTVKRGLSQSTCAGEKAKPKITEPTASQLAFSEESSFQELLAQRSSRDSRLGQARDEEKLIKIQEGNLRPGTNPHKEICPEKLSYKHDDLEPDDSLGLRVLQERVTPQDALHECDSQGPGKDPMTDARNNPYTCTECGKGFSKKWALVRHQQIHAGVKPYECNECGKACRYMADVIRHMRLHTGEKPYKCIECGKAFKRRFHLTEHQRIHTGDKPYECKECGKAFTHRSSFIQHNMTHTREKPFLCKECGKAFYYSSSFAQHMRIHTGKKLYECGECGKAFTHRSTFIQHNVTHTGEKPFLCKECGKTFCLNSSFTQHMRIHTGEKPYECGECGKAFTHRSTFIRHKRTHTGEKPFECKECGKAFCDSSSLIQHMRIHTGEKPYECSECGKAFTHHSVFIRHNRTHSGQKPLECKECAKAFYYSSSFTRHMRIHTGEKPYVCRECGKAFTQPANFVRHNRIHTGEKPFECKECEKAFCDNFALTQHMRTHTGEKPFECNECGKTFSHSSSFTHHRKIHTRV>sp|Q96NL3-2|ZN599_HUMAN Isoform 2 of Zinc finger protein 599 OS=Homosapiens OX=9606 GN=ZNF599MAAPALALVSFEDVVVTFTGEEWGHLDLAQRTLYQEVMLETCRLLVSLGHPVPKPELIYLLEHGQELWTVKRGLSQSTCAASFSLLWKSYHPGHG>sp|P51522|ZNF83_HUMAN Zinc finger protein 83 OS=Homo sapiens OX=9606GN=ZNF83 PE=2 SV=3MHGRKDDAQKQPVKNQLGLNPQSHLPELQLFQAEGKIYKYDHMEKSVNSSSLVSPPQRISSTVKTHISHTYECNFVDSLFTQKEKANIGTEHYKCSERGKAFHQGLHFTIHQIIHTKETQFKCDICGKIFNKKSNLASHQRIHTGEKPYKCNECGKVFHNMSHLAQHRRIHTGEKPYKCNECGKVFNQISHLAQHQRIHTGEKPYKCNECGKVFHQISHLAQHRTIHTGEKPYECNKCGKVFSRNSYLVQHLIIHTGEKPYRCNVCGKVFHHISHLAQHQRIHTGEKPYKCNECGKVFSHKSSLVNHWRIHTGEKPYKCNECGKVFSHKSSLVNHWRIHTGEKPYKCNECGKVFSRNSYLAQHLIIHAGEKPYKCDECDKAFSQNSHLVQHHRIHTGEKPYKCDECGKVFSQNSYLAYHWRIHTGEKAYKCNECGKVFGLNSSLAHHRKIHTGEKPFKCNECGKAFSMRSSLTNHHAIHTGEKHFKCNECGKLFRDNSYLVRHQRFHAGKKSNTCN>sp|P51522-2|ZNF83_HUMAN Isoform 2 of Zinc finger protein 83 OS=Homosapiens OX=9606 GN=ZNF83MHGRKDDAQKQPVKNQLGLNPQSHLPELQLFQAEGKIYKYDHMEKSVNSSSLVSPPQRISSTVKTHISHTYECNFVDSLFTQKEKANIGTEHYKCSERGKAFHQGLHFTIHQIIHTKETQFKCDICGKIFNKKSNLASHQRIHTGEKPYKCNECGKVFHNMSHLAQHRRIHTGEKPYKCNECGKVFNQISHLAQHQRIHTGEKPYKCNECGKVFHQISHLAQHRTIHTGEKPYECNKCGKVFSRNSYLVQHLIIHTGEKPYRCNVCGKVFSHKSSLVNHWRIHTGEKPYKCNECGKVFSHKSSLVNHWRIHTGEKPYKCNECGKVFSRNSYLAQHLIIHAGEKPYKCDECDKAFSQNSHLVQHHRIHTGEKPYKCDECGKVFSQNSYLAYHWRIHTGEKAYKCNECGKVFGLNSSLAHHRKIHTGEKPFKCNECGKAFSMRSSLTNHHAIHTGEKHFKCNECGKLFRDNSYLVRHQRFHAGKKSNTCN>sp|Q8ND25|ZNRF1_HUMAN E3 ubiquitin-protein ligase ZNRF1 OS=Homo sapiensOX=9606 GN=ZNRF1 PE=1 SV=2MGGKQSTAARSRGPFPGVSTDDSAVPPPGGAPHFGHYRTGGGAMGLRSRSVSSVAGMGMDPSTAGGVPFGLYTPASRGTGDSERAPGGGGSASDSTYAHGNGYQETGGGHHRDGMLYLGSRASLADALPLHIAPRWFSSHSGFKCPICSKSVASDEMEMHFIMCLSKPRLSYNDDVLTKDAGECVICLEELLQGDTIARLPCLCIYHKSCIDSWFEVNRSCPEHPAD>sp|Q8ND25-2|ZNRF1_HUMAN Isoform 2 of E3 ubiquitin-protein ligase ZNRF1OS=Homo sapiens OX=9606 GN=ZNRF1MGGKQSTAARSRGPFPGVSTDDSAVPPPGGAPHFGHYRTGGGAMGLRSRSVSSVAGMGMDPSTAGGVPFGLYTPASRGTGDSERAPGGGGSASDSTYAHGNGYQETGGGHHRDGMLYLGSRASLADALPLHIAPRWFSSHSGFKCPICSKSVASDEMEMHFIMCLSKPRLSYNGRIQRSLRGAQPEKTWLSGRTLQEQPWRTECSWAPMAQMQSYPHCPVENREDDVLTKDAGECVICLEELLQGDTIARLPCLCIYHKSCIDSWFEVNRSCPEHPAD>sp|Q8NGI6|OR4DA_HUMAN Olfactory receptor 4D10 OS=Homo sapiens OX=9606GN=OR4D10 PE=2 SV=1MEMENCTRVKEFIFLGLTQNREVSLVLFLFLLLVYVTTLLGNLLIMVTVTCESRLHTPMYFLLHNLSIADICFSSITVPKVLVDLLSERKTISFNHCFTQMFLFHLIGGVDVFSLSVMALDRYVAISKPLHYATIMSRDHCIGLTVAAWLGGFVHSIVQISLLLPLPFCGPNVLDTFYCDVHRVLKLAHTDIFILELLMISNNGLLTTLWFFLLLVSYIVILSLPKSQAGEGRRKAISTCTSHITVVTLHFVPCIYVYARPFTALPMDKAISVTFTVISPLLNPLIYTLRNHEMKSAMRRLKRRLVPSDRK>sp|O75832|PSD10_HUMAN 26S proteasome non-ATPase regulatory subunit 10OS=Homo sapiens OX=9606 GN=PSMD10 PE=1 SV=1MEGCVSNLMVCNLAYSGKLEELKESILADKSLATRTDQDSRTALHWACSAGHTEIVEFLLQLGVPVNDKDDAGWSPLHIAASAGRDEIVKALLGKGAQVNAVNQNGCTPLHYAASKNRHEIAVMLLEGGANPDAKDHYEATAMHRAAAKGNLKMIHILLYYKASTNIQDTEGNTPLHLACDEERVEEAKLLVSQGASIYIENKEEKTPLQVAKGGLGLILKRMVEG>sp|O75832-2|PSD10_HUMAN Isoform 2 of 26S proteasome non-ATPaseregulatory subunit 10 OS=Homo sapiens OX=9606 GN=PSMD10MEGCVSNLMVCNLAYSGKLEELKESILADKSLATRTDQDSRTALHWACSAGHTEIVEFLLQLGVPVNDKDDAGWSPLHIAASAGRDEIVKALLGKGAQVNAVNQNGCTPLHYAASKNRHEIAVMLLEGGANPDAKDHYEATAMHRAAAKDT>sp|Q9BZG2|PPAT_HUMAN Testicular acid phosphatase OS=Homo sapiens OX=9606GN=ACP4 PE=1 SV=1MAGLGFWGHPAGPLLLLLLLVLPPRALPEGPLVFVALVFRHGDRAPLASYPMDPHKEVASTLWPRGLGQLTTEGVRQQLELGRFLRSRYEAFLSPEYRREEVYIRSTDFDRTLESAQANLAGLFPEAAPGSPEARWRPIPVHTVPVAEDKLLRFPMRSCPRYHELLREATEAAEYQEALEGWTGFLSRLENFTGLSLVGEPLRRAWKVLDTLMCQQAHGLPLPAWASPDVLRTLAQISALDIGAHVGPPRAAEKAQLTGGILLNAILANFSRVQRLGLPLKMVMYSAHDSTLLALQGALGLYDGHTPPYAACLGFEFRKHLGNPAKDGGNVTVSLFYRNDSAHLPLPLSLPGCPAPCPLGRFYQLTAPARPPAHGVSCHGPYEAAIPPAPVVPLLAGAVAVLVALSLGLGLLAWRPGCLRALGGPV>sp|Q9BZG2-2|PPAT_HUMAN Isoform 2 of Testicular acid phosphatase OS=Homosapiens OX=9606 GN=ACP4MAGLGFWGHPAGPLLLLLLLVLPPRALPEGPLVFVALVFRHGDRAPLASYPMDPHKEVASTLWPRGLGQLTTEGVRQQLELGRFLRSRYEGFLSRLENFTGLSLVGEPLRRAWKVLDTLMCQQAHGLPLPAWASPDVLRTLAQISALDIGAHVGPPRAAEKAQLTGGILLNAILANFSRVQRLGLPLKMVMYSAHDSTLLALQGALGLYDGHTPPYAACLGFEFRKHLGNPAKDGGNVTVSLFYRNDSAHLPLPLSLPGCPAPCPLGRFYQLTAPARPPAHGVSCHGPYEAAIPPAPVVPLLAGAVAVLVALSLGLGLLAWRPGCLRALGGPV>sp|Q9BZG2-3|PPAT_HUMAN Isoform 3 of Testicular acid phosphatase OS=Homosapiens OX=9606 GN=ACP4MAGLGFWGHPAGPLLLLLLLVLPPRALPEGPLVFVALVRRPHPGLPLAPPGLALTSPVPRYSAMATGPRWPPTPWTHTRRWPPPCGHEAWAS>sp|A5PKW4|PSD1_HUMAN PH and SEC7 domain-containing protein 1 OS=Homosapiens OX=9606 GN=PSD PE=1 SV=2MAQGAMRFCSEGDCAISPPRCPRRWLPEGPVPQSPPASMYGSTGSLLRRVAGPGPRGRELGRVTAPCTPLRGPPSPRVAPSPWAPSSPTGQPPPGAQSSVVIFRFVEKASVRPLNGLPAPGGLSRSWDLGGVSPPRPTPALGPGSNRKLRLEASTSDPLPARGGSALPGSRNLVHGPPAPPQVGADGLYSSLPNGLGGPPERLATLFGGPADTGFLNQGDTWSSPREVSSHAQRIARAKWEFFYGSLDPPSSGAKPPEQAPPSPPGVGSRQGSGVAVGRAAKYSETDLDTVPLRCYRETDIDEVLAEREEADSAIESQPSSEGPPGTAYPPAPRPGPLPGPHPSLGSGNEDEDDDEAGGEEDVDDEVFEASEGARPGSRMPLKSPVPFLPGTSPSADGPDSFSCVFEAILESHRAKGTSYTSLASLEALASPGPTQSPFFTFELPPQPPAPRPDPPAPAPLAPLEPDSGTSSAADGPWTQRGEEEEAEARAKLAPGREPPSPCHSEDSLGLGAAPLGSEPPLSQLVSDSDSELDSTERLALGSTDTLSNGQKADLEAAQRLAKRLYRLDGFRKADVARHLGKNNDFSKLVAGEYLKFFVFTGMTLDQALRVFLKELALMGETQERERVLAHFSQRYFQCNPEALSSEDGAHTLTCALMLLNTDLHGHNIGKRMTCGDFIGNLEGLNDGGDFPRELLKALYSSIKNEKLQWAIDEEELRRSLSELADPNPKVIKRISGGSGSGSSPFLDLTPEPGAAVYKHGALVRKVHADPDCRKTPRGKRGWKSFHGILKGMILYLQKEEYKPGKALSETELKNAISIHHALATRASDYSKRPHVFYLRTADWRVFLFQAPSLEQMQSWITRINVVAAMFSAPPFPAAVSSQKKFSRPLLPSAATRLSQEEQVRTHEAKLKAMASELREHRAAQLGKKGRGKEAEEQRQKEAYLEFEKSRYSTYAALLRVKLKAGSEELDAVEAALAQAGSTEDGLPPSHSSPSLQPKPSSQPRAQRHSSEPRPGAGSGRRKP>sp|A5PKW4-2|PSD1_HUMAN Isoform 2 of PH and SEC7 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=PSDMPLKSPVPFLPGTSPSADGPDSFSCVFEAILESHRAKGTSYTSLASLEALASPGPTQSPFFTFELPPQPPAPRPDPPAPAPLAPLEPDSGTSSAADGPWTQRGEEEEAEARAKLAPGREPPSPCHSEDSLGLGAAPLGSEPPLSQLVSDSDSELDSTERLALGSTDTLSNGQKADLEAAQRLAKRLYRLDGFRKADVARHLGKNNDFSKLVAGEYLKFFVFTGMTLDQALRVFLKELALMGETQERERVLAHFSQRYFQCNPEALSSEDGAHTLTCALMLLNTDLHGHNIGKRMTCGDFIGNLEGLNDGGDFPRELLKALYSSIKNEKLQWAIDEEELRRSLSELADPNPKVIKRISGGSGSGSSPFLDLTPEPGAAVYKHGALVRKVHADPDCRKTPRGKRGWKSFHGILKGMILYLQKEEYKPGKALSETELKNAISIHHALATRASDYSKRPHVFYLRTADWRVFLFQAPSLEQMQSWITRINVVAAMFSAPPFPAAVSSQKKFSRPLLPSAATRLSQEEQVRTHEAKLKAMASELREHRAAQLGKKGRGKEAEEQRQKEAYLEFEKSRYSTYAALLRVKLKAGSEELDAVEAALAQAGSTEDGLPPSHSSPSLQPKPSSQPRAQRHSSEPRPGAGSGRRKP>sp|P31939|PUR9_HUMAN Bifunctional purine biosynthesis protein ATICOS=Homo sapiens OX=9606 GN=ATIC PE=1 SV=3MAPGQLALFSVSDKTGLVEFARNLTALGLNLVASGGTAKALRDAGLAVRDVSELTGFPEMLGGRVKTLHPAVHAGILARNIPEDNADMARLDFNLIRVVACNLYPFVKTVASPGVTVEEAVEQIDIGGVTLLRAAAKNHARVTVVCEPEDYVVVSTEMQSSESKDTSLETRRQLALKAFTHTAQYDEAISDYFRKQYSKGVSQMPLRYGMNPHQTPAQLYTLQPKLPITVLNGAPGFINLCDALNAWQLVKELKEALGIPAAASFKHVSPAGAAVGIPLSEDEAKVCMVYDLYKTLTPISAAYARARGADRMSSFGDFVALSDVCDVPTAKIISREVSDGIIAPGYEEEALTILSKKKNGNYCVLQMDQSYKPDENEVRTLFGLHLSQKRNNGVVDKSLFSNVVTKNKDLPESALRDLIVATIAVKYTQSNSVCYAKNGQVIGIGAGQQSRIHCTRLAGDKANYWWLRHHPQVLSMKFKTGVKRAEISNAIDQYVTGTIGEDEDLIKWKALFEEVPELLTEAEKKEWVEKLTEVSISSDAFFPFRDNVDRAKRSGVAYIAAPSGSAADKVVIEACDELGIILAHTNLRLFHH>sp|P31939-2|PUR9_HUMAN Isoform 2 of Bifunctional purine biosynthesisprotein ATIC OS=Homo sapiens OX=9606 GN=ATICMSSLSALFSVSDKTGLVEFARNLTALGLNLVASGGTAKALRDAGLAVRDVSELTGFPEMLGGRVKTLHPAVHAGILARNIPEDNADMARLDFNLIRVVACNLYPFVKTVASPGVTVEEAVEQIDIGGVTLLRAAAKNHARVTVVCEPEDYVVVSTEMQSSESKDTSLETRRQLALKAFTHTAQYDEAISDYFRKQYSKGVSQMPLRYGMNPHQTPAQLYTLQPKLPITVLNGAPGFINLCDALNAWQLVKELKEALGIPAAASFKHVSPAGAAVGIPLSEDEAKVCMVYDLYKTLTPISAAYARARGADRMSSFGDFVALSDVCDVPTAKIISREVSDGIIAPGYEEEALTILSKKKNGNYCVLQMDQSYKPDENEVRTLFGLHLSQKRNNGVVDKSLFSNVVTKNKDLPESALRDLIVATIAVKYTQSNSVCYAKNGQVIGIGAGQQSRIHCTRLAGDKANYWWLRHHPQVLSMKFKTGVKRAEISNAIDQYVTGTIGEDEDLIKWKALFEEVPELLTEAEKKEWVEKLTEVSISSDAFFPFRDNVDRAKRSGVAYIAAPSGSAADKVVIEACDELGIILAHTNLRLFHH>sp|O95758|PTBP3_HUMAN Polypyrimidine tract-binding protein 3 OS=Homosapiens OX=9606 GN=PTBP3 PE=1 SV=2MDGVVTDLITVGLKRGSDELLSSGIINGPFTMNSSTPSTANGNDSKKFKRDRPPCSPSRVLHLRKIPCDVTEAEIISLGLPFGKVTNLLMLKGKSQAFLEMASEEAAVTMVNYYTPITPHLRSQPVYIQYSNHRELKTDNLPNQARAQAALQAVSAVQSGSLALSGGPSNEGTVLPGQSPVLRIIIENLFYPVTLEVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVNAHYAKMALDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDFTRLDLPTGDGQPSLEPPMAAAFGAPGIISSPYAGAAGFAPAIGFPQATGLSVPAVPGALGPLTITSSAVTGRMAIPGASGIPGNSVLLVTNLNPDLITPHGLFILFGVYGDVHRVKIMFNKKENALVQMADANQAQLAMNHLSGQRLYGKVLRATLSKHQAVQLPREGQEDQGLTKDFSNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVTVDDLKNLFIEAGCSVKAFKFFQKDRKMALIQLGSVEEAIQALIELHNHDLGENHHLRVSFSKSTI>sp|O95758-1|PTBP3_HUMAN Isoform 1 of Polypyrimidine tract-bindingprotein 3 OS=Homo sapiens OX=9606 GN=PTBP3MNSSTPSTANGNDSKKFKRDRPPCSPSRVLHLRKIPCDVTEAEIISLGLPFGKVTNLLMLKGKSQAFLEMASEEAAVTMVNYYTPITPHLRSQPVYIQYSNHRELKTDNLPNQARAQAALQAVSAVQSGSLALSGGPSNEGTVLPGQSPVLRIIIENLFYPVTLEVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVNAHYAKMALDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDFTRLDLPTGDGQPSLEPPMAAAFGAPGIISSPYAGAAGFAPAIGFPQATGLSVPAVPGALGPLTITSSAVTGRMAIPGASGIPGNSVLLVTNLNPDLITPHGLFILFGVYGDVHRVKIMFNKKENALVQMADANQAQLAMNHLSGQRLYGKVLRATLSKHQAVQLPREGQEDQGLTKDFSNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVTVDDLKNLFIEAGCSVKAFKFFQKDRKMALIQLGSVEEAIQALIELHNHDLGENHHLRVSFSKSTI>sp|O95758-2|PTBP3_HUMAN Isoform 2 of Polypyrimidine tract-bindingprotein 3 OS=Homo sapiens OX=9606 GN=PTBP3MNSSTPSTGVYANGNDSKKFKRDRPPCSPSRVLHLRKIPCDVTEAEIISLGLPFGKVTNLLMLKGKSQAFLEMASEEAAVTMVNYYTPITPHLRSQPVYIQYSNHRELKTDNLPNQARAQAALQAVSAVQSGSLALSGGPSNEGTVLPGQSPVLRIIIENLFYPVTLEVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVNAHYAKMALDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDFTRLDLPTGDGQPSLEPPMAAAFGAPGIISSPYAGAAGFAPAIGFPQATGLSVPAVPGALGPLTITSSAVTGRMAIPGASGIPGNSVLLVTNLNPDLITPHGLFILFGVYGDVHRVKIMFNKKENALVQMADANQAQLAMNHLSGQRLYGKVLRATLSKHQAVQLPREGQEDQGLTKDFSNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVTVDDLKNLFIEAGCSVKAFKFFQGLANSWAQVILLLPPPHSAGITGMSHHAWLSVLFSVSVPSVSSAYMFSILSCSFSSVPTRYFWTKN>sp|O95758-4|PTBP3_HUMAN Isoform 4 of Polypyrimidine tract-bindingprotein 3 OS=Homo sapiens OX=9606 GN=PTBP3MDASPSPFSLPKKLNELSARRGSDELLSSGIINGPFTMNSSTPSTANGNDSKKFKRDRPPCSPSRVLHLRKIPCDVTEAEIISLGLPFGKVTNLLMLKGKSQAFLEMASEEAAVTMVNYYTPITPHLRSQPVYIQYSNHRELKTDNLPNQARAQAALQAVSAVQSGSLALSGGPSNEGTVLPGQSPVLRIIIENLFYPVTLEVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVNAHYAKMALDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDFTRLDLPTGDGQPSLEPPMAAAFGAPGIISSPYAGAAGFAPAIGFPQATGLSVPAVPGALGPLTITSSAVTGRMAIPGASGIPGNSVLLVTNLNPDLITPHGLFILFGVYGDVHRVKIMFNKKENALVQMADANQAQLAMNHLSGQRLYGKVLRATLSKHQAVQLPREGQEDQGLTKDFSNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVTVDDLKNLFIEAGCSVKAFKFFQKDRKMALIQLGSVEEAIQALIELHNHDLGENHHLRVSFSKSTI>sp|O95758-5|PTBP3_HUMAN Isoform 5 of Polypyrimidine tract-bindingprotein 3 OS=Homo sapiens OX=9606 GN=PTBP3MDGVVTDLITVGLKRGSDELLSSGIINGPFTMNSSTPSTGVYANGNDSKKFKRDRPPCSPSRVLHLRKIPCDVTEAEIISLGLPFGKVTNLLMLKGKSQAFLEMASEEAAVTMVNYYTPITPHLRSQPVYIQYSNHRELKTDNLPNQARAQAALQAVSAVQSGSLALSGGPSNEGTVLPGQSPVLRIIIENLFYPVTLEVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVNAHYAKMALDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDFTRLDLPTGDGQPSLEPPMAAAFGAPGIISSPYAGAAGFAPAIGFPQATGLSVPAVPGALGPLTITSSAVTGRMAIPGASGIPGNSVLLVTNLNPDLITPHGLFILFGVYGDVHRVKIMFNKKENALVQMADANQAQLAMNHLSGQRLYGKVLRATLSKHQAVQLPREGQEDQGLTKDFSNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVTVDDLKNLFIEAGCSVKAFKFFQKDRKMALIQLGSVEEAIQALIELHNHDLGENHHLRVSFSKSTI>sp|O95758-6|PTBP3_HUMAN Isoform 6 of Polypyrimidine tract-bindingprotein 3 OS=Homo sapiens OX=9606 GN=PTBP3MNSSTPSTGVYANGNDSKKFKRDRPPCSPSRVLHLRKIPCDVTEAEIISLGLPFGKVTNLLMLKGKSQAFLEMASEEAAVTMVNYYTPITPHLRSQPVYIQYSNHRELKTDNLPNQARAQAALQAVSAVQSGSLALSGGPSNEGTVLPGQSPVLRIIIENLFYPVTLEVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVNAHYAKMALDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDFTRLDLPTGDGQPSLEPPMAAAFGAPGIISSPYAGAAGFAPAIGFPQATGLSVPAVPGALGPLTITSSAVTGRMAIPGASGIPGNSVLLVTNLNPDLITPHGLFILFGVYGDVHRVKIMFNKKENALVQMADANQAQLAMNHLSGQRLYGKVLRATLSKHQAVQLPREGQEDQGLTKDFSNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVTVDDLKNLFIEAGCSVKAFKFFQKDRKMALIQLGSVEEAIQALIELHNHDLGENHHLRVSFSKSTI>sp|O95758-7|PTBP3_HUMAN Isoform 7 of Polypyrimidine tract-bindingprotein 3 OS=Homo sapiens OX=9606 GN=PTBP3MAFLEMASEEAAVTMVNYYTPITPHLRSQPVYIQYSNHRELKTDNLPNQARAQAALQAVSAVQSGSLALSGGPSNEGTVLPGQSPVLRIIIENLFYPVTLEVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVNAHYAKMALDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDFTRLDLPTGDGQPSLEPPMAAAFGAPGIISSPYAGAAGFAPAIGFPQATGLSVPAVPGALGPLTITSSAVTGRMAIPGASGIPGNSVLLVTNLNPDLITPHGLFILFGVYGDVHRVKIMFNKKENALVQMADANQAQLAMNHLSGQRLYGKVLRATLSKHQAVQLPREGQEDQGLTKDFSNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVTVDDLKNLFIEAGCSVKAFKFFQKDRKMALIQLGSVEEAIQALIELHNHDLGENHHLRVSFSKSTI>sp|Q8TBF2|PXL2B_HUMAN Prostamide/prostaglandin F synthase OS=Homosapiens OX=9606 GN=PRXL2B PE=1 SV=1MSTVDLARVGACILKHAVTGEAVELRSLWREHACVVAGLRRFGCVVCRWIAQDLSSLAGLLDQHGVRLVGVGPEALGLQEFLDGDYFAGELYLDESKQLYKELGFKRYNSLSILPAALGKPVRDVAAKAKAVGIQGNLSGDLLQSGGLLVVSKGGDKVLLHFVQKSPGDYVPKEHILQVLGISAEVCASDPPQCDREV>sp|Q8TBF2-2|PXL2B_HUMAN Isoform 2 of Prostamide/prostaglandin F synthaseOS=Homo sapiens OX=9606 GN=PRXL2BMSTVDLARVGACILKHAVTGEAVELRSLWREHACVVAGLRRFGCVVCRWIAQDLSSLAGLLDQHGVRLVGVGPEALGLQEFLDGDYFAGELYLDESKQLYKELGFKRYNSLSILPAALGKPVRDVAAKAKAVGIQGNLSGDLLQSGGLLVVSKEVPRRLRPQGAHPAGPGHLCGGLCQRPASV>sp|Q8TBF2-3|PXL2B_HUMAN Isoform 3 of Prostamide/prostaglandin F synthaseOS=Homo sapiens OX=9606 GN=PRXL2BMSTVDLARVGACILKHAVTGEAVELRSLWREHACVVAGLRRFGCVVCRWIAQDLSSLAGLLDQHGVRLVGVGPEALGLQEFLDGDYFAGELYLDESKQLYKELGFKRLWTQASPEFGQATWCLRRYNSLSILPAALGKPVRDVAAKAKAVGIQGNLSGDLLQSGGLLVVSKGGDKVLLHFVQKSPGDYVPKEHILQVLGISAEVCASDPPQCDREV>sp|Q8TBF2-4|PXL2B_HUMAN Isoform 4 of Prostamide/prostaglandin F synthaseOS=Homo sapiens OX=9606 GN=PRXL2BMSTVDLARVGACILKHAVTGEAVELRSLWREHACVVAGLRRFGCVVCRWIAQDLSSLAGLLDQHGVRLVGVGPEALGLQEFLDGDYFAGELYLDESKQLYKELGFKRYNSLSILPAALGKPVRDVAAKKSPGDYVPKEHILQVLGISAEVCASDPPQCDREV>sp|Q8TBF2-6|PXL2B_HUMAN Isoform 5 of Prostamide/prostaglandin F synthaseOS=Homo sapiens OX=9606 GN=PRXL2BMSTVDLARVGACILKHAVTGEAVELRSLWREHACVVAGLRRFGCVVCRWIAQDLSSLAGLLDQHGVRLVGVGPEALGLQEFLDGDYFAGELYLDESKQLYKELGFKRYNSLSILPAALGKPVRDVAAKAVPTPDRPRLLASRGTCLGTCCRAEGCWWSAKKSPGDYVPKEHILQVLGISAEVCASDPPQCDREV>sp|Q8TBF2-7|PXL2B_HUMAN Isoform 6 of Prostamide/prostaglandin F synthaseOS=Homo sapiens OX=9606 GN=PRXL2BMSTVDLARVGACILKHAVTGEAVELRSLWREHACVVAGLRRFGCVVCRWIAQDLSSLAGLLDQHGVRLVGVGPEALGLQEFLDGDYFAGELYLDESKQLYKELGFKRLWTQASPEFGQATWCLRRYNSLSILPAALGKPVRDVAAKAKAVGIQGNLSGDLLQSGGLLVVSKEVPRRLRPQGAHPAGPGHLCGGLCQRPASV>sp|Q9NRI6|PYY2_HUMAN Putative peptide YY-2 OS=Homo sapiens OX=9606GN=PYY2 PE=5 SV=1MATVLLALLVYLGALVDAYPIKPEAPGEDAFLG>sp|Q8WXC3|PYDC1_HUMAN Pyrin domain-containing protein 1 OS=Homo sapiensOX=9606 GN=PYDC1 PE=1 SV=1MGTKREAILKVLENLTPEELKKFKMKLGTVPLREGFERIPRGALGQLDIVDLTDKLVASYYEDYAAELVVAVLRDMRMLEEAARLQRAA>sp|Q96PZ0|PUS7_HUMAN Pseudouridylate synthase 7 homolog OS=Homo sapiensOX=9606 GN=PUS7 PE=1 SV=2MEMTEMTGVSLKRGALVVEDNDSGVPVEETKKQKLSECSLTKGQDGLQNDFLSISEDVPRPPDTVSTGKGGKNSEAQLEDEEEEEEDGLSEECEEEESESFADMMKHGLTEADVGITKFVSSHQGFSGILKERYSDFVVHEIGKDGRISHLNDLSIPVDEEDPSEDIFTVLTAEEKQRLEELQLFKNKETSVAIEVIEDTKEKRTIIHQAIKSLFPGLETKTEDREGKKYIVAYHAAGKKALANPRKHSWPKSRGSYCHFVLYKENKDTMDAINVLSKYLRVKPNIFSYMGTKDKRAITVQEIAVLKITAQRLAHLNKCLMNFKLGNFSYQKNPLKLGELQGNHFTVVLRNITGTDDQVQQAMNSLKEIGFINYYGMQRFGTTAVPTYQVGRAILQNSWTEVMDLILKPRSGAEKGYLVKCREEWAKTKDPTAALRKLPVKRCVEGQLLRGLSKYGMKNIVSAFGIIPRNNRLMYIHSYQSYVWNNMVSKRIEDYGLKPVPGDLVLKGATATYIEEDDVNNYSIHDVVMPLPGFDVIYPKHKIQEAYREMLTADNLDIDNMRHKIRDYSLSGAYRKIIIRPQNVSWEVVAYDDPKIPLFNTDVDNLEGKTPPVFASEGKYRALKMDFSLPPSTYATMAIREVLKMDTSIKNQTQLNTTWLR>sp|Q96PZ0-2|PUS7_HUMAN Isoform 2 of Pseudouridylate synthase 7 homologOS=Homo sapiens OX=9606 GN=PUS7MEMTEMTGVSLKRGALVVEDNDSGVPVEETKKQKLSECSLTKGQDGLQNDFLSISEDVPRPPDTVSTGKGGKNSEAQLEDEEEEEEDGLSEECEEEESESFADMMKHGLTEADVGITKFVSSHQGFSGILKERYSDFVVHEIGKDGRISHLNDLSIPVDEEDPSEDIFTVLTAEEKQRLEELQLFKNKETSVAIEVIEDTKEKRTIIHQAIKSLFPGLETKTEDREGKKYIVAYHAAGKKALAKVRTAADPRKHSWPKSRGSYCHFVLYKENKDTMDAINVLSKYLRVKPNIFSYMGTKDKRAITVQEIAVLKITAQRLAHLNKCLMNFKLGNFSYQKNPLKLGELQGNHFTVVLRNITGTDDQVQQAMNSLKEIGFINYYGMQRFGTTAVPTYQVGRAILQNSWTEVMDLILKPRSGAEKGYLVKCREEWAKTKDPTAALRKLPVKRCVEGQLLRGLSKYGMKNIVSAFGIIPRNNRLMYIHSYQSYVWNNMVSKRIEDYGLKPVPGDLVLKGATATYIEEDDVNNYSIHDVVMPLPGFDVIYPKHKIQEAYREMLTADNLDIDNMRHKIRDYSLSGAYRKIIIRPQNVSWEVVAYDDPKIPLFNTDVDNLEGKTPPVFASEGKYRALKMDFSLPPSTYATMAIREVLKMDTSIKNQTQLNTTWLR>sp|Q9BZE2|PUS3_HUMAN tRNA pseudouridine(38/39) synthase OS=Homo sapiensOX=9606 GN=PUS3 PE=1 SV=3MAYNDTDRNQTEKLLKRVRELEQEVQRLKKEQAKNKEDSNIRENSAGAGKTKRAFDFSAHGRRHVALRIAYMGWGYQGFASQENTNNTIEEKLFEALTKTRLVESRQTSNYHRCGRTDKGVSAFGQVISLDLRSQFPRGRDSEDFNVKEEANAAAEEIRYTHILNRVLPPDIRILAWAPVEPSFSARFSCLERTYRYFFPRADLDIVTMDYAAQKYVGTHDFRNLCKMDVANGVINFQRTILSAQVQLVGQSPGEGRWQEPFQLCQFEVTGQAFLYHQVRCMMAILFLIGQGMEKPEIIDELLNIEKNPQKPQYSMAVEFPLVLYDCKFENVKWIYDQEAQEFNITHLQQLWANHAVKTHMLYSMLQGLDTVPVPCGIGPKMDGMTEWGNVKPSVIKQTSAFVEGVKMRTYKPLMDRPKCQGLESRIQHFVRRGRIEHPHLFHEEETKAKRDCNDTLEEENTNLETPTKRVCVDTEIKSII>sp|O95980|RECK_HUMAN Reversion-inducing cysteine-rich protein with Kazalmotifs OS=Homo sapiens OX=9606 GN=RECK PE=1 SV=1MATVRASLRGALLLLLAVAGVAEVAGGLAPGSAGALCCNHSKDNQMCRDVCEQIFSSKSESRLKHLLQRAPDYCPETMVEIWNCMNSSLPGVFKKSDGWVGLGCCELAIALECRQACKQASSKNDISKVCRKEYENALFSCISRNEMGSVCCSYAGHHTNCREYCQAIFRTDSSPGPSQIKAVENYCASISPQLIHCVNNYTQSYPMRNPTDSLYCCDRAEDHACQNACKRILMSKKTEMEIVDGLIEGCKTQPLPQDPLWQCFLESSQSVHPGVTVHPPPSTGLDGAKLHCCSKANTSTCRELCTKLYSMSWGNTQSWQEFDRFCEYNPVEVSMLTCLADVREPCQLGCRNLTYCTNFNNRPTELFRSCNAQSDQGAMNDMKLWEKGSIKMPFINIPVLDIKKCQPEMWKAIACSLQIKPCHSKSRGSIICKSDCVEILKKCGDQNKFPEDHTAESICELLSPTDDLKNCIPLDTYLRPSTLGNIVEEVTHPCNPNPCPANELCEVNRKGCPSGDPCLPYFCVQGCKLGEASDFIVRQGTLIQVPSSAGEVGCYKICSCGQSGLLENCMEMHCIDLQKSCIVGGKRKSHGTSFSIDCNVCSCFAGNLVCSTRLCLSEHSSEDDRRTFTGLPCNCADQFVPVCGQNGRTYPSACIARCVGLQDHQFEFGSCMSKDPCNPNPCQKNQRCIPKPQVCLTTFDKFGCSQYECVPRQLACDQVQDPVCDTDHMEHNNLCTLYQRGKSLSYKGPCQPFCRATEPVCGHNGETYSSVCAAYSDRVAVDYYGDCQAVGVLSEHSSVAECASVKCPSLLAAGCKPIIPPGACCPLCAGMLRVLFDKEKLDTIAKVTNKKPITVLEILQKIRMHVSVPQCDVFGYFSIESEIVILIIPVDHYPKALQIEACNKEAEKIESLINSDSPTLASHVPLSALIISQVQVSSSVPSAGVRARPSCHSLLLPLSLGLALHLLWTYN>sp|Q9NS91|RAD18_HUMAN E3 ubiquitin-protein ligase RAD18 OS=Homo sapiensOX=9606 GN=RAD18 PE=1 SV=2MDSLAESRWPPGLAVMKTIDDLLRCGICFEYFNIAMIIPQCSHNYCSLCIRKFLSYKTQCPTCCVTVTEPDLKNNRILDELVKSLNFARNHLLQFALESPAKSPASSSSKNLAVKVYTPVASRQSLKQGSRLMDNFLIREMSGSTSELLIKENKSKFSPQKEASPAAKTKETRSVEEIAPDPSEAKRPEPPSTSTLKQVTKVDCPVCGVNIPESHINKHLDSCLSREEKKESLRSSVHKRKPLPKTVYNLLSDRDLKKKLKEHGLSIQGNKQQLIKRHQEFVHMYNAQCDALHPKSAAEIVREIENIEKTRMRLEASKLNESVMVFTKDQTEKEIDEIHSKYRKKHKSEFQLLVDQARKGYKKIAGMSQKTVTITKEDESTEKLSSVCMGQEDNMTSVTNHFSQSKLDSPEELEPDREEDSSSCIDIQEVLSSSESDSCNSSSSDIIRDLLEEEEAWEASHKNDLQDTEISPRQNRRTRAAESAEIEPRNKRNRN>sp|P51159|RB27A_HUMAN Ras-related protein Rab-27A OS=Homo sapiensOX=9606 GN=RAB27A PE=1 SV=3MSDGDYDYLIKFLALGDSGVGKTSVLYQYTDGKFNSKFITTVGIDFREKRVVYRASGPDGATGRGQRIHLQLWDTAGQERFRSLTTAFFRDAMGFLLLFDLTNEQSFLNVRNWISQLQMHAYCENPDIVLCGNKSDLEDQRVVKEEEAIALAEKYGIPYFETSAANGTNISQAIEMLLDLIMKRMERCVDKSWIPEGVVRSNGHASTDQLSEEKEKGACGC>sp|P51159-2|RB27A_HUMAN Isoform Short of Ras-related protein Rab-27AOS=Homo sapiens OX=9606 GN=RAB27AMSDGDYDYLIKFLALGDSGVGKTSVLYQYTDGKFNSKFITTVGIDFREKRVVYRASGPDGATGRGQRIHLQLWDTAGQERFRSLTTAFFRDAMGFLLLFDLTNEQSFLNVRNWISQLQMHAYCENPDIVLCGNKSDLEDQRVVKEKYGIPYFETSAANGTNISQAIEMLLDLIMKRMERCVDKSWIPEGVVRSNGHASTDQLSEEKEKGACGC>sp|Q6MZT1|R7BP_HUMAN Regulator of G-protein signaling 7-binding proteinOS=Homo sapiens OX=9606 GN=RGS7BP PE=2 SV=3MSSAPNGRKKRPSRSTRSSIFQISKPPLQSGDWERRGSGSESAHKTQRALDDCKMLVQEFNTQVALYRELVISIGDVSVSCPSLRAEMHKTRTKGCEMARQAHQKLAAISGPEDGEIHPEICRLYIQLQCCLEMYTTEMLKSICLLGSLQFHRKGKEPGGGTKSLDCKIEESAETPALEDSSSSPVDSQQHSWQVSTDIENTERDMREMKNLLSKLRETMPLPLKNQDDSSLLNLTPYPLVRRRKRRFFGLCCLISS>sp|Q8N4Z0|RAB42_HUMAN Ras-related protein Rab-42 OS=Homo sapiens OX=9606GN=RAB42 PE=1 SV=2MEAEGCRYQFRVALLGDAAVGKTSLLRSYVAGAPGAPEPEPEPEPTVGAECYRRALQLRAGPRVKLQLWDTAGHERFRCITRSFYRNVVGVLLVFDVTNRKSFEHIQDWHQEVMATQGPDKVIFLLVGHKSDLQSTRCVSAQEAEELAASLGMAFVETSVKNNCNVDLAFDTLADAIQQALQQGDIKLEEGWGGVRLIHKTQIPRSPSRKQHSGPCQC>sp|Q8N4Z0-1|RAB42_HUMAN Isoform 2 of Ras-related protein Rab-42 OS=Homosapiens OX=9606 GN=RAB42MATQGPDKVIFLLVGHKSDLQSTRCVSAQEAEELAASLGMAFVETSVKNNCNVDLAFDTLADAIQQALQQGDIKLEEGWGGVRLIHKTQIPRSPSRKQHSGPCQC>sp|Q9H082|RB33B_HUMAN Ras-related protein Rab-33B OS=Homo sapiensOX=9606 GN=RAB33B PE=1 SV=1MAEEMESSLEASFSSSGAVSGASGFLPPARSRIFKIIVIGDSNVGKTCLTYRFCAGRFPDRTEATIGVDFRERAVEIDGERIKIQLWDTAGQERFRKSMVQHYYRNVHAVVFVYDMTNMASFHSLPSWIEECKQHLLANDIPRILVGNKCDLRSAIQVPTDLAQKFADTHSMPLFETSAKNPNDNDHVEAIFMTLAHKLKSHKPLMLSQPPDNGIILKPEPKPAMTCWC>sp|Q9Y3P9|RBGP1_HUMAN Rab GTPase-activating protein 1 OS=Homo sapiensOX=9606 GN=RABGAP1 PE=1 SV=3MDDKASVGKISVSSDSVSTLNSEDFVLVSRQGDETPSTNNGSDDEKTGLKIVGNGSEQQLQKELADVLMDPPMDDQPGEKELVKRSQLDGEGDGPLSNQLSASSTINPVPLVGLQKPEMSLPVKPGQGDSEASSPFTPVADEDSVVFSKLTYLGCASVNAPRSEVEALRMMSILRSQCQISLDVTLSVPNVSEGIVRLLDPQTNTEIANYPIYKILFCVRGHDGTPESDCFAFTESHYNAELFRIHVFRCEIQEAVSRILYSFATAFRRSAKQTPLSATAAPQTPDSDIFTFSVSLEIKEDDGKGYFSAVPKDKDRQCFKLRQGIDKKIVIYVQQTTNKELAIERCFGLLLSPGKDVRNSDMHLLDLESMGKSSDGKSYVITGSWNPKSPHFQVVNEETPKDKVLFMTTAVDLVITEVQEPVRFLLETKVRVCSPNERLFWPFSKRSTTENFFLKLKQIKQRERKNNTDTLYEVVCLESESERERRKTTASPSVRLPQSGSQSSVIPSPPEDDEEEDNDEPLLSGSGDVSKECAEKILETWGELLSKWHLNLNVRPKQLSSLVRNGVPEALRGEVWQLLAGCHNNDHLVEKYRILITKESPQDSAITRDINRTFPAHDYFKDTGGDGQDSLYKICKAYSVYDEEIGYCQGQSFLAAVLLLHMPEEQAFSVLVKIMFDYGLRELFKQNFEDLHCKFYQLERLMQEYIPDLYNHFLDISLEAHMYASQWFLTLFTAKFPLYMVFHIIDLLLCEGISVIFNVALGLLKTSKDDLLLTDFEGALKFFRVQLPKRYRSEENAKKLMELACNMKISQKKLKKYEKEYHTMREQQAQQEDPIERFERENRRLQEANMRLEQENDDLAHELVTSKIALRKDLDNAEEKADALNKELLMTKQKLIDAEEEKRRLEEESAQLKEMCRRELDKAESEIKKNSSIIGDYKQICSQLSERLEKQQTANKVEIEKIRQKVDDCERCREFFNKEGRVKGISSTKEVLDEDTDEEKETLKNQLREMELELAQTKLQLVEAECKIQDLEHHLGLALNEVQAAKKTWFNRTLSSIKTATGVQGKETC>sp|Q9Y3P9-2|RBGP1_HUMAN Isoform 2 of Rab GTPase-activating protein 1OS=Homo sapiens OX=9606 GN=RABGAP1MDPPMDDQPGEKELVKRSQLDGEGDGPLSNQLSASSTINPVPLVGLQKPEMSLPVKPGQGDSEASSPFTPVADEDSVVFSKLTYLGCASVNAPRSEVEALRMMSILRSQCQISLDVTLSVPNVSEGIVRLLDPQTNTEIANYPIYKILFCVRGHDGTPESDCFAFTESHYNAELFRIHVFRCEIQEAVSRILYSFATAFRRSAKQTPLSATAAPQTPDSDIFTFSVSLEIKEDDGKGYFSAVPKDKDRQCFKLRQGIDKKIVIYVQQTTNKELAIERCFGLLLSPGKDVRNSDMHLLDLESMGKSSDGKSYVITGSWNPKSPHFQVVNEETPKDKVLFMTTAVDLVITEVQEPVRFLLETKVRVCSPNERLFWPFSKRSTTENFFLKLKQIKQRERKNNTDTLYEVVCLESESERERRKTTASPSVRLPQSGSQSSVIPSPPEDDEEEDNDEPLLSGSGDVSKECAEKILETWGELLSKWHLNLNVRPKQLSSLVRNGVPEALRGEVWQLLAGCHNNDHLVEKYRILITKESPQDSAITRDINRTFPAHDYFKDTGGDGQDSLYKICKVFHVKKKKDSILSGGSTLKLHKKQLQSVICI>sp|Q9Y3P9-3|RBGP1_HUMAN Isoform 3 of Rab GTPase-activating protein 1OS=Homo sapiens OX=9606 GN=RABGAP1MDDKASVGKISVSSDSVSTLNSEDFVLVSRQGDETPSTNNGSDDEKTGLKIVGNGSEQQLQKELADVLMDPPMDDQPGEKELVKRSQLDGEGDGPLSNQLSASSTINPVPLVGLQKPEMSLPVKPGQGDSEASSPFTPVADEDSVVFSKLTYLGCASVNAPRSEVEALRMMSILRSQCQISLDVTLSVPNVSEGIVRLLDPQTNTEIANYPIYKILFCVRGHDGTPESDCFAFTESHYNAELFRIHVFRCEIQEAVSRILYSFATAFRRSAKQTPLSATAAPQTPDSDIFTFSVSLEIKEDDGKGYFSAVPKDKDRQCFKLRQGIDKKIVIYVQQTTNKELAIERCFGLLLSPGKDVRNSDMHLLDLESMGKSSDGKSYVITGSWNPKSPHFQVVNEETPKDKVLFMTTAVDLVITEVQEPVRFLLETKVRVCSPNERLFWPFSKRSTTENFFLKLKQIKQRERKNNTDTLYEVVCLES>sp|Q9Y3P9-4|RBGP1_HUMAN Isoform 4 of Rab GTPase-activating protein 1OS=Homo sapiens OX=9606 GN=RABGAP1MDDKASVGKISVSSDSVSTLNSEDFVLVSRQGDETPSTNNGSDDEKTGLKIVGNGSEQQLQKELADVLMDPPMDDQPGEKELVKRSQLDGEGDGPLSNQLSASSTINPVPLVGLQKPEMSLPVKPGQGDSEASSPFTPVADEDSVVFSKLTYLGCASVNAPRSEVEALRMMSILRSQCQISLDVTLSVPNVSEGIVRLLDPQTNTEIANYPIYKILFCVRGHDGTPESDCFAFTESHYNAELFRIHVFRCEIQEAVSPQEKTLCK>sp|Q32P51|RA1L2_HUMAN Heterogeneous nuclear ribonucleoprotein A1-like 2OS=Homo sapiens OX=9606 GN=HNRNPA1L2 PE=2 SV=2MSKSASPKEPEQLRKLFIGGLSFETTDESLRSHFEQWGTLTDCVVMRDPNTKRSRGFGFVTYATVEEVDAAMNTTPHKVDGRVVEPKRAVSREDSQRPGAHLTVKKIFVGGIKEDTEEHHLRDYFEQYGKIEVIEIMTDRGSGKKRGFAFVTFDDHDSVDKIVIQKYHTVKGHNCEVRKALPKQEMASASSSQRGRRGSGNFGGGRGDGFGGNDNFGRGGNFSGRGGFGGSCGGGGYGGSGDGYNGFGNDGSNFGGGGSYNDFGNYNNQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPQNQGGYGVSSSSSSYGSGRRF>sp|Q96S21|RB40C_HUMAN Ras-related protein Rab-40C OS=Homo sapiensOX=9606 GN=RAB40C PE=1 SV=1MGSQGSPVKSYDYLLKFLLVGDSDVGKGEILESLQDGAAESPYAYSNGIDYKTTTILLDGRRVKLELWDTSGQGRFCTIFRSYSRGAQGILLVYDITNRWSFDGIDRWIKEIDEHAPGVPRILVGNRLHLAFKRQVPTEQARAYAEKNCMTFFEVSPLCNFNVIESFTELSRIVLMRHGMEKIWRPNRVFSLQDLCCRAIVSCTPVHLIDKLPLPVTIKSHLKSFSMANGMNAVMMHGRSYSLASGAGGGGSKGNSLKRSKSIRPPQSPPQNCSRSNCKIS>sp|Q96S21-2|RB40C_HUMAN Isoform 2 of Ras-related protein Rab-40C OS=Homosapiens OX=9606 GN=RAB40CMGSQGSPVKSYDYLLKFLLVGDSDVGKGEILESLQDGAAESPYAYSNGIDYKTTTILLDGRRVKLELWDTSGQGRFCTIFRSYSRGAQGILLVYDITNRWSFDGIDRWIKEIDERQVPTEQARAYAEKNCMTFFEVSPLCNFNVIESFTELSRIVLMRHGMEKIWRPNRVFSLQDLCCRAIVSCTPVHLIDKLPLPVTIKSHLKSFSMANGMNAVMMHGRSYSLASGAGGGGSKGNSLKRSKSIRPPQSPPQNCSRSNCKIS>sp|Q96NR8|RDH12_HUMAN Retinol dehydrogenase 12 OS=Homo sapiens OX=9606GN=RDH12 PE=1 SV=3MLVTLGLLTSFFSFLYMVAPSIRKFFAGGVCRTNVQLPGKVVVITGANTGIGKETARELASRGARVYIACRDVLKGESAASEIRVDTKNSQVLVRKLDLSDTKSIRAFAEGFLAEEKQLHILINNAGVMMCPYSKTADGFETHLGVNHLGHFLLTYLLLERLKVSAPARVVNVSSVAHHIGKIPFHDLQSEKRYSRGFAYCHSKLANVLFTRELAKRLQGTGVTTYAVHPGVVRSELVRHSSLLCLLWRLFSPFVKTAREGAQTSLHCALAEGLEPLSGKYFSDCKRTWVSPRARNNKTAERLWNVSCELLGIRWE>sp|Q9Y2K5|R3HD2_HUMAN R3H domain-containing protein 2 OS=Homo sapiensOX=9606 GN=R3HDM2 PE=1 SV=3MSNSNTTQETLEIMKESEKKLVEESVNKNKFISKTPSKEEIEKECEDTSLRQETQRRTSNHGHARKRAKSNSKLKLVRSLAVCEESSTPFADGPLETQDIIQLHISCPSDKEEEKSTKDVSEKEDKDKNKEKIPRKMLSRDSSQEYTDSTGIDLHEFLVNTLKKNPRDRMMLLKLEQEILEFINDNNNQFKKFPQMTSYHRMLLHRVAAYFGMDHNVDQTGKAVIINKTSNTRIPEQRFSEHIKDEKNTEFQQRFILKRDDASMDRDDNQTGQNGYLNDIRLSKEAFSSSSHKRRQIFRGNREGLSRTSSSRQSSTDSELKSLEPRPWSSTDSDGSVRSMRPPVTKASSFSGISILTRGDSIGSSKGGSAGRISRPGMALGAPEVCNQVTSSQSVRGLLPCTAQQQQQQQQQQLPALPPTPQQQPPLNNHMISQADDLSNPFGQMSLSRQGSTEAADPSAALFQTPLISQHPQQTSFIMASTGQPLPTSNYSTSSHAPPTQQVLPPQGYMQPPQQIQVSYYPPGQYPNSNQQYRPLSHPVAYSPQRGQQLPQPSQQPGLQPMMPNQQQAAYQGMIGVQQPQNQGLLSSQRSSMGGQMQGLVVQYTPLPSYQVPVGSDSQNVVQPPFQQPMLVPVSQSVQGGLPAAGVPVYYSMIPPAQQNGTSPSVGFLQPPGSEQYQMPQSPSPCSPPQMPQQYSGVSPSGPGVVVMQLNVPNGPQPPQNPSMVQWSHCKYYSMDQRGQKPGDLYSPDSSPQANTQMSSSPVTSPTQSPAPSPVTSLSSVCTGLSPLPVLTQFPRPGGPAQGDGRYSLLGQPLQYNLSICPPLLHGQSTYTVHQGQSGLKHGNRGKRQALKSASTDLGTADVVLGRVLEVTDLPEGITRTEADKLFTQLAMSGAKIQWLKDAQGLPGGGGGDNSGTAENGRHSDLAALYTIVAVFPSPLAAQNASLRLNNSVSRFKLRMAKKNYDLRILERASSQ>sp|Q9Y2K5-2|R3HD2_HUMAN Isoform 2 of R3H domain-containing protein 2OS=Homo sapiens OX=9606 GN=R3HDM2MITRGNREGLSRTSSSRQSSTDSELKSLEPRPWSSTDSDGSVRSMRPPVTKASSFSGISILTRGDSIGSSKGGSAGRISRPGMALGAPEVCNQVTSSQSVRGLLPCTAQQQQQQQQQQLPALPPTPQQQPPLNNHMISQADDLSNPFGQMSLSRQGSTEAADPSAALFQTPLISQHPQQTSFIMASTGQPLPTSNYSTSSHAPPTQQVLPPQGYMQPPQQIQVSYYPPGQYPNSNQQYRPLSHPVAYSPQRGQQLPQPSQQPGLQPMMPNQQQAAYQGMIGVQQPQNQGLLSSQRSSMGGQMQGLVVQYTPLPSYQVPVGSDSQNVVQPPFQQPMLVPVSQSVQGGLPAAGVPVYYSMIPPAQQNGTSPSVGFLQPPGSEQYQMPQSPSPCSPPQMPQQYSGVSPSGPGVVVMQLNVPNGPQPPQNPSMVQWSHCKYYSMDQRGQKPGDLYSPDSSPQANTQMSSSPVTSPTQSPAPSPVTSLSSVCTGLSPLPVLTQFPRPGGPAQGDGRYSLLGQPLQYNLSICPPLLHGQSTYTVHQGQSGLKHGNRGKRQALKSASTDLGTADVVLGRVLEVTDLPEGITRTEADKLFTQLAMSGAKIQWLKDAQGLPGGGGGDNSGTAENGRHSDLAALYTIVAVFPSPLAAQNASLRLNNSVSRFKLRMAKKNYDLRILERASSQ>sp|Q9Y2K5-3|R3HD2_HUMAN Isoform 3 of R3H domain-containing protein 2OS=Homo sapiens OX=9606 GN=R3HDM2MRPPVTKASSFSGISILTRGDSIGSSKGGSAGRISRPGMALGAPEVCNQVTSSQSVRGLLPCTAQQQQQQQQQQLPALPPTPQQQPPLNNHMISQPVPALQPSPQPVQFSPSSCPQVLLPVSPPQQYNMADDLSNPFGQMSLSRQGSTEAADPSAALFQTPLISQHPQQTSFIMASTGQPLPTSNYSTSSHAPPTQQVLPPQGYMQPPQQIQVSYYPPGQYPNSNQQYRPLSHPVAYSPQRGQQLPQPSQQPGLQPMMPNQQQAAYQGMIGVQQPQNQGLLSSQRSSMGGQMQGLVVQYTPLPSYQVPVGSDSQNVVQPPFQQPMLVPVSQSVQGGLPAAGVPVYYSMIPPAQQNGTSPSVGFLQPPGSEQYQMPQSPSPCSPPQMPQQYSGVSPSGPGVVVMQLNVPNGPQPPQNPSMVQWSHCKYYSMDQRGQKPGDLYSPDSSPQANTQMSSSPVTSPTQSPAPSPVTSLSSVCTGLSPLPVLTQFPRPGGPAQGDGRYSLLGQPLQYNLSICPPLLHGQSTYTVHQGQSGLKHGNRGKRQALKSASTDLGTADVVLGRVLEVTDLPEGITRTEADKLFTQLAMSGAKIQWLKDAQGLPGGGGGDNSGTAENGRHSDLAALYTIVAVFPSPLAAQNASLRLNNSVSRFKLRMAKKNYDLRILERASSQ>sp|A6NED2|RCCD1_HUMAN RCC1 domain-containing protein 1 OS=Homo sapiensOX=9606 GN=RCCD1 PE=1 SV=1MAEERPGAWFGFGFCGFGQELGSGRGRQVHSPSPLRAGVDICRVSASWSYTAFVTRGGRLELSGSASGAAGRCKDAWASEGLLAVLRAGPGPEALLQVWAAESALRGEPLWAQNVVPEAEGEDDPAGEAQAGRLPLLPCARAYVSPRAPFYRPLAPELRARQLELGAEHALLLDAAGQVFSWGGGRHGQLGHGTLEAELEPRLLEALQGLVMAEVAAGGWHSVCVSETGDIYIWGWNESGQLALPTRNLAEDGETVAREATELNEDGSQVKRTGGAEDGAPAPFIAVQPFPALLDLPMGSDAVKASCGSRHTAVVTRTGELYTWGWGKYGQLGHEDTTSLDRPRRVEYFVDKQLQVKAVTCGPWNTYVYAVEKGKS>sp|Q969Q5|RAB24_HUMAN Ras-related protein Rab-24 OS=Homo sapiens OX=9606GN=RAB24 PE=1 SV=1MSGQRVDVKVVMLGKEYVGKTSLVERYVHDRFLVGPYQNTIGAAFVAKVMSVGDRTVTLGIWDTAGSERYEAMSRIYYRGAKAAIVCYDLTDSSSFERAKFWVKELRSLEEGCQIYLCGTKSDLLEEDRRRRRVDFHDVQDYADNIKAQLFETSSKTGQSVDELFQKVAEDYVSVAAFQVMTEDKGVDLGQKPNPYFYSCCHH>sp|P20336|RAB3A_HUMAN Ras-related protein Rab-3A OS=Homo sapiens OX=9606GN=RAB3A PE=1 SV=1MASATDSRYGQKESSDQNFDYMFKILIIGNSSVGKTSFLFRYADDSFTPAFVSTVGIDFKVKTIYRNDKRIKLQIWDTAGQERYRTITTAYYRGAMGFILMYDITNEESFNAVQDWSTQIKTYSWDNAQVLLVGNKCDMEDERVVSSERGRQLADHLGFEFFEASAKDNINVKQTFERLVDVICEKMSESLDTADPAVTGAKQGPQLSDQQVPPHQDCAC>sp|Q6NUK4|REEP3_HUMAN Receptor expression-enhancing protein 3 OS=Homosapiens OX=9606 GN=REEP3 PE=1 SV=1MVSWMISRAVVLVFGMLYPAYYSYKAVKTKNVKEYVRWMMYWIVFALYTVIETVADQTVAWFPLYYELKIAFVIWLLSPYTKGASLIYRKFLHPLLSSKEREIDDYIVQAKERGYETMVNFGRQGLNLAATAAVTAAVKSQGAITERLRSFSMHDLTTIQGDEPVGQRPYQPLPEAKKKSKPAPSESAGYGIPLKDGDEKTDEEAEGPYSDNEMLTHKGLRRSQSMKSVKTTKGRKEVRYGSLKYKVKKRPQVYF>sp|Q6NUK4-2|REEP3_HUMAN Isoform 2 of Receptor expression-enhancingprotein 3 OS=Homo sapiens OX=9606 GN=REEP3MVSWMISRAVVLVFGMLYPAYYSYKAVKTKNVKEYVRWMMYWIVFALYTVIETVADQTVAWFPLYYELKIAFVIWLLSPYTKGASLIYRKFLHPLLSSKEREIDDYIVQAKERGYETMVNFGRQGLNLAATAAVTAAVKVIVHLPF>sp|Q9H902|REEP1_HUMAN Receptor expression-enhancing protein 1 OS=Homosapiens OX=9606 GN=REEP1 PE=1 SV=1MVSWIISRLVVLIFGTLYPAYYSYKAVKSKDIKEYVKWMMYWIIFALFTTAETFTDIFLCWFPFYYELKIAFVAWLLSPYTKGSSLLYRKFVHPTLSSKEKEIDDCLVQAKDRSYDALVHFGKRGLNVAATAAVMAASKGQGALSERLRSFSMQDLTTIRGDGAPAPSGPPPPGSGRASGKHGQPKMSRSASESASSSGTA>sp|Q9H902-2|REEP1_HUMAN Isoform 2 of Receptor expression-enhancingprotein 1 OS=Homo sapiens OX=9606 GN=REEP1MDHLQAGGVKWMMYWIIFALFTTAETFTDIFLCWFPFYYELKIAFVAWLLSPYTKGSSLLYRKFVHPTLSSKEKEIDDCLVQAKDRSYDALVHFGKRGLNVAATAAVMAASKGQGALSERLRSFSMQDLTTIRGDGAPAPSGPPPPGSGRASGKHGQPKMSRSASESASSSGTA>sp|Q9H902-3|REEP1_HUMAN Isoform 3 of Receptor expression-enhancingprotein 1 OS=Homo sapiens OX=9606 GN=REEP1MQKVLSNGQTEEVRSGSRLIFGTLYPAYYSYKAVKSKDIKEYVKWMMYWIIFALFTTAETFTDIFLCWFPFYYELKIAFVAWLLSPYTKGSSLLYRKFVHPTLSSKEKEIDDCLVQAKDRSYDALVHFGKRGLNVAATAAVMAASKGQGALSERLRSFSMQDLTTIRGDGAPAPSGPPPPGSGRASGKHGQPKMSRSASESASSSGTA>sp|Q9H902-4|REEP1_HUMAN Isoform 4 of Receptor expression-enhancingprotein 1 OS=Homo sapiens OX=9606 GN=REEP1MVSWIISRLVVLIFGTLYPAYYSYKAVKSKDIKEYVKWMMYWIIFALFTTAETFTDIFLCWDRVPYRRDCGASACRTSPPSGETAPLLPRAPHHRGLGGPAANTASLRCPGVLLRALAAQAPPRILRSRFRKKSTSSSATETT>sp|Q9Y3P4|RHBD3_HUMAN Rhomboid domain-containing protein 3 OS=Homosapiens OX=9606 GN=RHBDD3 PE=2 SV=1MHARGPHGQLSPALPLASSVLMLLMSTLWLVGAGPGLVLAPELLLDPWQVHRLLTHALGHTALPGLLLSLLLLPTVGWQQECHLGTLRFLHASALLALASGLLAVLLAGLGLSSAAGSCGYMPVHLAMLAGEGHRPRRPRGALPPWLSPWLLLALTPLLSSEPPFLQLLCGLLAGLAYAAGAFRWLEPSERRLQVLQEGVLCRTLAGCWPLRLLATPGSLAELPVTHPAGVRPPIPGPPYVASPDLWSHWEDSALPPPSLRPVQPTWEGSSEAGLDWAGASFSPGTPMWAALDEQMLQEGIQASLLDGPAQEPQSAPWLSKSSVSSLRLQQLERMGFPTEQAVVALAATGRVEGAVSLLVGGQVGTETLVTHGKGGPAHSEGPGPP>sp|Q9H1A7|RPB1C_HUMAN DNA-directed RNA polymerase II subunit RPB11-b2OS=Homo sapiens OX=9606 GN=POLR2J3 PE=1 SV=1MNAPPAFESFLLFEGEKITINKDTKVPNACLFTMNKEDHTLGNIIKSQLLKDPQVLFAGYKVPHPLEHKIIIRVQTTPDYSPQEAFTNAITDLISELSLLEERFRTCLLPLRLLP>sp|Q6ZUM4|RHG27_HUMAN Rho GTPase-activating protein 27 OS=Homo sapiensOX=9606 GN=ARHGAP27 PE=1 SV=3MAADVVGDVYVLVEHPFEYTGKDGRRVAIRPNERYRLLRRSTEHWWHVRREPGGRPFYLPAQYVRELPALGNPAAAAPPGPHPSPAAPEPLAYDYRFVSAAATAGPDGAPEESGGRASSLCGPAQRGAATQRSSLAPGLPACLYLRPAAPVRPAQSLNDLACAAVSPPAGLLGSSGSFKACSVAGSWVCPRPLARSDSENVYEVIQDLHVPPPEESAEQVDDPPEPVYANIERQPRATSPGAAAAPLPSPVWETHTDAGTGRPYYYNPDTGVTTWESPFEAAEGAASPATSPASVDSHVSLETEWGQYWDEESRRVFFYNPLTGETAWEDEAENEPEEELEMQPGLSPGSPGDPRPPTPETDYPESLTSYPEEDYSPVGSFGEPGPTSPLTTPPGWSCHVSQDKQMLYTNHFTQEQWVRLEDPHGKPYFYNPEDSSVRWELPQVPVPAPRSIHKSSQDGDTPAQASPPEEKVPAELDEVGSWEEVSPATAAVRTKTLDKAGVLHRTKTADKGKRLRKKHWSASWTVLEGGVLTFFKDSKTSAAGGLRQPSKFSTPEYTVELRGATLSWAPKDKSSRKNVLELRSRDGSEYLIQHDSEAIISTWHKAIAQGIQELSAELPPEESESSRVDFGSSERLGSWQEKEEDARPNAAAPALGPVGLESDLSKVRHKLRKFLQRRPTLQSLREKGYIKDQVFGCALAALCERERSRVPRFVQQCIRAVEARGLDIDGLYRISGNLATIQKLRYKVDHDERLDLDDGRWEDVHVITGALKLFFRELPEPLFPFSHFRQFIAAIKLQDQARRSRCVRDLVRSLPAPNHDTLRMLFQHLCRVIEHGEQNRMSVQSVAIVFGPTLLRPEVEETSMPMTMVFQNQVVELILQQCADIFPPH>sp|Q6ZUM4-2|RHG27_HUMAN Isoform 2 of Rho GTPase-activating protein 27OS=Homo sapiens OX=9606 GN=ARHGAP27MQPGLSPGSPGDPRPPTPETDYPESLTSYPEEDYSPVGSFGEPGPTSPLTTPPGWSCHVSQDKQMLYTNHFTQEQWVRLEDPHGKPYFYNPEDSSVRWELPQVPVPAPRSIHKSSQDGDTPAQASPPEEKVPAELDEVGSWEEVSPATAAVRTKTLDKAGVLHRTKTADKGKRLRKKHWSASWTVLEGGVLTFFKDSKTSAAGGLRQPSKFSTPEYTVELRGATLSWAPKDKSSRKNVLELRSRDGSEYLIQHDSEAIISTWHKAIAQGIQELSAELPPEESESSRVDFGSSERLGSWQEKEEDARPNAAAPALGPVGLESDLSKVRHKLRKFLQRRPTLQSLREKGYIKDQVFGCALAALCERERSRVPRFVQQCIRAVEARGLDIDGLYRISGNLATIQKLRYKVDHDERLDLDDGRWEDVHVITGALKLFFRELPEPLFPFSHFRQFIAAIKLQDQARRSRCVRDLVRSLPAPNHDTLRMLFQHLCRVIEHGEQNRMSVQSVAIVFGPTLLRPEVEETSMPMTMVFQNQVVELILQQCADIFPPH>sp|Q6ZUM4-3|RHG27_HUMAN Isoform 3 of Rho GTPase-activating protein 27OS=Homo sapiens OX=9606 GN=ARHGAP27MAADVVGDVYVLVEHPFEYTGKDGRRVAIRPNERYRLLRRSTEHWWHVRREPGGRPFYLPAQYVRELPALGNPAAAAPPGPHPSPAAPEPLAYDYRFVSAAATAGPDGAPEESGGRASSLCGPAQRGAATQRSSLAPGLPACLYLRPAAPVRPAQSLNDLACAAVSPPAGLLGSSGSFKACSVAGSWVCPRPLARSDSENVYEVIQDLHVPPPEESAEQVDDPPEPVYANIERQPRATSPGAAAAPLPSPVWETHTDAGTGRPYYYNPDTGVTTWESPFEAAEGAASPATSPASVDSHVSLETEWGQYWDEESRRVFFYNPLTGETAWEDEAENEPEEELEMQPGLSPGSPGDPRPPTPETDYPESLTSYPEEDYSPVGSFGEPGPTSPLTTPPGWSCHVSQDKQMLYTNHFTQEQVPVPAPRSIHKSSQDGDTPAQASPPEEKVPAELDEVGSWEEVSPATAAVRTKTLDKAGVLHRTKTADKGKRLRKKHWSASWTVLEGGVLTFFKDSKTSAAGGLRQPSKFSTPEYTVELRGATLSWAPKDKSSRKNVLELRSRDGSEYLIQHDSEAIISTWHKAIAQGIQELSAELPPEESESSRVDFGSSERLGSWQEKEEDARPNAAAPALGPVGLESDLSKVRHKLRKFLQRRPTLQSLREKGYIKDQVFGCALAALCERERSRVPRFVQQCIRAVEARGLDIDGLYRISGNLATIQKLRYKVDHDERLDLDDGRWEDVHVITGALKLFFRELPEPLFPFSHFRQFIAAIKLQDQARRSRCVRDLVRSLPAPNHDTLRMLFQHLCRVIEHGEQNRMSVQSVAIVFGPTLLRPEVEETSMPMTMVFQNQVVELILQQCADIFPPH>sp|Q6ZUM4-4|RHG27_HUMAN Isoform 4 of Rho GTPase-activating protein 27OS=Homo sapiens OX=9606 GN=ARHGAP27MAADVVGDVYVLVEHPFEYTGKDGRRVAIRPNERYRLLRRSTEHWWHVRREPGGRPFYLPAQYVRELPALGNPAAAAPPGPHPSPAAPEPLAYDYRFVSAAATAGPDGAPEESGGRASSLCGPAQRGAATQRSSLAPGLPACLYLRPAAPVRPAQSLNDLACAAVSPPAGLLGSSGSFKACSVAGSWVCPRPLARSDSENVYEVIQDLHVPPPEESAEQVPPRALGRGGGWRARDRARTEPGRKETRSAQRRARRPPLSEDFG>sp|Q6NW40|RGMB_HUMAN Repulsive guidance molecule B OS=Homo sapiensOX=9606 GN=RGMB PE=1 SV=3MGLRAAPSSAAAAAAEVEQRRSPGLCPPPLELLLLLLFSLGLLHAGDCQQPAQCRIQKCTTDFVSLTSHLNSAVDGFDSEFCKALRAYAGCTQRTSKACRGNLVYHSAVLGISDLMSQRNCSKDGPTSSTNPEVTHDPCNYHSHAGAREHRRGDQNPPSYLFCGLFGDPHLRTFKDNFQTCKVEGAWPLIDNNYLSVQVTNVPVVPGSSATATNKITIIFKAHHECTDQKVYQAVTDDLPAAFVDGTTSGGDSDAKSLRIVERESGHYVEMHARYIGTTVFVRQVGRYLTLAIRMPEDLAMSYEESQDLQLCVNGCPLSERIDDGQGQVSAILGHSLPRTSLVQAWPGYTLETANTQCHEKMPVKDIYFQSCVFDLLTTGDANFTAAAHSALEDVEALHPRKERWHIFPSSGNGTPRGGSDLSVSLGLTCLILIVFL>sp|Q5TAB7|RIPP2_HUMAN Protein ripply2 OS=Homo sapiens OX=9606 GN=RIPPLY2PE=1 SV=1MENAGGAEGTESGAAACAATDGPTRRAGADSGYAGFWRPWVDAGGKKEEETPNHAAEAMPDGPGMTAASGKLYQFRHPVRLFWPKSKCYDYLYQEAEALLKNFPIQATISFYEDSDSEDEIEDLTCEN>sp|Q5TAB7-2|RIPP2_HUMAN Isoform 2 of Protein ripply2 OS=Homo sapiensOX=9606 GN=RIPPLY2MPDGPGMTAASGKLYQFRHPVRLFWPKSKCYDYLYQEAEALLKNFPIQATISFYEDSDSEDEIEDLTCEN>sp|Q9HB40|RISC_HUMAN Retinoid-inducible serine carboxypeptidase OS=Homosapiens OX=9606 GN=SCPEP1 PE=1 SV=1MELALRRSPVPRWLLLLPLLLGLNAGAVIDWPTEEGKEVWDYVTVRKDAYMFWWLYYATNSCKNFSELPLVMWLQGGPGGSSTGFGNFEEIGPLDSDLKPRKTTWLQAASLLFVDNPVGTGFSYVNGSGAYAKDLAMVASDMMVLLKTFFSCHKEFQTVPFYIFSESYGGKMAAGIGLELYKAIQRGTIKCNFAGVALGDSWISPVDSVLSWGPYLYSMSLLEDKGLAEVSKVAEQVLNAVNKGLYREATELWGKAEMIIEQNTDGVNFYNILTKSTPTSTMESSLEFTQSHLVCLCQRHVRHLQRDALSQLMNGPIRKKLKIIPEDQSWGGQATNVFVNMEEDFMKPVISIVDELLEAGINVTVYNGQLDLIVDTMGQEAWVRKLKWPELPKFSQLKWKALYSDPKSLETSAFVKSYKNLAFYWILKAGHMVPSDQGDMALKMMRLVTQQE>sp|Q9HB40-2|RISC_HUMAN Isoform 2 of Retinoid-inducible serinecarboxypeptidase OS=Homo sapiens OX=9606 GN=SCPEP1MELALRRSPVPRWLLLLPLLLGLNAGAVIDWPTEEGKEVWDYVTVRKDAYMFWWLYYATNSCKNFSELPLVMWLQGGPGGSSTGFGNFEEIGPLDSDLKPRKTTWLQAASLLFVDNPVGTGFSYVNGSGAYAKDLAMVASDMMVLLKTFFSCHKEFQTVPFYIFSESYGGKMAAGIGLELYKAIQRGTIKCNFAGVALGDSWISPVDSVLSWGPYLYSMSLLEDKGLAEVSKVAEQVLNAVNKGLYREATELWGKAEMIIEQNTDGVNFYNILTKSTPTSTMESSLEFTQSHLVWF>sp|Q9UNX3|RL26L_HUMAN 60S ribosomal protein L26-like 1 OS=Homo sapiensOX=9606 GN=RPL26L1 PE=1 SV=1MKFNPFVTSDRSKNRKRHFNAPSHVRRKIMSSPLSKELRQKYNVRSMPIRKDDEVQVVRGHYKGQQIGKVVQVYRKKYVIYIERVQREKANGTTVHVGIHPSKVVITRLKLDKDRKKILERKAKSRQVGKEKGKYKEELIEKMQE>sp|P62829|RL23_HUMAN 60S ribosomal protein L23 OS=Homo sapiens OX=9606GN=RPL23 PE=1 SV=1MSKRGRGGSSGAKFRISLGLPVGAVINCADNTGAKNLYIISVKGIKGRLNRLPAAGVGDMVMATVKKGKPELRKKVHPAVVIRQRKSYRRKDGVFLYFEDNAGVIVNNKGEMKGSAITGPVAKECADLWPRIASNAGSIA>sp|Q969S9|RRF2M_HUMAN Ribosome-releasing factor 2, mitochondrial OS=Homosapiens OX=9606 GN=GFM2 PE=1 SV=1MLTNLRIFAMSHQTIPSVYINNICCYKIRASLKRLKPHVPLGRNCSSLPGLIGNDIKSLHSIINPPIAKIRNIGIMAHIDAGKTTTTERILYYSGYTRSLGDVDDGDTVTDFMAQERERGITIQSAAVTFDWKGYRVNLIDTPGHVDFTLEVERCLRVLDGAVAVFDASAGVEAQTLTVWRQADKHNIPRICFLNKMDKTGASFKYAVESIREKLKAKPLLLQLPIGEAKTFKGVVDVVMKEKLLWNCNSNDGKDFERKPLLEMNDPELLKETTEARNALIEQVADLDDEFADLVLEEFSENFDLLPAEKLQTAIHRVTLAQTAVPVLCGSALKNKGIQPLLDAVTMYLPSPEERNYEFLQWYKDDLCALAFKVLHDKQRGPLVFMRIYSGTIKPQLAIHNINGNCTERISRLLLPFADQHVEIPSLTAGNIALTVGLKHTATGDTIVSSKSSALAAARRAEREGEKKHRQNNEAERLLLAGVEIPEPVFFCTIEPPSLSKQPDLEHALKCLQREDPSLKVRLDPDSGQTVLCGMGELHIEIIHDRIKREYGLETYLGPLQVAYRETILNSVRATDTLDRTLGDKRHLVTVEVEARPIETSSVMPVIEFEYAESINEGLLKVSQEAIENGIHSACLQGPLLGSPIQDVAITLHSLTIHPGTSTTMISACVSRCVQKALKKADKQVLEPLMNLEVTVARDYLSPVLADLAQRRGNIQEIQTRQDNKVVIGFVPLAEIMGYSTVLRTLTSGSATFALELSTYQAMNPQDQNTLLNRRSGLT>sp|Q969S9-2|RRF2M_HUMAN Isoform 2 of Ribosome-releasing factor 2,mitochondrial OS=Homo sapiens OX=9606 GN=GFM2MLTNLRIFAMSHQTIPSVYINNICCYKIRASLKRLKPHVPLGRNCSSLPGLIGNDIKSLHSIINPPIAKIRNIGIMAHIDAGKTTTTERILYYSGYTRSLGDVDDGDTVTDFMAQERERGITIQSAAVTFDWKGYRVNLIDTPGHVDFTLEVERCLRVLDGAVAVFDASAGVEAQTLTVWRQADKHNIPRICFLNKMDKTGASFKYAVESIREKLKAKPLLLQLPIGEAKTFKGVVDVVMKEKLLWNCNSNDGKDFERKPLLEMNDPELLKETTEARNALIEQVADLDDEFADLVLEEFSENFDLLPAEKLQTAIHRVTLAQTAVPVLCGSALKNKGIQPLLDAVTMYLPSPEERNYEFLERISRLLLPFADQHVEIPSLTAGNIALTVGLKHTATGDTIVSSKSSALAAARRAEREGEKKHRQNNEAERLLLAGVEIPEPVFFCTIEPPSLSKQPDLEHALKCLQREDPSLKVRLDPDSGQTVLCGMGELHIEIIHDRIKREYGLETYLGPLQVAYRETILNSVRATDTLDRTLGDKRHLVTVEVEARPIETSSVMPVIEFEYAESINEGLLKVSQEAIENGIHSACLQGPLLGSPIQDVAITLHSLTIHPGTSTTMISACVSRCVQKALKKADKQVLEPLMNLEVTVARDYLSPVLADLAQRRGNIQEIQTRQDNKVVIGFVPLAEIMGYSTVLRTLTSGSATFALELSTYQAMNPQDQNTLLNRRSGLT>sp|Q969S9-3|RRF2M_HUMAN Isoform 3 of Ribosome-releasing factor 2,mitochondrial OS=Homo sapiens OX=9606 GN=GFM2MLTNLRIFAMSHQTIPSVYINNICCYKIRASLKRLKPHVPLGRNCSSLPGLIGNDIKSLHSIINPPIAKIRNIGIMAHIDAGKTTTTERILYYSGYTRSLGDVDDGDTVTDFMAQERERGITIQSAAVTFDWKGYRVNLIDTPGHVDFTLEVERCLRVLDGAVAVFDASAGVEAQTLTVWRQADKHNIPRICFLNKMDKTGASFKYAVESIREKLKAKPLLLQLPIGEAKTFKGVVDVVMKEKLLWNCNSNDGKDFERKPLLEMNDPELLKETTEARNALIEQVADLDDEFADLVLEEFSENFDLLPAEKLQTAIHRVTLAQTAVPVLCGSALKNKGIQPLLDAVTMYLPSPEERNYEFLQWYKDDLCALAFKVLHDKQRGPLVFMRIYSGTIKPQLAIHNINGNCTERISRLLLPFADQHVEIPSLTAGNIALTVGLKHTATGDTIVSSKSSALAAARRAEREGEKKHRQNNEAERLLLAGVEIPEPVFFCTIEPPSLSKQPDLEHALKCLQREDPSLKVRLDPDSGQTVLCGMGELHIEIIHDRIKREYGLETYLGPLQVAYRETILNSVRATDTLDRTLGDKRHLVTVEVEARPIETSSVMPVIEYAESINEGLLKVSQEAIENGIHSACLQGPLLGSPIQDVAITLHSLTIHPGTSTTMISACVSRCVQKALKKADKQVLEPLMNLEVTVARDYLSPVLADLAQRRGNIQEIQTRQDNKVVIGFVPLAEIMGYSTVLRTLTSGSATFALELSTYQAMNPQDQNTLLNRRSGLT>sp|Q969S9-4|RRF2M_HUMAN Isoform 4 of Ribosome-releasing factor 2,mitochondrial OS=Homo sapiens OX=9606 GN=GFM2MLTNLRIFAMSHQTIPSVYINNICCYKIRASLKRLKPHVPLGRNCSSLPGLIGNDIKSLHSIINPPIAKIRNIGIMAHIDAGKTTTTERILYYSGYTRSLGDVDDGDTVTDFMAQERERGITIQSAAVTFDWKGYRVNLIDTPGHVDFTLEVERCLRVLDGAVAVFDASAGVEAQTLTVWRQADKHNIPRICFLNKMDKTGASFKYAVESIREKLKAKPLLLQLPIGEAKTFKGVVDVVMKEKLLWNCNSNDGKDFERKPLLEMNDPELLKETTEARNALIEQVADLDDEFADLVLEEFSENFDLLPAEKLQTAIHRVTLAQTAVPVLCGSALKNKGIQPLLDAVTMYLPSPEERNYEFLQWYKDDLCALAFKVLHDKQRGPLVFMRIYSGTIKPQLAIHNINGNCTERISRLLLPFADQHVEIPSLTAGNIALTVGLKHTATGDTIVSSKSSALAAARRAEREGEKKHRQNNEAERLLLAGVEIPEPVFFCTIEPPSLSKQPDLEHALKCLQREDPSLKVRLDPDSGQIPQRRGNIQEIQTRQDNKVVIGFVPLAEIMGYSTVLRTLTSGSATFALELSTYQAMNPQDQNTLLNRRSGLT>sp|Q969S9-5|RRF2M_HUMAN Isoform 5 of Ribosome-releasing factor 2,mitochondrial OS=Homo sapiens OX=9606 GN=GFM2MLTNLRIFAMSHQTIPSVYINNICCYKIRASLKRLKPHVPLGRNCSSLPGLIGNDIKSLHSIINPPIAKIRNIGIMAHIDAGKTTTTERILYYSGYTRSLGDVDDGDTVTDFMAQERERGITIQSAAVTFDWKGYRVNLIDTPGHVDFTLEVERCLRVLDGAVAVFDASAGVEAQTLTVWRQADKHNIPRICFLNKMDKTGASFKYAVESIREKLKAKPLLLQLPIGEAKTFKGVVDVVMKEKLLWNCNSNDGKDFERKPLLEMNDPELLKETTEARNALIEQVADLDDEFADLVLEEFSENFDLLPAEKLQTAIHRVTLAQTAVPVLCGSALKNKGIQPLLDAVTMYLPSPEERNYEFLQWYKDDLCALAFKVLHDKQRGPLVFMRIYSGTIKPQLAIHNINGNCTERISRLLLPFADQHVEIPSLTAGNIALTVGLKHTATGDTIVSSKSSALAAARRAEREGEKKHRQNNEAERLLLAGVEIPEPVFFCTIEPPSLSKQPGINGLSVSTN>sp|Q96E11|RRFM_HUMAN Ribosome-recycling factor, mitochondrial OS=Homosapiens OX=9606 GN=MRRF PE=1 SV=1MALGLKCFRMVHPTFRNYLAASIRPVSEVTLKTVHERQHGHRQYMAYSAVPVRHFATKKAKAKGKGQSQTRVNINAALVEDIINLEEVNEEMKSVIEALKDNFNKTLNIRTSPGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPECTAAAIKAIRESGMNLNPEVEGTLIRVPIPQVTREHREMLVKLAKQNTNKAKDSLRKVRTNSMNKLKKSKDTVSEDTIRLIEKQISQMADDTVAELDRHLAVKTKELLG>sp|Q96E11-2|RRFM_HUMAN Isoform 2 of Ribosome-recycling factor,mitochondrial OS=Homo sapiens OX=9606 GN=MRRFMALGLKCFRMVHPTFRNYLAASIRPVSEVTLKTVHERQHGHRQYMAYSAVPVRHFATKKAKAKGKGQSQTRVNINAALVEDIINLEEVNEEMKSVIEALKDNFNKTLNIRTSPGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPECTAAAIKAIRESGMNLNPEVEGTLIRVPIPQSAKWPMTQWQNWTGIWQ>sp|Q96E11-3|RRFM_HUMAN Isoform 3 of Ribosome-recycling factor,mitochondrial OS=Homo sapiens OX=9606 GN=MRRFMAYSAVPVRHFATKKAKAKGKGQSQTRVNINAALVEDIINLEEVNEEMKSVIEALKDNFNKTLNIRTSPGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPECTAAAIKAIRESGMNLNPEVEGTLIRVPIPQVTREHREMLVKLAKQNTNKAKDSLRKVRTNSMNKLKKSKDTVSEDTIRLIEKQISQMADDTVAELDRHLAVKTKELLG>sp|Q96E11-4|RRFM_HUMAN Isoform 4 of Ribosome-recycling factor,mitochondrial OS=Homo sapiens OX=9606 GN=MRRFMALGLKCFRMVHPTFRNYLAASIRPVSEVTLKTVHERQHGHRQYMAYSAVPVRHFATKKAKAKGKGQSQTRVNINAALVEDIINLEEVNEEMKSVIEALKDNFNKTLNIRTSPGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPEELAWIRSLRVPGIRSHLYHQLAV>sp|Q96E11-5|RRFM_HUMAN Isoform 5 of Ribosome-recycling factor,mitochondrial OS=Homo sapiens OX=9606 GN=MRRFMALGLKCFRMVHPTFRNYLAASIRPVSEVTLKTVHERQHGHRQYMAYSAVPVRHFATKKAKAKGKGQSQTRVNINAALVEDIINLEEVNEEMKSVIEALKDNFNKTLNIRTSPGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPEVRWPC>sp|Q96E11-6|RRFM_HUMAN Isoform 6 of Ribosome-recycling factor,mitochondrial OS=Homo sapiens OX=9606 GN=MRRFMALGLKCFRMVHPTFRNYLAASIRPVSEVTLKTVHERQHGHRQYMAYSAVPVRHFATKKAKAKGKGQSQTRVNINAALVEDIINLEEVNEEMKSVIEALKDNFNKTLNIRTSPGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPETMKQIKQYFNGPNVA>sp|Q96E11-7|RRFM_HUMAN Isoform 7 of Ribosome-recycling factor,mitochondrial OS=Homo sapiens OX=9606 GN=MRRFMAYSAVPVRHFATKKAKAKGKGQSQTRVNINAALVEDIINLEEVNEEMKSVIEALKDNFNKTLNIRTSPGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPETMKQIKQYFNGPNVA>sp|Q96E11-8|RRFM_HUMAN Isoform 8 of Ribosome-recycling factor,mitochondrial OS=Homo sapiens OX=9606 GN=MRRFMALGLKCFRMVHPTFRNYLAASIRPVSEVTLKTVHERQHGHRQYMAYSAVPVRHFATKKAKGSLDKIAVVTADGKLALNQISQISMKSPQLILVNMASFPECTAAAIKAIRESGMNLNPEVEGTLIRVPIPQVTREHREMLVKLAKQNTNKAKDSLRKVRTNSMNKLKKSKDTVSEDTIRLIEKQISQMADDTVAELDRHLAVKTKELLG>sp|O14543|SOCS3_HUMAN Suppressor of cytokine signaling 3 OS=Homo sapiensOX=9606 GN=SOCS3 PE=1 SV=1MVTHSKFPAAGMSRPLDTSLRLKTFSSKSEYQLVVNAVRKLQESGFYWSAVTGGEANLLLSAEPAGTFLIRDSSDQRHFFTLSVKTQSGTKNLRIQCEGGSFSLQSDPRSTQPVPRFDCVLKLVHHYMPPPGAPSFPSPPTEPSSEVPEQPSAQPLPGSPPRRAYYIYSGGEKIPLVLSRPLSSNVATLQHLCRKTVNGHLDSYEKVTQLPGPIREFLDQYDAPL>sp|P57768|SNX16_HUMAN Sorting nexin-16 OS=Homo sapiens OX=9606 GN=SNX16PE=1 SV=2MATPYVPVPMPIGNSASSFTTNRNQRSSSFGSVSTSSNSSKGQLEDSNMGNFKQTSVPDQMDNTSSVCSSPLIRTKFTGTASSIEYSTRPRDTEEQNPETVNWEDRPSTPTILGYEVMEERAKFTVYKILVKKTPEESWVVFRRYTDFSRLNDKLKEMFPGFRLALPPKRWFKDNYNADFLEDRQLGLQAFLQNLVAHKDIANCLAVREFLCLDDPPGPFDSLEESRAFCETLEETNYRLQKELLEKQKEMESLKKLLSEKQLHIDTLENRIRTLSLEPEESLDVSETEGEQILKVESSALEVDQDVLDEESRADNKPCLSFSEPENAVSEIEVAEVAYDAEED>sp|P57768-2|SNX16_HUMAN Isoform 2 of Sorting nexin-16 OS=Homo sapiensOX=9606 GN=SNX16MATPYVPVPMPIGNSASSFTTNRNQRSSSFGSVSTSSNSSKGQLEDSNMGNFKQTSVPDQMDNTSSVCSSPLIRTKFTGTASSIEYSTRPRDTEEQNPETVNWEDRPSTPTILGYEVMEERAKFTLKEMFPGFRLALPPKRWFKDNYNADFLEDRQLGLQAFLQNLVAHKDIANCLAVREFLCLDDPPGPFDSLEESRAFCETLEETNYRLQKELLEKQKEMESLKKLLSEKQLHIDTLENRIRTLSLEPEESLDVSETEGEQILKVESSALEVDQDVLDEESRADNKPCLSFSEPENAVSEIEVAEVAYDAEED>sp|Q8NB12|SMYD1_HUMAN Histone-lysine N-methyltransferase SMYD1 OS=Homosapiens OX=9606 GN=SMYD1 PE=1 SV=1MTIGRMENVEVFTAEGKGRGLKATKEFWAADIIFAERAYSAVVFDSLVNFVCHTCFKRQEKLHRCGQCKFAHYCDRTCQKDAWLNHKNECSAIKRYGKVPNENIRLAARIMWRVEREGTGLTEGCLVSVDDLQNHVEHFGEEEQKDLRVDVDTFLQYWPPQSQQFSMQYISHIFGVINCNGFTLSDQRGLQAVGVGIFPNLGLVNHDCWPNCTVIFNNGNHEAVKSMFHTQMRIELRALGKISEGEELTVSYIDFLNVSEERKRQLKKQYYFDCTCEHCQKKLKDDLFLGVKDNPKPSQEVVKEMIQFSKDTLEKIDKARSEGLYHEVVKLCRECLEKQEPVFADTNIYMLRMLSIVSEVLSYLQAFEEASFYARRMVDGYMKLYHPNNAQLGMAVMRAGLTNWHAGNIEVGHGMICKAYAILLVTHGPSHPITKDLEAMRVQTEMELRMFRQNEFMYYKMREAALNNQPMQVMAEPSNEPSPALFHKKQ>sp|P53814|SMTN_HUMAN Smoothelin OS=Homo sapiens OX=9606 GN=SMTN PE=1SV=7MADEALAGLDEGALRKLLEVTADLAERRRIRSAIRELQRQELEREEEALASKRFRAERQDNKENWLHSQQREAEQRAALARLAGQLESMNDVEELTALLRSAGEYEERKLIRAAIRRVRAQEIEAATLAGRLYSGRPNSGSREDSKGLAAHRLEQCEVPEREEQEQQAEVSKPTPTPEGTSQDVTTVTLLLRAPPGSTSSSPASPSSSPTPASPEPPLEPAEAQCLTAEVPGSPEPPPSPPKTTSPEPQESPTLPSTEGQVVNKLLSGPKETPAAQSPTRGPSDTKRADVAGPRPCQRSLSVLSPRQPAQNRESTPLASGPSSFQRAGSVRDRVHKFTSDSPMAARLQDGTPQAALSPLTPARLLGPSLTSTTPASSSSGSSSRGPSDTSSRFSKEQRGVAQPLAQLRSCPQEEGPRGRGLAARPLENRAGGPVARSEEPGAPLPVAVGTAEPGGSMKTTFTIEIKDGRGQASTGRVLLPTGNQRAELTLGLRAPPTLLSTSSGGKSTITRVNSPGTLARLGSVTHVTSFSHAPPSSRGGCSIKMEAEPAEPLAAAVEAANGAEQTRVNKAPEGRSPLSAEELMTIEDEGVLDKMLDQSTDFEERKLIRAALRELRQRKRDQRDKERERRLQEARGRPGEGRGNTATETTTRHSQRAADGSAVSTVTKTERLVHSNDGTRTARTTTVESSFVRRSENGSGSTMMQTKTFSSSSSSKKMGSIFDREDQASPRAGSLAALEKRQAEKKKELMKAQSLPKTSASQARKAMIEKLEKEGAAGSPGGPRAAVQRSTSFGVPNANSIKQMLLDWCRAKTRGYEHVDIQNFSSSWSDGMAFCALVHNFFPEAFDYGQLSPQNRRQNFEVAFSSAEMLVDCVPLVEVDDMMIMGKKPDPKCVFTYVQSLYNHLRRHELRLRGKNV>sp|P53814-2|SMTN_HUMAN Isoform A of Smoothelin OS=Homo sapiens OX=9606GN=SMTNMKTTFTIEIKDGRGQASTGRVLLPTGNQRAELTLGLRAPPTLLSTSSGGKSTITRVNSPGTLARLGSVTHVTSFSHAPPSSRGGCSIKMEAEPAEPLAAAVEAANGAEQTRVNKAPEGRSPLSAEELMTIEDEGVLDKMLDQSTDFEERKLIRAALRELRQRKRDQRDKERERRLQEARGRPGEGRGNTATETTTRHSQRAADGSAVSTVTKTERLVHSNDGTRTARTTTVESSFVRRSENGSGSTMMQTKTFSSSSSSKKMGSIFDREDQASPRAGSLAALEKRQAEKKKELMKAQSLPKTSASQARKAMIEKLEKEGAAGSPGGPRAAVQRSTSFGVPNANSIKQMLLDWCRAKTRGYEHVDIQNFSSSWSDGMAFCALVHNFFPEAFDYGQLSPQNRRQNFEVAFSSAEMLVDCVPLVEVDDMMIMGKKPDPKCVFTYVQSLYNHLRRHELRLRGKNV>sp|P53814-5|SMTN_HUMAN Isoform B2 of Smoothelin OS=Homo sapiens OX=9606GN=SMTNMADEALAGLDEGALRKLLEVTADLAERRRIRSAIRELQRQELEREEEALASKRFRAERQDNKENWLHSQQREAEQRAALARLAGQLESMNDVEELTALLRSAGEYEERKLIRAAIRRVRAQEIEAATLAGRLYSGRPNSGSREDSKGLAAHRLEQCEVPEREEQEQQAEVSKPTPTPEGTSQDVTTVTLLLRAPPGSTSSSPASPSSSPTPASPEPPLEPAEAQCLTAEVPGSPEPPPSPPKTTSPEPQESPTLPSTEGQVVNKLLSGPKETPAAQSPTRGPSDTKRADVAGPRPCQRSLSVLSPRQPAQNRESTPLASGPSSFQRAGSVRDRVHKFTSDSPMAARLQDGTPQAALSPLTPARLLGPSLTSTTPASSSSGSSSRGPSDTSSRFSKEQRGVAQPLAQLRSCPQEEGPRGRGLAARPLENRAGGPVARSEEPGAPLPVAVGTAEPGGSMKTTFTIEIKDGRGQASTGRVLLPTGNQRAELTLGLRAPPTLLSTSSGGKSTITRVNSPGTLARLGSVTHVTSFSHAPPSSRGGCSIKMEAEPAEPLAAAVEAANGAEQTRVNKAPEGRSPLSAEELMTIEDEGVLDKMLDQSTDFEERKLIRAALRELRQRKRDQRDKERERRLQEARGRPGEGRGNTATETTTRHSQRAADGSAVSTVTKTERLVHSNDGTRTARTTTVESSFVRRSENGSGSTMMQTKTFSSSSSSKKMGSIFDREDQASPRAGSLAALEKRQAEKKKELMKAQSLPKTSASQARKAMIEKLEKEGAAGSPGGPRAAVQRSTSFGVPNANSIKQMLLDWCRAKTRGYEHVDIQNFSSSWSDGMAFCALVHNFFPEAFDYGQLSPQNRRQNFEVAFSSAETHADCPQLLDTEDMVRLREPDWKCVYTYIQEFYRCLVQKGLVKTKKS>sp|P53814-6|SMTN_HUMAN Isoform B3 of Smoothelin OS=Homo sapiens OX=9606GN=SMTNMADEALAGLDEGALRKLLEVTADLAERRRIRSAIRELQRQELEREEEALASKRFRAERQDNKENWLHSQQREAEQRAALARLAGQLESMNDVEELTALLRSAGEYEERKLIRAAIRRVRAQEIEAATLAGRLYSGRPNSGSREDSKGLAAHRLEQCEVPEREEQEQQAEVSKPTPTPEGTSQDVTTVTLLLRAPPGSTSSSPASPSSSPTPASPEPPLEPAEAQCLTAEVPGSPEPPPSPPKTTSPEPQESPTLPSTEGQVVNKLLSGPKETPAAQSPTRGPSDTKRADVAGPRPCQRSLSVLSPRQPAQNRESTPLASGPSSFQRAGSVRDRVHKFTSDSPMAARLQDGTPQAALSPLTPARLLGPSLTSTTPASSSSGSSSRGPSDTSSRFSKEQRGVAQPLAQLRSCPQEEGPRGRGLAARPLENRAGGPVARSEEPGAPLPVAVGTAEPGGSMKTTFTIEIKDGRGQASTGRVLLPTGNQRAELTLGLRAPPTLLSTSSGGKSTITRVNSPGTLARLGSVTHVTSFSHAPPSSRGGCSIKMEAEPAEPLAAAVEAANGAEQTRVNKAPEGRSPLSAEELMTIEDEGVLDKMLDQSTDFEERKLIRAALRELRQRKRDQRDKERERRLQEARGRPGEGRGNTATETTTRHSQRAADGSAVSTVTKTERLVHSNDGTRTARTTTVESSFVRRSENGSGSTMMQTKTFSSSSSSKKMGSIFDREDQASPRAGSLAALEKRQAEKKKELMKAQSLPKTSASQARKAMIEKLEKEGAAGSPGGPRAAVQRSTSFGVPNANSIKQMLLDWCRAKTRGYEHVDIQNFSSSWSDGMAFCALVHNFFPEAFDYGQLSPQNRRQNFEVAFSSAETHADCPQLLDTEDMVRLREPDWKMLVDCVPLVEVDDMMIMGKKPDPKCVFTYVQSLYNHLRRHELRLRGKNV>sp|Q68CJ6|SLIP_HUMAN Nuclear GTPase SLIP-GC OS=Homo sapiens OX=9606GN=NUGGC PE=2 SV=3MAETKDVFGQEPHPVEDDLYKERTRKRRKSDRDQRFRAFPSMEQSALKEYEKLESRTRRVLSNTYQKLIQSVFLDDSIPNGVKYLINRLLALIEKPTVDPIYIALFGSTGAGKSSLINAIIQQAMFLPVSGESICTSCIVQVSSGCCVQYEAKIHLLSDQEWREELKNLTKLLHRTEELSREEADAWNRDEAVEEATWKLQMIYGNGAESKNYEELLRAKPKRKIPTSRVITLKAEEAEELSIKLDPYIRTQRRDWDGEAAEMRIWPLIKHVEVTLPKSDLIPEGVVLVDIPGTGDFNSKRDEMWKKTIDKCSVIWVISDIERVSGGQAHEDLLNESIKACQRGFCRDVALVVTKMDKLHLPEYLRERKAGNQAIQSQREAVLERNEMIKLQRTRILKEKLKRKLPADFKVLEASDLVYTVSAQEYWQQALLTEEETEIPKLREYIRKSLLDKKKRTVTKYVTEAFGLLLLTDSFNSTQNLPNEHLHMSVLRRFAEEKVELLEKAIAQCFACMEQPLQEGVRTARTSYRCILRACLVRSKGNQGFHQTLKAVCLKNGIYASRTLARIDLNEALTQPVYDQIDPVFGSIFRTGKPTGSALMPHIDAFKQSLQEKMTEIGIRSGWKYDSCKKNFLIQEISAILGGLEDHILRRKRRIYESLTASVQSDLKLCYEEAAQITGKKACERMKDAIRRGVDRQVAEGMFERAQERMQHQFQQLKTGIVEKVKGSITTMLALASSQGDGLYKELADVGSEYKEMEKLHRSLREVAENARLRKGMQEFLLRASPSKAGPPGTSL>sp|P51531|SMCA2_HUMAN Probable global transcription activator SNF2L2OS=Homo sapiens OX=9606 GN=SMARCA2 PE=1 SV=2MSTPTDPGAMPHPGPSPGPGPSPGPILGPSPGPGPSPGSVHSMMGPSPGPPSVSHPMPTMGSTDFPQEGMHQMHKPIDGIHDKGIVEDIHCGSMKGTGMRPPHPGMGPPQSPMDQHSQGYMSPHPSPLGAPEHVSSPMSGGGPTPPQMPPSQPGALIPGDPQAMSQPNRGPSPFSPVQLHQLRAQILAYKMLARGQPLPETLQLAVQGKRTLPGLQQQQQQQQQQQQQQQQQQQQQQQPQQQPPQPQTQQQQQPALVNYNRPSGPGPELSGPSTPQKLPVPAPGGRPSPAPPAAAQPPAAAVPGPSVPQPAPGQPSPVLQLQQKQSRISPIQKPQGLDPVEILQEREYRLQARIAHRIQELENLPGSLPPDLRTKATVELKALRLLNFQRQLRQEVVACMRRDTTLETALNSKAYKRSKRQTLREARMTEKLEKQQKIEQERKRRQKHQEYLNSILQHAKDFKEYHRSVAGKIQKLSKAVATWHANTEREQKKETERIEKERMRRLMAEDEEGYRKLIDQKKDRRLAYLLQQTDEYVANLTNLVWEHKQAQAAKEKKKRRRRKKKAEENAEGGESALGPDGEPIDESSQMSDLPVKVTHTETGKVLFGPEAPKASQLDAWLEMNPGYEVAPRSDSEESDSDYEEEDEEEESSRQETEEKILLDPNSEEVSEKDAKQIIETAKQDVDDEYSMQYSARGSQSYYTVAHAISERVEKQSALLINGTLKHYQLQGLEWMVSLYNNNLNGILADEMGLGKTIQTIALITYLMEHKRLNGPYLIIVPLSTLSNWTYEFDKWAPSVVKISYKGTPAMRRSLVPQLRSGKFNVLLTTYEYIIKDKHILAKIRWKYMIVDEGHRMKNHHCKLTQVLNTHYVAPRRILLTGTPLQNKLPELWALLNFLLPTIFKSCSTFEQWFNAPFAMTGERVDLNEEETILIIRRLHKVLRPFLLRRLKKEVESQLPEKVEYVIKCDMSALQKILYRHMQAKGILLTDGSEKDKKGKGGAKTLMNTIMQLRKICNHPYMFQHIEESFAEHLGYSNGVINGAELYRASGKFELLDRILPKLRATNHRVLLFCQMTSLMTIMEDYFAFRNFLYLRLDGTTKSEDRAALLKKFNEPGSQYFIFLLSTRAGGLGLNLQAADTVVIFDSDWNPHQDLQAQDRAHRIGQQNEVRVLRLCTVNSVEEKILAAAKYKLNVDQKVIQAGMFDQKSSSHERRAFLQAILEHEEENEEEDEVPDDETLNQMIARREEEFDLFMRMDMDRRREDARNPKRKPRLMEEDELPSWIIKDDAEVERLTCEEEEEKIFGRGSRQRRDVDYSDALTEKQWLRAIEDGNLEEMEEEVRLKKRKRRRNVDKDPAKEDVEKAKKRRGRPPAEKLSPNPPKLTKQMNAIIDTVINYKDRCNVEKVPSNSQLEIEGNSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLGDLEKDVMLLCHNAQTFNLEGSQIYEDSIVLQSVFKSARQKIAKEEESEDESNEEEEEEDEEESESEAKSVKVKIKLNKKDDKGRDKGKGKKRPNRGKAKPVVSDFDSDEEQDEREQSEGSGTDDE>sp|P51531-2|SMCA2_HUMAN Isoform Short of Probable global transcriptionactivator SNF2L2 OS=Homo sapiens OX=9606 GN=SMARCA2MSTPTDPGAMPHPGPSPGPGPSPGPILGPSPGPGPSPGSVHSMMGPSPGPPSVSHPMPTMGSTDFPQEGMHQMHKPIDGIHDKGIVEDIHCGSMKGTGMRPPHPGMGPPQSPMDQHSQGYMSPHPSPLGAPEHVSSPMSGGGPTPPQMPPSQPGALIPGDPQAMSQPNRGPSPFSPVQLHQLRAQILAYKMLARGQPLPETLQLAVQGKRTLPGLQQQQQQQQQQQQQQQQQQQQQQQPQQQPPQPQTQQQQQPALVNYNRPSGPGPELSGPSTPQKLPVPAPGGRPSPAPPAAAQPPAAAVPGPSVPQPAPGQPSPVLQLQQKQSRISPIQKPQGLDPVEILQEREYRLQARIAHRIQELENLPGSLPPDLRTKATVELKALRLLNFQRQLRQEVVACMRRDTTLETALNSKAYKRSKRQTLREARMTEKLEKQQKIEQERKRRQKHQEYLNSILQHAKDFKEYHRSVAGKIQKLSKAVATWHANTEREQKKETERIEKERMRRLMAEDEEGYRKLIDQKKDRRLAYLLQQTDEYVANLTNLVWEHKQAQAAKEKKKRRRRKKKAEENAEGGESALGPDGEPIDESSQMSDLPVKVTHTETGKVLFGPEAPKASQLDAWLEMNPGYEVAPRSDSEESDSDYEEEDEEEESSRQETEEKILLDPNSEEVSEKDAKQIIETAKQDVDDEYSMQYSARGSQSYYTVAHAISERVEKQSALLINGTLKHYQLQGLEWMVSLYNNNLNGILADEMGLGKTIQTIALITYLMEHKRLNGPYLIIVPLSTLSNWTYEFDKWAPSVVKISYKGTPAMRRSLVPQLRSGKFNVLLTTYEYIIKDKHILAKIRWKYMIVDEGHRMKNHHCKLTQVLNTHYVAPRRILLTGTPLQNKLPELWALLNFLLPTIFKSCSTFEQWFNAPFAMTGERVDLNEEETILIIRRLHKVLRPFLLRRLKKEVESQLPEKVEYVIKCDMSALQKILYRHMQAKGILLTDGSEKDKKGKGGAKTLMNTIMQLRKICNHPYMFQHIEESFAEHLGYSNGVINGAELYRASGKFELLDRILPKLRATNHRVLLFCQMTSLMTIMEDYFAFRNFLYLRLDGTTKSEDRAALLKKFNEPGSQYFIFLLSTRAGGLGLNLQAADTVVIFDSDWNPHQDLQAQDRAHRIGQQNEVRVLRLCTVNSVEEKILAAAKYKLNVDQKVIQAGMFDQKSSSHERRAFLQAILEHEEENEEEDEVPDDETLNQMIARREEEFDLFMRMDMDRRREDARNPKRKPRLMEEDELPSWIIKDDAEVERLTCEEEEEKIFGRGSRQRRDVDYSDALTEKQWLRAIEDGNLEEMEEEVRLKKRKRRRNVDKDPAKEDVEKAKKRRGRPPAEKLSPNPPKLTKQMNAIIDTVINYKDSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLGDLEKDVMLLCHNAQTFNLEGSQIYEDSIVLQSVFKSARQKIAKEEESEDESNEEEEEEDEEESESEAKSVKVKIKLNKKDDKGRDKGKGKKRPNRGKAKPVVSDFDSDEEQDEREQSEGSGTDDE>sp|Q8NBJ7|SUMF2_HUMAN Inactive C-alpha-formylglycine-generating enzyme 2OS=Homo sapiens OX=9606 GN=SUMF2 PE=1 SV=2MARHGLPLLPLLSLLVGAWLKLGNGQATSMVQLQGGRFLMGTNSPDSRDGDGPVREATVKPFAIDIFPVTNKDFRDFVREKKYRTEAEMFGWSFVFEDFVSDELRNKATQPMKSVLWWLPVEKAFWRQPAGPGSGIRERLEHPVLHVSWNDARAYCAWRGKRLPTEEEWEFAARGGLKGQVYPWGNWFQPNRTNLWQGKFPKGDKAEDGFHGVSPVNAFPAQNNYGLYDLLGNVWEWTASPYQAAEQDMRVLRGASWIDTADGSANHRARVTTRMGNTPDSASDNLGFRCAADAGRPPGEL>sp|Q8NBJ7-2|SUMF2_HUMAN Isoform 2 of Inactive C-alpha-formylglycine-generating enzyme 2 OS=Homo sapiens OX=9606 GN=SUMF2MFGWSFVFEDFVSDELRNKATQPMKSVLWWLPVEKAFWRQPAGPGSGIRERLEHPVLHVSWNDARAYCAWRGKRLPTEEEWEFAARGGLKGQVYPWGNWFQPNRTNLWQGKFPKGDKAEDGFHGVSPVNAFPAQNNYGLYDLLGNVWEWTASPYQAAEQDMRVLRGASWIDTADGSANHRARVTTRMGNTPDSASDNLGFRCAADAGRPPGEL>sp|Q8NBJ7-3|SUMF2_HUMAN Isoform 3 of Inactive C-alpha-formylglycine-generating enzyme 2 OS=Homo sapiens OX=9606 GN=SUMF2MARHGLPLLPLLSLLVGAWLKLGNGQATSMVQLQGGRFLMGTNSPDSRDGDGPVREATVKPFAIDIFPVTNKDFRDFVREKKYRTEAEMFGWSFVFEDFVSDELRNKATQPMKSVLWWLPVEKAFWRQPAGPGSGIRERLEHPVLHVSWNDARAYCAWRGKRLPTEEEWEFAARGGLKGQVYPWGNWFQPNRTNLWQGKFPKGDKAEDGFHGVSPVNAFPAQNNYGWATLQIQPQTTSVSAVLQTQAGRQGSCKQPGGDKEKSLLGSLSFPGHVANSAIPSSRASASGKNFPFPVSHPSVAGASHQGRRGLSLLCFGEGAQCVLTMAGGQVFLLEAKYY>sp|Q8NBJ7-5|SUMF2_HUMAN Isoform 5 of Inactive C-alpha-formylglycine-generating enzyme 2 OS=Homo sapiens OX=9606 GN=SUMF2MARHGLPLLPLLSLLVGAWLKLGNGQATSMVQLQGGRFLMGTNSPDSRDGDGPVREATVKPFAIDIFPVTNKDFRDFVREKKYRTEAEMFGWSFVFEDFVSDELRNKATQPMKGKFPKGDKAEDGFHGVSPVNAFPAQNNYGLYDLLGNVWEWTASPYQAAEQDMRVLRGASWIDTADGSANHRARVTTRMGNTPDSASDNLGFRCAADAGRPPGEL>sp|Q8NBJ7-4|SUMF2_HUMAN Isoform 4 of Inactive C-alpha-formylglycine-generating enzyme 2 OS=Homo sapiens OX=9606 GN=SUMF2MARHGLPLLPLLSLLVGAWLKLGNGQATSMVQLQGGRFLMGTNSPDSRDGDGPVREATVKPFAIDIFPVTNKDFRDFVREKKYRTEAEMFGWSFVFEDFVSDELRNKATQPMKVKFTHGGTGSSQTAPTCGRESSPRETKLRMASMESPQMLSPPRTTTGSMTSWGTCGSGQHHRTRLLSRTCASSGGHPGSTQLMALPITGPGSPPGWATLQIQPQTTSVSAVLQTQAGRQGSCKQPGGDKEKSLLGSLSFPGHVANSAIPSSRASASGKNFPFPVSHPSVAGASHQGRRGLSLLCFGEGAQCVLTMAGGQVFLLEAKYY>sp|P0CL85|ST3L3_HUMAN STAG3-like protein 3 OS=Homo sapiens OX=9606GN=STAG3L3 PE=2 SV=1MIFSMLRKLPKVTCRDVLPEIRAICIEEIGCWMQSYSTSFLTDSYLKYIGWTLHDKHREVRVKCVKALKGLYGNRDLTARLELFTGCFKDWMVSMIMDREYSVAVEAVRLLILILKNMEGVLMDVDCESVYPIV>sp|P0CL85-2|ST3L3_HUMAN Isoform 2 of STAG3-like protein 3 OS=Homosapiens OX=9606 GN=STAG3L3MIFSMLRKLPKVTCRDVLPEIRAICIEEIGCWMQSYSTSFLTDSYLKYIGWTLHDKHREVRVKCVKALKGLYGNRDLTARLELFTGCFKDWMVSMIMDREYSVAVEAVRLLILILK>sp|Q9P2F5|STOX2_HUMAN Storkhead-box protein 2 OS=Homo sapiens OX=9606GN=STOX2 PE=2 SV=2MKKTRSTTLRRAWPSSDFSDRASDRMRSRSEKDYRLHKRFPAAFAPQASRGYMTSGDVSPISMSPISQSQFIPLGEILCLAISAMNSARKPVTQEALMEHLTTCFPGVPTPSQEILRHTLNTLVRERKIYPTPDGYFIVTPQTYFITPSLIRTNSKWYHLDERIPDRSQCTSPQPGTITPSASGCVRERTLPRNHCDSCHCCREDVHSTHAPTLQRKSAKDCKDPYCPPSLCQVPPTEKSKSTVNFSYKTETLSKPKDSEKQSKKFGLKLFRLSFKKDKTKQLANFSAQFPPEEWPLRDEDTPATIPREVEMEIIRRINPDLTVENVMRHTALMKKLEEEKAQRSKAGSSAHHSGRSKKSRTHRKSHGKSRSHSKTRVSKGDPSDGSHLDIPAEREYDFCDPLTRVPREGCFIIEHKGDNFIMHSNTNVLESHFPMTPEWDVSGELAKRRTEMPFPEPSRGSSHSKVHRSHSHTQDRRSRNERSNKAKERSRSMDNSKGPLGASSLGTPEDLAEGCSQDDQTPSQSYIDDSTLRPAQTVSLQRAHISSTSYKEVCIPEIVSGSKEPSSACSLLEPGKPPESLPSYGELNSCPTKTATDDYFQCNTSSETVLTAPSPLGKNKEDHDTLTLAEGVKKLSPSDRQVPHSSREPVGHKEESPKGPGGGPAASGGVAEGIANGRLVQHHGAEPSSLDKRKEIFSKDTLFKPLHSTLSVNSYHKSSLSLLKSHPKTPADTLPGRCEKLEPSLGTSAAQAMPASQRQQESGGNQEASFDYYNVSDDDDSEEGANKNTEEEKNREDVGTMQWLLEREKERDLQRKFEKNLTLLAPKETDSSSNQRATHSARLDSMDSSSITVDSGFNSPRTRESLASNTSSIVESNRRQNPALSPAHGGAGPAFNFRASAEPPTNEAEKLQKPSNCLQASVTSV>sp|Q9P2F5-2|STOX2_HUMAN Isoform 2 of Storkhead-box protein 2 OS=Homosapiens OX=9606 GN=STOX2MKKTRSTTLRRAWPSSDFSDRASDRMRSRSEKDYRLHKRFPAAFAPQASRGYMTSGDVSPISMSPISQSQFIPLGEILCLAISAMNSARKPVTQEALMEHLTTCFPGVPTPSQEILRHTLNTLVRERKIYPTPDGYFIVTPQTYFITPSLIRTNSKWYHLDERIPDRSQCTSPQPGTITPSASGCVRERTLPRNHCDSCHCCREDVHSTHAPTLQRKSAKDCKDPYCPPSLCQVPPTEKSKSTVNFSYKTETLSKPKDSEKQSKKFGLKLFRLSFKKDKTKQLANFSAQFPPEEWPLRDEDTPATIPREVEMEIIRRINPDLTVENVMRHTALMKKLEEEKAQRSKAGSSAHHSGRSKKSRTHRKSHGKSRSHSKTRVSKGDPSDGSHLDIPAEREYDFCDPLTRVPREGCFIIEHKGDNFIMHSNTNVLESHFPMTPEWDVSGELAKRRTEMPFPEPSRGSSHSKVHRSHSHTQDRRSRNERSNKAKERSRSMDNSKGPLGASSLGTPEDLAEGCSQDDQTPSQSYIDDSTLRPAQTVSLQRAHISSTSYKEVCIPEIVSGSKEPSSACSLLEPGKPPESLPSYGELNSCPTKTATDDYFQCNTSSETVLTAPSPLGKNKEDHDTLTLAEGVKKLSPSDRQVPHSSREPVGHKEESPKGPGGGPAASGGVAEGIANGRLVQHHGAEPSSLDKRKEIFSKDTLFKPLHSTLSVNSYHKSSLSLLKSHPKTPADTLPGRCEKLEPSLGTSAAQAMPASQRQQESGGNQEASFDYYNVSDDDDSEEGANKNTEEEKNREDVGTMQWLLEREKERDLQRKFEKNLTLLAPKETDSSSNQRATHSARLDSMDSSSITVDSGFNSPRN>sp|Q9UH99|SUN2_HUMAN SUN domain-containing protein 2 OS=Homo sapiensOX=9606 GN=SUN2 PE=1 SV=3MSRRSQRLTRYSQGDDDGSSSSGGSSVAGSQSTLFKDSPLRTLKRKSSNMKRLSPAPQLGPSSDAHTSYYSESLVHESWFPPRSSLEELHGDANWGEDLRVRRRRGTGGSESSRASGLVGRKATEDFLGSSSGYSSEDDYVGYSDVDQQSSSSRLRSAVSRAGSLLWMVATSPGRLFRLLYWWAGTTWYRLTTAASLLDVFVLTRRFSSLKTFLWFLLPLLLLTCLTYGAWYFYPYGLQTFHPALVSWWAAKDSRRPDEGWEARDSSPHFQAEQRVMSRVHSLERRLEALAAEFSSNWQKEAMRLERLELRQGAPGQGGGGGLSHEDTLALLEGLVSRREAALKEDFRRETAARIQEELSALRAEHQQDSEDLFKKIVRASQESEARIQQLKSEWQSMTQESFQESSVKELRRLEDQLAGLQQELAALALKQSSVAEEVGLLPQQIQAVRDDVESQFPAWISQFLARGGGGRVGLLQREEMQAQLRELESKILTHVAEMQGKSAREAAASLSLTLQKEGVIGVTEEQVHHIVKQALQRYSEDRIGLADYALESGGASVISTRCSETYETKTALLSLFGIPLWYHSQSPRVILQPDVHPGNCWAFQGPQGFAVVRLSARIRPTAVTLEHVPKALSPNSTISSAPKDFAIFGFDEDLQQEGTLLGKFTYDQDGEPIQTFHFQAPTMATYQVVELRILTNWGHPEYTCIYRFRVHGEPAH>sp|Q9UH99-2|SUN2_HUMAN Isoform 2 of SUN domain-containing protein 2OS=Homo sapiens OX=9606 GN=SUN2MSRRSQRLTRYSQGDDDGSSSSGGSSVAGSQSTLFKDSPLRTLKRKSSNMKRLSPAPQLGPSSDAHTSYYSESLVHESWFPPRSSLEELHGDANWGEDLRVRRRRGTGGSESSRASGLVGRKATEDFLGSSSGYSSEDDYVEDSEGRGSKVTETEPVSSFPAGYSDVDQQSSSSRLRSAVSRAGSLLWMVATSPGRLFRLLYWWAGTTWYRLTTAASLLDVFVLTRRFSSLKTFLWFLLPLLLLTCLTYGAWYFYPYGLQTFHPALVSWWAAKDSRRPDEGWEARDSSPHFQAEQRVMSRVHSLERRLEALAAEFSSNWQKEAMRLERLELRQGAPGQGGGGGLSHEDTLALLEGLVSRREAALKEDFRRETAARIQEELSALRAEHQQDSEDLFKKIVRASQESEARIQQLKSEWQSMTQESFQESSVKELRRLEDQLAGLQQELAALALKQSSVAEEVGLLPQQIQAVRDDVESQFPAWISQFLARGGGGRVGLLQREEMQAQLRELESKILTHVAEMQGKSAREAAASLSLTLQKEGVIGVTEEQVHHIVKQALQRYSEDRIGLADYALESGGASVISTRCSETYETKTALLSLFGIPLWYHSQSPRVILQPDVHPGNCWAFQGPQGFAVVRLSARIRPTAVTLEHVPKALSPNSTISSAPKDFAIFGFDEDLQQEGTLLGKFTYDQDGEPIQTFHFQAPTMATYQVVELRILTNWGHPEYTCIYRFRVHGEPAH>sp|Q9UH99-3|SUN2_HUMAN Isoform 3 of SUN domain-containing protein 2OS=Homo sapiens OX=9606 GN=SUN2MSRRSQRLTRYSQGDDDGSSSSGGSSVAGSQSTLFKDSPLRTLKRKSSNMKRLSPAPQLGPSSDAHTSYYSESLVHESWFPPRSSLEELHGDANWGEDLRVRRRRGTGGSESSRASGLVGRKATEDFLGSSSGYSSEDDYVGYSDVDQQSSSSRLRSAVSRAGSLLWMVATSPGRLFRLLYWWAGTTWYRLTTAASLLDVFVLTRRFSSLKTFLWFLLPLLLLTCLTYGAWYFYPYGLQTFHPALVSWWAAKDSRRPDEGWEARDSSPHFQAEQRVMSRVHSLERRLEALAAEFSSNWQKEAMRLERLELRQGAPGQGGGGGLSHEDTLALLEGLVSRREAALKEDFRRETAARIQEELSALRAEHQQDSEDLFKKIVRASQESEARIQQLKSEWQSMTQESFQESSVKELRRLEDQLAGLQQELAALALKQSSVAEEVGLLPQQIQAVRDDVESQFPAWISQFLARGGGGRVGLLQREEMQAQLRELESKILTHVAEMQGKSAREAAASLSLTLQKEGVIGVTEEQVHHIVKQALQRYSEDRIGLADYALESGGASVISTRCSETYETKTALLSLFGIPLWYHSQSPRVILQPDVHPGNCWAFQGPQGFAVVRLSARIRPTAVTLEHVPKALSPNSTISSAPKDFAIFGFDEDLQQEGTLLGKFTYDQDGEPIQTFHFQAPSSFPLCPWRLLPILGVCIYVAYHGGLGSWER>sp|Q6ZMT1|STAC2_HUMAN SH3 and cysteine-rich domain-containing protein 2OS=Homo sapiens OX=9606 GN=STAC2 PE=1 SV=1MTEMSEKENEPDDAATHSPPGTVSALQETKLQRFKRSLSLKTILRSKSLENFFLRSGSELKCPTEVLLTPPTPLPPPSPPPTASDRGLATPSPSPCPVPRPLAALKPVRLHSFQEHVFKRASPCELCHQLIVGNSKQGLRCKMCKVSVHLWCSEEISHQQCPGKTSTSFRRNFSSPLLVHEPPPVCATSKESPPTGDSGKVDPVYETLRYGTSLALMNRSSFSSTSESPTRSLSERDELTEDGEGSIRSSEEGPGDSASPVFTAPAESEGPGPEEKSPGQQLPKATLRKDVGPMYSYVALYKFLPQENNDLALQPGDRIMLVDDSNEDWWKGKIGDRVGFFPANFVQRVRPGENVWRCCQPFSGNKEQGYMSLKENQICVGVGRSKDADGFIRVSSGKKRGLVPVDALTEI>sp|Q6ZMT1-2|STAC2_HUMAN Isoform 2 of SH3 and cysteine-rich domain-containing protein 2 OS=Homo sapiens OX=9606 GN=STAC2MCKVSVHLWCSEEISHQQCPGKTSTSFRRNFSSPLLVHEPPPVCATSKESPPTGDSGKVDPVYETLRYGTSLALMNRSSFSSTSESPTRSLSERDELTEDGEGSIRSSEEGPGDSASPVFTAPAESEGPGPEEKSPGQQLPKATLRKDVGPMYSYVALYKFLPQENNDLALQPGDRIMLVDDSNEDWWKGKIGDRVGFFPANFVQRVRPGENVWRCCQPFSGNKEQGYMSLKENQICVGVGRSKDADGFIRVSSGKKRGLVPVDALTEI>sp|Q9P2R7|SUCB1_HUMAN Succinate--CoA ligase [ADP-forming] subunit beta,mitochondrial OS=Homo sapiens OX=9606 GN=SUCLA2 PE=1 SV=3MAASMFYGRLVAVATLRNHRPRTAQRAAAQVLGSSGLFNNHGLQVQQQQQRNLSLHEYMSMELLQEAGVSVPKGYVAKSPDEAYAIAKKLGSKDVVIKAQVLAGGRGKGTFESGLKGGVKIVFSPEEAKAVSSQMIGKKLFTKQTGEKGRICNQVLVCERKYPRREYYFAITMERSFQGPVLIGSSHGGVNIEDVAAESPEAIIKEPIDIEEGIKKEQALQLAQKMGFPPNIVESAAENMVKLYSLFLKYDATMIEINPMVEDSDGAVLCMDAKINFDSNSAYRQKKIFDLQDWTQEDERDKDAAKANLNYIGLDGNIGCLVNGAGLAMATMDIIKLHGGTPANFLDVGGGATVHQVTEAFKLITSDKKVLAILVNIFGGIMRCDVIAQGIVMAVKDLEIKIPVVVRLQGTRVDDAKALIADSGLKILACDDLDEAARMVVKLSEIVTLAKQAHVDVKFQLPI>sp|Q9P2R7-2|SUCB1_HUMAN Isoform 2 of Succinate--CoA ligase [ADP-forming]subunit beta, mitochondrial OS=Homo sapiens OX=9606 GN=SUCLA2MAASMFYGRLVAVATLRNHRPRTAQQQQRNLSLHEYMSMELLQEAGVSVPKGYVAKSPDEAYAIAKKLGSKDVVIKAQVLAGGRGKGTFESGLKGGVKIVFSPEEAKAVSSQMIGKKLFTKQTGEKGRICNQVLVCERKYPRREYYFAITMERSFQGPVLIGSSHGGVNIEDVAAESPEAIIKEPIDIEEGIKKEQALQLAQKMGFPPNIVESAAENMVKLYSLFLKYDATMIEINPMVEDSDGAVLCMDAKINFDSNSAYRQKKIFDLQDWTQEDERDKDAAKANLNYIGLDGNIGCLVNGAGLAMATMDIIKLHGGTPANFLDVGGGATVHQVTEAFKLITSDKKVLAILVNIFGGIMRCDVIAQGIVMAVKDLEIKIPVVVRLQGTRVDDAKALIADSGLKILACDDLDEAARMVVKLSEIVTLAKQAHVDVKFQLPI>sp|M5A8F1|SUPYN_HUMAN Suppressyn OS=Homo sapiens OX=9606 GN=ERVH48-1PE=1 SV=1MACIYPTTFYTSLPTKSLNMGISLTTILILSVAVLLSTAAPPSCRECYQSLHYRGEMQQYFTYHTHIERSCYGNLIEECVESGKSYYKVKNLGVCGSRNGAICPRGKQWLCFTKIGQWGVNTQVLEDIKREQIIAKAKASKPTTPPENRPRHFHSFIQKL>sp|Q9BX79|STRA6_HUMAN Receptor for retinol uptake STRA6 OS=Homo sapiensOX=9606 GN=STRA6 PE=1 SV=1MSSQPAGNQTSPGATEDYSYGSWYIDEPQGGEELQPEGEVPSCHTSIPPGLYHACLASLSILVLLLLAMLVRRRQLWPDCVRGRPGLPSPVDFLAGDRPRAVPAAVFMVLLSSLCLLLPDEDALPFLTLASAPSQDGKTEAPRGAWKILGLFYYAALYYPLAACATAGHTAAHLLGSTLSWAHLGVQVWQRAECPQVPKIYKYYSLLASLPLLLGLGFLSLWYPVQLVRSFSRRTGAGSKGLQSSYSEEYLRNLLCRKKLGSSYHTSKHGFLSWARVCLRHCIYTPQPGFHLPLKLVLSATLTGTAIYQVALLLLVGVVPTIQKVRAGVTTDVSYLLAGFGIVLSEDKQEVVELVKHHLWALEVCYISALVLSCLLTFLVLMRSLVTHRTNLRALHRGAALDLSPLHRSPHPSRQAIFCWMSFSAYQTAFICLGLLVQQIIFFLGTTALAFLVLMPVLHGRNLLLFRSLESSWPFWLTLALAVILQNMAAHWVFLETHDGHPQLTNRRVLYAATFLLFPLNVLVGAMVATWRVLLSALYNAIHLGQMDLSLLPPRAATLDPGYYTYRNFLKIEVSQSHPAMTAFCSLLLQAQSLLPRTMAAPQDSLRPGEEDEGMQLLQTKDSMAKGARPGASRGRARWGLAYTLLHNPTLQVFRKTALLGANGAQP>sp|Q9BX79-2|STRA6_HUMAN Isoform 2 of Receptor for retinol uptake STRA6OS=Homo sapiens OX=9606 GN=STRA6MSSQPAGNQTSPGATEDYSYGSWYIDEPQGGEELQPEGEVPSCHTSIPPGLYHACLASLSILVLLLLAMLVRRRQLWPDCVRGRPGLPSPVDFLAGDRPRAVPAAVFMVLLSSLCLLLPDEDALPFLTLASAPSQDGKTEAPRGNLPKITELRLVRAWI>sp|Q9BX79-3|STRA6_HUMAN Isoform 3 of Receptor for retinol uptake STRA6OS=Homo sapiens OX=9606 GN=STRA6MSSQPAGNQTSPGATEDYSYGSWYIDEPQGGEELQPEGEVPSCHTSIPPGLYHACLASLSILVLLLLAMLVRRRQLWPDCVRGRPGLPRPRAVPAAVFMVLLSSLCLLLPDEDALPFLTLASAPSQDGKTEAPRGAWKILGLFYYAALYYPLAACATAGHTAAHLLGSTLSWAHLGVQVWQRAECPQVPKIYKYYSLLASLPLLLGLGFLSLWYPVQLVRSFSRRTGAGSKGLQSSYSEEYLRNLLCRKKLGSSYHTSKHGFLSWARVCLRHCIYTPQPGFHLPLKLVLSATLTGTAIYQVALLLLVGVVPTIQKVRAGVTTDVSYLLAGFGIVLSEDKQEVVELVKHHLWALEVCYISALVLSCLLTFLVLMRSLVTHRTNLRALHRGAALDLSPLHRSPHPSRQAIFCWMSFSAYQTAFICLGLLVQQIIFFLGTTALAFLVLMPVLHGRNLLLFRSLESSWPFWLTLALAVILQNMAAHWVFLETHDGHPQLTNRRVLYAATFLLFPLNVLVGAMVATWRVLLSALYNAIHLGQMDLSLLPPRAATLDPGYYTYRNFLKIEVSQSHPAMTAFCSLLLQAQSLLPRTMAAPQDSLRPGEEDEGMQLLQTKDSMAKGARPGASRGRARWGLAYTLLHNPTLQVFRKTALLGANGAQP>sp|Q9BX79-4|STRA6_HUMAN Isoform 4 of Receptor for retinol uptake STRA6OS=Homo sapiens OX=9606 GN=STRA6MGGKGGGDTRGPVLFPCQLAQALSPRRAFPRELKEKGQRMSSQPAGNQTSPGATEDYSYGSWYIDEPQGGEELQPEGEVPSCHTSIPPGLYHACLASLSILVLLLLAMLVRRRQLWPDCVRGRPGLPSPVDFLAGDRPRAVPAAVFMVLLSSLCLLLPDEDALPFLTLASAPSQDGKTEAPRGAWKILGLFYYAALYYPLAACATAGHTAAHLLGSTLSWAHLGVQVWQRAECPQVPKIYKYYSLLASLPLLLGLGFLSLWYPVQLVRSFSRRTGAGSKGLQSSYSEEYLRNLLCRKKLGSSYHTSKHGFLSWARVCLRHCIYTPQPGFHLPLKLVLSATLTGTAIYQVALLLLVGVVPTIQKVRAGVTTDVSYLLAGFGIVLSEDKQEVVELVKHHLWALEVCYISALVLSCLLTFLVLMRSLVTHRTNLRALHRGAALDLSPLHRSPHPSRQAIFCWMSFSAYQTAFICLGLLVQQIIFFLGTTALAFLVLMPVLHGRNLLLFRSLESSWPFWLTLALAVILQNMAAHWVFLETHDGHPQLTNRRVLYAATFLLFPLNVLVGAMVATWRVLLSALYNAIHLGQMDLSLLPPRAATLDPGYYTYRNFLKIEVSQSHPAMTAFCSLLLQAQSLLPRTMAAPQDSLRPGEEDEGMQLLQTKDSMAKGARPGASRGRARWGLAYTLLHNPTLQVFRKTALLGANGAQP>sp|Q9BX79-5|STRA6_HUMAN Isoform 5 of Receptor for retinol uptake STRA6OS=Homo sapiens OX=9606 GN=STRA6MQIRLLRAELVVPLWQFIRQWPPGSDGWGQMEEKGQRMSSQPAGNQTSPGATEDYSYGSWYIDEPQGGEELQPEGEVPSCHTSIPPGLYHACLASLSILVLLLLAMLVRRRQLWPDCVRGRPGLPSPVDFLAGDRPRAVPAAVFMVLLSSLCLLLPDEDALPFLTLASAPSQDGKTEAPRGAWKILGLFYYAALYYPLAACATAGHTAAHLLGSTLSWAHLGVQVWQRAECPQVPKIYKYYSLLASLPLLLGLGFLSLWYPVQLVRSFSRRTGAGSKGLQSSYSEEYLRNLLCRKKLGSSYHTSKHGFLSWARVCLRHCIYTPQPGFHLPLKLVLSATLTGTAIYQVALLLLVGVVPTIQKVRAGVTTDVSYLLAGFGIVLSEDKQEVVELVKHHLWALEVCYISALVLSCLLTFLVLMRSLVTHRTNLRALHRGAALDLSPLHRSPHPSRQAIFCWMSFSAYQTAFICLGLLVQQIIFFLGTTALAFLVLMPVLHGRNLLLFRSLESSWPFWLTLALAVILQNMAAHWVFLETHDGHPQLTNRRVLYAATFLLFPLNVLVGAMVATWRVLLSALYNAIHLGQMDLSLLPPRAATLDPGYYTYRNFLKIEVSQSHPAMTAFCSLLLQAQSLLPRTMAAPQDSLRPGEEDEGMQLLQTKDSMAKGARPGASRGRARWGLAYTLLHNPTLQVFRKTALLGANGAQP>sp|Q9BX79-6|STRA6_HUMAN Isoform 6 of Receptor for retinol uptake STRA6OS=Homo sapiens OX=9606 GN=STRA6MDSQGDWAAQEKGQRMSSQPAGNQTSPGATEDYSYGSWYIDEPQGGEELQPEGEVPSCHTSIPPGLYHACLASLSILVLLLLAMLVRRRQLWPDCVRGRPGLPSPVDFLAGDRPRAVPAAVFMVLLSSLCLLLPDEDALPFLTLASAPSQDGKTEAPRGAWKILGLFYYAALYYPLAACATAGHTAAHLLGSTLSWAHLGVQVWQRAECPQVPKIYKYYSLLASLPLLLGLGFLSLWYPVQLVRSFSRRTGAGSKGLQSSYSEEYLRNLLCRKKLGSSYHTSKHGFLSWARVCLRHCIYTPQPGFHLPLKLVLSATLTGTAIYQVALLLLVGVVPTIQKVRAGVTTDVSYLLAGFGIVLSEDKQEVVELVKHHLWALEVCYISALVLSCLLTFLVLMRSLVTHRTNLRALHRGAALDLSPLHRSPHPSRQAIFCWMSFSAYQTAFICLGLLVQQIIFFLGTTALAFLVLMPVLHGRNLLLFRSLESSWPFWLTLALAVILQNMAAHWVFLETHDGHPQLTNRRVLYAATFLLFPLNVLVGAMVATWRVLLSALYNAIHLGQMDLSLLPPRAATLDPGYYTYRNFLKIEVSQSHPAMTAFCSLLLQAQSLLPRTMAAPQDSLRPGEEDEGMQLLQTKDSMAKGARPGASRGRARWGLAYTLLHNPTLQVFRKTALLGANGAQP>sp|P51692|STA5B_HUMAN Signal transducer and activator of transcription5B OS=Homo sapiens OX=9606 GN=STAT5B PE=1 SV=2MAVWIQAQQLQGEALHQMQALYGQHFPIEVRHYLSQWIESQAWDSVDLDNPQENIKATQLLEGLVQELQKKAEHQVGEDGFLLKIKLGHYATQLQNTYDRCPMELVRCIRHILYNEQRLVREANNGSSPAGSLADAMSQKHLQINQTFEELRLVTQDTENELKKLQQTQEYFIIQYQESLRIQAQFGPLAQLSPQERLSRETALQQKQVSLEAWLQREAQTLQQYRVELAEKHQKTLQLLRKQQTIILDDELIQWKRRQQLAGNGGPPEGSLDVLQSWCEKLAEIIWQNRQQIRRAEHLCQQLPIPGPVEEMLAEVNATITDIISALVTSTFIIEKQPPQVLKTQTKFAATVRLLVGGKLNVHMNPPQVKATIISEQQAKSLLKNENTRNDYSGEILNNCCVMEYHQATGTLSAHFRNMSLKRIKRSDRRGAESVTEEKFTILFESQFSVGGNELVFQVKTLSLPVVVIVHGSQDNNATATVLWDNAFAEPGRVPFAVPDKVLWPQLCEALNMKFKAEVQSNRGLTKENLVFLAQKLFNNSSSHLEDYSGLSVSWSQFNRENLPGRNYTFWQWFDGVMEVLKKHLKPHWNDGAILGFVNKQQAHDLLINKPDGTFLLRFSDSEIGGITIAWKFDSQERMFWNLMPFTTRDFSIRSLADRLGDLNYLIYVFPDRPKDEVYSKYYTPVPCESATAKAVDGYVKPQIKQVVPEFVNASADAGGGSATYMDQAPSPAVCPQAHYNMYPQNPDSVLDTDGDFDLEDTMDVARRVEELLGRPMDSQWIPHAQS>sp|Q99619|SPSB2_HUMAN SPRY domain-containing SOCS box protein 2 OS=Homosapiens OX=9606 GN=SPSB2 PE=1 SV=1MGQTALAGGSSSTPTPQALYPDLSCPEGLEELLSAPPPDLGAQRRHGWNPKDCSENIEVKEGGLYFERRPVAQSTDGARGKRGYSRGLHAWEISWPLEQRGTHAVVGVATALAPLQTDHYAALLGSNSESWGWDIGRGKLYHQSKGPGAPQYPAGTQGEQLEVPERLLVVLDMEEGTLGYAIGGTYLGPAFRGLKGRTLYPAVSAVWGQCQVRIRYLGERRAEPHSLLHLSRLCVRHNLGDTRLGQVSALPLPPAMKRYLLYQ>sp|Q99619-2|SPSB2_HUMAN Isoform 2 of SPRY domain-containing SOCS boxprotein 2 OS=Homo sapiens OX=9606 GN=SPSB2MGQTALAGGSSSTPTPQALYPDLSCPEGLEELLSAPPPDLGAQRRHGWNPKDCSENIEVKEGGLYFERRPVAQSTDGARGKRGYSRGLHAWEISWPLEQRGTHAVVGVATALAPLQTDHYAALLGSNSESWGWDIGRGKLYHQSKGPGAPQYPAGTQGEQLEVPERLLVVLDMEEGTLGYAIGGTYLGPAFRGLKGRTLYPAVSAVWGQCQVRIRYLGERRGEAWGRRGENFLSLVAVVWDGNSSDKSRGDGPSSSLPQPLFSAGKG>sp|Q9NQZ5|STAR7_HUMAN StAR-related lipid transfer protein 7,mitochondrial OS=Homo sapiens OX=9606 GN=STARD7 PE=1 SV=2MLPRRLLAAWLAGTRGGGLLALLANQCRFVTGLRVRRAQQIAQLYGRLYSESSRRVLLGRLWRRLHGRPGHASALMAALAGVFVWDEERIQEEELQRSINEMKRLEEMSNMFQSSGVQHHPPEPKAQTEGNEDSEGKEQRWEMVMDKKHFKLWRRPITGTHLYQYRVFGTYTDVTPRQFFNVQLDTEYRKKWDALVIKLEVIERDVVSGSEVLHWVTHFPYPMYSRDYVYVRRYSVDQENNMMVLVSRAVEHPSVPESPEFVRVRSYESQMVIRPHKSFDENGFDYLLTYSDNPQTVFPRYCVSWMVSSGMPDFLEKLHMATLKAKNMEIKVKDYISAKPLEMSSEAKATSQSSERKNEGSCGPARIEYA>sp|P49223|SPIT3_HUMAN Kunitz-type protease inhibitor 3 OS=Homo sapiensOX=9606 GN=SPINT3 PE=3 SV=3MQLQASLSFLLILTLCLELRSELARDTIKDLLPNVCAFPMEKGPCQTYMTRWFFNFETGECELFAYGGCGGNSNNFLRKEKCEKFCKFT>sp|Q9UGT4|SUSD2_HUMAN Sushi domain-containing protein 2 OS=Homo sapiensOX=9606 GN=SUSD2 PE=1 SV=1MKPALLPWALLLLATALGPGPGPTADAQESCSMRCGALDGPCSCHPTCSGLGTCCLDFRDFCLEILPYSGSMMGGKDFVVRHFKMSSPTDASVICRFKDSIQTLGHVDSSGQVHCVSPLLYESGRIPFTVSLDNGHSFPRAGTWLAVHPNKVSMMEKSELVNETRWQYYGTANTSGNLSLTWHVKSLPTQTITIELWGYEETGMPYSQEWTAKWSYLYPLATHIPNSGSFTFTPKPAPPSYQRWRVGALRIIDSKNYAGQKDVQALWTNDHALAWHLSDDFREDPVAWARTQCQAWEELEDQLPNFLEELPDCPCTLTQARADSGRFFTDYGCDMEQGSVCTYHPGAVHCVRSVQASLRYGSGQQCCYTADGTQLLTADSSGGSTPDRGHDWGAPPFRTPPRVPSMSHWLYDVLSFYYCCLWAPDCPRYMQRRPSNDCRNYRPPRLASAFGDPHFVTFDGTNFTFNGRGEYVLLEAALTDLRVQARAQPGTMSNGTETRGTGLTAVAVQEGNSDVVEVRLANRTGGLEVLLNQEVLSFTEQSWMDLKGMFLSVAAGDRVSIMLASGAGLEVSVQGPFLSVSVLLPEKFLTHTHGLLGTLNNDPTDDFTLHSGRVLPPGTSPQELFLFGANWTVHNASSLLTYDSWFLVHNFLYQPKHDPTFEPLFPSETTLNPSLAQEAAKLCGDDHFCNFDVAATGSLSTGTATRVAHQLHQRRMQSLQPVVSCGWLAPPPNGQKEGNRYLAGSTIYFHCDNGYSLAGAETSTCQADGTWSSPTPKCQPGRSYAVLLGIIFGGLAVVAAVALVYVLLRRRKGNTHVWGAQP>sp|Q08AE8|SPIR1_HUMAN Protein spire homolog 1 OS=Homo sapiens OX=9606GN=SPIRE1 PE=1 SV=3MAQAAGPAGGGEPRTEAVGGEGPREPGAAGGAAGGSRDALSLEEILRLYNQPINEEQAWAVCYQCCGSLRAAARRRQPRHRVRSAAQIRVWRDGAVTLAPAADDAGEPPPVAGKLGYSQCMETEVIESLGIIIYKALDYGLKENEERELSPPLEQLIDHMANTVEADGSNDEGYEAAEEGLGDEDEKRKISAIRSYRDVMKLCAAHLPTESDAPNHYQAVCRALFAETMELHTFLTKIKSAKENLKKIQEMEKSDESSTDLEELKNADWARFWVQVMRDLRNGVKLKKVQERQYNPLPIEYQLTPYEMLMDDIRCKRYTLRKVMVNGDIPPRLKKSAHEIILDFIRSRPPLNPVSARKLKPTPPRPRSLHERILEEIKAERKLRPVSPEEIRRSRLAMRPLSMSYSFDLSDVTTPESTKNLVESSMVNGGLTSQTKENGLSTSQQVPAQRKKLLRAPTLAELDSSESEEETLHKSTSSSSVSPSFPEEPVLEAVSTRKKPPKFLPISSTPQPERRQPPQRRHSIEKETPTNVRQFLPPSRQSSRSLEEFCYPVECLALTVEEVMHIRQVLVKAELEKYQQYKDIYTALKKGKLCFCCRTRRFSFFTWSYTCQFCKRPVCSQCCKKMRLPSKPYSTLPIFSLGPSALQRGESSMRSEKPSTAHHRPLRSIARFSSKSKSMDKSDEELQFPKELMEDWSTMEVCVDCKKFISEIISSSRRSLVLANKRARLKRKTQSFYMSSPGPSEYCPSERTISEI>sp|Q08AE8-5|SPIR1_HUMAN Isoform 5 of Protein spire homolog 1 OS=Homosapiens OX=9606 GN=SPIRE1METEVIESLGIIIYKALDYGLKENEERELSPPLEQLIDHMANTVEADGSNDEGYEAAEEGLGDEDEKRKISAIRSYRDVMKLCAAHLPTESDAPNHYQAVCRALFAETMELHTFLTKIKSAKENLKKIQEMEKSDESSTDLEELKNADWARFWVQVMRDLRNGVKLKKVQERQYNPLPIEYQLTPYEMLMDDIRCKRYTLRKVMVNGDIPPRLKKSAHEIILDFIRSRPPLNPVSARKLKPTPPRPRSLHERILEEIKAERKLRPVSPEEIRRSRLDVTTPESTKNLVESSMVNGGLTSQTKENGLSTSQQVPAQRKKLLRAPTLAELDSSESEEETLHKSTSSSSVSPSFPEEPVLEAVSTRKKPPKFLPISSTPQPERRQPPQRRHSIEKETPTNVRQFLPPSRQSSRSLEEFCYPVECLALTVEEVMHIRQVLVKAELEKYQQYKDIYTALKKGKLCFCCRTRRFSFFTWSYTCQFCKRPVCSQCCKKMRLPSKPYSTLPIFSLGPSALQRGESSMRSEKPSTAHHRPLRSIARFSSKSKSMDKSDEELQFPKELMEDWSTMEVCVDCKKFISEIISSSRRSLVLANKRARLKRKTQSFYMSSPGPSEYCPSERTISEI>sp|Q08AE8-2|SPIR1_HUMAN Isoform 2 of Protein spire homolog 1 OS=Homosapiens OX=9606 GN=SPIRE1MAQAAGPAGGGEPRTEAVGGEGPREPGAAGGAAGGSRDALSLEEILRLYNQPINEEQAWAVCYQCCGSLRAAARRRQPRHRVRSAAQIRVWRDGAVTLAPAADDAGEPPPVAGKLGYSQCMETEVIESLGIIIYKALDYGLKENEERELSPPLEQLIDHMANTVEADGSNDEGYEAAEEGLGDEDEKRKISAIRSYRDVMKLCAAHLPTESDAPNHYQAVCRALFAETMELHTFLTKIKSAKENLKKIQEMEKSDESSTDLEELKNADWARFWVQVMRDLRNGVKLKKVQERQYNPLPIEYQLTPYEMLMDDIRCKRYTLRKVMVNGDIPPRLKKSAHEIILDFIRSRPPLNPVSARKLKPTPPRPRSLHERILEEIKAERKLRPVSPEEIRRSRLDVTTPESTKNLVESSMVNGGLTSQTKENGLSTSQQVPAQRKKLLRAPTLAELDSSESEEETLHKSTSSSSVSPSFPEEPVLEAVSTRKKPPKFLPISSTPQPERRQPPQRRHSIEKETPTNVRQFLPPSRQSSRSLEEFCYPVECLALTVEEVMHIRQVLVKAELEKYQQYKDIYTALKKGKLCFCCRTRRFSFFTWSYTCQFCKRPVCSQCCKKMRLPSKPYSTLPIFSLGPSALQRGESSMRSEKPSTAHHRPLRSIARFSSKSKSMDKSDEELQFPKELMEDWSTMEVCVDCKKFISEIISSSRRSLVLANKRARLKRKTQSFYMSSPGPSEYCPSERTISEI>sp|Q08AE8-3|SPIR1_HUMAN Isoform 3 of Protein spire homolog 1 OS=Homosapiens OX=9606 GN=SPIRE1MANTVEADGSNDEGYEAAEEGLGDEDEKRKISAIRSYRDVMKLCAAHLPTESDAPNHYQAVCRALFAETMELHTFLTKIKSAKENLKKIQEMEKSDESSTDLEELKNADWARFWVQVMRDLRNGVKLKKVQERQYNPLPIEYQLTPYEMLMDDIRCKRYTLRKVMVNGDIPPRLKKSAHEIILDFIRSRPPLNPVSARKLKPTPPRPRSLHERILEEIKAERKLRPVSPEEIRRSRLDVTTPESTKNLVESSMVNGGLTSQTKENGLSTSQQVPAQRKKLLRAPTLAELDSSESEEETLHKSTSSSSVSPSFPEEPVLEAVSTRKKPPKFLPISSTPQPERRQPPQRRHSIEKETPTNVRQFLPPSRQSSRSLEEFCYPVECLALTVEEVMHIRQVLVKAELEKYQQYKDIYTALKKGKLCFCCRTRRFSFFTWSYTCQFCKRPVCSQCCKKMRLPSKPYSTLPIFSLGPSALQRGESSMRSEKPSTAHHRPLRSIARFSSKSKSMDKSDEELQFPKELMEDWSTMEVCVDCKKFISEIISSSRRSLVLANKRARLKRKTQSFYMSSPGPSEYCPSERTISEI>sp|Q08AE8-4|SPIR1_HUMAN Isoform 4 of Protein spire homolog 1 OS=Homosapiens OX=9606 GN=SPIRE1MANTVEADGSNDEGYEAAEEGLGDEDEKRKISAIRSYRDVMKLCAAHLPTESDAPNHYQAVCRALFAETMELHTFLTKIKSAKENLKKIQEMEKSDESSTDLEELKNADWARFWVQVMRDLRNGVKLKKVQERQYNPLPIEYQLTPYEMLMDDIRCKRYTLRKVMVNGDIPPRLKKSAHEIILDFIRSRPPLNPVSARKLKPTPPRPRSLHERILEEIKAERKLRPVSPEEIRRSRLDVTTPESTKNLVESSMVNGGLTSQTKENGLSTSQQVPAQRKKLLRAPTLAELDSSESEEETLHKSTSSSSVSPSFPEEPVLEAVSTRKKPPKFLPISSTPQPERRQPPQRRHSIEKETPTNVRQFLPPSRQSSRSLEEFCYPVECLALTVEEVMHIRQVLVKAELEKYQQYKDIYTALKKGKLCFCCRTRRFSFFTWSYTCQFCKSDCLFNGTAHCQFYLG>sp|Q8NBB2|STAS1_HUMAN Putative uncharacterized protein ST20-AS1 OS=Homosapiens OX=9606 GN=ST20-AS1 PE=5 SV=1MPRPASESWSPIQSRIPAYKAVSHLRLLPTANSPSGSNQPTNPNRAQHPEGPQSREGATSPVLASLEPPTPTDLPSARARPRVPAESGPGWLHKARRPTRGILRDVLRHRGVPAQPRPAPGAHQLSSPSS>sp|Q5VX71|SUSD4_HUMAN Sushi domain-containing protein 4 OS=Homo sapiensOX=9606 GN=SUSD4 PE=1 SV=1MYHGMNPSNGDGFLEQQQQQQQPQSPQRLLAVILWFQLALCFGPAQLTGGFDDLQVCADPGIPENGFRTPSGGVFFEGSVARFHCQDGFKLKGATKRLCLKHFNGTLGWIPSDNSICVQEDCRIPQIEDAEIHNKTYRHGEKLIITCHEGFKIRYPDLHNMVSLCRDDGTWNNLPICQGCLRPLASSNGYVNISELQTSFPVGTVISYRCFPGFKLDGSAYLECLQNLIWSSSPPRCLALEVCPLPPMVSHGDFVCHPRPCERYNHGTVVEFYCDPGYSLTSDYKYITCQYGEWFPSYQVYCIKSEQTWPSTHETLLTTWKIVAFTATSVLLVLLLVILARMFQTKFKAHFPPRGPPRSSSSDPDFVVVDGVPVMLPSYDEAVSGGLSALGPGYMASVGQGCPLPVDDQSPPAYPGSGDTDTGPGESETCDSVSGSSELLQSLYSPPRCQESTHPASDNPDIIASTAEEVASTSPGIDIADEIPLMEEDP>sp|Q5VX71-2|SUSD4_HUMAN Isoform 2 of Sushi domain-containing protein 4OS=Homo sapiens OX=9606 GN=SUSD4MYHGMNPSNGDGFLEQQQQQQQPQSPQRLLAVILWFQLALCFGPAQLTGGFDDLQVCADPGIPENGFRTPSGGVFFEGSVARFHCQDGFKLKGATKRLCLKHFNGTLGWIPSDNSICVQEDCRIPQIEDAEIHNKTYRHGEKLIITCHEGFKIRYPDLHNMVSLCRDDGTWNNLPICQGCLRPLASSNGYVNISELQTSFPVGTVISYRCFPGFKLDGSAYLECLQNLIWSSSPPRCLALEAQVCPLPPMVSHGDFVCHPRPCERYNHGTVVEFYCDPGYSLTSDYKYITCQYGEWFPSYQVYCIKSEQTWPSTHETLLTTWKIVAFTATSVLLVLLLVILARMFQTKFKAHFPPRGPPRSSSSDPDFVVVDGVPVMLPSYDEAVSGGLSALGPGYMASVGQGCPLPVDDQSPPAYPGSGDTDTGPGESETCDSVSGSSELLQSLYSPPRCQESTHPASDNPDIIASTAEEVASTSPGIHHAHWVLFLRN>sp|Q5VX71-3|SUSD4_HUMAN Isoform 3 of Sushi domain-containing protein 4OS=Homo sapiens OX=9606 GN=SUSD4MYHGMNPSNGDGFLEQQQQQQQPQSPQRLLAVILWFQLALCFGPAQLTGGFDDLQVCADPGIPENGFRTPSGGVFFEGSVARFHCQDGFKLKGATKRLCLKHFNGTLGWIPSDNSICVQEDCRIPQIEDAEIHNKTYRHGEKLIITCHEGFKIRYPDLHNMVSLCRDDGTWNNLPICQGCLRPLASSNGYVNISELQTSFPVGTVISYRCFPGFKLDGSAYLECLQNLIWSSSPPRCLALEGGRPEHLFPVLYFPHIRLAAAVLYFCPVLKSSPTPAPTCSSTSTTTSLF>sp|Q5VX71-4|SUSD4_HUMAN Isoform 4 of Sushi domain-containing protein 4OS=Homo sapiens OX=9606 GN=SUSD4MYHGMNPSNGDGFLEQQQQQQQPQSPQRLLAVILWFQLALCFGPAQLTGGFDDLQVCADPGIPENGFRTPSGGVFFEGSVARFHCQDGFKLKGATKRLCLKHFNGTLGWIPSDNSICVQEDCRIPQIEDAEIHNKTYRHGEKLIITCHEGFKIRYPDLHNMVSLCRDDGTWNNLPICQGCLRPLAPQHTPAQGTRTQAQGSQKPVTASQALLSCSKVCIHLPGAKRAPTLLRTTLT>sp|P08842|STS_HUMAN Steryl-sulfatase OS=Homo sapiens OX=9606 GN=STS PE=1SV=2MPLRKMKIPFLLLFFLWEAESHAASRPNIILVMADDLGIGDPGCYGNKTIRTPNIDRLASGGVKLTQHLAASPLCTPSRAAFMTGRYPVRSGMASWSRTGVFLFTASSGGLPTDEITFAKLLKDQGYSTALIGKWHLGMSCHSKTDFCHHPLHHGFNYFYGISLTNLRDCKPGEGSVFTTGFKRLVFLPLQIVGVTLLTLAALNCLGLLHVPLGVFFSLLFLAALILTLFLGFLHYFRPLNCFMMRNYEIIQQPMSYDNLTQRLTVEAAQFIQRNTETPFLLVLSYLHVHTALFSSKDFAGKSQHGVYGDAVEEMDWSVGQILNLLDELRLANDTLIYFTSDQGAHVEEVSSKGEIHGGSNGIYKGGKANNWEGGIRVPGILRWPRVIQAGQKIDEPTSNMDIFPTVAKLAGAPLPEDRIIDGRDLMPLLEGKSQRSDHEFLFHYCNAYLNAVRWHPQNSTSIWKAFFFTPNFNPVGSNGCFATHVCFCFGSYVTHHDPPLLFDISKDPRERNPLTPASEPRFYEILKVMQEAADRHTQTLPEVPDQFSWNNFLWKPWLQLCCPSTGLSCQCDREKQDKRLSR>sp|Q14765|STAT4_HUMAN Signal transducer and activator of transcription 4OS=Homo sapiens OX=9606 GN=STAT4 PE=1 SV=1MSQWNQVQQLEIKFLEQVDQFYDDNFPMEIRHLLAQWIENQDWEAASNNETMATILLQNLLIQLDEQLGRVSKEKNLLLIHNLKRIRKVLQGKFHGNPMHVAVVISNCLREERRILAAANMPVQGPLEKSLQSSSVSERQRNVEHKVAAIKNSVQMTEQDTKYLEDLQDEFDYRYKTIQTMDQSDKNSAMVNQEVLTLQEMLNSLDFKRKEALSKMTQIIHETDLLMNTMLIEELQDWKRRQQIACIGGPLHNGLDQLQNCFTLLAESLFQLRRQLEKLEEQSTKMTYEGDPIPMQRTHMLERVTFLIYNLFKNSFVVERQPCMPTHPQRPLVLKTLIQFTVKLRLLIKLPELNYQVKVKASIDKNVSTLSNRRFVLCGTNVKAMSIEESSNGSLSVEFRHLQPKEMKSSAGGKGNEGCHMVTEELHSITFETQICLYGLTIDLETSSLPVVMISNVSQLPNAWASIIWYNVSTNDSQNLVFFNNPPPATLSQLLEVMSWQFSSYVGRGLNSDQLHMLAEKLTVQSSYSDGHLTWAKFCKEHLPGKSFTFWTWLEAILDLIKKHILPLWIDGYVMGFVSKEKERLLLKDKMPGTFLLRFSESHLGGITFTWVDHSESGEVRFHSVEPYNKGRLSALPFADILRDYKVIMAENIPENPLKYLYPDIPKDKAFGKHYSSQPCEVSRPTERGDKGYVPSVFIPISTIRSDSTEPHSPSDLLPMSPSVYAVLRENLSPTTIETAMKSPYSAE>sp|P11277|SPTB1_HUMAN Spectrin beta chain, erythrocytic OS=Homo sapiensOX=9606 GN=SPTB PE=1 SV=5MTSATEFENVGNQPPYSRINARWDAPDDELDNDNSSARLFERSRIKALADEREVVQKKTFTKWVNSHLARVSCRITDLYKDLRDGRMLIKLLEVLSGEMLPKPTKGKMRIHCLENVDKALQFLKEQRVHLENMGSHDIVDGNHRLVLGLIWTIILRFQIQDIVVQTQEGRETRSAKDALLLWCQMKTAGYPHVNVTNFTSSWKDGLAFNALIHKHRPDLIDFDKLKDSNARHNLEHAFNVAERQLGIIPLLDPEDVFTENPDEKSIITYVVAFYHYFSKMKVLAVEGKRVGKVIDHAIETEKMIEKYSGLASDLLTWIEQTITVLNSRKFANSLTGVQQQLQAFSTYRTVEKPPKFQEKGNLEVLLFTIQSRMRANNQKVYTPHDGKLVSDINRAWESLEEAEYRRELALRNELIRQEKLEQLARRFDRKAAMRETWLSENQRLVAQDNFGYDLAAVEAAKKKHEAIETDTAAYEERVRALEDLAQELEKENYHDQKRITARKDNILRLWSYLQELLQSRRQRLETTLALQKLFQDMLHSIDWMDEIKAHLLSAEFGKHLLEVEDLLQKHKLMEADIAIQGDKVKAITAATLKFTEGKGYQPCDPQVIQDRISHLEQCFEELSNMAAGRKAQLEQSKRLWKFFWEMDEAESWIKEKEQIYSSLDYGKDLTSVLILQRKHKAFEDELRGLDAHLEQIFQEAHGMVARKQFGHPQIEARIKEVSAQWDQLKDLAAFCKKNLQDAENFFQFQGDADDLKAWLQDAHRLLSGEDVGQDEGATRALGKKHKDFLEELEESRGVMEHLEQQAQGFPEEFRDSPDVTHRLQALRELYQQVVAQADLRQQRLQEALDLYTVFGETDACELWMGEKEKWLAEMEMPDTLEDLEVVQHRFDILDQEMKTLMTQIDGVNLAANSLVESGHPRSREVKQYQDHLNTRWQAFQTLVSERREAVDSALRVHNYCVDCEETSKWITDKTKVVESTKDLGRDLAGIIAIQRKLSGLERDVAAIQARVDALERESQQLMDSHPEQKEDIGQRQKHLEELWQGLQQSLQGQEDLLGEVSQLQAFLQDLDDFQAWLSITQKAVASEDMPESLPEAEQLLQQHAGIKDEIDGHQDSYQRVKESGEKVIQGQTDPEYLLLGQRLEGLDTGWNALGRMWESRSHTLAQCLGFQEFQKDAKQAEAILSNQEYTLAHLEPPDSLEAAEAGIRKFEDFLGSMENNRDKVLSPVDSGNKLVAEGNLYSDKIKEKVQLIEDRHRKNNEKAQEASVLLRDNLELQNFLQNCQELTLWINDKLLTSQDVSYDEARNLHNKWLKHQAFVAELASHEGWLENIDAEGKQLMDEKPQFTALVSQKLEALHRLWDELQATTKEKTQHLSAARSSDLRLQTHADLNKWISAMEDQLRSDDPGKDLTSVNRMLAKLKRVEDQVNVRKEELGELFAQVPSMGEEGGDADLSIEKRFLDLLEPLGRRKKQLESSRAKLQISRDLEDETLWVEERLPLAQSADYGTNLQTVQLFMKKNQTLQNEILGHTPRVEDVLQRGQQLVEAAEIDCQDLEERLGHLQSSWDRLREAAAGRLQRLRDANEAQQYYLDADEAEAWIGEQELYVISDEIPKDEEGAIVMLKRHLRQQRAVEDYGRNIKQLASRAQGLLSAGHPEGEQIIRLQGQVDKHYAGLKDVAEERKRKLENMYHLFQLKRETDDLEQWISEKELVASSPEMGQDFDHVTLLRDKFRDFARETGAIGQERVDNVNAFIERLIDAGHSEAATIAEWKDGLNEMWADLLELIDTRMQLLAASYDLHRYFYTGAEILGLIDEKHRELPEDVGLDASTAESFHRVHTAFERELHLLGVQVQQFQDVATRLQTAYAGEKAEAIQNKEQEVSAAWQALLDACAGRRTQLVDTADKFRFFSMARDLLSWMESIIRQIETQERPRDVSSVELLMKYHQGINAEIETRSKNFSACLELGESLLQRQHQASEEIREKLQQVMSRRKEMNEKWEARWERLRMLLEVCQFSRDASVAEAWLIAQEPYLASGDFGHTVDSVEKLIKRHEAFEKSTASWAERFAALEKPTTLELKERQIAERPAEETGPQEEEGETAGEAPVSHHAATERTSPVSLWSRLSSSWESLQPEPSHPY>sp|P11277-2|SPTB1_HUMAN Isoform 2 of Spectrin beta chain, erythrocyticOS=Homo sapiens OX=9606 GN=SPTBMTSATEFENVGNQPPYSRINARWDAPDDELDNDNSSARLFERSRIKALADEREVVQKKTFTKWVNSHLARVSCRITDLYKDLRDGRMLIKLLEVLSGEMLPKPTKGKMRIHCLENVDKALQFLKEQRVHLENMGSHDIVDGNHRLVLGLIWTIILRFQIQDIVVQTQEGRETRSAKDALLLWCQMKTAGYPHVNVTNFTSSWKDGLAFNALIHKHRPDLIDFDKLKDSNARHNLEHAFNVAERQLGIIPLLDPEDVFTENPDEKSIITYVVAFYHYFSKMKVLAVEGKRVGKVIDHAIETEKMIEKYSGLASDLLTWIEQTITVLNSRKFANSLTGVQQQLQAFSTYRTVEKPPKFQEKGNLEVLLFTIQSRMRANNQKVYTPHDGKLVSDINRAWESLEEAEYRRELALRNELIRQEKLEQLARRFDRKAAMRETWLSENQRLVAQDNFGYDLAAVEAAKKKHEAIETDTAAYEERVRALEDLAQELEKENYHDQKRITARKDNILRLWSYLQELLQSRRQRLETTLALQKLFQDMLHSIDWMDEIKAHLLSAEFGKHLLEVEDLLQKHKLMEADIAIQGDKVKAITAATLKFTEGKGYQPCDPQVIQDRISHLEQCFEELSNMAAGRKAQLEQSKRLWKFFWEMDEAESWIKEKEQIYSSLDYGKDLTSVLILQRKHKAFEDELRGLDAHLEQIFQEAHGMVARKQFGHPQIEARIKEVSAQWDQLKDLAAFCKKNLQDAENFFQFQGDADDLKAWLQDAHRLLSGEDVGQDEGATRALGKKHKDFLEELEESRGVMEHLEQQAQGFPEEFRDSPDVTHRLQALRELYQQVVAQADLRQQRLQEALDLYTVFGETDACELWMGEKEKWLAEMEMPDTLEDLEVVQHRFDILDQEMKTLMTQIDGVNLAANSLVESGHPRSREVKQYQDHLNTRWQAFQTLVSERREAVDSALRVHNYCVDCEETSKWITDKTKVVESTKDLGRDLAGIIAIQRKLSGLERDVAAIQARVDALERESQQLMDSHPEQKEDIGQRQKHLEELWQGLQQSLQGQEDLLGEVSQLQAFLQDLDDFQAWLSITQKAVASEDMPESLPEAEQLLQQHAGIKDEIDGHQDSYQRVKESGEKVIQGQTDPEYLLLGQRLEGLDTGWNALGRMWESRSHTLAQCLGFQEFQKDAKQAEAILSNQEYTLAHLEPPDSLEAAEAGIRKFEDFLGSMENNRDKVLSPVDSGNKLVAEGNLYSDKIKEKVQLIEDRHRKNNEKAQEASVLLRDNLELQNFLQNCQELTLWINDKLLTSQDVSYDEARNLHNKWLKHQAFVAELASHEGWLENIDAEGKQLMDEKPQFTALVSQKLEALHRLWDELQATTKEKTQHLSAARSSDLRLQTHADLNKWISAMEDQLRSDDPGKDLTSVNRMLAKLKRVEDQVNVRKEELGELFAQVPSMGEEGGDADLSIEKRFLDLLEPLGRRKKQLESSRAKLQISRDLEDETLWVEERLPLAQSADYGTNLQTVQLFMKKNQTLQNEILGHTPRVEDVLQRGQQLVEAAEIDCQDLEERLGHLQSSWDRLREAAAGRLQRLRDANEAQQYYLDADEAEAWIGEQELYVISDEIPKDEEGAIVMLKRHLRQQRAVEDYGRNIKQLASRAQGLLSAGHPEGEQIIRLQGQVDKHYAGLKDVAEERKRKLENMYHLFQLKRETDDLEQWISEKELVASSPEMGQDFDHVTLLRDKFRDFARETGAIGQERVDNVNAFIERLIDAGHSEAATIAEWKDGLNEMWADLLELIDTRMQLLAASYDLHRYFYTGAEILGLIDEKHRELPEDVGLDASTAESFHRVHTAFERELHLLGVQVQQFQDVATRLQTAYAGEKAEAIQNKEQEVSAAWQALLDACAGRRTQLVDTADKFRFFSMARDLLSWMESIIRQIETQERPRDVSSVELLMKYHQGINAEIETRSKNFSACLELGESLLQRQHQASEEIREKLQQVMSRRKEMNEKWEARWERLRMLLEVCQFSRDASVAEAWLIAQEPYLASGDFGHTVDSVEKLIKRHEAFEKSTASWAERFAALEKPTTLELKERQIAERPAEETGPQEEEGETAGEAPVSHHAATERTSPGEEEGTWPQNLQQPPPPGQHKDGQKSTGDERPTTEPLFKVLDTPLSEGDEPATLPAPRDHGQSVQMEGYLGRKHDLEGPNKKASNRSWNNLYCVLRNSELTFYKDAKNLALGMPYHGEEPLALRHAICEIAANYKKKKHVFKLRLSNGSEWLFHGKDEEEMLSWLQGVSTAINESQSIRVKAQSLPLPSLSGPDASLGKKDKEKRFSFFPKKK>sp|P11277-3|SPTB1_HUMAN Isoform 3 of Spectrin beta chain, erythrocyticOS=Homo sapiens OX=9606 GN=SPTBMTSATEFENVGNQPPYSRINARWDAPDDELDNDNSSARLFERSRIKALADEREVVQKKTFTKWVNSHLARVSCRITDLYKDLRDGRMLIKLLEVLSGEMLPKPTKGKMRIHCLENVDKALQFLKEQRVHLENMGSHDIVDGNHRLVLGLIWTIILRFQIQDIVVQTQEGRETRSAKDALLLWCQMKTAGYPHVNVTNFTSSWKDGLAFNALIHKHRPDLIDFDKLKDSNARHNLEHAFNVAERQLGIIPLLDPEDVFTENPDEKSIITYVVAFYHYFSKMKVLAVEGKRVGKVIDHAIETEKMIEKYSGLASDLLTWIEQTITVLNSRKFANSLTGVQQQLQAFSTYRTVEKPPKFQEKGNLEVLLFTIQSRMRANNQKVYTPHDGKLVSDINRAWESLEEAEYRRELALRNELIRQEKLEQLARRFDRKAAMRETWLSENQRLVAQDNFGYDLAAVEAAKKKHEAIETDTAAYEERVRALEDLAQELEKENYHDQKRITARKDNILRLWSYLQELLQSRRQRLETTLALQKLFQDMLHSIDWMDEIKAHLLSAEFGKHLLEVEDLLQKHKLMEADIAIQGDKVKAITAATLKFTEGKGYQPCDPQVIQDRISHLEQCFEELSNMAAGRKAQLEQSKRLWKFFWEMDEAESWIKEKEQIYSSLDYGKDLTSVLILQRKHKAFEDELRGLDAHLEQIFQEAHGMVARKQFGHPQIEARIKEVSAQWDQLKDLAAFCKKNLQDAENFFQFQGDADDLKAWLQDAHRLLSGEDVGQDEGATRALGKKHKDFLEELEESRGVMEHLEQQAQGFPEEFRDSPDVTHRLQALRELYQQVVAQADLRQQRLQEALDLYTVFGETDACELWMGEKEKWLAEMEMPDTLEDLEVVQHRFDILDQEMKTLMTQIDGVNLAANSLVESGHPRSREVKQYQDHLNTRWQAFQTLVSERREAVDSALRVHNYCVDCEETSKWITDKTKVVESTKDLGRDLAGIIAIQRKLSGLERDVAAIQARVDALERESQQLMDSHPEQKEDIGQRQKHLEELWQGLQQSLQGQEDLLGEVSQLQAFLQDLDDFQAWLSITQKAVASEDMPESLPEAEQLLQQHAGIKDEIDGHQDSYQRVKESGEKVIQGQTDPEYLLLGQRLEGLDTGWNALGRMWESRSHTLAQCLGFQEFQKDAKQAEAILSNQEYTLAHLEPPDSLEAAEAGIRKFEDFLGSMENNRDKVLSPVDSGNKLVAEGNLYSDKIKEKVQLIEDRHRKNNEKAQEASVLLRDNLELQNFLQNCQELTLWINDKLLTSQDVSYDEARNLHNKWLKHQAFVAELASHEGWLENIDAEGKQLMDEKPQFTALVSQKLEALHRLWDELQATTKEKTQHLSAARSSDLRLQTHADLNKWISAMEDQLRSDDPGKDLTSVNRMLAKLKRVEDQVNVRKEELGELFAQVPSMGEEGGDADLSIEKRFLDLLEPLGRRKKQLESSRAKLQISRDLEDETLWVEERLPLAQSADYGTNLQTVQLFMKKNQTLQNEILGHTPRVEDVLQRGQQLVEAAEIDCQDLEERLGHLQSSWDRLREAAAGRLQRLRDANEAQQYYLDADEAEAWIGEQELYVISDEIPKDEEGAIVMLKRHLRQQRAVEDYGRNIKQLASRAQGLLSAGHPEGEQIIRLQGQVDKHYAGLKDVAEERKRKLENMYHLFQLKRETDDLEQWISEKELVASSPEMGQDFDHVTLLRDKFRDFARETGAIGQERVDNVNAFIERLIDAGHSEAATIAEWKDGLNEMWADLLELIDTRMQLLAASYDLHRYFYTGAEILGLIDEKHRELPEDVGLDASTAESFHRVHTAFERELHLLGVQVQQFQDVATRLQTAYAGEKAEAIQNKEQEVSAAWQALLDACAGRRTQLVDTADKFRFFSMARDLLSWMESIIRQIETQERPRDVSSVELLMKYHQGINAEIETRSKNFSACLELGESLLQRQHQASEEIREKLQQVMSRRKEMNEKWEARWERLRMLLEVCQFSRDASVAEAWLIAQEPYLASGDFGHTVDSVEKLIKRHEAFEKSTASWAERFAALEKPTTASRGGRRDSRGGSSFPPCGHRENVPGQSLVSFV>sp|Q8IYB8|SUV3_HUMAN ATP-dependent RNA helicase SUPV3L1, mitochondrialOS=Homo sapiens OX=9606 GN=SUPV3L1 PE=1 SV=1MSFSRALLWARLPAGRQAGHRAAICSALRPHFGPFPGVLGQVSVLATASSSASGGSKIPNTSLFVPLTVKPQGPSADGDVGAELTRPLDKNEVKKVLDKFYKRKEIQKLGADYGLDARLFHQAFISFRNYIMQSHSLDVDIHIVLNDICFGAAHADDLFPFFLRHAKQIFPVLDCKDDLRKISDLRIPPNWYPDARAMQRKIIFHSGPTNSGKTYHAIQKYFSAKSGVYCGPLKLLAHEIFEKSNAAGVPCDLVTGEERVTVQPNGKQASHVSCTVEMCSVTTPYEVAVIDEIQMIRDPARGWAWTRALLGLCAEEVHLCGEPAAIDLVMELMYTTGEEVEVRDYKRLTPISVLDHALESLDNLRPGDCIVCFSKNDIYSVSRQIEIRGLESAVIYGSLPPGTKLAQAKKFNDPNDPCKILVATDAIGMGLNLSIRRIIFYSLIKPSINEKGERELEPITTSQALQIAGRAGRFSSRFKEGEVTTMNHEDLSLLKEILKRPVDPIRAAGLHPTAEQIEMFAYHLPDATLSNLIDIFVDFSQVDGQYFVCNMDDFKFSAELIQHIPLSLRVRYVFCTAPINKKQPFVCSSLLQFARQYSRNEPLTFAWLRRYIKWPLLPPKNIKDLMDLEAVHDVLDLYLWLSYRFMDMFPDASLIRDLQKELDGIIQDGVHNITKLIKMSETHKLLNLEGFPSGSQSRLSGTLKSQARRTRGTKALGSKATEPPSPDAGELSLASRLVQQGLLTPDMLKQLEKEWMTQQTEHNKEKTESGTHPKGTRRKKKEPDSD>sp|A0A075B6S0|TRGJ1_HUMAN T cell receptor gamma joining 1 OS=Homosapiens OX=9606 GN=TRGJ1 PE=1 SV=2NYYKKLFGSGTTLVVT>sp|Q96SB4|SRPK1_HUMAN SRSF protein kinase 1 OS=Homo sapiens OX=9606GN=SRPK1 PE=1 SV=2MERKVLALQARKKRTKAKKDKAQRKSETQHRGSAPHSESDLPEQEEEILGSDDDEQEDPNDYCKGGYHLVKIGDLFNGRYHVIRKLGWGHFSTVWLSWDIQGKKFVAMKVVKSAEHYTETALDEIRLLKSVRNSDPNDPNREMVVQLLDDFKISGVNGTHICMVFEVLGHHLLKWIIKSNYQGLPLPCVKKIIQQVLQGLDYLHTKCRIIHTDIKPENILLSVNEQYIRRLAAEATEWQRSGAPPPSGSAVSTAPQPKPADKMSKNKKKKLKKKQKRQAELLEKRMQEIEEMEKESGPGQKRPNKQEESESPVERPLKENPPNKMTQEKLEESSTIGQDQTLMERDTEGGAAEINCNGVIEVINYTQNSNNETLRHKEDLHNANDCDVQNLNQESSFLSSQNGDSSTSQETDSCTPITSEVSDTMVCQSSSTVGQSFSEQHISQLQESIRAEIPCEDEQEQEHNGPLDNKGKSTAGNFLVNPLEPKNAEKLKVKIADLGNACWVHKHFTEDIQTRQYRSLEVLIGSGYNTPADIWSTACMAFELATGDYLFEPHSGEEYTRDEDHIALIIELLGKVPRKLIVAGKYSKEFFTKKGDLKHITKLKPWGLFEVLVEKYEWSQEEAAGFTDFLLPMLELIPEKRATAAECLRHPWLNS>sp|Q96SB4-3|SRPK1_HUMAN Isoform 1 of SRSF protein kinase 1 OS=Homosapiens OX=9606 GN=SRPK1MERKGERWSGLRHEGQWSPGRGPGQRRELRLTAAVRFPDVRRPSTEVAPPHTPCLWAAGPRPSFRASSGAGRSRPLFPARPARALGPLQGPALGGRRRPPPARPLTRPETPPAHPARALLCAPWAASPTPAASPSPQPPPRQAPQPGLAPLLGLHPHLGRLLSSTFALHPSLSPAVLALQARKKRTKAKKDKAQRKSETQHRGSAPHSESDLPEQEEEILGSDDDEQEDPNDYCKGGYHLVKIGDLFNGRYHVIRKLGWGHFSTVWLSWDIQGKKFVAMKVVKSAEHYTETALDEIRLLKSVRNSDPNDPNREMVVQLLDDFKISGVNGTHICMVFEVLGHHLLKWIIKSNYQGLPLPCVKKIIQQVLQGLDYLHTKCRIIHTDIKPENILLSVNEQYIRRLAAEATEWQRSGAPPPSGSAVSTAPQPKPADKMSKNKKKKLKKKQKRQAELLEKRMQEIEEMEKESGPGQKRPNKQEESESPVERPLKENPPNKMTQEKLEESSTIGQDQTLMERDTEGGAAEINCNGVIEVINYTQNSNNETLRHKEDLHNANDCDVQNLNQESSFLSSQNGDSSTSQETDSCTPITSEVSDTMVCQSSSTVGQSFSEQHISQLQESIRAEIPCEDEQEQEHNGPLDNKGKSTAGNFLVNPLEPKNAEKLKVKIADLGNACWVHKHFTEDIQTRQYRSLEVLIGSGYNTPADIWSTACMAFELATGDYLFEPHSGEEYTRDEDHIALIIELLGKVPRKLIVAGKYSKEFFTKKGDLKHITKLKPWGLFEVLVEKYEWSQEEAAGFTDFLLPMLELIPEKRATAAECLRHPWLNS>sp|Q96SB4-4|SRPK1_HUMAN Isoform 3 of SRSF protein kinase 1 OS=Homosapiens OX=9606 GN=SRPK1MGIFVSFLRSETQHRGSAPHSESDLPEQEEEILGSDDDEQEDPNDYCKGGYHLVKIGDLFNGRYHVIRKLGWGHFSTVWLSWDIQGKKFVAMKVVKSAEHYTETALDEIRLLKSVRNSDPNDPNREMVVQLLDDFKISGVNGTHICMVFEVLGHHLLKWIIKSNYQGLPLPCVKKIIQQVLQGLDYLHTKCRIIHTDIKPENILLSVNEQYIRRLAAEATEWQRSGAPPPSGSAVSTAPQPKPADKMSKNKKKKLKKKQKRQAELLEKRMQEIEEMEKESGPGQKRPNKQEESESPVERPLKENPPNKMTQEKLEESSTIGQDQTLMERDTEGGAAEINCNGVIEVINYTQNSNNETLRHKEDLHNANDCDVQNLNQESSFLSSQNGDSSTSQETDSCTPITSEVSDTMVCQSSSTVGQSFSEQHISQLQESIRAEIPCEDEQEQEHNGPLDNKGKSTAGNFLVNPLEPKNAEKLKVKIADLGNACWVHKHFTEDIQTRQYRSLEVLIGSGYNTPADIWSTACMAFELATGDYLFEPHSGEEYTRDEDHIALIIELLGKVPRKLIVAGKYSKEFFTKKGDLKHITKLKPWGLFEVLVEKYEWSQEEAAGFTDFLLPMLELIPEKRATAAECLRHPWLNS>sp|Q9BX66|SRBS1_HUMAN Sorbin and SH3 domain-containing protein 1 OS=Homosapiens OX=9606 GN=SORBS1 PE=1 SV=3MSSECDGGSKAVMNGLAPGSNGQDKATADPLRARSISAVKIIPVKTVKNASGLVLPTDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDATSSSAAQPEVIVVPLYLVNTDRGQEGTARPPTPLGPLGCVPTIPATASAASPLTFPTLDDFIPPHLQRWPHHSQPARASGSFAPISQTPPSFSPPPPLVPPAPEDLRRVSEPDLTGAVSSTDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDTPEENPYFPTYKFPELPEIQQTSEEDNPYTPTYQFPASTPSPKSEDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPPPKKIWDYTPGDCSILPREDRKTNLDKDLSLCQTELEADLEKMETLNKAPSANVPQSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQFSSHSKLITPAPSSLPHSRRALSPEMHAVTSEWISLTVGVPGRRSLALTPPLPPLPEASIYNTDHLALSPRASPSLSLSLPHLSWSDRPTPRSVASPLALPSPHKTYSLAPTSQASLHMNGDGGVHTPSSGIHQDSFLQLPLGSSDSVISQLSDAFSSQSKRQPWREESGQYERKAERGAGERGPGGPKISKKSCLKPSDVVRCLSTEQRLSDLNTPEESRPGKPLGSAFPGSEAEQTERHRGGEQAGRKAARRGGSQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-2|SRBS1_HUMAN Isoform 2 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKATADPLRARSISAVKIIPVKTVKNASGLVLPTDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDATSSSAAQPEVIVVPLYLVNTDRGQEGTARPPTPLGPLGCVPTIPATASAASPLTFPTLDDFIPPHLQRWPHHSQPARASGSFAPISQTPPSFSPPPPLVPPAPEDLRRVSEPDLTGAVSSTDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDTPEENPYFPTYKFPELPEIQQTSEETKSCSVMSPRLECSGTVIAHCSLKLLDSSNPPTSASQVAGTADDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPPPKKIWDYTPGDCSILPREDRKTNLDKDLSLCQTELEADLEKMETLNKAPSANVPQSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQPWREESGQYERKAERGAGERGPGGPKISKKSCLKPSDVVRCLSTEQRLSDLNTPEESRPGKPLGSAFPGSEAEQTERHRGGEQAGRKAARRGGSQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-3|SRBS1_HUMAN Isoform 3 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKATADPLRARSISAVKIIPVKTVKNASGLVLPTDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQRWPHHSQPARASGSFAPISQTPPSFSPPPPLVPPAPEDLRRVSEPDLTGAVSSTDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPPPKKIWDYTPGDCSILPREDRKSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQLSHHSLRAGPDLTESEKSYVQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-4|SRBS1_HUMAN Isoform 4 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPDEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-5|SRBS1_HUMAN Isoform 5 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKATADPLRARSISAVKIIPVKTVKNASGLVLPTDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPDEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDATSSSAAQPEVIVVPLYLVNTDRGQEGTARPPTPLGPLGCVPTIPATASAASPLTFPTLDDFIPPHLQRWPHHSQPARASGSFAPISQTPPSFSPPPPLVPPAPEDLRRVSEPDLTGAVSSTDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDTPEENPYFPTYKFPELPEIQQTSEDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPPPKKIWDYTPGDCSILPREDRKTNLDKDLSLCQTELEADLEKMETLNKAPSANVPQSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-6|SRBS1_HUMAN Isoform 6 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKATADPLRARSISAVKIIPVKTVKNASGLVLPTDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPDEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDTPEENPYFPTYKFPELPEIQQTSEEDNPYTPTYQFPASTPSPKSEDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-7|SRBS1_HUMAN Isoform 7 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPDEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDATSSSAAQPEVIVVPLYLVNTDRGQEGTARPPTPLGPLGCVPTIPATASAASPLTFPTLDDFIPPHLQRWPHHSQPARASGSFAPISQTPPSFSPPPPLVPPAPEDLRRVSEPDLTGAVSSTDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEKYDWA>sp|Q9BX66-8|SRBS1_HUMAN Isoform 8 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPTNLDKDLSLCQTELEADLEKMETLNKAPSANVPQSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-9|SRBS1_HUMAN Isoform 9 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKATADPLRARSISAVKIIPVKTVKNASGLVLPTDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-10|SRBS1_HUMAN Isoform 10 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDATSSSAAQPEVIVVPLYLVNTDRGQEGTARPPTPLGPLGCVPTIPATASAASPLTFPTLDDFIPPHLQRWPHHSQPARASGSFAPISQTPPSFSPPPPLVPPAPEDLRRVSEPDLTGAVSSTDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-11|SRBS1_HUMAN Isoform 11 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKATADPLRARSISAVKIIPVKTVKNASGLVLPTDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDATSSSAAQPEVIVVPLYLVNTDRGQEGTARPPTPLGPLGCVPTIPATASAASPLTFPTLDDFIPPHLQRWPHHSQPARASGSFAPISQTPPSFSPPPPLVPPAPEDLRRVSEPDLTGAVSSTDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNREQQKRLSSLSDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPPPKKIWDYTPGDCSILPREDRKTNLDKDLSLCQTELEADLEKMETLNKAPSANVPQSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQFSSHSKLITPAPSSLPHSRRALSPEMHAVTSEWISLTVGVPGRRSLALTPPLPPLPEASIYNTDHLALSPRASPSLSLSLPHLSWSDRPTPRSVASPLALPSPHKTYSLAPTSQASLHMNGDGGVHTPSSGIHQDSFLQLPLGSSDSVISQLSDAFSSQSKRQPWREESGQYERKAERGAGERGPGGPKISKKSCLKPSDVVRCLSTEQRLSDLNTPEESRPGKPLGSAFPGSEAEQTERHRGGEQAGRKAARRGGSQLSHHSLRAGPDLTESEKSYVQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9BX66-12|SRBS1_HUMAN Isoform 12 of Sorbin and SH3 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SORBS1MSSECDGGSKAVMNGLAPGSNGQDKDMDLTKICTGKGAVTLRASSSYRETPSSSPASPQETRQHESKPGLEPEPSSADEWRLSSSADANGNAQPSSLAAKGYRSVHPNLPSDKSQDSSPLLNEVSSSLIGTDSQAFPSVSKPSSAYPSTTIVNPTIVLLQHNRDPVSERRVGEQDSAPTQEKPTSPGKAIEKRAKDDSRRVVKSTQDLSDVSMDEVGIPLRNTERSKDWYKTMFKQIHKLNRDDDSDLYSPRYSFSEDTKSPLSVPRSKSEMSYIDGEKVVKRSATLPLPARSSSLKSSSERNDWEPPDKKVDTRKYRAEPKSIYEYQPGKSSVLTNEKMSRDISPEEIDLKNEPWYKFFSELEFGKPTNLDKDLSLCQTELEADLEKMETLNKAPSANVPQSSAISPTPEISSETPGYIYSSNFHAVKRESDGAPGDLTSLENERQIYKSVLEGGDIPLQGLSGLKRPSSSASTKVDRKGGNAHMISSSSVHSRTFNTSNALGPVCKHKKPLSAAKACISEILPSKFKPRLSAPSALLQEQKSILLPSEKAQSCENLCVSGSLNDSKRGLPLQVGGSIENLLMRSRRDYDSKSSSTMSLQEYSTSGRRPCPLSRKAGMQFTMLYRDMHQINRSGLFLGSISSSSSVRDLASHFEKSSLALSRGELGPSQEGSEHIPKHTVSSRITAFEQLIQRSRSMPSLDLSGRLSKSPTPVLSRGSLTSARSAESLLESTKLHPKEMDGMNSSGVYASPTCSNMAHHALSFRGLVPSEPLSTCSDDVDRCSNISTDSREGSGGSVHGDFPKHRLNKCKGTCPASYTRFTTIRKHEQQQTSRQPEWRLDARGDKSTLLRNIYLMSPLPFRLKKPLHHHPRQPSPGDSSGLLVGQKPDLPSQPHQDQPPSGGKPVVPTRLSSRHTMARLSRSSEPSQERPTALEDYPRAINNGNSVPYSDHSLDRNNNPQSELAPSRGDSESPRHFIPADYLESTEEFIRRRHDDKEKLLADQRRLKREQEEADIAARRHTGVIPTHHQFITNERFGDLLNIDDTAKRKSGSEMRPARAKFDFKAQTLKELPLQKGDIVYIYKQIDQNWYEGEHHGRVGIFPRTYIELLPPAEKAQPKKLTPVQVLEYGEAIAKFNFNGDTQVEMSFRKGERITLLRQVDENWYEGRIPGTSRQGIFPITYVDVIKRPLVKNPVDYMDLPFSSSPSRSATASPQQPQAQQRRVTPDRSQTSQDLFSYQALYSYIPQNDDELELRDGDIVDVMEKCDDGWFVGTSRRTKQFGTFPGNYVKPLYL>sp|Q9NZD8|SPG21_HUMAN Maspardin OS=Homo sapiens OX=9606 GN=SPG21 PE=1SV=1MGEIKVSPDYNWFRGTVPLKKIIVDDDDSKIWSLYDAGPRSIRCPLIFLPPVSGTADVFFRQILALTGWGYRVIALQYPVYWDHLEFCDGFRKLLDHLQLDKVHLFGASLGGFLAQKFAEYTHKSPRVHSLILCNSFSDTSIFNQTWTANSFWLMPAFMLKKIVLGNFSSGPVDPMMADAIDFMVDRLESLGQSELASRLTLNCQNSYVEPHKIRDIPVTIMDVFDQSALSTEAKEEMYKLYPNARRAHLKTGGNFPYLCRSAEVNLYVQIHLLQFHGTKYAAIDPSMVSAEELEVQKGSLGISQEEQ>sp|Q9NZD8-2|SPG21_HUMAN Isoform 2 of Maspardin OS=Homo sapiens OX=9606GN=SPG21MGEIKVSPDYNWFRGTVPLKKIIVDDDDSKIWSLYDAGPRSIRCPLIFLPPVSGTADVFFRQILALTGWGYRVIAVHLFGASLGGFLAQKFAEYTHKSPRVHSLILCNSFSDTSIFNQTWTANSFWLMPAFMLKKIVLGNFSSGPVDPMMADAIDFMVDRLESLGQSELASRLTLNCQNSYVEPHKIRDIPVTIMDVFDQSALSTEAKEEMYKLYPNARRAHLKTGGNFPYLCRSAEVNLYVQIHLLQFHGTKYAAIDPSMVSAEELEVQKGSLGISQEEQ>sp|Q9NUQ6|SPS2L_HUMAN SPATS2-like protein OS=Homo sapiens OX=9606GN=SPATS2L PE=1 SV=2MAELNTHVNVKEKIYAVRSVVPNKSNNEIVLVLQQFDFNVDKAVQAFVDGSAIQVLKEWNMTGKKKNNKRKRSKSKQHQGNKDAKDKVERPEAGPLQPQPPQIQNGPMNGCEKDSSSTDSANEKPALIPREKKISILEEPSKALRGVTEGNRLLQQKLSLDGNPKPIHGTTERSDGLQWSAEQPCNPSKPKAKTSPVKSNTPAAHLEIKPDELAKKRGPNIEKSVKDLQRCTVSLTRYRVMIKEEVDSSVKKIKAAFAELHNCIIDKEVSLMAEMDKVKEEAMEILTARQKKAEELKRLTDLASQMAEMQLAELRAEIKHFVSERKYDEELGKAARFSCDIEQLKAQIMLCGEITHPKNNYSSRTPCSSLLPLLNAHAATSGKQSNFSRKSSTHNKPSEGKAANPKMVSSLPSTADPSHQTMPANKQNGSSNQRRRFNPQYHNNRLNGPAKSQGSGNEAEPLGKGNSRHEHRRQPHNGFRPKNKGGAKNQEASLGMKTPEAPAHSEKPRRRQHAADTSEARPFRGSVGRVSQCNLCPTRIEVSTDAAVLSVPAVTLVA>sp|Q9NUQ6-2|SPS2L_HUMAN Isoform 2 of SPATS2-like protein OS=Homo sapiensOX=9606 GN=SPATS2LMAELNTHVNVKEKIYAVRSVVPNKSNNEIVLVLQQFDFNVDKAVQAFVDGSAIQVLKEWNMTGKKKNNKRKRSKSKQHQGNKDAKDKVERPEAGPLQPQPPQIQNGPMNGCEKDSSSTDSANEKPALIPREKKISILEEPSKALRGVTGPNIEKSVKDLQRCTVSLTRYRVMIKEEVDSSVKKIKAAFAELHNCIIDKEVSLMAEMDKVKEEAMEILTARQKKAEELKRLTDLASQMAEMQLAELRAEIKHFVSERKYDEELGKAARFSCDIEQLKAQIMLCGEITHPKNNYSSRTPCSSLLPLLNAHAATSGKQSNFSRKSSTHNKPSEGKAANPKMVSSLPSTADPSHQTMPANKQNGSSNQRRRFNPQYHNNRLNGPAKSQGSGNEAEPLGKGNSRHEHRRQPHNGFRPKNKGGAKNQEASLGMKTPEAPAHSEKPRRRQHAADTSEARPFRGSVGRVSQCNLCPTRIEVSTDAAVLSVPAVTLVA>sp|Q9NUQ6-3|SPS2L_HUMAN Isoform 3 of SPATS2-like protein OS=Homo sapiensOX=9606 GN=SPATS2LMDPFCHSSSETRLLSGTLLWIPRAYSTRSKMAELNTHVNVKEKIYAVRSVVPNKSNNEIVLVLQQFDFNVDKAVQAFVDGSAIQVLKEWNMTGKKKNNKRKRSKSKQHQGNKDAKDKVERPEAGPLQPQPPQIQNGPMNGCEKDSSSTDSANEKPALIPREKKISILEEPSKALRGVTEGNRLLQQKLSLDGNPKPIHGTTERSDGLQWSAEQPCNPSKPKAKTSPVKSNTPAAHLEIKPDELAKKRGPNIEKSVKDLQRCTVSLTRYRVMIKEEVDSSVKKIKAAFAELHNCIIDKEVSLMAEMDKVKEEAMEILTARQKKAEELKRLTDLASQMAEMQLAELRAEIKHFVSERKYDEELGKAARFSCDIEQLKAQIMLCGEITHPKNNYSSRTPCSSLLPLLNAHAATSGKQSNFSRKSSTHNKPSEGKAANPKMVSSLPSTADPSHQTMPANKQNGSSNQRRRFNPQYHNNRLNGPAKSQGSGNEAEPLGKGNSRHEHRRQPHNGFRPKNKGGAKNQEASLGMKTPEAPAHSEKPRRRQHAADTSEARPFRGSVGRVSQCNLCPTRIEVSTDAAVLSVPAVTLVA>sp|Q9NUQ6-4|SPS2L_HUMAN Isoform 4 of SPATS2-like protein OS=Homo sapiensOX=9606 GN=SPATS2LMAYSTRSKMAELNTHVNVKEKIYAVRSVVPNKSNNEIVLVLQQFDFNVDKAVQAFVDGSAIQVLKEWNMTGKKKNNKRKRSKSKQHQGNKDAKDKVERPEAGPLQPQPPQIQNGPMNGCEKDSSSTDSANEKPALIPREKKISILEEPSKALRGVTEGNRLLQQKLSLDGNPKPIHGTTERSDGLQWSAEQPCNPSKPKAKTSPVKSNTPAAHLEIKPDELAKKRGPNIEKSVKDLQRCTVSLTRYRVMIKEEVDSSVKKIKAAFAELHNCIIDKEVSLMAEMDKVKEEAMEILTARQKKAEELKRLTDLASQMAEMQLAELRAEIKHFVSERKYDEELGKAARFSCDIEQLKAQIMLCGEITHPKNNYSSRTPCSSLLPLLNAHAATSGKQSNFSRKSSTHNKPSEGKAANPKMVSSLPSTADPSHQTMPANKQNGSSNQRRRFNPQYHNNRLNGPAKSQGSGNEAEPLGKGNSRHEHRRQPHNGFRPKNKGGAKNQEASLGMKTPEAPAHSEKPRRRQHAADTSEARPFRGSVGRVSQCNLCPTRIEVSTDAAVLSVPAVTLVA>sp|Q14247|SRC8_HUMAN Src substrate cortactin OS=Homo sapiens OX=9606GN=CTTN PE=1 SV=2MWKASAGHAVSIAQDDAGADDWETDPDFVNDVSEKEQRWGAKTVQGSGHQEHINIHKLRENVFQEHQTLKEKELETGPKASHGYGGKFGVEQDRMDKSAVGHEYQSKLSKHCSQVDSVRGFGGKFGVQMDRVDQSAVGFEYQGKTEKHASQKDYSSGFGGKYGVQADRVDKSAVGFDYQGKTEKHESQRDYSKGFGGKYGIDKDKVDKSAVGFEYQGKTEKHESQKDYVKGFGGKFGVQTDRQDKCALGWDHQEKLQLHESQKDYKTGFGGKFGVQSERQDSAAVGFDYKEKLAKHESQQDYSKGFGGKYGVQKDRMDKNASTFEDVTQVSSAYQKTVPVEAVTSKTSNIRANFENLAKEKEQEDRRKAEAERAQRMAKERQEQEEARRKLEEQARAKTQTPPVSPAPQPTEERLPSSPVYEDAASFKAELSYRGPVSGTEPEPVYSMEAADYREASSQQGLAYATEAVYESAEAPGHYPAEDSTYDEYENDLGITAVALYDYQAAGDDEISFDPDDIITNIEMIDDGWWRGVCKGRYGLFPANYVELRQ>sp|Q14247-2|SRC8_HUMAN Isoform 2 of Src substrate cortactin OS=Homosapiens OX=9606 GN=CTTNMWKASAGHAVSIAQDDAGADDWETDPDFVNDVSEKEQRWGAKTVQGSGHQEHINIHKLRENVFQEHQTLKEKELETGPKASHGYGGKFGVEQDRMDKSAVGHEYQSKLSKHCSQVDSVRGFGGKFGVQMDRVDQSAVGFEYQGKTEKHASQKDYSSGFGGKYGVQADRVDKSAVGFDYQGKTEKHESQRDYSKGFGGKYGIDKDKVDKSAVGFEYQGKTEKHESQKDYVKGFGGKFGVQTDRQDKCALGWDHQEKLQLHESQKDYSKGFGGKYGVQKDRMDKNASTFEDVTQVSSAYQKTVPVEAVTSKTSNIRANFENLAKEKEQEDRRKAEAERAQRMAKERQEQEEARRKLEEQARAKTQTPPVSPAPQPTEERLPSSPVYEDAASFKAELSYRGPVSGTEPEPVYSMEAADYREASSQQGLAYATEAVYESAEAPGHYPAEDSTYDEYENDLGITAVALYDYQAAGDDEISFDPDDIITNIEMIDDGWWRGVCKGRFRELAFSCVRVALVPIKCSRDLPGQARGLRSALWRVGRKDCPRRGASSRVSLLGRRGLGLMEVNPELSHPEHRSCHVRWEICLCHTVTARRIRKLISFLRSREAGPVPSCSQVGGVSFQKVTWKCLGTWVPECP>sp|Q14247-3|SRC8_HUMAN Isoform 3 of Src substrate cortactin OS=Homosapiens OX=9606 GN=CTTNMWKASAGHAVSIAQDDAGADDWETDPDFVNDVSEKEQRWGAKTVQGSGHQEHINIHKLRENVFQEHQTLKEKELETGPKASHGYGGKFGVEQDRMDKSAVGHEYQSKLSKHCSQVDSVRGFGGKFGVQMDRVDQSAVGFEYQGKTEKHASQKDYSSGFGGKYGVQADRVDKSAVGFDYQGKTEKHESQRDYSKGFGGKYGIDKDKVDKSAVGFEYQGKTEKHESQKDYVKGFGGKFGVQTDRQDKCALGWDHQEKLQLHESQKDYSKGFGGKYGVQKDRMDKNASTFEDVTQVSSAYQKTVPVEAVTSKTSNIRANFENLAKEKEQEDRRKAEAERAQRMAKERQEQEEARRKLEEQARAKTQTPPVSPAPQPTEERLPSSPVYEDAASFKAELSYRGPVSGTEPEPVYSMEAADYREASSQQGLAYATEAVYESAEAPGHYPAEDSTYDEYENDLGITAVALYDYQAAGDDEISFDPDDIITNIEMIDDGWWRGVCKGRYGLFPANYVELRQ>sp|Q9Y3C8|UFC1_HUMAN Ubiquitin-fold modifier-conjugating enzyme 1OS=Homo sapiens OX=9606 GN=UFC1 PE=1 SV=3MADEATRRVVSEIPVLKTNAGPRDRELWVQRLKEEYQSLIRYVENNKNADNDWFRLESNKEGTRWFGKCWYIHDLLKYEFDIEFDIPITYPTTAPEIAVPELDGKTAKMYRGGKICLTDHFKPLWARNVPKFGLAHLMALGLGPWLAVEIPDLIQKGVIQHKEKCNQ>sp|Q9Y285|SYFA_HUMAN Phenylalanine--tRNA ligase alpha subunit OS=Homosapiens OX=9606 GN=FARSA PE=1 SV=3MADGQVAELLLRRLEASDGGLDSAELAAELGMEHQAVVGAVKSLQALGEVIEAELRSTKHWELTAEGEEIAREGSHEARVFRSIPPEGLAQSELMRLPSGKVGFSKAMSNKWIRVDKSAADGPRVFRVVDSMEDEVQRRLQLVRGGQAEKLGEKERSELRKRKLLAEVTLKTYWVSKGSAFSTSISKQETELSPEMISSGSWRDRPFKPYNFLAHGVLPDSGHLHPLLKVRSQFRQIFLEMGFTEMPTDNFIESSFWNFDALFQPQQHPARDQHDTFFLRDPAEALQLPMDYVQRVKRTHSQGGYGSQGYKYNWKLDEARKNLLRTHTTSASARALYRLAQKKPFTPVKYFSIDRVFRNETLDATHLAEFHQIEGVVADHGLTLGHLMGVLREFFTKLGITQLRFKPAYNPYTEPSMEVFSYHQGLKKWVEVGNSGVFRPEMLLPMGLPENVSVIAWGLSLERPTMIKYGINNIRELVGHKVNLQMVYDSPLCRLDAEPRPPPTQEAA>sp|Q9Y285-2|SYFA_HUMAN Isoform 2 of Phenylalanine--tRNA ligase alphasubunit OS=Homo sapiens OX=9606 GN=FARSAMADGQVAELLLRRLEASDGGLDSAELAAELGMEHQAVVGAVKSLQALGEVIEAELRSTKHWELTAEGEEIAREGSHEARVFRSIPPEGLAQSELMRLPSGKVGFSKAMSNKWIRVDKSAADGPRVFRVVDSMEDEVQRRLQLVRGGQAEKLGEKERSELRKRKLLAEVGSWRDRPFKPYNFLAHGVLPDSGHLHPLLKVRSQFRQIFLEMGFTEMPTDNFIESSFWNFDALFQPQQHPARDQHDTFFLRDPAEALQLPMDYVQRVKRTHSQGGYGSQGYKYNWKLDEARKNLLRTHTTSASARALYRLAQKKPFTPVKYFSIDRVFRNETLDATHLAEFHQIEGVVADHGLTLGHLMGVLREFFTKLGITQLRFKPAYNPYTEPSMEVFSYHQGLKKWVEVGNSGVFRPEMLLPMGLPENVSVIAWGLSLERPTMIKYGINNIRELVGHKVNLQMVYDSPLCRLDAEPRPPPTQEAA>sp|Q9P2J5|SYLC_HUMAN Leucine--tRNA ligase, cytoplasmic OS=Homo sapiensOX=9606 GN=LARS1 PE=1 SV=2MAERKGTAKVDFLKKIEKEIQQKWDTERVFEVNASNLEKQTSKGKYFVTFPYPYMNGRLHLGHTFSLSKCEFAVGYQRLKGKCCLFPFGLHCTGMPIKACADKLKREIELYGCPPDFPDEEEEEEETSVKTEDIIIKDKAKGKKSKAAAKAGSSKYQWGIMKSLGLSDEEIVKFSEAEHWLDYFPPLAIQDLKRMGLKVDWRRSFITTDVNPYYDSFVRWQFLTLRERNKIKFGKRYTIYSPKDGQPCMDHDRQTGEGVGPQEYTLLKLKVLEPYPSKLSGLKGKNIFLVAATLRPETMFGQTNCWVRPDMKYIGFETVNGDIFICTQKAARNMSYQGFTKDNGVVPVVKELMGEEILGASLSAPLTSYKVIYVLPMLTIKEDKGTGVVTSVPSDSPDDIAALRDLKKKQALRAKYGIRDDMVLPFEPVPVIEIPGFGNLSAVTICDELKIQSQNDREKLAEAKEKIYLKGFYEGIMLVDGFKGQKVQDVKKTIQKKMIDAGDALIYMEPEKQVMSRSSDECVVALCDQWYLDYGEENWKKQTSQCLKNLETFCEETRRNFEATLGWLQEHACSRTYGLGTHLPWDEQWLIESLSDSTIYMAFYTVAHLLQGGNLHGQAESPLGIRPQQMTKEVWDYVFFKEAPFPKTQIAKEKLDQLKQEFEFWYPVDLRVSGKDLVPNHLSYYLYNHVAMWPEQSDKWPTAVRANGHLLLNSEKMSKSTGNFLTLTQAIDKFSADGMRLALADAGDTVEDANFVEAMADAGILRLYTWVEWVKEMVANWDSLRSGPASTFNDRVFASELNAGIIKTDQNYEKMMFKEALKTGFFEFQAAKDKYRELAVEGMHRELVFRFIEVQTLLLAPFCPHLCEHIWTLLGKPDSIMNASWPVAGPVNEVLIHSSQYLMEVTHDLRLRLKNYMMPAKGKKTDKQPLQKPSHCTIYVAKNYPPWQHTTLSVLRKHFEANNGKLPDNKVIASELGSMPELKKYMKKVMPFVAMIKENLEKMGPRILDLQLEFDEKAVLMENIVYLTNSLELEHIEVKFASEAEDKIREDCCPGKPLNVFRIEPGVSVSLVNPQPSNGHFSTKIEIRQGDNCDSIIRRLMKMNRGIKDLSKVKLMRFDDPLLGPRRVPVLGKEYTEKTPISEHAVFNVDLMSKKIHLTENGIRVDIGDTIIYLVH>sp|Q9P2J5-2|SYLC_HUMAN Isoform 2 of Leucine--tRNA ligase, cytoplasmicOS=Homo sapiens OX=9606 GN=LARS1MNGRLHLGHTFSLSKCEFAVGYQRLKGKCCLFPFGLHCTGMPIKACADKLKREIELYGCPPDFPDEEEEEEETSVKTEDIIIKDKAKGKKSKAAAKAGSSKYQWGIMKSLGLSDEEIVKFSEAEHWLDYFPPLAIQDLKRMGLKVDWRRSFITTDVNPYYDSFVRWQFLTLRERNKIKFGKRYTIYSPKDGQPCMDHDRQTGEGVGPQEYTLLKLKVLEPYPSKLSGLKGKNIFLVAATLRPETMFGQTNCWVRPDMKYIGFETVNGDIFICTQKAARNMSYQGFTKDNGVVPVVKELMGEEILGASLSAPLTSYKVIYVLPMLTIKEDKGTGVVTSVPSDSPDDIAALRDLKKKQALRAKYGIRDDMVLPFEPVPVIEIPGFGNLSAVTICDELKIQSQNDREKLAEAKEKIYLKGFYEGIMLVDGFKGQKVQDVKKTIQKKMIDAGDALIYMEPEKQVMSRSSDECVVALCDQWYLDYGEENWKKQTSQCLKNLETFCEETRRNFEATLGWLQEHACSRTYGLGTHLPWDEQWLIESLSDSTIYMAFYTVAHLLQGGNLHGQAESPLGIRPQQMTKEVWDYVFFKEAPFPKTQIAKEKLDQLKQEFEFWYPVDLRVSGKDLVPNHLSYYLYNHVAMWPEQSDKWPTAVRANGHLLLNSEKMSKSTGNFLTLTQAIDKFSADGMRLALADAGDTVEDANFVEAMADAGILRLYTWVEWVKEMVANWDSLRSGPASTFNDRVFASELNAGIIKTDQNYEKMMFKEALKTGFFEFQAAKDKYRELAVEGMHRELVFRFIEVQTLLLAPFCPHLCEHIWTLLGKPDSIMNASWPVAGPVNEVLIHSSQYLMEVTHDLRLRLKNYMMPAKGKKTDKQPLQKPSHCTIYVAKNYPPWQHTTLSVLRKHFEANNGKLPDNKVIASELGSMPELKKYMKKVMPFVAMIKENLEKMGPRILDLQLEFDEKAVLMENIVYLTNSLELEHIEVKFASEAEDKIREDCCPGKPLNVFRIEPGVSVSLVNPQPSNGHFSTKIEIRQGDNCDSIIRRLMKMNRGIKDLSKVKLMRFDDPLLGPRRVPVLGKEYTEKTPISEHAVFNVDLMSKKIHLTENGIRVDIGDTIIYLVH>sp|Q9P2J5-3|SYLC_HUMAN Isoform 3 of Leucine--tRNA ligase, cytoplasmicOS=Homo sapiens OX=9606 GN=LARS1MWPEQSDKWPTAVRANGHLLLNSEKMSKSTGNFLTLTQAIDKFSADGMRLALADAGDTVEDANFVEAMADAGILRLYTWVEWVKEMVANWDSLRSGPASTFNDRVFASELNAGIIKTDQNYEKMMFKEALKTGFFEFQAAKDKYRELAVEGMHRELVFRFIEVQTLLLAPFCPHLCEHIWTLLGKPDSIMNASWPVAGPVNEVLIHSSQYLMEVTHDLRLRLKNYMMPAKGKKTDKQPLQKPSHCTIYVAKNYPPWQHTTLSVLRKHFEANNGKLPDNKVIASELGSMPELKKYMKKVMPFVAMIKENLEKMGPRILDLQLEFDEKAVLMENIVYLTNSLELEHIEVKFASEAEDKIREDCCPGKPLNVFRIEPGVSVSLVNPQPSNGHFSTKIEIRQGDNCDSIIRRLMKMNRGIKDLSKVKLMRFDDPLLGPRRVPVLGKEYTEKTPISEHAVFNVDLMSKKIHLTENGIRVDIGDTIIYLVH>sp|Q14DG7|T132B_HUMAN Transmembrane protein 132B OS=Homo sapiens OX=9606GN=TMEM132B PE=2 SV=2MFGAASRMDTTAVCTGGVTESRGIVDSLQKFSSLPAYLPTNLHISNAEESFFLKEANQDLTRNSSLQARVEPFFIYRARTPPIINASYGPFSVEKIIPQELLLTSTAFGNMDKFPFNWKLKSHILDSSIYSNRPKVQTLFYVTGMGWDDSDLTEDLPCVKMFAFPEAREVAASCRLQGAPGLCVAELELLPEWFSSGLDLEPEEEIPALLGGTTMELFFTLYPADKAGQCPLEEEGKWENNIHSGLESPQQAFPARERIGSVVVYPTQDDLKWSLVSLDENVVISVPLNLVREGDTATFLVSLTSSSVADQFTLRIKAAAGVKITAVRVSSEDQWAVQEEIDNGSTQTSATLTCMGHRPDTQSRVNGSFYEILQVDFGIDNSSDLAGAQQITWQVEYPIEDSMSELVVSEIFVSQTTFVGIVPLAMDTEVLNTAILTGKPVSVPVKVVGVQEDGSVVDVSESVECKSADEDVIKVSNNCDSIFVNGKEMKSKVDTIVNFTHQHFTSQFEVTVWAPRLPLQIEISDTELSQIKGWRIPVAANRRPTRESDDEDDEEKKGRGCSLQYQHATVRVLTQFVAESPDLGQLTYMLGPDWQFDITDLVTEFMKVEEPKIAQLQDGRTLAGREPGITTVQVLSPLSDSILAEKTVIVLDDRVTIAELGVQLVAGMSLSLQPHRADKRAIVSTAAALDVLQSPQQEAIVSSWILFSDGSVTPLDIYDPKDYSVTVSSLDEMVVSVQANLESKWPIVVAEGEGQGPLIKLEMMISEPCQKTKRKSVLAVGKGNVKVKFEPSSDEHQGGSNDIEGINREYKDHLSNSIEREGNQERAVQEWFHRGTPVGQEESTNKSTTPQSPMEGKNKLLKSGGPDAFTSFPTQGKSPDPNNPSDLTVTSRGLTDLEIGMYALLCVFCLAILVFLINCVAFAWKYRHKRFAVSEQGNIPHSHDWVWLGNEVELLENPVDITLPSEECTTMIDRGLQFEERNFLLNGSSQKTFHSQLLRPSDYVYEKEIKNEPMNSSGPKRKRVKFTSYTTILPEDGGPYTNSILFDSDDNIKWVCQDMGLGDSQDFRDYMESLQDQM>sp|Q14DG7-2|T132B_HUMAN Isoform 2 of Transmembrane protein 132B OS=Homosapiens OX=9606 GN=TMEM132BMFGAASRMDTTAVCTGGVTESRGIVDSLQKFSSLPAYLPTNLHISNAEESFFLKEANQDLTRNSSLQARVEPFFIYRARTPPIINASYGPFSVEKIIPQELLLTSTAFGNMDKFPFNWKLKSHILDSSIYSNRPKVQTLFYVTGMGWDDSDLTEDLPCVKMFAFPEAREVAASCRLQGAPGLCVAELELLPEWFSSGLDLEPEEEIPALLGGTTMELFFTLYPADKAGQCPLEEEGKWENNIHSGLESPQQAFPARERIGSVVVYPTQDDLKWSLVSLDENVVISVPLNLVREGDTATFLVSLTSSSVADQFTLRIKAAAGVKITAVRVSSEDQWAVQEEIDNGSTQTSATLTCMGHRPDTQSRVNGSFYEILQVDFGIDNSSDLAGAQQITWQVEYPIEDSMSELVVSEIFVSQTTFVGIVPLAMDTEVLNTAILTGKPVSVPVKVVGVQEDGSVVDVSESVECKSADEDVIKVRGDLSTAVLSAQSFLSFLLLSPRSCSH>sp|Q14DG7-3|T132B_HUMAN Isoform 3 of Transmembrane protein 132B OS=Homosapiens OX=9606 GN=TMEM132BMKSKVDTIVNFTHQHFTSQFEVTVWAPRLPLQIEISDTELSQIKGWRIPVAANRRPTRESDDEDDEEKKGRGCSLQYQHATVRVLTQFVAESPDLGQLTYMLGPDWQFDITDLVTEFMKVEEPKIAQLQDGRTLAGREPGITTVQVLSPLSDSILAEKTVIVLDDRVTIAELGVQLVAGMSLSLQPHRADKRAIVSTAAALDVLQSPQQEAIVSSWILFSDGSVTPLDIYDPKDYSVTVSSLDEMVVSVQANLESKWPIVVAEGEGQGPLIKLEMMISEPCQKTKRKSVLAVGKGNVKVKFEPSSDEHQGGSNDIEGINREYKDHLSNSIEREGNQERAVQEWFHRGTPVGQEESTNKSTTPQSPMEGKNKLLKSGGPDAFTSFPTQGKSPDPNNPSDLTVTSRGLTDLEIGMYALLCVFCLAILVFLINCVAFAWKYRHKRFAVSEQGNIPHSHDWVWLGNEVELLENPVDITLPSEECTTMIDRGLQFEERNFLLNGSSQKTFHSQLLRPSDYVYEKEIKNEPMNSSGPKRKRVKFTSYTTILPEDGGPYTNSILFDSDDNIKWVCQDMGLGDSQDFRDYMESLQDQM>sp|Q9BXQ6|T121B_HUMAN Transmembrane protein 121B OS=Homo sapiens OX=9606GN=TMEM121B PE=2 SV=1MRPALGHPRSVSSASGSFPPPPAAARLQPLFLRGGSFRGRRGSGDSSTSTSTSRGGGGGRRGGGGGSPSSSTGAEREDDDESLSVSKPLVPNAALLGPPAQVGAPAGPAPVAFSSSAATSSSTSTPTSSCSMTAADFGGGAAAGAVGGPGSRSAGGAGGTGTGSGASCCPCCCCCGCPDRPGRRGRRRGCAPSPRCRWGYQALSVVLLLAQGGLLDLYLIAVTDLYWCSWIATDLVVVVGWAIFFAKNSRGRRGGAASGAHNHHLHHHHAAPPLHLPAPSAATAGAKARGARGGAGGAGGGLGAAAAAGEFAFAYLAWLIYSIAFTPKVVLILGTSILDLIELRAPFGTTGFRLTMALSVPLLYSLVRAISEAGAPPGSAGPLLLQPQRHRAAGCFLGTCLDLLDSFTLVELMLEGRVPLPAHLRYLLIAVYFLTLASPVLWLYELNAAAAAAASWGQASGPGSCSRLLRLLGGCLVDVPLLALRCLLVVSYQQPLSIFMLKNLFFLGCRGLEALEGCWDRGNRASPSRARGGYGAPPSAPPPPPPPPQGGSQLGHCISENEGGAHGYVNTLAVASQN>sp|Q9BXQ6-2|T121B_HUMAN Isoform 2 of Transmembrane protein 121B OS=Homosapiens OX=9606 GN=TMEM121BMALSVPLLYSLVRAISEAGAPPGSAGPLLLQPQRHRAAGCFLGTCLDLLDSFTLVELMLEGRVPLPAHLRYLLIAVYFLTLASPVLWLYELNAAAAAAASWGQASGPGSCSRLLRLLGGCLVDVPLLALRCLLVVSYQQPLSIFMLKNLFFLGCRGLEALEGCWDRGNRASPSRARGGYGAPPSAPPPPPPPPQGGSQLGHCISENEGGAHGYVNTLAVASQN>sp|Q6IEE7|T132E_HUMAN Transmembrane protein 132E OS=Homo sapiens OX=9606GN=TMEM132E PE=1 SV=2MAPGMSGRGGAALLCLSALLAHASGRSHPASPSPPGPQASPVLPVSYRLSHTRLAFFLREARPPSPAVANSSLQRSEPFVVFQTKELPVLNVSLGPFSTSQVVARELLQPSSTLDIPERLTVNWKVRAFIVRSHVPASQPVVQVLFYVAGRDWDDFGVTERLPCVRLHAFRDAREVKSSCRLSGGLATCLVRAELPLAWFGPPAPAAPPTARRKSPDGLEPEATGESQQAELYYTLHAPDASGGCGGSRRGAGPGVGARAESPTQHPLLRIGSISLFRPPPRRTLQEHRLDSNLMIRLPDRPLKPGEVLSILLYLAPNSSSPSSPSVEHFTLRVKAKKGVTLLGTKSRSGQWHVTSELLTGAKHSTATVDVAWAQSTPLPPREGQGPLEILQLDFEMENFTSQSVKRRIMWHIDYRGHGALPDLERAVTELTVIQRDVQAILPLAMDTEIINTAILTGRTVAIPVKVIAIEVNGLVLDISALVECESDNEDIIKVSSSCDYVFVSGKESRGSMNARVTFRYDVLNAPLEMTVWVPKLPLHIELSDARLSQVKGWRVPILPDRRSVRESEDEDEEEEERRQSASRGCTLQYQHATLQVFTQFHTTSSEGTDQVVTMLGPDWLVEVTDLVSDFMRVGDPRVAHMVDSSTLAGLEPGTTPFKVVSPLTEAVLGETLLTVTEEKVSITQLQAQVVASLALSLRPSPGSSHTILATTAAQQTLSFLKQEALLSLWLSYSDGTTAPLSLYSPRDYGLLVSSLDEHVATVTQDRAFPLVVAEAEGSGELLRAELTIAESCQKTKRKSVLATTPVGLRVHFGRDEEDPTYDYPGPSQPGPGGGEDEARGAGPPGSALPAPEAPGPGTASPVVPPTEDFLPLPTGFLQVPRGLTDLEIGMYALLGVFCLAILVFLINCIVFVLRYRHKRIPPEGQTSMDHSHHWVFLGNGQPLRVQGELSPPAGNPLETVPAFCHGDHHSSGSSQTSVQSQVHGRGDGSSGGSARDQAEDPASSPTSKRKRVKFTTFTTLPSEELAYDSVPAGEEDEEEEEDLGWGCPDVAGPTRPTAPPDLHNYMRRIKEIA>sp|B9EJG8|T150C_HUMAN Transmembrane protein 150C OS=Homo sapiens OX=9606GN=TMEM150C PE=2 SV=1MDGKKCSVWMFLPLVFTLFTSAGLWIVYFIAVEDDKILPLNSAERKPGVKHAPYISIAGDDPPASCVFSQVMNMAAFLALVVAVLRFIQLKPKVLNPWLNISGLVALCLASFGMTLLGNFQLTNDEEIHNVGTSLTFGFGTLTCWIQAALTLKVNIKNEGRRVGIPRVILSASITLCVVLYFILMAQSIHMYAARVQWGLVMCFLSYFGTFAVEFRHYRYEIVCSEYQENFLSFSESLSEASEYQTDQV>sp|B9EJG8-2|T150C_HUMAN Isoform 2 of Transmembrane protein 150C OS=Homosapiens OX=9606 GN=TMEM150CMDGKKCSVWMFLPLVFTLFTSAGLWIVYFIAVEDDKILPLNSAERKPGVKHAPYISIAGDDPPASCVFSQVMNMAAFLALVVAVLRFIQLKPKVLNPWLNISGLVALCLASFGMTLLGNFQLTNDEEIHNVGTSLTFGFGTFAVEFRHYRYEIVCSEYQENFLSFSESLSEASEYQTDQV>sp|Q9Y228|T3JAM_HUMAN TRAF3-interacting JNK-activating modulator OS=Homosapiens OX=9606 GN=TRAF3IP3 PE=1 SV=2MISPDPRPSPGLARWAESYEAKCERRQEIRESRRCRPNVTTCRQVGKTLRIQQREQLQRARLQQFFRRRNLELEEKGKAQHPQAREQGPSRRPGQVTVLKEPLSCARRISSPREQVTGTSSEVFPAQHPPPSGICRDLSDHLSSQAGGLPPQDTPIKKPPKHHRGTQTKAEGPTIKNDASQQTNYGVAVLDKEIIQLSDYLKEALQRELVLKQKMVILQDLLSTLIQASDSSWKGQLNEDKLKGKLRSLENQLYTCTQKYSPWGMKKVLLEMEDQKNSYEQKAKESLQKVLEEKMNAEQQLQSTQRSLALAEQKCEEWRSQYEALKEDWRTLGTQHRELESQLHVLQSKLQGADSRDLQMNQALRFLENEHQQLQAKIECLQGDRDLCSLDTQDLQDQLKRSEAEKLTLVTRVQQLQGLLQNQSLQLQEQEKLLTKKDQALPVWSPKSFPNEVEPEGTGKEKDWDLRDQLQKKTLQLQAKEKECRELHSELDNLSDEYLSCLRKLQHCREELNQSQQLPPRRQCGRWLPVLMVVIAAALAVFLANKDNLMI>sp|Q9Y228-2|T3JAM_HUMAN Isoform 2 of TRAF3-interacting JNK-activatingmodulator OS=Homo sapiens OX=9606 GN=TRAF3IP3MISPDPRPSPGLARWAESYEAKCERRQEIRESRRCRPNVTTCRQVGKTLRIQQREQLQRARLQQFFRRRNLELEEKGKAQHPQAREQGPSRRPGQVTGTSSEVFPAQHPPPSGICRDLSDHLSSQAGGLPPQDTPIKKPPKHHRGTQTKAEGPTIKNDASQQTNYGVAVLDKEIIQLSDYLKEALQRELVLKQKMVILQDLLSTLIQASDSSWKGQLNEDKLKGKLRSLENQLYTCTQKYSPWGMKKVLLEMEDQKNSYEQKAKESLQKVLEEKMNAEQQLQSTQRSLALAEQKCEEWRSQYEALKEDWRTLGTQHRELESQLHVLQSKLQGADSRDLQMNQALRFLENEHQQLQAKIECLQGDRDLCSLDTQDLQDQLKRSEAEKLTLVTRVQQLQGLLQNQSLQLQEQEKLLTKKDQALPVWSPKSFPNEVEPEGTGKEKDWDLRDQLQKKTLQLQAKEKECRELHSELDNLSDEYLSCLRKLQHCREELNQSQQLPPRRQCGRWLPVLMVVIAAALAVFLANKDNLMI>sp|Q9Y228-3|T3JAM_HUMAN Isoform 3 of TRAF3-interacting JNK-activatingmodulator OS=Homo sapiens OX=9606 GN=TRAF3IP3MISPDPRPSPGLARWAESYEAKCERRQEIRESRRCRPNVTTCRQVGKTLRIQQREQLQRARLQQFFRRRNLELEEKGKAQHPQAREQGPSRRPGQVTVLKEPLSCARRISSPREQVTGTSSEVFPAQHPPPSGICRDLSDHLSSQAGGLPPQDTPIKKPPKHHRGTQTKAEGPTIKNDASQQTNYGVAVLDKEIIQLSDYLKEALQRELVLKQKMVILQDLLSTLIQASDSSWKGQLNEDKLKGKLRSLENQLYTCTQKYSPWGMKKVLLEMEDQKNSYEQKAKESLQKVLEEKMNAEQQLQSTQRSLALAEQKCEEWRSQYEALKEDWRTLGTQHRELESQLHVLQSKLQIN>sp|Q9BSW7|SYT17_HUMAN Synaptotagmin-17 OS=Homo sapiens OX=9606 GN=SYT17PE=1 SV=1MAYIQLEPLNEGFLSRISGLLLCRWTCRHCCQKCYESSCCQSSEDEVEILGPFPAQTPPWLMASRSSDKDGDSVHTASEVPLTPRTNSPDGRRSSSDTSKSTYSLTRRISSLESRRPSSPLIDIKPIEFGVLSAKKEPIQPSVLRRTYNPDDYFRKFEPHLYSLDSNSDDVDSLTDEEILSKYQLGMLHFSTQYDLLHNHLTVRVIEARDLPPPISHDGSRQDMAHSNPYVKICLLPDQKNSKQTGVKRKTQKPVFEERYTFEIPFLEAQRRTLLLTVVDFDKFSRHCVIGKVSVPLCEVDLVKGGHWWKALIPSSQNEVELGELLLSLNYLPSAGRLNVDVIRAKQLLQTDVSQGSDPFVKIQLVHGLKLVKTKKTSFLRGTIDPFYNESFSFKVPQEELENASLVFTVFGHNMKSSNDFIGRIVIGQYSSGPSETNHWRRMLNTHRTAVEQWHSLRSRAECDRVSPASLEVT>sp|P47897|SYQ_HUMAN Glutamine--tRNA ligase OS=Homo sapiens OX=9606GN=QARS1 PE=1 SV=1MAALDSLSLFTSLGLSEQKARETLKNSALSAQLREAATQAQQTLGSTIDKATGILLYGLASRLRDTRRLSFLVSYIASKKIHTEPQLSAALEYVRSHPLDPIDTVDFERECGVGVIVTPEQIEEAVEAAINRHRPQLLVERYHFNMGLLMGEARAVLKWADGKMIKNEVDMQVLHLLGPKLEADLEKKFKVAKARLEETDRRTAKDVVENGETADQTLSLMEQLRGEALKFHKPGENYKTPGYVVTPHTMNLLKQHLEITGGQVRTRFPPEPNGILHIGHAKAINFNFGYAKANNGICFLRFDDTNPEKEEAKFFTAICDMVAWLGYTPYKVTYASDYFDQLYAWAVELIRRGLAYVCHQRGEELKGHNTLPSPWRDRPMEESLLLFEAMRKGKFSEGEATLRMKLVMEDGKMDPVAYRVKYTPHHRTGDKWCIYPTYDYTHCLCDSIEHITHSLCTKEFQARRSSYFWLCNALDVYCPVQWEYGRLNLHYAVVSKRKILQLVATGAVRDWDDPRLFTLTALRRRGFPPEAINNFCARVGVTVAQTTMEPHLLEACVRDVLNDTAPRAMAVLESLRVIITNFPAAKSLDIQVPNFPADETKGFHQVPFAPIVFIERTDFKEEPEPGFKRLAWGQPVGLRHTGYVIELQHVVKGPSGCVESLEVTCRRADAGEKPKAFIHWVSQPLMCEVRLYERLFQHKNPEDPTEVPGGFLSDLNLASLHVVDAALVDCSVALAKPFDKFQFERLGYFSVDPDSHQGKLVFNRTVTLKEDPGKV>sp|P47897-2|SYQ_HUMAN Isoform 2 of Glutamine--tRNA ligase OS=Homosapiens OX=9606 GN=QARS1MAALDSLSLFTSLGLSEQKARETLKNSALSAQLREAATQAQQTLGSTIDKATGILLYGLASRLRDTRRLSFLVSYIATALEYVRSHPLDPIDTVDFERECGVGVIVTPEQIEEAVEAAINRHRPQLLVERYHFNMGLLMGEARAVLKWADGKMIKNEVDMQVLHLLGPKLEADLEKKFKVAKARLEETDRRTAKDVVENGETADQTLSLMEQLRGEALKFHKPGENYKTPGYVVTPHTMNLLKQHLEITGGQVRTRFPPEPNGILHIGHAKAINFNFGYAKANNGICFLRFDDTNPEKEEAKFFTAICDMVAWLGYTPYKVTYASDYFDQLYAWAVELIRRGLAYVCHQRGEELKGHNTLPSPWRDRPMEESLLLFEAMRKGKFSEGEATLRMKLVMEDGKMDPVAYRVKYTPHHRTGDKWCIYPTYDYTHCLCDSIEHITHSLCTKEFQARRSSYFWLCNALDVYCPVQWEYGRLNLHYAVVSKRKILQLVATGAVRDWDDPRLFTLTALRRRGFPPEAINNFCARVGVTVAQTTMEPHLLEACVRDVLNDTAPRAMAVLESLRVIITNFPAAKSLDIQVPNFPADETKGFHQVPFAPIVFIERTDFKEEPEPGFKRLAWGQPVGLRHTGYVIELQHVVKGPSGCVESLEVTCRRADAGEKPKAFIHWVSQPLMCEVRLYERLFQHKNPEDPTEVPGGFLSDLNLASLHVVDAALVDCSVALAKPFDKFQFERLGYFSVDPDSHQGKLVFNRTVTLKEDPGKV>sp|Q9NYW3|TA2R7_HUMAN Taste receptor type 2 member 7 OS=Homo sapiensOX=9606 GN=TAS2R7 PE=1 SV=1MADKVQTTLLFLAVGEFSVGILGNAFIGLVNCMDWVKKRKIASIDLILTSLAISRICLLCVILLDCFILVLYPDVYATGKEMRIIDFFWTLTNHLSIWFATCLSIYYFFKIGNFFHPLFLWMKWRIDRVISWILLGCVVLSVFISLPATENLNADFRFCVKAKRKTNLTWSCRVNKTQHASTKLFLNLATLLPFCVCLMSFFLLILSLRRHIRRMQLSATGCRDPSTEAHVRALKAVISFLLLFIAYYLSFLIATSSYFMPETELAVIFGESIALIYPSSHSFILILGNNKLRHASLKVIWKVMSILKGRKFQQHKQI>sp|Q9UGM6|SYWM_HUMAN Tryptophan--tRNA ligase, mitochondrial OS=Homosapiens OX=9606 GN=WARS2 PE=1 SV=1MALHSMRKARERWSFIRALHKGSAAAPALQKDSKKRVFSGIQPTGILHLGNYLGAIESWVRLQDEYDSVLYSIVDLHSITVPQDPAVLRQSILDMTAVLLACGINPEKSILFQQSQVSEHTQLSWILSCMVRLPRLQHLHQWKAKTTKQKHDGTVGLLTYPVLQAADILLYKSTHVPVGEDQVQHMELVQDLAQGFNKKYGEFFPVPESILTSMKKVKSLRDPSAKMSKSDPDKLATVRITDSPEEIVQKFRKAVTDFTSEVTYDPAGRAGVSNIVAVHAAVTGLSVEEVVRRSAGMNTARYKLAVADAVIEKFAPIKREIEKLKLDKDHLEKVLQIGSAKAKELAYTVCQEVKKLVGFL>sp|Q9UGM6-2|SYWM_HUMAN Isoform 2 of Tryptophan--tRNA ligase,mitochondrial OS=Homo sapiens OX=9606 GN=WARS2MALHSMRKARERWSFIRALHKGSAAAPALQKDSKKRVFSGIQPTGILHLGNYLGAIESWVRLQDEYDSVLYSIVDLHSITVPQDPAVLRQSILDMTAVLLACGINPEKSILFQQSQVSEHTQLSWILSCMVRLPRLQHLHQWKAKTTKQKHDGTVGLLTYPVLQAADILLYKSTHVPVGEDQVQHMELVQDLAQGFNKKYGEFFPVPESILSMCVLVFLT>sp|Q5JRV8|T255A_HUMAN Transmembrane protein 255A OS=Homo sapiens OX=9606GN=TMEM255A PE=2 SV=1MHQSLTQQRSSDMSLPDSMGAFNRRKRNSIYVTVTLLIVSVLILTVGLAATTRTQNVTVGGYYPGVILGFGSFLGIIGSNLIENKRQMLVASIVFISFGVIAAFCCAIVDGVFAARHIDLKPLYANRCHYVPKTSQKEAEEVISSSTKNSPSTRVMRNLTQAAREVNCPHLSREFCTPRIRGNTCFCCDLYNCGNRVEITGGYYEYIDVSSCQDIIHLYHLLWSATILNIVGLFLGIITAAVLGGFKDMNPTLPALNCSVENTHPTVSYYAHPQVASYNTYYHSPPHLPPYSAYDFQHSGVFPSSPPSGLSDEPQSASPSPSYMWSSSAPPRYSPPYYPPFEKPPPYSP>sp|Q5JRV8-2|T255A_HUMAN Isoform 2 of Transmembrane protein 255A OS=Homosapiens OX=9606 GN=TMEM255AMVNCPHLSREFCTPRIRGNTCFCCDLYNCGNRVEITGGYYEYIDVSSCQDIIHLYHLLWSATILNIVGLFLGIITAAVLGGFKDMNPTLPALNCSVENTHPTVSYYAHPQVASYNTYYHSPPHLPPYSAYDFQHSGVFPSSPPSGLSDEPQSASPSPSYMWSSSAPPRYSPPYYPPFEKPPPYSP>sp|Q5JRV8-3|T255A_HUMAN Isoform 3 of Transmembrane protein 255A OS=Homosapiens OX=9606 GN=TMEM255AMHQSLTQQRSSDMSLPDSMGAFNRRKRNSIYVTVTLLIVSVLILTVGLAATTRTQNVTVGGYYPGVILGFGSFLGIIGSNLIENKRQMLVASIVFISFGVIAAFCCAIVDGVFAARHIDLKPLYANRCHYVPKTSQKEAEEVNCPHLSREFCTPRIRGNTCFCCDLYNCGNRVEITGGYYEYIDVSSCQDIIHLYHLLWSATILNIVGLFLGIITAAVLGGFKDMNPTLPALNCSVENTHPTVSYYAHPQVASYNTYYHSPPHLPPYSAYDFQHSGVFPSSPPSGLSDEPQSASPSPSYMWSSSAPPRYSPPYYPPFEKPPPYSP>sp|Q5JRV8-4|T255A_HUMAN Isoform 4 of Transmembrane protein 255A OS=Homosapiens OX=9606 GN=TMEM255AMHQSLTQQRSSDMSLPDSMGAFNRRKRNSIYVTVTLLIVSVLILTVGLAATTRTQNVTVGGYYPGVILGFGSFLGIIGSNLIENKRQMLVASIVFISFGVIAAFCCAIVDGVFAARHIDLKPLYANRCHYVPKTSQKEAEENPTLPALNCSVENTHPTVSYYAHPQVASYNTYYHSPPHLPPYSAYDFQHSGVFPSSPPSGLSDEPQSASPSPSYMWSSSAPPRYSPPYYPPFEKPPPYSP>sp|Q9NYV9|T2R13_HUMAN Taste receptor type 2 member 13 OS=Homo sapiensOX=9606 GN=TAS2R13 PE=1 SV=1MESALPSIFTLVIIAEFIIGNLSNGFIVLINCIDWVSKRELSSVDKLLIILAISRIGLIWEILVSWFLALHYLAIFVSGTGLRIMIFSWIVSNHFNLWLATIFSIFYLLKIASFSSPAFLYLKWRVNKVILMILLGTLVFLFLNLIQINMHIKDWLDRYERNTTWNFSMSDFETFSVSVKFTMTMFSLTPFTVAFISFLLLIFSLQKHLQKMQLNYKGHRDPRTKVHTNALKIVISFLLFYASFFLCVLISWISELYQNTVIYMLCETIGVFSPSSHSFLLILGNAKLRQAFLLVAAKVWAKR>sp|P26640|SYVC_HUMAN Valine--tRNA ligase OS=Homo sapiens OX=9606GN=VARS1 PE=1 SV=4MSTLYVSPHPDAFPSLRALIAARYGEAGEGPGWGGAHPRICLQPPPTSRTPFPPPRLPALEQGPGGLWVWGATAVAQLLWPAGLGGPGGSRAAVLVQQWVSYADTELIPAACGATLPALGLRSSAQDPQAVLGALGRALSPLEEWLRLHTYLAGEAPTLADLAAVTALLLPFRYVLDPPARRIWNNVTRWFVTCVRQPEFRAVLGEVVLYSGARPLSHQPGPEAPALPKTAAQLKKEAKKREKLEKFQQKQKIQQQQPPPGEKKPKPEKREKRDPGVITYDLPTPPGEKKDVSGPMPDSYSPRYVEAAWYPWWEQQGFFKPEYGRPNVSAANPRGVFMMCIPPPNVTGSLHLGHALTNAIQDSLTRWHRMRGETTLWNPGCDHAGIATQVVVEKKLWREQGLSRHQLGREAFLQEVWKWKEEKGDRIYHQLKKLGSSLDWDRACFTMDPKLSAAVTEAFVRLHEEGIIYRSTRLVNWSCTLNSAISDIEVDKKELTGRTLLSVPGYKEKVEFGVLVSFAYKVQGSDSDEEVVVATTRIETMLGDVAVAVHPKDTRYQHLKGKNVIHPFLSRSLPIVFDEFVDMDFGTGAVKITPAHDQNDYEVGQRHGLEAISIMDSRGALINVPPPFLGLPRFEARKAVLVALKERGLFRGIEDNPMVVPLCNRSKDVVEPLLRPQWYVRCGEMAQAASAAVTRGDLRILPEAHQRTWHAWMDNIREWCISRQLWWGHRIPAYFVTVSDPAVPPGEDPDGRYWVSGRNEAEAREKAAKEFGVSPDKISLQQDEDVLDTWFSSGLFPLSILGWPNQSEDLSVFYPGTLLETGHDILFFWVARMVMLGLKLTGRLPFREVYLHAIVRDAHGRKMSKSLGNVIDPLDVIYGISLQGLHNQLLNSNLDPSEVEKAKEGQKADFPAGIPECGTDALRFGLCAYMSQGRDINLDVNRILGYRHFCNKLWNATKFALRGLGKGFVPSPTSQPGGHESLVDRWIRSRLTEAVRLSNQGFQAYDFPAVTTAQYSFWLYELCDVYLECLKPVLNGVDQVAAECARQTLYTCLDVGLRLLSPFMPFVTEELFQRLPRRMPQAPPSLCVTPYPEPSECSWKDPEAEAALELALSITRAVRSLRADYNLTRIRPDCFLEVADEATGALASAVSGYVQALASAGVVAVLALGAPAPQGCAVALASDRCSIHLQLQGLVDPARELGKLQAKRVEAQRQAQRLRERRAASGYPVKVPLEVQEADEAKLQQTEAELRKVDEAIALFQKML>sp|P26640-2|SYVC_HUMAN Isoform 2 of Valine--tRNA ligase OS=Homo sapiensOX=9606 GN=VARS1MPDSYSPRYVEAAWYPWWEQQGFFKPEYGRPNVSAANPRGVFMMCIPPPNVTGSLHLGHALTNAIQDSLTRWHRMRGETTLWNPGCDHAGIATQVVVEKKLWREQGLSRHQLGREAFLQEVWKWKEEKGDRIYHQLKKLGSSLDWDRACFTMDPKLSAAVTEAFVRLHEEGIIYRSTRLVNWSCTLNSAISDIEVDKKELTGRTLLSVPGYKEKVEFGVLVSFAYKVQGSDSDEEVVVATTRIETMLGDVAVAVHPKDTRYQHLKGKNVIHPFLSRSLPIVFDEFVDMDFGTGPAQV>sp|Q15544|TAF11_HUMAN Transcription initiation factor TFIID subunit 11OS=Homo sapiens OX=9606 GN=TAF11 PE=1 SV=1MDDAHESPSDKGGETGESDETAAVPGDPGATDTDGIPEETDGDADVDLKEAAAEEGELESQDVSDLTTVEREDSSLLNPAAKKLKIDTKEKKEKKQKVDEDEIQKMQILVSSFSEEQLNRYEMYRRSAFPKAAIKRLIQSITGTSVSQNVVIAMSGISKVFVGEVVEEALDVCEKWGEMPPLQPKHMREAVRRLKSKGQIPNSKHKKIIFF>sp|Q15544-2|TAF11_HUMAN Isoform 2 of Transcription initiation factorTFIID subunit 11 OS=Homo sapiens OX=9606 GN=TAF11MDDAHESPSDKGGETGESDETAAVPGDPGATDTDGIPEETDGDADVDLKEAAAEEGELESQDVSDLTTVEREDSSLLNPAAKKLKIDTKEKKEKKQKVDEDEIQKMQILVSSFSEEQLNRYEMYRRSAFPKAAIKRHWMCVRSGEKCHHYNPNI>sp|Q9NYV7|T2R16_HUMAN Taste receptor type 2 member 16 OS=Homo sapiensOX=9606 GN=TAS2R16 PE=1 SV=1MIPIQLTVFFMIIYVLESLTIIVQSSLIVAVLGREWLQVRRLMPVDMILISLGISRFCLQWASMLNNFCSYFNLNYVLCNLTITWEFFNILTFWLNSLLTVFYCIKVSSFTHHIFLWLRWRILRLFPWILLGSLMITCVTIIPSAIGNYIQIQLLTMEHLPRNSTVTDKLENFHQYQFQAHTVALVIPFILFLASTIFLMASLTKQIQHHSTGHCNPSMKARFTALRSLAVLFIVFTSYFLTILITIIGTLFDKRCWLWVWEAFVYAFILMHSTSLMLSSPTLKRILKGKC>sp|Q9Y6M0|TEST_HUMAN Testisin OS=Homo sapiens OX=9606 GN=PRSS21 PE=1SV=1MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTGWGYIKEDEALPSPHTLQEVQVAIINNSMCNHLFLKYSFRKDIFGDMVCAGNAQGGKDACFGDSGGPLACNKNGLWYQIGVVSWGVGCGRPNRPGVYTNISHHFEWIQKLMAQSGMSQPDPSWPLLFFPLLWALPLLGPV>sp|Q9Y6M0-2|TEST_HUMAN Isoform 2 of Testisin OS=Homo sapiens OX=9606GN=PRSS21MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETDLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTGWGYIKEDEALPSPHTLQEVQVAIINNSMCNHLFLKYSFRKDIFGDMVCAGNAQGGKDACFGDSGGPLACNKNGLWYQIGVVSWGVGCGRPNRPGVYTNISHHFEWIQKLMAQSGMSQPDPSWPLLFFPLLWALPLLGPV>sp|Q9Y6M0-3|TEST_HUMAN Isoform 3 of Testisin OS=Homo sapiens OX=9606GN=PRSS21MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTGWGYIKEDEALPSPHTLQEVQVAIINNSMCNHLFLKYSFRKDIFGDMGDSGGPLACNKNGLWYQIGVVSWGVGCGRPNRPGVYTNISHHFEWIQKLMAQSGMSQPDPSWPLLFFPLLWALPLLGPV>sp|Q01085|TIAR_HUMAN Nucleolysin TIAR OS=Homo sapiens OX=9606 GN=TIAL1PE=1 SV=1MMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEHTSNDPYCFVEFYEHRDAAAALAAMNGRKILGKEVKVNWATTPSSQKKDTSNHFHVFVGDLSPEITTEDIKSAFAPFGKISDARVVKDMATGKSKGYGFVSFYNKLDAENAIVHMGGQWLGGRQIRTNWATRKPPAPKSTQENNTKQLRFEDVVNQSSPKNCTVYCGGIASGLTDQLMRQTFSPFGQIMEIRVFPEKGYSFVRFSTHESAAHAIVSVNGTTIEGHVVKCYWGKESPDMTKNFQQVDYSQWGQWSQVYGNPQQYGQYMANGWQVPPYGVYGQPWNQQGFGVDQSPSAAWMGGFGAQPPQGQAPPPVIPPPNQAGYGMASYQTQ>sp|Q01085-2|TIAR_HUMAN Isoform 2 of Nucleolysin TIAR OS=Homo sapiensOX=9606 GN=TIAL1MMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEQPDSRRVNSSVGFSVLQHTSNDPYCFVEFYEHRDAAAALAAMNGRKILGKEVKVNWATTPSSQKKDTSNHFHVFVGDLSPEITTEDIKSAFAPFGKISDARVVKDMATGKSKGYGFVSFYNKLDAENAIVHMGGQWLGGRQIRTNWATRKPPAPKSTQENNTKQLRFEDVVNQSSPKNCTVYCGGIASGLTDQLMRQTFSPFGQIMEIRVFPEKGYSFVRFSTHESAAHAIVSVNGTTIEGHVVKCYWGKESPDMTKNFQQVDYSQWGQWSQVYGNPQQYGQYMANGWQVPPYGVYGQPWNQQGFGVDQSPSAAWMGGFGAQPPQGQAPPPVIPPPNQAGYGMASYQTQ>sp|Q9C0I4|THS7B_HUMAN Thrombospondin type-1 domain-containing protein 7BOS=Homo sapiens OX=9606 GN=THSD7B PE=2 SV=3MFPKSNLTVTCWVWRSMRKLFLLLSLLLSHAAHLEGKKDNQFIWKPGPWGRCTGDCGPGGVQSRAVWCFHVDGWTSHLSNCGESNRPPKERSCFRVCDWHSDLFQWEVSDWHHCVLVPYARGEVKPRTAECVTAQHGLQHRMVRCIQKLNRTVVANEICEHFALQPPTEQACLIPCPRDCVVSEFLPWSNCSKGCGKKLQHRTRAVIAPPLFGGLQCPNLTESRACDAPISCPLGEEEYTFSLKVGPWSKCRLPHLKEINPSGRTVLDFNSDSNERVTFKHQSYKAHHHSKSWAIEIGYQTRQVSCTRSDGQNAMLSLCLQDSFPLTVQSCIMPKDCETSQWSSWSPCSKTCRSGSLLPGFRSRSRNVKHMAIGGGKECPELLEKEACIVEGELLQQCPRYSWRTSEWKECQVSLLLEQQDPHWHVTGPVCGGGIQTREVYCAQSVPAAAALRAKEVSRPVEKALCVGPAPLPSQLCNIPCSTDCIVSSWSAWGLCIHENCHDPQGKKGFRTRQRHVLMESTGPAGHCPHLVESVPCEDPMCYRWLASEGICFPDHGKCGLGHRILKAVCQNDRGEDVSGSLCPVPPPPERKSCEIPCRMDCVLSEWTEWSSCSQSCSNKNSDGKQTRSRTILALAGEGGKPCPPSQALQEHRLCNDHSCMQLHWETSPWGPCSEDTLVTALNATIGWNGEATCGVGIQTRRVFCVKSHVGQVMTKRCPDSTRPETVRPCFLPCKKDCIVTAFSEWTPCPRMCQAGNATVKQSRYRIIIQEAANGGQECPDTLYEERECEDVSLCPVYRWKPQKWSPCILVPESVWQGITGSSEACGKGLQTRAVSCISDDNRSAEMMECLKQTNGMPLLVQECTVPCREDCTFTAWSKFTPCSTNCEATKSRRRQLTGKSRKKEKCQDSDLYPLVETELCPCDEFISQPYGNWSDCILPEGRREPHRGLRVQADSKECGEGLRFRAVACSDKNGRPVDPSFCSSSGYIQEKCVIPCPFDCKLSDWSSWGSCSSSCGIGVRIRSKWLKEKPYNGGRPCPKLDLKNQVHEAVPCYSECNQYSWVVEHWSSCKINNELRSLRCGGGTQSRKIRCVNTADGEGGAVDSNLCNQDEIPPETQSCSLMCPNECVMSEWGLWSKCPQSCDPHTMQRRTRHLLRPSLNSRTCAEDSQVQPCLLNENCFQFQYNLTEWSTCQLSENAPCGQGVRTRLLSCVCSDGKPVSMDQCEQHNLEKPQRMSIPCLVECVVNCQLSGWTAWTECSQTCGHGGRMSRTRFIIMPTQGEGRPCPTELTQEKTCPVTPCYSWVLGNWSACKLEGGDCGEGVQIRSLSCMVHSGSISHAAGRVEDALCGEMPFQDSILKQLCSVPCPGDCHLTEWSEWSTCELTCIDGRSFETVGRQSRSRTFIIQSFENQDSCPQQVLETRPCTGGKCYHYTWKASLWNNNERTVWCQRSDGVNVTGGCSPQARPAAIRQCIPACRKPFSYCTQGGVCGCEKGYTEIMKSNGFLDYCMKVPGSEDKKADVKNLSGKNRPVNSKIHDIFKGWSLQPLDPDGRVKIWVYGVSGGAFLIMIFLIFTSYLVCKKPKPHQSTPPQQKPLTLAYDGDLDM>sp|P49368|TCPG_HUMAN T-complex protein 1 subunit gamma OS=Homo sapiensOX=9606 GN=CCT3 PE=1 SV=4MMGHRPVLVLSQNTKRESGRKVQSGNINAAKTIADIIRTCLGPKSMMKMLLDPMGGIVMTNDGNAILREIQVQHPAAKSMIEISRTQDEEVGDGTTSVIILAGEMLSVAEHFLEQQMHPTVVISAYRKALDDMISTLKKISIPVDISDSDMMLNIINSSITTKAISRWSSLACNIALDAVKMVQFEENGRKEIDIKKYARVEKIPGGIIEDSCVLRGVMINKDVTHPRMRRYIKNPRIVLLDSSLEYKKGESQTDIEITREEDFTRILQMEEEYIQQLCEDIIQLKPDVVITEKGISDLAQHYLMRANITAIRRVRKTDNNRIARACGARIVSRPEELREDDVGTGAGLLEIKKIGDEYFTFITDCKDPKACTILLRGASKEILSEVERNLQDAMQVCRNVLLDPQLVPGGGASEMAVAHALTEKSKAMTGVEQWPYRAVAQALEVIPRTLIQNCGASTIRLLTSLRAKHTQENCETWGVNGETGTLVDMKELGIWEPLAVKLQTYKTAVETAVLLLRIDDIVSGHKKKGDDQSRQGGAPDAGQE>sp|P49368-2|TCPG_HUMAN Isoform 2 of T-complex protein 1 subunit gammaOS=Homo sapiens OX=9606 GN=CCT3MMGHRPVLVLSQNTKRESGRKVQSGNINAAKIQVQHPAAKSMIEISRTQDEEVGDGTTSVIILAGEMLSVAEHFLEQQMHPTVVISAYRKALDDMISTLKKISIPVDISDSDMMLNIINSSITTKAISRWSSLACNIALDAVKMVQFEENGRKEIDIKKYARVEKIPGGIIEDSCVLRGVMINKDVTHPRMRRYIKNPRIVLLDSSLEYKKGESQTDIEITREEDFTRILQMEEEYIQQLCEDIIQLKPDVVITEKGISDLAQHYLMRANITAIRRVRKTDNNRIARACGARIVSRPEELREDDVGTGAGLLEIKKIGDEYFTFITDCKDPKACTILLRGASKEILSEVERNLQDAMQVCRNVLLDPQLVPGGGASEMAVAHALTEKSKAMTGVEQWPYRAVAQALEVIPRTLIQNCGASTIRLLTSLRAKHTQENCETWGVNGETGTLVDMKELGIWEPLAVKLQTYKTAVETAVLLLRIDDIVSGHKKKGDDQSRQGGAPDAGQE>sp|Q9BV44|THUM3_HUMAN THUMP domain-containing protein 3 OS=Homo sapiensOX=9606 GN=THUMPD3 PE=1 SV=1MCDIEEATNQLLDVNLHENQKSVQVTESDLGSESELLVTIGATVPTGFEQTAADEVREKLGSSCKISRDRGKIYFVISVESLAQVHCLRSVDNLFVVVQEFQDYQFKQTKEEVLKDFEDLAGKLPWSNPLKVWKINASFKKKKAKRKKINQNSSKEKINNGQEVKIDQRNVKKEFTSHALDSHILDYYENPAIKEDVSTLIGDDLASCKDETDESSKEETEPQVLKFRVTCNRAGEKHCFTSNEAARDFGGAVQDYFKWKADMTNFDVEVLLNIHDNEVIVGIALTEESLHRRNITHFGPTTLRSTLAYGMLRLCDPLPYDIIVDPMCGTGAIPIEGATEWSDCFHIAGDNNPLAVNRAANNIASLLTKSQIKEGKPSWGLPIDAVQWDICNLPLRTGSVDIIVTDLPFGKRMGSKKRNWNLYPACLREMSRVCTPTTGRAVLLTQDTKCFTKALSGMRHVWRKVDTVWVNVGGLRAAVYVLIRTPQAFVHPSEQDGERGTLWQCKE>sp|Q92526|TCPW_HUMAN T-complex protein 1 subunit zeta-2 OS=Homo sapiensOX=9606 GN=CCT6B PE=1 SV=5MAAIKAVNSKAEVARARAALAVNICAARGLQDVLRTNLGPKGTMKMLVSGAGDIKLTKDGNVLLDEMQIQHPTASLIAKVATAQDDVTGDGTTSNVLIIGELLKQADLYISEGLHPRIIAEGFEAAKIKALEVLEEVKVTKEMKRKILLDVARTSLQTKVHAELADVLTEVVVDSVLAVRRPGYPIDLFMVEIMEMKHKLGTDTKLIQGLVLDHGARHPDMKKRVEDAFILICNVSLEYEKTEVNSGFFYKTAEEKEKLVKAERKFIEDRVQKIIDLKDKVCAQSNKGFVVINQKGIDPFSLDSLAKHGIVALRRAKRRNMERLSLACGGMAVNSFEDLTVDCLGHAGLVYEYTLGEEKFTFIEECVNPCSVTLLVKGPNKHTLTQVKDAIRDGLRAIKNAIEDGCMVPGAGAIEVAMAEALVTYKNSIKGRARLGVQAFADALLIIPKVLAQNAGYDPQETLVKVQAEHVESKQLVGVDLNTGEPMVAADAGVWDNYCVKKQLLHSCTVIATNILLVDEIMRAGMSSLK>sp|Q92526-2|TCPW_HUMAN Isoform 2 of T-complex protein 1 subunit zeta-2OS=Homo sapiens OX=9606 GN=CCT6BMAAIKAVNSKAEVARARAALAVNICAARGLQDVLRTNLGPKGTMKMLVSGAGDIKLTKDGNVLLDEMGLHPRIIAEGFEAAKIKALEVLEEVKVTKEMKRKILLDVARTSLQTKVHAELADVLTEVVVDSVLAVRRPGYPIDLFMVEIMEMKHKLGTDTKLIQGLVLDHGARHPDMKKRVEDAFILICNVSLEYEKTEVNSGFFYKTAEEKEKLVKAERKFIEDRVQKIIDLKDKVCAQSNKGFVVINQKGIDPFSLDSLAKHGIVALRRAKRRNMERLSLACGGMAVNSFEDLTVDCLGHAGLVYEYTLGEEKFTFIEECVNPCSVTLLVKGPNKHTLTQVKDAIRDGLRAIKNAIEDGCMVPGAGAIEVAMAEALVTYKNSIKGRARLGVQAFADALLIIPKVLAQNAGYDPQETLVKVQAEHVESKQLVGVDLNTGEPMVAADAGVWDNYCVKKQLLHSCTVIATNILLVDEIMRAGMSSLK>sp|Q92526-3|TCPW_HUMAN Isoform 3 of T-complex protein 1 subunit zeta-2OS=Homo sapiens OX=9606 GN=CCT6BMAAIKAVNSKAEVARARAALAVNICAARGLQDVLRTNLGPKGTMKMLVSGAGDIKLTKDGNVLLDEMQIQHPTASLIAKVATAQDDVTGDGTTSNVLIIGELLKQADLYISEGLHPRIIAEGFEAAKIKALEVLEEVKVTKEMKRKILLDVARTSLQTKVHAELADVLTEVVVDSVLAVRRPGYPIDLFMVEIMEMKHKLGTDTKEVNSGFFYKTAEEKEKLVKAERKFIEDRVQKIIDLKDKVCAQSNKGFVVINQKGIDPFSLDSLAKHGIVALRRAKRRNMERLSLACGGMAVNSFEDLTVDCLGHAGLVYEYTLGEEKFTFIEECVNPCSVTLLVKGPNKHTLTQVKDAIRDGLRAIKNAIEDGCMVPGAGAIEVAMAEALVTYKNSIKGRARLGVQAFADALLIIPKVLAQNAGYDPQETLVKVQAEHVESKQLVGVDLNTGEPMVAADAGVWDNYCVKKQLLHSCTVIATNILLVDEIMRAGMSSLK>sp|Q9BXU0|TEX12_HUMAN Testis-expressed protein 12 OS=Homo sapiensOX=9606 GN=TEX12 PE=1 SV=1MMANHLVKPDNRNCKRPRELESPVPDSPQLSSLGKSDSSFSEISGLFYKDEALEKDLNDVSKEINLMLSTYAKLLSERAAVDASYIDEIDELFKEANAIENFLIQKREFLRQRFTVIANTLHR>sp|Q9UNN4|TF2AY_HUMAN TFIIA-alpha and beta-like factor OS=Homo sapiensOX=9606 GN=GTF2A1L PE=1 SV=2MACLNPVPKLYRSVIEDVIEGVRNLFAEEGIEEQVLKDLKQLWETKVLQSKATEDFFRNSIQSPLFTLQLPHSLHQTLQSSTASLVIPAGRTLPSFTTAELGTSNSSANFTFPGYPIHVPAGVTLQTVSGHLYKVNVPIMVTETSGRAGILQHPIQQVFQQLGQPSVIQTSVPQLNPWSLQATTEKSQRIETVLQQPAILPSGPVDRKHLENATSDILVSPGNEHKIVPEALLCHQESSHYISLPGVVFSPQVSQTNSNVESVLSGSASMAQNLHDESLSTSPHGALHQHVTDIQLHILKNRMYGCDSVKQPRNIEEPSNIPVSEKDSNSQVDLSIRVTDDDIGEIIQVDGSGDTSSNEEIGSTRDADENEFLGNIDGGDLKVPEEEADSISNEDSATNSSDNEDPQVNIVEEDPLNSGDDVSEQDVPDLFDTDNVIVCQYDKIHRSKNKWKFYLKDGVMCFGGRDYVFAKAIGDAEW>sp|Q9UNN4-2|TF2AY_HUMAN Isoform 2 of TFIIA-alpha and beta-like factorOS=Homo sapiens OX=9606 GN=GTF2A1LMACLNPVLWETKVLQSKATEDFFRNSIQSPLFTLQLPHSLHQTLQSSTASLVIPAGRTLPSFTTAELGTSNSSANFTFPGYPIHVPAGVTLQTVSGHLYKVNVPIMVTETSGRAGILQHPIQQVFQQLGQPSVIQTSVPQLNPWSLQATTEKSQRIETVLQQPAILPSGPVDRKHLENATSDILVSPGNEHKIVPEALLCHQESSHYISLPGVVFSPQVSQTNSNVESVLSGSASMAQNLHDESLSTSPHGALHQHVTDIQLHILKNRMYGCDSVKQPRNIEEPSNIPVSEKDSNSQVDLSIRVTDDDIGEIIQVDGSGDTSSNEEIGSTRDADENEFLGNIDGGDLKVPEEEADSISNEDSATNSSDNEDPQVNIVEEDPLNSGDDVSEQDVPDLFDTDNVIVCQYDKIHRSKNKWKFYLKDGVMCFGGRDYVFAKAIGDAEW>sp|Q9UHQ7|TCAL9_HUMAN Transcription elongation factor A protein-like 9OS=Homo sapiens OX=9606 GN=TCEAL9 PE=3 SV=1MKSCQKMEGKPENESEPKHEEEPKPEEKPEEEEKLEEEAKAKGTFRERLIQSLQEFKEDIHNRHLSNEDMFREVDEIDEIRRVRNKLIVMRWKVNRNHPYPYLM>sp|Q9P2Z0|THA10_HUMAN THAP domain-containing protein 10 OS=Homo sapiensOX=9606 GN=THAP10 PE=1 SV=1MPARCVAAHCGNTTKSGKSLFRFPKDRAVRLLWDRFVRGCRADWYGGNDRSVICSDHFAPACFDVSSVIQKNLRFSQRLRLVAGAVPTLHRVPAPAPKRGEEGDQAGRLDTRGELQAARHSEAAPGPVSCTRPRAGKQAAASQITCENELVQTQPHADNPSNTVTSVPTHCEEGPVHKSTQISLKRPRHRSVGIQAKVKAFGKRLCNATTQTEELWSRTSSLFDIYSSDSETDTDWDIKSEQSDLSYMAVQVKEETC>sp|Q00403|TF2B_HUMAN Transcription initiation factor IIB OS=Homo sapiensOX=9606 GN=GTF2B PE=1 SV=1MASTSRLDALPRVTCPNHPDAILVEDYRAGDMICPECGLVVGDRVIDVGSEWRTFSNDKATKDPSRVGDSQNPLLSDGDLSTMIGKGTGAASFDEFGNSKYQNRRTMSSSDRAMMNAFKEITTMADRINLPRNIVDRTNNLFKQVYEQKSLKGRANDAIASACLYIACRQEGVPRTFKEICAVSRISKKEIGRCFKLILKALETSVDLITTGDFMSRFCSNLCLPKQVQMAATHIARKAVELDLVPGRSPISVAAAAIYMASQASAEKRTQKEIGDIAGVADVTIRQSYRLIYPRAPDLFPTDFKFDTPVDKLPQL>sp|A3KMH1|VWA8_HUMAN von Willebrand factor A domain-containing protein 8OS=Homo sapiens OX=9606 GN=VWA8 PE=1 SV=2MQSRLLLLGAPGGHGGPASRRMRLLLRQVVQRRPGGDRQRPEVRLLHAGSGADTGDTVNIGDVSYKLKIPKNPELVPQNYISDSLAQSVVQHLRWIMQKDLLGQDVFLIGPPGPLRRSIAMQYLELTKREVEYIALSRDTTETDLKQRREIRAGTAFYIDQCAVRAATEGRTLILEGLEKAERNVLPVLNNLLENREMQLEDGRFLMSAERYDKLLRDHTKKELDSWKIVRVSENFRVIALGLPVPRYSGNPLDPPLRSRFQARDIYYLPFKDQLKLLYSIGANVSAEKVSQLLSFATTLCSQESSTLGLPDFPLDSLAAAVQILDSFPMMPIKHAIQWLYPYSILLGHEGKMAVEGVLKRFELQDSGSSLLPKEIVKVEKMMENHVSQASVTIRIADKEVTIKVPAGTRLLSQPCASDRFIQTLSHKQLQAEMMQSHMVKDICLIGGKGCGKTVIAKNFADTLGYNIEPIMLYQDMTARDLLQQRYTLPNGDTAWRSSPLVNAALEGKLVLLDGIHRVNAGTLAVLQRLIHDRELSLYDGSRLLREDRYMRLKEELQLSDEQLQKRSIFPIHPSFRIIALAEPPVIGSTAHQWLGPEFLTMFFFHYMKPLVKSEEIQVIKEKVPNVPQEALDKLLSFTHKLRETQDPTAQSLAASLSTRQLLRISRRLSQYPNENLHSAVTKACLSRFLPSLARSALEKNLADATIEINTDDNLEPELKDYKCEVTSGTLRIGAVSAPIYNAHEKMKVPDVLFYDNIQHVIVMEDMLKDFLLGEHLLLVGNQGVGKNKIVDRFLHLLNRPREYIQLHRDTTVQTLTLQPSVKDGLIVYEDSPLVKAVKLGHILVVDEADKAPTNVTCILKTLVENGEMILADGRRIVANSANVNGRENVVVIHPDFRMIVLANRPGFPFLGNDFFGTLGDIFSCHAVDNPKPHSELEMLRQYGPNVPEPILQKLVAAFGELRSLADQGIINYPYSTREVVNIVKHLQKFPTEGLSSVVRNVFDFDSYNNDMREILINTLHKYGIPIGAKPTSVQLAKELTLPEQTFMGYWTIGQARSGMQKLLCPVETHHIDIKGPALINIQEYPIERHEERSLNFTEECASWRIPLDEINIICDIATSHENEQNTLYVVTCNPASLYFMNMTGKSGFFVDFFDIFPRTANGVWHPFVTVAPLGSPLKGQVVLHEQQSNVILLLDTTGRALHRLILPSEKFTSKKPFWWNKEEAETYKMCKEFSHKNWLVFYKEKGNSLTVLDVLEGRTHTISLPINLKTVFLVAEDKWLLVESKTNQKYLLTKPAHIESEGSGVCQLYVLKEEPPSTGFGVTQETEFSIPHKISSDQLSSEHLSSAVEQKIASPNRILSDEKNYATIVVGFPDLMSPSEVYSWKRPSSLHKRSGTDTSFYRGKKKRGTPKQSNCVTLLDTNQVVRILPPGEVPLKDIYPKDVTPPQTSGYIEVTDLQSKKLRYIPIPRSESLSPYTTWLSTISDTDALLAEWDKSGVVTVDMGGHIRLWETGLERLQRSLMEWRNMIGQDDRNMQITINRDSGEDVSSPKHGKEDPDNMPHVGGNTWAGGTGGRDTAGLGGKGGPYRLDAGHTVYQVSQAEKDAVPEEVKRAAREMGQRAFQQRLKEIQMSEYDAATYERFSGAVRRQVHSLRIILDNLQAKGKERQWLRHQATGELDDAKIIDGLTGEKAIYKRRGELEPQLGSPQQKPKRLRLVVDVSGSMYRFNRMDGRLERTMEAVCMVMEAFENYEEKFQYDIVGHSGDGYNIGLVPMNKIPKDNKQRLEILKTMHAHSQFCMSGDHTLEGTEHAIKEIVKEEADEYFVIVLSDANLSRYGIHPAKFAQILTRDPQVNAFAIFIGSLGDQATRLQRTLPAGRSFVAMDTKDIPQILQQIFTSTMLSSV>sp|A3KMH1-2|VWA8_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 8 OS=Homo sapiens OX=9606 GN=VWA8MQSRLLLLGAPGGHGGPASRRMRLLLRQVVQRRPGGDRQRPEVRLLHAGSGADTGDTVNIGDVSYKLKIPKNPELVPQNYISDSLAQSVVQHLRWIMQKDLLGQDVFLIGPPGPLRRSIAMQYLELTKREVEYIALSRDTTETDLKQRREIRAGTAFYIDQCAVRAATEGRTLILEGLEKAERNVLPVLNNLLENREMQLEDGRFLMSAERYDKLLRDHTKKELDSWKIVRVSENFRVIALGLPVPRYSGNPLDPPLRSRFQARDIYYLPFKDQLKLLYSIGANVSAEKVSQLLSFATTLCSQESSTLGLPDFPLDSLAAAVQILDSFPMMPIKHAIQWLYPYSILLGHEGKMAVEGVLKRFELQDSGSSLLPKEIVKVEKMMENHVSQASVTIRIADKEVTIKVPAGTRLLSQPCASDRFIQTLSHKQLQAEMMQSHMVKDICLIGGKGCGKTVIAKNFADTLGYNIEPIMLYQDMTARDLLQQRYTLPNGDTAWRSSPLVNAALEGKLVLLDGIHRVNAGTLAVLQRLIHDRELSLYDGSRLLREDRYMRLKEELQLSDEQLQKRSIFPIHPSFRIIALAEPPVIGSTAHQWLGPEFLTMFFFHYMKPLVKSEEIQVIKEKVPNVPQEALDKLLSFTHKLRETQDPTAQSLAASLSTRQLLRISRRLSQYPNENLHSAVTKACLSRFLPSLARSALEKNLADATIEINTDDNLEPELKDYKCEVTSGTLRIGAVSAPIYNAHEKMKVPDVLFYDNIQHVIVMEDMLKDFLLGEHLLLVGNQGVGKNKIVDRFLHLLNRPREYIQLHRDTTVQTLTLQPSVKDGLIVYEDSPLVKAVKLGHILVVDEADKAPTNVTCILKTLVENGEMILADGRRIVANSANVNGRENVVVIHPDFRMIVLANRPGFPFLGNDFFGTLGDIFSCHAVDNPKPHSELEMLRQYGPNVPEPILQKLVAAFGELRSLADQGIINYPYSTREVVNIVKHLQKFPTEGLSSVVRNVFDFDSYNNDMREILINTLHKYGIPIGAKPTSVQLAKE>sp|A3KMH1-3|VWA8_HUMAN Isoform 3 of von Willebrand factor A domain-containing protein 8 OS=Homo sapiens OX=9606 GN=VWA8GTPLDPRAPSPSPTAGSGADTGDTVNIGDVSYKLKIPKNPELVPQNYISDSLAQSVVQHLRWIMQKDLLGQDVFLIGPPGPLRRSIAMQYLELTKREVEYIALSRDTTETDLKQRREIRAGTAFYIDQCAVRAATEGRTLILEGLEKAERNVLPVLNNLLENREMQLEDGRFLMSAERYDKLLRDHTKKELDSWKIVRVSENFRVIALGLPVPRYSGNPLDPPLRSRFQARDIYYLPFKDQLKLLYSIGANVSAEKVSQLLSFATTLCSQESSTLGLPDFPLDSLAAAVQILDSFPMMPIKHAIQWLYPYSILLGHEGKMAVEGVLKRFELQDSGSSLLPKEIVKVEKMMENHVSQASVTIRIADKEVTIKVPAGTRLLSQPCASDRFIQTLSHKQLQAEMMQSHMVKDICLIGGKGCGKTVIAKNFADTLGYNIEPIMLYQDMTARDLLQQRYTLPNGDTAWRSSPLVNAALEGKLVLLDGIHRVNAGTLAVLQRLIHDRELSLYDGSRLLREDRYMRLKEELQLSDEQLQKRSIFPIHPSFRIIALAEPPVIGSTAHQWLGPEFLTMFFFHYMKPLVKSEEIQVIKEKVPNVPQEALDKLLSFTHKLRETQDPTAQSLAASLSTRQLLRISRRLSQYPNENLHSAVTKACLSRFLPSLARSALEKNLADATIEINTDDNLEPELKDYKCEVTSGTLRIGAVSAPIYNAHEKMKVPDVLFYDNIQHVIVMEDMLKDFLLGEHLLLVGNQGVGKNKIVDRFLHLLNRPREYIQLHRDTTVQTLTLQPSVKDGLIVYEDSPLVKAVKLGHILVVDEADKAPTNVTCILKTLVENGEMILADGRRIVANSANVNGRENVVVIHPDFRMIVLANRPGFPFLGNDFFGTLGDIFSCHAVDNPKPHSELEMLRQYGPNVPEPILQKLVAAFGELRSLADQGIINYPYSTREVVNIVKHLQKFPTEGLSSVVRNVFDFDSYNNDMREILINTLHKYGIPIGAKPTSVQLAKELTLPEQTFMGYWTIGQARSGMQKLLCPVETHHIDIKGPALINIQEYPIERHEERSLNFTEECASWRIPLDEINIICDIATSHENEQNTLYVVTCNPASLYFMNMTGKSGFFVDFFDIFPRTANGVWHPFVTVAPLGSPLKGQVVLHEQQSNVILLLDTTGRALHRLILPSEKFTSKKPFWWNKEEAETYKMCKEFSHKNWLVFYKEKGNSLTVLDVLEGRTHTISLPINLKTVFLVAEDKWLLVESKTNQKYLLTKPAHIESEGSGVCQLYVLKEEPPSTGFGVTQETEFSIPHKISSDQLSSEHLSSAVEQKIASPNRILSDEKNYATIVVGFPDLMSPSEVYSWKRPSSLHKRSGTDTSFYRGKKKRGTPKQSNCVTLLDTNQVVRILPPGEVPLKDIYPKDVTPPQTSGYIEVTDLQSKKLRYIPIPRSESLSPYTTWLSTISDTDALLAEWDKSGVVTVDMGGHIRLWETGLERLQRSLMEWRNMIGQDDRNMQITINRDSGEDVSSPKHGKEDPDNMPHVGGNTWAGGTGGRDTAGLGGKGGPYRLDAGHTVYQVSQAEKDAVPEEVKRAAREMGQRAFQQRLKEIQMSEYDAATYERFSGAVRRQVHSLRIILDNLQAKGKERQWLRHQATGELDDAKIIDGLTGEKAIYKRRGELEPQLGSPQQKPKRLRLVVDVSGSMYRFNRMDGRLERTMEAVCMVMEAFENYEEKFQYDIVGHSGDGYNIGLVPMNKIPKDNKQRLEILKTMHAHSQFCMSGDHTLEGTEHAIKEIVKEEADEYFVIVLSDANLSRYGIHPAKFAQILTRDPQVNAFAIFIGSLGDQATRLQRTLPAGRSFVAMDTKDIPQILQQIFTSTMLSSV>sp|Q8WUY1|THEM6_HUMAN Protein THEM6 OS=Homo sapiens OX=9606 GN=THEM6PE=1 SV=2MLGLLVALLALGLAVFALLDVWYLVRLPCAVLRARLLQPRVRDLLAEQRFPGRVLPSDLDLLLHMNNARYLREADFARVAHLTRCGVLGALRELRAHTVLAASCARHRRSLRLLEPFEVRTRLLGWDDRAFYLEARFVSLRDGFVCALLRFRQHLLGTSPERVVQHLCQRRVEPPELPADLQHWISYNEASSQLLRMESGLSDVTKDQ>sp|Q9H7E2|TDRD3_HUMAN Tudor domain-containing protein 3 OS=Homo sapiensOX=9606 GN=TDRD3 PE=1 SV=1MLRLQMTDGHISCTAVEFSYMSKISLNTPPGTKVKLSGIVDIKNGFLLLNDSNTTVLGGEVEHLIEKWELQRSLSKHNRSNIGTEGGPPPFVPFGQKCVSHVQVDSRELDRRKTLQVTMPVKPTNDNDEFEKQRTAAIAEVAKSKETKTFGGGGGGARSNLNMNAAGNRNREVLQKEKSTKSEGKHEGVYRELVDEKALKHITEMGFSKEASRQALMDNGNNLEAALNVLLTSNKQKPVMGPPLRGRGKGRGRIRSEDEEDLGNARPSAPSTLFDFLESKMGTLNVEEPKSQPQQLHQGQYRSSNTEQNGVKDNNHLRHPPRNDTRQPRNEKPPRFQRDSQNSKSVLEGSGLPRNRGSERPSTSSVSEVWAEDRIKCDRPYSRYDRTKDTSYPLGSQHSDGAFKKRDNSMQSRSGKGPSFAEAKENPLPQGSVDYNNQKRGKRESQTSIPDYFYDRKSQTINNEAFSGIKIEKHFNVNTDYQNPVRSNSFIGVPNGEVEMPLKGRRIGPIKPAGPVTAVPCDDKIFYNSGPKRRSGPIKPEKILESSIPMEYAKMWKPGDECFALYWEDNKFYRAEVEALHSSGMTAVVKFIDYGNYEEVLLSNIKPIQTEAWEEEGTYDQTLEFRRGGDGQPRRSTRPTQQFYQPPRARN>sp|Q9H7E2-2|TDRD3_HUMAN Isoform 2 of Tudor domain-containing protein 3OS=Homo sapiens OX=9606 GN=TDRD3MLRLQMTDGHISCTAVEFSYMSKISLNTPPGTKVKLSGIVDIKNGFLLLNDSNTTVLGGEVEHLIEKWELQRSLSKHNRSNIGTEGGPPPFVPFGQCVSHVQVDSRELDRRKTLQVTMPVKPTNDNDEFEKQRTAAIAEVAKSKETKTFGGGGGGARSNLNMNAAGNRNREVLQKEKSTKSEGKHEGVYRELVDEKALKHITEMGFSKEASRQALMDNGNNLEAALNVLLTSNKQKPVMGPPLRGRGKGRGRIRSEDEEDLGNARPSAPSTLFDFLESKMGTLNVEEPKSQPQQLHQGQYRSSNTEQNGVKDNNHLRHPPRNDTRQPRNEKPPRFQRDSQNSKSVLEGSGLPRNRGSERPSTSSVSEVWAEDRIKCDRPYSRYDRTKDTSYPLGSQHSDGAFKKRDNSMQSRSGKGPSFAEAKENPLPQGSVDYNNQKRGKRESQTSIPDYFYDRKSQTINNEAFSGIKIEKHFNVNTDYQNPVRSNSFIGVPNGEVEMPLKGRRIGPIKPAGPVTAVPCDDKIFYNSGPKRRSGPIKPEKILESSIPMEYAKMWKPGDECFALYWEDNKFYRAEVEALHSSGMTAVVKFIDYGNYEEVLLSNIKPIQTEAWEEEGTYDQTLEFRRGGDGQPRRSTRPTQQFYQPPRARN>sp|Q9H7E2-3|TDRD3_HUMAN Isoform 3 of Tudor domain-containing protein 3OS=Homo sapiens OX=9606 GN=TDRD3MAQVAGAALSQAGWYLSDEGIEACTSSPDKVNVNDIILIALNTDLRTIGKKFLPSDINSGKVEKLEGPCVLQIQKIRNVAAPKDNEESQAAPRMLRLQMTDGHISCTAVEFSYMSKISLNTPPGTKVKLSGIVDIKNGFLLLNDSNTTVLGGEVEHLIEKWELQRSLSKHNRSNIGTEGGPPPFVPFGQKCVSHVQVDSRELDRRKTLQVTMPVKPTNDNDEFEKQRTAAIAEVAKSKETKTFGGGGGGARSNLNMNAAGNRNREVLQKEKSTKSEGKHEGVYRELVDEKALKHITEMGFSKEASRQALMDNGNNLEAALNVLLTSNKQKPVMGPPLRGRGKGRGRIRSEDEEDLGNARPSAPSTLFDFLESKMGTLNVEEPKSQPQQLHQGQYRSSNTEQNGVKDNNHLRHPPRNDTRQPRNEKPPRFQRDSQNSKSVLEGSGLPRNRGSERPSTSSVSEVWAEDRIKCDRPYSRYDRTKDTSYPLGSQHSDGAFKKRDNSMQSRSGKGPSFAEAKENPLPQGSVDYNNQKRGKRESQTSIPDYFYDRKSQTINNEAFSGIKIEKHFNVNTDYQNPVRSNSFIGVPNGEVEMPLKGRRIGPIKPAGPVTAVPCDDKIFYNSGPKRRSGPIKPEKILESSIPMEYAKMWKPGDECFALYWEDNKFYRAEVEALHSSGMTAVVKFIDYGNYEEVLLSNIKPIQTEAWEEEGTYDQTLEFRRGGDGQPRRSTRPTQQFYQPPRARN>sp|Q9UQP3|TENN_HUMAN Tenascin-N OS=Homo sapiens OX=9606 GN=TNN PE=1 SV=2MSLQEMFRFPMGLLLGSVLLVASAPATLEPPGCSNKEQQVTVSHTYKIDVPKSALVQVDADPQPLSDDGASLLALGEAREEQNIIFRHNIRLQTPQKDCELAGSVQDLLARVKKLEEEMVEMKEQCSAQRCCQGVTDLSRHCSGHGTFSLETCSCHCEEGREGPACERLACPGACSGHGRCVDGRCLCHEPYVGADCGYPACPENCSGHGECVRGVCQCHEDFMSEDCSEKRCPGDCSGHGFCDTGECYCEEGFTGLDCAQVVTPQGLQLLKNTEDSLLVSWEPSSQVDHYLLSYYPLGKELSGKQIQVPKEQHSYEILGLLPGTKYIVTLRNVKNEVSSSPQHLLATTDLAVLGTAWVTDETENSLDVEWENPSTEVDYYKLRYGPMTGQEVAEVTVPKSSDPKSRYDITGLHPGTEYKITVVPMRGELEGKPILLNGRTEIDSPTNVVTDRVTEDTATVSWDPVQAVIDKYVVRYTSADGDTKEMAVHKDESSTVLTGLKPGEAYKVYVWAERGNQGSKKADTNALTEIDSPANLVTDRVTENTATISWDPVQATIDKYVVRYTSADDQETREVLVGKEQSSTVLTGLRPGVEYTVHVWAQKGDRESKKADTNAPTDIDSPKNLVTDRVTENMATVSWDPVQAAIDKYVVRYTSAGGETREVPVGKEQSSTVLTGLRPGMEYMVHVWAQKGDQESKKADTKAQTDIDSPQNLVTDRVTENMATVSWDPVRATIDRYVVRYTSAKDGETREVPVGKEQSSTVLTGLRPGVEYTVHVWAQKGAQESKKADTKAQTDIDSPQNLVTDWVTENTATVSWDPVQATIDRYVVHYTSANGETREVPVGKEQSSTVLTGLRPGMEYTVHVWAQKGNQESKKADTKAQTEIDGPKNLVTDWVTENMATVSWDPVQATIDKYMVRYTSADGETREVPVGKEHSSTVLTGLRPGMEYMVHVWAQKGAQESKKADTKAQTELDPPRNLRPSAVTQSGGILTWTPPSAQIHGYILTYQFPDGTVKEMQLGREDQRFALQGLEQGATYPVSLVAFKGGRRSRNVSTTLSTVGARFPHPSDCSQVQQNSNAASGLYTIYLHGDASRPLQVYCDMETDGGGWIVFQRRNTGQLDFFKRWRSYVEGFGDPMKEFWLGLDKLHNLTTGTPARYEVRVDLQTANESAYAIYDFFQVASSKERYKLTVGKYRGTAGDALTYHNGWKFTTFDRDNDIALSNCALTHHGGWWYKNCHLANPNGRYGETKHSEGVNWEPWKGHEFSIPYVELKIRPHGYSREPVLGRKKRTLRGRLRTF>sp|Q03403|TFF2_HUMAN Trefoil factor 2 OS=Homo sapiens OX=9606 GN=TFF2PE=1 SV=2MGRRDAQLLAALLVLGLCALAGSEKPSPCQCSRLSPHNRTNCGFPGITSDQCFDNGCCFDSSVTGVPWCFHPLPKQESDQCVMEVSDRRNCGYPGISPEECASRKCCFSNFIFEVPWCFFPKSVEDCHY>sp|Q5TEJ8|THMS2_HUMAN Protein THEMIS2 OS=Homo sapiens OX=9606 GN=THEMIS2PE=1 SV=1MEPVPLQDFVRALDPASLPRVLRVCSGVYFEGSIYEISGNECCLSTGDLIKVTQVRLQKVVCENPKTSQTMELAPNFQGYFTPLNTPQSYETLEELVSATTQSSKQLPTCFMSTHRIVTEGRVVTEDQLLMLEAVVMHLGIRSARCVLGMEGQQVILHLPLSQKGPFWTWEPSAPRTLLQVLQDPALKDLVLTCPTLPWHSLILRPQYEIQAIMHMRRTIVKIPSTLEVDVEDVTASSRHVHFIKPLLLSEVLAWEGPFPLSMEILEVPEGRPIFLSPWVGSLQKGQRLCVYGLASPPWRVLASSKGRKVPRHFLVSGGYQGKLRRRPREFPTAYDLLGAFQPGRPLRVVATKDCEGEREENPEFTSLAVGDRLEVLGPGQAHGAQGSDVDVLVCQRLSDQAGEDEEEECKEEAESPERVLLPFHFPGSFVEEMSDSRRYSLADLTAQFSLPCEVKVVAKDTSHPTDPLTSFLGLRLEEKITEPFLVVSLDSEPGMCFEIPPRWLDLTVVKAKGQPDLPEGSLPIATVEELTDTFYYRLRKLPACEIQAPPPRPPKNQGLSKQRRHSSEGGVKSSQVLGLQQHARLPKPKAKTLPEFIKDGSSTYSKIPAHRKGHRPAKPQRQDLDDDEHDYEEILEQFQKTI>sp|Q5TEJ8-2|THMS2_HUMAN Isoform 2 of Protein THEMIS2 OS=Homo sapiensOX=9606 GN=THEMIS2MEPVPLQDFVRALDPASLPRVLRVCSGVYFEGSIYEISGNECCLSTGDLIKVTQVRLQKVVCENPKTSQTMELAPNFQGYFTPLNTPQSYETLEELVSATTQSSKQLPTCFMSTHRIVTEGRVVTEDQLLMLEAVVMHLGIRSARCVLGMEGQQVILHLPLSQKGPFWTWEPSAPRTLLQVLQDPALKDLVLTCPTLPWHSLILRPQYEIQAIMHIFSSLRIAATRSAAQTQGEDLARVHQGWLQYVQQDSCPQEGPQAR>sp|Q5TEJ8-3|THMS2_HUMAN Isoform 3 of Protein THEMIS2 OS=Homo sapiensOX=9606 GN=THEMIS2MEPVPLQDFVRALDPASLPRVLRVCSGVYFEGSIYEISGNECCLSTGDLIKVTQVRLQKVVCENPKTSQTMELAPNFQGYFTPLNTPQSYETLEELVSATTQSSKQLPTCFMSTHRIVTEGRVVTEDQLLMLEAVVMHLGIRSARCVLGMEGQQVILHLPLSQKGPFWTWEPSAPRTLLQVLQDPALKDLVLTCPTLPWHSLILRPQYEIQAIMHMRRTIVKIPSTLEVDVEDVTASSRHVHFIKPLLLSERLSDQAGEDEEEECKEEAESPERVLLPFHFPGSFVEEMSDSRRYSLADLTAQFSLPCEVKVVAKDTSHPTDPLTSFLGLRLEEKITEPFLVVSLDSEPGMCFEIPPRWLDLTVVKAKGQPDLPEGSLPIATVEELTDTFYYRLRKLPACEIQAPPPRPPKNQGLSKQRRHSSEGGVKSSQVLGLQQHARLPKPKAKTLPEFIKDGSSTYSKIPAHRKGHRPAKPQRQDLDDDEHDYEEILEQFQKTI>sp|Q5TEJ8-4|THMS2_HUMAN Isoform 4 of Protein THEMIS2 OS=Homo sapiensOX=9606 GN=THEMIS2MEPVPLQDFVRALDPASLPRVLRVCSGVYFEGSIYEISGNECCLSTGDLIKVTQVRLQKVVCENPKTSQTMELAPNFQVFSSLRIAATRSAAQTQGEDLARVHQGWLQYVQQDSCPQEGPQAR>sp|Q5TEJ8-5|THMS2_HUMAN Isoform 5 of Protein THEMIS2 OS=Homo sapiensOX=9606 GN=THEMIS2MEPVPLQDFVRALDPASLPRVLRVCSGVYFEGSIYEISGNECCLSTGDLIKVTQVRLQKVVCENPKTSQTMELAPNFQGYFTPLNTPQSYETLEELVSATTQSSKQLPTCFMSTHRIVTEGRVVTEDQLLMLEAVVMHLGIRSARCVLGMEGQQVILHLPLSQKGPFWTWEPSAPRTLLQVLQDPALKDLVLTCPTLPWHSLILRPQYEIQAIMHMRRTIVKIPSTLEVDVEDVTASSRHVHFIKPLLLSEVLAWEGPFPLSMEILERLSDQAGEDEEEECKEEAESPERVLLPFHFPGSFVEEMSDSRRYSLADLTAQFSLPCEVKVVAKDTSHPTDPLTSFLGLRLEEKITEPFLVVSLDSEPGMCFEIPPRWLDLTVVKAKGQPDLPEGSLPIATVEELTDTFYYRLRKLPACEIQAPPPRPPKNQGLSKQRRHSSEGGVKSSQVLGLQQHARLPKPKAKTLPEFIKDGSSTYSKIPAHRKGHRPAKPQRQDLDDDEHDYEEILEQFQKTI>sp|Q5TEJ8-6|THMS2_HUMAN Isoform 6 of Protein THEMIS2 OS=Homo sapiensOX=9606 GN=THEMIS2MEPVPLQDFVRALDPASLPRVLRVCSGVYFEGSIYEISGNECCLSTGDLIKVTQVRLQKVVCENPKTSQTMELAPNFQGYFTPLNTPQSYETLEELVSATTQSSKQLPTCFMSTHRIVTEGRVVTEDQLLMLEAVVMHLGIRSARCVLGMEGQQVILHLPLSQKGPFWTWEPSAPRTLLQVLQDPAHGAQGSDVDVLVCQRLSDQAGEDEEEECKEEAESPERVLLPFHFPGSFVEEMSDSRRYSLADLTAQFSLPCEVKVVAKDTSHPTDPLTSFLGLRLEEKITEPFLVVSLDSEPGMCFEIPPRWLDLTVVKAKGQPDLPEGSLPIATVEELTDTFYYRLRKLPACEIQAPPPRPPKNQGLSKQRRHSSEGGVKSSQVLGLQQHARLPKPKAKTLPEFIKDGSSTYSKIPAHRKGHRPAKPQRQDLDDDEHDYEEILEQFQKTI>sp|P24821|TENA_HUMAN Tenascin OS=Homo sapiens OX=9606 GN=TNC PE=1 SV=3MGAMTQLLAGVFLAFLALATEGGVLKKVIRHKRQSGVNATLPEENQPVVFNHVYNIKLPVGSQCSVDLESASGEKDLAPPSEPSESFQEHTVDGENQIVFTHRINIPRRACGCAAAPDVKELLSRLEELENLVSSLREQCTAGAGCCLQPATGRLDTRPFCSGRGNFSTEGCGCVCEPGWKGPNCSEPECPGNCHLRGRCIDGQCICDDGFTGEDCSQLACPSDCNDQGKCVNGVCICFEGYAGADCSREICPVPCSEEHGTCVDGLCVCHDGFAGDDCNKPLCLNNCYNRGRCVENECVCDEGFTGEDCSELICPNDCFDRGRCINGTCYCEEGFTGEDCGKPTCPHACHTQGRCEEGQCVCDEGFAGVDCSEKRCPADCHNRGRCVDGRCECDDGFTGADCGELKCPNGCSGHGRCVNGQCVCDEGYTGEDCSQLRCPNDCHSRGRCVEGKCVCEQGFKGYDCSDMSCPNDCHQHGRCVNGMCVCDDGYTGEDCRDRQCPRDCSNRGLCVDGQCVCEDGFTGPDCAELSCPNDCHGQGRCVNGQCVCHEGFMGKDCKEQRCPSDCHGQGRCVDGQCICHEGFTGLDCGQHSCPSDCNNLGQCVSGRCICNEGYSGEDCSEVSPPKDLVVTEVTEETVNLAWDNEMRVTEYLVVYTPTHEGGLEMQFRVPGDQTSTIIQELEPGVEYFIRVFAILENKKSIPVSARVATYLPAPEGLKFKSIKETSVEVEWDPLDIAFETWEIIFRNMNKEDEGEITKSLRRPETSYRQTGLAPGQEYEISLHIVKNNTRGPGLKRVTTTRLDAPSQIEVKDVTDTTALITWFKPLAEIDGIELTYGIKDVPGDRTTIDLTEDENQYSIGNLKPDTEYEVSLISRRGDMSSNPAKETFTTGLDAPRNLRRVSQTDNSITLEWRNGKAAIDSYRIKYAPISGGDHAEVDVPKSQQATTKTTLTGLRPGTEYGIGVSAVKEDKESNPATINAATELDTPKDLQVSETAETSLTLLWKTPLAKFDRYRLNYSLPTGQWVGVQLPRNTTSYVLRGLEPGQEYNVLLTAEKGRHKSKPARVKASTEQAPELENLTVTEVGWDGLRLNWTAADQAYEHFIIQVQEANKVEAARNLTVPGSLRAVDIPGLKAATPYTVSIYGVIQGYRTPVLSAEASTGETPNLGEVVVAEVGWDALKLNWTAPEGAYEYFFIQVQEADTVEAAQNLTVPGGLRSTDLPGLKAATHYTITIRGVTQDFSTTPLSVEVLTEEVPDMGNLTVTEVSWDALRLNWTTPDGTYDQFTIQVQEADQVEEAHNLTVPGSLRSMEIPGLRAGTPYTVTLHGEVRGHSTRPLAVEVVTEDLPQLGDLAVSEVGWDGLRLNWTAADNAYEHFVIQVQEVNKVEAAQNLTLPGSLRAVDIPGLEAATPYRVSIYGVIRGYRTPVLSAEASTAKEPEIGNLNVSDITPESFNLSWMATDGIFETFTIEIIDSNRLLETVEYNISGAERTAHISGLPPSTDFIVYLSGLAPSIRTKTISATATTEALPLLENLTISDINPYGFTVSWMASENAFDSFLVTVVDSGKLLDPQEFTLSGTQRKLELRGLITGIGYEVMVSGFTQGHQTKPLRAEIVTEAEPEVDNLLVSDATPDGFRLSWTADEGVFDNFVLKIRDTKKQSEPLEITLLAPERTRDITGLREATEYEIELYGISKGRRSQTVSAIATTAMGSPKEVIFSDITENSATVSWRAPTAQVESFRITYVPITGGTPSMVTVDGTKTQTRLVKLIPGVEYLVSIIAMKGFEESEPVSGSFTTALDGPSGLVTANITDSEALARWQPAIATVDSYVISYTGEKVPEITRTVSGNTVEYALTDLEPATEYTLRIFAEKGPQKSSTITAKFTTDLDSPRDLTATEVQSETALLTWRPPRASVTGYLLVYESVDGTVKEVIVGPDTTSYSLADLSPSTHYTAKIQALNGPLRSNMIQTIFTTIGLLYPFPKDCSQAMLNGDTTSGLYTIYLNGDKAEALEVFCDMTSDGGGWIVFLRRKNGRENFYQNWKAYAAGFGDRREEFWLGLDNLNKITAQGQYELRVDLRDHGETAFAVYDKFSVGDAKTRYKLKVEGYSGTAGDSMAYHNGRSFSTFDKDTDSAITNCALSYKGAFWYRNCHRVNLMGRYGDNNHSQGVNWFHWKGHEHSIQFAEMKLRPSNFRNLEGRRKRA>sp|P24821-2|TENA_HUMAN Isoform 2 of Tenascin OS=Homo sapiens OX=9606GN=TNCMGAMTQLLAGVFLAFLALATEGGVLKKVIRHKRQSGVNATLPEENQPVVFNHVYNIKLPVGSQCSVDLESASGEKDLAPPSEPSESFQEHTVDGENQIVFTHRINIPRRACGCAAAPDVKELLSRLEELENLVSSLREQCTAGAGCCLQPATGRLDTRPFCSGRGNFSTEGCGCVCEPGWKGPNCSEPECPGNCHLRGRCIDGQCICDDGFTGEDCSQLACPSDCNDQGKCVNGVCICFEGYAGADCSREICPVPCSEEHGTCVDGLCVCHDGFAGDDCNKPLCLNNCYNRGRCVENECVCDEGFTGEDCSELICPNDCFDRGRCINGTCYCEEGFTGEDCGKPTCPHACHTQGRCEEGQCVCDEGFAGVDCSEKRCPADCHNRGRCVDGRCECDDGFTGADCGELKCPNGCSGHGRCVNGQCVCDEGYTGEDCSQLRCPNDCHSRGRCVEGKCVCEQGFKGYDCSDMSCPNDCHQHGRCVNGMCVCDDGYTGEDCRDRQCPRDCSNRGLCVDGQCVCEDGFTGPDCAELSCPNDCHGQGRCVNGQCVCHEGFMGKDCKEQRCPSDCHGQGRCVDGQCICHEGFTGLDCGQHSCPSDCNNLGQCVSGRCICNEGYSGEDCSEVSPPKDLVVTEVTEETVNLAWDNEMRVTEYLVVYTPTHEGGLEMQFRVPGDQTSTIIQELEPGVEYFIRVFAILENKKSIPVSARVATYLPAPEGLKFKSIKETSVEVEWDPLDIAFETWEIIFRNMNKEDEGEITKSLRRPETSYRQTGLAPGQEYEISLHIVKNNTRGPGLKRVTTTRLDAPSQIEVKDVTDTTALITWFKPLAEIDGIELTYGIKDVPGDRTTIDLTEDENQYSIGNLKPDTEYEVSLISRRGDMSSNPAKETFTTGLDAPRNLRRVSQTDNSITLEWRNGKAAIDSYRIKYAPISGGDHAEVDVPKSQQATTKTTLTGLRPGTEYGIGVSAVKEDKESNPATINAATELDTPKDLQVSETAETSLTLLWKTPLAKFDRYRLNYSLPTGQWVGVQLPRNTTSYVLRGLEPGQEYNVLLTAEKGRHKSKPARVKASTAKEPEIGNLNVSDITPESFNLSWMATDGIFETFTIEIIDSNRLLETVEYNISGAERTAHISGLPPSTDFIVYLSGLAPSIRTKTISATATTEAEPEVDNLLVSDATPDGFRLSWTADEGVFDNFVLKIRDTKKQSEPLEITLLAPERTRDITGLREATEYEIELYGISKGRRSQTVSAIATTAMGSPKEVIFSDITENSATVSWRAPTAQVESFRITYVPITGGTPSMVTVDGTKTQTRLVKLIPGVEYLVSIIAMKGFEESEPVSGSFTTALDGPSGLVTANITDSEALARWQPAIATVDSYVISYTGEKVPEITRTVSGNTVEYALTDLEPATEYTLRIFAEKGPQKSSTITAKFTTDLDSPRDLTATEVQSETALLTWRPPRASVTGYLLVYESVDGTVKEVIVGPDTTSYSLADLSPSTHYTAKIQALNGPLRSNMIQTIFTTIGLLYPFPKDCSQAMLNGDTTSGLYTIYLNGDKAEALEVFCDMTSDGGGWIVFLRRKNGRENFYQNWKAYAAGFGDRREEFWLGLDNLNKITAQGQYELRVDLRDHGETAFAVYDKFSVGDAKTRYKLKVEGYSGTAGDSMAYHNGRSFSTFDKDTDSAITNCALSYKGAFWYRNCHRVNLMGRYGDNNHSQGVNWFHWKGHEHSIQFAEMKLRPSNFRNLEGRRKRA>sp|P24821-3|TENA_HUMAN Isoform 3 of Tenascin OS=Homo sapiens OX=9606GN=TNCMGAMTQLLAGVFLAFLALATEGGVLKKVIRHKRQSGVNATLPEENQPVVFNHVYNIKLPVGSQCSVDLESASGEKDLAPPSEPSESFQEHTVDGENQIVFTHRINIPRRACGCAAAPDVKELLSRLEELENLVSSLREQCTAGAGCCLQPATGRLDTRPFCSGRGNFSTEGCGCVCEPGWKGPNCSEPECPGNCHLRGRCIDGQCICDDGFTGEDCSQLACPSDCNDQGKCVNGVCICFEGYAGADCSREICPVPCSEEHGTCVDGLCVCHDGFAGDDCNKPLCLNNCYNRGRCVENECVCDEGFTGEDCSELICPNDCFDRGRCINGTCYCEEGFTGEDCGKPTCPHACHTQGRCEEGQCVCDEGFAGVDCSEKRCPADCHNRGRCVDGRCECDDGFTGADCGELKCPNGCSGHGRCVNGQCVCDEGYTGEDCSQLRCPNDCHSRGRCVEGKCVCEQGFKGYDCSDMSCPNDCHQHGRCVNGMCVCDDGYTGEDCRDRQCPRDCSNRGLCVDGQCVCEDGFTGPDCAELSCPNDCHGQGRCVNGQCVCHEGFMGKDCKEQRCPSDCHGQGRCVDGQCICHEGFTGLDCGQHSCPSDCNNLGQCVSGRCICNEGYSGEDCSEVSPPKDLVVTEVTEETVNLAWDNEMRVTEYLVVYTPTHEGGLEMQFRVPGDQTSTIIQELEPGVEYFIRVFAILENKKSIPVSARVATYLPAPEGLKFKSIKETSVEVEWDPLDIAFETWEIIFRNMNKEDEGEITKSLRRPETSYRQTGLAPGQEYEISLHIVKNNTRGPGLKRVTTTRLDAPSQIEVKDVTDTTALITWFKPLAEIDGIELTYGIKDVPGDRTTIDLTEDENQYSIGNLKPDTEYEVSLISRRGDMSSNPAKETFTTGLDAPRNLRRVSQTDNSITLEWRNGKAAIDSYRIKYAPISGGDHAEVDVPKSQQATTKTTLTGLRPGTEYGIGVSAVKEDKESNPATINAATELDTPKDLQVSETAETSLTLLWKTPLAKFDRYRLNYSLPTGQWVGVQLPRNTTSYVLRGLEPGQEYNVLLTAEKGRHKSKPARVKASTAKEPEIGNLNVSDITPESFNLSWMATDGIFETFTIEIIDSNRLLETVEYNISGAERTAHISGLPPSTDFIVYLSGLAPSIRTKTISATATTEALPLLENLTISDINPYGFTVSWMASENAFDSFLVTVVDSGKLLDPQEFTLSGTQRKLELRGLITGIGYEVMVSGFTQGHQTKPLRAEIVTEAEPEVDNLLVSDATPDGFRLSWTADEGVFDNFVLKIRDTKKQSEPLEITLLAPERTRDITGLREATEYEIELYGISKGRRSQTVSAIATTAMGSPKEVIFSDITENSATVSWRAPTAQVESFRITYVPITGGTPSMVTVDGTKTQTRLVKLIPGVEYLVSIIAMKGFEESEPVSGSFTTALDGPSGLVTANITDSEALARWQPAIATVDSYVISYTGEKVPEITRTVSGNTVEYALTDLEPATEYTLRIFAEKGPQKSSTITAKFTTDLDSPRDLTATEVQSETALLTWRPPRASVTGYLLVYESVDGTVKEVIVGPDTTSYSLADLSPSTHYTAKIQALNGPLRSNMIQTIFTTIGLLYPFPKDCSQAMLNGDTTSGLYTIYLNGDKAEALEVFCDMTSDGGGWIVFLRRKNGRENFYQNWKAYAAGFGDRREEFWLGLDNLNKITAQGQYELRVDLRDHGETAFAVYDKFSVGDAKTRYKLKVEGYSGTAGDSMAYHNGRSFSTFDKDTDSAITNCALSYKGAFWYRNCHRVNLMGRYGDNNHSQGVNWFHWKGHEHSIQFAEMKLRPSNFRNLEGRRKRA>sp|P24821-4|TENA_HUMAN Isoform 4 of Tenascin OS=Homo sapiens OX=9606GN=TNCMGAMTQLLAGVFLAFLALATEGGVLKKVIRHKRQSGVNATLPEENQPVVFNHVYNIKLPVGSQCSVDLESASGEKDLAPPSEPSESFQEHTVDGENQIVFTHRINIPRRACGCAAAPDVKELLSRLEELENLVSSLREQCTAGAGCCLQPATGRLDTRPFCSGRGNFSTEGCGCVCEPGWKGPNCSEPECPGNCHLRGRCIDGQCICDDGFTGEDCSQLACPSDCNDQGKCVNGVCICFEGYAGADCSREICPVPCSEEHGTCVDGLCVCHDGFAGDDCNKPLCLNNCYNRGRCVENECVCDEGFTGEDCSELICPNDCFDRGRCINGTCYCEEGFTGEDCGKPTCPHACHTQGRCEEGQCVCDEGFAGVDCSEKRCPADCHNRGRCVDGRCECDDGFTGADCGELKCPNGCSGHGRCVNGQCVCDEGYTGEDCSQLRCPNDCHSRGRCVEGKCVCEQGFKGYDCSDMSCPNDCHQHGRCVNGMCVCDDGYTGEDCRDRQCPRDCSNRGLCVDGQCVCEDGFTGPDCAELSCPNDCHGQGRCVNGQCVCHEGFMGKDCKEQRCPSDCHGQGRCVDGQCICHEGFTGLDCGQHSCPSDCNNLGQCVSGRCICNEGYSGEDCSEVSPPKDLVVTEVTEETVNLAWDNEMRVTEYLVVYTPTHEGGLEMQFRVPGDQTSTIIQELEPGVEYFIRVFAILENKKSIPVSARVATYLPAPEGLKFKSIKETSVEVEWDPLDIAFETWEIIFRNMNKEDEGEITKSLRRPETSYRQTGLAPGQEYEISLHIVKNNTRGPGLKRVTTTRLDAPSQIEVKDVTDTTALITWFKPLAEIDGIELTYGIKDVPGDRTTIDLTEDENQYSIGNLKPDTEYEVSLISRRGDMSSNPAKETFTTGLDAPRNLRRVSQTDNSITLEWRNGKAAIDSYRIKYAPISGGDHAEVDVPKSQQATTKTTLTGLRPGTEYGIGVSAVKEDKESNPATINAATELDTPKDLQVSETAETSLTLLWKTPLAKFDRYRLNYSLPTGQWVGVQLPRNTTSYVLRGLEPGQEYNVLLTAEKGRHKSKPARVKASTEQAPELENLTVTEVGWDGLRLNWTAADQAYEHFIIQVQEANKVEAARNLTVPGSLRAVDIPGLKAATPYTVSIYGVIQGYRTPVLSAEASTGETPNLGEVVVAEVGWDALKLNWTAPEGAYEYFFIQVQEADTVEAAQNLTVPGGLRSTDLPGLKAATHYTITIRGVTQDFSTTPLSVEVLTEEVPDMGNLTVTEVSWDALRLNWTTPDGTYDQFTIQVQEADQVEEAHNLTVPGSLRSMEIPGLRAGTPYTVTLHGEVRGHSTRPLAVEVVTEDLPQLGDLAVSEVGWDGLRLNWTAADNAYEHFVIQVQEVNKVEAAQNLTLPGSLRAVDIPGLEAATPYRVSIYGVIRGYRTPVLSAEASTAKEPEIGNLNVSDITPESFNLSWMATDGIFETFTIEIIDSNRLLETVEYNISGAERTAHISGLPPSTDFIVYLSGLAPSIRTKTISATATTEAEPEVDNLLVSDATPDGFRLSWTADEGVFDNFVLKIRDTKKQSEPLEITLLAPERTRDITGLREATEYEIELYGISKGRRSQTVSAIATTAMGSPKEVIFSDITENSATVSWRAPTAQVESFRITYVPITGGTPSMVTVDGTKTQTRLVKLIPGVEYLVSIIAMKGFEESEPVSGSFTTALDGPSGLVTANITDSEALARWQPAIATVDSYVISYTGEKVPEITRTVSGNTVEYALTDLEPATEYTLRIFAEKGPQKSSTITAKFTTDLDSPRDLTATEVQSETALLTWRPPRASVTGYLLVYESVDGTVKEVIVGPDTTSYSLADLSPSTHYTAKIQALNGPLRSNMIQTIFTTIGLLYPFPKDCSQAMLNGDTTSGLYTIYLNGDKAEALEVFCDMTSDGGGWIVFLRRKNGRENFYQNWKAYAAGFGDRREEFWLGLDNLNKITAQGQYELRVDLRDHGETAFAVYDKFSVGDAKTRYKLKVEGYSGTAGDSMAYHNGRSFSTFDKDTDSAITNCALSYKGAFWYRNCHRVNLMGRYGDNNHSQGVNWFHWKGHEHSIQFAEMKLRPSNFRNLEGRRKRA>sp|P24821-5|TENA_HUMAN Isoform 5 of Tenascin OS=Homo sapiens OX=9606GN=TNCMGAMTQLLAGVFLAFLALATEGGVLKKVIRHKRQSGVNATLPEENQPVVFNHVYNIKLPVGSQCSVDLESASGEKDLAPPSEPSESFQEHTVDGENQIVFTHRINIPRRACGCAAAPDVKELLSRLEELENLVSSLREQCTAGAGCCLQPATGRLDTRPFCSGRGNFSTEGCGCVCEPGWKGPNCSEPECPGNCHLRGRCIDGQCICDDGFTGEDCSQLACPSDCNDQGKCVNGVCICFEGYAGADCSREICPVPCSEEHGTCVDGLCVCHDGFAGDDCNKPLCLNNCYNRGRCVENECVCDEGFTGEDCSELICPNDCFDRGRCINGTCYCEEGFTGEDCGKPTCPHACHTQGRCEEGQCVCDEGFAGVDCSEKRCPADCHNRGRCVDGRCECDDGFTGADCGELKCPNGCSGHGRCVNGQCVCDEGYTGEDCSQLRCPNDCHSRGRCVEGKCVCEQGFKGYDCSDMSCPNDCHQHGRCVNGMCVCDDGYTGEDCRDRQCPRDCSNRGLCVDGQCVCEDGFTGPDCAELSCPNDCHGQGRCVNGQCVCHEGFMGKDCKEQRCPSDCHGQGRCVDGQCICHEGFTGLDCGQHSCPSDCNNLGQCVSGRCICNEGYSGEDCSEVSPPKDLVVTEVTEETVNLAWDNEMRVTEYLVVYTPTHEGGLEMQFRVPGDQTSTIIQELEPGVEYFIRVFAILENKKSIPVSARVATYLPAPEGLKFKSIKETSVEVEWDPLDIAFETWEIIFRNMNKEDEGEITKSLRRPETSYRQTGLAPGQEYEISLHIVKNNTRGPGLKRVTTTRLDAPSQIEVKDVTDTTALITWFKPLAEIDGIELTYGIKDVPGDRTTIDLTEDENQYSIGNLKPDTEYEVSLISRRGDMSSNPAKETFTTGLDAPRNLRRVSQTDNSITLEWRNGKAAIDSYRIKYAPISGGDHAEVDVPKSQQATTKTTLTGLRPGTEYGIGVSAVKEDKESNPATINAATELDTPKDLQVSETAETSLTLLWKTPLAKFDRYRLNYSLPTGQWVGVQLPRNTTSYVLRGLEPGQEYNVLLTAEKGRHKSKPARVKASTEAEPEVDNLLVSDATPDGFRLSWTADEGVFDNFVLKIRDTKKQSEPLEITLLAPERTRDITGLREATEYEIELYGISKGRRSQTVSAIATTAMGSPKEVIFSDITENSATVSWRAPTAQVESFRITYVPITGGTPSMVTVDGTKTQTRLVKLIPGVEYLVSIIAMKGFEESEPVSGSFTTALDGPSGLVTANITDSEALARWQPAIATVDSYVISYTGEKVPEITRTVSGNTVEYALTDLEPATEYTLRIFAEKGPQKSSTITAKFTTDLDSPRDLTATEVQSETALLTWRPPRASVTGYLLVYESVDGTVKEVIVGPDTTSYSLADLSPSTHYTAKIQALNGPLRSNMIQTIFTTIGLLYPFPKDCSQAMLNGDTTSGLYTIYLNGDKAEALEVFCDMTSDGGGWIVFLRRKNGRENFYQNWKAYAAGFGDRREEFWLGLDNLNKITAQGQYELRVDLRDHGETAFAVYDKFSVGDAKTRYKLKVEGYSGTAGDSMAYHNGRSFSTFDKDTDSAITNCALSYKGAFWYRNCHRVNLMGRYGDNNHSQGVNWFHWKGHEHSIQFAEMKLRPSNFRNLEGRRKRA>sp|P24821-6|TENA_HUMAN Isoform 6 of Tenascin OS=Homo sapiens OX=9606GN=TNCMGAMTQLLAGVFLAFLALATEGGVLKKVIRHKRQSGVNATLPEENQPVVFNHVYNIKLPVGSQCSVDLESASGEKDLAPPSEPSESFQEHTVDGENQIVFTHRINIPRRACGCAAAPDVKELLSRLEELENLVSSLREQCTAGAGCCLQPATGRLDTRPFCSGRGNFSTEGCGCVCEPGWKGPNCSEPECPGNCHLRGRCIDGQCICDDGFTGEDCSQLACPSDCNDQGKCVNGVCICFEGYAGADCSREICPVPCSEEHGTCVDGLCVCHDGFAGDDCNKPLCLNNCYNRGRCVENECVCDEGFTGEDCSELICPNDCFDRGRCINGTCYCEEGFTGEDCGKPTCPHACHTQGRCEEGQCVCDEGFAGVDCSEKRCPADCHNRGRCVDGRCECDDGFTGADCGELKCPNGCSGHGRCVNGQCVCDEGYTGEDCSQLRCPNDCHSRGRCVEGKCVCEQGFKGYDCSDMSCPNDCHQHGRCVNGMCVCDDGYTGEDCRDRQCPRDCSNRGLCVDGQCVCEDGFTGPDCAELSCPNDCHGQGRCVNGQCVCHEGFMGKDCKEQRCPSDCHGQGRCVDGQCICHEGFTGLDCGQHSCPSDCNNLGQCVSGRCICNEGYSGEDCSEVSPPKDLVVTEVTEETVNLAWDNEMRVTEYLVVYTPTHEGGLEMQFRVPGDQTSTIIQELEPGVEYFIRVFAILENKKSIPVSARVATYLPAPEGLKFKSIKETSVEVEWDPLDIAFETWEIIFRNMNKEDEGEITKSLRRPETSYRQTGLAPGQEYEISLHIVKNNTRGPGLKRVTTTRLDAPSQIEVKDVTDTTALITWFKPLAEIDGIELTYGIKDVPGDRTTIDLTEDENQYSIGNLKPDTEYEVSLISRRGDMSSNPAKETFTTGLDAPRNLRRVSQTDNSITLEWRNGKAAIDSYRIKYAPISGGDHAEVDVPKSQQATTKTTLTGLRPGTEYGIGVSAVKEDKESNPATINAATELDTPKDLQVSETAETSLTLLWKTPLAKFDRYRLNYSLPTGQWVGVQLPRNTTSYVLRGLEPGQEYNVLLTAEKGRHKSKPARVKASTAMGSPKEVIFSDITENSATVSWRAPTAQVESFRITYVPITGGTPSMVTVDGTKTQTRLVKLIPGVEYLVSIIAMKGFEESEPVSGSFTTALDGPSGLVTANITDSEALARWQPAIATVDSYVISYTGEKVPEITRTVSGNTVEYALTDLEPATEYTLRIFAEKGPQKSSTITAKFTTDLDSPRDLTATEVQSETALLTWRPPRASVTGYLLVYESVDGTVKEVIVGPDTTSYSLADLSPSTHYTAKIQALNGPLRSNMIQTIFTTIGLLYPFPKDCSQAMLNGDTTSGLYTIYLNGDKAEALEVFCDMTSDGGGWIVFLRRKNGRENFYQNWKAYAAGFGDRREEFWLGLDNLNKITAQGQYELRVDLRDHGETAFAVYDKFSVGDAKTRYKLKVEGYSGTAGDSMAYHNGRSFSTFDKDTDSAITNCALSYKGAFWYRNCHRVNLMGRYGDNNHSQGVNWFHWKGHEHSIQFAEMKLRPSNFRNLEGRRKRA>sp|Q8N5D0|WDTC1_HUMAN WD and tetratricopeptide repeats protein 1 OS=Homosapiens OX=9606 GN=WDTC1 PE=1 SV=2MAKVNITRDLIRRQIKERGALSFERRYHVTDPFIRRLGLEAELQGHSGCVNCLEWNEKGDLLASGSDDQHTIVWDPLHHKKLLSMHTGHTANIFSVKFLPHAGDRILITGAADSKVHVHDLTVKETIHMFGDHTNRVKRIATAPMWPNTFWSAAEDGLIRQYDLRENSKHSEVLIDLTEYCGQLVEAKCLTVNPQDNNCLAVGASGPFVRLYDIRMIHNHRKSMKQSPSAGVHTFCDRQKPLPDGAAQYYVAGHLPVKLPDYNNRLRVLVATYVTFSPNGTELLVNMGGEQVYLFDLTYKQRPYTFLLPRKCHSSGEVQNGKMSTNGVSNGVSNGLHLHSNGFRLPESRGHVSPQVELPPYLERVKQQANEAFACQQWTQAIQLYSKAVQRAPHNAMLYGNRAAAYMKRKWDGDHYDALRDCLKAISLNPCHLKAHFRLARCLFELKYVAEALECLDDFKGKFPEQAHSSACDALGRDITAALFSKNDGEEKKGPGGGAPVRLRSTSRKDSISEDEMVLRERSYDYQFRYCGHCNTTTDIKEANFFGSNAQYIVSGSDDGSFFIWEKETTNLVRVLQGDESIVNCLQPHPSYCFLATSGIDPVVRLWNPRPESEDLTGRVVEDMEGASQANQRRMNADPLEVMLLNMGYRITGLSSGGAGASDDEDSSEGQVQCRPS>sp|Q8N5D0-2|WDTC1_HUMAN Isoform 2 of WD and tetratricopeptide repeatsprotein 1 OS=Homo sapiens OX=9606 GN=WDTC1MAKVNITRDLIRRQIKERGALSFERRYHVTDPFIRRLGLEAELQGHSGCVNCLEWNEKGDLLASGSDDQHTIVWDPLHHKKLLSMHTGHTANIFSVKFLPHAGDRILITGAADSKVHVHDLTVKETIHMFGDHTNRVKRIATAPMWPNTFWSAAEDGLIRQYDLRENSKHSEVLIDLTEYCGQLVEAKCLTVNPQDNNCLAVGASGPFVRLYDIRMIHNHRKSMKQSPSAGVHTFCDRQKPLPDGAAQYYVAGHLPVKLPDYNNRLRVLVATYVTFSPNGTELLVNMGGEQVYLFDLTYKQRPYTFLLPRKCHSSGEVQNGKMSTNGVSNGVSNGLHLHSNGFRLPESRGHVSPQVELPPYLERVKQQANEAFACQQWTQAIQLYSKAVQRAPHNAMLYGNRAAAYMKRKWDGDHYDALRDCLKAISLNPCHLKAHFRLARCLFELKYVAEALECLDDFKGKFPEQAHSSACDALGRDITAALFSKNDGEEKKGPGGGAPVRLRSTSRKDSISEDEMVLRERSYDYQFRYCGHCNTTTDIKEANFFGRRPPTWSVCSKGMSPLSTACSHTPATASWPPVASILLCGSGTPDQRVKTSQAESWKIWRVLHRPTSGA>sp|Q8N5D0-3|WDTC1_HUMAN Isoform 3 of WD and tetratricopeptide repeatsprotein 1 OS=Homo sapiens OX=9606 GN=WDTC1MAKVNITRDLIRRQIKERGALSFERRYHVTDPFIRRLGLEAELQGHSGCVNCLEWNEKGDLLASGSDDQHTIVWDPLHHKKLLSMHTGHTANIFSVKFLPHAGDRILITGAADSKVHVHDLTVKETIHMFGDHTNRVKRIATAPMWPNTFWSAAEDGLIRQYDLRENSKHSEVLIDLTEYCGQLVEAKCLTVNPQDNNCLAVGASGPFVRLYDIRMIHNHRKSMKQSPSAGVHTFCDRQKPLPDGAAQYYVAGHLPVKLPDYNNRLRVLVATYVTFSPNGTELLVNMGGEQVYLFDLTYKQRPYTFLLPRKCHSSGEVQNGKMSTNGVSNGVSNGLHLHSNGFRLPESRGHVSPQVELPPYLERVKQQANEAFACQQWTQAIQLYSKAVQRAPHNAMLYGNRAAAYMKRKWDGDHYDALRDCLKAISLNPCHLKAHFRLARCLFELKYVAEALECLDDFKGKFPEQAHSSACDALGRDITAALFSKNDGEEKKGPGGGAPVRLRSTSRKDSISEDEMVLRERSYDYQFRYCGHCNTTTDIKEANFFGRSEALKRRVQPSWQREVEWGVLGHNGFREESQIPALPLYPWANGFTFVSL>sp|Q8N5D0-4|WDTC1_HUMAN Isoform 4 of WD and tetratricopeptide repeatsprotein 1 OS=Homo sapiens OX=9606 GN=WDTC1MAKVNITRDLIRRQIKERGALSFERRYHVTDPFIRRLGLEAELQGHSGCVNCLEWNEKGDLLASGSDDQHTIVWDPLHHKKLLSMHTGHTANIFSVKFLPHAGDRILITGAADSKVHVHDLTVKETIHMFGDHTNRVKRIATAPMWPNTFWSAAEDGLIRQYDLRENSKHSEVLIDLTEYCGQLVEAKCLTVNPQDNNCLAVGASGPFVRLYDIRMIHNHRKSMKQSPSAGVHTFCDRQKPLPDGAAQYYVAGHLPVKLPDYNNRLRVLVATYVTFSPNGTELLVNMGGEQVYLFDLTYKQRPYTFLLPRKCHSSGVQNGKMSTNGVSNGVSNGLHLHSNGFRLPESRGHVSPQVELPPYLERVKQQANEAFACQQWTQAIQLYSKAVQRAPHNAMLYGNRAAAYMKRKWDGDHYDALRDCLKAISLNPCHLKAHFRLARCLFELKYVAEALECLDDFKGKFPEQAHSSACDALGRDITAALFSKNDGEEKKGPGGGAPVRLRSTSRKDSISEDEMVLRERSYDYQFRYCGHCNTTTDIKEANFFGSNAQYIVSGSDDGSFFIWEKETTNLVRVLQGDESIVNCLQPHPSYCFLATSGIDPVVRLWNPRPESEDLTGRVVEDMEGASQANQRRMNADPLEVMLLNMGYRITGLSSGGAGASDDEDSSEGQVQCRPS>sp|Q8N5D0-5|WDTC1_HUMAN Isoform 5 of WD and tetratricopeptide repeatsprotein 1 OS=Homo sapiens OX=9606 GN=WDTC1MAKVNITRDLIRRQIKERGALSFERRYHVTDPFIRRLGLEAELQGHSGCVNCLEWNEKGDLLASGSDDQHTIVWDPLHHKKLLSMHTGHTANIFSVKFLPHAGDRILITGAADSKVHVHDLTVKETIHMFGDHTNRVKRIATAPMWPNTFWSAAEDGLIRQYDLRENSKHSEVLIDLTEYCGQLVEAKCLTVNPQDNNCLAVGASGPFVRLYDIRMIHNHRKSMKQSPSAGVHTFCDRQKPLPDGAAQYYVAGHLPVKLPDYNNRLRVLVATYVTFSPNGTELLVNMGGEQVYLFDLTYKQRPYTFLLPRKCHSSGVQNGKMSTNGVSNGVSNGLHLHSNGFRLPESRGHVSPQVELPPYLERVKQQANEAFACQQWTQAIQLYSKAVQRAPHNAMLYGNRAAAYMKRKWDGDHYDALRDCLKAISLNPCHLKAHFRLARCLFELKYVAEALECLDDFKGKFPEQAHSSACDALGRDITAALFSKNDGEEKKGPGGGAPVRLRSTSRKDSISEDEMVLRERSYDYQFRYCGHCNTTTDIKEANFFGRSEALKRRVQPSWQREVEWGVLGHNGFREESQIPALPLYPWANGFTFVSL>sp|Q8N5D0-6|WDTC1_HUMAN Isoform 6 of WD and tetratricopeptide repeatsprotein 1 OS=Homo sapiens OX=9606 GN=WDTC1MAKVNITRDLIRRQIKERGALSFERRYHVTDPFIRRLGLEAELQGHSGCVNCLEWNEKGDLLASGSDDQHTIVWDPLHHKKLLSMHTGHTANIFSVKFLPHAGDRILITGAADSKVHVHDLTVKETIHMFGDHTNRVKRIATAPMWPNTFWSAAEDGLIRQYDLRENSKHSEVLIDLTEYCGQLVEAKCLTVNPQDNNCLAVGASGPFVRLYDIRMIHNHRKSMKQSPSAGVHTFCDRQKPLPDGAAQYYVAGHLPVKLPDYNNRLRVLVATYVTFSPNGTELLVNMGGEQVYLFDLTYKQRPYTFLLPRKCHSSGVQNGKMSTNGVSNGVSNGLHLHSNGFRLPESRGHVSPQVELPPYLERVKQQANEAFACQQWTQAIQLYSKAVQRAPHNAMLYGNRAAAYMKRKWDGDHYDALRDCLKAISLNPCHLKAHFRLARCLFELKYVAEALECLDDFKGKFPEQAHSSACDALGRDITAALFSKNDGEEKKGPGGGAPVRLRSTSRKDSISEDEMVLRERSYDYQFRYCGHCNTTTDIKEANFFGRRPPTWSVCSKGMSPLSTACSHTPATASWPPVASILLCGSGTPDQRVKTSQAESWKIWRVLHRPTSGA>sp|O60347|TBC12_HUMAN TBC1 domain family member 12 OS=Homo sapiensOX=9606 GN=TBC1D12 PE=1 SV=3MVGPEDAGACSGRNPKLLPVPAPDPVGQDRKVIRATGGFGGGVGAVEPPEEADEEEEADEEEETPPRQLLQRYLAAAGEQLEPGLCYCPLPAGQAGAPPPSAAPRSDACLLGSGSKHRGAEVADGRAPRHEGMTNGDSGFLPGRDCRDLEEARGLARAGGRESRRRRPYGRLRLEGPGDEDADGAGSPSDWASPLEDPLRSCCLVAADAQEPEGAGSDSGDSPASSCSSSEDSEQRGVGAGGPEEGAPPATSAERTNGGAEPRLGFSDIHFNSRNTFQVSRGQSARDHLPPAGPPVPLPAAEQGPAGASARARRSGGFADFFTRNLFPKRTKELKSVVHSAPGWKLFGKVPPRENLQKTSKIIQQEYEARTGRTCKPPPQSSRRKNFEFEPLSTTALILEDRPSNLPAKSVEEALRHRQEYDEMVAEAKKREIKEAHKRKRIMKERFKQEENIASAMVIWINEILPNWEVMRSTRRVRELWWQGLPPSVRGKVWSLAVGNELNITPELYEIFLSRAKERWKSFSETSSENDTEGVSVADREASLELIKLDISRTFPSLYIFQKGGPYHDVLHSILGAYTCYRPDVGYVQGMSFIAAVLILNLEEADAFIAFANLLNKPCQLAFFRVDHSMMLKYFATFEVFFEENLSKLFLHFKSYSLTPDIYLIDWIFTLYSKSLPLDLACRVWDVFCRDGEEFLFRTGLGILRLYEDILLQMDFIHIAQFLTKLPEDITSEKLFSCIAAIQMQNSTKKWTQVFASVMKDIKEGDKNSSPALKS>sp|Q7Z5S9|TM144_HUMAN Transmembrane protein 144 OS=Homo sapiens OX=9606GN=TMEM144 PE=1 SV=1MSNNGADLTFGYISCFVAILLFGSNFVPLKKFDTGDGMFLQWVLCAAIWLVALVVNLILHCPKFWPFAMLGGCIWATGNIAVVPIIKTIGLGLGILIWGSFNALTGWASSRFGWFGLDAEEVSNPLLNYIGAGLSVVSAFIFLFIKSEIPNNTCSMDTTPLITEHVINTTQDPCSWVDKLSTVHHRIVGCSLAVISGVLYGSTFVPIIYIKDHSKRNDSIYAGASQYDLDYVFAHFSGIFLTSTVYFLAYCIAMKNSPKLYPEAVLPGFLSGVLWAIATCCWFIANHSLSAVVSFPIITAGPGFIAAMWGIFMFKEIKGLQNYLLMILAFCIILTGALCTAFSKI>sp|Q7Z5S9-2|TM144_HUMAN Isoform 2 of Transmembrane protein 144 OS=Homosapiens OX=9606 GN=TMEM144MSNNGADLTFGYISCFVAILLFGSNFVPLKKFDTGDGMFLQWVLCAAIWLVALVVNLILHCPKFWPFAMLGGCIWATGNIAVVPIIKTIGLGLGILIWGSFNALTGWASSRFGWFGLDAEEVSNPLLNYIGAGLSVVSAFIFLFIKSEIPNNTCSMDTTPLITEHVSIV>sp|Q9NY65|TBA8_HUMAN Tubulin alpha-8 chain OS=Homo sapiens OX=9606GN=TUBA8 PE=1 SV=1MRECISVHVGQAGVQIGNACWELFCLEHGIQADGTFDAQASKINDDDSFTTFFSETGNGKHVPRAVMIDLEPTVVDEVRAGTYRQLFHPEQLITGKEDAANNYARGHYTVGKESIDLVLDRIRKLTDACSGLQGFLIFHSFGGGTGSGFTSLLMERLSLDYGKKSKLEFAIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLISQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLVTYAPIISAEKAYHEQLSVAEITSSCFEPNSQMVKCDPRHGKYMACCMLYRGDVVPKDVNVAIAAIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLDHKFDLMYAKRAFVHWYVGEGMEEGEFSEAREDLAALEKDYEEVGTDSFEEENEGEEF>sp|Q9NY65-2|TBA8_HUMAN Isoform 2 of Tubulin alpha-8 chain OS=Homosapiens OX=9606 GN=TUBA8MIDLEPTVVDEVRAGTYRQLFHPEQLITGKEDAANNYARGHYTVGKESIDLVLDRIRKLTDACSGLQGFLIFHSFGGGTGSGFTSLLMERLSLDYGKKSKLEFAIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLISQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLVTYAPIISAEKAYHEQLSVAEITSSCFEPNSQMVKCDPRHGKYMACCMLYRGDVVPKDVNVAIAAIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLDHKFDLMYAKRAFVHWYVGEGMEEGEFSEAREDLAALEKDYEEVGTDSFEEENEGEEF>sp|Q9UJA5|TRM6_HUMAN tRNA (adenine(58)-N(1))-methyltransferase non-catalytic subunit TRM6 OS=Homo sapiens OX=9606 GN=TRMT6 PE=1 SV=1MEGSGEQPGPQPQHPGDHRIRDGDFVVLKREDVFKAVQVQRRKKVTFEKQWFYLDNVIGHSYGTAFEVTSGGSLQPKKKREEPTAETKEAGTDNRNIVDDGKSQKLTQDDIKALKDKGIKGEEIVQQLIENSTTFRDKTEFAQDKYIKKKKKKYEAIITVVKPSTRILSIMYYAREPGKINHMRYDTLAQMLTLGNIRAGNKMIVMETCAGLVLGAMMERMGGFGSIIQLYPGGGPVRAATACFGFPKSFLSGLYEFPLNKVDSLLHGTFSAKMLSSEPKDSALVEESNGTLEEKQASEQENEDSMAEAPESNHPEDQETMETISQDPEHKGPKERGSKKDYIQEKQRRQEEQRKRHLEAAALLSERNADGLIVASRFHPTPLLLSLLDFVAPSRPFVVYCQYKEPLLECYTKLRERGGVINLRLSETWLRNYQVLPDRSHPKLLMSGGGGYLLSGFTVAMDNLKADTSLKSNASTLESHETEEPAAKKRKCPESDS>sp|Q9UJA5-2|TRM6_HUMAN Isoform 2 of tRNA (adenine(58)-N(1))-methyltransferase non-catalytic subunit TRM6 OS=Homo sapiens OX=9606GN=TRMT6MEGSGEQPGPQPQHPGDHRIRDGDFVVLKREDVFKAVQVQRRKKVTFEKQWFYLDNVIGHSYGTAFEVTSGGSLQPKKKREEPTAETKEAGTDNRNIVDDGKSQKLTQDDIKALKDKGIKGEEIVQQLIENSTTFRDKTEFAQDKYIKKKKKKYEAIITVVKPSTRILSIMYYAREPGKINHMRYDTLAQMLTLGNIRAGNKMIVMETCAGLVLGAMMERMGGFGSIIQLYPGGGPVRAATACFGFPKSFLSGLYEFPLNKVDSLLHGTFSAKMLSSEPKDSALVEESNGTLEEKQASEQENEDSMAEAPESNHPEDQETMETISQDPEHKGPKERGSKKDYIQEKQRRQEEQRKRHLEAAALLSERNADGCVDGRRQETPQCMWALLQTDWHSLSPCL>sp|Q9UJA5-3|TRM6_HUMAN Isoform 3 of tRNA (adenine(58)-N(1))-methyltransferase non-catalytic subunit TRM6 OS=Homo sapiens OX=9606GN=TRMT6MEGSGEQPGPQPQHPGDHRIRDGDFVVLKREDVFKAVQVQRRKKVTFEKQWFYLDNVIGHSYGTAFEVTSGGSLQPKKKREEPTAETKEAGTDNRNIVDDGKSQKLTQDDIKALKDKGIKGEEIVQQLIENSTTFRDKTEFAQDKYIKKKKKKYEAIITVVKPSTRILSIMYYAREPGKINHMRYDTLAQMLTLGNIRAGNKMIVMETCAGLVLGAMMERMGGFGSIIQLYPGGGPVRAATACFGFPKSFLSGLYEFPLNKVDSLLHGTFSAKMLSSEPKDSALVEESNGTLEEKQASEQENEDSMAEAPESNHPEDQETMETISQDPEHKGPKERGSKKDYISGKNRGRQGRSSGKDFWGCRFA>sp|Q9UJA5-4|TRM6_HUMAN Isoform 4 of tRNA (adenine(58)-N(1))-methyltransferase non-catalytic subunit TRM6 OS=Homo sapiens OX=9606GN=TRMT6MYYAREPGKINHMRYDTLAQMLTLGNIRAGNKMIVMETCAGLVLGAMMERMGGFGSIIQLYPGGGPVRAATACFGFPKSFLSGLYEFPLNKVDSLLHGTFSAKMLSSEPKDSALVEESNGTLEEKQASEQENEDSMAEAPESNHPEDQETMETISQDPEHKGPKERGSKKDYIQEKQRRQEEQRKRHLEAAALLSERNADGLIVASRFHPTPLLLSLLDFVAPSRPFVVYCQYKEPLLECYTKLRERGGVINLRLSETWLRNYQVLPDRSHPKLLMSGGGGYLLSGFTVAMDNLKADTSLKSNASTLESHETEEPAAKKRKCPESDS>sp|Q96BZ9|TBC20_HUMAN TBC1 domain family member 20 OS=Homo sapiensOX=9606 GN=TBC1D20 PE=1 SV=1MALRSAQGDGPTSGHWDGGAEKADFNAKRKKKVAEIHQALNSDPTDVAALRRMAISEGGLLTDEIRRKVWPKLLNVNANDPPPISGKNLRQMSKDYQQVLLDVRRSLRRFPPGMPEEQREGLQEELIDIILLILERNPQLHYYQGYHDIVVTFLLVVGERLATSLVEKLSTHHLRDFMDPTMDNTKHILNYLMPIIDQVNPELHDFMQSAEVGTIFALSWLITWFGHVLSDFRHVVRLYDFFLACHPLMPIYFAAVIVLYREQEVLDCDCDMASVHHLLSQIPQDLPYETLISRAGDLFVQFPPSELAREAAAQQQAERTAASTFKDFELASAQQRPDMVLRQRFRGLLRPEDRTKDVLTKPRTNRFVKLAVMGLTVALGAAALAVVKSALEWAPKFQLQLFP>sp|Q96BZ9-2|TBC20_HUMAN Isoform 2 of TBC1 domain family member 20OS=Homo sapiens OX=9606 GN=TBC1D20MPIIDQVNPELHDFMQRYICVCISVCMHTHAHTPPHLKHSSQAERSFLIVLGGFVKFSPVVPVTSNLGNSVLGAFLGTVLFGGHSPSLEFTSSGERWIRYVCQGKMLRLLPQEKHKVLWDPVARRGRPTMGCFISQVPKRRNIFLQIPCDVLFLLCLVGNVFLANASFFKIF>sp|Q96BZ9-3|TBC20_HUMAN Isoform 3 of TBC1 domain family member 20OS=Homo sapiens OX=9606 GN=TBC1D20MPSGCYVPRSEPRLLPAPPPAGARVGALRSAQGDGPTSGHWDGGAEKADFNAKRKKKVAEIHQALNSDPTDVAALRRMAISEGGLLTDEIRRKVWPKLLNVNANDPPPISGKNLRQMSKDYQQVLLDVRRSLRRFPPGMPEEQREGLQEELIDIILLILERNPQLHYYQGYHDIVVTFLLVVGERLATSLVEKLSTHHLRDFMDPTMDNTKHILNYLMPIIDQVNPELHDFMQSAEVGTIFALSWLITWFGHVLSDFRHVVRLYDFFLACHPLMPIYFAAVIVLYREQEVLDCDCDMASVHHLLSQIPQDLPYETLISRAGDLFVQFPPSELAREAAAQQQAERTAASTFKDFELASAQQRPDMVLRQRFRGLLRPEDRTKDVLTKPRTNRFVKLAVMGLTVALGAAALAVVKSALEWAPKFQLQLFP>sp|O95271|TNKS1_HUMAN Poly [ADP-ribose] polymerase tankyrase-1 OS=Homosapiens OX=9606 GN=TNKS PE=1 SV=2MAASRRSQHHHHHHQQQLQPAPGASAPPPPPPPPLSPGLAPGTTPASPTASGLAPFASPRHGLALPEGDGSRDPPDRPRSPDPVDGTSCCSTTSTICTVAAAPVVPAVSTSSAAGVAPNPAGSGSNNSPSSSSSPTSSSSSSPSSPGSSLAESPEAAGVSSTAPLGPGAAGPGTGVPAVSGALRELLEACRNGDVSRVKRLVDAANVNAKDMAGRKSSPLHFAAGFGRKDVVEHLLQMGANVHARDDGGLIPLHNACSFGHAEVVSLLLCQGADPNARDNWNYTPLHEAAIKGKIDVCIVLLQHGADPNIRNTDGKSALDLADPSAKAVLTGEYKKDELLEAARSGNEEKLMALLTPLNVNCHASDGRKSTPLHLAAGYNRVRIVQLLLQHGADVHAKDKGGLVPLHNACSYGHYEVTELLLKHGACVNAMDLWQFTPLHEAASKNRVEVCSLLLSHGADPTLVNCHGKSAVDMAPTPELRERLTYEFKGHSLLQAAREADLAKVKKTLALEIINFKQPQSHETALHCAVASLHPKRKQVTELLLRKGANVNEKNKDFMTPLHVAAERAHNDVMEVLHKHGAKMNALDTLGQTALHRAALAGHLQTCRLLLSYGSDPSIISLQGFTAAQMGNEAVQQILSESTPIRTSDVDYRLLEASKAGDLETVKQLCSSQNVNCRDLEGRHSTPLHFAAGYNRVSVVEYLLHHGADVHAKDKGGLVPLHNACSYGHYEVAELLVRHGASVNVADLWKFTPLHEAAAKGKYEICKLLLKHGADPTKKNRDGNTPLDLVKEGDTDIQDLLRGDAALLDAAKKGCLARVQKLCTPENINCRDTQGRNSTPLHLAAGYNNLEVAEYLLEHGADVNAQDKGGLIPLHNAASYGHVDIAALLIKYNTCVNATDKWAFTPLHEAAQKGRTQLCALLLAHGADPTMKNQEGQTPLDLATADDIRALLIDAMPPEALPTCFKPQATVVSASLISPASTPSCLSAASSIDNLTGPLAELAVGGASNAGDGAAGTERKEGEVAGLDMNISQFLKSLGLEHLRDIFETEQITLDVLADMGHEELKEIGINAYGHRHKLIKGVERLLGGQQGTNPYLTFHCVNQGTILLDLAPEDKEYQSVEEEMQSTIREHRDGGNAGGIFNRYNVIRIQKVVNKKLRERFCHRQKEVSEENHNHHNERMLFHGSPFINAIIHKGFDERHAYIGGMFGAGIYFAENSSKSNQYVYGIGGGTGCPTHKDRSCYICHRQMLFCRVTLGKSFLQFSTMKMAHAPPGHHSVIGRPSVNGLAYAEYVIYRGEQAYPEYLITYQIMKPEAPSQTATAAEQKT>sp|O95271-2|TNKS1_HUMAN Isoform 2 of Poly [ADP-ribose] polymerasetankyrase-1 OS=Homo sapiens OX=9606 GN=TNKSMAASRRSQHHHHHHQQQLQPAPGASAPPPPPPPPLSPGLAPGTTPASPTASGLAPFASPRHGLALPEGDGSRDPPDRPRSPDPVDGTSCCSTTSTICTVAAAPVVPAVSTSSAAGVAPNPAGSGSNNSPSSSSSPTSSSSSSPSSPGSSLAESPEAAGVSSTAPLGPGAAGPGTGVPAVSGALRELLEACRNGDVSRVKRLVDAANVNAKDMAGRKSSPLHFAAGFGRKDVVEHLLQMGANVHARDDGGLIPLHNACSFGHAEVVSLLLCQGADPNARDNWNYTPLHEAAIKGKIDVCIVLLQHGADPNIRNTDGKSALDLADPSAKAVLTGEYKKDELLEAARSGNEEKLMALLTPLNVNCHASDGRKSTPLHLAAGYNRVRIVQLLLQHGADVHAKDKGGLVPLHNACSYGHYEVTELLLKHGACVNAMDLWQFTPLHEAASKNRVEVCSLLLSHGADPTLVNCHGKSAVDMAPTPELRERLTYEFKGHSLLQAAREADLAKVKKTLALEIINFKQPQSHETALHCAVASLHPKRKQVTELLLRKGANVNEKNKDFMTPLHVAAERAHNDVMEVLHKHGAKMNALDTLGQTALHRAALAGHLQTCRLLLSYGSDPSIISLQGFTAAQMGNEAVQQILSGHS>sp|Q9BXI6|TB10A_HUMAN TBC1 domain family member 10A OS=Homo sapiensOX=9606 GN=TBC1D10A PE=1 SV=1MAKSNGENGPRAPAAGESLSGTRESLAQGPDAATTDELSSLGSDSEANGFAERRIDKFGFIVGSQGAEGALEEVPLEVLRQRESKWLDMLNNWDKWMAKKHKKIRLRCQKGIPPSLRGRAWQYLSGGKVKLQQNPGKFDELDMSPGDPKWLDVIERDLHRQFPFHEMFVSRGGHGQQDLFRVLKAYTLYRPEEGYCQAQAPIAAVLLMHMPAEQAFWCLVQICEKYLPGYYSEKLEAIQLDGEILFSLLQKVSPVAHKHLSRQKIDPLLYMTEWFMCAFSRTLPWSSVLRVWDMFFCEGVKIIFRVGLVLLKHALGSPEKVKACQGQYETIERLRSLSPKIMQEAFLVQEVVELPVTERQIEREHLIQLRRWQETRGELQCRSPPRLHGAKAILDAEPGPRPALQPSPSIRLPLDAPLPGSKAKPKPPKQAQKEQRKQMKGRGQLEKPPAPNQAMVVAAAGDACPPQHVPPKDSAPKDSAPQDLAPQVSAHHRSQESLTSQESEDTYL>sp|Q9BXI6-2|TB10A_HUMAN Isoform 2 of TBC1 domain family member 10AOS=Homo sapiens OX=9606 GN=TBC1D10AMAKSNGENGPRAPAAGESLSGTRESLAQGPDAATTDELSSLGSDSEANGFAERRIDKFGFIVGSQGAEGAPCPLLHRLEEVPLEVLRQRESKWLDMLNNWDKWMAKKHKKIRLRCQKGIPPSLRGRAWQYLSGGKVKLQQNPGKFDELDMSPGDPKWLDVIERDLHRQFPFHEMFVSRGGHGQQDLFRVLKAYTLYRPEEGYCQAQAPIAAVLLMHMPAEQAFWCLVQICEKYLPGYYSEKLEAIQLDGEILFSLLQKVSPVAHKHLSRQKIDPLLYMTEWFMCAFSRTLPWSSVLRVWDMFFCEGVKIIFRVGLVLLKHALGSPEKVKACQGQYETIERLRSLSPKIMQEAFLVQEVVELPVTERQIEREHLIQLRRWQETRGELQCRSPPRLHGAKAILDAEPGPRPALQPSPSIRLPLDAPLPGSKAKPKPPKQAQKEQRKQMKGRGQLEKPPAPNQAMVVAAAGDACPPQHVPPKDSAPKDSAPQDLAPQVSAHHRSQESLTSQESEDTYL>sp|Q86T26|TM11B_HUMAN Transmembrane protease serine 11B OS=Homo sapiensOX=9606 GN=TMPRSS11B PE=2 SV=3MYRHGISSQRSWPLWTTIFIFLGVAAILGVTIGLLVHFLAVEKTYYYQGDFHISGVTYNDNCENAASQASTNLSKDIETKMLNAFQNSSIYKEYVKSEVIKLLPNANGSNVQLQLKFKFPPAEGVSMRTKIKAKLHQMLKNNMASWNAVPASIKLMEISKAASEMLTNNCCGRQVANSIITGNKIVNGKSSLEGAWPWQASMQWKGRHYCGASLISSRWLLSAAHCFAKKNNSKDWTVNFGIVVNKPYMTRKVQNIIFHENYSSPGLHDDIALVQLAEEVSFTEYIRKICLPEAKMKLSENDNVVVTGWGTLYMNGSFPVILQEDFLKIIDNKICNASYAYSGFVTDTMLCAGFMSGEADACQNDSGGPLAYPDSRNIWHLVGIVSWGDGCGKKNKPGVYTRVTSYRNWITSKTGL>sp|A0A0B4J276|TVA25_HUMAN T cell receptor alpha variable 25 OS=Homosapiens OX=9606 GN=TRAV25 PE=3 SV=1MLLITSMLVLWMQLSQVNGQQVMQIPQYQHVQEGEDFTTYCNSSTTLSNIQWYKQRPGGHPVFLIQLVKSGEVKKQKRLTFQFGEAKKNSSLHITATQTTDVGTYFCAG>sp|Q00888|PSG4_HUMAN Pregnancy-specific beta-1-glycoprotein 4 OS=Homosapiens OX=9606 GN=PSG4 PE=2 SV=3MGPLSAPPCTQRITWKGVLLTASLLNFWNPPTTAQVTIEAQPPKVSEGKDVLLLVHNLPQNLAGYIWYKGQMTYLYHYITSYVVDGQRIIYGPAYSGRERVYSNASLLIQNVTQEDAGSYTLHIIKRRDGTGGVTGHFTFTLHLETPKPSISSSNLNPREAMEAVILTCDPATPAASYQWWMNGQSLPMTHRLQLSKTNRTLFIFGVTKYIAGPYECEIRNPVSASRSDPVTLNLLPKLSKPYITINNLNPRENKDVLTFTCEPKSKNYTYIWWLNGQSLPVSPRVKRPIENRILILPNVTRNETGPYQCEIRDRYGGIRSDPVTLNVLYGPDLPSIYPSFTYYRSGENLYLSCFAESNPRAQYSWTINGKFQLSGQKLSIPQITTKHSGLYACSVRNSATGKESSKSITVKVSDWILP>sp|Q00888-2|PSG4_HUMAN Isoform 2 of Pregnancy-specific beta-1-glycoprotein 4 OS=Homo sapiens OX=9606 GN=PSG4MGPLSAPPCTQRITWKGVLLTASLLNFWNPPTTAQVTIEAQPPKVSEGKDVLLLVHNLPQNLAGYIWYKGQMTYLYHYITSYVVDGQRIIYGPAYSGRERVYSNASLLIQNVTQEDAGSYTLHIIKRRDGTGGVTGHFTFTLHLETPKPSISSSNLNPREAMEAVILTCDPATPAASYQWWMNGQSLPMTHRLQLSKTNRTLFIFGVTKYIAGPYECEIRNPVSASRSDPVTLNLLHGPDLPSIYPSFTYYRSGENLYLSCFAESNPRAQYSWTINGKFQLSGQKLSIPQITTKHSGLYACSVRNSATGKESSKSITVKVSDWILP>sp|Q00888-3|PSG4_HUMAN Isoform 3 of Pregnancy-specific beta-1-glycoprotein 4 OS=Homo sapiens OX=9606 GN=PSG4MGPLSAPPCTQRITWKGVLLTASLLNFWNPPTTAQVTIEAQPPKVSEGKDVLLLVHNLPQNLAGYIWYKGQMTYLYHYITSYVVDGQRIIYGPAYSGRERVYSNASLLIQNVTQEDAGSYTLHIIKRRDGTGGVTGHFTFTLHPKLSKPYITINNLNPRENKDVLTFTCEPKSKNYTYIWWLNGQSLPVSPRVKRPIENRILILPNVTRNETGPYQCEIRDRYGGIRSDPVTLNVLYGPDLPSIYPSFTYYRSGENLYLSCFAESNPRAQYSWTINGKFQLSGQKLSIPQITTKHSGLYACSVRNSATGKESSKSITVKVSDWILP>sp|P23469|PTPRE_HUMAN Receptor-type tyrosine-protein phosphatase epsilonOS=Homo sapiens OX=9606 GN=PTPRE PE=1 SV=1MEPLCPLLLVGFSLPLARALRGNETTADSNETTTTSGPPDPGASQPLLAWLLLPLLLLLLVLLLAAYFFRFRKQRKAVVSTSDKKMPNGILEEQEQQRVMLLSRSPSGPKKYFPIPVEHLEEEIRIRSADDCKQFREEFNSLPSGHIQGTFELANKEENREKNRYPNILPNDHSRVILSQLDGIPCSDYINASYIDGYKEKNKFIAAQGPKQETVNDFWRMVWEQKSATIVMLTNLKERKEEKCHQYWPDQGCWTYGNIRVCVEDCVVLVDYTIRKFCIQPQLPDGCKAPRLVSQLHFTSWPDFGVPFTPIGMLKFLKKVKTLNPVHAGPIVVHCSAGVGRTGTFIVIDAMMAMMHAEQKVDVFEFVSRIRNQRPQMVQTDMQYTFIYQALLEYYLYGDTELDVSSLEKHLQTMHGTTTHFDKIGLEEEFRKLTNVRIMKENMRTGNLPANMKKARVIQIIPYDFNRVILSMKRGQEYTDYINASFIDGYRQKDYFIATQGPLAHTVEDFWRMIWEWKSHTIVMLTEVQEREQDKCYQYWPTEGSVTHGEITIEIKNDTLSEAISIRDFLVTLNQPQARQEEQVRVVRQFHFHGWPEIGIPAEGKGMIDLIAAVQKQQQQTGNHPITVHCSAGAGRTGTFIALSNILERVKAEGLLDVFQAVKSLRLQRPHMVQTLEQYEFCYKVVQDFIDIFSDYANFK>sp|P23469-2|PTPRE_HUMAN Isoform 2 of Receptor-type tyrosine-proteinphosphatase epsilon OS=Homo sapiens OX=9606 GN=PTPREMSNRSSFSRLTWFRKQRKAVVSTSDKKMPNGILEEQEQQRVMLLSRSPSGPKKYFPIPVEHLEEEIRIRSADDCKQFREEFNSLPSGHIQGTFELANKEENREKNRYPNILPNDHSRVILSQLDGIPCSDYINASYIDGYKEKNKFIAAQGPKQETVNDFWRMVWEQKSATIVMLTNLKERKEEKCHQYWPDQGCWTYGNIRVCVEDCVVLVDYTIRKFCIQPQLPDGCKAPRLVSQLHFTSWPDFGVPFTPIGMLKFLKKVKTLNPVHAGPIVVHCSAGVGRTGTFIVIDAMMAMMHAEQKVDVFEFVSRIRNQRPQMVQTDMQYTFIYQALLEYYLYGDTELDVSSLEKHLQTMHGTTTHFDKIGLEEEFRKLTNVRIMKENMRTGNLPANMKKARVIQIIPYDFNRVILSMKRGQEYTDYINASFIDGYRQKDYFIATQGPLAHTVEDFWRMIWEWKSHTIVMLTEVQEREQDKCYQYWPTEGSVTHGEITIEIKNDTLSEAISIRDFLVTLNQPQARQEEQVRVVRQFHFHGWPEIGIPAEGKGMIDLIAAVQKQQQQTGNHPITVHCSAGAGRTGTFIALSNILERVKAEGLLDVFQAVKSLRLQRPHMVQTLEQYEFCYKVVQDFIDIFSDYANFK>sp|P23469-3|PTPRE_HUMAN Isoform 3 of Receptor-type tyrosine-proteinphosphatase epsilon OS=Homo sapiens OX=9606 GN=PTPREMPNGILEEQEQQRVMLLSRSPSGPKKYFPIPVEHLEEEIRIRSADDCKQFREEFNSLPSGHIQGTFELANKEENREKNRYPNILPNDHSRVILSQLDGIPCSDYINASYIDGYKEKNKFIAAQGPKQETVNDFWRMVWEQKSATIVMLTNLKERKEEKCHQYWPDQGCWTYGNIRVCVEDCVVLVDYTIRKFCIQPQLPDGCKAPRLVSQLHFTSWPDFGVPFTPIGMLKFLKKVKTLNPVHAGPIVVHCSAGVGRTGTFIVIDAMMAMMHAEQKVDVFEFVSRIRNQRPQMVQTDMQYTFIYQALLEYYLYGDTELDVSSLEKHLQTMHGTTTHFDKIGLEEEFRKLTNVRIMKENMRTGNLPANMKKARVIQIIPYDFNRVILSMKRGQEYTDYINASFIDGYRQKDYFIATQGPLAHTVEDFWRMIWEWKSHTIVMLTEVQEREQDKCYQYWPTEGSVTHGEITIEIKNDTLSEAISIRDFLVTLNQPQARQEEQVRVVRQFHFHGWPEIGIPAEGKGMIDLIAAVQKQQQQTGNHPITVHCSAGAGRTGTFIALSNILERVKAEGLLDVFQAVKSLRLQRPHMVQTLEQYEFCYKVVQDFIDIFSDYANFK>sp|O14684|PTGES_HUMAN Prostaglandin E synthase OS=Homo sapiens OX=9606GN=PTGES PE=1 SV=2MPAHSLVMSSPALPAFLLCSTLLVIKMYVVAIITGQVRLRKKAFANPEDALRHGGPQYCRSDPDVERCLRAHRNDMETIYPFLFLGFVYSFLGPNPFVAWMHFLVFLVGRVAHTVAYLGKLRAPIRSVTYTLAQLPCASMALQILWEAARHL>sp|P10586|PTPRF_HUMAN Receptor-type tyrosine-protein phosphatase FOS=Homo sapiens OX=9606 GN=PTPRF PE=1 SV=2MAPEPAPGRTMVPLVPALVMLGLVAGAHGDSKPVFIKVPEDQTGLSGGVASFVCQATGEPKPRITWMKKGKKVSSQRFEVIEFDDGAGSVLRIQPLRVQRDEAIYECTATNSLGEINTSAKLSVLEEEQLPPGFPSIDMGPQLKVVEKARTATMLCAAGGNPDPEISWFKDFLPVDPATSNGRIKQLRSGALQIESSEESDQGKYECVATNSAGTRYSAPANLYVRVRRVAPRFSIPPSSQEVMPGGSVNLTCVAVGAPMPYVKWMMGAEELTKEDEMPVGRNVLELSNVVRSANYTCVAISSLGMIEATAQVTVKALPKPPIDLVVTETTATSVTLTWDSGNSEPVTYYGIQYRAAGTEGPFQEVDGVATTRYSIGGLSPFSEYAFRVLAVNSIGRGPPSEAVRARTGEQAPSSPPRRVQARMLSASTMLVQWEPPEEPNGLVRGYRVYYTPDSRRPPNAWHKHNTDAGLLTTVGSLLPGITYSLRVLAFTAVGDGPPSPTIQVKTQQGVPAQPADFQAEVESDTRIQLSWLLPPQERIIMYELVYWAAEDEDQQHKVTFDPTSSYTLEDLKPDTLYRFQLAARSDMGVGVFTPTIEARTAQSTPSAPPQKVMCVSMGSTTVRVSWVPPPADSRNGVITQYSVAYEAVDGEDRGRHVVDGISREHSSWDLVGLEKWTEYRVWVRAHTDVGPGPESSPVLVRTDEDVPSGPPRKVEVEPLNSTAVHVYWKLPVPSKQHGQIRGYQVTYVRLENGEPRGLPIIQDVMLAEAQWRPEESEDYETTISGLTPETTYSVTVAAYTTKGDGARSKPKIVTTTGAVPGRPTMMISTTAMNTALLQWHPPKELPGELLGYRLQYCRADEARPNTIDFGKDDQHFTVTGLHKGTTYIFRLAAKNRAGLGEEFEKEIRTPEDLPSGFPQNLHVTGLTTSTTELAWDPPVLAERNGRIISYTVVFRDINSQQELQNITTDTRFTLTGLKPDTTYDIKVRAWTSKGSGPLSPSIQSRTMPVEQVFAKNFRVAAAMKTSVLLSWEVPDSYKSAVPFKILYNGQSVEVDGHSMRKLIADLQPNTEYSFVLMNRGSSAGGLQHLVSIRTAPDLLPHKPLPASAYIEDGRFDLSMPHVQDPSLVRWFYIVVVPIDRVGGSMLTPRWSTPEELELDELLEAIEQGGEEQRRRRRQAERLKPYVAAQLDVLPETFTLGDKKNYRGFYNRPLSPDLSYQCFVLASLKEPMDQKRYASSPYSDEIVVQVTPAQQQEEPEMLWVTGPVLAVILIILIVIAILLFKRKRTHSPSSKDEQSIGLKDSLLAHSSDPVEMRRLNYQTPGMRDHPPIPITDLADNIERLKANDGLKFSQEYESIDPGQQFTWENSNLEVNKPKNRYANVIAYDHSRVILTSIDGVPGSDYINANYIDGYRKQNAYIATQGPLPETMGDFWRMVWEQRTATVVMMTRLEEKSRVKCDQYWPARGTETCGLIQVTLLDTVELATYTVRTFALHKSGSSEKRELRQFQFMAWPDHGVPEYPTPILAFLRRVKACNPLDAGPMVVHCSAGVGRTGCFIVIDAMLERMKHEKTVDIYGHVTCMRSQRNYMVQTEDQYVFIHEALLEAATCGHTEVPARNLYAHIQKLGQVPPGESVTAMELEFKLLASSKAHTSRFISANLPCNKFKNRLVNIMPYELTRVCLQPIRGVEGSDYINASFLDGYRQQKAYIATQGPLAESTEDFWRMLWEHNSTIIVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTIRQFQFTDWPEQGVPKTGEGFIDFIGQVHKTKEQFGQDGPITVHCSAGVGRTGVFITLSIVLERMRYEGVVDMFQTVKTLRTQRPAMVQTEDQYQLCYRAALEYLGSFDHYAT>sp|P10586-2|PTPRF_HUMAN Isoform 2 of Receptor-type tyrosine-proteinphosphatase F OS=Homo sapiens OX=9606 GN=PTPRFMAPEPAPGRTMVPLVPALVMLGLVAGAHGDSKPVFIKVPEDQTGLSGGVASFVCQATGEPKPRITWMKKGKKVSSQRFEVIEFDDGAGSVLRIQPLRVQRDEAIYECTATNSLGEINTSAKLSVLEEEQLPPGFPSIDMGPQLKVVEKARTATMLCAAGGNPDPEISWFKDFLPVDPATSNGRIKQLRSGALQIESSEESDQGKYECVATNSAGTRYSAPANLYVRVRRVAPRFSIPPSSQEVMPGGSVNLTCVAVGAPMPYVKWMMGAEELTKEDEMPVGRNVLELSNVVRSANYTCVAISSLGMIEATAQVTVKALPKPPIDLVVTETTATSVTLTWDSGNSEPVTYYGIQYRAAGTEGPFQEVDGVATTRYSIGGLSPFSEYAFRVLAVNSIGRGPPSEAVRARTGEQAPSSPPRRVQARMLSASTMLVQWEPPEEPNGLVRGYRVYYTPDSRRPPNAWHKHNTDAGLLTTVGSLLPGITYSLRVLAFTAVGDGPPSPTIQVKTQQGVPAQPADFQAEVESDTRIQLSWLLPPQERIIMYELVYWAAEDEDQQHKVTFDPTSSYTLEDLKPDTLYRFQLAARSDMGVGVFTPTIEARTAQSTPSAPPQKVMCVSMGSTTVRVSWVPPPADSRNGVITQYSVAYEAVDGEDRGRHVVDGISREHSSWDLVGLEKWTEYRVWVRAHTDVGPGPESSPVLVRTDEDVPSGPPRKVEVEPLNSTAVHVYWKLPVPSKQHGQIRGYQVTYVRLENGEPRGLPIIQDVMLAEAQETTISGLTPETTYSVTVAAYTTKGDGARSKPKIVTTTGAVPGRPTMMISTTAMNTALLQWHPPKELPGELLGYRLQYCRADEARPNTIDFGKDDQHFTVTGLHKGTTYIFRLAAKNRAGLGEEFEKEIRTPEDLPSGFPQNLHVTGLTTSTTELAWDPPVLAERNGRIISYTVVFRDINSQQELQNITTDTRFTLTGLKPDTTYDIKVRAWTSKGSGPLSPSIQSRTMPVEQVFAKNFRVAAAMKTSVLLSWEVPDSYKSAVPFKILYNGQSVEVDGHSMRKLIADLQPNTEYSFVLMNRGSSAGGLQHLVSIRTAPDLLPHKPLPASAYIEDGRFDLSMPHVQDPSLVRWFYIVVVPIDRVGGSMLTPRWSTPEELELDELLEAIEQGGEEQRRRRRQAERLKPYVAAQLDVLPETFTLGDKKNYRGFYNRPLSPDLSYQCFVLASLKEPMDQKRYASSPYSDEIVVQVTPAQQQEEPEMLWVTGPVLAVILIILIVIAILLFKRKRTHSPSSKDEQSIGLKDSLLAHSSDPVEMRRLNYQTPGMRDHPPIPITDLADNIERLKANDGLKFSQEYESIDPGQQFTWENSNLEVNKPKNRYANVIAYDHSRVILTSIDGVPGSDYINANYIDGYRKQNAYIATQGPLPETMGDFWRMVWEQRTATVVMMTRLEEKSRVKCDQYWPARGTETCGLIQVTLLDTVELATYTVRTFALHKSGSSEKRELRQFQFMAWPDHGVPEYPTPILAFLRRVKACNPLDAGPMVVHCSAGVGRTGCFIVIDAMLERMKHEKTVDIYGHVTCMRSQRNYMVQTEDQYVFIHEALLEAATCGHTEVPARNLYAHIQKLGQVPPGESVTAMELEFKLLASSKAHTSRFISANLPCNKFKNRLVNIMPYELTRVCLQPIRGVEGSDYINASFLDGYRQQKAYIATQGPLAESTEDFWRMLWEHNSTIIVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTIRQFQFTDWPEQGVPKTGEGFIDFIGQVHKTKEQFGQDGPITVHCSAGVGRTGVFITLSIVLERMRYEGVVDMFQTVKTLRTQRPAMVQTEDQYQLCYRAALEYLGSFDHYAT>sp|Q15257|PTPA_HUMAN Serine/threonine-protein phosphatase 2A activatorOS=Homo sapiens OX=9606 GN=PTPA PE=1 SV=3MAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAYADYIGFILTLNEGVKGKKLTFEYRVSEMWNEVHEEKEQAAKQSVSCDECIPLPRAGHCAPSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFGSLLPIHPVTSG>sp|Q15257-2|PTPA_HUMAN Isoform 1 of Serine/threonine-protein phosphatase2A activator OS=Homo sapiens OX=9606 GN=PTPAMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFGSLLPIHPVTSG>sp|Q15257-3|PTPA_HUMAN Isoform 3 of Serine/threonine-protein phosphatase2A activator OS=Homo sapiens OX=9606 GN=PTPAMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFGSLLPIHPVTSG>sp|Q15257-4|PTPA_HUMAN Isoform 4 of Serine/threonine-protein phosphatase2A activator OS=Homo sapiens OX=9606 GN=PTPAMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAYADYIGFILTLNEGVKGKKLTFEYRVSEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFGSLLPIHPVTSG>sp|Q7Z6K3|PTAR1_HUMAN Protein prenyltransferase alpha subunit repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=PTAR1 PE=1 SV=2MAETSEEVAVLVQRVVKDITNAFRRNPHIDEIGLIPCPEARYNRSPIVLVENKLGVESWCVKFLLPYVHNKLLLYRTRKQWLNRDELIDVTCTLLLLNPDFTTAWNVRKELILSGTLNPIKDLHLGKLALTKFPKSPETWIHRRWVLQQLIQETSLPSFVTKGNLGTIPTERAQRLIQEEMEVCGEAAGRYPSNYNAWSHRIWVLQHLAKLDVKILLDELSSTKHWASMHVSDHSGFHYRQFLLKSLISQTVIDSSVMEQNPLRSEPALVPPKDEEAAVSTEEPRINLPHLLEEEVEFSTDLIDSYPGHETLWCHRRHIFYLQHHLNAGSQLSQAMEVDGLNDSSKQGYSQETKRLKRTPVPDSLGLEMEHRFIDQVLSTCRNVEQARFASAYRKWLVTLSQ>sp|P26599|PTBP1_HUMAN Polypyrimidine tract-binding protein 1 OS=Homosapiens OX=9606 GN=PTBP1 PE=1 SV=1MDGIVPDIAVGTKRGSDELFSTCVTNGPFIMSSNSASAANGNDSKKFKGDSRSAGVPSRVIHIRKLPIDVTEGEVISLGLPFGKVTNLLMLKGKNQAFIEMNTEEAANTMVNYYTSVTPVLRGQPIYIQFSNHKELKTDSSPNQARAQAALQAVNSVQSGNLALAASAAAVDAGMAMAGQSPVLRIIVENLFYPVTLDVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVSAQHAKLSLDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDYTRPDLPSGDSQPSLDQTMAAAFGLSVPNVHGALAPLAIPSAAAAAAAAGRIAIPGLAGAGNSVLLVSNLNPERVTPQSLFILFGVYGDVQRVKILFNKKENALVQMADGNQAQLAMSHLNGHKLHGKPIRITLSKHQNVQLPREGQEDQGLTKDYGNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVSEEDLKVLFSSNGGVVKGFKFFQKDRKMALIQMGSVEEAVQALIDLHNHDLGENHHLRVSFSKSTI>sp|P26599-2|PTBP1_HUMAN Isoform 2 of Polypyrimidine tract-bindingprotein 1 OS=Homo sapiens OX=9606 GN=PTBP1MDGIVPDIAVGTKRGSDELFSTCVTNGPFIMSSNSASAANGNDSKKFKGDSRSAGVPSRVIHIRKLPIDVTEGEVISLGLPFGKVTNLLMLKGKNQAFIEMNTEEAANTMVNYYTSVTPVLRGQPIYIQFSNHKELKTDSSPNQARAQAALQAVNSVQSGNLALAASAAAVDAGMAMAGQSPVLRIIVENLFYPVTLDVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVSAQHAKLSLDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDYTRPDLPSGDSQPSLDQTMAAAFASPYAGAGFPPTFAIPQAAGLSVPNVHGALAPLAIPSAAAAAAAAGRIAIPGLAGAGNSVLLVSNLNPERVTPQSLFILFGVYGDVQRVKILFNKKENALVQMADGNQAQLAMSHLNGHKLHGKPIRITLSKHQNVQLPREGQEDQGLTKDYGNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVSEEDLKVLFSSNGGVVKGFKFFQKDRKMALIQMGSVEEAVQALIDLHNHDLGENHHLRVSFSKSTI>sp|P26599-3|PTBP1_HUMAN Isoform 3 of Polypyrimidine tract-bindingprotein 1 OS=Homo sapiens OX=9606 GN=PTBP1MDGIVPDIAVGTKRGSDELFSTCVTNGPFIMSSNSASAANGNDSKKFKGDSRSAGVPSRVIHIRKLPIDVTEGEVISLGLPFGKVTNLLMLKGKNQAFIEMNTEEAANTMVNYYTSVTPVLRGQPIYIQFSNHKELKTDSSPNQARAQAALQAVNSVQSGNLALAASAAAVDAGMAMAGQSPVLRIIVENLFYPVTLDVLHQIFSKFGTVLKIITFTKNNQFQALLQYADPVSAQHAKLSLDGQNIYNACCTLRIDFSKLTSLNVKYNNDKSRDYTRPDLPSGDSQPSLDQTMAAAFGAPGIISASPYAGAGFPPTFAIPQAAGLSVPNVHGALAPLAIPSAAAAAAAAGRIAIPGLAGAGNSVLLVSNLNPERVTPQSLFILFGVYGDVQRVKILFNKKENALVQMADGNQAQLAMSHLNGHKLHGKPIRITLSKHQNVQLPREGQEDQGLTKDYGNSPLHRFKKPGSKNFQNIFPPSATLHLSNIPPSVSEEDLKVLFSSNGGVVKGFKFFQKDRKMALIQMGSVEEAVQALIDLHNHDLGENHHLRVSFSKSTI>sp|Q9NR77|PXMP2_HUMAN Peroxisomal membrane protein 2 OS=Homo sapiensOX=9606 GN=PXMP2 PE=1 SV=3MAPAASRLRAEAGLGALPRRALAQYLLFLRLYPVLTKAATSGILSALGNFLAQMIEKKRKKENSRSLDVGGPLRYAVYGFFFTGPLSHFFYFFMEHWIPPEVPLAGLRRLLLDRLVFAPAFLMLFFLIMNFLEGKDASAFAAKMRGGFWPALRMNWRVWTPLQFININYVPLKFRVLFANLAALFWYAYLASLGK>sp|Q9BRQ0|PYGO2_HUMAN Pygopus homolog 2 OS=Homo sapiens OX=9606 GN=PYGO2PE=1 SV=2MAASAPPPPDKLEGGGGPAPPPAPPSTGRKQGKAGLQMKSPEKKRRKSNTQGPAYSHLTEFAPPPTPMVDHLVASNPFEDDFGAPKVGVAAPPFLGSPVPFGGFRVQGGMAGQVPPGYSTGGGGGPQPLRRQPPPFPPNPMGPAFNMPPQGPGYPPPGNMNFPSQPFNQPLGQNFSPPSGQMMPGPVGGFGPMISPTMGQPPRAELGPPSLSQRFAQPGAPFGPSPLQRPGQGLPSLPPNTSPFPGPDPGFPGPGGEDGGKPLNPPASTAFPQEPHSGSPAAAVNGNQPSFPPNSSGRGGGTPDANSLAPPGKAGGGSGPQPPPGLVYPCGACRSEVNDDQDAILCEASCQKWFHRECTGMTESAYGLLTTEASAVWACDLCLKTKEIQSVYIREGMGQLVAANDG>sp|Q6ZRY4|RBPS2_HUMAN RNA-binding protein with multiple splicing 2OS=Homo sapiens OX=9606 GN=RBPMS2 PE=1 SV=1MSNLKPDGEHGGSTGTGSGAGSGGALEEEVRTLFVSGLPVDIKPRELYLLFRPFKGYEGSLIKLTARQPVGFVIFDSRAGAEAAKNALNGIRFDPENPQTLRLEFAKANTKMAKSKLMATPNPSNVHPALGAHFIARDPYDLMGAALIPASPEAWAPYPLYTTELTPAISHAAFTYPTATAAAAALHAQVRWYPSSDTTQQGWKYRQFC>sp|Q6ZRY4-2|RBPS2_HUMAN Isoform 2 of RNA-binding protein with multiplesplicing 2 OS=Homo sapiens OX=9606 GN=RBPMS2MAKSKLMATPNPSNVHPALGAHFIARDPYDLMGAALIPASPEAWAPYPLYTTELTPAISHAAFTYPTATAAAAALHAQVRWYPSSDTTQQGWKYRQFC>sp|Q9H0Z9|RBM38_HUMAN RNA-binding protein 38 OS=Homo sapiens OX=9606GN=RBM38 PE=1 SV=2MLLQPAPCAPSAGFPRPLAAPGAMHGSQKDTTFTKIFVGGLPYHTTDASLRKYFEGFGDIEEAVVITDRQTGKSRGYGFVTMADRAAAERACKDPNPIIDGRKANVNLAYLGAKPRSLQTGFAIGVQQLHPTLIQRTYGLTPHYIYPPAIVQPSVVIPAAPVPSLSSPYIEYTPASPAYAQYPPATYDQYPYAASPATAASFVGYSYPAAVPQALSAAAPAGTTFVQYQAPQLQPDRMQ>sp|Q9H0Z9-2|RBM38_HUMAN Isoform 2 of RNA-binding protein 38 OS=Homosapiens OX=9606 GN=RBM38MLLQPAPCAPSAGFPRPLAAPGAMHGSQKDTTFTKIFVGGLPYHTTDASLRKYFEGFGDIEEAVVITDRQTGKSRGYGFVTMADRAAAERACKDPNPIIDGRKANVNLAYLGAKPRSLQTG>sp|Q8IZ41|RASEF_HUMAN Ras and EF-hand domain-containing protein OS=Homosapiens OX=9606 GN=RASEF PE=1 SV=1MEADGDGEELARLRSVFAACDANRSGRLEREEFRALCTELRVRPADAEAVFQRLDADRDGAITFQEFARGFLGSLRGGRRRDWGPLDPAPAVSEAGPETHDSEEDEGDEDAAAALATSCGPASPGRAWQDFQARLGDEAKFIPREEQVSTLYQNINLVEPRLIQPYEHVIKNFIREIRLQSTEMENLAIAVKRAQDKAAMQLSELEEEMDQRIQAAEHKTRKDEKRKAEEALSDLRRQYETEVGDLQVTIKKLRKLEEQSKRVSQKEDVAALKKQIYDLSMENQKVKKDLLEAQTNIAFLQSELDALKSDYADQSLNTERDLEIIRAYTEDRNSLERQIEILQTANRKLHDSNDGLRSALENSYSKFNRSLHINNISPGNTISRSSPKFIGHSPQPLGYDRSSRSSYVDEDCDSLALCDPLQRTNCEVDSLPESCFDSGLSTLRDPNEYDSEVEYKHQRGFQRSHGVQESFGGDASDTDVPDIRDEETFGLEDVASVLDWKPQGSVSEGSIVSSSRKPISALSPQTDLVDDNAKSFSSQKAYKIVLAGDAAVGKSSFLMRLCKNEFRENISATLGVDFQMKTLIVDGERTVLQLWDTAGQERFRSIAKSYFRKADGVLLLYDVTCEKSFLNIREWVDMIEDAAHETVPIMLVGNKADIRDTAATEGQKCVPGHFGEKLAMTYGALFCETSAKDGSNIVEAVLHLAREVKKRTDKDDSRSITNLTGTNSKKSPQMKNCCNG>sp|Q8IZ41-2|RASEF_HUMAN Isoform 2 of Ras and EF-hand domain-containingprotein OS=Homo sapiens OX=9606 GN=RASEFMEADGDGEELARLRSVFAACDANRSGRLEREEFRALCTELRVRPADAEAVFQRLDADRDGAITFQEFARGFLGSLRGGRRRDWGPLDPAPAVSEAGPETHDSEEDEGDEDAAAALATSCGPASPGRAWQDFQARLGDEAKFIPRFGYTISKPAFVFVRHLITLCALSWAKKEGRETLWTIEEGGAKMAE>sp|Q5T8P6|RBM26_HUMAN RNA-binding protein 26 OS=Homo sapiens OX=9606GN=RBM26 PE=1 SV=3MVSKMIIENFEALKSWLSKTLEPICDADPSALAKYVLALVKKDKSEKELKALCIDQLDVFLQKETQIFVEKLFDAVNTKSYLPPPEQPSSGSLKVEFFPHQEKDIKKEEITKEEEREKKFSRRLNHSPPQSSSRYRENRSRDERKKDDRSRKRDYDRNPPRRDSYRDRYNRRRGRSRSYSRSRSRSWSKERLRERDRDRSRTRSRSRTRSRERDLVKPKYDLDRTDPLENNYTPVSSVPSISSGHYPVPTLSSTITVIAPTHHGNNTTESWSEFHEDQVDHNSYVRPPMPKKRCRDYDEKGFCMRGDMCPFDHGSDPVVVEDVNLPGMLPFPAQPPVVEGPPPPGLPPPPPILTPPPVNLRPPVPPPGPLPPSLPPVTGPPPPLPPLQPSGMDAPPNSATSSVPTVVTTGIHHQPPPAPPSLFTADTYDTDGYNPEAPSITNTSRPMYRHRVHAQRPNLIGLTSGDMDLPPREKPPNKSSMRIVVDSESRKRTIGSGEPGVPTKKTWFDKPNFNRTNSPGFQKKVQFGNENTKLELRKVPPELNNISKLNEHFSRFGTLVNLQVAYNGDPEGALIQFATYEEAKKAISSTEAVLNNRFIKVYWHREGSTQQLQTTSPKVMQPLVQQPILPVVKQSVKERLGPVPSSTIEPAEAQSASSDLPQNVTKLSVKDRLGFVSKPSVSATEKVLSTSTGLTKTVYNPAALKAAQKTLLVSTSAVDNNEAQKKKQEALKLQQDVRKRKQEILEKHIETQKMLISKLEKNKTMKSEDKAEIMKTLEVLTKNITKLKDEVKAASPGRCLPKSIKTKTQMQKELLDTELDLYKKMQAGEEVTELRRKYTELQLEAAKRGILSSGRGRGIHSRGRGAVHGRGRGRGRGRGVPGHAVVDHRPRALEISAFTESDREDLLPHFAQYGEIEDCQIDDSSLHAVITFKTRAEAEAAAVHGARFKGQDLKLAWNKPVTNISAVETEEVEPDEEEFQEESLVDDSLLQDDDEEEEDNESRSWRR>sp|Q5T8P6-2|RBM26_HUMAN Isoform 2 of RNA-binding protein 26 OS=Homosapiens OX=9606 GN=RBM26MVSKMIIENFEALKSWLSKTLEPICDADPSALAKYVLALVKKDKSEKELKALCIDQLDVFLQKETQIFVEKLFDAVNTKSYLPPPEQPSSGSLKVEFFPHQEKDIKKEEITKEEEREKKFSRRLNHSPPQSSSRYRENRSRDERKKDDRSRKRDYDRNPPRRDSYRDRYNRRRGRSRSYSRSRSRSWSKERLRERDRDRSRTRSRSRTRSRERDLVKPKYDLDRTDPLENNYTPVSSVPSISSGHYPVPTLSSTITVIAPTHHGNNTTESWSEFHEDQVDHNSYVRPPMPKKRCRDYDEKGFCMRGDMCPFDHGSDPVVVEDVNLPGMLPFPAQPPVVEGPPPPGLPPPPPILTPPPVNLRPPVPPPGPLPPSLPPVTGPPPPLPPLQPSGMDAPPNSATSSVPTVVTTGIHHQPPPAPPSLFTADTYDTDGYNPEAPSITNTSRPMYRHRVHAQRPNLIGLTSGDMDLPPREKPPNKSSMRIVVDSESRKRTIGSGEPGVPTKKTWFDKPNFNRTNSPGFQKKVQFGNENTKLELRKVPPELNNISKLNEHFSRFGTLVNLQVAYNGDPEGALIQFATYEEAKKAISSTEAVLNNRFIKVYWHREGSTQQLQTTSPKVMQPLVQQPILPVVKQSVKERLGPVPSSTIEPAEAQSASSDLPQVLSTSTGLTKTVYNPAALKAAQKTLLVSTSAVDNNEAQKKKQEALKLQQDVRKRKQEILEKHIETQKMLISKLEKNKTMKSEDKAEIMKTLEVLTKNITKLKDEVKAASPGRCLPKSIKTKTQMQKELLDTELDLYKKMQAGEEVTELRRKYTELQLEAAKRGILSSGRGRGIHSRGRGAVHGRGRGRGRGRGVPGHAVVDHRPRALEISAFTESDREDLLPHFAQYGEIEDCQIDDSSLHAVITFKTRAEAEAAAVHGARFKGQDLKLAWNKPVTNISAVETEEVEPDEEEFQEESLVDDSLLQDDDEEEEDNESRSWRR>sp|Q5T8P6-3|RBM26_HUMAN Isoform 3 of RNA-binding protein 26 OS=Homosapiens OX=9606 GN=RBM26MVSKMIIENFEALKSWLSKTLEPICDADPSALAKYVLALVKKDKSEKELKALCIDQLDVFLQKETQIFVEKLFDAVNTKSYLPPPEQPSSGSLKVEFFPHQEKDIKKEEITKEEEREKKFSRRLNHSPPQSSSRYRENRSRDERKKDDRSRKRDYDRNPPRRDSYRDRYNRRRGRSRSYSRSRSRSWSKERLRERDRDRSRTRSRSRTRSRERDLVKPKYDLDRTDPLENNYTPVSSVPSISSGHYPVPTLSSTITVIAPTHHGNNTTESWSEFHEDQVDHNSYVRPPMPKKRCRDYDEKGFCMRGDMCPFDHGSDPVVVEDVNLPGMLPFPAQPPVVEGPPPPGLPPPPPILTPPPVNLRPPVPPPGPLPPSLPPVTGPPPPLPPLQPSGMDAPPNSATSSVPTVVTTGIHHQPPPAPPSLFTADTYDTDGYNPEAPSITNTSRPMYRHRVHAQRPNLIGLTSGDMDLPPREKPPNKSSMRIVVDSESRKRTIGSGEPGVPTKKTWFDKPNFNRTNSPGFQKKVQFGNENTKLELRKVPPELNNISKLNEHFSRFGTLVNLQVAYNGDPEGALIQFATYEEAKKAISSTEAVLNNRFIKVYWHREGSTQQLQTTSPKPLVQQPILPVVKQSVKERLGPVPSSTIEPAEAQSASSDLPQVLSTSTGLTKTVYNPAALKAAQKTLLVSTSAVDNNEAQKKKQEALKLQQDVRKRKQEILEKHIETQKMLISKLEKNKTMKSEDKAEIMKTLEVLTKNITKLKDEVKAASPGRCLPKSIKTKTQMQKELLDTELDLYKKMQAGEEVTELRRKYTELQLEAAKRGILSSGRGRGIHSRGRGAVHGRGRGRGRGRGVPGHAVVDHRPRALEISAFTESDREDLLPHFAQYGEIEDCQIDDSSLHAVITFKTRAEAEAAAVHGARFKGQDLKLAWNKPVTNISAVETEEVEPDEEEFQEESLVDDSLLQDDDEEEEDNESRSWRR>sp|Q5T8P6-4|RBM26_HUMAN Isoform 4 of RNA-binding protein 26 OS=Homosapiens OX=9606 GN=RBM26MYRHRVHAQRPNLIGLTSGDMDLPPREKPPNKSSMRIVVDSESRKRTIGSGEPGVPTKKTWFDKPNFNRTNSPGFQKKVQFGNENTKLELRKVPPELNNISKLNEHFSRFGTLVNLQVAYNGDPEGALIQFATYEEAKKAISSTEAVLNNRFIKVYWHREGSTQQLQTTSPKPLVQQPILPVVKQSVKERLGPVPSSTIEPAEAQSASSDLPQNVTKLSVKDRLGFVSKPSVSATEKVLSTSTGLTKTVYNPAALKAAQKTLLVSTSAVDNNEAQKKKQEALKLQQDVRKRKQEILEKHIETQKMLISKLEKNKTMKSEDKAEIMKTLEVLTKNITKLKDEVKAASPGRCLPKSIKTKTQMQKELLDTELDLYKKMQAGEEVTELRRKYTELQLEAAKRGILSSGRGRGIHSRGRGAVHGRGRGRGRGRGVPGHAVVDHRPRALEISAFTESDREDLLPHFAQYGEIEDCQIDDSSLHAVITFKTRAEAEAAAVHGARFKGQDLKLAWNKPVTNISAVETEEVEPDEEEFQEESLVDDSLLQDDDEEEEDNESRSWRR>sp|Q5T8P6-5|RBM26_HUMAN Isoform 5 of RNA-binding protein 26 OS=Homosapiens OX=9606 GN=RBM26MYRHRVHAQRPNLIGLTSGDMDLPPREKPPNKSSMRIVVDSESRKRTIGSGEPGVPTKKTWFDKPNFNRTNSPGFQKKVQFGNENTKLELRKVPPELNNISKLNEHFSRFGTLVNLQVAYNGDPEGALIQFATYEEAKKAISSTEAVLNNRFIKVYWHREGSTQQLQTTSPKPLVQQPILPVVKQSVKERLGPVPSSTIEPAEAQSASSDLPQVLSTSTGLTKTVYNPAALKAAQKTLLVSTSAVDNNEAQKKKQEALKLQQDVRKRKQEILEKHIETQKMLISKLEKNKTMKSEDKAEIMKTLEVLTKNITKLKDEVKAASPGRCLPKSIKTKTQMQKELLDTELDLYKKMQAGEEVTELRRKYTELQLEAAKRGILSSGRGRGIHSRGRGAVHGRGRGRGRGRGVPGHAVVDHRPRALEISAFTESDREDLLPHFAQYGEIEDCQIDDSSLHAVITFKTRAEAEAAAVHGARFKGQDLKLAWNKPVTNISAVETEEVEPDEEEFQEESLVDDSLLQDDDEEEEDNESRSWRR>sp|Q5T8P6-6|RBM26_HUMAN Isoform 6 of RNA-binding protein 26 OS=Homosapiens OX=9606 GN=RBM26MVSKMIIENFEALKSWLSKTLEPICDADPSALAKYVLALVKKDKSEKELKALCIDQLDVFLQKETQIFVEKLFDAVNTKSYLPPPEQPSSGSLKVEFFPHQEKDIKKEEVTICVNTLQVI>sp|P62979|RS27A_HUMAN Ubiquitin-40S ribosomal protein S27a OS=Homosapiens OX=9606 GN=RPS27A PE=1 SV=2MQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGAKKRKKKSYTTPKKNKHKRKKVKLAVLKYYKVDENGKISRLRRECPSDECGAGVFMASHFDRHYCGKCCLTYCFNKPEDK>sp|P62306|RUXF_HUMAN Small nuclear ribonucleoprotein F OS=Homo sapiensOX=9606 GN=SNRPF PE=1 SV=1MSLPLNPKPFLNGLTGKPVMVKLKWGMEYKGYLVSVDGYMNMQLANTEEYIDGALSGHLGEVLIRCNNVLYIRGVEEEEEDGEMRE>sp|Q9BYN8|RT26_HUMAN 28S ribosomal protein S26, mitochondrial OS=Homosapiens OX=9606 GN=MRPS26 PE=1 SV=1MLRALSRLGAGTPCRPRAPLVLPARGRKTRHDPLAKSKIERVNMPPAVDPAEFFVLMERYQHYRQTVRALRMEFVSEVQRKVHEARAGVLAERKALKDAAEHRELMAWNQAENRRLHELRIARLRQEEREQEQRQALEQARKAEEVQAWAQRKEREVLQLQEEVKNFITRENLEARVEAALDSRKNYNWAITREGLVVRPQRRDS>sp|Q9H446|RWDD1_HUMAN RWD domain-containing protein 1 OS=Homo sapiensOX=9606 GN=RWDD1 PE=1 SV=1MTDYGEEQRNELEALESIYPDSFTVLSENPPSFTITVTSEAGENDETVQTTLKFTYSEKYPDEAPLYEIFSQENLEDNDVSDILKLLALQAEENLGMVMIFTLVTAVQEKLNEIVDQIKTRREEEKKQKEKEAEEAEKQLFHGTPVTIENFLNWKAKFDAELLEIKKKRMKEEEQAGKNKLSGKQLFETDHNLDTSDIQFLEDAGNNVEVDESLFQEMDDLELEDDEDDPDYNPADPESDSAD>sp|Q9H446-2|RWDD1_HUMAN Isoform 2 of RWD domain-containing protein 1OS=Homo sapiens OX=9606 GN=RWDD1MVMIFTLVTAVQEKLNEIVDQIKTRREEEKKQKEKEAEEAEKQLFHGTPVTIENFLNWKAKFDAELLEIKKKRMKEEEQAGKNKLSGKQLFETDHNLDTSDIQFLEDAGNNVEVDESLFQEMDDLELEDDEDDPDYNPADPESDSAD>sp|Q9Y291|RT33_HUMAN 28S ribosomal protein S33, mitochondrial OS=Homosapiens OX=9606 GN=MRPS33 PE=1 SV=1MSSLSEYAFRMSRLSARLFGEVTRPTNSKSMKVVKLFSELPLAKKKETYDWYPNHHTYAELMQTLRFLGLYRDEHQDFMDEQKRLKKLRGKEKPKKGEGKRAAKRK>sp|Q9BQC6|RT63_HUMAN Ribosomal protein 63, mitochondrial OS=Homo sapiensOX=9606 GN=MRPL57 PE=1 SV=1MFLTALLWRGRIPGRQWIGKHRRPRFVSLRAKQNMIRRLEIEAENHYWLSMPYMTREQERGHAAVRRREAFEAIKAAATSKFPPHRFIADQLDHLNVTKKWS>sp|Q9BY42|RTF2_HUMAN Replication termination factor 2 OS=Homo sapiensOX=9606 GN=RTF2 PE=1 SV=3MGCDGGTIPKRHELVKGPKKVEKVDKDAELVAQWNYCTLSQEILRRPIVACELGRLYNKDAVIEFLLDKSAEKALGKAASHIKSIKNVTELKLSDNPAWEGDKGNTKGDKHDDLQRARFICPVVGLEMNGRHRFCFLRCCGCVFSERALKEIKAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNLAPKSTAMNESSSGKAGKPPCGATKRSIADSEESEAYKSLFTTHSSAKRSKEESAHWVTHTSYCF>sp|Q5HYW3|RTL5_HUMAN Retrotransposon Gag-like protein 5 OS=Homo sapiensOX=9606 GN=RTL5 PE=2 SV=1MSEASGNLNSLRMANVALREELNALRGENANLGLQLGRALAEVNSLRGNVSSYIRWPVPIVPVLAEENLEFALSEIEVIPGGELPFLCRPPPRAEPDCISDDLLINVIQDRSTPDGPADPPLLPIPPPPALPPPASKEPPPQPPLAPLERPEIEPFSGDPVYLAEFLMQLETFIADHEVHFPGGAERVAFLISFFTGEAKDWAISVTQEGSPLHANFPRFLDEIRKEFCGPIPPRVAKKAIRKLKQGHCTLGSYADAFQFLAQFLSWDDCRLQNQFLKGLSEFFRKELLWSTEMADLDELILECVEIERKVRVPKPIPLPGVRNIIFPFAPSPNEEESEDEEYYSEDEDQEARRHRLHSKDQRKRMRAFQQEMKEKEEEEMKKEEEMKKKEEKEEEEEEEMKQKEEEEEIRNKNEEEGESKDEEDEDEDGGQKPEGEPQQDPGTEETYGEVEEEPLDEAQDDDLDELMEMEPTFVHASSQTSGPTSGYHAENFLGASPPIIQPSRRRNQNRVPLLEGLPGTNSPFYSSPQLIRRTGRLGQRQVRRRPPVLFRLTPRQGGHRAARGRIRV>sp|A6ZKI3|RTL8C_HUMAN Retrotransposon Gag-like protein 8C OS=Homosapiens OX=9606 GN=RTL8C PE=1 SV=1MDGRVQLIKALLALPIRPATRRWRNPIPFPETFDGDTDRLPEFIVQTGSYMFVDENTFSSDALKVTFLITRLTGPALQWVIPYIKKESPLLNDYRGFLAEMKRVFGWEEDEDF>sp|Q6ICC9|RTL6_HUMAN Retrotransposon Gag-like protein 6 OS=Homo sapiensOX=9606 GN=RTL6 PE=2 SV=1MVQPQTSKAESPALAASPNAQMDDVIDTLTSLRLTNSALRREASTLRAEKANLTNMLESVMAELTLLRTRARIPGALQITPPISSITSNGTRPMTTPPTSLPEPFSGDPGRLAGFLMQMDRFMIFQASRFPGEAERVAFLVSRLTGEAEKWAIPHMQPDSPLRNNYQGFLAELRRTYKSPLRHARRAQIRKTSASNRAVRERQMLCRQLASAGTGPCPVHPASNGTSPAPALPARARNL>sp|P08621|RU17_HUMAN U1 small nuclear ribonucleoprotein 70 kDa OS=Homosapiens OX=9606 GN=SNRNP70 PE=1 SV=2MTQFLPPNLLALFAPRDPIPYLPPLEKLPHEKHHNQPYCGIAPYIREFEDPRDAPPPTRAETREERMERKRREKIERRQQEVETELKMWDPHNDPNAQGDAFKTLFVARVNYDTTESKLRREFEVYGPIKRIHMVYSKRSGKPRGYAFIEYEHERDMHSAYKHADGKKIDGRRVLVDVERGRTVKGWRPRRLGGGLGGTRRGGADVNIRHSGRDDTSRYDERPGPSPLPHRDRDRDRERERRERSRERDKERERRRSRSRDRRRRSRSRDKEERRRSRERSKDKDRDRKRRSSRSRERARRERERKEELRGGGGDMAEPSEAGDAPPDDGPPGELGPDGPDGPEEKGRDRDRERRRSHRSERERRRDRDRDRDRDREHKRGERGSERGRDEARGGGGGQDNGLEGLGNDSRDMYMESEGGDGYLAPENGYLMEAAPE>sp|P08621-2|RU17_HUMAN Isoform 2 of U1 small nuclear ribonucleoprotein70 kDa OS=Homo sapiens OX=9606 GN=SNRNP70MTQFLPPNLLALFAPRDPIPYLPPLEKLPHEKHHNQPYCGIAPYIREFEDPRDAPPPTRAETREERMERKRREKIERRQQEVETELKMWDPHNDPNAQGDAFKTLFVARVNYDTTESKLRREFEVYGPIKRIHMVYSKRSGKPRGYAFIEYEHERDMHSAYKHADGKKIDGRRVLVDVERGRTVKGWRPRRLGGGLGGTRRGGADVNIRHSGRDDTSRYDERDRDRDRERERRERSRERDKERERRRSRSRDRRRRSRSRDKEERRRSRERSKDKDRDRKRRSSRSRERARRERERKEELRGGGGDMAEPSEAGDAPPDDGPPGELGPDGPDGPEEKGRDRDRERRRSHRSERERRRDRDRDRDRDREHKRGERGSERGRDEARGGGGGQDNGLEGLGNDSRDMYMESEGGDGYLAPENGYLMEAAPE>sp|P08621-3|RU17_HUMAN Isoform 3 of U1 small nuclear ribonucleoprotein70 kDa OS=Homo sapiens OX=9606 GN=SNRNP70MTQFLPPNLLALFAPRDPIPYLPPLEKLPHEKHHNQPYCGIAPYIREFEDPRDAPPPTRAETREERMERKRREKIERRQQEVETELKMWDPHNDPNAQGDAFKTLFVARVNYDTTESKLRREFEVYGPIKRIHMVYSKRSGKPRGYAFIEYEHERDMHSTTQLACS>sp|P08621-4|RU17_HUMAN Isoform 4 of U1 small nuclear ribonucleoprotein70 kDa OS=Homo sapiens OX=9606 GN=SNRNP70MEQALHRFGRGLVWLSVAWLSVGRVRVRDDGDTGRGFCRAGPVLTRGPSGDSSPLPLPTSVTAAYKHADGKKIDGRRVLVDVERGRTVKGWRPRRLGGGLGGTRRGGADVNIRHSGRDDTSRYDERPGPSPLPHRDRDRDRERERRERSRERDKERERRRSRSRDRRRRSRSRDKEERRRSRERSKDKDRDRKRRSSRSRERARRERERKEELRGGGGDMAEPSEAGDAPPDDGPPGELGPDGPDGPEEKGRDRDRERRRSHRSERERRRDRDRDRDRDREHKRGERGSERGRDEARGGGGGQDNGLEGLGNDSRDMYMESEGGDGYLAPENGYLMEAAPE>sp|O00442|RTCA_HUMAN RNA 3'-terminal phosphate cyclase OS=Homo sapiensOX=9606 GN=RTCA PE=1 SV=1MAGPRVEVDGSIMEGGGQILRVSTALSCLLGLPLRVQKIRAGRSTPGLRPQHLSGLEMIRDLCDGQLEGAEIGSTEITFTPEKIKGGIHTADTKTAGSVCLLMQVSMPCVLFAASPSELHLKGGTNAEMAPQIDYTVMVFKPIVEKFGFIFNCDIKTRGYYPKGGGEVIVRMSPVKQLNPINLTERGCVTKIYGRAFVAGVLPFKVAKDMAAAAVRCIRKEIRDLYVNIQPVQEPKDQAFGNGNGIIIIAETSTGCLFAGSSLGKRGVNADKVGIEAAEMLLANLRHGGTVDEYLQDQLIVFMALANGVSRIKTGPVTLHTQTAIHFAEQIAKAKFIVKKSEDEEDAAKDTYIIECQGIGMTNPNL>sp|O00442-2|RTCA_HUMAN Isoform 2 of RNA 3'-terminal phosphate cyclaseOS=Homo sapiens OX=9606 GN=RTCAMAGPRVEVDGSIMEGGGQILRVSTALSCLLGLPLRVQKIRAGRSTPGLSSGGWKSKIKVLTRPQHLSGLEMIRDLCDGQLEGAEIGSTEITFTPEKIKGGIHTADTKTAGSVCLLMQVSMPCVLFAASPSELHLKGGTNAEMAPQIDYTVMVFKPIVEKFGFIFNCDIKTRGYYPKGGGEVIVRMSPVKQLNPINLTERGCVTKIYGRAFVAGVLPFKVAKDMAAAAVRCIRKEIRDLYVNIQPVQEPKDQAFGNGNGIIIIAETSTGCLFAGSSLGKRGVNADKVGIEAAEMLLANLRHGGTVDEYLQDQLIVFMALANGVSRIKTGPVTLHTQTAIHFAEQIAKAKFIVKKSEDEEDAAKDTYIIECQGIGMTNPNL>sp|B5MCN3|S14L6_HUMAN Putative SEC14-like protein 6 OS=Homo sapiensOX=9606 GN=SEC14L6 PE=5 SV=1MSGQVGDLSPSQEKSLAQFRENIQDVLSALPNPDDYFLLRWLQARSFDLQKSEDMLRKHMEFRKQQDLANILAWQPPEVVRLYNANGICGHDGEGSPVWYHIVGSLDPKGLLLSASKQELLRDSFRSCELLLRECELQSQKLGKRVEKIIAIFGLEGLGLRDLWKPGIELLQEFFSALEANYPEILKSLIVVRAPKLFAVAFNLVKSYMSEETRRKVVILGDNWKQELTKFISPDQLPVEFGGTMTDPDGNPKCLTKINYGGEVPKSYYLCKQVRLQYEHTRSVGRGSSLQVENEILFPGCVLRWQFASDGGDIGFGVFLKTKMGERQRAREMTEVLPSQRYNAHMVPEDGILTCLQAGSYVLRFYNTYSLVHSKRISYTVEVLLPDQTFMEKMEKF>sp|Q59EK9|RUN3A_HUMAN RUN domain-containing protein 3A OS=Homo sapiensOX=9606 GN=RUNDC3A PE=1 SV=2MEASFVQTTMALGLSSKKASSRNVAVERKNLITVCRFSVKTLLEKYTAEPIDDSSEEFVNFAAILEQILSHRFKACAPAGPVSWFSSDGQRGFWDYIRLACSKVPNNCVSSIENMENISTARAKGRAWIRVALMEKRMSEYITTALRDTRTTRRFYDSGAIMLRDEATILTGMLIGLSAIDFSFCLKGEVLDGKTPVVIDYTPYLKFTQSYDYLTDEEERHSAESSTSEDNSPEHPYLPLVTDEDSWYSKWHKMEQKFRIVYAQKGYLEELVRLRESQLKDLEAENRRLQLQLEEAAAQNQREKRELEGVILELQEQLTGLIPSDHAPLAQGSKELTTPLVNQWPSLGTLNGAEGASNSKLYRRHSFMSTEPLSAEASLSSDSQRLGEGTRDEEPWGPIGKDPTPSMLGLCGSLASIPSCKSLASFKSNECLVSDSPEGSPALSPS>sp|Q59EK9-2|RUN3A_HUMAN Isoform 2 of RUN domain-containing protein 3AOS=Homo sapiens OX=9606 GN=RUNDC3AMEASFVQTTMALGLSSKKASSRNVAVERKNLITVCRFSVKTLLEKYTAEPIDDSSEEFVNFAAILEQILSHRFKGPVSWFSSDGQRGFWDYIRLACSKVPNNCVSSIENMENISTARAKGRAWIRVALMEKRMSEYITTALRDTRTTRRFYDSGAIMLRDEATILTGMLIGLSAIDFSFCLKGEVLDGKTPVVIDYTPYLKFTQSYDYLTDEEERHSAESSTSEDNSPEHPYLPLVTDEDSWYSKWHKMEQKFRIVYAQKGYLEELVRLRESQLKDLEAENRRLQLQLEEAAAQNQREKRELEGVILELQEQLTGLIPSDHAPLAQGSKELTTPLVNQWPSLGTLNGAEGASNSKLYRRHSFMSTEPLSAEASLSSDSQRLGEGTRDEEPWGPIGSSEPN>sp|Q59EK9-3|RUN3A_HUMAN Isoform 3 of RUN domain-containing protein 3AOS=Homo sapiens OX=9606 GN=RUNDC3AMEASFVQTTMALGLSSKKASSRNVAVERKNLITVCRFSVKTLLEKYTAEPIDDSSEEFVNFAAILEQILSHRFKACAPAGPVSWFSSDGQRGFWDYIRLACSKVPNNCVSSIENMENISTARAKGRAWIRVALMEKRMSEYITTALRDTRTTRRFYDSGAIMLRDEATILTGMLIGLSAIDFSFCLKGEVLDGKTPVVIDYTPYLKFTQSYDYLTDEEERHSAESSTSEDNSPEHPYLPLVTDEDSWYSKWHKMEQKFRIVYAQKGYLEELVRLRESQLKDLEAENRRLQLQLEEAAAQNQREKRELEGVILELQEQLTGLIPSDHAPLAQGSKELTTPLVNQWPSLGTLNGAEGASNSKLYRRHSFMSTEPLSAEASLSSDSQRLGEGTRDEEPWGPIGSSEPN>sp|Q59EK9-4|RUN3A_HUMAN Isoform 4 of RUN domain-containing protein 3AOS=Homo sapiens OX=9606 GN=RUNDC3AMEASFVQTTMALGLSSKKASSRNVAVERKNLITVCRFSVKTLLEKYTAEPIDDSSEEFVNFAAILEQILSHRFKACAPAGPVSWFSSDGQRGFWDYIRLACSKVPNNCVSSIENMENISTARAKGRAWIRVALMEKRMSEYITTALRDTRTTRRFYDSGAIMLRDEATILTGMLIGLSAIDFSFCLKGEVLDGKTPVVIDYTPYLKFTQSYDYLTDEEERHSAESSTSEDNSPEHPYLPLVTDEDSWYSKWHKMEQKFRIVYAQKGYLEELVRLRESQLKDLEAENRRLQLQLEEAAAQNQREKRELEGVILELQEQLTGLIPSDHAPLAQGSKELTTPLVNQWPSLGTLNGAEGASNSKLYRR>sp|Q9Y3D9|RT23_HUMAN 28S ribosomal protein S23, mitochondrial OS=Homosapiens OX=9606 GN=MRPS23 PE=1 SV=2MAGSRLETVGSIFSRTRDLVRAGVLKEKPLWFDVYDAFPPLREPVFQRPRVRYGKAKAPIQDIWYHEDRIRAKFYSVYGSGQRAFDLFNPNFKSTCQRFVEKYTELQKLGETDEEKLFVETGKALLAEGVILRRVGEARTQHGGSHVSRKSEHLSVRPQTALEENETQKEVPQDQHLEAPADQSKGLLPP>sp|Q8IY34|S15A3_HUMAN Solute carrier family 15 member 3 OS=Homo sapiensOX=9606 GN=SLC15A3 PE=1 SV=2MPAPRAREQPRVPGERQPLLPRGARGPRRWRRAAGAAVLLVEMLERAAFFGVTANLVLYLNSTNFNWTGEQATRAALVFLGASYLLAPVGGWLADVYLGRYRAVALSLLLYLAASGLLPATAFPDGRSSFCGEMPASPLGPACPSAGCPRSSPSPYCAPVLYAGLLLLGLAASSVRSNLTSFGADQVMDLGRDATRRFFNWFYWSINLGAVLSLLVVAFIQQNISFLLGYSIPVGCVGLAFFIFLFATPVFITKPPMGSQVSSMLKLALQNCCPQLWQRHSARDRQCARVLADERSPQPGASPQEDIANFQVLVKILPVMVTLVPYWMVYFQMQSTYVLQGLHLHIPNIFPANPANISVALRAQGSSYTIPEAWLLLANVVVVLILVPLKDRLIDPLLLRCKLLPSALQKMALGMFFGFTSVIVAGVLEMERLHYIHHNETVSQQIGEVLYNAAPLSIWWQIPQYLLIGISEIFASIPGLEFAYSEAPRSMQGAIMGIFFCLSGVGSLLGSSLVALLSLPGGWLHCPKDFGNINNCRMDLYFFLLAGIQAVTALLFVWIAGRYERASQGPASHSRFSRDRG>sp|P82921|RT21_HUMAN 28S ribosomal protein S21, mitochondrial OS=Homosapiens OX=9606 GN=MRPS21 PE=1 SV=3MAKHLKFIARTVMVQEGNVESAYRTLNRILTMDGLIEDIKHRRYYEKPCCRRQRESYERCRRIYNMEMARKINFLMRKNRADPWQGC>sp|P63162|RSMN_HUMAN Small nuclear ribonucleoprotein-associated proteinN OS=Homo sapiens OX=9606 GN=SNRPN PE=1 SV=1MTVGKSSKMLQHIDYRMRCILQDGRIFIGTFKAFDKHMNLILCDCDEFRKIKPKNAKQPEREEKRVLGLVLLRGENLVSMTVEGPPPKDTGIARVPLAGAAGGPGVGRAAGRGVPAGVPIPQAPAGLAGPVRGVGGPSQQVMTPQGRGTVAAAAVAATASIAGAPTQYPPGRGTPPPPVGRATPPPGIMAPPPGMRPPMGPPIGLPPARGTPIGMPPPGMRPPPPGIRGPPPPGMRPPRP>sp|P63162-2|RSMN_HUMAN Isoform 2 of Small nuclear ribonucleoprotein-associated protein N OS=Homo sapiens OX=9606 GN=SNRPNMMDSQTVGKSSKMLQHIDYRMRCILQDGRIFIGTFKAFDKHMNLILCDCDEFRKIKPKNAKQPEREEKRVLGLVLLRGENLVSMTVEGPPPKDTGIARVPLAGAAGGPGVGRAAGRGVPAGVPIPQAPAGLAGPVRGVGGPSQQVMTPQGRGTVAAAAVAATASIAGAPTQYPPGRGTPPPPVGRATPPPGIMAPPPGMRPPMGPPIGLPPARGTPIGMPPPGMRPPPPGIRGPPPPGMRPPRP>sp|Q13183|S13A2_HUMAN Solute carrier family 13 member 2 OS=Homo sapiensOX=9606 GN=SLC13A2 PE=1 SV=1MATCWQALWAYRSYLIVFFVPILLLPLPILVPSKEAYCAYAIILMALFWCTEALPLAVTALFPLILFPMMGIVDASEVAVEYLKDSNLLFFGGLLVAIAVEHWNLHKRIALRVLLIVGVRPAPLILGFMLVTAFLSMWISNTATSAMMVPIAHAVLDQLHSSQASSNVEEGSNNPTFELQEPSPQKEVTKLDNGQALPVTSASSEGRAHLSQKHLHLTQCMSLCVCYSASIGGIATLTGTAPNLVLQGQINSLFPQNGNVVNFASWFSFAFPTMVILLLLAWLWLQILFLGFNFRKNFGIGEKMQEQQQAAYCVIQTEHRLLGPMTFAEKAISILFVILVLLWFTREPGFFLGWGNLAFPNAKGESMVSDGTVAIFIGIIMFIIPSKFPGLTQDPENPGKLKAPLGLLDWKTVNQKMPWNIVLLLGGGYALAKGSERSGLSEWLGNKLTPLQSVPAPAIAIILSLLVATFTECTSNVATTTIFLPILASMAQAICLHPLYVMLPCTLATSLAFMLPVATPPNAIVFSFGDLKVLDMARAGFLLNIIGVLIIALAINSWGIPLFSLHSFPSWAQSNTTAQCLPSLANTTTPSP>sp|Q13183-2|S13A2_HUMAN Isoform 2 of Solute carrier family 13 member 2OS=Homo sapiens OX=9606 GN=SLC13A2MALFWCTEALPLAVTALFPLILFPMMGIVDASEIIQRPFPSSFESPGECQSVGMSVTASHNLGGTVGDSRVFPPLSHVSTCQVAVEYLKDSNLLFFGGLLVAIAVEHWNLHKRIALRVLLIVGVRPAPLILGFMLVTAFLSMWISNTATSAMMVPIAHAVLDQLHSSQASSNVEEGSNNPTFELQEPSPQKEVTKLDNGQALPVTSASSEGRAHLSQKHLHLTQCMSLCVCYSASIGGIATLTGTAPNLVLQGQINSLFPQNGNVVNFASWFSFAFPTMVILLLLAWLWLQILFLGFNFRKNFGIGEKMQEQQQAAYCVIQTEHRLLGPMTFAEKAISILFVILVLLWFTREPGFFLGWGNLAFPNAKGESMVSDGTVAIFIGIIMFIIPSKFPGLTQDPENPGKLKAPLGLLDWKTVNQKMPWNIVLLLGGGYALAKGSERSGLSEWLGNKLTPLQSVPAPAIAIILSLLVATFTECTSNVATTTIFLPILASMAQAICLHPLYVMLPCTLATSLAFMLPVATPPNAIVFSFGDLKVLDMARAGFLLNIIGVLIIALAINSWGIPLFSLHSFPSWAQSNTTAQCLPSLANTTTPSP>sp|Q13183-3|S13A2_HUMAN Isoform 3 of Solute carrier family 13 member 2OS=Homo sapiens OX=9606 GN=SLC13A2MATCWQALWAYRSYLIVFFVPILLLPLPILVPSKEAYCAYAIILMALFWCTEALPLAVTALFPLILFPMMGIVDASEIIQRPFPSSFESPGECQSVGMSVTASHNLGGTVGDSRVFPPLSHVSTCQVAVEYLKDSNLLFFGGLLVAIAVEHWNLHKRIALRVLLIVGVRPAPLILGFMLVTAFLSMWISNTATSAMMVPIAHAVLDQLHSSQASSNVEEGSNNPTFELQEPSPQKEVTKLDNGQALPVTSASSEGRAHLSQKHLHLTQCMSLCVCYSASIGGIATLTGTAPNLVLQGQINSLFPQNGNVVNFASWFSFAFPTMVILLLLAWLWLQILFLGFNFRKNFGIGEKMQEQQQAAYCVIQTEHRLLGPMTFAEKAISILFVILVLLWFTREPGFFLGWGNLAFPNAKGESMVSDGTVAIFIGIIMFIIPSKFPGLTQDPENPGKLKAPLGLLDWKTVNQKMPWNIVLLLGGGYALAKGSERSGLSEWLGNKLTPLQSVPAPAIAIILSLLVATFTECTSNVATTTIFLPILASMAQAICLHPLYVMLPCTLATSLAFMLPVATPPNAIVFSFGDLKVLDMARAGFLLNIIGVLIIALAINSWGIPLFSLHSFPSWAQSNTTAQCLPSLANTTTPSP>sp|Q13621|S12A1_HUMAN Solute carrier family 12 member 1 OS=Homo sapiensOX=9606 GN=SLC12A1 PE=1 SV=2MSLNNSSNVFLDSVPSNTNRFQVSVINENHESSAAADDNTDPPHYEETSFGDEAQKRLRISFRPGNQECYDNFLQSGETAKTDASFHAYDSHTNTYYLQTFGHNTMDAVPKIEYYRNTGSISGPKVNRPSLLEIHEQLAKNVAVTPSSADRVANGDGIPGDEQAENKEDDQAGVVKFGWVKGVLVRCMLNIWGVMLFIRLSWIVGEAGIGLGVLIILLSTMVTSITGLSTSAIATNGFVRGGGAYYLISRSLGPEFGGSIGLIFAFANAVAVAMYVVGFAETVVDLLKESDSMMVDPTNDIRIIGSITVVILLGISVAGMEWEAKAQVILLVILLIAIANFFIGTVIPSNNEKKSRGFFNYQASIFAENFGPRFTKGEGFFSVFAIFFPAATGILAGANISGDLEDPQDAIPRGTMLAIFITTVAYLGVAICVGACVVRDATGNMNDTIISGMNCNGSAACGLGYDFSRCRHEPCQYGLMNNFQVMSMVSGFGPLITAGIFSATLSSALASLVSAPKVFQALCKDNIYKALQFFAKGYGKNNEPLRGYILTFLIAMAFILIAELNTIAPIISNFFLASYALINFSCFHASYAKSPGWRPAYGIYNMWVSLFGAVLCCAVMFVINWWAAVITYVIEFFLYVYVTCKKPDVNWGSSTQALSYVSALDNALELTTVEDHVKNFRPQCIVLTGGPMTRPALLDITHAFTKNSGLCICCEVFVGPRKLCVKEMNSGMAKKQAWLIKNKIKAFYAAVAADCFRDGVRSLLQASGLGRMKPNTLVIGYKKNWRKAPLTEIENYVGIIHDAFDFEIGVVIVRISQGFDISQVLQVQEELERLEQERLALEATIKDNECEEESGGIRGLFKKAGKLNITKTTPKKDGSINTSQSMHVGEFNQKLVEASTQFKKKQEKGTIDVWWLFDDGGLTLLIPYILTLRKKWKDCKLRIYVGGKINRIEEEKIVMASLLSKFRIKFADIHIIGDINIRPNKESWKVFEEMIEPYRLHESCKDLTTAEKLKRETPWKITDAELEAVKEKSYRQVRLNELLQEHSRAANLIVLSLPVARKGSISDLLYMAWLEILTKNLPPVLLVRGNHKNVLTFYS>sp|Q13621-3|S12A1_HUMAN Isoform F of Solute carrier family 12 member 1OS=Homo sapiens OX=9606 GN=SLC12A1MSLNNSSNVFLDSVPSNTNRFQVSVINENHESSAAADDNTDPPHYEETSFGDEAQKRLRISFRPGNQECYDNFLQSGETAKTDASFHAYDSHTNTYYLQTFGHNTMDAVPKIEYYRNTGSISGPKVNRPSLLEIHEQLAKNVAVTPSSADRVANGDGIPGDEQAENKEDDQAGVVKFGWVKGVLVRCMLNIWGVMLFIRLSWIVGEAGIGLGVIIIGLSVVVTTLTGISMSAICTNGVVRGGGAYYLISRSLGPEFGGSIGLIFAFANAVAVAMYVVGFAETVVDLLKESDSMMVDPTNDIRIIGSITVVILLGISVAGMEWEAKAQVILLVILLIAIANFFIGTVIPSNNEKKSRGFFNYQASIFAENFGPRFTKGEGFFSVFAIFFPAATGILAGANISGDLEDPQDAIPRGTMLAIFITTVAYLGVAICVGACVVRDATGNMNDTIISGMNCNGSAACGLGYDFSRCRHEPCQYGLMNNFQVMSMVSGFGPLITAGIFSATLSSALASLVSAPKVFQALCKDNIYKALQFFAKGYGKNNEPLRGYILTFLIAMAFILIAELNTIAPIISNFFLASYALINFSCFHASYAKSPGWRPAYGIYNMWVSLFGAVLCCAVMFVINWWAAVITYVIEFFLYVYVTCKKPDVNWGSSTQALSYVSALDNALELTTVEDHVKNFRPQCIVLTGGPMTRPALLDITHAFTKNSGLCICCEVFVGPRKLCVKEMNSGMAKKQAWLIKNKIKAFYAAVAADCFRDGVRSLLQASGLGRMKPNTLVIGYKKNWRKAPLTEIENYVGIIHDAFDFEIGVVIVRISQGFDISQVLQVQEELERLEQERLALEATIKDNECEEESGGIRGLFKKAGKLNITKTTPKKDGSINTSQSMHVGEFNQKLVEASTQFKKKQEKGTIDVWWLFDDGGLTLLIPYILTLRKKWKDCKLRIYVGGKINRIEEEKIVMASLLSKFRIKFADIHIIGDINIRPNKESWKVFEEMIEPYRLHESCKDLTTAEKLKRETPWKITDAELEAVKEKSYRQVRLNELLQEHSRAANLIVLSLPVARKGSISDLLYMAWLEILTKNLPPVLLVRGNHKNVLTFYS>sp|Q9BXP2|S12A9_HUMAN Solute carrier family 12 member 9 OS=Homo sapiensOX=9606 GN=SLC12A9 PE=1 SV=1MASESSPLLAYRLLGEEGVALPANGAGGPGGASARKLSTFLGVVVPTVLSMFSIVVFLRIGFVVGHAGLLQALAMLLVAYFILALTVLSVCAIATNGAVQGGGAYFMISRTLGPEVGGSIGLMFYLANVCGCAVSLLGLVESVLDVFGADATGPSGLRVLPQGYGWNLLYGSLLLGLVGGVCTLGAGLYARASFLTFLLVSGSLASVLISFVAVGPRDIRLTPRPGPNGSSLPPRFGHFTGFNSSTLKDNLGAGYAEDYTTGAVMNFASVFAVLFNGCTGIMAGANMSGELKDPSRAIPLGTIVAVAYTFFVYVLLFFLSSFTCDRTLLQEDYGFFRAISLWPPLVLIGIYATALSASMSSLIGASRILHALARDDLFGVILAPAKVVSRGGNPWAAVLYSWGLVQLVLLAGKLNTLAAVVTVFYLVAYAAVDLSCLSLEWASAPNFRPTFSLFSWHTCLLGVASCLLMMFLISPGAAGGSLLLMGLLAALLTARGGPSSWGYVSQALLFHQVRKYLLRLDVRKDHVKFWRPQLLLLVGNPRGALPLLRLANQLKKGGLYVLGHVTLGDLDSLPSDPVQPQYGAWLSLVDRAQVKAFVDLTLSPSVRQGAQHLLRISGLGGMKPNTLVLGFYDDAPPQDHFLTDPAFSEPADSTREGSSPALSTLFPPPRAPGSPRALNPQDYVATVADALKMNKNVVLARASGALPPERLSRGSGGTSQLHHVDVWPLNLLRPRGGPGYVDVCGLFLLQMATILGMVPAWHSARLRIFLCLGPREAPGAAEGRLRALLSQLRIRAEVQEVVWGEGAGAGEPEAEEEGDFVNSGRGDAEAEALARSANALVRAQQGRGTGGGPGGPEGGDAEGPITALTFLYLPRPPADPARYPRYLALLETLTRDLGPTLLVHGVTPVTCTDL>sp|Q9BXP2-2|S12A9_HUMAN Isoform 2 of Solute carrier family 12 member 9OS=Homo sapiens OX=9606 GN=SLC12A9MASESSPLLAYRLLGEEGVALPANGAGGPGGASARKLSTFLGVVVPTVLSMFSIVVFLRIDATGPSGLRVLPQGYGWNLLYGSLLLGLVGGVCTLGAGLYARASFLTFLLVSGSLASVLISFVAVGPRDIRLTPRPGPNGSSLPPRFGHFTGFNSSTLKDNLGAGYAEDYTTGAVMNFASVFAVLFNGCTGIMAGANMSGELKDPSRAIPLGTIVAVAYTFFVYVLLFFLSSFTCDRTLLQEDYGFFRAISLWPPLVLIGIYATALSASMSSLIGASRILHALARDDLFGVILAPAKVVSRGGNPWAAVLYSWGLVQLVLLAGKLNTLAAVVTVFYLVAYAAVDLSCLSLEWASAPNFRPTFSLFSWHTCLLGVASCLLMMFLISPGAAGGSLLLMGLLAALLTARGGPSSWGYVSQALLFHQVRKYLLRLDVRKDHVKFWRPQLLLLVGNPRGALPLLRLANQLKKGGLYVLGHVTLGDLDSLPSDPVQPQYGAWLSLVDRAQVKAFVDLTLSPSVRQGAQHLLRISGLESNSHPLP>sp|Q9BXP2-3|S12A9_HUMAN Isoform 3 of Solute carrier family 12 member 9OS=Homo sapiens OX=9606 GN=SLC12A9MASESSPLLAYRLLGEEGVALPANGAGGPGGASARKLSTFLGVVVPTVLSMFSIVVFLRIGFVVGHAGLLQALAMLLVAYFILALTVLSVCAIATNGAVQGGGAYFMISRTLGPEVGGSIGLMFYLANVCGCAVSLLGLVESVLDVFGADATGPSGLRVLPQGYGWNLLYGSLLLGLVGGVCTLGAGLYARASFLTFLLVSGSLASVLISFVAVGPRDIRLTPRPGPNGSSLPPRFGHFTGFNSSTLKDNLGAGYAEDYTTGAVMNFASVFAVLFNGCTGIMAGANMSGELKDPSRAIPLGTIVAVAYTFFVYVLLFFLSSFTCDRTLLQEDYGFFRAISLWPPLVLIGIYATALSASMSSLIGASRILHALARDDLFGVILAPAKVVSRGGNPWAAVLYSWGLVQLVLLAGKLNTLAAVVTVFYLVAYAAVDLSCLSLEWASAPNFRPTFSLFSWHTCLLGVASCLLMMFLISPGAAGGSLLLMGLLAALLTARGGPSSWGYVSQALLFHQVRKYLLRLDVRKDHVKFWRPQLLLLVGNPRGALPLLRLANQLKKGGLYVLGHVTLGDLDSLPSDPVQPQYGAWLSLVDRAQVKAFVDLTLSPSVRQGAQHLLRISGLESNSHPLP>sp|Q9BXP2-4|S12A9_HUMAN Isoform 4 of Solute carrier family 12 member 9OS=Homo sapiens OX=9606 GN=SLC12A9MASESSPLLAYRLLGEEGVALPANGAGGPGGASARKLSTFLGVVVPTVLSMFSIVVFLRIGFVVGHAGLLQALAMLLVAYFILALTVLSVCAIATNGAVQGGGAYFMISRTLGPEVGGSIGLMFYLANVCGCAVSLLGLVESVLDVFGADATGPSGLRVLPQGYGWNLLYGSLLLGLVGGVCTLGAGLYARASFLTFLLVSGSLASVLISFVAVGPRDIRLTPRPGPNGSSLPPRFGHFTGFNSSTLKDNLGAGYAEDYTTGAVMNFASVFAVLFNGCTGIMAGANMSGELKDPSRAIPLGTIVAVAYTFFVYVLLFFLSSFTCDRTLLQEDYGFFRAISLWPPLVLIGIYATALSASMSSLIGASRILHALARDDLFGVILAPAKVVSRGGNPWAAVLYSWGLVQLVLLAGKLNTLAAVVTVFYLVAYAAVDLSCLSLEWASAPNFRPTFSLFSWHTCLLGVASCLLMMFLISPGAAGGSLLLMGLLAALLTARGGPSSWGYVSQALLFHQVRKYLLRLDVRKDHVKFWRPQLLLLVGNPRGALPLLRLANQLKKGGLYVLGHVTLGDLDSLPSDPVQPQYGAWLSLVDRAQVKAFVDLTLSPSVRQGAQHLLRISGLESGTLLPWGFRS>sp|O14804|TAAR5_HUMAN Trace amine-associated receptor 5 OS=Homo sapiensOX=9606 GN=TAAR5 PE=2 SV=2MRAVFIQGAEEHPAAFCYQVNGSCPRTVHTLGIQLVIYLACAAGMLIIVLGNVFVAFAVSYFKALHTPTNFLLLSLALADMFLGLLVLPLSTIRSVESCWFFGDFLCRLHTYLDTLFCLTSIFHLCFISIDRHCAICDPLLYPSKFTVRVALRYILAGWGVPAAYTSLFLYTDVVETRLSQWLEEMPCVGSCQLLLNKFWGWLNFPLFFVPCLIMISLYVKIFVVATRQAQQITTLSKSLAGAAKHERKAAKTLGIAVGIYLLCWLPFTIDTMVDSLLHFITPPLVFDIFIWFAYFNSACNPIIYVFSYQWFRKALKLTLSQKVFSPQTRTVDLYQE>sp|Q96RI8|TAAR6_HUMAN Trace amine-associated receptor 6 OS=Homo sapiensOX=9606 GN=TAAR6 PE=2 SV=1MSSNSSLLVAVQLCYANVNGSCVKIPFSPGSRVILYIVFGFGAVLAVFGNLLVMISILHFKQLHSPTNFLVASLACADFLVGVTVMPFSMVRTVESCWYFGRSFCTFHTCCDVAFCYSSLFHLCFISIDRYIAVTDPLVYPTKFTVSVSGICISVSWILPLMYSGAVFYTGVYDDGLEELSDALNCIGGCQTVVNQNWVLTDFLSFFIPTFIMIILYGNIFLVARRQAKKIENTGSKTESSSESYKARVARRERKAAKTLGVTVVAFMISWLPYSIDSLIDAFMGFITPACIYEICCWCAYYNSAMNPLIYALFYPWFRKAIKVIVTGQVLKNSSATMNLFSEHI>sp|Q969N4|TAAR8_HUMAN Trace amine-associated receptor 8 OS=Homo sapiensOX=9606 GN=TAAR8 PE=2 SV=1MTSNFSQPVVQLCYEDVNGSCIETPYSPGSRVILYTAFSFGSLLAVFGNLLVMTSVLHFKQLHSPTNFLIASLACADFLVGVTVMLFSMVRTVESCWYFGAKFCTLHSCCDVAFCYSSVLHLCFICIDRYIVVTDPLVYATKFTVSVSGICISVSWILPLTYSGAVFYTGVNDDGLEELVSALNCVGGCQIIVSQGWVLIDFLLFFIPTLVMIILYSKIFLIAKQQAIKIETTSSKVESSSESYKIRVAKRERKAAKTLGVTVLAFVISWLPYTVDILIDAFMGFLTPAYIYEICCWSAYYNSAMNPLIYALFYPWFRKAIKLILSGDVLKASSSTISLFLE>sp|Q96RI9|TAAR9_HUMAN Trace amine-associated receptor 9 OS=Homo sapiensOX=9606 GN=TAAR9 PE=1 SV=1MVNNFSQAEAVELCYKNVNESCIKTPYSPGPRSILYAVLGFGAVLAAFGNLLVMIAILHFKQLHTPTNFLIASLACADFLVGVTVMPFSTVRSVESCWYFGDSYCKFHTCFDTSFCFASLFHLCCISVDRYIAVTDPLTYPTKFTVSVSGICIVLSWFFSVTYSFSIFYTGANEEGIEELVVALTCVGGCQAPLNQNWVLLCFLLFFIPNVAMVFIYSKIFLVAKHQARKIESTASQAQSSSESYKERVAKRERKAAKTLGIAMAAFLVSWLPYLVDAVIDAYMNFITPPYVYEILVWCVYYNSAMNPLIYAFFYQWFGKAIKLIVSGKVLRTDSSTTNLFSEEVETD>sp|Q9P0U3|SENP1_HUMAN Sentrin-specific protease 1 OS=Homo sapiensOX=9606 GN=SENP1 PE=1 SV=2MDDIADRMRMDAGEVTLVNHNSVFKTHLLPQTGFPEDQLSLSDQQILSSRQGHLDRSFTCSTRSAAYNPSYYSDNPSSDSFLGSGDLRTFGQSANGQWRNSTPSSSSSLQKSRNSRSLYLETRKTSSGLSNSFAGKSNHHCHVSAYEKSFPIKPVPSPSWSGSCRRSLLSPKKTQRRHVSTAEETVQEEEREIYRQLLQMVTGKQFTIAKPTTHFPLHLSRCLSSSKNTLKDSLFKNGNSCASQIIGSDTSSSGSASILTNQEQLSHSVYSLSSYTPDVAFGSKDSGTLHHPHHHHSVPHQPDNLAASNTQSEGSDSVILLKVKDSQTPTPSSTFFQAELWIKELTSVYDSRARERLRQIEEQKALALQLQNQRLQEREHSVHDSVELHLRVPLEKEIPVTVVQETQKKGHKLTDSEDEFPEITEEMEKEIKNVFRNGNQDEVLSEAFRLTITRKDIQTLNHLNWLNDEIINFYMNMLMERSKEKGLPSVHAFNTFFFTKLKTAGYQAVKRWTKKVDVFSVDILLVPIHLGVHWCLAVVDFRKKNITYYDSMGGINNEACRILLQYLKQESIDKKRKEFDTNGWQLFSKKSQEIPQQMNGSDCGMFACKYADCITKDRPINFTQQHMPYFRKRMVWEILHRKLL>sp|Q9P0U3-2|SENP1_HUMAN Isoform 2 of Sentrin-specific protease 1 OS=Homosapiens OX=9606 GN=SENP1MDDIADRMRMDAGEVTLVNHNSVFKTHLLPQTGFPEDQLSLSDQQILSSRQGHLDRSFTCSTRSAAYNPSYYSDNPSSDSFLGSGDLRTFGQSANGQWRNSTPSSSSSLQKSRNSRSLYLETRKTSSGLSNSFAGKSNHHCHVSAYEKSFPIKPVPSPSWSGSCRRSLLSPKKTQRRHVSTAEETVQEEEREIYRQLLQMVTGKQFTIAKPTTHFPLHLSRCLSSSKNTLKDSLFKNGNSCASQIIGSDTSSSGSASILTNQEQLSHSVYSLSSYTPDVAFGSKDSGTLHHPHHHHSVPHQPDNLAASNTQSEGSDSVILLKVKDSQTPTPSSTFFQAELWIKELTSVYDSRARERLRQIEEQKALALQLQNQRLQEREHSVHDSVELHLRVPLEKEIPVTVVQETQKKGHKLTDSEDEFPEITEEMEKEIKNVFRNGNQDEVLSEAFRLTITRKDIQTLNHLNWLNDEIINFYMNMLMERSKEKGLPSVHAFNTFFFTKLKTAGYQAVKRWTKKVDVFSVDILLVPIHLGVHWCLAVVDFRKKNITYYDSMGGINNEACRILLQYLKQESIDKKRKEFDTNGWQLFSKKSQIPQQMNGSDCGMFACKYADCITKDRPINFTQQHMPYFRKRMVWEILHRKLL>sp|Q9BY07|S4A5_HUMAN Electrogenic sodium bicarbonate cotransporter 4OS=Homo sapiens OX=9606 GN=SLC4A5 PE=2 SV=2MKVKEEKAGVGKLDHTNHRRRFPDQKECPPIHIGLPVPTYPQRKTDQKGHLSGLQKVHWGLRPDQPQQELTGPGSGASSQDSSMDLISRTRSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKVRALVADFSIVFSILMFCGIDACFGLETPKLHVPSVIKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKKAAGYHLDLFWVGILMALCSFMGLPWYVAATVISIAHIDSLKMETETSAPGEQPQFLGVREQRVTGIIVFILTGISVFLAPILKCIPLPVLYGVFLYMGVASLNGIQMGTGGSEFKIQKKLTPFWERCKLFLMPAKHQPDHAFLRHVPLRRIHLFTLVQILCLAVLWILKSTVAAIIFPVMILGLIIVRRLLDFIFSQHDLAWIDNILPEKEKKETDKKRKRKKGAHEDCDEEPQFPPPSVIKIPMESVQSDPQNGIHCIARKRSSSWSYSL>sp|Q9BY07-2|S4A5_HUMAN Isoform 2 of Electrogenic sodium bicarbonatecotransporter 4 OS=Homo sapiens OX=9606 GN=SLC4A5MKVKEEKAGVGKLDHTNHRRRFPDQKECPPIHIGLPVPTYPQRKTDQKGHLSGLQKVHWGLRPDQPQQELTGPGSGASSQDSSMDLISRTRSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKVRALVADFSIVFSILMFCGIDACFGLETPKLHVPSVIKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKKAAGYHLDLFWVGILMALCSFMGLPWYVAATVISIAHIDSLKMETETSAPGEQPQFLGVREQRVTGIIVFILTGISVFLAPILKCIPLPVLYGVFLYMGVASLNGIQMGTGGSEFKIQKKLTPFWERCKLFLMPAKHQPDHAFLRHVPLRRIHLFTLVQILCLAVLWILKSTVAAIIFPVMSLSTTDILGLIIVRRLLDFIFSQHDLAWIDNILPEKEKKETDKKRKRKKGAHEDCDEEPQFPPPSVIKIPMESVQSDPQNGIHCIARKRSSSWSYSL>sp|Q9BY07-3|S4A5_HUMAN Isoform 3 of Electrogenic sodium bicarbonatecotransporter 4 OS=Homo sapiens OX=9606 GN=SLC4A5MKVKEEKAGVGKLDHTNHRRRFPDQKECPPIHIGLPVPTYPQRKTDQKGHLSGLQKVHWGLRPDQPQQELTGPGSGASSQDSSMDLISRTRSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKVRALVADFSIVFSILMFCGIDACFGLETPKLHVPSVIKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKKAAGYHLDLFWVGILMALCSFMGLPWYVAATVISIAHIDSLKMETETSAPGEQPQFLGVREQRVTGIIVFILTGISVFLAPILKCIPLPVLYGVFLYMGVASLNGIQFWERCKLFLMPAKHQPDHAFLRHVPLRRIHLFTLVQILCLAVLWILKSTVAAIIFPVMILGLIIVRRLLDFIFSQHDLAWIDNILPEKEKKETDKKRKRKKGAHEDCDEEPQFPPPSVIKIPMESVQSDPQNGIHCIARKRSSSWSYSL>sp|Q9BY07-4|S4A5_HUMAN Isoform 4 of Electrogenic sodium bicarbonatecotransporter 4 OS=Homo sapiens OX=9606 GN=SLC4A5MKVKEEKAGVGKLDHTNHRRRFPDQKECPPIHIGLPVPTYPQRKTDQKGHLSGLQKVHWGLRPDQPQQELTGPGSGASSQDSSMDLISRTRSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKVRALVADFSIVFSILMFCGIDACFGLETPKLHVPSVIKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKKAAGYHLDLFWVGILMALCSFMGLPWYVAATVISIAHIDSLKMETETSAPGEQPQFLGVREQRVTGIIVFILTGISVFLAPILKILGLIIVRRLLDFIFSQHDLAWIDNILPEKEKKETDKKRKRKKGAHEDCDEEPQFPPPSVIKIPMESVQSDPQNGIHCIARKRSSSWSYSL>sp|Q9BY07-5|S4A5_HUMAN Isoform 5 of Electrogenic sodium bicarbonatecotransporter 4 OS=Homo sapiens OX=9606 GN=SLC4A5MKVKEEKAGVGKLDHTNHRRRFPDQKECPPIHIGLPVPTYPQRKTDQKGHLSGLQKVHWGLRPDQPQQELTGPGSGASSQDSSMDLIEHKGSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKVRALVADFSIVFSILMFCGIDACFGLETPKLHVPSVIKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKGTESNRHHRLHPDGNLCLPGSHPKVYPPAGAVRSLPLHGRGLPEWHPVLGTLQALPDASQAPAGPCLPAARAAAPDPPLHPGADPLPGGALDPQIHGGCHHLPGHDPGPHHRSKASGFHLFPARPGLD>sp|Q9BY07-6|S4A5_HUMAN Isoform 6 of Electrogenic sodium bicarbonatecotransporter 4 OS=Homo sapiens OX=9606 GN=SLC4A5MKVKEEKAGVGKLDHTNHRRRFPDQKECPPIHIGLPVPTYPQRKTDQKGHLSGLQKVHWGLRPDQPQQELTGPGSGASSQDSSMDLISRTRSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKREQRVTGIIVFILTGISVFLAPILKCIPLPVLYGVFLYMGVASLNGIQFWERCKLFLMPAKHQPDHAFLRHVPLRRIHLFTLVQILCLAVLWILKSTVAAIIFPVMSLSTTDILGLIIVRRLLDFIFSQHDLAWIDKIEFP>sp|Q9BY07-7|S4A5_HUMAN Isoform 7 of Electrogenic sodium bicarbonatecotransporter 4 OS=Homo sapiens OX=9606 GN=SLC4A5MKVKEEKAGVGKLDHTNHRRRFPDQKGSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKKAAGYHLDLFWVGILMALCSFMGLPWYVAATVISIAHIDSLKMETETSAPGEQPQFLGVREQRVTGIIVFILTGISVFLAPILKCIPLPVLYGVFLYMGVASLNGIQFWERCKLFLMPAKHQPDHAFLRHVPLRRIHLFTLVQILCLAVLWILKSTVAAIIFPVMILGLIIVRRLLDFIFSQHDLAWIDNILPEKEKKETDKKRKRKKGAHEDCDEEPQFPPPSVIKIPMESVQSDPQNGIHCIARKRSSSWSYSL>sp|Q9BY07-8|S4A5_HUMAN Isoform 8 of Electrogenic sodium bicarbonatecotransporter 4 OS=Homo sapiens OX=9606 GN=SLC4A5MKVKEEKAGVGKLDHTNHRRRFPDQKECPPIHIGLPVPTYPQRKTDQKGHLSGLQKVHWGLRPDQPQQELTGPGSGASSQDSSMDLISRTRSPAAEQLQDILGEEDEAPNPTLFTEMDTLQHDGDQMEWKESARWIKFEEKVEEGGERWSKPHVSTLSLHSLFELRTCLQTGTVLLDLDSGSLPQIIDDVIEKQIEDGLLRPELRERVSYVLLRRHRHQTKKPIHRSLADIGKSVSTTNRSPARSPGAGPSLHHSTEDLRMRQSANYGRLCHAQSRSMNDISLTPNTDQRKNKFMKKIPKDSEASNVLVGEVDFLDQPFIAFVRLIQSAMLGGVTEVPVPTRFLFILLGPSGRAKSYNEIGRAIATLMVDDLFSDVAYKARNREDLIAGIDEFLDEVIVLPPGEWDPNIRIEPPKKVPSADKRKSVFSLAELGQMNGSVGGGGGAPGGGNGGGGGGGSGGGAGSGGAGGTSSGDDGEMPAMHEIGEELIWTGRFFGGLCLDIKRKLPWFPSDFYDGFHIQSISAILFIYLGCITNAITFGGLLGDATDNYQGVMESFLGTAMAGSLFCLFSGQPLIILSSTGPILIFEKLLFDFSKGNGLDYMEFRLWIGLHSAVQCLILVATDASFIIKYITRFTEEGFSTLISFIFIYDAIKKMIGAFKYYPINMDFKPNFITTYKCECVAPDTVNTTVFNASAPLAPDTNASLYNLLNLTALDWSLLSKKECLSYGGRLLGNSCKFIPDLALMSFILFFGTYSMTLTLKKFKFSRYFPTKVRALVADFSIVFSILMFCGIDACFGLETPKLHVPSVIKPTRPDRGWFVAPFGKNPWWVYPASILPALLVTILIFMDQQITAVIVNRKENKLKKAAGYHLDLFWVGILMALCSFMGLPWYVAATVISIAHIDSLKMETETSAPGEQPQFLGVREQRVTGIIVFILTGISVFLAPILKCIPLPVLYGVFLYMGVASLNGIQMGTGGSEFKIQKKLTPFWERCKLFLMPAKHQPDHAFLRHVPLRRIHLFTLVQILCLAVLWILKSTVAAIIFPVMILGLIIVRRLLDFIFSQHDLA>sp|O75845|SC5D_HUMAN Lathosterol oxidase OS=Homo sapiens OX=9606 GN=SC5DPE=1 SV=2MDLVLRVADYYFFTPYVYPATWPEDDIFRQAISLLIVTNVGAYILYFFCATLSYYFVFDHALMKHPQFLKNQVRREIKFTVQALPWISILTVALFLLEIRGYSKLHDDLGEFPYGLFELVVSIISFLFFTDMFIYWIHRGLHHRLVYKRLHKPHHIWKIPTPFASHAFHPIDGFLQSLPYHIYPFIFPLHKVVYLSLYILVNIWTISIHDGDFRVPQILQPFINGSAHHTDHHMFFDYNYGQYFTLWDRIGGSFKNPSSFEGKGPLSYVKEMTEGKRSSHSGNGCKNEKLFNGEFTKTE>sp|Q15750|TAB1_HUMAN TGF-beta-activated kinase 1 and MAP3K7-bindingprotein 1 OS=Homo sapiens OX=9606 GN=TAB1 PE=1 SV=1MAAQRRSLLQSEQQPSWTDDLPLCHLSGVGSASNRSYSADGKGTESHPPEDSWLKFRSENNCFLYGVFNGYDGNRVTNFVAQRLSAELLLGQLNAEHAEADVRRVLLQAFDVVERSFLESIDDALAEKASLQSQLPEGVPQHQLPPQYQKILERLKTLEREISGGAMAVVAVLLNNKLYVANVGTNRALLCKSTVDGLQVTQLNVDHTTENEDELFRLSQLGLDAGKIKQVGIICGQESTRRIGDYKVKYGYTDIDLLSAAKSKPIIAEPEIHGAQPLDGVTGFLVLMSEGLYKALEAAHGPGQANQEIAAMIDTEFAKQTSLDAVAQAVVDRVKRIHSDTFASGGERARFCPRHEDMTLLVRNFGYPLGEMSQPTPSPAPAAGGRVYPVSVPYSSAQSTSKTSVTLSLVMPSQGQMVNGAHSASTLDEATPTLTNQSPTLTLQSTNTHTQSSSSSSDGGLFRSRPAHSLPPGEDGRVEPYVDFAEFYRLWSVDHGEQSVVTAP>sp|Q15750-2|TAB1_HUMAN Isoform 2 of TGF-beta-activated kinase 1 andMAP3K7-binding protein 1 OS=Homo sapiens OX=9606 GN=TAB1MAAQRRSLLQSEQQPSWTDDLPLCHLSGVGSASNRSYSADGKGTESHPPEDSWLKFRSENNCFLYGVFNGYDGNRVTNFVAQRLSAELLLGQLNAEHAEADVRRVLLQAFDVVERSFLESIDDALAEKASLQSQLPEGVPQHQLPPQYQKILERLKTLEREISGGAMAVVAVLLNNKLYVANVGTNRALLCKSTVDGLQVTQLNVDHTTENEDELFRLSQLGLDAGKIKQVGIICGQESTRRIGDYKVKYGYTDIDLLSAAKSKPIIAEPEIHGAQPLDGVTGFLVLMSEGLYKALEAAHGPGQANQEIAAMIDTEFAKQTSLDAVAQAVVDRVKRIHSDTFASGGERARFCPRHEDMTLLVRNFGYPLGEMSQPTPSPAPAAGGRVYPVSVPYSSAQSTSKTSVTLSLVMPSQGQMVNGAHSASTLDEATPTLTKDPSRPASDLTAIPQCQLNLLGSLTPG>sp|Q9H4B6|SAV1_HUMAN Protein salvador homolog 1 OS=Homo sapiens OX=9606GN=SAV1 PE=1 SV=2MLSRKKTKNEVSKPAEVQGKYVKKETSPLLRNLMPSFIRHGPTIPRRTDICLPDSSPNAFSTSGDVVSRNQSFLRTPIQRTPHEIMRRESNRLSAPSYLARSLADVPREYGSSQSFVTEVSFAVENGDSGSRYYYSDNFFDGQRKRPLGDRAHEDYRYYEYNHDLFQRMPQNQGRHASGIGRVAATSLGNLTNHGSEDLPLPPGWSVDWTMRGRKYYIDHNTNTTHWSHPLEREGLPPGWERVESSEFGTYYVDHTNKKAQYRHPCAPSVPRYDQPPPVTYQPQQTERNQSLLVPANPYHTAEIPDWLQVYARAPVKYDHILKWELFQLADLDTYQGMLKLLFMKELEQIVKMYEAYRQALLTELENRKQRQQWYAQQHGKNF>sp|Q8IX30|SCUB3_HUMAN Signal peptide, CUB and EGF-like domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=SCUBE3 PE=1 SV=1MGSGRVPGLCLLVLLVHARAAQYSKAAQDVDECVEGTDNCHIDAICQNTPRSYKCICKSGYTGDGKHCKDVDECEREDNAGCVHDCVNIPGNYRCTCYDGFHLAHDGHNCLDVDECAEGNGGCQQSCVNMMGSYECHCREGFFLSDNQHTCIQRPEEGMNCMNKNHGCAHICRETPKGGIACECRPGFELTKNQRDCKLTCNYGNGGCQHTCDDTEQGPRCGCHIKFVLHTDGKTCIETCAVNNGGCDSKCHDAATGVHCTCPVGFMLQPDRKTCKDIDECRLNNGGCDHICRNTVGSFECSCKKGYKLLINERNCQDIDECSFDRTCDHICVNTPGSFQCLCHRGYLLYGITHCGDVDECSINRGGCRFGCINTPGSYQCTCPAGQGRLHWNGKDCTEPLKCQGSPGASKAMLSCNRSGKKDTCALTCPSRARFLPESENGFTVSCGTPSPRAAPARAGHNGNSTNSNHCHEAAVLSIKQRASFKIKDAKCRLHLRNKGKTEEAGRITGPGGAPCSECQVTFIHLKCDSSRKGKGRRARTPPGKEVTRLTLELEAEVRAEETTASCGLPCLRQRMERRLKGSLKMLRKSINQDRFLLRLAGLDYELAHKPGLVAGERAEPMESCRPGQHRAGTKCVSCPQGTYYHGQTEQCVPCPAGTFQEREGQLSCDLCPGSDAHGPLGATNVTTCAGQCPPGQHSVDGFKPCQPCPRGTYQPEAGRTLCFPCGGGLTTKHEGAISFQDCDTKVQCSPGHYYNTSIHRCIRCAMGSYQPDFRQNFCSRCPGNTSTDFDGSTSVAQCKNRQCGGELGEFTGYIESPNYPGNYPAGVECIWNINPPPKRKILIVVPEIFLPSEDECGDVLVMRKNSSPSSITTYETCQTYERPIAFTARSRKLWINFKTSEANSARGFQIPYVTYDEDYEQLVEDIVRDGRLYASENHQEILKDKKLIKAFFEVLAHPQNYFKYTEKHKEMLPKSFIKLLRSKVSSFLRPYK>sp|Q8IX30-2|SCUB3_HUMAN Isoform 2 of Signal peptide, CUB and EGF-likedomain-containing protein 3 OS=Homo sapiens OX=9606 GN=SCUBE3MGSGRVPGLCLLVLLVHARAAQYSKAAQDVDECVEGTDNCHIDAICQNTPRSYKCICKSGYTGDGKHCKDVDECEREDNAGCVHDCVNIPGNYRCTCYDGFHLAHDGHNCLDVDECAEGNGGCQQSCVNMMGSYECHCREGFFLSDNQHTCIQRPEEGMNCMNKNHGCAHICRETPKGGIACECRPGFELTKNQRDCKLTCNYGNGGCQHTCDDTEQGPRCGCHIKFVLHTDGKTCIGERRLEQHIPTQAVSNETCAVNNGGCDSKCHDAATGVHCTCPVGFMLQPDRKTCKDIDECRLNNGGCDHICRNTVGSFECSCKKGYKLLINERNCQDIDECSFDRTCDHICVNTPGSFQCLCHRGYLLYGITHCGDVDECSINRGGCRFGCINTPGSYQCTCPAGQGRLHWNGKDCTEPLKCQGSPGASKAMLSCNRSGKKDTCALTCPSRARFLPESENGFTVSCGTPSPRAAPARAGHNGNSTNSNHCHEAAVLSIKQRASFKIKDAKCRLHLRNKGKTEEAGRITGPGGAPCSECQVTFIHLKCDSSRKGKGRRARTPPGKEVTRLTLELEAEVRAEETTASCGLPCLRQRMERRLKGSLKMLRKSINQDRFLLRLAGLDYELAHKPGLVAGERAEPMESCRPGQHRAGTKCVSCPQGTYYHGQTEQCVPCPAGTFQEREGQLSCDLCPGSDAHGPLGATNVTTCAGQCPPGQHSVDGFKPCQPCPRGTYQPEAGRTLCFPCGGGLTTKHEGAISFQDCDTKVQCSPGHYYNTSIHRCIRCAMGSYQPDFRQNFCSRCPGNTSTDFDGSTSVAQCKNRQCGGELGEFTGYIESPNYPGNYPAGVECIWNINPPPKRKILIVVPEIFLPSEDECGDVLVMRKNSSPSSITTYETCQTYERPIAFTARSRKLWINFKTSEANSARGFQIPYVTYDEDYEQLVEDIVRDGRLYASENHQEILKDKKLIKAFFEVLAHPQNYFKYTEKHKEMLPKSFIKLLRSKVSSFLRPYK>sp|P60059|SC61G_HUMAN Protein transport protein Sec61 subunit gammaOS=Homo sapiens OX=9606 GN=SEC61G PE=1 SV=1MDQVMQFVEPSRQFVKDSIRLVKRCTKPDRKEFQKIAMATAIGFAIMGFIGFFVKLIHIPINNIIVGG>sp|P31213|S5A2_HUMAN 3-oxo-5-alpha-steroid 4-dehydrogenase 2 OS=Homosapiens OX=9606 GN=SRD5A2 PE=1 SV=1MQVQCQQSPVLAGSATLVALGALALYVAKPSGYGKHTESLKPAATRLPARAAWFLQELPSFAVPAGILARQPLSLFGPPGTVLLGLFCVHYFHRTFVYSLLNRGRPYPAILILRGTAFCTGNGVLQGYYLIYCAEYPDGWYTDIRFSLGVFLFILGMGINIHSDYILRQLRKPGEISYRIPQGGLFTYVSGANFLGEIIEWIGYALATWSLPALAFAFFSLCFLGLRAFHHHRFYLKMFEDYPKSRKALIPFIF>sp|Q92791|SC65_HUMAN Endoplasmic reticulum protein SC65 OS=Homo sapiensOX=9606 GN=P3H4 PE=1 SV=1MARVAWGLLWLLLGSAGAQYEKYSFRGFPPEDLMPLAAAYGHALEQYEGESWRESARYLEAALRLHRLLRDSEAFCHANCSGPAPAAKPDPDGGRADEWACELRLFGRVLERAACLRRCKRTLPAFQVPYPPRQLLRDFQSRLPYQYLHYALFKANRLEKAVAAAYTFLQRNPKHELTAKYLNYYQGMLDVADESLTDLEAQPYEAVFLRAVKLYNSGDFRSSTEDMERALSEYLAVFARCLAGCEGAHEQVDFKDFYPAIADLFAESLQCKVDCEANLTPNVGGYFVDKFVATMYHYLQFAYYKLNDVRQAARSAASYMLFDPKDSVMQQNLVYYRFHRARWGLEEEDFQPREEAMLYHNQTAELRELLEFTHMYLQSDDEMELEETEPPLEPEDALSDAEFEGEGDYEEGMYADWWQEPDAKGDEAEAEPEPELA>sp|Q658L1|SAXO2_HUMAN Stabilizer of axonemal microtubules 2 OS=Homosapiens OX=9606 GN=SAXO2 PE=1 SV=1MGAKSMRSWCLCQICSCGSDYCPYEIVKQPRHVPEEYKPKQGKIDLGTTYKRDLNSYKVQPVAIVRPLERQVKKGKLDTVPTYKDDYRAWDLHKSELYKPEQTYHPPTVKFGNSTTFQDDFVPQEIKPRQSFKPSSVVKRSTAPFNGITSHRLDYIPHQLELKFERPKEVYKPTDQRFEDLTTHRCDFQGLIGETAKLCRPVHTRVTQNALFEGSTEFRESFQPWEIPPPEVKKVPEYVPPTGSMLLNSTSHLDYVPYQANHVVPIRPVSQKRSNNFPFQGKSIMKEDFPAWESCRQGLIKKQQQIPNPSGKFDGLSTFRSHYVPHELIPTESCKPLNIAFKSSVPFDDVTMYSVEYTPKRQEICPASYPSPPGYIFDNTNSQGHKFFRKIIPAVKAF>sp|Q658L1-2|SAXO2_HUMAN Isoform 2 of Stabilizer of axonemal microtubules2 OS=Homo sapiens OX=9606 GN=SAXO2MPWSDYCPYEIVKQPRHVPEEYKPKQGKIDLGTTYKRDLNSYKVQPVAIVRPLERQVKKGKLDTVPTYKDDYRAWDLHKSELYKPEQTYHPPTVKFGNSTTFQDDFVPQEIKPRQSFKPSSVVKRSTAPFNGITSHRLDYIPHQLELKFERPKEVYKPTDQRFEDLTTHRCDFQGLIGETAKLCRPVHTRVTQNALFEGSTEFRESFQPWEIPPPEVKKVPEYVPPTGSMLLNSTSHLDYVPYQANHVVPIRPVSQKRSNNFPFQGKSIMKEDFPAWESCRQGLIKKQQQIPNPSGKFDGLSTFRSHYVPHELIPTESCKPLNIAFKSSVPFDDVTMYSVEYTPKRQEICPASYPSPPGYIFDNTNSQGHKFFRKIIPAVKAF>sp|Q9NVA2|SEP11_HUMAN Septin-11 OS=Homo sapiens OX=9606 GN=SEPTIN11 PE=1SV=3MAVAVGRPSNEELRNLSLSGHVGFDSLPDQLVNKSTSQGFCFNILCVGETGIGKSTLMDTLFNTKFESDPATHNEPGVRLKARSYELQESNVRLKLTIVDTVGFGDQINKDDSYKPIVEYIDAQFEAYLQEELKIKRSLFNYHDTRIHACLYFIAPTGHSLKSLDLVTMKKLDSKVNIIPIIAKADTIAKNELHKFKSKIMSELVSNGVQIYQFPTDEETVAEINATMSVHLPFAVVGSTEEVKIGNKMAKARQYPWGVVQVENENHCDFVKLREMLIRVNMEDLREQTHTRHYELYRRCKLEEMGFKDTDPDSKPFSLQETYEAKRNEFLGELQKKEEEMRQMFVMRVKEKEAELKEAEKELHEKFDLLKRTHQEEKKKVEDKKKELEEEVNNFQKKKAAAQLLQSQAQQSGAQQTKKDKDKKNASFT>sp|Q9NVA2-2|SEP11_HUMAN Isoform 2 of Septin-11 OS=Homo sapiens OX=9606GN=SEPTIN11MEERKPAHVLRSFKYAAFMNEELRNLSLSGHVGFDSLPDQLVNKSTSQGFCFNILCVGETGIGKSTLMDTLFNTKFESDPATHNEPGVRLKARSYELQESNVRLKLTIVDTVGFGDQINKDDSYKPIVEYIDAQFEAYLQEELKIKRSLFNYHDTRIHACLYFIAPTGHSLKSLDLVTMKKLDSKVNIIPIIAKADTIAKNELHKFKSKIMSELVSNGVQIYQFPTDEETVAEINATMSVHLPFAVVGSTEEVKIGNKMAKARQYPWGVVQVENENHCDFVKLREMLIRVNMEDLREQTHTRHYELYRRCKLEEMGFKDTDPDSKPFSLQETYEAKRNEFLGELQKKEEEMRQMFVMRVKEKEAELKEAEKELHEKFDLLKRTHQEEKKKVEDKKKELEEEVNNFQKKKAAAQLLQSQAQQSGAQQTKKDKDKKNASFT>sp|P30531|SC6A1_HUMAN Sodium- and chloride-dependent GABA transporter 1OS=Homo sapiens OX=9606 GN=SLC6A1 PE=1 SV=2MATNGSKVADGQISTEVSEAPVANDKPKTLVVKVQKKAADLPDRDTWKGRFDFLMSCVGYAIGLGNVWRFPYLCGKNGGGAFLIPYFLTLIFAGVPLFLLECSLGQYTSIGGLGVWKLAPMFKGVGLAAAVLSFWLNIYYIVIISWAIYYLYNSFTTTLPWKQCDNPWNTDRCFSNYSMVNTTNMTSAVVEFWERNMHQMTDGLDKPGQIRWPLAITLAIAWILVYFCIWKGVGWTGKVVYFSATYPYIMLIILFFRGVTLPGAKEGILFYITPNFRKLSDSEVWLDAATQIFFSYGLGLGSLIALGSYNSFHNNVYRDSIIVCCINSCTSMFAGFVIFSIVGFMAHVTKRSIADVAASGPGLAFLAYPEAVTQLPISPLWAILFFSMLLMLGIDSQFCTVEGFITALVDEYPRLLRNRRELFIAAVCIISYLIGLSNITQGGIYVFKLFDYYSASGMSLLFLVFFECVSISWFYGVNRFYDNIQEMVGSRPCIWWKLCWSFFTPIIVAGVFIFSAVQMTPLTMGNYVFPKWGQGVGWLMALSSMVLIPGYMAYMFLTLKGSLKQRIQVMVQPSEDIVRPENGPEQPQAGSSTSKEAYI>sp|P61619|S61A1_HUMAN Protein transport protein Sec61 subunit alphaisoform 1 OS=Homo sapiens OX=9606 GN=SEC61A1 PE=1 SV=2MAIKFLEVIKPFCVILPEIQKPERKIQFKEKVLWTAITLFIFLVCCQIPLFGIMSSDSADPFYWMRVILASNRGTLMELGISPIVTSGLIMQLLAGAKIIEVGDTPKDRALFNGAQKLFGMIITIGQSIVYVMTGMYGDPSEMGAGICLLITIQLFVAGLIVLLLDELLQKGYGLGSGISLFIATNICETIVWKAFSPTTVNTGRGMEFEGAIIALFHLLATRTDKVRALREAFYRQNLPNLMNLIATIFVFAVVIYFQGFRVDLPIKSARYRGQYNTYPIKLFYTSNIPIILQSALVSNLYVISQMLSARFSGNLLVSLLGTWSDTSSGGPARAYPVGGLCYYLSPPESFGSVLEDPVHAVVYIVFMLGSCAFFSKTWIEVSGSSAKDVAKQLKEQQMVMRGHRETSMVHELNRYIPTAAAFGGLCIGALSVLADFLGAIGSGTGILLAVTIIYQYFEIFVKEQSEVGSMGALLF>sp|P61619-3|S61A1_HUMAN Isoform 3 of Protein transport protein Sec61subunit alpha isoform 1 OS=Homo sapiens OX=9606 GN=SEC61A1MIITIGQSIVYVMTGMYGDPSEMGAGICLLITIQLFVAGLIVLLLDELLQKGYGLGSGISLFIATNICETIVWKAFSPTTVNTGRGMEFEGAIIALFHLLATRTDKVRALREAFYRQNLPNLMNLIATIFVFAVVIYFQGFRVDLPIKSARYRGQYNTYPIKLFYTSNIPIILQSALVSNLYVISQMLSARFSGNLLVSLLGTWSDTSSGGPARAYPVGGLCYYLSPPESFGSVLEDPVHAVVYIVFMLGSCAFFSKTWIEVSGSSAKDVAKQLKEQQMVMRGHRETSMVHELNRYIPTAAAFGGLCIGALSVLADFLGAIGSGTGILLAVTIIYQYFEIFVKEQSEVGSMGALLF>sp|Q86SK9|SCD5_HUMAN Stearoyl-CoA desaturase 5 OS=Homo sapiens OX=9606GN=SCD5 PE=1 SV=2MPGPATDAGKIPFCDAKEEIRAGLESSEGGGGPERPGARGQRQNIVWRNVVLMSLLHLGAVYSLVLIPKAKPLTLLWAYFCFLLAALGVTAGAHRLWSHRSYRAKLPLRIFLAVANSMAFQNDIFEWSRDHRAHHKYSETDADPHNARRGFFFSHIGWLFVRKHRDVIEKGRKLDVTDLLADPVVRIQRKYYKISVVLMCFVVPTLVPWYIWGESLWNSYFLASILRYTISLNISWLVNSAAHMYGNRPYDKHISPRQNPLVALGAIGEGFHNYHHTFPFDYSASEFGLNFNPTTWFIDFMCWLGLATDRKRATKPMIEARKARTGDSSA>sp|Q86SK9-2|SCD5_HUMAN Isoform 2 of Stearoyl-CoA desaturase 5 OS=Homosapiens OX=9606 GN=SCD5MPGPATDAGKIPFCDAKEEIRAGLESSEGGGGPERPGARGQRQNIVWRNVVLMSLLHLGAVYSLVLIPKAKPLTLLWAYFCFLLAALGVTAGAHRLWSHRSYRAKLPLRIFLAVANSMAFQNDIFEWSRDHRAHHKYSETDADPHNARRGFFFSHIGWLFVRKHRDVIEKGRKLDVTDLLADPVVRIQRNTQHIQKEGRALNQEAACEMLREWHQGHILKVTLPGLHILALLHTHCNHSEKCCLMLRALSVSLEVF>sp|Q9H9S3|S61A2_HUMAN Protein transport protein Sec61 subunit alphaisoform 2 OS=Homo sapiens OX=9606 GN=SEC61A2 PE=2 SV=3MGIKFLEVIKPFCAVLPEIQKPERKIQFREKVLWTAITLFIFLVCCQIPLFGIMSSDSADPFYWMRVILASNRGTLMELGISPIVTSGLIMQLLAGAKIIEVGDTPKDRALFNGAQKLFGMIITIGQAIVYVMTGMYGDPAEMGAGICLLIIIQLFVAGLIVLLLDELLQKGYGLGSGISLFIATNICETIVWKAFSPTTINTGRGTEFEGAVIALFHLLATRTDKVRALREAFYRQNLPNLMNLIATVFVFAVVIYFQGFRVDLPIKSARYRGQYSSYPIKLFYTSNIPIILQSALVSNLYVISQMLSVRFSGNFLVNLLGQWADVSGGGPARSYPVGGLCYYLSPPESMGAIFEDPVHVVVYIIFMLGSCAFFSKTWIEVSGSSAKDVAKQLKEQQMVMRGHRDTSMVHELNRYIPTAAAFGGLCIGALSVLADFLGAIGSGTGILLAVTIIYQYFEIFVKEQAEVGGMGALFF>sp|Q9H9S3-2|S61A2_HUMAN Isoform 2 of Protein transport protein Sec61subunit alpha isoform 2 OS=Homo sapiens OX=9606 GN=SEC61A2MGIKFLEVIKPFCAVLPEIQKPERKIQFREKVLWTAITLFIFLVCCQIPLFGIMSSDSADPFYWMRVILASNRGTLMELGISPIVTSGLIMQLLAGAKIIEVGDTPKDRALFNGAQKLFGMIITIGQAIVYVMTGMYGDPAEMGAGICLLIIIQLFVAGLIVLLLDELLQKGYGLGSGISLFIATNICETIVWKAFSPTTINTGRGTEFEGAVIALFHLLATRTDKVRALREAFYRQNLPNLMNLIATVFVFAVVIYFQGFRVDLPIKSARYRGQYSSYPIKLFYTSNIPIILQSALVSNLYVISQMLSVRFSGNFLVNLLGQWADVSGGGPARSYPVGGLCYYLSPPESMGAIFEDPVHVVVYIIFMLGSCAFFSKTWIEVSGSSAKDVAKQLKEQQMVMRGHRDTSMVHELNRPKVKLRRWKGEGRHFTKRILFY>sp|Q9H9S3-3|S61A2_HUMAN Isoform 3 of Protein transport protein Sec61subunit alpha isoform 2 OS=Homo sapiens OX=9606 GN=SEC61A2MGIKFLEVIKPFCAVLPEIQKPERKIPLFGIMSSDSADPFYWMRVILASNRGTLMELGISPIVTSGLIMQLLAGAKIIEVGDTPKDRALFNGAQKLFGMIITIGQAIVYVMTGMYGDPAEMGAGICLLIIIQLFVAGLIVLLLDELLQKGYGLGSGISLFIATNICETIVWKAFSPTTINTGRGTEFEGAVIALFHLLATRTDKVRALREAFYRQNLPNLMNLIATVFVFAVVIYFQGFRVDLPIKSARYRGQYSSYPIKLFYTSNIPIILQSALVSNLYVISQMLSVRFSGNFLVNLLGQWADVSGGGPARSYPVGGLCYYLSPPESMGAIFEDPVHVVVYIIFMLGSCAFFSKTWIEVSGSSAKDVAKQLKEQQMVMRGHRDTSMVHELNRYIPTAAAFGGLCIGALSVLADFLGAIGSGTGILLAVTIIYQYFEIFVKEQAEVGGMGALFF>sp|Q9BY12|SCAPE_HUMAN S phase cyclin A-associated protein in theendoplasmic reticulum OS=Homo sapiens OX=9606 GN=SCAPER PE=1 SV=2MMASFQRSNSHDKVRRIVAEEGRTARNLIAWSVPLESKDDDGKPKCQTGGKSKRTIQGTHKTTKQSTAVDCKITSSTTGDKHFDKSPTKTRHPRKIDLRARYWAFLFDNLRRAVDEIYVTCESDQSVVECKEVLMMLDNYVRDFKALIDWIQLQEKLEKTDAQSRPTSLAWEVKKMSPGRHVIPSPSTDRINVTSNARRSLNFGGSTGTVPAPRLAPTGVSWADKVKAHHTGSTASSEITPAQSCPPMTVQKASRKNERKDAEGWETVQRGRPIRSRSTAVMPKVSLATEATRSKDDSDKENVCLLPDESIQKGQFVGDGTSNTIESHPKDSLHSCDHPLAEKTQFTVSTLDDVKNSGSIRDNYVRTSEISAVHIDTECVSVMLQAGTPPLQVNEEKFPAEKARIENEMDPSDISNSMAEVLAKKEELADRLEKANEEAIASAIAEEEQLTREIEAEENNDINIETDNDSDFSASMGSGSVSFCGMSMDWNDVLADYEARESWRQNTSWGDIVEEEPARPPGHGIHMHEKLSSPSRKRTIAESKKKHEEKQMKAQQLREKLREEKTLKLQKLLEREKDVRKWKEELLDQRRRMMEEKLLHAEFKREVQLQAIVKKAQEEEAKVNEIAFINTLEAQNKRHDVLSKLKEYEQRLNELQEERQRRQEEKQARDEAVQERKRALEAERQARVEELLMKRKEQEARIEQQRQEKEKAREDAARERARDREERLAALTAAQQEAMEELQKKIQLKHDESIRRHMEQIEQRKEKAAELSSGRHANTDYAPKLTPYERKKQCSLCNVLISSEVYLFSHVKGRKHQQAVRENTSIQGRELSDEEVEHLSLKKYIIDIVVESTAPAEALKDGEERQKNKKKAKKIKARMNFRAKEYESLMETKNSGSDSPYKAKLQRLAKDLLKQVQVQDSGSWANNKVSALDRTLGEITRILEKENVADQIAFQAAGGLTALEHILQAVVPATNVNTVLRIPPKSLCNAINVYNLTCNNCSENCSDVLFSNKITFLMDLLIHQLTVYVPDENNTILGRNTNKQVFEGLTTGLLKVSAVVLGCLIANRPDGNCQPATPKIPTQEMKNKPSQGDPFNNRVQDLISYVVNMGLIDKLCACFLSVQGPVDENPKMAIFLQHAAGLLHAMCTLCFAVTGRSYSIFDNNRQDPTGLTAALQATDLAGVLHMLYCVLFHGTILDPSTASPKENYTQNTIQVAIQSLRFFNSFAALHLPAFQSIVGAEGLSLAFRHMASSLLGHCSQVSCESLLHEVIVCVGYFTVNHPDNQVIVQSGRHPTVLQKLCQLPFQYFSDPRLIKVLFPSLIAACYNNHQNKIILEQEMSCVLLATFIQDLAQTPGQAENQPYQPKGKCLGSQDYLELANRFPQQAWEEARQFFLKKEKK>sp|Q9BY12-2|SCAPE_HUMAN Isoform 2 of S phase cyclin A-associated proteinin the endoplasmic reticulum OS=Homo sapiens OX=9606 GN=SCAPERREATPPLRGLPAPPRHAPFPAGRFEPPRTKQGGRGSHTPWDYVINDLGIEENLKSDGKPKCQTGGKSKRTIQGTHKTTKQSTAVDCKITSSTTGDKHFDKSPTKTRHPRKIDLRARYWAFLFDNLRRAVDEIYVTCESDQSVVECKEVLMMLDNYVRDFKALIDWIQLQEKLEKTDAQSRPTSLAWEVKKMSPGRHVIPSPSTDRINVTSNARRSLNFGGSTGTVPAPRLAPTGVSWADKVKAHHTGSTASSEITPAQSCPPMTVQKASRKNERKDAEGWETVQRGRPIRSRSTAVMPKVSLATEATRSKDDSDKENVCLLPDESIQKGQFVGDGTSNTIESHPKDSLHSCDHPLAEKTQFTVSTLDDVKNSGSIRDNYVRTSEISAVHIDTECVSVMLQAGTPPLQVNEEKFPAEKARIENEMDPSDISNVSAANLSMAEVLAKKEELADRLEKANEEAIASAIAEEEQLTREIEAEENNDINIETDNDSDFSASMGSGSVSFCGMSMDWNDVLADYEARESWRQNTSWGDIVEEEPARPPGHGIHMHEKLSSPSRKRTIAESKKKHEEKQMKAQQLREKLREEKTLKLQKLLEREKDVRKWKEELLDQRRRMMEEKLLHAEFKREVQLQAIVKKAQEEEAKVNEIAFINTLEAQNKRHDVLSKLKEYEQRLNELQEERQRRQEEKQARDEAVQERKRALEAERQARVEELLMKRKEQEARIEQQRQEKEKAREDAARERARDREERLAALTAAQQEAMEELQKKIQLKHDESIRRHMEQIEQRKEKAAELSSGRHANTDYAPKLTPYERKKQCSLCNVLISSEVYLFSHVKGRKHQQAVRENTSIQGRELSDEEVEHLSLKKYIIDIVVESTAPAEALKDGEERQKNKKKAKKIKARMNFRAKEYESLMETKNSGSDSPYKAKLQRLAKDLLKQVQVQDSGSWANNKVSALDRTLGEITRILEKENVADQIAFQAAGGLTALEHILQAVVPATNVNTVLRIPPKSLCNAINVYNLTCNNCSENCSDVLFSNKITFLMDLLIHQLTVYVPDENNTILGRNTNKQVFEGLTTGLLKVSAVVLGCLIANRPDGNCQPATPKIPTQEMKNKPSQGDPFNNRVQDLISYVVNMGLIDKLCACFLSVQGPVDENPKMAIFLQHAAGLLHAMCTLCFAVTGRSYSIFDNNRQDPTGLTAALQATDLAGVLHMLYCVLFHGTILDPSTASPKENYTQNTIQVAIQSLRFFNSFAALHLPAFQVPSIGLYRC>sp|Q9BY12-3|SCAPE_HUMAN Isoform 3 of S phase cyclin A-associated proteinin the endoplasmic reticulum OS=Homo sapiens OX=9606 GN=SCAPERMKTKYIFCNITERKDAEGWETVQRGRPIRSRSTAVMPKVSLATEATRSKDDSDKENVCLLPDESIQKGQFVGDGTSNTIESHPKDSLHSCDHPLAEKTQFTVSTLDDVKNSGSIRDNYVRTSEISAVHIDTECVSVMLQAGTPPLQVNEEKFPAEKARIENEMDPSDISNSMAEVLAKKEELADRLEKANEEAIASAIAEEEQLTREIEAEENNDINIETDNDSDFSASMGSGSVSFCGMSMDWNDVLADYEARESWRQNTSWGDIVEEEPARPPGHGIHMHEKLSSPSRKRTIAESKKKHEEKQMKAQQLREKLREEKTLKLQKLLEREKDVRKWKEELLDQRRRMMEEKLLHAEFKREVQLQAIVKKAQEEEAKVNEIAFINTLEAQNKRHDVLSKLKEYEQRLNELQEERQRRQEEKQARDEAVQERKRALEAERQARVEELLMKRKEQEARIEQQRQEKEKAREDAARERARDREERLAALTAAQQEAMEELQKKIQLKHDESIRRHMEQIEQRKEKAAELSSGRHANTDYAPKLTPYERKKQCSLCNVLISSEVYLFSHVKGRKHQQAVRENTSIQGRELSDEEVEHLSLKKYIIDIVVESTAPAEALKDGEERQKNKKKAKKIKARMNFRAKEYESLMETKNSGSDSPYKAKLQRLAKDLLKQVQVQDSGSWANNKVSALDRTLGEITRILEKENVADQIAFQAAGGLTALEHILQAVVPATNVNTVLRIPPKSLCNAINVYNLTCNNCSENCSDVLFSNKITFLMDLLIHQLTVYVPDENNTILGRNTNKQVFEGLTTGLLKVSAVVLGCLIANRPDGNCQPATPKIPTQEMKNKPSQGDPFNNRVQDLISYVVNMGLIDKLCACFLSVQGPVDENPKMAIFLQHAAGLLHAMCTLCFAVTGRSYSIFDNNRQDPTGLTAALQATDLAGVLHMLYCVLFHGTILDPSTASPKENYTQNTIQVAIQSLRFFNSFAALHLPAFQSIVGAEGLSLAFRHMASSLLGHCSQVSCESLLHEVIVCVGYFTVNHPDNQVIVQSGRHPTVLQKLCQLPFQYFSDPRLIKVLFPSLIAACYNNHQNKIILEQEMSCVLLATFIQDLAQTPGQAENQPYQPKGKCLGSQDYLELANRFPQQAWEEARQFFLKKEKK>sp|Q8IXA5|SACA3_HUMAN Sperm acrosome membrane-associated protein 3OS=Homo sapiens OX=9606 GN=SPACA3 PE=1 SV=1MVSALRGAPLIRVHSSPVSSPSVSGPRRLVSCLSSQSSALSQSGGGSTSAAGIEARSRALRRRWCPAGIMLLALVCLLSCLLPSSEAKLYGRCELARVLHDFGLDGYRGYSLADWVCLAYFTSGFNAAALDYEADGSTNNGIFQINSRRWCSNLTPNVPNVCRMYCSDLLNPNLKDTVICAMKITQEPQGLGYWEAWRHHCQGKDLTEWVDGCDF>sp|Q8IXA5-2|SACA3_HUMAN Isoform 2 of Sperm acrosome membrane-associatedprotein 3 OS=Homo sapiens OX=9606 GN=SPACA3MLLALVCLLSCLLPSSEAKLYGRCELARVLHDFGLDGYRGYSLADWVCLAYFTSGFNAAALDYEADGSTNNGIFQINSRRWCSNLTPNVPNVCRMYCSDLLNPNLKDTVICAMKITQEPQGLGYWEAWRHHCQGKDLTEWVDGCDF>sp|Q8N2U9|S66A2_HUMAN Solute carrier family 66 member 2 OS=Homo sapiensOX=9606 GN=SLC66A2 PE=1 SV=1MEAEGLDWLLVPLHQLVSWGAAAAMVFGGVVPYVPQYRDIRRTQNADGFSTYVCLVLLVANILRILFWFGRRFESPLLWQSAIMILTMLLMLKLCTEVRVANELNARRRSFTAADSKDEEVKVAPRRSFLDFDPHHFWQWSSFSDYVQCVLAFTGVAGYITYLSIDSALFVETLGFLAVLTEAMLGVPQLYRNHRHQSTEGMSIKMVLMWTSGDAFKTAYFLLKGAPLQFSVCGLLQVLVDLAILGQAYAFARHPQKPAPHAVHPTGTKAL>sp|Q8N2U9-2|S66A2_HUMAN Isoform 2 of Solute carrier family 66 member 2OS=Homo sapiens OX=9606 GN=SLC66A2MEAEGLDWLLVPLHQLVSWGAAAAMVFGGVVPYVPQYRDIRRTQNADGFSTYVCLVLLVANILRILFWFGRRFESPLLWQSAIMILTMLLMLKLCTEVRVANELNARRRSFTDFDPHHFWQWSSFSDYVQCVLAFTGVAGYITYLSIDSALFVETLGFLAVLTEAMLGVPQLYRNHRHQSTEGMSIKMVLMWTSGDAFKTAYFLLKGAPLQFSVCGLLQVLVDLAILGQAYAFARHPQKPAPHAVHPTGTKAL>sp|Q8N2U9-3|S66A2_HUMAN Isoform 3 of Solute carrier family 66 member 2OS=Homo sapiens OX=9606 GN=SLC66A2MEAEGLDWLLVPLHQLVSWGAAAAMVFGGVVPYVPQYRDIRRTQNADGFSTYVCLVLLVANILRILFWFGRRFESPLLWQSAIMILTMLLMLKLCTEVRVANELNARRRSFTASRWCSCGPVVTPSRRPTSC>sp|O00767|SCD_HUMAN Stearoyl-CoA desaturase OS=Homo sapiens OX=9606GN=SCD PE=1 SV=2MPAHLLQDDISSSYTTTTTITAPPSRVLQNGGDKLETMPLYLEDDIRPDIKDDIYDPTYKDKEGPSPKVEYVWRNIILMSLLHLGALYGITLIPTCKFYTWLWGVFYYFVSALGITAGAHRLWSHRSYKARLPLRLFLIIANTMAFQNDVYEWARDHRAHHKFSETHADPHNSRRGFFFSHVGWLLVRKHPAVKEKGSTLDLSDLEAEKLVMFQRRYYKPGLLMMCFILPTLVPWYFWGETFQNSVFVATFLRYAVVLNATWLVNSAAHLFGYRPYDKNISPRENILVSLGAVGEGFHNYHHSFPYDYSASEYRWHINFTTFFIDCMAALGLAYDRKKVSKAAILARIKRTGDGNYKSG>sp|Q9Y3A5|SBDS_HUMAN Ribosome maturation protein SBDS OS=Homo sapiensOX=9606 GN=SBDS PE=1 SV=4MSIFTPTNQIRLTNVAVVRMKRAGKRFEIACYKNKVVGWRSGVEKDLDEVLQTHSVFVNVSKGQVAKKEDLISAFGTDDQTEICKQILTKGEVQVSDKERHTQLEQMFRDIATIVADKCVNPETKRPYTVILIERAMKDIHYSVKTNKSTKQQALEVIKQLKEKMKIERAHMRLRFILPVNEGKKLKEKLKPLIKVIESEDYGQQLEIVCLIDPGCFREIDELIKKETKGKGSLEVLNLKDVEEGDEKFE>sp|Q9NR31|SAR1A_HUMAN GTP-binding protein SAR1a OS=Homo sapiens OX=9606GN=SAR1A PE=1 SV=1MSFIFEWIYNGFSSVLQFLGLYKKSGKLVFLGLDNAGKTTLLHMLKDDRLGQHVPTLHPTSEELTIAGMTFTTFDLGGHEQARRVWKNYLPAINGIVFLVDCADHSRLVESKVELNALMTDETISNVPILILGNKIDRTDAISEEKLREIFGLYGQTTGKGNVTLKELNARPMEVFMCSVLKRQGYGEGFRWLSQYID>sp|Q9NR31-2|SAR1A_HUMAN Isoform 2 of GTP-binding protein SAR1a OS=Homosapiens OX=9606 GN=SAR1AMLKDDRLGQHVPTLHPTSEELTIAGMTFTTFDLGGHEQARRVWKNYLPAINGIVFLVDCADHSRLVESKVELNALMTDETISNVPILILGNKIDRTDAISEEKLREIFGLYGQTTGKGNVTLKELNARPMEVFMCSVLKRQGYGEGFRWLSQYID>sp|P05060|SCG1_HUMAN Secretogranin-1 OS=Homo sapiens OX=9606 GN=CHGBPE=1 SV=2MQPTLLLSLLGAVGLAAVNSMPVDNRNHNEGMVTRCIIEVLSNALSKSSAPPITPECRQVLKTSRKDVKDKETTENENTKFEVRLLRDPADASEAHESSSRGEAGAPGEEDIQGPTKADTEKWAEGGGHSRERADEPQWSLYPSDSQVSEEVKTRHSEKSQREDEEEEEGENYQKGERGEDSSEEKHLEEPGETQNAFLNERKQASAIKKEELVARSETHAAGHSQEKTHSREKSSQESGEETGSQENHPQESKGQPRSQEESEEGEEDATSEVDKRRTRPRHHHGRSRPDRSSQGGSLPSEEKGHPQEESEESNVSMASLGEKRDHHSTHYRASEEEPEYGEEIKGYPGVQAPEDLEWERYRGRGSEEYRAPRPQSEESWDEEDKRNYPSLELDKMAHGYGEESEEERGLEPGKGRHHRGRGGEPRAYFMSDTREEKRFLGEGHHRVQENQMDKARRHPQGAWKELDRNYLNYGEEGAPGKWQQQGDLQDTKENREEARFQDKQYSSHHTAEKRKRLGELFNPYYDPLQWKSSHFERRDNMNDNFLEGEEENELTLNEKNFFPEYNYDWWEKKPFSEDVNWGYEKRNLARVPKLDLKRQYDRVAQLDQLLHYRKKSAEFPDFYDSEEPVSTHQEAENEKDRADQTVLTEDEKKELENLAAMDLELQKIAEKFSQRG>sp|P13521|SCG2_HUMAN Secretogranin-2 OS=Homo sapiens OX=9606 GN=SCG2PE=1 SV=2MAEAKTHWLGAALSLIPLIFLISGAEAASFQRNQLLQKEPDLRLENVQKFPSPEMIRALEYIENLRQQAHKEESSPDYNPYQGVSVPLQQKENGDESHLPERDSLSEEDWMRIILEALRQAENEPQSAPKENKPYALNSEKNFPMDMSDDYETQQWPERKLKHMQFPPMYEENSRDNPFKRTNEIVEEQYTPQSLATLESVFQELGKLTGPNNQKRERMDEEQKLYTDDEDDIYKANNIAYEDVVGGEDWNPVEEKIESQTQEEVRDSKENIEKNEQINDEMKRSGQLGIQEEDLRKESKDQLSDDVSKVIAYLKRLVNAAGSGRLQNGQNGERATRLFEKPLDSQSIYQLIEISRNLQIPPEDLIEMLKTGEKPNGSVEPERELDLPVDLDDISEADLDHPDLFQNRMLSKSGYPKTPGRAGTEALPDGLSVEDILNLLGMESAANQKTSYFPNPYNQEKVLPRLPYGAGRSRSNQLPKAAWIPHVENRQMAYENLNDKDQELGEYLARMLVKYPEIINSNQVKRVPGQGSSEDDLQEEEQIEQAIKEHLNQGSSQETDKLAPVSKRFPVGPPKNDDTPNRQYWDEDLLMKVLEYLNQEKAEKGREHIAKRAMENM>sp|Q8WXD2|SCG3_HUMAN Secretogranin-3 OS=Homo sapiens OX=9606 GN=SCG3PE=1 SV=3MGFLGTGTWILVLVLPIQAFPKPGGSQDKSLHNRELSAERPLNEQIAEAEEDKIKKTYPPENKPGQSNYSFVDNLNLLKAITEKEKIEKERQSIRSSPLDNKLNVEDVDSTKNRKLIDDYDSTKSGLDHKFQDDPDGLHQLDGTPLTAEDIVHKIAARIYEENDRAVFDKIVSKLLNLGLITESQAHTLEDEVAEVLQKLISKEANNYEEDPNKPTSWTENQAGKIPEKVTPMAAIQDGLAKGENDETVSNTLTLTNGLERRTKTYSEDNFEELQYFPNFYALLKSIDSEKEAKEKETLITIMKTLIDFVKMMVKYGTISPEEGVSYLENLDEMIALQTKNKLEKNATDNISKLFPAPSEKSHEETDSTKEEAAKMEKEYGSLKDSTKDDNSNPGGKTDEPKGKTEAYLEAIRKNIEWLKKHDKKGNKEDYDLSKMRDFINKQADAYVEKGILDKEEAEAIKRIYSSL>sp|Q8WXD2-2|SCG3_HUMAN Isoform 2 of Secretogranin-3 OS=Homo sapiensOX=9606 GN=SCG3MAAIQDGLAKGENDETVSNTLTLTNGLERRTKTYSEDNFEELQYFPNFYALLKSIDSEKEAKEKETLITIMKTLIDFVKMMVKYGTISPEEGVSYLENLDEMIALQTKNKLEKNATDNISKLFPAPSEKSHEETDSTKEEAAKMEKEYGSLKDSTKDDNSNPGGKTDEPKGKTEAYLEAIRKNIEWLKKHDKKGNKEDYDLSKMRDFINKQADAYVEKGILDKEEAEAIKRIYSSL>sp|A0A286YEV6|SCGR4_HUMAN Small cysteine and glycine repeat-containingprotein 4 OS=Homo sapiens OX=9606 GN=SCYGR4 PE=1 SV=1MGCCGCGSCGGCGGRCGGGCGGGCSGGCGGGCGGGCGGGCGSCTTCRCYRVGCCSSCCPCCRGCCGGCCSTPVICCCRRTCGSCGCGYGKGCCQQKCCCQKQCCC>sp|Q96CW6|S7A6O_HUMAN Probable RNA polymerase II nuclear localizationprotein SLC7A6OS OS=Homo sapiens OX=9606 GN=SLC7A6OS PE=1 SV=2MEAARTAVLRVKRKRSAEPAEALVLACKRLRSDAVESAAQKTSEGLERAAENNVFHLVATVCSQEEPVQPLLREVLRPSRDSQQRVRRNLRASAREVRQEGRYRVLSSRRSLGTTSSGQESEYTPGNPEAAGNSGFQLLDLVHEEGEPEAASAGSCKTSDPDVILCNSVELIRERLTVSEDGPGVRRQEEQKHDDYVYDIYYLETATPGWIENILSVQPYSQEWELVNDDQEPEDIYDDEDDENSENNWRNEYPEEESSDGDEDSRGSADYNSLSEEERGSSRQRMWSKYPLDVQKEFGYDSPHDLDSD>sp|Q99590|SCAFB_HUMAN Protein SCAF11 OS=Homo sapiens OX=9606 GN=SCAF11PE=1 SV=2MKKKTVCTLNMGDKKYEDMEGEENGDNTISTGLLYSEADRCPICLNCLLEKEVGFPESCNHVFCMTCILKWAETLASCPIDRKPFQAVFKFSALEGYVKVQVKKQLRETKDKKNENSFEKQVSCHENSKSCIRRKAIVREDLLSAKVCDLKWIHRNSLYSETGGKKNAAIKINKPQRSNWSTNQCFRNFFSNMFSSVSHSGESSFTYRAYCTEFIEASEISALIRQKRHELELSWFPDTLPGIGRIGFIPWNVETEVLPLISSVLPRTIFPTSTISFEHFGTSCKGYALAHTQEGEEKKQTSGTSNTRGSRRKPAMTTPTRRSTRNTRAETASQSQRSPISDNSGCDAPGNSNPSLSVPSSAESEKQTRQAPKRKSVRRGRKPPLLKKKLRSSVAAPEKSSSNDSVDEETAESDTSPVLEKEHQPDVDSSNICTVQTHVENQSANCLKSCNEQIEESEKHTANYDTEERVGSSSSESCAQDLPVLVGEEGEVKKLENTGIEANVLCLESEISENILEKGGDPLEKQDQISGLSQSEVKTDVCTVHLPNDFPTCLTSESKVYQPVSCPLSDLSENVESVVNEEKITESSLVEITEHKDFTLKTEELIESPKLESSEGEIIQTVDRQSVKSPEVQLLGHVETEDVEIIATCDTFGNEDFNNIQDSENNLLKNNLLNTKLEKSLEEKNESLTEHPRSTELPKTHIEQIQKHFSEDNNEMIPMECDSFCSDQNESEVEPSVNADLKQMNENSVTHCSENNMPSSDLADEKVETVSQPSESPKDTIDKTKKPRTRRSRFHSPSTTWSPNKDTPQEKKRPQSPSPRRETGKESRKSQSPSPKNESARGRKKSRSQSPKKDIARERRQSQSRSPKRDTTRESRRSESLSPRRETSRENKRSQPRVKDSSPGEKSRSQSRERESDRDGQRRERERRTRKWSRSRSHSRSPSRCRTKSKSSSFGRIDRDSYSPRWKGRWANDGWRCPRGNDRYRKNDPEKQNENTRKEKNDIHLDADDPNSADKHRNDCPNWITEKINSGPDPRTRNPEKLKESHWEENRNENSGNSWNKNFGSGWVSNRGRGRGNRGRGTYRSSFAYKDQNENRWQNRKPLSGNSNSSGSESFKFVEQQSYKRKSEQEFSFDTPADRSGWTSASSWAVRKTLPADVQNYYSRRGRNSSGPQSGWMKQEEETSGQDSSLKDQTNQQVDGSQLPINMMQPQMNVMQQQMNAQHQPMNIFPYPVGVHAPLMNIQRNPFNIHPQLPLHLHTGVPLMQVATPTSVSQGLPPPPPPPPPSQQVNYIASQPDGKQLQGIPSSSHVSNNMSTPVLPAPTAAPGNTGMVQGPSSGNTSSSSHSKASNAAVKLAESKVSVAVEASADSSKTDKKLQIQEKAAQEVKLAIKPFYQNKDITKEEYKEIVRKAVDKVCHSKSGEVNSTKVANLVKAYVDKYKYSRKGSQKKTLEEPVSTEKNIG>sp|Q99590-2|SCAFB_HUMAN Isoform 2 of Protein SCAF11 OS=Homo sapiensOX=9606 GN=SCAF11MTTPTRRSTRNTRAETASQSQRSPISDNSGCDAPGNSNPSLSVPSSAESEKQTRQAPKRKSVRRGRKPPLLKKKLRSSVAAPEKSSSNDSVDEETAESDTSPVLEKEHQPDVDSSNICTVQTHVENQSANCLKSCNEQIEESEKHTANYDTEERVGSSSSESCAQDLPVLVGEEGEVKKLENTGIEANVLCLESEISENILEKGGDPLEKQDQISGLSQSEVKTDVCTVHLPNDFPTCLTSESKVYQPVSCPLSDLSENVESVVNEEKITESSLVEITEHKDFTLKTEELIESPKLESSEGEIIQTVDRQSVKSPEVQLLGHVETEDVEIIATCDTFGNEDFNNIQDSENNLLKNNLLNTKLEKSLEEKNESLTEHPRSTELPKTHIEQIQKHFSEDNNEMIPMECDSFCSDQNESEVEPSVNADLKQMNENSVTHCSENNMPSSDLADEKVETVSQPSESPKDTIDKTKKPRTRRSRFHSPSTTWSPNKDTPQEKKRPQSPSPRRETGKESRKSQSPSPKNESARGRKKSRSQSPKKDIARERRQSQSRSPKRDTTRESRRSESLSPRRETSRENKRSQPRVKDSSPGEKSRSQSRERESDRDGQRRERERRTRKWSRSRSHSRSPSRCRTKSKSSSFGRIDRDSYSPRWKGRWANDGWRCPRGNDRYRKNDPEKQNENTRKEKNDIHLDADDPNSADKHRNDCPNWITEKINSGPDPRTRNPEKLKESHWEENRNENSGNSWNKNFGSGWVSNRGRGRGNRGRGTYRSSFAYKDQNENRWQNRKPLSGNSNSSGSESFKFVEQQSYKRKSEQEFSFDTPADRSGWTSASSWAVRKTLPADVQNYYSRRGRNSSGPQSGWMKQEEETSGQDSSLKDQTNQQVDGSQLPINMMQPQMNVMQQQMNAQHQPMNIFPYPVGVHAPLMNIQRNPFNIHPQLPLHLHTGVPLMQVATPTSVSQGLPPPPPPPPPSQQVNYIASQPDGKQLQGIPSSSHVSNNMSTPVLPAPTAAPGNTGMVQGPSSGNTSSSSHSKASNAAVKLAESKVSVAVEASADSSKTDKKLQIQEKAAQEVKLAIKPFYQNKDITKEEYKEIVRKAVDKVCHSKSGEVNSTKVANLVKAYVDKYKYSRKGSQKKTLEEPVSTEKNIG>sp|A6NKF1|SAC31_HUMAN SAC3 domain-containing protein 1 OS=Homo sapiensOX=9606 GN=SAC3D1 PE=1 SV=2MAGRRAQTGSAPPRPAAPHPRPASRAFPQHCRPRDAERPPSPRSPLMPGCELPVGTCPDMCPAAERAQREREHRLHRLEVVPGCRQDPPRADPQRAVKEYSRPAAGKPRPPPSQLRPPSVLLATVRYLAGEVAESADIARAEVASFVADRLRAVLLDLALQGAGDAEAAVVLEAALATLLTVVARLGPDAARGPADPVLLQAQVQEGFGSLRRCYARGAGPHPRQPAFQGLFLLYNLGSVEALHEVLQLPAALRACPPLRKALAVDAAFREGNAARLFRLLQTLPYLPSCAVQCHVGHARREALARFARAFSTPKGQTLPLGFMVNLLALDGLREARDLCQAHGLPLDGEERVVFLRGRYVEEGLPPASTCKVLVESKLRGRTLEEVVMAEEEDEGTDRPGSPA>sp|A6NKF1-2|SAC31_HUMAN Isoform 2 of SAC3 domain-containing protein 1OS=Homo sapiens OX=9606 GN=SAC3D1MAGRRAQTGSAPPRPAAPHPRPASRAFPQHCRPRDAERPPSPRSPLMPGCELPVGTCPDMCPAAERAQREREHRLHRLEVVPGCRQDPPRADPQRAVKEYSRPAAGKPRPPPSQLRPPSVLLATVRYLAGEVAESADIARAEVASFVADRLRAVLLDLALQGAGDAEAAVVLEAALATLLTVVARLGPDAARGPADPVLLQAQVQEGFGSLRRCYARGAGPHPRQPAFQGLFLLYNLGESGSWRLGRAWGQEPTMTVEARWKPCMRFYSCLLPCAPARPSARPWR>sp|O14828|SCAM3_HUMAN Secretory carrier-associated membrane protein 3OS=Homo sapiens OX=9606 GN=SCAMP3 PE=1 SV=3MAQSRDGGNPFAEPSELDNPFQDPAVIQHRPSRQYATLDVYNPFETREPPPAYEPPAPAPLPPPSAPSLQPSRKLSPTEPKNYGSYSTQASAAAATAELLKKQEELNRKAEELDRRERELQHAALGGTATRQNNWPPLPSFCPVQPCFFQDISMEIPQEFQKTVSTMYYLWMCSTLALLLNFLACLASFCVETNNGAGFGLSILWVLLFTPCSFVCWYRPMYKAFRSDSSFNFFVFFFIFFVQDVLFVLQAIGIPGWGFSGWISALVVPKGNTAVSVLMLLVALLFTGIAVLGIVMLKRIHSLYRRTGASFQKAQQEFAAGVFSNPAVRTAAANAAAGAAENAFRAP>sp|O14828-2|SCAM3_HUMAN Isoform 2 of Secretory carrier-associatedmembrane protein 3 OS=Homo sapiens OX=9606 GN=SCAMP3MAQSRDGGNPFAEPSELDNPFQPPPAYEPPAPAPLPPPSAPSLQPSRKLSPTEPKNYGSYSTQASAAAATAELLKKQEELNRKAEELDRRERELQHAALGGTATRQNNWPPLPSFCPVQPCFFQDISMEIPQEFQKTVSTMYYLWMCSTLALLLNFLACLASFCVETNNGAGFGLSILWVLLFTPCSFVCWYRPMYKAFRSDSSFNFFVFFFIFFVQDVLFVLQAIGIPGWGFSGWISALVVPKGNTAVSVLMLLVALLFTGIAVLGIVMLKRIHSLYRRTGASFQKAQQEFAAGVFSNPAVRTAAANAAAGAAENAFRAP>sp|Q9BW04|SARG_HUMAN Specifically androgen-regulated gene proteinOS=Homo sapiens OX=9606 GN=SARG PE=1 SV=2MPERELWPAGTGSEPVTRVGSCDSMMSSTSTRSGSSDSSYDFLSTEEKECLLFLEETIGSLDTEADSGLSTDESEPATTPRGFRALPITQPTPRGGPEETITQQGRTPRTVTESSSSHPPEPQGLGLRSGSYSLPRNIHIARSQNFRKSTTQASSHNPGEPGRLAPEPEKEQVSQSSQPRQAPASPQEAALDLDVVLIPPPEAFRDTQPEQCREASLPEGPGQQGHTPQLHTPSSSQEREQTPSEAMSQKAKETVSTRYTQPQPPPAGLPQNARAEDAPLSSGEDPNSRLAPLTTPKPRKLPPNIVLKSSRSSFHSDPQHWLSRHTEAAPGDSGLISCSLQEQRKARKEALEKLGLPQDQDEPGLHLSKPTSSIRPKETRAQHLSPAPGLAQPAAPAQASAAIPAAGKALAQAPAPAPGPAQGPLPMKSPAPGNVAASKSMPISIPKAPRANSALTPPKPESGLTLQESNTPGLRQMNFKSNTLERSGVGLSSYLSTEKDASPKTSTSLGKGSFLDKISPSVLRNSRPRPASLGTGKDFAGIQVGKLADLEQEQSSKRLSYQGQSRDKLPRPPCVSVKISPKGVPNEHRREALKKLGLLKE>sp|Q9BW04-2|SARG_HUMAN Isoform 2 of Specifically androgen-regulated geneprotein OS=Homo sapiens OX=9606 GN=SARGMSQKAKETVSTRYTQPQPPPAGLPQNARAEDAPLSSGEDPNSRLAPLTTPKPRKLPPNIVLKSSRSSFHSDPQHWLSRHTEAAPGDSGLISCSLQEQRKARKEALEKLGLPQDQDEPGLHLSKPTSSIRPKETRAQHLSPAPGLAQPAAPAQASAAIPAAGKALAQAPAPAPGPAQGPLPMKSPAPGNVAASKSMPISIPKAPRANSALTPPKPESGLTLQESNTPGLRQMNFKSNTLERSGVGLSSYLSTEKDASPKTSTSLGKGSFLDKISPSVLRNSRPRPASLGTGKDFAGIQVGKLADLEQEQSSKRLSYQGQSRDKLPRPPCVSVKISPKGVPNEHRREALKKLGLLKE>sp|Q6P3W7|SCYL2_HUMAN SCY1-like protein 2 OS=Homo sapiens OX=9606GN=SCYL2 PE=1 SV=1MESMLNKLKSTVTKVTADVTSAVMGNPVTREFDVGRHIASGGNGLAWKIFNGTKKSTKQEVAVFVFDKKLIDKYQKFEKDQIIDSLKRGVQQLTRLRHPRLLTVQHPLEESRDCLAFCTEPVFASLANVLGNWENLPSPISPDIKDYKLYDVETKYGLLQVSEGLSFLHSSVKMVHGNITPENIILNKSGAWKIMGFDFCVSSTNPSEQEPKFPCKEWDPNLPSLCLPNPEYLAPEYILSVSCETASDMYSLGTVMYAVFNKGKPIFEVNKQDIYKSFSRQLDQLSRLGSSSLTNIPEEVREHVKLLLNVTPTVRPDADQMTKIPFFDDVGAVTLQYFDTLFQRDNLQKSQFFKGLPKVLPKLPKRVIVQRILPCLTSEFVNPDMVPFVLPNVLLIAEECTKEEYVKLILPELGPVFKQQEPIQILLIFLQKMDLLLTKTPPDEIKNSVLPMVYRALEAPSIQIQELCLNIIPTFANLIDYPSMKNALIPRIKNACLQTSSLAVRVNSLVCLGKILEYLDKWFVLDDILPFLQQIPSKEPAVLMGILGIYKCTFTHKKLGITKEQLAGKVLPHLIPLSIENNLNLNQFNSFISVIKEMLNRLESEHKTKLEQLHIMQEQQKSLDIGNQMNVSEEMKVTNIGNQQIDKVFNNIGADLLTGSESENKEDGLQNKHKRASLTLEEKQKLAKEQEQAQKLKSQQPLKPQVHTPVATVKQTKDLTDTLMDNMSSLTSLSVSTPKSSASSTFTSVPSMGIGMMFSTPTDNTKRNLTNGLNANMGFQTSGFNMPVNTNQNFYSSPSTVGVTKMTLGTPPTLPNFNALSVPPAGAKQTQQRPTDMSALNNLFGPQKPKVSMNQLSQQKPNQWLNQFVPPQGSPTMGSSVMGTQMNVIGQSAFGMQGNPFFNPQNFAQPPTTMTNSSSASNDLKDLFG>sp|P63302|SELW_HUMAN Selenoprotein W OS=Homo sapiens OX=9606 GN=SELENOWPE=1 SV=3MALAVRVVYCGAUGYKSKYLQLKKKLEDEFPGRLDICGEGTPQATGFFEVMVAGKLIHSKKKGDGYVDTESKFLKLVAAIKAALAQG>sp|O75995|SASH3_HUMAN SAM and SH3 domain-containing protein 3 OS=Homosapiens OX=9606 GN=SASH3 PE=1 SV=2MLRRKPSNASEKEPTQKKKLSLQRSSSFKDFAKSKPSSPVVSEKEFNLDDNIPEDDSGVPTPEDAGKSGKKLGKKWRAVISRTMNRKMGKMMVKALSEEMADTLEEGSASPTSPDYSLDSPGPEKMALAFSEQEEHELPVLSRQASTGSELCSPSPGSGSFGEEPPAPQYTGPFCGRARVHTDFTPSPYDHDSLKLQKGDVIQIIEKPPVGTWLGLLNGKVGSFKFIYVDVLPEEAVGHARPSRRQSKGKRPKPKTLHELLERIGLEEHTSTLLLNGYQTLEDFKELRETHLNELNIMDPQHRAKLLTAAELLLDYDTGSEEAEEGAESSQEPVAHTVSEPKVDIPRDSGCFEGSESGRDDAELAGTEEQLQGLSLAGAP>sp|Q01826|SATB1_HUMAN DNA-binding protein SATB1 OS=Homo sapiens OX=9606GN=SATB1 PE=1 SV=1MDHLNEATQGKEHSEMSNNVSDPKGPPAKIARLEQNGSPLGRGRLGSTGAKMQGVPLKHSGHLMKTNLRKGTMLPVFCVVEHYENAIEYDCKEEHAEFVLVRKDMLFNQLIEMALLSLGYSHSSAAQAKGLIQVGKWNPVPLSYVTDAPDATVADMLQDVYHVVTLKIQLHSCPKLEDLPPEQWSHTTVRNALKDLLKDMNQSSLAKECPLSQSMISSIVNSTYYANVSAAKCQEFGRWYKHFKKTKDMMVEMDSLSELSQQGANHVNFGQQPVPGNTAEQPPSPAQLSHGSQPSVRTPLPNLHPGLVSTPISPQLVNQQLVMAQLLNQQYAVNRLLAQQSLNQQYLNHPPPVSRSMNKPLEQQVSTNTEVSSEIYQWVRDELKRAGISQAVFARVAFNRTQGLLSEILRKEEDPKTASQSLLVNLRAMQNFLQLPEAERDRIYQDERERSLNAASAMGPAPLISTPPSRPPQVKTATIATERNGKPENNTMNINASIYDEIQQEMKRAKVSQALFAKVAATKSQGWLCELLRWKEDPSPENRTLWENLSMIRRFLSLPQPERDAIYEQESNAVHHHGDRPPHIIHVPAEQIQQQQQQQQQQQQQQQAPPPPQPQQQPQTGPRLPPRQPTVASPAESDEENRQKTRPRTKISVEALGILQSFIQDVGLYPDEEAIQTLSAQLDLPKYTIIKFFQNQRYYLKHHGKLKDNSGLEVDVAEYKEEELLKDLEESVQDKNTNTLFSVKLEEELSVEGNTDINTDLKD>sp|Q01826-2|SATB1_HUMAN Isoform 2 of DNA-binding protein SATB1 OS=Homosapiens OX=9606 GN=SATB1MDHLNEATQGKEHSEMSNNVSDPKGPPAKIARLEQNGSPLGRGRLGSTGAKMQGVPLKHSGHLMKTNLRKGTMLPVFCVVEHYENAIEYDCKEEHAEFVLVRKDMLFNQLIEMALLSLGYSHSSAAQAKGLIQVGKWNPVPLSYVTDAPDATVADMLQDVYHVVTLKIQLHSCPKLEDLPPEQWSHTTVRNALKDLLKDMNQSSLAKECPLSQSMISSIVNSTYYANVSAAKCQEFGRWYKHFKKTKDMMVEMDSLSELSQQGANHVNFGQQPVPGNTAEQPPSPAQLSHGSQPSVRTPLPNLHPGLVSTPISPQLVNQQLVMAQLLNQQYAVNRLLAQQSLNQQYLNHPPPVSRSMNKPLEQQVSTNTEVSSEIYQWVRDELKRAGISQAVFARVAFNRTQGLLSEILRKEEDPKTASQSLLVNLRAMQNFLQLPEAERDRIYQDERERSLNAASAMGPAPLISTPPSRPPQVKTATIATERNGKPENNTMNINASIYDEIQQEMKRAKVSQALFAKVAATKSQGWLCELLRWKEDPSPENRTLWENLSMIRRFLSLPQPERDAIYEQESNAVHHHGDRPPHIIHVPAEQIQSPSPTTLGKGESRGVFLPGLPTPAPWLGAAPQQQQQQQQQQQQQQQAPPPPQPQQQPQTGPRLPPRQPTVASPAESDEENRQKTRPRTKISVEALGILQSFIQDVGLYPDEEAIQTLSAQLDLPKYTIIKFFQNQRYYLKHHGKLKDNSGLEVDVAEYKEEELLKDLEESVQDKNTNTLFSVKLEEELSVEGNTDINTDLKD>sp|Q8IWT1|SCN4B_HUMAN Sodium channel subunit beta-4 OS=Homo sapiensOX=9606 GN=SCN4B PE=1 SV=1MPGAGDGGKAPARWLGTGLLGLFLLPVTLSLEVSVGKATDIYAVNGTEILLPCTFSSCFGFEDLHFRWTYNSSDAFKILIEGTVKNEKSDPKVTLKDDDRITLVGSTKEKMNNISIVLRDLEFSDTGKYTCHVKNPKENNLQHHATIFLQVVDRLEEVDNTVTLIILAVVGGVIGLLILILLIKKLIIFILKKTREKKKECLVSSSGNDNTENGLPGSKAEEKPPSKV>sp|Q8IWT1-2|SCN4B_HUMAN Isoform 2 of Sodium channel subunit beta-4OS=Homo sapiens OX=9606 GN=SCN4BMNNISIVLRDLEFSDTGKYTCHVKNPKENNLQHHATIFLQVVDRLEEVDNTVTLIILAVVGGVIGLLILILLIKKLIIFILKKTREKKKECLVSSSGNDNTENGLPGSKAEEKPPSKV>sp|Q8IWT1-3|SCN4B_HUMAN Isoform 3 of Sodium channel subunit beta-4OS=Homo sapiens OX=9606 GN=SCN4BMPGAGDGGKAPARWLGTGLLVEEVDNTVTLIILAVVGGVIGLLILILLIKKLIIFILKKTREKKKECLVSSSGNDNTENGLPGSKAEEKPPSKV>sp|Q92854|SEM4D_HUMAN Semaphorin-4D OS=Homo sapiens OX=9606 GN=SEMA4DPE=1 SV=1MRMCTPIRGLLMALAVMFGTAMAFAPIPRITWEHREVHLVQFHEPDIYNYSALLLSEDKDTLYIGAREAVFAVNALNISEKQHEVYWKVSEDKKAKCAEKGKSKQTECLNYIRVLQPLSATSLYVCGTNAFQPACDHLNLTSFKFLGKNEDGKGRCPFDPAHSYTSVMVDGELYSGTSYNFLGSEPIISRNSSHSPLRTEYAIPWLNEPSFVFADVIRKSPDSPDGEDDRVYFFFTEVSVEYEFVFRVLIPRIARVCKGDQGGLRTLQKKWTSFLKARLICSRPDSGLVFNVLRDVFVLRSPGLKVPVFYALFTPQLNNVGLSAVCAYNLSTAEEVFSHGKYMQSTTVEQSHTKWVRYNGPVPKPRPGACIDSEARAANYTSSLNLPDKTLQFVKDHPLMDDSVTPIDNRPRLIKKDVNYTQIVVDRTQALDGTVYDVMFVSTDRGALHKAISLEHAVHIIEETQLFQDFEPVQTLLLSSKKGNRFVYAGSNSGVVQAPLAFCGKHGTCEDCVLARDPYCAWSPPTATCVALHQTESPSRGLIQEMSGDASVCPDKSKGSYRQHFFKHGGTAELKCSQKSNLARVFWKFQNGVLKAESPKYGLMGRKNLLIFNLSEGDSGVYQCLSEERVKNKTVFQVVAKHVLEVKVVPKPVVAPTLSVVQTEGSRIATKVLVASTQGSSPPTPAVQATSSGAITLPPKPAPTGTSCEPKIVINTVPQLHSEKTMYLKSSDNRLLMSLFLFFFVLFLCLFFYNCYKGYLPRQCLKFRSALLIGKKKPKSDFCDREQSLKETLVEPGSFSQQNGEHPKPALDTGYETEQDTITSKVPTDREDSQRIDDLSARDKPFDVKCELKFADSDADGD>sp|Q92854-2|SEM4D_HUMAN Isoform 2 of Semaphorin-4D OS=Homo sapiensOX=9606 GN=SEMA4DMRMCTPIRGLLMALAVMFGTAMAFAPIPRITWEHREVHLVQFHEPDIYNYSALLLSEDKDTLYIGAREAVFAVNALNISEKQHEVYWKVSEDKKAKCAEKGKSKQTECLNYIRVLQPLSATSLYVCGTNAFQPACDHLNLTSFKFLGKNEDGKGRCPFDPAHSYTSVMVDGELYSGTSYNFLGSEPIISRNSSHSPLRTEYAIPWLNEPSFVFADVIRKSPDSPDGEDDRVYFFFTEVSVEYEFVFRVLIPRIARVCKGDQGGLRTLQKKWTSFLKARLICSRPDSGLVFNVLRDVFVLRSPGLKVPVFYALFTPQLNNVGLSAVCAYNLSTAEEVFSHGKYMQSTTVEQSHTKWVRYNGPVPKPRPGACIDSEARAANYTSSLNLPDKTLQFVKDHPLMDDSVTPIDNRPRLIKKDVNYTQIVVDRTQALDGTVYDVMFVSTDRGALHKAISLEHAVHIIEETQLFQDFEPVQTLLLSSKKGNRFVYAGSNSGVVQAPLAFCGKHGTCEDCVLARDPYCAWSPPTATCVALHQTESPSRGLIQEMSGDASVCPASSPKPLPPPGSSSLSCLGHVGDRRLSSPWTPWPASGAGPDSSSRVSLLPPFLSDQAQHVHALGNFYLFCQATGPADIRFVWEKNGRALETCVPVQTHALPDGRAHALSWLQDAIRESAEYRCSVLSSAGNKTSKVQVAVMRPEVTHQERWTRELSAWRAVAGEHDRMMQSWRKAWESCSKDTL>sp|Q5VXD3|SAM13_HUMAN Sterile alpha motif domain-containing protein 13OS=Homo sapiens OX=9606 GN=SAMD13 PE=2 SV=1MANSLLEGVFAEVKEPCSLPMLSVDMENKENGSVGVKNSMENGRPPDPADWAVMDVVNYFRTVGFEEQASAFQEQEIDGKSLLLMTRNDVLTGLQLKLGPALKIYEYHVKPLQTKHLKNNSS>sp|Q5VXD3-2|SAM13_HUMAN Isoform 2 of Sterile alpha motif domain-containing protein 13 OS=Homo sapiens OX=9606 GN=SAMD13MRGVAEVKEPCSLPMLSVDMENKENGSVGVKNSMENGRPPDPADWAVMDVVNYFRTVGFEEQASAFQEQEIDGKSLLLMTRNDVLTGLQLKLGPALKIYEYHVKPLQTKHLKNNSS>sp|Q5VXD3-3|SAM13_HUMAN Isoform 3 of Sterile alpha motif domain-containing protein 13 OS=Homo sapiens OX=9606 GN=SAMD13MRSCLMPGNEMSMTSPEGTEPKGKQRRWQRQKTFGGGTMHSQDSQEIDGKSLLLMTRNDVLTGLQLKLGPALKIYEYHVKPLQTKHLKNNSS>sp|Q5VXD3-4|SAM13_HUMAN Isoform 4 of Sterile alpha motif domain-containing protein 13 OS=Homo sapiens OX=9606 GN=SAMD13MLSVDMENKENGSVGVKNSMENGRPPDPADWAVMDVVNYFRTVGFEEQASAFQEQEIDGKSLLLMTRNDVLTGLQLKLGPALKIYEYHVKPLQTKHLKNNSS>sp|Q9NTN9|SEM4G_HUMAN Semaphorin-4G OS=Homo sapiens OX=9606 GN=SEMA4GPE=1 SV=1MWGRLWPLLLSILTATAVPGPSLRRPSRELDATPRMTIPYEELSGTRHFKGQAQNYSTLLLEEASARLLVGARGALFSLSANDIGDGAHKEIHWEASPEMQSKCHQKGKNNQTECFNHVRFLQRLNSTHLYACGTHAFQPLCAAIDAEAFTLPTSFEEGKEKCPYDPARGFTGLIIDGGLYTATRYEFRSIPDIRRSRHPHSLRTEETPMHWLNDAEFVFSVLVRESKASAVGDDDKVYYFFTERATEEGSGSFTQSRSSHRVARVARVCKGDLGGKKILQKKWTSFLKARLICHIPLYETLRGVCSLDAETSSRTHFYAAFTLSTQWKTLEASAICRYDLAEIQAVFAGPYMEYQDGSRRWGRYEGGVPEPRPGSCITDSLRSQGYNSSQDLPSLVLDFVKLHPLMARPVVPTRGRPLLLKRNIRYTHLTGTPVTTPAGPTYDLLFLGTADGWIHKAVVLGSGMHIIEETQVFRESQSVENLVISLLQHSLYVGAPSGVIQLPLSSCSRYRSCYDCILARDPYCGWDPGTHACAAATTIANRTALIQDIERGNRGCESSRDTGPPPPLKTRSVLRGDDVLLPCDQPSNLARALWLLNGSMGLSDGQGGYRVGVDGLLVTDAQPEHSGNYGCYAEENGLRTLLASYSLTVRPATPAPAPKAPATPGAQLAPDVRLLYVLAIAALGGLCLILASSLLYVACLREGRRGRRRKYSLGRASRAGGSAVQLQTVSGQCPGEEDEGDDEGAGGLEGSCLQIIPGEGAPAPPPPPPPPPPAELTNGLVALPSRLRRMNGNSYVLLRQSNNGVPAGPCSFAEELSRILEKRKHTQLVEQLDESSV>sp|Q9NTN9-2|SEM4G_HUMAN Isoform 2 of Semaphorin-4G OS=Homo sapiensOX=9606 GN=SEMA4GMWGRLWPLLLSILTATAVPGPSLRRPSRELDATPRMTIPYEELSGTRHFKGQAQNYSTLLLEEASARLLVGARGALFSLSANDIGDGAHKEIHWEASPEMQSKCHQKGKNNQTECFNHVRFLQRLNSTHLYACGTHAFQPLCAAIDAEAFTLPTSFEEGKEKCPYDPARGFTGLIIDGGLYTATRYEFRSIPDIRRSRHPHSLRTEETPMHWLNDAEFVFSVLVRESKASAVGDDDKVYYFFTERATEEGSGSFTQSRSSHRVARVARVCKGDLGGKKILQKKWTSFLKARLICHIPLYETLRGVCSLDAETSSRTHFYAAFTLSTQWKTLEASAICRYDLAEIQAVFAGPYMEYQDGSRRWGRYEGGVPEPRPGSCITDSLRSQGYNSSQDLPSLVLDFVKLHPLMARPVVPTRGRPLLLKRNIRYTHLTGTPVTTPAGPTYDLLFLGTADGWIHKAVVLGSGMHIIEETQVFRESQSVENLVISLLQHSLYVGAPSGVIQLPLSSCSRYRSCYDCILARDPYCGWDPGTHACAAATTIANRSQGSRTALIQDIERGNRGCESSRDTGPPPPLKTRSVLRGDDVLLPCDQPSNLARALWLLNGSMGLSDGQGGYRVGVDGLLVTDAQPEHSGNYGCYAEENGLRTLLASYSLTVRPATPAPAPKAPATPGAQLAPDVRLLYVLAIAALGGLCLILASSLLYVACLREGRRGRRRKYSLGRASRAGGSAVQLQTVSGQCPGEEDEGDDEGAGGLEGSCLQIIPGEGAPAPPPPPPPPPPAELTNGLVALPSRLRRMNGNSYVLLRQSNNGVPAGPCSFAEELSRILEKRKHTQLVEQLDESSV>sp|Q9NTN9-3|SEM4G_HUMAN Isoform 3 of Semaphorin-4G OS=Homo sapiensOX=9606 GN=SEMA4GMWGRLWPLLLSILTATAVPGPSLRRPSRELDATPRMTIPYEELSGTRHFKGQAQNYSTLLLEEASARLLVGARGALFSLSANDIGDGAHKEIHWEASPEMQSKCHQKGKNNQTECFNHVRFLQRLNSTHLYACGTHAFQPLCAAIDAEAFTLPTSFEEGKEKCPYDPARGFTGLIIDGGLYTATRYEFRSIPDIRRSRHPHSLRTEETPMHWLNDAEFVFSVLVRESKASAVGDDDKVYYFFTERATEEGSGSFTQSRSSHRVARVARVCKGDLGGKKILQKKWTSFLKARLICHIPLYETLRGVCSLDAETSSRTHFYAAFTLSTQWKTLEASAICRYDLAEIQAVFAGPYMEYQDGSRRWGRYEGGVPEPRPGSCITDSLRSQGYNSSQDLPSLVLDFVKLHPLMARPVVPTRGRPLLLKRNIRYTHLTGTPVTTPAGPTYDLLFLGTADGWIHKAVVLGSGMHIIEETQVFRESQSVENLVISLLQHSLYVGAPSGVIQLPLSSCSRYRSCYDCILARDPYCGWDPGTHACAAATTIANRSQGSRTALIQDIERGNRGCESSRDTGRALQVHMGSMSPPSAWPCVLDGPETRQDLCQPPKPCVHSHAHMEECLSAGLQCPHPHLLLVHSCFIPASGLGVPSQLPHPIWSSSPAPCGDLFVKSLGTGQPGEVRLHHSPPLPSCVALVNQPPHSPWSFSRV>sp|A2RU30|TESP1_HUMAN Protein TESPA1 OS=Homo sapiens OX=9606 GN=TESPA1PE=1 SV=2MEASVLSPTSWEKRRAWLRQSRNWQTQVLEEEAAAALQDVPDPEPSSLDDVFQEGNPINKIEDWLQDCGYSEEGFSEEAGQFIYNGFCSHGTSFEDDLTLGAEATLLAANGKLFSRSFLETARPCQLLDLGCSLASSSMTGGTNKTSSSISEILDKVQEDAEDVLFSLGFGQEDHKDTSRIPARFFTTPSQAKGIDFQLFLKSQVRRIEMEDPCLMLASRFKQVQTLAVTADAFFCLYSYVSKTPVQKFTPSHMFWNCNHPTDVPSIRILSREPEPQSPRDRLRKAISKMCLYTCPRDRPPPPHNTPKRNSLDQVVLEVMDKVKEEKQFLQQDSDLGQFSQEDPVPPAEGKKLPTSPYPCVFCCEEETQQRMSTVLAPSQTLDSNPKVPCCTHSLPIEDPQWSTDPAQIRRELCSLPATNTETHPAKDETFWKRKSRARKSLFQKNLMGRKVKSLDLSITQQKWKQSVDRPELRRSLSQQPQDTFDLEEVQSNSEEEQSQSRWPSRPRHPHHHQTFAGKDS>sp|A2RU30-2|TESP1_HUMAN Isoform 2 of Protein TESPA1 OS=Homo sapiensOX=9606 GN=TESPA1MTGGTNKTSSSISEILDKVQEDAEDVLFSLGFGQEDHKDTSRIPARFFTTPSQAKGIDFQLFLKSQVRRIEMEDPCLMLASRFKQVQTLAVTADAFFCLYSYVSKTPVQKFTPSHMFWNCNHPTDVPSIRILSREPEPQSPRDRLRKAISKMCLYTCPRDRPPPPHNTPKRNSLDQVVLEVMDKVKEEKQFLQQDSDLGQFSQEDPVPPAEGKKLPTSPYPCVFCCEEETQQRMSTVLAPSQTLDSNPKVPCCTHSLPIEDPQWSTDPAQIRRELCSLPATNTETHPAKDETFWKRKSRARKSLFQKNLMGRKVKSLDLSITQQKWKQSVDRPELRRSLSQQPQDTFDLEEVQSNSEEEQSQSRWPSRPRHPHHHQTFAGKDS>sp|A2RU30-3|TESP1_HUMAN Isoform 3 of Protein TESPA1 OS=Homo sapiensOX=9606 GN=TESPA1MTGGTNKTSSSISEILDKVQEDAEDVLFSLGFGQEDHKDTSRIPARFFTTPSQAKGIDFQLFLKSQVRRIEMEDPCLMLASRFKQVQTLAVTADAFFCLYSYVSKTPVQKFTPSHMFWNCNHPTDVPSIRILSREPEPQSPRDRLRKAISKMCLYTCPRDRPPPPHNTPKRNSLDQVVLEVMDKVKEEKQFLQQDSDLGQFSQEDPVPPAEGKKLPTSPYPCVFCCEEETQQRMSTVLAPSQTLDSNPKVPCCTHSLPIEDPQWSTDPAQIRRELCSLPATNTETHPAKDETFWKRKSRARKSLFQKNLMGRKVKSLDLSITQQKWKQSVDRPELRRSLSQQPQDTFDLEEVQSNSEEEQSQSRWPSRPRHPHHHQTFAGKFVKLSPPPQQHVV>sp|O75326|SEM7A_HUMAN Semaphorin-7A OS=Homo sapiens OX=9606 GN=SEMA7APE=1 SV=1MTPPPPGRAAPSAPRARVPGPPARLGLPLRLRLLLLLWAAAASAQGHLRSGPRIFAVWKGHVGQDRVDFGQTEPHTVLFHEPGSSSVWVGGRGKVYLFDFPEGKNASVRTVNIGSTKGSCLDKRDCENYITLLERRSEGLLACGTNARHPSCWNLVNGTVVPLGEMRGYAPFSPDENSLVLFEGDEVYSTIRKQEYNGKIPRFRRIRGESELYTSDTVMQNPQFIKATIVHQDQAYDDKIYYFFREDNPDKNPEAPLNVSRVAQLCRGDQGGESSLSVSKWNTFLKAMLVCSDAATNKNFNRLQDVFLLPDPSGQWRDTRVYGVFSNPWNYSAVCVYSLGDIDKVFRTSSLKGYHSSLPNPRPGKCLPDQQPIPTETFQVADRHPEVAQRVEPMGPLKTPLFHSKYHYQKVAVHRMQASHGETFHVLYLTTDRGTIHKVVEPGEQEHSFAFNIMEIQPFRRAAAIQTMSLDAERRKLYVSSQWEVSQVPLDLCEVYGGGCHGCLMSRDPYCGWDQGRCISIYSSERSVLQSINPAEPHKECPNPKPDKAPLQKVSLAPNSRYYLSCPMESRHATYSWRHKENVEQSCEPGHQSPNCILFIENLTAQQYGHYFCEAQEGSYFREAQHWQLLPEDGIMAEHLLGHACALAASLWLGVLPTLTLGLLVH>sp|O75326-2|SEM7A_HUMAN Isoform 2 of Semaphorin-7A OS=Homo sapiensOX=9606 GN=SEMA7AMTPPPPGRAAPSAPRARVPGPPARLGLPLRLRLLLLLWAAAASAQGHLRSGPRIFAVWKGHVGQDRVDFGQTEPHTVLFHEPGSSSVWVGGRGKVYLFDFPEGKNASVRTDCENYITLLERRSEGLLACGTNARHPSCWNLVNGTVVPLGEMRGYAPFSPDENSLVLFEGDEVYSTIRKQEYNGKIPRFRRIRGESELYTSDTVMQNPQFIKATIVHQDQAYDDKIYYFFREDNPDKNPEAPLNVSRVAQLCRGDQGGESSLSVSKWNTFLKAMLVCSDAATNKNFNRLQDVFLLPDPSGQWRDTRVYGVFSNPWNYSAVCVYSLGDIDKVFRTSSLKGYHSSLPNPRPGKCLPDQQPIPTETFQVADRHPEVAQRVEPMGPLKTPLFHSKYHYQKVAVHRMQASHGETFHVLYLTTDRGTIHKVVEPGEQEHSFAFNIMEIQPFRRAAAIQTMSLDAERRKLYVSSQWEVSQVPLDLCEVYGGGCHGCLMSRDPYCGWDQGRCISIYSSERSVLQSINPAEPHKECPNPKPDKAPLQKVSLAPNSRYYLSCPMESRHATYSWRHKENVEQSCEPGHQSPNCILFIENLTAQQYGHYFCEAQEGSYFREAQHWQLLPEDGIMAEHLLGHACALAASLWLGVLPTLTLGLLVH>sp|Q96LT4|SAMD8_HUMAN Sphingomyelin synthase-related protein 1 OS=Homosapiens OX=9606 GN=SAMD8 PE=1 SV=2MAGPNQLCIRRWTTKHVAVWLKDEGFFEYVDILCNKHRLDGITLLTLTEYDLRSPPLEIKVLGDIKRLMLSVRKLQKIHIDVLEEMGYNSDSPMGSMTPFISALQSTDWLCNGELSHDCDGPITDLNSDQYQYMNGKNKHSVRRLDPEYWKTILSCIYVFIVFGFTSFIMVIVHERVPDMQTYPPLPDIFLDSVPRIPWAFAMTEVCGMILCYIWLLVLLLHKHRSILLRRLCSLMGTVFLLRCFTMFVTSLSVPGQHLQCTGKIYGSVWEKLHRAFAIWSGFGMTLTGVHTCGDYMFSGHTVVLTMLNFFVTEYTPRSWNFLHTLSWVLNLFGIFFILAAHEHYSIDVFIAFYITTRLFLYYHTLANTRAYQQSRRARIWFPMFSFFECNVNGTVPNEYCWPFSKPAIMKRLIG>sp|Q96LT4-2|SAMD8_HUMAN Isoform 2 of Sphingomyelin synthase-relatedprotein 1 OS=Homo sapiens OX=9606 GN=SAMD8MAGPNQLCIRRWTTKHVAVWLKDEGFFEYVDILCNKHRLDGITLLTLTEYDLRSPPLEIKVLGDIKRLMLSVRKLQKIHIDVLEEMGYNSDSPMGSMTPFISALQSTDWLCNGELSHDCDGPITDLNSDQYQYMNGKNKHSVRRLDPEYWKTILSCIYVFIVFGFTSFIMVIVHERVPDMQTYPPLPDIFLDSVPRIPWAFAMTEVCGMILCYIWLLVLLLHKHRSILLRRLCSLMGTVFLLRCFTMFVTSLSVPGQHLQCTGKIYGSVWEKLHRAFAIWSGFGMTLTGVHTCGDYMFSGHTVVLTMLNFFVTECKYLFSASMRIR>sp|P31639|SC5A2_HUMAN Sodium/glucose cotransporter 2 OS=Homo sapiensOX=9606 GN=SLC5A2 PE=1 SV=1MEEHTEAGSAPEMGAQKALIDNPADILVIAAYFLLVIGVGLWSMCRTNRGTVGGYFLAGRSMVWWPVGASLFASNIGSGHFVGLAGTGAASGLAVAGFEWNALFVVLLLGWLFAPVYLTAGVITMPQYLRKRFGGRRIRLYLSVLSLFLYIFTKISVDMFSGAVFIQQALGWNIYASVIALLGITMIYTVTGGLAALMYTDTVQTFVILGGACILMGYAFHEVGGYSGLFDKYLGAATSLTVSEDPAVGNISSFCYRPRPDSYHLLRHPVTGDLPWPALLLGLTIVSGWYWCSDQVIVQRCLAGKSLTHIKAGCILCGYLKLTPMFLMVMPGMISRILYPDEVACVVPEVCRRVCGTEVGCSNIAYPRLVVKLMPNGLRGLMLAVMLAALMSSLASIFNSSSTLFTMDIYTRLRPRAGDRELLLVGRLWVVFIVVVSVAWLPVVQAAQGGQLFDYIQAVSSYLAPPVSAVFVLALFVPRVNEQGAFWGLIGGLLMGLARLIPEFSFGSGSCVQPSACPAFLCGVHYLYFAIVLFFCSGLLTLTVSLCTAPIPRKHLHRLVFSLRHSKEEREDLDADEQQGSSLPVQNGCPESAMEMNEPQAPAPSLFRQCLLWFCGMSRGGVGSPPPLTQEEAAAAARRLEDISEDPSWARVVNLNALLMMAVAVFLWGFYA>sp|P31639-2|SC5A2_HUMAN Isoform 2 of Sodium/glucose cotransporter 2OS=Homo sapiens OX=9606 GN=SLC5A2MEEHTEAGSAPEMGAQKALIDNPADILVIAAYFLLVIGVGLWSMCRTNRGTVGGYFLAGRSMVWWPVGASLFASNIGSGHFVGLAGTGAASGLAVAGFEWNALFVVLLLGWLFAPVYLTAGVITMPQYLRKRFGGRRIRLYLSVLSLFLYIFTKISVDMFSGAVFIQQALGWNIYASVIALLGITMIYTVTGGLAALMYTDTVQTFVILGGACILMGYAFHEVGGYSGLFDKYLGAATSLTVSEDPAVGNISSFCYRPRPDSYHLLRHPVTGDLPWPALLLGLTIVSGWYWCSDQVIVQRCLAGKSLTHIKAGCILCGYLKLTPMFLMVMPGMISRILYPDEVACVVPEVCRRVCGTEVGCSNIAYPRLVVKLMPNGRLLGTHRGPADGPGTPDSRVLLRLGQLCAALGVPSFPLRRALPLLRHCAVLLLWPPHPHGLPVHRAHPQKAPPPPGLQSPA>sp|Q495N2|S36A3_HUMAN Proton-coupled amino acid transporter 3 OS=Homosapiens OX=9606 GN=SLC36A3 PE=2 SV=2MSLLGRDYNSELNSLDNGPQSPSESSSSITSENVHPAGEAGLSMMQTLIHLLKCNIGTGLLGLPLAIKNAGLLVGPVSLLAIGVLTVHCMVILLNCAQHLSQRLQKTFVNYGEATMYGLETCPNTWLRAHAVWGRYTVSFLLVITQLGFCSVYFMFMADNLQQMVEKAHVTSNICQPREILTLTPILDIRFYMLIILPFLILLVFIQNLKVLSVFSTLANITTLGSMALIFEYIMEGIPYPSNLPLMANWKTFLLFFGTAIFTFEGVGMVLPLKNQMKHPQQFSFVLYLGMSIVIILYILLGTLGYMKFGSDTQASITLNLPNCWLYQSVKLMYSIGIFFTYALQFHVPAEIIIPFAISQVSESWALFVDLSVRSALVCLTCVSAILIPRLDLVISLVGSVSSSALALIIPALLEIVIFYSEDMSCVTIAKDIMISIVGLLGCIFGTYQALYELPQPISHSMANSTGVHA>sp|Q495N2-2|S36A3_HUMAN Isoform 2 of Proton-coupled amino acidtransporter 3 OS=Homo sapiens OX=9606 GN=SLC36A3MGVIISGSLPPFSSPLQVGPVSLLAIGVLTVHCMVILLNCAQHLSQRLQKTFVNYGEATMYGLETCPNTWLRAHAVWGRWNLALSPRLECSGKISAHCNPHLQGSSNSPAQASRVAGIYRYTVSFLLVITQLGFCSVYFMFMADNLQQMVEKAHVTSNICQPREILTLTPILDIRFYMLIILPFLILLVFIQNLKVLSVFSTLANITTLGSMALIFEYIMEGIPYPSNLPLMANWKTFLLFFGTAIFTFEGVGMVLPLKNQMKHPQQFSFVLYLGMSIVIILYILLGTLGYMKFGSDTQASITLNLPNCWLYQSVKLMYSIGIFFTYALQFHVPAEIIIPFAISQVSESWALFVDLSVRSALVCLTCVSAILIPRLDLVISLVGSVSSSALALIIPALLEIVIFYSEDMSCVTIAKDIMISIVGLLGCIFGTYQALYELPQPISHSMANSTGVHA>sp|Q495N2-3|S36A3_HUMAN Isoform 3 of Proton-coupled amino acidtransporter 3 OS=Homo sapiens OX=9606 GN=SLC36A3MSLLGRDYNSELNSLDNGPQSPSESSSSITSENVHPAGEAGLSMMQTLIHLLKCNIGTGLLGLPLAIKNAGLLVGPVSLLAIGVLTVHCMVILLNCAQHLSQRLQKTFVNYGEATMYGLETCPNTWLRAHAVWGRWNLALSPRLECSGKISAHCNPHLQGSSNSPAQASRVAGIYRYTVSFLLVITQLGFCSVYFMFMADNLQQMVEKAHVTSNICQPREILTLTPILDIRFYMLIILPFLILLVFIQNLKVLSVFSTLANITTLGSMALIFEYIMEGIPYPSNLPLMANWKTFLLFFGTAIFTFEGVGMVLPLKNQMKHPQQFSFVLYLGMSIVIILYILLGTLGYMKFGSDTQASITLNLPNCWLYQSVKLMYSIGIFFTYALQFHVPAEIIIPFAISQVSESWALFVDLSVRSALVCLTCVSAILIPRLDLVISLVGSVSSSALALIIPALLEIVIFYSEDMSCVTIAKDIMISIVGLLGCIFGTYQALYELPQPISHSMANSTGVHA>sp|Q9H1U9|S2551_HUMAN Mitochondrial nicotinamide adenine dinucleotidetransporter SLC25A51 OS=Homo sapiens OX=9606 GN=SLC25A51 PE=1 SV=1MMDSEAHEKRPPILTSSKQDISPHITNVGEMKHYLCGCCAAFNNVAITFPIQKVLFRQQLYGIKTRDAILQLRRDGFRNLYRGILPPLMQKTTTLALMFGLYEDLSCLLHKHVSAPEFATSGVAAVLAGTTEAIFTPLERVQTLLQDHKHHDKFTNTYQAFKALKCHGIGEYYRGLVPILFRNGLSNVLFFGLRGPIKEHLPTATTHSAHLVNDFICGGLLGAMLGFLFFPINVVKTRIQSQIGGEFQSFPKVFQKIWLERDRKLINLFRGAHLNYHRSLISWGIINATYEFLLKVI>sp|Q13424|SNTA1_HUMAN Alpha-1-syntrophin OS=Homo sapiens OX=9606GN=SNTA1 PE=1 SV=1MASGRRAPRTGLLELRAGAGSGAGGERWQRVLLSLAEDVLTVSPADGDPGPEPGAPREQEPAQLNGAAEPGAGPPQLPEALLLQRRRVTVRKADAGGLGISIKGGRENKMPILISKIFKGLAADQTEALFVGDAILSVNGEDLSSATHDEAVQVLKKTGKEVVLEVKYMKDVSPYFKNSTGGTSVGWDSPPASPLQRQPSSPGPTPRNFSEAKHMSLKMAYVSKRCTPNDPEPRYLEICSADGQDTLFLRAKDEASARSWATAIQAQVNTLTPRVKDELQALLAATSTAGSQDIKQIGWLTEQLPSGGTAPTLALLTEKELLLYLSLPETREALSRPARTAPLIATRLVHSGPSKGSVPYDAELSFALRTGTRHGVDTHLFSVESPQELAAWTRQLVDGCHRAAEGVQEVSTACTWNGRPCSLSVHIDKGFTLWAAEPGAARAVLLRQPFEKLQMSSDDGASLLFLDFGGAEGEIQLDLHSCPKTIVFIIHSFLSAKVTRLGLLA>sp|Q13424-2|SNTA1_HUMAN Isoform 2 of Alpha-1-syntrophin OS=Homo sapiensOX=9606 GN=SNTA1MASGRRAPRTGLLELRAGAGSGAGGERWQRVLLSLAEDVLTVSPADGDPGPEPGAPREQEPAQLNGAAEPGAGPPQLPEALLLQRRRVTVRKADAGGLGISIKGGRENKMPILISKIFKGLAADQTEALFVGDAILSVNGEDLSSATHDEAVQVLKKTGKEVVLEVKYMKDVSPYFKNSTGGTSVGWDSPPASPLQRQPSSPGPTPRNFSEAKHMSLKMAYVSKRCTPNDPEPRYLEICSADGQDTLFLRAKDETREALSRPARTAPLIATRLVHSGPSKGSVPYDAELSFALRTGTRHGVDTHLFSVESPQELAAWTRQLVDGCHRAAEGVQEVSTACTWNGRPCSLSVHIDKGFTLWAAEPGAARAVLLRQPFEKLQMSSDDGASLLFLDFGGAEGEIQLDLHSCPKTIVFIIHSFLSAKVTRLGLLA>sp|Q96EQ0|SGTB_HUMAN Small glutamine-rich tetratricopeptide repeat-containing protein beta OS=Homo sapiens OX=9606 GN=SGTB PE=1 SV=1MSSIKHLVYAVIRFLREQSQMDTYTSDEQESLEVAIQCLETVFKISPEDTHLAVSQPLTEMFTSSFCKNDVLPLSNSVPEDVGKADQLKDEGNNHMKEENYAAAVDCYTQAIELDPNNAVYYCNRAAAQSKLGHYTDAIKDCEKAIAIDSKYSKAYGRMGLALTALNKFEEAVTSYQKALDLDPENDSYKSNLKIAEQKLREVSSPTGTGLSFDMASLINNPAFISMAASLMQNPQVQQLMSGMMTNAIGGPAAGVGGLTDLSSLIQAGQQFAQQIQQQNPELIEQLRNHIRSRSFSSSAEEHS>sp|Q9NPD5|SO1B3_HUMAN Solute carrier organic anion transporter familymember 1B3 OS=Homo sapiens OX=9606 GN=SLCO1B3 PE=1 SV=1MDQHQHLNKTAESASSEKKKTRRCNGFKMFLAALSFSYIAKALGGIIMKISITQIERRFDISSSLAGLIDGSFEIGNLLVIVFVSYFGSKLHRPKLIGIGCLLMGTGSILTSLPHFFMGYYRYSKETHINPSENSTSSLSTCLINQTLSFNGTSPEIVEKDCVKESGSHMWIYVFMGNMLRGIGETPIVPLGISYIDDFAKEGHSSLYLGSLNAIGMIGPVIGFALGSLFAKMYVDIGYVDLSTIRITPKDSRWVGAWWLGFLVSGLFSIISSIPFFFLPKNPNKPQKERKISLSLHVLKTNDDRNQTANLTNQGKNVTKNVTGFFQSLKSILTNPLYVIFLLLTLLQVSSFIGSFTYVFKYMEQQYGQSASHANFLLGIITIPTVATGMFLGGFIIKKFKLSLVGIAKFSFLTSMISFLFQLLYFPLICESKSVAGLTLTYDGNNSVASHVDVPLSYCNSECNCDESQWEPVCGNNGITYLSPCLAGCKSSSGIKKHTVFYNCSCVEVTGLQNRNYSAHLGECPRDNTCTRKFFIYVAIQVINSLFSATGGTTFILLTVKIVQPELKALAMGFQSMVIRTLGGILAPIYFGALIDKTCMKWSTNSCGAQGACRIYNSVFFGRVYLGLSIALRFPALVLYIVFIFAMKKKFQGKDTKASDNERKVMDEANLEFLNNGEHFVPSAGTDSKTCNLDMQDNAAAN>sp|Q9NPD5-2|SO1B3_HUMAN Isoform 2 of Solute carrier organic aniontransporter family member 1B3 OS=Homo sapiens OX=9606 GN=SLCO1B3MDQHQHLNKTAESASSEKKKTRRCNGFKMFLAALSFSYIAKALGGIIMKISITQIERRFDISSSLAGLIDGSFEIGNLLVIVFVSYFGSKLHRPKLIGIGCLLMGTGSILTSLPHFFMGYYRYSKETHINPSENSTSSLSTCLINQTLSFNGTSPEIVEKDCVKESGSHMWIYVFMGNMLRGIGETPIVPLGISYIDDFAKEGHSSLYLGSLNAIGMIGPVIGFALGSLFAKMYVDIGYVDLSTIRITPKDSRWVGAWWLGFLVSGLFSIISSIPFFFLPKNPNKPQKERKISLSLHVLKTNDDRNQTANLTNQGKNVTKNVTGFFQSLKSILTNPLYVIFLLLTLLQVSSFIGSFTYVFKYMEQQYGQSASHANFLLGIITIPTVATGMFLGGFIIKKFKLSLVGIAKFSFLTSMISFLFQLLYFPLICESKSVAGLTLTYDGNNSVASHVDVPLSYCNSECNCDESQWEPVCGNNGITYLSPCLAGCKSSSGIKKHTVFYNCSCVEVTGLQNRNYSAHLGECPRDNTCTRKFFIYVAIQVINSLFSATGGTTFILLTVKIVQPELKALAMGFQSMVIRTLGGILAPIYFGALIDKTCMKWSTNSCGAQGACRIYNSVFFGIVQPELKALAIGFHSMIMRSLGGILVPIYFGALIDTTCMKWSTNSCGARGACRIYNSTYLGRAFFGLKVALIFPVLVLLTVFIFVVRKKSHGKDTKVLENERQVMDEANLEFLNDSEHFVPSAEEQ>sp|P50452|SPB8_HUMAN Serpin B8 OS=Homo sapiens OX=9606 GN=SERPINB8 PE=1SV=2MDDLCEANGTFAISLFKILGEEDNSRNVFFSPMSISSALAMVFMGAKGSTAAQMSQALCLYKDGDIHRGFQSLLSEVNRTGTQYLLRTANRLFGEKTCDFLPDFKEYCQKFYQAELEELSFAEDTEECRKHINDWVAEKTEGKISEVLDAGTVDPLTKLVLVNAIYFKGKWNEQFDRKYTRGMLFKTNEEKKTVQMMFKEAKFKMGYADEVHTQVLELPYVEEELSMVILLPDDNTDLAVVEKALTYEKFKAWTNSEKLTKSKVQVFLPRLKLEESYDLEPFLRRLGMIDAFDEAKADFSGMSTEKNVPLSKVAHKCFVEVNEEGTEAAAATAVVRNSRCSRMEPRFCADHPFLFFIRHHKTNCILFCGRFSSP>sp|P50452-2|SPB8_HUMAN Isoform 2 of Serpin B8 OS=Homo sapiens OX=9606GN=SERPINB8MDDLCEANGTFAISLFKILGEEDNSRNVFFSPMSISSALAMVFMGAKGSTAAQMSQALCLYKDGDIHRGFQSLLSEVNRTGTQYLLRTANRLFGEKTCDFLPDFKEYCQKFYQAELEELSFAEDTEECRKHINDWVAEKTEGKISEVLDAGTVDPLTKLVLVNAIYFKGKWNEQFDRKYTRGMLFKTNEEKKTVQMMFKEAKFKMGYADEVHTQVLELPYVEEELSMVILLPDDNTDLAVKE>sp|P50452-3|SPB8_HUMAN Isoform 3 of Serpin B8 OS=Homo sapiens OX=9606GN=SERPINB8MLFKTNEEKKTVQMMFKEAKFKMGYADEVHTQVLELPYVEEELSMVILLPDDNTDLAVVEKALTYEKFKAWTNSEKLTKSKVQVFLPRLKLEESYDLEPFLRRLGMIDAFDEAKADFSGMSTEKNVPLSKVAHKCFVEVNEEGTEAAAATAVVRNSRCSRMEPRFCADHPFLFFIRHHKTNCILFCGRFSSP>sp|Q9NYB5|SO1C1_HUMAN Solute carrier organic anion transporter familymember 1C1 OS=Homo sapiens OX=9606 GN=SLCO1C1 PE=2 SV=1MDTSSKENIQLFCKTSVQPVGRPSFKTEYPSSEEKQPCCGELKVFLCALSFVYFAKALAEGYLKSTITQIERRFDIPSSLVGVIDGSFEIGNLLVITFVSYFGAKLHRPKIIGAGCVIMGVGTLLIAMPQFFMEQYKYERYSPSSNSTLSISPCLLESSSQLPVSVMEKSKSKISNECEVDTSSSMWIYVFLGNLLRGIGETPIQPLGIAYLDDFASEDNAAFYIGCVQTVAIIGPIFGFLLGSLCAKLYVDIGFVNLDHITITPKDPQWVGAWWLGYLIAGIISLLAAVPFWYLPKSLPRSQSREDSNSSSEKSKFIIDDHTDYQTPQGENAKIMEMARDFLPSLKNLFGNPVYFLYLCTSTVQFNSLFGMVTYKPKYIEQQYGQSSSRANFVIGLINIPAVALGIFSGGIVMKKFRISVCGAAKLYLGSSVFGYLLFLSLFALGCENSDVAGLTVSYQGTKPVSYHERALFSDCNSRCKCSETKWEPMCGENGITYVSACLAGCQTSNRSGKNIIFYNCTCVGIAASKSGNSSGIVGRCQKDNGCPQMFLYFLVISVITSYTLSLGGIPGYILLLRCIKPQLKSFALGIYTLAIRVLAGIPAPVYFGVLIDTSCLKWGFKRCGSRGSCRLYDSNVFRHIYLGLTVILGTVSILLSIAVLFILKKNYVSKHRSFITKRERTMVSTRFQKENYTTSDHLLQPNYWPGKETQL>sp|Q9NYB5-2|SO1C1_HUMAN Isoform 2 of Solute carrier organic aniontransporter family member 1C1 OS=Homo sapiens OX=9606 GN=SLCO1C1MDTSSKENIQLFCKTSVQPVGRPSFKTEYPSSEEKQPCCGELKVFLCALSFVYFAKALAEGYLKSTITQIERRFDIPSSLVGVIDGSFEIGNLLVITFVSYFGAKLHRPKIIGAGCVIMGVGTLLIAMPQFFMEQYKYERYSPSSNSTLSISPCLLESSSQLPVSVMEKSKSKISNGCVQTVAIIGPIFGFLLGSLCAKLYVDIGFVNLDHITITPKDPQWVGAWWLGYLIAGIISLLAAVPFWYLPKSLPRSQSREDSNSSSEKSKFIIDDHTDYQTPQGENAKIMEMARDFLPSLKNLFGNPVYFLYLCTSTVQFNSLFGMVTYKPKYIEQQYGQSSSRANFVIGLINIPAVALGIFSGGIVMKKFRISVCGAAKLYLGSSVFGYLLFLSLFALGCENSDVAGLTVSYQGTKPVSYHERALFSDCNSRCKCSETKWEPMCGENGITYVSACLAGCQTSNRSGKNIIFYNCTCVGIAASKSGNSSGIVGRCQKDNGCPQMFLYFLVISVITSYTLSLGGIPGYILLLRCIKPQLKSFALGIYTLAIRVLAGIPAPVYFGVLIDTSCLKWGFKRCGSRGSCRLYDSNVFRHIYLGLTVILGTVSILLSIAVLFILKKNYVSKHRSFITKRERTMVSTRFQKENYTTSDHLLQPNYWPGKETQL>sp|Q9NYB5-3|SO1C1_HUMAN Isoform 3 of Solute carrier organic aniontransporter family member 1C1 OS=Homo sapiens OX=9606 GN=SLCO1C1MDTSSKENIQLFCKTSVQPVGRPSFKTEYPSSEEKQPCCGELKVFLCALSFVYFAKALAEGYLKSTITQIERRFDIPSSLVGVIDGSFEIGNLLVITFVSYFGAKLHRPKIIGAGCVIMGVGTLLIAMPQFFMEQYKYERYSPSSNSTLSISPCLLESSSQLPVSVMEKSKSKISNECEVDTSSSMWIYVFLGNLLRGIGETPIQPLGIAYLDDFASEDNAAFYIGCVQTVAIIGPIFGFLLGSLCAKLYVDIGFVNLDHITITPKDPQWVGAWWLGYLIAGIISLLAAVPFWYLPKSLPRSQSREDSNSSSEKSKFIIDDHTDYQTPQGENAKIMEMARDFLPSLKNLFGNPVYFLYLCTSTVQFNSLFGMVTYKPKYIEQQYGQSSSRANFVIGLINIPAVALGIFSGGIVMKKFRISVCGAAKLYLGSSVFGYLLFLSLFALGCENSDVAGLTVSYQGTKPVSYHERALFSDCNSRCKCSETKWEPMCGENGITYVSACLAGCQTSNRSGKNIIFYNCTCVGIAASKSGNSSGIVGRCQKDNGCPQMFLYFLVISVITSYTLSLGGIPGYILLLRCIKPQLKSFALGIYTLAIRVLAGIPAPVYFGVLIDTSCLKWGFKRCGSRGSCRLYDSNVFRYQIKSIPASHCYSIPDLHNATDTNKFSCHFTACKTYISGTNCDTGHSVNSPKHCSTFHFKEKLCFKTQKFYNQERKNNGVYKIPKGKLHYK>sp|Q9NYB5-4|SO1C1_HUMAN Isoform 4 of Solute carrier organic aniontransporter family member 1C1 OS=Homo sapiens OX=9606 GN=SLCO1C1MGVGTLLIAMPQFFMEQYKYERYSPSSNSTLSISPCLLESSSQLPVSVMEKSKSKISNECEVDTSSSMWIYVFLGNLLRGIGETPIQPLGIAYLDDFASEDNAAFYIGCVQTVAIIGPIFGFLLGSLCAKLYVDIGFVNLDHITITPKDPQWVGAWWLGYLIAGIISLLAAVPFWYLPKSLPRSQSREDSNSSSEKSKFIIDDHTDYQTPQGENAKIMEMARDFLPSLKNLFGNPVYFLYLCTSTVQFNSLFGMVTYKPKYIEQQYGQSSSRANFVIGLINIPAVALGIFSGGIVMKKFRISVCGAAKLYLGSSVFGYLLFLSLFALGCENSDVAGLTVSYQGTKPVSYHERALFSDCNSRCKCSETKWEPMCGENGITYVSACLAGCQTSNRSGKNIIFYNCTCVGIAASKSGNSSGIVGRCQKDNGCPQMFLYFLVISVITSYTLSLGGIPGYILLLRCIKPQLKSFALGIYTLAIRVLAGIPAPVYFGVLIDTSCLKWGFKRCGSRGSCRLYDSNVFRYQIKSIPASHCYSIPDLHNATDTNKFSCHFTACKTYISGTNCDTGHSVNSPKHCSTFHFKEKLCFKTQKFYNQERKNNGVYKIPKGKLHYK>sp|Q9BV90|SNR25_HUMAN U11/U12 small nuclear ribonucleoprotein 25 kDaprotein OS=Homo sapiens OX=9606 GN=SNRNP25 PE=1 SV=1MDVFQEGLAMVVQDPLLCDLPIQVTLEEVNSQIALEYGQAMTVRVCKMDGEVMPVVVVQSATVLDLKKAIQRYVQLKQEREGGIQHISWSYVWRTYHLTSAGEKLTEDRKKLRDYGIRNRDEVSFIKKLRQK>sp|Q9H7B4|SMYD3_HUMAN Histone-lysine N-methyltransferase SMYD3 OS=Homosapiens OX=9606 GN=SMYD3 PE=1 SV=4MEPLKVEKFATAKRGNGLRAVTPLRPGELLFRSDPLAYTVCKGSRGVVCDRCLLGKEKLMRCSQCRVAKYCSAKCQKKAWPDHKRECKCLKSCKPRYPPDSVRLLGRVVFKLMDGAPSESEKLYSFYDLESNINKLTEDKKEGLRQLVMTFQHFMREEIQDASQLPPAFDLFEAFAKVICNSFTICNAEMQEVGVGLYPSISLLNHSCDPNCSIVFNGPHLLLRAVRDIEVGEELTICYLDMLMTSEERRKQLRDQYCFECDCFRCQTQDKDADMLTGDEQVWKEVQESLKKIEELKAHWKWEQVLAMCQAIISSNSERLPDINIYQLKVLDCAMDACINLGLLEEALFYGTRTMEPYRIFFPGSHPVRGVQVMKVGKLQLHQGMFPQAMKNLRLAFDIMRVTHGREHSLIEDLILLLEECDANIRAS>sp|Q9H7B4-2|SMYD3_HUMAN Isoform 2 of Histone-lysine N-methyltransferaseSMYD3 OS=Homo sapiens OX=9606 GN=SMYD3MEEEEEKVICNSFTICNAEMQEVGVGLYPSISLLNHSCDPNCSIVFNGPHLLLRAVRDIEVGEELTICYLDMLMTSEERRKQLRDQYCFECDCFRCQTQDKDADMLTGDEQVWKEVQESLKKIEELKAHWKWEQVLAMCQAIISSNSERLPDINIYQLKVLDCAMDACINLGLLEEALFYGTRTMEPYRIFFPGSHPVRGVQVMKVGKLQLHQGMFPQAMKNLRLAFDIMRVTHGREHSLIEDLILLLEECDANIRAS>sp|Q9H7B4-3|SMYD3_HUMAN Isoform 3 of Histone-lysine N-methyltransferaseSMYD3 OS=Homo sapiens OX=9606 GN=SMYD3MRCSQCRVAKYCSAKCQKKAWPDHKRECKCLKSCKPRYPPDSVRLLGRVVFKLMDGAPSESEKLYSFYDLESNINKLTEDKKEGLRQLVMTFQHFMREEIQDASQLPPAFDLFEAFAKVICNSFTICNAEMQEVGVGLYPSISLLNHSCDPNCSIVFNGPHLLLRAVRDIEVGEELTICYLDMLMTSEERRKQLRDQYCFECDCFRCQTQDKDADMLTGDEQVWKEVQESLKKIEELKAHWKWEQVLAMCQAIISSNSERLPDINIYQLKVLDCAMDACINLGLLEEALFYGTRTMEPYRIFFPGSHPVRGVQVMKVGKLQLHQGMFPQAMKNLRLAFDIMRVTHGREHSLIEDLILLLEECDANIRAS>sp|A0A087WXS9|TBC3I_HUMAN TBC1 domain family member 3I OS=Homo sapiensOX=9606 GN=TBC1D3I PE=3 SV=1MDVVEVAGSWWAQEREDIIMKYEKGHRAGLPEDKGPKPFRSYNNNVDHLGIVHETELPPLTAREAKQIRREISRKSKWVDMLGDWEKYKSSRKLIDRAYKGMPMNIRGPMWSVLLNTEEMKMKNPGRYQIMKEKGKRSSEHIQRIDRDVSGTLRKHIFFRDRYGTKQRELLHILLAYEEYNPEVGYCRDLSHIAALFLLYLPEEDAFWALVQLLASERHSLQGFHSPNGGTVQGLQDQQEHVVATSQPKTMGHQDKKDLCGQCSPLGCLIRILIDGISLGLTLRLWDVYLVEGEQALMPITRIAFKVQQKRLTKTSRCGPWARFCNRFVDTWARDEDTVLKHLRASMKKLTRKQGDLPPPAKPEQGSSASRPVPASRGGKTLCKGDRQAPPGPPARFPRPIWSASPPRAPRSSTPCPGGAVREDTYPVGTQGVPSPALAQGGPQGSWRFLQWNSMPRLPTDLDVEGPWFRHYDFRQSCWVRAISQEDQLAPCWQAEHPAERVRSAFAAPSTDSDQGTPFRARDEQQCAPTSGPCLCGLHLESSQFPPGF>sp|Q8IXZ3|SP8_HUMAN Transcription factor Sp8 OS=Homo sapiens OX=9606GN=SP8 PE=1 SV=3MLAATCNKIGSPSPSPSSLSDSSSSFGKGFHPWKRSSSSSSASCNVVGSSLSSFGVSGASRNGGSSSAAAAAAAAAAAAAALVSDSFSCGGSPGSSAFSLTSSSAAAAAAAAAAAASSSPFANDYSVFQAPGVSGGSGGGGGGGGGGSSAHSQDGSHQPVFISKVHTSVDGLQGIYPRVGMAHPYESWFKPSHPGLGAAGEVGSAGASSWWDVGAGWIDVQNPNSAAALPGSLHPAAGGLQTSLHSPLGGYNSDYSGLSHSAFSSGASSHLLSPAGQHLMDGFKPVLPGSYPDSAPSPLAGAGGSMLSAGPSAPLGGSPRSSARRYSGRATCDCPNCQEAERLGPAGASLRRKGLHSCHIPGCGKVYGKTSHLKAHLRWHTGERPFVCNWLFCGKRFTRSDELQRHLRTHTGEKRFACPVCNKRFMRSDHLSKHVKTHSGGGGGGGSAGSGSGGKKGSDTDSEHSAAGSPPCHSPELLQPPEPGHRNGLE>sp|Q8IXZ3-1|SP8_HUMAN Isoform 1 of Transcription factor Sp8 OS=Homosapiens OX=9606 GN=SP8MLAATCNKIGSPSPSPSSLSDSSSSFGKGFHPWKRSSSSSSASCNVVGSSLSSFGVSGASRNGGSSSAAAAAAAAAAAAAALVSDSFSCGGSPGSSAFSLTSSGGSSAHSQDGSHQPVFISKVHTSVDGLQGIYPRVGMAHPYESWFKPSHPGLGAAGEVGSAGASSWWDVGAGWIDVQNPNSAAALPGSLHPAAGGLQTSLHSPLGGYNSDYSGLSHSAFSSGASSHLLSPAGQHLMDGFKPVLPGSYPDSAPSPLAGAGGSMLSAGPSAPLGGSPRSSARRYSGRATCDCPNCQEAERLGPAGASLRRKGLHSCHIPGCGKVYGKTSHLKAHLRWHTGERPFVCNWLFCGKRFTRSDELQRHLRTHTGEKRFACPVCNKRFMRSDHLSKHVKTHSGGGGGGGSAGSGSGGKKGSDTDSEHSAAGSPPCHSPELLQPPEPGHRNGLE>sp|Q8IXZ3-2|SP8_HUMAN Isoform 2 of Transcription factor Sp8 OS=Homosapiens OX=9606 GN=SP8MLAATCNKIGSPSPSPSSLSDSSSSFGKGFHPWKRSSSSSSASCNVVGSSLSSFGVSGASRNGGSSSAAAAAAAAAAAAAALVSDSFSCGGSSAHSQDGSHQPVFISKVHTSVDGLQGIYPRVGMAHPYESWFKPSHPGLGAAGEVGSAGASSWWDVGAGWIDVQNPNSAAALPGSLHPAAGGLQTSLHSPLGGYNSDYSGLSHSAFSSGASSHLLSPAGQHLMDGFKPVLPGSYPDSAPSPLAGAGGSMLSAGPSAPLGGSPRSSARRYSGRATCDCPNCQEAERLGPAGASLRRKGLHSCHIPGCGKVYGKTSHLKAHLRWHTGERPFVCNWLFCGKRFTRSDELQRHLRTHTGEKRFACPVCNKRFMRSDHLSKHVKTHSGGGGGGGSAGSGSGGKKGSDTDSEHSAAGSPPCHSPELLQPPEPGHRNGLE>sp|Q8IXZ3-4|SP8_HUMAN Isoform 4 of Transcription factor Sp8 OS=Homosapiens OX=9606 GN=SP8MATSLLGEEPRLGSTPLAMLAATCNKIGSPSPSPSSLSDSSSSFGKGFHPWKRSSSSSSASCNVVGSSLSSFGVSGASRNGGSSSAAAAAAAAAAAAAALVSDSFSCGGSPGSSAFSLTSSSAAAAAAAAAAAASSSPFANDYSVFQAPGVSGGSGGGGGGGGGGSSAHSQDGSHQPVFISKVHTSVDGLQGIYPRVGMAHPYESWFKPSHPGLGAAGEVGSAGASSWWDVGAGWIDVQNPNSAAALPGSLHPAAGGLQTSLHSPLGGYNSDYSGLSHSAFSSGASSHLLSPAGQHLMDGFKPVLPGSYPDSAPSPLAGAGGSMLSAGPSAPLGGSPRSSARRYSGRATCDCPNCQEAERLGPAGASLRRKGLHSCHIPGCGKVYGKTSHLKAHLRWHTGERPFVCNWLFCGKRFTRSDELQRHLRTHTGEKRFACPVCNKRFMRSDHLSKHVKTHSGGGGGGGSAGSGSGGKKGSDTDSEHSAAGSPPCHSPELLQPPEPGHRNGLE>sp|P35712|SOX6_HUMAN Transcription factor SOX-6 OS=Homo sapiens OX=9606GN=SOX6 PE=1 SV=3MSSKQATSPFACAADGEDAMTQDLTSREKEEGSDQHVASHLPLHPIMHNKPHSEELPTLVSTIQQDADWDSVLSSQQRMESENNKLCSLYSFRNTSTSPHKPDEGSRDREIMTSVTFGTPERRKGSLADVVDTLKQKKLEEMTRTEQEDSSCMEKLLSKDWKEKMERLNTSELLGEIKGTPESLAEKERQLSTMITQLISLREQLLAAHDEQKKLAASQIEKQRQQMDLARQQQEQIARQQQQLLQQQHKINLLQQQIQVQGHMPPLMIPIFPHDQRTLAAAAAAQQGFLFPPGITYKPGDNYPVQFIPSTMAAAAASGLSPLQLQKGHVSHPQINQRLKGLSDRFGRNLDTFEHGGGHSYNHKQIEQLYAAQLASMQVSPGAKMPSTPQPPNTAGTVSPTGIKNEKRGTSPVTQVKDEAAAQPLNLSSRPKTAEPVKSPTSPTQNLFPASKTSPVNLPNKSSIPSPIGGSLGRGSSLDILSSLNSPALFGDQDTVMKAIQEARKMREQIQREQQQQQPHGVDGKLSSINNMGLNSCRNEKERTRFENLGPQLTGKSNEDGKLGPGVIDLTRPEDAEGSKAMNGSAAKLQQYYCWPTGGATVAEARVYRDARGRASSEPHIKRPMNAFMVWAKDERRKILQAFPDMHNSNISKILGSRWKSMSNQEKQPYYEEQARLSKIHLEKYPNYKYKPRPKRTCIVDGKKLRIGEYKQLMRSRRQEMRQFFTVGQQPQIPITTGTGVVYPGAITMATTTPSPQMTSDCSSTSASPEPSLPVIQSTYGMKTDGGSLAGNEMINGEDEMEMYDDYEDDPKSDYSSENEAPEAVSAN>sp|P35712-2|SOX6_HUMAN Isoform 2 of Transcription factor SOX-6 OS=Homosapiens OX=9606 GN=SOX6MGRMSSKQATSPFACAADGEDAMTQDLTSREKEEGSDQHVASHLPLHPIMHNKPHSEELPTLVSTIQQDADWDSVLSSQQRMESENNKLCSLYSFRNTSTSPHKPDEGSRDREIMTSVTFGTPERRKGSLADVVDTLKQKKLEEMTRTEQEDSSCMEKLLSKDWKEKMERLNTSELLGEIKGTPESLAEKERQLSTMITQLISLREQLLAAHDEQKKLAASQIEKQRQQMDLARQQQEQIARQQQQLLQQQHKINLLQQQIQVQGHMPPLMIPIFPHDQRTLAAAAAAQQGFLFPPGITYKPGDNYPVQFIPSTMAAAAASGLSPLQLQQLYAAQLASMQVSPGAKMPSTPQPPNTAGTVSPTGIKNEKRGTSPVTQVKDEAAAQPLNLSSRPKTAEPVKSPTSPTQNLFPASKTSPVNLPNKSSIPSPIGGSLGRGSSLGKWKSQHQEETYELDILSSLNSPALFGDQDTVMKAIQEARKMREQIQREQQQQQPHGVDGKLSSINNMGLNSCRNEKERTRFENLGPQLTGKSNEDGKLGPGVIDLTRPEDAEGSKAMNGSAAKLQQYYCWPTGGATVAEARVYRDARGRASSEPHIKRPMNAFMVWAKDERRKILQAFPDMHNSNISKILGSRWKSMSNQEKQPYYEEQARLSKIHLEKYPNYKYKPRPKRTCIVDGKKLRIGEYKQLMRSRRQEMRQFFTVGQQPQIPITTGTGVVYPGAITMATTTPSPQMTSDCSSTSASPEPSLPVIQSTYGMKTDGGSLAGNEMINGEDEMEMYDDYEDDPKSDYSSENEAPEAVSAN>sp|P35712-3|SOX6_HUMAN Isoform 3 of Transcription factor SOX-6 OS=Homosapiens OX=9606 GN=SOX6MSSKQATSPFACAADGEDAMTQDLTSREKEEGSDQHVASHLPLHPIMHNKPHSEELPTLVSTIQQDADWDSVLSSQQRMESENNKLCSLYSFRNTSTSPHKPDEGSRDREIMTSVTFGTPERRKGSLADVVDTLKQKKLEEMTRTEQEDSSCMEKLLSKDWKEKMERLNTSELLGEIKGTPESLAEKERQLSTMITQLISLREQLLAAHDEQKKLAASQIEKQRQQMDLARQQQEQIARQQQQLLQQQHKINLLQQQIQVQGHMPPLMIPIFPHDQRTLAAAAAAQQGFLFPPGITYKPGDNYPVQFIPSTMAAAAASGLSPLQLQKGHVSHPQINQRLKGLSDRFGRNLDTFEHGGGHSYNHKQIEQLYAAQLASMQVSPGAKMPSTPQPPNTAGTVSPTGIKNEKRGTSPVTQVKDEAAAQPLNLSSRPKTAEPVKSPTSPTQNLFPASKTSPVNLPNKSSIPSPIGGSLGRGSSLDILSSLNSPALFGDQDTVMKAIQEARKMREQIQREQQQQQPHGVDGKLSSINNMGLNSCRNEKERTRFENLGPQLTGKSNEDGKLGPGVIDLTRPEDAEGGATVAEARVYRDARGRASSEPHIKRPMNAFMVWAKDERRKILQAFPDMHNSNISKILGSRWKSMSNQEKQPYYEEQARLSKIHLEKYPNYKYKPRPKRTCIVDGKKLRIGEYKQLMRSRRQEMRQFFTVGQQPQIPITTGTGVVYPGAITMATTTPSPQMTSDCSSTSASPEPSLPVIQSTYGMKTDGGSLAGNEMINGEDEMEMYDDYEDDPKSDYSSENEAPEAVSAN>sp|P35712-4|SOX6_HUMAN Isoform 4 of Transcription factor SOX-6 OS=Homosapiens OX=9606 GN=SOX6MSSKQATSPFACAADGEDAMTQDLTSREKEEGSDQHVASHLPLHPIMHNKPHSEELPTLVSTIQQDADWDSVLSSQQRMESENNKLCSLYSFRNTSTSPHKPDEGSRDREIMTSVTFGTPERRKGSLADVVDTLKQKKLEEMTRTEQEDSSCMEKLLSKDWKEKMERLNTSELLGEIKGTPESLAEKERQLSTMITQLISLREQLLAAHDEQKKLAASQIEKQRQQMDLARQQQEQIARQQQQLLQQQHKINLLQQQIQVQGHMPPLMIPIFPHDQRTLAAAAAAQQGFLFPPGITYKPGDNYPVQFIPSTMAAAAASGLSPLQLQQLYAAQLASMQVSPGAKMPSTPQPPNTAGTVSPTGIKNEKRGTSPVTQVKDEAAAQPLNLSSRPKTAEPVKSPTSPTQNLFPASKTSPVNLPNKSSIPSPIGGSLGRGSSLGKWKSQHQEETYELDILSSLNSPALFGDQDTVMKAIQEARKMREQIQREQQQQQPHGVDGKLSSINNMGLNSCRNEKERTRFENLGPQLTGKSNEDGKLGPGVIDLTRPEDAEGSKAMNGSAAKLQQYYCWPTGGATVAEARVYRDARGRASSEPHIKRPMNAFMVWAKDERRKILQAFPDMHNSNISKILGSRWKSMSNQEKQPYYEEQARLSKIHLEKYPNYKYKPRPKRTCIVDGKKLRIGEYKQLMRSRRQEMRQFFTVGQQPQIPITTGTGVVYPGAITMATTTPSPQMTSDCSSTSASPEPSLPVIQSTYGMKTDGGSLAGNEMINGEDEMEMYDDYEDDPKSDYSSENEAPEAVSAN>sp|Q96RF0|SNX18_HUMAN Sorting nexin-18 OS=Homo sapiens OX=9606 GN=SNX18PE=1 SV=2MALRARALYDFRSENPGEISLREHEVLSLCSEQDIEGWLEGVNSRGDRGLFPASYVQVIRAPEPGPAGDGGPGAPARYANVPPGGFEPLPVAPPASFKPPPDAFQALLQPQQAPPPSTFQPPGAGFPYGGGALQPSPQQLYGGYQASQGSDDDWDDEWDDSSTVADEPGALGSGAYPDLDGSSSAGVGAAGRYRLSTRSDLSLGSRGGSVPPQHHPSGPKSSATVSRNLNRFSTFVKSGGEAFVLGEASGFVKDGDKLCVVLGPYGPEWQENPYPFQCTIDDPTKQTKFKGMKSYISYKLVPTHTQVPVHRRYKHFDWLYARLAEKFPVISVPHLPEKQATGRFEEDFISKRRKGLIWWMNHMASHPVLAQCDVFQHFLTCPSSTDEKAWKQGKRKAEKDEMVGANFFLTLSTPPAAALDLQEVESKIDGFKCFTKKMDDSALQLNHTANEFARKQVTGFKKEYQKVGQSFRGLSQAFELDQQAFSVGLNQAIAFTGDAYDAIGELFAEQPRQDLDPVMDLLALYQGHLANFPDIIHVQKGKAWPLEQVIWSVLCRLKGATLTAVPLWVSESYSTGEEASRDVDAWVFSLECKLDCSTGSFLLEYLALGNEYSFSKVQRVPLMTVLSF>sp|Q96RF0-2|SNX18_HUMAN Isoform 2 of Sorting nexin-18 OS=Homo sapiensOX=9606 GN=SNX18MALRARALYDFRSENPGEISLREHEVLSLCSEQDIEGWLEGVNSRGDRGLFPASYVQVIRAPEPGPAGDGGPGAPARYANVPPGGFEPLPVAPPASFKPPPDAFQALLQPQQAPPPSTFQPPGAGFPYGGGALQPSPQQLYGGYQASQGSDDDWDDEWDDSSTVADEPGALGSGAYPDLDGSSSAGVGAAGRYRLSTRSDLSLGSRGGSVPPQHHPSGPKSSATVSRNLNRFSTFVKSGGEAFVLGEASGFVKDGDKLCVVLGPYGPEWQENPYPFQCTIDDPTKQTKFKGMKSYISYKLVPTHTQVPVHRRYKHFDWLYARLAEKFPVISVPHLPEKQATGRFEEDFISKRRKGLIWWMNHMASHPVLAQCDVFQHFLTCPSSTDEKAWKQGKRKAEKDEMVGANFFLTLSTPPAAALDLQEVESKIDGFKCFTKKMDDSALQLNHTANEFARKQVTGFKKEYQKVGQSFRGLSQAFELDQQAFSVGLNQAIAFTGDAYDAIGELFAEQPRQDLDPVMDLLALYQGHLANFPDIIHVQKGALTKVKESRRHVEEGKMEVQKADGIQDRCNTISFATLAEIHHFHQIRVRDFKSQMQHFLQQQIIFFQKVTQKLEEALHKYDSV>sp|Q96RF0-3|SNX18_HUMAN Isoform 3 of Sorting nexin-18 OS=Homo sapiensOX=9606 GN=SNX18MALRARALYDFRSENPGEISLREHEVLSLCSEQDIEGWLEGVNSRGDRGLFPASYVQVIRAPEPGPAGDGGPGAPARYANVPPGGFEPLPVAPPASFKPPPDAFQALLQPQQAPPPSTFQPPGAGFPYGGGALQPSPQQLYGGYQASQGSDDDWDDEWDDSSTVADEPGALGSGAYPDLDGSSSAGVGAAGRYRLSTRSDLSLGSRGGSVPPQHHPSGPKSSATVSRNLNRFSTFVKSGGEAFVLGEASGFVKDGDKLCVVLGPYGPEWQENPYPFQCTIDDPTKQTKFKGMKSYISYKLVPTHTQVPVHRRYKHFDWLYARLAEKFPVISVPHLPEKQATGRFEEDFISKRRKGLIWWMNHMASHPVLAQCDVFQHFLTCPSSTDEKAWKQGKRKAEKDEMVGANFFLTLSTPPAAALDLQEVESKIDGFKCFTKKMDDSALQLNHTANEFARKQVTGFKKEYQKVGQSFRGLSQAFELDQQAFSVGLNQAIAFTGDAYDAIGELFAEQPRQDLDPVMDLLALYQGHLANFPDIIHVQKGKAWPLEQVIWSVLCRLKGATLTAVPLWVSESYSTGEEASRDVDAWVFSLE>sp|Q8TEJ3|SH3R3_HUMAN E3 ubiquitin-protein ligase SH3RF3 OS=Homo sapiensOX=9606 GN=SH3RF3 PE=1 SV=2MLLGASWLCASKAAAAAAQSEGDEDRPGERRRRRAAATAAGAGEDMDESSLLDLLECSVCLERLDTTAKVLPCQHTFCRRCLESIVCSRHELRCPECRILVGCGVDELPANILLVRLLDGIRQRPRAGTSPGGSPPARPIPGQSAAPTLAGGGGGAAGSTPGSPVFLSAAAGSTAGSLRELATSRTAPAAKNPCLLPYGKALYSYEGKEPGDLKFNKGDIIVLRRKVDEQWYHGELHGTQGFLPASYIQCIQPLPHAPPQGKALYDFEMKDKDQDKDCLTFTKDEILTVLRRVDENWAEGMLGDKIGIFPLLYVELNDSAKQLIEMDKPCPAAASSCNASLPSDSGAVASVAPSPTLSSSGAVSAFQRRVDGKKNTKKRHSFTALSVTHRSSQAASHRHSMEISAPVLISSSDPRAAARIGDLAHLSCAAPTQDVSSSAGSTPTAVPRAASVSGEQGTPPKVQLPLNVYLALYAYKPQKSDELELHKGEMYRVLEKCQDGWFKGASLRTGVSGVFPGNYVTPVSRVPAGGAGPPRNNVVGGSPLAKGITTTMHPGSGSLSSLATATRPALPITTPQAHAQHPTASPPTGSCLRHSAQPTASQARSTISTAAHSAAQAQDRPTATVSPLRTQNSPSRLPATSLRPHSVVSPQHSHQPPVQMCPRPAIPLTSAASAITPPNVSAANLNGEAGGGPIGVLSTSSPTNTGCKLDEKKSEKKEKKSGLLKLLAGASTKKKSRSPPSVSPTHDPQVAVDALLQGAVGPEVSSLSIHGRAGSCPIESEMQGAMGMEPLHRKAGSLDLNFTSPSRQAPLSMAAIRPEPKLLPRERYRVVVSYPPQSEAEIELKEGDIVFVHKKREDGWYKGTLQRNGRTGLFPGSFVESF>sp|Q8TAQ2|SMRC2_HUMAN SWI/SNF complex subunit SMARCC2 OS=Homo sapiensOX=9606 GN=SMARCC2 PE=1 SV=1MAVRKKDGGPNVKYYEAADTVTQFDNVRLWLGKNYKKYIQAEPPTNKSLSSLVVQLLQFQEEVFGKHVSNAPLTKLPIKCFLDFKAGGSLCHILAAAYKFKSDQGWRRYDFQNPSRMDRNVEMFMTIEKSLVQNNCLSRPNIFLCPEIEPKLLGKLKDIIKRHQGTVTEDKNNASHVVYPVPGNLEEEEWVRPVMKRDKQVLLHWGYYPDSYDTWIPASEIEASVEDAPTPEKPRKVHAKWILDTDTFNEWMNEEDYEVNDDKNPVSRRKKISAKTLTDEVNSPDSDRRDKKGGNYKKRKRSPSPSPTPEAKKKNAKKGPSTPYTKSKRGHREEEQEDLTKDMDEPSPVPNVEEVTLPKTVNTKKDSESAPVKGGTMTDLDEQEDESMETTGKDEDENSTGNKGEQTKNPDLHEDNVTEQTHHIIIPSYAAWFDYNSVHAIERRALPEFFNGKNKSKTPEIYLAYRNFMIDTYRLNPQEYLTSTACRRNLAGDVCAIMRVHAFLEQWGLINYQVDAESRPTPMGPPPTSHFHVLADTPSGLVPLQPKTPQQTSASQQMLNFPDKGKEKPTDMQNFGLRTDMYTKKNVPSKSKAAASATREWTEQETLLLLEALEMYKDDWNKVSEHVGSRTQDECILHFLRLPIEDPYLEDSEASLGPLAYQPIPFSQSGNPVMSTVAFLASVVDPRVASAAAKSALEEFSKMKEEVPTALVEAHVRKVEEAAKVTGKADPAFGLESSGIAGTTSDEPERIEESGNDEARVEGQATDEKKEPKEPREGGGAIEEEAKEKTSEAPKKDEEKGKEGDSEKESEKSDGDPIVDPEKEKEPKEGQEEVLKEVVESEGERKTKVERDIGEGNLSTAAAAALAAAAVKAKHLAAVEERKIKSLVALLVETQMKKLEIKLRHFEELETIMDREREALEYQRQQLLADRQAFHMEQLKYAEMRARQQHFQQMHQQQQQPPPALPPGSQPIPPTGAAGPPAVHGLAVAPASVVPAPAGSGAPPGSLGPSEQIGQAGSTAGPQQQQPAGAPQPGAVPPGVPPPGPHGPSPFPNQQTPPSMMPGAVPGSGHPGVAGNAPLGLPFGMPPPPPPPAPSIIPFGSLADSISINLPAPPNLHGHHHHLPFAPGTLPPPNLPVSMANPLHPNLPATTTMPSSLPLGPGLGSAAAQSPAIVAAVQGNLLPSASPLPDPGTPLPPDPTAPSPGTVTPVPPPQ>sp|Q8TAQ2-2|SMRC2_HUMAN Isoform 2 of SWI/SNF complex subunit SMARCC2OS=Homo sapiens OX=9606 GN=SMARCC2MAVRKKDGGPNVKYYEAADTVTQFDNVRLWLGKNYKKYIQAEPPTNKSLSSLVVQLLQFQEEVFGKHVSNAPLTKLPIKCFLDFKAGGSLCHILAAAYKFKSDQGWRRYDFQNPSRMDRNVEMFMTIEKSLVQNNCLSRPNIFLCPEIEPKLLGKLKDIIKRHQGTVTEDKNNASHVVYPVPGNLEEEEWVRPVMKRDKQVLLHWGYYPDSYDTWIPASEIEASVEDAPTPEKPRKVHAKWILDTDTFNEWMNEEDYEVNDDKNPVSRRKKISAKTLTDEVNSPDSDRRDKKGGNYKKRKRSPSPSPTPEAKKKNAKKGPSTPYTKSKRGHREEEQEDLTKDMDEPSPVPNVEEVTLPKTVNTKKDSESAPVKGGTMTDLDEQEDESMETTGKDEDENSTGNKGEQTKNPDLHEDNVTEQTHHIIIPSYAAWFDYNSVHAIERRALPEFFNGKNKSKTPEIYLAYRNFMIDTYRLNPQEYLTSTACRRNLAGDVCAIMRVHAFLEQWGLINYQVDAESRPTPMGPPPTSHFHVLADTPSGLVPLQPKTPQGRQVDADTKAGRKGKELDDLVPETAKGKPELQTSASQQMLNFPDKGKEKPTDMQNFGLRTDMYTKKNVPSKSKAAASATREWTEQETLLLLEALEMYKDDWNKVSEHVGSRTQDECILHFLRLPIEDPYLEDSEASLGPLAYQPIPFSQSGNPVMSTVAFLASVVDPRVASAAAKSALEEFSKMKEEVPTALVEAHVRKVEEAAKVTGKADPAFGLESSGIAGTTSDEPERIEESGNDEARVEGQATDEKKEPKEPREGGGAIEEEAKEKTSEAPKKDEEKGKEGDSEKESEKSDGDPIVDPEKEKEPKEGQEEVLKEVVESEGERKTKVERDIGEGNLSTAAAAALAAAAVKAKHLAAVEERKIKSLVALLVETQMKKLEIKLRHFEELETIMDREREALEYQRQQLLADRQAFHMEQLKYAEMRARQQHFQQMHQQQQQPPPALPPGSQPIPPTGAAGPPAVHGLAVAPASVVPAPAGSGAPPGSLGPSEQIGQAGSTAGPQQQQPAGAPQPGAVPPGVPPPGPHGPSPFPNQQTPPSMMPGAVPGSGHPGVADPGTPLPPDPTAPSPGTVTPVPPPQ>sp|Q8TAQ2-3|SMRC2_HUMAN Isoform 3 of SWI/SNF complex subunit SMARCC2OS=Homo sapiens OX=9606 GN=SMARCC2MAVRKKDGGPNVKYYEAADTVTQFDNVRLWLGKNYKKYIQAEPPTNKSLSSLVVQLLQFQEEVFGKHVSNAPLTKLPIKCFLDFKAGGSLCHILAAAYKFKSDQGWRRYDFQNPSRMDRNVEMFMTIEKSLVQNNCLSRPNIFLCPEIEPKLLGKLKDIIKRHQGTVTEDKNNASHVVYPVPGNLEEEEWVRPVMKRDKQVLLHWGYYPDSYDTWIPASEIEASVEDAPTPEKPRKVHAKWILDTDTFNEWMNEEDYEVNDDKNPVSRRKKISAKTLTDEVNSPDSDRRDKKGGNYKKRKRSPSPSPTPEAKKKNAKKGPSTPYTKSKRGHREEEQEDLTKDMDEPSPVPNVEEVTLPKTVNTKKDSESAPVKGGTMTDLDEQEDESMETTGKDEDENSTGNKGEQTKNPDLHEDNVTEQTHHIIIPSYAAWFDYNSVHAIERRALPEFFNGKNKSKTPEIYLAYRNFMIDTYRLNPQEYLTSTACRRNLAGDVCAIMRVHAFLEQWGLINYQVDAESRPTPMGPPPTSHFHVLADTPSGLVPLQPKTPQGRQVDADTKAGRKGKELDDLVPETAKGKPELQTSASQQMLNFPDKGKEKPTDMQNFGLRTDMYTKKNVPSKSKAAASATREWTEQETLLLLEALEMYKDDWNKVSEHVGSRTQDECILHFLRLPIEDPYLEDSEASLGPLAYQPIPFSQSGNPVMSTVAFLASVVDPRVASAAAKSALEEFSKMKEEVPTALVEAHVRKVEEAAKVTGKADPAFGLESSGIAGTTSDEPERIEESGNDEARVEGQATDEKKEPKEPREGGGAIEEEAKEKTSEAPKKDEEKGKEGDSEKESEKSDGDPIVDPEKEKEPKEGQEEVLKEVVESEGERKTKVERDIGEGNLSTAAAAALAAAAVKAKHLAAVEERKIKSLVALLVETQMKKLEIKLRHFEELETIMDREREALEYQRQQLLADRQAFHMEQLKYAEMRARQQHFQQMHQQQQQPPPALPPGSQPIPPTGAAGPPAVHGLAVAPASVVPAPAGSGAPPGSLGPSEQIGQAGSTAGPQQQQPAGAPQPGAVPPGVPPPGPHGPSPFPNQQTPPSMMPGAVPGSGHPGVAAQSPAIVAAVQGNLLPSASPLPDPGTPLPPDPTAPSPGTVTPVPPPQ>sp|Q8NEM7|SP20H_HUMAN Transcription factor SPT20 homolog OS=Homo sapiensOX=9606 GN=SUPT20H PE=1 SV=2MQQALELALDRAEYVIESARQRPPKRKYLSSGRKSVFQKLYDLYIEECEKEPEVKKLRRNVNLLEKLVMQETLSCLVVNLYPGNEGYSLMLRGKNGSDSETIRLPYEEGELLEYLDAEELPPILVDLLEKSQVNIFHCGCVIAEIRDYRQSSNMKSPGYQSRHILLRPTMQTLICDVHSITSDNHKWTQEDKLLLESQLILATAEPLCLDPSIAVTCTANRLLYNKQKMNTRPMKRCFKRYSRSSLNRQQDLSHCPPPPQLRLLDFLQKRKERKAGQHYDLKISKAGNCVDMWKRSPCNLAIPSEVDVEKYAKVEKSIKSDDSQPTVWPAHDVKDDYVFECEAGTQYQKTKLTILQSLGDPLYYGKIQPCKADEESDSQMSPSHSSTDDHSNWFIIGSKTDAERVVNQYQELVQNEAKCPVKMSHSSSGSASLSQVSPGKETDQTETVSVQSSVLGKGVKHRPPPIKLPSSSGNSSSGNYFTPQQTSSFLKSPTPPPSSKPSSIPRKSSVDLNQVSMLSPAALSPASSSQRTTATQVMANSAGLNFINVVGSVCGAQALMSGSNPMLGCNTGAITPAGINLSGLLPSGGLLPNALPSAMQAASQAGVPFGLKNTSSLRPLNLLQLPGGSLIFNTLQQQQQQLSQFTPQQPQQPTTCSPQQPGEQGSEQGSTSQEQALSAQQAAVINLTGVGSFMQSQAAVLSQLGSAENRPEQSLPQQRFQLSSAFQQQQQQIQQLRFLQHQMAMAAAAAQTAQLHHHRHTGSQSKSKMKRGTPTTPKF>sp|Q8NEM7-2|SP20H_HUMAN Isoform 2 of Transcription factor SPT20 homologOS=Homo sapiens OX=9606 GN=SUPT20HMQQALELALDRAEYVIESARQRPPKRKYLSSGRKSVFQKLYDLYIEECEKEPEVKQKLRRNVNLLEKLVMQETLSCLVVNLYPGNEGYSLMLRGKNGSDSETIRLPYEEGELLEYLDAEELPPILVDLLEKSQVNIFHCGCVIAEIRDYRQSSNMKSPGYQSRHILLRPTMQTLICDVHSITSDNHKWTQEDKLLLESQLILATAEPLCLDPSIAVTCTANRLLYNKQKMNTRPMKRCFKRYSRSSLNRQQDLSHCPPPPQLRLLDFLQKRKERKAGQHYDLKISKAGNCVDMWKRSPCNLAIPSEVDVEKYAKVEKSIKSDDSQPTVWPAHDVKDDYVFECEAGTQYQKTKLTILQSLGDPLYYGKIQPCKADEESDSQMSPSHSSTDDHSNWFIIGSKTDAERVVNQYQELVQNEAKCPVKMSHSSSGSASLSQVSPGKETDQTETVSVQSSVLGKGVKHRPPPIKLPSSSGNSSSGNYFTPQQTSSFLKSPTPPPSSKPSSIPRKSSVDLNQVSMLSPAALSPASSSQRTTATQVMANSAGLNFINVVGSVCGAQALMSGSNPMLGCNTGAITPAGINLSGLLPSGGLLPNALPSAMQAASQAGVPFGLKNTSSLRPLNLLQLPGGSLIFNTLQQQQQQLSQFTPQQPQQPTTCSPQQPGEQGSEQGSTSQEQALSAQQAAVINLTGVGSFMQSQAAAVAILAASNGYGSSSSTNSSATSSSAYRQPVKK>sp|Q8NEM7-3|SP20H_HUMAN Isoform 3 of Transcription factor SPT20 homologOS=Homo sapiens OX=9606 GN=SUPT20HMQQALELALDRAEYVIESARQRPPKRKYLSSGRKSVFQKLYDLYIEECEKEPEVKKLRRNVNLLEKLVMQETLSCLVVNLYPGNEGYSLMLRGKNGSDSETIRLPYEEGELLEYLDAEELPPILVDLLEKSQVNIFHCGCVIAEIRDYRQSSNMKSPGYQSRHILLRPTMQTLICDVHSITSDNHKWTQEDKLLLESQLILATAEPLCLDPSIAVTCTANRLLYNKQKMNTRPMKRCFKRYSRSSLNRQQDLSHCPPPPQLRLLDFLQKRKERKAGQHYDLKISKAGNCVDMWKRSPCNLAIPSEVDVEKYAKVEKSIKSDDSQPTVWPAHDVKDDYVFECEAGTQYQKTKLTILQSLGDPLYYGKIQPCKADEESDSQMSPSHSSTDDHSNWFIIGSKTDAERVVNQYQELVQNEAKCPVKMSHSSSGSASLSQVSPGKETDQTETVSVQSSVLGKGVKHRPPPIKLPSSSGNSSSGNYFTPQQTSSFLKSPTPPPSSKPSSIPRKSSVDLNQVSMLSPAALSPASSSQRSGTPKPSTPTPTPSSTPHPPDAQSSTPSTPSATPTPQDSGFTPQPTLLTQFAQQQRSLSQAMPVTTIPLSTMVTSITPGTTATQVMANSAGLNFINVVGSVCGAQALMSGSNPMLGCNTGAITPAGINLSGLLPSGGLLPNALPSAMQAASQAGVPFGLKNTSSLRPLNLLQLPGGSLIFNTLQQQQQQLSQFTPQQPQQPTTCSPQQPGEQGSEQGSTSQEQALSAQQAAVINLTGVGSFMQSQAAAVAILAASNGYGSSSSTNSSATSSSAYRQPVKK>sp|Q96HL8|SH3Y1_HUMAN SH3 domain-containing YSC84-like protein 1 OS=Homosapiens OX=9606 GN=SH3YL1 PE=1 SV=1MNNPIPSNLKSEAKKAAKILREFTEITSRNGPDKIIPAHVIAKAKGLAILSVIKAGFLVTARGGSGIVVARLPDGKWSAPSAIGIAGLGGGFEIGIEVSDLVIILNYDRAVEAFAKGGNLTLGGNLTVAVGPLGRNLEGNVALRSSAAVFTYCKSRGLFAGVSLEGSCLIERKETNRKFYCQDIRAYDILFGDTPRPAQAEDLYEILDSFTEKYENEGQRINARKAAREQRKSSAKELPPKPLSRPQQSSAPVQLNSGSQSNRNEYKLYPGLSSYHERVGNLNQPIEVTALYSFEGQQPGDLNFQAGDRITVISKTDSHFDWWEGKLRGQTGIFPANYVTMN>sp|Q96HL8-2|SH3Y1_HUMAN Isoform 2 of SH3 domain-containing YSC84-likeprotein 1 OS=Homo sapiens OX=9606 GN=SH3YL1MNNPIPSNLKSEAKKAAKILREFTEITSRNGPDKIIPAHVIAKAKGLAILSVIKAGFLVTARGGSGIVVARLPDGKWSAPSAIGIAGLGGGFEIGIEVSDLVIILNYDRAVEAFAKGGNLTLGGNLTVAVGPLGRNLEGNVALRSSAAVFTYCKSRGLFAGVSLEGSCLIERKETNRKFYCQDIRAYDILFGDTPRPAQAEDLYEILDSFTEKYENEGQRINARKAAREQRKSSAKELPPKPLSRPQQSSAPVQLNSGSQSNLNQPIEVTALYSFEGQQPGDLNFQAGDRITVISKTDSHFDWWEGKLRGQTGIFPANYVTMN>sp|Q96HL8-3|SH3Y1_HUMAN Isoform 3 of SH3 domain-containing YSC84-likeprotein 1 OS=Homo sapiens OX=9606 GN=SH3YL1MVSDLVIILNYDRAVEAFAKGGNLTLGGNLTVAVGPLGRNLEGNVALRSSAAVFTYCKSRGLFAGVSLEGSCLIERKETNRKFYCQDIRAYDILFGDTPRPAQAEDLYEILDSFTEKYENEGQRINARKAAREQRKSSAKELPPKPLSRPQQSSAPVQLNSGSQSNRNEYKLYPGLSSYHERVGNLNQPIEVTALYSFEGQQPGDLNFQAGDRITVISKTDSHFDWWEGKLRGQTGIFPANYVTMN>sp|Q96HL8-4|SH3Y1_HUMAN Isoform 4 of SH3 domain-containing YSC84-likeprotein 1 OS=Homo sapiens OX=9606 GN=SH3YL1MVSDLVIILNYDRAVEAFAKGGNLTLGGNLTVAVGPLGRNLEGNVALRSSAAVFTYCKSRGLFAGVSLEGSCLIERKETNRKFYCQDIRAYDILFGDTPRPAQAEDLYEILDSFTEKYENEGQRINARKAAREQRKSSAKELPPKPLSRPQQSSAPVQLNSGSQSNLNQPIEVTALYSFEGQQPGDLNFQAGDRITVISKTDSHFDWWEGKLRGQTGIFPANYVTMN>sp|Q96HL8-5|SH3Y1_HUMAN Isoform 5 of SH3 domain-containing YSC84-likeprotein 1 OS=Homo sapiens OX=9606 GN=SH3YL1MNNPIPSNLKSEAKKAAKILREFTEITSRNGPDKIIPAHVIAKAKGLAILSVIKAGFLVTARGGSGIVVARLPDGKWSAPSAIGIAGLGGGFEIGIETHLQLHIPSEHCPGCLP>sp|Q6PDA7|SG11A_HUMAN Sperm-associated antigen 11A OS=Homo sapiensOX=9606 GN=SPAG11A PE=2 SV=3MRQRLLPSVTSLLLVALLFPGSSQARHVNHSATEALGELRERAPGQGTNGFQLLRHAVKRDLLPPRTPPYQVHISHQEARGPSFKICVGFLGPRWARGCSTGNEKYHLPYAARDLQTFFLPFW>sp|Q6PDA7-2|SG11A_HUMAN Isoform 2 of Sperm-associated antigen 11AOS=Homo sapiens OX=9606 GN=SPAG11AMRQRLLPSVTSLLLVALLFPGSSQARHVNHSATEALGELRERAPGQGTNGFQLLRHAVKRDLLPPRTPPYQGDVPLGIRNTICHMQQGICRLFFCHSGTGQQHRQRCG>sp|Q6PDA7-3|SG11A_HUMAN Isoform 3 of Sperm-associated antigen 11AOS=Homo sapiens OX=9606 GN=SPAG11AMRQRLLPSVTSLLLVALLFPGSSQARHVNHSATEALGELRERAPGQGTNGFQLLRHAVKRDLLPPRTPPYQGTGQQHRQRCG>sp|Q6PDA7-4|SG11A_HUMAN Isoform 4 of Sperm-associated antigen 11AOS=Homo sapiens OX=9606 GN=SPAG11AMRQRLLPSVTSLLLVALLFPGSSQARHVNHSATEALGELRERAPGQGTNGFQLLRHAVKRDLLPPRTPPYQEMK>sp|Q92922|SMRC1_HUMAN SWI/SNF complex subunit SMARCC1 OS=Homo sapiensOX=9606 GN=SMARCC1 PE=1 SV=3MAAAAGGGGPGTAVGATGSGIAAAAAGLAVYRRKDGGPATKFWESPETVSQLDSVRVWLGKHYKKYVHADAPTNKTLAGLVVQLLQFQEDAFGKHVTNPAFTKLPAKCFMDFKAGGALCHILGAAYKYKNEQGWRRFDLQNPSRMDRNVEMFMNIEKTLVQNNCLTRPNIYLIPDIDLKLANKLKDIIKRHQGTFTDEKSKASHHIYPYSSSQDDEEWLRPVMRKEKQVLVHWGFYPDSYDTWVHSNDVDAEIEDPPIPEKPWKVHVKWILDTDIFNEWMNEEDYEVDENRKPVSFRQRISTKNEEPVRSPERRDRKASANARKRKHSPSPPPPTPTESRKKSGKKGQASLYGKRRSQKEEDEQEDLTKDMEDPTPVPNIEEVVLPKNVNLKKDSENTPVKGGTVADLDEQDEETVTAGGKEDEDPAKGDQSRSVDLGEDNVTEQTNHIIIPSYASWFDYNCIHVIERRALPEFFNGKNKSKTPEIYLAYRNFMIDTYRLNPQEYLTSTACRRNLTGDVCAVMRVHAFLEQWGLVNYQVDPESRPMAMGPPPTPHFNVLADTPSGLVPLHLRSPQVPAAQQMLNFPEKNKEKPVDLQNFGLRTDIYSKKTLAKSKGASAGREWTEQETLLLLEALEMYKDDWNKVSEHVGSRTQDECILHFLRLPIEDPYLENSDASLGPLAYQPVPFSQSGNPVMSTVAFLASVVDPRVASAAAKAALEEFSRVREEVPLELVEAHVKKVQEAARASGKVDPTYGLESSCIAGTGPDEPEKLEGAEEEKMEADPDGQQPEKAENKVENETDEGDKAQDGENEKNSEKEQDSEVSEDTKSEEKETEENKELTDTCKERESDTGKKKVEHEISEGNVATAAAAALASAATKAKHLAAVEERKIKSLVALLVETQMKKLEIKLRHFEELETIMDREKEALEQQRQQLLTERQNFHMEQLKYAELRARQQMEQQQHGQNPQQAHQHSGGPGLAPLGAAGHPGMMPHQQPPPYPLMHHQMPPPHPPQPGQIPGPGSMMPGQHMPGRMIPTVAANIHPSGSGPTPPGMPPMPGNILGPRVPLTAPNGMYPPPPQQQPPPPPPADGVPPPPAPGPPASAAP>sp|P61278|SMS_HUMAN Somatostatin OS=Homo sapiens OX=9606 GN=SST PE=1SV=1MLSCRLQCALAALSIVLALGCVTGAPSDPRLRQFLQKSLAAAAGKQELAKYFLAELLSEPNQTENDALEPEDLSQAAEQDEMRLELQRSANSNPAMAPRERKAGCKNFFWKTFTSC>sp|Q8TDD2|SP7_HUMAN Transcription factor Sp7 OS=Homo sapiens OX=9606GN=SP7 PE=1 SV=1MASSLLEEEVHYGSSPLAMLTAACSKFGGSSPLRDSTTLGKAGTKKPYSVGSDLSASKTMGDAYPAPFTSTNGLLSPAGSPPAPTSGYANDYPPFSHSFPGPTGTQDPGLLVPKGHSSSDCLPSVYTSLDMTHPYGSWYKAGIHAGISPGPGNTPTPWWDMHPGGNWLGGGQGQGDGLQGTLPTGPAQPPLNPQLPTYPSDFAPLNPAPYPAPHLLQPGPQHVLPQDVYKPKAVGNSGQLEGSGGAKPPRGASTGGSGGYGGSGAGRSSCDCPNCQELERLGAAAAGLRKKPIHSCHIPGCGKVYGKASHLKAHLRWHTGERPFVCNWLFCGKRFTRSDELERHVRTHTREKKFTCLLCSKRFTRSDHLSKHQRTHGEPGPGPPPSGPKELGEGRSTGEEEASQTPRPSASPATPEKAPGGSPEQSNLLEI>sp|Q8TDD2-2|SP7_HUMAN Isoform 2 of Transcription factor Sp7 OS=Homosapiens OX=9606 GN=SP7MLTAACSKFGGSSPLRDSTTLGKAGTKKPYSVGSDLSASKTMGDAYPAPFTSTNGLLSPAGSPPAPTSGYANDYPPFSHSFPGPTGTQDPGLLVPKGHSSSDCLPSVYTSLDMTHPYGSWYKAGIHAGISPGPGNTPTPWWDMHPGGNWLGGGQGQGDGLQGTLPTGPAQPPLNPQLPTYPSDFAPLNPAPYPAPHLLQPGPQHVLPQDVYKPKAVGNSGQLEGSGGAKPPRGASTGGSGGYGGSGAGRSSCDCPNCQELERLGAAAAGLRKKPIHSCHIPGCGKVYGKASHLKAHLRWHTGERPFVCNWLFCGKRFTRSDELERHVRTHTREKKFTCLLCSKRFTRSDHLSKHQRTHGEPGPGPPPSGPKELGEGRSTGEEEASQTPRPSASPATPEKAPGGSPEQSNLLEI>sp|Q96GM5|SMRD1_HUMAN SWI/SNF-related matrix-associated actin-dependentregulator of chromatin subfamily D member 1 OS=Homo sapiens OX=9606GN=SMARCD1 PE=1 SV=2MAARAGFQSVAPSGGAGASGGAGAAAALGPGGTPGPPVRMGPAPGQGLYRSPMPGAAYPRPGMLPGSRMTPQGPSMGPPGYGGNPSVRPGLAQSGMDQSRKRPAPQQIQQVQQQAVQNRNHNAKKKKMADKILPQRIRELVPESQAYMDLLAFERKLDQTIMRKRLDIQEALKRPIKQKRKLRIFISNTFNPAKSDAEDGEGTVASWELRVEGRLLEDSALSKYDATKQKRKFSSFFKSLVIELDKDLYGPDNHLVEWHRTATTQETDGFQVKRPGDVNVRCTVLLMLDYQPPQFKLDPRLARLLGIHTQTRPVIIQALWQYIKTHKLQDPHEREFVICDKYLQQIFESQRMKFSEIPQRLHALLMPPEPIIINHVISVDPNDQKKTACYDIDVEVDDTLKTQMNSFLLSTASQQEIATLDNKIHETIETINQLKTQREFMLSFARDPQGFINDWLQSQCRDLKTMTDVVGNPEEERRAEFYFQPWAQEAVCRYFYSKVQQRRQELEQALGIRNT>sp|Q96GM5-2|SMRD1_HUMAN Isoform 2 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily D member 1 OS=Homosapiens OX=9606 GN=SMARCD1MAARAGFQSVAPSGGAGASGGAGAAAALGPGGTPGPPVRMGPAPGQGLYRSPMPGAAYPRPGMLPGSRMTPQGPSMGPPGYGGNPSVRPGLAQSGMDQSRKRPAPQQIQQVQQQAVQNRNHNAKKKKMADKILPQRIRELVPESQAYMDLLAFERKLDQTIMRKRLDIQEALKRPIKQKRKLRIFISNTFNPAKSDAEDGEGTVASWELRVEGRLLEDSALSKYDATKQKRKFSSFFKSLVIELDKDLYGPDNHLVEWHRTATTQETDGFQVKRPGDVNVRCTVLLMLDYQPPQFKLDPRLARLLGIHTQTRPVIIQALWQYIKTHKLQDPHEREFVICDKYLQQIFESQRMKFSEIPQRLHALLMPPEPIIINHVISVDPNDQKKTACYDIDVEVDDTLKTQMNSFLLSTASQQEIATLDNKTMTDVVGNPEEERRAEFYFQPWAQEAVCRYFYSKVQQRRQELEQALGIRNT>sp|Q8NDV3|SMC1B_HUMAN Structural maintenance of chromosomes protein 1BOS=Homo sapiens OX=9606 GN=SMC1B PE=2 SV=2MAHLELLLVENFKSWRGRQVIGPFRRFTCIIGPNGSGKSNVMDALSFVMGEKIANLRVKNIQELIHGAHIGKPISSSASVKIIYVEESGEEKTFARIIRGGCSEFRFNDNLVSRSVYIAELEKIGIIVKAQNCLVFQGTVESISVKKPKERTQFFEEISTSGELIGEYEEKKRKLQKAEEDAQFNFNKKKNIAAERRQAKLEKEEAERYQSLLEELKMNKIQLQLFQLYHNEKKIHLLNTKLEHVNRDLSVKRESLSHHENIVKARKKEHGMLTRQLQQTEKELKSVETLLNQKRPQYIKAKENTSHHLKKLDVAKKSIKDSEKQCSKQEDDIKALETELADLDAAWRSFEKQIEEEILHKKRDIELEASQLDRYKELKEQVRKKVATMTQQLEKLQWEQKTDEERLAFEKRRHGEVQGNLKQIKEQIEDHKKRIEKLEEYTKTCMDCLKEKKQQEETLVDEIEKTKSRMSEFNEELNLIRSELQNAGIDTHEGKRQQKRAEVLEHLKRLYPDSVFGRLFDLCHPIHKKYQLAVTKVFGRFITAIVVASEKVAKDCIRFLKEERAEPETFLALDYLDIKPINERLRELKGCKMVIDVIKTQFPQLKKVIQFVCGNGLVCETMEEARHIALSGPERQKTVALDGTLFLKSGVISGGSSDLKYKARCWDEKELKNLRDRRSQKIQELKGLMKTLRKETDLKQIQTLIQGTQTRLKYSQNELEMIKKKHLVAFYQEQSQLQSELLNIESQCIMLSEGIKERQRRIKEFQEKIDKVEDDIFQHFCEEIGVENIREFENKHVKRQQEIDQKRYFYKKMLTRLNVQLEYSRSHLKKKLNKINTLKETIQKGSEDIDHLKKAEENCLQTVNELMAKQQQLKDIRVTQNSSAEKVQTQIEEERKKFLAVDREVGKLQKEVVSIQTSLEQKRLEKHNLLLDCKVQDIEIILLSGSLDDIIEVEMGTEAESTQATIDIYEKEEAFEIDYSSLKEDLKALQSDQEIEAHLRLLLQQVASQEDILLKTAAPNLRALENLKTVRDKFQESTDAFEASRKEARLCRQEFEQVKKRRYDLFTQCFEHVSISIDQIYKKLCRNNSAQAFLSPENPEEPYLEGISYNCVAPGKRFMPMDNLSGGEKCVAALALLFAVHSFRPAPFFVLDEVDAALDNTNIGKVSSYIKEQTQDQFQMIVISLKEEFYSRADALIGIYPEYDDCMFSRVLTLDLSQYPDTEGQESSKRHGESR>sp|Q8NDV3-2|SMC1B_HUMAN Isoform 2 of Structural maintenance ofchromosomes protein 1B OS=Homo sapiens OX=9606 GN=SMC1BMAHLELLLVENFKSWRGRQVIGPFRRFTCIIGPNGSGKSNVMDALSFVMGEKIANLRVKNIQELIHGAHIGKPISSSASVKIIYVEESGEEKTFARIIRGGCSEFRFNDNLVSRSVYIAELEKIGIIVKAQNCLVFQGTVESISVKKPKERTQFFEEISTSGELIGEYEEKKRKLQKAEEDAQFNFNKKKNIAAERRQAKLEKEEAERYQSLLEELKMNKIQLQLFQLYHNEKKIHLLNTKLEHVNRDLSVKRESLSHHENIVKARKKEHGMLTRQLQQTEKELKSVETLLNQKRPQYIKAKENTSHHLKKLDVAKKSIKDSEKQCSKQEDDIKALETELADLDAAWRSFEKQIEEEILHKKRDIELEASQLDRYKELKEQVRKKVATMTQQLEKLQWEQKTDEERLAFEKRRHGEVQGNLKQIKEQIEDHKKRIEKLEEYTKTCMDCLKEKKQQEETLVDEIEKTKSRMSEFNEELNLIRSELQNAGIDTHEGKRQQKRAEVLEHLKRLYPDSVFGRLFDLCHPIHKKYQLAVTKVFGRFITAIVVASEKVAKDCIRFLKEERAEPETFLALDYLDIKPINERLRELKGCKMVIDVIKTQFPQLKKVIQFVCGNGLVCETMEEARHIALSGPERQKTVALDGTLFLKSGVISGGSSDLKYKARCWDEKELKNLRDRRSQKIQELKGLMKTLRKETDLKQIQTLIQGTQTRLKYSQNELEMIKKKHLVAFYQEQSQLQSELLNIESQCIMLSEGIKERQRRIKEFQEKIDKVEDDIFQHFCEEIGVENIREFENKHVKRQQEIDQKRLEFEKQKTRLNVQLEYSRSHLKKKLNKINTLKETIQKGSEDIDHLKKAEENCLQTVNELMAKQQQLKDIRVTQNSSAEKVQTQIEEERKKFLAVDREVGKLQKEVVSIQTSLEQKRLEKHNLLLDCKVQDIEIILLSGSLDDIIEVEMGTEAESTQATIDIYEKEEAFEIDYSSLKEDLKALQSDQEIEAHLRLLLQQVASQEDILLKTAAPNLRALENLKTVRDKFQESTDAFEASRKEARLCRQEFEQVKKRRYDLFTQCFEHVSISIDQIYKKLCRNNSAQVSSYIKEQTQDQFQMIVISLKEEFYSRADALIGIYPEYDDCMFSRVLTLDLSQYPDTEGQESSKRHGESR>sp|Q8NDV3-3|SMC1B_HUMAN Isoform 3 of Structural maintenance ofchromosomes protein 1B OS=Homo sapiens OX=9606 GN=SMC1BMAHLELLLVENFKSWRGRQVIGPFRRFTCIIGPNGSGKSNVMDALSFVMGEKIANLRVKNIQELIHGAHIGKPISSSASVKIIYVEESGEEKTFARIIRGGCSEFRFNDNLVSRSVYIAELEKIGIIVKAQNCLVFQGTVESISVKKPKERTQFFEEISTSGELIGEYEEKKRKLQKAEEDAQFNFNKKKNIAAERRQAKLEKEEAERYQSLLEELKMNKIQLQLFQLYHNEKKIHLLNTKLEHVNRDLSVKRESLSHHENIVKARKKEHGMLTRQLQQTEKELKSVETLLNQKRPQYIKAKENTSHHLKKLDVAKKSIKDSEKQCSKQEDDIKALETELADLDAAWRSFEKQIEEEILHKKRDIELEASQLDRYKELKEQVRKKVATMTQQLEKLQWEQKTDEERLAFEKRRHGEVQGNLKQIKEQIEDHKKRIEKLEEYTKTCMDCLKEKKQQEETLVDEIEKTKSRMSEFNEELNLIRSELQNAGIDTHEGKRQQKRAEVLEHLKRLYPDSVFGRLFDLCHPIHKKYQLAVTKVFGRFITAIVVASEKVAKDCIRFLKEERAEPETFLALDYLDIKPINERLRELKGCKMVIDVIKTQFPQLKKVIQFVCGNGLVCETMEEARHIALSGPERQKTVALDGTLFLKSGVISGGSSDLKYKARCWDEKELKNLRDRRSQKIQELKGLMKTLRKETDLKQIQTLIQGTQTRLKYSQNELEMIKKKHLVAFYQEQSQLQSELLNIESQCIMLSEGIKERQRRIKEFQEKIDKVEDDIFQHFCEEIGVENIREFENKHVKRQQEIDQKRLEFEKQKTRLNVQLEYSRSHLKKKLNKINTLKETIQKGSEDIDHLKKAEENCLQTVNELMAKQQQLKDIRVTQNSSAEKVQTQIEEERKKFLAVDREVGKLQKEVVSIQTSLEQKRLEKHNLLLDCKVQDIEIILLSGSLDDIIEVEMGTEAESTQATIDIYEKEEAFEIDYSSLKEDLKALQSDQEIEAHLRLLLQQVASQEDILLKTAAPNLRALENLKTVRDKFQESTDAFEASRKEARLCRQEFEQVKKRRYDLFTQCFEHVSISIDQIYKKLCRNNSAQAFLSPENPEEPYLEGISYNCVAPGKRFMPMDNLSGGEKCVAALALLFAVHSFRPAPFFVLDEVDAALDNTNIGKVSSYIKEQTQDQFQMIVISLKEEFYSRADALIGIYPEYDDCMFSRVLTLDLSQYPDTEGQESSKRHGESR>sp|A0A1B0GUW6|SPEM3_HUMAN Uncharacterized protein SPEM3 OS=Homo sapiensOX=9606 GN=SPEM3 PE=3 SV=1MGERAYHGAQVCSGTNPRKCQDLGDSILLLLGSFILLNVWINVVTLLWKHLKSSLRILFRHFFPKDKQPSGSHPICICSSVDPKNLCSKVSSRVHPRPGFLLRRVNHLDSWIPDTNDEKVSACCCVPPKCGHAGVPRESARGLYKAGMMGGGEAPQVTASKAQASLLSRPETSSQFPKMSKLDTGPCHLPQESKTKTPDCAPAEAPAQAQVHSPTHTPVCTPTHPWTRSTDHTAVHTPAHSWTHSKARTPEGTHSQAQDTSAQAQAHTSAPTPAQTPAHIQAHTPAPTPAKASAHTKAHTSAQAQTHSPPHTPEYTHSQAHSPEHTSAHSPAQAPMPVPAHPQAHAPEYTSAHAPAYIPDHSHLVRSSVPVPTSAPAPPGTLAPATTPVLAPTPAPVPASAPSPAPALVMALTTTPVPDPVPATTPAPIITPIPSTPPAFSHDLSTGHVVYDARREKQNFFHMSSPQNPEYSRKDLATLFRPQEGQDLVSSGISEQTKQCSGDSAKLPAGSILGYLELRNMEWKNSDDAKDKFPQTKTSPYCSFHPCSSEKNTDSQAPFYPKFLAYSRDTACAKTCFHSATTAQSSVCTLPPPFTLSLPLVPPRSFVPPQPTNHQRPSTLIQTPTVLPTSKSPQSILTSQFPIPSLFATISQPLIQPQCPECHESLGLTQDSGLQRTPGPSKDSRVPRNLDLAQNPDLYKNPGLTQDPGLHENPGLAPNQGLHEFPGLPQDSYLCQNPSPSQDFGLHKNSGITQDSHPQKNTGLTQEAGILRSPCLTQSPGLHKKTPFTQTSDLQRSSGFTQDSGIYRNLEPNQETVIYKNQDLSQATDHQKNLGSSKDSGGHKNTGNVQDPGVCSTAGLTEDSGSQKGPYVPQDSEVNKSSGVIQESFLHKSPGLVQTSGLPKCSGLTQNSGDYKNPGLIQDCGGHKVKGLTQDSNLPSLTQATKVERRFSLPQDVGVYRSSEHSQDSNLHKCPGINQDPGPHKDPALVQDSGLPKISGLTQESGPYKSSCLIPDPSLYKNPSPALGSDFVQLLSLLQTPKSTLSLMKSSVPEKAAQKEDAQRHVLWARVQLNENSCPSKAQVVSNDLQTFSEVPVLIELQSSSWRAGSQHGAYRPVDTVPSGYQNYRQMSMPTHINWKSHCPGPGTQAGHVVFDARQRRLAVGKDKCEALSPRRLHQEAPSNSGKPSRSGDIRM>sp|P22531|SPR2E_HUMAN Small proline-rich protein 2E OS=Homo sapiensOX=9606 GN=SPRR2E PE=2 SV=2MSYQQQQCKQPCQPPPVCPTPKCPEPCPPPKCPEPCPPPKCPQPCPPQQCQQKCPPVTPSPPCQPKCPPKSK>sp|Q99865|SPI2A_HUMAN Spindlin-2A OS=Homo sapiens OX=9606 GN=SPIN2A PE=1SV=3MKTPNAQEAEGQQTRAAAGRATGSANMTKKKVSQKKQRGRPSSQPRRNIVGCRISHGWKEGDEPITQWKGTVLDQVPINPSLYLVKYDGIDCVYGLELHRDERVLSLKILSDRVASSHISDANLANTIIGKAVEHMFEGEHGSKDEWRGMVLAQAPIMKAWFYITYEKDPVLYMYQLLDDYKEGDLRIMPESSESPPTEREPGGVVDGLIGKHVEYTKEDGSKRIGMVIHQVETKPSVYFIKFDDDFHIYVYDLVKKS>sp|P35326|SPR2A_HUMAN Small proline-rich protein 2A OS=Homo sapiensOX=9606 GN=SPRR2A PE=1 SV=1MSYQQQQCKQPCQPPPVCPTPKCPEPCPPPKCPEPCPPPKCPQPCPPQQCQQKYPPVTPSPPCQSKYPPKSK>sp|Q658P3|STEA3_HUMAN Metalloreductase STEAP3 OS=Homo sapiens OX=9606GN=STEAP3 PE=1 SV=2MPEEMDKPLISLHLVDSDSSLAKVPDEAPKVGILGSGDFARSLATRLVGSGFKVVVGSRNPKRTARLFPSAAQVTFQEEAVSSPEVIFVAVFREHYSSLCSLSDQLAGKILVDVSNPTEQEHLQHRESNAEYLASLFPTCTVVKAFNVISAWTLQAGPRDGNRQVPICGDQPEAKRAVSEMALAMGFMPVDMGSLASAWEVEAMPLRLLPAWKVPTLLALGLFVCFYAYNFVRDVLQPYVQESQNKFFKLPVSVVNTTLPCVAYVLLSLVYLPGVLAAALQLRRGTKYQRFPDWLDHWLQHRKQIGLLSFFCAALHALYSFCLPLRRAHRYDLVNLAVKQVLANKSHLWVEEEVWRMEIYLSLGVLALGTLSLLAVTSLPSIANSLNWREFSFVQSSLGFVALVLSTLHTLTYGWTRAFEESRYKFYLPPTFTLTLLVPCVVILAKALFLLPCISRRLARIRRGWERESTIKFTLPTDHALAEKTSHV>sp|Q658P3-2|STEA3_HUMAN Isoform 2 of Metalloreductase STEAP3 OS=Homosapiens OX=9606 GN=STEAP3MSHQPAVATKMPEEMDKPLISLHLVDSDSSLAKVPDEAPKVGILGSGDFARSLATRLVGSGFKVVVGSRNPKRTARLFPSAAQVTFQEEAVSSPEVIFVAVFREHYSSLCSLSDQLAGKILVDVSNPTEQEHLQHRESNAEYLASLFPTCTVVKAFNVISAWTLQAGPRDGNRQVPICGDQPEAKRAVSEMALAMGFMPVDMGSLASAWEVEAMPLRLLPAWKVPTLLALGLFVCFYAYNFVRDVLQPYVQESQNKFFKLPVSVVNTTLPCVAYVLLSLVYLPGVLAAALQLRRGTKYQRFPDWLDHWLQHRKQIGLLSFFCAALHALYSFCLPLRRAHRYDLVNLAVKQVLANKSHLWVEEEVWRMEIYLSLGVLALGTLSLLAVTSLPSIANSLNWREFSFVQSSLGFVALVLSTLHTLTYGWTRAFEESRYKFYLPPTFTLTLLVPCVVILAKALFLLPCISRRLARIRRGWERESTIKFTLPTDHALAEKTSHV>sp|Q658P3-3|STEA3_HUMAN Isoform 3 of Metalloreductase STEAP3 OS=Homosapiens OX=9606 GN=STEAP3MPEEMDKPLISLHLVDSDSSLAKVPDEAPKVGILGSGDFARSLATRLVGSGFKVVVGSRNPKRTARLFPSAAQVTFQEEAVSSPEVIFVAVFREHYSSLCSLSDQLAGKILVDVSNPTEQEHLQHRESNAEYLASLFPTCTVVKAFNVISAWTLQAGPRDGNRQVPICGDQPEAKRAVSEMALAMGFMPVDMGSLASAWEVEAMPLRLLPAWKVPTLLALGLFVCFYAYNFVRDVLQPYVQESQNKFFKLPVSVVNTTLPCVAYVLLSLVYLPGVLAAALQLRRGTKYQRFPDWLDHWLQHRKQIGLLSFFCAALHALYSFCLPLRRAHRYDLVNLAVKQVLANKSHLWVEEVWRMEIYLSLGVLALGTLSLLAVTSLPSIANSLNWREFSFVQSSLGFVALVLSTLHTLTYGWTRAFEESRYKFYLPPTFTLTLLVPCVVILAKALFLLPCISRRLARIRRGWERESTIKFTLPTDHALAEKTSHV>sp|Q658P3-4|STEA3_HUMAN Isoform 4 of Metalloreductase STEAP3 OS=Homosapiens OX=9606 GN=STEAP3MPEEMDKPLISLHLVDSDSSLAKVPDEAPKVGILGSGDFARSLATRLVGSGFKVVVGSRNPKRTARLFPSAAQVTFQEEAVSSPEVIFVAVFREHYSSLCSLSDQLAGKILVDVSNPTEQEHLQHRESNAEYLASLFPTCTVVKAFNVISAWTLQAGPRDGNRQVPICGDQPEAKRAVSEMALAMGFMPVDMGSLASAWEVEAMPLRLLPAWKVPTLLALGLFVCFYAYNFVRDVLQPYVQESQNKFFKLPVSVVNTTLPCVAYVLLSLVYLPGVLAAALQLRRGTKYQRFPDWLDHWLQHRKQIGLLSFFCAALHALYSFCLPLRRAHRYDLVNLAVKQVLANKSHLWVEEVWRMEIYLSLGVLALGTLSLLAVTSLPSIANSLNWREFSFVQCVATSSAGNTGSGTRRPESQSQDPHLPAPHHQTSFLGPRSFCCSLVPVSTPYGHQEDLSWTR>sp|Q8TCT7|SPP2B_HUMAN Signal peptide peptidase-like 2B OS=Homo sapiensOX=9606 GN=SPPL2B PE=1 SV=2MAAAVAAALARLLAAFLLLAAQVACEYGMVHVVSQAGGPEGKDYCILYNPQWAHLPHDLSKASFLQLRNWTASLLCSAADLPARGFSNQIPLVARGNCTFYEKVRLAQGSGARGLLIVSRERLVPPGGNKTQYDEIGIPVALLSYKDMLDIFTRFGRTVRAALYAPKEPVLDYNMVIIFIMAVGTVAIGGYWAGSRDVKKRYMKHKRDDGPEKQEDEAVDVTPVMTCVFVVMCCSMLVLLYYFYDLLVYVVIGIFCLASATGLYSCLAPCVRRLPFGKCRIPNNSLPYFHKRPQARMLLLALFCVAVSVVWGVFRNEDQWAWVLQDALGIAFCLYMLKTIRLPTFKACTLLLLVLFLYDIFFVFITPFLTKSGSSIMVEVATGPSDSATREKLPMVLKVPRLNSSPLALCDRPFSLLGFGDILVPGLLVAYCHRFDIQVQSSRVYFVACTIAYGVGLLVTFVALALMQRGQPALLYLVPCTLVTSCAVALWRRELGVFWTGSGFAKVLPPSPWAPAPADGPQPPKDSATPLSPQPPSEEPATSPWPAEQSPKSRTSEEMGAGAPMREPGSPAESEGRDQAQPSPVTQPGASA>sp|Q8TCT7-2|SPP2B_HUMAN Isoform 2 of Signal peptide peptidase-like 2BOS=Homo sapiens OX=9606 GN=SPPL2BMAAAVAAALARLLAAFLLLAAQVACEYGMVHVVSQAGGPEGKDYCILYNPQWAHLPHDLSKASFLQLRNWTASLLCSAADLPARGFSNQIPLVARGNCTFYEKVRLAQGSGARGLLIVSRERLVPPGGNKTQYDEIGIPVALLSYKDMLDIFTRFGRTVRAALYAPKEPVLDYNMVIIFIMAVGTVAIGGYWAGSRDVKKRYMKHKRDDGPEKQEDEAVDVTPVMTCVFVVMCCSMLVLLYYFYDLLVYVVIGIFCLASATGLYSCLAPCVRRLPFGKCRIPNNSLPYFHKRPQARMLLLALFCVAVSVVWGVFRNEDQ>sp|Q8TCT7-4|SPP2B_HUMAN Isoform 4 of Signal peptide peptidase-like 2BOS=Homo sapiens OX=9606 GN=SPPL2BMAAAVAAALARLLAAFLLLAAQVACEYGMVHVVSQAGGPEGKDYCILYNPQWAHLPHDLSKASFLQLRNWTASLLCSAADLPARGFSNQIPLVARGNCTFYEKVRLAQGSGARGLLIVSRERLVPPGGNKTQYDEIGIPVALLSYKDMLDIFTRFGRTVRAALYAPKEPVLDYNMVIIFIMAVGTVAIGGYWAGSRDVKKRYMKHKRDDGPEKQEDEAVDVTPVMTCVFVVMCCSMLVLLYYFYDLLVYVVIGIFCLASATGLYSCLAPCVRRLPFGKCRIPNNSLPYFHKRPQARMLLLALFCVAVSVVWGVFRNEDQWAWVLQDALGIAFCLYMLKTIRLPTFKACTLLLLVLFLYDIFFVFITPFLTKSGSSIMVEVATGPSDSATREKLPMVLKVPRLNSSPLALCDRPFSLLGFGDILVPGLLVAYCHRFDIQVQSSRVYFVACTIAYGVGLLVTFVALALMQRGQPALLYLVPCTLVTSCAVALWRRELGVFWTGSGFAVNTSLL>sp|P0DMP2|SRG2B_HUMAN SLIT-ROBO Rho GTPase-activating protein 2B OS=Homosapiens OX=9606 GN=SRGAP2B PE=3 SV=1MTSPAKFKKDKEIIAEYDTQVKEIRAQLTEQMKCLDQQCELRVQLLQDLQDFFRKKAEIEMDYSRNLEKLAERFLAKTCSTKDQQFKKDQNVLSPVNCWNLLLNQVKRESRDHTTLSDIYLNNIIPRFVQVSEDSGRLFKKSKEVGQQLQDDLMKVLNELYSVMKTYHMYNADSISAQSKLKEAEKQEEKQIGKSVKQEDRQTPRSPDSTANVRIEEKHVRRSSVKKIEKMKEKRQAKYTENKLKAIKARNEYLLALEATNASVFKYYIHDLSDLIDCCDLGYHASLNRALRTFLSAELNLEQSKHEGLDAIENAVENLDATSDKQRLMEMYNNVFCPPMKFEFQPHMGDMASQLCAQQPVQSELLQRCQQLQSRLSTLKIENEEVKKTMEATLQTIQDIVTVEDFDVSDCFQYSNSMESVKSTVSETFMSKPSIAKRRANQQETEQFYFTVRECYGF>sp|Q9UHE8|STEA1_HUMAN Metalloreductase STEAP1 OS=Homo sapiens OX=9606GN=STEAP1 PE=1 SV=1MESRKDITNQEELWKMKPRRNLEEDDYLHKDTGETSMLKRPVLLHLHQTAHADEFDCPSELQHTQELFPQWHLPIKIAAIIASLTFLYTLLREVIHPLATSHQQYFYKIPILVINKVLPMVSITLLALVYLPGVIAAIVQLHNGTKYKKFPHWLDKWMLTRKQFGLLSFFFAVLHAIYSLSYPMRRSYRYKLLNWAYQQVQQNKEDAWIEHDVWRMEIYVSLGIVGLAILALLAVTSIPSVSDSLTWREFHYIQSKLGIVSLLLGTIHALIFAWNKWIDIKQFVWYTPPTFMIAVFLPIVVLIFKSILFLPCLRKKILKIRHGWEDVTKINKTEICSQL>sp|Q6Q759|SPG17_HUMAN Sperm-associated antigen 17 OS=Homo sapiensOX=9606 GN=SPAG17 PE=2 SV=1MAPKKEKGGTVNTSSKIWEPSLIAAQFNQNDWQASIAFVVGNQIEDDLLIQALTVAVQVPQRKLFSMVSWQDILQQINEINTLVGSASSKKAKKPVGGNAPLYYEVLTAAKAIMDSGEKLTLPLIGKLLKFQLLQIKFKDQQRRENEKKVIEDKPKLEKDKGKAKSPKEKKAPSAKPAKGKGKDQPEANAPVKKTTQLKRRGEDDHTNRYIDDEPDDGAQHYIIVVGFNNPQLLAIMAELGIPITSVIKISSENYEPLQTHLAAVNQQQEVLLQSEDLEAEKLKKENAIKELKTFWKYLEPVLNNEKPETNLFDVARLEYMVKAADFPSDWSDGEMMLKLGTDIFENIACLMYDILDWKRQHQHYLESMQLINVPQVVNEKPVLEAMPTSEAPQPAVPAPGKKKAQYEEPQAPPPVTSVITTEVDMRYYNYLLNPIREEFISVPLILHCMLEQVVATEEDLVPPSLREPSPRADGLDHRIAAHIVSLLPSLCLSEREKKNLHDIFLSEEENESKAVPKGPLLLNYHDAHAHKKYALQDQKNFDPVQIEQEMQSKLPLWEFLQFPLPPPWNNTKRLATIHELMHFCTSDVLSWNEVERAFKVFTFESLKLSEVDEKGKLKPSGMMCGSDSEMFNIPWDNPARFAKQIRQQYVMKMNTQEAKQKADIKIKDRTLFVDQNLSMSVQDNESNREPSDPSQCDANNMKHSDLNNLKLSVPDNRQLLEQESIMKAQPQHESLEQTTNNEIKDDAVTKADSHEKKPKKMMVEADLEDIKKTQQRSLMDWSFTEHFKPKVLLQVLQEAHKQYRCVDSYYHTQDNSLLLVFHNPMNRQRLHCEYWNIALHSNVGFRNYLELVAKSIQDWITKEEAIYQESKMNEKIIRTRAELELKSSANAKLTSASKIFSIKESKSNKGISKTEISDQEKEKEKEKIPFILEGSLKAWKEEQHRLAEEERLREEKKAEKKGKEAGKKKGKDNAEKEDSRSLKKKSPYKEKSKEEQVKIQEVTEESPHQPEPKITYPFHGYNMGNIPTQISGSNYYLYPSDGGQIEVEKTMFEKGPTFIKVRVVKDNHNFMIHLNDPKEIVKKEEKGDYYLEEEEEGDEEQSLETEVSDAKNKAFSKFGSFSATLENGICLSISYYGSNGMAPEDKDPDLETILNIPSALTPTVVPVIVTVPQSKAKGKIKGKEKPKESLKEEEHPKEEEKKEEEVEPEPVLQETLDVPTFQSLNVSCPSGLLLTFIGQESTGQYVIDEEPTWDIMVRQSYPQRVKHYEFYKTVMPPAEQEASRVITSQGTVVKYMLDGSTQILFADGAVSRSPNSGLICPPSEMPATPHSGDLMDSISQQKSETIPSEITNTKKGKSHKSQSSMAHKGEIHDPPPEAVQTVTPVEVHIGTWFTTTPEGNRIGTKGLERIADLTPLLSFQATDPVNGTVMTTREDKVVIVERKDGTRIVDHADGTRITTFYQVYEDQIILPDDQETTEGPRTVTRQVKCMRVESSRYATVIANCEDSSCCATFGDGTTIIAKPQGTYQVLPPNTGSLYIDKDCSAVYCHESSSNIYYPFQKREQLRAGRYIMRHTSEVICEVLDPEGNTFQVMADGSISTILPEKKLEDDLNEKTEGYDSLSSMHLEKNHQQIYGEHVPRFFVMYADGSGMELLRDSDIEEYLSLAYKESNTVVLQEPVQEQPGTLTITVLRPFHEASPWQVKKEDTIVPPNLRSRSWETFPSVEKKTPGPPFGTQIWKGLCIESKQLVSAPGAILKSPSVLQMRQFIQHEVIKNEVKLRLQVSLKDYINYILKKEDELQEMMVKDSRTEEERGNAADLLKLVMSFPKMEETTKSHVTEVAAHLTDLFKQSLATPPKCPPDTFGKDFFEKTWRHTASSKRWKEKIDKTRKEIETTQNYLMDIKNRIIPPFFKSELNQLYQSQYNHLDSLSKKLPSFTKKNEDANETAVQDTSDLNLDFKPHKVSEQKSSSVPSLPKPEISADKKDFTAQNQTENLTKSPEEAESYEPVKIPTQSLLQDVAGQTRKEKVKLPHYLLSSKPKSQPLAKVQDSVGGKVNTSSVASAAINNAKSSLFGFHLLPSSVKFGVLKEGHTYATVVKLKNVGVDFCRFKVKQPPPSTGLKVTYKPGPVAAGMQTELNIELFATAVGEDGAKGSAHISHNIEIMTEHEVLFLPVEATVLTSSNYDKRPKDFPQGKENPMVQRTSTIYSSTLGVFMSRKVSPH>sp|O43295|SRGP3_HUMAN SLIT-ROBO Rho GTPase-activating protein 3 OS=Homosapiens OX=9606 GN=SRGAP3 PE=1 SV=3MSSQTKFKKDKEIIAEYEAQIKEIRTQLVEQFKCLEQQSESRLQLLQDLQEFFRRKAEIELEYSRSLEKLAERFSSKIRSSREHQFKKDQYLLSPVNCWYLVLHQTRRESRDHATLNDIFMNNVIVRLSQISEDVIRLFKKSKEIGLQMHEELLKVTNELYTVMKTYHMYHAESISAESKLKEAEKQEEKQFNKSGDLSMNLLRHEDRPQRRSSVKKIEKMKEKRQAKYSENKLKCTKARNDYLLNLAATNAAISKYYIHDVSDLIDCCDLGFHASLARTFRTYLSAEYNLETSRHEGLDVIENAVDNLDSRSDKHTVMDMCNQVFCPPLKFEFQPHMGDEVCQVSAQQPVQTELLMRYHQLQSRLATLKIENEEVRKTLDATMQTLQDMLTVEDFDVSDAFQHSRSTESVKSAASETYMSKINIAKRRANQQETEMFYFTKFKEYVNGSNLITKLQAKHDLLKQTLGEGERAECGTTRPPCLPPKPQKMRRPRPLSVYSHKLFNGSMEAFIKDSGQAIPLVVESCIRYINLYGLQQQGIFRVPGSQVEVNDIKNSFERGEDPLVDDQNERDINSVAGVLKLYFRGLENPLFPKERFQDLISTIKLENPAERVHQIQQILVTLPRVVIVVMRYLFAFLNHLSQYSDENMMDPYNLAICFGPTLMHIPDGQDPVSCQAHINEVIKTIIIHHEAIFPSPRELEGPVYEKCMAGGEEYCDSPHSEPGAIDEVDHDNGTEPHTSDEEVEQIEAIAKFDYMGRSPRELSFKKGASLLLYHRASEDWWEGRHNGVDGLIPHQYIVVQDMDDAFSDSLSQKADSEASSGPLLDDKASSKNDLQSPTEHISDYGFGGVMGRVRLRSDGAAIPRRRSGGDTHSPPRGLGPSIDTPPRAAACPSSPHKIPLTRGRIESPEKRRMATFGSAGSINYPDKKALSEGHSMRSTCGSTRHSSLGDHKSLEAEALAEDIEKTMSTALHELRELERQNTVKQAPDVVLDTLEPLKNPPGPVSSEPASPLHTIVIRDPDAAMRRSSSSSTEMMTTFKPALSARLAGAQLRPPPMRPVRPVVQHRSSSSSSSGVGSPAVTPTEKMFPNSSADKSGTM>sp|O43295-2|SRGP3_HUMAN Isoform 2 of SLIT-ROBO Rho GTPase-activatingprotein 3 OS=Homo sapiens OX=9606 GN=SRGAP3MSSQTKFKKDKEIIAEYEAQIKEIRTQLVEQFKCLEQQSESRLQLLQDLQEFFRRKAEIELEYSRSLEKLAERFSSKIRSSREHQFKKDQYLLSPVNCWYLVLHQTRRESRDHATLNDIFMNNVIVRLSQISEDVIRLFKKSKEIGLQMHEELLKVTNELYTVMKTYHMYHAESISAESKLKEAEKQEEKQFNKSGDLSMNLLRHEDRPQRRSSVKKIEKMKEKRQAKYSENKLKCTKARNDYLLNLAATNAAISKYYIHDVSDLIDCCDLGFHASLARTFRTYLSAEYNLETSRHEGLDVIENAVDNLDSRSDKHTVMDMCNQVFCPPLKFEFQPHMGDEVCQVSAQQPVQTELLMRYHQLQSRLATLKIENEEVRKTLDATMQTLQDMLTVEDFDVSDAFQHSRSTESVKSAASETYMSKINIAKRRANQQETEMFYFTKFKEYVNGSNLITKLQAKHDLLKQTLGEGERAECGTTRGRRNARTRNQDSGQAIPLVVESCIRYINLYGLQQQGIFRVPGSQVEVNDIKNSFERGEDPLVDDQNERDINSVAGVLKLYFRGLENPLFPKERFQDLISTIKLENPAERVHQIQQILVTLPRVVIVVMRYLFAFLNHLSQYSDENMMDPYNLAICFGPTLMHIPDGQDPVSCQAHINEVIKTIIIHHEAIFPSPRELEGPVYEKCMAGGEEYCDSPHSEPGAIDEVDHDNGTEPHTSDEEVEQIEAIAKFDYMGRSPRELSFKKGASLLLYHRASEDWWEGRHNGVDGLIPHQYIVVQDMDDAFSDSLSQKADSEASSGPLLDDKASSKNDLQSPTEHISDYGFGGVMGRVRLRSDGAAIPRRRSGGDTHSPPRGLGPSIDTPPRAAACPSSPHKIPLTRGRIESPEKRRMATFGSAGSINYPDKKALSEGHSMRSTCGSTRHSSLGDHKSLEAEALAEDIEKTMSTALHELRELERQNTVKQAPDVVLDTLEPLKNPPGPVSSEPASPLHTIVIRDPDAAMRRSSSSSTEMMTTFKPALSARLAGAQLRPPPMRPVRPVVQHRSSSSSSSGVGSPAVTPTEKMFPNSSADKSGTM>sp|O43295-3|SRGP3_HUMAN Isoform 3 of SLIT-ROBO Rho GTPase-activatingprotein 3 OS=Homo sapiens OX=9606 GN=SRGAP3MSSQTKFKKDKEIIAEYEAQIKEIRTQLVEQFKCLEQQSESRLQLLQDLQEFFRRKAEIELEYSRSLEKLAERFSSKIRSSREHQFKKDQYLLSPVNCWYLVLHQTRRESRDHATLNDIFMNNVIVRLSQISEDVIRLFKKSKEIGLQMHEELLKVTNELYTVMKTYHMYHAESISAESKLKEAEKQEEKQFNKSGDLSMNLLRHEDRPQRRSSVKKIEKMKEKRQAKYSENKLKCTKARNDYLLNLAATNAAISKYYIHDVSDLIDCCDLGFHASLARTFRTYLSAEYNLETSRHEGLDVIENAVDNLDSRSDKHTVMDMCNQVFCPPLKFEFQPHMGDEVCQVSAQQPVQTELLMRYHQLQSRLATLKIENEEVRKTLDATMQTLQDMLTVEDFDVSDAFQHSRSTESVKSAASETYMSKINIAKRRANQQETEMFYFTKFKEYVNGSNLITKLQAKHDLLKQTLGEGERAECGTTRIQDKLYRL>sp|Q9C004|SPY4_HUMAN Protein sprouty homolog 4 OS=Homo sapiens OX=9606GN=SPRY4 PE=1 SV=2MEPPIPQSAPLTPNSVMVQPLLDSRMSHSRLQHPLTILPIDQVKTSHVENDYIDNPSLALTTGPKRTRGGAPELAPTPARCDQDVTHHWISFSGRPSSVSSSSSTSSDQRLLDHMAPPPVADQASPRAVRIQPKVVHCQPLDLKGPAVPPELDKHFLLCEACGKCKCKECASPRTLPSCWVCNQECLCSAQTLVNYGTCMCLVQGIFYHCTNEDDEGSCADHPCSCSRSNCCARWSFMGALSVVLPCLLCYLPATGCVKLAQRGYDRLRRPGCRCKHTNSVICKAASGDAKTSRPDKPF>sp|Q9C004-2|SPY4_HUMAN Isoform C of Protein sprouty homolog 4 OS=Homosapiens OX=9606 GN=SPRY4MEPPIPQSAPLTPNSVMVQPLLDSRMSHSRLQHPLTILPIDQVKTSHVENDYIDNPSLALTTGPKRTRGGAPELAPTPARCDQDVTHHWISFSGRPCSATCLPPAA>sp|A6NJT0|UNC4_HUMAN Homeobox protein unc-4 homolog OS=Homo sapiensOX=9606 GN=UNCX PE=3 SV=1MMDGRLLEHPHAQFGGSLGGVVGFPYPLGHHHVYELAGHQLQSAAAAASVPFSIDGLLGGSCAAAASVVNPTPLLPAACGVGGDGQPFKLSDSGDPDKESPGCKRRRTRTNFTGWQLEELEKAFNESHYPDVFMREALALRLDLVESRVQVWFQNRRAKWRKKENTKKGPGRPAHNSHPTTCSGEPMDPEEIARKELEKMEKKKRKHEKKLLKSQGRHLHSPGGLSLHSAPSSDSDSGGGGLSPEPPEPPPPAAKGPGAHASGAAGTAPAPPGEPPAPGTCDPAFYPSQRSGAGPQPRPGRPADKDAASCGPGAAVAAVERGAAGLPKASPFSVESLLSDSPPRRKAASNAAAAAAAGLDFAPGLPCAPRTLIGKGHFLLYPITQPLGFLVPQAALKGGAGLEPAPKDAPPAPAVPPAPPAQASFGAFSGPGGAPDSAFARRSPDAVASPGAPAPAPAPFRDLASAAATEGGGGDCADAGTAGPAPPPPAPSPRPGPRPPSPAEEPATCGVPEPGAAAGPSPPEGEELDMD>sp|Q9P2K2|TXD16_HUMAN Thioredoxin domain-containing protein 16 OS=Homosapiens OX=9606 GN=TXNDC16 PE=1 SV=4MFSGFNVFRVGISFVIMCIFYMPTVNSLPELSPQKYFSTLQPGKASLAYFCQADSPRTSVFLEELNEAVRPLQDYGISVAKVNCVKEEISRYCGKEKDLMKAYLFKGNILLREFPTDTLFDVNAIVAHVLFALLFSEVKYITNLEDLQNIENALKGKANIIFSYVRAIGIPEHRAVMEAAFVYGTTYQFVLTTEIALLESIGSEDVEYAHLYFFHCKLVLDLTQQCRRTLMEQPLTTLNIHLFIKTMKAPLLTEVAEDPQQVSTVHLQLGLPLVFIVSQQATYEADRRTAEWVAWRLLGKAGVLLLLRDSLEVNIPQDANVVFKRAEEGVPVEFLVLHDVDLIISHVENNMHIEEIQEDEDNDMEGPDIDVQDDEVAETVFRDRKRKLPLELTVELTEETFNATVMASDSIVLFYAGWQAVSMAFLQSYIDVAVKLKGTSTMLLTRINCADWSDVCTKQNVTEFPIIKMYKKGENPVSYAGMLGTEDLLKFIQLNRISYPVNITSIQEAEEYLSGELYKDLILYSSVSVLGLFSPTMKTAKEDFSEAGNYLKGYVITGIYSEEDVLLLSTKYAASLPALLLARHTEGKIESIPLASTHAQDIVQIITDALLEMFPEITVENLPSYFRLQKPLLILFSDGTVNPQYKKAILTLVKQKYLDSFTPCWLNLKNTPVGRGILRAYFDPLPPLPLLVLVNLHSGGQVFAFPSDQAIIEENLVLWLKKLEAGLENHITILPAQEWKPPLPAYDFLSMIDAATSQRGTRKVPKCMKETDVQENDKEQHEDKSAVRKEPIETLRIKHWNRSNWFKEAEKSFRRDKELGCSKVN>sp|Q15431|SYCP1_HUMAN Synaptonemal complex protein 1 OS=Homo sapiensOX=9606 GN=SYCP1 PE=1 SV=2MEKQKPFALFVPPRSSSSQVSAVKPQTLGGDSTFFKSFNKCTEDDFEFPFAKTNLSKNGENIDSDPALQKVNFLPVLEQVGNSDCHYQEGLKDSDLENSEGLSRVYSKLYKEAEKIKKWKVSTEAELRQKESKLQENRKIIEAQRKAIQELQFGNEKVSLKLEEGIQENKDLIKENNATRHLCNLLKETCARSAEKTKKYEYEREETRQVYMDLNNNIEKMITAFEELRVQAENSRLEMHFKLKEDYEKIQHLEQEYKKEINDKEKQVSLLLIQITEKENKMKDLTFLLEESRDKVNQLEEKTKLQSENLKQSIEKQHHLTKELEDIKVSLQRSVSTQKALEEDLQIATKTICQLTEEKETQMEESNKARAAHSFVVTEFETTVCSLEELLRTEQQRLEKNEDQLKILTMELQKKSSELEEMTKLTNNKEVELEELKKVLGEKETLLYENKQFEKIAEELKGTEQELIGLLQAREKEVHDLEIQLTAITTSEQYYSKEVKDLKTELENEKLKNTELTSHCNKLSLENKELTQETSDMTLELKNQQEDINNNKKQEERMLKQIENLQETETQLRNELEYVREELKQKRDEVKCKLDKSEENCNNLRKQVENKNKYIEELQQENKALKKKGTAESKQLNVYEIKVNKLELELESAKQKFGEITDTYQKEIEDKKISEENLLEEVEKAKVIADEAVKLQKEIDKRCQHKIAEMVALMEKHKHQYDKIIEERDSELGLYKSKEQEQSSLRASLEIELSNLKAELLSVKKQLEIEREEKEKLKREAKENTATLKEKKDKKTQTFLLETPEIYWKLDSKAVPSQTVSRNFTSVDHGISKDKRDYLWTSAKNTLSTPLPKAYTVKTPTKPKLQQRENLNIPIEESKKKRKMAFEFDINSDSSETTDLLSMVSEEETLKTLYRNNNPPASHLCVKTPKKAPSSLTTPGSTLKFGAIRKMREDRWAVIAKMDRKKKLKEAEKLFV>sp|Q9NSD9|SYFB_HUMAN Phenylalanine--tRNA ligase beta subunit OS=Homosapiens OX=9606 GN=FARSB PE=1 SV=3MPTVSVKRDLLFQALGRTYTDEEFDELCFEFGLELDEITSEKEIISKEQGNVKAAGASDVVLYKIDVPANRYDLLCLEGLVRGLQVFKERIKAPVYKRVMPDGKIQKLIITEETAKIRPFAVAAVLRNIKFTKDRYDSFIELQEKLHQNICRKRALVAIGTHDLDTLSGPFTYTAKRPSDIKFKPLNKTKEYTACELMNIYKTDNHLKHYLHIIENKPLYPVIYDSNGVVLSMPPIINGDHSRITVNTRNIFIECTGTDFTKAKIVLDIIVTMFSEYCENQFTVEAAEVVFPNGKSHTFPELAYRKEMVRADLINKKVGIRETPENLAKLLTRMYLKSEVIGDGNQIEIEIPPTRADIIHACDIVEDAAIAYGYNNIQMTLPKTYTIANQFPLNKLTELLRHDMAAAGFTEALTFALCSQEDIADKLGVDISATKAVHISNPKTAEFQVARTTLLPGLLKTIAANRKMPLPLKLFEISDIVIKDSNTDVGAKNYRHLCAVYYNKNPGFEIIHGLLDRIMQLLDVPPGEDKGGYVIKASEGPAFFPGRCAEIFARGQSVGKLGVLHPDVITKFELTMPCSSLEINVGPFL>sp|Q9NSD9-2|SYFB_HUMAN Isoform 2 of Phenylalanine--tRNA ligase betasubunit OS=Homo sapiens OX=9606 GN=FARSBMPDGKIQKLIITEETAKIRPFAVAAVLRNIKFTKDRYDSFIELQEKLHQNICRKRALVAIGTHDLDTLSGPFTYTAKRPSDIKFKPLNKTKEYTACELMNIYKTDNHLKHYLHIIENKPLYPVIYDSNGVVLSMPPIINGDHSRITVNTRNIFIECTGTDFTKAKIVLDIIVTMFSEYCENQFTVEAAEVVFPNGKSHTFPELAYRKEMVRADLINKKVGIRETPENLAKLLTRMYLKSEVIGDGNQIEIEIPPTRADIIHACDIVEDAAIAYGYNNIQMTLPKTYTIANQFPLNKLTELLRHDMAAAGFTEALTFALCSQEDIADKLGVDISATKAVHISNPKTAEFQVARTTLLPGLLKTIAANRKMPLPLKLFEISDIVIKDSNTDVGAKNYRHLCAVYYNKNPGFEIIHGLLDRIMQLLDVPPGEDKGGYVIKASEGPAFFPGRCAEIFARGQSVGKLGVLHPDVITKFELTMPCSSLEINVGPFL>sp|Q6ZW31|SYDE1_HUMAN Rho GTPase-activating protein SYDE1 OS=Homosapiens OX=9606 GN=SYDE1 PE=1 SV=1MAEPLLRKTFSRLRGREKLPRKKSDAKERGHPAQRPEPSPPEPEPQAPEGSQAGAEGPSSPEASRSPARGAYLQSLEPSSRRWVLGGAKPAEDTSLGPGVPGTGEPAGEIWYNPIPEEDPRPPAPEPPGPQPGSAESEGLAPQGAAPASPPTKASRTKSPGPARRLSIKMKKLPELRRRLSLRGPRAGRERERAAPAGSVISRYHLDSSVGGPGPAAGPGGTRSPRAGYLSDGDSPERPAGPPSPTSFRPYEVGPAARAPPAALWGRLSLHLYGLGGLRPAPGATPRDLCCLLQVDGEARARTGPLRGGPDFLRLDHTFHLELEAARLLRALVLAWDPGVRRHRPCAQGTVLLPTVFRGCQAQQLAVRLEPQGLLYAKLTLSEQQEAPATAEPRVFGLPLPLLVERERPPGQVPLIIQKCVGQIERRGLRVVGLYRLCGSAAVKKELRDAFERDSAAVCLSEDLYPDINVITGILKDYLRELPTPLITQPLYKVVLEAMARDPPNRVPPTTEGTRGLLSCLPDVERATLTLLLDHLRLVSSFHAYNRMTPQNLAVCFGPVLLPARQAPTRPRARSSGPGLASAVDFKHHIEVLHYLLQSWPDPRLPRQSPDVAPYLRPKRQPPLHLPLADPEVVTRPRGRGGPESPPSNRYAGDWSVCGRDFLPCGRDFLSGPDYDHVTGSDSEDEDEEVGEPRVTGDFEDDFDAPFNPHLNLKDFDALILDLERELSKQINVCL>sp|Q6ZW31-2|SYDE1_HUMAN Isoform 2 of Rho GTPase-activating protein SYDE1OS=Homo sapiens OX=9606 GN=SYDE1MAEPLLRKTFSRLRGREKLPRKKSDAKERGPGVPGTGEPAGEIWYNPIPEEDPRPPAPEPPGPQPGSAESEGLAPQGAAPASPPTKASRTKSPGPARRLSIKMKKLPELRRRLSLRGPRAGRERERAAPAGSVISRYHLDSSVGGPGPAAGPGGTRSPRAGYLSDGDSPERPAGPPSPTSFRPYEVGPAARAPPAALWGRLSLHLYGLGGLRPAPGATPRDLCCLLQVDGEARARTGPLRGGPDFLRLDHTFHLELEAARLLRALVLAWDPGVRRHRPCAQGTVLLPTVFRGCQAQQLAVRLEPQGLLYAKLTLSEQQEAPATAEPRVFGLPLPLLVERERPPGQVPLIIQKCVGQIERRGLRVVGLYRLCGSAAVKKELRDAFERDSAAVCLSEDLYPDINVITGILKDYLRELPTPLITQPLYKVVLEAMARDPPNRVPPTTEGTRGLLSCLPDVERATLTLLLDHLRLVSSFHAYNRMTPQNLAVCFGPVLLPARQAPTRPRARSSGPGLASAVDFKHHIEVLHYLLQSWPDPRLPRQSPDVAPYLRPKRQPPLHLPLADPEVVTRPRGRGGPESPPSNRYAGDWSVCGRDFLPCGRDFLSGPDYDHVTGSDSEDEDEEVGEPRVTGDFEDDFDAPFNPHLNLKDFDALILDLERELSKQINVCL>sp|P14868|SYDC_HUMAN Aspartate--tRNA ligase, cytoplasmic OS=Homo sapiensOX=9606 GN=DARS1 PE=1 SV=2MPSASASRKSQEKPREIMDAAEDYAKERYGISSMIQSQEKPDRVLVRVRDLTIQKADEVVWVRARVHTSRAKGKQCFLVLRQQQFNVQALVAVGDHASKQMVKFAANINKESIVDVEGVVRKVNQKIGSCTQQDVELHVQKIYVISLAEPRLPLQLDDAVRPEAEGEEEGRATVNQDTRLDNRVIDLRTSTSQAVFRLQSGICHLFRETLINKGFVEIQTPKIISAASEGGANVFTVSYFKNNAYLAQSPQLYKQMCICADFEKVFSIGPVFRAEDSNTHRHLTEFVGLDIEMAFNYHYHEVMEEIADTMVQIFKGLQERFQTEIQTVNKQFPCEPFKFLEPTLRLEYCEALAMLREAGVEMGDEDDLSTPNEKLLGHLVKEKYDTDFYILDKYPLAVRPFYTMPDPRNPKQSNSYDMFMRGEEILSGAQRIHDPQLLTERALHHGIDLEKIKAYIDSFRFGAPPHAGGGIGLERVTMLFLGLHNVRQTSMFPRDPKRLTP>sp|P14868-2|SYDC_HUMAN Isoform 2 of Aspartate--tRNA ligase, cytoplasmicOS=Homo sapiens OX=9606 GN=DARS1MVKFAANINKESIVDVEGVVRKVNQKIGSCTQQDVELHVQKIYVISLAEPRLPLQLDDAVRPEAEGEEEGRATVNQDTRLDNRVIDLRTSTSQAVFRLQSGICHLFRETLINKGFVEIQTPKIISAASEGGANVFTVSYFKNNAYLAQSPQLYKQMCICADFEKVFSIGPVFRAEDSNTHRHLTEFVGLDIEMAFNYHYHEVMEEIADTMVQIFKGLQERFQTEIQTVNKQFPCEPFKFLEPTLRLEYCEALAMLREAGVEMGDEDDLSTPNEKLLGHLVKEKYDTDFYILDKYPLAVRPFYTMPDPRNPKQSNSYDMFMRGEEILSGAQRIHDPQLLTERALHHGIDLEKIKAYIDSFRFGAPPHAGGGIGLERVTMLFLGLHNVRQTSMFPRDPKRLTP>sp|Q2M3V2|SWAHA_HUMAN Ankyrin repeat domain-containing protein SOWAHAOS=Homo sapiens OX=9606 GN=SOWAHA PE=1 SV=3MALAAAAAAAAAGVSQAAVLGFLQEHGGKVRNSELLSRFKPLLDAGDPRGRAARRDRFKQFVNNVAVVKELDGVKFVVLRKKPRPPEPEPAPFGPPGAAAQPSKPTSTVLPRSASAPGAPPLVRVPRPVEPPGDLGLPTEPQDTPGGPASEPAQPPGERSADPPLPALELAQATERPSADAAPPPRAPSEAASPCSDPPDAEPGPGAAKGPPQQKPCMLPVRCVPAPATLRLRAEEPGLRRQLSEEPSPRSSPLLLRRLSVEESGLGLGLGPGRSPHLRRLSRAGPRLLSPDAEELPAAPPPSAVPLEPSEHEWLVRTAGGRWTHQLHGLLLRDRGLAAKRDFMSGFTALHWAAKSGDGEMALQLVEVARRSGAPVDVNARSHGGYTPLHLAALHGHEDAAVLLVVRLGAQVHVRDHSGRRAYQYLRPGSSYALRRLLGDPGLRGTTEPDATGGGSGSLAARRPVQVAATILSSTTSAFLGVLADDLMLQDLARGLKKSSSFSKFLSASPMAPRKKTKIRGGLPAFSEISRRPTPGPLAGLVPSFPPTT>sp|Q14142|TRI14_HUMAN Tripartite motif-containing protein 14 OS=Homosapiens OX=9606 GN=TRIM14 PE=1 SV=2MAGAATGSRTPGRSELVEGCGWRCPEHGDRVAELFCRRCRRCVCALCPVLGAHRGHPVGLALEAAVHVQKLSQECLKQLAIKKQQHIDNITQIEDATEKLKANAESSKTWLKGKFTELRLLLDEEEALAKKFIDKNTQLTLQVYREQADSCREQLDIMNDLSNRVWSISQEPDPVQRLQAYTATEQEMQQQMSLGELCHPVPLSFEPVKSFFKGLVEAVESTLQTPLDIRLKESINCQLSDPSSTKPGTLLKTSPSPERSLLLKYARTPTLDPDTMHARLRLSADRLTVRCGLLGSLGPVPVLRFDALWQVLARDCFATGRHYWEVDVQEAGAGWWVGAAYASLRRRGASAAARLGCNRQSWCLKRYDLEYWAFHDGQRSRLRPRDDLDRLGVFLDYEAGVLAFYDVTGGMSHLHTFRATFQEPLYPALRLWEGAISIPRLP>sp|Q14142-2|TRI14_HUMAN Isoform Beta of Tripartite motif-containingprotein 14 OS=Homo sapiens OX=9606 GN=TRIM14MAGAATGSRTPGRSELVEGCGWRCPEHGDRVAELFCRRCRRCVCALCPVLGAHRGHPVGLALEAAVHVQKLSQECLKQLAIKKQQHIDNITQIEDATEKLKANAESSKTWLKGKFTELRLLLDEEEALAKKFIDKNTQLTLQVYREQADSCREQLDIMNDLSNRVWSISQEPDPVQRLQAYTATEQEMQQQMSLGELCHPVPLSFEPVKSFFKGLVEAVESTLQTPLDIRLSPTNHAYSALKVSSPRLVSNRP>sp|Q14142-3|TRI14_HUMAN Isoform 3 of Tripartite motif-containing protein14 OS=Homo sapiens OX=9606 GN=TRIM14MAGAATGSRTPGRSELVEGCGWRCPEHGDRVAELFCRRCRRCVCALCPVLGAHRGHPVGLALEAAVHVQKLSQECLKQLAIKKQQHIDNITQIEDATEKLKANAESSKTWLKGKFTELRLLLDEEEALAKKFIDKNTQLTLQVYREQADSCREQLDIMNDLSNRVWSISQEPDPVQRLQAYTATEQEMQQQMSLGELCHPVPLSFEPVKSFFKGLVEAVESTLQTPLDIRLKESINCQLSDPSSTKPGTLLKTSPSPERSLLLKYARTPTLDPDTMHARLRLSADRLTVRCGLLGSLGPVPVLRFDALWQVLARDCFATGRHYWEVDVQEAGAGWWVGAAYASLRRRGASAAARLGCNRQSWCLKRYDLEYWAFHDGQRSACGPATTSTGSASSWTTRPASSPSTT>sp|Q14142-4|TRI14_HUMAN Isoform 4 of Tripartite motif-containing protein14 OS=Homo sapiens OX=9606 GN=TRIM14MNDLSNRVWSISQEPDPVQRLQAYTATEQEMQQQMSLGELCHPVPLSFEPVKSFFKGLVEAVESTLQTPLDIRLKESINCQLSDPSSTKPGTLLKTSPSPERSLLLKSCWAAWGPCPCCGSTRSGKCWLVTASPPAATTGRLTCRRRAPAGGWARPTPPFGAAGPRPPPAWAATASPGASSATTLSTGPSTTASAAACGPATTSTGSASSWTTRPASSPSTT>sp|Q8N511|TM199_HUMAN Transmembrane protein 199 OS=Homo sapiens OX=9606GN=TMEM199 PE=1 SV=1MASSLLAGERLVRALGPGGELEPERLPRKLRAELEAALGKKHKGGDSSSGPQRLVSFRLIRDLHQHLRERDSKLYLHELLEGSEIYLPEVVKPPRNPELVARLEKIKIQLANEEYKRITRNVTCQDTRHGGTLSDLGKQVRSLKALVITIFNFIVTVVAAFVCTYLGSQYIFTEMASRVLAALIVASVVGLAELYVMVRAMEGELGEL>sp|P04350|TBB4A_HUMAN Tubulin beta-4A chain OS=Homo sapiens OX=9606GN=TUBB4A PE=1 SV=2MREIVHLQAGQCGNQIGAKFWEVISDEHGIDPTGTYHGDSDLQLERINVYYNEATGGNYVPRAVLVDLEPGTMDSVRSGPFGQIFRPDNFVFGQSGAGNNWAKGHYTEGAELVDAVLDVVRKEAESCDCLQGFQLTHSLGGGTGSGMGTLLISKIREEFPDRIMNTFSVVPSPKVSDTVVEPYNATLSVHQLVENTDETYCIDNEALYDICFRTLKLTTPTYGDLNHLVSATMSGVTTCLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTSRGSQQYRALTVPELTQQMFDAKNMMAACDPRHGRYLTVAAVFRGRMSMKEVDEQMLSVQSKNSSYFVEWIPNNVKTAVCDIPPRGLKMAATFIGNSTAIQELFKRISEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATAEEGEFEEEAEEEVA>sp|Q9NR96|TLR9_HUMAN Toll-like receptor 9 OS=Homo sapiens OX=9606GN=TLR9 PE=1 SV=2MGFCRSALHPLSLLVQAIMLAMTLALGTLPAFLPCELQPHGLVNCNWLFLKSVPHFSMAAPRGNVTSLSLSSNRIHHLHDSDFAHLPSLRHLNLKWNCPPVGLSPMHFPCHMTIEPSTFLAVPTLEELNLSYNNIMTVPALPKSLISLSLSHTNILMLDSASLAGLHALRFLFMDGNCYYKNPCRQALEVAPGALLGLGNLTHLSLKYNNLTVVPRNLPSSLEYLLLSYNRIVKLAPEDLANLTALRVLDVGGNCRRCDHAPNPCMECPRHFPQLHPDTFSHLSRLEGLVLKDSSLSWLNASWFRGLGNLRVLDLSENFLYKCITKTKAFQGLTQLRKLNLSFNYQKRVSFAHLSLAPSFGSLVALKELDMHGIFFRSLDETTLRPLARLPMLQTLRLQMNFINQAQLGIFRAFPGLRYVDLSDNRISGASELTATMGEADGGEKVWLQPGDLAPAPVDTPSSEDFRPNCSTLNFTLDLSRNNLVTVQPEMFAQLSHLQCLRLSHNCISQAVNGSQFLPLTGLQVLDLSHNKLDLYHEHSFTELPRLEALDLSYNSQPFGMQGVGHNFSFVAHLRTLRHLSLAHNNIHSQVSQQLCSTSLRALDFSGNALGHMWAEGDLYLHFFQGLSGLIWLDLSQNRLHTLLPQTLRNLPKSLQVLRLRDNYLAFFKWWSLHFLPKLEVLDLAGNQLKALTNGSLPAGTRLRRLDVSCNSISFVAPGFFSKAKELRELNLSANALKTVDHSWFGPLASALQILDVSANPLHCACGAAFMDFLLEVQAAVPGLPSRVKCGSPGQLQGLSIFAQDLRLCLDEALSWDCFALSLLAVALGLGVPMLHHLCGWDLWYCFHLCLAWLPWRGRQSGRDEDALPYDAFVVFDKTQSAVADWVYNELRGQLEECRGRWALRLCLEERDWLPGKTLFENLWASVYGSRKTLFVLAHTDRVSGLLRASFLLAQQRLLEDRKDVVVLVILSPDGRRSRYVRLRQRLCRQSVLLWPHQPSGQRSFWAQLGMALTRDNHHFYNRNFCQGPTAE>sp|Q9NR96-2|TLR9_HUMAN Isoform 2 of Toll-like receptor 9 OS=Homo sapiensOX=9606 GN=TLR9MAAPRGNVTSLSLSSNRIHHLHDSDFAHLPSLRHLNLKWNCPPVGLSPMHFPCHMTIEPSTFLAVPTLEELNLSYNNIMTVPALPKSLISLSLSHTNILMLDSASLAGLHALRFLFMDGNCYYKNPCRQALEVAPGALLGLGNLTHLSLKYNNLTVVPRNLPSSLEYLLLSYNRIVKLAPEDLANLTALRVLDVGGNCRRCDHAPNPCMECPRHFPQLHPDTFSHLSRLEGLVLKDSSLSWLNASWFRGLGNLRVLDLSENFLYKCITKTKAFQGLTQLRKLNLSFNYQKRVSFAHLSLAPSFGSLVALKELDMHGIFFRSLDETTLRPLARLPMLQTLRLQMNFINQAQLGIFRAFPGLRYVDLSDNRISGASELTATMGEADGGEKVWLQPGDLAPAPVDTPSSEDFRPNCSTLNFTLDLSRNNLVTVQPEMFAQLSHLQCLRLSHNCISQAVNGSQFLPLTGLQVLDLSHNKLDLYHEHSFTELPRLEALDLSYNSQPFGMQGVGHNFSFVAHLRTLRHLSLAHNNIHSQVSQQLCSTSLRALDFSGNALGHMWAEGDLYLHFFQGLSGLIWLDLSQNRLHTLLPQTLRNLPKSLQVLRLRDNYLAFFKWWSLHFLPKLEVLDLAGNQLKALTNGSLPAGTRLRRLDVSCNSISFVAPGFFSKAKELRELNLSANALKTVDHSWFGPLASALQILDVSANPLHCACGAAFMDFLLEVQAAVPGLPSRVKCGSPGQLQGLSIFAQDLRLCLDEALSWDCFALSLLAVALGLGVPMLHHLCGWDLWYCFHLCLAWLPWRGRQSGRDEDALPYDAFVVFDKTQSAVADWVYNELRGQLEECRGRWALRLCLEERDWLPGKTLFENLWASVYGSRKTLFVLAHTDRVSGLLRASFLLAQQRLLEDRKDVVVLVILSPDGRRSRYVRLRQRLCRQSVLLWPHQPSGQRSFWAQLGMALTRDNHHFYNRNFCQGPTAE>sp|Q9NR96-3|TLR9_HUMAN Isoform 3 of Toll-like receptor 9 OS=Homo sapiensOX=9606 GN=TLR9MPMKWSGWRWSWGPATHTALPPPQGFCRSALHPLSLLVQAIMLAMTLALGTLPAFLPCELQPHGLVNCNWLFLKSVPHFSMAAPRGNVTSLSLSSNRIHHLHDSDFAHLPSLRHLNLKWNCPPVGLSPMHFPCHMTIEPSTFLAVPTLEELNLSYNNIMTVPALPKSLISLSLSHTNILMLDSASLAGLHALRFLFMDGNCYYKNPCRQALEVAPGALLGLGNLTHLSLKYNNLTVVPRNLPSSLEYLLLSYNRIVKLAPEDLANLTALRVLDVGGNCRRCDHAPNPCMECPRHFPQLHPDTFSHLSRLEGLVLKDSSLSWLNASWFRGLGNLRVLDLSENFLYKCITKTKAFQGLTQLRKLNLSFNYQKRVSFAHLSLAPSFGSLVALKELDMHGIFFRSLDETTLRPLARLPMLQTLRLQMNFINQAQLGIFRAFPGLRYVDLSDNRISGASELTATMGEADGGEKVWLQPGDLAPAPVDTPSSEDFRPNCSTLNFTLDLSRNNLVTVQPEMFAQLSHLQCLRLSHNCISQAVNGSQFLPLTGLQVLDLSHNKLDLYHEHSFTELPRLEALDLSYNSQPFGMQGVGHNFSFVAHLRTLRHLSLAHNNIHSQVSQQLCSTSLRALDFSGNALGHMWAEGDLYLHFFQGLSGLIWLDLSQNRLHTLLPQTLRNLPKSLQVLRLRDNYLAFFKWWSLHFLPKLEVLDLAGNQLKALTNGSLPAGTRLRRLDVSCNSISFVAPGFFSKAKELRELNLSANALKTVDHSWFGPLASALQILDVSANPLHCACGAAFMDFLLEVQAAVPGLPSRVKCGSPGQLQGLSIFAQDLRLCLDEALSWDCFALSLLAVALGLGVPMLHHLCGWDLWYCFHLCLAWLPWRGRQSGRDEDALPYDAFVVFDKTQSAVADWVYNELRGQLEECRGRWALRLCLEERDWLPGKTLFENLWASVYGSRKTLFVLAHTDRVSGLLRASFLLAQQRLLEDRKDVVVLVILSPDGRRSRYVRLRQRLCRQSVLLWPHQPSGQRSFWAQLGMALTRDNHHFYNRNFCQGPTAE>sp|Q9NR96-4|TLR9_HUMAN Isoform 4 of Toll-like receptor 9 OS=Homo sapiensOX=9606 GN=TLR9MLYSSCKSRLLDSVEQDFHLEIAKKGFCRSALHPLSLLVQAIMLAMTLALGTLPAFLPCELQPHGLVNCNWLFLKSVPHFSMAAPRGNVTSLSLSSNRIHHLHDSDFAHLPSLRHLNLKWNCPPVGLSPMHFPCHMTIEPSTFLAVPTLEELNLSYNNIMTVPALPKSLISLSLSHTNILMLDSASLAGLHALRFLFMDGNCYYKNPCRQALEVAPGALLGLGNLTHLSLKYNNLTVVPRNLPSSLEYLLLSYNRIVKLAPEDLANLTALRVLDVGGNCRRCDHAPNPCMECPRHFPQLHPDTFSHLSRLEGLVLKDSSLSWLNASWFRGLGNLRVLDLSENFLYKCITKTKAFQGLTQLRKLNLSFNYQKRVSFAHLSLAPSFGSLVALKELDMHGIFFRSLDETTLRPLARLPMLQTLRLQMNFINQAQLGIFRAFPGLRYVDLSDNRISGASELTATMGEADGGEKVWLQPGDLAPAPVDTPSSEDFRPNCSTLNFTLDLSRNNLVTVQPEMFAQLSHLQCLRLSHNCISQAVNGSQFLPLTGLQVLDLSHNKLDLYHEHSFTELPRLEALDLSYNSQPFGMQGVGHNFSFVAHLRTLRHLSLAHNNIHSQVSQQLCSTSLRALDFSGNALGHMWAEGDLYLHFFQGLSGLIWLDLSQNRLHTLLPQTLRNLPKSLQVLRLRDNYLAFFKWWSLHFLPKLEVLDLAGNQLKALTNGSLPAGTRLRRLDVSCNSISFVAPGFFSKAKELRELNLSANALKTVDHSWFGPLASALQILDVSANPLHCACGAAFMDFLLEVQAAVPGLPSRVKCGSPGQLQGLSIFAQDLRLCLDEALSWDCFALSLLAVALGLGVPMLHHLCGWDLWYCFHLCLAWLPWRGRQSGRDEDALPYDAFVVFDKTQSAVADWVYNELRGQLEECRGRWALRLCLEERDWLPGKTLFENLWASVYGSRKTLFVLAHTDRVSGLLRASFLLAQQRLLEDRKDVVVLVILSPDGRRSRYVRLRQRLCRQSVLLWPHQPSGQRSFWAQLGMALTRDNHHFYNRNFCQGPTAE>sp|Q9NR96-5|TLR9_HUMAN Isoform 5 of Toll-like receptor 9 OS=Homo sapiensOX=9606 GN=TLR9MAIMLAMTLALGTLPAFLPCELQPHGLVNCNWLFLKSVPHFSMAAPRGNVTSLSLSSNRIHHLHDSDFAHLPSLRHLNLKWNCPPVGLSPMHFPCHMTIEPSTFLAVPTLEELNLSYNNIMTVPALPKSLISLSLSHTNILMLDSASLAGLHALRFLFMDGNCYYKNPCRQALEVAPGALLGLGNLTHLSLKYNNLTVVPRNLPSSLEYLLLSYNRIVKLAPEDLANLTALRVLDVGGNCRRCDHAPNPCMECPRHFPQLHPDTFSHLSRLEGLVLKDSSLSWLNASWFRGLGNLRVLDLSENFLYKCITKTKAFQGLTQLRKLNLSFNYQKRVSFAHLSLAPSFGSLVALKELDMHGIFFRSLDETTLRPLARLPMLQTLRLQMNFINQAQLGIFRAFPGLRYVDLSDNRISGASELTATMGEADGGEKVWLQPGDLAPAPVDTPSSEDFRPNCSTLNFTLDLSRNNLVTVQPEMFAQLSHLQCLRLSHNCISQAVNGSQFLPLTGLQVLDLSHNKLDLYHEHSFTELPRLEALDLSYNSQPFGMQGVGHNFSFVAHLRTLRHLSLAHNNIHSQVSQQLCSTSLRALDFSGNALGHMWAEGDLYLHFFQGLSGLIWLDLSQNRLHTLLPQTLRNLPKSLQVLRLRDNYLAFFKWWSLHFLPKLEVLDLAGNQLKALTNGSLPAGTRLRRLDVSCNSISFVAPGFFSKAKELRELNLSANALKTVDHSWFGPLASALQILDVSANPLHCACGAAFMDFLLEVQAAVPGLPSRVKCGSPGQLQGLSIFAQDLRLCLDEALSWDCFALSLLAVALGLGVPMLHHLCGWDLWYCFHLCLAWLPWRGRQSGRDEDALPYDAFVVFDKTQSAVADWVYNELRGQLEECRGRWALRLCLEERDWLPGKTLFENLWASVYGSRKTLFVLAHTDRVSGLLRASFLLAQQRLLEDRKDVVVLVILSPDGRRSRYVRLRQRLCRQSVLLWPHQPSGQRSFWAQLGMALTRDNHHFYNRNFCQGPTAE>sp|Q6ZUI0|TPRG1_HUMAN Tumor protein p63-regulated gene 1 protein OS=Homosapiens OX=9606 GN=TPRG1 PE=1 SV=1MSTIGSFEGFQAVSLKQEGDDQPSETDHLSMEEEDPMPRQISRQSSVTESTLYPNPYHQPYISRKYFATRPGAIETAMEDLKGHVAETSGETIQGFWLLTKIDHWNNEKERILLVTDKTLLICKYDFIMLSCVQLQRIPLSAVYRICLGKFTFPGMSLDKRQGEGLRIYWGSPEEQSLLSRWNPWSTEVPYATFTEHPMKYTSEKFLEICKLSGFMSKLVPAIQNAHKNSTGSGRGKKLMVLTEPILIETYTGLMSFIGNRNKLGYSLARGSIGF>sp|Q9H2S6|TNMD_HUMAN Tenomodulin OS=Homo sapiens OX=9606 GN=TNMD PE=1SV=1MAKNPPENCEDCHILNAEAFKSKKICKSLKICGLVFGILALTLIVLFWGSKHFWPEVPKKAYDMEHTFYSNGEKKKIYMEIDPVTRTEIFRSGNGTDETLEVHDFKNGYTGIYFVGLQKCFIKTQIKVIPEFSEPEEEIDENEEITTTFFEQSVIWVPAEKPIENRDFLKNSKILEICDNVTMYWINPTLISVSELQDFEEEGEDLHFPANEKKGIEQNEQWVVPQVKVEKTRHARQASEEELPINDYTENGIEFDPMLDERGYCCIYCRRGNRYCRRVCEPLLGYYPYPYCYQGGRVICRVIMPCNWWVARMLGRV>sp|Q9H2S6-2|TNMD_HUMAN Isoform 2 of Tenomodulin OS=Homo sapiens OX=9606GN=TNMDMAKNPPENCEDCHILNAEAFKSKKICKSLKICGLVFGILALTLIVLFWGSKHFWPEVPKKAYDMEHTFYSNGEKKKIYMEIDPVTRTEIFRSGNGTDETLEVHDFKNGYTGIYFVGLQKCFIKTQIKVIPEFSEPEEEIDENEEITTTFFEQSVIWVPAEKPIENRDFLKNSKILEICDNVTMYWINPTLISGMTFLSSSSSYFLRQ>sp|Q9H2S6-3|TNMD_HUMAN Isoform 3 of Tenomodulin OS=Homo sapiens OX=9606GN=TNMDMEHTFYSNGEKKKIYMEIDPVTRTEIFRSGNGTDETLEVHDFKNGYTGIYFVGLQKCFIKTQIKVIPEFSEPEEEIDENEEITTTFFEQSVIWVPAEKPIENRDFLKNSKILEICDNVTMYWINPTLISVSELQDFEEEGEDLHFPANEKKGIEQNEQWVVPQVKVEKTRHARQASEEELPINDYTENGIEFDPMLDERGYCCIYCRRGNRYCRRVCEPLLGYYPYPYCYQGGRVICRVIMPCNWWVARMLGRV>sp|Q12931|TRAP1_HUMAN Heat shock protein 75 kDa, mitochondrial OS=Homosapiens OX=9606 GN=TRAP1 PE=1 SV=3MARELRALLLWGRRLRPLLRAPALAAVPGGKPILCPRRTTAQLGPRRNPAWSLQAGRLFSTQTAEDKEEPLHSIISSTESVQGSTSKHEFQAETKKLLDIVARSLYSEKEVFIRELISNASDALEKLRHKLVSDGQALPEMEIHLQTNAEKGTITIQDTGIGMTQEELVSNLGTIARSGSKAFLDALQNQAEASSKIIGQFGVGFYSAFMVADRVEVYSRSAAPGSLGYQWLSDGSGVFEIAEASGVRTGTKIIIHLKSDCKEFSSEARVRDVVTKYSNFVSFPLYLNGRRMNTLQAIWMMDPKDVREWQHEEFYRYVAQAHDKPRYTLHYKTDAPLNIRSIFYVPDMKPSMFDVSRELGSSVALYSRKVLIQTKATDILPKWLRFIRGVVDSEDIPLNLSRELLQESALIRKLRDVLQQRLIKFFIDQSKKDAEKYAKFFEDYGLFMREGIVTATEQEVKEDIAKLLRYESSALPSGQLTSLSEYASRMRAGTRNIYYLCAPNRHLAEHSPYYEAMKKKDTEVLFCFEQFDELTLLHLREFDKKKLISVETDIVVDHYKEEKFEDRSPAAECLSEKETEELMAWMRNVLGSRVTNVKVTLRLDTHPAMVTVLEMGAARHFLRMQQLAKTQEERAQLLQPTLEINPRHALIKKLNQLRASEPGLAQLLVDQIYENAMIAAGLVDDPRAMVGRLNELLVKALERH>sp|Q12931-2|TRAP1_HUMAN Isoform 2 of Heat shock protein 75 kDa,mitochondrial OS=Homo sapiens OX=9606 GN=TRAP1MARELRALLLWGRRLRPLLRAPALAAVPGGSTSKHEFQAETKKLLDIVARSLYSEKEVFIRELISNASDALEKLRHKLVSDGQALPEMEIHLQTNAEKGTITIQDTGIGMTQEELVSNLGTIARSGSKAFLDALQNQAEASSKIIGQFGVGFYSAFMVADRVEVYSRSAAPGSLGYQWLSDGSGVFEIAEASGVRTGTKIIIHLKSDCKEFSSEARVRDVVTKYSNFVSFPLYLNGRRMNTLQAIWMMDPKDVREWQHEEFYRYVAQAHDKPRYTLHYKTDAPLNIRSIFYVPDMKPSMFDVSRELGSSVALYSRKVLIQTKATDILPKWLRFIRGVVDSEDIPLNLSRELLQESALIRKLRDVLQQRLIKFFIDQSKKDAEKYAKFFEDYGLFMREGIVTATEQEVKEDIAKLLRYESSALPSGQLTSLSEYASRMRAGTRNIYYLCAPNRHLAEHSPYYEAMKKKDTEVLFCFEQFDELTLLHLREFDKKKLISVETDIVVDHYKEEKFEDRSPAAECLSEKETEELMAWMRNVLGSRVTNVKVTLRLDTHPAMVTVLEMGAARHFLRMQQLAKTQEERAQLLQPTLEINPRHALIKKLNQLRASEPGLAQLLVDQIYENAMIAAGLVDDPRAMVGRLNELLVKALERH>sp|P12270|TPR_HUMAN Nucleoprotein TPR OS=Homo sapiens OX=9606 GN=TPRPE=1 SV=3MAAVLQQVLERTELNKLPKSVQNKLEKFLADQQSEIDGLKGRHEKFKVESEQQYFEIEKRLSHSQERLVNETRECQSLRLELEKLNNQLKALTEKNKELEIAQDRNIAIQSQFTRTKEELEAEKRDLIRTNERLSQELEYLTEDVKRLNEKLKESNTTKGELQLKLDELQASDVSVKYREKRLEQEKELLHSQNTWLNTELKTKTDELLALGREKGNEILELKCNLENKKEEVSRLEEQMNGLKTSNEHLQKHVEDLLTKLKEAKEQQASMEEKFHNELNAHIKLSNLYKSAADDSEAKSNELTRAVEELHKLLKEAGEANKAIQDHLLEVEQSKDQMEKEMLEKIGRLEKELENANDLLSATKRKGAILSEEELAAMSPTAAAVAKIVKPGMKLTELYNAYVETQDQLLLEKLENKRINKYLDEIVKEVEAKAPILKRQREEYERAQKAVASLSVKLEQAMKEIQRLQEDTDKANKQSSVLERDNRRMEIQVKDLSQQIRVLLMELEEARGNHVIRDEEVSSADISSSSEVISQHLVSYRNIEELQQQNQRLLVALRELGETREREEQETTSSKITELQLKLESALTELEQLRKSRQHQMQLVDSIVRQRDMYRILLSQTTGVAIPLHASSLDDVSLASTPKRPSTSQTVSTPAPVPVIESTEAIEAKAALKQLQEIFENYKKEKAENEKIQNEQLEKLQEQVTDLRSQNTKISTQLDFASKRYEMLQDNVEGYRREITSLHERNQKLTATTQKQEQIINTMTQDLRGANEKLAVAEVRAENLKKEKEMLKLSEVRLSQQRESLLAEQRGQNLLLTNLQTIQGILERSETETKQRLSSQIEKLEHEISHLKKKLENEVEQRHTLTRNLDVQLLDTKRQLDTETNLHLNTKELLKNAQKEIATLKQHLSNMEVQVASQSSQRTGKGQPSNKEDVDDLVSQLRQTEEQVNDLKERLKTSTSNVEQYQAMVTSLEESLNKEKQVTEEVRKNIEVRLKESAEFQTQLEKKLMEVEKEKQELQDDKRRAIESMEQQLSELKKTLSSVQNEVQEALQRASTALSNEQQARRDCQEQAKIAVEAQNKYERELMLHAADVEALQAAKEQVSKMASVRQHLEETTQKAESQLLECKASWEERERMLKDEVSKCVCRCEDLEKQNRLLHDQIEKLSDKVVASVKEGVQGPLNVSLSEEGKSQEQILEILRFIRREKEIAETRFEVAQVESLRYRQRVELLERELQELQDSLNAEREKVQVTAKTMAQHEELMKKTETMNVVMETNKMLREEKERLEQDLQQMQAKVRKLELDILPLQEANAELSEKSGMLQAEKKLLEEDVKRWKARNQHLVSQQKDPDTEEYRKLLSEKEVHTKRIQQLTEEIGRLKAEIARSNASLTNNQNLIQSLKEDLNKVRTEKETIQKDLDAKIIDIQEKVKTITQVKKIGRRYKTQYEELKAQQDKVMETSAQSSGDHQEQHVSVQEMQELKETLNQAETKSKSLESQVENLQKTLSEKETEARNLQEQTVQLQSELSRLRQDLQDRTTQEEQLRQQITEKEEKTRKAIVAAKSKIAHLAGVKDQLTKENEELKQRNGALDQQKDELDVRITALKSQYEGRISRLERELREHQERHLEQRDEPQEPSNKVPEQQRQITLKTTPASGERGIASTSDPPTANIKPTPVVSTPSKVTAAAMAGNKSTPRASIRPMVTPATVTNPTTTPTATVMPTTQVESQEAMQSEGPVEHVPVFGSTSGSVRSTSPNVQPSISQPILTVQQQTQATAFVQPTQQSHPQIEPANQELSSNIVEVVQSSPVERPSTSTAVFGTVSATPSSSLPKRTREEEEDSTIEASDQVSDDTVEMPLPKKLKSVTPVGTEEEVMAEESTDGEVETQVYNQDSQDSIGEGVTQGDYTPMEDSEETSQSLQIDLGPLQSDQQTTTSSQDGQGKGDDVIVIDSDDEEEDDDENDGEHEDYEEDEEDDDDDEDDTGMGDEGEDSNEGTGSADGNDGYEADDAEGGDGTDPGTETEESMGGGEGNHRAADSQNSGEGNTGAAESSFSQEVSREQQPSSASERQAPRAPQSPRRPPHPLPPRLTIHAPPQELGPPVQRIQMTRRQSVGRGLQLTPGIGGMQQHFFDDEDRTVPSTPTLVVPHRTDGFAEAIHSPQVAGVPRFRFGPPEDMPQTSSSHSDLGQLASQGGLGMYETPLFLAHEEESGGRSVPTTPLQVAAPVTVFTESTTSDASEHASQSVPMVTTSTGTLSTTNETATGDDGDEVFVEAESEGISSEAGLEIDSQQEEEPVQASDESDLPSTSQDPPSSSSVDTSSSQPKPFRRVRLQTTLRQGVRGRQFNRQRGVSHAMGGRGGINRGNIN>sp|P12270-2|TPR_HUMAN Isoform 2 of Nucleoprotein TPR OS=Homo sapiensOX=9606 GN=TPRMAAVLQQVLERTELNKLPKSVQNKLEKFLADQQSEIDGLKGRHEKFKVESEQQYFEIEKRLSHSQERLVNETRECQSLRLELEKLNNQLKALTEKNKELEIAQDRNIAIQSQFTRTKEELEAEKRDLIRTNERLSQELEYLTEDVKRLNEKLKESNTTKGELQLKLDELQASDVSVKYREKRLEQEKELLHSQNTWLNTELKTKTDELLALGREKGNEILELKCNLENKKEEVSRLEEQMNGLKTSNEHLQKHVEDLLTKLKEAKEQQASMEEKFHNELNAHIKLSNLYKSAADDSEAKSNELTRAVEELHKLLKEAGEANKAIQDHLLEVEQSKDQMEKEMLEKIGRLEKELENANDLLSATKRKGAILSEEELAAMSPTAAAVAKIVKPGMKLTELYNAYVETQDQLLLEKLENKRINKYLDEIVKEVEAKAPILKRQREEYERAQKAVASLSVKLEQAMKEIQRLQEDTDKANKQSSVLERDNRRMEIQVKDLSQQIRVLLMELEEARGNHVIRDEEVSSADISSSSEVISQHLVSYRNIEELQQQNQRLLVALRELGETREREEQETTSSKITELQLKLESALTELEQLRKSRQHQMQLVDSIVRQRDMYRILLSQTTGVAIPLHASSLDDVSLASTPKRPSTSQTVSTPAPVPVIESTEAIEAKAALKQLQEIFENYKKEKAENEKIQNEQLEKLQEQVTDLRSQNTKISTQLDFASKRYL>sp|A6NK02|TRI75_HUMAN Putative tripartite motif-containing protein 75OS=Homo sapiens OX=9606 GN=TRIM75P PE=5 SV=2MAVAAALTGLQAEAKCSICLDYLSDPVTIECGHNFCRSCIQQSWLDLQELFPCPVCRHQCQEGHFRSNTQLGRMIEIAKLLQSTKSNKRKQEETTLCEKHNQPLSVFCKEDLMVLCPLCTQPPDHQGHHVRPIEKAAIHYRKRFCSYIQPLKKQLADLQKLISTQSKKPLELREMVENQRQELSSEFEHLNQFLDREQQAVLSRLAEEEKDNQQKLSANITAFSNYSATLKSQLSKVVELSELSELELLSQIKIFYESENESSPSIFSIHLKRDGCSFPPQYSALQRIIKKFKVEIILDPETAHPNLIVSEDKKRVRFTKRKQKVPGFPKRFTVKPVVLGFPYFHSGRHFWEIEVGDKSEWAIGICKDSLPTKARRPSSAQQECWRIELQDDGYHAPGAFPTPLLLEVKARAIGIFLDYEMGEISFYNMAEKSHICTFTDTFTGPLRPYFYVGPDSQPLRICTGTVCE>sp|Q12816|TROP_HUMAN Trophinin OS=Homo sapiens OX=9606 GN=TRO PE=1 SV=3MDRRNDYGYRVPLFQGPLPPPGSLGLPFPPDIQTETTEEDSVLLMHTLLAATKDSLAMDPPVVNRPKKSKTKKAPIKTITKAAPAAPPVPAANEIATNKPKITWQALNLPVITQISQALPTTEVTNTQASSVTAQPKKANKMKRVTAKAAQGSQSPTGHEGGTIQLKSPLQVLKLPVISQNIHAPIANESASSQALITSIKPKKASKAKKAANKAIASATEVSLAATATHTATTQGQITNETASIHTTAASIRTKKASKARKTIAKVINTDTEHIEALNVTDAATRQIEASVVAIRPKKSKGKKAASRGPNSVSEISEAPLATQIVTNQALAATLRVKRGSRARKAATKARATESQTPNADQGAQAKIASAQTNVSALETQVAAAVQALADDYLAQLSLEPTTRTRGKRNRKSKHLNGDERSGSNYRRIPWGRRPAPPRDVAILQERANKLVKYLLVKDQTKIPIKRSDMLRDVIQEYDEYFPEIIERASYTLEKMFRVNLKEIDKQSSLYILISTQESSAGILGTTKDTPKLGLLMVILSVIFMNGNKASEAVIWEVLRKLGLRPGVRHSLFGEVRKLITDEFVKQKYLEYKRVPNSRPPEYEFFWGLRSYHETSKMKVLKFACRVQKKDPKDWAVQYREAVEMEVQAAAVAVAEAEARAEARAQMGIGEEAVAGPWNWDDMDIDCLTREELGDDAQAWSRFSFEIEARAQENADASTNVNFSRGASTRAGFSDGASISFNGAPSSSGGFSGGPGITFGVAPSTSASFSNTASISFGGTLSTSSSFSSAASISFGCAHSTSTSFSSEASISFGGMPCTSASFSGGVSSSFSGPLSTSATFSGGASSGFGGTLSTTAGFSGVLSTSTSFGSAPTTSTVFSSALSTSTGFGGILSTSVCFGGSPSSSGSFGGTLSTSICFGGSPCTSTGFGGTLSTSVSFGGSSSTSANFGGTLSTSICFDGSPSTGAGFGGALNTSASFGSVLNTSTGFGGAMSTSADFGGTLSTSVCFGGSPGTSVSFGSALNTNAGYGGAVSTNTDFGGTLSTSVCFGGSPSTSAGFGGALNTNASFGCAVSTSASFSGAVSTSACFSGAPITNPGFGGAFSTSAGFGGALSTAADFGGTPSNSIGFGAAPSTSVSFGGAHGTSLCFGGAPSTSLCFGSASNTNLCFGGPPSTSACFSGATSPSFCDGPSTSTGFSFGNGLSTNAGFGGGLNTSAGFGGGLGTSAGFSGGLSTSSGFDGGLGTSAGFGGGPGTSTGFGGGLGTSAGFSGGLGTSAGFGGGLVTSDGFGGGLGTNASFGSTLGTSAGFSGGLSTSDGFGSRPNASFDRGLSTIIGFGSGSNTSTGFTGEPSTSTGFSSGPSSIVGFSGGPSTGVGFCSGPSTSGFSGGPSTGAGFGGGPNTGAGFGGGPSTSAGFGSGAASLGACGFSYG>sp|Q12816-2|TROP_HUMAN Isoform 2 of Trophinin OS=Homo sapiens OX=9606GN=TROMDRRNDYGYRVPLFQGPLPPPGSLGLPFPPDIQTETTEEDSVLLMHTLLAATKDSLAMDPPVVNRPKKSKTKKAPIKTITKAAPAAPPVPAANEIATNKPKITWQALNLPVITQISQALPTTEVTNTQASSVTAQPKKANKMKRVTAKAAQGSQSPTGHEGGTIQLKSPLQVLKLPVISQNIHAPIANESASSQALITSIKPKKASKAKKAANKAIASATEVSLAATATHTATTQGQITNETASIHTTAASIRTKKASKARKTIAKVINTDTEHIEALNVTDAATRQIEASVVAIRPKKSKGKKAASRGPNSVSEISEAPLATQIVTNQALAATLRVKRGSRARKAATKARATESQTPNADQGAQAKIASAQTNVSALETQVAAAVQALADDYLAQLSLEPTTRTRGKRNRKSKHLNGDERSGSNYRRIPWGRRPAPPRDVAILQERANKLVKYLLVKDQTKIPIKRSDMLRDVIQEYDEYFPEIIERASYTLEKMFRVNLKEIDKQSSLYILISTQESSAGILGTTKDTPKLGLLMVILSVIFMNGNKASEAVIWEVLRKLGLRPGVRHSLFGEVRKLITDEFVKQKYLEYKRVPNSRPPEYEFFWGLRSYHETSKMKVLKFACRVQKKDPKDWAVQYREAVEMEVQAAAVAVAEAEARAEIYSPCLQIPLINCSSPSHGAKVHPWNLCPHSSQGSYGQSAEGVM>sp|Q12816-3|TROP_HUMAN Isoform 3 of Trophinin OS=Homo sapiens OX=9606GN=TROMLRDVIQEYDEYFPEIIERASYTLEKMFRVNLKEIDKQSSLYILISTQESSAGILGTTKDTPKLGLLMVILSVIFMNGNKASEAVIWEVLRKLGLRPGVRHSLFGEVRKLITDEFVKQKYLEYKRVPNSRPPEYEFFWGLRSYHETSKMKVLKFACRVQKKDPKDWAVQYREAVEMEVQAAAVAVAEAEARAEARAQMGIGEEAVAGPWNWDDMDIDCLTREELGDDAQAWSRFSFEIEARAQENADASTNVNFSRGASTRAGFSDGASISFNGAPSSSGGFSGGPGITFGVAPSTSASFSNTASISFGGTLSTSSSFSSAASISFGCAHSTSTSFSSEASISFGGMPCTSASFSGGVSSSFSGPLSTSATFSGGASSGFGGTLSTTAGFSGVLSTSTSFGSAPTTSTVFSSALSTSTGFGGILSTSVCFGGSPSSSGSFGGTLSTSICFGGSPCTSTGFGGTLSTSVSFGGSSSTSANFGGTLSTSICFDGSPSTGAGFGGALNTSASFGSVLNTSTGFGGAMSTSADFGGTLSTSVCFGGSPGTSVSFGSALNTNAGYGGAVSTNTDFGGTLSTSVCFGGSPSTSAGFGGALNTNASFGCAVSTSASFSGAVSTSACFSGAPITNPGFGGAFSTSAGFGGALSTAADFGGTPSNSIGFGAAPSTSVSFGGAHGTSLCFGGAPSTSLCFGSASNTNLCFGGPPSTSACFSGATSPSFCDGPSTSTGFSFGNGLSTNAGFGGGLNTSAGFGGGLGTSAGFSGGLSTSSGFDGGLGTSAGFGGGPGTSTGFGGGLGTSAGFSGGLGTSAGFGGGLVTSDGFGGGLGTNASFGSTLGTSAGFSGGLSTSDGFGSRPNASFDRGLSTIIGFGSGSNTSTGFTGEPSTSTGFSSGPSSIVGFSGGPSTGVGFCSGPSTSGFSGGPSTGAGFGGGPNTGAGFGGGPSTSAGFGSGAASLGACGFSYG>sp|Q12816-4|TROP_HUMAN Isoform 4 of Trophinin OS=Homo sapiens OX=9606GN=TROMDRRNDYGYRVPLFQSKHLNGDERSGSNYRRIPWGRRPAPPRDVAILQERANKLVKYLLVKDQTKIPIKRSDMLRDVIQEYDEYFPEIIERASYTLEKMFRVNLKEIDKQSSLYILISTQESSAGILGTTKDTPKLGLLMVILSVIFMNGNKASEAVIWEVLRKLGLRPGVRHSLFGEVRKLITDEFVKQKYLEYKRVPNSRPPEYEFFWGLRSYHETSKMKVLKFACRVQKKDPKDWAVQYREAVEMEVQAAAVAVAEAEARAEARAQMGIGEEAVAGPWNWDDMDIDCLTREELGDDAQAWSRFSFEIEARAQENADASTNVNFSRGASTRAGFSDGASISFNGAPSSSGGFSGGPGITFGVAPSTSASFSNTASISFGGTLSTSSSFSSAASISFGCAHSTSTSFSSEASISFGGMPCTSASFSGGVSSSFSGPLSTSATFSGGASSGFGGTLSTTAGFSGVLSTSTSFGSAPTTSTVFSSALSTSTGFGGILSTSVCFGGSPSSSGSFGGTLSTSICFGGSPCTSTGFGGTLSTSVSFGGSSSTSANFGGTLSTSICFDGSPSTGAGFGGALNTSASFGSVLNTSTGFGGAMSTSADFGGTLSTSVCFGGSPGTSVSFGSALNTNAGYGGAVSTNTDFGGTLSTSVCFGGSPSTSAGFGGALNTNASFGCAVSTSASFSGAVSTSACFSGAPITNPGFGGAFSTSAGFGGALSTAADFGGTPSNSIGFGAAPSTSVSFGGAHGTSLCFGGAPSTSLCFGSASNTNLCFGGPPSTSACFSGATSPSFCDGPSTSTGFSFGNGLSTNAGFGGGLNTSAGFGGGLGTSAGFSGGLSTSSGFDGGLGTSAGFGGGPGTSTGFGGGLGTSAGFSGGLGTSAGFGGGLVTSDGFGGGLGTNASFGSTLGTSAGFSGGLSTSDGFGSRPNASFDRGLSTIIGFGSGSNTSTGFTGEPSTSTGFSSGPSSIVGFSGGPSTGVGFCSGPSTSGFSGGPSTGAGFGGGPNTGAGFGGGPSTSAGFGSGAASLGACGFSYG>sp|Q12816-5|TROP_HUMAN Isoform 5 of Trophinin OS=Homo sapiens OX=9606GN=TROMDRRNDYGYRVPLFQSKHLNGDERSGSNYRRIPWGRRPAPPRDVAILQERANKLVKYLLVKDQTKIPIKRSDMLRDVIQEYDEYFPEIIERASYTLEKMFRVNLKEIDKQSSLYILISTQESSAGILGTTKDTPKLGLLMVILSVIFMNGNKASEAVIWEVLRKLGLRPGVRHSLFGEVRKLITDEFVKQKYLEYKRVPNSRPPEYEFFWGLRSYHETSKMKVLKFACRVQKKDPKDWAVQYREAVEMEVQAAAVAVAEAEARAEIYSPCLQIPLINCSSPSHGAKVHPWNLCPHSSQGSYGQSAEGVM>sp|Q9Y490|TLN1_HUMAN Talin-1 OS=Homo sapiens OX=9606 GN=TLN1 PE=1 SV=3MVALSLKISIGNVVKTMQFEPSTMVYDACRIIRERIPEAPAGPPSDFGLFLSDDDPKKGIWLEAGKALDYYMLRNGDTMEYRKKQRPLKIRMLDGTVKTIMVDDSKTVTDMLMTICARIGITNHDEYSLVRELMEEKKEEITGTLRKDKTLLRDEKKMEKLKQKLHTDDELNWLDHGRTLREQGVEEHETLLLRRKFFYSDQNVDSRDPVQLNLLYVQARDDILNGSHPVSFDKACEFAGFQCQIQFGPHNEQKHKAGFLDLKDFLPKEYVKQKGERKIFQAHKNCGQMSEIEAKVRYVKLARSLKTYGVSFFLVKEKMKGKNKLVPRLLGITKECVMRVDEKTKEVIQEWNLTNIKRWAASPKSFTLDFGDYQDGYYSVQTTEGEQIAQLIAGYIDIILKKKKSKDHFGLEGDEESTMLEDSVSPKKSTVLQQQYNRVGKVEHGSVALPAIMRSGASGPENFQVGSMPPAQQQITSGQMHRGHMPPLTSAQQALTGTINSSMQAVQAAQATLDDFDTLPPLGQDAASKAWRKNKMDESKHEIHSQVDAITAGTASVVNLTAGDPAETDYTAVGCAVTTISSNLTEMSRGVKLLAALLEDEGGSGRPLLQAAKGLAGAVSELLRSAQPASAEPRQNLLQAAGNVGQASGELLQQIGESDTDPHFQDALMQLAKAVASAAAALVLKAKSVAQRTEDSGLQTQVIAAATQCALSTSQLVACTKVVAPTISSPVCQEQLVEAGRLVAKAVEGCVSASQAATEDGQLLRGVGAAATAVTQALNELLQHVKAHATGAGPAGRYDQATDTILTVTENIFSSMGDAGEMVRQARILAQATSDLVNAIKADAEGESDLENSRKLLSAAKILADATAKMVEAAKGAAAHPDSEEQQQRLREAAEGLRMATNAAAQNAIKKKLVQRLEHAAKQAAASATQTIAAAQHAASTPKASAGPQPLLVQSCKAVAEQIPLLVQGVRGSQAQPDSPSAQLALIAASQSFLQPGGKMVAAAKASVPTIQDQASAMQLSQCAKNLGTALAELRTAAQKAQEACGPLEMDSALSVVQNLEKDLQEVKAAARDGKLKPLPGETMEKCTQDLGNSTKAVSSAIAQLLGEVAQGNENYAGIAARDVAGGLRSLAQAARGVAALTSDPAVQAIVLDTASDVLDKASSLIEEAKKAAGHPGDPESQQRLAQVAKAVTQALNRCVSCLPGQRDVDNALRAVGDASKRLLSDSLPPSTGTFQEAQSRLNEAAAGLNQAATELVQASRGTPQDLARASGRFGQDFSTFLEAGVEMAGQAPSQEDRAQVVSNLKGISMSSSKLLLAAKALSTDPAAPNLKSQLAAAARAVTDSINQLITMCTQQAPGQKECDNALRELETVRELLENPVQPINDMSYFGCLDSVMENSKVLGEAMTGISQNAKNGNLPEFGDAISTASKALCGFTEAAAQAAYLVGVSDPNSQAGQQGLVEPTQFARANQAIQMACQSLGEPGCTQAQVLSAATIVAKHTSALCNSCRLASARTTNPTAKRQFVQSAKEVANSTANLVKTIKALDGAFTEENRAQCRAATAPLLEAVDNLSAFASNPEFSSIPAQISPEGRAAMEPIVISAKTMLESAGGLIQTARALAVNPRDPPSWSVLAGHSRTVSDSIKKLITSMRDKAPGQLECETAIAALNSCLRDLDQASLAAVSQQLAPREGISQEALHTQMLTAVQEISHLIEPLANAARAEASQLGHKVSQMAQYFEPLTLAAVGAASKTLSHPQQMALLDQTKTLAESALQLLYTAKEAGGNPKQAAHTQEALEEAVQMMTEAVEDLTTTLNEAASAAGVVGGMVDSITQAINQLDEGPMGEPEGSFVDYQTTMVRTAKAIAVTVQEMVTKSNTSPEELGPLANQLTSDYGRLASEAKPAAVAAENEEIGSHIKHRVQELGHGCAALVTKAGALQCSPSDAYTKKELIECARRVSEKVSHVLAALQAGNRGTQACITAASAVSGIIADLDTTIMFATAGTLNREGTETFADHREGILKTAKVLVEDTKVLVQNAAGSQEKLAQAAQSSVATITRLADVVKLGAASLGAEDPETQVVLINAVKDVAKALGDLISATKAAAGKVGDDPAVWQLKNSAKVMVTNVTSLLKTVKAVEDEATKGTRALEATTEHIRQELAVFCSPEPPAKTSTPEDFIRMTKGITMATAKAVAAGNSCRQEDVIATANLSRRAIADMLRACKEAAYHPEVAPDVRLRALHYGRECANGYLELLDHVLLTLQKPSPELKQQLTGHSKRVAGSVTELIQAAEAMKGTEWVDPEDPTVIAENELLGAAAAIEAAAKKLEQLKPRAKPKEADESLNFEEQILEAAKSIAAATSALVKAASAAQRELVAQGKVGAIPANALDDGQWSQGLISAARMVAAATNNLCEAANAAVQGHASQEKLISSAKQVAASTAQLLVACKVKADQDSEAMKRLQAAGNAVKRASDNLVKAAQKAAAFEEQENETVVVKEKMVGGIAQIIAAQEEMLRKERELEEARKKLAQIRQQQYKFLPSELRDEH>sp|Q9UKI8|TLK1_HUMAN Serine/threonine-protein kinase tousled-like 1OS=Homo sapiens OX=9606 GN=TLK1 PE=1 SV=2MSVQSSSGSLEGPPSWSQLSTSPTPGSAAAARSLLNHTPPSGRPREGAMDELHSLDPRRQELLEARFTGVASGSTGSTGSCSVGAKASTNNESSNHSFGSLGSLSDKESETPEKKQSESSRGRKRKAENQNESSQGKSIGGRGHKISDYFEYQGGNGSSPVRGIPPAIRSPQNSHSHSTPSSSVRPNSPSPTALAFGDHPIVQPKQLSFKIIQTDLTMLKLAALESNKIQDLEKKEGRIDDLLRANCDLRRQIDEQQKLLEKYKERLNKCISMSKKLLIEKSTQEKLSSREKSMQDRLRLGHFTTVRHGASFTEQWTDGFAFQNLVKQQEWVNQQREDIERQRKLLAKRKPPTANNSQAPSTNSEPKQRKNKAVNGAENDPFVRPNLPQLLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRINNEDNSQFKDHPTLNERYLLLHLLGRGGFSEVYKAFDLYEQRYAAVKIHQLNKSWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDTFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIVMQIVNALRYLNEIKPPIIHYDLKPGNILLVDGTACGEIKITDFGLSKIMDDDSYGVDGMDLTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFFQCLYGRKPFGHNQSQQDILQENTILKATEVQFPVKPVVSSEAKAFIRRCLAYRKEDRFDVHQLANDPYLLPHMRRSNSSGNLHMAGLTASPTPPSSSIITY>sp|Q9UKI8-2|TLK1_HUMAN Isoform 2 of Serine/threonine-protein kinasetousled-like 1 OS=Homo sapiens OX=9606 GN=TLK1MSVQSSSGSLEGPPSWSQLSTSPTPGSAAAARSLLNHTPPSGRPREGAMDELHSLDPRRQELLEARFTGVASGSTGSTGSCSVGAKASTNNESSNHSFGSLGSLSDKESETPEKKQSESSRGRKRKAENQNESSQGFPNLPVFQSLAYWEMGRTAGGKSIGGRGHKISDYFEYQGGNGSSPVRGIPPAIRSPQNSHSHSTPSSSVRPNSPSPTALAFGDHPIVQPKQLSFKIIQTDLTMLKLAALESNKIQDLEKKEGRIDDLLRANCDLRRQIDEQQKLLEKYKERLNKCISMSKKLLIEKSTQEKLSSREKSMQDRLRLGHFTTVRHGASFTEQWTDGFAFQNLVKQQEWVNQQREDIERQRKLLAKRKPPTANNSQAPSTNSEPKQRKNKAVNGAENDPFVRPNLPQLLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRINNEDNSQFKDHPTLNERYLLLHLLGRGGFSEVYKAFDLYEQRYAAVKIHQLNKSWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDTFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIVMQIVNALRYLNEIKPPIIHYDLKPGNILLVDGTACGEIKITDFGLSKIMDDDSYGVDGMDLTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFFQCLYGRKPFGHNQSQQDILQENTILKATEVQFPVKPVVSSEAKAFIRRCLAYRKEDRFDVHQLANDPYLLPHMRRSNSSGNLHMAGLTASPTPPSSSIITY>sp|Q9UKI8-3|TLK1_HUMAN Isoform 3 of Serine/threonine-protein kinasetousled-like 1 OS=Homo sapiens OX=9606 GN=TLK1MLKLAALESNKIQDLEKKEGRIDDLLRANCDLRRQIDEQQKLLEKYKERLNKCISMSKKLLIEKSTQEKLSSREKSMQDRLRLGHFTTVRHGASFTEQWTDGFAFQNLVKQQEWVNQQREDIERQRKLLAKRKPPTANNSQAPSTNSEPKQRKNKAVNGAENDPFVRPNLPQLLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRINNEDNSQFKDHPTLNERYLLLHLLGRGGFSEVYKAFDLYEQRYAAVKIHQLNKSWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDTFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIVMQIVNALRYLNEIKPPIIHYDLKPGNILLVDGTACGEIKITDFGLSKIMDDDSYGVDGMDLTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFFQCLYGRKPFGHNQSQQDILQENTILKATEVQFPVKPVVSSEAKAFIRRCLAYRKEDRFDVHQLANDPYLLPHMRRSNSSGNLHMAGLTASPTPPSSSIITY>sp|Q9UKI8-4|TLK1_HUMAN Isoform 4 of Serine/threonine-protein kinasetousled-like 1 OS=Homo sapiens OX=9606 GN=TLK1MAVLFLYDLKTTGKTPEKKQSESSRGRKRKAENQNESSQGKSIGGRGHKISDYFEYQGGNGSSPVRGIPPAIRSPQNSHSHSTPSSSVRPNSPSPTALAFGDHPIVQPKQLSFKIIQTDLTMLKLAALESNKIQDLEKKEGRIDDLLRANCDLRRQIDEQQKLLEKYKERLNKCISMSKKLLIEKSTQEKLSSREKSMQDRLRLGHFTTVRHGASFTEQWTDGFAFQNLVKQQEWVNQQREDIERQRKLLAKRKPPTANNSQAPSTNSEPKQRKNKAVNGAENDPFVRPNLPQLLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRINNEDNSQFKDHPTLNERYLLLHLLGRGGFSEVYKAFDLYEQRYAAVKIHQLNKSWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDTFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIVMQIVNALRYLNEIKPPIIHYDLKPGNILLVDGTACGEIKITDFGLSKIMDDDSYGVDGMDLTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFFQCLYGRKPFGHNQSQQDILQENTILKATEVQFPVKPVVSSEAKAFIRRCLAYRKEDRFDVHQLANDPYLLPHMRRSNSSGNLHMAGLTASPTPPSSSIITY>sp|Q9UKI8-5|TLK1_HUMAN Isoform 5 of Serine/threonine-protein kinasetousled-like 1 OS=Homo sapiens OX=9606 GN=TLK1MDELHSLDPRRQELLEARFTGVASGSTGSTGSCSVGAKASTNNESSNHSFGSLGSLSDKESETPEKKQSESSRGRKRKAENQNESSQGKSIGGRGHKISDYFEYQGGNGSSPVRGIPPAIRSPQNSHSHSTPSSSVRPNSPSPTALAFGDHPIVQPKQLSFKIIQTDLTMLKLAALESNKIQDLEKKEGRIDDLLRANCDLRRQIDEQQKLLEKYKERLNKCISMSKKLLIEKSTQEKLSSREKSMQDRLRLGHFTTVRHGASFTEQWTDGFAFQNLVKQQEWVNQQREDIERQRKLLAKRKPPTANNSQAPSTNSEPKQRKNKAVNGAENDPFVRPNLPQLLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRINNEDNSQFKDHPTLNERYLLLHLLGRGGFSEVYKAFDLYEQRYAAVKIHQLNKSWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDTFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIVMQIVNALRYLNEIKPPIIHYDLKPGNILLVDGTACGEIKITDFGLSKIMDDDSYGVDGMDLTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFFQCLYGRKPFGHNQSQQDILQENTILKATEVQFPVKPVVSSEAKAFIRRCLAYRKEDRFDVHQLANDPYLLPHMRRSNSSGNLHMAGLTASPTPPSSSIITY>sp|Q6ZT98|TTLL7_HUMAN Tubulin polyglutamylase TTLL7 OS=Homo sapiensOX=9606 GN=TTLL7 PE=1 SV=2MPSLPQEGVIQGPSPLDLNTELPYQSTMKRKVRKKKKKGTITANVAGTKFEIVRLVIDEMGFMKTPDEDETSNLIWCDSAVQQEKISELQNYQRINHFPGMGEICRKDFLARNMTKMIKSRPLDYTFVPRTWIFPAEYTQFQNYVKELKKKRKQKTFIVKPANGAMGHGISLIRNGDKLPSQDHLIVQEYIEKPFLMEGYKFDLRIYILVTSCDPLKIFLYHDGLVRMGTEKYIPPNESNLTQLYMHLTNYSVNKHNEHFERDETENKGSKRSIKWFTEFLQANQHDVAKFWSDISELVVKTLIVAEPHVLHAYRMCRPGQPPGSESVCFEVLGFDILLDRKLKPWLLEINRAPSFGTDQKIDYDVKRGVLLNALKLLNIRTSDKRRNLAKQKAEAQRRLYGQNSIKRLLPGSSDWEQQRHQLERRKEELKERLAQVRKQISREEHENRHMGNYRRIYPPEDKALLEKYENLLAVAFQTFLSGRAASFQRELNNPLKRMKEEDILDLLEQCEIDDEKLMGKTTKTRGPKPLCSMPESTEIMKRPKYCSSDSSYDSSSSSSESDENEKEEYQNKKREKQVTYNLKPSNHYKLIQQPSSIRRSVSCPRSISAQSPSSGDTRPFSAQQMISVSRPTSASRSHSLNRASSYMRHLPHSNDACSTNSQVSESLRQLKTKEQEDDLTSQTLFVLKDMKIRFPGKSDAESELLIEDIIDNWKYHKTKVASYWLIKLDSVKQRKVLDIVKTSIRTVLPRIWKVPDVEEVNLYRIFNRVFNRLLWSRGQGLWNCFCDSGSSWESIFNKSPEVVTPLQLQCCQRLVELCKQCLLVVYKYATDKRGSLSGIGPDWGNSRYLLPGSTQFFLRTPTYNLKYNSPGMTRSNVLFTSRYGHL>sp|Q6ZT98-2|TTLL7_HUMAN Isoform 2 of Tubulin polyglutamylase TTLL7OS=Homo sapiens OX=9606 GN=TTLL7MPSLPQEGVIQGPSPLDLNTELPYQSTMKRKVRKKKKKGTITANVAGTKFEIVRLVIDEMGFMKTPDEDETSNLIWCDSAVQQEKISELQNYQRINHFPGMGEICRKDFLARNMTKMIKSRPLDYTFVPRTWIFPAEYTQFQNYVKELKKKRKQKTFIVKPANGAMGHGISLIRNGDKLPSQDHLIVQEYIEKPFLMEGYKFDLRIYILVTSCDPLKIFLYHDGLVRMGTEKYIPPNESNLTQLYMHLTNYSVNKHNEHFERDETENKGSKRSIKWFTEFLQANQHDVAKFWSDISELVVKTLIVAEPHVLHAYRMCRPGQPPGSESVCFEVLGFDILLDRKLKPWLLEINRAPSFGTDQKIDYDVKRGVLLNALKLLNIRTSDKRRNLAKQKAEAQRRLYGQNSIKRLLPGSSDWEQQRHQLERRKEELKERLAQVRKQISREEHENRHMGNYRRIYPPEDKALLEKYENLLAVAFQTFLSGRAASFQRELNNPLKRMKEEDILDLLEQCEIDDEKLMGKTTKTRGPKPLCSMPESTEIMKRPKYCSSDSSYDSSSSSSESDENEKEEYQNKKREKQVTYNLKPSNHYKLIQQPSSIRRSVSCPRSISAQSPSSGDTRPFSAQQMISVSRPTSASRSHSLNRASSYMRHLPHSNDACSTNSQVIILAQ>sp|Q6ZT98-3|TTLL7_HUMAN Isoform 3 of Tubulin polyglutamylase TTLL7OS=Homo sapiens OX=9606 GN=TTLL7MPSLPQEGVIQGPSPLDLNTELPYQSTMKRKVRKKKKKGTITANVAGTKFEIVRLVIDEMGFMKTPDEDETSNLIWCDSAVQQEKISELQNYQRINHFPGMGEICRKDFLARNMTKMIKSRPLDYTFVPRTWIFPAEYTQFQNYVKELKKKRKQKTFIVKPANGAMGHGISLIRNGDKLPSQDHLIVQEYIEKPFLMEGYKFDLRIYILVTSCDPLKIFLYHDGLVRMGTEKYIPPNESNLTQLYMHLTNYSVNKHNEHFERDETENKGSKRSIKWFTEFLQANQHDVAKFWSDISELVVKTLIVAEPHVLHAYRMCRPGQPPGSESVCFEVLGFDILLDRKLKPWLLEINRAPSFGTDQKIDYDVKRGVLLNALKLLNIRTSDKRRNLAKQKAEAQRRLYGQNSIKRLLPGSSDWEQQRHQLERRKEELKERLAQVRKQISREEHENRHMGNYRRIYPPEDKALLEKYENLLAVAFQTFLSGRAASFQRELNNPLKRMKEEDILDLLEQCEIDDEKLMGKTTKTRGPKPLCSMPESTEIMKRPKYCSSDSSYDSSSSSSESDENEKEEYQNKKREKQVTYNLKPSNHYKLIQQPSSIRRSVSCPRSISAQSPSSGDTRPFSAQQMISVSRPTSASRSHSLNRASSYMRHLPHSNDACSTNSQVSESLRQLKTKEQEDDLTSQTLFVLKDMKIRFPGKSDAESELLIEDIIDNWKYHKTKVASYWLIKLDSVKQRKVLDIVKTSIRTVLPRIWKVPDVEEVNLYRIFNRVFNRLLWSRGQGLWNCFCDSGYV>sp|Q8NET8|TRPV3_HUMAN Transient receptor potential cation channelsubfamily V member 3 OS=Homo sapiens OX=9606 GN=TRPV3 PE=1 SV=2MKAHPKEMVPLMGKRVAAPSGNPAILPEKRPAEITPTKKSAHFFLEIEGFEPNPTVAKTSPPVFSKPMDSNIRQCISGNCDDMDSPQSPQDDVTETPSNPNSPSAQLAKEEQRRKKRRLKKRIFAAVSEGCVEELVELLVELQELCRRRHDEDVPDFLMHKLTASDTGKTCLMKALLNINPNTKEIVRILLAFAEENDILGRFINAEYTEEAYEGQTALNIAIERRQGDIAALLIAAGADVNAHAKGAFFNPKYQHEGFYFGETPLALAACTNQPEIVQLLMEHEQTDITSRDSRGNNILHALVTVAEDFKTQNDFVKRMYDMILLRSGNWELETTRNNDGLTPLQLAAKMGKAEILKYILSREIKEKRLRSLSRKFTDWAYGPVSSSLYDLTNVDTTTDNSVLEITVYNTNIDNRHEMLTLEPLHTLLHMKWKKFAKHMFFLSFCFYFFYNITLTLVSYYRPREEEAIPHPLALTHKMGWLQLLGRMFVLIWAMCISVKEGIAIFLLRPSDLQSILSDAWFHFVFFIQAVLVILSVFLYLFAYKEYLACLVLAMALGWANMLYYTRGFQSMGMYSVMIQKVILHDVLKFLFVYIVFLLGFGVALASLIEKCPKDNKDCSSYGSFSDAVLELFKLTIGLGDLNIQQNSKYPILFLFLLITYVILTFVLLLNMLIALMGETVENVSKESERIWRLQRARTILEFEKMLPEWLRSRFRMGELCKVAEDDFRLCLRINEVKWTEWKTHVSFLNEDPGPVRRTDFNKIQDSSRNNSKTTLNAFEEVEEFPETSV>sp|Q8NET8-2|TRPV3_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily V member 3 OS=Homo sapiens OX=9606 GN=TRPV3MKAHPKEMVPLMGKRVAAPSGNPAILPEKRPAEITPTKKSAHFFLEIEGFEPNPTVAKTSPPVFSKPMDSNIRQCISGNCDDMDSPQSPQDDVTETPSNPNSPSAQLAKEEQRRKKRRLKKRIFAAVSEGCVEELVELLVELQELCRRRHDEDVPDFLMHKLTASDTGKTCLMKALLNINPNTKEIVRILLAFAEENDILGRFINAEYTEEAYEGQTALNIAIERRQGDIAALLIAAGADVNAHAKGAFFNPKYQHEGFYFGETPLALAACTNQPEIVQLLMEHEQTDITSRDSRGNNILHALVTVAEDFKTQNDFVKRMYDMILLRSGNWELETTRNNDGLTPLQLAAKMGKAEILKYILSREIKEKRLRSLSRKFTDWAYGPVSSSLYDLTNVDTTTDNSVLEITVYNTNIDNRHEMLTLEPLHTLLHMKWKKFAKHMFFLSFCFYFFYNITLTLVSYYRPREEEAIPHPLALTHKMGWLQLLGRMFVLIWAMCISVKEGIAIFLLRPSDLQSILSDAWFHFVFFIQAVLVILSVFLYLFAYKEYLACLVLAMALGWANMLYYTRGFQSMGMYSVMIQKVILHDVLKFLFVYIVFLLGFGVALASLIEKCPKDNKDCSSYGSFSDAVLELFKLTIGLGDLNIQQNSKYPILFLFLLITYVILTFVLLLNMLIALMGETVENVSKESERIWRLQRARTILEFEKMLPEWLRSRFRMGELCKVAEDDFRLCLRINEVKWTEWKTHVSFLNEDPGPVRRTADFNKIQDSSRNNSKTTLNAFEEVEEFPETSV>sp|Q8NET8-3|TRPV3_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily V member 3 OS=Homo sapiens OX=9606 GN=TRPV3MKAHPKEMVPLMGKRVAAPSGNPAILPEKRPAEITPTKKSAHFFLEIEGFEPNPTVAKTSPPVFSKPMDSNIRQCISGNCDDMDSPQSPQDDVTETPSNPNSPSAQLAKEEQRRKKRRLKKRIFAAVSEGCVEELVELLVELQELCRRRHDEDVPDFLMHKLTASDTGKTCLMKALLNINPNTKEIVRILLAFAEENDILGRFINAEYTEEAYEGQTALNIAIERRQGDIAALLIAAGADVNAHAKGAFFNPKYQHEGFYFGETPLALAACTNQPEIVQLLMEHEQTDITSRDSRGNNILHALVTVAEDFKTQNDFVKRMYDMILLRSGNWELETTRNNDGLTPLQLAAKMGKAEILKYILSREIKEKRLRSLSRKFTDWAYGPVSSSLYDLTNVDTTTDNSVLEITVYNTNIDNRHEMLTLEPLHTLLHMKWKKFAKHMFFLSFCFYFFYNITLTLVSYYRPREEEAIPHPLALTHKMGWLQLLGRMFVLIWAMCISVKEGIAIFLLRPSDLQSILSDAWFHFVFFIQAVLVILSVFLYLFAYKEYLACLVLAMALGWANMLYYTRGFQSMGMYSVMIQKVILHDVLKFLFVYIVFLLGFGVALASLIEKCPKDNKDCSSYGSFSDAVLELFKLTIGLGDLNIQQNSKYPILFLFLLITYVILTFVLLLNMLIALMGETVENVSKESERIWRLQRARTILEFEKMLPEWLRSRFRMGELCKVAEDDFRLCLRINEVKWTEWKTHVSFLNEDPGPVRRTGTVAVR>sp|Q49AM3|TTC31_HUMAN Tetratricopeptide repeat protein 31 OS=Homosapiens OX=9606 GN=TTC31 PE=1 SV=3MAPIPKTVGRIKLDCSLRPSCPLEVAAAPKLCKEFGPEDYGEEDIVDFLRRLVESDPQGLHRIHVDGSSGRLQLWHHDYLLGHLDDEGKSTGQSDRGKGAEGLGTYCGLRKSFLYPPQESEPCPQSPSASATFPSVSDSLLQVAMPQKLLVTEEEANRLAEELVAEEERMKQKAEKKRLKKKRQKERKRQERLEQYCGEPKASTTSDGDESPPSSPGNPVQGQCGEEEDSLDLSSTFVSLALRKVGDWPLSARREKGLNQEPQGRGLALQKMGQEEESPPREERPQQSPKVQASPGLLAAALQQSQELAKLGTSFAQNGFYHEAVVLFTQALKLNPQDHRLFGNRSFCHERLGQPAWALADAQVALTLRPGWPRGLFRLGKALMGLQRFREAAAVFQETLRGGSQPDAARELRSCLLHLTLQGQRGGICAPPLSPGALQPLPHAELAPSGLPSLRCPRSTALRSPGLSPLLHYPSCHRSHPNQPLSQTQSRRPHPLKPQDPSKGWDILGLGLQHLSQAR>sp|Q49AM3-2|TTC31_HUMAN Isoform 2 of Tetratricopeptide repeat protein 31OS=Homo sapiens OX=9606 GN=TTC31MAPIPKTVGRIKLDCSLRPSCPLEVAAAPKLCKEFGPEDYGEEDIVDFLRRLVESDPQGLHRIHVDGSSGRLQLWHHDYLLGHLDDEGKSTGQSDRGKGAEGLGTYCGLRKSFLYPPQESEPCPQSPSASATFPSVSDSLLQVAMPQKLLVTEEEANRLAEELVAEEERMKQKAEKKRLKKKRQKERKRQERLEQYCGEPKASTTSDGDESPPSSPGNPVQGQCGEEEDSLDLSSTFVSLALRKVGDWPLSARREKGLNQEPQGRGLALQKMGQEEESPPATSPC>sp|P98066|TSG6_HUMAN Tumor necrosis factor-inducible gene 6 proteinOS=Homo sapiens OX=9606 GN=TNFAIP6 PE=1 SV=2MIILIYLFLLLWEDTQGWGFKDGIFHNSIWLERAAGVYHREARSGKYKLTYAEAKAVCEFEGGHLATYKQLEAARKIGFHVCAAGWMAKGRVGYPIVKPGPNCGFGKTGIIDYGIRLNRSERWDAYCYNPHAKECGGVFTDPKQIFKSPGFPNEYEDNQICYWHIRLKYGQRIHLSFLDFDLEDDPGCLADYVEIYDSYDDVHGFVGRYCGDELPDDIISTGNVMTLKFLSDASVTAGGFQIKYVAMDPVSKSSQGKNTSTTSTGNKNFLAGRFSHL>sp|Q8IV45|UN5CL_HUMAN UNC5C-like protein OS=Homo sapiens OX=9606GN=UNC5CL PE=1 SV=2MCPQESSFQPSQFLLLVGVPVASVLLLAQCLRWHCPRRLLGACWTLNGQEEPVSQPTPQLENEVSRQHLPATLPEMVAFYQELHTPTQGQTMVRQLMHKLLVFSAREVDHRGGCLMLQDTGISLLIPPGAVAVGRQERVSLILVWDLSDAPSLSQAQGLVSPVVACGPHGASFLKPCTLTFKHCAEQPSHARTYSSNTTLLDAKVWRPLGRPGAHASRDECRIHLSHFSLYTCVLEAPVGREARKWLQLAVFCSPLVPGQSHLQLRIYFLNNTPCALQWALTNEQPHGGRLRGPCQLFDFNGARGDQCLKLTYISEGWENVDDSSCQLVPHLHIWHGKCPFRSFCFRRKAADENEDCSALTNEIIVTMHTFQDGLETKYMEILRFQASEEESWAAPPPVSQPPPCNRLPPELFEQLRMLLEPNSITGNDWRRLASHLGLCGMKIRFLSCQRSPAAAILELFEEQNGSLQELHYLMTVMERLDCASAIQNYLSGTHGGSPGPERGGARDNQGLELDEKL>sp|O95292|VAPB_HUMAN Vesicle-associated membrane protein-associatedprotein B/C OS=Homo sapiens OX=9606 GN=VAPB PE=1 SV=3MAKVEQVLSLEPQHELKFRGPFTDVVTTNLKLGNPTDRNVCFKVKTTAPRRYCVRPNSGIIDAGASINVSVMLQPFDYDPNEKSKHKFMVQSMFAPTDTSDMEAVWKEAKPEDLMDSKLRCVFELPAENDKPHDVEINKIISTTASKTETPIVSKSLSSSLDDTEVKKVMEECKRLQGEVQRLREENKQFKEEDGLRMRKTVQSNSPISALAPTGKEEGLSTRLLALVVLFFIVGVIIGKIAL>sp|O95292-2|VAPB_HUMAN Isoform 2 of Vesicle-associated membrane protein-associated protein B/C OS=Homo sapiens OX=9606 GN=VAPBMAKVEQVLSLEPQHELKFRGPFTDVVTTNLKLGNPTDRNVCFKVKTTAPRRYCVRPNSGIIDAGASINVSGRRWTADEEDSAEQQPHFSISPNWEGRRP>sp|O94888|UBXN7_HUMAN UBX domain-containing protein 7 OS=Homo sapiensOX=9606 GN=UBXN7 PE=1 SV=2MAAHGGSAASSALKGLIQQFTTITGASESVGKHMLEACNNNLEMAVTMFLDGGGIAEEPSTSSASVSTVRPHTEEEVRAPIPQKQEILVEPEPLFGAPKRRRPARSIFDGFRDFQTETIRQEQELRNGGAIDKKLTTLADLFRPPIDLMHKGSFETAKECGQMQNKWLMINIQNVQDFACQCLNRDVWSNEAVKNIIREHFIFWQVYHDSEEGQRYIQFYKLGDFPYVSILDPRTGQKLVEWHQLDVSSFLDQVTGFLGEHGQLDGLSSSPPKKCARSESLIDASEDSQLEAAIRASLQETHFDSTQTKQDSRSDEESESELFSGSEEFISVCGSDEEEEVENLAKSRKSPHKDLGHRKEENRRPLTEPPVRTDPGTATNHQGLPAVDSEILEMPPEKADGVVEGIDVNGPKAQLMLRYPDGKREQITLPEQAKLLALVKHVQSKGYPNERFELLTNFPRRKLSHLDYDITLQEAGLCPQETVFVQERN>sp|O14598|VCY1_HUMAN Testis-specific basic protein Y 1 OS=Homo sapiensOX=9606 GN=VCY PE=1 SV=1MSPKPRASGPPAKAKETGKRKSSSQPSPSGPKKKTTKVAEKGEAVRGGRRGKKGAATKMAAVTAPEAESGPAAPGPSDQPSQELPQHELPPEEPVSEGTQHDPLSQESELEEPLSKGRPSTPLSP>sp|Q96GC9|VMP1_HUMAN Vacuole membrane protein 1 OS=Homo sapiens OX=9606GN=VMP1 PE=1 SV=1MAENGKNCDQRRVAMNKEHHNGNFTDPSSVNEKKRREREERQNIVLWRQPLITLQYFSLEILVILKEWTSKLWHRQSIVVSFLLLLAVLIATYYVEGVHQQYVQRIEKQFLLYAYWIGLGILSSVGLGTGLHTFLLYLGPHIASVTLAAYECNSVNFPEPPYPDQIICPDEEGTEGTISLWSIISKVRIEACMWGIGTAIGELPPYFMARAARLSGAEPDDEEYQEFEEMLEHAESAQDFASRAKLAVQKLVQKVGFFGILACASIPNPLFDLAGITCGHFLVPFWTFFGATLIGKAIIKMHIQKIFVIITFSKHIVEQMVAFIGAVPGIGPSLQKPFQEYLEAQRQKLHHKSEMGTPQGENWLSWMFEKLVVVMVCYFILSIINSMAQSYAKRIQQRLNSEEKTK>sp|Q96GC9-2|VMP1_HUMAN Isoform 2 of Vacuole membrane protein 1 OS=Homosapiens OX=9606 GN=VMP1MWGIGTAIGELPPYFMARAARLSGAEPDDEEYQEFEEMLEHAESAQDFASRAKLAVQKLVQKVGFFGILACASIPNPLFDLAGITCGHFLVPFWTFFGATLIGKAIIKMHIQKIFVIITFSKHIVEQMVAFIGAVPGIGPSLQKPFQEYLEAQRQKLHHKSEMGTPQGENWLSWMFEKLVVVMVCYFILSIINSMAQSYAKRIQQRLNSEEKTK>sp|Q8N9V3|WSDU1_HUMAN WD repeat, SAM and U-box domain-containing protein1 OS=Homo sapiens OX=9606 GN=WDSUB1 PE=1 SV=3MVKLIHTLADHGDDVNCCAFSFSLLATCSLDKTIRLYSLRDFTELPHSPLKFHTYAVHCCCFSPSGHILASCSTDGTTVLWNTENGQMLAVMEQPSGSPVRVCQFSPDSTCLASGAADGTVVLWNAQSYKLYRCGSVKDGSLAACAFSPNGSFFVTGSSCGDLTVWDDKMRCPHSEKAHDLGITCCDFSSQPVSDGEQGLQFFRLASCGQDCQVKIWIVSFTHILGFELKYKSTLSGHCAPVLACAFSHDGQMLVSGSVDKSVIVYDTNTENILHTLTQHTRYVTTCAFAPNTLLLATGSMDKTVNIWQFDLETLCQARRTEHQLKQFTEDWSEEDVSTWLCAQDLKDLVGIFKMNNIDGKELLNLTKESLADDLKIESLGLRSKVLRKIEELRTKVKSLSSGIPDEFICPITRELMKDPVIASDGYSYEKEAMENWISKKKRTSPMTNLVLPSAVLTPNRTLKMAINRWLETHQK>sp|Q8N9V3-2|WSDU1_HUMAN Isoform 2 of WD repeat, SAM and U-box domain-containing protein 1 OS=Homo sapiens OX=9606 GN=WDSUB1MVKLIHTLADHGDDVNCCAFSFSLLATCSLDKTIRLYSLRDFTELPHSPLKFHTYAVHCCCFSPSGHILASCSTDGTTVLWNTENGQMLAVMEQPSGSPVRVCQFSPDSTCLASGAADGTVVLWNAQSYKLYRCGSVKDGSLAACAFSPNGSFFVTGSSCGDLTVWDDKMRCPHSEKAHDLGITCCDFSSQPVSDGEQGLQFFRLASCGQDCQVKIWIVSFTHILARRTEHQLKQFTEDWSEEDVSTWLCAQDLKDLVGIFKMNNIDGKELLNLTKESLADDLKIESLGLRSKVLRKIEELRTKVKSLSSGIPDEFICPITRELMKDPVIASDGYSYEKEAMENWISKKKRTSPMTNLVLPSAVLTPNRTLKMAINRWLETHQK>sp|P30291|WEE1_HUMAN Wee1-like protein kinase OS=Homo sapiens OX=9606GN=WEE1 PE=1 SV=2MSFLSRQQPPPPRRAGAACTLRQKLIFSPCSDCEEEEEEEEEEGSGHSTGEDSAFQEPDSPLPPARSPTEPGPERRRSPGPAPGSPGELEEDLLLPGACPGADEAGGGAEGDSWEEEGFGSSSPVKSPAAPYFLGSSFSPVRCGGPGDASPRGCGARRAGEGRRSPRPDHPGTPPHKTFRKLRLFDTPHTPKSLLSKARGIDSSSVKLRGSSLFMDTEKSGKREFDVRQTPQVNINPFTPDSLLLHSSGQCRRRKRTYWNDSCGEDMEASDYELEDETRPAKRITITESNMKSRYTTEFHELEKIGSGEFGSVFKCVKRLDGCIYAIKRSKKPLAGSVDEQNALREVYAHAVLGQHSHVVRYFSAWAEDDHMLIQNEYCNGGSLADAISENYRIMSYFKEAELKDLLLQVGRGLRYIHSMSLVHMDIKPSNIFISRTSIPNAASEEGDEDDWASNKVMFKIGDLGHVTRISSPQVEEGDSRFLANEVLQENYTHLPKADIFALALTVVCAAGAEPLPRNGDQWHEIRQGRLPRIPQVLSQEFTELLKVMIHPDPERRPSAMALVKHSVLLSASRKSAEQLRIELNAEKFKNSLLQKELKKAQMAKAAAEERALFTDRMATRSTTQSNRTSRLIGKKMNRSVSLTIY>sp|P30291-2|WEE1_HUMAN Isoform 2 of Wee1-like protein kinase OS=Homosapiens OX=9606 GN=WEE1MDTEKSGKREFDVRQTPQVNINPFTPDSLLLHSSGQCRRRKRTYWNDSCGEDMEASDYELEDETRPAKRITITESNMKSRYTTEFHELEKIGSGEFGSVFKCVKRLDGCIYAIKRSKKPLAGSVDEQNALREVYAHAVLGQHSHVVRYFSAWAEDDHMLIQNEYCNGGSLADAISENYRIMSYFKEAELKDLLLQVGRGLRYIHSMSLVHMDIKPSNIFISRTSIPNAASEEGDEDDWASNKVMFKIGDLGHVTRISSPQVEEGDSRFLANEVLQENYTHLPKADIFALALTVVCAAGAEPLPRNGDQWHEIRQGRLPRIPQVLSQEFTELLKVMIHPDPERRPSAMALVKHSVLLSASRKSAEQLRIELNAEKFKNSLLQKELKKAQMAKAAAEERALFTDRMATRSTTQSNRTSRLIGKKMNRSVSLTIY>sp|Q96S15|WDR24_HUMAN GATOR complex protein WDR24 OS=Homo sapiensOX=9606 GN=WDR24 PE=1 SV=2MEKMSRVTTALGGSVLTGRTMHCHLDAPANAISVCRDAAQVVVAGRSIFKIYAIEEEQFVEKLNLRVGRKPSLNLSCADVVWHQMDENLLATAATNGVVVTWNLGRPSRNKQDQLFTEHKRTVNKVCFHPTEAHVLLSGSQDGFMKCFDLRRKDSVSTFSGQSESVRDVQFSIRDYFTFASTFENGNVQLWDIRRPDRCERMFTAHNGPVFCCDWHPEDRGWLATGGRDKMVKVWDMTTHRAKEMHCVQTIASVARVKWRPECRHHLATCSMMVDHNIYVWDVRRPFVPAAMFEEHRDVTTGIAWRHPHDPSFLLSGSKDSSLCQHLFRDASQPVERANPEGLCYGLFGDLAFAAKESLVAAESGRKPYTGDRRHPIFFKRKLDPAEPFAGLASSALSVFETEPGGGGMRWFVDTAERYALAGRPLAELCDHNAKVARELGRNQVAQTWTMLRIIYCSPGLVPTANLNHSVGKGGSCGLPLMNSFNLKDMAPGLGSETRLDRSKGDARSDTVLLDSSATLITNEDNEETEGSDVPADYLLGDVEGEEDELYLLDPEHAHPEDPECVLPQEAFPLRHEIVDTPPGPEHLQDKADSPHVSGSEADVASLAPVDSSFSLLSVSHALYDSRLPPDFFGVLVRDMLHFYAEQGDVQMAVSVLIVLGERVRKDIDEQTQEHWYTSYIDLLQRFRLWNVSNEVVKLSTSRAVSCLNQASTTLHVNCSHCKRPMSSRGWVCDRCHRCASMCAVCHHVVKGLFVWCQGCSHGGHLQHIMKWLEGSSHCPAGCGHLCEYS>sp|Q8IUB5|WFD13_HUMAN WAP four-disulfide core domain protein 13 OS=Homosapiens OX=9606 GN=WFDC13 PE=1 SV=1MKPVLPLQFLVVFCLALQLVPGSPKQRVLKYILEPPPCISAPENCTHLCTMQEDCEKGFQCCSSFCGIVCSSETFQKRNRIKHKGSEVIMPAN>sp|Q9HBT7|ZN287_HUMAN Zinc finger protein 287 OS=Homo sapiens OX=9606GN=ZNF287 PE=2 SV=2MLASSKRMNSSSRSQILLRWKSDKAQSGPYNVEKEILTSRFLRDTETCRQNFRNFPYPDLAGPRKALSQLRELCLKWLRPEIHSKEQILELLVLEQFLTILPGEVRTWVKSQYPESSEEAVTLVEDLTQILEEEAPQNSTLSQDTPEEDPRGKHAFQTGWLNDLVTKESMTFKDVAVDITQEDWELMRPVQKELYKTVTLQNYWNMVSLGLTVYRPTVIPILEEPWMVIKEILEGPSPEWETKAQACTPVEDMSKLTKEETHTIKLEDSYDYDDRLERRGKGGFWKIHTDERGFSLKSVLSQEYDPTEECLSKYDIYRNNFEKHSNLIVQFDTQLDNKTSVYNEGRATFNHVSYGIVHRKILPGEKPYKCNVCGKKFRKYPSLLKHQSTHAKEKSYECEECGKEFRHISSLIAHQRMHTGEKPYECHQCGKAFSQRAHLTIHQRIHTGEKPYKCDDCGKDFSQRAHLTIHQRTHTGEKPYKCLECGKTFSHSSSLINHQRVHTGEKPYICNECGKTFSQSTHLLQHQKIHTGKKPYKCNECWKVFSQSTYLIRHQRIHSGEKCYKCNECGKAFAHSSTLIQHQTTHTGEKSYICNICGKAFSQSANLTQHHRTHTGEKPYKCSVCGKAFSQSVHLTQHQRIHNGEKPFKCNICGKAYRQGANLTQHQRIHTGEKPYKCNECGKAFIYSSSLNQHQRTHTGERPYKCNECDKDFSQRTCLIQHQRIHTGEKPYACRICGKTFTQSTNLIQHQRVHTGAKHRN>sp|P30954|O10J1_HUMAN Olfactory receptor 10J1 OS=Homo sapiens OX=9606GN=OR10J1 PE=2 SV=2MLLCFRFGNQSMKRENFTLITDFVFQGFSSFHEQQITLFGVFLALYILTLAGNIIIVTIIRMDLHLHTPMYFFLSMLSTSETVYTLVILPRMLSSLVGMSQPISLAGCATQMFFFVTFGITNCFLLTAMGYDRYVAICNPLRYMVIMNKRLRIQLVLGACSIGLIVAITQVTSVFRLPFCARKVPHFFCDIRPVMKLSCIDTTVNEILTLIISVLVLVVPMGLVFISYVLIISTILKIASVEGRKKAFATCASHLTVVIVHYSCASIAYLKPKSENTREHDQLISVTYTVITPLLNPVVYTLRNKEVKDALCRAVGGKFS>sp|Q13416|ORC2_HUMAN Origin recognition complex subunit 2 OS=Homosapiens OX=9606 GN=ORC2 PE=1 SV=2MSKPELKEDKMLEVHFVGDDDVLNHILDREGGAKLKKERAQLLVNPKKIIKKPEYDLEEDDQEVLKDQNYVEIMGRDVQESLKNGSATGGGNKVYSFQNRKHSEKMAKLASELAKTPQKSVSFSLKNDPEITINVPQSSKGHSASDKVQPKNNDKSEFLSTAPRSLRKRLIVPRSHSDSESEYSASNSEDDEGVAQEHEEDTNAVIFSQKIQAQNRVVSAPVGKETPSKRMKRDKTSDLVEEYFEAHSSSKVLTSDRTLQKLKRAKLDQQTLRNLLSKVSPSFSAELKQLNQQYEKLFHKWMLQLHLGFNIVLYGLGSKRDLLERFRTTMLQDSIHVVINGFFPGISVKSVLNSITEEVLDHMGTFRSILDQLDWIVNKFKEDSSLELFLLIHNLDSQMLRGEKSQQIIGQLSSLHNIYLIASIDHLNAPLMWDHAKQSLFNWLWYETTTYSPYTEETSYENSLLVKQSGSLPLSSLTHVLRSLTPNARGIFRLLIKYQLDNQDNPSYIGLSFQDFYQQCREAFLVNSDLTLRAQLTEFRDHKLIRTKKGTDGVEYLLIPVDNGTLTDFLEKEEEEA>sp|O15259|NPHP1_HUMAN Nephrocystin-1 OS=Homo sapiens OX=9606 GN=NPHP1PE=1 SV=1MLARRQRDPLQALRRRNQELKQQVDSLLSESQLKEALEPNKRQHIYQRCIQLKQAIDENKNALQKLSKADESAPVANYNQRKEEEHTLLDKLTQQLQGLAVTISRENITEVGAPTEEEEESESEDSEDSGGEEEDAEEEEEEKEENESHKWSTGEEYIAVGDFTAQQVGDLTFKKGEILLVIEKKPDGWWIAKDAKGNEGLVPRTYLEPYSEEEEGQESSEEGSEEDVEAVDETADGAEVKQRTDPHWSAVQKAISEAGIFCLVNHVSFCYLIVLMRNRMETVEDTNGSETGFRAWNVQSRGRIFLVSKPVLQINTVDVLTTMGAIPAGFRPSTLSQLLEEGNQFRANYFLQPELMPSQLAFRDLMWDATEGTIRSRPSRISLILTLWSCKMIPLPGMSIQVLSRHVRLCLFDGNKVLSNIHTVRATWQPKKPKTWTFSPQVTRILPCLLDGDCFIRSNSASPDLGILFELGISYIRNSTGERGELSCGWVFLKLFDASGVPIPAKTYELFLNGGTPYEKGIEVDPSISRRAHGSVFYQIMTMRRQPQLLVKLRSLNRRSRNVLSLLPETLIGNMCSIHLLIFYRQILGDVLLKDRMSLQSTDLISHPMLATFPMLLEQPDVMDALRSSWAGKESTLKRSEKRDKEFLKSTFLLVYHDCVLPLLHSTRLPPFRWAEEETETARWKVITDFLKQNQENQGALQALLSPDGVHEPFDLSEQTYDFLGEMRKNAV>sp|O15259-2|NPHP1_HUMAN Isoform 2 of Nephrocystin-1 OS=Homo sapiensOX=9606 GN=NPHP1MLARRQRDPLQALRRRNQELKQQVDSLLSESQLKEALEPNKRQHIYQRCIQLKQAIDENKNALQKLSKADESAPVANYNQRKEEEHTLLDKLTQQLQGLAVTISRENITEVGAPTEEEEESESEDSEDSGGEEEDAEEEEEEKEENESHKWSTGEEYIAVGDFTAQQVGDLTFKKGEILLVIEKKPDGWWIAKDAKGNEGLVPRTYLEPYSEEEEGQESSEEGSEEDVEAVDETADGAEVKQRTDPHWSAVQKAISEQINTVDVLTTMGAIPAGFRPSTLSQLLEEGNQFRANYFLQPELMPSQLAFRDLMWDATEGTIRSRPSRISLILTLWSCKMIPLPGMSIQVLSRHVRLCLFDGNKVLSNIHTVRATWQPKKPKTWTFSPQVTRILPCLLDGDCFIRSNSASPDLGILFELGISYIRNSTGERGELSCGWVFLKLFDASGVPIPAKTYELFLNGGTPYEKGIEVDPSISRRAHGSVFYQIMTMRRQPQLLVKLRSLNRRSRNVLSLLPETLIGNMCSIHLLIFYRQILGDVLLKDRMSLQSTDLISHPMLATFPMLLEQPDVMDALRSSWAGKESTLKRSEKRDKEFLKSTFLLVYHDCVLPLLHSTRLPPFRWAEEETETARWKVITDFLKQNQENQGALQALLSPDGVHEPFDLSEQTYDFLGEMRKNAV>sp|O15259-3|NPHP1_HUMAN Isoform 3 of Nephrocystin-1 OS=Homo sapiensOX=9606 GN=NPHP1MLARRQRDPLQALRRRNQELKQQVDSLLSESQLKEALEPNKRQHIYQRVGAPTEEEEESESEDSEDSGGEEEDAEEEEEEKEENESHKWSTGEEYIAVGDFTAQQVGDLTFKKGEILLVIEKKPDGWWIAKDAKGNEGLVPRTYLEPYSEEEEGQESSEEGSEEDVEAVDETADGAEVKQRTDPHWSAVQKAISEINTVDVLTTMGAIPAGFRPSTLSQLLEEGNQFRANYFLQPELMPSQLAFRDLMWDATEGTIRSRPSRISLILTLWSCKMIPLPGMSIQVLSRHVRLCLFDGNKVLSNIHTVRATWQPKKPKTWTFSPQVTRILPCLLDGDCFIRSNSASPDLGILFELGISYIRNSTGERGELSCGWVFLKLFDASGVPIPAKTYELFLNGGTPYEKGIEVDPSISRRAHGSVFYQIMTMRRQPQLLVKLRSLNRRSRNVLSLLPETLIGNMCSIHLLIFYRQILGDVLLKDRMSLQSTDLISHPMLATFPMLLEQPDVMDALRSSWAGKESTLKRSEKRDKEFLKSTFLLVYHDCVLPLLHSTRLPPFRWAEEETETARWKVITDFLKQNQENQGALQALLSPDGVHEPFDLSEQTYDFLGEMRKNAV>sp|O15259-4|NPHP1_HUMAN Isoform 4 of Nephrocystin-1 OS=Homo sapiensOX=9606 GN=NPHP1MLARRQRDPLQALRRRNQELKQQVDSLLSESQLKEALEPNKRQHIYQRCIQLKQAIDENKNALQKLSKADESAPVANYNQRKEEEHTLLDKLTQQLQGLAVTISRENITEVGAPTEEEEESESEDSEDSGGEEEDAEEEEEEKEENESHKWSTGEEYIAVGDFTAQQVGDLTFKKGEILLVIEKKPDGWWIAKDAKGNEGLVPRTYLEPYSEEEEGQESSEEGSEEDVEAVDETADGAEVKQRTDPHWSAVQKAISEAGIFCLVNHVSFCYLIVLMRNRMETVEDTNGSETGFRAWNVQSRGRIFLVSKPVLQQINTVDVLTTMGAIPAGFRPSTLSQLLEEGNQFRANYFLQPELMPSQLAFRDLMWDATEGTIRSRPSRISLILTLWSCKMIPLPGMSIQVLSRHVRLCLFDGNKVLSNIHTVRATWQPKKPKTWTFSPQVTRILPCLLDGDCFIRSNSASPDLGILFELGISYIRNSTGERGELSCGWVFLKLFDASGVPIPAKTYELFLNGGTPYEKGIEVDPSISRRAHGSVFYQIMTMRRQPQLLVKLRSLNRRSRNVLSLLPETLIGNMCSIHLLIFYRQILGDVLLKDRMSLQSTDLISHPMLATFPMLLEQPDVMDALRSSWAGKESTLKRSEKRDKEFLKSTFLLVYHDCVLPLLHSTRLPPFRWAEEETETARWKVITDFLKQNQENQGALQALLSPDGVHEPFDLSEQTYDFLGEMRKNAV>sp|Q9H208|O10A2_HUMAN Olfactory receptor 10A2 OS=Homo sapiens OX=9606GN=OR10A2 PE=2 SV=2MSFSSLPTEIQSLLFLTFLTIYLVTLMGNCLIILVTLADPMLHSPMYFFLRNLSFLEIGFNLVIVPKMLGTLLAQDTTISFLGCATQMYFFFFFGVAECFLLATMAYDRYVAICSPLHYPVIMNQRTRAKLAAASWFPGFPVATVQTTWLFSFPFCGTNKVNHFFCDSPPVLRLVCADTALFEIYAIVGTILVVMIPCLLILCSYTHIAAAILKIPSAKGKNKAFSTCSSHLLVVSLFYISLSLTYFRPKSNNSPEGKKLLSLSYTVMTPMLNPIIYSLRNNEVKNALSRTVSKALALRNCIP>sp|Q9BZF1|OSBL8_HUMAN Oxysterol-binding protein-related protein 8OS=Homo sapiens OX=9606 GN=OSBPL8 PE=1 SV=3MEGGLADGEPDRTSLLGDSKDVLGPSTVVANSDESQLLTPGKMSQRQGKEAYPTPTKDLHQPSLSPASPHSQGFERGKEDISQNKDESSLSMSKSKSESKLYNGSEKDSSTSSKLTKKESLKVQKKNYREEKKRATKELLSTITDPSVIVMADWLKIRGTLKSWTKLWCVLKPGVLLIYKTQKNGQWVGTVLLNACEIIERPSKKDGFCFKLFHPLEQSIWAVKGPKGEAVGSITQPLPSSYLIIRATSESDGRCWMDALELALKCSSLLKRTMIREGKEHDLSVSSDSTHVTFYGLLRANNLHSGDNFQLNDSEIERQHFKDQDMYSDKSDKENDQEHDESDNEVMGKSEESDTDTSERQDDSYIEPEPVEPLKETTYTEQSHEELGEAGEASQTETVSEENKSLIWTLLKQVRPGMDLSKVVLPTFILEPRSFLDKLSDYYYHADFLSEAALEENPYFRLKKVVKWYLSGFYKKPKGLKKPYNPILGETFRCLWIHPRTNSKTFYIAEQVSHHPPISAFYVSNRKDGFCLSGSILAKSKFYGNSLSAILEGEARLTFLNRGEDYVMTMPYAHCKGILYGTMTLELGGTVNITCQKTGYSAILEFKLKPFLGSSDCVNQISGKLKLGKEVLATLEGHWDSEVFITDKKTDNSEVFWNPTPDIKQWRLIRHTVKFEEQGDFESEKLWQRVTRAINAKDQTEATQEKYVLEEAQRQAARDRKTKNEEWSCKLFELDPLTGEWHYKFADTRPWDPLNDMIQFEKDGVIQTKVKHRTPMVSVPKMKHKPTRQQKKVAKGYSSPEPDIQDSSGSEAQSVKPSTRRKKGIELGDIQSSIESIKQTQEEIKRNIMALRNHLVSSTPATDYFLQQKDYFIIFLLILLQVIINFMFK>sp|Q9BZF1-2|OSBL8_HUMAN Isoform 2 of Oxysterol-binding protein-relatedprotein 8 OS=Homo sapiens OX=9606 GN=OSBPL8MEGGLADGEPDRTSANSDESQLLTPGKMSQRQGKEAYPTPTKDLHQPSLSPASPHSQGFERGKEDISQNKDESSLSMSKSKSESKLYNGSEKDSSTSSKLTKKESLKVQKKNYREEKKRATKELLSTITDPSVIVMADWLKIRGTLKSWTKLWCVLKPGVLLIYKTQKNGQWVGTVLLNACEIIERPSKKDGFCFKLFHPLEQSIWAVKGPKGEAVGSITQPLPSSYLIIRATSESDGRCWMDALELALKCSSLLKRTMIREGKEHDLSVSSDSTHVTFYGLLRANNLHSGDNFQLNDSEIERQHFKDQDMYSDKSDKENDQEHDESDNEVMGKSEESDTDTSERQDDSYIEPEPVEPLKETTYTEQSHEELGEAGEASQTETVSEENKSLIWTLLKQVRPGMDLSKVVLPTFILEPRSFLDKLSDYYYHADFLSEAALEENPYFRLKKVVKWYLSGFYKKPKGLKKPYNPILGETFRCLWIHPRTNSKTFYIAEQVSHHPPISAFYVSNRKDGFCLSGSILAKSKFYGNSLSAILEGEARLTFLNRGEDYVMTMPYAHCKGILYGTMTLELGGTVNITCQKTGYSAILEFKLKPFLGSSDCVNQISGKLKLGKEVLATLEGHWDSEVFITDKKTDNSEVFWNPTPDIKQWRLIRHTVKFEEQGDFESEKLWQRVTRAINAKDQTEATQEKYVLEEAQRQAARDRKTKNEEWSCKLFELDPLTGEWHYKFADTRPWDPLNDMIQFEKDGVIQTKVKHRTPMVSVPKMKHKPTRQQKKVAKGYSSPEPDIQDSSGSEAQSVKPSTRRKKGIELGDIQSSIESIKQTQEEIKRNIMALRNHLVSSTPATDYFLQQKDYFIIFLLILLQVIINFMFK>sp|Q9BZF1-3|OSBL8_HUMAN Isoform 3 of Oxysterol-binding protein-relatedprotein 8 OS=Homo sapiens OX=9606 GN=OSBPL8MSQRQGKEAYPTPTKDLHQPSLSPASPHSQGFERGKEDISQNKDESSLSMSKSKSESKLYNGSEKDSSTSSKLTKKESLKVQKKNYREEKKRATKELLSTITDPSVIVMADWLKIRGTLKSWTKLWCVLKPGVLLIYKTQKNGQWVGTVLLNACEIIERPSKKDGFCFKLFHPLEQSIWAVKGPKGEAVGSITQPLPSSYLIIRATSESDGRCWMDALELALKCSSLLKRTMIREGKEHDLSVSSDSTHVTFYGLLRANNLHSGDNFQLNDSEIERQHFKDQDMYSDKSDKENDQEHDESDNEVMGKSEESDTDTSERQDDSYIEPEPVEPLKETTYTEQSHEELGEAGEASQTETVSEENKSLIWTLLKQVRPGMDLSKVVLPTFILEPRSFLDKLSDYYYHADFLSEAALEENPYFRLKKVVKWYLSGFYKKPKGLKKPYNPILGETFRCLWIHPRTNSKTFYIAEQVSHHPPISAFYVSNRKDGFCLSGSILAKSKFYGNSLSAILEGEARLTFLNRGEDYVMTMPYAHCKGILYGTMTLELGGTVNITCQKTGYSAILEFKLKPFLGSSDCVNQISGKLKLGKEVLATLEGHWDSEVFITDKKTDNSEVFWNPTPDIKQWRLIRHTVKFEEQGDFESEKLWQRVTRAINAKDQTEATQEKYVLEEAQRQAARDRKTKNEEWSCKLFELDPLTGEWHYKFADTRPWDPLNDMIQFEKDGVIQTKVKHRTPMVSVPKMKHKPTRQQKKVAKGYSSPEPDIQDSSGSEAQSVKPSTRRKKGIELGDIQSSIESIKQTQEEIKRNIMALRNHLVSSTPATDYFLQQKDYFIIFLLILLQVIINFMFK>sp|Q8N2R0|OSR2_HUMAN Protein odd-skipped-related 2 OS=Homo sapiensOX=9606 GN=OSR2 PE=1 SV=2MGSKALPAPIPLHPSLQLTNYSFLQAVNTFPATVDHLQGLYGLSAVQTMHMNHWTLGYPNVHEITRSTITEMAAAQGLVDARFPFPALPFTTHLFHPKQGAIAHVLPALHKDRPRFDFANLAVAATQEDPPKMGDLSKLSPGLGSPISGLSKLTPDRKPSRGRLPSKTKKEFICKFCGRHFTKSYNLLIHERTHTDERPYTCDICHKAFRRQDHLRDHRYIHSKEKPFKCQECGKGFCQSRTLAVHKTLHMQESPHKCPTCGRTFNQRSNLKTHLLTHTDIKPYSCEQCGKVFRRNCDLRRHSLTHTPRQDF>sp|Q8N2R0-2|OSR2_HUMAN Isoform 2 of Protein odd-skipped-related 2OS=Homo sapiens OX=9606 GN=OSR2MGSKALPAPIPLHPSLQLTNYSFLQAVNTFPATVDHLQGLYGLSAVQTMHMNHWTLGYPNVHEITRSTITEMAAAQGLVDARFPFPALPFTTHLFHPKQGAIAHVLPALHKDRPRFDFANLAVAATQEDPPKMGDLSKLSPGLGSPISGLSKLTPDRKPSRGRLPSKTKKEFICKFCGRHFTKSYNLLIHERTHTDERPYTCDICHKAFRRQDHLRDHRYIHSKEKPFKCQECGKGFCQSRTLAVHKTLHMQTSSPTAASSAAKCSGETVICGGTA>sp|Q8N2R0-3|OSR2_HUMAN Isoform 3 of Protein odd-skipped-related 2OS=Homo sapiens OX=9606 GN=OSR2MGLRAEEGKRKPPRSVRGEVSPSQGPLAQEDEARRLRSCTPACHPGKRGKGGHRARRQRSAWDLTTHPLTHRSQELRGAAATEGFLYVLLSHWVFVGAPRPPASDSWKKGLVPSAPPASRKMGSKALPAPIPLHPSLQLTNYSFLQAVNTFPATVDHLQGLYGLSAVQTMHMNHWTLGYPNVHEITRSTITEMAAAQGLVDARFPFPALPFTTHLFHPKQGAIAHVLPALHKDRPRFDFANLAVAATQEDPPKMGDLSKLSPGLGSPISGLSKLTPDRKPSRGRLPSKTKKEFICKFCGRHFTKSYNLLIHERTHTDERPYTCDICHKAFRRQDHLRDHRYIHSKEKPFKCQECGKGFCQSRTLAVHKTLHMQESPHKCPTCGRTFNQRSNLKTHLLTHTDIKPYSCEQCGKVFRRNCDLRRHSLTHTPRQDF>sp|O60313|OPA1_HUMAN Dynamin-like 120 kDa protein, mitochondrial OS=Homosapiens OX=9606 GN=OPA1 PE=1 SV=3MWRLRRAAVACEVCQSLVKHSSGIKGSLPLQKLHLVSRSIYHSHHPTLKLQRPQLRTSFQQFSSLTNLPLRKLKFSPIKYGYQPRRNFWPARLATRLLKLRYLILGSAVGGGYTAKKTFDQWKDMIPDLSEYKWIVPDIVWEIDEYIDFEKIRKALPSSEDLVKLAPDFDKIVESLSLLKDFFTSGSPEETAFRATDRGSESDKHFRKVSDKEKIDQLQEELLHTQLKYQRILERLEKENKELRKLVLQKDDKGIHHRKLKKSLIDMYSEVLDVLSDYDASYNTQDHLPRVVVVGDQSAGKTSVLEMIAQARIFPRGSGEMMTRSPVKVTLSEGPHHVALFKDSSREFDLTKEEDLAALRHEIELRMRKNVKEGCTVSPETISLNVKGPGLQRMVLVDLPGVINTVTSGMAPDTKETIFSISKAYMQNPNAIILCIQDGSVDAERSIVTDLVSQMDPHGRRTIFVLTKVDLAEKNVASPSRIQQIIEGKLFPMKALGYFAVVTGKGNSSESIEAIREYEEEFFQNSKLLKTSMLKAHQVTTRNLSLAVSDCFWKMVRESVEQQADSFKATRFNLETEWKNNYPRLRELDRNELFEKAKNEILDEVISLSQVTPKHWEEILQQSLWERVSTHVIENIYLPAAQTMNSGTFNTTVDIKLKQWTDKQLPNKAVEVAWETLQEEFSRFMTEPKGKEHDDIFDKLKEAVKEESIKRHKWNDFAEDSLRVIQHNALEDRSISDKQQWDAAIYFMEEALQARLKDTENAIENMVGPDWKKRWLYWKNRTQEQCVHNETKNELEKMLKCNEEHPAYLASDEITTVRKNLESRGVEVDPSLIKDTWHQVYRRHFLKTALNHCNLCRRGFYYYQRHFVDSELECNDVVLFWRIQRMLAITANTLRQQLTNTEVRRLEKNVKEVLEDFAEDGEKKIKLLTGKRVQLAEDLKKVREIQEKLDAFIEALHQEK>sp|O60313-2|OPA1_HUMAN Isoform 2 of Dynamin-like 120 kDa protein,mitochondrial OS=Homo sapiens OX=9606 GN=OPA1MWRLRRAAVACEVCQSLVKHSSGIKGSLPLQKLHLVSRSIYHSHHPTLKLQRPQLRTSFQQFSSLTNLPLRKLKFSPIKYGYQPRRNFWPARLATRLLKLRYLILGSAVGGGYTAKKTFDQWKDMIPDLSEYKWIVPDIVWEIDEYIDFEKIRKALPSSEDLVKLAPDFDKIVESLSLLKDFFTSGSPEETAFRATDRGSESDKHFRKGLLGELILLQQQIQEHEEEARRAAGQYSTSYAQQKRKVSDKEKIDQLQEELLHTQLKYQRILERLEKENKELRKLVLQKDDKGIHHRKLKKSLIDMYSEVLDVLSDYDASYNTQDHLPRVVVVGDQSAGKTSVLEMIAQARIFPRGSGEMMTRSPVKVTLSEGPHHVALFKDSSREFDLTKEEDLAALRHEIELRMRKNVKEGCTVSPETISLNVKGPGLQRMVLVDLPGVINTVTSGMAPDTKETIFSISKAYMQNPNAIILCIQDGSVDAERSIVTDLVSQMDPHGRRTIFVLTKVDLAEKNVASPSRIQQIIEGKLFPMKALGYFAVVTGKGNSSESIEAIREYEEEFFQNSKLLKTSMLKAHQVTTRNLSLAVSDCFWKMVRESVEQQADSFKATRFNLETEWKNNYPRLRELDRNELFEKAKNEILDEVISLSQVTPKHWEEILQQSLWERVSTHVIENIYLPAAQTMNSGTFNTTVDIKLKQWTDKQLPNKAVEVAWETLQEEFSRFMTEPKGKEHDDIFDKLKEAVKEESIKRHKWNDFAEDSLRVIQHNALEDRSISDKQQWDAAIYFMEEALQARLKDTENAIENMVGPDWKKRWLYWKNRTQEQCVHNETKNELEKMLKCNEEHPAYLASDEITTVRKNLESRGVEVDPSLIKDTWHQVYRRHFLKTALNHCNLCRRGFYYYQRHFVDSELECNDVVLFWRIQRMLAITANTLRQQLTNTEVRRLEKNVKEVLEDFAEDGEKKIKLLTGKRVQLAEDLKKVREIQEKLDAFIEALHQEK>sp|O60313-9|OPA1_HUMAN Isoform 3 of Dynamin-like 120 kDa protein,mitochondrial OS=Homo sapiens OX=9606 GN=OPA1MWRLRRAAVACEVCQSLVKHSSGIKGSLPLQKLHLVSRSIYHSHHPTLKLQRPQLRTSFQQFSSLTNLPLRKLKFSPIKYGYQPRRNFWPARLATRLLKLRYLILGSAVGGGYTAKKTFDQWKDMIPDLSEYKWIVPDIVWEIDEYIDFGSPEETAFRATDRGSESDKHFRKGLLGELILLQQQIQEHEEEARRAAGQYSTSYAQQKRKVSDKEKIDQLQEELLHTQLKYQRILERLEKENKELRKLVLQKDDKGIHHRKLKKSLIDMYSEVLDVLSDYDASYNTQDHLPRVVVVGDQSAGKTSVLEMIAQARIFPRGSGEMMTRSPVKVTLSEGPHHVALFKDSSREFDLTKEEDLAALRHEIELRMRKNVKEGCTVSPETISLNVKGPGLQRMVLVDLPGVINTVTSGMAPDTKETIFSISKAYMQNPNAIILCIQDGSVDAERSIVTDLVSQMDPHGRRTIFVLTKVDLAEKNVASPSRIQQIIEGKLFPMKALGYFAVVTGKGNSSESIEAIREYEEEFFQNSKLLKTSMLKAHQVTTRNLSLAVSDCFWKMVRESVEQQADSFKATRFNLETEWKNNYPRLRELDRNELFEKAKNEILDEVISLSQVTPKHWEEILQQSLWERVSTHVIENIYLPAAQTMNSGTFNTTVDIKLKQWTDKQLPNKAVEVAWETLQEEFSRFMTEPKGKEHDDIFDKLKEAVKEESIKRHKWNDFAEDSLRVIQHNALEDRSISDKQQWDAAIYFMEEALQARLKDTENAIENMVGPDWKKRWLYWKNRTQEQCVHNETKNELEKMLKCNEEHPAYLASDEITTVRKNLESRGVEVDPSLIKDTWHQVYRRHFLKTALNHCNLCRRGFYYYQRHFVDSELECNDVVLFWRIQRMLAITANTLRQQLTNTEVRRLEKNVKEVLEDFAEDGEKKIKLLTGKRVQLAEDLKKVREIQEKLDAFIEALHQEK>sp|O60313-10|OPA1_HUMAN Isoform 4 of Dynamin-like 120 kDa protein,mitochondrial OS=Homo sapiens OX=9606 GN=OPA1MWRLRRAAVACEVCQSLVKHSSGIKGSLPLQKLHLVSRSIYHSHHPTLKLQRPQLRTSFQQFSSLTNLPLRKLKFSPIKYGYQPRRNFWPARLATRLLKLRYLILGSAVGGGYTAKKTFDQWKDMIPDLSEYKWIVPDIVWEIDEYIDFEKIRKALPSSEDLVKLAPDFDKIVESLSLLKDFFTSGHKLVSEVIGASDLLLLLGSPEETAFRATDRGSESDKHFRKGLLGELILLQQQIQEHEEEARRAAGQYSTSYAQQKRKVSDKEKIDQLQEELLHTQLKYQRILERLEKENKELRKLVLQKDDKGIHHRKLKKSLIDMYSEVLDVLSDYDASYNTQDHLPRVVVVGDQSAGKTSVLEMIAQARIFPRGSGEMMTRSPVKVTLSEGPHHVALFKDSSREFDLTKEEDLAALRHEIELRMRKNVKEGCTVSPETISLNVKGPGLQRMVLVDLPGVINTVTSGMAPDTKETIFSISKAYMQNPNAIILCIQDGSVDAERSIVTDLVSQMDPHGRRTIFVLTKVDLAEKNVASPSRIQQIIEGKLFPMKALGYFAVVTGKGNSSESIEAIREYEEEFFQNSKLLKTSMLKAHQVTTRNLSLAVSDCFWKMVRESVEQQADSFKATRFNLETEWKNNYPRLRELDRNELFEKAKNEILDEVISLSQVTPKHWEEILQQSLWERVSTHVIENIYLPAAQTMNSGTFNTTVDIKLKQWTDKQLPNKAVEVAWETLQEEFSRFMTEPKGKEHDDIFDKLKEAVKEESIKRHKWNDFAEDSLRVIQHNALEDRSISDKQQWDAAIYFMEEALQARLKDTENAIENMVGPDWKKRWLYWKNRTQEQCVHNETKNELEKMLKCNEEHPAYLASDEITTVRKNLESRGVEVDPSLIKDTWHQVYRRHFLKTALNHCNLCRRGFYYYQRHFVDSELECNDVVLFWRIQRMLAITANTLRQQLTNTEVRRLEKNVKEVLEDFAEDGEKKIKLLTGKRVQLAEDLKKVREIQEKLDAFIEALHQEK>sp|O60313-11|OPA1_HUMAN Isoform 5 of Dynamin-like 120 kDa protein,mitochondrial OS=Homo sapiens OX=9606 GN=OPA1MWRLRRAAVACEVCQSLVKHSSGIKGSLPLQKLHLVSRSIYHSHHPTLKLQRPQLRTSFQQFSSLTNLPLRKLKFSPIKYGYQPRRNFWPARLATRLLKLRYLILGSAVGGGYTAKKTFDQWKDMIPDLSEYKWIVPDIVWEIDEYIDFEKIRKALPSSEDLVKLAPDFDKIVESLSLLKDFFTSGHKLVSEVIGASDLLLLLGSPEETAFRATDRGSESDKHFRKVSDKEKIDQLQEELLHTQLKYQRILERLEKENKELRKLVLQKDDKGIHHRKLKKSLIDMYSEVLDVLSDYDASYNTQDHLPRVVVVGDQSAGKTSVLEMIAQARIFPRGSGEMMTRSPVKVTLSEGPHHVALFKDSSREFDLTKEEDLAALRHEIELRMRKNVKEGCTVSPETISLNVKGPGLQRMVLVDLPGVINTVTSGMAPDTKETIFSISKAYMQNPNAIILCIQDGSVDAERSIVTDLVSQMDPHGRRTIFVLTKVDLAEKNVASPSRIQQIIEGKLFPMKALGYFAVVTGKGNSSESIEAIREYEEEFFQNSKLLKTSMLKAHQVTTRNLSLAVSDCFWKMVRESVEQQADSFKATRFNLETEWKNNYPRLRELDRNELFEKAKNEILDEVISLSQVTPKHWEEILQQSLWERVSTHVIENIYLPAAQTMNSGTFNTTVDIKLKQWTDKQLPNKAVEVAWETLQEEFSRFMTEPKGKEHDDIFDKLKEAVKEESIKRHKWNDFAEDSLRVIQHNALEDRSISDKQQWDAAIYFMEEALQARLKDTENAIENMVGPDWKKRWLYWKNRTQEQCVHNETKNELEKMLKCNEEHPAYLASDEITTVRKNLESRGVEVDPSLIKDTWHQVYRRHFLKTALNHCNLCRRGFYYYQRHFVDSELECNDVVLFWRIQRMLAITANTLRQQLTNTEVRRLEKNVKEVLEDFAEDGEKKIKLLTGKRVQLAEDLKKVREIQEKLDAFIEALHQEK>sp|O60313-13|OPA1_HUMAN Isoform 7 of Dynamin-like 120 kDa protein,mitochondrial OS=Homo sapiens OX=9606 GN=OPA1MWRLRRAAVACEVCQSLVKHSSGIKGSLPLQKLHLVSRSIYHSHHPTLKLQRPQLRTSFQQFSSLTNLPLRKLKFSPIKYGYQPRRNFWPARLATRLLKLRYLILGSAVGGGYTAKKTFDQWKDMIPDLSEYKWIVPDIVWEIDEYIDFGSPEETAFRATDRGSESDKHFRKVSDKEKIDQLQEELLHTQLKYQRILERLEKENKELRKLVLQKDDKGIHHRKLKKSLIDMYSEVLDVLSDYDASYNTQDHLPRVVVVGDQSAGKTSVLEMIAQARIFPRGSGEMMTRSPVKVTLSEGPHHVALFKDSSREFDLTKEEDLAALRHEIELRMRKNVKEGCTVSPETISLNVKGPGLQRMVLVDLPGVINTVTSGMAPDTKETIFSISKAYMQNPNAIILCIQDGSVDAERSIVTDLVSQMDPHGRRTIFVLTKVDLAEKNVASPSRIQQIIEGKLFPMKALGYFAVVTGKGNSSESIEAIREYEEEFFQNSKLLKTSMLKAHQVTTRNLSLAVSDCFWKMVRESVEQQADSFKATRFNLETEWKNNYPRLRELDRNELFEKAKNEILDEVISLSQVTPKHWEEILQQSLWERVSTHVIENIYLPAAQTMNSGTFNTTVDIKLKQWTDKQLPNKAVEVAWETLQEEFSRFMTEPKGKEHDDIFDKLKEAVKEESIKRHKWNDFAEDSLRVIQHNALEDRSISDKQQWDAAIYFMEEALQARLKDTENAIENMVGPDWKKRWLYWKNRTQEQCVHNETKNELEKMLKCNEEHPAYLASDEITTVRKNLESRGVEVDPSLIKDTWHQVYRRHFLKTALNHCNLCRRGFYYYQRHFVDSELECNDVVLFWRIQRMLAITANTLRQQLTNTEVRRLEKNVKEVLEDFAEDGEKKIKLLTGKRVQLAEDLKKVREIQEKLDAFIEALHQEK>sp|Q9H344|O51I2_HUMAN Olfactory receptor 51I2 OS=Homo sapiens OX=9606GN=OR51I2 PE=2 SV=1MGLFNVTHPAFFLLTGIPGLESSHSWLSGPLCVMYAVALGGNTVILQAVRVEPSLHEPMYYFLSMLSFSDVAISMATLPTVLRTFCLNARNITFDACLIQMFLIHFFSMMESGILLAMSFDRYVAICDPLRYATVLTTEVIAAMGLGAAARSFITLFPLPFLIKRLPICRSNVLSHSYCLHPDMMRLACADISINSIYGLFVLVSTFGMDLFFIFLSYVLILRSVMATASREERLKALNTCVSHILAVLAFYVPMIGVSTVHRFGKHVPCYIHVLMSNVYLFVPPVLNPLIYSAKTKEIRRAIFRMFHHIKI>sp|P57721|PCBP3_HUMAN Poly(rC)-binding protein 3 OS=Homo sapiens OX=9606GN=PCBP3 PE=1 SV=2MGEGDAFWAPSVLPHSTLSTLSHHPQPQFGRRMESKVSEGGLNVTLTIRLLMHGKEVGSIIGKKGETVKKMREESGARINISEGNCPERIVTITGPTDAIFKAFAMIAYKFEEDIINSMSNSPATSKPPVTLRLVVPASQCGSLIGKGGSKIKEIRESTGAQVQVAGDMLPNSTERAVTISGTPDAIIQCVKQICVVMLESPPKGATIPYRPKPASTPVIFAGGQAYTIQGQYAIPHPDQLTKLHQLAMQQTPFPPLGQTNPAFPGEKLPLHSSEEAQNLMGQSSGLDASPPASTHELTIPNDLIGCIIGRQGTKINEIRQMSGAQIKIANATEGSSERQITITGTPANISLAQYLINARLTSEVTGMGTL>sp|P57721-2|PCBP3_HUMAN Isoform 2 of Poly(rC)-binding protein 3 OS=Homosapiens OX=9606 GN=PCBP3MGEGDAFWAPSVLPHSTLSTLSHHPQPQFGRRMESKVSEGGLNVTLTIRLLMHGKEVGSIIGKKGETVKKMREESGARINISEGNCPERIVTITGPTDAIFKAFAMIAYKFEEDIINSMSNSPATSKPPVTLRLVVPASQCGSLIGKGGSKIKEIRESTGAQVQVAGDMLPNSTERAVTISGTPDAIIQCVKQICVVMLEAYTIQGQYAIPHPDLTKLHQLAMQQTPFPPLGQTNPAFPGEKLPLHSSEEAQNLMGQSSGLDASPPASTHELTIPNDLIGCIIGRQGTKINEIRQMSGAQIKIANATEGSSERQITITGTPANISLAQYLINARLTSEVTGMGTL>sp|P57721-3|PCBP3_HUMAN Isoform 3 of Poly(rC)-binding protein 3 OS=Homosapiens OX=9606 GN=PCBP3MGEGDAFWAPSVLPHSTLSTLSHHPQPQFGRRMESKVSEGGLNVTLTIRLLMHGKEVGSIIGKKGETVKKMREESGARINISEGNCPERIVTITGPTDAIFKAFAMIAYKFEEDIINSMSNSPATSKPPVTLRLVVPASQCGSLIGKGGSKIKEIRESTGAQVQVAGDMLPNSTERAVTISGTPDAIIQCVKQICVVMLEAYTIQGQYAIPHPDQLTKLHQLAMQQTPFPPLGQTNPAFPGEKLPLHSSEEAQNLMGQSSGLDASPPASTHELTIPNDLIGCIIGRQGTKINEIRQMSGAQIKIANATEGSSERQITITGTPANISLAQYLINARLTSEVTGMGTL>sp|P57721-4|PCBP3_HUMAN Isoform 4 of Poly(rC)-binding protein 3 OS=Homosapiens OX=9606 GN=PCBP3MGEGDAFWAPSVLPHSTLSTLSHHPQPQFGRRMESKVSEGGLNVTLTIRLLMHGKEVGSIIGKKGETVKKMREESGARINISEGNCPERIVTITGPTDAIFKAFAMIAYKFEEDIINSMSNSPATSKPPVTLRLVVPASQCGSLIGKGGSKIKEIRESTGAQVQVAGDMLPNSTERAVTISGTPDAIIQCVKQICVVMLESPPKGATIPYRPKPASTPVIFAGGQAYTIQGQYAIPHPDLTKLHQLAMQQTPFPPLGQTNPAFPGEKLPLHSSEEAQNLMGQSSGLDASPPASTHELTIPNDLIGCIIGRQGTKINEIRQMSGAQIKIANATEGSSERQITITGTPANISLAQYLINARLTSEVTGMGTL>sp|P57721-5|PCBP3_HUMAN Isoform 5 of Poly(rC)-binding protein 3 OS=Homosapiens OX=9606 GN=PCBP3MGEGDAFWAPSVLPHSTLSTLSHHPQPQFGRRMESKVSEGGLNVTLTIRLLMHGKEVGSIIGKKGETVKKMREESGARINISEGNCPERIVTITGPTDAIFKAFAMIAYKFEEDIINSMSNSPATSKPPVTLRLVVPASQCGSLIGKGGSKIKEIRESTGAQVQVAGDMLPNSTERAVTISGTPDAIIQCVKQICVVMLESPPKGATIPYRPKPASTPVIFAGGQAYTIQGQYAIPHPDQLTKLHQLAMQQTPFPPLGQTNPAFPGLDASPPASTHELTIPNDLIGCIIGRQGTKINEIRQMSGAQIKIANATEGSSERQITITGTPANISLAQYLINARLTSEVTGMGTL>sp|Q8WZ94|OR5P3_HUMAN Olfactory receptor 5P3 OS=Homo sapiens OX=9606GN=OR5P3 PE=2 SV=1MGTGNDTTVVEFTLLGLSEDTTVCAILFLVFLGIYVVTLMGNISIIVLIRRSHHLHTPMYIFLCHLAFVDIGYSSSVTPVMLMSFLRKETSLPVAGCVAQLCSVVTFGTAECFLLAAMAYDRYVAICSPLLYSTCMSPGVCIILVGMSYLGGCVNAWTFIGCLLRLSFCGPNKVNHFFCDYSPLLKLACSHDFTFEIIPAISSGSIIVATVCVIAISYIYILITILKMHSTKGRHKAFSTCTSHLTAVTLFYGTITFIYVMPKSSYSTDQNKVVSVFYTVVIPMLNPLIYSLRNKEIKGALKRELRIKIFS>sp|Q8NGJ8|O51S1_HUMAN Olfactory receptor 51S1 OS=Homo sapiens OX=9606GN=OR51S1 PE=2 SV=1MSTLPTQIAPNSSTSMAPTFLLVGMPGLSGAPSWWTLPLIAVYLLSALGNGTILWIIALQPALHRPMHFFLFLLSVSDIGLVTALMPTLLGIALAGAHTVPASACLLQMVFIHVFSVMESSVLLAMSIDRALAICRPLHYPALLTNGVISKISLAISFRCLGLHLPLPFLLAYMPYCLPQVLTHSYCLHPDVARLACPEAWGAAYSLFVVLSAMGLDPLLIFFSYGLIGKVLQGVESREDRWKAGQTCAAHLSAVLLFYIPMILLALINHPELPITQHTHTLLSYVHFLLPPLINPILYSVKMKEIRKRILNRLQPRKVGGAQ>sp|Q460N3|PAR15_HUMAN Protein mono-ADP-ribosyltransferase PARP15 OS=Homosapiens OX=9606 GN=PARP15 PE=1 SV=2MAAPGPLPAAALSPGAPTPRELMHGVAGVTSRAGRDREAGSVLPAGNRGARKASRRSSSRSMSRDNKFSKKDCLSIRNVVASIQTKEGLNLKLISGDVLYIWADVIVNSVPMNLQLGGGPLSRAFLQKAGPMLQKELDDRRRETEEKVGNIFMTSGCNLDCKAVLHAVAPYWNNGAETSWQIMANIIKKCLTTVEVLSFSSITFPMIGTGSLQFPKAVFAKLILSEVFEYSSSTRPITSPLQEVHFLVYTNDDEGCQAFLDEFTNWSRINPNKARIPMAGDTQGVVGTVSKPCFTAYEMKIGAITFQVATGDIATEQVDVIVNSTARTFNRKSGVSRAILEGAGQAVESECAVLAAQPHRDFIITPGGCLKCKIIIHVPGGKDVRKTVTSVLEECEQRKYTSVSLPAIGTGNAGKNPITVADNIIDAIVDFSSQHSTPSLKTVKVVIFQPELLNIFYDSMKKRDLSASLNFQSTFSMTTCNLPEHWTDMNHQLFCMVQLEPGQSEYNTIKDKFTRTCSSYAIEKIERIQNAFLWQSYQVKKRQMDIKNDHKNNERLLFHGTDADSVPYVNQHGFNRSCAGKNAVSYGKGTYFAVDASYSAKDTYSKPDSNGRKHMYVVRVLTGVFTKGRAGLVTPPPKNPHNPTDLFDSVTNNTRSPKLFVVFFDNQAYPEYLITFTA>sp|Q460N3-2|PAR15_HUMAN Isoform 2 of Protein mono-ADP-ribosyltransferasePARP15 OS=Homo sapiens OX=9606 GN=PARP15MLQRIGLIFLHNIVVVSNCFYFQAFLDEFTNWSRINPNKARIPMAGDTQGVVGTVSKPCFTAYEMKIGAITFQVATGDIATEQVDVIVNSTARTFNRKSGVSRAILEGAGQAVESECAVLAAQPHRDFIITPGGCLKCKIIIHVPGGKDVRKTVTSVLEECEQRKYTSVSLPAIGTGNAGKNPITVADNIIDAIVDFSSQHSTPSLKTVKVVIFQPELLNIFYDSMKKRDLSASLNFQSTFSMTTCNLPEHWTDMNHQLFCMVQLEPGQSEYNTIKDKFTRTCSSYAIEKIERIQNAFLWQSYQVKKRQMDIKNDHKNNERLLFHGTDADSVPYVNQHGFNRSCAGKNAVSYGKGTYFAVDASYSAKDTYSKPDSNGRKHMYVVRVLTGVFTKGRAGLVTPPPKNPHNPTDLFDSVTNNTRSPKLFVVFFDNQAYPEYLITFTA>sp|Q8NH21|OR4F5_HUMAN Olfactory receptor 4F5 OS=Homo sapiens OX=9606GN=OR4F5 PE=3 SV=1MVTEFIFLGLSDSQELQTFLFMLFFVFYGGIVFGNLLIVITVVSDSHLHSPMYFLLANLSLIDLSLSSVTAPKMITDFFSQRKVISFKGCLVQIFLLHFFGGSEMVILIAMGFDRYIAICKPLHYTTIMCGNACVGIMAVTWGIGFLHSVSQLAFAVHLLFCGPNEVDSFYCDLPRVIKLACTDTYRLDIMVIANSGVLTVCSFVLLIISYTIILMTIQHRPLDKSSKALSTLTAHITVVLLFFGPCVFIYAWPFPIKSLDKFLAVFYSVITPLLNPIIYTLRNKDMKTAIRQLRKWDAHSSVKF>sp|Q99572|P2RX7_HUMAN P2X purinoceptor 7 OS=Homo sapiens OX=9606GN=P2RX7 PE=1 SV=4MPACCSCSDVFQYETNKVTRIQSMNYGTIKWFFHVIIFSYVCFALVSDKLYQRKEPVISSVHTKVKGIAEVKEEIVENGVKKLVHSVFDTADYTFPLQGNSFFVMTNFLKTEGQEQRLCPEYPTRRTLCSSDRGCKKGWMDPQSKGIQTGRCVVYEGNQKTCEVSAWCPIEAVEEAPRPALLNSAENFTVLIKNNIDFPGHNYTTRNILPGLNITCTFHKTQNPQCPIFRLGDIFRETGDNFSDVAIQGGIMGIEIYWDCNLDRWFHHCRPKYSFRRLDDKTTNVSLYPGYNFRYAKYYKENNVEKRTLIKVFGIRFDILVFGTGGKFDIIQLVVYIGSTLSYFGLAAVFIDFLIDTYSSNCCRSHIYPWCKCCQPCVVNEYYYRKKCESIVEPKPTLKYVSFVDESHIRMVNQQLLGRSLQDVKGQEVPRPAMDFTDLSRLPLALHDTPPIPGQPEEIQLLRKEATPRSRDSPVWCQCGSCLPSQLPESHRCLEELCCRKKPGACITTSELFRKLVLSRHVLQFLLLYQEPLLALDVDSTNSRLRHCAYRCYATWRFGSQDMADFAILPSCCRWRIRKEFPKSEGQYSGFKSPY>sp|Q99572-2|P2RX7_HUMAN Isoform B of P2X purinoceptor 7 OS=Homo sapiensOX=9606 GN=P2RX7MPACCSCSDVFQYETNKVTRIQSMNYGTIKWFFHVIIFSYVCFALVSDKLYQRKEPVISSVHTKVKGIAEVKEEIVENGVKKLVHSVFDTADYTFPLQGNSFFVMTNFLKTEGQEQRLCPEYPTRRTLCSSDRGCKKGWMDPQSKGIQTGRCVVYEGNQKTCEVSAWCPIEAVEEAPRPALLNSAENFTVLIKNNIDFPGHNYTTRNILPGLNITCTFHKTQNPQCPIFRLGDIFRETGDNFSDVAIQGGIMGIEIYWDCNLDRWFHHCRPKYSFRRLDDKTTNVSLYPGYNFRYAKYYKENNVEKRTLIKVFGIRFDILVFGTGGKFDIIQLVVYIGSTLSYFGLVRDSLFHALGKWFGEGSD>sp|Q99572-3|P2RX7_HUMAN Isoform C of P2X purinoceptor 7 OS=Homo sapiensOX=9606 GN=P2RX7MPACCSCSDVFQYETNKVTRIQSMNYGTIKWFFHVIIFSYVCFALVSDKLYQRKEPVISSVHTKVKGIAEVKEEIVENGVKKLVHSVFDTADYTFPLQGNSFFVMTNFLKTEGQEQRLCPEEFRPEGV>sp|Q99572-4|P2RX7_HUMAN Isoform D of P2X purinoceptor 7 OS=Homo sapiensOX=9606 GN=P2RX7MDGPAEQRPALLNSAENFTVLIKNNIDFPGHNYTTRNILPGLNITCTFHKTQNPQCPIFRLGDIFRETGDNFSDVAIQGGIMGIEIYWDCNLDRWFHHCRPKYSFRRLDDKTTNVSLYPGYNFRYAKYYKENNVEKRTLIKVFGIRFDILVFGTGGKFDIIQLVVYIGSTLSYFGLAAVFIDFLIDTYSSNCCRSHIYPWCKCCQPCVVNEYYYRKKCESIVEPKPTLKYVSFVDESHIRMVNQQLLGRSLQDVKGQEVPRPAMDFTDLSRLPLALHDTPPIPGQPEEIQLLRKEATPRSRDSPVWCQCGSCLPSQLPESHRCLEELCCRKKPGACITTSELFRKLVLSRHVLQFLLLYQEPLLALDVDSTNSRLRHCAYRCYATWRFGSQDMADFAILPSCCRWRIRKEFPKSEGQYSGFKSPY>sp|Q99572-5|P2RX7_HUMAN Isoform E of P2X purinoceptor 7 OS=Homo sapiensOX=9606 GN=P2RX7MPACCSCSDVFQYETNKVTRIQSMNYGTIKWFFHVIIFSYVCFALVSDKLYQRKEPVISSVHTKVKGIAEVKEEIVENGVKKLVHSVFDTADYTFPLQGNSFFVMTNFLKTEGQEQRLCPEYPTRRTLCSSDRGCKKGWMDPQSKGIQTGRCVVYEGNQKTCEVSAWCPIEAVEEAPRPALLNSAENFTVLIKNNIDFPGHNYTTYAKYYKENNVEKRTLIKVFGIRFDILVFGTGGKFDIIQLVVYIGSTLSYFGLVRDSLFHALGKWFGEGSD>sp|Q99572-6|P2RX7_HUMAN Isoform F of P2X purinoceptor 7 OS=Homo sapiensOX=9606 GN=P2RX7MWQFRYAKYYKENNVEKRTLIKVFGIRFDILVFGTGGKFDIIQLVVYIGSTLSYFGLAAVFIDFLIDTYSSNCCRSHIYPWCKCCQPCVVNEYYYRKKCESIVEPKPTLKYVSFVDESHIRMVNQQLLGRSLQDVKGQEVPRPAMDFTDLSRLPLALHDTPPIPGQPEEIQLLRKEATPRSRDSPVWCQCGSCLPSQLPESHRCLEELCCRKKPGACITTSELFRKLVLSRHVLQFLLLYQEPLLALDVDSTNSRLRHCAYRCYATWRFGSQDMADFAILPSCCRWRIRKEFPKSEGQYSGFKSPY>sp|Q99572-7|P2RX7_HUMAN Isoform G of P2X purinoceptor 7 OS=Homo sapiensOX=9606 GN=P2RX7MTPGDHSWGNSFFVMTNFLKTEGQEQRLCPEYPTRRTLCSSDRGCKKGWMDPQSKGIQTGRCVVYEGNQKTCEVSAWCPIEAVEEAPRPALLNSAENFTVLIKNNIDFPGHNYTTRNILPGLNITCTFHKTQNPQCPIFRLGDIFRETGDNFSDVAIQGGIMGIEIYWDCNLDRWFHHCRPKYSFRRLDDKTTNVSLYPGYNFRYAKYYKENNVEKRTLIKVFGIRFDILVFGTGGKFDIIQLVVYIGSTLSYFGLVRDSLFHALGKWFGEGSD>sp|Q99572-8|P2RX7_HUMAN Isoform H of P2X purinoceptor 7 OS=Homo sapiensOX=9606 GN=P2RX7MTPGDHSWGNSFFVMTNFLKTEGQEQRLCPEYPTRRTLCSSDRGCKKGWMDPQSKGIQTGRCVVYEGNQKTCEVSAWCPIEAVEEAPRPALLNSAENFTVLIKNNIDFPGHNYTTRNILPGLNITCTFHKTQNPQCPIFRLGDIFRETGDNFSDVAIQGGIMGIEIYWDCNLDRWFHHCRPKYSFRRLDDKTTNVSLYPGYNFRYAKYYKENNVEKRTLIKVFGIRFDILVFGTGGKFDIIQLVVYIGSTLSYFGLAAVFIDFLIDTYSSNCCRSHIYPWCKCCQPCVVNEYYYRKKCESIVEPKPTLKYVSFVDESHIRMVNQQLLGRSLQDVKGQEVPRPAMDFTDLSRLPLALHDTPPIPGQPEEIQLLRKEATPRSRDSPVWCQCGSCLPSQLPESHRCLEELCCRKKPGACITTSELFRKLVLSRHVLQFLLLYQEPLLALDVDSTNSRLRHCAYRCYATWRFGSQDMADFAILPSCCRWRIRKEFPKSEGQYSGFKSPY>sp|Q68DD2|PA24F_HUMAN Cytosolic phospholipase A2 zeta OS=Homo sapiensOX=9606 GN=PLA2G4F PE=1 SV=3MLWALWPRWLADKMLPLLGAVLLQKREKRGPLWRHWRRETYPYYDLQVKVLRATNIRGTDLLSKADCYVQLWLPTASPSPAQTRIVANCSDPEWNETFHYQIHGAVKNVLELTLYDKDILGSDQLSLLLFDLRSLKCGQPHKHTFPLNHQDSQELQVEFVLEKSQVPASEVITNGVLVAHPCLRIQGTLRGDGTAPREEYGSRQLQLAVPGAYEKPQLLPLQPPTEPGLPPTFTFHVNPVLSSRLHVELMELLAAVQSGPSAELEAQTSKLGEGGILLSSLPLGQEEQCSVALGEGQEVALSMKVEMSSGDLDLRLGFDLSDGEQEFLDRRKQVVSKALQQVLGLSEALDSGQVPVVAVLGSGGGTRAMSSLYGSLAGLQELGLLDTVTYLSGVSGSTWCISTLYRDPAWSQVALQGPIERAQVHVCSSKMGALSTERLQYYTQELGVRERSGHSVSLIDLWGLLVEYLLYQEENPAKLSDQQEAVRQGQNPYPIYTSVNVRTNLSGEDFAEWCEFTPYEVGFPKYGAYVPTELFGSELFMGRLLQLQPEPRICYLQGMWGSAFATSLDEIFLKTAGSGLSFLEWYRGSVNITDDCQKPQLHNPSRLRTRLLTPQGPFSQAVLDIFTSRFTSAQSFNFTRGLCLHKDYVAGREFVAWKDTHPDAFPNQLTPMRDCLYLVDGGFAINSPFPLALLPQRAVDLILSFDYSLEAPFEVLKMTEKYCLDRGIPFPSIEVGPEDMEEARECYLFAKAEDPRSPIVLHFPLVNRTFRTHLAPGVERQTAEEKAFGDFVINRPDTPYGMMNFTYEPQDFYRLVALSRYNVLNNVETLKCALQLALDRHQARERAGA>sp|Q68DD2-2|PA24F_HUMAN Isoform 2 of Cytosolic phospholipase A2 zetaOS=Homo sapiens OX=9606 GN=PLA2G4FMLWALWPRWLADKMLPLLGAVLLQKREKRGPLWRHWRRETYPYYDLQVKVLRATNIRGTDLLSKADCYVQLWLPTASPSPAQTRIVANCSDPEWNETFHYQIHGAVKNVLELTLYDKDILGSDQLSLLLFDLRSLKCGQPHKHTFPLNHQDSQELQVEFVLEKSQVPASEVITNGVLVAHPCLRIQGTLRGDGTAPREEYGSRQLQLAVPGAYEKPQLLPLQPPTEPGLPPTFTFHVNPVLSSRLHVELMELLAAVQSGPSAELEAQTSKLGEGGILLSSLPLGQEEQCSVALGEGQEVALSMKVEMSSGDLDLRLGFDLSDGEQEFLDRRKQVVSKALQQVLGLSEALDSGQVPVVAVLGSGGGTRAMSSLYGSLAGLQELGLLDTVTYLSGVSGSTWCISTLYRDPAWSQVALQGPIERAQVHVCSSKMGDVRVSPCQLPRLHSSNLDHSLW>sp|Q68DD2-3|PA24F_HUMAN Isoform 3 of Cytosolic phospholipase A2 zetaOS=Homo sapiens OX=9606 GN=PLA2G4FMLWALWPRWLADKMLPLLGAVLLQKREKRGPLWRHWRRETYPYYDLQVKVLRATNIRGTDLLSKADCYVQLWLPTASPSPAQTRIVANCSDPEWNETFHYQIHGAVKNVLELTLYDKDILGSDQLSLLLFDLRSLKCGQPHKHTFPLNHQDSQELQVEFVLEKSQVPASEVITNGVLVAHPCLRIQGTLRGDGTAPREEYGSRQLQLAVPGAYEKPQLLPLQPPTEPGLPPTFTFHVNPVLSSRLHVELMELLAAVQSGPSAELEAQTSKLGEGGILLSSLPLGQEEQCSVALGEGQEVALSMKVEMSSGDLDLRLGFDLSDGEQEFLDRRKQVVSKALQQVLGLSEALDSGQVQVPVVAVLGSGGGTRAMSSLYGSLAGLQELGLLDTVTYLSGVSGSTWCISTLYRDPAWSQVALQGPIERAQVHVCSSKMGALSTERLQYYTQELGVRERSGHSVSLIDLWGLLVEYLLYQEENPAKLSDQQEAVRQGQNPYPIYTSVNVRTNLSGEDFAEWCEFTPYEVGFPKYGAYVPTELFGSELFMGRLLQLQPEPRICYLQGMWGSAFATSLDEIFLKTAGSGLSFLEWYRGSVNITDDCQKPQLHNPSRLRTRLLTPQGPFSQAVLDIFTSRFTSAQSFNFTRGLCLHKDYVAGREFVAWKDTHPDAFPNQLTPMRDCLYLVDGGFAINSPFPLALLPQRAVDLILSFDYSLEAPFEVLKMTEKYCLDRGIPFPSIEVGPEDMEEARECYLFAKAEDPRSPIVLHFPLVNRTFRTHLAPGVERQTAEEKAFGDFVINRPDTPYGMMNFTYEPQDFYRLVALSRYNVLNNVETLKCALQLALDRHQARERAGA>sp|Q96FM1|PGAP3_HUMAN Post-GPI attachment to proteins factor 3 OS=Homosapiens OX=9606 GN=PGAP3 PE=1 SV=2MAGLAARLVLLAGAAALASGSQGDREPVYRDCVLQCEEQNCSGGALNHFRSRQPIYMSLAGWTCRDDCKYECMWVTVGLYLQEGHKVPQFHGKWPFSRFLFFQEPASAVASFLNGLASLVMLCRYRTFVPASSPMYHTCVAFAWVSLNAWFWSTVFHTRDTDLTEKMDYFCASTVILHSIYLCCVRTVGLQHPAVVSAFRALLLLMLTVHVSYLSLIRFDYGYNLVANVAIGLVNVVWWLAWCLWNQRRLPHVRKCVVVVLLLQGLSLLELLDFPPLFWVLDAHAIWHISTIPVHVLFFSFLEDDSLYLLKESEDKFKLD>sp|Q96FM1-2|PGAP3_HUMAN Isoform 2 of Post-GPI attachment to proteinsfactor 3 OS=Homo sapiens OX=9606 GN=PGAP3MAGLAARLVLLAGAAALASGSQGDREPVYRDCVLQCEEQNCSGGALNHFRSRQPIYMSLAGWTCRDDCKYECMWVTVGLYLQEGHKVPQFHGKVSLNAWFWSTVFHTRDTDLTEKMDYFCASTVILHSIYLCCVRTVGLQHPAVVSAFRALLLLMLTVHVSYLSLIRFDYGYNLVANVAIGLVNVVWWLAWCLWNQRRLPHVRKCVVVVLLLQGLSLLELLDFPPLFWVLDAHAIWHISTIPVHVLFFSFLEDDSLYLLKESEDKFKLD>sp|Q96FM1-3|PGAP3_HUMAN Isoform 3 of Post-GPI attachment to proteinsfactor 3 OS=Homo sapiens OX=9606 GN=PGAP3MAGLAARLVLLAGAAALASGSQGDREPVYRDCVLQCEEQNCSGGALNHFRSRQPIYMSLAGWTCRDDCKYECMWVTVGLYLQEGHKVPQFHGKWPFSRFLFFQEPASAVASFLNGLASLVMLCRYRTFVPASSPMYHTCVAFAWKMDYFCASTVILHSIYLCCVRTVGLQHPAVVSAFRALLLLMLTVHVSYLSLIRFDYGYNLVANVAIGLVNVVWWLAWCLWNQRRLPHVRKCVVVVLLLQGLSLLELLDFPPLFWVLDAHAIWHISTIPVHVLFFSFLEDDSLYLLKESEDKFKLD>sp|Q8N0Y7|PGAM4_HUMAN Probable phosphoglycerate mutase 4 OS=Homo sapiensOX=9606 GN=PGAM4 PE=3 SV=1MAAYKLVLIRHGESTWNLENRFSCWYDADLSPAGHEEAKRGGQALRDAGYEFDICLTSVQKRVIRTLWTVLDAIDQMWLPVVRTWRLNERHYGGLTGLNKAETAAKHGEAQVKIWRRSYDVPPPPMEPDHPFYSNISKDRRYADLTEDQLPSYESPKDTIARALPFWNEEIVPQIKEGKRVLIAAHGNSLQGIAKHVEGLSEEAIMELNLPTGIPIVYELDKNLKPIKPMQFLGDEETVCKAIEAVAAQGKAKK>sp|Q15042|RB3GP_HUMAN Rab3 GTPase-activating protein catalytic subunitOS=Homo sapiens OX=9606 GN=RAB3GAP1 PE=1 SV=3MAADSEPESEVFEITDFTTASEWERFISKVEEVLNDWKLIGNSLGKPLEKGIFTSGTWEEKSDEISFADFKFSVTHHYLVQESTDKEGKDELLEDVVPQSMQDLLGMNNDFPPRAHCLVRWYGLREFVVIAPAAHSDAVLSESKCNLLLSSVSIALGNTGCQVPLFVQIHHKWRRMYVGECQGPGVRTDFEMVHLRKVPNQYTHLSGLLDIFKSKIGCPLTPLPPVSIAIRFTYVLQDWQQYFWPQQPPDIDALVGGEVGGLEFGKLPFGACEDPISELHLATTWPHLTEGIIVDNDVYSDLDPIQAPHWSVRVRKAENPQCLLGDFVTEFFKICRRKESTDEILGRSAFEEEGKETADITHALSKLTEPASVPIHKLSVSNMVHTAKKKIRKHRGVEESPLNNDVLNTILLFLFPDAVSEKPLDGTTSTDNNNPPSESEDYNLYNQFKSAPSDSLTYKLALCLCMINFYHGGLKGVAHLWQEFVLEMRFRWENNFLIPGLASGPPDLRCCLLHQKLQMLNCCIERKKARDEGKKTSASDVTNIYPGDAGKAGDQLVPDNLKETDKEKGEVGKSWDSWSDSEEEFFECLSDTEELKGNGQESGKKGGPKEMANLRPEGRLYQHGKLTLLHNGEPLYIPVTQEPAPMTEDLLEEQSEVLAKLGTSAEGAHLRARMQSACLLSDMESFKAANPGCSLEDFVRWYSPRDYIEEEVIDEKGNVVLKGELSARMKIPSNMWVEAWETAKPIPARRQRRLFDDTREAEKVLHYLAIQKPADLARHLLPCVIHAAVLKVKEEESLENISSVKKIIKQIISHSSKVLHFPNPEDKKLEEIIHQITNVEALIARARSLKAKFGTEKCEQEEEKEDLERFVSCLLEQPEVLVTGAGRGHAGRIIHKLFVNAQRAAAMTPPEEELKRMGSPEERRQNSVSDFPPPAGREFILRTTVPRPAPYSKALPQRMYSVLTKEDFRLAGAFSSDTSFF>sp|Q15042-3|RB3GP_HUMAN Isoform 2 of Rab3 GTPase-activating proteincatalytic subunit OS=Homo sapiens OX=9606 GN=RAB3GAP1MAADSEPESEVFEITDFTTASEWERFISKVEEVLNDWKLIGNSLGKPLEKGIFTSGTWEEKSDEISFADFKFSVTHHYLVQESTDKEGKDELLEDVVPQSMQDLLGMNNDFPPRAHCLVRWYGLREFVVIAPAAHSDAVLSESKCNLLLSSVSIALGNTGCQVPLFVQIHHKWRRMYVGECQGPGVRTDFEMVHLRKVPNQYTHLSGLLDIFKSKIGCPLTPLPPVSIAIRFTYVLQDWQQYFWPQQPPDIDALVGGEVGGLEFGKLPFGACEDPISELHLATTWPHLTEGIIVDNDVYSDLDPIQAPHWSVRVRKAENPQCLLGDFVTEFFKICRRKESTDEILGRSAFEEEGKETADITHALSKLTEPASVPIHKLSVSNMVHTAKKKIRKHRGVEESPLNNDVLNTILLFLFPDAVSEKPLDGTTSTDNNNPPSESEDYNLYNQFKSAPSDSLTYKLALCLCMINFYHGGLKGVAHLWQEFVLEMRFRWENNFLIPGLASGPPDLRCCLLHQKLQMLNCCIERKKARDEGKKTSASDVTNIYPGDAGKAGDQLVPDNLKETDKEKGEVGKSWDSWSDSEEEFFECLSDTEELKGNGQESGKKGGPKEMANLRPEGRLYQHGKLTLLHNGEPLYIPVTQEPAPMTEDLLEEQSEVLAKLGTSAEGAHLRARMQSACLLSDMESFKAANPGCSLEDFVRWYSPRDYIEEEVIDEKGNVVLKGELSARMKIPSNMWVEAWETAKPIPARRQRRLFDDTREAEKVLHYLAIQKPADLARHLLPCVIHAAVLKVKEEESLENISSVKKIIKQIISHSSKVLHFPNPEDKKLEEIIHQITNVEALIARARSLKAKFGTEKCEQEEEKEDLERFVSCLLEQPEVLVTGAGRGHAGRIIHKLFVNAQRLTESSDEAAAMTPPEEELKRMGSPEERRQNSVSDFPPPAGREFILRTTVPRPAPYSKALPQRMYSVLTKEDFRLAGAFSSDTSFF>sp|Q15042-4|RB3GP_HUMAN Isoform 3 of Rab3 GTPase-activating proteincatalytic subunit OS=Homo sapiens OX=9606 GN=RAB3GAP1MFSLISGIFTSGTWEEKSDEISFADFKFSVTHHYLVQESTDKEGKDELLEDVVPQSMQDLLGMNNDFPPRAHCLVRWYGLREFVVIAPAAHSDAVLSESKCNLLLSSVSIALGNTGCQVPLFVQIHHKWRRMYVGECQGPGVRTDFEMVHLRKVPNQYTHLSGLLDIFKSKIGCPLTPLPPVSIAIRFTYVLQDWQQYFWPQQPPDIDALVGGEVGGLEFGKLPFGACEDPISELHLATTWPHLTEGIIVDNDVYSDLDPIQAPHWSVRVRKAENPQCLLGDFVTEFFKICRRKESTDEILGRSAFEEEGKETADITHALSKLTEPASVPIHKLSVSNMVHTAKKKIRKHRGVEESPLNNDVLNTILLFLFPDAVSEKPLDGTTSTDNNNPPSESEDYNLYNQFKSAPSDSLTYKLALCLCMINFYHGGLKGVAHLWQEFVLEMRFRWENNFLIPGLASGPPDLRCCLLHQKLQMLNCCIERKKARDEGKKTSASDVTNIYPGDAGKAGDQLVPDNLKETDKEKGEVGKSWDSWSDSEEEFFECLSDTEELKGNGQESGKKGGPKEMANLRPEGRLYQHGKLTLLHNGEPLYIPVTQEPAPMTEDLLEEQSEVLAKLGTSAEGAHLRARMQSACLLSDMESFKAANPGCSLEDFVRWYSPRDYIEEEVIDEKGNVVLKGELSARMKIPSNMWVEAWETAKPIPARRQRRLFDDTREAEKVLHYLAIQKPADLARHLLPCVIHAAVLKVKEEESLENISSVKKIIKQIISHSSKVLHFPNPEDKKLEEIIHQITNVEALIARARSLKAKFGTEKCEQEEEKEDLERFVSCLLEQPEVLVTGAGRGHAGRIIHKLFVNAQRAAAMTPPEEELKRMGSPEERRQNSVSDFPPPAGREFILRTTVPRPAPYSKALPQRMYSVLTKEDFRLAVKIIDGDV>sp|P35913|PDE6B_HUMAN Rod cGMP-specific 3',5'-cyclic phosphodiesterasesubunit beta OS=Homo sapiens OX=9606 GN=PDE6B PE=1 SV=2MSLSEEQARSFLDQNPDFARQYFGKKLSPENVAAACEDGCPPDCDSLRDLCQVEESTALLELVQDMQESINMERVVFKVLRRLCTLLQADRCSLFMYRQRNGVAELATRLFSVQPDSVLEDCLVPPDSEIVFPLDIGVVGHVAQTKKMVNVEDVAECPHFSSFADELTDYKTKNMLATPIMNGKDVVAVIMAVNKLNGPFFTSEDEDVFLKYLNFATLYLKIYHLSYLHNCETRRGQVLLWSANKVFEELTDIERQFHKAFYTVRAYLNCERYSVGLLDMTKEKEFFDVWSVLMGESQPYSGPRTPDGREIVFYKVIDYVLHGKEEIKVIPTPSADHWALASGLPSYVAESGFICNIMNASADEMFKFQEGALDDSGWLIKNVLSMPIVNKKEEIVGVATFYNRKDGKPFDEQDEVLMESLTQFLGWSVMNTDTYDKMNKLENRKDIAQDMVLYHVKCDRDEIQLILPTRARLGKEPADCDEDELGEILKEELPGPTTFDIYEFHFSDLECTELDLVKCGIQMYYELGVVRKFQIPQEVLVRFLFSISKGYRRITYHNWRHGFNVAQTMFTLLMTGKLKSYYTDLEAFAMVTAGLCHDIDHRGTNNLYQMKSQNPLAKLHGSSILERHHLEFGKFLLSEETLNIYQNLNRRQHEHVIHLMDIAIIATDLALYFKKRAMFQKIVDESKNYQDKKSWVEYLSLETTRKEIVMAMMMTACDLSAITKPWEVQSKVALLVAAEFWEQGDLERTVLDQQPIPMMDRNKAAELPKLQVGFIDFVCTFVYKEFSRFHEEILPMFDRLQNNRKEWKALADEYEAKVKALEEKEEEERVAAKKVGTEICNGGPAPKSSTCCIL>sp|P35913-2|PDE6B_HUMAN Isoform 2 of Rod cGMP-specific 3',5'-cyclicphosphodiesterase subunit beta OS=Homo sapiens OX=9606 GN=PDE6BMSLSEEQARSFLDQNPDFARQYFGKKLSPENVAAACEDGCPPDCDSLRDLCQVEESTALLELVQDMQESINMERVVFKVLRRLCTLLQADRCSLFMYRQRNGVAELATRLFSVQPDSVLEDCLVPPDSEIVFPLDIGVVGHVAQTKKMVNVEDVAECPHFSSFADELTDYKTKNMLATPIMNGKDVVAVIMAVNKLNGPFFTSEDEDVFLKYLNFATLYLKIYHLSYLHNCETRRGQVLLWSANKVFEELTDIERQFHKAFYTVRAYLNCERYSVGLLDMTKEKEFFDVWSVLMGESQPYSGPRTPDGREIVFYKVIDYVLHGKEEIKVIPTPSADHWALASGLPSYVAESGFICNIMNASADEMFKFQEGALDDSGWLIKNVLSMPIVNKKEEIVGVATFYNRKDGKPFDEQDEVLMESLTQFLGWSVMNTDTYDKMNKLENRKDIAQDMVLYHVKCDRDEIQLILPTRARLGKEPADCDEDELGEILKEELPGPTTFDIYEFHFSDLECTELDLVKCGIQMYYELGVVRKFQIPQEVLVRFLFSISKGYRRITYHNWRHGFNVAQTMFTLLMTGKLKSYYTDLEAFAMVTAGLCHDIDHRGTNNLYQMKSQNPLAKLHGSSILERHHLEFGKFLLSEETLNIYQNLNRRQHEHVIHLMDIAIIATDLALYFKKRAMFQKIVDESKNYQDKKSWVEYLSLETTRKEIVMAMMMTACDLSAITKPWEVQSKVALLVAAEFWEQGDLERTVLDQQPIPMMDRNKAAELPKLQVGFIDFVCTFVYKEFSRFHEEILPMFDRLQNNRKEWKALADEYEAKVKALEEKEEEERVAAKKGTEICNGGPAPKSSTCCIL>sp|P35913-3|PDE6B_HUMAN Isoform 3 of Rod cGMP-specific 3',5'-cyclicphosphodiesterase subunit beta OS=Homo sapiens OX=9606 GN=PDE6BMTKEKEFFDVWSVLMGESQPYSGPRTPDGREIVFYKVIDYVLHGKEEIKVIPTPSADHWALASGLPSYVAESGFICNIMNASADEMFKFQEGALDDSGWLIKNVLSMPIVNKKEEIVGVATFYNRKDGKPFDEQDEVLMESLTQFLGWSVMNTDTYDKMNKLENRKDIAQDMVLYHVKCDRDEIQLILPTRARLGKEPADCDEDELGEILKEELPGPTTFDIYEFHFSDLECTELDLVKCGIQMYYELGVVRKFQIPQEVLVRFLFSISKGYRRITYHNWRHGFNVAQTMFTLLMTGKLKSYYTDLEAFAMVTAGLCHDIDHRGTNNLYQMKSQNPLAKLHGSSILERHHLEFGKFLLSEETLNIYQNLNRRQHEHVIHLMDIAIIATDLALYFKKRAMFQKIVDESKNYQDKKSWVEYLSLETTRKEIVMAMMMTACDLSAITKPWEVQSKVALLVAAEFWEQGDLERTVLDQQPIPMMDRNKAAELPKLQVGFIDFVCTFVYKEFSRFHEEILPMFDRLQNNRKEWKALADEYEAKVKALEEKEEEERVAAKKVGTEICNGGPAPKSSTCCIL>sp|Q53GG5|PDLI3_HUMAN PDZ and LIM domain protein 3 OS=Homo sapiensOX=9606 GN=PDLIM3 PE=1 SV=1MPQTVILPGPAPWGFRLSGGIDFNQPLVITRITPGSKAAAANLCPGDVILAIDGFGTESMTHADAQDRIKAAAHQLCLKIDRGETHLWSPQVSEDGKAHPFKINLESEPQDGNYFEHKHNIRPKPFVIPGRSSGCSTPSGIDCGSGRSTPSSVSTVSTICPGDLKVAAKLAPNIPLEMELPGVKIVHAQFNTPMQLYSDDNIMETLQGQVSTALGETPLMSEPTASVPPESDVYRMLHDNRNEPTQPRQSGSFRVLQGMVDDGSDDRPAGTRSVRAPVTKVHGGSGGAQRMPLCDKCGSGIVGAVVKARDKYRHPECFVCADCNLNLKQKGYFFIEGELYCETHARARTKPPEGYDTVTLYPKA>sp|Q53GG5-2|PDLI3_HUMAN Isoform 2 of PDZ and LIM domain protein 3OS=Homo sapiens OX=9606 GN=PDLIM3MPQTVILPGPAPWGFRLSGGIDFNQPLVITRITPGSKAAAANLCPGDVILAIDGFGTESMTHADAQDRIKAAAHQLCLKIDRGETHLWSPQVSEDGKAHPFKINLESEPQEFKPIGTAHNRRAQPFVAAANIDDKRQVVSASYNSPIGLYSTSNIQDALHGQLRGLIPSSPQNEPTASVPPESDVYRMLHDNRNEPTQPRQSGSFRVLQGMVDDGSDDRPAGTRSVRAPVTKVHGGSGGAQRMPLCDKCGSGIVGAVVKARDKYRHPECFVCADCNLNLKQKGYFFIEGELYCETHARARTKPPEGYDTVTLYPKA>sp|Q53GG5-3|PDLI3_HUMAN Isoform 3 of PDZ and LIM domain protein 3OS=Homo sapiens OX=9606 GN=PDLIM3MPQTVILPGPAPWGFRLSGGIDFNQPLVITRITPGSKAAAANLCPGDVILAIDGFGTESMTHADAQDRIKAAAHQLCLKIDRGETHLWSPQVSEDGKAHPFKINLESEPQEFKPIGTAHNRRAQPFVAAANIDDKRQVVSASYNSPIGLYSTSNIQDALHGQLRGLIPSSPQKTGTTLNTSIIFGPNLS>sp|P43088|PF2R_HUMAN Prostaglandin F2-alpha receptor OS=Homo sapiensOX=9606 GN=PTGFR PE=1 SV=1MSMNNSKQLVSPAAALLSNTTCQTENRLSVFFSVIFMTVGILSNSLAIAILMKAYQRFRQKSKASFLLLASGLVITDFFGHLINGAIAVFVYASDKEWIRFDQSNVLCSIFGICMVFSGLCPLLLGSVMAIERCIGVTKPIFHSTKITSKHVKMMLSGVCLFAVFIALLPILGHRDYKIQASRTWCFYNTEDIKDWEDRFYLLLFSFLGLLALGVSLLCNAITGITLLRVKFKSQQHRQGRSHHLEMVIQLLAIMCVSCICWSPFLVTMANIGINGNHSLETCETTLFALRMATWNQILDPWVYILLRKAVLKNLYKLASQCCGVHVISLHIWELSSIKNSLKVAAISESPVAEKSAST>sp|P43088-2|PF2R_HUMAN Isoform 2 of Prostaglandin F2-alpha receptorOS=Homo sapiens OX=9606 GN=PTGFRMSMNNSKQLVSPAAALLSNTTCQTENRLSVFFSVIFMTVGILSNSLAIAILMKAYQRFRQKSKASFLLLASGLVITDFFGHLINGAIAVFVYASDKEWIRFDQSNVLCSIFGICMVFSGLCPLLLGSVMAIERCIGVTKPIFHSTKITSKHVKMMLSGVCLFAVFIALLPILGHRDYKIQASRTWCFYNTEDIKDWEDRFYLLLFSFLGLLALGVSLLCNAITGITLLRVKFKSQQHRQGRSHHLEMVIQLLAIMCVSCICWSPFLGYRIILNGKEKYKVYEEQSDFLHRLQWPTLE>sp|P43088-3|PF2R_HUMAN Isoform 3 of Prostaglandin F2-alpha receptorOS=Homo sapiens OX=9606 GN=PTGFRMSMNNSKQLVSPAAALLSNTTCQTENRLSVFFSVIFMTVGILSNSLAIAILMKAYQRFRQKSKASFLLLASGLVITDFFGHLINGAIAVFVYASDKEWIRFDQSNVLCSIFGICMVFSGLCPLLLGSVMAIERCIGVTKPIFHSTKITSKHVKMMLSGVCLFAVFIALLPILGHRDYKIQASRTWCFYNTEDIKDWEDRFYLLLFSFLGLLALGVSLLCNAITGITLLRVKFKSQQHRQGRSHHLEMVIQLLAIMCVSCICWSPFLKIEGKIKVT>sp|P43088-4|PF2R_HUMAN Isoform 4 of Prostaglandin F2-alpha receptorOS=Homo sapiens OX=9606 GN=PTGFRMSMNNSKQLVSPAAALLSNTTCQTENRLSVFFSVIFMTVGILSNSLAIAILMKAYQRFRQKSKASFLLLASGLVITDFFGHLINGAIAVFVYASDKEWIRFDQSNVLCSIFGICMVFSGLCPLLLGSVMAIERCIGVTKPIFHSTKITSKHVKMMLSGVCLFAVFIALLPILGHRDYKIQASRTWCFYNTEDIKDWEDRFYLLLFSFLGLLALGVSLLCNAITGITLLRVKFKSQQHRQGRSHHLEMVIQLLAIMCVSCICWSPFLGYRIILNGKEKYKVYEEQSDFLHRK>sp|P43088-5|PF2R_HUMAN Isoform 5 of Prostaglandin F2-alpha receptorOS=Homo sapiens OX=9606 GN=PTGFRMSMNNSKQLVSPAAALLSNTTCQTENRLSVFFSVIFMTVGILSNSLAIAILMKAYQRFRQKSKASFLLLASGLVITDFFGHLINGAIAVFVYASDKEWIRFDQSNVLCSIFGICMVFSGLCPLLLGSVMAIERCIGVTKPIFHSTKITSKHVKMMLSGVCLFAVFIALLPILGHRDYKIQASRTWCFYNTEDIKDWEDRFYLLLFSFLGLLALGVSLLCNAITGITLLRVKFKSQQHRQGRSHHLEMVIQLLAIMCVSCICWSPFLVKETHLQMRLWTWDFRVNALEDYCEGLTVF>sp|P43088-6|PF2R_HUMAN Isoform 6 of Prostaglandin F2-alpha receptorOS=Homo sapiens OX=9606 GN=PTGFRMSMNNSKQLVSPAAALLSNTTCQTENRLSVFFSVIFMTVGILSNSLAIAILMKAYQRFRQKSKASFLLLASGLVITDFFGHLINGAIAVFVYASDKEWIRFDQSNVLCSIFGICMVFSGLCPLLLGSVMAIERCIGVTKPIFHSTKITSKHVKMMLSGVCLFAVFIALLPILGHRDYKIQASRTWCFYNTEDIKDWEDRFYLLLFSFLGLLALGVSLLCNAITGITLLRVKFKSQQHRQGRSHHLEMVIQLLAIMCVSCICWSPFLR>sp|P43088-7|PF2R_HUMAN Isoform 7 of Prostaglandin F2-alpha receptorOS=Homo sapiens OX=9606 GN=PTGFRMSMNNSKQLVSPAAALLSNTTCQTENRLSVFFSVIFMTVGILSNSLAIAILMKAYQRFRQKSKASFLLLASGLVITDFFGHLINGAIAVFVYASDKEWIRFDQSNVLCSIFGICMVFSGLCPLLLGSVMAIERCIGVTKPIFHSTKITSKHVKMMLSGVCLFAVFIALLPILGHRDYKIQASRTWCFYNTEDIKDWEDRFYLLLFSFLGLLALGVSLLCNAITGITLLRVKFKSQQHRQGRSHHLEMVIQLLAIMCVSCICWSPFLTHWGKEIP>sp|Q9HBH5|RDH14_HUMAN Retinol dehydrogenase 14 OS=Homo sapiens OX=9606GN=RDH14 PE=1 SV=1MAVATAAAVLAALGGALWLAARRFVGPRVQRLRRGGDPGLMHGKTVLITGANSGLGRATAAELLRLGARVIMGCRDRARAEEAAGQLRRELRQAAECGPEPGVSGVGELIVRELDLASLRSVRAFCQEMLQEEPRLDVLINNAGIFQCPYMKTEDGFEMQFGVNHLGHFLLTNLLLGLLKSSAPSRIVVVSSKLYKYGDINFDDLNSEQSYNKSFCYSRSKLANILFTRELARRLEGTNVTVNVLHPGIVRTNLGRHIHIPLLVKPLFNLVSWAFFKTPVEGAQTSIYLASSPEVEGVSGRYFGDCKEEELLPKAMDESVARKLWDISEVMVGLLK>sp|P51160|PDE6C_HUMAN Cone cGMP-specific 3',5'-cyclic phosphodiesterasesubunit alpha' OS=Homo sapiens OX=9606 GN=PDE6C PE=1 SV=2MGEINQVAVEKYLEENPQFAKEYFDRKLRVEVLGEIFKNSQVPVQSSMSFSELTQVEESALCLELLWTVQEEGGTPEQGVHRALQRLAHLLQADRCSMFLCRSRNGIPEVASRLLDVTPTSKFEDNLVGPDKEVVFPLDIGIVGWAAHTKKTHNVPDVKKNSHFSDFMDKQTGYVTKNLLATPIVVGKEVLAVIMAVNKVNASEFSKQDEEVFSKYLNFVSIILRLHHTSYMYNIESRRSQILMWSANKVFEELTDVERQFHKALYTVRSYLNCERYSIGLLDMTKEKEFYDEWPIKLGEVEPYKGPKTPDGREVNFYKIIDYILHGKEEIKVIPTPPADHWTLISGLPTYVAENGFICNMMNAPADEYFTFQKGPVDETGWVIKNVLSLPIVNKKEDIVGVATFYNRKDGKPFDEHDEYITETLTQFLGWSLLNTDTYDKMNKLENRKDIAQEMLMNQTKATPEEIKSILKFQEKLNVDVIDDCEEKQLVAILKEDLPDPRSAELYEFRFSDFPLTEHGLIKCGIRLFFEINVVEKFKVPVEVLTRWMYTVRKGYRAVTYHNWRHGFNVGQTMFTLLMTGRLKKYYTDLEAFAMLAAAFCHDIDHRGTNNLYQMKSTSPLARLHGSSILERHHLEYSKTLLQDESLNIFQNLNKRQFETVIHLFEVAIIATDLALYFKKRTMFQKIVDACEQMQTEEEAIKYVTVDPTKKEIIMAMMMTACDLSAITKPWEVQSQVALMVANEFWEQGDLERTVLQQQPIPMMDRNKRDELPKLQVGFIDFVCTFVYKEFSRFHKEITPMLSGLQNNRVEWKSLADEYDAKMKVIEEEAKKQEGGAEKAAEDSGGGDDKKSKTCLML>sp|P20337|RAB3B_HUMAN Ras-related protein Rab-3B OS=Homo sapiens OX=9606GN=RAB3B PE=1 SV=2MASVTDGKTGVKDASDQNFDYMFKLLIIGNSSVGKTSFLFRYADDTFTPAFVSTVGIDFKVKTVYRHEKRVKLQIWDTAGQERYRTITTAYYRGAMGFILMYDITNEESFNAVQDWATQIKTYSWDNAQVILVGNKCDMEEERVVPTEKGQLLAEQLGFDFFEASAKENISVRQAFERLVDAICDKMSDSLDTDPSMLGSSKNTRLSDTPPLLQQNCSC>sp|P62877|RBX1_HUMAN E3 ubiquitin-protein ligase RBX1 OS=Homo sapiensOX=9606 GN=RBX1 PE=1 SV=1MAAAMDVDTPSGTNSGAGKKRFEVKKWNAVALWAWDIVVDNCAICRNHIMDLCIECQANQASATSEECTVAWGVCNHAFHFHCISRWLKTRQVCPLDNREWEFQKYGH>sp|O75452|RDH16_HUMAN Retinol dehydrogenase 16 OS=Homo sapiens OX=9606GN=RDH16 PE=1 SV=2MWLYLAVFVGLYYLLHWYRERQVLSHLRDKYVFITGCDSGFGKLLARQLDARGLRVLAACLTEKGAEQLRGQTSDRLETVTLDVTKTESVAAAAQWVKECVRDKGLWGLVNNAGISLPTAPNELLTKQDFVTILDVNLLGVIDVTLSLLPLVRRARGRVVNVSSVMGRVSLFGGGYCISKYGVEAFSDSLRRELSYFGVKVAMIEPGYFKTAVTSKERFLKSFLEIWDRSSPEVKEAYGEKFVADYKKSAEQMEQKCTQDLSLVTNCMEHALIACHPRTRYSAGWDAKLLYLPMSYMPTFLVDAIMYWVSPSPAKAL>sp|Q8IUD2|RB6I2_HUMAN ELKS/Rab6-interacting/CAST family member 1 OS=Homosapiens OX=9606 GN=ERC1 PE=1 SV=1MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMTLGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLSSSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRLHAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSMLREEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSKEAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELERQVKDQNKKVANLKHKEQVEKKKSAQMLEEARRREDNLNDSSQQLQDSLRKKDDRIEELEEALRESVQITAEREMVLAQEESARTNAEKQVEELLMAMEKVKQELESMKAKLSSTQQSLAEKETHLTNLRAERRKHLEEVLEMKQEALLAAISEKDANIALLELSSSKKKTQEEVAALKREKDRLVQQLKQQTQNRMKLMADNYEDDHFKSSHSNQTNHKPSPDQIIQPLLELDQNRSKLKLYIGHLTTLCHDRDPLILRGLTPPASYNLDDDQAAWENELQKMTRGQLQDELEKGERDNAELQEFANAILQQIADHCPDILEQVVNALEESS>sp|Q8IUD2-2|RB6I2_HUMAN Isoform 2 of ELKS/Rab6-interacting/CAST familymember 1 OS=Homo sapiens OX=9606 GN=ERC1MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMTLGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLSSSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRLHAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSMLREEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESLTSRQVKDQNKKVANLKHKEQVEKKKSAQMLEEARRREDNLNDSSQQLQDSLRKKDDRIEELEEALRESVQITAEREMVLAQEESARTNAEKQVEELLMAMEKVKQELESMKAKLSSTQQSLAEKETHLTNLRAERRKHLEEVLEMKQEALLAAISEKDANIALLELSSSKKKTQEEVAALKREKDRLVQQLKQQTQNRMKLMADNYEDDHFKSSHSNQTNHKPSPDQDEEEGIWA>sp|Q8IUD2-3|RB6I2_HUMAN Isoform 3 of ELKS/Rab6-interacting/CAST familymember 1 OS=Homo sapiens OX=9606 GN=ERC1MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMTLGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLSSSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRLHAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSMLREEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELERQVKDQNKKVANLKHKEQVEKKKSAQMLEEARRREDNLNDSSQQLQDSLRKKDDRIEELEEALRESVQITAEREMVLAQEESARTNAEKQVEELLMAMEKVKQELESMKAKLSSTQQSLAEKETHLTNLRAERRKHLEEVLEMKQEALLAAISEKDANIALLELSSSKKKTQEEVAALKREKDRLVQQLKQQTQNRMKLMADNYEDDHFKSSHSNQTNHKPSPDQIIQPLLELDQNRSKLKLYIGHLTTLCHDRDPLILRGLTPPASYNLDDDQAAWENELQKMTRGQLQDELEKGERDNAELQEFANAILQQIADHCPDILEQVVNALEESS>sp|Q8IUD2-4|RB6I2_HUMAN Isoform 4 of ELKS/Rab6-interacting/CAST familymember 1 OS=Homo sapiens OX=9606 GN=ERC1MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMTLGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLSSSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRLHAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSMLREEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESLTSRQVKDQNKKVANLKHKEQVEKKKSAQMLEEARRREDNLNDSSQQLQVEELLMAMEKVKQELESMKAKLSSTQQSLAEKETHLTNLRAERRKHLEEVLEMKQEALLAAISEKDANIALLELSSSKKKTQEEVAALKREKDRLVQQLKQQTQNRMKLMADNYEDDHFKSSHSNQTNHKPSPDQDEEEGIWA>sp|Q8IUD2-5|RB6I2_HUMAN Isoform 5 of ELKS/Rab6-interacting/CAST familymember 1 OS=Homo sapiens OX=9606 GN=ERC1MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMTLGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLSSSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQVDALRLRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESLTSRQVKDQNKKVANLKHKEQVEKKKSAQMLEEARRREDNLNDSSQQLQDSLRKKDDRIEELEEALRESVQITAEREMVLAQEESARTNAEKQVEELLMAMEKVKQELESMKAKLSSTQQSLAEKETHLTNLRAERRKHLEEVLEMKQEALLAAISEKDANIALLELSSSKKKTQEEVAALKREKDRLVQQLKQQTQNRMKLMADNYEDDHFKSSHSNQTNHKPSPDQDEEEGIWA>sp|Q96E17|RAB3C_HUMAN Ras-related protein Rab-3C OS=Homo sapiens OX=9606GN=RAB3C PE=1 SV=1MRHEAPMQMASAQDARYGQKDSSDQNFDYMFKLLIIGNSSVGKTSFLFRYADDSFTSAFVSTVGIDFKVKTVFKNEKRIKLQIWDTAGQERYRTITTAYYRGAMGFILMYDITNEESFNAVQDWSTQIKTYSWDNAQVILVGNKCDMEDERVISTERGQHLGEQLGFEFFETSAKDNINVKQTFERLVDIICDKMSESLETDPAITAAKQNTRLKETPPPPQPNCAC>sp|Q9UBF6|RBX2_HUMAN RING-box protein 2 OS=Homo sapiens OX=9606 GN=RNF7PE=1 SV=1MADVEDGEETCALASHSGSSGSKSGGDKMFSLKKWNAVAMWSWDVECDTCAICRVQVMDACLRCQAENKQEDCVVVWGECNHSFHNCCMSLWVKQNNRCPLCQQDWVVQRIGK>sp|Q9UBF6-2|RBX2_HUMAN Isoform 2 of RING-box protein 2 OS=Homo sapiensOX=9606 GN=RNF7MADVEDGEETCALASHSGSSGSKSGGDKMFSLKKWNAVAMWSWDVECDTCAICRVQVMDEGIGVRNWSEALNLINASEMGFDCRSGSTALAVPSVSLASHQPCLDDHR>sp|Q9UBF6-3|RBX2_HUMAN Isoform 3 of RING-box protein 2 OS=Homo sapiensOX=9606 GN=RNF7MADVEDGEETCALASHSGSSGSKSGGDKMFSLKKWNAVAMWSWDVECDTCAICRVQMPVLDVKLKTNKRTVLWSGENVIIPSTTAACPCG>sp|Q9UBF6-4|RBX2_HUMAN Isoform 4 of RING-box protein 2 OS=Homo sapiensOX=9606 GN=RNF7MADVEDGEETCALASHSGSSGSKSGGDKMFSLKKWNAVAMWSWDVECDTCAICRVQVMVVWGECNHSFHNCCMSLWVKQNNRCPLCQQDWVVQRIGK>sp|Q8NC74|RB8NL_HUMAN RBBP8 N-terminal-like protein OS=Homo sapiensOX=9606 GN=RBBP8NL PE=1 SV=3MESFMESLNRLKEIHEKEVLGLQNKLLELNSERCRDAQRIEELFSKNHQLREQQKTLKENLRVLENRLRAGLCDRCMVTQELARKRQQEFESSHLQNLQRIFILTNEMNGLKEENETLKEEVKRLRGLGDRPKPRAKEGTSDPPSPLLLPSPGGWKAITEKPPGGHEEAEEDHQGVGLRGEEKPAGHRTSPVAKISPGATLPESRAPDMSPQRISNQLHGTIAVVRPGSQACPADRGPANGTPPPLPARSSPPSPAYERGLSLDSFLRASRPSAMTHEAPKLSPKVDRLCLLNRPLSLHLQSPHSSPLAPAAAPSDPRLQDLKAREAEAWEEPTELLGLPSALAGMQDLRLEGALHLLLAQQQLRARARAGSVRPRGQPTPGEMLPSLPVGSDSEGPENEGTRAALAAAGLSGGRHTQPAGPGRAQRTEAAATQDCALDKPLDLSEWGRARGQDTPKPAGQHGSLSPAAAHTASPEPPTQSGPLTRSPQALSNGTKGTRVPEQEEASTPMDPSRPLPGSQLSLSSPGSTEDEDTGRPLPPPHPQPPPHPQPPDLDGHPEPSKAEVLRPESDELDETDTPGSEVGLSSQAEATTSTTGEGPECICTQEHGQGPPRKRKRASEPGDKASKKPSRGRRKLTATEGPGSPRDAEDHSPSPNSSPWEET>sp|P52945|PDX1_HUMAN Pancreas/duodenum homeobox protein 1 OS=Homosapiens OX=9606 GN=PDX1 PE=1 SV=1MNGEEQYYAATQLYKDPCAFQRGPAPEFSASPPACLYMGRQPPPPPPHPFPGALGALEQGSPPDISPYEVPPLADDPAVAHLHHHLPAQLALPHPPAGPFPEGAEPGVLEEPNRVQLPFPWMKSTKAHAWKGQWAGGAYAAEPEENKRTRTAYTRAQLLELEKEFLFNKYISRPRRVELAVMLNLTERHIKIWFQNRRMKWKKEEDKKRGGGTAVGGGGVAEPEQDCAVTSGEELLALPPPPPPGGAVPPAAPVAAREGRLPPGLSASPQPSSVAPRRPQEPR>sp|O43502|RA51C_HUMAN DNA repair protein RAD51 homolog 3 OS=Homo sapiensOX=9606 GN=RAD51C PE=1 SV=1MRGKTFRFEMQRDLVSFPLSPAVRVKLVSAGFQTAEELLEVKPSELSKEVGISKAEALETLQIIRRECLTNKPRYAGTSESHKKCTALELLEQEHTQGFIITFCSALDDILGGGVPLMKTTEICGAPGVGKTQLCMQLAVDVQIPECFGGVAGEAVFIDTEGSFMVDRVVDLATACIQHLQLIAEKHKGEEHRKALEDFTLDNILSHIYYFRCRDYTELLAQVYLLPDFLSEHSKVRLVIVDGIAFPFRHDLDDLSLRTRLLNGLAQQMISLANNHRLAVILTNQMTTKIDRNQALLVPALGESWGHAATIRLIFHWDRKQRLATLYKSPSQKECTVLFQIKPQGFRDTVVTSACSLQTEGSLSTRKRSRDPEEEL>sp|O43502-2|RA51C_HUMAN Isoform 2 of DNA repair protein RAD51 homolog 3OS=Homo sapiens OX=9606 GN=RAD51CMRGKTFRFEMQRDLVSFPLSPAVRVKLVSAGFQTAEELLEVKPSELSKEVGISKAEALETLQIIRRECLTNKPRYAGTSESHKKCTALELLEQEHTQGFIITFCSALDDILGGGVPLMKTTEICGAPGVGKTQLW>sp|Q96AH8|RAB7B_HUMAN Ras-related protein Rab-7b OS=Homo sapiens OX=9606GN=RAB7B PE=1 SV=1MNPRKKVDLKLIIVGAIGVGKTSLLHQYVHKTFYEEYQTTLGASILSKIIILGDTTLKLQIWDTGGQERFRSMVSTFYKGSDGCILAFDVTDLESFEALDIWRGDVLAKIVPMEQSYPMVLLGNKIDLADRKVPQEVAQGWCREKDIPYFEVSAKNDINVVQAFEMLASRALSRYQSILENHLTESIKLSPDQSRSRCC>sp|O75771|RA51D_HUMAN DNA repair protein RAD51 homolog 4 OS=Homo sapiensOX=9606 GN=RAD51D PE=1 SV=1MGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKALVALRRVLLAQFSAFPVNGADLYEELKTSTAILSTGIGSLDKLLDAGLYTGEVTEIVGGPGSGKTQVCLCMAANVAHGLQQNVLYVDSNGGLTASRLLQLLQAKTQDEEEQAEALRRIQVVHAFDIFQMLDVLQELRGTVAQQVTGSSGTVKVVVVDSVTAVVSPLLGGQQREGLALMMQLARELKTLARDLGMAVVVTNHITRDRDSGRLKPALGRSWSFVPSTRILLDTIEGAGASGGRRMACLAKSSRQPTGFQEMVDIGTWGTSEQSATLQGDQT>sp|O75771-2|RA51D_HUMAN Isoform 2 of DNA repair protein RAD51 homolog 4OS=Homo sapiens OX=9606 GN=RAD51DMGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKS>sp|O75771-3|RA51D_HUMAN Isoform 3 of DNA repair protein RAD51 homolog 4OS=Homo sapiens OX=9606 GN=RAD51DMGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKAEALRRIQVVHAFDIFQMLDVLQELRGTVAQQVTGSSGTVKVVVVDSVTAVVSPLLGGQQREGLALMMQLARELKTLARDLGMAVVVTNHITRDRDSGRLKPALGRSWSFVPSTRILLDTIEGAGASGGRRMACLAKSSRQPTGFQEMVDIGTWGTSEQSATLQGDQT>sp|O75771-4|RA51D_HUMAN Isoform 4 of DNA repair protein RAD51 homolog 4OS=Homo sapiens OX=9606 GN=RAD51DMGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKALVALRRVLLAQFSAFPVNGADLYEELKTSTAILSTGIGSLDKLLDAGLYTGEVTEIVGGPGSGKTQAEALRRIQVVHAFDIFQMLDVLQELRGTVAQQVTGSSGTVKVVVVDSVTAVVSPLLGGQQREGLALMMQLARELKTLARDLGMAVVVTNHITRDRDSGRLKPALGRSWSFVPSTRILLDTIEGAGASGGRRMACLAKSSRQPTGFQEMVDIGTWGTSEQSATLQGDQT>sp|O75771-5|RA51D_HUMAN Isoform 5 of DNA repair protein RAD51 homolog 4OS=Homo sapiens OX=9606 GN=RAD51DMGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKALVALRRVLLAQFSAFPVNGADLYEELKTSTAILSTGIGRQKLSGGSRWCMHLVTEIVGGPGSGKTQVCLCMAANVAHGLQQNVLYVDSNGGLTASRLLQLLQAKTQDEEEQAEALRRIQVVHAFDIFQMLDVLQELRGTVAQQVTGSSGTVKVVVVDSVTAVVSPLLGGQQREGLALMMQLARELKTLARDLGMAVVVTNHITRDRDSGRLKPALGRSWSFVPSTRILLDTIEGAGASGGRRMACLAKSSRQPTGFQEMVDIGTWGTSEQSATLQGDQT>sp|O75771-6|RA51D_HUMAN Isoform 6 of DNA repair protein RAD51 homolog 4OS=Homo sapiens OX=9606 GN=RAD51DMGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKALVALRRVLLAQFSAFPVNGADLYEELKTSTAILSTGIGRHGGRTQVGTWEDCSCLRSPQGDRGVGSGML>sp|O75771-7|RA51D_HUMAN Isoform 7 of DNA repair protein RAD51 homolog 4OS=Homo sapiens OX=9606 GN=RAD51DMGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKALVALRRVLLAQFSAFPVNGADLYEELKTSTAILSTGIGSLDKLLDAGLYTGEVTEIVGGPGSGKTQVCLCMAANVAHGLQQNVLYVDSNGGLTASRLLQLLQAKTQDEEEQAEALRRIQVVHAFDIFQMLDVLQELRGTVAQQDGIPEHLNHIPHCLHVHLPC>sp|O75771-8|RA51D_HUMAN Isoform 8 of DNA repair protein RAD51 homolog 4OS=Homo sapiens OX=9606 GN=RAD51DMGVLRVGLCPGLTEEMIQLLRSHRIKTVVDLVSADLEEVAQKCGLSYKTWRAHSSGNLGGLQLPQVPAGRSWSGVRNALKKAGLGHGGTDGLSLNAFDERGTAVSTSRLDKLLDAGLYTGEVTEIVGGPGSGKTQVCLCMAANVAHGLQQNVLYVDSNGGLTASRLLQLLQAKTQDEEEQAEALRRIQVVHAFDIFQMLDVLQELRGTVAQQVTGSSGTVKVVVVDSVTAVVSPLLGGQQREGLALMMQLARELKTLARDLGMAVVVTNHITRDRDSGRLKPALGRSWSFVPSTRILLDTIEGAGASGGRRMACLAKSSRQPTGFQEMVDIGTWGTSEQSATLQGDQT>sp|O14966|RAB7L_HUMAN Ras-related protein Rab-7L1 OS=Homo sapiensOX=9606 GN=RAB29 PE=1 SV=1MGSRDHLFKVLVVGDAAVGKTSLVQRYSQDSFSKHYKSTVGVDFALKVLQWSDYEIVRLQLWDIAGQERFTSMTRLYYRDASACVIMFDVTNATTFSNSQRWKQDLDSKLTLPNGEPVPCLLLANKCDLSPWAVSRDQIDRFSKENGFTGWTETSVKENKNINEAMRVLIEKMMRNSTEDIMSLSTQGDYINLQTKSSSWSCC>sp|O14966-2|RAB7L_HUMAN Isoform 2 of Ras-related protein Rab-7L1 OS=Homosapiens OX=9606 GN=RAB29MGSRDHLFKVLVVGDAAVGKTSLVQRYSQDSFSKHYKSTVGGQERFTSMTRLYYRDASACVIMFDVTNATTFSNSQRWKQDLDSKLTLPNGEPVPCLLLANKCDLSPWAVSRDQIDRFSKENGFTGWTETSVKENKNINEAMRVLIEKMMRNSTEDIMSLSTQGDYINLQTKSSSWSCC>sp|O14966-3|RAB7L_HUMAN Isoform 3 of Ras-related protein Rab-7L1 OS=Homosapiens OX=9606 GN=RAB29MTRLYYRDASACVIMFDVTNATTFSNSQRWKQDLDSKLTLPNGEPVPCLLLANKCDLSPWAVSRDQIDRFSKENGFTGWTETSVKENKNINEAMRVLIEKMMRNSTEDIMSLSTQGDYINLQTKSSSWSCC>sp|Q9Y620|RA54B_HUMAN DNA repair and recombination protein RAD54BOS=Homo sapiens OX=9606 GN=RAD54B PE=1 SV=1MRRSAAPSQLQGNSFKKPKFIPPGRSNPGLNEEITKLNPDIKLFEGVAINNTFLPSQNDLRICSLNLPSEESTREINNRDNCSGKYCFEAPTLATLDPPHTVHSAPKEVAVSKEQEEKSDSLVKYFSVVWCKPSKKKHKKWEGDAVLIVKGKSFILKNLEGKDIGRGIGYKFKELEKIEEGQTLMICGKEIEVMGVISPDDFSSGRCFQLGGGSTAISHSSQVARKCFSNPFKSVCKPSSKENRQNDFQNCKPRHDPYTPNSLVMPRPDKNHQWVFNKNCFPLVDVVIDPYLVYHLRPHQKEGIIFLYECVMGMRMNGRCGAILADEMGLGKTLQCISLIWTLQCQGPYGGKPVIKKTLIVTPGSLVNNWKKEFQKWLGSERIKIFTVDQDHKVEEFIKSIFYSVLIISYEMLLRSLDQIKNIKFDLLICDEGHRLKNSAIKTTTALISLSCEKRIILTGTPIQNDLQEFFALIDFVNPGILGSLSSYRKIYEEPIILSREPSASEEEKELGERRAAELTCLTGLFILRRTQEIINKYLPPKIENVVFCRPGALQIELYRKLLNSQVVRFCLQGLLENSPHLICIGALKKLCNHPCLLFNSIKEKECSSTCDKNEEKSLYKGLLSVFPADYNPLLFTEKESGKLQVLSKLLAVIHELRPTEKVVLVSNYTQTLNILQEVCKRHGYAYTRLDGQTPISQRQQIVDGFNSQHSSFFIFLLSSKAGGVGLNLIGGSHLILYDIDWNPATDIQAMSRVWRDGQKYPVHIYRLLTTGTIEEKIYQRQISKQGLCGAVVDLTKTSEHIQFSVEELKNLFTLHESSDCVTHDLLDCECTGEEVHTGDSLEKFIVSRDCQLGPHHQKSNSLKPLSMSQLKQWKHFSGDHLNLTDPFLERITENVSFIFQNITTQATGT>sp|Q9Y620-2|RA54B_HUMAN Isoform 2 of DNA repair and recombinationprotein RAD54B OS=Homo sapiens OX=9606 GN=RAD54BMRRSAAPSQLQGNSFKKPKFIPPGRSNPGLNEEITKLNPDIKLFEGVAINNTFLPSQNDLRICSLNLPSEESTREINNRDNCSGKYCFEAPTLATLDPPHTVQTWMRRHRLVPVHYR>sp|P61006|RAB8A_HUMAN Ras-related protein Rab-8A OS=Homo sapiens OX=9606GN=RAB8A PE=1 SV=1MAKTYDYLFKLLLIGDSGVGKTCVLFRFSEDAFNSTFISTIGIDFKIRTIELDGKRIKLQIWDTAGQERFRTITTAYYRGAMGIMLVYDITNEKSFDNIRNWIRNIEEHASADVEKMILGNKCDVNDKRQVSKERGEKLALDYGIKFMETSAKANINVENAFFTLARDIKAKMDKKLEGNSPQGSNQGVKITPDQQKRSSFFRCVLL>sp|P61006-2|RAB8A_HUMAN Isoform 2 of Ras-related protein Rab-8A OS=Homosapiens OX=9606 GN=RAB8AMAKTYDYLFKLLLIGDSGVGKTCVLFRFSEDAFNSTFISTIGIDFKIRTIELDGKRIKLQIWDTAGQERFRTITTAYYRGAMGIMLVYDITNEKSFDNIRNWIRNIEEHASADVEKMILGNKCDVNDKRQVSKERGEKLALDYGIKFMETSAKANINVENRYQSKNGQKIGRQQPPGEQPGSQNHTGPAEEEQLFPMCSSVRNTALL>sp|Q8N165|PDK1L_HUMAN Serine/threonine-protein kinase PDIK1L OS=Homosapiens OX=9606 GN=PDIK1L PE=1 SV=1MVSSQPKYDLIREVGRGSYGVVYEAVIRKTSARVAVKKIRCHAPENVELALREFWALSSIKSQHPNVIHLEECILQKDGMVQKMSHGSNSSLYLQLVETSLKGEIAFDPRSAYYLWFVMDFCDGGDMNEYLLSRKPNRKTNTSFMLQLSSALAFLHKNQIIHRDLKPDNILISQTRLDTSDLEPTLKVADFGLSKVCSASGQNPEEPVSVNKCFLSTACGTDFYMAPEVWEGHYTAKADIFALGIIIWAMLERITFIDTETKKELLGSYVKQGTEIVPVGEALLENPKMELLIPVKKKSMNGRMKQLIKEMLAANPQDRPDAFELELRLVQIAFKDSSWET>sp|Q15120|PDK3_HUMAN [Pyruvate dehydrogenase (acetyl-transferring)]kinase isozyme 3, mitochondrial OS=Homo sapiens OX=9606 GN=PDK3 PE=1 SV=1MRLFRWLLKQPVPKQIERYSRFSPSPLSIKQFLDFGRDNACEKTSYMFLRKELPVRLANTMREVNLLPDNLLNRPSVGLVQSWYMQSFLELLEYENKSPEDPQVLDNFLQVLIKVRNRHNDVVPTMAQGVIEYKEKFGFDPFISTNIQYFLDRFYTNRISFRMLINQHTLLFGGDTNPVHPKHIGSIDPTCNVADVVKDAYETAKMLCEQYYLVAPELEVEEFNAKAPDKPIQVVYVPSHLFHMLFELFKNSMRATVELYEDRKEGYPAVKTLVTLGKEDLSIKISDLGGGVPLRKIDRLFNYMYSTAPRPSLEPTRAAPLAGFGYGLPISRLYARYFQGDLKLYSMEGVGTDAVIYLKALSSESFERLPVFNKSAWRHYKTTPEADDWSNPSSEPRDASKYKAKQ>sp|Q15120-2|PDK3_HUMAN Isoform 2 of [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 3, mitochondrial OS=Homo sapiens OX=9606GN=PDK3MRLFRWLLKQPVPKQIERYSRFSPSPLSIKQFLDFGRDNACEKTSYMFLRKELPVRLANTMREVNLLPDNLLNRPSVGLVQSWYMQSFLELLEYENKSPEDPQVLDNFLQVLIKVRNRHNDVVPTMAQGVIEYKEKFGFDPFISTNIQYFLDRFYTNRISFRMLINQHTLLFGGDTNPVHPKHIGSIDPTCNVADVVKDAYETAKMLCEQYYLVAPELEVEEFNAKAPDKPIQVVYVPSHLFHMLFELFKNSMRATVELYEDRKEGYPAVKTLVTLGKEDLSIKISDLGGGVPLRKIDRLFNYMYSTAPRPSLEPTRAAPLAGFGYGLPISRLYARYFQGDLKLYSMEGVGTDAVIYLKALSSESFERLPVFNKSAWRHYKTTPEADDWSNPSSEPRDASKYKAKQDKIKTNRTF>sp|Q9Y263|PLAP_HUMAN Phospholipase A-2-activating protein OS=Homosapiens OX=9606 GN=PLAA PE=1 SV=2MTSGATRYRLSCSLRGHELDVRGLVCCAYPPGAFVSVSRDRTTRLWAPDSPNRSFTEMHCMSGHSNFVSCVCIIPSSDIYPHGLIATGGNDHNICIFSLDSPMPLYILKGHKNTVCSLSSGKFGTLLSGSWDTTAKVWLNDKCMMTLQGHTAAVWAVKILPEQGLMLTGSADKTVKLWKAGRCERTFSGHEDCVRGLAILSETEFLSCANDASIRRWQITGECLEVYYGHTNYIYSISVFPNCRDFVTTAEDRSLRIWKHGECAQTIRLPAQSIWCCCVLDNGDIVVGASDGIIRVFTESEDRTASAEEIKAFEKELSHATIDSKTGDLGDINAEQLPGREHLNEPGTREGQTRLIRDGEKVEAYQWSVSEGRWIKIGDVVGSSGANQQTSGKVLYEGKEFDYVFSIDVNEGGPSYKLPYNTSDDPWLTAYNFLQKNDLNPMFLDQVAKFIIDNTKGQMLGLGNPSFSDPFTGGGRYVPGSSGSSNTLPTADPFTGAGRYVPGSASMGTTMAGVDPFTGNSAYRSAASKTMNIYFPKKEAVTFDQANPTQILGKLKELNGTAPEEKKLTEDDLILLEKILSLICNSSSEKPTVQQLQILWKAINCPEDIVFPALDILRLSIKHPSVNENFCNEKEGAQFSSHLINLLNPKGKPANQLLALRTFCNCFVGQAGQKLMMSQRESLMSHAIELKSGSNKNIHIALATLALNYSVCFHKDHNIEGKAQCLSLISTILEVVQDLEATFRLLVALGTLISDDSNAVQLAKSLGVDSQIKKYSSVSEPAKVSECCRFILNLL>sp|Q9UM63|PLAL1_HUMAN Zinc finger protein PLAGL1 OS=Homo sapiens OX=9606GN=PLAGL1 PE=1 SV=2MATFPCQLCGKTFLTLEKFTIHNYSHSRERPYKCVQPDCGKAFVSRYKLMRHMATHSPQKSHQCAHCEKTFNRKDHLKNHLQTHDPNKMAFGCEECGKKYNTMLGYKRHLALHAASSGDLTCGVCALELGSTEVLLDHLKAHAEEKPPSGTKEKKHQCDHCERCFYTRKDVRRHLVVHTGCKDFLCQFCAQRFGRKDHLTRHTKKTHSQELMKESLQTGDLLSTFHTISPSFQLKAAALPPFPLGASAQNGLASSLPAEVHSLTLSPPEQAAQPMQPLPESLASLHPSVSPGSPPPPLPNHKYNTTSTSYSPLASLPLKADTKGFCNISLFEDLPLQEPQSPQKLNPGFDLAKGNAGKVNLPKELPADAVNLTIPASLDLSPLLGFWQLPPPATQNTFGNSTLALGPGESLPHRLSCLGQQQQEPPLAMGTVSLGQLPLPPIPHVFSAGTGSAILPHFHHAFR>sp|Q9UM63-2|PLAL1_HUMAN Isoform 2 of Zinc finger protein PLAGL1 OS=Homosapiens OX=9606 GN=PLAGL1MATHSPQKSHQCAHCEKTFNRKDHLKNHLQTHDPNKMAFGCEECGKKYNTMLGYKRHLALHAASSGDLTCGVCALELGSTEVLLDHLKAHAEEKPPSGTKEKKHQCDHCERCFYTRKDVRRHLVVHTGCKDFLCQFCAQRFGRKDHLTRHTKKTHSQELMKESLQTGDLLSTFHTISPSFQLKAAALPPFPLGASAQNGLASSLPAEVHSLTLSPPEQAAQPMQPLPESLASLHPSVSPGSPPPPLPNHKYNTTSTSYSPLASLPLKADTKGFCNISLFEDLPLQEPQSPQKLNPGFDLAKGNAGKVNLPKELPADAVNLTIPASLDLSPLLGFWQLPPPATQNTFGNSTLALGPGESLPHRLSCLGQQQQEPPLAMGTVSLGQLPLPPIPHVFSAGTGSAILPHFHHAFR>sp|Q9NRX1|PNO1_HUMAN RNA-binding protein PNO1 OS=Homo sapiens OX=9606GN=PNO1 PE=1 SV=1MESEMETQSARAEEGFTQVTRKGGRRAKKRQAEQLSAAGEGGDAGRMDTEEARPAKRPVFPPLCGDGLLSGKEETRKIPVPANRYTPLKENWMKIFTPIVEHLGLQIRFNLKSRNVEIRTCKETKDVSALTKAADFVKAFILGFQVEDALALIRLDDLFLESFEITDVKPLKGDHLSRAIGRIAGKGGKTKFTIENVTRTRIVLADVKVHILGSFQNIKMARTAICNLILGNPPSKVYGNIRAVASRSADRF>sp|Q9UPG8|PLAL2_HUMAN Zinc finger protein PLAGL2 OS=Homo sapiens OX=9606GN=PLAGL2 PE=1 SV=1MTTFFTSVPPWIQDAKQEEEVGWKLVPRPRGREAESQVKCQCEISGTPFSNGEKLRPHSLPQPEQRPYSCPQLHCGKAFASKYKLYRHMATHSAQKPHQCMYCDKMFHRKDHLRNHLQTHDPNKEALHCSECGKNYNTKLGYRRHLAMHAASSGDLSCKVCLQTFESTQALLEHLKAHSRRVAGGAKEKKHPCDHCDRRFYTRKDVRRHLVVHTGRKDFLCQYCAQRFGRKDHLTRHVKKSHSQELLKIKTEPVDMLGLLSCSSTVSVKEELSPVLCMASRDVMGTKAFPGMLPMGMYGAHIPTMPSTGVPHSLVHNTLPMGMSYPLESSPISSPAQLPPKYQLGSTSYLPDKLPKVEVDSFLAELPGSLSLSSAEPQPASPQPAAAAALLDEALLAKSPANLSEALCAANVDFSHLLGFLPLNLPPCNPPGATGGLVMGYSQAEAQPLLTTLQAQPQDSPGAGGPLNFGPLHSLPPVFTSGLSSTTLPRFHQAFQ>sp|Q13401|PM2P3_HUMAN Putative postmeiotic segregation increased 2-likeprotein 3 OS=Homo sapiens OX=9606 GN=PMS2P3 PE=5 SV=2MNTLQGPVSFKDVAVDFTQEEWRQLDPDEKIAYGDVMLENYSHLVSVGYDYHQAKHHHGVEVKEVEQGEEPWIMEGEFPCQHSPEPAKAIKPIDRKSVHQICSGPVVLSLSTAVKELVENSLDAGATNIDLKLKDYGVDLIEVSDNGCGVEEENFEGLISFSSETSHM>sp|Q13401-2|PM2P3_HUMAN Isoform 2 of Putative postmeiotic segregationincreased 2-like protein 3 OS=Homo sapiens OX=9606 GN=PMS2P3MNTLQGPVSFKDVAVDFTQEEWRQLDPDEKIAYGDVMLENYSHLVSVGYDYHQAKHHHGVEVKEVEQGEEPWIMEGEFPCQHSPEPAKAIKPIDRKSVHQICSGPVVLSLSTAVKELVENSLDAGATNIDLKLKDYGVDLIEVSDNGCGVEEENFEGLTMSPFLPATRR>sp|Q13401-3|PM2P3_HUMAN Isoform 3 of Putative postmeiotic segregationincreased 2-like protein 3 OS=Homo sapiens OX=9606 GN=PMS2P3MNTLQGPVSFKDVAVDFTQEEWRQLDPDEKIAYGDVMLENYSHLVSVGYDYHQAKHHHGVEVKEVEQGEEPWIMEGEFPCQHSPVQNLLRPSNLLIGSQSIRFALGQWY>sp|Q8N2A8|PLD6_HUMAN Mitochondrial cardiolipin hydrolase OS=Homo sapiensOX=9606 GN=PLD6 PE=1 SV=1MGRLSWQVAAAAAVGLALTLEALPWVLRWLRSRRRRPRREALFFPSQVTCTEALLRAPGAELAELPEGCPCGLPHGESALSRLLRALLAARASLDLCLFAFSSPQLGRAVQLLHQRGVRVRVVTDCDYMALNGSQIGLLRKAGIQVRHDQDPGYMHHKFAIVDKRVLITGSLNWTTQAIQNNRENVLITEDDEYVRLFLEEFERIWEQFNPTKYTFFPPKKSHGSCAPPVSRAGGRLLSWHRTCGTSSESQT>sp|P51153|RAB13_HUMAN Ras-related protein Rab-13 OS=Homo sapiens OX=9606GN=RAB13 PE=1 SV=1MAKAYDHLFKLLLIGDSGVGKTCLIIRFAEDNFNNTYISTIGIDFKIRTVDIEGKKIKLQVWDTAGQERFKTITTAYYRGAMGIILVYDITDEKSFENIQNWMKSIKENASAGVERLLLGNKCDMEAKRKVQKEQADKLAREHGIRFFETSAKSSMNVDEAFSSLARDILLKSGGRRSGNGNKPPSTDLKTCDKKNTNKCSLG>sp|Q6S8J7|POTEA_HUMAN POTE ankyrin domain family member A OS=Homosapiens OX=9606 GN=POTEA PE=2 SV=1MVAEVSPKLAASPMKKPFGFRGKMGKWCCCCFPCCRGSGKNNMGAWRDHDDSAFTEPRYHVRREDLGKLHRAAWWGEVPRADLIVMLRGPGINKRDKKKRTALHLACANGNSEVVSLLLDRQCQLHVFDSKKRTALIKAVQCQEDECALMLLQHGTDPNLPDMYGNTALHYAVYNEDKLMAKTLLLYGADIESKNKGGLTPLLLAVHGQKQRMVKFLIKKKANLNALDRFGRTALILAVRCGSASIVSLLLQQNIDVFSQDVFGQTAEDYAVSSHHSIICQLLSDYKENQMPNNSSGNSNPEQDLKLTSEEEPQRLKGSENSQHEKVTQEPDINKDCDREVEEEMQKHGSNNVGLSENLTDGAAAGNGDGGLVPQRKSRKHENQQFPNTEIEEYHRPEKKSNEKNKVKSQIHSVDNLDDITWPSEIASEDYDLLFSNYETFTLLIEQLKMDFNDSASLSKIQDAVISEEHLLELKNSHYEQLTVEVEQMENMVHVLQK>sp|Q6S8J7-2|POTEA_HUMAN Isoform 2 of POTE ankyrin domain family member AOS=Homo sapiens OX=9606 GN=POTEAMVAEVSPKLAASPMKKPFGFRGKMGKWCCCCFPCCRGSGKNNMGAWRDHDDSAFTEPRYHVRREDLGKLHRAAWWGEVPRADLIVMLRGPGINKRDKKKRTALHLACANGNSEVVSLLLDRQCQLHVFDSKKRTALIKAVQCQEDECALMLLQHGTDPNLPDMYGNTALHYAVYNEDKLMAKTLLLYGADIESKNKGGLTPLLLAVHGQKQRMVKFLIKKKANLNALDRFGRICQLLSDYKENQMPNNSSGNSNPEQDLKLTSEEEPQRLKGSENSQHEKVTQEPDINKDCDREVEEEMQKHGSNNVGLSENLTDGAAAGNGDGGLVPQRKSRKHENQQFPNTEIEEYHRPEKKSNEKNKVKSQIHSVDNLDDITWPSEIASEDYDLLFSNYETFTLLIEQLKMDFNDSASLSKIQDAVISEEHLLELKNSHYEQLTVEVEQMENMVHVLQK>sp|A0A0B4J2F0|PIOS1_HUMAN Protein PIGBOS1 OS=Homo sapiens OX=9606GN=PIGBOS1 PE=1 SV=1MFRRLTFAQLLFATVLGIAGGVYIFQPVFEQYAKDQKELKEKMQLVQESEEKKS>sp|A6NEE1|PLHD1_HUMAN Pleckstrin homology domain-containing family Dmember 1 OS=Homo sapiens OX=9606 GN=PLEKHD1 PE=2 SV=3MFTSKSNSVSPSPSLEQADSDALDISTKVQLYGVLWKRPFGRPSAKWSRRFFIIKESFLLYYSESEKKSFETNKYFNIHPKGVIPLGGCLVEPKEEPSMPYAMKISHQDFHGNILLAAESEFEQTQWLEMLQESGKVTWKNAQLGEAMIKSLEAQGLQLAKEKQEYLDKLMEETEELCLQREQREELERLNQVLEAEKQQFEEVVQELRMEQEQIKRELELTARCLKGVEQEKKELRHLTESLQQTLEELSIEKKKTLEMLEENENHLQTLANQSEQPPPSGGLHSNLRQIEEKMQQLLEEKLLAEKRMKENEERSRALEEEREFYSSQSQALQNSLQELTAEKQQAERELKAEVKVRMDLERRLREAEGALRSLEQGLNSKVRNKEKEERMRADVSHLKRFFEECIRNAELEAKMPVIMKNSVYIHKAATRRIKSCRFHRRRSSTSWNDMKPSQSFMTSQLDANNMEELKEVAKRLSRDQRFRESIYHIMATQPGAPSALSRGGK>sp|P00747|PLMN_HUMAN Plasminogen OS=Homo sapiens OX=9606 GN=PLG PE=1SV=2MEHKEVVLLLLLFLKSGQGEPLDDYVNTQGASLFSVTKKQLGAGSIEECAAKCEEDEEFTCRAFQYHSKEQQCVIMAENRKSSIIIRMRDVVLFEKKVYLSECKTGNGKNYRGTMSKTKNGITCQKWSSTSPHRPRFSPATHPSEGLEENYCRNPDNDPQGPWCYTTDPEKRYDYCDILECEEECMHCSGENYDGKISKTMSGLECQAWDSQSPHAHGYIPSKFPNKNLKKNYCRNPDRELRPWCFTTDPNKRWELCDIPRCTTPPPSSGPTYQCLKGTGENYRGNVAVTVSGHTCQHWSAQTPHTHNRTPENFPCKNLDENYCRNPDGKRAPWCHTTNSQVRWEYCKIPSCDSSPVSTEQLAPTAPPELTPVVQDCYHGDGQSYRGTSSTTTTGKKCQSWSSMTPHRHQKTPENYPNAGLTMNYCRNPDADKGPWCFTTDPSVRWEYCNLKKCSGTEASVVAPPPVVLLPDVETPSEEDCMFGNGKGYRGKRATTVTGTPCQDWAAQEPHRHSIFTPETNPRAGLEKNYCRNPDGDVGGPWCYTTNPRKLYDYCDVPQCAAPSFDCGKPQVEPKKCPGRVVGGCVAHPHSWPWQVSLRTRFGMHFCGGTLISPEWVLTAAHCLEKSPRPSSYKVILGAHQEVNLEPHVQEIEVSRLFLEPTRKDIALLKLSSPAVITDKVIPACLPSPNYVVADRTECFITGWGETQGTFGAGLLKEAQLPVIENKVCNRYEFLNGRVQSTELCAGHLAGGTDSCQGDSGGPLVCFEKDKYILQGVTSWGLGCARPNKPGVYVRVSRFVTWIEGVMRNN>sp|Q8N131|PORIM_HUMAN Porimin OS=Homo sapiens OX=9606 GN=TMEM123 PE=1SV=1MGLGARGAWAALLLGTLQVLALLGAAHESAAMAASANIENSGLPHNSSANSTETLQHVPSDHTNETSNSTVKPPTSVASDSSNTTVTTMKPTAASNTTTPGMVSTNMTSTTLKSTPKTTSVSQNTSQISTSTMTVTHNSSVTSAASSVTITTTMHSEAKKGSKFDTGSFVGGIVLTLGVLSILYIGCKMYYSRRGIRYRTIDEHDAII>sp|Q8N131-2|PORIM_HUMAN Isoform 2 of Porimin OS=Homo sapiens OX=9606GN=TMEM123MGLGARGAWAALLLGTLQVLALLGAAHESAAMAETLQHVPSDHTNETSNSTVKPPTSVASDSSNTTVTTMKPTAASNTTTPGMVSTNMTSTTLKSTPKTTSVSQNTSQISTSTMTVTHNSSVTSAASSVTITTTMHSEAKKGSKFDTGSFVGGIVLTLGVLSILYIGCKMYYSRRGIRYRTIDEHDAII>sp|Q99541|PLIN2_HUMAN Perilipin-2 OS=Homo sapiens OX=9606 GN=PLIN2 PE=1SV=2MASVAVDPQPSVVTRVVNLPLVSSTYDLMSSAYLSTKDQYPYLKSVCEMAENGVKTITSVAMTSALPIIQKLEPQIAVANTYACKGLDRIEERLPILNQPSTQIVANAKGAVTGAKDAVTTTVTGAKDSVASTITGVMDKTKGAVTGSVEKTKSVVSGSINTVLGSRMMQLVSSGVENALTKSELLVEQYLPLTEEELEKEAKKVEGFDLVQKPSYYVRLGSLSTKLHSRAYQQALSRVKEAKQKSQQTISQLHSTVHLIEFARKNVYSANQKIQDAQDKLYLSWVEWKRSIGYDDTDESHCAEHIESRTLAIARNLTQQLQTTCHTLLSNIQGVPQNIQDQAKHMGVMAGDIYSVFRNAASFKEVSDSLLTSSKGQLQKMKESLDDVMDYLVNNTPLNWLVGPFYPQLTESQNAQDQGAEMDKSSQETQRSEHKTH>sp|Q8IY26|PLPP6_HUMAN Phospholipid phosphatase 6 OS=Homo sapiens OX=9606GN=PLPP6 PE=1 SV=3MPSPRRSMEGRPLGVSASSSSSSPGSPAHGGGGGGSRFEFQSLLSSRATAVDPTCARLRASESPVHRRGSFPLAAAGPSQSPAPPLPEEDRMDLNPSFLGIALRSLLAIDLWLSKKLGVCAGESSSWGSVRPLMKLLEISGHGIPWLLGTLYCLCRSDSWAGREVLMNLLFALLLDLLLVALIKGLVRRRRPAHNQMDMFVTLSVDKYSFPSGHATRAALMSRFILNHLVLAIPLRVLVVLWAFVLGLSRVMLGRHNVTDVAFGFFLGYMQYSIVDYCWLSPHNAPVLFLLWSQR>sp|P54277|PMS1_HUMAN PMS1 protein homolog 1 OS=Homo sapiens OX=9606GN=PMS1 PE=1 SV=1MKQLPAATVRLLSSSQIITSVVSVVKELIENSLDAGATSVDVKLENYGFDKIEVRDNGEGIKAVDAPVMAMKYYTSKINSHEDLENLTTYGFRGEALGSICCIAEVLITTRTAADNFSTQYVLDGSGHILSQKPSHLGQGTTVTALRLFKNLPVRKQFYSTAKKCKDEIKKIQDLLMSFGILKPDLRIVFVHNKAVIWQKSRVSDHKMALMSVLGTAVMNNMESFQYHSEESQIYLSGFLPKCDADHSFTSLSTPERSFIFINSRPVHQKDILKLIRHHYNLKCLKESTRLYPVFFLKIDVPTADVDVNLTPDKSQVLLQNKESVLIALENLMTTCYGPLPSTNSYENNKTDVSAADIVLSKTAETDVLFNKVESSGKNYSNVDTSVIPFQNDMHNDESGKNTDDCLNHQISIGDFGYGHCSSEISNIDKNTKNAFQDISMSNVSWENSQTEYSKTCFISSVKHTQSENGNKDHIDESGENEEEAGLENSSEISADEWSRGNILKNSVGENIEPVKILVPEKSLPCKVSNNNYPIPEQMNLNEDSCNKKSNVIDNKSGKVTAYDLLSNRVIKKPMSASALFVQDHRPQFLIENPKTSLEDATLQIEELWKTLSEEEKLKYEEKATKDLERYNSQMKRAIEQESQMSLKDGRKKIKPTSAWNLAQKHKLKTSLSNQPKLDELLQSQIEKRRSQNIKMVQIPFSMKNLKINFKKQNKVDLEEKDEPCLIHNLRFPDAWLMTSKTEVMLLNPYRVEEALLFKRLLENHKLPAEPLEKPIMLTESLFNGSHYLDVLYKMTADDQRYSGSTYLSDPRLTANGFKIKLIPGVSITENYLEIEGMANCLPFYGVADLKEILNAILNRNAKEVYECRPRKVISYLEGEAVRLSRQLPMYLSKEDIQDIIYRMKHQFGNEIKECVHGRPFFHHLTYLPETT>sp|P54277-2|PMS1_HUMAN Isoform 2 of PMS1 protein homolog 1 OS=Homosapiens OX=9606 GN=PMS1MKQLPAATVRLLSSSQIITSVVSVVKELIENSLDAGATSVDVKLENYGFDKIEVRDNGEGIKAVDAPVMAMKYYTSKINSHEDLENLTTYGFRGEALGSICCIAEVLITTRTAADNFSTQYVLDGSGHILSQKPSHLGQGTTVTALRLFKNLPVRKQFYSTAKKCKDEIKKIQDLLMSFGILKPDLRIVFVHNKAVIWQKSRVSDHKMALMSVLGTAVMNNMESFQYHSEESQIYLSGFLPKCDADHSFTSLSTPERSFIFINSRPVHQKDILKLIRHHYNLKCLKESTRLYPVFFLKIDVPTADVDVNLTPDKSQVLLQNKESVLIALENLMTTCYGPLPSTNSYENNKTDVSAADIVLSKTAETDVLFNKVESSGKNYSNVDTSVIPFQNDMHNDESGKNTDDCLNHQISIGDFGYGHCSSEISNIDKNTKNAFQDISMSNVSWENSQTEYSKTCFISSVKHTQSENGNKDHIDESGENEEEAGLENSSEISADEWSRGNILKNSVGENIEPVKILVPEKSLPCKVSNNNYPIPEQMNLNEDSCNKKSNVIDNKSGKVTAYDLLSNRVIKKPMSASALFVQDHRPQFLIENPKTSLEDATLQIEELWKTLSEEEKLNLFNGSHYLDVLYKMTADDQRYSGSTYLSDPRLTANGFKIKLIPGVSITENYLEIEGMANCLPFYGVADLKEILNAILNRNAKEVYECRPRKVISYLEGEAVRLSRQLPMYLSKEDIQDIIYRMKHQFGNEIKECVHGRPFFHHLTYLPETT>sp|P54277-3|PMS1_HUMAN Isoform 3 of PMS1 protein homolog 1 OS=Homosapiens OX=9606 GN=PMS1MKQLPAATVRLLSSSQIITSVVSVVKELIENSLDAGATSVDVKLENYGFDKIEVRDNGEGIKAVDAPVMAMKYYTSKINSHEDLENLTTYGFRGEALGSICCIAEVLITTRTAADNFSTQYVLDGSGHILSQKPSHLGQGTTVTALRLFKNLPVRKQFYSTAKKCKDEIKKIQDLLMSFGILKPDLRIVFVHNKIYLSGFLPKCDADHSFTSLSTPERSFIFINSRPVHQKDILKLIRHHYNLKCLKESTRLYPVFFLKIDVPTADVDVNLTPDKSQVLLQNKESVLIALENLMTTCYGPLPSTNSYENNKTDVSAADIVLSKTAETDVLFNKVESSGKNYSNVDTSVIPFQNDMHNDESGKNTDDCLNHQISIGDFGYGHCSSEISNIDKNTKNAFQDISMSNVSWENSQTEYSKTCFISSVKHTQSENGNKDHIDESGENEEEAGLENSSEISADEWSRGNILKNSVGENIEPVKILVPEKSLPCKVSNNNYPIPEQMNLNEDSCNKKSNVIDNKSGKVTAYDLLSNRVIKKPMSASALFVQDHRPQFLIENPKTSLEDATLQIEELWKTLSEEEKLKYEEKATKDLERYNSQMKRAIEQESQMSLKDGRKKIKPTSAWNLAQKHKLKTSLSNQPKLDELLQSQIEKRRSQNIKMVQIPFSMKNLKINFKKQNKVDLEEKDEPCLIHNLRFPDAWLMTSKTEVMLLNPYRVEEALLFKRLLENHKLPAEPLEKPIMLTESLFNGSHYLDVLYKMTADDQRYSGSTYLSDPRLTANGFKIKLIPGVSITENYLEIEGMANCLPFYGVADLKEILNAILNRNAKEVYECRPRKVISYLEGEAVRLSRQLPMYLSKEDIQDIIYRMKHQFGNEIKECVHGRPFFHHLTYLPETT>sp|P54277-4|PMS1_HUMAN Isoform 4 of PMS1 protein homolog 1 OS=Homosapiens OX=9606 GN=PMS1MSFGILKPDLRIVFVHNKIYLSGFLPKCDADHSFTSLSTPERSFIFINSRPVHQKDILKLIRHHYNLKCLKESTRLYPVFFLKIDVPTADVDVNLTPDKSQVLLQNKESVLIALENLMTTCYGPLPSTNSYENNKTDVSAADIVLSKTAETDVLFNKVESSGKNYSNVDTSVIPFQNDMHNDESGKNTDDCLNHQISIGDFGYGHCSSEISNIDKNTKNAFQDISMSNVSWENSQTEYSKTCFISSVKHTQSENGNKDHIDESGENEEEAGLENSSEISADEWSRGNILKNSVGENIEPVKILVPEKSLPCKVSNNNYPIPEQMNLNEDSCNKKSNVIDNKSGKVTAYDLLSNRVIKKPMSASALFVQDHRPQFLIENPKTSLEDATLQIEELWKTLSEEEKLNLFNGSHYLDVLYKMTADDQRYSGSTYLSDPRLTANGFKIKLIPGVSITENYLEIEGMANCLPFYGVADLKEILNAILNRNAKEVYECRPRKVISYLEGEAVRLSRQLPMYLSKEDIQDIIYRMKHQFGNEIKECVHGRPFFHHLTYLPETT>sp|Q8TBJ4|PLPR1_HUMAN Phospholipid phosphatase-related protein type 1OS=Homo sapiens OX=9606 GN=PLPPR1 PE=1 SV=1MAVGNNTQRSYSIIPCFIFVELVIMAGTVLLAYYFECTDTFQVHIQGFFCQDGDLMKPYPGTEEESFITPLVLYCVLAATPTAIIFIGEISMYFIKSTRESLIAQEKTILTGECCYLNPLLRRIIRFTGVFAFGLFATDIFVNAGQVVTGHLTPYFLTVCKPNYTSADCQAHHQFINNGNICTGDLEVIEKARRSFPSKHAALSIYSALYATMYITSTIKTKSSRLAKPVLCLGTLCTAFLTGLNRVSEYRNHCSDVIAGFILGTAVALFLGMCVVHNFKGTQGSPSKPKPEDPRGVPLMAFPRIESPLETLSAQNHSASMTEVT>sp|Q8NFJ6|PKR2_HUMAN Prokineticin receptor 2 OS=Homo sapiens OX=9606GN=PROKR2 PE=1 SV=1MAAQNGNTSFTPNFNPPQDHASSLSFNFSYGDYDLPMDEDEDMTKTRTFFAAKIVIGIALAGIMLVCGIGNFVFIAALTRYKKLRNLTNLLIANLAISDFLVAIICCPFEMDYYVVRQLSWEHGHVLCASVNYLRTVSLYVSTNALLAIAIDRYLAIVHPLKPRMNYQTASFLIALVWMVSILIAIPSAYFATETVLFIVKSQEKIFCGQIWPVDQQLYYKSYFLFIFGVEFVGPVVTMTLCYARISRELWFKAVPGFQTEQIRKRLRCRRKTVLVLMCILTAYVLCWAPFYGFTIVRDFFPTVFVKEKHYLTAFYVVECIAMSNSMINTVCFVTVKNNTMKYFKKMMLLHWRPSQRGSKSSADLDLRTNGVPTTEEVDCIRLK>sp|O15162|PLS1_HUMAN Phospholipid scramblase 1 OS=Homo sapiens OX=9606GN=PLSCR1 PE=1 SV=1MDKQNSQMNASHPETNLPVGYPPQYPPTAFQGPPGYSGYPGPQVSYPPPPAGHSGPGPAGFPVPNQPVYNQPVYNQPVGAAGVPWMPAPQPPLNCPPGLEYLSQIDQILIHQQIELLEVLTGFETNNKYEIKNSFGQRVYFAAEDTDCCTRNCCGPSRPFTLRIIDNMGQEVITLERPLRCSSCCCPCCLQEIEIQAPPGVPIGYVIQTWHPCLPKFTIQNEKREDVLKISGPCVVCSCCGDVDFEIKSLDEQCVVGKISKHWTGILREAFTDADNFGIQFPLDLDVKMKAVMIGACFLIDFMFFESTGSQEQKSGVW>sp|O15162-2|PLS1_HUMAN Isoform 2 of Phospholipid scramblase 1 OS=Homosapiens OX=9606 GN=PLSCR1MLLTRKQTCQLGILLSIHRQHSKIDQILIHQQIELLEVLTGFETNNKYEIKNSFGQRVYFAAEDTDCCTRNCCGPSRPFTLRIIDNMGQEVITLERPLRCSSCCCPCCLQEIEIQAPPGVPIGYVIQTWHPCLPKFTIQNEKREDVLKISGPCVVCSCCGDVDFEIKSLDEQCVVGKISKHWTGILREAFTDADNFGIQFPLDLDVKMKAVMIGACFLIDFMFFESTGSQEQKSGVW>sp|Q6ZWK4|RHEX_HUMAN Regulator of hemoglobinization and erythroid cellexpansion protein OS=Homo sapiens OX=9606 GN=RHEX PE=1 SV=1MLTEVMEVWHGLVIAVVSLFLQACFLTAINYLLSRHMAHKSEQILKAASLQVPRPSPGHHHPPAVKEMKETQTERDIPMSDSLYRHDSDTPSDSLDSSCSSPPACQATEDVDYTQVVFSDPGELKNDSPLDYENIKEITDYVNVNPERHKPSFWYFVNPALSEPAEYDQVAM>sp|P17081|RHOQ_HUMAN Rho-related GTP-binding protein RhoQ OS=Homosapiens OX=9606 GN=RHOQ PE=1 SV=2MAHGPGALMLKCVVVGDGAVGKTCLLMSYANDAFPEEYVPTVFDHYAVSVTVGGKQYLLGLYDTAGQEDYDRLRPLSYPMTDVFLICFSVVNPASFQNVKEEWVPELKEYAPNVPFLLIGTQIDLRDDPKTLARLNDMKEKPICVEQGQKLAKEIGACCYVECSALTQKGLKTVFDEAIIAILTPKKHTVKKRIGSRCINCCLIT>sp|O60486|PLXC1_HUMAN Plexin-C1 OS=Homo sapiens OX=9606 GN=PLXNC1 PE=1SV=1MEVSRRKAPPRPPRPAAPLPLLAYLLALAAPGRGADEPVWRSEQAIGAIAASQEDGVFVASGSCLDQLDYSLEHSLSRLYRDQAGNCTEPVSLAPPARPRPGSSFSKLLLPYREGAAGLGGLLLTGWTFDRGACEVRPLGNLSRNSLRNGTEVVSCHPQGSTAGVVYRAGRNNRWYLAVAATYVLPEPETASRCNPAASDHDTAIALKDTEGRSLATQELGRLKLCEGAGSLHFVDAFLWNGSIYFPYYPYNYTSGAATGWPSMARIAQSTEVLFQGQASLDCGHGHPDGRRLLLSSSLVEALDVWAGVFSAAAGEGQERRSPTTTALCLFRMSEIQARAKRVSWDFKTAESHCKEGDQPERVQPIASSTLIHSDLTSVYGTVVMNRTVLFLGTGDGQLLKVILGENLTSNCPEVIYEIKEETPVFYKLVPDPVKNIYIYLTAGKEVRRIRVANCNKHKSCSECLTATDPHCGWCHSLQRCTFQGDCVHSENLENWLDISSGAKKCPKIQIIRSSKEKTTVTMVGSFSPRHSKCMVKNVDSSRELCQNKSQPNRTCTCSIPTRATYKDVSVVNVMFSFGSWNLSDRFNFTNCSSLKECPACVETGCAWCKSARRCIHPFTACDPSDYERNQEQCPVAVEKTSGGGRPKENKGNRTNQALQVFYIKSIEPQKVSTLGKSNVIVTGANFTRASNITMILKGTSTCDKDVIQVSHVLNDTHMKFSLPSSRKEMKDVCIQFDGGNCSSVGSLSYIALPHCSLIFPATTWISGGQNITMMGRNFDVIDNLIISHELKGNINVSEYCVATYCGFLAPSLKSSKVRTNVTVKLRVQDTYLDCGTLQYREDPRFTGYRVESEVDTELEVKIQKENDNFNISKKDIEITLFHGENGQLNCSFENITRNQDLTTILCKIKGIKTASTIANSSKKVRVKLGNLELYVEQESVPSTWYFLIVLPVLLVIVIFAAVGVTRHKSKELSRKQSQQLELLESELRKEIRDGFAELQMDKLDVVDSFGTVPFLDYKHFALRTFFPESGGFTHIFTEDMHNRDANDKNESLTALDALICNKSFLVTVIHTLEKQKNFSVKDRCLFASFLTIALQTKLVYLTSILEVLTRDLMEQCSNMQPKLMLRRTESVVEKLLTNWMSVCLSGFLRETVGEPFYLLVTTLNQKINKGPVDVITCKALYTLNEDWLLWQVPEFSTVALNVVFEKIPENESADVCRNISVNVLDCDTIGQAKEKIFQAFLSKNGSPYGLQLNEIGLELQMGTRQKELLDIDSSSVILEDGITKLNTIGHYEISNGSTIKVFKKIANFTSDVEYSDDHCHLILPDSEAFQDVQGKRHRGKHKFKVKEMYLTKLLSTKVAIHSVLEKLFRSIWSLPNSRAPFAIKYFFDFLDAQAENKKITDPDVVHIWKTNSLPLRFWVNILKNPQFVFDIKKTPHIDGCLSVIAQAFMDAFSLTEQQLGKEAPTNKLLYAKDIPTYKEEVKSYYKAIRDLPPLSSSEMEEFLTQESKKHENEFNEEVALTEIYKYIVKYFDEILNKLERERGLEEAQKQLLHVKVLFDEKKKCKWM>sp|O14921|RGS13_HUMAN Regulator of G-protein signaling 13 OS=Homosapiens OX=9606 GN=RGS13 PE=1 SV=1MSRRNCWICKMCRDESKRPPSNLTLEEVLQWAQSFENLMATKYGPVVYAAYLKMEHSDENIQFWMACETYKKIASRWSRISRAKKLYKIYIQPQSPREINIDSSTRETIIRNIQEPTETCFEEAQKIVYMHMERDSYPRFLKSEMYQKLLKTMQSNNSF>sp|O60733|PLPL9_HUMAN 85/88 kDa calcium-independent phospholipase A2OS=Homo sapiens OX=9606 GN=PLA2G6 PE=1 SV=2MQFFGRLVNTFSGVTNLFSNPFRVKEVAVADYTSSDRVREEGQLILFQNTPNRTWDCVLVNPRNSQSGFRLFQLELEADALVNFHQYSSQLLPFYESSPQVLHTEVLQHLTDLIRNHPSWSVAHLAVELGIRECFHHSRIISCANCAENEEGCTPLHLACRKGDGEILVELVQYCHTQMDVTDYKGETVFHYAVQGDNSQVLQLLGRNAVAGLNQVNNQGLTPLHLACQLGKQEMVRVLLLCNARCNIMGPNGYPIHSAMKFSQKGCAEMIISMDSSQIHSKDPRYGASPLHWAKNAEMARMLLKRGCNVNSTSSAGNTALHVAVMRNRFDCAIVLLTHGANADARGEHGNTPLHLAMSKDNVEMIKALIVFGAEVDTPNDFGETPTFLASKIGRLVTRKAILTLLRTVGAEYCFPPIHGVPAEQGSAAPHHPFSLERAQPPPISLNNLELQDLMHISRARKPAFILGSMRDEKRTHDHLLCLDGGGVKGLIIIQLLIAIEKASGVATKDLFDWVAGTSTGGILALAILHSKSMAYMRGMYFRMKDEVFRGSRPYESGPLEEFLKREFGEHTKMTDVRKPKVMLTGTLSDRQPAELHLFRNYDAPETVREPRFNQNVNLRPPAQPSDQLVWRAARSSGAAPTYFRPNGRFLDGGLLANNPTLDAMTEIHEYNQDLIRKGQANKVKKLSIVVSLGTGRSPQVPVTCVDVFRPSNPWELAKTVFGAKELGKMVVDCCTDPDGRAVDRARAWCEMVGIQYFRLNPQLGTDIMLDEVSDTVLVNALWETEVYIYEHREEFQKLIQLLLSP>sp|O60733-2|PLPL9_HUMAN Isoform SH-iPLA2 of 85/88 kDa calcium-independent phospholipase A2 OS=Homo sapiens OX=9606 GN=PLA2G6MQFFGRLVNTFSGVTNLFSNPFRVKEVAVADYTSSDRVREEGQLILFQNTPNRTWDCVLVNPRNSQSGFRLFQLELEADALVNFHQYSSQLLPFYESSPQVLHTEVLQHLTDLIRNHPSWSVAHLAVELGIRECFHHSRIISCANCAENEEGCTPLHLACRKGDGEILVELVQYCHTQMDVTDYKGETVFHYAVQGDNSQVLQLLGRNAVAGLNQVNNQGLTPLHLACQLGKQEMVRVLLLCNARCNIMGPNGYPIHSAMKFSQKGCAEMIISMDSSQIHSKDPRYGASPLHWAKNAEMARMLLKRGCNVNSTSSAGNTALHVAVMRNRFDCAIVLLTHGANADARGEHGNTPLHLAMSKDNVEMIKALIVFGAEVDTPNDFGETPTFLASKIGRQLQDLMHISRARKPAFILGSMRDEKRTHDHLLCLDGGGVKGLIIIQLLIAIEKASGVATKDLFDWVAGTSTGGILALAILHSKSMAYMRGMYFRMKDEVFRGSRPYESGPLEEFLKREFGEHTKMTDVRKPKVMLTGTLSDRQPAELHLFRNYDAPETVREPRFNQNVNLRPPAQPSDQLVWRAARSSGAAPTYFRPNGRFLDGGLLANNPTLDAMTEIHEYNQDLIRKGQANKVKKLSIVVSLGTGRSPQVPVTCVDVFRPSNPWELAKTVFGAKELGKMVVDCCTDPDGRAVDRARAWCEMVGIQYFRLNPQLGTDIMLDEVSDTVLVNALWETEVYIYEHREEFQKLIQLLLSP>sp|O60733-3|PLPL9_HUMAN Isoform Ankyrin-iPLA2-1 of 85/88 kDa calcium-independent phospholipase A2 OS=Homo sapiens OX=9606 GN=PLA2G6MQFFGRLVNTFSGVTNLFSNPFRVKEVAVADYTSSDRVREEGQLILFQNTPNRTWDCVLVNPRNSQSGFRLFQLELEADALVNFHQYSSQLLPFYESSPQVLHTEVLQHLTDLIRNHPSWSVAHLAVELGIRECFHHSRIISCANCAENEEGCTPLHLACRKGDGEILVELVQYCHTQMDVTDYKGETVFHYAVQGDNSQVLQLLGRNAVAGLNQVNNQGLTPLHLACQLGKQEMVRVLLLCNARCNIMGPNGYPIHSAMKFSQKGCAEMIISMDSSQIHSKDPRYGASPLHWAKNAEMARMLLKRGCNVNSTSSAGNTALHVAVMRNRFDCAIVLLTHGANADARGEHGNTPLHLAMSKDNVEMIKALIVFGAEVDTPNDFGETPTFLASKIGRLVTRKAILTLLRTVGAEYCFPPIHGVPAEQGSAAPHHPFSLERAQPPPISLNNLELQDLMHISRARKPAFILGSMRDEKRTCRT>sp|O60733-4|PLPL9_HUMAN Isoform Ankyrin-iPLA2-2 of 85/88 kDa calcium-independent phospholipase A2 OS=Homo sapiens OX=9606 GN=PLA2G6MQFFGRLVNTFSGVTNLFSNPFRVKEVAVADYTSSDRVREEGQLILFQNTPNRTWDCVLVNPRNSQSGFRCANCAENEEGCTPLHLACRKGDGEILVELVQYCHTQMDVTDYKGETVFHYAVQGDNSQVLQLLGRNAVAGLNQVNNQGLTPLHLACQLGKQEMVRVLLLCNARCNIMGPNGYPIHSAMKFSQKGCAEMIISMDSSQIHSKDPRYGASPLHWAKNAEMARMLLKRGCNVNSTSSAGNTALHVAVMRNRFDCAIVLLTHGANADARGEHGNTPLHLAMSKDNVEMIKALIVFGAEVDTPNDFGETPTFLASKIGRLVTRKAILTLLRTVGAEYCFPPIHGVPAEQGSAAPHHPFSLERAQPPPISLNNLGSHPSQAGWWAWGAVSDGTTGSHAHLTGPEASVHPGLHEGREADMQNLSP>sp|O43566|RGS14_HUMAN Regulator of G-protein signaling 14 OS=Homosapiens OX=9606 GN=RGS14 PE=1 SV=4MPGKPKHLGVPNGRMVLAVSDGELSSTTGPQGQGEGRGSSLSIHSLPSGPSSPFPTEEQPVASWALSFERLLQDPLGLAYFTEFLKKEFSAENVTFWKACERFQQIPASDTQQLAQEARNIYQEFLSSQALSPVNIDRQAWLGEEVLAEPRPDMFRAQQLQIFNLMKFDSYARFVKSPLYRECLLAEAEGRPLREPGSSRLGSPDATRKKPKLKPGKSLPLGVEELGQLPPVEGPGGRPLRKSFRRELGGTANAALRRESQGSLNSSASLDLGFLAFVSSKSESHRKSLGSTEGESESRPGKYCCVYLPDGTASLALARPGLTIRDMLAGICEKRGLSLPDIKVYLVGNEQALVLDQDCTVLADQEVRLENRITFELELTALERVVRISAKPTKRLQEALQPILEKHGLSPLEVVLHRPGEKQPLDLGKLVSSVAAQRLVLDTLPGVKISKARDKSPCRSQGCPPRTQDKATHPPPASPSSLVKVPSSATGKRQTCDIEGLVELLNRVQSSGAHDQRGLLRKEDLVLPEFLQLPAQGPSSEETPPQTKSAAQPIGGSLNSTTDSAL>sp|O43566-4|RGS14_HUMAN Isoform 2 of Regulator of G-protein signaling 14OS=Homo sapiens OX=9606 GN=RGS14MFRAQQLQIFNLMKFDSYARFVKSPLYRECLLAEAEGRPLREPGSSRLGSPDATRKKPKLKPGKSLPLGVEELGQLPPVEGPGGRPLRKSFRRELGGTANAALRRESQGSLNSSASLDLGFLAFVSSKSESHRKSLGSTEGESESRPGKYCCVYLPDGTASLALARPGLTIRDMLAGICEKRGLSLPDIKVYLVGNEQVGT>sp|O43566-5|RGS14_HUMAN Isoform 3 of Regulator of G-protein signaling 14OS=Homo sapiens OX=9606 GN=RGS14MFRAQQLQIFNLMKFDSYARFVKSPLYRECLLAEAEGRPLREPGSSRLGSPDATRKKPKLKPGKSLPLGVEELGQLPPVEGPGGRPLRKSFRRELGGTANAALRRESQGSLNSSASLDLGFLAFVSSKSESHRKSLGSTEGESESRPGKYCCVYLPDGTASLALARPGLTIRDMLAGICEKRGLSLPDIKVYLVGNEQKALVLDQDCTVLADQEVRLENRITFELELTALERVVRISAKPTKRLQEALQPILEKHGLSPLEVVLHRPGEKQPLDLGKLVSSVAAQRLVLDTLPGVKISKARDKSPCRSQGCPPRTQDKATHPPPASPSSLVKVPSSATGKRQTCDIEGLVELLNRVQSSGAHDQRGLLRKEDLVLPEFLQLPAQGPSSEETPPQTKSAAQPIGGSLNSTTDSAL>sp|O43566-6|RGS14_HUMAN Isoform 4 of Regulator of G-protein signaling 14OS=Homo sapiens OX=9606 GN=RGS14MPGKPKHLGVPNGRMVLAVSDGELSSTTGPQGQGEGRGSSLSIHSLPSGPSSPFLAFVSSKSESHRKSLGSTEGESESRPGKYCCVYLPDGTASLALARPGLTIRDMLAGICEKRGLSLPDIKVYLVGNEQKALVLDQDCTVLADQEVRLENRITFELELTALERVVRISAKPTKRLQEALQPILEKHGLSPLEVVLHRPGEKQPLDLGKLVSSVAAQRLVLDTLPGVKISKARDKSPCRSQGCPPRTQDKATHPPPASPSSLVKVPSSATGKRQTCDIEGLVELLNRVQSSGAHDQRGLLRKEDLVLPEFLQLPAQGPSSEETPPQTKSAAQPIGGSLNSTTDSAL>sp|Q9ULL1|PKHG1_HUMAN Pleckstrin homology domain-containing family Gmember 1 OS=Homo sapiens OX=9606 GN=PLEKHG1 PE=1 SV=2MELSDSDRPVSFGSTSSSASSRDSHGSFGSRMTLVSNSHMGLFNQDKEVGAIKLELIPARPFSSSELQRDNPATGQQNADEGSERPPRAQWRVDSNGAPKTIADSATSPKLLYVDRVVQEILETERTYVQDLKSIVEDYLDCIRDQTKLPLGTEERSALFGNIQDIYHFNSELLQDLENCENDPVAIAECFVSKSEEFHIYTQYCTNYPRSVAVLTECMRNKILAKFFRERQETLKHSLPLGSYLLKPVQRILKYHLLLHEIENHLDKDTEGYDVVLDAIDTMQRVAWHINDMKRKHEHAVRLQEIQSLLTNWKGPDLTSYGELVLEGTFRIQRAKNERTLFLFDKLLLITKKRDDTFTYKAHILCGNLMLVEVIPKEPLSFSVFHYKNPKLQHTVQAKSQQDKRLWVLHLKRLILENHAAKIPAKAKQAILEMDAIHHPGFCYSPEGGTKALFGSKEGSAPYRLRRKSEPSSRSHKVLKTSETAQDIQKVSREEGSPQLSSARPSPAQRNSQPSSSTMISVLRAGGALRNIWTDHQIRQALFPSRRSPQENEDDEDDYQMFVPSFSSSDLNSTRLCEDSTSSRPCSWHMGQMESTETSSSGHRIVRRASSAGESNTCPPEIGTSDRTRELQNSPKTEGQEEMTPFGSSIELTIDDIDHVYDNISYEDLKLMVAKREEAESTPSKSARDSVRPKSTPELAFTKRQAGHSKGSLYAQTDGTLSGGEASSQSTHELQAVEENIYDTIGLPDPPSLGFKCSSLKRAKRSTFLGLEADFVCCDSLRPFVSQDSLQLSEDEAPYHQATPDHGYLSLLYDSPSGNLSMPHKPVSDKLSEEVDEIWNDLENYIKKNEDKARDRLLAAFPVSKDDVPDRLHAESTPELSRDVGRSVSTLSLPESQALLTPVKSRAGRASRANCPFEEDLISKEGSFMSLNRLSLASEMPLMDNPYDLANSGLSQTDPENPDLGMEATDKTKSRVFMMARQYSQKIKKANQLLKVKSLELEQPPASQHQKSMHKDLAAILEEKKQGGPAIGARIAEYSQLYDQIVFRESPLKIQKDGWASPQESSLLRSVSPSQVHHGSGDWLLHSTYSNGELADFCLPPEQDLRSRYPTFEINTKSTPRQLSAACSVPSLQTSDPLPGSVQRCSVVVSQPNKENWCQDHLYNSLGRKGISAKSQPYHRSQSSSSVLINKSMDSINYPSDVGKQQLLSLHRSSRCESHQDLLPDIADSHQQGTEKLSDLTLQDSQKVVVVNRNLPLNAQIATQNYFSNFKETDGDEDDYVEIKSEEDESELELSHNRRRKSDSKFVDADFSDNVCSGNTLHSLNSPRTPKKPVNSKLGLSPYLTPYNDSDKLNDYLWRGPSPNQQNIVQSLREKFQCLSSSSFA>sp|Q9H7P9|PKHG2_HUMAN Pleckstrin homology domain-containing family Gmember 2 OS=Homo sapiens OX=9606 GN=PLEKHG2 PE=1 SV=3MPEGAQGLSLSKPSPSLGCGRRGEVCDCGTVCETRTAPAAPTMASPRGSGSSTSLSTVGSEGDPAPGPTPACSASRPEPLPGPPIRLHLSPVGIPGSARPSRLERVAREIVETERAYVRDLRSIVEDYLGPLLDGGVLGLSVEQVGTLFANIEDIYEFSSELLEDLENSSSAGGIAECFVQRSEDFDIYTLYCMNYPSSLALLRELSLSPPAALWLQERQAQLRHSLPLQSFLLKPVQRILKYHLLLQELGKHWAEGPGTGGREMVEEAIVSMTAVAWYINDMKRKQEHAARLQEVQRRLGGWTGPELSAFGELVLEGAFRGGGGGGPRLRGGERLLFLFSRMLLVAKRRGLEYTYKGHIFCCNLSVSESPRDPLGFKVSDLTIPKHRHLLQAKNQEEKRLWIHCLQRLFFENHPASIPAKAKQVLLENSLHCAPKSKPVLEPLTPPLGSPRPRDARSFTPGRRNTAPSPGPSVIRRGRRQSEPVKDPYVMFPQNAKPGFKHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRGLRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLTKIPDVPNLPEIPSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGEPPSGGKAGPEEDEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERTASRVRELARLYSERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAIPLSKQGGSPDGQGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRSHMVIPAPSTAFCPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGSSLDPQGPGDTLPPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQGPAAAPPLPEPSLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARLESSDLTPPHSPPPSSRQLLGPNAAALSRYLAASYISQSLARRQGPGGGAPAASRGSWSSAPTSRASSPPPQPQPPPPPARRLSYATTVNIHVGGGGRLRPAKAQVRLNHPALLASTQESMGLHRAQGAPDAPFHM>sp|Q9H7P9-2|PKHG2_HUMAN Isoform 2 of Pleckstrin homology domain-containing family G member 2 OS=Homo sapiens OX=9606 GN=PLEKHG2MPEGAQGLSLSKPSPSLGCGRRGEVCDCGTVCETRTAPAAPTMASPRGSGSSTSLSTVGSEGDPAPGPTPACSASRPEPLPGPPIRLHLSPVGIPGSARPSRLERVAREIVETERAYVRDLRSIVEDYLGPLLDGGVLGLSVEQVGTLFANIEDIYEFSSELLEDLENSSSAGGIAECFVQRSEDFDIYTLYCMNYPSSLALLRELSLSPPAALWLQERQAQLRHSLPLQSFLLKPVQRILKYHLLLQELGKHWAEGPGTGGREMVEEAIVSMTAVAWYINDMKRKQEHAARLQEVQRRLGGWTGPELSAFGELVLEGAFRGGGGGGPRLRGGERLLFLFSRMLLVAKRRGLEYTYKGHIFCCNLSVSESPRDPLGFKVSDLTIPKHRHLLQAKNQEEKRLWIHCLQRLFFENHPASIPAKAKQVLLENSLHCAPKSKPVLEPLTPPLGSPRPRDARSFTPGRRNTAPSPGPSVIRRGRRQSEPVKDPYVMFPQNAKPGFKHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRGLRDPGESMGLHRAQGAPDAPFHM>sp|Q9H7P9-3|PKHG2_HUMAN Isoform 3 of Pleckstrin homology domain-containing family G member 2 OS=Homo sapiens OX=9606 GN=PLEKHG2MPEGAQGLSLSKPSPSLGCGRRGEVCDCGTVCETRTAPAAPTMASPRGSGSSTSLSTVGSEGDPAPGPTPACSASRPEPLPGPPIRLHLSPVGIPGSARPSRLERVAREIVETERAYVRDLRSIVEDYLGPLLDGGVLGLSVEQVGTLFANIEDIYEFSSELLEDLENSSSAGGIAECFVQRSEDFDIYTLYCMNYPSSLALLRELSLSPPAALWLQERQAQLRHSLPLQSFLLKPVQRILKYHLLLQELGKHWAEGPGTGGREMVEEAIVSMTAVAWYINDMKRKQEHAARLQEVQRRLGGWTGPELSAFGELVLEGAFRGGGGGGPRLRGGERLLFLFSRMLLVAKRRGLEYTYKGHIFCCNLSVSESPRDPLGFKVSDLTIPKHRHLLQAKNQEEKRLWIHCLQRLFFENHPASIPAKAKQVLLENSLHCAPKSKPVLEPLTPPLGSPRPRDARSFTPGRRNTAKPGFKHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRGLRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLTKIPDVPNLPEIPSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGEPPSGGKAGPEEDEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERTASRVRELARLYSERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAIPLSKQGGSPDGQGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRSHMVIPAPSTAFCPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGSSLDPQGPGDTLPPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQGPAAAPPLPEPSLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARLESSDLTPPHSPPPSSRQLLGPNAAALSRYLAASYISQSLARRQGPGGGAPAASRGSWSSAPTSRASSPPPQPQPPPPPARRLSYATTVNIHVGGGGRLRPAKAQVRLNHPALLASTQESMGLHRAQGAPDAPFHM>sp|B2RU33|POTEC_HUMAN POTE ankyrin domain family member C OS=Homosapiens OX=9606 GN=POTEC PE=2 SV=2MVTEVCSMPAASAVKKPFDLRSKMGKWFHHRFPCCKGSGKSNMGTSGDHDDSFMKMLRSKMGKCCHHCFPCCRGSGTSNVGTSGDHDNSFMKTLRSKMGKWCCHCFPCCRGSGKSNVGAWGDYDDSAFMEPRYHVRREDLDKLHRAAWWGKVPRKDLIVMLRDTDMNKRDKQKRTALHLASANGNSEVVQLLLDRRCQLNVLDNKKRTALIKAVQCQEDECVLMLLEHGADQNIPDEYGNTTLHYAVHNEDKLMAKALLLYGADIESKNKCGLTPLLLGVHEQKQQVVKFLIKKKANLNALDRYGRTALILAVCCGSASIVNLLLEQNVDVSSQDLSGQTAREYAVSSHHHVICELLSDYKEKQMLKISSENSNPEQDLKLTSEEESQRLKVSENSQPEKMSQEPEINKDCDREVEEEIKKHGSNPVGLPENLTNGASAGNGDDGLIPQRRSRKPENQQFPDTENEEYHSDEQNDTRKQLSEEQNTGISQDEILTNKQKQIEVAEKKMNSELSLSHKKEEDLLRENSMLQEEIAMLISGDWN>sp|O14495|PLPP3_HUMAN Phospholipid phosphatase 3 OS=Homo sapiens OX=9606GN=PLPP3 PE=1 SV=1MQNYKYDKAIVPESKNGGSPALNNNPRRSGSKRVLLICLDLFCLFMAGLPFLIIETSTIKPYHRGFYCNDESIKYPLKTGETINDAVLCAVGIVIAILAIITGEFYRIYYLKKSRSTIQNPYVAALYKQVGCFLFGCAISQSFTDIAKVSIGRLRPHFLSVCNPDFSQINCSEGYIQNYRCRGDDSKVQEARKSFFSGHASFSMYTMLYLVLYLQARFTWRGARLLRPLLQFTLIMMAFYTGLSRVSDHKHHPSDVLAGFAQGALVACCIVFFVSDLFKTKTTLSLPAPAIRKEILSPVDIIDRNNHHNMM>sp|A1L390|PKHG3_HUMAN Pleckstrin homology domain-containing family Gmember 3 OS=Homo sapiens OX=9606 GN=PLEKHG3 PE=1 SV=1MPVSTSLHQDGSQERPVSLTSTTSSSGSSCDSRSAMEEPSSSEAPAKNGAGSLRSRHLPNSNNNSSSWLNVKGPLSPFNSRAAAGPAHHKLSYLGRVVREIVETERMYVQDLRSIVEDYLLKIIDTPGLLKPEQVSALFGNIENIYALNSQLLRDLDSCNSDPVAVASCFVERSQEFDIYTQYCNNYPNSVAALTECMRDKQQAKFFRDRQELLQHSLPLGSYLLKPVQRILKYHLLLQEIAKHFDEEEDGFEVVEDAIDTMTCVAWYINDMKRRHEHAVRLQEIQSLLINWKGPDLTTYGELVLEGTFRVHRVRNERTFFLFDKTLLITKKRGDHFVYKGNIPCSSLMLIESTRDSLCFTVTHYKHSKQQYSIQAKTVEEKRNWTHHIKRLILENHHATIPQKAKEAILEMDSYYPNRYRCSPERLKKAWSSQDEVSTNVRQGRRQSEPTKHLLRQLNEKARAAGMKGKGRRESESSRSSRRPSGRSPTSTEKRMSFESISSLPEVEPDPEAGSEQEVFSAVEGPSAEETPSDTESPEVLETQLDAHQGLLGMDPPGDMVDFVAAESTEDLKALSSEEEEEMGGAAQEPESLLPPSVLDQASVIAERFVSSFSRRSSVAQEDSKSSGFGSPRLVSRSSSVLSLEGSEKGLARHGSATDSLSCQLSPEVDISVGVATEDSPSVNGMEPPSPGCPVEPDRSSCKKKESALSTRDRLLLDKIKSYYENAEHHDAGFSVRRRESLSYIPKGLVRNSISRFNSLPRPDPEPVPPVGSKRQVGSRPTSWALFELPGPSQAVKGDPPPISDAEFRPSSEIVKIWEGMESSGGSPGKGPGQGQANGFDLHEPLFILEEHELGAITEESATASPESSSPTEGRSPAHLARELKELVKELSSSTQGELVAPLHPRIVQLSHVMDSHVSERVKNKVYQLARQYSLRIKSNKPVMARPPLQWEKVAPERDGKSPTVPCLQEEAGEPLGGKGKRKPVLSLFDYEQLMAQEHSPPKPSSAGEMSPQRFFFNPSAVSQRTTSPGGRPSARSPLSPTETFSWPDVRELCSKYASRDEARRAGGGRPRGPPVNRSHSVPENMVEPPLSGRVGRCRSLSTKRGRGGGEAAQSPGPLPQSKPDGGETLYVTADLTLEDNRRVIVMEKGPLPSPTAGLEESSGQGPSSPVALLGQVQDFQQSAECQPKEEGSRDPADPSQQGRVRNLREKFQALNSVG>sp|A1L390-2|PKHG3_HUMAN Isoform 2 of Pleckstrin homology domain-containing family G member 3 OS=Homo sapiens OX=9606 GN=PLEKHG3MGKGRRESESSRSSRRPSGRSPTSTEKRMSFESISSLPEVEPDPEAGSEQEVFSAVEGPSAEETPSDTESPEVLETQLDAHQGLLGMDPPGDMVDFVAAESTEDLKALSSEEEEEMGGAAQEPESLLPPSVLDQASVIAERFVSSFSRRSSVAQEDSKSSGFGSPRLVSRSSSVLSLEGSEKGLARHGSATDSLSCQLSPEVDISVGVATEDSPSVNGMEPPSPGCPVEPDRSSCKKKESALSTRDRLLLDKIKSYYENAEHHDAGFSVRRRESLSYIPKGLVRNSISRFNSLPRPDPEPVPPVGSKRQVGSRPTSWALFELPGPSQAVKGDPPPISDAEFRPSSEIVKIWEGMESSGGSPGKGPGQGQANGFDLHEPLFILEEHELGAITEESATASPESSSPTEGRSPAHLARELKELVKELSSSTQGELVAPLHPRIVQLSHVMDSHVSERVKNKVYQLARQYSLRIKSNKPVMARPPLQWEKVAPERDGKSPTVPCLQEEAGEPLGGKGKRKPVLSLFDYEQLMAQEHSPPKPSSAGEMSPQRFFFNPSAVSQRTTSPGGRPSARSPLSPTETFSWPDVRELCSKYASRDEARRAGGGRPRGPPVNRSHSVPENMVEPPLSGRVGRCRSLSTKRGRGGGEAAQSPGPLPQSKPDGGETLYVTADLTLEDNRRVIVMEKGPLPSPTAGLEESSGQGPSSPVALLGQVQDFQQSAECQPKEEGSRDPADPSQQGRVRNLREKFQALNSVG>sp|A1L390-3|PKHG3_HUMAN Isoform 3 of Pleckstrin homology domain-containing family G member 3 OS=Homo sapiens OX=9606 GN=PLEKHG3MPVSTSLHQDGSQERPVSLTSTTSSSGSSCDSRSAMEEPSSSEAPAKNGAGSLRSRHLPNSNNNSSSWLNVKGPLSPFNSRAAAGPAHHKLSYLGRVVREIVETERMYVQDLRSIVESQEFDIYTQYCNNYPNSVAALTECMRDKQQAKFFRDRQELLQHSLPLGSYLLKPVQRILKYHLLLQEIAKHFDEEEDGFEVVEDAIDTMTCVAWYINDMKRRHEHAVRLQEIQSLLINWKGPDLTTYGELVLEGTFRVHRVRNERTFFLFDKTLLITKKRGDHFVYKGNIPCSSLMLIESTRDSLCFTVTHYKHSKQQYSIQAKTVEEKRNWTHHIKRLILENHHATIPQKAKEAILEMDSYYPNRYRCSPERLKKAWSSQDEVSTNVRQGRRQSEPTKHLLRQLNEKARAAGMKGKGRRESESSRSSRRPSGRSPTSTEKRMSFESISSLPEVEPDPEAGSEQEVFSAVEGPSAEETPSDTESPEVLETQLDAHQGLLGMDPPGDMVDFVAAESTEDLKALSSEEEEEMGGAAQEPESLLPPSVLDQASVIAERFVSSFSRRSSVAQEDSKSSGFGSPRLVSRSSSVLSLEGSEKGLARHGSATDSLSCQLSPEVDISVGVATEDSPSVNGMEPPSPGCPVEPDRSSCKKKESALSTRDRLLLDKIKSYYENAEHHDAGFSVRRRESLSYIPKGLVRNSISRFNSLPRPDPEPVPPVGSKRQVGSRPTSWALFELPGPSQAVKGDPPPISDAEFRPSSEIVKIWEGMESSGGSPGKGPGQGQANGFDLHEPLFILEEHELGAITEESATASPESSSPTEGRSPAHLARELKELVKELSSSTQGELVAPLHPRIVQLSHVMDSHVSERVKNKVYQLARQYSLRIKSNKPVMARPPLQWEKVAPERDGKSPTVPCLQEEAGEPLGGKGKRKPVLSLFDYEQLMAQEHSPPKPSSAGEMSPQRFFFNPSAVSQRTTSPGGRPSARSPLSPTETFSWPDVRELCSKYASRDEARRAGGGRPRGPPVNRSHSVPENMVEPPLSGRVGRCRSLSTKRGRGGGEAAQSPGPLPQSKPDGGETLYVTADLTLEDNRRVIVMEKGPLPSPTAGLEESSGQGPSSPVALLGQVQDFQQSAECQPKEEGSRDPADPSQQGRVRNLREKFQALNSVG>sp|Q8NBT0|POC1A_HUMAN POC1 centriolar protein homolog A OS=Homo sapiensOX=9606 GN=POC1A PE=1 SV=2MAAPCAEDPSLERHFKGHRDAVTCVDFSINTKQLASGSMDSCLMVWHMKPQSRAYRFTGHKDAVTCVNFSPSGHLLASGSRDKTVRIWVPNVKGESTVFRAHTATVRSVHFCSDGQSFVTASDDKTVKVWATHRQKFLFSLSQHINWVRCAKFSPDGRLIVSASDDKTVKLWDKSSRECVHSYCEHGGFVTYVDFHPSGTCIAAAGMDNTVKVWDVRTHRLLQHYQLHSAAVNGLSFHPSGNYLITASSDSTLKILDLMEGRLLYTLHGHQGPATTVAFSRTGEYFASGGSDEQVMVWKSNFDIVDHGEVTKVPRPPATLASSMGNLPEVDFPVPPGRGRSVESVQSQPQEPVSVPQTLTSTLEHIVGQLDVLTQTVSILEQRLTLTEDKLKQCLENQQLIMQRATP>sp|Q8NBT0-2|POC1A_HUMAN Isoform 2 of POC1 centriolar protein homolog AOS=Homo sapiens OX=9606 GN=POC1AMAAPCAEDPSLERHFKGHRDAVTCVDFSINTKQLASGSMDSCLMVWHMKPQSRAYRFTGHKDAVTCVNFSPSGHLLASGSRDKTVRIWVPNVKGESTVFRAHTATVRSVHFCSDGQSFVTASDDKTVKVWATHRQKFLFSLSQHINWVRCAKFSPDGRLIVSASDDKTVKLWDKSSRECVHSYCEHGGFVTYVDFHPSGTCIAAAGMDNTVKVWDVRTHRLLQHYQLHSAAVNGLSFHPSGNYLITASSDSTLKILDLMEGRLLYTLHGHQGPATTVAFSRTGEYFASGGSDEQVMVWKSNFDIVDHGEVTKVPRPPATLASSMGNLTVSILEQRLTLTEDKLKQCLENQQLIMQRATP>sp|Q8NBT0-3|POC1A_HUMAN Isoform 3 of POC1 centriolar protein homolog AOS=Homo sapiens OX=9606 GN=POC1AMDSCLMVWHMKPQSRAYRFTGHKDAVTCVNFSPSGHLLASGSRDKTVRIWVPNVKGESTVFRAHTATVRSVHFCSDGQSFVTASDDKTVKVWATHRQKFLFSLSQHINWVRCAKFSPDGRLIVSASDDKTVKLWDKSSRECVHSYCEHGGFVTYVDFHPSGTCIAAAGMDNTVKVWDVRTHRLLQHYQLHSAAVNGLSFHPSGNYLITASSDSTLKILDLMEGRLLYTLHGHQGPATTVAFSRTGEYFASGGSDEQVMVWKSNFDIVDHGEVTKVPRPPATLASSMGNLPEVDFPVPPGRGRSVESVQSQPQEPVSVPQTLTSTLEHIVGQLDVLTQTVSILEQRLTLTEDKLKQCLENQQLIMQRATP>sp|Q53GL0|PKHO1_HUMAN Pleckstrin homology domain-containing family Omember 1 OS=Homo sapiens OX=9606 GN=PLEKHO1 PE=1 SV=2MMKKNNSAKRGPQDGNQQPAPPEKVGWVRKFCGKGIFREIWKNRYVVLKGDQLYISEKEVKDEKNIQEVFDLSDYEKCEELRKSKSRSKKNHSKFTLAHSKQPGNTAPNLIFLAVSPEEKESWINALNSAITRAKNRILDEVTVEEDSYLAHPTRDRAKIQHSRRPPTRGHLMAVASTSTSDGMLTLDLIQEEDPSPEEPTSCAESFRVDLDKSVAQLAGSRRRADSDRIQPSADRASSLSRPWEKTDKGATYTPQAPKKLTPTEKGRCASLEEILSQRDAASARTLQLRAEEPPTPALPNPGQLSRIQDLVARKLEETQELLAEVQGLGDGKRKAKDPPRSPPDSESEQLLLETERLLGEASSNWSQAKRVLQEVRELRDLYRQMDLQTPDSHLRQTTPHSQYRKSLM>sp|Q53GL0-2|PKHO1_HUMAN Isoform 2 of Pleckstrin homology domain-containing family O member 1 OS=Homo sapiens OX=9606 GN=PLEKHO1MMKKNNSAKRGPQDGNQQPAPPEKVGWVRKFCGKGIFREIWKNRYVVLKGDQLYISEKEVKDEKNIQEVFDLSDYEKCEELRKSKSRSKKNHSKFTLAHSKQPGNTAPNLIFLAVSPEEKESWINALNSAITRAKNRILDEASTSTSDGMLTLDLIQEEDPSPEEPTSCAESFRVDLDKSVAQLAGSRRRADSDRIQPSADRASSLSRPWEKTDKGATYTPQAPKKLTPTEKGRCASLEEILSQRDAASARTLQLRAEEPPTPALPNPGQLSRIQDLVARKLEETQELLAEVQGLGDGKRKAKDPPRSPPDSESEQLLLETERLLGEASSNWSQAKRVLQEVRELRDLYRQMDLQTPDSHLRQTTPHSQYRKSLM>sp|P57054|PIGP_HUMAN Phosphatidylinositol N-acetylglucosaminyltransferase subunit P OS=Homo sapiens OX=9606 GN=PIGPPE=1 SV=4MVPRSTSLTLIVFLFHRLSKAPGKMVENSPSPLPERAIYGFVLFLSSQFGFILYLVWAFIPESWLNSLGLTYWPQKYWAVALPVYLLIAIVIGYVLLFGINMMSTSPLDSIHTITDNYAKNQQQKKYQEEAIPALRDISISEVNQMFFLAAKELYTKN>sp|P57054-2|PIGP_HUMAN Isoform A of Phosphatidylinositol N-acetylglucosaminyltransferase subunit P OS=Homo sapiens OX=9606 GN=PIGPMVENSPSPLPERAIYGFVLFLSSQFGFILYLVWAFIPESWLNSLGLTYWPQKYWAVALPVYLLIAIVIGYVLLFGINMMSTSPLDSIHTITDNYAKNQQQKKYQEEAIPALRDISISEVNQMFFLAAKELYTKN>sp|P57054-3|PIGP_HUMAN Isoform C of Phosphatidylinositol N-acetylglucosaminyltransferase subunit P OS=Homo sapiens OX=9606 GN=PIGPMVLYLVWAFIPESWLNSLGLTYWPQKYWAVALPVYLLIAIVIGYVLLFGINMMSTSPLDSIHTITDNYAKNQQQKKYQEEAIPALRDISISEVNQMFFLAAKELYTKN>sp|Q01201|RELB_HUMAN Transcription factor RelB OS=Homo sapiens OX=9606GN=RELB PE=1 SV=2MLRSGPASGPSVPTGRAMPSRRVARPPAAPELGALGSPDLSSLSLAVSRSTDELEIIDEYIKENGFGLDGGQPGPGEGLPRLVSRGAASLSTVTLGPVAPPATPPPWGCPLGRLVSPAPGPGPQPHLVITEQPKQRGMRFRYECEGRSAGSILGESSTEASKTLPAIELRDCGGLREVEVTACLVWKDWPHRVHPHSLVGKDCTDGICRVRLRPHVSPRHSFNNLGIQCVRKKEIEAAIERKIQLGIDPYNAGSLKNHQEVDMNVVRICFQASYRDQQGQMRRMDPVLSEPVYDKKSTNTSELRICRINKESGPCTGGEELYLLCDKVQKEDISVVFSRASWEGRADFSQADVHRQIAIVFKTPPYEDLEIVEPVTVNVFLQRLTDGVCSEPLPFTYLPRDHDSYGVDKKRKRGMPDVLGELNSSDPHGIESKRRKKKPAILDHFLPNHGSGPFLPPSALLPDPDFFSGTVSLPGLEPPGGPDLLDDGFAYDPTAPTLFTMLDLLPPAPPHASAVVCSGGAGAVVGETPGPEPLTLDSYQAPGPGDGGTASLVGSNMFPNHYREAAFGGGLLSPGPEAT>sp|Q8N3S3|PHTF2_HUMAN Protein PHTF2 OS=Homo sapiens OX=9606 GN=PHTF2PE=2 SV=2MASKVTDAIVWYQKKEFLSVATTAPGPQQVLPGYCQCSLKDQGLFIQCLIGAYDQQIWEKSVEQREIKFIKLGLRNKPKKTAHVKPDLIDVDLVRGSAFAKAKPESPWTSLTRKGIVRVVFFPFFFRWWLQVTSKVIFFWLLVLYLLQVAAIVLFCSTSSPHSIPLTEVIGPIWLMLLLGTVHCQIVSTRTPKPPLSTGGKRRRKLRKAAHLEVHREGDGSSTTDNTQEGAVQNHGTSTSHSVGTVFRDLWHAAFFLSGSKKAKNSIDKSTETDNGYVSLDGKKTVKSGEDGIQNHEPQCETIRPEETAWNTGTLRNGPSKDTQRTITNVSDEVSSEEGPETGYSLRRHVDRTSEGVLRNRKSHHYKKHYPNEDAPKSGTSCSSRCSSSRQDSESARPESETEDVLWEDLLHCAECHSSCTSETDVENHQINPCVKKEYRDDPFHQSHLPWLHSSHPGLEKISAIVWEGNDCKKADMSVLEISGMIMNRVNSHIPGIGYQIFGNAVSLILGLTPFVFRLSQATDLEQLTAHSASELYVIAFGSNEDVIVLSMVIISFVVRVSLVWIFFFLLCVAERTYKQRLLFAKLFGHLTSARRARKSEVPHFRLKKVQNIKMWLSLRSYLKRRGPQRSVDVIVSSAFLLTISVVFICCAQLLHVHEIFLDCHYNWELVIWCISLTLFLLRFVTLGSETSKKYSNTSILLTEQINLYLKMEKKPNKKEELTLVNNVLKLATKLLKELDSPFRLYGLTMNPLLYNITQVVILSAVSGVISDLLGFNLKLWKIKS>sp|Q8N3S3-2|PHTF2_HUMAN Isoform 2 of Protein PHTF2 OS=Homo sapiensOX=9606 GN=PHTF2MASKVTDAIVWYQKKIGAYDQQIWEKSVEQREIKFIKLGLRNKPKKTAHVKPDLIDVDLVRGSAFAKAKPESPWTSLTRKGIVRVVFFPFFFRWWLQVTSKVIFFWLLVLYLLQVAAIVLFCSTSSPHSIPLTEVIGPIWLMLLLGTVHCQIVSTRTPKPPLSTGGKRRRKLRKAAHLEVHREGDGSSTTDNTQEGAVQNHGTSTSHSVGTVFRDLWHAAFFLSGSKKAKNSIDKSTETDNGYVSLDGKKTVKSGEDGIQNHEPQCETIRPEETAWNTGTLRNGPSKDTQRTITNVSDEVSSEEGPETGYSLRRHVDRTSEGVLRNRKSHHYKKHYPNEDAPKSGTSCSSRCSSSRQDSESARPESETEDVLWEDLLHCAECHSSCTSETDVENHQINPCVKKEYRDDPFHQSHLPWLHSSHPGLEKISAIVWEGNDCKKADMSVLEISGMIMNRVNSHIPGIGYQIFGNAVSLILGLTPFVFRLSQATDLEQLTAHSASELYVIAFGSNEDVIVLSMVIISFVVRVSLVWIFFFLLCVAERTYKQRLLFAKLFGHLTSARRARKSEVPHFRLKKVQNIKMWLSLRSYLKRRGPQRSVDVIVSSAFLLTISVVFICCAQLLHVHEIFLDCHYNWELVIWCISLTLFLLRFVTLGSETSKKYSNTSILLTEQINLYLKMEKKPNKKEELTLVNNVLKLATKLLKELDSPFRLYGLTMNPLLYNITQVVILSAVSGVISDLLGFNLKLWKIKS>sp|Q8N3S3-3|PHTF2_HUMAN Isoform 3 of Protein PHTF2 OS=Homo sapiensOX=9606 GN=PHTF2MASKVTDAIVWYQKKIGAYDQQIWEKSVEQREIKGLRNKPKKTAHVKPDLIDVDLVRGSAFAKAKPESPWTSLTRKGIVRVVFFPFFFRWWLQVTSKVIFFWLLVLYLLQVAAIVLFCSTSSPHSIPLTEVIGPIWLMLLLGTVHCQIVSTRTPKPPLSTGGKRRRKLRKAAHLEVHREGDGSSTTDNTQEGAVQNHGTSTSHSVGTVFRDLWHAAFFLSGSKKAKNSIDKSTETDNGYVSLDGKKTVKSGEDGIQNHEPQCETIRPEETAWNTGTLRNGPSKDTQRTITNVSDEVSSEEGPETGYSLRRHVDRTSEGVLRNRKSHHYKKHYPNEDAPKSGTSCSSRCSSSRQDSESARPESETEDVLWEDLLHCAECHSSCTSETDVENHQINPCVKKEYRDDPFHQSHLPWLHSSHPGLEKISAIVWEGNDCKKADMSVLEISGMIMNRVNSHIPGIGYQIFGNAVSLILGLTPFVFRLSQATDLEQLTAHSASELYVIAFGSNEDVIVLSMVIISFVVRVSLVWIFFFLLCVAERTYKQRLLFAKLFGHLTSARRARKSEVPHFRLKKVQNIKMWLSLRSYLKRRGPQRSVDVIVSSAFLLTISVVFICCAQLLHVHEIFLDCHYNWELVIWCISLTLFLLRFVTLGSETSKKYSNTSILLTEQINLYLKMEKKPNKKEELTLVNNVLKLATKLLKELDSPFRLYGLTMNPLLYNITQVVILSAVSGVISDLLGFNLKLWKIKS>sp|Q8N3S3-4|PHTF2_HUMAN Isoform 4 of Protein PHTF2 OS=Homo sapiensOX=9606 GN=PHTF2MASKVTDAIVWYQKKIGAYDQQIWEKSVEQREIKGLRNKPKKTAHVKPDLIDVDLVRGSAFAKAKPESPWTSLTRKGIVRVVFFPFFFRWWLQVTSKVIFFWLLVLYLLQVAAIVLFCSTSSPHSIPLTEVIGPIWLMLLLGTVHCQIVSTRTPKPPLSTGGKRRRKLRKAAHLEVHREGDGSSTTDNTQEGAVQNHGTSTSHSVGTVFRDLWHAAFFLSGSKKAKNSIDKSTETDNGYVSLDGKKTVKSGEDGIQNHEPQCETIRPEETAWNTGTLRNGPSKDTQRTITNVSDEVSSEEGPETGYSLRRHVDRTSEGVLRNRKSHHYKKHYPNEDAPKSGTSCSSRCSSSRQDSESARPESETEDVLWEDLLHCAECHSSCTSETDVENHQINPCVKKEYRDDPFHQSHLPWLHSSHPGLEKISAIVWEGNDCKKADMSVLEISGMIMNRVNSHIPGIGYQIFGNAVSLILGLTPFVFRLSQATDLEQLTAHSASELYVIAFGSNEDVIVLSMVIISFVVRVSLVWIFFFLLCVAERTYKQRLLFAKLFGHLTSARRARKSEVPHFRLKKVQNIKMWLSLRSYLKRRGPQRSVDVIVSSAFLLTISVVFICCAQINLYLKMEKKPNKKEELTLVNNVLKLATKLLKELDSPFRLYGLTMNPLLYNITQVVILSAVSGVISDLLGFNLKLWKIKS>sp|Q8N3S3-5|PHTF2_HUMAN Isoform 5 of Protein PHTF2 OS=Homo sapiensOX=9606 GN=PHTF2MASKVTDAIVWYQKKIGAYDQQIWEKSVEQREIKFIKLGLRNKPKKTAHVKPDLIDVDLVRGSAFAKAKPESPWTSLTRKGIVRVVFFPFFFRWWLQVTSKVIFFWLLVLYLLQVAAIVLFCSTSSPHSIPLTEVIGPIWLMLLLGTVHCQIVSTRTPKPPLSTGGKRRRKLRKAAHLEVHREGDGSSTTDNTQEGAVQNHGTSTSHSVGTVFRDLWHAAFFLSGSKKAKNSIDKSTETDNGYVSLDGKKTVKSGEDGIQNHEPQCETIRPEETAWNTGTLRNGPSKDTQRTITNVSDEVSSEEGPETGYSLRRHVDRTSEGVLRNRKSHHYKKHYPNEVYTLSLSVYIRIYFICY>sp|Q8N3S3-6|PHTF2_HUMAN Isoform 6 of Protein PHTF2 OS=Homo sapiensOX=9606 GN=PHTF2MASKVTDAIVWYQKKIGAYDQQIWEKSVEQREIKGLRNKPKKTAHVKPDLIDVDLVRGSAFAKAKPESPWTSLTRKGIVRVVFFPFFFRWWLQVTSKVIFFWLLVLYLLQVAAIVLFCSTSSPHSIPLTEVIGPIWLMLLLGTVHCQIVSTRTPKPPLSTGGKRRRKLRKAAHLEVHREGDGSSTTDNTQEGAVQNHGTSTSHSVGTVFRDLWHAAFFLSGSKKAKNSIDKSTETDNGYVSLDGKKTVKSGEDGIQNHEPQCETIRPEETAWNTGTLRNGPSKDTQRTITNVSDEVSSEEGPETGYSLRRHVDRTSEGVLRNRKSHHYKKHYPNEVYTLSLSVYIRIYFICY>sp|Q8N3S3-7|PHTF2_HUMAN Isoform 7 of Protein PHTF2 OS=Homo sapiensOX=9606 GN=PHTF2MASKVTDAIVWYQKKIGAYDQQIWEKSVEQREIKGLRNKPKKTAHVKPDLIDVDLVRGSAFAKAKPESPWTSLTRKGIVRVVFFPFFFRWWLQVTSKVIFFWLLVLYLLQVAAIVLFCSTSSPHSIPLTEVIGPIWLMLLLGTVHCQIVSTRTPKPPLSTGGKRRRKLRKAAHLEVHREGDGSSTTDNTQEGAVQNHGTSTSHSVGTVFRDLWHAAFFLSGSKKAKNSIDKSTETDNGYVSLDGKKTVKSGEDGIQNHEPQCETIRPEETAWNTGTLRNGPSKDTQRTITNVSDEVSSEEGPETGYSLRRHVDRTSEGVLRNRKSHHYKKHYPNEDAPKSGTSCSSRCSSSRQDSESARPESETEDVLWEDLLHCAECHSSCTSETDVENHQINPCVKKEYRDDPFHQSHLPWLHSSHPGLEKISAIVWEGNDCKKADMSVLEISGMIMNRVNSHIPGIGYQIFGNAVSLILGLTPFVFRLSQATDLEQLTAHSASELYVIAFGSNEDVIVLSMVIISFVVRVSLVWIFFFLLCVAERTYKQVGIM>sp|P01833|PIGR_HUMAN Polymeric immunoglobulin receptor OS=Homo sapiensOX=9606 GN=PIGR PE=1 SV=4MLLFVLTCLLAVFPAISTKSPIFGPEEVNSVEGNSVSITCYYPPTSVNRHTRKYWCRQGARGGCITLISSEGYVSSKYAGRANLTNFPENGTFVVNIAQLSQDDSGRYKCGLGINSRGLSFDVSLEVSQGPGLLNDTKVYTVDLGRTVTINCPFKTENAQKRKSLYKQIGLYPVLVIDSSGYVNPNYTGRIRLDIQGTGQLLFSVVINQLRLSDAGQYLCQAGDDSNSNKKNADLQVLKPEPELVYEDLRGSVTFHCALGPEVANVAKFLCRQSSGENCDVVVNTLGKRAPAFEGRILLNPQDKDGSFSVVITGLRKEDAGRYLCGAHSDGQLQEGSPIQAWQLFVNEESTIPRSPTVVKGVAGGSVAVLCPYNRKESKSIKYWCLWEGAQNGRCPLLVDSEGWVKAQYEGRLSLLEEPGNGTFTVILNQLTSRDAGFYWCLTNGDTLWRTTVEIKIIEGEPNLKVPGNVTAVLGETLKVPCHFPCKFSSYEKYWCKWNNTGCQALPSQDEGPSKAFVNCDENSRLVSLTLNLVTRADEGWYWCGVKQGHFYGETAAVYVAVEERKAAGSRDVSLAKADAAPDEKVLDSGFREIENKAIQDPRLFAEEKAVADTRDQADGSRASVDSGSSEEQGGSSRALVSTLVPLGLVLAVGAVAVGVARARHRKNVDRVSIRSYRTDISMSDFENSREFGANDNMGASSITQETSLGGKEEFVATTESTTETKEPKKAKRSSKEEAEMAYKDFLLQSSTVAAEAQDGPQEA>sp|P48378|RFX2_HUMAN DNA-binding protein RFX2 OS=Homo sapiens OX=9606GN=RFX2 PE=1 SV=2MQNSEGGADSPASVALRPSAAAPPVPASPQRVLVQAASSNPKGAQMQPISLPRVQQVPQQVQPVQHVYPAQVQYVEGGDAVYTNGAIRTAYTYNPEPQMYAPSSTASYFEAPGGAQVTVAASSPPAVPSHSMVGITMDVGGSPIVSSAGAYLIHGGMDSTRHSLAHTSRSSPATLEMAIENLQKSEGITSHKSGLLNSHLQWLLDNYETAEGVSLPRSSLYNHYLRHCQEHKLDPVNAASFGKLIRSVFMGLRTRRLGTRGNSKYHYYGIRLKPDSPLNRLQEDTQYMAMRQQPMHQKPRYRPAQKTDSLGDSGSHSGLHSTPEQTMAVQSQHHQQYIDVSHVFPEFPAPDLGSFLLQDGVTLHDVKALQLVYRRHCEATVDVVMNLQFHYIEKLWLSFWNSKASSSDGPTSLPASDEDPEGAVLPKDKLISLCQCDPILRWMRSCDHILYQALVEILIPDVLRPVPSTLTQAIRNFAKSLEGWLTNAMSDFPQQVIQTKVGVVSAFAQTLRRYTSLNHLAQAARAVLQNTSQINQMLSDLNRVDFANVQEQASWVCQCEESVVQRLEQDFKLTLQQQSSLDQWASWLDSVVTQVLKQHAGSPSFPKAARQFLLKWSFYSSMVIRDLTLRSAASFGSFHLIRLLYDEYMFYLVEHRVAEATGETPIAVMGEFNDLASLSLTLLDKDDMGDEQRGSEAGPDARSLGEPLVKRERSDPNHSLQGI>sp|P48378-2|RFX2_HUMAN Isoform 2 of DNA-binding protein RFX2 OS=Homosapiens OX=9606 GN=RFX2MQNSEGGADSPASVALRPSAAAPPVPASPQRVLVQAASSNPKGAQMQPISLPRVQQVPQQVQPVQHVYPAQVQYVEGGDAVYTNGAIRTAYTYNPEPQMYAPSSTASYFEAPGGAQVTVAASSPPAVPSHSMVGITMDVGGSPIVSSAGAYLIHGGMDSTRHSLAHTSRSSPATLQWLLDNYETAEGVSLPRSSLYNHYLRHCQEHKLDPVNAASFGKLIRSVFMGLRTRRLGTRGNSKYHYYGIRLKPDSPLNRLQEDTQYMAMRQQPMHQKPRYRPAQKTDSLGDSGSHSGLHSTPEQTMAVQSQHHQQYIDVSHVFPEFPAPDLGSFLLQDGVTLHDVKALQLVYRRHCEATVDVVMNLQFHYIEKLWLSFWNSKASSSDGPTSLPASDEDPEGAVLPKDKLISLCQCDPILRWMRSCDHILYQALVEILIPDVLRPVPSTLTQAIRNFAKSLEGWLTNAMSDFPQQVIQTKVGVVSAFAQTLRRYTSLNHLAQAARAVLQNTSQINQMLSDLNRVDFANVQEQASWVCQCEESVVQRLEQDFKLTLQQQSSLDQWASWLDSVVTQVLKQHAGSPSFPKAARQFLLKWSFYSSMVIRDLTLRSAASFGSFHLIRLLYDEYMFYLVEHRVAEATGETPIAVMGEFNDLASLSLTLLDKDDMGDEQRGSEAGPDARSLGEPLVKRERSDPNHSLQGI>sp|P40937|RFC5_HUMAN Replication factor C subunit 5 OS=Homo sapiensOX=9606 GN=RFC5 PE=1 SV=1METSALKQQEQPAATKIRNLPWVEKYRPQTLNDLISHQDILSTIQKFINEDRLPHLLLYGPPGTGKTSTILACAKQLYKDKEFGSMVLELNASDDRGIDIIRGPILSFASTRTIFKKGFKLVILDEADAMTQDAQNALRRVIEKFTENTRFCLICNYLSKIIPALQSRCTRFRFGPLTPELMVPRLEHVVEEEKVDISEDGMKALVTLSSGDMRRALNILQSTNMAFGKVTEETVYTCTGHPLKSDIANILDWMLNQDFTTAYRNITELKTLKGLALHDILTEIHLFVHRVDFPSSVRIHLLTKMADIEYRLSVGTNEKIQLSSLIAAFQVTRDLIVAEA>sp|P40937-2|RFC5_HUMAN Isoform 2 of Replication factor C subunit 5OS=Homo sapiens OX=9606 GN=RFC5MVEKYRPQTLNDLISHQDILSTIQKFINEDRLPHLLLYGPPGTGKTSTILACAKQLYKDKEFGSMVLELNASDDRGIDIIRGPILSFASTRTIFKKGFKLVILDEADAMTQDAQNALRRVIEKFTENTRFCLICNYLSKIIPALQSRCTRFRFGPLTPELMVPRLEHVVEEEKVDISEDGMKALVTLSSGDMRRALNILQSTNMAFGKVTEETVYTCTGHPLKSDIANILDWMLNQDFTTAYRNITELKTLKGLALHDILTEIHLFVHRVDFPSSVRIHLLTKMADIEYRLSVGTNEKIQLSSLIAAFQVTRDLIVAEA>sp|Q04864|REL_HUMAN Proto-oncogene c-Rel OS=Homo sapiens OX=9606 GN=RELPE=1 SV=1MASGAYNPYIEIIEQPRQRGMRFRYKCEGRSAGSIPGEHSTDNNRTYPSIQIMNYYGKGKVRITLVTKNDPYKPHPHDLVGKDCRDGYYEAEFGQERRPLFFQNLGIRCVKKKEVKEAIITRIKAGINPFNVPEKQLNDIEDCDLNVVRLCFQVFLPDEHGNLTTALPPVVSNPIYDNRAPNTAELRICRVNKNCGSVRGGDEIFLLCDKVQKDDIEVRFVLNDWEAKGIFSQADVHRQVAIVFKTPPYCKAITEPVTVKMQLRRPSDQEVSESMDFRYLPDEKDTYGNKAKKQKTTLLFQKLCQDHVETGFRHVDQDGLELLTSGDPPTLASQSAGITVNFPERPRPGLLGSIGEGRYFKKEPNLFSHDAVVREMPTGVSSQAESYYPSPGPISSGLSHHASMAPLPSSSWSSVAHPTPRSGNTNPLSSFSTRTLPSNSQGIPPFLRIPVGNDLNASNACIYNNADDIVGMEASSMPSADLYGISDPNMLSNCSVNMMTTSSDSMGETDNPRLLSMNLENPSCNSVLDPRDLRQLHQMSSSSMSAGANSNTTVFVSQSDAFEGSDFSCADNSMINESGPSNSTNPNSHGFVQDSQYSGIGSMQNEQLSDSFPYEFFQV>sp|Q04864-2|REL_HUMAN Isoform 2 of Proto-oncogene c-Rel OS=Homo sapiensOX=9606 GN=RELMASGAYNPYIEIIEQPRQRGMRFRYKCEGRSAGSIPGEHSTDNNRTYPSIQIMNYYGKGKVRITLVTKNDPYKPHPHDLVGKDCRDGYYEAEFGQERRPLFFQNLGIRCVKKKEVKEAIITRIKAGINPFNVPEKQLNDIEDCDLNVVRLCFQVFLPDEHGNLTTALPPVVSNPIYDNRAPNTAELRICRVNKNCGSVRGGDEIFLLCDKVQKDDIEVRFVLNDWEAKGIFSQADVHRQVAIVFKTPPYCKAITEPVTVKMQLRRPSDQEVSESMDFRYLPDEKDTYGNKAKKQKTTLLFQKLCQDHVNFPERPRPGLLGSIGEGRYFKKEPNLFSHDAVVREMPTGVSSQAESYYPSPGPISSGLSHHASMAPLPSSSWSSVAHPTPRSGNTNPLSSFSTRTLPSNSQGIPPFLRIPVGNDLNASNACIYNNADDIVGMEASSMPSADLYGISDPNMLSNCSVNMMTTSSDSMGETDNPRLLSMNLENPSCNSVLDPRDLRQLHQMSSSSMSAGANSNTTVFVSQSDAFEGSDFSCADNSMINESGPSNSTNPNSHGFVQDSQYSGIGSMQNEQLSDSFPYEFFQV>sp|Q4ADV7|RIC1_HUMAN Guanine nucleotide exchange factor subunit RIC1OS=Homo sapiens OX=9606 GN=RIC1 PE=1 SV=2MYFLSGWPKRLLCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEWRPDSTMIAVSTANGYILFFHITSTRGDKYLYEPVYPKGSPQMKGTPHFKEEQCAPALNLEMRKILDLQAPIMSLQSVLEDLLVATSDGLLHLIHWEGMTNGRKAINLCTVPFSVDLQSSRVGSFLGFTDVHIRDMEYCATLDGFAVVFNDGKVGFITPVSSRFTAEQLHGVWPQDVVDGTCVAVNNKYRLMAFGCVSGSVQVYTIDNSTGAMLLSHKLELTAKQYPDIWNKTGAVKLMRWSPDNSVVIVTWEYGGLSLWSVFGAQLICTLGGDFAYRSDGTKKDPLKINSMSWGAEGYHLWVISGFGSQNTEIESDLRSVVKQPSILLFQFIKSVLTVNPCMSNQEQVLLQGEDRLYLNCGEASQTQNPRSSSTHSEHKPSREKSPFADGGLESQGLSTLLGHRHWHVVQISSTYLESNWPIRFSAIDKLGQNIAVVGKFGFAHYSLLTKKWKLFGNITQEQNMIVTGGLAWWNDFMVLACYNINDRQEELRVYLRTSNLDNAFAHVTKAQAETLLLSVFQDMVIVFRADCSICLYSIERKSDGPNTTAGIQVLQEVSMSRYIPHPFLVVSVTLTSVSTENGITLKMPQQARGAESIMLNLAGQLIMMQRDRSGPQIREKDSNPNNQRKLLPFCPPVVLAQSVENVWTTCRANKQKRHLLEALWLSCGGAGMKVWLPLFPRDHRKPHSFLSQRIMLPFHINIYPLAVLFEDALVLGAVNDTLLYDSLYTRNNAREQLEVLFPFCVVERTSQIYLHHILRQLLVRNLGEQALLLAQSCATLPYFPHVLELMLHEVLEEEATSREPIPDPLLPTVAKFITEFPLFLQTVVHCARKTEYALWNYLFAAVGNPKDLFEECLMAQDLDTAASYLIILQNMEVPAVSRQHATLLFNTALEQGKWDLCRHMIRFLKAIGSGESETPPSTPTAQEPSSSGGFEFFRNRSISLSQSAENVPASKFSLQKTLSMPSGPSGKRWSKDSDCAENMYIDMMLWRHARRLLEDVRLKDLGCFAAQLGFELISWLCKERTRAARVDNFVIALKRLHKDFLWPLPIIPASSISSPFKNGKYRTVGEQLLKSQSADPFLNLEMDAGISNIQRSQSWLSNIGPTHHEIDTASSHGPQMQDAFLSPLSNKGDECSIGSATDLTESSSMVDGDWTMVDENFSTLSLTQSELEHISMELASKGPHKSQVQLRYLLHIFMEAGCLDWCIVIGLILRESSIINQILVITQSSEVDGEMLQNIKTGLHAVDRWASTDCPGYKPFLNIIKPQLQKLSEITEEQVQPDAFQPITMGKTPEQTSPRAEESRGSSSHGSIPQGEVGSSNMVSRKEEDTAQAEEEEPFQDGTYDCSVS>sp|Q4ADV7-2|RIC1_HUMAN Isoform 2 of Guanine nucleotide exchange factorsubunit RIC1 OS=Homo sapiens OX=9606 GN=RIC1MYFLSGWPKRLLCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEWRPDSTMIAVSTANGYILFFHITSTRGDKYLYEPVYPKGSPQMKGTPHFKEEQCAPALNLEMRKILDLQAPIMSLQSVLEDLLVATSDGLLHLIHWEGMTNGRKAINLCTVPFSVDLQSSRVGSFLGFTDVHIRDMEYCATLDGFAVVFNDGKVGFITPVSSRFTAEQLHGVWPQDVVDGTCVAVNNKYRLMAFGCVSGSVQVYTIDNSTGAMLLSHKLELTAKQYPDIWNKTGAVKLMRWSPDNSVVIVTWEYGGLSLWSVFGAQLICTLGGDFAYRSDGTKKDPLKINSMSWGAEGYHLWVISGFGSQNTEIESDLRSVVKQPSILLFQFIKSVLTVNPCMSNQEQVLLQGEDRLYLNCGEASQTQNPRSSSTHSEHKPSREKSPFADGGLESQGLSTLLGHRHWHVVQISSTYLESNWPIRFSAIDKLGQNIAVVGKFGFAHYSLLTKKWKLFGNITQEQNMIVTGGLAWWNDFMVLACYNINDRQEELRVYLRTSNLDNAFAHVTKAQAETLLLSVFQDMVIVFRADCSICLYSIERKSDGPNTTAGIQVLQEVSMSRYIPHPFLVVSVTLTSVSTENGITLKMPQQARGAESIMLNLAGQLIMMQRDRSGPQIREKDSNPNNQRKLLPFCPPVVLAQSVENVWTTCRANKQKRHLLEALWLSCGGAGMKVWLPLFPRDHRKPHSFLSQRIMLPFHINIYPLAVLFEDALVLGAVNDTLLYDSLYTRNNAREQLEVLFPFCVVERTSQIYLHHILRQLLVRNLGEQALLLAQSCATLPYFPHVLELMLHEVLEEEATSREPIPDPLLPTVAKFITEFPLFLQTVVHCARKTEYALWNYLFAAVGNPKDLFEECLMAQDLDTAASYLIILQNMEVPAVSRQHATLLFNTALEQGKWDLCRHMIRFLKAIGSGESETPPSTPTAQEPSSSGGFEFFRNRSISLSQSAENVPASKFSLQKTLSMPSGPSGKRWSKDSDCAENMYIDMMLWRHARRLLEDVRLKDLGCFAAQLGFELISWLCKERTRAARVDNFVIALKRLHKDFLWPLPIIPASSISSPFKNGKYRTGNVDFMSLVQGELYFTPCIYTFCY>sp|Q4ADV7-3|RIC1_HUMAN Isoform 3 of Guanine nucleotide exchange factorsubunit RIC1 OS=Homo sapiens OX=9606 GN=RIC1MYFLSGWPKRLLCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEWRPDSTMIAVSTANGYILFFHITSTRGDKYLYEPVYPKGSPQMKGTPHFKEEQCAPALNLEMRKILDLQAPIMSLQSVLEDLLVATSDGLLHLIHWEGMTNGRKAINLCTVPFSVDLQSSRVGSFLGFTDVHIRDMEYCATLDGFAVVFNDGKVGFITPVSSRFTAEQLHGVWPQDVVDGTCVAVNNKYRLMAFGCVSGSVQVYTIDNSTGAMLLSHKLELTAKQYPDIWNKTGAVKLMRWSPDNSVVIVTWEYGGLSLWSVFGAQLICTLGGDFAYRSDGTKKDPLKINSMSWGAEGYHLWVISGFGSQNTEIESDLRSVVKQPSILLFQFIKSVLTVNPCMSNQEQVLLQGEDRLYLNCGEASQTQNPRSSSTHSEHKPSREKSPFADGGLESQGLSTLLGHRHWHVVQISSTYLESNWPIREQNMIVTGGLAWWNDFMVLACYNINDRQEELRVYLRTSNLDNAFAHVTKAQAETLLLSVFQDMVIVFRADCSICLYSIERKSDGPNTTAGIQVLQEVSMSRYIPHPFLVVSVTLTSVSTENGITLKMPQQARGAESIMLNLAGQLIMMQRDRSGPQIREKDSNPNNQRKLLPFCPPVVLAQSVENVWTTCRANKQKRHLLEALWLSCGGAGMKVWLPLFPRDHRKPHSFLSQRIMLPFHINIYPLAVLFEDALVLGAVNDTLLYDSLYTRNNAREQLEVLFPFCVVERTSQIYLHHILRQLLVRNLGEQALLLAQSCATLPYFPHVLELMLHEVLEEEATSREPIPDPLLPTVAKFITEFPLFLQTVVHCARKTEYALWNYLFAAVGNPKDLFEECLMAQDLDTAASYLIILQNMEVPAVSRQHATLLFNTALEQGKWDLCRHMIRFLKAIGSGESETPPSTPTAQEPSSSGGFEFFRNRSISLSQSAENVPASKFSLQKTLSMPSGPSGKRWSKDSDCAENMYIDMMLWRHARRLLEDVRLKDLGCFAAQLGFELISWLCKERTRAARVDNFVIALKRLHKDFLWPLPIIPASSISSPFKNGKYRTVGEQLLKSQSADPFLNLEMDAGISNIQRSQSWLSNIGPTHHEIDTASSHGPQMQDAFLSPLSNKGDECSIGSATDLTESSSMVDGDWTMVDENFSTLSLTQSELEHISMELASKGPHKSQVQLRYLLHIFMEAGCLDWCIVIGLILRESSIINQILVITQSSEVDGEMLQNIKTGLHAVDRWASTDCPGYKPFLNIIKPQLQKLSEITEEQVQPDAFQPITMGKTPEQTSPRAEESRGSSSHGSIPQGEVGSSNMVSRKEEDTAQAEEEEPFQDGTYDCSVS>sp|O75628|REM1_HUMAN GTP-binding protein REM 1 OS=Homo sapiens OX=9606GN=REM1 PE=1 SV=2MTLNTEQEAKTPLHRRASTPLPLSPRGHQPGRLSTVPSTQSQHPRLGQSASLNPPTQKPSPAPDDWSSESSDSEGSWEALYRVVLLGDPGVGKTSLASLFAGKQERDLHEQLGEDVYERTLTVDGEDTTLVVVDTWEAEKLDKSWSQESCLQGGSAYVIVYSIADRGSFESASELRIQLRRTHQADHVPIILVGNKADLARCREVSVEEGRACAVVFDCKFIETSATLQHNVAELFEGVVRQLRLRRRDSAAKEPPAPRRPASLAQRARRFLARLTARSARRRALKARSKSCHNLAVL>sp|P27694|RFA1_HUMAN Replication protein A 70 kDa DNA-binding subunitOS=Homo sapiens OX=9606 GN=RPA1 PE=1 SV=2MVGQLSEGAIAAIMQKGDTNIKPILQVINIRPITTGNSPPRYRLLMSDGLNTLSSFMLATQLNPLVEEEQLSSNCVCQIHRFIVNTLKDGRRVVILMELEVLKSAEAVGVKIGNPVPYNEGLGQPQVAPPAPAASPAASSRPQPQNGSSGMGSTVSKAYGASKTFGKAAGPSLSHTSGGTQSKVVPIASLTPYQSKWTICARVTNKSQIRTWSNSRGEGKLFSLELVDESGEIRATAFNEQVDKFFPLIEVNKVYYFSKGTLKIANKQFTAVKNDYEMTFNNETSVMPCEDDHHLPTVQFDFTGIDDLENKSKDSLVDIIGICKSYEDATKITVRSNNREVAKRNIYLMDTSGKVVTATLWGEDADKFDGSRQPVLAIKGARVSDFGGRSLSVLSSSTIIANPDIPEAYKLRGWFDAEGQALDGVSISDLKSGGVGGSNTNWKTLYEVKSENLGQGDKPDYFSSVATVVYLRKENCMYQACPTQDCNKKVIDQQNGLYRCEKCDTEFPNFKYRMILSVNIADFQENQWVTCFQESAEAILGQNAAYLGELKDKNEQAFEEVFQNANFRSFIFRVRVKVETYNDESRIKATVMDVKPVDYREYGRRLVMSIRRSALM>sp|Q8IYK8|REM2_HUMAN GTP-binding protein REM 2 OS=Homo sapiens OX=9606GN=REM2 PE=1 SV=2MHTDLDTDMDMDTETTALCPSGSRRASPPGTPTPEADATLLKKSEKLLAELDRSGLPSAPGAPRRRGSMPVPYKHQLRRAQAVDELDWPPQASSSGSSDSLGSGEAAPAQKDGIFKVMLVGESGVGKSTLAGTFGGLQGDSAHEPENPEDTYERRIMVDKEEVTLVVYDIWEQGDAGGWLRDHCLQTGDAFLIVFSVTDRRSFSKVPETLLRLRAGRPHHDLPVILVGNKSDLARSREVSLEEGRHLAGTLSCKHIETSAALHHNTRELFEGAVRQIRLRRGRNHAGGQRPDPGSPEGPAPPARRESLTKKAKRFLANLVPRNAKFFKQRSRSCHDLSVL>sp|Q8IYK8-2|REM2_HUMAN Isoform 2 of GTP-binding protein REM 2 OS=Homosapiens OX=9606 GN=REM2MHTDLDTDMDMDTETTALCPSGSRRASPPGTPTPEADATLLKKSEKLLAELDRSGLPSAPGAPRRRGSMPVPYKHQLRRAQAVDELDWPPQASSSGSSDSLGSGEAAPAQKDGIFKVMLVGESGVGKSTLAGTFGGLQGDSAHEPENPGGCRRVAAGPLPSDRGRLSHRLLSHRPTEFLQSSRDPTSAPGWEAAPRPTRYPRWKQERLGPLPGGITGGCVS>sp|Q7Z5B4|RIC3_HUMAN Protein RIC-3 OS=Homo sapiens OX=9606 GN=RIC3 PE=1SV=1MAYSTVQRVALASGLVLALSLLLPKAFLSRGKRQEPPPTPEGKLGRFPPMMHHHQAPSDGQTPGARFQRSHLAEAFAKAKGSGGGAGGGGSGRGLMGQIIPIYGFGIFLYILYILFKLSKGKTTAEDGKCYTAMPGNTHRKITSFELAQLQEKLKETEAAMEKLINRVGPNGESRAQTVTSDQEKRLLHQLREITRVMKEGKFIDRFSPEKEAEEAPYMEDWEGYPEETYPIYDLSDCIKRRQETILVDYPDPKELSAEEIAERMGMIEEEESDHLGWESLPTDPRAQEDNSVTSCDPKPETCSCCFHEDEDPAVLAENAGFSADSYPEQEETTKEEWSQDFKDEGLGISTDKAYTGSMLRKRNPQGLE>sp|Q7Z5B4-2|RIC3_HUMAN Isoform 2 of Protein RIC-3 OS=Homo sapiensOX=9606 GN=RIC3MAYSTVQRVALASGLVLALSLLLPKAFLSRGKRQEPPPTPEGKLGRFPPMMHHHQAPSDGQTPGARFQRSHLAEAFAKAKGSGGGAGGGGSGRGLMGQIIPIYGFGIFLYILYILFKVSRIILIILHQ>sp|Q7Z5B4-3|RIC3_HUMAN Isoform 3 of Protein RIC-3 OS=Homo sapiensOX=9606 GN=RIC3MAYSTVQRVALASGLVLALSLLLPKAFLSRGKRQEPPPTPEGYPEETYPIYDLSDCIKRRQETILVDYPDPKELSAEEIAERMGMIEEEESDHLGWESLPTDPRAQEDNSVTSCDPKPETCSCCFHEDEDPAVLAENAGFSADSYPEQEETTKEEWSQDFKDEGLGISTDKAYTGSMLRKRNPQGLE>sp|Q7Z5B4-5|RIC3_HUMAN Isoform 4 of Protein RIC-3 OS=Homo sapiensOX=9606 GN=RIC3MAYSTVQRVALASGLVLALSLLLPKAFLSRGKRQEPPPTPEGKLGRFPPMMHHHQAPSDGQTPGARFQRSHLAEAFAKAKGSGGGAGGGGSGRGLMGQIIPIYGFGIFLYILYILFKLSKGKTTAEDGKCYTAMPGNTHRKITSFELAQLQEKLKETEAAMEKLINRVGPNGERAQTVTSDQEKRLLHQLREITRVMKEGKFIDRFSPEKEAEEAPYMEDWEGYPEETYPIYDLSDCIKRRQETILVDYPDPKELSAEEIAERMGMIEEEESDHLGWESLPTDPRAQEDNSVTSCDPKPETCSCCFHEDEDPAVLAENAGFSADSYPEQEETTKEEWSQDFKDEGLGISTDKAYTGSMLRKRNPQGLE>sp|Q7Z5B4-6|RIC3_HUMAN Isoform 5 of Protein RIC-3 OS=Homo sapiensOX=9606 GN=RIC3MAYSTVQRVALASGLVLALSLLLPKAFLSRGKRQEPPPTPEGKLGRFPPMMHHHQAPSDGQTPGARFQRSHLAEAFAKAKGSGGGAGGGGSGRGLMGQIIPIYGFGIFLYILYILFKLSKGKTTAEDGKCYTAMPGNTHRKISYPEETYPIYDLSDCIKRRQETILVDYPDPKELSAEEIAERMGMIEEEESDHLGWESLPTDPRAQEDNSVTSCDPKPETCSCCFHEDEDPAVLAENAGFSADSYPEQEETTKEEWSQDFKDEGLGISTDKAYTGSMLRKRNPQGLE>sp|Q9H0H5|RGAP1_HUMAN Rac GTPase-activating protein 1 OS=Homo sapiensOX=9606 GN=RACGAP1 PE=1 SV=1MDTMMLNVRNLFEQLVRRVEILSEGNEVQFIQLAKDFEDFRKKWQRTDHELGKYKDLLMKAETERSALDVKLKHARNQVDVEIKRRQRAEADCEKLERQIQLIREMLMCDTSGSIQLSEEQKSALAFLNRGQPSSSNAGNKRLSTIDESGSILSDISFDKTDESLDWDSSLVKTFKLKKREKRRSTSRQFVDGPPGPVKKTRSIGSAVDQGNESIVAKTTVTVPNDGGPIEAVSTIETVPYWTRSRRKTGTLQPWNSDSTLNSRQLEPRTETDSVGTPQSNGGMRLHDFVSKTVIKPESCVPCGKRIKFGKLSLKCRDCRVVSHPECRDRCPLPCIPTLIGTPVKIGEGMLADFVSQTSPMIPSIVVHCVNEIEQRGLTETGLYRISGCDRTVKELKEKFLRVKTVPLLSKVDDIHAICSLLKDFLRNLKEPLLTFRLNRAFMEAAEITDEDNSIAAMYQAVGELPQANRDTLAFLMIHLQRVAQSPHTKMDVANLAKVFGPTIVAHAVPNPDPVTMLQDIKRQPKVVERLLSLPLEYWSQFMMVEQENIDPLHVIENSNAFSTPQTPDIKVSLLGPVTTPEHQLLKTPSSSSLSQRVRSTLTKNTPRFGSKSKSATNLGRQGNFFASPMLK>sp|F8VTS6|RFAL1_HUMAN Ret finger protein-like 4A-like protein 1 OS=Homosapiens OX=9606 GN=RFPL4AL1 PE=2 SV=1MAEHFKQIIRCPVCLKDLEEAVQLKCGYACCLQCLNSLQKEPDGEGLLCRFCSVVSQKDDIKPKYKLRALVSIIKELEPKLKSVLTMNPRMRKFQVDMTFDVDTANNYLIISEDLRSFRSGDLSQNRKEQAERFDTALCVLGTPRFTSGRHYWEVDVGTSQVWDVGVCKESVNRQGKIELSSEHGFLTVGCREGKVFAASTVPMTPLWVSPQLHRVGIFLDVGMRSIAFYNVSDGCHINTFIEIPVCEPWRPFFAHKRGSQDDQSILSICSVINPSTASAPVSSEGK>sp|Q6WKZ4|RFIP1_HUMAN Rab11 family-interacting protein 1 OS=Homo sapiensOX=9606 GN=RAB11FIP1 PE=1 SV=3MSLMVSAGRGLGAVWSPTHVQVTVLQARGLRAKGPGGTSDAYAVIQVGKEKYATSVSERSLGAPVWREEATFELPSLLSSGPAAAATLQLTVLHRALLGLDKFLGRAEVDLRDLHRDQGRRKTQWYKLKSKPGKKDKERGEIEVDIQFMRNNMTASMFDLSMKDKSRNPFGKLKDKIKGKNKDSGSDTASAIIPSTTPSVDSDDESVVKDKKKKSKIKTLLSKSNLQKTPLSQSMSVLPTSKPEKVLLRPGDFQSQWDEDDNEDESSSASDVMSHKRTASTDLKQLNQVNFTLPKKEGLSFLGGLRSKNDVLSRSNVCINGNHVYLEQPEAKGEIKDSSPSSSPSPKGFRKKHLFSSTENLAAGSWKEPAEGGGLSSDRQLSESSTKDSLKSMTLPSYRPAPLVSGDLRENMAPANSEATKEAKESKKPESRRSSLLSLMTGKKDVAKGSEGENPLTVPGREKEGMLMGVKPGEDASGPAEDLVRRSEKDTAAVVSRQGSSLNLFEDVQITEPEAEPESKSEPRPPISSPRAPQTRAVKPRLEVSPEAQPTARLPSPTDSPSSLPPLPSSSGQASVPSELGHGADTQSSESPSVFSSLSSPIAAPISTSTPIESWPLVDRGQAKSEGPPLLPKAELQTESLTPVPNSGSSALGSLFKQPSFPANKGTEDSLMGRTRETGTEKNTSSLELEESLPEQPETGRQEEELPRFPCKKQDYSPSSGEAQEVPFALSLSSDGAVSPVGELAAGGDRDLESQAGSLVESKARDAAEEVAPPLPMGASVPSIDSMMRKLEEMGLNLRKDQKKTKKRVSFSEQLFTEEAVAGAALLVEGHSSCPQELNPAWSVAGNASDGEPPESPHAEDSERESVTTPGPATCGAPASPADHLLLPSQEESFSEVPMSEASSAKDTPLFRMEGEDALVTQYQSKASDHEGLLSDPLSDLQLVSDFKSPIMADLNLSLPSIPEVASDDERIDQVEDDGDQVEDDGETAKSSTLDIGALSLGLVVPCPERGKGPSGEADRLVLGEGLCDFRLQAPQASVTAPSEQTTEFGIHKPHLGKSSSLDKQLPGPSGGEEEKPMGNGSPSPPPGTSLDNPVPSPSPSEIFPVTHSFPSSAHSDTHHTSTAESQKKATAEGSAGRVENFGKRKPLLQAWVSPSETHPVSAQPGAGTGSAKHRLHPVKPMNAMATKVANCSLGTATIISENLNNEVMMKKYSPSDPAFAYAQLTHDELIQLVLKQKETISKKEFQVRELEDYIDNLLVRVMEETPNILRIPTQVGKKAGKM>sp|Q6WKZ4-3|RFIP1_HUMAN Isoform 2 of Rab11 family-interacting protein 1OS=Homo sapiens OX=9606 GN=RAB11FIP1MSLMVSAGRGLGAVWSPTHVQVTVLQARGLRAKGPGGTSDAYAVIQVGKEKYATSVSERSLGAPVWREEATFELPSLLSSGPAAAATLQLTVLHRALLGLDKFLGRAEVDLRDLHRDQGRRKTQWYKLKSKPGKKDKERGEIEVDIQFMRNNMTASMFDLSMKDKSRNPFGKLKDKIKGKNKDSGSDTASAIIPSTTPSVDSDDESVVKDKKKKSKIKTLLSKSNLQKTPLSQSMSVLPTSKPEKVLLRPGDFQSQWDEDDNEDESSSASDVMSHKRTASTDLKQLNQVNFTLPKKEGLSFLGGLRSKNDVLSRSNVCINGNHVYLEQPEAKGEIKDSSPSSSPSPKGFRKKHLFSSTENLAAGSWKEPAEGGGLSSDRQLSESSTKDSLKSMTLPSYRPAPLVSGDLRENMAPANSEATKEAKESKKPESRRSSLLSLMTGKKDVAKGSEGENPLTVPGREKEGMLMGVKPGEDASGPAEDLVRRSEKDTAAVVSRQGSSLNLFEDVQITEPEAEPESKSEPRPPISSPRAPQTRAVKPRLHPVKPMNAMATKVANCSLGTATIISENLNNEVMMKKYSPSDPAFAYAQLTHDELIQLVLKQKETISKKEFQVRELEDYIDNLLVRVMEETPNILRIPTQVGKKAGKM>sp|Q6WKZ4-1|RFIP1_HUMAN Isoform 3 of Rab11 family-interacting protein 1OS=Homo sapiens OX=9606 GN=RAB11FIP1MGRTRETGTEKNTSSLELEESLPEQPETGRQEEELPRFPCKKQDYSPSSGEAQEVPFALSLSSDGAVSPVGELAAGGDRDLESQAGSLVESKARDAAEEVAPPLPMGASVPSIDSMMRKLEEMGLNLRKDQKKTKKRVSFSEQLFTEEAVAGAALLVEGHSSCPQELNPAWSVAGNASDGEPPESPHAEDSERESVTTPGPATCGAPASPADHLLLPSQEESFSEVPMSEASSAKDTPLFRMEGEDALVTQYQSKASDHEGLLSDPLSDLQLVSDFKSPIMADLNLSLPSIPEVASDDERIDQVEDDGDQVEDDGETAKSSTLDIGALSLGLVVPCPERGKGPSGEADRLVLGEGLCDFRLQAPQASVTAPSEQTTEFGIHKPHLGKSSSLDKQLPGPSGGEEEKPMGNGSPSPPPGTSLDNPVPSPSPSEIFPVTHSFPSSAHSDTHHTSTAESQKKATAEGSAGRVENFGKRKPLLQAWVSPSETHPVSAQPGAGTGSAKHRLHPVKPMNAMATKVANCSLGTATIISENLNNEVMMKKYSPSDPAFAYAQLTHDELIQLVLKQKETISKKEFQVRELEDYIDNLLVRVMEETPNILRIPTQVGKKAGKM>sp|Q6WKZ4-2|RFIP1_HUMAN Isoform 4 of Rab11 family-interacting protein 1OS=Homo sapiens OX=9606 GN=RAB11FIP1MRNNMTASMFDLSMKDKSRNPFGKLKDKIKGKNKDSGSDTASAIIPSTTPSVDSDDESVVKDKKKKSKIKTLLSKSNLQKTPLSQSMSVLPTSKPEKVLLRPGDFQSQWDEDDNEDESSSASDVMSHKRTASTDLKQLNQVNFTLPKKEGLSFLGGLRSKNDVLSRSNVCINGNHVYLEQPEAKGEIKDSSPSSSPSPKGFRKKHLFSSTENLAAGSWKEPAEGGGLSSDRQLSESSTKDSLKSMTLPSYRPAPLVSGDLRENMAPANSEATKEAKESKKPESRRSSLLSLMTGKKDVAKGSEGENPLTVPGREKEGMLMGVKPGEDASGPAEDLVRRSEKDTAAVVSRQGSSLNLFEDVQITEPEAEPESKSEPRPPISSPRAPQTRAVKPRLHPVKPMNAMATKVANCSLGTATIISENLNNEVMMKVCPLRSWCVR>sp|Q6WKZ4-5|RFIP1_HUMAN Isoform 5 of Rab11 family-interacting protein 1OS=Homo sapiens OX=9606 GN=RAB11FIP1MSLMVSAGRGLGAVWSPTHVQVTVLQARGLRAKGPGGTSDAYAVIQVGKEKYATSVSERSLGAPVWREEATFELPSLLSSGPAAAATLQLTVLHRALLGLDKFLGRAEVDLRDLHSSLGKSFFKTLKKRAWAIFLRLCLKKN>sp|Q9HAU5|RENT2_HUMAN Regulator of nonsense transcripts 2 OS=Homosapiens OX=9606 GN=UPF2 PE=1 SV=1MPAERKKPASMEEKDSLPNNKEKDCSERRTVSSKERPKDDIKLTAKKEVSKAPEDKKKRLEDDKRKKEDKERKKKDEEKVKAEEESKKKEEEEKKKHQEEERKKQEEQAKRQQEEEAAAQMKEKEESIQLHQEAWERHHLRKELRSKNQNAPDSRPEENFFSRLDSSLKKNTAFVKKLKTITEQQRDSLSHDFNGLNLSKYIAEAVASIVEAKLKISDVNCAVHLCSLFHQRYADFAPSLLQVWKKHFEARKEEKTPNITKLRTDLRFIAELTIVGIFTDKEGLSLIYEQLKNIINADRESHTHVSVVISFCRHCGDDIAGLVPRKVKSAAEKFNLSFPPSEIISPEKQQPFQNLLKEYFTSLTKHLKRDHRELQNTERQNRRILHSKGELSEDRHKQYEEFAMSYQKLLANSQSLADLLDENMPDLPQDKPTPEEHGPGIDIFTPGKPGEYDLEGGIWEDEDARNFYENLIDLKAFVPAILFKDNEKSCQNKESNKDDTKEAKESKENKEVSSPDDLELELENLEINDDTLELEGGDEAEDLTKKLLDEQEQEDEEASTGSHLKLIVDAFLQQLPNCVNRDLIDKAAMDFCMNMNTKANRKKLVRALFIVPRQRLDLLPFYARLVATLHPCMSDVAEDLCSMLRGDFRFHVRKKDQINIETKNKTVRFIGELTKFKMFTKNDTLHCLKMLLSDFSHHHIEMACTLLETCGRFLFRSPESHLRTSVLLEQMMRKKQAMHLDARYVTMVENAYYYCNPPPAEKTVKKKRPPLQEYVRKLLYKDLSKVTTEKVLRQMRKLPWQDQEVKDYVICCMINIWNVKYNSIHCVANLLAGLVLYQEDVGIHVVDGVLEDIRLGMEVNQPKFNQRRISSAKFLGELYNYRMVESAVIFRTLYSFTSFGVNPDGSPSSLDPPEHLFRIRLVCTILDTCGQYFDRGSSKRKLDCFLVYFQRYVWWKKSLEVWTKDHPFPIDIDYMISDTLELLRPKIKLCNSLEESIRQVQDLEREFLIKLGLVNDKDSKDSMTEGENLEEDEEEEEGGAETEEQSGNESEVNEPEEEEGSDNDDDEGEEEEEENTDYLTDSNKENETDEENTEVMIKGGGLKHVPCVEDEDFIQALDKMMLENLQQRSGESVKVHQLDVAIPLHLKSQLRKGPPLGGGEGEAESADTMPFVMLTRKGNKQQFKILNVPMSSQLAANHWNQQQAEQEERMRMKKLTLDINERQEQEDYQEMLQSLAQRPAPANTNRERRPRYQHPKGAPNADLIFKTGGRRR>sp|Q9BXF6|RFIP5_HUMAN Rab11 family-interacting protein 5 OS=Homo sapiensOX=9606 GN=RAB11FIP5 PE=1 SV=1MALVRGAEPAAGPSRWLPTHVQVTVLRARGLRGKSSGAGSTSDAYTVIQVGREKYSTSVVEKTHGCPEWREECSFELPPGALDGLLRAQEADAGPAPWAASSAAACELVLTTMHRSLIGVDKFLGQATVALDEVFGAGRAQHTQWYKLHSKPGKKEKERGEIEVTIQFTRNNLSASMFDLSMKDKPRSPFSKIRDKMKGKKKYDLESASAILPSSAIEDPDLGSLGKMGKAKGFFLRNKLRKSSLTQSNTSLGSDSTLSSASGSLAYQGPGAELLTRSPSRSSWLSTEGGRDSAQSPKLFTHKRTYSDEANQMRVAPPRALLDLQGHLDAASRSSLCVNGSHIYNEEPQGPVRHRSSISGSLPSSGSLQAVSSRFSEEGPRSTDDTWPRGSRSNSSSEAVLGQEELSAQAKVLAPGASHPGEEEGARLPEGKPVQVATPIVASSEAVAEKEGARKEERKPRMGLFHHHHQGLSRSELGRRSSLGEKGGPILGASPHHSSSGEEKAKSSWFGLREAKDPTQKPSPHPVKPLSAAPVEGSPDRKQSRSSLSIALSSGLEKLKTVTSGSIQPVTQAPQAGQMVDTKRLKDSAVLDQSAKYYHLTHDELISLLLQRERELSQRDEHVQELESYIDRLLVRIMETSPTLLQIPPGPPK>sp|P0C7P2|RFL3S_HUMAN Putative protein RFPL3S OS=Homo sapiens OX=9606GN=RFPL3S PE=2 SV=1MQTDTSNLSARSCRFCVMSPLRTLLRSSEMRRKLLAVSASKVISTVKRKTSCSASGQKPTPCLSSTSKAQISPDFSFFNSVSSSKIKTFHEETSLFQIFIGMLCGNT>sp|Q86YS3|RFIP4_HUMAN Rab11 family-interacting protein 4 OS=Homo sapiensOX=9606 GN=RAB11FIP4 PE=1 SV=1MAGGAGWSGAPAALLRSVRRLREVFEVCGRDPDGFLRVERVAALGLRFGQGEEVEKLVKYLDPNDLGRINFKDFCRGVFAMKGCEELLKDVLSVESAGTLPCAPEIPDCVEQGSEVTGPTFADGELIPREPGFFPEDEEEAMTLAPPEGPQELYTDSPMESTQSLEGSVGSPAEKDGGLGGLFLPEDKSLVHTPSMTTSDLSTHSTTSLISNEEQFEDYGEGDDVDCAPSSPCPDDETRTNVYSDLGSSVSSSAGQTPRKMRHVYNSELLDVYCSQCCKKINLLNDLEARLKNLKANSPNRKISSTAFGRQLMHSSNFSSSNGSTEDLFRDSIDSCDNDITEKVSFLEKKVTELENDSLTNGDLKSKLKQENTQLVHRVHELEEMVKDQETTAEQALEEEARRHREAYGKLEREKATEVELLNARVQQLEEENTELRTTVTRLKSQTEKLDEERQRMSDRLEDTSLRLKDEMDLYKRMMDKLRQNRLEFQKEREATQELIEDLRKELEHLQMYKLDCERPGRGRSASSGLGEFNARAREVELEHEVKRLKQENYKLRDQNDDLNGQILSLSLYEAKNLFAAQTKAQSLAAEIDTASRDELMEALKEQEEINFRLRQYMDKIILAILDHNPSILEIKH>sp|Q86YS3-2|RFIP4_HUMAN Isoform 2 of Rab11 family-interacting protein 4OS=Homo sapiens OX=9606 GN=RAB11FIP4MRTPPALGSQGSEVTGPTFADGELIPREPGFFPEDEEEAMTLAPPEGPQELYTDSPMESTQSLEGSVGSPAEKDGGLGGLFLPEDKSLVHTPSMTTSDLSTHSTTSLISNEEQFEDYGEGDDVDCAPSSPCPDDETRTNVYSDLGSSVSSSAGQTPRKMRHVYNSELLDVYCSQCCKKINLLNDLEARLKNLKANSPNRKISSTAFGRQLMHSSNFSSSNGSTEDLFRDSIDSCDNDITEKVSFLEKKVTELENDSLTNGDLKSKLKQENTQLVHRVHELEEMVKDQETTAEQALEEEARRHREAYGKLEREKATEVELLNARVQQLEEENTELRTTVTRLKSQTEKLDEERQRMSDRLEDTSLRLKDEMDLYKRMMDKLRQNRLEFQKEREATQELIEDLRKELEHLQMYKLDCERPGRGRSASSGLGEFNARAREVELEHEVKRLKQENYKLRDQNDDLNGQILSLSLYEAKNLFAAQTKAQSLAAEIDTASRDELMEALKEQEEINFRLRQYMDKIILAILDHNPSILEIKH>sp|Q3MIN7|RGL3_HUMAN Ral guanine nucleotide dissociation stimulator-like3 OS=Homo sapiens OX=9606 GN=RGL3 PE=1 SV=2MERTAGKELALAPLQDWGEETEDGAVYSVSLRRQRSQRRSPAEGPGGSQAPSPIANTFLHYRTSKVRVLRAARLERLVGELVFGDREQDPSFMPAFLATYRTFVPTACLLGFLLPPMPPPPPPGVEIKKTAVQDLSFNKNLRAVVSVLGSWLQDHPQDFRDPPAHSDLGSVRTFLGWAAPGSAEAQKAEKLLEDFLEEAEREQEEEPPQVWTGPPRVAQTSDPDSSEACAEEEEGLMPQGPQLLDFSVDEVAEQLTLIDLELFSKVRLYECLGSVWSQRDRPGAAGASPTVRATVAQFNTVTGCVLGSVLGAPGLAAPQRAQRLEKWIRIAQRCRELRNFSSLRAILSALQSNPIYRLKRSWGAVSREPLSTFRKLSQIFSDENNHLSSREILFQEEATEGSQEEDNTPGSLPSKPPPGPVPYLGTFLTDLVMLDTALPDMLEGDLINFEKRRKEWEILARIQQLQRRCQSYTLSPHPPILAALHAQNQLTEEQSYRLSRVIEPPAASCPSSPRIRRRISLTKRLSAKLAREKSSSPSGSPGDPSSPTSSVSPGSPPSSPRSRDAPAGSPPASPGPQGPSTKLPLSLDLPSPRPFALPLGSPRIPLPAQQSSEARVIRVSIDNDHGNLYRSILLTSQDKAPSVVRRALQKHNVPQPWACDYQLFQVLPGDRVLLIPDNANVFYAMSPVAPRDFMLRRKEGTRNTLSVSPS>sp|Q3MIN7-2|RGL3_HUMAN Isoform 2 of Ral guanine nucleotide dissociationstimulator-like 3 OS=Homo sapiens OX=9606 GN=RGL3MERTAGKELALAPLQDWGEETEDGAVYSVSLRRQRSQRRSPAEGPGGSQAPSPIANTFLHYRTSKVRVLRAARLERLVGELVFGDREQDPSFMPAFLATYRTFVPTACLLGFLLPPMPPPPPPGVEIKKTAVQDLSFNKNLRAVVSVLGSWLQDHPQDFRDPPAHSDLGSVRTFLGWAAPGSAEAQKAEKLLEDFLEEAEREQEEEPPQVWTGPPRVAQTSDPDSSEACAEEEEGLMPQGPQLLDFSVDEVAEQLTLIDLELFSKVRLYECLGSVWSQRDRPGAAGASPTVRATVAQFNTVTGCVLGSVLGAPGLAAPQRAQRLEKWIRIAQRCRELRNFSSLRAILSALQSNPIYRLKRSWGAVSREPLSTFRKLSQIFSDENNHLSSREILFQEEATEGSQEEDNTPGSLPSKPPPGPVPYLGTFLTDLVMLDTALPDMLEGDLINFEKRRKEWEILARIQQLQRRCQSYTLSPHPPILAALHAQNQLTEEQSYRLSRVIEPPAASCPSSPRIRRRISLTKRLSAKLAREKSSSPSGSPGDPSSPTSSLCISPSVSPGSPPSSPRSRDAPAGSPPASPGPQGPSTKLPLSLDLPSPRPFALPLGSPRIPLPAQQSSEARVIRVSIDNDHGNLYRSILLTSQDKAPSVVRRALQKHNVPQPWACDYQLFQVLPGDRVLLIPDNANVFYAMSPVAPRDFMLRRKEGTRNTLSVSPS>sp|Q5VT98|PRA20_HUMAN PRAME family member 20 OS=Homo sapiens OX=9606GN=PRAMEF20 PE=3 SV=2MSIRTPPRLLELAGRSLLRDEALAISTLEELPTELFPPLFMEAFSRRHCEALKLMVQAWPFLRLPLGSLMKRPCPETFQAVLDGLDALLTHRVRLRRWKLQVLDLQDVSENFWMVWSEAMARRCLPNAMMNRKPLQDCPRMRGQQPLTVFIDLCLKNRTLDEYFTCLFLWVKQREGLVHLCCKKLKMLGMLFHNIRNILKTVNLDCIQEVEVNCNWTLPVLAEFTPYLGQMRNLRKLVLSDIDSRYISPEQKKEFVTQFTTQFLKLRCLQKLYMNSVSFLEGHLDQMLSCLKTSLNILAITNCVLLESDLKHLSKYPSIGQLKTLDLSGTRLANFSLVPLQVLLEKVAATLEYLDLDDCGIVDSQVNAILPALSRCFELTTFSFRGNPISTATLENLLCHTIRLNNLCLELYPAPRESYDVRGIVCRSRFAQLGAELMGRVRALREPERILFCTDYCPQCGNRSLYDLEVDRCCC>sp|O43251|RFOX2_HUMAN RNA binding protein fox-1 homolog 2 OS=Homosapiens OX=9606 GN=RBFOX2 PE=1 SV=3MQNEPLTPGYHGFPARDSQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLISLPLVPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYGGYAAYRYAQPATATAATAAAAAAAAYSDGYGRVYTADPYHALAPAASYGVGAVASLYRGGYSRFAPY>sp|O43251-2|RFOX2_HUMAN Isoform 2 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MEKKKMVTQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTQTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLISLPLVPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYGGYAAYRYAQPATATAATAAAAAAAAYSDGYGRVYTADPYHALAPAASYGVGAVASLYRGGYSRFAPY>sp|O43251-3|RFOX2_HUMAN Isoform 3 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MEKKKMVTQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLIIPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYGGYAAYRYAQPATATAATAAAAAAAAYSDGYGRVYTADPYHALAPAASYGVGAVASLYRGGYSRFAPY>sp|O43251-4|RFOX2_HUMAN Isoform 4 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MEKKKMVTQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLISLPLVPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVDMQPTDMHSLLLQPQPPLLQPLQPLTVTVMAGCTQPTPTMPLPLPLAMELALWRVYTEVATADLPPTEVT>sp|O43251-5|RFOX2_HUMAN Isoform 5 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MEKKKMVTQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLIIPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYGGYAAYRYAQPATATAATAAAAAAAAYSDGYGRVYTADPYHALAPAASYGVGAVASLYRGGYSRFAPY>sp|O43251-6|RFOX2_HUMAN Isoform 6 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MAEGAQPHQPPQLGPGAAARGMKRESELELPVPGAGGDGADPGLSKRPRTEEAAADGGGGMQNEPLTPGYHGFPARDSQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLISLPLVPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYGGYAAYRYAQPATATAATAAAAAAAAYSDGYGRVYTADPYHALAPAASYGVGAVASLYRGGYSRFAPY>sp|O43251-7|RFOX2_HUMAN Isoform 7 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MQNEPLTPGYHGFPARDSQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLIIPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYIESANCFRSNRVDMQPTDMHSLLLQPQPPLLQPLQPLTVTVMAGCTQPTPTMPLPLPLAMELALWRVYTEVATADLPPTEVT>sp|O43251-8|RFOX2_HUMAN Isoform 8 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MAEGAQPHQPPQLGPGAAARGMKRESELELPVPGAGGDGADPGLSKRPRTEEAAADGGGGMQNEPLTPGYHGFPARDSQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTQTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLISLPLVPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYGGYAAYRYAQPATATAATAAAAAAAAYSDGYGRVYTADPYHALAPAASYGVGAVASLYRGGYSRFAPY>sp|O43251-9|RFOX2_HUMAN Isoform 9 of RNA binding protein fox-1 homolog 2OS=Homo sapiens OX=9606 GN=RBFOX2MEKKKMVTQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTQTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLIIPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVDMQPTDMHSLLLQPQPPLLQPLQPLTVTVMAGCTQPTPTMPLPLPLAMELALWRVYTEVATADLPPTEVT>sp|O43251-10|RFOX2_HUMAN Isoform 10 of RNA binding protein fox-1 homolog2 OS=Homo sapiens OX=9606 GN=RBFOX2MEKKKMVTQGNQEPTTTPDAMVQPFTTIPFPPPPQNGIPTEYGVPHTQDYAGQTGEHNLTLYGSTQAHGEQSSNSPSTQNGSLTTEGGAQTDGQQSQTQSSENSESKSTPKRLHVSNIPFRFRDPDLRQMFGQFGKILDVEIIFNERGSKGFGFVTFENSADADRAREKLHGTVVEGRKIEVNNATARVMTNKKMVTPYANGWKLSPVVGAVYGPELYAASSFQADVSLGNDAAVPLSGRGGINTYIPLISLPLVPGFPYPTAATTAAAFRGAHLRGRGRTVYGAVRAVPPTAIPAYPGVVYQDGFYGADLYGGYAAYRYAQPATATAATAAAAAAAAYSDGYGRVYTADPYHALAPAASYGVGAVASLYRGGYSRFAPY>sp|Q9UBK2|PRGC1_HUMAN Peroxisome proliferator-activated receptor gammacoactivator 1-alpha OS=Homo sapiens OX=9606 GN=PPARGC1A PE=1 SV=1MAWDMCNQDSESVWSDIECAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNDPKGSPFENKTIERTLSVELSGTAGLTPPTTPPHKANQDNPFRASPKLKSSCKTVVPPPSKKPRYSESSGTQGNNSTKKGPEQSELYAQLSKSSVLTGGHEERKTKRPSLRLFGDHDYCQSINSKTEILINISQELQDSRQLENKDVSSDWQGQICSSTDSDQCYLRETLEASKQVSPCSTRKQLQDQEIRAELNKHFGHPSQAVFDDEADKTGELRDSDFSNEQFSKLPMFINSGLAMDGLFDDSEDESDKLSYPWDGTQSYSLFNVSPSCSSFNSPCRDSVSPPKSLFSQRPQRMRSRSRSFSRHRSCSRSPYSRSRSRSPGSRSSSRSCYYYESSHYRHRTHRNSPLYVRSRSRSPYSRRPRYDSYEEYQHERLKREEYRREYEKRESERAKQRERQRQKAIEERRVIYVGKIRPDTTRTELRDRFEVFGEIEECTVNLRDDGDSYGFITYRYTCDAFAALENGYTLRRSNETDFELYFCGRKQFFKSNYADLDSNSDDFDPASTKSKYDSLDFDSLLKEAQRSLRR>sp|Q9UBK2-2|PRGC1_HUMAN Isoform NT-7a of Peroxisome proliferator-activated receptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606GN=PPARGC1AMAWDMCNQDSESVWSDIECAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNLFL>sp|Q9UBK2-3|PRGC1_HUMAN Isoform B5 of Peroxisome proliferator-activatedreceptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606 GN=PPARGC1AMDETSPRLEEDWKKVLQREAGWQCAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNDPKGSPFENKTIERTLSVELSGTAGLTPPTTPPHKANQDNPFRASPKLKSSCKTVVPPPSKKPRYSESSGTQGNNSTKKGPEQSELYAQLSKSSVLTGGHEERKTKRPSLRLFGDHDYCQSINSKTEILINISQELQDSRQLENKDVSSDWQGQICSSTDSDQCYLRETLEASKQVSPCSTRKQLQDQEIRAELNKHFGHPSQAVFDDEADKTGELRDSDFSNEQFSKLPMFINSGLAMDGLFDDSEDESDKLSYPWDGTQSYSLFNVSPSCSSFNSPCRDSVSPPKSLFSQRPQRMRSRSRSFSRHRSCSRSPYSRSRSRSPGSRSSSRSCYYYESSHYRHRTHRNSPLYVRSRSRSPYSRRPRYDSYEEYQHERLKREEYRREYEKRESERAKQRERQRQKAIEERRVIYVGKIRPDTTRTELRDRFEVFGEIEECTVNLRDDGDSYGFITYRYTCDAFAALENGYTLRRSNETDFELYFCGRKQFFKSNYADLDSNSDDFDPASTKSKYDSLDFDSLLKEAQRSLRR>sp|Q9UBK2-4|PRGC1_HUMAN Isoform B4 of Peroxisome proliferator-activatedreceptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606 GN=PPARGC1AMDEGYFCAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNDPKGSPFENKTIERTLSVELSGTAGLTPPTTPPHKANQDNPFRASPKLKSSCKTVVPPPSKKPRYSESSGTQGNNSTKKGPEQSELYAQLSKSSVLTGGHEERKTKRPSLRLFGDHDYCQSINSKTEILINISQELQDSRQLENKDVSSDWQGQICSSTDSDQCYLRETLEASKQVSPCSTRKQLQDQEIRAELNKHFGHPSQAVFDDEADKTGELRDSDFSNEQFSKLPMFINSGLAMDGLFDDSEDESDKLSYPWDGTQSYSLFNVSPSCSSFNSPCRDSVSPPKSLFSQRPQRMRSRSRSFSRHRSCSRSPYSRSRSRSPGSRSSSRSCYYYESSHYRHRTHRNSPLYVRSRSRSPYSRRPRYDSYEEYQHERLKREEYRREYEKRESERAKQRERQRQKAIEERRVIYVGKIRPDTTRTELRDRFEVFGEIEECTVNLRDDGDSYGFITYRYTCDAFAALENGYTLRRSNETDFELYFCGRKQFFKSNYADLDSNSDDFDPASTKSKYDSLDFDSLLKEAQRSLRR>sp|Q9UBK2-5|PRGC1_HUMAN Isoform B4-8a of Peroxisome proliferator-activated receptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606GN=PPARGC1AMDEGYFCAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNDPKGSPFENKTIERTLSVELSGTAGVKTNLISK>sp|Q9UBK2-6|PRGC1_HUMAN Isoform B5-NT of Peroxisome proliferator-activated receptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606GN=PPARGC1AMDETSPRLEEDWKKVLQREAGWQCAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNLFL>sp|Q9UBK2-7|PRGC1_HUMAN Isoform B4-3ext of Peroxisome proliferator-activated receptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606GN=PPARGC1AMDEGYFCAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLVRTLPTV>sp|Q9UBK2-8|PRGC1_HUMAN Isoform 8a of Peroxisome proliferator-activatedreceptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606 GN=PPARGC1AMAWDMCNQDSESVWSDIECAALVGEDQPLCPDLPELDLSELDVNDLDTDSFLGGLKWCSDQSEIISNQYNNEPSNIFEKIDEENEANLLAVLTETLDSLPVDEDGLPSFDALTDGDVTTDNEASPSSMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNDPKGSPFENKTIERTLSVELSGTAGVKTNLISK>sp|Q9UBK2-9|PRGC1_HUMAN Isoform 9 of Peroxisome proliferator-activatedreceptor gamma coactivator 1-alpha OS=Homo sapiens OX=9606 GN=PPARGC1AMPDGTPPPQEAEEPSLLKKLLLAPANTQLSYNECSGLSTQNHANHNHRIRTNPAIVKTENSWSNKAKSICQQQKPQRRPCSELLKYLTTNDDPPHTKPTENRNSSRDKCTSKKKSHTQSQSQHLQAKPTTLSLPLTPESPNDPKGSPFENKTIERTLSVELSGTAGLTPPTTPPHKANQDNPFRASPKLKSSCKTVVPPPSKKPRYSESSGTQGNNSTKKGPEQSELYAQLSKSSVLTGGHEERKTKRPSLRLFGDHDYCQSINSKTEILINISQELQDSRQLENKDVSSDWQGQICSSTDSDQCYLRETLEASKQVSPCSTRKQLQDQEIRAELNKHFGHPSQAVFDDEADKTGELRDSDFSNEQFSKLPMFINSGLAMDGLFDDSEDESDKLSYPWDGTQSYSLFNVSPSCSSFNSPCRDSVSPPKSLFSQRPQRMRSRSRSFSRHRSCSRSPYSRSRSRSPGSRSSSRSCYYYESSHYRHRTHRNSPLYVRSRSRSPYSRRPRYDSYEEYQHERLKREEYRREYEKRESERAKQRERQRQKAIEERRVIYVGKIRPDTTRTELRDRFEVFGEIEECTVNLRDDGDSYGFITYRYTCDAFAALENGYTLRRSNETDFELYFCGRKQFFKSNYADLDSNSDDFDPASTKSKYDSLDFDSLLKEAQRSLRR>sp|P0DUQ2|PRAM9_HUMAN PRAME family member 9 OS=Homo sapiens OX=9606GN=PRAMEF9 PE=1 SV=1MKMSIRTPPRLLELAGRSLLRDQALAMSTLEELPTELFPPLFMEAFSRRRCEALKLMVQAWPFRRLPLRPLIKMPCLEAFQAVLDGLDALLTQGVRPRRWKLQVLDLQDVCENFWMVWSEAMAHGCFLNAKRNKKPVQDCPRMRGRQPLTVFVELWLKNRTLDEYLTYLLLWVKQRKDLLHLCCKKLKILGMPFRNIRSILKMVNLDCIQEVEVNCKWVLPILTQFTPYLGHMRNLQKLVLSHMDVSRYVSPEQKKEIVTQFTTQFLKLRCLQKLYMNSVSFLEGHLDQLLSCLKTSLKVLTITNCVLLESDLKHLSQCPSISQLKTLDLSGIRLTNYSLVPLQILLEKVAATLEYLDLDDCGIIDSQVNAILPALSRCFELNTFSFCGNPICMATLENLLSHTIILKNLCVELYPAPRESYGADGTLCWSRFAQIRAELMNRVRDLRHPKRILFCTDYCPDCGNRSFYDLEADQYCC>sp|O60811|PRAM2_HUMAN PRAME family member 2 OS=Homo sapiens OX=9606GN=PRAMEF2 PE=2 SV=2MSIQAPPRLLELAGQSLLRDQALSISAMEELPRVLYLPLFREAFSRRHFQTLTVMVQAWPFTCLPLVSLMKTLHLEPLKALLEGLHMLLTQKDRPRRWKLQVLDLRDVDENFWARWPGAWALSCFPEAMSKRQTAEDCPRTGEHQPLKVFIDICLKEIPQDECLRYLFQWVYQRRGLVHLCCSKLVNYLTPIKYLRKSLKIIYINSIGELEIHNTCWPHLIRKLYCYLKEMKTLCKLVFSRCHHYTSDNELEGWLVTRFTSVFLRLEHLQLLKIKLITFFSGHLEQLIRCLQNPLENLELTCGNLLEEDLKCLSQFPSLGYLKHLNLSYVLLFRISLEPLGALLEKIAASLETLVLEGCQIHYSQLSAILPGLSCCSQLTTFYFGSNCMSIDALKDLLRHTSGLSKLSLETYPAPEESLNSLVRVNWEIFTPLRAELMCTLREFRQPKRIFIGPTPCPSCGSSPSEELELHLCC>sp|P78395|PRAME_HUMAN Melanoma antigen preferentially expressed intumors OS=Homo sapiens OX=9606 GN=PRAME PE=1 SV=1MERRRLWGSIQSRYISMSVWTSPRRLVELAGQSLLKDEALAIAALELLPRELFPPLFMAAFDGRHSQTLKAMVQAWPFTCLPLGVLMKGQHLHLETFKAVLDGLDVLLAQEVRPRRWKLQVLDLRKNSHQDFWTVWSGNRASLYSFPEPEAAQPMTKKRKVDGLSTEAEQPFIPVEVLVDLFLKEGACDELFSYLIEKVKRKKNVLRLCCKKLKIFAMPMQDIKMILKMVQLDSIEDLEVTCTWKLPTLAKFSPYLGQMINLRRLLLSHIHASSYISPEKEEQYIAQFTSQFLSLQCLQALYVDSLFFLRGRLDQLLRHVMNPLETLSITNCRLSEGDVMHLSQSPSVSQLSVLSLSGVMLTDVSPEPLQALLERASATLQDLVFDECGITDDQLLALLPSLSHCSQLTTLSFYGNSISISALQSLLQHLIGLSNLTHVLYPVPLESYEDIHGTLHLERLAYLHARLRELLCELGRPSMVWLSANPCPHCGDRTFYDPEPILCPCFMPN>sp|Q5TYX0|PRAM5_HUMAN PRAME family member 5 OS=Homo sapiens OX=9606GN=PRAMEF5 PE=2 SV=2MSIRTPPRLLELAGRSLLRDQALAMSTLEELPTELFPPLFMEAFSRRRCEALKLMVQAWPFRRLPLRPLIKMPCLEAFQAVLDGLDALLTQGVHPRRWKLQVLDLQDVCENFWMVWSEAMAHGCFLNAKRNKKPVQDCPRMRGQQPLTVFVELWLKNRTLDEYLTCLLLWVKQRKDLLHLCCKKLKILGMPFRNIRSILKMVNLDCIQEVEVNCKWVLPILTQFTPYLGHMRNLQKLVLSHMDVSRYVSPEQKKEIVTQFTTQFLKLCCLQKLSMNSVSFLEGHLDQLLSCLKTSLKVLTITNCVLLESDLKHLSQCPSISQLKTLDLSGIRLTNYSLVPLQILLEKVAATLEYLDLDDCGIIDSQVNAILPALSRCFELNTFSFCGNPISMATLENLLSHTIILKNLCVELYPAPRESYDADGTLCWSRFPQIRAELMKRVRDLRHPKRILFCTDCCPDCGNRSFYDLEADQCCC>sp|P48634|PRC2A_HUMAN Protein PRRC2A OS=Homo sapiens OX=9606 GN=PRRC2APE=1 SV=3MSDRSGPTAKGKDGKKYSSLNLFDTYKGKSLEIQKPAVAPRHGLQSLGKVAIARRMPPPANLPSLKAENKGNDPNVSLVPKDGTGWASKQEQSDPKSSDASTAQPPESQPLPASQTPASNQPKRPPAAPENTPLVPSGVKSWAQASVTHGAHGDGGRASSLLSRFSREEFPTLQAAGDQDKAAKERESAEQSSGPGPSLRPQNSTTWRDGGGRGPDELEGPDSKLHHGHDPRGGLQPSGPPQFPPYRGMMPPFMYPPYLPFPPPYGPQGPYRYPTPDGPSRFPRVAGPRGSGPPMRLVEPVGRPSILKEDNLKEFDQLDQENDDGWAGAHEEVDYTEKLKFSDEEDGRDSDEEGAEGHRDSQSASGEERPPEADGKKGNSPNSEPPTPKTAWAETSRPPETEPGPPAPKPPLPPPHRGPAGNWGPPGDYPDRGGPPCKPPAPEDEDEAWRQRRKQSSSEISLAVERARRRREEEERRMQEERRAACAEKLKRLDEKFGAPDKRLKAEPAAPPAAPSTPAPPPAVPKELPAPPAPPPASAPTPETEPEEPAQAPPAQSTPTPGVAAAPTLVSGGGSTSSTSSGSFEASPVEPQLPSKEGPEPPEEVPPPTTPPVPKVEPKGDGIGPTRQPPSQGLGYPKYQKSLPPRFQRQQQEQLLKQQQQHQWQQHQQGSAPPTPVPPSPPQPVTLGAVPAPQAPPPPPKALYPGALGRPPPMPPMNFDPRWMMIPPYVDPRLLQGRPPLDFYPPGVHPSGLVPRERSDSGGSSSEPFDRHAPAMLRERGTPPVDPKLAWVGDVFTATPAEPRPLTSPLRQAADEDDKGMRSETPPVPPPPPYLASYPGFPENGAPGPPISRFPLEEPGPRPLPWPPGSDEVAKIQTPPPKKEPPKEETAQLTGPEAGRKPARGVGSGGQGPPPPRRESRTETRWGPRPGSSRRGIPPEEPGAPPRRAGPIKKPPPPTKVEELPPKPLEQGDETPKPPKPDPLKITKGKLGGPKETPPNGNLSPAPRLRRDYSYERVGPTSCRGRGRGEYFARGRGFRGTYGGRGRGARSREFRSYREFRGDDGRGGGTGGPNHPPAPRGRTASETRSEGSEYEEIPKRRRQRGSETGSETHESDLAPSDKEAPTPKEGTLTQVPLAPPPPGAPPSPAPARFTARGGRVFTPRGVPSRRGRGGGRPPPQVCPGWSPPAKSLAPKKPPTGPLPPSKEPLKEKLIPGPLSPVARGGSNGGSNVGMEDGERPRRRRHGRAQQQDKPPRFRRLKQERENAARGSEGKPSLTLPASAPGPEEALTTVTVAPAPRRAAAKSPDLSNQNSDQANEEWETASESSDFTSERRGDKEAPPPVLLTPKAVGTPGGGGGGAVPGISAMSRGDLSQRAKDLSKRSFSSQRPGMERQNRRPGPGGKAGSSGSSSGGGGGGPGGRTGPGRGDKRSWPSPKNRSRPPEERPPGLPLPPPPPSSSAVFRLDQVIHSNPAGIQQALAQLSSRQGSVTAPGGHPRHKPGLPQAPQGPSPRPPTRYEPQRVNSGLSSDPHFEEPGPMVRGVGGTPRDSAGVSPFPPKRRERPPRKPELLQEESLPPPHSSGFLGSKPEGPGPQAESRDTGTEALTPHIWNRLHTATSRKSYRPSSMEPWMEPLSPFEDVAGTEMSQSDSGVDLSGDSQVSSGPCSQRSSPDGGLKGAAEGPPKRPGGSSPLNAVPCEGPPGSEPPRRPPPAPHDGDRKELPREQPLPPGPIGTERSQRTDRGTEPGPIRPSHRPGPPVQFGTSDKDSDLRLVVGDSLKAEKELTASVTEAIPVSRDWELLPSAAASAEPQSKNLDSGHCVPEPSSSGQRLYPEVFYGSAGPSSSQISGGAMDSQLHPNSGGFRPGTPSLHPYRSQPLYLPPGPAPPSALLSGLALKGQFLDFSTMQATELGKLPAGGVLYPPPSFLYSPAFCPSPLPDTSLLQVRQDLPSPSDFYSTPLQPGGQSGFLPSGAPAQQMLLPMVDSQLPVVNFGSLPPAPPPAPPPLSLLPVGPALQPPSLAVRPPPAPATRVLPSPARPFPASLGRAELHPVELKPFQDYQKLSSNLGGPGSSRTPPTGRSFSGLNSRLKATPSTYSGVFRTQRVDLYQQASPPDALRWIPKPWERTGPPPREGPSRRAEEPGSRGDKEPGLPPPR>sp|P48634-2|PRC2A_HUMAN Isoform 2 of Protein PRRC2A OS=Homo sapiensOX=9606 GN=PRRC2AMSDRSGPTAKGKDGKKYSSLNLFDTYKGKSLEIQKPAVAPRHGLQSLGKVAIARRMPPPANLPSLKAENKGNDPNVSLVPKDGTGWASKQEQSDPKSSDASTAQPPESQPLPASQTPASNQPKRPPAAPENTPLVPSGVKSWAQASVTHGAHGDGGRASSLLSRFSREEFPTLQAAGDQDKAAKERESAEQSSGPGPSLRPQNSTTWRDGGGRGPDELEGPDSKLHHGHDPRGGLQPSGPPQFPPYRGMMPPFMYPPYLPFPPPYGPQGPYRYPTPDGPSRFPRVAGPRGSGPPMRLVEPVGRPSILKEDNLKEFDQLDQENDDGWAGAHEEVDYTEKLKFSDEEDGRDSDEEGAEGHRDSQSASGEERPPEADGKKGNSPNSEPPTPKTAWAETSRPPETEPGPPAPKPPLPPGDYPDRGGPPCKPPAPEDEDEAWRQRRKQSSSEISLAVERARRRREEEERRMQEERRAACAEKLKRLDEKFGAPDKRLKAEPAAPPAAPSTPAPPPAVPKELPAPPAPPPASAPTPETEPEEPAQAPPAQSTPTPGVAAAPTLVSGGGSTSSTSSGSFEASPVEPQLPSKEGPEPPEEVPPPTTPPVPKVEPKGDGIGPTRQPPSQGLGYPKYQKSLPPRFQRQQQEQLLKQQQQHQWQQHQQGSAPPTPVPPSPPQPVTLGAVPAPQAPPPPPKALYPGALGRPPPMPPMNFDPRWMMIPPYVDPRLLQGRPPLDFYPPGVHPSGLVPRERSDSGGSSSEPFDRHAPAMLRERGTPPVDPKLAWVGDVFTATPAEPRPLTSPLRQAADEDDKGMRSETPPVPPPPPYLASYPGFPENGAPGPPISRFPLEEPGPRPLPWPPGSDEVAKIQTPPPKKEPPKEETAQLTGPEAGRKPARGVGSGGQGPPPPRRESRTETRWGPRPGSSRRGIPPEEPGAPPRRAGPIKKPPPPTKVEELPPKPLEQGDETPKPPKPDPLKITKGKLGGPKETPPNGNLSPAPRLRRDYSYERVGPTSCRGRGRGEYFARGRGFRGTYGGRGRGAQANSAVTESFEEMMGVEVGQGDQTTLLLPEAAMPARHGARVQSMRKSPSGAGSGAQKQAARPMRVIWLLQTRRLPHPRREHSPRSSRSPTTRSPTLHRAPARFTCPGVGESSLPEGAISPGPRRREAPPQVCPGWSPPAKSLAPKKPPTGPLPPSKEPLKEKLIPGPLSPVARGGSNGGSNVGMEDGERPRRRRHGRAQQQDKPPRFRRLKQERENAARGSEGKPSLTLPASAPGPEEALTTVTVAPAPRRAAAKSPDLSNQNSDQANEEWETASESSDFTSERRGDKEAPPPVLLTPKAVGTPGGGGGGAVPGISAMSRGDLSQRAKDLSKRSFSSQRPGMERQNRRPGPGGKAGSSGSSSGGGGGGPGGRTGPGRGDKRSWPSPKNRSRPPEERPPGLPLPPPPPSSSAVFRLDQVIHSNPAGIQQALAQLSSRQGSVTAPGGHPRHKPGLPQAPQGPSPRPPTRYEPQRVNSGLSSDPHFEEPGPMVRGVGGTPRDSAGVSPFPPKRRERPPRKPELLQEESLPPPHSSGFLGSKPEGPGPQAESRDTGTEALTPHIWNRLHTATSRKSYRPSSMEPWMEPLSPFEDVAGTEMSQSDSGVDLSGDSQVSSGPCSQRSSPDGGLKGAAEGPPKRPGGSSPLNAVPCEGPPGSEPPRRPPPAPHDGDRKELPREQPLPPGPIGTERSQRTDRGTEPGPIRPSHRPGPPVQFGTSDKDSDLRLVVGDSLKAEKELTASVTEAIPVSRDWELLPSAAASAEPQSKNLDSGHCVPEPSSSGQRLYPEVFYGSAGPSSSQISGGSHGLSITSKQWRLRPGTPSLHPYRSQPLYLPPGPAPPSALLSGLALKGQFLDFSTMQATELGKLPAGGVLYPPPSFLYSPAFCPSPLPDTSLLQVRQDLPSPSDFYSTPLQPGGQSGFLPSGAPAQQMLLPMVDSQLPVVNFGSLPPAPPPAPPPLSLLPVGPALQPPSLAVRPPPAPATRVLPSPARPFPASLGRAELHPVELKPFQDYQKLSSNLGGPGSSRTPPTGRSFSGLNSRLKATPSTYSGVFRTQRVDLYQQASPPDALRWIPKPWERTGPPPREGPSRRAEEPGSRGDKEPGLPPPR>sp|P48634-3|PRC2A_HUMAN Isoform 3 of Protein PRRC2A OS=Homo sapiensOX=9606 GN=PRRC2AMSDRSGPTAKGKDGKKYSSLNLFDTYKGKSLEIQKPAVAPRHGLQSLGKVAIARRMPPPANLPSLKAENKGNDPNVSLVPKDGTGWASKQEQSDPKSSDASTAQPPESQPLPASQTPASNQPKRPPAAPENTPLVPSGVKSWAQASVTHGAHGDGGRASSLLSRFSREEFPTLQAAGDQDKAAKERESAEQSSGPGPSLRPQNSTTWRDGGGRGPDELEGPDSKLHHGHDPRGGLQPSGPPQFPPYRGMMPPFMYPPYLPFPPPYGPQGPYRYPTPDGPSRFPRVAGPRGSGPPMRLVEPVGRPSILKEDNLKEFDQLDQENDDGWAGAHEEVDYTEKLKFSDEEDGRDSDEEGAEGHRDSQSASGEERPPEADGKKGNSPNSEPPTPKTAWAETSRPPETEPGPPAPKPPLPPPHRGPAGNWGPPGDYPDRGGPPCKPPAPEDEDEAWRQRRKQSSSEISLAVERARRRREEEERRMQEERRAACAEKLKRLDEKFGAPDKRLKAEPAAPPAAPSTPAPPPAVPKELPAPPAPPPASAPTPETEPEEPAQAPPAQSTPTPGVAAAPTLVSGGGSTSSTSSGSFEASPVEPQLPSKEGPEPPEEVPPPTTPPVPKVEPKGDGIGPTRQPPSQGLGYPKYQKSLPPRFQRQQQEQLLKQQQQHQWQQHQQGSAPPTPVPPSPPQPVTLGAVPAPQAPPPPPKALYPGALGRPPPMPPMNFDPRWMMIPPYVDPRLLQGRPPLDFYPPGVHPSGLVPRERSDSGGSSSEPFDRHAPAMLRERGTPPVDPKLAWVGDVFTATPAEPRPLTSPLRQAADEDDKGMRSETPPVPPPPPYLASYPGFPENGAPGPPISRFPLEEPGPRPLPWPPGSDEVAKIQTPPPKKEPPKEETAQLTGPEAGRKPARGVGSGGQGPPPPRRESRTETRWGPRPGSSRRGIPPEEPGAPPRRAGPIKKPPPPTKVEELPPKPLEQGDETPKPPKPDPLKITKGKLGGPKETPPNGNLSPAPRLRRDYSYERVGPTSCRGRGRGEYFARGRGFRGTYGGRGRGAQANSAVTESFEEMMGVEVGQGDQTTLLLPEAAMPARHGARVQSMRKSPSGAGSGAQKQAARPMRVIWLLQTRRLPHPRREHSPRSSRSPTTRSPTLHRAPARFTCPGVGESSLPEGAISPGPRRREAPPQVCPGWSPPAKSLAPKKPPTGPLPPSKEPLKEKLIPGPLSPVARGGSNGGSNVGMEDGERPRRRRHGRAQQQDKPPRFRRLKQERENAARGSEGKPSLTLPASAPGPEEALTTVTVAPAPRRAAAKSPDLSNQNSDQANEEWETASESSDFTSERRGDKEAPPPVLLTPKAVGTPGGGGGGAVPGISAMSRGDLSQRAKDLSKRSFSSQRPGMERQNRRPGPGGKAGSSGSSSGGGGGGPGGRTGPGRGDKRSWPSPKNRSRPPEERPPGLPLPPPPPSSSAVFRLDQVIHSNPAGIQQALAQLSSRQGSVTAPGGHPRHKPGLPQAPQGPSPRPPTRYEPQRVNSGLSSDPHFEEPGPMVRGVGGTPRDSAGVSPFPPKRRERPPRKPELLQEESLPPPHSSGFLGSKPEGPGPQAESRDTGTEALTPHIWNRLHTATSRKSYRPSSMEPWMEPLSPFEDVAGTEMSQSDSGVDLSGDSQVSSGPCSQRSSPDGGLKGAAEGPPKRPGGSSPLNAVPCEGPPGSEPPRRPPPAPHDGDRKELPREQPLPPGPIGTERSQRTDRGTEPGPIRPSHRPGPPVQFGTSDKDSDLRLVVGDSLKAEKELTASVTEAIPVSRDWELLPSAAASAEPQSKNLDSGHCVPEPSSSGQRLYPEVFYGSAGPSSSQISGGSHGLSITSKQWRLRPGTPSLHPYRSQPLYLPPGPAPPSALLSGLALKGQFLDFSTMQATELGKLPAGGVLYPPPSFLYSPAFCPSPLPDTSLLQVRQDLPSPSDFYSTPLQPGGQSGFLPSGAPAQQMLLPMVDSQLPVVNFGSLPPAPPPAPPPLSLLPVGPALQPPSLAVRPPPAPATRVLPSPARPFPASLGRAELHPVELKPFQDYQKLSSNLGGPGSSRTPPTGRSFSGLNSRLKATPSTYSGVFRTQRVDLYQQASPPDALRWIPKPWERTGPPPREGPSRRAEEPGSRGDKEPGLPPPR>sp|P48634-4|PRC2A_HUMAN Isoform 4 of Protein PRRC2A OS=Homo sapiensOX=9606 GN=PRRC2AMSDRSGPTAKGKDGKKYSSLNLFDTYKGKSLEIQKPAVAPRHGLQSLGKVAIARRMPPPANLPSLKAENKGNDPNVSLVPKDGTGWASKQEQSDPKSSDASTAQPPESQPLPASQTPASNQPKRPPAAPENTPLVPSGVKSWAQASVTHGAHGDGGRASSLLSRFSREEFPTLQAAGDQDKAAKERESAEQSSGPGPSLRPQNSTTWRDGGGRGPDELEGPDSKLHHGHDPRGGLQPSGPPQFPPYRGMMPPFMYPPYLPFPPPYGPQGPYRYPTPDGPSRFPRVAGPRGSGPPMRLVEPVGRPSILKEDNLKEFDQLDQENDDGWAGAHEEVDYTEKLKFSDEEDGRDSDEEGAEGHRDSQSASGEERPPEADGKKGNSPNSEPPTPKTAWAETSRPPETEPGPPAPKPPLPPPHRGPAGNWGPPGDYPDRGGPPCKPPAPEDEDEAWRQRRKQSSSEISLAVERARRRREEEERRMQEERRAACAEKLKRLDEKFGAPDKRLKAEPAAPPAAPSTPAPPPAVPKELPAPPAPPPASAPTPETEPEEPAQAPPAQSTPTPGVAAAPTLVSGGGSTSSTSSGSFEASPVEPQLPSKEGPEPPEEVPPPTTPPVPKVEPKGDGIGPTRQPPSQGLGYPKYQKSLPPRFQRQQQEQLLKQQQQHQWQQHQQGSAPPTPVPPSPPQPVTLGAVPAPQAPPPPPKALYPGALGRPPPMPPMNFDPRWMMIPPYVDPRLLQGRPPLDFYPPGVHPSGLVPRERSDSGGSSSEPFDRHAPAMLRERGTPPVDPKLAWVGDVFTATPAEPRPLTSPLRQAADEDDKGMRSETPPVPPPPPSSSAVFRLDQVIHSNPAGIQQALAQLSSRQGSVTAPGGHPRHKPGLPQAPQGPSPRPPTRYEPQRVNSGLSSDPHFEEPGPMVRGVGGTPRDSAGVSPFPPKRRERPPRKPELLQEESLPPPHSSGFLGSKPEGPGPQAESRDTGTEALTPHIWNRLHTATSRKSYRPSSMEPWMEPLSPFEDVAGTEMSQSDSGVDLSGDSQVSSGPCSQRSSPDGGLKGAAEGPPKRPGGSSPLNAVPCEGPPGSEPPRRPPPAPHDGDRKELPREQPLPPGPIGTERSQRTDRGTEPGPIRPSHRPGPPVQFGTSDKDSDLRLVVGDSLKAEKELTASVTEAIPVSRDWELLPSAAASAEPQSKNLDSGHCVPEPSSSGQRLYPEVFYGSAGPSSSQISGGAMDSQLHPNSGGFRPGTPSLHPYRSQPLYLPPGPAPPSALLSGLALKGQFLDFSTMQATELGKLPAGGVLYPPPSFLYSPAFCPSPLPDTSLLQVRQDLPSPSDFYSTPLQPGGQSGFLPSGAPAQQMLLPMVDSQLPVVNFGSLPPAPPPAPPPLSLLPVGPALQPPSLAVRPPPAPATRVLPSPARPFPASLGRAELHPVELKPFQDYQKLSSNLGGPGSSRTPPTGRSFSGLNSRLKATPSTYSGVFRTQRVDLYQQASPPDALRWIPKPWERTGPPPREGPSRRAEEPGSRGDKEPGLPPPR>sp|Q2VWP7|PRTG_HUMAN Protogenin OS=Homo sapiens OX=9606 GN=PRTG PE=2SV=1MAPPLRPLARLRPPGMLLRALLLLLLLSPLPGVWCFSELSFVKEPQDVTVTRKDPVVLDCQAHGEVPIKVTWLKNGAKMSENKRIEVLSNGSLYISEVEGRRGEQSDEGFYQCLAMNKYGAILSQKAHLALSTISAFEVQPISTEVHEGGVARFACKISSHPPAVITWEFNRTTLPMTMDRITALPTGVLQIYDVSQRDSGNYRCIAATVAHRRKSMEASLTVIPAKESKSFHTPTIIAGPQNITTSLHQTVVLECMATGNPKPIISWSRLDHKSIDVFNTRVLGNGNLMISDVRLQHAGVYVCRATTPGTRNFTVAMATLTVLAPPSFVEWPESLTRPRAGTARFVCQAEGIPSPKMSWLKNGRKIHSNGRIKMYNSKLVINQIIPEDDAIYQCMAENSQGSILSRARLTVVMSEDRPSAPYNVHAETMSSSAILLAWERPLYNSDKVIAYSVHYMKAEGLNNEEYQVVIGNDTTHYIIDDLEPASNYTFYIVAYMPMGASQMSDHVTQNTLEDVPLRPPEISLTSRSPTDILISWLPIPAKYRRGQVVLYRLSFRLSTENSIQVLELPGTTHEYLLEGLKPDSVYLVRITAATRVGLGESSVWTSHRTPKATSVKAPKSPELHLEPLNCTTISVRWQQDVEDTAAIQGYKLYYKEEGQQENGPIFLDTKDLLYTLSGLDPRRKYHVRLLAYNNIDDGYQADQTVSTPGCVSVRDRMVPPPPPPHHLYAKANTSSSIFLHWRRPAFTAAQIINYTIRCNPVGLQNASLVLYLQTSETHMLVQGLEPNTKYEFAVRLHVDQLSSPWSPVVYHSTLPEAPAGPPVGVKVTLIEDDTALVSWKPPDGPETVVTRYTILYASRKAWIAGEWQVLHREGAITMALLENLVAGNVYIVKISASNEVGEGPFSNSVELAVLPKETSESNQRPKRLDSADAKVYSGYYHLDQKSMTGIAVGVGIALTCILICVLILIYRSKARKSSASKTAQNGTQQLPRTSASLASGNEVGKNLEGAVGNEESLMPMIMPNSFIDAKGGTDLIINSYGPIIKNNSKKKWFFFQDSKKIQVEQPQRRFTPAVCFYQPGTTVLISDEDSPSSPGQTTSFSRPFGVAADTEHSANSEGSHETGDSGRFSHESNDEIHLSSVISTTPPNL>sp|P49642|PRI1_HUMAN DNA primase small subunit OS=Homo sapiens OX=9606GN=PRIM1 PE=1 SV=1METFDPTELPELLKLYYRRLFPYSQYYRWLNYGGVIKNYFQHREFSFTLKDDIYIRYQSFNNQSDLEKEMQKMNPYKIDIGAVYSHRPNQHNTVKLGAFQAQEKELVFDIDMTDYDDVRRCCSSADICPKCWTLMTMAIRIIDRALKEDFGFKHRLWVYSGRRGVHCWVCDESVRKLSSAVRSGIVEYLSLVKGGQDVKKKVHLSEKIHPFIRKSINIIKKYFEEYALVNQDILENKESWDKILALVPETIHDELQQSFQKSHNSLQRWEHLKKVASRYQNNIKNDKYGPWLEWEIMLQYCFPRLDINVSKGINHLLKSPFSVHPKTGRISVPIDLQKVDQFDPFTVPTISFICRELDAISTNEEEKEENEAESDVKHRTRDYKKTSLAPYVKVFEHFLENLDKSRKGELLKKSDLQKDF>sp|Q9NV39|PRR34_HUMAN Proline-rich protein 34 OS=Homo sapiens OX=9606GN=PRR34 PE=1 SV=1MPASATAAWHCPPLCLPPLPASAPTSPPNPATRPAPGPGRRARCPQSAHPAPTRGALTFWAPGSWPRVLLVPRSPGPVLRAPRLPHPAARARRRAWHGARLPGSPARAGRTFQRGLVSNSWAHAIFLPRPPNVLELQV>sp|Q6NWY9|PR40B_HUMAN Pre-mRNA-processing factor 40 homolog B OS=Homosapiens OX=9606 GN=PRPF40B PE=1 SV=1MMPPPFMPPPGIPPPFPPMGLPPMSQRPPAIPPMPPGILPPMLPPMGAPPPLTQIPGMVPPMMPGMLMPAVPVTAATAPGADTASSAVAGTGPPRALWSEHVAPDGRIYYYNADDKQSVWEKPSVLKSKAELLLSQCPWKEYKSDTGKPYYYNNQSKESRWTRPKDLDDLEVLVKQEAAGKQQQQLPQTLQPQPPQPQPDPPPVPPGPTPVPTGLLEPEPGGSEDCDVLEATQPLEQGFLQQLEEGPSSSGQHQPQQEEEESKPEPERSGLSWSNREKAKQAFKELLRDKAVPSNASWEQAMKMVVTDPRYSALPKLSEKKQAFNAYKAQREKEEKEEARLRAKEAKQTLQHFLEQHERMTSTTRYRRAEQTFGELEVWAVVPERDRKEVYDDVLFFLAKKEKEQAKQLRRRNIQALKSILDGMSSVNFQTTWSQAQQYLMDNPSFAQDHQLQNMDKEDALICFEEHIRALEREEEEERERARLRERRQQRKNREAFQTFLDELHETGQLHSMSTWMELYPAVSTDVRFANMLGQPGSTPLDLFKFYVEELKARFHDEKKIIKDILKDRGFCVEVNTAFEDFAHVISFDKRAAALDAGNIKLTFNSLLEKAEAREREREKEEARRMRRREAAFRSMLRQAVPALELGTAWEEVRERFVCDSAFEQITLESERIRLFREFLQVLEQTECQHLHTKGRKHGRKGKKHHHKRSHSPSGSESEEEELPPPSLRPPKRRRRNPSESGSEPSSSLDSVESGGAALGGRGSPSSHLLGADHGLRKAKKPKKKTKKRRHKSNSPESETDPEEKAGKESDEKEQEQDKDRELQQAELPNRSPGFGIKKEKTGWDTSESELSEGELERRRRTLLQQLDDHQ>sp|Q6NWY9-2|PR40B_HUMAN Isoform 2 of Pre-mRNA-processing factor 40homolog B OS=Homo sapiens OX=9606 GN=PRPF40BMPPPGIPPPFPPMGLPPMSQRPPAIPPMPPGILPPMLPPMGAPPPLTQIPGMVPPMMPGMLMPAVPVTAATAPGADTASSAVAGTGPPRALWSEHVAPDGRIYYYNADDKQSVWEKPSVLKSKAELLLSQCPWKEYKSDTGKPYYYNNQSKESRWTRPKDLDDLEVLVKQEAAGKQQQQLPQTLQPQPPQPQPDPPPVPPGPTPVPTGLLEPEPGGSEDCDVLEATQPLEQGFLQQLEEGPSSSGQHQPQQEEEESKPEPERSGLSWSNREKAKQAFKELLRDKAVPSNASWEQAMKMVVTDPRYSALPKLSEKKQAFNAYKAQREKEEKEEARLRAKEAKQTLQHFLEQHERMTSTTRYRRAEQTFGELEVWAVVPERDRKEVYDDVLFFLAKKEKEQAKQLRRRNIQALKSILDGMSSVNFQTTWSQAQQYLMDNPSFAQDHQLQNMDKEDALICFEEHIRALEREEEEERERARLRERRQQRKNREAFQTFLDELHETGQLHSMSTWMELYPAVSTDVRFANMLGQPGSTPLDLFKFYVEELKARFHDEKKIIKDILKVNTAFEDFAHVISFDKRAAALDAGNIKLTFNSLLEKAEAREREREKEEARRMRRREAAFRSMLRQAVPALELGTAWEEVRERFVCDSAFEQITLESERIRLFREFLQVLEQTECQHLHTKGRKHGRKGKKHHHKRSHSPSGSESEEEELPPPSLRPPKRRRRNPSESGSEPSSSLDSVESGGAALGGRGSPSSHLLGADHGLRKAKKPKKKTKKRRHKSNSPESETDPEEKAGKESDEKEQEQDKDRELQQAELPNRSPGFGIKKEKTGWDTSESELSEGELERRRRTLLQQLDDHQ>sp|Q6NWY9-3|PR40B_HUMAN Isoform 3 of Pre-mRNA-processing factor 40homolog B OS=Homo sapiens OX=9606 GN=PRPF40BMMPPPFMPPPGIPPPFPPMGLPPMSQRPPAIPPMPPGILPPMLPPMGAPPPLTQIPGMVPPMMPGMLMPAVPVTAATAPGADTASSAVAGTGPPRALWSEHVAPDGRIYYYNADDKQSVWEKPSVLKSKAELLLSQCPWKEYKSDTGKPYYYNNQSKESRWTRPKDLDDLEVLVKQEAAGKQQQQLPQTLQPQPPQPQPDPPPVPPGPTPVPTGLLEPEPGGSEDCDVLEATQPLEQGFLQQLEEGPSSSGQHQPQQEEEESKPEPERSGLSWSNREKAKQAFKELLRDKAVPSNASWEQAMKMVVTDPRYSALPKLSEKKQAFNAYKAQREKEEKEEARLRAKEAKQTLQHFLEQHERMTSTTRYRRAEQTFGELEVWAVVPERDRKEVYDDVLFFLAKKEKEQAKQLRRRNIQALKSILDGMSSVNFQTTWSQAQQYLMDNPSFAQDHQLQNMDKEDALICFEEHIRALEREEEEERERARLRERRQQRKNREAFQTFLDELHETGQLHSMSTWMELYPAVSTDVRFANMLGQPGSTPLDLFKFYVEELKARFHDEKKIIKDILKDRGFCVEVNTAFEDFAHVISFDKRAAALDAGNIKLTFNSLLEKAEAREREREKEEARRMRRREAAFRSMLRQAVPALELGTAWEEVRERFVCDSAFEQITLESERIRLFREFLQVLETECQHLHTKGRKHGRKGKKHHHKRSHSPSGSESEEEELPPPSLRPPKRRRRNPSESGSEPSSSLDSVESGGAALGGRGSPSSHLLGADHGLRKAKKPKKKTKKRRHKSNSPESETDPEEKAGKESDEKEQEQDKDRELQQAELPNRSPGFGIKKEKTGWDTSESELSEGELERRRRTLLQQLDDHQ>sp|Q6NWY9-4|PR40B_HUMAN Isoform 4 of Pre-mRNA-processing factor 40homolog B OS=Homo sapiens OX=9606 GN=PRPF40BMMPPPGIPPPFPPMGLPPMSQRPPAIPPMPPGILPPMLPPMGAPPPLTQIPGMVPPMMPGMLMPAVPVTAAVSTRGQQVAGSALQSRESDLECRTMTSILSLFSSHPPRSPAALPTLKSFSPAMYSALLVSHSSPKAYTFSCYSRALSSSLKEHTYPHRATHCGHMNIVLHILFVPRRVSSTWGSCCAFLCYRSV>sp|Q6PEW0|PRS54_HUMAN Inactive serine protease 54 OS=Homo sapiensOX=9606 GN=PRSS54 PE=2 SV=3MVSAAGLSGDGKMRGVLLVLLGLLYSSTSCGVQKASVFYGPDPKEGLVSSMEFPWVVSLQDSQYTHLAFGCILSEFWVLSIASAIQNRKDIVVIVGISNMDPSKIAHTEYPVNTIIIHEDFDNNSMSNNIALLKTDTAMHFGNLVQSICFLGRMLHTPPVLQNCWVSGWNPTSATGNHMTMSVLRKIFVKDLDMCPLYKLQKTECGSHTKEETKTACLGDPGSPMMCQLQQFDLWVLRGVLNFGGETCPGLFLYTKVEDYSKWITSKAERAGPPLSSLHHWEKLISFSHHGPNATMTQKTYSDSELGHVGSYLQGQRRTITHSRLGNSSRDSLDVREKDVKESGRSPEASVQPLYYDYYGGEVGEGRIFAGQNRLYQPEEIILVSFVLVFFCSSI>sp|Q9NPH0|PPA6_HUMAN Lysophosphatidic acid phosphatase type 6 OS=Homosapiens OX=9606 GN=ACP6 PE=1 SV=3MITGVFSMRLWTPVGVLTSLAYCLHQRRVALAELQEADGQCPVDRSLLKLKMVQVVFRHGARSPLKPLPLEEQVEWNPQLLEVPPQTQFDYTVTNLAGGPKPYSPYDSQYHETTLKGGMFAGQLTKVGMQQMFALGERLRKNYVEDIPFLSPTFNPQEVFIRSTNIFRNLESTRCLLAGLFQCQKEGPIIIHTDEADSEVLYPNYQSCWSLRQRTRGRRQTASLQPGISEDLKKVKDRMGIDSSDKVDFFILLDNVAAEQAHNLPSCPMLKRFARMIEQRAVDTSLYILPKEDRESLQMAVGPFLHILESNLLKAMDSATAPDKIRKLYLYAAHDVTFIPLLMTLGIFDHKWPPFAVDLTMELYQHLESKEWFVQLYYHGKEQVPRGCPDGLCPLDMFLNAMSVYTLSPEKYHALCSQTQVMEVGNEE>sp|Q9NPH0-2|PPA6_HUMAN Isoform 2 of Lysophosphatidic acid phosphatasetype 6 OS=Homo sapiens OX=9606 GN=ACP6MITGVFSMRLWTPVGVLTSLAYCLHQRRVALAELQEADGQCPVDRSLLKLKMVQVVFRHGARSPLKPLPLEEQVEWNPQLLEVPPQTQFDYTVTNLAGGPKPYSPYDSQYHETTLKGGMFAGQLTKVGMQQMFALGERLRKNYVEDIPFLSPTFNPQEVFIRSTNIFRNLESTRCLLAGLFQCQKEGPIIIHTDEADSEVLYPNYQSCWSLRQRTRGRRQTASLQPGISEDLKKVKDRMGIDSSDKVDFFILLDNVAAEQEKMGSCRFHGS>sp|O43447|PPIH_HUMAN Peptidyl-prolyl cis-trans isomerase H OS=Homosapiens OX=9606 GN=PPIH PE=1 SV=1MAVANSSPVNPVVFFDVSIGGQEVGRMKIELFADVVPKTAENFRQFCTGEFRKDGVPIGYKGSTFHRVIKDFMIQGGDFVNGDGTGVASIYRGPFADENFKLRHSAPGLLSMANSGPSTNGCQFFITCSKCDWLDGKHVVFGKIIDGLLVMRKIENVPTGPNNKPKLPVVISQCGEM>sp|O43447-2|PPIH_HUMAN Isoform 2 of Peptidyl-prolyl cis-trans isomeraseH OS=Homo sapiens OX=9606 GN=PPIHMIAGDSDRRKDGVPIGYKGSTFHRVIKDFMIQGGDFVNGDGTGVASIYRGPFADENFKLRHSAPGLLSMANSGPSTNGCQFFITCSKCDWLDGKHVVFGKIIDGLLVMRKIENVPTGPNNKPKLPVVISQCGEM>sp|Q9P1A2|PP4RL_HUMAN Putative serine/threonine-protein phosphatase 4regulatory subunit 1-like OS=Homo sapiens OX=9606 GN=PPP4R1L PE=5 SV=3MAEIPLYFVDLQDDLDDYGFEDYGTDCDNMRVTAFLDIPGQDNLPPLTRLEKYAFSENTFNRQIIARGLLDIFRDFGNNEEDFLTVMEIVVRLSEDAEPTVRTELMEQIPPIAIFLQENRSNFPVVLSEYLIPIVVRYLTDPNNQIICKMASMLSKSTVERLLLPRFCELCGDRKLFQVRKVCAANFGDICHAVGQEATEKFLIPKFFELCSDAVWGMRKACAECFTAVSHSSSPGVRRTQLFPLFIRLVSDPCRWVHQAAFQSLGPFTSTFANPSRAGLYLREDGALSIWPLTQDLDSGFASGSPAPSSGGNTSPASLTRSAKPVRSEPELPVEGTSAKTSDCPHSSSSSDGPAESPVESCVSAGAEWTRVSPETSACSKLSDMNDLPISSYPGSDSWACPGNTEDVFSHFLYW>sp|Q9P1A2-3|PP4RL_HUMAN Isoform 2 of Putative serine/threonine-proteinphosphatase 4 regulatory subunit 1-like OS=Homo sapiens OX=9606GN=PPP4R1LMQIICKMASMLSKSTVERLLLPRFCELCGDRKLFQVRKVCAANFGDICHAVGQEATEKFLIPKFFELCSDAVWGMRKACAECFTAVSHSSSPGVRRTQLFPLFIRLVSDPCRWVHQAAFQSLGPFTSTFANPSRAGLYLREDGALSIWPLTQDLDSGFASGSPAPSSGGNTSPASLTRSAKPVRSEPELPVEGTSAKTSDCPHSSSSSDGPAESPVESCVSAGAEWTRVSPETSACSKLSDMNDLPISSYPGSDSWACPGNTEDVFSHFLYW>sp|Q8WUK0|PTPM1_HUMAN Phosphatidylglycerophosphatase and protein-tyrosine phosphatase 1 OS=Homo sapiens OX=9606 GN=PTPMT1 PE=1 SV=1MAATALLEAGLARVLFYPTLLYTLFRGKVPGRAHRDWYHRIDPTVLLGALPLRSLTRQLVQDENVRGVITMNEEYETRFLCNSSQEWKRLGVEQLRLSTVDMTGIPTLDNLQKGVQFALKYQSLGQCVYVHCKAGRSRSATMVAAYLIQVHKWSPEEAVRAIAKIRSYIHIRPGQLDVLKEFHKQITARATKDGTFVISKT>sp|Q8WUK0-2|PTPM1_HUMAN Isoform 2 of Phosphatidylglycerophosphatase andprotein-tyrosine phosphatase 1 OS=Homo sapiens OX=9606 GN=PTPMT1MAATALLEAGLARVLFYPTLLYTLFRGKVPGRAHRDWYHRIDPTVLLGALPLRSLTRQLVQDENVRGVITMNEEYETRFLCNSSQVHKWSPEEAVRAIAKIRSYIHIRPGQLDVLKEFHKQITARATKDGTFVISKT>sp|Q8WUK0-3|PTPM1_HUMAN Isoform 3 of Phosphatidylglycerophosphatase andprotein-tyrosine phosphatase 1 OS=Homo sapiens OX=9606 GN=PTPMT1MAATALLEAGLARVLFYPTLLYTLFRGKVPGRAHRDWYHRIDPTVLLGALPLRSLTRQVSRAGEPGPLPRPRRSVPVGPLGSPPSLLSHLFASAAGTGRERARGDHHERGVRDEVPVQLFTGAQMESRGGCKSHRQDPVIHPHQAWPAGCS>sp|P23467|PTPRB_HUMAN Receptor-type tyrosine-protein phosphatase betaOS=Homo sapiens OX=9606 GN=PTPRB PE=1 SV=3MLSHGAGLALWITLSLLQTGLAEPERCNFTLAESKASSHSVSIQWRILGSPCNFSLIYSSDTLGAALCPTFRIDNTTYGCNLQDLQAGTIYNFRIISLDEERTVVLQTDPLPPARFGVSKEKTTSTSLHVWWTPSSGKVTSYEVQLFDENNQKIQGVQIQESTSWNEYTFFNLTAGSKYNIAITAVSGGKRSFSVYTNGSTVPSPVKDIGISTKANSLLISWSHGSGNVERYRLMLMDKGILVHGGVVDKHATSYAFHGLTPGYLYNLTVMTEAAGLQNYRWKLVRTAPMEVSNLKVTNDGSLTSLKVKWQRPPGNVDSYNITLSHKGTIKESRVLAPWITETHFKELVPGRLYQVTVSCVSGELSAQKMAVGRTFPDKVANLEANNNGRMRSLVVSWSPPAGDWEQYRILLFNDSVVLLNITVGKEETQYVMDDTGLVPGRQYEVEVIVESGNLKNSERCQGRTVPLAVLQLRVKHANETSLSIMWQTPVAEWEKYIISLADRDLLLIHKSLSKDAKEFTFTDLVPGRKYMATVTSISGDLKNSSSVKGRTVPAQVTDLHVANQGMTSSLFTNWTQAQGDVEFYQVLLIHENVVIKNESISSETSRYSFHSLKSGSLYSVVVTTVSGGISSRQVVVEGRTVPSSVSGVTVNNSGRNDYLSVSWLLAPGDVDNYEVTLSHDGKVVQSLVIAKSVRECSFSSLTPGRLYTVTITTRSGKYENHSFSQERTVPDKVQGVSVSNSARSDYLRVSWVHATGDFDHYEVTIKNKNNFIQTKSIPKSENECVFVQLVPGRLYSVTVTTKSGQYEANEQGNGRTIPEPVKDLTLRNRSTEDLHVTWSGANGDVDQYEIQLLFNDMKVFPPFHLVNTATEYRFTSLTPGRQYKILVLTISGDVQQSAFIEGFTVPSAVKNIHISPNGATDSLTVNWTPGGGDVDSYTVSAFRHSQKVDSQTIPKHVFEHTFHRLEAGEQYQIMIASVSGSLKNQINVVGRTVPASVQGVIADNAYSSYSLIVSWQKAAGVAERYDILLLTENGILLRNTSEPATTKQHKFEDLTPGKKYKIQILTVSGGLFSKEAQTEGRTVPAAVTDLRITENSTRHLSFRWTASEGELSWYNIFLYNPDGNLQERAQVDPLVQSFSFQNLLQGRMYKMVIVTHSGELSNESFIFGRTVPASVSHLRGSNRNTTDSLWFNWSPASGDFDFYELILYNPNGTKKENWKDKDLTEWRFQGLVPGRKYVLWVVTHSGDLSNKVTAESRTAPSPPSLMSFADIANTSLAITWKGPPDWTDYNDFELQWLPRDALTVFNPYNNRKSEGRIVYGLRPGRSYQFNVKTVSGDSWKTYSKPIFGSVRTKPDKIQNLHCRPQNSTAIACSWIPPDSDFDGYSIECRKMDTQEVEFSRKLEKEKSLLNIMMLVPHKRYLVSIKVQSAGMTSEVVEDSTITMIDRPPPPPPHIRVNEKDVLISKSSINFTVNCSWFSDTNGAVKYFTVVVREADGSDELKPEQQHPLPSYLEYRHNASIRVYQTNYFASKCAENPNSNSKSFNIKLGAEMESLGGKCDPTQQKFCDGPLKPHTAYRISIRAFTQLFDEDLKEFTKPLYSDTFFSLPITTESEPLFGAIEGVSAGLFLIGMLVAVVALLICRQKVSHGRERPSARLSIRRDRPLSVHLNLGQKGNRKTSCPIKINQFEGHFMKLQADSNYLLSKEYEELKDVGRNQSCDIALLPENRGKNRYNNILPYDATRVKLSNVDDDPCSDYINASYIPGNNFRREYIVTQGPLPGTKDDFWKMVWEQNVHNIVMVTQCVEKGRVKCDHYWPADQDSLYYGDLILQMLSESVLPEWTIREFKICGEEQLDAHRLIRHFHYTVWPDHGVPETTQSLIQFVRTVRDYINRSPGAGPTVVHCSAGVGRTGTFIALDRILQQLDSKDSVDIYGAVHDLRLHRVHMVQTECQYVYLHQCVRDVLRARKLRSEQENPLFPIYENVNPEYHRDPVYSRH>sp|P23467-2|PTPRB_HUMAN Isoform 2 of Receptor-type tyrosine-proteinphosphatase beta OS=Homo sapiens OX=9606 GN=PTPRBMLSHGAGLALWITLSLLQTGLAEPERCNFTLAESKASSHSVSIQWRILGSPCNFSLIYSSDTLGAALCPTFRIDNTTYGCNLQDLQAGTIYNFRIISLDEERTVVLQTDPLPPARFGVSKEKTTSTSLHVWWTPSSGKVTSYEVQLFDENNQKIQGVQIQESTSWNEYTFFNLTAGSKYNIAITAVSGGKRSFSVYTNGSTVPSPVKDIGISTKANSLLISWSHGSGNVERYRLMLMDKGILVHGGVVDKHATSYAFHGLTPGYLYNLTVMTEAAGLQNYRWKLVRTAPMEVSNLKVTNDGSLTSLKVKWQRPPGNVDSYNITLSHKGTIKESRVLAPWITETHFKELVPGRLYQVTVSCVSGELSAQKMAVGRTFPLAVLQLRVKHANETSLSIMWQTPVAEWEKYIISLADRDLLLIHKSLSKDAKEFTFTDLVPGRKYMATVTSISGDLKNSSSVKGRTVPAQVTDLHVANQGMTSSLFTNWTQAQGDVEFYQVLLIHENVVIKNESISSETSRYSFHSLKSGSLYSVVVTTVSGGISSRQVVVEGRTVPSSVSGVTVNNSGRNDYLSVSWLLAPGDVDNYEVTLSHDGKVVQSLVIAKSVRECSFSSLTPGRLYTVTITTRSGKYENHSFSQERTVPDKVQGVSVSNSARSDYLRVSWVHATGDFDHYEVTIKNKNNFIQTKSIPKSENECVFVQLVPGRLYSVTVTTKSGQYEANEQGNGRTIPEPVKDLTLRNRSTEDLHVTWSGANGDVDQYEIQLLFNDMKVFPPFHLVNTATEYRFTSLTPGRQYKILVLTISGDVQQSAFIEGFTVPSAVKNIHISPNGATDSLTVNWTPGGGDVDSYTVSAFRHSQKVDSQTIPKHVFEHTFHRLEAGEQYQIMIASVSGSLKNQINVVGRTVPASVQGVIADNAYSSYSLIVSWQKAAGVAERYDILLLTENGILLRNTSEPATTKQHKFEDLTPGKKYKIQILTVSGGLFSKEAQTEGRTVPAAVTDLRITENSTRHLSFRWTASEGELSWYNIFLYNPDGNLQERAQVDPLVQSFSFQNLLQGRMYKMVIVTHSGELSNESFIFGRTVPASVSHLRGSNRNTTDSLWFNWSPASGDFDFYELILYNPNGTKKENWKDKDLTEWRFQGLVPGRKYVLWVVTHSGDLSNKVTAESRTAPSPPSLMSFADIANTSLAITWKGPPDWTDYNDFELQWLPRDALTVFNPYNNRKSEGRIVYGLRPGRSYQFNVKTVSGDSWKTYSKPIFGSVRTKPDKIQNLHCRPQNSTAIACSWIPPDSDFDGYSIECRKMDTQEVEFSRKLEKEKSLLNIMMLVPHKRYLVSIKVQSAGMTSEVVEDSTITMIDRPPPPPPHIRVNEKDVLISKSSINFTVNCSWFSDTNGAVKYFTVVVREADGSDELKPEQQHPLPSYLEYRHNASIRVYQTNYFASKCAENPNSNSKSFNIKLGAEMESLGGKCDPTQQKFCDGPLKPHTAYRISIRAFTQLFDEDLKEFTKPLYSDTFFSLPITTESEPLFGAIEGVSAGLFLIGMLVAVVALLICRQKVSHGRERPSARLSIRRDRPLSVHLNLGQKGNRKTSCPIKINQFEGHFMKLQADSNYLLSKEYEELKDVGRNQSCDIALLPENRGKNRYNNILPYDATRVKLSNVDDDPCSDYINASYIPGNNFRREYIVTQGPLPGTKDDFWKMVWEQNVHNIVMVTQCVEKGRVKCDHYWPADQDSLYYGDLILQMLSESVLPEWTIREFKICGEEQLDAHRLIRHFHYTVWPDHGVPETTQSLIQFVRTVRDYINRSPGAGPTVVHCSAGVGRTGTFIALDRILQQLDSKDSVDIYGAVHDLRLHRVHMVQTECQYVYLHQCVRDVLRARKLRSEQENPLFPIYENVNPEYHRDPVYSRH>sp|P23467-3|PTPRB_HUMAN Isoform 3 of Receptor-type tyrosine-proteinphosphatase beta OS=Homo sapiens OX=9606 GN=PTPRBMEAEFYMVILTCLIFRNSEGFQIVHVQKQQCLFKNEKVVVGSCNRTIQNQQWMWTEDEKLLHVKSALCLAISNSSRGPSRSAILDRCSQAPRWTCYDQEGFLEVENASLFLQKQGSRVVVKKARKYLHSWMKIDVNKEGKLVNESLCLQKAGLGAEVSVRSTRNTAPPQILTTFNAVPDGLVFLIRNTTEAFIRNAAENYSQNSSERQHPNLHMTGITDTSWVLSTTQPFSSTTEETGLAEPERCNFTLAESKASSHSVSIQWRILGSPCNFSLIYSSDTLGAALCPTFRIDNTTYGCNLQDLQAGTIYNFRIISLDEERTVVLQTDPLPPARFGVSKEKTTSTSLHVWWTPSSGKVTSYEVQLFDENNQKIQGVQIQESTSWNEYTFFNLTAGSKYNIAITAVSGGKRSFSVYTNGSTVPSPVKDIGISTKANSLLISWSHGSGNVERYRLMLMDKGILVHGGVVDKHATSYAFHGLTPGYLYNLTVMTEAAGLQNYRWKLVRTAPMEVSNLKVTNDGSLTSLKVKWQRPPGNVDSYNITLSHKGTIKESRVLAPWITETHFKELVPGRLYQVTVSCVSGELSAQKMAVGRTFPDKVANLEANNNGRMRSLVVSWSPPAGDWEQYRILLFNDSVVLLNITVGKEETQYVMDDTGLVPGRQYEVEVIVESGNLKNSERCQGRTVPLAVLQLRVKHANETSLSIMWQTPVAEWEKYIISLADRDLLLIHKSLSKDAKEFTFTDLVPGRKYMATVTSISGDLKNSSSVKGRTVPAQVTDLHVANQGMTSSLFTNWTQAQGDVEFYQVLLIHENVVIKNESISSETSRYSFHSLKSGSLYSVVVTTVSGGISSRQVVVEGRTVPSSVSGVTVNNSGRNDYLSVSWLLAPGDVDNYEVTLSHDGKVVQSLVIAKSVRECSFSSLTPGRLYTVTITTRSGKYENHSFSQERTVPDKVQGVSVSNSARSDYLRVSWVHATGDFDHYEVTIKNKNNFIQTKSIPKSENECVFVQLVPGRLYSVTVTTKSGQYEANEQGNGRTIPEPVKDLTLRNRSTEDLHVTWSGANGDVDQYEIQLLFNDMKVFPPFHLVNTATEYRFTSLTPGRQYKILVLTISGDVQQSAFIEGFTVPSAVKNIHISPNGATDSLTVNWTPGGGDVDSYTVSAFRHSQKVDSQTIPKHVFEHTFHRLEAGEQYQIMIASVSGSLKNQINVVGRTVPASVQGVIADNAYSSYSLIVSWQKAAGVAERYDILLLTENGILLRNTSEPATTKQHKFEDLTPGKKYKIQILTVSGGLFSKEAQTEGRTVPAAVTDLRITENSTRHLSFRWTASEGELSWYNIFLYNPDGNLQERAQVDPLVQSFSFQNLLQGRMYKMVIVTHSGELSNESFIFGRTVPASVSHLRGSNRNTTDSLWFNWSPASGDFDFYELILYNPNGTKKENWKDKDLTEWRFQGLVPGRKYVLWVVTHSGDLSNKVTAESRTAPSPPSLMSFADIANTSLAITWKGPPDWTDYNDFELQWLPRDALTVFNPYNNRKSEGRIVYGLRPGRSYQFNVKTVSGDSWKTYSKPIFGSVRTKPDKIQNLHCRPQNSTAIACSWIPPDSDFDGYSIECRKMDTQEVEFSRKLEKEKSLLNIMMLVPHKRYLVSIKVQSAGMTSEVVEDSTITMIDRPPPPPPHIRVNEKDVLISKSSINFTVNCSWFSDTNGAVKYFTVVVREADGSDELKPEQQHPLPSYLEYRHNASIRVYQTNYFASKCAENPNSNSKSFNIKLGAEMESLGGKCDPTQQKFCDGPLKPHTAYRISIRAFTQLFDEDLKEFTKPLYSDTFFSLPITTESEPLFGAIEGVSAGLFLIGMLVAVVALLICRQKVSHGRERPSARLSIRRDRPLSVHLNLGQKGNRKTSCPIKINQFEGHFMKLQADSNYLLSKEYEELKDVGRNQSCDIALLPENRGKNRYNNILPYDATRVKLSNVDDDPCSDYINASYIPGNNFRREYIVTQGPLPGTKDDFWKMVWEQNVHNIVMVTQCVEKGRVKCDHYWPADQDSLYYGDLILQMLSESVLPEWTIREFKICGEEQLDAHRLIRHFHYTVWPDHGVPETTQSLIQFVRTVRDYINRSPGAGPTVVHCSAGVGRTGTFIALDRILQQLDSKDSVDIYGAVHDLRLHRVHMVQTECQYVYLHQCVRDVLRARKLRSEQENPLFPIYENVNPEYHRDPVYSRH>sp|P23467-4|PTPRB_HUMAN Isoform 4 of Receptor-type tyrosine-proteinphosphatase beta OS=Homo sapiens OX=9606 GN=PTPRBMLSHGAGLALWITLSLLQTGLAEPERCNFTLAESKASSHSVSIQWRILGSPCNFSLIYSSDTLGAALCPTFRIDNTTYGCNLQDLQAGTIYNFRIISLDEERTVVLQTDPLPPARFGVSKEKTTSTSLHVWWTPSSGKVTSYEVQLFDENNQKIQGVQIQESTSWNEYTFFNLTAGSKYNIAITAVSGGKRSFSVYTNGSTVPSPVKDIGISTKANSLLISWSHGSGNVERYRLMLMDKGILVHGGVVDKHATSYAFHGLTPGYLYNLTVMTEAAGLQNYRWKLVRTAPMEVSNLKVTNDGSLTSLKVKWQRPPGNVDSYNITLSHKGTIKESRVLAPWITETHFKELVPGRLYQVTVSCVSGELSAQKMAVGRTFPDKVANLEANNNGRMRSLVVSWSPPAGDWEQYRILLFNDSVVLLNITVGKEETQYVMDDTGLVPGRQYEVEVIVESGNLKNSERCQGRTVPLAVLQLRVKHANETSLSIMWQTPVAEWEKYIISLADRDLLLIHKSLSKDAKEFTFTDLVPGRKYMATVTSISGDLKNSSSVKGRTVPAQVTDLHVANQGMTSSLFTNWTQAQGDVEFYQVLLIHENVVIKNESISSETSRYSFHSLKSGSLYSVVVTTVSGGISSRQVVVEGRTVPSSVSGVTVNNSGRNDYLSVSWLLAPGDVDNYEVTLSHDGKVVQSLVIAKSVRECSFSSLTPGRLYTVTITTRSGKYENHSFSQERTVPDKVQGVSVSNSARSDYLRVSWVHATGDFDHYEVTIKNKNNFIQTKSIPKSENECVFVQLVPGRLYSVTVTTKSGQYEANEQGNGRTIPEPVKDLTLRNRSTEDLHVTWSGANGDVDQYEIQLLFNDMKVFPPFHLVNTATEYRFTSLTPGRQYKILVLTISGDVQQSAFIEGFTVPSAVKNIHISPNGATDSLTVNWTPGGGDVDSYTVSAFRHSQKVDSQTIPKHVFEHTFHRLEAGEQYQIMIASVSGSLKNQINVVGRTVPAAVTDLRITENSTRHLSFRWTASEGELSWYNIFLYNPDGNLQERAQVDPLVQSFSFQNLLQGRMYKMVIVTHSGELSNESFIFGRTVPASVSHLRGSNRNTTDSLWFNWSPASGDFDFYELILYNPNGTKKENWKDKDLTEWRFQGLVPGRKYVLWVVTHSGDLSNKVTAESRTAPSPPSLMSFADIANTSLAITWKGPPDWTDYNDFELQWLPRDALTVFNPYNNRKSEGRIVYGLRPGRSYQFNVKTVSGDSWKTYSKPIFGSVRTKPDKIQNLHCRPQNSTAIACSWIPPDSDFDGYSIECRKMDTQEVEFSRKLEKEKSLLNIMMLVPHKRYLVSIKVQSAGMTSEVVEDSTITMIDRPPPPPPHIRVNEKDVLISKSSINFTVNCSWFSDTNGAVKYFTVVVREADGSDELKPEQQHPLPSYLEYRHNASIRVYQTNYFASKCAENPNSNSKSFNIKLGAEMESLGGKCDPTQQKFCDGPLKPHTAYRISIRAFTQLFDEDLKEFTKPLYSDTFFSLPITTESEPLFGAIEGVSAGLFLIGMLVAVVALLICRQKVSHGRERPSARLSIRRDRPLSVHLNLGQKGNRKTSCPIKINQFEGHFMKLQADSNYLLSKEYEELKDVGRNQSCDIALLPENRGKNRYNNILPYDATRVKLSNVDDDPCSDYINASYIPGNNFRREYIVTQGPLPGTKDDFWKMVWEQNVHNIVMVTQCVEKGRVKCDHYWPADQDSLYYGDLILQMLSESVLPEWTIREFKICGEEQLDAHRLIRHFHYTVWPDHGVPETTQSLIQFVRTVRDYINRSPGAGPTVVHCSAGVGRTGTFIALDRILQQLDSKDSVDIYGAVHDLRLHRVHMVQTECQYVYLHQCVRDVLRARKLRSEQENPLFPIYENVNPEYHRDPVYSRH>sp|P55036|PSMD4_HUMAN 26S proteasome non-ATPase regulatory subunit 4OS=Homo sapiens OX=9606 GN=PSMD4 PE=1 SV=1MVLESTMVCVDNSEYMRNGDFLPTRLQAQQDAVNIVCHSKTRSNPENNVGLITLANDCEVLTTLTPDTGRILSKLHTVQPKGKITFCTGIRVAHLALKHRQGKNHKMRIIAFVGSPVEDNEKDLVKLAKRLKKEKVNVDIINFGEEEVNTEKLTAFVNTLNGKDGTGSHLVTVPPGPSLADALISSPILAGEGGAMLGLGASDFEFGVDPSADPELALALRVSMEEQRQRQEEEARRAAAASAAEAGIATTGTEDSDDALLKMTISQQEFGRTGLPDLSSMTEEEQIAYAMQMSLQGAEFGQAESADIDASSAMDTSEPAKEEDDYDVMQDPEFLQSVLENLPGVDPNNEAIRNAMGSLASQATKDGKKDKKEEDKK>sp|P55036-2|PSMD4_HUMAN Isoform Rpn10E of 26S proteasome non-ATPaseregulatory subunit 4 OS=Homo sapiens OX=9606 GN=PSMD4MVLESTMVCVDNSEYMRNGDFLPTRLQAQQDAVNIVCHSKTRSNPENNVGLITLANDCEVLTTLTPDTGRILSKLHTVQPKGKITFCTGIRVAHLALKHRQGKNHKMRIIAFVGSPVEDNEKDLVKLAKRLKKEKVNVDIINFGEEEVNTEKLTAFVNTLNGKDGTGSHLVTVPPGPSLADALISSPILAGEGGAMLGLGASDFEFGVDPSADPELALALRVSMEEQRQRQEEEARRAAAASAAEAGIATTGTEGERGGIRSPGTAGC>sp|Q8N2H3|PYRD2_HUMAN Pyridine nucleotide-disulfide oxidoreductasedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=PYROXD2 PE=1 SV=2MAASGRGLCKAVAASPFPAWRRDNTEARGGLKPEYDAVVIGAGHNGLVAAAYLQRLGVNTAVFERRHVIGGAAVTEEIIPGFKFSRASYLLSLLRPQIYTDLELKKHGLRLHLRNPYSFTPMLEEGAGSKVPRCLLLGTDMAENQKQIAQFSQKDAQVFPKYEEFMHRLALAIDPLLDAAPVDMAAFQHGSLLQRMRSLSTLKPLLKAGRILGAQLPRYYEVLTAPITKVLDQWFESEPLKATLATDAVIGAMTSPHTPGSGYVLLHHVMGGLEGMQGAWGYVQGGMGALSDAIASSATTHGASIFTEKTVAKVQVNSEGCVQGVVLEDGTEVRSKMVLSNTSPQITFLKLTPQEWLPEEFLERISQLDTRSPVTKINVAVDRLPSFLAAPNAPRGQPLPHHQCSIHLNCEDTLLLHQAFEDAMDGLPSHRPVIELCIPSSLDPTLAPPGCHVVSLFTQYMPYTLAGGKAWDEQERDAYADRVFDCIEVYAPGFKDSVVGRDILTPPDLERIFGLPGGNIFHCAMSLDQLYFARPVPLHSGYRCPLQGLYLCGSGAHPGGGVMGAAGRNAAHVAFRDLKSM>sp|P83881|RL36A_HUMAN 60S ribosomal protein L36a OS=Homo sapiens OX=9606GN=RPL36A PE=1 SV=2MVNVPKTRRTFCKKCGKHQPHKVTQYKKGKDSLYAQGKRRYDRKQSGYGGQTKPIFRKKAKTTKKIVLRLECVEPNCRSKRMLAIKRCKHFELGGDKKRKGQVIQF>sp|Q14515|SPRL1_HUMAN SPARC-like protein 1 OS=Homo sapiens OX=9606GN=SPARCL1 PE=1 SV=2MKTGLFFLCLLGTAAAIPTNARLLSDHSKPTAETVAPDNTAIPSLRAEAEENEKETAVSTEDDSHHKAEKSSVLKSKEESHEQSAEQGKSSSQELGLKDQEDSDGHLSVNLEYAPTEGTLDIKEDMSEPQEKKLSENTDFLAPGVSSFTDSNQQESITKREENQEQPRNYSHHQLNRSSKHSQGLRDQGNQEQDPNISNGEEEEEKEPGEVGTHNDNQERKTELPREHANSKQEEDNTQSDDILEESDQPTQVSKMQEDEFDQGNQEQEDNSNAEMEEENASNVNKHIQETEWQSQEGKTGLEAISNHKETEEKTVSEALLMEPTDDGNTTPRNHGVDDDGDDDGDDGGTDGPRHSASDDYFIPSQAFLEAERAQSIAYHLKIEEQREKVHENENIGTTEPGEHQEAKKAENSSNEEETSSEGNMRVHAVDSCMSFQCKRGHICKADQQGKPHCVCQDPVTCPPTKPLDQVCGTDNQTYASSCHLFATKCRLEGTKKGHQLQLDYFGACKSIPTCTDFEVIQFPLRMRDWLKNILMQLYEANSEHAGYLNEKQRNKVKKIYLDEKRLLAGDHPIDLLLRDFKKNYHMYVYPVHWQFSELDQHPMDRVLTHSELAPLRASLVPMEHCITRFFEECDPNKDKHITLKEWGHCFGIKEEDIDENLLF>sp|Q14515-2|SPRL1_HUMAN Isoform 2 of SPARC-like protein 1 OS=Homosapiens OX=9606 GN=SPARCL1MSEPQEKKLSENTDFLAPGVSSFTDSNQQESITKREENQEQPRNYSHHQLNRSSKHSQGLRDQGNQEQDPNISNGEEEEEKEPGEVGTHNDNQERKTELPREHANSKQEEDNTQSDDILEESDQPTQVSKMQEDEFDQGNQEQEDNSNAEMEEENASNVNKHIQETEWQSQEGKTGLEAISNHKETEEKTVSEALLMEPTDDGNTTPRNHGVDDDGDDDGDDGGTDGPRHSASDDYFIPSQAFLEAERAQSIAYHLKIEEQREKVHENENIGTTEPGEHQEAKKAENSSNEEETSSEGNMRVHAVDSCMSFQCKRGHICKADQQGKPHCVCQDPVTCPPTKPLDQVCGTDNQTYASSCHLFATKCRLEGTKKGHQLQLDYFGACKSIPTCTDFEVIQFPLRMRDWLKNILMQLYEANSEHAGYLNEKQRNKVKKIYLDEKRLLAGDHPIDLLLRDFKKNYHMYVYPVHWQFSELDQHPMDRVLTHSELAPLRASLVPMEHCITRFFEECDPNKDKHITLKEWGHCFGIKEEDIDENLLF>sp|P61077|UB2D3_HUMAN Ubiquitin-conjugating enzyme E2 D3 OS=Homo sapiensOX=9606 GN=UBE2D3 PE=1 SV=1MALKRINKELSDLARDPPAQCSAGPVGDDMFHWQATIMGPNDSPYQGGVFFLTIHFPTDYPFKPPKVAFTTRIYHPNINSNGSICLDILRSQWSPALTISKVLLSICSLLCDPNPDDPLVPEIARIYKTDRDKYNRISREWTQKYAM>sp|P61077-2|UB2D3_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 D3OS=Homo sapiens OX=9606 GN=UBE2D3MALKRINKELSDLARDPPAQCSAGPVGDDMFHWQATIMGPNDSPYQGGVFFLTIHFPTDYPFKPPKVAFTTRIYHPNINSNGSICLDILRSQWSPALTISKVLLSICSLLCDPNPDDPLVPEIARIYKTDRDKYNRLAREWTEKYAML>sp|P61077-3|UB2D3_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 D3OS=Homo sapiens OX=9606 GN=UBE2D3MLSNRKCLSKELSDLARDPPAQCSAGPVGDDMFHWQATIMGPNDSPYQGGVFFLTIHFPTDYPFKPPKVAFTTRIYHPNINSNGSICLDILRSQWSPALTISKVLLSICSLLCDPNPDDPLVPEIARIYKTDRDKYNRISREWTQKYAM>sp|A8MT33|SYC1L_HUMAN Synaptonemal complex central element protein 1-like OS=Homo sapiens OX=9606 GN=SYCE1L PE=2 SV=3MAGKLKPLNVEAPEATEEAEGQAKSLKTEDLLAMVIKLQKEGSLEPQIEDLISRINDLQQAKKKSSEELRETHSLWEALHRELDSLNGEKVHLEEVLGKKQEALRILQMHCQEKESEAQRLDVRGQLEDLMGQHKDLWEFHMLEQRLAREIRALERSKEQLLSERRLVRAKLREVERRLHSPPEVEGAMAVNDGLKAELEIFGEQVRSAPEVGAGEGEAGPELPRARDEEDPEPPVAAPDAL>sp|Q7L7X3|TAOK1_HUMAN Serine/threonine-protein kinase TAO1 OS=Homosapiens OX=9606 GN=TAOK1 PE=1 SV=1MPSTNRAGSLKDPEIAELFFKEDPEKLFTDLREIGHGSFGAVYFARDVRTNEVVAIKKMSYSGKQSTEKWQDIIKEVKFLQRIKHPNSIEYKGCYLREHTAWLVMEYCLGSASDLLEVHKKPLQEVEIAAITHGALQGLAYLHSHTMIHRDIKAGNILLTEPGQVKLADFGSASMASPANSFVGTPYWMAPEVILAMDEGQYDGKVDVWSLGITCIELAERKPPLFNMNAMSALYHIAQNESPTLQSNEWSDYFRNFVDSCLQKIPQDRPTSEELLKHIFVLRERPETVLIDLIQRTKDAVRELDNLQYRKMKKLLFQEAHNGPAVEAQEEEEEQDHGVGRTGTVNSVGSNQSIPSMSISASSQSSSVNSLPDVSDDKSELDMMEGDHTVMSNSSVIHLKPEEENYREEGDPRTRASDPQSPPQVSRHKSHYRNREHFATIRTASLVTRQMQEHEQDSELREQMSGYKRMRRQHQKQLMTLENKLKAEMDEHRLRLDKDLETQRNNFAAEMEKLIKKHQAAMEKEAKVMSNEEKKFQQHIQAQQKKELNSFLESQKREYKLRKEQLKEELNENQSTPKKEKQEWLSKQKENIQHFQAEEEANLLRRQRQYLELECRRFKRRMLLGRHNLEQDLVREELNKRQTQKDLEHAMLLRQHESMQELEFRHLNTIQKMRCELIRLQHQTELTNQLEYNKRRERELRRKHVMEVRQQPKSLKSKELQIKKQFQDTCKIQTRQYKALRNHLLETTPKSEHKAVLKRLKEEQTRKLAILAEQYDHSINEMLSTQALRLDEAQEAECQVLKMQLQQELELLNAYQSKIKMQAEAQHDRELRELEQRVSLRRALLEQKIEEEMLALQNERTERIRSLLERQAREIEAFDSESMRLGFSNMVLSNLSPEAFSHSYPGASGWSHNPTGGPGPHWGHPMGGPPQAWGHPMQGGPQPWGHPSGPMQGVPRGSSMGVRNSPQALRRTASGGRTEQGMSRSTSVTSQISNGSHMSYT>sp|Q7L7X3-2|TAOK1_HUMAN Isoform 2 of Serine/threonine-protein kinaseTAO1 OS=Homo sapiens OX=9606 GN=TAOK1MASPANSFVGTPYWMAPEVILAMDEGQYDGKVDVWSLGITCIELAERKPPLFNMNAMSALYHIAQNESPTLQSNEWSDYFRNFVDSCLQKIPQDRPTSEELLKHIFVLRERPETVLIDLIQRTKDAVRELDNLQYRKMKKLLFQEAHNGPAVEAQEEEEEQDHGVGRTGTVNSVGSNQSIPSMSISASSQSSSVNSLPDVSDDKSELDMMEGDHTVMSNSSVIHLKPEEENYREEGDPRTRASDPQSPPQVSRHKSHYRNREHFATIRTASLVTRQMQEHEQDSELREQMSGYKRMRRQHQKQLMTLENKLKAEMDEHRLRLDKDLETQRNNFAAEMEKLIKKHQAAMEKEAKVMSNEEKKFQQHIQAQQKKELNSFLESQKREYKLRKEQLKEVLMS>sp|Q7L7X3-3|TAOK1_HUMAN Isoform 3 of Serine/threonine-protein kinaseTAO1 OS=Homo sapiens OX=9606 GN=TAOK1MPSTNRAGSLKDPEIAELFFKEDPEKLFTDLREIGHGSFGAVYFARDVRTNEVVAIKKMSYSGKQSTEKWQDIIKEVKFLQRIKHPNSIEYKGCYLREHTAWLVMEYCLGSASDLLEVHKKPLQEVEIAAITHGALQGLAYLHSHTMIHRDIKAGNILLTEPGQVKLADFGSASMASPANSFVGTPYWMAPEVILAMDEGQYDGKVDVWSLGITCIELAERKPPLFNMNAMSALYHIAQNESPTLQSNEWSDYFRNFVDSCLQKIPQDRPTSEELLKHIFVLRERPETVLIDLIQRTKDAVRELDNLQYRKMKKLLFQEAHNGPAVEAQEEEEEQDHGVGRTGTVNSVGSNQSIPSMSISASSQSSSVNSLPDVSDDKSELDMMEGDHTVMSNSSVIHLKPEEENYREEGDPRTRASDPQSPPQVSRHKSHYRNREHFATIRTASLVTRQMQEHEQDSELREQMSGYKRMRRQHQKQLMTLENKLKAEMDEHRLRLDKDLETQRNNFAAEMEKLIKKHQAAMEKEAKVMSNEEKKFQQHIQAQQKKELNSFLESQKREYKLRKEQLKESKELQIKKQFQDTCKIQTRQYKALRNHLLETTPKSEHKAVLKRLKEEQTRKLAILAEQYDHSINEMLSTQALRLDEAQEAECQVLKMQLQQELELLNAYQSKIKMQAEAQHDRELRELEQRVSLRRALLEQKIEEEMLALQNERTERIRSLLERQAREIEAFDSESMRLGFSNMVLSNLSPEAFSHSYPGASGWSHNPTGGPGPHWGHPMGGPPQAWGHPMQGGPQPWGHPSGPMQGVPRGSSMGVRNSPQALRRTASGGRTEQGMSRSTSVTSQISNGSHMSYT>sp|Q53T94|TAF1B_HUMAN TATA box-binding protein-associated factor RNApolymerase I subunit B OS=Homo sapiens OX=9606 GN=TAF1B PE=1 SV=1MDLEEAEEFKERCTQCAAVSWGLTDEGKYYCTSCHNVTERYQEVTNTDLIPNTQIKALNRGLKKKNNTEKGWDWYVCEGFQYILYQQAEALKNLGVGPELKNDVLHNFWKRYLQKSKQAYCKNPVYTTGRKPTVLEDNLSHSDWASEPELLSDVSCPPFLESGAESQSDIHTRKPFPVSKASQSETSVCSGSLDGVEYSQRKEKGIVKMTMPQTLAFCYLSLLWQREAITLSDLLRFVEEDHIPYINAFQHFPEQMKLYGRDRGIFGIESWPDYEDIYKKTVEVGTFLDLPRFPDITEDCYLHPNILCMKYLMEVNLPDEMHSLTCHVVKMTGMGEVDFLTFDPIAKMAKTVKYDVQAVAIIVVVLKLLFLLDDSFEWSLSNLAEKHNEKNKKDKPWFDFRKWYQIMKKAFDEKKQKWEEARAKYLWKSEKPLYYSFVDKPVAYKKREMVVNLQKQFSTLVESTATAGKKSPSSFQFNWTEEDTDRTCFHGHSLQGVLKEKGQSLLTKNSLYWLSTQKFCRCYCTHVTTYEESNYSLSYQFILNLFSFLLRIKTSLLHEEVSLVEKKLFEKKYSVKRKKSRSKKVRRH>sp|Q53T94-2|TAF1B_HUMAN Isoform 2 of TATA box-binding protein-associatedfactor RNA polymerase I subunit B OS=Homo sapiens OX=9606 GN=TAF1BMDLEEAEEFKERCTQCAAVSWGLTDEGKYYCTSCHNVTERYQEVTNTDLIPNTQIKALNRGLKKKNNTEKGWDWYVCEGFQYILYQQAEALKNLGVGPELKNDVLHNFWKRYLQKSKQAYCKNPVYTTGRKPTVLEDNLSHSDWASEPELLSDVSCPPFLESGAESQSDIHTRKPFPVSKASQSETSVCSGSLDGVEYSQRKEKGIVKMTMPQTLAFCYLSLLWQREAITLSDLLRFVEEDHIPYINAFQHFPEQMKLYGRDRGIFGIESWPDYEDIYKKTVEVGTFLDLPRFPDITEDCYLHPNILCMKYLMEVNLPDEMHSLTCHVVKMTGMGEVDFLTFDPIAKMAKTVKYDVQAVAIIVVVLKLLFLLDDSFEWSLSNLAEKHNEKNKKDKPWFDFRKWYQIMKKAFDEKKQKWEEARAKYLWKSEKPLYYSFVDKPVAYKKREMVVNLQKQFSTLVESTATAGKKSPSSFQFNWTEEDTDRTCFHGHSLQGVLKEKGQSLLTKNSLYWLSTQKFCRC>sp|Q53T94-3|TAF1B_HUMAN Isoform 3 of TATA box-binding protein-associatedfactor RNA polymerase I subunit B OS=Homo sapiens OX=9606 GN=TAF1BMKLYGRDRGIFGIESWPDYEDIYKKTVEVGTFLDLPRFPDITEDCYLHPNILCMKYLMEVNLPDEMHSLTCHVVKMTGMGEVDFLTFDPIAKMAKTVKYDVQAVAIIVVVLKLLFLLDDSFEWSLSNLAEKHNEKNKKDKPWFDFRKWYQIMKKAFDEKKQKWEEARAKYLWKSEKPLYYSFVDKPVAYKKREMVVNLQKQFSTLVESTATAGKKSPSSFQFNWTEEDTDRTCFHGHSLQGVLKEKGQSLLTKNSLYWLSTQKFCRCYCTHVTTYEESNYSLSYQFILNLFSFLLRIKTSLLHEEVSLVEKKLFEKKYSVKRKKSRSKKVRRH>sp|Q9H0W7|THAP2_HUMAN THAP domain-containing protein 2 OS=Homo sapiensOX=9606 GN=THAP2 PE=1 SV=1MPTNCAAAGCATTYNKHINISFHRFPLDPKRRKEWVRLVRRKNFVPGKHTFLCSKHFEASCFDLTGQTRRLKMDAVPTIFDFCTHIKSMKLKSRNLLKKNNSCSPAGPSNLKSNISSQQVLLEHSYAFRNPMEAKKRIIKLEKEIASLRRKMKTCLQKERRATRRWIKATCLVKNLEANSVLPKGTSEHMLPTALSSLPLEDFKILEQDQQDKTLLSLNLKQTKSTFI>sp|P10646|TFPI1_HUMAN Tissue factor pathway inhibitor OS=Homo sapiensOX=9606 GN=TFPI PE=1 SV=1MIYTMKKVHALWASVCLLLNLAPAPLNADSEEDEEHTIITDTELPPLKLMHSFCAFKADDGPCKAIMKRFFFNIFTRQCEEFIYGGCEGNQNRFESLEECKKMCTRDNANRIIKTTLQQEKPDFCFLEEDPGICRGYITRYFYNNQTKQCERFKYGGCLGNMNNFETLEECKNICEDGPNGFQVDNYGTQLNAVNNSLTPQSTKVPSLFEFHGPSWCLTPADRGLCRANENRFYYNSVIGKCRPFKYSGCGGNENNFTSKQECLRACKKGFIQRISKGGLIKTKRKRKKQRVKIAYEEIFVKNM>sp|P10646-2|TFPI1_HUMAN Isoform Beta of Tissue factor pathway inhibitorOS=Homo sapiens OX=9606 GN=TFPIMIYTMKKVHALWASVCLLLNLAPAPLNADSEEDEEHTIITDTELPPLKLMHSFCAFKADDGPCKAIMKRFFFNIFTRQCEEFIYGGCEGNQNRFESLEECKKMCTRDNANRIIKTTLQQEKPDFCFLEEDPGICRGYITRYFYNNQTKQCERFKYGGCLGNMNNFETLEECKNICEDGPNGFQVDNYGTQLNAVNNSLTPQSTKVPSLFVTKEGTNDGWKNAAHIYQVFLNAFCIHASMFFLGLDSISCLC>sp|O60830|TI17B_HUMAN Mitochondrial import inner membrane translocasesubunit Tim17-B OS=Homo sapiens OX=9606 GN=TIMM17B PE=1 SV=1MEEYAREPCPWRIVDDCGGAFTMGVIGGGVFQAIKGFRNAPVGIRHRLRGSANAVRIRAPQIGGSFAVWGGLFSTIDCGLVRLRGKEDPWNSITSGALTGAVLAARSGPLAMVGSAMMGGILLALIEGVGILLTRYTAQQFRNAPPFLEDPSQLPPKDGTPAPGYPSYQQYH>sp|O60830-2|TI17B_HUMAN Isoform 2 of Mitochondrial import inner membranetranslocase subunit Tim17-B OS=Homo sapiens OX=9606 GN=TIMM17BMEEYAREPCPWRIVDDCGGAFTMGVIGGGVFQAIKGFRNAPVCRLLSEAPLFIYSCSRSVSPTVNVSSERAESRPTLFMAVSLHMAWCLAHIGIRHRLRGSANAVRIRAPQIGGSFAVWGGLFSTIDCGLVRLRGKEDPWNSITSGALTGAVLAARSGPLAMVGSAMMGGILLALIEGVGILLTRYTAQQFRNAPPFLEDPSQLPPKDGTPAPGYPSYQQYH>sp|A4D1P6|WDR91_HUMAN WD repeat-containing protein 91 OS=Homo sapiensOX=9606 GN=WDR91 PE=1 SV=2MAEAVERTDELVREYLLFRGFTHTLRQLDAEIKADKEKGFRVDKIVDQLQQLMQVYDLAALRDYWSYLERRLFSRLEDIYRPTIHKLKTSLFRFYLVYTIQTNRNDKAQEFFAKQATELQNQAEWKDWFVLPFLPSPDTNPTFATYFSRQWADTFIVSLHNFLSVLFQCMPVPVILNFDAECQRTNQVQEENEVLRQKLFALQAEIHRLKKEEQQPEEEEALVQHKLPPYVSNMDRLGDSELAMVCSQRNASLSQSPRVGFLSSLLPQSKKSPSRLSPAQGPPQPQSSAKKESFGGQGTKGKDPTSGAKDGKSLLSGLATGESGWSQHRQRRLQDHGKERKELFSTTTSQCAEKKPEASGPEAEPCPELHTEPVEPLTRASSAGPEGGGVRPEQPFIVLGQEEYGEHHSSIMHCRVDCSGRRVASLDVDGVIKVWSFNPIMQTKASSISKSPLLSLEWATKRDRLLLLGSGVGTVRLYDTEAKKNLCEININDNMPRILSLACSPNGASFVCSAAAPSLTSQVDFSAPDIGSKGMNQVPGRLLLWDTKTMKQQLQFSLDPEPIAINCTAFNHNGNLLVTGAADGVIRLFDMQQHECAMSWRAHYGEVYSVEFSYDENTVYSIGEDGKFIQWNIHKSGLKVSEYSLPSDATGPFVLSGYSGYKQVQVPRGRLFAFDSEGNYMLTCSATGGVIYKLGGDEKVLESCLSLGGHRAPVVTVDWSTAMDCGTCLTASMDGKIKLTTLLAHKA>sp|A4D1P6-2|WDR91_HUMAN Isoform 2 of WD repeat-containing protein 91OS=Homo sapiens OX=9606 GN=WDR91MAEAVERTDELVREYLLFRGFTHTLRQLDAEIKADKEKGFRVDKIVDQLQQLMQVYDLAALRDYWSYLERRLFSRLEDIYRPTIHKLKTSLFRFYLVYTIQTNRNDKAQEFFAKQATELQNQAEWKDWFVLPFLPSPDTNPTFATYFSRQWADTFIVSLHNFLSVLFQCMPVPVILNFDAECQRTNQVQEENEVLRQKLFALQAEIHRLKKEEQQPEEEEALVQHKLPPYVSNMDRLGDSELAMVCSQRNASLSQSPRVGFLSSLLPQSKKSPSRLSPAQGPPQPQSSAKKESFGGQGTKGKDPTSGAKDGKSLLSGLATGESGWSQHRQRRLQDHGKERKELFSTTTSQCAEKKPEASGPEAEPCPELHTEPVEPLTRASSAGPEGGGVRPEQPFIVLGQEEYGEHHSSIMHCRVDCSGRRVASLDVDGVIKVWSFNPIMQTKASSISKSPLLSLEWATKRDRLLLLGSGVGTVRLYDTEAKKNLCEININDNMPRILSLACSPNGASFVCSAAAPSLTSQVDFSAPDIGSKGMNQVPGRLLLWDTKTMKQQLQFSLDPEPIAINCTAFNHNGNLLVTGAADGVIRLFVHPVEHPQEWPQGIRVQPPLRCHGPLCAVWIQRLQAGSSPQGPTLRF>sp|A4D1P6-3|WDR91_HUMAN Isoform 3 of WD repeat-containing protein 91OS=Homo sapiens OX=9606 GN=WDR91MAEAVERTDELVREYLLFRGFTHTLRQLDAEIKADKEKGFRVDKIVDQLQQLMQVYDLAALRDYWSYLERRLFSRLEDIYRPTIHKLKTSLFRFYLVYTIQTNRNDKAQEFFAKQATELQNQAEWKDWFVLPFLPSPDTNPTFATYFSRQWADTFIVSLHNFLSVLFQCMPVPVILNFDAECQRTNQVQEENEVLRQKLFALQAEIHRLKKEEQQPEEEEALVQHKLPPYVSNMDRLGDSELAMVCSQRNASLSQSPRVGFLSSLLPQSKKSPSRLSPAQGPPQPQSSAKKESFGGQGTKGKDPTSGAKDGKSLLSGLATGESGWSQHRQRRLQDHGKERKELFSTTTSQVWGCPEHPWGHSCSY>sp|Q8N1Q8|THEM5_HUMAN Acyl-coenzyme A thioesterase THEM5 OS=Homo sapiensOX=9606 GN=THEM5 PE=1 SV=2MIRRCFQVAARLGHHRGLLEAPRILPRLNPASAFGSSTDSMFSRFLPEKTDLKDYALPNASWCSDMLSLYQEFLEKTKSSGWIKLPSFKSNRDHIRGLKLPSGLAVSSDKGDCRIFTRCIQVEGQGFEYVIFFQPTQKKSVCLFQPGSYLEGPPGFAHGGSLAAMMDETFSKTAFLAGEGLFTLSLNIRFKNLIPVDSLVVMDVELDKIEDQKLYMSCIAHSRDQQTVYAKSSGVFLQLQLEEESPQ>sp|Q5VZ19|TDR10_HUMAN Tudor domain-containing protein 10 OS=Homo sapiensOX=9606 GN=TDRD10 PE=2 SV=3MSWNISHPQLSDKLFGKNGVLEEQKSPGFKKRETEVYVGNLPLDISKEEILYLLKDFNPLDVHKIQNGCKCFAFVDLGSMQKVTLAIQELNGKLFHKRKLFVNTSKRPPKRTPDMIQQPRAPLVLEKASGEGFGKTAAIIQLAPKAPVDLCETEKLRAAFFAVPLEMRGSFLVLLLRECFRDLSWLALIHSVRGEAGLLVTSIVPKTPFFWAMHVTEALHQNMQALFSTLAQAEEQQPYLEGSTVMRGTRCLAEYHLGDYGHAWNRCWVLDRVDTWAVVMFIDFGQLATIPVQSLRSLDSDDFWTIPPLTQPFMLEKDILSSYEVVHRILKGKITGALNSAVTAPASNLAVVPPLLPLGCLQQAAA>sp|Q5VZ19-2|TDR10_HUMAN Isoform 2 of Tudor domain-containing protein 10OS=Homo sapiens OX=9606 GN=TDRD10MSWNISHPQLSDKLFGKNGVLEEQKSPGFKKRETEVYVGNLPLDISKEEILYLLKDFNPLDVHKIQNGCKCFAFVDLGSMQKVTLAIQELNGKLFHKRKLFVNTSKRPPKRTPDMIQQPRAPLVLEKASGEGFGKTAAIIQLAPKAPVDLCETEKLRAAFFAVPLEMRGSFLVLLLRECFRDLSWLALIHSVRGEAGLLVTSIVPKTPFFWAMHVTEALHQNMQALFSTLAQAEEQQPYLEGSTVMRGTRCLAEYHLGDYGHAWNRCWVLDRVDTWAVVMFIDFGQLATIPVQSLRSLDSDDFWTIPPLTQPFMLEKDILSSYEVVHRILKGKITGALNSALHILKFEESK>sp|A6NE52|WDR97_HUMAN WD repeat-containing protein 97 OS=Homo sapiensOX=9606 GN=WDR97 PE=2 SV=2MEAEVWEAEGYNLVLDSDLYDADGYDVPDPGLLTEKNELTFTEPSQVLPFLTSSQQWQSLTPRARARRLWLLLRTSLHEVVEKEKRAELRAARLTHGLEPLRRLEVAAGLRSVAQDPVGGRFVVLDGAGRLHLHKEDGWAQETLLAPVRLTGLVTVLGPLGAVGRFVGWGPAGLAILRPNLSLLWLSEQGVGRAPGWAPTCCLPVPDLRLLLVAEMNSSLALWQFRSGGRRLVLRGSALHPPPSPTGRLMRLAVAPVPPHHVLRCFAAYGSAVLTFDLHAWTLVDVRRDLHKTTISDLAYCEEVEAMVTASRDSTVKVWEADWQIRMVFVGHTGPVTAMTVLPNTTLVLSASQDGTLRTWDLQAAAQVGEVALGFWGQDKLSRRVGRLLAPVRPGWPVLSLCASSMQLWRVRELYSPLAQLPAKVLHVQVAPALPAPAHQSLPTRLVCACADGSVYLLSAATGRIVSSLLLEPEDCAAAVAYCLPREALWLLTRAGHLVRANAARCPMSVLHRVCPPPPPAPQPCCLHLYSHLTDLEGAFSSWEIVRQHWGELRCSSVACAWKNKNRYLPVVGHTDGTLSVLEWLSSKTVFQTEAHSPGPVVAIASTWNSIVSSGGDLTVKMWRVFPYAEESLSLLRTFSCCYPAVALCALGRRVTAGFEDPDSATYGLVQFGLGDSPRLDHRPQDDPTDHITGLCCCPTLKLYACSSLDCTVRIWTAENRLLRLLQLNGAPQALAFCSNSGDLVLALGSRLCLVSHRLYLPTSYLVKKMCRKAPDVVDDPPLPLMSQESLTSAQLQRLTNLHGAASLSEALSLIHRRRATSQHLVPKEDLDAIVARDRDLQQLRLGLVVPAAQPPPSWQQRQEGFDNYLRLIYGSGLLGMQSGRGSQQWSAGTLRVERETRDVCAVPQAAHCLARAEVSTAAQTVPTALSPQDLGALGQHFSQSPRVTVPIPPTHRRVHSKASQLLARSSLSHYLGISLDLQLQLEQLRGRTTMALDLPSSHLQCRIPLLPKRWDKEPLSSLRGFFPATVQPHKHCLRPICFPGYVPNSAVLQQMWLNAEPGASQDALWLWRPRPSQTQWQRKLLQWMGEKPGEEGEEDKKEEEEEKEDEELDWALASLSPHSNQQLDSWELEDQSAVDWTQEPRRRSCKVARTHPHPWHRHGSLLLDEHYGHLPKFLHFFIYQTWFKKLFPIFSLQAYPEAGTIEGLASLLVALLEKTTWVDRVHILQVLLRLLPNMSSDLQGQLQGLLVHLLNLDQPPSLQDQTQKKFVILALQLLLACSLESRDVVLELMSYFLYSPVHCRPELKKLLHGLGLQDPEGFLFKEMMTWVQGPDLDSKAGLRTCCHQKLEDMIQELQETPSQTSVVSGAPTRASVIPSGTSWSASGIFGRLSQVSEVPLMVVSPAEPHSLAPELQAQRMLAPKRSWGTPQLRLRVLSETLKSFCLEPEARLHPAGPAQLPGEPPPLEETDWSHSQLLDLGPIDALNFFCEQLRAQQRSSLQEKAAHPHPPEPYTVAPVPDMVVPPPREHWYHPILRLQEAKPQRSARSAMRLRGPMRSRLCAGRTLDGPIRTLKLPLPRVEPQPFPLDWPMPPRPLPPRLLQPALQRYFLPADADPDTYS>sp|A6NE52-2|WDR97_HUMAN Isoform 2 of WD repeat-containing protein 97OS=Homo sapiens OX=9606 GN=WDR97MEAEVWEAEGYNLVLDSDLYDADGYDVPDPGLLTEKNELTFTEPSQVLPFLTSSQQWQSLTPRARARRLWLLLRTSLHEVVEKEKRAELRAARLTHGLEPLRRLEVAAGLRSVAQDPVGGRFVVLDGAGRLHLHKEDGWAQETLLAPVRLTGLVTVLGPLGAVGRFVGWGPAGLAILRPNLSLLWLSEQGVGRAPGWAPTCCLPVPDLRLLLVAEMNSSLALWQFRSGGRRLVLRGSALHPPPSPTGRLMRLAVAPVPPHHVLRCFAAYGSAVLTFDLHAWTLVDVRRDLHKTTISDLAYCEEVEAMVTASRDSTVKVWEADWQIRMVFVGHTGPVTAMTVLPNTTLVLSASQDGTLRTWDLQAAAQVGEVALGFWGQDKLSRRVGRLLAPVRPGWPVLSLCASSMQLWRVRELYSPLAQLPAKVLHVQVAPALPAPAHQSLPTRLVCACADGSVYLLSAATGRIVSSLLLEPEDCAAAVAYCLPREALWLLTRAGHLVRANAARCPMSVLHRVCPPPPPAPQPCCLHLYSHLTDLEGAFSSWEIVRQHWGELRCSSVACAWKNKNRYLPVVGHTDGTLSVLEWLSSKTVFQTEAHSPGPVVAIASTWNSIVSSGGDLTVKMWRVFPYAEESLSLLRTFSCCYPAVALCALGRRVTAGFEDPDSATYGLVQFGLGDSPRLDHRPQDDPTDHITGLCCCPTLKLYACSSLDCTVRIWTAENRLLRLLQLNGAPQALAFCSNSGDLVLALGSRLCLVSHRLYLPTSYLVKKMCRKAPDVVDDPPLPLMSQESLTSAQLQRLTNLHGAASLRSHGGLLSPPGGPPFPLWVGAWRCGALWS>sp|P42765|THIM_HUMAN 3-ketoacyl-CoA thiolase, mitochondrial OS=Homosapiens OX=9606 GN=ACAA2 PE=1 SV=2MALLRGVFVVAAKRTPFGAYGGLLKDFTATDLSEFAAKAALSAGKVSPETVDSVIMGNVLQSSSDAIYLARHVGLRVGIPKETPALTINRLCGSGFQSIVNGCQEICVKEAEVVLCGGTESMSQAPYCVRNVRFGTKLGSDIKLEDSLWVSLTDQHVQLPMAMTAENLAVKHKISREECDKYALQSQQRWKAANDAGYFNDEMAPIEVKTKKGKQTMQVDEHARPQTTLEQLQKLPPVFKKDGTVTAGNASGVADGAGAVIIASEDAVKKHNFTPLARIVGYFVSGCDPSIMGIGPVPAISGALKKAGLSLKDMDLVEVNEAFAPQYLAVERSLDLDISKTNVNGGAIALGHPLGGSGSRITAHLVHELRRRGGKYAVGSACIGGGQGIAVIIQSTA>sp|O95497|VNN1_HUMAN Pantetheinase OS=Homo sapiens OX=9606 GN=VNN1 PE=1SV=2MTTQLPAYVAILLFYVSRASCQDTFTAAVYEHAAILPNATLTPVSREEALALMNRNLDILEGAITSAADQGAHIIVTPEDAIYGWNFNRDSLYPYLEDIPDPEVNWIPCNNRNRFGQTPVQERLSCLAKNNSIYVVANIGDKKPCDTSDPQCPPDGRYQYNTDVVFDSQGKLVARYHKQNLFMGENQFNVPKEPEIVTFNTTFGSFGIFTCFDILFHDPAVTLVKDFHVDTIVFPTAWMNVLPHLSAVEFHSAWAMGMRVNFLASNIHYPSKKMTGSGIYAPNSSRAFHYDMKTEEGKLLLSQLDSHPSHSAVVNWTSYASSIEALSSGNKEFKGTVFFDEFTFVKLTGVAGNYTVCQKDLCCHLSYKMSENIPNEVYALGAFDGLHTVEGRYYLQICTLLKCKTTNLNTCGDSAETASTRFEMFSLSGTFGTQYVFPEVLLSENQLAPGEFQVSTDGRLFSLKPTSGPVLTVTLFGRLYEKDWASNASSGLTAQARIIMLIVIAPIVCSLSW>sp|Q8N1K5|THMS1_HUMAN Protein THEMIS OS=Homo sapiens OX=9606 GN=THEMISPE=1 SV=3MALSLEEFVHSLDLRTLPRVLEIQAGIYLEGSIYEMFGNECCFSTGEVIKITGLKVKKIIAEICEQIEGCESLQPFELPMNFPGLFKIVADKTPYLTMEEITRTIHIGPSRLGHPCFYHQKDIKLENLIIKQGEQIMLNSVEEIDGEIMVSCAVARNHQTHSFNLPLSQEGEFYECEDERIYTLKEIVEWKIPKNRTRTVNLTDFSNKWDSTNPFPKDFYGTLILKPVYEIQGVMKFRKDIIRILPSLDVEVKDITDSYDANWFLQLLSTEDLFEMTSKEFPIVTEVIEAPEGNHLPQSILQPGKTIVIHKKYQASRILASEIRSNFPKRHFLIPTSYKGKFKRRPREFPTAYDLEIAKSEKEPLHVVATKAFHSPHDKLSSVSVGDQFLVHQSETTEVLCEGIKKVVNVLACEKILKKSYEAALLPLYMEGGFVEVIHDKKQYPISELCKQFRLPFNVKVSVRDLSIEEDVLAATPGLQLEEDITDSYLLISDFANPTECWEIPVGRLNMTVQLVSNFSRDAEPFLVRTLVEEITEEQYYMMRRYESSASHPPPRPPKHPSVEETKLTLLTLAEERTVDLPKSPKRHHVDITKKLHPNQAGLDSKVLIGSQNDLVDEEKERSNRGATAIAETFKNEKHQK>sp|Q8N1K5-2|THMS1_HUMAN Isoform 2 of Protein THEMIS OS=Homo sapiensOX=9606 GN=THEMISMFGNECCFSTGEVIKITGLKVKKIIAEICEQIEGCESLQPFELPMNFPGLFKIVADKTPYLTMEEITRTIHIGPSRLGHPCFYHQKDIKLENLIIKQGEQIMLNSVEEIDGEIMVSCAVARNHQTHSFNLPLSQEGEFYECEDERIYTLKEIVEWKIPKNRTRTVNLTDFSNKWDSTNPFPKDFYGTLILKPVYEIQGVMKFRKDIIRILPSLDVEVKDITDSYDANWFLQLLSTEDLFEMTSKEFPIVTEVIEAPEGNHLPQSILQPGKTIVIHKKYQASRILASEIRSNFPKRHFLIPTSYKGKFKRRPREFPTAYDLEIAKSEKEPLHVVATKAFHSPHDKLSSVSVGDQFLVHQSETTEVLCEGIKKVVNVLACEKILKKSYEAALLPLYMEGGFVEVIHDKKQYPISELCKQFRLPFNVKVSVRDLSIEEDVLAATPGLQLEEDITDSYLLISDFANPTECWEIPVGRLNMTVQLVSNFSRDAEPFLVRTLVEEITEEQYYMMRRYESSASHPPPRPPKHPSVEETKLTLLTLAEERTVDLPKSPKRHHVDITKKLHPNQAGLDSKVLIGSQNDLVDEEKERSNRGATAIAETFKNEKHQK>sp|Q8N1K5-3|THMS1_HUMAN Isoform 3 of Protein THEMIS OS=Homo sapiensOX=9606 GN=THEMISMEEITRTIHIGPSRLGHPCFYHQKDIKLENLIIKQGEQIMLNSVEEIDGEIMVSCAVARNHQTHSFNLPLSQEGEFYECEDERIYTLKEIVEWKIPKNRTRTVNLTDFSNKWDSTNPFPKDFYGTLILKPVYEIQGVMKFRKDIIRILPSLDVEVKDITDSYDANWFLQLLSTEDLFEMTSKEFPIVTEVIEAPEGNHLPQSILQPGKTIVIHKKYQASRILASEIRSNFPKRHFLIPTSYKGKFKRRPREFPTAYDLEIAKSEKEPLHVVATKAFHSPHDKLSSVSVGDQFLVHQSETTEVLCEGIKKVVNVLACEKILKKSYEAALLPLYMEGGFVEVIHDKKQYPISELCKQFRLPFNVKVSVRDLSIEEDVLAATPGLQLEEDITDSYLLISDFANPTECWEIPVGRLNMTVQLVSNFSRDAEPFLVRTLVEEITEEQYYMMRRYESSASHPPPRPPKHPSVEETKLTLLTLAEERTVDLPKSPKRHHVDITKKLHPNQAGLDSKVLIGSQNDLVDEEKERSNRGATAIAETFKNEKHQK>sp|Q8N1K5-4|THMS1_HUMAN Isoform 4 of Protein THEMIS OS=Homo sapiensOX=9606 GN=THEMISMALSLEEFVHSLDLRTLPRVLEIQAGIYLEGSIYEMFGNECCFSTGEVIKITGLKVKKIIAEICEQIEGCESLQPFELPMNFPGLFKIVADKTPYLTMEEITRTIHIGPSRLGHPCFYHQKDIKLENLIIKQGEQIMLNSVEEIDGEIMVSCAVARNHQTHSFNLPLSQEGEFYECEDERIYTLKEIVEWKIPKNRTRTVNLTDFSNKWDSTNPFPKDFYGTLILKPVYEIQGVMKFRKDIIRILPSLDVEVKDITDSYDANWFLQLLSTEDLFEMTSKEFPIVTEVIEAPEGNHLPQSILQPGKTIVIHKKYQASRILASEIRSNFPKRHFLIPTSYKGKFKRRPREFPTAYDLEIAKSEKEPLHVVATKAFHSPHDKLSSVSVGDQFLVHQSETTEVLCEGIKKVVNVLACEKILKKSYEAALLPLYMEGGFVEVIHDKKQYPISELCKQFRLPFNVKVSVRDLSIEEDVLAATPGLQLEEDITDSYLLISDFANPTECWEIPVGRLNMTVQLVSNFSRDAEPFLVRTLVEEITEEQYYMMRRYESSASHPPPRPPKHPSVEETKLTLLTLAEERTVDLPKSPKAGVQWRDLGSLQPLPPGFKQFSASASHVAGITGTPHHVQRHHVDITKKLHPNQAGLDSKVLIGSQNDLVDEEKERSNRGATAIAETFKNEKHQK>sp|Q99426|TBCB_HUMAN Tubulin-folding cofactor B OS=Homo sapiens OX=9606GN=TBCB PE=1 SV=2MEVTGVSAPTVTVFISSSLNTFRSEKRYSRSLTIAEFKCKLELLVGSPASCMELELYGVDDKFYSKLDQEDALLGSYPVDDGCRIHVIDHSGARLGEYEDVSRVEKYTISQEAYDQRQDTVRSFLKRSKLGRYNEEERAQQEAEAAQRLAEEKAQASSIPVGSRCEVRAAGQSPRRGTVMYVGLTDFKPGYWIGVRYDEPLGKNDGSVNGKRYFECQAKYGAFVKPAVVTVGDFPEEDYGLDEI>sp|Q99426-2|TBCB_HUMAN Isoform 2 of Tubulin-folding cofactor B OS=Homosapiens OX=9606 GN=TBCBMELELYGVDDKFYSKLDQEDALLGSYPVDDGCRIHVIDHSGARLGEYEDVSRVEKYTISQEAYDQRQDTVRSFLKRSKLGRYNEEERAQQEAEAAQRLAEEKAQASSIPVGSRCEVRAAGQSPRRGTVMYVGLTDFKPGYWIGVRYDEPLGKNDGSVNGKRYFECQAKYGAFVKPAVVTVGDFPEEDYGLDEI>sp|Q96MN5|TEAN2_HUMAN Transcription elongation factor A N-terminal andcentral domain-containing protein 2 OS=Homo sapiens OX=9606 GN=TCEANC2PE=1 SV=1MDKFVIRTPRIQNSPQKKDSGGKVYKQATIESLKRVVVVEDIKRWKTMLELPDQTKENLVEALQELKKKIPSREVLKSTRIGHTVNKMRKHSDSEVASLAREVYTEWKTFTEKHSNRPSIEVRSDPKTESLRKNAQKLLSEALELKMDHLLVENIERETFHLCSRLINGPYRRTVRALVFTLKHRAEIRAQVKSGSLPVGTFVQTHKK>sp|Q96MN5-2|TEAN2_HUMAN Isoform 2 of Transcription elongation factor AN-terminal and central domain-containing protein 2 OS=Homo sapiensOX=9606 GN=TCEANC2MRKHSDSEVASLAREVYTEWKTFTEKHSNRPSIEVRSDPKTESLRKNAQKLLSEALELKMDHLLVENIERETFHLCSRLINGPYRRTVRALVFTLKHRAEIRAQVKSGSLPVGTFVQTHKK>sp|Q14656|TM187_HUMAN Transmembrane protein 187 OS=Homo sapiens OX=9606GN=TMEM187 PE=1 SV=1MNPEWGQAFVHVAVAGGLCAVAVFTGIFDSVSVQVGYEHYAEAPVAGLPAFLAMPFNSLVNMAYTLLGLSWLHRGGAMGLGPRYLKDVFAAMALLYGPVQWLRLWTQWRRAAVLDQWLTLPIFAWPVAWCLYLDRGWRPWLFLSLECVSLASYGLALLHPQGFEVALGAHVVAAVGQALRTHRHYGSTTSATYLALGVLSCLGFVVLKLCDHQLARWRLFQCLTGHFWSKVCDVLQFHFAFLFLTHFNTHPRFHPSGGKTR>sp|Q92545|TM131_HUMAN Transmembrane protein 131 OS=Homo sapiens OX=9606GN=TMEM131 PE=1 SV=3MGKRAGGGATGATTAAVSTSAGAGLEPAAARSGGPRSAAAGLLGALHLVMTLVVAAARAEKEAFVQSESIIEVLRFDDGGLLQTETTLGLSSYQQKSISLYRGNCRPIRFEPPMLDFHEQPVGMPKMEKVYLHNPSSEETITLVSISATTSHFHASFFQNRKILPGGNTSFDVVFLARVVGNVENTLFINTSNHGVFTYQVFGVGVPNPYRLRPFLGARVPVNSSFSPIINIHNPHSEPLQVVEMYSSGGDLHLELPTGQQGGTRKLWEIPPYETKGVMRASFSSREADNHTAFIRIKTNASDSTEFIILPVEVEVTTAPGIYSSTEMLDFGTLRTQDLPKVLNLHLLNSGTKDVPITSVRPTPQNDAITVHFKPITLKASESKYTKVASISFDASKAKKPSQFSGKITVKAKEKSYSKLEIPYQAEVLDGYLGFDHAATLFHIRDSPADPVERPIYLTNTFSFAILIHDVLLPEEAKTMFKVHNFSKPVLILPNESGYIFTLLFMPSTSSMHIDNNILLITNASKFHLPVRVYTGFLDYFVLPPKIEERFIDFGVLSATEASNILFAIINSNPIELAIKSWHIIGDGLSIELVAVERGNRTTIISSLPEFEKSSLSDQSSVTLASGYFAVFRVKLTAKKLEGIHDGAIQITTDYEILTIPVKAVIAVGSLTCFPKHVVLPPSFPGKIVHQSLNIMNSFSQKVKIQQIRSLSEDVRFYYKRLRGNKEDLEPGKKSKIANIYFDPGLQCGDHCYVGLPFLSKSEPKVQPGVAMQEDMWDADWDLHQSLFKGWTGIKENSGHRLSAIFEVNTDLQKNIISKITAELSWPSILSSPRHLKFPLTNTNCSSEEEITLENPADVPVYVQFIPLALYSNPSVFVDKLVSRFNLSKVAKIDLRTLEFQVFRNSAHPLQSSTGFMEGLSRHLILNLILKPGEKKSVKVKFTPVHNRTVSSLIIVRNNLTVMDAVMVQGQGTTENLRVAGKLPGPGSSLRFKITEALLKDCTDSLKLREPNFTLKRTFKVENTGQLQIHIETIEISGYSCEGYGFKVVNCQEFTLSANASRDIIILFTPDFTASRVIRELKFITTSGSEFVFILNASLPYHMLATCAEALPRPNWELALYIIISGIMSALFLLVIGTAYLEAQGIWEPFRRRLSFEASNPPFDVGRPFDLRRIVGISSEGNLNTLSCDPGHSRGFCGAGGSSSRPSAGSHKQCGPSVHPHSSHSNRNSADVENVRAKNSSSTSSRTSAQAASSQSANKTSPLVLDSNTVTQGHTAGRKSKGAKQSQHGSQHHAHSPLEQHPQPPLPPPVPQPQEPQPERLSPAPLAHPSHPERASSARHSSEDSDITSLIEAMDKDFDHHDSPALEVFTEQPPSPLPKSKGKGKPLQRKVKPPKKQEEKEKKGKGKPQEDELKDSLADDDSSSTTTETSNPDTEPLLKEDTEKQKGKQAMPEKHESEMSQVKQKSKKLLNIKKEIPTDVKPSSLELPYTPPLESKQRRNLPSKIPLPTAMTSGSKSRNAQKTKGTSKLVDNRPPALAKFLPNSQELGNTSSSEGEKDSPPPEWDSVPVHKPGSSTDSLYKLSLQTLNADIFLKQRQTSPTPASPSPPAAPCPFVARGSYSSIVNSSSSSDPKIKQPNGSKHKLTKAASLPGKNGNPTFAAVTAGYDKSPGGNGFAKVSSNKTGFSSSLGISHAPVDSDGSDSSGLWSPVSNPSSPDFTPLNSFSAFGNSFNLTGEVFSKLGLSRSCNQASQRSWNEFNSGPSYLWESPATDPSPSWPASSGSPTHTATSVLGNTSGLWSTTPFSSSIWSSNLSSALPFTTPANTLASIGLMGTENSPAPHAPSTSSPADDLGQTYNPWRIWSPTIGRRSSDPWSNSHFPHEN>sp|P07101|TY3H_HUMAN Tyrosine 3-monooxygenase OS=Homo sapiens OX=9606GN=TH PE=1 SV=5MPTPDATTPQAKGFRRAVSELDAKQAEAIMVRGQGAPGPSLTGSPWPGTAAPAASYTPTPRSPRFIGRRQSLIEDARKEREAAVAAAAAAVPSEPGDPLEAVAFEEKEGKAVLNLLFSPRATKPSALSRAVKVFETFEAKIHHLETRPAQRPRAGGPHLEYFVRLEVRRGDLAALLSGVRQVSEDVRSPAGPKVPWFPRKVSELDKCHHLVTKFDPDLDLDHPGFSDQVYRQRRKLIAEIAFQYRHGDPIPRVEYTAEEIATWKEVYTTLKGLYATHACGEHLEAFALLERFSGYREDNIPQLEDVSRFLKERTGFQLRPVAGLLSARDFLASLAFRVFQCTQYIRHASSPMHSPEPDCCHELLGHVPMLADRTFAQFSQDIGLASLGASDEEIEKLSTLYWFTVEFGLCKQNGEVKAYGAGLLSSYGELLHCLSEEPEIRAFDPEAAAVQPYQDQTYQSVYFVSESFSDAKDKLRSYASRIQRPFSVKFDPYTLAIDVLDSPQAVRRSLEGVQDELDTLAHALSAIG>sp|P07101-2|TY3H_HUMAN Isoform 1 of Tyrosine 3-monooxygenase OS=Homosapiens OX=9606 GN=THMPTPDATTPQAKGFRRAVSELDAKQAEAIMGAPGPSLTGSPWPGTAAPAASYTPTPRSPRFIGRRQSLIEDARKEREAAVAAAAAAVPSEPGDPLEAVAFEEKEGKAVLNLLFSPRATKPSALSRAVKVFETFEAKIHHLETRPAQRPRAGGPHLEYFVRLEVRRGDLAALLSGVRQVSEDVRSPAGPKVPWFPRKVSELDKCHHLVTKFDPDLDLDHPGFSDQVYRQRRKLIAEIAFQYRHGDPIPRVEYTAEEIATWKEVYTTLKGLYATHACGEHLEAFALLERFSGYREDNIPQLEDVSRFLKERTGFQLRPVAGLLSARDFLASLAFRVFQCTQYIRHASSPMHSPEPDCCHELLGHVPMLADRTFAQFSQDIGLASLGASDEEIEKLSTLYWFTVEFGLCKQNGEVKAYGAGLLSSYGELLHCLSEEPEIRAFDPEAAAVQPYQDQTYQSVYFVSESFSDAKDKLRSYASRIQRPFSVKFDPYTLAIDVLDSPQAVRRSLEGVQDELDTLAHALSAIG>sp|P07101-3|TY3H_HUMAN Isoform 2 of Tyrosine 3-monooxygenase OS=Homosapiens OX=9606 GN=THMPTPDATTPQAKGFRRAVSELDAKQAEAIMSPRFIGRRQSLIEDARKEREAAVAAAAAAVPSEPGDPLEAVAFEEKEGKAVLNLLFSPRATKPSALSRAVKVFETFEAKIHHLETRPAQRPRAGGPHLEYFVRLEVRRGDLAALLSGVRQVSEDVRSPAGPKVPWFPRKVSELDKCHHLVTKFDPDLDLDHPGFSDQVYRQRRKLIAEIAFQYRHGDPIPRVEYTAEEIATWKEVYTTLKGLYATHACGEHLEAFALLERFSGYREDNIPQLEDVSRFLKERTGFQLRPVAGLLSARDFLASLAFRVFQCTQYIRHASSPMHSPEPDCCHELLGHVPMLADRTFAQFSQDIGLASLGASDEEIEKLSTLYWFTVEFGLCKQNGEVKAYGAGLLSSYGELLHCLSEEPEIRAFDPEAAAVQPYQDQTYQSVYFVSESFSDAKDKLRSYASRIQRPFSVKFDPYTLAIDVLDSPQAVRRSLEGVQDELDTLAHALSAIG>sp|P07101-4|TY3H_HUMAN Isoform 4 of Tyrosine 3-monooxygenase OS=Homosapiens OX=9606 GN=THMPTPDATTPQAKGFRRAVSELDAKQAEAIMVRGQSPRFIGRRQSLIEDARKEREAAVAAAAAAVPSEPGDPLEAVAFEEKEGKAVLNLLFSPRATKPSALSRAVKVFETFEAKIHHLETRPAQRPRAGGPHLEYFVRLEVRRGDLAALLSGVRQVSEDVRSPAGPKVPWFPRKVSELDKCHHLVTKFDPDLDLDHPGFSDQVYRQRRKLIAEIAFQYRHGDPIPRVEYTAEEIATWKEVYTTLKGLYATHACGEHLEAFALLERFSGYREDNIPQLEDVSRFLKERTGFQLRPVAGLLSARDFLASLAFRVFQCTQYIRHASSPMHSPEPDCCHELLGHVPMLADRTFAQFSQDIGLASLGASDEEIEKLSTLYWFTVEFGLCKQNGEVKAYGAGLLSSYGELLHCLSEEPEIRAFDPEAAAVQPYQDQTYQSVYFVSESFSDAKDKLRSYASRIQRPFSVKFDPYTLAIDVLDSPQAVRRSLEGVQDELDTLAHALSAIG>sp|P07101-5|TY3H_HUMAN Isoform 5 of Tyrosine 3-monooxygenase OS=Homosapiens OX=9606 GN=THMPTPDATTPQAKGFRRAVSELDAKQAEAIMVRGQSPRFIGRRQSLIEDARKEREAAVAAAAAAVPSEPGDPLEAVAFEEKEGKAVLNLLFSPRATKPSALSRAVKVFETFEAKIHHLETRPAQRPRAGGPHLEYFVRLEVRRGDLAALLSGVRQVSEDVRSPAGPKVPWFPRKVSELDKCHHLVTKFDPDLDLDHPGFSDQVYRQRRKLIAEIAFQYRHGDPIPRVEYTAEEIATWDCCHELLGHVPMLADRTFAQFSQDIGLASLGASDEEIEKLSTLYWFTVEFGLCKQNGEVKAYGAGLLSSYGELLHCLSEEPEIRAFDPEAAAVQPYQDQTYQSVYFVSESFSDAKDKLRSYASRIQRPFSVKFDPYTLAIDVLDSPQAVRRSLEGVQDELDTLAHALSAIG>sp|P07101-6|TY3H_HUMAN Isoform 6 of Tyrosine 3-monooxygenase OS=Homosapiens OX=9606 GN=THMPTPDATTPQAKGFRRAVSELDAKQAEAIMSPRFIGRRQSLIEDARKEREAAVAAAAAAVPSEPGDPLEAVAFEEKEGKAVLNLLFSPRATKPSALSRAVKVFETFEAKIHHLETRPAQRPRAGGPHLEYFVRLEVRRGDLAALLSGVRQVSEDVRSPAGPKVPWFPRKVSELDKCHHLVTKFDPDLDLDHPGFSDQVYRQRRKLIAEIAFQYRHGDPIPRVEYTAEEIATWDCCHELLGHVPMLADRTFAQFSQDIGLASLGASDEEIEKLSTLYWFTVEFGLCKQNGEVKAYGAGLLSSYGELLHCLSEEPEIRAFDPEAAAVQPYQDQTYQSVYFVSESFSDAKDKLRSYASRIQRPFSVKFDPYTLAIDVLDSPQAVRRSLEGVQDELDTLAHALSAIG>sp|Q9H9P5|UNKL_HUMAN Putative E3 ubiquitin-protein ligase UNKL OS=Homosapiens OX=9606 GN=UNKL PE=1 SV=3MPSVSKAAAAALSGSPPQTEKPTHYRYLKEFRTEQCPLFSQHKCAQHRPFTCFHWHFLNQRRRRPLRRRDGTFNYSPDVYCSKYNEATGVCPDGDECPYLHRTTGDTERKYHLRYYKTGTCIHETDARGHCVKNGLHCAFAHGPLDLRPPVCDVRELQAQEALQNGQLGGGEGVPDLQPGVLASQAMIEKILSEDPRWQDANFVLGSYKTEQCPKPPRLCRQGYACPHYHNSRDRRRNPRRFQYRSTPCPSVKHGDEWGEPSRCDGGDGCQYCHSRTEQQFHPESTKCNDMRQTGYCPRGPFCAFAHVEKSLGMVNEWGCHDLHLTSPSSTGSGQPGNAKRRDSPAEGGPRGSEQDSKQNHLAVFAAVHPPAPSVSSSVASSLASSAGSGSSSPTALPAPPARALPLGPASSTVEAVLGSALDLHLSNVNIASLEKDLEEQDGHDLGAAGPRSLAGSAPVAIPGSLPRAPSLHSPSSASTSPLGSLSQPLPGPVGSSAMTPPQQPPPLRSEPGTLGSAASSYSPLGLNGVPGSIWDFVSGSFSPSPSPILSAGPPSSSSASPNGAELARVRRQLDEAKRKIRQWEESWQQVKQVCDAWQREAQEAKERARVADSDRQLALQKKEEVEAQVIFQLRAKQCVACRERAHGAVLRPCQHHILCEPCAATAPECPYCKGQPLQW>sp|Q9H9P5-1|UNKL_HUMAN Isoform 1 of Putative E3 ubiquitin-protein ligaseUNKL OS=Homo sapiens OX=9606 GN=UNKLMTPPQQPPPLRSEPGTLGSAASSYSPLGLNGVPGSIWDFVSGSFSPSPSPILSAGPPSSSSASPNGAELARVRRQLDEAKRKIRQWEESWQQVKQVCDAWQREAQEAKERARVADSDRQLALQKKEEVEAQVKQLQEELEGLGVASTLPGLRGCGDIGTIPLPKLHSLQSQLRLDLEAVDGVIFQLRAKQCVACRERAHGAVLRPCQHHILCEPCAATAPECPYCKGQPLQW>sp|Q9H9P5-2|UNKL_HUMAN Isoform 2 of Putative E3 ubiquitin-protein ligaseUNKL OS=Homo sapiens OX=9606 GN=UNKLMTPPQQPPPLRSEPGTLGSAASSYSPLGLNGVPGSIWDFVSGSFSPSPSPILSAGPPSSSSASPNGAELARVRRQLDEAKRKIRQWEESWQQVKQVCDAWQREAQEAKERARVADSDRQLALQKKEEVEAQVIFQLRAKQCVACRERAHGAVLRPCQHHILCEPCAATAPECPYCKGQPLQW>sp|Q9H9P5-3|UNKL_HUMAN Isoform 3 of Putative E3 ubiquitin-protein ligaseUNKL OS=Homo sapiens OX=9606 GN=UNKLMTCCSQVPPRRRPSLALSPRLDCNGLNGVPGSIWDFVSGSFSPSPSPILSAGPPSSSSASPNGAELARVRRQLDEAKRKIRQWEESWQQVKQVCDAWQREAQEAKERARVADSDRQLALQKKEEVEAQVKQLQEELEGLGVASTLPGLRGCGDIGTIPLPKLHSLQSQLRLDLEAVDGVIFQLRAKQCVACRERAHGAVLRPCQHHILCEPCAATAPECPYCKGQPLQW>sp|Q9H9P5-5|UNKL_HUMAN Isoform 5 of Putative E3 ubiquitin-protein ligaseUNKL OS=Homo sapiens OX=9606 GN=UNKLMPSVSKAAAAALSGSPPQTEKPTHYRYLKEFRTEQCPLFSQHKCAQHRPFTCFHWHFLNQRRRRPLRRRDGTFNYSPDVYCSKYNEATGVCPDGDECPYLHRTTGDTERKYHLRYYKTGTCIHETDARGHCVKNGLHCAFAHGPLDLRPPVCDVRELQAQEALQNGQLGGGEGVPDLQPGVLASQAMIEKILSEDPRWQDANFVLGSYKTEQCPKPPRLCRQGYACPHYHNSRDRRRNPRRFQYSWQLGRRVLRLSPRANNPRVALPRVHTGPSSTA>sp|Q9H9P5-6|UNKL_HUMAN Isoform 6 of Putative E3 ubiquitin-protein ligaseUNKL OS=Homo sapiens OX=9606 GN=UNKLMPSVSKAAAAALSGSPPQTEKPTHYRYLKEFRTEQCPLFSQHKCAQHRPFTCFHWHFLNQRRRRPLRRRDGTFNYSPDVYCSKYNEATGVCPDGDESLLGVLYPLWAPPPVPAPVGAPTVHPFLARWFSHVPWEPAGSADPRASSTPAGGTTWATGLLGDFDACGSQSRECVKGVWWTLLGFRCPYLHRTTGDTERKYHLRYYKTGTCIHETDARGHCVKNGLHCAFAHGPLDLRPPVCDVRELQAQEALQNGQLGGGEGVPDLQPGVLASQAMIEKILSEDPRWQALLPVALLRHRVAHFSDANFVLGSYKTEQCPKPPRLCRQGYACPHYHNSRDRRRNPRRFQYRSTPCPSVKHGDEWGEPSRCDGGDGCQYCHSRTEQQFHPEGPVGSPVSGAFSVFSHAGLVADPSLWYPAEWSWHHVGHSRTINPEGDKPSRLGPAPENIKRGNDFACDGRADAAGMAPHVCVFPIYKSTKCNDMRQTGYCPRGPFCAFAHVEKSLGMVNEWGCHDLHLTSPSSTGSGQPGNAKRRDSPAEGGPRGSEQDSKQGVRAHGVYVFEQNHLAVFAAVHPPAPSVSSSVASSLASSAGSGSSSPTALPAPPARALPLGPASSTVEAVLALEPTPSSPTSSAVQGVAGELGMGSGGQGCWSHVVGALAAVPAWTHSGDLEWDPSTIRTRVNVGGGPAARPAMTLAREPQLLVVGGCPTRNCSGPAASPQQLLDDAGQGGRGERDSSQRPLRPQTTHRQDTRPVPS>sp|O75385|ULK1_HUMAN Serine/threonine-protein kinase ULK1 OS=Homosapiens OX=9606 GN=ULK1 PE=1 SV=2MEPGRGGTETVGKFEFSRKDLIGHGAFAVVFKGRHREKHDLEVAVKCINKKNLAKSQTLLGKEIKILKELKHENIVALYDFQEMANSVYLVMEYCNGGDLADYLHAMRTLSEDTIRLFLQQIAGAMRLLHSKGIIHRDLKPQNILLSNPAGRRANPNSIRVKIADFGFARYLQSNMMAATLCGSPMYMAPEVIMSQHYDGKADLWSIGTIVYQCLTGKAPFQASSPQDLRLFYEKNKTLVPTIPRETSAPLRQLLLALLQRNHKDRMDFDEFFHHPFLDASPSVRKSPPVPVPSYPSSGSGSSSSSSSTSHLASPPSLGEMQQLQKTLASPADTAGFLHSSRDSGGSKDSSCDTDDFVMVPAQFPGDLVAEAPSAKPPPDSLMCSGSSLVASAGLESHGRTPSPSPPCSSSPSPSGRAGPFSSSRCGASVPIPVPTQVQNYQRIERNLQSPTQFQTPRSSAIRRSGSTSPLGFARASPSPPAHAEHGGVLARKMSLGGGRPYTPSPQVGTIPERPGWSGTPSPQGAEMRGGRSPRPGSSAPEHSPRTSGLGCRLHSAPNLSDLHVVRPKLPKPPTDPLGAVFSPPQASPPQPSHGLQSCRNLRGSPKLPDFLQRNPLPPILGSPTKAVPSFDFPKTPSSQNLLALLARQGVVMTPPRNRTLPDLSEVGPFHGQPLGPGLRPGEDPKGPFGRSFSTSRLTDLLLKAAFGTQAPDPGSTESLQEKPMEIAPSAGFGGSLHPGARAGGTSSPSPVVFTVGSPPSGSTPPQGPRTRMFSAGPTGSASSSARHLVPGPCSEAPAPELPAPGHGCSFADPITANLEGAVTFEAPDLPEETLMEQEHTEILRGLRFTLLFVQHVLEIAALKGSASEAAGGPEYQLQESVVADQISLLSREWGFAEQLVLYLKVAELLSSGLQSAIDQIRAGKLCLSSTVKQVVRRLNELYKASVVSCQGLSLRLQRFFLDKQRLLDRIHSITAERLIFSHAVQMVQSAALDEMFQHREGCVPRYHKALLLLEGLQHMLSDQADIENVTKCKLCIERRLSALLTGICA>sp|P15374|UCHL3_HUMAN Ubiquitin carboxyl-terminal hydrolase isozyme L3OS=Homo sapiens OX=9606 GN=UCHL3 PE=1 SV=1MEGQRWLPLEANPEVTNQFLKQLGLHPNWQFVDVYGMDPELLSMVPRPVCAVLLLFPITEKYEVFRTEEEEKIKSQGQDVTSSVYFMKQTISNACGTIGLIHAIANNKDKMHFESGSTLKKFLEESVSMSPEERARYLENYDAIRVTHETSAHEGQTEAPSIDEKVDLHFIALVHVDGHLYELDGRKPFPINHGETSDETLLEDAIEVCKKFMERDPDELRFNAIALSAA>sp|Q9UPU5|UBP24_HUMAN Ubiquitin carboxyl-terminal hydrolase 24 OS=Homosapiens OX=9606 GN=USP24 PE=1 SV=3MESEEEQHMTTLLCMGFSDPATIRKALRLAKNDINEAVALLTNERPGLDYGGYEPMDSGGGPSPGPGGGPRGDGGGDGGGGGPSRGGSTGGGGGFDPPPAYHEVVDAEKNDENGNCSGEGIEFPTTNLYELESRVLTDHWSIPYKREESLGKCLLASTYLARLGLSESDENCRRFMDRCMPEAFKKLLTSSAVHKWGTEIHEGIYNMLMLLIELVAERIKQDPIPTGLLGVLTMAFNPDNEYHFKNRMKVSQRNWAEVFGEGNMFAVSPVSTFQKEPHGWVVDLVNKFGELGGFAAIQAKLHSEDIELGAVSALIQPLGVCAEYLNSSVVQPMLDPVILTTIQDVRSVEEKDLKDKRLVSIPELLSAVKLLCMRFQPDLVTIVDDLRLDILLRMLKSPHFSAKMNSLKEVTKLIEDSTLSKSVKNAIDTDRLLDWLVENSVLSIALEGNIDQAQYCDRIKGIIELLGSKLSLDELTKIWKIQSGQSSTVIENIHTIIAAAAVKFNSDQLNHLFVLIQKSWETESDRVRQKLLSLIGRIGREARFETTSGKVLDVLWELAHLPTLPSSLIQQALEEHLTILSDAYAVKEAIKRSYIIKCIEDIKRPGEWSGLEKNKKDGFKSSQLNNPQFVWVVPALRQLHEITRSFIKQTYQKQDKSIIQDLKKNFEIVKLVTGSLIACHRLAAAVAGPGGLSGSTLVDGRYTYREYLEAHLKFLAFFLQEATLYLGWNRAKEIWECLVTGQDVCELDREMCFEWFTKGQHDLESDVQQQLFKEKILKLESYEITMNGFNLFKTFFENVNLCDHRLKRQGAQLYVEKLELIGMDFIWKIAMESPDEEIANEAIQLIINYSYINLNPRLKKDSVSLHKKFIADCYTRLEAASSALGGPTLTHAVTRATKMLTATAMPTVATSVQSPYRSTKLVIIERLLLLAERYVITIEDFYSVPRTILPHGASFHGHLLTLNVTYESTKDTFTVEAHSNETIGSVRWKIAKQLCSPVDNIQIFTNDSLLTVNKDQKLLHQLGFSDEQILTVKTSGSGTPSGSSADSSTSSSSSSSGVFSSSYAMEQEKSLPGVVMALVCNVFDMLYQLANLEEPRITLRVRKLLLLIPTDPAIQEALDQLDSLGRKKTLLSESSSQSSKSPSLSSKQQHQPSASSILESLFRSFAPGMSTFRVLYNLEVLSSKLMPTADDDMARSCAKSFCENFLKAGGLSLVVNVMQRDSIPSEVDYETRQGVYSICLQLARFLLVGQTMPTLLDEDLTKDGIEALSSRPFRNVSRQTSRQMSLCGTPEKSSYRQLSVSDRSSIRVEEIIPAARVAIQTMEVSDFTSTVACFMRLSWAAAAGRLDLVGSSQPIKESNSLCPAGIRNRLSSSGSNCSSGSEGEPVALHAGICVRQQSVSTKDSLIAGEALSLLVTCLQLRSQQLASFYNLPCVADFIIDILLGSPSAEIRRVACDQLYTLSQTDTSAHPDVQKPNQFLLGVILTAQLPLWSPTSIMRGVNQRLLSQCMEYFDLRCQLLDDLTTSEMEQLRISPATMLEDEITWLDNFEPNRTAECETSEADNILLAGHLRLIKTLLSLCGAEKEMLGSSLIKPLLDDFLFRASRIILNSHSPAGSAAISQQDFHPKCSTANSRLAAYEVLVMLADSSPSNLQIIIKELLSMHHQPDPALTKEFDYLPPVDSRSSSGFVGLRNGGATCYMNAVFQQLYMQPGLPESLLSVDDDTDNPDDSVFYQVQSLFGHLMESKLQYYVPENFWKIFKMWNKELYVREQQDAYEFFTSLIDQMDEYLKKMGRDQIFKNTFQGIYSDQKICKDCPHRYEREEAFMALNLGVTSCQSLEISLDQFVRGEVLEGSNAYYCEKCKEKRITVKRTCIKSLPSVLVIHLMRFGFDWESGRSIKYDEQIRFPWMLNMEPYTVSGMARQDSSSEVGENGRSVDQGGGGSPRKKVALTENYELVGVIVHSGQAHAGHYYSFIKDRRGCGKGKWYKFNDTVIEEFDLNDETLEYECFGGEYRPKVYDQTNPYTDVRRRYWNAYMLFYQRVSDQNSPVLPKKSRVSVVRQEAEDLSLSAPSSPEISPQSSPRPHRPNNDRLSILTKLVKKGEKKGLFVEKMPARIYQMVRDENLKFMKNRDVYSSDYFSFVLSLASLNATKLKHPYYPCMAKVSLQLAIQFLFQTYLRTKKKLRVDTEEWIATIEALLSKSFDACQWLVEYFISSEGRELIKIFLLECNVREVRVAVATILEKTLDSALFYQDKLKSLHQLLEVLLALLDKDVPENCKNCAQYFFLFNTFVQKQGIRAGDLLLRHSALRHMISFLLGASRQNNQIRRWSSAQAREFGNLHNTVALLVLHSDVSSQRNVAPGIFKQRPPISIAPSSPLLPLHEEVEALLFMSEGKPYLLEVMFALRELTGSLLALIEMVVYCCFCNEHFSFTMLHFIKNQLETAPPHELKNTFQLLHEILVIEDPIQVERVKFVFETENGLLALMHHSNHVDSSRCYQCVKFLVTLAQKCPAAKEYFKENSHHWSWAVQWLQKKMSEHYWTPQSNVSNETSTGKTFQRTISAQDTLAYATALLNEKEQSGSSNGSESSPANENGDRHLQQGSESPMMIGELRSDLDDVDP>sp|Q96RP3|UCN2_HUMAN Urocortin-2 OS=Homo sapiens OX=9606 GN=UCN2 PE=1SV=1MTRCALLLLMVLMLGRVLVVPVTPIPTFQLRPQNSPQTTPRPAASESPSAAPTWPWAAQSHCSPTRHPGSRIVLSLDVPIGLLQILLEQARARAAREQATTNARILARVGHC>sp|P45974|UBP5_HUMAN Ubiquitin carboxyl-terminal hydrolase 5 OS=Homosapiens OX=9606 GN=USP5 PE=1 SV=2MAELSEEALLSVLPTIRVPKAGDRVHKDECAFSFDTPESEGGLYICMNTFLGFGKQYVERHFNKTGQRVYLHLRRTRRPKEEDPATGTGDPPRKKPTRLAIGVEGGFDLSEEKFELDEDVKIVILPDYLEIARDGLGGLPDIVRDRVTSAVEALLSADSASRKQEVQAWDGEVRQVSKHAFSLKQLDNPARIPPCGWKCSKCDMRENLWLNLTDGSILCGRRYFDGSGGNNHAVEHYRETGYPLAVKLGTITPDGADVYSYDEDDMVLDPSLAEHLSHFGIDMLKMQKTDKTMTELEIDMNQRIGEWELIQESGVPLKPLFGPGYTGIRNLGNSCYLNSVVQVLFSIPDFQRKYVDKLEKIFQNAPTDPTQDFSTQVAKLGHGLLSGEYSKPVPESGDGERVPEQKEVQDGIAPRMFKALIGKGHPEFSTNRQQDAQEFFLHLINMVERNCRSSENPNEVFRFLVEEKIKCLATEKVKYTQRVDYIMQLPVPMDAALNKEELLEYEEKKRQAEEEKMALPELVRAQVPFSSCLEAYGAPEQVDDFWSTALQAKSVAVKTTRFASFPDYLVIQIKKFTFGLDWVPKKLDVSIEMPEELDISQLRGTGLQPGEEELPDIAPPLVTPDEPKGSLGFYGNEDEDSFCSPHFSSPTSPMLDESVIIQLVEMGFPMDACRKAVYYTGNSGAEAAMNWVMSHMDDPDFANPLILPGSSGPGSTSAAADPPPEDCVTTIVSMGFSRDQALKALRATNNSLERAVDWIFSHIDDLDAEAAMDISEGRSAADSISESVPVGPKVRDGPGKYQLFAFISHMGTSTMCGHYVCHIKKEGRWVIYNDQKVCASEKPPKDLGYIYFYQRVAS>sp|P45974-2|UBP5_HUMAN Isoform Short of Ubiquitin carboxyl-terminalhydrolase 5 OS=Homo sapiens OX=9606 GN=USP5MAELSEEALLSVLPTIRVPKAGDRVHKDECAFSFDTPESEGGLYICMNTFLGFGKQYVERHFNKTGQRVYLHLRRTRRPKEEDPATGTGDPPRKKPTRLAIGVEGGFDLSEEKFELDEDVKIVILPDYLEIARDGLGGLPDIVRDRVTSAVEALLSADSASRKQEVQAWDGEVRQVSKHAFSLKQLDNPARIPPCGWKCSKCDMRENLWLNLTDGSILCGRRYFDGSGGNNHAVEHYRETGYPLAVKLGTITPDGADVYSYDEDDMVLDPSLAEHLSHFGIDMLKMQKTDKTMTELEIDMNQRIGEWELIQESGVPLKPLFGPGYTGIRNLGNSCYLNSVVQVLFSIPDFQRKYVDKLEKIFQNAPTDPTQDFSTQVAKLGHGLLSGEYSKPVPESGDGERVPEQKEVQDGIAPRMFKALIGKGHPEFSTNRQQDAQEFFLHLINMVERNCRSSENPNEVFRFLVEEKIKCLATEKVKYTQRVDYIMQLPVPMDAALNKEELLEYEEKKRQAEEEKMALPELVRAQVPFSSCLEAYGAPEQVDDFWSTALQAKSVAVKTTRFASFPDYLVIQIKKFTFGLDWVPKKLDVSIEMPEELDISQLRGTGLQPGEEELPDIAPPLVTPDEPKAPMLDESVIIQLVEMGFPMDACRKAVYYTGNSGAEAAMNWVMSHMDDPDFANPLILPGSSGPGSTSAAADPPPEDCVTTIVSMGFSRDQALKALRATNNSLERAVDWIFSHIDDLDAEAAMDISEGRSAADSISESVPVGPKVRDGPGKYQLFAFISHMGTSTMCGHYVCHIKKEGRWVIYNDQKVCASEKPPKDLGYIYFYQRVAS>sp|P40818|UBP8_HUMAN Ubiquitin carboxyl-terminal hydrolase 8 OS=Homosapiens OX=9606 GN=USP8 PE=1 SV=1MPAVASVPKELYLSSSLKDLNKKTEVKPEKISTKSYVHSALKIFKTAEECRLDRDEERAYVLYMKYVTVYNLIKKRPDFKQQQDYFHSILGPGNIKKAVEEAERLSESLKLRYEEAEVRKKLEEKDRQEEAQRLQQKRQETGREDGGTLAKGSLENVLDSKDKTQKSNGEKNEKCETKEKGAITAKELYTMMTDKNISLIIMDARRMQDYQDSCILHSLSVPEEAISPGVTASWIEAHLPDDSKDTWKKRGNVEYVVLLDWFSSAKDLQIGTTLRSLKDALFKWESKTVLRNEPLVLEGGYENWLLCYPQYTTNAKVTPPPRRQNEEVSISLDFTYPSLEESIPSKPAAQTPPASIEVDENIELISGQNERMGPLNISTPVEPVAASKSDVSPIIQPVPSIKNVPQIDRTKKPAVKLPEEHRIKSESTNHEQQSPQSGKVIPDRSTKPVVFSPTLMLTDEEKARIHAETALLMEKNKQEKELRERQQEEQKEKLRKEEQEQKAKKKQEAEENEITEKQQKAKEEMEKKESEQAKKEDKETSAKRGKEITGVKRQSKSEHETSDAKKSVEDRGKRCPTPEIQKKSTGDVPHTSVTGDSGSGKPFKIKGQPESGILRTGTFREDTDDTERNKAQREPLTRARSEEMGRIVPGLPSGWAKFLDPITGTFRYYHSPTNTVHMYPPEMAPSSAPPSTPPTHKAKPQIPAERDREPSKLKRSYSSPDITQAIQEEEKRKPTVTPTVNRENKPTCYPKAEISRLSASQIRNLNPVFGGSGPALTGLRNLGNTCYMNSILQCLCNAPHLADYFNRNCYQDDINRSNLLGHKGEVAEEFGIIMKALWTGQYRYISPKDFKITIGKINDQFAGYSQQDSQELLLFLMDGLHEDLNKADNRKRYKEENNDHLDDFKAAEHAWQKHKQLNESIIVALFQGQFKSTVQCLTCHKKSRTFEAFMYLSLPLASTSKCTLQDCLRLFSKEEKLTDNNRFYCSHCRARRDSLKKIEIWKLPPVLLVHLKRFSYDGRWKQKLQTSVDFPLENLDLSQYVIGPKNNLKKYNLFSVSNHYGGLDGGHYTAYCKNAARQRWFKFDDHEVSDISVSSVKSSAAYILFYTSLGPRVTDVAT>sp|P40818-2|UBP8_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 8 OS=Homo sapiens OX=9606 GN=USP8MPAVASVPKELYLSSSLKDLNKKTEVKPEKISTKRYEEAEVRKKLEEKDRQEEAQRLQQKRQETGREDGGTLAKGSLENVLDSKDKTQKSNGEKNEKCETKEKGAITAKELYTMMTDKNISLIIMDARRMQDYQDSCILHSLSVPEEAISPGVTASWIEAHLPDDSKDTWKKRGNVEYVVLLDWFSSAKDLQIGTTLRSLKDALFKWESKTVLRNEPLVLEGGYENWLLCYPQYTTNAKVTPPPRRQNEEVSISLDFTYPSLEESIPSKPAAQTPPASIEVDENIELISGQNERMGPLNISTPVEPVAASKSDVSPIIQPVPSIKNVPQIDRTKKPAVKLPEEHRIKSESTNHEQQSPQSGKVIPDRSTKPVVFSPTLMLTDEEKARIHAETALLMEKNKQEKELRERQQEEQKEKLRKEEQEQKAKKKQEAEENEITEKQQKAKEEMEKKESEQAKKEDKETSAKRGKEITGVKRQSKSEHETSDAKKSVEDRGKRCPTPEIQKKSTGDVPHTSVTGDSGSGKAQREPLTRARSEEMGRIVPGLPSGWAKFLDPITGTFRYYHSPTNTVHMYPPEMAPSSAPPSTPPTHKAKPQIPAERDREPSKLKRSYSSPDITQAIQEEEKRKPTVTPTVNRENKPTCYPKAEISRLSASQIRNLNPVFGGSGPALTGLRNLGNTCYMNSILQCLCNAPHLADYFNRNCYQDDINRSNLLGHKGEVAEEFGIIMKALWTGQYRYISPKDFKITIGKINDQFAGYSQQDSQELLLFLMDGLHEDLNKADNRKRYKEENNDHLDDFKAAEHAWQKHKQLNESIIVALFQGQFKSTVQCLTCHKKSRTFEAFMYLSLPLASTSKCTLQDCLRLFSKEEKLTDNNRFYCSHCRARRDSLKKIEIWKLPPVLLVHLKRFSYDGRWKQKLQTSVDFPLENLDLSQYVIGPKNNLKKYNLFSVSNHYGGLDGGHYTAYCKNAARQRWFKFDDHEVSDISVSSVKSSAAYILFYTSLGPRVTDVAT>sp|Q6UWM9|UD2A3_HUMAN UDP-glucuronosyltransferase 2A3 OS=Homo sapiensOX=9606 GN=UGT2A3 PE=2 SV=2MRSDKSALVFLLLQLFCVGCGFCGKVLVWPCDMSHWLNVKVILEELIVRGHEVTVLTHSKPSLIDYRKPSALKFEVVHMPQDRTEENEIFVDLALNVLPGLSTWQSVIKLNDFFVEIRGTLKMMCESFIYNQTLMKKLQETNYDVMLIDPVIPCGDLMAELLAVPFVLTLRISVGGNMERSCGKLPAPLSYVPVPMTGLTDRMTFLERVKNSMLSVLFHFWIQDYDYHFWEEFYSKALGRPTTLCETVGKAEIWLIRTYWDFEFPQPYQPNFEFVGGLHCKPAKALPKEMENFVQSSGEDGIVVFSLGSLFQNVTEEKANIIASALAQIPQKVLWRYKGKKPSTLGANTRLYDWIPQNDLLGHPKTKAFITHGGMNGIYEAIYHGVPMVGVPIFGDQLDNIAHMKAKGAAVEINFKTMTSEDLLRALRTVITDSSYKENAMRLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRSAAHDLTWFQHYSIDVIGFLLACVATAIFLFTKCFLFSCQKFNKTRKIEKRE>sp|Q86UV5|UBP48_HUMAN Ubiquitin carboxyl-terminal hydrolase 48 OS=Homosapiens OX=9606 GN=USP48 PE=1 SV=1MAPRLQLEKAAWRWAETVRPEEVSQEHIETAYRIWLEPCIRGVCRRNCKGNPNCLVGIGEHIWLGEIDENSFHNIDDPNCERRKKNSFVGLTNLGATCYVNTFLQVWFLNLELRQALYLCPSTCSDYMLGDGIQEEKDYEPQTICEHLQYLFALLQNSNRRYIDPSGFVKALGLDTGQQQDAQEFSKLFMSLLEDTLSKQKNPDVRNIVQQQFCGEYAYVTVCNQCGRESKLLSKFYELELNIQGHKQLTDCISEFLKEEKLEGDNRYFCENCQSKQNATRKIRLLSLPCTLNLQLMRFVFDRQTGHKKKLNTYIGFSEILDMEPYVEHKGGSYVYELSAVLIHRGVSAYSGHYIAHVKDPQSGEWYKFNDEDIEKMEGKKLQLGIEEDLAEPSKSQTRKPKCGKGTHCSRNAYMLVYRLQTQEKPNTTVQVPAFLQELVDRDNSKFEEWCIEMAEMRKQSVDKGKAKHEEVKELYQRLPAGAEPYEFVSLEWLQKWLDESTPTKPIDNHACLCSHDKLHPDKISIMKRISEYAADIFYSRYGGGPRLTVKALCKECVVERCRILRLKNQLNEDYKTVNNLLKAAVKGSDGFWVGKSSLRSWRQLALEQLDEQDGDAEQSNGKMNGSTLNKDESKEERKEEEELNFNEDILCPHGELCISENERRLVSKEAWSKLQQYFPKAPEFPSYKECCSQCKILEREGEENEALHKMIANEQKTSLPNLFQDKNRPCLSNWPEDTDVLYIVSQFFVEEWRKFVRKPTRCSPVSSVGNSALLCPHGGLMFTFASMTKEDSKLIALIWPSEWQMIQKLFVVDHVIKITRIEVGDVNPSETQYISEPKLCPECREGLLCQQQRDLREYTQATIYVHKVVDNKKVMKDSAPELNVSSSETEEDKEEAKPDGEKDPDFNQSNGGTKRQKISHQNYIAYQKQVIRRSMRHRKVRGEKALLVSANQTLKELKIQIMHAFSVAPFDQNLSIDGKILSDDCATLGTLGVIPESVILLKADEPIADYAAMDDVMQVCMPEEGFKGTGLLGH>sp|Q86UV5-2|UBP48_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 48 OS=Homo sapiens OX=9606 GN=USP48MAPRLQLEKAAWRWAETVRPEEVSQEHIETAYRIWLEPCIRGVCRRNCKGNPNCLVGIGEHIWLGEIDENSFHNIDDPNCERRKKNSFVGLTNLGATCYVNTFLQVWFLNLELRQALYLCPSTCSDYMLGDGIQEEKDYEPQTICEHLQYLFALLQNSNRRYIDPSGFVKALGLDTGQQQDAQEFSKLFMSLLEDTLSKQKNPDVRNIVQQQFCGEYAYVTVCNQCGRESKLLSKFYELELNIQGHKQLTDCISEFLKEEKLEGDNRYFCENCQSKQNATRKIRLLSLPCTLNLQLMRFVFDRQTGHKKKLNTYIGFSEILDMEPYVEHKGGSYVYELSAVLIHRGVSAYSGHYIAHVKDPQSGEWYKFNDEDIEKMEGKKLQLGIEEDLAEPSKSQTRKPKCGKGTHCSRNAYMLVYRLQTQEKPNTTVQVPAFLQELVDRDNSKFEEWCIEMAEMRKQSVDKGKAKHEEVKELYQRLPAGAEPYEFVSLEWLQKWLDESTPTKPIDNHACLCSHDKLHPDKISIMKRISEYAADIFYSRYGGGPRLTVKALCKECVVERCRILRLKNQLNEDYKTVNNLLKAAVKGSDGFWVGKSSLRSWRQLALEQLDEQDGDAEQSNGKMNGSTLNKDESKEERKEEEELNFNEDILCPHGELCISENERRLVSKEAWSKLQQYFPKAPEFPSYKECCSQCKILEREGEENEALHKMIANEQKTSLPNLFQDKNRPCLSNWPEDTDVLYIVSQFFVEEWRKFVRKPTRCSPVSSVGNSALLCPHGGLMFTFASMTKEDSKLIALIWPSEWQMIQKLFVVDHVIKITRIEVGDVNPSETQYISEPKLCPECREGLLCQQQRDLREYTQATIYVHKVVDNKKVMKDSAPELNVSSSETEEDKEEAKPDGEKDPDFNQIMHAFSVAPFDQNLSIDGKILSDDCATLGTLGVIPESVILLKADEPIADYAAMDDVMQVCMPEEGFKGTGLLGH>sp|Q86UV5-3|UBP48_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 48 OS=Homo sapiens OX=9606 GN=USP48MAPRLQLEKAAWRWAETVRPEEVSQEHIETAYRIWLEPCIRGVCRRNCKGNPNCLVGIGEHIWLGEIDENSFHNIDDPNCERRKKNSFVGLTNLGATCYVNTFLQVWFLNLELRQALYLCPSTCSDYMLGDGIQEEKDYEPQTICEHLQYLFALLQNSNRRYIDPSGFVKALGLDTGQQQDAQEFSKLFMSLLEDTLSKQKNPDVRNIVQQQFCGEYAYVTVCNQCGRESKLLSKFYELELNIQGHKQLTDCISEFLKEEKLEGDNRYFCENCQSKQNATRKIRLLSLPCTLNLQLMRFVFDRQTGHKKKLNTYIGFSEILDMEPYVEHKGGSYVYELSAVLIHRGVSAYSGHYIAHVKDPQSGEWYKFNDEDIEKMEGKKLQLGIEEDLAEPSKSQTRKPKCGKGTHCSRNAYMLVYRLQTQEKPNTTVQVPAFLQELVDRDNSKFEEWCIEMAEMRKQSVDKGKAKHEEVKELYQRLPAGAEPYEFVSLEWLQKWLDESTPTKPIDNHACLCSHDKLHPDKISIMKRISEYAADIFYSRYGGGPRLTVKALCKECVVERCRILRLKNQLNEDYKTVNNLLKAAVKGSDGFWVGKSSLRSWRQLALEQLDEQDGDAEQSNGKMNGSTLNKDESKEERKEEEELNFNEDILCPHGELCISENERRLVSKEAWSKLQQYFPKAPEFPSYKECCSQCKILEREGE>sp|Q86UV5-4|UBP48_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase 48 OS=Homo sapiens OX=9606 GN=USP48MAPRLQLEKAAWRWAETVRPEEVSQEHIETAYRIWLEPCIRGVCRRNCKGNPNCLVGIGEHIWLGEIDENSFHNIDDPNCERRKKNSFVGLTNLGATCYVNTFLQVWFLNLELRQALYLCPSTCSDYMLGDGIQEEKDYEPQTICEHLQYLFALLQNSNRRYIDPSGFVKALGLDTGQQQDAQEFSKLFMSLLEDTLSKQKNPDVRNIVQQQFCGEYAYVTVCNQCGRESKLLSKFYELELNIQGHKQLTDCISEFLKEEKLEGDNRYFCENCQSKQNATRKIRLLSLPCTLNLQLMRFVFDRQTGHKKKLNTYIGFSEILDMEPYVEHKGGSYVYELSAVLIHRGVSAYSGHYIAHVKDPQSGEWYKLILNTNYHLPPSPKPIKIKNYNKP>sp|Q86UV5-5|UBP48_HUMAN Isoform 5 of Ubiquitin carboxyl-terminalhydrolase 48 OS=Homo sapiens OX=9606 GN=USP48MNLSLSQKTVKIHRLFPMLAFSEPYEFVSLEWLQKWLDESTPTKPIDNHACLCSHDKLHPDKISIMKRISEYAADIFYSRYGGGPRLTVKALCKECVVERCRILRLKNQLNEDYKTVNNLLKAAVKGDGFWVGKSSLRSWRQLALEQLDEQDGDAEQSNGKMNGSTLNKDESKEERKEEEELNFNEDILCPHGELCISENERRLVSKEAWSKLQQYFPKAPEFPSYKECCSQCKILEREGEENEALHKMIANEQKTSLPNLFQDKNRPCLSNWPEDTDVLYIVSQFFVEEWRKFVRKPTRCSPVSSVGNSALLCPHGGLMFTFASMTKEDSKLIALIWPSEWQMIQKLFVVDHVIKITRIEVGDVNPSETQYISEPKLCPECREGLLCQQQRDLREYTQATIYVHKVVDNKKVMKDSAPELNVSSSETEEDKEEAKPDGEKDPDFNQIMHAFSVAPFDQNLSIDGKILSDDCATLGTLGVIPESVILLKADEPIADYAAMDDVMQVCMPEEGFKGTGLLGH>sp|Q86UV5-6|UBP48_HUMAN Isoform 6 of Ubiquitin carboxyl-terminalhydrolase 48 OS=Homo sapiens OX=9606 GN=USP48MKDSAPELNVSSSETEEDKEEAKPDGEKDPDFNQSNGGTKRQKISHQNYIAYQKQVIRRSMRHRKVRGEKALLVSANQTLKELKIQIMHAFSVAPFDQNLSIDGKILSDDCATLGTLGVIPESVILLKADEPIADYAAMDDVMQGKDEFVLGIC>sp|Q86UV5-7|UBP48_HUMAN Isoform 7 of Ubiquitin carboxyl-terminalhydrolase 48 OS=Homo sapiens OX=9606 GN=USP48MAPRLQLEKAAWRWAETVRPEEVSQEHIETAYRIWLEPCIRGVCRRNCKGNPNCLVGIGEHIWLGEIDENSFHNIDDPNCERRKKNSFVGLTNLGATCYVNTFLQVWFLNLELRQALYLCPSTCSDYMLGDGIQEEKDYEPQTICEHLQYLFALLQNSNRRYIDPSGFVKALGLDTGQQQDAQEFSKLFMSLLEDTLSKQKNPDVRNIVQQQFCGEYAYVTVCNQCGRESKLLSKFYELELNIQGHKQLTDCISEFLKEEKLEGDNRYFCENCQSKQNATRKIRLLSLPCTLNLQLMRFVFDRQTGHKKKLNTYIGFSEILDMEPYVEHKGGSYVYELSAVLIHRGVSAYSGHYIAHVKDPQSGEWYKFNDEDIEKMEGKKLQLGIEEDLAEPSKSQTRKPKCGKGTHCSRNAYMLVYRLQTQEKPNTTVQVPAFLQELVDRDNSKFEEWCIEMAEMRKQSVDKGKAKHEEVKELYQRLPAGAGL>sp|Q86UV5-8|UBP48_HUMAN Isoform 8 of Ubiquitin carboxyl-terminalhydrolase 48 OS=Homo sapiens OX=9606 GN=USP48MAPRLQLEKAAWRWAETVRPEEVSQEHIETAYRIWLEPCIRGVCRRNCKGNPNCLVGIGEHIWLGEIDENSFHNIDDPNCERRKKNSFVGLTNLGATCYVNTFLQVWFLNLELRQALYLCPSTCSDYMLGDGIQEEKDYEPQTICEHLQYLFALLQNSNRRYIDPSGFVKALGLDTGQQQDAQEFSKLFMSLLEDTLSKQKNPDVRNIVQQQFCGEYAYVTVCNQCGRESKLLSKFYELELNIQGHKQLTDCISEFLKEEKLEGDNRYFCENCQSKQNATRKIRLLSLPCTLNLQLMRFVFDRQTGHKKKLNTYIGFSEILDMEPYVEHKGGSYVYELSAVLIHRGVSAYSGHYIAHVKDPQSGEWYKFNDEDIEKMEGKKLQLGIEEDLEPSKSQTRKPKCGKGTHCSRNAYMLVYRLQTQEKPNTTVQVPAFLQELVDRDNSKFEEWCIEMAEMRKQSVDKGKAKHEEVKELYQRLPAGAEPYEFVSLEWLQKWLDESTPTKPIDNHACLCSHDKLHPDKISIMKRISEYAADIFYSRYGGGPRLTVKALCKECVVERCRILRLKNQLNEDYKTVNNLLKAAVKGSDGFWVGKSSLRSWRQLALEQLDEQDGDAEQSNGKMNGSTLNKDESKEERKEEEELNFNEDILCPHAVFFFSKYIFLNSGELCISENERRLVSKEAWSKLQQYFPKAPEFPSYKECCSQCKILEREGEENEALHKMIANEQKTSLPNLFQDKNRPCLSNWPEDTDVLYIVSQFFVEEWRKFVRKPTRCSPVSSVGNSALLCPHGGLMFTFASMTKEDSKLIALIWPSEWQMIQKLFVVDHVIKITRIEVGDVNPSETQYISEPKLCPECREGLLCQQQRDLREYTQATIYVHKVVDNKKVMKDSAPELNVSSSETEEDKEEAKPDGEKDPDFNQSNGGTKRQKISHQNYIAYQKQVIRRSMRHRKVRGEKALLVSANQTLKELKIQIMHAFSVAPFDQNLSIDGKILSDDCATLGTLGVIPESVILLKADEPIADYAAMDDVMQVCMPEEGFKGTGLLGH>sp|Q8IYN6|UBAD2_HUMAN UBA-like domain-containing protein 2 OS=Homosapiens OX=9606 GN=UBALD2 PE=1 SV=1MSVNMDELRHQVMINQFVLAAGCAADQAKQLLQAAHWQFETALSTFFQETNIPNSHHHHQMMCTPSNTPATPPNFPDALAMFSKLRASEGLQSSNSPMTAAACSPPANFSPFWASSPPSHQAPWIPPSSPTTFHHLHRPQPTWPPGAQQGGAQQKAMAAMDGQR>sp|P49810|PSN2_HUMAN Presenilin-2 OS=Homo sapiens OX=9606 GN=PSEN2 PE=1SV=1MLTFMASDSEEEVCDERTSLMSAESPTPRSCQEGRQGPEDGENTAQWRSQENEEDGEEDPDRYVCSGVPGRPPGLEEELTLKYGAKHVIMLFVPVTLCMIVVVATIKSVRFYTEKNGQLIYTPFTEDTPSVGQRLLNSVLNTLIMISVIVVMTIFLVVLYKYRCYKFIHGWLIMSSLMLLFLFTYIYLGEVLKTYNVAMDYPTLLLTVWNFGAVGMVCIHWKGPLVLQQAYLIMISALMALVFIKYLPEWSAWVILGAISVYDLVAVLCPKGPLRMLVETAQERNEPIFPALIYSSAMVWTVGMAKLDPSSQGALQLPYDPEMEEDSYDSFGEPSYPEVFEPPLTGYPGEELEEEEERGVKLGLGDFIFYSVLVGKAAATGSGDWNTTLACFVAILIGLCLTLLLLAVFKKALPALPISITFGLIFYFSTDNLVRPFMDTLASHQLYI>sp|P49810-2|PSN2_HUMAN Isoform 2 of Presenilin-2 OS=Homo sapiens OX=9606GN=PSEN2MLTFMASDSEEEVCDERTSLMSAESPTPRSCQEGRQGPEDGENTAQWRSQENEEDGEEDPDRYVCSGVPGRPPGLEEELTLKYGAKHVIMLFVPVTLCMIVVVATIKSVRFYTEKNGQLIYTPFTEDTPSVGQRLLNSVLNTLIMISVIVVMTIFLVVLYKYRCYKFIHGWLIMSSLMLLFLFTYIYLGEVLKTYNVAMDYPTLLLTVWNFGAVGMVCIHWKGPLVLQQAYLIMISALMALVFIKYLPEWSAWVILGAISVYAMVWTVGMAKLDPSSQGALQLPYDPEMEEDSYDSFGEPSYPEVFEPPLTGYPGEELEEEEERGVKLGLGDFIFYSVLVGKAAATGSGDWNTTLACFVAILIGLCLTLLLLAVFKKALPALPISITFGLIFYFSTDNLVRPFMDTLASHQLYI>sp|P49810-3|PSN2_HUMAN Isoform 3 of Presenilin-2 OS=Homo sapiens OX=9606GN=PSEN2MLTFMASDSEEEVCDERTSLMSAESPTPRSCQEGRQGPEDGENTAQWRSQENEEDGEEDPDRYVCSGVPGRPPGLEEELTLKYGAKHVIMLFVPVTLCMIVVVATIKSVRFYTEKNGQLIYTPFTEDTPSVGQRLLNSVLNTLIMISVIVVMTIFLVVLYKYRCYKFIHGWLIMSSLMLLFLFTYIYLGEVLKTYNVAMDYPTLLLTVWNFGAVGMVCIHWKGPLVLQQAYLIMISALMALVFIKYLPEWSAWVILGAISVYDLVAVLCPKGPLRMLVETAQERNEPIFPALIYSSAMVWTVGMAKLDPSSQGALQLPYDPEMEDSYDSFGEPSYPEVFEPPLTGYPGEELEEEEERGVKLGLGDFIFYSVLVGKAAATGSGDWNTTLACFVAILIGLCLTLLLLAVFKKALPALPISITFGLIFYFSTDNLVRPFMDTLASHQLYI>sp|Q16401|PSMD5_HUMAN 26S proteasome non-ATPase regulatory subunit 5OS=Homo sapiens OX=9606 GN=PSMD5 PE=1 SV=3MAAQALALLREVARLEAPLEELRALHSVLQAVPLNELRQQAAELRLGPLFSLLNENHREKTTLCVSILERLLQAMEPVHVARNLRVDLQRGLIHPDDSVKILTLSQIGRIVENSDAVTEILNNAELLKQIVYCIGGENLSVAKAAIKSLSRISLTQAGLEALFESNLLDDLKSVMKTNDIVRYRVYELIIEISSVSPESLNYCTTSGLVTQLLRELTGEDVLVRATCIEMVTSLAYTHHGRQYLAQEGVIDQISNIIVGADSDPFSSFYLPGFVKFFGNLAVMDSPQQICERYPIFVEKVFEMIESQDPTMIGVAVDTVGILGSNVEGKQVLQKTGTRFERLLMRIGHQSKNAPVELKIRCLDAISSLLYLPPEQQTDDLLRMTESWFSSLSRDPLELFRGISSQPFPELHCAALKVFTAIANQPWAQKLMFNSPGFVEYVVDRSVEHDKASKDAKYELVKALANSKTIAEIFGNPNYLRLRTYLSEGPYYVKPVSTTAVEGAE>sp|Q16401-2|PSMD5_HUMAN Isoform 2 of 26S proteasome non-ATPaseregulatory subunit 5 OS=Homo sapiens OX=9606 GN=PSMD5MAAQALALLREVARLEAPLEELRALHSVLQAVPLNELRQQAAELRLGPLFSLLNENHREKTTLCVSILERLLQAMEPVHVARNLRVDLQRGLIHPDDSVKILTLSQIGRIVENSDAVTEILNNAELLKQIVYCIGGENLSVAKALIIEISSVSPESLNYCTTSGLVTQLLRELTGEDVLVRATCIEMVTSLAYTHHGRQYLAQEGVIDQISNIIVGADSDPFSSFYLPGFVKFFGNLAVMDSPQQICERYPIFVEKVFEMIESQDPTMIGVAVDTVGILGSNVEGKQVLQKTGTRFERLLMRIGHQSKNAPVELKIRCLDAISSLLYLPPEQQTDDLLRMTESWFSSLSRDPLELFRGISSQPFPELHCAALKVFTAIANQPWAQKLMFNSPGFVEYVVDRSVEHDKASKDAKYELVKALANSKTIAEIFGNPNYLRLRTYLSEGPYYVKPVSTTAVEGAE>sp|P61574|RE113_HUMAN Endogenous retrovirus group K member 113 Recprotein OS=Homo sapiens OX=9606 GN=HERVK_113 PE=1 SV=1MNPSEMQRKAPPRRRRHRNRAPLTHKMNKMVTSEEQMKLPSTKKAEPPTWAQLKKLTQLATKYLENTKVTQTPESMLLAALMIVSMVSYGVPNSSEETATIENGP>sp|Q08257|QOR_HUMAN Quinone oxidoreductase OS=Homo sapiens OX=9606GN=CRYZ PE=1 SV=1MATGQKLMRAVRVFEFGGPEVLKLRSDIAVPIPKDHQVLIKVHACGVNPVETYIRSGTYSRKPLLPYTPGSDVAGVIEAVGDNASAFKKGDRVFTSSTISGGYAEYALAADHTVYKLPEKLDFKQGAAIGIPYFTAYRALIHSACVKAGESVLVHGASGGVGLAACQIARAYGLKILGTAGTEEGQKIVLQNGAHEVFNHREVNYIDKIKKYVGEKGIDIIIEMLANVNLSKDLSLLSHGGRVIVVGSRGTIEINPRDTMAKESSIIGVTLFSSTKEEFQQYAAALQAGMEIGWLKPVIGSQYPLEKVAEAHENIIHGSGATGKMILLL>sp|Q08257-2|QOR_HUMAN Isoform 2 of Quinone oxidoreductase OS=Homosapiens OX=9606 GN=CRYZMHLLSSACVKAGESVLVHGASGGVGLAACQIARAYGLKILGTAGTEEGQKIVLQNGAHEVFNHREVNYIDKIKKYVGEKGIDIIIEMLANVNLSKDLSLLSHGGRVIVVGSRGTIEINPRDTMAKESSIIGVTLFSSTKEEFQQYAAALQAGMEIGWLKPVIGSQYPLEKVAEAHENIIHGSGATGKMILLL>sp|Q08257-3|QOR_HUMAN Isoform 3 of Quinone oxidoreductase OS=Homosapiens OX=9606 GN=CRYZMATGQKLMRAVRVFEFGGPEVLKLRSDIAVPIPKDHQVLIKVHACGVNPVETYIRSGTYSRKPLLPYTPGSDVAGVIEAVGDNASAFKKGDRVFTSSTISGGYAEYALAADHTVYKLPEKLDFKQGAAIGIPYFTAYRALIHSACVKAGESVLVHGASGGVGLAACQIARAYGLKILGTAGTEEGQKIVLQNGAHEVFNHREVNYIDKIKVVGSRGTIEINPRDTMAKESSIIGVTLFSSTKEEFQQYAAALQAGMEIGWLKPVIGSQYPLEKVAEAHENIIHGSGATGKMILLL>sp|Q8WU10|PYRD1_HUMAN Pyridine nucleotide-disulfide oxidoreductasedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=PYROXD1 PE=1 SV=1MEAARPPPTAGKFVVVGGGIAGVTCAEQLATHFPSEDILLVTASPVIKAVTNFKQISKILEEFDVEEQSSTMLGKRFPNIKVIESGVKQLKSEEHCIVTEDGNQHVYKKLCLCAGAKPKLICEGNPYVLGIRDTDSAQEFQKQLTKAKRIMIIGNGGIALELVYEIEGCEVIWAIKDKAIGNTFFDAGAAEFLTSKLIAEKSEAKIAHKRTRYTTEGRKKEARSKSKADNVGSALGPDWHEGLNLKGTKEFSHKIHLETMCEVKKIYLQDEFRILKKKSFTFPRDHKSVTADTEMWPVYVELTNEKIYGCDFIVSATGVTPNVEPFLHGNSFDLGEDGGLKVDDHMHTSLPDIYAAGDICTTSWQLSPVWQQMRLWTQARQMGWYAAKCMAAASSGDSIDMDFSFELFAHVTKFFNYKVVLLGKYNAQGLGSDHELMLRCTKGREYIKVVMQNGRMMGAVLIGETDLEETFENLILNQMNLSSYGEDLLDPNIDIEDYFD>sp|Q8WU10-2|PYRD1_HUMAN Isoform 2 of Pyridine nucleotide-disulfideoxidoreductase domain-containing protein 1 OS=Homo sapiens OX=9606GN=PYROXD1MLGKRFPNIKVIESGVKQLKSEEHCIVTEDGNQHVYKKLCLCAGAKPKLICEGNPYVLGIRDTDSAQEFQKQLTKAKRIMIIGNGGIALELVYEIEGCEVIWAIKDKAIGNTFFDAGAAEFLTSKLIAEKSEAKIAHKRTRYTTEGRKKEARSKSKADNVGSALGPDWHEGLNLKGTKEFSHKIHLETMCEVKKIYLQDEFRILKKKSFTFPRDHKSVTADTEMWPVYVELTNEKIYGCDFIVSATGVTPNVEPFLHGNSFDLGEDGGLKVDDHMHTSLPDIYAAGDICTTSWQLSPVWQQMRLWTQARQMGWYAAKCMAAASSGDSIDMDFSFELFAHVTKFFNYKVVLLGKYNAQGLGSDHELMLRCTKGREYIKVVMQNGRMMGAVLIGETDLEETFENLILNQMNLSSYGEDLLDPNIDIEDYFD>sp|P61572|REC19_HUMAN Endogenous retrovirus group K member 19 Recprotein OS=Homo sapiens OX=9606 GN=ERVK-19 PE=1 SV=1MNPSEMQRKAPPRRRRHRNRAPLTHKMNKMVTSEEQMKLPSTKKAEPPTWAQLKKLTQLATKYLENTKVTQTPESMLLAALMIVSMVSAGVPNSSEETATIENGP>sp|Q7Z5J4|RAI1_HUMAN Retinoic acid-induced protein 1 OS=Homo sapiensOX=9606 GN=RAI1 PE=1 SV=2MQSFRERCGFHGKQQNYQQTSQETSRLENYRQPSQAGLSCDRQRLLAKDYYNPQPYPSYEGGAGTPSGTAAAVAADKYHRGSKALPTQQGLQGRPAFPGYGVQDSSPYPGRYAGEESLQAWGAPQPPPPQPQPLPAGVAKYDENLMKKTAVPPSRQYAEQGAQVPFRTHSLHVQQPPPPQQPLAYPKLQRQKLQNDIASPLPFPQGTHFPQHSQSFPTSSTYSSSVQGGGQGAHSYKSCTAPTAQPHDRPLTASSSLAPGQRVQNLHAYQSGRLSYDQQQQQQQQQQQQQQALQSRHHAQETLHYQNLAKYQHYGQQGQGYCQPDAAVRTPEQYYQTFSPSSSHSPARSVGRSPSYSSTPSPLMPNLENFPYSQQPLSTGAFPAGITDHSHFMPLLNPSPTDATSSVDTQAGNCKPLQKDKLPENLLSDLSLQSLTALTSQVENISNTVQQLLLSKAAVPQKKGVKNLVSRTPEQHKSQHCSPEGSGYSAEPAGTPLSEPPSSTPQSTHAEPQEADYLSGSEDPLERSFLYCNQARGSPARVNSNSKAKPESVSTCSVTSPDDMSTKSDDSFQSLHGSLPLDSFSKFVAGERDCPRLLLSALAQEDLASEILGLQEAIGEKADKAWAEAPSLVKDSSKPPFSLENHSACLDSVAKSAWPRPGEPEALPDSLQLDKGGNAKDFSPGLFEDPSVAFATPDPKKTTGPLSFGTKPTLGVPAPDPTTAAFDCFPDTTAASSADSANPFAWPEENLGDACPRWGLHPGELTKGLEQGGKASDGISKGDTHEASACLGFQEEDPPGEKVASLPGDFKQEEVGGVKEEAGGLLQCPEVAKADRWLEDSRHCCSTADFGDLPLLPPTSRKEDLEAEEEYSSLCELLGSPEQRPGMQDPLSPKAPLICTKEEVEEVLDSKAGWGSPCHLSGESVILLGPTVGTESKVQSWFESSLSHMKPGEEGPDGERAPGDSTTSDASLAQKPNKPAVPEAPIAKKEPVPRGKSLRSRRVHRGLPEAEDSPCRAPVLPKDLLLPESCTGPPQGQMEGAGAPGRGASEGLPRMCTRSLTALSEPRTPGPPGLTTTPAPPDKLGGKQRAAFKSGKRVGKPSPKAASSPSNPAALPVASDSSPMGSKTKETDSPSTPGKDQRSMILRSRTKTQEIFHSKRRRPSEGRLPNCRATKKLLDNSHLPATFKVSSSPQKEGRVSQRARVPKPGAGSKLSDRPLHALKRKSAFMAPVPTKKRNLVLRSRSSSSSNASGNGGDGKEERPEGSPTLFKRMSSPKKAKPTKGNGEPATKLPPPETPDACLKLASRAAFQGAMKTKVLPPRKGRGLKLEAIVQKITSPSLKKFACKAPGASPGNPLSPSLSDKDRGLKGAGGSPVGVEEGLVNVGTGQKLPTSGADPLCRNPTNRSLKGKLMNSKKLSSTDCFKTEAFTSPEALQPGGTALAPKKRSRKGRAGAHGLSKGPLEKRPYLGPALLLTPRDRASGTQGASEDNSGGGGKKPKMEELGLASQPPEGRPCQPQTRAQKQPGHTNYSSYSKRKRLTRGRAKNTTSSPCKGRAKRRRQQQVLPLDPAEPEIRLKYISSCKRLRSDSRTPAFSPFVRVEKRDAFTTICTVVNSPGDAPKPHRKPSSSASSSSSSSSFSLDAAGASLATLPGGSILQPRPSLPLSSTMHLGPVVSKALSTSCLVCCLCQNPANFKDLGDLCGPYYPEHCLPKKKPKLKEKVRPEGTCEEASLPLERTLKGPECAAAATAGKPPRPDGPADPAKQGPLRTSARGLSRRLQSCYCCDGREDGGEEAAPADKGRKHECSKEAPAEPGGEAQEHWVHEACAVWTGGVYLVAGKLFGLQEAMKVAVDMMCSSCQEAGATIGCCHKGCLHTYHYPCASDAGCIFIEENFSLKCPKHKRLP>sp|Q7Z5J4-2|RAI1_HUMAN Isoform 2 of Retinoic acid-induced protein 1OS=Homo sapiens OX=9606 GN=RAI1MQSFRERCGFHGKQQNYQQTSQETSRLENYRQPSQAGLSCDRQRLLAKDYYNPQPYPSYEGGAGTPSGTAAAVAADKYHRGSKALPTQQGLQGRPAFPGYGVQDSSPYPGRYAGEESLQAWGAPQPPPPQPQPLPAGVAKYDENLMKKTAVPPSRQYAEQGAQVPFRTHSLHVQQPPPPQQPLAYPKLQRQKLQNDIASPLPFPQGWWAGGHSYKSCTAPTAQPHDRPLTASSSLAPGQRVQNLHAYQSGRLSYDQQQQQQQQQQQQQQALQSRHHAQETLHYQNLAKYQHYGQQGQGYCQPDAAVRTPEQYYQTFSPSSSHSPARSVGRSPSYSSTPSPLMPNLENFPYSQQPLSTGAFPAGITDHSHFMPLLNPSPTDATSSPADLTALTSQVENISNTVQQLLLSKAAVPQKKGVKNLVSRTPEQHKSQHCSPEGSGYSAEPAGTPLSEPPSSTPQSTHAEPQEADYLSGSEDPLERSFLYCNQARGSPARVNSNSKAKPESVSTCSVTSPDDMSTKSDDSFQSLHGSLPLDSFSKFVAGERDCPRLLLSALAQEDLASEILGLQEAIGEKADKAWAEAPSLVKDSSKPPFSLENHSACLDSVAKSAWPRPGEPEALPDSLQLDKGGNAKDFSPGLFEDPSVAFATPDPKKTTGPLSFGTKPTLGVPAPDPTTAAFDCFPDTTAASSADSANPFAWPEENLGDACPRWGLHPGELTKGLEQGGKASDGISKGDTHEASACLGFQEEDPPGEKVASLPGDFKQEEVGGVKEEAGGLLQCPEVAKADRWLEDSRHCCSTADFGDLPLLPPTSRKEDLEAEEEYSSLCELLGSPEQRPGMQDPLSPKAPLICTKEEVEEVLDSKAGWGSPCHLSGESVILLGPTVGTESKVQSWFESSLSHMKPGEEGPDGERAPGDSTTSDASLAQKPNKPAVPEAPIAKKEPVPRGKSLRSRRVHRGLPEAEDSPCRAPVLPKDLLLPESCTGPPQGQMEGAGAPGRGASEGLPRMCTRSLTALSEPRTPGPPGLTTTPAPPDKLGGKQRAAFKSGKRVGKPSPKAASSPSNPAALPVASDSSPMGSKTKETDSPSTPGKDQRSMILRSRTKTQEIFHSKRRRPSEGRLPNCRATKKLLDNSHLPATFKVSSSPQKEGRVSQRARVPKPGAGSKLSDRPLHALKRKSAFMAPVPTKKRNLVLRSRSSSSSNASGNGGDGKEERPEGSPTLFKRMSSPKKAKPTKGNGEPATKLPPPETPDACLKLASRAAFQGAMKTKVLPPRKGRGLKLEAIVQKITSPSLKKFACKAPGASPGNPLSPSLSDKDRGLKGAGGSPVGVEEGLVNVGTGQKLPTSGADPLCRNPTNRSLKGKLMNRASGTQGASEDNSGGGGKKPKMEELGLASQPPEGRPCQPQTRAQKQPGHTNYSSYSKRKRLTRGRAKNTTSSPCKGRAKRRRQQQVLPLDPAEPEIRLKYISSCKRLRSDSRTPAFSPFVRVEKRDAFTTICTVVNSPGDAPKPHRKPSSSASSSSSSSSFSLDAAGASLATLPGGSILQPRPSLPLSSTMHLGPVVSKALSTSCLVCCLCQNPANFKDLGDLCGPYYPEHCLPKKKPKLKEKVRPEGTCEEASLPLERTLKGPECAAAATAGKPPRPDGPADPAKQGPLRTSARGLSRRLQSCYCCDGREDGGEEAAPADKGHWVHEACAVWTGGVYLVAGKLFGLQEAMKVAVDMHGGTVALAPGDFSLPGLRFASLFQGPSWCDCPVLATSTPSSWSRCVPAAKKPGPPLGAATKDASTPTTTRVPAMQVRARPGTGGHWSPSKQSRGTLPGHSSPNPGPISLFSFPPLLPQQFFYPSVCLDLCWAMPGTWK>sp|Q7Z5J4-3|RAI1_HUMAN Isoform 3 of Retinoic acid-induced protein 1OS=Homo sapiens OX=9606 GN=RAI1MQSFRERCGFHGKQQNYQQTSQETSRLENYRQPSQAGLSCDRQRLLAKDYYNPQPYPSYEGGAGTPSGTAAAVAADKYHRGSKALPTQQGLQGRPAFPGYGVQDSSPYPGRYAGEESLQAWGAPQPPPPQPQPLPAGVAKYDENLMKKTAVPPSRQYAEQGAQVPFRTHSLHVQQPPPPQQPLAYPKLQRQKLQNDIASPLPFPQGTHFPQHSQSFPTSSTYSSSVQGGGQGAHSYKSCTAPTAQPHDRPLTASSSLAPGQRVQNLHAYQSGRLSYDQQQQQQQQQQQQQQALQSRHHAQETLHYQNLAKYQHYGQQGQGYCQPDAAVRTPEQYYQTFSPSSSHSPARSVGRSPSYSSTPSPLMPNLENFPYSQQPLSTGAFPAGITDHSHFMPLLNPSPTDATSSVDTQAGNCKPLQKDKLPENLLSDLSLQSLTALTSQVENISNTVQQLLLSKAAVPQKKGVKNLVSRTPEQHKSQHCSPEGSGYSAEPAGTPLSEPPSSTPQSTHAEPQEADYLSGSEDPLERSFLYCNQARGSPARVNSNSKAKPESVSTCSVTSPDDMSTKSDDSFQSLHGSLPLDSFSKFVAGERDCPRLLLSALAQEDLASEILGLQEAIGEKADKAWAEAPSLVKDSSKPPFSLENHSACLDSVAKSAWPRPGEPEALPDSLQLDKGGNAKDFSPGLFEDPSVAFATPDPKKTTGPLSFGTKPTLGVPAPDPTTAAFDCFPDTTAASSADSANPFAWPEENLGDACPRWGLHPGELTKGLEQGGKASDGISKGDTHEASACLGFQEEDPPGEKVASLPGDFKQEEVGGVKEEAGGLLQCPEVAKADRWLEDSRHCCSTADFGDLPLLPPTSRKEDLEAEEEYSSLCELLGSPEQRPGMQDPLSPKAPLICTKEEVEEVLDSKAGWGSPCHLSGESVILLGPTVGTESKVQSWFESSLSHMKPGEEGPDGERAPGDSTTSDASLAQKPNKPAVPEAPIAKKEPVPRGKSLRSRRVHRGLPEAEDSPCRAPVLPKDLLLPESCTGPPQGQMEGAGAPGRGASEGLPRMCTRSLTALSEPRTPGPPGLTTTPAPPDKLGGKQRAAFKSGKRVGKPSPKAASSPSNPAALPVASDSSPMGSKTKETDSPSTPGKDQRSMILRSRTKTQEIFHSKRRRPSEGRLPNCRATKKLLDNSHLPATFKVSSSPQKEGRVSQRARVPKPGAGSKLSDRPLHALKRKSAFMAPVPTKKRNLVLRSRSSSSSNASGNGGDGKEERPEGSPTLFKRMSSPKKAKPTKGNGEPATKLPPPETPDACLKLASRAAFQGAMKTKVLPPRKGRGLKLEAIVQKITSPSLKKFACKAPGASPGNPLSPSLSDKDRGLKGAGGSPVGVEEGLVNVGTGQKLPTSGADPLCRNPTNRSLKGKLMNSKKLSSTDCFKTEAFTSPEALQPGGTALAPKKRSRKGRAGAHGLSKGPLEKRPYLGPALLLTPRDRASGTQGASEDNSGGGGKKPKMEELGLASQPPEGRPCQPQTRAQKQPGHTNYSSYSKRKRLTRGRAKNTTSSPCKGRAKRRRQQQVLPLDPAEPEIRLKYISSCKRLRSDSRTPAFSPLEPSLGAQNPRSGQNAPPAPADARPLCTTRDRRAYSAREQGQR>sp|Q7Z5J4-4|RAI1_HUMAN Isoform 4 of Retinoic acid-induced protein 1OS=Homo sapiens OX=9606 GN=RAI1MQSFRERCGFHGKQQNYQQTSQETSRLENYRQPSQAGLSCDRQRLLAKDYYNPQPYPSYEGGAGTPSGTAAAVAADKYHRGSKALPTQQGLQGRPAFPGYGVQDSSPYPGRYAGEESLQAWGAPQPPPPQPQPLPAGVAKYDENLMKKTAVPPSRQYAEQGAQVPFRTHSLHVQQPPPPQQPLAYPKLQRQKLQNDIASPLPFPQGTHFPQHSQSFPTSSTYSSSVQGGGQGAHSYKSCTAPTAQPHDRPLTASSSLAPGQRVQNLHAYQSGRLSYDQQQQQQQQQQQQQQALQSRHHAQETLHYQNLAKYQHYGQQGQGYCQPDAAVRTPEQYYQTFSPSSSHSPARSVGRSPSYSSTPSPLMPNLENFPYSQQPLSTGAFPAGITDHSHFMPLLNPSPTDATSSVDTQAGNCKPLQKDKLPENLLSDLSLQSLTALTSQVENISNTVQQLLLSKAAVPQKKGVKNLVSRTPEQHKSQHCSPEGSGYSAEPAGTPLSEPPSSTPQSTHAEPQEADYLSGSEDPLERSFLYCNQARGSPARVNSNSKAKPESVSTCSVTSPDDMSTKSDDSFQSLHGSLPLDSFSKFVAGERDCPRLLLSALAQEDLASEILGLQEAIGEKADKAWAEAPSLVKDSSKPPFSLENHSACLDSVAKSAWPRPGEPEALPDSLQLDKGGNAKDFSPGLFEDPSVAFATPDPKKTTGPLSFGTKPTLGVPAPDPTTAAFDCFPDTTAASSADSANPFAWPEENLGDACPRWGLHPGELTKGLEQGGKASDGISKGDTHEASACLGFQEEDPPGEKVASLPGDFKQEEVGGVKEEAGGLLQCPEVAKADRWLEDSRHCCSTADFGDLPLLPPTSRKEDLEAEEEYSSLCELLGSPEQRPGMQDPLSPKAPLICTKEEVEEVLDSKAGWGSPCHLSGESVILLGPTVGTESKVQSWFESSLYSVYICIHIHIYNIYEDCKC>sp|Q6ZTQ3|RASF6_HUMAN Ras association domain-containing protein 6OS=Homo sapiens OX=9606 GN=RASSF6 PE=1 SV=1MLWEETGAAPAPARASDLPYRISSDHLKKEEKMTMMAHQYPSWIFINEKTFITREQLNSLLKTYNIFYENQKNLHILYGETEDGKLIVEGMLDIFWGVKRPIQLKIQDEKPFSSFTSMKSSDVFSSKGMTRWGEFDDLYRISELDRTQIPMSEKRNSQEDYLSYHSNTLKPHAKDEPDSPVLYRTMSEAALVRKRMKPLMMDRKERQKNRASINGHFYNHETSIFIPAFESETKVRVNSNMRTEEVIKQLLQKFKIENSPQDFALHIIFATGEQRRLKKTDIPLLQRLLQGPSEKNARIFLMDKDAEEISSDVAQYINFHFSLLESILQRLNEEEKREIQRIVTKFNKEKAIILKCLQNKLVIKTETTV>sp|Q6ZTQ3-2|RASF6_HUMAN Isoform 2 of Ras association domain-containingprotein 6 OS=Homo sapiens OX=9606 GN=RASSF6MTMMAHQYPSWIFINEKTFITREQLNSLLKTYNIFYENQKNLHILYGETEDGKLIVEGMLDIFWGVKRPIQLKIQDEKPFSSFTSMKSSDVFSSKGMTRWGEFDDLYRISELDRTQIPMSEKRNSQEDYLSYHSNTLKPHAKDEPDSPVLYRTMSEAALVRKRMKPLMMDRKERQKNRASINGHFYNHETSIFIPAFESETKVRVNSNMRTEEVIKQLLQKFKIENSPQDFALHIIFATGEQRRLKKTDIPLLQRLLQGPSEKNARIFLMDKDAEEISSDVAQYINFHFSLLESILQRLNEEEKREIQRIVTKFNKEKAIILKCLQNKLVIKTETTV>sp|Q6ZTQ3-3|RASF6_HUMAN Isoform 3 of Ras association domain-containingprotein 6 OS=Homo sapiens OX=9606 GN=RASSF6MLWEETGAAPAPARASDLPYRIHFLSSGLILVTRQLTEDGKLIVEGMLDIFWGVKRPIQLKIQDEKPFSSFTSMKSSDVFSSKGMTRWGEFDDLYRISELDRTQIPMSEKRNSQEDYLSYHSNTLKPHAKDEPDSPVLYRTMSEAALVRKRMKPLMMDRKERQKNRASINGHFYNHETSIFIPAFESETKVRVNSNMRTEEVIKQLLQKFKIENSPQDFALHIIFATGEQRRLKKTDIPLLQRLLQGPSEKNARIFLMDKDAEEISSDVAQYINFHFSLLESILQRLNEEEKREIQRIVTKFNKEKAIILKCLQNKLVIKTETTV>sp|Q6ZTQ3-4|RASF6_HUMAN Isoform 4 of Ras association domain-containingprotein 6 OS=Homo sapiens OX=9606 GN=RASSF6MTMMAHQYPSWIFINEKTFITREQLNSLLKTYNIFYENQKNLHILYGETEDGKLIVEGMLDIFWGVKRPIQLKIQDEKPFSSFTSMKSSDVFSSKGMTRWGEFDDLYRISELDRTQIPMSEKRNSQEDYLSYHSNTLKPHAKDEPDSPVLYRTMSEAALVRKRMKPLMMDRKERQKNRASINGHFYNHEIENSPQDFALHIIFATGEQRRLKKTDIPLLQRLLQGPSEKNARIFLMDKDAEEISSDVAQYINFHFSLLESILQRLNEEEKREIQRIVTKFNKEKAIILKCLQNKLVIKTETTV>sp|Q96H35|RBM18_HUMAN Probable RNA-binding protein 18 OS=Homo sapiensOX=9606 GN=RBM18 PE=2 SV=1MEAETKTLPLENASILSEGSLQEGHRLWIGNLDPKITEYHLLKLLQKFGKVKQFDFLFHKSGALEGQPRGYCFVNFETKQEAEQAIQCLNGKLALSKKLVVRWAHAQVKRYDHNKNDKILPISLEPSSSTEPTQSNLSVTAKIKAIEAKLKMMAENPDAEYPAAPVYSYFKPPDKKRTTPYSRTAWKSRR>sp|P78332|RBM6_HUMAN RNA-binding protein 6 OS=Homo sapiens OX=9606GN=RBM6 PE=1 SV=5MWGDSRPANRTGPFRGSQEERFAPGWNRDYPPPPLKSHAQERHSGNFPGRDSLPFDFQGHSGPPFANVEEHSFSYGARDGPHGDYRGGEGPGHDFRGGDFSSSDFQSRDSSQLDFRGRDIHSGDFRDREGPPMDYRGGDGTSMDYRGREAPHMNYRDRDAHAVDFRGRDAPPSDFRGRGTYDLDFRGRDGSHADFRGRDLSDLDFRAREQSRSDFRNRDVSDLDFRDKDGTQVDFRGRGSGTTDLDFRDRDTPHSDFRGRHRSRTDQDFRGREMGSCMEFKDREMPPVDPNILDYIQPSTQDREHSGMNVNRREESTHDHTIERPAFGIQKGEFEHSETREGETQGVAFEHESPADFQNSQSPVQDQDKSQLSGREEQSSDAGLFKEEGGLDFLGRQDTDYRSMEYRDVDHRLPGSQMFGYGQSKSFPEGKTARDAQRDLQDQDYRTGPSEEKPSRLIRLSGVPEDATKEEILNAFRTPDGMPVKNLQLKEYNTGYDYGYVCVEFSLLEDAIGCMEANQGTLMIQDKEVTLEYVSSLDFWYCKRCKANIGGHRSSCSFCKNPREVTEAKQELITYPQPQKTSIPAPLEKQPNQPLRPADKEPEPRKREEGQESRLGHQKREAERYLPPSRREGPTFRRDRERESWSGETRQDGESKTIMLKRIYRSTPPEVIVEVLEPYVRLTTANVRIIKNRTGPMGHTYGFIDLDSHAEALRVVKILQNLDPPFSIDGKMVAVNLATGKRRNDSGDHSDHMHYYQGKKYFRDRRGGGRNSDWSSDTNRQGQQSSSDCYIYDSATGYYYDPLAGTYYDPNTQQEVYVPQDPGLPEEEEIKEKKPTSQGKSSSKKEMSKRDGKEKKDRGVTRFQENASEGKAPAEDVFKKPLPPTVKKEESPPPPKVVNPLIGLLGEYGGDSDYEEEEEEEQTPPPQPRTAQPQKREEQTKKENEEDKLTDWNKLACLLCRRQFPNKEVLIKHQQLSDLHKQNLEIHRKIKQSEQELAYLERREREGKFKGRGNDRREKLQSFDSPERKRIKYSRETDSDRKLVDKEDIDTSSKGGCVQQATGWRKGTGLGYGHPGLASSEEAEGRMRGPSVGASGRTSKRQSNETYRDAVRRVMFARYKELD>sp|P78332-2|RBM6_HUMAN Isoform 2 of RNA-binding protein 6 OS=Homosapiens OX=9606 GN=RBM6MIQDKEVTLEYVSSLDFWYCKRCKANIGGHRSSCSFCKNPREVTEAKQELITYPQPQKTSIPAPLEKQPNQPLRPADKEPEPRKREEGQESRLGHQKREAERYLPPSRREGPTFRRDRERESWSGETRQDGESKTIMLKRIYRSTPPEVIVEVLEPYVRLTTANVRIIKNRTGPMGHTYGFIDLDSHAEALRVVKILQNLDPPFSIDGKMVAVNLATGKRRNDSGDHSDHMHYYQGKKYFRDRRGGGRNSDWSSDTNRQGQQSSSDCYIYDSATGYYYDPLAGTYYDPNTQQEVYVPQDPGLPEEEEIKEKKPTSQGKSSSKKEMSKRDGKEKKDRGVTRFQENASEGKAPAEDVFKKPLPPTVKKEESPPPPKVVNPLIGLLGEYGGDSDYEEEEEEEQTPPPQPRTAQPQKREEQTKKENEEDKLTDWNKLACLLCRRQFPNKEVLIKHQQLSDLHKQNLEIHRKIKQSEQELAYLERREREGKFKGRGNDRREKLQSFDSPERKRIKYSRETDSDRKLVDKEDIDTSSKGGCVQQATGWRKGTGLGYGHPGLASSEEAEGRMRGPSVGASGRTSKRQSNETYRDAVRRVMFARYKELD>sp|P78332-3|RBM6_HUMAN Isoform 3 of RNA-binding protein 6 OS=Homosapiens OX=9606 GN=RBM6MWGDSRPANRTGPFRGSQEERFAPGWNRDYPPPPLKSHAQERHSGNFPGRDSLPFDFQGHSGPPFANVEEHSFSYGARDGPHGDYRGGEGPGHDFRGGDFSSSDFQSRDSSQLDFRGRDIHSGDFRDREGPPMDYRGGDGTSMDYRGREAPHMNYRDRDAHAVDFRGRDAPPSDFRGRGTYDLDFRGRDGSHADFRGRDLSDLDFRAREQSRSDFRNRDVSDLDFRDKDGTQVDFRGRGSGTTDLDFRDRDTPHSDFRGRHRSRTDQDFRGREMGSCMEFKDREMPPVDPNILDYIQPSTQDREHSGMNVNRREESTHDHTIERPAFGIQKGEFEHSETREGETQGVAFEHESPADFQNSQSPVQDQDKSQLSGREEQSSDAGLFKEEGGLDFLGRQDTDYRSMEYRDVDHRLPGSQMFGYGQSKSFPEGKTARDAQRDLQDQDYRTGPSEEKPSRLIRLSGVPEDATKEEILNAFRTPDGMPVKNLQLKEYNTGNSNDPGQRSYPGVCIKPGFLVLQTM>sp|Q8TDY2|RBCC1_HUMAN RB1-inducible coiled-coil protein 1 OS=Homosapiens OX=9606 GN=RB1CC1 PE=1 SV=3MKLYVFLVNTGTTLTFDTELTVQTVADLKHAIQSKYKIAIQHQVLVVNGGECMAADRRVCTYSAGTDTNPIFLFNKEMILCDRPPAIPKTTFSTENDMEIKVEESLMMPAVFHTVASRTQLALEMYEVAKKLCSFCEGLVHDEHLQHQGWAAIMANLEDCSNSYQKLLFKFESIYSNYLQSIEDIKLKLTHLGTAVSVMAKIPLLECLTRHSYRECLGRLDSLPEHEDSEKAEMKRSTELVLSPDMPRTTNESLLTSFPKSVEHVSPDTADAESGKEIRESCQSTVHQQDETTIDTKDGDLPFFNVSLLDWINVQDRPNDVESLVRKCFDSMSRLDPRIIRPFIAECRQTIAKLDNQNMKAIKGLEDRLYALDQMIASCGRLVNEQKELAQGFLANQKRAENLKDASVLPDLCLSHANQLMIMLQNHRKLLDIKQKCTTAKQELANNLHVRLKWCCFVMLHADQDGEKLQALLRLVIELLERVKIVEALSTVPQMYCLAVVEVVRRKMFIKHYREWAGALVKDGKRLYEAEKSKRESFGKLFRKSFLRNRLFRGLDSWPPSFCTQKPRKFDCELPDISLKDLQFLQSFCPSEVQPFLRVPLLCDFEPLHQHVLALHNLVKAAQSLDEMSQTITDLLSEQKASVSQTSPQSASSPRMESTAGITTTTSPRTPPPLTVQDPLCPAVCPLEELSPDSIDAHTFDFETIPHPNIEQTIHQVSLDLDSLAESPESDFMSAVNEFVIEENLSSPNPISDPQSPEMMVESLYSSVINAIDSRRMQDTNVCGKEDFGDHTSLNVQLERCRVVAQDSHFSIQTIKEDLCHFRTFVQKEQCDFSNSLKCTAVEIRNIIEKVKCSLEITLKEKHQKELLSLKNEYEGKLDGLIKETEENENKIKKLKGELVCLEEVLQNKDNEFALVKHEKEAVICLQNEKDQKLLEMENIMHSQNCEIKELKQSREIVLEDLKKLHVENDEKLQLLRAELQSLEQSHLKELEDTLQVRHIQEFEKVMTDHRVSLEELKKENQQIINQIQESHAEIIQEKEKQLQELKLKVSDLSDTRCKLEVELALKEAETDEIKILLEESRAQQKETLKSLLEQETENLRTEISKLNQKIQDNNENYQVGLAELRTLMTIEKDQCISELISRHEEESNILKAELNKVTSLHNQAFEIEKNLKEQIIELQSKLDSELSALERQKDEKITQQEEKYEAIIQNLEKDRQKLVSSQEQDREQLIQKLNCEKDEAIQTALKEFKLEREVVEKELLEKVKHLENQIAKSPAIDSTRGDSSSLVAELQEKLQEEKAKFLEQLEEQEKRKNEEMQNVRTSLIAEQQTNFNTVLTREKMRKENIINDLSDKLKSTMQQQERDKDLIESLSEDRARLLEEKKKLEEEVSKLRSSSFVPSPYVATAPELYGACAPELPGESDRSAVETADEGRVDSAMETSMMSVQENIHMLSEEKQRIMLLERTLQLKEEENKRLNQRLMSQSMSSVSSRHSEKIAIRDFQVGDLVLIILDERHDNYVLFTVSPTLYFLHSESLPALDLKPGEGASGASRRPWVLGKVMEKEYCQAKKAQNRFKVPLGTKFYRVKAVSWNKKV>sp|Q8TDY2-2|RBCC1_HUMAN Isoform 2 of RB1-inducible coiled-coil protein 1OS=Homo sapiens OX=9606 GN=RB1CC1MKLYVFLVNTGTTLTFDTELTVQTVADLKHAIQSKYKIAIQHQVLVVNGGECMAADRRVCTYSAGTDTNPIFLFNKEMILCDRPPAIPKTTFSTENDMEIKVEESLMMPAVFHTVASRTQLALEMYEVAKKLCSFCEGLVHDEHLQHQGWAAIMANLEDCSNSYQKLLFKFESIYSNYLQSIEDIKLKLTHLGTAVSVMAKIPLLECLTRHSYRECLGRLDSLPEHEDSEKAEMKRSTELVLSPDMPRTTNESLLTSFPKSVEHVSPDTADAESGKEIRESCQSTVHQQDETTIDTKDGDLPFFNVSLLDWINVQDRPNDVESLVRKCFDSMSRLDPRIIRPFIAECRQTIAKLDNQNMKAIKGLEDRLYALDQMIASCGRLVNEQKELAQGFLANQKRAENLKDASVLPDLCLSHANQLMIMLQNHRKLLDIKQKCTTAKQELANNLHVRLKWCCFVMLHADQDGEKLQALLRLVIELLERVKIVEALSTVPQMYCLAVVEVVRRKMFIKHYREWAGALVKDGKRLYEAEKSKRESFGKLFRKSFLRNRLFRGLDSWPPSFCTQKPRKFDCELPDISLKDLQFLQSFCPSEVQPFLRVPLLCDFEPLHQHVLALHNLVKAAQSLDEMSQTITDLLSEQKASVSQTSPQSASSPRMESTAGITTTTSPRTPPPLTVQDPLCPAVCPLEELSPDSIDAHTFDFETIPHPNIEQTIHQVSLDLDSLAESPESDFMSAVNEFVIEENLSSPNPISDPQSPEMMVESLYSSVINAIDSRRMQDTNVCGKEDFGDHTSLNVQLERCRVVAQDSHFSIQTIKEDLCHFRTFVQKEQCDFSNSLKCTAVEIRNIIEKVKCSLEITLKEKHQKELLSLKNEYEGKLDGLIKETEENENKIKKLKGELVCLEEVLQNKDNEFALVKHEKEAVICLQNEKDQKLLEMENIMHSQNCEIKELKQSREIVLEDLKKLHVENDEKLQLLRAELQSLEQSHLKELEDTLQVRHIQEFEKVMTDHRVSLEELKKENQQIINQIQESHAEIIQEKEKQLQELKLKVSDLSDTRCKLEVELALKEAETDEIKILLEESRAQQKETLKSLLEQETENLRTEISKLNQKIQDNNENYQVGLAELRTLMTIEKDQCISELISRHEEESNILKAELNKVTSLHNQAFEIEKNLKEQIIELQSKLDSELSALERQKDEKITQQEEKYEAIIQNLEKDRQKLVSSQEQDREQLIQKLNCEKDEAIQTALKEFKLEREVVEKELLEKVKHLENQIAKSPAIDSTRGDSSSLVAELQEKLQEEKAKFLEQLEEQEKRKNEEMQNVRTSLIAEQQTNFNTVLTREKMRKENIINDLSDKLKSTMQQQERDKDLIESLSEDRARLLEEKKKLEEEVSKLRSSSFVPSPYVATAPELYGACAPELPGESDRSAVETADEGRVDSAMETSMMSVQENIHMLSEEKQRIMLLERTLQLKEEENKRLNQRLMSQSMSSVSSRHSEKIAIRDFQVGDLVLIILDERHDNYVLFTVSPTLYFLHSESLPALDLKPASGASRRPWVLGKVMEKEYCQAKKAQNRFKVPLGTKFYRVKAVSWNKKV>sp|P53805|RCAN1_HUMAN Calcipressin-1 OS=Homo sapiens OX=9606 GN=RCAN1PE=1 SV=4MEDGVAGPQLGAAAEAAEAAEARARPGVTLRPFAPLSGAAEADEGGGDWSFIDCEMEEVDLQDLPSATIACHLDPRVFVDGLCRAKFESLFRTYDKDITFQYFKSFKRVRINFSNPFSAADARLQLHKTEFLGKEMKLYFAQTLHIGSSHLAPPNPDKQFLISPPASPPVGWKQVEDATPVINYDLLYAISKLGPGEKYELHAATDTTPSVVVHVCESDQEKEEEEEMERMRRPKPKIIQTRRPEYTPIHLS>sp|P53805-2|RCAN1_HUMAN Isoform 2 of Calcipressin-1 OS=Homo sapiensOX=9606 GN=RCAN1MHFRNFNYSFSSLIACVANSDIFSESETRAKFESLFRTYDKDITFQYFKSFKRVRINFSNPFSAADARLQLHKTEFLGKEMKLYFAQTLHIGSSHLAPPNPDKQFLISPPASPPVGWKQVEDATPVINYDLLYAISKLGPGEKYELHAATDTTPSVVVHVCESDQEKEEEEEMERMRRPKPKIIQTRRPEYTPIHLS>sp|P53805-3|RCAN1_HUMAN Isoform 3 of Calcipressin-1 OS=Homo sapiensOX=9606 GN=RCAN1MVYAKFESLFRTYDKDITFQYFKSFKRVRINFSNPFSAADARLQLHKTEFLGKEMKLYFAQTLHIGSSHLAPPNPDKQFLISPPASPPVGWKQVEDATPVINYDLLYAISKLGPGEKYELHAATDTTPSVVVHVCESDQEKEEEEEMERMRRPKPKIIQTRRPEYTPIHLS>sp|P53805-4|RCAN1_HUMAN Isoform 4 of Calcipressin-1 OS=Homo sapiensOX=9606 GN=RCAN1MKLYFAQTLHIGSSHLAPPNPDKQFLISPPASPPVGWKQVEDATPVINYDLLYAISKLGPGEKYELHAATDTTPSVVVHVCESDQEKEEEEEMERMRRPKPKIIQTRRPEYTPIHLS>sp|Q13636|RAB31_HUMAN Ras-related protein Rab-31 OS=Homo sapiens OX=9606GN=RAB31 PE=1 SV=1MAIRELKVCLLGDTGVGKSSIVCRFVQDHFDHNISPTIGASFMTKTVPCGNELHKFLIWDTAGQERFHSLAPMYYRGSAAAVIVYDITKQDSFYTLKKWVKELKEHGPENIVMAIAGNKCDLSDIREVPLKDAKEYAESIGAIVVETSAKNAINIEELFQGISRQIPPLDPHENGNNGTIKVEKPTMQASRRCC>sp|Q13637|RAB32_HUMAN Ras-related protein Rab-32 OS=Homo sapiens OX=9606GN=RAB32 PE=1 SV=3MAGGGAGDPGLGAAAAPAPETREHLFKVLVIGELGVGKTSIIKRYVHQLFSQHYRATIGVDFALKVLNWDSRTLVRLQLWDIAGQERFGNMTRVYYKEAVGAFVVFDISRSSTFEAVLKWKSDLDSKVHLPNGSPIPAVLLANKCDQNKDSSQSPSQVDQFCKEHGFAGWFETSAKDNINIEEAARFLVEKILVNHQSFPNEENDVDKIKLDQETLRAENKSQCC>sp|Q9UBK7|RBL2A_HUMAN Rab-like protein 2A OS=Homo sapiens OX=9606GN=RABL2A PE=1 SV=1MAEDKTKPSELDQGKYDADDNVKIICLGDSAVGKSKLMERFLMDGFQPQQLSTYALTLYKHTATVDGKTILVDFWDTAGQERFQSMHASYYHKAHACIMVFDIQRKVTYRNLSTWYTELREFRPEIPCIVVANKIDDINVTQKSFNFAKKFSLPLYFVSAADGTNVVKLFNDAIRLAVSYKQNSQDFMDEIFQELENFSLEQEEEDVPDQEQSSSIETPSEEVASPHS>sp|Q9UBK7-2|RBL2A_HUMAN Isoform 2 of Rab-like protein 2A OS=Homo sapiensOX=9606 GN=RABL2AMAEDKTKPSELDQGKYDADDNVKIICLGDSAVGKSKLMERFLMDGFQPQQLSTYALTLYKHTATVDGKTILVDFWDTAGQERFQSMHASYYHKAHACIMVFDIQRKVTYRNLSTWYTELREFRPEIPCIVVANKIDADINVTQKSFNFAKKFSLPLYFVSAADGTNVVKLFNDAIRLAVSYKQNSQDFMDEIFQELENFSLEQEEEDVPDQEQSSSIETPSEEVASPHS>sp|Q9UBK7-3|RBL2A_HUMAN Isoform 3 of Rab-like protein 2A OS=Homo sapiensOX=9606 GN=RABL2AMAEDKTKPSELDQGKYDADDNVKIICLGDSAVGKSKLMERFLMDGFQPQQLSTYALTLYKHTATVDGKTILVDFWDTAGQERFQSMHASYYHKAHACIMVFDIQRKVTYRNLSTWYTELREFRPEIPCIVVANKIDDINVTQKSFNFAKKFSLPLYFVSAADGTNVVKVWLTAEVASKLFNDAIRLAVSYKQNSQDFMDEIFQELENFSLEQEEEDVPDQEQSSSIETPSEEVASPHS>sp|Q5GAN3|RNS13_HUMAN Probable inactive ribonuclease-like protein 13OS=Homo sapiens OX=9606 GN=RNASE13 PE=2 SV=1MAPAVTRLLFLQLVLGPTLVMDIKMQIGSRNFYTLSIDYPRVNYPKGFRGYCNGLMSYMRGKMQNSDCPKIHYVIHAPWKAIQKFCKYSDSFCENYNEYCTLTQDSLPITVCSLSHQQPPTSCYYNSTLTNQKLYLLCSRKYEADPIGIAGLYSGI>sp|Q9BYD6|RM01_HUMAN 39S ribosomal protein L1, mitochondrial OS=Homosapiens OX=9606 GN=MRPL1 PE=1 SV=2MAAAVRCMGRALIHHQRHSLSKMVYQTSLCSCSVNIRVPNRHFAAATKSAKKTKKGAKEKTPDEKKDEIEKIKAYPYMEGEPEDDVYLKRLYPRQIYEVEKAVHLLKKFQILDFTSPKQSVYLDLTLDMALGKKKNVEPFTSVLSLPYPFASEINKVAVFTENASEVKIAEENGAAFAGGTSLIQKIWDDEIVADFYVAVPEIMPELNRLRKKLNKKYPKLSRNSIGRDIPKMLELFKNGHEIKVDEERENFLQTKIATLDMSSDQIAANLQAVINEVCRHRPLNLGPFVVRAFLRSSTSEGLLLKIDPLLPKEVKNEESEKEDA>sp|Q8TAA1|RNS11_HUMAN Probable ribonuclease 11 OS=Homo sapiens OX=9606GN=RNASE11 PE=1 SV=1METFPLLLLSLGLVLAEASESTMKIIKEEFTDEEMQYDMAKSGQEKQTIEILMNPILLVKNTSLSMSKDDMSSTLLTFRSLHYNDPKGNSSGNDKECCNDMTVWRKVSEANGSCKWSNNFIRSSTEVMRRVHRAPSCKFVQNPGISCCESLELENTVCQFTTGKQFPRCQYHSVTSLEKILTVLTGHSLMSWLVCGSKL>sp|Q14242|SELPL_HUMAN P-selectin glycoprotein ligand 1 OS=Homo sapiensOX=9606 GN=SELPLG PE=1 SV=1MPLQLLLLLILLGPGNSLQLWDTWADEAEKALGPLLARDRRQATEYEYLDYDFLPETEPPEMLRNSTDTTPLTGPGTPESTTVEPAARRSTGLDAGGAVTELTTELANMGNLSTDSAAMEIQTTQPAATEAQTTQPVPTEAQTTPLAATEAQTTRLTATEAQTTPLAATEAQTTPPAATEAQTTQPTGLEAQTTAPAAMEAQTTAPAAMEAQTTPPAAMEAQTTQTTAMEAQTTAPEATEAQTTQPTATEAQTTPLAAMEALSTEPSATEALSMEPTTKRGLFIPFSVSSVTHKGIPMAASNLSVNYPVGAPDHISVKQCLLAILILALVATIFFVCTVVLAVRLSRKGHMYPVRNYSPTEMVCISSLLPDGGEGPSATANGGLSKAKSPGLTPEPREDREGDDLTLHSFLP>sp|Q14242-2|SELPL_HUMAN Isoform 2 of P-selectin glycoprotein ligand 1OS=Homo sapiens OX=9606 GN=SELPLGMAVGASGLEGDKMAGAMPLQLLLLLILLGPGNSLQLWDTWADEAEKALGPLLARDRRQATEYEYLDYDFLPETEPPEMLRNSTDTTPLTGPGTPESTTVEPAARRSTGLDAGGAVTELTTELANMGNLSTDSAAMEIQTTQPAATEAQTTQPVPTEAQTTPLAATEAQTTRLTATEAQTTPLAATEAQTTPPAATEAQTTQPTGLEAQTTAPAAMEAQTTAPAAMEAQTTPPAAMEAQTTQTTAMEAQTTAPEATEAQTTQPTATEAQTTPLAAMEALSTEPSATEALSMEPTTKRGLFIPFSVSSVTHKGIPMAASNLSVNYPVGAPDHISVKQCLLAILILALVATIFFVCTVVLAVRLSRKGHMYPVRNYSPTEMVCISSLLPDGGEGPSATANGGLSKAKSPGLTPEPREDREGDDLTLHSFLP>sp|O00631|SARCO_HUMAN Sarcolipin OS=Homo sapiens OX=9606 GN=SLN PE=1SV=1MGINTRELFLNFTIVLITVILMWLLVRSYQY>sp|P35542|SAA4_HUMAN Serum amyloid A-4 protein OS=Homo sapiens OX=9606GN=SAA4 PE=1 SV=2MRLFTGIVFCSLVMGVTSESWRSFFKEALQGVGDMGRAYWDIMISNHQNSNRYLYARGNYDAAQRGPGGVWAAKLISRSRVYLQGLIDCYLFGNSSTVLEDSKSNEKAEEWGRSGKDPDRFRPDGLPKKY>sp|P52434|RPAB3_HUMAN DNA-directed RNA polymerases I, II, and IIIsubunit RPABC3 OS=Homo sapiens OX=9606 GN=POLR2H PE=1 SV=4MAGILFEDIFDVKDIDPEGKKFDRVSRLHCESESFKMDLILDVNIQIYPVDLGDKFRLVIASTLYEDGTLDDGEYNPTDDRPSRADQFEYVMYGKVYRIEGDETSTEAATRLSAYVSYGGLLMRLQGDANNLHGFEVDSRVYLLMKKLAF>sp|P52434-2|RPAB3_HUMAN Isoform 2 of DNA-directed RNA polymerases I, II,and III subunit RPABC3 OS=Homo sapiens OX=9606 GN=POLR2HMAGILFEDIFDVKDIDPEGKKFDRVSRLHCESESFKMDLILDVNIQIYPVDLGDKFRLVIASTLYEDGTLDDGEYNPTDDRPSSSAYVSYGGLLMRLQGDANNLHGFEVDSRVYLLMKKLAF>sp|P52434-3|RPAB3_HUMAN Isoform 3 of DNA-directed RNA polymerases I, II,and III subunit RPABC3 OS=Homo sapiens OX=9606 GN=POLR2HMDLILDVNIQIYPVDLGDKFRLVIASTLYEDGTLDDGEYNPTDDRPSRADQFEYVMYGKVYRIEGDETSTEAATRLSAYVSYGGLLMRLQGDANNLHGFEVDSRVYLLMKKLAF>sp|P52434-4|RPAB3_HUMAN Isoform 4 of DNA-directed RNA polymerases I, II,and III subunit RPABC3 OS=Homo sapiens OX=9606 GN=POLR2HMAGILFEDIFDVKDIDPEGKKFDRVSRLHCESESFKMDLILDVNIQIYPVDLGDKFRLVIASTLYEDGTLDDGEYNPTDDRPSRADQFEYVMYGKVYRIEGDETSTEAATRLLRLRAAEWQCSRITGWGLLFQLCVRVLWGPAHEAAGGCQQPAWIRGGLQSLSPDEEASLLNLA>sp|P52434-5|RPAB3_HUMAN Isoform 5 of DNA-directed RNA polymerases I, II,and III subunit RPABC3 OS=Homo sapiens OX=9606 GN=POLR2HMDLILDVNIQIYPVDLGDKFRLVIASTLYEDGTLDDGEYNPTDDRPSSSAYVSYGGLLMRLQGDANNLHGFEVDSRVYLLMKKLAF>sp|Q9UL12|SARDH_HUMAN Sarcosine dehydrogenase, mitochondrial OS=Homosapiens OX=9606 GN=SARDH PE=1 SV=1MASLSRALRVAAAHPRQSPTRGMGPCNLSSAAGPTAEKSVPYQRTLKEGQGTSVVAQGPSRPLPSTANVVVIGGGSLGCQTLYHLAKLGMSGAVLLERERLTSGTTWHTAGLLWQLRPSDVEVELLAHTRRVVSRELEEETGLHTGWIQNGGLFIASNRQRLDEYKRLMSLGKAYGVESHVLSPAETKTLYPLMNVDDLYGTLYVPHDGTMDPAGTCTTLARAASARGAQVIENCPVTGIRVWTDDFGVRRVAGVETQHGSIQTPCVVNCAGVWASAVGRMAGVKVPLVAMHHAYVVTERIEGIQNMPNVRDHDASVYLRLQGDALSVGGYEANPIFWEEVSDKFAFGLFDLDWEVFTQHIEGAINRVPVLEKTGIKSTVCGPESFTPDHKPLMGEAPELRGFFLGCGFNSAGMMLGGGCGQELAHWIIHGRPEKDMHGYDIRRFHHSLTDHPRWIRERSHESYAKNYSVVFPHDEPLAGRNMRRDPLHEELLGQGCVFQERHGWERPGWFHPRGPAPVLEYDYYGAYGSRAHEDYAYRRLLADEYTFAFPPHHDTIKKECLACRGAAAVFDMSYFGKFYLVGLDARKAADWLFSADVSRPPGSTVYTCMLNHRGGTESDLTVSRLAPSHQASPLAPAFEGDGYYLAMGGAVAQHNWSHITTVLQDQKSQCQLIDSSEDLGMISIQGPASRAILQEVLDADLSNEAFPFSTHKLLRAAGHLVRAMRLSFVGELGWELHIPKASCVPVYRAVMAAGAKHGLINAGYRAIDSLSIEKGYRHWHADLRPDDSPLEAGLAFTCKLKSPVPFLGREALEQQRAAGLRRRLVCFTMEDKVPMFGLEAIWRNGQVVGHVRRADFGFAIDKTIAYGYIHDPSGGPVSLDFVKSGDYALERMGVTYGAQAHLKSPFDPNNKRVKGIY>sp|Q9UL12-2|SARDH_HUMAN Isoform 2 of Sarcosine dehydrogenase,mitochondrial OS=Homo sapiens OX=9606 GN=SARDHMSLGKAYGVESHVLSPAETKTLYPLMNVDDLYGTLYVPHDGTMDPAGTCTTLARAASARGAQVIENCPVTGIRVWTDDFGVRRVAGVETQHGSIQTPCVVNCAGVWASAVGRMAGVKVPLVAMHHAYVVTERIEGIQNMPNVRDHDASVYLRLQGDALSVGGYEANPIFWEEVSDKFAFGLFDLDWEVFTQHIEGAINRVPVLEKTGIKSTVCGPESFTPDHKPLMGEAPELRGFFLGCGFNSAGMMLGGGCGQELAHWIIHGRPEKDMHGYDIRRFHHSLTDHPRWIRERSHESYAKNYSVVFPHDEPLAGRNMRRDPLHEELLGQGCVFQERHGWERPGWFHPRGPAPVLEYDYYGAYGSRAHEDYAYRRLLADEYTFAFPPHHDTIKKECLACRGAAAVFDMSYFGKFYLVGLDARKAADWLFSADVSRPPGSTVYTCMLNHRGGTESDLTVSRLAPSHQASPLAPAFEGDGYYLAMGGAVAQHNWSHITTVLQDQKSQCQLIDSSEDLGMISIQGPASRAILQEVLDADLSNEAFPFSTHKLLRAAGHLVRAMRLSFVGELGWELHIPKASCVPVYRAVMAAGAKHGLINAGYRAIDSLSIEKGYRHWHADLRPDDSPLEAGLAFTCKLKSPVPFLGREALEQQRAAGLRRRLVCFTMEDKVPMFGLEAIWRNGQVVGHVRRADFGFAIDKTIAYGYIHDPSGGPVSLDFVKSGDYALERMGVTYGAQAHLKSPFDPNNKRVKGIY>sp|Q8N9R8|SCAI_HUMAN Protein SCAI OS=Homo sapiens OX=9606 GN=SCAI PE=1SV=2MVRGARQPQQPRSRLAPRLTGTVEKPPRKRRSRTEFALKEIMSSGGAEDDIPQGERKTVTDFCYLLDKSKQLFNGLRDLPQYGQKQWQSYFGRTFDVYTKLWKFQQQHRQVLDNRYGLKRWQIGEIASKIGQLYYHYYLRTSETSYLNEAFSFYSAIRQRSYYSQVNKEDRPELVVKKLRYYARFIVVCLLLNKMDVVKDLVKELSDEIEDYTHRFNTEDQVEWNLVLQEVAAFIEADPVMVLNDDNTIVITSNRLAETGAPLLEQGMIVGQLSLADALIIGNCNNQVKFSELTVDMFRMLQALEREPMNLASQMNKPGMQESADKPTRRENPHKYLLYKPTFSQLYTFLAASFKELPANSVLLIYLSATGVFPTGRSDSEGPYDFGGVLTNSNRDIINGDAIHKRNQSHKEMHCLHPGDLYPFTRKPLFIIVDSSNSVAYKNFTNLFGQPLVCLLSPTAYPKALQDQSQRGSLFTLFLNNPLMAFLFVSGLSSMRRGLWEKCQEYLRKINRDIAQLLTHSRSIDQAFLQFFGDEFLRLLLTRFIFCSATMRMHKIFRETRNYPESYPQLPRDETVENPHLQKHILELASILDVRNVFFENTIDDY>sp|Q8N9R8-2|SCAI_HUMAN Isoform 2 of Protein SCAI OS=Homo sapiens OX=9606GN=SCAIMVRGARQPQQPRSRLAPRLTGTVEKPPRKRRSSIRGSGDSSHSQSQGERYQHFTEKTEFALKEIMSSGGAEDDIPQGERKTVTDFCYLLDKSKQLFNGLRDLPQYGQKQWQSYFGRTFDVYTKLWKFQQQHRQVLDNRYGLKRWQIGEIASKIGQLYYHYYLRTSETSYLNEAFSFYSAIRQRSYYSQVNKEDRPELVVKKLRYYARFIVVCLLLNKMDVVKDLVKELSDEIEDYTHRFNTEDQVEWNLVLQEVAAFIEADPVMVLNDDNTIVITSNRLAETGAPLLEQGMIVGQLSLADALIIGNCNNQVKFSELTVDMFRMLQALEREPMNLASQMNKPGMQESADKPTRRENPHKYLLYKPTFSQLYTFLAASFKELPANSVLLIYLSATGVFPTGRSDSEGPYDFGGVLTNSNRDIINGDAIHKRNQSHKEMHCLHPGDLYPFTRKPLFIIVDSSNSVAYKNFTNLFGQPLVCLLSPTAYPKALQDQSQRGSLFTLFLNNPLMAFLFVSGLSSMRRGLWEKCQEYLRKINRDIAQLLTHSRSIDQAFLQFFGDEFLRLLLTRFIFCSATMRMHKIFRETRNYPESYPQLPRDETVENPHLQKHILELASILDVRNVFFENTIDDY>sp|Q96E14|RMI2_HUMAN RecQ-mediated genome instability protein 2 OS=Homosapiens OX=9606 GN=RMI2 PE=1 SV=2MAAAADSFSGGPAGVRLPRSPPLKVLAEQLRRDAEGGPGAWRLSRAAAGRGPLDLAAVWMQGRVVMADRGEARLRDPSGDFSVRGLERVPRGRPCLVPGKYVMVMGVVQACSPEPCLQAVKMTDLSDNPIHESMWELEVEDLHRNIP>sp|Q96E14-2|RMI2_HUMAN Isoform 2 of RecQ-mediated genome instabilityprotein 2 OS=Homo sapiens OX=9606 GN=RMI2MKQTQVGSLFSLGIRNPEPGPVSGTAVPRQLAWKSGKYVMVMGVVQACSPEPCLQAVKMTDLSDNPIHESMWELEVEDLHRNIP>sp|Q9UHV5|RPGFL_HUMAN Rap guanine nucleotide exchange factor-like 1OS=Homo sapiens OX=9606 GN=RAPGEFL1 PE=1 SV=2MKPLEKFLKKQTSQLAGRTVAGGPGGGLGSCGGPGGGGGPGGGGGPAGGQRSLQRRQSVSRLLLPAFLREPPAEPGLEPPVPEEGGEPAGVAEEPGSGGPCWLQLEEVPGPGPLGGGGPLRSPSSYSSDELSPGEPLTSPPWAPLGAPERPEHLLNRVLERLAGGATRDSAASDILLDDIVLTHSLFLPTEKFLQELHQYFVRAGGMEGPEGLGRKQACLAMLLHFLDTYQGLLQEEEGAGHIIKDLYLLIMKDESLYQGLREDTLRLHQLVETVELKIPEENQPPSKQVKPLFRHFRRIDSCLQTRVAFRGSDEIFCRVYMPDHSYVTIRSRLSASVQDILGSVTEKLQYSEEPAGREDSLILVAVSSSGEKVLLQPTEDCVFTALGINSHLFACTRDSYEALVPLPEEIQVSPGDTEIHRVEPEDVANHLTAFHWELFRCVHELEFVDYVFHGERGRRETANLELLLQRCSEVTHWVATEVLLCEAPGKRAQLLKKFIKIAALCKQNQDLLSFYAVVMGLDNAAVSRLRLTWEKLPGKFKNLFRKFENLTDPCRNHKSYREVISKMKPPVIPFVPLILKDLTFLHEGSKTLVDGLVNIEKLHSVAEKVRTIRKYRSRPLCLDMEASPNHLQTKAYVRQFQVIDNQNLLFELSYKLEANSQ>sp|Q9UHV5-2|RPGFL_HUMAN Isoform 2 of Rap guanine nucleotide exchangefactor-like 1 OS=Homo sapiens OX=9606 GN=RAPGEFL1MEGPEGLGRKQACLAMLLHFLDTYQGLLQEEEGAGHIIKDLYLLIMKDESLYQGLREDTLRLHQLVETVELKIPEENQPPSKQVKPLFRHFRRIDSCLQTRVAFRGSDEIFCRVYMPDHSYVTIRSRLSASVQDILGSVTEKLQYSEEPAGREDSLILVAVSSSGEKVLLQPTEDCVFTALGINSHLFACTRDSYEALVPLPEEIQVSPGDTEIHRVEPEDVANHLTAFHWELFRCVHELEFVDYVFHGERGRRETANLELLLQRCSEVTHWVATEVLLCEAPGKRAQLLKKFIKIAALCKQNQDLLSFYAVVMGLDNAAVSRLRLTWEKLPGKFKNLFRKFENLTDPCRNHKSYREVISKMKPPVIPFVPLILKDLTFLHEGSKTLVDGLVNIEKLHSVAEKVRTIRKYRSRPLCLDMEASPNHLQTKAYVRQFQVIDNQNLLFELSYKLEANSQ>sp|Q9UHV5-3|RPGFL_HUMAN Isoform 3 of Rap guanine nucleotide exchangefactor-like 1 OS=Homo sapiens OX=9606 GN=RAPGEFL1MLIHPRGLPSSSHRRKINSTYFYILLDDIVLTHSLFLPTEKFLQELHQYFVRAGGMEGPEGLGRKQACLAMLLHFLDTYQGLLQEEEGAGHIIKDLYLLIMKDESLYQGLREDTLRLHQLVETVELKIPEENQPPSKQVKPLFRHFRRIDSCLQTRVAFRGSDEIFCRVYMPDHSYVTIRSRLSASVQDILGSVTEKLQYSEEPAGREDSLILVAVSSSGEKVLLQPTEDCVFTALGINSHLFACTRDSYEALVPLPEEIQVSPGDTEIHRVEPEDVANHLTAFHWELFRCVHELEFVDYVFHGERGRRETANLELLLQRCSEVTHWVATEVLLCEAPGKRAQLLKKFIKIAALCKQNQDLLSFYAVVMGLDNAAVSRLRLTWEKLPGKFKNLFRKFENLTDPCRNHKSYREVISKMKPPVIPFVPLILKDLTFLHEGSKTLVDGLVNIEKLHSVAEKVRTIRKYRSRPLCLDMEASPNHLQTKAYVRQFQVIDNQNLLFELSYKLEANSQ>sp|Q684P5|RPGP2_HUMAN Rap1 GTPase-activating protein 2 OS=Homo sapiensOX=9606 GN=RAP1GAP2 PE=1 SV=2MFGRKRSVSFGGFGWIDKTMLASLKVKKQELANSSDATLPDRPLSPPLTAPPTMKSSEFFEMLEKMQGIKLEEQKPGPQKNKDDYIPYPSIDEVVEKGGPYPQVILPQFGGYWIEDPENVGTPTSLGSSICEEEEEDNLSPNTFGYKLECKGEARAYRRHFLGKDHLNFYCTGSSLGNLILSVKCEEAEGIEYLRVILRSKLKTVHERIPLAGLSKLPSVPQIAKAFCDDAVGLRFNPVLYPKASQMIVSYDEHEVNNTFKFGVIYQKARQTLEEELFGNNEESPAFKEFLDLLGDTITLQDFKGFRGGLDVTHGQTGVESVYTTFRDREIMFHVSTKLPFTDGDAQQLQRKRHIGNDIVAIIFQEENTPFVPDMIASNFLHAYIVVQVETPGTETPSYKVSVTAREDVPTFGPPLPSPPVFQKGPEFREFLLTKLTNAENACCKSDKFAKLEDRTRAALLDNLHDELHAHTQAMLGLGPEEDKFENGGHGGFLESFKRAIRVRSHSMETMVGGQKKSHSGGIPGSLSGGISHNSMEVTKTTFSPPVVAATVKNQSRSPIKRRSGLFPRLHTGSEGQGDSRARCDSTSSTPKTPDGGHSSQEIKSETSSNPSSPEICPNKEKPFMKLKENGRAISRSSSSTSSVSSTAGEGEAMEEGDSGGSQPSTTSPFKQEVFVYSPSPSSESPSLGAAATPIIMSRSPTDAKSRNSPRSNLKFRFDKLSHASSGAGH>sp|Q684P5-2|RPGP2_HUMAN Isoform 2 of Rap1 GTPase-activating protein 2OS=Homo sapiens OX=9606 GN=RAP1GAP2MFGRKRSVSFGGFGWIDKTMLASLKVKKQELANSSDATLPDRPLSPPLTAPPTMKSSEFFEMLEKMQDDYIPYPSIDEVVEKGGPYPQVILPQFGGYWIEDPENVGTPTSLGSSICEEEEEDNLSPNTFGYKLECKGEARAYRRHFLGKDHLNFYCTGSSLGNLILSVKCEEAEGIEYLRVILRSKLKTVHERIPLAGLSKLPSVPQIAKAFCDDAVGLRFNPVLYPKASQMIVSYDEHEVNNTFKFGVIYQKARQTLEEELFGNNEESPAFKEFLDLLGDTITLQDFKGFRGGLDVTHGQTGVESVYTTFRDREIMFHVSTKLPFTDGDAQQLQRKRHIGNDIVAIIFQEENTPFVPDMIASNFLHAYIVVQVETPGTETPSYKVSVTAREDVPTFGPPLPSPPVFQKGPEFREFLLTKLTNAENACCKSDKFAKLEDRTRAALLDNLHDELHAHTQAMLGLGPEEDKFENGGHGGFLESFKRAIRVRSHSMETMVGGQKKSHSGGIPGSLSGGISHNSMEVTKTTFSPPVVAATVKNQSRSPIKRRSGLFPRLHTGSEGQGDSRARCDSTSSTPKTPDGGHSSQEIKSETSSNPSSPEICPNKEKPFMKLKENGRAISRSSSSTSSVSSTAGEGEAMEEGDSGGSQPSTTSPFKQEVFVYSPSPSSESPSLGAAATPIIMSRSPTDAKSRNSPRSNLKFRFDKLSHASSGAGH>sp|Q684P5-3|RPGP2_HUMAN Isoform 3 of Rap1 GTPase-activating protein 2OS=Homo sapiens OX=9606 GN=RAP1GAP2MLASLKVKKQELANSSDATLPDRPLSPPLTAPPTMKSSEFFEMLEKMQGIKLEEQKPGPQKNKDDYIPYPSIDEVVEKGGPYPQVILPQFGGYWIEDPENVGTPTSLGSSICEEEEEDNLSPNTFGYKLECKGEARAYRRHFLGKDHLNFYCTGSSLGNLILSVKCEEAEGIEYLRVILRSKLKTVHERIPLAGLSKLPSVPQIAKAFCDDAVGLRFNPVLYPKASQMIVSYDEHEVNNTFKFGVIYQKARQTLEEELFGNNEESPAFKEFLDLLGDTITLQDFKGFRGGLDVTHGQTGVESVYTTFRDREIMFHVSTKLPFTDGDAQQLQRKRHIGNDIVAIIFQEENTPFVPDMIASNFLHAYIVVQVETPGTETPSYKVSVTAREDVPTFGPPLPSPPVFQKGPEFREFLLTKLTNAENACCKSDKFAKLEDRTRAALLDNLHDELHAHTQAMLGLGPEEDKFENGGHGGFLESFKRAIRVRSHSMETMVGGQKKSHSGGIPGSLSGGISHNSMEVTKTTFSPPVVAATVKNQSRSPIKRRSGLFPRLHTGSEGQGDSRARCDSTSSTPKTPDGGHSSQEIKSETSSNPSSPEICPNKEKPFMKLKENGRAISRSSSSTSSVSSTAGEGEAMEEGDSGGSQPSTTSPFKQEVFVYSPSPSSESPSLGAAATPIIMSRSPTDAKSRNSPRSNLKFRFDKLSHASSGAGH>sp|A6NIE6|RN3P2_HUMAN Putative RRN3-like protein RRN3P2 OS=Homo sapiensOX=9606 GN=RRN3P2 PE=5 SV=3MAAPLLHTRLPGDAAASPSAVKMLGASRTGISNMRALENDFFNSPPRKTVQFGGTVTEVLLKYKTGETNDFELLKNQLLDPDIKDDQIINWLLEFRSSIMYLTKDFEQLISIILRLPWLNRSQTVVEEYLAFLGNLVSAQTVFLRPCLSMIASHFVPPRVIIKEGDVDVSDSDDEDDNLPANFDTSQSLANNSKICTIECYVHNLLRISVYFPTLRHEILELIIEKLLKLDVNASRQGIEDAEETANQTCGGTDSTEGLCNMGFAEAFLEPLWKKLQDPSNPAIIRQAAGNYIGSFLARAKFIPLMIREQRHSAMLLSMDHFTQPAKLCSTPLFLDTSSF>sp|P19387|RPB3_HUMAN DNA-directed RNA polymerase II subunit RPB3 OS=Homosapiens OX=9606 GN=POLR2C PE=1 SV=2MPYANQPTVRITELTDENVKFIIENTDLAVANSIRRVFIAEVPIIAIDWVQIDANSSVLHDEFIAHRLGLIPLISDDIVDKLQYSRDCTCEEFCPECSVEFTLDVRCNEDQTRHVTSRDLISNSPRVIPVTSRNRDNDPNDYVEQDDILIVKLRKGQELRLRAYAKKGFGKEHAKWNPTAGVAFEYDPDNALRHTVYPKPEEWPKSEYSELDEDESQAPYDPNGKPERFYYNVESCGSLRPETIVLSALSGLKKKLSDLQTQLSHEIQSDVLTIN>sp|O60930|RNH1_HUMAN Ribonuclease H1 OS=Homo sapiens OX=9606 GN=RNASEH1PE=1 SV=2MSWLLFLAHRVALAALPCRRGSRGFGMFYAVRRGRKTGVFLTWNECRAQVDRFPAARFKKFATEDEAWAFVRKSASPEVSEGHENQHGQESEAKASKRLREPLDGDGHESAEPYAKHMKPSVEPAPPVSRDTFSYMGDFVVVYTDGCCSSNGRRRPRAGIGVYWGPGHPLNVGIRLPGRQTNQRAEIHAACKAIEQAKTQNINKLVLYTDSMFTINGITNWVQGWKKNGWKTSAGKEVINKEDFVALERLTQGMDIQWMHVPGHSGFIGNEEADRLAREGAKQSED>sp|Q9H2W6|RM46_HUMAN 39S ribosomal protein L46, mitochondrial OS=Homosapiens OX=9606 GN=MRPL46 PE=1 SV=1MAAPVRRTLLGVAGGWRRFERLWAGSLSSRSLALAAAPSSNGSPWRLLGALCLQRPPVVSKPLTPLQEEMASLLQQIEIERSLYSDHELRALDENQRLAKKKADLHDEEDEQDILLAQDLEDMWEQKFLQFKLGARITEADEKNDRTSLNRKLDRNLVLLVREKFGDQDVWILPQAEWQPGETLRGTAERTLATLSENNMEAKFLGNAPCGHYTFKFPQAMRTESNLGAKVFFFKALLLTGDFSQAGNKGHHVWVTKDELGDYLKPKYLAQVRRFVSDL>sp|Q8WVZ7|RN133_HUMAN E3 ubiquitin-protein ligase RNF133 OS=Homo sapiensOX=9606 GN=RNF133 PE=2 SV=1MHLLKVGTWRNNTASSWLMKFSVLWLVSQNCCRASVVWMAYMNISFHVGNHVLSELGETGVFGRSSTLKRVAGVIVPPEGKIQNACNPNTIFSRSKYSETWLALIERGGCTFTQKIKVATEKGASGVIIYNVPGTGNQVFPMFHQAFEDVVVVMIGNLKGTEIFHLIKKGVLITAVVEVGRKHIIWMNHYLVSFVIVTTATLAYFIFYHIHRLCLARIQNRRWQRLTTDLQNTFGQLQLRVVKEGDEEINPNGDSCVICFERYKPNDIVRILTCKHFFHKNCIDPWILPHGTCPICKCDILKVLGIQVVVENGTEPLQVLMSNELPETLSPSEEETNNEVSPAGTSDKVIHVEENPTSQNNDIQPHSVVEDVHPSP>sp|Q9HAT0|ROP1A_HUMAN Ropporin-1A OS=Homo sapiens OX=9606 GN=ROPN1 PE=1SV=2MAQTDKPTCIPPELPKMLKEFAKAAIRVQPQDLIQWAADYFEALSRGETPPVRERSERVALCNRAELTPELLKILHSQVAGRLIIRAEELAQMWKVVNLPTDLFNSVMNVGRFTEEIEWLKFLALACSALGVTITKTLKIVCEVLSCDHNGGSPRIPFSTFQFLYTYIAKVDGEISASHVSRMLNYMEQEVIGPDGIITVNDFTQNPRVQLE>sp|Q9HAT0-2|ROP1A_HUMAN Isoform 2 of Ropporin-1A OS=Homo sapiens OX=9606GN=ROPN1MAQTDKPTCIPPELPKMLKEFAKAAIRVQPQDLIQWAAEYVLLSRLHPLEDGRRQRVL>sp|Q9NXI6|RN186_HUMAN E3 ubiquitin-protein ligase RNF186 OS=Homo sapiensOX=9606 GN=RNF186 PE=1 SV=1MACTKTLQQSQPISAGATTTTTAVAPAGGHSGSTECDLECLVCREPYSCPRLPKLLACQHAFCAICLKLLLCVQDNTWSITCPLCRKVTAVPGGLICSLRDHEAVVGQLAQPCTEVSLCPQGLVDPADLAAGHPSLVGEDGQDEVSANHVAARRLAAHLLLLALLIILIGPFIYPGVLRWVLTFIIALALLMSTLFCCLPSTRGSCWPSSRTLFCREQKHSHISSIA>sp|Q5VTB9|RN220_HUMAN E3 ubiquitin-protein ligase RNF220 OS=Homo sapiensOX=9606 GN=RNF220 PE=1 SV=1MDLHRAAFKMENSSYLPNPLASPALMVLASTAEASRDASIPCQQPRPFGVPVSVDKDVHIPFTNGSYTFASMYHRQGGVPGTFANRDFPPSLLHLHPQFAPPNLDCTPISMLNHSGVGAFRPFASTEDRESYQSAFTPAKRLKNCHDTESPHLRFSDADGKEYDFGTQLPSSSPGSLKVDDTGKKIFAVSGLISDREASSSPEDRNDRCKKKAAALFDSQAPICPICQVLLRPSELQEHMEQELEQLAQLPSSKNSLLKDAMAPGTPKSLLLSASIKREGESPTASPHSSATDDLHHSDRYQTFLRVRANRQTRLNARIGKMKRRKQDEGQREGSCMAEDDAVDIEHENNNRFEEYEWCGQKRIRATTLLEGGFRGSGFIMCSGKENPDSDADLDVDGDDTLEYGKPQYTEADVIPCTGEEPGEAKEREALRGAVLNGGPPSTRITPEFSKWASDEMPSTSNGESSKQEAMQKTCKNSDIEKITEDSAVTTFEALKARVRELERQLSRGDRYKCLICMDSYSMPLTSIQCWHVHCEECWLRTLGAKKLCPQCNTITAPGDLRRIYL>sp|Q5VTB9-3|RN220_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF220OS=Homo sapiens OX=9606 GN=RNF220MEQELEQLAQLPSSKNSLLKDAMAPGTPKSLLLSASIKREGESPTASPHSSATDDLHHSDRYQTFLRVRANRQTRLNARIGKMKRRKQDEGQVCPLCNRPLAGSEQEMSRHVEHCLSKREGSCMAEDDAVDIEHENNNRFEEYEWCGQKRIRATTLLEGGFRGSGFIMCSGKENPDSDADLDVDGDDTLEYGKPQYTEADVIPCTGEEPGEAKEREALRGAVLNGGPPSTRITPEFSKWASDEMPSTSNGESSKQEAMQKTCKNSDIEKITEDSAVTTFEALKARVRELERQLSRGDRYKCLICMDSYSMPLTSIQCWHVHCEECWLRTLGAKKLCPQCNTITAPGDLRRIYL>sp|Q63HN8|RN213_HUMAN E3 ubiquitin-protein ligase RNF213 OS=Homo sapiensOX=9606 GN=RNF213 PE=1 SV=3MECPSCQHVSKEETPKFCSQCGERLPPAAPIADSENNNSTMASASEGEMECGQELKEEGGPCLFPGSDSWQENPEEPCSKASWTVQESKKKKRKKKKKGNKSASSELASLPLSPASPCHLTLLSNPWPQDTALPHSQAQQSGPTGQPSQPPGTATTPLEGDGLSAPTEVGDSPLQAQALGEAGVATGSEAQSSPQFQDHTEGEDQDASIPSGGRGLSQEGTGPPTSAGEGHSRTEDAAQELLLPESKGGSSEPGTELQTTEQQAGASASMAVDAVAEPANAVKGAGKEMKEKTQRMKQPPATTPPFKTHCQEAETKTKDEMAAAEEKVGKNEQGEPEDLKKPEGKNRSAAAVKNEKEQKNQEADVQEVKASTLSPGGGVTVFFHAIISLHFPFNPDLHKVFIRGGEEFGESKWDSNICELHYTRDLGHDRVLVEGIVCISKKHLDKYIPYKYVIYNGESFEYEFIYKHQQKKGEYVNRCLFIKSSLLGSGDWHQYYDIVYMKPHGRLQKVMNHITDGPRKDLVKGKQIAAALMLDSTFSILQTWDTINLNSFFTQFEQFCFVLQQPMIYEGQAQLWTDLQYREKEVKRYLWQHLKKHVVPLPDGKSTDFLPVDCPVRSKLKTGLIVLFVVEKIELLLEGSLDWLCHLLTSDASSPDEFHRDLSHILGIPQSWRLYLVNLCQRCMDTRTYTWLGALPVLHCCMELAPRHKDAWRQPEDTWAALEGLSFSPFREQMLDTSSLLQFMREKQHLLSIDEPLFRSWFSLLPLSHLVMYMENFIEHLGRFPAHILDCLSGIYYRLPGLEQVLNTQDVQDVQNVQNILEMLLRLLDTYRDKIPEEALSPSYLTVCLKLHEAICSSTKLLKFYELPALSAEIVCRMIRLLSLVDSAGQRDETGNNSVQTVFQGTLAATKRWLREVFTKNMLTSSGASFTYVKEIEVWRRLVEIQFPAEHGWKESLLGDMEWRLTKEEPLSQITAYCNSCWDTKGLEDSVAKTFEKCIIEAVSSACQSQTSILQGFSYSDLRKFGIVLSAVITKSWPRTADNFNDILKHLLTLADVKHVFRLCGTDEKILANVTEDAKRLIAVADSVLTKVVGDLLSGTILVGQLELIIKHKNQFLDIWQLREKSLSPQDEQCAVEEALDWRREELLLLKKEKRCVDSLLKMCGNVKHLIQVDFGVLAVRHSQDLSSKRLNDTVTVRLSTSSNSQRATHYHLSSQVQEMAGKIDLLRDSHIFQLFWREAAEPLSEPKEDQEAAELLSEPEEESERHILELEEVYDYLYQPSYRKFIKLHQDLKSGEVTLAEIDVIFKDFVNKYTDLDSELKIMCTVDHQDQRDWIKDRVEQIKEYHHLHQAVHAAKVILQVKESLGLNGDFSVLNTLLNFTDNFDDFRRETLDQINQELIQAKKLLQDISEARCKGLQALSLRKEFICWVREALGGINELKVFVDLASISAGENDIDVDRVACFHDAVQGYASLLFKLDPSVDFSAFMKHLKKLWKALDKDQYLPRKLCDSARNLEWLKTVNESHGSVERSSLTLATAINQRGIYVIQAPKGGQKISPDTVLHLILPESPGSHEESREYSLEEVKELLNKLMLMSGKKDRNNTEVERFSEVFCSVQRLSQAFIDLHSAGNMLFRTWIAMAYCSPKQGVSLQMDFGLDLVTELKEGGDVTELLAALCRQMEHFLDSWKRFVTQKRMEHFYLNFYTAEQLVYLSTELRKQPPSDAALTMLSFIKSNCTLRDVLRASVGCGSEAARYRMRRVMEELPLMLLSEFSLVDKLRIIMEQSMRCLPAFLPDCLDLETLGHCLAHLAGMGGSPVERCLPRGLQVGQPNLVVCGHSEVLPAALAVYMQTPSQPLPTYDEVLLCTPATTFEEVALLLRRCLTLGSLGHKVYSLLFADQLSYEVARQAEELFHNLCTQQHREDYQLVMVCDGDWEHCYLPSAFSQHKVFVTPQAPLEAIQAYLAGHYRVPKQTLSAAAVFNDRLCVGIVASERAGVGKSLYVKRLHDKMKMQLNVKNVPLKTIRLIDPQVDESRVLGALLPFLDAQYQKVPVLFHLDVTSSVQTGIWVFLFKLLILQYLMDINGKMWLRNPCHLYIVEILERRTSVPSRSSSALRTRVPQFSFLDIFPKVTCRPPKEVIDMELSALRSDTEPGMDLWEFCSETFQRPYQYLRRFNQNQDLDTFQYQEGSVEGTPEECLQHFLFHCGVINPSWSELRNFARFLNYQLRDCEASLFCNPSFIGDTLRGFKKFVVTFMIFMARDFATPSLHTSDQSPGKHMVTMDGVREEDLAPFSLRKRWESEPHPYVFFNDDHTTMTFIGFHLQPNINGSVDAISHLTGKVIKRDVMTRDLYQGLLLQRVPFNVDFDKLPRHKKLERLCLTLGIPQATDPDKTYELTTDNMLKILAIEMRFRCGIPVIIMGETGCGKTRLIKFLSDLRRGGTNADTIKLVKVHGGTTADMIYSRVREAENVAFANKDQHQLDTILFFDEANTTEAISCIKEVLCDHMVDGQPLAEDSGLHIIAACNPYRKHSEEMICRLESAGLGYRVSMEETADRLGSIPLRQLVYRVHALPPSLIPLVWDFGQLSDVAEKLYIQQIVQRLVESISLDENGTRVITEVLCASQGFMRKTEDECSFVSLRDVERCVKVFRWFHEHSAMLLAQLNAFLSKSSVSKNHTERDPVLWSLMLAIGVCYHASLEKKDSYRKAIARFFPKPYDDSRLLLDEITRAQDLFLDGVPLRKTIAKNLALKENVFMMVVCIELKIPLFLVGKPGSSKSLAKTIVADAMQGPAAYSDLFRSLKQVHLVSFQCSPHSTPQGIISTFRQCARFQQGKDLQQYVSVVVLDEVGLAEDSPKMPLKTLHPLLEDGCIEDDPAPHKKVGFVGISNWALDPAKMNRGIFVSRGSPNETELIESAKGICSSDILVQDRVQGYFASFAKAYETVCKRQDKEFFGLRDYYSLIKMVFAAAKASNRKPSPQDIAQAVLRNFSGKDDIQALDIFLANLPEAKCSEEVSPMQLIKQNIFGPSQKVPGGEQEDAESRYLLVLTKNYVALQILQQTFFEGDQQPEIIFGSGFPKDQEYTQLCRNINRVKICMETGKMVLLLNLQNLYESLYDALNQYYVHLGGQKYVDLGLGTHRVKCRVHPNFRLIVIEEKDVVYKHFPIPLINRLEKHYLDINTVLEKWQKSIVEELCAWVEKFINVKAHHFQKRHKYSPSDVFIGYHSDACASVVLQVIERQGPRALTEELHQKVSEEAKSILLNCATPDAVVRLSAYSLGGFAAEWLSQEYFHRQRHNSFADFLQAHLHTADLERHAIFTEITTFSRLLTSHDCEILESEVTGRAPKPTLLWLQQFDTEYSFLKEVRNCLTNTAKCKILIFQTDFEDGIRSAQLIASAKYSVINEINKIRENEDRIFVYFITKLSRVGRGTAYVGFHGGLWQSVHIDDLRRSTLMVSDVTRLQHVTISQLFAPGDLPELGLEHRAEDGHEEAMETEASTSGEVAEVAEEAMETESSEKVGKETSELGGSDVSILDTTRLLRSCVQSAVGMLRDQNESCTRNMRRVVLLLGLLNEDDACHASFLRVSKMRLSVFLKKQEESQFHPLEWLAREACNQDALQEAGTFRHTLWKRVQGAVTPLLASMISFIDRDGNLELLTRPDTPPWARDLWMFIFSDTMLLNIPLVMNNERHKGEMAYIVVQNHMNLSENASNNVPFSWKIKDYLEELWVQAQYITDAEGLPKKFVDIFQQTPLGRFLAQLHGEPQQELLQCYLKDFILLTMRVSTEEELKFLQMALWSCTRKLKAASEAPEEEVSLPWVHLAYQRFRSRLQNFSRILTIYPQVLHSLMEARWNHELAGCEMTLDAFAAMACTEMLTRNTLKPSPQAWLQLVKNLSMPLELICSDEHMQGSGSLAQAVIREVRAQWSRIFSTALFVEHVLLGTESRVPELQGLVTEHVFLLDKCLRENSDVKTHGPFEAVMRTLCECKETASKTLSRFGIQPCSICLGDAKDPVCLPCDHVHCLRCLRAWFASEQMICPYCLTALPDEFSPAVSQAHREAIEKHARFRQMCNSFFVDLVSTICFKDNAPPEKEVIESLLSLLFVQKGRLRDAAQRHCEHTKSLSPFNDVVDKTPVIRSVILKLLLKYSFHDVKDYIQEYLTLLKKKAFITEDKTELYMLFINCLEDSILEKTSAYSRNDELNHLEEEGRFLKAYSPASRGREPANEASVEYLQEVARIRLCLDRAADFLSEPEGGPEMAKEKQCYLQQVKQFCIRVENDWHRVYLVRKLSSQRGMEFVQGLSKPGRPHQWVFPKDVVKQQGLRQDHPGQMDRYLVYGDEYKALRDAVAKAVLECKPLGIKTALKACKTPQSQQSAYFLLTLFREVAILYRSHNASLHPTPEQCEAVSKFIGECKILSPPDISRFATSLVDNSVPLLRAGPSDSNLDGTVTEMAIHAAAVLLCGQNELLEPLKNLAFSPATMAHAFLPTMPEDLLAQARRWKGLERVHWYTCPNGHPCSVGECGRPMEQSICIDCHAPIGGIDHKPRDGFHLVKDKADRTQTGHVLGNPQRRDVVTCDRGLPPVVFLLIRLLTHLALLLGASQSSQALINIIKPPVRDPKGFLQQHILKDLEQLAKMLGHSADETIGVVHLVLRRLLQEQHQLSSRRLLNFDTELSTKEMRNNWEKEIAAVISPELEHLDKTLPTMNNLISQDKRISSNPVAKIIYGDPVTFLPHLPRKSVVHCSKIWSCRKRITVEYLQHIVEQKNGKERVPILWHFLQKEAELRLVKFLPEILALQRDLVKQFQNVQQVEYSSIRGFLSKHSSDGLRQLLHNRITVFLSTWNKLRRSLETNGEINLPKDYCSTDLDLDTEFEILLPRRRGLGLCATALVSYLIRLHNEIVYAVEKLSKENNSYSVDAAEVTELHVISYEVERDLTPLILSNCQYQVEEGRETVQEFDLEKIQRQIVSRFLQGKPRLSLKGIPTLVYRHDWNYEHLFMDIKNKMAQDSLPSSVISAISGQLQSYSDACEVLSVVEVTLGFLSTAGGDPNMQLNVYTQDILQMGDQTIHVLKALNRCQLKHTIALWQFLSAHKSEQLLRLHKEPFGEISSRYKADLSPENAKLLSTFLNQTGLDAFLLELHEMIILKLKNPQTQTEERFRPQWSLRDTLVSYMQTKESEILPEMASQFPEEILLASCVSVWKTAAVLKWNREMR>sp|Q63HN8-4|RN213_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF213OS=Homo sapiens OX=9606 GN=RNF213MECPSCQHVSKEETPKFCSQCGERLPPAAPIADSENNNSTMASASEGEMECGQELKEEGGPCLFPGSDSWQENPEEPCSKASWTVQEGATSEVLVDAAVDLISDEWEAANAIPSKRRKQDAAPLEAASVPSADCEQSKKKKRKKKKKGNKSASSELASLPLSPASPCHLTLLSNPWPQDTALPHSQAQQSGPTGQPSQPPGTATTPLEGDGLSAPTEVGDSPLQAQALGEAGVATGSEAQSSPQFQDHTEGEDQDASIPSGGRGLSQEGTGPPTSAGEGHSRTEDAAQELLLPESKGGSSEPGTELQTTEQQAGASASMAVDAVAEPANAVKGAGKEMKEKTQRMKQPPATTPPFKTHCQEAETKTKDEMAAAEEKVGKNEQGEPEDLKKPEGKNRSAAAVKNEKEQKNQEADVQEVKASTLSPGGGVTVFFHAIISLHFPFNPDLHKVFIRGGEEFGESKWDSNICELHYTRDLGHDRVLVEGIVCISKKHLDKYIPYKYVIYNGESFEYEFIYKHQQKKGEYVNRCLFIKSSLLGSGDWHQYYDIVYMKPHGRLQKVMNHITDGPRKDLVKGKQIAAALMLDSTFSILQTWDTINLNSFFTQFEQFCFVLQQPMIYEGQAQLWTDLQYREKEVKRYLWQHLKKHVVPLPDGKSTDFLPVDCPVRSKLKTGLIVLFVVEKIELLLEGSLDWLCHLLTSDASSPDEFHRDLSHILGIPQSWRLYLVNLCQRCMDTRTYTWLGALPVLHCCMELAPRHKDAWRQPEDTWAALEGLSFSPFREQMLDTSSLLQFMREKQHLLSIDEPLFRSWFSLLPLSHLVMYMENFIEHLGRFPAHILDCLSGIYYRLPGLEQVLNTQDVQDVQNVQNILEMLLRLLDTYRDKIPEEALSPSYLTVCLKLHEAICSSTKLLKFYELPALSAEIVCRMIRLLSLVDSAGQRDETGNNSVQTVFQGTLAATKRWLREVFTKNMLTSSGASFTYVKEIEVWRRLVEIQFPAEHGWKESLLGDMEWRLTKEEPLSQITAYCNSCWDTKGLEDSVAKTFEKCIIEAVSSACQSQTSILQGFSYSDLRKFGIVLSAVITKSWPRTADNFNDILKHLLTLADVKHVFRLCGTDEKILANVTEDAKRLIAVADSVLTKVVGDLLSGTILVGQLELIIKHKNQFLDIWQLREKSLSPQDEQCAVEEALDWRREELLLLKKEKRCVDSLLKMCGNVKHLIQVDFGVLAVRHSQDLSSKRLNDTVTVRLSTSSNSQRATHYHLSSQVQEMAGKIDLLRDSHIFQLFWREAAEPLSEPKEDQEAAELLSEPEEESERHILELEEVYDYLYQPSYRKFIKLHQDLKSGEVTLAEIDVIFKDFVNKYTDLDSELKIMCTVDHQDQRDWIKDRVEQIKEYHHLHQAVHAAKVILQVKESLGLNGDFSVLNTLLNFTDNFDDFRRETLDQINQELIQAKKLLQDISEARCKGLQALSLRKEFICWVREALGGINELKVFVDLASISAGENDIDVDRVACFHDAVQGYASLLFKLDPSVDFSAFMKHLKKLWKALDKDQYLPRKLCDSARNLEWLKTVNESHGSVERSSLTLATAINQRGIYVIQAPKGGQKISPDTVLHLILPESPGSHEESREYSLEEVKELLNKLMLMSGKKDRNNTEVERFSEVFCSVQRLSQAFIDLHSAGNMLFRTWIAMAYCSPKQGVSLQMDFGLDLVTELKEGGDVTELLAALCRQMEHFLDSWKRFVTQKRMEHFYLNFYTAEQLVYLSTELRKQPPSDAALTMLSFIKSNCTLRDVLRASVGCGSEAARYRMRRVMEELPLMLLSEFSLVDKLRIIMEQSMRCLPAFLPDCLDLETLGHCLAHLAGMGGSPVERCLPRGLQVGQPNLVVCGHSEVLPAALAVYMQTPSQPLPTYDEVLLCTPATTFEEVALLLRRCLTLGSLGHKVYSLLFADQLSYEVARQAEELFHNLCTQQHREDYQLVMVCDGDWEHCYLPSAFSQHKVFVTPQAPLEAIQAYLAGHYRVPKQTLSAAAVFNDRLCVGIVASERAGVGKSLYVKRLHDKMKMQLNVKNVPLKTIRLIDPQVDESRVLGALLPFLDAQYQKVPVLFHLDVTSSVQTGIWVFLFKLLILQYLMDINGKMWLRNPCHLYIVEILERRTSVPSRSSSALRTRVPQFSFLDIFPKVTCRPPKEVIDMELSALRSDTEPGMDLWEFCSETFQRPYQYLRRFNQNQDLDTFQYQEGSVEGTPEECLQHFLFHCGVINPSWSELRNFARFLNYQLRDCEASLFCNPSFIGDTLRGFKKFVVTFMIFMARDFATPSLHTSDQSPGKHMVTMDGVREEDLAPFSLRKRWESEPHPYVFFNDDHTTMTFIGFHLQPNINGSVDAISHLTGKVIKRDVMTRDLYQGLLLQRVPFNVDFDKLPRHKKLERLCLTLGIPQATDPDKTYELTTDNMLKILAIEMRFRCGIPVIIMGETGCGKTRLIKFLSDLRRGGTNADTIKLVKVHGGTTADMIYSRVREAENVAFANKDQHQLDTILFFDEANTTEAISCIKEVLCDHMVDGQPLAEDSGLHIIAACNPYRKHSEEMICRLESAGLGYRVSMEETADRLGSIPLRQLVYRVHALPPSLIPLVWDFGQLSDVAEKLYIQQIVQRLVESISLDENGTRVITEVLCASQGFMRKTEDECSFVSLRDVERCVKVFRWFHEHSAMLLAQLNAFLSKSSVSKNHTERDPVLWSLMLAIGVCYHASLEKKDSYRKAIARFFPKPYDDSRLLLDEITRAQDLFLDGVPLRKTIAKNLALKENVFMMVVCIELKIPLFLVGKPGSSKSLAKTIVADAMQGPAAYSDLFRSLKQVHLVSFQCSPHSTPQGIISTFRQCARFQQGKDLQQYVSVVVLDEVGLAEDSPKMPLKTLHPLLEDGCIEDDPAPHKKVGFVGISNWALDPAKMNRGIFVSRGSPNETELIESAKGICSSDILVQDRVQGYFASFAKAYETVCKRQDKEFFGLRDYYSLIKMVFAAAKASNRKPSPQDIAQAVLRNFSGKDDIQALDIFLANLPEAKCSEEVSPMQLIKQNIFGPSQKVPGGEQEDAESRYLLVLTKNYVALQILQQTFFEGDQQPEIIFGSGFPKDQEYTQLCRNINRVKICMETGKMVLLLNLQNLYESLYDALNQYYVHLGGQKYVDLGLGTHRVKCRVHPNFRLIVIEEKDVVYKHFPIPLINRLEKHYLDINTVLEKWQKSIVEELCAWVEKFINVKAHHFQKRHKYSPSDVFIGYHSDACASVVLQVIERQGPRALTEELHQKVSEEAKSILLNCATPDAVVRLSAYSLGGFAAEWLSQEYFHRQRHNSFADFLQAHLHTADLERHAIFTEITTFSRLLTSHDCEILESEVTGRAPKPTLLWLQQFDTEYSFLKEVRNCLTNTAKCKILIFQTDFEDGIRSAQLIASAKYSVINEINKIRENEDRIFVYFITKLSRVGRGTAYVGFHGGLWQSVHIDDLRRSTLMVSDVTRLQHVTISQLFAPGDLPELGLEHRAEDGHEEAMETEASTSGEVAEVAEEAMETESSEKVGKETSELGGSDVSILDTTRLLRSCVQSAVGMLRDQNESCTRNMRRVVLLLGLLNEDDACHASFLRVSKMRLSVFLKKQEESQFHPLEWLAREACNQDALQEAGTFRHTLWKRVQGAVTPLLASMISFIDRDGNLELLTRPDTPPWARDLWMFIFSDTMLLNIPLVMNNERHKGEMAYIVVQNHMNLSENASNNVPFSWKIKDYLEELWVQAQYITDAEGLPKKFVDIFQQTPLGRFLAQLHGEPQQELLQCYLKDFILLTMRVSTEEELKFLQMALWSCTRKLKAASEAPEEEVSLPWVHLAYQRFRSRLQNFSRILTIYPQVLHSLMEARWNHELAGCEMTLDAFAAMACTEMLTRNTLKPSPQAWLQLVKNLSMPLELICSDEHMQGSGSLAQAVIREVRAQWSRIFSTALFVEHVLLGTESRVPELQGLVTEHVFLLDKCLRENSDVKTHGPFEAVMRTLCECKETASKTLSRFGIQPCSICLGDAKDPVCLPCDHVHCLRCLRAWFASEQMICPYCLTALPDEFSPAVSQAHREAIEKHARFRQMCNSFFVDLVSTICFKDNAPPEKEVIESLLSLLFVQKGRLRDAAQRHCEHTKSLSPFNDVVDKTPVIRSVILKLLLKYSFHDVKDYIQEYLTLLKKKAFITEDKTELYMLFINCLEDSILEKTSAYSRNDELNHLEEEGRFLKAYSPASRGREPANEASVEYLQEVARIRLCLDRAADFLSEPEGGPEMAKEKQCYLQQVKQFCIRVENDWHRVYLVRKLSSQRGMEFVQGLSKPGRPHQWVFPKDVVKQQGLRQDHPGQMDRYLVYGDEYKALRDAVAKAVLECKPLGIKTALKACKTPQSQQSAYFLLTLFREVAILYRSHNASLHPTPEQCEAVSKFIGECKILSPPDISRFATSLVDNSVPLLRAGPSDSNLDGTVTEMAIHAAAVLLCGQNELLEPLKNLAFSPATMAHAFLPTMPEDLLAQARRWKGLERVHWYTCPNGHPCSVGECGRPMEQSICIDCHAPIGGIDHKPRDGFHLVKDKADRTQTGHVLGNPQRRDVVTCDRGLPPVVFLLIRLLTHLALLLGASQSSQALINIIKPPVRDPKGFLQQHILKDLEQLAKMLGHSADETIGVVHLVLRRLLQEQHQLSSRRLLNFDTELSTKEMRNNWEKEIAAVISPELEHLDKTLPTMNNLISQDKRISSNPVAKIIYGDPVTFLPHLPRKSVVHCSKIWSCRKRITVEYLQHIVEQKNGKERVPILWHFLQKEAELRLVKFLPEILALQRDLVKQFQNVQQVEYSSIRGFLSKHSSDGLRQLLHNRITVFLSTWNKLRRSLETNGEINLPKDYCSTDLDLDTEFEILLPRRRGLGLCATALVSYLIRLHNEIVYAVEKLSKENNSYSVDAAEVTELHVISYEVERDLTPLILSNCQYQVEEGRETVQEFDLEKIQRQIVSRFLQGKPRLSLKGIPTLVYRHDWNYEHLFMDIKNKMAQDSLPSSVISAISGQLQSYSDACEVLSVVEVTLGFLSTAGGDPNMQLNVYTQDILQMGDQTIHVLKALNRCQLKHTIALWQFLSAHKSEQLLRLHKEPFGEISSRYKADLSPENAKLLSTFLNQTGLDAFLLELHEMIILKLKNPQTQTEERFRPQWSLRDTLVSYMQTKESEILPEMASQFPEEILLASCVSVWKTAAVLKWNREMR>sp|Q63HN8-5|RN213_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNF213OS=Homo sapiens OX=9606 GN=RNF213MECPSCQHVSKEETPKFCSQCGERLPPAAPIADSENNNSTMASASEGEMECGQELKEEGGPCLFPGSDSWQENPEEPCSKASWTVQESKKKKRKKKKKGNKSASSELASLPLSPASPCHLTLLSNPWPQDTALPHSQAQQSGPTGQPSQPPGTATTPLEGDGLSAPTEVGDSPLQAQALGEAGVATGSEAQSSPQFQDHTEGEDQDASIPSGGRGLSQEGTGPPTSAGEGHSRTEDAAQELLLPESKGGSSEPGTELQTTEQQAGASASMAVDAVAEPANAVKGAGKEMKEKTQRMKQPPATTPPFKTHCQEAETKTKDEMAAAEEKVGKNEQGEPEDLKKPEGKNRSAAAVKNEKEQKNQEADVQEVKASTLSPGGGVTVFFHAIISLHFPFNPDLHKVFIRGGEEFGESKWDSNICELHYTRDLGHDRVLVEGIVCISKKHLDKYIPYKYVIYNGESFEYEFIYKHQQKKGEYVNRCLFIKSSLLGSGDWHQYYDIVYMKPHGRLQKVMNHITDGPRKDLVKGKQIAAALMLDSTFSILQTWDTINLNSFFTQFEQFCFVLQQPMIYEGQAQLWTDLQYREKEVKRYLWQHLKKHVVPLPDGKSTDFLPVDCPVRSKLKTGLIVLFVVEKIELLLEGSLDWLCHLLTSDASSPDEFHRDLSHILGIPQSWRLYLVNLCQRCMDTRTYTWLGALPVLHCCMELAPRHKDAWRQPEDTWAALEGLSFSPFREQMLDTSSLLQFMREKQHLLSIDEPLFRSWFSLLPLSHLVMYMENFIEHLGRFPAHILDCLSGIYYRLPGLEQVLNTQDVQDVQNVQNILEMLLRLLDTYRDKIPEEALSPSYLTVCLKLHEAICSSTKLLKFYELPALSAEIVCRMIRLLSLVDSAGQRDETGNNSVQTVFQGTLAATKRWLREVFTKNMLTSSGASFTYVKEIEVWRRLVEIQFPAEHGWKESLLGDMEWRLTKEEPLSQITAYCNSCWDTKGLEDSVAKTFEKCIIEAVSSACQVNNLSSWETDSGSQLCSAMTQLRAMKHPLGLSSSANSEIGKWAPSSLAKGNGAEI>sp|Q63HN8-6|RN213_HUMAN Isoform 4 of E3 ubiquitin-protein ligase RNF213OS=Homo sapiens OX=9606 GN=RNF213MTRKSAPTSGLLNFDTELSTKEMRNNWEKEIAAVISPELEHLDKTLPTMNNLISQDKRISSNPVAKIIYGDPVTFLPHLPRKSVVHCSKIWSCRKRITVEYLQHIVEQKNGKERVPILWHFLQKEAELRLVKFLPEILALQRDLVKQFQNVQQVEYSSIRGFLSKHSSDGLRQLLHNRITVFLSTWNKLRRSLETNGEINLPKDYCSTDLDLDTEFEILLPRRRGLGLCATALVSYLIRLHNEIVYAVEKLSKENNSYSVDAAEVTELHVISYEVERDLTPLILSNCQYQVEEGRETVQEFDLEKIQRQIVSRFLQGKPRLSLKGIPTLVYRHDWNYEHLFMDIKNKMAQDSLPSSVISAISGQLQSYSDACEVLSVVEVTLGFLSTAGGDPNMQLNVYTQDILQMGDQTIHVLKALNRCQLKHTIALWQFLSAHKSEQLLRLHKEPFGEISSRYKADLSPENAKLLSTFLNQTGLDAFLLELHEMIILKLKNPQTQTEERFRPQWSLRDTLVSYMQTKESEILPEMASQFPEEILLASCVSVWKTAAVLKWNREMR>sp|P08922|ROS1_HUMAN Proto-oncogene tyrosine-protein kinase ROS OS=Homosapiens OX=9606 GN=ROS1 PE=1 SV=3MKNIYCLIPKLVNFATLGCLWISVVQCTVLNSCLKSCVTNLGQQLDLGTPHNLSEPCIQGCHFWNSVDQKNCALKCRESCEVGCSSAEGAYEEEVLENADLPTAPFASSIGSHNMTLRWKSANFSGVKYIIQWKYAQLLGSWTYTKTVSRPSYVVKPLHPFTEYIFRVVWIFTAQLQLYSPPSPSYRTHPHGVPETAPLIRNIESSSPDTVEVSWDPPQFPGGPILGYNLRLISKNQKLDAGTQRTSFQFYSTLPNTIYRFSIAAVNEVGEGPEAESSITTSSSAVQQEEQWLFLSRKTSLRKRSLKHLVDEAHCLRLDAIYHNITGISVDVHQQIVYFSEGTLIWAKKAANMSDVSDLRIFYRGSGLISSISIDWLYQRMYFIMDELVCVCDLENCSNIEEITPPSISAPQKIVADSYNGYVFYLLRDGIYRADLPVPSGRCAEAVRIVESCTLKDFAIKPQAKRIIYFNDTAQVFMSTFLDGSASHLILPRIPFADVKSFACENNDFLVTDGKVIFQQDALSFNEFIVGCDLSHIEEFGFGNLVIFGSSSQLHPLPGRPQELSVLFGSHQALVQWKPPALAIGANVILISDIIELFELGPSAWQNWTYEVKVSTQDPPEVTHIFLNISGTMLNVPELQSAMKYKVSVRASSPKRPGPWSEPSVGTTLVPASEPPFIMAVKEDGLWSKPLNSFGPGEFLSSDIGNVSDMDWYNNSLYYSDTKGDVFVWLLNGTDISENYHLPSIAGAGALAFEWLGHFLYWAGKTYVIQRQSVLTGHTDIVTHVKLLVNDMVVDSVGGYLYWTTLYSVESTRLNGESSLVLQTQPWFSGKKVIALTLDLSDGLLYWLVQDSQCIHLYTAVLRGQSTGDTTITEFAAWSTSEISQNALMYYSGRLFWINGFRIITTQEIGQKTSVSVLEPARFNQFTIIQTSLKPLPGNFSFTPKVIPDSVQESSFRIEGNASSFQILWNGPPAVDWGVVFYSVEFSAHSKFLASEQHSLPVFTVEGLEPYALFNLSVTPYTYWGKGPKTSLSLRAPETVPSAPENPRIFILPSGKCCNKNEVVVEFRWNKPKHENGVLTKFEIFYNISNQSITNKTCEDWIAVNVTPSVMSFQLEGMSPRCFIAFQVRAFTSKGPGPYADVVKSTTSEINPFPHLITLLGNKIVFLDMDQNQVVWTFSAERVISAVCYTADNEMGYYAEGDSLFLLHLHNRSSSELFQDSLVFDITVITIDWISRHLYFALKESQNGMQVFDVDLEHKVKYPREVKIHNRNSTIISFSVYPLLSRLYWTEVSNFGYQMFYYSIISHTLHRILQPTATNQQNKRNQCSCNVTEFELSGAMAIDTSNLEKPLIYFAKAQEIWAMDLEGCQCWRVITVPAMLAGKTLVSLTVDGDLIYWIITAKDSTQIYQAKKGNGAIVSQVKALRSRHILAYSSVMQPFPDKAFLSLASDTVEPTILNATNTSLTIRLPLAKTNLTWYGITSPTPTYLVYYAEVNDRKNSSDLKYRILEFQDSIALIEDLQPFSTYMIQIAVKNYYSDPLEHLPPGKEIWGKTKNGVPEAVQLINTTVRSDTSLIISWRESHKPNGPKESVRYQLAISHLALIPETPLRQSEFPNGRLTLLVTRLSGGNIYVLKVLACHSEEMWCTESHPVTVEMFNTPEKPYSLVPENTSLQFNWKAPLNVNLIRFWVELQKWKYNEFYHVKTSCSQGPAYVCNITNLQPYTSYNVRVVVVYKTGENSTSLPESFKTKAGVPNKPGIPKLLEGSKNSIQWEKAEDNGCRITYYILEIRKSTSNNLQNQNLRWKMTFNGSCSSVCTWKSKNLKGIFQFRVVAANNLGFGEYSGISENIILVGDDFWIPETSFILTIIVGIFLVVTIPLTFVWHRRLKNQKSAKEGVTVLINEDKELAELRGLAAGVGLANACYAIHTLPTQEEIENLPAFPREKLTLRLLLGSGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKARMATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPESLMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFFLNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHADKDFCQEKQVAYCPSGKPEGLNYACLTHSGYGDGSD>sp|Q9H4I8|SEHL2_HUMAN Serine hydrolase-like protein 2 OS=Homo sapiensOX=9606 GN=SERHL2 PE=2 SV=1MSENAAPGLISELKLAVPWGHIAAKAWGSLQGPPVLCLHGWLDNASSFDRLIPLLPQDFYYVAMDFGGHGLSSHYSPGVPYYLQTFVSEIRRVVAALKWNRFSILGHSFGGVVGGMFFCTFPEMVDKLILLDTPLFLLESDEMENLLTYKRRAIEHVLQVEASQEPSHVFSLKQLLQRLLKSNSHLSEECGELLLQRGTTKVATGLVLNRDQRLAWAENSIDFISRELCAHSIRKLQAHVLLIKAVHGYFDSRQNYSEKESLSFMIDTMKSTLKEQFQFVEVPGNHCVHMSEPQHVASIISSFLQCTHMLPAQL>sp|Q9H4I8-2|SEHL2_HUMAN Isoform 2 of Serine hydrolase-like protein 2OS=Homo sapiens OX=9606 GN=SERHL2MSENAAPDFYYVAMDFGGHGLSSHYSPGVPYYLQTFVSEIRRVVAGGVVGGMFFCTFPEMVDKLILLDTPLFLLESDEMENLLTYKRRAIEHVLQVEASQEPSHVFSLKQLLQRLLKSNSHLSEECGELLLQRGTTKVATGLVLNRDQRLAWAENSIDFISRELCAHSIRKLQAHVLLIKAVHGYFDSRQNYSEKESLSFMIDTMKSTLKEQFQFVEVPGNHCVHMSEPQHVASIISSFLQCTHMLPAQL>sp|Q9H4I8-3|SEHL2_HUMAN Isoform 3 of Serine hydrolase-like protein 2OS=Homo sapiens OX=9606 GN=SERHL2MSENAAPGLISELLLQRGTTKVATGLVLNRDQRLAWAENSIDFISRELCAHSIRKLQAHVLLIKAVHGYFDSRQNYSEKESLSFMIDTMKSTLKEQFQFVEVPGNHCVHMSEPQHVASIISSFLQCTHMLPAQL>sp|Q68CR1|SE1L3_HUMAN Protein sel-1 homolog 3 OS=Homo sapiens OX=9606GN=SEL1L3 PE=1 SV=2MQRRGAGLGWPRQQQQQPPPLAVGPRAAAMVPSGGVPQGLGGRSACALLLLCYLNVVPSLGRQTSLTTSVIPKAEQSVAYKDFIYFTVFEGNVRNVSEVSVEYLCSQPCVVNLEAVVSSEFRSSIPVYKKRWKNEKHLHTSRTQIVHVKFPSIMVYRDDYFIRHSISVSAVIVRAWITHKYSGRDWNVKWEENLLHAVAKNYTLLQTIPPFERPFKDHQVCLEWNMGYIWNLRANRIPQCPLENDVVALLGFPYASSGENTGIVKKFPRFRNRELEATRRQRMDYPVFTVSLWLYLLHYCKANLCGILYFVDSNEMYGTPSVFLTEEGYLHIQMHLVKGEDLAVKTKFIIPLKEWFRLDISFNGGQIVVTTSIGQDLKSYHNQTISFREDFHYNDTAGYFIIGGSRYVAGIEGFFGPLKYYRLRSLHPAQIFNPLLEKQLAEQIKLYYERCAEVQEIVSVYASAAKHGGERQEACHLHNSYLDLQRRYGRPSMCRAFPWEKELKDKHPSLFQALLEMDLLTVPRNQNESVSEIGGKIFEKAVKRLSSIDGLHQISSIVPFLTDSSCCGYHKASYYLAVFYETGLNVPRDQLQGMLYSLVGGQGSERLSSMNLGYKHYQGIDNYPLDWELSYAYYSNIATKTPLDQHTLQGDQAYVETIRLKDDEILKVQTKEDGDVFMWLKHEATRGNAAAQQRLAQMLFWGQQGVAKNPEAAIEWYAKGALETEDPALIYDYAIVLFKGQGVKKNRRLALELMKKAASKGLHQAVNGLGWYYHKFKKNYAKAAKYWLKAEEMGNPDASYNLGVLHLDGIFPGVPGRNQTLAGEYFHKAAQGGHMEGTLWCSLYYITGNLETFPRDPEKAVVWAKHVAEKNGYLGHVIRKGLNAYLEGSWHEALLYYVLAAETGIEVSQTNLAHICEERPDLARRYLGVNCVWRYYNFSVFQIDAPSFAYLKMGDLYYYGHQNQSQDLELSVQMYAQAALDGDSQGFFNLALLIEEGTIIPHHILDFLEIDSTLHSNNISILQELYERCWSHSNEESFSPCSLAWLYLHLRLLWGAILHSALIYFLGTFLLSILIAWTVQYFQSVSASDPPPRPSQASPDTATSTASPAVTPAADASDQDQPTVTNNPEPRG>sp|Q68CR1-2|SE1L3_HUMAN Isoform 2 of Protein sel-1 homolog 3 OS=Homosapiens OX=9606 GN=SEL1L3MAPRPKKQPDKNPLHGRELNVVPSLGRQTSLTTSVIPKAEQSVAYKDFIYFTVFEGNVRNVSEVSVEYLCSQPCVVNLEAVVSSEFRSSIPVYKKRWKNEKHLHTSRTQIVHVKFPSIMVYRDDYFIRHSISVSAVIVRAWITHKYSGRDWNVKWEENLLHAVAKNYTLLQTIPPFERPFKDHQVCLEWNMGYIWNLRANRIPQCPLENDVVALLGFPYASSGENTGIVKKFPRFRNRELEATRRQRMDYPVFTVSLWLYLLHYCKANLCGILYFVDSNEMYGTPSVFLTEEGYLHIQMHLVKGEDLAVKTKFIIPLKEWFRLDISFNGGQIVVTTSIGQDLKSYHNQTISFREDFHYNDTAGYFIIGGSRYVAGIEGFFGPLKYYRLRSLHPAQIFNPLLEKQLAEQIKLYYERCAEVQEIVSVYASAAKHGGERQEACHLHNSYLDLQRRYGRPSMCRAFPWEKELKDKHPSLFQALLEMDLLTVPRNQNESVSEIGGKIFEKAVKRLSSIDGLHQISSIVPFLTDSSCCGYHKASYYLAVFYETGLNVPRDQLQGMLYSLVGGQGSERLSSMNLGYKHYQGIDNYPLDWELSYAYYSNIATKTPLDQHTLQGDQAYVETIRLKDDEILKVQTKEDGDVFMWLKHEATRGNAAAQQRLAQMLFWGQQGVAKNPEAAIEWYAKGALETEDPALIYDYAIVLFKGQGVKKNRRLALELMKKAASKGLHQAVNGLGWYYHKFKKNYAKAAKYWLKAEEMGNPDASYNLGVLHLDGIFPGVPGRNQTLAGEYFHKAAQGGHMEGTLWCSLYYITGNLETFPRDPEKAVVWAKHVAEKNGYLGHVIRKGLNAYLEGSWHEALLYYVLAAETGIEVSQTNLAHICEERPDLARRYLGVNCVWRYYNFSVFQIDAPSFAYLKMGDLYYYGHQNQSQDLELSVQMYAQAALDGDSQGFFNLALLIEEGTIIPHHILDFLEIDSTLHSNNISILQELYERCWSHSNEESFSPCSLAWLYLHLRLLWGAILHSALIYFLGTFLLSILIAWTVQYFQSVSASDPPPRPSQASPDTATSTASPAVTPAADASDQDQPTVTNNPEPRG>sp|Q68CR1-3|SE1L3_HUMAN Isoform 3 of Protein sel-1 homolog 3 OS=Homosapiens OX=9606 GN=SEL1L3MVYRDDYFIRHSISVSAVIVRAWITHKYSGRDWNVKWEENLLHAVAKNYTLLQTIPPFERPFKDHQVCLEWNMGYIWNLRANRIPQCPLENDVVALLGFPYASSGENTGIVKKFPRFRNRELEATRRQRMDYPVFTVSLWLYLLHYCKANLCGILYFVDSNEMYGTPSVFLTEEGYLHIQMHLVKGEDLAVKTKFIIPLKEWFRLDISFNGGQIVVTTSIGQDLKSYHNQTISFREDFHYNDTAGYFIIGGSRYVAGIEGFFGPLKYYRLRSLHPAQIFNPLLEKQLAEQIKLYYERCAEVQEIVSVYASAAKHGGERQEACHLHNSYLDLQRRYGRPSMCRAFPWEKELKDKHPSLFQALLEMDLLTVPRNQNESVSEIGGKIFEKAVKRLSSIDGLHQISSIVPFLTDSSCCGYHKASYYLAVFYETGLNVPRDQLQGMLYSLVGGQGSERLSSMNLGYKHYQGIDNYPLDWELSYAYYSNIATKTPLDQHTLQGDQAYVETIRLKDDEILKVQTKEDGDVFMWLKHEATRGNAAAQQRLAQMLFWGQQGVAKNPEAAIEWYAKGALETEDPALIYDYAIVLFKGQGVKKNRRLALELMKKAASKGLHQAVNGLGWYYHKFKKNYAKAAKYWLKAEEMGNPDASYNLGVLHLDGIFPGVPGRNQTLAGEYFHKAAQGGHMEGTLWCSLYYITGNLETFPRDPEKAVVWAKHVAEKNGYLGHVIRKGLNAYLEGSWHEALLYYVLAAETGIEVSQTNLAHICEERPDLARRYLGVNCVWRYYNFSVFQIDAPSFAYLKMGDLYYYGHQNQSQDLELSVQMYAQAALDGDSQGFFNLALLIEEGTIIPHHILDFLEIDSTLHSNNISILQELYERCWSHSNEESFSPCSLAWLYLHLRLLWGAILHSALIYFLGTFLLSILIAWTVQYFQSVSASDPPPRPSQASPDTATSTASPAVTPAADASDQDQPTVTNNPEPRG>sp|Q7L523|RRAGA_HUMAN Ras-related GTP-binding protein A OS=Homo sapiensOX=9606 GN=RRAGA PE=1 SV=1MPNTAMKKKVLLMGKSGSGKTSMRSIIFANYIARDTRRLGATIDVEHSHVRFLGNLVLNLWDCGGQDTFMENYFTSQRDNIFRNVEVLIYVFDVESRELEKDMHYYQSCLEAILQNSPDAKIFCLVHKMDLVQEDQRDLIFKEREEDLRRLSRPLECACFRTSIWDETLYKAWSSIVYQLIPNVQQLEMNLRNFAQIIEADEVLLFERATFLVISHYQCKEQRDVHRFEKISNIIKQFKLSCSKLAASFQSMEVRNSNFAAFIDIFTSNTYVMVVMSDPSIPSAATLINIRNARKHFEKLERVDGPKHSLLMR>sp|Q9P2W9|STX18_HUMAN Syntaxin-18 OS=Homo sapiens OX=9606 GN=STX18 PE=1SV=1MAVDITLLFRASVKTVKTRNKALGVAVGGGVDGSRDELFRRSPRPKGDFSSRAREVISHIGKLRDFLLEHRKDYINAYSHTMSEYGRMTDTERDQIDQDAQIFMRTCSEAIQQLRTEAHKEIHSQQVKEHRTAVLDFIEDYLKRVCKLYSEQRAIRVKRVVDKKRLSKLEPEPNTKTRESTSSEKVSQSPSKDSEENPATEERPEKILAETQPELGTWGDGKGEDELSPEEIQMFEQENQRLIGEMNSLFDEVRQIEGRVVEISRLQEIFTEKVLQQEAEIDSIHQLVVGATENIKEGNEDIREAIKNNAGFRVWILFFLVMCSFSLLFLDWYDS>sp|P25398|RS12_HUMAN 40S ribosomal protein S12 OS=Homo sapiens OX=9606GN=RPS12 PE=1 SV=3MAEEGIAAGGVMDVNTALQEVLKTALIHDGLARGIREAAKALDKRQAHLCVLASNCDEPMYVKLVEALCAEHQINLIKVDDNKKLGEWVGLCKIDREGKPRKVVGCSCVVVKDYGKESQAKDVIEEYFKCKK>sp|Q76I76|SSH2_HUMAN Protein phosphatase Slingshot homolog 2 OS=Homosapiens OX=9606 GN=SSH2 PE=1 SV=1MALVTVQRSPTPSTTSSPCASEADSGEEECRSQPRSISESFLTVKGAALFLPRGNGSSTPRISHRRNKHAGDLQQHLQAMFILLRPEDNIRLAVRLESTYQNRTRYMVVVSTNGRQDTEESIVLGMDFSSNDSSTCTMGLVLPLWSDTLIHLDGDGGFSVSTDNRVHIFKPVSVQAMWSALQSLHKACEVARAHNYYPGSLFLTWVSYYESHINSDQSSVNEWNAMQDVQSHRPDSPALFTDIPTERERTERLIKTKLREIMMQKDLENITSKEIRTELEMQMVCNLREFKEFIDNEMIVILGQMDSPTQIFEHVFLGSEWNASNLEDLQNRGVRYILNVTREIDNFFPGVFEYHNIRVYDEEATDLLAYWNDTYKFISKAKKHGSKCLVHCKMGVSRSASTVIAYAMKEYGWNLDRAYDYVKERRTVTKPNPSFMRQLEEYQGILLASKQRHNKLWRSHSDSDLSDHHEPICKPGLELNKKDITTSADQIAEVKTMESHPPIPPVFVEHMVPQDANQKGLCTKERMICLEFTSREFHAGQIEDELNLNDINGCSSGCCLNESKFPLDNCHASKALIQPGHVPEMANKFPDLTVEDLETDALKADMNVHLLPMEELTSPLKDPPMSPDPESPSPQPSCQTEISDFSTDRIDFFSALEKFVELSQETRSRSFSHSRMEELGGGRNESCRLSVVEVAPSKVTADDQRSSSLSNTPHASEESSMDEEQSKAISELVSPDIFMQSHSENAISVKEIVTEIESISQGVGQIQLKGDILPNPCHTPKKNSIHELLLERAQTPENKPGHMEQDEDSCTAQPELAKDSGMCNPEGCLTTHSSIADLEEGEPAEGEQELQGSGMHPGAKWYPGSVRRATLEFEERLRQEQEHHGAAPTCTSLSTRKNSKNDSSVADLAPKGKSDEAPPEHSFVLKEPEMSKGKGKYSGSEAGSLSHSEQNATVPAPRVLEFDHLPDPQEGPGSDTGTQQEGVLKDLRTVIPYQESETQAVPLPLPKRVEIIEYTHIVTSPNHTGPGSEIATSEKSGEQGLRKVNMEKSVTVLCTLDENLNRTLDPNQVSLHPQVLPLPHSSSPEHNRPTDHPTSILSSPEDRGSSLSTALETAAPFVSHTTHLLSASLDYLHPQTMVHLEGFTEQSSTTDEPSAEQVSWEESQESPLSSGSEVPYKDSQLSSADLSLISKLGDNTGELQEKMDPLPVACRLPHSSSSENIKSLSHSPGVVKERAKEIESRVVFQAGLTKPSQMRRSASLAKLGYLDLCKDCLPEREPASCESPHLKLLQPFLRTDSGMHAMEDQESLENPGAPHNPEPTKSFVEQLTTTECIVQSKPVERPLVQYAKEFGSSQQYLLPRAGLELTSSEGGLPVLQTQGLQCACPAPGLAVAPRQQHGRTHPLRRLKKANDKKRTTNPFYNTM>sp|Q76I76-2|SSH2_HUMAN Isoform 2 of Protein phosphatase Slingshothomolog 2 OS=Homo sapiens OX=9606 GN=SSH2MTLSTLARKRKAPLACTCSLGGPDMIPYFSANAVISQNAINQLISESFLTVKGAALFLPRGNGSSTPRISHRRNKHAGDLQQHLQAMFILLRPEDNIRLAVRLESTYQNRTRYMVVVSTNGRQDTEESIVLGMDFSSNDSSTCTMGLVLPLWSDTLIHLDGDGGFSVSTDNRVHIFKPVSVQAMWVDRDSRNKHCYVLLVEE>sp|Q76I76-3|SSH2_HUMAN Isoform 3 of Protein phosphatase Slingshothomolog 2 OS=Homo sapiens OX=9606 GN=SSH2MALVTVQRSPTPSTTSSPCASEADSGEEECRSQPRSISESFLTVKGAALFLPRGNGSSTPRISHRRNKHAGDLQQHLQAMFILLRPEDNIRLAVRLESTYQNRTRYMVVVSTNGRQDTEESIVLGMDFSSNDSSTCTMGLVLPLWSDTLIHLDGDGGFSVSTDNRVHIFKPVSVQAMWVDRDSRNKHCYVLLVEE>sp|Q76I76-4|SSH2_HUMAN Isoform 4 of Protein phosphatase Slingshothomolog 2 OS=Homo sapiens OX=9606 GN=SSH2MALVTVQRSPTPSTTSSPCASEADSGEEECRSQPRSISESFLTVKGAALFLPRGNGSSTPRISHRRNKHAGDLQQHLQAMFILLRPEDNIRLAVRLESTYQNRTRYMVVVSTNGRQDTEESIVLGMDFSSNDSSTCTMGLVLPLWSDTLIHLDGDGGFSVSTDNRVHIFKPVSVQAMWSALQSLHKACEVARAHNYYPGSLFLTWVSYYESHINSDQSSVNEWNAMQDVQSHRPDSPALFTDIPTERERTERLIKTKLREIMMQKDLENITSKEIRTELEMQMVCNLREFKEFIDNEMIVILGQMDSPTQIFEHVFLGSEWNASNLEDLQNRGVRYILNVTREIDNFFPGVFEYHNIRVYDEEATDLLAYWNDTYKFISKAKKHGSKCLVHCKMGVSRSASTVIAYAMKEYGWNLDRAYDYVKERRTVTKPNPSFMRQLEEYQGILLAR>sp|Q71UM5|RS27L_HUMAN 40S ribosomal protein S27-like OS=Homo sapiensOX=9606 GN=RPS27L PE=1 SV=3MPLARDLLHPSLEEEKKKHKKKRLVQSPNSYFMDVKCPGCYKITTVFSHAQTVVLCVGCSTVLCQPTGGKARLTEGCSFRRKQH>sp|O15079|SNPH_HUMAN Syntaphilin OS=Homo sapiens OX=9606 GN=SNPH PE=1SV=2MAMSLPGSRRTSAGSRRRTSPPVSVRDAYGTSSLSSSSNSGSYKGSDSSPTPRRSMKYTLCSDNHGIKPPTPEQYLTPLQQKEVCIRHLKARLKDTQDRLQDRDTEIDDLKTQLSRMQEDWIEEECHRVEAQLALKEARKEIKQLKQVIDTVKNNLIDKDKGLQKYFVDINIQNKKLETLLHSMEVAQNGMAKEDGTGESAGGSPARSLTRSSTYTKLSDPAVCGDRQPGDPSSGSAEDGADSGFAAADDTLSRTDALEASSLLSSGVDCGTEETSLHSSFGLGPRFPASNTYEKLLCGMEAGVQASCMQERAIQTDFVQYQPDLDTILEKVTQAQVCGTDPESGDRCPELDAHPSGPRDPNSAVVVTVGDELEAPEPITRGPTPQRPGANPNPGQSVSVVCPMEEEEEAAVAEKEPKSYWSRHYIVDLLAVVVPAVPTVAWLCRSQRRQGQPIYNISSLLRGCCTVALHSIRRISCRSLSQPSPSPAGGGSQL>sp|O15079-2|SNPH_HUMAN Isoform 2 of Syntaphilin OS=Homo sapiens OX=9606GN=SNPHMPGSGPSERMTWPGPALSAGPPTRPLSSAPGIPPIPPLTRTHSLMAMSLPGSRRTSAGSRRRTSPPVSVRDAYGTSSLSSSSNSGSYKGSDSSPTPRRSMKYTLCSDNHGIKPPTPEQYLTPLQQKEVCIRHLKARLKDTQDRLQDRDTEIDDLKTQLSRMQEDWIEEECHRVEAQLALKEARKEIKQLKQVIDTVKNNLIDKDKGLQKYFVDINIQNKKLETLLHSMEVAQNGMAKEDGTGESAGGSPARSLTRSSTYTKLSDPAVCGDRQPGDPSSGSAEDGADSGFAAADDTLSRTDALEASSLLSSGVDCGTEETSLHSSFGLGPRFPASNTYEKLLCGMEAGVQASCMQERAIQTDFVQYQPDLDTILEKVTQAQVCGTDPESGDRCPELDAHPSGPRDPNSAVVVTVGDELEAPEPITRGPTPQRPGANPNPGQSVSVVCPMEEEEEAAVAEKEPKSYWSRHYIVDLLAVVVPAVPTVAWLCRSQRRQGQPIYNISSLLRGCCTVALHSIRRISCRSLSQPSPSPAGGGSQL>sp|Q6ZQN7|SO4C1_HUMAN Solute carrier organic anion transporter familymember 4C1 OS=Homo sapiens OX=9606 GN=SLCO4C1 PE=1 SV=1MKSAKGIENLAFVPSSPDILRRLSASPSQIEVSALSSDPQRENSQPQELQKPQEPQKSPEPSLPSAPPNVSEEKLRSLSLSEFEEGSYGWRNFHPQCLQRCNTPGGFLLHYCLLAVTQGIVVNGLVNISISTVEKRYEMKSSLTGLISSSYDISFCLLSLFVSFFGERGHKPRWLAFAAFMIGLGALVFSLPQFFSGEYKLGSLFEDTCVTTRNSTSCTSSTSSLSNYLYVFILGQLLLGAGGTPLYTLGTAFLDDSVPTHKSSLYIGTGYAMSILGPAIGYVLGGQLLTIYIDVAMGESTDVTEDDPRWLGAWWIGFLLSWIFAWSLIIPFSCFPKHLPGTAEIQAGKTSQAHQSNSNADVKFGKSIKDFPAALKNLMKNAVFMCLVLSTSSEALITTGFATFLPKFIENQFGLTSSFAATLGGAVLIPGAALGQILGGFLVSKFRMTCKNTMKFALFTSGVALTLSFVFMYAKCENEPFAGVSESYNGTGELGNLIAPCNANCNCSRSYYYPVCGDGVQYFSPCFAGCSNPVAHRKPKVYYNCSCIERKTEITSTAETFGFEAKAGKCETHCAKLPIFLCIFFIVIIFTFMAGTPITVSILRCVNHRQRSLALGIQFMVLRLLGTIPGPIIFGFTIDSTCILWDINDCGIKGACWIYDNIKMAHMLVAISVTCKVITMFFNGFAIFLYKPPPSATDVSFHKENAVVTNVLAEQDLNKIVKEG>sp|Q8TEC5|SH3R2_HUMAN E3 ubiquitin-protein ligase SH3RF2 OS=Homo sapiensOX=9606 GN=SH3RF2 PE=1 SV=3MDDLTLLDLLECPVCFEKLDVTAKVLPCQHTFCKPCLQRVFKAHKELRCPECRTPVFSNIEALPANLLLVRLLDGVRSGQSSGRGGSFRRPGTMTLQDGRKSRTNPRRLQASPFRLVPNVRIHMDGVPRAKALCNYRGQNPGDLRFNKGDIILLRRQLDENWYQGEINGISGNFPASSVEVIKQLPQPPPLCRALYNFDLRGKDKSENQDCLTFLKDDIITVISRVDENWAEGKLGDKVGIFPILFVEPNLTARHLLEKNKGRQSSRTKNLSLVSSSSRGNTSTLRRGPGSRRKVPGQFSITTALNTLNRMVHSPSGRHMVEISTPVLISSSNPSVITQPMEKADVPSSCVGQVSTYHPAPVSPGHSTAVVSLPGSQQHLSANMFVALHSYSAHGPDELDLQKGEGVRVLGKCQDGWLRGVSLVTGRVGIFPNNYVIPIFRKTSSFPDSRSPGLYTTWTLSTSSVSSQGSISEGDPRQSRPFKSVFVPTAIVNPVRSTAGPGTLGQGSLRKGRSSMRKNGSLQRPLQSGIPTLVVGSLRRSPTMVLRPQQFQFYQPQGIPSSPSAVVVEMGSKPALTGEPALTCISRGSEAWIHSAASSLIMEDKEIPIKSEPLPKPPASAPPSILVKPENSRNGIEKQVKTVRFQNYSPPPTKHYTSHPTSGKPEQPATLKASQPEAASLGPEMTVLFAHRSGCHSGQQTDLRRKSALGKATTLVSTASGTQTVFPSK>sp|Q8TEC5-2|SH3R2_HUMAN Isoform 2 of E3 ubiquitin-protein ligase SH3RF2OS=Homo sapiens OX=9606 GN=SH3RF2MRKSKWWQRDGSLQRPLQSGIPTLVVGSLRRSPTMVLRPQQFQFYQPQGIPSSPSAVVVEMGSKPALTGEPALTCISRGSEAWIHSAASSLIMEDKEIPIKSEPLPKPPASAPPSILVKPENSRNGIEKQVKTVRFQNYSPPPTKHYTSHPTSGKPEQPATLKASQPEAASLGPEMTVLFAHRSGCHSGQQTDLRRKSALGKATTLVSTASGTQTVFPSK>sp|Q8TEC5-3|SH3R2_HUMAN Isoform 3 of E3 ubiquitin-protein ligase SH3RF2OS=Homo sapiens OX=9606 GN=SH3RF2MVLRPQQFQFYQPQGIPSSPSAVVVEMGSKPALTGEPALTCISRGSEAWIHSAASSLIMEDKEIPIKSEPLPKPPASAPPSILVKPENSRNGIEKQVKTVRFQNYSPPPTKHYTSHPTSGKPEQPATLKASQPEAASLGPEMTVLFAHRSGCHSGQQTDLRRKSALGKATTLVSTASGTQTVFPSK>sp|Q8TEQ0|SNX29_HUMAN Sorting nexin-29 OS=Homo sapiens OX=9606 GN=SNX29PE=1 SV=3MSGSQNNDKRQFLLERLLDAVKQCQIRFGGRKEIASDSDSRVTCLCAQFEAVLQHGLKRSRGLALTAAAIKQAAGFASKTETEPVFWYYVKEVLNKHELQRFYSLRHIASDVGRGRAWLRCALNEHSLERYLHMLLADRCRLSTFYEDWSFVMDEERSSMLPTMAAGLNSILFAINIDNKDLNGQSKFAPTVSDLLKESTQNVTSLLKESTQGVSSLFREITASSAVSILIKPEQETDPLPVVSRNVSADAKCKKERKKKKKVTNIISFDDEEDEQNSGDVFKKTPGAGESSEDNSDRSSVNIMSAFESPFGPNSNGSQSSNSWKIDSLSLNGEFGYQKLDVKSIDDEDVDENEDDVYGNSSGRKHRGHSESPEKPLEGNTCLSQMHSWAPLKVLHNDSDILFPVSGVGSYSPADAPLGSLENGTGPEDHVLPDPGLRYSVEASSPGHGSPLSSLLPSASVPESMTISELRQATVAMMNRKDELEEENRSLRNLLDGEMEHSAALRQEVDTLKRKVAEQEERQGMKVQALARENEVLKVQLKKYVGAVQMLKREGQTAEVPNLWSVDGEVTVAEQKPGEIAEELASSYERKLIEVAEMHGELIEFNERLHRALVAKEALVSQMRQELIDLRGPVPGDLSQTSEDQSLSDFEISNRALINVWIPSVFLRGKAANAFHVYQVYIRIKDDEWNIYRRYTEFRSLHHKLQNKYPQVRAYNFPPKKAIGNKDAKFVEERRKQLQNYLRSVMNKVIQMVPEFAASPKKETLIQLMPFFVDITPPGEPVNSRPKAASRFPKLSRGQPRETRNVEPQSGDL>sp|Q8TEQ0-2|SNX29_HUMAN Isoform 2 of Sorting nexin-29 OS=Homo sapiensOX=9606 GN=SNX29MSGSQNNDKRQFLLERLLDAVKQCQIRFGGRKEIASDSDSRVTCLCAQFEAVLQHGLKRSRGLALTAAAIKQAAGFASKTETEPVFWYYVKEVLNKHELQRFYSLRHIASDVGRGRAWLRCALNEHSLERYLHMLLADRCRLSTFYEDWSFVMDEERSSMLPTMAAGLNSILFAINIDNKDLNGQSKFAPTVSDLLKESTQNVTSLLKESTQGVSSLFREITASSAVSILIKPEQETDPLPVVSRNVSADAKCKKERKKKKKVTNIISFDDEEDEQNSGDVFKKTPGAGESSEDNSDRSSVNIMSAFESPFGPNSNGSQSSNSWKIDSLSLNGEFGYQKLDVKSIDDEDVDENEDDVYGNSSGRKHRGHSESPEKPLEGNTCLSQMHSWAPLKVLHNDSDILFPVSGVGSYSPADAPLGSLENGTGPEDHVLPDPGLRYSVEASSPGHGSPLSSLLPSASVPESMTISELRQATVAMMNRKDELEEENRSLRNLLDGEMEHSAALRQEVDTLKRKVAEQEERQGMKVQALARENEVLKVQLKKYVGAVQMLKREGQTAEVPNLWSVDGEVTVAEQKPGEIAEELASSYERKLIEVAEMHGELIEFNERLHRALVAKEALVSQMRQELIDLRGPVPGDLSQTSEDQSLSDFEISNRALINVWIPSVFLRGKAANAFHVYQVYIRIKDDEWNIYRRYTEFRSLHHKLQNKYPQVRAYNFPPKKAIGNKDAKFVEERRKQLQNYLRSVMNKVIQMVPEFAASPKKETLIQLMPFFVDWISLFGNGRDSSREEFSSS>sp|Q9Y5B9|SP16H_HUMAN FACT complex subunit SPT16 OS=Homo sapiens OX=9606GN=SUPT16H PE=1 SV=1MAVTLDKDAYYRRVKRLYSNWRKGEDEYANVDAIVVSVGVDEEIVYAKSTALQTWLFGYELTDTIMVFCDDKIIFMASKKKVEFLKQIANTKGNENANGAPAITLLIREKNESNKSSFDKMIEAIKESKNGKKIGVFSKDKFPGEFMKSWNDCLNKEGFDKIDISAVVAYTIAVKEDGELNLMKKAASITSEVFNKFFKERVMEIVDADEKVRHSKLAESVEKAIEEKKYLAGADPSTVEMCYPPIIQSGGNYNLKFSVVSDKNHMHFGAITCAMGIRFKSYCSNLVRTLMVDPSQEVQENYNFLLQLQEELLKELRHGVKICDVYNAVMDVVKKQKPELLNKITKNLGFGMGIEFREGSLVINSKNQYKLKKGMVFSINLGFSDLTNKEGKKPEEKTYALFIGDTVLVDEDGPATVLTSVKKKVKNVGIFLKNEDEEEEEEEKDEAEDLLGRGSRAALLTERTRNEMTAEEKRRAHQKELAAQLNEEAKRRLTEQKGEQQIQKARKSNVSYKNPSLMPKEPHIREMKIYIDKKYETVIMPVFGIATPFHIATIKNISMSVEGDYTYLRINFYCPGSALGRNEGNIFPNPEATFVKEITYRASNIKAPGEQTVPALNLQNAFRIIKEVQKRYKTREAEEKEKEGIVKQDSLVINLNRSNPKLKDLYIRPNIAQKRMQGSLEAHVNGFRFTSVRGDKVDILYNNIKHALFQPCDGEMIIVLHFHLKNAIMFGKKRHTDVQFYTEVGEITTDLGKHQHMHDRDDLYAEQMEREMRHKLKTAFKNFIEKVEALTKEELEFEVPFRDLGFNGAPYRSTCLLQPTSSALVNATEWPPFVVTLDEVELIHFERVQFHLKNFDMVIVYKDYSKKVTMINAIPVASLDPIKEWLNSCDLKYTEGVQSLNWTKIMKTIVDDPEGFFEQGGWSFLEPEGEGSDAEEGDSESEIEDETFNPSEDDYEEEEEDSDEDYSSEAEESDYSKESLGSEEESGKDWDELEEEARKADRESRYEEEEEQSRSMSRKRKASVHSSGRGSNRGSRHSSAPPKKKRK>sp|O95343|SIX3_HUMAN Homeobox protein SIX3 OS=Homo sapiens OX=9606GN=SIX3 PE=1 SV=1MVFRSPLDLYSSHFLLPNFADSHHRSILLASSGGGNGAGGGGGAGGGSGGGNGAGGGGAGGAGGGGGGGSRAPPEELSMFQLPTLNFSPEQVASVCETLEETGDIERLGRFLWSLPVAPGACEAINKHESILRARAVVAFHTGNFRDLYHILENHKFTKESHGKLQAMWLEAHYQEAEKLRGRPLGPVDKYRVRKKFPLPRTIWDGEQKTHCFKERTRSLLREWYLQDPYPNPSKKRELAQATGLTPTQVGNWFKNRRQRDRAAAAKNRLQHQAIGPSGMRSLAEPGCPTHGSAESPSTAASPTTSVSSLTERADTGTSILSVTSSDSECDV>sp|O00241|SIRB1_HUMAN Signal-regulatory protein beta-1 OS=Homo sapiensOX=9606 GN=SIRPB1 PE=1 SV=5MPVPASWPHLPSPFLLMTLLLGRLTGVAGEDELQVIQPEKSVSVAAGESATLRCAMTSLIPVGPIMWFRGAGAGRELIYNQKEGHFPRVTTVSELTKRNNLDFSISISNITPADAGTYYCVKFRKGSPDDVEFKSGAGTELSVRAKPSAPVVSGPAVRATPEHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPAGDSVSYSIHSTARVVLTRGDVHSQVICEIAHITLQGDPLRGTANLSEAIRVPPTLEVTQQPMRAENQANVTCQVSNFYPRGLQLTWLENGNVSRTETASTLIENKDGTYNWMSWLLVNTCAHRDDVVLTCQVEHDGQQAVSKSYALEISAHQKEHGSDITHEAALAPTAPLLVALLLGPKLLLVVGVSAIYICWKQKA>sp|O00241-2|SIRB1_HUMAN Isoform 2 of Signal-regulatory protein beta-1OS=Homo sapiens OX=9606 GN=SIRPB1MPVPASWPHLPSPFLLMTLLLGRLTGVAGEDELQVIQPEKSVSVAAGESATLRCAMTSLIPVGPIMWFRGAGAGRELIYNQKEGHFPRVTTVSELTKRNNLDFSISISNITPADAGTYYCVKFRKGSPDDVEFKSGAGTELSVREAALAPTAPLLVALLLGPKLLLVVGVSAIYICWKQKA>sp|Q15005|SPCS2_HUMAN Signal peptidase complex subunit 2 OS=Homo sapiensOX=9606 GN=SPCS2 PE=1 SV=3MAAAAVQGGRSGGSGGCSGAGGASNCGTGSGRSGLLDKWKIDDKPVKIDKWDGSAVKNSLDDSAKKVLLEKYKYVENFGLIDGRLTICTISCFFAIVALIWDYMHPFPESKPVLALCVISYFVMMGILTIYTSYKEKSIFLVAHRKDPTGMDPDDIWQLSSSLKRFDDKYTLKLTFISGRTKQQREAEFTKSIAKFFDHSGTLVMDAYEPEISRLHDSLAIERKIK>sp|Q9Y6H5|SNCAP_HUMAN Synphilin-1 OS=Homo sapiens OX=9606 GN=SNCAIP PE=1SV=2MEAPEYLDLDEIDFSDDISYSVTSLKTIPELCRRCDTQNEDRSVSSSSWNCGISTLITNTQKPTGIADVYSKFRPVKRVSPLKHQPETLENNESDDQKNQKVVEYQKGGESDLGPQPQELGPGDGVGGPPGKSSEPSTSLGELEHYDLDMDEILDVPYIKSSQQLASFTKVTSEKRILGLCTTINGLSGKACSTGSSESSSSNMAPFCVLSPVKSPHLRKASAVIHDQHKLSTEETEISPPLVKCGSAYEPENQSKDFLNKTFSDPHGRKVEKTTPDCQLRAFHLQSSAAESKPEEQVSGLNRTSSQGPEERSEYLKKVKSILNIVKEGQISLLPHLAADNLDKIHDENGNNLLHIAASQGHAECLQHLTSLMGEDCLNERNTEKLTPAGLAIKNGQLECVRWMVSETEAIAELSCSKDFPSLIHYAGCYGQEKILLWLLQFMQEQGISLDEVDQDGNSAVHVASQHGYLGCIQTLVEYGANVTMQNHAGEKPSQSAERQGHTLCSRYLVVVETCMSLASQVVKLTKQLKEQTVERVTLQNQLQQFLEAQKSEGKSLPSSPSSPSSPASRKSQWKSPDADDDSVAKSKPGVQEGIQVLGSLSASSRARPKAKDEDSDKILRQLLGKEISENVCTQEKLSLEFQDAQASSRNSKKIPLEKRELKLARLRQLMQRSLSESDTDSNNSEDPKTTPVRKADRPRPQPIVESVESMDSAESLHLMIKKHTLASGGRRFPFSIKASKSLDGHSPSPTSESSEPDLESQYPGSGSIPPNQPSGDPQQPSPDSTAAQKVATSPKSALKSPSSKRRTSQNLKLRVTFEEPVVQMEQPSLELNGEKDKDKGRTLQRTSTSNESGDQLKRPFGAFRSIMETLSGNQNNNNNYQAANQLKTSTLPLTSLGRKTDAKGNPASSASKGKNKAA>sp|Q9Y6H5-2|SNCAP_HUMAN Isoform 2 of Synphilin-1 OS=Homo sapiens OX=9606GN=SNCAIPMTYLIQSHHSRRSQNCAEDVIRKTKTDQNGQLECVRWMVSETEAIAELSCSKDFPSLIHYAGCYGQEKILLWLLQFMQEQGISLDEVDQDGNSAVHVASQHGYLGCIQTLVEYGANVTMQNHAGEKPSQSAERQGHTLCSRYLVVVETCMSLASQVVKLTKQLKEQTVERVTLQNQLQQFLEAQKSEGKSLPSSPSSPSSPASRKSQWKSPDADDDSVAKSKPGVQEGIQVLGSLSASSRARPKAKDEDSDKILRQLLGKEISENVCTQEKLSLEFQDAQASSRNSKKIPLEKRELKLARLRQLMQRSLSESDTDSNNSEDPKTTPVRKADRPRPQPIVESVESMDSAESLHLMIKKHTLASGGRRFPFSIKASKSLDGHSPSPTSESSEPDLESQYPGSGSIPPNQPSGDPQQPSPDSTAAQKVATSPKSALKSPSSKRRTSQNLKLRVTFEEPVVQMEQPSLELNGEKDKDKGRTLQRTSTSNESGDQLKRPFGAFRSIMETLSGNQNNNNNYQAANQLKTSTLPLTSLGRKTDAKGNPASSASKGKNKAEMYSSCINLSSNMLIEEHLCNDTRHNDINRKMKKSYSIKHIAEPESKELFL>sp|Q9Y6H5-3|SNCAP_HUMAN Isoform 3 of Synphilin-1 OS=Homo sapiens OX=9606GN=SNCAIPMEAPEYLDLDEIDFSDDISDNRSQGNRLQKLGLEDTDREDAMGFGSHRAKLTVVAALGACHCPENEYSVTSLKTIPELCRRCDTQNEDRSVSSSSWNCGISTLITNTQKPTGIADVYSKFRPVKRVSPLKHQPETLENNESDDQKNQKVVEYQKGGESDLGPQPQELGPGDGVGGPPGKSSEPSTSLGELEHYDLDMDEILDVPYIKSSQQLASFTKVTSEKRILGLCTTINGLSGKACSTGSSESSSSNMAPFCVLSPVKSPHLRKASAVIHDQHKLSTEETEISPPLVKCGSAYEPENQSKDFLNKTFSDPHGRKVEKTTPDCQLRAFHLQSSAAESKPEEQVSGLNRTSSQGPEERSEYLKKVKSILNIVKEGQISLLPHLAADNLDKIHDENGNNLLHIAASQGHAECLQHLTSLMGEDCLNERNTEKLTPAGLAIKNGQLECVRWMVSETEAIAELSCSKDFPSLIHYAGCYGQEKILLWLLQFMQEQGISLDEVDQDGNSAVHVASQHGYLGCIQTLVEYGANVTMQNHAGEKPSQSAERQGHTLCSRYLVVVETCMSLASQVVKLTKQLKEQTVERVTLQNQLQQFLEAQKSEGKSLPSSPSSPSSPASRKSQWKSPDADDDSVAKSKPGVQEGIQVLGSLSASSRARPKAKDEDSDKILRQLLGKEISENVCTQEKLSLEFQDAQASSRNSKKIPLEKRELKLARLRQLMQRSLSESDTDSNNSEDPKTTPVRKADRPRPQPIVESVESMDSAESLHLMIKKHTLASGGRRFPFSIKASKSLDGHSPSPTSESSEPDLESQYPGSGSIPPNQPSGDPQQPSPDSTAAQKVATSPKSALKSPSSKRRTSQNLKLRVTFEEPVVQMEQPSLELNGEKDKDKGRTLQRTSTSNESGDQLKRPFGAFRSIMETLSGNQNNNNNYQAANQLKTSTLPLTSLGRKTDAKGNPASSASKGKNKAEMYSSCINLSSNMLIEEHLCNDTRHNDINRKMKKSYSIKHIAEPESKELFL>sp|Q9Y6H5-4|SNCAP_HUMAN Isoform 4 of Synphilin-1 OS=Homo sapiens OX=9606GN=SNCAIPMEAPEYLDLDEIDFSDDISYSVTSLKTIPELCRRCDTQNEDRSVSSSSWNCGISTLITNTQKPTGIADVYSKFRPVKRVSPLKHQPETLENNESDDQKNQKVVEYQKGGESDLGPQPQELGPGDGVGGPPGKSSEPSTSLGELEHYDLDMDEILDVPYIKSSQQLASFTKVTSEKRILGLCTTINGLSGKACSTGSSESSSSNMAPFCVLSPVKSPHLRKASAVIHDQHKLSTEETEISPPLVKCGSAYEPENQSKDFLNKTFSDPHGRKVEKTTPDCQLRAFHLQSSAAESKPEEQVSGLNRTSSQGPEERSEYLKKVKSILNIVKEGQISLLNGQLECVRWMVSETEAIAELSCSKDFPSLIHYAGCYGQEKILLWLLQFMQEQGISLDEVDQDGNSAVHVASQHGYLGCIQTLVEYGANVTMQNHAGEKPSQSAERQGHTLCSRYLVVVETCMSLASQVVKLTKQLKEQTVERVTLQNQLQQFLEAQKSEGKSLPSSPSSPSSPASRKSQWKSPDADDDSVAKSKPGVQEGIQVLGSLSASSRARPKAKDEDSDKILRQLLGKEISENVCTQEKLSLEFQDAQASSRNSKKIPLEKRELKLARLRQLMQRSLSESDTDSNNSEDPKTTPVRKADRPRPQPIVESVESMDSAESLHLMIKKHTLASGGRRFPFSIKASKSLDGHSPSPTSESSEPDLESQYPGSGSIPPNQPSGDPQQPSPDSTAAQKVATSPKSALKSPSSKRRTSQNLKLRVTFEEPVVQMEQPSLELNGEKDKDKGRTLQRTSTSNESGDQLKRPFGAFRSIMETLSGNQNNNNNYQAANQLKTSTLPLTSLGRKTDAKGNPASSASKGKNKAA>sp|Q9Y6H5-5|SNCAP_HUMAN Isoform 5 of Synphilin-1 OS=Homo sapiens OX=9606GN=SNCAIPMTYLIQSHHSRRSQNCAEDVIRKTKTDQNGQLECVRWMVSETEAIAELSCSKDFPSLIHYAGCYGQEKILLWLLQFMQEQGISLDEVDQDGNSAVHVASQHGYLGCIQTLVEYGANVTMQNHAGEKPSQSAERQGHTLCSRYLVVVETCMSLASQVVKLTKQLKEQTVERVTLQNQLQQFLEAQKSEGKSLPSSPSSPSSPASRKSQWKSPDADDDSVAKSKPGVQEGIQVLGSLSASSRARPKAKDEDSDKILRQLLGKEISENVCTQEKLSLEFQDAQASSRNSKKIPLEKRELKLARLRQLMQRSLSESDTDSNNSEDPKTTPVRKADRPRPQPIVESVESMDSAESLHLMIKKHTLASGGRRFPFSIKASKSLDGHSPSPTSESSEPDLESQYPGSGSIPPNQPSGDPQQPSPDSTAAQKVATSPKSALKSPSSKRRTSQNLKLRVTFEEPVVQMEQPSLELNGEKDKDKGRTLQRTSTSNESGDQLKRPFGAFRSIMETLSGNQNNNNNYQAANQLKTSTLPLTSLGRKTDAKGNPASSASKGKNKAA>sp|Q9Y6H5-6|SNCAP_HUMAN Isoform 6 of Synphilin-1 OS=Homo sapiens OX=9606GN=SNCAIPMEAPEYLDLDEIDFSDDISDNRSQGNRLQKLGLEDTDREDAMGFGSHRAKLTVVAALGACHCPENEYSVTSLKTIPELCRRCDTQNEDRSVSSSSWNCGISTLITNTQKPTGIADVYSKFRPVKRVSPLKHQPETLENNESDDQKNQKVVEYQKGGESDLGPQPQELGPGDGVGGPPGKSSEPSTSLGELEHYDLDMDEILDVPYIKSSQQLASFTKVTSEKRILGLCTTINGLSGKACSTGSSESSSSNMAPFCVLSPVKSPHLRKASAVIHDQHKLSTEETEISPPLVKCGSAYEPENQSKDFLNKTFSDPHGRKVEKTTPDCQLRAFHLQSSAAESKPEEQVSGLNRTSSQGPEERSEYLKKVKSILNIVKEGQISLLPHLAADNLDKIHDENGNNLLHIAASQGHAECLQHLTSLMGEDCLNERNTEKLTPAGLAIKNGQLECVRWMVSETEAIAELSCSKDFPSLIHYAGCYGQEKILLWLLQFMQEQGISLDEVDQDGNSAVHVASQHGYLGCIQTRLKIQGTWNGSETCLFTHHFSSYPPISSGLQCQGQEGVLFIPDQVGAATNKQVLFQNQLPETKSSY>sp|Q9NTJ3|SMC4_HUMAN Structural maintenance of chromosomes protein 4OS=Homo sapiens OX=9606 GN=SMC4 PE=1 SV=2MPRKGTQPSTARRREEGPPPPSPDGASSDAEPEPPSGRTESPATAAETASEELDNRSLEEILNSIPPPPPPAMTNEAGAPRLMITHIVNQNFKSYAGEKILGPFHKRFSCIIGPNGSGKSNVIDSMLFVFGYRAQKIRSKKLSVLIHNSDEHKDIQSCTVEVHFQKIIDKEGDDYEVIPNSNFYVSRTACRDNTSVYHISGKKKTFKDVGNLLRSHGIDLDHNRFLILQGEVEQIAMMKPKGQTEHDEGMLEYLEDIIGCGRLNEPIKVLCRRVEILNEHRGEKLNRVKMVEKEKDALEGEKNIAIEFLTLENEIFRKKNHVCQYYIYELQKRIAEMETQKEKIHEDTKEINEKSNILSNEMKAKNKDVKDTEKKLNKITKFIEENKEKFTQLDLEDVQVREKLKHATSKAKKLEKQLQKDKEKVEEFKSIPAKSNNIINETTTRNNALEKEKEKEEKKLKEVMDSLKQETQGLQKEKESREKELMGFSKSVNEARSKMDVAQSELDIYLSRHNTAVSQLTKAKEALIAASETLKERKAAIRDIEGKLPQTEQELKEKEKELQKLTQEETNFKSLVHDLFQKVEEAKSSLAMNRSRGKVLDAIIQEKKSGRIPGIYGRLGDLGAIDEKYDVAISSCCHALDYIVVDSIDIAQECVNFLKRQNIGVATFIGLDKMAVWAKKMTEIQTPENTPRLFDLVKVKDEKIRQAFYFALRDTLVADNLDQATRVAYQKDRRWRVVTLQGQIIEQSGTMTGGGSKVMKGRMGSSLVIEISEEEVNKMESQLQNDSKKAMQIQEQKVQLEERVVKLRHSEREMRNTLEKFTASIQRLIEQEEYLNVQVKELEANVLATAPDKKKQKLLEENVSAFKTEYDAVAEKAGKVEAEVKRLHNTIVEINNHKLKAQQDKLDKINKQLDECASAITKAQVAIKTADRNLQKAQDSVLRTEKEIKDTEKEVDDLTAELKSLEDKAAEVVKNTNAAEESLPEIQKEHRNLLQELKVIQENEHALQKDALSIKLKLEQIDGHIAEHNSKIKYWHKEISKISLHPIEDNPIEEISVLSPEDLEAIKNPDSITNQIALLEARCHEMKPNLGAIAEYKKKEELYLQRVAELDKITYERDSFRQAYEDLRKQRLNEFMAGFYIITNKLKENYQMLTLGGDAELELVDSLDPFSEGIMFSVRPPKKSWKKIFNLSGGEKTLSSLALVFALHHYKPTPLYFMDEIDAALDFKNVSIVAFYIYEQTKNAQFIIISLRNNMFEISDRLIGIYKTYNITKSVAVNPKEIASKGLC>sp|Q9NTJ3-2|SMC4_HUMAN Isoform 2 of Structural maintenance ofchromosomes protein 4 OS=Homo sapiens OX=9606 GN=SMC4MPRKGTQPSTARRREEGPPPPSPDGASSDAEPEPPSGRTESPATAAETASEELDNRSLEEILNSIPPPPPPAMTNEAGAPRLMITHIVNQNFKSYAGEKILGPFHKRFSCIIGPNGSGKSNVIDSMLFVFGYRAQKIRSKKLSVLIHNSDEHKDIQSCTVEVHFQKIIDKEGDDYEVIPNSNFYVSRTACRDNTSVYHISGKKKTFKDVGNLLRSHGIDLDHNRFLILQGEVEQIAMMKPKGQTEHDEGMLEYLEDIIGCGRLNEPIKVLCRRVEILNEHRGEKLNRVKMVEKEKDALEGEKNIAIEFLTLENEIFRKKNHVCQYYIYELQKRIAEMETQKEKIHEDTKEINEKSNILSNEMKAKNKDVKDTEKKLNKITKFIEENKEKFTQLDLEDVQVREKLKHATSKAKKLEKQLQKDKEKVEEFKSIPAKSNNIINETTTRNNALEKEKEKEEKKLKEVMDSLKQETQGLQKEKESREKELMGFSKSVNEARSKMDVAQSELDIYLSRHNTAVSQLTKAKEALIAASETLKERKAAIRDIEGKLPQTEQELKEKEKELQKLTQEETNFKSLVHDLFQKVEEAKSSLAMNRSRGKVLDAIIQEKKSGRIPGIYGRLGDLGAIDEKYDVAISSCCHALDYIVVDSIDIAQECVNFLKRQNIGVATFIGLDKMAVWAKKMTEIQTPENTPRLFDLVKVKDEKIRQAFYFALRDTLVADNLDQATRVAYQKDRRWRVVTLQGQIIEQSGTMTGGGSKVMKGRMGSSLVIEISEEEVNKMESQLQNDSKKAMQIQEQKVQLEERVVKLRHSEREMRNTLEKFTASIQRLIEQEEYLNVQVKELEANVLATAPDKKKQKLLEENVSAFKTEYDAVAEKAGKVEAEVKRLHNTIVEINNHKLKAQQDKLDKINKQLDECASAITKAQVAIKTADRNLQKAQDSVLRTEKEIKDTEKEVDDLTAELKSLEDKAAEVVKNTNAAEISKISLHPIEDNPIEEISVLSPEDLEAIKNPDSITNQIALLEARCHEMKPNLGAIAEYKKKEELYLQRVAELDKITYERDSFRQAYEDLRKQRLNEFMAGFYIITNKLKENYQMLTLGGDAELELVDSLDPFSEGIMFSVRPPKKSWKKIFNLSGGEKTLSSLALVFALHHYKPTPLYFMDEIDAALDFKNVSIVAFYIYEQTKNAQFIIISLRNNMFEISDRLIGIYKTYNITKSVAVNPKEIASKGLC>sp|P51532|SMCA4_HUMAN Transcription activator BRG1 OS=Homo sapiensOX=9606 GN=SMARCA4 PE=1 SV=2MSTPDPPLGGTPRPGPSPGPGPSPGAMLGPSPGPSPGSAHSMMGPSPGPPSAGHPIPTQGPGGYPQDNMHQMHKPMESMHEKGMSDDPRYNQMKGMGMRSGGHAGMGPPPSPMDQHSQGYPSPLGGSEHASSPVPASGPSSGPQMSSGPGGAPLDGADPQALGQQNRGPTPFNQNQLHQLRAQIMAYKMLARGQPLPDHLQMAVQGKRPMPGMQQQMPTLPPPSVSATGPGPGPGPGPGPGPGPAPPNYSRPHGMGGPNMPPPGPSGVPPGMPGQPPGGPPKPWPEGPMANAAAPTSTPQKLIPPQPTGRPSPAPPAVPPAASPVMPPQTQSPGQPAQPAPMVPLHQKQSRITPIQKPRGLDPVEILQEREYRLQARIAHRIQELENLPGSLAGDLRTKATIELKALRLLNFQRQLRQEVVVCMRRDTALETALNAKAYKRSKRQSLREARITEKLEKQQKIEQERKRRQKHQEYLNSILQHAKDFKEYHRSVTGKIQKLTKAVATYHANTEREQKKENERIEKERMRRLMAEDEEGYRKLIDQKKDKRLAYLLQQTDEYVANLTELVRQHKAAQVAKEKKKKKKKKKAENAEGQTPAIGPDGEPLDETSQMSDLPVKVIHVESGKILTGTDAPKAGQLEAWLEMNPGYEVAPRSDSEESGSEEEEEEEEEEQPQAAQPPTLPVEEKKKIPDPDSDDVSEVDARHIIENAKQDVDDEYGVSQALARGLQSYYAVAHAVTERVDKQSALMVNGVLKQYQIKGLEWLVSLYNNNLNGILADEMGLGKTIQTIALITYLMEHKRINGPFLIIVPLSTLSNWAYEFDKWAPSVVKVSYKGSPAARRAFVPQLRSGKFNVLLTTYEYIIKDKHILAKIRWKYMIVDEGHRMKNHHCKLTQVLNTHYVAPRRLLLTGTPLQNKLPELWALLNFLLPTIFKSCSTFEQWFNAPFAMTGEKVDLNEEETILIIRRLHKVLRPFLLRRLKKEVEAQLPEKVEYVIKCDMSALQRVLYRHMQAKGVLLTDGSEKDKKGKGGTKTLMNTIMQLRKICNHPYMFQHIEESFSEHLGFTGGIVQGLDLYRASGKFELLDRILPKLRATNHKVLLFCQMTSLMTIMEDYFAYRGFKYLRLDGTTKAEDRGMLLKTFNEPGSEYFIFLLSTRAGGLGLNLQSADTVIIFDSDWNPHQDLQAQDRAHRIGQQNEVRVLRLCTVNSVEEKILAAAKYKLNVDQKVIQAGMFDQKSSSHERRAFLQAILEHEEQDESRHCSTGSGSASFAHTAPPPAGVNPDLEEPPLKEEDEVPDDETVNQMIARHEEEFDLFMRMDLDRRREEARNPKRKPRLMEEDELPSWIIKDDAEVERLTCEEEEEKMFGRGSRHRKEVDYSDSLTEKQWLKAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEED>sp|P51532-2|SMCA4_HUMAN Isoform 2 of Transcription activator BRG1OS=Homo sapiens OX=9606 GN=SMARCA4MSTPDPPLGGTPRPGPSPGPGPSPGAMLGPSPGPSPGSAHSMMGPSPGPPSAGHPIPTQGPGGYPQDNMHQMHKPMESMHEKGMSDDPRYNQMKGMGMRSGGHAGMGPPPSPMDQHSQGYPSPLGGSEHASSPVPASGPSSGPQMSSGPGGAPLDGADPQALGQQNRGPTPFNQNQLHQLRAQIMAYKMLARGQPLPDHLQMAVQGKRPMPGMQQQMPTLPPPSVSATGPGPGPGPGPGPGPGPAPPNYSRPHGMGGPNMPPPGPSGVPPGMPGQPPGGPPKPWPEGPMANAAAPTSTPQKLIPPQPTGRPSPAPPAVPPAASPVMPPQTQSPGQPAQPAPMVPLHQKQSRITPIQKPRGLDPVEILQEREYRLQARIAHRIQELENLPGSLAGDLRTKATIELKALRLLNFQRQLRQEVVVCMRRDTALETALNAKAYKRSKRQSLREARITEKLEKQQKIEQERKRRQKHQEYLNSILQHAKDFKEYHRSVTGKIQKLTKAVATYHANTEREQKKENERIEKERMRRLMAEDEEGYRKLIDQKKDKRLAYLLQQTDEYVANLTELVRQHKAAQVAKEKKKKKKKKKAENAEGQTPAIGPDGEPLDETSQMSDLPVKVIHVESGKILTGTDAPKAGQLEAWLEMNPGYEVAPRSDSEESGSEEEEEEEEEEQPQAAQPPTLPVEEKKKIPDPDSDDVSEVDARHIIENAKQDVDDEYGVSQALARGLQSYYAVAHAVTERVDKQSALMVNGVLKQYQIKGLEWLVSLYNNNLNGILADEMGLGKTIQTIALITYLMEHKRINGPFLIIVPLSTLSNWAYEFDKWAPSVVKVSYKGSPAARRAFVPQLRSGKFNVLLTTYEYIIKDKHILAKIRWKYMIVDEGHRMKNHHCKLTQVLNTHYVAPRRLLLTGTPLQNKLPELWALLNFLLPTIFKSCSTFEQWFNAPFAMTGEKVDLNEEETILIIRRLHKVLRPFLLRRLKKEVEAQLPEKVEYVIKCDMSALQRVLYRHMQAKGVLLTDGSEKDKKGKGGTKTLMNTIMQLRKICNHPYMFQHIEESFSEHLGFTGGIVQGLDLYRASGKFELLDRILPKLRATNHKVLLFCQMTSLMTIMEDYFAYRGFKYLRLDGTTKAEDRGMLLKTFNEPGSEYFIFLLSTRAGGLGLNLQSADTVIIFDSDWNPHQDLQAQDRAHRIGQQNEVRVLRLCTVNSVEEKILAAAKYKLNVDQKVIQAGMFDQKSSSHERRAFLQAILEHEEQDEEEDEVPDDETVNQMIARHEEEFDLFMRMDLDRRREEARNPKRKPRLMEEDELPSWIIKDDAEVERLTCEEEEEKMFGRGSRHRKEVDYSDSLTEKQWLKAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEED>sp|P51532-3|SMCA4_HUMAN Isoform 3 of Transcription activator BRG1OS=Homo sapiens OX=9606 GN=SMARCA4MSTPDPPLGGTPRPGPSPGPGPSPGAMLGPSPGPSPGSAHSMMGPSPGPPSAGHPIPTQGPGGYPQDNMHQMHKPMESMHEKGMSDDPRYNQMKGMGMRSGGHAGMGPPPSPMDQHSQGYPSPLGGSEHASSPVPASGPSSGPQMSSGPGGAPLDGADPQALGQQNRGPTPFNQNQLHQLRAQIMAYKMLARGQPLPDHLQMAVQGKRPMPGMQQQMPTLPPPSVSATGPGPGPGPGPGPGPGPAPPNYSRPHGMGGPNMPPPGPSGVPPGMPGQPPGGPPKPWPEGPMANAAAPTSTPQKLIPPQPTGRPSPAPPAVPPAASPVMPPQTQSPGQPAQPAPMVPLHQKQSRITPIQKPRGLDPVEILQEREYRLQARIAHRIQELENLPGSLAGDLRTKATIELKALRLLNFQRQLRQEVVVCMRRDTALETALNAKAYKRSKRQSLREARITEKLEKQQKIEQERKRRQKHQEYLNSILQHAKDFKEYHRSVTGKIQKLTKAVATYHANTEREQKKENERIEKERMRRLMAEDEEGYRKLIDQKKDKRLAYLLQQTDEYVANLTELVRQHKAAQVAKEKKKKKKKKKAENAEGQTPAIGPDGEPLDETSQMSDLPVKVIHVESGKILTGTDAPKAGQLEAWLEMNPGYEVAPRSDSEESGSEEEEEEEEEEQPQAAQPPTLPVEEKKKIPDPDSDDVSEVDARHIIENAKQDVDDEYGVSQALARGLQSYYAVAHAVTERVDKQSALMVNGVLKQYQIKGLEWLVSLYNNNLNGILADEMGLGKTIQTIALITYLMEHKRINGPFLIIVPLSTLSNWAYEFDKWAPSVVKVSYKGSPAARRAFVPQLRSGKFNVLLTTYEYIIKDKHILAKIRWKYMIVDEGHRMKNHHCKLTQVLNTHYVAPRRLLLTGTPLQNKLPELWALLNFLLPTIFKSCSTFEQWFNAPFAMTGEKVDLNEEETILIIRRLHKVLRPFLLRRLKKEVEAQLPEKVEYVIKCDMSALQRVLYRHMQAKGVLLTDGSEKDKKGKGGTKTLMNTIMQLRKICNHPYMFQHIEESFSEHLGFTGGIVQGLDLYRASGKFELLDRILPKLRATNHKVLLFCQMTSLMTIMEDYFAYRGFKYLRLDGTTKAEDRGMLLKTFNEPGSEYFIFLLSTRAGGLGLNLQSADTVIIFDSDWNPHQDLQAQDRAHRIGQQNEVRVLRLCTVNSVEEKILAAAKYKLNVDQKVIQAGMFDQKSSSHERRAFLQAILEHEEQDEEEDEVPDDETVNQMIARHEEEFDLFMRMDLDRRREEARNPKRKPRLMEEDELPSWIIKDDAEVERLTCEEEEEKMFGRGSRHRKEVDYSDSLTEKQWLKTLKAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEED>sp|P51532-4|SMCA4_HUMAN Isoform 4 of Transcription activator BRG1OS=Homo sapiens OX=9606 GN=SMARCA4MSTPDPPLGGTPRPGPSPGPGPSPGAMLGPSPGPSPGSAHSMMGPSPGPPSAGHPIPTQGPGGYPQDNMHQMHKPMESMHEKGMSDDPRYNQMKGMGMRSGGHAGMGPPPSPMDQHSQGYPSPLGGSEHASSPVPASGPSSGPQMSSGPGGAPLDGADPQALGQQNRGPTPFNQNQLHQLRAQIMAYKMLARGQPLPDHLQMAVQGKRPMPGMQQQMPTLPPPSVSATGPGPGPGPGPGPGPGPAPPNYSRPHGMGGPNMPPPGPSGVPPGMPGQPPGGPPKPWPEGPMANAAAPTSTPQKLIPPQPTGRPSPAPPAVPPAASPVMPPQTQSPGQPAQPAPMVPLHQKQSRITPIQKPRGLDPVEILQEREYRLQARIAHRIQELENLPGSLAGDLRTKATIELKALRLLNFQRQLRQEVVVCMRRDTALETALNAKAYKRSKRQSLREARITEKLEKQQKIEQERKRRQKHQEYLNSILQHAKDFKEYHRSVTGKIQKLTKAVATYHANTEREQKKENERIEKERMRRLMAEDEEGYRKLIDQKKDKRLAYLLQQTDEYVANLTELVRQHKAAQVAKEKKKKKKKKKAENAEGQTPAIGPDGEPLDETSQMSDLPVKVIHVESGKILTGTDAPKAGQLEAWLEMNPGYEVAPRSDSEESGSEEEEEEEEEEQPQAAQPPTLPVEEKKKIPDPDSDDVSEVDARHIIENAKQDVDDEYGVSQALARGLQSYYAVAHAVTERVDKQSALMVNGVLKQYQIKGLEWLVSLYNNNLNGILADEMGLGKTIQTIALITYLMEHKRINGPFLIIVPLSTLSNWAYEFDKWAPSVVKVSYKGSPAARRAFVPQLRSGKFNVLLTTYEYIIKDKHILAKIRWKYMIVDEGHRMKNHHCKLTQVLNTHYVAPRRLLLTGTPLQNKLPELWALLNFLLPTIFKSCSTFEQWFNAPFAMTGEKVDLNEEETILIIRRLHKVLRPFLLRRLKKEVEAQLPEKVEYVIKCDMSALQRVLYRHMQAKGVLLTDGSEKDKKGKGGTKTLMNTIMQLRKICNHPYMFQHIEESFSEHLGFTGGIVQGLDLYRASGKFELLDRILPKLRATNHKVLLFCQMTSLMTIMEDYFAYRGFKYLRLDGTTKAEDRGMLLKTFNEPGSEYFIFLLSTRAGGLGLNLQSADTVIIFDSDWNPHQDLQAQDRAHRIGQQNEVRVLRLCTVNSVEEKILAAAKYKLNVDQKVIQAGMFDQKSSSHERRAFLQAILEHEEQDEEEDEVPDDETVNQMIARHEEEFDLFMRMDLDRRREEARNPKRKPRLMEEDELPSWIIKDDAEVERLTCEEEEEKMFGRGSRHRKEVDYSDSLTEKQWLKTLKAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEED>sp|P51532-5|SMCA4_HUMAN Isoform 5 of Transcription activator BRG1OS=Homo sapiens OX=9606 GN=SMARCA4MSTPDPPLGGTPRPGPSPGPGPSPGAMLGPSPGPSPGSAHSMMGPSPGPPSAGHPIPTQGPGGYPQDNMHQMHKPMESMHEKGMSDDPRYNQMKGMGMRSGGHAGMGPPPSPMDQHSQGYPSPLGGSEHASSPVPASGPSSGPQMSSGPGGAPLDGADPQALGQQNRGPTPFNQNQLHQLRAQIMAYKMLARGQPLPDHLQMAVQGKRPMPGMQQQMPTLPPPSVSATGPGPGPGPGPGPGPGPAPPNYSRPHGMGGPNMPPPGPSGVPPGMPGQPPGGPPKPWPEGPMANAAAPTSTPQKLIPPQPTGRPSPAPPAVPPAASPVMPPQTQSPGQPAQPAPMVPLHQKQSRITPIQKPRGLDPVEILQEREYRLQARIAHRIQELENLPGSLAGDLRTKATIELKALRLLNFQRQLRQEVVVCMRRDTALETALNAKAYKRSKRQSLREARITEKLEKQQKIEQERKRRQKHQEYLNSILQHAKDFKEYHRSVTGKIQKLTKAVATYHANTEREQKKENERIEKERMRRLMAEDEEGYRKLIDQKKDKRLAYLLQQTDEYVANLTELVRQHKAAQVAKEKKKKKKKKKAENAEGQTPAIGPDGEPLDETSQMSDLPVKVIHVESGKILTGTDAPKAGQLEAWLEMNPGYEVAPRSDSEESGSEEEEEEEEEEQPQAAQPPTLPVEEKKKIPDPDSDDVSEVDARHIIENAKQDVDDEYGVSQALARGLQSYYAVAHAVTERVDKQSALMVNGVLKQYQIKGLEWLVSLYNNNLNGILADEMGLGKTIQTIALITYLMEHKRINGPFLIIVPLSTLSNWAYEFDKWAPSVVKVSYKGSPAARRAFVPQLRSGKFNVLLTTYEYIIKDKHILAKIRWKYMIVDEGHRMKNHHCKLTQVLNTHYVAPRRLLLTGTPLQNKLPELWALLNFLLPTIFKSCSTFEQWFNAPFAMTGEKVDLNEEETILIIRRLHKVLRPFLLRRLKKEVEAQLPEKVEYVIKCDMSALQRVLYRHMQAKGVLLTDGSEKDKKGKGGTKTLMNTIMQLRKICNHPYMFQHIEESFSEHLGFTGGIVQGLDLYRASGKFELLDRILPKLRATNHKVLLFCQMTSLMTIMEDYFAYRGFKYLRLDGTTKAEDRGMLLKTFNEPGSEYFIFLLSTRAGGLGLNLQSADTVIIFDSDWNPHQDLQAQDRAHRIGQQNEVRVLRLCTVNSVEEKILAAAKYKLNVDQKVIQAGMFDQKSSSHERRAFLQAILEHEEQDEEEDEVPDDETVNQMIARHEEEFDLFMRMDLDRRREEARNPKRKPRLMEEDELPSWIIKDDAEVERLTCEEEEEKMFGRGSRHRKEVDYSDSLTEKQWLKAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEED>sp|Q6RVD6|SPAT8_HUMAN Spermatogenesis-associated protein 8 OS=Homosapiens OX=9606 GN=SPATA8 PE=1 SV=1MAPAGMSGAQDNSCLYQEIAPSFQRLPCPRTSSRHFSEAMTCPCGWRPFKGGPGGLKGPVWPAKEENSCSHGRIQRVQRRRVPSASPLIQKINRRSVLFHPYCWS>sp|Q6RVD6-2|SPAT8_HUMAN Isoform 2 of Spermatogenesis-associated protein8 OS=Homo sapiens OX=9606 GN=SPATA8MAPAGMSGAQDNSCLYQEIAPSFQRLPCPRYLMSCPWQFSTPDVGLTPIRLPFLCGKTGMKLQHS>sp|P0DUD3|SPD14_HUMAN Putative speedy protein E14 OS=Homo sapiensOX=9606 GN=SPDYE14 PE=5 SV=1MGQILGKIMMSHQPQPQEERSPQRSTSGYPLQEVVDDEVLGPSAPGVDPSPPRRSLGWKRKRECLDESDDEPEKELAPEPEETWVAETLCGLKMKAKRRRVSLVLPEYYEAFNRLLEDPVIKRLLAWDKDLRVSDKYLLAMVIAYFSRAGLPSWQYQRIHFFLALYLANDMEEDDEAPKQNIFYFLYEETRSHIPLLSELWFQLCRYMNPRARKNCSQIALFRKYRFHFFCSMRCRAWVSLEELEEIQAYDPEHWVWARDRAHLS>sp|Q96SB8|SMC6_HUMAN Structural maintenance of chromosomes protein 6OS=Homo sapiens OX=9606 GN=SMC6 PE=1 SV=2MAKRKEENFSSPKNAKRPRQEELEDFDKDGDEDECKGTTLTAAEVGIIESIHLKNFMCHSMLGPFKFGSNVNFVVGNNGSGKSAVLTALIVGLGGRAVATNRGSSLKGFVKDGQNSADISITLRNRGDDAFKASVYGNSILIQQHISIDGSRSYKLKSATGSVVSTRKEELIAILDHFNIQVDNPVSVLTQEMSKQFLQSKNEGDKYKFFMKATQLEQMKEDYSYIMETKERTKEQIHQGEERLTELKRQCVEKEERFQSIAGLSTMKTNLESLKHEMAWAVVNEIEKQLNAIRDNIKIGEDRAARLDRKMEEQQVRLNEAEQKYKDIQDKLEKISEETNARAPECMALKADVVAKKRAYNEAEVLYNRSLNEYKALKKDDEQLCKRIEELKKSTDQSLEPERLERQKKISWLKERVKAFQNQENSVNQEIEQFQQAIEKDKEEHGKIKREELDVKHALSYNQRQLKELKDSKTDRLKRFGPNVPALLEAIDDAYRQGHFTYKPVGPLGACIHLRDPELALAIESCLKGLLQAYCCHNHADERVLQALMKRFYLPGTSRPPIIVSEFRNEIYDVRHRAAYHPDFPTVLTALEIDNAVVANSLIDMRGIETVLLIKNNSVARAVMQSQKPPKNCREAFTADGDQVFAGRYYSSENTRPKFLSRDVDSEISDLENEVENKTAQILNLQQHLSALEKDIKHNEELLKRCQLHYKELKMKIRKNISEIRELENIEEHQSVDIATLEDEAQENKSKMKMVEEHMEQQKENMEHLKSLKIEAENKYDAIKFKINQLSELADPLKDELNLADSEVDNQKRGKRHYEEKQKEHLDTLNKKKRELDMKEKELEEKMSQARQICPERIEVEKSASILDKEINRLRQKIQAEHASHGDREEIMRQYQEARETYLDLDSKVRTLKKFIKLLGEIMEHRFKTYQQFRRCLTLRCKLYFDNLLSQRAYCGKMNFDHKNETLSISVQPGEGNKAAFNDMRALSGGERSFSTVCFILSLWSIAESPFRCLDEFDVYMDMVNRRIAMDLILKMADSQRFRQFILLTPQSMSSLPSSKLIRILRMSDPERGQTTLPFRPVTQEEDDDQR>sp|Q96SB8-2|SMC6_HUMAN Isoform 2 of Structural maintenance ofchromosomes protein 6 OS=Homo sapiens OX=9606 GN=SMC6MAKRKEENFSSPKNAKRPRQEELEDFDKDGDEDECKGTTLTAAEVGIIESIHLKNFMCHSMLGPFKFGSNVNFVVGNNGSWSAVVRSRLNATSASQVQAILLFQPCGKSAVLTALIVGLGGRAVATNRGSSLKGFVKDGQNSADISITLRNRGDDAFKASVYGNSILIQQHISIDGSRSYKLKSATGSVVSTRKEELIAILDHFNIQVDNPVSVLTQEMSKQFLQSKNEGDKYKFFMKATQLEQMKEDYSYIMETKERTKEQIHQGEERLTELKRQCVEKEERFQSIAGLSTMKTNLESLKHEMAWAVVNEIEKQLNAIRDNIKIGEDRAARLDRKMEEQQVRLNEAEQKYKDIQDKLEKISEETNARAPECMALKADVVAKKRAYNEAEVLYNRSLNEYKALKKDDEQLCKRIEELKKSTDQSLEPERLERQKKISWLKERVKAFQNQENSVNQEIEQFQQAIEKDKEEHGKIKREELDVKHALSYNQRQLKELKDSKTDRLKRFGPNVPALLEAIDDAYRQGHFTYKPVGPLGACIHLRDPELALAIESCLKGLLQAYCCHNHADERVLQALMKRFYLPGTSRPPIIVSEFRNEIYDVRHRAAYHPDFPTVLTALEIDNAVVANSLIDMRGIETVLLIKNNSVARAVMQSQKPPKNCREAFTADGDQVFAGRYYSSENTRPKFLSRDVDSEISDLENEVENKTAQILNLQQHLSALEKDIKHNEELLKRCQLHYKELKMKIRKNISEIRELENIEEHQSVDIATLEDEAQENKSKMKMVEEHMEQQKENMEHLKSLKIEAENKYDAIKFKINQLSELADPLKDELNLADSEVDNQKRGKRHYEEKQKEHLDTLNKKKRELDMKEKELEEKMSQARQICPERIEVEKSASILDKEINRLRQKIQAEHASHGDREEIMRQYQEARETYLDLDSKVRTLKKFIKLLGEIMEHRFKTYQQFRRCLTLRCKLYFDNLLSQRAYCGKMNFDHKNETLSISVQPGEGNKAAFNDMRALSGGERSFSTVCFILSLWSIAESPFRCLDEFDVYMDMVNRRIAMDLILKMADSQRFRQFILLTPQSMSSLPSSKLIRILRMSDPERGQTTLPFRPVTQEEDDDQR>sp|Q9HAJ7|SP30L_HUMAN Histone deacetylase complex subunit SAP30L OS=Homosapiens OX=9606 GN=SAP30L PE=1 SV=1MNGFSTEEDSREGPPAAPAAAAPGYGQSCCLIEDGERCVRPAGNASFSKRVQKSISQKKLKLDIDKSVRHLYICDFHKNFIQSVRNKRKRKTSDDGGDSPEHDTDIPEVDLFQLQVNTLRRYKRHYKLQTRPGFNKAQLAETVSRHFRNIPVNEKETLAYFIYMVKSNKSRLDQKSEGGKQLE>sp|Q9HAJ7-2|SP30L_HUMAN Isoform 2 of Histone deacetylase complex subunitSAP30L OS=Homo sapiens OX=9606 GN=SAP30LMNGFSTEEDSREGPPAAPAAAAPGYGQSCCLIEDGERCVRPAGNASFSKRVQKSISQKKLKLDIDKSLQVNTLRRYKRHYKLQTRPGFNKAQLAETVSRHFRNIPVNEKETLAYFIYMVKSNKSRLDQKSEGGKQLE>sp|Q9HAJ7-3|SP30L_HUMAN Isoform 3 of Histone deacetylase complex subunitSAP30L OS=Homo sapiens OX=9606 GN=SAP30LMNGFSTEEDSREGPPAAPAAAAPGYGQSCCLIEDGERCVRPAGNASFSKRVQKSISQKKLKLDIDKSVDLFQLQVNTLRRYKRHYKLQTRPGFNKAQLAETVSRHFRNIPVNEKETLAYFIYMVKSNKSRLDQKSEGGKQLE>sp|Q9BQI5|SGIP1_HUMAN SH3-containing GRB2-like protein 3-interactingprotein 1 OS=Homo sapiens OX=9606 GN=SGIP1 PE=1 SV=2MMEGLKKRTRKAFGIRKKEKDTDSTGSPDRDGIQPSPHEPPYNSKAECAREGGKKVSKKSNGAPNGFYAEIDWERYNSPELDEEGYSIRPEEPGSTKGKHFYSSSESEEEEESHKKFNIKIKPLQSKDILKNAATVDELKASIGNIALSPSPVRKSPRRSPGAIKRNLSSEEVARPRRSTPTPELISKKPPDDTTALAPLFGPPLESAFDEQKTEVLLDQPEIWGSGQPINPSMESPKLTRPFPTGTPPPLPPKNVPATPPRTGSPLTIGPGNDQSATEVKIEKLPSINDLDSIFGPVLSPKSVAVNAEEKWVHFSDTSPEHVTPELTPREKVVSPPATPDNPADSPAPGPLGPPGPTGPPGPPGPPRNVLSPLNLEEVQKKVAEQTFIKDDYLETISSPKDFGLGQRATPPPPPPPTYRTVVSSPGPGSGPGPGTTSGASSPARPATPLVPCRSTTPPPPPPRPPSRPKLPPGKPGVGDVSRPFSPPIHSSSPPPIAPLARAESTSSISSTNSLSAATTPTVENEQPSLVWFDRGKFYLTFEGSSRGPSPLTMGAQDTLPVAAAFTETVNAYFKGADPSKCIVKITGEMVLSFPAGITRHFANNPSPAALTFRVINFSRLEHVLPNPQLLCCDNTQNDANTKEFWVNMPNLMTHLKKVSEQKPQATYYNVDMLKYQVSAQGIQSTPLNLAVNWRCEPSSTDLRIDYKYNTDAMTTAVALNNVQFLVPIDGGVTKLQAVLPPAVWNAEQQRILWKIPDISQKSENGGVGSLLARFQLSEGPSKPSPLVVQFTSEGSTLSGCDIELVGAGYRFSLIKKRFAAGKYLADN>sp|Q9BQI5-2|SGIP1_HUMAN Isoform 2 of SH3-containing GRB2-like protein 3-interacting protein 1 OS=Homo sapiens OX=9606 GN=SGIP1MMEGLKKRTRKAFGIRKKEKDTDSTGSPDRDGIQGKKKTQKTQLLLTSCFWLRALSLTLSQKKSNGAPNGFYAEIDWERYNSPELDEEGYSIRPEEPGSTKGKHFYSSSESEEEEESHKKFNIKIKPLQSKDILKNAATVDELKASIGNIALSPSPVRKSPRRSPGAIKRNLSSEEVARPRRSTPTPELISKKPPDDTTALAPLFGPPLESAFDEQKTEVLLDQPEIWGSGQPINPSMESPKLTRPFPTGTPPPLPPKNVPATPPRTGSPLTIGPGNDQSATEVKIEKLPSINDLDSIFGPVLSPKSVAVNAEEKWVHFSDTSPEHVTPELTPREKVVSPPATPDNPADSPAPGPLGPPGPTGPPGPPGPPRNVLSPLNLEEVQKKVAEQTFIKDDYLETISSPKDFGLGQRATPPPPPPPTYRTVVSSPGPGSGPGPGTTSGASSPARPATPLVPCRSTTPPPPPPRPPSRPKLPPGKPGVGDVSRPFSPPIHSSSPPPIAPLARAESTSSISSTNSLSAATTPTVENEQPSLVWFDRGKFYLTFEGSSRGPSPLTMGAQDTLPVAAAFTETVNAYFKGADPSKCIVKITGEMVLSFPAGITRHFANNPSPAALTFRVINFSRLEHVLPNPQLLCCDNTQNDANTKEFWVNMPNLMTHLKKVSEQKPQATYYNVDMLKYQVSAQGIQSTPLNLAVNWRCEPSSTDLRIDYKYNTDAMTTAVALNNVQFLVPIDGGVTKLQAVLPPAVWNAEQQRILWKIPDISQKSENGGVGSLLARFQLSEGPSKPSPLVVQFTSEGSTLSGCDIELVGAGYRFSLIKKRFAAGKYLADN>sp|Q9BQI5-3|SGIP1_HUMAN Isoform 3 of SH3-containing GRB2-like protein 3-interacting protein 1 OS=Homo sapiens OX=9606 GN=SGIP1MMEGLKKRTRKAFGIRKKEKDTDSTGSPDRDGIQGKKKTQKTQLLLTSCFWLRALSLTLSQKKSNGAPNGFYAEIDWERYNSPELDEEGYSIRPEEPGSTKGKHFYSSSESEEEEESHKKFNIKIKPLQSKDILKNAATVDELKASIGNIALSPSPVRKSPRRSPGAIKRNLSSEEVARPRRSTPTPELISKKPPDDTTALAPLFGPPLESAFDEQKTEVLLDQPEIWGSGQPINPSMESPKLTRPFPTGTPPPLPPKNVPATPPRTGSPLTIGPGNDQSATEVKIEKLPSINDLDSIFGPVLSPKSVAVNAEEKWVHFSDTSPEHVTPELTPREKVVSPPATPDNPADSPAPGPLGPPGPTGPPGPPGPPRNVLSPLNLEEVQKKVAEQTFIKDDYLETISSPKDFGLGQRATPPPPPPPTYRTVVSSPGPGSGPGPGTTSDGKTEAQRYQVICPSLQAGGNELDSYSGASSPARPATPLVPCRSTTPPPPPPRPPSRPKLPPGKPGVGDVSRPFSPPIHSSSPPPIAPLARAESTSSISSTNSLSAATTPTVENEQPSLVWFDRGKFYLTFEGSSRGPSPLTMGAQDTLPVAAAFTETVNAYFKGADPSKCIVKITGEMVLSFPAGITRHFANNPSPAALTFRVINFSRLEHVLPNPQLLCCDNTQNDANTKEFWVNMPNLMTHLKKVSEQKPQATYYNVDMLKYQVSAQGIQSTPLNLAVNWRCEPSSTDLRIDYKYNTDAMTTAVALNNVQFLVPIDGGVTKLQAVLPPAVWNAEQQRILWKIPDISQKSENGGVGSLLARFQLSEGPSKPSPLVVQFTSEGSTLSGCDIELVGAGYRFSLIKKRFAAGKYLADN>sp|Q9BQI5-4|SGIP1_HUMAN Isoform 4 of SH3-containing GRB2-like protein 3-interacting protein 1 OS=Homo sapiens OX=9606 GN=SGIP1MMEGLKKRTRKAFGIRKKEKDTDSTGSPDRDGIKKSNGAPNGFYAEIDWERYNSPELDEEGYSIRPEEPGSTKGKHFYSSSESEEEEESHKKFNIKIKPLQSKDILKNAATVDELKASIGNIALSPSPVGAIKRNLSSEEVARPRRSTPTPELISKKPPDDTTALAPLFGPPLESAFDEQKTEVLLDQPEIWGSGQPINPSMESPKLTRPFPTGTPPPLPPKNVPATPPRTGSPLTIGPGASSPARPATPLVPCRSTTPPPPPPRPPSRPKLPPGKPGVGDVSRPFSPPIHSSSPPPIAPLARAESTSSISSTNSLSAATTPTVENEQPSLVWFDRGKFYLTFEGSSRGPSPLTMGAQDTLPVAAAFTETVNAYFKGADPSKCIVKITGEMVLSFPAGITRHFANNPSPAALTFRVINFSRLEHVLPNPQLLCCDNTQNDANTKEFWVNMPNLMTHLKKVSEQKPQATYYNVDMLKYQVSAQGIQSTPLNLAVNWRCEPSSTDLRIDYKYNTDAMTTAVALNNVQFLVPIDGGVTKLQAVLPPAVWNAEQQRILWKIPDISQKSENGGVGSLLARFQLSEGPSKPSPLVVQFTSEGSTLSGCDIELVGAGYRFSLIKKRFAAGKYLADN>sp|Q9BQI5-5|SGIP1_HUMAN Isoform 5 of SH3-containing GRB2-like protein 3-interacting protein 1 OS=Homo sapiens OX=9606 GN=SGIP1MMEGLKKRTRKAFGIRKKEKDTDSTGSPDRDGIKKSNGAPNGFYAEIDWERYNSPELDEEGYSIRPEEPGSTKGKHFYSSSESEEEEESHKKFNIKIKPLQSKDILKNAATVDELKASIGNIALSPSPVGAIKRNLSSEEVARPRRSTPTPELISKKPPDDTTALAPLFGPPLESAFDEQKTEVLLDQPEIWGSGQPINPSMESPKLTRPFPTGTPPPLPPKNVPATPPRTGSPLTIGPGASSPARPATPLVPCRSTTPPPPPPRPPSRPKLPPGKPGVGDVSRPFSPPIHSSSPPPIAPLARAESTSSISSTNSLSAATTPTVVSEDDVFYDKLPSFERRCETPAGSSRGPSPLTMGAQDTLPVAAAFTETVNAYFKGADPSKCIVKITGEMVLSFPAGITRHFANNPSPAALTFRVINFSRLEHVLPNPQLLCCDNTQNDANTKEFWVNMPNLMTHLKKVSEQKPQATYYNVDMLKYQVSAQGIQSTPLNLAVNWRCEPSSTDLRIDYKYNTDAMTTAVALNNVQFLVPIDGGVTKLQAVLPPAVWNAEQQRILWKIPDISQKSENGGVGSLLARFQLSEGPSKPSPLVVQFTSEGSTLSGCDIELVGAGYRFSLIKKRFAAGKYLADN>sp|P0DUX1|SPD12_HUMAN Speedy protein E12 OS=Homo sapiens OX=9606GN=SPDYE12 PE=3 SV=1MGQILGKIMMSHQPQPQEEQSPQRSTSGYPLQEVVDDEVSGPSAPGVDPSPPRRSLGWKRKRECLDESDDEPEKELAPEPEETWVAETLCGLKMKAKRRRVSLVLPEYYEAFNRLLEDPVIKRLLAWDKDLRVSDKYLLAMVIAYFSRAGLPSWQYQRIHFFLALYLANDMEEDDEAPKQNIFYFLYEETRSHIPLLRELWFQLCRYMNPRARKNCSQIALFRKYRFHFFCSMRCRAWVSLEELEEIQAYDPEHWVWARDRAHLS>sp|A0A494C086|SPD21_HUMAN Putative speedy protein E21 OS=Homo sapiensOX=9606 GN=SPDYE21 PE=5 SV=1MDRTETRFRKRGQITGKITTSRQLHPQNEQSPQRSTSGYPLQEVVDDEVLGPSAPGVDPSPPCRSLGWKRKKEWSDESEEEPEKELAPEPEETWVVETLCGLKMKLKQQRVSPILPEHHKDFNSQLAPGVDPSPPHRSFCWKRKREWWDESEESLEEEPRKVLAPEPEEIWVAEMLCGLKMKLKRRRVLLVLPEHHEAFNRLLEDPVIKRFLAWDKDLRVSDKYLLAMVIVYFSRAGLPSWQYQRIHFFLALYLANDMEEDDEDSKQNIFHFLYGKTRSRIPLLRKRWFQLGRSMNPRARKNRSRIPLLRKRRFQLGRSMNPRARKYRSRIPLVRKRRFQLRRCMNPRARKNRSQIVLFQKLRFQFFCSMSGRAWVSPEELEEIQAYDPEHWVWARDRAHLS>sp|A6NLX3|SPDE4_HUMAN Speedy protein E4 OS=Homo sapiens OX=9606GN=SPDYE4 PE=1 SV=2MASGQARPPFEEESPQPSTTVRSPEVVVDDEVPGPSAPWIDPSPQPQSLGLKRKSEWSDESEEELEEELELERAPEPEDTWVVETLCGLKMKLKRKRASSVLPEHHEAFNRLLGDPVVQKFLAWDKDLRVSDKYLLAMVIAYFSRAGLFSWQYQRIHFFLALYLASDMEEDNQAPKQDIFSFLYGKNYSQRPLFHKLRYQLLCSMRWRTWVSPEEMEEIQAYDPEHWVWARDRTLIS>sp|Q8NBN3|TM87A_HUMAN Transmembrane protein 87A OS=Homo sapiens OX=9606GN=TMEM87A PE=1 SV=3MAAAAWLQVLPVILLLLGAHPSPLSFFSAGPATVAAADRSKWHIPIPSGKNYFSFGKILFRNTTIFLKFDGEPCDLSLNITWYLKSADCYNEIYNFKAEEVELYLEKLKEKRGLSGKYQTSSKLFQNCSELFKTQTFSGDFMHRLPLLGEKQEAKENGTNLTFIGDKTAMHEPLQTWQDAPYIFIVHIGISSSKESSKENSLSNLFTMTVEVKGPYEYLTLEDYPLMIFFMVMCIVYVLFGVLWLAWSACYWRDLLRIQFWIGAVIFLGMLEKAVFYAEFQNIRYKGESVQGALILAELLSAVKRSLARTLVIIVSLGYGIVKPRLGVTLHKVVVAGALYLLFSGMEGVLRVTGAQTDLASLAFIPLAFLDTALCWWIFISLTQTMKLLKLRRNIVKLSLYRHFTNTLILAVAASIVFIIWTTMKFRIVTCQSDWRELWVDDAIWRLLFSMILFVIMVLWRPSANNQRFAFSPLSEEEEEDEQKEPMLKESFEGMKMRSTKQEPNGNSKVNKAQEDDLKWVEENVPSSVTDVALPALLDSDEERMITHFERSKME>sp|Q8NBN3-2|TM87A_HUMAN Isoform 2 of Transmembrane protein 87A OS=Homosapiens OX=9606 GN=TMEM87AMAAAAWLQVLPVILLLLGAHPSPLSFFSAGPATVAAADRSKWHIPIPSGKNYFSFGKILFRNTTIFLKFDGEPCDLSLNITWYLKSADCYNEIYNFKAEEVELYLEKLKEKRGLSGKYQTSSKLFQNCSELFKTQTFSGDFMHRLPLLGEKQEAKENGTNLTFIGDKTIQMPFLKKHFLDC>sp|Q8NBN3-3|TM87A_HUMAN Isoform 3 of Transmembrane protein 87A OS=Homosapiens OX=9606 GN=TMEM87AMAHSDTVVDGEPCDLSLNITWYLKSADCYNEIYNFKAEEVELYLEKLKEKRGLSGKYQTSSKLFQNCSELFKTQTFSGDFMHRLPLLGEKQEAKENGTNLTFIGDKTAMHEPLQTWQDAPYIFIVHIGISSSKESSKENSLSNLFTMTVEVKGPYEYLTLEDYPLMIFFMVMCIVYVLFGVLWLAWSACYWRDLLRIQFWIGAVIFLGMLEKAVFYAEFQNIRYKGESVQGALILAELLSAVKRSLARTLVIIVSLGYGIVKPRLGVTLHKVVVAGALYLLFSGMEGVLRVTGAQTDLASLAFIPLAFLDTALCWWIFISLTQTMKLLKLRRNIVKLSLYRHFTNTLILAVAASIVFIIWTTMKFRIVTCQSDWRELWVDDAIWRLLFSMILFVIMVLWRPSANNQRFAFSPLSEEEEEDEQKEPMLKESFEGMKMRSTKQEPNGNSKVNKAQEDDLKWVEENVPSSVTDVALPALLDSDEERMITHFERSKME>sp|P01286|SLIB_HUMAN Somatoliberin OS=Homo sapiens OX=9606 GN=GHRH PE=1SV=1MPLWVFFFVILTLSNSSHCSPPPPLTLRMRRYADAIFTNSYRKVLGQLSARKLLQDIMSRQQGESNQERGARARLGRQVDSMWAEQKQMELESILVALLQKHSRNSQG>sp|P01286-2|SLIB_HUMAN Isoform 2 of Somatoliberin OS=Homo sapiensOX=9606 GN=GHRHMPLWVFFFVILTLSNSSHCSPPPPLTLRMRRYADAIFTNSYRKVLGQLSARKLLQDIMSRQQGESNQERGARARLGRQVDSMWAEQKQMELESILVALLQKHRNSQG>sp|P63208|SKP1_HUMAN S-phase kinase-associated protein 1 OS=Homo sapiensOX=9606 GN=SKP1 PE=1 SV=2MPSIKLQSSDGEIFEVDVEIAKQSVTIKTMLEDLGMDDEGDDDPVPLPNVNAAILKKVIQWCTHHKDDPPPPEDDENKEKRTDDIPVWDQEFLKVDQGTLFELILAANYLDIKGLLDVTCKTVANMIKGKTPEEIRKTFNIKNDFTEEEEAQVRKENQWCEEK>sp|P63208-2|SKP1_HUMAN Isoform 2 of S-phase kinase-associated protein 1OS=Homo sapiens OX=9606 GN=SKP1MPSIKLQSSDGEIFEVDVEIAKQSVTIKTMLEDLGMDDEGDDDPVPLPNVNAAILKKVIQWCTHHKDDPPPPEDDENKEKRTDDIPVWDQEFLKVDQGTLFELILAANYLDIKGLLDVTCKTVANMIKGKTPEEIRKTFNIKNDFTEEEEAQVGSTQFCL>sp|Q8N394|TMTC2_HUMAN Protein O-mannosyl-transferase TMTC2 OS=Homosapiens OX=9606 GN=TMTC2 PE=1 SV=1MIAELVSSALGLALYLNTLSADFCYDDSRAIKTNQDLLPETPWTHIFYNDFWGTLLTHSGSHKSYRPLCTLSFRLNHAIGGLNPWSYHLVNVLLHAAVTGLFTSFSKILLGDGYWTFMAGLMFASHPIHTEAVAGIVGRADVGASLFFLLSLLCYIKHCSTRGYSARTWGWFLGSGLCAGCSMLWKEQGVTVLAVSAVYDVFVFHRLKIKQILPTIYKRKNLSLFLSISLLIFWGSSLLGARLYWMGNKPPSFSNSDNPAADSDSLLTRTLTFFYLPTKNLWLLLCPDTLSFDWSMDAVPLLKTVCDWRNLHTVAFYTGLLLLAYYGLKSPSVDRECNGKTVTNGKQNANGHSCLSDVEYQNSETKSSFASKVENGIKNDVSQRTQLPSTENIVVLSLSLLIIPFVPATNLFFYVGFVIAERVLYIPSMGFCLLITVGARALYVKVQKRFLKSLIFYATATLIVFYGLKTAIRNGDWQNEEMLYRSGIKVNPAKAWGNLGNVLKSQSKISEAESAYRNALYYRSNMADMLYNLGLLLQENSRFAEALHYYKLAIGSRPTLASAYLNTGIILMNQGRTEEARRTFLKCSEIPDENLKDPHAHKSSVTSCLYNLGKLYHEQGHYEEALSVYKEAIQKMPRQFAPQSLYNMMGEAYMRLSKLPEAEHWYMESLRSKTDHIPAHLTYGKLLALTGRKSEAEKLFLKAIELDPTKGNCYMHYGQFLLEEARLIEAAEMAKKAAELDSTEFDVVFNAAHMLRQASLNEAAEKYYDLAARLRPNYPAALMNLGAILHLNGRLQKAEANYLRALQLKPDDVITQSNLRKLWNIMEKQGLKTSKT>sp|Q15427|SF3B4_HUMAN Splicing factor 3B subunit 4 OS=Homo sapiensOX=9606 GN=SF3B4 PE=1 SV=1MAAGPISERNQDATVYVGGLDEKVSEPLLWELFLQAGPVVNTHMPKDRVTGQHQGYGFVEFLSEEDADYAIKIMNMIKLYGKPIRVNKASAHNKNLDVGANIFIGNLDPEIDEKLLYDTFSAFGVILQTPKIMRDPDTGNSKGYAFINFASFDASDAAIEAMNGQYLCNRPITVSYAFKKDSKGERHGSAAERLLAAQNPLSQADRPHQLFADAPPPPSAPNPVVSSLGSGLPPPGMPPPGSFPPPVPPPGALPPGIPPAMPPPPMPPGAAGHGPPSAGTPGAGHPGHGHSHPHPFPPGGMPHPGMSQMQLAHHGPHGLGHPHAGPPGSGGQPPPRPPPGMPHPGPPPMGMPPRGPPFGSPMGHPGPMPPHGMRGPPPLMPPHGYTGPPRPPPYGYQRGPLPPPRPTPRPPVPPRGPLRGPLPQ>sp|Q11206|SIA4C_HUMAN CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 4 OS=Homo sapiens OX=9606 GN=ST3GAL4 PE=1 SV=1MVSKSRWKLLAMLALVLVVMVWYSISREDRYIELFYFPIPEKKEPCLQGEAESKASKLFGNYSRDQPIFLRLEDYFWVKTPSAYELPYGTKGSEDLLLRVLAITSSSIPKNIQSLRCRRCVVVGNGHRLRNSSLGDAINKYDVVIRLNNAPVAGYEGDVGSKTTMRLFYPESAHFDPKVENNPDTLLVLVAFKAMDFHWIETILSDKKRVRKGFWKQPPLIWDVNPKQIRILNPFFMEIAADKLLSLPMQQPRKIKQKPTTGLLAITLALHLCDLVHIAGFGYPDAYNKKQTIHYYEQITLKSMAGSGHNVSQEALAIKRMLEMGAIKNLTSF>sp|Q11206-2|SIA4C_HUMAN Isoform 2 of CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 4 OS=Homo sapiens OX=9606GN=ST3GAL4MCPAGWKLLAMLALVLVVMVWYSISREDRYIELFYFPIPEKKEPCLQGEAESKASKLFGNYSRDQPIFLRLEDYFWVKTPSAYELPYGTKGSEDLLLRVLAITSSSIPKNIQSLRCRRCVVVGNGHRLRNSSLGDAINKYDVVIRLNNAPVAGYEGDVGSKTTMRLFYPESAHFDPKVENNPDTLLVLVAFKAMDFHWIETILSDKKRVRKGFWKQPPLIWDVNPKQIRILNPFFMEIAADKLLSLPMQQPRKIKQKPTTGLLAITLALHLCDLVHIAGFGYPDAYNKKQTIHYYEQITLKSMAGSGHNVSQEALAIKRMLEMGAIKNLTSF>sp|Q11206-3|SIA4C_HUMAN Isoform 3 of CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 4 OS=Homo sapiens OX=9606GN=ST3GAL4MLALVLVVMVWYSISREDRYIELFYFPIPEKKEPCLQGEAESKASKLFGNYSRDQPIFLRLEDYFWVKTPSAYELPYGTKGSEDLLLRVLAITSSSIPKNIQSLRCRRCVVVGNGHRLRNSSLGDAINKYDVVIRLNNAPVAGYEGDVGSKTTMRLFYPESAHFDPKVENNPDTLLVLVAFKAMDFHWIETILSDKKRVRKGFWKQPPLIWDVNPKQIRILNPFFMEIAADKLLSLPMQQPRKIKQKPTTGLLAITLALHLCDLVHIAGFGYPDAYNKKQTIHYYEQITLKSMAGSGHNVSQEALAIKRMLEMGAIKNLTSF>sp|Q11206-4|SIA4C_HUMAN Isoform 4 of CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 4 OS=Homo sapiens OX=9606GN=ST3GAL4MVSKSRWKLLAMLALVLVVMVWYSISREDRYIELFYFPIPEKKEPCLQGEAESKASKLFGKLSPLCSYSRDQPIFLRLEDYFWVKTPSAYELPYGTKGSEDLLLRVLAITSSSIPKNIQSLRCRRCVVVGNGHRLRNSSLGDAINKYDVVIRLNNAPVAGYEGDVGSKTTMRLFYPESAHFDPKVENNPDTLLVLVAFKAMDFHWIETILSDKKRVRKGFWKQPPLIWDVNPKQIRILNPFFMEIAADKLLSLPMQQPRKIKQKPTTGLLAITLALHLCDLVHIAGFGYPDAYNKKQTIHYYEQITLKSMAGSGHNVSQEALAIKRMLEMGAIKNLTSF>sp|Q11206-5|SIA4C_HUMAN Isoform 5 of CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 4 OS=Homo sapiens OX=9606GN=ST3GAL4MVSKSRWKLLAMLALVLVVMVWYSISREDSFYFPIPEKKEPCLQGEAESKASKLFGNYSRDQPIFLRLEDYFWVKTPSAYELPYGTKGSEDLLLRVLAITSSSIPKNIQSLRCRRCVVVGNGHRLRNSSLGDAINKYDVVIRLNNAPVAGYEGDVGSKTTMRLFYPESAHFDPKVENNPDTLLVLVAFKAMDFHWIETILSDKKRVRKGFWKQPPLIWDVNPKQIRILNPFFMEIAADKLLSLPMQQPRKIKQKPTTGLLAITLALHLCDLVHIAGFGYPDAYNKKQTIHYYEQITLKSMAGSGHNVSQEALAIKRMLEMGAIKNLTSF>sp|Q11206-6|SIA4C_HUMAN Isoform 6 of CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 4 OS=Homo sapiens OX=9606GN=ST3GAL4MCPAGWKLLAMLALVLVVMVWYSISREDSFYFPIPEKKEPCLQGEAESKASKLFGNYSRDQPIFLRLEDYFWVKTPSAYELPYGTKGSEDLLLRVLAITSSSIPKNIQSLRCRRCVVVGNGHRLRNSSLGDAINKYDVVIRLNNAPVAGYEGDVGSKTTMRLFYPESAHFDPKVENNPDTLLVLVAFKAMDFHWIETILSDKKRVRKGFWKQPPLIWDVNPKQIRILNPFFMEIAADKLLSLPMQQPRKIKQKPTTGLLAITLALHLCDLVHIAGFGYPDAYNKKQTIHYYEQITLKSMAGSGHNVSQEALAIKRMLEMGAIKNLTSF>sp|Q11206-7|SIA4C_HUMAN Isoform 7 of CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 4 OS=Homo sapiens OX=9606GN=ST3GAL4MLALVLVVMVWYSISREDSFYFPIPEKKEPCLQGEAESKASKLFGNYSRDQPIFLRLEDYFWVKTPSAYELPYGTKGSEDLLLRVLAITSSSIPKNIQSLRCRRCVVVGNGHRLRNSSLGDAINKYDVVIRLNNAPVAGYEGDVGSKTTMRLFYPESAHFDPKVENNPDTLLVLVAFKAMDFHWIETILSDKKRVRKGFWKQPPLIWDVNPKQIRILNPFFMEIAADKLLSLPMQQPRKIKQKPTTGLLAITLALHLCDLVHIAGFGYPDAYNKKQTIHYYEQITLKSMAGSGHNVSQEALAIKRMLEMGAIKNLTSF>sp|P01242|SOM2_HUMAN Growth hormone variant OS=Homo sapiens OX=9606GN=GH2 PE=1 SV=3MAAGSRTSLLLAFGLLCLSWLQEGSAFPTIPLSRLFDNAMLRARRLYQLAYDTYQEFEEAYILKEQKYSFLQNPQTSLCFSESIPTPSNRVKTQQKSNLELLRISLLLIQSWLEPVQLLRSVFANSLVYGASDSNVYRHLKDLEEGIQTLMWRLEDGSPRTGQIFNQSYSKFDTKSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF>sp|P01242-2|SOM2_HUMAN Isoform 2 of Growth hormone variant OS=Homosapiens OX=9606 GN=GH2MAAGSRTSLLLAFGLLCLSWLQEGSAFPTIPLSRLFDNAMLRARRLYQLAYDTYQEFEEAYILKEQKYSFLQNPQTSLCFSESIPTPSNRVKTQQKSNLELLRISLLLIQSWLEPVQLLRSVFANSLVYGASDSNVYRHLKDLEEGIQTLMWVRVAPGIPNPGAPLASRDWGEKHCCPLFSSQALTQENSPYSSFPLVNPPGLSLQPGGEGGKWMNERGREQCPSAWPLLLFLHFAEAGRWQPPDWADLQSVLQQV>sp|P01242-3|SOM2_HUMAN Isoform 3 of Growth hormone variant OS=Homosapiens OX=9606 GN=GH2MAAGSRTSLLLAFGLLCLSWLQEGSAFPTIPLSRLFDNAMLRARRLYQLAYDTYQEFNPQTSLCFSESIPTPSNRVKTQQKSNLELLRISLLLIQSWLEPVQLLRSVFANSLVYGASDSNVYRHLKDLEEGIQTLMWRLEDGSPRTGQIFNQSYSKFDTKSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF>sp|P01242-4|SOM2_HUMAN Isoform 4 of Growth hormone variant OS=Homosapiens OX=9606 GN=GH2MAAGSRTSLLLAFGLLCLSWLQEGSAFPTIPLSRLFDNAMLRARRLYQLAYDTYQEFEEAYILKEQKYSFLQNPQTSLCFSESIPTPSNRVKTQQKSNLELLRISLLLIQSWLEPVQLLRSVFANSLVYGASDSNVYRHLKDLEEGIQTLIGWKMAAPGLGRSSISPTASLTQNRTTMTHCSRTTGCSTASGRTWTRSRHSCASCSAALWRAAVASSCPGGIPVTPPQCLSWSWKVLLQCPPALS>sp|Q8IVB4|SL9A9_HUMAN Sodium/hydrogen exchanger 9 OS=Homo sapiensOX=9606 GN=SLC9A9 PE=1 SV=1MERQSRVMSEKDEYQFQHQGAVELLVFNFLLILTILTIWLFKNHRFRFLHETGGAMVYGLIMGLILRYATAPTDIESGTVYDCVKLTFSPSTLLVNITDQVYEYKYKREISQHNINPHQGNAILEKMTFDPEIFFNVLLPPIIFHAGYSLKKRHFFQNLGSILTYAFLGTAISCIVIGLIMYGFVKAMIHAGQLKNGDFHFTDCLFFGSLMSATDPVTVLAIFHELHVDPDLYTLLFGESVLNDAVAIVLTYSISIYSPKENPNAFDAAAFFQSVGNFLGIFAGSFAMGSAYAIITALLTKFTKLCEFPMLETGLFFLLSWSAFLSAEAAGLTGIVAVLFCGVTQAHYTYNNLSSDSKIRTKQLFEFMNFLAENVIFCYMGLALFTFQNHIFNALFILGAFLAIFVARACNIYPLSFLLNLGRKQKIPWNFQHMMMFSGLRGAIAFALAIRNTESQPKQMMFTTTLLLVFFTVWVFGGGTTPMLTWLQIRVGVDLDENLKEDPSSQHQEANNLDKNMTKAESARLFRMWYSFDHKYLKPILTHSGPPLTTTLPEWCGPISRLLTSPQAYGEQLKEDDVECIVNQDELAINYQEQASSPCSPPARLGLDQKASPQTPGKENIYEGDLGLGGYELKLEQTLGQSQLN>sp|Q86VW0|SESD1_HUMAN SEC14 domain and spectrin repeat-containingprotein 1 OS=Homo sapiens OX=9606 GN=SESTD1 PE=1 SV=2MEASVILPILKKKLAFLSGGKDRRSGLILTIPLCLEQTNMDELSVTLDYLLSIPSEKCKARGFTVIVDGRKSQWNVVKTVVVMLQNVVPAEVSLVCVVKPDEFWDKKVTHFCFWKEKDRLGFEVILVSANKLTRYIEPCQLTEDFGGSLTYDHMDWLNKRLVFEKFTKESTSLLDELALINNGSDKGNQQEKERSVDLNFLPSVDPETVLQTGHELLSELQQRRFNGSDGGVSWSPMDDELLAQPQVMKLLDSLREQYTRYQEVCRQRSKRTQLEEIQQKVMQVVNWLEGPGSEQLRAQWGIGDSIRASQALQQKHEEIESQHSEWFAVYVELNQQIAALLNAGDEEDLVELKSLQQQLSDVCYRQASQLEFRQNLLQAALEFHGVAQDLSQQLDGLLGMLCVDVAPADGASIQQTLKLLEEKLKSVDVGLQGLREKGQGLLDQISNQASWAYGKDVTIENKENVDHIQGVMEDMQLRKQRCEDMVDVRRLKMLQMVQLFKCEEDAAQAVEWLSELLDALLKTHIRLGDDAQETKVLLEKHRKFVDVAQSTYDYGRQLLQATVVLCQSLRCTSRSSGDTLPRLNRVWKQFTIASEERVHRLEMAIAFHSNAEKILQDCPEEPEAINDEEQFDEIEAVGKSLLDRLTVPVVYPDGTEQYFGSPSDMASTAENIRDRMKLVNLKRQQLRHPEMVTTES>sp|Q4ZJI4|SL9B1_HUMAN Sodium/hydrogen exchanger 9B1 OS=Homo sapiensOX=9606 GN=SLC9B1 PE=2 SV=2MHTTESKNEHLEDENFQTSTTPQSLIDPNNTAQEETKTVLSDTEEIKPQTKKETYISCPLRGVLNVIITNGVILFVIWCMTWSILGSEALPGGNLFGLFIIFYSAIIGGKILQLIRIPLVPPLPPLLGMLLAGFTIRNVPFINEHVHVPNTWSSILRSIALTIILIRAGLGLDPQALRHLKVVCFRLAVGPCLMEASAAAVFSHFIMKFPWQWAFLLGFVLGAVSPAVVVPYMMVLQENGYGVEEGIPTLLMAASSMDDILAITGFNTCLSIVFSSGGILNNAIASIRNVCISLLAGIVLGFFVRYFPSEDQKKLTLKRGFLVLTMCVSAVLGSQRIGLHGSGGLCTLVLSFIAGTKWSQEKMKVQKIITTVWDIFQPLLFGLVGAEVSVSSLESNIVGISVATLSLALCVRILTTYLLMCFAGFSFKEKIFIALAWMPKATVQAVLGPLALETARVSAPHLEPYAKDVMTVAFLAILITAPNGALLMGILGPKMLTRHYDPSKIKLQLSTLEHH>sp|Q4ZJI4-2|SL9B1_HUMAN Isoform 2 of Sodium/hydrogen exchanger 9B1OS=Homo sapiens OX=9606 GN=SLC9B1MMVLQENGYGVEEGIPTLLMAASSMDDILAITGFNTCLSIVFSSGGILNNAIASIRNVCISLLAGIVLGFFVRYFPSEDQKKLTLKRGFLVLTMCVSAVLGSQRIGLHGSGGLCTLVLSFIAGTKWSQEKMKVQKIITTVWDIFQPLLFGLVGAEVSVSSLESNIVGISVATLSLALCVRILTTYLLMCFAGFSFKEKIFIALAWMPKATVQINQAILLLFLLREEWTNCKVAKKCEYTKERQ>sp|Q4ZJI4-3|SL9B1_HUMAN Isoform 3 of Sodium/hydrogen exchanger 9B1OS=Homo sapiens OX=9606 GN=SLC9B1MHTTESKNEHLEDENFQTSTTPQSLIDPNNTAQEETKTVLSDTEEIKPQTKKETYISCPLRGVLNVIITNGVILFVIWCMTWSILGSEALPGGNLFGLFIIFYSAIIGGKILQLIRIPLVPPLPPLLGMLLAGFTIRNVPFINEHVHVPNTWSSILRSIALTIILIRAGLGLDPQALRHLKVVCFRLAVGPCLMEASAAAVFSHFIMKFPWQWAFLLGFVLGAVSPAVVVPYMMVLQENGYGVEEGIPTLLMAASSMDDILAITGFNTCLSIVFSSGGILNNAIASIRNVCISLLAGIVLGFFVRYFPSEDQKKLTLKRGFLVLTMCVSAVLGSQRIGLHGSGGLCTLVLSFIAGTKWSQEKMKVQKIITTVWDIFQPLLFGLVGAEVSVSSLESNIVGISVATLSLALCVRILTTYLLMCFAGFSFKEKIFIALAWMPKATVQINQAILLLFLLREEWTNCKVAKKCEYTKERQ>sp|Q4ZJI4-5|SL9B1_HUMAN Isoform 4 of Sodium/hydrogen exchanger 9B1OS=Homo sapiens OX=9606 GN=SLC9B1MHTTESKNEHLEDENFQTSTTPQSLIDPNNTAQEETKTVLSDTEEIKPQTKKETYISCPLRGVLNVIITNVLF>sp|Q9Y6P5|SESN1_HUMAN Sestrin-1 OS=Homo sapiens OX=9606 GN=SESN1 PE=1SV=2MRLAAAANEAYTAPLAVSGLLGCKQCGGGRDQDEELGIRIPRPLGQGPSRFIPEKEILQVGSEDAQMHALFADSFAALGRLDNITLVMVFHPQYLESFLKTQHYLLQMDGPLPLHYRHYIGIMAAARHQCSYLVNLHVNDFLHVGGDPKWLNGLENAPQKLQNLGELNKVLAHRPWLITKEHIEGLLKAEEHSWSLAELVHAVVLLTHYHSLASFTFGCGISPEIHCDGGHTFRPPSVSNYCICDITNGNHSVDEMPVNSAENVSVSDSFFEVEALMEKMRQLQECRDEEEASQEEMASRFEIEKRESMFVFSSDDEEVTPARAVSRHFEDTSYGYKDFSRHGMHVPTFRVQDYCWEDHGYSLVNRLYPDVGQLIDEKFHIAYNLTYNTMAMHKDVDTSMLRRAIWNYIHCMFGIRYDDYDYGEINQLLDRSFKVYIKTVVCTPEKVTKRMYDSFWRQFKHSEKVHVNLLLIEARMQAELLYALRAITRYMT>sp|Q9Y6P5-2|SESN1_HUMAN Isoform T1 of Sestrin-1 OS=Homo sapiens OX=9606GN=SESN1MAEGENEVRWDGLCSRDSTTRETALENIRQTILRKTEYLRSVKETPHRPSDGLSNTESSDGLNKLLAHLLMLSKRCPFKDVREKSEFILKSIQELGIRIPRPLGQGPSRFIPEKEILQVGSEDAQMHALFADSFAALGRLDNITLVMVFHPQYLESFLKTQHYLLQMDGPLPLHYRHYIGIMAAARHQCSYLVNLHVNDFLHVGGDPKWLNGLENAPQKLQNLGELNKVLAHRPWLITKEHIEGLLKAEEHSWSLAELVHAVVLLTHYHSLASFTFGCGISPEIHCDGGHTFRPPSVSNYCICDITNGNHSVDEMPVNSAENVSVSDSFFEVEALMEKMRQLQECRDEEEASQEEMASRFEIEKRESMFVFSSDDEEVTPARAVSRHFEDTSYGYKDFSRHGMHVPTFRVQDYCWEDHGYSLVNRLYPDVGQLIDEKFHIAYNLTYNTMAMHKDVDTSMLRRAIWNYIHCMFGIRYDDYDYGEINQLLDRSFKVYIKTVVCTPEKVTKRMYDSFWRQFKHSEKVHVNLLLIEARMQAELLYALRAITRYMT>sp|Q9Y6P5-3|SESN1_HUMAN Isoform T3 of Sestrin-1 OS=Homo sapiens OX=9606GN=SESN1MHALFADSFAALGRLDNITLVMVFHPQYLESFLKTQHYLLQMDGPLPLHYRHYIGIMAAARHQCSYLVNLHVNDFLHVGGDPKWLNGLENAPQKLQNLGELNKVLAHRPWLITKEHIEGLLKAEEHSWSLAELVHAVVLLTHYHSLASFTFGCGISPEIHCDGGHTFRPPSVSNYCICDITNGNHSVDEMPVNSAENVSVSDSFFEVEALMEKMRQLQECRDEEEASQEEMASRFEIEKRESMFVFSSDDEEVTPARAVSRHFEDTSYGYKDFSRHGMHVPTFRVQDYCWEDHGYSLVNRLYPDVGQLIDEKFHIAYNLTYNTMAMHKDVDTSMLRRAIWNYIHCMFGIRYDDYDYGEINQLLDRSFKVYIKTVVCTPEKVTKRMYDSFWRQFKHSEKVHVNLLLIEARMQAELLYALRAITRYMT>sp|A8MV23|SERP3_HUMAN Serpin E3 OS=Homo sapiens OX=9606 GN=SERPINE3 PE=2SV=2MPPFLITLFLFHSCCLRANGHLREGMTLLKTEFALHLYQSVAACRNETNFVISPAGVSLPLEILQFGAEGSTGQQLADALGYTVHDKRVKDFLHAVYATLPTSSQGTEMELACSLFVQVGTPLSPCFVEHVSWWANSSLEPADLSEPNSTAIQTSEGASRETAGGGPSEGPGGWPWEQVSAAFAQLVLVSTMSFQGTWRKRFSSTDTQILPFTCAYGLVLQVPMMHQTTEVNYGQFQDTAGHQVGVLELPYLGSAVSLFLVLPRDKDTPLSHIEPHLTASTIHLWTTSLRRARMDVFLPRFRIQNQFNLKSILNSWGVTDLFDPLKANLKGISGQDGFYVSEAIHKAKIEVLEEGTKASGATALLLLKRSRIPIFKADRPFIYFLREPNTGITVFFDRIQIIYQCLSSNKGSFVHYPLKNKHSF>sp|A8MV23-2|SERP3_HUMAN Isoform 2 of Serpin E3 OS=Homo sapiens OX=9606GN=SERPINE3MPPFLITLFLFHSCCLRANGHLREGMTLLKTEFALHLYQSVAACRNETNFVISPAGVSLPLEILQFGAEGSTGQQLADALGYTVHDKRVKDFLHAVYATLPTSSQGTEMELACSLFVQVGTPLSPCFVEHVSWWANSSLEPADLSEPNSTAIQTSEGASRETAGGGPSEGPGGWPWEQVSAAFAQLVLVSTMSFQGTWRKRFSSTDTQILPFTCAYGLVLQVPMMHQTTEVNYGQFQDTAGHQVGVLELPYLGSAVSLFLVLPRDKDTPLSHIEPHLTASTIHLWTTSLRRARMDVFLPRFRIQNQFNLKSILNSWGVTDLFDPLKANLKGISGQDGFYVSEAIHKAKIEVLEEGTKASGATALLLLKRSRIPIFKADRPFIYFLREPNTGFVFSIGRVSNPLD>sp|Q86UD5|SL9B2_HUMAN Sodium/hydrogen exchanger 9B2 OS=Homo sapiensOX=9606 GN=SLC9B2 PE=1 SV=2MGDEDKRITYEDSEPSTGMNYTPSMHQEAQEETVMKLKGIDANEPTEGSILLKSSEKKLQETPTEANHVQRLRQMLACPPHGLLDRVITNVTIIVLLWAVVWSITGSECLPGGNLFGIIILFYCAIIGGKLLGLIKLPTLPPLPSLLGMLLAGFLIRNIPVINDNVQIKHKWSSSLRSIALSIILVRAGLGLDSKALKKLKGVCVRLSMGPCIVEACTSALLAHYLLGLPWQWGFILGFVLGAVSPAVVVPSMLLLQGGGYGVEKGVPTLLMAAGSFDDILAITGFNTCLGIAFSTGSTVFNVLRGVLEVVIGVATGSVLGFFIQYFPSRDQDKLVCKRTFLVLGLSVLAVFSSVHFGFPGSGGLCTLVMAFLAGMGWTSEKAEVEKIIAVAWDIFQPLLFGLIGAEVSIASLRPETVGLCVATVGIAVLIRILTTFLMVCFAGFNLKEKIFISFAWLPKATVQAAIGSVALDTARSHGEKQLEDYGMDVLTVAFLSILITAPIGSLLIGLLGPRLLQKVEHQNKDEEVQGETSVQV>sp|Q86UD5-2|SL9B2_HUMAN Isoform 2 of Sodium/hydrogen exchanger 9B2OS=Homo sapiens OX=9606 GN=SLC9B2MGDEDKRITYEDSEPSTGMNYTPSMHQEAQEETVMKLKGIDANEPTEGSILLKSSEKKLQETPTEANHVQRLRQMLACPPHGLLDRVITNVTIIVLLWAVVWSITGSECLPGGNLFGIIILFYCAIIGGKLLGLIKLPTLPPLPSLLGMLLAGFLIRNIPVINDNVQIKHKWSSSLRSIALSIILVRAGLGLDSKALKKLKGVCVRLSMGPCIVEACTSALLAHYLLGLPWQWGFILGFVLGAVSPAVVVPSMLLLQGGGYGVEKGVPTLLMAAGSFDDILAITGFNTCLGIAFSTGSTVFNVLRGVLEVVIGVATGSVLGFFIQYFPSRDQDKLVCKRTFLVLGLSVLAVFSSVHFGFPGSGGLCTLVMAFLAGMGWTSEKAEVEKIIAVAWDIFQPLLFGLIGAEVSIASLRPETVGSADSITGNFGTERPKLLGPPSTQLRFHFFHIQLST>sp|Q6ICB4|SESQ2_HUMAN Sesquipedalian-2 OS=Homo sapiens OX=9606 GN=PHETA2PE=1 SV=1MKLNERSVAHYALSDSPADHMGFLRTWGGPGTPPTPSGTGRRCWFVLKGNLLFSFESREGRAPLSLVVLEGCTVELAEAPVPEEFAFAICFDAPGVRPHLLAAEGPAAQEAWVKVLSRASFGYMRLVVRELESQLQDARQSLALQRRSSWKSVASRCKPQAPNHRAAGLENGHCLSKDSSPVGLVEEAGSRSAGWGLAEWELQGPASLLLGKGQSPVSPETSCFSTLHDWYGQEIVELRQCWQKRAQGSHSKCEEQDRP>sp|Q4G0N8|SL9C1_HUMAN Sodium/hydrogen exchanger 10 OS=Homo sapiensOX=9606 GN=SLC9C1 PE=2 SV=2MAGIFKEFFFSTEDLPEVILTLSLISSIGAFLNRHLEDFPIPVPVILFLLGCSFEVLSFTSSQVQRYANAIQWMSPDLFFRIFTPVVFFTTAFDMDTYMLQKLFWQILLISIPGFLVNYILVLWHLASVNQLLLKPTQWLLFSAILVSSDPMLTAAAIRDLGLSRSLISLINGESLMTSVISLITFTSIMDFDQRLQSKRNHTLAEEIVGGICSYIIASFLFGILSSKLIQFWMSTVFGDDVNHISLIFSILYLIFYICELVGMSGIFTLAIVGLLLNSTSFKAAIEETLLLEFWTFLSRIAFLMVFTFFGLLIPAHTYLYIEFVDIYYSLNIYLTLIVLRFLTLLLISPVLSRVGHEFSWRWIFIMVCSEMKGMPNINMALLLAYSDLYFGSDKEKSQILFHGVLVCLITLVVNRFILPVAVTILGLRDATSTKYKSVCCTFQHFQELTKSAASALKFDKDLANADWNMIEKAITLENPYMLNEEETTEHQKVKCPHCNKEIDEIFNTEAMELANRRLLSAQIASYQRQYRNEILSQSAVQVLVGAAESFGEKKGKCMSLDTIKNYSESQKTVTFARKLLLNWVYNTRKEKEGPSKYFFFRICHTIVFTEEFEHVGYLVILMNIFPFIISWISQLNVIYHSELKHTNYCFLTLYILEALLKIAAMRKDFFSHAWNIFELAITLIGILHVILIEIDTIKYIFNETEVIVFIKVVQFFRILRIFKLIAPKLLQIIDKRMSHQKTFWYGILKGYVQGEADIMTIIDQITSSKQIKQMLLKQVIRNMEHAIKELGYLEYDHPEIAVTVKTKEEINVMLNMATEILKAFGLKGIISKTEGAGINKLIMAKKKEVLDSQSIIRPLTVEEVLYHIPWLDKNKDYINFIQEKAKVVTFDCGNDIFEEGDEPKGIYIIISGMVKLEKSKPGLGIDQMVESKEKDFPIIDTDYMLSGEIIGEINCLTNEPMKYSATCKTVVETCFIPKTHLYDAFEQCSPLIKQKMWLKLGLAITARKIREHLSYEDWNYNMQLKLSNIYVVDIPMSTKTDIYDENLIYVILIHGAVEDCLLRKTYRAPFLIPITCHQIQSIEDFTKVVIIQTPINMKTFRRNIRKFVPKHKSYLTPGLIGSVGTLEEGIQEERNVKEDGAHSAATARSPQPCSLLGTKFNCKESPRINLRKVRKE>sp|Q4G0N8-2|SL9C1_HUMAN Isoform 2 of Sodium/hydrogen exchanger 10OS=Homo sapiens OX=9606 GN=SLC9C1MAGIFKEFFFSTEDLPEVILTLSLISSIGAFLNRHLEDFPIPVPVILFLLGCSFEVLSFTSSQVQRYANAIQWMSPDLFFRIFTPVVFFTTAFDMDTYMLQKLFWQILLISIPGFLVNYILVLWHLASVNQLLLKPTQWLLFSAILVSSDPMLTAAAIRDLGLSRSLISLINGESLMTSVISLITFTSIMDFDQRLQSKRNHTLAEEIVGGICSYIIASFLFGILSSKLIQFWMSTVFGDDVNHISLIFSILYLIFYICELVGMSGIFTLAIVGLLLNSTSFKAAIEETLLLEFLTLLLISPVLSRVGHEFSWRWIFIMVCSEMKGMPNINMALLLAYSDLYFGSDKEKSQILFHGVLVCLITLVVNRFILPVAVTILGLRDATSTKYKSVCCTFQHFQELTKSAASALKFDKDLANADWNMIEKAITLENPYMLNEEETTEHQKVKCPHCNKEIDEIFNTEAMELANRRLLSAQIASYQRQYRNEILSQSAVQVLVGAAESFGEKKGKCMSLDTIKNYSESQKTVTFARKLLLNWVYNTRKEKEGPSKYFFFRICHTIVFTEEFEHVGYLVILMNIFPFIISWISQLNVIYHSELKHTNYCFLTLYILEALLKIAAMRKDFFSHAWNIFELAITLIGILHVILIEIDTIKYIFNETEVIVFIKVVQFFRILRIFKLIAPKLLQIIDKRMSHQKTFWYGILKGYVQGEADIMTIIDQITSSKQIKQMLLKQVIRNMEHAIKELGYLEYDHPEIAVTVKTKEEINVMLNMATEILKAFGLKGIISKTEGAGINKLIMAKKKEVLDSQSIIRPLTVEEVLYHIPWLDKNKDYINFIQEKAKVVTFDCGNDIFEEGDEPKGIYIIISGMVKLEKSKPGLGIDQMVESKEKDFPIIDTDYMLSGEIIGEINCLTNEPMKYSATCKTVVETCFIPKTHLYDAFEQCSPLIKQKMWLKLGLAITARKIREHLSYEDWNYNMQLKLSNIYVVDIPMSTKTDIYDENLIYVILIHGAVEDCLLRKTYRAPFLIPITCHQIQSIEDFTKVVIIQTPINMKTFRRNIRKFVPKHKSYLTPGLIGSVGTLEEGIQEERNVKEDGAHSAATARSPQPCSLLGTKFNCKESPRINLRKVRKE>sp|Q5VXU9|SHOC1_HUMAN Protein shortage in chiasmata 1 ortholog OS=Homosapiens OX=9606 GN=SHOC1 PE=1 SV=1MTDTSVLDQWKASFFVEDFLEKKTITRMVTQINCEFEEVVPSSNPDSQIEVEEVSLYTHMDYNEVFTPVSCLEKCSALQNQNQDLFIDDKGILFVSSRKHLPTLPTLLSRLKLFLVKDPLLDFKGQIFTEANFSRECFSLQETLEAFVKEDFCMDKVNFCQEKLEDTICLNEPSSFLIEYEFLIPPSLKPEIDIPSLSELKELLNPVPEIINYVDEKEKLFERDLTNKHGIEDIGDIKFSSTEILTIQSQSEPEECSKPGELEMPLTPLFLTCQHSSVNSLRTELQTFPLSPVCKINLLTAEESANEYYMMWQLERCRSPLNPFLLTVPRIQEPHSQYSVTDLKKIFSVKEESLVINLEKAEWWKQAGLNLKMMETLEHLNTYLCHDNLSSNDTKIEIFLPTKVLQLESCLEHKSHSSPIALIDEKSTNAHLSLPQKSPSLAKEVPDLCFSDDYFSDKGAAKEEKPKNDQEPVNRIIQKKENNDHFELDCTGPSIKSPSSSIIKKASFEHGKKQENDLDLLSDFIMLRNKYKTCTSKTEVTNSDEKHDKEACSLTLQEESPIVHINKTLEEINQERGTDSVIEIQASDSQCQAFCLLEAAASPILKNLVSLCTLPTANWKFATVIFDQTRFLLKEQEKVVSDAVRQGTIDEREMTFKHAALLHLLVTIRDVLLTCSLDTALGYLSKAKDIYNSILGPYLGDIWRQLEIVQFIRGKKPETNYKIQELQCQILSWMQSQQQIKVLIIIRMDSDGEKHFLIKILNKIEGLTLTVLHSNERKDFLESEGVLRGTSSCVVVHNQYIGADFPWSNFSFVVEYNYVEDSCWTKHCKELNIPYMAFKVILPDTVLERSTLLDRFGGFLLEIQIPYVFFASEGLLNTPDILQLLESNYNISLVERGCSESLKLFGSSECYVVVTIDEHTAIILQDLEELNYEKASDNIIMRLMALSLQYRYCWIILYTKETLNSEYLLTEKTLHHLALIYAALVSFGLNSEELDVKLIIAPGVEATALIIRQIADHSLMTSKRDPHEWLDKSWLKVSPSEEEMYLLDFPCINPLVAQLMLNKGPSLHWILLATLCQLQELLPEVPEKVLKHFCSITSLFKIGSSSITKSPQISSPQENRNQISTLSSQSSASDLDSVIQEHNEYYQYLGLGETVQEDKTTILNDNSSIMELKEISSFLPPVTSYNQTSYWKDSSCKSNIGQNTPFLINIESRRPAYNSFLNHSDSESDVFSLGLTQMNCETIKSPTDTQKRVSVVPRFINSQKRRTHEAKGFINKDVSDPIFSLEGTQSPLHWNFKKNIWEQENHPFNLQYGAQQTACNKLYSQKGNLFTDQQKCLSDESEGLTCESSKDETFWRELPSVPSLDLFRASDSNANQKEFNSLYFYQRAGKSLGQKRHHESSFNSGDKESLTGFMCSQLPQFKKRRLAYEKVPGRVDGQTRLRFF>sp|Q5VXU9-2|SHOC1_HUMAN Isoform 2 of Protein shortage in chiasmata 1ortholog OS=Homo sapiens OX=9606 GN=SHOC1MFSALKYHAIDYLYENVVRKKFYRDALLLRIPSCLYQDESYHVAVTDNKFRRPWTRVSAVSVPGMTDTSVLDQWKASFFVEDFLEKKTITRMVTQINCEFEEVVPSSNPDSQIEVEEVSLYTHMDYNEVFTPVSCLEKCSALQNQNQDLFIDDKGILFVSSRKHLPTLPTLLSRLKLFLVKDPLLDFKGQIFTEANFSRECFSLQETLEAFVKEDFCMDKVNFCQEKLEDTICLNEPSSFLIEYEFLIPPSLKPEIDIPSLSELKELLNPVPEIINYVDEKEKLFERDLTNKHGIEDIGDIKFSSTEILTIQSQSEPEECSKPGELEMPLTPLFLTCQHSSVNSLRTELQTFPLSPVCKINLLTAEESANEYYMMWQLERCRSPLNPFLLTVPRIQEPHSQYSVTDLKKIFSVKEESLVINLEKAEWWKQAGLNLKMMETLEHLNTYLCHDNLSSNDTKIEIFLPTKVLQLECKYITVNISYVNIFRM>sp|Q5VXU9-3|SHOC1_HUMAN Isoform 3 of Protein shortage in chiasmata 1ortholog OS=Homo sapiens OX=9606 GN=SHOC1MSETLGDELEILRGKMMQRRPRSAEVKYFYFFKILLRLRLAILKYLFIDDKGILFVSSRKHLPTLPTLLSRLKLFLVKDPLLDFKGQIFTEANFSRECFSLQETLEAFVKEDFCMDKVNFCQEKLEDTICLNEPSSFLIEYEFLIPPSLKPEIDIPSLSELKELLNPVPEIINYVDEKEKLFERDLTNKHGIEDIGDIKFSSTEILTIQSQSEPEECSKPGELEMPLTPLFLTCQHSSVNSLRTELQTFPLSPVCKINLLTAEESANEYYMMWQLERCRSPLNPFLLTVPRIQEPHSQYSVTDLKKIFSVKEESLVINLEKAEWWKQAGLNLKMMETLEHLNTYLCHDNLSSNDTKIEIFLPTKVLQLESCLEHKSHSSPIALIDEKSTNAHLSLPQKSPSLAKEVPDLCFSDDYFSDKGAAKEEKPKNDQEPVNRIIQKKENNDHFELDCTGPSIKSPSSSIIKKASFEHGKKQENDLDLLSDFIMLRNKYKTCTSKTEVTNSDEKHDKEACSLTLQEESPIVHINKTLEEINQERGTDSVIEIQASDSQCQAFCLLEAAASPILKNLVSLCTLPTANWKFATVIFDQTRFLLKEQEKVVSDAVRQGTIDEREMTFKHAALLHLLVTIRDVLLTCSLDTALGYLSKAKDIYNSILGPYLGDIWRQLEIVQFIRGKKPETNYKIQELQCQILSWMQSQQQIKVLIIIRMDSDGEKHFLIKILNKIEGLTLTVLHSNERKDFLESEGVLRGTSSCVVVHNQYIGADFPWSNFSFVVEYNYVEDSCWTKHCKELNIPYMAFKVILPDTVLERSTLLDRFGGFLLEIQIPYVFFASEGLLNTPDILQLLESNYNISLVERGCSESLKLFGSSECYVVVTIDEHTAIILQDLEELNYEKASDNIIMRLMALSLQYRYCWIILYTKETLNSEYLLTEKTLHHLALIYAALVSFGLNSEELDVKLIIAPGVEATALIIRQIADHSLMTSKRDPHEWLDKSWLKVSPSEEEMYLLDFPCINPLVAQLMLNKGPSLHWILLATLCQLQELLPEVPEKVLKHFCSITSLFKIGSSSITKSPQISSPQENRNQISTLSSQSSASDLDSVIQEHNEYYQYLGLGETVQEDKTTILNDNSSIMELKEISSFLPPVTSYNQTSYWKDSSCKSNIGQNTPFLINIESRRPAYNSFLNHSDSESDVFSLGLTQMNCETIKSPTDTQKRVSVVPRFINSQKRRTHEAKGFINKDVSDPIFSLEGTQSPLHWNFKKNIWEQENHPFNLQYGAQQTACNKLYSQKGNLFTDQQKCLSDESEGLTCESSKDETFWRELPSVPSLDLFRASDSNANQKEFNSLYFYQRAGKSLGQKRHHESSFNSGDKESLTGFMCSQLPQFKKRRLAYEKVPGRVDGQTRLRFF>sp|O15047|SET1A_HUMAN Histone-lysine N-methyltransferase SETD1A OS=Homosapiens OX=9606 GN=SETD1A PE=1 SV=3MDQEGGGDGQKAPSFQWRNYKLIVDPALDPALRRPSQKVYRYDGVHFSVNDSKYIPVEDLQDPRCHVRSKNRDFSLPVPKFKLDEFYIGQIPLKEVTFARLNDNVRETFLKDMCRKYGEVEEVEILLHPRTRKHLGLARVLFTSTRGAKETVKNLHLTSVMGNIIHAQLDIKGQQRMKYYELIVNGSYTPQTVPTGGKALSEKFQGSGAATETAESRRRSSSDTAAYPAGTTAVGTPGNGTPCSQDTSFSSSRQDTPSSFGQFTPQSSQGTPYTSRGSTPYSQDSAYSSSTTSTSFKPRRSENSYQDAFSRRHFSASSASTTASTAIAATTAATASSSASSSSLSSSSSSSSSSSSSQFRSSDANYPAYYESWNRYQRHTSYPPRRATREEPPGAPFAENTAERFPPSYTSYLPPEPSRPTDQDYRPPASEAPPPEPPEPGGGGGGGGPSPEREEVRTSPRPASPARSGSPAPETTNESVPFAQHSSLDSRIEMLLKEQRSKFSFLASDTEEEEENSSMVLGARDTGSEVPSGSGHGPCTPPPAPANFEDVAPTGSGEPGATRESPKANGQNQASPCSSGDDMEISDDDRGGSPPPAPTPPQQPPPPPPPPPPPPPYLASLPLGYPPHQPAYLLPPRPDGPPPPEYPPPPPPPPHIYDFVNSLELMDRLGAQWGGMPMSFQMQTQMLTRLHQLRQGKGLIAASAGPPGGAFGEAFLPFPPPQEAAYGLPYALYAQGQEGRGAYSREAYHLPMPMAAEPLPSSSVSGEEARLPPREEAELAEGKTLPTAGTVGRVLAMLVQEMKSIMQRDLNRKMVENVAFGAFDQWWESKEEKAKPFQNAAKQQAKEEDKEKTKLKEPGLLSLVDWAKSGGTTGIEAFAFGSGLRGALRLPSFKVKRKEPSEISEASEEKRPRPSTPAEEDEDDPEQEKEAGEPGRPGTKPPKRDEERGKTQGKHRKSFALDSEGEEASQESSSEKDEEDDEEDEEDEDREEAVDTTKKETEVSDGEDEESDSSSKCSLYADSDGENDSTSDSESSSSSSSSSSSSSSSSSSSSSSSSESSSEDEEEEERPAALPSASPPPREVPVPTPAPVEVPVPERVAGSPVTPLPEQEASPARPAGPTEESPPSAPLRPPEPPAGPPAPAPRPDERPSSPIPLLPPPKKRRKTVSFSAIEVVPAPEPPPATPPQAKFPGPASRKAPRGVERTIRNLPLDHASLVKSWPEEVSRGGRSRAGGRGRLTEEEEAEPGTEVDLAVLADLALTPARRGLPALPAVEDSEATETSDEAERPRPLLSHILLEHNYALAVKPTPPAPALRPPEPVPAPAALFSSPADEVLEAPEVVVAEAEEPKPQQLQQQREEGEEEGEEEGEEEEEESSDSSSSSDGEGALRRRSLRSHARRRRPPPPPPPPPPRAYEPRSEFEQMTILYDIWNSGLDSEDMSYLRLTYERLLQQTSGADWLNDTHWVHHTITNLTTPKRKRRPQDGPREHQTGSARSEGYYPISKKEKDKYLDVCPVSARQLEGVDTQGTNRVLSERRSEQRRLLSAIGTSAIMDSDLLKLNQLKFRKKKLRFGRSRIHEWGLFAMEPIAADEMVIEYVGQNIRQMVADMREKRYVQEGIGSSYLFRVDHDTIIDATKCGNLARFINHCCTPNCYAKVITIESQKKIVIYSKQPIGVDEEITYDYKFPLEDNKIPCLCGTESCRGSLN>sp|O14656|TOR1A_HUMAN Torsin-1A OS=Homo sapiens OX=9606 GN=TOR1A PE=1SV=1MKLGRAVLGLLLLAPSVVQAVEPISLGLALAGVLTGYIYPRLYCLFAECCGQKRSLSREALQKDLDDNLFGQHLAKKIILNAVFGFINNPKPKKPLTLSLHGWTGTGKNFVSKIIAENIYEGGLNSDYVHLFVATLHFPHASNITLYKDQLQLWIRGNVSACARSIFIFDEMDKMHAGLIDAIKPFLDYYDLVDGVSYQKAMFIFLSNAGAERITDVALDFWRSGKQREDIKLKDIEHALSVSVFNNKNSGFWHSSLIDRNLIDYFVPFLPLEYKHLKMCIRVEMQSRGYEIDEDIVSRVAEEMTFFPKEERVFSDKGCKTVFTKLDYYYDD>sp|O14656-2|TOR1A_HUMAN Isoform 2 of Torsin-1A OS=Homo sapiens OX=9606GN=TOR1AMKLGRAVLGLLLLAPSVVQAVEPISLGLALAGVLTGYIYPRLYCLFAECCGQKRSLSREALQKDLDDNLFGQHLAKKIILNAVFGFINNPKPKKPLTLSLHGWTGTGKNFVSKIIAENIYEGGLNSDYVHLFVATLHFPHASNITLYKARMEVWNPFLDVIGFGVSLLWDEIWEFYVEMSEPGKRFMSQFPLERCRS>sp|Q9P0V8|SLAF8_HUMAN SLAM family member 8 OS=Homo sapiens OX=9606GN=SLAMF8 PE=1 SV=1MVMRPLWSLLLWEALLPITVTGAQVLSKVGGSVLLVAARPPGFQVREAIWRSLWPSEELLATFFRGSLETLYHSRFLGRAQLHSNLSLELGPLESGDSGNFSVLMVDTRGQPWTQTLQLKVYDAVPRPVVQVFIAVERDAQPSKTCQVFLSCWAPNISEITYSWRRETTMDFGMEPHSLFTDGQVLSISLGPGDRDVAYSCIVSNPVSWDLATVTPWDSCHHEAAPGKASYKDVLLVVVPVSLLLMLVTLFSAWHWCPCSGKKKKDVHADRVGPETENPLVQDLP>sp|Q9P0V8-2|SLAF8_HUMAN Isoform 2 of SLAM family member 8 OS=Homosapiens OX=9606 GN=SLAMF8MVMRPLWSLLLWEDAVPRPVVQVFIAVERDAQPSKTCQVFLSCWAPNISEITYSWRRETTMDFGMEPHSLFTDGQVLSISLGPGDRDVAYSCIVSNPVSWDLATVTPWDSCHHEAAPGKASYKDVLLVVVPVSLLLMLVTLFSAWHWCPCSGKKKKDVHADRVGPETENPLVQDLP>sp|Q13291|SLAF1_HUMAN Signaling lymphocytic activation molecule OS=Homosapiens OX=9606 GN=SLAMF1 PE=1 SV=1MDPKGLLSLTFVLFLSLAFGASYGTGGRMMNCPKILRQLGSKVLLPLTYERINKSMNKSIHIVVTMAKSLENSVENKIVSLDPSEAGPPRYLGDRYKFYLENLTLGIRESRKEDEGWYLMTLEKNVSVQRFCLQLRLYEQVSTPEIKVLNKTQENGTCTLILGCTVEKGDHVAYSWSEKAGTHPLNPANSSHLLSLTLGPQHADNIYICTVSNPISNNSQTFSPWPGCRTDPSETKPWAVYAGLLGGVIMILIMVVILQLRRRGKTNHYQTTVEKKSLTIYAQVQKPGPLQKKLDSFPAQDPCTTIYVAATEPVPESVQETNSITVYASVTLPES>sp|Q13291-2|SLAF1_HUMAN Isoform 2 of Signaling lymphocytic activationmolecule OS=Homo sapiens OX=9606 GN=SLAMF1MDPKGLLSLTFVLFLSLAFGASYGTGGRMMNCPKILRQLGSKVLLPLTYERINKSMNKSIHIVVTMAKSLENSVENKIVSLDPSEAGPPRYLGDRYKFYLENLTLGIRESRKEDEGWYLMTLEKNVSVQRFCLQLRLYEQVSTPEIKVLNKTQENGTCTLILGCTVEKGDHVAYSWSEKAGTHPLNPANSSHLLSLTLGPQHADNIYICTVSNPISNNSQTFSPWPGCRTDPSETKPWAVYAGLLGGVIMILIMVVILQLRRRGKTNHYQTTVEKKSLTIYAQVQKPGDTHHQTSDLF>sp|Q13291-3|SLAF1_HUMAN Isoform 3 of Signaling lymphocytic activationmolecule OS=Homo sapiens OX=9606 GN=SLAMF1MDPKGLLSLTFVLFLSLAFGASYGTGGRMMNCPKILRQLGSKVLLPLTYERINKSMNKSIHIVVTMAKSLENSVENKIVSLDPSEAGPPRYLGDRYKFYLENLTLGIRESRKEDEGWYLMTLEKNVSVQRFCLQLRLYEQVSTPEIKVLNKTQENGTCTLILGCTVEKGDHVAYSWSEKAGTHPLNPANSSHLLSLTLGPQHADNIYICTVSNPISNNSQTFSPWPGCRTDPSGKTNHYQTTVEKKSLTIYAQVQKPGPLQKKLDSFPAQDPCTTIYVAATEPVPESVQETNSITVYASVTLPES>sp|Q13291-4|SLAF1_HUMAN Isoform 4 of Signaling lymphocytic activationmolecule OS=Homo sapiens OX=9606 GN=SLAMF1MDPKGLLSLTFVLFLSLAFGASYGTGGRMMNCPKILRQLGSKVLLPLTYERINKSMNKSIHIVVTMAKSLENSVENKIVSLDPSEAGPPRYLGDRYKFYLENLTLGIRESRKEDEGWYLMTLEKNVSVQRFCLQLRLYEQVSTPEIKVLNKTQENGTCTLILGCTVEKGDHVAYSWSEKAGTHPLNPANSSHLLSLTLGPQHADNIYICTVSNPISNNSQTFSPWPGCRTDPSETKPWAVYAGLLGGVIMILIMVVILQLRRRATLTTTNQYWSQNVLTQDQERCPGCLPMVKRTITRQQWKKKALRSMPKSRNQVLFRRNLTPSQLRTLAPPYMLLPQSLSQSLSRKQIPSQSMLV>sp|Q9UIB8|SLAF5_HUMAN SLAM family member 5 OS=Homo sapiens OX=9606GN=CD84 PE=1 SV=1MAQHHLWILLLCLQTWPEAAGKDSEIFTVNGILGESVTFPVNIQEPRQVKIIAWTSKTSVAYVTPGDSETAPVVTVTHRNYYERIHALGPNYNLVISDLRMEDAGDYKADINTQADPYTTTKRYNLQIYRRLGKPKITQSLMASVNSTCNVTLTCSVEKEEKNVTYNWSPLGEEGNVLQIFQTPEDQELTYTCTAQNPVSNNSDSISARQLCADIAMGFRTHHTGLLSVLAMFFLLVLILSSVFLFRLFKRRQGRIFPEGSCLNTFTKNPYAASKKTIYTYIMASRNTQPAESRIYDEILQSKVLPSKEEPVNTVYSEVQFADKMGKASTQDSKPPGTSSYEIVI>sp|Q9UIB8-2|SLAF5_HUMAN Isoform 2 of SLAM family member 5 OS=Homosapiens OX=9606 GN=CD84MAQHHLWILLLCLQTWPEAAGKDSEIFTVNGILGESVTFPVNIQEPRQVKIIAWTSKTSVAYVTPGDSETAPVVTVTHRNYYERIHALGPNYNLVISDLRMEDAGDYKADINTQADPYTTTKRYNLQIYRRLGKPKITQSLMASVNSTCNVTLTCSVEKEEKNVTYNWSPLGEEGNVLQIFQTPEDQELTYTCTAQNPVSNNSDSISARQLCADIAMGFRTHHTGLLSVLAMFFLLVLILSSVFLFRLFKRRQGSCLNTFTKNPYAASKKTIYTYIMASRNTQPAESRIYDEILQSKVLPSKEEPVNTVYSEVQFADKMGKASTQDSKPPGTSSYEIVI>sp|Q9UIB8-3|SLAF5_HUMAN Isoform 3 of SLAM family member 5 OS=Homosapiens OX=9606 GN=CD84MAQHHLWILLLCLQTWPEAAGKDSEIFTVNGILGESVTFPVNIQEPRQVKIIAWTSKTSVAYVTPGDSETAPVVTVTHRNYYERIHALGPNYNLVISDLRMEDAGDYKADINTQADPYTTTKRYNLQIYRRLGKPKITQSLMASVNSTCNVTLTCSVEKEEKNVTYNWSPLGEEGNVLQIFQTPEDQELTYTCTAQNPVSNNSDSISARQLCADIAMGFRTHHTGLLSVLAMFFLLVLILSSVFLFRLFKRRQDAASKKTIYTYIMASRNTQPAESRIYDEILQSKVLPSKEEPVNTVYSEVQFADKMGKASTQDSKPPGTSSYEIVI>sp|Q9UIB8-4|SLAF5_HUMAN Isoform 4 of SLAM family member 5 OS=Homosapiens OX=9606 GN=CD84MAQHHLWILLLCLQTWPEAAGKDSEIFTVNGILGESVTFPVNIQEPRQVKIIAWTSKTSVAYVTPGDSETAPVVTVTHRNYYERIHALGPNYNLVISDLRMEDAGDYKADINTQADPYTTTKRYNLQIYRRLGKPKITQSLMASVNSTCNVTLTCSVEKEEKNVTYNWSPLGEEGNVLQIFQTPEDQELTYTCTAQNPVSNNSDSISARQLCADIAMGFRTHHTGLLSVLAMFFLLVLILSSVFLFRLFKRRQGRIFPEGKMWKLTFSPPGTEAIYPRFS>sp|Q9UIB8-5|SLAF5_HUMAN Isoform 5 of SLAM family member 5 OS=Homosapiens OX=9606 GN=CD84MAQHHLWILLLCLQTWPEAAGKDSEIFTVNGILGESVTFPVNIQEPRQVKIIAWTSKTSVAYVTPGDSETAPVVTVTHRNYYERIHALGPNYNLVISDLRMEDAGDYKADINTQADPYTTTKRYNLQIYRRLGKPKITQSLMASVNSTCNVTLTCSVEKEEKNVTYNWSPLGEEGNVLQIFQTPEDQELTYTCTAQNPVSNNSDSISARQLCADIAMGFRTHHTGLLSVLAMFFLLVLILSSVFLFRLFKRRQGASLQGRASEHSLFRSAVC>sp|Q9UIB8-6|SLAF5_HUMAN Isoform 6 of SLAM family member 5 OS=Homosapiens OX=9606 GN=CD84MAQHHLWILLLCLQTWPEAAGKDSEIFTVNGILGESVTFPVNIQEPRQVKIIAWTSKTSVAYVTPGDSETAPVVTVTHRNYYERIHALGPNYNLVISDLRMEDAGDYKADINTQADPYTTTKRYNLQIYRRLGKPKITQSLMASVNSTCNVTLTCSVEKEEKNVTYNWSPLGEEGNVLQIFQTPEDQELTYTCTAQNPVSNNSDSISARQLCAGNQLCPSLLVSLRDHSEELQGLNVGHIL>sp|Q9UIB8-7|SLAF5_HUMAN Isoform 7 of SLAM family member 5 OS=Homosapiens OX=9606 GN=CD84MAQHHLWILLLCLQTCRLGKPKITQSLMASVNSTCNVTLTCSVEKEEKNVTYNWSPLGEEGNVLQIFQTPEDQELTYTCTAQNPVSNNSDSISARQLCADIAMGFRTHHTGLLSVLAMFFLLVLILSSVFLFRLFKRRQDAASKKTIYTYIMASRNTQPAESRIYDEILQSKVLPSKEEPVNTVYSEVQFADKMGKASTQDSKPPGTSSYEIVI>sp|Q9NQ25|SLAF7_HUMAN SLAM family member 7 OS=Homo sapiens OX=9606GN=SLAMF7 PE=1 SV=1MAGSPTCLTLIYILWQLTGSAASGPVKELVGSVGGAVTFPLKSKVKQVDSIVWTFNTTPLVTIQPEGGTIIVTQNRNRERVDFPDGGYSLKLSKLKKNDSGIYYVGIYSSSLQQPSTQEYVLHVYEHLSKPKVTMGLQSNKNGTCVTNLTCCMEHGEEDVIYTWKALGQAANESHNGSILPISWRWGESDMTFICVARNPVSRNFSSPILARKLCEGAADDPDSSMVLLCLLLVPLLLSLFVLGLFLWFLKRERQEEYIEEKKRVDICRETPNICPHSGENTEYDTIPHTNRTILKEDPANTVYSTVEIPKKMENPHSLLTMPDTPRLFAYENVI>sp|Q9NQ25-2|SLAF7_HUMAN Isoform 2 of SLAM family member 7 OS=Homosapiens OX=9606 GN=SLAMF7MAGSPTCLTLIYILWQLTEHLSKPKVTMGLQSNKNGTCVTNLTCCMEHGEEDVIYTWKALGQAANESHNGSILPISWRWGESDMTFICVARNPVSRNFSSPILARKLCEGAADDPDSSMVLLCLLLVPLLLSLFVLGLFLWFLKRERQEEYIEEKKRVDICRETPNICPHSGENTEYDTIPHTNRTILKEDPANTVYSTVEIPKKMENPHSLLTMPDTPRLFAYENVI>sp|Q9NQ25-3|SLAF7_HUMAN Isoform 3 of SLAM family member 7 OS=Homosapiens OX=9606 GN=SLAMF7MAGSPTCLTLIYILWQLTGSAASGPVKELVGSVGGAVTFPLKSKVKQVDSIVWTFNTTPLVTIQPEGGTIIVTQNRNRERVDFPDGGYSLKLSKLKKNDSGIYYVGIYSSSLQQPSTQEYVLHVYEHLSKPKVTMGLQSNKNGTCVTNLTCCMEHGEEDVIYTWKALGQAANESHNGSILPISWRWGESDMTFICVARNPVSRNFSSPILARKLCEGAADDPDSSMVLLCLLLVPLLLSLFVLGLFLWFLKRERQEENNPKGRSSKYGLLHCGNTEKDGKSPLTAHDARHTKAICLEDPANTVYSTVEIPKKMENPHSLLTMPDTPRLFAYENVI>sp|Q9NQ25-4|SLAF7_HUMAN Isoform 4 of SLAM family member 7 OS=Homosapiens OX=9606 GN=SLAMF7MAGSPTCLTLIYILWQLTGSAASGPVKELVGSVGGAVTFPLKSKVKQVDSIVWTFNTTPLVTIQPEGGTIIVTQNRNRERVDFPDGGYSLKLSKLKKNDSGIYYVGIYSSSLQQPSTQEYVLHVYENNPKGRSSKYGLLHCGNTEKDGKSPLTAHDARHTKAICL>sp|Q9NQ25-5|SLAF7_HUMAN Isoform 5 of SLAM family member 7 OS=Homosapiens OX=9606 GN=SLAMF7MAGSPTCLTLIYILWQLTGSAASGPVKELVGSVGGAVTFPLKSKVKQVDSIVWTFNTTPLVTIQPEGGTIIVTQNRNRERVDFPDGGYSLKLSKLKKNDSGIYYVGIYSSSLQQPSTQEYVLHVYEHLSKPKVTMGLQSNKNGTCVTNLTCCMEHGEEDVIYTWKALGQAANESHNGSILPISWRWGESDMTFICVARNPVSRNFSSPILARKLCEGAADDPDSSMVLLCLLLVPLLLSLFVLGLFLWFLKRERQEENNPKGRSSKYGLLHCGNTEKDGKSPLTAHDARHTKAICL>sp|Q9NQ25-6|SLAF7_HUMAN Isoform 6 of SLAM family member 7 OS=Homosapiens OX=9606 GN=SLAMF7MAGSPTCLTLIYILWQLTGSAASGPVKELVGSVGGAVTFPLKSKVKQVDSIVWTFNTTPLVTIQPEGGTIIVTQNRNRERVDFPDGGYSLKLSKLKKNDSGIYYVGIYSSSLQQPSTQEYVLHVYEYIEEKKRVDICRETPNICPHSGENTEYDTIPHTNRTILKEDPANTVYSTVEIPKKMENPHSLLTMPDTPRLFAYENVI>sp|Q9NQ25-7|SLAF7_HUMAN Isoform 7 of SLAM family member 7 OS=Homosapiens OX=9606 GN=SLAMF7MAGSPTCLTLIYILWQLTEHLSKPKVTMGLQSNKNGTCVTNLTCCMEHGEEDVIYTWKALGQAANESHNGSILPISWRWGESDMTFICVARNPVSRNFSSPILARKLCEEYIEEKKRVDICRETPNICPHSGENTEYDTIPHTNRTILKEDPANTVYSTVEIPKKMENPHSLLTMPDTPRLFAYENVI>sp|Q9ULS5|TMCC3_HUMAN Transmembrane and coiled-coil domain protein 3OS=Homo sapiens OX=9606 GN=TMCC3 PE=1 SV=3MPGSDTALTVDRTYSYPGRHHRCKSRVERHDMNTLSLPLNIRRGGSDTNLNFDVPDGILDFHKVKLTADSLKQKILKVTEQIKIEQTSRDGNVAEYLKLVNNADKQQAGRIKQVFEKKNQKSAHSIAQLQKKLEQYHRKLREIEQNGASRSSKDISKDHLKDIHRSLKDAHVKSRTAPHCMESSKSGMPGVSLTPPVFVFNKSREFANLIRNKFGSADNIAHLKNSLEEFRPEASARAYGGSATIVNKPKYGSDDECSSGTSGSADSNGNQSFGAGGASTLDSQGKLAVILEELREIKDTQAQLAEDIEALKVQFKREYGFISQTLQEERYRYERLEDQLHDLTDLHQHETANLKQELASIEEKVAYQAYERSRDIQEALESCQTRISKLELHQQEQQALQTDTVNAKVLLGRCINVILAFMTVILVCVSTIAKFVSPMMKSRCHILGTFFAVTLLAIFCKNWDHILCAIERMIIPR>sp|Q9BYW2|SETD2_HUMAN Histone-lysine N-methyltransferase SETD2 OS=Homosapiens OX=9606 GN=SETD2 PE=1 SV=3MKQLQPQPPPKMGDFYDPEHPTPEEEENEAKIENVQKTGFIKGPMFKGVASSRFLPKGTKTKVNLEEQGRQKVSFSFSLTKKTLQNRFLTALGNEKQSDTPNPPAVPLQVDSTPKMKMEIGDTLSTAEESSPPKSRVELGKIHFKKHLLHVTSRPLLATTTAVASPPTHAAPLPAVIAESTTVDSPPSSPPPPPPPAQATTLSSPAPVTEPVALPHTPITVLMAAPVPLPVDVAVRSLKEPPIIIVPESLEADTKQDTISNSLEEHVTQILNEQADISSKKEDSHIGKDEEIPDSSKISLSCKKTGSKKKSSQSEGIFLGSESDEDSVRTSSSQRSHDLKFSASIEKERDFKKSSAPLKSEDLGKPSRSKTDRDDKYFSYSKLERDTRYVSSRCRSERERRRSRSHSRSERGSRTNLSYSRSERSHYYDSDRRYHRSSPYRERTRYSRPYTDNRARESSDSEEEYKKTYSRRTSSHSSSYRDLRTSSYSKSDRDCKTETSYLEMERRGKYSSKLERESKRTSENEAIKRCCSPPNELGFRRGSSYSKHDSSASRYKSTLSKPIPKSDKFKNSFCCTELNEEIKQSHSFSLQTPCSKGSELRMINKNPEREKAGSPAPSNRLNDSPTLKKLDELPIFKSEFITHDSHDSIKELDSLSKVKNDQLRSFCPIELNINGSPGAESDLATFCTSKTDAVLMTSDDSVTGSELSPLVKACMLSSNGFQNISRCKEKDLDDTCMLHKKSESPFRETEPLVSPHQDKLMSMPVMTVDYSKTVVKEPVDTRVSCCKTKDSDIYCTLNDSNPSLCNSEAENIEPSVMKISSNSFMNVHLESKPVICDSRNLTDHSKFACEEYKQSIGSTSSASVNHFDDLYQPIGSSGIASSLQSLPPGIKVDSLTLLKCGENTSPVLDAVLKSKKSSEFLKHAGKETIVEVGSDLPDSGKGFASRENRRNNGLSGKCLQEAQEEGNSILPERRGRPEISLDERGEGGHVHTSDDSEVVFSSCDLNLTMEDSDGVTYALKCDSSGHAPEIVSTVHEDYSGSSESSNDESDSEDTDSDDSSIPRNRLQSVVVVPKNSTLPMEETSPCSSRSSQSYRHYSDHWEDERLESRRHLYEEKFESIASKACPQTDKFFLHKGTEKNPEISFTQSSRKQIDNRLPELSHPQSDGVDSTSHTDVKSDPLGHPNSEETVKAKIPSRQQEELPIYSSDFEDVPNKSWQQTTFQNRPDSRLGKTELSFSSSCEIPHVDGLHSSEELRNLGWDFSQEKPSTTYQQPDSSYGACGGHKYQQNAEQYGGTRDYWQGNGYWDPRSGRPPGTGVVYDRTQGQVPDSLTDDREEEENWDQQDGSHFSDQSDKFLLSLQKDKGSVQAPEISSNSIKDTLAVNEKKDFSKNLEKNDIKDRGPLKKRRQEIESDSESDGELQDRKKVRVEVEQGETSVPPGSALVGPSCVMDDFRDPQRWKECAKQGKMPCYFDLIEENVYLTERKKNKSHRDIKRMQCECTPLSKDERAQGEIACGEDCLNRLLMIECSSRCPNGDYCSNRRFQRKQHADVEVILTEKKGWGLRAAKDLPSNTFVLEYCGEVLDHKEFKARVKEYARNKNIHYYFMALKNDEIIDATQKGNCSRFMNHSCEPNCETQKWTVNGQLRVGFFTTKLVPSGSELTFDYQFQRYGKEAQKCFCGSANCRGYLGGENRVSIRAAGGKMKKERSRKKDSVDGELEALMENGEGLSDKNQVLSLSRLMVRIETLEQKLTCLELIQNTHSQSCLKSFLERHGLSLLWIWMAELGDGRESNQKLQEEIIKTLEHLPIPTKNMLEESKVLPIIQRWSQTKTAVPPLSEGDGYSSENTSRAHTPLNTPDPSTKLSTEADTDTPKKLMFRRLKIISENSMDSAISDATSELEGKDGKEDLDQLENVPVEEEEELQSQQLLPQQLPECKVDSETNIEASKLPTSEPEADAEIEPKESNGTKLEEPINEETPSQDEEEGVSDVESERSQEQPDKTVDISDLATKLLDSWKDLKEVYRIPKKSQTEKENTTTERGRDAVGFRDQTPAPKTPNRSRERDPDKQTQNKEKRKRRSSLSPPSSAYERGTKRPDDRYDTPTSKKKVRIKDRNKLSTEERRKLFEQEVAQREAQKQQQQMQNLGMTSPLPYDSLGYNAPHHPFAGYPPGYPMQAYVDPSNPNAGKVLLPTPSMDPVCSPAPYDHAQPLVGHSTEPLSAPPPVPVVPHVAAPVEVSSSQYVAQSDGVVHQDSSVAVLPVPAPGPVQGQNYSVWDSNQQSVSVQQQYSPAQSQATIYYQGQTCPTVYGVTSPYSQTTPPIVQSYAQPSLQYIQGQQIFTAHPQGVVVQPAAAVTTIVAPGQPQPLQPSEMVVTNNLLDLPPPSPPKPKTIVLPPNWKTARDPEGKIYYYHVITRQTQWDPPTWESPGDDASLEHEAEMDLGTPTYDENPMKASKKPKTAEADTSSELAKKSKEVFRKEMSQFIVQCLNPYRKPDCKVGRITTTEDFKHLARKLTHGVMNKELKYCKNPEDLECNENVKHKTKEYIKKYMQKFGAVYKPKEDTELE>sp|Q9BYW2-2|SETD2_HUMAN Isoform 2 of Histone-lysine N-methyltransferaseSETD2 OS=Homo sapiens OX=9606 GN=SETD2MKQLQPQPPPKMGDFYDPEHPTPEEEENEAKIENVQKTGFIKGPMFKGVASSRFLPKGTKTKVNLEEQGRQKVSFSFSLTKKTLQNRFLTALGNEKQSDTPNPPAVPLQVDSTPKMKMEIGDTLSTAEESSPPKSRVELGKIHFKKHLLHVTSRPLLATTTAVASPPTHAAPLPAVIAESTTVDSPPSSPPPPPPPAQATTLSSPAPVTEPVALPHTPITVLMAAPVPLPVDVAVRSLKEPPIIIVPESLEADTKQDTISNSLEEHVTQILNEQADISSKKEDSHIGKDEEIPDSSKISLSCKKTGSKKKSSQSEGIFLGSESDEDSVRTSSSQRSHDLKFSASIEKERDFKKSSAPLKSEDLGKPSRSKTDRDDKYFSYSKLERDTRYVSSRCRSERERRRSRSHSRSERGSRTNLSYSRSERSHYYDSDRRYHRSSPYRERTRYSRPYTDNRARESSDSEEEYKKTYSRRTSSHSSSYRDLRTSSYSKSDRDCKTETSYLEMERRGKYSSKLERESKRTSENEAIKRCCSPPNELGFRRGSSYSKHDSSASRYKSTLSKPIPKSDKFKNSFCCTELNEEIKQSHSFSLQTPCSKGSELRMINKNPEREKAGSPAPSNRLNDSPTLKKLDELPIFKSEFITHDSHDSIKELDSLSKVKNDQLRSFCPIELNINGSPGAESDLATFCTSKTDAVLMTSDDSVTGSELSPLVKACMLSSNGFQNISRCKEKDLDDTCMLHKKSESPFRETEPLVSPHQDKLMSMPVMTVDYSKTVVKEPVDTRVSCCKTKDSDIYCTLNDSNPSLCNSEAENIEPSVMKISSNSFMNVHLESKPVICDSRNLTDHSKFACEEYKQSIGSTSSASVNHFDDLYQPIGSSGIASSLQSLPPGIKVDSLTLLKCGENTSPVLDAVLKSKKSSEFLKHAGKETIVEVGSDLPDSGKGFASRENRRNNGLSGKCLQEAQEEGNSILPERRGRPEISLDERGEGGHVHTSDDSEVVFSSCDLNLTMEDSDGVTYALKCDSSGHAPEIVSTVHEDYSGSSESSNDESDSEDTDSDDSSIPRNRLQSVVVVPKNSTLPMEETSPCSSRSSQSYRHYSDHWEDERLESRRHLYEEKFESIASKACPQTDKFFLHKGTEKNPEISFTQSSRKQIDNRLPELSHPQSDGVDSTSHTDVKSDPLGHPNSEETVKAKIPSRQQEELPIYSSDFEDVPNKSWQQTTFQNRPDSRLGKTELSFSSSCEIPHVDGLHSSEELRNLGWDFSQEKPSTTYQQPDSSYGACGGHKYQQNAEQYGGTRDYWQGNGYWDPRSGRPPGTGVVYDRTQGQVPDSLTDDREEEENWDQQDGSHFSDQSDKFLLSLQKDKGSVQAPEISSNSIKDTLAVNEKKDFSKNLEKNDIKDRGPLKKRRQEIESDSESDGELQDRKKVRVEVEQGETSVPPGSALVGPSCVMDDFRDPQRWKECAKQGKMPCYFDLIEENVYLTERKKNKSHRDIKRMQCECTPLSKDERAQGEIACGEDCLNRLLMIECSSRCPNGDYCSNRRFQRKQHADVEVILTEKKGWGLRAAKDLPSNTFVLEYCGEVLDHKEFKARVKEYARNKNIHYYFMALKNDEIIDATQKGNCSRFMNHSCEPNCETQKWTVNGQLRVGFFTTKLVPSGSELTFDYQFQRYGKEAQKCFCGSANCRGYLGGENRVSIRAAGGKMKKERSRKKDS>sp|Q9BYW2-3|SETD2_HUMAN Isoform 3 of Histone-lysine N-methyltransferaseSETD2 OS=Homo sapiens OX=9606 GN=SETD2MKQLQPQPPPKMGDFYDPEHPTPEEEENEAKIENVQKTGFIKGPMFKGVASSRFLPKGTKTKVNLEEQGRQKVSFSFSLTKKTLQNRFLTALGNEKQSDTPNPPAVPLQVDSTPKMKMEIGDTLSTAEESSPPKSRVELGKIHFKKHLLHVTSRPLLATTTAVASPPTHAAPLPAVIAESTTVDSPPSSPPPPPPPAQATTLSSPAPVTEPVALPHTPITVLMAAPVPLPVDVAVRSLKEPPIIIVPESLEADTKQDTISNSLEEHVTQILNEQADISSKKEDSHIGKDEEIPDSSKISLSCKKTGSKKKSSQSEGIFLGSESDEDSVRTSSSQRSHDLKFSASIEKERDFKKSSAPLKSEDLGKPSRSKTDRDDKYFSYSKLERDTRYVSSRCRSERERRRSRSHSRSERGSRTNLSYSRSERSHYYDSDRRYHRSSPYRERTRYSRPYTDNRARESSDSEEEYKKTYSRRTSSHSSSYRDLRTSSYSKSDRDCKTETSYLEMERRGKYSSKLERESKRTSENEAIKRCCSPPNELGFRRGSSYSKHDSSASRYKSTLSKPIPKSDKFKNSFCCTELNEEIKQSHSFSLQTPCSKGSELRMINKNPEREKAGSPAPSNRLNDSPTLKKLDELPIFKSEFITHDSHDSIKELDSLSKVKNDQLRSFCPIELNINGSPGAESDLATFCTSKTDAVLMTSDDSVTGSELSPLVKACMLSSNGFQNISRCKEKDLDDTCMLHKKSESPFRETEPLVSPHQDKLMSMPVMTVDYSKTVVKEPVDTRVSCCKTKDSDIYCTLNDSNPSLCNSEAENIEPSVMKISSNSFMNVHLESKPVICDSRNLTDHSKFACEEYKQSIGSTSSASVNHFDDLYQPIGSSGIASSLQSLPPGIKVDSLTLLKCGENTSPVLDAVLKSKKSSEFLKHAGKETIVEVGSDLPDSGKGFASRENRRNNGLSGKCLQEAQEEGNSILPERRGRPEISLDERGEGGHVHTSDDSEVVFSSCDLNLTMEDSDGVTYALKCDSSGHAPEIVSTVHEDYSGSSESSNDESDSEDTDSDDSSIPRNRLQSVVVVPKNSTLPMEETSPCSSRSSQSYRHYSDHWEDERLESRRHLYEEKFESIASKACPQTDKFFLHKGTEKNPEISFTQSSRKQIDNRLPELSHPQSDGVDSTSHTDVKSDPLGHPNSEETVKAKIPSRQQEELPIYSSDFEDVPNKSWQQTTFQNRPDSRLGKTELSFSSSCEIPHVDGLHSSEELRNLGWDFSQEKPSTTYQQPDSSYGACGGHKYQQNAEQYGGTRDYWQGNGYWDPRSGRPPGTGVVYDRTQGQVPDSLTDDREEEENWDQQDGSHFSDQSDKFLLSLQKDKGSVQAPEISSNSIKDTLAVNEKKDFSKNLEKNDIKDRGPLKKRRQEIESDSESDGELQDRKKVRVEVEQGETSVPPGSALVGPSCVMDDFRDPQRWKECAKQGKMPCYFDLIEENVYLTERKKNKSHRDIKRMQCECTPLSKDERAQGEIACGEDCLNRLLMIECSSRCPNGDYCSNRRFQRKQHADVEVILTEKKGWGLRAAKDLPS>sp|Q69YW2|STUM_HUMAN Protein stum homolog OS=Homo sapiens OX=9606GN=STUM PE=1 SV=1MEPSHKDAETAAAAAAVAAADPRGASSSSGVVVQVREKKGPLRAAIPYMPFPVAVICLFLNTFVPGLGTFVSAFTVLCGARTDLPDRHVCCVFWLNIAAALIQILTAIVMVGWIMSIFWGMDMVILAISQGYKEQGIPQQL>sp|O60499|STX10_HUMAN Syntaxin-10 OS=Homo sapiens OX=9606 GN=STX10 PE=1SV=1MSLEDPFFVVRGEVQKAVNTARGLYQRWCELLQESAAVGREELDWTTNELRNGLRSIEWDLEDLEETIGIVEANPGKFKLPAGDLQERKVFVERMREAVQEMKDHMVSPTAVAFLERNNREILAGKPAAQKSPSDLLDASAVSATSRYIEEQQATQQLIMDEQDQQLEMVSGSIQVLKHMSGRVGEELDEQGIMLDAFAQEMDHTQSRMDGVLRKLAKVSHMTSDRRQWCAIAVLVGVLLLVLILLFSL>sp|O60499-2|STX10_HUMAN Isoform 2 of Syntaxin-10 OS=Homo sapiens OX=9606GN=STX10MSLEDPFFVVRGEVQKAVNTARGLYQRWCELLQESAAVGREELDWTTNELRNGLRSIEWDLEDLEETIGIVEANPGKPAAQKSPSDLLDASAVSATSRYIEEQQATQQLIMDEQDQQLEMVSGSIQVLKHMSGRVGEELDEQGIMLDAFAQEMDHTQSRMDGVLRKLAKVSHMTSDRRQWCAIAVLVGVLLLVLILLFSL>sp|Q9Y2M2|SSUH2_HUMAN Protein SSUH2 homolog OS=Homo sapiens OX=9606GN=SSUH2 PE=1 SV=1MPSPVGLLRALPLPWPQFLACTLRRLAGPRESTGPSQKPPPLCSVPCRVPAMTEEVAREALLSFVDSKCCYSSTVAGDLVIQELKRQTLCRYRLETFSESRISEWTFQPFTNHSVDGPQRGASPRLWDIKVQGPPMFQEDTRKFQVPHSSLVKECHKCHGRGRYKCSGCHGAGTVRCPSCCGAKRKAKQSRRCQLCAGSGRRRCSTCSGRGNKTCATCKGEKKLLHFIQLVIMWKNSLFEFVSEHRLNCPRELLAKAKGENLFKDENSVVYPIVDFPLRDISLASQRGIAEHSAALASRARVLQQRQTIELIPLTEVHYWYQGKTYVYYIYGTDHQVYAVDYPERYCCGCTIV>sp|Q9Y2M2-2|SSUH2_HUMAN Isoform 2 of Protein SSUH2 homolog OS=Homosapiens OX=9606 GN=SSUH2MDRDLNEDDSVVDLSFEAESPLAPPTELLERLPSYDWLLQGGRGQIFFPPLEAPGRPQEQRSWPSFLEHRVPAMTEEVAREALLSFVDSKCCYSSTVAGDLVIQELKRQTLCRYRLETFSESRISEWTFQPFTNHSVDGPQRGASPRLWDIKVQGPPMFQEDTRKFQVPHSSLVKECHKCHGRGRYKCSGCHGAGTVRCPSCCGAKRKAKQSRRCQLCAGSGRRRCSTCSGRGNKTCATCKGEKKLLHFIQLVIMWKNSLFEFVSEHRLNCPRELLAKAKGENLFKDENSVVYPIVDFPLRDISLASQRGIAEHSAALASRARVLQQRQTIELIPLTEVHYWYQGKTYVYYIYGTDHQVYAVDYPERYCCGCTIV>sp|Q5TGY1|TMCO4_HUMAN Transmembrane and coiled-coil domain-containingprotein 4 OS=Homo sapiens OX=9606 GN=TMCO4 PE=1 SV=1MAMWNRPCQRLPQQPLVAEPTAEGEPHLPTGRELTEANRFAYAALCGISLSQLFPEPEHSSFCTEFMAGLVQWLELSEAVLPTMTAFASGLGGEGADVFVQILLKDPILKDDPTVITQDLLSFSLKDGHYDARARVLVCHMTSLLQVPLEELDVLEEMFLESLKEIKEEESEMAEASRKKKENRRKWKRYLLIGLATVGGGTVIGVTGGLAAPLVAAGAATIIGSAGAAALGSAAGIAIMTSLFGAAGAGLTGYKMKKRVGAIEEFTFLPLTEGRQLHITIAVTGWLASGKYRTFSAPWAALAHSREQYCLAWEAKYLMELGNALETILSGLANMVAQEALKYTVLSGIVAALTWPASLLSVANVIDNPWGVCLHRSAEVGKHLAHILLSRQQGRRPVTLIGFSLGARVIYFCLQEMAQEKDCQGIIEDVILLGAPVEGEAKHWEPFRKVVSGRIINGYCRGDWLLSFVYRTSSVQLRVAGLQPVLLQDRRVENVDLTSVVSGHLDYAKQMDAILKAVGIRTKPGWDEKGLLLAPGCLPSEEPRQAAAAASSGETPHQVGQTQGPISGDTSKLAMSTDPSQAQVPVGLDQSEGASLPAAASPERPPICSHGMDPNPLGCPDCACKTQGPSTGLD>sp|Q5TGY1-2|TMCO4_HUMAN Isoform 2 of Transmembrane and coiled-coildomain-containing protein 4 OS=Homo sapiens OX=9606 GN=TMCO4MAMWNRPCQRLPQQPLVAEPTAEGEPHLPTGRELTEANRFAYAALCGISLSQLFPEPEHSSFCTEFMAGLVQWLELSEAVLPTMTAFASGLGGEGADVFVQILLKDPILKDDPTVITQDLLSFSLKDGHYDARARVLVCHMTSLLQVPLEELDVLEEMFLESLKEIKEEESEMAEASRKKKENRRKWKRYLLIGLATVGGGTVIGVTGGLAAPLVAAGAATIIGSAGAAALGSAAGIAIMTSLFGAAGAGLTGTFSAPWAALAHSREQYCLAWEAKYLMELGNALETILSGLANMVAQEALKYTVLSGIVAALTWPASLLSVANVIDNPWGVCLHRSAEVGKHLAHILLSRQQGRRPVTLIGFSLGARVIYFCLQEMAQEKDCQGIIEDVILLGAPVEGEAKHWEPFRKVVSGRIINGYCRGDWLLSFVYRTSSVQLRVAGLQPVLLQDRRVENVDLTSVVSGHLDYAKQMDAILKAVGIRTKPGWDEKGLLLAPGCLPSEEPRQAAAAASSGETPHQVGQTQGPISGDTSKLAMSTDPSQAQVPVGLDQSEGASLPAAASPERPPICSHGMDPNPLGCPDCACKTQGPSTGLD>sp|Q16623|STX1A_HUMAN Syntaxin-1A OS=Homo sapiens OX=9606 GN=STX1A PE=1SV=1MKDRTQELRTAKDSDDDDDVAVTVDRDRFMDEFFEQVEEIRGFIDKIAENVEEVKRKHSAILASPNPDEKTKEELEELMSDIKKTANKVRSKLKSIEQSIEQEEGLNRSSADLRIRKTQHSTLSRKFVEVMSEYNATQSDYRERCKGRIQRQLEITGRTTTSEELEDMLESGNPAIFASGIIMDSSISKQALSEIETRHSEIIKLENSIRELHDMFMDMAMLVESQGEMIDRIEYNVEHAVDYVERAVSDTKKAVKYQSKARRKKIMIIICCVILGIVIASTVGGIFA>sp|Q16623-2|STX1A_HUMAN Isoform 2 of Syntaxin-1A OS=Homo sapiens OX=9606GN=STX1AMKDRTQELRTAKDSDDDDDVAVTVDRDRFMDEFFEQVEEIRGFIDKIAENVEEVKRKHSAILASPNPDEKTKEELEELMSDIKKTANKVRSKLKSIEQSIEQEEGLNRSSADLRIRKTQHSTLSRKFVEVMSEYNATQSDYRERCKGRIQRQLEITGRTTTSEELEDMLESGNPAIFASGIIMDSSISKQALSEIETRHSEIIKLENSIRELHDMFMDMAMLVESQPQGAFLKSCPEPQPNREEGALWSSGAPGPAGRDD>sp|Q16623-3|STX1A_HUMAN Isoform 3 of Syntaxin-1A OS=Homo sapiens OX=9606GN=STX1AMKDRTQELRTAKDSDDDDDVAVTVDRDRFMDEFFEQVEEIRGFIDKIAENVEEVKRKHSAILASPNPDEKTKEELEELMSDIKKTANKVRSKLKSIEQSIEQEEGLNRSSADLRIRKTQHSTLSRKFVEVMSEYNATQSDYRERCKGRIQRQLEITGRTTTSEELEDMLESGNPAIFASGIIMDSSISKQALSEIETRHSEIIKLENSIRELHDMFMDMAMLVESQTMWRGPCLTPRRPSSTRARRAGRKS>sp|Q15363|TMED2_HUMAN Transmembrane emp24 domain-containing protein 2OS=Homo sapiens OX=9606 GN=TMED2 PE=1 SV=1MVTLAELLVLLAALLATVSGYFVSIDAHAEECFFERVTSGTKMGLIFEVAEGGFLDIDVEITGPDNKGIYKGDRESSGKYTFAAHMDGTYKFCFSNRMSTMTPKIVMFTIDIGEAPKGQDMETEAHQNKLEEMINELAVAMTAVKHEQEYMEVRERIHRAINDNTNSRVVLWSFFEALVLVAMTLGQIYYLKRFFEVRRVV>sp|Q7Z7H5|TMED4_HUMAN Transmembrane emp24 domain-containing protein 4OS=Homo sapiens OX=9606 GN=TMED4 PE=1 SV=1MAGVGAGPLRAMGRQALLLLALCATGAQGLYFHIGETEKRCFIEEIPDETMVIGNYRTQMWDKQKEVFLPSTPGLGMHVEVKDPDGKVVLSRQYGSEGRFTFTSHTPGDHQICLHSNSTRMALFAGGKLRVHLDIQVGEHANNYPEIAAKDKLTELQLRARQLLDQVEQIQKEQDYQRYREERFRLTSESTNQRVLWWSIAQTVILILTGIWQMRHLKSFFEAKKLV>sp|Q7Z7H5-2|TMED4_HUMAN Isoform 2 of Transmembrane emp24 domain-containing protein 4 OS=Homo sapiens OX=9606 GN=TMED4MAGVGAGPLRAMGRQALLLLALCATGAQGLYFHIGETEKRCFIEEIPDETMVIGNYRTLGMHVEVKDPDGKVVLSRQYGSEGRFTFTSHTPGDHQICLHSNSTRMALFAGGKLRVHLDIQVGEHANNYPEIAAKDKLTELQLRARQLLDQVEQIQKEQDYQRYREERFRLTSESTNQRVLWWSIAQTVILILTGIWQMRHLKSFFEAKKLV>sp|Q7Z7H5-3|TMED4_HUMAN Isoform 3 of Transmembrane emp24 domain-containing protein 4 OS=Homo sapiens OX=9606 GN=TMED4MAGVGAGPLRAMGRQALLLLALCATGAQGLYFHIGETEKRCFIEEIPDETMVIGNYRTQMWDKQKEVFLPSTPGLGMHVEVKDPDGKVVLSRQYGSEGRFTFTSHTPGDHQICLHSNSTRMALFAGGKLRVHLDIQVGEHANNYPEIAAKDKLTELQLRARQLLDQVEQIQKEQDYQRASAYLLVI>sp|O14925|TIM23_HUMAN Mitochondrial import inner membrane translocasesubunit Tim23 OS=Homo sapiens OX=9606 GN=TIMM23 PE=1 SV=1MEGGGGSGNKTTGGLAGFFGAGGAGYSHADLAGVPLTGMNPLSPYLNVDPRYLVQDTDEFILPTGANKTRGRFELAFFTIGGCCMTGAAFGAMNGLRLGLKETQNMAWSKPRNVQILNMVTRQGALWANTLGSLALLYSAFGVIIEKTRGAEDDLNTVAAGTMTGMLYKCTGGLRGIARGGLTGLTLTSLYALYNNWEHMKGSLLQQSL>sp|Q9BR01|ST4A1_HUMAN Sulfotransferase 4A1 OS=Homo sapiens OX=9606GN=SULT4A1 PE=1 SV=2MAESEAETPSTPGEFESKYFEFHGVRLPPFCRGKMEEIANFPVRPSDVWIVTYPKSGTSLLQEVVYLVSQGADPDEIGLMNIDEQLPVLEYPQPGLDIIKELTSPRLIKSHLPYRFLPSDLHNGDSKVIYMARNPKDLVVSYYQFHRSLRTMSYRGTFQEFCRRFMNDKLGYGSWFEHVQEFWEHRMDSNVLFLKYEDMHRDLVTMVEQLARFLGVSCDKAQLEALTEHCHQLVDQCCNAEALPVGRGRVGLWKDIFTVSMNEKFDLVYKQKMGKCDLTFDFYL>sp|Q9BR01-2|ST4A1_HUMAN Isoform 2 of Sulfotransferase 4A1 OS=Homosapiens OX=9606 GN=SULT4A1MAESEAETPSTPGEFESKYFEFHGVRLPPFCRGKMEEIANFPVRPSDVWIVTYPKSGTSLLQEVVYLVSQGADPDEIGLMNIDEQLPVLEYPQPGLDIIKELTSPRLIKSHLPYRFLPSDLHNGDSKVIYMARNPKDLVVSYYQFHRSLRTMSYRGTFQEFCRRFMNDKLGYGSWFEHVQEFWEHRMDSNVLFLKYEDMHRDLVTMVEQLARFLGVSCDKAQLEALTEHCHQLVDQCCNAEALPVGRAHCVFARKIFLSW>sp|Q6ZRR5|TLCD5_HUMAN TLC domain-containing protein 5 OS=Homo sapiensOX=9606 GN=TLCD5 PE=2 SV=2MALALCLQVLCSLCGWLSLYISFCHLNKHRSYEWSCRLVTFTHGVLSIGLSAYIGFIDGPWPFTHPGSPNTPLQVHVLCLTLGYFIFDLGWCVYFQSEGALMLAHHTLSILGIIMALVLGESGTEVNAVLFGSELTNPLLQMRWFLRETGHYHSFTGDVVDFLFVALFTGVRIGVGACLLFCEMVSPTPKWFVKAGGVAMYAVSWCFMFSIWRFAWRKSIKKYHAWRSRRSEERQLKHNGHLKIH>sp|Q6ZRR5-2|TLCD5_HUMAN Isoform 2 of TLC domain-containing protein 5OS=Homo sapiens OX=9606 GN=TLCD5MALALCLQVLCSLCGWLSLYISFCHLNKHRSYEWSCRLVTFTHGVLSIGLSAYIGFIDGPWPFTHPGSPNTPLQVHVLCLTLGYFIFDLGCIWRFAWRKSIKKYHAWRSRRSEERQLKHNGHLKIH>sp|Q6ZRR5-3|TLCD5_HUMAN Isoform 3 of TLC domain-containing protein 5OS=Homo sapiens OX=9606 GN=TLCD5MTQCCFLRVHPLFFWFWSFHHRMALALCLQVLCSLCGWLSLYISFCHLNKHRSYEWSCRLVTFTHGVLSIGLSAYIGFIDGPWPFTHPGSPNTPLQVHVLCLTLGYFIFDLGWCVYFQSEGALMLAHHTLSILGIIMALVLGESGTEVNAVLFGSELTNPLLQMRWFLRETGHYHSFTGDVVDFLFVALFTGVRIGVGACLLFCEMVSPTPKWFVKAGGVAMYAVSWCFMFSIWRFAWRKSIKKYHAWRSRRSEERQLKHNGHLKIH>sp|Q6ZRR5-4|TLCD5_HUMAN Isoform 4 of TLC domain-containing protein 5OS=Homo sapiens OX=9606 GN=TLCD5MTQCCFLRVHPLFFWFWSFHHRMALALCLQVLCSLCGWLSLYISFCHLNKHRSYEWSCRLVTFTHGVLSIGLSAYIGFIDGPWPFTHPGSPNTPLQVHVLCLTLGYFIFDLGCIWRFAWRKSIKKYHAWRSRRSEERQLKHNGHLKIH>sp|O00186|STXB3_HUMAN Syntaxin-binding protein 3 OS=Homo sapiens OX=9606GN=STXBP3 PE=1 SV=2MAPPVAERGLKSVVWQKIKATVFDDCKKEGEWKIMLLDEFTTKLLASCCKMTDLLEEGITVVENIYKNREPVRQMKALYFITPTSKSVDCFLHDFASKSENKYKAAYIYFTDFCPDNLFNKIKASCSKSIRRCKEINISFIPHESQVYTLDVPDAFYYCYSPDPGNAKGKDAIMETMADQIVTVCATLDENPGVRYKSKPLDNASKLAQLVEKKLEDYYKIDEKSLIKGKTHSQLLIIDRGFDPVSTVLHELTFQAMAYDLLPIENDTYKYKTDGKEKEAILEEEDDLWVRIRHRHIAVVLEEIPKLMKEISSTKKATEGKTSLSALTQLMKKMPHFRKQITKQVVHLNLAEDCMNKFKLNIEKLCKTEQDLALGTDAEGQKVKDSMRVLLPVLLNKNHDNCDKIRAILLYIFSINGTTEENLDRLIQNVKIENESDMIRNWSYLGVPIVPQSQQGKPLRKDRSAEETFQLSRWTPFIKDIMEDAIDNRLDSKEWPYCSQCPAVWNGSGAVSARQKPRANYLEDRKNGSKLIVFVIGGITYSEVRCAYEVSQAHKSCEVIIGSTHVLTPKKLLDDIKMLNKPKDKVSLIKDE>sp|Q15468|STIL_HUMAN SCL-interrupting locus protein OS=Homo sapiensOX=9606 GN=STIL PE=1 SV=2MEPIYPFARPQMNTRFPSSRMVPFHFPPSKCALWNPTPTGDFIYLHLSYYRNPKLVVTEKTIRLAYRHAKQNKKNSSCFLLGSLTADEDEEGVTLTVDRFDPGREVPECLEITPTASLPGDFLIPCKVHTQELCSREMIVHSVDDFSSALKALQCHICSKDSLDCGKLLSLRVHITSRESLDSVEFDLHWAAVTLANNFKCTPVKPIPIIPTALARNLSSNLNISQVQGTYKYGYLTMDETRKLLLLLESDPKVYSLPLVGIWLSGITHIYSPQVWACCLRYIFNSSVQERVFSESGNFIIVLYSMTHKEPEFYECFPCDGKIPDFRFQLLTSKETLHLFKNVEPPDKNPIRCELSAESQNAETEFFSKASKNFSIKRSSQKLSSGKMPIHDHDSGVEDEDFSPRPIPSPHPVSQKISKIQPSVPELSLVLDGNFIESNPLPTPLEMVNNENPPLINHLEHLKPLQPQLYDEKHSPEVEAGEPSLRGIPNQLNQDKPALLRHCKVRQPPAYKKGNPHTRNSIKPSSHNGPSHDIFEKLQTVSAGNVQNEEYPIRPSTLNSRQSSLAPQSQPHDFVFSPHNSGRPMELQIPTPPLPSYCSTNVCRCCQHHSHIQYSPLNSWQGANTVGSIQDVQSEALQKHSLFHPSGCPALYCNAFCSSSSPIALRPQGDMGSCSPHSNIEPSPVARPPSHMDLCNPQPCTVCMHTPKTESDNGMMGLSPDAYRFLTEQDRQLRLLQAQIQRLLEAQSLMPCSPKTTAVEDTVQAGRQMELVSVEAQSSPGLHMRKGVSIAVSTGASLFWNAAGEDQEPDSQMKQDDTKISSEDMNFSVDINNEVTSLPGSASSLKAVDIPSFEESNIAVEEEFNQPLSVSNSSLVVRKEPDVPVFFPSGQLAESVSMCLQTGPTGGASNNSETSEEPKIEHVMQPLLHQPSDNQKIYQDLLGQVNHLLNSSSKETEQPSTKAVIISHECTRTQNVYHTKKKTHHSRLVDKDCVLNATLKQLRSLGVKIDSPTKVKKNAHNVDHASVLACISPEAVISGLNCMSFANVGMSGLSPNGVDLSMEANAIALKYLNENQLSQLSVTRSNQNNCDPFSLLHINTDRSTVGLSLISPNNMSFATKKYMKRYGLLQSSDNSEDEEEPPDNADSKSEYLLNQNLRSIPEQLGGQKEPSKNDHEIINCSNCESVGTNADTPVLRNITNEVLQTKAKQQLTEKPAFLVKNLKPSPAVNLRTGKAEFTQHPEKENEGDITIFPESLQPSETLKQMNSMNSVGTFLDVKRLRQLPKLF>sp|Q15468-2|STIL_HUMAN Isoform 2 of SCL-interrupting locus proteinOS=Homo sapiens OX=9606 GN=STILMEPIYPFARPQMNTRFPSSRMVPFHFPPSKCALWNPTPTGDFIYLHLSYYRNPKLVVTEKTIRLAYRHAKQNKKNSSCFLLGSLTADEDEEGVTLTVDRFDPGREVPECLEITPTASLPGDFLIPCKVHTQELCSREMIVHSVDDFSSALKALQCHICSKDSLDCGKLLSLRVHITSRESLDSVEFDLHWAAVTLANNFKCTPVKPIPIIPTALARNLSSNLNISQVQGTYKYGYLTMDETRKLLLLLESDPKVYSLPLVGIWLSGITHIYSPQVWACCLRYIFNSSVQERVFSESGNFIIVLYSMTHKEPEFYECFPCDGKIPDFRFQLLTSKETLHLFKNVEPPDKNPIRCELSAESQNAETEFFSKASKNFSIKRSSQKLSSGKMPIHDHDSGVEDEDFSPRPIPSPHPVSQKISKIQPSVPELSLVLDGNFIESNPLPTPLEMVNNENPPLINHLEHLKPLQPQLYDEKHSPEVEAGEPSLRGIPNQLNQDKPALLRHCKVRQPPAYKKGNPHTRNSIKPSSHNGPSHDIFEKLQTVSAGNVQNEEYPIRPSTLNSRQSSLAPQSQPHDFVFSPHNSGRPMELQIPTPPLPSYCSTNVCRCCQHHSHIQYSPLNSWQGANTVGSIQDVQSEALQKHSLFHPSGCPALYCNAFCSSSSPIALRPQGDMGSCSPHSNIEPSPVARPPSHMDLCNPQPCTVCMHTPKTESDNGMMGLSPDAYRFLTEQDRQLRLLQAQIQRLLEAQSLMPCSPKTTAVEDTVQAGRQMELVSVEAQSSPGLHMRKGVSIAVSTGASLFWNAAGEDQEPDSQMKQDDTKISSEDMNFSVDINNEVTSLPGSASSLKAVDIPSFEESNIAVEEEFNQPLSVSNSSSLVVRKEPDVPVFFPSGQLAESVSMCLQTGPTGGASNNSETSEEPKIEHVMQPLLHQPSDNQKIYQDLLGQVNHLLNSSSKETEQPSTKAVIISHECTRTQNVYHTKKKTHHSRLVDKDCVLNATLKQLRSLGVKIDSPTKVKKNAHNVDHASVLACISPEAVISGLNCMSFANVGMSGLSPNGVDLSMEANAIALKYLNENQLSQLSVTRSNQNNCDPFSLLHINTDRSTVGLSLISPNNMSFATKKYMKRYGLLQSSDNSEDEEEPPDNADSKSEYLLNQNLRSIPEQLGGQKEPSKNDHEIINCSNCESVGTNADTPVLRNITNEVLQTKAKQQLTEKPAFLVKNLKPSPAVNLRTGKAEFTQHPEKENEGDITIFPESLQPSETLKQMNSMNSVGTFLDVKRLRQLPKLF>sp|Q5T5C0|STXB5_HUMAN Syntaxin-binding protein 5 OS=Homo sapiens OX=9606GN=STXBP5 PE=1 SV=1MRKFNIRKVLDGLTAGSSSASQQQQQQHPPGNREPEIQETLQSEHFQLCKTVRHGFPYQPSALAFDPVQKILAVGTQTGALRLFGRPGVECYCQHDSGAAVIQLQFLINEGALVSALADDTLHLWNLRQKRPAILHSLKFCRERVTFCHLPFQSKWLYVGTERGNIHIVNVESFTLSGYVIMWNKAIELSSKSHPGPVVHISDNPMDEGKLLIGFESGTVVLWDLKSKKADYRYTYDEAIHSVAWHHEGKQFICSHSDGTLTIWNVRSPAKPVQTITPHGKQLKDGKKPEPCKPILKVEFKTTRSGEPFIILSGGLSYDTVGRRPCLTVMHGKSTAVLEMDYSIVDFLTLCETPYPNDFQEPYAVVVLLEKDLVLIDLAQNGYPIFENPYPLSIHESPVTCCEYFADCPVDLIPALYSVGARQKRQGYSKKEWPINGGNWGLGAQSYPEIIITGHADGSVKFWDASAITLQVLYKLKTSKVFEKSRNKDDRPNTDIVDEDPYAIQIISWCPESRMLCIAGVSAHVIIYRFSKQEVITEVIPMLEVRLLYEINDVETPEGEQPPPLPTPVGGSNPQPIPPQSHPSTSSSSSDGLRDNVPCLKVKNSPLKQSPGYQTELVIQLVWVGGEPPQQITSLAVNSSYGLVVFGNCNGIAMVDYLQKAVLLNLGTIELYGSNDPYRREPRSPRKSRQPSGAGLCDISEGTVVPEDRCKSPTSGSSSPHNSDDEQKMNNFIEKVKTKSRKFSKMVANDIAKMSRKLSLPTDLKPDLDVKDNSFSRSRSSSVTSIDKESREAISALHFCETFTRKTDSSPSPCLWVGTTLGTVLVIALNLPPGGEQRLLQPVIVSPSGTILRLKGAILRMAFLDTTGCLIPPAYEPWREHNVPEEKDEKEKLKKRRPVSVSPSSSQEISENQYAVICSEKQAKVISLPTQNCAYKQNITETSFVLRGDIVALSNSICLACFCANGHIMTFSLPSLRPLLDVYYLPLTNMRIARTFCFTNNGQALYLVSPTEIQRLTYSQETCENLQEMLGELFTPVETPEAPNRGFFKGLFGGGAQSLDREELFGESSSGKASRSLAQHIPGPGGIEGVKGAASGVVGELARARLALDERGQKLGDLEERTAAMLSSAESFSKHAHEIMLKYKDKKWYQF>sp|Q5T5C0-2|STXB5_HUMAN Isoform 2 of Syntaxin-binding protein 5 OS=Homosapiens OX=9606 GN=STXBP5MRKFNIRKVLDGLTAGSSSASQQQQQQHPPGNREPEIQETLQSEHFQLCKTVRHGFPYQPSALAFDPVQKILAVGTQTGALRLFGRPGVECYCQHDSGAAVIQLQFLINEGALVSALADDTLHLWNLRQKRPAILHSLKFCRERVTFCHLPFQSKWLYVGTERGNIHIVNVESFTLSGYVIMWNKAIELSSKSHPGPVVHISDNPMDEGKLLIGFESGTVVLWDLKSKKADYRYTYDEAIHSVAWHHEGKQFICSHSDGTLTIWNVRSPAKPVQTITPHGKQLKDGKKPEPCKPILKVEFKTTRSGEPFIILSGGLSYDTVGRRPCLTVMHGKSTAVLEMDYSIVDFLTLCETPYPNDFQEPYAVVVLLEKDLVLIDLAQNGYPIFENPYPLSIHESPVTCCEYFADCPVDLIPALYSVGARQKRQGYSKKEWPINGGNWGLGAQSYPEIIITGHADGSVKFWDASAITLQVLYKLKTSKVFEKSRNKDDRPNTDIVDEDPYAIQIISWCPESRMLCIAGVSAHVIIYRFSKQEVITEVIPMLEVRLLYEINDVETPEGEQPPPLPTPVGGSNPQPIPPQSHPSTSSSSSDGLRDNVPCLKVKNSPLKQSPGYQTELVIQLVWVGGEPPQQITSLAVNSSYGLVVFGNCNGIAMVDYLQKAVLLNLGTIELYGSNDPYRREPRSPRKSRQPSGAGLCDISEGTVVPEDRCKSPTSAKMSRKLSLPTDLKPDLDVKDNSFSRSRSSSVTSIDKESREAISALHFCETFTRKTDSSPSPCLWVGTTLGTVLVIALNLPPGGEQRLLQPVIVSPSGTILRLKGAILRMAFLDTTGCLIPPAYEPWREHNVPEEKDEKEKLKKRRPVSVSPSSSQEISENQYAVICSEKQAKVISLPTQNCAYKQNITETSFVLRGDIVALSNSICLACFCANGHIMTFSLPSLRPLLDVYYLPLTNMRIARTFCFTNNGQALYLVSPTEIQRLTYSQETCENLQEMLGELFTPVETPEAPNRGFFKGLFGGGAQSLDREELFGESSSGKASRSLAQHIPGPGGIEGVKGAASGVVGELARARLALDERGQKLGDLEERTAAMLSSAESFSKHAHEIMLKYKDKKWYQF>sp|Q5T5C0-3|STXB5_HUMAN Isoform 3 of Syntaxin-binding protein 5 OS=Homosapiens OX=9606 GN=STXBP5MRKFNIRKVLDGLTAGSSSASQQQQQQHPPGNREPEIQETLQSEHFQLCKTVRHGFPYQPSALAFDPVQKILAVGTQTGALRLFGRPGVECYCQHDSGAAVIQLQFLINEGALVSALADDTLHLWNLRQKRPAILHSLKFCRERVTFCHLPFQSKWLYVGTERGNIHIVNVESFTLSGYVIMWNKAIELSSKSHPGPVVHISDNPMDEGKLLIGFESGTVVLWDLKSKKADYRYTYDEAIHSVAWHHEGKQFICSHSDGTLTIWNVRSPAKPVQTITPHGKQLKDGKKPEPCKPILKVEFKTTRSGEPFIILSGGLSYDTVGRRPCLTVMHGKSTAVLEMDYSIVDFLTLCETPYPNDFQEPYAVVVLLEKDLVLIDLAQNGYPIFENPYPLSIHESPVTCCEYFADCPVDLIPALYSVGARQKRQGYSKKEWPINGGNWGLGAQSYPEIIITGHADGSVKFWDASAITLQVLYKLKTSKVFEKSRNKDDRPNTDIVDEDPYAIQIISWCPESRMLCIAGVSAHVIIYRFSKQEVITEVIPMLEVRLLYEINDVETPEGEQPPPLPTPVGGSNPQPIPPQSHPSTSSSSSDGLRDNVPCLKVKNSPLKQSPGYQTELVIQLVWVGGEPPQQITSLAVNSSYGLVVFGNCNGIAMVDYLQKAVLLNLGTIELYGSNDPYRREPRSPRKSRQPSGAGLCDISEGTVVPEDRCKSPTSDVKDNSFSRSRSSSVTSIDKESREAISALHFCETFTRKTDSSPSPCLWVGTTLGTVLVIALNLPPGGEQRLLQPVIVSPSGTILRLKGAILRMAFLDTTGCLIPPAYEPWREHNVPEEKDEKEKLKKRRPVSVSPSSSQEISENQYAVICSEKQAKVISLPTQNCAYKQNITETSFVLRGDIVALSNSICLACFCANGHIMTFSLPSLRPLLDVYYLPLTNMRIARTFCFTNNGQALYLVSPTEIQRLTYSQETCENLQEMLGELFTPVETPEAPNRGFFKGLFGGGAQSLDREELFGESSSGKASRSLAQHIPGPGGIEGVKGAASGVVGELARARLALDERGQKLGDLEERTAAMLSSAESFSKHAHEIMLKYKDKKWYQF>sp|Q8TBR4|ST3L4_HUMAN Putative STAG3-like protein 4 OS=Homo sapiensOX=9606 GN=STAG3L4 PE=5 SV=1MSGWIATSKTRMQDFWSLLTFSSDLVDVKDSGDYPLTAPGLSWKKFQGSFCEFVGTLVCRCQYILLHDDFPMDNLISLLTGFSDSQVCAFCHTSTLAAMKLMTSLVRVALQLSLHEDINQRQYEAERNKGPGQRAPERLESLLEKHKELH>sp|Q9HBF5|ST20_HUMAN Suppressor of tumorigenicity 20 protein OS=Homosapiens OX=9606 GN=ST20 PE=2 SV=2MARSRLTATSVSQVQENGFVKKLEPKSGWMTFLEVTGKICEMLFCPEAILLTRKDTPYCETGLIFLTLTKTIANTYFYF>sp|P61764|STXB1_HUMAN Syntaxin-binding protein 1 OS=Homo sapiens OX=9606GN=STXBP1 PE=1 SV=1MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISDFKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLCATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSGIGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQGTVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPIVTDSTLRRRSKPERKERISEQTYQLSRWTPIIKDIMEDTIEDKLDTKHYPYISTRSSASFSTTAVSARYGHWHKNKAPGEYRSGPRLIIFILGGVSLNEMRCAYEVTQANGKWEVLIGSTHILTPQKLLDTLKKLNKTDEEISS>sp|P61764-2|STXB1_HUMAN Isoform 2 of Syntaxin-binding protein 1 OS=Homosapiens OX=9606 GN=STXBP1MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISDFKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLCATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSGIGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQGTVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPIVTDSTLRRRSKPERKERISEQTYQLSRWTPIIKDIMEDTIEDKLDTKHYPYISTRSSASFSTTAVSARYGHWHKNKAPGEYRSGPRLIIFILGGVSLNEMRCAYEVTQANGKWEVLIGSTHILTPTKFLMDLRHPDFRESSRVSFEDQAPTME>sp|Q9P289|STK26_HUMAN Serine/threonine-protein kinase 26 OS=Homo sapiensOX=9606 GN=STK26 PE=1 SV=2MAHSPVAVQVPGMQNNIADPEELFTKLERIGKGSFGEVFKGIDNRTQQVVAIKIIDLEEAEDEIEDIQQEITVLSQCDSSYVTKYYGSYLKGSKLWIIMEYLGGGSALDLLRAGPFDEFQIATMLKEILKGLDYLHSEKKIHRDIKAANVLLSEQGDVKLADFGVAGQLTDTQIKRNTFVGTPFWMAPEVIQQSAYDSKADIWSLGITAIELAKGEPPNSDMHPMRVLFLIPKNNPPTLVGDFTKSFKEFIDACLNKDPSFRPTAKELLKHKFIVKNSKKTSYLTELIDRFKRWKAEGHSDDESDSEGSDSESTSRENNTHPEWSFTTVRKKPDPKKVQNGAEQDLVQTLSCLSMIITPAFAELKQQDENNASRNQAIEELEKSIAVAEAACPGITDKMVKKLIEKFQKCSADESP>sp|Q9P289-2|STK26_HUMAN Isoform 2 of Serine/threonine-protein kinase 26OS=Homo sapiens OX=9606 GN=STK26MAHSPVAVQVPGMQGSKLWIIMEYLGGGSALDLLRAGPFDEFQIATMLKEILKGLDYLHSEKKIHRDIKAANVLLSEQGDVKLADFGVAGQLTDTQIKRNTFVGTPFWMAPEVIQQSAYDSKADIWSLGITAIELAKGEPPNSDMHPMRVLFLIPKNNPPTLVGDFTKSFKEFIDACLNKDPSFRPTAKELLKHKFIVKNSKKTSYLTELIDRFKRWKAEGHSDDESDSEGSDSESTSRENNTHPEWSFTTVRKKPDPKKVQNGAEQDLVQTLSCLSMIITPAFAELKQQDENNASRNQAIEELEKSIAVAEAACPGITDKMVKKLIEKFQKCSADESP>sp|Q9P289-3|STK26_HUMAN Isoform 3 of Serine/threonine-protein kinase 26OS=Homo sapiens OX=9606 GN=STK26MAHSPVAVQVPGMQNNIADPEELFTKLERIGKGSFGEVFKGIDNRTQQVVAIKIIDLEEAEDEIEDIQQEITVLSQCDSSYVTKYYGSYLKGSKLWIIMEYLGGGSALDLLRAGPFDEFQIATMLKEILKGLDYLHSEKKIHRDIKAANVLLSEQGDVKLADFGVAGQLTDTQIKRNTFVGTPFWMAPEVIQQSAYDSKRPTAKELLKHKFIVKNSKKTSYLTELIDRFKRWKAEGHSDDESDSEGSDSESTSRENNTHPEWSFTTVRKKPDPKKVQNGAEQDLVQTLSCLSMIITPAFAELKQQDENNASRNQAIEELEKSIAVAEAACPGITDKMVKKLIEKFQKCSADESP>sp|P42229|STA5A_HUMAN Signal transducer and activator of transcription5A OS=Homo sapiens OX=9606 GN=STAT5A PE=1 SV=1MAGWIQAQQLQGDALRQMQVLYGQHFPIEVRHYLAQWIESQPWDAIDLDNPQDRAQATQLLEGLVQELQKKAEHQVGEDGFLLKIKLGHYATQLQKTYDRCPLELVRCIRHILYNEQRLVREANNCSSPAGILVDAMSQKHLQINQTFEELRLVTQDTENELKKLQQTQEYFIIQYQESLRIQAQFAQLAQLSPQERLSRETALQQKQVSLEAWLQREAQTLQQYRVELAEKHQKTLQLLRKQQTIILDDELIQWKRRQQLAGNGGPPEGSLDVLQSWCEKLAEIIWQNRQQIRRAEHLCQQLPIPGPVEEMLAEVNATITDIISALVTSTFIIEKQPPQVLKTQTKFAATVRLLVGGKLNVHMNPPQVKATIISEQQAKSLLKNENTRNECSGEILNNCCVMEYHQATGTLSAHFRNMSLKRIKRADRRGAESVTEEKFTVLFESQFSVGSNELVFQVKTLSLPVVVIVHGSQDHNATATVLWDNAFAEPGRVPFAVPDKVLWPQLCEALNMKFKAEVQSNRGLTKENLVFLAQKLFNNSSSHLEDYSGLSVSWSQFNRENLPGWNYTFWQWFDGVMEVLKKHHKPHWNDGAILGFVNKQQAHDLLINKPDGTFLLRFSDSEIGGITIAWKFDSPERNLWNLKPFTTRDFSIRSLADRLGDLSYLIYVFPDRPKDEVFSKYYTPVLAKAVDGYVKPQIKQVVPEFVNASADAGGSSATYMDQAPSPAVCPQAPYNMYPQNPDHVLDQDGEFDLDETMDVARHVEELLRRPMDSLDSRLSPPAGLFTSARGSLS>sp|P42229-2|STA5A_HUMAN Isoform 2 of Signal transducer and activator oftranscription 5A OS=Homo sapiens OX=9606 GN=STAT5AMAGWIQAQQLQGDALRQMQVLYGQHFPIEVRHYLAQWIESQPWDAIDLDNPQDRAQATQLLEGLVQELQKKAEHQVGEDGFLLKIKLGHYATQLQCSSPAGILVDAMSQKHLQINQTFEELRLVTQDTENELKKLQQTQEYFIIQYQESLRIQAQFAQLAQLSPQERLSRETALQQKQVSLEAWLQREAQTLQQYRVELAEKHQKTLQLLRKQQTIILDDELIQWKRRQQLAGNGGPPEGSLDVLQSWCEKLAEIIWQNRQQIRRAEHLCQQLPIPGPVEEMLAEVNATITDIISALVTSTFIIEKQPPQVLKTQTKFAATVRLLVGGKLNVHMNPPQVKATIISEQQAKSLLKNENTRNECSGEILNNCCVMEYHQATGTLSAHFRNMSLKRIKRADRRGAESVTEEKFTVLFESQFSVGSNELVFQVKTLSLPVVVIVHGSQDHNATATVLWDNAFAEPGRVPFAVPDKVLWPQLCEALNMKFKAEVQSNRGLTKENLVFLAQKLFNNSSSHLEDYSGLSVSWSQFNRENLPGWNYTFWQWFDGVMEVLKKHHKPHWNDGAILGFVNKQQAHDLLINKPDGTFLLRFSDSEIGGITIAWKFDSPERNLWNLKPFTTRDFSIRSLADRLGDLSYLIYVFPDRPKDEVFSKYYTPVLAKAVDGYVKPQIKQVVPEFVNASADAGGSSATYMDQAPSPAVCPQAPYNMYPQNPDHVLDQDGEFDLDETMDVARHVEELLRRPMDSLDSRLSPPAGLFTSARGSLS>sp|Q8WWQ8|STAB2_HUMAN Stabilin-2 OS=Homo sapiens OX=9606 GN=STAB2 PE=1SV=3MMLQHLVIFCLGLVVQNFCSPAETTGQARRCDRKSLLTIRTECRSCALNLGVKCPDGYTMITSGSVGVRDCRYTFEVRTYSLSLPGCRHICRKDYLQPRCCPGRWGPDCIECPGGAGSPCNGRGSCAEGMEGNGTCSCQEGFGGTACETCADDNLFGPSCSSVCNCVHGVCNSGLDGDGTCECYSAYTGPKCDKPIPECAALLCPENSRCSPSTEDENKLECKCLPNYRGDGKYCDPINPCLRKICHPHAHCTYLGPNRHSCTCQEGYRGDGQVCLPVDPCQINFGNCPTKSTVCKYDGPGQSHCECKEHYQNFVPGVGCSMTDICKSDNPCHRNANCTTVAPGRTECICQKGYVGDGLTCYGNIMERLRELNTEPRGKWQGRLTSFISLLDKAYAWPLSKLGPFTVLLPTDKGLKGFNVNELLVDNKAAQYFVKLHIIAGQMNIEYMNNTDMFYTLTGKSGEIFNSDKDNQIKLKLHGGKKKVKIIQGDIIASNGLLHILDRAMDKLEPTFESNNEQTIMTMLQPRYSKFRSLLEETNLGHALDEDGVGGPYTIFVPNNEALNNMKDGTLDYLLSPEGSRKLLELVRYHIVPFTQLEVATLISTPHIRSMANQLIQFNTTDNGQILANDVAMEEIEITAKNGRIYTLTGVLIPPSIVPILPHRCDETKREMKLGTCVSCSLVYWSRCPANSEPTALFTHRCVYSGRFGSLKSGCARYCNATVKIPKCCKGFYGPDCNQCPGGFSNPCSGNGQCADSLGGNGTCICEEGFQGSQCQFCSDPNKYGPRCNKKCLCVHGTCNNRIDSDGACLTGTCRDGSAGRLCDKQTSACGPYVQFCHIHATCEYSNGTASCICKAGYEGDGTLCSEMDPCTGLTPGGCSRNAECIKTGTGTHTCVCQQGWTGNGRDCSEINNCLLPSAGGCHDNASCLYVGPGQNECECKKGFRGNGIDCEPITSCLEQTGKCHPLASCQSTSSGVWSCVCQEGYEGDGFLCYGNAAVELSFLSEAAIFNRWINNASLQPTLSATSNLTVLVPSQQATEDMDQDEKSFWLSQSNIPALIKYHMLLGTYRVADLQTLSSSDMLATSLQGNFLHLAKVDGNITIEGASIVDGDNAATNGVIHIINKVLVPQRRLTGSLPNLLMRLEQMPDYSIFRGYIIQYNLANAIEAADAYTVFAPNNNAIENYIREKKVLSLEEDVLRYHVVLEEKLLKNDLHNGMHRETMLGFSYFLSFFLHNDQLYVNEAPINYTNVATDKGVIHGLGKVLEIQKNRCDNNDTTIIRGRCRTCSSELTCPFGTKSLGNEKRRCIYTSYFMGRRTLFIGCQPKCVRTVITRECCAGFFGPQCQPCPGNAQNVCFGNGICLDGVNGTGVCECGEGFSGTACETCTEGKYGIHCDQACSCVHGRCNQGPLGDGSCDCDVGWRGVHCDNATTEDNCNGTCHTSANCLTNSDGTASCKCAAGFQGNGTICTAINACEISNGGCSAKADCKRTTPGRRVCTCKAGYTGDGIVCLEINPCLENHGGCDKNAECTQTGPNQAACNCLPAYTGDGKVCTLINVCLTKNGGCSEFAICNHTGQVERTCTCKPNYIGDGFTCRGSIYQELPKNPKTSQYFFQLQEHFVKDLVGPGPFTVFAPLSAAFDEEARVKDWDKYGLMPQVLRYHVVACHQLLLENLKLISNATSLQGEPIVISVSQSTVYINNKAKIISSDIISTNGIVHIIDKLLSPKNLLITPKDNSGRILQNLTTLATNNGYIKFSNLIQDSGLLSVITDPIHTPVTLFWPTDQALHALPAEQQDFLFNQDNKDKLKEYLKFHVIRDAKVLAVDLPTSTAWKTLQGSELSVKCGAGRDIGDLFLNGQTCRIVQRELLFDLGVAYGIDCLLIDPTLGGRCDTFTTFDASGECGSCVNTPSCPRWSKPKGVKQKCLYNLPFKRNLEGCRERCSLVIQIPRCCKGYFGRDCQACPGGPDAPCNNRGVCLDQYSATGECKCNTGFNGTACEMCWPGRFGPDCLPCGCSDHGQCDDGITGSGQCLCETGWTGPSCDTQAVLPAVCTPPCSAHATCKENNTCECNLDYEGDGITCTVVDFCKQDNGGCAKVARCSQKGTKVSCSCQKGYKGDGHSCTEIDPCADGLNGGCHEHATCKMTGPGKHKCECKSHYVGDGLNCEPEQLPIDRCLQDNGQCHADAKCVDLHFQDTTVGVFHLRSPLGQYKLTFDKAREACANEAATMATYNQLSYAQKAKYHLCSAGWLETGRVAYPTAFASQNCGSGVVGIVDYGPRPNKSEMWDVFCYRMKDVNCTCKVGYVGDGFSCSGNLLQVLMSFPSLTNFLTEVLAYSNSSARGRAFLEHLTDLSIRGTLFVPQNSGLGENETLSGRDIEHHLANVSMFFYNDLVNGTTLQTRLGSKLLITASQDPLQPTETRFVDGRAILQWDIFASNGIIHVISRPLKAPPAPVTLTHTGLGAGIFFAIILVTGAVALAAYSYFRINRRTIGFQHFESEEDINVAALGKQQPENISNPLYESTTSAPPEPSYDPFTDSEERQLEGNDPLRTL>sp|Q7Z2R9|SSAS1_HUMAN Putative uncharacterized protein SSBP3-AS1 OS=Homosapiens OX=9606 GN=SSBP3-AS1 PE=5 SV=1MWGFLVLKARWLVTPVRTLATEAGQKPSLRGLLDVGNIQHRAARARGLTRGVIRVSPQERSQQNQSAPKGPTPSTRPKPRTLGPQAHSLALQSVDLLFRP>sp|Q9Y6J8|STYL1_HUMAN Serine/threonine/tyrosine-interacting-like protein1 OS=Homo sapiens OX=9606 GN=STYXL1 PE=1 SV=1MPGLLLCEPTELYNILNQATKLSRLTDPNYLCLLDVRSKWEYDESHVITALRVKKKNNEYLLPESVDLECVKYCVVYDNNSSTLEILLKDDDDDSDSDGDGKDLVPQAAIEYGRILTRLTHHPVYILKGGYERFSGTYHFLRTQKIIWMPQELDAFQPYPIEIVPGKVFVGNFSQACDPKIQKDLKIKAHVNVSMDTGPFFAGDADKLLHIRIEDSPEAQILPFLRHMCHFIEIHHHLGSVILIFSTQGISRSCAAIIAYLMHSNEQTLQRSWAYVKKCKNNMCPNRGLVSQLLEWEKTILGDSITNIMDPLY>sp|Q9Y6J8-2|STYL1_HUMAN Isoform 2 of Serine/threonine/tyrosine-interacting-like protein 1 OS=Homo sapiens OX=9606 GN=STYXL1MPGLLLCEPTELYNILNQATKLSRLTDPNYLCLLDVRSKWEYDESHVITALRVKKKNNEYLLPESVDLECVKYCVVYDNNSSTLEILLKDDDDDSDSDGDGKDLVPQAAIEYGRILTRLTHHPVYILKGGYERFSGTYHFLRTQKIIWMPQELDAFQPYPIEIVPGKVFVGNFSQACDPKIQKDLKIKAHVNVSMDTGPFFAGDADKLLHIRIEDSPEAQILPFLRHMCHFIGYQPQLCRHHSLPHA>sp|Q9Y6J8-3|STYL1_HUMAN Isoform 3 of Serine/threonine/tyrosine-interacting-like protein 1 OS=Homo sapiens OX=9606 GN=STYXL1MPGLLLCEPTELYNILNQATKLSRLTDPNYLCLLDVRSKWEYDESHVITALRVKKKNNEYLLPESVDLECVKYCVVYDNNSSTLEILLKDDDDDSDSDGDGKDLVPQAAIEYGRILTRLTHHPVYILKGGYERFSGTYHFLRTQKIIWMPQELDAFQPYPIEIVPGKVFVGNFSQACDPKIQKDLKIKAHVNVSMDTGPFFAGDADKLLHIRIEDSPEAQILPFLRHMCHFIEVLGLCQEVQKQHVSKSGIGEPAAGMGEDYPWRFHHKHHGSALLIFSEAHRRVLKSLTWGHFVGGGPECVYPGLSGRRRPLLPESL>sp|Q9Y6J8-4|STYL1_HUMAN Isoform 4 of Serine/threonine/tyrosine-interacting-like protein 1 OS=Homo sapiens OX=9606 GN=STYXL1MPGLLLCEPTELYNILNQATKLSRLTDPNYLCLLDVRSKWEYDESHVITALRVKKELDAFQPYPIEIVPGKVFVGNFSQACDPKIQKDLKIKAHVNVSMDTGPFFAGDADKLLHIRIEDSPEAQILPFLRHMCHFIEIHHHLGSVILIFSTQGISRSCAAIIAYLMHSNEQTLQRSWAYVKKCKNNMCPNRGLVSQLLEWEKTILGDSITNIMDPLY>sp|Q9Y6J8-5|STYL1_HUMAN Isoform 5 of Serine/threonine/tyrosine-interacting-like protein 1 OS=Homo sapiens OX=9606 GN=STYXL1MPGLLLCEPTELYNILNQATKLSRLTDPNYLCLLDVRSKWEYDESHVITALRVKKKNNEYLLPESVDLECVKYCVVYDNNSSTLEILLKDDDDDSDSDGDGKGTGCISAIP>sp|O95630|STABP_HUMAN STAM-binding protein OS=Homo sapiens OX=9606GN=STAMBP PE=1 SV=1MSDHGDVSLPPEDRVRALSQLGSAVEVNEDIPPRRYFRSGVEIIRMASIYSEEGNIEHAFILYNKYITLFIEKLPKHRDYKSAVIPEKKDTVKKLKEIAFPKAEELKAELLKRYTKEYTEYNEEKKKEAEELARNMAIQQELEKEKQRVAQQKQQQLEQEQFHAFEEMIRNQELEKERLKIVQEFGKVDPGLGGPLVPDLEKPSLDVFPTLTVSSIQPSDCHTTVRPAKPPVVDRSLKPGALSNSESIPTIDGLRHVVVPGRLCPQFLQLASANTARGVETCGILCGKLMRNEFTITHVLIPKQSAGSDYCNTENEEELFLIQDQQGLITLGWIHTHPTQTAFLSSVDLHTHCSYQMMLPESVAIVCSPKFQETGFFKLTDHGLEEISSCRQKGFHPHSKDPPLFCSCSHVTVVDRAVTITDLR>sp|O95630-2|STABP_HUMAN Isoform 2 of STAM-binding protein OS=Homosapiens OX=9606 GN=STAMBPMSDHGDVSLPPEDRVRALSQLGSAVEVNEDIPPRRYFRSGVEIIRMASIYSEEGNIEHAFILYNKYITLFIEKLPKHRDYKSAVIPEKKDTVKKLKEIAFPKAEELKAELLKRYTKEYTEYNEEKKKEAEELARNMAIQQELEKEKQRVAQQKQQQLEQEQFHAFEEMIRNQELEKERLKIVQEFGKVDPGLGGPLVPDLEKPSLDVFPTLTVSSIQPSDCHTTVRPAKPPVVDRSLKPGALSNSESIPTIDGLRHVVVPGRLCPQFLQLASANTARGVETCGILCGKLMRNEFTITHVLIPKQSAGSDYCNTENEEELFLIQDQQGLITLGWIHVETLWSLKSLHAP>sp|P53597|SUCA_HUMAN Succinate--CoA ligase [ADP/GDP-forming] subunitalpha, mitochondrial OS=Homo sapiens OX=9606 GN=SUCLG1 PE=1 SV=4MTATLAAAADIATMVSGSSGLAAARLLSRSFLLPQNGIRHCSYTASRQHLYVDKNTKIICQGFTGKQGTFHSQQALEYGTKLVGGTTPGKGGQTHLGLPVFNTVKEAKEQTGATASVIYVPPPFAAAAINEAIEAEIPLVVCITEGIPQQDMVRVKHKLLRQEKTRLIGPNCPGVINPGECKIGIMPGHIHKKGRIGIVSRSGTLTYEAVHQTTQVGLGQSLCVGIGGDPFNGTDFIDCLEIFLNDSATEGIILIGEIGGNAEENAAEFLKQHNSGPNSKPVVSFIAGLTAPPGRRMGHAGAIIAGGKGGAKEKISALQSAGVVVSMSPAQLGTTIYKEFEKRKML>sp|Q9NRP7|STK36_HUMAN Serine/threonine-protein kinase 36 OS=Homo sapiensOX=9606 GN=STK36 PE=1 SV=2MEKYHVLEMIGEGSFGRVYKGRRKYSAQVVALKFIPKLGRSEKELRNLQREIEIMRGLRHPNIVHMLDSFETDKEVVVVTDYAEGELFQILEDDGKLPEDQVQAIAAQLVSALYYLHSHRILHRDMKPQNILLAKGGGIKLCDFGFARAMSTNTMVLTSIKGTPLYMSPELVEERPYDHTADLWSVGCILYELAVGTPPFYATSIFQLVSLILKDPVRWPSTISPCFKNFLQGLLTKDPRQRLSWPDLLYHPFIAGHVTIITEPAGPDLGTPFTSRLPPELQVLKDEQAHRLAPKGNQSRILTQAYKRMAEEAMQKKHQNTGPALEQEDKTSKVAPGTAPLPRLGATPQESSLLAGILASELKSSWAKSGTGEVPSAPRENRTTPDCERAFPEERPEVLGQRSTDVVDLENEEPDSDNEWQHLLETTEPVPIQLKAPLTLLCNPDFCQRIQSQLHEAGGQILKGILEGASHILPAFRVLSSLLSSCSDSVALYSFCREAGLPGLLLSLLRHSQESNSLQQQSWYGTFLQDLMAVIQAYFACTFNLERSQTSDSLQVFQEAANLFLDLLGKLLAQPDDSEQTLRRDSLMCFTVLCEAMDGNSRAISKAFYSSLLTTQQVVLDGLLHGLTVPQLPVHTPQGAPQVSQPLREQSEDIPGAISSALAAICTAPVGLPDCWDAKEQVCWHLANQLTEDSSQLRPSLISGLQHPILCLHLLKVLYSCCLVSEGLCRLLGQEPLALESLFMLIQGKVKVVDWEESTEVTLYFLSLLVFRLQNLPCGMEKLGSDVATLFTHSHVVSLVSAAACLLGQLGQQGVTFDLQPMEWMAAATHALSAPAEVRLTPPGSCGFYDGLLILLLQLLTEQGKASLIRDMSSSEMWTVLWHRFSMVLRLPEEASAQEGELSLSSPPSPEPDWTLISPQGMAALLSLAMATFTQEPQLCLSCLSQHGSILMSILKHLLCPSFLNQLRQAPHGSEFLPVVVLSVCQLLCFPFALDMDADLLIGVLADLRDSEVAAHLLQVCCYHLPLMQVELPISLLTRLALMDPTSLNQFVNTVSASPRTIVSFLSVALLSDQPLLTSDLLSLLAHTARVLSPSHLSFIQELLAGSDESYRPLRSLLGHPENSVRAHTYRLLGHLLQHSMALRGALQSQSGLLSLLLLGLGDKDPVVRCSASFAVGNAAYQAGPLGPALAAAVPSMTQLLGDPQAGIRRNVASALGNLGPEGLGEELLQCEVPQRLLEMACGDPQPNVKEAALIALRSLQQEPGIHQVLVSLGASEKLSLLSLGNQSLPHSSPRPASAKHCRKLIHLLRPAHSM>sp|Q9NRP7-2|STK36_HUMAN Isoform 2 of Serine/threonine-protein kinase 36OS=Homo sapiens OX=9606 GN=STK36MEKYHVLEMIGEGSFGRVYKGRRKYSAQVVALKFIPKLGRSEKELRNLQREIEIMRGLRHPNIVHMLDSFETDKEVVVVTDYAEGELFQILEDDGKLPEDQVQAIAAQLVSALYYLHSHRILHRDMKPQNILLAKGGGIKLCDFGFARAMSTNTMVLTSIKGTPLYMSPELVEERPYDHTADLWSVGCILYELAVGTPPFYATSIFQLVSLILKDPVRWPSTISPCFKNFLQGLLTKDPRQRLSWPDLLYHPFIAGHVTIITEPAGPDLGTPFTSRLPPELQVLKDEQAHRLAPKGNQSRILTQAYKRMAEEAMQKKHQNTGPALEQEDKTSKVAPGTAPLPRLGATPQESSLLAGILASELKSSWAKSGTGEVPSAPRENRTTPDCERAFPEERPEVLGQRSTDVVDLENEEPDSDNEWQHLLETTEPVPIQLKAPLTLLCNPDFCQRIQSQLHEAGGQILKGILEGASHILPAFRVLSSLLSSCSDSVALYSFCREAGLPGLLLSLLRHSQESNSLQQQSWYGTFLQDLMAVIQAYFACTFNLERSQTSDSLQVFQEAANLFLDLLGKLLAQPDDSEQTLRRDSLMCFTVLCEAMDGNSRAISKAFYSSLLTTQQVVLDGLLHGLTVPQLPVHTPQGAPQVSQPLREQSEDIPGAISSALAAICTAPVGLPDCWDAKEQVCWHLANQLTEDSSQLRPSLISGLQHPILCLHLLKVLYSCCLVSEGLCRLLGQEPLALESLFMLIQGKVKVVDWEESTEVTLYFLSLLVFRLQNLPCGMEKLGSDVATLFTHSHVVSLVSAAACLLGQLGQQGVTFDLQPMEWMAAATHALSAPAELLTEQGKASLIRDMSSSEMWTVLWHRFSMVLRLPEEASAQEGELSLSSPPSPEPDWTLISPQGMAALLSLAMATFTQEPQLCLSCLSQHGSILMSILKHLLCPSFLNQLRQAPHGSEFLPVVVLSVCQLLCFPFALDMDADLLIGVLADLRDSEVAAHLLQVCCYHLPLMQVELPISLLTRLALMDPTSLNQFVNTVSASPRTIVSFLSVALLSDQPLLTSDLLSLLAHTARVLSPSHLSFIQELLAGSDESYRPLRSLLGHPENSVRAHTYRLLGHLLQHSMALRGALQSQSGLLSLLLLGLGDKDPVVRCSASFAVGNAAYQAGPLGPALAAAVPSMTQLLGDPQAGIRRNVASALGNLGPEGLGEELLQCEVPQRLLEMACGDPQPNVKEAALIALRSLQQEPGIHQVLVSLGASEKLSLLSLGNQSLPHSSPRPASAKHCRKLIHLLRPAHSM>sp|Q9NP77|SSU72_HUMAN RNA polymerase II subunit A C-terminal domainphosphatase SSU72 OS=Homo sapiens OX=9606 GN=SSU72 PE=1 SV=1MPSSPLRVAVVCSSNQNRSMEAHNILSKRGFSVRSFGTGTHVKLPGPAPDKPNVYDFKTTYDQMYNDLLRKDKELYTQNGILHMLDRNKRIKPRPERFQNCKDLFDLILTCEERVYDQVVEDLNSREQETCQPVHVVNVDIQDNHEEATLGAFLICELCQCIQHTEDMENEIDELLQEFEEKSGRTFLHTVCFY>sp|Q9NP77-2|SSU72_HUMAN Isoform 2 of RNA polymerase II subunit A C-terminal domain phosphatase SSU72 OS=Homo sapiens OX=9606 GN=SSU72MPSSPLRVAVVCSSNQNRSMEAHNILSKRGFSVRSFGTGTHVKLPGPAPDKPNVYDFKTTYDQMYNDLLRKDKELYPSGLPFKNPPCGPPWKVLRVARAQEACHPVQCTHWLLCLCESLVSIPGARRIVHGLVPVPPMAVGVVRRTDTVWGSP>sp|Q7Z6I5|SPT12_HUMAN Spermatogenesis-associated protein 12 OS=Homosapiens OX=9606 GN=SPATA12 PE=1 SV=1MSSSALTCGSTLEKSGDTWEMKALDSSRLVPWPPRGLGSSTQHPNKPHCALASCQGPGVLPGAASALPELTFQGDVCQSETCQRYLQAAISLDIAVSQINLLGRPSSPPALLIQQGSCEQVIHNSTPQFLGMEDGDNERTTGWLWRLCEDIDAEPSSTGCSRSNQLTFTEGCFVRSLSTVYSNTHIHTHL>sp|Q9C0K7|STRAB_HUMAN STE20-related kinase adapter protein beta OS=Homosapiens OX=9606 GN=STRADB PE=1 SV=1MSLLDCFCTSRTQVESLRPEKQSETSIHQYLVDEPTLSWSRPSTRASEVLCSTNVSHYELQVEIGRGFDNLTSVHLARHTPTGTLVTIKITNLENCNEERLKALQKAVILSHFFRHPNITTYWTVFTVGSWLWVISPFMAYGSASQLLRTYFPEGMSETLIRNILFGAVRGLNYLHQNGCIHRSIKASHILISGDGLVTLSGLSHLHSLVKHGQRHRAVYDFPQFSTSVQPWLSPELLRQDLHGYNVKSDIYSVGITACELASGQVPFQDMHRTQMLLQKLKGPPYSPLDISIFPQSESRMKNSQSGVDSGIGESVLVSSGTHTVNSDRLHTPSSKTFSPAFFSLVQLCLQQDPEKRPSASSLLSHVFFKQMKEESQDSILSLLPPAYNKPSISLPPVLPWTEPECDFPDEKDSYWEF>sp|Q9C0K7-2|STRAB_HUMAN Isoform 2 of STE20-related kinase adapterprotein beta OS=Homo sapiens OX=9606 GN=STRADBMSLLDCFCTSRTQVESLRPEKQSETSIHQYLVDEPTLSWSRPSTRASEVLCSTNVSHYELQVEIGRGFDNLTSVHLARHTPTGTLVTIKITNLENCNEERLKALQKAVILSHFFRHPNITTYWTVFTVGSWLWVISPFMAYGSASQLLRTYFPEGMSETLIRNILFGAVRGLNYLHQNGCIHRSIKASHILISGDGLVTLSGLSHLHSLVKHGQRHRAVYDFPQFSTSVQPWLSPELLRQDLHGYNVKSDIYSVGITACELASGQVPFQDMHRTQMLLQKLKGPPYSPLDISIFPQSESRMKNSQSGVDSGIGESVLVSSGTHTVNSDRLHTPSSKTFSPAFFSLVQLCLQQDPEKRPSASSLLSHVFFKQPYFEFL>sp|Q9C0K7-3|STRAB_HUMAN Isoform 3 of STE20-related kinase adapterprotein beta OS=Homo sapiens OX=9606 GN=STRADBMAYGSASQLLRTYFPEGMSETLIRNILFGAVRGLNYLHQNGCIHRSIKASHILISGDGLVTLSGLSHLHSLVKHGQRHRAVYDFPQFSTSVQPWLSPELLRQDLHGYNVKSDIYSVGITACELASGQVPFQDMHRTQMLLQKLKGPPYSPLDISIFPQSESRMKNSQSGVDSGIGESVLVSSGTHTVNSDRLHTPSSKTFSPAFFSLVQLCLQQDPEKRPSASSLLSHVFFKQMKEESQDSILSLLPPAYNKPSISLPPVLPWTEPECDFPDEKDSYWEF>sp|Q4KMG9|TM52B_HUMAN Transmembrane protein 52B OS=Homo sapiens OX=9606GN=TMEM52B PE=1 SV=1MGVRVHVVAASALLYFILLSGTRCEENCGNPEHCLTTDWVHLWYIWLLVVIGALLLLCGLTSLCFRCCCLSRQQNGEDGGPPPCEVTVIAFDHDSTLQSTITSLQSVFGPAARRILAVAHSHSSLGQLPSSLDTLPGYEEALHMSRFTVAMCGQKAPDLPPVPEEKQLPPTEKESTRIVDSWN>sp|Q4KMG9-2|TM52B_HUMAN Isoform 2 of Transmembrane protein 52B OS=Homosapiens OX=9606 GN=TMEM52BMSWRPQPCCISSCCLTTDWVHLWYIWLLVVIGALLLLCGLTSLCFRCCCLSRQQNGEDGGPPPCEVTVIAFDHDSTLQSTITSLQSVFGPAARRILAVAHSHSSLGQLPSSLDTLPGYEEALHMSRFTVAMCGQKAPDLPPVPEEKQLPPTEKESTRIVDSWN>sp|Q13033|STRN3_HUMAN Striatin-3 OS=Homo sapiens OX=9606 GN=STRN3 PE=1SV=3MDELAGGGGGGPGMAAPPRQQQGPGGNLGLSPGGNGAAGGGGPPASEGAGPAAGPELSRPQQYTIPGILHYIQHEWARFEMERAHWEVERAELQARIAFLQGERKGQENLKKDLVRRIKMLEYALKQERAKYHKLKYGTELNQGDLKMPTFESEETKDTEAPTAPQNSQLTWKQGRQLLRQYLQEVGYTDTILDVRSQRVRSLLGLSNSEPNGSVETKNLEQILNGGESPKQKGQEIKRSSGDVLETFNFLENADDSDEDEENDMIEGIPEGKDKHRMNKHKIGNEGLAADLTDDPDTEEALKEFDFLVTAEDGEGAGEARSSGDGTEWDKDDLSPTAEVWDVDQGLISKLKEQYKKERKGKKGVKRANRTKLYDMIADLGDDELPHIPSGIINQSRSASTRMTDHEGARAEEAEPITFPSGGGKSFIMGSDDVLLSVLGLGDLADLTVTNDADYSYDLPANKDAFRKTWNPKYTLRSHFDGVRALAFHPVEPVLVTASEDHTLKLWNLQKTVPAKKSASLDVEPIYTFRAHIGPVLSLAISSNGEQCFSGGIDATIQWWNMPSPSVDPYDTYEPNVLAGTLVGHTDAVWGLAYSGIKNQLLSCSADGTVRLWNPQEKLPCICTYNGDKKHGIPTSVDFIGCDPAHMVTSFNTGSAVIYDLETSQSLVILSSQVDSGLQSNNHINRVVSHPTLPVTITAHEDRHIKFFDNKTGKMIHSMVAHLDAVTSLAVDPNGIYLMSGSHDCSIRLWNLDSKTCVQEITAHRKKLDESIYDVAFHSSKAYIASAGADALAKVFV>sp|Q13033-2|STRN3_HUMAN Isoform Alpha of Striatin-3 OS=Homo sapiensOX=9606 GN=STRN3MDELAGGGGGGPGMAAPPRQQQGPGGNLGLSPGGNGAAGGGGPPASEGAGPAAGPELSRPQQYTIPGILHYIQHEWARFEMERAHWEVERAELQARIAFLQGERKGQENLKKDLVRRIKMLEYALKQERAKYHKLKYGTELNQGDLKMPTFESEETKDTEAPTAPQNSQLTWKQGRQLLRQYLQEVGYTDTILDVRSQRVRSLLGLSNSEPNGSVETKNLEQILNGGESPKQKGQEIKRSSGDVLETFNFLENADDSDEDEENDMIEGIPEGKDKHRMNKHKIGNEGLAADLTDDPDTEEALKEFDFLVTAEDGEGAGEARSSGDGTEWAEPITFPSGGGKSFIMGSDDVLLSVLGLGDLADLTVTNDADYSYDLPANKDAFRKTWNPKYTLRSHFDGVRALAFHPVEPVLVTASEDHTLKLWNLQKTVPAKKSASLDVEPIYTFRAHIGPVLSLAISSNGEQCFSGGIDATIQWWNMPSPSVDPYDTYEPNVLAGTLVGHTDAVWGLAYSGIKNQLLSCSADGTVRLWNPQEKLPCICTYNGDKKHGIPTSVDFIGCDPAHMVTSFNTGSAVIYDLETSQSLVILSSQVDSGLQSNNHINRVVSHPTLPVTITAHEDRHIKFFDNKTGKMIHSMVAHLDAVTSLAVDPNGIYLMSGSHDCSIRLWNLDSKTCVQEITAHRKKLDESIYDVAFHSSKAYIASAGADALAKVFV>sp|O75886|STAM2_HUMAN Signal transducing adapter molecule 2 OS=Homosapiens OX=9606 GN=STAM2 PE=1 SV=1MPLFTANPFEQDVEKATNEYNTTEDWSLIMDICDKVGSTPNGAKDCLKAIMKRVNHKVPHVALQALTLLGACVANCGKIFHLEVCSRDFATEVRAVIKNKAHPKVCEKLKSLMVEWSEEFQKDPQFSLISATIKSMKEEGITFPPAGSQTVSAAAKNGTSSNKNKEDEDIAKAIELSLQEQKQQHTETKSLYPSSEIQLNNKVARKVRALYDFEAVEDNELTFKHGEIIIVLDDSDANWWKGENHRGIGLFPSNFVTTNLNIETEAAAVDKLNVIDDDVEEIKKSEPEPVYIDEDKMDRALQVLQSIDPTDSKPDSQDLLDLEDICQQMGPMIDEKLEEIDRKHSELSELNVKVLEALELYNKLVNEAPVYSVYSKLHPPAHYPPASSGVPMQTYPVQSHGGNYMGQSIHQVTVAQSYSLGPDQIGPLRSLPPNVNSSVTAQPAQTSYLSTGQDTVSNPTYMNQNSNLQSATGTTAYTQQMGMSVDMSSYQNTTSNLPQLAGFPVTVPAHPVAQQHTNYHQQPLL>sp|O75886-2|STAM2_HUMAN Isoform 2 of Signal transducing adapter molecule2 OS=Homo sapiens OX=9606 GN=STAM2MPLFTANPFEQDVEKATNEYNTTEDWSLIMDICDKVGSTPNGAKDCLKAIMKRVNHKVPHVALQALTLLGACVANCGKIFHLEVCSRDFATEVRAVIKNKAHPKVCEKLKSLMVEWSEEFQKDPQFSLISATIKSMKEEGITFPPAGSQTVSAAAKNGTSSNKNKEDEDIAKAIELSLQEQKQQHTETKSLYPSSEIQLNNKVARKVRALYDFEAVEDNELTFKHGEIIIVLDDSDANWWKGENHRGIGLFPSNFVTTNLNIETEAAAVDKLNVIDDDVEEIKKSEPEPVYIDEDKMDRALQVLQSIDPTDSKPDSQDLLDLEDICQQMGPMIDEKLEEIDR>sp|Q04727|TLE4_HUMAN Transducin-like enhancer protein 4 OS=Homo sapiensOX=9606 GN=TLE4 PE=1 SV=3MIRDLSKMYPQTRHPAPHQPAQPFKFTISESCDRIKEEFQFLQAQYHSLKLECEKLASEKTEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLNAICAQVIPFLSQEHQQQVVQAVERAKQVTMAELNAIIGQQLQAQHLSHGHGLPVPLTPHPSGLQPPAIPPIGSSAGLLALSSALGGQSHLPIKDEKKHHDNDHQRDRDSIKSSSVSPSASFRGAEKHRNSADYSSESKKQKTEEKEIAARYDSDGEKSDDNLVVDVSNEDPSSPRGSPAHSPRENGLDKTRLLKKDAPISPASIASSSSTPSSKSKELSLNEKSTTPVSKSNTPTPRTDAPTPGSNSTPGLRPVPGKPPGVDPLASSLRTPMAVPCPYPTPFGIVPHAGMNGELTSPGAAYAGLHNISPQMSAAAAAAAAAAAYGRSPVVGFDPHHHMRVPAIPPNLTGIPGGKPAYSFHVSADGQMQPVPFPPDALIGPGIPRHARQINTLNHGEVVCAVTISNPTRHVYTGGKGCVKVWDISHPGNKSPVSQLDCLNRDNYIRSCRLLPDGRTLIVGGEASTLSIWDLAAPTPRIKAELTSSAPACYALAISPDSKVCFSCCSDGNIAVWDLHNQTLVRQFQGHTDGASCIDISNDGTKLWTGGLDNTVRSWDLREGRQLQQHDFTSQIFSLGYCPTGEWLAVGMENSNVEVLHVTKPDKYQLHLHESCVLSLKFAHCGKWFVSTGKDNLLNAWRTPYGASIFQSKESSSVLSCDISVDDKYIVTGSGDKKATVYEVIY>sp|Q04727-2|TLE4_HUMAN Isoform 2 of Transducin-like enhancer protein 4OS=Homo sapiens OX=9606 GN=TLE4MIRDLSKMYPQTRHPAPHQPAQPFKFTISESCDRIKEEFQFLQAQYHSLKLECEKLASEKTEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLNAICAQVIPFLSQEHQQQVVQAVERAKQVTMAELNAIIGQQLQAQHLSHGHGLPVPLTPHPSGLQPPAIPPIGSSAGLLALSSALGGQSHLPIKDEKKHHDNDHQRDRDSIKSSSVSPSASFRGAEKHRNSADYSSESKKQKTEEKEIAARYNEKSTTPVSKSNTPTPRTDAPTPGSNSTPGLRPVPGKPPGVDPLASSLRTPMAVPCPYPTPFGIVPHAGMNGELTSPGAAYAGLHNISPQMSAAAAAAAAAAAYGRSPVVGFDPHHHMRVPAIPPNLTGIPGGKPAYSFHVSADGQMQPVPFPPDALIGPGIPRHARQINTLNHGEVVCAVTISNPTRHVYTGGKGCVKVWDISHPGNKSPVSQLDCLNRDNYIRSCRLLPDGRTLIVGGEASTLSIWDLAAPTPRIKAELTSSAPACYALAISPDSKVCFSCCSDGNIAVWDLHNQTLVRQFQGHTDGASCIDISNDGTKLWTGGLDNTVRSWDLREGRQLQQHDFTSQIFSLGYCPTGEWLAVGMENSNVEVLHVTKPDKYQLHLHESCVLSLKFAHCGKWFVSTGKDNLLNAWRTPYGASIFQSKESSSVLSCDISVDDKYIVTGSGDKKATVYEVIY>sp|Q04727-3|TLE4_HUMAN Isoform 3 of Transducin-like enhancer protein 4OS=Homo sapiens OX=9606 GN=TLE4MIRDLSKMYPQTRHPAPHQPAQPFKFTISESCDRIKEEFQFLQAQYHSLKLECEKLASEKTEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLNAICAQVIPFLSQEHQQQVVQAVERAKQVTMAELNAIIGQQLQAQHLSHGHGLPVPLTPHPSGLQPPAIPPIGSSAGLLALSSALGGQSHLPIKDEKKHHDNDHQRDRDSIKSSSVSPSASFRGAEKHRNSADYSSESKKQKTEEKEIAARYDSDGEKSDDNLVVDVSNEDPSSPRGSPAHSPRENGLDKTRLLKKDAPISPASIASSSSTPSSKSKELSLKRDMGKLSETRLSEDEQCTLGLQRWFCRLWFMNEKSTTPVSKSNTPTPRTDAPTPGSNSTPGLRPVPGKPPGVDPLASSLRTPMAVPCPYPTPFGIVPHAGMNGELTSPGAAYAGLHNISPQMSAAAAAAAAAAAYGRSPVVGFDPHHHMRVPAIPPNLTGIPGGKPAYSFHVSADGQMQPVPFPPDALIGPGIPRHARQINTLNHGEVVCAVTISNPTRHVYTGGKGCVKVWDISHPGNKSPVSQLDCLNRDNYIRSCRLLPDGRTLIVGGEASTLSIWDLAAPTPRIKAELTSSAPACYALAISPDSKVCFSCCSDGNIAVWDLHNQTLVRQFQGHTDGASCIDISNDGTKLWTGGLDNTVRSWDLREGRQLQQHDFTSQIFSLGYCPTGEWLAVGMENSNVEVLHVTKPDKYQLHLHESCVLSLKFAHCGKWFVSTGKDNLLNAWRTPYGASIFQSKESSSVLSCDISVDDKYIVTGSGDKKATVYEVIY>sp|Q04727-4|TLE4_HUMAN Isoform 4 of Transducin-like enhancer protein 4OS=Homo sapiens OX=9606 GN=TLE4MIRDLSKMYPQTRHPAPHQPAQPFKFTISESCDRIKEEFQFLQAQYHSLKLECEKLASEKTEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLNAICAQVIPFLSQEQQLQAQHLSHGHGLPVPLTPHPSGLQPPAIPPIGSSAGLLALSSALGGQSHLPIKDEKKHHDNDHQRDRDSIKSSSVSPSASFRGAEKHRNSADYSSESKKQKTEEKEIAARYDSDGEKSDDNLVVDVSNEDPSSPRGSPAHSPRENGLDKTRLLKKDAPISPASIASSSSTPSSKSKELSLNEKSTTPVSKSNTPTPRTDAPTPGSNSTPGLRPVPGKPPGVDPLASSLRTPMAVPCPYPTPFGIVPHAGMNGELTSPGAAYAGLHNISPQMSAAAAAAAAAAAYGRSPVVGFDPHHHMRVPAIPPNLTGIPGGKPAYSFHVSADGQMQPVPFPPDALIGPGIPRHARQINTLNHGEVVCAVTISNPTRHVYTGGKGCVKVWDISHPGNKSPVSQLDCLNRDNYIRSCRLLPDGRTLIVGGEASTLSIWDLAAPTPRIKAELTSSAPACYALAISPDSKVCFSCCSDGNIAVWDLHNQTLVRQFQGHTDGASCIDISNDGTKLWTGGLDNTVRSWDLREGRQLQQHDFTSQIFSLGYCPTGEWLAVGMENSNVEVLHVTKPDKYQLHLHESCVLSLKFAHCGKWFVSTGKDNLLNAWRTPYGASIFQSKESSSVLSCDISVDDKYIVTGSGDKKATVYEVIY>sp|Q7Z5L4|SPT19_HUMAN Spermatogenesis-associated protein 19,mitochondrial OS=Homo sapiens OX=9606 GN=SPATA19 PE=2 SV=2MIITTWIVYILARKGVGLPFLPITSSDIDVVESEAVSVLHHWLKKTEEEASRGIKEKLSINHPSQGVREKMSTDSPPTHGQDIHVTRDVVKHHLSKSDLLANQSQEVLEERTRIQFIRWSHTRIFQVPSEMTEDIMRDRIEQVRRSISRLTDVSAQDFSMRPSSSDC>sp|Q96N06|SPT33_HUMAN Spermatogenesis-associated protein 33 OS=Homosapiens OX=9606 GN=SPATA33 PE=1 SV=1MVTHAAGARTFCEEQKKGSTYSVPKSKEKLMEKHSQEARQADRESEKPVDSLHPGAGTAKHPPPAASLEEKPDVKQKSSRKKVVVPQIIITRASNETLVSCSSSGSDQQRTIREPEDWGPYRRHRNPSTADAYNSHLKE>sp|Q96N06-2|SPT33_HUMAN Isoform 2 of Spermatogenesis-associated protein33 OS=Homo sapiens OX=9606 GN=SPATA33MGLSKSKEKPRKGEEQKKGSTYSVPKSKEKLMEKHSQEARQADRESEKPVDSLHPGAGTAKHPPPAASLEEKPDVKQKSSRKKVVVPQIIITRASNETLVSCSSSGSDQQRTIREPEDWGPYRRHRNPSTADAYNSHLKE>sp|Q7Z572|SPT21_HUMAN Spermatogenesis-associated protein 21 OS=Homosapiens OX=9606 GN=SPATA21 PE=2 SV=3MDNRNTQMYTEEEKTVNPFLPSTPGPKKAKGGGEAVETHPAPGPLPPPEVRDIGERREPDRAQQQPQKPAVAAGTQSLGNFRQGFMKCLLEVEKMEASHRRASKARSQTAQKSPRTLTPVPTSAPSLPQTPASVPASGPSWARLPAPGPEPAPMGAPVPTSMPCPVLLGPALDLGWRRMELLHQSSERTLSYAKARQEPEEQSLQKLYQNREKSEEQLTLKQEEAFRSYFEIFNGPGEVDAQSLKNILLLMGFSVTLAQVEDALMSADVNGDGRVDFKDFLAVMTDTRRFFCSVEQNALSDMAPHNPHTLLFEILSLLVEMLALPEAVLEEITNYYQKKLKEGTCKAQEMEAAVGRLRLQKLPYNPQQEESSEVPERKVLSILSRLKQQNYAPNLQSPYAQVPCILLCPQLDKKMVRRQPSNHYALDQCTPPGLDPDIRSPFFQSGSQGNREHNSDSRKWLSSVPARTH>sp|Q7Z572-2|SPT21_HUMAN Isoform 2 of Spermatogenesis-associated protein21 OS=Homo sapiens OX=9606 GN=SPATA21MAQPGAVEHACHPSTLGGQGGGSLEEVRDIGERREPDRAQQQPQKPAVAAGTQSLGNFRQGFMKCLLEVEKMEASHRRASKARSQTAQKSPRTLTPVPTSAPSLPQTPASVPASGPSWARLPAPGPEPAPMGAPVPTSMPCPVLLGPALDLGWRRMELLHQSSERTLSYAKARQEPEEQSLQKLYQNREKSEEQLTLKQEEAFRSYFEIFNGPGEVDAQSLKNILLLMGFSVTLAQVEDALMSADVNGDGRVDFKDFLAVMTDTRRFFCSVEQNALSDMAPHNPHTLLFEILSLLVEMLALPEAVLEEITNYYQKKLKEGTCKAQEMEAAVGRLRLQKLPYNPQQEESSEVPERKVLSILSRLKQQNYAPNLQSPYAQVPCILLCPQLDKKMVRRQPSNHYALDQCTPPGLDPDIRSPFFQSGSQGNREHNSDSRKWLSSVPARTH>sp|Q2M3C7|SPKAP_HUMAN A-kinase anchor protein SPHKAP OS=Homo sapiensOX=9606 GN=SPHKAP PE=1 SV=1MDGNSLLSVPSNLESSRMYDVLEPQQGRGCGSSGSGPGNSITACKKVLRSNSLLESTDYWLQNQRMPCQIGFVEDKSENCASVCFVNLDVNKDECSTEHLQQKLVNVSPDLPKLISSMNVQQPKENEIVVLSGLASGNLQADFEVSQCPWLPDICLVQCARGNRPNSTNCIIFEINKFLIGLELVQERQLHLETNILKLEDDTNCSLSSIEEDFLTASEHLEEESEVDESRNDYENINVSANVLESKQLKGATQVEWNCNKEKWLYALEDKYINKYPTPLIKTERSPENLTKNTALQSLDPSAKPSQWKREAVGNGRQATHYYHSEAFKGQMEKSQALYIPKDAYFSMMDKDVPSACAVAEQRSNLNPGDHEDTRNALPPRQDGEVTTGKYATNLAESVLQDAFIRLSQSQSTLPQESAVSVSVGSSLLPSCYSTKDTVVSRSWNELPKIVVVQSPDGSDAAPQPGISSWPEMEVSVETSSILSGENSSRQPQSALEVALACAATVIGTISSPQATERLKMEQVVSNFPPGSSGALQTQAPQGLKEPSINEYSFPSALCGMTQVASAVAVCGLGEREEVTCSVAPSGSLPPAAEASEAMPPLCGLASMELGKEAIAKGLLKEAALVLTRPNTYSSIGDFLDSMNRRIMETASKSQTLCSENVVRNELAHTLSNVILRHSIDEVHHKNMIIDPNDNRHSSEILDTLMESTNQLLLDVICFTFKKMSHIVRLGECPAVLSKETIRRRETEPSCQPSDPGASQAWTKATESSSSSPLSNSHNTSLVINNLVDGMYSKQDKGGVRPGLFKNPTLQSQLSRSHRVPDSSTATTSSKEIYLKGIAGEDTKSPHHSENECRASSEGQRSPTVSQSRSGSQEAEESIHPNTQEKYNCATSRINEVQVNLSLLGDDLLLPAQSTLQTKHPDIYCITDFAEELADTVVSMATEIAAICLDNSSGKQPWFCAWKRGSEFLMTPNVPCRSLKRKKESQGSGTAVRKHKPPRLSEIKRKTDEHPELKEKLMNRVVDESMNLEDVPDSVNLFANEVAAKIMNLTEFSMVDGMWQAQGYPRNRLLSGDRWSRLKASSCESIPEEDSEARAYVNSLGLMSTLSQPVSRASSVSKQSSCESITDEFSRFMVNQMENEGRGFELLLDYYAGKNASSILNSAMQQACRKSDHLSVRPSCPSKQSSTESITEEFYRYMLRDIERDSRESASSRRSSQDWTAGLLSPSLRSPVCHRQSSMPDSRSPCSRLTVNVPIKANSLDGFAQNCPQDFLSVQPVSSASSSGLCKSDSCLYRRGGTDHITNMLIHETWASSIEALMRKNKIIVDDAEEADTEPVSGGSPSQAEKCANRLAASRMCSGPTLLVQESLDCPRKDSVTECKQPPVSSLSKTASLTNHSPLDSKKETSSCQDPVPINHKRRSLCSREVPLIQIETDQREACAGEPEPFLSKSSLLEEAEGHSNDKNIPDVVRGGDTAVSACQIHSDSLDTRDVPEAEASTEARAPDEAPNPPSSSEESTGSWTQLANEEDNPDDTSSFLQLSERSMSNGNSSATSSLGIMDLDIYQESMPSSPMINELVEEKKILKGQSESTEAPASGPPTGTASPQRSLLVINFDLEPECPDAELRATLQWIAASELGIPTIYFKKSQENRIEKFLDVVQLVHRKSWKVGDIFHAVVQYCKMHEEQKDGRLSLFDWLLELG>sp|Q2M3C7-2|SPKAP_HUMAN Isoform 2 of A-kinase anchor protein SPHKAPOS=Homo sapiens OX=9606 GN=SPHKAPMDGNSLLSVPSNLESSRMYDVLEPQQGRGCGSSGSGPGNSITACKKVLRSNSLLESTDYWLQNQRMPCQIGFVEDKSENCASVCFVNLDVNKDECSTEHLQQKLVNVSPDLPKLISSMNVQQPKENEIVVLSGLASGNLQADFEVSQCPWLPDICLVQCARGNRPNSTNCIIFEINKFLIGLELVQERQLHLETNILKLEDDTNCSLSSIEEDFLTASEHLEEESEVDESRNDYENINVSANVLESKQLKGATQVEWNCNKEKWLYALEDKYINKYPTPLIKTERSPENLTKNTALQSLDPSAKPSQWKREAVGNGRQATHYYHSEAFKGQMEKSQALYIPKDAYFSMMDKDVPSACAVAEQRSNLNPGDHEDTRNALPPRQDGEVTTGKYATNLAESVLQDAFIRLSQSQSTLPQESAVSVSVGSSLLPSCYSTKDTVVSRSWNELPKIVVVQSPDGSDAAPQPGISSWPEMEVSVETSSILSGENSSRQPQSALEVALACAATVIGTISSPQATERLKMEQVVSNFPPGSSGALQTQAPQGLKEPSINEYSFPSALCGMTQVASAVAVCGLGEREEVTCSVAPSGSLPPAAEASEAMPPLCGLASMELGKEAIAKGLLKEAALVLTRPNTYSSIGDFLDSMNRRIMETASKSQTLCSENVVRNELAHTLSNVILRHSIDEVHHKNMIIDPNDNRHSSEILDTLMESTNQLLLDVICFTFKKMSHIVRLGECPAVLSKETIRRRETEPSCQPSDPGASQAWTKATESSSSSPLSNSHNTSLVINNLVDGMYSKQDKGGVRPGLFKNPTLQSQLSRSHRVPDSSTATTSSKEIYLKGIAGEDTKSPHHSENECRASSEGQRSPTVSQSRSGSQEAEESIHPNTQEKYNCATSRINEVQVNLSLLGDDLLLPAQSTLQTKHPDIYCITDFAEELADTVVSMATEIAAICLDNSSGKQPWFCAWKRGSEFLMTPNVPCRSLKRKKESQGSGTAVRKHKPPRLSEIKRKTDEHPELKEKLMNRVVDESMNLEDVPDSVNLFANEVAAKIMNLTEFSMVDGMWQAQGYPRNRLLSGDRWSRLKASSCESIPEEDSEARAYVNSLGLMSTLSQPVSRASSVSKQSSCESITDEFSRFMVNQMENEGRGFELLLDYYAGKNASSILNSAMQQACRKSDHLSVRPSCPSKQSSTESITEEFYRYMLRDIERDSRESASSRRSSQDWTAGLLSPSLRSPVCHRQSSMPDSRSPCSRLTVNVPIKANSLDGFAQNCPQDFLSVQPVSSASSSGLCKSDSCLYRRGGTDHITNMLIHETWASSIEALMRKNKIIVDDAEEADTEPVSGGSPSQAEKCANRLAASRMCSGPTLLVQESLDCPRKDSVTECKQPPVSSLSKTASLTNHSPLDSKKETSSCQDPVPINHKRRSLCSREVPLIQIETDQREACAGEPEPFLSKSSLLEEAEGHSNDKNIPDVVRGGDTAVSACQIHSDSLDTRDVPEAEASTEARAPDEAPNPPSSSEESTGSWTQLANEEDNPDDTSSFLQLSERSMSELVEEKKILKGQSESTEAPASGPPTGTASPQRSLLVINFDLEPECPDAELRATLQWIAASELGIPTIYFKKSQENRIEKFLDVVQLVHRKSWKVGDIFHAVVQYCKMHEEQKDGRLSLFDWLLELG>sp|O00267|SPT5H_HUMAN Transcription elongation factor SPT5 OS=Homosapiens OX=9606 GN=SUPT5H PE=1 SV=1MSDSEDSNFSEEEDSERSSDGEEAEVDEERRSAAGSEKEEEPEDEEEEEEEEEYDEEEEEEDDDRPPKKPRHGGFILDEADVDDEYEDEDQWEDGAEDILEKEEIEASNIDNVVLDEDRSGARRLQNLWRDQREEELGEYYMKKYAKSSVGETVYGGSDELSDDITQQQLLPGVKDPNLWTVKCKIGEERATAISLMRKFIAYQFTDTPLQIKSVVAPEHVKGYIYVEAYKQTHVKQAIEGVGNLRLGYWNQQMVPIKEMTDVLKVVKEVANLKPKSWVRLKRGIYKDDIAQVDYVEPSQNTISLKMIPRIDYDRIKARMSLKDWFAKRKKFKRPPQRLFDAEKIRSLGGDVASDGDFLIFEGNRYSRKGFLFKSFAMSAVITEGVKPTLSELEKFEDQPEGIDLEVVTESTGKEREHNFQPGDNVEVCEGELINLQGKILSVDGNKITIMPKHEDLKDMLEFPAQELRKYFKMGDHVKVIAGRFEGDTGLIVRVEENFVILFSDLTMHELKVLPRDLQLCSETASGVDVGGQHEWGELVQLDPQTVGVIVRLERETFQVLNMYGKVVTVRHQAVTRKKDNRFAVALDSEQNNIHVKDIVKVIDGPHSGREGEIRHLFRSFAFLHCKKLVENGGMFVCKTRHLVLAGGSKPRDVTNFTVGGFAPMSPRISSPMHPSAGGQRGGFGSPGGGSGGMSRGRGRRDNELIGQTVRISQGPYKGYIGVVKDATESTARVELHSTCQTISVDRQRLTTVGSRRPGGMTSTYGRTPMYGSQTPMYGSGSRTPMYGSQTPLQDGSRTPHYGSQTPLHDGSRTPAQSGAWDPNNPNTPSRAEEEYEYAFDDEPTPSPQAYGGTPNPQTPGYPDPSSPQVNPQYNPQTPGTPAMYNTDQFSPYAAPSPQGSYQPSPSPQSYHQVAPSPAGYQNTHSPASYHPTPSPMAYQASPSPSPVGYSPMTPGAPSPGGYNPHTPGSGIEQNSSDWVTTDIQVKVRDTYLDTQVVGQTGVIRSVTGGMCSVYLKDSEKVVSISSEHLEPITPTKNNKVKVILGEDREATGVLLSIDGEDGIVRMDLDEQLKILNLRFLGKLLEA>sp|O00267-2|SPT5H_HUMAN Isoform 2 of Transcription elongation factorSPT5 OS=Homo sapiens OX=9606 GN=SUPT5HMSDSEDSNFSEEEDSERSSDGEEAEVDEERRSAAGSEKEEEPEDEEEEEEEEEYDEEEEEEDDDRPPKKPRHGGFILDEADVDDEYEDEDQWEDGAEDILEKASNIDNVVLDEDRSGARRLQNLWRDQREEELGEYYMKKYAKSSVGETVYGGSDELSDDITQQQLLPGVKDPNLWTVKCKIGEERATAISLMRKFIAYQFTDTPLQIKSVVAPEHVKGYIYVEAYKQTHVKQAIEGVGNLRLGYWNQQMVPIKEMTDVLKVVKEVANLKPKSWVRLKRGIYKDDIAQVDYVEPSQNTISLKMIPRIDYDRIKARMSLKDWFAKRKKFKRPPQRLFDAEKIRSLGGDVASDGDFLIFEGNRYSRKGFLFKSFAMSAVITEGVKPTLSELEKFEDQPEGIDLEVVTESTGKEREHNFQPGDNVEVCEGELINLQGKILSVDGNKITIMPKHEDLKDMLEFPAQELRKYFKMGDHVKVIAGRFEGDTGLIVRVEENFVILFSDLTMHELKVLPRDLQLCSETASGVDVGGQHEWGELVQLDPQTVGVIVRLERETFQVLNMYGKVVTVRHQAVTRKKDNRFAVALDSEQNNIHVKDIVKVIDGPHSGREGEIRHLFRSFAFLHCKKLVENGGMFVCKTRHLVLAGGSKPRDVTNFTVGGFAPMSPRISSPMHPSAGGQRGGFGSPGGGSGGMSRGRGRRDNELIGQTVRISQGPYKGYIGVVKDATESTARVELHSTCQTISVDRQRLTTVGSRRPGGMTSTYGRTPMYGSQTPMYGSGSRTPMYGSQTPLQDGSRTPHYGSQTPLHDGSRTPAQSGAWDPNNPNTPSRAEEEYEYAFDDEPTPSPQAYGGTPNPQTPGYPDPSSPQVNPQYNPQTPGTPAMYNTDQFSPYAAPSPQGSYQPSPSPQSYHQVAPSPAGYQNTHSPASYHPTPSPMAYQASPSPSPVGYSPMTPGAPSPGGYNPHTPGSGIEQNSSDWVTTDIQVKVRDTYLDTQVVGQTGVIRSVTGGMCSVYLKDSEKVVSISSEHLEPITPTKNNKVKVILGEDREATGVLLSIDGEDGIVRMDLDEQLKILNLRFLGKLLEA>sp|Q9NUL3|STAU2_HUMAN Double-stranded RNA-binding protein Staufenhomolog 2 OS=Homo sapiens OX=9606 GN=STAU2 PE=1 SV=2MANPKEKTAMCLVNELARFNRVQPQYKLLNERGPAHSKMFSVQLSLGEQTWESEGSSIKKAQQAVANKALTESTLPKPVQKPPKSNVNNNPGSITPTVELNGLAMKRGEPAIYRPLDPKPFPNYRANYNFRGMYNQRYHCPVPKIFYVQLTVGNNEFFGEGKTRQAARHNAAMKALQALQNEPIPERSPQNGESGKDVDDDKDANKSEISLVFEIALKRNMPVSFEVIKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPVVEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLARIQGFQAALSALKQFSEQGLDPIDGAMNIEKGSLEKQAKHLREKADNNQAPPGSIAQDCKKSNSAV>sp|Q9NUL3-2|STAU2_HUMAN Isoform 2 of Double-stranded RNA-binding proteinStaufen homolog 2 OS=Homo sapiens OX=9606 GN=STAU2MLQINQMFSVQLSLGEQTWESEGSSIKKAQQAVANKALTESTLPKPVQKPPKSNVNNNPGSITPTVELNGLAMKRGEPAIYRPLDPKPFPNYRANYNFRGMYNQRYHCPVPKIFYVQLTVGNNEFFGEGKTRQAARHNAAMKALQALQNEPIPERSPQNGESGKDVDDDKDANKSEISLVFEIALKRNMPVSFEVIKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPVVEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLARIQGFQAALSALKQFSEQGLDPIDGAMNIEKGSLEKQAKHLREKADNNQAPPGSIAQDCKKSNSAV>sp|Q9NUL3-3|STAU2_HUMAN Isoform 3 of Double-stranded RNA-binding proteinStaufen homolog 2 OS=Homo sapiens OX=9606 GN=STAU2MLQINQMFSVQLSLGEQTWESEGSSIKKAQQAVANKALTESTLPKPVQKPPKSNVNNNPGSITPTVELNGLAMKRGEPAIYRPLDPKPFPNYRANYNFRGMYNQRYHCPVPKIFYVQLTVGNNEFFGEGKTRQAARHNAAMKALQALQNEPIPERSPQNGESGKDVDDDKDANKSEISLVFEIALKRNMPVSFEVIKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPVVEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLARIQGFQV>sp|Q9NUL3-4|STAU2_HUMAN Isoform 4 of Double-stranded RNA-binding proteinStaufen homolog 2 OS=Homo sapiens OX=9606 GN=STAU2MPVSFEVIKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPVVEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLARIQGFQV>sp|Q9NUL3-5|STAU2_HUMAN Isoform 5 of Double-stranded RNA-binding proteinStaufen homolog 2 OS=Homo sapiens OX=9606 GN=STAU2MLQINQMFSVQLSLGEQTWESEGSSIKKAQQAVANKALTESTLPKPVQKPPKSNVNNNPGSITPTVELNGLAMKRGEPAIYRPLDPKPFPNYRANYNFRGMYNQR>sp|Q9NUL3-6|STAU2_HUMAN Isoform 6 of Double-stranded RNA-binding proteinStaufen homolog 2 OS=Homo sapiens OX=9606 GN=STAU2MKALQALQNEPIPERSPQNGESGKDVDDDKDANKSEISLVFEIALKRNMPVSFEVIKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPVVEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLARIQGFQAALSALKQFSEQGLDPIDGAMNIEKGSLEKQAKHLREKADNNQAPPGSIAQDCKKSNSAV>sp|Q9NUL3-7|STAU2_HUMAN Isoform 7 of Double-stranded RNA-binding proteinStaufen homolog 2 OS=Homo sapiens OX=9606 GN=STAU2MKRGEPAIYRPLDPKPFPNYRANYNFRGMYNQRYHCPVPKIFYVQLTVGNNEFFGEGKTRQAARHNAAMKALQALQNEPIPERSPQNGESGKDVDDDKDANKSEISLVFEIALKRNMPVSFEVIKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPVVEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLARIQGFQVHYCDRQSGKECVTCLTLAPVQMTFHAIGSSIEASHDQAALSALKQFSEQGLDPIDGAMNIEKGSLEKQAKHLREKADNNQAPPGSIAQDCKKSNSAV>sp|Q9NUL3-8|STAU2_HUMAN Isoform 8 of Double-stranded RNA-binding proteinStaufen homolog 2 OS=Homo sapiens OX=9606 GN=STAU2MFSVQLSLGEQTWESEGSSIKKAQQAVANKALTESTLPKPVQKPPKSNVNNNPGSITPTVELNGLAMKRGEPAIYRPLDPKPFPNYRANYNFRGMYNQRYHCPVPKIFYVQLTVGNNEFFGEGKTRQAARHNAAMKALQALQNEPIPERSPQNGESGKDVDDDKDANKSEISLVFEIALKRNMPVSFEVIKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPVVEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLARIQGFQV>sp|Q15022|SUZ12_HUMAN Polycomb protein SUZ12 OS=Homo sapiens OX=9606GN=SUZ12 PE=1 SV=3MAPQKHGGGGGGGSGPSAGSGGGGFGGSAAVAAATASGGKSGGGSCGGGGSYSASSSSSAAAAAGAAVLPVKKPKMEHVQADHELFLQAFEKPTQIYRFLRTRNLIAPIFLHRTLTYMSHRNSRTNIKRKTFKVDDMLSKVEKMKGEQESHSLSAHLQLTFTGFFHKNDKPSPNSENEQNSVTLEVLLVKVCHKKRKDVSCPIRQVPTGKKQVPLNPDLNQTKPGNFPSLAVSSNEFEPSNSHMVKSYSLLFRVTRPGRREFNGMINGETNENIDVNEELPARRKRNREDGEKTFVAQMTVFDKNRRLQLLDGEYEVAMQEMEECPISKKRATWETILDGKRLPPFETFSQGPTLQFTLRWTGETNDKSTAPIAKPLATRNSESLHQENKPGSVKPTQTIAVKESLTTDLQTRKEKDTPNENRQKLRIFYQFLYNNNTRQQTEARDDLHCPWCTLNCRKLYSLLKHLKLCHSRFIFNYVYHPKGARIDVSINECYDGSYAGNPQDIHRQPGFAFSRNGPVKRTPITHILVCRPKRTKASMSEFLESEDGEVEQQRTYSSGHNRLYFHSDTCLPLRPQEMEVDSEDEKDPEWLREKTITQIEEFSDVNEGEKEVMKLWNLHVMKHGFIADNQMNHACMLFVENYGQKIIKKNLCRNFMLHLVSMHDFNLISIMSIDKAVTKLREMQQKLEKGESASPANEEITEEQNGTANGFSEINSKEKALETDSVSGVSKQSKKQKL>sp|Q7L0J3|SV2A_HUMAN Synaptic vesicle glycoprotein 2A OS=Homo sapiensOX=9606 GN=SV2A PE=1 SV=1MEEGFRDRAAFIRGAKDIAKEVKKHAAKKVVKGLDRVQDEYSRRSYSRFEEEDDDDDFPAPSDGYYRGEGTQDEEEGGASSDATEGHDEDDEIYEGEYQGIPRAESGGKGERMADGAPLAGVRGGLSDGEGPPGGRGEAQRRKEREELAQQYEAILRECGHGRFQWTLYFVLGLALMADGVEVFVVGFVLPSAEKDMCLSDSNKGMLGLIVYLGMMVGAFLWGGLADRLGRRQCLLISLSVNSVFAFFSSFVQGYGTFLFCRLLSGVGIGGSIPIVFSYFSEFLAQEKRGEHLSWLCMFWMIGGVYAAAMAWAIIPHYGWSFQMGSAYQFHSWRVFVLVCAFPSVFAIGALTTQPESPRFFLENGKHDEAWMVLKQVHDTNMRAKGHPERVFSVTHIKTIHQEDELIEIQSDTGTWYQRWGVRALSLGGQVWGNFLSCFGPEYRRITLMMMGVWFTMSFSYYGLTVWFPDMIRHLQAVDYASRTKVFPGERVEHVTFNFTLENQIHRGGQYFNDKFIGLRLKSVSFEDSLFEECYFEDVTSSNTFFRNCTFINTVFYNTDLFEYKFVNSRLINSTFLHNKEGCPLDVTGTGEGAYMVYFVSFLGTLAVLPGNIVSALLMDKIGRLRMLAGSSVMSCVSCFFLSFGNSESAMIALLCLFGGVSIASWNALDVLTVELYPSDKRTTAFGFLNALCKLAAVLGISIFTSFVGITKAAPILFASAALALGSSLALKLPETRGQVLQ>sp|Q7L0J3-2|SV2A_HUMAN Isoform 2 of Synaptic vesicle glycoprotein 2AOS=Homo sapiens OX=9606 GN=SV2AMEEGFRDRAAFIRGAKDIAKEVKKHAAKKVVKGLDRVQDEYSRRSYSRFEEEDDDDDFPAPSDGYYRGEGTQDEEEGGASSDATEGHDEDDEIYEGEYQGIPRAESGGKGERMADGAPLAGVRGGLSDGEGPPGGRGEAQRRKEREELAQQYEAILRECGHGRFQWTLYFVLGLALMADGVEVFVVGFVLPSAEKDMCLSDSNKGMLGLIVYLGMMVGAFLWGGLADRLGRRQCLLISLSVNSVFAFFSSFVQGYGTFLFCRLLSGVGIGGSIPIVFSYFSEFLAQEKRGEHLSWLCMFWMIGGVYAAAMAWAIIPHYGWSFQMGSAYQFHSWRVFVLVCAFPSVFAIGALTTQPESPRFFLENGKHDEAWMVLKQVHDTNMRAKGHPERVFSVTHIKTIHQEDELIEIQSDTGTWYQRWGVRALSLGGQVWGNFLSCFGPEYRRITLMMMGVWFTMSFSYYGLTVWFPDMIRHLQAVDYASRTKVFPGERVEHVTFNFTLENQIHRGGQYFNDKFIGLRLKSVSFEDSLFEECYFEDVTSSNTFFRNCTFINTVFYNTDLFEYKFVNSRLINSTFLHNKEGCPLDVTGTGEGAYMVYFVSFLGTLAVLPGNIVSALLMDKIGRLRMLAGSSVMSCVSCFFLSFGNSESAMIALLCLFGGVSIASWNALDVLTVELYPSDKR>sp|P0CF51|TRGC1_HUMAN T cell receptor gamma constant 1 OS=Homo sapiensOX=9606 GN=TRGC1 PE=1 SV=1DKQLDADVSPKPTIFLPSIAETKLQKAGTYLCLLEKFFPDVIKIHWQEKKSNTILGSQEGNTMKTNDTYMKFSWLTVPEKSLDKEHRCIVRHENNKNGVDQEIIFPPIKTDVITMDPKDNCSKDANDTLLLQLTNTSAYYMYLLLLLKSVVYFAIITCCLLRRTAFCCNGEKS>sp|P52823|STC1_HUMAN Stanniocalcin-1 OS=Homo sapiens OX=9606 GN=STC1PE=1 SV=1MLQNSAVLLVLVISASATHEAEQNDSVSPRKSRVAAQNSAEVVRCLNSALQVGCGAFACLENSTCDTDGMYDICKSFLYSAAKFDTQGKAFVKESLKCIANGVTSKVFLAIRRCSTFQRMIAEVQEECYSKLNVCSIAKRNPEAITEVVQLPNHFSNRYYNRLVRSLLECDEDTVSTIRDSLMEKIGPNMASLFHILQTDHCAQTHPRADFNRRRTNEPQKLKVLLRNLRGEEDSPSHIKRTSHESA>sp|P52823-2|STC1_HUMAN Isoform 2 of Stanniocalcin-1 OS=Homo sapiensOX=9606 GN=STC1MYDICKSFLYSAAKFDTQGKAFVKESLKCIANGVTSKVFLAIRRCSTFQRMIAEVQEECYSKLNVCSIAKRNPEAITEVVQLPNHFSNRYYNRLVRSLLECDEDTVSTIRDSLMEKIGPNMASLFHILQTDHCAQTHPRADFNRRRTNEPQKLKVLLRNLRGEEDSPSHIKRTSHESA>sp|O15020|SPTN2_HUMAN Spectrin beta chain, non-erythrocytic 2 OS=Homosapiens OX=9606 GN=SPTBN2 PE=1 SV=3MSSTLSPTDFDSLEIQGQYSDINNRWDLPDSDWDNDSSSARLFERSRIKALADEREAVQKKTFTKWVNSHLARVTCRVGDLYSDLRDGRNLLRLLEVLSGEILPKPTKGRMRIHCLENVDKALQFLKEQKVHLENMGSHDIVDGNHRLTLGLVWTIILRFQIQDISVETEDNKEKKSAKDALLLWCQMKTAGYPNVNVHNFTTSWRDGLAFNAIVHKHRPDLLDFESLKKCNAHYNLQNAFNLAEKELGLTKLLDPEDVNVDQPDEKSIITYVATYYHYFSKMKALAVEGKRIGKVLDHAMEAERLVEKYESLASELLQWIEQTIVTLNDRQLANSLSGVQNQLQSFNSYRTVEKPPKFTEKGNLEVLLFTIQSKLRANNQKVYTPREGRLISDINKAWERLEKAEHERELALRTELIRQEKLEQLAARFDRKAAMRETWLSENQRLVSQDNFGLELAAVEAAVRKHEAIETDIVAYSGRVQAVDAVAAELAAERYHDIKRIAARQHNVARLWDFLRQMVAARRERLLLNLELQKVFQDLLYLMDWMEEMKGRLQSQDLGRHLAGVEDLLQLHELVEADIAVQAERVRAVSASALRFCNPGKEYRPCDPQLVSERVAKLEQSYEALCELAAARRARLEESRRLWRFLWEVGEAEAWVREQQHLLASADTGRDLTGALRLLNKHTALRGEMSGRLGPLKLTLEQGQQLVAEGHPGASQASARAAELQAQWERLEALAEERAQRLAQAASLYQFQADANDMEAWLVDALRLVSSPELGHDEFSTQALARQHRALEEEIRSHRPTLDALREQAAALPPTLSRTPEVQSRVPTLERHYEELQARAGERARALEAALALYTMLSEAGACGLWVEEKEQWLNGLALPERLEDLEVVQQRFETLEPEMNTLAAQITAVNDIAEQLLKANPPGKDRIVNTQEQLNHRWQQFRRLADGKKAALTSALSIQNYHLECTETQAWMREKTKVIESTQGLGNDLAGVLALQRKLAGTERDLEAIAARVGELTREANALAAGHPAQAVAINARLREVQTGWEDLRATMRRREESLGEARRLQDFLRSLDDFQAWLGRTQTAVASEEGPATLPEAEALLAQHAALRGEVERAQSEYSRLRALGEEVTRDQADPQCLFLRQRLEALGTGWEELGRMWESRQGRLAQAHGFQGFLRDARQAEGVLSSQEYVLSHTEMPGTLQAADAAIKKLEDFMSTMDANGERIHGLLEAGRQLVSEGNIHADKIREKADSIERRHKKNQDAAQQFLGRLRDNREQQHFLQDCHELKLWIDEKMLTAQDVSYDEARNLHTKWQKHQAFMAELAANKDWLDKVDKEGRELTLEKPELKALVSEKLRDLHRRWDELETTTQAKARSLFDANRAELFAQSCCALESWLESLQAQLHSDDYGKDLTSVNILLKKQQMLEWEMAVREKEVEAIQAQAKALAQEDQGAGEVERTSRAVEEKFRALCQPMRERCRRLQASREQHQFHRDVEDEILWVTERLPMASSMEHGKDLPSVQLLMKKNQTLQKEIQGHEPRIADLRERQRALGAAAAGPELAELQEMWKRLGHELELRGKRLEDALRAQQFYRDAAEAEAWMGEQELHMMGQEKAKDELSAQAEVKKHQVLEQALADYAQTIHQLAASSQDMIDHEHPESTRISIRQAQVDKLYAGLKELAGERRERLQEHLRLCQLRRELDDLEQWIQEREVVAASHELGQDYEHVTMLRDKFREFSRDTSTIGQERVDSANALANGLIAGGHAARATVAEWKDSLNEAWADLLELLDTRGQVLAAAYELQRFLHGARQALARVQHKQQQLPDGTGRDLNAAEALQRRHCAYEHDIQALSPQVQQVQDDGHRLQKAYAGDKAEEIGRHMQAVAEAWAQLQGSSAARRQLLLDTTDKFRFFKAVRELMLWMDEVNLQMDAQERPRDVSSADLVIKNQQGIKAEIEARADRFSSCIDMGKELLARSHYAAEEISEKLSQLQARRQETAEKWQEKMDWLQLVLEVLVFGRDAGMAEAWLCSQEPLVRSAELGCTVDEVESLIKRHEAFQKSAVAWEERFCALEKLTALEEREKERKRKREEEERRKQPPAPEPTASVPPGDLVGGQTASDTTWDGTQPRPPPSTQAPSVNGVCTDGEPSQPLLGQQRLEHSSFPEGPGPGSGDEANGPRGERQTRTRGPAPSAMPQSRSTESAHAATLPPRGPEPSAQEQMEGMLCRKQEMEAFGKKAANRSWQNVYCVLRRGSLGFYKDAKAASAGVPYHGEVPVSLARAQGSVAFDYRKRKHVFKLGLQDGKEYLFQAKDEAEMSSWLRVVNAAIATASSASGEPEEPVVPSTTRGMTRAMTMPPVSPVGAEGPVVLRSKDGREREREKRFSFFKKNK>sp|O15020-2|SPTN2_HUMAN Isoform 2 of Spectrin beta chain, non-erythrocytic 2 OS=Homo sapiens OX=9606 GN=SPTBN2MSSTLSPTDFDSLEIQGQYSDINNRWDLPDSDWDNDSSSARLFERSRIKALADEREAVQKKTFTKWVNSHLARVTCRVGDLYSDLRDGRNLLRLLEVLSGEILPKPTKGRMRIHCLENVDKALQFLKEQKVHLENMGSHDIVDGNHRLTLGLVWTIILRFQIQDISVETEDNKEKKSAKDALLLWCQMKTAGYPNVNVHNFTTSWRDGLAFNAIVHKHRPDLLDFESLKKCNAHYNLQNAFNLAEKELGLTKLLDPEDVNVDQPDEKSIITYVATYYHYFSKMKALAVEGKRIGKVLDHAMEAERLVEKYESLASELLQWIEQTIVTLNDRQLANSLSGVQNQLQSFNSYRTVEKPPKFTEKGNLEVLLFTIQSKLRANNQKVYTPREGRLISDINKAWERLEKAEHERELALRTELIRQEKLEQLAARFDRKAAMRETWLSENQRLVSQDNFGLELAAVEAAVRKHEAIETDIVAYSGRVQAVDAVAAELAAERYHDIKRIAARQHNVARLWDFLRQMVAARRERLLLNLELQKVFQDLLYLMDWMEEMKGRLQSQDLGRHLAGVEDLLQLHELVEADIAVQAERVRAVSASALRFCNPGKEYRPCDPQLVSERVAKLEQSYEALCELAAARRARLEESRRLWRFLWEVGEAEAWVREQQHLLASADTGRDLTGALRLLNKHTALRGEMSGRLGPLKLTLEQGQQLVAEGHPGASQASARAAELQAQWERLEALAEERAQRLAQAASLYQFQADANDMEAWLVDALRLVSSPELGHDEFSTQALARQHRALEEEIRSHRPTLDALREQAAALPPTLSRTPEVQSRVPTLERHYEELQARAGERARALEAALALYTMLSEAGACGLWVEEKEQWLNGLALPERLEDLEVVQQRFETLEPEMNTLAAQITAVNDIAEQLLKANPPGKDRIVNTQEQLNHRWQQFRRLADGKKAALTSALSIQNYHLECTETQAWMREKTKVIESTQGLGNDLAGVLALQRKLAGTERDLEAIAARVGELTREANALAAGHPAQAVAINARLREVQTGWEDLRATMRRREESLGEARRLQDFLRSLDDFQAWLGRTQTAVASEEGPATLPEAEALLAQHAALRGEVERAQSEYSRLRALGEEVTRDQADPQCLFLRQRLEALGTGWEELGRMWESRQGRLAQAHGFQGFLRDARQAEGVLSSQEYVLSHTEMPGTLQAADAAIKKLEDFMSTMDANGERIHGLLEAGRQLVSEGNIHADKIREKADSIERRHKKNQDAAQQFLGRLRDNREQQHFLQDCHELKLWIDEKMLTAQDVSYDEARNLHTKWQKHQAFMAELAANKDWLDKVDKEGRELTLEKPELKALVSEKLRDLHRRWDELETTTQAKARSLFDANRAELFAQSCCALESWLESLQAQLHSDDYGKDLTSVNILLKKQQMLEWEMAVREKEVEAIQAQAKALAQEDQGAGEVERTSRAVEEKFRALCQPMRERCRRLQASREQHQFHRDVEDEILWVTERLPMASSMEHGKDLPSVQLLMKKNQTLQKEIQGHEPRIADLRERQRALGAAAAGPELAELQEMWKRLGHELELRGKRLEDALRAQQFYRDAAEAEAWMGEQELHMMGQEKAKDELSAQAEVKKHQVLEQALADYAQTIHQLAASSQDMIDHEHPESTRISIRQAQVDKLYAGLKELAGERRERLQEHLRLCQLRRELDDLEQWIQEREVVAASHELGQDYEHVTMLRDKFREFSRDTSTIGQERVDSANALANGLIAGGHAARATVAEWKDSLNEAWADLLELLDTRGQVLAAAYELQRFLHGARQALARVQHKQQQLPDGTGRDLNAAEALQRRHCAYEHDIQALSPQVQQVQDDGHRLQKAYAGDKAEEIGRHMQAVAEAWAQLQGSSAARRQLLLDTTDKFRFFKAVRELMLWMDEVNLQMDAQERPRDVSSADLVIKNQQGIKAEIEARADRFSSCIDMGKELLARSHYAAEEISEKLSQLQARRQETAEKWQEKMDWLQLVLEVLVFGRDAGMAEAWLCSQEPLVRSAELGCTVDEVESLIKRHEAFQKSAVAWEERFCALEKLTALEEREKERKRKREEEERRKQPPAPEPTASVPPGDLVGGQTASDTTWDGTQPRPPPSTQAPSVNGVCTDGEPSQPLLGQQRLEHSSFPEGPGPGSGDEANGPRGERQTRTRGPAPSAMPQSRSTESAHAATLPPRGPEPSAQEQMEGMLCRKQEMEAFGKKAANRSWQNVYCVLRRGSLGFYKDAKAASAGVPYHGEVPVSLARAQGSVAFDYRKRKHVFKLGLQDGKEYLFQAKDEVSCPSCSSLSVPFQKLPAADSPSFPVLPLFPGLVLCGKTGCVRRPHQAALPV>sp|Q8NHX4|SPTA3_HUMAN Spermatogenesis-associated protein 3 OS=Homosapiens OX=9606 GN=SPATA3 PE=2 SV=2MKKVKKKRSEARRHRDSTSQHASSNSTSQQPSPESTPQQPSPESTPQQPSPESTPQHSSLETTSRQPAFQALPAPEIRRSSCCLLSPDANVKAAPQSRKAGPLIRAGPHSCSCATCPCSSACWRRLGLCHSRIFDVLLPRDWQMAPGRGLPNLLTFYRKSSRKPSSHRNACPPSPRNCGCGSGGSRSCLLHH>sp|Q9H5I1|SUV92_HUMAN Histone-lysine N-methyltransferase SUV39H2 OS=Homosapiens OX=9606 GN=SUV39H2 PE=1 SV=2MAAVGAEARGAWCVPCLVSLDTLQELCRKEKLTCKSIGITKRNLNNYEVEYLCDYKVVKDMEYYLVKWKGWPDSTNTWEPLQNLKCPLLLQQFSNDKHNYLSQVKKGKAITPKDNNKTLKPAIAEYIVKKAKQRIALQRWQDELNRRKNHKGMIFVENTVDLEGPPSDFYYINEYKPAPGISLVNEATFGCSCTDCFFQKCCPAEAGVLLAYNKNQQIKIPPGTPIYECNSRCQCGPDCPNRIVQKGTQYSLCIFRTSNGRGWGVKTLVKIKRMSFVMEYVGEVITSEEAERRGQFYDNKGITYLFDLDYESDEFTVDAARYGNVSHFVNHSCDPNLQVFNVFIDNLDTRLPRIALFSTRTINAGEELTFDYQMKGSGDISSDSIDHSPAKKRVRTVCKCGAVTCRGYLN>sp|Q9H5I1-2|SUV92_HUMAN Isoform 1 of Histone-lysine N-methyltransferaseSUV39H2 OS=Homo sapiens OX=9606 GN=SUV39H2MEYYLVKWKGWPDSTNTWEPLQNLKCPLLLQQFSNDKHNYLSQVKKGKAITPKDNNKTLKPAIAEYIVKKAKQRIALQRWQDELNRRKNHKGMIFVENTVDLEGPPSDFYYINEYKPAPGISLVNEATFGCSCTDCFFQKCCPAEAGVLLAYNKNQQIKIPPGTPIYECNSRCQCGPDCPNRIVQKGTQYSLCIFRTSNGRGWGVKTLVKIKRMSFVMEYVGEVITSEEAERRGQFYDNKGITYLFDLDYESDEFTVDAARYGNVSHFVNHSCDPNLQVFNVFIDNLDTRLPRIALFSTRTINAGEELTFDYQMKGSGDISSDSIDHSPAKKRVRTVCKCGAVTCRGYLN>sp|Q9H5I1-3|SUV92_HUMAN Isoform 2 of Histone-lysine N-methyltransferaseSUV39H2 OS=Homo sapiens OX=9606 GN=SUV39H2MAAVGAEARGAWCVPCLVSLDTLQELCRKEKLTCKSIGITKRNLNNYEVEYLCDYKVVKDMEYYLVKWKGWPDSTNTWEPLQNLKCPLLLQQFSNDKHNYLSQVITSEEAERRGQFYDNKGITYLFDLDYESDEFTVDAARYGNVSHFVNHSCDPNLQVFNVFIDNLDTRLPRIALFSTRTINAGEELTFDYQMKGSGDISSDSIDHSPAKKRVRTVCKCGAVTCRGYLN>sp|Q9P246|STIM2_HUMAN Stromal interaction molecule 2 OS=Homo sapiensOX=9606 GN=STIM2 PE=1 SV=2MLVLGLLVAGAADGCELVPRHLRGRRATGSAATAASSPAAAAGDSPALMTDPCMSLSPPCFTEEDRFSLEALQTIHKQMDDDKDGGIEVEESDEFIREDMKYKDATNKHSHLHREDKHITIEDLWKRWKTSEVHNWTLEDTLQWLIEFVELPQYEKNFRDNNVKGTTLPRIAVHEPSFMISQLKISDRSHRQKLQLKALDVVLFGPLTRPPHNWMKDFILTVSIVIGVGGCWFAYTQNKTSKEHVAKMMKDLESLQTAEQSLMDLQERLEKAQEENRNVAVEKQNLERKMMDEINYAKEEACRLRELREGAECELSRRQYAEQELEQVRMALKKAEKEFELRSSWSVPDALQKWLQLTHEVEVQYYNIKRQNAEMQLAIAKDEAEKIKKKRSTVFGTLHVAHSSSLDEVDHKILEAKKALSELTTCLRERLFRWQQIEKICGFQIAHNSGLPSLTSSLYSDHSWVVMPRVSIPPYPIAGGVDDLDEDTPPIVSQFPGTMAKPPGSLARSSSLCRSRRSIVPSSPQPQRAQLAPHAPHPSHPRHPHHPQHTPHSLPSPDPDILSVSSCPALYRNEEEEEAIYFSAEKQWEVPDTASECDSLNSSIGRKQSPPLSLEIYQTLSPRKISRDEVSLEDSSRGDSPVTVDVSWGSPDCVGLTETKSMIFSPASKVYNGILEKSCSMNQLSSGIPVPKPRHTSCSSAGNDSKPVQEAPSVARISSIPHDLCHNGEKSKKPSKIKSLFKKKSK>sp|Q9P246-2|STIM2_HUMAN Isoform 2 of Stromal interaction molecule 2OS=Homo sapiens OX=9606 GN=STIM2MNAAGIRAPEAAGADGTRLAPGGSPCLRRRGRPEESPAAVVAPRGAGELQAAGAPLRFYPASPRRLHRASTPGPAWGWLLRRRRWAALLVLGLLVAGAADGCELVPRHLRGRRATGSAATAASSPAAAAGDSPALMTDPCMSLSPPCFTEEDRFSLEALQTIHKQMDDDKDGGIEVEESDEFIREDMKYKDATNKHSHLHREDKHITIEDLWKRWKTSEVHNWTLEDTLQWLIEFVELPQYEKNFRDNNVKGTTLPRIAVHEPSFMISQLKISDRSHRQKLQLKALDVVLFGPLTRPPHNWMKDFILTVSIVIGVGGCWFAYTQNKTSKEHVAKMMKDLESLQTAEQSLMDLQERLEKAQEENRNVAVEKQNLERKMMDEINYAKEEACRLRELREGAECELSRRQYAEQELEQVRMALKKAEKEFELRSSWSVPDALQKWLQLTHEVEVQYYNIKRQNAEMQLAIAKDEVAASYLIQAEKIKKKRSTVFGTLHVAHSSSLDEVDHKILEAKKALSELTTCLRERLFRWQQIEKICGFQIAHNSGLPSLTSSLYSDHSWVVMPRVSIPPYPIAGGVDDLDEDTPPIVSQFPGTMAKPPGSLARSSSLCRSRRSIVPSSPQPQRAQLAPHAPHPSHPRHPHHPQHTPHSLPSPDPDILSVSSCPALYRNEEEEEAIYFSAEKQWEVPDTASECDSLNSSIGRKQSPPLSLEIYQTLSPRKISRDEVSLEDSSRGDSPVTVDVSWGSPDCVGLTETKSMIFSPASKVYNGILEKSCSMNQLSSGIPVPKPRHTSCSSAGNDSKPVQEAPSVARISSIPHDLCHNGEKSKKPSKIKSLFKKKSK>sp|Q9P246-3|STIM2_HUMAN Isoform 3 of Stromal interaction molecule 2OS=Homo sapiens OX=9606 GN=STIM2MLVLGLLVAGAADGCELVPRHLRGRRATGSAATAASSPAAAAGDSPALMTDPCMSLSPPCFTEEDRFSLEALQTIHKQMDDDKDGGIEVEESDEFIREDMKYKDATNKHSHLHREDKHITIEDLWKRWKTSEVHNWTLEDTLQWLIEFVELPQYEKNFRDNNVKGTTLPRIAVHEPSFMISQLKISDRSHRQKLQLKALDVVLFGPLTRPPHNWMKDFILTVSIVIGVGGCWFAYTQNKTSKEHVAKMMKDLESLQTAEQSLMDLQERLEKAQEENRNVAVEKQNLERKMMDEINYAKEEACRLRELREGAECELSRRQYAEQELEQVRMALKKAEKEFELRSSWSVPDALQKWLQLTHEVEVQYYNIKRQNAEMQLAIAKDEAEKIKKKRSTVFGTLHVAHSSSLDEVDHKILEAKKALSELTTCLRERLFRWQQIEKICGFQIAHNSGLPSLTSSLYSDHSWVVMPRVSIPPYPIAGGVDDLDEDTPPIVSQFPGTMAKPPGSLARSSSLCRSRRSIVPSSPQPQRAQLAPHAPHPSHPRHPHHPQHTPHSLPSPDPDILSVSSCPALYRNEEEEEAIYFSAEKQCIHLGLGACKSE>sp|Q6UW49|SPESP_HUMAN Sperm equatorial segment protein 1 OS=Homo sapiensOX=9606 GN=SPESP1 PE=1 SV=2MKPLVLLVALLLWPSSVPAYPSITVTPDEEQNLNHYIQVLENLVRSVPSGEPGREKKSNSPKHVYSIASKGSKFKELVTHGDASTENDVLTNPISEETTTFPTGGFTPEIGKKKHTESTPFWSIKPNNVSIVLHAEEPYIENEEPEPEPEPAAKQTEAPRMLPVVTESSTSPYVTSYKSPVTTLDKSTGIGISTESEDVPQLSGETAIEKPEEFGKHPESWNNDDILKKILDINSQVQQALLSDTSNPAYREDIEASKDHLKRSLALAAAAEHKLKTMYKSQLLPVGRTSNKIDDIETVINMLCNSRSKLYEYLDIKCVPPEMREKAATVFNTLKNMCRSRRVTALLKVY>sp|P78539|SRPX_HUMAN Sushi repeat-containing protein SRPX OS=Homosapiens OX=9606 GN=SRPX PE=1 SV=1MGSPAHRPALLLLLPPLLLLLLLRVPPSRSFPGSGDSPLEDDEVGYSHPRYKDTPWCSPIKVKYGDVYCRAPQGGYYKTALGTRCDIRCQKGYELHGSSLLICQSNKRWSDKVICKQKRCPTLAMPANGGFKCVDGAYFNSRCEYYCSPGYTLKGERTVTCMDNKAWSGRPASCVDMEPPRIKCPSVKERIAEPNKLTVRVSWETPEGRDTADGILTDVILKGLPPGSNFPEGDHKIQYTVYDRAENKGTCKFRVKVRVKRCGKLNAPENGYMKCSSDGDNYGATCEFSCIGGYELQGSPARVCQSNLAWSGTEPTCAAMNVNVGVRTAAALLDQFYEKRRLLIVSTPTARNLLYRLQLGMLQQAQCGLDLRHITVVELVGVFPTLIGRIGAKIMPPALALQLRLLLRIPLYSFSMVLVDKHGMDKERYVSLVMPVALFNLIDTFPLRKEEMVLQAEMSQTCNT>sp|P78539-2|SRPX_HUMAN Isoform 2 of Sushi repeat-containing protein SRPXOS=Homo sapiens OX=9606 GN=SRPXMDFDVGRTTHLSSSPCSASNGGESGQVSKRRCLIGESGHDTPWCSPIKVKYGDVYCRAPQGGYYKTALGTRCDIRCQKGYELHGSSLLICQSNKRWSDKVICKQKRCPTLAMPANGGFKCVDGAYFNSRCEYYCSPGYTLKGERTVTCMDNKAWSGRPASCVDMEPPRIKCPSVKERIAEPNKLTVRVSWETPEGRDTADGILTDVILKGLPPGSNFPEGDHKIQYTVYDRAENKGTCKFRVKVRVKRCGKLNAPENGYMKCSSDGDNYGATCEFSCIGGYELQGSPARVCQSNLAWSGTEPTCAAMNVNVGVRTAAALLDQFYEKRRLLIVSTPTARNLLYRLQLGMLQQAQCGLDLRHITVVELVGVFPTLIGRIGAKIMPPALALQLRLLLRIPLYSFSMVLVDKHGMDKERYVSLVMPVALFNLIDTFPLRKEEMVLQAEMSQTCNT>sp|P78539-3|SRPX_HUMAN Isoform 3 of Sushi repeat-containing protein SRPXOS=Homo sapiens OX=9606 GN=SRPXMGSPAHRPALLLLLPPLLLLLLLRVPPSRSFPGSGDSPLEDDEVGYSHPRYKDTPWCSPIKVKYGDVYCRAPQGGYYKTALGTRCDIRCQKGYELHGSSLLICQSNKRWSDKVICKHMEPPRIKCPSVKERIAEPNKLTVRVSWETPEGRDTADGILTDVILKGLPPGSNFPEGDHKIQYTVYDRAENKGTCKFRVKVRVKRCGKLNAPENGYMKCSSDGDNYGATCEFSCIGGYELQGSPARVCQSNLAWSGTEPTCAAMNVNVGVRTAAALLDQFYEKRRLLIVSTPTARNLLYRLQLGMLQQAQCGLDLRHITVVELVGVFPTLIGRIGAKIMPPALALQLRLLLRIPLYSFSMVLVDKHGMDKERYVSLVMPVALFNLIDTFPLRKEEMVLQAEMSQTCNT>sp|P78539-4|SRPX_HUMAN Isoform 4 of Sushi repeat-containing protein SRPXOS=Homo sapiens OX=9606 GN=SRPXMGSPAHRPALLLLLPPLLLLLLLRVPPSRSFPGSGDSPLEDDEVGYSHPRYKDTPWCSPIKVKYGDVYCRAPQGGYYKTALGTRCDIRCQKGYELHGSSLLICQSNKRWSDKVICKQKRCPTLAMPANGGFKCVDGAYFNSRCEYYCSPGYTLKGERTVTCMDNKAWSGRPASCVDMEPPRIKCPSVKERIAEPNKLTVRVSWETPEGRDTADGILTDVILKGLPPGSNFPEGDHKIQYTVYDRAENKGTCKFRVKVRVKRCGKLNAPENGYMKCSSDGDNYGATCEFSCIGGYELQGSPARVCQSNLAWSGTEPTCAAMNVNVGVRTAAALLDQFYEKRRLLIVSTPTARNLLYRLQLGMLQAVAANPTLLLQYGASG>sp|P78539-5|SRPX_HUMAN Isoform 5 of Sushi repeat-containing protein SRPXOS=Homo sapiens OX=9606 GN=SRPXMGSPAHRPALLLLLPPLLLLLLLRVPPSRSFPDTPWCSPIKVKYGDVYCRAPQGGYYKTALGTRCDIRCQKGYELHGSSLLICQSNKRWSDKVICKQKRCPTLAMPANGGFKCVDGAYFNSRCEYYCSPGYTLKGERTVTCMDNKAWSGRPASCVDMEPPRIKCPSVKERIAEPNKLTVRVSWETPEGRDTADGILTDVILKGLPPGSNFPEGDHKIQYTVYDRAENKGTCKFRVKVRVKRCGKLNAPENGYMKCSSDGDNYGATCEFSCIGGYELQGSPARVCQSNLAWSGTEPTCAAMNVNVGVRTAAALLDQFYEKRRLLIVSTPTARNLLYRLQLGMLQQAQCGLDLRHITVVELVGVFPTLIGRIGAKIMPPALALQLRLLLRIPLYSFSMVLVDKHGMDKERYVSLVMPVALFNLIDTFPLRKEEMVLQAEMSQTCNT>sp|P63313|TYB10_HUMAN Thymosin beta-10 OS=Homo sapiens OX=9606 GN=TMSB10PE=1 SV=2MADKPDMGEIASFDKAKLKKTETQEKNTLPTKETIEQEKRSEIS>sp|Q8N2H4|SYS1_HUMAN Protein SYS1 homolog OS=Homo sapiens OX=9606GN=SYS1 PE=1 SV=1MAGQFRSYVWDPLLILSQIVLMQTVYYGSLGLWLALVDGLVRSSPSLDQMFDAEILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGCWFYSSRFPSALTWWLVQAVCIALMAVIGEYLCMRTELKEIPLNSAPKSNV>sp|Q8N2H4-2|SYS1_HUMAN Isoform 2 of Protein SYS1 homolog OS=Homo sapiensOX=9606 GN=SYS1MAGQFRSYVWDPLLILSQIVLMQTVYYGSLGLWLALVDGLVRSSPSLDQMFDAEILGFSTPPGRLSMMSFILNALT>sp|Q15572|TAF1C_HUMAN TATA box-binding protein-associated factor RNApolymerase I subunit C OS=Homo sapiens OX=9606 GN=TAF1C PE=1 SV=2MDFPSSLRPALFLTGPLGLSDVPDLSFMCSWRDALTLPEAQPQNSENGALHVTKDLLWEPATPGPLPMLPPLIDPWDPGLTARDLLFRGGCRYRKRPRVVLDVTEQISRFLLDHGDVAFAPLGKLMLENFKLEGAGSRTKKKTVVSVKKLLQDLGGHQPWGCPWAYLSNRQRRFSILGGPILGTSVASHLAELLHEELVLRWEQLLLDEACTGGALAWVPGRTPQFGQLVYPAGGAQDRLHFQEVVLTPGDNPQFLGKPGRIQLQGPVRQVVTCTVQGESKALIYTFLPHWLTCYLTPGPFHPSSALLAVRSDYHCAVWKFGKQWQPTLLQAMQVEKGATGISLSPHLPGELAICSRSGAVCLWSPEDGLRQIYRDPETLVFRDSSSWRWADFTAHPRVLTVGDRTGVKMLDTQGPPGCGLLLFRLGAEASCQKGERVLLTQYLGHSSPKCLPPTLHLVCTQFSLYLVDERLPLVPMLKWNHGLPSPLLLARLLPPPRPSCVQPLLLGGQGGQLQLLHLAGEGASVPRLAGPPQSLPSRIDSLPAFPLLEPKIQWRLQERLKAPTIGLAAVVPPLPSAPTPGLVLFQLSAAGDVFYQQLRPQVDSSLRRDAGPPGDTQPDCHAPTASWTSQDTAGCSQWLKALLKVPLAPPVWTAPTFTHRQMLGSTELRREEEEGQRLGVLRKAMARGQLLLQRDLGSLPAAEPPPAPESGLEDKLSERLGEAWAGRGAAWWERQQGRTSEPGRQTRRPKRRTQLSSSFSLSGHVDPSEDTSSPHSPEWPPADALPLPPTTPPSQELTPDACAQGVPSEQRQMLRDYMAKLPPQRDTPGCATTPPHSQASSVRATRSQQHTPVLSSSQPLRKKPRMGF>sp|Q15572-2|TAF1C_HUMAN Isoform 2 of TATA box-binding protein-associatedfactor RNA polymerase I subunit C OS=Homo sapiens OX=9606 GN=TAF1CMLPPLIDPWDPGLTARDLLFRGGCRYRKRPRVVLDVTEQISRFLLDHGDVAFAPLGKLMLENFKLEGAGSRTKKKTVVSVKKLLQDLGGHQPWGCPWAYLSNRQRRFSILGGPILGTSVASHLAELLHEELVLRWEQLLLDEACTGGALAWVPGRTPQFGQLVYPAGGAQDRLHFQEVVLTPGDNPQFLGKPGRIQLQGPVRQVVTCTVQGETLLAVRSDYHCAVWKFGKQWQPTLLQAMQVEKGATGISLSPHLPGELAICSRSGAVCLWSPEDGLRQIYRDPETLVFRDSSSWRWADFTAHPRVLTVGDRTGVKMLDTQGPPGCGLLLFRLGAEASCQKGERVLLTQYLGHSSPKCLPPTLHLVCTQFSLYLVDERLPLVPMLKWNHGLPSPLLLARLLPPPRPSCVQPLLLGGQGGQLQLLHLAEGASVPRLAGPPQSLPSRIDSLPAFPLLEPKIQWRLQERLKAPTIGLAAVVPPLPSAPTPGLVLFQLSAAGDVFYQQLRPQVDSSLRRDAGPPGDTQPDCHAPTASWTSQDTAGCSQWLKALLKVPLAPPVWTAPTFTHRQMLGSTELRREEEEGQRLGVLRKAMARGQLLLQRDLGSLPAAEPPPAPESGLEDKLSERLGEAWAGRGAAWWERQQGRTSEPGRQTRRPKRRTQLSSSFSLSGHVDPSEDTSSPHSPEWPPADALPLPPTTPPSQELTPDACAQGVPSEQRQMLRDYMAKLPPQRDTPGCATTPPHSQASSVRATRSQQHTPVLSSSQPLRKKPRMGF>sp|Q15572-4|TAF1C_HUMAN Isoform 4 of TATA box-binding protein-associatedfactor RNA polymerase I subunit C OS=Homo sapiens OX=9606 GN=TAF1CMQVEKGATGISLSPHLPGELAICSRSGAVCLWSPEDGLRQIYRDPETLVFRDSSSWRWADFTAHPRVLTVGDRTGVKMLDTQGPPGCGLLLFRLGAEASCQKGERVLLTQYLGHSSPKCLPPTLHLVCTQFSLYLVDERLPLVPMLKWNHGLPSPLLLARLLPPPRPSCVQPLLLGGQGGQLQLLHLAGEGASVPRLAGPPQSLPSRIDSLPAFPLLEPKIQWRLQERLKAPTIGLAAVVPPLPSAPTPGLVLFQLSAAGDVFYQQLRPQVDSSLRRDAGPPGDTQPDCHAPTASWTSQDTAGCSQWLKALLKVPLAPPVWTAPTFTHRQMLGSTELRREEEEGQRLGVLRKAMARGQLLLQRDLGSLPAAEPPPAPESGLEDKLSERLGEAWAGRGAAWWERQQGRTSEPGRQTRRPKRRTQLSSSFSLSGHVDPSEDTSSPHSPEWPPADALPLPPTTPPSQELTPDACAQGVPSEQRQMLRDYMAKLPPQRDTPGCATTPPHSQASSVRATRSQQHTPVLSSSQPLRKKPRMGF>sp|Q15572-5|TAF1C_HUMAN Isoform 5 of TATA box-binding protein-associatedfactor RNA polymerase I subunit C OS=Homo sapiens OX=9606 GN=TAF1CMLDTQGPPGCGLLLFRLGAEASCQKGERVLLTQYLGHSSPKCLPPTLHLVCTQFSLYLVDERLPLVPMLKWNHGLPSPLLLARLLPPPRPSCVQPLLLGGQGGQLQLLHLAGEGASVPRLAGPPQSLPSRIDSLPAFPLLEPKIQWRLQERLKAPTIGLAAVVPPLPSAPTPGLVLFQLSAAGDVFYQQLRPQVDSSLRRDAGPPGDTQPDCHAPTASWTSQDTAGCSQWLKALLKVPLAPPVWTAPTFTHRQMLGSTELRREEEEGQRLGVLRKAMARGQLLLQRDLGSLPAAEPPPAPESGLEDKLSERLGEAWAGRGAAWWERQQGRTSEPGRQTRRPKRRTQLSSSFSLSGHVDPSEDTSSPHSPEWPPADALPLPPTTPPSQELTPDACAQGVPSEQRQMLRDYMAKLPPQRDTPGCATTPPHSQASSVRATRSQQHTPVLSSSQPLRKKPRMGF>sp|Q15572-6|TAF1C_HUMAN Isoform 6 of TATA box-binding protein-associatedfactor RNA polymerase I subunit C OS=Homo sapiens OX=9606 GN=TAF1CMDFPSSLRPALFLTGPLGLSDVPDLSFMCSWRDALTLPEAQPQNSENGALHVTKDLLWEPATPGPLPMLPPLIDPWDPGLTARDLLFRGGCRYRKRPRVVLDVTEQISRFLLDHGDVAFAPLGKLMLENFKLEGAGSRTKKKTVVSVKKLLQDLGGHQPWGCPWAYLSNRQRRFSILGGPILGTSVASHLAELLHEELVLRWEQLLLDEACTGGALAWVPGRTPQFGQLVYPAGGAQDRLHFQEVVLTPGDNPQFLGKPGRIQLQGPVRQVVTCTVQGETLLAVRSDYHCAVWKFGKQWQPTLLQAMQVEKGATGISLSPHLPGELAICSRSGAVCLWSPEDGLRQIYRDPETLVFRDSSSWRWADFTAHPRVLTVGDRTGVKMLDTQGPPGCGLLLFRLGAEASCQKGERVLLTQYLGHSSPKCLPPTLHLVCTQFSLYLVDERLPLVPMLKWNHGLPSPLLLARLLPPPRPSCVQPLLLGGQGGQLQLLHLAGEGASVPRLAGPPQSLPSRIDSLPAFPLLEPKIQWRLQERLKAPTIGLAAVVPPLPSAPTPGLVLFQLSAAGDVFYQQLRPQVDSSLRRDAGPPGDTQPDCHAPTASWTSQDTAGCSQWLKALLKVPLAPPVWTAPTFTHRQMLGSTELRREEEEGQRLGVLRKAMARGQLLLQRDLGSLPAAEPPPAPESGLEDKLSERLGEAWAGRGAAWWERQQGRTSEPGRQTRRPKRRTQLSSSFSLSGHVDPSEDTSSPHSPEWPPADALPLPPTTPPSQELTPDACAQGVPSEQRQMLRDYMAKLPPQRDTPGCATTPPHSQASSVRATRSQQHTPVLSSSQPLRKKPRMGF>sp|Q8IZX4|TAF1L_HUMAN Transcription initiation factor TFIID subunit 1-like OS=Homo sapiens OX=9606 GN=TAF1L PE=1 SV=1MRPGCDLLLRAAATVTAAIMSDSDSEEDSSGGGPFTLAGILFGNISGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTGGALVNDEGWIRSTEDAVDYSDINEVAEDESQRHQQTMGSLQPLYHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDAITCVSESGEDIILPSIIAPSFLASEKVDFSSYSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLHLFGPGKNVPSVWRSARRKRKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLADDEITMMVPVESKFSQSTGDVDKVTDTKPRVAEWRYGPARLWYDMLGVSEDGSGFDYGFKLRKTQHEPVIKSRMMEEFRKLEESNGTDLLADENFLMVTQLHWEDSIIWDGEDIKHKGTKPQGASLAGWLPSIKTRNVMAYNVQQGFAPTLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLALDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIREEPQQNMSQPEVKDPWNLSNDEYYFPKQQGLRGTFGGNIIQHSIPAMELWQPFFPTHMGPIKIRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGELFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQALENNLFRAPVYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSRRANMHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAKVSPEQCCAYYSMIAAKQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVHAAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQAVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQAHSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSISAEDSDFEEMGKNIENMLQNKKTSSQLSREWEEQERKELRRMLLVAGSAASGNNHRDDVTASMTSLKSSATGHCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEKFIQKFALFDEKHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNVPPSKPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVFGKQLIENVHEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNIPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTHPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKCLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKMIVNPVDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNICYQTITEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTSQPPDMYDTNTSLSTSRDASVFQDESNLSVLDISTATPEKQMCQGQGRLGEEDSDVDVEGYDDEEEDGKPKPPAPEGGDGDLADEEEGTVQQPEASVLYEDLLISEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGYGGIRPKQPFMLQHASGEHKDGHGK>sp|Q86V40|TIKI1_HUMAN Metalloprotease TIKI1 OS=Homo sapiens OX=9606GN=TRABD2A PE=2 SV=3MSPWSWFLLQTLCLLPTGAASRRGAPGTANCELKPQQSELNSFLWTIKRDPPSYFFGTIHVPYTRVWDFIPDNSKEAFLQSSIVYFELDLTDPYTISALTSCQMLPQGENLQDVLPRDIYCRLKRHLEYVKLMMPLWMTPDQRGKGLYADYLFNAIAGNWERKRPVWVMLMVNSLTEVDIKSRGVPVLDLFLAQEAERLRKQTGAVEKVEEQCHPLNGLNFSQVIFALNQTLLQQESLRAGSLQIPYTTEDLIKHYNCGDLSSVILSHDSSQVPNFINATLPPQERITAQEIDSYLRRELIYKRNERIGKRVKALLEEFPDKGFFFAFGAGHFMGNNTVLDVLRREGYEVEHAPAGRPIHKGKSKKTSTRPTLSTIFAPKVPTLEVPAPEAVSSGHSTLPPLVSRPGSADTPSEAEQRFRKKRRRSQRRPRLRQFSDLWVRLEESDIVPQLQVPVLDRHISTELRLPRRGHSHHSQMVASSACLSLWTPVFWVLVLAFQTETPLL>sp|Q86V40-2|TIKI1_HUMAN Isoform 2 of Metalloprotease TIKI1 OS=Homosapiens OX=9606 GN=TRABD2AMSPWSWFLLQTLCLLPTGAASRRGAPGTANCELKPQQSELNSFLWTIKRDPPSYFFGTIHVPYTRVWDFIPDNSKEAFLQSSIVYFELDLTDPYTISALTSCQMLPQGENLQDVLPRDIYCRLKRHLEYVKLMMPLWMTPDQRGKGLYADYLFNAIAGNWERKRPVWVMLMVNSLTEVDIKSRGVPVLDLFLAQEAERLRKQTGAVEKVEEQCHPLNGLNFSQVPNFINATLPPQERITAQEIDSYLRRELIYKRNERIGKRVKALLEEFPDKGFFFAFGAGHFMGNNTVLDVLRREGYEVEHAPAGRPIHKGKSKKTSTRPTLSTIFAPKVPTLEVPAPEAVSSGHSTLPPLVSRPGSADTPSEAEQRFRKKRRRSQRRPRLRQFSDLWVRLEESDIVPQLQVPVLDRHISTELRLPRRGHSHHSQMVASSACLSLWTPVFWVLVLAFQTETPLL>sp|A0A1B0GUA7|TEX51_HUMAN Testis-expressed protein 51 OS=Homo sapiensOX=9606 GN=TEX51 PE=3 SV=1MLPLLIICLLPAIEGKNCLRCWPELSALIDYDLQILWVTPGPPTELSQNRDHLEEETAKFFTQVHQAIKTLRDDKTVLLEEIYTHKNLFTERLNKISDGLKEKDIQSTLKVTSCADCRTHFLSCNDPTFCPARNRRTSLWAVSLSSALLLAIAGDVSFTGKGRRRQ>sp|Q99595|TI17A_HUMAN Mitochondrial import inner membrane translocasesubunit Tim17-A OS=Homo sapiens OX=9606 GN=TIMM17A PE=1 SV=1MEEYAREPCPWRIVDDCGGAFTMGTIGGGIFQAIKGFRNSPVGVNHRLRGSLTAIKTRAPQLGGSFAVWGGLFSMIDCSMVQVRGKEDPWNSITSGALTGAILAARNGPVAMVGSAAMGGILLALIEGAGILLTRFASAQFPNGPQFAEDPSQLPSTQLPSSPFGDYRQYQ>sp|Q9BVA1|TBB2B_HUMAN Tubulin beta-2B chain OS=Homo sapiens OX=9606GN=TUBB2B PE=1 SV=1MREIVHIQAGQCGNQIGAKFWEVISDEHGIDPTGSYHGDSDLQLERINVYYNEATGNKYVPRAILVDLEPGTMDSVRSGPFGQIFRPDNFVFGQSGAGNNWAKGHYTEGAELVDSVLDVVRKESESCDCLQGFQLTHSLGGGTGSGMGTLLISKIREEYPDRIMNTFSVMPSPKVSDTVVEPYNATLSVHQLVENTDETYCIDNEALYDICFRTLKLTTPTYGDLNHLVSATMSGVTTCLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTSRGSQQYRALTVPELTQQMFDSKNMMAACDPRHGRYLTVAAIFRGRMSMKEVDEQMLNVQNKNSSYFVEWIPNNVKTAVCDIPPRGLKMSATFIGNSTAIQELFKRISEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATADEQGEFEEEEGEDEA>sp|Q03169|TNAP2_HUMAN Tumor necrosis factor alpha-induced protein 2OS=Homo sapiens OX=9606 GN=TNFAIP2 PE=1 SV=2MSEASSEDLVPPLEAGAAPYREEEEAAKKKKEKKKKSKGLANVFCVFTKGKKKKGQPSSAEPEDAAGSRQGLDGPPPTVEELKAALERGQLEAARPLLALERELAAAAAAGGVSEEELVRRQSKVEALYELLRDQVLGVLRRPLEAPPERLRQALAVVAEQEREDRQAAAAGPGTSGLAATRPRRWLQLWRRGVAEAAEERMGQRPAAGAEVPESVFLHLGRTMKEDLEAVVERLKPLFPAEFGVVAAYAESYHQHFAAHLAAVAQFELCERDTYMLLLWVQNLYPNDIINSPKLVGELQGMGLGSLLPPRQIRLLEATFLSSEAANVRELMDRALELEARRWAEDVPPQRLDGHCHSELAIDIIQITSQAQAKAESITLDLGSQIKRVLLVELPAFLRSYQRAFNEFLERGKQLTNYRANVIANINNCLSFRMSMEQNWQVPQDTLSLLLGPLGELKSHGFDTLLQNLHEDLKPLFKRFTHTRWAAPVETLENIIATVDTRLPEFSELQGCFREELMEALHLHLVKEYIIQLSKGRLVLKTAEQQQQLAGYILANADTIQHFCTQHGSPATWLQPALPTLAEIIRLQDPSAIKIEVATYATCYPDFSKGHLSAILAIKGNLSNSEVKRIRSILDVSMGAQEPSRPLFSLIKVG>sp|Q66K14|TBC9B_HUMAN TBC1 domain family member 9B OS=Homo sapiensOX=9606 GN=TBC1D9B PE=1 SV=3MWLSPEEVLVANALWVTERANPFFVLQRRRGHGRGGGLTGLLVGTLDVVLDSSARVAPYRILHQTQDSQVYWTVACGSSRKEITKHWEWLENNLLQTLSIFDSEEDITTFVKGKIHGIIAEENKNLQPQGDEDPGKFKEAELKMRKQFGMPEGEKLVNYYSCSYWKGRVPRQGWLYLTVNHLCFYSFLLGKEVSLVVQWVDITRLEKNATLLFPESIRVDTRDQELFFSMFLNIGETFKLMEQLANLAMRQLLDSEGFLEDKALPRPIRPHRNISALKRDLDARAKNECYRATFRLPRDERLDGHTSCTLWTPFNKLHIPGQMFISNNYICFASKEEDACHLIIPLREVTIVEKADSSSVLPSPLSISTKSKMTFLFANLKDRDFLVQRISDFLQKTPSKQPGSIGSRKASVVDPSTESSPAPQEGSEQPASPASPLSSRQSFCAQEAPTASQGLLKLFQKNSPMEDLGAKGAKEKMKEESWHIHFFEYGRGVCMYRTAKTRALVLKGIPESLRGELWLLFSGAWNEMVTHPGYYAELVEKSTGKYSLATEEIERDLHRSMPEHPAFQNELGIAALRRVLTAYAFRNPTIGYCQAMNIVTSVLLLYGSEEEAFWLLVALCERMLPDYYNTRVVGALVDQGIFEELTRDFLPQLSEKMQDLGVISSISLSWFLTLFLSVMPFESAVVIVDCFFYEGIKVILQVALAVLDANMEQLLGCSDEGEAMTMLGRYLDNVVNKQSVSPPIPHLRALLSSSDDPPAEVDIFELLKVSYEKFSSLRAEDIEQMRFKQRLKVIQSLEDTAKRSVVRAIPVDIGFSIEELEDLYMVFKAKHLASQYWGCSRTMAGRRDPSLPYLEQYRIDASQFRELFASLTPWACGSHTPLLAGRMFRLLDENKDSLINFKEFVTGMSGMYHGDLTEKLKVLYKLHLPPALSPEEAESALEAAHYFTEDSSSEASPLASDLDLFLPWEAQEALPQEEQEGSGSEERGEEKGTSSPDYRHYLRMWAKEKEAQKETIKDLPKMNQEQFIELCKTLYNMFSEDPMEQDLYHAIATVASLLLRIGEVGKKFSARTGRKPRDCATEEDEPPAPELHQDAARELQPPAAGDPQAKAGGDTHLGKAPQESQVVVEGGSGEGQGSPSQLLSDDETKDDMSMSSYSVVSTGSLQCEDLADDTVLVGGEACSPTARIGGTVDTDWCISFEQILASILTESVLVNFFEKRVDIGLKIKDQKKVERQFSTASDHEQPGVSG>sp|Q66K14-2|TBC9B_HUMAN Isoform 2 of TBC1 domain family member 9BOS=Homo sapiens OX=9606 GN=TBC1D9BMWLSPEEVLVANALWVTERANPFFVLQRRRGHGRGGGLTGLLVGTLDVVLDSSARVAPYRILHQTQDSQVYWTVACGSSRKEITKHWEWLENNLLQTLSIFDSEEDITTFVKGKIHGIIAEENKNLQPQGDEDPGKFKEAELKMRKQFGMPEGEKLVNYYSCSYWKGRVPRQGWLYLTVNHLCFYSFLLGKEVSLVVQWVDITRLEKNATLLFPESIRVDTRDQELFFSMFLNIGETFKLMEQLANLAMRQLLDSEGFLEDKALPRPIRPHRNISALKRDLDARAKNECYRATFRLPRDERLDGHTSCTLWTPFNKLHIPGQMFISNNYICFASKEEDACHLIIPLREVTIVEKADSSSVLPSPLSISTKSKMTFLFANLKDRDFLVQRISDFLQKTPSKQPGSIGSRKASVVDPSTESSPAPQEGSEQPASPASPLSSRQSFCAQEAPTASQGLLKLFQKNSPMEDLGAKGAKEKMKEESWHIHFFEYGRGVCMYRTAKTRALVLKGIPESLRGELWLLFSGAWNEMVTHPGYYAELVEKSTGKYSLATEEIERDLHRSMPEHPAFQNELGIAALRRVLTAYAFRNPTIGYCQAMNIVTSVLLLYGSEEEAFWLLVALCERMLPDYYNTRVVGALVDQGIFEELTRDFLPQLSEKMQDLGVISSISLSWFLTLFLSVMPFESAVVIVDCFFYEGIKVILQVALAVLDANMEQLLGCSDEGEAMTMLGRYLDNVVNKQSVSPPIPHLRALLSSSDDPPAEVDIFELLKVSYEKFSSLRAEDIEQMRFKQRLKVIQSLEDTAKRSVVRAIPVDIGFSIEELEDLYMVFKAKHLASQYWGCSRTMAGRRDPSLPYLEQYRIDASQFRELFASLTPWACGSHTPLLAGRMFRLLDENKDSLINFKEFVTGMSGMYHGDLTEKLKVLYKLHLPPALSPEEAESALEAAHYFTEDSSSEEALPQEEQEGSGSEERGEEKGTSSPDYRHYLRMWAKEKEAQKETIKDLPKMNQEQFIELCKTLYNMFSEDPMEQDLYHAIATVASLLLRIGEVGKKFSARTGRKPRDCATEEDEPPAPELHQDAARELQPPAAGDPQAKAGGDTHLGKAPQESQVVVEGGSGEGQGSPSQLLSDDETKDDMSMSSYSVVSTGSLQCEDLADDTVLVGGEACSPTARIGGTVDTDWCISFEQILASILTESVLVNFFEKRVDIGLKIKDQKKVERQFSTASDHEQPGVSG>sp|P57738|TCTA_HUMAN T-cell leukemia translocation-altered gene proteinOS=Homo sapiens OX=9606 GN=TCTA PE=1 SV=1MAESWSGQALQALPATVLGALGSEFLREWEAQDMRVTLFKLLLLWLVLSLLGIQLAWGFYGNTVTGLYHRPGLGGQNGSTPDGSTHFPSWEMAANEPLKTHRE>sp|Q8IUR0|TPPC5_HUMAN Trafficking protein particle complex subunit 5OS=Homo sapiens OX=9606 GN=TRAPPC5 PE=1 SV=1MEARFTRGKSALLERALARPRTEVSLSAFALLFSELVQHCQSRVFSVAELQSRLAALGRQVGARVLDALVAREKGARRETKVLGALLFVKGAVWKALFGKEADKLEQANDDARTFYIIEREPLINTYISVPKENSTLNCASFTAGIVEAVLTHSGFPAKVTAHWHKGTTLMIKFEEAVIARDRALEGR>sp|Q14258|TRI25_HUMAN E3 ubiquitin/ISG15 ligase TRIM25 OS=Homo sapiensOX=9606 GN=TRIM25 PE=1 SV=2MAELCPLAEELSCSICLEPFKEPVTTPCGHNFCGSCLNETWAVQGSPYLCPQCRAVYQARPQLHKNTVLCNVVEQFLQADLAREPPADVWTPPARASAPSPNAQVACDHCLKEAAVKTCLVCMASFCQEHLQPHFDSPAFQDHPLQPPVRDLLRRKCSQHNRLREFFCPEHSECICHICLVEHKTCSPASLSQASADLEATLRHKLTVMYSQINGASRALDDVRNRQQDVRMTANRKVEQLQQEYTEMKALLDASETTSTRKIKEEEKRVNSKFDTIYQILLKKKSEIQTLKEEIEQSLTKRDEFEFLEKASKLRGISTKPVYIPEVELNHKLIKGIHQSTIDLKNELKQCIGRLQEPTPSSGDPGEHDPASTHKSTRPVKKVSKEEKKSKKPPPVPALPSKLPTFGAPEQLVDLKQAGLEAAAKATSSHPNSTSLKAKVLETFLAKSRPELLEYYIKVILDYNTAHNKVALSECYTVASVAEMPQNYRPHPQRFTYCSQVLGLHCYKKGIHYWEVELQKNNFCGVGICYGSMNRQGPESRLGRNSASWCVEWFNTKISAWHNNVEKTLPSTKATRVGVLLNCDHGFVIFFAVADKVHLMYKFRVDFTEALYPAFWVFSAGATLSICSPK>sp|Q8WZ59|TM190_HUMAN Transmembrane protein 190 OS=Homo sapiens OX=9606GN=TMEM190 PE=1 SV=1MLGCGIPALGLLLLLQGSADGNGIQGFFYPWSCEGDIWDRESCGGQAAIDSPNLCLRLRCCYRNGVCYHQRPDENVRRKHMWALVWTCSGLLLLSCSICLFWWAKRRDVLHMPGFLAGPCDMSKSVSLLSKHRGTKKTPSTGSVPVALSKESRDVEGGTEGEGTEEGEETEGEEEED>sp|P21283|VATC1_HUMAN V-type proton ATPase subunit C 1 OS=Homo sapiensOX=9606 GN=ATP6V1C1 PE=1 SV=4MTEFWLISAPGEKTCQQTWEKLHAATSKNNNLAVTSKFNIPDLKVGTLDVLVGLSDELAKLDAFVEGVVKKVAQYMADVLEDSKDKVQENLLANGVDLVTYITRFQWDMAKYPIKQSLKNISEIIAKGVTQIDNDLKSRASAYNNLKGNLQNLERKNAGSLLTRSLAEIVKKDDFVLDSEYLVTLLVVVPKLNHNDWIKQYETLAEMVVPRSSNVLSEDQDSYLCNVTLFRKAVDDFRHKARENKFIVRDFQYNEEEMKADKEEMNRLSTDKKKQFGPLVRWLKVNFSEAFIAWIHVKALRVFVESVLRYGLPVNFQAMLLQPNKKTLKKLREVLHELYKHLDSSAAAIIDAPMDIPGLNLSQQEYYPYVYYKIDCNLLEFK>sp|Q9NQA3|WASH6_HUMAN WAS protein family homolog 6 OS=Homo sapiensOX=9606 GN=WASH6P PE=1 SV=3MAFHEMQAHKNALGTSGEQQAADITGPTPHQGGWKQVEQSRSQVQAIGEKVSLAQAKIEKIKGSKKAIKVFSSAKYPAPERLQEYGSIFTGAQDPGLQRRPRHRIQSKHRPLDERALQEKLKDFPVCVSTKPEPEDDAEEGLGGLPSNISSVSSLLLFNTTENLYKKYVFLDPLAGAVTKTHVMLGAETEEKLFDAPLSISKREQLEQQVPENYFYVPDLGQVPEIDVPSYLPDLPSIANDLMYSADLGPGIAPSAPGTIPELPTFHTEVAEPLKADLQDGVLTPPPPPPPPPPAPEVLASAPPLPPSTAAPVGQGARQDDGSSSASPSVQGAPREVVDPSGGWATLLESIRQAGGIGKAKLRSMKERKLEKKKQKEQEQVRATSQGGHLMSDLFNKLVMRRKGISGKGPGAGEGPGGAFARVSDSIPPVPPPQQPQAEEDEDDWES>sp|Q5THJ4|VP13D_HUMAN Vacuolar protein sorting-associated protein 13DOS=Homo sapiens OX=9606 GN=VPS13D PE=1 SV=2MLEGLVAWVLNTYLGKYVNNLNTDQLSVALLKGAVELENLPLKKDALKELELPFEVKAGFIGKVTLQIPFYRPHVDPWVISISSLHLIGAPEKIQDFNDEKEKLLERERKKALLQALEEKWKNDRQQKGESYWYSVTASVVTRIVENIELKIQDVHLRFEDGVTNPSHPFAFGICIKNVSMQNAVNEPVQKLMRKKQLDVAEFSIYWDVDCTLLGDLPQMELQEAMARSMESRSHHYVLEPVFASALLKRNCSKKPLRSRHSPRIDCDIQLETIPLKLSQLQYRQIMEFLKELERKERQVKFRRWKPKVAISKNCREWWYFALNANLYEIREQRKRCTWDFMLHRARDAVSYTDKYFNKLKGGLLSTDDKEEMCRIEEEQSFEELKILRELVHDRFHKQEELAESLREPQFDSPGACPGAPEPGGGSGMLQYLQSWFPGWGGWYGQQTPEGNVVEGLSAEQQEQWIPEEILGTEEFFDPTADASCMNTYTKRDHVFAKLNLQLQRGTVTLLHKEQGTPQMNESAFMQLEFSDVKLLAESLPRRNSSLLSVRLGGLFLRDLATEGTMFPLLVFPNPQKEVGRVSQSFGLQTTSADRSDHYPAADPDGPVFEMLYERNPAHSHFERRLNVSTRPLNIIYNPQAIKKVADFFYKGKVHTSGFGYQSELELRVAEAARRQYNKLKMQTKAEIRQTLDRLLVGDFIEESKRWTVRLDISAPQVIFPDDFKFKNPVLVVVDLGRMLLTNTQDNSRRKSRDGSASEETQFSDDEYKTPLATPPNTPPPESSSSNGEKTPPFSGVEFSEEQLQAHLMSTKMYERYSLSFMDLQIMVGRVKDNWKHVQDIDVGPTHVVEKFNVHLQLERRLIYTSDPKYPGAVLSGNLPDLKIHINEDKISALKNCFALLTTPEMKTSDTQIKEKIFPQEEQRGSLQDSVMNLTQSIVLLEQHTREVLVESQLLLAEFKVNCMQLGVESNGRYISVLKVFGTNAHFVKRPYDAEVSLTVHGLLLVDTMQTYGADFDLLMASHKNLSFDIPTGSLRDSRAQSPVSGPNVAHLTDGATLNDRSATSVSLDKILTKEQESLIKLEYQFVSSECPSMNLDSTLQVISLQVNNLDIILNPETIVELIGFLQKSFPKEKDDLSPQPLMTDFERSFREQGTYQSTYEQNTEVAVEIHRLNLLLLRTVGMANREKYGRKIATASIGGTKVNVSMGSTFDMNGSLGCLQLMDLTQDNVKNQYVVSIGNSVGYENIISDIGYFESVFVRMEDAALTEALSFTFVERSKQECFLNLKMASLHYNHSAKFLKELTLSMDELEENFRGMLKSAATKVTTVLATKTAEYSEMVSLFETPRKTREPFILEENEIYGFDLASSHLDTVKLILNINIESPVVSIPRKPGSPELLVGHLGQIFIQNFVAGDDESRSDRLQVEIKDIKLYSLNCTQLAGREAVGSEGSRMFCPPSGSGSANSQEEAHFTRHDFFESLHRGQAFHILNNTTIQFKLEKIPIERESELTFSLSPDDLGTSSIMKIEGKFVNPVQVVLAKHVYEQVLQTLDNLVYSEDLNKYPASATSSPCPDSPLPPLSTCGESSVERKENGLFSHSSLSNTSQKSLSVKEVKSFTQIQATFCISELQVQLSGDLTLGAQGLVSLKFQDFEVEFSKDHPQTLSIQIALHSLLMEDLLEKNPDSKYKNLMVSRGAPKPSSLAQKEYLSQSCPSVSNVEYPDMPRSLPSHMEEAPNVFQLYQRPTSASRKKQKEVQDKDYPLTPPPSPTVDEPKILVGKSKFDDSLVHINIFLVDKKHPEFSSSYNRVNRSIDVDFNCLDVLITLQTWVVILDFFGIGSTADNHAMRLPPEGILHNVKLEPHASMESGLQDPVNTKLDLKVHSLSLVLNKTTSELAKANVSKLVAHLEMIEGDLALQGSIGSLSLSDLTCHGEFYRERFTTSGEEALIFQTFKYGRPDPLLRREHDIRVSLRMASVQYVHTQRFQAEVVAFIQHFTQLQDVLGRQRAAIEGQTVRDQAQRCSRVLLDIEAGAPVLLIPESSRSNNLIVANLGKLKVKNKFLFAGFPGTFSLQDKESVPSASPTGIPKHSLRKTTSTEEPRGTHSQGQFTMPLAGMSLGSLKSEFVPSTSTKQQGPQPTLSVGQESSSPEDHVCLLDCVVVDLQDMDIFAAERHPREYSKAPEDSSGDLIFPSYFVRQTGGSLLTEPCRLKLQVERNLDKEISHTVPDISIHGNLSSVHCSLDLYKYKLIRGLLENNLGEPIEEFMRPYDLQDPRIHTVLSGEVYTCMCFLIDMVNVSLELKDPKRKEGAGSLARFDFKKCKLLYESFSNQTKSINLVSHSMMAFDTRYAGQKTSPGMTNVFSCIFQPAKNSSTTQGSIQIELHFRSTKDSSCFTVVLNNLRVFLIFDWLLLVHDFLHTPSDIKKQNHVTPSRHRNSSSESAIVPKTVKSGVVTKRSSLPVSNERHLEVKVNVTGTEFVVIEDVSCFDTNAIILKGTTVLTYKPRFVDRPFSGSLFGIEVFSCRLGNEHDTALSIVDPVQIQMELVGNSSYQNSSGLMDAFNSEDFPPVLEIQLQALDIRLSYNDVQLFLAIAKSIPEQANAAVPDSVALESDSVGTYLPGASRVGEEIREGTRHTLDPVLELQLARLQELGFSMDDCRKALLACQGQLKKAASWLFKNAEPLKSLSLASTSRDSPGAVAAPLISGVEIKAESVCICFIDDCMDCDVPLAELTFSRLNFLQRVRTSPEGYAHFTLSGDYYNRALSGWEPFIEPWPCSVSWQQQAASRLHPPRLKLEAKAKPRLDINITSVLIDQYVSTKESWMADYCKDDKDIESAKSEDWMGSSVDPPCFGQSLPLVYLRTRSTASLTNLEHQIYARAEVKTPKRRQPFVPFALRNHTGCTLWFATLTTTPTRAALSHSGSPGVVPEGNGTFLDDTHNVSEWREVLTGEEIPFEFEARGKLRHRHTHDLRIHQLQVRVNGWEQVSPVSVDKVGTFFRYAAPDKNSSSSTIGSPSSRTNIIHPQVYFSSLPPVRVVFAVTMEGSARKVITVRSALIVRNRLETPMELRLDSPSAPDKPVVLPAIMPGDSFAVPLHLTSWRLQARPKGLGVFFCKAPIHWTNVVKTAEISSSKRECHSMDTEKSRFFRFCVAIKKENYPDYMPSNIFSDSAKQIFRQPGHTIYLLPTVVICNLLPCELDFYVKGMPINGTLKPGKEAALHTADTSQNIELGVSLENFPLCKELLIPPGTQNYMVRMRLYDVNRRQLNLTIRIVCRAEGSLKIFISAPYWLINKTGLPLIFRQDNAKTDAAGQFEEHELARSLSPLLFCYADKEQPNLCTMRIGRGIHPEGMPGWCQGFSLDGGSGVRALKVIQQGNRPGLIYNIGIDVKKGRGRYIDTCMVIFAPRYLLDNKSSHKLAFAQREFARGQGTANPEGYISTLPGSSVVFHWPRNDYDQLLCVRLMDVPNCIWSGGFEVNKNNSFHINMRDTLGKCFFLRVEITLRGATYRISFSDTDQLPPPFRIDNFSKVPVVFTQHGVAEPRLRTEVKPMTSLDYAWDEPTLPPFITLTVKGAGSSEINCNMNDFQDNRQLYYENFIYIAATYTFSGLQEGTGRPVASNKAITCAELVLDVSPKTQRVILKKKEPGKRSQLWRMTGTGMLAHEGSSVPHNPNKPSAARSTEGSAILDIAGLAAVTDNRYEPLMLRKPDRRRSTTQTWSFREGKLTCGLHGLVVQAKGGLSGLFDGAEVVLGPDTSMELLGPVPPEQQFINQKMRPGSGMLSIRVIPDGPTRALQITDFCHRKSSRSYEVDELPVTEQELQKLKNPDTEQELEVLVRLEGGIGLSLINKVPEELVFASLTGINVHYTQLATSHMLELSIQDVQVDNQLIGTTQPFMLYVTPLSNENEVIETGPAVQVNAVKFPSKSALTNIYKHLMITAQRFTVQIEEKLLLKLLSFFGYDQAESEVEKYDENLHEKTAEQGGTPIRYYFENLKISIPQIKLSVFTSNKLPLDLKALKSTLGFPLIRFEDAVINLDPFTRVHPYETKEFIINDILKHFQEELLSQAARILGSVDFLGNPMGLLNDVSEGVTGLIKYGNVGGLIRNVTHGVSNSAAKFAGTLSDGLGKTMDNRHQSEREYIRYHAATSGEHLVAGIHGLAHGIIGGLTSVITSTVEGVKTEGGVSGFISGLGKGLVGTVTKPVAGALDFASETAQAVRDTATLSGPRTQAQRVRKPRCCTGPQGLLPRYSESQAEGQEQLFKLTDNIQDEFFIAVENIDSYCVLISSKAVYFLKSGDYVDREAIFLEVKYDDLYHCLVSKDHGKVYVQVTKKAVSTSSGVSIPGPSHQKPMVHVKSEVLAVKLSQEINYAKSLYYEQQLMLRLSENREQLELDS>sp|Q5THJ4-2|VP13D_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 13D OS=Homo sapiens OX=9606 GN=VPS13DMLEGLVAWVLNTYLGKYVNNLNTDQLSVALLKGAVELENLPLKKDALKELELPFEVKAGFIGKVTLQIPFYRPHVDPWVISISSLHLIGAPEKIQDFNDEKEKLLERERKKALLQALEEKWKNDRQQKGESYWYSVTASVVTRIVENIELKIQDVHLRFEDGVTNPSHPFAFGICIKNVSMQNAVNEPVQKLMRKKQLDVAEFSIYWDVDCTLLGDLPQMELQEAMARSMESRSHHYVLEPVFASALLKRNCSKKPLRSRHSPRIDCDIQLETIPLKLSQLQYRQIMEFLKELERKERQVKFRRWKPKVAISKNCREWWYFALNANLYEIREQRKRCTWDFMLHRARDAVSYTDKYFNKLKGGLLSTDDKEEMCRIEEEQSFEELKILRELVHDRFHKQEELAESLREPQFDSPGACPGAPEPGGGSGMLQYLQSWFPGWGGWYGQQTPEGNVVEGLSAEQQEQWIPEEILGTEEFFDPTADASCMNTYTKRDHVFAKLNLQLQRGTVTLLHKEQGTPQMNESAFMQLEFSDVKLLAESLPRRNSSLLSVRLGGLFLRDLATEGTMFPLLVFPNPQKEVGRVSQSFGLQTTSADRSDHYPAADPDGPVFEMLYERNPAHSHFERRLNVSTRPLNIIYNPQAIKKVADFFYKGKVHTSGFGYQSELELRVAEAARRQYNKLKMQTKAEIRQTLDRLLVGDFIEESKRWTVRLDISAPQVIFPDDFKFKNPVLVVVDLGRMLLTNTQDNSRRKSRDGSASEETQFSDDEYKTPLATPPNTPPPESSSSNGEKTPPFSGVEFSEEQLQAHLMSTKMYERYSLSFMDLQIMVGRVKDNWKHVQDIDVGPTHVVEKFNVHLQLERRLIYTSDPKYPGAVLSGNLPDLKIHINEDKISALKNCFALLTTPEMKTSDTQIKEKIFPQEEQRGSLQDSVMNLTQSIVLLEQHTREVLVESQLLLAEFKVNCMQLGVESNGRYISVLKVFGTNAHFVKRPYDAEVSLTVHGLLLVDTMQTYGADFDLLMASHKNLSFDIPTGSLRDSRAQSPVSGPNVAHLTDGATLNDRSATSVSLDKILTKEQESLIKLEYQFVSSECPSMNLDSTLQVISLQVNNLDIILNPETIVELIGFLQKSFPKEKDDLSPQPLMTDFERSFREQGTYQSTYEQNTEVAVEIHRLNLLLLRTVGMANREKYGRKIATASIGGTKVNVSMGSTFDMNGSLGCLQLMDLTQDNVKNQYVVSIGNSVGYENIISDIGYFESVFVRMEDAALTEALSFTFVERSKQECFLNLKMASLHYNHSAKFLKELTLSMDELEENFRGMLKSAATKVTTVLATKTAEYSEMVSLFETPRKTREPFILEENEIYGFDLASSHLDTVKLILNINIESPVVSIPRKPGSPELLVGHLGQIFIQNFVAGDDESRSDRLQVEIKDIKLYSLNCTQLAGREAVGSEGSRMFCPPSGSGSANSQEEAHFTRHDFFESLHRGQAFHILNNTTIQFKLEKIPIERESELTFSLSPDDLGTSSIMKIEGKFVNPVQVVLAKHVYEQVLQTLDNLVYSEDLNKYPASATSSPCPDSPLPPLSTCGESSVERKENGLFSHSSLSNTSQKSLSVKEVKSFTQIQATFCISELQVQLSGDLTLGAQGLVSLKFQDFEVEFSKDHPQTLSIQIALHSLLMEDLLEKNPDSKYKNLMVSRGAPKPSSLAQKEYLSQSCPSVSNVEYPDMPRSLPSHMEEAPNVFQLYQRPTSASRKKQKEVQDKDYPLTPPPSPTVDEPKILVGKSKFDDSLVHINIFLVDKKHPEFSSSYNRVNRSIDVDFNCLDVLITLQTWVVILDFFGIGSTADNHAMRLPPEGILHNVKLEPHASMESGLQDPVNTKLDLKVHSLSLVLNKTTSELAKANVSKLVAHLEMIEGDLALQGSIGSLSLSDLTCHGEFYRERFTTSGEEALIFQTFKYGRPDPLLRREHDIRVSLRMASVQYVHTQRFQAEVVAFIQHFTQLQDVLGRQRAAIEGQTVRDQAQRCSRVLLDIEAGAPVLLIPESSRSNNLIVANLGKLKVKNKFLFAGFPGTFSLQDKESVPSASPTGIPKHSLRKTTSTEEPRGTHSQGQFTMPLAGMSLGSLKSEFVPSTSTKQQGPQPTLSVGQESSSPEDHVCLLDCVVVDLQDMDIFAAERHPREYSKAPEDSSGDLIFPSYFVRQTGGSLLTEPCRLKLQVERNLDKEISHTVPDISIHGNLSSVHCSLDLYKYKLIRGLLENNLGEPIEEFMRPYDLQDPRIHTVLSGEVYTCMCFLIDMVNVSLELKDPKRKEGAGSLARFDFKKCKLLYESFSNQTKSINLVSHSMMAFDTRYAGQKTSPGMTNVFSCIFQPAKNSSTTQGSIQIELHFRSTKDSSCFTVVLNNLRVFLIFDWLLLVHDFLHTPSDIKKQNHVTPSRHRNSSSESAIVPKTVKSGVVTKRSSLPVSNERHLEVKVNVTGTEFVVIEDVSCFDTNAIILKGTTVLTYKPRFVDRPFSGSLFGIEVFSCRLGNEHDTALSIVDPVQIQMELVGNSSYQNSSGLMDAFNSEDFPPVLEIQLQALDIRLSYNDVQLFLAIAKSIPEQANAAVPDSVALESDSVGTYLPGASRVGEEIREGTRHTLDPVLELQLARLQELGFSMDDCRKALLACQGQLKKAASWLFKNAEPLKSLSLASTSRDSPGAVAAPLISGVEIKAESVCICFIDDCMDCDVPLAELTFSRLNFLQRVRTSPEGYAHFTLSGDYYNRALSGWEPFIEPWPCSVSWQQQAASRLHPPRLKLEAKAKPRLDINITSVLIDQYVSTKESWMADYCKDDKDIESAKSEDWMGSSVDPPCFGQTEVKTPKRRQPFVPFALRNHTGCTLWFATLTTTPTRAALSHSGSPGVVPEGNGTFLDDTHNVSEWREVLTGEEIPFEFEARGKLRHRHTHDLRIHQLQVRVNGWEQVSPVSVDKVGTFFRYAAPDKNSSSSTIGSPSSRTNIIHPQVYFSSLPPVRVVFAVTMEGSARKVITVRSALIVRNRLETPMELRLDSPSAPDKPVVLPAIMPGDSFAVPLHLTSWRLQARPKGLGVFFCKAPIHWTNVVKTAEISSSKRECHSMDTEKSRFFRFCVAIKKENYPDYMPSNIFSDSAKQIFRQPGHTIYLLPTVVICNLLPCELDFYVKGMPINGTLKPGKEAALHTADTSQNIELGVSLENFPLCKELLIPPGTQNYMVRMRLYDVNRRQLNLTIRIVCRAEGSLKIFISAPYWLINKTGLPLIFRQDNAKTDAAGQFEEHELARSLSPLLFCYADKEQPNLCTMRIGRGIHPEGMPGWCQGFSLDGGSGVRALKVIQQGNRPGLIYNIGIDVKKGRGRYIDTCMVIFAPRYLLDNKSSHKLAFAQREFARGQGTANPEGYISTLPGSSVVFHWPRNDYDQLLCVRLMDVPNCIWSGGFEVNKNNSFHINMRDTLGKCFFLRVEITLRGATYRISFSDTDQLPPPFRIDNFSKVPVVFTQHGVAEPRLRTEVKPMTSLDYAWDEPTLPPFITLTVKGAGSSEINCNMNDFQDNRQLYYENFIYIAATYTFSGLQEGTGRPVASNKAITCAELVLDVSPKTQRVILKKKEPGKRSQLWRMTGTGMLAHEGSSVPHNPNKPSAARSTEGSAILDIAGLAAVTDNRYEPLMLRKPDRRRSTTQTWSFREGKLTCGLHGLVVQAKGGLSGLFDGAEVVLGPDTSMELLGPVPPEQQFINQKMRPGSGMLSIRVIPDGPTRALQITDFCHRKSSRSYEVDELPVTEQELQKLKNPDTEQELEVLVRLEGGIGLSLINKVPEELVFASLTGINVHYTQLATSHMLELSIQDVQVDNQLIGTTQPFMLYVTPLSNENEVIETGPAVQVNAVKFPSKSALTNIYKHLMITAQRFTVQIEEKLLLKLLSFFGYDQAESEVEKYDENLHEKTAEQGGTPIRYYFENLKISIPQIKLSVFTSNKLPLDLKALKSTLGFPLIRFEDAVINLDPFTRVHPYETKEFIINDILKHFQEELLSQAARILGSVDFLGNPMGLLNDVSEGVTGLIKYGNVGGLIRNVTHGVSNSAAKFAGTLSDGLGKTMDNRHQSEREYIRYHAATSGEHLVAGIHGLAHGIIGGLTSVITSTVEGVKTEGGVSGFISGLGKGLVGTVTKPVAGALDFASETAQAVRDTATLSGPRTQAQRVRKPRCCTGPQGLLPRYSESQAEGQEQLFKLTDNIQDEFFIAVENIDSYCVLISSKAVYFLKSGDYVDREAIFLEVKYDDLYHCLVSKDHGKVYVQVTKKAVSTSSGVSIPGPSHQKPMVHVKSEVLAVKLSQEINYAKSLYYEQQLMLRLSENREQLELDS>sp|Q9H967|WDR76_HUMAN WD repeat-containing protein 76 OS=Homo sapiensOX=9606 GN=WDR76 PE=1 SV=2MSRSGAAAEKADSRQRPQMKVNEYKENQNIAYVSLRPAQTTVLIKTAKVYLAPFSLSNYQLDQLMCPKSLSEKNSNNEVACKKTKIKKTCRRIIPPKMKNTSSKAESTLQNSSSAVHTESNKLQPKRTADAMNLSVDVESSQDGDSDEDTTPSLDFSGLSPYERKRLKNISENADFFASLQLSESAARLREMIEKRQPPKSKRKKPKRENGIGCRRSMRLLKVDPSGVSLPAAPTPPTLVADETPLLPPGPLEMTSENQEDNNERFKGFLHTWAGMSKPSSKNTEKGLSSIKSYKANLNGMVISEDTVYKVTTGPIFSMALHPSETRTLVAVGAKFGQVGLCDLTQQPKEDGVYVFHPHSQPVSCLYFSPANPAHILSLSYDGTLRCGDFSRAIFEEVYRNERSSFSSFDFLAEDASTLIVGHWDGNMSLVDRRTPGTSYEKLTSSSMGKIRTVHVHPVHRQYFITAGLRDTHIYDARRLNSRRSQPLISLTEHTKSIASAYFSPLTGNRVVTTCADCNLRIFDSSCISSKIPLLTTIRHNTFTGRWLTRFQAMWDPKQEDCVIVGSMAHPRRVEIFHETGKRVHSFGGEYLVSVCSINAMHPTRYILAGGNSSGKIHVFMNEKSC>sp|Q9UBH6|XPR1_HUMAN Xenotropic and polytropic retrovirus receptor 1OS=Homo sapiens OX=9606 GN=XPR1 PE=1 SV=1MKFAEHLSAHITPEWRKQYIQYEAFKDMLYSAQDQAPSVEVTDEDTVKRYFAKFEEKFFQTCEKELAKINTFYSEKLAEAQRRFATLQNELQSSLDAQKESTGVTTLRQRRKPVFHLSHEERVQHRNIKDLKLAFSEFYLSLILLQNYQNLNFTGFRKILKKHDKILETSRGADWRVAHVEVAPFYTCKKINQLISETEAVVTNELEDGDRQKAMKRLRVPPLGAAQPAPAWTTFRVGLFCGIFIVLNITLVLAAVFKLETDRSIWPLIRIYRGGFLLIEFLFLLGINTYGWRQAGVNHVLIFELNPRSNLSHQHLFEIAGFLGILWCLSLLACFFAPISVIPTYVYPLALYGFMVFFLINPTKTFYYKSRFWLLKLLFRVFTAPFHKVGFADFWLADQLNSLSVILMDLEYMICFYSLELKWDESKGLLPNNSEESGICHKYTYGVRAIVQCIPAWLRFIQCLRRYRDTKRAFPHLVNAGKYSTTFFMVTFAALYSTHKERGHSDTMVFFYLWIVFYIISSCYTLIWDLKMDWGLFDKNAGENTFLREEIVYPQKAYYYCAIIEDVILRFAWTIQISITSTTLLPHSGDIIATVFAPLEVFRRFVWNFFRLENEHLNNCGEFRAVRDISVAPLNADDQTLLEQMMDQDDGVRNRQKNRSWKYNQSISLRRPRLASQSKARDTKVLIEDTDDEANT>sp|Q9UBH6-2|XPR1_HUMAN Isoform 2 of Xenotropic and polytropic retrovirusreceptor 1 OS=Homo sapiens OX=9606 GN=XPR1MKFAEHLSAHITPEWRKQYIQYEAFKDMLYSAQDQAPSVEVTDEDTVKRYFAKFEEKFFQTCEKELAKINTFYSEKLAEAQRRFATLQNELQSSLDAQKESTGVTTLRQRRKPVFHLSHEERVQHRNIKDLKLAFSEFYLSLILLQNYQNLNFTGFRKILKKHDKILETSRGADWRVAHVEVAPFYTCKKINQLISETEAVVTNELEDGDRQKAMKRLRVPPLGAAQPAPAWTTFRVGLFCGIFIVLNITLVLAAVFKLETDRSIWPLIRIYRGGFLLIEFLFLLGINTYGWRQAGVNHVLIFELNPRSNLSHQHLFEIAGFLGILWCLSLLACFFAPISVIPTYVYPLALYGFMVFFLINPTKTFYYKSRFWLLKLLFRVFTAPFHKVGFADFWLADQLNSLSVILMDLEYMICFYSLELKWDESKGLLPNNSEERGHSDTMVFFYLWIVFYIISSCYTLIWDLKMDWGLFDKNAGENTFLREEIVYPQKAYYYCAIIEDVILRFAWTIQISITSTTLLPHSGDIIATVFAPLEVFRRFVWNFFRLENEHLNNCGEFRAVRDISVAPLNADDQTLLEQMMDQDDGVRNRQKNRSWKYNQSISLRRPRLASQSKARDTKVLIEDTDDEANT>sp|O00566|MPP10_HUMAN U3 small nucleolar ribonucleoprotein protein MPP10OS=Homo sapiens OX=9606 GN=MPHOSPH10 PE=1 SV=2MAPQVWRRRTLERCLTEVGKATGRPECFLTIQEGLASKFTSLTKVLYDFNKILENGRIHGSPLQKLVIENFDDEQIWQQLELQNEPILQYFQNAVSETINDEDISLLPESEEQEREEDGSEIEADDKEDLEDLEEEEVSDMGNDDPEMGERAENSSKSDLRKSPVFSDEDSDLDFDISKLEQQSKVQNKGQGKPREKSIVDDKFFKLSEMEAYLENIEKEEERKDDNDEEEEDIDFFEDIDSDEDEGGLFGSKKLKSGKSSRNLKYKDFFDPVESDEDITNVHDDELDSNKEDDEIAEEEAEELSISETDEDDDLQENEDNKQHKESLKRVTFALPDDAETEDTGVLNVKKNSDEVKSSFEKRQEKMNEKIASLEKELLEKKPWQLQGEVTAQKRPENSLLEETLHFDHAVRMAPVITEETTLQLEDIIKQRIRDQAWDDVVRKEKPKEDAYEYKKRLTLDHEKSKLSLAEIYEQEYIKLNQQKTAEEENPEHVEIQKMMDSLFLKLDALSNFHFIPKPPVPEIKVVSNLPAITMEEVAPVSVSDAALLAPEEIKEKNKAGDIKTAAEKTATDKKRERRKKKYQKRMKIKEKEKRRKLLEKSSVDQAGKYSKTVASEKLKQLTKTGKASFIKDEGKDKALKSSQAFFSKLQDQVKMQINDAKKTEKKKKKRQDISVHKLKL>sp|O95371|OR2C1_HUMAN Olfactory receptor 2C1 OS=Homo sapiens OX=9606GN=OR2C1 PE=2 SV=3MDGVNDSSLQGFVLMGISDHPQLEMIFFIAILFSYLLTLLGNSTIILLSRLEARLHTPMYFFLSNLSSLDLAFATSSVPQMLINLWGPGKTISYGGCITQLYVFLWLGATECILLVVMAFDRYVAVCRPLRYTAIMNPQLCWLLAVIACLGGLGNSVIQSTFTLQLPLCGHRRVEGFLCEVPAMIKLACGDTSLNQAVLNGVCTFFTAVPLSIIVISYCLIAQAVLKIRSAEGRRKAFNTCLSHLLVVFLFYGSASYGYLLPAKNSKQDQGKFISLFYSLVTPMVNPLIYTLRNMEVKGALRRLLGKGREVG>sp|P50219|MNX1_HUMAN Motor neuron and pancreas homeobox protein 1OS=Homo sapiens OX=9606 GN=MNX1 PE=1 SV=3MEKSKNFRIDALLAVDPPRAASAQSAPLALVTSLAAAASGTGGGGGGGGASGGTSGSCSPASSEPPAAPADRLRAESPSPPRLLAAHCALLPKPGFLGAGGGGGGTGGGHGGPHHHAHPGAAAAAAAAAAAAAAGGLALGLHPGGAQGGAGLPAQAALYGHPVYGYSAAAAAAALAGQHPALSYSYPQVQGAHPAHPADPIKLGAGTFQLDQWLRASTAGMILPKMPDFNSQAQSNLLGKCRRPRTAFTSQQLLELEHQFKLNKYLSRPKRFEVATSLMLTETQVKIWFQNRRMKWKRSKKAKEQAAQEAEKQKGGGGGAGKGGAEEPGAEELLGPPAPGDKGSGRRLRDLRDSDPEEDEDEDDEDHFPYSNGASVHAASSDCSSEDDSPPPRPSHQPAPQ>sp|P50219-2|MNX1_HUMAN Isoform 2 of Motor neuron and pancreas homeoboxprotein 1 OS=Homo sapiens OX=9606 GN=MNX1MGGLSTVGACPGILGAQQAQAQSNLLGKCRRPRTAFTSQQLLELEHQFKLNKYLSRPKRFEVATSLMLTETQVKIWFQNRRMKWKRSKKAKEQAAQEAEKQKGGGGGAGKGGAEEPGAEELLGPPAPGDKGSGRRLRDLRDSDPEEDEDEDDEDHFPYSNGASVHAASSDCSSEDDSPPPRPSHQPAPQ>sp|Q15777|MPPD2_HUMAN Metallophosphoesterase MPPED2 OS=Homo sapiensOX=9606 GN=MPPED2 PE=1 SV=1MAHGIPSQGKVTITVDEYSSNPTQAFTHYNINQSRFQPPHVHMVDPIPYDTPKPAGHTRFVCISDTHSRTDGIQMPYGDILLHTGDFTELGLPSEVKKFNDWLGNLPYEYKIVIAGNHELTFDKEFMADLVKQDYYRFPSVSKLKPEDFDNVQSLLTNSIYLQDSEVTVKGFRIYGAPWTPWFNGWGFNLPRGQSLLDKWNLIPEGIDILMTHGPPLGFRDWVPKELQRVGCVELLNTVQRRVRPKLHVFGGIHEGYGIMTDGYTTYINASTCTVSFQPTNPPIIFDLPNPQGS>sp|Q15777-2|MPPD2_HUMAN Isoform 2 of Metallophosphoesterase MPPED2OS=Homo sapiens OX=9606 GN=MPPED2MAHGIPSQGKVTITVDEYSSNPTQAFTHYNINQSRFQPPHVHMVDPIPYDTPKPAGHTRFVCISDTHSRTDGIQMPYGDILLHTGDFTELGLPSEVKKFNDWLGNLPYEYKIVIAGNHELTFDKEFMADLVKQDYYRFPSVSKLKPEDFDNVQSLLTNSIYLQDSEVTVKGFRIYGAPWTPWFNGWGFNLPRGQSLLDKWNLIPEGIDILMTHGPPLGFRDWVPKELQRVGCVELLNTVQRRVRPKLHVFGGIHEVNPVSISKALRTKICSLPSKTS>sp|Q99549|MPP8_HUMAN M-phase phosphoprotein 8 OS=Homo sapiens OX=9606GN=MPHOSPH8 PE=1 SV=2MEQVAEGARVTAVPVSAADSTEELAEVEEGVGVVGEDNDAAARGAEAFGDSEEDGEDVFEVEKILDMKTEGGKVLYKVRWKGYTSDDDTWEPEIHLEDCKEVLLEFRKKIAENKAKAVRKDIQRLSLNNDIFEANSDSDQQSETKEDTSPKKKKKKLRQREEKSPDDLKKKKAKAGKLKDKSKPDLESSLESLVFDLRTKKRISEAKEELKESKKPKKDEVKETKELKKVKKGEIRDLKTKTREDPKENRKTKKEKFVESQVESESSVLNDSPFPEDDSEGLHSDSREEKQNTKSARERAGQDMGLEHGFEKPLDSAMSAEEDTDVRGRRKKKTPRKAEDTRENRKLENKNAFLEKKTVPKKQRNQDRSKSAAELEKLMPVSAQTPKGRRLSGEERGLWSTDSAEEDKETKRNESKEKYQKRHDSDKEEKGRKEPKGLKTLKEIRNAFDLFKLTPEEKNDVSENNRKREEIPLDFKTIDDHKTKENKQSLKERRNTRDETDTWAYIAAEGDQEVLDSVCQADENSDGRQQILSLGMDLQLEWMKLEDFQKHLDGKDENFAATDAIPSNVLRDAVKNGDYITVKVALNSNEEYNLDQEDSSGMTLVMLAAAGGQDDLLRLLITKGAKVNGRQKNGTTALIHAAEKNFLTTVAILLEAGAFVNVQQSNGETALMKACKRGNSDIVRLVIECGADCNILSKHQNSALHFAKQSNNVLVYDLLKNHLETLSRVAEETIKDYFEARLALLEPVFPIACHRLCEGPDFSTDFNYKPPQNIPEGSGILLFIFHANFLGKEVIARLCGPCSVQAVVLNDKFQLPVFLDSHFVYSFSPVAGPNKLFIRLTEAPSAKVKLLIGAYRVQLQ>sp|Q99549-2|MPP8_HUMAN Isoform 2 of M-phase phosphoprotein 8 OS=Homosapiens OX=9606 GN=MPHOSPH8MEQVAEGARVTAVPVSAADSTEELAEVEEGVGVVGEDNDAAARGAEAFGDSEEDGEDVFEVEKILDMKTEGGKVLYKVRWKGYTSDDDTWEPEIHLEDCKEVLLEFRKKIAENKAKAVRKDIQRLSLNNDIFEANSDSDQQSETKEDTSPKKKKKKLRQREEKSPDDLKKKKAKAGKLKDKSKPDLESSLESLVFDLRTKKRISEAKEELKESKKPKKDEVKETKELKKVKKGEIRDLKTKTREDPKENRKTKKEKFVESQVESESSVLNDSPFPEDDSEGLHSDSREEKQNTKSARERAGQDMGLEHGFEKPLDSAMSAEEDTDVRGRRKKKTPRKAEDTRENRKLENKNAFLEKKTVPKKQRNQDRSKSAAELEKLMPVSAQTPKGRRLSGEERGLWSTDSAEEDKETKRNESKEKYQKRHDSDKEEKGRKEPKGLKTLKEIRNAFDLFKLTPEEKNDVSENNRKREEIPLDFKTIDDHKTKENKQSLKERRNTRDETDTWAYIAAEGDQEVLDSVCQADENSDGRQQILSLGMDLQLEWMKLEDFQKHLDGKDENFAATDAIPSNVLRDAVKNGDYITVKVALNSNEEYNLDQEDSSGMTLVMLAAAGGQDDLLRLLITKGAKVNGRQKNGTTALIHAAEKNFLTTVAILLEAGAFVNVQQSNGETALMKACKRGNSDIVRLVIECGADCNILSKHQNSALHFAKQSNNVLVYDLLKNHLETLSRVAEETIKDYFEARLALLEPVFPIACHRLCEGPDFSTDFNYKPPQNIPEGSGILLFIFHANFLGKEVIARLCGPCSVQAVVLNDKFQLPVFLTGSRSVVQAGVQWRGLQLTGVLTSQAQAILPPQPPNYLGLKMHATTSG>sp|P42898|MTHR_HUMAN Methylenetetrahydrofolate reductase OS=Homo sapiensOX=9606 GN=MTHFR PE=1 SV=3MVNEARGNSSLNPCLEGSASSGSESSKDSSRCSTPGLDPERHERLREKMRRRLESGDKWFSLEFFPPRTAEGAVNLISRFDRMAAGGPLYIDVTWHPAGDPGSDKETSSMMIASTAVNYCGLETILHMTCCRQRLEEITGHLHKAKQLGLKNIMALRGDPIGDQWEEEEGGFNYAVDLVKHIRSEFGDYFDICVAGYPKGHPEAGSFEADLKHLKEKVSAGADFIITQLFFEADTFFRFVKACTDMGITCPIVPGIFPIQGYHSLRQLVKLSKLEVPQEIKDVIEPIKDNDAAIRNYGIELAVSLCQELLASGLVPGLHFYTLNREMATTEVLKRLGMWTEDPRRPLPWALSAHPKRREEDVRPIFWASRPKSYIYRTQEWDEFPNGRWGNSSSPAFGELKDYYLFYLKSKSPKEELLKMWGEELTSEESVFEVFVLYLSGEPNRNGHKVTCLPWNDEPLAAETSLLKEELLRVNRQGILTINSQPNINGKPSSDPIVGWGPSGGYVFQKAYLEFFTSRETAEALLQVLKKYELRVNYHLVNVKGENITNAPELQPNAVTWGIFPGREIIQPTVVDPVSFMFWKDEAFALWIERWGKLYEEESPSRTIIQYIHDNYFLVNLVDNDFPLDNCLWQVVEDTLELLNRPTQNARETEAP>sp|P42898-2|MTHR_HUMAN Isoform 2 of Methylenetetrahydrofolate reductaseOS=Homo sapiens OX=9606 GN=MTHFRMDHRKARVLPAGHYCPSLGIWASQVGSVRSSVPPSISRNPAMVNEARGNSSLNPCLEGSASSGSESSKDSSRCSTPGLDPERHERLREKMRRRLESGDKWFSLEFFPPRTAEGAVNLISRFDRMAAGGPLYIDVTWHPAGDPGSDKETSSMMIASTAVNYCGLETILHMTCCRQRLEEITGHLHKAKQLGLKNIMALRGDPIGDQWEEEEGGFNYAVDLVKHIRSEFGDYFDICVAGYPKGHPEAGSFEADLKHLKEKVSAGADFIITQLFFEADTFFRFVKACTDMGITCPIVPGIFPIQGYHSLRQLVKLSKLEVPQEIKDVIEPIKDNDAAIRNYGIELAVSLCQELLASGLVPGLHFYTLNREMATTEVLKRLGMWTEDPRRPLPWALSAHPKRREEDVRPIFWASRPKSYIYRTQEWDEFPNGRWGNSSSPAFGELKDYYLFYLKSKSPKEELLKMWGEELTSEESVFEVFVLYLSGEPNRNGHKVTCLPWNDEPLAAETSLLKEELLRVNRQGILTINSQPNINGKPSSDPIVGWGPSGGYVFQKAYLEFFTSRETAEALLQVLKKYELRVNYHLVNVKGENITNAPELQPNAVTWGIFPGREIIQPTVVDPVSFMFWKDEAFALWIERWGKLYEEESPSRTIIQYIHDNYFLVNLVDNDFPLDNCLWQVVEDTLELLNRPTQNARETEAP>sp|Q9BT17|MTG1_HUMAN Mitochondrial ribosome-associated GTPase 1 OS=Homosapiens OX=9606 GN=MTG1 PE=1 SV=2MRLTPRALCSAAQAAWRENFPLCGRDVARWFPGHMAKGLKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADLTEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTELIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEPGITRAVMSKIQVSERPLMFLLDTPGVLAPRIESVETGLKLALCGTVLDHLVGEETMADYLLYTLNKHQRFGYVQHYGLGSACDNVERVLKSVAVKLGKTQKVKVLTGTGNVNIIQPNYPAAARDFLQTFRRGLLGSVMLDLDVLRGHPPAETLP>sp|Q9BT17-2|MTG1_HUMAN Isoform 2 of Mitochondrial ribosome-associatedGTPase 1 OS=Homo sapiens OX=9606 GN=MTG1MRLTPRALCSAAQAAWRENFPLCGRDVARWFPGHMAKGLKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADLTEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTELIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEPGITRAVMSKIQVESSGARPSTLSRALQASGTCRPLCGFRLLTTLPSPPLSVPAEHPRGRHCPCPYSTVVIVFAPNLWGRHAVFPISR>sp|Q15390|MTFR1_HUMAN Mitochondrial fission regulator 1 OS=Homo sapiensOX=9606 GN=MTFR1 PE=1 SV=2MLGWIKRLIRMVFQQVGVSMQSVLWSRKPYGSSRSIVRKIGTNLSLIQCPRVQFQINSHATEWSPSHPGEDAVASFADVGWVAKEEGECSARLRTEVRSRPPLQDDLLFFEKAPSRQISLPDLSQEEPQLKTPALANEEALQKICALENELAALRAQIAKIVTQQEQQNLTAGDLDSTTFGTIPPHPPPPPPPLPPPALGLHQSTSAVDLIKERREKRANAGKTLVKNNPKKPEMPNMLEILKEMNSVKLRSVKRSEQDVKPKPVDATDPAALIAEALKKKFAYRYRSDSQDEVEKGIPKSESEATSERVLFGPHMLKPTGKMKALIENVSDS>sp|Q15390-2|MTFR1_HUMAN Isoform 2 of Mitochondrial fission regulator 1OS=Homo sapiens OX=9606 GN=MTFR1MLGWIKRLIRMVFQQVGVSMQSINSHATEWSPSHPGEDAVASFADVGWVAKEEGECSARLRTEVRSRPPLQDDLLFFEKAPSRQISLPDLSQEEPQLKTPALANEEALQKICALENELAALRAQIAKIVTQQEQQNLTAGDLDSTTFGTIPPHPPPPPPPLPPPALGLHQSTSAVDLIKERREKRANAGKTLVKNNPKKPEMPNMLEILKEMNSVKLRSVKRSEQDVKPKPVDATDPAALIAEALKKKFAYRYRSDSQDEVEKGIPKSESEATSERVLFGPHMLKPTGKMKALIENVSDS>sp|Q9UKN1|MUC12_HUMAN Mucin-12 OS=Homo sapiens OX=9606 GN=MUC12 PE=1SV=2MLVIWILTLALRLCASVTTVTPEGSAVHKAISQQGTLWTGEVLEKQTVEQGKSTLRRQKNHFHRSAGELRCRNALKDEGASAGWSVMFAGESVVVLVHLWMTGARVKNLGLVEFASPGDDGDGRAEGFSLGLPLSEQARAAGAREKERQETVINHSTFSGFSQITGSTVNTSIGGNTTSASTPSSSDPFTTFSDYGVSVTFITGSTATKHFLDSSTNSGHSEESTVSHSGPGATGTTLFPSHSATSVFVGEPKTSPITSASMETTALPGSTTTAGLSEKSTTFYSSPRSPDRTLSPARTTSSGVSEKSTTSHSRPGPTHTIAFPDSTTMPGVSQESTASHSIPGSTDTTLSPGTTTPSSLGPESTTFHSSPGYTKTTRLPDNTTTSGLLEASTPVHSSTGSPHTTLSPSSSTTHEGEPTTFQSWPSSKDTSPAPSGTTSAFVKLSTTYHSSPSSTPTTHFSASSTTLGHSEESTPVHSSPVATATTPPPARSATSGHVEESTAYHRSPGSTQTMHFPESSTTSGHSEESATFHGSTTHTKSSTPSTTAALAHTSYHSSLGSTETTHFRDSSTISGRSEESKASHSSPDAMATTVLPAGSTPSVLVGDSTPSPISSGSMETTALPGSTTKPGLSEKSTTFYSSPRSPDTTHLPASMTSSGVSEESTTSHSRPGSTHTTAFPGSTTMPGLSQESTASHSSPGPTDTTLSPGSTTASSLGPEYTTFHSRPGSTETTLLPDNTTASGLLEASMPVHSSTRSPHTTLSPAGSTTRQGESTTFHSWPSSKDTRPAPPTTTSAFVEPSTTSHGSPSSIPTTHISARSTTSGLVEESTTYHSSPGSTQTMHFPESDTTSGRGEESTTSHSSTTHTISSAPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSERSTTFHSSPRSPATTLSPASTTSSGVSEESTTSRSRPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGPSQESTTSHSSSGSTDTALSPGSTTALSFGQESTTFHSNPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTAFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSRGSTETTVFPHSTTTSVHGEEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTKLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTSDLSQEPTTSHSSQGSTEATLSPGSTTASSLGQQSTTFHSSPGDTETTLLPDDTITSGLVEASTPTHSSTGSLHTTLTPASSTSAGLQEESTTFQSWPSSSDTTPSPPGTTAAPVEVSTTYHSRPSSTPTTHFSASSTTLGRSEESTTVHSSPGATGTALFPTRSATSVLVGEPTTSPISSGSTETTALPGSTTTAGLSEKSTTFYSSPRSPDTTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPGSTTMPGVSQESTASHSSPGSTDTTLSPGSTTASSLGPESTTFHSSPGSTETTLLPDNTTASGLLEASTPVHSSTGSPHTTLSPAGSTTRQGESTTFQSWPSSKDTMPAPPTTTSAFVELSTTSHGSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTAYHSSPGSTQTMHFPESSTASGRSEESRTSHSSTTHTISSPPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSEKSTTFHSSPRSPATTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGPSQESTTSHSSPGSTDTALSPGSTTALSFGQESTTFHSSPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTAFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSPGSTETTVFPRTPTTSVRGEEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTTLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGPSQESTTSHSSPGSTDTALSPGSTTALSFGQESTTFHSSPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTTFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSPGSTETTVFPRSTTTSVRGEEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTTLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTSGLSQEPTASHSSQGSTEATLSPGSTTASSLGQQSTTFHSSPGDTETTLLPDDTITSGLVEASTPTHSSTGSLHTTLTPASSTSAGLQEESTTFQSWPSSSDTTPSPPGTTAAPVEVSTTYHSRPSSTPTTHFSASSTTLGRSEESTTVHSSPGATGTALFPTRSATSVLVGEPTTSPISSGSTETTALPGSTTTAGLSEKSTTFYSSPRSPDTTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPGSTTMPGVSQESTASHSSPGSTDTTLSPGSTTASSLGPESTTFHSGPGSTETTLLPDNTTASGLLEASTPVHSSTGSPHTTLSPAGSTTRQGESTTFQSWPNSKDTTPAPPTTTSAFVELSTTSHGSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTTYHSSPGSTQTMHFPESDTTSGRGEESTTSHSSTTHTISSAPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSEKSTTFHSSPRSPATTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGSSQESTTSHSSSGSTDTALSPGSTTALSFGQESTTFHSSPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTAFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSPGSTETTVFPRSTTTSVRREEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTKLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTSGLSQEPTTSHSSQGSTEATLSPGSTTASSLGQQSTTFHSSPGDTETTLLPDDTITSGLVEASTPTHSSTGSLHTTLTPASSTSTGLQEESTTFQSWPSSSDTTPSPPSTTAVPVEVSTTYHSRPSSTPTTHFSASSTTLGRSEESTTVHSSPGATGTALFPTRSATSVLVGEPTTSPISSGSTETTALPGSTTTAGLSEKSTTFYSSPRSPDTTLSPASTTSSGVSEESTTSHSRPGSMHTTAFPSSTTMPGVSQESTASHSSPGSTDTTLSPGSTTASSLGPESTTFHSSPGSTETTLLPDNTTASGLLEASTPVHSSTGSPHTTLSPAGSTTRQGESTTFQSWPNSKDTTPAPPTTTSAFVELSTTSHGSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTTYHSSPGSTQTMHFPESNTTSGRGEESTTSHSSTTHTISSAPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSEKSTTFHSSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTAYHSSPGSTQTMHFPESSTASGRSEESRTSHSSTTHTISSPPSTTSALVEEPTSYHSSPGSIATTHFPESSTTSGRSEESTASHSSPDTNGITPLPAHFTTSGRIAESTTFYISPGSMETTLASTATTPGLSAKSTILYSSSRSPDQTLSPASMTSSSISGEPTSLYSQAESTHTTAFPASTTTSGLSQESTTFHSKPGSTETTLSPGSITTSSFAQEFTTPHSQPGSALSTVSPASTTVPGLSEESTTFYSSPGSTETTAFSHSNTMSIHSQQSTPFPDSPGFTHTVLPATLTTTDIGQESTAFHSSSDATGTTPLPARSTASDLVGEPTTFYISPSPTYTTLFPASSSTSGLTEESTTFHTSPSFTSTIVSTESLETLAPGLCQEGQIWNGKQCVCPQGYVGYQCLSPLESFPVETPEKLNATLGMTVKVTYRNFTEKMNDASSQEYQNFSTLFKNRMDVVLKGDNLPQYRGVNIRRLLNGSIVVKNDVILEADYTLEYEELFENLAEIVKAKIMNETRTTLLDPDSCRKAILCYSEEDTFVDSSVTPGFDFQEQCTQKAAEGYTQFYYVDVLDGKLACVNKCTKGTKSQMNCNLGTCQLQRSGPRCLCPNTNTHWYWGETCEFNIAKSLVYGIVGAVMAVLLLALIILIILFSLSQRKRHREQYDVPQEWRKEGTPGIFQKTAIWEDQNLRESRFGLENAYNNFRPTLETVDSGTELHIQRPEMVASTV>sp|Q9UKN1-2|MUC12_HUMAN Isoform 2 of Mucin-12 OS=Homo sapiens OX=9606GN=MUC12MLVIWILTLALRLCASVTTVTPGSTVNTSIGGNTTSASTPSSSDPFTTFSDYGVSVTFITGSTATKHFLDSSTNSGHSEESTVSHSGPGATGTTLFPSHSATSVFVGEPKTSPITSASMETTALPGSTTTAGLSEKSTTFYSSPRSPDRTLSPARTTSSGVSEKSTTSHSRPGPTHTIAFPDSTTMPGVSQESTASHSIPGSTDTTLSPGTTTPSSLGPESTTFHSSPGYTKTTRLPDNTTTSGLLEASTPVHSSTGSPHTTLSPSSSTTHEGEPTTFQSWPSSKDTSPAPSGTTSAFVKLSTTYHSSPSSTPTTHFSASSTTLGHSEESTPVHSSPVATATTPPPARSATSGHVEESTAYHRSPGSTQTMHFPESSTTSGHSEESATFHGSTTHTKSSTPSTTAALAHTSYHSSLGSTETTHFRDSSTISGRSEESKASHSSPDAMATTVLPAGSTPSVLVGDSTPSPISSGSMETTALPGSTTKPGLSEKSTTFYSSPRSPDTTHLPASMTSSGVSEESTTSHSRPGSTHTTAFPGSTTMPGLSQESTASHSSPGPTDTTLSPGSTTASSLGPEYTTFHSRPGSTETTLLPDNTTASGLLEASMPVHSSTRSPHTTLSPAGSTTRQGESTTFHSWPSSKDTRPAPPTTTSAFVEPSTTSHGSPSSIPTTHISARSTTSGLVEESTTYHSSPGSTQTMHFPESDTTSGRGEESTTSHSSTTHTISSAPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSERSTTFHSSPRSPATTLSPASTTSSGVSEESTTSRSRPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGPSQESTTSHSSSGSTDTALSPGSTTALSFGQESTTFHSNPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTAFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSRGSTETTVFPHSTTTSVHGEEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTKLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTSDLSQEPTTSHSSQGSTEATLSPGSTTASSLGQQSTTFHSSPGDTETTLLPDDTITSGLVEASTPTHSSTGSLHTTLTPASSTSAGLQEESTTFQSWPSSSDTTPSPPGTTAAPVEVSTTYHSRPSSTPTTHFSASSTTLGRSEESTTVHSSPGATGTALFPTRSATSVLVGEPTTSPISSGSTETTALPGSTTTAGLSEKSTTFYSSPRSPDTTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPGSTTMPGVSQESTASHSSPGSTDTTLSPGSTTASSLGPESTTFHSSPGSTETTLLPDNTTASGLLEASTPVHSSTGSPHTTLSPAGSTTRQGESTTFQSWPSSKDTMPAPPTTTSAFVELSTTSHGSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTAYHSSPGSTQTMHFPESSTASGRSEESRTSHSSTTHTISSPPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSEKSTTFHSSPRSPATTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGPSQESTTSHSSPGSTDTALSPGSTTALSFGQESTTFHSSPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTAFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSPGSTETTVFPRTPTTSVRGEEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTTLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGPSQESTTSHSSPGSTDTALSPGSTTALSFGQESTTFHSSPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTTFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSPGSTETTVFPRSTTTSVRGEEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTTLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTSGLSQEPTASHSSQGSTEATLSPGSTTASSLGQQSTTFHSSPGDTETTLLPDDTITSGLVEASTPTHSSTGSLHTTLTPASSTSAGLQEESTTFQSWPSSSDTTPSPPGTTAAPVEVSTTYHSRPSSTPTTHFSASSTTLGRSEESTTVHSSPGATGTALFPTRSATSVLVGEPTTSPISSGSTETTALPGSTTTAGLSEKSTTFYSSPRSPDTTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPGSTTMPGVSQESTASHSSPGSTDTTLSPGSTTASSLGPESTTFHSGPGSTETTLLPDNTTASGLLEASTPVHSSTGSPHTTLSPAGSTTRQGESTTFQSWPNSKDTTPAPPTTTSAFVELSTTSHGSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTTYHSSPGSTQTMHFPESDTTSGRGEESTTSHSSTTHTISSAPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSEKSTTFHSSPRSPATTLSPASTTSSGVSEESTTSHSRPGSTHTTAFPDSTTTPGLSRHSTTSHSSPGSTDTTLLPASTTTSGSSQESTTSHSSSGSTDTALSPGSTTALSFGQESTTFHSSPGSTHTTLFPDSTTSSGIVEASTRVHSSTGSPRTTLSPASSTSPGLQGESTAFQTHPASTHTTPSPPSTATAPVEESTTYHRSPGSTPTTHFPASSTTSGHSEKSTIFHSSPDASGTTPSSAHSTTSGRGESTTSRISPGSTEITTLPGSTTTPGLSEASTTFYSSPRSPTTTLSPASMTSLGVGEESTTSRSQPGSTHSTVSPASTTTPGLSEESTTVYSSSPGSTETTVFPRSTTTSVRREEPTTFHSRPASTHTTLFTEDSTTSGLTEESTAFPGSPASTQTGLPATLTTADLGEESTTFPSSSGSTGTKLSPARSTTSGLVGESTPSRLSPSSTETTTLPGSPTTPSLSEKSTTFYTSPRSPDATLSPATTTSSGVSEESSTSHSQPGSTHTTAFPDSTTTSGLSQEPTTSHSSQGSTEATLSPGSTTASSLGQQSTTFHSSPGDTETTLLPDDTITSGLVEASTPTHSSTGSLHTTLTPASSTSTGLQEESTTFQSWPSSSDTTPSPPSTTAVPVEVSTTYHSRPSSTPTTHFSASSTTLGRSEESTTVHSSPGATGTALFPTRSATSVLVGEPTTSPISSGSTETTALPGSTTTAGLSEKSTTFYSSPRSPDTTLSPASTTSSGVSEESTTSHSRPGSMHTTAFPSSTTMPGVSQESTASHSSPGSTDTTLSPGSTTASSLGPESTTFHSSPGSTETTLLPDNTTASGLLEASTPVHSSTGSPHTTLSPAGSTTRQGESTTFQSWPNSKDTTPAPPTTTSAFVELSTTSHGSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTTYHSSPGSTQTMHFPESNTTSGRGEESTTSHSSTTHTISSAPSTTSALVEEPTSYHSSPGSTATTHFPDSSTTSGRSEESTASHSSQDATGTIVLPARSTTSVLLGESTTSPISSGSMETTALPGSTTTPGLSEKSTTFHSSPSSTPTTHFSASSTTLGRSEESTTVHSSPVATATTPSPARSTTSGLVEESTAYHSSPGSTQTMHFPESSTASGRSEESRTSHSSTTHTISSPPSTTSALVEEPTSYHSSPGSIATTHFPESSTTSGRSEESTASHSSPDTNGITPLPAHFTTSGRIAESTTFYISPGSMETTLASTATTPGLSAKSTILYSSSRSPDQTLSPASMTSSSISGEPTSLYSQAESTHTTAFPASTTTSGLSQESTTFHSKPGSTETTLSPGSITTSSFAQEFTTPHSQPGSALSTVSPASTTVPGLSEESTTFYSSPGSTETTAFSHSNTMSIHSQQSTPFPDSPGFTHTVLPATLTTTDIGQESTAFHSSSDATGTTPLPARSTASDLVGEPTTFYISPSPTYTTLFPASSSTSGLTEESTTFHTSPSFTSTIVSTESLETLAPGLCQEGQIWNGKQCVCPQGYVGYQCLSPLESFPVETPEKLNATLGMTVKVTYRNFTEKMNDASSQEYQNFSTLFKNRMDVVLKGDNLPQYRGVNIRRLLNGSIVVKNDVILEADYTLEYEELFENLAEIVKAKIMNETRTTLLDPDSCRKAILCYSEEDTFVDSSVTPGFDFQEQCTQKAAEGYTQFYYVDVLDGKLACVNKCTKGTKSQMNCNLGTCQLQRSGPRCLCPNTNTHWYWGETCEFNIAKSLVYGIVGAVMAVLLLALIILIILFSLSQRKRHREQYDVPQEWRKEGTPGIFQKTAIWEDQNLRESRFGLENAYNNFRPTLETVDSGTELHIQRPEMVASTV>sp|O75081|MTG16_HUMAN Protein CBFA2T3 OS=Homo sapiens OX=9606 GN=CBFA2T3PE=1 SV=2MPASRLRDRAASSASGSTCGSMSQTHPVLESGLLASAGCSAPRGPRKGGPAPVDRKAKASAMPDSPAEVKTQPRSTPPSMPPPPPAASQGATRPPSFTPHTHREDGPATLPHGRFHGCLKWSMVCLLMNGSSHSPTAINGAPCTPNGFSNGPATSSTASLSTQHLPPACGARQLSKLKRFLTTLQQFGSDISPEIGERVRTLVLGLVNSTLTIEEFHSKLQEATNFPLRPFVIPFLKANLPLLQRELLHCARLAKQTPAQYLAQHEQLLLDASASSPIDSSELLLEVNENGKRRTPDRTKENGSDRDPLHPEHLSKRPCTLNPAQRYSPSNGPPQPTPPPHYRLEDIAMAHHFRDAYRHPDPRELRERHRPLVVPGSRQEEVIDHKLTEREWAEEWKHLNNLLNCIMDMVEKTRRSLTVLRRCQEADREELNHWARRYSDAEDTKKGPAPAAARPRSSSAGPEGPQLDVPREFLPRTLTGYVPEDIWRKAEEAVNEVKRQAMSELQKAVSDAERKAHELITTERAKMERALAEAKRQASEDALTVINQQEDSSESCWNCGRKASETCSGCNAARYCGSFCQHRDWEKHHHVCGQSLQGPTAVVADPVPGPPEAAHSLGPSLPVGAASPSEAGSAGPSRPGSPSPPGPLDTVPR>sp|O75081-2|MTG16_HUMAN Isoform 2 of Protein CBFA2T3 OS=Homo sapiensOX=9606 GN=CBFA2T3MPDSPAEVKTQPRSTPPSMPPPPPAASQGATRPPSFTPHTLMNGSSHSPTAINGAPCTPNGFSNGPATSSTASLSTQHLPPACGARQLSKLKRFLTTLQQFGSDISPEIGERVRTLVLGLVNSTLTIEEFHSKLQEATNFPLRPFVIPFLKANLPLLQRELLHCARLAKQTPAQYLAQHEQLLLDASASSPIDSSELLLEVNENGKRRTPDRTKENGSDRDPLHPEHLSKRPCTLNPAQRYSPSNGPPQPTPPPHYRLEDIAMAHHFRDAYRHPDPRELRERHRPLVVPGSRQEEVIDHKLTEREWAEEWKHLNNLLNCIMDMVEKTRRSLTVLRRCQEADREELNHWARRYSDAEDTKKGPAPAAARPRSSSAGPEGPQLDVPREFLPRTLTGYVPEDIWRKAEEAVNEVKRQAMSELQKAVSDAERKAHELITTERAKMERALAEAKRQASEDALTVINQQEDSSESCWNCGRKASETCSGCNAARYCGSFCQHRDWEKHHHVCGQSLQGPTAVVADPVPGPPEAAHSLGPSLPVGAASPSEAGSAGPSRPGSPSPPGPLDTVPR>sp|O75081-4|MTG16_HUMAN Isoform 3 of Protein CBFA2T3 OS=Homo sapiensOX=9606 GN=CBFA2T3MPASRLRDRAASSASGSTCGSMSQTHPVLESGLLASAGCSAPRGPRKGGPVMNGSSHSPTAINGAPCTPNGFSNGPATSSTASLSTQHLPPACGARQLSKLKRFLTTLQQFGSDISPEIGERVRTLVLGLVNSTLTIEEFHSKLQEATNFPLRPFVIPFLKANLPLLQRELLHCARLAKQTPAQYLAQHEQLLLDASASSPIDSSELLLEVNENGKRRTPDRTKENGSDRDPLHPEHLSKRPCTLNPAQRYSPSNGPPQPTPPPHYRLEDIAMAHHFRDAYRHPDPRELRERHRPLVVPGSRQEEVIDHKLTEREWAEEWKHLNNLLNCIMDMVEKTRRSLTVLRRCQEADREELNHWARRYSDAEDTKKGPAPAAARPRSSSAGPEGPQLDVPREFLPRTLTGYVPEDIWRKAEEAVNEVKRQAMSELQKAVSDAERKAHELITTERAKMERALAEAKRQASEDALTVINQQEDSSESCWNCGRKASETCSGCNAARYCGSFCQHRDWEKHHHVCGQSLQGPTAVVADPVPGPPEAAHSLGPSLPVGAASPSEAGSAGPSRPGSPSPPGPLDTVPR>sp|O75081-5|MTG16_HUMAN Isoform 4 of Protein CBFA2T3 OS=Homo sapiensOX=9606 GN=CBFA2T3MPASRLRDRAASSASGSTCGSMSQTHPVLESGLLASAGCSAPRGPRKGGPGKPALAAAGAPALCTPGQADARPVLGPA>sp|Q96QE2|MYCT_HUMAN Proton myo-inositol cotransporter OS=Homo sapiensOX=9606 GN=SLC2A13 PE=1 SV=3MSRKASENVEYTLRSLSSLMGERRRKQPEPDAASAAGECSLLAAAESSTSLQSAGAGGGGVGDLERAARRQFQQDETPAFVYVVAVFSALGGFLFGYDTGVVSGAMLLLKRQLSLDALWQELLVSSTVGAAAVSALAGGALNGVFGRRAAILLASALFTAGSAVLAAANNKETLLAGRLVVGLGIGIASMTVPVYIAEVSPPNLRGRLVTINTLFITGGQFFASVVDGAFSYLQKDGWRYMLGLAAVPAVIQFFGFLFLPESPRWLIQKGQTQKARRILSQMRGNQTIDEEYDSIKNNIEEEEKEVGSAGPVICRMLSYPPTRRALIVGCGLQMFQQLSGINTIMYYSATILQMSGVEDDRLAIWLASVTAFTNFIFTLVGVWLVEKVGRRKLTFGSLAGTTVALIILALGFVLSAQVSPRITFKPIAPSGQNATCTRYSYCNECMLDPDCGFCYKMNKSTVIDSSCVPVNKASTNEAAWGRCENETKFKTEDIFWAYNFCPTPYSWTALLGLILYLVFFAPGMGPMPWTVNSEIYPLWARSTGNACSSGINWIFNVLVSLTFLHTAEYLTYYGAFFLYAGFAAVGLLFIYGCLPETKGKKLEEIESLFDNRLCTCGTSDSDEGRYIEYIRVKGSNYHLSDNDASDVE>sp|Q92614|MY18A_HUMAN Unconventional myosin-XVIIIa OS=Homo sapiensOX=9606 GN=MYO18A PE=1 SV=3MFNLMKKDKDKDGGRKEKKEKKEKKERMSAAELRSLEEMSLRRGFFNLNRSSKRESKTRLEISNPIPIKVASGSDLHLTDIDSDSNRGSVILDSGHLSTASSSDDLKGEEGSFRGSVLQRAAKFGSLAKQNSQMIVKRFSFSQRSRDESASETSTPSEHSAAPSPQVEVRTLEGQLVQHPGPGIPRPGHRSRAPELVTKKFPVDLRLPPVVPLPPPTLRELELQRRPTGDFGFSLRRTTMLDRGPEGQACRRVVHFAEPGAGTKDLALGLVPGDRLVEINGHNVESKSRDEIVEMIRQSGDSVRLKVQPIPELSELSRSWLRSGEGPRREPSDAKTEEQIAAEEAWNETEKVWLVHRDGFSLASQLKSEELNLPEGKVRVKLDHDGAILDVDEDDVEKANAPSCDRLEDLASLVYLNESSVLHTLRQRYGASLLHTYAGPSLLVLGPRGAPAVYSEKVMHMFKGCRREDMAPHIYAVAQTAYRAMLMSRQDQSIILLGSSGSGKTTSCQHLVQYLATIAGISGNKVFSVEKWQALYTLLEAFGNSPTIINGNATRFSQILSLDFDQAGQVASASIQTMLLEKLRVARRPASEATFNVFYYLLACGDGTLRTELHLNHLAENNVFGIVPLAKPEEKQKAAQQFSKLQAAMKVLGISPDEQKACWFILAAIYHLGAAGATKEAAEAGRKQFARHEWAQKAAYLLGCSLEELSSAIFKHQHKGGTLQRSTSFRQGPEESGLGDGTGPKLSALECLEGMAAGLYSELFTLLVSLVNRALKSSQHSLCSMMIVDTPGFQNPEQGGSARGASFEELCHNYTQDRLQRLFHERTFVQELERYKEENIELAFDDLEPPTDDSVAAVDQASHQSLVRSLARTDEARGLLWLLEEEALVPGASEDTLLERLFSYYGPQEGDKKGQSPLLHSSKPHHFLLGHSHGTNWVEYNVTGWLNYTKQNPATQNAPRLLQDSQKKIISNLFLGRAGSATVLSGSIAGLEGGSQLALRRATSMRKTFTTGMAAVKKKSLCIQMKLQVDALIDTIKKSKLHFVHCFLPVAEGWAGEPRSASSRRVSSSSELDLPSGDHCEAGLLQLDVPLLRTQLRGSRLLDAMRMYRQGYPDHMVFSEFRRRFDVLAPHLTKKHGRNYIVVDERRAVEELLECLDLEKSSCCMGLSRVFFRAGTLARLEEQRDEQTSRNLTLFQAACRGYLARQHFKKRKIQDLAIRCVQKNIKKNKGVKDWPWWKLFTTVRPLIEVQLSEEQIRNKDEEIQQLRSKLEKAEKERNELRLNSDRLESRISELTSELTDERNTGESASQLLDAETAERLRAEKEMKELQTQYDALKKQMEVMEMEVMEARLIRAAEINGEVDDDDAGGEWRLKYERAVREVDFTKKRLQQEFEDKLEVEQQNKRQLERRLGDLQADSEESQRALQQLKKKCQRLTAELQDTKLHLEGQQVRNHELEKKQRRFDSELSQAHEEAQREKLQREKLQREKDMLLAEAFSLKQQLEEKDMDIAGFTQKVVSLEAELQDISSQESKDEASLAKVKKQLRDLEAKVKDQEEELDEQAGTIQMLEQAKLRLEMEMERMRQTHSKEMESRDEEVEEARQSCQKKLKQMEVQLEEEYEDKQKVLREKRELEGKLATLSDQVNRRDFESEKRLRKDLKRTKALLADAQLMLDHLKNSAPSKREIAQLKNQLEESEFTCAAAVKARKAMEVEIEDLHLQIDDIAKAKTALEEQLSRLQREKNEIQNRLEEDQEDMNELMKKHKAAVAQASRDLAQINDLQAQLEEANKEKQELQEKLQALQSQVEFLEQSMVDKSLVSRQEAKIRELETRLEFERTQVKRLESLASRLKENMEKLTEERDQRIAAENREKEQNKRLQRQLRDTKEEMGELARKEAEASRKKHELEMDLESLEAANQSLQADLKLAFKRIGDLQAAIEDEMESDENEDLINSLQDMVTKYQKRKNKLEGDSDVDSELEDRVDGVKSWLSKNKGPSKAASDDGSLKSSSPTSYWKSLAPDRSDDEHDPLDNTSRPRYSHSYLSDSDTEAKLTETNA>sp|Q92614-2|MY18A_HUMAN Isoform 2 of Unconventional myosin-XVIIIaOS=Homo sapiens OX=9606 GN=MYO18AMRAKTEEQIAAEEAWNETEKVWLVHRDGFSLASQLKSEELNLPEGKVRVKLDHDGAILDVDEDDVEKANAPSCDRLEDLASLVYLNESSVLHTLRQRYGASLLHTYAGPSLLVLGPRGAPAVYSEKVMHMFKGCRREDMAPHIYAVAQTAYRAMLMSRQDQSIILLGSSGSGKTTSCQHLVQYLATIAGISGNKVFSVEKWQALYTLLEAFGNSPTIINGNATRFSQILSLDFDQAGQVASASIQTMLLEKLRVARRPASEATFNVFYYLLACGDGTLRTELHLNHLAENNVFGIVPLAKPEEKQKAAQQFSKLQAAMKVLGISPDEQKACWFILAAIYHLGAAGATKEAAEAGRKQFARHEWAQKAAYLLGCSLEELSSAIFKHQHKGGTLQRSTSFRQGPEESGLGDGTGPKLSALECLEGMAAGLYSELFTLLVSLVNRALKSSQHSLCSMMIVDTPGFQNPEQGGSARGASFEELCHNYTQDRLQRLFHERTFVQELERYKEENIELAFDDLEPPTDDSVAAVDQASHQSLVRSLARTDEARGLLWLLEEEALVPGASEDTLLERLFSYYGPQEGDKKGQSPLLHSSKPHHFLLGHSHGTNWVEYNVTGWLNYTKQNPATQNAPRLLQDSQKKIISNLFLGRAGSATVLSGSIAGLEGGSQLALRRATSMRKTFTTGMAAVKKKSLCIQMKLQVDALIDTIKKSKLHFVHCFLPVAEGWAGEPRSASSRRVSSSSELDLPSGDHCEAGLLQLDVPLLRTQLRGSRLLDAMRMYRQGYPDHMVFSEFRRRFDVLAPHLTKKHGRNYIVVDERRAVEELLECLDLEKSSCCMGLSRVFFRAGTLARLEEQRDEQTSRNLTLFQAACRGYLARQHFKKRKIQDLAIRCVQKNIKKNKGVKDWPWWKLFTTVRPLIEVQLSEEQIRNKDEEIQQLRSKLEKAEKERNELRLNSDRLESRISELTSELTDERNTGESASQLLDAETAERLRAEKEMKELQTQYDALKKQMEVMEMEVMEARLIRAAEINGEVDDDDAGGEWRLKYERAVREVDFTKKRLQQEFEDKLEVEQQNKRQLERRLGDLQADSEESQRALQQLKKKCQRLTAELQDTKLHLEGQQVRNHELEKKQRRFDSELSQAHEEAQREKLQREKLQREKDMLLAEAFSLKQQLEEKDMDIAGFTQKVVSLEAELQDISSQESKDEASLAKVKKQLRDLEAKVKDQEEELDEQAGTIQMLEQAKLRLEMEMERMRQTHSKEMESRDEEVEEARQSCQKKLKQMEVQLEEEYEDKQKVLREKRELEGKLATLSDQVNRRDFESEKRLRKDLKRTKALLADAQLMLDHLKNSAPSKREIAQLKNQLEESEFTCAAAVKARKAMEVEIEDLHLQIDDIAKAKTALEEQLSRLQREKNEIQNRLEEDQEDMNELMKKHKAAVAQASRDLAQINDLQAQLEEANKEKQELQEKLQALQSQVEFLEQSMVDKSLVSRQEAKIRELETRLEFERTQVKRLESLASRLKENMEKLTEERDQRIAAENREKEQNKRLQRQLRDTKEEMGELARKEAEASRKKHELEMDLESLEAANQSLQADLKLAFKRIGDLQAAIEDEMESDENEDLINSLQDMVTKYQKRKNKLEGDSDVDSELEDRVDGVKSWLSKNKGPSKAASDDGSLKSSSPTSYWKSLAPDRSDDEHDPLDNTSRPRYSHSYLSDSDTEAKLTETNA>sp|Q92614-3|MY18A_HUMAN Isoform 3 of Unconventional myosin-XVIIIaOS=Homo sapiens OX=9606 GN=MYO18AMFNLMKKDKDKDGGRKEKKEKKEKKERMSAAELRSLEEMSLRRGFFNLNRSSKRESKTRLEISNPIPIKVASGSDLHLTDIDSDSNRGSVILDSGHLSTASSSDDLKGEEGSFRGSVLQRAAKFGSLAKQNSQMIVKRFSFSQRSRDESASETSTPSEHSAAPSPQVEVRTLEGQLVQHPGPGIPRPGHRSRAPELVTKKFPVDLRLPPVVPLPPPTLRELELQRRPTGDFGFSLRRTTMLDRGPEGQACRRVVHFAEPGAGTKDLALGLVPGDRLVEINGHNVESKSRDEIVEMIRQSGDSVRLKVQPIPELSELSRSWLRSGEGPRREPSDAKTEEQIAAEEAWNETEKVWLVHRDGFSLASQLKSEELNLPEGKVRVKLDHDGAILDVDEDDVEKANAPSCDRLEDLASLVYLNESSVLHTLRQRYGASLLHTYAGPSLLVLGPRGAPAVYSEKVMHMFKGCRREDMAPHIYAVAQTAYRAMLMSRQDQSIILLGSSGSGKTTSCQHLVQYLATIAGISGNKVFSVEKWQALYTLLEAFGNSPTIINGNATRFSQILSLDFDQAGQVASASIQTMLLEKLRVARRPASEATFNVFYYLLACGDGTLRTELHLNHLAENNVFGIVPLAKPEEKQKAAQQFSKLQAAMKVLGISPDEQKACWFILAAIYHLGAAGATKEAAEAGRKQFARHEWAQKAAYLLGCSLEELSSAIFKHQHKGGTLQRSTSFRQGPEESGLGDGTGPKLSALECLEGMAAGLYSELFTLLVSLVNRALKSSQHSLCSMMIVDTPGFQNPEQGGSARGASFEELCHNYTQDRLQRLFHERTFVQELERYKEENIELAFDDLEPPTDDSVAAVDQASHQSLVRSLARTDEARGLLWLLEEEALVPGASEDTLLERLFSYYGPQEGDKKGQSPLLHSSKPHHFLLGHSHGTNWVEYNVTGWLNYTKQNPATQNAPRLLQDSQKKIISNLFLGRAGSATVLSGSIAGLEGGSQLALRRATSMRKTFTTGMAAVKKKSLCIQMKLQVDALIDTIKKSKLHFVHCFLPVAEGWAGEPRSASSRRVSSSSELDLPSGDHCEAGLLQLDVPLLRTQLRGSRLLDAMRMYRQGYPDHMVFSEFRRRFDVLAPHLTKKHGRNYIVVDERRAVEELLECLDLEKSSCCMGLSRVFFRAGTLARLEEQRDEQTSRNLTLFQAACRGYLARQHFKKRKIQDLAIRCVQKNIKKNKGVKDWPWWKLFTTVRPLIEVQLSEEQIRNKDEEIQQLRSKLEKAEKERNELRLNSDRLESRISELTSELTDERNTGESASQLLDAETAERLRAEKEMKELQTQYDALKKQMEVMEMEVMEARLIRAAEINGEVDDDDAGGEWRLKYERAVREVDFTKKRLQQEFEDKLEVEQQNKRQLERRLGDLQADSEESQRALQQLKKKCQRLTAELQDTKLHLEGQQVRNHELEKKQRRFDSELSQAHEEAQREKLQREKLQREKDMLLAEAFSLKQQLEEKDMDIAGFTQKVVSLEAELQDISSQESKDEASLAKVKKQLRDLEAKVKDQEEELDEQAGTIQMLEQLKQMEVQLEEEYEDKQKVLREKRELEGKLATLSDQVNRRDFESEKRLRKDLKRTKALLADAQLMLDHLKNSAPSKREIAQLKNQLEESEFTCAAAVKARKAMEVEIEDLHLQIDDIAKAKTALEEQLSRLQREKNEIQNRLEEDQEDMNELMKKHKAAVAQASRDLAQINDLQAQLEEANKEKQELQEKLQALQSQVEFLEQSMVDKSLVSRQEAKIRELETRLEFERTQVKRLESLASRLKENMEKLTEERDQRIAAENREKEQNKRLQRQLRDTKEEMGELARKEAEASRKKHELEMDLESLEAANQSLQADLKLAFKRIGDLQAAIEDEMESDENEDLINSEGDSDVDSELEDRVDGVKSWLSKNKGPSKAASDDGSLKSSSPTSYWKSLAPDRSDDEHDPLDNTSRPRYSHSYLSDSDTEAKLTETNA>sp|Q92614-4|MY18A_HUMAN Isoform 4 of Unconventional myosin-XVIIIaOS=Homo sapiens OX=9606 GN=MYO18AMFNLMKKDKDKDGGRKEKKEKKEKKERMSAAELRSLEEMSLRRGFFNLNRSSKRESKTRLEISNPIPIKVASGSDLHLTDIDSDSNRGSVILDSGHLSTASSSDDLKGEEGSFRGSVLQRAAKFGSLAKQNSQMIVKRFSFSQRSRDESASETSTPSEHSAAPSPQVEVRTLEGQLVQHPGPGIPRPGHRSRAPELVTKKFPVDLRLPPVVPLPPPTLRELELQRRPTGDFGFSLRRTTMLDRGPEGQACRRVVHFAEPGAGTKDLALGLVPGDRLVEINGHNVESKSRDEIVEMIRQSGDSVRLKVQPIPELSELSRSWLRSGEGPRREPSDAKTEEQIAAEEAWNETEKVWLVHRDGFSLASQLKSEELNLPEGKVRVKLDHDGAILDVDEDDVEKANAPSCDRLEDLASLVYLNESSVLHTLRQRYGASLLHTYAGPSLLVLGPRGAPAVYSEKVMHMFKGCRREDMAPHIYAVAQTAYRAMLMSRQDQSIILLGSSGSGKTTSCQHLVQYLATIAGISGNKVFSVEKWQALYTLLEAFGNSPTIINGNATRFSQILSLDFDQAGQVASASIQTMLLEKLRVARRPASEATFNVFYYLLACGDGTLRTELHLNHLAENNVFGIVPLAKPEEKQKAAQQFSKLQAAMKVLGISPDEQKACWFILAAIYHLGAAGATKEAAEAGRKQFARHEWAQKAAYLLGCSLEELSSAIFKHQHKGGTLQRSTSFRQGPEESGLGDGTGPKLSALECLEGMAAGLYSELFTLLVSLVNRALKSSQHSLCSMMIVDTPGFQNPEQGGSARGASFEELCHNYTQDRLQRLFHERTFVQELERYKEENIELAFDDLEPPTDDSVAAVDQASHQSLVRSLARTDEARGLLWLLEEEALVPGASEDTLLERLFSYYGPQEGDKKGQSPLLHSSKPHHFLLGHSHGTNWVEYNVTGWLNYTKQNPATQNAPRLLQDSQKKIISNLFLGRAGSATVLSGSIAGLEGGSQLALRRATSMRKTFTTGMAAVKKKSLCIQMKLQVDALIDTIKKSKLHFVHCFLPVAEGWAGEPRSASSRRVSSSSELDLPSGDHCEAGLLQLDVPLLRTQLRGSRLLDAMRMYRQGYPDHMVFSEFRRRFDVLAPHLTKKHGRNYIVVDERRAVEELLECLDLEKSSCCMGLSRVFFRAGTLARLEEQRDEQTSRNLTLFQAACRGYLARQHFKKRKIQDLAIRCVQKNIKKNKGVKDWPWWKLFTTVRPLIEVQLSEEQIRNKDEEIQQLRSKLEKAEKERNELRLNSDRLESRISELTSELTDERNTGESASQLLDAETAERLRAEKEMKELQTQYDALKKQMEVMEMEVMEARLIRAAEINGEVDDDDAGGEWRLKYERAVREVDFTKKRLQQEFEDKLEVEQQNKRQLERRLGDLQADSEESQRALQQLKKKCQRLTAELQDTKLHLEGQQVRNHELEKKQRRFDSELSQAHEEAQREKLQREKLQREKDMLLAEAFSLKQQLEEKDMDIAGFTQKVVSLEAELQDISSQESKDEASLAKVKKQLRDLEAKVKDQEEELDEQAGTIQMLEQAKLRLEMEMERMRQTHSKEMESRDEEVEEARQSCQKKLKQMEVQLEEEYEDKQKVLREKRELEGKLATLSDQVNRRDFESEKRLRKDLKRTKALLADAQLMLDHLKNSAPSKREIAQLKNQLEESEFTCAAAVKARKAMEVEIEDLHLQIDDIAKAKTALEEQLSRLQREKNEIQNRLEEDQEDMNELMKKHKAAVAQASRDLAQINDLQAQLEEANKEKQELQEKLQALQSQVEFLEQSMVDKSLVSRQEAKIRELETRLEFERTQVKRLESLASRLKENMEKLTEERDQRIAAENREKEQNKRLQRQLRDTKEEMGELARKEAEASRKKHELEMDLESLEAANQSLQADLKLAFKRIGDLQAAIEDEMESDENEDLINSEGDSDVDSELEDRVDGVKSWLSKNKGPSKAASDDGSLKSSSPTSYWKSLAPDRSDDEHDPLDNTSRPRYSHSYLSDSDTEAKLTETNA>sp|Q92614-5|MY18A_HUMAN Isoform 5 of Unconventional myosin-XVIIIaOS=Homo sapiens OX=9606 GN=MYO18AMHMFKGCRREDMAPHIYAVAQTAYRAMLMSRQDQSIILLGSSGSGKTTSCQHLVQYLATIAGISGNKVFSVEKWQALYTLLEAFGNSPTIINGNATRFSQILSLDFDQAGQVASASIQTMLLEKLRVARRPASEATFNVFYYLLACGDGTLRTELHLNHLAENNVFGIVPLAKPEEKQKAAQQFSKLQAAMKVLGISPDEQKACWFILAAIYHLGAAGATKEAAEAGRKQFARHEWAQKAAYLLGCSLEELSSAIFKHQHKGGTLQRSTSFRQGPEESGLGDGTGPKLSALECLEGMAAGLYSELFTLLVSLVNRALKSSQHSLCSMMIVDTPGFQNPEQGGSARGASFEELCHNYTQDRLQRLFHERTFVQELERYKEENIELAFDDLEPPTDDSVAAVDQASHQSLVRSLARTDEARGLLWLLEEEALVPGASEDTLLERLFSYYGPQEGDKKGQSPLLHSSKPHHFLLGHSHGTNWVEYNVTGWLNYTKQNPATQNAPRLLQDSQKKIISNLFLGRAGSATVLSGSIAGLEGGSQLALRRATSMRKTFTTGMAAVKKKSLCIQMKLQVDALIDTIKKSKLHFVHCFLPVAEGWAGEPRSASSRRVSSSSELDLPSGDHCEAGLLQLDVPLLRTQLRGSRLLDAMRMYRQGYPDHMVFSEFRRRFDVLAPHLTKKHGRNYIVVDERRAVEELLECLDLEKSSCCMGLSRVFFRAGTLARLEEQRDEQTSRNLTLFQAACRGYLARQHFKKRKIQDLAIRCVQKNIKKNKGVKDWPWWKLFTTVRPLIEVQLSEEQIRNKDEEIQQLRSKLEKAEKERNELRLNSDRLESRISELTSELTDERNTGESASQLLDAETAERLRAEKEMKELQTQYDALKKQMEVMEMEVMEARLIRAAEINGEVDDDDAGGEWRLKYERAVREVDFTKKRLQQEFEDKLEVEQQNKRQLERRLGDLQADSEESQRALQQLKKKCQRLTAELQDTKLHLEGQQVRNHELEKKQRRFDSELSQAHEEAQREKLQREKLQREKDMLLAEAFSLKQQLEEKDMDIAGFTQKVVSLEAELQDISSQESKDEASLAKVKKQLRDLEAKVKDQEEELDEQAGTIQMLEQAKLRLEMEMERMRQTHSKEMESRDEEVEEARQSCQKKLKQMEVQLEEEYEDKQKVLREKRELEGKLATLSDQVNRRDFESEKRLRKDLKRTKALLADAQLMLDHLKNSAPSKREIAQLKNQLEESEFTCAAAVKARKAMEVEIEDLHLQIDDIAKAKTALEEQLSRLQREKNEIQNRLEEDQEDMNELMKKHKAAVAQASRDLAQINDLQAQLEEANKEKQELQEKLQALQSQVEFLEQSMVDKSLVSRQEAKIRELETRLEFERTQVKRLESLASRLKENMEKLTEERDQRIAAENREKEQNKRLQRQLRDTKEEMGELARKEAEASRKKHELEMDLESLEAANQSLQADLKLAFKRIGDLQAAIEDEMESDENEDLINSEGDSDVDSELEDRVDGVKSWLSKNKGPSKAASDDGSLKSSSPTSYWKSLAPDRSDDEHDPLDNTSRPRYSHSYLSDSDTEAKLTETNA>sp|Q53FP2|NACHO_HUMAN Novel acetylcholine receptor chaperone OS=Homosapiens OX=9606 GN=TMEM35A PE=1 SV=2MASPRTVTIVALSVALGLFFVFMGTIKLTPRLSKDAYSEMKRAYKSYVRALPLLKKMGINSILLRKSIGALEVACGIVMTLVPGRPKDVANFFLLLLVLAVLFFHQLVGDPLKRYAHALVFGILLTCRLLIARKPEDRSSEKKPLPGNAEEQPSLYEKAPQGKVKVS>sp|Q02045|MYL5_HUMAN Myosin light chain 5 OS=Homo sapiens OX=9606GN=MYL5 PE=2 SV=1MASRKTKKKEGGALRAQRASSNVFSNFEQTQIQEFKEAFTLMDQNRDGFIDKEDLKDTYASLGKTNVKDDELDAMLKEASGPINFTMFLNLFGEKLSGTDAEETILNAFKMLDPDGKGKINKEYIKRLLMSQADKMTAEEVDQMFQFASIDVAGNLDYKALSYVITHGEEKEE>sp|Q02045-2|MYL5_HUMAN Isoform 2 of Myosin light chain 5 OS=Homo sapiensOX=9606 GN=MYL5MDQNRDGFIDKEDLKDTYASLGKTNVKDDELDAMLKEASGPINFTMFLNLFGEKLSGTDAEETILNAFKMLDPDGKGKINKEYIKRLLMSQADKMTAEEVDQMFQFASIDVAGNLDYKALSYVITHGEEKEE>sp|Q13516|OLIG2_HUMAN Oligodendrocyte transcription factor 2 OS=Homosapiens OX=9606 GN=OLIG2 PE=1 SV=2MDSDASLVSSRPSSPEPDDLFLPARSKGSSGSAFTGGTVSSSTPSDCPPELSAELRGAMGSAGAHPGDKLGGSGFKSSSSSTSSSTSSAAASSTKKDKKQMTEPELQQLRLKINSRERKRMHDLNIAMDGLREVMPYAHGPSVRKLSKIATLLLARNYILMLTNSLEEMKRLVSEIYGGHHAGFHPSACGGLAHSAPLPAATAHPAAAAHAAHHPAVHHPILPPAAAAAAAAAAAAAVSSASLPGSGLPSVGSIRPPHGLLKSPSAAAAAPLGGGGGGSGASGGFQHWGGMPCPCSMCQVPPPHHHVSAMGAGSLPRLTSDAK>sp|O95156|NXPH2_HUMAN Neurexophilin-2 OS=Homo sapiens OX=9606 GN=NXPH2PE=2 SV=2MRLRPLPLVVVPGLLQLLFCDSKEVVHATEGLDWEDKDAPGTLVGNVVHSRIISPLRLFVKQSPVPKPGPMAYADSMENFWDWLANITEIQEPLARTKRRPIVKTGKFKKMFGWGDFHSNIKTVKLNLLITGKIVDHGNGTFSVYFRHNSTGLGNVSVSLVPPSKVVEFEVSPQSTLETKESKSFNCRIEYEKTDRAKKTALCNFDPSKICYQEQTQSHVSWLCSKPFKVICIYIAFYSVDYKLVQKVCPDYNYHSETPYLSSG>sp|Q86Y26|NUTM1_HUMAN NUT family member 1 OS=Homo sapiens OX=9606GN=NUTM1 PE=1 SV=2MASDGASALPGPDMSMKPSAAPSPSPALPFLPPTSDPPDHPPREPPPQPIMPSVFSPDNPLMLSAFPSSLLVTGDGGPCLSGAGAGKVIVKVKTEGGSAEPSQTQNFILTQTALNSTAPGTPCGGLEGPAPPFVTASNVKTILPSKAVGVSQEGPPGLPPQPPPPVAQLVPIVPLEKAWPGPHGTTGEGGPVATLSKPSLGDRSKISKDVYENFRQWQRYKALARRHLSQSPDTEALSCFLIPVLRSLARLKPTMTLEEGLPLAVQEWEHTSNFDRMIFYEMAERFMEFEAEEMQIQNTQLMNGSQGLSPATPLKLDPLGPLASEVCQQPVYIPKKAASKTRAPRRRQRKAQRPPAPEAPKEIPPEAVKEYVDIMEWLVGTHLATGESDGKQEEEGQQQEEEGMYPDPGLLSYINELCSQKVFVSKVEAVIHPQFLADLLSPEKQRDPLALIEELEQEEGLTLAQLVQKRLMALEEEEDAEAPPSFSGAQLDSSPSGSVEDEDGDGRLRPSPGLQGAGGAACLGKVSSSGKRAREVHGGQEQALDSPRGMHRDGNTLPSPSSWDLQPELAAPQGTPGPLGVERRGSGKVINQVSLHQDGHLGGAGPPGHCLVADRTSEALPLCWQGGFQPESTPSLDAGLAELAPLQGQGLEKQVLGLQKGQQTGGRGVLPQGKEPLAVPWEGSSGAMWGDDRGTPMAQSYDQNPSPRAAGERDDVCLSPGVWLSSEMDAVGLELPVQIEEVIESFQVEKCVTEYQEGCQGLGSRGNISLGPGETLVPGDTESSVIPCGGTVAAAALEKRNYCSLPGPLRANSPPLRSKENQEQSCETVGHPSDLWAEGCFPLLESGDSTLGSSKETLPPTCQGNLLIMGTEDASSLPEASQEAGSRGNSFSPLLETIEPVNILDVKDDCGLQLRVSEDTCPLNVHSYDPQGEGRVDPDLSKPKNLAPLQESQESYTTGTPKATSSHQGLGSTLPRRGTRNAIVPRETSVSKTHRSADRAKGKEKKKKEAEEEDEELSNFAYLLASKLSLSPREHPLSPHHASGGQGSQRASHLLPAGAKGPSKLPYPVAKSGKRALAGGPAPTEKTPHSGAQLGVPREKPLALGVVRPSQPRKRRCDSFVTGRRKKRRRSQ>sp|Q86Y26-2|NUTM1_HUMAN Isoform 2 of NUT family member 1 OS=Homo sapiensOX=9606 GN=NUTM1MASDGASALPGPDMSMKPSAAPSPSPALPFLPPTSDPPDHPPREPPPQPIMPSVFSPDNPLMLSAFPSSLLVTGDGGPCLSGAGAGKVIVKVKTEGGSAEPSQTQNFILTQTALNSTAPGTPCGGLEGPAPPFVTASNVKTILPSKAVGVSQEGPPGLPPQPPPPVAQLVPIVPLEKAWPGPHGTTGEGGPVATLSKPSLGDRSKISKDVYENFRQWQRYKALARRHLSQSPDTEAVKEYVDIMEWLVGTHLATGESDGKQEEEGQQQEEEGMYPDPGLLSYINELCSQKVFVSKVEAVIHPQFLADLLSPEKQRDPLALIEELEQEEGLTLAQLVQKRLMALEEEEDAEAPPSFSGAQLDSSPSGSVEDEDGDGRLRPSPGLQGAGGAACLGKVSSSGKRAREVHGGQEQALDSPRGMHRDGNTLPSPSSWDPPTNGESQC>sp|Q86Y26-3|NUTM1_HUMAN Isoform 3 of NUT family member 1 OS=Homo sapiensOX=9606 GN=NUTM1MFQRSNQDLKLGPYRKFSALSYGASALPGPDMSMKPSAAPSPSPALPFLPPTSDPPDHPPREPPPQPIMPSVFSPDNPLMLSAFPSSLLVTGDGGPCLSGAGAGKVIVKVKTEGGSAEPSQTQNFILTQTALNSTAPGTPCGGLEGPAPPFVTASNVKTILPSKAVGVSQEGPPGLPPQPPPPVAQLVPIVPLEKAWPGPHGTTGEGGPVATLSKPSLGDRSKISKDVYENFRQWQRYKALARRHLSQSPDTEALSCFLIPVLRSLARLKPTMTLEEGLPLAVQEWEHTSNFDRMIFYEMAERFMEFEAEEMQIQNTQLMNGSQGLSPATPLKLDPLGPLASEVCQQPVYIPKKAASKTRAPRRRQRKAQRPPAPEAPKEIPPEAVKEYVDIMEWLVGTHLATGESDGKQEEEGQQQEEEGMYPDPGLLSYINELCSQKVFVSKVEAVIHPQFLADLLSPEKQRDPLALIEELEQEEGLTLAQLVQKRLMALEEEEDAEAPPSFSGAQLDSSPSGSVEDEDGDGRLRPSPGLQGAGGAACLGKVSSSGKRAREVHGGQEQALDSPRGMHRDGNTLPSPSSWDLQPELAAPQGTPGPLGVERRGSGKVINQVSLHQDGHLGGAGPPGHCLVADRTSEALPLCWQGGFQPESTPSLDAGLAELAPLQGQGLEKQVLGLQKGQQTGGRGVLPQGKEPLAVPWEGSSGAMWGDDRGTPMAQSYDQNPSPRAAGERDDVCLSPGVWLSSEMDAVGLELPVQIEEVIESFQVEKCVTEYQEGCQGLGSRGNISLGPGETLVPGDTESSVIPCGGTVAAAALEKRNYCSLPGPLRANSPPLRSKENQEQSCETVGHPSDLWAEGCFPLLESGDSTLGSSKETLPPTCQGNLLIMGTEDASSLPEASQEAGSRGNSFSPLLETIEPVNILDVKDDCGLQLRVSEDTCPLNVHSYDPQGEGRVDPDLSKPKNLAPLQESQESYTTGTPKATSSHQGLGSTLPRRGTRNAIVPRETSVSKTHRSADRAKGKEKKKKEAEEEDEELSNFAYLLASKLSLSPREHPLSPHHASGGQGSQRASHLLPAGAKGPSKLPYPVAKSGKRALAGGPAPTEKTPHSGAQLGVPREKPLALGVVRPSQPRKRRCDSFVTGRRKKRRRSQ>sp|Q86Y26-4|NUTM1_HUMAN Isoform 4 of NUT family member 1 OS=Homo sapiensOX=9606 GN=NUTM1MVVTLGPGPDCLILEASRQPQLVPKPERMASDGASALPGPDMSMKPSAAPSPSPALPFLPPTSDPPDHPPREPPPQPIMPSVFSPDNPLMLSAFPSSLLVTGDGGPCLSGAGAGKVIVKVKTEGGSAEPSQTQNFILTQTALNSTAPGTPCGGLEGPAPPFVTASNVKTILPSKAVGVSQEGPPGLPPQPPPPVAQLVPIVPLEKAWPGPHGTTGEGGPVATLSKPSLGDRSKISKDVYENFRQWQRYKALARRHLSQSPDTEALSCFLIPVLRSLARLKPTMTLEEGLPLAVQEWEHTSNFDRMIFYEMAERFMEFEAEEMQIQNTQLMNGSQGLSPATPLKLDPLGPLASEVCQQPVYIPKKAASKTRAPRRRQRKAQRPPAPEAPKEIPPEAVKEYVDIMEWLVGTHLATGESDGKQEEEGQQQEEEGMYPDPGLLSYINELCSQKVFVSKVEAVIHPQFLADLLSPEKQRDPLALIEELEQEEGLTLAQLVQKRLMALEEEEDAEAPPSFSGAQLDSSPSGSVEDEDGDGRLRPSPGLQGAGGAACLGKVSSSGKRAREVHGGQEQALDSPRGMHRDGNTLPSPSSWDLQPELAAPQGTPGPLGVERRGSGKVINQVSLHQDGHLGGAGPPGHCLVADRTSEALPLCWQGGFQPESTPSLDAGLAELAPLQGQGLEKQVLGLQKGQQTGGRGVLPQGKEPLAVPWEGSSGAMWGDDRGTPMAQSYDQNPSPRAAGERDDVCLSPGVWLSSEMDAVGLELPVQIEEVIESFQVEKCVTEYQEGCQGLGSRGNISLGPGETLVPGDTESSVIPCGGTVAAAALEKRNYCSLPGPLRANSPPLRSKENQEQSCETVGHPSDLWAEGCFPLLESGDSTLGSSKETLPPTCQGNLLIMGTEDASSLPEASQEAGSRGNSFSPLLETIEPVNILDVKDDCGLQLRVSEDTCPLNVHSYDPQGEGRVDPDLSKPKNLAPLQESQESYTTGTPKATSSHQGLGSTLPRRGTRNAIVPRETSVSKTHRSADRAKGKEKKKKEAEEEDEELSNFAYLLASKLSLSPREHPLSPHHASGGQGSQRASHLLPAGAKGPSKLPYPVAKSGKRALAGGPAPTEKTPHSGAQLGVPREKPLALGVVRPSQPRKRRCDSFVTGRRKKRRRSQ>sp|Q9UBU9|NXF1_HUMAN Nuclear RNA export factor 1 OS=Homo sapiens OX=9606GN=NXF1 PE=1 SV=1MADEGKSYSEHDDERVNFPQRKKKGRGPFRWKYGEGNRRSGRGGSGIRSSRLEEDDGDVAMSDAQDGPRVRYNPYTTRPNRRGDTWHDRDRIHVTVRRDRAPPERGGAGTSQDGTSKNWFKITIPYGRKYDKAWLLSMIQSKCSVPFTPIEFHYENTRAQFFVEDASTASALKAVNYKILDRENRRISIIINSSAPPHTILNELKPEQVEQLKLIMSKRYDGSQQALDLKGLRSDPDLVAQNIDVVLNRRSCMAATLRIIEENIPELLSLNLSNNRLYRLDDMSSIVQKAPNLKILNLSGNELKSERELDKIKGLKLEELWLDGNSLCDTFRDQSTYISAIRERFPKLLRLDGHELPPPIAFDVEAPTTLPPCKGSYFGTENLKSLVLHFLQQYYAIYDSGDRQGLLDAYHDGACCSLSIPFIPQNPARSSLAEYFKDSRNVKKLKDPTLRFRLLKHTRLNVVAFLNELPKTQHDVNSFVVDISAQTSTLLCFSVNGVFKEVDGKSRDSLRAFTRTFIAVPASNSGLCIVNDELFVRNASSEEIQRAFAMPAPTPSSSPVPTLSPEQQEMLQAFSTQSGMNLEWSQKCLQDNNWDYTRSAQAFTHLKAKGEIPEVAFMK>sp|Q9UBU9-2|NXF1_HUMAN Isoform 2 of Nuclear RNA export factor 1 OS=Homosapiens OX=9606 GN=NXF1MADEGKSYSEHDDERVNFPQRKKKGRGPFRWKYGEGNRRSGRGGSGIRSSRLEEDDGDVAMSDAQDGPRVRYNPYTTRPNRRGDTWHDRDRIHVTVRRDRAPPERGGAGTSQDGTSKNWFKITIPYGRKYDKAWLLSMIQSKCSVPFTPIEFHYENTRAQFFVEDASTASALKAVNYKILDRENRRISIIINSSAPPHTILNELKPEQVEQLKLIMSKRYDGSQQALDLKGLRSDPDLVAQNIDVVLNRRSCMAATLRIIEENIPELLSLNLSNNRLYRLDDMSSIVQKAPNLKILNLSGNELKSERELDKIKGLKLEELWLDGNSLCDTFRDQSTYIRSVVACVSPPGDLHPLGG>sp|P22059|OSBP1_HUMAN Oxysterol-binding protein 1 OS=Homo sapiensOX=9606 GN=OSBP PE=1 SV=1MAATELRGVVGPGPAAIAALGGGGAGPPVVGGGGGRGDAGPGSGAASGTVVAAAAGGPGPGAGGVAAAGPAPAPPTGGSGGSGAGGSGSAREGWLFKWTNYIKGYQRRWFVLSNGLLSYYRSKAEMRHTCRGTINLATANITVEDSCNFIISNGGAQTYHLKASSEVERQRWVTALELAKAKAVKMLAESDESGDEESVSQTDKTELQNTLRTLSSKVEDLSTCNDLIAKHGTALQRSLSELESLKLPAESNEKIKQVNERATLFRITSNAMINACRDFLMLAQTHSKKWQKSLQYERDQRIRLEETLEQLAKQHNHLERAFRGATVLPANTPGNVGSGKDQCCSGKGDMSDEDDENEFFDAPEIITMPENLGHKRTGSNISGASSDISLDEQYKHQLEETKKEKRTRIPYKPNYSLNLWSIMKNCIGKELSKIPMPVNFNEPLSMLQRLTEDLEYHELLDRAAKCENSLEQLCYVAAFTVSSYSTTVFRTSKPFNPLLGETFELDRLEENGYRSLCEQVSHHPPAAAHHAESKNGWTLRQEIKITSKFRGKYLSIMPLGTIHCIFHATGHHYTWKKVTTTVHNIIVGKLWIDQSGEIDIVNHKTGDKCNLKFVPYSYFSRDVARKVTGEVTDPSGKVHFALLGTWDEKMECFKVQPVIGENGGDARQRGHEAEESRVMLWKRNPLPKNAENMYYFSELALTLNAWESGTAPTDSRLRPDQRLMENGRWDEANAEKQRLEEKQRLSRKKREAEAMKATEDGTPYDPYKALWFERKKDPVTKELTHIYRGEYWECKEKQDWSSCPDIF>sp|Q8NGB6|OR4M2_HUMAN Olfactory receptor 4M2 OS=Homo sapiens OX=9606GN=OR4M2 PE=2 SV=2METANYTKVTEFVLTGLSQTPEVQLVLFVIFLSFYLFILPGNILIICTISLDPHLTSPMYFLLANLAFLDIWYSSITAPEMLIDFFVERKIISFDGCIAQLFFLHFAGASEMFLLTVMAFDLYTAICRPLHYATIMNQRLCCILVALSWRGGFIHSIIQVALIVRLPFCGPNELDSYFCDITQVVRIACANTFPEELVMICSSGLISVVCLIALLMSYAFLLALFKKLSGSGENTNRAMSTCYSHITIVVLMFGPSIYIYARPFDSFSLDKVVSVFNTLIFPLRNPIIYTLRNKEVKAAMRKLVTKYILCKEK>sp|Q8NGX0|O11L1_HUMAN Olfactory receptor 11L1 OS=Homo sapiens OX=9606GN=OR11L1 PE=2 SV=1MEPQNTSTVTNFQLLGFQNLLEWQALLFVIFLLIYCLTIIGNVVIITVVSQGLRLHSPMYMFLQHLSFLEVWYTSTTVPLLLANLLSWGQAISFSACMAQLYFFVFLGATECFLLAFMAYDRYLAICSPLRYPFLMHRGLCARLVVVSWCTGVSTGFLPSLMISRLDFCGRNQINHFFCDLPPLMQLSCSRVYITEVTIFILSIAVLCICFFLTLGPYVFIVSSILRIPSTSGRRKTFSTCGSHLAVVTLYYGTMISMYVCPSPHLLPEINKIISVFYTVVTPLLNPVIYSLRNKDFKEAVRKVMRRKCGILWSTSKRKFLY>sp|Q8NH67|O52I2_HUMAN Olfactory receptor 52I2 OS=Homo sapiens OX=9606GN=OR52I2 PE=2 SV=3MCQQILRDCILLIHHLCINRKKVSLVMLGPAYNHTMETPASFLLVGIPGLQSSHLWLAISLSAMYIIALLGNTIIVTAIWMDSTRHEPMYCFLCVLAAVDIVMASSVVPKMVSIFCSGDSSISFSACFTQMFFVHLATAVETGLLLTMAFDRYVAICKPLHYKRILTPQVMLGMSMAITIRAIIAITPLSWMVSHLPFCGSNVVVHSYCEHIALARLACADPVPSSLYSLIGSSLMVGSDVAFIAASYILILKAVFGLSSKTAQLKALSTCGSHVGVMALYYLPGMASIYAAWLGQDVVPLHTQVLLADLYVIIPATLNPIIYGMRTKQLRERIWSYLMHVLFDHSNLGS>sp|Q99460|PSMD1_HUMAN 26S proteasome non-ATPase regulatory subunit 1OS=Homo sapiens OX=9606 GN=PSMD1 PE=1 SV=2MITSAAGIISLLDEDEPQLKEFALHKLNAVVNDFWAEISESVDKIEVLYEDEGFRSRQFAALVASKVFYHLGAFEESLNYALGAGDLFNVNDNSEYVETIIAKCIDHYTKQCVENADLPEGEKKPIDQRLEGIVNKMFQRCLDDHKYKQAIGIALETRRLDVFEKTILESNDVPGMLAYSLKLCMSLMQNKQFRNKVLRVLVKIYMNLEKPDFINVCQCLIFLDDPQAVSDILEKLVKEDNLLMAYQICFDLYESASQQFLSSVIQNLRTVGTPIASVPGSTNTGTVPGSEKDSDSMETEEKTSSAFVGKTPEASPEPKDQTLKMIKILSGEMAIELHLQFLIRNNNTDLMILKNTKDAVRNSVCHTATVIANSFMHCGTTSDQFLRDNLEWLARATNWAKFTATASLGVIHKGHEKEALQLMATYLPKDTSPGSAYQEGGGLYALGLIHANHGGDIIDYLLNQLKNASNDIVRHGGSLGLGLAAMGTARQDVYDLLKTNLYQDDAVTGEAAGLALGLVMLGSKNAQAIEDMVGYAQETQHEKILRGLAVGIALVMYGRMEEADALIESLCRDKDPILRRSGMYTVAMAYCGSGNNKAIRRLLHVAVSDVNDDVRRAAVESLGFILFRTPEQCPSVVSLLSESYNPHVRYGAAMALGICCAGTGNKEAINLLEPMTNDPVNYVRQGALIASALIMIQQTEITCPKVNQFRQLYSKVINDKHDDVMAKFGAILAQGILDAGGHNVTISLQSRTGHTHMPSVVGVLVFTQFWFWFPLSHFLSLAYTPTCVIGLNKDLKMPKVQYKSNCKPSTFAYPAPLEVPKEKEKEKVSTAVLSITAKAKKKEKEKEKKEEEKMEVDEAEKKEEKEKKKEPEPNFQLLDNPARVMPAQLKVLTMPETCRYQPFKPLSIGGIIILKDTSEDIEELVEPVAAHGPKIEEEEQEPEPPEPFEYIDD>sp|Q99460-2|PSMD1_HUMAN Isoform 2 of 26S proteasome non-ATPaseregulatory subunit 1 OS=Homo sapiens OX=9606 GN=PSMD1MITSAAGIISLLDEDEPQLKEFALHKLNAVVNDFWAEISESVDKIEVLYEDEGFRSRQFAALVASKVFYHLGAFEESLNYALGAGDLFNVNDNSEYVETIIAKCIDHYTKQCVENADLPEGEKKPIDQRLEGIVNKMFQRCLDDHKYKQAIGIALETRRLDVFEKTILESNDVPGMLAYSLKLCMSLMQNKQFRNKVLRVLVKIYMNLEKPDFINVCQCLIFLDDPQAVSDILEKLVKEDNLLMAYQICFDLYESASQQFLSSVIQNLRTVGTPIASVPGSTNTGTVPGSEKDSDSMETEEKTSSAFVGKTPEASPEPKDQTLKMIKILSGEMAIELHLQFLIRNNNTDLMILKNTKDAVRNSVCHTATVIANSFMHCGTTSDQFLRDNLEWLARATNWAKFTATASLGVIHKGHEKEALQLMATYLPKDTSPGSAYQEGGGLYALGLIHANHGGDIIDYLLNQLKNASNDIVRHGGSLGLGLAAMGTARQDVYDLLKTNLYQDDAVTGEAAGLALGLVMLGSKNAQAIEDMVGYAQETQHEKILRGLAVGIALVMYGRMEEADALIESLCRDKDPILRRSGMYTVAMAYCGSGNNKAIRRLLHVAVSDVNDDVRRAAVESLGFILFRTPEQCPSVVSLLSESYNPHVRYGAAMALGICCAGTGNKEAINLLEPMTNDPVNYVRQGALIASALIMIQQTEITCPKVNQFRQLYSKVINDKHDDVMAKFGAILAQGILDAGGHNVTISLQSRTGHTHMPSVVGVLVFTQFWFWFPLSHFLSLAYTPTCVIGLNKDLKVSTAVLSITAKAKKKEKEKEKKEEEKMEVDEAEKKEEKEKKKEPEPNFQLLDNPARVMPAQLKVLTMPETCRYQPFKPLSIGGIIILKDTSEDIEELVEPVAAHGPKIEEEEQEPEPPEPFEYIDD>sp|Q92626|PXDN_HUMAN Peroxidasin homolog OS=Homo sapiens OX=9606 GN=PXDNPE=1 SV=2MAKRSRGPGRRCLLALVLFCAWGTLAVVAQKPGAGCPSRCLCFRTTVRCMHLLLEAVPAVAPQTSILDLRFNRIREIQPGAFRRLRNLNTLLLNNNQIKRIPSGAFEDLENLKYLYLYKNEIQSIDRQAFKGLASLEQLYLHFNQIETLDPDSFQHLPKLERLFLHNNRITHLVPGTFNHLESMKRLRLDSNTLHCDCEILWLADLLKTYAESGNAQAAAICEYPRRIQGRSVATITPEELNCERPRITSEPQDADVTSGNTVYFTCRAEGNPKPEIIWLRNNNELSMKTDSRLNLLDDGTLMIQNTQETDQGIYQCMAKNVAGEVKTQEVTLRYFGSPARPTFVIQPQNTEVLVGESVTLECSATGHPPPRISWTRGDRTPLPVDPRVNITPSGGLYIQNVVQGDSGEYACSATNNIDSVHATAFIIVQALPQFTVTPQDRVVIEGQTVDFQCEAKGNPPPVIAWTKGGSQLSVDRRHLVLSSGTLRISGVALHDQGQYECQAVNIIGSQKVVAHLTVQPRVTPVFASIPSDTTVEVGANVQLPCSSQGEPEPAITWNKDGVQVTESGKFHISPEGFLTINDVGPADAGRYECVARNTIGSASVSMVLSVNVPDVSRNGDPFVATSIVEAIATVDRAINSTRTHLFDSRPRSPNDLLALFRYPRDPYTVEQARAGEIFERTLQLIQEHVQHGLMVDLNGTSYHYNDLVSPQYLNLIANLSGCTAHRRVNNCSDMCFHQKYRTHDGTCNNLQHPMWGASLTAFERLLKSVYENGFNTPRGINPHRLYNGHALPMPRLVSTTLIGTETVTPDEQFTHMLMQWGQFLDHDLDSTVVALSQARFSDGQHCSNVCSNDPPCFSVMIPPNDSRARSGARCMFFVRSSPVCGSGMTSLLMNSVYPREQINQLTSYIDASNVYGSTEHEARSIRDLASHRGLLRQGIVQRSGKPLLPFATGPPTECMRDENESPIPCFLAGDHRANEQLGLTSMHTLWFREHNRIATELLKLNPHWDGDTIYYETRKIVGAEIQHITYQHWLPKILGEVGMRTLGEYHGYDPGINAGIFNAFATAAFRFGHTLVNPLLYRLDENFQPIAQDHLPLHKAFFSPFRIVNEGGIDPLLRGLFGVAGKMRVPSQLLNTELTERLFSMAHTVALDLAAINIQRGRDHGIPPYHDYRVYCNLSAAHTFEDLKNEIKNPEIREKLKRLYGSTLNIDLFPALVVEDLVPGSRLGPTLMCLLSTQFKRLRDGDRLWYENPGVFSPAQLTQIKQTSLARILCDNADNITRVQSDVFRVAEFPHGYGSCDEIPRVDLRVWQDCCEDCRTRGQFNAFSYHFRGRRSLEFSYQEDKPTKKTRPRKIPSVGRQGEHLSNSTSAFSTRSDASGTNDFREFVLEMQKTITDLRTQIKKLESRLSTTECVDAGGESHANNTKWKKDACTICECKDGQVTCFVEACPPATCAVPVNIPGACCPVCLQKRAEEKP>sp|Q92626-2|PXDN_HUMAN Isoform 2 of Peroxidasin homolog OS=Homo sapiensOX=9606 GN=PXDNMAKRSRGPGRRCLLALVLFCAWGTLAVVAQKPGAGCPSRCLCFRTTVRCMHLLLEAVPAVAPQTSILDLRFNRIREIQPGAFRRLRNLNTLLLNNNQIKRIPSGAFEDLENLKYLYLYKNEIQSIDRQAFKGLASLEQLYLHFNQIETLDPDSFQHLPKLERLFLHNNRITHLVPGTFNHLESMKRLRLDSNTLHCDCEILWLADLLKTYAESGNAQAAAICEYPRRIQGRSVATITPEELNCERPRITSEPQDADVTSGNTVYFTCRAEGNPKPEIIWLRNNNELSMKTDSRLNLLDDGTLMIQNTQETDQGIYQCMAKNVAGEVKTQEVTLRYFGSPARPTFVIQPQNTEVLVGESVTLECSATGHPPPRISWTRGDRTPLPVDPRVNITPSGGLYIQNVVQGDSGEYACSATNNIDSVHATAFIIVQALPQFTVTPQDRVVIEGQTVDFQCEAKGNPPPVIAWTKGGSQLSVDRRHLVLSSGTLRISGVALHDQGQYECQAVNIIGSQKVVAHLTVQPRVTPVFASIPSDTTVEVGANVQLPCSSQGEPEPAITWNKDGVQVTESGKFHISPEGFLTINDVGPADAGRYECVARNTIGSASVSMVLSVNVPDVSRNGDPFVATSIVEAIATVDRAINSTRTHLFDSRPRSPNDLLALFRYPRDPYTVEQARAGEIFERTLQLIQEHVQHGLMVDLNGTSQCQSLFFLLHGLSNGVEHASVKSHS>sp|Q96P65|QRFPR_HUMAN Pyroglutamylated RF-amide peptide receptor OS=Homosapiens OX=9606 GN=QRFPR PE=1 SV=2MQALNITPEQFSRLLRDHNLTREQFIALYRLRPLVYTPELPGRAKLALVLTGVLIFALALFGNALVFYVVTRSKAMRTVTNIFICSLALSDLLITFFCIPVTMLQNISDNWLGGAFICKMVPFVQSTAVVTEILTMTCIAVERHQGLVHPFKMKWQYTNRRAFTMLGVVWLVAVIVGSPMWHVQQLEIKYDFLYEKEHICCLEEWTSPVHQKIYTTFILVILFLLPLMVMLILYSKIGYELWIKKRVGDGSVLRTIHGKEMSKIARKKKRAVIMMVTVVALFAVCWAPFHVVHMMIEYSNFEKEYDDVTIKMIFAIVQIIGFSNSICNPIVYAFMNENFKKNVLSAVCYCIVNKTFSPAQRHGNSGITMMRKKAKFSLRENPVEETKGEAFSDGNIEVKLCEQTEEKKKLKRHLALFRSELAENSPLDSGH>sp|Q9H0J4|QRIC2_HUMAN Glutamine-rich protein 2 OS=Homo sapiens OX=9606GN=QRICH2 PE=1 SV=1MKDAAEELSFARVLLQRVDELEKLFKDREQFLELVSRKLSLVPGAEEVTMVTWEELEQAITDGWRASQAGSETLMGFSKHGGFTSLTSPEGTLSGDSTKQPSIEQALDSASGLGPDRTASGSGGTAHPSDGVSSREQSKVPSGTGRQQQPRARDEAGVPRLHQSSTFQFKSDSDRHRSREKLTSTQPRRNARPGPVQQDLPLARDQPSSVPASQSQVHLRPDRRGLEPTGMNQPGLVPASTYPHGVVPLSMGQLGVPPPEMDDRELIPFVVDEQRMLPPSVPGRDQQGLELPSTDQHGLVSVSAYQHGMTFPGTDQRSMEPLGMDQRGCVISGMGQQGLVPPGIDQQGLTLPVVDQHGLVLPFTDQHGLVSPGLMPISADQQGFVQPSLEATGFIQPGTEQHDLIQSGRFQRALVQRGAYQPGLVQPGADQRGLVRPGMDQSGLAQPGADQRGLVWPGMDQSGLAQPGRDQHGLIQPGTGQHDLVQSGTGQGVLVQPGVDQPGMVQPGRFQRALVQPGAYQPGLVQPGADQIDVVQPGADQHGLVQSGADQSDLAQPGAVQHGLVQPGVDQRGLAQPRADHQRGLVPPGADQRGLVQPGADQHGLVQPGVDQHGLAQPGEVQRSLVQPGIVQRGLVQPGAVQRGLVQPGAVQRGLVQPGVDQRGLVQPGAVQRGLVQPGAVQHGLVQPGADQRGLVQPGVDQRGLVQPGVDQRGLVQPGMDQRGLIQPGADQPGLVQPGAGQLGMVQPGIGQQGMVQPQADPHGLVQPGAYPLGLVQPGAYLHDLSQSGTYPRGLVQPGMDQYGLRQPGAYQPGLIAPGTKLRGSSTFQADSTGFISVRPYQHGMVPPGREQYGQVSPLLASQGLASPGIDRRSLVPPETYQQGLMHPGTDQHSPIPLSTGLGSTHPDQQHVASPGPGEHDQVYPDAAQHGHAFSLFDSHDSMYPGYRGPGYLSADQHGQEGLDPNRTRASDRHGIPAQKAPGQDVTLFRSPDSVDRVLSEGSEVSSEVLSERRNSLRRMSSSFPTAVETFHLMGELSSLYVGLKESMKDLDEEQAGQTDLEKIQFLLAQMVKRTIPPELQEQLKTVKTLAKEVWQEKAKVERLQRILEGEGNQEAGKELKAGELRLQLGVLRVTVADIEKELAELRESQDRGKAAMENSVSEASLYLQDQLDKLRMIIESMLTSSSTLLSMSMAPHKAHTLAPGQIDPEATCPACSLDVSHQVSTLVRRYEQLQDMVNSLAVSRPSKKAKLQRQDEELLGRVQSAILQVQGDCEKLNITTSNLIEDHRQKQKDIAMLYQGLEKLEKEKANREHLEMEIDVKADKSALATKVSRVQFDATTEQLNHMMQELVAKMSGQEQDWQKMLDRLLTEMDNKLDRLELDPVKQLLEDRWKSLRQQLRERPPLYQADEAAAMRRQLLAHFHCLSCDRPLETPVTGHAIPVTPAGPGLPGHHSIRPYTVFELEQVRQHSRNLKLGSAFPRGDLAQMEQSVGRLRSMHSKMLMNIEKVQIHFGGSTKASSQIIRELLHAQCLGSPCYKRVTDMADYTYSTVPRRCGGSHTLTYPYHRSRPQHLPRGLYPTEEIQIAMKHDEVDILGLDGHIYKGRMDTRLPGILRKDSSGTSKRKSQQPRPHVHRPPSLSSNGQLPSRPQSAQISAGNTSER>sp|Q9H0J4-2|QRIC2_HUMAN Isoform 2 of Glutamine-rich protein 2 OS=Homosapiens OX=9606 GN=QRICH2MKDAAEELSFARVLLQRVDELEKLFKDREQFLELVSRKLSLVPGAEEVTMVTWEELEQAITDGWRASQAGSETLMGFSKHGGFTSLTSPEGTLSGDSTKQPSIEQALDSASGLGPDRTASGSGGTAHPSDGVSSREQSKVPSGTGRQQQPRARDEAGVPRLHQSSTFQFKSDSDRHRSREKLTSTQPRRNARPGPVQQDLPLARDQPSSVPASQSQVHLRPDRRGLEPTGMNQPGLVPASTYPHGVVPLSMGQLGVPPPEMDDRELIPFVVDEQRMLPPSVPGRDQQGLELPSTDQHGLVSVSAYQHGMTFPGTDQRSMEPLGMDQRGCVISGMGQQGLVPPGIDQQGLTLPVVDQHGLVLPFTDQHGLVSPGLMPISADQQGFVQPSLEATGFIQPGTEQHDLIQSGRFQRALVQRGAYQPGLVQPGADQRGLVRPGMDQSGLAQPGADQRGLVWPGMDQSGLAQPGRDQHGLIQPGTGQHDLVQSGTGQGVLVQPGVDQPGMVQPGRFQRALVQPGAYQPGLVQPGADQIDVVQPGADQHGLVQSGADQSDLAQPGAVQHGLVQPGVDQRGLAQPRADHQRGLVPPGADQRGLVQPGADQHGLVQPGVDQHGLAQPGEVQRSLVQPGIVQRGLVQPGAVQRGLVQPGAVQRGLVQPGVDQRGLVQPGAVQRGLVQPGAVQHGLVQPGADQRGLVQPGVDQRGLVQPGVDQRGLVQPGMDQRGLIQPGADQPGLVQPGAGQLGMVQPGIGQQGMVQPQADPHGLVQPGAYPLGLVQPGAYLHDLSQSGTYPRGLVQPGMDQYGLRQPGAYQPGLIAPGTKLRGSSTFQADSTGFISVRPYQHGMVPPGREQYGQVSPLLASQGLASPGIDRRSLVPPETYQQGLMHPGTDQHSPIPLSTGLGSTHPDQQHVASPGPGEHDQVYPDAAQHGHAFSLFDSHDSMYPGYRGPGYLSADQHGQEGLDPNRTRASDRHGIPAQKAPGQDVTLFRSPDSVDRVLSEGSEVSSEVLSERRNSLRRMSSSFPTAVETFHLMGELSSLYVGLKESMKDLDEEQAGQTDLEKIQFLLAQMVKRTIPPELQEQLKTVKTLAKEVWQEKAKVERLQRILEGEGNQEAGKELKAGELRLQLGVLRVTVADIEKELAELRESQDRGKAAMENSVSEASLYLQDQLDKLRMIIESMLTSSSTLLSMSMAPHKAHTLAPGQIDPEATCPACSLDVSHQVSTLVRRYEQLQDMVNSLAVSRPSKKAKLQRQDEELLGRVQSAILQVQGDCEKLNITTSNLIEDHRQKQKDIAMLYQGLEKLEKEKANREHLEMEIDVKADKSALATKVSRVQFDATTEQLNHMMQELVAKMSGQEQDWQKMLDRLLTEMDARLPGILRKDSSGTSKRKSQQPRPHVHRPPSLSSNGQLPSRPQSAQISAGNTSER>sp|Q9H0J4-3|QRIC2_HUMAN Isoform 3 of Glutamine-rich protein 2 OS=Homosapiens OX=9606 GN=QRICH2MENSVSEASLYLQDQLDKLRMIIESMLTSSSTLLSMSMAPHKAHTLAPGQIDPEATCPACSLDVSHQVSTLVRRYEQLQDMVNSLAVSRPSKKAKLQRQDEELLGRVQSAILQVQGDCEKLNITTSNLIEDHRQKQKDIAMLYQGLEKLEKEKANREHLEMEIDVKADKSALATKVSRVQFDATTEQLNHMMQELVAKMSGQEQDWQKMLDRLLTEMDNKLDRLELDPVKQLLEDRWKSLRQQLRERPPLYQADEAAAMRRQLLAHFHCLSCDRPLETPVTGHAIPVTPAGPGLPGHHSIRPYTVFELEQVRQHSRNLKLGSAFPRGDLAQMEQSVGRLRSMHSKMLMNIEKVQIHFGGSTKASSQIIRELLHAQCLGSPCYKRVTDMADYTYSTVPRRCGGSHTLTYPYHRSRPQHLPRGLYPTEEIQIAMKHDEVDILGLDGHIYKGRMDTRLPGILRKDSSGTSKRKSQQPRPHVHRPPSLSSNGQLPSRPQSAQISAGNTSER>sp|Q9P2N5|RBM27_HUMAN RNA-binding protein 27 OS=Homo sapiens OX=9606GN=RBM27 PE=1 SV=2MLIEDVDALKSWLAKLLEPICDADPSALANYVVALVKKDKPEKELKAFCADQLDVFLQKETSGFVDKLFESLYTKNYLPLLEPVKPEPKPLVQEKEEIKEEVFQEPAEEERDGRKKKYPSPQKTRSESSERRTREKKREDGKWRDYDRYYERNELYREKYDWRRGRSKSRSKSRGLSRSRSRSRGRSKDRDPNRNVEHRERSKFKSERNDLESSYVPVSAPPPNSSEQYSSGAQSIPSTVTVIAPAHHSENTTESWSNYYNNHSSSNSFGRNLPPKRRCRDYDERGFCVLGDLCQFDHGNDPLVVDEVALPSMIPFPPPPPGLPPPPPPGMLMPPMPGPGPGPGPGPGPGPGPGPGPGHSMRLPVPQGHGQPPPSVVLPIPRPPITQSSLINSRDQPGTSAVPNLASVGTRLPPPLPQNLLYTVSERQPMYSREHGAAASERLQLGTPPPLLAARLVPPRNLMGSSIGYHTSVSSPTPLVPDTYEPDGYNPEAPSITSSGRSQYRQFFSRTQTQRPNLIGLTSGDMDVNPRAANIVIQTEPPVPVSINSNITRVVLEPDSRKRAMSGLEGPLTKKPWLGKQGNNNQNKPGFLRKNQYTNTKLEVKKIPQELNNITKLNEHFSKFGTIVNIQVAFKGDPEAALIQYLTNEEARKAISSTEAVLNNRFIRVLWHRENNEQPTLQSSAQLLLQQQQTLSHLSQQHHHLPQHLHQQQVLVAQSAPSTVHGGIQKMMSKPQTSGAYVLNKVPVKHRLGHAGGNQSDASHLLNQSGGAGEDCQIFSTPGHPKMIYSSSNLKTPSKLCSGSKSHDVQEVLKKKQEAMKLQQDMRKKRQEVLEKQIECQKMLISKLEKNKNMKPEERANIMKTLKELGEKISQLKDELKTSSAVSTPSKVKTKTEAQKELLDTELDLHKRLSSGEDTTELRKKLSQLQVEAARLGILPVGRGKTMSSQGRGRGRGRGGRGRGSLNHMVVDHRPKALTVGGFIEEEKEDLLQHFSTANQGPKFKDRRLQISWHKPKVPSISTETEEEEVKEEETETSDLFLPDDDDEDEDEYESRSWRR>sp|A8MTL3|R212B_HUMAN RING finger protein 212B OS=Homo sapiens OX=9606GN=RNF212B PE=2 SV=1MDWFHCNQCFRKDGAHFFVTSCGHIFCKKCVTLEKCAVCGTACKHLALSDNLKPQEKMFFKSPVETALQYFSHISQVWSFQKKQTDLLIAFYKHRITKLETAMQEAQQALVSQDKELSVLRKENGELKKFLAILKESPSRYQGSRSITPRPVGITSPSQSVTPRPSFQHSSQVVSRSSSAESIPYREAGFGSLGQGGRGLQGRRTPRDSYNETPSPASTHSLSYRTSSASSGQGIFSFRPSPNGHSGHTRVLTPNNFAQRESTTTLESLPSFQLPVLQTLYQQRRHMGLPSGREAWTTSR>sp|Q15276|RABE1_HUMAN Rab GTPase-binding effector protein 1 OS=Homosapiens OX=9606 GN=RABEP1 PE=1 SV=2MAQPGPASQPDVSLQQRVAELEKINAEFLRAQQQLEQEFNQKRAKFKELYLAKEEDLKRQNAVLQAAQDDLGHLRTQLWEAQAEMENIKAIATVSENTKQEAIDEVKRQWREEVASLQAVMKETVRDYEHQFHLRLEQERTQWAQYRESAEREIADLRRRLSEGQEEENLENEMKKAQEDAEKLRSVVMPMEKEIAALKDKLTEAEDKIKELEASKVKELNHYLEAEKSCRTDLEMYVAVLNTQKSVLQEDAEKLRKELHEVCHLLEQERQQHNQLKHTWQKANDQFLESQRLLMRDMQRMEIVLTSEQLRQVEELKKKDQEDDEQQRLNKRKDHKKADVEEEIKIPVVCALTQEESSAQLSNEEEHLDSTRGSVHSLDAGLLLPSGDPFSKSDNDMFKDGLRRAQSTDSLGTSGSLQSKALGYNYKAKSAGNLDESDFGPLVGADSVSENFDTASLGSLQMPSGFMLTKDQERAIKAMTPEQEETASLLSSVTQGMESAYVSPSGYRLVSETEWNLLQKEVHNAGNKLGRRCDMCSNYEKQLQGIQIQEAETRDQVKKLQLMLRQANDQLEKTMKDKQELEDFIKQSSEDSSHQISALVLRAQASEILLEELQQGLSQAKRDVQEQMAVLMQSREQVSEELVRLQKDNDSLQGKHSLHVSLQQAEDFILPDTTEALRELVLKYREDIINVRTAADHVEEKLKAEILFLKEQIQAEQCLKENLEETLQLEIENCKEEIASISSLKAELERIKVEKGQLESTLREKSQQLESLQEIKISLEEQLKKETAAKATVEQLMFEEKNKAQRLQTELDVSEQVQRDFVKLSQTLQVQLERIRQADSLERIRAILNDTKLTDINQLPET>sp|Q15276-2|RABE1_HUMAN Isoform 2 of Rab GTPase-binding effector protein1 OS=Homo sapiens OX=9606 GN=RABEP1MAQPGPASQPDVSLQQRVAELEKINAEFLRAQQQLEQEFNQKRAKFKELYLAKEEDLKRQNAVLQAAQDDLGHLRTQLWEAQAEMENIKAIATVSENTKQEAIDEVKRQWREEVASLQAVMKETVRDYEHQFHLRLEQERTQWAQYRESAEREIADLRRRLSEGQEEENLENEMKKAQEDAEKLRSVVMPMEKEIAALKDKLTEAEDKIKELEASKVKELNHYLEAEKSCRTDLEMYVAVLNTQKSVLQEDAEKLRKELHEVCHLLEQERQQHNQLKHTWQKANDQFLESQRLLMRDMQRMEIVLTSEQLRQVEELKKKDQEDDEQQRLNKRKDHKKADVEEEIKIPVVCALTQEESSAQLSNEEEHLDSTRGSVHSLDAGLLLPSGDPFSKSDNDMFKDGLRRAQSTDSLGTSGSLQSKALGYNYKAKSAGNLDESDFGPLVGADSVSENFDTASLGSLQMPSGFMLTKDQERAIKAMTPEQEETASLLSSVTQGMESAYVSPSGYRLVSETEWNLLQKEVHNAGNKLGRRCDMCSNYEKQLQGIQIQEAETRDQVKKLQLMLRQANDQLEKTMKDKQELEDFIKQSSEDSSHQISALVLRAQASEILLEELQQGLSQAKRDVQEQMAVLMQSREQVSEELVRLQKDNDSLQGKHSLHVSLQQAEDFILPDTTEALRELVLKYREDIINVRTAADHVEEKLKAEILFLKEQIQAEQCLKENLEETLQLEIENCKEEIASISSLKAELERIKVEKGQATVEQLMFEEKNKAQRLQTELDVSEQVQRDFVKLSQTLQVQLERIRQADSLERIRAILNDTKLTDINQLPET>sp|Q9NX57|RAB20_HUMAN Ras-related protein Rab-20 OS=Homo sapiens OX=9606GN=RAB20 PE=1 SV=1MRKPDSKIVLLGDMNVGKTSLLQRYMERRFPDTVSTVGGAFYLKQWRSYNISIWDTAGREQFHGLGSMYCRGAAAIILTYDVNHRQSLVELEDRFLGLTDTASKDCLFAIVGNKVDLTEEGALAGQEKEECSPNMDAGDRVSPRAPKQVQLEDAVALYKKILKYKMLDEQDVPAAEQMCFETSAKTGYNVDLLFETLFDLVVPMILQQRAERPSHTVDISSHKPPKRTRSGCCA>sp|P63000|RAC1_HUMAN Ras-related C3 botulinum toxin substrate 1 OS=Homosapiens OX=9606 GN=RAC1 PE=1 SV=1MQAIKCVVVGDGAVGKTCLLISYTTNAFPGEYIPTVFDNYSANVMVDGKPVNLGLWDTAGQEDYDRLRPLSYPQTDVFLICFSLVSPASFENVRAKWYPEVRHHCPNTPIILVGTKLDLRDDKDTIEKLKEKKLTPITYPQGLAMAKEIGAVKYLECSALTQRGLKTVFDEAIRAVLCPPPVKKRKRKCLLL>sp|P63000-2|RAC1_HUMAN Isoform B of Ras-related C3 botulinum toxinsubstrate 1 OS=Homo sapiens OX=9606 GN=RAC1MQAIKCVVVGDGAVGKTCLLISYTTNAFPGEYIPTVFDNYSANVMVDGKPVNLGLWDTAGQEDYDRLRPLSYPQTVGETYGKDITSRGKDKPIADVFLICFSLVSPASFENVRAKWYPEVRHHCPNTPIILVGTKLDLRDDKDTIEKLKEKKLTPITYPQGLAMAKEIGAVKYLECSALTQRGLKTVFDEAIRAVLCPPPVKKRKRKCLLL>sp|Q9NYW8|RBAK_HUMAN RB-associated KRAB zinc finger protein OS=Homosapiens OX=9606 GN=RBAK PE=1 SV=1MNTLQGPVSFKDVAVDFTQEEWQQLDPDEKITYRDVMLENYSHLVSVGYDTTKPNVIIKLEQGEEPWIMGGEFPCQHSPEAWRVDDLIERIQENEDKHSRQAACINSKTLTEEKENTFSQIYMETSLVPSSIIAHNCVSCGKNLESISQLISSDGSYARTKPDECNECGKTYHGEKMCEFNQNGDTYSHNEENILQKISILEKPFEYNECMEALDNEAVFIAHKRAYIGEKPYEWNDSGPDFIQMSNFNAYQRSQMEMKPFECSECGKSFCKKSKFIIHQRAHTGEKPYECNVCGKSFSQKGTLTVHRRSHLEEKPYKCNECGKTFCQKLHLTQHLRTHSGEKPYECSECGKTFCQKTHLTLHQRNHSGERPYPCNECGKSFSRKSALSDHQRTHTGEKLYKCNECGKSYYRKSTLITHQRTHTGEKPYQCSECGKFFSRVSYLTIHYRSHLEEKPYECNECGKTFNLNSAFIRHRKVHTEEKSHECSECGKFSQLYLTDHHTAHLEEKPYECNECGKTFLVNSAFDGHQPLPKGEKSYECNVCGKLFNELSYYTEHYRSHSEEKPYGCSECGKTFSHNSSLFRHQRVHTGEKPYECYECGKFFSQKSYLTIHHRIHSGEKPYECSKCGKVFSRMSNLTVHYRSHSGEKPYECNECGKVFSQKSYLTVHYRTHSGEKPYECNECGKKFHHRSAFNSHQRIHRRGNMNVLDVENL>sp|Q9NYW8-2|RBAK_HUMAN Isoform 2 of RB-associated KRAB zinc fingerprotein OS=Homo sapiens OX=9606 GN=RBAKMNTLQGPVSFKDVAVDFTQEEWQQLDPDEKITYRDVMLENYSHLVSVGYDTTKPNVIIKLEQGEEPWIMGGEFPCQHSPAALPAGHVAPAVAAAAAAPGRPGPHRQSRSPPGC>sp|O94844|RHBT1_HUMAN Rho-related BTB domain-containing protein 1OS=Homo sapiens OX=9606 GN=RHOBTB1 PE=1 SV=2MDADMDYERPNVETIKCVVVGDNAVGKTRLICARACNTTLTQYQLLATHVPTVWAIDQYRVCQEVLERSRDVVDEVSVSLRLWDTFGDHHKDRRFAYGRSDVVVLCFSIANPNSLNHVKSMWYPEIKHFCPRTPVILVGCQLDLRYADLEAVNRARRPLARPIKRGDILPPEKGREVAKELGLPYYETSVFDQFGIKDVFDNAIRAALISRRHLQFWKSHLKKVQKPLLQAPFLPPKAPPPVIKIPECPSMGTNEAACLLDNPLCADVLFILQDQEHIFAHRIYLATSSSKFYDLFLMECEESPNGSEGACEKEKQSRDFQGRILSVDPEEEREEGPPRIPQADQWKSSNKSLVEALGLEAEGAVPETQTLTGWSKGFIGMHREMQVNPISKRMGPMTVVRMDASVQPGPFRTLLQFLYTGQLDEKEKDLVGLAQIAEVLEMFDLRMMVENIMNKEAFMNQEITKAFHVRKANRIKECLSKGTFSDVTFKLDDGAISAHKPLLICSCEWMAAMFGGSFVESANSEVYLPNINKISMQAVLDYLYTKQLSPNLDLDPLELIALANRFCLPHLVALAEQHAVQELTKAATSGVGIDGEVLSYLELAQFHNAHQLAAWCLHHICTNYNSVCSKFRKEIKSKSADNQEYFERHRWPPVWYLKEEDHYQRVKREREKEDIALNKHRSRRKWCFWNSSPAVA>sp|O43567|RNF13_HUMAN E3 ubiquitin-protein ligase RNF13 OS=Homo sapiensOX=9606 GN=RNF13 PE=1 SV=1MLLSIGMLMLSATQVYTILTVQLFAFLNLLPVEADILAYNFENASQTFDDLPARFGYRLPAEGLKGFLINSKPENACEPIVPPPVKDNSSGTFIVLIRRLDCNFDIKVLNAQRAGYKAAIVHNVDSDDLISMGSNDIEVLKKIDIPSVFIGESSANSLKDEFTYEKGGHLILVPEFSLPLEYYLIPFLIIVGICLILIVIFMITKFVQDRHRARRNRLRKDQLKKLPVHKFKKGDEYDVCAICLDEYEDGDKLRILPCSHAYHCKCVDPWLTKTKKTCPVCKQKVVPSQGDSDSDTDSSQEENEVTEHTPLLRPLASVSAQSFGALSESRSHQNMTESSDYEEDDNEDTDSSDAENEINEHDVVVQLQPNGERDYNIANTV>sp|O43567-2|RNF13_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF13OS=Homo sapiens OX=9606 GN=RNF13MLILMTSLAWDPTTVSTVEVLKKIDIPSVFIGESSANSLKDEFTYEKGGHLILVPEFSLPLEYYLIPFLIIVGICLILIVIFMITKFVQDRHRARRNRLRKDQLKKLPVHKFKKGDEYDVCAICLDEYEDGDKLRILPCSHAYHCKCVDPWLTKTKKTCPVCKQKVVPSQGDSDSDTDSSQEENEVTEHTPLLRPLASVSAQSFGALSESRSHQNMTESSDYEEDDNEDTDSSDAENEINEHDVVVQLQPNGERDYNIANTV>sp|P18577|RHCE_HUMAN Blood group Rh(CE) polypeptide OS=Homo sapiensOX=9606 GN=RHCE PE=1 SV=2MSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGALFLWMFWPSVNSPLLRSPIQRKNAMFNTYYALAVSVVTAISGSSLAHPQRKISMTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISIGGAKCLPVCCNRVLGIHHISVMHSIFSLLGLLGEITYIVLLVLHTVWNGNGMIGFQVLLSIGELSLAIVIALTSGLLTGLLLNLKIWKAPHVAKYFDDQVFWKFPHLAVGF>sp|P18577-2|RHCE_HUMAN Isoform RHIV of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGALFLWMFWPSVNSPLLRSPIQRKNAMFNTYYALAVSVVTAISGSSLAHPQRKISMTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISIGGAKCLPDWLPGPPQHWGTQLGHRDSSHVWSPDRFAPKSQNMESTSCG>sp|P18577-3|RHCE_HUMAN Isoform RHVI of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISIGGAKCLPVCCNRVLGIHHISVMHSIFSLLGLLGEITYIVLLVLHTVWNGNGMFAPKSQNMESTSCG>sp|P18577-4|RHCE_HUMAN Isoform RHVIII of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNVCCNRVLGIHHISVMHSIFSLLGLLGEITYIVLLVLHTVWNGNGMIGFQVLLSIGELSLAIVIALTSGLLTGLLLNLKIWKAPHVAKYFDDQVFWKFPHLAVGF>sp|P18577-5|RHCE_HUMAN Isoform 1c of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGALFLWMFWPSVNSPLLRSPIQRKNAMFNTYYALAVSVVTAISGSSLAHPQRKISMTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISIGGAKCLPVCCNRVLGIHHISVMHSIFSLLGLLGEITYIVLLVLHTVWNGNGMFAPKSQNMESTSCG>sp|P18577-6|RHCE_HUMAN Isoform 1d of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGALFLWMFWPSVNSPLLRSPIQRKNAMFNTYYALAVSVVTAISGSSLAHPQRKISMTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISIGGAKCLPVCCNRVLGIHHISVMHSIFSLLGLLGEITYIVLLVLHTVWNGNGIFLIWLLDFKQKHPRKTRPVQKQDNFLSLLPAVREKRS>sp|P18577-7|RHCE_HUMAN Isoform 1h of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGALFLWMFWPSVNSPLLRSPIQRKNAMFNTYYALAVSVVTAISGSSLAHPQRKISMTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISIGGAKCLPFPHLAVGF>sp|P18577-8|RHCE_HUMAN Isoform 2e of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGALFLWMFWPSVNSPLLRSPIQRKNAMFNTYYALAVSVVTAISGSSLAHPQRKISMDWLPGPPQHWGTQLGHRDSSHVWSPDRFAPKSQNMESTSCG>sp|P18577-9|RHCE_HUMAN Isoform 4g of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGLLLNLKIWKAPHVAKYFDDQVFWKFPHLAVGF>sp|P18577-10|RHCE_HUMAN Isoform 7a of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISIGGAKCLPVCCNRVLGIHHISVMHSIFSLLGLLGEITYIVLLVLHTVWNGNGMIGFQVLLSIGELSLAIVIALTSGLLTGLLLNLKIWKAPHVAKYFDDQVFWKFPHLAVGF>sp|P18577-11|RHCE_HUMAN Isoform 8a of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNPSVNSPLLRSPIQRKNAMFNTYYALAVSVVTAISGSSLAHPQRKISMTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVVCCNRVLGIHHISVMHSIFSLLGLLGEITYIVLLVLHTVWNGNGMIGFQVLLSIGELSLAIVIALTSGLLTGLLLNLKIWKAPHVAKYFDDQVFWKFPHLAVGF>sp|P18577-12|RHCE_HUMAN Isoform 8e of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNDWLPGPPQHWGTQLGHRDSSHVWSPDRFAPKSQNMESTSCG>sp|P18577-13|RHCE_HUMAN Isoform 8h of Blood group Rh(CE) polypeptideOS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNFPHLAVGF>sp|P18577-14|RHCE_HUMAN Isoform RhPI-Alpha of Blood group Rh(CE)polypeptide OS=Homo sapiens OX=9606 GN=RHCEMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAALGLGFLTSNFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPPGKVVITLFSIRLATMSAMSVLISAGAVLGKVNLAQLVVMVLVEVTALGTLRMVISNIFNTDYHMNLRHFYVFAAYFGLTVAWCLPKPLPKGTEDNDQRATIPSLSAMLGALFLWMFWPSVNSPDRFAPKSQNMESTSCG>sp|Q9BWJ2|RHAS1_HUMAN Putative uncharacterized protein encoded by RHPN1-AS1 OS=Homo sapiens OX=9606 GN=RHPN1-AS1 PE=5 SV=1MPAFFSLPAERRLQAWPQSEAPLSVSSCFQNRPPEPASFQNLRPEPASLQNLRTEPTSF>sp|Q9HAU8|RNPL1_HUMAN Aminopeptidase RNPEPL1 OS=Homo sapiens OX=9606GN=RNPEPL1 PE=1 SV=3MAAQCCCRQAPGAEAAPVRPPPEPPPALDVASASSAQLFRLRHLQLGLELRPEARELAGCLVLELCALRPAPRALVLDAHPALRLHSAAFRRAPAAAAETPCAFAFSAPGPGPAPPPPLPAFPEAPGSEPACCPLAFRVDPFTDYGSSLTVTLPPELQAHQPFQVILRYTSTDAPAIWWLDPELTYGCAKPFVFTQGHSVCNRSFFPCFDTPAVKCTYSAVVKAPSGVQVLMSATRSAYMEEEGVFHFHMEHPVPAYLVALVAGDLKPADIGPRSRVWAEPCLLPTATSKLSGAVEQWLSAAERLYGPYMWGRYDIVFLPPSFPIVAMENPCLTFIISSILESDEFLVIDVIHEVAHSWFGNAVTNATWEEMWLSEGLATYAQRRITTETYGAAFTCLETAFRLDALHRQMKLLGEDSPVSKLQVKLEPGVNPSHLMNLFTYEKGYCFVYYLSQLCGDPQRFDDFLRAYVEKYKFTSVVAQDLLDSFLSFFPELKEQSVDCRAGLEFERWLNATGPPLAEPDLSQGSSLTRPVEALFQLWTAEPLDQAAASASAIDISKWRTFQTALFLDRLLDGSPLPQEVVMSLSKCYSSLLDSMNAEIRIRWLQIVVRNDYYPDLHRVRRFLESQMSRMYTIPLYEDLCTGALKSFALEVFYQTQGRLHPNLRRAIQQILSQGLGSSTEPASEPSTELGKAEADTDSDAQALLLGDEAPSSAISLRDVNVSA>sp|Q15382|RHEB_HUMAN GTP-binding protein Rheb OS=Homo sapiens OX=9606GN=RHEB PE=1 SV=1MPQSKSRKIAILGYRSVGKSSLTIQFVEGQFVDSYDPTIENTFTKLITVNGQEYHLQLVDTAGQDEYSIFPQTYSIDINGYILVYSVTSIKSFEVIKVIHGKLLDMVGKVQIPIMLVGNKKDLHMERVISYEEGKALAESWNAAFLESSAKENQTAVDVFRRIILEAEKMDGAASQGKSSCSVM>sp|P84095|RHOG_HUMAN Rho-related GTP-binding protein RhoG OS=Homosapiens OX=9606 GN=RHOG PE=1 SV=1MQSIKCVVVGDGAVGKTCLLICYTTNAFPKEYIPTVFDNYSAQSAVDGRTVNLNLWDTAGQEEYDRLRTLSYPQTNVFVICFSIASPPSYENVRHKWHPEVCHHCPDVPILLVGTKKDLRAQPDTLRRLKEQGQAPITPQQGQALAKQIHAVRYLECSALQQDGVKEVFAEAVRAVLNPTPIKRGRSCILL>sp|O94761|RECQ4_HUMAN ATP-dependent DNA helicase Q4 OS=Homo sapiensOX=9606 GN=RECQL4 PE=1 SV=2MERLRDVRERLQAWERAFRRQRGRRPSQDDVEAAPEETRALYREYRTLKRTTGQAGGGLRSSESLPAAAEEAPEPRCWGPHLNRAATKSPQSTPGRSRQGSVPDYGQRLKANLKGTLQAGPALGRRPWPLGRASSKASTPKPPGTGPVPSFAEKVSDEPPQLPEPQPRPGRLQHLQASLSQRLGSLDPGWLQRCHSEVPDFLGAPKACRPDLGSEESQLLIPGESAVLGPGAGSQGPEASAFQEVSIRVGSPQPSSSGGEKRRWNEEPWESPAQVQQESSQAGPPSEGAGAVAVEEDPPGEPVQAQPPQPCSSPSNPRYHGLSPSSQARAGKAEGTAPLHIFPRLARHDRGNYVRLNMKQKHYVRGRALRSRLLRKQAWKQKWRKKGECFGGGGATVTTKESCFLNEQFDHWAAQCPRPASEEDTDAVGPEPLVPSPQPVPEVPSLDPTVLPLYSLGPSGQLAETPAEVFQALEQLGHQAFRPGQERAVMRILSGISTLLVLPTGAGKSLCYQLPALLYSRRSPCLTLVVSPLLSLMDDQVSGLPPCLKAACIHSGMTRKQRESVLQKIRAAQVHVLMLTPEALVGAGGLPPAAQLPPVAFACIDEAHCLSQWSHNFRPCYLRVCKVLRERMGVHCFLGLTATATRRTASDVAQHLAVAEEPDLHGPAPVPTNLHLSVSMDRDTDQALLTLLQGKRFQNLDSIIIYCNRREDTERIAALLRTCLHAAWVPGSGGRAPKTTAEAYHAGMCSRERRRVQRAFMQGQLRVVVATVAFGMGLDRPDVRAVLHLGLPPSFESYVQAVGRAGRDGQPAHCHLFLQPQGEDLRELRRHVHADSTDFLAVKRLVQRVFPACTCTCTRPPSEQEGAVGGERPVPKYPPQEAEQLSHQAAPGPRRVCMGHERALPIQLTVQALDMPEEAIETLLCYLELHPHHWLELLATTYTHCRLNCPGGPAQLQALAHRCPPLAVCLAQQLPEDPGQGSSSVEFDMVKLVDSMGWELASVRRALCQLQWDHEPRTGVRRGTGVLVEFSELAFHLRSPGDLTAEEKDQICDFLYGRVQARERQALARLRRTFQAFHSVAFPSCGPCLEQQDEERSTRLKDLLGRYFEEEEGQEPGGMEDAQGPEPGQARLQDWEDQVRCDIRQFLSLRPEEKFSSRAVARIFHGIGSPCYPAQVYGQDRRFWRKYLHLSFHALVGLATEELLQVAR>sp|Q9P1U0|RPA12_HUMAN DNA-directed RNA polymerase I subunit RPA12OS=Homo sapiens OX=9606 GN=POLR1H PE=1 SV=1MSVMDLANTCSSFQSDLDFCSDCGSVLPLPGAQDTVTCIRCGFNINVRDFEGKVVKTSVVFHQLGTAMPMSVEEGPECQGPVVDRRCPRCGHEGMAYHTRQMRSADEGQTVFYTCTNCKFQEKEDS>sp|O43665|RGS10_HUMAN Regulator of G-protein signaling 10 OS=Homosapiens OX=9606 GN=RGS10 PE=1 SV=3MFNRAVSRLSRKRPPSDIHDSDGSSSSSHQSLKSTAKWAASLENLLEDPEGVKRFREFLKKEFSEENVLFWLACEDFKKMQDKTQMQEKAKEIYMTFLSSKASSQVNVEGQSRLNEKILEEPHPLMFQKLQDQIFNLMKYDSYSRFLKSDLFLKHKRTEEEEEDLPDAQTAAKRASRIYNT>sp|O43665-1|RGS10_HUMAN Isoform 1 of Regulator of G-protein signaling 10OS=Homo sapiens OX=9606 GN=RGS10MQSELCFADIHDSDGSSSSSHQSLKSTAKWAASLENLLEDPEGVKRFREFLKKEFSEENVLFWLACEDFKKMQDKTQMQEKAKEIYMTFLSSKASSQVNVEGQSRLNEKILEEPHPLMFQKLQDQIFNLMKYDSYSRFLKSDLFLKHKRTEEEEEDLPDAQTAAKRASRIYNT>sp|O43665-2|RGS10_HUMAN Isoform 2 of Regulator of G-protein signaling 10OS=Homo sapiens OX=9606 GN=RGS10MEHIHDSDGSSSSSHQSLKSTAKWAASLENLLEDPEGVKRFREFLKKEFSEENVLFWLACEDFKKMQDKTQMQEKAKEIYMTFLSSKASSQVNVEGQSRLNEKILEEPHPLMFQKLQDQIFNLMKYDSYSRFLKSDLFLKHKRTEEEEEDLPDAQTAAKRASRIYNT>sp|P05423|RPC4_HUMAN DNA-directed RNA polymerase III subunit RPC4OS=Homo sapiens OX=9606 GN=POLR3D PE=1 SV=2MSEGNAAGEPSTPGGPRPLLTGARGLIGRRPAPPLTPGRLPSIRSRDLTLGGVKKKTFTPNIISRKIKEEPKEEVTVKKEKRERDRDRQREGHGRGRGRPEVIQSHSIFEQGPAEMMKKKGNWDKTVDVSDMGPSHIINIKKEKRETDEETKQILRMLEKDDFLDDPGLRNDTRNMPVQLPLAHSGWLFKEENDEPDVKPWLAGPKEEDMEVDIPAVKVKEEPRDEEEEAKMKAPPKAARKTPGLPKDVSVAELLRELSLTKEEELLFLQLPDTLPGQPPTQDIKPIKTEVQGEDGQVVLIKQEKDREAKLAENACTLADLTEGQVGKLLIRKSGRVQLLLGKVTLDVTMGTACSFLQELVSVGLGDSRTGEMTVLGHVKHKLVCSPDFESLLDHKHR>sp|O75575|RPC9_HUMAN DNA-directed RNA polymerase III subunit RPC9OS=Homo sapiens OX=9606 GN=CRCP PE=1 SV=1MEVKDANSALLSNYEVFQLLTDLKEQRKESGKNKHSSGQQNLNTITYETLKYISKTPCRHQSPEIVREFLTALKSHKLTKAEKLQLLNHRPVTAVEIQLMVEESEERLTEEQIEALLHTVTSILPAEPEAEQKKNTNSNVAMDEEDPA>sp|O75575-2|RPC9_HUMAN Isoform 2 of DNA-directed RNA polymerase IIIsubunit RPC9 OS=Homo sapiens OX=9606 GN=CRCPMEVKDANSALLSNYETLKYISKTPCRHQSPEIVREFLTALKSHKLTKAEKLQLLNHRPVTAVEIQLMVEESEERLTEEQIEALLHTVTSILPAEPEAEQKKNTNSNVAMDEEDPA>sp|O75575-3|RPC9_HUMAN Isoform 3 of DNA-directed RNA polymerase IIIsubunit RPC9 OS=Homo sapiens OX=9606 GN=CRCPMQRGDPGEHLGARSWHLGAVGGGGDSCEVKDANSALLSNYETLKYISKTPCRHQSPEIVREFLTALKSHKLTKAEKLQLLNHRPVTAVEIQLMVEESEERLTEEQIEALLHTVTSILPAEPEAEQKKNTNSNVAMDEEDPA>sp|O75575-4|RPC9_HUMAN Isoform 4 of DNA-directed RNA polymerase IIIsubunit RPC9 OS=Homo sapiens OX=9606 GN=CRCPMEVAEKLQLLNHRPVTAVEIQLMVEESEERLTEEQIEALLHTVTSILPAEPEAEQKKNTNSNVAMDEEDPA>sp|Q13972|RGRF1_HUMAN Ras-specific guanine nucleotide-releasing factor 1OS=Homo sapiens OX=9606 GN=RASGRF1 PE=1 SV=2MQKGIRLNDGHVASLGLLARKDGTRKGYLSKRSSDNTKWQTKWFALLQNLLFYFESDSSSRPSGLYLLEGCVCDRAPSPKPALSAKEPLEKQHYFTVNFSHENQKALELRTEDAKDCDEWVAAIAHASYRTLATEHEALMQKYLHLLQIVETEKTVAKQLRQQIEDGEIEIERLKAEITSLLKDNERIQSTQTVAPNDEDSDIKKIKKVQSFLRGWLCRRKWKTIIQDYIRSPHADSMRKRNQVVFSMLEAEAEYVQQLHILVNNFLRPLRMAASSKKPPITHDDVSSIFLNSETIMFLHQIFYQGLKARISSWPTLVLADLFDILLPMLNIYQEFVRNHQYSLQILAHCKQNRDFDKLLKHYEAKPDCEERTLETFLTYPMFQIPRYILTLHELLAHTPHEHVERNSLDYAKSKLEELSRIMHDEVSETENIRKNLAIERMIIEGCEILLDTSQTFVRQGSLIQVPMSEKGKITRGRLGSLSLKKEGERQCFLFSKHLIICTRGSGGKLHLTKNGVISLIDCTLLEEPESTEEEAKGSGQDIDHLDFKIGVEPKDSPPFTVILVASSRQEKAAWTSDISQCVDNIRCNGLMMNAFEENSKVTVPQMIKRTREGTREAEMSRSDASLYCDDVDIRFSKTMNSCKVLQIRYASVERLLERLTDLRFLSIDFLNTFLHSYRVFTTAIVVLDKLITIYKKPISAIPARWLRSLELLFASGQNNKLLYGEPPKSPRATRKFSSPPPLSITKTSSPSRRRKLSLNIPIITGGKALDLAALSCNSNGYTSMYSAMSPFSKATLDTSKLYVSSSFTNKIPDEGDTTPEKPEDPSALSKQSSEVSMREESDIDQNQSDDGDTETSPTKSPTTPKSVKNKNSSEFPLFSYNNGVVMTSCRELDNNRSALSAASAFAIATAGANEGTPNKEKYRRMSLASAGFPPDQRNGDKEFVIRRAATNRVLNVLRHWVSKHSQDFETNDELKCKVIGFLEEVMHDPELLTQERKAAANIIRTLTQEDPGDNQITLEEITQMAEGVKAEPFENHSALEIAEQLTLLDHLVFKKIPYEEFFGQGWMKLEKNERTPYIMKTTKHFNDISNLIASEIIRNEDINARVSAIEKWVAVADICRCLHNYNAVLEITSSMNRSAIFRLKKTWLKVSKQTKALIDKLQKLVSSEGRFKNLREALKNCDPPCVPYLGMYLTDLAFIEEGTPNYTEDGLVNFSKMRMISHIIREIRQFQQTAYKIEHQAKVTQYLLDQSFVMDEESLYESSLRIEPKLPT>sp|Q13972-2|RGRF1_HUMAN Isoform 2 of Ras-specific guanine nucleotide-releasing factor 1 OS=Homo sapiens OX=9606 GN=RASGRF1MYSAMSPFSKATLDTSKLYVSSSFTNKIPDEGDTTPEKPEDPSALSKQSSEVSMREESDIDQNQSDDGDTETSPTKSPTTPKSVKNKNSSEFPLFSYNNGVVMTSCRELDNNRSALSAASAFAIATAGANEGTPNKEKYRRMSLASAGFPPDQRNGDKEFVIRRAATNRVLNVLRHWVSKHSQDFETNDELKCKVIGFLEEVMHDPELLTQERKAAANIIRTLTQEDPGDNQITLEEITQMAEGVKAEPFENHSALEIAEQLTLLDHLVFKKIPYEEFFGQGWMKLEKNERTPYIMKTTKHFNDISNLIASEIIRNEDINARVSAIEKWVAVADICRCLHNYNAVLEITSSMNRSAIFRLKKTWLKVSKQTKALIDKLQKLVSSEGRFKNLREALKNCDPPCVPYLGMYLTDLAFIEEGTPNYTEDGLVNFSKMRMISHIIREIRQFQQTAYKIEHQAKVTQYLLDQSFVMDEESLYESSLRIEPKLPT>sp|Q13972-3|RGRF1_HUMAN Isoform 3 of Ras-specific guanine nucleotide-releasing factor 1 OS=Homo sapiens OX=9606 GN=RASGRF1MQKGIRLNDGHVASLGLLARKDGTRKGYLSKRSSDNTKWQTKWFALLQNLLFYFESDSSSRPSGLYLLEGCVCDRAPSPKPALSAKEPLEKQHYFTVNFSHENQKALELRTEDAKDCDEWVAAIAHASYRTLATEHEALMQKYLHLLQIVETEKTVAKQLRQQIEDGEIEIERLKAEITSLLKDNERIQSTQTVAPNDEDSDIKKIKKVQSFLRGWLCRRKWKTIIQDYIRSPHADSMRKRNQVVFSMLEAEAEYVQQLHILVNNFLRPLRMAASSKKPPITHDDVSSIFLNSETIMFLHQIFYQGLKARISSWPTLVLADLFDILLPMLNIYQEFVRNHQYSLQILAHCKQNRDFDKLLKHYEAKPDCEERTLETFLTYPMFQIPRYILTLHELLAHTPHEHVERNSLDYAKSKLEELSRIMHDEVSETENIRKNLAIERMIIEGCEILLDTSQTFVRQGSLIQVPMSEKGKITRGRLGSLSLKKEGERQCFLFSKHLIICTRGSGGKLHLTKNGVISLIDCTLLEEPESTEEEAKGSGQDIDHLDFKIGVEPKDSPPFTVILVASSRQEKAAWTSDISQCVDNIRCNGLMMNAFEENSKVTVPQMIKSDASLYCDDVDIRFSKTMNSCKVLQIRYASVERLLERLTDLRFLSIDFLNTFLHSYRVFTTAIVVLDKLITIYKKPISAIPARSLELLFASGQNNKLLYGEPPKSPRATRKFSSPPPLSITKTSSPSRRRKLSLNIPIITGGKALDLAALSCNSNGYTSMYSAMSPFSKATLDTSKLYVSSSFTNKIPDEGDTTPEKPEDPSALSKQSSEVSMREESDIDQNQSDDGDTETSPTKSPTTPKSVKNKNSSEFPLFSYNNGVVMTSCRELDNNRSALSAASAFAIATAGANEGTPNKEKYRRMSLASAGFPPDQRNGDKEFVIRRAATNRVLNVLRHWVSKHSQDFETNDELKCKVIGFLEEVMHDPELLTQERKAAANIIRTLTQEDPGDNQITLEEITQMAEGVKAEPFENHSALEIAEQLTLLDHLVFKKIPYEEFFGQGWMKLEKNERTPYIMKTTKHFNDISNLIASEIIRNEDINARVSAIEKWVAVADICRCLHNYNAVLEITSSMNRSAIFRLKKTWLKVSKQTKALIDKLQKLVSSEGRFKNLREALKNCDPPCVPYLGMYLTDLAFIEEGTPNYTEDGLVNFSKMRMISHIIREIRQFQQTAYKIEHQAKVTQYLLDQSFVMDEESLYESSLRIEPKLPT>sp|Q3B726|RPA43_HUMAN DNA-directed RNA polymerase I subunit RPA43OS=Homo sapiens OX=9606 GN=POLR1F PE=1 SV=1MAAGCSEAPRPAAASDGSLVGQAGVLPCLELPTYAAACALVNSRYSCLVAGPHQRHIALSPRYLNRKRTGIREQLDAELLRYSESLLGVPIAYDNIKVVGELGDIYDDQGHIHLNIEADFVIFCPEPGQKLMGIVNKVSSSHIGCLVHGCFNASIPKPEQLSAEQWQTMEINMGDELEFEVFRLDSDAAGVFCIRGKLNITSLQFKRSEVSEEVTENGTEEAAKKPKKKKKKKDPETYEVDSGTTKLADDADDTPMEESALQNTNNANGIWEEEPKKKKKKKKHQEVQDQDPVFQGSDSSGYQSDHKKKKKKRKHSEEAEFTPPLKCSPKRKGKSNFL>sp|O00584|RNT2_HUMAN Ribonuclease T2 OS=Homo sapiens OX=9606 GN=RNASET2PE=1 SV=2MRPAALRGALLGCLCLALLCLGGADKRLRDNHEWKKLIMVQHWPETVCEKIQNDCRDPPDYWTIHGLWPDKSEGCNRSWPFNLEEIKDLLPEMRAYWPDVIHSFPNRSRFWKHEWEKHGTCAAQVDALNSQKKYFGRSLELYRELDLNSVLLKLGIKPSINYYQVADFKDALARVYGVIPKIQCLPPSQDEEVQTIGQIELCLTKQDQQLQNCTEPGEQPSPKQEVWLANGAAESRGLRVCEDGPVFYPPPKKTKH>sp|O00584-2|RNT2_HUMAN Isoform 2 of Ribonuclease T2 OS=Homo sapiensOX=9606 GN=RNASET2MRPAALRGALLGCLCLALLCLGGADKRLRDNHEWKKLIMVQHWPETVCEKIQNDCRDPPDYWTIHGLWPDKSEGCNRSWPFNLEEIKKNWMEITDSSLPSPSTLPIINIFYSVLHLLQLMN>sp|Q96DM3|RMC1_HUMAN Regulator of MON1-CCZ1 complex OS=Homo sapiensOX=9606 GN=RMC1 PE=1 SV=2MGEEDYYLELCERPVQFEKANPVNCVFFDEANKQVFAVRSGGATGVVVKGPDDRNPISFRMDDKGEVKCIKFSLENKILAVQRTSKTVDFCNFIPDNSQLEYTQECKTKNANILGFCWTSSTEIVFITDQGIEFYQVLPEKRSLKLLKSHNLNVNWYMYCPESAVILLSTTVLENVLQPFHFRAGTMSKLPKFEIELPAAPKSTKPSLSERDIAMATIYGQLYVLFLRHHSRTSNSTGAEVVLYHLPREGACKKMHILKLNRTGKFALNVVDNLVVVHHQDTETSVIFDIKLRGEFDGSVTFHHPVLPARSIQPYQIPITGPAAVTSQSPVPCKLYSSSWIVFQPDIIISASQGYLWNLQVKLEPIVNLLPDKGRLMDFLLQRKECKMVILSVCSQMLSESDRASLPVIATVFDKLNHEYKKYLDAEQSYAMAVEAGQSRSSPLLKRPVRTQAVLDQSDVYTHVLSAFVEKKEMPHKFVIAVLMEYIRSLNQFQIAVQHYLHELVIKTLVQHNLFYMLHQFLQYHVLSDSKPLACLLLSLESFYPPAHQLSLDMLKRLSTANDEIVEVLLSKHQVLAALRFIRGIGGHDNISARKFLDAAKQTEDNMLFYTIFRFFEQRNQRLRGSPNFTPGEHCEEHVAFFKQIFGDQALMRPTTF>sp|Q9GZS1|RPA49_HUMAN DNA-directed RNA polymerase I subunit RPA49OS=Homo sapiens OX=9606 GN=POLR1E PE=1 SV=3MAAEVLPSARWQYCGAPDGSQRAVLVQFSNGKLQSPGNMRFTLYENKDSTNPRKRNQRILAAETDRLSYVGNNFGTGALKCNTLCRHFVGILNKTSGQMEVYDAELFNMQPLFSDVSVESELALESQTKTYREKMDSCIEAFGTTKQKRALNTRRMNRVGNESLNRAVAKAAETIIDTKGVTALVSDAIHNDLQDDSLYLPPCYDDAAKPEDVYKFEDLLSPAEYEALQSPSEAFRNVTSEEILKMIEENSHCTFVIEALKSLPSDVESRDRQARCIWFLDTLIKFRAHRVVKRKSALGPGVPHIINTKLLKHFTCLTYNNGRLRNLISDSMKAKITAYVIILALHIHDFQIDLTVLQRDLKLSEKRMMEIAKAMRLKISKRRVSVAAGSEEDHKLGTLSLPLPPAQTSDRLAKRRKIT>sp|Q9GZS1-1|RPA49_HUMAN Isoform 1 of DNA-directed RNA polymerase Isubunit RPA49 OS=Homo sapiens OX=9606 GN=POLR1EMYQASAVSLLPRDIPSCHSPSPGFSHLPTSSSQLAPDLLQFPLGQDPSFLAIPILTLPPSDSLVPPYIVWYIVWPSALISFLGCTLTVQFSNGKLQSPGNMRFTLYENKDSTNPRKRNQRILAAETDRLSYVGNNFGTGALKCNTLCRHFVGILNKTSGQMEVYDAELFNMQPLFSDVSVESELALESQTKTYREKMDSCIEAFGTTKQKRALNTRRMNRVGNESLNRAVAKAAETIIDTKGVTALVSDAIHNDLQDDSLYLPPCYDDAAKPEDVYKFEDLLSPAEYEALQSPSEAFRNVTSEEILKMIEENSHCTFVIEALKSLPSDVESRDRQARCIWFLDTLIKFRAHRVVKRKSALGPGVPHIINTKLLKHFTCLTYNNGRLRNLISDSMKAKITAYVIILALHIHDFQIDLTVLQRDLKLSEKRMMEIAKAMRLKISKRRVSVAAGSEEDHKLGTLSLPLPPAQTSDRLAKRRKIT>sp|Q96DB5|RMD1_HUMAN Regulator of microtubule dynamics protein 1 OS=Homosapiens OX=9606 GN=RMDN1 PE=1 SV=1MALAARLWRLLPFRRGAAPGSRLPAGTSGSRGHCGPCRFRGFEVMGNPGTFKRGLLLSALSYLGFETYQVISQAAVVHATAKVEEILEQADYLYESGETEKLYQLLTQYKESEDAELLWRLARASRDVAQLSRTSEEEKKLLVYEALEYAKRALEKNESSFASHKWYAICLSDVGDYEGIKAKIANAYIIKEHFEKAIELNPKDATSIHLMGIWCYTFAEMPWYQRRIAKMLFATPPSSTYEKALGYFHRAEQVDPNFYSKNLLLLGKTYLKLHNKKLAAFWLMKAKDYPAHTEEDKQIQTEAAQLLTSFSEKN>sp|Q96DB5-2|RMD1_HUMAN Isoform 2 of Regulator of microtubule dynamicsprotein 1 OS=Homo sapiens OX=9606 GN=RMDN1MALAARLWRLLPFRRGAAPGSRLPAGTSGSRGHCGPCRFRGFEVMGNPGTFKRGLLLSALSYLGFETYQVISQAAVVHATAKVEEILEQADYLYESGETEKLYQLLTQYKESEDAELLWRLARASRDVAQLSRTSEEEKKLLVYEALEYAKRALEKNESSFASHKKAIELNPKDATSIHLMGIWCYTFAEMPWYQRRIAKMLFATPPSSTYEKALGYFHRAEQVDPNFYSKNLLLLGKTYLKLHNKKLAAFWLMKAKDYPAHTEEDKQIQTEAAQLLTSFSEKN>sp|Q96DB5-3|RMD1_HUMAN Isoform 3 of Regulator of microtubule dynamicsprotein 1 OS=Homo sapiens OX=9606 GN=RMDN1MALAARLWRLLPFRRGAAPGSRLPAGTSGSRGHCGPCRFRGFEVMGNPGTFKRGLLLSALSYLGFETYQVISQAAVVHATAKVEEILEQADYLYESGETEKLYQLLTQYKESEDAELLWRLARASRDVAQLSRTSEEEKKLLVYEALEYAKRALEKNESSFASHKKAIELNPKDATSIHLMGIWCYTFAEMPWYQRRIAKMLFATPPSSTYEKALGYFHRAEQGKTYLKLHNKKLAAFWLMKAKDYPAHTEEDKQIQTEAAQLLTSFSEKN>sp|Q96G75|RMD5B_HUMAN E3 ubiquitin-protein transferase RMND5B OS=Homosapiens OX=9606 GN=RMND5B PE=1 SV=1MEQCACVERELDKVLQKFLTYGQHCERSLEELLHYVGQLRAELASAALQGTPLSATLSLVMSQCCRKIKDTVQKLASDHKDIHSSVSRVGKAIDRNFDSEICGVVSDAVWDAREQQQQILQMAIVEHLYQQGMLSVAEELCQESTLNVDLDFKQPFLELNRILEALHEQDLGPALEWAVSHRQRLLELNSSLEFKLHRLHFIRLLAGGPAKQLEALSYARHFQPFARLHQREIQVMMGSLVYLRLGLEKSPYCHLLDSSHWAEICETFTRDACSLLGLSVESPLSVSFASGCVALPVLMNIKAVIEQRQCTGVWNHKDELPIEIELGMKCWYHSVFACPILRQQTSDSNPPIKLICGHVISRDALNKLINGGKLKCPYCPMEQNPADGKRIIF>sp|Q96G75-2|RMD5B_HUMAN Isoform 2 of E3 ubiquitin-protein transferaseRMND5B OS=Homo sapiens OX=9606 GN=RMND5BMSQCCRKIKDTVQKLASDHKDIHSSVSRVGKAIDRNFDSEICGVVSDAVWDAREQQQQILQMAIVEHLYQQGMLSVAEELCQESTLNVDLDFKQPFLELNRILEALHEQDLGPALEWAVSHRQRLLELNSSLEFKLHRLHFIRLLAGGPAKQLEALSYARHFQPFARLHQREIQVMMGSLVYLRLGLEKSPYCHLLDSSHWAEICETFTRDACSLLGLSVESPLSVSFASGCVALPVLMNIKAVIEQRQCTGVWNHKDELPIEIELGMKCWYHSVFACPILRQQTSDSNPPIKLICGHVISRDALNKLINGGKLKCPYCPMEQNPADGKRIIF>sp|Q16518|RPE65_HUMAN Retinoid isomerohydrolase OS=Homo sapiens OX=9606GN=RPE65 PE=1 SV=3MSIQVEHPAGGYKKLFETVEELSSPLTAHVTGRIPLWLTGSLLRCGPGLFEVGSEPFYHLFDGQALLHKFDFKEGHVTYHRRFIRTDAYVRAMTEKRIVITEFGTCAFPDPCKNIFSRFFSYFRGVEVTDNALVNVYPVGEDYYACTETNFITKINPETLETIKQVDLCNYVSVNGATAHPHIENDGTVYNIGNCFGKNFSIAYNIVKIPPLQADKEDPISKSEIVVQFPCSDRFKPSYVHSFGLTPNYIVFVETPVKINLFKFLSSWSLWGANYMDCFESNETMGVWLHIADKKRKKYLNNKYRTSPFNLFHHINTYEDNGFLIVDLCCWKGFEFVYNYLYLANLRENWEEVKKNARKAPQPEVRRYVLPLNIDKADTGKNLVTLPNTTATAILCSDETIWLEPEVLFSGPRQAFEFPQINYQKYCGKPYTYAYGLGLNHFVPDRLCKLNVKTKETWVWQEPDSYPSEPIFVSHPDALEEDDGVVLSVVVSPGAGQKPAYLLILNAKDLSEVARAEVEINIPVTFHGLFKKS>sp|A6NI28|RHG42_HUMAN Rho GTPase-activating protein 42 OS=Homo sapiensOX=9606 GN=ARHGAP42 PE=1 SV=3MGLPTLEFSDSYLDSPDFRERLQCHEIELERTNKFIKELIKDGSLLIGALRNLSMAVQKFSQSLQDFQFECIGDAETDDEISIAQSLKEFARLLIAVEEERRRLIQNANDVLIAPLEKFRKEQIGAAKDGKKKFDKESEKYYSILEKHLNLSAKKKESHLQEADTQIDREHQNFYEASLEYVFKIQEVQEKKKFEFVEPLLSFLQGLFTFYHEGYELAQEFAPYKQQLQFNLQNTRNNFESTRQEVERLMQRMKSANQDYRPPSQWTMEGYLYVQEKRPLGFTWIKHYCTYDKGSKTFTMSVSEMKSSGKMNGLVTSSPEMFKLKSCIRRKTDSIDKRFCFDIEVVERHGIITLQAFSEANRKLWLEAMDGKEPIYTLPAIISKKEEMYLNEAGFNFVRKCIQAVETRGITILGLYRIGGVNSKVQKLMNTTFSPKSPPDIDIDIELWDNKTITSGLKNYLRCLAEPLMTYKLHKDFIIAVKSDDQNYRVEAVHALVHKLPEKNREMLDILIKHLVKVSLHSQQNLMTVSNLGVIFGPTLMRAQEETVAAMMNIKFQNIVVEILIEHYEKIFHTAPDPSIPLPQPQSRSGSRRTRAICLSTGSRKPRGRYTPCLAEPDSDSYSSSPDSTPMGSIESLSSHSSEQNSTTKSASCQPREKSGGIPWIATPSSSNGQKSLGLWTTSPESSSREDATKTDAESDCQSVASVTSPGDVSPPIDLVKKEPYGLSGLKRASASSLRSISAAEGNKSYSGSIQSLTSVGSKETPKASPNPDLPPKMCRRLRLDTASSNGYQRPGSVVAAKAQLFENVGSPKPVSSGRQAKAMYSCKAEHSHELSFPQGAIFSNVYPSVEPGWLKATYEGKTGLVPENYVVFL>sp|Q8N443|RIBC1_HUMAN RIB43A-like with coiled-coils protein 1 OS=Homosapiens OX=9606 GN=RIBC1 PE=1 SV=1MYNIKQSTDTKEAAAIEARRNREKERQNRFFNVRNRVMGVDVQALNNQVGDRKRREAAERSKEAAYGTSQVQYDVVVQMLEKEEADRTRQLAKKVQEFREQKQQLKNGREFSLWDPGQVWKGLPTYLSYSNTYPGPASLQYFSGEDLDRDTRLRMQQGQFRYNLERQQQEQQQAKVDENYTDALSNQLRLAMDAQATHLARLEESCRAAMMCAMANANKAQAAVQAGRQRCERQREQKANLAEIQHQSTSDLLTENPQVAQHPMAPYRVLPYCWKGMTPEQQAAIRKEQEVQRSKKQAHRQAEKTLDTEWKSQTMSSAQAVLELEEQERELCAVFQRGLGSFNQQLANEQKAQQDYLNSVIYTNQPTAQYHQQFNTSSR>sp|Q8N443-2|RIBC1_HUMAN Isoform 2 of RIB43A-like with coiled-coilsprotein 1 OS=Homo sapiens OX=9606 GN=RIBC1MYNIKQSTDTKEAAAIEARRNREKERQNRFFNVRNRVMGVDVQALNNQVGDRKRREAAERSKEAAYGTSQVQYDVVVQMLEKEEADRTRQLAKKVQEFREQKQQLKNGREFSLWDPGQVWKGLPTYLSYSNTYPGPASLQYFSGEDLDRDTRLRMQQGQFRYNLERQQQEQQQAKVDENYTGKQPGPPDSET>sp|Q8N443-3|RIBC1_HUMAN Isoform 3 of RIB43A-like with coiled-coilsprotein 1 OS=Homo sapiens OX=9606 GN=RIBC1MYNIKQSTDTKEAAAIEARRNREKERQNRFFNVRNRVMGVDVQALNNQVGDRKRREAAERSKEAAYDALSNQLRLAMDAQATHLARLEESCRAAMMCAMANANKAQAAVQAGRQRCERQREQKANLAEIQHQSTSDLLTENPQVAQHPMAPYRVLPYCWKGMTPEQQAAIRKEQEVQRSKKQAHRQAEKTLDTEWKSQTMSSAQAVLELEEQERELCAVFQRGLGSFNQQLANEQKAQ>sp|Q96K30|RITA1_HUMAN RBPJ-interacting and tubulin-associated protein 1OS=Homo sapiens OX=9606 GN=RITA1 PE=1 SV=1MKTPVELAVSGMQTLGLQHRCRGGYRVKARTSYVDETLFGSPAGTRPTPPDFDPPWVEKANRTRGVGKEASKALGAKGSCETTPSRGSTPTLTPRKKNKYRPISHTPSYCDESLFGSRSEGASFGAPRMAKGDAAKLRALLWTPPPTPRGSHSPRPREAPLRAIHPAGPSKTEPGPAADSQKLSMGGLHSSRPLKRGLSHSLTHLNVPSTGHPATSAPHTNGPQDLRPSTSGVTFRSPLVTSRARSVSISVPSTPRRGGATQKPKPPWK>sp|Q96K30-2|RITA1_HUMAN Isoform 2 of RBPJ-interacting and tubulin-associated protein 1 OS=Homo sapiens OX=9606 GN=RITA1MKTPVELAVSGMQTLGLQHRCRGGYRVKARTSYVDETLFGSPAGTRPTPPDFDPPWVEKANRTRGVGKEASKALGAKGSCETTPSRGSTPTLTPRKKNKYRPISHTPSYCDESLFGSRSEGASFGAPRMAKGDAAKLRALLWTPPPTPRGSHSPRPREAPVPPTQMGLRISGLPRQG>sp|Q96K30-3|RITA1_HUMAN Isoform 3 of RBPJ-interacting and tubulin-associated protein 1 OS=Homo sapiens OX=9606 GN=RITA1MLREPRKQGLAGRAHLLSPGTTGSMKTPVELAVSGMQTLGLQHRCRGGYRVKARTSYVDETLFGSPAGTRPTPPDFDPPWVEKANRTRGVGKEASKALGAKGSCETTPSRGSTPTLTPRKKNKYRPISHTPSYCDESLFGSRSEGASFGAPRMAKGDAAKLRALLWTPPPTPRGSHSPRPREAPLRAIHPAGPSKTEPGPAADSQKLSMGGLHSSRPLKRGLSHSLTHLNVPSTGHPATSAPHTNGPQDLRPSTSGVTFRSPLVTSRARSVSISVPSTPRRGGATQKPKPPWK>sp|P62917|RL8_HUMAN 60S ribosomal protein L8 OS=Homo sapiens OX=9606GN=RPL8 PE=1 SV=2MGRVIRGQRKGAGSVFRAHVKHRKGAARLRAVDFAERHGYIKGIVKDIIHDPGRGAPLAKVVFRDPYRFKKRTELFIAAEGIHTGQFVYCGKKAQLNIGNVLPVGTMPEGTIVCCLEEKPGDRGKLARASGNYATVISHNPETKKTRVKLPSGSKKVISSANRAVVGVVAGGGRIDKPILKAGRAYHKYKAKRNCWPRVRGVAMNPVEHPFGGGNHQHIGKPSTIRRDAPAGRKVGLIAARRTGRLRGTKTVQEKEN>sp|Q9Y3U8|RL36_HUMAN 60S ribosomal protein L36 OS=Homo sapiens OX=9606GN=RPL36 PE=1 SV=3MALRYPMAVGLNKGHKVTKNVSKPRHSRRRGRLTKHTKFVRDMIREVCGFAPYERRAMELLKVSKDKRALKFIKKRVGTHIRAKRKREELSNVLAAMRKAAAKKD>sp|Q5TFQ8|SIRBL_HUMAN Signal-regulatory protein beta-1 isoform 3 OS=Homosapiens OX=9606 GN=SIRPB1 PE=1 SV=1MPVPASWPHLPSPFLLMTLLLGRLTGVAGEEELQVIQPDKSISVAAGESATLHCTVTSLIPVGPIQWFRGAGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRISNITPADAGTYYCVKFRKGSPDHVEFKSGAGTELSVRAKPSAPVVSGPAARATPQHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPAGDSVSYSIHSTAKVVLTREDVHSQVICEVAHVTLQGDPLRGTANLSETIRVPPTLEVTQQPVRAENQVNVTCQVRKFYPQRLQLTWLENGNVSRTETASTLTENKDGTYNWMSWLLVNVSAHRDDVKLTCQVEHDGQPAVSKSHDLKVSAHPKEQGSNTAPGPALASAAPLLIAFLLGPKVLLVVGVSVIYVYWKQKA>sp|Q9NPC8|SIX2_HUMAN Homeobox protein SIX2 OS=Homo sapiens OX=9606GN=SIX2 PE=1 SV=1MSMLPTFGFTQEQVACVCEVLQQGGNIERLGRFLWSLPACEHLHKNESVLKAKAVVAFHRGNFRELYKILESHQFSPHNHAKLQQLWLKAHYIEAEKLRGRPLGAVGKYRVRRKFPLPRSIWDGEETSYCFKEKSRSVLREWYAHNPYPSPREKRELAEATGLTTTQVSNWFKNRRQRDRAAEAKERENNENSNSNSHNPLNGSGKSVLGSSEDEKTPSGTPDHSSSSPALLLSPPPPGLPSLHSLGHPPGPSAVPVPVPGGGGADPLQHHHGLQDSILNPMSANLVDLGS>sp|A7XYQ1|SOBP_HUMAN Sine oculis-binding protein homolog OS=Homo sapiensOX=9606 GN=SOBP PE=1 SV=2MAEMEKEGRPPENKRSRKPAHPVKREINEEMKNFAENTMNELLGWYGYDKVELKDGEDIEFRSYPTDGESRQHISVLKENSLPKPKLPEDSVISPYNISTGYSGLATGNGLSDSPAGSKDHGSVPIIVPLIPPPFIKPPAEDDVSNVQIMCAWCQKVGIKRYSLSMGSEVKSFCSEKCFAACRRAYFKRNKARDEDGHAENFPQQHYAKETPRLAFKNNCELLVCDWCKHIRHTKEYLDFGDGERRLQFCSAKCLNQYKMDIFYKETQANLPAGLCSTLHPPMENKAEGTGVQLLTPDSWNIPLTDARRKAPSPVATAGQSQGPGPSASTTVSPSDTANCSVTKIPTPVPKSIPISETPNIPPVSVQPPASIGPPLGVPPRSPPMVMTNRGPVPLPIFMEQQIMQQIRPPFIRGPPHHASNPNSPLSNPMLPGIGPPPGGPRNLGPTSSPMHRPMLSPHIHPPSTPTMPGNPPGLLPPPPPGAPLPSLPFPPVSMMPNGPMPVPQMMNFGLPSLAPLVPPPTLLVPYPVIVPLPVPIPIPIPIPHVSDSKPPNGFSSNGENFIPNAPGDSAAAGGKPSGHSLSPRDSKQGSSKSADSPPGCSGQALSLAPTPAEHGRSEVVDLTRRAGSPPGPPGAGGQLGFPGVLQGPQDGVIDLTVGHRARLHNVIHRALHAHVKAEREPSAAERRTCGGCRDGHCSPPAAGDPGPGAPAGPEAAAACNVIVNGTRGAAAEGAKSAEPPPEQPPPPPPPAPPKKLLSPEEPAVSELESVKENNCASNCHLDGEAAKKLMGEEALAGGDKSDPNLNNPADEDHAYALRMLPKTGCVIQPVPKPAEKAAMAPCIISSPMLSAGPEDLEPPLKRRCLRIRNQNK>sp|Q8IW75|SPA12_HUMAN Serpin A12 OS=Homo sapiens OX=9606 GN=SERPINA12PE=1 SV=1MNPTLGLAIFLAVLLTVKGLLKPSFSPRNYKALSEVQGWKQRMAAKELARQNMDLGFKLLKKLAFYNPGRNIFLSPLSISTAFSMLCLGAQDSTLDEIKQGFNFRKMPEKDLHEGFHYIIHELTQKTQDLKLSIGNTLFIDQRLQPQRKFLEDAKNFYSAETILTNFQNLEMAQKQINDFISQKTHGKINNLIENIDPGTVMLLANYIFFRARWKHEFDPNVTKEEDFFLEKNSSVKVPMMFRSGIYQVGYDDKLSCTILEIPYQKNITAIFILPDEGKLKHLEKGLQVDTFSRWKTLLSRRVVDVSVPRLHMTGTFDLKKTLSYIGVSKIFEEHGDLTKIAPHRSLKVGEAVHKAELKMDERGTEGAAGTGAQTLPMETPLVVKIDKPYLLLIYSEKIPSVLFLGKIVNPIGK>sp|Q9P1W8|SIRPG_HUMAN Signal-regulatory protein gamma OS=Homo sapiensOX=9606 GN=SIRPG PE=1 SV=3MPVPASWPHPPGPFLLLTLLLGLTEVAGEEELQMIQPEKLLLVTVGKTATLHCTVTSLLPVGPVLWFRGVGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRISSITPADVGTYYCVKFRKGSPENVEFKSGPGTEMALGAKPSAPVVLGPAARTTPEHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPTGQSVAYSIRSTARVVLDPWDVRSQVICEVAHVTLQGDPLRGTANLSEAIRVPPTLEVTQQPMRVGNQVNVTCQVRKFYPQSLQLTWSENGNVCQRETASTLTENKDGTYNWTSWFLVNISDQRDDVVLTCQVKHDGQLAVSKRLALEVTVHQKDQSSDATPGPASSLTALLLIAVLLGPIYVPWKQKT>sp|Q9P1W8-2|SIRPG_HUMAN Isoform 2 of Signal-regulatory protein gammaOS=Homo sapiens OX=9606 GN=SIRPGMIQPEKLLLVTVGKTATLHCTVTSLLPVGPVLWFRGVGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRISSITPADVGTYYCVKFRKGSPENVEFKSGPGTEMALGAKPSAPVVLGPAARTTPEHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPTGQSVAYSIRSTARVVLDPWDVRSQVICEVAHVTLQGDPLRGTANLSEAIRVPPTLEVTQQPMRVGNQVNVTCQVRKFYPQSLQLTWSENGNVCQRETASTLTENKDGTYNWTSWFLVNISDQRDDVVLTCQVKHDGQLAVSKRLALEVTVHQKDQSSDATPGPASSLTALLLIAVLLGPIYVPWKQKT>sp|Q9P1W8-3|SIRPG_HUMAN Isoform 3 of Signal-regulatory protein gammaOS=Homo sapiens OX=9606 GN=SIRPGMPVPASWPHPPGPFLLLTLLLGLTEVAGEEELQMIQPEKLLLVTVGKTATLHCTVTSLLPVGPVLWFRGVGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRISSITPADVGTYYCVKFRKGSPENVEFKSGPGTEMALGGPASSLTALLLIAVLLGPIYVPWKQKT>sp|Q9P1W8-4|SIRPG_HUMAN Isoform 4 of Signal-regulatory protein gammaOS=Homo sapiens OX=9606 GN=SIRPGMPVPASWPHPPGPFLLLTLLLGLTEVAGEEELQMIQPEKLLLVTVGKTATLHCTVTSLLPVGPVLWFRGVGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRISSITPADVGTYYCVKFRKGSPENVEFKSGPGTEMALGAKPSAPVVLGPAARTTPEHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPTGQSVAYSIRSTARVVLDPWDVRSQVICEVAHVTLQGDPLRGTANLSEAIRGPASSLTALLLIAVLLGPIYVPWKQKT>sp|Q16650|TBR1_HUMAN T-box brain protein 1 OS=Homo sapiens OX=9606GN=TBR1 PE=1 SV=1MQLEHCLSPSIMLSKKFLNVSSSYPHSGGSELVLHDHPIISTTDNLERSSPLKKITRGMTNQSDTDNFPDSKDSPGDVQRSKLSPVLDGVSELRHSFDGSAADRYLLSQSSQPQSAATAPSAMFPYPGQHGPAHPAFSIGSPSRYMAHHPVITNGAYNSLLSNSSPQGYPTAGYPYPQQYGHSYQGAPFYQFSSTQPGLVPGKAQVYLCNRPLWLKFHRHQTEMIITKQGRRMFPFLSFNISGLDPTAHYNIFVDVILADPNHWRFQGGKWVPCGKADTNVQGNRVYMHPDSPNTGAHWMRQEISFGKLKLTNNKGASNNNGQMVVLQSLHKYQPRLHVVEVNEDGTEDTSQPGRVQTFTFPETQFIAVTAYQNTDITQLKIDHNPFAKGFRDNYDTIYTGCDMDRLTPSPNDSPRSQIVPGARYAMAGSFLQDQFVSNYAKARFHPGAGAGPGPGTDRSVPHTNGLLSPQQAEDPGAPSPQRWFVTPANNRLDFAASAYDTATDFAGNAATLLSYAAAGVKALPLQAAGCTGRPLGYYADPSGWGARSPPQYCGTKSGSVLPCWPNSAAAAARMAGANPYLGEEAEGLAAERSPLPPGAAEDAKPKDLSDSSWIETPSSIKSIDSSDSGIYEQAKRRRISPADTPVSESSSPLKSEVLAQRDCEKNCAKDISGYYGFYSHS>sp|Q16650-2|TBR1_HUMAN Isoform 2 of T-box brain protein 1 OS=Homosapiens OX=9606 GN=TBR1MHPDSPNTGAHWMRQEISFGKLKLTNNKGASNNNGQMVVLQSLHKYQPRLHVVEVNEDGTEDTSQPGRVQTFTFPETQFIAVTAYQNTDITQLKIDHNPFAKGFRDNYDTIYTGCDMDRLTPSPNDSPRSQIVPGARYAMAGSFLQDQFVSNYAKARFHPGAGAGPGPGTDRSVPHTNGLLSPQQAEDPGAPSPQRWFVTPANNRLDFAASAYDTATDFAGNAATLLSYAAAGVKALPLQAAGCTGRPLGYYADPSGWGARSPPQYCGTKSGSVLPCWPNSAAAAARMAGANPYLGEEAEGLAAERSPLPPGAAEDAKPKDLSDSSWIETPSSIKSIDSSDSGIYEQAKRRRISPADTPVSESSSPLKSEVLAQRDCEKNCAKDISGYYGFYSHS>sp|Q9UMY4|SNX12_HUMAN Sorting nexin-12 OS=Homo sapiens OX=9606 GN=SNX12PE=1 SV=4MSDTAVADTRRLNSKPQDLTDAYGPPSNFLEIDIFNPQTVGVGRARFTTYEVRMRTNLPIFKLKESCVRRRYSDFEWLKNELERDSKIVVPPLPGKALKRQLPFRGDEGIFEESFIEERRQGLEQFINKIAGHPLAQNERCLHMFLQEEAIDRNYVPGKVRQ>sp|Q9UMY4-1|SNX12_HUMAN Isoform 1 of Sorting nexin-12 OS=Homo sapiensOX=9606 GN=SNX12MSDTAVADTRRLNSKPQDLTDAYGPPSNFLEIDIFNPQTVGVGRARFTTYEVRMRTNLPIFKLKESCVRRRYSDFEWLKNELERDSKIVVPPLPGKALKRQLPFRGDEGIFEESFIEERRQGLEQFINKIAGHPLAQNERCLHMFLQEEAIDRNYVPGKSLAVSCPGWSAVA>sp|Q9UMY4-3|SNX12_HUMAN Isoform 3 of Sorting nexin-12 OS=Homo sapiensOX=9606 GN=SNX12MSDTAVADTRRLNSKPQDLTDAYGPPSNFLEIDIFNPQTVGVGRARFTTYETNLPIFKLKESCVRRRYSDFEWLKNELERDSKIVVPPLPGKALKRQLPFRGDEGIFEESFIEERRQGLEQFINKIAGHPLAQNERCLHMFLQEEAIDRNYVPGKVRQ>sp|Q99932|SPAG8_HUMAN Sperm-associated antigen 8 OS=Homo sapiens OX=9606GN=SPAG8 PE=1 SV=3METNESTEGSRSRSRSLDIQPSSEGLGPTSEPFPSSDDSPRSALAAATAAAAAAASAAAATAAFTTAKAAALSTKTPAPCSEFMEPSSDPSLLGEPCAGPGFTHNIAHGSLGFEPVYVSCIAQDTCTTTDHSSNPGPVPGSSSGPVLGSSSGAGHGSGSGSGPGCGSVPGSGSGPGPGSGPGSGPGHGSGSHPGPASGPGPDTGPDSELSPCIPPGFRNLVADRVPNYTSWSQHCPWEPQKQPPWEFLQVLEPGARGLWKPPDIKGKLMVCYETLPRGQCLLYNWEEERATNHLDQVPSMQDGSESFFFRHGHRGLLTMQLKSPMPSSTTQKDSYQPPGNVYWPLRGKREAMLEMLLQHQICKEVQAEQEPTRKLFEVESVTHHDYRMELAQAGTPAPTKPHDYRQEQPETFWIQRAPQLPGVSNIRTLDTPFRKNCSFSTPVPLSLGKLLPYEPENYPYQLGEISSLPCPGGRLGGGGGRMTPF>sp|Q99932-1|SPAG8_HUMAN Isoform 1 of Sperm-associated antigen 8 OS=Homosapiens OX=9606 GN=SPAG8METNESTEGSRSRSRSLDIQPSSEGLGPTSEPFPSSDDSPRSALAAATAAAAAAASAAAATAAFTTAKAAALSTKTPAPCSEFMEPSSDPSLLGEPCAGPGFTHNIAHGSLGFEPVYVSCIAQDTCTTTDHSSNPGPVPGSSSGPVLGSSSGAGHGSGSGSGPGCGSVPGSGSGPGPGSGPGSGPGHGSGSHPGPASGPGPDTGPDSELSPCIPPGFRNLVADRVPNYTSWSQHCPWEPQKQPPWEFLQVLEPGARGLWKPPDIKGKLMVCYETLPRGQCLLYNWEEERATNHLDQVPSMQDGSESFFFRHGHRGLLTMQLKSPMPSSTTQKDSYQPPGNVYWPLRGKREAMLEMLLQHQICKEVQAEQEPTRKLFEVESVTHHDYRMELAQAGTPAPTKPHDYRQEQPETFWIQRAPQLPVCEGD>sp|Q99932-2|SPAG8_HUMAN Isoform 2 of Sperm-associated antigen 8 OS=Homosapiens OX=9606 GN=SPAG8METNESTEGSRSRSRSLDIQPSSEGLGPTSEPFPSSDDSPRSALAAATAAAAAAASAAAATAAFTTAKAAALSTKTPAPCSEFMEPSSDPSLLGEPCAGPGFTHNIAHGSLGFEPVYVSCIAQDTCTTTDHSSNPGPVPGSSSGPVLGSSSGAGHGSGSGSGPGCGSVPGSGSGPGPGSGPGSGPGHGSGSHPGPASGPGPDTGPDSELSPCIPPGFRNLVADRVPNYTSWSQHCPWEPQKQPPWEFLQVLEPGARGLWKPPDIKGKLMVCYETLPRGQCLLYNWEEERATNHLDQVPSMQDGSESFFFRHGHRGLLTMQLKSPMPSSTTQKDSYQPPGNVYWPLRGKREAMLEMLLQHQICKEVQAEQEPTRKLFEVESVTHHDYRMELAQAGTPAPTKPHDYRQEQPETFWIQRAPQLPTWWPLPTQVPAAEDYLTWKEWGFTGVQEVLSALLRATPGEYSVNICGMNEHPVCSRTWTNRLCHQEMGSKKTVTQEDRGW>sp|Q86XZ4|SPAS2_HUMAN Spermatogenesis-associated serine-rich protein 2OS=Homo sapiens OX=9606 GN=SPATS2 PE=1 SV=1MSRKQNQKDSSGFIFDLQSNTVLAQGGAFENMKEKINAVRAIVPNKSNNEIILVLQHFDNCVDKTVQAFMEGSASEVLKEWTVTGKKKNKKKKNKPKPAAEPSNGIPDSSKSVSIQEEQSAPSSEKGGMNGYHVNGAINDTESVDSLSEGLETLSIDARELEDPESAMLDTLDRTGSMLQNGVSDFETKSLTMHSIHNSQQPRNAAKSLSRPTTETQFSNMGMEDVPLATSKKLSSNIEKSVKDLQRCTVSLARYRVVVKEEMDASIKKMKQAFAELESCLMDREVALLAEMDKVKAEAMEILLSRQKKAELLKKMTHVAVQMSEQQLVELRADIKHFVSERKYDEDLGRVARFTCDVETLKKSIDSFGQVSHPKNSYSTRSRCSSVTSVSLSSPSDASAASSSTCASPPSLTSANKKNFAPGETPAAIANSSGQPYQPLREVLPGNRRGGQGYRPQGQKSNDPMNQGRHDSMGRYRNSSWYSSGSRYQSAPSQAPGNTIERGQTHSAGTNGTGVSMEPSPPTPSFKKGLPQRKPRTSQTEAVNS>sp|Q9Y5X0|SNX10_HUMAN Sorting nexin-10 OS=Homo sapiens OX=9606 GN=SNX10PE=1 SV=2MFPEQQKEEFVSVWVRDPRIQKEDFWHSYIDYEICIHTNSMCFTMKTSCVRRRYREFVWLRQRLQSNALLVQLPELPSKNLFFNMNNRQHVDQRRQGLEDFLRKVLQNALLLSDSSLHLFLQSHLNSEDIEACVSGQTKYSVEEAIHKFALMNRRFPEEDEEGKKENDIDYDSESSSSGLGHSSDDSSSHGCKVNTAPQES>sp|Q9Y5X0-2|SNX10_HUMAN Isoform 2 of Sorting nexin-10 OS=Homo sapiensOX=9606 GN=SNX10MNNRQHVDQRRQGLEDFLRKVLQNALLLSDSSLHLFLQSHLNSEDIEACVSGQTKYSVEEAIHKFALMNRRFPEEDEEGKKENDIDYDSESSSSGLGHSSDDSSSHGCKVNTAPQES>sp|Q969G3|SMCE1_HUMAN SWI/SNF-related matrix-associated actin-dependentregulator of chromatin subfamily E member 1 OS=Homo sapiens OX=9606GN=SMARCE1 PE=1 SV=2MSKRPSYAPPPTPAPATQMPSTPGFVGYNPYSHLAYNNYRLGGNPGTNSRVTASSGITIPKPPKPPDKPLMPYMRYSRKVWDQVKASNPDLKLWEIGKIIGGMWRDLTDEEKQEYLNEYEAEKIEYNESMKAYHNSPAYLAYINAKSRAEAALEEESRQRQSRMEKGEPYMSIQPAEDPDDYDDGFSMKHTATARFQRNHRLISEILSESVVPDVRSVVTTARMQVLKRQVQSLMVHQRKLEAELLQIEERHQEKKRKFLESTDSFNNELKRLCGLKVEVDMEKIAAEIAQAEEQARKRQEEREKEAAEQAERSQSSIVPEEEQAANKGEEKKDDENIPMETEETHLEETTESQQNGEEGTSTPEDKESGQEGVDSMAEEGTSDSNTGSESNSATVEEPPTDPIPEDEKKE>sp|Q969G3-2|SMCE1_HUMAN Isoform 2 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily E member 1 OS=Homosapiens OX=9606 GN=SMARCE1MSKRPSYAPPPTPAPATQMPSTPGFVGYNPYSHLAYNNYRLGGNPGTNSRVTASSGITIPKPPKPPDKPLMPYMRYSRKVWDQVKASNPDLKLWEIGKIIGGMWRDLTDEEKQEYLNEYEAEKIEYNESMKAYHNSPAYLAYINAKSRAEAALEEESRQRQSRMEKGEPYMSIQPAEDPDDYDDGFSMKHTATARFQRNHRLISEILSESVVPDVRSVVTTARMQVLKRQVQSLMVHQRKLEAELLQIEERHQEKKRKFLESTDSFNNELKRLCGLKVEVDMEKIAAEIAQAEEQARKRQEEREKEAAEQAERSQSSIVPEEEQAANKGEEKKDDENIPMETEKNCQLCPRKTLTSRYTDFPD>sp|Q969G3-3|SMCE1_HUMAN Isoform 3 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily E member 1 OS=Homosapiens OX=9606 GN=SMARCE1MPYMRYSRKVWDQVKASNPDLKLWEIGKIIGGMWRDLTDEEKQEYLNEYEAEKIEYNESMKAYHNSPAYLAYINAKSRAEAALEEESRQRQSRMEKGEPYMSIQPAEDPDDYDDGFSMKHTATARFQRNHRLISEILSESVVPDVRSVVTTARMQVLKRQVQSLMVHQRKLEAELLQIEERHQEKKRKFLESTDSFNNELKRLCGLKVEVDMEKIAAEIAQAEEQARKRQEEREKEAAEQAERSQSSIVPEEEQAANKGEEKKDDENIPMETEETHLEETTESQQNGEEGTSTPEDKESGQEGVDSMAEEGTSDSNTGSESNSATVEEPPTDPIPEDEKKE>sp|Q969G3-4|SMCE1_HUMAN Isoform 4 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily E member 1 OS=Homosapiens OX=9606 GN=SMARCE1MSKRPSYAPPPTPAPATASSGITIPKPPKPPDKPLMPYMRYSRKVWDQVKASNPDLKLWEIGKIIGGMWRDLTDEEKQEYLNEYEAEKIEYNESMKAYHNSPAYLAYINAKSRAEAALEEESRQRQSRMEKGEPYMSIQPAEDPDDYDDGFSMKHTATARFQRNHRLISEILSESVVPDVRSVVTTARMQVLKRQVQSLMVHQRKLEAELLQIEERHQEKKRKFLESTDSFNNELKRLCGLKVEVDMEKIAAEIAQAEEQARKRQEEREKEAAEQAERSQSSIVPEEEQAANKGEEKKDDENIPMETEETHLEETTESQQNGEEGTSTPEDKESGQEGVDSMAEEGTSDSNTGSESNSATVEEPPTDPIPEDEKKE>sp|Q969G3-5|SMCE1_HUMAN Isoform 5 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily E member 1 OS=Homosapiens OX=9606 GN=SMARCE1MSKRPSYAPPPTPAPATASSGITIPKPPKPPDKPLMPYMRYSRKVWDQVKASNPDLKLWEIGKIIGGMWRDLTDEEKQEYLNEYEAEKIEYNESMKAYHNSPAYLAYINAKSRAEAALEEESRQRQSRMEKGEPYMSIQPAEDPDDYDDGFSMKHTATARFQRNHRLISEILSESVVPDVRSVVTTARMQVLKRQVQSLMVHQRKLEAELLQIEERHQEKKRKFLESTDSFNNELKRLCGLKVEVDMEKIAAEIAQAEEQARKRQEEREKEAAEQAERSQSSIVPEEEQAANKGEEKKDDENIPMETEKNCQLCPRKTLTSRYTDFPD>sp|Q969G3-6|SMCE1_HUMAN Isoform 6 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily E member 1 OS=Homosapiens OX=9606 GN=SMARCE1MPYMRYSRKVWDQVKASNPDLKLWEIGKIIGGMWRDLTDEEKQEYLNEYEAEKIEYNESMKAYHNSPAYLAYINAKSRAEAALEEESRQRQSRMEKGEPYMSIQPAEDPDDYDDGFSMKHTATARFQRNHRLISEILSESVVPDVRSVVTTARMQVLKRQVQSLMVHQRKLEAELLQIEERHQEKKRKFLESTDSFNNELKRLCGLKVEVDMEKIAAEIAQAEEQARKRQEEREKEAAEQAERSQSSIVPEEEQAANKGEEKKDDENIPMETEKNCQLCPRKTLTSRYTDFPD>sp|Q12824|SNF5_HUMAN SWI/SNF-related matrix-associated actin-dependentregulator of chromatin subfamily B member 1 OS=Homo sapiens OX=9606GN=SMARCB1 PE=1 SV=2MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEVGNYLRMFRGSLYKRYPSLWRRLATVEERKKIVASSHGKKTKPNTKDHGYTTLATSVTLLKASEVEEILDGNDEKYKAVSISTEPPTYLREQKAKRNSQWVPTLPNSSHHLDAVPCSTTINRNRMGRDKKRTFPLCFDDHDPAVIHENASQPEVLVPIRLDMEIDGQKLRDAFTWNMNEKLMTPEMFSEILCDDLDLNPLTFVPAIASAIRQQIESYPTDSILEDQSDQRVIIKLNIHVGNISLVDQFEWDMSEKENSPEKFALKLCSELGLGGEFVTTIAYSIRGQLSWHQKTYAFSENPLPTVEIAIRNTGDADQWCPLLETLTDAEMEKKIRDQDRNTRRMRRLANTAPAW>sp|Q12824-2|SNF5_HUMAN Isoform B of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily B member 1 OS=Homosapiens OX=9606 GN=SMARCB1MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEVGNYLRMFRGSLYKRYPSLWRRLATVEERKKIVASSHDHGYTTLATSVTLLKASEVEEILDGNDEKYKAVSISTEPPTYLREQKAKRNSQWVPTLPNSSHHLDAVPCSTTINRNRMGRDKKRTFPLCFDDHDPAVIHENASQPEVLVPIRLDMEIDGQKLRDAFTWNMNEKLMTPEMFSEILCDDLDLNPLTFVPAIASAIRQQIESYPTDSILEDQSDQRVIIKLNIHVGNISLVDQFEWDMSEKENSPEKFALKLCSELGLGGEFVTTIAYSIRGQLSWHQKTYAFSENPLPTVEIAIRNTGDADQWCPLLETLTDAEMEKKIRDQDRNTRRMRRLANTAPAW>sp|Q92629|SGCD_HUMAN Delta-sarcoglycan OS=Homo sapiens OX=9606 GN=SGCDPE=1 SV=2MPQEQYTHHRSTMPGSVGPQVYKVGIYGWRKRCLYFFVLLLMILILVNLAMTIWILKVMNFTIDGMGNLRITEKGLKLEGDSEFLQPLYAKEIQSRPGNALYFKSARNVTVNILNDQTKVLTQLITGPKAVEAYGKKFEVKTVSGKLLFSADNNEVVVGAERLRVLGAEGTVFPKSIETPNVRADPFKELRLESPTRSLVMEAPKGVEINAEAGNMEATCRTELRLESKDGEIKLDAAKIRLPRLPHGSYTPTGTRQKVFEICVCANGRLFLSQAGAGSTCQINTSVCL>sp|Q92629-2|SGCD_HUMAN Isoform 2 of Delta-sarcoglycan OS=Homo sapiensOX=9606 GN=SGCDMMPQEQYTHHRSTMPGSVGPQVYKVGIYGWRKRCLYFFVLLLMILILVNLAMTIWILKVMNFTIDGMGNLRITEKGLKLEGDSEFLQPLYAKEIQSRPGNALYFKSARNVTVNILNDQTKVLTQLITGPKAVEAYGKKFEVKTVSGKLLFSADNNEVVVGAERLRVLGAEGTVFPKSIETPNVRADPFKELRLESPTRSLVMEAPKGVEINAEAGNMEATCRTELRLESKDGEIKLDAAKIRLPRLPHGSYTPTGTRQKVFEICVCANGRLFLSQAGAGSTCQINTSVCL>sp|Q92629-3|SGCD_HUMAN Isoform 3 of Delta-sarcoglycan OS=Homo sapiensOX=9606 GN=SGCDMMPQEQYTHHRSTMPGSVGPQVYKVGIYGWRKRCLYFFVLLLMILILVNLAMTIWILKVMNFTIDGMGNLRITEKGLKLEGDSEFLQPLYAKEIQSRPGNALYFKSARNVTVNILNDQTKVLTQLITGPKAVEAYGKKFEVKTVSGKLLFSADNNEVVVGAERLRVLGAEGTVFPKSIETPNVRADPFKELRLESPTRSLVMEAPKGVEINAEAGNMEATCRTELRLESKDGEVRDEKDRSSKSYSFNRPTLPITG>sp|Q5MJ09|SPXN3_HUMAN Sperm protein associated with the nucleus on the Xchromosome N3 OS=Homo sapiens OX=9606 GN=SPANXN3 PE=1 SV=1MEQPTSSTNGEKTKSPCESNNKKNDEMQEVPNRVLAPEQSLKKTKTSEYPIIFVYYLRKGKKINSNQLENEQSQENSINPIQKEEDEGVDLSEGSSNEDEDLGPCEGPSKEDKDLDSSEGSSQEDEDLGLSEGSSQDSGED>sp|Q6IQ16|SPOPL_HUMAN Speckle-type POZ protein-like OS=Homo sapiensOX=9606 GN=SPOPL PE=1 SV=1MSREPTPPLPGDMSTGPIAESWCYTQVKVVKFSYMWTINNFSFCREEMGEVLKSSTFSSGPSDKMKWCLRVNPKGLDDESKDYLSLYLLLVSCPKSEVRAKFKFSLLNAKREETKAMESQRAYRFVQGKDWGFKKFIRRDFLLDEANGLLPDDKLTLFCEVSVVQDSVNISGHTNTNTLKVPECRLAEDLGNLWENTRFTDCSFFVRGQEFKAHKSVLAARSPVFNAMFEHEMEESKKNRVEINDLDPEVFKEMMRFIYTGRAPNLDKMADNLLAAADKYALERLKVMCEEALCSNLSVENVADTLVLADLHSAEQLKAQAIDFINRCSVLRQLGCKDGKNWNSNQATDIMETSGWKSMIQSHPHLVAEAFRALASAQCPQFGIPRKRLKQS>sp|O43791|SPOP_HUMAN Speckle-type POZ protein OS=Homo sapiens OX=9606GN=SPOP PE=1 SV=1MSRVPSPPPPAEMSSGPVAESWCYTQIKVVKFSYMWTINNFSFCREEMGEVIKSSTFSSGANDKLKWCLRVNPKGLDEESKDYLSLYLLLVSCPKSEVRAKFKFSILNAKGEETKAMESQRAYRFVQGKDWGFKKFIRRDFLLDEANGLLPDDKLTLFCEVSVVQDSVNISGQNTMNMVKVPECRLADELGGLWENSRFTDCCLCVAGQEFQAHKAILAARSPVFSAMFEHEMEESKKNRVEINDVEPEVFKEMMCFIYTGKAPNLDKMADDLLAAADKYALERLKVMCEDALCSNLSVENAAEILILADLHSADQLKTQAVDFINYHASDVLETSGWKSMVVSHPHLVAEAYRSLASAQCPFLGPPRKRLKQS>sp|Q8IUH8|SPP2C_HUMAN Signal peptide peptidase-like 2C OS=Homo sapiensOX=9606 GN=SPPL2C PE=1 SV=3MACLGFLLPVGFLLLISTVAGGKYGVAHVVSENWSKDYCILFSSDYITLPRDLHHAPLLPLYDGTKAPWCPGEDSPHQAQLRSPSQRPLRQTTAMVMRGNCSFHTKGWLAQGQGAHGLLIVSRVSDQQCSDTTLAPQDPRQPLADLTIPVAMLHYADMLDILSHTRGEAVVRVAMYAPPEPIIDYNMLVIFILAVGTVAAGGYWAGLTEANRLQRRRARRGGGSGGHHQLQEAAAAEGAQKEDNEDIPVDFTPAMTGVVVTLSCSLMLLLYFFYDHFVYVTIGIFGLGAGIGLYSCLSPLVCRLSLRQYQRPPHSLWASLPLPLLLLASLCATVIIFWVAYRNEDRWAWLLQDTLGISYCLFVLHRVRLPTLKNCSSFLLALLAFDVFFVFVTPFFTKTGESIMAQVALGPAESSSHERLPMVLKVPRLRVSALTLCSQPFSILGFGDIVVPGFLVAYCCRFDVQVCSRQIYFVACTVAYAVGLLVTFMAMVLMQMGQPALLYLVSSTLLTSLAVAACRQELSLFWTGQGRAKMCGLGCAPSAGSRQKQEGAADAHTASTLERGTSRGAGDLDSNPGEDTTEIVTISENEATNPEDRSDSSEGWSDAHLDPNELPFIPPGASEELMPLMPMAMLIPLMPLMPPPSELGHVHAQAQAHETGLPWAGLHKRKGLKVRKSMSTQAPL>sp|O75830|SPI2_HUMAN Serpin I2 OS=Homo sapiens OX=9606 GN=SERPINI2 PE=1SV=1MDTIFLWSLLLLFFGSQASRCSAQKNTEFAVDLYQEVSLSHKDNIIFSPLGITLVLEMVQLGAKGKAQQQIRQTLKQQETSAGEEFFVLKSFFSAISEKKQEFTFNLANALYLQEGFTVKEQYLHGNKEFFQSAIKLVDFQDAKACAEMISTWVERKTDGKIKDMFSGEEFGPLTRLVLVNAIYFKGDWKQKFRKEDTQLINFTKKNGSTVKIPMMKALLRTKYGYFSESSLNYQVLELSYKGDEFSLIIILPAEGMDIEEVEKLITAQQILKWLSEMQEEEVEISLPRFKVEQKVDFKDVLYSLNITEIFSGGCDLSGITDSSEVYVSQVTQKVFFEINEDGSEAATSTGIHIPVIMSLAQSQFIANHPFLFIMKHNPTESILFMGRVTNPDTQEIKGRDLDSL>sp|A0A087WV53|SPEGN_HUMAN SPEG neighbor protein OS=Homo sapiens OX=9606GN=SPEGNB PE=4 SV=1MSKAAPAKKPVAVAPAPGCTLDINDPQVQSAAIRIQASYRGHRSRKELREKGPPRVLEPLKDVVLIEGSAAKLTCRISAFPDPFIRWSKDGKELRDGPKYRYVFEDPDVVALVVRDGELADLGQYSINVTNPFGQCSDSARILVEVPTKIQKGPDNTKARKGTTVTLTAEILGEPAPDVGWTKDGEDIEEDDRVFFEIGSTTTTLTIRRATPQDSGKYEVYVENSLGMDQSFARVDVA>sp|O95363|SYFM_HUMAN Phenylalanine--tRNA ligase, mitochondrial OS=Homosapiens OX=9606 GN=FARS2 PE=1 SV=1MVGSALRRGAHAYVYLVSKASHISRGHQHQAWGSRPPAAECATQRAPGSVVELLGKSYPQDDHSNLTRKVLTRVGRNLHNQQHHPLWLIKERVKEHFYKQYVGRFGTPLFSVYDNLSPVVTTWQNFDSLLIPADHPSRKKGDNYYLNRTHMLRAHTSAHQWDLLHAGLDAFLVVGDVYRRDQIDSQHYPIFHQLEAVRLFSKHELFAGIKDGESLQLFEQSSRSAHKQETHTMEAVKLVEFDLKQTLTRLMAHLFGDELEIRWVDCYFPFTHPSFEMEINFHGEWLEVLGCGVMEQQLVNSAGAQDRIGWAFGLGLERLAMILYDIPDIRLFWCEDERFLKQFCVSNINQKVKFQPLSKYPAVINDISFWLPSENYAENDFYDLVRTIGGDLVEKVDLIDKFVHPKTHKTSHCYRITYRHMERTLSQREVRHIHQALQEAAVQLLGVEGRF>sp|Q8IWV7|UBR1_HUMAN E3 ubiquitin-protein ligase UBR1 OS=Homo sapiensOX=9606 GN=UBR1 PE=1 SV=1MADEEAGGTERMEISAELPQTPQRLASWWDQQVDFYTAFLHHLAQLVPEIYFAEMDPDLEKQEESVQMSIFTPLEWYLFGEDPDICLEKLKHSGAFQLCGRVFKSGETTYSCRDCAIDPTCVLCMDCFQDSVHKNHRYKMHTSTGGGFCDCGDTEAWKTGPFCVNHEPGRAGTIKENSRCPLNEEVIVQARKIFPSVIKYVVEMTIWEEEKELPPELQIREKNERYYCVLFNDEHHSYDHVIYSLQRALDCELAEAQLHTTAIDKEGRRAVKAGAYAACQEAKEDIKSHSENVSQHPLHVEVLHSEIMAHQKFALRLGSWMNKIMSYSSDFRQIFCQACLREEPDSENPCLISRLMLWDAKLYKGARKILHELIFSSFFMEMEYKKLFAMEFVKYYKQLQKEYISDDHDRSISITALSVQMFTVPTLARHLIEEQNVISVITETLLEVLPEYLDRNNKFNFQGYSQDKLGRVYAVICDLKYILISKPTIWTERLRMQFLEGFRSFLKILTCMQGMEEIRRQVGQHIEVDPDWEAAIAIQMQLKNILLMFQEWCACDEELLLVAYKECHKAVMRCSTSFISSSKTVVQSCGHSLETKSYRVSEDLVSIHLPLSRTLAGLHVRLSRLGAVSRLHEFVSFEDFQVEVLVEYPLRCLVLVAQVVAEMWRRNGLSLISQVFYYQDVKCREEMYDKDIIMLQIGASLMDPNKFLLLVLQRYELAEAFNKTISTKDQDLIKQYNTLIEEMLQVLIYIVGERYVPGVGNVTKEEVTMREIIHLLCIEPMPHSAIAKNLPENENNETGLENVINKVATFKKPGVSGHGVYELKDESLKDFNMYFYHYSKTQHSKAEHMQKKRRKQENKDEALPPPPPPEFCPAFSKVINLLNCDIMMYILRTVFERAIDTDSNLWTEGMLQMAFHILALGLLEEKQQLQKAPEEEVTFDFYHKASRLGSSAMNIQMLLEKLKGIPQLEGQKDMITWILQMFDTVKRLREKSCLIVATTSGSESIKNDEITHDKEKAERKRKAEAARLHRQKIMAQMSALQKNFIETHKLMYDNTSEMPGKEDSIMEEESTPAVSDYSRIALGPKRGPSVTEKEVLTCILCQEEQEVKIENNAMVLSACVQKSTALTQHRGKPIELSGEALDPLFMDPDLAYGTYTGSCGHVMHAVCWQKYFEAVQLSSQQRIHVDLFDLESGEYLCPLCKSLCNTVIPIIPLQPQKINSENADALAQLLTLARWIQTVLARISGYNIRHAKGENPIPIFFNQGMGDSTLEFHSILSFGVESSIKYSNSIKEMVILFATTIYRIGLKVPPDERDPRVPMLTWSTCAFTIQAIENLLGDEGKPLFGALQNRQHNGLKALMQFAVAQRITCPQVLIQKHLVRLLSVVLPNIKSEDTPCLLSIDLFHVLVGAVLAFPSLYWDDPVDLQPSSVSSSYNHLYLFHLITMAHMLQILLTVDTGLPLAQVQEDSEEAHSASSFFAEISQYTSGSIGCDIPGWYLWVSLKNGITPYLRCAALFFHYLLGVTPPEELHTNSAEGEYSALCSYLSLPTNLFLLFQEYWDTVRPLLQRWCADPALLNCLKQKNTVVRYPRKRNSLIELPDDYSCLLNQASHFRCPRSADDERKHPVLCLFCGAILCSQNICCQEIVNGEEVGACIFHALHCGAGVCIFLKIRECRVVLVEGKARGCAYPAPYLDEYGETDPGLKRGNPLHLSRERYRKLHLVWQQHCIIEEIARSQETNQMLFGFNWQLL>sp|Q8IWV7-2|UBR1_HUMAN Isoform 2 of E3 ubiquitin-protein ligase UBR1OS=Homo sapiens OX=9606 GN=UBR1MADEEAGGTERMEISAELPQTPQRLASWWDQQVDFYTAFLHHLAQLVPEIYFAEMDPDLEKQEESVQMSIFTPLEWYLFGEDPDICLEKLKHSGAFQLCGRVFKSGETTYSCRDCAIDPTCVLCMDCFQDSVHKNHRYKMHTSTGGGFCDCGDTEAWKTGPFCVNHEPGRAGTIKENSRCPLNEEVIVQARKIFPSVIKYVVEMTIWEEEKELPPELQIREKNERYYCVLFNDEHHSYDHVIYSLQRALDCELAEAQLHTTAIDKEGRRAVKAGAYAACQEAKEDIKSHSENVSQHPLHVEVLHSEIMAHQKFALRLGSWMNKIMSYSSDFRQIFCQACLREEPDSENPCLISRLMLWDAKLYKGARKILHELIFSSFFMEMEYKKLFAMEFVKYYKQLQKEYISDDHDRSISITALSVQMFTVPTLARHLIEEQNVISVITETLLEVLPEYLDRNNKFNFQGYSQDKLGRVYAVICDLKYILISKPTIWTERLRMQFLEGFRSFLKILTCMQGMEEIRRQVGQHIEVDPDWEAAIAIQMQLKNILLMFQEWCACDEELLLVAYKECHKAVMRCSTSFISSSKTVVQSCGHSLETKSYRVSEDLVSIHLPLSRTLAGLHVRLSRLGAVSRLHEFVSFEDFQVEVLVEYPLRCLVLVAQVVAEMWRRNGLSLISQVFYYQDVKCREEMYDKDIIMLQIGASLMDPNKFLLLVLQRYELAEAFNKTISTKDQDLIKQYNTLIEEMLQVLIYIVGERYVPGVGNVTKEEVTMREIIHLLCIEPMPHSAIAKNLPENETRCIRPWSL>sp|P60508|SYCY2_HUMAN Syncytin-2 OS=Homo sapiens OX=9606 GN=ERVFRD-1PE=1 SV=1MGLLLLVLILTPSLAAYRHPDFPLLEKAQQLLQSTGSPYSTNCWLCTSSSTETPGTAYPASPREWTSIEAELHISYRWDPNLKGLMRPANSLLSTVKQDFPDIRQKPPIFGPIFTNINLMGIAPICVMAKRKNGTNVGTLPSTVCNVTFTVDSNQQTYQTYTHNQFRHQPRFPKPPNITFPQGTLLDKSSRFCQGRPSSCSTRNFWFRPADYNQCLQISNLSSTAEWVLLDQTRNSLFWENKTKGANQSQTPCVQVLAGMTIATSYLGISAVSEFFGTSLTPLFHFHISTCLKTQGAFYICGQSIHQCLPSNWTGTCTIGYVTPDIFIAPGNLSLPIPIYGNSPLPRVRRAIHFIPLLAGLGILAGTGTGIAGITKASLTYSQLSKEIANNIDTMAKALTTMQEQIDSLAAVVLQNRRGLDMLTAAQGGICLALDEKCCFWVNQSGKVQDNIRQLLNQASSLRERATQGWLNWEGTWKWFSWVLPLTGPLVSLLLLLLFGPCLLNLITQFVSSRLQAIKLQTNLSAGRHPRNIQESPF>sp|P0DP42|T225B_HUMAN Transmembrane protein 225B OS=Homo sapiens OX=9606GN=TMEM225B PE=1 SV=1MLTLEDKDMKGFSWAIVPALTSLGYLIILVVSIFPFWVRLTNEESHEVFFSGLFENCFNAKCWKPRPLSIYIILGRVFLLSAVFLAFVTTFIMMPFASEFFPRTWKQNFVLACISFFTGACAFLALVLHALEIKALRMKLGPLQFSVLWPYYVLGFGIFLFIVAGTICLIQEMVCPCWHLLSTSQSMEEDHGSLYLDNLESLGGEPSSVQKETQVTAETVI>sp|Q6PEY2|TBA3E_HUMAN Tubulin alpha-3E chain OS=Homo sapiens OX=9606GN=TUBA3E PE=1 SV=2MRECISIHVGQAGVQIGNACWELYCLEHGIQPDGQMPSDKTIGGGDDSFNTFFSETGAGKHVPRAVFVDLEPTVVDEVRTGTYRQLFHPEQLITGKEDAASNYARGHYTIGKEIVDLVLDRIRKLADLCTGLQGFLIFHSFGGGTGSGFASLLMERLSVDYSKKSKLEFAIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLIGQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLATYAPVISAEKAYHEQLSVAEITNACFEPANQMVKCDPRHGKYMACCMLYRGDVVPKDVNAAIATIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLVHKFDLMYAKWAFVHWYVGEGMEEGEFSEAREDLAALEKDCEEVGVDSVEAEAEEGEAY>sp|Q9P0N9|TBCD7_HUMAN TBC1 domain family member 7 OS=Homo sapiensOX=9606 GN=TBC1D7 PE=1 SV=1MTEDSQRNFRSVYYEKVGFRGVEEKKSLEILLKDDRLDTEKLCTFSQRFPLPSMYRALVWKVLLGILPPHHESHAKVMMYRKEQYLDVLHALKVVRFVSDATPQAEVYLRMYQLESGKLPRSPSFPLEPDDEVFLAIAKAMEEMVEDSVDCYWITRRFVNQLNTKYRDSLPQLPKAFEQYLNLEDGRLLTHLRMCSAAPKLPYDLWFKRCFAGCLPESSLQRVWDKVVSGSCKILVFVAVEILLTFKIKVMALNSAEKITKFLENIPQDSSDAIVSKAIDLWHKHCGTPVHSS>sp|Q9P0N9-2|TBCD7_HUMAN Isoform 2 of TBC1 domain family member 7 OS=Homosapiens OX=9606 GN=TBC1D7MTEDSQRNFRSVYYEKVGFRGVEEKKSLEILLKDDRLGILPPHHESHAKVMMYRKEQYLDVLHALKVVRFVSDATPQAEVYLRMYQLESGKLPRSPSFPLEPDDEVFLAIAKAMEEMVEDSVDCYWITRRFVNQLNTKYRDSLPQLPKAFEQYLNLEDGRLLTHLRMCSAAPKLPYDLWFKRCFAGCLPESSLQRVWDKVVSGSCKILVFVAVEILLTFKIKVMALNSAEKITKFLENIPQDSSDAIVSKAIDLWHKHCGTPVHSS>sp|Q9P0N9-3|TBCD7_HUMAN Isoform 3 of TBC1 domain family member 7 OS=Homosapiens OX=9606 GN=TBC1D7MEGASRNLASTPRVHAKVMMYRKEQYLDVLHALKVVRFVSDATPQAEVYLRMYQLESGKLPRSPSFPLEPDDEVFLAIAKAMEEMVEDSVDCYWITRRFVNQLNTKYRDSLPQLPKAFEQYLNLEDGRLLTHLRMCSAAPKLPYDLWFKRCFAGCLPESSLQRVWDKVVSGSCKILVFVAVEILLTFKIKVMALNSAEKITKFLENIPQDSSDAIVSKAIDLWHKHCGTPVHSS>sp|Q9P0N9-4|TBCD7_HUMAN Isoform 4 of TBC1 domain family member 7 OS=Homosapiens OX=9606 GN=TBC1D7MTEDSQRNFRSVYYEKVGFRGVEEKKSLEILLKDDRLDTEKLCTFSQRFPLPSMYRALVWKVLLGILPPHHESHAKVMMYRKEQYLDVLHALKVVRFVSDATPQAEVYLRMYQLESGKLPRSPSFPLPKAFEQYLNLEDGRLLTHLRMCSAAPKLPYDLWFKRCFAGCLPESSLQRVWDKVVSGSCKILVFVAVEILLTFKIKVMALNSAEKITKFLENIPQDSSDAIVSKAIDLWHKHCGTPVHSS>sp|Q2M2D7|TBC28_HUMAN TBC1 domain family member 28 OS=Homo sapiensOX=9606 GN=TBC1D28 PE=2 SV=1MEMDEDPDNLPAQGQGNIIITKYEQGHRAGAAVDLGHEQVDVRKYTNNLGIVHEMELPRVSALEVKQRRKESKRTNKWQKMLADWTKYRSTKKLSQRVCKVIPLAVRGRALSLLLDIDKIKSQNPGKYKVMKEKGKRSSRIIHCIQLDVSHTLQKHMMFIQRFGVKQQELCDILVAYSAYNPVSIPGQRYSWYLCPYSQAWVSLGGVATS>sp|Q8WUA7|TB22A_HUMAN TBC1 domain family member 22A OS=Homo sapiensOX=9606 GN=TBC1D22A PE=1 SV=2MASDGARKQFWKRSNSKLPGSIQHVYGAQHPPFDPLLHGTLLRSTAKMPTTPVKAKRVSTFQEFESNTSDAWDAGEDDDELLAMAAESLNSEVVMETANRVLRNHSQRQGRPTLQEGPGLQQKPRPEAEPPSPPSGDLRLVKSVSESHTSCPAESASDAAPLQRSQSLPHSATVTLGGTSDPSTLSSSALSEREASRLDKFKQLLAGPNTDLEELRRLSWSGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWAIRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRIDEQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWDDEDISLLLAEAYRLKFAFADAPNHYKK>sp|Q8WUA7-2|TB22A_HUMAN Isoform 2 of TBC1 domain family member 22AOS=Homo sapiens OX=9606 GN=TBC1D22AMASDGARKQFWKRSNSKLPGSLLRSTAKMPTTPVKAKRVSTFQEFESNTSDAWDAGEDDDELLAMAAESLNSEVVMETANRVLRNHSQRQGRPTLQEGPGLQQKPRPEAEPPSPPSGDLRLVKSVSESHTSCPAEELRRLSWSGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWAIRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRIDEQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWDDEDISLLLAEAYRLKFAFADAPNHYKK>sp|Q8WUA7-3|TB22A_HUMAN Isoform 3 of TBC1 domain family member 22AOS=Homo sapiens OX=9606 GN=TBC1D22AMPTTPVKAKRVSTFQEFESNTSDAWDAGEDDDELLAMAAESLNSEVVMETANRVLRNHSQRQGRPTLQEGPGLQQKPRPEAEPPSPPSGDLRLVKSVSESHTSCPAESASDAAPLQRSQSLPHSATVTLGGTSDPSTLSSSALSEREASRLDKFKQLLAGPNTDLEELRRLSWSGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWAIRHPASGYVQGINDLVTPFFVVFICEYIAFPGCGRPQIPILAVIWRDEPYPRTDEQIILRR>sp|Q8WUA7-4|TB22A_HUMAN Isoform 4 of TBC1 domain family member 22AOS=Homo sapiens OX=9606 GN=TBC1D22AMPTTPVKAKRVSTFQEFESNTSDAWDAGEDDDELLAMAAESLNSEVVMETANRVLRNHSQRQGRPTLQEGPGLQQKPRPEAEPPSPPSGDLRLVKSVSESHTSCPAESASDAAPLQRSQSLPHSATVTLGGTSDPSTLSSSALSEREASRLDKFKQLLAGPNTDLEELRRLSWSGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWAIRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRIDEQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWDDEDISLLLAEAYRLKFAFADAPNHYKK>sp|A6NNZ2|TBB8B_HUMAN Tubulin beta 8B OS=Homo sapiens OX=9606 GN=TUBB8BPE=1 SV=1MREIVLTQTGQCGNQIGAKFWEVISDEHAIDSAGTYHGDSHLQLERINVHHHEASGGRYVPRAVLVDLEPGTMDSVHSGPFGQVFRPDNFISGQCGAGNNWAKGRYTEGAELTESVMDVVRKEAESCDCLQGFQLTHSLGGGTGSGMGTLLISKIREEYPDRIINTFSILPSPKVSDTVVEPYNATLSVHQLIENADETFCIDNEALYDICSRTLKLPTPTYGDLNHLVSATMSGVTTCLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTSRGSQQYRALTVAELTQQMFDAKNMMAACDPRHGCYLTVAAIFRGRMPMREVDEQMFNIQDKNSSYFADWFPDNVKTAVCDIPPRGLKMSATFIGNNAAIQELFTCVSEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATAEEEEDEEYAEEEVA>sp|Q9UKE5|TNIK_HUMAN TRAF2 and NCK-interacting protein kinase OS=Homosapiens OX=9606 GN=TNIK PE=1 SV=1MASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYIRRQLEEEQRQLEILQQQLLHEQALLLEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEVEERSRLNRQSSPAMPHKVANRISDPNLPPRSESFSISGVQPARTPPMLRPVDPQIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPASYKKAIDEDLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9UKE5-2|TNIK_HUMAN Isoform 2 of TRAF2 and NCK-interacting proteinkinase OS=Homo sapiens OX=9606 GN=TNIKMASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEVEERSRLNRQSSPAMPHKVANRISDPNLPPRSESFSISGVQPARTPPMLRPVDPQIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPASYKKAIDEDLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9UKE5-3|TNIK_HUMAN Isoform 3 of TRAF2 and NCK-interacting proteinkinase OS=Homo sapiens OX=9606 GN=TNIKMASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYIRRQLEEEQRQLEILQQQLLHEQALLLEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPASYKKAIDEDLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9UKE5-4|TNIK_HUMAN Isoform 4 of TRAF2 and NCK-interacting proteinkinase OS=Homo sapiens OX=9606 GN=TNIKMASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYIRRQLEEEQRQLEILQQQLLHEQALLLEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEVEERSRLNRQSSPAMPHKVANRISDPNLPPRSESFSISGVQPARTPPMLRPVDPQIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPADLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9UKE5-5|TNIK_HUMAN Isoform 5 of TRAF2 and NCK-interacting proteinkinase OS=Homo sapiens OX=9606 GN=TNIKMASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPASYKKAIDEDLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9UKE5-6|TNIK_HUMAN Isoform 6 of TRAF2 and NCK-interacting proteinkinase OS=Homo sapiens OX=9606 GN=TNIKMASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEVEERSRLNRQSSPAMPHKVANRISDPNLPPRSESFSISGVQPARTPPMLRPVDPQIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPADLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9UKE5-7|TNIK_HUMAN Isoform 7 of TRAF2 and NCK-interacting proteinkinase OS=Homo sapiens OX=9606 GN=TNIKMASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYIRRQLEEEQRQLEILQQQLLHEQALLLEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPADLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9UKE5-8|TNIK_HUMAN Isoform 8 of TRAF2 and NCK-interacting proteinkinase OS=Homo sapiens OX=9606 GN=TNIKMASDSPARSLDEIDLSALRDPAGIFELVELVGNGTYGQVYKGRHVKTGQLAAIKVMDVTGDEEEEIKQEINMLKKYSHHRNIATYYGAFIKKNPPGMDDQLWLVMEFCGAGSVTDLIKNTKGNTLKEEWIAYICREILRGLSHLHQHKVIHRDIKGQNVLLTENAEVKLVDFGVSAQLDRTVGRRNTFIGTPYWMAPEVIACDENPDATYDFKSDLWSLGITAIEMAEGAPPLCDMHPMRALFLIPRNPAPRLKSKKWSKKFQSFIESCLVKNHSQRPATEQLMKHPFIRDQPNERQVRIQLKDHIDRTKKKRGEKDETEYEYSGSEEEEEENDSGEPSSILNLPGESTLRRDFLRLQLANKERSEALRRQQLEQQQRENEEHKRQLLAERQKRIEEQKEQRRRLEEQQRREKELRKQQEREQRRHYEEQMRREEERRRAEHEQEYKRKQLEEQRQAERLQRQLKQERDYLVSLQHQRQEQRPVEKKPLYHYKEGMSPSEKPAWAKEIPHLVAVKSQGPALTASQSVHEQPTKGLSGFQEALNVTSHRVEMPRQNSDPTSENPPLPTRIEKFDRSSWLRQEEDIPPKVPQRTTSISPALARKNSPGNGSALGPRLGSQPIRASNPDLRRTEPILESPLQRTSSGSSSSSSTPSSQPSSQGGSQPGSQAGSSERTRVRANSKSEGSPVLPHEPAKVKPEESRDITRPSRPADLTALAKELRELRIEETNRPMKKVTDYSSSSEESESSEEEEEDGESETHDGTVAVSDIPRLIPTGAPGSNEQYNVGMVGTHGLETSHADSFSGSISREGTLMIRETSGEKKRSGHSDSNGFAGHINLPDLVQQSHSPAGTPTEGLGRVSTHSQEMDSGTEYGMGSSTKASFTPFVDPRVYQTSPTDEDEEDEESSAAALFTSELLRQEQAKLNEARKISVVNVNPTNIRPHSDTPEIRKYKKRFNSEILCAALWGVNLLVGTENGLMLLDRSGQGKVYNLINRRRFQQMDVLEGLNVLVTISGKKNKLRVYYLSWLRNRILHNDPEVEKKQGWITVGDLEGCIHYKVVKYERIKFLVIALKNAVEIYAWAPKPYHKFMAFKSFADLQHKPLLVDLTVEEGQRLKVIFGSHTGFHVIDVDSGNSYDIYIPSHIQGNITPHAIVILPKTDGMEMLVCYEDEGVYVNTYGRITKDVVLQWGEMPTSVAYIHSNQIMGWGEKAIEIRSVETGHLDGVFMHKRAQRLKFLCERNDKVFFASVRSGGSSQVFFMTLNRNSMMNW>sp|Q9P2C4|TM181_HUMAN Transmembrane protein 181 OS=Homo sapiens OX=9606GN=TMEM181 PE=1 SV=2MGAAPSPTQASSRGGGPGPPAPTRAVSSSSRARGGALSALGPSPARPLTTSPAPAPPPRSRPARQQPDPQCWEKRGGAGGDTKGGAAGPGPGRLRGMDAEYPAFEPPLCSELKHLCRRLREAYRELKEDLTPFKDDRYYRLAPMRLYTLSKRHFVLVFVVFFICFGLTIFVGIRGPKVIQTSAANFSLNNSKKLKPIQILSNPLSTYNQQLWLTCVVELDQSKETSIKTSFPMTVKVDGVAQDGTTMYIHNKVHNRTRTLTCAGKCAEIIVAHLGYLNYTQYTVIVGFEHLKLPIKGMNFTWKTYNPAFSRLEIWFRFFFVVLTFIVTCLFAHSLRKFSMRDWGIEQKWMSVLLPLLLLYNDPFFPLSFLVNSWLPGMLDDLFQSMFLCALLLFWLCVYHGIRVQGERKCLTFYLPKFFIVGLLWLASVTLGIWQTVNELHDPMYQYRVDTGNFQGMKVFFMVVAAVYILYLLFLIVRACSELRHMPYVDLRLKFLTALTFVVLVISIAILYLRFGAQVLQDNFVAELSTHYQNSAEFLSFYGLLNFYLYTLAFVYSPSKNALYESQLKDNPAFSMLNDSDDDVIYGSDYEEMPLQNGQAIRAKYKEESDSD>sp|Q9BTX3|TM208_HUMAN Transmembrane protein 208 OS=Homo sapiens OX=9606GN=TMEM208 PE=1 SV=1MAPKGKVGTRGKKQIFEENRETLKFYLRIILGANAIYCLVTLVFFYSSASFWAWLALGFSLAVYGASYHSMSSMARAAFSEDGALMDGGMDLNMEQGMAEHLKDVILLTAIVQVLSCFSLYVWSFWLLAPGRALYLLWVNVLGPWFTADSGTPAPEHNEKRQRRQERRQMKRL>sp|Q9BTX3-2|TM208_HUMAN Isoform 2 of Transmembrane protein 208 OS=Homosapiens OX=9606 GN=TMEM208MAPKGKVGTRGKKQIFEENRETLKFYLRIILGANAIYCLVTLVFFYSSASFWAWLALGFSLAVYGASYHSMSSMARAAFSEDGALMDGGMDLNMEQGMAE>sp|Q969S6|TM203_HUMAN Transmembrane protein 203 OS=Homo sapiens OX=9606GN=TMEM203 PE=1 SV=1MLFSLRELVQWLGFATFEIFVHLLALLVFSVLLALRVDGLVPGLSWWNVFVPFFAADGLSTYFTTIVSVRLFQDGEKRLAVLRLFWVLTVLSLKFVFEMLLCQKLAEQTRELWFGLITSPLFILLQLLMIRACRVN>sp|Q9P0N5|TM216_HUMAN Transmembrane protein 216 OS=Homo sapiens OX=9606GN=TMEM216 PE=1 SV=3MLPRGLKMAPRGKRLSSTPLEILFFLNGWYNATYFLLELFIFLYKGVLLPYPTANLVLDVVMLLLYLGIEVIRLFFGTKGNLCQRKMPLSISVALTFPSAMMASYYLLLQTYVLRLEAIMNGILLFFCGSELLLEVLTLAAFSRI>sp|Q9P0N5-2|TM216_HUMAN Isoform 2 of Transmembrane protein 216 OS=Homosapiens OX=9606 GN=TMEM216MLLLYLGIEVIRLFFGTKGNLCQRKMPLSISVALTFPSAMMASYYLLLQTYVLRLEAIMNGILLFFCGSELLLEVLTLAAFSSMDRI>sp|Q9P0N5-3|TM216_HUMAN Isoform 3 of Transmembrane protein 216 OS=Homosapiens OX=9606 GN=TMEM216MLPRGLKMAPRGKRLSSTPLEILFFLNGWYNATYFLLELFIFLYKGVLLPYPTANLVLDVVMLLLYLGIEVIRLFFGTKGNLCQRKMPLSISVALTFPSAMMASYYLLLQTYVLRLEAIMNGILLFFCGSELLLEVLTLAAFSSMDRI>sp|Q9NQ86|TRI36_HUMAN E3 ubiquitin-protein ligase TRIM36 OS=Homo sapiensOX=9606 GN=TRIM36 PE=1 SV=2MSESGEMSEFGYIMELIAKGKVTIKNIERELICPACKELFTHPLILPCQHSICHKCVKELLLTLDDSFNDVGSDNSNQSSPRLRLPSPSMDKIDRINRPGWKRNSLTPRTTVFPCPGCEHDVDLGERGINGLFRNFTLETIVERYRQAARAATAIMCDLCKPPPQESTKSCMDCSASYCNECFKIHHPWGTIKAQHEYVGPTTNFRPKILMCPEHETERINMYCELCRRPVCHLCKLGGNHANHRVTTMSSAYKTLKEKLSKDIDYLIGKESQVKSQISELNLLMKETECNGERAKEEAITHFEKLFEVLEERKSSVLKAIDSSKKLRLDKFQTQMEEYQGLLENNGLVGYAQEVLKETDQSCFVQTAKQLHLRIQKATESLKSFRPAAQTSFEDYVVNTSKQTELLGELSFFSSGIDVPEINEEQSKVYNNALINWHHPEKDKADSYVLEYRKINRDDEMSWNEIEVCGTSKIIQDLENSSTYAFRVRAYKGSICSPCSRELILHTPPAPVFSFLFDEKCGYNNEHLLLNLKRDRVESRAGFNLLLAAERIQVGYYTSLDYIIGDTGITKGKHFWAFRVEPYSYLVKVGVASSDKLQEWLRSPRDAVSPRYEQDSGHDSGSEDACFDSSQPFTLVTIGMQKFFIPKSPTSSNEPENRVLPMPTSIGIFLDCDKGKVDFYDMDQMKCLYERQVDCSHTLYPAFALMGSGGIQLEEPITAKYLEYQEDM>sp|Q9NQ86-2|TRI36_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM36OS=Homo sapiens OX=9606 GN=TRIM36MSESGEMSEFGYIMELIAKGKMPDWRRGYRCRQGCGKTTELATATDFSQTGNKSGKHFKT>sp|Q9NQ86-3|TRI36_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM36OS=Homo sapiens OX=9606 GN=TRIM36MSESGEMSEFGYIMELIAKGKASAMGLQQTHEHSRLTSKGGEARCPFEISEVGKQSLPRRT>sp|Q9NQ86-4|TRI36_HUMAN Isoform 4 of E3 ubiquitin-protein ligase TRIM36OS=Homo sapiens OX=9606 GN=TRIM36MEGDGSDSPVTIKNIERELICPACKELFTHPLILPCQHSICHKCVKELLLTLDDSFNDVGSDNSNQSSPRLRLPSPSMDKIDRINRPGWKRNSLTPRTTVFPCPGCEHDVDLGERGINGLFRNFTLETIVERYRQAARAATAIMCDLCKPPPQESTKSCMDCSASYCNECFKIHHPWGTIKAQHEYVGPTTNFRPKILMCPEHETERINMYCELCRRPVCHLCKLGGNHANHRVTTMSSAYKTLKEKLSKDIDYLIGKESQVKSQISELNLLMKETECNGERAKEEAITHFEKLFEVLEERKSSVLKAIDSSKKLRLDKFQTQMEEYQGLLENNGLVGYAQEVLKETDQSCFVQTAKQLHLRIQKATESLKSFRPAAQTSFEDYVVNTSKQTELLGELSFFSSGIDVPEINEEQSKVYNNALINWHHPEKDKADSYVLEYRKINRDDEMSWNEIEVCGTSKIIQDLENSSTYAFRVRAYKGSICSPCSRELILHTPPAPVFSFLFDEKCGYNNEHLLLNLKRDRVESRAGFNLLLAAERIQVGYYTSLDYIIGDTGITKGKHFWAFRVEPYSYLVKVGVASSDKLQEWLRSPRDAVSPRYEQDSGHDSGSEDACFDSSQPFTLVTIGMQKFFIPKSPTSSNEPENRVLPMPTSIGIFLDCDKGKVDFYDMDQMKCLYERQVDCSHTLYPAFALMGSGGIQLEEPITAKYLEYQEDM>sp|Q9HAV5|TNR27_HUMAN Tumor necrosis factor receptor superfamily member27 OS=Homo sapiens OX=9606 GN=EDA2R PE=1 SV=2MDCQENEYWDQWGRCVTCQRCGPGQELSKDCGYGEGGDAYCTACPPRRYKSSWGHHRCQSCITCAVINRVQKVNCTATSNAVCGDCLPRFYRKTRIGGLQDQECIPCTKQTPTSEVQCAFQLSLVEADTPTVPPQEATLVALVSSLLVVFTLAFLGLFFLYCKQFFNRHCQRGGLLQFEADKTAKEESLFPVPPSKETSAESQVSENIFQTQPLNPILEDDCSSTSGFPTQESFTMASCTSESHSHWVHSPIECTELDLQKFSSSASYTGAETLGGNTVESTGDRLELNVPFEVPSP>sp|Q9HAV5-2|TNR27_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 27 OS=Homo sapiens OX=9606 GN=EDA2RMDCQENEYWDQWGRCVTCQRCGPGQELSKDCGYGEGGDAYCTACPPRRYKSSWGHHRCQSCITCAVINRVQKVNCTATSNAVCGDCLPRFYRKTRIGGLQDQECIPCTKQTPTSEVQCAFQLSLVEADTPTVPPQEATLVALVSSLLVVFTLAFLGLFFLYCKQFFNRHCQREKLIIFSDPVPASLNLIPEFAGGLLQFEADKTAKEESLFPVPPSKETSAESQVSENIFQTQPLNPILEDDCSSTSGFPTQESFTMASCTSESHSHWVHSPIECTELDLQKFSSSASYTGAETLGGNTVESTGDRLELNVPFEVPSP>sp|Q9HAV5-3|TNR27_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 27 OS=Homo sapiens OX=9606 GN=EDA2RMDCQENEYWDQWGRCVTCQRCGPGQELSKDCGYGEGGDAYCTACPPRRYKSSWGHHRCQSCITCAVINRVQKVNCTATSNAVCGDCLPRFYRKTRIGGLQDQECIPCTKQTPTSEVQCAFQLSLVEADTPTVPPQEATLVALVSSLLVVFTLAFLGLFFLYCKQFFNRHCQRVTGGLLQFEADKTAKEESLFPVPPSKETSAESQVSENIFQTQPLNPILEDDCSSTSGFPTQESFTMASCTSESHSHWVHSPIECTELDLQKFSSSASYTGAETLGGNTVESTGDRLELNVPFEVPSP>sp|Q7Z4G4|TRM11_HUMAN tRNA (guanine(10)-N2)-methyltransferase homologOS=Homo sapiens OX=9606 GN=TRMT11 PE=1 SV=1MALSCTLNRYLLLMAQEHLEFRLPEIKSLLLLFGGQFASSQETYGKSPFWILSIPSEDIARNLMKRTVCAKSIFELWGHGQSPEELYSSLKNYPVEKMVPFLHSDSTYKIKIHTFNKTLTQEEKIKRIDALEFLPFEGKVNLKKPQHVFSVLEDYGLDPNCIPENPHNIYFGRWIADGQRELIESYSVKKRHFIGNTSMDAGLSFIMANHGKVKENDIVFDPFVGTGGLLIACAHFGAYVYGTDIDYNTVHGLGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHVPVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKVKKFENRDQYSHLLSDHFLPYQGHNSFREKYFSGVTKRIAKEEKSTQE>sp|Q7Z4G4-2|TRM11_HUMAN Isoform 2 of tRNA (guanine(10)-N2)-methyltransferase homolog OS=Homo sapiens OX=9606 GN=TRMT11MALSCTLNRYLLLMAQEHLEFRLPEIKSLLLLFGGQFASSQETYGKSPFWILSIPSEDIARNLMKRTVCAKSIFELWGHGQSPEELYSSLKNYPVEKMVPFLHSDSTYKIKIHTFNKTLTQEEKIKRIDALEFLPFEGKVNLKKPQHVFSVLEDYGLDPNCIPENPHNIYFGRWIADGQRELIESYSVKKRHFIGNTSMDAGLSFIMANHGKVKENDIVFDPFVGTGGLLIACAHFGAYVYGTDIDYNTVHGLGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHVPVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKNRDQYSHLLSDHFLPYQGHNSFREKYFSGVTKRIAKEEKSTQE>sp|Q7Z4G4-3|TRM11_HUMAN Isoform 3 of tRNA (guanine(10)-N2)-methyltransferase homolog OS=Homo sapiens OX=9606 GN=TRMT11MALSCTLNRYLLLMAQEHLEFRLPEIKSLLLLFGGQFASSQETYGKSPFWILSIPSEDIARNLMKRTVCAKSIFELWGHGQSPEELYSSLKNYPVEKMVPFLHSDSTYKIKIHTFNKTLTQEEKIKRIDALEFLPFEGKVNLKKPQHVFSVLEDYGLDPNCIPENPHNIYFGRWIADGQRELIESYSVKKRHFIGNTSMDAGLSFIMANHGKVKENDIVFDPFVGTGGLLIACAHFGAYVYGTDIDYNTVHGLACST>sp|O94811|TPPP_HUMAN Tubulin polymerization-promoting protein OS=Homosapiens OX=9606 GN=TPPP PE=1 SV=1MADKAKPAKAANRTPPKSPGDPSKDRAAKRLSLESEGAGEGAAASPELSALEEAFRRFAVHGDARATGREMHGKNWSKLCKDCQVIDGRNVTVTDVDIVFSKIKGKSCRTITFEQFQEALEELAKKRFKDKSSEEAVREVHRLIEGKAPIISGVTKAISSPTVSRLTDTTKFTGSHKERFDPSGKGKGKAGRVDLVDESGYVSGYKHAGTYDQKVQGGK>sp|Q96RJ3|TR13C_HUMAN Tumor necrosis factor receptor superfamily member13C OS=Homo sapiens OX=9606 GN=TNFRSF13C PE=1 SV=1MRRGPRSLRGRDAPAPTPCVPAECFDLLVRHCVACGLLRTPRPKPAGASSPAPRTALQPQESVGAGAGEAALPLPGLLFGAPALLGLALVLALVLVGLVSWRRRQRRLRGASSAEAPDGDKDAPEPLDKVIILSPGISDATAPAWPPPGEDPGTTPPGHSVPVPATELGSTELVTTKTAGPEQQ>sp|Q96RJ3-2|TR13C_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 13C OS=Homo sapiens OX=9606 GN=TNFRSF13CMRRGPRSLRGRDAPAPTPCVPAECFDLLVRHCVACGLLRTPRPKPAGASSPAPRTALQPQESVGAGAGEAALPLPGLLFGAPALLGLALVLALVLVGLVSWRRRQRRLRGASSAEAPDGDKDAPEPLDKVIILSPGISDATAPAAWPPPGEDPGTTPPGHSVPVPATELGSTELVTTKTAGPEQQ>sp|O15016|TRI66_HUMAN Tripartite motif-containing protein 66 OS=Homosapiens OX=9606 GN=TRIM66 PE=1 SV=4MARNCSECKEKRAAHILCTYCNRWLCSSCTEEHRHSPVPGGPFFPRAQKGSPGVNGGPGDFTLYCPLHTQEVLKLFCETCDMLTCHSCLVVEHKEHRCRHVEEVLQNQRMLLEGVTTQVAHKKSSLQTSAKQIEDRIFEVKHQHRKVENQIKMAKMVLMNELNKQANGLIEELEGITNERKRKLEQQLQSIMVLNRQFEHVQNFINWAVCSKTSVPFLFSKELIVFQMQRLLETSCNTDPGSPWSIRFTWEPNFWTKQLASLGCITTEGGQMSRADAPAYGGLQGSSPFYQSHQSPVAQQEALSHPSHKFQSPAVCSSSVCCSHCSPVSPSLKGQVPPPSIHPAHSFRQPPEMVPQQLGSLQCSALLPREKELACSPHPPKLLQPWLETQPPVEQESTSQRLGQQLTSQPVCIVPPQDVQQGAHAQPTLQTPSIQVQFGHHQKLKLSHFQQQPQQQLPPPPPPLPHPPPPLPPPPQQPHPPLPPSQHLASSQHESPPGPACSQNMDIMHHKFELEEMQKDLELLLQAQQPSLQLSQTKSPQHLQQTIVGQINYIVRQPAPVQSQSQEETLQATDEPPASQGSKPALPLDKNTAAALPQASGEETPLSVPPVDSTIQHSSPNVVRKHSTSLSIMGFSNTLEMELSSTRLERPLEPQIQSVSNLTAGAPQAVPSLLSAPPKMVSSLTSVQNQAMPSLTTSHLQTVPSLVHSTFQSMPNLISDSPQAMASLASDHPQAGPSLMSGHTQAVPSLATCPLQSIPPVSDMQPETGSSSSSGRTSGSLCPRDGADPSLENALCKVKLEEPINLSVKKPPLAPVVSTSTALQQYQNPKECENFEQGALELDAKENQSIRAFNSEHKIPYVRLERLKICAASSGEMPVFKLKPQKNDQDGSFLLIIECGTESSSMSIKVSQDRLSEATQAPGLEGRKVTVTSLAGQRPPEVEGTSPEEHRLIPRTPGAKKGPPAPIENEDFCAVCLNGGELLCCDRCPKVFHLSCHVPALLSFPGGEWVCTLCRSLTQPEMEYDCENACYNQPGMRASPGLSMYDQKKCEKLVLSLCCNNLSLPFHEPVSPLARHYYQIIKRPMDLSIIRRKLQKKDPAHYTTPEEVVSDVRLMFWNCAKFNYPDSEVAEAGRCLEVFFEGWLKEIYPEKRFAQPRQEDSDSEEVSSESGCSTPQGFPWPPYMQEGIQPKRRRRHMENERAKRMSFRLANSISQV>sp|O15016-2|TRI66_HUMAN Isoform 2 of Tripartite motif-containing protein66 OS=Homo sapiens OX=9606 GN=TRIM66MARNCSECKEKRAAHILCTYCNRWLCSSCTEEHRHSPVPGGPFFPRAQKGSPGVNGGPGDFTLYCPLHTQEVLKLFCETCDMLTCHSCLVVEHKEHRHVEEVLQNQRMLLEGVTTQVAHKKSSLQTSAKQIEDRIFEVKHQHRKVENQIKMAKMVLMNELNKQANGLIEELEGITNERKRKLEQQLQSIMVLNRQFEHVQNFINWAVCSKTSVPFLFSKELIVFQMQRLLETSCNTDPGSPWSIRFTWEPNFWTKQLASLGCITTEGGQMSRADAPAYGGLQGSSPFYQSHQSPVAQQEALSHPSHKFQSPAVCSSSVCCSHCSPVSPSLKGQVPPPSIHPAHSFRQPPEMVPQQLGSLQCSALLPREKELACSPHPPKLLQPWLETQPPVEQESTSQRLGQQLTSQPVCIVPPQDVQQGAHAQPTLQTPSIQVQFGHHQKLKLSHFQQQPQQQLPPPPPPLPHPPPPLPPPPQQPHPPLPPSQHLASSQHESPPGPACSQNMDIMHHKFELEEMQKDLELLLQAQQPSLQLSQTKSPQHLQQTIVGQINYIVRQPAPVQSQSQEETLQATDEPPASQGSKPALPLDKNTAAALPQASGEETPLSVPPVDSTIQHSSPNVVRKHSTSLSIMGFSNTLEMELSSTRLERPLEPQIQSVSNLTAGAPQAVPSLLSAPPKMVSSLTSVQNQAMPSLTTSHLQTVPSLVHSTFQSMPNLISDSPQAMASLASDHPQAGPSLMSGHTQAVPSLATCPLQSIPPVSDMQPETGSSSSSGRTSGSLCPRDGADPSLENALCKVKLEEPINLSVKKPPLAPVVSTSTALQQYQNPKECENFEQGALELDAKENQSIRAFNSEHKIPYVRLERLKICAASSGEMPVFKLKPQKNDQDGSFLLIIECGTESSSMSIKVSQDRLSEATQAPGLEGRKVTVTSLAGQRPPEVEGTSPEEHRLIPRTPGAKKGPPAPIENEDFCAVCLNGGELLCCDRCPKVFHLSCHVPALLSFPGGEWVCTLCRSLTQPEMEYDCENACYNQPGMRASPGLSMYDQKKCEKLVLSLCCNNLSLPFHEPVSPLARHYYQIIKRPMDLSIIRRKLQKKDPAHYTTPEEVVSDVRLMFWNCAKFNYPDSEVAEAGRCLEVFFEGWLKEIYPEKRFAQPRQEDSDSEEVSSESGCSTPQGFPWPPYMQEGIQPKRRRRHMENERAKRMSFRLANSISQV>sp|O00635|TRI38_HUMAN E3 ubiquitin-protein ligase TRIM38 OS=Homo sapiensOX=9606 GN=TRIM38 PE=1 SV=1MASTTSTKKMMEEATCSICLSLMTNPVSINCGHSYCHLCITDFFKNPSQKQLRQETFCCPQCRAPFHMDSLRPNKQLGSLIEALKETDQEMSCEEHGEQFHLFCEDEGQLICWRCERAPQHKGHTTALVEDVCQGYKEKLQKAVTKLKQLEDRCTEQKLSTAMRITKWKEKVQIQRQKIRSDFKNLQCFLHEEEKSYLWRLEKEEQQTLSRLRDYEAGLGLKSNELKSHILELEEKCQGSAQKLLQNVNDTLSRSWAVKLETSEAVSLELHTMCNVSKLYFDVKKMLRSHQVSVTLDPDTAHHELILSEDRRQVTRGYTQENQDTSSRRFTAFPCVLGCEGFTSGRRYFEVDVGEGTGWDLGVCMENVQRGTGMKQEPQSGFWTLRLCKKKGYVALTSPPTSLHLHEQPLLVGIFLDYEAGVVSFYNGNTGCHIFTFPKASFSDTLRPYFQVYQYSPLFLPPPGD>sp|Q9UBP6|TRMB_HUMAN tRNA (guanine-N(7)-)-methyltransferase OS=Homosapiens OX=9606 GN=METTL1 PE=1 SV=1MAAETRNVAGAEAPPPQKRYYRQRAHSNPMADHTLRYPVKPEEMDWSELYPEFFAPLTQNQSHDDPKDKKEKRAQAQVEFADIGCGYGGLLVELSPLFPDTLILGLEIRVKVSDYVQDRIRALRAAPAGGFQNIACLRSNAMKHLPNFFYKGQLTKMFFLFPDPHFKRTKHKWRIISPTLLAEYAYVLRVGGLVYTITDVLELHDWMCTHFEEHPLFERVPLEDLSEDPVVGHLGTSTEEGKKVLRNGGKNFPAIFRRIQDPVLQAVTSQTSLPGH>sp|Q9UBP6-2|TRMB_HUMAN Isoform 2 of tRNA (guanine-N(7)-)-methyltransferase OS=Homo sapiens OX=9606 GN=METTL1MAAETRNVAGAEAPPPQKRYYRQRAHSNPMADHTLRYPVKPEEMDWSELYPEFFAPLTQNQSHDDPKDKKEKRAQAQVEFADIGCGYGGLLADKDVLPLPRPTFQADKAQVANHQSHPASRICLRAKSWGAGVYHNRCAGATRLDVHSFRRAPTV>sp|Q8N7C4|TM217_HUMAN Transmembrane protein 217 OS=Homo sapiens OX=9606GN=TMEM217 PE=2 SV=1MKQQQWCGMTAKMGTVLSGVFTIMAVDMYLIFEQKHLGNGSCTEITPKYRGASNIINNFIICWSFKIVLFLSFITILISCFLLYSVYAQIFRGLVIYIVWIFFYETANVVIQILTNNDFDIKEVRIMRWFGLVSRTVMHCFWMFFVINYAHITYKNRSQGNIISYKRRISTAEILHSRNKRLSISSGFSGSHLESQYFERQSFHTSIFTCLSPVPSSAPSTCRYTIDVC>sp|Q8N7C4-2|TM217_HUMAN Isoform 2 of Transmembrane protein 217 OS=Homosapiens OX=9606 GN=TMEM217MKQQQWCGMTAKMGTVLSGVFTIMAVDMYLIFEQKHLGNGSCTEITPKYRGASNIINNFIICWSFKIVLFLSFITILISCFLLYSVYAQIFRGLVIYIVWIFFYETANVVIQILTNNDFDIKEVRIMRWFGLVSRTVMHCFWMFFVINYAHITYKNRSQGNIISYKRRISTAEILHSRNKRLSISSGFSGSHLESQYFERQRRCSGKTSIK>sp|O14787|TNPO2_HUMAN Transportin-2 OS=Homo sapiens OX=9606 GN=TNPO2PE=1 SV=3MDWQPDEQGLQQVLQLLKDSQSPNTATQRIVQDKLKQLNQFPDFNNYLIFVLTRLKSEDEPTRSLSGLILKNNVKAHYQSFPPPVADFIKQECLNNIGDASSLIRATIGILITTIASKGELQMWPELLPQLCNLLNSEDYNTCEGAFGALQKICEDSSELLDSDALNRPLNIMIPKFLQFFKHCSPKIRSHAIACVNQFIMDRAQALMDNIDTFIEHLFALAVDDDPEVRKNVCRALVMLLEVRIDRLIPHMHSIIQYMLQRTQDHDENVALEACEFWLTLAEQPICKEVLASHLVQLIPILVNGMKYSEIDIILLKGDVEEDEAVPDSEQDIKPRFHKSRTVTLPHEAERPDGSEDAEDDDDDDALSDWNLRKCSAAALDVLANVFREELLPHLLPLLKGLLFHPEWVVKESGILVLGAIAEGCMQGMVPYLPELIPHLIQCLSDKKALVRSIACWTLSRYAHWVVSQPPDMHLKPLMTELLKRILDGNKRVQEAACSAFATLEEEACTELVPYLSYILDTLVFAFGKYQHKNLLILYDAIGTLADSVGHHLNQPEYIQKLMPPLIQKWNELKDEDKDLFPLLECLSSVATALQSGFLPYCEPVYQRCVTLVQKTLAQAMMYTQHPEQYEAPDKDFMIVALDLLSGLAEGLGGHVEQLVARSNIMTLLFQCMQDSMPEVRQSSFALLGDLTKACFIHVKPCIAEFMPILGTNLNPEFISVCNNATWAIGEICMQMGAEMQPYVQMVLNNLVEIINRPNTPKTLLENTGRLTSPSAIPAITIGRLGYVCPQEVAPMLQQFIRPWCTSLRNIRDNEEKDSAFRGICMMIGVNPGGVVQDFIFFCDAVASWVSPKDDLRDMFYKILHGFKDQVGEDNWQQFSEQFPPLLKERLAAFYGV>sp|O14787-2|TNPO2_HUMAN Isoform 2 of Transportin-2 OS=Homo sapiensOX=9606 GN=TNPO2MDWQPDEQGLQQVLQLLKDSQSPNTATQRIVQDKLKQLNQFPDFNNYLIFVLTRLKSEDEPTRSLSGLILKNNVKAHYQSFPPPVADFIKQECLNNIGDASSLIRATIGILITTIASKGELQMWPELLPQLCNLLNSEDYNTCEGAFGALQKICEDSSELLDSDALNRPLNIMIPKFLQFFKHCSPKIRSHAIACVNQFIMDRAQALMDNIDTFIEHLFALAVDDDPEVRKNVCRALVMLLEVRIDRLIPHMHSIIQYMLQRTQDHDENVALEACEFWLTLAEQPICKEVLASHLVQLIPILVNGMKYSEIDIILLKGDVEEDEAVPDSEQDIKPRFHKSRTVTLPHEAERPDGSEDAEDDDDDDALSDWNLRKCSAAALDVLANVFREELLPHLLPLLKGLLFHPEWVVKESGILVLGAIAEGCMQGMVPYLPELIPHLIQCLSDKKALVRSIACWTLSRYAHWVVSQPPDMHLKPLMTELLKRILDGNKRVQEAACSAFATLEEEACTELVPYLSYILDTLVFAFGKYQHKNLLILYDAIGTLADSVGHHLNQPEYIQKLMPPLIQKWNELKDEDKDLFPLLECLSSVATALQSGFLPYCEPVYQRCVTLVQKTLAQAMMYTQHPEQYEAPDKDFMIVALDLLSGLAEGLGGHVEQLVARSNIMTLLFQCMQDSMPEVRQSSFALLGDLTKACFIHVKPCIAEFMPILGTNLNPEFISVCNNATWAIGEICMQMGAEMQPYVQMVLNNLVEIINRPNTPKTLLENTAITIGRLGYVCPQEVAPMLQQFIRPWCTSLRNIRDNEEKDSAFRGICMMIGVNPGGVVQDFIFFCDAVASWVSPKDDLRDMFYKILHGFKDQVGEDNWQQFSEQFPPLLKERLAAFYGV>sp|Q6PF06|TM10B_HUMAN tRNA methyltransferase 10 homolog B OS=Homosapiens OX=9606 GN=TRMT10B PE=1 SV=1MDWKLEGSTQKVESPVLQGQEGILEETGEDGLPEGFQLLQIDAEGECQEGEILATGSTAWCSKNVQRKQRHWEKIVAAKKSKRKQEKERRKANRAENPGICPQHSKRFLRALTKDKLLEAKHSGPRLCIDLSMTHYMSKKELSRLAGQIRRLYGSNKKADRPFWICLTGFTTDSPLYEECVRMNDGFSSYLLDITEEDCFSLFPLETLVYLTPDSEHALEDVDLNKVYILGGLVDESIQKKVTFQKAREYSVKTARLPIQEYMVRNQNGKNYHSEILAINQVFDILSTYLETHNWPEALKKGVSSGKGYILRNSVE>sp|Q6PF06-2|TM10B_HUMAN Isoform 2 of tRNA methyltransferase 10 homolog BOS=Homo sapiens OX=9606 GN=TRMT10BMVLGICPQHSKRFLRALTKDKLLEAKHSGPRLCIDLSMTHYMSKKELSRLAGQIRRLYGSNKKADRPFWICLTGFTTDSPLYEECVRMNDGFSSYLLDITEEDCFSLFPLETLVYLTPDSEHALEDVDLNKVYILGGLVDESIQKKVTFQKAREYSVKTARLPIQEYMVRNQNGKNYHSEILAINQVFDILSTYLETHNWPEALKKGVSSGKGYILRNSVE>sp|Q6PF06-5|TM10B_HUMAN Isoform 5 of tRNA methyltransferase 10 homolog BOS=Homo sapiens OX=9606 GN=TRMT10BMDWKLEGSTQKVESPVLQGQEGILEETGEDGLPEGFQLLQIDAEGECQEGEILATGSTAWCSKNVQRKQRHWEKIVAAKKSKRKQEKERRKANRAENPGICPQHSKRFLRALTKDKLLEAKHSGPRLCIDLSMTHYMSKKLDITEEDCFSLFPLETLVYLTPDSEHALEDVDLNKVYILGGLVDESIQKKVTFQKAREYSVKTARLPIQEYMVRNQNGKNYHSEILAINQETHNWPEALKKGVSSGKGYILRNSVE>sp|Q6PF06-3|TM10B_HUMAN Isoform 3 of tRNA methyltransferase 10 homolog BOS=Homo sapiens OX=9606 GN=TRMT10BMDWKLEGSTQKVESPVLQGQEGILEETGEDGLPEGFQLLQIDAEGECQEGEILATGSTAWCSKNVQRKQRHWEKIVAAKKSKRKQEKERRKANRAENPGICPQHSKRFLRALTKDKLLEAKHSGPRLCIDLSMTHYMSKKVEHPLSLEFLLAMREAQKGTAFRRIWSTPASGIP>sp|Q6PF06-4|TM10B_HUMAN Isoform 4 of tRNA methyltransferase 10 homolog BOS=Homo sapiens OX=9606 GN=TRMT10BMDWKLEGSTQKVESPVLQGQEGILEETGEDGLPEGFQLLQIDAEGECQEGEILATGSTAWCSELSRLAGQIRRLYGSNKKADRPFWICLTGFTTDSPLYEECVRMNDGFSSYLLDITEEDCFSLFPLETLVYLTPDSEHALEDVDLNKVYILGGLVDESIQKKVTFQKAREYSVKTARLPIQEYMVRNQNGKNYHSEILAINQETHNWPEALKKGVSSGKGYILRNSVE>sp|Q9BVG3|TRI62_HUMAN E3 ubiquitin-protein ligase TRIM62 OS=Homo sapiensOX=9606 GN=TRIM62 PE=1 SV=1MACSLKDELLCSICLSIYQDPVSLGCEHYFCRRCITEHWVRQEAQGARDCPECRRTFAEPALAPSLKLANIVERYSSFPLDAILNARRAARPCQAHDKVKLFCLTDRALLCFFCDEPALHEQHQVTGIDDAFDELQRELKDQLQALQDSEREHTEALQLLKRQLAETKSSTKSLRTTIGEAFERLHRLLRERQKAMLEELEADTARTLTDIEQKVQRYSQQLRKVQEGAQILQERLAETDRHTFLAGVASLSERLKGKIHETNLTYEDFPTSKYTGPLQYTIWKSLFQDIHPVPAALTLDPGTAHQRLILSDDCTIVAYGNLHPQPLQDSPKRFDVEVSVLGSEAFSSGVHYWEVVVAEKTQWVIGLAHEAASRKGSIQIQPSRGFYCIVMHDGNQYSACTEPWTRLNVRDKLDKVGVFLDYDQGLLIFYNADDMSWLYTFREKFPGKLCSYFSPGQSHANGKNVQPLRINTVRI>sp|Q9BVG3-2|TRI62_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM62OS=Homo sapiens OX=9606 GN=TRIM62MPEKTAVDQPWTQALRELKDQLQALQDSEREHTEALQLLKRQLAETKSSTKSLRTTIGEAFERLHRLLRERQKAMLEELEADTARTLTDIEQKVQRYSQQLRKVQEGAQILQERLAETDRHTFLAGVASLSERLKGKIHETNLTYEDFPTSKYTGPLQYTIWKSLFQDIHPVPAALTLDPGTAHQRLILSDDCTIVAYGNLHPQPLQDSPKRFDVEVSVLGSEAFSSGVHYWEVVVAEKTQWVIGLAHEAASRKGSIQIQPSRGFYCIVMHDGNQYSACTEPWTRLNVRDKLDKVGVFLDYDQGLLIFYNADDMSWLYTFREKFPGKLCSYFSPGQSHANGKNVQPLRINTVRI>sp|A6NI03|TR64B_HUMAN Putative tripartite motif-containing protein 64BOS=Homo sapiens OX=9606 GN=TRIM64B PE=5 SV=3MDSDDLQVFQNELICCICVNYFIDPVTIDCGHSFCRPCLCLCSEEGRAPMRCPSCRKTSEKPNFNTNLVLKKLSSLARQTRPQNINSSDNICVLHEETKELFCEADKRLLCGPCSESPEHMAHSHSPIGWAAEECREKLIKEMDYLWEINQETRNNLNQETSTFHSLKDYVSVRKRIITIQYQKMPIFLDEEEQRHLQALEREAEELFQQLQDSQVRMTQHLERMKDMYRELWETCHMPDVVLLQDVRNVSARTDLAQMQKPQPVNPELTSWCITGVLDMLNNFRVDSALSTEMIPCYISLSEDVRYVIFGDDHLSAPTDPQGVDSFAVWGAQAFTSGKHYWEVDVTLSSNWILGVCRDSRTADANFVIDSDERFFLISSKRSNHYSLSTNSPPLIQYVQRPLGRVGVFLDYDNGSVSFFDVSKGSLIYGFPPSSFSSPLRPFFCFGCT>sp|P0CI26|TR49C_HUMAN Tripartite motif-containing protein 49C OS=Homosapiens OX=9606 GN=TRIM49C PE=1 SV=1MNSGILQVFQGELICPLCMNYFIDPVTIDCGHSFCRPCFYLNWQDIPFLVQCSECTKSTEQINLKTNIHLKKMASLARKVSLWLFLSSEEQMCGTHRETKKIFCEVDRSLLCLLCSSSQEHRYHRHRPIEWAAEEHREKLLQKMQSLWEKACENHRNLNVETTRTRCWKDYVNLRLEAIRAEYQKMPAFHHEEEKHNLEMLKKKGKEIFHRLHLSKAKMAHRMEILRGMYEELNEMCHKPDVELLQAFGDILHRSESVLLHMPQPLNPELSAGPITGLRDRLNQFRVHITLHHEEANSDIFLYEILRSMCIGCDHQDVPYFTATPRSFLAWGVQTFTSGKYYWEVHVGDSWNWAFGVCNMYRKEKNQNEKIDGKEGLFLLGCIKNDIQCSLFTTSPLMLQYIPKPTSRVGLFLDCEAKTVSFVDVNQSSLIYTIPNCSFSPPLRPIFCCIHF>sp|O15321|TM9S1_HUMAN Transmembrane 9 superfamily member 1 OS=Homosapiens OX=9606 GN=TM9SF1 PE=2 SV=2MTVVGNPRSWSCQWLPILILLLGTGHGPGVEGVTHYKAGDPVILYVNKVGPYHNPQETYHYYQLPVCCPEKIRHKSLSLGEVLDGDRMAESLYEIRFRENVEKRILCHMQLSSAQVEQLRQAIEELYYFEFVVDDLPIRGFVGYMEESGFLPHSHKIGLWTHLDFHLEFHGDRIIFANVSVRDVKPHSLDGLRPDEFLGLTHTYSVRWSETSVERRSDRRRGDDGGFFPRTLEIHWLSIINSMVLVFLLVGFVAVILMRVLRNDLARYNLDEETTSAGSGDDFDQGDNGWKIIHTDVFRFPPYRGLLCAVLGVGAQFLALGTGIIVMALLGMFNVHRHGAINSAAILLYALTCCISGYVSSHFYRQIGGERWVWNIILTTSLFSVPFFLTWSVVNSVHWANGSTQALPATTILLLLTVWLLVGFPLTVIGGIFGKNNASPFDAPCRTKNIAREIPPQPWYKSTVIHMTVGGFLPFSAISVELYYIFATVWGREQYTLYGILFFVFAILLSVGACISIALTYFQLSGEDYRWWWRSVLSVGSTGLFIFLYSVFYYARRSNMSGAVQTVEFFGYSLLTGYVFFLMLGTISFFSSLKFIRYIYVNLKMD>sp|O15321-2|TM9S1_HUMAN Isoform 2 of Transmembrane 9 superfamily member1 OS=Homo sapiens OX=9606 GN=TM9SF1MTVVGNPRSWSCQWLPILILLLGTGHGPGVEGVTHYKAGDPVILYVNKVGPYHNPQETYHYYQLPVCCPEKIRHKSLSLGEVLDGDRMAESLYEIRFRENVEKRILCHMQLSSAQVEQLRQAIEELYYFEFVVDDLPIRGFVGYMEESGFLPHSHKIGLWTHLDFHLEFHGDRIIFANVSVRDVKPHSLDGLRPDEFLGLTHTYSVRWSETSVERRSDRRRGDDGGFFPRTLEIHWLSIINSMVLVFLLVGFVAVILMRVLRNDLARYNLDEETTSAGSGDDFDQGDNGWKIIHTDVFRFPPYRGLLCAVLGVGAQFLALGTGIIVMALLGMFNVHRHGAINSAAILLYALTCCISGYVSSHFYRQIGGERWVWNIILTTSLFSVPFFLTWSVVNSVHWANGSTQALPATTILLLLTVWLLVGFPLTVIGGIFGKNNASPFDAPCRTKNIAREIPPQPWYKSTVIHMTVGGFLPFRYPPFIPWLLLSGS>sp|Q9H3N1|TMX1_HUMAN Thioredoxin-related transmembrane protein 1 OS=Homosapiens OX=9606 GN=TMX1 PE=1 SV=1MAPSGSLAVPLAVLVLLLWGAPWTHGRRSNVRVITDENWRELLEGDWMIEFYAPWCPACQNLQPEWESFAEWGEDLEVNIAKVDVTEQPGLSGRFIITALPTIYHCKDGEFRRYQGPRTKKDFINFISDKEWKSIEPVSSWFGPGSVLMSSMSALFQLSMWIRTCHNYFIEDLGLPVWGSYTVFALATLFSGLLLGLCMIFVADCLCPSKRRRPQPYPYPSKKLLSESAQPLKKVEEEQEADEEDVSEEEAESKEGTNKDFPQNAIRQRSLGPSLATDKS>sp|Q8NCS4|TM35B_HUMAN Transmembrane protein 35B OS=Homo sapiens OX=9606GN=TMEM35B PE=1 SV=1MALLLSVLRVLLGGFFALVGLAKLSEEISAPVSERMNALFVQFAEVFPLKVFGYQPDPLNYQIAVGFLELLAGLLLVMGPPMLQEISNLFLILLMMGAIFTLAALKESLSTCIPAIVCLGFLLLLNVGQLLAQTKKVVRPTRKKTLSTFKESWK>sp|Q9H497|TOR3A_HUMAN Torsin-3A OS=Homo sapiens OX=9606 GN=TOR3A PE=1SV=1MLRGPWRQLWLFFLLLLPGAPEPRGASRPWEGTDEPGSAWAWPGFQRLQEQLRAAGALSKRYWTLFSCQVWPDDCDEDEEAATGPLGWRLPLLGQRYLDLLTTWYCSFKDCCPRGDCRISNNFTGLEWDLNVRLHGQHLVQQLVLRTVRGYLETPQPEKALALSFHGWSGTGKNFVARMLVENLYRDGLMSDCVRMFIATFHFPHPKYVDLYKEQLMSQIRETQQLCHQTLFIFDEAEKLHPGLLEVLGPHLERRAPEGHRAESPWTIFLFLSNLRGDIINEVVLKLLKAGWSREEITMEHLEPHLQAEIVETIDNGFGHSRLVKENLIDYFIPFLPLEYRHVRLCARDAFLSQELLYKEETLDEIAQMMVYVPKEEQLFSSQGCKSISQRINYFLS>sp|Q9H497-2|TOR3A_HUMAN Isoform 2 of Torsin-3A OS=Homo sapiens OX=9606GN=TOR3AMLRGPWRQLWLFFLLLLPGAPEPRGASRPWEGTDEPGSAWAWPGFQRLQEQLRAAGALSKRYWTLFSCQVWPDDCDEDEEAATGPLGWRLPLLGQRYLDLLTTWYCSFKDCCPRGDCRISNNFTGLEWDLNVRLHGQHLVQQLVLRTVRGYLETPQPEKALALSFHGWSGTGKNFVARMLVENLYRDGLMSDCVRMFIATFHFPHPKYVDLYKEQLMSQIRETQQLCHQTLFIFDEAEKLHPGLLEVLGPHLERRAPEGHRAESPWTIFLFLSNLRGDIINEVVLKLLKAGWSREEITMEHLEPHLQAEIVETIGFSFLTTRWPHLDLPTSSVAPT>sp|Q9H497-3|TOR3A_HUMAN Isoform 3 of Torsin-3A OS=Homo sapiens OX=9606GN=TOR3AMSQIRETQQLCHQTLFIFDEAEKLHPGLLEVLGPHLERRAPEGHRAESPWTIFLFLSNLRGDIINEVVLKLLKAGWSREEITMEHLEPHLQAEIVETIDNGFGHSRLVKENLIDYFIPFLPLEYRHVRLCARDAFLSQELLYKEETLDEIAQMMVYVPKEEQLFSSQGCKSISQRINYFLS>sp|Q96HV5|TM41A_HUMAN Transmembrane protein 41A OS=Homo sapiens OX=9606GN=TMEM41A PE=1 SV=1MRPLLGLLLVFAGCTFALYLLSTRLPRGRRLGSTEEAGGRSLWFPSDLAELRELSEVLREYRKEHQAYVFLLFCGAYLYKQGFAIPGSSFLNVLAGALFGPWLGLLLCCVLTSVGATCCYLLSSIFGKQLVVSYFPDKVALLQRKVEENRNSLFFFLLFLRLFPMTPNWFLNLSAPILNIPIVQFFFSVLIGLIPYNFICVQTGSILSTLTSLDALFSWDTVFKLLAIAMVALIPGTLIKKFSQKHLQLNETSTANHIHSRKDT>sp|Q9BRN9|TM2D3_HUMAN TM2 domain-containing protein 3 OS=Homo sapiensOX=9606 GN=TM2D3 PE=2 SV=2MAGGVLPLRGLRALCRVLLFLSQFCILSGGEQSQALAQSIKDPGPTRTFTVVPRAAESTEIPPYVMKCPSNGLCSRLPADCIDCTTNFSCTYGKPVTFDCAVKPSVTCVDQDFKSQKNFIINMTCRFCWQLPETDYECTNSTSCMTVSCPRQRYPANCTVRDHVHCLGNRTFPKMLYCNWTGGYKWSTALALSITLGGFGADRFYLGQWREGLGKLFSFGGLGIWTLIDVLLIGVGYVGPADGSLYI>sp|Q9BRN9-2|TM2D3_HUMAN Isoform 2 of TM2 domain-containing protein 3OS=Homo sapiens OX=9606 GN=TM2D3MAGGVLPLRGLRALCRVLLFLSQFCILSGGESTEIPPYVMKCPSNGLCSRLPADCIDCTTNFSCTYGKPVTFDCAVKPSVTCVDQDFKSQKNFIINMTCRFCWQLPETDYECTNSTSCMTVSCPRQRYPANCTVRDHVHCLGNRTFPKMLYCNWTGGYKWSTALALSITLGGFGADRFYLGQWREGLGKLFSFGGLGIWTLIDVLLIGVGYVGPADGSLYI>sp|Q6UWJ1|TMCO3_HUMAN Transmembrane and coiled-coil domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=TMCO3 PE=1 SV=1MKVLGRSFFWVLFPVLPWAVQAVEHEEVAQRVIKLHRGRGVAAMQSRQWVRDSCRKLSGLLRQKNAVLNKLKTAIGAVEKDVGLSDEEKLFQVHTFEIFQKELNESENSVFQAVYGLQRALQGDYKDVVNMKESSRQRLEALREAAIKEETEYMELLAAEKHQVEALKNMQHQNQSLSMLDEILEDVRKAADRLEEEIEEHAFDDNKSVKGVNFEAVLRVEEEEANSKQNITKREVEDDLGLSMLIDSQNNQYILTKPRDSTIPRADHHFIKDIVTIGMLSLPCGWLCTAIGLPTMFGYIICGVLLGPSGLNSIKSIVQVETLGEFGVFFTLFLVGLEFSPEKLRKVWKISLQGPCYMTLLMIAFGLLWGHLLRIKPTQSVFISTCLSLSSTPLVSRFLMGSARGDKEGDIDYSTVLLGMLVTQDVQLGLFMAVMPTLIQAGASASSSIVVEVLRILVLIGQILFSLAAVFLLCLVIKKYLIGPYYRKLHMESKGNKEILILGISAFIFLMLTVTELLDVSMELGCFLAGALVSSQGPVVTEEIATSIEPIRDFLAIVFFASIGLHVFPTFVAYELTVLVFLTLSVVVMKFLLAALVLSLILPRSSQYIKWIVSAGLAQVSEFSFVLGSRARRAGVISREVYLLILSVTTLSLLLAPVLWRAAITRCVPRPERRSSL>sp|Q6UWJ1-2|TMCO3_HUMAN Isoform 2 of Transmembrane and coiled-coildomain-containing protein 3 OS=Homo sapiens OX=9606 GN=TMCO3MKVLGRSFFWVLFPVLPWAVQAVEHEEVAQRVIKLHRGRGVAAMQSRQWVRDSCRKLSGLLRQKNAVLNKLKTAIGAVEKDVGLSDEEKLFQVHTFEIFQKELNESENSVFQAVYGLQRALQGDYKDVVNMKESSRQRLEALREAAIKEETEYMELLAAEKHQVEALKNMQHQNQSLSMLDEILEDVRKAADRLEEEIEEHAFDDNKSVKGVNFEAVLRVEEEEANSKQNITKREVEDDLGLSMLIDSQNNQYILTKPRDSTIPRADHHFIKDIVTIGMLSLPCGWLCTAIGLPTMFGYIICGVLLGPSGLNSIKSIVQVETLGEFGVFFTLFLVGLEFSPEKLRKVWKISLQGPCYMTLLMIAFGLLWGHLLRIKPTQSVFISTCLSLSSTPLVSRFLMGSARGDKEGDIDYSTVLLGMLVTQDVQLGLFMAVMPTLIQAGASASSSIVVEVLRILVLIGQILFSLAAVFLLCLVIKKYLIGPYYRKLHMESKGNKEILILGISAFIFLMLTVILKLCVIYVI>sp|Q6UWJ1-3|TMCO3_HUMAN Isoform 3 of Transmembrane and coiled-coildomain-containing protein 3 OS=Homo sapiens OX=9606 GN=TMCO3MKVLGRSFFWVLFPVLPWAVQAVEHEEVAQRVIKLHRGRGVAAMQSRQWVRDSCRKLSGLLRQKNAVLNKLKTAIGAVEKDVGLSDEEKLFQVHTFEIFQKELNESENSVFQAVYGLQRALQGDYKDVVNMKESSRQRLEALREAAIKEETEYMELLAAEKHQVEALKNMQHQNQSLSMLDEILEDVRKAADRLEEEIEEHAFDDNKSVKGVNFEAVLRVEEEEANSKQNITKREVEDDLGLSMLIDSQNNQYILTKPRDSTIPRADHHFIKDIVTIGMLSLPCGWLCTAIGLPTMFGYIICGVLLGPSGLNSIKSIVQVETLGEFGVFFTLFLVGLEFSPEKLRKVWKISLQGPCYMTLLMIAFGLLWGHLLRIKPTQSVFISTCLSLSSTPLVSRFLMGSARGDKEGNRTAL>sp|Q69YG0|TMM42_HUMAN Transmembrane protein 42 OS=Homo sapiens OX=9606GN=TMEM42 PE=1 SV=2MAERPGPPGGAVSATAYPDTPAEFPPHLQAGAMRRRFWGVFNCLCAGAFGALAAASAKLAFGSEVSMGLCVLGIIVMASTNSLMWTFFSRGLSFSMSSAIASVTVTFSNILSSAFLGYVLYGECQEVLWWGGVFLILCGLTLIHRKLPPTWKPLPHKQQ>sp|Q99727|TIMP4_HUMAN Metalloproteinase inhibitor 4 OS=Homo sapiensOX=9606 GN=TIMP4 PE=2 SV=1MPGSPRPAPSWVLLLRLLALLRPPGLGEACSCAPAHPQQHICHSALVIRAKISSEKVVPASADPADTEKMLRYEIKQIKMFKGFEKVKDVQYIYTPFDSSLCGVKLEANSQKQYLLTGQVLSDGKVFIHLCNYIEPWEDLSLVQRESLNHHYHLNCGCQITTCYTVPCTISAPNECLWTDWLLERKLYGYQAQHYVCMKHVDGTCSWYRGHLPLRKEFVDIVQP>sp|Q5BVD1|TTMP_HUMAN TPA-induced transmembrane protein OS=Homo sapiensOX=9606 GN=TTMP PE=1 SV=2MDLAQPSQPVDELELSVLERQPEENTPLNGADKVFPSLDEEVPPAEANKESPWSSCNKNVVGRCKLWMIITSIFLGVITVIIIGLCLAAVTYVDEDENEILELSSNKTFFIMLKIPEECVAEEELPHLLTERLTDVYSTSPSLGRYFTSVEIVDFSGENATVTYDLQFGVPSDDENFMKYMMSEELVLGILLQDFRDQNIPGCESLGLDPTSLLLYE>sp|Q5BVD1-2|TTMP_HUMAN Isoform 2 of TPA-induced transmembrane proteinOS=Homo sapiens OX=9606 GN=TTMPMDLAQPSQPVDELELSVLERQPEENTPLNGADKVFPSLDEEVPPAEANKESPWSSCNKNVVGRCKLWMIITSIFLGVITVIIIGLCLAAVTYVDEDENEILELSSNKTFFIMLKIPEECVAEEELPHLLTEREVGLKPNPEALVGFE>sp|Q5BVD1-3|TTMP_HUMAN Isoform 3 of TPA-induced transmembrane proteinOS=Homo sapiens OX=9606 GN=TTMPMDLAQPSQPVDELELSVLERQPEENTPLNGADKVFPSLDEEVPPAEANKESPWSSCNKNVVGRCKLWMIITSIFLGVITVIIIGLCLAAVTYVDEDENEILELSSNKTFFIMLKIPEECVAEEELPHLLTERNEVMEAGLCLKAVLYQVLEMKGIHSVLQKRFCGLIQKHQQHQRGGDSFLSRFYSLALSPVKQLPSTASAGSSLDKGRKPARVGAIGSAGMSHCWRSLVFCLFLFCFVLFFETGSRSVA>sp|P17152|TMM11_HUMAN Transmembrane protein 11, mitochondrial OS=Homosapiens OX=9606 GN=TMEM11 PE=1 SV=1MAAWGRRRLGPGSSGGSARERVSLSATDCYIVHEIYNGENAQDQFEYELEQALEAQYKYIVIEPTRIGDETARWITVGNCLHKTAVLAGTACLFTPLALPLDYSHYISLPAGVLSLACCTLYGISWQFDPCCKYQVEYDAYKLSRLPLHTLTSSTPVVLVRKDDLHRKRLHNTIALAALVYCVKKIYELYAV>sp|Q8NG68|TTL_HUMAN Tubulin--tyrosine ligase OS=Homo sapiens OX=9606GN=TTL PE=1 SV=2MYTFVVRDENSSVYAEVSRLLLATGHWKRLRRDNPRFNLMLGERNRLPFGRLGHEPGLVQLVNYYRGADKLCRKASLVKLIKTSPELAESCTWFPESYVIYPTNLKTPVAPAQNGIQPPISNSRTDEREFFLASYNRKKEDGEGNVWIAKSSAGAKGEGILISSEASELLDFIDNQGQVHVIQKYLEHPLLLEPGHRKFDIRSWVLVDHQYNIYLYREGVLRTASEPYHVDNFQDKTCHLTNHCIQKEYSKNYGKYEEGNEMFFKEFNQYLTSALNITLESSILLQIKHIIRNCLLSVEPAISTKHLPYQSFQLFGFDFMVDEELKVWLIEVNGAPACAQKLYAELCQGIVDIAISSVFPPPDVEQPQTQPAAFIKL>sp|Q86UF1|TSN33_HUMAN Tetraspanin-33 OS=Homo sapiens OX=9606 GN=TSPAN33PE=1 SV=1MARRPRAPAASGEEFSFVSPLVKYLLFFFNMLFWVISMVMVAVGVYARLMKHAEAALACLAVDPAILLIVVGVLMFLLTFCGCIGSLRENICLLQTFSLCLTAVFLLQLAAGILGFVFSDKARGKVSEIINNAIVHYRDDLDLQNLIDFGQKKFSCCGGISYKDWSQNMYFNCSEDNPSRERCSVPYSCCLPTPDQAVINTMCGQGMQAFDYLEASKVIYTNGCIDKLVNWIHSNLFLLGGVALGLAIPQLVGILLSQILVNQIKDQIKLQLYNQQHRADPWY>sp|Q5TCY1|TTBK1_HUMAN Tau-tubulin kinase 1 OS=Homo sapiens OX=9606GN=TTBK1 PE=1 SV=2MQCLAAALKDETNMSGGGEQADILPANYVVKDRWKVLKKIGGGGFGEIYEAMDLLTRENVALKVESAQQPKQVLKMEVAVLKKLQGKDHVCRFIGCGRNEKFNYVVMQLQGRNLADLRRSQPRGTFTLSTTLRLGKQILESIEAIHSVGFLHRDIKPSNFAMGRLPSTYRKCYMLDFGLARQYTNTTGDVRPPRNVAGFRGTVRYASVNAHKNREMGRHDDLWSLFYMLVEFAVGQLPWRKIKDKEQVGMIKEKYEHRMLLKHMPSEFHLFLDHIASLDYFTKPDYQLIMSVFENSMKERGIAENEAFDWEKAGTDALLSTSTSTPPQQNTRQTAAMFGVVNVTPVPGDLLRENTEDVLQGEHLSDQENAPPILPGRPSEGLGPSPHLVPHPGGPEAEVWEETDVNRNKLRINIGKSPCVEEEQSRGMGVPSSPVRAPPDSPTTPVRSLRYRRVNSPESERLSTADGRVELPERRSRMDLPGSPSRQACSSQPAQMLSVDTGHADRQASGRMDVSASVEQEALSNAFRSVPLAEEEDFDSKEWVIIDKETELKDFPPGAEPSTSGTTDEEPEELRPLPEEGEERRRLGAEPTVRPRGRSMQALAEEDLQHLPPQPLPPQLSQGDGRSETSQPPTPGSPSHSPLHSGPRPRRRESDPTGPQRQVFSVAPPFEVNGLPRAVPLSLPYQDFKRDLSDYRERARLLNRVRRVGFSHMLLTTPQVPLAPVQPQANGKEEEEEEEEDEEEEEEDEEEEEEEEEEEEEEEEEEEEEEEAAAAVALGEVLGPRSGSSSEGSERSTDRSQEGAPSTLLADDQKESRGRASMADGDLEPEEGSKTLVLVSPGDMKKSPVTAELAPDPDLGTLAALTPQHERPQPTGSQLDVSEPGTLSSVLKSEPKPPGPGAGLGAGTVTTGVGGVAVTSSPFTKVERTFVHIAEKTHLNVMSSGGQALRSEEFSAGGELGLELASDGGAVEEGARAPLENGLALSGLNGAEIEGSALSGAPRETPSEMATNSLPNGPALADGPAPVSPLEPSPEKVATISPRRHAMPGSRPRSRIPVLLSEEDTGSEPSGSLSAKERWSKRARPQQDLARLVMEKRQGRLLLRLASGASSSSSEEQRRASETLSGTGSEEDTPASEPAAALPRKSGRAAATRSRIPRPIGLRMPMPVAAQQPASRSHGAAPALDTAITSRLQLQTPPGSATAADLRPKQPPGRGLGPGRAQAGARPPAPRSPRLPASTSAARNASASPRSQSLSRRESPSPSHQARPGVPPPRGVPPARAQPDGTPSPGGSKKGPRGKLQAQRATTKGRAGGAEGRAGAR>sp|Q5TCY1-2|TTBK1_HUMAN Isoform 2 of Tau-tubulin kinase 1 OS=Homosapiens OX=9606 GN=TTBK1MDLLTRENVALKVESAQQPKQVLKMEVAVLKKLQGKDHVCRFIGCGRNEKFNYVVMQLQGRNLADLRRSQPRGTFTLSTTLRLGKQILESIEAIHSVGFLHRDIKPSNFAMGRLPSTYRKCYMLDFGLARQYTNTTGDVRPPRNVAGFRGTVRYASVNAHKNREMGRHDDLWSLFYMLVEFAVGQLPWRKIKDKEQVGMIKEKYEHRMLLKHMPSEFHLFLDHIASLDYFTKPDYQLIMSVFENSMKERGIAENEAFDWEKAGTDALLSTSTSTPPQQNTRQTAAMFGVVNVTPVPGDLLRENTEDVLQGEHLSDQENAPPILPGRPSEGLGPSPHLVPHPGGPEAEVWEETDVNRNKLRINIGKSPCVEEEQSRGMGVPSSPVRAPPDSPTTPVRSLRYRRVNSPESERLSTADGRVELPERRSRMDLPGSPSRQACSSQPAQMLSVDTGHADRQASGRMDVSASVEQEALSNAFRSVPLAEEEDFDSKEWVIIDKETELKDFPPGAEPSTSGTTDEEPEELRPLPEEGEERRRLGAEPFPLTPALGTPPSTERVGPHRPTETVGGGQTLGALPPAVQPPATTGVLRVLLLHAGDGALPSPRRRRLLGLLRFPHSAQPLG>sp|P53007|TXTP_HUMAN Tricarboxylate transport protein, mitochondrialOS=Homo sapiens OX=9606 GN=SLC25A1 PE=1 SV=2MPAPRAPRALAAAAPASGKAKLTHPGKAILAGGLAGGIEICITFPTEYVKTQLQLDERSHPPRYRGIGDCVRQTVRSHGVLGLYRGLSSLLYGSIPKAAVRFGMFEFLSNHMRDAQGRLDSTRGLLCGLGAGVAEAVVVVCPMETIKVKFIHDQTSPNPKYRGFFHGVREIVREQGLKGTYQGLTATVLKQGSNQAIRFFVMTSLRNWYRGDNPNKPMNPLITGVFGAIAGAASVFGNTPLDVIKTRMQGLEAHKYRNTWDCGLQILKKEGLKAFYKGTVPRLGRVCLDVAIVFVIYDEVVKLLNKVWKTD>sp|Q70EK9|UBP51_HUMAN Ubiquitin carboxyl-terminal hydrolase 51 OS=Homosapiens OX=9606 GN=USP51 PE=1 SV=1MAQVRETSLPSGSGVRWISGGGGGASPEEAVEKAGKMEEAAAGATKASSRREAEEMKLEPLQEREPAPEENLTWSSSGGDEKVLPSIPLRCHSSSSPVCPRRKPRPRPQPRARSRSQPGLSAPPPPPARPPPPPPPPPPPAPRPRAWRGSRRRSRPGSRPQTRRSCSGDLDGSGDPGGLGDWLLEVEFGQGPTGCSHVESFKVGKNWQKNLRLIYQRFVWSGTPETRKRKAKSCICHVCSTHMNRLHSCLSCVFFGCFTEKHIHKHAETKQHHLAVDLYHGVIYCFMCKDYVYDKDIEQIAKETKEKILRLLTSTSTDVSHQQFMTSGFEDKQSTCETKEQEPKLVKPKKKRRKKSVYTVGLRGLINLGNTCFMNCIVQALTHIPLLKDFFLSDKHKCIMTSPSLCLVCEMSSLFHAMYSGSRTPHIPYKLLHLIWIHAEHLAGYRQQDAHEFLIAILDVLHRHSKDDSGGQEANNPNCCNCIIDQIFTGGLQSDVTCQACHSVSTTIDPCWDISLDLPGSCATFDSQNPERADSTVSRDDHIPGIPSLTDCLQWFTRPEHLGSSAKIKCNSCQSYQESTKQLTMKKLPIVACFHLKRFEHVGKQRRKINTFISFPLELDMTPFLASTKESRMKEGQPPTDCVPNENKYSLFAVINHHGTLESGHYTSFIRQQKDQWFSCDDAIITKATIEDLLYSEGYLLFYHKQGLEKD>sp|Q8N427|TXND3_HUMAN Thioredoxin domain-containing protein 3 OS=Homosapiens OX=9606 GN=NME8 PE=2 SV=2MASKKREVQLQTVINNQSLWDEMLQNKGLTVIDVYQAWCGPCRAMQPLFRKLKNELNEDEILHFAVAEADNIVTLQPFRDKCEPVFLFSVNGKIIEKIQGANAPLVNKKVINLIDEERKIAAGEMARPQYPEIPLVDSDSEVSEESPCESVQELYSIAIIKPDAVISKKVLEIKRKITKAGFIIEAEHKTVLTEEQVVNFYSRIADQCDFEEFVSFMTSGLSYILVVSQGSKHNPPSEETEPQTDTEPNERSEDQPEVEAQVTPGMMKNKQDSLQEYLERQHLAQLCDIEEDAANVAKFMDAFFPDFKKMKSMKLEKTLALLRPNLFHERKDDVLRIIKDEDFKILEQRQVVLSEKEAQALCKEYENEDYFNKLIENMTSGPSLALVLLRDNGLQYWKQLLGPRTVEEAIEYFPESLCAQFAMDSLPVNQLYGSDSLETAEREIQHFFPLQSTLGLIKPHATSEQREQILKIVKEAGFDLTQVKKMFLTPEQIEKIYPKVTGKDFYKDLLEMLSVGPSMVMILTKWNAVAEWRRLMGPTDPEEAKLLSPDSIRAQFGISKLKNIVHGASNAYEAKEVVNRLFEDPEEN>sp|Q9HAW8|UD110_HUMAN UDP-glucuronosyltransferase 1A10 OS=Homo sapiensOX=9606 GN=UGT1A10 PE=1 SV=1MARAGWTSPVPLCVCLLLTCGFAEAGKLLVVPMDGSHWFTMQSVVEKLILRGHEVVVVMPEVSWQLERSLNCTVKTYSTSYTLEDQNREFMVFAHAQWKAQAQSIFSLLMSSSSGFLDLFFSHCRSLFNDRKLVEYLKESSFDAVFLDPFDTCGLIVAKYFSLPSVVFTRGIFCHHLEEGAQCPAPLSYVPNDLLGFSDAMTFKERVWNHIVHLEDHLFCQYLFRNALEIASEILQTPVTAYDLYSHTSIWLLRTDFVLDYPKPVMPNMIFIGGINCHQGKPLPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|Q9HAW8-2|UD110_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A10OS=Homo sapiens OX=9606 GN=UGT1A10MARAGWTSPVPLCVCLLLTCGFAEAGKLLVVPMDGSHWFTMQSVVEKLILRGHEVVVVMPEVSWQLERSLNCTVKTYSTSYTLEDQNREFMVFAHAQWKAQAQSIFSLLMSSSSGFLDLFFSHCRSLFNDRKLVEYLKESSFDAVFLDPFDTCGLIVAKYFSLPSVVFTRGIFCHHLEEGAQCPAPLSYVPNDLLGFSDAMTFKERVWNHIVHLEDHLFCQYLFRNALEIASEILQTPVTAYDLYSHTSIWLLRTDFVLDYPKPVMPNMIFIGGINCHQGKPLPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|O95071|UBR5_HUMAN E3 ubiquitin-protein ligase UBR5 OS=Homo sapiensOX=9606 GN=UBR5 PE=1 SV=2MTSIHFVVHPLPGTEDQLNDRLREVSEKLNKYNLNSHPPLNVLEQATIKQCVVGPNHAAFLLEDGRVCRIGFSVQPDRLELGKPDNNDGSKLNSNSGAGRTSRPGRTSDSPWFLSGSETLGRLAGNTLGSRWSSGVGGSGGGSSGRSSAGARDSRRQTRVIRTGRDRGSGLLGSQPQPVIPASVIPEELISQAQVVLQGKSRSVIIRELQRTNLDVNLAVNNLLSRDDEDGDDGDDTASESYLPGEDLMSLLDADIHSAHPSVIIDADAMFSEDISYFGYPSFRRSSLSRLGSSRVLLLPLERDSELLRERESVLRLRERRWLDGASFDNERGSTSKEGEPNLDKKNTPVQSPVSLGEDLQWWPDKDGTKFICIGALYSELLAVSSKGELYQWKWSESEPYRNAQNPSLHHPRATFLGLTNEKIVLLSANSIRATVATENNKVATWVDETLSSVASKLEHTAQTYSELQGERIVSLHCCALYTCAQLENSLYWWGVVPFSQRKKMLEKARAKNKKPKSSAGISSMPNITVGTQVCLRNNPLYHAGAVAFSISAGIPKVGVLMESVWNMNDSCRFQLRSPESLKNMEKASKTTEAKPESKQEPVKTEMGPPPSPASTCSDASSIASSASMPYKRRRSTPAPKEEEKVNEEQWSLREVVFVEDVKNVPVGKVLKVDGAYVAVKFPGTSSNTNCQNSSGPDADPSSLLQDCRLLRIDELQVVKTGGTPKVPDCFQRTPKKLCIPEKTEILAVNVDSKGVHAVLKTGNWVRYCIFDLATGKAEQENNFPTSSIAFLGQNERNVAIFTAGQESPIILRDGNGTIYPMAKDCMGGIRDPDWLDLPPISSLGMGVHSLINLPANSTIKKKAAVIIMAVEKQTLMQHILRCDYEACRQYLMNLEQAVVLEQNLQMLQTFISHRCDGNRNILHACVSVCFPTSNKETKEEEEAERSERNTFAERLSAVEAIANAISVVSSNGPGNRAGSSSSRSLRLREMMRRSLRAAGLGRHEAGASSSDHQDPVSPPIAPPSWVPDPPAMDPDGDIDFILAPAVGSLTTAATGTGQGPSTSTIPGPSTEPSVVESKDRKANAHFILKLLCDSVVLQPYLRELLSAKDARGMTPFMSAVSGRAYPAAITILETAQKIAKAEISSSEKEEDVFMGMVCPSGTNPDDSPLYVLCCNDTCSFTWTGAEHINQDIFECRTCGLLESLCCCTECARVCHKGHDCKLKRTSPTAYCDCWEKCKCKTLIAGQKSARLDLLYRLLTATNLVTLPNSRGEHLLLFLVQTVARQTVEHCQYRPPRIREDRNRKTASPEDSDMPDHDLEPPRFAQLALERVLQDWNALKSMIMFGSQENKDPLSASSRIGHLLPEEQVYLNQQSGTIRLDCFTHCLIVKCTADILLLDTLLGTLVKELQNKYTPGRREEAIAVTMRFLRSVARVFVILSVEMASSKKKNNFIPQPIGKCKRVFQALLPYAVEELCNVAESLIVPVRMGIARPTAPFTLASTSIDAMQGSEELFSVEPLPPRPSSDQSSSSSQSQSSYIIRNPQQRRISQSQPVRGRDEEQDDIVSADVEEVEVVEGVAGEEDHHDEQEEHGEENAEAEGQHDEHDEDGSDMELDLLAAAETESDSESNHSNQDNASGRRSVVTAATAGSEAGASSVPAFFSEDDSQSNDSSDSDSSSSQSDDIEQETFMLDEPLERTTNSSHANGAAQAPRSMQWAVRNTQHQRAASTAPSSTSTPAASSAGLIYIDPSNLRRSGTISTSAAAAAAALEASNASSYLTSASSLARAYSIVIRQISDLMGLIPKYNHLVYSQIPAAVKLTYQDAVNLQNYVEEKLIPTWNWMVSIMDSTEAQLRYGSALASAGDPGHPNHPLHASQNSARRERMTAREEASLRTLEGRRRATLLSARQGMMSARGDFLNYALSLMRSHNDEHSDVLPVLDVCSLKHVAYVFQALIYWIKAMNQQTTLDTPQLERKRTRELLELGIDNEDSEHENDDDTNQSATLNDKDDDSLPAETGQNHPFFRRSDSMTFLGCIPPNPFEVPLAEAIPLADQPHLLQPNARKEDLFGRPSQGLYSSSASSGKCLMEVTVDRNCLEVLPTKMSYAANLKNVMNMQNRQKKEGEEQPVLPEETESSKPGPSAHDLAAQLKSSLLAEIGLTESEGPPLTSFRPQCSFMGMVISHDMLLGRWRLSLELFGRVFMEDVGAEPGSILTELGGFEVKESKFRREMEKLRNQQSRDLSLEVDRDRDLLIQQTMRQLNNHFGRRCATTPMAVHRVKVTFKDEPGEGSGVARSFYTAIAQAFLSNEKLPNLECIQNANKGTHTSLMQRLRNRGERDREREREREMRRSSGLRAGSRRDRDRDFRRQLSIDTRPFRPASEGNPSDDPEPLPAHRQALGERLYPRVQAMQPAFASKITGMLLELSPAQLLLLLASEDSLRARVDEAMELIIAHGRENGADSILDLGLVDSSEKVQQENRKRHGSSRSVVDMDLDDTDDGDDNAPLFYQPGKRGFYTPRPGKNTEARLNCFRNIGRILGLCLLQNELCPITLNRHVIKVLLGRKVNWHDFAFFDPVMYESLRQLILASQSSDADAVFSAMDLAFAIDLCKEEGGGQVELIPNGVNIPVTPQNVYEYVRKYAEHRMLVVAEQPLHAMRKGLLDVLPKNSLEDLTAEDFRLLVNGCGEVNVQMLISFTSFNDESGENAEKLLQFKRWFWSIVEKMSMTERQDLVYFWTSSPSLPASEEGFQPMPSITIRPPDDQHLPTANTCISRLYVPLYSSKQILKQKLLLAIKTKNFGFV>sp|O95071-2|UBR5_HUMAN Isoform 2 of E3 ubiquitin-protein ligase UBR5OS=Homo sapiens OX=9606 GN=UBR5MTSIHFVVHPLPGTEDQLNDRLREVSEKLNKYNLNSHPPLNVLEQATIKQCVVGPNHAAFLLEDGRVCRIGFSVQPDRLELGKPDNNDGSKLNSNSGAGRTSRPGRTSDSPWFLSGSETLGRLAGNTLGSRWSSGVGGSGGGSSGRSSAGARDSRRQTRVIRTGRDRGSGLLGSQPQPVIPASVIPEELISQAQVVLQGKSRSVIIRELQRTNLDVNLAVNNLLSRDDEDGDDGDDTASESYLPGEDLMSLLDADIHSAHPSVIIDADAMFSEDISYFGYPSFRRSSLSRLGSSRVLLLPLERDSELLRERESVLRLRERRWLDGASFDNERGSTSKEGEPNLDKKNTPVQSPVSLGEDLQWWPDKDGTKFICIGALYSELLAVSSKGELYQWKWSESEPYRNAQNPSLHHPRATFLGLTNEKIVLLSANSIRATVATENNKVATWVDETLSSVASKLEHTAQTYSELQGERIVSLHCCALYTCAQLENSLYWWGVVPFSQRKKMLEKARAKNKKPKSSAGISSMPNITVGTQVCLRNNPLYHAGAVAFSISAGIPKVGVLMESVWNMNDSCRFQLRSPESLKNMEKASKTTEAKPESKQEPVKTEMGPPPSPASTCSDASSIASSASMPYKRRRSTPAPKEEEKVNEEQWSLREVVFVEDVKNVPVGKVLKVDGAYVAVKFPGTSSNTNCQNSSGPDADPSSLLQDCRLLRIDELQVVKTGGTPKVPDCFQRTPKKLCIPEKTEILAVNVDSKGVHAVLKTGNWVRYCIFDLATGKAEQENNFPTSSIAFLGQNERNVAIFTAGQESPIILRDGNGTIYPMAKDCMGGIRDPDWLDLPPISSLGMGVHSLINLPANSTIKKKAAVIIMAVEKQTLMQHILRCDYEACRQYLMNLEQAVVLEQNLQMLQTFISHRCDGNRNILHACVSVCFPTSNKETKEEEEAERSERNTFAERLSAVEAIANAISVVSSNGPGNRAGSSSSRSLRLREMMRRSLRAAGLGRHEAGASSSDHQDPVSPPIAPPSWVPDPPAMDPDGDIDFILAPAVGSLTTAATGTGQGPSTSTIPGPSTEPSVVESKDRKANAHFILKLLCDSVVLQPYLRELLSAKDARGMTPFMSAVSGRAYPAAITILETAQKIAKAEISSSEKEEDVFMGMVCPSGTNPDDSPLYVLCCNDTCSFTWTGAEHINQDIFECRTCGLLESLCCCTECARVCHKGHDCKLKRTSPTAYCDCWEKCKCKTLIAGQKSARLDLLYRLLTATNLVTLPNSRGEHLLLFLVQTVARQTVEHCQYRPPRIREDRNRKTASPEDSDMPDHDLEPPRFAQLALERVLQDWNALKSMIMFGSQENKDPLSASSRIGHLLPEEQVYLNQQSGTIRLDCFTHCLIVKCTADILLLDTLLGTLVKELQNKYTPGRREEAIAVTMRFLRSVARVFVILSVEMASSKKKNNFIPQPIGKCKRVFQALLPYAVEELCNVAESLIVPVRMGIARPTAPFTLASTSIDAMQGSEELFSVEPLPPRPSSDQSSSSSQSQSSYIIRNPQQRRISQSQPVRGRDEEQDDIVSADVEEVEVVEGVAGEEDHHDEQEEHGEENAEAEGQHDEHDEDGSDMELDLLAAAETESDSESNHSNQDNASGRRSVVTAATAGSEAGASSVPAFFSEDDSQSNDSSDSDSSSSQSDDIEQETFMLDEPLERTTNSSHANGAAQAPRSMQWAVRNTQHQRAASTAPSSTSTPAASSAGLIYIDPSNLRRSGTISTSAAAAAAALEASNASSYLTSASSLARAYSIVIRQISDLMGLIPKYNHLVYSQIPAAVKLTYQDAVNLQNYVEEKLIPTWNWMVSIMDSTEAQLRYGSALASAGDPGHPNHPLHASQNSARRERMTAREEASLRTLEGRRRATLLSARQGMMSARGDFLNYALSLMRSHNDEHSDVLPVLDVCSLKHVAYVFQALIYWIKAMNQQTTLDTPQLERKRTRELLELGIDNEDSEHENDDDTNQSATLNDKDDDSLPAETGQNHPFFRRSDSMTFLGCIPPNPFEVPLAEAIPLADQPHLLQPNARKEDLFGRPSQGLYSSSASSGKCLMEVTVDRNCLEVLPTKMSYAANLKNVMNMQNRQKKEGEEQPVLPEETESSKPGPSAHDLAAQLKSSLLAEIGLTESEGPPLTSFRPQCSFMGMVISHDMLLGRWRLSLELFGRVFMEDVGAEPGSILTELGGFEVKESKFRREMEKLRNQQSRDLSLEVDRDRDLLIQQTMRQLNNHFGRRCATTPMAVHRVKVTFKDEPGEGSGVARSFYTAIAQAFLSNEKLPNLECIQNANKGTHTSLMQRLRNRGERDREREREREMRRSSGLRAGSRRDRDRDFRRQLSIDTRPFRPASEGNPSDDPEPLPAHRQALGERLYPRVQAMQPAFASKITGMLLELSPAQLLLLLASEDSLRARVDEAMELIIAHGRENGADSILDLGLVDSSEKVQENRKRHGSSRSVVDMDLDDTDDGDDNAPLFYQPGKRGFYTPRPGKNTEARLNCFRNIGRILGLCLLQNELCPITLNRHVIKVLLGRKVNWHDFAFFDPVMYESLRQLILASQSSDADAVFSAMDLAFAIDLCKEEGGGQVELIPNGVNIPVTPQNVYEYVRKYAEHRMLVVAEQPLHAMRKGLLDVLPKNSLEDLTAEDFRLLVNGCGEVNVQMLISFTSFNDESGENAEKLLQFKRWFWSIVEKMSMTERQDLVYFWTSSPSLPASEEGFQPMPSITIRPPDDQHLPTANTCISRLYVPLYSSKQILKQKLLLAIKTKNFGFV>sp|P07911|UROM_HUMAN Uromodulin OS=Homo sapiens OX=9606 GN=UMOD PE=1SV=1MGQPSLTWMLMVVVASWFITTAATDTSEARWCSECHSNATCTEDEAVTTCTCQEGFTGDGLTCVDLDECAIPGAHNCSANSSCVNTPGSFSCVCPEGFRLSPGLGCTDVDECAEPGLSHCHALATCVNVVGSYLCVCPAGYRGDGWHCECSPGSCGPGLDCVPEGDALVCADPCQAHRTLDEYWRSTEYGEGYACDTDLRGWYRFVGQGGARMAETCVPVLRCNTAAPMWLNGTHPSSDEGIVSRKACAHWSGHCCLWDASVQVKACAGGYYVYNLTAPPECHLAYCTDPSSVEGTCEECSIDEDCKSNNGRWHCQCKQDFNITDISLLEHRLECGANDMKVSLGKCQLKSLGFDKVFMYLSDSRCSGFNDRDNRDWVSVVTPARDGPCGTVLTRNETHATYSNTLYLADEIIIRDLNIKINFACSYPLDMKVSLKTALQPMVSALNIRVGGTGMFTVRMALFQTPSYTQPYQGSSVTLSTEAFLYVGTMLDGGDLSRFALLMTNCYATPSSNATDPLKYFIIQDRCPHTRDSTIQVVENGESSQGRFSVQMFRFAGNYDLVYLHCEVYLCDTMNEKCKPTCSGTRFRSGSVIDQSRVLNLGPITRKGVQATVSRAFSSLGLLKVWLPLLLSATLTLTFQ>sp|P07911-2|UROM_HUMAN Isoform 2 of Uromodulin OS=Homo sapiens OX=9606GN=UMODMGQPSLTWMLMVVVASWFITTAATDTSEARWCSECHSNATCTEDEAVTTCTCQEGFTGDGLTCVDLRGWYRFVGQGGARMAETCVPVLRCNTAAPMWLNGTHPSSDEGIVSRKACAHWSGHCCLWDASVQVKACAGGYYVYNLTAPPECHLAYCTDPSSVEGTCEECSIDEDCKSNNGRWHCQCKQDFNITDISLLEHRLECGANDMKVSLGKCQLKSLGFDKVFMYLSDSRCSGFNDRDNRDWVSVVTPARDGPCGTVLTRNETHATYSNTLYLADEIIIRDLNIKINFACSYPLDMKVSLKTALQPMVSALNIRVGGTGMFTVRMALFQTPSYTQPYQGSSVTLSTEAFLYVGTMLDGGDLSRFALLMTNCYATPSSNATDPLKYFIIQDRCPHTRDSTIQVVENGESSQGRFSVQMFRFAGNYDLVYLHCEVYLCDTMNEKCKPTCSGTRFRSGSVIDQSRVLNLGPITRKGVQATVSRAFSSLGLLKVWLPLLLSATLTLTFQ>sp|P07911-3|UROM_HUMAN Isoform 3 of Uromodulin OS=Homo sapiens OX=9606GN=UMODMGQPSLTWMLMVVVASWFITTAATDTSEARWCSECHSNATCTEDEAVTTCTCQEGFTGDGLTCVDLDECAIPGAHNCSANSSCVNTPGSFSCVCPEGFRLSPGLGCTDVDECAEPGLSHCHALATCVNVVGSYLCVCPAGYRGDGWHCECSPGSCGPGLDCVPEGDALVCADPCQAHRTLDEYWRSTEYGEGYACDTDLRGWYRPHPSSDEGIVSRKACAHWSGHCCLWDASVQVKACAGGYYVYNLTAPPECHLAYCTDPSSVEGTCEECSIDEDCKSNNGRWHCQCKQDFNITDISLLEHRLECGANDMKVSLGKCQLKSLGFDKVFMYLSDSRCSGFNDRDNRDWVSVVTPARDGPCGTVLTRNETHATYSNTLYLADEIIIRDLNIKINFACSYPLDMKVSLKTALQPMVSALNIRVGGTGMFTVRMALFQTPSYTQPYQGSSVTLSTEAFLYVGTMLDGGDLSRFALLMTNCYATPSSNATDPLKYFIIQDRCPHTRDSTIQVVENGESSQGRFSVQMFRFAGNYDLVYLHCEVYLCDTMNEKCKPTCSGTRFRSGSVIDQSRVLNLGPITRKGVQATVSRAFSSLGLLKVWLPLLLSATLTLTFQ>sp|P07911-4|UROM_HUMAN Isoform 4 of Uromodulin OS=Homo sapiens OX=9606GN=UMODMGQPSLTWMLMVVVASWFITTAATDTSEARWCSECHSNATCTEDEAVTTCTCQEGFTGDGLTCVDLDECAIPGAHNCSANSSCVNTPGSFSCVCPEGFRLSPGLGCTDVDECAEPGLSHCHALATCVNVVGSCGPGLDCVPEGDALVCADPCQAHRTLDEYWRSTEYGEGYACDTDLRGWYRFVGQGGARMAETCVPVLRCNTAAPMWLNGTHPSSDEGIVSRKACAHWSGHCCLWDASVQVKACAGGYYVYNLTAPPECHLAYCTDPSSVEGTCEECSIDEDCKSNNGRWHCQCKQDFNITDISLLEHRLECGANDMKVSLGKCQLKSLGFDKVFMYLSDSRCSGFNDRDNRDWVSVVTPARDGPCGTVLTRNETHATYSNTLYLADEIIIRDLNIKINFACSYPLDMKVSLKTALQPMVSALNIRVGGTGMFTVRMALFQTPSYTQPYQGSSVTLSTEAFLYVGTMLDGGDLSRFALLMTNCYATPSSNATDPLKYFIIQDRCPHTRDSTIQVVENGESSQGRFSVQMFRFAGNYDLVYLHCEVYLCDTMNEKCKPTCSGTRFRSGSVIDQSRVLNLGPITRKGVQATVSRAFSSLGLLKVWLPLLLSATLTLTFQ>sp|P07911-5|UROM_HUMAN Isoform 5 of Uromodulin OS=Homo sapiens OX=9606GN=UMODMGQPSLTWMLMVVVASWFITTAATDTSEARTKYNCPARWSWRTPQRGGDTEQGPDEDFTSQGRWCSECHSNATCTEDEAVTTCTCQEGFTGDGLTCVDLDECAIPGAHNCSANSSCVNTPGSFSCVCPEGFRLSPGLGCTDVDECAEPGLSHCHALATCVNVVGSYLCVCPAGYRGDGWHCECSPGSCGPGLDCVPEGDALVCADPCQAHRTLDEYWRSTEYGEGYACDTDLRGWYRFVGQGGARMAETCVPVLRCNTAAPMWLNGTHPSSDEGIVSRKACAHWSGHCCLWDASVQVKACAGGYYVYNLTAPPECHLAYCTDPSSVEGTCEECSIDEDCKSNNGRWHCQCKQDFNITDISLLEHRLECGANDMKVSLGKCQLKSLGFDKVFMYLSDSRCSGFNDRDNRDWVSVVTPARDGPCGTVLTRNETHATYSNTLYLADEIIIRDLNIKINFACSYPLDMKVSLKTALQPMVSALNIRVGGTGMFTVRMALFQTPSYTQPYQGSSVTLSTEAFLYVGTMLDGGDLSRFALLMTNCYATPSSNATDPLKYFIIQDRCPHTRDSTIQVVENGESSQGRFSVQMFRFAGNYDLVYLHCEVYLCDTMNEKCKPTCSGTRFRSGSVIDQSRVLNLGPITRKGVQATVSRAFSSLGLLKVWLPLLLSATLTLTFQ>sp|Q96JG6|VPS50_HUMAN Syndetin OS=Homo sapiens OX=9606 GN=VPS50 PE=1SV=3MQKIKSLMTRQGLKSPQESLSDLGAIESLRVPGKEEFRELREQPSDPQAEQELINSIEQVYFSVDSFDIVKYELEKLPPVLNLQELEAYRDKLKQQQAAVSKKVADLILEKQPAYVKELERVTSLQTGLQLAAVICTNGRRHLNIAKEGFTQASLGLLANQRKRQLLIGLLKSLRTIKTLQRTDVRLSEMLEEEDYPGAIQLCLECQKAASTFKHYSCISELNSKLQDTLEQIEEQLDVALSKICKNFDINHYTKVQQAYRLLGKTQTAMDQLHMHFTQAIHNTVFQVVLGYVELCAGNTDTKFQKLQYKDLCTHVTPDSYIPCLADLCKALWEVMLSYYRTMEWHEKHDNEDTASASEGSNMIGTEETNFDRGYIKKKLEHGLTRIWQDVQLKVKTYLLGTDLSIFKYDDFIFVLDIISRLMQVGEEFCGSKSEVLQESIRKQSVNYFKNYHRTRLDELRMFLENETWELCPVKSNFSILQLHEFKFMEQSRSPSVSPSKQPVSTSSKTVTLFEQYCSGGNPFEIQANHKDEETEDVLASNGYESDEQEKSAYQEYDSDSDVPEELKRDYVDEQTGDGPVKSVSRETLKSRKKSDYSLNKVNAPILTNTTLNVIRLVGKYMQMMNILKPIAFDVIHFMSQLFDYYLYAIYTFFGRNDSLESTGLGLSSSRLRTTLNRIQESLIDLEVSADPTATLTAAEERKEKVPSPHLSHLVVLTSGDTLYGLAERVVATESLVFLAEQFEFLQPHLDAVMPAVKKPFLQQFYSQTVSTASELRKPIYWIVAGKALDYEQMLLLMANVKWDVKEIMSQHNIYVDALLKEFEQFNRRLNEVSKRVRIPLPVSNILWEHCIRLANRTIVEGYANVKKCSNEGRALMQLDFQQFLMKLEKLTDIRPIPDKEFVETYIKAYYLTENDMERWIKEHREYSTKQLTNLVNVCLGSHINKKARQKLLAAIDDIDRPKR>sp|Q96JG6-2|VPS50_HUMAN Isoform 2 of Syndetin OS=Homo sapiens OX=9606GN=VPS50MQKIKSLMTRQGLKSPQESLSDLGAIESLRVPGKEEFRELREQPSDPQAEQELINSIEQVYFSVDSFDIVKYELEKLPPVLNLQELEAYRDKLKQQQAAVSKKVADLILEKQPAYVKELERVTSLQTGLQLAAVICTNGRRHLNIAKEGFTQASLGLLANQRKRQLLIGLLKSLRTIKTLQRTDVRLSEMLEEEDYPGAIQLCLECQKAASTFKHYSCISELNSKLQDTLEQIEEQLDVALSKICKNFDINHYTKVQQAYRLLGKTQTAMDQLHMHFTQAIHNTVFQVVLGYVELCAGNTDTKFQKLQYKDLCTVCSDLITIHISLL>sp|Q96JG6-3|VPS50_HUMAN Isoform 3 of Syndetin OS=Homo sapiens OX=9606GN=VPS50MLTLEEFRELREQPSDPQAEQELINSIEQVYFSVDSFDIVKYELEKLPPVLNLQELEAYRDKLKQQQAAVSKKVADLILEKQPAYVKELERVTSLQTGLQLAAVICTNGRRHLNIAKEGFTQASLGLLANQRKRQLLIGLLKSLRTIKTLQRTDVRLSEMLEEEDYPGAIQLCLECQKAASTFKHYSCISELNSKLQDTLEQIEEQLDVALSKICKNFDINHYTKVQQAYRLLGKTQTAMDQLHMHFTQAIHNTVFQVVLGYVELCAGNTDTKFQKLQYKDLCTHVTPDSYIPCLADLCKALWEVMLSYYRTMEWHEKHDNEDTASASEGSNMIGTEETNFDRGYIKKKLEHGLTRIWQDVQLKVKTYLLGTDLSIFKYDDFIFVLDIISRLMQVGEEFCGSKSEVLQESIRKQSVNYFKNYHRTRLDELRMFLENETWELCPVKSNFSILQLHEFKFMEQSRSPSVSPSKQPVSTSSKTVTLFEQYCSGGNPFEIQANHKDEETEDVLASNGYESDEQEKSAYQEYDSDSDVPEELKRDYVDEQTGDGPVKSVSRETLKSRKKSDYSLNKVNAPILTNTTLNVIRLVGKYMQMMNILKPIAFDVIHFMSQLFDYYLYAIYTFFGRNDSLESTGLGLSSSRLRTTLNRIQESLIDLEVSADPTATLTAAEERKEKVPSPHLSHLVVLTSGDTLYGLAERVVATESLVFLAEQFEFLQPHLDAVMPAVKKPFLQQFYSQTVSTASELRKPIYWIVAGKALDYEQMLLLMANVKWDVKEIMSQHNIYVDALLKEFEQFNRRLNEVSKRVRIPLPVSNILWEHCIRLANRTIVEGYANVKKCSNEGRALMQLDFQQFLMKLEKLTDIRPIPDKEFVETYIKAYYLTENDMERWIKEHREYSTKQLTNLVNVCLGSHINKKARQKLLAAIDDIDRPKR>sp|Q2NL98|VMAC_HUMAN Vimentin-type intermediate filament-associatedcoiled-coil protein OS=Homo sapiens OX=9606 GN=VMAC PE=1 SV=1MSAPPALQIREANAHLAAVHRRAAELEARLDAAERTVHAQAERLALHDQQLRAALDELGRAKDREIATLQEQLMTSEATVHSLQATVHQRDELIRQLQPRAELLQDICRRRPPLAGLLDALAEAERLGPLPASDPGHPPPGGPGPPLDNSTGEEADRDHLQPAVFGTTV>sp|A5D8V6|VP37C_HUMAN Vacuolar protein sorting-associated protein 37COS=Homo sapiens OX=9606 GN=VPS37C PE=1 SV=2METLKDKTLQELEELQNDSEAIDQLALESPEVQDLQLEREMALATNRSLAERNLEFQGPLEISRSNLSDRYQELRKLVERCQEQKAKLEKFSSALQPGTLLDLLQVEGMKIEEESEAMAEKFLEGEVPLETFLENFSSMRMLSHLRRVRVEKLQEVVRKPRASQELAGDAPPPRPPPPVRPVPQGTPPVVEEQPQPPLAMPPYPLPYSPSPSLPVGPTAHGALPPAPFPVVSQPSFYSGPLGPTYPAAQLGPRGAAGYSWSPQRSMPPRPGYPGTPMGASGPGYPLRGGRAPSPGYPQQSPYPATGGKPPYPIQPQLPSFPGQPQPSVPLQPPYPPGPAPPYGFPPPPGPAWPGY>sp|Q16557|PSG3_HUMAN Pregnancy-specific beta-1-glycoprotein 3 OS=Homosapiens OX=9606 GN=PSG3 PE=2 SV=2MGPLSAPPCTQRITWKGLLLTALLLNFWNLPTTAQVTIEAEPTKVSKGKDVLLLVHNLPQNLAGYIWYKGQMKDLYHYITSYVVDGQIIIYGPAYSGRETVYSNASLLIQNVTREDAGSYTLHIVKRGDGTRGETGHFTFTLYLETPKPSISSSNLYPREDMEAVSLTCDPETPDASYLWWMNGQSLPMTHSLQLSKNKRTLFLFGVTKYTAGPYECEIRNPVSASRSDPVTLNLLPKLPKPYITINNLNPRENKDVLAFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIQDRYGGIRSYPVTLNVLYGPDLPRIYPSFTYYHSGENLYLSCFADSNPPAEYSWTINGKFQLSGQKLFIPQITTKHSGLYACSVRNSATGMESSKSMTVKVSAPSGTGHLPGLNPL>sp|O00231|PSD11_HUMAN 26S proteasome non-ATPase regulatory subunit 11OS=Homo sapiens OX=9606 GN=PSMD11 PE=1 SV=3MAAAAVVEFQRAQSLLSTDREASIDILHSIVKRDIQENDEEAVQVKEQSILELGSLLAKTGQAAELGGLLKYVRPFLNSISKAKAARLVRSLLDLFLDMEAATGQEVELCLECIEWAKSEKRTFLRQALEARLVSLYFDTKRYQEALHLGSQLLRELKKMDDKALLVEVQLLESKTYHALSNLPKARAALTSARTTANAIYCPPKLQATLDMQSGIIHAAEEKDWKTAYSYFYEAFEGYDSIDSPKAITSLKYMLLCKIMLNTPEDVQALVSGKLALRYAGRQTEALKCVAQASKNRSLADFEKALTDYRAELRDDPIISTHLAKLYDNLLEQNLIRVIEPFSRVQIEHISSLIKLSKADVERKLSQMILDKKFHGILDQGEGVLIIFDEPPVDKTYEAALETIQNMSKVVDSLYNKAKKLT>sp|O00231-2|PSD11_HUMAN Isoform 2 of 26S proteasome non-ATPaseregulatory subunit 11 OS=Homo sapiens OX=9606 GN=PSMD11MAAAAVVEFQRAQSLLSTDREASIDILHSIVKRDIQENDEEAVQVKEQSILELGSLLAKTGQAAELGGLLKYVRPFLNSISKAKAARLVRSLLDLFLDMEAATGQEVELCLECIEWAKSEKRTFLRQALEARLVSLYFDTKRYQEALHLGSQLLRELKKMDDKALLVEVQLLESKTYHALSNLPKARAALTSARTTANAIYCPPKLQATLDMQSGIIHAAEEKDWKTAYSYFYEAFEGYDSIDSPKAITSLKYMLLCKIMLNTPEDVQALVSGKLALRYAGRQTEALKCVAQASKNRSLADFEKALTDYRAELRDDPIISTHLAKLYDNLLEQNLIRVIEPFSRVQIEHISSLIKLSKADVERKLSQMILDKKFHAGILDQGEGVLIIFDEPPVDKTYEAALETIQNMSKVVDSLYNKAKKLT>sp|P48651|PTSS1_HUMAN Phosphatidylserine synthase 1 OS=Homo sapiensOX=9606 GN=PTDSS1 PE=1 SV=1MASCVGSRTLSKDDVNYKMHFRMINEQQVEDITIDFFYRPHTITLLSFTIVSLMYFAFTRDDSVPEDNIWRGILSVIFFFLIISVLAFPNGPFTRPHPALWRMVFGLSVLYFLFLVFLLFLNFEQVKSLMYWLDPNLRYATREADVMEYAVNCHVITWERIISHFDIFAFGHFWGWAMKALLIRSYGLCWTISITWELTELFFMHLLPNFAECWWDQVILDILLCNGGGIWLGMVVCRFLEMRTYHWASFKDIHTTTGKIKRAVLQFTPASWTYVRWFDPKSSFQRVAGVYLFMIIWQLTELNTFFLKHIFVFQASHPLSWGRILFIGGITAPTVRQYYAYLTDTQCKRVGTQCWVFGVIGFLEAIVCIKFGQDLFSKTQILYVVLWLLCVAFTTFLCLYGMIWYAEHYGHREKTYSECEDGTYSPEISWHHRKGTKGSEDSPPKHAGNNESHSSRRRNRHSKSKVTNGVGKK>sp|P48651-2|PTSS1_HUMAN Isoform 2 of Phosphatidylserine synthase 1OS=Homo sapiens OX=9606 GN=PTDSS1MEYAVNCHVITWERIISHFDIFAFGHFWGWAMKALLIRSYGLCWTISITWELTELFFMHLLPNFAECWWDQVILDILLCNGGGIWLGMVVCRFLEMRTYHWASFKDIHTTTGKIKRAVLQFTPASWTYVRWFDPKSSFQRVAGVYLFMIIWQLTELNTFFLKHIFVFQASHPLSWGRILFIGGITAPTVRQYYAYLTDTQCKRVGTQCWVFGVIGFLEAIVCIKFGQDLFSKTQILYVVLWLLCVAFTTFLCLYGMIWYAEHYGHREKTYSECEDGTYSPEISWHHRKGTKGSEDSPPKHAGNNESHSSRRRNRHSKSKVTNGVGKK>sp|P48651-3|PTSS1_HUMAN Isoform 3 of Phosphatidylserine synthase 1OS=Homo sapiens OX=9606 GN=PTDSS1MHLLPNFAECWWDQVILDILLCNGGGIWLGMVVCRFLEMRTYHWASFKDIHTTTGKIKRAVLQFTPASWTYVRWFDPKSSFQRVAGVYLFMIIWQLTELNTFFLKHIFVFQASHPLSWGRILFIGGITAPTVRQYYAYLTDTQCKRVGTQCWVFGVIGFLEAIVCIKFGQDLFSKTQILYVVLWLLCVAFTTFLCLYGMIWYAEHYGHREKTYSECEDGTYSPEISWHHRKGTKGSEDSPPKHAGEGTWGSLFEIVSLVSHRPGRVRQIIAWGAFANVGSLLTSALDMRSPVAARCVEGKR>sp|Q13200|PSMD2_HUMAN 26S proteasome non-ATPase regulatory subunit 2OS=Homo sapiens OX=9606 GN=PSMD2 PE=1 SV=3MEEGGRDKAPVQPQQSPAAAPGGTDEKPSGKERRDAGDKDKEQELSEEDKQLQDELEMLVERLGEKDTSLYRPALEELRRQIRSSTTSMTSVPKPLKFLRPHYGKLKEIYENMAPGENKRFAADIISVLAMTMSGERECLKYRLVGSQEELASWGHEYVRHLAGEVAKEWQELDDAEKVQREPLLTLVKEIVPYNMAHNAEHEACDLLMEIEQVDMLEKDIDENAYAKVCLYLTSCVNYVPEPENSALLRCALGVFRKFSRFPEALRLALMLNDMELVEDIFTSCKDVVVQKQMAFMLGRHGVFLELSEDVEEYEDLTEIMSNVQLNSNFLALARELDIMEPKVPDDIYKTHLENNRFGGSGSQVDSARMNLASSFVNGFVNAAFGQDKLLTDDGNKWLYKNKDHGMLSAAASLGMILLWDVDGGLTQIDKYLYSSEDYIKSGALLACGIVNSGVRNECDPALALLSDYVLHNSNTMRLGSIFGLGLAYAGSNREDVLTLLLPVMGDSKSSMEVAGVTALACGMIAVGSCNGDVTSTILQTIMEKSETELKDTYARWLPLGLGLNHLGKGEAIEAILAALEVVSEPFRSFANTLVDVCAYAGSGNVLKVQQLLHICSEHFDSKEKEEDKDKKEKKDKDKKEAPADMGAHQGVAVLGIALIAMGEEIGAEMALRTFGHLLRYGEPTLRRAVPLALALISVSNPRLNILDTLSKFSHDADPEVSYNSIFAMGMVGSGTNNARLAAMLRQLAQYHAKDPNNLFMVRLAQGLTHLGKGTLTLCPYHSDRQLMSQVAVAGLLTVLVSFLDVRNIILGKSHYVLYGLVAAMQPRMLVTFDEELRPLPVSVRVGQAVDVVGQAGKPKTITGFQTHTTPVLLAHGERAELATEEFLPVTPILEGFVILRKNPNYDL>sp|Q13200-2|PSMD2_HUMAN Isoform 2 of 26S proteasome non-ATPaseregulatory subunit 2 OS=Homo sapiens OX=9606 GN=PSMD2MSMSGEVAKEWQELDDAEKVQREPLLTLVKEIVPYNMAHNAEHEACDLLMEIEQVDMLEKDIDENAYAKVCLYLTSCVNYVPEPENSALLRCALGVFRKFSRFPEALRLALMLNDMELVEDIFTSCKDVVVQKQMAFMLGRHGVFLELSEDVEEYEDLTEIMSNVQLNSNFLALARELDIMEPKVPDDIYKTHLENNRFGGSGSQVDSARMNLASSFVNGFVNAAFGQDKLLTDDGNKWLYKNKDHGMLSAAASLGMILLWDVDGGLTQIDKYLYSSEDYIKSGALLACGIVNSGVRNECDPALALLSDYVLHNSNTMRLGSIFGLGLAYAGSNREDVLTLLLPVMGDSKSSMEVAGVTALACGMIAVGSCNGDVTSTILQTIMEKSETELKDTYARWLPLGLGLNHLGKGEAIEAILAALEVVSEPFRSFANTLVDVCAYAGSGNVLKVQQLLHICSEHFDSKEKEEDKDKKEKKDKDKKEAPADMGAHQGVAVLGIALIAMGEEIGAEMALRTFGHLLRYGEPTLRRAVPLALALISVSNPRLNILDTLSKFSHDADPEVSYNSIFAMGMVGSGTNNARLAAMLRQLAQYHAKDPNNLFMVRLAQGLTHLGKGTLTLCPYHSDRQLMSQVAVAGLLTVLVSFLDVRNIILGKSHYVLYGLVAAMQPRMLVTFDEELRPLPVSVRVGQAVDVVGQAGKPKTITGFQTHTTPVLLAHGERAELATEEFLPVTPILEGFVILRKNPNYDL>sp|Q13200-3|PSMD2_HUMAN Isoform 3 of 26S proteasome non-ATPaseregulatory subunit 2 OS=Homo sapiens OX=9606 GN=PSMD2MTMSGERECLKYRLVGSQEELASWGHEYVRHLAGEVAKEWQELDDAEKVQREPLLTLVKEIVPYNMAHNAEHEACDLLMEIEQVDMLEKDIDENAYAKVCLYLTSCVNYVPEPENSALLRCALGVFRKFSRFPEALRLALMLNDMELVEDIFTSCKDVVVQKQMAFMLGRHGVFLELSEDVEEYEDLTEIMSNVQLNSNFLALARELDIMEPKVPDDIYKTHLENNRFGGSGSQVDSARMNLASSFVNGFVNAAFGQDKLLTDDGNKWLYKNKDHGMLSAAASLGMILLWDVDGGLTQIDKYLYSSEDYIKSGALLACGIVNSGVRNECDPALALLSDYVLHNSNTMRLGSIFGLGLAYAGSNREDVLTLLLPVMGDSKSSMEVAGVTALACGMIAVGSCNGDVTSTILQTIMEKSETELKDTYARWLPLGLGLNHLGKGEAIEAILAALEVVSEPFRSFANTLVDVCAYAGSGNVLKVQQLLHICSEHFDSKEKEEDKDKKEKKDKDKKEAPADMGAHQGVAVLGIALIAMGEEIGAEMALRTFGHLLRYGEPTLRRAVPLALALISVSNPRLNILDTLSKFSHDADPEVSYNSIFAMGMVGSGTNNARLAAMLRQLAQYHAKDPNNLFMVRLAQGLTHLGKGTLTLCPYHSDRQLMSQVAVAGLLTVLVSFLDVRNIILGKSHYVLYGLVAAMQPRMLVTFDEELRPLPVSVRVGQAVDVVGQAGKPKTITGFQTHTTPVLLAHGERAELATEEFLPVTPILEGFVILRKNPNYDL>sp|O00391|QSOX1_HUMAN Sulfhydryl oxidase 1 OS=Homo sapiens OX=9606GN=QSOX1 PE=1 SV=3MRRCNSGSGPPPSLLLLLLWLLAVPGANAAPRSALYSPSDPLTLLQADTVRGAVLGSRSAWAVEFFASWCGHCIAFAPTWKALAEDVKAWRPALYLAALDCAEETNSAVCRDFNIPGFPTVRFFKAFTKNGSGAVFPVAGADVQTLRERLIDALESHHDTWPPACPPLEPAKLEEIDGFFARNNEEYLALIFEKGGSYLGREVALDLSQHKGVAVRRVLNTEANVVRKFGVTDFPSCYLLFRNGSVSRVPVLMESRSFYTAYLQRLSGLTREAAQTTVAPTTANKIAPTVWKLADRSKIYMADLESALHYILRIEVGRFPVLEGQRLVALKKFVAVLAKYFPGRPLVQNFLHSVNEWLKRQKRNKIPYSFFKTALDDRKEGAVLAKKVNWIGCQGSEPHFRGFPCSLWVLFHFLTVQAARQNVDHSQEAAKAKEVLPAIRGYVHYFFGCRDCASHFEQMAAASMHRVGSPNAAVLWLWSSHNRVNARLAGAPSEDPQFPKVQWPPRELCSACHNERLDVPVWDVEATLNFLKAHFSPSNIILDFPAAGSAARRDVQNVAAAPELAMGALELESRNSTLDPGKPEMMKSPTNTTPHVPAEGPEASRPPKLHPGLRAAPGQEPPEHMAELQRNEQEQPLGQWHLSKRDTGAALLAESRAEKNRLWGPLEVRRVGRSSKQLVDIPEGQLEARAGRGRGQWLQVLGGGFSYLDISLCVGLYSLSFMGLLAMYTYFQAKIRALKGHAGHPAA>sp|O00391-2|QSOX1_HUMAN Isoform 2 of Sulfhydryl oxidase 1 OS=Homosapiens OX=9606 GN=QSOX1MRRCNSGSGPPPSLLLLLLWLLAVPGANAAPRSALYSPSDPLTLLQADTVRGAVLGSRSAWAVEFFASWCGHCIAFAPTWKALAEDVKAWRPALYLAALDCAEETNSAVCRDFNIPGFPTVRFFKAFTKNGSGAVFPVAGADVQTLRERLIDALESHHDTWPPACPPLEPAKLEEIDGFFARNNEEYLALIFEKGGSYLGREVALDLSQHKGVAVRRVLNTEANVVRKFGVTDFPSCYLLFRNGSVSRVPVLMESRSFYTAYLQRLSGLTREAAQTTVAPTTANKIAPTVWKLADRSKIYMADLESALHYILRIEVGRFPVLEGQRLVALKKFVAVLAKYFPGRPLVQNFLHSVNEWLKRQKRNKIPYSFFKTALDDRKEGAVLAKKVNWIGCQGSEPHFRGFPCSLWVLFHFLTVQAARQNVDHSQEAAKAKEVLPAIRGYVHYFFGCRDCASHFEQMAAASMHRVGSPNAAVLWLWSSHNRVNARLAGAPSEDPQFPKVQWPPRELCSACHNERLDVPVWDVEATLNFLKAHFSPSNIILDFPAAGSAARRDVQNVAAAPELAMGALELESRNSTLDPGKPEMMKSPTNTTPHVPAEGPELI>sp|Q9H0K6|PUS7L_HUMAN Pseudouridylate synthase 7 homolog-like proteinOS=Homo sapiens OX=9606 GN=PUS7L PE=1 SV=1MEEDTDYRIRFSSLCFFNDHVGFHGTIKSSPSDFIVIEIDEQGQLVNKTIDEPIFKISEIQLEPNNFPKKPKLDLQNLSLEDGRNQEVHTLIKYTDGDQNHQSGSEKEDTIVDGTSKCEEKADVLSSFLDEKTHELLNNFACDVREKWLSKTELIGLPPEFSIGRILDKNQRASLHSAIRQKFPFLVTVGKNSEIVVKPNLEYKELCHLVSEEEAFDFFKYLDAKKENSKFTFKPDTNKDHRKAVHHFVNKKFGNLVETKSFSKMNCSAGNPNVVVTVRFREKAHKRGKRPLSECQEGKVIYTAFTLRKENLEMFEAIGFLAIKLGVIPSDFSYAGLKDKKAITYQAMVVRKVTPERLKNIEKEIEKKRMNVFNIRSVDDSLRLGQLKGNHFDIVIRNLKKQINDSANLRERIMEAIENVKKKGFVNYYGPQRFGKGRKVHTDQIGLALLKNEMMKAIKLFLTPEDLDDPVNRAKKYFLQTEDAKGTLSLMPEFKVRERALLEALHRFGMTEEGCIQAWFSLPHSMRIFYVHAYTSKIWNEAVSYRLETYGARVVQGDLVCLDEDIDDENFPNSKIHLVTEEEGSANMYAIHQVVLPVLGYNIQYPKNKVGQWYHDILSRDGLQTCRFKVPTLKLNIPGCYRQILKHPCNLSYQLMEDHDIDVKTKGSHIDETALSLLISFDLDASCYATVCLKEIMKHDV>sp|Q9H0K6-2|PUS7L_HUMAN Isoform 2 of Pseudouridylate synthase 7 homolog-like protein OS=Homo sapiens OX=9606 GN=PUS7LMFEAIGFLAIKLGVIPSDFSYAGLKDKKAITYQAMVVRKVTPERLKNIEKEIEKKRMNVFNIRSVDDSLRLGQLKGNHFDIVIRNLKKQINDSANLRERIMEAIENVKKKGFVNYYGPQRFGKGRKVHTDQIGLALLKNEMMKAIKLFLTPEDLDDPVNRAKKYFLQTEDAKGTLSLMPEFKVRERALLEALHRFGMTEEGCIQAWFSLPHSMRIFYVHAYTSKIWNEAVSYRLETYGARVVQGDLVCLDEDIDDENFPNSKIHLVTEEEGSANMYAIHQVVLPVLGYNIQYPKNKVGQWYHDILSRDGLQTCRFKVPTLKLNIPGCYRQILKHPCNLSYQLMEDHDIDVKTKGSHIDETALSLLISFDLDASCYATVCLKEIMKHDV>sp|Q8N0Z8|PUSL1_HUMAN tRNA pseudouridine synthase-like 1 OS=Homo sapiensOX=9606 GN=PUSL1 PE=1 SV=1MSSAPASGSVRARYLVYFQYVGTDFNGVAAVRGTQRAVGVQNYLEEAAERLNSVEPVRFTISSRTDAGVHALSNAAHLDVQRRSGRPPFPPEVLAEALNTHLRHPAIRVLRAFRVPSDFHARHAATSRTYLYRLATGCHRRDELPVFERNLCWTLPADCLDMVAMQEAAQHLLGTHDFSAFQSAGSPVPSPVRTLRRVSVSPGQASPLVTPEESRKLRFWNLEFESQSFLYRQVRRMTAVLVAVGLGALAPAQVKTILESQDPLGKHQTRVAPAHGLFLKSVLYGNLGAASCTLQGPQFGSHG>sp|Q8N0Z8-2|PUSL1_HUMAN Isoform 2 of tRNA pseudouridine synthase-like 1OS=Homo sapiens OX=9606 GN=PUSL1MVAMQEAAQHLLGTHDFSAFQSAGSPVPSPVRTLRRVSVSPGQASPLVTPEESRKLRFWNLEFESQSFLYRQVRRMTAVLVAVGLGALAPAQVKTILESQDPLGKHQTRVAPAHGLFLKSVLYGNLGAASCTLQGPQFGSHG>sp|P61571|REC21_HUMAN Endogenous retrovirus group K member 21 Recprotein OS=Homo sapiens OX=9606 GN=ERVK-21 PE=1 SV=1MHPSEMQRKAPPRRRRHRNRAPLTHKMNKMVTSEQMKLPSTKKAEPPTWAQLKKLTQLATKYLENTKVTQTPESMLLAALMIVSMVSAGVPNSSEETATIENGP>sp|Q96IS3|RAX2_HUMAN Retina and anterior neural fold homeobox protein 2OS=Homo sapiens OX=9606 GN=RAX2 PE=1 SV=1MFLSPGEGPATEGGGLGPGEEAPKKKHRRNRTTFTTYQLHQLERAFEASHYPDVYSREELAAKVHLPEVRVQVWFQNRRAKWRRQERLESGSGAVAAPRLPEAPALPFARPPAMSLPLEPWLGPGPPAVPGLPRLLGPGPGLQASFGPHAFAPTFADGFALEEASLRLLAKEHAQALDRAWPPA>sp|O75677|RFPL1_HUMAN Ret finger protein-like 1 OS=Homo sapiens OX=9606GN=RFPL1 PE=1 SV=2MKRLSLVTTNRLSPHGNFLPLCTFPLAVDMAALFQEASSCPVCSDYLEKPMSLECGCAVCFKCINSLQKEPHGEDLLCCCCSMVSQKNKIRPSWQLERLASHIKELEPKLKKILQMNPRMRKFQVDMTLDADTANNFLLISDDLRSVRSGCITQNRQDLAERFDVSICILGSPRFTCGRHYWEVDVGTSTEWDLGVCRESVHRKGRIHLTTERGFWTVSLRDGSRLSASTVPLTFLFVDRKLQRVGIFLDMGMQNVSFFDAEGGSHVYTFRSVSAEEPLHLFFAPPSPPNGDKSVLSICPVINPGTTDAPVHPGEAK>sp|P30050|RL12_HUMAN 60S ribosomal protein L12 OS=Homo sapiens OX=9606GN=RPL12 PE=1 SV=1MPPKFDPNEIKVVYLRCTGGEVGATSALAPKIGPLGLSPKKVGDDIAKATGDWKGLRITVKLTIQNRQAQIEVVPSASALIIKALKEPPRDRKKQKNIKHSGNITFDEIVNIARQMRHRSLARELSGTIKEILGTAQSVGCNVDGRHPHDIIDDINSGAVECPAS>sp|P30050-2|RL12_HUMAN Isoform 2 of 60S ribosomal protein L12 OS=Homosapiens OX=9606 GN=RPL12MPPKFDPNEIKVVYLRCTGGEVGATSALAPKIGPLGLIEVVPSASALIIKALKEPPRDRKKQKNIKHSGNITFDEIVNIARQMRHRSLARELSGTIKEILGTAQSVGCNVDGRHPHDIIDDINSGAVECPAS>sp|Q9Y4F9|RIPR2_HUMAN Rho family-interacting cell polarization regulator2 OS=Homo sapiens OX=9606 GN=RIPOR2 PE=1 SV=4MLVGSQSFSPGGPNGIIRSQSFAGFSGLQERRSRCNSFIENSSALKKPQAKLKKMHNLGHKNNNPPKEPQPKRVEEVYRALKNGLDEYLEVHQTELDKLTAQLKDMKRNSRLGVLYDLDKQIKTIERYMRRLEFHISKVDELYEAYCIQRRLQDGASKMKQAFATSPASKAARESLTEINRSFKEYTENMCTIEVELENLLGEFSIKMKGLAGFARLCPGDQYEIFMKYGRQRWKLKGKIEVNGKQSWDGEETVFLPLIVGFISIKVTELKGLATHILVGSVTCETKELFAARPQVVAVDINDLGTIKLNLEITWYPFDVEDMTASSGAGNKAAALQRRMSMYSQGTPETPTFKDHSFFRWLHPSPDKPRRLSVLSALQDTFFAKLHRSRSFSDLPSLRPSPKAVLELYSNLPDDIFENGKAAEEKMPLSLSFSDLPNGDCALTSHSTGSPSNSTNPEITITPAEFNLSSLASQNEGMDDTSSASSRNSLGEGQEPKSHLKEEDPEEPRKPASAPSEACRRQSSGAGAEHLFLENDVAEALLQESEEASELKPVELDTSEGNITKQLVKRLTSAEVPMATDRLLSEGSVGGESEGCRSFLDGSLEDAFNGLLLALEPHKEQYKEFQDLNQEVMNLDDILKCKPAVSRSRSSSLSLTVESALESFDFLNTSDFDEEEDGDEVCNVGGGADSVFSDTETEKHSYRSVHPEARGHLSEALTEDTGVGTSVAGSPLPLTTGNESLDITIVRHLQYCTQLVQQIVFSSKTPFVARSLLEKLSRQIQVMEKLAAVSDENIGNISSVVEAIPEFHKKLSLLSFWTKCCSPVGVYHSPADRVMKQLEASFARTVNKEYPGLADPVFRTLVSQILDRAEPLLSSSLSSEVVTVFQYYSYFTSHGVSDLESYLSQLARQVSMVQTLQSLRDEKLLQTMSDLAPSNLLAQQEVLRTLALLLTREDNEVSEAVTLYLAAASKNQHFREKALLYYCEALTKTNLQLQKAACLALKILEATESIKMLVTLCQSDTEEIRNVASETLLSLGEDGRLAYEQLDKFPRDCVKVGGRHGTEVATAF>sp|Q9Y4F9-2|RIPR2_HUMAN Isoform 2 of Rho family-interacting cellpolarization regulator 2 OS=Homo sapiens OX=9606 GN=RIPOR2MLVGSQSFSPGGPNGIIRSQSFAGFSGLQERRSRCNSFIENSSALKKPQAKLKKMHNLGHKNNNPPKEPQPKRVEEVYRALKNGLDEYLEVHQTELDKLTAQLKDMKRNSRLGVLYDLDKQIKTIERYMRRLEFHISKVDELYEAYCIQRRLQDGASKMKQAFATSPASKAARESLTEINRSFKEYTENMCTIEVELENLLGEFSIKMKGLAGFARLCPGDQYEIFMKYGRQRWKLKGKIEVNGKQSWDGEETVFLPLIVGFISIKVTELKGLATHILVGSVTCETKELFAARPQVVAVDINDLGTIKLNLEITWYPFDVEDMTASSGAGNKAAALQRRMSMYSQGTPETPTFKDHSFFSNLPDDIFENGKAAEEKMPLSLSFSDLPNGDCALTSHSTGSPSNSTNPEITITPAEFNLSSLASQNEGMDDTSSASSRNSLGEGQEPKSHLKEEDPEEPRKPASAPSEACRRQSSGAGAEHLFLENDVAEALLQESEEASELKPVELDTSEGNITKQLVKRLTSAEVPMATDRLLSEGSVGGESEGCRSFLDGSLEDAFNGLLLALEPHKEQYKEFQDLNQEVMNLDDILKK>sp|Q96AA3|RFT1_HUMAN Protein RFT1 homolog OS=Homo sapiens OX=9606GN=RFT1 PE=1 SV=1MGSQEVLGHAARLASSGLLLQVLFRLITFVLNAFILRFLSKEIVGVVNVRLTLLYSTTLFLAREAFRRACLSGGTQRDWSQTLNLLWLTVPLGVFWSLFLGWIWLQLLEVPDPNVVPHYATGVVLFGLSAVVELLGEPFWVLAQAHMFVKLKVIAESLSVILKSVLTAFLVLWLPHWGLYIFSLAQLFYTTVLVLCYVIYFTKLLGSPESTKLQTLPVSRITDLLPNITRNGAFINWKEAKLTWSFFKQSFLKQILTEGERYVMTFLNVLNFGDQGVYDIVNNLGSLVARLIFQPIEESFYIFFAKVLERGKDATLQKQEDVAVAAAVLESLLKLALLAGLTITVFGFAYSQLALDIYGGTMLSSGSGPVLLRSYCLYVLLLAINGVTECFTFAAMSKEEVDRYNFVMLALSSSFLVLSYLLTRWCGSVGFILANCFNMGIRITQSLCFIHRYYRRSPHRPLAGLHLSPVLLGTFALSGGVTAVSEVFLCCEQGWPARLAHIAVGAFCLGATLGTAFLTETKLIHFLRTQLGVPRRTDKMT>sp|P62906|RL10A_HUMAN 60S ribosomal protein L10a OS=Homo sapiens OX=9606GN=RPL10A PE=1 SV=2MSSKVSRDTLYEAVREVLHGNQRKRRKFLETVELQISLKNYDPQKDKRFSGTVRLKSTPRPKFSVCVLGDQQHCDEAKAVDIPHMDIEALKKLNKNKKLVKKLAKKYDAFLASESLIKQIPRILGPGLNKAGKFPSLLTHNENMVAKVDEVKSTIKFQMKKVLCLAVAVGHVKMTDDELVYNIHLAVNFLVSLLKKNWQNVRALYIKSTMGKPQRLY>sp|P31350|RIR2_HUMAN Ribonucleoside-diphosphate reductase subunit M2OS=Homo sapiens OX=9606 GN=RRM2 PE=1 SV=1MLSLRVPLAPITDPQQLQLSPLKGLSLVDKENTPPALSGTRVLASKTARRIFQEPTEPKTKAAAPGVEDEPLLRENPRRFVIFPIEYHDIWQMYKKAEASFWTAEEVDLSKDIQHWESLKPEERYFISHVLAFFAASDGIVNENLVERFSQEVQITEARCFYGFQIAMENIHSEMYSLLIDTYIKDPKEREFLFNAIETMPCVKKKADWALRWIGDKEATYGERVVAFAAVEGIFFSGSFASIFWLKKRGLMPGLTFSNELISRDEGLHCDFACLMFKHLVHKPSEERVREIIINAVRIEQEFLTEALPVKLIGMNCTLMKQYIEFVADRLMLELGFSKVFRVENPFDFMENISLEGKTNFFEKRVGEYQRMGVMSSPTENSFTLDADF>sp|P31350-2|RIR2_HUMAN Isoform 2 of Ribonucleoside-diphosphate reductasesubunit M2 OS=Homo sapiens OX=9606 GN=RRM2MGRVGGMAQPMGRAGAPKPMGRAGSARRGRFKGCWSEGSPVHPVPAVLSWLLALLRCASTMLSLRVPLAPITDPQQLQLSPLKGLSLVDKENTPPALSGTRVLASKTARRIFQEPTEPKTKAAAPGVEDEPLLRENPRRFVIFPIEYHDIWQMYKKAEASFWTAEEVDLSKDIQHWESLKPEERYFISHVLAFFAASDGIVNENLVERFSQEVQITEARCFYGFQIAMENIHSEMYSLLIDTYIKDPKEREFLFNAIETMPCVKKKADWALRWIGDKEATYGERVVAFAAVEGIFFSGSFASIFWLKKRGLMPGLTFSNELISRDEGLHCDFACLMFKHLVHKPSEERVREIIINAVRIEQEFLTEALPVKLIGMNCTLMKQYIEFVADRLMLELGFSKVFRVENPFDFMENISLEGKTNFFEKRVGEYQRMGVMSSPTENSFTLDADF>sp|P27635|RL10_HUMAN 60S ribosomal protein L10 OS=Homo sapiens OX=9606GN=RPL10 PE=1 SV=4MGRRPARCYRYCKNKPYPKSRFCRGVPDAKIRIFDLGRKKAKVDEFPLCGHMVSDEYEQLSSEALEAARICANKYMVKSCGKDGFHIRVRLHPFHVIRINKMLSCAGADRLQTGMRGAFGKPQGTVARVHIGQVIMSIRTKLQNKEHVIEALRRAKFKFPGRQKIHISKKWGFTKFNADEFEDMVAEKRLIPDGCGVKYIPNRGPLDKWRALHS>sp|Q5K651|SAMD9_HUMAN Sterile alpha motif domain-containing protein 9OS=Homo sapiens OX=9606 GN=SAMD9 PE=1 SV=1MAKQLNLPENTDDWTKEDVNQWLESHKIDQKHREILTEQDVNGAVLKWLKKEHLVDMGITHGPAIQIEELFKELRKTAIEDSIQTSKMGKPSKNAPKDQTVSQKERRETSKQKQKGKENPDMANPSAMSTTAKGSKSLKVELIEDKIDYTKERQPSIDLTCVSYPFDEFSNPYRYKLDFSLQPETGPGNLIDPIHEFKAFTNTATATEEDVKMKFSNEVFRFASACMNSRTNGTIHFGVKDKPHGKIVGIKVTNDTKEALINHFNLMINKYFEDHQVQQAKKCIREPRFVEVLLPNSTLSDRFVIEVDIIPQFSECQYDYFQIKMQNYNNKIWEQSKKFSLFVRDGTSSKDITKNKVDFRAFKADFKTLAESRKAAEEKFRAKTNKKEREGPKLVKLLTGNQDLLDNSYYEQYILVTNKCHPDQTKHLDFLKEIKWFAVLEFDPESNINGVVKAYKESRVANLHFPSVYVEQKTTPNETISTLNLYHQPSWIFCNGRLDLDSEKYKPFDPSSWQRERASDVRKLISFLTHEDIMPRGKFLVVFLLLSSVDDPRDPLIETFCAFYQDLKGMENILCICVHPHIFQGWKDLLEARLIKHQDEISSQCISALSLEEINGTILKLKSVTQSSKRLLPSIGLSTVLLKKEEDIMTALEIICENECEGTLLEKDKNKFLEFKASKEEDFYRGGKVSWWNFYFSSESYSSPFVKRDKYERLEAMIQNCADSSKPTSTKIIHLYHHPGCGGTTLAMHILWELRKKFRCAVLKNKTVDFSEIGEQVTSLITYGAMNRQEYVPVLLLVDDFEEQDNVYLLQYSIQTAIAKKYIRYEKPLVIILNCMRSQNPEKSARIPDSIAVIQQLSPKEQRAFELKLKEIKEQHKNFEDFYSFMIMKTNFNKEYIENVVRNILKGQNIFTKEAKLFSFLALLNSYVPDTTISLSQCEKFLGIGNKKAFWGTEKFEDKMGTYSTILIKTEVIECGNYCGVRIIHSLIAEFSLEELKKSYHLNKSQIMLDMLTENLFFDTGMGKSKFLQDMHTLLLTRHRDEHEGETGNWFSPFIEALHKDEGNEAVEAVLLESIHRFNPNAFICQALARHFYIKKKDFGNALNWAKQAKIIEPDNSYISDTLGQVYKSKIRWWIEENGGNGNISVDDLIALLDLAEHASSAFKESQQQSEDREYEVKERLYPKSKRRYDTYNIAGYQGEIEVGLYTIQILQLIPFFDNKNELSKRYMVNFVSGSSDIPGDPNNEYKLALKNYIPYLTKLKFSLKKSFDFFDEYFVLLKPRNNIKQNEEAKTRRKVAGYFKKYVDIFCLLEESQNNTGLGSKFSEPLQVERCRRNLVALKADKFSGLLEYLIKSQEDAISTMKCIVNEYTFLLEQCTVKIQSKEKLNFILANIILSCIQPTSRLVKPVEKLKDQLREVLQPIGLTYQFSEPYFLASLLFWPENQQLDQHSEQMKEYAQALKNSFKGQYKHMHRTKQPIAYFFLGKGKRLERLVHKGKIDQCFKKTPDINSLWQSGDVWKEEKVQELLLRLQGRAENNCLYIEYGINEKITIPITPAFLGQLRSGRSIEKVSFYLGFSIGGPLAYDIEIV>sp|Q5M8T2|S35D3_HUMAN Solute carrier family 35 member D3 OS=Homo sapiensOX=9606 GN=SLC35D3 PE=2 SV=1MRQLCRGRVLGISVAIAHGVFSGSLNILLKFLISRYQFSFLTLVQCLTSSTAALSLELLRRLGLIAVPPFGLSLARSFAGVAVLSTLQSSLTLWSLRGLSLPMYVVFKRCLPLVTMLIGVLVLKNGAPSPGVLAAVLITTCGAALAGAGDLTGDPIGYVTGVLAVLVHAAYLVLIQKASADTEHGPLTAQYVIAVSATPLLVICSFASTDSIHAWTFPGWKDPAMVCIFVACILIGCAMNFTTLHCTYINSAVTTSFVGVVKSIATITVGMVAFSDVEPTSLFIAGVVVNTLGSIIYCVAKFMETRKQSNYEDLEAQPRGEEAQLSGDQLPFVMEELPGEGGNGRSEGGEAAGGPAQESRQEVRGSPRGVPLVAGSSEEGSRRSLKDAYLEVWRLVRGTRYMKKDYLIENEELPSP>sp|Q9HB31|SEBOX_HUMAN Homeobox protein SEBOX OS=Homo sapiens OX=9606GN=SEBOX PE=3 SV=3MPSPVDASSADGGSGLGSHRRKRTTFSKGQLLELERAFAAWPYPNISTHEHLAWVTCLPEAKVQVWFQKRWAKIIKNRKSGILSPGSECPQSSCSLPDTLQQPWDPQMPGQPPPSSGTPQRTSVCRHSSCPAPGLSPRQGWEGAKAVAPWGSAGASEVHPSLERATPQTSLGSLSDLIYALAIVVNVDHS>sp|P0CK97|S35E2_HUMAN Solute carrier family 35 member E2A OS=Homosapiens OX=9606 GN=SLC35E2A PE=1 SV=1MSSSVKTPALEELVPGSEEKPKGRSPLSWGSLFGHRSEKIVFAKSDGGTDENVLTVTITETTVIESDLGVWSSRALLYLTLWFFFSFCTLFLNKYILSLLGGEPSMLGAVQMLSTTVIGCVKTLVPCCLYQHKARLSYPPNFLMTMLFVGLMRFATVVLGLVSLKNVAVSFAETVKSSAPIFTVIMSRMILGEYTGRPSDREEREELQLQPGRGAAASDRRSPVPPSERHGVRPHGENLPGDFQVPQALHRVALSMALPCPMLPAS>sp|P0CK97-2|S35E2_HUMAN Isoform 2 of Solute carrier family 35 member E2AOS=Homo sapiens OX=9606 GN=SLC35E2AMSSSVKTPALEELVPGSEEKPKGRSPLSWGSLFGHRSEKIVFAKSDGGTDENVLTVTITETTVIESDLGVWSSRALLYLTLWFFFSFCTLFLNKYILSLLGGEPSMLGAVQMLSTTVIGCVKTLVPCCLYQHKARLSYPPNFLMTMLFVGLMRFATVVLGLVSLKNVAVSFAETVKSSAPIFTVIMSRMILGEYTGRPSDREEREELQLQPGRGAAASDRRSPVPPSERHGVRPHGENLPGDFQAQ>sp|Q0VDG4|SCRN3_HUMAN Secernin-3 OS=Homo sapiens OX=9606 GN=SCRN3 PE=1SV=1MEPFSCDTFVALPPATVDNRIIFGKNSDRLYDEVQEVVYFPAVVHDNLGERLKCTYIEIDQVPETYAVVLSRPAWLWGAEMGANEHGVCIGNEAVWGREEVCDEEALLGMDLVRLGLERADTAEKALNVIVDLLEKYGQGGNCTEGRMVFSYHNSFLIADRNEAWILETAGKYWAAEKVQEGVRNISNQLSITTKIAREHPDMRNYAKRKGWWDGKKEFDFAAAYSYLDTAKMMTSSGRYCEGYKLLNKHKGNITFETMMEILRDKPSGINMEGEFLTTASMVSILPQDSSLPCIHFFTGTPDPERSVFKPFIFVPHISQLLDTSSPTFELEDLVKKKSHFKPDRRHPLYQKHQQALEVVNNNEEKAKIMLDNMRKLEKELFREMESILQNKHLDVEKIVNLFPQCTKDEIQIYQSNLSVKVSS>sp|Q0VDG4-2|SCRN3_HUMAN Isoform 2 of Secernin-3 OS=Homo sapiens OX=9606GN=SCRN3MPPLATPPSVHLSLRVAGRPDRLYDEVQEVVYFPAVVHDNLGERLKCTYIEIDQVPETYAVVLSRPAWLWGAEMGANEHGVCIGNEAVWGREEVCDEEALLGMDLVRLGLERADTAEKALNVIVDLLEKYGQGGNCTEGRMVFSYHNSFLIADRNEAWILETAGKYWAAEKVQEGVRNISNQLSITTKIAREHPDMRNYAKRKGWWDGKKEFDFAAAYSYLDTAKMMTSSGRYCEGYKLLNKHKGNITFETMMEILRDKPSGINMEGEFLTTASMVSILPQDSSLPCIHFFTGTPDPERSVFKPFIFVPHISQLLDTSSPTFELEDLVKKKSHFKPDRRHPLYQKHQQALEVVNNNEEKAKIMLDNMRKLEKELFREMESILQNKHLDVEKIVNLFPQCTKDEIQIYQSNLSVKVSS>sp|Q14108|SCRB2_HUMAN Lysosome membrane protein 2 OS=Homo sapiensOX=9606 GN=SCARB2 PE=1 SV=2MGRCCFYTAGTLSLLLLVTSVTLLVARVFQKAVDQSIEKKIVLRNGTEAFDSWEKPPLPVYTQFYFFNVTNPEEILRGETPRVEEVGPYTYRELRNKANIQFGDNGTTISAVSNKAYVFERDQSVGDPKIDLIRTLNIPVLTVIEWSQVHFLREIIEAMLKAYQQKLFVTHTVDELLWGYKDEILSLIHVFRPDISPYFGLFYEKNGTNDGDYVFLTGEDSYLNFTKIVEWNGKTSLDWWITDKCNMINGTDGDSFHPLITKDEVLYVFPSDFCRSVYITFSDYESVQGLPAFRYKVPAEILANTSDNAGFCIPEGNCLGSGVLNVSICKNGAPIIMSFPHFYQADERFVSAIEGMHPNQEDHETFVDINPLTGIILKAAKRFQINIYVKKLDDFVETGDIRTMVFPVMYLNESVHIDKETASRLKSMINTTLIITNIPYIIMALGVFFGLVFTWLACKGQGSMDEGTADERAPLIRT>sp|Q14108-2|SCRB2_HUMAN Isoform 2 of Lysosome membrane protein 2 OS=Homosapiens OX=9606 GN=SCARB2MGRCCFYTAGTLSLLLLVTSVTLLVARVFQKAVDQSIEKKIVLRNGTEAFDSWEKPPLPVYTQFYFFNVTNPEEILRGETPRVEEVGPYTYRSLDWWITDKCNMINGTDGDSFHPLITKDEVLYVFPSDFCRSVYITFSDYESVQGLPAFRYKVPAEILANTSDNAGFCIPEGNCLGSGVLNVSICKNGAPIIMSFPHFYQADERFVSAIEGMHPNQEDHETFVDINPLTGIILKAAKRFQINIYVKKLDDFVETGDIRTMVFPVMYLNESVHIDKETASRLKSMINTTLIITNIPYIIMALGVFFGLVFTWLACKGQGSMDEGTADERAPLIRT>sp|Q96FV2|SCRN2_HUMAN Secernin-2 OS=Homo sapiens OX=9606 GN=SCRN2 PE=1SV=3MASSSPDSPCSCDCFVSVPPASAIPAVIFAKNSDRPRDEVQEVVFVPAGTHTPGSRLQCTYIEVEQVSKTHAVILSRPSWLWGAEMGANEHGVCIGNEAVWTKEPVGEGEALLGMDLLRLALERSSSAQEALHVITGLLEHYGQGGNCLEDAAPFSYHSTFLLADRTEAWVLETAGRLWAAQRIQEGARNISNQLSIGTDISAQHPELRTHAQAKGWWDGQGAFDFAQIFSLTQQPVRMEAAKARFQAGRELLRQRQGGITAEVMMGILRDKESGICMDSGGFRTTASMVSVLPQDPTQPCVHFLTATPDPSRSVFKPFIFGMGVAQAPQVLSPTFGAQDPVRTLPRFQTQVDRRHTLYRGHQAALGLMERDQDRGQQLQQKQQDLEQEGLEATQGLLAGEWAPPLWELGSLFQAFVKRESQAYA>sp|Q96FV2-2|SCRN2_HUMAN Isoform 2 of Secernin-2 OS=Homo sapiens OX=9606GN=SCRN2MASSSPDSPCSCDCFVSVPPASAIPAVIFAKNSDRPRDEVQEVVFVPAGTHTPGSRLQCTYIEVEQVSKTHAVILSRPSWLWGAEMGANEHGVCIGNEAVWTKEPVGEGEALLGMDLLRLALERSSSAQEALHVITGLLEHYGQGGNCLEDAAPFSYHSTFLLADRTEAWVLETAGRLWAAQRIQEGARNISNQLSIGTDISAQHPELRTHAQAKGWWDGQGAFDFAQIFSLTQQPVRMEAAKARFQAGRELLRQRQGGITAEVMMGILRDKESGICMDSGGFRTTASMVSVLPQDPTQPCVHFLTATPDPSRSVFKPFIFGMGVAQAPQVLSPTFGAQDPVRTLPRFQTQVDRRHTLYRGHQAALGLMERDQVSPRE>sp|Q96KT7|S35G5_HUMAN Solute carrier family 35 member G5 OS=Homo sapiensOX=9606 GN=SLC35G5 PE=1 SV=1MAGSHPYFNLPDSTHPSPPSAPPSLRWHQRCQPSGATNGLLVALLGGGLPAGFVGPLSRMAYQGSNLPSLELLICRCLFHLPIALLLKLRGDPLLGPPDIRGWACFCALLNVLSIGCAYSAVQVVPAGNAATVRKGSSTVCSAVLTLCLESQGLGGYEWCGLLGSILGLIIILGPGLWTLQEGTTGVYTTLGYVQAFLGGLALSLGLLVYRSLHFPSCLPTVAFLSGLVGLLGCVPGLFVLQTPVLPSDLLSWSCVGAEGILALVSFTCVGYAVTKAHPALVCAVLHSEVVVALILQYYMLHETVALSDIMGAGVVLGSIAIITARNLSCERTGKVEE>sp|Q9NVC3|S38A7_HUMAN Putative sodium-coupled neutral amino acidtransporter 7 OS=Homo sapiens OX=9606 GN=SLC38A7 PE=1 SV=1MAQVSINNDYSEWDLSTDAGERARLLQSPCVDTAPKSEWEASPGGLDRGTTSTLGAIFIVVNACLGAGLLNFPAAFSTAGGVAAGIALQMGMLVFIISGLVILAYCSQASNERTYQEVVWAVCGKLTGVLCEVAIAVYTFGTCIAFLIIIGDQQDKIIAVMAKEPEGASGPWYTDRKFTISLTAFLFILPLSIPREIGFQKYASFLSVVGTWYVTAIVIIKYIWPDKEMTPGNILTRPASWMAVFNAMPTICFGFQCHVSSVPVFNSMQQPEVKTWGGVVTAAMVIALAVYMGTGICGFLTFGAAVDPDVLLSYPSEDMAVAVARAFIILSVLTSYPILHFCGRAVVEGLWLRYQGVPVEEDVGRERRRRVLQTLVWFLLTLLLALFIPDIGKVISVIGGLAACFIFVFPGLCLIQAKLSEMEEVKPASWWVLVSYGVLLVTLGAFIFGQTTANAIFVDLLA>sp|Q9NVC3-2|S38A7_HUMAN Isoform 2 of Putative sodium-coupled neutralamino acid transporter 7 OS=Homo sapiens OX=9606 GN=SLC38A7MAQVSINNDYSEWDLSTDAGERARLLQSPCVDTAPKSEWEASPGGLDRGTTSTLGAIFIVVNACLGAGLLNFPAAFSTAGGVAAGIALQMGMLVFIISGLVILAYCSQASNERTYQEVVWAVCGKLTGVLCEVAIAVYTFGTCIAFLIIIGDQQDKIIAVMAKEPEGASGPWYTDRKFTISLTAFLFILPLSIPREIGFQKYASFLSVVGTWYVTAIVIIKYIWPDKEMTPGNILTRPASWMAVFNAMPTICFGFQCHVSSVPVFNSMQQPEVKTWGGVVTAAMVIALAVYMGTGICGFLTFGAAVDPDVLLSYPSEDMAVAVARAFIILSVLTSYPILHFCGR>sp|Q9BRY0|S39A3_HUMAN Zinc transporter ZIP3 OS=Homo sapiens OX=9606GN=SLC39A3 PE=1 SV=2MVKLLVAKILCMVGVFFFMLLGSLLPVKIIETDFEKAHRSKKILSLCNTFGGGVFLATCFNALLPAVREKLQKVLSLGHISTDYPLAETILLLGFFMTVFLEQLILTFRKEKPSFIDLETFNAGSDVGSDSEYESPFMGGARGHALYVEPHGHGPSLSVQGLSRASPVRLLSLAFALSAHSVFEGLALGLQEEGEKVVSLFVGVAVHETLVAVALGISMARSAMPLRDAAKLAVTVSAMIPLGIGLGLGIESAQGVPGSVASVLLQGLAGGTFLFITFLEILAKELEEKSDRLLKVLFLVLGYTVLAGMVFLKW>sp|Q9BRY0-2|S39A3_HUMAN Isoform 2 of Zinc transporter ZIP3 OS=Homosapiens OX=9606 GN=SLC39A3MVKLLVAKILCMVGVFFFMLLGSLLPVKIIETDFEKAHRSKKILSLCNTFGGGVFLATCFNALLPAVREKVRAPWALAAALGTLWPRDSDAFSTLMPSSVKALML>sp|Q6P5W5|S39A4_HUMAN Zinc transporter ZIP4 OS=Homo sapiens OX=9606GN=SLC39A4 PE=1 SV=4MASLVSLELGLLLAVLVVTATASPPAGLLSLLTSGQGALDQEALGGLLNTLADRVHCANGPCGKCLSVEDALGLGEPEGSGLPPGPVLEARYVARLSAAAVLYLSNPEGTCEDARAGLWASHADHLLALLESPKALTPGLSWLLQRMQARAAGQTPKMACVDIPQLLEEAVGAGAPGSAGGVLAALLDHVRSGSCFHALPSPQYFVDFVFQQHSSEVPMTLAELSALMQRLGVGREAHSDHSHRHRGASSRDPVPLISSSNSSSVWDTVCLSARDVMAAYGLSEQAGVTPEAWAQLSPALLQQQLSGACTSQSRPPVQDQLSQSERYLYGSLATLLICLCAVFGLLLLTCTGCRGVTHYILQTFLSLAVGAVTGDAVLHLTPKVLGLHTHSEEGLSPQPTWRLLAMLAGLYAFFLFENLFNLLLPRDPEDLEDGPCGHSSHSHGGHSHGVSLQLAPSELRQPKPPHEGSRADLVAEESPELLNPEPRRLSPELRLLPYMITLGDAVHNFADGLAVGAAFASSWKTGLATSLAVFCHELPHELGDFAALLHAGLSVRQALLLNLASALTAFAGLYVALAVGVSEESEAWILAVATGLFLYVALCDMLPAMLKVRDPRPWLLFLLHNVGLLGGWTVLLLLSLYEDDITF>sp|Q6P5W5-2|S39A4_HUMAN Isoform 2 of Zinc transporter ZIP4 OS=Homosapiens OX=9606 GN=SLC39A4MVDVVGLERETGPRGSPWPGLPLPSLVGPAPLLTCLCPQCLSVEDALGLGEPEGSGLPPGPVLEARYVARLSAAAVLYLSNPEGTCEDARAGLWASHADHLLALLESPKALTPGLSWLLQRMQARAAGQTPKMACVDIPQLLEEAVGAGAPGSAGGVLAALLDHVRSGSCFHALPSPQYFVDFVFQQHSSEVPMTLAELSALMQRLGVGREAHSDHSHRHRGASSRDPVPLISSSNSSSVWDTVCLSARDVMAAYGLSEQAGVTPEAWAQLSPALLQQQLSGACTSQSRPPVQDQLSQSERYLYGSLATLLICLCAVFGLLLLTCTGCRGVTHYILQTFLSLAVGAVTGDAVLHLTPKVLGLHTHSEEGLSPQPTWRLLAMLAGLYAFFLFENLFNLLLPRDPEDLEDGPCGHSSHSHGGHSHGVSLQLAPSELRQPKPPHEGSRADLVAEESPELLNPEPRRLSPELRLLPYMITLGDAVHNFADGLAVGAAFASSWKTGLATSLAVFCHELPHELGDFAALLHAGLSVRQALLLNLASALTAFAGLYVALAVGVSEESEAWILAVATGLFLYVALCDMLPAMLKVRDPRPWLLFLLHNVGLLGGWTVLLLLSLYEDDITF>sp|Q8TE54|S26A7_HUMAN Anion exchange transporter OS=Homo sapiens OX=9606GN=SLC26A7 PE=2 SV=2MTGAKRKKKSMLWSKMHTPQCEDIIQWCRRRLPILDWAPHYNLKENLLPDTVSGIMLAVQQVTQGLAFAVLSSVHPVFGLYGSLFPAIIYAIFGMGHHVATGTFALTSLISANAVERIVPQNMQNLTTQSNTSVLGLSDFEMQRIHVAAAVSFLGGVIQVAMFVLQLGSATFVVTEPVISAMTTGAATHVVTSQVKYLLGMKMPYISGPLGFFYIYAYVFENIKSVRLEALLLSLLSIVVLVLVKELNEQFKRKIKVVLPVDLVLIIAASFACYCTNMENTYGLEVVGHIPQGIPSPRAPPMNILSAVITEAFGVALVGYVASLALAQGSAKKFKYSIDDNQEFLAHGLSNIVSSFFFCIPSAAAMGRTAGLYSTGAKTQVACLISCIFVLIVIYAIGPLLYWLPMCVLASIIVVGLKGMLIQFRDLKKYWNVDKIDWGIWVSTYVFTICFAANVGLLFGVVCTIAIVIGRFPRAMTVSIKNMKEMEFKVKTEMDSETLQQVKIISINNPLVFLNAKKFYTDLMNMIQKENACNQPLDDISKCEQNTLLNSLSNGNCNEEASQSCPNEKCYLILDCSGFTFFDYSGVSMLVEVYMDCKGRSVDVLLAHCTASLIKAMTYYGNLDSEKPIFFESVSAAISHIHSNKNLSKLSDHSEV>sp|Q8TE54-2|S26A7_HUMAN Isoform 2 of Anion exchange transporter OS=Homosapiens OX=9606 GN=SLC26A7MTGAKRKKKSMLWSKMHTPQCEDIIQWCRRRLPILDWAPHYNLKENLLPDTVSGIMLAVQQVTQGLAFAVLSSVHPVFGLYGSLFPAIIYAIFGMGHHVATGTFALTSLISANAVERIVPQNMQNLTTQSNTSVLGLSDFEMQRIHVAAAVSFLGGVIQVAMFVLQLGSATFVVTEPVISAMTTGAATHVVTSQVKYLLGMKMPYISGPLGFFYIYAYVFENIKSVRLEALLLSLLSIVVLVLVKELNEQFKRKIKVVLPVDLVLIIAASFACYCTNMENTYGLEVVGHIPQGIPSPRAPPMNILSAVITEAFGVALVGYVASLALAQGSAKKFKYSIDDNQEFLAHGLSNIVSSFFFCIPSAAAMGRTAGLYSTGAKTQVACLISCIFVLIVIYAIGPLLYWLPMCVLASIIVVGLKGMLIQFRDLKKYWNVDKIDWGIWVSTYVFTICFAANVGLLFGVVCTIAIVIGRFPRAMTVSIKNMKEMEFKVKTEMDSETLQQVKIISINNPLVFLNAKKFYTDLMNMIQKENACNQPLDDISKCEQNTLLNSLSNGNCNEEASQSCPNEKCYLILDCSGFTFFDYSGVSMLVEVYMDCKGRSVDVLLAHCTASLIKAMTYYGNLDSEKPIFFESVSAAISHIHSNKASYKLLFDNLDLPTMPPL>sp|Q8ND04|SMG8_HUMAN Protein SMG8 OS=Homo sapiens OX=9606 GN=SMG8 PE=1SV=1MAGPVSLRDLLMGASAWMGSESPGGSPTEGGGSAAGGPEPPWREDEICVVGIFGKTALRLNSEKFSLVNTVCDRQVFPLFRHQDPGDPGPGIRTEAGAVGEAGGAEDPGAAAGGSVRGSGAVAEGNRTEAGSQDYSLLQAYYSQESKVLYLLLTSICDNSQLLRACRALQSGEAGGGLSLPHAEAHEFWKHQEKLQCLSLLYLFSVCHILLLVHPTCSFDITYDRVFRALDGLRQKVLPLLKTAIKDCPVGKDWKLNCRPCPPRLLFLFQLNGALKVEPPRNQDPAHPDKPKKHSPKRRLQHALEDQIYRIFRKSRVLTNQSINCLFTVPANQAFVYIVPGSQEEDPVGMLLDQLRSHCTVKDPESLLVPAPLSGPRRYQVMRQHSRQQLSFHIDSSSSSSSGQLVDFTLREFLWQHVELVLSKKGFDDSVGRNPQPSHFELPTYQKWISAASKLYEVAIDGKEEDLGSPTGELTSKILSSIKVLEGFLDIDTKFSENRCQKALPMAHSAYQSNLPHNYTMTVHKNQLAQALRVYSQHARGPAFHKYAMQLHEDCYKFWSNGHQLCEERSLTDQHCVHKFHSLPKSGEKPEADRNPPVLYHNSRARSTGACNCGRKQAPRDDPFDIKAANYDFYQLLEEKCCGKLDHINFPVFEPSTPDPAPAKNESSPAPPDSDADKLKEKEPQTQGESTSLSLALSLGQSTDSLGTYPADPQAGGDNPEVHGQVEVKTEKRPNFVDRQASTVEYLPGMLHSNCPKGLLPKFSSWSLVKLGPAKSYNFHTGLDQQGFIPGTNYLMPWDIVIRTRAEDEGDLDTNSWPAPNKAIPGKRSAVVMGRGRRRDDIARAFVGFEYEDSRGRRFMCSGPDKVMKVMGSGPKESALKALNSDMPLYILSSSQGRGLKPHYAQLMRLFVVVPDAPLQIILMPQVQPGPPPCPVFYPEKQEITLPPDGLWVLRFPYAYVTERGPCFPPKENVQLMSYKVLRGVLKAVTQ>sp|Q8ND04-2|SMG8_HUMAN Isoform 2 of Protein SMG8 OS=Homo sapiens OX=9606GN=SMG8MAGPVSLRDLLMGASAWMGSESPGGSPTEGGGSAAGGPEPPWREDEICVVGIFGKTALRLNSEKFSLVNTVCDRQVFPLFRHQDPGDPGPGIRTEAGAVGEAGGAEDPGAAAGGSVRGSGAVAEGNRTEAGSQDYSLLQAYYSQESKVLYLLLTSICDNSQLLRACRALQSGEAGGGLSLPHAEAHEFWKHQEKLQCLSLLYLFSVCHILLLVHPTCSFDITYDRVFRALDGLRQKVLPLLKTAIKDCPVGKDWKLNCRPCPPRLLFLFQLNGALKVEPPRNQDPAHPDKPKKHSPKRRLQHALEDQIYRIFRKSRVLTNQSINCLFTVPANQAFVYIVPGSQEEDPVGMLLDQLRSHCTVKDPESLLVPAPLSGPRRYQVMRQHSRQQLSFHIDSSSSSSSGQLVDFTLREFLWQHVELVLSKKGFDDSVGRNPQPSHFELPTYQKWISAASKLYEVAIDGKEEDLGSPTGELTSKILSSIKVLEGFLDIDTKFSENRCQKALPMAHSAYQSNLPHNYTMTVHKNQLAQALRVYSQHARGPAFHKYAMQLHEDCYKFWSNGHQLCEERSLTDQHCVHKFHSLPKSGEKPEADRNPPVLYHNSRARSTGACNCGRKQAPRDDPFDIKAANYDFYQLLEEKCCGKLDHINFPVFEPSTPDPAPAKNESSPAPPDSDADKLKEKEPQTQGESTSLSLALSLGQSTDSLGTYPADPQAGGDNPEVHGQVEVKTEKRPNFVDRQASTVEYLPGMLHSNCPKGLLPKFSSWSLVKLGPAKSYNFHTGLDQQGFIPGTNYLMPWDIVIRTRAEDEGDLDTNSWPAPNKAIPGKRSAVVMGRGRRRDDIARAFVGFEYEDSRGRRFMCSGPDKVMKVMGSGPKESALKALNSDMPLYILSSSQGRGLKPHYAQLMRLFVVVPDAPLQIILMPQVQPGPPPCPVFYPEKQEITLPPDGLWVLRFPYAYGLREDLVSPXGKKQEIPLPPDGLWVLRFPYAYVTERGPCFPPKENVQLMSYKVLRGVLKAVTQ>sp|Q8ND04-3|SMG8_HUMAN Isoform 3 of Protein SMG8 OS=Homo sapiens OX=9606GN=SMG8MAGPVSLRDLLMGASAWMGSESPGGSPTEGGGSAAGGPEPPWREDEICVVGIFGKTALRLNSEKFSLVNTVCDRQVFPLFRHQDPGDPGPGIRTEAGAVGEAGGAEDPGAAAGGSVRGSGAVAEGNRTEAGSQDYSLLQAYYSQESKVLYLLLTSICDNSQLLRACRALQSGEAGGGLSLPHAEAHEFWKHQEKLQCLSLLYLFSVCHILLLVHPTCSFDITYDRVFRALDGLRQKVLPLLKTAIKDCPVGKDWKLNCRPCPPRLLFLFQLNGALKVEPPRNQDPAHPDKPKKHSPKRRLQHALEDQIYRIFRKSRVLTNQSINCLFTVPANQAFVYIVPGSQEEDPVGMLLDQLRSHCTVKDPESLLVPAPLSGPRRYQVMRQHSRQQLSFHIDSSSSSSSGQLVDFTLREFLWQHVELVLSKKGFDDSVGRNPQPSHFELPTYQKWISAASKLYEVAIDGKEEDLGSPTGELTSKILSSIKVLEGFLDIDTKFSENRCQKALPMAHSAYQSNLPHNYTMTVHKNQLAQALRVYSQHARGPAFHKYAMQLHEDCYKFWSNGHQLCEERSLTDQHCVHKFHSLPKSGS>sp|Q9UIV8|SPB13_HUMAN Serpin B13 OS=Homo sapiens OX=9606 GN=SERPINB13PE=1 SV=2MDSLGAVSTRLGFDLFKELKKTNDGNIFFSPVGILTAIGMVLLGTRGATASQLEEVFHSEKETKSSRIKAEEKEVIENTEAVHQQFQKFLTEISKLTNDYELNITNRLFGEKTYLFLQKYLDYVEKYYHASLEPVDFVNAADESRKKINSWVESKTNEKIKDLFPDGSISSSTKLVLVNMVYFKGQWDREFKKENTKEEKFWMNKSTSKSVQMMTQSHSFSFTFLEDLQAKILGIPYKNNDLSMFVLLPNDIDGLEKIIDKISPEKLVEWTSPGHMEERKVNLHLPRFEVEDGYDLEAVLAAMGMGDAFSEHKADYSGMSSGSGLYAQKFLHSSFVAVTEEGTEAAAATGIGFTVTSAPGHENVHCNHPFLFFIRHNESNSILFFGRFSSP>sp|Q9UIV8-2|SPB13_HUMAN Isoform 2 of Serpin B13 OS=Homo sapiens OX=9606GN=SERPINB13MDSLGAVSTRLGFDLFKELKKTNDGNIFFSPVGILTAIGMVLLGTRGATASQLEEVFHSEKETKSSRIKAEEKEVIENTEAVHQQFQKFLTEISKLTNDYELNITNRLFGEKTYLFLQKYLDYVEKYYHASLEPVDFVNAADESRKKINSWVESKTNEKIKDLFPDGSISSSTKLVLVNMVYFKGQWDREFKKENTKEEKFWMNKIIDKISPEKLVEWTSPGHMEERKVNLHLPRFEVEDGYDLEAVLAAMGMGDAFSEHKADYSGMSSGSGLYAQKFLHSSFVAVTEEGTEAAAATGIGFTVTSAPGHENVHCNHPFLFFIRHNESNSILFFGRFSSP>sp|O00161|SNP23_HUMAN Synaptosomal-associated protein 23 OS=Homo sapiensOX=9606 GN=SNAP23 PE=1 SV=1MDNLSSEEIQQRAHQITDESLESTRRILGLAIESQDAGIKTITMLDEQKEQLNRIEEGLDQINKDMRETEKTLTELNKCCGLCVCPCNRTKNFESGKAYKTTWGDGGENSPCNVVSKQPGPVTNGQLQQPTTGAASGGYIKRITNDAREDEMEENLTQVGSILGNLKDMALNIGNEIDAQNPQIKRITDKADTNRDRIDIANARAKKLIDS>sp|O00161-2|SNP23_HUMAN Isoform SNAP-23b of Synaptosomal-associatedprotein 23 OS=Homo sapiens OX=9606 GN=SNAP23MDNLSSEEIQQRAHQITDESLESTRRILGLAIESQDAGIKTITMLDEQKEQLNRIEEGLDQINKDMRETEKTLTELNKCCGLCVCPCNSITNDAREDEMEENLTQVGSILGNLKDMALNIGNEIDAQNPQIKRITDKADTNRDRIDIANARAKKLIDS>sp|Q2NKQ1|SGSM1_HUMAN Small G protein signaling modulator 1 OS=Homosapiens OX=9606 GN=SGSM1 PE=1 SV=2MASAPAEAETRQRLLRTVKKEVKQIMEEAVTRKFVHEDSSHIISFCAAVEACVLHGLRRRAAGFLRSNKIAALFMKVGKNFPPAEDLSRKVQDLEQLIESARNQIQGLQENVRKLPKLPNLSPLAIKHLWIRTALFEKVLDKIVHYLVENSSKYYEKEALLMDPVDGPILASLLVGPCALEYTKMKTADHFWTDPSADELVQRHRIHSSHVRQDSPTKRPALCIQKRHSSGSMDDRPSLSARDYVESLHQNSRATLLYGKNNVLVQPRDDMEAVPGYLSLHQTADVMTLKWTPNQLMNGSVGDLDYEKSVYWDYAMTIRLEEIVYLHCHQQVDSGGTVVLVSQDGIQRPPFRFPKGGHLLQFLSCLENGLLPHGQLDPPLWSQRGKGKVFPKLRKRSPQGSAESTSSDKDDDEATDYVFRIIYPGMQSEFVAPDFLGSTSSVSVGPAWMMVPAGRSMLVVARGSQWEPARWDTTLPTPSPKEQPPMPQDLMDVSVSNLPSLWQPSPRKSSCSSCSQSGSADGSSTNGCNHERAPLKLLCDNMKYQILSRAFYGWLAYCRHLSTVRTHLSALVNHMIVSPDLPCDAGQGLTARIWEQYLHDSTSYEEQELLRLIYYGGIQPEIRKAVWPFLLGHYQFGMTETERKEVDEQIHACYAQTMAEWLGCEAIVRQRERESHAAALAKCSSGASLDSHLHRMLHRDSTISNESSQSCSSGRQNIRLHSDSSSSTQVFESVDEVEQVEAEGRLEEKQPKIPNGNLVNGTCSPDSGHPSSHNFSSGLSEHSEPSLSTEDSVLDAQRNTPTVLRPRDGSVDDRQSSEATTSQDEAPREELAVQDSLESDLLANESMDEFMSITGSLDMALPEKDDVVMEGWRSSETEKHGQADSEDNLSEEPEMESLFPALASLAVTTSANEVSPVSSSGVTYSPELLDLYTVNLHRIEKDVQRCDRNYWYFTPANLEKLRNIMCSYIWQHIEIGYVQGMCDLLAPLLVILDDEALAFSCFTELMKRMNQNFPHGGAMDTHFANMRSLIQILDSELFELMHQNGDYTHFYFCYRWFLLDFKRELVYDDVFLVWETIWAAKHVSSAHYVLFIALALVEVYRDIILENNMDFTDIIKFFNEMAERHNTKQVLKLARDLVYKVQTLIENK>sp|Q2NKQ1-3|SGSM1_HUMAN Isoform 2 of Small G protein signaling modulator1 OS=Homo sapiens OX=9606 GN=SGSM1MEEAVTRKFVHEDSSHIISFCAAVEACVLHGLRRRAAGFLRSNKIAALFMKVGKNFPPAEDLSRKVQDLEQLIESARNQIQGLQENVRKLPKLPNLSPLAIKHLWIRTALFEKVLDKIVHYLVENSSKYYEKEALLMDPVDGPILASLLVGPCALEYTKMKTADHFWTDPSADELVQRHRIHSSHVRQDSPTKRPALCIQKRHSSGSMDDRPSLSARDYVESLHQNSRATLLYGKNNVLVQPRDDMEAVPGYLSLHQTADVMTLKSALFEKVLDKIVHYLVENSSKYYEKEALLMDPVDGPILASLLVGPCALEYTKMKTADHFWTDPSADELVQRHRIHSSHVRQDSPTKRPALCIQKRHSSGSMDDRPSLSARDYVESLHQNSRATLLYGKNNVLVQPRDDMEAVPGYLSLHQTADVMTLKWTPNQLMNGSVGDLDYEKSVYWDYAMTIRLEEIVYLHCHQQVDSGGTVVLVSQDGIQRPPFRFPKGGHLLQFLSCLENGLLPHGQLDPPLWSQRGKGKVFPKLRKRSPQGSAESTSSDKDDDEATDYVFRIIYPGMQSEFVPQDLMDVSVSNLPSLWQPSPRKSSCSSCSQSGSADGSSTNGCNHERAPLKLLCDNMKYQILSRAFYGWLAYCRHLSTVRTHLSALVNHMIVSPDLPCDAGQGLTARIWEQYLHDSTSYEEQELLRLIYYGGIQPEIRKAVWPFLLGHYQFGMTETERKESSQSCSSGRQNIRLHSDSSSSTQVFESVDEVEQVEAEGRLEEKQPKIPNGNLVNGTCSPDSGHPSSHNFSSGLSEHSEPSLSTEDSVLDAQRNTPTVLRPRDGSVDDRQSSEATTSQDEAPREELAVQDSLESDLLANESMDEFMSITGSLDMALPEKDDVVMEGWRSSETEKHGQADSEDNLSEEPEMESLFPALASLAVTTSANEVSPVSSSGVTYSPELLDLYTVNLHRIEKDVQRCDRNYWYFTPANLEKLRNIMCSYIWQHIEIGYVQGMCDLLAPLLVILDDEALAFSCFTELMKRMNQNFPHGGAMDTHFANMRSLIQILDSELFELMHQNGDYTHFYFCYRWFLLDFKRELVYDDVFLVWETIWAAKHVSSAHYVLFIALALVEVYRDIILENNMDFTDIIKFFNEMAERHNTKQVLKLARDLVYKVQTLIENK>sp|Q2NKQ1-4|SGSM1_HUMAN Isoform 3 of Small G protein signaling modulator1 OS=Homo sapiens OX=9606 GN=SGSM1MASAPAEAETRQRLLRTVKKEVKQIMEEAVTRKFVHEDSSHIISFCAAVEACVLHGLRRRAAGFLRSNKIAALFMKVGKNFPPAEDLSRKVQDLEQLIESARNQIQGLQENVRKLPKLPNLSPLAIKHLWIRTALFEKVLDKIVHYLVENSSKYYEKEALLMDPVDGPILASLLVGPCALEYTKMKTADHFWTDPSADELVQRHRIHSSHVRQDSPTKRPALCIQKRHSSGSMDDRPSLSARDYVESLHQNSRATLLYGKNNVLVQPRDDMEAVPGYLSLHQTADVMTLKWTPNQLMNGSVGDLDYEKSVYWDYAMTIRLEEIVYLHCHQQVDSGGTVVLVSQDGIQRPPFRFPKGGHLLQFLSCLENGLLPHGQLDPPLWSQRGKGKVFPKLRKRSPQGSAESTSSDKDDDEATDYVFRIIYPGMQSEFVPQDLMDVSVSNLPSLWQPSPRKSSCSSCSQSGSADGSSTNGCNHERAPLKLLCDNMKYQILSRAFYGWLAYCRHLSTVRTHLSALVNHMIVSPDLPCDAGQGLTARIWEQYLHDSTSYEEQELLRLIYYGGIQPEIRKAVWPFLLGHYQFGMTETERKEVDEQIHACYAQTMAEWLGCEAIVRQRERESHAAALAKCSSGASLDSHLHRMLHRDSTISNESSQSCSSGRQNIRLHSDSSSSTQVFESVDEVEQVEAEGRLEEKQPKIPNGNLVNGTCSPDSGHPSSHNFSSGLSEHSEPSLSTEDSVLDAQRNTPTVLRPRDGSVDDRQSSEATTSQDEAPREELAVQDSLESDLLANESMDEFMSITGSLDMALPEKDDVVMEGWRSSETEKHGQADSEDNLSEEPEMESLFPALASLAVTTSANEVSPVSSSGVTYSPELLDLYTVNLHRIEKDVQRCDRNYWYFTPANLEKLRNIMCSYIWQHIEIGYVQGMCDLLAPLLVILDDEALAFSCFTELMKRMNQNFPHGGAMDTHFANMRSLIQILDSELFELMHQNGDYTHFYFCYRWFLLDFKRELVYDDVFLVWETIWAAKHVSSAHYVLFIALALVEVYRDIILENNMDFTDIIKFFNEMAERHNTKQVLKLARDLVYKVQTLIENK>sp|Q9Y2Z0|SGT1_HUMAN Protein SGT1 homolog OS=Homo sapiens OX=9606GN=SUGT1 PE=1 SV=3MAAAAAGTATSQRFFQSFSDALIDEDPQAALEELTKALEQKPDDAQYYCQRAYCHILLGNYCVAVADAKKSLELNPNNSTAMLRKGICEYHEKNYAAALETFTEGQKLDIETGFHRVGQAGLQLLTSSDPPALDSQSAGITGADANFSVWIKRCQEAQNGSESEVWTHQSKIKYDWYQTESQVVITLMIKNVQKNDVNVEFSEKELSALVKLPSGEDYNLKLELLHPIIPEQSTFKVLSTKIEIKLKKPEAVRWEKLEGQGDVPTPKQFVADVKNLYPSSSPYTRNWDKLVGEIKEEEKNEKLEGDAALNRLFQQIYSDGSDEVKRAMNKSFMESGGTVLSTNWSDVGKRKVEINPPDDMEWKKY>sp|Q9Y2Z0-2|SGT1_HUMAN Isoform 2 of Protein SGT1 homolog OS=Homo sapiensOX=9606 GN=SUGT1MAAAAAGTATSQRFFQSFSDALIDEDPQAALEELTKALEQKPDDAQYYCQRAYCHILLGNYCVAVADAKKSLELNPNNSTAMLRKGICEYHEKNYAAALETFTEGQKLDSADANFSVWIKRCQEAQNGSESEVWTHQSKIKYDWYQTESQVVITLMIKNVQKNDVNVEFSEKELSALVKLPSGEDYNLKLELLHPIIPEQSTFKVLSTKIEIKLKKPEAVRWEKLEGQGDVPTPKQFVADVKNLYPSSSPYTRNWDKLVGEIKEEEKNEKLEGDAALNRLFQQIYSDGSDEVKRAMNKSFMESGGTVLSTNWSDVGKRKVEINPPDDMEWKKY>sp|Q96E16|SMI19_HUMAN Small integral membrane protein 19 OS=Homo sapiensOX=9606 GN=SMIM19 PE=1 SV=2MAGGYGVMGDDGSIDYTVHEAWNEATNVYLIVILVSFGLFMYAKRNKRRIMRIFSVPPTEETLSEPNFYDTISKIRLRQQLEMYSISRKYDYQQPQNQADSVQLSLE>sp|A4FU49|SH321_HUMAN SH3 domain-containing protein 21 OS=Homo sapiensOX=9606 GN=SH3D21 PE=2 SV=2MVQSELQLQPRAGGRAEAASWGDRGNDKGGLGNPDMPSVSPGPQRPPKLSSLAYDSPPDYLQTVSHPEVYRVLFDYQPEAPDELALRRGDVVKVLSKTTEDKGWWEGECQGRRGVFPDNFVLPPPPIKKLVPRKVVSRESAPIKEPKKLMPKTSLPTVKKLATATTGPSKAKTSRTPSRDSQKLTSRDSGPNGGFQSGGSYHPGRKRSKTQTPQQRSVSSQEEEHSSPVKAPSVKRTPMPDKTATPERPPAPENAPSSKKIPAPDKVPSPEKTLTLGDKASIPGNSTSGKIPAPDKVPTPEKMVTPEDKASIPENSIIPEETLTVDKPSTPERVFSVEESPALEAPPMDKVPNPKMAPLGDEAPTLEKVLTPELSEEEVSTRDDIQFHHFSSEEALQKVKYFVAKEDPSSQEEAHTPEAPPPQPPSSERCLGEMKCTLVRGDSSPRQAELKSGPASRPALEKPHPHEEATTLPEEAPSNDERTPEEEAPPNEQRPLREEVLPKEGVASKEEVTLKEELPPKEEVAPKEEVPPIERAFAQKTRPIKPPPDSQETLALPSLVPQNYTENKNEGVDVTSLRGEVESLRRALELMEVQLERKLTDIWEELKSEKEQRRRLEVQVMQGTQKSQTPRVIHTQTQTY>sp|A4FU49-3|SH321_HUMAN Isoform 2 of SH3 domain-containing protein 21OS=Homo sapiens OX=9606 GN=SH3D21MIKEIEDGWWLGKKNGQLGAFPSNFVELLDSGPPSLGNPDMPSVSPGPQRPPKLSSLAYDSPPDYLQTVSHPEVYRVLFDYQPEAPDELALRRGDVVKVLSKTTEDKGWWEGECQGRRGVFPDNFVLPPPPIKKLVPRKVVSRESAPIKEPKKLMPKTSLPTVKKLATATTGPSKAKTSRTPSRDSQKLTSRDSGPNGGFQSGGSYHPGRKRSKTQTPQQRSVSSQEEEHSSPVKAPSVKRTPMPDKTATPERPPAPENAPSSKKIPAPDKVPSPEKTLTLGDKASIPGNSTSGKIPAPDKVPTPEKMVTPEDKASIPENSIIPEETLTVDKPSTPERVFSVEESPALEAPPMDKVPNPKMAPLGDEAPTLEKVLTPELSEEEVSTRDDIQFHHFSSEEALQKVKYFVAKEDPSSQEEAHTPEAPPPQPPSSERCLGEMKCTLVRGDSSPRQAELKSGPASRPALEKPHPHEEATTLPEEAPSNDERTPEEEAPPNEQRPLREEVLPKEGVASKEEVTLKEELPPKEEVAPKEEVPPIERAFAQKTRPIKPPPDSQETLALPSLVPQNYTENKNEGVDVTSLRGEVESLRRALELMEVQLERKLTDIWEELKSEKEQRRRLEVQVMQGTQKSQTPRVIHTQTQTY>sp|A4FU49-4|SH321_HUMAN Isoform 3 of SH3 domain-containing protein 21OS=Homo sapiens OX=9606 GN=SH3D21MIKEIEDGWWLGKRNGQLGAFPSNFVELLDSGPPSLGNPDMPSVSPGPQRPPKTTEDKGWWEGECQGRRGVFPDNFVLPPPPIKKLVPRKVVSRESAPIKEPKKLMPKTSLPTVKKLATATTGPSKAKRKSTAAR>sp|A4FU49-5|SH321_HUMAN Isoform 4 of SH3 domain-containing protein 21OS=Homo sapiens OX=9606 GN=SH3D21MVQSELQLQPRAGGRAEAASWGDRGNDKGGLGNPDMPSVSPGPQRPPKLSSLAYDSPPDYLQTVSHPEVYRVLFDYQPEAPDELALRRGDVVKVLSKTTEDKGWWEGECQGRRGVFPDNFVLPPPPIKKLVPRKVVSRESAPIKEPKKLMPKTSLPTVKKLATATTGPSKAKTSRTPSRDSQKLTSRDSGGRAQQPGKGPLCEENPHAGQDCHPREAPSSRERPQLQEDPGS>sp|A4FU49-6|SH321_HUMAN Isoform 5 of SH3 domain-containing protein 21OS=Homo sapiens OX=9606 GN=SH3D21MEVLVLAGYRAQKEDELSLAPGDVVRQVRWVPARGWLRGEFGGRYGLFPERLVQEIPETLRGSGEARRPRCARRRGHPAKHPRPQRWCKVNFSYSPEQADELKLQAGEIVEMIKEIEDGWWLGKKNGQLGAFPSNFVELLDSGPPSLGNPDMPSVSPGPQRPPKLSSLAYDSPPDYLQTVSHPEVYRVLFDYQPEAPDELALRRGDVVKVLSKTTEDKGWWEGECQGRRGVFPDNFVLPPPPIKKLVPRKVVSRESAPIKEPKKLMPKTSLPTVKKLATATTGPSKAKTSRTPSRDSQKLTSRDSGPNGGFQSGGSYHPGRKRSKTQTPQQRSVSSQEEEHSSPVKAPSVKRTPMPDKTATPERPPAPENAPSSKKIPAPDKVPSPEKTLTLGDKASIPGNSTSGKIPAPDKVPTPEKMVTPEDKASIPENSIIPEETLTVDKPSTPERVFSVEESPALEAPPMDKVPNPKMAPLGDEAPTLEKVLTPELSEEEVSTRDDIQFHHFSSEEALQKVKYFVAKEDPSSQEEAHTPEAPPPQPPSSERCLGEMKCTLVRGDSSPRQAELKSGPASRPALEKPHPHEEATTLPEEAPSNDERTPEEEAPPNEQRPLREEVLPKEGVASKEEVTLKEELPPKEEVAPKEEVPPIERAFAQKTRPIKPPPDSQETLALPSLVPQNYTENKNEGVDVTSLRGEVESLRRALELMEVQLERKLTDIWEELKSEKEQRRRLEVQVMQGTQKSQTPRVIHTQTQTY>sp|Q13487|SNPC2_HUMAN snRNA-activating protein complex subunit 2 OS=Homosapiens OX=9606 GN=SNAPC2 PE=1 SV=1MKPPPRRRAAPARYLGEVTGPATWSAREKRQLVRLLQARQGQPEPDATELARELRGRSEAEIRVFLQQLKGRVAREAIQKVHPGGLQGPRRREAQPPAPIEVWTDLAEKITGPLEEALAVAFSQVLTIAATEPVTLLHSKPPKPTQARGKPLLLSAPGGQEDPAPEIPSSAPAAPSSAPRTPDPAPEKPSESSAGPSTEEDFAVDFEKIYKYLSSVSRSGRSPELSAAESAVVLDLLMSLPEELPLLPCTALVEHMTETYLRLTAPQPIPAGGSLGPAAEGDGAGSKAPEETPPATEKAEHSELKSPWQAAGICPLNPFLVPLELLGRAATPAR>sp|Q9UNH6|SNX7_HUMAN Sorting nexin-7 OS=Homo sapiens OX=9606 GN=SNX7PE=1 SV=1MDMNSFSPMMPTSPLSMINQIKFEDEPDLKDLFITVDEPESHVTTIETFITYRIITKTSRGEFDSSEFEVRRRYQDFLWLKGKLEEAHPTLIIPPLPEKFIVKGMVERFNDDFIETRRKALHKFLNRIADHPTLTFNEDFKIFLTAQAWELSSHKKQGPGLLSRMGQTVRAVASSMRGVKNRPEEFMEMNNFIELFSQKINLIDKISQRIYKEEREYFDEMKEYGPIHILWSASEEDLVDTLKDVASCIDRCCKATEKRMSGLSEALLPVVHEYVLYSEMLMGVMKRRDQIQAELDSKVEVLTYKKADTDLLPEEIGKLEDKVECANNALKADWERWKQNMQNDIKLAFTDMAEENIHYYEQCLATWESFLTSQTNLHLEEASEDKP>sp|Q9UNH6-2|SNX7_HUMAN Isoform 2 of Sorting nexin-7 OS=Homo sapiensOX=9606 GN=SNX7MDMNSFSPMMPTSPLSMINQIKFEDEPDLKDLFITVDEPESHVTTIETFITYRIITKTSRGEFDSSEFEVRRRYQDFLWLKGKLEEAHPTLIIPPLPEKFIVKGMVERFNDDFIETRRKALHKFLNRIADHPTLTFNEDFKIFLTAQAWELSSHKKQGPGLLSRMGQTVRAVASSMRGVKNRPEEFMEMNNFIELFSQKINLIDKISQRIYKEEREYFDEMKEYGPIHILWSASEEDLVDTLKDVASCIDRCCKATEKRMSGLSEALLPVVHEYVLYSEMLMGVMKRRDQIQAELDSKVEVLTYKKADTDLCLATWESFLTSQTNLHLEEASEDKP>sp|Q9UNH6-3|SNX7_HUMAN Isoform 3 of Sorting nexin-7 OS=Homo sapiensOX=9606 GN=SNX7MEGERRASQAPSSGLPAGGANGESPGGGAPFPGSSGSSALLQAEVLDLDEDEDDLEVFSKDASLMDMNSFSPMMPTSPLSMINQIKFEDEPDLKDLFITVDEPESHVTTIETFITYRIITKTSRGEFDSSEFEVRRRYQDFLWLKGKLEEAHPTLIIPPLPEKFIVKGMVERFNDDFIETRRKALHKFLNRIADHPTLTFNEDFKIFLTAQAWELSSHKKQGPGLLSRMGQTVRAVASSMRGVKNRPEEFMEMNNFIELFSQKINLIDKISQRIYKEEREYFDEMKEYGPIHILWSASEEDLVDTLKDVASCIDRCCKATEKRMSGLSEALLPVVHEYVLYSEMLMGVMKRRDQIQAELDSKVEVLTYKKADTDLLPEEIGKLEDKVECANNALKADWERWKQNMQNDIKLAFTDMAEENIHYYEQCLATWESFLTSQTNLHLEEASEDKP>sp|Q86UG4|SO6A1_HUMAN Solute carrier organic anion transporter familymember 6A1 OS=Homo sapiens OX=9606 GN=SLCO6A1 PE=1 SV=2MFVGVARHSGSQDEVSRGVEPLEAARAQPAKDRRAKGTPKSSKPGKKHRYLRLLPEALIRFGGFRKRKKAKSSVSKKPGEVDDSLEQPCGLGCLVSTCCECCNNIRCFMIFYCILLICQGVVFGLIDVSIGDFQKEYQLKTIEKLALEKSYDISSGLVAIFIAFYGDRKKVIWFVASSFLIGLGSLLCAFPSINEENKQSKVGIEDICEEIKVVSGCQSSGISFQSKYLSFFILGQTVQGIAGMPLYILGITFIDENVATHSAGIYLGIAECTSMIGYALGYVLGAPLVKVPENTTSATNTTVNNGSPEWLWTWWINFLFAAVVAWCTLIPLSCFPNNMPGSTRIKARKRKQLHFFDSRLKDLKLGTNIKDLCAALWILMKNPVLICLALSKATEYLVIIGASEFLPIYLENQFILTPTVATTLAGLVLIPGGALGQLLGGVIVSTLEMSCKALMRFIMVTSVISLILLVFIIFVRCNPVQFAGINEDYDGTGKLGNLTAPCNEKCRCSSSIYSSICGRDDIEYFSPCFAGCTYSKAQNQKKMYYNCSCIKEGLITADAEGDFIDARPGKCDAKCYKLPLFIAFIFSTLIFSGFSGVPIVLAMTRVVPDKLRSLALGVSYVILRIFGTIPGPSIFKMSGETSCILRDVNKCGHTGRCWIYNKTKMAFLLVGICFLCKLCTIIFTTIAFFIYKRRLNENTDFPDVTVKNPKVKKKEETDL>sp|Q86UG4-2|SO6A1_HUMAN Isoform 2 of Solute carrier organic aniontransporter family member 6A1 OS=Homo sapiens OX=9606 GN=SLCO6A1MFVGVARHSGSQDEVSRGVEPLEAARAQPAKDRRAKGTPKSSKPGKKHRYLRLLPEALIRFGGFRKRKKAKSSVSKKPGEVDDSLEQPCGLGCLVSTCCECCNNIRCFMIFYCILLICQGVVFGLIDVSIGDFQKEYQLKTIEKLALEKSYDISSGLVAIFIAFYGDRKKVIWFVASSFLIGLGSLLCAFPSINEENKQSKVGIEGIAECTSMIGYALGYVLGAPLVKVPENTTSATNTTVNNGSPEWLWTWWINFLFAAVVAWCTLIPLSCFPNNMPGSTRIKARKRKQLHFFDSRLKDLKLGTNIKDLCAALWILMKNPVLICLALSKATEYLVIIGASEFLPIYLENQFILTPTVATTLAGLVLIPGGALGQLLGGVIVSTLEMSCKALMRFIMVTSVISLILLVFIIFVRCNPVQFAGINEDYDGTGKLGNLTAPCNEKCRCSSSIYSSICGRDDIEYFSPCFAGCTYSKAQNQKKMYYNCSCIKEGLITADAEGDFIDARPGKCDAKCYKLPLFIAFIFSTLIFSGFSGVPIVLAMTRVVPDKLRSLALGVSYVILRIFGTIPGPSIFKMSGETSCILRDVNKCGHTGRCWIYNKTKMAFLLVGICFLCKLCTIIFTTIAFFIYKRRLNENTDFPDVTVKNPKVKKKEETDL>sp|Q86UG4-3|SO6A1_HUMAN Isoform 3 of Solute carrier organic aniontransporter family member 6A1 OS=Homo sapiens OX=9606 GN=SLCO6A1MFVGVARHSGSQDEVSRGVEPLEAARAQPAKDRRAKGTPKSSKPGKKHRYLRLLPEALIRFGGFRKRKKAKSSVSKKPGEVDDSLEQPCGLGCLVSTCCECCNNIRCFMIFYCILLICQGVVFGLIDVSIGDFQKEYQLKTIEKLALEKSYDISSGLVAIFIAFYGDRKKVIWFVASSFLIGLGSLLCAFPSINEENKQSKVGIEGIAECTSMIGYALGYVLGAPLVKVPENTTSATNTGKLGNLTAPCNEKCRCSSSIYSSICGRDDIEYFSPCFAGCTYSKAQNQKKMYYNCSCIKEGLITADAEGDFIDARPGKCDAKCYKLPLFIAFIFSTLIFSGFSGVPIVLAMTRVVPDKLRSLALGVSYVILRIFGTIPGPSIFKMSGETSCILRDVNKCGHTGRCWIYNKTKMAFLLVGICFLCKLCTIIFTTIAFFIYKRRLNENTDFPDVTVKNPKVKKKEETDL>sp|B2RUZ4|SMIM1_HUMAN Small integral membrane protein 1 OS=Homo sapiensOX=9606 GN=SMIM1 PE=1 SV=1MQPQESHVHYSRWEDGSRDGVSLGAVSSTEEASRCRRISQRLCTGKLGIAMKVLGGVALFWIIFILGYLTGYYVHKCK>sp|O60880|SH21A_HUMAN SH2 domain-containing protein 1A OS=Homo sapiensOX=9606 GN=SH2D1A PE=1 SV=1MDAVAVYHGKISRETGEKLLLATGLDGSYLLRDSESVPGVYCLCVLYHGYIYTYRVSQTETGSWSAETAPGVHKRYFRKIKNLISAFQKPDQGIVIPLQYPVEKKSSARSTQGTTGIREDPDVCLKAP>sp|O60880-2|SH21A_HUMAN Isoform B of SH2 domain-containing protein 1AOS=Homo sapiens OX=9606 GN=SH2D1AMDAVAVYHGKISRETGEKLLLATGLDGSYLLRDSESVPGVYCLCVLYHGYIYTYRVSQTETGSWSAEHFRSQIKA>sp|O60880-3|SH21A_HUMAN Isoform C of SH2 domain-containing protein 1AOS=Homo sapiens OX=9606 GN=SH2D1AMDAVAVYHGKISRETGEKLLLATGLDGSYLLRDSESVPGVYCLCVLQHLGYIKDISGK>sp|O60880-4|SH21A_HUMAN Isoform D of SH2 domain-containing protein 1AOS=Homo sapiens OX=9606 GN=SH2D1AMDAVAVYHGKISRETGEKLLLATGLDGSYLLRDSESVPGVYCLCVLYHGYIYTYRVSQTETGSWSAETAPGVHKRYFRKIKNLISAFQKPDQGIVIPLQYPVEKKSSARSTQGIREDPDVCLKAP>sp|O60880-5|SH21A_HUMAN Isoform E of SH2 domain-containing protein 1AOS=Homo sapiens OX=9606 GN=SH2D1AMDAVAVYHGKISRETGEKLLLATGLDGSYLLRDSESVPGITVTFIHTECPRQKQVLGVLSISEARSRHCNTSAVSS>sp|O60880-6|SH21A_HUMAN Isoform F of SH2 domain-containing protein 1AOS=Homo sapiens OX=9606 GN=SH2D1AMDAVAVYHGKISRETGEKLLLATGLDGSYLLRDSESVPGVYCLCVLISEARSRHCNTSAVSS>sp|Q9H2Y9|SO5A1_HUMAN Solute carrier organic anion transporter familymember 5A1 OS=Homo sapiens OX=9606 GN=SLCO5A1 PE=2 SV=2MDEGTGLQPGAGEQLEAPATAEAVQERCEPETLRSKSLPVLSSASCRPSLSPTSGDANPAFGCVDSSGHQELKQGPNPLAPSPSAPSTSAGLGDCNHRVDLSKTFSVSSALAMLQERRCLYVVLTDSRCFLVCMCFLTFIQALMVSGYLSSVITTIERRYSLKSSESGLLVSCFDIGNLVVVVFVSYFGGRGRRPLWLAVGGLLIAFGAALFALPHFISPPYQIQELNASAPNDGLCQGGNSTATLEPPACPKDSGGNNHWVYVALFICAQILIGMGSTPIYTLGPTYLDDNVKKENSSLYLAIMYVMGALGPAVGYLLGGLLIGFYVDPRNPVHLDQNDPRFIGNWWSGFLLCAIAMFLVIFPMFTFPKKLPPRHKKKKKKKFSVDAVSDDDVLKEKSNNSEQADKKVSSMGFGKDVRDLPRAAVRILSNMTFLFVSLSYTAESAIVTAFITFIPKFIESQFGIPASNASIYTGVIIVPSAGVGIVLGGYIIKKLKLGARESAKLAMICSGVSLLCFSTLFIVGCESINLGGINIPYTTGPSLTMPHRNLTGSCNVNCGCKIHEYEPVCGSDGITYFNPCLAGCVNSGNLSTGIRNYTECTCVQSRQVITPPTVGQRSQLRVVIVKTYLNENGYAVSGKCKRTCNTLIPFLVFLFIVTFITACAQPSAIIVTLRSVEDEERPFALGMQFVLLRTLAYIPTPIYFGAVIDTTCMLWQQECGVQGSCWEYNVTSFRFVYFGLAAGLKFVGFIFIFLAWYSIKYKEDGLQRRRQREFPLSTVSERVGHPDNARTRSCPAFSTQGEFHEETGLQKGIQCAAQTYPGPFPEAISSSADPGLEESPAALEPPS>sp|Q9H2Y9-2|SO5A1_HUMAN Isoform 2 of Solute carrier organic aniontransporter family member 5A1 OS=Homo sapiens OX=9606 GN=SLCO5A1MDEGTGLQPGAGEQLEAPATAEAVQERCEPETLRSKSLPVLSSASCRPSLSPTSGDANPAFGCVDSSGHQELKQGPNPLAPSPSAPSTSAGLGDCNHRVDLSKTFSVSSALAMLQERRCLYVVLTDSRCFLVCMCFLTFIQALMVSGYLSSVITTIERRYSLKSSESGLLVSCFDIGNLVVVVFVSYFGGRGRRPLWLAVGGLLIAFGAALFALPHFISPPYQIQELNASAPNDGLCQGGNSTATLEPPACPKDSGGNNHWVYVALFICAQILIGMGSTPIYTLGPTYLDDNVKKENSSLYLAIMYVMGALGPAVGYLLGGLLIGFYVDPRNPVHLDQNDPRFIGNWWSGFLLCAIAMFLVIFPMFTFPKKLPPRHKKKKKKKFSVDAVSDDDVLKEKSNNSEQADKKVSSMGFGKDVRGVIIVPSAGVGIVLGGYIIKKLKLGARESAKLAMICSGVSLLCFSTLFIVGCESINLGGINIPYTTGPSLTMPHRNLTGSCNVNCGCKIHEYEPVCGSDGITYFNPCLAGCVNSGNLSTGIRNYTECTCVQSRQVITPPTVGQRSQLRVVIVKTYLNENGYAVSGKCKRTCNTLIPFLVFLFIVTFITACAQPSAIIVTLRSVEDEERPFALGMQFVLLRTLAYIPTPIYFGAVIDTTCMLWQQECGVQGSCWEYNVTSFRFVYFGLAAGLKFVGFIFIFLAWYSIKYKEDGLQRRRQREFPLSTVSERVGHPDNARTRSCPAFSTQGEFHEETGLQKGIQCAAQTYPGPFPEAISSSADPGLEESPAALEPPS>sp|Q9H2Y9-3|SO5A1_HUMAN Isoform 3 of Solute carrier organic aniontransporter family member 5A1 OS=Homo sapiens OX=9606 GN=SLCO5A1MDEGTGLQPGAGEQLEAPATAEAVQERCEPETLRSKSLPVLSSASCRPSLSPTSGDANPAFGCVDSSGHQELKQGPNPLAPSPSAPSTSAGLGDCNHRVDLSKTFSVSSALAMLQERRCLYVVLTDSRCFLVCMCFLTFIQALMVSGYLSSVITTIERRYSLKSSESGLLVSCFDIGNLVVVVFVSYFGGRGRRPLWLAVGGLLIAFGAALFALPHFISPPYQIQELNASAPNDGLCQGGNSTATLEPPACPKDSGGNNHWVYVALFICAQILIGMGSTPIYTLGPTYLDDNVKKENSSLYLAIMYVMGALGPAVGYLLGGLLIGFYVDPRNPVHLDQNDPRFIGNWWSGFLLCAIAMFLVIFPMFTFPKKLPPRHKKKKKKKFSVDAVSDDDVLKEKSNNSEQADKKVSSMGFGKDVRDLPRAAVRILSNMTFLFVSLSYTAESAIVTAFITFIPKFIESQFGIPASNASIYTGVIIVPSAGVGIVLGGYIIKKLKLGARESAKLAMICSGVSLLCFSTLFIVGCESINLGGINIPYTTGPSLTMPHRNLTGSCNVNCGCKIHEYEPVCGSDGITYFNPCLAGCVNSGNLSTGIRNYTECTCVQSRQVITPPTVGQRSQLRVVIVKTYLNENGYAVSGKCKRTCNTLIPFLVFLFIVTFITACAQPSAIIVTLSIHSYSNLLWSSH>sp|A6NGZ8|SMIM9_HUMAN Small integral membrane protein 9 OS=Homo sapiensOX=9606 GN=SMIM9 PE=3 SV=1MEPQKLLIIGFLLCSLTCLLLETVASSPLPLSALGIQEKTGSKPRSGGNHRSWLNNFRDYLWQLIKSALPPAAIVAFLLTSALMGILCCFTILVVDPVH>sp|Q9BT81|SOX7_HUMAN Transcription factor SOX-7 OS=Homo sapiens OX=9606GN=SOX7 PE=1 SV=1MASLLGAYPWPEGLECPALDAELSDGQSPPAVPRPPGDKGSESRIRRPMNAFMVWAKDERKRLAVQNPDLHNAELSKMLGKSWKALTLSQKRPYVDEAERLRLQHMQDYPNYKYRPRRKKQAKRLCKRVDPGFLLSSLSRDQNALPEKRSGSRGALGEKEDRGEYSPGTALPSLRGCYHEGPAGGGGGGTPSSVDTYPYGLPTPPEMSPLDVLEPEQTFFSSPCQEEHGHPRRIPHLPGHPYSPEYAPSPLHCSHPLGSLALGQSPGVSMMSPVPGCPPSPAYYSPATYHPLHSNLQAHLGQLSPPPEHPGFDALDQLSQVELLGDMDRNEFDQYLNTPGHPDSATGAMALSGHVPVSQVTPTGPTETSLISVLADATATYYNSYSVS>sp|Q9BT81-2|SOX7_HUMAN Isoform 2 of Transcription factor SOX-7 OS=Homosapiens OX=9606 GN=SOX7MSMLAERRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQEQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGKSWKALTLSQKRPYVDEAERLRLQHMQDYPNYKYRPRRKKQAKRLCKRVDPGFLLSSLSRDQNALPEKRSGSRGALGEKEDRGEYSPGTALPSLRGCYHEGPAGGGGGGTPSSVDTYPYGLPTPPEMSPLDVLEPEQTFFSSPCQEEHGHPRRIPHLPGHPYSPEYAPSPLHCSHPLGSLALGQSPGVSMMSPVPGCPPSPAYYSPATYHPLHSNLQAHLGQLSPPPEHPGFDALDQLSQVELLGDMDRNEFDQYLNTPGHPDSATGAMALSGHVPVSQVTPTGPTETSLISVLADATATYYNSYSVS>sp|B1AK76|SNUFL_HUMAN Putative SNURF-like protein OS=Homo sapiensOX=9606 GN=SNURFL PE=5 SV=2MEQARDHLHLRWTTEQHMPEVEVQVKYRTAALSNQECQLYLRHSQQQQVLVVDFQAKLRQVFITETPRCGKKPYWNNEEAESKQNPGSIYCLLLLIRGGMSDSLIKREISNFEIVSKNKKN>sp|Q7Z4S9|SH2D6_HUMAN SH2 domain-containing protein 6 OS=Homo sapiensOX=9606 GN=SH2D6 PE=2 SV=1MYASSYPPPPQLSPRSHLCPPPPHPTPPQLNNLLLLEGRKSSLPSVAPTGSASAAEDSDLLTQPWYSGNCDRYAVESALLHLQKDGAYTVRPSSGPHGSQPFTLAVLLRGRVFNIPIRRLDGGRHYALGREGRNREELFSSVAAMVQHFMWHPLPLVDRHSGSRELTCLLFPTKP>sp|Q7Z4S9-2|SH2D6_HUMAN Isoform 2 of SH2 domain-containing protein 6OS=Homo sapiens OX=9606 GN=SH2D6MPSGPLPRTSVVPRPTTAPQETRNGTADAASKEGRKSSLPSVAPTGSASAAEDGAYTVRPSSGPHGSQPFTLAVLLRGRVFNIPIRRLDGGRHYALGREGRNREELFSSVAAMVQHFMWHPLPLVDRHSGSRELTCLLFPTKP>sp|Q9Y5W9|SNX11_HUMAN Sorting nexin-11 OS=Homo sapiens OX=9606 GN=SNX11PE=1 SV=2MGFWCRMSENQEQEEVITVRVQDPRVQNEGSWNSYVDYKIFLHTNSKAFTAKTSCVRRRYREFVWLRKQLQRNAGLVPVPELPGKSTFFGTSDEFIEKRRQGLQHFLEKVLQSVVLLSDSQLHLFLQSQLSVPEIEACVQGRSTMTVSDAILRYAMSNCGWAQEERQSSSHLAKGDQPKSCCFLPRSGRRSSPSPPPSEEKDHLEVWAPVVDSEVPSLESPTLPPLSSPLCCDFGRPKEGTSTLQSVRRAVGGDHAVPLDPGQLETVLEK>sp|Q9Y5W9-2|SNX11_HUMAN Isoform 2 of Sorting nexin-11 OS=Homo sapiensOX=9606 GN=SNX11MVCREQEVITVRVQDPRVQNEGSWNSYVDYKIFLHTNSKAFTAKTSCVRRRYREFVWLRKQLQRNAGLVPVPELPGKSTFFGTSDEFIEKRRQGLQHFLEKVLQSVVLLSDSQLHLFLQSQLSVPEIEACVQGRSTMTVSDAILRYAMSNCGWAQEERQSSSHLAKGDQPKSCCFLPRSGRRSSPSPPPSEEKDHLEVWAPVVDSEVPSLESPTLPPLSSPLCCDFGRPKEGTSTLQSVRRAVGGDHAVPLDPGQLETVLEK>sp|Q9NRC8|SIR7_HUMAN NAD-dependent protein deacetylase sirtuin-7 OS=Homosapiens OX=9606 GN=SIRT7 PE=1 SV=1MAAGGLSRSERKAAERVRRLREEQQRERLRQVSRILRKAAAERSAEEGRLLAESADLVTELQGRSRRREGLKRRQEEVCDDPEELRGKVRELASAVRNAKYLVVYTGAGISTAASIPDYRGPNGVWTLLQKGRSVSAADLSEAEPTLTHMSITRLHEQKLVQHVVSQNCDGLHLRSGLPRTAISELHGNMYIEVCTSCVPNREYVRVFDVTERTALHRHQTGRTCHKCGTQLRDTIVHFGERGTLGQPLNWEAATEAASRADTILCLGSSLKVLKKYPRLWCMTKPPSRRPKLYIVNLQWTPKDDWAALKLHGKCDDVMRLLMAELGLEIPAYSRWQDPIFSLATPLRAGEEGSHSRKSLCRSREEAPPGDRGAPLSSAPILGGWFGRGCTKRTKRKKVT>sp|Q9NRC8-2|SIR7_HUMAN Isoform 2 of NAD-dependent protein deacetylasesirtuin-7 OS=Homo sapiens OX=9606 GN=SIRT7MAAGGLSRSERKAAERVRRLREEQQRERLRQVSRILRKAAAERSAEEGRLLAESADLVTELQGRSRRREGLKRRQEEVCDDPEELRGKVRELASAVRNAKYLVVYTGAGISTAASIPDYRGPNGVWTLLQKGRSVSAADLSEAEPTLTHMSITRLHEQKLVRALGGWYTCQGPGRAPWCPVGN>sp|Q9NRC8-3|SIR7_HUMAN Isoform 3 of NAD-dependent protein deacetylasesirtuin-7 OS=Homo sapiens OX=9606 GN=SIRT7MPGPRRRSPSACPQVSRILRKAAAERSAEEGRLLAESADLVTELQGRSRRREGLKRRQEEVCDDPEELRGKVRELASAVRNAKYLVVYTGAGISTAASIPDYRGPNGVWTLLQKGRSVSAADLSEAEPTLTHMSITRLHEQKLVQHVVSQNCDGLHLRSGLPRTAISELHGNMYIEVCTSCVPNREYVRVFDVTERTALHRHQTGRTCHKCGTQLRDTIVHFGERGTLGQPLNWEAATEAASRADTILCLGSSLKVLKKYPRLWCMTKPPSRRPKLYIVNLQWTPKDDWAALKLHGKCDDVMRLLMAELGLEIPAYSRVL>sp|Q15036|SNX17_HUMAN Sorting nexin-17 OS=Homo sapiens OX=9606 GN=SNX17PE=1 SV=1MHFSIPETESRSGDSGGSAYVAYNIHVNGVLHCRVRYSQLLGLHEQLRKEYGANVLPAFPPKKLFSLTPAEVEQRREQLEKYMQAVRQDPLLGSSETFNSFLRRAQQETQQVPTEEVSLEVLLSNGQKVLVNVLTSDQTEDVLEAVAAKLDLPDDLIGYFSLFLVREKEDGAFSFVRKLQEFELPYVSVTSLRSQEYKIVLRKSYWDSAYDDDVMENRVGLNLLYAQTVSDIERGWILVTKEQHRQLKSLQEKVSKKEFLRLAQTLRHYGYLRFDACVADFPEKDCPVVVSAGNSELSLQLRLPGQQLREGSFRVTRMRCWRVTSSVPLPSGSTSSPGRGRGEVRLELAFEYLMSKDRLQWVTITSPQAIMMSICLQSMVDELMVKKSGGSIRKMLRRRVGGTLRRSDSQQAVKSPPLLESPDATRESMVKLSSKLSAVSLRGIGSPSTDASASDVHGNFAFEGIGDEDL>sp|Q15036-2|SNX17_HUMAN Isoform 2 of Sorting nexin-17 OS=Homo sapiensOX=9606 GN=SNX17MHFSIPETESRSGDSGGSAYVLRKEYGANVLPAFPPKKLFSLTPAEVEQRREQLEKYMQAVRQDPLLGSSETFNSFLRRAQQETQQVPTEEVSLEVLLSNGQKVLVNVLTSDQTEDVLEAVAAKLDLPDDLIGYFSLFLVREKEDGAFSFVRKLQEFELPYVSVTSLRSQEYKIVLRKSYWDSAYDDDVMENRVGLNLLYAQTVSDIERGWILVTKEQHRQLKSLQEKVSKKEFLRLAQTLRHYGYLRFDACVADFPEKDCPVVVSAGNSELSLQLRLPGQQLREGSFRVTRMRCWRVTSSVPLPSGSTSSPGRGRGEVRLELAFEYLMSKDRLQWVTITSPQAIMMSICLQSMVDELMVKKSGGSIRKMLRRRVGGTLRRSDSQQAVKSPPLLESPDATRESMVKLSSKLSAVSLRGIGSPSTDASASDVHGNFAFEGIGDEDL>sp|Q3KNW1|SNAI3_HUMAN Zinc finger protein SNAI3 OS=Homo sapiens OX=9606GN=SNAI3 PE=2 SV=1MPRSFLVKTHSSHRVPNYRRLETQREINGACSACGGLVVPLLPRDKEAPSVPGDLPQPWDRSSAVACISLPLLPRIEEALGASGLDALEVSEVDPRASRAAIVPLKDSLNHLNLPPLLVLPTRWSPTLGPDRHGAPEKLLGAERMPRAPGGFECFHCHKPYHTLAGLARHRQLHCHLQVGRVFTCKYCDKEYTSLGALKMHIRTHTLPCTCKICGKAFSRPWLLQGHVRTHTGEKPYACSHCSRAFADRSNLRAHLQTHSDAKKYRCRRCTKTFSRMSLLARHEESGCCPGP>sp|Q9H299|SH3L3_HUMAN SH3 domain-binding glutamic acid-rich-like protein3 OS=Homo sapiens OX=9606 GN=SH3BGRL3 PE=1 SV=1MSGLRVYSTSVTGSREIKSQQSEVTRILDGKRIQYQLVDISQDNALRDEMRALAGNPKATPPQIVNGDQYCGDYELFVEAVEQNTLQEFLKLA>sp|Q9H115|SNAB_HUMAN Beta-soluble NSF attachment protein OS=Homo sapiensOX=9606 GN=NAPB PE=1 SV=2MDNAGKEREAVQLMAEAEKRVKASHSFLRGLFGGNTRIEEACEMYTRAANMFKMAKNWSAAGNAFCQAAKLHMQLQSKHDSATSFVDAGNAYKKADPQEAINCLNAAIDIYTDMGRFTIAAKHHITIAEIYETELVDIEKAIAHYEQSADYYKGEESNSSANKCLLKVAAYAAQLEQYQKAIEIYEQVGANTMDNPLLKYSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQGDGEGDGDLK>sp|Q9H115-2|SNAB_HUMAN Isoform 2 of Beta-soluble NSF attachment proteinOS=Homo sapiens OX=9606 GN=NAPBMDNAGKEREAVQLMAEAEKRVKASHSFLRGLFGGNTRIEEACEMYTRAANMFKMAKNWSEAINCLNAAIDIYTDMGRFTIAAKHHITIAEIYETELVDIEKAIAHYEQSADYYKGEESNSSANKCLLKVAAYAAQLEQYQKAIEIYEQVGANTMDNPLLKYSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQGDGEGDGDLK>sp|Q9H115-3|SNAB_HUMAN Isoform 3 of Beta-soluble NSF attachment proteinOS=Homo sapiens OX=9606 GN=NAPBMTLLPALWMLEMLTKRQIPKGRFTIAAKHHITIAEIYETELVDIEKAIAHYEQSADYYKGEESNSSANKCLLKVAAYAAQLEQYQKAIEIYEQVGANTMDNPLLKYSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQGDGEGDGDLK>sp|Q9BSE5|SPEB_HUMAN Agmatinase, mitochondrial OS=Homo sapiens OX=9606GN=AGMAT PE=1 SV=2MLRLLASGCARGPGPGVGARPAAGLFHPGRRQSRQASDAPRNQPPSPEFVARPVGVCSMMRLPVQTSPEGLDAAFIGVPLDTGTSNRPGARFGPRRIREESVMLGTVNPSTGALPFQSLMVADLGDVNVNLYNLQDSCRRIQEAYEKIVAAGCIPLTLGGDHTITYPILQAMAKKHGPVGLLHVDAHTDTTDKALGEKLYHGAPFRRCVDEGLLDCKRVVQIGIRGSSTTLDPYRYNRSQGFRVVLAEDCWMKSLVPLMGEVRQQMGGKPIYISFDIDALDPAYAPGTGTPEIAGLTPSQALEIIRGCQGLNVMGCDLVEVSPPYDLSGNTALLAANLLFEMLCALPKVTTV>sp|Q8IX90|SKA3_HUMAN Spindle and kinetochore-associated protein 3OS=Homo sapiens OX=9606 GN=SKA3 PE=1 SV=2MDPIRSFCGKLRSLASTLDCETARLQRALDGEESDFEDYPMRILYDLHSEVQTLKDDVNILLDKARLENQEGIDFIKATKVLMEKNSMDIMKIREYFQKYGYSPRVKKNSVHEQEAINSDPELSNCENFQKTDVKDDLSDPPVASSCISEKSPRSPQLSDFGLERYIVSQVLPNPPQAVNNYKEEPVIVTPPTKQSLVKVLKTPKCALKMDDFECVTPKLEHFGISEYTMCLNEDYTMGLKNARNNKSEEAIDTESRLNDNVFATPSPIIQQLEKSDAEYTNSPLVPTFCTPGLKIPSTKNSIALVSTNYPLSKTNSSSNDLEVEDRTSLVLNSDTCFENLTDPSSPTISSYENLLRTPTPPEVTKIPEDILQLLSKYNSNLATPIAIKAVPPSKRFLKHGQNIRDVSNKEN>sp|Q8IX90-2|SKA3_HUMAN Isoform 2 of Spindle and kinetochore-associatedprotein 3 OS=Homo sapiens OX=9606 GN=SKA3MDPIRSFCGKLRSLASTLDCETARLQRALDGEESG>sp|Q8IX90-3|SKA3_HUMAN Isoform 3 of Spindle and kinetochore-associatedprotein 3 OS=Homo sapiens OX=9606 GN=SKA3MDPIRSFCGKLRSLASTLDCETARLQRALDGEESDFEDYPMRILYDLHSEVQTLKDDVNILLDKARLENQEGIDFIKATKVLMEKNSMDIMKIREYFQKYGYSPRVKKNSVHEQEAINSDPELSNCENFQKTDVKDDLSDPPVASSCISEKSPRSPQLSDFGLERYIVSQVLPNPPQAVNNYKEEPVIVTPPTKQSLVKVLKTPKCALKMDDFECVTPKLEHFGISEYTMCLNEDYTMGLKNARNNKSEEAIDTESRLNDNVFATPSPIIQQLEKSDAEYTNSPLVPTFCTPGLKIPSTKNSIALVSTNYPLSKTNSSSNDLEVEDRTSLVLNSDTCFENLTDPSSPTISSYENLLRTPTPPEVTKIPEDILQKFQWIYPTQKLNKMR>sp|O95473|SNG4_HUMAN Synaptogyrin-4 OS=Homo sapiens OX=9606 GN=SYNGR4PE=2 SV=2MHIPKSLQELANSEAVQFLRRPKTITRVFEGVFSLIVFSSLLTDGYQNKMESPQLHCILNSNSVACSFAVGAGFLAFLSCLAFLVLDTQETRIAGTRFKTAFQLLDFILAVLWAVVWFMGFCFLANQWQHSPPKEFLLGSSSAQAAIAFTFFSILVWIFQAYLAFQDLRNDAPVPYKRFLDEGGMVLTTLPLPSANSPVNMPTTGPNSLSYASSALSPCLTAPKSPRLAMMPDN>sp|O43609|SPY1_HUMAN Protein sprouty homolog 1 OS=Homo sapiens OX=9606GN=SPRY1 PE=1 SV=2MDPQNQHGSGSSLVVIQQPSLDSRQRLDYEREIQPTAILSLDQIKAIRGSNEYTEGPSVVKRPAPRTAPRQEKHERTHEIIPINVNNNYEHRHTSHLGHAVLPSNARGPILSRSTSTGSAASSGSNSSASSEQGLLGRSPPTRPVPGHRSERAIRTQPKQLIVDDLKGSLKEDLTQHKFICEQCGKCKCGECTAPRTLPSCLACNRQCLCSAESMVEYGTCMCLVKGIFYHCSNDDEGDSYSDNPCSCSQSHCCSRYLCMGAMSLFLPCLLCYPPAKGCLKLCRRCYDWIHRPGCRCKNSNTVYCKLESCPSRGQGKPS>sp|Q8N5J4|SPIC_HUMAN Transcription factor Spi-C OS=Homo sapiens OX=9606GN=SPIC PE=1 SV=1MTCVEQDKLGQAFEDAFEVLRQHSTGDLQYSPDYRNYLALINHRPHVKGNSSCYGVLPTEEPVYNWRTVINSAADFYFEGNIHQSLQNITENQLVQPTLLQQKGGKGRKKLRLFEYLHESLYNPEMASCIQWVDKTKGIFQFVSKNKEKLAELWGKRKGNRKTMTYQKMARALRNYGRSGEITKIRRKLTYQFSEAILQRLSPSYFLGKEIFYSQCVQPDQEYLSLNNWNANYNYTYANYHELNHHDC>sp|Q99611|SPS2_HUMAN Selenide, water dikinase 2 OS=Homo sapiens OX=9606GN=SEPHS2 PE=1 SV=3MAEASATGACGEAMAAAEGSSGPAGLTLGRSFSNYRPFEPQALGLSPSWRLTGFSGMKGUGCKVPQEALLKLLAGLTRPDVRPPLGRGLVGGQEEASQEAGLPAGAGPSPTFPALGIGMDSCVIPLRHGGLSLVQTTDFFYPLVEDPYMMGRIACANVLSDLYAMGITECDNMLMLLSVSQSMSEEEREKVTPLMVKGFRDAAEEGGTAVTGGQTVVNPWIIIGGVATVVCQPNEFIMPDSAVVGDVLVLTKPLGTQVAVNAHQWLDNPERWNKVKMVVSREEVELAYQEAMFNMATLNRTAAGLMHTFNAHAATDITGFGILGHSQNLAKQQRNEVSFVIHNLPIIAKMAAVSKASGRFGLLQGTSAETSGGLLICLPREQAARFCSEIKSSKYGEGHQAWIVGIVEKGNRTARIIDKPRVIEVLPRGATAAVLAPDSSNASSEPSS>sp|Q96RM1|SPR2F_HUMAN Small proline-rich protein 2F OS=Homo sapiensOX=9606 GN=SPRR2F PE=3 SV=1MSYQQQQCKQPCQPPPVCPAPKCPEPCPPPKCPEPCPPSKCPQSCPPQQCQQKCPPVTPSPPCQPKCPPKSK>sp|O94875|SRBS2_HUMAN Sorbin and SH3 domain-containing protein 2 OS=Homosapiens OX=9606 GN=SORBS2 PE=1 SV=3MSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKGGDDSKICPSLCSYSGLNGNPSSELDYCSTYRQHLDVPRDSPRAISFKNGWQMARQNAEIWSSTEETVSPKIKSRSCDDLLNDDCDSFPDPKVKSESMGSLLCEEDSKESCPMAWGSPYVPEVRSNGRSRIRHRSARNAPGFLKMYKKMHRINRKDLMNSEVICSVKSRILQYESEQQHKDLLRAWSQCSTEEVPRDMVPTRISEFEKLIQKSKSMPNLGDDMLSPVTLEPPQNGLCPKRRFSIEYLLEEENQSGPPARGRRGCQSNALVPIHIEVTSDEQPRAHVEFSDSDQDGVVSDHSDYIHLEGSSFCSESDFDHFSFTSSESFYGSSHHHHHHHHHHHRHLISSCKGRCPASYTRFTTMLKHERARHENTEEPRRQEMDPGLSKLAFLVSPVPFRRKKNSAPKKQTEKAKCKASVFEALDSALKDICDQIKAEKKRGSLPDNSILHRLISELLPDVPERNSSLRALRRSPLHQPLHPLPPDGAIHCPPYQNDCGRMPRSASFQDVDTANSSCHHQDRGGALQDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-2|SRBS2_HUMAN Isoform 2 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MNTGRDSQSPDSAKGFRSVRPNLQDKRSPTQSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPTDRINPDDIDLENEPWYKFFSELEFGRPPPKKPLDYVQDHSSGVFNEASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-3|SRBS2_HUMAN Isoform 3 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPPPLPTTPTPVPREPGRKPLSSSRLGEVTGSPSPPPRSGAPTPSSRAPALSPTRPPKKPLDYVQDHSSGVFNEASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-4|SRBS2_HUMAN Isoform 4 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MNTGRDSQSPDSAKGFRSVRPNLQDKRSPTQSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPPPLPTTPTPVPREPGRKPLSSSRLGEVTGSPSPPPRSGAPTPSSRAPALSPTRPPKKPLDYVQDHSSGVFNEASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-5|SRBS2_HUMAN Isoform 5 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MNTGRDSQSPDSAKGFRSVRPNLQDKRSPTQSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPPPLPTTPTPVPREPGRKPLSSSRLGEVTGSPSPPPRSGAPTPSSRAPALSPTRPPKKPLDYVQDHSSGVFNEASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALGYTLT>sp|O94875-6|SRBS2_HUMAN Isoform 6 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MKATTPLQTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPVSKPQAGRR>sp|O94875-7|SRBS2_HUMAN Isoform 7 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MKATTPLQTVDRPKDWYKTMFKQIHMVHKPGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKGGDDSKICPSLCSYSGLNGNPSSELDYCSTYRQHLDVPRDSPRAISFKNGWQMARQNAEIWSSTEETVSPKIKSRSCDDLLNDDCDSFPDPKVKSESMGSLLCEEDSKESCPMAWGSPYVPEVRSNGRSRIRHRSARNAPGFLKMYKKMHRINRKDLMNSEVICSVKSRILQYESEQQHKDLLRAWSQCSTEEVPRDMVPTRISEFEKLIQKSKSMPNLGDDMLSPVTLEPPQNGLCPKRRFSIEYLLEEENQSGPPARGRRGCQSNALVPIHIEVTSDEQPRAHVEFSDSDQDGVVSDHSDYIHLEGSSFCSESDFDHFSFTSSESFYGSSHHHHHHHHHHHRHLISSCKGRCPASYTRFTTMLKHERARHENTEEPRRQEMDPGLSKLAFLVSPVPFRRKKNSAPKKQTEKAKCKASVFEALDSALKDICDQIKAEKKRGSLPDNSILHRLISELLPDVPERNSSLRALRRSPLHQPLHPLPPDGAIHCPPYQNDCGRMPRSASFQDVDTANSSCHHQDRGGALQDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-8|SRBS2_HUMAN Isoform 8 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MNTGRDSQSPDSAWRSYNDGNQETLNGDATYSSLAAKGFRSVRPNLQDKRSPTQSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPPPKKPLDYVQDHSSGVFNEASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-9|SRBS2_HUMAN Isoform 9 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MSVTLTSVKRVQSSPNLLAAGRDSQSPDSAWRSYNDGNQETLNGDATYSSLAAKGFRSVRPNLQDKRSPTQSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-10|SRBS2_HUMAN Isoform 10 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MYSNEDSRQTIVYSEESNTTMSYTQKITNPLPAASSTDPAPFANINTPVLQEDYRQDSQTRRISTLKLTHNQDLGSSSPISTPQFSKSVEVPSFLKRPRSLTPNPVPETHTASLSIQIAPLSGQDLESHKQLPELSPETAKIPLQQERQKSAVAAASQSSDCRVSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPPPLPTTPTPVPREPGRKPLSSSRLGEVTGSPSPPPRSGAPTPSSRAPALSPTRPPKKPLDYVQDHSSGVFNEASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-11|SRBS2_HUMAN Isoform 11 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MNTDSGGCARKRAAMSVTLTSVKRVQSSPNLLAAGRDSQSPDSAWRSYNDGNQETLNGDATYSSLAAKGFRSVRPNLQDKRSPTQSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKGGDDSKICPSLCSYSGLNGNPSSELDYCSTYRQHLDVPRDSPRAISFKNGWQMARQNAEIWSSTEETVSPKIKSRSCDDLLNDDCDSFPDPKVKSESMGSLLCEEDSKESCPMAWGSPYVPEVRSNGRSRIRHRSARNAPGFLKMYKKMHRINRKDLMNSEVICSVKSRILQYESEQQHKDLLRAWSQCSTEEVPRDMVPTRISEFEKLIQKSKSMPNLGDDMLSPVTLEPPQNGLCPKRRFSIEYLLEEENQSGPPARGRRGCQSNALVPIHIEVTSDEQPRAHVEFSDSDQDGVVSDHSDYIHLEGSSFCSESDFDHFSFTSSESFYGSSHHHHHHHHHHHRHLISSCKGRCPASYTRFTTMLKHERARHENTEEPRRQEMDPGLSKLAFLVSPVPFRRKKNSAPKKQTEKAKCKASVFEALDSALKDICDQIKAEKKRGSLPDNSILHRLISELLPDVPERNSSLRALRRSPLHQPLHPLPPDGAIHCPPYQNDCGRMPRSASFQDVDTANSSCHHQDRGGALQDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|O94875-12|SRBS2_HUMAN Isoform 12 of Sorbin and SH3 domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=SORBS2MSVTLTSVKRVQSSPNLLAAGRDSQSPDSAWRSYNDGNQETLNGDATYSSLAAKGFRSVRPNLQDKRSPTQSQITVNGNSGGAVSPMSYYQRPFSPSAYSLPASLNSSIVMQHGTSLDSTDTYPQHAQSLDGTTSSSIPLYRSSEEEKRVTVIKAPHYPGIGPVDESGIPTAIRTTVDRPKDWYKTMFKQIHMVHKPDDDTDMYNTPYTYNAGLYNPPYSAQSHPAAKTQTYRPLSKSHSDNSPNAFKDASSPVPPPHVPPPVPPLRPRDRSSTEKHDWDPPDRKVDTRKFRSEPRSIFEYEPGKSSILQHERPPPLPTTPTPVPREPGRKPLSSSRLGEVTGSPSPPPRSGAPTPSSRAPALSPTRPPKKPLDYVQDHSSGVFNEASLYQSSIDRSLERPMSSASMASDFRKRRKSEPAVGPPRGLGDQSASRTSPGRVDLPGSSTTLTKSFTSSSPSSPSRAKDRESPRSYSSTLTDMGRSAPRERRGTPEKEKLPAKAVYDFKAQTSKELSFKKGDTVYILRKIDQNWYEGEHHGRVGIFPISYVEKLTPPEKAQPARPPPPAQPGEIGEAIAKYNFNADTNVELSLRKGDRVILLKRVDQNWYEGKIPGTNRQGIFPVSYVEVVKKNTKGAEDYPDPPIPHSYSSDRIHSLSSNKPQRPVFTHENIQGGGEPFQALYNYTPRNEDELELRESDVIDVMEKCDDGWFVGTSRRTKFFGTFPGNYVKRL>sp|Q9C0H9|SRCN1_HUMAN SRC kinase signaling inhibitor 1 OS=Homo sapiensOX=9606 GN=SRCIN1 PE=1 SV=4MGNAPSQDPERSSPPMLSADDAEYPREYRTLGGGGGGGSGGRRFSNVGLVHTSERRHTVIAAQSLEALSGLQKADADRKRDAFMDHLKSKYPQHALALRGQQDRMREQPNYWSFKTRSSRHTQGAQPGLADQAAKLSYASAESLETMSEAELPLGFSRMNRFRQSLPLSRSASQTKLRSPGVLFLQFGEETRRVHITHEVSSLDTLHALIAHMFPQKLTMGMLKSPNTAILIKDEARNVFYELEDVRDIQDRSIIKIYRKEPLYAAFPGSHLTNGDLRREMVYASRESSPTRRLNNLSPAPHLASGSPPPGLPSGLPSGLQSGSPSRSRLSYAGGRPPSYAGSPVHHAAERLGGAPAAQGVSPSPSAILERRDVKPDEDLASKAGGMVLVKGEGLYADPYGLLHEGRLSLAAAAGDPFAYPGAGGLYKRGSVRSLSTYSAAALQSDLEDSLYKAAGGGGPLYGDGYGFRLPPSSPQKLADVAAPPGGPPPPHSPYSGPPSRGSPVRQSFRKDSGSSSVFAESPGGKTRSAGSASTAGAPPSELFPGPGERSLVGFGPPVPAKDTETRERMEAMEKQIASLTGLVQSALLRGSEPETPSEKIEGSNGAATPSAPCGSGGRSSGATPVSGPPPPSASSTPAGQPTAVSRLQMQLHLRGLQNSASDLRGQLQQLRKLQLQNQESVRALLKRTEAELSMRVSEAARRQEDPLQRQRTLVEEERLRYLNDEELITQQLNDLEKSVEKIQRDVSHNHRLVPGPELEEKALVLKQLGETLTELKAHFPGLQSKMRVVLRVEVEAVKFLKEEPQRLDGLLKRCRGVTDTLAQIRRQVDEGVWPPPNNLLSQSPKKVTAETDFNKSVDFEMPPPSPPLNLHELSGPAEGASLTPKGGNPTKGLDTPGKRSVDKAVSVEAAERDWEEKRAALTQYSAKDINRLLEETQAELLKAIPDLDCASKAHPGPAPTPDHKPPKAPHGQKAAPRTEPSGRRGSDELTVPRYRTEKPSKSPPPPPPRRSFPSSHGLTTTRTGEVVVTSKKDSAFIKKAESEELEVQKPQVKLRRAVSEVARPASTPPIMASAIKDEDDEDRIIAELESGGGSVPPMKVVTPGASRLKAAQGQAGSPDKSKHGKQRAEYMRIQAQQQATKPSKEMSGSNETSSPVSEKPSASRTSIPVLTSFGARNSSISF>sp|Q9C0H9-2|SRCN1_HUMAN Isoform 2 of SRC kinase signaling inhibitor 1OS=Homo sapiens OX=9606 GN=SRCIN1MRGAWVHLHSGAASSLRPCRCGAGAAPKSSPRSPGGRRGDGSSDSEGGVSFAGVLFLQFGEETRRVHITHEVSSLDTLHALIAHMFPQKLTMGMLKSPNTAILIKDEARNVFYELEDVRDIQDRSIIKIYRKEPLYAAFPGSHLTNGDLRREMVYASRESSPTRRLNNLSPAPHLASGSPPPGLPSGLPSGLQSGSPSRSRLSYAGGRPPSYAGSPVHHAAERLGGAPAAQGVSPSPSAILERRDVKPDEDLASKAGGMVLVKGEGLYADPYGLLHEGRLSLAAAAGDPFAYPGAGGLYKRGSVRSLSTYSAAALQSDLEDSLYKAAGGGGPLYGDGYGFRLPPSSPQKLADVAAPPGGPPPPHSPYSGPPSRGSPVRQSFRKDSGSSSVFAESPGGKTRSAGSASTAGAPPSELFPGPGERSLVGFGPPVPAKDTETRERMEAMEKQIASLTGLVQSALLRGSEPETPSEKIEGSNGAATPSAPCGSGGRSSGATPVSGPPPPSASSTPAGQPTAVSRLQMQLHLRGLQNSASDLRGQLQQLRKLQLQNQESVRALLKRTEAELSMRVSEAARRQEDPLQRQRTLVEEERLRYLNDEELITQQLNDLEKSVEKIQRDVSHNHRLVPGPELEEKALVLKQLGETLTELKAHFPGLQSKMRVVLRVEVEAVKFLKEEPQRLDGLLKRCRGVTDTLAQIRRQVDEGVWPPPNNLLSQSPKKVTAETDFNKSVDFEMPPPSPPLNLHELSGPAEGASLTPKGGNPTKGLDTPGKRSVDKAVSVEAAERDWEEKRAALTQYSAKDINRLLEETQAELLKAIPDLDCASKAHPGPAPTPDHKPPKAPHGQKAAPRTEPSGRRGSDELTVPRYRTEKPSKSPPPPPPRRSFPSSHGLTTTRTGEVVVTSKKDSAFIKKAESEELEVQKPQVKLRRAVSEVARPASTPPIMASAIKDEDDEDRIIAELESGGGSVPPMKVVTPGASRLKAAQGQAGSPDKSKHGKQRAEYMRIQAQQQA>sp|Q9C0H9-4|SRCN1_HUMAN Isoform 3 of SRC kinase signaling inhibitor 1OS=Homo sapiens OX=9606 GN=SRCIN1MRVSEAARRQEDPLQRQRTLVEEERLRYLNDEELITQQLNDLEKSVEKIQRDVSHNHRLVPGPELEEKALVLKQLGETLTELKAHFPGLQSKMRVVLRVEVEAVKFLKEEPQRLDGLLKRCRGVTDTLAQIRRQVDEGVWPPPNNLLSQSPKKVTAETDFNKSVDFEMPPPSPPLNLHELSGPAEGASLTPKGGNPTKGLDTPGKRSVDKAVSVEVLGPGIVGGAMSQVHTFLRPSFLEWGVPILWVFFLGGGGPVP>sp|Q8WYL5|SSH1_HUMAN Protein phosphatase Slingshot homolog 1 OS=Homosapiens OX=9606 GN=SSH1 PE=1 SV=2MALVTLQRSPTPSAASSSASNSELEAGSEEDRKLNLSLSESFFMVKGAALFLQQGSSPQGQRSLQHPHKHAGDLPQHLQVMINLLRCEDRIKLAVRLESAWADRVRYMVVVYSSGRQDTEENILLGVDFSSKESKSCTIGMVLRLWSDTKIHLDGDGGFSVSTAGRMHIFKPVSVQAMWSALQVLHKACEVARRHNYFPGGVALIWATYYESCISSEQSCINEWNAMQDLESTRPDSPALFVDKPTEGERTERLIKAKLRSIMMSQDLENVTSKEIRNELEKQMNCNLKELKEFIDNEMLLILGQMDKPSLIFDHLYLGSEWNASNLEELQGSGVDYILNVTREIDNFFPGLFAYHNIRVYDEETTDLLAHWNEAYHFINKAKRNHSKCLVHCKMGVSRSASTVIAYAMKEFGWPLEKAYNYVKQKRSITRPNAGFMRQLSEYEGILDASKQRHNKLWRQQTDSSLQQPVDDPAGPGDFLPETPDGTPESQLPFLDDAAQPGLGPPLPCCFRRLSDPLLPSPEDETGSLVHLEDPEREALLEEAAPPAEVHRPARQPQQGSGLCEKDVKKKLEFGSPKGRSGSLLQVEETEREEGLGAGRWGQLPTQLDQNLLNSENLNNNSKRSCPNGMEDDAIFGILNKVKPSYKSCADCMYPTASGAPEASRERCEDPNAPAICTQPAFLPHITSSPVAHLASRSRVPEKPASGPTEPPPFLPPAGSRRADTSGPGAGAALEPPASLLEPSRETPKVLPKSLLLKNSHCDKNPPSTEVVIKEESSPKKDMKPAKDLRLLFSNESEKPTTNSYLMQHQESIIQLQKAGLVRKHTKELERLKSVPADPAPPSRDGPASRLEASIPEESQDPAALHELGPLVMPSQAGSDEKSEAAPASLEGGSLKSPPPFFYRLDHTSSFSKDFLKTICYTPTSSSMSSNLTRSSSSDSIHSVRGKPGLVKQRTQEIETRLRLAGLTVSSPLKRSHSLAKLGSLTFSTEDLSSEADPSTVADSQDTTLSESSFLHEPQGTPRDPAATSKPSGKPAPENLKSPSWMSKS>sp|Q8WYL5-2|SSH1_HUMAN Isoform 2 of Protein phosphatase Slingshothomolog 1 OS=Homo sapiens OX=9606 GN=SSH1MALVTLQRSPTPSAASSSASNSELEAGSEEDRKLNLSLSESFFMVKGAALFLQQGSSPQGQRSLQHPHKHAGDLPQHLQVMINLLRCEDRIKLAVRLESAWADRVRYMVVVYSSGRQDTEENILLGVDFSSKESKSCTIGMVLRLWSDTKIHLDGDGGFSVSTAGRMHIFKPVSVQAMWSALQVLHKACEVARRHNYFPGGVALIWATYYESCISSEQSCINEWNAMQDLESTRPDSPALFVDKPTEGERTERLIKAKLRSIMMSQDLENVTSKEIRNELEKQMNCNLKELKEFIDNEMLLILGQMDKPSLIFDHLYLGSEWNASNLEELQGSGVDYILNVTREIDNFFPGLFAYHNIRVYDEETTDLLAHWNEAYHFINKAKRNHSKCLVHCKMGVSRSASTVIAYAMKEFGWPLEKAYNYVKQKRSITRPNAGFMRQLSEYEGILDASKQRHNKLWRQQTDSSLQQPVDDPAGPGDFLPETPDGTPESQLPFLDDAAQPGLGPPLPCCFRRLSDPLLPSPEDETGSLVHLEDPEREALLEEAAPPAEVHRPARQPQQGSGLCEKDVKKKLEFGSPKGRSGSLLQVEETEREEGLGAGRWGQLPTQLDQNLLNSENLNNNSKRSCPNGMEVGRARPAGWHTPSLPSHSNWPTSASVVGTTGTRHHTQLIFFYCLLWAPSSHLQGPEGSFTG>sp|Q8WYL5-3|SSH1_HUMAN Isoform 3 of Protein phosphatase Slingshothomolog 1 OS=Homo sapiens OX=9606 GN=SSH1MGGRHHLQRQVSESMSALFQAVRLESAWADRVRYMVVVYSSGRQDTEENILLGVDFSSKESGFSVSTAGRMHIFKPVSVQAMWSALQVLHKACEVARRHNYFPGGVALIWATYYESCISSEQSCINEWNAMQDLESTRPDSPALFVDK>sp|Q8WYL5-4|SSH1_HUMAN Isoform 4 of Protein phosphatase Slingshothomolog 1 OS=Homo sapiens OX=9606 GN=SSH1MRCYLSWDRWTSPPLSSIIFISVDYILNVTREIDNFFPGLFAYHNIRVYDEETTDLLAHWNEAYHFINKAKRNHSKCLVHCKMGVSRSASTVIAYAMKEFGWPLEKAYNYVKQKRSITRPNAGFMRQLSEYEGILDASKQRHNKLWRQQTDSSLQQPVDDPAGPGDFLPETPDGTPESQLPFLDDAAQPGLGPPLPCCFRRLSDPLLPSPEDETGSLVHLEDPEREALLEEAAPPAEVHRPARQPQQGSGLCEKDVKKKLEFGSPKGRSGSLLQVEETEREEGLGAGRWGQLPTQLDQNLLNSENLNNNSKRSCPNGMEDDAIFGILNKVKPSYKSCADCMYPTASGAPEASRERCEDPNAPAICTQPAFLPHITSSPVAHLASRSRVPEKPASGPTEPPPFLPPAGSRRADTSGPGAGAALEPPASLLEPSRETPKVLPKSLLLKNSHCDKNPPSTEVVIKEESSPKKDMKPAKDLRLLFSNESEKPTTNSYLMQHQESIIQLQKAGLVRKHTKELERLKSVPADPAPPSRDGPASRLEASIPEESQDPAALHELGPLVMPSQAGSDEKSEAAPASLEGGSLKSPPPFFYRLDHTSSFSKDFLKTICYTPTSSSMSSNLTRSSSSDSIHSVRGKPGLVKQRTQEIETRLRLAGLTVSSPLKRSHSLAKLGSLTFSTEDLSSEADPSTVADSQDTTLSESSFLHEPQGTPRDPAATSKPSGKPAPENLKSPSWMSKS>sp|Q8WYL5-5|SSH1_HUMAN Isoform 5 of Protein phosphatase Slingshothomolog 1 OS=Homo sapiens OX=9606 GN=SSH1MARARRAVVGSVRDVSTAATNLFYFTDFCIFLQPTHCFCCPEVSSSNYLSESFFMVKGAALFLQQGSSPQGQRSLQHPHKHAGDLPQHLQVMINLLRCEDRIKLAVRLESAWADRVRYMVVVYSSGRQDTEENILLGVDFSSKESKSCTIGMVLRLWSDTKIHLDGDGGFSVSTAGRMHIFKPVSVQAMWSALQVLHKACEVARRHNYFPGGVALIWATYYESCISSEQSCINEWNAMQDLESTRPDSPALFVDKPTEGERTERLIKAKLRSIMMSQDLENVTSKEIRNELEKQMNCNLKELKEFIDNEMLLILGQMDKPSLIFDHLYLGSEWNASNLEELQGSGVDYILNVTREIDNFFPGLFAYHNIRVYDEETTDLLAHWNEAYHFINKAKRNHSKCLVHCKMGVSRSASTVIAYAMKEFGWPLEKAYNYVKQKRSITRPNAGFMRQLSEYEGILDASKQRHNKLWRQQTDSSLQQPVDDPAGPGDFLPETPDGTPESQLPFLDDAAQPGLGPPLPCCFRRLSDPLLPSPEDETGSLVHLEDPEREALLEEAAPPAEVHRPARQPQQGSGLCEKDVKKKLEFGSPKGRSGSLLQVEETEREEGLGAGRWGQLPTQLDQNLLNSENLNNNSKRSCPNGMEVGRARPAGWHTPSLPSHSNWPTSASVVGTTGTRHHTQLIFFYCLLWAPSSHLQGPEGSFTG>sp|Q14714|SSPN_HUMAN Sarcospan OS=Homo sapiens OX=9606 GN=SSPN PE=2 SV=3MGKNKQPRGQQRQGGPPAADAAGPDDMEPKKGTGAPKECGEEEPRTCCGCRFPLLLALLQLALGIAVTVVGFLMASISSSLLVRDTPFWAGIIVCLVAYLGLFMLCVSYQVDERTCIQFSMKLLYFLLSALGLTVCVLAVAFAAHHYSQLTQFTCETTLDSCQCKLPSSEPLSRTFVYRDVTDCTSVTGTFKLFLLIQMILNLVCGLVCLLACFVMWKHRYQVFYVGVRICSLTASEGPQQKI>sp|Q14714-2|SSPN_HUMAN Isoform 2 of Sarcospan OS=Homo sapiens OX=9606GN=SSPNMGKNKQPRGQQRQGGPPAADAAGPDDMEPKKGTGAPKECGEEEPRTCCGCRFPLLLALLQLALGIAVTVVGFLMASISSSLLVRDTPFWAGIIVCLVAYLGLFMLCVHRYQVFYVGVRICSLTASEGPQQKI>sp|Q14714-3|SSPN_HUMAN Isoform 3 of Sarcospan OS=Homo sapiens OX=9606GN=SSPNMLCVSYQVDERTCIQFSMKLLYFLLSALGLTVCVLAVAFAAHHYSQLTQFTCETTLDSCQCKLPSSEPLSRTFVYRDVTDCTSVTGTFKLFLLIQMILNLVCGLVCLLACFVMWKHRYQVFYVGVRICSLTASEGPQQKI>sp|Q5W111|SPRY7_HUMAN SPRY domain-containing protein 7 OS=Homo sapiensOX=9606 GN=SPRYD7 PE=1 SV=2MATSVLCCLRCCRDGGTGHIPLKEMPAVQLDTQHMGTDVVIVKNGRRICGTGGCLASAPLHQNKSYFEFKIQSTGIWGIGVATQKVNLNQIPLGRDMHSLVMRNDGALYHNNEEKNRLPANSLPQEGDVVGITYDHVELNVYLNGKNMHCPASGIRGTVYPVVYVDDSAILDCQFSEFYHTPPPGFEKILFEQQIF>sp|Q5W111-2|SPRY7_HUMAN Isoform 2 of SPRY domain-containing protein 7OS=Homo sapiens OX=9606 GN=SPRYD7MATSVLCCLRCCRDGGTGHIPLKEMPAVQLDTQHMGIWGIGVATQKVNLNQIPLGRDMHSLVMRNDGALYHNNEEKNRLPANSLPQEGDVVGITYDHVELNVYLNGKNMHCPASGIRGTVYPVVYVDDSAILDCQFSEFYHTPPPGFEKILFEQQIF>sp|Q8IYB3|SRRM1_HUMAN Serine/arginine repetitive matrix protein 1OS=Homo sapiens OX=9606 GN=SRRM1 PE=1 SV=2MDAGFFRGTSAEQDNRFSNKQKKLLKQLKFAECLEKKVDMSKVNLEVIKPWITKRVTEILGFEDDVVIEFIFNQLEVKNPDSKMMQINLTGFLNGKNAREFMGELWPLLLSAQENIAGIPSAFLELKKEEIKQRQIEQEKLASMKKQDEDKDKRDKEEKESSREKRERSRSPRRRKSRSPSPRRRSSPVRRERKRSHSRSPRHRTKSRSPSPAPEKKEKTPELPEPSVKVKEPSVQEATSTSDILKVPKPEPIPEPKEPSPEKNSKKEKEKEKTRPRSRSRSKSRSRTRSRSPSHTRPRRRHRSRSRSYSPRRRPSPRRRPSPRRRTPPRRMPPPPRHRRSRSPVRRRRRSSASLSGSSSSSSSSRSRSPPKKPPKRTSSPPRKTRRLSPSASPPRRRHRPSPPATPPPKTRHSPTPQQSNRTRKSRVSVSPGRTSGKVTKHKGTEKRESPSPAPKPRKVELSESEEDKGGKMAAADSVQQRRQYRRQNQQSSSDSGSSSSSEDERPKRSHVKNGEVGRRRRHSPSRSASPSPRKRQKETSPRGRRRRSPSPPPTRRRRSPSPAPPPRRRRTPTPPPRRRTPSPPPRRRSPSPRRYSPPIQRRYSPSPPPKRRTASPPPPPKRRASPSPPPKRRVSHSPPPKQRSSPVTKRRSPSLSSKHRKGSSPSRSTREARSPQPNKRHSPSPRPRAPQTSSSPPPVRRGASSSPQRRQSPSPSTRPIRRVSRTPEPKKIKKAASPSPQSVRRVSSSRSVSGSPEPAAKKPPAPPSPVQSQSPSTNWSPAVPVKKAKSPTPSPSPPRNSDQEGGGKKKKKKKDKKHKKDKKHKKHKKHKKEKAVAAAAAAAVTPAAIAAATTTLAQEEPVAAPEPKKETESEAEDNLDDLEKHLREKALRSMRKAQVSPQS>sp|Q8IYB3-2|SRRM1_HUMAN Isoform 2 of Serine/arginine repetitive matrixprotein 1 OS=Homo sapiens OX=9606 GN=SRRM1MDAGFFRGTSAEQDNRFSNKQKKLLKQLKFAECLEKKVDMSKVNLEVIKPWITKRVTEILGFEDDVVIEFIFNQLEVKNPDSKMMQINLTGFLNGKNAREFMGELWPLLLSAQENIAGIPSAFLELKKEEIKQRQIEQEKLASMKKQDEDKDKRDKEEKESSREKRERSRSPRRRKSRSPSPRRRSSPVRRERKRSHSRSPRHRTKSRSPSPAPEKKEKTPELPEPSVKVKEPSVQEATSTSDILKVPKPEPIPEPKEPSPEKNSKKEKEKEKTRPRSRSRSKSRSRTRSRSPSHTRPRRRHRSDKMYSPRRRPSPRRRPSPRRRTPPRRMPPPPRHRRSRSPVRRRRRSSASLSGSSSSSSSSRSRSPPKKPPKRTSSPPRKTRRLSPSASPPRRRHRPSPPATPPKTRHSPTPQQSNRTRKSRVSVSPGRTSGKVTKHKGTEKRESPSPAPKPRKVELSESEEDKGGKMAAADSVQQRRQYRRQNQQSSSDSGSSSSSEDERPKRSHVKNGEVGRRRRHSPSRSASPSPRKRQKETSPRGRRRRSPSPPPTRRRRSPSPAPPPRRRRTPTPPPRRRTPSPPPRRRSPSPRRYSPPIQRRYSPSPPPKRRTASPPPPPKRRASPSPPPKRRVSHSPPPKQRSSPVTKRRSPSLSSKHRKGSSPSRSTREARSPQPNKRHSPSPRPRAPQTSSSPPPVRRGASSSPQRRQSPSPSTRPIRRVSRTPEPKKIKKAASPSPQSVRRVSSSRSVSGSPEPAAKKPPAPPSPVQSQSPSTNWSPAVPVKKAKSPTPSPSPPRNSDQEGGGKKKKKKKDKKHKKDKKHKKHKKHKKEKAVAAAAAAAVTPAAIAAATTTLAQEEPVAAPEPKKETESEAEDNLDDLEKHLREKALRSMRKAQVSPQS>sp|Q9NYA1|SPHK1_HUMAN Sphingosine kinase 1 OS=Homo sapiens OX=9606GN=SPHK1 PE=1 SV=1MDPAGGPRGVLPRPCRVLVLLNPRGGKGKALQLFRSHVQPLLAEAEISFTLMLTERRNHARELVRSEELGRWDALVVMSGDGLMHEVVNGLMERPDWETAIQKPLCSLPAGSGNALAASLNHYAGYEQVTNEDLLTNCTLLLCRRLLSPMNLLSLHTASGLRLFSVLSLAWGFIADVDLESEKYRRLGEMRFTLGTFLRLAALRTYRGRLAYLPVGRVGSKTPASPVVVQQGPVDAHLVPLEEPVPSHWTVVPDEDFVLVLALLHSHLGSEMFAAPMGRCAAGVMHLFYVRAGVSRAMLLRLFLAMEKGRHMEYECPYLVYVPVVAFRLEPKDGKGVFAVDGELMVSEAVQGQVHPNYFWMVSGCVEPPPSWKPQQMPPPEEPL>sp|Q9NYA1-2|SPHK1_HUMAN Isoform 2 of Sphingosine kinase 1 OS=Homosapiens OX=9606 GN=SPHK1MSAQVLGFLRSWTPLPLAAPRGPAAAGNDAGAPAATAPGGEGEPHSRPCDARLGSTDKELKAGAAATGSAPTAPGTPWQREPRVEVMDPAGGPRGVLPRPCRVLVLLNPRGGKGKALQLFRSHVQPLLAEAEISFTLMLTERRNHARELVRSEELGRWDALVVMSGDGLMHEVVNGLMERPDWETAIQKPLCSLPAGSGNALAASLNHYAGYEQVTNEDLLTNCTLLLCRRLLSPMNLLSLHTASGLRLFSVLSLAWGFIADVDLESEKYRRLGEMRFTLGTFLRLAALRTYRGRLAYLPVGRVGSKTPASPVVVQQGPVDAHLVPLEEPVPSHWTVVPDEDFVLVLALLHSHLGSEMFAAPMGRCAAGVMHLFYVRAGVSRAMLLRLFLAMEKGRHMEYECPYLVYVPVVAFRLEPKDGKGVFAVDGELMVSEAVQGQVHPNYFWMVSGCVEPPPSWKPQQMPPPEEPL>sp|Q9NYA1-3|SPHK1_HUMAN Isoform 3 of Sphingosine kinase 1 OS=Homosapiens OX=9606 GN=SPHK1MDPVVGCGRGLFGFVFSAGGPRGVLPRPCRVLVLLNPRGGKGKALQLFRSHVQPLLAEAEISFTLMLTERRNHARELVRSEELGRWDALVVMSGDGLMHEVVNGLMERPDWETAIQKPLCSLPAGSGNALAASLNHYAGYEQVTNEDLLTNCTLLLCRRLLSPMNLLSLHTASGLRLFSVLSLAWGFIADVDLESEKYRRLGEMRFTLGTFLRLAALRTYRGRLAYLPVGRVGSKTPASPVVVQQGPVDAHLVPLEEPVPSHWTVVPDEDFVLVLALLHSHLGSEMFAAPMGRCAAGVMHLFYVRAGVSRAMLLRLFLAMEKGRHMEYECPYLVYVPVVAFRLEPKDGKGVFAVDGELMVSEAVQGQVHPNYFWMVSGCVEPPPSWKPQQMPPPEEPL>sp|Q9Y4P9|SPEF1_HUMAN Sperm flagellar protein 1 OS=Homo sapiens OX=9606GN=SPEF1 PE=1 SV=3MASSVDEEALHQLYLWVDNIPLSRPKRNLSRDFSDGVLVAEVIKFYFPKMVEMHNYVPANSLQQKLSNWGHLNRKVLKRLNFSVPDDVMRKIAQCAPGVVELVLIPLRQRLEERQRRRKQGAGSLQELAPQDGSGYMDVGVSQKARGEGVPDPQGGGQLSWDRPPAPRPPAYNRALQGDPSFVLQIAEKEQELLASQETVQVLQMKVRRLEHLLQLKNVRIEDLSRRLQQAERKQR>sp|Q9Y4P9-2|SPEF1_HUMAN Isoform 2 of Sperm flagellar protein 1 OS=Homosapiens OX=9606 GN=SPEF1MASSVDEEALHQLYLWVDNIPLSRPKRNLSRDFSDGVLVAEVIKFYFPKMVEMHNYVPANSLQQKLSNWGHLNRKVLKRLNFSVPDDVMRKIAQCAPGVVELVLIPLRQRLEERQRRRKQGAGSLQELAPQDGSGYMDVGKVAFSISPSRLELSFCPSSCHL>sp|Q0P670|SPEM2_HUMAN Uncharacterized protein SPEM2 OS=Homo sapiensOX=9606 GN=SPEM2 PE=2 SV=2MENQLWHNTVRCCNQYQESPHDAEDILLLLLGLIVLVNIGINVATMMWHGLQNALDKMIDWATQKNEIQASESPPSGPPDKAQDVHIHCILDPVQVKMSRPTQYSSFSCHHFSNHHSSSLLRCVRRRRRRHRRCRRRCCNHQQRPQNYRQIPHSHSVFRNPHRSQKMSQLHRVPFFDQEDPDSYLEEEDNLPFPYPKYPRRGWGGFYQRAGLPSNVGLWGHQGGILASLPPPSLYLSPELRCMPKRVEARSELRLQSYGRHGSQSRLWGNVEAEQWASSPPPPHRLPPNPSWVPVGHSPYPSVGWMLYDSWDQRRRGTEGFERPPASVSRNARPEAQGCREHHSPQSHQQSLLGHAYGQSHRSPHPSTEPLGYSSQDPREVRRRAADWAEALPAWRPLTTSASLTVLDEASHQRTPAPSSVLVPHSSQPWPKVQAADPAPPPTMFVPLSRNPGGNANYQVYDSLELKRQVQKSRARSSSLPPASTSTLRPSLHRSQTEKLN>sp|Q9NWZ5|UCKL1_HUMAN Uridine-cytidine kinase-like 1 OS=Homo sapiensOX=9606 GN=UCKL1 PE=1 SV=2MAAPPARADADPSPTSPPTARDTPGRQAEKSETACEDRSNAESLDRLLPPVGTGRSPRKRTTSQCKSEPPLLRTSKRTIYTAGRPPWYNEHGTQSKEAFAIGLGGGSASGKTTVARMIIEALDVPWVVLLSMDSFYKVLTEQQQEQAAHNNFNFDHPDAFDFDLIISTLKKLKQGKSVKVPIYDFTTHSRKKDWKTLYGANVIIFEGIMAFADKTLLELLDMKIFVDTDSDIRLVRRLRRDISERGRDIEGVIKQYNKFVKPSFDQYIQPTMRLADIVVPRGSGNTVAIDLIVQHVHSQLEERELSVRAALASAHQCHPLPRTLSVLKSTPQVRGMHTIIRDKETSRDEFIFYSKRLMRLLIEHALSFLPFQDCVVQTPQGQDYAGKCYAGKQITGVSILRAGETMEPALRAVCKDVRIGTILIQTNQLTGEPELHYLRLPKDISDDHVILMDCTVSTGAAAMMAVRVLLDHDVPEDKIFLLSLLMAEMGVHSVAYAFPRVRIITTAVDKRVNDLFRIIPGIGNFGDRYFGTDAVPDGSDEEEVAYTG>sp|Q9NWZ5-2|UCKL1_HUMAN Isoform 2 of Uridine-cytidine kinase-like 1OS=Homo sapiens OX=9606 GN=UCKL1MAAPPARADADPSPTSPPTARDTPGRQAEKSETACEDRSNAESLDRLLPPVGTGRSPRKRTTSQCKSEPPLLRTSKRTIYTAGRPPWYNEHGTQSKEAFAIGLGGGSASGKTTVARMIIEALDVPWVVLLSMDSFYKVLTEQQQEQAAHNNFNFDHPDAFDFDLIISTLKKLKQGKSVKVPIYDFTTHSRKKDWKTLYGANVIIFEGIMAFADKTLLELLDMKIFVDTDSDIRLVRRLRRDISERGRDIEGVIKQYNKFVKPSFDQYIQPTMRLADIVVPRGSGNTVAIDLIVQHVHSQLEEGCAGLGTPVPPAAPDAERPEEHAAGTGHAHHHQVRAHLGTGRPRARAPAQLLAPQGQGDQSRRVHLLLQETDAAAHRARALLPALSGLRRTDPAGAGLCGQVLCGEADHRCVHSARR>sp|Q9NWZ5-3|UCKL1_HUMAN Isoform 3 of Uridine-cytidine kinase-like 1OS=Homo sapiens OX=9606 GN=UCKL1MAAPPARADADPSPTSPPTARDTPGRQAEKSETACEDRSNAESLDRLLPPVGTGRSPRKRTTSQCKSEPPLLRTSKRTIYTAGRPPWYNEHGTQSKEAFAIGLGGGSASGKTTVARMIIEALDVPWVVLLSMDSFYKVLTEQQQEQAAHNNFNFDHPDAFDFDLIISTLKKLKQGKSVKVPIYDFTTHSRKKDWKTLYGANVIIFEGIMAFADKTLLELLDMKIFVDTDSDIRLVRRLRRDISERGRDIEGVIKQYNKFVKPSFDQYIQPTMRLADIVVPRGSGNTVAIDLIVQHVHSQLEERELSVRAALASAHQCHPLPRTLSVLKSTPQVRGMHTIIRDKETSRDEFIFYSKRLMRLLIEHALSFLPFQDCVVQTPQGQDYADHRCVHSARR>sp|Q9NWZ5-4|UCKL1_HUMAN Isoform 4 of Uridine-cytidine kinase-like 1OS=Homo sapiens OX=9606 GN=UCKL1MSSPPAYPGIRISGCRALGAEGSSNAESLDRLLPPVGTGRSPRKRTTSQCKSEPPLLRTSKRTIYTAGRPPWYNEHGTQSKEAFAIGLGGGSASGKTTVARMIIEALDVPWVVLLSMDSFYKVLTEQQQEQAAHNNFNFDHPDAFDFDLIISTLKKLKQGKSVKVPIYDFTTHSRKKDWKTLYGANVIIFEGIMAFADKTLLELLDMKIFVDTDSDIRLVRRLRRDISERGRDIEGVIKQYNKFVKPSFDQYIQPTMRLADIVVPRGSGNTVAIDLIVQHVHSQLEERELSVRAALASAHQCHPLPRTLSVLKSTPQVRGMHTIIRDKETSRDEFIFYSKRLMRLLIEHALSFLPFQDCVVQTPQGQDYAGKCYAGKQITGVSILRAGETMEPALRAVCKDVRIGTILIQTNQLTGEPELHYLRLPKDISDDHVILMDCTVSTGAAAMMAVRVLLDHDVPEDKIFLLSLLMAEMGVHSVAYAFPRVRIITTAVDKRVNDLFRIIPGIGNFGDRYFGTDAVPDGSDEEEVAYTG>sp|A6NNY8|UBP27_HUMAN Ubiquitin carboxyl-terminal hydrolase 27 OS=Homosapiens OX=9606 GN=USP27X PE=1 SV=3MCKDYVYDKDIEQIAKEEQGEALKLQASTSTEVSHQQCSVPGLGEKFPTWETTKPELELLGHNPRRRRITSSFTIGLRGLINLGNTCFMNCIVQALTHTPILRDFFLSDRHRCEMPSPELCLVCEMSSLFRELYSGNPSPHVPYKLLHLVWIHARHLAGYRQQDAHEFLIAALDVLHRHCKGDDVGKAANNPNHCNCIIDQIFTGGLQSDVTCQACHGVSTTIDPCWDISLDLPGSCTSFWPMSPGRESSVNGESHIPGITTLTDCLRRFTRPEHLGSSAKIKCGSCQSYQESTKQLTMNKLPVVACFHFKRFEHSAKQRRKITTYISFPLELDMTPFMASSKESRMNGQLQLPTNSGNNENKYSLFAVVNHQGTLESGHYTSFIRHHKDQWFKCDDAVITKASIKDVLDSEGYLLFYHKQVLEHESEKVKEMNTQAY>sp|Q9UQF0|SYCY1_HUMAN Syncytin-1 OS=Homo sapiens OX=9606 GN=ERVW-1 PE=1SV=1MALPYHIFLFTVLLPSFTLTAPPPCRCMTSSSPYQEFLWRMQRPGNIDAPSYRSLSKGTPTFTAHTHMPRNCYHSATLCMHANTHYWTGKMINPSCPGGLGVTVCWTYFTQTGMSDGGGVQDQAREKHVKEVISQLTRVHGTSSPYKGLDLSKLHETLRTHTRLVSLFNTTLTGLHEVSAQNPTNCWICLPLNFRPYVSIPVPEQWNNFSTEINTTSVLVGPLVSNLEITHTSNLTCVKFSNTTYTTNSQCIRWVTPPTQIVCLPSGIFFVCGTSAYRCLNGSSESMCFLSFLVPPMTIYTEQDLYSYVISKPRNKRVPILPFVIGAGVLGALGTGIGGITTSTQFYYKLSQELNGDMERVADSLVTLQDQLNSLAAVVLQNRRALDLLTAERGGTCLFLGEECCYYVNQSGIVTEKVKEIRDRIQRRAEELRNTGPWGLLSQWMPWILPFLGPLAAIILLLLFGPCIFNLLVNFVSSRIEAVKLQMEPKMQSKTKIYRRPLDRPASPRSDVNDIKGTPPEEISAAQPLLRPNSAGSS>sp|A6NH52|TV23A_HUMAN Golgi apparatus membrane protein TVP23 homolog AOS=Homo sapiens OX=9606 GN=TVP23A PE=1 SV=3MKQALVDDTEDVSLDFGNEEELAFRKAKIRHPLATFFHLFFRVSAIVTYVSCDWFSKSFVGCFVMVLLLLSLDFWSVKNVTGRLLVGLRWWNQIDEDGKSHWIFEARKVSPNSIAATEAEARIFWLGLIICPMIWIVFFFSTLFSLKLKWLALVVAGISLQAANLYGYILCKMGGNSDIGKVTASFLSQTVFQTACPGDFQKPGLEGLEIHQH>sp|A6NH52-2|TV23A_HUMAN Isoform 2 of Golgi apparatus membrane proteinTVP23 homolog A OS=Homo sapiens OX=9606 GN=TVP23AMKQALVDDTEDVSLDFGNEEELAFRKAKIRDRVSKLLASVILLPWPPKVLGLKNVTGRLLVGLRWWNQIDEDGKSHWIFEARKVSPNSIAATEAEARIFWLGLIICPMIWIVFFFSTLFSLKLKWLALVVAGISLQAANLYGYILCKMGGNSDIGKVTASFLSQTVFQTACPGDFQKPGLEGLEIHQH>sp|A0A087WSZ9|TVA30_HUMAN T cell receptor alpha variable 30 OS=Homosapiens OX=9606 GN=TRAV30 PE=3 SV=1METLLKVLSGTLLWQLTWVRSQQPVQSPQAVILREGEDAVINCSSSKALYSVHWYRQKHGEAPVFLMILLKGGEQKGHDKISASFNEKKQQSSLYLTASQLSYSGTYFCGTE>sp|Q5T4T1|T170B_HUMAN Transmembrane protein 170B OS=Homo sapiens OX=9606GN=TMEM170B PE=1 SV=1MKAEGGDHSMINLSVQQVLSLWAHGTVLRNLTEMWYWIFLWALFSSLFVHGAAGVLMFVMLQRHRQGRVISVIAVSIGFLASVTGAMITSAAVAGIYRVAGKNMAPLEALVWGVGQTVLTLIISFSRILATL>sp|A0A075B6V5|TVA36_HUMAN T cell receptor alpha variable 36/deltavariable 7 OS=Homo sapiens OX=9606 GN=TRAV36DV7 PE=3 SV=1MMKCPQALLAIFWLLLSWVSSEDKVVQSPLSLVVHEGDTVTLNCSYEVTNFRSLLWYKQEKKAPTFLFMLTSSGIEKKSGRLSSILDKKELFSILNITATQTGDSAIYLCAVE>sp|Q9UMZ2|SYNRG_HUMAN Synergin gamma OS=Homo sapiens OX=9606 GN=SYNRGPE=1 SV=2MALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQAGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGPSLEEKFLVSCDISTSGQEQIKLNTSEVGHKALGPGSSKKYPSLMASNGVAVDGCVSGTTTAEAENTSDQNLSIEESGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQRGVPAMSPDALNQFPAAPIPTLSGFSMTLPTPVSQPTVIPSGPAGSMPLSLGQPVMGINLVGPVGGAAAQASSGFIPTYPANQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAADIEDLKYAAFGSYSSNFAVSTLTSYDWSDRDDATQGRKLSPFVLSAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRKEEKPAEEHPKKAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|Q9UMZ2-3|SYNRG_HUMAN Isoform 2 of Synergin gamma OS=Homo sapiensOX=9606 GN=SYNRGMALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQAGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQRGVPAMSPDALNQFPAAPIPTLSGFSMTLPTPVSQPTVIPSGPAGSMPLSLGQPVMGINLVGPVGGAAAQASSGFIPTYPANQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAADIEDLKYAAFGSYSSNFAVSTLTSYDWSDRDDATQGRKLSPFVLSAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRKEEKPAEEHPKKAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|Q9UMZ2-4|SYNRG_HUMAN Isoform 3 of Synergin gamma OS=Homo sapiensOX=9606 GN=SYNRGMALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQAGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQRGVPAMSPDALNQFPAAPIPTLSGFSMTLPTPVSQPTVIPSGPAGSMPLSLGQPVMGINLVGPVGGAAAQASSGFIPTYPANQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAADIEDLKYAAFGSYSSNFAVSTLTSYDWSDRDDATQGRKLSPFVLSAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|Q9UMZ2-5|SYNRG_HUMAN Isoform 4 of Synergin gamma OS=Homo sapiensOX=9606 GN=SYNRGMALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQAGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGPSLEEKFLVSCDISTSGQEQIKLNTSEVGHKALGPGSSKKYPSLMASNGVAVDGCVSGTTTAEAENTSDQNLSIEESGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQRGVPAMSPDALNQFPAAPIPTLSGFSMTLPTPVSQPTVIPSGPAGSMPLSLGQPVMGINLVGPVGGAAAQASSGFIPTYPANQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAADIEDLKYAAFGSYSSNFAVSTLTSYDWSDRDDATQGRKLSPFVLSAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|Q9UMZ2-6|SYNRG_HUMAN Isoform 5 of Synergin gamma OS=Homo sapiensOX=9606 GN=SYNRGMALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQAGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAAAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRKEEKPAEEHPKKAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|Q9UMZ2-7|SYNRG_HUMAN Isoform 6 of Synergin gamma OS=Homo sapiensOX=9606 GN=SYNRGMALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQAGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQRGVPAMSPDALNQFPAAPIPTLSGFSMTLPTPVSQPTVIPSGPAGSMPLSLGQPVMGINLVGPVGGAAAQASSGFIPTYPANQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAADIEDLKYAAFGSYSSNFAVSTLTSYDWSDRDDATQGRKLSPFVLSAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTCCWEKMTVITKHLSPYHELLEEKPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRKEEKPAEEHPKKAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|Q9UMZ2-8|SYNRG_HUMAN Isoform 7 of Synergin gamma OS=Homo sapiensOX=9606 GN=SYNRGMALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQRGVPAMSPDALNQFPAAPIPTLSGFSMTLPTPVSQPTVIPSGPAGSMPLSLGQPVMGINLVGPVGGAAAQASSGFIPTYPANQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAADIEDLKYAAFGSYSSNFAVSTLTSYDWSDRDDATQGRKLSPFVLSAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRKEEKPAEEHPKKAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|Q9UMZ2-9|SYNRG_HUMAN Isoform 8 of Synergin gamma OS=Homo sapiensOX=9606 GN=SYNRGMALRPGAGSGGGGAAGAGAGSAGGGGFMFPVAGGIRPPQAGLMPMQQQGFPMVSVMQPNMQGIMGMNYSSQMSQGPIAMQAGIPMGPMPAAGMPYLGQAPFLGMRPPGPQYTPDMQKQFAEEQQKRFEQQQKLLEEERKRRQFEEQKQKLRLLSSVKPKTGEKSRDDALEAIKGNLDGFSRDAKMHPTPASHPKKPGVGVFPSQDPAQPRMPPWIYNESLVPDAYKKILETTMTPTGIDTAKLYPILMSSGLPRETLGQIWALANRTTPGKLTKEELYTVLAMIAVTQRGVPAMSPDALNQFPAAPIPTLSGFSMTLPTPVSQPTVIPSGPAGSMPLSLGQPVMGINLVGPVGGAAAQASSGFIPTYPANQVVKPEEDDFQDFQDASKSGSLDDSFSDFQELPASSKTSNSQHGNSAPSLLMPLPGTKALPSMDKYAVFKGIAADKSSENTVPPGDPGDKYSAFRELEQTAENKPLGESFAEFRSAGTDDGFTDFKTADSVSPLEPPTKDKTFPPSFPSGTIQQKQQTQVKNPLNLADLDMFSSVNCSSEKPLSFSAVFSTSKSVSTPQSTGSAATMTALAATKTSSLADDFGEFSLFGEYSGLAPVGEQDDFADFMAFSNSSISSEQKPDDKYDALKEEASPVPLTSNVGSTVKGGQNSTAASTKYDVFRQLSLEGSGLGVEDLKDNTPSGKSDDDFADFHSSKFSSINSDKSLGEKAVAFRHTKEDSASVKSLDLPSIGGSSVGKEDSEDALSVQFDMKLADVGGDLKHVMSDSSLDLPTVSGQHPPAAAGSGSPSATSILQKKETSFGSSENITMTSLSKVTTFVSEDALPETTFPALASFKDTIPQTSEQKEYENRDYKDFTKQDLPTAERSQEATCPSPASSGASQETPNECSDDFGEFQSEKPKISKFDFLVATSQSKMKSSEEMIKSELATFDLSVQGSHKRSLSLGDKEISRSSPSPALEQPFRDRSNTLNEKPALPVIRDKYKDLTGEVEENERYAYEWQRCLGSALNVIKKANDTLNGISSSSVCTEVIQSAQGMEYLLGVVEVYRVTKRVELGIKATAVCSEKLQQLLKDIDKVWNNLIGFMSLATLTPDENSLDFSSCMLRPGIKNAQELACGVCLLNVDSRSRAFNSETDSFKLAYGGHQYHASCANFWINCVEPKPPGLVLPDLL>sp|A0A0B4J244|TVA3_HUMAN T cell receptor alpha variable 3 OS=Homosapiens OX=9606 GN=TRAV3 PE=3 SV=1MASAPISMLAMLFTLSGLRAQSVAQPEDQVNVAEGNPLTVKCTYSVSGNPYLFWYVQYPNRGLQFLLKYITGDNLVKGSYGFEAEFNKSQTSFHLKKPSALVSDSALYFCAVRD>sp|Q2T9J0|TYSD1_HUMAN Peroxisomal leader peptide-processing proteaseOS=Homo sapiens OX=9606 GN=TYSND1 PE=1 SV=3MRRQWGSAMRAAEQAGCMVSASRAGQPEAGPWSCSGVILSRSPGLVLCHGGIFVPFLRAGSEVLTAAGAVFLPGDSCRDDLRLHVQWAPTAAGPGGGAERGRPGLCTPQCASLEPGPPAPSRGRPLQPRLPAELLLLLSCPAFWAHFARLFGDEAAEQWRFSSAARDDEVSEDEEADQLRALGWFALLGVRLGQEEVEEERGPAMAVSPLGAVPKGAPLLVCGSPFGAFCPDIFLNTLSCGVLSNVAGPLLLTDARCLPGTEGGGVFTARPAGALVALVVAPLCWKAGEWVGFTLLCAAAPLFRAARDALHRLPHSTAALAALLPPEVGVPWGLPLRDSGPLWAAAAVLVECGTVWGSGVAVAPRLVVTCRHVSPREAARVLVRSTTPKSVAIWGRVVFATQETCPYDIAVVSLEEDLDDVPIPVPAEHFHEGEAVSVVGFGVFGQSCGPSVTSGILSAVVQVNGTPVMLQTTCAVHSGSSGGPLFSNHSGNLLGIITSNTRDNNTGATYPHLNFSIPITVLQPALQQYSQTQDLGGLRELDRAAEPVRVVWRLQRPLAEAPRSKL>sp|Q2T9J0-2|TYSD1_HUMAN Isoform 2 of Peroxisomal leader peptide-processing protease OS=Homo sapiens OX=9606 GN=TYSND1MRRQWGSAMRAAEQAGCMVSASRAGQPEAGPWSCSGVILSRSPGLVLCHGGIFVPFLRAGSEVLTAAGAVFLPGDSCRDDLRLHVQWAPTAAGPGGGAERGRPGLCTPQCASLEPGPPAPSRGRPLQPRLPAELLLLLSCPAFWAHFARLFGDEAAEQWRFSSAARDDEVSEDEEADQLRALGWFALLGVRLGQEEVEEERGPAMAVSPLGAVPKGAPLLVCGSPFGAFCPDIFLNTLSCGVLSNVAGPLLLTDARCLPGTEGGGVFTARPAGALVALVVAPLCWKAGEWVGFTLLCAAAPLFRAARDALHRLPHSTAALAALLPPEVGVPWGLPLRDSGPLWAAAAVLVECGTVWGSGVAVAPRLVVTCRHVSPREAARVLVRSTTPKHNHQQHPGQ>sp|A0A0B4J280|TVA40_HUMAN T cell receptor alpha variable 40 OS=Homosapiens OX=9606 GN=TRAV40 PE=3 SV=1MNSSLDFLILILMFGGTSSNSVKQTGQITVSEGASVTMNCTYTSTGYPTLFWYVEYPSKPLQLLQRETMENSKNFGGGNIKDKNSPIVKYSVQVSDSAVYYCLLG>sp|A0A0B4J266|TVA41_HUMAN T cell receptor alpha variable 41 OS=Homosapiens OX=9606 GN=TRAV41 PE=3 SV=1MVKIRQFLLAILWLQLSCVSAAKNEVEQSPQNLTAQEGEFITINCSYSVGISALHWLQQHPGGGIVSLFMLSSGKKKHGRLIATINIQEKHSSLHITASHPRDSAVYICAVR>sp|A0A0B4J268|TVA4_HUMAN T cell receptor alpha variable 4 OS=Homosapiens OX=9606 GN=TRAV4 PE=1 SV=1MRQVARVIVFLTLSTLSLAKTTQPISMDSYEGQEVNITCSHNNIATNDYITWYQQFPSQGPRFIIQGYKTKVTNEVASLFIPADRKSSTLSLPRVSLSDTAVYYCLVGD>sp|A0A0B4J249|TVA5_HUMAN T cell receptor alpha variable 5 OS=Homosapiens OX=9606 GN=TRAV5 PE=3 SV=1MKTFAGFSFLFLWLQLDCMSRGEDVEQSLFLSVREGDSSVINCTYTDSSSTYLYWYKQEPGAGLQLLTYIFSNMDMKQDQRLTVLLNKKDKHLSLRIADTQTGDSAIYFCAES>sp|A0A075B6T7|TVA6_HUMAN T cell receptor alpha variable 6 OS=Homosapiens OX=9606 GN=TRAV6 PE=3 SV=2MAFWLRSLGLHFRPHLGRRMESFLGGVLLILWLQVDWVKSQKIEQNSEALNIQEGKTATLTCNYTNYSPAYLQWYRQDPGRGPVFLLLIRENEKEKRKERLKVTFDTTLKQSLFHITASQPADSATYLCALD>sp|P0CG48|UBC_HUMAN Polyubiquitin-C OS=Homo sapiens OX=9606 GN=UBC PE=1SV=3MQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGV>sp|A0A075B6U4|TVA7_HUMAN T cell receptor alpha variable 7 OS=Homosapiens OX=9606 GN=TRAV7 PE=3 SV=1MEKMRRPVLIIFCLCLGWANGENQVEHSPHFLGPQQGDVASMSCTYSVSRFNNLQWYRQNTGMGPKHLLSMYSAGYEKQKGRLNATLLKNGSSLYITAVQPEDSATYFCAVD>sp|A0A0A6YYK1|TVA81_HUMAN T cell receptor alpha variable 8-1 OS=Homosapiens OX=9606 GN=TRAV8-1 PE=3 SV=5MLLLLIPVLGMIFALRDARAQSVSQHNHHVILSEAASLELGCNYSYGGTVNLFWYVQYPGQHLQLLLKYFSGDPLVKGIKGFEAEFIKSKFSFNLRKPSVQWSDTAEYFCAVN>sp|A2RUC4|TYW5_HUMAN tRNA wybutosine-synthesizing protein 5 OS=Homosapiens OX=9606 GN=TYW5 PE=1 SV=1MAGQHLPVPRLEGVSREQFMQHLYPQRKPLVLEGIDLGPCTSKWTVDYLSQVGGKKEVKIHVAAVAQMDFISKNFVYRTLPFDQLVQRAAEEKHKEFFVSEDEKYYLRSLGEDPRKDVADIRKQFPLLKGDIKFPEFFKEEQFFSSVFRISSPGLQLWTHYDVMDNLLIQVTGKKRVVLFSPRDAQYLYLKGTKSEVLNIDNPDLAKYPLFSKARRYECSLEAGDVLFIPALWFHNVISEEFGVGVNIFWKHLPSECYDKTDTYGNKDPTAASRAAQILDRALKTLAELPEEYRDFYARRMVLHIQDKAYSKNSE>sp|A2RUC4-2|TYW5_HUMAN Isoform 2 of tRNA wybutosine-synthesizing protein5 OS=Homo sapiens OX=9606 GN=TYW5MDNLLIQVTGKKRVVLFSPRDAQYLYLKGTKSEVLNIDNPDLAKYPLFSKARRYECSLEAGDVLFIPALWFHNVISEEFGVGVNIFWKHLPSECYDKTDTYGNKDPTAASRAAQILDRALKTLAELPEEYRDFYARRMVLHIQDKAYSKNSE>sp|A0A0B4J237|TVA82_HUMAN T cell receptor alpha variable 8-2 OS=Homosapiens OX=9606 GN=TRAV8-2 PE=3 SV=1MLLLLVPVLEVIFTLGGTRAQSVTQLDSHVSVSEGTPVLLRCNYSSSYSPSLFWYVQHPNKGLQLLLKYTSAATLVKGINGFEAEFKKSETSFHLTKPSAHMSDAAEYFCVVS>sp|A0A0A6YYJ7|TVA83_HUMAN T cell receptor alpha variable 8-3 OS=Homosapiens OX=9606 GN=TRAV8-3 PE=3 SV=5MLLELIPLLGIHFVLRTARAQSVTQPDIHITVSEGASLELRCNYSYGATPYLFWYVQSPGQGLQLLLKYFSGDTLVQGIKGFEAEFKRSQSSFNLRKPSVHWSDAAEYFCAVG>sp|P01737|TVA84_HUMAN T cell receptor alpha variable 8-4 OS=Homo sapiensOX=9606 GN=TRAV8-4 PE=2 SV=2MLLLLVPVLEVIFTLGGTRAQSVTQLGSHVSVSEGALVLLRCNYSSSVPPYLFWYVQYPNQGLQLLLKYTSAATLVKGINGFEAEFKKSETSFHLTKPSAHMSDAAEYFCAVS>sp|A0A0B4J262|TVA86_HUMAN T cell receptor alpha variable 8-6 OS=Homosapiens OX=9606 GN=TRAV8-6 PE=3 SV=1MLLLLVPAFQVIFTLGGTRAQSVTQLDSQVPVFEEAPVELRCNYSSSVSVYLFWYVQYPNQGLQLLLKYLSGSTLVESINGFEAEFNKSQTSFHLRKPSVHISDTAEYFCAVS>sp|P25490|TYY1_HUMAN Transcriptional repressor protein YY1 OS=Homosapiens OX=9606 GN=YY1 PE=1 SV=2MASGDTLYIATDGSEMPAEIVELHEIEVETIPVETIETTVVGEEEEEDDDDEDGGGGDHGGGGGHGHAGHHHHHHHHHHHPPMIALQPLVTDDPTQVHHHQEVILVQTREEVVGGDDSDGLRAEDGFEDQILIPVPAPAGGDDDYIEQTLVTVAAAGKSGGGGSSSSGGGRVKKGGGKKSGKKSYLSGGAGAAGGGGADPGNKKWEQKQVQIKTLEGEFSVTMWSSDEKKDIDHETVVEEQIIGENSPPDYSEYMTGKKLPPGGIPGIDLSDPKQLAEFARMKPRKIKEDDAPRTIACPHKGCTKMFRDNSAMRKHLHTHGPRVHVCAECGKAFVESSKLKRHQLVHTGEKPFQCTFEGCGKRFSLDFNLRTHVRIHTGDRPYVCPFDGCNKKFAQSTNLKSHILTHAKAKNNQ>sp|A0A075B6T8|TVA91_HUMAN T cell receptor alpha variable 9-1 OS=Homosapiens OX=9606 GN=TRAV9-1 PE=3 SV=1MNSSPGPAIALFLMFGGINGDSVVQTEGQVLPSEGDSLIVNCSYETTQYPSLFWYVQYPGEGPQLHLKAMKANDKGRNKGFEAMYRKETTSFHLEKDSVQESDSAVYFCALS>sp|A0A087WT02|TVA92_HUMAN T cell receptor alpha variable 9-2 OS=Homosapiens OX=9606 GN=TRAV9-2 PE=3 SV=1MNYSPGLVSLILLLLGRTRGDSVTQMEGPVTLSEEAFLTINCTYTATGYPSLFWYVQYPGEGLQLLLKATKADDKGSNKGFEATYRKETTSFHLEKGSVQVSDSAVYFCALS>sp|O15205|UBD_HUMAN Ubiquitin D OS=Homo sapiens OX=9606 GN=UBD PE=1 SV=2MAPNASCLCVHVRSEEWDLMTFDANPYDSVKKIKEHVRSKTKVPVQDQVLLLGSKILKPRRSLSSYGIDKEKTIHLTLKVVKPSDEELPLFLVESGDEAKRHLLQVRRSSSVAQVKAMIETKTGIIPETQIVTCNGKRLEDGKMMADYGIRKGNLLFLACYCIGG>sp|A0A0B4J245|TVAL1_HUMAN T cell receptor alpha variable 12-1 OS=Homosapiens OX=9606 GN=TRAV12-1 PE=3 SV=1MISLRVLLVILWLQLSWVWSQRKEVEQDPGPFNVPEGATVAFNCTYSNSASQSFFWYRQDCRKEPKLLMSVYSSGNEDGRFTAQLNRASQYISLLIRDSKLSDSATYLCVVN>sp|A0A075B6T6|TVAL2_HUMAN T cell receptor alpha variable 12-2 OS=Homosapiens OX=9606 GN=TRAV12-2 PE=1 SV=1MKSLRVLLVILWLQLSWVWSQQKEVEQNSGPLSVPEGAIASLNCTYSDRGSQSFFWYRQYSGKSPELIMFIYSNGDKEDGRFTAQLNKASQYVSLLIRDSQPSDSATYLCAVN>sp|O15391|TYY2_HUMAN Transcription factor YY2 OS=Homo sapiens OX=9606GN=YY2 PE=2 SV=1MASNEDFSITQDLEIPADIVELHDINVEPLPMEDIPTESVQYEDVDGNWIYGGHNHPPLMVLQPLFTNTGYGDHDQEMLMLQTQEEVVGYCDSDNQLGNDLEDQLALPDSIEDEHFQMTLASLSASAASTSTSTQSRSKKPSKKPSGKSATSTEANPAGSSSSLGTRKWEQKQMQVKTLEGEFSVTMWSPNDNNDQGAVGEGQAENPPDYSEYLKGKKLPPGGLPGIDLSDPKQLAEFTKVKPKRSKGEPPKTVPCSYSGCEKMFRDYAAMRKHLHIHGPRVHVCAECGKAFLESSKLRRHQLVHTGEKPFQCTFEGCGKRFSLDFNLRTHLRIHTGDKPFVCPFDVCNRKFAQSTNLKTHILTHVKTKNNP>sp|A0A0B4J271|TVAL3_HUMAN T cell receptor alpha variable 12-3 OS=Homosapiens OX=9606 GN=TRAV12-3 PE=1 SV=1MMKSLRVLLVILWLQLSWVWSQQKEVEQDPGPLSVPEGAIVSLNCTYSNSAFQYFMWYRQYSRKGPELLMYTYSSGNKEDGRFTAQVDKSSKYISLFIRDSQPSDSATYLCAMS>sp|A0A0B4J241|TVAM1_HUMAN T cell receptor alpha variable 13-1 OS=Homosapiens OX=9606 GN=TRAV13-1 PE=3 SV=1MTSIRAVFIFLWLQLDLVNGENVEQHPSTLSVQEGDSAVIKCTYSDSASNYFPWYKQELGKGPQLIIDIRSNVGEKKDQRIAVTLNKTAKHFSLHITETQPEDSAVYFCAAS>sp|A0A0B4J235|TVAM2_HUMAN T cell receptor alpha variable 13-2 OS=Homosapiens OX=9606 GN=TRAV13-2 PE=3 SV=1MAGIRALFMYLWLQLDWVSRGESVGLHLPTLSVQEGDNSIINCAYSNSASDYFIWYKQESGKGPQFIIDIRSNMDKRQGQRVTVLLNKTVKHLSLQIAATQPGDSAVYFCAEN>sp|A0A087WT03|TVAZ1_HUMAN T cell receptor alpha variable 26-1 OS=Homosapiens OX=9606 GN=TRAV26-1 PE=3 SV=1MRLVARVTVFLTFGTIIDAKTTQPTSMDCAEGRAANLPCNHSTISGNEYVYWYRQIHSQGPQYIIHGLKNNETNEMASLIITEDRKSSTLILPHATLRDTAVYYCIVRV>sp|A0A0B4J265|TVAZ2_HUMAN T cell receptor alpha variable 26-2 OS=Homosapiens OX=9606 GN=TRAV26-2 PE=3 SV=1MKLVTSITVLLSLGIMGDAKTTQPNSMESNEEEPVHLPCNHSTISGTDYIHWYRQLPSQGPEYVIHGLTSNVNNRMASLAIAEDRKSSTLILHRATLRDAAVYYCILRD>sp|P49459|UBE2A_HUMAN Ubiquitin-conjugating enzyme E2 A OS=Homo sapiensOX=9606 GN=UBE2A PE=1 SV=2MSTPARRRLMRDFKRLQEDPPAGVSGAPSENNIMVWNAVIFGPEGTPFEDGTFKLTIEFTEEYPNKPPTVRFVSKMFHPNVYADGSICLDILQNRWSPTYDVSSILTSIQSLLDEPNPNSPANSQAAQLYQENKREYEKRVSAIVEQSWRDC>sp|P49459-2|UBE2A_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 AOS=Homo sapiens OX=9606 GN=UBE2AMSTPARRRLMRDFKRLQEDPPAGVSGAPSENNIMVWNAVIFGPEGTPFEDVYADGSICLDILQNRWSPTYDVSSILTSIQSLLDEPNPNSPANSQAAQLYQENKREYEKRVSAIVEQSWRDC>sp|P49459-3|UBE2A_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 AOS=Homo sapiens OX=9606 GN=UBE2AMFHPNVYADGSICLDILQNRWSPTYDVSSILTSIQSLLDEPNPNSPANSQAAQLYQENKREYEKRVSAIVEQSWRDC>sp|A0A0A6YYD4|TVB13_HUMAN T cell receptor beta variable 13 OS=Homosapiens OX=9606 GN=TRBV13 PE=3 SV=5MLSPDLPDSAWNTRLLCRVMLCLLGAGSVAAGVIQSPRHLIKEKRETATLKCYPIPRHDTVYWYQQGPGQDPQFLISFYEKMQSDKGSIPDRFSAQQFSDYHSELNMSSLELGDSALYFCASSL>sp|P10074|TZAP_HUMAN Telomere zinc finger-associated protein OS=Homosapiens OX=9606 GN=ZBTB48 PE=1 SV=2MDGSFVQHSVRVLQELNKQREKGQYCDATLDVGGLVFKAHWSVLACCSHFFQSLYGDGSGGSVVLPAGFAEIFGLLLDFFYTGHLALTSGNRDQVLLAARELRVPEAVELCQSFKPKTSVGQAAGGQSGLGPPASQNVNSHVKEPAGLEEEEVSRTLGLVPRDQEPRGSHSPQRPQLHSPAQSEGPSSLCGKLKQALKPCPLEDKKPEDCKVPPRPLEAEGAQLQGGSNEWEVVVQVEDDGDGDYMSEPEAVLTRRKSNVIRKPCAAEPALSAGSLAAEPAENRKGTAVPVECPTCHKKFLSKYYLKVHNRKHTGEKPFECPKCGKCYFRKENLLEHEARNCMNRSEQVFTCSVCQETFRRRMELRVHMVSHTGEMPYKCSSCSQQFMQKKDLQSHMIKLHGAPKPHACPTCAKCFLSRTELQLHEAFKHRGEKLFVCEECGHRASSRNGLQMHIKAKHRNERPHVCEFCSHAFTQKANLNMHLRTHTGEKPFQCHLCGKTFRTQASLDKHNRTHTGERPFSCEFCEQRFTEKGPLLRHVASRHQEGRPHFCQICGKTFKAVEQLRVHVRRHKGVRKFECTECGYKFTRQAHLRRHMEIHDRVENYNPRQRKLRNLIIEDEKMVVVALQPPAELEVGSAEVIVESLAQGGLASQLPGQRLCAEESFTGPGVLEPSLIITAAVPEDCDT>sp|A0A5B0|TVB14_HUMAN T cell receptor beta variable 14 OS=Homo sapiensOX=9606 GN=TRBV14 PE=3 SV=1MVSRLLSLVSLCLLGAKHIEAGVTQFPSHSVIEKGQTVTLRCDPISGHDNLYWYRRVMGKEIKFLLHFVKESKQDESGMPNNRFLAERTGGTYSTLKVQPAELEDSGVYFCASSQ>sp|A0A087WV62|TVB16_HUMAN T cell receptor beta variable 16 OS=Homosapiens OX=9606 GN=TRBV16 PE=3 SV=6MSPIFTCITILCLLAAGSPGEEVAQTPKHLVRGEGQKAKLYCAPIKGHSYVFWYQQVLKNEFKFLISFQNENVFDETGMPKERFSAKCLPNSPCSLEIQATKLEDSAVYFCASSQ>sp|P63146|UBE2B_HUMAN Ubiquitin-conjugating enzyme E2 B OS=Homo sapiensOX=9606 GN=UBE2B PE=1 SV=1MSTPARRRLMRDFKRLQEDPPVGVSGAPSENNIMQWNAVIFGPEGTPFEDGTFKLVIEFSEEYPNKPPTVRFLSKMFHPNVYADGSICLDILQNRWSPTYDVSSILTSIQSLLDEPNPNSPANSQAAQLYQENKREYEKRVSAIVEQSWNDS>sp|A0A087X0K7|TVB17_HUMAN Probable non-functional T cell receptor betavariable 17 OS=Homo sapiens OX=9606 GN=TRBV17 PE=1 SV=6MDIWLLCWVTLCLLAAGHSEPGVSQTPRHKVTNMGQEVILRCDPSSGHMFVHWYRQNLRQEMKLLISFQYQNIAVDSGMPKERFTAERPNGTSSTLKIHPAEPRDSAVYLYSSG>sp|A0A087X0M5|TVB18_HUMAN T cell receptor beta variable 18 OS=Homosapiens OX=9606 GN=TRBV18 PE=3 SV=6MDTRLLCCAVICLLGAGLSNAGVMQNPRHLVRRRGQEARLRCSPMKGHSHVYWYRQLPEEGLKFMVYLQKENIIDESGMPKERFSAEFPKEGPSILRIQQVVRGDSAAYFCASSP>sp|A0A075B6N1|TVB19_HUMAN T cell receptor beta variable 19 OS=Homosapiens OX=9606 GN=TRBV19 PE=1 SV=2MSNQVLCCVVLCLLGANTVDGGITQSPKYLFRKEGQNVTLSCEQNLNHDAMYWYRQDPGQGLRLIYYSQIVNDFQKGDIAEGYSVSREKKESFPLTVTSAQKNPTAFYLCASSI>sp|A0A0A0MS06|TVB23_HUMAN Probable non-functional T cell receptor betavariable 23-1 OS=Homo sapiens OX=9606 GN=TRBV23-1 PE=1 SV=6MGTRLLGCAALCLLAADSFHAKVTQTPGHLVKGKGQKTKMDCTPEKGHTFVYWYQQNQNKEFMLLISFQNEQVLQETEMHKKRFSSQCPKNAPCSLAILSSEPGDTALYLCASSQ>sp|A0A0K0K1C4|TVB27_HUMAN T cell receptor beta variable 27 OS=Homosapiens OX=9606 GN=TRBV27 PE=3 SV=3MGPQLLGYVVLCLLGAGPLEAQVTQNPRYLITVTGKKLTVTCSQNMNHEYMSWYRQDPGLGLRQIYYSMNVEVTDKGDVPEGYKVSRKEKRNFPLILESPSPNQTSLYFCASSL>sp|A0A5B6|TVB28_HUMAN T cell receptor beta variable 28 OS=Homo sapiensOX=9606 GN=TRBV28 PE=1 SV=1MGIRLLCRVAFCFLAVGLVDVKVTQSSRYLVKRTGEKVFLECVQDMDHENMFWYRQDPGLGLRLIYFSYDVKMKEKGDIPEGYSVSREKKERFSLILESASTNQTSMYLCASSL>sp|O00762|UBE2C_HUMAN Ubiquitin-conjugating enzyme E2 C OS=Homo sapiensOX=9606 GN=UBE2C PE=1 SV=1MASQNRDPAATSVAAARKGAEPSGGAARGPVGKRLQQELMTLMMSGDKGISAFPESDNLFKWVGTIHGAAGTVYEDLRYKLSLEFPSGYPYNAPTVKFLTPCYHPNVDTQGNICLDILKEKWSALYDVRTILLSIQSLLGEPNIDSPLNTHAAELWKNPTAFKKYLQETYSKQVTSQEP>sp|O00762-2|UBE2C_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 COS=Homo sapiens OX=9606 GN=UBE2CMTLMMSGDKGISAFPESDNLFKWVGTIHGAAGTVYEDLRYKLSLEFPSGYPYNAPTVKFLTPCYHPNVDTQGNICLDILKEKWSALYDVRTILLSIQSLLGEPNIDSPLNTHAAELWKNPTAFKKYLQETYSKQVTSQEP>sp|O00762-3|UBE2C_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 COS=Homo sapiens OX=9606 GN=UBE2CMASQNRDPAATSVAAARKGAEPSGGAARGPVGKRLQQELMTLMVYEDLRYKLSLEFPSGYPYNAPTVKFLTPCYHPNVDTQGNICLDILKEKWSALYDVRTILLSIQSLLGEPNIDSPLNTHAAELWKNPTAFKKYLQETYSKQVTSQEP>sp|O00762-4|UBE2C_HUMAN Isoform 4 of Ubiquitin-conjugating enzyme E2 COS=Homo sapiens OX=9606 GN=UBE2CMASQNRDPAATSVAAARKGAEPSGGAARGPVGKRLQQELMTLMMSGDKGISAFPESDNLFKWVGTIHGAAGTAVGSIRTSSTVCLLSGPRETQDSSKPLVWGLGWDMRLLLELTLQLFLQMPEPNIDSPLNTHAAELWKNPTAFKKYLQETYSKQVTSQEP>sp|A0A5B7|TVB29_HUMAN T cell receptor beta variable 29-1 OS=Homo sapiensOX=9606 GN=TRBV29-1 PE=3 SV=1MLSLLLLLLGLGSVFSAVISQKPSRDICQRGTSLTIQCQVDSQVTMMFWYRQQPGQSLTLIATANQGSEATYESGFVIDKFPISRPNLTFSTLTVSNMSPEDSSIYLCSVE>sp|A0A1B0GX68|TVB2_HUMAN T cell receptor beta variable 2 OS=Homo sapiensOX=9606 GN=TRBV2 PE=3 SV=1MDTWLVCWAIFSLLKAGLTEPEVTQTPSHQVTQMGQEVILRCVPISNHLYFYWYRQILGQKVEFLVSFYNNEISEKSEIFDDQFSVERPDGSNFTLKIRSTKLEDSAMYFCASSE>sp|A0A0K0K1B3|TVB30_HUMAN T cell receptor beta variable 30 OS=Homosapiens OX=9606 GN=TRBV30 PE=3 SV=3MLCSLLALLLGTFFGVRSQTIHQWPATLVQPVGSPLSLECTVEGTSNPNLYWYRQAAGRGLQLLFYSVGIGQISSEVPQNLSASRPQDRQFILSSKKLLLSDSGFYLCAWS>sp|A0A576|TVB31_HUMAN T cell receptor beta variable 3-1 OS=Homo sapiensOX=9606 GN=TRBV3-1 PE=3 SV=1MGCRLLCCVVFCLLQAGPLDTAVSQTPKYLVTQMGNDKSIKCEQNLGHDTMYWYKQDSKKFLKIMFSYNNKELIINETVPNRFSPKSPDKAHLNLHINSLELGDSAVYFCASSQ>sp|Q13432|U119A_HUMAN Protein unc-119 homolog A OS=Homo sapiens OX=9606GN=UNC119 PE=1 SV=1MKVKKGGGGAGTATESAPGPSGQSVAPIPQPPAESESGSESEPDAGPGPRPGPLQRKQPIGPEDVLGLQRITGDYLCSPEENIYKIDFVRFKIRDMDSGTVLFEIKKPPVSERLPINRRDLDPNAGRFVRYQFTPAFLRLRQVGATVEFTVGDKPVNNFRMIERHYFRNQLLKSFDFHFGFCIPSSKNTCEHIYDFPPLSEELISEMIRHPYETQSDSFYFVDDRLVMHNKADYSYSGTP>sp|Q13432-2|U119A_HUMAN Isoform B of Protein unc-119 homolog A OS=Homosapiens OX=9606 GN=UNC119MKVKKGGGGAGTATESAPGPSGQSVAPIPQPPAESESGSESEPDAGPGPRPGPLQRKQPIGPEDVLGLQRITGDYLCSPEENIYKIDFVRFKIRDMDSGTVLFEIKKPPVSERLPINRRDLDPNAGRFVRYQFTPAFLRLRQVGATVEFTVGDKPVNNFRMIERHYFRNQLLKSFDFHFGFCIPSSKNTCEHIYDFPPLSEELSARAGSSGSGEVGASRD>sp|A0A577|TVB41_HUMAN T cell receptor beta variable 4-1 OS=Homo sapiensOX=9606 GN=TRBV4-1 PE=3 SV=1MGCRLLCCAVLCLLGAVPIDTEVTQTPKHLVMGMTNKKSLKCEQHMGHRAMYWYKQKAKKPPELMFVYSYEKLSINESVPSRFSPECPNSSLLNLHLHALQPEDSALYLCASSQ>sp|Q969M7|UBE2F_HUMAN NEDD8-conjugating enzyme UBE2F OS=Homo sapiensOX=9606 GN=UBE2F PE=1 SV=1MLTLASKLKRDDGLKGSRTAATASDSTRRVSVRDKLLVKEVAELEANLPCTCKVHFPDPNKLHCFQLTVTPDEGYYQGGKFQFETEVPDAYNMVPPKVKCLTKIWHPNITETGEICLSLLREHSIDGTGWAPTRTLKDVVWGLNSLFTDLLNFDDPLNIEAAEHHLRDKEDFRNKVDDYIKRYAR>sp|Q969M7-2|UBE2F_HUMAN Isoform 2 of NEDD8-conjugating enzyme UBE2FOS=Homo sapiens OX=9606 GN=UBE2FMLTLASKLKRDDGLKGSRTAATASDSTRRVSVRDKLLVKEVAELEANLPCTCKVHFPDPNKLHCFQLTVTPDEGYYQGGKFQFETEVPDAYNMVPPKVKCLTKIWHPNITETGEICLSLLREHSIDGTGWAPTRTLKDVVWGLNSLFTDLLNFDDPLNIEAAEHHLRDKSPMLLLHRRTSGIKWMTTSNVMPDNKRGRLQAHGLCYSLSLT>sp|Q969M7-3|UBE2F_HUMAN Isoform 3 of NEDD8-conjugating enzyme UBE2FOS=Homo sapiens OX=9606 GN=UBE2FMLTLASKLKRDDGLKGSRTAATASDSTRRVSVRDKLLVKDEGYYQGGKFQFETEVPDAYNMVPPKVKCLTKIWHPNITETGEICLSLLREHSIDGTGWAPTRTLKDVVWGLNSLFTDLLNFDDPLNIEAAEHHLRDKEDFRNKVDDYIKRYAR>sp|Q969M7-4|UBE2F_HUMAN Isoform 4 of NEDD8-conjugating enzyme UBE2FOS=Homo sapiens OX=9606 GN=UBE2FMLTLASKLKRDDGLKGSRTAATASDSTRRVSVRDKLLVKEVAELEANLPCTCKVHFPDPNKLHCFQLTVTPDEGYYQGGKFQFETEVPDAYNMVPPKVKCLTKIWHPNITETGEICLRIF>sp|Q969M7-5|UBE2F_HUMAN Isoform 5 of NEDD8-conjugating enzyme UBE2FOS=Homo sapiens OX=9606 GN=UBE2FMLTLASKLKRDDGLKGSRTAATASDSTRRVSVRDKLLVKEVAELEANLPCTCKVHFPDPNKLHCFQLTVTPASQSEMPDQDLAPQHHRDRGNMSEFIERTFN>sp|Q969M7-6|UBE2F_HUMAN Isoform 6 of NEDD8-conjugating enzyme UBE2FOS=Homo sapiens OX=9606 GN=UBE2FMLTLASKLKRDDGLKGSRTAATASDSTRRVSVRDKLLVKEVAELEANLPCTCKVHFPDPNKLHCFQLTVTPDEGYYQGGKFQFETEVPDAYNMVPPKVKCLTKIWHPNITETGEICLSLLREHSIDGTGWAPTRTLKDVVWGLNSLFTEDFRNKVDDYIKRYAR>sp|Q969M7-7|UBE2F_HUMAN Isoform 7 of NEDD8-conjugating enzyme UBE2FOS=Homo sapiens OX=9606 GN=UBE2FMVLGAGPASPVSGSPEVAELEANLPCTCKVHFPDPNKLHCFQLTVTPDEGYYQGGKFQFETEVPDAYNMVPPKVKCLTKIWHPNITETGEICLSLLREHSIDGTGWAPTRTLKDVVWGLNSLFTDLLNFDDPLNIEAAEHHLRDKEDFRNKVDDYIKRYAR>sp|A0A539|TVB42_HUMAN T cell receptor beta variable 4-2 OS=Homo sapiensOX=9606 GN=TRBV4-2 PE=3 SV=1MGCRLLCCAVLCLLGAVPMETGVTQTPRHLVMGMTNKKSLKCEQHLGHNAMYWYKQSAKKPLELMFVYNFKEQTENNSVPSRFSPECPNSSHLFLHLHTLQPEDSALYLCASSQ>sp|A0A589|TVB43_HUMAN T cell receptor beta variable 4-3 OS=Homo sapiensOX=9606 GN=TRBV4-3 PE=3 SV=1MGCRLLCCAVLCLLGAVPMETGVTQTPRHLVMGMTNKKSLKCEQHLGHNAMYWYKQSAKKPLELMFVYSLEERVENNSVPSRFSPECPNSSHLFLHLHTLQPEDSALYLCASSQ>sp|A0A578|TVB51_HUMAN T cell receptor beta variable 5-1 OS=Homo sapiensOX=9606 GN=TRBV5-1 PE=1 SV=1MGSRLLCWVLLCLLGAGPVKAGVTQTPRYLIKTRGQQVTLSCSPISGHRSVSWYQQTPGQGLQFLFEYFSETQRNKGNFPGRFSGRQFSNSRSEMNVSTLELGDSALYLCASSL>sp|A0A0A0MS03|TVB53_HUMAN Probable non-functional T cell receptor betavariable 5-3 OS=Homo sapiens OX=9606 GN=TRBV5-3 PE=1 SV=1MGPGLLCWELLYLLGAGPVEAGVTQSPTHLIKTRGQQVTLRCSPISGHSSVSWYQQAPGQGPQFIFEYANELRRSEGNFPNRFSGRQFHDYCSEMNVSALELGDSALYLCARSL>sp|P62256|UBE2H_HUMAN Ubiquitin-conjugating enzyme E2 H OS=Homo sapiensOX=9606 GN=UBE2H PE=1 SV=1MSSPSPGKRRMDTDVVKLIESKHEVTILGGLNEFVVKFYGPQGTPYEGGVWKVRVDLPDKYPFKSPSIGFMNKIFHPNIDEASGTVCLDVINQTWTALYDLTNIFESFLPQLLAYPNPIDPLNGDAAAMYLHRPEEYKQKIKEYIQKYATEEALKEQEEGTGDSSSESSMSDFSEDEAQDMEL>sp|P62256-2|UBE2H_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 HOS=Homo sapiens OX=9606 GN=UBE2HMSSPSPGKRRMDTDVVKLIESKHEVTILGGLNEFVVKFYGPQGTPYEGGVWKVRVDLPDKYPFKSPSIDLTNIFESFLPQLLAYPNPIDPLNGDAAAMYLHRPEEYKQKIKEYIQKYATEEALKEQEEGTGDSSSESSMSDFSEDEAQDMEL>sp|A6NIH7|U119B_HUMAN Protein unc-119 homolog B OS=Homo sapiens OX=9606GN=UNC119B PE=1 SV=1MSGSNPKAAAAASAAGPGGLVAGKEEKKKAGGGVLNRLKARRQAPHHAADDGVGAAVTEQELLALDTIRPEHVLRLSRVTENYLCKPEDNIYSIDFTRFKIRDLETGTVLFEIAKPCVSDQEEDEEEGGGDVDISAGRFVRYQFTPAFLRLRTVGATVEFTVGDKPVSNFRMIERHYFREHLLKNFDFDFGFCIPSSRNTCEHIYEFPQLSEDVIRLMIENPYETRSDSFYFVDNKLIMHNKADYAYNGGQ>sp|A0A0C4DH59|TVB54_HUMAN T cell receptor beta variable 5-4 OS=Homosapiens OX=9606 GN=TRBV5-4 PE=3 SV=1MGPGLLCWALLCLLGAGSVETGVTQSPTHLIKTRGQQVTLRCSSQSGHNTVSWYQQALGQGPQFIFQYYREEENGRGNFPPRFSGLQFPNYSSELNVNALELDDSALYLCASSL>sp|A0A597|TVB55_HUMAN T cell receptor beta variable 5-5 OS=Homo sapiensOX=9606 GN=TRBV5-5 PE=3 SV=1MGPGLLCWVLLCLLGAGPVDAGVTQSPTHLIKTRGQQVTLRCSPISGHKSVSWYQQVLGQGPQFIFQYYEKEERGRGNFPDRFSARQFPNYSSELNVNALLLGDSALYLCASSL>sp|A0A599|TVB56_HUMAN T cell receptor beta variable 5-6 OS=Homo sapiensOX=9606 GN=TRBV5-6 PE=3 SV=1MGPGLLCWALLCLLGAGLVDAGVTQSPTHLIKTRGQQVTLRCSPKSGHDTVSWYQQALGQGPQFIFQYYEEEERQRGNFPDRFSGHQFPNYSSELNVNALLLGDSALYLCASSL>sp|A0A0A0MS05|TVB57_HUMAN Probable non-functional T cell receptor betavariable 5-7 OS=Homo sapiens OX=9606 GN=TRBV5-7 PE=1 SV=1MGPGLLCWVLLCPLGEGPVDAGVTQSPTHLIKTRGQHVTLRCSPISGHTSVSSYQQALGQGPQFIFQYYEKEERGRGNFPDQFSGHQFPNYSSELNVNALLLGDSALYLCASSL>sp|P61086|UBE2K_HUMAN Ubiquitin-conjugating enzyme E2 K OS=Homo sapiensOX=9606 GN=UBE2K PE=1 SV=3MANIAVQRIKREFKEVLKSEETSKNQIKVDLVDENFTELRGEIAGPPDTPYEGGRYQLEIKIPETYPFNPPKVRFITKIWHPNISSVTGAICLDILKDQWAAAMTLRTVLLSLQALLAAAEPDDPQDAVVANQYKQNPEMFKQTARLWAHVYAGAPVSSPEYTKKIENLCAMGFDRNAVIVALSSKSWDVETATELLLSN>sp|P61086-2|UBE2K_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 KOS=Homo sapiens OX=9606 GN=UBE2KMANIAVQRIKREFKEVLKSEEVRFITKIWHPNISSVTGAICLDILKDQWAAAMTLRTVLLSLQALLAAAEPDDPQDAVVANQYKQNPEMFKQTARLWAHVYAGAPVSSPEYTKKIENLCAMGFDRNAVIVALSSKSWDVETATELLLSN>sp|P61086-3|UBE2K_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 KOS=Homo sapiens OX=9606 GN=UBE2KMANIAVQRIKREFKEVLKSEETSKNQIKVDLVDENFTELRGEIAGPPDTPYEGGRYQLEIKIPETYPFNPPKVRFITKIWHPNISSVTGAICLDILKDQWAAAMTLRTVLLSLQALLAAAEPDDPQDAVVANQNAVIVALSSKSWDVETATELLLSN>sp|A0A5A2|TVB58_HUMAN T cell receptor beta variable 5-8 OS=Homo sapiensOX=9606 GN=TRBV5-8 PE=3 SV=1MGPRLLFWALLCLLGTGPVEAGVTQSPTHLIKTRGQQATLRCSPISGHTSVYWYQQALGLGLQFLLWYDEGEERNRGNFPPRFSGRQFPNYSSELNVNALELEDSALYLCASSL>sp|A0A0K0K1D8|TVB61_HUMAN T cell receptor beta variable 6-1 OS=Homosapiens OX=9606 GN=TRBV6-1 PE=3 SV=3MSIGLLCCVAFSLLWASPVNAGVTQTPKFQVLKTGQSMTLQCAQDMNHNSMYWYRQDPGMGLRLIYYSASEGTTDKGEVPNGYNVSRLNKREFSLRLESAAPSQTSVYFCASSE>sp|A0A0J9YXY3|TVB62_HUMAN T cell receptor beta variable 6-2 OS=Homosapiens OX=9606 GN=TRBV6-2 PE=3 SV=3MSLGLLCCGAFSLLWAGPVNAGVTQTPKFRVLKTGQSMTLLCAQDMNHEYMYWYRQDPGMGLRLIHYSVGEGTTAKGEVPDGYNVSRLKKQNFLLGLESAAPSQTSVYFCASSY>sp|P0DPF7|TVB63_HUMAN T cell receptor beta variable 6-3 OS=Homo sapiensOX=9606 GN=TRBV6-3 PE=3 SV=1MSLGLLCCGAFSLLWAGPVNAGVTQTPKFRVLKTGQSMTLLCAQDMNHEYMYWYRQDPGMGLRLIHYSVGEGTTAKGEVPDGYNVSRLKKQNFLLGLESAAPSQTSVYFCASSY>sp|Q7RTZ2|U17L1_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 1 OS=Homo sapiens OX=9606 GN=USP17L1 PE=3 SV=1MGDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSSETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYENASLQCLTYTLPLANYMLSREHSQTCQRPKCCMLCTMQAHITWALHSPGHVIQPSQALAAGFHRGKQEDVHEFLMFTVDAMKKACLPGHKQVDHHCKDTTLIHQIFGGCWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVKQALEQLVKPEELNGENAYHCGLCLQRAPASNTLTLHTSAKVLILVLKRFSDVAGNKLAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHDGHYFSYVKAQEVQWYKMDDAEVTVCSIISVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRAKQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVGKVEGTLPPNALVIHQSKYKCGMKNHHPEQQSSLLNLSSTTRTDQESMNTGTLASLQGRTRRAKGKNKHSKRALLVCQ>sp|A0A1B0GX49|TVB64_HUMAN T cell receptor beta variable 6-4 OS=Homosapiens OX=9606 GN=TRBV6-4 PE=3 SV=1MSIRLLCCVAFSLLWAGPVTAGITQAPTSQILAAGRSMTLRCTQDMRHNAMYWYRQDLGLGLRLIHYSNTAGTTGKGEVPDGYSVSRANTDDFPLTLASAVPSQTSVYFCASSD>sp|A0A0K0K1A5|TVB65_HUMAN T cell receptor beta variable 6-5 OS=Homosapiens OX=9606 GN=TRBV6-5 PE=1 SV=3MSIGLLCCAALSLLWAGPVNAGVTQTPKFQVLKTGQSMTLQCAQDMNHEYMSWYRQDPGMGLRLIHYSVGAGITDQGEVPNGYNVSRSTTEDFPLRLLSAAPSQTSVYFCASSY>sp|Q6R6M4|U17L2_HUMAN Ubiquitin carboxyl-terminal hydrolase 17 OS=Homosapiens OX=9606 GN=USP17L2 PE=1 SV=2MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSSEARVDLCDDLAPVARQLAPRKKLPLSSRRPAAVGAGLQNMGNTCYENASLQCLTYTPPLANYMLSREHSQTCQRPKCCMLCTMQAHITWALHSPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGCWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVKQALEQLVKPEELNGENAYHCGLCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKLAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHDGHYFSYVKAQEGQWYKMDDAKVTACSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDERLVERATQESTLDHWKFPQEQNKTKPEFNVRKVEGTLPPNVLVIHQSKYKCGMKNHHPEQQSSLLNLSSTTRTDQESVNTGTLASLQGRTRRSKGKNKHSKRALLVCQ>sp|A0A0A6YYG2|TVB66_HUMAN T cell receptor beta variable 6-6 OS=Homosapiens OX=9606 GN=TRBV6-6 PE=3 SV=5MSISLLCCAAFPLLWAGPVNAGVTQTPKFRILKIGQSMTLQCAQDMNHNYMYWYRQDPGMGLKLIYYSVGAGITDKGEVPNGYNVSRSTTEDFPLRLELAAPSQTSVYFCASSY>sp|A6NCW0|U17L3_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 3 OS=Homo sapiens OX=9606 GN=USP17L3 PE=3 SV=1MGDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSSETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYENASLQCLTYTLPLANYMLSREHSQTCQRPKCCMLCTMQAHITWALHSPGHVIQPSQALASGFHRGKQEDVHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGCWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVKQALEQLVKPEELNGENAYHCGLCLQRAPASNTLTLHTSAKVLILVLKRFSDVAGNKLAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHDGHYFSYVKAQEGQWYKMDDAEVTVCSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRAKQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVGKVEGTLPPNALVIHQSKYKCGMKNHHPEQQSSLLNLSSTTRTDQESMNTGTLASLQGRTRRAKGKNKHSKRALLVCQ>sp|P61088|UBE2N_HUMAN Ubiquitin-conjugating enzyme E2 N OS=Homo sapiensOX=9606 GN=UBE2N PE=1 SV=1MAGLPRRIIKETQRLLAEPVPGIKAEPDESNARYFHVVIAGPQDSPFEGGTFKLELFLPEEYPMAAPKVRFMTKIYHPNVDKLGRICLDILKDKWSPALQIRTVLLSIQALLSAPNPDDPLANDVAEQWKTNEAQAIETARAWTRLYAMNNI>sp|A0A0A0MS04|TVB67_HUMAN Probable non-functional T cell receptor betavariable 6-7 OS=Homo sapiens OX=9606 GN=TRBV6-7 PE=1 SV=6MSLGLLCCVAFSLLWAGPMNAGVTQTPKFHVLKTGQSMTLLCAQDMNHEYMYRYRQDPGKGLRLIYYSVAAALTDKGEVPNGYNVSRSNTEDFPLKLESAAPSQTSVYFCASSY>sp|A6NCW7|U17L4_HUMAN Inactive ubiquitin carboxyl-terminal hydrolase 17-like protein 4 OS=Homo sapiens OX=9606 GN=USP17L4 PE=3 SV=3MGDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSSETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYENASLQCLTYTLPLANYMLSREHSQTCQRPKCCMLCTMQAHITWALHSPGHVIQPSQALAAGFHRGKQEDVHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGCWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVKQALEQLVKPEELNGENAYHCGLCLQRAPASNTLTLHTSAKVLILVLKRFSDVAGNKLAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHDGYYFSYVKAQEGQWYKMDDAEVTVCSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRPATQGELKRDHPCLQVPELDEHLVERATEESTLDHWKFPQEQNKMKPEFNVRKVEGTLPPNVLVIHQSKYKCGMKNHHPEQQSSLLNLSSMNSTDQESMNTGTLASLQGRTRRSKGKNKHSKRSLLVCQ>sp|A0A0A6YYG3|TVB68_HUMAN T cell receptor beta variable 6-8 OS=Homosapiens OX=9606 GN=TRBV6-8 PE=3 SV=5MSLGLLCCAAFSLLWAGPVNAGVTQTPKFHILKTGQSMTLQCAQDMNHGYMSWYRQDPGMGLRLIYYSAAAGTTDKEVPNGYNVSRLNTEDFPLRLVSAAPSQTSVYLCASSY>sp|A8MUK1|U17L5_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 5 OS=Homo sapiens OX=9606 GN=USP17L5 PE=3 SV=2MEDDSLYLRGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLAKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQPNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSSTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|A0A0J9YX75|TVB69_HUMAN T cell receptor beta variable 6-9 OS=Homosapiens OX=9606 GN=TRBV6-9 PE=3 SV=3MSIGLLCCVAFSLLWAGPVNAGVTQTPKFHILKTGQSMTLQCAQDMNHGYLSWYRQDPGMGLRRIHYSVAAGITDKGEVPDGYNVSRSNTEDFPLRLESAAPSQTSVYFCASSY>sp|Q6QN14|U17L6_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 6 OS=Homo sapiens OX=9606 GN=USP17L6P PE=1 SV=2MEDDSLYLRGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGSED>sp|A0A0A6YYK4|TVB71_HUMAN Probable non-functional T cell receptor betavariable 7-1 OS=Homo sapiens OX=9606 GN=TRBV7-1 PE=1 SV=5MGTRLLCWAAICLLGADHTGAGVSQSLRHKVAKKGKDVALRYDPISGHNALYWYRQSLGQGLEFPIYFQGKDAADKSGLPRDRFSAQRSEGSISTLKFQRTQQGDLAVYLCASSS>sp|A0A1B0GXF2|TVB72_HUMAN T cell receptor beta variable 7-2 OS=Homosapiens OX=9606 GN=TRBV7-2 PE=3 SV=1MGTRLLFWVAFCLLGADHTGAGVSQSPSNKVTEKGKDVELRCDPISGHTALYWYRQSLGQGLEFLIYFQGNSAPDKSGLPSDRFSAERTGGSVSTLTIQRTQQEDSAVYLCASSL>sp|A0A075B6L6|TVB73_HUMAN Probable non-functional T cell receptor betavariable 7-3 OS=Homo sapiens OX=9606 GN=TRBV7-3 PE=1 SV=7MGTRLLCWAALCLLGADHTGAGVSQTPSNKVTEKGKDVELRCDPISGHTALYWYRQSLGQGPEFLIYFQGTGAADDSGLPKDRFFAVRPEGSVSTLKIQRTEQGDSAAYLRASSL>sp|A0A1B0GX95|TVB74_HUMAN T cell receptor beta variable 7-4 OS=Homosapiens OX=9606 GN=TRBV7-4 PE=3 SV=1MGTRLLCWVVLGFLGTDHTGAGVSQSPRYKVAKRGRDVALRCDSISGHVTLYWYRQTLGQGSEVLTYSQSDAQRDKSGRPSGRFSAERPERSVSTLKIQRTEQGDSAVYLCASSL>sp|A0A1B0GX31|TVB76_HUMAN T cell receptor beta variable 7-6 OS=Homosapiens OX=9606 GN=TRBV7-6 PE=3 SV=1MGTSLLCWVVLGFLGTDHTGAGVSQSPRYKVTKRGQDVALRCDPISGHVSLYWYRQALGQGPEFLTYFNYEAQQDKSGLPNDRFSAERPEGSISTLTIQRTEQRDSAMYRCASSL>sp|Q9C0C9|UBE2O_HUMAN (E3-independent) E2 ubiquitin-conjugating enzymeOS=Homo sapiens OX=9606 GN=UBE2O PE=1 SV=3MADPAAPTPAAPAPAQAPAPAPEAVPAPAAAPVPAPAPASDSASGPSSDSGPEAGSQRLLFSHDLVSGRYRGSVHFGLVRLIHGEDSDSEGEEEGRGSSGCSEAGGAGHEEGRASPLRRGYVRVQWYPEGVKQHVKETKLKLEDRSVVPRDVVRHMRSTDSQCGTVIDVNIDCAVKLIGTNCIIYPVNSKDLQHIWPFMYGDYIAYDCWLGKVYDLKNQIILKLSNGARCSMNTEDGAKLYDVCPHVSDSGLFFDDSYGFYPGQVLIGPAKIFSSVQWLSGVKPVLSTKSKFRVVVEEVQVVELKVTWITKSFCPGGTDSVSPPPSVITQENLGRVKRLGCFDHAQRQLGERCLYVFPAKVEPAKIAWECPEKNCAQGEGSMAKKVKRLLKKQVVRIMSCSPDTQCSRDHSMEDPDKKGESKTKSEAESASPEETPDGSASPVEMQDEGAEEPHEAGEQLPPFLLKEGRDDRLHSAEQDADDEAADDTDDTSSVTSSASSTTSSQSGSGTSRKKSIPLSIKNLKRKHKRKKNKITRDFKPGDRVAVEVVTTMTSADVMWQDGSVECNIRSNDLFPVHHLDNNEFCPGDFVVDKRVQSCPDPAVYGVVQSGDHIGRTCMVKWFKLRPSGDDVELIGEEEDVSVYDIADHPDFRFRTTDIVIRIGNTEDGAPHKEDEPSVGQVARVDVSSKVEVVWADNSKTIILPQHLYNIESEIEESDYDSVEGSTSGASSDEWEDDSDSWETDNGLVEDEHPKIEEPPIPPLEQPVAPEDKGVVISEEAATAAVQGAVAMAAPMAGLMEKAGKDGPPKSFRELKEAIKILESLKNMTVEQLLTGSPTSPTVEPEKPTREKKFLDDIKKLQENLKKTLDNVAIVEEEKMEAVPDVERKEDKPEGQSPVKAEWPSETPVLCQQCGGKPGVTFTSAKGEVFSVLEFAPSNHSFKKIEFQPPEAKKFFSTVRKEMALLATSLPEGIMVKTFEDRMDLFSALIKGPTRTPYEDGLYLFDIQLPNIYPAVPPHFCYLSQCSGRLNPNLYDNGKVCVSLLGTWIGKGTERWTSKSSLLQVLISIQGLILVNEPYYNEAGFDSDRGLQEGYENSRCYNEMALIRVVQSMTQLVRRPPEVFEQEIRQHFSTGGWRLVNRIESWLETHALLEKAQALPNGVPKASSSPEPPAVAELSDSGQQEPEDGGPAPGEASQGSDSEGGAQGLASASRDHTDQTSETAPDASVPPSVKPKKRRKSYRSFLPEKSGYPDIGFPLFPLSKGFIKSIRGVLTQFRAALLEAGMPECTEDK>sp|A0A0K0K1E9|TVB77_HUMAN T cell receptor beta variable 7-7 OS=Homosapiens OX=9606 GN=TRBV7-7 PE=3 SV=3MGTSLLCWVVLGFLGTDHTGAGVSQSPRYKVTKRGQDVTLRCDPISSHATLYWYQQALGQGPEFLTYFNYEAQPDKSGLPSDRFSAERPEGSISTLTIQRTEQRDSAMYRCASSL>sp|A0A1B0GX51|TVB78_HUMAN T cell receptor beta variable 7-8 OS=Homosapiens OX=9606 GN=TRBV7-8 PE=3 SV=1MGTRLLCWVVLGFLGTDHTGAGVSQSPRYKVAKRGQDVALRCDPISGHVSLFWYQQALGQGPEFLTYFQNEAQLDKSGLPSDRFFAERPEGSVSTLKIQRTQQEDSAVYLCASSL>sp|P04435|TVB79_HUMAN T cell receptor beta variable 7-9 OS=Homo sapiensOX=9606 GN=TRBV7-9 PE=1 SV=2MGTSLLCWMALCLLGADHADTGVSQNPRHKITKRGQNVTFRCDPISEHNRLYWYRQTLGQGPEFLTYFQNEAQLEKSRLLSDRFSAERPKGSFSTLEIQRTEQGDSAMYLCASSL>sp|A0A0B4J1U6|TVB9_HUMAN T cell receptor beta variable 9 OS=Homo sapiensOX=9606 GN=TRBV9 PE=3 SV=1MGFRLLCCVAFCLLGAGPVDSGVTQTPKHLITATGQRVTLRCSPRSGDLSVYWYQQSLDQGLQFLIHYYNGEERAKGNILERFSAQQFPDLHSELNLSSLELGDSALYFCASSV>sp|A0A0K0K1A3|TVBJ1_HUMAN T cell receptor beta variable 10-1 OS=Homosapiens OX=9606 GN=TRBV10-1 PE=3 SV=3MGTRLFFYVALCLLWAGHRDAEITQSPRHKITETGRQVTLACHQTWNHNNMFWYRQDLGHGLRLIHYSYGVHDTNKGEVSDGYSVSRSNTEDLPLTLESAASSQTSVYFCASSE>sp|A0A0K0K1G8|TVBJ2_HUMAN T cell receptor beta variable 10-2 OS=Homosapiens OX=9606 GN=TRBV10-2 PE=3 SV=3MGTRLFFYVALCLLWAGHRDAGITQSPRYKITETGRQVTLMCHQTWSHSYMFWYRQDLGHGLRLIYYSAAADITDKGEVPDGYVVSRSKTENFPLTLESATRSQTSVYFCASSE>sp|A0A0K0K1G6|TVBJ3_HUMAN T cell receptor beta variable 10-3 OS=Homosapiens OX=9606 GN=TRBV10-3 PE=3 SV=3MGTRLFFYVALCLLWTGHMDAGITQSPRHKVTETGTPVTLRCHQTENHRYMYWYRQDPGHGLRLIHYSYGVKDTDKGEVSDGYSVSRSKTEDFLLTLESATSSQTSVYFCAISE>sp|A0A0K0K1C0|TVBK1_HUMAN T cell receptor beta variable 11-1 OS=Homosapiens OX=9606 GN=TRBV11-1 PE=3 SV=3MSTRLLCWMALCLLGAELSEAEVAQSPRYKITEKSQAVAFWCDPISGHATLYWYRQILGQGPELLVQFQDESVVDDSQLPKDRFSAERLKGVDSTLKIQPAELGDSAMYLCASSL>sp|A0A584|TVBK2_HUMAN T cell receptor beta variable 11-2 OS=Homo sapiensOX=9606 GN=TRBV11-2 PE=1 SV=1MGTRLLCWAALCLLGAELTEAGVAQSPRYKIIEKRQSVAFWCNPISGHATLYWYQQILGQGPKLLIQFQNNGVVDDSQLPKDRFSAERLKGVDSTLKIQPAKLEDSAVYLCASSL>sp|A0A5A6|TVBK3_HUMAN T cell receptor beta variable 11-3 OS=Homo sapiensOX=9606 GN=TRBV11-3 PE=3 SV=1MGTRLLCWVAFCLLVEELIEAGVVQSPRYKIIEKKQPVAFWCNPISGHNTLYWYLQNLGQGPELLIRYENEEAVDDSQLPKDRFSAERLKGVDSTLKIQPAELGDSAVYLCASSL>sp|P01733|TVBL3_HUMAN T cell receptor beta variable 12-3 OS=Homo sapiensOX=9606 GN=TRBV12-3 PE=1 SV=2MDSWTFCCVSLCILVAKHTDAGVIQSPRHEVTEMGQEVTLRCKPISGHNSLFWYRQTMMRGLELLIYFNNNVPIDDSGMPEDRFSAKMPNASFSTLKIQPSEPRDSAVYFCASSL>sp|A0A0B4J2E0|TVBL4_HUMAN T cell receptor beta variable 12-4 OS=Homosapiens OX=9606 GN=TRBV12-4 PE=1 SV=5MGSWTLCCVSLCILVAKHTDAGVIQSPRHEVTEMGQEVTLRCKPISGHDYLFWYRQTMMRGLELLIYFNNNVPIDDSGMPEDRFSAKMPNASFSTLKIQPSEPRDSAVYFCASSL>sp|Q16763|UBE2S_HUMAN Ubiquitin-conjugating enzyme E2 S OS=Homo sapiensOX=9606 GN=UBE2S PE=1 SV=2MNSNVENLPPHIIRLVYKEVTTLTADPPDGIKVFPNEEDLTDLQVTIEGPEGTPYAGGLFRMKLLLGKDFPASPPKGYFLTKIFHPNVGANGEICVNVLKRDWTAELGIRHVLLTIKCLLIHPNPESALNEEAGRLLLENYEEYAARARLLTEIHGGAGGPSGRAEAGRALASGTEASSTDPGAPGGPGGAEGPMAKKHAGERDKKLAAKKKTDKKRALRRL>sp|A0A1B0GX78|TVBL5_HUMAN T cell receptor beta variable 12-5 OS=Homosapiens OX=9606 GN=TRBV12-5 PE=3 SV=1MATRLLCCVVLCLLGEELIDARVTQTPRHKVTEMGQEVTMRCQPILGHNTVFWYRQTMMQGLELLAYFRNRAPLDDSGMPKDRFSAEMPDATLATLKIQPSEPRDSAVYFCASGL>sp|A0A075B6N2|TVBT1_HUMAN T cell receptor beta variable 20-1 OS=Homosapiens OX=9606 GN=TRBV20-1 PE=3 SV=1MLLLLLLLGPGSGLGAVVSQHPSRVICKSGTSVKIECRSLDFQATTMFWYRQFPKQSLMLMATSNEGSKATYEQGVEKDKFLINHASLTLSTLTVTSAHPEDSSFYICSAR>sp|A0A075B6N3|TVBX1_HUMAN T cell receptor beta variable 24-1 OS=Homosapiens OX=9606 GN=TRBV24-1 PE=3 SV=1MASLLFFCGAFYLLGTGSMDADVTQTPRNRITKTGKRIMLECSQTKGHDRMYWYRQDPGLGLQLIYYSFDVKDINKGEISDGYSVSRQAQAKFSLSLESAIPNQTALYFCATSDL>sp|A0A075B6N4|TVBY1_HUMAN T cell receptor beta variable 25-1 OS=Homosapiens OX=9606 GN=TRBV25-1 PE=3 SV=1MTIRLLCYVGFYFLGAGLMEADIYQTPRYLVIGTGKKITLECSQTMGHDKMYWYQQDPGMELHLIHYSYGVNSTEKGDLSSESTVSRIRTEHFPLTLESARPSHTSQYLCASSE>sp|Q9NPD8|UBE2T_HUMAN Ubiquitin-conjugating enzyme E2 T OS=Homo sapiensOX=9606 GN=UBE2T PE=1 SV=1MQRASRLKRELHMLATEPPPGITCWQDKDQMDDLRAQILGGANTPYEKGVFKLEVIIPERYPFEPPQIRFLTPIYHPNIDSAGRICLDVLKLPPKGAWRPSLNIATVLTSIQLLMSEPNPDDPLMADISSEFKYNKPAFLKNARQWTEKHARQKQKADEEEMLDNLPEAGDSRVHNSTQKRKASQLVGIEKKFHPDV>sp|Q5VVX9|UBE2U_HUMAN Ubiquitin-conjugating enzyme E2 U OS=Homo sapiensOX=9606 GN=UBE2U PE=1 SV=1MHGRAYLLLHRDFCDLKENNYKGITAKPVSEDMMEWEVEIEGLQNSVWQGLVFQLTIHFTSEYNYAPPVVKFITIPFHPNVDPHTGQPCIDFLDNPEKWNTNYTLSSILLALQVMLSNPVLENPVNLEAARILVKDESLYRTILRLFNRPLQMKDDSQELPKDPRKCIRPIKTTSFSDYYQTWSRIATSKATEYYRTPLLKVPNFIGQYYKWKKMDLQHQKEWNLKYSVIKCWLARKRMPHEVTHSMEEIKLCPTLIPTTDEIFLESPTAINSITDIYETEEEGWKSDTSLYENDTDEPREEEVEDLISWTNTLNTNTSED>sp|Q5VVX9-2|UBE2U_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 UOS=Homo sapiens OX=9606 GN=UBE2UMHGRAYLLLHRDFCDLKENNYKGITAKPVSEDMMEWEVEIEGLQNSVWQGLVFQLTIHFTSEYNYAPPVVKFITIPFHPNVDPHTGQPCIDFLDNPEKWNTNYTLSSILLALQVMLSNPVLENPVNLEAARILVKDESLYRTILRLFNRPLQMKDDSQELPKDPRKCIRPIKTTSFSDYYQTWSRIATSKATEYYRTPLLKVPNFIGQYYKWKKMDLQHQKEWNLK>sp|Q96B02|UBE2W_HUMAN Ubiquitin-conjugating enzyme E2 W OS=Homo sapiensOX=9606 GN=UBE2W PE=1 SV=1MASMQKRLQKELLALQNDPPPGMTLNEKSVQNSITQWIVDMEGAPGTLYEGEKFQLLFKFSSRYPFDSPQVMFTGENIPVHPHVYSNGHICLSILTEDWSPALSVQSVCLSIISMLSSCKEKRRPPDNSFYVRTCNKNPKKTKWWYHDDTC>sp|Q96B02-2|UBE2W_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 WOS=Homo sapiens OX=9606 GN=UBE2WMASMQTTGRRVEVWFPKRLQKELLALQNDPPPGMTLNEKSVQNSITQWIVDMEGAPGTLYEGEKFQLLFKFSSRYPFDSPQVMFTGENIPVHPHVYSNGHICLSILTEDWSPALSVQSVCLSIISMLSSCKEKRRPPDNSFYVRTCNKNPKKTKWWYHDDTC>sp|Q96B02-3|UBE2W_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 WOS=Homo sapiens OX=9606 GN=UBE2WMLSPRGVTRARQLLPLRLWPRRSWGDGSIMASMQKRLQKELLALQNDPPPGMTLNEKSVQNSITQWIVDMEGAPGTLYEGEKFQLLFKFSSRYPFDSPQVMFTGENIPVHPHVYSNGHICLSILTEDWSPALSVQSVCLSIISMLSSCKEKRRPPDNSFYVRTCNKNPKKTKWWYHDDTC>sp|Q9H832|UBE2Z_HUMAN Ubiquitin-conjugating enzyme E2 Z OS=Homo sapiensOX=9606 GN=UBE2Z PE=1 SV=2MAESPTEEAATAGAGAAGPGASSVAGVVGVSGSGGGFGPPFLPDVWAAAAAAGGAGGPGSGLAPLPGLPPSAAAHGAALLSHWDPTLSSDWDGERTAPQCLLRIKRDIMSIYKEPPPGMFVVPDTVDMTKIHALITGPFDTPYEGGFFLFVFRCPPDYPIHPPRVKLMTTGNNTVRFNPNFYRNGKVCLSILGTWTGPAWSPAQSISSVLISIQSLMTENPYHNEPGFEQERHPGDSKNYNECIRHETIRVAVCDMMEGKCPCPEPLRGVMEKSFLEYYDFYEVACKDRLHLQGQTMQDPFGEKRGHFDYQSLLMRLGLIRQKVLERLHNENAEMDSDSSSSGTETDLHGSLRV>sp|Q9H832-2|UBE2Z_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 ZOS=Homo sapiens OX=9606 GN=UBE2ZMSIYKEPPPGMFVVPDTVDMTKIHALITGPFDTPYEGGFFLFVFRCPPDYPIHPPRVKLMTTGNNTVRFNPNFYRNGKVCLSILGTWTGPAWSPAQSISSVLISIQSLMTENPYHNEPGFEQERHPGDSKNYNECIRHETIRVAVCDMMEGKCPCPEPLRGVMEKSFLEYYDFYEVACKDRLHLQGQTMQDPFGEKRGHFDYQSLLMRLGLIRQKVLERLHNENAEMDSDSSSSGTETDLHGSLRV>sp|Q05086|UBE3A_HUMAN Ubiquitin-protein ligase E3A OS=Homo sapiensOX=9606 GN=UBE3A PE=1 SV=4MEKLHQCYWKSGEPQSDDIEASRMKRAAAKHLIERYYHQLTEGCGNEACTNEFCASCPTFLRMDNNAAAIKALELYKINAKLCDPHPSKKGASSAYLENSKGAPNNSCSEIKMNKKGARIDFKDVTYLTEEKVYEILELCREREDYSPLIRVIGRVFSSAEALVQSFRKVKQHTKEELKSLQAKDEDKDEDEKEKAACSAAAMEEDSEASSSRIGDSSQGDNNLQKLGPDDVSVDIDAIRRVYTRLLSNEKIETAFLNALVYLSPNVECDLTYHNVYSRDPNYLNLFIIVMENRNLHSPEYLEMALPLFCKAMSKLPLAAQGKLIRLWSKYNADQIRRMMETFQQLITYKVISNEFNSRNLVNDDDAIVAASKCLKMVYYANVVGGEVDTNHNEEDDEEPIPESSELTLQELLGEERRNKKGPRVDPLETELGVKTLDCRKPLIPFEEFINEPLNEVLEMDKDYTFFKVETENKFSFMTCPFILNAVTKNLGLYYDNRIRMYSERRITVLYSLVQGQQLNPYLRLKVRRDHIIDDALVRLEMIAMENPADLKKQLYVEFEGEQGVDEGGVSKEFFQLVVEEIFNPDIGMFTYDESTKLFWFNPSSFETEGQFTLIGIVLGLAIYNNCILDVHFPMVVYRKLMGKKGTFRDLGDSHPVLYQSLKDLLEYEGNVEDDMMITFQISQTDLFGNPMMYDLKENGDKIPITNENRKEFVNLYSDYILNKSVEKQFKAFRRGFHMVTNESPLKYLFRPEEIELLICGSRNLDFQALEETTEYDGGYTRDSVLIREFWEIVHSFTDEQKRLFLQFTTGTDRAPVGGLGKLKMIIAKNGPDTERLPTSHTCFNVLLLPEYSSKEKLKERLLKAITYAKGFGML>sp|Q05086-2|UBE3A_HUMAN Isoform I of Ubiquitin-protein ligase E3AOS=Homo sapiens OX=9606 GN=UBE3AMKRAAAKHLIERYYHQLTEGCGNEACTNEFCASCPTFLRMDNNAAAIKALELYKINAKLCDPHPSKKGASSAYLENSKGAPNNSCSEIKMNKKGARIDFKDVTYLTEEKVYEILELCREREDYSPLIRVIGRVFSSAEALVQSFRKVKQHTKEELKSLQAKDEDKDEDEKEKAACSAAAMEEDSEASSSRIGDSSQGDNNLQKLGPDDVSVDIDAIRRVYTRLLSNEKIETAFLNALVYLSPNVECDLTYHNVYSRDPNYLNLFIIVMENRNLHSPEYLEMALPLFCKAMSKLPLAAQGKLIRLWSKYNADQIRRMMETFQQLITYKVISNEFNSRNLVNDDDAIVAASKCLKMVYYANVVGGEVDTNHNEEDDEEPIPESSELTLQELLGEERRNKKGPRVDPLETELGVKTLDCRKPLIPFEEFINEPLNEVLEMDKDYTFFKVETENKFSFMTCPFILNAVTKNLGLYYDNRIRMYSERRITVLYSLVQGQQLNPYLRLKVRRDHIIDDALVRLEMIAMENPADLKKQLYVEFEGEQGVDEGGVSKEFFQLVVEEIFNPDIGMFTYDESTKLFWFNPSSFETEGQFTLIGIVLGLAIYNNCILDVHFPMVVYRKLMGKKGTFRDLGDSHPVLYQSLKDLLEYEGNVEDDMMITFQISQTDLFGNPMMYDLKENGDKIPITNENRKEFVNLYSDYILNKSVEKQFKAFRRGFHMVTNESPLKYLFRPEEIELLICGSRNLDFQALEETTEYDGGYTRDSVLIREFWEIVHSFTDEQKRLFLQFTTGTDRAPVGGLGKLKMIIAKNGPDTERLPTSHTCFNVLLLPEYSSKEKLKERLLKAITYAKGFGML>sp|Q05086-3|UBE3A_HUMAN Isoform III of Ubiquitin-protein ligase E3AOS=Homo sapiens OX=9606 GN=UBE3AMATACKRSGEPQSDDIEASRMKRAAAKHLIERYYHQLTEGCGNEACTNEFCASCPTFLRMDNNAAAIKALELYKINAKLCDPHPSKKGASSAYLENSKGAPNNSCSEIKMNKKGARIDFKDVTYLTEEKVYEILELCREREDYSPLIRVIGRVFSSAEALVQSFRKVKQHTKEELKSLQAKDEDKDEDEKEKAACSAAAMEEDSEASSSRIGDSSQGDNNLQKLGPDDVSVDIDAIRRVYTRLLSNEKIETAFLNALVYLSPNVECDLTYHNVYSRDPNYLNLFIIVMENRNLHSPEYLEMALPLFCKAMSKLPLAAQGKLIRLWSKYNADQIRRMMETFQQLITYKVISNEFNSRNLVNDDDAIVAASKCLKMVYYANVVGGEVDTNHNEEDDEEPIPESSELTLQELLGEERRNKKGPRVDPLETELGVKTLDCRKPLIPFEEFINEPLNEVLEMDKDYTFFKVETENKFSFMTCPFILNAVTKNLGLYYDNRIRMYSERRITVLYSLVQGQQLNPYLRLKVRRDHIIDDALVRLEMIAMENPADLKKQLYVEFEGEQGVDEGGVSKEFFQLVVEEIFNPDIGMFTYDESTKLFWFNPSSFETEGQFTLIGIVLGLAIYNNCILDVHFPMVVYRKLMGKKGTFRDLGDSHPVLYQSLKDLLEYEGNVEDDMMITFQISQTDLFGNPMMYDLKENGDKIPITNENRKEFVNLYSDYILNKSVEKQFKAFRRGFHMVTNESPLKYLFRPEEIELLICGSRNLDFQALEETTEYDGGYTRDSVLIREFWEIVHSFTDEQKRLFLQFTTGTDRAPVGGLGKLKMIIAKNGPDTERLPTSHTCFNVLLLPEYSSKEKLKERLLKAITYAKGFGML>sp|Q7Z3V4|UBE3B_HUMAN Ubiquitin-protein ligase E3B OS=Homo sapiensOX=9606 GN=UBE3B PE=1 SV=3MFTLSQTSRAWFIDRARQAREERLVQKERERAAVVIQAHVRSFLCRSRLQRDIRREIDDFFKADDPESTKRSALCIFKIARKLLFLFRIKEDNERFEKLCRSILSSMDAENEPKVWYVSLACSKDLTLLWIQQIKNILWYCCDFLKQLKPEILQDSRLITLYLTMLVTFTDTSTWKILRGKGESLRPAMNHICANIMGHLNQHGFYSVLQILLTRGLARPRPCLSKGTLTAAFSLALRPVIAAQFSDNLIRPFLIHIMSVPALVTHLSTVTPERLTVLESHDMLRKFIIFLRDQDRCRDVCESLEGCHTLCLMGNLLHLGSLSPRVLEEETDGFVSLLTQTLCYCRKYVSQKKSNLTHWHPVLGWFSQSVDYGLNESMHLITKQLQFLWGVPLIRIFFCDILSKKLLESQEPAHAQPASPQNVLPVKSLLKRAFQKSASVRNILRPVGGKRVDSAEVQKVCNICVLYQTSLTTLTQIRLQILTGLTYLDDLLPKLWAFICELGPHGGLKLFLECLNNDTEESKQLLAMLMLFCDCSRHLITILDDIEVYEEQISFKLEELVTISSFLNSFVFKMIWDGIVENAKGETLELFQSVHGWLMVLYERDCRRRFTPEDHWLRKDLKPSVLFQELDRDRKRAQLILQYIPHVIPHKNRVLLFRTMVTKEKEKLGLVETSSASPHVTHITIRRSRMLEDGYEQLRQLSQHAMKGVIRVKFVNDLGVDEAGIDQDGVFKEFLEEIIKRVFDPALNLFKTTSGDERLYPSPTSYIHENYLQLFEFVGKMLGKAVYEGIVVDVPFASFFLSQLLGHHHSVFYSSVDELPSLDSEFYKNLTSIKRYDGDITDLGLTLSYDEDVMGQLVCHELIPGGKTIPVTNENKISYIHLMAHFRMHTQIKNQTAALISGFRSIIKPEWIRMFSTPELQRLISGDNAEIDLEDLKKHTVYYGGFHGSHRVIIWLWDILASDFTPDERAMFLKFVTSCSRPPLLGFAYLKPPFSIRCVEVSDDQDTGDTLGSVLRGFFTIRKREPGGRLPTSSTCFNLLKLPNYSKKSVLREKLRYAISMNTGFELS>sp|Q7Z3V4-2|UBE3B_HUMAN Isoform 2 of Ubiquitin-protein ligase E3BOS=Homo sapiens OX=9606 GN=UBE3BMFTLSQTSRAWFIDRARQAREERLVQKERERAAVVIQAHVRSFLCRSRLQRDIRREIDDFFKADDPESTKRSALCIFKIARKLLFLFRIKEDNERFEKLCRSILSSMDAENEPKVWYVSLACSKDLTLLWIQQIKNILWYCCDFLKQLKPEILQDSRLITLYLTMLVTFTDTSTWKILRGKGESLRPAMNHICANIMGHLNQHGFYSVLQILLTRGLARPRPCLSKGTLTAAFSLALRPVIAAQFSDNLIRPFLIHIMSVPALVTHLSTVTPERLTVLESHDMLRKFIIFLRDQDRCRDVCESLEGCHTLCLMGNLLHLGSLSPRVLEEETDGFVSLLTQTLCYCRKYVSQKKSNLTHWHPVLGWFSQSVDYGLNESMHLITKQLQFLWGVPLIRIFFCDILSKKLLESQEPAHAQPASPQNVLPVKSLLKRAFQKSASVRNILRPVGGKRVDSAEVQKVCNICVLYQTSLTTLTQIRLQILTGLTYLDDLLPKLWAFICELGPHGGLKLFLECLNNDTEESKQLLAMLMLFCDCSRHLITILDDIEVYEEQISFKLEELVTISSFLNSFVFKMIWDGIVENAKGETLELFQSVHGWLMVLYERDCRRRFTPEDHWLRKDLKPSVLFQELDRDRKRAQLILQYIPHVIPHKNRVLLFRTMVTKEKEKLGLVETSSASPHVTHITIRRSRMLESLFECPWPLVINAESC>sp|Q7Z3V4-3|UBE3B_HUMAN Isoform 3 of Ubiquitin-protein ligase E3BOS=Homo sapiens OX=9606 GN=UBE3BMFTLSQTSRAWFIDRARQAREERLVQKERERAAVVIQAHVRSFLCRSRLQRDIRREIDDFFKADDPESTKRSALCIFKIARKLLFLFRIKEDNERFEKLCRSILSSMDAENEPKVWYVSLACSKDLTLLWIQQIKNILWYCCDFLKQLKPEILQDSRLITLYLTMLVTFTDTSTWKILRGKGESLRPAMNHICANIMGHLNQHGFYSVLQCCDGLFPDLVSYAPHNNPVRWSVGRSWYDWQLSR>sp|Q15386|UBE3C_HUMAN Ubiquitin-protein ligase E3C OS=Homo sapiensOX=9606 GN=UBE3C PE=1 SV=3MFSFEGDFKTRPKVSLGGASRKEEKASLLHRTQEERRKREEERRRLKNAIIIQSFIRGYRDRKQQYSIQRSAFDRCATLSQSGGAFPIANGPNLTLLVRQLLFFYKQNEDSKRLIWLYQNLIKHSSLFVKQLDGSERLTCLFQIKRLMSLCCRLLQNCNDDSLNVALPMRMLEVFSSENTYLPVLQDASYVVSVIEQILHYMIHNGYYRSLYLLINSKLPSSIEYSDLSRVPIAKILLENVLKPLHFTYNSCPEGARQQVFTAFTEEFLAAPFTDQIFHFIIPALADAQTVFPYEPFLNALLLIESRCSRKSGGAPWLFYFVLTVGENYLGALSEEGLLVYLRVLQTFLSQLPVSPASASCHDSASDSEEESEEADKPSSPEDGRLSVSYITEECLKKLDTKQQTNTLLNLVWRDSASEEVFTTMASVCHTLMVQHRMMVPKVRLLYSLAFNARFLRHLWFLISSMSTRMITGSMVPLLQVISRGSPMSFEDSSRIIPLFYLFSSLFSHSLISIHDNEFFGDPIEVVGQRQSSMMPFTLEELIMLSRCLRDACLGIIKLAYPETKPEVREEYITAFQSIGVTTSSEMQQCIQMEQKRWIQLFKVITNLVKMLKSRDTRRNFCPPNHWLSEQEDIKADKVTQLYVPASRHVWRFRRMGRIGPLQSTLDVGLESPPLSVSEERQLAVLTELPFVVPFEERVKIFQRLIYADKQEVQGDGPFLDGINVTIRRNYIYEDAYDKLSPENEPDLKKRIRVHLLNAHGLDEAGIDGGGIFREFLNELLKSGFNPNQGFFKTTNEGLLYPNPAAQMLVGDSFARHYYFLGRMLGKALYENMLVELPFAGFFLSKLLGTSADVDIHHLASLDPEVYKNLLFLKSYEDDVEELGLNFTVVNNDLGEAQVVELKFGGKDIPVTSANRIAYIHLVADYRLNRQIRQHCLAFRQGLANVVSLEWLRMFDQQEIQVLISGAQVPISLEDLKSFTNYSGGYSADHPVIKVFWRVVEGFTDEEKRKLLKFVTSCSRPPLLGFKELYPAFCIHNGGSDLERLPTASTCMNLLKLPEFYDETLLRSKLLYAIECAAGFELS>sp|Q15386-2|UBE3C_HUMAN Isoform 2 of Ubiquitin-protein ligase E3COS=Homo sapiens OX=9606 GN=UBE3CMFSFEGDFKTRPKVSLGGASRKEEKASLLHRTQEERRKREEERRRLKNAIIIQSFIRGYRDRKQQYSIQRSAFDRCATLSQSGGAFPIANGPNLTLLVRQLLFFYKQNEDSKRLIWLYQNLIKHSSLFVKQLDGSERLTCLFQIKRLMSLCCRLLQNCNDDSLNVALPMRMLEVFSSENTYLPVLQDASYVVSVIEQILHYMIHNGYYRSLYLLINSKLPSSIEYSDLSRVPIAKILLENVLKPLHFTYNSCPEGARQQVFTAFTEEFLAAPFTDQIFHFIIPALADAQTVFPYEPFLNALLLIESRCSRKSGGAPWLFYFVLTVGENYLGALSEEGLLVYLRVLQTFLSQLPVSPASASCHDSASDSEEESEEADKPSSPEDGRLSVSYITEECLKKLDTKQQTNTLLNLVWRDSASEEVFTTMASVCHTLMVQHRMMVPKVRLLYSLAFNARFLRHLWFLISSMSTRMITGSMVPLLQVISRGSPMSFEDSSRIIPLFYLFSSLFSHSLISIHDNEFFGDPIEVVGQRQSSMMPFTLEELIMLSRCLRDACLGIIKLAYPETKPEVREEYITAFQSIGVTTSSEMQQCIQMEQKRWIQLFKVITNLVKMLKSRDTRRNFCPPNHWLSEQEDIKADKVLLKDLFNIYH>sp|Q15386-3|UBE3C_HUMAN Isoform 3 of Ubiquitin-protein ligase E3COS=Homo sapiens OX=9606 GN=UBE3CMFSFEGDFKTRPKVSLGGASRKYSIQRSAFDRCATLSQSGGAFPIANGPNLTLLVRQLLFFYKQNEDSKRLIWLYQNLIKHSSLFVKQLDGSERLTCLFQIKRLMSLCCRLLQNCNDDSLNVALPMRMLEVFSSENTYLPVLQDASYVVSVIEQILHYMIHNGYYRSLYLLINSKLPSSIEYSDLSRVPIAKILLENVLKPLHFTYNSCPEGARQQVFTAFTEEFLAAPFTDQIFHFIIPALADAQTVFPYEPFLNALLLIESRCSRKSGGAPWLFYFVLTVGENYLGALSEEGLLVYLRVLQTFLSQLPVSPASASCHDSASDSEEESEEADKPSSPEDGRLSVSYITEECLKKLDTKQQTNTLLNLVWRDSASEEVFTTMASVCHTLMVQHRMMVPKVRVYK>sp|Q7Z6J8|UBE3D_HUMAN E3 ubiquitin-protein ligase E3D OS=Homo sapiensOX=9606 GN=UBE3D PE=1 SV=2MAASAAETRVFLEVRGQLQSALLILGEPKEGGMPMNISIMPSSLQMKTPEGCTEIQLPAEVRLVPSSCRGLQFVVGDGLHLRLQTQAKLGTKLISMFNQSSQTQECCTFYCQSCGEVIIKDRKLLRVLPLPSENWGALVGEWCCHPDPFANKSLHPQENDCFIGDSFFLVNLRTSLWQQRPELSPVEMCCVSSDNHCKLEPKANTKVICKRCKVMLGETVSSETTKFYMTEIIIQSSERSFPIIPRSWFVQSVIAQCLVQLSSARSTFRFTIQGQDDKVYILLWLLNSDSLVIESLRNSKYIKKFPLLENTFKADSSSAWSAVKVLYQPCIKSRNEKLVSLWESDISVHPLTLPSATCLELLLILSKSNANLPSSLRRVNSFQVAFLKM>sp|Q14139|UBE4A_HUMAN Ubiquitin conjugation factor E4 A OS=Homo sapiensOX=9606 GN=UBE4A PE=1 SV=2MTDQENNNNISSNPFAALFGSLADAKQFAAIQKEQLKQQSDELPASPDDSDNSVSESLDEFDYSVAEISRSFRSQQEICEQLNINHMIQRIFLITLDNSDPSLKSGNGIPSRCVYLEEMAVELEDQDWLDMSNVEQALFARLLLQDPGNHLINMTSSTTLNLSADRDAGERHIFCYLYSCFQRAKEEITKVPENLLPFAVQCRNLTVSNTRTVLLTPEIYVDQNIHEQLVDLMLEAIQGAHFEDVTEFLEEVIEALILDEEVRTFPEVMIPVFDILLGRIKDLELCQILLYAYLDILLYFTRQKDMAKVFVEYIQPKDPTNGQMYQKTLLGVILSISCLLKTPGVVENHGYFLNPSRSSPQEIKVQEANIHQFMAQFHEKIYQMLKNLLQLSPETKHCILSWLGNCLHANAGRTKIWANQMPEIFFQMYASDAFFLNLGAALLKLCQPFCKPRSSRLLTFNPTYCALKELNDEERKIKNVHMRGLDKETCLIPAVQEPKFPQNYNLVTENLALTEYTLYLGFHRLHDQMVKINQNLHRLQVAWRDAQQSSSPAADNLREQFERLMTIYLSTKTAMTEPQMLQNCLNLQVSMAVLLVQLAIGNEGSQPIELTFPLPDGYSSLAYVPEFFADNLGDFLIFLRRFADDILETSADSLEHVLHFITIFTGSIERMKNPHLRAKLAEVLEAVMPHLDQTPNPLVSSVFHRKRVFCNFQYAPQLAEALIKVFVDIEFTGDPHQFEQKFNYRRPMYPILRYMWGTDTYRESIKDLADYASKNLEAMNPPLFLRFLNLLMNDAIFLLDEAIQYLSKIKIQQIEKDRGEWDSLTPEARREKEAGLQMFGQLARFHNIMSNETIGTLAFLTSEIKSLFVHPFLAERIISMLNYFLQHLVGPKMGALKVKDFSEFDFKPQQLVSDICTIYLNLGDEENFCATVPKDGRSYSPTLFAQTVRVLKKINKPGNMIMAFSNLAERIKSLADLQQQEEETYADACDEFLDPIMSTLMCDPVVLPSSRVTVDRSTIARHLLSDQTDPFNRSPLTMDQIRPNTELKEKIQRWLAERKQQKEQLE>sp|Q14139-2|UBE4A_HUMAN Isoform 2 of Ubiquitin conjugation factor E4 AOS=Homo sapiens OX=9606 GN=UBE4AMTDQENNNNISSNPFAALFGSLADAKQFAAIQKEQLKQQSDELPASPDDSDNSVSESLDEFDYSVAEISRSFRSQQEICEQLNINHMIQRIFLITLDNSDPSLKSGNGIPSRCVYLEEMAVELEDQDWLDMSNVEQALFARLLLQDPGNHLINMTSSTTLNLSADRDAGERHIFCYLYSCFQRAKEEITKVPENLLPFAVQCRNLTVSNTRTVLLTPEIYVDQNIHEQLVDLMLEAIQGAREYMNKIYFEDVTEFLEEVIEALILDEEVRTFPEVMIPVFDILLGRIKDLELCQILLYAYLDILLYFTRQKDMAKVFVEYIQPKDPTNGQMYQKTLLGVILSISCLLKTPGVVENHGYFLNPSRSSPQEIKVQEANIHQFMAQFHEKIYQMLKNLLQLSPETKHCILSWLGNCLHANAGRTKIWANQMPEIFFQMYASDAFFLNLGAALLKLCQPFCKPRSSRLLTFNPTYCALKELNDEERKIKNVHMRGLDKETCLIPAVQEPKFPQNYNLVTENLALTEYTLYLGFHRLHDQMVKINQNLHRLQVAWRDAQQSSSPAADNLREQFERLMTIYLSTKTAMTEPQMLQNCLNLQVSMAVLLVQLAIGNEGSQPIELTFPLPDGYSSLAYVPEFFADNLGDFLIFLRRFADDILETSADSLEHVLHFITIFTGSIERMKNPHLRAKLAEVLEAVMPHLDQTPNPLVSSVFHRKRVFCNFQYAPQLAEALIKVFVDIEFTGDPHQFEQKFNYRRPMYPILRYMWGTDTYRESIKDLADYASKNLEAMNPPLFLRFLNLLMNDAIFLLDEAIQYLSKIKIQQIEKDRGEWDSLTPEARREKEAGLQMFGQLARFHNIMSNETIGTLAFLTSEIKSLFVHPFLAERIISMLNYFLQHLVGPKMGALKVKDFSEFDFKPQQLVSDICTIYLNLGDEENFCATVPKDGRSYSPTLFAQTVRVLKKINKPGNMIMAFSNLAERIKSLADLQQQEEETYADACDEFLDPIMSTLMCDPVVLPSSRVTVDRSTIARHLLSDQTDPFNRSPLTMDQIRPNTELKEKIQRWLAERKQQKEQLE>sp|O95155|UBE4B_HUMAN Ubiquitin conjugation factor E4 B OS=Homo sapiensOX=9606 GN=UBE4B PE=1 SV=1MEELSADEIRRRRLARLAGGQTSQPTTPLTSPQRENPPGPPIAASAPGPSQSLGLNVHNMTPATSPIGASGVAHRSQSSEGVSSLSSSPSNSLETQSQSLSRSQSMDIDGVSCEKSMSQVDVDSGIENMEVDENDRREKRSLSDKEPSSGPEVSEEQALQLVCKIFRVSWKDRDRDVIFLSSLSAQFKQNPKEVFSDFKDLIGQILMEVLMMSTQTRDENPFASLTATSQPIAAAARSPDRNLLLNTGSNPGTSPMFCSVASFGASSLSSLYESSPAPTPSFWSSVPVMGPSLASPSRAASQLAVPSTPLSPHSAASGTAAGSQPSSPRYRPYTVTHPWASSGVSILSSSPSPPALASSPQAVPASSSRQRPSSTGPPLPPASPSATSRRPSSLRISPSLGASGGASNWDSYSDHFTIETCKETDMLNYLIECFDRVGIEEKKAPKMCSQPAVSQLLSNIRSQCISHTALVLQGSLTQPRSLQQPSFLVPYMLCRNLPYGFIQELVRTTHQDEEVFKQIFIPILQGLALAAKECSLDSDYFKYPLMALGELCETKFGKTHPVCNLVASLRLWLPKSLSPGCGRELQRLSYLGAFFSFSVFAEDDVKVVEKYFSGPAITLENTRVVSQSLQHYLELGRQELFKILHSILLNGETREAALSYMAAVVNANMKKAQMQTDDRLVSTDGFMLNFLWVLQQLSTKIKLETVDPTYIFHPRCRITLPNDETRVNATMEDVNDWLTELYGDQPPFSEPKFPTECFFLTLHAHHLSILPSCRRYIRRLRAIRELNRTVEDLKNNESQWKDSPLATRHREMLKRCKTQLKKLVRCKACADAGLLDESFLRRCLNFYGLLIQLLLRILDPAYPDITLPLNSDVPKVFAALPEFYVEDVAEFLFFIVQYSPQALYEPCTQDIVMFLVVMLCNQNYIRNPYLVAKLVEVMFMTNPAVQPRTQKFFEMIENHPLSTKLLVPSLMKFYTDVEHTGATSEFYDKFTIRYHISTIFKSLWQNIAHHGTFMEEFNSGKQFVRYINMLINDTTFLLDESLESLKRIHEVQEEMKNKEQWDQLPRDQQQARQSQLAQDERVSRSYLALATETVDMFHILTKQVQKPFLRPELGPRLAAMLNFNLQQLCGPKCRDLKVENPEKYGFEPKKLLDQLTDIYLQLDCARFAKAIADDQRSYSKELFEEVISKMRKAGIKSTIAIEKFKLLAEKVEEIVAKNARAEIDYSDAPDEFRDPLMDTLMTDPVRLPSGTIMDRSIILRHLLNSPTDPFNRQTLTESMLEPVPELKEQIQAWMREKQNSDH>sp|O95155-2|UBE4B_HUMAN Isoform 2 of Ubiquitin conjugation factor E4 BOS=Homo sapiens OX=9606 GN=UBE4BMEELSADEIRRRRLARLAGGQTSQPTTPLTSPQRENPPGPPIAASAPGPSQSLGLNVHNMTPATSPIGASGVAHRSQSSEGVSSLSSSPSNSLETQSQSLSRSQSMDIDGVSCEKSMSQVDVDSGIENMEVDENDRREKRSLSDKEPSSGPEVSEEQALQLVCKIFRVSWKDRDRDVIFLSSLSAQFKQNPKEVFSDFKDLIGQILMEVLMMSTQTRDENPFASLTATSQPIAAAARSPDRNLLLNTGSNPGTSPMFCSVASFGASSLSSLGASGGASNWDSYSDHFTIETCKETDMLNYLIECFDRVGIEEKKAPKMCSQPAVSQLLSNIRSQCISHTALVLQGSLTQPRSLQQPSFLVPYMLCRNLPYGFIQELVRTTHQDEEVFKQIFIPILQGLALAAKECSLDSDYFKYPLMALGELCETKFGKTHPVCNLVASLRLWLPKSLSPGCGRELQRLSYLGAFFSFSVFAEDDVKVVEKYFSGPAITLENTRVVSQSLQHYLELGRQELFKILHSILLNGETREAALSYMAAVVNANMKKAQMQTDDRLVSTDGFMLNFLWVLQQLSTKIKLETVDPTYIFHPRCRITLPNDETRVNATMEDVNDWLTELYGDQPPFSEPKFPTECFFLTLHAHHLSILPSCRRYIRRLRAIRELNRTVEDLKNNESQWKDSPLATRHREMLKRCKTQLKKLVRCKACADAGLLDESFLRRCLNFYGLLIQLLLRILDPAYPDITLPLNSDVPKVFAALPEFYVEDVAEFLFFIVQYSPQALYEPCTQDIVMFLVVMLCNQNYIRNPYLVAKLVEVMFMTNPAVQPRTQKFFEMIENHPLSTKLLVPSLMKFYTDVEHTGATSEFYDKFTIRYHISTIFKSLWQNIAHHGTFMEEFNSGKQFVRYINMLINDTTFLLDESLESLKRIHEVQEEMKNKEQWDQLPRDQQQARQSQLAQDERVSRSYLALATETVDMFHILTKQVQKPFLRPELGPRLAAMLNFNLQQLCGPKCRDLKVENPEKYGFEPKKLLDQLTDIYLQLDCARFAKAIADDQRSYSKELFEEVISKMRKAGIKSTIAIEKFKLLAEKVEEIVAKNARAEIDYSDAPDEFRDPLMDTLMTDPVRLPSGTIMDRSIILRHLLNSPTDPFNRQTLTESMLEPVPELKEQIQAWMREKQNSDH>sp|O95155-3|UBE4B_HUMAN Isoform 3 of Ubiquitin conjugation factor E4 BOS=Homo sapiens OX=9606 GN=UBE4BMSQVDVDSGIENMEVDENDRREKRSLSDKEPSSGPEVSEEQALQLVCKIFRVSWKDRDRDVIFLSSLSAQFKQNPKEVFSDFKDLIGQILMEVLMMSTQTRDENPFASLTATSQPIAAAARSPDRNLLLNTGSNPGTSPMFCSVASFGASSLSSLGASGGASNWDSYSDHFTIETCKETDMLNYLIECFDRVGIEEKKAPKMCSQPAVSQLLSNIRSQCISHTALVLQGSLTQPRSLQQPSFLVPYMLCRNLPYGFIQELVRTTHQDEEVFKQIFIPILQGLALAAKECSLDSDYFKYPLMALGELCETKFGKTHPVCNLVASLRLWLPKSLSPGCGRELQRLSYLGAFFSFSVFAEDDVKVVEKYFSGPAITLENTRVVSQSLQHYLELGRQELFKILHSILLNGETREAALSYMAAVVNANMKKAQMQTDDRLVSTDGFMLNFLWVLQQLSTKIKLETVDPTYIFHPRCRITLPNDETRVNATMEDVNDWLTELYGDQPPFSEPKFPTECFFLTLHAHHLSILPSCRRYIRRLRAIRELNRTVEDLKNNESQWKDSPLATRHREMLKRCKTQLKKLVRCKACADAGLLDESFLRRCLNFYGLLIQLLLRILDPAYPDITLPLNSDVPKVFAALPEFYVEDVAEFLFFIVQYSPQALYEPCTQDIVMFLVVMLCNQNYIRNPYLVAKLVEVMFMTNPAVQPRTQKFFEMIENHPLSTKLLVPSLMKFYTDVEHTGATSEFYDKFTIRYHISTIFKSLWQNIAHHGTFMEEFNSGKQFVRYINMLINDTTFLLDESLESLKRIHEVQEEMKNKEQWDQLPRDQQQARQSQLAQDERVSRSYLALATETVDMFHILTKQVQKPFLRPELGPRLAAMLNFNLQQLCGPKCRDLKVENPEKYGFEPKKLLDQLTDIYLQLDCARFAKAIADDQRSYSKELFEEVISKMRKAGIKSTIAIEKFKLLAEKVEEIVAKNARAEIDYSDAPDEFRGKWTHPLMDTLMTDPVRLPSGTIMDRSIILRHLLNSPTDPFNRQTLTESMLEPVPELKEQIQAWMREKQNSDH>sp|O95155-4|UBE4B_HUMAN Isoform 4 of Ubiquitin conjugation factor E4 BOS=Homo sapiens OX=9606 GN=UBE4BMEELSADEIRRRRLARLAGGQTSQPTTPLTSPQRENPPGPPIAASAPGPSQSLGLNVHNMTPATSPIGASGVAHRSQSSEGVSSLSSSPSNSLETQSQSLSRSQSMDIDGVSCEKSMSQVDVDSGIENMEVDENDRREKRSLSDKEPSSGPEVSEEQALQLVCKIFRVSWKDRDRDVIFLSSLSAQFKQNPKEVFSDFKDLIGQILMEVLMMSTQTRDENPFASLTATSQPIAAAARSPDRNLLLNTGSNPGTSPMFCSVASFGASSLSSLYESSPAPTPSFWSSVPVMGPSLASPSRAASQLAVPSTPLSPHSAASGTAAGSQPSSPRYRPYTVTHPWASSGVSILSSSPSPPALASSPQAVPASSSRQRPSSTGPPLPPASPSATSRRPSSLRISPSMYDNPFSFLFLALSGDSSDEEDEEEDDDDGDGDDEGGGGGDDFSCVQFGSSLGASGGASNWDSYSDHFTIETCKETDMLNYLIECFDRVGIEEKKAPKMCSQPAVSQLLSNIRSQCISHTALVLQGSLTQPRSLQQPSFLVPYMLCRNLPYGFIQELVRTTHQDEEVFKQIFIPILQGLALAAKECSLDSDYFKYPLMALGELCETKFGKTHPVCNLVASLRLWLPKSLSPGCGRELQRLSYLGAFFSFSVFAEDDVKVVEKYFSGPAITLENTRVVSQSLQHYLELGRQELFKILHSILLNGETREAALSYMAAVVNANMKKAQMQTDDRLVSTDGFMLNFLWVLQQLSTKIKLETVDPTYIFHPRCRITLPNDETRVNATMEDVNDWLTELYGDQPPFSEPKFPTECFFLTLHAHHLSILPSCRRYIRRLRAIRELNRTVEDLKNNESQWKDSPLATRHREMLKRCKTQLKKLVRCKACADAGLLDESFLRRCLNFYGLLIQLLLRILDPAYPDITLPLNSDVPKVFAALPEFYVEDVAEFLFFIVQYSPQALYEPCTQDIVMFLVVMLCNQNYIRNPYLVAKLVEVMFMTNPAVQPRTQKFFEMIENHPLSTKLLVPSLMKFYTDVEHTGATSEFYDKFTIRYHISTIFKSLWQNIAHHGTFMEEFNSGKQFVRYINMLINDTTFLLDESLESLKRIHEVQEEMKNKEQWDQLPRDQQQARQSQLAQDERVSRSYLALATETVDMFHILTKQVQKPFLRPELGPRLAAMLNFNLQQLCGPKCRDLKVENPEKYGFEPKKLLDQLTDIYLQLDCARFAKAIADDQRSYSKELFEEVISKMRKAGIKSTIAIEKFKLLAEKVEEIVAKNARAEIDYSDAPDEFRDPLMDTLMTDPVRLPSGTIMDRSIILRHLLNSPTDPFNRQTLTESMLEPVPELKEQIQAWMREKQNSDH>sp|P17480|UBF1_HUMAN Nucleolar transcription factor 1 OS=Homo sapiensOX=9606 GN=UBTF PE=1 SV=1MNGEADCPTDLEMAAPKGQDRWSQEDMLTLLECMKNNLPSNDSSKFKTTESHMDWEKVAFKDFSGDMCKLKWVEISNEVRKFRTLTELILDAQEHVKNPYKGKKLKKHPDFPKKPLTPYFRFFMEKRAKYAKLHPEMSNLDLTKILSKKYKELPEKKKMKYIQDFQREKQEFERNLARFREDHPDLIQNAKKSDIPEKPKTPQQLWYTHEKKVYLKVRPDATTKEVKDSLGKQWSQLSDKKRLKWIHKALEQRKEYEEIMRDYIQKHPELNISEEGITKSTLTKAERQLKDKFDGRPTKPPPNSYSLYCAELMANMKDVPSTERMVLCSQQWKLLSQKEKDAYHKKCDQKKKDYEVELLRFLESLPEEEQQRVLGEEKMLNINKKQATSPASKKPAQEGGKGGSEKPKRPVSAMFIFSEEKRRQLQEERPELSESELTRLLARMWNDLSEKKKAKYKAREAALKAQSERKPGGEREERGKLPESPKRAEEIWQQSVIGDYLARFKNDRVKALKAMEMTWNNMEKKEKLMWIKKAAEDQKRYERELSEMRAPPAATNSSKKMKFQGEPKKPPMNGYQKFSQELLSNGELNHLPLKERMVEIGSRWQRISQSQKEHYKKLAEEQQKQYKVHLDLWVKSLSPQDRAAYKEYISNKRKSMTKLRGPNPKSSRTTLQSKSESEEDDEEDEDDEDEDEEEEDDENGDSSEDGGDSSESSSEDESEDGDENEEDDEDEDDDEDDDEDEDNESEGSSSSSSSSGDSSDSDSN>sp|P17480-2|UBF1_HUMAN Isoform UBF2 of Nucleolar transcription factor 1OS=Homo sapiens OX=9606 GN=UBTFMNGEADCPTDLEMAAPKGQDRWSQEDMLTLLECMKNNLPSNDSSKFKTTESHMDWEKVAFKDFSGDMCKLKWVEISNEVRKFRTLTELILDAQEHVKNPYKGKKLKKHPDFPKKPLTPYFRFFMEKRAKYAKLHPEMSNLDLTKILSKKYKELPEKKKMKYIQDFQREKQEFERNLARFREDHPDLIQNAKKSDIPEKPKTPQQLWYTHEKKVYLKVRPDEIMRDYIQKHPELNISEEGITKSTLTKAERQLKDKFDGRPTKPPPNSYSLYCAELMANMKDVPSTERMVLCSQQWKLLSQKEKDAYHKKCDQKKKDYEVELLRFLESLPEEEQQRVLGEEKMLNINKKQATSPASKKPAQEGGKGGSEKPKRPVSAMFIFSEEKRRQLQEERPELSESELTRLLARMWNDLSEKKKAKYKAREAALKAQSERKPGGEREERGKLPESPKRAEEIWQQSVIGDYLARFKNDRVKALKAMEMTWNNMEKKEKLMWIKKAAEDQKRYERELSEMRAPPAATNSSKKMKFQGEPKKPPMNGYQKFSQELLSNGELNHLPLKERMVEIGSRWQRISQSQKEHYKKLAEEQQKQYKVHLDLWVKSLSPQDRAAYKEYISNKRKSMTKLRGPNPKSSRTTLQSKSESEEDDEEDEDDEDEDEEEEDDENGDSSEDGGDSSESSSEDESEDGDENEEDDEDEDDDEDDDEDEDNESEGSSSSSSSSGDSSDSDSN>sp|O14562|UBFD1_HUMAN Ubiquitin domain-containing protein UBFD1 OS=Homosapiens OX=9606 GN=UBFD1 PE=1 SV=2MAAAGAPDGMEEPGMDTEAETVATEAPARPVNCLEAEAAAGAAAEDSGAARGSLQPAPAQPPGDPAAQASVSNGEDAGGGAGRELVDLKIIWNKTKHDVKFPLDSTGSELKQKIHSITGLPPAMQKVMYKGLVPEDKTLREIKVTSGAKIMVVGSTINDVLAVNTPKDAAQQDAKAEENKKEPLCRQKQHRKVLDKGKPEDVMPSVKGAQERLPTVPLSGMYNKSGGKVRLTFKLEQDQLWIGTKERTEKLPMGSIKNVVSEPIEGHEDYHMMAFQLGPTEASYYWVYWVPTQYVDAIKDTVLGKWQYF>sp|P0CB47|UBFL1_HUMAN Upstream-binding factor 1-like protein 1 OS=Homosapiens OX=9606 GN=UBTFL1 PE=1 SV=1MALPRSQGHWSNKDILRLLECMENNRPSDDNSTFSSTQSHMDWGKVAFKNFSGEMCRLKWLEISCNLRKFGTLKELVLEAKKCVKKMNKSQKYRNGPDFPKRPLTAYNRFFKESWPQYSQMYPGMRSQELTKILSKKYRELPEQMKQKYIQDFRKEKQEFEEKLARFREEHPDLVQKAKKSSVSKRTQNKVQKKFQKNIEEVRSLPKTDRFFKKVKFHGEPQKPPMNGYHKFHQDSWSSKEMQHLSVRERMVEIGRRWQRIPQSQKDHFKSQAEELQKQYKVKLDLWLKTLSPENYAAYKESTYAKGKNMAMTGGPDPRLKQADPQSSSAKGLQEGFGEGQGLQAAGTDSSQTIWVNCHVSMEPEENRKKDREKEESSNSSDCSSGEEIEVDV>sp|P0CB48|UBFL6_HUMAN Putative upstream-binding factor 1-like protein 6OS=Homo sapiens OX=9606 GN=UBTFL6 PE=5 SV=1MPAKDIKVALPRSQGHWSNADILRLLECMENNLPYDDNGTFSSTQSHMDWGKVAFKNFSGEMCRLKWLEISCSLRKFSTLKKLVLEAKKCVKNTNKSQKGRNHPDFPKRLLTAYIRFFKENWPQYSQMYPGMRSQEVTKILSKKYKELPEQMKQKHIQDFRKEKQEFEEKLARFREEHPDLDQKGKKSDICKRVQTKVQKKVQKNIEEVRSLPKTDQFFKKVKFHGEPQKPPMNGYQKFHQDSWSSKELQHLSLRERMVEIGRRWQRIPQSQKDHYKSQAELLQKEYKVELDLWLKTLSPEDYAAYKESTYAKGKNMAMMGGPAPSLKQTDPQSSSAKGLQEGFGEGQGLQAAGTEASQTIWVNCQVSMEPEDNRKKDGEEEESSNSLDCSSGEDMEVDV>sp|Q9Y5K8|VATD_HUMAN V-type proton ATPase subunit D OS=Homo sapiensOX=9606 GN=ATP6V1D PE=1 SV=1MSGKDRIEIFPSRMAQTIMKARLKGAQTGRNLLKKKSDALTLRFRQILKKIIETKMLMGEVMREAAFSLAEAKFTAGDFSTTVIQNVNKAQVKIRAKKDNVAGVTLPVFEHYHEGTDSYELTGLARGGEQLAKLKRNYAKAVELLVELASLQTSFVTLDEAIKITNRRVNAIEHVIIPRIERTLAYIITELDEREREEFYRLKKIQEKKKILKEKSEKDLEQRRAAGEVLEPANLLAEEKDEDLLFE>sp|Q08AM6|VAC14_HUMAN Protein VAC14 homolog OS=Homo sapiens OX=9606GN=VAC14 PE=1 SV=1MNPEKDFAPLTPNIVRALNDKLYEKRKVAALEIEKLVREFVAQNNTVQIKHVIQTLSQEFALSQHPHSRKGGLIGLAACSIALGKDSGLYLKELIEPVLTCFNDADSRLRYYACEALYNIVKVARGAVLPHFNVLFDGLSKLAADPDPNVKSGSELLDRLLKDIVTESNKFDLVSFIPLLRERIYSNNQYARQFIISWILVLESVPDINLLDYLPEILDGLFQILGDNGKEIRKMCEVVLGEFLKEIKKNPSSVKFAEMANILVIHCQTTDDLIQLTAMCWMREFIQLAGRVMLPYSSGILTAVLPCLAYDDRKKSIKEVANVCNQSLMKLVTPEDDELDELRPGQRQAEPTPDDALPKQEGTASGGPDGSCDSSFSSGISVFTAASTERAPVTLHLDGIVQVLNCHLSDTAIGMMTRIAVLKWLYHLYIKTPRKMFRHTDSLFPILLQTLSDESDEVILKDLEVLAEIASSPAGQTDDPGPLDGPDLQASHSELQVPTPGRAGLLNTSGTKGLECSPSTPTMNSYFYKFMINLLKRFSSERKLLEVRGPFIIRQLCLLLNAENIFHSMADILLREEDLKFASTMVHALNTILLTSTELFQLRNQLKDLKTLESQNLFCCLYRSWCHNPVTTVSLCFLTQNYRHAYDLIQKFGDLEVTVDFLAEVDKLVQLIECPIFTYLRLQLLDVKNNPYLIKALYGLLMLLPQSSAFQLLSHRLQCVPNPELLQTEDSLKAAPKSQKADSPSIDYAELLQHFEKVQNKHLEVRHQRSGRGDHLDRRVVL>sp|Q08AM6-2|VAC14_HUMAN Isoform 2 of Protein VAC14 homolog OS=Homosapiens OX=9606 GN=VAC14MADILLREEDLKFASTMVHALNTILLTSTELFQLRNQLKDLKTLESQNLFCCLYRSWCHNPVTTVSLCFLTQNYRHAYDLIQKFGDLEVTVDFLAEVDKLVQLIECPIFTYLRLQLLDVKNNPYLIKALYGLLMLLPQSSAFQLLSHRLQCVPNPELLQTEDSLKAAPKSQKADSPSIDYAELLQHFEKVQNKHLEVRHQRSGRGDHLDRRVVL>sp|Q6P1N9|TATD1_HUMAN Putative deoxyribonuclease TATDN1 OS=Homo sapiensOX=9606 GN=TATDN1 PE=1 SV=2MSRFKFIDIGINLTDPMFRGIYRGVQKHQDDLQDVIGRAVEIGVKKFMITGGNLQDSKDALHLAQTNGMFFSTVGCHPTRCGEFEKNNPDLYLKELLNLAENNKGKVVAIGECGLDFDRLQFCPKDTQLKYFEKQFELSEQTKLPMFLHCRNSHAEFLDIMKRNRDRCVGGVVHSFDGTKEAAAALIDLDLYIGFNGCSLKTEANLEVLKSIPSEKLMIETDAPWCGVKSTHAGSKYIRTAFPTKKKWESGHCLKDRNEPCHIIQILEIMSAVRDEDPLELANTLYNNTIKVFFPGI>sp|Q6P1N9-2|TATD1_HUMAN Isoform 2 of Putative deoxyribonuclease TATDN1OS=Homo sapiens OX=9606 GN=TATDN1MITGGNLQDSKDALHLAQTNGMFFSTVGCHPTRCGEFEKNNPDLYLKELLNLAENNKGKVVAIGECGLDFDRLQFCPKDTQLKYFEKQFELSEQTKLPMFLHCRNSHAEFLDIMKRNRDRCVGGVVHSFDGTKEAAAALIDLDLYIGFNGCSLKTEANLEVLKSIPSEKLMIETDAPWCGVKSTHAGSKYIRTAFPTKKKWESGHCLKDRNEPCHIIQILEIMSAVRDEDPLELANTLYNNTIKVFFPGI>sp|Q9H5J8|TAF1D_HUMAN TATA box-binding protein-associated factor RNApolymerase I subunit D OS=Homo sapiens OX=9606 GN=TAF1D PE=1 SV=1MDKSGIDSLDHVTSDAVELANRSDNSSDSSLFKTQCIPYSPKGEKRNPIRKFVRTPESVHASDSSSDSSFEPIPLTIKAIFERFKNRKKRYKKKKKRRYQPTGRPRGRPEGRRNPIYSLIDKKKQFRSRGSGFPFLESENEKNAPWRKILTFEQAVARGFFNYIEKLKYEHHLKESLKQMNVGEDLENEDFDSRRYKFLDDDGSISPIEESTAEDEDATHLEDNECDIKLAGDSFIVSSEFPVRLSVYLEEEDITEEAALSKKRATKAKNTGQRGLKM>sp|A0A1W2PP97|THSD8_HUMAN Thrombospondin type-1 domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=THSD8 PE=3 SV=2MARTPGALLLAPLLLLQLATPALVYQDYQYLGQQGEGDSWEQLRLQHLKEVEDSILGPWGKWRCLCDLGKQERSREVVGTAPGPVFMDPEKLIQLRPCRQRDCPSCKPFDCDWRL>sp|Q53EQ6|TIGD5_HUMAN Tigger transposable element-derived protein 5OS=Homo sapiens OX=9606 GN=TIGD5 PE=1 SV=3MYPAGPPAGPVPRRGRRPLPGPPAPAPAPVPAARPPPPAPGPRPRVAVKMAFRKAYSIKDKLQAIERVKGGERQASVCRDFGVPGGTLRGWLKDEPKLRWFLEQLGGEVGTQRKKMRLANEEEIDRAVYAWFLALRQHGVPLSGPLIQAQAEAFARQIYGPECTFKASHGWFWRWQKRHGISSQRFYGEAGPPAPSPAPGPPVKEEPALPSGAGPLPDRAPAPPPPAEGGYGDEQIYSASVTGLYWKLLPEQAAPPGAGDPGAGGCGRRWRGDRVTVLLAANLTGSHKLKPLVIGRLPDPPSLRHHNQDKFPASYRYSPDAWLSRPLLRGWFFEEFVPGVKRYLRRSCLQQKAVLLVAHPPCPSPAASMPALDSEDAPVRCRPEPLGPPEELQTPDGAVRVLFLSKGSSRAHIPAPLEQGVVAAFKQLYKRELLRLAVSCASGSPLDFMRSFMLKDMLYLAGLSWDLVQAGSIERCWLLGLRAAFEPRPGEDSAGQPAQAEEAAEHSRVLSDLTHLAALAYKCLAPEEVAEWLHLDDDGGPPEGCREEVGPALPPAAPPAPASLPSAMGGGEDEEEATDYGGTSVPTAGEAVRGLETALRWLENQDPREVGPLRLVQLRSLISMARRLGGIGHTPAGPYDGV>sp|Q53EQ6-2|TIGD5_HUMAN Isoform 2 of Tigger transposable element-derivedprotein 5 OS=Homo sapiens OX=9606 GN=TIGD5MAFRKAYSIKDKLQAIERVKGGERQASVCRDFGVPGGTLRGWLKDEPKLRWFLEQLGGEVGTQRKKMRLANEEEIDRAVYAWFLALRQHGVPLSGPLIQAQAEAFARQIYGPECTFKASHGWFWRWQKRHGISSQRFYGEAGPPAPSPAPGPPVKEEPALPSGAGPLPDRAPAPPPPAEGGYGDEQIYSASVTGLYWKLLPEQAAPPGAGDPGAGGCGRRWRGDRVTVLLAANLTGSHKLKPLVIGRLPDPPSLRHHNQDKFPASYRYSPDAWLSRPLLRGWFFEEFVPGVKRYLRRSCLQQKAVLLVAHPPCPSPAASMPALDSEDAPVRCRPEPLGPPEELQTPDGAVRVLFLSKGSSRAHIPAPLEQGVVAAFKQLYKRELLRLAVSCASGSPLDFMRSFMLKDMLYLAGLSWDLVQAGSIERCWLLGLRAAFEPRPGEDSAGQPAQAEEAAEHSRVLSDLTHLAALAYKCLAPEEVAEWLHLDDDGGPPEGCREEVGPALPPAAPPAPASLPSAMGGGEDEEEATDYGGTSVPTAGEAVRGLETALRWLENQDPREVGPLRLVQLRSLISMARRLGGIGHTPAGPYDGV>sp|Q4W5G0|TIGD2_HUMAN Tigger transposable element-derived protein 2OS=Homo sapiens OX=9606 GN=TIGD2 PE=3 SV=1MLGKRKRVVLTIKDKLDIIKKLEEGISFKKLSVVYGIGESTVRDIKKNKERIINYANSSDPTSGVSKRKSMKSSTYEELDRVMIEWFNQQKTDGIPVSGTICAKQAKFFFDALGMEGDFNASSGWLTRFKQRHGIPKAAGKGTKLKGDETAAREFCGSFQEFVEKENLQPEQIYGADQTGLFWKCLPSRTLTLETDQSTSGCRSSRERIIIMCCANATGLHKLNLCVVGKAKKPRAFKGTDLSNLPVTYYSQKGAWIEQSVFRQWFEKYFVPQVQKHLKSKGLLEKAVLLLDFPPARPNEEMLSSDDGRIIVKYLPPNVTSLIQPMSQGVLATVKRYYRAGLLQKYMDEGNDPKIFWKNLTVLDAIYEVSRAWNMVKSSTITKAWKKLFPGNEENSGMNIDEGAILAANLATVLQNTEECEHVDIENIDQWFDSRSSDSSCQVLTDSESAEDQTKAAEQKPSSKSRKTELNPEKHISHKAALEWTENLLDYLEQQDDMLLSDKLVLRRLRTIIRKKQKIQNNKNH>sp|Q8NA69|TEX45_HUMAN Testis-expressed protein 45 OS=Homo sapiensOX=9606 GN=TEX45 PE=1 SV=2MATGALLPCSRPCPMSRLDFLKASHFSLGPDLRLHEGTMRTTSHRDFAYPAATREPPSLQPPPALLFPMDPRWDREERVSEAHRAFPPPSTPPWELLQAQARERTLAMQAGNLHLHEDAHAGIGLSNAHAAYGWPELPARTRERIRGARLIFDRDSLPPGDRDKLRIPPTTHQALFPPHDARPQPRAPSCHLGGPNTLKWDYTRQDGTSYQRQFQALPGPPALRCKRASSGVELGDCKISYGSTCSEQKQAYRPQDLPEDRYDKAQATAHIHCVNIRPGDGLFRDRTTKAEHFYAREPEPFVLHHDQTPESHILKGNWCPGPGSLDTFMQYFYGQPPPPTQPPSRHVPHEKLQSHVTLGEPKLLKRFFKTTMGSDYCPSEWRQVQKAPNLHLQQSYLPRGTGEFDFLTMNQKMLKPHRTPPAPVTEEMLQRCKYSHMEPPLGGLRFFSTQYKDEFPFKYQGPAALRLKNPQEGFVPLGTPHQRGCREKIDPLVPQPPMYLCPSQQ>sp|P57082|TBX4_HUMAN T-box transcription factor TBX4 OS=Homo sapiensOX=9606 GN=TBX4 PE=1 SV=2MLQDKGLSESEEAFRAPGPALGEASAANAPEPALAAPGLSGAALGSPPGPGADVVAAAAAEQTIENIKVGLHEKELWKKFHEAGTEMIITKAGRRMFPSYKVKVTGMNPKTKYILLIDIVPADDHRYKFCDNKWMVAGKAEPAMPGRLYVHPDSPATGAHWMRQLVSFQKLKLTNNHLDPFGHIILNSMHKYQPRLHIVKADENNAFGSKNTAFCTHVFPETSFISVTSYQNHKITQLKIENNPFAKGFRGSDDSDLRVARLQSKEYPVISKSIMRQRLISPQLSATPDVGPLLGTHQALQHYQHENGAHSQLAEPQDLPLSTFPTQRDSSLFYHCLKRRDGTRHLDLPCKRSYLEAPSSVGEDHYFRSPPPYDQQMLSPSYCSEVTPREACMYSGSGPEIAGVSGVDDLPPPPLSCNMWTSVSPYTSYSVQTMETVPYQPFPTHFTATTMMPRLPTLSAQSSQPPGNAHFSVYNQLSQSQVRERGPSASFPRERGLPQGCERKPPSPHLNAANEFLYSQTFSLSRESSLQYHSGMGTVENWTDG>sp|P57082-2|TBX4_HUMAN Isoform 2 of T-box transcription factor TBX4OS=Homo sapiens OX=9606 GN=TBX4MLQDKGLSESEEAFRAPGPALGEASAANAPEPALAAPGLSGAALGSPPGPGADVVAAAAAEQTIENIKVGLHEKELWKKFHEAGTEMIITKAGRRMFPSYKVKVTGMNPKTKYILLIDIVPADDHRYKFCDNKWMVAGKAEPAMPGRLYVHPDSPATGAHWMRQLVSFQKLKLTNNHLDPFGHIILNSMHKYQPRLHIVKADENNAFGSKNTAFCTHVFPETSFISVTSYQNHKITQLKIENNPFAKGFRGSDDSDLRVARLQSKEYPVISKSIMRQRLISPQLSATPDVGPLLGTHQALQHYQHENGAHSQLAEPQDLPLSTFPTQRDSSLFYHCLKRRADGTRHLDLPCKRSYLEAPSSVGEDHYFRSPPPYDQQMLSPSYCSEVTPREACMYSGSGPEIAGVSGVDDLPPPPLSCNMWTSVSPYTSYSVQTMETVPYQPFPTHFTATTMMPRLPTLSAQSSQPPGNAHFSVYNQLSQSQVRERGPSASFPRERGLPQGCERKPPSPHLNAANEFLYSQTFSLSRESSLQYHSGMGTVENWTDG>sp|Q12789|TF3C1_HUMAN General transcription factor 3C polypeptide 1OS=Homo sapiens OX=9606 GN=GTF3C1 PE=1 SV=4MDALESLLDEVALEGLDGLCLPALWSRLETRVPPFPLPLEPCTQEFLWRALATHPGISFYEEPRERPDLQLQDRYEEIDLETGILESRRDPVALEDVYPIHMILENKDGIQGSCRYFKERKNITNDIRTKSLQPRCTMVEAFDRWGKKLIIVASQAMRYRALIGQEGDPDLKLPDFSYCILERLGRSRWQGELQRDLHTTAFKVDAGKLHYHRKILNKNGLITMQSHVIRLPTGAQQHSILLLLNRFHVDRRSKYDILMEKLSVMLSTRTNHIETLGKLREELGLCERTFKRLYQYMLNAGLAKVVSLRLQEIHPECGPCKTKKGTDVMVRCLKLLKEFKRNDHDDDEDEEVISKTVPPVDIVFERDMLTQTYDLIERRGTKGISQAEIRVAMNVGKLEARMLCRLLQRFKVVKGFMEDEGRQRTTKYISCVFAEESDLSRQYQREKARSELLTTVSLASMQEESLLPEGEDTFLSESDSEEERSSSKRRGRGSQKDTRASANLRPKTQPHHSTPTKGGWKVVNLHPLKKQPPSFPGAAEERACQSLASRDSLLDTSSVSEPNVSFVSHCADSNSGDIAVIEEVRMENPKESSSSLKTGRHSSGQDKPHETYRLLKRRNLIIEAVTNLRLIESLFTIQKMIMDQEKQEGVSTKCCKKSIVRLVRNLSEEGLLRLYRTTVIQDGIKKKVDLVVHPSMDQNDPLVRSAIEQVRFRISNSSTANRVKTSQPPVPQGEAEEDSQGKEGPSGSGDSQLSASSRSESGRMKKSDNKMGITPLRNYHPIVVPGLGRSLGFLPKMPRLRVVHMFLWYLIYGHPASNTVEKPSFISERRTIKQESGRAGVRPSSSGSAWEACSEAPSKGSQDGVTWEAEVELATETVYVDDASWMRYIPPIPVHRDFGFGWALVSDILLCLPLSIFIQIVQVSYKVDNLEEFLNDPLKKHTLIRFLPRPIRQQLLYKRRYIFSVVENLQRLCYMGLLQFGPTEKFQDKDQVFIFLKKNAVIVDTTICDPHYNLARSSRPFERRLYVLNSMQDVENYWFDLQCVCLNTPLGVVRCPRVRKNSSTDQGSDEEGSLQKEQESAMDKHNLERKCAMLEYTTGSREVVDEGLIPGDGLGAAGLDSSFYGHLKRNWIWTSYIINQAKKENTAAENGLTVRLQTFLSKRPMPLSARGNSRLNIWGEARVGSELCAGWEEQFEVDREPSLDRNRRVRGGKSQKRKRLKKDPGKKIKRKKKGEFPGEKSKRLRYHDEADQSALQRMTRLRVTWSMQEDGLLVLCRIASNVLNTKVKGPFVTWQVVRDILHATFEESLDKTSHSVGRRARYIVKNPQAYLNYKVCLAEVYQDKALVGDFMNRRGDYDDPKVCANEFKEFVEKLKEKFSSALRNSNLEIPDTLQELFARYRVLAIGDEKDQTRKEDELNSVDDIHFLVLQNLIQSTLALSDSQMKSYQSFQTFRLYREYKDHVLVKAFMECQKRSLVNRRRVNHTLGPKKNRALPFVPMSYQLSQTYYRIFTWRFPSTICTESFQFLDRMRAAGKLDQPDRFSFKDQDNNEPTNDMVAFSLDGPGGNCVAVLTLFSLGLISVDVRIPEQIIVVDSSMVENEVIKSLGKDGSLEDDEDEEDDLDEGVGGKRRSMEVKPAQASHTNYLLMRGYYSPGIVSTRNLNPNDSIVVNSCQMKFQLRCTPVPARLRPAAAPLEELTMGTSCLPDTFTKLINPQENTCSLEEFVLQLELSGYSPEDLTAALEILEAIIATGCFGIDKEELRRRFSALEKAGGGRTRTFADCIQALLEQHQVLEVGGNTARLVAMGSAWPWLLHSVRLKDREDADIQREDPQARPLEGSSSEDSPPEGQAPPSHSPRGTKRRASWASENGETDAEGTQMTPAKRPALQDSNLAPSLGPGAEDGAEAQAPSPPPALEDTAAAGAAQEDQEGVGEFSSPGQEQLSGQAQPPEGSEDPRGFTESFGAANISQAARERDCESVCFIGRPWRVVDGHLNLPVCKGMMEAMLYHIMTRPGIPESSLLRHYQGVLQPVAVLELLQGLESLGCIRKRWLRKPRPVSLFSTPVVEEVEVPSSLDESPMAFYEPTLDCTLRLGRVFPHEVNWNKWIHL>sp|Q12789-3|TF3C1_HUMAN Isoform 2 of General transcription factor 3Cpolypeptide 1 OS=Homo sapiens OX=9606 GN=GTF3C1MDALESLLDEVALEGLDGLCLPALWSRLETRVPPFPLPLEPCTQEFLWRALATHPGISFYEEPRERPDLQLQDRYEEIDLETGILESRRDPVALEDVYPIHMILENKDGIQGSCRYFKERKNITNDIRTKSLQPRCTMVEAFDRWGKKLIIVASQAMRYRALIGQEGDPDLKLPDFSYCILERLGRSRWQGELQRDLHTTAFKVDAGKLHYHRKILNKNGLITMQSHVIRLPTGAQQHSILLLLNRFHVDRRSKYDILMEKLSVMLSTRTNHIETLGKLREELGLCERTFKRLYQYMLNAGLAKVVSLRLQEIHPECGPCKTKKGTDVMVRCLKLLKEFKRNDHDDDEDEEVISKTVPPVDIVFERDMLTQTYDLIERRGTKGISQAEIRVAMNVGKLEARMLCRLLQRFKVVKGFMEDEGRQRTTKYISCVFAEESDLSRQYQREKARSELLTTVSLASMQEESLLPEGEDTFLSESDSEEERSSSKRRGRGSQKDTRASANLRPKTQPHHSTPTKGGWKVVNLHPLKKQPPSFPGAAEERACQSLASRDSLLDTSSVSEPNVSFVSHCADSNSGDIAVIEEVRMENPKESSSSLKTGRHSSGQDKPHETYRLLKRRNLIIEAVTNLRLIESLFTIQKMIMDQEKQEGVSTKCCKKSIVRLVRNLSEEGLLRLYRTTVIQDGIKKKVDLVVHPSMDQNDPLVRSAIEQVRFRISNSSTANRVKTSQPPVPQGEAEEDSQGKEGPSGSGDSQLSASSRSESGRMKKSDNKMGITPLRNYHPIVVPGLGRSLGFLPKMPRLRVVHMFLWYLIYGHPASNTVEKPSFISERRTIKQESGRAGVRPSSSGSAWEACSEAPSKGSQDGVTWEAEVELATETVYVDDASWMRYIPPIPVHRDFGFGWALVSDILLCLPLSIFIQIVQVSYKVDNLEEFLNDPLKKHTLIRFLPRPIRQQLLYKRRYIFSVVENLQRLCYMGLLQFGPTEKFQDKDQVFIFLKKNAVIVDTTICDPHYNLARSSRPFERRLYVLNSMQDVENYWFDLQCVCLNTPLGVVRCPRVRKNSSTDQGSDEEGSLQKEQESAMDKHNLERKCAMLEYTTGSREVVDEGLIPGDGLGAAGLDSSFYGHLKRNWIWTSYIINQAKKENTAAENGLTVRLQTFLSKRPMPLSARGNSRLNIWGEARVGSELCAGWEEQFEVDREPSLDRNRRVRGGKSQKRKRLKKDPGKKIKRKKKGEFPGEKSKRLRYHDEADQSALQRMTRLRVTWSMQEDGLLVLCRIASNVLNTKVKGPFVTWQVVRDILHATFEESLDKTSHSVGRRARYIVKNPQAYLNYKVCLAEVYQDKALVGDFMNRRGDYDDPKVCANEFKEFVEKLKEKFSSALRNSNLEIPDTLQELFARYRVLAIGDEKDQTRKEDELNSVDDIHFLVLQNLIQSTLALSDSQMKSYQSFQTFRLYREYKDHVLVKAFMECQKRSLVNRRRVNHTLGPKKNRALPFVPMSYQLSQTYYRIFTWRFPSTICTESFQFLDRMRAAGKLDQPDRFSFKDQDNNEPTNDMVAFSLDGPGGNCVAVLTLFSLGLISVDVRIPEQIIVVDSSMVENEVIKSLGKDGSLEDDEDEEDDLDEGVGGKRRSMEVKPAQASHTNYLLMRGYYSPGIVSTRNLNPNDSIVVNSCQMKFQLRCTPVPARLRPAAAPLEELTMGTSCLPDTFTKLINPQENTCSLEEFVLQLELSGYSPEDLTAALEILEAIIATGCFGIDKEELRRRFSALEKAGGGRTRTFADCIQALLEQHQVLEVGGNTARLVAMGSAWPWLLHSVRLKDREDADIQREDPQARPLEGSSSEDSPPEGQAPPSHSPRGTKRRASWASENGETDAEGTQMTPAKRPALQDSNLAPSLGPGAEDGAEAQAPSPPPALEDTAAAGAAQEDQEGVGFTESFGAANISQAARERDCESVCFIGRPWRVVDGHLNLPVCKGMMEAMLYHIMTRPGIPESSLLRHYQGVLQPVAVLELLQGLESLGCIRKRWLRKPRPVSLFSTPVVEEVEVPSSLDESPMAFYEPTLDCTLRLGRVFPHEVNWNKWIHL>sp|H3BTG2|TEX46_HUMAN Testis-expressed protein 46 OS=Homo sapiensOX=9606 GN=TEX46 PE=2 SV=1MSLHGILASAGTIGAVAAWLMSYKPALFGFLFLLLLLSNWLVKYEHKLTLPEPQQDEILQRLLFSEMKMKVLENQMFIIWNKMNHHGRSSRHRNFPMKKHRMRRHESICPTLSDCTSSSPS>sp|H3BTG2-2|TEX46_HUMAN Isoform 2 of Testis-expressed protein 46 OS=Homosapiens OX=9606 GN=TEX46MSYKPALFGFLFLLLLLSNWLVKYEHKLTLPEPQQEEEKPKTSENDSKNSKAVNTKEVNRTHACFALQDEILQRLLFSEMKMKVLENQMFIIWNKMNHHGRSSRHRNFPMKKHRMRRHESICPTLSDCTSSSPS>sp|Q5QJ38|TCHL1_HUMAN Trichohyalin-like protein 1 OS=Homo sapiensOX=9606 GN=TCHHL1 PE=2 SV=1MPQLLRNVLCVIETFHKYASEDSNGATLTGRELKQLIQGEFGDFFQPCVLHAVEKNSNLLNIDSNGIISFDEFVLAIFNLLNLCYLDIKSLLSSELRQVTKPEKEKLDDVDVQATTGDGQWTVGTSPTQEKRMLPSGMASSSQLIPEESGAVGNNRVDPWREAKTHNFPGEASEHNDPKNKHLEGDEQSQEVAQDIQTTEDNEGQLKTNKPMAGSKKTSSPTERKGQDKEISQEGDEPAREQSVSKIRDQFGEQEGNLATQSSPPKEATQRPCEDQEVRTEKEKHSNIQEPPLQREDEPSSQHADLPEQAAARSPSQTQKSTDSKDVCRMFDTQEPGKDADQTPAKTKNLGEPEDYGRTSETQEKECETKDLPVQYGSRNGSETSDMRDERKERRGPEAHGTAGQKERDRKTRPLVLETQTQDGKYQELQGLSKSKDAEKGSETQYLSSEGGDQTHPELEGTAVSGEEAEHTKEGTAEAFVNSKNAPAAERTLGARERTQDLAPLEKQSVGENTRVTKTHDQPVEEEDGYQGEDPESPFTQSDEGSSETPNSLASEEGNSSSETGELPVQGDSQSQGDQHGESVQGGHNNNPDTQRQGTPGEKNRALEAVVPAVRGEDVQLTEDQEQPARGEHKNQGPGTKGPGAAVEPNGHPEAQESTAGDENRKSLEIEITGALDEDFTDQLSLMQLPGKGDSRNELKVQGPSSKEEKGRATEAQNTLLESLDEDNSASLKIQLETKEPVTSEEEDESPQELAGEGGDQKSPAKKEHNSSVPWSSLEKQMQRDQEPCSVERGAVYSSPLYQYLQEKILQQTNVTQEEHQKQVQIAQASGPELCSVSLTSEISDCSVFFNYSQASQPYTRGLPLDESPAGAQETPAPQALEDKQGHPQRERLVLQREASTTKQ>sp|P10599|THIO_HUMAN Thioredoxin OS=Homo sapiens OX=9606 GN=TXN PE=1SV=3MVKQIESKTAFQEALDAAGDKLVVVDFSATWCGPCKMIKPFFHSLSEKYSNVIFLEVDVDDCQDVASECEVKCMPTFQFFKKGQKVGEFSGANKEKLEATINELV>sp|P10599-2|THIO_HUMAN Isoform 2 of Thioredoxin OS=Homo sapiens OX=9606GN=TXNMVKQIESKTAFQEALDAAGDKLVVVDFSATWCGPCKMIKPFFHDVASECEVKCMPTFQFFKKGQKVGEFSGANKEKLEATINELV>sp|Q9BT92|TCHP_HUMAN Trichoplein keratin filament-binding proteinOS=Homo sapiens OX=9606 GN=TCHP PE=1 SV=1MALPTLPSYWCSQQRLNQQLARQREQEARLRQQWEQNSRYFRMSDICSSKQAEWSSKTSYQRSMHAYQREKMKEEKRRSLEARREKLRQLMQEEQDLLARELEELRLSMNLQERRIREQHGKLKSAKEEQRKLIAEQLLYEHWKKNNPKLREMELDLHQKHVVNSWEMQKEEKKQQEATAEQENKRYENEYERARREALERMKAEEERRQLEDKLQAEALLQQMEELKLKEVEATKLKKEQENLLKQRWELERLEEERKQMEAFRQKAELGRFLRHQYNAQLSRRTQQIQEELEADRRILQALLEKEDESQRLHLARREQVMADVAWMKQAIEEQLQLERAREAELQMLLREEAKEMWEKREAEWARERSARDRLMSEVLTGRQQQIQEKIEQNRRAQEESLKHREQLIRNLEEVRELARREKEESEKLKSARKQELEAQVAERRLQAWEADQQEEEEEEEARRVEQLSDALLQQEAETMAEQGYRPKPYGHPKIAWN>sp|B5MCY1|TDR15_HUMAN Tudor domain-containing protein 15 OS=Homo sapiensOX=9606 GN=TDRD15 PE=2 SV=1MDSTSFLPTFLDVDLTISHIKCLPKDILVKFQGIKSNECEFDYHVLQREIQHTPKVKNNVEIDEFCLVEERVSGEWQRGRVMEKKNELYTVLLIDRGEELRVAGPQIASACGNLFELPPRVVFGIFANILPVGEKWSPKALNYFKSLVGIQVKGYVQAILPLQMFLFEVPKIISQALELQLGRLVDGDSFRLIVEMLEEFPQQMPDLLQHKRPELSLGNKDTSLDIQHVLDKLQPSLSVGSTESVKVSSALSPSKFYCQLIKWTPELENLTAHMTLHYDTVCQETSPTCDNFGLLCVARRRNGQWHRGILQQLLPPNQVKIWFMDYGSSEAIPSIYVKKLKQDFILVPLFSFPCSLTCLHSPDRDARIFQLSIFKQALLGQVVYAHIDWFNKDECLYYVTLQTQESTVNSKCLLKTVGTQVLCPMSDSKISNILSETSVSDVNSFAVESFMGNIEWSIDSLNKKGILKVGFPIKTVQMEIEAAYIAFIAYVLNPSNFWVRTNDHRNEFQEIMKNINKFYDLCENDEMILRKPEPGLFCCARYSKDRRFYRAVITEINGYKINVYFLDYGNTDSIPFFDVKILLPEFCELPALAMCCSLAHIFPVEDLWTKAAIDYFKKLVLNKAILLQVIAKKDDKYTVNIQSVEASENIDVISLMLQAGYAEYFQVELEYFPKSVSEYSMLNSESKNKVNIKKVISALLEGPKSKKYHSNNLVENNLSLPKSLAVNISEFKNPFTLSVGPESSWPYKEYIFRPGTVLEVKCSCYYGPGDFSCQLQCKSEDLKLLMEQIQNYYSIHSDPYEIGQTACVAKYSGKWCRAAVLTQVSKEVDIVFVDYGYQKRVLIEDLCAINPRFLLLESQAFRCCLNHFIEPVSCKLFSWTRKAFRDLWNFISSSRGLLTCIIYALVIIHPNHLYNLVDLQSSFTSAKEFLMNRGSAQYITLSETFPSLFSLYSYCYSSFNIQIGSEEEVYISHIYSPQKFYCQLGRNNKDLEMIETKITESVNLQNFPKYDSNKMRVCISKYVEDGLSYRALAIPTDSSSEFQVYFVDFGNKQLVGENMLRAISAQFPELLFTPMQAIKCFLSDLRDVDIPAEISSWFKDNFLGRSLKAIILSQESDGQLGIELYDGSQYINEKIKVLLHAYGKRHCDQACCMEKSNKINENKRFTTSLKGKTGNNYRHNVINKPSPVTYSERKIDQLMHPKNIHARFLKPSVCYKMEPVSKNKMKTSLNDGLKGIKIVPGAAHILENRRVGQKSVKVVSQSFIRALNQTTSQNPYDLIRPQIKDLPQPQIYLNAKVKGYVSNISNPANFHIQLAENESVIIRLADALNATARRLRERKSVKPLVGDLVVAEYSGDNAIYRAVIKKILPGNSFEVEFIDYGNSAIVNTSKIYELQREFLTVPQLGIHAFLSGVKWNEPDEIWDDKTVDYFTSKVHNKTVYCEFLKKHDQKWEVNMICDEKCVINELLKWKACSKLQKSALQMPQVLSQKVRPGDNEMKKGKSNESEGSMNSNQQLFKIPLEEFKLGQLEKAEMLNVSKSGRFYVKLSKNKKILSDLIVLITKEEKKSPFLSMESIEKGLECLAKSKNTLKWHRSKVEEKYVDDKVLVFLVDCGIYEIVPVCNTKLLSNEIRNIPRQAVPCKWIWFENSKNISFECLFADLEINILFLKYLDAVWEVEILVDDLLLLEYLNLNTVPVEENKLRLAEIVYNIESKTPVSSCTIKSFTWVQFQNDRQYSGIATAVSDPSDFSIQLEDFFDIMKYLFMLLSDLPETLQTLPQEFIIPGSSCLFKYKSEDQWNRVEISEVSPQSLCLVLVDYGFSFYIRYSEIINLKVVPEELLNLPRLSYPCILYGILPAKGKHWSEEAKIFFRDFLSKPDLVFQFREYHSETKLKVDVIHEKNNLADILVASGLATYSKDSPHLDAITATESAKNPI>sp|Q6P2C0|WDR93_HUMAN WD repeat-containing protein 93 OS=Homo sapiensOX=9606 GN=WDR93 PE=2 SV=1MSFPRGSQTQKIKHPIGTRKGPLEVPPPTEKDWPKDDEQDHVLVDPDEELDSLPQPYRMINKLVNLLFDQSWEIIEERNALREAESSQIQPTVYPPLGEIQLNKMPNCMAVSQDYVFIGGAKGFSIYNLYSAKQIYAWEKLKVDVTSIWATDLGNEILIAPVDEMGIIRLFYFYKEGLYLVKAINEVDDTSKQTTCIKMEISQGGDFAAFLLQGAGDIWLDVYKLPKETWLKKLEHPQLTSNPKKKVRQPQLNSLGPISADPLEMDANVSFKGDIKLSLPVYIMKIKPPKPVTGTTFKSPLEVFAKIKDCYGLGSGQNHFIKDSQWEQQAEIFNASYKKYLDREWEEEPLSTATFYFLLPSCLFAMPPEVKGPSGMACVLGIHWTRSHNFFLYSLNRTLKDKADPEGVWPCAAPIAVSQLSCSSSYLVLACEDGVLTLWDLAKGFPLGVAALPQGCFCQSIHFLKYFSVHKGQNMYPEGQVKSQMKCVVLCTDASLHLVEASGTQGPTISVLVERPVKHLDKTICAVAPVPALPGMVLIFSKNGSVCLMDVAKREIICAFAPPGAFPLEVPWKPVFAVSPDHPCFLLRGDYSHETASTDDAGIQYSVFYFNFEACPLLENISKNCTIPQRDLDNMAFPQALPLEKRCERFLQKSYRKLEKNPEKEEEHWARLQRYSLSLQRENFKK>sp|Q6P2C0-2|WDR93_HUMAN Isoform 2 of WD repeat-containing protein 93OS=Homo sapiens OX=9606 GN=WDR93MSFPRGSQTQKIKHPIGTRKGPLEVPPPTEKDWPKDDEQDHVLVDPDEELDSLPQPYRMINKLVNLLFDQSWEIIEERNALREAESSQIQPTVYPPLGEIQLNKMPNCMAVSQDYVFIGGAKGFSIYNLYSAKQIYAWEKLKVDVTSIWATDLGNEILIAPVDEMGIIRLFYFYKEGLYLVKAINEVDDTSKQTTCIKMEISQGGDFAAFLLQGAGDIWLDVYKLPKETWLKKLEHPQLTSNPKKKVRQPQLNSLGPISADPLEMDANVSFKGDIKLSLPVYIMKIKPPKPVTGTTFKSPLEVFAKIKDCYGLGSGQNHFIKDSQWEQQAEIFNASYKKYLDREWEEEPLSTATFYFLLPSCLFAMPPEVKGPSGMACVLGIHWTRSHNFFLYSLNRTLKDKADPEGVWPCAAPIAVSQLSCSSSYLVLACEDGVLTLWDLAKGQNMYPEGQVKSQMKCVVLCTDASLHLVEASGTQGPTISVLVERPVKHLDKTICAVAPVPALPGMVLIFSKNGSVCLMDVAKREIICAFAPPGAFPLEVPWKPVFAVSPDHPCFLLRGDYSHETASTDDAGIQYSVFYFNFEACPLLENISKNCTIPQRDLDNMAFPQALPLEKRCERFLQKSYRKLEKNPEKEEEHWARLQRYSLSLQRENFKK>sp|Q9UKZ4|TEN1_HUMAN Teneurin-1 OS=Homo sapiens OX=9606 GN=TENM1 PE=1SV=2MEQTDCKPYQPLPKVKHEMDLAYTSSSDESEDGRKPRQSYNSRETLHEYNQELRMNYNSQSRKRKEVEKSTQEMEFCETSHTLCSGYQTDMHSVSRHGYQLEMGSDVDTETEGAASPDHALRMWIRGMKSEHSSCLSSRANSALSLTDTDHERKSDGENGFKFSPVCCDMEAQAGSTQDVQSSPHNQFTFRPLPPPPPPPHACTCARKPPPAADSLQRRSMTTRSQPSPAAPAPPTSTQDSVHLHNSWVLNSNIPLETRHFLFKHGSGSSAIFSAASQNYPLTSNTVYSPPPRPLPRSTFSRPAFTFNKPYRCCNWKCTALSATAITVTLALLLAYVIAVHLFGLTWQLQPVEGELYANGVSKGNRGTESMDTTYSPIGGKVSDKSEKKVFQKGRAIDTGEVDIGAQVMQTIPPGLFWRFQITIHHPIYLKFNISLAKDSLLGIYGRRNIPPTHTQFDFVKLMDGKQLVKQDSKGSDDTQHSPRNLILTSLQETGFIEYMDQGPWYLAFYNDGKKMEQVFVLTTAIEIMDDCSTNCNGNGECISGHCHCFPGFLGPDCARDSCPVLCGGNGEYEKGHCVCRHGWKGPECDVPEEQCIDPTCFGHGTCIMGVCICVPGYKGEICEEEDCLDPMCSNHGICVKGECHCSTGWGGVNCETPLPVCQEQCSGHGTFLLDAGVCSCDPKWTGSDCSTELCTMECGSHGVCSRGICQCEEGWVGPTCEERSCHSHCTEHGQCKDGKCECSPGWEGDHCTIAHYLDAVRDGCPGLCFGNGRCTLDQNGWHCVCQVGWSGTGCNVVMEMLCGDNLDNDGDGLTDCVDPDCCQQSNCYISPLCQGSPDPLDLIQQSQTLFSQHTSRLFYDRIKFLIGKDSTHVIPPEVSFDSRRACVIRGQVVAIDGTPLVGVNVSFLHHSDYGFTISRQDGSFDLVAIGGISVILIFDRSPFLPEKRTLWLPWNQFIVVEKVTMQRVVSDPPSCDISNFISPNPIVLPSPLTSFGGSCPERGTIVPELQVVQEEIPIPSSFVRLSYLSSRTPGYKTLLRILLTHSTIPVGMIKVHLTVAVEGRLTQKWFPAAINLVYTFAWNKTDIYGQKVWGLAEALVSVGYEYETCPDFILWEQRTVVLQGFEMDASNLGGWSLNKHHILNPQSGIIHKGNGENMFISQQPPVISTIMGNGHQRSVACTNCNGPAHNNKLFAPVALASGPDGSVYVGDFNFVRRIFPSGNSVSILELSTSPAHKYYLAMDPVSESLYLSDTNTRKVYKLKSLVETKDLSKNFEVVAGTGDQCLPFDQSHCGDGGRASEASLNSPRGITVDRHGFIYFVDGTMIRKIDENAVITTVIGSNGLTSTQPLSCDSGMDITQVRLEWPTDLAVNPMDNSLYVLDNNIVLQISENRRVRIIAGRPIHCQVPGIDHFLVSKVAIHSTLESARAISVSHSGLLFIAETDERKVNRIQQVTTNGEIYIIAGAPTDCDCKIDPNCDCFSGDGGYAKDAKMKAPSSLAVSPDGTLYVADLGNVRIRTISRNQAHLNDMNIYEIASPADQELYQFTVNGTHLHTLNLITRDYVYNFTYNSEGDLGAITSSNGNSVHIRRDAGGMPLWLVVPGGQVYWLTISSNGVLKRVSAQGYNLALMTYPGNTGLLATKSNENGWTTVYEYDPEGHLTNATFPTGEVSSFHSDLEKLTKVELDTSNRENVLMSTNLTATSTIYILKQENTQSTYRVNPDGSLRVTFASGMEIGLSSEPHILAGAVNPTLGKCNISLPGEHNANLIEWRQRKEQNKGNVSAFERRLRAHNRNLLSIDFDHITRTGKIYDDHRKFTLRILYDQTGRPILWSPVSRYNEVNITYSPSGLVTFIQRGTWNEKMEYDQSGKIISRTWADGKIWSYTYLEKSVMLLLHSQRRYIFEYDQPDCLLSVTMPSMVRHSLQTMLSVGYYRNIYTPPDSSTSFIQDYSRDGRLLQTLHLGTGRRVLYKYTKQARLSEVLYDTTQVTLTYEESSGVIKTIHLMHDGFICTIRYRQTGPLIGRQIFRFSEEGLVNARFDYSYNNFRVTSMQAVINETPLPIDLYRYVDVSGRTEQFGKFSVINYDLNQVITTTVMKHTKIFSANGQVIEVQYEILKAIAYWMTIQYDNVGRMVICDIRVGVDANITRYFYEYDADGQLQTVSVNDKTQWRYSYDLNGNINLLSHGKSARLTPLRYDLRDRITRLGEIQYKMDEDGFLRQRGNDIFEYNSNGLLQKAYNKASGWTVQYYYDGLGRRVASKSSLGQHLQFFYADLTNPIRVTHLYNHTSSEITSLYYDLQGHLIAMELSSGEEYYVACDNTGTPLAVFSSRGQVIKEILYTPYGDIYHDTYPDFQVIIGFHGGLYDFLTKLVHLGQRDYDVVAGRWTTPNHHIWKQLNLLPKPFNLYSFENNYPVGKIQDVAKYTTDIRSWLELFGFQLHNVLPGFPKPELENLELTYELLRLQTKTQEWDPGKTILGIQCELQKQLRNFISLDQLPMTPRYNDGRCLEGGKQPRFAAVPSVFGKGIKFAIKDGIVTADIIGVANEDSRRLAAILNNAHYLENLHFTIEGRDTHYFIKLGSLEEDLVLIGNTGGRRILENGVNVTVSQMTSVLNGRTRRFADIQLQHGALCFNIRYGTTVEEEKNHVLEIARQRAVAQAWTKEQRRLQEGEEGIRAWTEGEKQQLLSTGRVQGYDGYFVLSVEQYLELSDSANNIHFMRQSEIGRR>sp|Q9UKZ4-2|TEN1_HUMAN Isoform 2 of Teneurin-1 OS=Homo sapiens OX=9606GN=TENM1MEQTDCKPYQPLPKVKHEMDLAYTSSSDESEDGRKPRQSYNSRETLHEYNQELRMNYNSQSRKRKEVEKSTQEMEFCETSHTLCSGYQTDMHSVSRHGYQLEMGSDVDTETEGAASPDHALRMWIRGMKSEHSSCLSSRANSALSLTDTDHERKSDGENGFKFSPVCCDMEAQAGSTQDVQSSPHNQFTFRPLPPPPPPPHACTCARKPPPAADSLQRRSMTTRSQPSPAAPAPPTSTQDSVHLHNSWVLNSNIPLETRHFLFKHGSGSSAIFSAASQNYPLTSNTVYSPPPRPLPRSTFSRPAFTFNKPYRCCNWKCTALSATAITVTLALLLAYVIAVHLFGLTWQLQPVEGELYANGVSKGNRGTESMDTTYSPIGGKVSDKSEKKVFQKGRAIDTGEVDIGAQVMQTIPPGLFWRFQITIHHPIYLKFNISLAKDSLLGIYGRRNIPPTHTQFDFVKLMDGKQLVKQDSKGSDDTQHSPRNLILTSLQETGFIEYMDQGPWYLAFYNDGKKMEQVFVLTTAIEIMDDCSTNCNGNGECISGHCHCFPGFLGPDCARDSCPVLCGGNGEYEKGHCVCRHGWKGPECDVPEEQCIDPTCFGHGTCIMGVCICVPGYKGEICEEEDCLDPMCSNHGICVKGECHCSTGWGGVNCETPLPVCQEQCSGHGTFLLDAGVCSCDPKWTGSDCSTELCTMECGSHGVCSRGICQCEEGWVGPTCEERSCHSHCTEHGQCKDGKCECSPGWEGDHCTIAHYLDAVRDGCPGLCFGNGRCTLDQNGWHCVCQVGWSGTGCNVVMEMLCGDNLDNDGDGLTDCVDPDCCQQSNCYISPLCQGSPDPLDLIQQSQTLFSQHTSRLFYDRIKFLIGKDSTHVIPPEVSFDSRRACVIRGQVVAIDGTPLVGVNVSFLHHSDYGFTISRQDGSFDLVAIGGISVILIFDRSPFLPEKRTLWLPWNQFIVVEKVTMQRVVSDPPSCDISNFISPNPIVLPSPLTSFGGSCPERGTIVPELQVVQEEIPIPSSFVRLSYLSSRTPGYKTLLRILLTHSTIPVGMIKVHLTVAVEGRLTQKWFPAAINLVYTFAWNKTDIYGQKVWGLAEALVSVGYEYETCPDFILWEQRTVVLQGFEMDASNLGGWSLNKHHILNPQSGIIHKGNGENMFISQQPPVISTIMGNGHQRSVACTNCNGPAHNNKLFAPVALASGPDGSVYVGDFNFVRRIFPSGNSVSILELRNRDTRHSTSPAHKYYLAMDPVSESLYLSDTNTRKVYKLKSLVETKDLSKNFEVVAGTGDQCLPFDQSHCGDGGRASEASLNSPRGITVDRHGFIYFVDGTMIRKIDENAVITTVIGSNGLTSTQPLSCDSGMDITQVRLEWPTDLAVNPMDNSLYVLDNNIVLQISENRRVRIIAGRPIHCQVPGIDHFLVSKVAIHSTLESARAISVSHSGLLFIAETDERKVNRIQQVTTNGEIYIIAGAPTDCDCKIDPNCDCFSGDGGYAKDAKMKAPSSLAVSPDGTLYVADLGNVRIRTISRNQAHLNDMNIYEIASPADQELYQFTVNGTHLHTLNLITRDYVYNFTYNSEGDLGAITSSNGNSVHIRRDAGGMPLWLVVPGGQVYWLTISSNGVLKRVSAQGYNLALMTYPGNTGLLATKSNENGWTTVYEYDPEGHLTNATFPTGEVSSFHSDLEKLTKVELDTSNRENVLMSTNLTATSTIYILKQENTQSTYRVNPDGSLRVTFASGMEIGLSSEPHILAGAVNPTLGKCNISLPGEHNANLIEWRQRKEQNKGNVSAFERRLRAHNRNLLSIDFDHITRTGKIYDDHRKFTLRILYDQTGRPILWSPVSRYNEVNITYSPSGLVTFIQRGTWNEKMEYDQSGKIISRTWADGKIWSYTYLEKSVMLLLHSQRRYIFEYDQPDCLLSVTMPSMVRHSLQTMLSVGYYRNIYTPPDSSTSFIQDYSRDGRLLQTLHLGTGRRVLYKYTKQARLSEVLYDTTQVTLTYEESSGVIKTIHLMHDGFICTIRYRQTGPLIGRQIFRFSEEGLVNARFDYSYNNFRVTSMQAVINETPLPIDLYRYVDVSGRTEQFGKFSVINYDLNQVITTTVMKHTKIFSANGQVIEVQYEILKAIAYWMTIQYDNVGRMVICDIRVGVDANITRYFYEYDADGQLQTVSVNDKTQWRYSYDLNGNINLLSHGKSARLTPLRYDLRDRITRLGEIQYKMDEDGFLRQRGNDIFEYNSNGLLQKAYNKASGWTVQYYYDGLGRRVASKSSLGQHLQFFYADLTNPIRVTHLYNHTSSEITSLYYDLQGHLIAMELSSGEEYYVACDNTGTPLAVFSSRGQVIKEILYTPYGDIYHDTYPDFQVIIGFHGGLYDFLTKLVHLGQRDYDVVAGRWTTPNHHIWKQLNLLPKPFNLYSFENNYPVGKIQDVAKYTTDIRSWLELFGFQLHNVLPGFPKPELENLELTYELLRLQTKTQEWDPGKTILGIQCELQKQLRNFISLDQLPMTPRYNDGRCLEGGKQPRFAAVPSVFGKGIKFAIKDGIVTADIIGVANEDSRRLAAILNNAHYLENLHFTIEGRDTHYFIKLGSLEEDLVLIGNTGGRRILENGVNVTVSQMTSVLNGRTRRFADIQLQHGALCFNIRYGTTVEEEKNHVLEIARQRAVAQAWTKEQRRLQEGEEGIRAWTEGEKQQLLSTGRVQGYDGYFVLSVEQYLELSDSANNIHFMRQSEIGRR>sp|Q07654|TFF3_HUMAN Trefoil factor 3 OS=Homo sapiens OX=9606 GN=TFF3PE=1 SV=2MKRVLSCVPEPTVVMAARALCMLGLVLALLSSSSAEEYVGLSANQCAVPAKDRVDCGYPHVTPKECNNRGCCFDSRIPGVPWCFKPLQEAECTF>sp|P0DPH7|TBA3C_HUMAN Tubulin alpha-3C chain OS=Homo sapiens OX=9606GN=TUBA3C PE=1 SV=1MRECISIHVGQAGVQIGNACWELYCLEHGIQPDGQMPSDKTIGGGDDSFNTFFSETGAGKHVPRAVFVDLEPTVVDEVRTGTYRQLFHPEQLITGKEDAANNYARGHYTIGKEIVDLVLDRIRKLADLCTGLQGFLIFHSFGGGTGSGFASLLMERLSVDYGKKSKLEFAIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLIGQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLATYAPVISAEKAYHEQLSVAEITNACFEPANQMVKCDPRHGKYMACCMLYRGDVVPKDVNAAIATIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLDHKFDLMYAKRAFVHWYVGEGMEEGEFSEAREDLAALEKDYEEVGVDSVEAEAEEGEEY>sp|P0DPH7-2|TBA3C_HUMAN Isoform 2 of Tubulin alpha-3C chain OS=Homosapiens OX=9606 GN=TUBA3CMRECISIHVGQAGVQIGNACWELYCLEHGIQPDGQMPSDKTIGGGDDSFNTFFSETGAGKHVPRAVFVDLEPTVVDEVRTGTYRQLFHPEQLITGKEDAANNYARGHYTIGKEIVDLVLDRIRKLADLCTGLQGFLIFHSFGGGTGSGFASLLMERLSVDYGKKSKLEFAIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLIGQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLATYAPVISAEKAYHEQLSVAEITNACFEPANQMVKCDPRHGKYMACCMLYRGDVVPKDVNAAIATIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLDLAALEKDYEEVGVDSVEAEAEEGEEY>sp|Q68CZ2|TENS3_HUMAN Tensin-3 OS=Homo sapiens OX=9606 GN=TNS3 PE=1 SV=2MEEGHGLDLTYITERIIAVSFPAGCSEESYLHNLQEVTRMLKSKHGDNYLVLNLSEKRYDLTKLNPKIMDVGWPELHAPPLDKMCTICKAQESWLNSNLQHVVVIHCRGGKGRIGVVISSYMHFTNVSASADQALDRFAMKKFYDDKVSALMQPSQKRYVQFLSGLLSGSVKMNASPLFLHFVILHGTPNFDTGGVCRPFLKLYQAMQPVYTSGIYNVGPENPSRICIVIEPAQLLKGDVMVKCYHKKYRSATRDVIFRLQFHTGAVQGYGLVFGKEDLDNASKDDRFPDYGKVELVFSATPEKIQGSEHLYNDHGVIVDYNTTDPLIRWDSYENLSADGEVLHTQGPVDGSLYAKVRKKSSSDPGIPGGPQAIPATNSPDHSDHTLSVSSDSGHSTASARTDKTEERLAPGTRRGLSAQEKAELDQLLSGFGLEDPGSSLKEMTDARSKYSGTRHVVPAQVHVNGDAALKDRETDILDDEMPHHDLHSVDSLGTLSSSEGPQSAHLGPFTCHKSSQNSLLSDGFGSNVGEDPQGTLVPDLGLGMDGPYERERTFGSREPKQPQPLLRKPSVSAQMQAYGQSSYSTQTWVRQQQMVVAHQYSFAPDGEARLVSRCPADNPGLVQAQPRVPLTPTRGTSSRVAVQRGVGSGPHPPDTQQPSPSKAFKPRFPGDQVVNGAGPELSTGPSPGSPTLDIDQSIEQLNRLILELDPTFEPIPTHMNALGSQANGSVSPDSVGGGLRASSRLPDTGEGPSRATGRQGSSAEQPLGGRLRKLSLGQYDNDAGGQLPFSKCAWGKAGVDYAPNLPPFPSPADVKETMTPGYPQDLDIIDGRILSSKESMCSTPAFPVSPETPYVKTALRHPPFSPPEPPLSSPASQHKGGREPRSCPETLTHAVGMSESPIGPKSTMLRADASSTPSFQQAFASSCTISSNGPGQRRESSSSAERQWVESSPKPMVSLLGSGRPTGSPLSAEFSGTRKDSPVLSCFPPSELQAPFHSHELSLAEPPDSLAPPSSQAFLGFGTAPVGSGLPPEEDLGALLANSHGASPTPSIPLTATGAADNGFLSHNFLTVAPGHSSHHSPGLQGQGVTLPGQPPLPEKKRASEGDRSLGSVSPSSSGFSSPHSGSTISIPFPNVLPDFSKASEAASPLPDSPGDKLVIVKFVQDTSKFWYKADISREQAIAMLKDKEPGSFIVRDSHSFRGAYGLAMKVATPPPSVLQLNKKAGDLANELVRHFLIECTPKGVRLKGCSNEPYFGSLTALVCQHSITPLALPCKLLIPERDPLEEIAESSPQTAANSAAELLKQGAACNVWYLNSVEMESLTGHQAIQKALSITLVQEPPPVSTVVHFKVSAQGITLTDNQRKLFFRRHYPVNSVIFCALDPQDRKWIKDGPSSKVFGFVARKQGSATDNVCHLFAEHDPEQPASAIVNFVSKVMIGSPKKV>sp|Q68CZ2-2|TENS3_HUMAN Isoform 2 of Tensin-3 OS=Homo sapiens OX=9606GN=TNS3MEEGHGLDLTYITERIIAVSFPAGCSEESYLHNLQEVTRMLKSKHGDNYLVLNLSEKRYDLTKLNPKIMDVGWPELHAPPLDKMCTICKAQESWLNSNLQHVVVIHCRGGKGRIGVVISSYMHFTNVSASADQALDRFAMKKFYDDKVSALMQPSQKRYVQFLSGLLSGSVKMNASPLFLHFVILHGTPNFDTGGVCRPFLKLYQAMQPVYTSGIYNVGPENPSRICIVIEPAQLLKGDVEMPHHDLHSVDSLGTLSSSEGPQSAHLGPFTCHKSSQNSLLSDGFGSNVGEDPQGTLVPDLGLGMDGPYERERTFGSREPKQPQPLLRKPSVSAQMQAYGQSSYSTQTWVRQQQMVVAHQYSFAPDGEARLVSRCPADNPGLVQAQPRVPLTPTRGTSSRVAVQRGVGSGPHPPDTQQPSPSKAFKPRFPGDQVVNGAGPELSTGPSPGSPTLDIDQSIEQLNRLILELDPTFEPIPTHMNALGSQANGSVSPDSVGGGLRASSRLPDTGEGPSRATGRQGSSAEQPLGGRLRKLSLGQYDNDAGGQLPFSKCAWGKAGVDYAPNLPPFPSPADVKETMTPGYPQDLDIIDGRILSSKESMCSTPAFPVSPETPYVKTALRHPPFSPPEPPLSSPASQHKGGREPRSCPETLTHAVGMSESPIGPKSTMLRADASSTPSFQQAFASSCTISSNGPGQRRESSSSAERQWVESSPKPMVSLLGSGRPTGSPLSAEFSGTRKDSPVLSCFPPSELQAPFHSHELSLAEPPDSLAPPSSQAFLGFGTAPVGSGLPPEEDLGALLANSHGASPTPSIPLTATGAADNGFLSHNFLTVAPGHSSHHSPGLQGQGVTLPGQPPLPEKKRASEGDRSLGSVSPSSSGFSSPHSGSTISIPFPNVLPDFSKASEAASPLPDSPGDKLVIVKFVQDTSKFWYKADISREQAIAMLKDKEPGSFIVRDSHSFRGAYGLAMKVATPPPSVLQLNKKAGDLANELVRHFLIECTPKGVRLKGCSNEPYFGSLTALVCQHSITPLALPCKLLIPERDPLEEIAESSPQTAANSAAELLKQGAACNVWYLNSVEMESLTGHQAIQKALSITLVQEPPPVSTVVHFKVSAQGITLTDNQRKLFFRRHYPVNSVIFCALDPQDRKWIKDGPSSKVFGFVARKQGSATDNVCHLFAEHDPEQPASAIVNFVSKVMIGSPKKV>sp|Q68CZ2-3|TENS3_HUMAN Isoform 3 of Tensin-3 OS=Homo sapiens OX=9606GN=TNS3MEEGHGLDLTYITERIIAVSFPAGCSEESYLHNLQEVTRMLKSKHGDNYLVLNLSEKRYDLTKLNPKIMDVGWPELHAPPLDKMCTICKAQESWLNSNLQHVVVIHCRGGKGRIGVVISSYMHFTNVSASADQALDRFAMKKFYDDKVSALMQPSQKRYVQFLSGLLSGSVKMNASPLFLHFVILHGTPNFDTGGVCRPFLKLYQAMQPVYTSGIYNVGPENPSRICIVIEPAQLLKGDVMVKCYHKKYRSATRDVIFRLQFHTGAVQGYGLVFGKEDLDNASKDDRFPDYGKVELVFSATPEKIQGSEHLYNDHGVIVDYNTTDPLIRWDSYENLSADGEVLHTQGPVDGSLYAKVRKKSSSDPGIPGGPQAIPATNSPANVLFELIGQV>sp|Q68CZ2-4|TENS3_HUMAN Isoform 4 of Tensin-3 OS=Homo sapiens OX=9606GN=TNS3MEEGHGLDLTYITERIIAVSFPAGCSEESYLHNLQEVTRMLKSKHGDNYLVLNLSEKRYDLTKLNPKIMDVGWPELHAPPLDKMCTICKAQESWLNSNLQHVVVIHCRGGKGRIGVVISSYMHFTNVSASADQALDRFAMKKFYDDKVSALMQPSQKRYVQFLSGLLSGSVKMNASPLFLHFVILHGTPNFDTGGVCRPFLKLYQAMQPVYTSGIYNVGPENPSRICIVIEPAQLLKGDVMVMNYNIANI>sp|Q9HBL0|TENS1_HUMAN Tensin-1 OS=Homo sapiens OX=9606 GN=TNS1 PE=1 SV=2MSVSRTMEDSCELDLVYVTERIIAVSFPSTANEENFRSNLREVAQMLKSKHGGNYLLFNLSERRPDITKLHAKVLEFGWPDLHTPALEKICSICKAMDTWLNADPHNVVVLHNKGNRGRIGVVIAAYMHYSNISASADQALDRFAMKRFYEDKIVPIGQPSQRRYVHYFSGLLSGSIKMNNKPLFLHHVIMHGIPNFESKGGCRPFLRIYQAMQPVYTSGIYNIPGDSQTSVCITIEPGLLLKGDILLKCYHKKFRSPARDVIFRVQFHTCAIHDLGVVFGKEDLDDAFKDDRFPEYGKVEFVFSYGPEKIQGMEHLENGPSVSVDYNTSDPLIRWDSYDNFSGHRDDGMEEVVGHTQGPLDGSLYAKVKKKDSLHGSTGAVNATRPTLSATPNHVEHTLSVSSDSGNSTASTKTDKTDEPVPGASSATAALSPQEKRELDRLLSGFGLEREKQGAMYHTQHLRSRPAGGSAVPSSGRHVVPAQVHVNGGALASERETDILDDELPNQDGHSAGSMGTLSSLDGVTNTSEGGYPEALSPLTNGLDKSYPMEPMVNGGGYPYESASRAGPAHAGHTAPMRPSYSAQEGLAGYQREGPHPAWPQPVTTSHYAHDPSGMFRSQSFSEAEPQLPPAPVRGGSSREAVQRGLNSWQQQQQQQQQPRPPPRQQERAHLESLVASRPSPQPLAETPIPSLPEFPRAASQQEIEQSIETLNMLMLDLEPASAAAPLHKSQSVPGAWPGASPLSSQPLSGSSRQSHPLTQSRSGYIPSGHSLGTPEPAPRASLESVPPGRSYSPYDYQPCLAGPNQDFHSKSPASSSLPAFLPTTHSPPGPQQPPASLPGLTAQPLLSPKEATSDPSRTPEEEPLNLEGLVAHRVAGVQAREKQPAEPPAPLRRRAASDGQYENQSPEATSPRSPGVRSPVQCVSPELALTIALNPGGRPKEPHLHSYKEAFEEMEGTSPSSPPPSGVRSPPGLAKTPLSALGLKPHNPADILLHPTGVTRRRIQPEEDEGKVVVRLSEEPRSYVESVARTAVAGPRAQDSEPKSFSAPATQAYGHEIPLRNGTLGGSFVSPSPLSTSSPILSADSTSVGSFPSGESSDQGPRTPTQPLLESGFRSGSLGQPSPSAQRNYQSSSPLPTVGSSYSSPDYSLQHFSSSPESQARAQFSVAGVHTVPGSPQARHRTVGTNTPPSPGFGWRAINPSMAAPSSPSLSHHQMMGPPGTGFHGSTVSSPQSSAATTPGSPSLCRHPAGVYQVSGLHNKVATTPGSPSLGRHPGAHQGNLASGLHSNAIASPGSPSLGRHLGGSGSVVPGSPCLDRHVAYGGYSTPEDRRPTLSRQSSASGYQAPSTPSFPVSPAYYPGLSSPATSPSPDSAAFRQGSPTPALPEKRRMSVGDRAGSLPNYATINGKVSSPVASGMSSPSGGSTVSFSHTLPDFSKYSMPDNSPETRAKVKFVQDTSKYWYKPEISREQAIALLKDQEPGAFIIRDSHSFRGAYGLAMKVSSPPPTIMQQNKKGDMTHELVRHFLIETGPRGVKLKGCPNEPNFGSLSALVYQHSIIPLALPCKLVIPNRDPTDESKDSSGPANSTADLLKQGAACNVLFVNSVDMESLTGPQAISKATSETLAADPTPAATIVHFKVSAQGITLTDNQRKLFFRRHYPLNTVTFCDLDPQERKWMKTEGGAPAKLFGFVARKQGSTTDNACHLFAELDPNQPASAIVNFVSKVMLNAGQKR>sp|Q9HBL0-2|TENS1_HUMAN Isoform 2 of Tensin-1 OS=Homo sapiens OX=9606GN=TNS1MVPFQQRKDCVLEGSTRVTPSVQPHLQPIRNMSVSRTMEDSCELDLVYVTERIIAVSFPSTANEENFRSNLREVAQMLKSKHGGNYLLFNLSERRPDITKLHAKVLEFGWPDLHTPALEKICSICKAMDTWLNADPHNVVVLHNKGNRGRIGVVIAAYMHYSNISASADQALDRFAMKRFYEDKIVPIGQPSQRRYVHYFSGLLSGSIKMNNKPLFLHHVIMHGIPNFESKGGCRPFLRIYQAMQPVYTSGIYNIPGDSQTSVCITIEPGLLLKGDILLKCYHKKFRSPARDVIFRVQFHTCAIHDLGVVFGKEDLDDAFKDDRFPEYGKVEFVFSYGPEKIQGMEHLENGPSVSVDYNTSDPLIRWDSYDNFSGHRDDGMEDGNKQNTNSQSIGSISGGLEDQYTWPDTHWPSQS>sp|Q96I45|TM141_HUMAN Transmembrane protein 141 OS=Homo sapiens OX=9606GN=TMEM141 PE=1 SV=1MVNLGLSRVDDAVAAKHPGLGEYAACQSHAFMKGVFTFVTGTGMAFGLQMFIQRKFPYPLQWSLLVAVVAGSVVSYGVTRVESEKCNNLWLFLETGQLPKDRSTDQRS>sp|P07437|TBB5_HUMAN Tubulin beta chain OS=Homo sapiens OX=9606 GN=TUBBPE=1 SV=2MREIVHIQAGQCGNQIGAKFWEVISDEHGIDPTGTYHGDSDLQLDRISVYYNEATGGKYVPRAILVDLEPGTMDSVRSGPFGQIFRPDNFVFGQSGAGNNWAKGHYTEGAELVDSVLDVVRKEAESCDCLQGFQLTHSLGGGTGSGMGTLLISKIREEYPDRIMNTFSVVPSPKVSDTVVEPYNATLSVHQLVENTDETYCIDNEALYDICFRTLKLTTPTYGDLNHLVSATMSGVTTCLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTSRGSQQYRALTVPELTQQVFDAKNMMAACDPRHGRYLTVAAVFRGRMSMKEVDEQMLNVQNKNSSYFVEWIPNNVKTAVCDIPPRGLKMAVTFIGNSTAIQELFKRISEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATAEEEEDFGEEAEEEA>sp|Q8TBP0|TBC16_HUMAN TBC1 domain family member 16 OS=Homo sapiensOX=9606 GN=TBC1D16 PE=2 SV=1MSLGRLLRRASSKASDLLTLTPGGSGSGSPSVLDGEIIYSKNNVCVHPPEGLQGLGEHHPGYLCLYMEKDEMLGATLILAWVPNSRIQRQDEEALRYITPESSPVRKAPRPRGRRTRSSGASHQPSPTELRPTLTPKDEDILVVAQSVPDRMLASPAPEDEEKLAQGLGVDGAQPASQPACSPSGILSTVSPQDVTEEGREPRPEAGEEDGSLELSAEGVSRDSSFDSDSDTFSSPFCLSPISAALAESRGSVFLESDSSPPSSSDAGLRFPDSNGLLQTPRWDEPQRVCALEQICGVFRVDLGHMRSLRLFFSDEACTSGQLVVASRESQYKVFHFHHGGLDKLSDVFQQWKYCTEMQLKDQQVAPDKTCMQFSIRRPKLPSSETHPEESMYKRLGVSAWLNHLNELGQVEEEYKLRKAIFFGGIDVSIRGEVWPFLLRYYSHESTSEEREALRLQKRKEYSEIQQKRLSMTPEEHRAFWRNVQFTVDKDVVRTDRNNQFFRGEDNPNVESMRRILLNYAVYNPAVGYSQGMSDLVAPILAEVLDESDTFWCFVGLMQNTIFVSSPRDEDMEKQLLYLRELLRLTHVRFYQHLVSLGEDGLQMLFCHRWLLLCFKREFPEAEALRIWEACWAHYQTDYFHLFICVAIVAIYGDDVIEQQLATDQMLLHFGNLAMHMNGELVLRKARSLLYQFRLLPRIPCSLHDLCKLCGSGMWDSGSMPAVECTGHHPGSESCPYGGTVEMPSPKSLREGKKGPKTPQDGFGFRR>sp|Q8TBP0-2|TBC16_HUMAN Isoform 2 of TBC1 domain family member 16OS=Homo sapiens OX=9606 GN=TBC1D16MKVAPDKTCMQFSIRRPKLPSSETHPEESMYKRLGVSAWLNHLNELGQVEEEYKLRKAIFFGGIDVSIRGEVWPFLLRYYSHESTSEEREALRLQKRKEYSEIQQKRLSMTPEEHRAFWRNVQFTVDKDVVRTDRNNQFFRGEDNPNVESMRRILLNYAVYNPAVGYSQGMSDLVAPILAEVLDESDTFWCFVGLMQNTIFVSSPRDEDMEKQLLYLRELLRLTHVRFYQHLVSLGEDGLQMLFCHRWLLLCFKREFPEAEALRIWEACWAHYQTDYFHLFICVAIVAIYGDDVIEQQLATDQMLLHFGNLAMHMNGELVLRKARSLLYQFRLLPRIPCSLHDLCKLCGSGMWDSGSMPAVECTGHHPGSESCPYGGTVEMPSPKSLREGKKGPKTPQDGFGFRR>sp|Q8TBP0-3|TBC16_HUMAN Isoform 3 of TBC1 domain family member 16OS=Homo sapiens OX=9606 GN=TBC1D16MKVAPDKTCMQFSIRRPKLPSSETHPEESMYKRLGVSAWLNHLNELGQVEEEYKLRKAIFFGGIDVSIRGEVWPFLLRYYSHESTSEEREALRLQKRKEYSEIQQKRLSMTPEEHRAFWRNVQFTVDKDVVRTDRNNQFFRGEDNPNVESMRRILLNYAVYNPAVGYSQGMSDLVAPILAEVLDESDTFWCFVGLMQNTIFVSSPRDEDMEKQLLYLRELLRLTHVRFYQHLVSLGEDGLQMLFCHRWLLLCFKREFPEAEALRIWEACWAHYQGADV>sp|Q8TBP0-4|TBC16_HUMAN Isoform 4 of TBC1 domain family member 16OS=Homo sapiens OX=9606 GN=TBC1D16MKQVAPDKTCMQFSIRRPKLPSSETHPEESMYKRLGVSAWLNHLNELGQVEEEYKLRKVWPFLLRYYSHESTSEEREALRLQKRKEYSEIQQKRLSMTPEEHRAFWRNVQFTVDKDVVRTDRNNQFFRGEDNPNVESMRRILLNYAVYNPAVGYSQGMSDLVAPILAEVLDESDTFWCFVGLMQNTIFVSSPRDEDMEKQLLYLRELLRLTHVRFYQHLVSLGEDGLQMLFCHRWLLLCFKREFPEAEALRIWEACWAHYQTDYFHLFICVAIVAIYGDDVIEQQLATDQMLLHFGNLAMHMNGELVLRKARSLLYQFRLLPRIPCSLHDLCKLCGSGMWDSGSMPAVECTGHHPGSESCPYGGTVEMPSPKSLREGKKGPKTPQDGFGFRR>sp|Q9UJT0|TBE_HUMAN Tubulin epsilon chain OS=Homo sapiens OX=9606GN=TUBE1 PE=2 SV=1MTQSVVVQVGQCGNQIGCCFWDLALREHAAVNQKGIYDEAISSFFRNVDTRVVGDGGSISKGKICSLKARAVLIDMEEGVVNEILQGPLRDVFDTKQLITDISGSGNNWAVGHKVFGSLYQDQILEKFRKSAEHCDCLQCFFIIHSMGGGTGSGLGTFLLKVLEDEFPEVYRFVTSIYPSGEDDVITSPYNSILAMKELNEHADCVLPIDNQSLFDIISKIDLMVNSGKLGTTVKPKSLVTSSSGALKKQHKKPFDAMNNIVANLLLNLTSSARFEGSLNMDLNEISMNLVPFPQLHYLVSSLTPLYTLTDVNIPPRRLDQMFSDAFSKDHQLLRADPKHSLYLACALMVRGNVQISDLRRNIERLKPSLQFVSWNQEGWKTSLCSVPPVGHSHSLLALANNTCVKPTFMELKERFMRLYKKKAHLHHYLQVEGMEESCFTEAVSSLSALIQEYDQLDATKNMPVQDLPRLSIAM>sp|Q6SJ96|TBPL2_HUMAN TATA box-binding protein-like 2 OS=Homo sapiensOX=9606 GN=TBPL2 PE=2 SV=1MASAPWPERVPRLLAPRLPSYPPPPPTVGLRSMEQEETYLELYLDQCAAQDGLAPPRSPLFSPVVPYDMYILNASNPDTAFNSNPEVKETSGDFSSVDLSFLPDEVTQENKDQPVISKHETEENSESQSPQSRLPSPSEQDVGLGLNSSSLSNSHSQLHPGDTDSVQPSPEKPNSDSLSLASITPMTPMTPISECCGIVPQLQNIVSTVNLACKLDLKKIALHAKNAEYNPKRFAAVIMRIREPRTTALIFSSGKMVCTGAKSEEQSRLAARKYARVVQKLGFPARFLDFKIQNMVGSCDVRFPIRLEGLVLTHQQFSSYEPELFPGLIYRMVKPRIVLLIFVSGKVVLTGAKERSEIYEAFENIYPILKGFKKA>sp|Q9BYJ4|TRI34_HUMAN Tripartite motif-containing protein 34 OS=Homosapiens OX=9606 GN=TRIM34 PE=1 SV=2MASKILLNVQEEVTCPICLELLTEPLSLDCGHSLCRACITVSNKEAVTSMGGKSSCPVCGISYSFEHLQANQHLANIVERLKEVKLSPDNGKKRDLCDHHGEKLLLFCKEDRKVICWLCERSQEHRGHHTVLTEEVFKECQEKLQAVLKRLKKEEEEAEKLEADIREEKTSWKYQVQTERQRIQTEFDQLRSILNNEEQRELQRLEEEEKKTLDKFAEAEDELVQQKQLVRELISDVECRSQWSTMELLQDMSGIMKWSEIWRLKKPKMVSKKLKTVFHAPDLSRMLQMFRELTAVRCYWVDVTLNSVNLNLNLVLSEDQRQVISVPIWPFQCYNYGVLGSQYFSSGKHYWEVDVSKKTAWILGVYCRTYSRHMKYVVRRCANRQNLYTKYRPLFGYWVIGLQNKCKYGVFEESLSSDPEVLTLSMAVPPCRVGVFLDYEAGIVSFFNVTSHGSLIYKFSKCCFSQPVYPYFNPWNCPAPMTLCPPSS>sp|Q9BYJ4-2|TRI34_HUMAN Isoform 2 of Tripartite motif-containing protein34 OS=Homo sapiens OX=9606 GN=TRIM34MASKILLNVQEEVTCPICLELLTEPLSLDCGHSLCRACITVSNKEAVTSMGGKSSCPVCGISYSFEHLQANQHLANIVERLKEVKLSPDNGKKRDLCDHHGEKLLLFCKEDRKVICWLCERSQEHRGHHTVLTEEVFKECQEKLQAVLKRLKKEEEEAEKLEADIREEKTSWKYQVQTERQRIQTEFDQLRSILNNEEQRELQRLEEEEKKTLDKFAEAEDELVQQKQLVRELISDVECRSQWSTMELLQDMSGIMKWCVWVATSGACEL>sp|Q9UJV3|TRIM1_HUMAN Probable E3 ubiquitin-protein ligase MID2 OS=Homosapiens OX=9606 GN=MID2 PE=1 SV=3MGESPASVVLNASGGLFSLKMETLESELTCPICLELFEDPLLLPCAHSLCFSCAHRILVSSCSSGESIEPITAFQCPTCRYVISLNHRGLDGLKRNVTLQNIIDRFQKASVSGPNSPSESRRERTYRPTTAMSSERIACQFCEQDPPRDAVKTCITCEVSYCDRCLRATHPNKKPFTSHRLVEPVPDTHLRGITCLDHENEKVNMYCVSDDQLICALCKLVGRHRDHQVASLNDRFEKLKQTLEMNLTNLVKRNSELENQMAKLIQICQQVEVNTAMHEAKLMEECDELVEIIQQRKQMIAVKIKETKVMKLRKLAQQVANCRQCLERSTVLINQAEHILKENDQARFLQSAKNIAERVAMATASSQVLIPDINFNDAFENFALDFSREKKLLEGLDYLTAPNPPSIREELCTASHDTITVHWISDDEFSISSYELQYTIFTGQANFISKSWCSWGLWPEIRKCKEAVSCSRLAGAPRGLYNSVDSWMIVPNIKQNHYTVHGLQSGTRYIFIVKAINQAGSRNSEPTRLKTNSQPFKLDPKMTHKKLKISNDGLQMEKDESSLKKSHTPERFSGTGCYGAAGNIFIDSGCHYWEVVMGSSTWYAIGIAYKSAPKNEWIGKNASSWVFSRCNSNFVVRHNNKEMLVDVPPHLKRLGVLLDYDNNMLSFYDPANSLHLHTFDVTFILPVCPTFTIWNKSLMILSGLPAPDFIDYPERQECNCRPQESPYVSGMKTCH>sp|Q9UJV3-2|TRIM1_HUMAN Isoform 2 of Probable E3 ubiquitin-proteinligase MID2 OS=Homo sapiens OX=9606 GN=MID2MGESPASVVLNASGGLFSLKMETLESELTCPICLELFEDPLLLPCAHSLCFSCAHRILVSSCSSGESIEPITAFQCPTCRYVISLNHRGLDGLKRNVTLQNIIDRFQKASVSGPNSPSESRRERTYRPTTAMSSERIACQFCEQDPPRDAVKTCITCEVSYCDRCLRATHPNKKPFTSHRLVEPVPDTHLRGITCLDHENEKVNMYCVSDDQLICALCKLVGRHRDHQVASLNDRFEKLKQTLEMNLTNLVKRNSELENQMAKLIQICQQVEVNTAMHEAKLMEECDELVEIIQQRKQMIAVKIKETKVMKLRKLAQQVANCRQCLERSTVLINQAEHILKENDQARFLQSAKNIAERVAMATASSQVLIPDINFNDAFENFALDFSREKKLLEGLDYLTAPNPPSIREELCTASHDTITVHWISDDEFSISSYELQYTIFTGQANFISLYNSVDSWMIVPNIKQNHYTVHGLQSGTRYIFIVKAINQAGSRNSEPTRLKTNSQPFKLDPKMTHKKLKISNDGLQMEKDESSLKKSHTPERFSGTGCYGAAGNIFIDSGCHYWEVVMGSSTWYAIGIAYKSAPKNEWIGKNASSWVFSRCNSNFVVRHNNKEMLVDVPPHLKRLGVLLDYDNNMLSFYDPANSLHLHTFDVTFILPVCPTFTIWNKSLMILSGLPAPDFIDYPERQECNCRPQESPYVSGMKTCH>sp|Q9HCJ0|TNR6C_HUMAN Trinucleotide repeat-containing gene 6C proteinOS=Homo sapiens OX=9606 GN=TNRC6C PE=1 SV=3MATGSAQGNFTGHTKKTNGNNGTNGALVQSPSNQSALGAGGANSNGSAARVWGVATGSSSGLAHCSVSGGDGKMDTMIGDGRSQNCWGASNSNAGINLNLNPNANPAAWPVLGHEGTVATGNPSSICSPVSAIGQNMGNQNGNPTGTLGAWGNLLPQESTEPQTSTSQNVSFSAQPQNLNTDGPNNTNPMNSSPNPINAMQTNGLPNWGMAVGMGAIIPPHLQGLPGANGSSVSQVSGGSAEGISNSVWGLSPGNPATGNSNSGFSQGNGDTVNSALSAKQNGSSSAVQKEGSGGNAWDSGPPAGPGILAWGRGSGNNGVGNIHSGAWGHPSRSTSNGVNGEWGKPPNQHSNSDINGKGSTGWESPSVTSQNPTVQPGGEHMNSWAKAASSGTTASEGSSDGSGNHNEGSTGREGTGEGRRRDKGIIDQGHIQLPRNDLDPRVLSNTGWGQTPVKQNTAWEFEESPRSERKNDNGTEAWGCAATQASNSGGKNDGSIMNSTNTSSVSGWVNAPPAAVPANTGWGDSNNKAPSGPGVWGDSISSTAVSTAAAAKSGHAWSGAANQEDKSPTWGEPPKPKSQHWGDGQRSNPAWSAGGGDWADSSSVLGHLGDGKKNGSGWDADSNRSGSGWNDTTRSGNSGWGNSTNTKANPGTNWGETLKPGPQQNWASKPQDNNVSNWGGAASVKQTGTGWIGGPVPVKQKDSSEATGWEEPSPPSIRRKMEIDDGTSAWGDPSNYNNKTVNMWDRNNPVIQSSTTTNTTTTTTTTTSNTTHRVETPPPHQAGTQLNRSPLLGPGRKVSSGWGEMPNVHSKTENSWGEPSSPSTLVDNGTAAWGKPPSSGSGWGDHPAEPPVAFGRAGAPVAASALCKPASKSMQEGWGSGGDEMNLSTSQWEDEEGDVWNNAASQESTSSCSSWGNAPKKGLQKGMKTSGKQDEAWIMSRLIKQLTDMGFPREPAEEALKSNNMNLDQAMSALLEKKVDVDKRGLGVTDHNGMAAKPLGCRPPISKESSVDRPTFLDKDGGLVEEPTPSPFLPSPSLKLPLSHSALPSQALGGIASGLGMQNLNSSRQIPSGNLGMFGNSGAAQARTMQQPPQPPVQPLNSSQPSLRAQVPQFLSPQVQAQLLQFAAKNIGLNPALLTSPINPQHMTMLNQLYQLQLAYQRLQIQQQMLQAQRNVSGSMRQQEQQVARTITNLQQQIQQHQRQLAQALLVKQPPPPPPPPHLSLHPSAGKSAMDSFPSHPQTPGLPDLQTKEQQSSPNTFAPYPLAGLNPNMNVNSMDMTGGLSVKDPSQSQSRLPQWTHPNSMDNLPSAASPLEQNPSKHGAIPGGLSIGPPGKSSIDDSYGRYDLIQNSESPASPPVAVPHSWSRAKSDSDKISNGSSINWPPEFHPGVPWKGLQNIDPENDPDVTPGSVPTGPTINTTIQDVNRYLLKSGGKLSDIKSTWSSGPTSHTQASLSHELWKVPRNSTAPTRPPPGLTNPKPSSTWGASPLGWTSSYSSGSAWSTDTSGRTSSWLVLRNLTPQIDGSTLRTLCLQHGPLITFHLNLTQGNAVVRYSSKEEAAKAQKSLHMCVLGNTTILAEFAGEEEVNRFLAQGQALPPTSSWQSSSASSQPRLSAAGSSHGLVRSDAGHWNAPCLGGKGSSELLWGGVPQYSSSLWGPPSADDSRVIGSPTPLTTLLPGDLLSGESL>sp|Q9HCJ0-2|TNR6C_HUMAN Isoform 2 of Trinucleotide repeat-containinggene 6C protein OS=Homo sapiens OX=9606 GN=TNRC6CMATGSAQGNFTGHTKKTNGNNGTNGALVQSPSNQSALGAGGANSNGSAARVWGVATGSSSGLAHCSVSGGDGKMDTMIGDGRSQNCWGASNSNAGINLNLNPNANPAAWPVLGHEGTVATGNPSSICSPVSAIGQNMGNQNGNPTGTLGAWGNLLPQESTEPQTSTSQNVSFSAQPQNLNTDGPNNTNPMNSSPNPINAMQTNGLPNWGMAVGMGAIIPPHLQGLPGANGSSVSQVSGGSAEGISNSVWGLSPGNPATGNSNSGFSQGNGDTVNSALSAKQNGSSSAVQKEGSGGNAWDSGPPAGPGILAWGRGSGNNGVGNIHSGAWGHPSRSTSNGVNGEWGKPPNQHSNSDINGKGSTGWESPSVTSQNPTVQPGGEHMNSWAKAASSGTTASEGSSDGSGNHNEGSTGREGTGEGRRRDKGIIDQGHIQLPRNDLDPRVLSNTGWGQTPVKQNTAWEFEESPRSERKNDNGTEAWGCAATQASNSGGKNDGSIMNSTNTSSVSGWVNAPPAAVPANTGWGDSNNKAPSGPGVWGDSISSTAVSTAAAAKSGHAWSGAANQEDKSPTWGEPPKPKSQHWGDGQRSNPAWSAGGGDWADSSSVLGHLGDGKKNGSGWDADSNRSGSGWNDTTRSGNSGWGNSTNTKANPGTNWGETLKPGPQQNWASKPQDNNVSNWGGAASVKQTGTGWIGGPVPVKQKDSSEATGWEEPSPPSIRRKMEIDDGTSAWGDPSNYNNKTVNMWDRNNPVIQSSTTTNTTTTTTTTTSNTTHRVETPPPHQAGTQLNRSPLLGPVSSGWGEMPNVHSKTENSWGEPSSPSTLVDNGTAAWGKPPSSGSGWGDHPAEPPVAFGRAGAPVAASALCKPASKSMQEGWGSGGDEMNLSTSQWEDEEGDVWNNAASQESTSSCSSWGNAPKKGLQKGMKTSGKQDEAWIMSRLIKQLTDMGFPREPAEEALKSNNMNLDQAMSALLEKKVDVDKRGLGVTDHNGMAAKPLGCRPPISKESSVDRPTFLDKDGGLVEEPTPSPFLPSPSLKLPLSHSALPSQALGGIASGLGMQNLNSSRQIPSGNLGMFGNSGAAQARTMQQPPQPPVQPLNSSQPSLRAQVPQFLSPQVQAQLLQFAAKNIGLNPALLTSPINPQHMTMLNQLYQLQLAYQRLQIQQQMLQAQRNVSGSMRQQEQQVARTITNLQQQIQQHQRQLAQALLVKQPPPPPPPPHLSLHPSAGKSAMDSFPSHPQTPGLPDLQTKEQQSSPNTFAPYPLAGLNPNMNVNSMDMTGGLSVKDPSQSQSRLPQWTHPNSMDNLPSAASPLEQNPSKHGAIPGGLSIGPPGKSSIDDSYGRYDLIQNSESPASPPVAVPHSWSRAKSDSDKISNGSSINWPPEFHPGVPWKGLQNIDPENDPDVTPGSVPTGPTINTTIQDVNRYLLKSGGSSPPSSQNATLPSSSAWPLSASGYSSSFSSIASAPSVAGKLSDIKSTWSSGPTSHTQASLSHELWKVPRNSTAPTRPPPGLTNPKPSSTWGASPLGWTSSYSSGSAWSTDTSGRTSSWLVLRNLTPQIDGSTLRTLCLQHGPLITFHLNLTQGNAVVRYSSKEEAAKAQKSLHMCVLGNTTILAEFAGEEEVNRFLAQGQALPPTSSWQSSSASSQPRLSAAGSSHGLVRSDAGHWNAPCLGGKGSSELLWGGVPQYSSSLWGPPSADDSRVIGSPTPLTTLLPGDLLSGESL>sp|Q7Z2W7|TRPM8_HUMAN Transient receptor potential cation channelsubfamily M member 8 OS=Homo sapiens OX=9606 GN=TRPM8 PE=1 SV=2MSFRAARLSMRNRRNDTLDSTRTLYSSASRSTDLSYSESDLVNFIQANFKKRECVFFTKDSKATENVCKCGYAQSQHMEGTQINQSEKWNYKKHTKEFPTDAFGDIQFETLGKKGKYIRLSCDTDAEILYELLTQHWHLKTPNLVISVTGGAKNFALKPRMRKIFSRLIYIAQSKGAWILTGGTHYGLMKYIGEVVRDNTISRSSEENIVAIGIAAWGMVSNRDTLIRNCDAEGYFLAQYLMDDFTRDPLYILDNNHTHLLLVDNGCHGHPTVEAKLRNQLEKYISERTIQDSNYGGKIPIVCFAQGGGKETLKAINTSIKNKIPCVVVEGSGQIADVIASLVEVEDALTSSAVKEKLVRFLPRTVSRLPEEETESWIKWLKEILECSHLLTVIKMEEAGDEIVSNAISYALYKAFSTSEQDKDNWNGQLKLLLEWNQLDLANDEIFTNDRRWESADLQEVMFTALIKDRPKFVRLFLENGLNLRKFLTHDVLTELFSNHFSTLVYRNLQIAKNSYNDALLTFVWKLVANFRRGFRKEDRNGRDEMDIELHDVSPITRHPLQALFIWAILQNKKELSKVIWEQTRGCTLAALGASKLLKTLAKVKNDINAAGESEELANEYETRAVELFTECYSSDEDLAEQLLVYSCEAWGGSNCLELAVEATDQHFIAQPGVQNFLSKQWYGEISRDTKNWKIILCLFIIPLVGCGFVSFRKKPVDKHKKLLWYYVAFFTSPFVVFSWNVVFYIAFLLLFAYVLLMDFHSVPHPPELVLYSLVFVLFCDEVRQWYVNGVNYFTDLWNVMDTLGLFYFIAGIVFRLHSSNKSSLYSGRVIFCLDYIIFTLRLIHIFTVSRNLGPKIIMLQRMLIDVFFFLFLFAVWMVAFGVARQGILRQNEQRWRWIFRSVIYEPYLAMFGQVPSDVDGTTYDFAHCTFTGNESKPLCVELDEHNLPRFPEWITIPLVCIYMLSTNILLVNLLVAMFGYTVGTVQENNDQVWKFQRYFLVQEYCSRLNIPFPFIVFAYFYMVVKKCFKCCCKEKNMESSVCCFKNEDNETLAWEGVMKENYLVKINTKANDTSEEMRHRFRQLDTKLNDLKGLLKEIANKIK>sp|Q7Z2W7-2|TRPM8_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily M member 8 OS=Homo sapiens OX=9606 GN=TRPM8MKYIGEVVRDNTISRSSEENIVAIGIAAWGMVSNRDTLIRNCDAEVPVGQEEVC>sp|Q7Z2W7-3|TRPM8_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily M member 8 OS=Homo sapiens OX=9606 GN=TRPM8MEGTQINQSEKWNYKKHTKEFPTDAFGDIQFETLGKKGKYIRLSCDTDAEILYELLTQHWHLKTPNLVISVTGGAKNFALKPRMRKIFSRLIYIAQSKGAWILTGGTHYGLMKYIGEVVRDNTISRSSEENIVAIGIAAWGMVSNRDTLIRNCDAEVPVGQEEVC>sp|Q7Z2W7-4|TRPM8_HUMAN Isoform 4 of Transient receptor potential cationchannel subfamily M member 8 OS=Homo sapiens OX=9606 GN=TRPM8MQAINTSIKNKIPCVVVEGSGQIADVIASLVEVEDALTSSAVKEKLVRFLPRTVSRLPEEETESWIKWLKEILECSHLLTVIKMEEAGDEIVSNAISYALYKAFSTSEQDKDNWNGQLKLLLEWNQLDLANDEIFTNDRRWESADLQEVMFTALIKDRPKFVRLFLENGLNLRKFLTHDVLTELFSNHFSTLVYRNLQIAKNSYNDALLTFVWKLVANFRRGFRKEDRNGRDEMDIELHDVSPITRHPLQALFIWAILQNKKELSKVIWEQTRGCTLAALGASKLLKTLAKVKNDINAAGESEELANEYETRAVELFTECYSSDEDLAEQLLVYSCEAWGGSNCLELAVEATDQHFIAQPGVQWYVNGVNYFTDLWNVMDTLGLFYFIAGIVFRLHSSNKSSLYSGRVIFCLDYIIFTLRLIHIFTVSRNLGPKIIMLQRMLIDVFFFLFLFAVWMVAFGVARQGILRQNEQRWRWIFRSVIYEPYLAMFGQVPSDVDGTTYDFAHCTFTGNESKPLCVELDEHNLPRFPEWITIPLVCIYMLSTNILLVNLLVAMFGYTVGTVQENNDQVWKFQRYFLVQEYCSRLNIPFPFIVFAYFYMVVKKCFKCCCKEKNMESSVCCFKNEDNETLAWEGVMKENYLVKINTKANDTSEEMRHRFRQLDTKLNDLKGLLKEIANKIK>sp|Q9BZJ3|TRYD_HUMAN Tryptase delta OS=Homo sapiens OX=9606 GN=TPSD1PE=2 SV=2MLLLAPQMLSLLLLALPVLASPAYVAPAPGQALQQTGIVGGQEAPRSKWPWQVSLRVRGPYWMHFCGGSLIHPQWVLTAAHCVEPDIKDLAALRVQLREQHLYYQDQLLPVSRIIVHPQFYIIQTGADIALLELEEPVNISSHIHTVTLPPASETFPPGMPCWVTGWGDVDNNVHLPPPYPLKEVEVPVVENHLCNAEYHTGLHTGHSFQIVRDDMLCAGSENHDSCQGDSGGPLVCKVNGT>sp|Q9BZJ3-2|TRYD_HUMAN Isoform 2 of Tryptase delta OS=Homo sapiensOX=9606 GN=TPSD1MLLLAPQMLSLLLLALPVLASPAYVAPAPGQALQQTGIVGGQEAPRSKWPWQVSLRVRGPYWMHFCGGSLIHPQWVLTAAHCVEPVQLREQHLYYQDQLLPVSRIIVHPQFYIIQTGADIALLELEEPVNISSHIHTVTLPPASETFPPGMPCWVTGWGDVDNNVHLPPPYPLKEVEVPVVENHLCNAEYHTGLHTGHSFQIVRDDMLCAGSENHDSCQGDSGGPLVCKVNGT>sp|O75762|TRPA1_HUMAN Transient receptor potential cation channelsubfamily A member 1 OS=Homo sapiens OX=9606 GN=TRPA1 PE=1 SV=3MKRSLRKMWRPGEKKEPQGVVYEDVPDDTEDFKESLKVVFEGSAYGLQNFNKQKKLKRCDDMDTFFLHYAAAEGQIELMEKITRDSSLEVLHEMDDYGNTPLHCAVEKNQIESVKFLLSRGANPNLRNFNMMAPLHIAVQGMNNEVMKVLLEHRTIDVNLEGENGNTAVIIACTTNNSEALQILLKKGAKPCKSNKWGCFPIHQAAFSGSKECMEIILRFGEEHGYSRQLHINFMNNGKATPLHLAVQNGDLEMIKMCLDNGAQIDPVEKGRCTAIHFAATQGATEIVKLMISSYSGSVDIVNTTDGCHETMLHRASLFDHHELADYLISVGADINKIDSEGRSPLILATASASWNIVNLLLSKGAQVDIKDNFGRNFLHLTVQQPYGLKNLRPEFMQMQQIKELVMDEDNDGCTPLHYACRQGGPGSVNNLLGFNVSIHSKSKDKKSPLHFAASYGRINTCQRLLQDISDTRLLNEGDLHGMTPLHLAAKNGHDKVVQLLLKKGALFLSDHNGWTALHHASMGGYTQTMKVILDTNLKCTDRLDEDGNTALHFAAREGHAKAVALLLSHNADIVLNKQQASFLHLALHNKRKEVVLTIIRSKRWDECLKIFSHNSPGNKCPITEMIEYLPECMKVLLDFCMLHSTEDKSCRDYYIEYNFKYLQCPLEFTKKTPTQDVIYEPLTALNAMVQNNRIELLNHPVCKEYLLMKWLAYGFRAHMMNLGSYCLGLIPMTILVVNIKPGMAFNSTGIINETSDHSEILDTTNSYLIKTCMILVFLSSIFGYCKEAGQIFQQKRNYFMDISNVLEWIIYTTGIIFVLPLFVEIPAHLQWQCGAIAVYFYWMNFLLYLQRFENCGIFIVMLEVILKTLLRSTVVFIFLLLAFGLSFYILLNLQDPFSSPLLSIIQTFSMMLGDINYRESFLEPYLRNELAHPVLSFAQLVSFTIFVPIVLMNLLIGLAVGDIAEVQKHASLKRIAMQVELHTSLEKKLPLWFLRKVDQKSTIVYPNKPRSGGMLFHIFCFLFCTGEIRQEIPNADKSLEMEILKQKYRLKDLTFLLEKQHELIKLIIQKMEIISETEDDDSHCSFQDRFKKEQMEQRNSRWNTVLRAVKAKTHHLEP>sp|Q9BWV7|TTLL2_HUMAN Probable tubulin polyglutamylase TTLL2 OS=Homosapiens OX=9606 GN=TTLL2 PE=2 SV=3MRGRDLCSSTQSQALGSLRTTTPAFTLNIPSEANHTEQPPAGLGARLQEAGVSIPPRRGRPTPTLEKKKKPHLMAEDEPSGALLKPLVFRVDETTPAVVQSVLLERGWNKFDKQEQNAEDWNLYWRTSSFRMTEHNSVKPWQQLNHHPGTTKLTRKDCLAKHLKHMRRMYGTSLYQFIPLTFVMPNDYTKFVAEYFQERQMLGTKHSYWICKPAELSRGRGILIFSDFKDFIFDDMYIVQKYISNPLLIGRYKCDLRIYVCVTGFKPLTIYVYQEGLVRFATEKFDLSNLQNNYAHLTNSSINKSGASYEKIKEVIGHGCKWTLSRFFSYLRSWDVDDLLLWKKIHRMVILTILAIAPSVPFAANCFELFGFDILIDDNLKPWLLEVNYSPALTLDCSTDVLVKRKLVHDIIDLIYLNGLRNEGREASNATHGNSNIDAAKSDRGGLDAPDCLPYDSLSFTSRMYNEDDSVVEKAVSVRPEAAPASQLEGEMSGQDFHLSTREMPQSKPKLRSRHTPHKTLMPYASLFQSHSCKTKTSPCVLSDRGKAPDPQAGNFVLVFPFNEATLGASRNGLNVKRIIQELQKLMNKQHS>sp|O43657|TSN6_HUMAN Tetraspanin-6 OS=Homo sapiens OX=9606 GN=TSPAN6PE=1 SV=1MASPSRRLQTKPVITCFKSVLLIYTFIFWITGVILLAVGIWGKVSLENYFSLLNEKATNVPFVLIATGTVIILLGTFGCFATCRASAWMLKLYAMFLTLVFLVELVAAIVGFVFRHEIKNSFKNNYEKALKQYNSTGDYRSHAVDKIQNTLHCCGVTDYRDWTDTNYYSEKGFPKSCCKLEDCTPQRDADKVNNEGCFIKVMTIIESEMGVVAGISFGVACFQLIGIFLAYCLSRAITNNQYEIV>sp|H0UI37|TSTD3_HUMAN Thiosulfate sulfurtransferase/rhodanese-likedomain-containing protein 3 OS=Homo sapiens OX=9606 GN=TSTD3 PE=3 SV=1MKIEKCGWSEGLTSIKGNCHNFYTAISKDVTYKELKNLLNSKNIMLIDVREIWEILEYQKIPESINVPLDEVGEALQMNPRDFKEKYNEVKPSKSDS>sp|P53804|TTC3_HUMAN E3 ubiquitin-protein ligase TTC3 OS=Homo sapiensOX=9606 GN=TTC3 PE=1 SV=2MDNFAEGDFTVADYALLEDCPHVDDCVFAAEFMSNDYVRVTQLYCDGVGVQYKDYIQSERNLEFDICSIWCSKPISVLQDYCDAIKINIFWPLLFQHQNSSVISRLHPCVDANNSRASEINLKKLQHLELMEDIVDLAKKVANDSFLIGGLLRIGCKIENKILAMEEALNWIKYAGDVTILTKLGSIDNCWPMLSIFFTEYKYHITKIVMEDCNLLEELKTQSCMDCIEEGELMKMKGNEEFSKERFDIAIIYYTRAIEYRPENYLLYGNRALCFLRTGQFRNALGDGKRATILKNTWPKGHYRYCDALSMLGEYDWALQANIKAQKLCKNDPEGIKDLIQQHVKLQKQIEDLQGRTANKDPIKAFYENRAYTPRSLSAPIFTTSLNFVEKERDFRKINHEMANGGNQNLKVADEALKVDDCDCHPEFSPPSSQPPKHKGKQKSRNNESEKFSSSSPLTLPADLKNILEKQFSKSSRAAHQDFANIMKMLRSLIQDGYMALLEQRCRSAAQAFTELLNGLDPQKIKQLNLAMINYVLVVYGLAISLLGIGQPEELSEAENQFKRIIEHYPSEGLDCLAYCGIGKVYLKKNRFLEALNHFEKARTLIYRLPGVLTWPTSNVIIEESQPQKIKMLLEKFVEECKFPPVPDAICCYQKCHGYSKIQIYITDPDFKGFIRISCCQYCKIEFHMNCWKKLKTTTFNDKIDKDFLQGICLTPDCEGVISKIIIFSSGGEVKCEFEHKVIKEKVPPRPILKQKCSSLEKLRLKEDKKLKRKIQKKEAKKLAQERMEEDLRESNPPKNEEQKETVDNVQRCQFLDDRILQCIKQYADKIKSGIQNTAMLLKELLSWKVLSTEDYTTCFSSRNFLNEAVDYVIRHLIQENNRVKTRIFLHVLSELKEVEPKLAAWIQKLNSFGLDATGTFFSRYGASLKLLDFSIMTFLWNEKYGHKLDSIEGKQLDYFSEPASLKEARCLIWLLEEHRDKFPALHSALDEFFDIMDSRCTVLRKQDSGEAPFSSTKVKNKSKKKKPKDSKPMLVGSGTTSVTSNNEIITSSEDHSNRNSDSAGPFAVPDHLRQDVEEFEALYDQHSNEYVVRNKKLWDMNPKQKCSTLYDYFSQFLEEHGPLDMSNKMFSAEYEFFPEETRQILEKAGGLKPFLLGCPRFVVIDNCIALKKVASRLKKKRKKKNIKTKVEEISKAGEYVRVKLQLNPAAREFKPDVKSKPVSDSSSAPAFENVKPKPVSANSPKPACEDVKAKPVSDNSSRQVSEDGQPKGVSSNSPKPGSEDANYKRVSCNSPKPVLEDVKPTYWAQSHLVTGYCTYLPFQRFDITQTPPAYINVLPGLPQYTSIYTPLASLSPEYQLPRSVPVVPSFVANDRADKNAAAYFEGHHLNAENVAGHQIASETQILEGSLGISVKSHCSTGDAHTVLSESNRNDEHCGNSNNKCEVIPESTSAVTNIPHVQMVAIQVSWNIIHQEVNTEPYNPFEERQGEISRIEKEHQVLQDQLQEVYENYEQIKLKGLEETRDLEEKLKRHLEENKISKTELDWFLQDLEREIKKWQQEKKEIQERLKSLKKKIKKVSNASEMYTQKNDGKEKEHELHLDQSLEISNTLTNEKMKIEEYIKKGKEDYEESHQRAVAAEVSVLENWKESEVYKLQIMESQAEAFLKKLGLISRDPAAYPDMESDIRSWELFLSNVTKEIEKAKSQFEEQIKAIKNGSRLSELSKVQISELSFPACNTVHPELLPESSGDDGQGLVTSASDVTGNHAALHRDPSVFSAGDSPGEAPSALLPGPPPGQPEATQLTGPKRAGQAALSERSPVADRKQPVPPGRAARSSQSPKKPFNSIIEHLSVVFPCYNSTELAGFIKKVRSKNKNSLSGLSIDEIVQRVTEHILDEQKKKKPNPGKDKRTYEPSSATPVTRSSQGSPSVVVAPSPKTKGQKAEDVPVRIALGASSCEICHEVFKSKNVRVLKCGHKYHKGCFKQWLKGQSACPACQGRDLLTEESPSGRGWPSQNQELPSCSSR>sp|P53804-2|TTC3_HUMAN Isoform TPRDII of E3 ubiquitin-protein ligaseTTC3 OS=Homo sapiens OX=9606 GN=TTC3MKMKGNEEFSKERFDIAIIYYTRAIEYRPENYLLYGNRALCFLRTGQFRNALGDGKRATILKNTWPKGHYRYCDALSMLGEYDWALQANIKAQKLCKNDPEGIKDLIQQHVKLQKQIEDLQGRTANKDPIKAFYENRAYTPRSLSAPIFTTSLNFVEKERDFRKINHEMANGGNQNLKVADEALKVDDCDCHPEFSPPSSQPPKHKGKQKSRNNESEKFSSSSPLTLPADLKNILEKQFSKSSRAAHQDFANIMKMLRSLIQDGYMALLEQRCRSAAQAFTELLNGLDPQKIKQLNLAMINYVLVVYGLAISLLGIGQPEELSEAENQFKRIIEHYPSEGLDCLAYCGIGKVYLKKNRFLEALNHFEKARTLIYRLPGVLTWPTSNVIIEESQPQKIKMLLEKFVEECKFPPVPDAICCYQKCHGYSKIQIYITDPDFKGFIRISCCQYCKIEFHMNCWKKLKTTTFNDKIDKDFLQGICLTPDCEGVISKIIIFSSGGEVKCEFEHKVIKEKVPPRPILKQKCSSLEKLRLKEDKKLKRKIQKKEAKKLAQERMEEDLRESNPPKNEEQKETVDNVQRCQFLDDRILQCIKQYADKIKSGIQNTAMLLKELLSWKVLSTEDYTTCFSSRNFLNEAVDYVIRHLIQENNRVKTRIFLHVLSELKEVEPKLAAWIQKLNSFGLDATGTFFSRYGASLKLLDFSIMTFLWNEKYGHKLDSIEGKQLDYFSEPASLKEARCLIWLLEEHRDKFPALHSALDEFFDIMDSRCTVLRKQDSGEAPFSSTKVKNKSKKKKPKDSKPMLVGSGTTSVTSNNEIITSSEDHSNRNSDSAGPFAVPDHLRQDVEEFEALYDQHSNEYVVRNKKLWDMNPKQKCSTLYDYFSQFLEEHGPLDMSNKMFSAEYEFFPEETRQILEKAGGLKPFLLGCPRFVVIDNCIALKKVASRLKKKRKKKNIKTKVEEISKAGEYVRVKLQLNPAAREFKPDVKSKPVSDSSSAPAFENVKPKPVSANSPKPACEDVKAKPVSDNSSRQVSEDGQPKGVSSNSPKPGSEDANYKRVSCNSPKPVLEDVKPTYWAQSHLVTGYCTYLPFQRFDITQTPPAYINVLPGLPQYTSIYTPLASLSPEYQLPRSVPVVPSFVANDRADKNAAAYFEGHHLNAENVAGHQIASETQILEGSLGISVKSHCSTGDAHTVLSESNRNDEHCGNSNNKCEVIPESTSAVTNIPHVQMVAIQVSWNIIHQEVNTEPYNPFEERQGEISRIEKEHQVLQDQLQEVYENYEQIKLKGLEETRDLEEKLKRHLEENKISKTELDWFLQDLEREIKKWQQEKKEIQERLKSLKKKIKKVSNASEMYTQKNDGKEKEHELHLDQSLEISNTLTNEKMKIEEYIKKGKEDYEESHQRAVAAEVSVLENWKESEVYKLQIMESQAEAFLKKLGLISRDPAAYPDMESDIRSWELFLSNVTKEIEKAKSQFEEQIKAIKNGSRLSELSKVQISELSFPACNTVHPELLPESSGDDGQGLVTSASDVTGNHAALHRDPSVFSAGDSPGEAPSALLPGPPPGQPEATQLTGPKRAGQAALSERSPVADRKQPVPPGRAARSSQSPKKPFNSIIEHLSVVFPCYNSTELAGFIKKVRSKNKNSLSGLSIDEIVQRVTEHILDEQKKKKPNPGKDKRTYEPSSATPVTRSSQGSPSVVVAPSPKTKGQKAEDVPVRIALGASSCEICHEVFKSKNVRVLKCGHKYHKGCFKQWLKGQSACPACQGRDLLTEESPSGRGWPSQNQELPSCSSR>sp|P53804-3|TTC3_HUMAN Isoform TPRDIII of E3 ubiquitin-protein ligaseTTC3 OS=Homo sapiens OX=9606 GN=TTC3MLGEYDWALQANIKAQKLCKNDPEGIKDLIQQHVKLQKQIEDLQGRTANKDPIKAFYENRAYTPRSLSAPIFTTSLNFVEKERDFRKINHEMANGGNQNLKVADEALKVDDCDCHPEFSPPSSQPPKHKGKQKSRNNESEKFSSSSPLTLPADLKNILEKQFSKSSRAAHQDFANIMKMLRSLIQDGYMALLEQRCRSAAQAFTELLNGLDPQKIKQLNLAMINYVLVVYGLAISLLGIGQPEELSEAENQFKRIIEHYPSEGLDCLAYCGIGKVYLKKNRFLEALNHFEKARTLIYRLPGVLTWPTSNVIIEESQPQKIKMLLEKFVEECKFPPVPDAICCYQKCHGYSKIQIYITDPDFKGFIRISCCQYCKIEFHMNCWKKLKTTTFNDKIDKDFLQGICLTPDCEGVISKIIIFSSGGEVKCEFEHKVIKEKVPPRPILKQKCSSLEKLRLKEDKKLKRKIQKKEAKKLAQERMEEDLRESNPPKNEEQKETVDNVQRCQFLDDRILQCIKQYADKIKSGIQNTAMLLKELLSWKVLSTEDYTTCFSSRNFLNEAVDYVIRHLIQENNRVKTRIFLHVLSELKEVEPKLAAWIQKLNSFGLDATGTFFSRYGASLKLLDFSIMTFLWNEKYGHKLDSIEGKQLDYFSEPASLKEARCLIWLLEEHRDKFPALHSALDEFFDIMDSRCTVLRKQDSGEAPFSSTKVKNKSKKKKPKDSKPMLVGSGTTSVTSNNEIITSSEDHSNRNSDSAGPFAVPDHLRQDVEEFEALYDQHSNEYVVRNKKLWDMNPKQKCSTLYDYFSQFLEEHGPLDMSNKMFSAEYEFFPEETRQILEKAGGLKPFLLGCPRFVVIDNCIALKKVASRLKKKRKKKNIKTKVEEISKAGEYVRVKLQLNPAAREFKPDVKSKPVSDSSSAPAFENVKPKPVSANSPKPACEDVKAKPVSDNSSRQVSEDGQPKGVSSNSPKPGSEDANYKRVSCNSPKPVLEDVKPTYWAQSHLVTGYCTYLPFQRFDITQTPPAYINVLPGLPQYTSIYTPLASLSPEYQLPRSVPVVPSFVANDRADKNAAAYFEGHHLNAENVAGHQIASETQILEGSLGISVKSHCSTGDAHTVLSESNRNDEHCGNSNNKCEVIPESTSAVTNIPHVQMVAIQVSWNIIHQEVNTEPYNPFEERQGEISRIEKEHQVLQDQLQEVYENYEQIKLKGLEETRDLEEKLKRHLEENKISKTELDWFLQDLEREIKKWQQEKKEIQERLKSLKKKIKKVSNASEMYTQKNDGKEKEHELHLDQSLEISNTLTNEKMKIEEYIKKGKEDYEESHQRAVAAEVSVLENWKESEVYKLQIMESQAEAFLKKLGLISRDPAAYPDMESDIRSWELFLSNVTKEIEKAKSQFEEQIKAIKNGSRLSELSKVQISELSFPACNTVHPELLPESSGDDGQGLVTSASDVTGNHAALHRDPSVFSAGDSPGEAPSALLPGPPPGQPEATQLTGPKRAGQAALSERSPVADRKQPVPPGRAARSSQSPKKPFNSIIEHLSVVFPCYNSTELAGFIKKVRSKNKNSLSGLSIDEIVQRVTEHILDEQKKKKPNPGKDKRTYEPSSATPVTRSSQGSPSVVVAPSPKTKGQKAEDVPVRIALGASSCEICHEVFKSKNVRVLKCGHKYHKGCFKQWLKGQSACPACQGRDLLTEESPSGRGWPSQNQELPSCSSR>sp|Q96AE7|TTC17_HUMAN Tetratricopeptide repeat protein 17 OS=Homosapiens OX=9606 GN=TTC17 PE=1 SV=1MAAAVGVRGRYELPPCSGPGWLLSLSALLSVAARGAFATTHWVVTEDGKIQQQVDSPMNLKHPHDLVILMRQEATVNYLKELEKQLVAQKIHIEENEDRDTGLEQRHNKEDPDCIKAKVPLGDLDLYDGTYITLESKDISPEDYIDTESPVPPDPEQPDCTKILELPYSIHAFQHLRGVQERVNLSAPLLPKEDPIFTYLSKRLGRSIDDIGHLIHEGLQKNTSSWVLYNMASFYWRIKNEPYQVVECAMRALHFSSRHNKDIALVNLANVLHRAHFSADAAVVVHAALDDSDFFTSYYTLGNIYAMLGEYNHSVLCYDHALQARPGFEQAIKRKHAVLCQQKLEQKLEAQHRSLQRTLNELKEYQKQHDHYLRQQEILEKHKLIQEEQILRNIIHETQMAKEAQLGNHQICRLVNQQHSLHCQWDQPVRYHRGDIFENVDYVQFGEDSSTSSMMSVNFDVQSNQSDINDSVKSSPVAHSILWIWGRDSDAYRDKQHILWPKRADCTESYPRVPVGGELPTYFLPPENKGLRIHELSSDDYSTEEEAQTPDCSITDFRKSHTLSYLVKELEVRMDLKAKMPDDHARKILLSRINNYTIPEEEIGSFLFHAINKPNAPIWLILNEAGLYWRAVGNSTFAIACLQRALNLAPLQYQDVPLVNLANLLIHYGLHLDATKLLLQALAINSSEPLTFLSLGNAYLALKNISGALEAFRQALKLTTKCPECENSLKLIRCMQFYPFLYNITSSVCSGTVVEESNGSDEMENSDETKMSEEILALVDEFQQAWPLEGFGGALEMKGRRLDLQGIRVLKKGPQDGVARSSCYGDCRSEDDEATEWITFQVKRVKKPKGDHKKTPGKKVETGQIENGHRYQANLEITGPKVASPGPQGKKRDYQRLGWPSPDECLKLRWVELTAIVSTWLAVSSKNIDITEHIDFATPIQQPAMEPLCNGNLPTSMHTLDHLHGVSNRASLHYTGESQLTEVLQNLGKDQYPQQSLEQIGTRIAKVLEKNQTSWVLSSMAALYWRVKGQGKKAIDCLRQALHYAPHQMKDVPLISLANILHNAKLWNDAVIVATMAVEIAPHFAVNHFTLGNVYVAMEEFEKALVWYESTLKLQPEFVPAKNRIQTIQCHLMLKKGRRSP>sp|Q96AE7-2|TTC17_HUMAN Isoform 2 of Tetratricopeptide repeat protein 17OS=Homo sapiens OX=9606 GN=TTC17MAAAVGVRGRYELPPCSGPGWLLSLSALLSVAARGAFATTHWVVTEDGKIQQQVDSPMNLKHPHDLVILMRQEATVNYLKELEKQLVAQKIHIEENEDRDTGLEQRHNKEDPDCIKAKVPLGDLDLYDGTYITLESKDISPEDYIDTESPVPPDPEQPDCTKILELPYSIHAFQHLRGVQERVNLSAPLLPKEDPIFTYLSKRLGRSIDDIGHLIHEGLQKNTSSWVLYNMASFYWRIKNEPYQVVECAMRALHFSSRHNKDIALVNLANVLHRAHFSADAAVVVHAALDDSDFFTSYYTLGNIYAMLGEYNHSVLCYDHALQARPGFEQAIKRKHAVLCQQKLEQKLEAQHRSLQRTLNELKEYQKQHDHYLRQQEILEKHKLIQEEQILRNIIHETQMAKEAQLGNHQICRLVNQQHSLHCQWDQPVRYHRGDIFENVDYVQFGEDSSTSSMMSVNFDVQSNQSDINDSVKSSPVAHSILWIWGRDSDAYRDKQHILWPKRADCTESYPRVPVGGELPTYFLPPENKGLRIHELSSDDYSTEEEAQTPDCSITDFRKSHTLSYLVKELEVRMDLKAKMPDDHARKILLSRINNYTIPEEEIGSFLFHAINKPNAPIWLILNEAGLYWRAVGNSTFAIACLQRALNLAPLQYQDVPLVNLANLLIHYGLHLDATKLLLQALAINSSEPLTFLSLGNAYLALKNISGALEAFRQALKLTTKCPECENSLKLIRCMQFYPFLYNITSSVCSGNCHEKTLDNSHDKQKYFDNSQSLDAAEEEPSERGTEEDPVFSVENSGRDSDALRLESTVVEESNGSDEMENSDETKMSEEILALVDEFQQAWPLEGFGGALEMKGRRLDLQGIRVLKKGPQDGVARSSCYGDCRSEDDEATEWITFQVKRVKKPKGDHKKTPGKKVETGQIENGHRYQANLEITGPKVASPGPQGLLDWKTRKVP>sp|Q8N0Z6|TTC5_HUMAN Tetratricopeptide repeat protein 5 OS=Homo sapiensOX=9606 GN=TTC5 PE=1 SV=2MMADEEEEVKPILQKLQELVDQLYSFRDCYFETHSVEDAGRKQQDVQKEMEKTLQQMEEVVGSVQGKAQVLMLTGKALNVTPDYSPKAEELLSKAVKLEPELVEAWNQLGEVYWKKGDVAAAHTCFSGALTHCRNKVSLQNLSMVLRQLRTDTEDEHSHHVMDSVRQAKLAVQMDVHDGRSWYILGNSYLSLYFSTGQNPKISQQALSAYAQAEKVDRKASSNPDLHLNRATLHKYEESYGEALEGFSRAAALDPAWPEPRQREQQLLEFLDRLTSLLESKGKVKTKKLQSMLGSLRPAHLGPCSDGHYQSASGQKVTLELKPLSTLQPGVNSGAVILGKVVFSLTTEEKVPFTFGLVDSDGPCYAVMVYNIVQSWGVLIGDSVAIPEPNLRLHRIQHKGKDYSFSSVRVETPLLLVVNGKPQGSSSQAVATVASRPQCE>sp|P57075|UBS3A_HUMAN Ubiquitin-associated and SH3 domain-containingprotein A OS=Homo sapiens OX=9606 GN=UBASH3A PE=1 SV=1MAAGETQLYAKVSNKLKSRSSPSLLEPLLAMGFPVHTALKALAATGRKTAEEALAWLHDHCNDPSLDDPIPQEYALFLCPTGPLLEKLQEFWRESKRQCAKNRAHEVFPHVTLCDFFTCEDQKVECLYEALKRAGDRLLGSFPTAVPLALHSSISYLGFFVSGSPADVIREFAMTFATEASLLAGTSVSRFWIFSQVPGHGPNLRLSNLTRASFVSHYILQKYCSVKPCTKQLHLTLAHKFYPHHQRTLEQLARAIPLGHSCQWTAALYSRDMRFVHYQTLRALFQYKPQNVDELTLSPGDYIFVDPTQQDEASEGWVIGISQRTGCRGFLPENYTDRASESDTWVKHRMYTFSLATDLNSRKDGEASSRCSGEFLPQTARSLSSLQALQATVARKSVLVVRHGERVDQIFGKAWLQQCSTPDGKYYRPDLNFPCSLPRRSRGIKDFENDPPLSSCGIFQSRIAGDALLDSGIRISSVFASPALRCVQTAKLILEELKLEKKIKIRVEPGIFEWTKWEAGKTTPTLMSLEELKEANFNIDTDYRPAFPLSALMPAESYQEYMDRCTASMVQIVNTCPQDTGVILIVSHGSTLDSCTRPLLGLPPRECGDFAQLVRKIPSLGMCFCEENKEEGKWELVNPPVKTLTHGANAAFNWRNWISGN>sp|P57075-2|UBS3A_HUMAN Isoform 2 of Ubiquitin-associated and SH3domain-containing protein A OS=Homo sapiens OX=9606 GN=UBASH3AMAAGETQLYAKVSNKLKSRSSPSLLEPLLAMGFPVHTALKALAATGRKTAEEALAWLHDHCNDPSLDDPIPQEYALFLCPTGPLLEKLQEFWRESKRQCAKNRAHEVFPHVTLCDFFTCEDQKVECLYEALKRAGDRLLGSFPTAVPLALHSSISYLGFFVSGSPADVIREFAMTFATEASLLADCSVKPCTKQLHLTLAHKFYPHHQRTLEQLARAIPLGHSCQWTAALYSRDMRFVHYQTLRALFQYKPQNVDELTLSPGDYIFVDPTQQDEASEGWVIGISQRTGCRGFLPENYTDRASESDTWVKHRMYTFSLATDLNSRKDGEASSRCSGEFLPQTARSLSSLQALQATVARKSVLVVRHGERVDQIFGKAWLQQCSTPDGKYYRPDLNFPCSLPRRSRGIKDFENDPPLSSCGIFQSRIAGDALLDSGIRISSVFASPALRCVQTAKLILEELKLEKKIKIRVEPGIFEWTKWEAGKTTPTLMSLEELKEANFNIDTDYRPAFPLSALMPAESYQEYMDRCTASMVQIVNTCPQDTGVILIVSHGSTLDSCTRPLLGLPPRECGDFAQLVRKIPSLGMCFCEENKEEGKWELVNPPVKTLTHGANAAFNWRNWISGN>sp|P57075-3|UBS3A_HUMAN Isoform 3 of Ubiquitin-associated and SH3domain-containing protein A OS=Homo sapiens OX=9606 GN=UBASH3AMAAGETQLYAKVSNKLKSRSSPSLLEPLLAMGFPVHTALKALAATGRKTAEEALAWLHDHCNDPSLDDPIPQEYALFLCPTGPLLEKLQEFWRESKRQCAKNRAHEVFPHVTLCDFFTCEDQKVECLYEALKRAGDRLLGSFPTAVPLALHSSISYLGFFVSGSPADVIREFAMTFATEASLLADCSVKPCTKQLHLTLAHKFYPHHQRTLEQLARAIPLGHSCQWTAALYSRDMRFVHYQTLRALFQYKPQNVDELTLSPGDYIFVDPTQQDEASEGWVIGISQRTGCRGFLPENYTDRASESDTWVKHRMYTFSLATDLNSRKDGEASSRCSGEFLPQTARSLSSLQALQATVARKSVLVVRHGERVDQIFGKAWLQQCSTPDGKYYRPDLNFPCSLPRRSRGIKDFENDPPLSSCGIFQSRIAGDALLDSGIRISSVFASPALRCVQTAKLILEELKLEKKIKIRVEPGIFEWTKWEAGKTTPTLMSLEELKEANFNIDTDYRSLPWACASVKKIKRKENGSW>sp|A6XGL0|YJEN3_HUMAN YjeF N-terminal domain-containing protein 3OS=Homo sapiens OX=9606 GN=YJEFN3 PE=1 SV=1MSSAAGPDPSEAPEERHFLRALELQPPLADMGRAELSSNATTSLVQRRKQAWGRQSWLEQIWNAGPVCQSTAEAAALERELLEDYRFGRQQLVELCGHASAVAVTKAFPLPALSRKQRTVLVVCGPEQNGAVGLVCARHLRVFEYEPTIFYPTRSLDLLHRDLTTQCEKMDIPFLSYLPTEVQLINEAYGLVVDAVLGPGVEPGEVGGPCTRALATLKLLSIPLVSLDIPSGWDAETGSDSEDGLRPDVLVSLAAPKRCAGRFSGRHHFVAGRFVPDDVRRKFALRLPGYTGTDCVAAL>sp|A6XGL0-2|YJEN3_HUMAN Isoform 2 of YjeF N-terminal domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=YJEFN3MSSAAGPDPSEAPEERHFLSTAEAAALERELLEDYRFGRQQLVELCGHASAVAVTKAFPLPALSRKQRTVLVVCGPEQNGAVGLVCARHLRVFEYEPTIFYPTRSLDLLHRDLTTQCEKMDIPFLSYLPTEVQLINEAYGLVVDAVLGPGVEPGEVGGPCTRALATLKLLSIPLVSLDIPSGWDAETGSDSEDGLRPDVLVSLAAPKRCAGRFSGRHHFVAGRFVPDDVRRKFALRLPGYTGTDCVAAL>sp|A6NEY8|PRXD1_HUMAN Putative prolyl-tRNA synthetase associated domain-containing protein 1 OS=Homo sapiens OX=9606 GN=PRORSD1P PE=5 SV=3MAGAELGAALEQRLGALAIHTEVVEHPEVFTVEEMMPHIQHLKGAHSKNLFLKDKKKKNYWLVTVLHDRQINLNELAKQLGVGSGNLRFADETAMLEKLKVGQGCATPLALFCDGGDVKFVLDSAFLEGGHEKVYFHPMTNAATMGLSPEDFLTFVKMTGHDPIILNFD>sp|P06454|PTMA_HUMAN Prothymosin alpha OS=Homo sapiens OX=9606 GN=PTMAPE=1 SV=2MSDAAVDTSSEITTKDLKEKKEVVEEAENGRDAPANGNAENEENGEQEADNEVDEEEEEGGEEEEEEEEGDGEEEDGDEDEEAESATGKRAAEDDEDDDVDTKKQKTDEDD>sp|P06454-2|PTMA_HUMAN Isoform 2 of Prothymosin alpha OS=Homo sapiensOX=9606 GN=PTMAMSDAAVDTSSEITTKDLKEKKEVVEEAENGRDAPANGNANEENGEQEADNEVDEEEEEGGEEEEEEEEGDGEEEDGDEDEEAESATGKRAAEDDEDDDVDTKKQKTDEDD>sp|Q9UHX1|PUF60_HUMAN Poly(U)-binding-splicing factor PUF60 OS=Homosapiens OX=9606 GN=PUF60 PE=1 SV=1MATATIALQVNGQQGGGSEPAAAAAVVAAGDKWKPPQGTDSIKMENGQSTAAKLGLPPLTPEQQEALQKAKKYAMEQSIKSVLVKQTIAHQQQQLTNLQMAAVTMGFGDPLSPLQSMAAQRQRALAIMCRVYVGSIYYELGEDTIRQAFAPFGPIKSIDMSWDSVTMKHKGFAFVEYEVPEAAQLALEQMNSVMLGGRNIKVGRPSNIGQAQPIIDQLAEEARAFNRIYVASVHQDLSDDDIKSVFEAFGKIKSCTLARDPTTGKHKGYGFIEYEKAQSSQDAVSSMNLFDLGGQYLRVGKAVTPPMPLLTPATPGGLPPAAAVAAAAATAKITAQEAVAGAAVLGTLGTPGLVSPALTLAQPLGTLPQAVMAAQAPGVITGVTPARPPIPVTIPSVGVVNPILASPPTLGLLEPKKEKEEEELFPESERPEMLSEQEHMSISGSSARHMVMQKLLRKQESTVMVLRNMVDPKDIDDDLEGEVTEECGKFGAVNRVIIYQEKQGEEEDAEIIVKIFVEFSIASETHKAIQALNGRWFAGRKVVAEVYDQERFDNSDLSA>sp|Q9UHX1-2|PUF60_HUMAN Isoform 2 of Poly(U)-binding-splicing factorPUF60 OS=Homo sapiens OX=9606 GN=PUF60MATATIALQVNGQQGGGSEPAAAAAVVAAGDKWKPPQGTDSIKMENGQSTAAKLGLPPLTPEQQEALQKAKKYAMEQSIKSVLVKQTIAHQQQQLTNLQMAAQRQRALAIMCRVYVGSIYYELGEDTIRQAFAPFGPIKSIDMSWDSVTMKHKGFAFVEYEVPEAAQLALEQMNSVMLGGRNIKVGRPSNIGQAQPIIDQLAEEARAFNRIYVASVHQDLSDDDIKSVFEAFGKIKSCTLARDPTTGKHKGYGFIEYEKAQSSQDAVSSMNLFDLGGQYLRVGKAVTPPMPLLTPATPGGLPPAAAVAAAAATAKITAQEAVAGAAVLGTLGTPGLVSPALTLAQPLGTLPQAVMAAQAPGVITGVTPARPPIPVTIPSVGVVNPILASPPTLGLLEPKKEKEEEELFPESERPEMLSEQEHMSISGSSARHMVMQKLLRKQESTVMVLRNMVDPKDIDDDLEGEVTEECGKFGAVNRVIIYQEKQGEEEDAEIIVKIFVEFSIASETHKAIQALNGRWFAGRKVVAEVYDQERFDNSDLSA>sp|Q9UHX1-3|PUF60_HUMAN Isoform 3 of Poly(U)-binding-splicing factorPUF60 OS=Homo sapiens OX=9606 GN=PUF60MENGQSTAAKLGLPPLTPEQQEALQKAKKYAMEQSIKSVLVKQTIAHQQQQLTNLQMAAVTMGFGDPLSPLQSMAAQRQRALAIMCRVYVGSIYYELGEDTIRQAFAPFGPIKSIDMSWDSVTMKHKGFAFVEYEVPEAAQLALEQMNSVMLGGRNIKVGRPSNIGQAQPIIDQLAEEARAFNRIYVASVHQDLSDDDIKSVFEAFGKIKSCTLARDPTTGKHKGYGFIEYEKAQSSQDAVSSMNLFDLGGQYLRVGKAVTPPMPLLTPATPGGLPPAAAVAAAAATAKITAQEAVAGAAVLGTLGTPGLVSPALTLAQPLGTLPQAVMAAQAPGVITGVTPARPPIPVTIPSVGVVNPILASPPTLGLLEPKKEKEEEELFPESERPEMLSEQEHMSISGSSARHMVMQKLLRKQESTVMVLRNMVDPKDIDDDLEGEVTEECGKFGAVNRVIIYQEKQGEEEDAEIIVKIFVEFSIASETHKAIQALNGRWFAGRKVVAEVYDQERFDNSDLSA>sp|Q9UHX1-4|PUF60_HUMAN Isoform 4 of Poly(U)-binding-splicing factorPUF60 OS=Homo sapiens OX=9606 GN=PUF60MENGQSTAAKLGLPPLTPEQQEALQKAKKYAMEQSIKSVLVKQTIAHQQQQLTNLQMAAQRQRALAIMCRVYVGSIYYELGEDTIRQAFAPFGPIKSIDMSWDSVTMKHKGFAFVEYEVPEAAQLALEQMNSVMLGGRNIKVGRPSNIGQAQPIIDQLAEEARAFNRIYVASVHQDLSDDDIKSVFEAFGKIKSCTLARDPTTGKHKGYGFIEYEKAQSSQDAVSSMNLFDLGGQYLRVGKAVTPPMPLLTPATPGGLPPAAAVAAAAATAKITAQEAVAGAAVLGTLGTPGLVSPALTLAQPLGTLPQAVMAAQAPGVITGVTPARPPIPVTIPSVGVVNPILASPPTLGLLEPKKEKEEEELFPESERPEMLSEQEHMSISGSSARHMVMQKLLRKQESTVMVLRNMVDPKDIDDDLEGEVTEECGKFGAVNRVIIYQEKQGEEEDAEIIVKIFVEFSIASETHKAIQALNGRWFAGRKVVAEVYDQERFDNSDLSA>sp|Q9UHX1-5|PUF60_HUMAN Isoform 5 of Poly(U)-binding-splicing factorPUF60 OS=Homo sapiens OX=9606 GN=PUF60MATATIALGTDSIKMENGQSTAAKLGLPPLTPEQQEALQKAKKYAMEQSIKSVLVKQTIAHQQQQLTNLQMAAVTMGFGDPLSPLQSMAAQRQRALAIMCRVYVGSIYYELGEDTIRQAFAPFGPIKSIDMSWDSVTMKHKGFAFVEYEVPEAAQLALEQMNSVMLGGRNIKVGRPSNIGQAQPIIDQLAEEARAFNRIYVASVHQDLSDDDIKSVFEAFGKIKSCTLARDPTTGKHKGYGFIEYEKAQSSQDAVSSMNLFDLGGQYLRVGKAVTPPMPLLTPATPGGLPPAAAVAAAAATAKITAQEAVAGAAVLGTLGTPGLVSPALTLAQPLGTLPQAVMAAQAPGVITGVTPARPPIPVTIPSVGVVNPILASPPTLGLLEPKKEKEEEELFPESERPEMLSEQEHMSISGSSARHMVMQKLLRKQESTVMVLRNMVDPKDIDDDLEGEVTEECGKFGAVNRVIIYQEKQGEEEDAEIIVKIFVEFSIASETHKAIQALNGRWFAGRKVVAEVYDQERFDNSDLSA>sp|Q9UHX1-6|PUF60_HUMAN Isoform 6 of Poly(U)-binding-splicing factorPUF60 OS=Homo sapiens OX=9606 GN=PUF60MATATIALGTDSIKMENGQSTAAKLGLPPLTPEQQEALQKAKKYAMEQSIKSVLVKQTIAHQQQQLTNLQMAAQRQRALAIMCRVYVGSIYYELGEDTIRQAFAPFGPIKSIDMSWDSVTMKHKGFAFVEYEVPEAAQLALEQMNSVMLGGRNIKVGRPSNIGQAQPIIDQLAEEARAFNRIYVASVHQDLSDDDIKSVFEAFGKIKSCTLARDPTTGKHKGYGFIEYEKAQSSQDAVSSMNLFDLGGQYLRVGKAVTPPMPLLTPATPGGLPPAAAVAAAAATAKITAQEAVAGAAVLGTLGTPGLVSPALTLAQPLGTLPQAVMAAQAPGVITGVTPARPPIPVTIPSVGVVNPILASPPTLGLLEPKKEKEEEELFPESERPEMLSEQEHMSISGSSARHMVMQKLLRKQESTVMVLRNMVDPKDIDDDLEGEVTEECGKFGAVNRVIIYQEKQGEEEDAEIIVKIFVEFSIASETHKAIQALNGRWFAGRKVVAEVYDQERFDNSDLSA>sp|Q6DKI7|PVRIG_HUMAN Transmembrane protein PVRIG OS=Homo sapiensOX=9606 GN=PVRIG PE=1 SV=1MRTEAQVPALQPPEPGLEGAMGHRTLVLPWVLLTLCVTAGTPEVWVQVRMEATELSSFTIRCGFLGSGSISLVTVSWGGPNGAGGTTLAVLHPERGIRQWAPARQARWETQSSISLILEGSGASSPCANTTFCCKFASFPEGSWEACGSLPPSSDPGLSAPPTPAPILRADLAGILGVSGVLLFGCVYLLHLLRRHKHRPAPRLQPSRTSPQAPRARAWAPSQASQAALHVPYATINTSCRPATLDTAHPHGGPSWWASLPTHAAHRPQGPAAWASTPIPARGSFVSVENGLYAQAGERPPHTGPGLTLFPDPRGPRAMEGPLGVR>sp|Q3MIT2|PUS10_HUMAN tRNA pseudouridine synthase Pus10 OS=Homo sapiensOX=9606 GN=PUS10 PE=1 SV=1MFPLTEENKHVAQLLLNTGTCPRCIFRFCGVDFHAPYKLPYKELLNELQKFLETEKDELILEVMNPPPKKIRLQELEDSIDNLSQNGEGRISVSHVGSTASKNSNLNVCNVCLGILQEFCEKDFIKKVCQKVEASGFEFTSLVFSVSFPPQLSVREHAAWLLVKQEMGKQSLSLGRDDIVQLKEAYKWITHPLFSEELGVPIDGKSLFEVSVVFAHPETVEDCHFLAAICPDCFKPAKNKQSVFTRMAVMKALNKIKEEDFLKQFPCPPNSPKAVCAVLEIECAHGAVFVAGRYNKYSRNLPQTPWIIDGERKLESSVEELISDHLLAVFKAESFNFSSSGREDVDVRTLGNGRPFAIELVNPHRVHFTSQEIKELQQKINNSSNKIQVRDLQLVTREAIGHMKEGEEEKTKTYSALIWTNKAIQKKDIEFLNDIKDLKIDQKTPLRVLHRRPLAVRARVIHFMETQYVDEHHFRLHLKTQAGTYIKEFVHGDFGRTKPNIGSLMNVTADILELDVESVDVDWPPALDD>sp|Q15434|RBMS2_HUMAN RNA-binding motif, single-stranded-interactingprotein 2 OS=Homo sapiens OX=9606 GN=RBMS2 PE=1 SV=1MLLSVTSRPGISTFGYNRNNKKPYVSLAQQMAPPSPSNSTPNSSSGSNGNDQLSKTNLYIRGLQPGTTDQDLVKLCQPYGKIVSTKAILDKTTNKCKGYGFVDFDSPSAAQKAVTALKASGVQAQMAKQQEQDPTNLYISNLPLSMDEQELEGMLKPFGQVISTRILRDTSGTSRGVGFARMESTEKCEAIITHFNGKYIKTPPGVPAPSDPLLCKFADGGPKKRQNQGKFVQNGRAWPRNADMGVMALTYDPTTALQNGFYPAPYNITPNRMLAQSALSPYLSSPVSSYQRVTQTSPLQVPNPSWMHHHSYLMQPSGSVLTPGMDHPISLQPASMMGPLTQQLGHLSLSSTGTYMPTAAAMQGAYISQYTPVPSSSVSVEESSGQQNQVAVDAPSEHGVYSFQFNK>sp|Q14644|RASA3_HUMAN Ras GTPase-activating protein 3 OS=Homo sapiensOX=9606 GN=RASA3 PE=1 SV=3MAVEDEGLRVFQSVKIKIGEAKNLPSYPGPSKMRDCYCTVNLDQEEVFRTKIVEKSLCPFYGEDFYCEIPRSFRHLSFYIFDRDVFRRDSIIGKVAIQKEDLQKYHNRDTWFQLQHVDADSEVQGKVHLELRLSEVITDTGVVCHKLATRIVECQGLPIVNGQCDPYATVTLAGPFRSEAKKTKVKRKTNNPQFDEVFYFEVTRPCSYSKKSHFDFEEEDVDKLEIRVDLWNASNLKFGDEFLGELRIPLKVLRQSSSYEAWYFLQPRDNGSKSLKPDDLGSLRLNVVYTEDHVFSSDYYSPLRDLLLKSADVEPVSASAAHILGEVCREKQEAAVPLVRLFLHYGRVVPFISAIASAEVKRTQDPNTIFRGNSLASKCIDETMKLAGMHYLHVTLKPAIEEICQSHKPCEIDPVKLKDGENLENNMENLRQYVDRVFHAITESGVSCPTVMCDIFFSLREAAAKRFQDDPDVRYTAVSSFIFLRFFAPAILSPNLFQLTPHHTDPQTSRTLTLISKTVQTLGSLSKSKSASFKESYMATFYEFFNEQKYADAVKNFLDLISSSGRRDPKSVEQPIVLKEGFMIKRAQGRKRFGMKNFKKRWFRLTNHEFTYHKSKGDQPLYSIPIENILAVEKLEEESFKMKNMFQVIQPERALYIQANNCVEAKDWIDILTKVSQCNQKRLTVYHPSAYLSGHWLCCRAPSDSAPGCSPCTGGLPANIQLDIDGDRETERIYSLFNLYMSKLEKMQEACGSKSVYDGPEQEEYSTFVIDDPQETYKTLKQVIAGVGALEQEHAQYKRDKFKKTKYGSQEHPIGDKSFQNYIRQQSETSTHSI>sp|Q14644-2|RASA3_HUMAN Isoform 2 of Ras GTPase-activating protein 3OS=Homo sapiens OX=9606 GN=RASA3MRDCYCTVNLDQEEVFRTKIVEKSLCPFYGEDFYCEIPRSFRHLSFYIFDRDVFRRDSIIGKVAIQKEDLQKYHNRDTWFQLQHVDADSEVQGKVHLELRLSEVITDTGVVCHKLATRIVECQGLPIVNGQCDPYATVTLAGPFRSEAKKTKVKRKTNNPQFDEVFYFEVTRPCSYSKKSHFDFEEEDVDKLEIRVDLWNASNLKFGDEFLGELRIPLKVLRQSSSYEAWYFLQPRDNGSKSLKPDDLGSLRLNVVYTEDHVFSSDYYSPLRDLLLKSADVEPVSASAAHILGEVCREKQEAAVPLVRLFLHYGRVVPFISAIASAEVKRTQDPNTIFRGNSLASKCIDETMKLAGMHYLHVTLKPAIEEICQSHKPCEIDPVKLKDGENLENNMENLRQYVDRVFHAITESGVSCPTVMCDIFFSLREAAAKRFQDDPDVRYTAVSSFIFLRFFAPAILSPNLFQLTPHHTDPQTSRTLTLISKTVQTLGSLSKSKSASFKESYMATFYEFFNEQKYADAVKNFLDLISSSGRRDPKSVEQPIVLKEGFMIKRAQGRKRFGMKNFKKRWFRLTNHEFTYHKSKGDQPLYSIPIENILAVEKLEEESFKMKNMFQVIQPERALYIQANNCVEAKDWIDILTKVSQCNQKRLTVYHPSAYLSGHWLCCRAPSDSAPGCSPCTGGLPANIQLDIDGDRETERIYSLFNLYMSKLEKMQEACGSKSVYDGPEQEEYSTFVIDDPQETYKTLKQVIAGVGALEQEHAQYKRDKFKKTKYGSQEHPIGDKSFQNYIRQQSETSTHSI>sp|A0AV96|RBM47_HUMAN RNA-binding protein 47 OS=Homo sapiens OX=9606GN=RBM47 PE=1 SV=2MTAEDSTAAMSSDSAAGSSAKVPEGVAGAPNEAALLALMERTGYSMVQENGQRKYGGPPPGWEGPHPQRGCEVFVGKIPRDVYEDELVPVFEAVGRIYELRLMMDFDGKNRGYAFVMYCHKHEAKRAVRELNNYEIRPGRLLGVCCSVDNCRLFIGGIPKMKKREEILEEIAKVTEGVLDVIVYASAADKMKNRGFAFVEYESHRAAAMARRKLMPGRIQLWGHQIAVDWAEPEIDVDEDVMETVKILYVRNLMIETTEDTIKKSFGQFNPGCVERVKKIRDYAFVHFTSREDAVHAMNNLNGTELEGSCLEVTLAKPVDKEQYSRYQKAARGGGAAEAAQQPSYVYSCDPYTLAYYGYPYNALIGPNRDYFVKAGSIRGRGRGAAGNRAPGPRGSYLGGYSAGRGIYSRYHEGKGKQQEKGYELVPNLEIPTVNPVAIKPGTVAIPAIGAQYSMFPAAPAPKMIEDGKIHTVEHMISPIAVQPDPASAAAAAAAAAAAAAAVIPTVSTPPPFQGRPITPVYTVAPNVQRIPTAGIYGASYVPFAAPATATIATLQKNAAAAAAMYGGYAGYIPQAFPAAAIQVPIPDVYQTY>sp|A0AV96-2|RBM47_HUMAN Isoform 2 of RNA-binding protein 47 OS=Homosapiens OX=9606 GN=RBM47MTAEDSTAAMSSDSAAGSSAKVPEGVAGAPNEAALLALMERTGYSMVQENGQRKYGGPPPGWEGPHPQRGCEVFVGKIPRDVYEDELVPVFEAVGRIYELRLMMDFDGKNRGYAFVMYCHKHEAKRAVRELNNYEIRPGRLLGVCCSVDNCRLFIGGIPKMKKREEILEEIAKVTEGVLDVIVYASAADKMKNRGFAFVEYESHRAAAMARRKLMPGRIQLWGHQIAVDWAEPEIDVDEDVMETVKILYVRNLMIETTEDTIKKSFGQFNPGCVERVKKIRDYAFVHFTSREDAVHAMNNLNGTELEGSCLEVTLAKPVDKEQYSRYQKAARGGGAAEAAQQPSYVYSCDPYTLAYYGYPYNALIGPNRDYFVKVAIPAIGAQYSMFPAAPAPKMIEDGKIHTVEHMISPIAVQPDPASAAAAAAAAAAAAAAVIPTVSTPPPFQGRPITPVYTVAPNVQRIPTAGIYGASYVPFAAPATATIATLQKNAAAAAAMYGGYAGYIPQAFPAAAIQVPIPDVYQTY>sp|P52756|RBM5_HUMAN RNA-binding protein 5 OS=Homo sapiens OX=9606GN=RBM5 PE=1 SV=2MGSDKRVSRTERSGRYGSIIDRDDRDERESRSRRRDSDYKRSSDDRRGDRYDDYRDYDSPERERERRNSDRSEDGYHSDGDYGEHDYRHDISDERESKTIMLRGLPITITESDIREMMESFEGPQPADVRLMKRKTGVSRGFAFVEFYHLQDATSWMEANQKKLVIQGKHIAMHYSNPRPKFEDWLCNKCCLNNFRKRLKCFRCGADKFDSEQEVPPGTTESVQSVDYYCDTIILRNIAPHTVVDSIMTALSPYASLAVNNIRLIKDKQTQQNRGFAFVQLSSAMDASQLLQILQSLHPPLKIDGKTIGVDFAKSARKDLVLSDGNRVSAFSVASTAIAAAQWSSTQSQSGEGGSVDYSYLQPGQDGYAQYAQYSQDYQQFYQQQAGGLESDASSASGTAVTTTSAAVVSQSPQLYNQTSNPPGSPTEEAQPSTSTSTQAPAASPTGVVPGTKYAVPDTSTYQYDESSGYYYDPTTGLYYDPNSQYYYNSLTQQYLYWDGEKETYVPAAESSSHQQSGLPPAKEGKEKKEKPKSKTAQQIAKDMERWAKSLNKQKENFKNSFQPVNSLREEERRESAAADAGFALFEKKGALAERQQLIPELVRNGDEENPLKRGLVAAYSGDSDNEEELVERLESEEEKLADWKKMACLLCRRQFPNKDALVRHQQLSDLHKQNMDIYRRSRLSEQELEALELREREMKYRDRAAERREKYGIPEPPEPKRKKQFDAGTVNYEQPTKDGIDHSNIGNKMLQAMGWREGSGLGRKCQGITAPIEAQVRLKGAGLGAKGSAYGLSGADSYKDAVRKAMFARFTEME>sp|P52756-2|RBM5_HUMAN Isoform 2 of RNA-binding protein 5 OS=Homosapiens OX=9606 GN=RBM5MGSDKRVSRTERSGRYGSIIDRDDRDERESRSRRRDSDYKRSSDDRRGDRYDDYRDYDSPERERERRNSDRSEDGYHSDGDYGEHDYRHDISDERESKTIMLRGLPITITESDIREMMESFEGPQPADVRLMKRKTGESLLSS>sp|P52756-3|RBM5_HUMAN Isoform 3 of RNA-binding protein 5 OS=Homosapiens OX=9606 GN=RBM5MGSDKRVSRTERSGRYGSIIDRDDRDERESRSRRRDSDYKRSSDDRRGDRYDDYRDYDSPERERYSRNDGVLRRPSACGCEADEEENRCKPWFRLRGVLSLARCYQLDGSQSEKVGDSRKAHCNAL>sp|P52756-4|RBM5_HUMAN Isoform 4 of RNA-binding protein 5 OS=Homosapiens OX=9606 GN=RBM5MGSDKRVSRTERSGRYGSIIDRDDRDERESRSRRRDSDYKRSSDDRRGDRYDDYRDYDSPERERERRNSDRSEDGYHSDGDYGEHDYRHDISDERESKTIMLRGLPITITESDIREMMESFEGPQPADVRLMKRKTGVSRG>sp|P52756-5|RBM5_HUMAN Isoform 5 of RNA-binding protein 5 OS=Homosapiens OX=9606 GN=RBM5MGSDKRVSRTERSGRYGSIIDRDDRDERESRSRRRDSDYKRSSDDRRGDRYDDYRDYDSPERERERRNSDRSEDGYHSDGDYGEHDYRHDISDERESKTIMLRGLPITITESDIREMMESFEGPQPADVRLMKRKTEKVGDSRKAHCNAL>sp|P61020|RAB5B_HUMAN Ras-related protein Rab-5B OS=Homo sapiens OX=9606GN=RAB5B PE=1 SV=1MTSRSTARPNGQPQASKICQFKLVLLGESAVGKSSLVLRFVKGQFHEYQESTIGAAFLTQSVCLDDTTVKFEIWDTAGQERYHSLAPMYYRGAQAAIVVYDITNQETFARAKTWVKELQRQASPSIVIALAGNKADLANKRMVEYEEAQAYADDNSLLFMETSAKTAMNVNDLFLAIAKKLPKSEPQNLGGAAGRSRGVDLHEQSQQNKSQCCSN>sp|P61020-2|RAB5B_HUMAN Isoform 2 of Ras-related protein Rab-5B OS=Homosapiens OX=9606 GN=RAB5BMTSRSTARPNGQPQASKICQFKLVLLGESAVGKSSLVLRFVKGQFHEYQESTIGAAFLTQSVCLDDTTVKFEIWDTAGQERYHSLAPMYYRGAQAAIVVYDITNQEAQAYADDNSLLFMETSAKTAMNVNDLFLAIAKKLPKSEPQNLGGAAGRSRGVDLHEQSQQNKSQCCSN>sp|Q9Y3T6|R3HC1_HUMAN R3H and coiled-coil domain-containing protein 1OS=Homo sapiens OX=9606 GN=R3HCC1 PE=1 SV=3MALLCLDGVFLSSAENDFVHRIQEELDRFLLQKQLSKVLLFPPLSSRLRYLIHRTAENFDLLSSFSVGEGWKRRTVICHQDIRVPSSDGLSGPCRAPASCPSRYHGPRPISNQGAAAVPRGARAGRWYRGRKPDQPLYVPRVLRRQEEWGLTSTSVLKREAPAGRDPEEPGDVGAGDPNSDQGLPVLMTQGTEDLKGPGQRCENEPLLDPVGPEPLGPESQSGKGDMVEMATRFGSTLQLDLEKGKESLLEKRLVAEEEEDEEEVEEDGPSSCSEDDYSELLQEITDNLTKKEIQIEKIHLDTSSFVEELPGEKDLAHVVEIYDFEPALKTEDLLATFSEFQEKGFRIQWVDDTHALGIFPCLASAAEALTREFSVLKIRPLTQGTKQSKLKALQRPKLLRLVKERPQTNATVARRLVARALGLQHKKKERPAVRGPLPP>sp|Q9Y3T6-3|R3HC1_HUMAN Isoform 2 of R3H and coiled-coil domain-containing protein 1 OS=Homo sapiens OX=9606 GN=R3HCC1MALLCLDGVFLSSAENDFVHRIQEELDRFLLQKQLSKVLLFPPLSSRLRYLIHRTAENFDLLSSFSVGEGWKRRTVICHQDIRVPSSDGLSGPCRAPASCPSRQEEWGLTSTSVLKREAPAGRDPEEPGDVGAGDPNSDQGLPVLMTQGTEDLKGPGQRCENEPLLDPVGPEPLGPESQSGKGDMVEMATRFGSTLQLDLEKGKESLLEKRLVAEEEEDEEEVEEDGPSSCSEDDYSELLQEITDNLTKKEIQIEKIHLDTSSFVEELPGEKDLAHVVEIYDFEPALKTEDLLATFSEFQEKGFRIQWVDDTHALGIFPCLASAAEALTREFSVLKIRPLTQGTKQSKLKALQRPKLLRLVKERPQTNATVARRLVARALGLQHKKKERPAVRGPLPP>sp|Q9UJ41|RABX5_HUMAN Rab5 GDP/GTP exchange factor OS=Homo sapiensOX=9606 GN=RABGEF1 PE=1 SV=3MSLKSERRGIHVDQSDLLCKKGCGYYGNPAWQGFCSKCWREEYHKARQKQIQEDWELAERLQREEEEAFASSQSSQGAQSLTFSKFEEKKTNEKTRKVTTVKKFFSASSRVGSKKEIQEAKAPSPSINRQTSIETDRVSKEFIEFLKTFHKTGQEIYKQTKLFLEGMHYKRDLSIEEQSECAQDFYHNVAERMQTRGKVPPERVEKIMDQIEKYIMTRLYKYVFCPETTDDEKKDLAIQKRIRALRWVTPQMLCVPVNEDIPEVSDMVVKAITDIIEMDSKRVPRDKLACITKCSKHIFNAIKITKNEPASADDFLPTLIYIVLKGNPPRLQSNIQYITRFCNPSRLMTGEDGYYFTNLCCAVAFIEKLDAQSLNLSQEDFDRYMSGQTSPRKQEAESWSPDACLGVKQMYKNLDLLSQLNERQERIMNEAKKLEKDLIDWTDGIAREVQDIVEKYPLEIKPPNQPLAAIDSENVENDKLPPPLQPQVYAG>sp|Q9UJ41-3|RABX5_HUMAN Isoform 2 of Rab5 GDP/GTP exchange factorOS=Homo sapiens OX=9606 GN=RABGEF1MSLKSERRGIHVDQSDLLCKKGCGYYGNPAWQGFCSKCWREEYHKARQKQIQEDWELAERALLCYPGWSAMVQFQLTATSASWAQVILLLQPPKWLGLQKLQREEEEAFASSQSSQGAQSLTFSKFEEKKTNEKTRKVTTVKKFFSASSRVGSKKEIQEAKAPSPSINRQTSIETDRVSKEFIEFLKTFHKTGQEIYKQTKLFLEGMHYKRDLSIEEQSECAQDFYHNVAERMQTRGKVPPERVEKIMDQIEKYIMTRLYKYVFCPETTDDEKKDLAIQKRIRALRWVTPQMLCVPVNEDIPEVSDMVVKAITDIIEMDSKRVPRDKLACITKCSKHIFNAIKITKNEPASADDFLPTLIYIVLKGNPPRLQSNIQYITRFCNPSRLMTGEDGYYFTNLCCAVAFIEKLDAQSLNLSQEDFDRYMSGQTSPRKQEAESWSPDACLGVKQMYKNLDLLSQLNERQERIMNEAKKLEKDLIDWTDGIAREVQDIVEKYPLEIKPPNQPLAAIDSENVENDKLPPPLQPQVYAG>sp|Q9UJ41-4|RABX5_HUMAN Isoform 3 of Rab5 GDP/GTP exchange factorOS=Homo sapiens OX=9606 GN=RABGEF1MMASSYHEVVSRKKMSLKSERRGIHVDQSDLLCKKGCGYYGNPAWQGFCSKCWREEYHKARQKQIQEDWELAERLQREEEEAFASSQSSQGAQSLTFSKFEEKKTNEKTRKVTTVKKFFSASSRVGSKKEIQEAKAPSPSINRQTSIETDRVSKEFIEFLKTFHKTGQEIYKQTKLFLEGMHYKRDLSIEEQSECAQDFYHNVAERMQTRGKVPPERVEKIMDQIEKYIMTRLYKYVFCPETTDDEKKDLAIQKRIRALRWVTPQMLCVPVNEDIPEVSDMVVKAITDIIEMDSKRVPRDKLACITKCSKHIFNAIKITKNEPASADDFLPTLIYIVLKGNPPRLQSNIQYITRFCNPSRLMTGEDGYYFTNLCCAVAFIEKLDAQSLNLSQEDFDRYMSGQTSPRKQEAESWSPDACLGVKQMYKNLDLLSQLNERQERIMNEAKKLEKDLIDWTDGIAREVQDIVEKYPLEIKPPNQPLAAIDSENVENDKLPPPLQPQVYAG>sp|Q7Z6M1|RABEK_HUMAN Rab9 effector protein with kelch motifs OS=Homosapiens OX=9606 GN=RABEPK PE=1 SV=1MKQLPVLEPGDKPRKATWYTLTVPGDSPCARVGHSCSYLPPVGNAKRGKVFIVGGANPNRSFSDVHTMDLGKHQWDLDTCKGLLPRYEHASFIPSCTPDRIWVFGGANQSGNRNCLQVLNPETRTWTTPEVTSPPPSPRTFHTSSAAIGNQLYVFGGGERGAQPVQDTKLHVFDANTLTWSQPETLGNPPSPRHGHVMVAAGTKLFIHGGLAGDRFYDDLHCIDISDMKWQKLNPTGAAPAGCAAHSAVAMGKHVYIFGGMTPAGALDTMYQYHTEEQHWTLLKFDTLLPPGRLDHSMCIIPWPVTCASEKEDSNSLTLNHEAEKEDSADKVMSHSGDSHEESQTATLLCLVFGGMNTEGEIYDDCIVTVVD>sp|Q7Z6M1-2|RABEK_HUMAN Isoform 2 of Rab9 effector protein with kelchmotifs OS=Homo sapiens OX=9606 GN=RABEPKMKQLPVLEPGDKPRKATWYTLTVPGDSPCARVGHSCSYLPPVGNAKRGKVFIVGGANPNRSFSDVHTMDLETRTWTTPEVTSPPPSPRTFHTSSAAIGNQLYVFGGGERGAQPVQDTKLHVFDANTLTWSQPETLGNPPSPRHGHVMVAAGTKLFIHGGLAGDRFYDDLHCIDISDMKWQKLNPTGAAPAGCAAHSAVAMGKHVYIFGGMTPAGALDTMYQYHTEEQHWTLLKFDTLLPPGRLDHSMCIIPWPVTCASEKEDSNSLTLNHEAEKEDSADKVMSHSGDSHEESQTATLLCLVFGGMNTEGEIYDDCIVTVVD>sp|P57729|RAB38_HUMAN Ras-related protein Rab-38 OS=Homo sapiens OX=9606GN=RAB38 PE=1 SV=1MQAPHKEHLYKLLVIGDLGVGKTSIIKRYVHQNFSSHYRATIGVDFALKVLHWDPETVVRLQLWDIAGQERFGNMTRVYYREAMGAFIVFDVTRPATFEAVAKWKNDLDSKLSLPNGKPVSVVLLANKCDQGKDVLMNNGLKMDQFCKEHGFVGWFETSAKENINIDEASRCLVKHILANECDLMESIEPDVVKPHLTSTKVASCSGCAKS>sp|P61026|RAB10_HUMAN Ras-related protein Rab-10 OS=Homo sapiens OX=9606GN=RAB10 PE=1 SV=1MAKKTYDLLFKLLLIGDSGVGKTCVLFRFSDDAFNTTFISTIGIDFKIKTVELQGKKIKLQIWDTAGQERFHTITTSYYRGAMGIMLVYDITNGKSFENISKWLRNIDEHANEDVERMLLGNKCDMDDKRVVPKGKGEQIAREHGIRFFETSAKANINIEKAFLTLAEDILRKTPVKEPNSENVDISSGGGVTGWKSKCC>sp|Q0D2K3|RIPP1_HUMAN Protein ripply1 OS=Homo sapiens OX=9606 GN=RIPPLY1PE=1 SV=1MDSAACAAAATPVPALALALAPDLAQAPLALPGLLSPSCLLSSGQEVNGSERGTCLWRPWLSSTNDSPRQMRKLVDLAAGGATAAEVTKAESKFHHPVRLFWPKSRSFDYLYSAGEILLQNFPVQATINLYEDSDSEEEEEDEEQEDEEEK>sp|Q0D2K3-2|RIPP1_HUMAN Isoform 2 of Protein ripply1 OS=Homo sapiensOX=9606 GN=RIPPLY1MDSAACAAAATPVPALALALAPDLAQAPLALPGLLSPSCLLSSGQEVNGSERLFWPKSRSFDYLYSAGEILLQNFPVQATINLYEDSDSEEEEEDEEQEDEEEK>sp|Q96L21|RL10L_HUMAN 60S ribosomal protein L10-like OS=Homo sapiensOX=9606 GN=RPL10L PE=1 SV=3MGRRPARCYRYCKNKPYPKSRFCRGVPDAKIRIFDLGRKKAKVDEFPLGGHMVSDEYEQLSSEALEAARICANKYMVKSCGRDGFHMRVRLHPFHVIRINKMLSCAGADRLQTGMRGAFGKPQGTVARVHIGQVIMSIRTKLQNEEHVIEALRRAKFKFPGRQKIHISKKWGFTKFNADEFEDMVAKKCLIPDGCGVKYVPSHGPLDKWRVLHS>sp|O76021|RL1D1_HUMAN Ribosomal L1 domain-containing protein 1 OS=Homosapiens OX=9606 GN=RSL1D1 PE=1 SV=3MEDSASASLSSAAATGTSTSTPAAPTARKQLDKEQVRKAVDALLTHCKSRKNNYGLLLNENESLFLMVVLWKIPSKELRVRLTLPHSIRSDSEDICLFTKDEPNSTPEKTEQFYRKLLNKHGIKTVSQIISLQTLKKEYKSYEAKLRLLSSFDFFLTDARIRRLLPSLIGRHFYQRKKVPVSVNLLSKNLSREINDCIGGTVLNISKSGSCSAIRIGHVGMQIEHIIENIVAVTKGLSEKLPEKWESVKLLFVKTEKSAALPIFSSFVSNWDEATKRSLLNKKKKEARRKRRERNFEKQKERKKKRQQARKTASVLSKDDVAPESGDTTVKKPESKKEQTPEHGKKKRGRGKAQVKATNESEDEIPQLVPIGKKTPANEKVEIQKHATGKKSPAKSPNPSTPRGKKRKALPASETPKAAESETPGKSPEKKPKIKEEAVKEKSPSLGKKDARQTPKKPEAKFFTTPSKSVRKASHTPKKWPKKPKVPQST>sp|O76021-2|RL1D1_HUMAN Isoform 2 of Ribosomal L1 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=RSL1D1MQIEHIIENIVAVTKGLSEKLPEKWESVKLLFVKTEKSAALPIFSSFVSNWDEATKRSLLNKKKKEARRKRRERNFEKQKERKKKRQQARKTASVLSKDDVAPESGDTTVKKPESKKEQTPEHGKKKRGRGKAQVKATNESEDEIPQLVPIGKKTPANEKVEIQKHATGKKSPAKSPNPSTPRGKKRKALPASETPKAAESETPGKSPEKKPKIKEEAVKEKSPSLGKKDARQTPKKPEAKFFTTPSKSVRKASHTPKKWPKKPKVPQST>sp|P49207|RL34_HUMAN 60S ribosomal protein L34 OS=Homo sapiens OX=9606GN=RPL34 PE=1 SV=3MVQRLTYRRRLSYNTASNKTRLSRTPGNRIVYLYTKKVGKAPKSACGVCPGRLRGVRAVRPKVLMRLSKTKKHVSRAYGGSMCAKCVRDRIKRAFLIEEQKIVVKVLKAQAQSQKAK>sp|Q96EX2|RNFT2_HUMAN RING finger and transmembrane domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RNFT2 PE=2 SV=2MWLFTVNQVLRKMQRRHSSNTDNIPPERNRSQALSSEASVDEGGVFESLKAEAASPPALFSGLSGSLPTSSFPSSLVLGSSAGGGDVFIQMPASREEGGGRGEGGAYHHRQPHHHFHHGGHRGGSLLQHVGGDHRGHSEEGGDEQPGTPAPALSELKAVICWLQKGLPFILILLAKLCFQHKLGIAVCIGMASTFAYANSTLREQVSLKEKRSVLVILWILAFLAGNTLYVLYTFSSQQLYNSLIFLKPNLEMLDFFDLLWIVGIADFVLKYITIALKCLIVALPKIILAVKSKGKFYLVIEELSQLFRSLVPIQLWYKYIMGDDSSNSYFLGGVLIVLYSLCKSFDICGRVGGVRKALKLLCTSQNYGVRATGQQCTEAGDICAICQAEFREPLILLCQHVFCEECLCLWLDRERTCPLCRSVAVDTLRCWKDGATSAHFQVY>sp|Q96EX2-2|RNFT2_HUMAN Isoform 2 of RING finger and transmembranedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RNFT2MWLFTVNQVLRKMQRRHSSNTDNIPPERNRSQALSSEASVDEGGVFESLKAEAASPPALFSGLSGSLPTSSFPSSLVLGSSAGGGDVFIQMPASREEGGGRGEGGAYHHRQPHHHFHHGGHRGGSLLQHVGGDHRGHSEEGGDEQPGTPAPALSELKAVICWLQKGLPFILILLAKLCFQHKLGIAVCIGMASTFAYANSTLREQVSLKEKRSVLVILWILAFLAGNTLYVLYTFSSEIAPQHSNLGDRVSETLSKKKKKERREGGRKEGRKERKKAQLWPRCGYPLVSCLYVFLLFLFCHLPHLSLRPVSSSCGHCHPLW>sp|Q96EX2-3|RNFT2_HUMAN Isoform 3 of RING finger and transmembranedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RNFT2MPASREEGGGRGEGGAYHHRQPHHHFHHGGHRGGSLLQHVGGDHRGHSEEGGDEQPGTPAPALSELKAVICWLQKGLPFILILLAKLCFQHKLGIAVCIGMASTFAYANSTLREQVSLKEKRSVLVILWILAFLAGNTLYVLYTFSSQQLYNSLIFLKPNLEMLDFFDLLWIVGIADFVLKYITIALKCLIVALPKIILAVKSKGKFYLVIEELSQLFRSLVPIQLWYKYIMGDDSSNSYFLGGVLIVLYSLCKSFDICGRVGGVRKALKLLCTSQNYGVRATGQQCTEAGDICAICQAEFREPLILLCQMLLKGHKKLELEKIDESAGV>sp|Q96EX2-4|RNFT2_HUMAN Isoform 4 of RING finger and transmembranedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RNFT2MLDFFDLLWIVGIADFVLKYITIALKCLIVALPKIILAVKSKGKFYLVIEELSQLFRSLVPIQLWYKYIMGDDSSNSYFLGGVLIVLYSLCKSFDICGRVGGVRKALKLLCTSQNYGVRATGQQCTEAGDICAICQAEFREPLILLCQHVFCEECLCLWLDRERTCPLCRSVAVDTLRCWKDGATSAHFQVY>sp|Q96EX2-5|RNFT2_HUMAN Isoform 5 of RING finger and transmembranedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RNFT2MWLFTVNQVLRKMQRRHSSNTDNIPPERNRSQALSSEASVDEGGVFESLKAEAASPPALFSGLSGSLPTSSFPSSLVLGSSAGGGDVFIQMPASREEGGGRGEGGAYHHRQPHHHFHHGGHRGGSLLQHVGGDHRGHSEEGGDEQPGTPAPALSELKAVICWLQKGLPFILILLAKLCFQHKLGIAVCIGMASTFAYANSTLREQVSLKEKRSVLVILWILAFLAGNTLYVLYTFSSQQLYNSLIFLKPNLEMLDFFDLLWIVGIADFVLKYITIALKCLIVALPKIILAVKSKGKFYLVIEELSQLFRSLVPIQLWYKYIMGDDSSNSYFLGGVLIVLYSLCKSFDICGRVGGVRKALKLLCTSQNYGVRATGQQCTEAGDICAICQAEFREPLILLCQMLLKGHKKLELEKIDESAGV>sp|Q96MT1|RN145_HUMAN RING finger protein 145 OS=Homo sapiens OX=9606GN=RNF145 PE=2 SV=2MAAKEKLEAVLNVALRVPSIMLLDVLYRWDVSSFFQQIQRSSLSNNPLFQYKYLALNMHYVGYILSVVLLTLPRQHLVQLYLYFLTALLLYAGHQISRDYVRSELEFAYEGPMYLEPLSMNRFTTALIGQLVVCTLCSCVMKTKQIWLFSAHMLPLLARLCLVPLETIVIINKFAMIFTGLEVLYFLGSNLLVPYNLAKSAYRELVQVVEVYGLLALGMSLWNQLVVPVLFMVFWLVLFALQIYSYFSTRDQPASRERLLFLFLTSIAECCSTPYSLLGLVFTVSFVALGVLTLCKFYLQGYRAFMNDPAMNRGMTEGVTLLILAVQTGLIELQVVHRAFLLSIILFIVVASILQSMLEIADPIVLALGASRDKSLWKHFRAVSLCLFLLVFPAYMAYMICQFFHMDFWLLIIISSSILTSLQVLGTLFIYVLFMVEEFRKEPVENMDDVIYYVNGTYRLLEFLVALCVVAYGVSETIFGEWTVMGSMIIFIHSYYNVWLRAQLGWKSFLLRRDAVNKIKSLPIATKEQLEKHNDICAICYQDMKSAVITPCSHFFHAGCLKKWLYVQETCPLCHCHLKNSSQLPGLGTEPVLQPHAGAEQNVMFQEGTEPPGQEHTPGTRIQEGSRDNNEYIARRPDNQEGAFDPKEYPHSAKDEAHPVESA>sp|Q96MT1-2|RN145_HUMAN Isoform 2 of RING finger protein 145 OS=Homosapiens OX=9606 GN=RNF145MMRNHRIASSLCGDQVFSKKKKKKKKNNMAAKEKLEAVLNVALRVPSIMLLDVLYRWDVSSFFQQIQRSSLSNNPLFQYKYLALNMHYVGYILSVVLLTLPRQHLVQLYLYFLTALLLYAGHQISRDYVRSELEFAYEGPMYLEPLSMNRFTTALIGQLVVCTLCSCVMKTKQIWLFSAHMLPLLARLCLVPLETIVIINKFAMIFTGLEVLYFLGSNLLVPYNLAKSAYRELVQVVEVYGLLALGMSLWNQLVVPVLFMVFWLVLFALQIYSYFSTRDQPASRERLLFLFLTSIAECCSTPYSLLGLVFTVSFVALGVLTLCKFYLQGYRAFMNDPAMNRGMTEGVTLLILAVQTGLIELQVVHRAFLLSIILFIVVASILQSMLEIADPIVLALGASRDKSLWKHFRAVSLCLFLLVFPAYMAYMICQFFHMDFWLLIIISSSILTSLQVLGTLFIYVLFMVEEFRKEPVENMDDVIYYVNGTYRLLEFLVALCVVAYGVSETIFGEWTVMGSMIIFIHSYYNVWLRAQLGWKSFLLRRDAVNKIKSLPIATKEQLEKHNDICAICYQDMKSAVITPCSHFFHAGCLKKWLYVQETCPLCHCHLKNSSQLPGLGTEPVLQPHAGAEQNVMFQEGTEPPGQEHTPGTRIQEGSRDNNEYIARRPDNQEGAFDPKEYPHSAKDEAHPVESA>sp|Q96MT1-3|RN145_HUMAN Isoform 3 of RING finger protein 145 OS=Homosapiens OX=9606 GN=RNF145MAEVVFSKKKKKKKKNNMAAKEKLEAVLNVALRVPSIMLLDVLYRWDVSSFFQQIQRSSLSNNPLFQYKYLALNMHYVGYILSVVLLTLPRQHLVQLYLYFLTALLLYAGHQISRDYVRSELEFAYEGPMYLEPLSMNRFTTALIGQLVVCTLCSCVMKTKQIWLFSAHMLPLLARLCLVPLETIVIINKFAMIFTGLEVLYFLGSNLLVPYNLAKSAYRELVQVVEVYGLLALGMSLWNQLVVPVLFMVFWLVLFALQIYSYFSTRDQPASRERLLFLFLTSIAECCSTPYSLLGLVFTVSFVALGVLTLCKFYLQGYRAFMNDPAMNRGMTEGVTLLILAVQTGLIELQVVHRAFLLSIILFIVVASILQSMLEIADPIVLALGASRDKSLWKHFRAVSLCLFLLVFPAYMAYMICQFFHMDFWLLIIISSSILTSLQVLGTLFIYVLFMVEEFRKEPVENMDDVIYYVNGTYRLLEFLVALCVVAYGVSETIFGEWTVMGSMIIFIHSYYNVWLRAQLGWKSFLLRRDAVNKIKSLPIATKEQLEKHNDICAICYQDMKSAVITPCSHFFHAGCLKKWLYVQETCPLCHCHLKNSSQLPGLGTEPVLQPHAGAEQNVMFQEGTEPPGQEHTPGTRIQEGSRDNNEYIARRPDNQEGAFDPKEYPHSAKDEAHPVESA>sp|Q96MT1-4|RN145_HUMAN Isoform 4 of RING finger protein 145 OS=Homosapiens OX=9606 GN=RNF145MVFSKKKKKKKKNNMAAKEKLEAVLNVALRVPSIMLLDVLYRWDVSSFFQQIQRSSLSNNPLFQYKYLALNMHYVGYILSVVLLTLPRQHLVQLYLYFLTALLLYAGHQISRDYVRSELEFAYEGPMYLEPLSMNRFTTALIGQLVVCTLCSCVMKTKQIWLFSAHMLPLLARLCLVPLETIVIINKFAMIFTGLEVLYFLGSNLLVPYNLAKSAYRELVQVVEVYGLLALGMSLWNQLVVPVLFMVFWLVLFALQIYSYFSTRDQPASRERLLFLFLTSIAECCSTPYSLLGLVFTVSFVALGVLTLCKFYLQGYRAFMNDPAMNRGMTEGVTLLILAVQTGLIELQVVHRAFLLSIILFIVVASILQSMLEIADPIVLALGASRDKSLWKHFRAVSLCLFLLVFPAYMAYMICQFFHMDFWLLIIISSSILTSLQVLGTLFIYVLFMVEEFRKEPVENMDDVIYYVNGTYRLLEFLVALCVVAYGVSETIFGEWTVMGSMIIFIHSYYNVWLRAQLGWKSFLLRRDAVNKIKSLPIATKEQLEKHNDICAICYQDMKSAVITPCSHFFHAGCLKKWLYVQETCPLCHCHLKNSSQLPGLGTEPVLQPHAGAEQNVMFQEGTEPPGQEHTPGTRIQEGSRDNNEYIARRPDNQEGAFDPKEYPHSAKDEAHPVESA>sp|Q96MT1-5|RN145_HUMAN Isoform 5 of RING finger protein 145 OS=Homosapiens OX=9606 GN=RNF145MHRDRISPSNSPTWSLQVFSKKKKKKKKNNMAAKEKLEAVLNVALRVPSIMLLDVLYRWDVSSFFQQIQRSSLSNNPLFQYKYLALNMHYVGYILSVVLLTLPRQHLVQLYLYFLTALLLYAGHQISRDYVRSELEFAYEGPMYLEPLSMNRFTTALIGQLVVCTLCSCVMKTKQIWLFSAHMLPLLARLCLVPLETIVIINKFAMIFTGLEVLYFLGSNLLVPYNLAKSAYRELVQVVEVYGLLALGMSLWNQLVVPVLFMVFWLVLFALQIYSYFSTRDQPASRERLLFLFLTSIAECCSTPYSLLGLVFTVSFVALGVLTLCKFYLQGYRAFMNDPAMNRGMTEGVTLLILAVQTGLIELQVVHRAFLLSIILFIVVASILQSMLEIADPIVLALGASRDKSLWKHFRAVSLCLFLLVFPAYMAYMICQFFHMDFWLLIIISSSILTSLQVLGTLFIYVLFMVEEFRKEPVENMDDVIYYVNGTYRLLEFLVALCVVAYGVSETIFGEWTVMGSMIIFIHSYYNVWLRAQLGWKSFLLRRDAVNKIKSLPIATKEQLEKHNDICAICYQDMKSAVITPCSHFFHAGCLKKWLYVQETCPLCHCHLKNSSQLPGLGTEPVLQPHAGAEQNVMFQEGTEPPGQEHTPGTRIQEGSRDNNEYIARRPDNQEGAFDPKEYPHSAKDEAHPVESA>sp|Q8NC42|RN149_HUMAN E3 ubiquitin-protein ligase RNF149 OS=Homo sapiensOX=9606 GN=RNF149 PE=2 SV=2MAWRRREASVGARGVLALALLALALCVPGARGRALEWFSAVVNIEYVDPQTNLTVWSVSESGRFGDSSPKEGAHGLVGVPWAPGGDLEGCAPDTRFFVPEPGGRGAAPWVALVARGGCTFKDKVLVAARRNASAVVLYNEERYGNITLPMSHAGTGNIVVIMISYPKGREILELVQKGIPVTMTIGVGTRHVQEFISGQSVVFVAIAFITMMIISLAWLIFYYIQRFLYTGSQIGSQSHRKETKKVIGQLLLHTVKHGEKGIDVDAENCAVCIENFKVKDIIRILPCKHIFHRICIDPWLLDHRTCPMCKLDVIKALGYWGEPGDVQEMPAPESPPGRDPAANLSLALPDDDGSDDSSPPSASPAESEPQCDPSFKGDAGENTALLEAGRSDSRHGGPIS>sp|Q9NWF9|RN216_HUMAN E3 ubiquitin-protein ligase RNF216 OS=Homo sapiensOX=9606 GN=RNF216 PE=1 SV=3MEEGNNNEEVIHLNNFHCHRGQEWINLRDGPITISDSSDEERIPMLVTPAPQQHEEEDLDDDVILTEDDSEDDYGEFLDLGPPGISEFTKPSGQTEREPKPGPSHNQAANDIVNPRSEQKVIILEEGSLLYTESDPLETQNQSSEDSETELLSNLGESAALADDQAIEEDCWLDHPYFQSLNQQPREITNQVVPQERQPEAELGRLLFQHEFPGPAFPRPEPQQGGISGPSSPQPAHPLGEFEDQQLASDDEEPGPAFPMQESQEPNLENIWGQEAAEVDQELVELLVKETEARFPDVANGFIEEIIHFKNYYDLNVLCNFLLENPDYPKREDRIIINPSSSLLASQDETKLPKIDFFDYSKLTPLDQRCFIQAADLLMADFKVLSSQDIKWALHELKGHYAITRKALSDAIKKWQELSPETSGKRKKRKQMNQYSYIDFKFEQGDIKIEKRMFFLENKRRHCRSYDRRALLPAVQQEQEFYEQKIKEMAEHEDFLLALQMNEEQYQKDGQLIECRCCYGEFPFEELTQCADAHLFCKECLIRYAQEAVFGSGKLELSCMEGSCTCSFPTSELEKVLPQTILYKYYERKAEEEVAAAYADELVRCPSCSFPALLDSDVKRFSCPNPHCRKETCRKCQGLWKEHNGLTCEELAEKDDIKYRTSIEEKMTAARIRKCHKCGTGLIKSEGCNRMSCRCGAQMCYLCRVSINGYDHFCQHPRSPGAPCQECSRCSLWTDPTEDDEKLIEEIQKEAEEEQKRKNGENTFKRIGPPLEKPVEKVQRVEALPRPVPQNLPQPQMPPYAFAHPPFPLPPVRPVFNNFPLNMGPIPAPYVPPLPNVRVNYDFGPIHMPLEHNLPMHFGPQPRHRF>sp|Q9NWF9-1|RN216_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF216OS=Homo sapiens OX=9606 GN=RNF216MEEGNNNEEVIHLNNFHCHRGQEWINLRDGPITISDSSDEERIPMLVTPAPQQHEEEDLDDDVILTETNKPQRSRPNLIKPAAQWQDLKRLGEERPKKSRAAFESDKSSYFSVCNNPLFDSGAQDDSEDDYGEFLDLGPPGISEFTKPSGQTEREPKPGPSHNQAANDIVNPRSEQKVIILEEGSLLYTESDPLETQNQSSEDSETELLSNLGESAALADDQAIEEDCWLDHPYFQSLNQQPREITNQVVPQERQPEAELGRLLFQHEFPGPAFPRPEPQQGGISGPSSPQPAHPLGEFEDQQLASDDEEPGPAFPMQESQEPNLENIWGQEAAEVDQELVELLVKETEARFPDVANGFIEEIIHFKNYYDLNVLCNFLLENPDYPKREDRIIINPSSSLLASQDETKLPKIDFFDYSKLTPLDQRCFIQAADLLMADFKVLSSQDIKWALHELKGHYAITRKALSDAIKKWQELSPETSGKRKKRKQMNQYSYIDFKFEQGDIKIEKRMFFLENKRRHCRSYDRRALLPAVQQEQEFYEQKIKEMAEHEDFLLALQMNEEQYQKDGQLIECRCCYGEFPFEELTQCADAHLFCKECLIRYAQEAVFGSGKLELSCMEGSCTCSFPTSELEKVLPQTILYKYYERKAEEEVAAAYADELVRCPSCSFPALLDSDVKRFSCPNPHCRKETCRKCQGLWKEHNGLTCEELAEKDDIKYRTSIEEKMTAARIRKCHKCGTGLIKSEGCNRMSCRCGAQMCYLCRVSINGYDHFCQHPRSPGAPCQECSRCSLWTDPTEDDEKLIEEIQKEAEEEQKRKNGENTFKRIGPPLEKPVEKVQRVEALPRPVPQNLPQPQMPPYAFAHPPFPLPPVRPVFNNFPLNMGPIPAPYVPPLPNVRVNYDFGPIHMPLEHNLPMHFGPQPRHRF>sp|Q9NWF9-3|RN216_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNF216OS=Homo sapiens OX=9606 GN=RNF216MADFKVLSSQDIKWALHELKGHYAITRKALSDAIKKWQELSPETSGKRKKRKQMNQYSYIDFKFEQGDIKIEKRMFFLENKRRHCRSYDRRALLPAVQQEQEFYEQKIKEMAEHEDFLLALQMNEEQYQKDGQLIECRCCYGEFPFEELTQCADAHLFCKECLIRYAQEAVFGSGKLELSCMEGSCTCSFPTSELEKVLPQTILYKYYERKAEEEVAAAYADELVRCPSCSFPALLDSDVKRFSCPNPHCRKETCRKCQGLWKEHNGLTCEELAEKDDIKYRTSIEEKMTAARIRKCHKCGTGLIKSEGCNRMSCRCGAQMCYLCRVSINGYDHFCQHPRSPGAPCQECSRCSLWTDPTEDDEKLIEEIQKEAEEEQKRKNGENTFKRIGPPLEKPVEKVQRVEALPRPVPQNLPQPQMPPYAFAHPPFPLPPVRPVFNNFPLNMGPIPAPYVPPLPNVRVNYDFGPIHMPLEHNLPMHFGPQPRHRF>sp|Q99442|SEC62_HUMAN Translocation protein SEC62 OS=Homo sapiensOX=9606 GN=SEC62 PE=1 SV=1MAERRRHKKRIQEVGEPSKEEKAVAKYLRFNCPTKSTNMMGHRVDYFIASKAVDCLLDSKWAKAKKGEEALFTTRESVVDYCNRLLKKQFFHRALKVMKMKYDKDIKKEKDKGKAESGKEEDKKSKKENIKDEKTKKEKEKKKDGEKEESKKEETPGTPKKKETKKKFKLEPHDDQVFLDGNEVYVWIYDPVHFKTFVMGLILVIAVIAATLFPLWPAEMRVGVYYLSVGAGCFVASILLLAVARCILFLIIWLITGGRHHFWFLPNLTADVGFIDSFRPLYTHEYKGPKADLKKDEKSETKKQQKSDSEEKSDSEKKEDEEGKVGPGNHGTEGSGGERHSDTDSDRREDDRSQHSSGNGNDFEMITKEELEQQTDGDCEEDEEEENDGETPKSSHEKS>sp|P10301|RRAS_HUMAN Ras-related protein R-Ras OS=Homo sapiens OX=9606GN=RRAS PE=1 SV=1MSSGAASGTGRGRPRGGGPGPGDPPPSETHKLVVVGGGGVGKSALTIQFIQSYFVSDYDPTIEDSYTKICSVDGIPARLDILDTAGQEEFGAMREQYMRAGHGFLLVFAINDRQSFNEVGKLFTQILRVKDRDDFPVVLVGNKADLESQRQVPRSEASAFGASHHVAYFEASAKLRLNVDEAFEQLVRAVRKYQEQELPPSPPSAPRKKGGGCPCVLL>sp|Q14690|RRP5_HUMAN Protein RRP5 homolog OS=Homo sapiens OX=9606GN=PDCD11 PE=1 SV=3MANLEESFPRGGTRKIHKPEKAFQQSVEQDNLFDISTEEGSTKRKKSQKGPAKTKKLKIEKRESSKSAREKFEILSVESLCEGMRILGCVKEVNELELVISLPNGLQGFVQVTEICDAYTKKLNEQVTQEQPLKDLLHLPELFSPGMLVRCVVSSLGITDRGKKSVKLSLNPKNVNRVLSAEALKPGMLLTGTVSSLEDHGYLVDIGVDGTRAFLPLLKAQEYIRQKNKGAKLKVGQYLNCIVEKVKGNGGVVSLSVGHSEVSTAIATEQQSWNLNNLLPGLVVKAQVQKVTPFGLTLNFLTFFTGVVDFMHLDPKKAGTYFSNQAVRACILCVHPRTRVVHLSLRPIFLQPGRPLTRLSCQNLGAVLDDVPVQGFFKKAGATFRLKDGVLAYARLSHLSDSKNVFNPEAFKPGNTHKCRIIDYSQMDELALLSLRTSIIEAQYLRYHDIEPGAVVKGTVLTIKSYGMLVKVGEQMRGLVPPMHLADILMKNPEKKYHIGDEVKCRVLLCDPEAKKLMMTLKKTLIESKLPVITCYADAKPGLQTHGFIIRVKDYGCIVKFYNNVQGLVPKHELSTEYIPDPERVFYTGQVVKVVVLNCEPSKERMLLSFKLSSDPEPKKEPAGHSQKKGKAINIGQLVDVKVLEKTKDGLEVAVLPHNIRAFLPTSHLSDHVANGPLLHHWLQAGDILHRVLCLSQSEGRVLLCRKPALVSTVEGGQDPKNFSEIHPGMLLIGFVKSIKDYGVFIQFPSGLSGLAPKAIMSDKFVTSTSDHFVEGQTVAAKVTNVDEEKQRMLLSLRLSDCGLGDLAITSLLLLNQCLEELQGVRSLMSNRDSVLIQTLAEMTPGMFLDLVVQEVLEDGSVVFSGGPVPDLVLKASRYHRAGQEVESGQKKKVVILNVDLLKLEVHVSLHQDLVNRKARKLRKGSEHQAIVQHLEKSFAIASLVETGHLAAFSLTSHLNDTFRFDSEKLQVGQGVSLTLKTTEPGVTGLLLAVEGPAAKRTMRPTQKDSETVDEDEEVDPALTVGTIKKHTLSIGDMVTGTVKSIKPTHVVVTLEDGIIGCIHASHILDDVPEGTSPTTKLKVGKTVTARVIGGRDMKTFKYLPISHPRFVRTIPELSVRPSELEDGHTALNTHSVSPMEKIKQYQAGQTVTCFLKKYNVVKKWLEVEIAPDIRGRIPLLLTSLSFKVLKHPDKKFRVGQALRATVVGPDSSKTLLCLSLTGPHKLEEGEVAMGRVVKVTPNEGLTVSFPFGKIGTVSIFHMSDSYSETPLEDFVPQKVVRCYILSTADNVLTLSLRSSRTNPETKSKVEDPEINSIQDIKEGQLLRGYVGSIQPHGVFFRLGPSVVGLARYSHVSQHSPSKKALYNKHLPEGKLLTARVLRLNHQKNLVELSFLPGDTGKPDVLSASLEGQLTKQEERKTEAEERDQKGEKKNQKRNEKKNQKGQEEVEMPSKEKQQPQKPQAQKRGGRECRESGSEQERVSKKPKKAGLSEEDDSLVDVYYREGKEEAEETNVLPKEKQTKPAEAPRLQLSSGFAWNVGLDSLTPALPPLAESSDSEEDEKPHQATIKKSKKERELEKQKAEKELSRIEEALMDPGRQPESADDFDRLVLSSPNSSILWLQYMAFHLQATEIEKARAVAERALKTISFREEQEKLNVWVALLNLENMYGSQESLTKVFERAVQYNEPLKVFLHLADIYAKSEKFQEAGELYNRMLKRFRQEKAVWIKYGAFLLRRSQAAASHRVLQRALECLPSKEHVDVIAKFAQLEFQLGDAERAKAIFENTLSTYPKRTDVWSVYIDMTIKHGSQKDVRDIFERVIHLSLAPKRMKFFFKRYLDYEKQHGTEKDVQAVKAKALEYVEAKSSVLED>sp|Q15050|RRS1_HUMAN Ribosome biogenesis regulatory protein homologOS=Homo sapiens OX=9606 GN=RRS1 PE=1 SV=2MEGQSVEELLAKAEQDEAEKLQRITVHKELELQFDLGNLLASDRNPPTGLRCAGPTPEAELQALARDNTQLLINQLWQLPTERVEEAIVARLPEPTTRLPREKPLPRPRPLTRWQQFARLKGIRPKKKTNLVWDEVSGQWRRRWGYQRARDDTKEWLIEVPGNADPLEDQFAKRIQAKKERVAKNELNRLRNLARAHKMQLPSAAGLHPTGHQSKEELGRAMQVAKVSTASVGRFQERLPKEKVPRGSGKKRKFQPLFGDFAAEKKNQLELLRVMNSKKPQLDVTRATNKQMREEDQEEAAKRRKMSQKGKRKGGRQGPGGKRKGGPPSQGGKRKGGLGGKMNSGPPGLGGKRKGGQRPGGKRRK>sp|Q99720|SGMR1_HUMAN Sigma non-opioid intracellular receptor 1 OS=Homosapiens OX=9606 GN=SIGMAR1 PE=1 SV=1MQWAVGRRWAWAALLLAVAAVLTQVVWLWLGTQSFVFQREEIAQLARQYAGLDHELAFSRLIVELRRLHPGHVLPDEELQWVFVNAGGWMGAMCLLHASLSEYVLLFGTALGSRGHSGRYWAEISDTIISGTFHQWREGTTKSEVFYPGETVVHGPGEATAVEWGPNTWMVEYGRGVIPSTLAFALADTVFSTQDFLTLFYTLRSYARGLRLELTTYLFGQDP>sp|Q99720-2|SGMR1_HUMAN Isoform 2 of Sigma non-opioid intracellularreceptor 1 OS=Homo sapiens OX=9606 GN=SIGMAR1MQWAVGRRWAWAALLLAVAAVLTQVVWLWLGLDHELAFSRLIVELRRLHPGHVLPDEELQWVFVNAGGWMGAMCLLHASLSEYVLLFGTALGSRGHSGRYWAEISDTIISGTFHQWREGTTKSEVFYPGETVVHGPGEATAVEWGPNTWMVEYGRGVIPSTLAFALADTVFSTQDFLTLFYTLRSYARGLRLELTTYLFGQDP>sp|Q99720-3|SGMR1_HUMAN Isoform 3 of Sigma non-opioid intracellularreceptor 1 OS=Homo sapiens OX=9606 GN=SIGMAR1MQWAVGRRWAWAALLLAVAAVLTQVVWLWLGTQSFVFQREEIAQLARQYAGLDHELAFSRLIVELRRLHPGHVLPDEELQWVFVNAGGWMGAMCLLHASLSEYVLLFGTALGSRGHSGETVVHGPGEATAVEWGPNTWMVEYGRGVIPSTLAFALADTVFSTQDFLTLFYTLRSYARGLRLELTTYLFGQDP>sp|Q99720-4|SGMR1_HUMAN Isoform 4 of Sigma non-opioid intracellularreceptor 1 OS=Homo sapiens OX=9606 GN=SIGMAR1MQWAVGRRWAWAALLLAVAAVLTQVVWLWLGTQSFVFQREEIAQLARQYAGLDHELAFSRLIVELRRLHPGHVLPDEELQWVFVNAGGWMGAMCLLHASLSEALLG>sp|Q99720-5|SGMR1_HUMAN Isoform 5 of Sigma non-opioid intracellularreceptor 1 OS=Homo sapiens OX=9606 GN=SIGMAR1MQWAVGRRWAWAALLLAVAAVLTQVVWLWLDHELAFSRLIEELQWVFVNAGGWMGAMCLLHASLSEYVLLFGTALGSRGHSGRYWAEISDTIISGTFHQWREGTTKSEVFYPGETVVHGPGEATAVEWGPNTWMVEYGRGVIPSTLAFALADTVFSTQDFLTLFYTLRSYARGLRLELTTYLFGQDP>sp|O95707|RPP29_HUMAN Ribonuclease P protein subunit p29 OS=Homo sapiensOX=9606 GN=POP4 PE=1 SV=2MKSVIYHALSQKEANDSDVQPSGAQRAEAFVRAFLKRSTPRMSPQAREDQLQRKAVVLEYFTRHKRKEKKKKAKGLSARQRRELRLFDIKPEQQRYSLFLPLHELWKQYIRDLCSGLKPDTQPQMIQAKLLKADLHGAIISVTKSKCPSYVGITGILLQETKHIFKIITKEDRLKVIPKLNCVFTVETDGFISYIYGSKFQLRSSERSAKKFKAKGTIDL>sp|Q9NWH9|SLTM_HUMAN SAFB-like transcription modulator OS=Homo sapiensOX=9606 GN=SLTM PE=1 SV=2MAAATGAVAASAASGQAEGKKITDLRVIDLKSELKRRNLDITGVKTVLISRLKQAIEEEGGDPDNIELTVSTDTPNKKPTKGKGKKHEADELSGDASVEDDAFIKDCELENQEAHEQDGNDELKDSEEFGENEEENVHSKELLSAEENKRAHELIEAEGIEDIEKEDIESQEIEAQEGEDDTFLTAQDGEEEENEKDIAGSGDGTQEVSKPLPSEGSLAEADHTAHEEMEAHTTVKEAEDDNISVTIQAEDAITLDFDGDDLLETGKNVKITDSEASKPKDGQDAIAQSPEKESKDYEMNANHKDGKKEDCVKGDPVEKEARESSKKAESGDKEKDTLKKGPSSTGASGQAKSSSKESKDSKTSSKDDKGSTSSTSGSSGSSTKNIWVSGLSSNTKAADLKNLFGKYGKVLSAKVVTNARSPGAKCYGIVTMSSSTEVSRCIAHLHRTELHGQLISVEKVKGDPSKKEMKKENDEKSSSRSSGDKKNTSDRSSKTQASVKKEEKRSSEKSEKKESKDTKKIEGKDEKNDNGASGQTSESIKKSEEKKRISSKSPGHMVILDQTKGDHCRPSRRGRYEKIHGRSKEKERASLDKKRDKDYRRKEILPFEKMKEQRLREHLVRFERLRRAMELRRRREIAERERRERERIRIIREREERERLQRERERLEIERQKLERERMERERLERERIRIEQERRKEAERIAREREELRRQQQQLRYEQEKRNSLKRPRDVDHRRDDPYWSENKKLSLDTDARFGHGSDYSRQQNRFNDFDHRERGRFPESSAVQSSSFERRDRFVGQSEGKKARPTARREDPSFERYPKNFSDSRRNEPPPPRNELRESDRREVRGERDERRTVIIHDRPDITHPRHPREAGPNPSRPTSWKSEGSMSTDKRETRVERPERSGREVSGHSVRGAPPGNRSSASGYGSREGDRGVITDRGGGSQHYPEERHVVERHGRDTSGPRKEWHGPPSQGPSYHDTRRMGDGRAGAGMITQHSSNASPINRIVQISGNSMPRGSGSGFKPFKGGPPRRF>sp|Q9NWH9-3|SLTM_HUMAN Isoform 2 of SAFB-like transcription modulatorOS=Homo sapiens OX=9606 GN=SLTMMSSSTEVSRCIAHLHRTELHGQLISVEKVKGDPSKKEMKKENDEKSSSRSSGDKKNTSDRSSKTQASVKKEEKRSSEKSEKKESKDTKKIEGKDEKNDNGASGQTSESIKKSEEKKRISSKSPGHMVILDQTKGDHCRPSRRGRYEKIHGRSKEKERASLDKKRDKDYRRKEILPFEKMKEQRLREHLVRFERLRRAMELRRRREIAERERRERERIRIIREREERERLQRERERLEIERQKLERERMERERLERERIRIEQERRKEAERIAREREELRRQQQQLRYEQEKRNSLKRPRDVDHRRDDPYWSENKKLSLDTDARFGHGSDYSRQQNRFNDFDHRERGRFPESSAVQSSSFERRDRFVGQSEGKKARPTARREDPSFERYPKNFSDSRRNEPPPPRNELRESDRREVRGERDERRTVIIHDRPDITHPRHPREAGPNPSRPTSWKSEGSMSTDKRETRVERPERSGREVSGHSVRGAPPGNRSSASGYGSREGDRGVITDRGGGSQHYPEERHVVERHGRDTSGPRKEWHGPPSQGPSYHDTRRMGDGRAGAGMITQHSSNASPINRIVQISGNSMPRGSGSGFKPFKGGPPRRF>sp|Q53H47|SETMR_HUMAN Histone-lysine N-methyltransferase SETMAR OS=Homosapiens OX=9606 GN=SETMAR PE=1 SV=2MFAEAAKTTRPCGMAEFKEKPEAPTEQLDVACGQENLPVGAWPPGAAPAPFQYTPDHVVGPGADIDPTQITFPGCICVKTPCLPGTCSCLRHGENYDDNSCLRDIGSGGKYAEPVFECNVLCRCSDHCRNRVVQKGLQFHFQVFKTHKKGWGLRTLEFIPKGRFVCEYAGEVLGFSEVQRRIHLQTKSDSNYIIAIREHVYNGQVMETFVDPTYIGNIGRFLNHSCEPNLLMIPVRIDSMVPKLALFAAKDIVPEEELSYDYSGRYLNLTVSEDKERLDHGKLRKPCYCGAKSCTAFLPFDSSLYCPVEKSNISCGNEKEPSMCGSAPSVFPSCKRLTLETMKMMLDKKQIRAIFLFEFKMGRKAAETTRNINNAFGPGTANERTVQWWFKKFCKGDESLEDEERSGRPSEVDNDQLRAIIEADPLTTTREVAEELNVNHSTVVRHLKQIGKVKKLDKWVPHELTENQKNRRFEVSSSLILRNHNEPFLDRIVTCDEKWILYDNRRRSAQWLDQEEAPKHFPKPILHPKKVMVTIWWSAAGLIHYSFLNPGETITSEKYAQEIDEMNQKLQRLQLALVNRKGPILLHDNARPHVAQPTLQKLNELGYEVLPHPPYSPDLLPTNYHVFKHLNNFLQGKRFHNQQDAENAFQEFVESQSTDFYATGINQLISRWQKCVDCNGSYFD>sp|Q53H47-2|SETMR_HUMAN Isoform 2 of Histone-lysine N-methyltransferaseSETMAR OS=Homo sapiens OX=9606 GN=SETMARMFAEAAKTTRPCGMAEFKEKPEAPTEQLDVACGQENLPVGAWPPGAAPAPFQYTPDHVVGPGADIDPTQITFPGCICVKTPCLPGTCSCLRHGENYDDNSCLRDIGSGGKYAEPVFECNVLCRCSDHCRNRVVQKGLQFHFQVFKTHKKGWGLRTLEFIPKGRFVCEYAGEVLGFSEVQRRIHLQTKSDSNYIIAIREHVYNGQVMETFVDPTYIGNIGRFLNHSCEPNLLMIPVRIDSMVPKLALFAAKDIVPEEELSYDYSGRYLNLTVSEDKERLDHGKLRKPCYCGAKSCTAFLPFDSSLYCPVEKSNISCGNEKEPSMCGSAPSVFPSCKRLTLEVSLFSDKQLAPPYSGRQWLASFTSA>sp|Q53H47-3|SETMR_HUMAN Isoform 3 of Histone-lysine N-methyltransferaseSETMAR OS=Homo sapiens OX=9606 GN=SETMARMFAEAAKTTRPCGMAEFKEKPEAPTEQLDVACGQENLPVGAWPPGAAPAPFQYTPDHVVGPGADIDPTQITFPGCICVKTPCLPGTCSCLRHGENYDDNSCLRDIGSGGKYAEPVFECNVLCRCSDHCRNRVVQKGLQFHFQVFKTHKKGWGLRTLEFIPKGSSLYCPVEKSNISCGNEKEPSMCGSAPSVFPSCKRLTLETMKMMLDKKQIRAIFLFEFKMGRKAAETTRNINNAFGPGTANERTVQWWFKKFCKGDESLEDEERSGRPSEVDNDQLRAIIEADPLTTTREVAEELNVNHSTVVRHLKQIGKVKKLDKWVPHELTENQKNRRFEVSSSLILRNHNEPFLDRIVTCDEKWILYDNRRRSAQWLDQEEAPKHFPKPILHPKKVMVTIWWSAAGLIHYSFLNPGETITSEKYAQEIDEMNQKLQRLQLALVNRKGPILLHDNARPHVAQPTLQKLNELGYEVLPHPPYSPDLLPTNYHVFKHLNNFLQGKRFHNQQDAENAFQEFVESQSTDFYATGINQLISRWQKCVDCNGSYFD>sp|Q9BPZ7|SIN1_HUMAN Target of rapamycin complex 2 subunit MAPKAP1OS=Homo sapiens OX=9606 GN=MAPKAP1 PE=1 SV=2MAFLDNPTIILAHIRQSHVTSDDTGMCEMVLIDHDVDLEKIHPPSMPGDSGSEIQGSNGETQGYVYAQSVDITSSWDFGIRRRSNTAQRLERLRKERQNQIKCKNIQWKERNSKQSAQELKSLFEKKSLKEKPPISGKQSILSVRLEQCPLQLNNPFNEYSKFDGKGHVGTTATKKIDVYLPLHSSQDRLLPMTVVTMASARVQDLIGLICWQYTSEGREPKLNDNVSAYCLHIAEDDGEVDTDFPPLDSNEPIHKFGFSTLALVEKYSSPGLTSKESLFVRINAAHGFSLIQVDNTKVTMKEILLKAVKRRKGSQKVSGPQYRLEKQSEPNVAVDLDSTLESQSAWEFCLVRENSSRADGVFEEDSQIDIATVQDMLSSHHYKSFKVSMIHRLRFTTDVQLGISGDKVEIDPVTNQKASTKFWIKQKPISIDSDLLCACDLAEEKSPSHAIFKLTYLSNHDYKHLYFESDAATVNEIVLKVNYILESRASTARADYFAQKQRKLNRRTSFSFQKEKKSGQQ>sp|Q9BPZ7-2|SIN1_HUMAN Isoform 2 of Target of rapamycin complex 2subunit MAPKAP1 OS=Homo sapiens OX=9606 GN=MAPKAP1MAFLDNPTIILAHIRQSHVTSDDTGMCEMVLIDHDVDLEKIHPPSMPGDSGSEIQGSNGETQGYVYAQSVDITSSWDFGIRRRSNTAQRLERLRKERQNQIKCKNIQWKERNSKQSAQELKSLFEKKSLKEKPPISGKQSILSVRLEQCPLQLNNPFNEYSKFDGKGHVGTTATKKIDVYLPLHSSQDRLLPMTVVTMASARVQDLIGLICWQYTSEGREPKLNDNVSAYCLHIAEDDGEVDTDFPPLDSNEPIHKFGFSTLALVEKYSSPGLTSKESLFVRINAAHGFSLIQVDNTKVTMKEILLKAVKRRKGSQKVSGSRADGVFEEDSQIDIATVQDMLSSHHYKSFKVSMIHRLRFTTDVQLGISGDKVEIDPVTNQKASTKFWIKQKPISIDSDLLCACDLAEEKSPSHAIFKLTYLSNHDYKHLYFESDAATVNEIVLKVNYILESRASTARADYFAQKQRKLNRRTSFSFQKEKKSGQQ>sp|Q9BPZ7-3|SIN1_HUMAN Isoform 3 of Target of rapamycin complex 2subunit MAPKAP1 OS=Homo sapiens OX=9606 GN=MAPKAP1MAFLDNPTIILAHIRQSHVTSDDTGMCEMVLIDHDVDLEKIHPPSMPGDSGSEIQGSNGETQGYVYAQSVDITSSWDFGIRRRSNTAQRLERLRKERQNQIKCKNIQWKERNSKQSAQELKSLFEKKSLKEKPPISGKQSILSVRLEQCPLQLNNPFNEYSKFDGKGHVGTTATKKIDVYLPLHSSQDRLLPMTVVTMASARVQDLIGLICWQYTSEGREPKLNDNVSAYCLHIAEDDGEVDTDFPPLDSNEPIHKFGFSTLALVEKYSSPGLTSKESLFVRINAAHGFSLIQVDNTKVTMKEILLKAVKRRKGSQKVSGPQYRLEKQSEPNVAVDLDSTLESQSAWEFCLVRENSISGDKVEIDPVTNQKASTKFWIKQKPISIDSDLLCACDLAEEKSPSHAIFKLTYLSNHDYKHLYFESDAATVNEIVLKVNYILESRASTARADYFAQKQRKLNRRTSFSFQKEKKSGQQ>sp|Q9BPZ7-4|SIN1_HUMAN Isoform 4 of Target of rapamycin complex 2subunit MAPKAP1 OS=Homo sapiens OX=9606 GN=MAPKAP1MTVVTMASARVQDLIGLICWQYTSEGREPKLNDNVSAYCLHIAEDDGEVDTDFPPLDSNEPIHKFGFSTLALVEKYSSPGLTSKESLFVRINAAHGFSLIQVDNTKVTMKEILLKAVKRRKGSQKVSGPQYRLEKQSEPNVAVDLDSTLESQSAWEFCLVRENSSRADGVFEEDSQIDIATVQDMLSSHHYKSFKVSMIHRLRFTTDVQLGISGDKVEIDPVTNQKASTKFWIKQKPISIDSDLLCACDLAEEKSPSHAIFKLTYLSNHDYKHLYFESDAATVNEIVLKVNYILESRASTARADYFAQKQRKLNRRTSFSFQKEKKSGQQ>sp|Q9BPZ7-5|SIN1_HUMAN Isoform 5 of Target of rapamycin complex 2subunit MAPKAP1 OS=Homo sapiens OX=9606 GN=MAPKAP1MAFLDNPTIILAHIRQSHVTSDDTGMCEMVLIDHDVDLEKIHPPSMPGDSGSEIQGSNGETQGYVYAQSVDITSSWDFGIRRRSNTAQRLERLRKERQNQIKCKNIQWKERNSKQSAQELKSLFEKKSLKEKPPISGKQSILSVRLEQCPLQLNNPFNEYSKFDGKGHVGTTATKKIDVYLPLHSSQDRLLPMTVVTMASARVQDLIGLICWQYTSEGREPKLNDNVSAYCLHIAEDDGEVDTDFPPLDSNEPIHKFGFSTLALVEKYSSPGLTSKESLFVRINAAHGFSLIQVDNTKVTMKEILLKAVKRRKGSQKVSGACD>sp|Q9BPZ7-6|SIN1_HUMAN Isoform 6 of Target of rapamycin complex 2subunit MAPKAP1 OS=Homo sapiens OX=9606 GN=MAPKAP1MAFLDNPTIILAHIRQSHVTSDDTGMCEMVLIDHDVDLEKIHPPSMPGDSGSEIQGSNGETQGYVYAQSVDITSSWDFGIRRRSNTAQRLERLRKERQNQIKCKNIQWKERNSKQSAQELKSLFEKKSLKEKPPISGKQSILSVRLEQCPLQLNNPFNEYSKFDGKGHVGTTATKKIDVYLPLHSSQDRLLPMTVVTMASARVQDLIGLICWQYTSEGREPKLNDNVSAYCLHIAEDDGEVDTDFPPLDSNEPIHKFGFSTLALVEKYSSPGLTSKESLFVRINAAHGFSLIQVDNTKVTMKEILLKAVKRRKGSQKVSGPQYRLEKQSEPNVAVDLDSTLESQSAWEFCLVRENSTLAASLHARFVRCKLA>sp|Q5TF21|SOGA3_HUMAN Protein SOGA3 OS=Homo sapiens OX=9606 GN=SOGA3PE=3 SV=1MSQPPIGGAAPATAAASPAAAATEARLHPEGSSRKQQRAQSPARPRDSSLRQTIAATRSPVGAGTKLNSVRQQQLQQQQQQGNKTGSRTGPPASIRGGGGGAEKATPLAPKGAAPGAVQPVAGAEAAPAATLAALGGRRPGPPEEPPRELESVPSKLGEPPPLGEGGGGGGEGGGAGGGSGEREGGAPQPPPPRGWRGKGVRAQQRGGSGGEGASPSPSSSSAGKTPGTGSRNSGSGVAGGGSGGGGSYWKEGCLQSELIQFHLKKERAAAAAAAAQMHAKNGGGSSSRSSPVSGPPAVCETLAVASASPMAAAAEGPQQSAEGSASGGGMQAAAPPSSQPHPQQLQEQEEMQEEMEKLREENETLKNEIDELRTEMDEMRDTFFEEDACQLQEMRHELERANKNCRILQYRLRKAERKRLRYAQTGEIDGELLRSLEQDLKVAKDVSVRLHHELENVEEKRTTTEDENEKLRQQLIEVEIAKQALQNELEKMKELSLKRRGSKDLPKSEKKAQQTPTEEDNEDLKCQLQFVKEEAALMRKKMAKIDKEKDRFEHELQKYRSFYGDLDSPLPKGEAGGPPSTREAELKLRLRLVEEEANILGRKIVELEVENRGLKAELDDLRGDDFNGSANPLMREQSESLSELRQHLQLVEDETELLRRNVADLEEQNKRITAELNKYKYKSGGHDSARHHDNAKTEALQEELKAARLQINELSGKVMQLQYENRVLMSNMQRYDLASHLGIRGSPRDSDAESDAGKKESDDDSRPPHRKREGPIGGESDSEEVRNIRCLTPTRSFYPAPGPWPKSFSDRQQMKDIRSEAERLGKTIDRLIADTSTIITEARIYVANGDLFGLMDEEDDGSRIREHELLYRINAQMKAFRKELQTFIDRLEVPKSADDRGAEEPISVSQMFQPIILLILILVLFSSLSYTTIFKLVFLFTLFFVL>sp|Q9NX45|SOLH2_HUMAN Spermatogenesis- and oogenesis-specific basichelix-loop-helix-containing protein 2 OS=Homo sapiens OX=9606 GN=SOHLH2PE=2 SV=2MASSIICQEHCQISGQAKIDILLVGDVTVGYLADTVQKLFANIAEVTITISDTKEAAALLDDCIFNMVLLKVPSSLSAEELEAIKLIRFGKKKNTHSLFVFIIPENFKGCISGHGMDIALTEPLTMEKMSNVVKYWTTCPSNTVKTENATGPEELGLPLQRSYSEHLGYFPTDLFACSESLRNGNGLELNASLSEFEKNKKISLLHSSKEKLRRERIKYCCEQLRTLLPYVKGRKNDAASVLEATVDYVKYIREKISPAVMAQITEALQSNMRFCKKQQTPIELSLPGTVMAQRENSVMSTYSPERGLQFLTNTCWNGCSTPDAESSLDEAVRVPSSSASENAIGDPYKTHISSAALSLNSLHTVRYYSKVTPSYDATAVTNQNISIHLPSAMPPVSKLLPRHCTSGLGQTCTTHPNCLQQFWAY>sp|Q9NX45-2|SOLH2_HUMAN Isoform 2 of Spermatogenesis- and oogenesis-specific basic helix-loop-helix-containing protein 2 OS=Homo sapiensOX=9606 GN=SOHLH2MASSIICQEHCQISGQAKIDILLVGDVTVGYLADTVQKLFANIAEVTITISDTKEAAALLDDCIFNMVLLKVPSSLSAEELEAIKLIRFGKKKNTHSLFVFIIPENFKGCISGHGMDIALTEPLTMEKMSNVVKYWTTCPSNTVKTENATGPEELGLPLQRSYSEHLGYFPTDLFACSESLRNGNGLELNASLSEFEKNKKISLLHSSKEKLRRLYRKHSSFCFW>sp|Q9NX45-3|SOLH2_HUMAN Isoform 3 of Spermatogenesis- and oogenesis-specific basic helix-loop-helix-containing protein 2 OS=Homo sapiensOX=9606 GN=SOHLH2METLQESLNTLLKQLEEEKKTLESQVKYYALKLEQESKAYQKINNERRTYLAEMSQGSGLHQVSKRQQVDQLPRMQENLVKTLLLKEELDPLKAKIDILLVGDVTVGYLADTVQKLFANIAEVTITISDTKEAAALLDDCIFNMVLLKVPSSLSAEELEAIKLIRFGKKKNTHSLFVFIIPENFKGCISGHGMDIALTEPLTMEKMSNVVKYWTTCPSNTVKTENATGPEELGLPLQRSYSEHLGYFPTDLFACSESLRNGNGLELNASLSEFEKNKKISLLHSSKEKLRRERIKYCCEQLRTLLPYVKGRKNDAASVLEATVDYVKYIREKISPAVMAQITEALQSNMRFCKKQQTPIELSLPGTVMAQRENSVMSTYSPERGLQFLTNTCWNGCSTPDAESSLDEAVRVPSSSASENAIGDPYKTHISSAALSLNSLHTVRYYSKVTPSYDATAVTNQNISIHLPSAMPPVSKLLPRHCTSGLGQTCTTHPNCLQQFWAY>sp|P54577|SYYC_HUMAN Tyrosine--tRNA ligase, cytoplasmic OS=Homo sapiensOX=9606 GN=YARS1 PE=1 SV=4MGDAPSPEEKLHLITRNLQEVLGEEKLKEILKERELKIYWGTATTGKPHVAYFVPMSKIADFLKAGCEVTILFADLHAYLDNMKAPWELLELRVSYYENVIKAMLESIGVPLEKLKFIKGTDYQLSKEYTLDVYRLSSVVTQHDSKKAGAEVVKQVEHPLLSGLLYPGLQALDEEYLKVDAQFGGIDQRKIFTFAEKYLPALGYSKRVHLMNPMVPGLTGSKMSSSEEESKIDLLDRKEDVKKKLKKAFCEPGNVENNGVLSFIKHVLFPLKSEFVILRDEKWGGNKTYTAYVDLEKDFAAEVVHPGDLKNSVEVALNKLLDPIREKFNTPALKKLASAAYPDPSKQKPMAKGPAKNSEPEEVIPSRLDIRVGKIITVEKHPDADSLYVEKIDVGEAEPRTVVSGLVQFVPKEELQDRLVVVLCNLKPQKMRGVESQGMLLCASIEGINRQVEPLDPPAGSAPGEHVFVKGYEKGQPDEELKPKKKVFEKLQADFKISEECIAQWKQTNFMTKLGSISCKSLKGGNIS>sp|O43294|TGFI1_HUMAN Transforming growth factor beta-1-inducedtranscript 1 protein OS=Homo sapiens OX=9606 GN=TGFB1I1 PE=1 SV=2MEDLDALLSDLETTTSHMPRSGAPKERPAEPLTPPPSYGHQPQTGSGESSGASGDKDHLYSTVCKPRSPKPAAPAAPPFSSSSGVLGTGLCELDRLLQELNATQFNITDEIMSQFPSSKVASGEQKEDQSEDKKRPSLPSSPSPGLPKASATSATLELDRLMASLSDFRVQNHLPASGPTQPPVVSSTNEGSPSPPEPTGKGSLDTMLGLLQSDLSRRGVPTQAKGLCGSCNKPIAGQVVTALGRAWHPEHFVCGGCSTALGGSSFFEKDGAPFCPECYFERFSPRCGFCNQPIRHKMVTALGTHWHPEHFCCVSCGEPFGDEGFHEREGRPYCRRDFLQLFAPRCQGCQGPILDNYISALSALWHPDCFVCRECFAPFSGGSFFEHEGRPLCENHFHARRGSLCATCGLPVTGRCVSALGRRFHPDHFTCTFCLRPLTKGSFQERAGKPYCQPCFLKLFG>sp|O43294-2|TGFI1_HUMAN Isoform 2 of Transforming growth factor beta-1-induced transcript 1 protein OS=Homo sapiens OX=9606 GN=TGFB1I1MPRSGAPKERPAEPLTPPPSYGHQPQTGSGESSGASGDKDHLYSTVCKPRSPKPAAPAAPPFSSSSGVLGTGLCELDRLLQELNATQFNITDEIMSQFPSSKVASGEQKEDQSEDKKRPSLPSSPSPGLPKASATSATLELDRLMASLSDFRVQNHLPASGPTQPPVVSSTNEGSPSPPEPTGKGSLDTMLGLLQSDLSRRGVPTQAKGLCGSCNKPIAGQVVTALGRAWHPEHFVCGGCSTALGGSSFFEKDGAPFCPECYFERFSPRCGFCNQPIRHKMVTALGTHWHPEHFCCVSCGEPFGDEGFHEREGRPYCRRDFLQLFAPRCQGCQGPILDNYISALSALWHPDCFVCRECFAPFSGGSFFEHEGRPLCENHFHARRGSLCATCGLPVTGRCVSALGRRFHPDHFTCTFCLRPLTKGSFQERAGKPYCQPCFLKLFG>sp|P0DPI4|TDB01_HUMAN T cell receptor beta diversity 1 OS=Homo sapiensOX=9606 GN=TRBD1 PE=4 SV=1GTGG>sp|Q15562|TEAD2_HUMAN Transcriptional enhancer factor TEF-4 OS=Homosapiens OX=9606 GN=TEAD2 PE=1 SV=2MGEPRAGAALDDGSGWTGSEEGSEEGTGGSEGAGGDGGPDAEGVWSPDIEQSFQEALAIYPPCGRRKIILSDEGKMYGRNELIARYIKLRTGKTRTRKQVSSHIQVLARRKSREIQSKLKDQVSKDKAFQTMATMSSAQLISAPSLQAKLGPTGPQASELFQFWSGGSGPPWNVPDVKPFSQTPFTLSLTPPSTDLPGYEPPQALSPLPPPTPSPPAWQARGLGTARLQLVEFSAFVEPPDAVDSYQRHLFVHISQHCPSPGAPPLESVDVRQIYDKFPEKKGGLRELYDRGPPHAFFLVKFWADLNWGPSGEEAGAGGSISSGGFYGVSSQYESLEHMTLTCSSKVCSFGKQVVEKVETERAQLEDGRFVYRLLRSPMCEYLVNFLHKLRQLPERYMMNSVLENFTILQVVTNRDTQELLLCTAYVFEVSTSERGAQHHIYRLVRD>sp|Q15562-2|TEAD2_HUMAN Isoform 2 of Transcriptional enhancer factorTEF-4 OS=Homo sapiens OX=9606 GN=TEAD2MGEPRAGAALDDGSGWTGSEEGSEEGTGGSEGAGGDGGPDAEGVWSPDIEQSFQEALAIYPPCGRRKIILSDEGKMYGRNELIARYIKLRTGKTRTRKQVSSHIQVLARRKSREIQSKLKDQVSKDKAFQTMATMSSAQLISAPSLQAKLGPTGPQVVQASELFQFWSGGSGPPWNVPDVKPFSQTPFTLSLTPPSTDLPGYEPPQALSPLPPPTPSPPAWQARGLGTARLQLVEFSAFVEPPDAVDSYQRHLFVHISQHCPSPGAPPLESVDVRQIYDKFPEKKGGLRELYDRGPPHAFFLVKFWADLNWGPSGEEAGAGGSISSGGFYGVSSQYESLEHMTLTCSSKVCSFGKQVVEKVETERAQLEDGRFVYRLLRSPMCEYLVNFLHKLRQLPERYMMNSVLENFTILQVVTNRDTQELLLCTAYVFEVSTSERGAQHHIYRLVRD>sp|Q15562-3|TEAD2_HUMAN Isoform 3 of Transcriptional enhancer factorTEF-4 OS=Homo sapiens OX=9606 GN=TEAD2MATMSSAQLISAPSLQAKLGPTGPQVVQASELFQFWSGGSGPPWNVPDVKPFSQTPFTLSLTPPSTDLPGYEPPQALSPLPPPTPSPPAWQARGLGTARLQLVEFSAFVEPPDAVDSYQRHLFVHISQHCPSPGAPPLESVDVRQIYDKFPEKKGGLRELYDRGPPHAFFLVKFWADLNWGPSGEEAGAGGSISSGGFYGVSSQYESLEHMTLTCSSKVCSFGKQVVEKVETERAQLEDGRFVYRLLRSPMCEYLVNFLHKLRQLPERYMMNSVLENFTILQVVTNRDTQELLLCTAYVFEVSTSERGAQHHIYRLVRD>sp|Q15562-4|TEAD2_HUMAN Isoform 4 of Transcriptional enhancer factorTEF-4 OS=Homo sapiens OX=9606 GN=TEAD2MGEPRAGAALDDGSGWTGSEEGSEEGTGGSEGAGGDGGPDAEGVWSPDIEQSFQEALAIYPPCGRRKIILSDEGKMYGRNELIARYIKLRTGKTRTRKQVSSHIQVLARRKSREIQSKLKALNVDQVSKDKAFQTMATMSSAQLISAPSLQAKLGPTGPQASELFQFWSGGSGPPWNVPDVKPFSQTPFTLSLTPPSTDLPGYEPPQALSPLPPPTPSPPAWQARGLGTARLQLVEFSAFVEPPDAVDSYQRHLFVHISQHCPSPGAPPLESVDVRQIYDKFPEKKGGLRELYDRGPPHAFFLVKFWADLNWGPSGEEAGAGGSISSGGFYGVSSQYESLEHMTLTCSSKVCSFGKQVVEKVETERAQLEDGRFVYRLLRSPMCEYLVNFLHKLRQLPERYMMNSVLENFTILQVVTNRDTQELLLCTAYVFEVSTSERGAQHHIYRLVRD>sp|Q0IIM8|TBC8B_HUMAN TBC1 domain family member 8B OS=Homo sapiensOX=9606 GN=TBC1D8B PE=1 SV=2MWLKPEEVLLKNALKLWLMERSNDYFVLQRRRGYGEEGGGGLTGLLVGTLDSVLDSTAKVAPFRILHQTPDSQVYLSIACGANREEITKHWDWLEQNIMKTLSVFDSNEDITNFVQGKIRGLIAEEGKHCFAKEDDPEKFREALLKFEKCFGLPEKEKLVTYYSCSYWKGRVPCQGWLYLSTNFLSFYSFLLGSEIKLIISWDEVSKLEKTSNVILTESIHVCSQGENHYFSMFLHINQTYLLMEQLANYAIRRLFDKETFDNDPVLYNPLQITKRGLENRAHSEQFNAFFRLPKGESLKEVHECFLWVPFSHFNTHGKMCISENYICFASQDGNQCSVIIPLREVLAIDKTNDSSKSVIISIKGKTAFRFHEVKDFEQLVAKLRLRCGAASTQYHDISTELAISSESTEPSDNFEVQSLTSQRECSKTVNTEALMTVFHPQNLETLNSKMLKEKMKEQSWKILFAECGRGVSMFRTKKTRDLVVRGIPETLRGELWMLFSGAVNDMATNPDYYTEVVEQSLGTCNLATEEIERDLRRSLPEHPAFQSDTGISALRRVLTAYAYRNPKIGYCQAMNILTSVLLLYAKEEEAFWLLVAVCERMLPDYFNRRIIGALVDQAVFEELIRDHLPQLTEHMTDMTFFSSVSLSWFLTLFISVLPIESAVNVVDCFFYDGIKAILQLGLAILDYNLDKLLTCKDDAEAVTALNRFFDNVTNKDSPLPSNVQQGSNVSDEKTSHTRVDITDLIRESNEKYGNIRYEDIHSMRCRNRLYVIQTLEETTKQNVLRVVSQDVKLSLQELDELYVIFKKELFLSCYWCLGCPVLKHHDPSLPYLEQYQIDCQQFRALYHLLSPWAHSANKDSLALWTFRLLDENSDCLINFKEFSSAIDIMYNGSFTEKLKLLFKLHIPPAYTEVKSKDASKGDELSKEELLYFSQLHVSKPANEKEAESAKHSPEKGKGKIDIQAYLSQWQDELFKKEENIKDLPRMNQSQFIQFSKTLYNLFHEDPEEESLYQAIAVVTSLLLRMEEVGRKLHSPTSSAKGFSGTVCGSGGPSEEKTGSHLEKDPCSFREEPQWSFAFEQILASLLNEPALVRFFEKPIDVKAKLENARISQLRSRTKM>sp|Q0IIM8-2|TBC8B_HUMAN Isoform 2 of TBC1 domain family member 8BOS=Homo sapiens OX=9606 GN=TBC1D8BMWLKPEEVLLKNALKLWLMERSNDYFVLQRRRGYGEEGGGGLTGLLVGTLDSVLDSTAKVAPFRILHQTPDSQVYLSIACGANREEITKHWDWLEQNIMKTLSVFDSNEDITNFVQGKIRGLIAEEGKHCFAKEDDPEKFREALLKFEKCFGLPEKEKLVTYYSCSYWKGRVPCQGWLYLSTNFLSFYSFLLGSEIKLIISWDEVSKLEKTSNVILTESIHVCSQGENHYFSMFLHINQTYLLMEQLANYAIRRLFDKETFDNDPVLYNPLQITKRGLENRAHSEQFNAFFRLPKGESLKEVHECFLWVPFSHFNTHGKMCISENYICFASQDGNQCSVIIPLREVLAIDKTNDSSKSVIISIKGKTAFRFHEVKDFEQLVAKLRLRCGAASTQYHDISTELAISSESTEPSDNFEVQSLTSQRECSKTVNTEALMTVFHPQNLETLNSKMLKEKMKEQSWKILFAECGRGVSMFRTKKTRDLVVRGIPETLRGELWMLFSGAVNDMATNPDYYTEVVEQSLGTCNLATEEIERDLRRSLPEHPAFQSDTGISALRRVLTAYAYRNPKIGYCQAMNILTSVLLLYAKEEEAFWLLVAVCERMLPDYFNRRIIGSDDFMPLVRIQGQCVIG>sp|Q0IIM8-3|TBC8B_HUMAN Isoform 3 of TBC1 domain family member 8BOS=Homo sapiens OX=9606 GN=TBC1D8BMWLKPEEVLLKNALKLWLMERSNDYFVLQRRRGYGEEGGGGLTGLLVGTLDSVLDSTAKVAPFRILHQTPDSQVYLSIACGANREEITKHWDWLEQNIMKTLSVFDSNEDITNFVQGKIRGLIAEEGKHCFAKEDDPEKFREALLKFEKCFGLPEKEKLVTYYSCSYWKGRVPCQGWLYLSTNFLSFYSFLLGSEIKLIISWDEVSKLEKTSNVILTESIHVCSQGENHYFSMFLHINQTYLLMEQLANYAIRRLFDKETFDNDPVLYNPLQITKRGLENRAHSEQFNAFFRLPKGESLKEVHECFLWVPFSHFNTHGKMCISENYICFASQDGNQCSVIIPLREVLAIDKTNDSSKSVIISIKGKTAFRFHEVKDFEQLVAKLRLRCGAASTQYHDISTELAISSESTEPSDNFEVQSLTSQRECSKTVNTEALMTVFHPQNLETLNSKMLKEKMKEQSWKILFAECGRGVSMFRTKKTRDLVVRGIPETLRGELWMLFSGAVNDMATNPDYYTEVVEQSLGTCNLATEEIERDLRRSLPEHPAFQSDTGISALRRVLTAYAYRNPKIGYCQAMNILTSVLLLYAKEEEAFWLLVAVCERMLPDYFNRRIIGSDDFMPLVRIQGQCVIGEK>sp|Q9ULP9|TBC24_HUMAN TBC1 domain family member 24 OS=Homo sapiensOX=9606 GN=TBC1D24 PE=1 SV=2MDSPGYNCFVDKDKMDAAIQDLGPKELSCTELQELKQLARQGYWAQSHALRGKVYQRLIRDIPCRTVTPDASVYSDIVGKIVGKHSSSCLPLPEFVDNTQVPSYCLNARGEGAVRKILLCLANQFPDISFCPALPAVVALLLHYSIDEAECFEKACRILACNDPGRRLIDQSFLAFESSCMTFGDLVNKYCQAAHKLMVAVSEDVLQVYADWQRWLFGELPLCYFARVFDVFLVEGYKVLYRVALAILKFFHKVRAGQPLESDSVKQDIRTFVRDIAKTVSPEKLLEKAFAIRLFSRKEIQLLQMANEKALKQKGITVKQKSVSLSKRQFVHLAVHAENFRSEIVSVREMRDIWSWVPERFALCQPLLLFSSLQHGYSLARFYFQCEGHEPTLLLIKTTQKEVCGAYLSTDWSERNKFGGKLGFFGTGECFVFRLQPEVQRYEWVVIKHPELTKPPPLMAAEPTAPLSHSASSDPADRLSPFLAARHFNLPSKTESMFMAGGSDCLIVGGGGGQALYIDGDLNRGRTSHCDTFNNQPLCSENFLIAAVEAWGFQDPDTQ>sp|Q9ULP9-2|TBC24_HUMAN Isoform 2 of TBC1 domain family member 24OS=Homo sapiens OX=9606 GN=TBC1D24MDSPGYNCFVDKDKMDAAIQDLGPKELSCTELQELKQLARQGYWAQSHALRGKVYQRLIRDIPCRTVTPDASVYSDIVGKIVGKHSSSCLPLPEFVDNTQVPSYCLNARGEGAVRKILLCLANQFPDISFCPALPAVVALLLHYSIDEAECFEKACRILACNDPGRRLIDQSFLAFESSCMTFGDLVNKYCQAAHKLMVAVSEDVLQVYADWQRWLFGELPLCYFARVFDVFLVEGYKVLYRVALAILKFFHKVRAGQPLESDSVKQDIRTFVRDIAKTVSPEKLLEKAFAIRLFSRKEIQLLQMANEKALKQKGITVKQKRQFVHLAVHAENFRSEIVSVREMRDIWSWVPERFALCQPLLLFSSLQHGYSLARFYFQCEGHEPTLLLIKTTQKEVCGAYLSTDWSERNKFGGKLGFFGTGECFVFRLQPEVQRYEWVVIKHPELTKPPPLMAAEPTAPLSHSASSDPADRLSPFLAARHFNLPSKTESMFMAGGSDCLIVGGGGGQALYIDGDLNRGRTSHCDTFNNQPLCSENFLIAAVEAWGFQDPDTQ>sp|O15344|TRI18_HUMAN E3 ubiquitin-protein ligase Midline-1 OS=Homosapiens OX=9606 GN=MID1 PE=1 SV=1METLESELTCPICLELFEDPLLLPCAHSLCFNCAHRILVSHCATNESVESITAFQCPTCRHVITLSQRGLDGLKRNVTLQNIIDRFQKASVSGPNSPSETRRERAFDANTMTSAEKVLCQFCDQDPAQDAVKTCVTCEVSYCDECLKATHPNKKPFTGHRLIEPIPDSHIRGLMCLEHEDEKVNMYCVTDDQLICALCKLVGRHRDHQVAALSERYDKLKQNLESNLTNLIKRNTELETLLAKLIQTCQHVEVNASRQEAKLTEECDLLIEIIQQRRQIIGTKIKEGKVMRLRKLAQQIANCKQCIERSASLISQAEHSLKENDHARFLQTAKNITERVSMATASSQVLIPEINLNDTFDTFALDFSREKKLLECLDYLTAPNPPTIREELCTASYDTITVHWTSDDEFSVVSYELQYTIFTGQANVVSLCNSADSWMIVPNIKQNHYTVHGLQSGTKYIFMVKAINQAGSRSSEPGKLKTNSQPFKLDPKSAHRKLKVSHDNLTVERDESSSKKSHTPERFTSQGSYGVAGNVFIDSGRHYWEVVISGSTWYAIGLAYKSAPKHEWIGKNSASWALCRCNNNWVVRHNSKEIPIEPAPHLRRVGILLDYDNGSIAFYDALNSIHLYTFDVAFAQPVCPTFTVWNKCLTIITGLPIPDHLDCTEQLP>sp|O15344-2|TRI18_HUMAN Isoform 2 of E3 ubiquitin-protein ligaseMidline-1 OS=Homo sapiens OX=9606 GN=MID1METLESELTCPICLELFEDPLLLPCAHSLCFNCAHRILVSHCATNESVESITAFQCPTCRHVITLSQRGLDGLKRNVTLQNIIDRFQKASVSGPNSPSETRRERAFDANTMTSAEKVLCQFCDQDPAQDAVKTCVTCEVSYCDECLKATHPNKKPFTGHRLIEPIPDSHIRGLMCLEHEDEKVNMYCVTDDQLICALCKLVGRHRDHQVAALSERYDKLKQNLESNLTNLIKRNTELETLLAKLIQTCQHVEVNASRQEAKLTEECDLLIEIIQQRRQIIGTKIKEGKVMRLRKLAQQIANCKQCIERSASLISQAEHSLKENDHARFLQTAKNITERVSMATASSQVLIPEINLNDTFDTFALDFSREKKLLECLDYLTAPNPPTIREELCTASYDTITVHWTSDDEFSVVSYELQYTIFTGQANVVSLCNSADSWMIVPNIKQNHYTVHGLQSGTKYIFMVKAINQAGSRSSEPGKLKTNSQPFKLDPKSAHRKLKVSHDNLTVERDESSSKKSHTPERFTSQGSYGVAGNVFIDSGRHYWEVVISGSTW>sp|P41273|TNFL9_HUMAN Tumor necrosis factor ligand superfamily member 9OS=Homo sapiens OX=9606 GN=TNFSF9 PE=1 SV=1MEYASDASLDPEAPWPPAPRARACRVLPWALVAGLLLLLLLAAACAVFLACPWAVSGARASPGSAASPRLREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE>sp|Q8IYX1|TBC21_HUMAN TBC1 domain family member 21 OS=Homo sapiensOX=9606 GN=TBC1D21 PE=1 SV=1MTTLSPENSLSARQSASFILVKRKPPIDKTEWDSFFDESGHLAKSRDFICVNILERGLHPFVRTEAWKFLTGYFSWQSSQDERLTVDSMRRKNYKALCQMYEKIQPLLENLHRNFTETRNNIARDIQKIYDKDPLGNVLIDKKRLEKILLLSYVCNTQAEYQQGFHEMMMLFQLMVEHDHETFWLFQFFLQKTEHSCVINIGVAKNLDMLSTLITFLDPVFAEHLKGKGAGAVQSLFPWFCFCFQRAFKSFDDVWRLWEVLLTGKPCRNFQVLVAYSMLQMVREQVLQESMGGDDILLACNNLIDLDADELISAACVVYAELIQKDVPQTLKDFFL>sp|Q8IYX1-2|TBC21_HUMAN Isoform 2 of TBC1 domain family member 21OS=Homo sapiens OX=9606 GN=TBC1D21MTTLSPENSLSARQSASFILGLHPFVRTEAWKFLTGYFSWQSSQDERLTVDSMRRKNYKALCQMYEKIQPLLENLHRNFTETRNNIARDIQKIYDKDPLGNVLIDKKRLEKILLLSYVCNTQAEYQQGFHEMMMLFQLMVEHDHETFWLFQFFLQKTEHSCVINIGVAKNLDMLSTLITFLDPVFAEHLKGKGAGAVQSLFPWFCFCFQRAFKSFDDVWRLWEVLLTGKPCRNFQVLVAYSMLQMVREQVLQESMGGDDILLACNNLIDLDADELISAACVVYAELIQKDVPQTLKDFFL>sp|Q8N614|TM156_HUMAN Transmembrane protein 156 OS=Homo sapiens OX=9606GN=TMEM156 PE=2 SV=2MTKTALLKLFVAIVITFILILPEYFKTPKERTLELSCLEVCLQSNFTYSLSSLNFSFVTFLQPVRETQIIMRIFLNPSNFRNFTRTCQDITGEFKMCSSCLVCESKGNMDFISQEQTSKVLIRRGSMEVKANDFHSPCQHFNFSVAPLVDHLEEYNTTCHLKNHTGRSTIMEDEPSKEKSINYTCRIMEYPNDCIHISLHLEMDIKNITCSMKITWYILVLLVFIFLIILTIRKILEGQRRVQKWQSHRDKPTSVLLRGSDSEKLRALNVQVLSAETTQRLPLDQVQEVLPPIPEL>sp|Q9HAU6|TCTP8_HUMAN Putative translationally-controlled tumor protein-like protein TPT1P8 OS=Homo sapiens OX=9606 GN=TPT1P8 PE=5 SV=2MIIFQDLISHNEMFSDIYKIWEITNGLCLEVEQKMLSKTTGNTDDSLIGRNSSSESTEDEVTESTIITSVDIVTNHHLQESIFTKEAYKKYIKDYMKSINEKLEEQRPERVKLFITGMKNKSSTSLLIFKTTSSLLVKT>sp|O75382|TRIM3_HUMAN Tripartite motif-containing protein 3 OS=Homosapiens OX=9606 GN=TRIM3 PE=1 SV=2MAKREDSPGPEVQPMDKQFLVCSICLDRYQCPKVLPCLHTFCERCLQNYIPAQSLTLSCPVCRQTSILPEQGVSALQNNFFISSLMEAMQQAPDGAHDPEDPHPLSVVAGRPLSCPNHEGKTMEFYCEACETAMCGECRAGEHREHGTVLLRDVVEQHKAALQRQLEAVRGRLPQLSAAIALVGGISQQLQERKAEALAQISAAFEDLEQALQQRKQALVSDLETICGAKQKVLQSQLDTLRQGQEHIGSSCSFAEQALRLGSAPEVLLVRKHMRERLAALAAQAFPERPHENAQLELVLEVDGLRRSVLNLGALLTTSATAHETVATGEGLRQALVGQPASLTVTTKDKDGRLVRTGSAELRAEITGPDGTRLPVPVVDHKNGTYELVYTARTEGELLLSVLLYGQPVRGSPFRVRALRPGDLPPSPDDVKRRVKSPGGPGSHVRQKAVRRPSSMYSTGGKRKDNPIEDELVFRVGSRGREKGEFTNLQGVSAASSGRIVVADSNNQCIQVFSNEGQFKFRFGVRGRSPGQLQRPTGVAVDTNGDIIVADYDNRWVSIFSPEGKFKTKIGAGRLMGPKGVAVDRNGHIIVVDNKSCCVFTFQPNGKLVGRFGGRGATDRHFAGPHFVAVNNKNEIVVTDFHNHSVKVYSADGEFLFKFGSHGEGNGQFNAPTGVAVDSNGNIIVADWGNSRIQVFDSSGSFLSYINTSAEPLYGPQGLALTSDGHVVVADAGNHCFKAYRYLQ>sp|O75382-2|TRIM3_HUMAN Isoform Beta of Tripartite motif-containingprotein 3 OS=Homo sapiens OX=9606 GN=TRIM3MAKREDSPGPEVQPMDKQFLVCSICLDRYQCPKVLPCLHTFCERCLQNYIPAQSLTLSCPVCRQTSILPEQGVSALQNNFFISSLMEAMQQAPDGAHDPEDPHPLSVVAGRPLSCPNHEGKTMEFYCEACETAMCGECRAGEHREQHKAALQRQLEAVRGRLPQLSAAIALVGGISQQLQERKAEALAQISAAFEDLEQALQQRKQALVSDLETICGAKQKVLQSQLDTLRQGQEHIGSSCSFAEQALRLGSAPEVLLVRKHMRERLAALAAQAFPERPHENAQLELVLEVDGLRRSVLNLGALLTTSATAHETVATGEGLRQALVGQPASLTVTTKDKDGRLVRTGSAELRAEITGPDGTRLPVPVVDHKNGTYELVYTARTEGELLLSVLLYGQPVRGSPFRVRALRPGDLPPSPDDVKRRVKSPGGPGSHVRQKAVRRPSSMYSTGGKRKDNPIEDELVFRVGSRGREKGEFTNLQGVSAASSGRIVVADSNNQCIQVFSNEGQFKFRFGVRGRSPGQLQRPTGVAVDTNGDIIVADYDNRWVSIFSPEGKFKTKIGAGRLMGPKGVAVDRNGHIIVVDNKSCCVFTFQPNGKLVGRFGGRGATDRHFAGPHFVAVNNKNEIVVTDFHNHSVKVYSADGEFLFKFGSHGEGNGQFNAPTGVAVDSNGNIIVADWGNSRIQVFDSSGSFLSYINTSAEPLYGPQGLALTSDGHVVVADAGNHCFKAYRYLQ>sp|O75382-3|TRIM3_HUMAN Isoform Gamma of Tripartite motif-containingprotein 3 OS=Homo sapiens OX=9606 GN=TRIM3MAKREDSPGPEVQPMDKQFLVCSICLDRYQCPKVLPCLHTFCERCLQNYIPAQSLTLSCPVCRQTSILPEQGVSALQNNFFISSLMEAMQQAPDGAHDPEDPHPLSVVAGRPLSCPNHEGKTMEFYCEACETAMCGECRAGEHREHGTVLLRDVVEQHKAALQRQLEAVRGRLPQLSAAIALVGGISQQLQERKAEALAQISAAFEDLEQALQQRKQALVSDLDGLRRSVLNLGALLTTSATAHETVATGEGLRQALVGQPASLTVTTKDKDGRLVRTGSAELRAEITGPDGTRLPVPVVDHKNGTYELVYTARTEGELLLSVLLYGQPVRGSPFRVRALRPGDLPPSPDDVKRRVKSPGGPGSHVRQKAVRRPSSMYSTGGKRKDNPIEDELVFRVGSRGREKGEFTNLQGVSAASSGRIVVADSNNQCIQVFSNEGQFKFRFGVRGRSPGQLQRPTGVAVDTNGDIIVADYDNRWVSIFSPEGKFKTKIGAGRLMGPKGVAVDRNGHIIVVDNKSCCVFTFQPNGKLVGRFGGRGATDRHFAGPHFVAVNNKNEIVVTDFHNHSVKVYSADGEFLFKFGSHGEGNGQFNAPTGVAVDSNGNIIVADWGNSRIQVFDSSGSFLSYINTSAEPLYGPQGLALTSDGHVVVADAGNHCFKAYRYLQ>sp|O75382-4|TRIM3_HUMAN Isoform 4 of Tripartite motif-containing protein3 OS=Homo sapiens OX=9606 GN=TRIM3MKTMEFYCEACETAMCGECRAGEHREHGTVLLRDVVEQHKAALQRQLEAVRGRLPQLSAAIALVGGISQQLQERKAEALAQISAAFEDLEQALQQRKQALVSDLETICGAKQKVLQSQLDTLRQGQEHIGSSCSFAEQALRLGSAPEVLLVRKHMRERLAALAAQAFPERPHENAQLELVLEVDGLRRSVLNLGALLTTSATAHETVATGEGLRQALVGQPASLTVTTKDKDGRLVRTGSAELRAEITGPDGTRLPVPVVDHKNGTYELVYTARTEGELLLSVLLYGQPVRGSPFRVRALRPGDLPPSPDDVKRRVKSPGGPGSHVRQKAVRRPSSMYSTGGKRKDNPIEDELVFRVGSRGREKGEFTNLQGVSAASSGRIVVADSNNQCIQVFSNEGQFKFRFGVRGRSPGQLQRPTGVAVDTNGDIIVADYDNRWVSIFSPEGKFKTKIGAGRLMGPKGVAVDRNGHIIVVDNKSCCVFTFQPNGKLVGRFGGRGATDRHFAGPHFVAVNNKNEIVVTDFHNHSVKVYSADGEFLFKFGSHGEGNGQFNAPTGVAVDSNGNIIVADWGNSRIQVFDSSGSFLSYINTSAEPLYGPQGLALTSDGHVVVADAGNHCFKAYRYLQ>sp|Q15035|TRAM2_HUMAN Translocating chain-associated membrane protein 2OS=Homo sapiens OX=9606 GN=TRAM2 PE=1 SV=1MAFRRRTKSYPLFSQEFVIHNHADIGFCLVLCVLIGLMFEVTAKTAFLFILPQYNISVPTADSETVHYHYGPKDLVTILFYIFITIILHAVVQEYILDKISKRLHLSKVKHSKFNESGQLVVFHFTSVIWCFYVVVTEGYLTNPRSLWEDYPHVHLPFQVKFFYLCQLAYWLHALPELYFQKVRKEEIPRQLQYICLYLVHIAGAYLLNLSRLGLILLLLQYSTEFLFHTARLFYFADENNEKLFSAWAAVFGVTRLFILTLAVLAIGFGLARMENQAFDPEKGNFNTLFCRLCVLLLVCAAQAWLMWRFIHSQLRHWREYWNEQSAKRRVPATPRLPARLIKRESGYHENGVVKAENGTSPRTKKLKSP>sp|Q5JXX7|TMM31_HUMAN Transmembrane protein 31 OS=Homo sapiens OX=9606GN=TMEM31 PE=1 SV=1MRLTEKSEGEQQLKPNNSNAPNEDQEEEIQQSEQHTPARQRTQRADTQPSRCRLPSRRTPTTSSDRTINLLEVLPWPTEWIFNPYRLPALFELYPEFLLVFKEAFHDISHCLKAQMEKIGLPIILHLFALSTLYFYKFFLPTILSLSFFILLVLLLLLFIIVFILIFF>sp|Q9NVH6|TMLH_HUMAN Trimethyllysine dioxygenase, mitochondrial OS=Homosapiens OX=9606 GN=TMLHE PE=1 SV=1MWYHRLSHLHSRLQDLLKGGVIYPALPQPNFKSLLPLAVHWHHTASKSLTCAWQQHEDHFELKYANTVMRFDYVWLRDHCRSASCYNSKTHQRSLDTASVDLCIKPKTIRLDETTLFFTWPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIRYNNYDRAVINTVPYDVVHRWYTAHRTLTIELRRPENEFWVKLKPGRVLFIDNWRVLHGRECFTGYRQLCGCYLTRDDVLNTARLLGLQA>sp|Q9NVH6-3|TMLH_HUMAN Isoform 2 of Trimethyllysine dioxygenase,mitochondrial OS=Homo sapiens OX=9606 GN=TMLHEMWYHRLSHLHSRLQDLLKGGVIYPALPQPNFKSLLPLAVHWHHTASKSLTCAWQQHEDHFELKYANTVMRFDYVWLRDHCRSASCYNSKTHQRSLDTASVDLCIKPKTIRLDETTLFFTWPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIRVLRSWCSTRTIEATSKEIKLYIVCRYSYFGETLFPRSKETVTSLPHMCAYKAAATNRPWLSGVFYTI>sp|Q9NVH6-4|TMLH_HUMAN Isoform 3 of Trimethyllysine dioxygenase,mitochondrial OS=Homo sapiens OX=9606 GN=TMLHEMWYHRLSHLHSRLQDLLKGGVIYPALPQPNFKSLLPLAVHWHHTASKSLTCAWQQHEDHFELKYANTVMRFDYVWLRDHCRSASCYNSKTHQRSLDTASVDLCIKPKTIRLDETTLFFTWPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIR>sp|Q9NVH6-2|TMLH_HUMAN Isoform 4 of Trimethyllysine dioxygenase,mitochondrial OS=Homo sapiens OX=9606 GN=TMLHEMWYHRLSHLHSRLQDLLKGGVIYPALPQPNFKSLLPLAVHWHHTASKSLTCAWQQHEDHFELKYANTVMRFDYVWLRDHCRSASCYNSKTHQRSLDTASVDLCIKPKTIRLDETTLFFTWPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIRLFKEKQNTVNRQWNSSLQCDIPERILTYRHFVSGTSIEHRGSLI>sp|Q9NVH6-5|TMLH_HUMAN Isoform 5 of Trimethyllysine dioxygenase,mitochondrial OS=Homo sapiens OX=9606 GN=TMLHEMWYHRLSHLHSRLQDLLKGGVIYPALPQPNFKSLLPLAVHWHHTASKSLTCAWQQHEDHFELKYANTVMRFDYVWLRDHCRSASCYNSKTHQRSLDTASVDLCIKPKTIRLDETTLFFTWPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIRYNNYDRAVINTVPYDVVHRWYTAHRTLTIELRRPENEFWVKLKPGRVGPN>sp|Q9NVH6-6|TMLH_HUMAN Isoform 6 of Trimethyllysine dioxygenase,mitochondrial OS=Homo sapiens OX=9606 GN=TMLHEMWYHRLSHLHSRLQDLLKGGVIYPALPQPNFKSLLPLAVHWHHTASKSLTCAWQQHEDHFGPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIRYNNYDRAVINTVPYDVVHRWYTAHRTLTIELRRPENEFWVKLKPGRVLFIDNWRVLHGRECFTGYRQLCGCYLTRDDVLNTARLLGLQA>sp|Q9NVH6-7|TMLH_HUMAN Isoform 7 of Trimethyllysine dioxygenase,mitochondrial OS=Homo sapiens OX=9606 GN=TMLHEMRFDYVWLRDHCRSASCYNSKTHQRSLDTASVDLCIKPKTIRLDETTLFFTWPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIRYNNYDRAVINTVPYDVVHRWYTAHRTLTIELRRPENEFWVKLKPGRVLFIDNWRVLHGRECFTGYRQLCGCYLTRDDVLNTARLLGLQA>sp|Q9NVH6-8|TMLH_HUMAN Isoform 8 of Trimethyllysine dioxygenase,mitochondrial OS=Homo sapiens OX=9606 GN=TMLHEMKIDSFLPILRMWYHRLSHLHSRLQDLLKGGVIYPALPQPNFKSLLPLAVHWHHTASKSLTCAWQQHEDHFELKYANTVMRFDYVWLRDHCRSASCYNSKTHQRSLDTASVDLCIKPKTIRLDETTLFFTWPDGHVTKYDLNWLVKNSYEGQKQKVIQPRILWNAEIYQQAQVPSVDCQSFLETNEGLKKFLQNFLLYGIAFVENVPPTQEHTEKLAERISLIRETIYGRMWYFTSDFSRGDTAYTKLALDRHTDTTYFQEPCGIQVFHCLKHEGTGGRTLLVDGFYAAEQVLQKAPEEFELLSKVPLKHEYIEDVGECHNHMIGIGPVLNIYPWNKELYLIRYNNYDRAVINTVPYDVVHRWYTAHRTLTIELRRPENEFWVKLKPGRVLFIDNWRVLHGRECFTGYRQLCGCYLTRDDVLNTARLLGLQA>sp|P07478|TRY2_HUMAN Trypsin-2 OS=Homo sapiens OX=9606 GN=PRSS2 PE=1SV=1MNLLLILTFVAAAVAAPFDDDDKIVGGYICEENSVPYQVSLNSGYHFCGGSLISEQWVVSAGHCYKSRIQVRLGEHNIEVLEGNEQFINAAKIIRHPKYNSRTLDNDILLIKLSSPAVINSRVSAISLPTAPPAAGTESLISGWGNTLSSGADYPDELQCLDAPVLSQAECEASYPGKITNNMFCVGFLEGGKDSCQGDSGGPVVSNGELQGIVSWGYGCAQKNRPGVYTKVYNYVDWIKDTIAANS>sp|O00295|TULP2_HUMAN Tubby-related protein 2 OS=Homo sapiens OX=9606GN=TULP2 PE=2 SV=2MSQDNDTLMRDILGHELAAMRLQKLEQQRRLFEKKQRQKRQELLMVQANPDASPWLWRSCLREERLLGDRGLGNPFLRKKVSEAHLPSGIHSALGTVSCGGDGRGERGLPTPRTEAVFRNLGLQSPFLSWLPDNSDAELEEVSVENGSVSPPPFKQSPRIRRKGWQAHQRPGTRAEGESDSQDMGDAHKSPNMGPNPGMDGDCVYENLAFQKEEDLEKKREASESTGTNSSAAHNEELSKALKGEGGTDSDHMRHEASLAIRSPCPGLEEDMEAYVLRPALPGTMMQCYLTRDKHGVDKGLFPLYYLYLETSDSLQRFLLAGRKRRRSKTSNYLISLDPTHLSRDGDNFVGKVRSNVFSTKFTIFDNGVNPDREHLTRNTARIRQELGAVCYEPNVLGYLGPRKMTVILPGTNSQNQRINVQPLNEQESLLSRYQRGDKQGLLLLHNKTPSWDKENGVYTLNFHGRVTRASVKNFQIVDPKHQEHLVLQFGRVGPDTFTMDFCFPFSPLQAFSICLSSFN>sp|Q86WB7|UN93A_HUMAN Protein unc-93 homolog A OS=Homo sapiens OX=9606GN=UNC93A PE=1 SV=1MDRSLRNVLVVSFGFLLLFTAYGGLQSLQSSLYSEEGLGVTALSTLYGGMLLSSMFLPPLLIERLGCKGTIILSMCGYVAFSVGNFFASWYTLIPTSILLGLGAAPLWSAQCTYLTITGNTHAEKAGKRGKDMVNQYFGIFFLIFQSSGVWGNLISSLVFGQTPSQETLPEEQLTSCGASDCLMATTTTNSTQRPSQQLVYTLLGIYTGSGVLAVLMIAAFLQPIRDVQRESEGEKKSVPFWSTLLSTFKLYRDKRLCLLILLPLYSGLQQGFLSSEYTRSYVTCTLGIQFVGYVMICFSATDALCSVLYGKVSQYTGRAVLYVLGAVTHVSCMIALLLWRPRADHLAVFFVFSGLWGVADAVWQTQNNALYGVLFEKSKEAAFANYRLWEALGFVIAFGYSMFLCVHVKLYILLGVLSLTMVAYGLVECVESKNPIRPHAPGQVNQAEDEEIQTKM>sp|Q86WB7-2|UN93A_HUMAN Isoform 2 of Protein unc-93 homolog A OS=Homosapiens OX=9606 GN=UNC93AMDRSLRNVLVVSFGFLLLFTAYGGLQSLQSSLYSEEGLGVTALSTLYGGMLLSSMFLPPLLIERLGCKGTIILSMCGYVAFSVGNFFASWYTLIPTSILLGLGAAPLWSAQCTYLTITGNTHAEKAGKRGKDMVNQYFGIFFLIFQSSGVWGNLISSLVFGQTPSQGSGVLAVLMIAAFLQPIRDVQRESEGEKKSVPFWSTLLSTFKLYRDKRLCLLILLPLYSGLQQGFLSSEYTRSYVTCTLGIQFVGYVMICFSATDALCSVLYGKVSQYTGRAVLYVLGAVTHVSCMIALLLWRPRADHLAVFFVFSGLWGVADAVWQTQNNALYGVLFEKSKEAAFANYRLWEALGFVIAFGYSMFLCVHVKLYILLGVLSLTMVAYGLVECVESKNPIRPHAPGQVNQAEDEEIQTKM>sp|Q9NRJ4|TULP4_HUMAN Tubby-related protein 4 OS=Homo sapiens OX=9606GN=TULP4 PE=1 SV=2MYAAVEHGPVLCSDSNILCLSWKGRVPKSEKEKPVCRRRYYEEGWLATGNGRGVVGVTFTSSHCRRDRSTPQRINFNLRGHNSEVVLVRWNEPYQKLATCDADGGIFVWIQYEGRWSVELVNDRGAQVSDFTWSHDGTQALISYRDGFVLVGSVSGQRHWSSEINLESQITCGIWTPDDQQVLFGTADGQVIVMDCHGRMLAHVLLHESDGVLGMSWNYPIFLVEDSSESDTDSDDYAPPQDGPAAYPIPVQNIKPLLTVSFTSGDISLMNNYDDLSPTVIRSGLKEVVAQWCTQGDLLAVAGMERQTQLGELPNGPLLKSAMVKFYNVRGEHIFTLDTLVQRPIISICWGHRDSRLLMASGPALYVVRVEHRVSSLQLLCQQAIASTLREDKDVSKLTLPPRLCSYLSTAFIPTIKPPIPDPNNMRDFVSYPSAGNERLHCTMKRTEDDPEVGGPCYTLYLEYLGGLVPILKGRRISKLRPEFVIMDPRTDSKPDEIYGNSLISTVIDSCNCSDSSDIELSDDWAAKKSPKISRASKSPKLPRISIEARKSPKLPRAAQELSRSPRLPLRKPSVGSPSLTRREFPFEDITQHNYLAQVTSNIWGTKFKIVGLAAFLPTNLGAVIYKTSLLHLQPRQMTIYLPEVRKISMDYINLPVFNPNVFSEDEDDLPVTGASGVPENSPPCTVNIPIAPIHSSAQAMSPTQSIGLVQSLLANQNVQLDVLTNQTTAVGTAEHAGDSATQYPVSNRYSNPGQVIFGSVEMGRIIQNPPPLSLPPPPQGPMQLSTVGHGDRDHEHLQKSAKALRPTPQLAAEGDAVVFSAPQEVQVTKINPPPPYPGTIPAAPTTAAPPPPLPPPQPPVDVCLKKGDFSLYPTSVHYQTPLGYERITTFDSSGNVEEVCRPRTRMLCSQNTYTLPGPGSSATLRLTATEKKVPQPCSSATLNRLTVPRYSIPTGDPPPYPEIASQLAQGRGAAQRSDNSLIHATLRRNNREATLKMAQLADSPRAPLQPLAKSKGGPGGVVTQLPARPPPALYTCSQCSGTGPSSQPGASLAHTASASPLASQSSYSLLSPPDSARDRTDYVNSAFTEDEALSQHCQLEKPLRHPPLPEAAVTLKRPPPYQWDPMLGEDVWVPQERTAQTSGPNPLKLSSLMLSQGQHLDVSRLPFISPKSPASPTATFQTGYGMGVPYPGSYNNPPLPGVQAPCSPKDALSPTQFAQQEPAVVLQPLYPPSLSYCTLPPMYPGSSTCSSLQLPPVALHPWSSYSACPPMQNPQGTLPPKPHLVVEKPLVSPPPADLQSHLGTEVMVETADNFQEVLSLTESPVPQRTEKFGKKNRKRLDSRAEEGSVQAITEGKVKKEARTLSDFNSLISSPHLGREKKKVKSQKDQLKSKKLNKTNEFQDSSESEPELFISGDELMNQSQGSRKGWKSKRSPRAAGELEEAKCRRASEKEDGRLGSQGFVYVMANKQPLWNEATQVYQLDFGGRVTQESAKNFQIELEGRQVMQFGRIDGSAYILDFQYPFSAVQAFAVALANVTQRLK>sp|Q9NRJ4-2|TULP4_HUMAN Isoform 2 of Tubby-related protein 4 OS=Homosapiens OX=9606 GN=TULP4MYAAVEHGPVLCSDSNILCLSWKGRVPKSEKEKPVCRRRYYEEGWLATGNGRGVVGVTFTSSHCRRDRSTPQRINFNLRGHNSEVVLVRWNEPYQKLATCDADGGIFVWIQYEGRWSVELVNDRGAQVSDFTWSHDGTQALISYRDGFVLVGSVSGQRHWSSEINLESQITCGIWTPDDQQVLFGTADGQVIVMDCHGRMLAHVLLHESDGVLGMSWNYPIFLVEDSSESDTDSDDYAPPQDGPAAYPIPVQNIKPLLTVSFTSGDISLMNNYDDLSPTVIRSGLKEVVAQWCTQGDLLAVAGMERQTQLGELPNGPLLKSAMVKFYNVRGEHIFTLDTLVQRPIISICWGHRDSRLLMASGPALYVVRVEHRVSSLQLLCQQAIASTLREDKDVSKLTLPPRLCSYLSTAFIPTIKPPIPDPNNMRDFVSYPSAGNERLHCTMKRTEDDPEVGGPCYTLYLEYLGGLVPILKGRRISKLRPEFVIMDPRTDSKPDEIYGNSLISTVIDSCNCSDSSDIELSDDWAAKKSPKISRASKSPKLPRISIEARKSPKLPRAAQELSRSPRLPLRKPSVGSPSLTRREFPFEDITQHNYLAQVTSNIWGTKFKIVGLAAFLPTNLGAVIYKTSLLHLQPRQMTIYLPEVRKISMDYINLPVFNPNVFSEDEDDLPGDAVWTD>sp|O95164|UBL3_HUMAN Ubiquitin-like protein 3 OS=Homo sapiens OX=9606GN=UBL3 PE=1 SV=1MSSNVPADMINLRLILVSGKTKEFLFSPNDSASDIAKHVYDNWPMDWEEEQVSSPNILRLIYQGRFLHGNVTLGALKLPFGKTTVMHLVARETLPEPNSQGQRNREKTGESNCCVIL>sp|Q86VY4|TSYL5_HUMAN Testis-specific Y-encoded-like protein 5 OS=Homosapiens OX=9606 GN=TSPYL5 PE=1 SV=2MSGRSRGRKSSRAKNRGKGRAKARVRPAPDDAPRDPDPSQYQSLGEDTQAAQVQAGAGWGGLEAAASAQLLRLGEEAACRLPLDCGLALRARAAGDHGQAAARPGPGKAASLSERLAADTVFVGTAGTVGRPKNAPRVGNRRGPAGKKAPETCSTAGRGPQVIAGGRQKKGAAGENTSVSAGEEKKEERDAGSGPPATEGSMDTLENVQLKLENMNAQADRAYLRLSRKFGQLRLQHLERRNHLIQNIPGFWGQAFQNHPQLASFLNSQEKEVLSYLNSLEVEELGLARLGYKIKFYFDRNPYFQNKVLIKEYGCGPSGQVVSRSTPIQWLPGHDLQSLSQGNPENNRSFFGWFSNHSSIESDKIVEIINEELWPNPLQFYLLSEGARVEKGKEKEGRQGPGKQPMETTQPGVSQSN>sp|P54578|UBP14_HUMAN Ubiquitin carboxyl-terminal hydrolase 14 OS=Homosapiens OX=9606 GN=USP14 PE=1 SV=3MPLYSVTVKWGKEKFEGVELNTDEPPMVFKAQLFALTGVQPARQKVMVKGGTLKDDDWGNIKIKNGMTLLMMGSADALPEEPSAKTVFVEDMTEEQLASAMELPCGLTNLGNTCYMNATVQCIRSVPELKDALKRYAGALRASGEMASAQYITAALRDLFDSMDKTSSSIPPIILLQFLHMAFPQFAEKGEQGQYLQQDANECWIQMMRVLQQKLEAIEDDSVKETDSSSASAATPSKKKSLIDQFFGVEFETTMKCTESEEEEVTKGKENQLQLSCFINQEVKYLFTGLKLRLQEEITKQSPTLQRNALYIKSSKISRLPAYLTIQMVRFFYKEKESVNAKVLKDVKFPLMLDMYELCTPELQEKMVSFRSKFKDLEDKKVNQQPNTSDKKSSPQKEVKYEPFSFADDIGSNNCGYYDLQAVLTHQGRSSSSGHYVSWVKRKQDEWIKFDDDKVSIVTPEDILRLSGGGDWHIAYVLLYGPRRVEIMEEESEQ>sp|P54578-2|UBP14_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 14 OS=Homo sapiens OX=9606 GN=USP14MPLYSVTVKWGKEKFEGVELNTDEPPMVFKAQLFALTGVQPARQKVMVKGGTLKDDDWGNIKIKNMELPCGLTNLGNTCYMNATVQCIRSVPELKDALKRYAGALRASGEMASAQYITAALRDLFDSMDKTSSSIPPIILLQFLHMAFPQFAEKGEQGQYLQQDANECWIQMMRVLQQKLEAIEDDSVKETDSSSASAATPSKKKSLIDQFFGVEFETTMKCTESEEEEVTKGKENQLQLSCFINQEVKYLFTGLKLRLQEEITKQSPTLQRNALYIKSSKISRLPAYLTIQMVRFFYKEKESVNAKVLKDVKFPLMLDMYELCTPELQEKMVSFRSKFKDLEDKKVNQQPNTSDKKSSPQKEVKYEPFSFADDIGSNNCGYYDLQAVLTHQGRSSSSGHYVSWVKRKQDEWIKFDDDKVSIVTPEDILRLSGGGDWHIAYVLLYGPRRVEIMEEESEQ>sp|P54578-3|UBP14_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 14 OS=Homo sapiens OX=9606 GN=USP14MPLYSVTVKWGKEKFEGVELNTDEPPMVFKAQLFALTGVQPARQKVMVKGGTLKGMTLLMMGSADALPEEPSAKTVFVEDMTEEQLASAMELPCGLTNLGNTCYMNATVQCIRSVPELKDALKRYAGALRASGEMASAQYITAALRDLFDSMDKTSSSIPPIILLQFLHMAFPQFAEKGEQGQYLQQDANECWIQMMRVLQQKLEAIEDDSVKETDSSSASAATPSKKKSLIDQFFGVEFETTMKCTESEEEEVTKGKENQLQLSCFINQEVKYLFTGLKLRLQEEITKQSPTLQRNALYIKSSKISRLPAYLTIQMVRFFYKEKESVNAKVLKDVKFPLMLDMYELCTPELQEKMVSFRSKFKDLEDKKVNQQPNTSDKKSSPQKEVKYEPFSFADDIGSNNCGYYDLQAVLTHQGRSSSSGHYVSWVKRKQDEWIKFDDDKVSIVTPEDILRLSGGGDWHIAYVLLYGPRRVEIMEEESEQ>sp|Q9C0B0|UNK_HUMAN RING finger protein unkempt homolog OS=Homo sapiensOX=9606 GN=UNK PE=1 SV=2MSKGPGPGGSAASSAPPAATAQVLQAQPEKPQHYTYLKEFRTEQCPLFVQHKCTQHRPYTCFHWHFVNQRRRRSIRRRDGTFNYSPDVYCTKYDEATGLCPEGDECPFLHRTTGDTERRYHLRYYKTGICIHETDSKGNCTKNGLHCAFAHGPHDLRSPVYDIRELQAMEALQNGQTTVEGSIEGQSAGAASHAMIEKILSEEPRWQETAYVLGNYKTEPCKKPPRLCRQGYACPYYHNSKDRRRSPRKHKYRSSPCPNVKHGDEWGDPGKCENGDACQYCHTRTEQQFHPEIYKSTKCNDMQQSGSCPRGPFCAFAHVEQPPLSDDLQPSSAVSSPTQPGPVLYMPSAAGDSVPVSPSSPHAPDLSALLCRNSSLGSPSNLCGSPPGSIRKPPNLEGIVFPGESGLAPGSYKKAPGFEREDQVGAEYLKNFKCQAKLKPHSLEPRSQEQPLLQPKQDMLGILPAGSPLTSSISSSITSSLAATPPSPVGTSSVPGMNANALPFYPTSDTVESVIESALDDLDLNEFGVAALEKTFDNSTVPHPGSITIGGSLLQSSAPVNIPGSLGSSASFHSASPSPPVSLSSHFLQQPQGHLSQSENTFLGTSASHGSLGLNGMNSSIWEHFASGSFSPGTSPAFLSGPGAAELARLRQELDEANSTIKQWEESWKQAKQACDAWKKEAEEAGERASAAGAECELAREQRDALEVQVKKLQEELERLHAGPEPQALPAFSDLEALSLSTLYSLQKQLRAHLEQVDKAVFHMQSVKCLKCQEQKRAVLPCQHAALCELCAEGSECPICQPGRAHTLQS>sp|Q9Y4E8|UBP15_HUMAN Ubiquitin carboxyl-terminal hydrolase 15 OS=Homosapiens OX=9606 GN=USP15 PE=1 SV=3MAEGGAADLDTQRSDIATLLKTSLRKGDTWYLVDSRWFKQWKKYVGFDSWDKYQMGDQNVYPGPIDNSGLLKDGDAQSLKEHLIDELDYILLPTEGWNKLVSWYTLMEGQEPIARKVVEQGMFVKHCKVEVYLTELKLCENGNMNNVVTRRFSKADTIDTIEKEIRKIFSIPDEKETRLWNKYMSNTFEPLNKPDSTIQDAGLYQGQVLVIEQKNEDGTWPRGPSTPKSPGASNFSTLPKISPSSLSNNYNNMNNRNVKNSNYCLPSYTAYKNYDYSEPGRNNEQPGLCGLSNLGNTCFMNSAIQCLSNTPPLTEYFLNDKYQEELNFDNPLGMRGEIAKSYAELIKQMWSGKFSYVTPRAFKTQVGRFAPQFSGYQQQDCQELLAFLLDGLHEDLNRIRKKPYIQLKDADGRPDKVVAEEAWENHLKRNDSIIVDIFHGLFKSTLVCPECAKISVTFDPFCYLTLPLPMKKERTLEVYLVRMDPLTKPMQYKVVVPKIGNILDLCTALSALSGIPADKMIVTDIYNHRFHRIFAMDENLSSIMERDDIYVFEININRTEDTEHVIIPVCLREKFRHSSYTHHTGSSLFGQPFLMAVPRNNTEDKLYNLLLLRMCRYVKISTETEETEGSLHCCKDQNINGNGPNGIHEEGSPSEMETDEPDDESSQDQELPSENENSQSEDSVGGDNDSENGLCTEDTCKGQLTGHKKRLFTFQFNNLGNTDINYIKDDTRHIRFDDRQLRLDERSFLALDWDPDLKKRYFDENAAEDFEKHESVEYKPPKKPFVKLKDCIELFTTKEKLGAEDPWYCPNCKEHQQATKKLDLWSLPPVLVVHLKRFSYSRYMRDKLDTLVDFPINDLDMSEFLINPNAGPCRYNLIAVSNHYGGMGGGHYTAFAKNKDDGKWYYFDDSSVSTASEDQIVSKAAYVLFYQRQDTFSGTGFFPLDRETKGASAATGIPLESDEDSNDNDNDIENENCMHTN>sp|Q9Y4E8-2|UBP15_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 15 OS=Homo sapiens OX=9606 GN=USP15MAEGGAADLDTQRSDIATLLKTSLRKGDTWYLVDSRWFKQWKKYVGFDSWDKYQMGDQNVYPGPIDNSGLLKDGDAQSLKEHLIDELDYILLPTEGWNKLVSWYTLMEGQEPIARKVVEQGMFVKHCKVEVYLTELKLCENGNMNNVVTRRFSKADTIDTIEKEIRKIFSIPDEKETRLWNKYMSNTFEPLNKPDSTIQDAGLYQGQVLVIEQKNEDGTWPRGPSTPNVKNSNYCLPSYTAYKNYDYSEPGRNNEQPGLCGLSNLGNTCFMNSAIQCLSNTPPLTEYFLNDKYQEELNFDNPLGMRGEIAKSYAELIKQMWSGKFSYVTPRAFKTQVGRFAPQFSGYQQQDCQELLAFLLDGLHEDLNRIRKKPYIQLKDADGRPDKVVAEEAWENHLKRNDSIIVDIFHGLFKSTLVCPECAKISVTFDPFCYLTLPLPMKKERTLEVYLVRMDPLTKPMQYKVVVPKIGNILDLCTALSALSGIPADKMIVTDIYNHRFHRIFAMDENLSSIMERDDIYVFEININRTEDTEHVIIPVCLREKFRHSSYTHHTGSSLFGQPFLMAVPRNNTEDKLYNLLLLRMCRYVKISTETEETEGSLHCCKDQNINGNGPNGIHEEGSPSEMETDEPDDESSQDQELPSENENSQSEDSVGGDNDSENGLCTEDTCKGQLTGHKKRLFTFQFNNLGNTDINYIKDDTRHIRFDDRQLRLDERSFLALDWDPDLKKRYFDENAAEDFEKHESVEYKPPKKPFVKLKDCIELFTTKEKLGAEDPWYCPNCKEHQQATKKLDLWSLPPVLVVHLKRFSYSRYMRDKLDTLVDFPINDLDMSEFLINPNAGPCRYNLIAVSNHYGGMGGGHYTAFAKNKDDGKWYYFDDSSVSTASEDQIVSKAAYVLFYQRQDTFSGTGFFPLDRETKGASAATGIPLESDEDSNDNDNDIENENCMHTN>sp|Q9Y4E8-3|UBP15_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 15 OS=Homo sapiens OX=9606 GN=USP15MAEGGAADLDTQRSDIATLLKTSLRKGDTWYLVDSRWFKQWKKYVGFDSWDKYQMGDQNVYPGPIDNSGLLKDGDAQSLKEHLIDELDYILLPTEGWNKLVSWYTLMEGQEPIARKVVEQGMFVKHCKVEVYLTELKLCENGNMNNVVTRRFSKADTIDTIEKEIRKIFSIPDEKETRLWNKYMSNTFEPLNKPDSTIQDAGLYQGQVLVIEQKNEQKNEDGTWPRGPSTPNVKNSNYCLPSYTAYKNYDYSEPGRNNEQPGLCGLSNLGNTCFMNSAIQCLSNTPPLTEYFLNDKYQEELNFDNPLGMRGEIAKSYAELIKQMWSGKFSYVTPRAFKTQVGRFAPQFSGYQQQDCQELLAFLLDGLHEDLNRIRKKPYIQLKDADGRPDKVVAEEAWENHLKRNDSIIVDIFHGLFKSTLVCPECAKISVTFDPFCYLTLPLPMKKERTLEVYLVRMDPLTKPMQYKVVVPKIGNILDLCTALSALSGIPADKMIVTDIYNHRFHRIFAMDENLSSIMERDDIYVFEININRTEDTEHVIIPVCLREKFRHSSYTHHTGSSLFGQPFLMAVPRNNTEDKLYNLLLLRMCRYVKISTETEETEGSLHCCKDQNINGNGPNGIHEEGSPSEMETDEPDDESSQDQELPSENENSQSEDSVGGDNDSENGLCTEDTCKGQLTGHKKRLFTFQFNNLGNTDINYIKDDTRHIRFDDRQLRLDERSFLALDWDPDLKKRYFDENAAEDFEKHESVEYKPPKKPFVKLKDCIELFTTKEKLGAEDPWYCPNCKEHQQATKKLDLWSLPPVLVVHLKRFSYSRYMRDKLDTLVDFPINDLDMSEFLINPNAGPCRYNLIAVSNHYGGMGGGHYTAFAKNKDDGKWYYFDDSSVSTASEDQIVSKAAYVLFYQRQDTFSGTGFFPLDRETKGASAATGIPLESDEDSNDNDNDIENENCMHTN>sp|Q9Y4E8-4|UBP15_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase 15 OS=Homo sapiens OX=9606 GN=USP15MAEGGAADLDTQRSDIATLLKTSLRKGDTWYLVDSRWFKQWKKYVGFDSWDKYQMGDQNVYPGPIDNSGLLKDGDAQSLKEHLIDELDYILLPTEGWNKLVSWYTLMEGQEPIARKVVEQGMFVKHCKVEVYLTELKLCENGNMNNVVTRRFSKADTIDTIEKEIRKIFSIPDEKETRLWNKYMSNTFEPLNKPDSTIQDAGLYQGQVLVIEQKNEDGTWPRGPSTPKKPLEQSC>sp|Q16222|UAP1_HUMAN UDP-N-acetylhexosamine pyrophosphorylase OS=Homosapiens OX=9606 GN=UAP1 PE=1 SV=3MNINDLKLTLSKAGQEHLLRFWNELEEAQQVELYAELQAMNFEELNFFFQKAIEGFNQSSHQKNVDARMEPVPREVLGSATRDQDQLQAWESEGLFQISQNKVAVLLLAGGQGTRLGVAYPKGMYDVGLPSRKTLFQIQAERILKLQQVAEKYYGNKCIIPWYIMTSGRTMESTKEFFTKHKYFGLKKENVIFFQQGMLPAMSFDGKIILEEKNKVSMAPDGNGGLYRALAAQNIVEDMEQRGIWSIHVYCVDNILVKVADPRFIGFCIQKGADCGAKVVEKTNPTEPVGVVCRVDGVYQVVEYSEISLATAQKRSSDGRLLFNAGNIANHFFTVPFLRDVVNVYEPQLQHHVAQKKIPYVDTQGQLIKPDKPNGIKMEKFVFDIFQFAKKFVVYEVLREDEFSPLKNADSQNGKDNPTTARHALMSLHHCWVLNAGGHFIDENGSRLPAIPRSATNGKSETITADVNHNLKDANDVPIQCEISPLISYAGEGLESYVADKEFHAPLIIDENGVHELVKNGI>sp|Q16222-2|UAP1_HUMAN Isoform AGX1 of UDP-N-acetylhexosaminepyrophosphorylase OS=Homo sapiens OX=9606 GN=UAP1MNINDLKLTLSKAGQEHLLRFWNELEEAQQVELYAELQAMNFEELNFFFQKAIEGFNQSSHQKNVDARMEPVPREVLGSATRDQDQLQAWESEGLFQISQNKVAVLLLAGGQGTRLGVAYPKGMYDVGLPSRKTLFQIQAERILKLQQVAEKYYGNKCIIPWYIMTSGRTMESTKEFFTKHKYFGLKKENVIFFQQGMLPAMSFDGKIILEEKNKVSMAPDGNGGLYRALAAQNIVEDMEQRGIWSIHVYCVDNILVKVADPRFIGFCIQKGADCGAKVVEKTNPTEPVGVVCRVDGVYQVVEYSEISLATAQKRSSDGRLLFNAGNIANHFFTVPFLRDVVNVYEPQLQHHVAQKKIPYVDTQGQLIKPDKPNGIKMEKFVFDIFQFAKKFVVYEVLREDEFSPLKNADSQNGKDNPTTARHALMSLHHCWVLNAGGHFIDENGSRLPAIPRLKDANDVPIQCEISPLISYAGEGLESYVADKEFHAPLIIDENGVHELVKNGI>sp|Q16222-3|UAP1_HUMAN Isoform 3 of UDP-N-acetylhexosaminepyrophosphorylase OS=Homo sapiens OX=9606 GN=UAP1MNINDLKLTLSKAGQEHLLRFWNELEEAQQVELYAELQAMNFEELNFFFQKAIEGFNQSSHQKNVDARMEPVPREVLGSATRDQDQLQAWESEGLFQISQNKVAVLLLAGGQGTRLGVAYPKGMYDVGLPSRKTLFQIQAERILKLQQVAEKYYGNKCIIPWYIMTSGRTMESTKEFFTKHKYFGLKKENVIFFQQGMLPAMSFDGKIILEEKNKVSMAPDGNGGLYRALAAQNIVEDMEQRGIWSIHVYCVDNILVKVADPRFIGFCIQKGADCGAKVVEKTNPTEPVGVVCRVDGVYQVVEYSEISLATAQKRSSDGRLLFNAGNIANHFFTVPFLRDVVNVYEPQLQHHVAQKKIPYVDTQGQLIKPDKPNGIKMEKFVFDIFQFAKKFVVYEVLREDEFSPLKNADSQNGKDNPTTARHALMSLHHCWVLNAGGHFIDENGSRLPAIPRATNGKSETITADVNHNLKDANDVPIQCEISPLISYAGEGLESYVADKEFHAPLIIDENGVHELVKNGI>sp|P51668|UB2D1_HUMAN Ubiquitin-conjugating enzyme E2 D1 OS=Homo sapiensOX=9606 GN=UBE2D1 PE=1 SV=1MALKRIQKELSDLQRDPPAHCSAGPVGDDLFHWQATIMGPPDSAYQGGVFFLTVHFPTDYPFKPPKIAFTTKIYHPNINSNGSICLDILRSQWSPALTVSKVLLSICSLLCDPNPDDPLVPDIAQIYKSDKEKYNRHAREWTQKYAM>sp|Q9H347|UBQL3_HUMAN Ubiquilin-3 OS=Homo sapiens OX=9606 GN=UBQLN3 PE=1SV=2MAKGGEALPQGSPAPVQDPHLIKVTVKTPKDKEDFSVTDTCTIQQLKEEISQRFKAHPDQLVLIFAGKILKDPDSLAQCGVRDGLTVHLVIKRQHRAMGNECPAASVPTQGPSPGSLPQPSSIYPADGPPAFSLGLLTGLSRLGLAYRGFPDQPSSLMRQHVSVPEFVTQLIDDPFIPGLLSNTGLVRQLVLDNPHMQQLIQHNPEIGHILNNPEIMRQTLEFLRNPAMMQEMIRSQDRVLSNLESIPGGYNVLCTMYTDIMDPMLNAVQEQFGGNPFATATTDNATTTTSQPSRMENCDPLPNPWTSTHGGSGSRQGRQDGDQDAPDIRNRFPNFLGIIRLYDYLQQLHENPQSLGTYLQGTASALSQSQEPPPSVNRVPPSSPSSQEPGSGQPLPEESVAIKGRSSCPAFLRYPTENSTGQGGDQDGAGKSSTGHSTNLPDLVSGLGDSANRVPFAPLSFSPTAAIPGIPEPPWLPSPAYPRSLRPDGMNPAPQLQDEIQPQLPLLMHLQAAMANPRALQALRQIEQGLQVLATEAPRLLLWFMPCLAGTGSVAGGIESREDPLMSEDPLPNPPPEVFPALDSAELGFLSPPFLHMLQDLVSTNPQQLQPEAHFQVQLEQLRSMGFLNREANLQALIATGGDVDAAVEKLRQS>sp|Q96LR5|UB2E2_HUMAN Ubiquitin-conjugating enzyme E2 E2 OS=Homo sapiensOX=9606 GN=UBE2E2 PE=1 SV=1MSTEAQRVDDSPSTSGGSSDGDQRESVQQEPEREQVQPKKKEGKISSKTAAKLSTSAKRIQKELAEITLDPPPNCSAGPKGDNIYEWRSTILGPPGSVYEGGVFFLDITFSPDYPFKPPKVTFRTRIYHCNINSQGVICLDILKDNWSPALTISKVLLSICSLLTDCNPADPLVGSIATQYMTNRAEHDRMARQWTKRYAT>sp|P63279|UBC9_HUMAN SUMO-conjugating enzyme UBC9 OS=Homo sapiensOX=9606 GN=UBE2I PE=1 SV=1MSGIALSRLAQERKAWRKDHPFGFVAVPTKNPDGTMNLMNWECAIPGKKGTPWEGGLFKLRMLFKDDYPSSPPKCKFEPPLFHPNVYPSGTVCLSILEEDKDWRPAITIKQILLGIQELLNEPNIQDPAQAEAYTIYCQNRVEYEKRVRAQAKKFAPS>sp|Q9Y2B5|VP9D1_HUMAN VPS9 domain-containing protein 1 OS=Homo sapiensOX=9606 GN=VPS9D1 PE=1 SV=2MAAAAGDGTVKPLQSAMKLANGAIELDTGNRPREAYTEYLRSIHYISQVLLEEVETTKEAGETVPPDTSKMLKLAQQCLERAQSTAAKLGKTRLKPTMPAAAPIPQPAGRHRRVYSDEGGKLSPFLPPEIFQKLQGAESQSCKKELTPLEEASLQNQKLKAAYEARMARLDPSQAMQKTSLTLSLQRQMMENLVIAKAREETLQRKMEERRLRLQEAANRRFCSQVALTPEEREQRALYAAILEYEQDHDWPKHWKAKLKRNPGDLSLVTSLVSHLLSLPDHPIAQLLRRLQCSVYSALYPAVSRAAAPAPGCCPPTPNPGSRRLRPSQSLHCMLSPPEPSAAPRPQDSPPTPPLQPGPVGSPSPLGDTASGLPDKDSSFEDLEQFLGTSERQGRGRGVQPEPQLQQLKTAVEEIHNAVDRLLSLTLLAFEGLNTAASKDRCLACIEEPFFSPLWPLLLALYRSVHRAREAALSRSMELYRNAPPTAIGIPTKLLPQNPEAKGATGYPYCAAAQELGLLVLESCPQKKLECIVRTLRIICVCAEDYCPTPEATPQAGPPPIAAAAIGADDLLPILSFVVLRSGLPQLVSECAALEEFIHEGYLIGEEGYCLTSLQSALSYVELLPRGGLAK>sp|Q9Y2B5-2|VP9D1_HUMAN Isoform 2 of VPS9 domain-containing protein 1OS=Homo sapiens OX=9606 GN=VPS9D1MLLCPAQKTVFRLQLTTAAQCLWVYLRDKQVVVFLAYPTRAPGRNNGVTSLHWPDPTLSLSWTQEAYTEYLRSIHYISQVLLEEVETTKEAGETVPPDTSKMLKLAQQCLERAQSTAAKLGKTRLKPTMPAAAPIPQPAGRHRRVYSDEGGKLSPFLPPEIFQKLQGAESQSCKKELTPLEEASLQNQKLKAAYEARMARLDPSQAMQKTSLTLSLQRQMMENLVIAKAREETLQRKMEERRLRLQEAANRRFCSQVALTPEEREQRALYAAILEYEQDHDWPKHWKAKLKRNPGDLSLVTSLVSHLLSLPDHPIAQLLRRLQCSVYSALYPAVSRAAAPAPGCCPPTPNPGSRRLRPSQSLHCMLSPPEPSAAPRPQDSPPTPPLQPGPVGSPSPLGDTASGLPDKDSSFEDLEQFLGTSERQGRGRGVQPEPQLQQLKTAVEEIHNAVDRLLSLTLLAFEGLNTAASKDRCLACIEEPFFSPLWPLLLALYRSVHRAREAALSRSMELYRNAPPTAIGIPTKLLPQNPEAKGATGYPYCAAAQELGLLVLESCPQKKLECIVRTLRIICVCAEDYCPTPEATPQAGPPPIAAAAIGADDLLPILSFVVLRSGLPQLVSECAALEEFIHEGYLIGEEGYCLTSLQSALSYVELLPRGGLAK>sp|Q9UKI3|VPRE3_HUMAN Pre-B lymphocyte protein 3 OS=Homo sapiens OX=9606GN=VPREB3 PE=2 SV=1MACRCLSFLLMGTFLSVSQTVLAQLDALLVFPGQVAQLSCTLSPQHVTIRDYGVSWYQQRAGSAPRYLLYYRSEEDHHRPADIPDRFSAAKDEAHNACVLTISPVQPEDDADYYCSVGYGFSP>sp|O00534|VMA5A_HUMAN von Willebrand factor A domain-containing protein5A OS=Homo sapiens OX=9606 GN=VWA5A PE=1 SV=2MVHFCGLLTLHREPVPLKSISVSVNIYEFVAGVSATLNYENEEKVPLEAFFVFPMDEDSAVYSFEALVDGKKIVAELQDKMKARTNYEKAISQGHQAFLLEGDSSSRDVFSCNVGNLQPGSKAAVTLKYVQELPLEADGALRFVLPAVLNPRYQFSGSSKDSCLNVKTPIVPVEDLPYTLSMVATIDSQHGIEKVQSNCPLSPTEYLGEDKTSAQVSLAAGHKFDRDVELLIYYNEVHTPSVVLEMGMPNMKPGHLMGDPSAMVSFYPNIPEDQPSNTCGEFIFLMDRSGSMQSPMSSQDTSQLRIQAAKETLILLLKSLPIGCYFNIYGFGSSYEACFPESVKYTQQTMEEALGRVKLMQADLGGTEILAPLQNIYRGPSIPGHPLQLFVFTDGEVTDTFSVIKEVRINRQKHRCFSFGIGEGTSTSLIKGIARASGGTSEFITGKDRMQSKALRTLKRSLQPVVEDVSLSWHLPPGLSAKMLSPEQTVIFRGQRLISYAQLTGRMPAAETTGEVCLKYTLQGKTFEDKVTFPLQPKPDVNLTIHRLAAKSLLQTKDMGLRETPASDKKDALNLSLESGVISSFTAFIAINKELNKPVQGPLAHRDVPRPILLGASAPLKIKCQSGFRKALHSDRPPSASQPRGELMCYKAKTFQMDDYSLCGLISHKDQHSPGFGENHLVQLIYHQNANGSWDLNEDLAKILGMSLEEIMAAQPAELVDSSGWATILAVIWLHSNGKDLKCEWELLERKAVAWMRAHAGSTMPSVVKAAITFLKSSVDPAIFAF>sp|O00534-2|VMA5A_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 5A OS=Homo sapiens OX=9606 GN=VWA5AMVHFCGLLTLHREPVPLKSISVSVNIYEFVAGVSATLNYENEEKVPLEAFFVFPMDEDSAVYSFEALVDGKKIVAELQDKMKARTNYEKAISQGHQAFLLEGDSSSRDVFSCNVGNLQPGSKAAVTLKYVQELPLEADGALRFVLPAVLNPRYQFSGSSKDSCLNVKTPIVPVEDLPYTLSMVATIDSQHGIEKVQSNCPLSPTEYLGEDKTSAQVSLAAGHKFDRDVELLIYYNEVHTPSVVLEMGMPNMKPGHLMGDPSAMVSFYPNIPEDQPSNTCGEFIFLMDRSGSMQSPMSSQDTSQLRIQAAKETLILLLKSLPIGCYFNIYGFGSSYEACFPESVKYTQQTMEEALGRVKLMQADLGGTEILAPLQNIYRGPSIPGHPLQVFERPYTLTVLLLHLSPEGNLCVIRPRHSRWTITVSVG>sp|O00534-3|VMA5A_HUMAN Isoform 3 of von Willebrand factor A domain-containing protein 5A OS=Homo sapiens OX=9606 GN=VWA5AMVHFCGLLTLHREPVPLKSISVSVNIYEFVAGVSATLNYENEEKVPLEAFFVFPMDEDSAVYSFEALVDGKKIVAELQDKMKARTNYEKAISQGHQAFLLEGDSSSRDVFSCNVGNLQPGSKAAVTLKYVQELPLEADGALRFVLPAVLNPRYQFSGSSKDSCLNVKTPIVPVEDLPYTLSMVATIDSQHGIEKVQSNCPLSPTEYLGEDKTSAQVSLAAGHKFDRDVELLIYYNEVHTPSVVLEMGMPNMKPGHLMGDPSAMVSFYPNIPEDQPSNTCGEFIFLMDRSGSMQSPMSSQDTSQLRIQAAKETLILLLKSLPIGCYFNIYGFGSSYEACFPESVKYTQQTMEEALGRVKLMQADLGGTEILAPLQNIYRGPSIPGHPLQLFVFTDGEVTDTFSVIKEVRINRQKHR>sp|O00534-4|VMA5A_HUMAN Isoform 4 of von Willebrand factor A domain-containing protein 5A OS=Homo sapiens OX=9606 GN=VWA5AMVHFCGLLTLHREPVPLKSISVSVNIYEFVAGVSATLNYENEEKVPLEAFFVFPMDEDSAVYSFEALVDGKKIVAELQDKMKARTNYEKAISQGHQAFLLEGDSSSRDVFSCNVGNLQPGSKAAVTLKYVQELPLEADGALRFVLPAVLNPRYQFSGSSKDSCLNVKTPIVPVEDLPYTLSMVATIDSQHGIEKVQSNCPLSPTEYLGEDKTSAQVSLAAGHKFDRDVELLIYYNEVHTPSVVLEMGMPNMKPGHLMGDPSAMVRT>sp|Q5GH72|XKR7_HUMAN XK-related protein 7 OS=Homo sapiens OX=9606GN=XKR7 PE=2 SV=1MAAKSDGAAASASPDPEGAAGGARGSAGGRGEAAAAAGPPGVVGAGGPGPRYELRDCCWVLCALLVFFSDGATDLWLAASYYLQNQHTYFSLTLLFVLLPSLVVQLLSFRWFVYDYSEPAGSPGPAVSTKDSVAGGAAISTKDSAGAFRTKEGSPEPGPQPAPSSASAYRRRCCRLCIWLLQTLVHLLQLGQVWRYLRALYLGLQSRWRGERLRRHFYWQMLFESADVSMLRLLETFLRSAPQLVLQLSLLVHRGGAPDLLPALSTSASLVSLAWTLASYQKVLRDSRDDKRPLSYKGAVAQVLWHLFSIAARGLAFALFASVYKLYFGIFIVAHWCVMTFWVIQGETDFCMSKWEEIIYNMVVGIIYIFCWFNVKEGRSRRRMTLYHCIVLLENAALTGFWYSSRNFSTDFYSLIMVCVVASSFALGIFFMCVYYCLLHPNGPMLGPQAPGCIFRKASEPCGPPADAITSPPRSLPRTTGAERDGASAGERAGTPTPPVFQVRPGLPPTPVARTLRTEGPVIRIDLPRKKYPAWDAHFIDRRLRKTILALEYSSPATPRLQYRSVGTSQELLEYETTV>sp|Q9H8Y1|VRTN_HUMAN Vertnin OS=Homo sapiens OX=9606 GN=VRTN PE=1 SV=1MTSRNQLVQKVLQELQEAVECEGLEGLIGASLEAKQVLSSFTLPTCREGGPGLQVLEVDSVALSLYPEDAPRNMLPLVCKGEGSLLFEAASMLLWGDAGLSLELRARTVVEMLLHRHYYLQGMIDSKVMLQAVRYSLCSEESPEMTSLPPATLEAIFDADVKASCFPSSFSNVWHLYALASVLQRNIYSIYPMRNLKIRPYFNRVIRPRRCDHVPSTLHIMWAGQPLTSHFFRHQYFAPVVGLEEVEAEGAPGVAPALPALAPLSSPAKTLELLNREPGLSYSHLCERYSVTKSTFYRWRRQSQEHRQKVAARFSAKHFLQDSFHRGGVVPLQQFLQRFPEISRSTYYAWKHELLGSGTCPALPPREVLGMEELEKLPEEQVAEEELECSALAVSSPGMVLMQRAKLYLEHCISLNTLVPYRCFKRRFPGISRSTYYNWRRKALRRNPSFKPAPALSAAGTPQLASVGEGAVIPWKSEAEEGAGNATGEDPPAPGELLPLRMPLSRWQRRLRRAARRQVLSGHLPFCRFRLRYPSLSPSAFWVWKSLARGWPRGLSKLQVPVPTLGKGGQEAEEKQEKEAGRDVTAVMAPPVGASSEDVEGGPSREGALQEGATAQGQPHSGPLLSQPVVAAAGGRDGRMLVMDMIATTKFKAQAKLFLQKRFQSKSFPSYKEFSALFPLTARSTYYMWKRALYDGLTLVDG>sp|Q96PQ6|ZN317_HUMAN Zinc finger protein 317 OS=Homo sapiens OX=9606GN=ZNF317 PE=1 SV=2MAALSPTFATSTQDSTCLQDSEFPVSSKDHSCPQNLDLFVCSGLEPHTPSVGSQESVTFQDVAVDFTEKEWPLLDSSQRKLYKDVMLENYSNLTSLGYQVGKPSLISHLEQEEEPRTEERGAHQGACADWETPSKTKWSLLMEDIFGKETPSGVTMERAGLGEKSTEYAHLFEVFGMDPHLTQPMGRHAGKRPYHRRDYGVAFKGRPHLTQHMSMYDGRKMHECHQCQKAFTTSASLTRHRRIHTGEKPYECSDCGKAFNDPSALRSHARTHLKEKPFDCSQCGNAFRTLSALKIHMRVHTGERPYKCDQCGKAYGRSCHLIAHKRTHTGERPYECHDCGKAFQHPSHLKEHVRNHTGEKPYACTQCGKAFRWKSNFNLHKKNHMVEKTYECKECGKSFGDLVSRRKHMRIHIVKKPVECRQCGKTFRNQSILKTHMNSHTGEKPYGCDLCGKAFSASSNLTAHRKIHTQERRYECAACGKVFGDYLSRRRHMSVHLVKKRVECRQCGKAFRNQSTLKTHMRSHTGEKPYECDHCGKAFSIGSNLNVHRRIHTGEKPYECLVCGKAFSDHSSLRSHVKTHRGEKLFVSSVWKRLQ>sp|Q96PQ6-2|ZN317_HUMAN Isoform 1 of Zinc finger protein 317 OS=Homosapiens OX=9606 GN=ZNF317MAALSPTFATSTQDSTCLQDSEFPVSSKDHSCPQNLDLFVCSGLEPHTPSVGSQESVTFQDVAVDFTEKEWPLLDSSQRKLYKDVMLENYSNLTSLDWETPSKTKWSLLMEDIFGKETPSGVTMERAGLGEKSTEYAHLFEVFGMDPHLTQPMGRHAGKRPYHRRDYGVAFKGRPHLTQHMSMYDGRKMHECHQCQKAFTTSASLTRHRRIHTGEKPYECSDCGKAFNDPSALRSHARTHLKEKPFDCSQCGNAFRTLSALKIHMRVHTGERPYKCDQCGKAYGRSCHLIAHKRTHTGERPYECHDCGKAFQHPSHLKEHVRNHTGEKPYACTQCGKAFRWKSNFNLHKKNHMVEKTYECKECGKSFGDLVSRRKHMRIHIVKKPVECRQCGKTFRNQSILKTHMNSHTGEKPYGCDLCGKAFSASSNLTAHRKIHTQERRYECAACGKVFGDYLSRRRHMSVHLVKKRVECRQCGKAFRNQSTLKTHMRSHTGEKPYECDHCGKAFSIGSNLNVHRRIHTGEKPYECLVCGKAFSDHSSLRSHVKTHRGEKLFVSSVWKRLQ>sp|Q96PQ6-3|ZN317_HUMAN Isoform 3 of Zinc finger protein 317 OS=Homosapiens OX=9606 GN=ZNF317MLENYSNLTSLDWETPSKTKWSLLMEDIFGKETPSGVTMERAGLGEKSTEYAHLFEVFGMDPHLTQPMGRHAGKRPYHRRDYGVAFKGRPHLTQHMSMYDGRKMHECHQCQKAFTTSASLTRHRRIHTGEKPYECSDCGKAFNDPSALRSHARTHLKEKPFDCSQCGNAFRTLSALKIHMRVHTGERPYKCDQCGKAYGRSCHLIAHKRTHTGERPYECHDCGKAFQHPSHLKEHVRNHTGEKPYACTQCGKAFRWKSNFNLHKKNHMVEKTYECKECGKSFGDLVSRRKHMRIHIVKKPVECRQCGKTFRNQSILKTHMNSHTGEKPYGCDLCGKAFSASSNLTAHRKIHTQERRYECAACGKVFGDYLSRRRHMSVHLVKKRVECRQCGKAFRNQSTLKTHMRSHTGEKPYECDHCGKAFSIGSNLNVHRRIHTGEKPYECLVCGKAFSDHSSLRSHVKTHRGEKLFVSSVWKRLQ>sp|Q96PQ6-4|ZN317_HUMAN Isoform 4 of Zinc finger protein 317 OS=Homosapiens OX=9606 GN=ZNF317MLENYSNLTSLGYQVGKPSLISHLEQEEEPRTEERGAHQGACADWETPSKTKWSLLMEDIFGKETPSGVTMERAGLGEKSTEYAHLFEVFGMDPHLTQPMGRHAGKRPYHRRDYGVAFKGRPHLTQHMSMYDGRKMHECHQCQKAFTTSASLTRHRRIHTGEKPYECSDCGKAFNDPSALRSHARTHLKEKPFDCSQCGNAFRTLSALKIHMRVHTGERPYKCDQCGKAYGRSCHLIAHKRTHTGERPYECHDCGKAFQHPSHLKEHVRNHTGEKPYACTQCGKAFRWKSNFNLHKKNHMVEKTYECKECGKSFGDLVSRRKHMRIHIVKKPVECRQCGKTFRNQSILKTHMNSHTGEKPYGCDLCGKAFSASSNLTAHRKIHTQERRYECAACGKVFGDYLSRRRHMSVHLVKKRVECRQCGKAFRNQSTLKTHMRSHTGEKPYECDHCGKAFSIGSNLNVHRRIHTGEKPYECLVCGKAFSDHSSLRSHVKTHRGEKLFVSSVWKRLQ>sp|Q13336|UT1_HUMAN Urea transporter 1 OS=Homo sapiens OX=9606GN=SLC14A1 PE=1 SV=2MEDSPTMVRVDSPTMVRGENQVSPCQGRRCFPKALGYVTGDMKELANQLKDKPVVLQFIDWILRGISQVVFVNNPVSGILILVGLLVQNPWWALTGWLGTVVSTLMALLLSQDRSLIASGLYGYNATLVGVLMAVFSDKGDYFWWLLLPVCAMSMTCPIFSSALNSMLSKWDLPVFTLPFNMALSMYLSATGHYNPFFPAKLVIPITTAPNISWSDLSALELLKSIPVGVGQIYGCDNPWTGGIFLGAILLSSPLMCLHAAIGSLLGIAAGLSLSAPFEDIYFGLWGFNSSLACIAMGGMFMALTWQTHLLALGCALFTAYLGVGMANFMAEVGLPACTWPFCLATLLFLIMTTKNSNIYKMPLSKVTYPEENRIFYLQAKKRMVESPL>sp|Q13336-2|UT1_HUMAN Isoform 2 of Urea transporter 1 OS=Homo sapiensOX=9606 GN=SLC14A1MNGRSLIGGAGDARHGPVWKDPFGTKAGDAARRGIARLSLALADGSQEQEPEEEIAMEDSPTMVRVDSPTMVRGENQVSPCQGRRCFPKALGYVTGDMKELANQLKDKPVVLQFIDWILRGISQVVFVNNPVSGILILVGLLVQNPWWALTGWLGTVVSTLMALLLSQDRSLIASGLYGYNATLVGVLMAVFSDKGDYFWWLLLPVCAMSMTCPIFSSALNSMLSKWDLPVFTLPFNMALSMYLSATGHYNPFFPAKLVIPITTAPNISWSDLSALELLKSIPVGVGQIYGCDNPWTGGIFLGAILLSSPLMCLHAAIGSLLGIAAGLSLSAPFEDIYFGLWGFNSSLACIAMGGMFMALTWQTHLLALGCALFTAYLGVGMANFMAEVGLPACTWPFCLATLLFLIMTTKNSNIYKMPLSKVTYPEENRIFYLQAKKRMVESPL>sp|Q5VUA4|ZN318_HUMAN Zinc finger protein 318 OS=Homo sapiens OX=9606GN=ZNF318 PE=1 SV=2MYRSSARSSVSSHRPKDDGGGGPRSGRSSGSSSGPARRSSPPPPPSGSSSRTPARRPRSPSGHRGRRASPSPPRGRRVSPSPPRARRGSPSPPRGRRLFPPGPAGFRGSSRGESRADYARDGRGDHPGDSGSRRRSPGLCSDSLEKSLRITVGNDHFCVSTPERRRLSDRLGSPVDNLEDMDRDDLTDDSVFTRSSQCSRGLERYISQEEGPLSPFLGQLDEDYRTKETFLHRSDYSPHISCHDELLRGTERNREKLKGYSIRSEERSREAKRPRYDDTVKINSMGGDHPSFTSGTRNYRQRRRSPSPRFLDPEFRELDLARRKREEEEERSRSLSQELVGVDGGGTGCSIPGLSGVLTASEPGYSLHRPEEVSVMPKKSILKKRIEVDIMEPSMQLESFSSSTSSSQDHPLYSGHPSLPLSGAIAAFASEIENKGTMVETALKEPQGNLYQWGPLPGIPKDNSPLREKFGSFLCHKDNLDLKAEGPERHTDFLLPHERASQDGSGFSRILSMLADSTSTQEKRRRSFPDIEDEEKFLYGDEEEDLKAESVPKPLGSSESEVMRQKASSLPSSAPAVKLESLEETNPEYAKIHDLLKTIGLDIGVAEISQLAARTQERLHGKKPSLRSSADRRSSVDRYFSADHCSSVDHRFSADRCSSVDHCFSADRRSSDPHRLESREAHHSNTHSPEVSHPHPPSPVDPYLLTKNSPPFLKSDHPVGHISGPEVVGSGFQSSVAVRCMLPSAPSAPIRLPHTAALSQFHMPRASQFAAARIPPNYQGPAIPPASFDAYRHYMAYAASRWPMYPTSQPSNHPVPEPHRIMPITKQATRSRPNLRVIPTVTPDKPKQKESLRGSIPAAQVPVQVSIPSLIRYNPEKISDEKNRASQKQKVIEEREKLKNDREARQKKMYYLRTELERLHKQQGEMLRKKRREKDGHKDPLLVEVSRLQDNIMKDIAELRQEAEEAEKKQSELDKVAQILGINIFDKSQKSLSDSREPTEKPGKAEKSKSPEKVSSFSNSSSNKESKVNNEKFRTKSPKPAESPQSATKQLDQPTAAYEYYDAGNHWCKDCNTICGTMFDFFTHMHNKKHTQTLDPYNRPWASKTQSEAKQDAIKRTDKITVPAKGSEFLVPISGFYCQLCEEFLGDPISGEQHVKGHQHNEKYKKYVDENPLYEERRNLDRQAGLAVVLETERRRQSELKRKLSEKPKEEKKEKKAKAVKEVKEDDKVSEKLEDQLSEGRNSPEKAENKRNTGIKLQLKEEVKKESPTSSSFGKFSWKKPEKEEEKSSLVTPSISKEEILESSKDKEDGKTEAGKAKPIKIKLSGKTVVAHTSPWMPVVTTSTQTKIRPNLPIPSTVLRKSCSATMSKPAPLNTFLSIKSSGTTAKPLPVVKESSADLLLPPDIISKAFGGEEVILKGSPEEKVVLAEKSEPSHLPEQILPPPPPPPPPPPPPPPVIPHPAAPSAAQANAILAPVKSNPVVSQTLSPGFVGPNILNPVLPVAIMASAQPAAIPSDETAPGVSESDRDQTLFSVLVRPPPPLSSVFSEQAKKLEKRNSCLATANAKDLYDIFYSSGGKGAPETKGAPETKLSGGPLANGENSNLSRTKSSDTSSTSPLNSSASQEELHQDEGLVAAPIVSNSEKPIAKTLVALGKWSVVEHVGPKSTGSTYGFLQPLTRLCQSRPYETITPKTDTLAIWTSSSFQSDTSRDISPEKSELDLGEPGPPGVEPPPQLLDIQCKESQKLVEIHLRESVNQDKESQELRKSEDCRESEIETNTELKERVKELSEGIVDEGVSTSIGPHSIDDSNLNHGNRYMWEGEVKQPNLLMIDKEAEQSNKLMTGSETPSKVVIKLSPQACSFTKAKLDSFLSEARSLLNPQDTPVKISAPELLLHSPARSAMCLTGSPQEQGVSVVSEEGLENSAPESASRTSRYRSLKLKRERSKDFQVKKIYELAVWDENKKRPETWESPEKPKTEALELQDVHPELTVTIESKALEDFEATDLKVEELTALGNLGDMPVDFCTTRVSPAHRSPTVLCQKVCEENSVSPIGCNSSDPADFEPIPSFSGFPLDSPKTLVLDFETEGERNSPNPRSVRIPSPNILKTGLTENVDRGLGGLEGTHQALDLLAGGMMPEEVKESSQLDKQESLGLELKTINSAGLGPSPCLPDLVDFVTRTSGVQKDKLCSPLSEPGDPSKCSSLELGPLQLEISNASTTEVAILQVDDDSGDPLNLVKAPVSRSPPREQVIEDNMVPQGMPEQETTVGAIQDHTESSVHN>sp|Q5VUA4-2|ZN318_HUMAN Isoform 2 of Zinc finger protein 318 OS=Homosapiens OX=9606 GN=ZNF318MYRSSARSSVSSHRPKDDGGGGPRSGRSSGSSSGPARRSSPPPPPSGSSSRTPARRPRSPSGHRGRRASPSPPRGRRVSPSPPRARRGSPSPPRGRRLFPPGPAGFRGSSRGESRADYARDGRGDHPGDSGSRRRSPGLCSDSLEKSLRITVGNDHFCVSTPERRRLSDRLGSPVDNLEDMDRDDLTDDSVFTRSSQCSRGLERYISQEEGPLSPFLGQLDEDYRTKETFLHRSDYSPHISCHDELLRGTERNREKLKGYSIRSEERSREAKRPRYDDTVKINSMGGDHPSFTSGTRNYRQRRRSPSPRFLDPEFRELDLARRKREEEEERSRSLSQELVGVDGGGTGCSIPGLSGVLTASEPGYSLHRPEEVSVMPKKSILKKRIEVDIMEPSMQLESFSSSTSSSQDHPLYSGHPSLPLSGAIAAFASEIENKGTMVETALKEPQGNLYQWGPLPGIPKDNSPLREKFGSFLCHKDNLDLKAEGPERHTDFLLPHERASQDGSGFSRILSMLADSTSTQEKRRRSFPDIEDEEKFLYGDEEEDLKAESVPKPLGSSESEVMRQKASSLPSSAPAVKLESLEETNPEYAKIHDLLKTIGLDIGVAEISQLAARTQERLHGKKPSLRSSADRRSSVDRYFSADHCSSVDHRFSADRCSSVDHCFSADRRSSDPHRLESREAHHSNTHSPEVSHPHPPSPVDPYLLTKNSPPFLKSDHPVGHISGPEVVGSGFQSSVAVRCMLPSAPSAPIRLPHTAALSQFHMPRASQFAAARIPPNYQGPAIPPASFDAYRHYMAYAASRWPMYPTSQPSNHPVPEPHRIMPITKQATRSRPNLRVIPTVTPDKPKQKESLRGSIPAAQVPVQVSIPSLIRYNPEKISDEKNRASQKQKVIEEREKLKNDREARQKKMYYLRTELERLHKQQGEMLRKKRREKDGHKDPLLVEVSRLQDNIMKDIAELRQEAEEAEKKQSELDKVAQILGINIFDKSQKSLSDSREPTEKPGKAEKSKSPEKVSSFSNSSSNKESKVNNEKFRTKSPKPAESPQSATKQLDQPTAAYEYYDAGNHWCKDCNTICGTMFDFFTHMHNKKHTQGQFQKSSDFQKEGLQQTFLPPERQG>sp|Q9H6Y2|WDR55_HUMAN WD repeat-containing protein 55 OS=Homo sapiensOX=9606 GN=WDR55 PE=1 SV=2MDRTCEERPAEDGSDEEDPDSMEAPTRIRDTPEDIVLEAPASGLAFHPARDLLAAGDVDGDVFVFSYSCQEGETKELWSSGHHLKACRAVAFSEDGQKLITVSKDKAIHVLDVEQGQLERRVSKAHGAPINSLLLVDENVLATGDDTGGICLWDQRKEGPLMDMRQHEEYIADMALDPAKKLLLTASGDGCLGIFNIKRRRFELLSEPQSGDLTSVTLMKWGKKVACGSSEGTIYLFNWNGFGATSDRFALRAESIDCMVPVTESLLCTGSTDGVIRAVNILPNRVVGSVGQHTGEPVEELALSHCGRFLASSGHDQRLKFWDMAQLRAVVVDDYRRRKKKGGPLRALSSKTWSTDDFFAGLREEGEDSMAQEEKEETGDDSD>sp|Q9H6Y2-2|WDR55_HUMAN Isoform 2 of WD repeat-containing protein 55OS=Homo sapiens OX=9606 GN=WDR55MKWGKKVACGSSEGTIYLFNWNGFGATSDRFALRAESIDCMVPVTESLLCTGSTDGVIRAVNILPNRVVGSVGQHTGEPVEELALSHCGRFLASSGHDQRLKFWDMAQLRAVVVDDYRRRKKKGGPLRALSSKTWSTDDFFAGLREEGEDSMAQEEKEETGDDSD>sp|A2RRD8|ZN320_HUMAN Zinc finger protein 320 OS=Homo sapiens OX=9606GN=ZNF320 PE=1 SV=1MALSQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCMMNTLSSTGQGNTEVIHTGTLQRQASYHIGAFCSQEIEKDIHDFVFQWQEDETNDHEAPMTEIKKLTSSTDRYDQRHAGNKPIKGQLESRFHLHLRRHRRIHTGEKPYKCEECEKVFSCKSHLEIHRIIHTGEKPYKCKVCDKAFKHDSHLAKHTRIHRGDKHYTCNECGKVFDQKATLACHHRSHTGEKPYKCNECGKTFSQTSHLVYHHRLHTGEKPYKCNECGKTFARNSVLVIHKAVHTAEKPYKCNECGKVFKQRATLAGHRRVHTGEKPYRCEECDKVFSRKSHLERHRRIHTGEKPYKCKVCDKAFRSDSRLAEHQRVHTGERPYTCNECGKVFSTKAYLACHQKLHTGEKLYECEECDKVYIRKSHLERHRRIHTGEKPHKCGDCGKAFNSPSHLIRHQRIHTGQKSYKCHQCGKVFSLRSLLAEHQKIPFGDNCFKCNEYSKPSSIN>sp|Q7Z7L7|ZER1_HUMAN Protein zer-1 homolog OS=Homo sapiens OX=9606GN=ZER1 PE=1 SV=1MASDTPESLMALCTDFCLRNLDGTLGYLLDKETLRLHPDIFLPSEICDRLVNEYVELVNAACNFEPHESFFSLFSDPRSTRLTRIHLREDLVQDQDLEAIRKQDLVELYLTNCEKLSAKSLQTLRSFSHTLVSLSLFGCTNIFYEEENPGGCEDEYLVNPTCQVLVKDFTFEGFSRLRFLNLGRMIDWVPVESLLRPLNSLAALDLSGIQTSDAAFLTQWKDSLVSLVLYNMDLSDDHIRVIVQLHKLRHLDISRDRLSSYYKFKLTREVLSLFVQKLGNLMSLDISGHMILENCSISKMEEEAGQTSIEPSKSSIIPFRALKRPLQFLGLFENSLCRLTHIPAYKVSGDKNEEQVLNAIEAYTEHRPEITSRAINLLFDIARIERCNQLLRALKLVITALKCHKYDRNIQVTGSAALFYLTNSEYRSEQSVKLRRQVIQVVLNGMESYQEVTVQRNCCLTLCNFSIPEELEFQYRRVNELLLSILNPTRQDESIQRIAVHLCNALVCQVDNDHKEAVGKMGFVVTMLKLIQKKLLDKTCDQVMEFSWSALWNITDETPDNCEMFLNFNGMKLFLDCLKEFPEKQELHRNMLGLLGNVAEVKELRPQLMTSQFISVFSNLLESKADGIEVSYNACGVLSHIMFDGPEAWGVCEPQREEVEERMWAAIQSWDINSRRNINYRSFEPILRLLPQGISPVSQHWATWALYNLVSVYPDKYCPLLIKEGGMPLLRDIIKMATARQETKEMARKVIEHCSNFKEENMDTSR>sp|P0DPA2|VSIG8_HUMAN V-set and immunoglobulin domain-containing protein8 OS=Homo sapiens OX=9606 GN=VSIG8 PE=2 SV=1MRVGGAFHLLLVCLSPALLSAVRINGDGQEVLYLAEGDNVRLGCPYVLDPEDYGPNGLDIEWMQVNSDPAHHRENVFLSYQDKRINHGSLPHLQQRVRFAASDPSQYDASINLMNLQVSDTATYECRVKKTTMATRKVIVTVQARPAVPMCWTEGHMTYGNDVVLKCYASGGSQPLSYKWAKISGHHYPYRAGSYTSQHSYHSELSYQESFHSSINQGLNNGDLVLKDISRADDGLYQCTVANNVGYSVCVVEVKVSDSRRIGVIIGIVLGSLLALGCLAVGIWGLVCCCCGGSGAGGARGAFGYGNGGGVGGGACGDLASEIREDAVAPGCKASGRGSRVTHLLGYPTQNVSRSLRRKYAPPPCGGPEDVALAPCTAAAACEAGPSPVYVKVKSAEPADCAEGPVQCKNGLLV>sp|Q6U7Q0|ZN322_HUMAN Zinc finger protein 322 OS=Homo sapiens OX=9606GN=ZNF322 PE=1 SV=2MYTSEEKCNQRTQKRKIYNVCPRKGKKIFIHMHEIIQIDGHIYQCLECKQNFCENLALIMCERTHTGEKPYKCDMCEKTFVQSSDLTSHQRIHNYEKPYKCSKCEKSFWHHLALSGHQRTHAGKKFYTCDICGKNFGQSSDLLVHQRSHTGEKPYLCSECDKCFSRSTNLIRHRRTHTGEKPFKCLECEKAFSGKSDLISHQRTHTGERPYKCNKCEKSYRHRSAFIVHKRVHTGEKPYKCGACEKCFGQKSDLIVHQRVHTGEKPYKCLECMRSFTRSANLIRHQATHTHTFKCLEYEKSFNCSSDLIVHQRIHMEEKPHQWSACESGFLLGMDFVAQQKMRTQTEELHYKYTVCDKSFHQSSALLQHQTVHIGEKPFVCNVSEKGLELSPPHASEASQMS>sp|Q86VZ2|WDR5B_HUMAN WD repeat-containing protein 5B OS=Homo sapiensOX=9606 GN=WDR5B PE=2 SV=1MATKESRDAKAQLALSSSANQSKEVPENPNYALKCTLVGHTEAVSSVKFSPNGEWLASSSADRLIIIWGAYDGKYEKTLYGHNLEISDVAWSSDSSRLVSASDDKTLKLWDVRSGKCLKTLKGHSNYVFCCNFNPPSNLIISGSFDETVKIWEVKTGKCLKTLSAHSDPVSAVHFNCSGSLIVSGSYDGLCRIWDAASGQCLKTLVDDDNPPVSFVKFSPNGKYILTATLDNTLKLWDYSRGRCLKTYTGHKNEKYCIFANFSVTGGKWIVSGSEDNLVYIWNLQTKEIVQKLQGHTDVVISAACHPTENLIASAALENDKTIKLWMSNH>sp|Q86Y25|Z354C_HUMAN Zinc finger protein 354C OS=Homo sapiens OX=9606GN=ZNF354C PE=1 SV=1MAVDLLSAQEPVTFRDVAVFFSQDEWLHLDSAQRALYREVMLENYSSLVSLGIPFSMPKLIHQLQQGEDPCMVEREVPSDTRLGFKTWLETEALPHRQDIFIEETSQGMVKKESIKDGHWDINFEEAVEFESEIEEEQEKKPLRQMIDSHEKTISEDGNHTSLELGKSLFTNTALVTQQSVPIERIPNMYYTFGKDFKQNFDLMKCFQIYPGGKPHICNECGKSFKQNLHLIEHQRIHTGEKPYKCNECEKTFSHRSSLLSHQRIHTGEKPYKCNECEKAFSNSSTLIKHLRVHTGEKPYRCRECGKAFSQCSTLTVHQRIHTGEKLYKCGECEKAFNCRAKLHRHQRIHTGEKPYKCSECGKGYSQFTSLAEHQRFHTGEQLYTCLECGRTFTRIVTLIEHQRIHTGQKPYQCNECEKAFNQYSSFNEHRKIHTGEKLYTCEECGKAFGCKSNLYRHQRIHTGEKPYQCNQCGKAFSQYSFLTEHERIHTGEKLYKCMECGKAYSYRSNLCRHKKVHTKEKLYKWKEYGKPFICSSSLTQYQRFFKGDKAYEV>sp|Q92889|XPF_HUMAN DNA repair endonuclease XPF OS=Homo sapiens OX=9606GN=ERCC4 PE=1 SV=3MESGQPARRIAMAPLLEYERQLVLELLDTDGLVVCARGLGADRLLYHFLQLHCHPACLVLVLNTQPAEEEYFINQLKIEGVEHLPRRVTNEITSNSRYEVYTQGGVIFATSRILVVDFLTDRIPSDLITGILVYRAHRIIESCQEAFILRLFRQKNKRGFIKAFTDNAVAFDTGFCHVERVMRNLFVRKLYLWPRFHVAVNSFLEQHKPEVVEIHVSMTPTMLAIQTAILDILNACLKELKCHNPSLEVEDLSLENAIGKPFDKTIRHYLDPLWHQLGAKTKSLVQDLKILRTLLQYLSQYDCVTFLNLLESLRATEKAFGQNSGWLFLDSSTSMFINARARVYHLPDAKMSKKEKISEKMEIKEGEETKKELVLESNPKWEALTEVLKEIEAENKESEALGGPGQVLICASDDRTCSQLRDYITLGAEAFLLRLYRKTFEKDSKAEEVWMKFRKEDSSKRIRKSHKRPKDPQNKERASTKERTLKKKKRKLTLTQMVGKPEELEEEGDVEEGYRREISSSPESCPEEIKHEEFDVNLSSDAAFGILKEPLTIIHPLLGCSDPYALTRVLHEVEPRYVVLYDAELTFVRQLEIYRASRPGKPLRVYFLIYGGSTEEQRYLTALRKEKEAFEKLIREKASMVVPEEREGRDETNLDLVRGTASADVSTDTRKAGGQEQNGTQQSIVVDMREFRSELPSLIHRRGIDIEPVTLEVGDYILTPEMCVERKSISDLIGSLNNGRLYSQCISMSRYYKRPVLLIEFDPSKPFSLTSRGALFQEISSNDISSKLTLLTLHFPRLRILWCPSPHATAELFEELKQSKPQPDAATALAITADSETLPESEKYNPGPQDFLLKMPGVNAKNCRSLMHHVKNIAELAALSQDELTSILGNAANAKQLYDFIHTSFAEVVSKGKGKK>sp|Q92889-2|XPF_HUMAN Isoform 2 of DNA repair endonuclease XPF OS=Homosapiens OX=9606 GN=ERCC4MESGQPARRIAMAPLLEYERQLVLELLDTDGLVVCARGLGADRLLYHFLQLHCHPACLVLVLNTQPAEEEYFINQLKIEGVEHLPRRVTNEITSNSRYEVYTQGGVIFATSRILVVDFLTDRIPSDLITGILVYRAHRIIESCQEAFILRLFRQKNKRGFIKAFTDNAVAFDTGFCHVERVMRNLFVRKLYLWPRFHVAVNSFLEQHKPEVVEIHVSMTPTMLAIQTAILDILNACLKELKCHNPSLEVEDLSLENAIGKPFDKTIRHYLDPLWHQLGAKTKSLVQDLKILRTLLQYLSQYDCVTFLNLLESLRATEKAFGQNSGWLFLDSSTSMFINARARVYHLPDAKMSKKEKISEKMEIKEGEGILWG>sp|Q8IZ20|ZN683_HUMAN Tissue-resident T-cell transcription regulatorprotein ZNF683 OS=Homo sapiens OX=9606 GN=ZNF683 PE=1 SV=3MKEESAAQLGCCHRPMALGGTGGSLSPSLDFQLFRGDQVFSACRPLPDMVDAHGPSCASWLCPLPLAPGRSALLACLQDLDLNLCTPQPAPLGTDLQGLQEDALSMKHEPPGLQASSTDDKKFTVKYPQNKDKLGKQPERAGEGAPCPAFSSHNSSSPPPLQNRKSPSPLAFCPCPPVNSISKELPFLLHAFYPGYPLLLPPPHLFTYGALPSDQCPHLLMLPQDPSYPTMAMPSLLMMVNELGHPSARWETLLPYPGAFQASGQALPSQARNPGAGAAPTDSPGLERGGMASPAKRVPLSSQTGTAALPYPLKKKNGKILYECNICGKSFGQLSNLKVHLRVHSGERPFQCALCQKSFTQLAHLQKHHLVHTGERPHKCSIPWVPGRNHWKSFQAWREREVCHKRFSSSSNLKTHLRLHSGARPFQCSVCRSRFTQHIHLKLHHRLHAPQPCGLVHTQLPLASLACLAQWHQGALDLMAVASEKHMGYDIDEVKVSSTSQGKARAVSLSSAGTPLVMGQDQNN>sp|Q8IZ20-2|ZN683_HUMAN Isoform 2 of Tissue-resident T-celltranscription regulator protein ZNF683 OS=Homo sapiens OX=9606 GN=ZNF683MKEESAAQLGCCHRPMALGGTGGSLSPSLDFQLFRGDQVFSACRPLPDMVDAHGPSCASWLCPLPLAPGRSALLACLQDLDLNLCTPQPAPLGTDLQGLQEDALSMKHEPPGLQASSTDDKKFTVKYPQNKDKLGKQPERAGEGAPCPAFSSHNSSSPPPLQNRKSPSPLAFCPCPPVNSISKELPFLLHAFYPGYPLLLPPPHLFTYGALPSDQCPHLLMLPQDPSYPTMAMPSLLMMVNELGHPSARWETLLPYPGAFQASGQALPSQARNPGAGAAPTDSPGLERGGMASPAKRVPLSSQTGTAALPYPLKKKNGKILYECNICGKSFGQLSNLKVHLRVHSGERPFQCALCQKSFTQLAHLQKHHLVHTGERPHKCSVCHKRFSSSSNLKTHLRLHSGARPFQCSVCRSRFTQHIHLKLHHRLHAPQPCGLVHTQLPLASLACLAQWHQGALDLMAVASEKHMGYDIDEVKVSSTSQGKARAVSLSSAGTPLVMGQDQNN>sp|Q96HQ0|ZN419_HUMAN Zinc finger protein 419 OS=Homo sapiens OX=9606GN=ZNF419 PE=1 SV=2MAAAALRDPAQVPVAADLLTDHEEGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGLASSKTHEITQLESWEEPFMPAWEVVTSAIPRGCWHGAEAEEAPEQIASVGLLSSNIQQHQKQHCGEKPLKRQEGRVPVLRSCKVHLSEKSLQSREVGKALLISSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHAGKKTYECSECGKLFRDMSNLFIHQIVHTGERPYGCSNCGKSFSRNAHLIEHQRVHTGEKPFTCSECGKAFRHNSTLVQHHKIHTGVRPYECSECGKLFSFNSSLMKHQRIHTGERPYKCSECGKFYSHKSNLIKHWRVHTGERPYKCSDCGKFFTQCSSLMQHQKVHTGEKPFKCNECGRFFRENSTLVRHQRVHTGAKPYECRECGKFFSQSSTLMQHRKVHIGEKPFKCNECGRLFRENSSLVKHQRVHTGAKPYECRECGKFFRHNSSLFKHRRIHTGEMQ>sp|Q96HQ0-2|ZN419_HUMAN Isoform 2 of Zinc finger protein 419 OS=Homosapiens OX=9606 GN=ZNF419MAAAALRDPAQVPVAADLLTDHEEQGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGCWHGAEAEEAPEQIASVGLLSSNIQQHQKQHCGEKPLKRQEGRVPVLRSCKVHLSEKSLQSREVGKALLISSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHAGKKTYECSECGKLFRDMSNLFIHQIVHTGERPYGCSNCGKSFSRNAHLIEHQRVHTGEKPFTCSECGKAFRHNSTLVQHHKIHTGVRPYECSECGKLFSFNSSLMKHQRIHTGERPYKCSECGKFYSHKSNLIKHWRVHTGERPYKCSDCGKFFTQCSSLMQHQKVHTGEKPFKCNECGRFFRENSTLVRHQRVHTGAKPYECRECGKFFSQSSTLMQHRKVHIGEKPFKCNECGRLFRENSSLVKHQRVHTGAKPYECRECGKFFRHNSSLFKHRRIHTGEMQ>sp|Q96HQ0-3|ZN419_HUMAN Isoform 3 of Zinc finger protein 419 OS=Homosapiens OX=9606 GN=ZNF419MAAAALRDPAQGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGLASSKTHEITQLESWEEPFMPAWEVVTSAIPRGCWHGAEAEEAPEQIASVGLLSSNIQQHQKQHCGEKPLKRQEGRVPVLRSCKVHLSEKSLQSREVGKALLISSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHAGKKTYECSECGKLFRDMSNLFIHQIVHTGERPYGCSNCGKSFSRNAHLIEHQRVHTGEKPFTCSECGKAFRHNSTLVQHHKIHTGVRPYECSECGKLFSFNSSLMKHQRIHTGERPYKCSECGKFYSHKSNLIKHWRVHTGERPYKCSDCGKFFTQCSSLMQHQKVHTGEKPFKCNECGRFFRENSTLVRHQRVHTGAKPYECRECGKFFSQSSTLMQHRKVHIGEKPFKCNECGRLFRENSSLVKHQRVHTGAKPYECRECGKFFRHNSSLFKHRRIHTGEMQ>sp|Q96HQ0-4|ZN419_HUMAN Isoform 4 of Zinc finger protein 419 OS=Homosapiens OX=9606 GN=ZNF419MAAAALRDPAQQGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGLASSKTHEITQLESWEEPFMPAWEVVTSAIPRGCWHGAEAEEAPEQIASVGLLSSNIQQHQKQHCGEKPLKRQEGRVPVLRSCKVHLSEKSLQSREVGKALLISSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHAGKKTYECSECGKLFRDMSNLFIHQIVHTGERPYGCSNCGKSFSRNAHLIEHQRVHTGEKPFTCSECGKAFRHNSTLVQHHKIHTGVRPYECSECGKLFSFNSSLMKHQRIHTGERPYKCSECGKFYSHKSNLIKHWRVHTGERPYKCSDCGKFFTQCSSLMQHQKVHTGEKPFKCNECGRFFRENSTLVRHQRVHTGAKPYECRECGKFFSQSSTLMQHRKVHIGEKPFKCNECGRLFRENSSLVKHQRVHTGAKPYECRECGKFFRHNSSLFKHRRIHTGEMQ>sp|Q96HQ0-5|ZN419_HUMAN Isoform 5 of Zinc finger protein 419 OS=Homosapiens OX=9606 GN=ZNF419MAAAALRDPAQVPVAADLLTDHEEQGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGLASSKTHEITQLESWEEPFMPAWEVVTSAIPRGCWHGAEAEEAPEQIASVGLLSSNIQQHQKQHCGEKPLKRQEGRVPVLRSCKVHLSEKSLQSREVGKALLISSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHAGKKTYECSECGKLFRDMSNLFIHQIVHTGERPYGCSNCGKSFSRNAHLIEHQRVHTGEKPFTCSECGKAFRHNSTLVQHHKIHTGVRPYECSECGKLFSFNSSLMKHQRIHTGERPYKCSECGKFYSHKSNLIKHWRVHTGERPYKCSDCGKFFTQCSSLMQHQKVHTGEKPFKCNECGRFFRENSTLVRHQRVHTGAKPYECRECGKFFSQSSTLMQHRKVHIGEKPFKCNECGRLFRENSSLVKHQRVHTGAKPYECRECGKFFRHNSSLFKHRRIHTGEMQ>sp|Q96HQ0-6|ZN419_HUMAN Isoform 6 of Zinc finger protein 419 OS=Homosapiens OX=9606 GN=ZNF419MAAAALRDPAQGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGCWHGAEAEEAPEQIASVGLLSSNIQQHQKQHCGEKPLKRQEGRVPVLRSCKVHLSEKSLQSREVGKALLISSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHAGKKTYECSECGKLFRDMSNLFIHQIVHTGERPYGCSNCGKSFSRNAHLIEHQRVHTGEKPFTCSECGKAFRHNSTLVQHHKIHTGVRPYECSECGKLFSFNSSLMKHQRIHTGERPYKCSECGKFYSHKSNLIKHWRVHTGERPYKCSDCGKFFTQCSSLMQHQKVHTGEKPFKCNECGRFFRENSTLVRHQRVHTGAKPYECRECGKFFSQSSTLMQHRKVHIGEKPFKCNECGRLFRENSSLVKHQRVHTGAKPYECRECGKFFRHNSSLFKHRRIHTGEMQ>sp|O43592|XPOT_HUMAN Exportin-T OS=Homo sapiens OX=9606 GN=XPOT PE=1SV=2MDEQALLGLNPNADSDFRQRALAYFEQLKISPDAWQVCAEALAQRTYSDDHVKFFCFQVLEHQVKYKYSELTTVQQQLIRETLISWLQAQMLNPQPEKTFIRNKAAQVFALLFVTEYLTKWPKFFFDILSVVDLNPRGVDLYLRILMAIDSELVDRDVVHTSEEARRNTLIKDTMREQCIPNLVESWYQILQNYQFTNSEVTCQCLEVVGAYVSWIDLSLIANDRFINMLLGHMSIEVLREEACDCLFEVVNKGMDPVDKMKLVESLCQVLQSAGFFSIDQEEDVDFLARFSKLVNGMGQSLIVSWSKLIKNGDIKNAQEALQAIETKVALMLQLLIHEDDDISSNIIGFCYDYLHILKQLTVLSDQQKANVEAIMLAVMKKLTYDEEYNFENEGEDEAMFVEYRKQLKLLLDRLAQVSPELLLASVRRVFSSTLQNWQTTRFMEVEVAIRLLYMLAEALPVSHGAHFSGDVSKASALQDMMRTLVTSGVSSYQHTSVTLEFFETVVRYEKFFTVEPQHIPCVLMAFLDHRGLRHSSAKVRSRTAYLFSRFVKSLNKQMNPFIEDILNRIQDLLELSPPENGHQSLLSSDDQLFIYETAGVLIVNSEYPAERKQALMRNLLTPLMEKFKILLEKLMLAQDEERQASLADCLNHAVGFASRTSKAFSNKQTVKQCGCSEVYLDCLQTFLPALSCPLQKDILRSGVRTFLHRMIICLEEEVLPFIPSASEHMLKDCEAKDLQEFIPLINQITAKFKIQVSPFLQQMFMPLLHAIFEVLLRPAEENDQSAALEKQMLRRSYFAFLQTVTGSGMSEVIANQGAENVERVLVTVIQGAVEYPDPIAQKTCFIILSKLVELWGGKDGPVGFADFVYKHIVPACFLAPLKQTFDLADAQTVLALSECAVTLKTIHLKRGPECVQYLQQEYLPSLQVAPEIIQEFCQALQQPDAKVFKNYLKVFFQRAKP>sp|P42768|WASP_HUMAN Wiskott-Aldrich syndrome protein OS=Homo sapiensOX=9606 GN=WAS PE=1 SV=4MSGGPMGGRPGGRGAPAVQQNIPSTLLQDHENQRLFEMLGRKCLTLATAVVQLYLALPPGAEHWTKEHCGAVCFVKDNPQKSYFIRLYGLQAGRLLWEQELYSQLVYSTPTPFFHTFAGDDCQAGLNFADEDEAQAFRALVQEKIQKRNQRQSGDRRQLPPPPTPANEERRGGLPPLPLHPGGDQGGPPVGPLSLGLATVDIQNPDITSSRYRGLPAPGPSPADKKRSGKKKISKADIGAPSGFKHVSHVGWDPQNGFDVNNLDPDLRSLFSRAGISEAQLTDAETSKLIYDFIEDQGGLEAVRQEMRRQEPLPPPPPPSRGGNQLPRPPIVGGNKGRSGPLPPVPLGIAPPPPTPRGPPPPGRGGPPPPPPPATGRSGPLPPPPPGAGGPPMPPPPPPPPPPPSSGNGPAPPPLPPALVPAGGLAPGGGRGALLDQIRQGIQLNKTPGAPESSALQPPPQSSEGLVGALMHVMQKRSRAIHSSDEGEDQAGDEDEDDEWDD>sp|Q8IWA0|WDR75_HUMAN WD repeat-containing protein 75 OS=Homo sapiensOX=9606 GN=WDR75 PE=1 SV=1MVEEENIRVVRCGGSELNFRRAVFSADSKYIFCVSGDFVKVYSTVTEECVHILHGHRNLVTGIQLNPNNHLQLYSCSLDGTIKLWDYIDGILIKTFIVGCKLHALFTLAQAEDSVFVIVNKEKPDIFQLVSVKLPKSSSQEVEAKELSFVLDYINQSPKCIAFGNEGVYVAAVREFYLSVYFFKKKTTSRFTLSSSRNKKHAKNNFTCVACHPTEDCIASGHMDGKIRLWRNFYDDKKYTYTCLHWHHDMVMDLAFSVTGTSLLSGGRESVLVEWRDATEKNKEFLPRLGATIEHISVSPAGDLFCTSHSDNKIIIIHRNLEASAVIQGLVKDRSIFTGLMIDPRTKALVLNGKPGHLQFYSLQSDKQLYNLDIIQQEYINDYGLIQIELTKAAFGCFGNWLATVEQRQEKETELELQMKLWMYNKKTQGFILNTKINMPHEDCITALCFCNAEKSEQPTLVTASKDGYFKVWILTDDSDIYKKAVGWTCDFVGSYHKYQATNCCFSEDGSLLAVSFEEIVTIWDSVTWELKCTFCQRAGKIRHLCFGRLTCSKYLLGATENGILCCWNLLSCALEWNAKLNVRVMEPDPNSENIAAISQSSVGSDLFVFKPSEPRPLYIQKGISREKVQWGVFVPRDVPESFTSEAYQWLNRSQFYFLTKSQSLLTFSTKSPEEKLTPTSKQLLAEESLPTTPFYFILGKHRQQQDEKLNETLENELVQLPLTENIPAISELLHTPAHVLPSAAFLCSMFVNSLLLSKETKSAKEIPEDVDMEEEKESEDSDEENDFTEKVQDTSNTGLGEDIIHQLSKSEEKELRKFRKIDYSWIAAL>sp|Q9H598|VIAAT_HUMAN Vesicular inhibitory amino acid transporterOS=Homo sapiens OX=9606 GN=SLC32A1 PE=2 SV=2MATLLRSKLSNVATSVSNKSQAKMSGMFARMGFQAATDEEAVGFAHCDDLDFEHRQGLQMDILKAEGEPCGDEGAEAPVEGDIHYQRGSGAPLPPSGSKDQVGGGGEFGGHDKPKITAWEAGWNVTNAIQGMFVLGLPYAILHGGYLGLFLIIFAAVVCCYTGKILIACLYEENEDGEVVRVRDSYVAIANACCAPRFPTLGGRVVNVAQIIELVMTCILYVVVSGNLMYNSFPGLPVSQKSWSIIATAVLLPCAFLKNLKAVSKFSLLCTLAHFVINILVIAYCLSRARDWAWEKVKFYIDVKKFPISIGIIVFSYTSQIFLPSLEGNMQQPSEFHCMMNWTHIAACVLKGLFALVAYLTWADETKEVITDNLPGSIRAVVNIFLVAKALLSYPLPFFAAVEVLEKSLFQEGSRAFFPACYSGDGRLKSWGLTLRCALVVFTLLMAIYVPHFALLMGLTGSLTGAGLCFLLPSLFHLRLLWRKLLWHQVFFDVAIFVIGGICSVSGFVHSLEGLIEAYRTNAED>sp|Q6XCG6|YA011_HUMAN Putative uncharacterized protein PP632 OS=Homosapiens OX=9606 GN=PP632 PE=4 SV=1MWLSPWSTCPPHPLPSCLTACCSPAHQPVRGSAQPPASDLCTCVTCCSGPHPNYPPAHLLPTSSLPICPGLICCLLTCLLVDCFSALLSACETRDLSPWKARRVLLR>sp|Q9Y2T7|YBOX2_HUMAN Y-box-binding protein 2 OS=Homo sapiens OX=9606GN=YBX2 PE=1 SV=2MSEVEAAAGATAVPAATVPATAAGVVAVVVPVPAGEPQKGGGAGGGGGAASGPAAGTPSAPGSRTPGNPATAVSGTPAPPARSQADKPVLAIQVLGTVKWFNVRNGYGFINRNDTKEDVFVHQTAIKRNNPRKFLRSVGDGETVEFDVVEGEKGAEATNVTGPGGVPVKGSRYAPNRRKSRRFIPRPPSVAPPPMVAEIPSAGTGPGSKGERAEDSGQRPRRWCPPPFFYRRRFVRGPRPPNQQQPIEGTDRVEPKETAPLEGHQQQGDERVPPPRFRPRYRRPFRPRPRQQPTTEGGDGETKPSQGPADGSRPEPQRPRNRPYFQRRRQQAPGPQQAPGPRQPAAPETSAPVNSGDPTTTILE>sp|Q96MT0|YJ006_HUMAN Putative uncharacterized protein FLJ31958 OS=Homosapiens OX=9606 PE=2 SV=1MFLHSGPARGPCTAAGRSASVRVPVQVAHELQGPDAIVFGAEVEQVHLVANELDAGRVQLLLAQGVAAAVLLVQVVMGEELGEQGHQQARGEVADGQAALLDTAKMLVAEQAVGAGQLQVGLGISNLSKSIGTSQIFLERHRSPLKLSSTLITEMSSGRLEEL>sp|A8MV72|YH009_HUMAN Putative UPF0607 protein ENSP00000382826 OS=Homosapiens OX=9606 PE=5 SV=2MLSARNSMMFGHLSPVRIPRLRGKFNLQLPSLDEQVIPARLLKMEVRAEEPKEATEVKDQVETQGQEDNKMGPCSNGEAASTSRPLETQGNLTSSWYNPRPLEGNVHLKSLTEKNQTDKAQVHAVSFYSKGHGVASSHSPAGGILPFGKPDPLPTVLPAPVPGCSLWPEKAALKVLGKDHLPSSPGLLMVGEDMQPKDPAVLGSSRSSPPRAAGHRSRKRKLSGPPLQLQLTPPLQLRWDRDGGPPPAKLPCLSPEALLVGQASQREGRLQQGNMRKNMRVLSRTSKFRRRKQLLRRRKKTRQGRRGGSCL>sp|Q8N680|ZBTB2_HUMAN Zinc finger and BTB domain-containing protein 2OS=Homo sapiens OX=9606 GN=ZBTB2 PE=1 SV=1MDLANHGLILLQQLNAQREFGFLCDCTVAIGDVYFKAHKSVLASFSNYFKMLFVHQTSECVRLKPTDIQPDIFSYLLHLMYTGKMAPQLIDPVRLEQGIKFLHAYPLIQEASLASQGAFSHPDQVFPLASSLYGIQIADHQLRQATKIASAPEKLGRDPRPQTSRISQEQVPEASQLSQLTSNLAQVNRTNMTPSDPLQTSLSPELVSTPVPPPPPGEETNLEASSSDEQPASLTIAHVKPSIMKRNGSFPKYYACHLCGRRFTLRSSLREHLQIHTGVPFTSSQQGESRVPLTLCSNAADLGKDAMEVPEAGMISDSELQHISDSPIIDGQQQSETPPPSDIADIDNLEQADQEREVKRRKYECTICGRKFIQKSHWREHMYIHTGKPFKCSTCDKSFCRANQAARHVCLNQSIDTYTMVDKQTLELCTFEEGSQMDNMLVQTNKPYKCNLCDKTFSTPNEVVKHSCQNQNSDVFALDEGRSILLGSGDSEVTEPDHPVLASIKKEQETVLLD>sp|Q9P0M6|H2AW_HUMAN Core histone macro-H2A.2 OS=Homo sapiens OX=9606GN=MACROH2A2 PE=1 SV=3MSGRSGKKKMSKLSRSARAGVIFPVGRLMRYLKKGTFKYRISVGAPVYMAAVIEYLAAEILELAGNAARDNKKARIAPRHILLAVANDEELNQLLKGVTIASGGVLPRIHPELLAKKRGTKGKSETILSPPPEKRGRKATSGKKGGKKSKAAKPRTSKKSKPKDSDKEGTSNSTSEDGPGDGFTILSSKSLVLGQKLSLTQSDISHIGSMRVEGIVHPTTAEIDLKEDIGKALEKAGGKEFLETVKELRKSQGPLEVAEAAVSQSSGLAAKFVIHCHIPQWGSDKCEEQLEETIKNCLSAAEDKKLKSVAFPPFPSGRNCFPKQTAAQVTLKAISAHFDDSSASSLKNVYFLLFDSESIGIYVQEMAKLDAK>sp|Q6ISB3|GRHL2_HUMAN Grainyhead-like protein 2 homolog OS=Homo sapiensOX=9606 GN=GRHL2 PE=1 SV=1MSQESDNNKRLVALVPMPSDPPFNTRRAYTSEDEAWKSYLENPLTAATKAMMSINGDEDSAAALGLLYDYYKVPRDKRLLSVSKASDSQEDQEKRNCLGTSEAQSNLSGGENRVQVLKTVPVNLSLNQDHLENSKREQYSISFPESSAIIPVSGITVVKAEDFTPVFMAPPVHYPRGDGEEQRVVIFEQTQYDVPSLATHSAYLKDDQRSTPDSTYSESFKDAATEKFRSASVGAEEYMYDQTSSGTFQYTLEATKSLRQKQGEGPMTYLNKGQFYAITLSETGDNKCFRHPISKVRSVVMVVFSEDKNRDEQLKYWKYWHSRQHTAKQRVLDIADYKESFNTIGNIEEIAYNAVSFTWDVNEEAKIFITVNCLSTDFSSQKGVKGLPLMIQIDTYSYNNRSNKPIHRAYCQIKVFCDKGAERKIRDEERKQNRKKGKGQASQTQCNSSSDGKLAAIPLQKKSDITYFKTMPDLHSQPVLFIPDVHFANLQRTGQVYYNTDDEREGGSVLVKRMFRPMEEEFGPVPSKQMKEEGTKRVLLYVRKETDDVFDALMLKSPTVKGLMEAISEKYGLPVEKIAKLYKKSKKGILVNMDDNIIEHYSNEDTFILNMESMVEGFKVTLMEI>sp|Q6ISB3-2|GRHL2_HUMAN Isoform 2 of Grainyhead-like protein 2 homologOS=Homo sapiens OX=9606 GN=GRHL2MPSDPPFNTRRAYTSEDEAWKSYLENPLTAATKAMMSINGDEDSAAALGLLYDYYKVPRDKRLLSVSKASDSQEDQEKRNCLGTSEAQSNLSGGENRVQVLKTVPVNLSLNQDHLENSKREQYSISFPESSAIIPVSGITVVKAEDFTPVFMAPPVHYPRGDGEEQRVVIFEQTQYDVPSLATHSAYLKDDQRSTPDSTYSESFKDAATEKFRSASVGAEEYMYDQTSSGTFQYTLEATKSLRQKQGEGPMTYLNKGQFYAITLSETGDNKCFRHPISKVRSVVMVVFSEDKNRDEQLKYWKYWHSRQHTAKQRVLDIADYKESFNTIGNIEEIAYNAVSFTWDVNEEAKIFITVNCLSTDFSSQKGVKGLPLMIQIDTYSYNNRSNKPIHRAYCQIKVFCDKGAERKIRDEERKQNRKKGKGQASQTQCNSSSDGKLAAIPLQKKSDITYFKTMPDLHSQPVLFIPDVHFANLQRTGQVYYNTDDEREGGSVLVKRMFRPMEEEFGPVPSKQMKEEGTKRVLLYVRKETDDVFDALMLKSPTVKGLMEAISEKYGLPVEKIAKLYKKSKKGILVNMDDNIIEHYSNEDTFILNMESMVEGFKVTLMEI>sp|P10916|MLRV_HUMAN Myosin regulatory light chain 2,ventricular/cardiac muscle isoform OS=Homo sapiens OX=9606 GN=MYL2 PE=1SV=3MAPKKAKKRAGGANSNVFSMFEQTQIQEFKEAFTIMDQNRDGFIDKNDLRDTFAALGRVNVKNEEIDEMIKEAPGPINFTVFLTMFGEKLKGADPEETILNAFKVFDPEGKGVLKADYVREMLTTQAERFSKEEVDQMFAAFPPDVTGNLDYKNLVHIITHGEEKD>sp|Q685J3|MUC17_HUMAN Mucin-17 OS=Homo sapiens OX=9606 GN=MUC17 PE=1SV=2MPRPGTMALCLLTLVLSLLPPQAAAEQDLSVNRAVWDGGGCISQGDVLNRQCQQLSQHVRTGSAANTATGTTSTNVVEPRMYLSCSTNPEMTSIESSVTSDTPGVSSTRMTPTESRTTSESTSDSTTLFPSSTEDTSSPTTPEGTDVPMSTPSEESISSTMAFVSTAPLPSFEAYTSLTYKVDMSTPLTTSTQASSSPTTPESTTIPKSTNSEGSTPLTSMPASTMKVASSEAITLLTTPVEISTPVTISAQASSSPTTAEGPSLSNSAPSGGSTPLTRMPLSVMLVVSSEASTLSTTPAATNIPVITSTEASSSPTTAEGTSIPTSTYTEGSTPLTSTPASTMPVATSEMSTLSITPVDTSTLVTTSTEPSSLPTTAEATSMLTSTLSEGSTPLTNMPVSTILVASSEASTTSTIPVDSKTFVTTASEASSSPTTAEDTSIATSTPSEGSTPLTSMPVSTTPVASSEASNLSTTPVDSKTQVTTSTEASSSPPTAEVNSMPTSTPSEGSTPLTSMSVSTMPVASSEASTLSTTPVDTSTPVTTSSEASSSSTTPEGTSIPTSTPSEGSTPLTNMPVSTRLVVSSEASTTSTTPADSNTFVTTSSEASSSSTTAEGTSMPTSTYSERGTTITSMSVSTTLVASSEASTLSTTPVDSNTPVTTSTEATSSSTTAEGTSMPTSTYTEGSTPLTSMPVNTTLVASSEASTLSTTPVDTSTPVTTSTEASSSPTTADGASMPTSTPSEGSTPLTSMPVSKTLLTSSEASTLSTTPLDTSTHITTSTEASCSPTTTEGTSMPISTPSEGSPLLTSIPVSITPVTSPEASTLSTTPVDSNSPVTTSTEVSSSPTPAEGTSMPTSTYSEGRTPLTSMPVSTTLVATSAISTLSTTPVDTSTPVTNSTEARSSPTTSEGTSMPTSTPGEGSTPLTSMPDSTTPVVSSEARTLSATPVDTSTPVTTSTEATSSPTTAEGTSIPTSTPSEGTTPLTSTPVSHTLVANSEASTLSTTPVDSNTPLTTSTEASSPPPTAEGTSMPTSTPSEGSTPLTRMPVSTTMVASSETSTLSTTPADTSTPVTTYSQASSSSTTADGTSMPTSTYSEGSTPLTSVPVSTRLVVSSEASTLSTTPVDTSIPVTTSTEASSSPTTAEGTSIPTSPPSEGTTPLASMPVSTTLVVSSEANTLSTTPVDSKTQVATSTEASSPPPTAEVTSMPTSTPGERSTPLTSMPVRHTPVASSEASTLSTSPVDTSTPVTTSAETSSSPTTAEGTSLPTSTTSEGSTLLTSIPVSTTLVTSPEASTLLTTPVDTKGPVVTSNEVSSSPTPAEGTSMPTSTYSEGRTPLTSIPVNTTLVASSAISILSTTPVDNSTPVTTSTEACSSPTTSEGTSMPNSNPSEGTTPLTSIPVSTTPVVSSEASTLSATPVDTSTPGTTSAEATSSPTTAEGISIPTSTPSEGKTPLKSIPVSNTPVANSEASTLSTTPVDSNSPVVTSTAVSSSPTPAEGTSIAISTPSEGSTALTSIPVSTTTVASSEINSLSTTPAVTSTPVTTYSQASSSPTTADGTSMQTSTYSEGSTPLTSLPVSTMLVVSSEANTLSTTPIDSKTQVTASTEASSSTTAEGSSMTISTPSEGSPLLTSIPVSTTPVASPEASTLSTTPVDSNSPVITSTEVSSSPTPAEGTSMPTSTYTEGRTPLTSITVRTTPVASSAISTLSTTPVDNSTPVTTSTEARSSPTTSEGTSMPNSTPSEGTTPLTSIPVSTTPVLSSEASTLSATPIDTSTPVTTSTEATSSPTTAEGTSIPTSTLSEGMTPLTSTPVSHTLVANSEASTLSTTPVDSNSPVVTSTAVSSSPTPAEGTSIATSTPSEGSTALTSIPVSTTTVASSETNTLSTTPAVTSTPVTTYAQVSSSPTTADGSSMPTSTPREGRPPLTSIPVSTTTVASSEINTLSTTLADTRTPVTTYSQASSSPTTADGTSMPTPAYSEGSTPLTSMPLSTTLVVSSEASTLSTTPVDTSTPATTSTEGSSSPTTAGGTSIQTSTPSERTTPLAGMPVSTTLVVSSEGNTLSTTPVDSKTQVTNSTEASSSATAEGSSMTISAPSEGSPLLTSIPLSTTPVASPEASTLSTTPVDSNSPVITSTEVSSSPIPTEGTSMQTSTYSDRRTPLTSMPVSTTVVASSAISTLSTTPVDTSTPVTNSTEARSSPTTSEGTSMPTSTPSEGSTPFTSMPVSTMPVVTSEASTLSATPVDTSTPVTTSTEATSSPTTAEGTSIPTSTLSEGTTPLTSIPVSHTLVANSEVSTLSTTPVDSNTPFTTSTEASSPPPTAEGTSMPTSTSSEGNTPLTRMPVSTTMVASFETSTLSTTPADTSTPVTTYSQAGSSPTTADDTSMPTSTYSEGSTPLTSVPVSTMPVVSSEASTHSTTPVDTSTPVTTSTEASSSPTTAEGTSIPTSPPSEGTTPLASMPVSTTPVVSSEAGTLSTTPVDTSTPMTTSTEASSSPTTAEDIVVPISTASEGSTLLTSIPVSTTPVASPEASTLSTTPVDSNSPVVTSTEISSSATSAEGTSMPTSTYSEGSTPLRSMPVSTKPLASSEASTLSTTPVDTSIPVTTSTETSSSPTTAKDTSMPISTPSEVSTSLTSILVSTMPVASSEASTLSTTPVDTRTLVTTSTGTSSSPTTAEGSSMPTSTPGERSTPLTNILVSTTLLANSEASTLSTTPVDTSTPVTTSAEASSSPTTAEGTSMRISTPSDGSTPLTSILVSTLPVASSEASTVSTTAVDTSIPVTTSTEASSSPTTAEVTSMPTSTPSETSTPLTSMPVNHTPVASSEAGTLSTTPVDTSTPVTTSTKASSSPTTAEGIVVPISTASEGSTLLTSIPVSTTPVASSEASTLSTTPVDTSIPVTTSTEGSSSPTTAEGTSMPISTPSEVSTPLTSILVSTVPVAGSEASTLSTTPVDTRTPVTTSAEASSSPTTAEGTSMPISTPGERRTPLTSMSVSTMPVASSEASTLSRTPADTSTPVTTSTEASSSPTTAEGTGIPISTPSEGSTPLTSIPVSTTPVAIPEASTLSTTPVDSNSPVVTSTEVSSSPTPAEGTSMPISTYSEGSTPLTGVPVSTTPVTSSAISTLSTTPVDTSTPVTTSTEAHSSPTTSEGTSMPTSTPSEGSTPLTYMPVSTMLVVSSEDSTLSATPVDTSTPVTTSTEATSSTTAEGTSIPTSTPSEGMTPLTSVPVSNTPVASSEASILSTTPVDSNTPLTTSTEASSSPPTAEGTSMPTSTPSEGSTPLTSMPVSTTTVASSETSTLSTTPADTSTPVTTYSQASSSPPIADGTSMPTSTYSEGSTPLTNMSFSTTPVVSSEASTLSTTPVDTSTPVTTSTEASLSPTTAEGTSIPTSSPSEGTTPLASMPVSTTPVVSSEVNTLSTTPVDSNTLVTTSTEASSSPTIAEGTSLPTSTTSEGSTPLSIMPLSTTPVASSEASTLSTTPVDTSTPVTTSSPTNSSPTTAEVTSMPTSTAGEGSTPLTNMPVSTTPVASSEASTLSTTPVDSNTFVTSSSQASSSPATLQVTTMRMSTPSEGSSSLTTMLLSSTYVTSSEASTPSTPSVDRSTPVTTSTQSNSTPTPPEVITLPMSTPSEVSTPLTIMPVSTTSVTISEAGTASTLPVDTSTPVITSTQVSSSPVTPEGTTMPIWTPSEGSTPLTTMPVSTTRVTSSEGSTLSTPSVVTSTPVTTSTEAISSSATLDSTTMSVSMPMEISTLGTTILVSTTPVTRFPESSTPSIPSVYTSMSMTTASEGSSSPTTLEGTTTMPMSTTSERSTLLTTVLISPISVMSPSEASTLSTPPGDTSTPLLTSTKAGSFSIPAEVTTIRISITSERSTPLTTLLVSTTLPTSFPGASIASTPPLDTSTTFTPSTDTASTPTIPVATTISVSVITEGSTPGTTIFIPSTPVTSSTADVFPATTGAVSTPVITSTELNTPSTSSSSTTTSFSTTKEFTTPAMTTAAPLTYVTMSTAPSTPRTTSRGCTTSASTLSATSTPHTSTSVTTRPVTPSSESSRPSTITSHTIPPTFPPAHSSTPPTTSASSTTVNPEAVTTMTTRTKPSTRTTSFPTVTTTAVPTNTTIKSNPTSTPTVPRTTTCFGDGCQNTASRCKNGGTWDGLKCQCPNLYYGELCEEVVSSIDIGPPETISAQMELTVTVTSVKFTEELKNHSSQEFQEFKQTFTEQMNIVYSGIPEYVGVNITKLRLGSVVVEHDVLLRTKYTPEYKTVLDNATEVVKEKITKVTTQQIMINDICSDMMCFNTTGTQVQNITVTQYDPEEDCRKMAKEYGDYFVVEYRDQKPYCISPCEPGFSVSKNCNLGKCQMSLSGPQCLCVTTETHWYSGETCNQGTQKSLVYGLVGAGVVLMLIILVALLMLVFRSKREVKRQKYRLSQLYKWQEEDSGPAPGTFQNIGFDICQDDDSIHLESIYSNFQPSLRHIDPETKIRIQRPQVMTTSF>sp|Q685J3-2|MUC17_HUMAN Isoform 2 of Mucin-17 OS=Homo sapiens OX=9606GN=MUC17MPRPGTMALCLLTLVLSLLPPQAAAEQDLSVNRAVWDGGGCISQGDVLNRQCQQLSQHVRTGSAANTATGTTSTNVVEPRMYLSCSTNPEMTSIESSVTSDTPGVSSTRMTPTESRTTSESTSDSTTLFPSSTEDTSSPTTPEGTDVPMSTPSEESISSTMAFVSTAPLPSFEAYTSLTYKVDMSTPLTTSTQASSSPTTPESTTIPKSTNSEGSTPLTSMPASTMKVASSEAITLLTTPVEISTPVTISAQASSSPTTAEGPSLSNSAPSGGSTPLTRMPLSVMLVVSSEASTLSTTPAATNIPVITSTEASSSPTTAEGTSIPTSTYTEGSTPLTSTPASTMPVATSEMSTLSITPVDTSTLVTTSTEPSSLPTTAEATSMLTSTLSEGSTPLTNMPVSTILVASSEASTTSTIPVDSKTFVTTASEASSSPTTAEDTSIATSTPSEGSTPLTSMPVSTTPVASSEASNLSTTPVDSKTQVTTSTEASSSPPTAEVNSMPTSTPSEGSTPLTSMSVSTMPVASSEASTLSTTPVDTSTPVTTSSEASSSSTTPEGTSIPTSTPSEGSTPLTNMPVSTRLVVSSEASTTSTTPADSNTFVTTSSEASSSSTTAEGTSMPTSTYSERGTTITSMSVSTTLVASSEASTLSTTPVDSNTPVTTSTEATSSSTTAEGTSMPTSTYTEGSTPLTSMPVNTTLVASSEASTLSTTPVDTSTPVTTSTEASSSPTTADGASMPTSTPSEGSTPLTSMPVSKTLLTSSEASTLSTTPLDTSTHITTSTEASCSPTTTEGTSMPISTPSEGSPLLTSIPVSITPVTSPEASTLSTTPVDSNSPVTTSTEVSSSPTPAEGTSMPTSTYSEGRTPLTSMPVSTTLVATSAISTLSTTPVDTSTPVTNSTEARSSPTTSEGTSMPTSTPGEGSTPLTSMPDSTTPVVSSEARTLSATPVDTSTPVTTSTEATSSPTTAEGTSIPTSTPSEGTTPLTSTPVSHTLVANSEASTLSTTPVDSNTPLTTSTEASSPPPTAEGTSMPTSTPSEGSTPLTRMPVSTTMVASSETSTLSTTPADTSTPVTTYSQASSSSTTADGTSMPTSTYSEGSTPLTSVPVSTRLVVSSEASTLSTTPVDTSIPVTTSTEASSSPTTAEGTSIPTSPPSEGTTPLASMPVSTTLVVSSEANTLSTTPVDSKTQVATSTEASSPPPTAEVTSMPTSTPGERSTPLTSMPVRHTPVASSEASTLSTSPVDTSTPVTTSAETSSSPTTAEGTSLPTSTTSEGSTLLTSIPVSTTLVTSPEASTLLTTPVDTKGPVVTSNEVSSSPTPAEGTSMPTSTYSEGRTPLTSIPVNTTLVASSAISILSTTPVDNSTPVTTSTEACSSPTTSEGTSMPNSNPSEGTTPLTSIPVSTTPVVSSEASTLSATPVDTSTPGTTSAEATSSPTTAEGISIPTSTPSEGKTPLKSIPVSNTPVANSEASTLSTTPVDSNSPVVTSTAVSSSPTPAEGTSIAISTPSEGSTALTSIPVSTTTVASSEINSLSTTPAVTSTPVTTYSQASSSPTTADGTSMQTSTYSEGSTPLTSLPVSTMLVVSSEANTLSTTPIDSKTQVTASTEASSSTTAEGSSMTISTPSEGSPLLTSIPVSTTPVASPEASTLSTTPVDSNSPVITSTEVSSSPTPAEGTSMPTSTYTEGRTPLTSITVRTTPVASSAISTLSTTPVDNSTPVTTSTEARSSPTTSEGTSMPNSTPSEGTTPLTSIPVSTTPVLSSEASTLSATPIDTSTPVTTSTEATSSPTTAEGTSIPTSTLSEGMTPLTSTPVSHTLVANSEASTLSTTPVDSNSPVVTSTAVSSSPTPAEGTSIATSTPSEGSTALTSIPVSTTTVASSETNTLSTTPAVTSTPVTTYAQVSSSPTTADGSSMPTSTPREGRPPLTSIPVSTTTVASSEINTLSTTLADTRTPVTTYSQASSSPTTADGTSMPTPAYSEGSTPLTSMPLSTTLVVSSEASTLSTTPVDTSTPATTSTEGSSSPTTAGGTSIQTSTPSERTTPLAGMPVSTTLVVSSEGNTLSTTPVDSKTQVTNSTEASSSATAEGSSMTISAPSEGSPLLTSIPLSTTPVASPEASTLSTTPVDSNSPVITSTEVSSSPIPTEGTSMQTSTYSDRRTPLTSMPVSTTVVASSAISTLSTTPVDTSTPVTNSTEARSSPTTSEGTSMPTSTPSEGSTPFTSMPVSTMPVVTSEASTLSATPVDTSTPVTTSTEATSSPTTAEGTSIPTSTLSEGTTPLTSIPVSHTLVANSEVSTLSTTPVDSNTPFTTSTEASSPPPTAEGTSMPTSTSSEGNTPLTRMPVSTTMVASFETSTLSTTPADTSTPVTTYSQAGSSPTTADDTSMPTSTYSEGSTPLTSVPVSTMPVVSSEASTHSTTPVDTSTPVTTSTEASSSPTTAEGTSIPTSPPSEGTTPLASMPVSTTPVVSSEAGTLSTTPVDTSTPMTTSTEASSSPTTAEDIVVPISTASEGSTLLTSIPVSTTPVASPEASTLSTTPVDSNSPVVTSTEISSSATSAEGTSMPTSTYSEGSTPLRSMPVSTKPLASSEASTLSTTPVDTSIPVTTSTETSSSPTTAKDTSMPISTPSEVSTSLTSILVSTMPVASSEASTLSTTPVDTRTLVTTSTGTSSSPTTAEGSSMPTSTPGERSTPLTNILVSTTLLANSEASTLSTTPVDTSTPVTTSAEASSSPTTAEGTSMRISTPSDGSTPLTSILVSTLPVASSEASTVSTTAVDTSIPVTTSTEASSSPTTAEVTSMPTSTPSETSTPLTSMPVNHTPVASSEAGTLSTTPVDTSTPVTTSTKASSSPTTAEGIVVPISTASEGSTLLTSIPVSTTPVASSEASTLSTTPVDTSIPVTTSTEGSSSPTTAEGTSMPISTPSEVSTPLTSILVSTVPVAGSEASTLSTTPVDTRTPVTTSAEASSSPTTAEGTSMPISTPGERRTPLTSMSVSTMPVASSEASTLSRTPADTSTPVTTSTEASSSPTTAEGTGIPISTPSEGSTPLTSIPVSTTPVAIPEASTLSTTPVDSNSPVVTSTEVSSSPTPAEGTSMPISTYSEGSTPLTGVPVSTTPVTSSAISTLSTTPVDTSTPVTTSTEAHSSPTTSEGTSMPTSTPSEGSTPLTYMPVSTMLVVSSEDSTLSATPVDTSTPVTTSTEATSSTTAEGTSIPTSTPSEGMTPLTSVPVSNTPVASSEASILSTTPVDSNTPLTTSTEASSSPPTAEGTSMPTSTPSEGSTPLTSMPVSTTTVASSETSTLSTTPADTSTPVTTYSQASSSPPIADGTSMPTSTYSEGSTPLTNMSFSTTPVVSSEASTLSTTPVDTSTPVTTSTEASLSPTTAEGTSIPTSSPSEGTTPLASMPVSTTPVVSSEVNTLSTTPVDSNTLVTTSTEASSSPTIAEGTSLPTSTTSEGSTPLSIMPLSTTPVASSEASTLSTTPVDTSTPVTTSSPTNSSPTTAEVTSMPTSTAGEGSTPLTNMPVSTTPVASSEASTLSTTPVDSNTFVTSSSQASSSPATLQVTTMRMSTPSEGSSSLTTMLLSSTYVTSSEASTPSTPSVDRSTPVTTSTQSNSTPTPPEVITLPMSTPSEVSTPLTIMPVSTTSVTISEAGTASTLPVDTSTPVITSTQVSSSPVTPEGTTMPIWTPSEGSTPLTTMPVSTTRVTSSEGSTLSTPSVVTSTPVTTSTEAISSSATLDSTTMSVSMPMEISTLGTTILVSTTPVTRFPESSTPSIPSVYTSMSMTTASEGSSSPTTLEGTTTMPMSTTSERSTLLTTVLISPISVMSPSEASTLSTPPGDTSTPLLTSTKAGSFSIPAEVTTIRISITSERSTPLTTLLVSTTLPTSFPGASIASTPPLDTSTTFTPSTDTASTPTIPVATTISVSVITEGSTPGTTIFIPSTPVTSSTADVFPATTGAVSTPVITSTELNTPSTSSSSTTTSFSTTKEFTTPAMTTAAPLTYVTMSTAPSTPRTTSRGCTTSASTLSATSTPHTSTSVTTRPVTPSSESSRPSTITSHTIPPTFPPAHSSTPPTTSASSTTVNPEAVTTMTTRTKPSTRTTSFPTVTTTAVPTNTTIKSNPTSTPTVPRTTTCFGDGCQNTASRCKNGGTWDGLKCQCPNLYYGELCEEVVSSIDIGPPETISAQMELTVTVTSVKFTEELKNHSSQEFQEFKQTFTEQMNIVYSGIPEYVGVNITKLHDVFQHHWHPSAKHYGDPVRPTVLDNATEVVKEKITKVTTQQIMINDICSDMMCFNTTGTQVQNITVTQYDPEEDCRKMAKEYGDYFVVEYRDQKPYCISPCEPGFSVSKNCNLGKCQMSL>sp|Q9H8L6|MMRN2_HUMAN Multimerin-2 OS=Homo sapiens OX=9606 GN=MMRN2 PE=1SV=2MILSLLFSLGGPLGWGLLGAWAQASSTSLSDLQSSRTPGVWKAEAEDTGKDPVGRNWCPYPMSKLVTLLALCKTEKFLIHSQQPCPQGAPDCQKVKVMYRMAHKPVYQVKQKVLTSLAWRCCPGYTGPNCEHHDSMAIPEPADPGDSHQEPQDGPVSFKPGHLAAVINEVEVQQEQQEHLLGDLQNDVHRVADSLPGLWKALPGNLTAAVMEANQTGHEFPDRSLEQVLLPHVDTFLQVHFSPIWRSFNQSLHSLTQAIRNLSLDVEANRQAISRVQDSAVARADFQELGAKFEAKVQENTQRVGQLRQDVEDRLHAQHFTLHRSISELQADVDTKLKRLHKAQEAPGTNGSLVLATPGAGARPEPDSLQARLGQLQRNLSELHMTTARREEELQYTLEDMRATLTRHVDEIKELYSESDETFDQISKVERQVEELQVNHTALRELRVILMEKSLIMEENKEEVERQLLELNLTLQHLQGGHADLIKYVKDCNCQKLYLDLDVIREGQRDATRALEETQVSLDERRQLDGSSLQALQNAVDAVSLAVDAHKAEGERARAATSRLRSQVQALDDEVGALKAAAAEARHEVRQLHSAFAALLEDALRHEAVLAALFGEEVLEEMSEQTPGPLPLSYEQIRVALQDAASGLQEQALGWDELAARVTALEQASEPPRPAEHLEPSHDAGREEAATTALAGLARELQSLSNDVKNVGRCCEAEAGAGAASLNASLHGLHNALFATQRSLEQHQRLFHSLFGNFQGLMEANVSLDLGKLQTMLSRKGKKQQKDLEAPRKRDKKEAEPLVDIRVTGPVPGALGAALWEAGSPVAFYASFSEGTAALQTVKFNTTYINIGSSYFPEHGYFRAPERGVYLFAVSVEFGPGPGTGQLVFGGHHRTPVCTTGQGSGSTATVFAMAELQKGERVWFELTQGSITKRSLSGTAFGGFLMFKT>sp|Q8WU39|MZB1_HUMAN Marginal zone B- and B1-cell-specific proteinOS=Homo sapiens OX=9606 GN=MZB1 PE=1 SV=1MRLSLPLLLLLLGAWAIPGGLGDRAPLTATAPQLDDEEMYSAHMPAHLRCDACRAVAYQMWQNLAKAETKLHTSNSGGRRELSELVYTDVLDRSCSRNWQDYGVREVDQVKRLTGPGLSEGPEPSISVMVTGGPWPTRLSRTCLHYLGEFGEDQIYEAHQQGRGALEALLCGGPQGACSEKVSATREEL>sp|Q8WU39-2|MZB1_HUMAN Isoform 2 of Marginal zone B- and B1-cell-specific protein OS=Homo sapiens OX=9606 GN=MZB1MRLSLPLLLLLLGAWAIPGGLGDRAPLTATAPQLDDEEMYSAHMPAHLRCDACRAVAYQSLLVPDVAKSGKGRDQTSYLKLWGAAGAERVGLHGCPGPELLPELAGLRSSRSGPSETSHRPRT>sp|Q8WU39-3|MZB1_HUMAN Isoform 3 of Marginal zone B- and B1-cell-specific protein OS=Homo sapiens OX=9606 GN=MZB1MPAELWLTSYGVREVDQVKRLTGPGLSEGPEPSISVMVTGGPWPTRLSRTCLHYLGEFGEDQIYEAHQQGRGALEALLCGGPQGACSEKVSATREEL>sp|Q8WU39-4|MZB1_HUMAN Isoform 4 of Marginal zone B- and B1-cell-specific protein OS=Homo sapiens OX=9606 GN=MZB1MRLSLPLLLLLLGAWAIPGGLGDRAPLTATAPQLDDEEMYSAHMPAHLRCDACRAVAYQRLCSYPPHLPLTEQQS>sp|Q8WU39-5|MZB1_HUMAN Isoform 5 of Marginal zone B- and B1-cell-specific protein OS=Homo sapiens OX=9606 GN=MZB1MRLSLPLLLLLLGAWAIPGGLGDRAPLTATAPQLDDEEMYSAHMPAHLRCDACRAVAYQAHP>sp|Q9GZZ1|NAA50_HUMAN N-alpha-acetyltransferase 50 OS=Homo sapiensOX=9606 GN=NAA50 PE=1 SV=1MKGSRIELGDVTPHNIKQLKRLNQVIFPVSYNDKFYKDVLEVGELAKLAYFNDIAVGAVCCRVDHSQNQKRLYIMTLGCLAPYRRLGIGTKMLNHVLNICEKDGTFDNIYLHVQISNESAIDFYRKFGFEIIETKKNYYKRIEPADAHVLQKNLKVPSGQNADVQKTDN>sp|Q9GZZ1-2|NAA50_HUMAN Isoform 2 of N-alpha-acetyltransferase 50OS=Homo sapiens OX=9606 GN=NAA50MKGSRIELGDVTPHNIKQLKRLNQVIFPVSYNDKFYRKFGFEIIETKKNYYKRIEPADAHVLQKNLKVPSGQNADVQKTDN>sp|P12524|MYCL_HUMAN Protein L-Myc OS=Homo sapiens OX=9606 GN=MYCL PE=1SV=2MDYDSYQHYFYDYDCGEDFYRSTAPSEDIWKKFELVPSPPTSPPWGLGPGAGDPAPGIGPPEPWPGGCTGDEAESRGHSKGWGRNYASIIRRDCMWSGFSARERLERAVSDRLAPGAPRGNPPKASAAPDCTPSLEAGNPAPAAPCPLGEPKTQACSGSESPSDSENEEIDVVTVEKRQSLGIRKPVTITVRADPLDPCMKHFHISIHQQQHNYAARFPPESCSQEEASERGPQEEVLERDAAGEKEDEEDEEIVSPPPVESEAAQSCHPKPVSSDTEDVTKRKNHNFLERKRRNDLRSRFLALRDQVPTLASCSKAPKVVILSKALEYLQALVGAEKRMATEKRQLRCRQQQLQKRIAYLTGY>sp|P12524-2|MYCL_HUMAN Isoform 2 of Protein L-Myc OS=Homo sapiensOX=9606 GN=MYCLMCVCAGCRAAPSRRGAGPLQVAGGWSEGADMDYDSYQHYFYDYDCGEDFYRSTAPSEDIWKKFELVPSPPTSPPWGLGPGAGDPAPGIGPPEPWPGGCTGDEAESRGHSKGWGRNYASIIRRDCMWSGFSARERLERAVSDRLAPGAPRGNPPKASAAPDCTPSLEAGNPAPAAPCPLGEPKTQACSGSESPSDSGKDLPEPSKRGPPHGWPKLCPCLRSGIGSSQALGPSPPLFG>sp|P12524-3|MYCL_HUMAN Isoform 3 of Protein L-Myc OS=Homo sapiensOX=9606 GN=MYCLMCVCAGCRAAPSRRGAGPLQVAGGWSEGADMDYDSYQHYFYDYDCGEDFYRSTAPSEDIWKKFELVPSPPTSPPWGLGPGAGDPAPGIGPPEPWPGGCTGDEAESRGHSKGWGRNYASIIRRDCMWSGFSARERLERAVSDRLAPGAPRGNPPKASAAPDCTPSLEAGNPAPAAPCPLGEPKTQACSGSESPSDSENEEIDVVTVEKRQSLGIRKPVTITVRADPLDPCMKHFHISIHQQQHNYAARFPPESCSQEEASERGPQEEVLERDAAGEKEDEEDEEIVSPPPVESEAAQSCHPKPVSSDTEDVTKRKNHNFLERKRRNDLRSRFLALRDQVPTLASCSKAPKVVILSKALEYLQALVGAEKRMATEKRQLRCRQQQLQKRIAYLTGY>sp|P12525|MYCP1_HUMAN Putative myc-like protein MYCLP1 OS=Homo sapiensOX=9606 GN=MYCLP1 PE=5 SV=2MDRDSYHHYFYDYDGGEDFYRSTTPSEDIWKKFELVPPPWDLGPAAGNPALSFGLLEPWPVGCAGDETESQDYWKAWDANYASLIRRDCMWSGFSTQEPLERAVSDLLAVGAPSGYSPKEFATPDYTPELEAGNLAPIFPCLLGEPKIQACSRSESPSDSEGEEIDVTVKKRQSLSTRKPVIIAVRADLLDPRMNLFHISIHQQQHNYAAPFPPESCFQEGAPKRMPPKEALEREAPGGKDDKEDEEIVSLPPVESEAAQSCQPKPIHYDTENWTKKKYHSYLERKRRNDQRSRFLALRDEVPALASCSRVSKVMILVKATEYLHELAEAEERMATEKRQLECQRRQLQKRIEYLSSY>sp|Q99836|MYD88_HUMAN Myeloid differentiation primary response proteinMyD88 OS=Homo sapiens OX=9606 GN=MYD88 PE=1 SV=1MAAGGPGAGSAAPVSSTSSLPLAALNMRVRRRLSLFLNVRTQVAADWTALAEEMDFEYLEIRQLETQADPTGRLLDAWQGRPGASVGRLLELLTKLGRDDVLLELGPSIEEDCQKYILKQQQEEAEKPLQVAAVDSSVPRTAELAGITTLDDPLGHMPERFDAFICYCPSDIQFVQEMIRQLEQTNYRLKLCVSDRDVLPGTCVWSIASELIEKRCRRMVVVVSDDYLQSKECDFQTKFALSLSPGAHQKRLIPIKYKAMKKEFPSILRFITVCDYTNPCTKSWFWTRLAKALSLP>sp|Q99836-2|MYD88_HUMAN Isoform 2 of Myeloid differentiation primaryresponse protein MyD88 OS=Homo sapiens OX=9606 GN=MYD88MAAGGPGAGSAAPVSSTSSLPLAALNMRVRRRLSLFLNVRTQVAADWTALAEEMDFEYLEIRQLETQADPTGRLLDAWQGRPGASVGRLLELLTKLGRDDVLLELGPSIGHMPERFDAFICYCPSDIQFVQEMIRQLEQTNYRLKLCVSDRDVLPGTCVWSIASELIEKRCRRMVVVVSDDYLQSKECDFQTKFALSLSPGAHQKRLIPIKYKAMKKEFPSILRFITVCDYTNPCTKSWFWTRLAKALSLP>sp|Q99836-3|MYD88_HUMAN Isoform 3 of Myeloid differentiation primaryresponse protein MyD88 OS=Homo sapiens OX=9606 GN=MYD88MAAGGPGAGSAAPVSSTSSLPLAALNMRVRRRLSLFLNVRTQVAADWTALAEEMDFEYLEIRQLETQADPTGRLLDAWQGRPGASVGRLLELLTKLGRDDVLLELGPSIEEDCQKYILKQQQEEAEKPLQVAAVDSSVPRTAELAGITTLDDPLGAAGWWWLSLMITCRARNVTSRPNLHSASLQVPIRSD>sp|Q99836-4|MYD88_HUMAN Isoform 4 of Myeloid differentiation primaryresponse protein MyD88 OS=Homo sapiens OX=9606 GN=MYD88MAAGGPGAGSAAPVSSTSSLPLAALNMRVRRRLSLFLNVRTQVAADWTALAEEMDFEYLEIRQLETQADPTGRLLDAWQGRPGASVGRLLELLTKLGRDDVLLELGPSIGAAGWWWLSLMITCRARNVTSRPNLHSASLQVPIRSD>sp|Q99836-5|MYD88_HUMAN Isoform 5 of Myeloid differentiation primaryresponse protein MyD88 OS=Homo sapiens OX=9606 GN=MYD88MAALNMRVRRRLSLFLNVRTQVAADWTALAEEMDFEYLEIRQLETQADPTGRLLDAWQGRPGASVGRLLELLTKLGRDDVLLELGPSIEEDCQKYILKQQQEEAEKPLQVAAVDSSVPRTAELAGITTLDDPLGHMPERFDAFICYCPSDIQFVQEMIRQLEQTNYRLKLCVSDRDVLPGTCVWSIASELIEKRCRRMVVVVSDDYLQSKECDFQTKFALSLSPGAHQKRLIPIKYKAMKKEFPSILRFITVCDYTNPCTKSWFWTRLAKALSLP>sp|Q99836-6|MYD88_HUMAN Isoform 6 of Myeloid differentiation primaryresponse protein MyD88 OS=Homo sapiens OX=9606 GN=MYD88MAAGGPGAGSAAPVSSTSSLPLAALNMRVRRRLSLFLNVRTQVAADWTALAEEMDFEYLEIRQLETQADPTGRLLDAWQGRPGASVGRLLELLTKLGRDDVLLELGPSIEEDCQKYILKQQQEEAEKPLQVAAVDSSVPRTAELAGITTLDDPLGHMPERFDAFICYCPSDIQFVQEMIRQLEQTNYRLKLCVSDRDVLPGTCVWSIASELIEKRLARRPRGGCRRMVVVVSDDYLQSKECDFQTKFALSLSPGAHQKRLIPIKYKAMKKEFPSILRFITVCDYTNPCTKSWFWTRLAKALSLP>sp|Q9Y5N5|N6MT1_HUMAN Methyltransferase N6AMT1 OS=Homo sapiens OX=9606GN=N6AMT1 PE=1 SV=4MAGENFATPFHGHVGRGAFSDVYEPAEDTFLLLDALEAAAAELAGVEICLEVGSGSGVVSAFLASMIGPQALYMCTDINPEAAACTLETARCNKVHIQPVITDLVKGLLPRLTEKVDLLVFNPPYVVTPPQEVGSHGIEAAWAGGRNGREVMDRFFPLVPDLLSPRGLFYLVTIKENNPEEILKIMKTKGLQGTTALSRQAGQETLSVLKFTKS>sp|Q9Y5N5-2|N6MT1_HUMAN Isoform 2 of Methyltransferase N6AMT1 OS=Homosapiens OX=9606 GN=N6AMT1MAGENFATPFHGHVGRGAFSDVYEPAEDTFLLLDALEAAAAELAGVEICLEVGSGSGVVSAFLASMIGPQALYMCTDINPEAAACTLETARCNKVHIQPVITDLVGSHGIEAAWAGGRNGREVMDRFFPLVPDLLSPRGLFYLVTIKENNPEEILKIMKTKGLQGTTALSRQAGQETLSVLKFTKS>sp|Q7Z406|MYH14_HUMAN Myosin-14 OS=Homo sapiens OX=9606 GN=MYH14 PE=1SV=2MAAVTMSVPGRKAPPRPGPVPEAAQPFLFTPRGPSAGGGPGSGTSPQVEWTARRLVWVPSELHGFEAAALRDEGEEEAEVELAESGRRLRLPRDQIQRMNPPKFSKAEDMAELTCLNEASVLHNLRERYYSGLIYTYSGLFCVVINPYKQLPIYTEAIVEMYRGKKRHEVPPHVYAVTEGAYRSMLQDREDQSILCTGESGAGKTENTKKVIQYLAHVASSPKGRKEPGVPGELERQLLQANPILEAFGNAKTVKNDNSSRFGKFIRINFDVAGYIVGANIETYLLEKSRAIRQAKDECSFHIFYQLLGGAGEQLKADLLLEPCSHYRFLTNGPSSSPGQERELFQETLESLRVLGFSHEEIISMLRMVSAVLQFGNIALKRERNTDQATMPDNTAAQKLCRLLGLGVTDFSRALLTPRIKVGRDYVQKAQTKEQADFALEALAKATYERLFRWLVLRLNRALDRSPRQGASFLGILDIAGFEIFQLNSFEQLCINYTNEKLQQLFNHTMFVLEQEEYQREGIPWTFLDFGLDLQPCIDLIERPANPPGLLALLDEECWFPKATDKSFVEKVAQEQGGHPKFQRPRHLRDQADFSVLHYAGKVDYKANEWLMKNMDPLNDNVAALLHQSTDRLTAEIWKDVEGIVGLEQVSSLGDGPPGGRPRRGMFRTVGQLYKESLSRLMATLSNTNPSFVRCIVPNHEKRAGKLEPRLVLDQLRCNGVLEGIRICRQGFPNRILFQEFRQRYEILTPNAIPKGFMDGKQACEKMIQALELDPNLYRVGQSKIFFRAGVLAQLEEERDLKVTDIIVSFQAAARGYLARRAFQKRQQQQSALRVMQRNCAAYLKLRHWQWWRLFTKVKPLLQVTRQDEVLQARAQELQKVQELQQQSAREVGELQGRVAQLEEERARLAEQLRAEAELCAEAEETRGRLAARKQELELVVSELEARVGEEEECSRQMQTEKKRLQQHIQELEAHLEAEEGARQKLQLEKVTTEAKMKKFEEDLLLLEDQNSKLSKERKLLEDRLAEFSSQAAEEEEKVKSLNKLRLKYEATIADMEDRLRKEEKGRQELEKLKRRLDGESSELQEQMVEQQQRAEELRAQLGRKEEELQAALARAEDEGGARAQLLKSLREAQAALAEAQEDLESERVARTKAEKQRRDLGEELEALRGELEDTLDSTNAQQELRSKREQEVTELKKTLEEETRIHEAAVQELRQRHGQALGELAEQLEQARRGKGAWEKTRLALEAEVSELRAELSSLQTARQEGEQRRRRLELQLQEVQGRAGDGERARAEAAEKLQRAQAELENVSGALNEAESKTIRLSKELSSTEAQLHDAQELLQEETRAKLALGSRVRAMEAEAAGLREQLEEEAAARERAGRELQTAQAQLSEWRRRQEEEAGALEAGEEARRRAAREAEALTQRLAEKTETVDRLERGRRRLQQELDDATMDLEQQRQLVSTLEKKQRKFDQLLAEEKAAVLRAVEERERAEAEGREREARALSLTRALEEEQEAREELERQNRALRAELEALLSSKDDVGKSVHELERACRVAEQAANDLRAQVTELEDELTAAEDAKLRLEVTVQALKTQHERDLQGRDEAGEERRRQLAKQLRDAEVERDEERKQRTLAVAARKKLEGELEELKAQMASAGQGKEEAVKQLRKMQAQMKELWREVEETRTSREEIFSQNRESEKRLKGLEAEVLRLQEELAASDRARRQAQQDRDEMADEVANGNLSKAAILEEKRQLEGRLGQLEEELEEEQSNSELLNDRYRKLLLQVESLTTELSAERSFSAKAESGRQQLERQIQELRGRLGEEDAGARARHKMTIAALESKLAQAEEQLEQETRERILSGKLVRRAEKRLKEVVLQVEEERRVADQLRDQLEKGNLRVKQLKRQLEEAEEEASRAQAGRRRLQRELEDVTESAESMNREVTTLRNRLRRGPLTFTTRTVRQVFRLEEGVASDEEAEEAQPGSGPSPEPEGSPPAHPQ>sp|Q7Z406-2|MYH14_HUMAN Isoform 2 of Myosin-14 OS=Homo sapiens OX=9606GN=MYH14MAAVTMSVPGRKAPPRPGPVPEAAQPFLFTPRGPSAGGGPGSGTSPQVEWTARRLVWVPSELHGFEAAALRDEGEEEAEVELAESGRRLRLPRDQIQRMNPPKFSKAEDMAELTCLNEASVLHNLRERYYSGLIYTYSGLFCVVINPYKQLPIYTEAIVEMYRGKKRHEVPPHVYAVTEGAYRSMLQDREDQSILCTGESGAGKTENTKKVIQYLAHVASSPKGRKEPGVPASVSTVSYGELERQLLQANPILEAFGNAKTVKNDNSSRFGKFIRINFDVAGYIVGANIETYLLEKSRAIRQAKDECSFHIFYQLLGGAGEQLKADLLLEPCSHYRFLTNGPSSSPGQERELFQETLESLRVLGFSHEEIISMLRMVSAVLQFGNIALKRERNTDQATMPDNTAAQKLCRLLGLGVTDFSRALLTPRIKVGRDYVQKAQTKEQADFALEALAKATYERLFRWLVLRLNRALDRSPRQGASFLGILDIAGFEIFQLNSFEQLCINYTNEKLQQLFNHTMFVLEQEEYQREGIPWTFLDFGLDLQPCIDLIERPANPPGLLALLDEECWFPKATDKSFVEKVAQEQGGHPKFQRPRHLRDQADFSVLHYAGKVDYKANEWLMKNMDPLNDNVAALLHQSTDRLTAEIWKDEHGGFQQFSFLGSFPPSPPGSAERCSSAISPPGVEGIVGLEQVSSLGDGPPGGRPRRGMFRTVGQLYKESLSRLMATLSNTNPSFVRCIVPNHEKRAGKLEPRLVLDQLRCNGVLEGIRICRQGFPNRILFQEFRQRYEILTPNAIPKGFMDGKQACEKMIQALELDPNLYRVGQSKIFFRAGVLAQLEEERDLKVTDIIVSFQAAARGYLARRAFQKRQQQQSALRVMQRNCAAYLKLRHWQWWRLFTKVKPLLQVTRQDEVLQARAQELQKVQELQQQSAREVGELQGRVAQLEEERARLAEQLRAEAELCAEAEETRGRLAARKQELELVVSELEARVGEEEECSRQMQTEKKRLQQHIQELEAHLEAEEGARQKLQLEKVTTEAKMKKFEEDLLLLEDQNSKLSKERKLLEDRLAEFSSQAAEEEEKVKSLNKLRLKYEATIADMEDRLRKEEKGRQELEKLKRRLDGESSELQEQMVEQQQRAEELRAQLGRKEEELQAALARAEDEGGARAQLLKSLREAQAALAEAQEDLESERVARTKAEKQRRDLGEELEALRGELEDTLDSTNAQQELRSKREQEVTELKKTLEEETRIHEAAVQELRQRHGQALGELAEQLEQARRGKGAWEKTRLALEAEVSELRAELSSLQTARQEGEQRRRRLELQLQEVQGRAGDGERARAEAAEKLQRAQAELENVSGALNEAESKTIRLSKELSSTEAQLHDAQELLQEETRAKLALGSRVRAMEAEAAGLREQLEEEAAARERAGRELQTAQAQLSEWRRRQEEEAGALEAGEEARRRAAREAEALTQRLAEKTETVDRLERGRRRLQQELDDATMDLEQQRQLVSTLEKKQRKFDQLLAEEKAAVLRAVEERERAEAEGREREARALSLTRALEEEQEAREELERQNRALRAELEALLSSKDDVGKSVHELERACRVAEQAANDLRAQVTELEDELTAAEDAKLRLEVTVQALKTQHERDLQGRDEAGEERRRQLAKQLRDAEVERDEERKQRTLAVAARKKLEGELEELKAQMASAGQGKEEAVKQLRKMQAQMKELWREVEETRTSREEIFSQNRESEKRLKGLEAEVLRLQEELAASDRARRQAQQDRDEMADEVANGNLSKAAILEEKRQLEGRLGQLEEELEEEQSNSELLNDRYRKLLLQVESLTTELSAERSFSAKAESGRQQLERQIQELRGRLGEEDAGARARHKMTIAALESKLAQAEEQLEQETRERILSGKLVRRAEKRLKEVVLQVEEERRVADQLRDQLEKGNLRVKQLKRQLEEAEEEASRAQAGRRRLQRELEDVTESAESMNREVTTLRNRLRRGPLTFTTRTVRQVFRLEEGVASDEEAEEAQPGSGPSPEPEGSPPAHPQ>sp|Q7Z406-4|MYH14_HUMAN Isoform 4 of Myosin-14 OS=Homo sapiens OX=9606GN=MYH14MAAVTMSVPGRKAPPRPGPVPEAAQPFLFTPRGPSAGGGPGSGTSPQVEWTARRLVWVPSELHGFEAAALRDEGEEEAEVELAESGRRLRLPRDQIQRMNPPKFSKAEDMAELTCLNEASVLHNLRERYYSGLIYTYSGLFCVVINPYKQLPIYTEAIVEMYRGKKRHEVPPHVYAVTEGAYRSMLQDREDQSILCTGESGAGKTENTKKVIQYLAHVASSPKGRKEPGVPGELERQLLQANPILEAFGNAKTVKNDNSSRFGKFIRINFDVAGYIVGANIETYLLEKSRAIRQAKDECSFHIFYQLLGGAGEQLKADLLLEPCSHYRFLTNGPSSSPGQERELFQETLESLRVLGFSHEEIISMLRMVSAVLQFGNIALKRERNTDQATMPDNTAAQKLCRLLGLGVTDFSRALLTPRIKVGRDYVQKAQTKEQADFALEALAKATYERLFRWLVLRLNRALDRSPRQGASFLGILDIAGFEIFQLNSFEQLCINYTNEKLQQLFNHTMFVLEQEEYQREGIPWTFLDFGLDLQPCIDLIERPANPPGLLALLDEECWFPKATDKSFVEKVAQEQGGHPKFQRPRHLRDQADFSVLHYAGKVDYKANEWLMKNMDPLNDNVAALLHQSTDRLTAEIWKDVEGIVGLEQVSSLGDGPPGGRPRRGMFRTVGQLYKESLSRLMATLSNTNPSFVRCIVPNHEKRAGKLEPRLVLDQLRCNGVLEGIRICRQGFPNRILFQEFRQRYEILTPNAIPKGFMDGKQACEKMIQALELDPNLYRVGQSKIFFRAGVLAQLEEERDLKVTDIIVSFQAAARGYLARRAFQKRQQQQSALRVMQRNCAAYLKLRHWQWWRLFTKVKPLLQVTRQDEVLQARAQELQKVQELQQQSAREVGELQGRVAQLEEERARLAEQLRAEAELCAEAEETRGRLAARKQELELVVSELEARVGEEEECSRQMQTEKKRLQQHIQELEAHLEAEEGARQKLQLEKVTTEAKMKKFEEDLLLLEDQNSKLSKERKLLEDRLAEFSSQAAEEEEKVKSLNKLRLKYEATIADMEDRLRKEEKGRQELEKLKRRLDGESSELQEQMVEQQQRAEELRAQLGRKEEELQAALARAEDEGGARAQLLKSLREAQAALAEAQEDLESERVARTKAEKQRRDLGEELEALRGELEDTLDSTNAQQELRSKREQEVTELKKTLEEETRIHEAAVQELRQRHGQALGELAEQLEQARRGKGAWEKTRLALEAEVSELRAELSSLQTARQEGEQRRRRLELQLQEVQGRAGDGERARAEAAEKLQRAQAELENVSGALNEALLSSKDDVGKSVHELERACRVAEQAANDLRAQVTELEDELTAAEDAKLRLEVTVQALKTQHERDLQGRDEAGEERRRQLAKQLRDAEVERDEERKQRTLAVAARKKLEGELEELKAQMASAGQGKEEAVKQLRKMQAQMKELWREVEETRTSREEIFSQNRESEKRLKGLEAEVLRLQEELAASDRARRQAQQDRDEMADEVANGNLSKAAILEEKRQLEGRLGQLEEELEEEQSNSELLNDRYRKLLLQVESLTTELSAERSFSAKAESGRQQLERQIQELRGRLGEEDAGARARHKMTIAALESKLAQAEEQLEQETRERILSGKLVRRAEKRLKEVVLQVEEERRVADQLRDQLEKGNLRVKQLKRQLEEAEEEASRAQAGRRRLQRELEDVTESAESMNREVTTLRNRLRRGPLTFTTRTVRQVFRLEEGVASDEEAEEAQPGSGPSPEPEGSPPAHPQ>sp|Q7Z406-5|MYH14_HUMAN Isoform 5 of Myosin-14 OS=Homo sapiens OX=9606GN=MYH14MAAVTMSVPGRKAPPRPGPVPEAAQPFLFTPRGPSAGGGPGSGTSPQVEWTARRLVWVPSELHGFEAAALRDEGEEEAEVELAESGRRLRLPRDQIQRMNPPKFSKAEDMAELTCLNEASVLHNLRERYYSGLIYTYSGLFCVVINPYKQLPIYTEAIVEMYRGKKRHEVPPHVYAVTEGAYRSMLQDREDQSILCTGESGAGKTENTKKVIQYLAHVASSPKGRKEPGVPGELERQLLQANPILEAFGNAKTVKNDNSSRFGKFIRINFDVAGYIVGANIETYLLEKSRAIRQAKDECSFHIFYQLLGGAGEQLKADLLLEPCSHYRFLTNGPSSSPGQERELFQETLESLRVLGFSHEEIISMLRMVSAVLQFGNIALKRERNTDQATMPDNTAAQKLCRLLGLGVTDFSRALLTPRIKVGRDYVQKAQTKEQADFALEALAKATYERLFRWLVLRLNRALDRSPRQGASFLGILDIAGFEIFQLNSFEQLCINYTNEKLQQLFNHTMFVLEQEEYQREGIPWTFLDFGLDLQPCIDLIERPANPPGLLALLDEECWFPKATDKSFVEKVAQEQGGHPKFQRPRHLRDQADFSVLHYAGKVDYKANEWLMKNMDPLNDNVAALLHQSTDRLTAEIWKDVEGIVGLEQVSSLGDGPPGGRPRRGMFRTVGQLYKESLSRLMATLSNTNPSFVRCIVPNHEKRAGKLEPRLVLDQLRCNGVLEGIRICRQGFPNRILFQEFRQRYEILTPNAIPKGFMDGKQACEKMIQALELDPNLYRVGQSKIFFRAGVLAQLEEERDLKVTDIIVSFQAAARGYLARRAFQKRQQQQSALRVMQRNCAAYLKLRHWQWWRLFTKVKPLLQVTRQDEVLQARAQELQKVQELQQQSAREVGELQGRVAQLEEERARLAEQLRAEAELCAEAEETRGRLAARKQELELVVSELEARVGEEEECSRQMQTEKKRLQQHIQELEAHLEAEEGARQKLQLEKVTTEAKMKKFEEDLLLLEDQNSKLSKERKLLEDRLAEFSSQAAEEEEKVKSLNKLRLKYEATIADMEDRLRKEEKGRQELEKLKRRLDGESSELQEQMVEQQQRAEELRAQLGRKEEELQAALARAEDEGGARAQLLKSLREAQAALAEAQEDLESERVARTKAEKQRRDLGEELEALRGELEDTLDSTNAQQELRSKREQEVTELKKTLEEETRIHEAAVQELRQRHGQALGELAEQLEQARRGKGAWEKTRLALEAEVSELRAELSSLQTARQEGEQRRRRLELQLQEVQGRAGDGERARAEAAEKLQRAQAELENVSGALNEAESKTIRLSKELSSTEAQLHDAQELLQEETRAKLALGSRVRAMEAEAAGLREQLEEEAAARERAGRELQTAQAQLSEWRRRQEEEAGALEAGEEARRRAAREAEALTQRLAEKTETVDRLERGRRRLQQELDDATLSPDALTDGAQPPSSLDPTGPCPRNPAL>sp|Q7Z406-6|MYH14_HUMAN Isoform 6 of Myosin-14 OS=Homo sapiens OX=9606GN=MYH14MAAVTMSVPGRKAPPRPGPVPEAAQPFLFTPRGPSAGGGPGSGTSPQVEWTARRLVWVPSELHGFEAAALRDEGEEEAEVELAESGRRLRLPRDQIQRMNPPKFSKAEDMAELTCLNEASVLHNLRERYYSGLIYTYSGLFCVVINPYKQLPIYTEAIVEMYRGKKRHEVPPHVYAVTEGAYRSMLQDREDQSILCTGESGAGKTENTKKVIQYLAHVASSPKGRKEPGVPASVSTVSYGELERQLLQANPILEAFGNAKTVKNDNSSRFGKFIRINFDVAGYIVGANIETYLLEKSRAIRQAKDECSFHIFYQLLGGAGEQLKADLLLEPCSHYRFLTNGPSSSPGQERELFQETLESLRVLGFSHEEIISMLRMVSAVLQFGNIALKRERNTDQATMPDNTAAQKLCRLLGLGVTDFSRALLTPRIKVGRDYVQKAQTKEQADFALEALAKATYERLFRWLVLRLNRALDRSPRQGASFLGILDIAGFEIFQLNSFEQLCINYTNEKLQQLFNHTMFVLEQEEYQREGIPWTFLDFGLDLQPCIDLIERPANPPGLLALLDEECWFPKATDKSFVEKVAQEQGGHPKFQRPRHLRDQADFSVLHYAGKVDYKANEWLMKNMDPLNDNVAALLHQSTDRLTAEIWKDVEGIVGLEQVSSLGDGPPGGRPRRGMFRTVGQLYKESLSRLMATLSNTNPSFVRCIVPNHEKRAGKLEPRLVLDQLRCNGVLEGIRICRQGFPNRILFQEFRQRYEILTPNAIPKGFMDGKQACEKMIQALELDPNLYRVGQSKIFFRAGVLAQLEEERDLKVTDIIVSFQAAARGYLARRAFQKRQQQQSALRVMQRNCAAYLKLRHWQWWRLFTKVKPLLQVTRQDEVLQARAQELQKVQELQQQSAREVGELQGRVAQLEEERARLAEQLRAEAELCAEAEETRGRLAARKQELELVVSELEARVGEEEECSRQMQTEKKRLQQHIQELEAHLEAEEGARQKLQLEKVTTEAKMKKFEEDLLLLEDQNSKLSKERKLLEDRLAEFSSQAAEEEEKVKSLNKLRLKYEATIADMEDRLRKEEKGRQELEKLKRRLDGESSELQEQMVEQQQRAEELRAQLGRKEEELQAALARAEDEGGARAQLLKSLREAQAALAEAQEDLESERVARTKAEKQRRDLGEELEALRGELEDTLDSTNAQQELRSKREQEVTELKKTLEEETRIHEAAVQELRQRHGQALGELAEQLEQARRGKGAWEKTRLALEAEVSELRAELSSLQTARQEGEQRRRRLELQLQEVQGRAGDGERARAEAAEKLQRAQAELENVSGALNEAESKTIRLSKELSSTEAQLHDAQELLQEETRAKLALGSRVRAMEAEAAGLREQLEEEAAARERAGRELQTAQAQLSEWRRRQEEEAGALEAGEEARRRAAREAEALTQRLAEKTETVDRLERGRRRLQQELDDATMDLEQQRQLVSTLEKKQRKFDQLLAEEKAAVLRAVEERERAEAEGREREARALSLTRALEEEQEAREELERQNRALRAELEALLSSKDDVGKSVHELERACRVAEQAANDLRAQVTELEDELTAAEDAKLRLEVTVQALKTQHERDLQGRDEAGEERRRQLAKQLRDAEVERDEERKQRTLAVAARKKLEGELEELKAQMASAGQGKEEAVKQLRKMQAQMKELWREVEETRTSREEIFSQNRESEKRLKGLEAEVLRLQEELAASDRARRQAQQDRDEMADEVANGNLSKAAILEEKRQLEGRLGQLEEELEEEQSNSELLNDRYRKLLLQVESLTTELSAERSFSAKAESGRQQLERQIQELRGRLGEEDAGARARHKMTIAALESKLAQAEEQLEQETRERILSGKLVRRAEKRLKEVVLQVEEERRVADQLRDQLEKGNLRVKQLKRQLEEAEEEASRAQAGRRRLQRELEDVTESAESMNREVTTLRNRLRRGPLTFTTRTVRQVFRLEEGVASDEEAEEAQPGSGPSPEPEGSPPAHPQ>sp|Q9Y2K3|MYH15_HUMAN Myosin-15 OS=Homo sapiens OX=9606 GN=MYH15 PE=1SV=5MVESCLLTFRAFFWWIALIKMDLSDLGEAAAFLRRSEAELLLLQATALDGKKKCWIPDGENAYIEAEVKGSEDDGTVIVETADGESLSIKEDKIQQMNPPEFEMIEDMAMLTHLNEASVLHTLKRRYGQWMIYTYSGLFCVTINPYKWLPVYQKEVMAAYKGKRRSEAPPHIFAVANNAFQDMLHNRENQSILFTGESGAGKTVNSKHIIQYFATIAAMIESRKKQGALEDQIMQANTILEAFGNAKTLRNDNSSRFGKFIRMHFGARGMLSSVDIDIYLLEKSRVIFQQAGERNYHIFYQILSGQKELHDLLLVSANPSDFHFCSCGAVTVESLDDAEELLATEQAMDILGFLPDEKYGCYKLTGAIMHFGNMKFKQKPREEQLEADGTENADKAAFLMGINSSELVKCLIHPRIKVGNEYVTRGQTIEQVTCAVGALSKSMYERMFKWLVARINRALDAKLSRQFFIGILDITGFEILEYNSLEQLCINFTNEKLQQFFNWHMFVLEQEEYKKESIEWVSIGFGLDLQACIDLIEKPMGILSILEEECMFPKATDLTFKTKLFDNHFGKSVHLQKPKPDKKKFEAHFELVHYAGVVPYNISGWLEKNKDLLNETVVAVFQKSSNRLLASLFENYMSTDSAIPFGEKKRKKGASFQTVASLHKENLNKLMTNLKSTAPHFVRCINPNVNKIPGILDPYLVLQQLRCNGVLEGTRICREGFPNRLQYADFKQRYCILNPRTFPKSKFVSSRKAAEELLGSLEIDHTQYRFGITKVFFKAGFLGQLEAIRDERLSKVFTLFQARAQGKLMRIKFQKILEERDALILIQWNIRAFMAVKNWPWMRLFFKIKPLVKSSEVGEEVAGLKEECAQLQKALEKSEFQREELKAKQVSLTQEKNDLILQLQAEQETLANVEEQCEWLIKSKIQLEARVKELSERVEEEEEINSELTARGRKLEDECFELKKEIDDLETMLVKSEKEKRTTEHKVKNLTEEVEFLNEDISKLNRAAKVVQEAHQQTLDDLHMEEEKLSSLSKANLKLEQQVDELEGALEQERKARMNCERELHKLEGNLKLNRESMENLESSQRHLAEELRKKELELSQMNSKVENEKGLVAQLQKTVKELQTQIKDLKEKLEAERTTRAKMERERADLTQDLADLNERLEEVGGSSLAQLEITKKQETKFQKLHRDMEEATLHFETTSASLKKRHADSLAELEGQVENLQQVKQKLEKDKSDLQLEVDDLLTRVEQMTRAKANAEKLCTLYEERLHEATAKLDKVTQLANDLAAQKTKLWSESGEFLRRLEEKEALINQLSREKSNFTRQIEDLRGQLEKETKSQSALAHALQKAQRDCDLLREQYEEEQEVKAELHRTLSKVNAEMVQWRMKYENNVIQRTEDLEDAKKELAIRLQEAAEAMGVANARNASLERARHQLQLELGDALSDLGKVRSAAARLDQKQLQSGKALADWKQKHEESQALLDASQKEVQALSTELLKLKNTYEESIVGQETLRRENKNLQEEISNLTNQVREGTKNLTEMEKVKKLIEEEKTEVQVTLEETEGALERNESKILHFQLELLEAKAELERKLSEKDEEIENFRRKQQCTIDSLQSSLDSEAKSRIEVTRLKKKMEEDLNEMELQLSCANRQVSEATKSLGQLQIQIKDLQMQLDDSTQLNSDLKEQVAVAERRNSLLQSELEDLRSLQEQTERGRRLSEEELLEATERINLFYTQNTSLLSQKKKLEADVARMQKEAEEVVQECQNAEEKAKKAAIEAANLSEELKKKQDTIAHLERTRENMEQTITDLQKRLAEAEQMALMGSRKQIQKLESRVRELEGELEGEIRRSAEAQRGARRLERCIKELTYQAEEDKKNLSRMQTQMDKLQLKVQNYKQQVEVAETQANQYLSKYKKQQHELNEVKERAEVAESQVNKLKIKAREFGKKVQEE>sp|Q86YV6|MYLK4_HUMAN Myosin light chain kinase family member 4 OS=Homosapiens OX=9606 GN=MYLK4 PE=1 SV=2MLKVKRLEEFNTCYNSNQLEKMAFFQCREEVEKVKCFLEKNSGDQDSRSGHNEAKEVWSNADLTERMPVKSKRTSALAVDIPAPPAPFDHRIVTAKQGAVNSFYTVSKTEILGGGRFGQVHKCEETATGLKLAAKIIKTRGMKDKEEVKNEISVMNQLDHANLIQLYDAFESKNDIVLVMEYVDGGELFDRIIDESYNLTELDTILFMKQICEGIRHMHQMYILHLDLKPENILCVNRDAKQIKIIDFGLARRYKPREKLKVNFGTPEFLAPEVVNYDFVSFPTDMWSVGVIAYMLLSGLSPFLGDNDAETLNNILACRWDLEDEEFQDISEEAKEFISKLLIKEKSWRISASEALKHPWLSDHKLHSRLNAQKKKNRGSDAQDFVTK>sp|Q86YV6-2|MYLK4_HUMAN Isoform 2 of Myosin light chain kinase familymember 4 OS=Homo sapiens OX=9606 GN=MYLK4MLKVKRLEEFNTCYNSNQLEKMAFFQCREEVEKVKCFLEKNSGDQDSRSGHNEAKEVWSNADLTERMPVKSKRTSALAVDIPAPPAPFDHRIVTAKQGAVNSFYTVSKTEILGGGRFGQVHKCEETATGLKLAAKIIKTRGMKDKEEVKNEISVMNQLDHANLIQLYDAFESKNDIVLVMEYVDGGELFDRIIDESYNLTELDTILFMKQICEGIRHMHQMYILHLDLKPENIQCSRFLIDTSILPLCLLNCRYKPREKLKVNFGTPEFLAPEVVNYDFVSFPTDMWSVGVIAYMLLSGLSPFLGDNDAETLNNILACRWDLEDEEFQDISEEAKEFISKLLIKEKSWRISASEALKHPWLSDHKLHSRLNAQKKKNRGSDAQDFVTK>sp|P00387|NB5R3_HUMAN NADH-cytochrome b5 reductase 3 OS=Homo sapiensOX=9606 GN=CYB5R3 PE=1 SV=3MGAQLSTLGHMVLFPVWFLYSLLMKLFQRSTPAITLESPDIKYPLRLIDREIISHDTRRFRFALPSPQHILGLPVGQHIYLSARIDGNLVVRPYTPISSDDDKGFVDLVIKVYFKDTHPKFPAGGKMSQYLESMQIGDTIEFRGPSGLLVYQGKGKFAIRPDKKSNPIIRTVKSVGMIAGGTGITPMLQVIRAIMKDPDDHTVCHLLFANQTEKDILLRPELEELRNKHSARFKLWYTLDRAPEAWDYGQGFVNEEMIRDHLPPPEEEPLVLMCGPPPMIQYACLPNLDHVGHPTERCFVF>sp|P00387-2|NB5R3_HUMAN Isoform 2 of NADH-cytochrome b5 reductase 3OS=Homo sapiens OX=9606 GN=CYB5R3MKLFQRSTPAITLESPDIKYPLRLIDREIISHDTRRFRFALPSPQHILGLPVGQHIYLSARIDGNLVVRPYTPISSDDDKGFVDLVIKVYFKDTHPKFPAGGKMSQYLESMQIGDTIEFRGPSGLLVYQGKGKFAIRPDKKSNPIIRTVKSVGMIAGGTGITPMLQVIRAIMKDPDDHTVCHLLFANQTEKDILLRPELEELRNKHSARFKLWYTLDRAPEAWDYGQGFVNEEMIRDHLPPPEEEPLVLMCGPPPMIQYACLPNLDHVGHPTERCFVF>sp|P00387-3|NB5R3_HUMAN Isoform 3 of NADH-cytochrome b5 reductase 3OS=Homo sapiens OX=9606 GN=CYB5R3MNRSLLVGCMQSKDIWGREESICERLKQDGLDVERAESWELGHMVLFPVWFLYSLLMKLFQRSTPAITLESPDIKYPLRLIDREIISHDTRRFRFALPSPQHILGLPVGQHIYLSARIDGNLVVRPYTPISSDDDKGFVDLVIKVYFKDTHPKFPAGGKMSQYLESMQIGDTIEFRGPSGLLVYQGKGKFAIRPDKKSNPIIRTVKSVGMIAGGTGITPMLQVIRAIMKDPDDHTVCHLLFANQTEKDILLRPELEELRNKHSARFKLWYTLDRAPEAWDYGQGFVNEEMIRDHLPPPEEEPLVLMCGPPPMIQYACLPNLDHVGHPTERCFVF>sp|Q9UKX2|MYH2_HUMAN Myosin-2 OS=Homo sapiens OX=9606 GN=MYH2 PE=1 SV=1MSSDSELAVFGEAAPFLRKSERERIEAQNRPFDAKTSVFVAEPKESFVKGTIQSREGGKVTVKTEGGATLTVKDDQVFPMNPPKYDKIEDMAMMTHLHEPAVLYNLKERYAAWMIYTYSGLFCVTVNPYKWLPVYKPEVVTAYRGKKRQEAPPHIFSISDNAYQFMLTDRENQSILITGESGAGKTVNTKRVIQYFATIAVTGEKKKEEITSGKIQGTLEDQIISANPLLEAFGNAKTVRNDNSSRFGKFIRIHFGTTGKLASADIETYLLEKSRVVFQLKAERSYHIFYQITSNKKPELIEMLLITTNPYDYPFVSQGEISVASIDDQEELMATDSAIDILGFTNEEKVSIYKLTGAVMHYGNLKFKQKQREEQAEPDGTEVADKAAYLQSLNSADLLKALCYPRVKVGNEYVTKGQTVEQVSNAVGALAKAVYEKMFLWMVARINQQLDTKQPRQYFIGVLDIAGFEIFDFNSLEQLCINFTNEKLQQFFNHHMFVLEQEEYKKEGIEWTFIDFGMDLAACIELIEKPMGIFSILEEECMFPKATDTSFKNKLYDQHLGKSANFQKPKVVKGKAEAHFALIHYAGVVDYNITGWLEKNKDPLNETVVGLYQKSAMKTLAQLFSGAQTAEGEGAGGGAKKGGKKKGSSFQTVSALFRENLNKLMTNLRSTHPHFVRCIIPNETKTPGAMEHELVLHQLRCNGVLEGIRICRKGFPSRILYADFKQRYKVLNASAIPEGQFIDSKKASEKLLASIDIDHTQYKFGHTKVFFKAGLLGLLEEMRDDKLAQLITRTQARCRGFLARVEYQRMVERREAIFCIQYNIRSFMNVKHWPWMKLFFKIKPLLKSAETEKEMATMKEEFQKIKDELAKSEAKRKELEEKMVTLLKEKNDLQLQVQAEAEGLADAEERCDQLIKTKIQLEAKIKEVTERAEDEEEINAELTAKKRKLEDECSELKKDIDDLELTLAKVEKEKHATENKVKNLTEEMAGLDETIAKLTKEKKALQEAHQQTLDDLQAEEDKVNTLTKAKIKLEQQVDDLEGSLEQEKKLRMDLERAKRKLEGDLKLAQESIMDIENEKQQLDEKLKKKEFEISNLQSKIEDEQALGIQLQKKIKELQARIEELEEEIEAERASRAKAEKQRSDLSRELEEISERLEEAGGATSAQIEMNKKREAEFQKMRRDLEEATLQHEATAATLRKKHADSVAELGEQIDNLQRVKQKLEKEKSEMKMEIDDLASNVETVSKAKGNLEKMCRTLEDQLSELKSKEEEQQRLINDLTAQRGRLQTESGEFSRQLDEKEALVSQLSRGKQAFTQQIEELKRQLEEEIKAKNALAHALQSSRHDCDLLREQYEEEQESKAELQRALSKANTEVAQWRTKYETDAIQRTEELEEAKKKLAQRLQAAEEHVEAVNAKCASLEKTKQRLQNEVEDLMLDVERTNAACAALDKKQRNFDKILAEWKQKCEETHAELEASQKEARSLGTELFKIKNAYEESLDQLETLKRENKNLQQEISDLTEQIAEGGKRIHELEKIKKQVEQEKCELQAALEEAEASLEHEEGKILRIQLELNQVKSEVDRKIAEKDEEIDQLKRNHIRIVESMQSTLDAEIRSRNDAIRLKKKMEGDLNEMEIQLNHANRMAAEALRNYRNTQGILKDTQIHLDDALRSQEDLKEQLAMVERRANLLQAEIEELRATLEQTERSRKIAEQELLDASERVQLLHTQNTSLINTKKKLETDISQMQGEMEDILQEARNAEEKAKKAITDAAMMAEELKKEQDTSAHLERMKKNMEQTVKDLQLRLDEAEQLALKGGKKQIQKLEARVRELEGEVESEQKRNAEAVKGLRKHERRVKELTYQTEEDRKNILRLQDLVDKLQAKVKSYKRQAEEAEEQSNTNLAKFRKLQHELEEAEERADIAESQVNKLRVKSREVHTKVISEE>sp|Q9UKX2-2|MYH2_HUMAN Isoform 2 of Myosin-2 OS=Homo sapiens OX=9606GN=MYH2MSSDSELAVFGEAAPFLRKSERERIEAQNRPFDAKTSVFVAEPKESFVKGTIQSREGGKVTVKTEGGATLTVKDDQVFPMNPPKYDKIEDMAMMTHLHEPAVLYNLKERYAAWMIYTYSGLFCVTVNPYKWLPVYKPEVVTAYRGKKRQEAPPHIFSISDNAYQFMLTDRENQSILITGESGAGKTVNTKRVIQYFATIAVTGEKKKEEITSGKIQGTLEDQIISANPLLEAFGNAKTVRNDNSSRFGKFIRIHFGTTGKLASADIETYLLEKSRVVFQLKAERSYHIFYQITSNKKPELIEMLLITTNPYDYPFVSQGEISVASIDDQEELMATDSAIDILGFTNEEKVSIYKLTGAVMHYGNLKFKQKQREEQAEPDGTEVADKAAYLQSLNSADLLKALCYPRVKVGNEYVTKGQTVEQVSNAVGALAKAVYEKMFLWMVARINQQLDTKQPRQYFIGVLDIAGFEIFDFNSLEQLCINFTNEKLQQFFNHHMFVLEQEEYKKEGIEWTFIDFGMDLAACIELIEKPMGIFSILEEECMFPKATDTSFKNKLYDQHLGKSANFQKPKVVKGKAEAHFALIHYAGVVDYNITGWLEKNKDPLNETVVGLYQKSAMKTLAQLFSGAQTAEGEGAGGGAKKGGKKKGSSFQTVSALFREEQSNTNLAKFRKLQHELEEAEERADIAESQVNKLRVKSREVHTKVISEE>sp|Q7RTU3|OLIG3_HUMAN Oligodendrocyte transcription factor 3 OS=Homosapiens OX=9606 GN=OLIG3 PE=1 SV=2MNSDSSSVSSRASSPDMDEMYLRDHHHRHHHHQESRLNSVSSTQGDMMQKMPGESLSRAGAKAAGESSKYKIKKQLSEQDLQQLRLKINGRERKRMHDLNLAMDGLREVMPYAHGPSVRKLSKIATLLLARNYILMLTSSLEEMKRLVGEIYGGHHSAFHCGTVGHSAGHPAHAANSVHPVHPILGGALSSGNASSPLSAASLPAIGTIRPPHSLLKAPSTPPALQLGSGFQHWAGLPCPCTICQMPPPPHLSALSTANMARLSAESKDLLK>sp|Q5W0B1|OBI1_HUMAN ORC ubiquitin ligase 1 OS=Homo sapiens OX=9606GN=OBI1 PE=1 SV=1MAQTVQNVTLSLTLPITCHICLGKVRQPVICINNHVFCSICIDLWLKNNSQCPACRVPITPENPCKEIIGGTSESEPMLSHTVRKHLRKTRLELLHKEYEDEIDCLQKEVEELKSKNLSLESQIKTILDPLTLVQGNQNEDKHLVTDNPSKINPETVAEWKKKLRTANEIYEKVKDDVDKLKEANKKLKLENGGLVRENLRLKAEVDNRSPQKFGRFAVAALQSKVEQYERETNRLKKALERSDKYIEELESQVAQLKNSSEEKEAMNSICQTALSADGKGSKGSEEDVVSKNQGDSARKQPGSSTSSSSHLAKPSSSRLCDTSSARQESTSKADLNCSKNKDLYQEQVEVMLDVTDTSMDTYLEREWGNKPSDCVPYKDEELYDLPAPCTPLSLSCLQLSTPENRESSVVQAGGSKKHSNHLRKLVFDDFCDSSNVSNKDSSEDDISRSENEKKSECFSSPKTGFWDCCSTSYAQNLDFESSEGNTIANSVGEISSKLSEKSGLCLSKRLNSIRSFEMNRTRTSSEASMDAAYLDKISELDSMMSESDNSKSPCNNGFKSLDLDGLSKSSQGSEFLEEPDKLEEKTELNLSKGSLTNDQLENGSEWKPTSFFLLSPSDQEMNEDFSLHSSSCPVTNEIKPPSCLFQTEFSQGILLSSSHRLFEDQRFGSSLFKMSSEMHSLHNHLQSPWSTSFVPEKRNKNVNQSTKRKIQSSLSSASPSKATKS>sp|O95007|OR6B1_HUMAN Olfactory receptor 6B1 OS=Homo sapiens OX=9606GN=OR6B1 PE=1 SV=1MELENQTRVTKFILVGFPGSLSMRAAMFLIFLVAYILTVAENVIIILLVLQNRPLHKPMYFFLANLSFLETWYISVTVPKLLFSFWSVNNSISFTLCMIQLYFFIALMCTECVLLAAMAYDRYVAICRPLHYPTIMSHGLCFRLALGSWAIGFGISLAKIYFISCLSFCGPNVINHFFCDISPVLNLSCTDMSITELVDFILALVIFLFPLFITVLSYGCILATILCMPTGKQKAFSTCASHLVVVTIFYSAIIFMYARPRVIHAFNMNKIISIFYAIVTPSLNPFIYCLRNREVKEALKKLAYCQASRSD>sp|O15294|OGT1_HUMAN UDP-N-acetylglucosamine--peptide N-acetylglucosaminyltransferase 110 kDa subunit OS=Homo sapiens OX=9606GN=OGT PE=1 SV=3MASSVGNVADSTEPTKRMLSFQGLAELAHREYQAGDFEAAERHCMQLWRQEPDNTGVLLLLSSIHFQCRRLDRSAHFSTLAIKQNPLLAEAYSNLGNVYKERGQLQEAIEHYRHALRLKPDFIDGYINLAAALVAAGDMEGAVQAYVSALQYNPDLYCVRSDLGNLLKALGRLEEAKACYLKAIETQPNFAVAWSNLGCVFNAQGEIWLAIHHFEKAVTLDPNFLDAYINLGNVLKEARIFDRAVAAYLRALSLSPNHAVVHGNLACVYYEQGLIDLAIDTYRRAIELQPHFPDAYCNLANALKEKGSVAEAEDCYNTALRLCPTHADSLNNLANIKREQGNIEEAVRLYRKALEVFPEFAAAHSNLASVLQQQGKLQEALMHYKEAIRISPTFADAYSNMGNTLKEMQDVQGALQCYTRAIQINPAFADAHSNLASIHKDSGNIPEAIASYRTALKLKPDFPDAYCNLAHCLQIVCDWTDYDERMKKLVSIVADQLEKNRLPSVHPHHSMLYPLSHGFRKAIAERHGNLCLDKINVLHKPPYEHPKDLKLSDGRLRVGYVSSDFGNHPTSHLMQSIPGMHNPDKFEVFCYALSPDDGTNFRVKVMAEANHFIDLSQIPCNGKAADRIHQDGIHILVNMNGYTKGARNELFALRPAPIQAMWLGYPGTSGALFMDYIITDQETSPAEVAEQYSEKLAYMPHTFFIGDHANMFPHLKKKAVIDFKSNGHIYDNRIVLNGIDLKAFLDSLPDVKIVKMKCPDGGDNADSSNTALNMPVIPMNTIAEAVIEMINRGQIQITINGFSISNGLATTQINNKAATGEEVPRTIIVTTRSQYGLPEDAIVYCNFNQLYKIDPSTLQMWANILKRVPNSVLWLLRFPAVGEPNIQQYAQNMGLPQNRIIFSPVAPKEEHVRRGQLADVCLDTPLCNGHTTGMDVLWAGTPMVTMPGETLASRVAASQLTCLGCLELIAKNRQEYEDIAVKLGTDLEYLKKVRGKVWKQRISSPLFNTKQYTMELERLYLQMWEHYAAGNKPDHMIKPVEVTESA>sp|O15294-2|OGT1_HUMAN Isoform 2 of UDP-N-acetylglucosamine--peptide N-acetylglucosaminyltransferase 110 kDa subunit OS=Homo sapiens OX=9606GN=OGTMLQGHFWLVREGIMISPSSPPPPNLFFFPLQIFPFPFTSFPSHLLSLTPPKACYLKAIETQPNFAVAWSNLGCVFNAQGEIWLAIHHFEKAVTLDPNFLDAYINLGNVLKEARIFDRAVAAYLRALSLSPNHAVVHGNLACVYYEQGLIDLAIDTYRRAIELQPHFPDAYCNLANALKEKGSVAEAEDCYNTALRLCPTHADSLNNLANIKREQGNIEEAVRLYRKALEVFPEFAAAHSNLASVLQQQGKLQEALMHYKEAIRISPTFADAYSNMGNTLKEMQDVQGALQCYTRAIQINPAFADAHSNLASIHKDSGNIPEAIASYRTALKLKPDFPDAYCNLAHCLQIVCDWTDYDERMKKLVSIVADQLEKNRLPSVHPHHSMLYPLSHGFRKAIAERHGNLCLDKINVLHKPPYEHPKDLKLSDGRLRVGYVSSDFGNHPTSHLMQSIPGMHNPDKFEVFCYALSPDDGTNFRVKVMAEANHFIDLSQIPCNGKAADRIHQDGIHILVNMNGYTKGARNELFALRPAPIQAMWLGYPGTSGALFMDYIITDQETSPAEVAEQYSEKLAYMPHTFFIGDHANMFPHLKKKAVIDFKSNGHIYDNRIVLNGIDLKAFLDSLPDVKIVKMKCPDGGDNADSSNTALNMPVIPMNTIAEAVIEMINRGQIQITINGFSISNGLATTQINNKAATGEEVPRTIIVTTRSQYGLPEDAIVYCNFNQLYKIDPSTLQMWANILKRVPNSVLWLLRFPAVGEPNIQQYAQNMGLPQNRIIFSPVAPKEEHVRRGQLADVCLDTPLCNGHTTGMDVLWAGTPMVTMPGETLASRVAASQLTCLGCLELIAKNRQEYEDIAVKLGTDLEYLKKVRGKVWKQRISSPLFNTKQYTMELERLYLQMWEHYAAGNKPDHMIKPVEVTESA>sp|O15294-3|OGT1_HUMAN Isoform 1 of UDP-N-acetylglucosamine--peptide N-acetylglucosaminyltransferase 110 kDa subunit OS=Homo sapiens OX=9606GN=OGTMASSVGNVADSTGLAELAHREYQAGDFEAAERHCMQLWRQEPDNTGVLLLLSSIHFQCRRLDRSAHFSTLAIKQNPLLAEAYSNLGNVYKERGQLQEAIEHYRHALRLKPDFIDGYINLAAALVAAGDMEGAVQAYVSALQYNPDLYCVRSDLGNLLKALGRLEEAKACYLKAIETQPNFAVAWSNLGCVFNAQGEIWLAIHHFEKAVTLDPNFLDAYINLGNVLKEARIFDRAVAAYLRALSLSPNHAVVHGNLACVYYEQGLIDLAIDTYRRAIELQPHFPDAYCNLANALKEKGSVAEAEDCYNTALRLCPTHADSLNNLANIKREQGNIEEAVRLYRKALEVFPEFAAAHSNLASVLQQQGKLQEALMHYKEAIRISPTFADAYSNMGNTLKEMQDVQGALQCYTRAIQINPAFADAHSNLASIHKDSGNIPEAIASYRTALKLKPDFPDAYCNLAHCLQIVCDWTDYDERMKKLVSIVADQLEKNRLPSVHPHHSMLYPLSHGFRKAIAERHGNLCLDKINVLHKPPYEHPKDLKLSDGRLRVGYVSSDFGNHPTSHLMQSIPGMHNPDKFEVFCYALSPDDGTNFRVKVMAEANHFIDLSQIPCNGKAADRIHQDGIHILVNMNGYTKGARNELFALRPAPIQAMWLGYPGTSGALFMDYIITDQETSPAEVAEQYSEKLAYMPHTFFIGDHANMFPHLKKKAVIDFKSNGHIYDNRIVLNGIDLKAFLDSLPDVKIVKMKCPDGGDNADSSNTALNMPVIPMNTIAEAVIEMINRGQIQITINGFSISNGLATTQINNKAATGEEVPRTIIVTTRSQYGLPEDAIVYCNFNQLYKIDPSTLQMWANILKRVPNSVLWLLRFPAVGEPNIQQYAQNMGLPQNRIIFSPVAPKEEHVRRGQLADVCLDTPLCNGHTTGMDVLWAGTPMVTMPGETLASRVAASQLTCLGCLELIAKNRQEYEDIAVKLGTDLEYLKKVRGKVWKQRISSPLFNTKQYTMELERLYLQMWEHYAAGNKPDHMIKPVEVTESA>sp|O15294-4|OGT1_HUMAN Isoform 4 of UDP-N-acetylglucosamine--peptide N-acetylglucosaminyltransferase 110 kDa subunit OS=Homo sapiens OX=9606GN=OGTMHYKEAIRISPTFADAYSNMGNTLKEMQDVQGALQCYTRAIQINPAFADAHSNLASIHKDSGNIPEAIASYRTALKLKPDFPDAYCNLAHCLQIVCDWTDYDERMKKLVSIVADQLEKNRLPSVHPHHSMLYPLSHGFRKAIAERHGNLCLDKINVLHKPPYEHPKDLKLSDGRLRVGYVSSDFGNHPTSHLMQSIPGMHNPDKFEVFCYALSPDDGTNFRVKVMAEANHFIDLSQIPCNGKAADRIHQDGIHILVNMNGYTKGARNELFALRPAPIQAMWLGYPGTSGALFMDYIITDQETSPAEVAEQYSEKLAYMPHTFFIGDHANMFPHLKKKAVIDFKSNGHIYDNRIVLNGIDLKAFLDSLPDVKIVKMKCPDGGDNADSSNTALNMPVIPMNTIAEAVIEMINRGQIQITINGFSISNGLATTQINNKAATGEEVPRTIIVTTRSQYGLPEDAIVYCNFNQLYKIDPSTLQMWANILKRVPNSVLWLLRFPAVGEPNIQQYAQNMGLPQNRIIFSPVAPKEEHVRRGQLADVCLDTPLCNGHTTGMDVLWAGTPMVTMPGETLASRVAASQLTCLGCLELIAKNRQEYEDIAVKLGTDLEYLKKVRGKVWKQRISSPLFNTKQYTMELERLYLQMWEHYAAGNKPDHMIKPVEVTESA>sp|Q15617|OR8G1_HUMAN Olfactory receptor 8G1 OS=Homo sapiens OX=9606GN=OR8G1 PE=2 SV=2MSGENNSSVTEFILAGLSEQPELQLPLFLLFLGIYVVTVVGNLGMTTLIWLSSHLHTPMYYFLSSLSFIDFCHSTVITPKMLVNFVTEKNIISYPECMTQLYFFLVFAIAECHMLAAMAYDRYMAICSPLLYSVIISNKACFSLILGVYIIGLVCASVHTGCMFRVQFCKFDLINHYFCDLLPLLKLSCSSIYVNKLLILCVGAFNILVPSLTILCSYIFIIASILHIRSTEGRSKAFSTCSSHMLAVVIFFGSAAFMYLQPSSISSMDQGKVSSVFYTIIVPMLNPLIYSLRNKDVHVSLKKMLQRRTLL>sp|Q6IFN5|O7E24_HUMAN Olfactory receptor 7E24 OS=Homo sapiens OX=9606GN=OR7E24 PE=2 SV=1MSYFPILFFFFLKRCPSYTEPQNLTGVSEFLLLGLSEDPELQPVLAGLFLSMYLVTVLGNLLIILAVSSDSHLHTPMYFFLSNLSLADIGFTSTTVPKMIVDMQTHSRVISYEGCLTQMSFFVLFACMDDMLLSVMAYDRFVAICHPLHYRIIMNPRLCGFLILLSFFISLLDSQLHNLIMLQLTCFKDVDISNFFCDPSQLLHLRCSDTFINEMVIYFMGAIFGCLPISGILFSYYKIVSPILRVPTSDGKYKAFSTCGSHLAVVCLFYGTGLVGYLSSAVLPSPRKSMVASVMYTVVTPMLNPFIYSLRNKDIQSALCRLHGRIIKSHHLHPFCYMG>sp|Q8N162|OR8H2_HUMAN Olfactory receptor 8H2 OS=Homo sapiens OX=9606GN=OR8H2 PE=3 SV=1MMGRRNNTNVADFILMGLTLSEEIQMALFMLFLLIYLITMLGNVGMILIIRLDLQLHTPMYFFLTHLSFIDLSYSTVVTPKTLANLLTSNYISFTGCFAQMFFFAFLGTAECYLLSSMAHDRYAAICSPLHYTVIMSKRLCLALITGPYVIGFIDSFVNVVSMSRLHFYDSNVIHHFFCDTSPILALSCTDTYNTEILIFIIVGSTLMVSLFTISASYVFILFTILKINSTSGKQKAFSTCVSHLLGVTIFYSTLIFTYLKPRKSYSLGRDQVASVFYTIVIPVLNPLIYSLRNKEVKNAVIRVMQRRQDSR>sp|Q8NGN4|O10G9_HUMAN Olfactory receptor 10G9 OS=Homo sapiens OX=9606GN=OR10G9 PE=3 SV=1MSKTSLVTAFILTGLPHAPGLDAPLFGIFLVVYVLTVLGNLLILLVIRVDSHLHTPMYYFLTNLSFIDMWFSTVTVPKMLMTLVSPSGRAISFHSCVAQLYFFHFLGSTECFLYTVMSYDRYLAISYPLRYTSMMSGSRCALLATSTWLSGSLHSAVQTILTFHLPYCGPNQIQHYLCDAPPILKLACADTSANEMVIFVDIGLVASGCFLLIVLSYVSIVCSILRIHTSEGRHRAFQTCASHCIVVLCFFVPCVFIYLRPGSRDVVDGVVAIFYTVLTPLLNPVVYTLRNKEVKKAVLKLRDKVAHSQGE>sp|Q8NGA2|OR7A2_HUMAN Putative olfactory receptor 7A2 OS=Homo sapiensOX=9606 GN=OR7A2P PE=5 SV=1MVKAGNETQISEFLLLGFSEKQELQPFLFGLFLSMYLVTVLGNLLIILAAISDSCLHTPMYFFLSNLSFVDICFASTMVPKMLVNIQTQSKVITYAGCITQMCFFVLFIVLDSLLLTVMAYDQFVAICHPLHYTVIMSPQLCGLLVLVSWIMSVLNSMLQSLVTLQLSFCTDLEIPHFFCELNEMIHLACSDTFVNNMVMHFAAVLLDGGPLVGILYSYCRIVSSIRAISSTQGKYKALSTCASHLSVVSIFYGTGLGVYLSSTMTQNLHSTAVASVMYTVVTPMLNPFIYSLRNKDIKGALTQFFRGKQ>sp|Q8NGT5|OR9A2_HUMAN Olfactory receptor 9A2 OS=Homo sapiens OX=9606GN=OR9A2 PE=2 SV=1MMDNHSSATEFHLLGFPGSQGLHHILFAIFFFFYLVTLMGNTVIIVIVCVDKRLQSPMYFFLSHLSTLEILVTTIIVPMMLWGLLFLGCRQYLSLHVSLNFSCGTMEFALLGVMAVDRYVAVCNPLRYNIIMNSSTCIWVVIVSWVFGFLSEIWPIYATFQFTFRKSNSLDHFYCDRGQLLKLSCDNTLLTEFILFLMAVFILIGSLIPTIVSYTYIISTILKIPSASGRRKAFSTFASHFTCVVIGYGSCLFLYVKPKQTQGVEYNKIVSLLVSVLTPFLNPFIFTLRNDKVKEALRDGMKRCCQLLKD>sp|Q8NGC4|O10G3_HUMAN Olfactory receptor 10G3 OS=Homo sapiens OX=9606GN=OR10G3 PE=3 SV=1MERINSTLLTAFILTGIPYPLRLRTLFFVFFFLIYILTQLGNLLILITVWADPRLHARPMYIFLGVLSVIDMSISSIIVPRLMMNFTLGVKPIPFGGCVAQLYFYHFLGSTQCFLYTLMAYDRYLAICQPLRYPVLMTAKLSALLVAGAWMAGSIHGALQAILTFRLPYCGPNQVDYFFCDIPAVLRLACADTTVNELVTFVDIGVVVASCFSLILLSYIQIIQAILRIHTADGRRRAFSTCGAHVTVVTVYYVPCAFIYLRPETNSPLDGAAALVPTAITPFLNPLIYTLRNQEVKLALKRMLRSPRTPSEV>sp|P58170|OR1D5_HUMAN Olfactory receptor 1D5 OS=Homo sapiens OX=9606GN=OR1D5 PE=2 SV=1MDGDNQSENSQFLLLGISESPEQQRILFWMFLSMYLVTVLGNVLIILAISSDSHLHTPMYFFLANLSFTDLFFVTNTIPKMLVNFQSQNKAISYAGCLTQLYFLVSLVTLDNLILAVMAYDRYVATCCPLHYVTAMSPGLCVLLLSLCWGLSVLYGLLLTFLLTRVTFCGPREIHYLFCDMYILLWLACSNTHIIHTALIATGCFIFLTPLGFMTTSYVRIVRTILQMPSASKKYKTFSTCASHLGVVSLFYGTLAMVYLQPLHTYSMKDSVATVMYAVLTPMMNPFIYRLRNKDMHGAPGRVLWRPFQRPK>sp|O60890|OPHN1_HUMAN Oligophrenin-1 OS=Homo sapiens OX=9606 GN=OPHN1PE=1 SV=1MGHPPLEFSDCYLDSPDFRERLKCYEQELERTNKFIKDVIKDGNALISAMRNYSSAVQKFSQTLQSFQFDFIGDTLTDDEINIAESFKEFAELLNEVENERMMMVHNASDLLIKPLENFRKEQIGFTKERKKKFEKDGERFYSLLDRHLHLSSKKKESQLQEADLQVDKERHNFFESSLDYVYQIQEVQESKKFNIVEPVLAFLHSLFISNSLTVELTQDFLPYKQQLQLSLQNTRNHFSSTREEMEELKKRMKEAPQTCKLPGQPTIEGYLYTQEKWALGISWVKYYCQYEKETKTLTMTPMEQKPGAKQGPLDLTLKYCVRRKTESIDKRFCFDIETNERPGTITLQALSEANRRLWMEAMDGKEPIYHSPITKQQEMELNEVGFKFVRKCINIIETKGIKTEGLYRTVGSNIQVQKLLNAFFDPKCPGDVDFHNSDWDIKTITSSLKFYLRNLSEPVMTYRLHKELVSAAKSDNLDYRLGAIHSLVYKLPEKNREMLELLIRHLVNVCEHSKENLMTPSNMGVIFGPTLMRAQEDTVAAMMNIKFQNIVVEILIEHFGKIYLGPPEESAAPPVPPPRVTARRHKPITISKRLLRERTVFYTSSLDESEDEIQHQTPNGTITSSIEPPKPPQHPKLPIQRSGETDPGRKSPSRPILDGKLEPCPEVDVGKLVSRLQDGGTKITPKATNGPMPGSGPTKTPSFHIKRPAPRPLAHHKEGDADSFSKVRPPGEKPTIIRPPVRPPDPPCRAATPQKPEPKPDIVAGNAGEITSSVVASRTRFFETASRKTGSSQGRLPGDES>sp|O60890-2|OPHN1_HUMAN Isoform 2 of Oligophrenin-1 OS=Homo sapiensOX=9606 GN=OPHN1MGHPPLEFSDCYLDSPDFRERLKCYEQELERTNKFIKDVIKDGNALISAMRNYSSAVQKFSQTLQSFQFDFIGDTLTDDEINIAESFKEFAELLNEVENERMMMVHNASDLLIKPLENFRKEQIGFTKERKKKFEKDGERFYSLLDRHLHLSSKKKESQLQEADLQVDKERHNFFESSLDYVYQIQEVQESKKFNIVEPVLAFLHSLFISNSLTVELTQDFLPYKQQLQLSLQNTRNHFSSTREEMEELKKRMKEAPQTCKLPGQPTIEGYLYTQEKCVWGHRGIHWVSISQELLPLVGCEFWAPLLFIDP>sp|Q8NGN3|O10G4_HUMAN Olfactory receptor 10G4 OS=Homo sapiens OX=9606GN=OR10G4 PE=1 SV=1MSNASLVTAFILTGLPHAPGLDALLFGIFLVVYVLTVLGNLLILLVIRVDSHLHTPMYYFLTNLSFIDMWFSTVTVPKMLMTLVSPSGRAISFHSCVAQLYFFHFLGSTECFLYTVMSYDRYLAISYPLRYTSMMSGSRCALLATGTWLSGSLHSAVQTILTFHLPYCGPNQIQHYFCDAPPILKLACADTSANVMVIFVDIGIVASGCFVLIVLSYVSIVCSILRIRTSDGRRRAFQTCASHCIVVLCFFVPCVVIYLRPGSMDAMDGVVAIFYTVLTPLLNPVVYTLRNKEVKKAVLKLRDKVAHPQRK>sp|Q9GZY0|NXF2_HUMAN Nuclear RNA export factor 2 OS=Homo sapiens OX=9606GN=NXF2 PE=1 SV=1MCSTLKKCGTYRTEVAECHDHGSTFQGRKKGGSSFRDNFDKRSCHYEHGGYERPPSHCQENDGSVEMRDVHKDQQLRHTPYSIRCERRMKWHSEDEIRITTWRNRKPPERKMSQNTQDGYTRNWFKVTIPYGIKYDKAWLMNSIQSHCSDRFTPVDFHYVRNRACFFVQDASAASALKDVSYKIYDDENQKICIFVNHSTAPYSVKNKLKPGQMEMLKLTMNKRYNVSQQALDLQNLRFDPDLMGRDIDIILNRRNCMAATLKIIERNFPELLSLNLCNNKLYQLDGLSDITEKAPKVKTLNLSKNKLESAWELGKVKGLKLEELWLEGNPLCSTFSDQSAYVSAIRDCFPKLLRLDGRELSAPVIVDIDSSETMKPCKENFTGSETLKHLVLQFLQQYYSIYDSGDRQGLLGAYHDEACFSLAIPFDPKDSAPSSLCKYFEDSRNMKTLKDPYLKGELLRRTKRDIVDSLSALPKTQHDLSSILVDVWCQTERMLCFSVNGVFKEVEGQSQGSVLAFTRTFIATPGSSSSLCIVNDELFVRDASPQETQSAFSIPVSTLSSSSEPSLSQEQQEMVQAFSAQSGMKLEWSQKCLQDNEWNYTRAGQAFTMLQTEGKIPAEAFKQIS>sp|Q9Y6K5|OAS3_HUMAN 2'-5'-oligoadenylate synthase 3 OS=Homo sapiensOX=9606 GN=OAS3 PE=1 SV=3MDLYSTPAAALDRFVARRLQPRKEFVEKARRALGALAAALRERGGRLGAAAPRVLKTVKGGSSGRGTALKGGCDSELVIFLDCFKSYVDQRARRAEILSEMRASLESWWQNPVPGLRLTFPEQSVPGALQFRLTSVDLEDWMDVSLVPAFNVLGQAGSGVKPKPQVYSTLLNSGCQGGEHAACFTELRRNFVNIRPAKLKNLILLVKHWYHQVCLQGLWKETLPPVYALELLTIFAWEQGCKKDAFSLAEGLRTVLGLIQQHQHLCVFWTVNYGFEDPAVGQFLQRQLKRPRPVILDPADPTWDLGNGAAWHWDLLAQEAASCYDHPCFLRGMGDPVQSWKGPGLPRAGCSGLGHPIQLDPNQKTPENSKSLNAVYPRAGSKPPSCPAPGPTGAASIVPSVPGMALDLSQIPTKELDRFIQDHLKPSPQFQEQVKKAIDIILRCLHENCVHKASRVSKGGSFGRGTDLRDGCDVELIIFLNCFTDYKDQGPRRAEILDEMRAQLESWWQDQVPSLSLQFPEQNVPEALQFQLVSTALKSWTDVSLLPAFDAVGQLSSGTKPNPQVYSRLLTSGCQEGEHKACFAELRRNFMNIRPVKLKNLILLVKHWYRQVAAQNKGKGPAPASLPPAYALELLTIFAWEQGCRQDCFNMAQGFRTVLGLVQQHQQLCVYWTVNYSTEDPAMRMHLLGQLRKPRPLVLDPADPTWNVGHGSWELLAQEAAALGMQACFLSRDGTSVQPWDVMPALLYQTPAGDLDKFISEFLQPNRQFLAQVNKAVDTICSFLKENCFRNSPIKVIKVVKGGSSAKGTALRGRSDADLVVFLSCFSQFTEQGNKRAEIISEIRAQLEACQQERQFEVKFEVSKWENPRVLSFSLTSQTMLDQSVDFDVLPAFDALGQLVSGSRPSSQVYVDLIHSYSNAGEYSTCFTELQRDFIISRPTKLKSLIRLVKHWYQQCTKISKGRGSLPPQHGLELLTVYAWEQGGKDSQFNMAEGFRTVLELVTQYRQLCIYWTINYNAKDKTVGDFLKQQLQKPRPIILDPADPTGNLGHNARWDLLAKEAAACTSALCCMGRNGIPIQPWPVKAAV>sp|Q96KK4|O10C1_HUMAN Olfactory receptor 10C1 OS=Homo sapiens OX=9606GN=OR10C1 PE=2 SV=3MSANTSMVTEFLLLGFSHLADLQGLLFSVFLTIYLLTVAGNFLIVVLVSTDAALQSPMYFFLRTLSALEIGYTSVTVPLLLHHLLTGRRHISRSGCALQMFFFLFFGATECCLLAAMAYDRYAAICEPLRYPLLLSHRVCLQLAGSAWACGVLVGLGHTPFIFSLPFCGPNTIPQFFCEIQPVLQLVCGDTSLNELQIILATALLILCPFGLILGSYGRILVTIFRIPSVAGRRKAFSTCSSHLIMVSLFYGTALFIYIRPKASYDPATDPLVSLFYAVVTPILNPIIYSLRNTEVKAALKRTIQKTVPMEI>sp|O00330|ODPX_HUMAN Pyruvate dehydrogenase protein X component,mitochondrial OS=Homo sapiens OX=9606 GN=PDHX PE=1 SV=3MAASWRLGCDPRLLRYLVGFPGRRSVGLVKGALGWSVSRGANWRWFHSTQWLRGDPIKILMPSLSPTMEEGNIVKWLKKEGEAVSAGDALCEIETDKAVVTLDASDDGILAKIVVEEGSKNIRLGSLIGLIVEEGEDWKHVEIPKDVGPPPPVSKPSEPRPSPEPQISIPVKKEHIPGTLRFRLSPAARNILEKHSLDASQGTATGPRGIFTKEDALKLVQLKQTGKITESRPTPAPTATPTAPSPLQATAGPSYPRPVIPPVSTPGQPNAVGTFTEIPASNIRRVIAKRLTESKSTVPHAYATADCDLGAVLKVRQDLVKDDIKVSVNDFIIKAAAVTLKQMPDVNVSWDGEGPKQLPFIDISVAVATDKGLLTPIIKDAAAKGIQEIADSVKALSKKARDGKLLPEEYQGGSFSISNLGMFGIDEFTAVINPPQACILAVGRFRPVLKLTEDEEGNAKLQQRQLITVTMSSDSRVVDDELATRFLKSFKANLENPIRLA>sp|O00330-2|ODPX_HUMAN Isoform 2 of Pyruvate dehydrogenase protein Xcomponent, mitochondrial OS=Homo sapiens OX=9606 GN=PDHXMAASWRLGCDPRLLRYLVGFPGRRSVGLVKGALGWSVSRGANWRWFHSTQWLRGDPIKILMPSLSPTMEEGNIVKWLKKEGEAVSAGDALCEIETDKAVVTLDASDDGILAKIVQMPDVNVSWDGEGPKQLPFIDISVAVATDKGLLTPIIKDAAAKGIQEIADSVKALSKKARDGKLLPEEYQGGSFSISNLGMFGIDEFTAVINPPQACILAVGRFRPVLKLTEDEEGNAKLQQRQLITVTMSSDSRVVDDELATRFLKSFKANLENPIRLA>sp|O00330-3|ODPX_HUMAN Isoform 3 of Pyruvate dehydrogenase protein Xcomponent, mitochondrial OS=Homo sapiens OX=9606 GN=PDHXMQSGGAEGSPGAGRTGRGPGSGKAPPAEISSGAPDFPGGDPIKILMPSLSPTMEEGNIVKWLKKEGEAVSAGDALCEIETDKAVVTLDASDDGILAKIVVEEGSKNIRLGSLIGLIVEEGEDWKHVEIPKDVGPPPPVSKPSEPRPSPEPQISIPVKKEHIPGTLRFRLSPAARNILEKHSLDASQGTATGPRGIFTKEDALKLVQLKQTGKITESRPTPAPTATPTAPSPLQATAGPSYPRPVIPPVSTPGQPNAVGTFTEIPASNIRRVIAKRLTESKSTVPHAYATADCDLGAVLKVRQDLVKDDIKVSVNDFIIKAAAVTLKQMPDVNVSWDGEGPKQLPFIDISVAVATDKGLLTPIIKDAAAKGIQEIADSVKALSKKARDGKLLPEEYQGGSFSISNLGMFGIDEFTAVINPPQACILAVGRFRPVLKLTEDEEGNAKLQQRQLITVTMSSDSRVVDDELATRFLKSFKANLENPIRLA>sp|P03999|OPSB_HUMAN Short-wave-sensitive opsin 1 OS=Homo sapiensOX=9606 GN=OPN1SW PE=1 SV=1MRKMSEEEFYLFKNISSVGPWDGPQYHIAPVWAFYLQAAFMGTVFLIGFPLNAMVLVATLRYKKLRQPLNYILVNVSFGGFLLCIFSVFPVFVASCNGYFVFGRHVCALEGFLGTVAGLVTGWSLAFLAFERYIVICKPFGNFRFSSKHALTVVLATWTIGIGVSIPPFFGWSRFIPEGLQCSCGPDWYTVGTKYRSESYTWFLFIFCFIVPLSLICFSYTQLLRALKAVAAQQQESATTQKAEREVSRMVVVMVGSFCVCYVPYAAFAMYMVNNRNHGLDLRLVTIPSFFSKSACIYNPIIYCFMNKQFQACIMKMVCGKAMTDESDTCSSQKTEVSTVSSTQVGPN>sp|P04001|OPSG_HUMAN Medium-wave-sensitive opsin 1 OS=Homo sapiensOX=9606 GN=OPN1MW PE=1 SV=1MAQQWSLQRLAGRHPQDSYEDSTQSSIFTYTNSNSTRGPFEGPNYHIAPRWVYHLTSVWMIFVVIASVFTNGLVLAATMKFKKLRHPLNWILVNLAVADLAETVIASTISVVNQVYGYFVLGHPMCVLEGYTVSLCGITGLWSLAIISWERWMVVCKPFGNVRFDAKLAIVGIAFSWIWAAVWTAPPIFGWSRYWPHGLKTSCGPDVFSGSSYPGVQSYMIVLMVTCCITPLSIIVLCYLQVWLAIRAVAKQQKESESTQKAEKEVTRMVVVMVLAFCFCWGPYAFFACFAAANPGYPFHPLMAALPAFFAKSATIYNPVIYVFMNRQFRNCILQLFGKKVDDGSELSSASKTEVSSVSSVSPA>sp|Q8NGS1|OR1J4_HUMAN Olfactory receptor 1J4 OS=Homo sapiens OX=9606GN=OR1J4 PE=2 SV=1MKRENQSSVSEFLLLDLPIWPEQQAVFFTLFLGMYLITVLGNLLIILLIRLDSHLHTPMFFFLSHLALTDISLSSVTVPKMLLSMQTQDQSILYAGCVTQMYFFIFFTDLDNFLLTSMAYDRYVAICHPLRYTTIMKEGLCNLLVTVSWILSCTNALSHTLLLAQLSFCADNTIPHFFCDLVALLKLSCSDISLNELVIFTVGQAVITLPLICILISYGHIGVTILKAPSTKGIFKALSTCGSHLSVVSLYYGTIIGLYFLPSSSASSDKDVIASVMYTVITPLLNPFIYSLRNRDIKGALERLFNRATVLSQ>sp|Q8NGT0|O13C9_HUMAN Olfactory receptor 13C9 OS=Homo sapiens OX=9606GN=OR13C9 PE=3 SV=1MEWENQTILVEFFLKGHSVHPRLELLFFVLIFIMYVVILLGNGTLILISILDPHLHTPMYFFLGNLSFLDICYTTTSIPSTLVSFLSERKTISFSGCAVQMFLGLAMGTTECVLLGMMAFDRYVAICNPLRYPIIMSKNAYVPMAVGSWFAGIVNSAVQTTFVVQLPFCRKNVINHFSCEILAVMKLACADISGNEFLMLVATILFTLMPLLLIVISYSLIISSILKIHSSEGRSKAFSTCSAHLTVVIIFYGTILFMYMKPKSKETLNSDDLDATDKIISMFYGVMTPMMNPLIYSLRNKDVKEAVKHLPNRRFFSK>sp|A0A2R8YFM6|OOSP3_HUMAN Oocyte-secreted protein 3 OS=Homo sapiensOX=9606 GN=OOSP3 PE=3 SV=1MKDFVRLQSSFLLCTILTLSEQESVSVGCTSSMFWVVAEPTLLGQDHILHSDEASLGTGCPVTNVTAKGYEFNYPATQCGIQKEVFSYVTVFYSALHCNIMHKGVTGKIPLMCIVYGSSLDTTSSTIHNNLTEFQNDPPATNSYSPWNLTNASLFGLTRIPYFQNSSVEASHQSLLLNMSHPLVHESANVAIF>sp|P0DN82|O12D1_HUMAN Olfactory receptor 12D1 OS=Homo sapiens OX=9606GN=OR12D1 PE=3 SV=1MLNTTSVTEFLLLGVTDIQELQPFLFVVFLTIYFISVAGNGAILMIVISDPRLHSPMYFFLGNLSCLDICYSSVTLPKMLQNFLSAHKAISFLGCISQLHFFHFLGSTEAMLLAVMAFDRFVAICKPLRYTVIMNPQLCTQMAITIWMIGFFHALLHSLMTSRLNFCGSNRIYHFFCDVKPLLKLSNQWLLSTVTGTIAMGPFFLTLLSYFYIITHLFFKTHSFSMLRKALSTCASHFMVVILLYAPVLFTYIHHASGTSMDQDRITAIMYTVVTPVLNPLIYTLRNKEVKGAFNRAMKRWLWPKEILK>sp|Q5TZ20|OR2G6_HUMAN Olfactory receptor 2G6 OS=Homo sapiens OX=9606GN=OR2G6 PE=1 SV=1MEETNNSSEKGFLLLGFSDQPQLERFLFAIILYFYVLSLLGNTALILVCCLDSRLHTPMYFFLSNLSCVDICFTTSVAPQLLVTMNKKDKTMSYGGCVAQLYVAMGLGSSECILLAVMAYDRYAAVCRPLRYIAIMHPRFCASLAGGAWLSGLITSLIQCSLTVQLPLCGHRTLDHIFCEVPVLIKLACVDTTFNEAELFVASVVFLIVPVLLILVSYGFITQAVLRIKSAAGRQKAFGTCSSHLVVVIIFYGTIIFMYLQPANRRSKNQGKFVSLFYTIVTPLLNPIIYTLRNKDVKGALRTLILGSAAGQSHKD>sp|Q8NGJ5|O51L1_HUMAN Olfactory receptor 51L1 OS=Homo sapiens OX=9606GN=OR51L1 PE=3 SV=1MGDWNNSDAVEPIFILRGFPGLEYVHSWLSILFCLAYLVAFMGNVTILSVIWIESSLHQPMYYFISILAVNDLGMSLSTLPTMLAVLWLDAPEIQASACYAQLFFIHTFTFLESSVLLAMAFDRFVAICHPLHYPTILTNSVIGKIGLACLLRSLGVVLPTPLLLRHYHYCHGNALSHAFCLHQDVLRLSCTDARTNSIYGLCVVIATLGVDSIFILLSYVLILNTVLDIASREEQLKALNTCVSHICVVLIFFVPVIGVSMVHRFGKHLSPIVHILMADIYLLLPPVLNPIVYSVRTKQIRLGILHKFVLRRRF>sp|Q96RB7|OR5MB_HUMAN Olfactory receptor 5M11 OS=Homo sapiens OX=9606GN=OR5M11 PE=2 SV=2MSNTNGSAITEFILLGLTDCPELQSLLFVLFLVVYLVTLLGNLGMIMLMRLDSRLHTPMYFFLTNLAFVDLCYTSNATPQMSTNIVSEKTISFAGCFTQCYIFIALLLTEFYMLAAMAYDRYVAIYDPLRYSVKTSRRVCICLATFPYVYGFSDGLFQAILTFRLTFCRSSVINHFYCADPPLIKLSCSDTYVKEHAMFISAGFNLSSSLTIVLVSYAFILAAILRIKSAEGRHKAFSTCGSHMMAVTLFYGTLFCMYIRPPTDKTVEESKIIAVFYTFVSPVLNPLIYSLRNKDVKQALKNVLR>sp|Q8NH43|OR4L1_HUMAN Olfactory receptor 4L1 OS=Homo sapiens OX=9606GN=OR4L1 PE=3 SV=1MDLKNGSLVTEFILLGFFGRWELQIFFFVTFSLIYGATVMGNILIMVTVTCRSTLHSPLYFLLGNLSFLDMCLSTATTPKMIIDLLTDHKTISVWGCVTQMFFMHFFGGAEMTLLIIMAFDRYVAICKPLHYRTIMSHKLLKGFAILSWIIGFLHSISQIVLTMNLPFCGHNVINNIFCDLPLVIKLACIETYTLELFVIADSGLLSFTCFILLLVSYIVILVSVPKKSSHGLSKALSTLSAHIIVVTLFFGPCIFIYVWPFSSLASNKTLAVFYTVITPLLNPSIYTLRNKKMQEAIRKLRFQYVSSAQNF>sp|Q8IXE1|OR4N5_HUMAN Olfactory receptor 4N5 OS=Homo sapiens OX=9606GN=OR4N5 PE=3 SV=1METQNLTVVTEFILLGLTQSQDAQLLVFVLVLIFYLIILPGNFLIIFTIKSDPGLTAPLYFFLGNLALLDASYSFIVVPRMLVDFLSEKKVISYRSCITQLFFLHFLGAGEMFLLVVMAFDRYIAICRPLHYSTIMNPRACYALSLVLWLGGFIHSIVQVALILHLPFCGPNQLDNFFCDVPQVIKLACTNTFVVELLMVSNSGLLSLLCFLGLLASYAVILCRIREHSSEGKSKAISTCTTHIIIIFLMFGPAIFIYTCPFQAFPADKVVSLFHTVIFPLMNPVIYTLRNQEVKASMRKLLSQHMFC>sp|Q8NG77|O2T12_HUMAN Olfactory receptor 2T12 OS=Homo sapiens OX=9606GN=OR2T12 PE=3 SV=1MEMRNTTPDFILLGLFNHTRAHQVLFMMLLATVLTSLFSNALMILLIHWDHRLHRPMYFLLSQLSLMDMMLVSTTVPKMAADYLTGNKAISRAGCGVQIFFLPTLGGGECFLLAAMAYDRYAAVCHPLRYPTLMSWQLCLRMTMSSWLLGAADGLLQAVATLSFPYCGAHEIDHFFCEAPVLVRLACADTSVFENAMYICCVLMLLVPFSLILSSYGLILAAVLLMRSTEARKKAFATCSSHVAVVGLFYGAGIFTYMRPKSHRSTNHDKVVSAFYTMFTPLLNPLIYSVRNSEVKEALKRWLGTCVNLKHQQNEAHRSR>sp|Q6IEY1|OR4F3_HUMAN Olfactory receptor 4F3/4F16/4F29 OS=Homo sapiensOX=9606 GN=OR4F3 PE=1 SV=1MDGENHSVVSEFLFLGLTHSWEIQLLLLVFSSVLYVASITGNILIVFSVTTDPHLHSPMYFLLASLSFIDLGACSVTSPKMIYDLFRKRKVISFGGCIAQIFFIHVVGGVEMVLLIAMAFDRYVALCKPLHYLTIMSPRMCLSFLAVAWTLGVSHSLFQLAFLVNLAFCGPNVLDSFYCDLPRLLRLACTDTYRLQFMVTVNSGFICVGTFFILLISYVFILFTVWKHSSGGSSKALSTLSAHSTVVLLFFGPPMFVYTRPHPNSQMDKFLAIFDAVLTPFLNPVVYTFRNKEMKAAIKRVCKQLVIYKRIS>sp|P51582|P2RY4_HUMAN P2Y purinoceptor 4 OS=Homo sapiens OX=9606GN=P2RY4 PE=1 SV=1MASTESSLLRSLGLSPGPGSSEVELDCWFDEDFKFILLPVSYAVVFVLGLGLNAPTLWLFIFRLRPWDATATYMFHLALSDTLYVLSLPTLIYYYAAHNHWPFGTEICKFVRFLFYWNLYCSVLFLTCISVHRYLGICHPLRALRWGRPRLAGLLCLAVWLVVAGCLVPNLFFVTTSNKGTTVLCHDTTRPEEFDHYVHFSSAVMGLLFGVPCLVTLVCYGLMARRLYQPLPGSAQSSSRLRSLRTIAVVLTVFAVCFVPFHITRTIYYLARLLEADCRVLNIVNVVYKVTRPLASANSCLDPVLYLLTGDKYRRQLRQLCGGGKPQPRTAASSLALVSLPEDSSCRWAATPQDSSCSTPRADRL>sp|Q7RTS5|OTOP3_HUMAN Proton channel OTOP3 OS=Homo sapiens OX=9606GN=OTOP3 PE=1 SV=1MGRGARAAAAQSRWGRASRASVSPGRTIRSAPAVGEAQETEAAPEKENRVDVGAEERAAATRPRQKSWLVRHFSLLLRRDRQAQKAGQLFSGLLALNVVFLGGAFICSMIFNKVAVTLGDVWILLATLKVLSLLWLLYYVASTTRRPHAVLYQDPHAGPLWVRGSLVLFGSCTFCLNIFRVGYDVSHIRCKSQLDLVFSVIEMVFIGVQTWVLWKHCKDCVRVQTNFTRCGLMLTLATNLLLWVLAVTNDSMHREIEAELGILMEKSTGNETNTCLCLNATACEAFRRGFLMLYPFSTEYCLICCAVLFVMWKNVGRHVAPHMGAHPATAPFHLHGAIFGPLLGLLVLLAGVCVFVLFQIEASGPAIACQYFTLYYAFYVAVLPTMSLACLAGTAIHGLEERELDTVKNPTRSLDVVLLMGAALGQMGIAYFSIVAIVAKRPHELLNRLILAYSLLLILQHIAQNLFIIEGLHRRPLWETVPEGLAGKQEAEPPRRGSLLELGQGLQRASLAYIHSYSHLNWKRRALKEISLFLILCNITLWMMPAFGIHPEFENGLEKDFYGYQIWFAIVNFGLPLGVFYRMHSVGGLVEVYLGA>sp|Q7Z4L9|PPR42_HUMAN Protein phosphatase 1 regulatory subunit 42OS=Homo sapiens OX=9606 GN=PPP1R42 PE=2 SV=3MVRLTLDLIARNSNLKPRKEETISQCLKKITHINFSDKNIDAIEDLSLCKNLSVLYLYDNCISQITNLNYATNLTHLYLQNNCISCIENLRSLKKLEKLYLGGNYIAVIEGLEGLGELRELHVENQRLPLGEKLLFDPRTLHSLAKSLCILNISNNNIDDITDLELLENLNQLIAVDNQLLHVKDLEFLLNKLMKLWKIDLNGNPVCLKPKYRDRLILVSKSLEFLDGKEIKNIERQFLMNWKASKDAKKISKKRSSKNEDASNSLISNFKTMHHIVPVYYPQVGKPKLAFFSEIQRYPVNANASPESS>sp|Q7Z4L9-2|PPR42_HUMAN Isoform 2 of Protein phosphatase 1 regulatorysubunit 42 OS=Homo sapiens OX=9606 GN=PPP1R42MVRLTLDLIARNSNLKPRKEETISQCLKKITHINFSDKNIDAIEDLSLCKNLSVLYLYDNCISQITNLNYATNLTHLYLQNNCISCIENLRSLKKLEKLYLGGNYIAVIEGLEGLGELRELHVENQRLPLGEKLLFDPRTLHSLAKSLCILNISNNNIDDITDLELLENLNQLIAVDNQLLHVKDLEFLLNKLMKLWKIDLNGNPVCLKPKYRDRLILVSKSLGTYLY>sp|O75170|PP6R2_HUMAN Serine/threonine-protein phosphatase 6 regulatorysubunit 2 OS=Homo sapiens OX=9606 GN=PPP6R2 PE=1 SV=2MFWKFDLNTTSHVDKLLDKEHVTLQELMDEDDILQECKAQNQKLLDFLCRQQCMEELVSLITQDPPLDMEEKVRFKYPNTACELLTCDVPQISDRLGGDESLLSLLYDFLDHEPPLNPLLASFFSKTIGNLIARKTEQVITFLKKKDKFISLVLKHIGTSALMDLLLRLVSCVEPAGLRQDVLHWLNEEKVIQRLVELIHPSQDEDRQSNASQTLCDIVRLGRDQGSQLQEALEPDPLLTALESQDCVEQLLKNMFDGDRTESCLVSGTQVLLTLLETRRVGTEGLVDSFSQGLERSYAVSSSVLHGIEPRLKDFHQLLLNPPKKKAILTTIGVLEEPLGNARLHGARLMAALLHTNTPSINQELCRLNTMDLLLDLFFKYTWNNFLHFQVELCIAAILSHAAREERTEASGSESRVEPPHENGNRSLETPQPAASLPDNTMVTHLFQKCCLVQRILEAWEANDHTQAAGGMRRGNMGHLTRIANAVVQNLERGPVQTHISEVIRGLPADCRGRWESFVEETLTETNRRNTVDLVSTHHLHSSSEDEDIEGAFPNELSLQQAFSDYQIQQMTANFVDQFGFNDEEFADQDDNINAPFDRIAEINFNIDADEDSPSAALFEACCSDRIQPFDDDEDEDIWEDSDTRCAARVMARPRFGAPHASESCSKNGPERGGQDGKASLEAHRDAPGAGAPPAPGKKEAPPVEGDSEGAMWTAVFDEPANSTPTAPGVVRDVGSSVWAAGTSAPEEKGWAKFTDFQPFCCSESGPRCSSPVDTECSHAEGSRSQGPEKASQASYFAVSPASPCAWNVCVTRKAPLLASDSSSSGGSHSEDGDQKAASAMDAVSRGPGREAPPLPTVARTEEAVGRVGCADSRLLSPACPAPKEVTAAPAVAVPPEATVAITTALSKAGPAIPTPAVSSALAVAVPLGPIMAVTAAPAMVATLGTVTKDGKTDAPPEGAALNGPV>sp|O75170-2|PP6R2_HUMAN Isoform 2 of Serine/threonine-proteinphosphatase 6 regulatory subunit 2 OS=Homo sapiens OX=9606 GN=PPP6R2MFWKFDLNTTSHVDKLLDKEHVTLQELMDEDDILQECKAQNQKLLDFLCRQQCMEELVSLITQDPPLDMEEKVRFKYPNTACELLTCDVPQISDRLGGDESLLSLLYDFLDHEPPLNPLLASFFSKTIGNLIARKTEQVITFLKKKDKFISLVLKHIGTSALMDLLLRLVSCVEPAGLRQDVLHWLNEEKVIQRLVELIHPSQDEDRQSNASQTLCDIVRLGRDQGSQLQEALEPDPLLTALESQDCVEQLLKNMFDGDRTESCLVSGTQVLLTLLETRRVGTEGLVDSFSQGLERSYAVSSSVLHGIEPRLKDFHQLLLNPPKKKAILTTIGVLEEPLGNARLHGARLMAALLHTNTPSINQELCRLNTMDLLLDLFFKYTWNNFLHFQVELCIAAILSHAAREERTEASGSESRVEPPHENGNRSLETPQPAASLPDNTMVTHLFQKCCLVQRILEAWEANDHTQAAGGMRRGNMGHLTRIANAVVQNLERGPVQTHISEVIRGLPADCRGRWESFVEETLTETNRRNTVDLAFSDYQIQQMTANFVDQFGFNDEEFADQDDNINAPFDRIAEINFNIDADEDSPSAALFEACCSDRIQPFDDDEDEDIWEDSDTRCAARVMARPRFGAPHASESCSKNGPERGGQDGKASLEAHRDAPGAGAPPAPGKKEAPPVEGDSEAGAMWTAVFDEPANSTPTAPGVVRDVGSSVWAAGTSAPEEKGWAKFTDFQPFCCSESGPRCSSPVDTECSHAEGSRSQGPEKAFSPASPCAWNVCVTRKAPLLASDSSSSGGSHSEDGDQKAASAMDAVSRGPGREAPPLPTVARTEEAVGRVGCADSRLLSPACPAPKEVTAAPAVAVPPEATVAITTALSKAGPAIPTPAVSSALAVAVPLGPIMAVTAAPAMVATLGTVTKDGQMPRQKELP>sp|O75170-3|PP6R2_HUMAN Isoform 3 of Serine/threonine-proteinphosphatase 6 regulatory subunit 2 OS=Homo sapiens OX=9606 GN=PPP6R2MFWKFDLNTTSHVDKLLDKEHVTLQELMDEDDILQECKAQNQKLLDFLCRQQCMEELVSLITQDPPLDMEEKVRFKYPNTACELLTCDVPQISDRLGGDESLLSLLYDFLDHEPPLNPLLASFFSKTIGNLIARKTEQVITFLKKKDKFISLVLKHIGTSALMDLLLRLVSCVEPAGLRQDVLHWLNEEKVIQRLVELIHPSQDEDRQSNASQTLCDIVRLGRDQGSQLQEALEPDPLLTALESRQDCVEQLLKNMFDGDRTESCLVSGTQVLLTLLETRRVGTEGLVDSFSQGLERSYAVSSSVLHGIEPRLKDFHQLLLNPPKKKAILTTIGVLEEPLGNARLHGARLMAALLHTNTPSINQELCRLNTMDLLLDLFFKYTWNNFLHFQVELCIAAILSHAAREERTEASGSESRVEPPHENGNRSLETPQPAASLPDNTMVTHLFQKCCLVQRILEAWEANDHTQAAGGMRRGNMGHLTRIANAVVQNLERGPVQTHISEVIRGLPADCRGRWESFVEETLTETNRRNTVDLAFSDYQIQQMTANFVDQFGFNDEEFADQDDNINAPFDRIAEINFNIDADEDSPSAALFEACCSDRIQPFDDDEDEDIWEDSDTRCAARVMARPRFGAPHASESCSKNGPERGGQDGKASLEAHRDAPGAGAPPAPGKKEAPPVEGDSEGAMWTAVFDEPANSTPTAPGVVRDVGSSVWAAGTSAPEEKGWAKFTDFQPFCCSESGPRCSSPVDTECSHAEGSRSQGPEKAFSPASPCAWNVCVTRKAPLLASDSSSSGGSHSEDGDQKAASAMDAVSRGPGREAPPLPTVARTEEAVGRVGCADSRLLSPACPAPKEVTAAPAVAVPPEATVAITTALSKAGPAIPTPAVSSALAVAVPLGPIMAVTAAPAMVATLGTVTKDGKTDAPPEGAALNGPV>sp|O75170-4|PP6R2_HUMAN Isoform 4 of Serine/threonine-proteinphosphatase 6 regulatory subunit 2 OS=Homo sapiens OX=9606 GN=PPP6R2MFWKFDLNTTSHVDKLLDKEHVTLQELMDEDDILQECKAQNQKLLDFLCRQQCMEELVSLITQDPPLDMEEKVRFKYPNTACELLTCDVPQISDRLGGDESLLSLLYDFLDHEPPLNPLLASFFSKTIGNLIARKTEQVITFLKKKDKFISLVLKHIGTSALMDLLLRLVSCVEPAGLRQDVLHWLNEEKVIQRLVELIHPSQDEDRQSNASQTLCDIVRLGRDQGSQLQEALEPDPLLTALESQDCVEQLLKNMFDGDRTESCLVSGTQVLLTLLETRRVGTEGLVDSFSQGLERSYAVSSSVLHGIEPRLKDFHQLLLNPPKKKAILTTIGVLEEPLGNARLHGARLMAALLHTNTPSINQELCRLNTMDLLLDLFFKYTWNNFLHFQVELCIAAILSHAAREERTEASGSESRVEPPHENGNRSLETPQPAASLPDNTMVTHLFQKCCLVQRILEAWEANDHTQAAGGMRRGNMGHLTRIANAVVQNLERGPVQTHISEVIRGLPADCRGRWESFVEETLTETNRRNTVDLAFSDYQIQQMTANFVDQFGFNDEEFADQDDNINAPFDRIAEINFNIDADEDSPSAALFEACCSDRIQPFDDDEDEDIWEDSDTRCAARVMARPRFGAPHASESCSKNGPERGGQDGKASLEAHRDAPGAGAPPAPGKKEAPPVEGDSEGAMWTAVFDEPANSTPTAPGVVRDVGSSVWAAGTSAPEEKGWAKFTDFQPFCCSESGPRCSSPVDTECSHAEGSRSQGPEKAFSPASPCAWNVCVTRKAPLLASDSSSSGGSHSEDGDQKAASAMDAVSRGPGREAPPLPTVARTEEAVGRVGCADSRLLSPACPAPKEVTAAPAVAVPPEATVAITTALSKAGPAIPTPAVSSALAVAVPLGPIMAVTAAPAMVATLGTVTKDGKTDAPPEGAALNGPV>sp|O75170-5|PP6R2_HUMAN Isoform 5 of Serine/threonine-proteinphosphatase 6 regulatory subunit 2 OS=Homo sapiens OX=9606 GN=PPP6R2MFWKFDLNTTSHVDKLLDKEHVTLQELMDEDDILQECKAQNQKLLDFLCRQQCMEELVSLITQDPPLDMEEKVRFKYPNTACELLTCDVPQISDRLGGDESLLSLLYDFLDHEPPLNPLLASFFSKTIGNLIARKTEQVITFLKKKDKFISLVLKHIGTSALMDLLLRLVSCVEPAGLRQDVLHWLNEEKVIQRLVELIHPSQDEDRQSNASQTLCDIVRLGRDQGSQLQEALEPDPLLTALESQDCVEQLLKNMFDGDRTESCLVSGTQVLLTLLETRRVGTEGLVDSFSQGLERSYAVSSSVLHGIEPRLKDFHQLLLNPPKKKAILTTIGVLEEPLGNARLHGARLMAALLHTNTPSINQELCRLNTMDLLLDLFFKYTWNNFLHFQVELCIAAILSHAAREERTEASGSESRVEPPHENGNRSLETPQPAASLPDNTMVTHLFQKCCLVQRILEAWEANDHTQAAGGMRRGNMGHLTRIANAVVQNLERGPVQTHISEVIRGLPADCRGRWESFVEETLTETNRRNTVDLVSTHHLHSSSEDEDIEGAFPNELSLQQAFSDYQIQQMTANFVDQFGFNDEEFADQDDNINAPFDRIAEINFNIDADEDSPSAALFEACCSDRIQPFDDDEDEDIWEDSDTRCAARVMARPRFGAPHASESCSKNGPERGGQDGKASLEAHRDAPGAGAPPAPGKKEAPPVEGDSEGAMWTAVFDEPANSTPTAPGVVRDVGSSVWAAGTSAPEEKGWAKFTDFQPFCCSESGPRCSSPVDTECSHAEGSRSQGPEKAFSPASPCAWNVCVTRKAPLLASDSSSSGGSHSEDGDQKAASAMDAVSRGPGREAPPLPTVARTEEAVGRVGCADSRLLSPACPAPKEVTAAPAVAVPPEATVAITTALSKAGPAIPTPAVSSALAVAVPLGPIMAVTAAPAMVATLGTVTKDGKTDAPPEGAALNGPV>sp|O75170-6|PP6R2_HUMAN Isoform 6 of Serine/threonine-proteinphosphatase 6 regulatory subunit 2 OS=Homo sapiens OX=9606 GN=PPP6R2MFWKFDLNTTSHVDKLLDKEHVTLQELMDEDDILQECKAQNQKLLDFLCRQQCMEELLTCDVPQISDRLGGDESLLSLLYDFLDHEPPLNPLLASFFSKTIGNLIARKTEQVITFLKKKDKFISLVLKHIGTSALMDLLLRLVSCVEPAGLRQDVLHWLNEEKVIQRLVELIHPSQDEDRQSNASQTLCDIVRLGRDQGSQLQEALEPDPLLTALESQDCVEQLLKNMFDGDRTESCLVSGTQVLLTLLETRRVGTEGLVDSFSQGLERSYAVSSSVLHGIEPRLKDFHQLLLNPPKKKAILTTIGVLEEPLGNARLHGARLMAALLHTNTPSINQELCRLNTMDLLLDLFFKYTWNNFLHFQVELCIAAILSHAAREERTEASGSESRVEPPHENGNRSLETPQPAASLPDNTMVTHLFQKCCLVQRILEAWEANDHTQAAGGMRRGNMGHLTRIANAVVQNLERGPVQTHISEVIRGLPADCRGRWESFVEETLTETNRRNTVDLAFSDYQIQQMTANFVDQFGFNDEEFADQDDNINAPFDRIAEINFNIDADEDSPSAALFEACCSDRIQPFDDDEDEDIWEDSDTRCAARVMARPRFGAPHASESCSKNGPERGGQDGKASLEAHRDAPGAGAPPAPGKKEAPPVEGDSEGAMWTAVFDEPANSTPTAPGVVRDVGSSVWAAGTSAPEEKGWAKFTDFQPFCCSESGPRCSSPVDTECSHAEGSRSQGPEKAFSPASPCAWNVCVTRKAPLLASDSSSSGGSHSEDGDQKAASAMDAVSRGPGREAPPLPTVARTEEAVGRVGCADSRLLSPACPAPKEVTAAPAVAVPPEATVAITTALSKAGPAIPTPAVSSALAVAVPLGPIMAVTAAPAMVATLGTVTKDGKTDAPPEGAALNGPV>sp|O95685|PPR3D_HUMAN Protein phosphatase 1 regulatory subunit 3DOS=Homo sapiens OX=9606 GN=PPP1R3D PE=1 SV=1MSRGPSSAVLPSALGSRKLGPRSLSCLSDLDGGVALEPRACRPPGSPGRAPPPTPAPSGCDPRLRPIILRRARSLPSSPERRQKAAGAPGAACRPGCSQKLRVRFADALGLELAQVKVFNAGDDPSVPLHVLSRLAINSDLCCSSQDLEFTLHCLVPDFPPPVEAADFGERLQRQLVCLERVTCSDLGISGTVRVCNVAFEKQVAVRYTFSGWRSTHEAVARWRGPAGPEGTEDVFTFGFPVPPFLLELGSRVHFAVRYQVAGAEYWDNNDHRDYSLTCRNHALHMPRGECEESWIHFI>sp|Q13427|PPIG_HUMAN Peptidyl-prolyl cis-trans isomerase G OS=Homosapiens OX=9606 GN=PPIG PE=1 SV=2MGIKVQRPRCFFDIAINNQPAGRVVFELFSDVCPKTCENFRCLCTGEKGTGKSTQKPLHYKSCLFHRVVKDFMVQGGDFSEGNGRGGESIYGGFFEDESFAVKHNKEFLLSMANRGKDTNGSQFFITTKPTPHLDGHHVVFGQVISGQEVVREIENQKTDAASKPFAEVRILSCGELIPKSKVKKEEKKRHKSSSSSSSSSSDSDSSSDSQSSSDSSDSESATEEKSKKRKKKHRKNSRKHKKEKKKRKKSKKSASSESEAENLEAQPQSTVRPEEIPPIPENRFLMRKSPPKADEKERKNRERERERECNPPNSQPASYQRRLLVTRSGRKIKGRGPRRYRTPSRSRSRDRFRRSETPPHWRQEMQRAQRMRVSSGERWIKGDKSELNEIKENQRSPVRVKERKITDHRNVSESPNRKNEKEKKVKDHKSNSKERDIRRNSEKDDKYKNKVKKRAKSKSRSKSKEKSKSKERDSKHNRNEEKRMRSRSKGRDHENVKEKEKQSDSKGKDQERSRSKEKSKQLESKSNEHDHSKSKEKDRRAQSRSRECDITKGKHSYNSRTRERSRSRDRSRRVRSRTHDRDRSRSKEYHRYREQEYRRRGRSRSRERRTPPGRSRSKDRRRRRRDSRSSEREESQSRNKDKYRNQESKSSHRKENSESEKRMYSKSRDHNSSNNSREKKADRDQSPFSKIKQSSQDNELKSSMLKNKEDEKIRSSVEKENQKSKGQENDHVHEKNKKFDHESSPGTDEDKSG>sp|Q13427-2|PPIG_HUMAN Isoform 2 of Peptidyl-prolyl cis-trans isomeraseG OS=Homo sapiens OX=9606 GN=PPIGMGIKVQRPRCFFDIAINNQPAGRVVFELFSDVCPKTCENFRCLCTGEKGTGKSTQKPLHYKSCLFHRVVKDFMVQGGDFSEGNGRGGESIYGGFFEDESFAVKHNKEFLLSMANRGKDTNGSQFFITTKPTPHLDGHHVVFGQVISGQEVVREIENQKTDAASKPFAEVRILSCGELIPKSKVKKEEKKRHKSSSSSSSSSSDSDSSSDSQSSSDSSDSESATEEKSKKRKKKHRKNSRKHKKEKKKRKKSKKSASSESEAENLEAQPQSTVRPEEIPPIPENRFLMRKSPPKADEKERKNRERERERECNPPNSQPASYQRRLLVTRSGRKIKGRGPRVGDSFPRDLHNIAFVFLK>sp|Q00887|PSG9_HUMAN Pregnancy-specific beta-1-glycoprotein 9 OS=Homosapiens OX=9606 GN=PSG9 PE=2 SV=2MGPLPAPSCTQRITWKGLLLTASLLNFWNPPTTAEVTIEAQPPKVSEGKDVLLLVHNLPQNLPGYFWYKGEMTDLYHYIISYIVDGKIIIYGPAYSGRETVYSNASLLIQNVTRKDAGTYTLHIIKRGDETREEIRHFTFTLYLETPKPYISSSNLNPREAMEAVRLICDPETLDASYLWWMNGQSLPVTHRLQLSKTNRTLYLFGVTKYIAGPYECEIRNPVSASRSDPVTLNLLPKLPIPYITINNLNPRENKDVLAFTCEPKSENYTYIWWLNGQSLPVSPGVKRPIENRILILPSVTRNETGPYQCEIRDRYGGLRSNPVILNVLYGPDLPRIYPSFTYYRSGENLDLSCFTESNPPAEYFWTINGKFQQSGQKLFIPQITRNHSGLYACSVHNSATGKEISKSMTVKVSGPCHGDLTESQS>sp|Q00887-2|PSG9_HUMAN Isoform 2 of Pregnancy-specific beta-1-glycoprotein 9 OS=Homo sapiens OX=9606 GN=PSG9MGPLPAPSCTQRITWKGLLLTASLLNFWNPPTTAEVTIEAQPPKVSEGKDVLLLVHNLPQNLPGYFWYKGEMTDLYHYIISYIVDGKIIIYGPAYSGRETVYSNASLLIQNVTRKDAGTYTLHIIKRGDETREEIRHFTFTLYLETPKPYISSSNLNPREAMEAVRLICDPETLDASYLWWMNGQSLPVTHRLQLSKTNRTLYLFGVTKYIAGPYECEIRNPVSASRSDPVTLNLLHGPDLPRIYPSFTYYRSGENLDLSCFTESNPPAEYFWTINGKFQQSGQKLFIPQITRNHSGLYACSVHNSATGKEISKSMTVKVSGKWIPASLAVGFYVESIWLSEKSQENIFIPSLCPMGTSKSQILLLNPPNLSLQTLFSLFFCFLMADLVSGLKKVGRGLYQP>sp|O15172|PSPHL_HUMAN Putative phosphoserine phosphatase-like proteinOS=Homo sapiens OX=9606 GN=PSPHP1 PE=5 SV=1MASASCSPGGALASPEPGRKILPRMISHSELRKLFYSADAVCFDVDSTVISEEGIGCFHWIWRKCDQATSQG>sp|O14957|QCR10_HUMAN Cytochrome b-c1 complex subunit 10 OS=Homo sapiensOX=9606 GN=UQCR11 PE=1 SV=1MVTRFLGPRYRELVKNWVPTAYTWGAVGAVGLVWATDWRLILDWVPYINGKFKKDN>sp|Q6NUR6|R216L_HUMAN Putative protein RNF216-like OS=Homo sapiensOX=9606 GN=RNF216P1 PE=5 SV=2MEEGNNNEEVIHLNNFHCHRGQDFVIFFWKTQIIQREKTESL>sp|O75884|RBBP9_HUMAN Serine hydrolase RBBP9 OS=Homo sapiens OX=9606GN=RBBP9 PE=1 SV=2MASPSKAVIVPGNGGGDVTTHGWYGWVKKELEKIPGFQCLAKNMPDPITARESIWLPFMETELHCDEKTIIIGHSSGAIAAMRYAETHRVYAIVLVSAYTSDLGDENERASGYFTRPWQWEKIKANCPYIVQFGSTDDPFLPWKEQQEVADRLETKLHKFTDCGHFQNTEFHELITVVKSLLKVPA>sp|O75884-2|RBBP9_HUMAN Isoform 2 of Serine hydrolase RBBP9 OS=Homosapiens OX=9606 GN=RBBP9MASPSKAVIVPGNGGGDVTTHGWYGWVKKELEKIPGFQCLAKNMPDPITARESIWLPFMETELHCDEKTIIIGHSSGAIAAMRYAETHRVYAIVLVSAYTSDLGDENERASGYFTRPWQWEKIKANCPYIVQFGSTDDPFLPWKEQQEVADSWTPNCTNSLTVVTFRTQSSMN>sp|Q9H6H4|REEP4_HUMAN Receptor expression-enhancing protein 4 OS=Homosapiens OX=9606 GN=REEP4 PE=1 SV=1MVSWMICRLVVLVFGMLCPAYASYKAVKTKNIREYVRWMMYWIVFALFMAAEIVTDIFISWFPFYYEIKMAFVLWLLSPYTKGASLLYRKFVHPSLSRHEKEIDAYIVQAKERSYETVLSFGKRGLNIAASAAVQAATKSQGALAGRLRSFSMQDLRSISDAPAPAYHDPLYLEDQVSHRRPPIGYRAGGLQDSDTEDECWSDTEAVPRAPARPREKPLIRSQSLRVVKRKPPVREGTSRSLKVRTRKKTVPSDVDS>sp|Q9H6H4-2|REEP4_HUMAN Isoform 2 of Receptor expression-enhancingprotein 4 OS=Homo sapiens OX=9606 GN=REEP4MVSWMICRLVVLVFGMLCPAYASYKAVKTKNIREYVRWMMYWIVFALFMAAEIVTDIFISWFPFYYEIKMAFVLWLLSPYTKGASLLYRKFVHPSLSRHEKEIDAYIVQAKERSYETVLSFGKRGLNIAASAAVQAATKGTGPGACRTATPRMSVGQILRQSPGRQPGPERSP>sp|Q6UW15|REG3G_HUMAN Regenerating islet-derived protein 3-gamma OS=Homosapiens OX=9606 GN=REG3G PE=1 SV=1MLPPMALPSVSWMLLSCLILLCQVQGEETQKELPSPRISCPKGSKAYGSPCYALFLSPKSWMDADLACQKRPSGKLVSVLSGAEGSFVSSLVRSISNSYSYIWIGLHDPTQGSEPDGDGWEWSSTDVMNYFAWEKNPSTILNPGHCGSLSRSTGFLKWKDYNCDAKLPYVCKFKD>sp|Q6UW15-2|REG3G_HUMAN Isoform 2 of Regenerating islet-derived protein3-gamma OS=Homo sapiens OX=9606 GN=REG3GMLPPMALPSVSWMLLSCLILLCQVQGEETQKELPSPRISCPKGSKAYGSPCYALFLSPKSWMDADGSEPDGDGWEWSSTDVMNYFAWEKNPSTILNPGHCGSLSRSTGFLKWKDYNCDAKLPYVCKFKD>sp|Q7Z5H3|RHG22_HUMAN Rho GTPase-activating protein 22 OS=Homo sapiensOX=9606 GN=ARHGAP22 PE=1 SV=1MLSPKIRQARRARSKSLVMGEQSRSPGRMPCPHRLGPVLKAGWLKKQRSIMKNWQQRWFVLRGDQLFYYKDKDEIKPQGFISLQGTQVTELPPGPEDPGKHLFEISPGGAGEREKVPANPEALLLMASSQRDMEDWVQAIRRVIWAPLGGGIFGQRLEETVHHERKYGPRLAPLLVEQCVDFIRERGLTEEGLFRMPGQANLVRDLQDSFDCGEKPLFDSTTDVHTVASLLKLYLRELPEPVVPFARYEDFLSCAQLLTKDEGEGTLELAKQVSNLPQANYNLLRYICKFLDEVQAYSNVNKMSVQNLATVFGPNILRPQVEDPVTIMEGTSLVQHLMTVLIRKHSQLFTAPVPEGPTSPRGGLQCAVGWGSEEVTRDSQGEPGGPGLPAHRTSSLDGAAVAVLSRTAPTGPGSRCSPGKKVQTLPSWKSSFRQPRSLSGSPKGGGSSLEVPIISSGGNWLMNGLSSLRGHRRASSGDRLKDSGSVQRLSTYDNVPAPGLVPGIPSVASMAWSGASSSESSVGGSLSSCTACRASDSSARSSLHTDWALEPSPLPSSSEDPKSLDLDHSMDEAGAGASNSEPSEPDSPTREHARRSEALQGLVTELRAELCRQRTEYERSVKRIEEGSADLRKRMSRLEEELDQEKKKYIMLEIKLRNSERAREDAERRNQLLQREMEEFFSTLGSLTVGAKGARAPK>sp|Q7Z5H3-2|RHG22_HUMAN Isoform 2 of Rho GTPase-activating protein 22OS=Homo sapiens OX=9606 GN=ARHGAP22MLSPKIRQARRARSKSLVMGEQSRSPGRMPCPHRLGPVLKAGWLKKQRSIMKNWQQRWFVLRGDQLFYYKDKDEIKPQGFISLQGTQVTELPPGPEDPGKHLFEISPGGAGEREKVPANPEALLLMASSQRDMEDWVQAIRRVIWAPLGGGTARRSHAHPLEPLPPGIFGQRLEETVHHERKYGPRLAPLLVEQCVDFIRERGLTEEGLFRMPGQANLVRDLQDSFDCGEKPLFDSTTDVHTVASLLKLYLRELPEPVVPFARYEDFLSCAQLLTKDEGEGTLELAKQVSNLPQANYNLLRYICKFLDEVQAYSNVNKMSVQNLATVFGPNILRPQVEDPVTIMEGTSLVQHLMTVLIRKHSQLFTAPVPEGPTSPRGGLQCAVGWGSEEVTRDSQGEPGGPGLPAHRTSSLDGAAVAVLSRTAPTGPGSRCSPGKKVQTLPSWKSSFRQPRSLSGSPKGGGSSLEVPIISSGGNWLMNGLSSLRGHRRASSGDRLKDSGSVQRLSTYDNVPAPGLVPGIPSVASMAWSGASSSESSVGGSLSSCTACRASDSSARSSLHTDWALEPSPLPSSSEDPKSLDLDHSMDEAGAGASNSEPSEPDSPTREHARRSEALQGLVTELRAELCRQRTEYERSVKRIEEGSADLRKRMSRLEEELDQEKKKYIMLEIKLRNSERAREDAERRNQLLQREMEEFFSTLGSLTVGAKGARAPK>sp|Q7Z5H3-3|RHG22_HUMAN Isoform 3 of Rho GTPase-activating protein 22OS=Homo sapiens OX=9606 GN=ARHGAP22MPFWPIRCLKRSRRMPRGGAGEREKVPANPEALLLMASSQRDMEDWVQAIRRVIWAPLGGGIFGQRLEETVHHERKYGPRLAPLLVEQCVDFIRERGLTEEGLFRMPGQANLVRDLQDSFDCGEKPLFDSTTDVHTVASLLKLYLRELPEPVVPFARYEDFLSCAQLLTKDEGEGTLELAKQVSNLPQANYNLLRYICKFLDEVQAYSNVNKMSVQNLATVFGPNILRPQVEDPVTIMEGTSLVQHLMTVLIRKHSQLFTAPVPEGPTSPRGGLQCAVGWGSEEVTRDSQGEPGGPGLPAHRTSSLDGAAVAVLSRTAPTGPGSRCSPGKKVQTLPSWKSSFRQPRSLSGSPKGGGSSLEVPIISSGGNWLMNGLSSLRGHRRASSGDRLKDSGSVQRLSTYDNVPAPGLVPGIPSVASMAWSGASSSESSVGGSLSSCTACRASDSSARSSLHTDWALEPSPLPSSSEDPKSLDLDHSMDEAGAGASNSEPSEPDSPTREHARRSEALQGLVTELRAELCRQRTEYERSVKRIEEGSADLRKRMSRLEEELDQEKKKYIMLEIKLRNSERAREDAERRNQLLQREMEEFFSTLGSLTVGAKGARAPK>sp|Q7Z5H3-4|RHG22_HUMAN Isoform 4 of Rho GTPase-activating protein 22OS=Homo sapiens OX=9606 GN=ARHGAP22MGQPREFWHLRSQVPVPTCHLLTVQPWCLLPHPTPAGGRERRHSASSLLAALCLRKAVLRPHPAVLPGVGGCVVLSSGRMKAPLRGGLALGTGPAPTKLQLLHDWQSEPGPSGWQQGPSPPLFPAGTSLVQHLMTVLIRKHSQLFTAPVPEGPTSPRGGLQCAVGWGSEEVTRDSQGEPGGPGLPAHRTSSLDGAAVAVLSRTAPTGPGSRCSPGKKVQTLPSWKSSFRQPRSLSGSPKGGGSSLEVPIISSGGNWLMNGLSSLRGHRRASSGDRLKDSGSVQRLSTYDNVPAPGLVPGIPSVASMAWSGASSSESSVGGSLSSCTACRASDSSARSSLHTDWALEPSPLPSSSEDPKSLDLDHSMDEAGAGASNSEPSEPDSPTREHARRSEALQGLVTELRAELCRQRTEYERSVKRIEEGSADLRKRMSRLEEELDQEKKKYIMLEIKLRNSERAREDAERRNQLLQREMEEFFSTLGSLTVGAKGARAPK>sp|Q7Z5H3-5|RHG22_HUMAN Isoform 5 of Rho GTPase-activating protein 22OS=Homo sapiens OX=9606 GN=ARHGAP22MLPTASSKRRTFAARYFTRSKSLVMGEQSRSPGRMPCPHRLGPVLKAGWLKKQRSIMKNWQQRWFVLRGDQLFYYKDKDEIKPQGFISLQGTQVTELPPGPEDPGKHLFEISPGGAGEREKVPANPEALLLMASSQRDMEDWVQAIRRVIWAPLGGGIFGQRLEETVHHERKYGPRLAPLLVEQCVDFIRERGLTEEGLFRMPGQANLVRDLQDSFDCGEKPLFDSTTDVHTVASLLKLYLRELPEPVVPFARYEDFLSCAQLLTKDEGEGTLELAKQVSNLPQANYNLLRYICKFLDEVQAYSNVNKMSVQNLATVFGPNILRPQVEDPVTIMEGTSLVQHLMTVLIRKHSQLFTAPVPEGPTSPRGGLQCAVGWGSEEVTRDSQGEPGGPGLPAHRTSSLDGAAVAVLSRTAPTGPGSRCSPGKKVQTLPSWKSSFRQPRSLSGSPKGGGSSLEVPIISSGGNWLMNGLSSLRGHRRASSGDRLKDSGSVQRLSTYDNVPAPGLVPGIPSVASMAWSGASSSESSVGGSLSSCTACRASDSSARSSLHTDWALEPSPLPSSSEDPKSLDLDHSMDEAGAGASNSEPSEPDSPTREHARRSEALQGLVTELRAELCRQRTEYERSVKRIEEGSADLRKRMSRLEEELDQEKKKYIMLEIKLRNSERAREDAERRNQLLQREMEEFFSTLGSLTVGAKGARAPK>sp|O14559|RHG33_HUMAN Rho GTPase-activating protein 33 OS=Homo sapiensOX=9606 GN=ARHGAP33 PE=1 SV=2MVARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRGPFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSYDDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNCGPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAVPRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC>sp|O14559-10|RHG33_HUMAN Isoform 2 of Rho GTPase-activating protein 33OS=Homo sapiens OX=9606 GN=ARHGAP33MLVPLLLQYLETLSGLVDSNLNCGPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAVPRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC>sp|O14559-11|RHG33_HUMAN Isoform 3 of Rho GTPase-activating protein 33OS=Homo sapiens OX=9606 GN=ARHGAP33MVARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRGPFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSYDDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNCGPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAVPRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLSSQASGAELLGAGGAPASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC>sp|O14559-12|RHG33_HUMAN Isoform 4 of Rho GTPase-activating protein 33OS=Homo sapiens OX=9606 GN=ARHGAP33MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRGPFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSYDDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNCGPVLTWMEVGLGRGLGDSEWVRGCVCHHAQHREILDGNRVASAVEDEGAEVDGEAFRWGSLWVGESWDM>sp|Q08116|RGS1_HUMAN Regulator of G-protein signaling 1 OS=Homo sapiensOX=9606 GN=RGS1 PE=1 SV=3MRAAAISTPKLDKMPGMFFSANPKELKGTTHSLLDDKMQKRRPKTFGMDMKAYLRSMIPHLESGMKSSKSKDVLSAAEVMQWSQSLEKLLANQTGQNVFGSFLKSEFSEENIEFWLACEDYKKTESDLLPCKAEEIYKAFVHSDAAKQINIDFRTRESTAKKIKAPTPTCFDEAQKVIYTLMEKDSYPRFLKSDIYLNLLNDLQANSLK>sp|Q08116-2|RGS1_HUMAN Isoform 2 of Regulator of G-protein signaling 1OS=Homo sapiens OX=9606 GN=RGS1MRAAAISTPKLDKMPGMFFSANPKELKGTTHSLLDDKMQKRRPKTFGMDMKAYLRSMIPHLESGMKSSKSKDVLSAAEVMQWSQSLEKLLANQTGQNVFGSFLKSEFSEENIEFWLACEDYKKTESDLLPCKAEEIYKAFVHSDAAKQVSIKLIIISFSIKDPICRNNI>sp|P49798|RGS4_HUMAN Regulator of G-protein signaling 4 OS=Homo sapiensOX=9606 GN=RGS4 PE=1 SV=1MCKGLAGLPASCLRSAKDMKHRLGFLLQKSDSCEHNSSHNKKDKVVICQRVSQEEVKKWAESLENLISHECGLAAFKAFLKSEYSEENIDFWISCEEYKKIKSPSKLSPKAKKIYNEFISVQATKEVNLDSCTREETSRNMLEPTITCFDEAQKKIFNLMEKDSYRRFLKSRFYLDLVNPSSCGAEKQKGAKSSADCASLVPQCA>sp|P49798-2|RGS4_HUMAN Isoform 2 of Regulator of G-protein signaling 4OS=Homo sapiens OX=9606 GN=RGS4MCKGLAGLPASCLRSAKDMKHRLGFLLQKSDSCEHNSSHNKKDKVVICQRVSQEEVKKWAESLENLISHECGLAAFKAFLKSEYSEENIDFWISCEEYKKIKSPSKLSPKAKKIYNEFISVQATKEVNLDSCTREETSRNMLEPTITCFDEAQKKIFNLMEKDSYRRFLKSRSYLDLVNPSSCGAEKQKGAKSSADCASLVPQCA>sp|P49798-3|RGS4_HUMAN Isoform 3 of Regulator of G-protein signaling 4OS=Homo sapiens OX=9606 GN=RGS4MYNMMLLIQKRKGIGSQLLRAGEAEGDRGAGTAERSSDWLDGRSWAIKETPTGLAGRRSEDSDNIFTGEEAKYAQSRSHSSSCRISFLLANSKLLNKMCKGLAGLPASCLRSAKDMKHRLGFLLQKSDSCEHNSSHNKKDKVVICQRVSQEEVKKWAESLENLISHECGLAAFKAFLKSEYSEENIDFWISCEEYKKIKSPSKLSPKAKKIYNEFISVQATKEVNLDSCTREETSRNMLEPTITCFDEAQKKIFNLMEKDSYRRFLKSRFYLDLVNPSSCGAEKQKGAKSSADCASLVPQCA>sp|P49798-4|RGS4_HUMAN Isoform 4 of Regulator of G-protein signaling 4OS=Homo sapiens OX=9606 GN=RGS4MCKGLAGLPASCLRSAKDMKHRLGFLLQKSDSCEHNSSHNKKDKVVICQRVSQEEVKKWAESLENLISHECEPGFLHQGRDKPEHARAYNNLL>sp|P49798-5|RGS4_HUMAN Isoform 5 of Regulator of G-protein signaling 4OS=Homo sapiens OX=9606 GN=RGS4MKHRLGFLLQKSDSCEHNSSHNKKDKVVICQRVSQEEVKKWAESLENLISHECGLAAFKAFLKSEYSEENIDFWISCEEYKKIKSPSKLSPKAKKIYNEFISVQATKEVNLDSCTREETSRNMLEPTITCFDEAQKKIFNLMEKDSYRRFLKSRFYLDLVNPSSCGAEKQKGAKSSADCASLVPQCA>sp|Q96A58|RERG_HUMAN Ras-related and estrogen-regulated growth inhibitorOS=Homo sapiens OX=9606 GN=RERG PE=1 SV=1MAKSAEVKLAIFGRAGVGKSALVVRFLTKRFIWEYDPTLESTYRHQATIDDEVVSMEILDTAGQEDTIQREGHMRWGEGFVLVYDITDRGSFEEVLPLKNILDEIKKPKNVTLILVGNKADLDHSRQVSTEEGEKLATELACAFYECSACTGEGNITEIFYELCREVRRRRMVQGKTRRRSSTTHVKQAINKMLTKISS>sp|Q96A58-2|RERG_HUMAN Isoform 2 of Ras-related and estrogen-regulatedgrowth inhibitor OS=Homo sapiens OX=9606 GN=RERGMAKSAEVKLAIFGRAGVGKSESTYRHQATIDDEVVSMEILDTAGQEDTIQREGHMRWGEGFVLVYDITDRGSFEEVLPLKNILDEIKKPKNVTLILVGNKADLDHSRQVSTEEGEKLATELACAFYECSACTGEGNITEIFYELCREVRRRRMVQGKTRRRSSTTHVKQAINKMLTKISS>sp|P40938|RFC3_HUMAN Replication factor C subunit 3 OS=Homo sapiensOX=9606 GN=RFC3 PE=1 SV=2MSLWVDKYRPCSLGRLDYHKEQAAQLRNLVQCGDFPHLLVYGPSGAGKKTRIMCILRELYGVGVEKLRIEHQTITTPSKKKIEISTIASNYHLEVNPSDAGNSDRVVIQEMLKTVAQSQQLETNSQRDFKVVLLTEVDKLTKDAQHALRRTMEKYMSTCRLILCCNSTSKVIPPIRSRCLAVRVPAPSIEDICHVLSTVCKKEGLNLPSQLAHRLAEKSCRNLRKALLMCEACRVQQYPFTADQEIPETDWEVYLRETANAIVSQQTPQRLLEVRGRLYELLTHCIPPEIIMKGLLSELLHNCDGQLKGEVAQMAAYYEHRLQLGSKAIYHLEAFVAKFMALYKKFMEDGLEGMMF>sp|P40938-2|RFC3_HUMAN Isoform 2 of Replication factor C subunit 3OS=Homo sapiens OX=9606 GN=RFC3MSLWVDKYRPCSLGRLDYHKEQAAQLRNLVQCGDFPHLLVYGPSGAGKKTRIMCILRELYGVGVEKLRIEHQTITTPSKKKIEISTIASNYHLEVNPSDAGNSDRVVIQEMLKTVAQSQQLETNSQRDFKVVLLTEVDKLTKDAQHALRRTMEKYMSTCRLILCCNSTSKVIPPIRSRCLAVRVPAPSIEDICHVLSTVCKKEGLNLPSQLAHRLAEKSCRNLRKALLMCEACRVQQYPFTADQEIPETDWEVYLRETANAIVSQQTPQRLLEVRGRLYELLTHCIPPEIIMKACKEESRSCDIF>sp|Q86UR5|RIMS1_HUMAN Regulating synaptic membrane exocytosis protein 1OS=Homo sapiens OX=9606 GN=RIMS1 PE=1 SV=1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTRHLVRHYKTLPPKMPLLQSSSHWNIYSSILPAHTKTKSVTRQDISLHHECFNSTVLRFTDEILVSELQPFLDRARSASTNCLRPDTSLHSPERERGRWSPSLDRRRPPSPRIQIQHASPENDRHSRKSERSSIQKQTRKGTASDAERVLPTCLSRRGHAAPRATDQPVIRGKHPARSRSSEHSSIRTLCSMHHLVPGGSAPPSPLLTRMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQASLVVEERTRQMKMKVHRFKQTTGSGSSQELDREQYSKYNIHKDQYRSCDNVSAKSSDSDVSDVSAISRTSSASRLSSTSFMSEQSERPRGRISSFTPKMQGRRMGTSGRSIMKSTSVSGEMYTLEHNDGSQSDTAVGTVGAGGKKRRSSLSAKVVAIVSRRSRSTSQLSQTESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-2|RIMS1_HUMAN Isoform 2 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTR>sp|Q86UR5-3|RIMS1_HUMAN Isoform 3 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTSELQPFLDRARSASTNCLRPDTSLHSPERERMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQASLVVEERTRQMKMKVHRFKQTTGSGSSQELDREQYSKYNIHKDQYRSCDNVSAKSSDSDVSDVSAISRTSSASRLSSTSFMSEQSERPRGRISSFTPKMQGRRMGTSGRSIMKSTSVSGEMYTLEHNDGSQSDTAVGTVGAGGKKRRSSLSAKVVAIVSRRSRSTSQLSQTESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-4|RIMS1_HUMAN Isoform 4 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTRHLVRHYKTLPPKMPLLQSSSHWNIYSELQPFLDRARSASTNCLRPDTSLHSPERERMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQASLVVEERTRQMKMKVHRFKQTTGSGSSQELDREQYSKYNIHKDQYRSCDNVSAKSSDSDVSDVSAISRTSSASRLSSTSFMSEQSERPRGRISSFTPKMQGRRMGTSGRSIMKSTSVSGEMYTLEHNDGSQSDTAVGTVGAGGKKRRSSLSAKVVAIVSRRSRSTSQLSQTESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-5|RIMS1_HUMAN Isoform 5 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTRMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQASLVVEERTRQMKMKVHRFKQTTGSGSSQELDREQYSKYNIHKDQYRSCDNVSAKSSDSDVSDVSAISRTSSASRLSSTSFMSEQSERPRGRIRRMGTSGRSIMKSTSVSGEMYTLEHNDGSQSDTAVGTVGAGGKKRRSSLSAKVVAIVSRRSRSTSQLSQTESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-6|RIMS1_HUMAN Isoform 6 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTSELQPFLDRARSASTNCLRPDTSLHSPERERGRWSPSLDRRRPPSPRIQIQHASPENDRMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-7|RIMS1_HUMAN Isoform 7 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTSELQPFLDRARSASTNCLRPDTSLHSPERERMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-8|RIMS1_HUMAN Isoform 8 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MSSAVGPRGPRPPTVPPPMQELPDLSHLTEEERNIIMAVMDRQKEEEEKEEAMLKCVVRDMAKPAACKTPRNAENQPHQPSPRLHQQFESYKEQVRKIGEEARRYQGEHKDDAPTCGICHKTKFADGCGHLCSYCRTKFCARCGGRVSLRSNNEDKVVMWVCNLCRKQQEILTKSGAWFFGSGPQQTSQDGTLSDTATGAGSEVPREKKARLQERSRSQTPLSTAAASSQDAAPPSAPPDRSKGAEPSQQALGPEQKQASSRSRSEPPRERKKTPGLSEQNGKGALKSERKRVPKTSAQPVEGAVEERERKERRESRRLEKGRSQDYPDTPEKRDEGKAADEEKQRKEEDYQTRYRSDPNLARYPVKPPPEEQQMRMHARVSRARHERRHSDVALPRTEAGAALPEGKAGKRAPAAARASPPDSPRAYSAERTAETRAPGAKQLTNHSPPAPRHGPVPAEAPELKAQEPLRKQSRLDPSSAVLMRKAKREKVETMLRNDSLSSDQSESVRPSPPKPHRSKRGGKKRQMSVSSSEEEGVSTPEYTSCEDVELESESVSEKGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDRMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-9|RIMS1_HUMAN Isoform 9 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MFAGFLQFLLLHTLHSGTGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTSELQPFLDRARSASTNCLRPDTSLHSPERERHSRKSERSSIQKQTRKGTASDAERMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-10|RIMS1_HUMAN Isoform 10 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTSELQPFLDRARSASTNCLRPDTSLHSPERERHSRKSERSSIQKQTRKGTASDAERMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-11|RIMS1_HUMAN Isoform 11 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-12|RIMS1_HUMAN Isoform 12 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MCAPGIHVSSEGWEEVRSVDSEEGTIEARRAVAGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTSELQPFLDRARSASTNCLRPDTSLHSPERERHSRKSERSSIQKQTRKGTASDAERMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQASLVVEERTRQMKMKVHRFKQTTGSGSSQELDREQYSKYNIHKDQYRSCDNVSAKSSDSDVSDVSAISRTSSASRLSSTSFMSEQSERPRGRISSFTPKMQGRRMGTSGRSIMKSTSVSGEMYTLEHNDGSQSDTAVGTVGAGGKKRRSSLSAKVVAIVSRRSRSTSQLSQTESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|Q86UR5-13|RIMS1_HUMAN Isoform 13 of Regulating synaptic membraneexocytosis protein 1 OS=Homo sapiens OX=9606 GN=RIMS1MCAPGIHVSSEGWEEVRSVDSEEGTIEARRAVAGDLDYYWLDPATWHSRETSPISSHPVTWQPSKEGDRLIGRVILNKRTTMPKDSGALLGLKVVGGKMTDLGRLGAFITKVKKGSLADVVGHLRAGDEVLEWNGKPLPGATNEEVYNIILESKSEPQVEIIVSRPIGDIPRIPESSHPPLESSSSSFESQKMERPSISVISPTSPGALKDAPQVLPGQLSVKLWYDKVGHQLIVNVLQATDLPARVDGRPRNPYVKMYFLPDRSDKSKRRTKTVKKILEPKWNQTFVYSHVHRRDFRERMLEITVWDQPRVQEEESEFLGEILIELETALLDDEPHWYKLQTHDESSLPLPQPSPFMPRRHIHGESSSKKLQRSQRISDSDISDYEVDDGIGVVPPVGYRSSARESKSTTLTVPEQQRTTHHRSRSVSPHRGNDQGKPRSRLPNVPLQRSLDEIHPTRRSRSPTRHHDASRSPVDHRTRDVDSQYLSEQDSELLMLPRAKRGRSAECLHTTSELQPFLDRARSASTNCLRPDTSLHSPERERMHRQRSPTQSPPADTSFSSRRGRQLPQVPVRSGSIEQESGHKKLKSTIQRSTETGMAAEMRKMVRQPSRESTDGSINSYSSEGNLIFPGVRLGADSQFSDFLDGLGPAQLVGRQTLATPAMGDIQIGMEDKKGQLEVEVIRARSLTQKPGSKSTPAPYVKVYLLENGACIAKKKTRIARKTLDPLYQQSLVFDESPQGKVLQVIVWGDYGRMDHKCFMGVAQILLEELDLSSMVIGWYKLFPPSSLVDPTLTPLTRRASQSSLESSTGPPCIRS>sp|P46776|RL27A_HUMAN 60S ribosomal protein L27a OS=Homo sapiens OX=9606GN=RPL27A PE=1 SV=2MPSRLRKTRKLRGHVSHGHGRIGKHRKHPGGRGNAGGLHHHRINFDKYHPGYFGKVGMKHYHLKRNQSFCPTVNLDKLWTLVSEQTRVNAAKNKTGAAPIIDVVRSGYYKVLGKGKLPKQPVIVKAKFFSRRAEEKIKSVGGACVLVA>sp|Q6ZNB5|TRC2L_HUMAN Putative short transient receptor potentialchannel 2-like protein OS=Homo sapiens OX=9606 PE=5 SV=1MAPVKISHVVSFSSQDPKYPVENLLNPDSPRRPWLGCPQDKSGQLKVELQLERAVPTGYIDVGNCGCAFLQIDVGHSSWPLDRPFITLLPATTLMSLTDSKQGKNRSGVRMFKDGKEGKSRKDGGGLYEKQRCSTKEDCECY>sp|O60602|TLR5_HUMAN Toll-like receptor 5 OS=Homo sapiens OX=9606GN=TLR5 PE=1 SV=4MGDHLDLLLGVVLMAGPVFGIPSCSFDGRIAFYRFCNLTQVPQVLNTTERLLLSFNYIRTVTASSFPFLEQLQLLELGSQYTPLTIDKEAFRNLPNLRILDLGSSKIYFLHPDAFQGLFHLFELRLYFCGLSDAVLKDGYFRNLKALTRLDLSKNQIRSLYLHPSFGKLNSLKSIDFSSNQIFLVCEHELEPLQGKTLSFFSLAANSLYSRVSVDWGKCMNPFRNMVLEILDVSGNGWTVDITGNFSNAISKSQAFSLILAHHIMGAGFGFHNIKDPDQNTFAGLARSSVRHLDLSHGFVFSLNSRVFETLKDLKVLNLAYNKINKIADEAFYGLDNLQVLNLSYNLLGELYSSNFYGLPKVAYIDLQKNHIAIIQDQTFKFLEKLQTLDLRDNALTTIHFIPSIPDIFLSGNKLVTLPKINLTANLIHLSENRLENLDILYFLLRVPHLQILILNQNRFSSCSGDQTPSENPSLEQLFLGENMLQLAWETELCWDVFEGLSHLQVLYLNHNYLNSLPPGVFSHLTALRGLSLNSNRLTVLSHNDLPANLEILDISRNQLLAPNPDVFVSLSVLDITHNKFICECELSTFINWLNHTNVTIAGPPADIYCVYPDSFSGVSLFSLSTEGCDEEEVLKSLKFSLFIVCTVTLTLFLMTILTVTKFRGFCFICYKTAQRLVFKDHPQGTEPDMYKYDAYLCFSSKDFTWVQNALLKHLDTQYSDQNRFNLCFEERDFVPGENRIANIQDAIWNSRKIVCLVSRHFLRDGWCLEAFSYAQGRCLSDLNSALIMVVVGSLSQYQLMKHQSIRGFVQKQQYLRWPEDFQDVGWFLHKLSQQILKKEKEKKKDNNIPLQTVATIS>sp|Q86XT9|TM219_HUMAN Insulin-like growth factor-binding protein 3receptor OS=Homo sapiens OX=9606 GN=TMEM219 PE=1 SV=1MGNCQAGHNLHLCLAHHPPLVCATLILLLLGLSGLGLGSFLLTHRTGLRSPDIPQDWVSFLRSFGQLTLCPRNGTVTGKWRGSHVVGLLTTLNFGDGPDRNKTRTFQATVLGSQMGLKGSSAGQLVLITARVTTERTAGTCLYFSAVPGILPSSQPPISCSEEGAGNATLSPRMGEECVSVWSHEGLVLTKLLTSEELALCGSRLLVLGSFLLLFCGLLCCVTAMCFHPRRESHWSRTRL>sp|P45378|TNNT3_HUMAN Troponin T, fast skeletal muscle OS=Homo sapiensOX=9606 GN=TNNT3 PE=1 SV=3MSDEEVEQVEEQYEEEEEAQEEAAEVHEEVHEPEEVQEDTAEEDAEEEKPRPKLTAPKIPEGEKVDFDDIQKKRQNKDLMELQALIDSHFEARKKEEEELVALKERIEKRRAERAEQQRIRAEKERERQNRLAEEKARREEEDAKRRAEDDLKKKKALSSMGANYSSYLAKADQKRGKKQTAREMKKKILAERRKPLNIDHLGEDKLRDKAKELWETLHQLEIDKFEFGEKLKRQKYDITTLRSRIDQAQKHSKKAGTPAKGKVGGRWK>sp|P45378-2|TNNT3_HUMAN Isoform 2 of Troponin T, fast skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT3MSDEEVEQVEEQYEEEEEAQEEEEVQEDTAEEDAEEEKPRPKLTAPKIPEGEKVDFDDIQKKRQNKDLMELQALIDSHFEARKKEEEELVALKERIEKRRAERAEQQRIRAEKERERQNRLAEEKARREEEDAKRRAEDDLKKKKALSSMGANYSSYLAKADQKRGKKQTAREMKKKILAERRKPLNIDHLGEDKLRDKAKELWETLHQLEIDKFEFGEKLKRQKYDITTLRSRIDQAQKHSKKAGTPAKGKVGGRWK>sp|P45378-3|TNNT3_HUMAN Isoform 3 of Troponin T, fast skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT3MSDEEVEQVEEQYEEEEEAQEEAAEVHEEVHEPEEVQEEEKPRPKLTAPKIPEGEKVDFDDIQKKRQNKDLMELQALIDSHFEARKKEEEELVALKERIEKRRAERAEQQRIRAEKERERQNRLAEEKARREEEDAKRRAEDDLKKKKALSSMGANYSSYLAKADQKRGKKQTAREMKKKILAERRKPLNIDHLGEDKLRDKAKELWETLHQLEIDKFEFGEKLKRQKYDITTLRSRIDQAQKHSKKAGTPAKGKVGGRWK>sp|P45378-4|TNNT3_HUMAN Isoform 4 of Troponin T, fast skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT3MSDEEVEQVEEQYEEEEEAQEEEEVQEEEKPRPKLTAPKIPEGEKVDFDDIQKKRQNKDLMELQALIDSHFEARKKEEEELVALKERIEKRRAERAEQQRIRAEKERERQNRLAEEKARREEEDAKRRAEDDLKKKKALSSMGANYSSYLAKADQKRGKKQTAREMKKKILAERRKPLNIDHLGEDKLRDKAKELWETLHQLEIDKFEFGEKLKRQKYDIMNVRARVQMLAKFSKKAGTPAKGKVGGRWK>sp|P45378-5|TNNT3_HUMAN Isoform 5 of Troponin T, fast skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT3MSDEEVEQVEEQYEEEEEAQEEEEKPRPKLTAPKIPEGEKVDFDDIQKKRQNKDLMELQALIDSHFEARKKEEEELVALKERIEKRRAERAEQQRIRAEKERERQNRLAEEKARREEEDAKRRAEDDLKKKKALSSMGANYSSYLAKADQKRGKKQTAREMKKKILAERRKPLNIDHLGEDKLRDKAKELWETLHQLEIDKFEFGEKLKRQKYDITTLRSRIDQAQKHSKKAGTPAKGKVGGRWK>sp|P45378-6|TNNT3_HUMAN Isoform 6 of Troponin T, fast skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT3MSDEEVEQVEEQYEEEEEAQEEAAEVHEEVHEPEEKPRPKLTAPKIPEGEKVDFDDIQKKRQNKDLMELQALIDSHFEARKKEEEELVALKERIEKRRAERAEQQRIRAEKERERQNRLAEEKARREEEDAKRRAEDDLKKKKALSSMGANYSSYLAKADQKRGKKQTAREMKKKILAERRKPLNIDHLGEDKLRDKAKELWETLHQLEIDKFEFGEKLKRQKYDITTLRSRIDQAQKHSKKAGTPAKGKVGGRWK>sp|P45378-7|TNNT3_HUMAN Isoform 7 of Troponin T, fast skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT3MSDEEVEQVEEQYEEEEEAQEEEEVQEEEKPRPKLTAPKIPEGEKVDFDDIQKKRQNKDLMELQALIDSHFEARKKEEEELVALKERIEKRRAERAEQQRIRAEKERERQNRLAEEKARREEEDAKRRAEDDLKKKKALSSMGANYSSYLAKADQKRGKKQTAREMKKKILAERRKPLNIDHLGEDKLRDKAKELWETLHQLEIDKFEFGEKLKRQKYDITTLRSRIDQAQKHSKKAGTPAKGKVGGRWK>sp|Q13114|TRAF3_HUMAN TNF receptor-associated factor 3 OS=Homo sapiensOX=9606 GN=TRAF3 PE=1 SV=2MESSKKMDSPGALQTNPPLKLHTDRSAGTPVFVPEQGGYKEKFVKTVEDKYKCEKCHLVLCSPKQTECGHRFCESCMAALLSSSSPKCTACQESIVKDKVFKDNCCKREILALQIYCRNESRGCAEQLMLGHLLVHLKNDCHFEELPCVRPDCKEKVLRKDLRDHVEKACKYREATCSHCKSQVPMIALQKHEDTDCPCVVVSCPHKCSVQTLLRSELSAHLSECVNAPSTCSFKRYGCVFQGTNQQIKAHEASSAVQHVNLLKEWSNSLEKKVSLLQNESVEKNKSIQSLHNQICSFEIEIERQKEMLRNNESKILHLQRVIDSQAEKLKELDKEIRPFRQNWEEADSMKSSVESLQNRVTELESVDKSAGQVARNTGLLESQLSRHDQMLSVHDIRLADMDLRFQVLETASYNGVLIWKIRDYKRRKQEAVMGKTLSLYSQPFYTGYFGYKMCARVYLNGDGMGKGTHLSLFFVIMRGEYDALLPWPFKQKVTLMLMDQGSSRRHLGDAFKPDPNSSSFKKPTGEMNIASGCPVFVAQTVLENGTYIKDDTIFIKVIVDTSDLPDP>sp|Q13114-2|TRAF3_HUMAN Isoform 2 of TNF receptor-associated factor 3OS=Homo sapiens OX=9606 GN=TRAF3MESSKKMDSPGALQTNPPLKLHTDRSAGTPVFVPEQGGYKEKFVKTVEDKYKCEKCHLVLCSPKQTECGHRFCESCMAALLSSSSPKCTACQESIVKDKVFKDNCCKREILALQIYCRNESRGCAEQLMLGHLLVHLKNDCHFEELPCVRPDCKEKVLRKDLRDHVEKACKYREATCSHCKSQVPMIALQVSLLQNESVEKNKSIQSLHNQICSFEIEIERQKEMLRNNESKILHLQRVIDSQAEKLKELDKEIRPFRQNWEEADSMKSSVESLQNRVTELESVDKSAGQVARNTGLLESQLSRHDQMLSVHDIRLADMDLRFQVLETASYNGVLIWKIRDYKRRKQEAVMGKTLSLYSQPFYTGYFGYKMCARVYLNGDGMGKGTHLSLFFVIMRGEYDALLPWPFKQKVTLMLMDQGSSRRHLGDAFKPDPNSSSFKKPTGEMNIASGCPVFVAQTVLENGTYIKDDTIFIKVIVDTSDLPDP>sp|Q8N7C3|TRIMM_HUMAN Probable E3 ubiquitin-protein ligase TRIML2OS=Homo sapiens OX=9606 GN=TRIML2 PE=1 SV=2MSKRLSPQLQHNITEDAYCETHLEPTRLFCDVDQITLCSKCFQSQEHKHHMVCGIQEAAENYRKLFQEILNTSREKLEAAKSILTDEQERMAMIQEEEQNFKKMIESEYSMRLRLLNEECEQNLQRQQECISDLNLRETLLNQAIKLATELEEMFQEMLQRLGRVGRENMEKLKESEARASEQVRSLLKLIVELEKKCGEGTLALLKNAKYSLERSKSLLLEHLEPAHITDLSLCHIRGLSSMFRVLQRHLTLDPETAHPCLALSEDLRTMRLRHGQQDGAGNPERLDFSAMVLAAESFTSGRHYWEVDVEKATRWQVGIYHGSADAKGSTARASGEKVLLTGSVMGTEWTLWVFPPLKRLFLEKKLDTVGVFLDCEHGQISFYNVTEMSLIYNFSHCAFQGALRPVFSLCIPNGDTSPDSLTILQHGPSCDATVSP>sp|Q8N7C3-2|TRIMM_HUMAN Isoform 2 of Probable E3 ubiquitin-proteinligase TRIML2 OS=Homo sapiens OX=9606 GN=TRIML2MSKRLSPQLQHNITEDAYCETHLEPTRLFCDVDQITLCSKCFQSQEHKHHMVCGIQEAAENYRKLFQEILNTSREKLEAAKSILTDEQERMAMIQEEEQNFKKMIESEYSMRLRLLNEECEQNLQRQQECISDLNLRETLLNQAIKLATELEEMFQEMLQRLGRVGRENMEKLKESEARASEQVRSLLKLIVELEKKCGEGTLALLKVRCWEKENKIHSSI>sp|O14773|TPP1_HUMAN Tripeptidyl-peptidase 1 OS=Homo sapiens OX=9606GN=TPP1 PE=1 SV=2MGLQACLLGLFALILSGKCSYSPEPDQRRTLPPGWVSLGRADPEEELSLTFALRQQNVERLSELVQAVSDPSSPQYGKYLTLENVADLVRPSPLTLHTVQKWLLAAGAQKCHSVITQDFLTCWLSIRQAELLLPGAEFHHYVGGPTETHVVRSPHPYQLPQALAPHVDFVGGLHRFPPTSSLRQRPEPQVTGTVGLHLGVTPSVIRKRYNLTSQDVGSGTSNNSQACAQFLEQYFHDSDLAQFMRLFGGNFAHQASVARVVGQQGRGRAGIEASLDVQYLMSAGANISTWVYSSPGRHEGQEPFLQWLMLLSNESALPHVHTVSYGDDEDSLSSAYIQRVNTELMKAAARGLTLLFASGDSGAGCWSVSGRHQFRPTFPASSPYVTTVGGTSFQEPFLITNEIVDYISGGGFSNVFPRPSYQEEAVTKFLSSSPHLPPSSYFNASGRAYPDVAALSDGYWVVSNRVPIPWVSGTSASTPVFGGILSLINEHRILSGRPPLGFLNPRLYQQHGAGLFDVTRGCHESCLDEEVEGQGFCSGPGWDPVTGWGTPNFPALLKTLLNP>sp|O14773-2|TPP1_HUMAN Isoform 2 of Tripeptidyl-peptidase 1 OS=Homosapiens OX=9606 GN=TPP1MRLFGGNFAHQASVARVVGQQGRGRAGIEASLDVQYLMSAGANISTWVYSSPGRHEGQEPFLQWLMLLSNESALPHVHTVSYGDDEDSLSSAYIQRVNTELMKAAARGLTLLFASGDSGAGCWSVSGRHQFRPTFPASSPYVTTVGGTSFQEPFLITNEIVDYISGGGFSNVFPRPSYQEEAVTKFLSSSPHLPPSSYFNASGRAYPDVAALSDGYWVVSNRVPIPWVSGTSASTPVFGGILSLINEHRILSGRPPLGFLNPRLYQQHGAGLFDVTRGCHESCLDEEVEGQGFCSGPGWDPVTGWGTPNFPALLKTLLNP>sp|P33981|TTK_HUMAN Dual specificity protein kinase TTK OS=Homo sapiensOX=9606 GN=TTK PE=1 SV=2MESEDLSGRELTIDSIMNKVRDIKNKFKNEDLTDELSLNKISADTTDNSGTVNQIMMMANNPEDWLSLLLKLEKNSVPLSDALLNKLIGRYSQAIEALPPDKYGQNESFARIQVRFAELKAIQEPDDARDYFQMARANCKKFAFVHISFAQFELSQGNVKKSKQLLQKAVERGAVPLEMLEIALRNLNLQKKQLLSEEEKKNLSASTVLTAQESFSGSLGHLQNRNNSCDSRGQTTKARFLYGENMPPQDAEIGYRNSLRQTNKTKQSCPFGRVPVNLLNSPDCDVKTDDSVVPCFMKRQTSRSECRDLVVPGSKPSGNDSCELRNLKSVQNSHFKEPLVSDEKSSELIITDSITLKNKTESSLLAKLEETKEYQEPEVPESNQKQWQSKRKSECINQNPAASSNHWQIPELARKVNTEQKHTTFEQPVFSVSKQSPPISTSKWFDPKSICKTPSSNTLDDYMSCFRTPVVKNDFPPACQLSTPYGQPACFQQQQHQILATPLQNLQVLASSSANECISVKGRIYSILKQIGSGGSSKVFQVLNEKKQIYAIKYVNLEEADNQTLDSYRNEIAYLNKLQQHSDKIIRLYDYEITDQYIYMVMECGNIDLNSWLKKKKSIDPWERKSYWKNMLEAVHTIHQHGIVHSDLKPANFLIVDGMLKLIDFGIANQMQPDTTSVVKDSQVGTVNYMPPEAIKDMSSSRENGKSKSKISPKSDVWSLGCILYYMTYGKTPFQQIINQISKLHAIIDPNHEIEFPDIPEKDLQDVLKCCLKRDPKQRISIPELLAHPYVQIQTHPVNQMAKGTTEEMKYVLGQLVGLNSPNSILKAAKTLYEHYSGGESHNSSSSKTFEKKRGKK>sp|P33981-2|TTK_HUMAN Isoform 2 of Dual specificity protein kinase TTKOS=Homo sapiens OX=9606 GN=TTKMESEDLSGRELTIDSIMNKVRDIKNKFKNEDLTDELSLNKISADTTDNSGTVNQIMMMANNPEDWLSLLLKLEKNSVPLSDALLNKLIGRYSQAIEALPPDKYGQNESFARIQVRFAELKAIQEPDDARDYFQMARANCKKFAFVHISFAQFELSQGNVKKSKQLLQKAVERGAVPLEMLEIALRNLNLQKKQLLSEEEKKNLSASTVLTAQESFSGSLGHLQNRNNSCDSRGQTTKARFLYGENMPPQDAEIGYRNSLRQTNKTKQSCPFGRVPVNLLNSPDCDVKTDDSVVPCFMKRQTSRSECRDLVVPGSKPSGNDSCELRNLKSVQNSHFKEPLVSDEKSSELIITDSITLKNKTESSLLAKLEETKEYQEPEVPESNQKQWQSKRKSECINQNPAASSNHWQIPELARKVNTEKHTTFEQPVFSVSKQSPPISTSKWFDPKSICKTPSSNTLDDYMSCFRTPVVKNDFPPACQLSTPYGQPACFQQQQHQILATPLQNLQVLASSSANECISVKGRIYSILKQIGSGGSSKVFQVLNEKKQIYAIKYVNLEEADNQTLDSYRNEIAYLNKLQQHSDKIIRLYDYEITDQYIYMVMECGNIDLNSWLKKKKSIDPWERKSYWKNMLEAVHTIHQHGIVHSDLKPANFLIVDGMLKLIDFGIANQMQPDTTSVVKDSQVGTVNYMPPEAIKDMSSSRENGKSKSKISPKSDVWSLGCILYYMTYGKTPFQQIINQISKLHAIIDPNHEIEFPDIPEKDLQDVLKCCLKRDPKQRISIPELLAHPYVQIQTHPVNQMAKGTTEEMKYVLGQLVGLNSPNSILKAAKTLYEHYSGGESHNSSSSKTFEKKRGKK>sp|Q5T7W7|TSTD2_HUMAN Thiosulfate sulfurtransferase/rhodanese-likedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=TSTD2 PE=1 SV=1MPSSTSPDQGDDLENCILRFSDLDLKDMSLINPSSSLKAELDGSTKKKYSFAKKKAFALFVKTKEVPTKRSFECKEKLWKCCRQLFTDQTSIHRHVATQHADEIYHQTASILKQLAVTLSTSKSLSSADEKNPLKECLPHSHDVSAWLPDISCFNPDELISGQGSEEGEVLLYYCYHDLEDPQWICAWQTALCQHLHLTGKIRIAAEGINGTVGGSKLATRLYVEVMLSFPLFKDDLCKDDFKTSKGGAHCFPELRVGVFEEIVPMGISPKKISYKKPGIHLSPGEFHKEVEKFLSQANQEQSDTILLDCRNFYESKIGRFQGCLAPDIRKFSYFPSYVDKNLELFREKRVLMYCTGGIRCERGSAYLKAKGVCKEVFQLKGGIHKYLEEFPDGFYKGKLFVFDERYALSYNSDVVSECSYCGARWDQYKLCSTPQCRQLVLTCPACQGQGFTACCVTCQDKGSRKVSGPMQDSFKEECECTARRPRIPRELLQHVRQPVSPEPGPDADEDGPVLM>sp|Q5T7W7-2|TSTD2_HUMAN Isoform 2 of Thiosulfatesulfurtransferase/rhodanese-like domain-containing protein 2 OS=Homosapiens OX=9606 GN=TSTD2MDLCLADSSVSAPAPHRQGIHLSPGEFHKEVEKFLSQANQEQSDTILLDCRNFYESKIGRFQGCLAPDIRKFSYFPSYVDKNLELFREKRVLMYCTGGIRCERGSAYLKAKGVCKEVFQLKGGIHKYLEEFPDGFYKGKLFVFDERYALSYNSDVVSGRSAQAQSPN>sp|P19075|TSN8_HUMAN Tetraspanin-8 OS=Homo sapiens OX=9606 GN=TSPAN8PE=1 SV=1MAGVSACIKYSMFTFNFLFWLCGILILALAIWVRVSNDSQAIFGSEDVGSSSYVAVDILIAVGAIIMILGFLGCCGAIKESRCMLLLFFIGLLLILLLQVATGILGAVFKSKSDRIVNETLYENTKLLSATGESEKQFQEAIIVFQEEFKCCGLVNGAADWGNNFQHYPELCACLDKQRPCQSYNGKQVYKETCISFIKDFLAKNLIIVIGISFGLAVIEILGLVFSMVLYCQIGNK>sp|P0C7T8|TM253_HUMAN Transmembrane protein 253 OS=Homo sapiens OX=9606GN=TMEM253 PE=4 SV=1MEDRAGEQEQERHSLRLEKLQHWARHRQSGHLLVLAVSQLWLAVVVVPLAVSVACLNSDCHMATALPLGPGASGLLTGTVTLELRRAPRLWKVRAMMIFNTFNLILGFIVVVVEVMKTALGPAPTASSQHAGLLVLELSAEAFTLGGVLVSVHALFLLSQRKPGCCRSQSLHYQELQEGFSELEEVPGLENGPTVASTGANERVGQREQTRAALLPP>sp|Q6ZU65|UBN2_HUMAN Ubinuclein-2 OS=Homo sapiens OX=9606 GN=UBN2 PE=1SV=2MAEPRRVAFISLSPVRRREAEYPGPEREPEYPREPPRLEPQPYREPARAEPPAPREPAPRSDAQPPSREKPLPQREVSRAEPPMSLQREPPRPEPPPPFPPLPLQPPPPRESASRAEQPPRPPRETVRLELVLKDPTDESCVEFSYPELLLCGEQRKKLIHTEDPFNDEHQERQEVEMLAKKFEMKYGGKPRKHRKDRLQDLIDIGFGYDETDPFIDNSEAYDELVPASLTTKYGGFYINTGTLQFRQASDTEEDDITDNQKHKPPKVPKIKEDDIEMKKRKRKEEGEKEKKPRKKVPKQLGVVALNSHKSEKKKKRYKDSLSLAAMIRKFQKEKDALKKESNPKVPVTLSTPSLNKPPCAAAALGNDVPDLNLSSGDPDLPIFVSTNEHELFQEAENALEMLDDFDFDRLLDAASDGSPLSESGGENGTTTQPTYTSQVMPKVVPTLPEGLPVLLEKRIEDLRVAAKLFDEEGRKKFFTQDMNNILLDIELQLQELGPVIRSGVYSHLEAFVPCNKETLVKRLKKLHLNVQDDRLREPLQKLKLAVSNVMPEQLFKYQEDCQARSQAKCAKLQTDEEREKNGSEEDDDEKPGKRVIGPRKKFHWDDTIRTLLCNLVEIKLGCYELEPNKSQSAEDYLKSFMETEVKPLWPKGWMQARMLFKESRSVHNHLTSAPAKKKVIPAPKPKVKEVMVKTLPLHSFPTMLKECSPKKDQKTPTSLVASVSGPPTSSSTAAIAAASSSSAPAQETICLDDSLDEDLSFHSPSLDLVSEALAVINNGNKGPPVGSRISMPTTKPRPGLREEKLASIMSKLPLATPKKLDSTQTTHSSSLIAGHTGPVPKKPQDLAHTGISSGLIAGSSIQNPKVSLEPLPARLLQQGLQRSSQIHTSSSSQTHVSSSSQAQIAASSHALGTSEAQDASSLTQVTKVHQHSAVQQNYVSPLQATISKSQTNPVVKLSNNPQLSCSSSLIKTSDKPLMYRLPLSTPSPGNGSQGSHPLVSRTVPSTTTSSNYLAKAMVSQISTQGFKSPFSMAASPKLAASPKPATSPKPLPSPKPSASPKPSLSAKPSVSTKLISKSNPTPKPTVSPSSSSPNALVAQGSHSSTNSPVHKQPSGMNISRQSPTLNLLPSSRTSGLPPTKNLQAPSKLTNSSSTGTVGKNSLSGIAMNVPASRGSNLNSSGANRTSLSGGTGSGTQGATKPLSTPHRPSTASGSSVVTASVQSTAGASLLANASPLTLMTSPLSVTNQNVTPFGMLGGLVPVTMPFQFPLEIFGFGTDTAGVTTTSGSTSAAFHHSLTQNLLKGLQPGGAQHAATLSHSPLPAHLQQAFHDGGQSKGDTKLPRKSQ>sp|Q6ZU65-2|UBN2_HUMAN Isoform 2 of Ubinuclein-2 OS=Homo sapiens OX=9606GN=UBN2MAEPRRVAFISLSPVRRREAEYPGPEREPEYPREPPRLEPQPYREPARAEPPAPREPAPRSDAQPPSREKPLPQREVSRAEPPMSLQREPPRPEPPPPFPPLPLQPPPPRESASRAEQPPRPPRETVRLELVLKDPTDESCVEFSYPELLLCGEQRKKLIHTEDPFNDEHQERQEVEMLAKKFEMKYGGKPRKHRKDRLQDLIDIGFGYDETDPFIDNSEAYDELVPASLTTKYGGFYINTGTLQFRQASDTEEDDITDNQKHKPPKVPKIKEDDIEMKKRKRKEEGEKEKKPRKKVPKQLGVVALNSHKSEKKKKRYKDSLSLAAMIRKFQKEKDALKKESNPKVPVTLSTPSLNKPPCAAAALGNDVPDLNLSSGDPDLPIFVSTNEHELFQEAENALEMLDDFDFDRLLDAASDGSPLSESGGENGTTTQPTYTSQVMPKVVPTLPEGLPVLLEKRIEDLRVAAKLFDEEGRKKFFTQDMNNILLDIELQLQELGPVIRSGVYSHLEAFVPCNKETLVKRLKKLHLNVQDDRLREPLQKLKLAVSNVMPEQLFKYQEDCQARSQAKCAKLQTDEEREKNGSEEDDDEKPGKRVIGPRKKFHWDDTIRTLLCNLVEIKLGCYELEPNKSQSAEDYLKSFMETEVKPLWPKGWMQARMLFKESRSVHNHLTSAPAKKKVIPAPKPKVKEVMVKTLPLHSFPTMLKECSPKKDQKTPTSLVASVSGPPTSSSTAAIAAASSSSAPAQETICLDDSLDEDLSFHSPSLDLVSEALAVINNGNKGPPVGSRISMPTTKPRPGLREEKLASIMSKLPLATPKKLDSTQTTHSSSLIAGHTGPVPKKPQDLAHTGISSGLIAGSSIQNPKVSLEPLPARLLQQGLQRSSQIHTSSSSQTHVSSSSQAQIAASSHALGTSEAQDASSLTQVTKVHQHSAVQQNYVSPLQATISKSQTNPVVKGPCLRDVSEQFGP>sp|Q9UI38|TSP50_HUMAN Probable threonine protease PRSS50 OS=Homo sapiensOX=9606 GN=PRSS50 PE=1 SV=1MGRWCQTVARGQRPRTSAPSRAGALLLLLLLLRSAGCWGAGEAPGALSTADPADQSVQCVPKATCPSSRPRLLWQTPTTQTLPSTTMETQFPVSEGKVDPYRSCGFSYEQDPTLRDPEAVARRWPWMVSVRANGTHICAGTIIASQWVLTVAHCLIWRDVIYSVRVGSPWIDQMTQTASDVPVLQVIMHSRYRAQRFWSWVGQANDIGLLKLKQELKYSNYVRPICLPGTDYVLKDHSRCTVTGWGLSKADGMWPQFRTIQEKEVIILNNKECDNFYHNFTKIPTLVQIIKSQMMCAEDTHREKFCYELTGEPLVCSMEGTWYLVGLVSWGAGCQKSEAPPIYLQVSSYQHWIWDCLNGQALALPAPSRTLLLALPLPLSLLAAL>sp|P35443|TSP4_HUMAN Thrombospondin-4 OS=Homo sapiens OX=9606 GN=THBS4PE=1 SV=2MLAPRGAAVLLLHLVLQRWLAAGAQATPQVFDLLPSSSQRLNPGALLPVLTDPALNDLYVISTFKLQTKSSATIFGLYSSTDNSKYFEFTVMGRLNKAILRYLKNDGKVHLVVFNNLQLADGRRHRILLRLSNLQRGAGSLELYLDCIQVDSVHNLPRAFAGPSQKPETIELRTFQRKPQDFLEELKLVVRGSLFQVASLQDCFLQQSEPLAATGTGDFNRQFLGQMTQLNQLLGEVKDLLRQQVKETSFLRNTIAECQACGPLKFQSPTPSTVVPPAPPAPPTRPPRRCDSNPCFRGVQCTDSRDGFQCGPCPEGYTGNGITCIDVDECKYHPCYPGVHCINLSPGFRCDACPVGFTGPMVQGVGISFAKSNKQVCTDIDECRNGACVPNSICVNTLGSYRCGPCKPGYTGDQIRGCKAERNCRNPELNPCSVNAQCIEERQGDVTCVCGVGWAGDGYICGKDVDIDSYPDEELPCSARNCKKDNCKYVPNSGQEDADRDGIGDACDEDADGDGILNEQDNCVLIHNVDQRNSDKDIFGDACDNCLSVLNNDQKDTDGDGRGDACDDDMDGDGIKNILDNCPKFPNRDQRDKDGDGVGDACDSCPDVSNPNQSDVDNDLVGDSCDTNQDSDGDGHQDSTDNCPTVINSAQLDTDKDGIGDECDDDDDNDGIPDLVPPGPDNCRLVPNPAQEDSNSDGVGDICESDFDQDQVIDRIDVCPENAEVTLTDFRAYQTVVLDPEGDAQIDPNWVVLNQGMEIVQTMNSDPGLAVGYTAFNGVDFEGTFHVNTQTDDDYAGFIFGYQDSSSFYVVMWKQTEQTYWQATPFRAVAEPGIQLKAVKSKTGPGEHLRNSLWHTGDTSDQVRLLWKDSRNVGWKDKVSYRWFLQHRPQVGYIRVRFYEGSELVADSGVTIDTTMRGGRLGVFCFSQENIIWSNLKYRCNDTIPEDFQEFQTQNFDRFDN>sp|Q9BZM5|ULBP2_HUMAN UL16-binding protein 2 OS=Homo sapiens OX=9606GN=ULBP2 PE=1 SV=1MAAAAATKILLCLPLLLLLSGWSRAGRADPHSLCYDITVIPKFRPGPRWCAVQGQVDEKTFLHYDCGNKTVTPVSPLGKKLNVTTAWKAQNPVLREVVDILTEQLRDIQLENYTPKEPLTLQARMSCEQKAEGHSSGSWQFSFDGQIFLLFDSEKRMWTTVHPGARKMKEKWENDKVVAMSFHYFSMGDCIGWLEDFLMGMDSTLEPSAGAPLAMSSGTTQLRATATTLILCCLLIILPCFILPGI>sp|P61960|UFM1_HUMAN Ubiquitin-fold modifier 1 OS=Homo sapiens OX=9606GN=UFM1 PE=1 SV=1MSKVSFKITLTSDPRLPYKVLSVPESTPFTAVLKFAAEEFKVPAATSAIITNDGIGINPAQTAGNVFLKHGSELRIIPRDRVGSC>sp|P61960-2|UFM1_HUMAN Isoform 2 of Ubiquitin-fold modifier 1 OS=Homosapiens OX=9606 GN=UFM1MIRAFPTTTPRSLHLFTSSTFLARALPGAFPTGACEERLSVPESTPFTAVLKFAAEEFKVPAATSAIITNDGIGINPAQTAGNVFLKHGSELRIIPRDRVGSC>sp|O14604|TYB4Y_HUMAN Thymosin beta-4, Y-chromosomal OS=Homo sapiensOX=9606 GN=TMSB4Y PE=1 SV=3MSDKPGMAEIEKFDKSKLKKTETQEKNPLSSKETIEQERQAGES>sp|Q70CQ2|UBP34_HUMAN Ubiquitin carboxyl-terminal hydrolase 34 OS=Homosapiens OX=9606 GN=USP34 PE=1 SV=2MCENCADLVEVLNEISDVEGGDGLQLRKEHTLKIFTYINSWTQRQCLCCFKEYKHLEIFNQVVCALINLVIAQVQVLRDQLCKHCTTINIDSTWQDESNQAEEPLNIDRECNEGSTERQKSIEKKSNSTRICNLTEEESSKSSDPFSLWSTDEKEKLLLCVAKIFQIQFPLYTAYKHNTHPTIEDISTQESNILGAFCDMNDVEVPLHLLRYVCLFCGKNGLSLMKDCFEYGTPETLPFLIAHAFITVVSNIRIWLHIPAVMQHIIPFRTYVIRYLCKLSDQELRQSAARNMADLMWSTVKEPLDTTLCFDKESLDLAFKYFMSPTLTMRLAGLSQITNQLHTFNDVCNNESLVSDTETSIAKELADWLISNNVVEHIFGPNLHIEIIKQCQVILNFLAAEGRLSTQHIDCIWAAAQLKHCSRYIHDLFPSLIKNLDPVPLRHLLNLVSALEPSVHTEQTLYLASMLIKALWNNALAAKAQLSKQSSFASLLNTNIPIGNKKEEEELRRTAPSPWSPAASPQSSDNSDTHQSGGSDIEMDEQLINRTKHVQQRLSDTEESMQGSSDETANSGEDGSSGPGSSSGHSDGSSNEVNSSHASQSAGSPGSEVQSEDIADIEALKEEDEDDDHGHNPPKSSCGTDLRNRKLESQAGICLGDSQGMSERNGTSSGTGKDLVFNTESLPSVDNRMRMLDACSHSEDPEHDISGEMNATHIAQGSQESCITRTGDFLGETIGNELFNCRQFIGPQHHHHHHHHHHHHDGHMVDDMLSADDVSCSSSQVSAKSEKNMADFDGEESGCEEELVQINSHAELTSHLQQHLPNLASIYHEHLSQGPVVHKHQFNSNAVTDINLDNVCKKGNTLLWDIVQDEDAVNLSEGLINEAEKLLCSLVCWFTDRQIRMRFIEGCLENLGNNRSVVISLRLLPKLFGTFQQFGSSYDTHWITMWAEKELNMMKLFFDNLVYYIQTVREGRQKHALYSHSAEVQVRLQFLTCVFSTLGSPDHFRLSLEQVDILWHCLVEDSECYDDALHWFLNQVRSKDQHAMGMETYKHLFLEKMPQLKPETISMTGLNLFQHLCNLARLATSAYDGCSNSELCGMDQFWGIALRAQSGDVSRAAIQYINSYYINGKTGLEKEQEFISKCMESLMIASSSLEQESHSSLMVIERGLLMLKTHLEAFRRRFAYHLRQWQIEGTGISSHLKALSDKQSLPLRVVCQPAGLPDKMTIEMYPSDQVADLRAEVTHWYENLQKEQINQQAQLQEFGQSNRKGEFPGGLMGPVRMISSGHELTTDYDEKALHELGFKDMQMVFVSLGAPRRERKGEGVQLPASCLPPPQKDNIPMLLLLQEPHLTTLFDLLEMLASFKPPSGKVAVDDSESLRCEELHLHAENLSRRVWELLMLLPTCPNMLMAFQNISDEQSNDGFNWKELLKIKSAHKLLYALEIIEALGKPNRRIRRESTGSYSDLYPDSDDSSEDQVENSKNSWSCKFVAAGGLQQLLEIFNSGILEPKEQESWTVWQLDCLACLLKLICQFAVDPSDLDLAYHDVFAWSGIAESHRKRTWPGKSRKAAGDHAKGLHIPRLTEVFLVLVQGTSLIQRLMSVAYTYDNLAPRVLKAQSDHRSRHEVSHYSMWLLVSWAHCCSLVKSSLADSDHLQDWLKKLTLLIPETAVRHESCSGLYKLSLSGLDGGDSINRSFLLLAASTLLKFLPDAQALKPIRIDDYEEEPILKPGCKEYFWLLCKLVDNIHIKDASQTTLLDLDALARHLADCIRSREILDHQDGNVEDDGLTGLLRLATSVVKHKPPFKFSREGQEFLRDIFNLLFLLPSLKDRQQPKCKSHSSRAAAYDLLVEMVKGSVENYRLIHNWVMAQHMQSHAPYKWDYWPHEDVRAECRFVGLTNLGATCYLASTIQQLYMIPEARQAVFTAKYSEDMKHKTTLLELQKMFTYLMESECKAYNPRPFCKTYTMDKQPLNTGEQKDMTEFFTDLITKIEEMSPELKNTVKSLFGGVITNNVVSLDCEHVSQTAEEFYTVRCQVADMKNIYESLDEVTIKDTLEGDNMYTCSHCGKKVRAEKRACFKKLPRILSFNTMRYTFNMVTMMKEKVNTHFSFPLRLDMTPYTEDFLMGKSERKEGFKEVSDHSKDSESYEYDLIGVTVHTGTADGGHYYSFIRDIVNPHAYKNNKWYLFNDAEVKPFDSAQLASECFGGEMTTKTYDSVTDKFMDFSFEKTHSAYMLFYKRMEPEEENGREYKFDVSSELLEWIWHDNMQFLQDKNIFEHTYFGFMWQLCSCIPSTLPDPKAVSLMTAKLSTSFVLETFIHSKEKPTMLQWIELLTKQFNNSQAACEWFLDRMADDDWWPMQILIKCPNQIVRQMFQRLCIHVIQRLRPVHAHLYLQPGMEDGSDDMDTSVEDIGGRSCVTRFVRTLLLIMEHGVKPHSKHLTEYFAFLYEFAKMGEEESQFLLSLQAISTMVHFYMGTKGPENPQVEVLSEEEGEEEEEEEDILSLAEEKYRPAALEKMIALVALLVEQSRSERHLTLSQTDMAALTGGKGFPFLFQHIRDGINIRQTCNLIFSLCRYNNRLAEHIVSMLFTSIAKLTPEAANPFFKLLTMLMEFAGGPPGMPPFASYILQRIWEVIEYNPSQCLDWLAVQTPRNKLAHSWVLQNMENWVERFLLAHNYPRVRTSAAYLLVSLIPSNSFRQMFRSTRSLHIPTRDLPLSPDTTVVLHQVYNVLLGLLSRAKLYVDAAVHGTTKLVPYFSFMTYCLISKTEKLMFSTYFMDLWNLFQPKLSEPAIATNHNKQALLSFWYNVCADCPENIRLIVQNPVVTKNIAFNYILADHDDQDVVLFNRGMLPAYYGILRLCCEQSPAFTRQLASHQNIQWAFKNLTPHASQYPGAVEELFNLMQLFIAQRPDMREEELEDIKQFKKTTISCYLRCLDGRSCWTTLISAFRILLESDEDRLLVVFNRGLILMTESFNTLHMMYHEATACHVTGDLVELLSIFLSVLKSTRPYLQRKDVKQALIQWQERIEFAHKLLTLLNSYSPPELRNACIDVLKELVLLSPHDFLHTLVPFLQHNHCTYHHSNIPMSLGPYFPCRENIKLIGGKSNIRPPRPELNMCLLPTMVETSKGKDDVYDRMLLDYFFSYHQFIHLLCRVAINCEKFTETLVKLSVLVAYEGLPLHLALFPKLWTELCQTQSAMSKNCIKLLCEDPVFAEYIKCILMDERTFLNNNIVYTFMTHFLLKVQSQVFSEANCANLISTLITNLISQYQNLQSDFSNRVEISKASASLNGDLRALALLLSVHTPKQLNPALIPTLQELLSKCRTCLQQRNSLQEQEAKERKTKDDEGATPIKRRRVSSDEEHTVDSCISDMKTETREVLTPTSTSDNETRDSSIIDPGTEQDLPSPENSSVKEYRMEVPSSFSEDMSNIRSQHAEEQSNNGRYDDCKEFKDLHCSKDSTLAEEESEFPSTSISAVLSDLADLRSCDGQALPSQDPEVALSLSCGHSRGLFSHMQQHDILDTLCRTIESTIHVVTRISGKGNQAAS>sp|Q70CQ2-2|UBP34_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 34 OS=Homo sapiens OX=9606 GN=USP34MRRKNSYYVWQKIFQIQFPLYTAYKHNTHPTIEDISTQESNILGAFCDMNDVEVPLHLLRYVCLFCGKNGLSLMKDCFEYGTPETLPFLIAHAFITVVSNIRIWLHIPAVMQHIIPFRTYVIRYLCKLSDQELRQSAARNMADLMWSTVKEPLDTTLCFDKESLDLAFKYFMSPTLTMRLAGLSQITNQLHTFNDVCNNESLVSDTETSIAKELADWLISNNVVEHIFGPNLHIEIIKQCQVILNFLAAEGRLSTQHIDCIWAAAQLKHCSRYIHDLFPSLIKNLDPVPLRHLLNLVSALEPSVHTEQTLYLASMLIKALWNNALAAKAQLSKQSSFASLLNTNIPIGNKKEEEELRRTAPSPWSPAASPQSSDNSDTHQSGGSDIEMDEQLINRTKHVQQRLSDTEESMQGSSDETANSGEDGSSGPGSSSGHSDGSSNEVNSSHASQSAGSPGSEVQSEDIADIEALKEEDEDDDHGHNPPKSSCGTDLRNRKLESQAGICLGDSQGMSERNGTSSGTGKDLVFNTESLPSVDNRMRMLDACSHSEDPEHDISGEMNATHIAQGSQESCITRTGDFLGETIGNELFNCRQFIGPQHHHHHHHHHHHHDGHMVDDMLSADDVSCSSSQVSAKSEKNMADFDGEESGCEEELVQINSHAELTSHLQQHLPNLASIYHEHLSQGPVVHKHQFNSNAVTDINLDNVCKKGNTLLWDIVQDEDAVNLSEGLINEAEKLLCSLVCWFTDRQIRMRFIEGCLENLGNNRSVVISLRLLPKLFGTFQQFGSSYDTHWITMWAEKELNMMKLFFDNLVYYIQTVREGRQKHALYSHSAEVQVRLQFLTCVFSTLGSPDHFRLSLEQVDILWHCLVEDSECYDDALHWFLNQVRSKDQHAMGMETYKHLFLEKMPQLKPETISMTGLNLFQHLCNLARLATSAYDGCSNSELCGMDQFWGIALRAQSGDVSRAAIQYINSYYINGKTGLEKEQEFISKCMESLMIASSSLEQESHSSLMVIERGLLMLKTHLEAFRRRFAYHLRQWQIEGTGISSHLKALSDKQSLPLRVVCQPAGLPDKMTIEMYPSDQVADLRAEVTHWYENLQKEQINQQAQLQEFGQSNRKGEFPGGLMGPVRMISSGHELTTDYDEKALHELGFKDMQMVFVSLGAPRRERKGEGVQLPASCLPPPQKDNIPMLLLLQEPHLTTLFDLLEMLASFKPPSGKVAVDDSESLRCEELHLHAENLSRRVWELLMLLPTCPNMLMAFQNISDEQSNDGFNWKELLKIKSAHKLLYALEIIEALGKPNRRIRRESTGSYSDLYPDSDDSSEDQVENSKNSWSCKFVAAGGLQQLLEIFNSGILEPKEQESWTVWQLDCLACLLKLICQFAVDPSDLDLAYHDVFAWSGIAESHRKRTWPGKSRKAAGDHAKGLHIPRLTEVFLVLVQGTSLIQRLMSVAYTYDNLAPRVLKAQSDHRSRHEVSHYSMWLLVSWAHCCSLVKSSLADSDHLQDWLKKLTLLIPETAVRHESCSGLYKLSLSGLDGGDSINRSFLLLAASTLLKFLPDAQALKPIRIDDYEEEPILKPGCKEYFWLLCKLVDNIHIKDASQTTLLDLDALARHLADCIRSREILDHQDGNVEDDGLTGLLRLATSVVKHKPPFKFSREGQEFLRDIFNLLFLLPSLKDRQQPKCKSHSSRAAAYDLLVEMVKGSVENYRLIHNWVMAQHMQSHAPYKWDYWPHEDVRAECRFVGLTNLGATCYLASTIQQLYMIPEARQAVFTAKYSEDMKHKTTLLELQKMFTYLMESECKAYNPRPFCKTYTMDKQPLNTGEQKDMTEFFTDLITKIEEMSPELKNTVKSLFGGVITNNVVSLDCEHVSQTAEEFYTVRCQVADMKNIYESLDEVTIKDTLEGDNMYTCSHCGKKVRAEKRACFKKLPRILSFNTMRYTFNMVTMMKEKVNTHFSFPLRLDMTPYTEDFLMGKSERKEGFKEVSDHSKDSESYEYDLIGVTVHTGTADGGHYYSFIRDIVNPHAYKNNKWYLFNDAEVKPFDSAQLASECFGGEMTTKTYDSVTDKFMDFSFEKTHSAYMLFYKRMEPEEENGREYKFDVSSELLEWIWHDNMQFLQDKNIFEHTYFGFMWQLCSCIPSTLPDPKAVSLMTAKLSTSFVLETFIHSKEKPTMLQWIELLTKQFNNSQAACEWFLDRMADDDWWPMQILIKCPNQIVRQMFQRLCIHVIQRLRPVHAHLYLQPGMEDGSDDMDTSVEDIGGRSCVTRFVRTLLLIMEHGVKPHSKHLTEYFAFLYEFAKMGEEESQFLLSLQAISTMVHFYMGTKGPENPQVEVLSEEEGEEEEEEEDILSLAEEKYRPAALEKMIALVALLVEQSRSERHLTLSQTDMAALTGGKGFPFLFQHIRDGINIRQTCNLIFSLCRYNNRLAEHIVSMLFTSIAKLTPEAANPFFKLLTMLMEFAGGPPGMPPFASYILQRIWEVIEYNPSQCLDWLAVQTPRNKLAHSWVLQNMENWVERFLLAHNYPRVRTSAAYLLVSLIPSNSFRQMFRSTRSLHIPTRDLPLSPDTTVVLHQVYNVLLGLLSRAKLYVDAAVHGTTKLVPYFSFMTYCLISKTEKLMFSTYFMDLWNLFQPKLSEPAIATNHNKQALLSFWYNVCADCPENIRLIVQNPVVTKNIAFNYILADHDDQDVVLFNRGMLPAYYGILRLCCEQSPAFTRQLASHQNIQWAFKNLTPHASQYPGAVEELFNLMQLFIAQRPDMREEELEDIKQFKKTTISCYLRCLDGRSCWTTLISAFRILLESDEDRLLVVFNRGLILMTESFNTLHMMYHEATACHVTGDLVELLSIFLSVLKSTRPYLQRKDVKQALIQWQERIEFAHKLLTLLNSYSPPELRNACIDVLKELVLLSPHDFLHTLVPFLQHNHCTYHHSNIPMSLGPYFPCRENIKLIGGKSNIRPPRPELNMCLLPTMVETSKGKDDVYDRMLLDYFFSYHQFIHLLCRVAINCEKFTETLVKLSVLVAYEGLPLHLALFPKLWTELCQTQSAMSKNCIKLLCEDPVFAEYIKCILMDERTFLNNNIVYTFMTHFLLKVQSQVFSEANCANLISTLITNLISQYQNLQSDFSNRVEISKASASLNGDLRALALLLSVHTPKQLNPALIPTLQELLSKCRTCLQQRNSLQEQEAKERKTKDDEGATPIKRRRVSSDEEHTVDSCISDMKTETREVLTPTSTSDNETRDSSIIDPGTEQDLPSPENSSVKEYRMEVPSSFSEDMSNIRSQHAEEQSNNGRYDDCKEFKDLHCSKDSTLAEEESEFPSTSISAVLSDLADLRSCDGQALPSQDPEVALSLSCGHSRGLFSHMQQHDILDTLCRTIESTIHVVTRISGKGNQAAS>sp|Q70CQ2-3|UBP34_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 34 OS=Homo sapiens OX=9606 GN=USP34MRRKNSYYVWQKIFQIQFPLYTAYKHNTHPTIEDISTQESNILGAFCDMNDVEVPLHLLRYVCLFCGKNGLSLMKDCFEYGTPETLPFLIAHAFITVVSNIRIWLHIPAVMQHIIPFRTYVIRYLCKLSDQELRQSAARNMADLMWSTVKEPLDTTLCFDKESLDLAFKYFMSPTLTMRLAGLSQITNQLHTFNDVCNNESLVSDTETSIAKELADWLISNNVVEHIFGPNLHIEIIKQCQVILNFLAAEGRLSTQHIDCIWAAAQLKHCSRYIHDLFPSLIKNLDPVPLRHLLNLVSALEPSVHTEQTLYLASMLIKALWNNALAAKAQLSKQSSFASLLNTNIPIGNKKEEEELRRTAPSPWSPAASPQSSDNSDTHQSGGSDIEMDEQLINRTKHVQQRLSDTEESMQGSSDETANSGEDGSSGPGSSSGHSDGSSNEVNSSHASQSAGSPGSEVQSEDIADIEALKEEDEDDDHGHNPPKSSCGTDLRNRKLESQAGICLGDSQGMSERNGTSSGTGKDLVFNTESLPSVDNRMRMLDACSHSEDPEHDISGEMNATHIAQGSQESCITRTGDFLGETIGNELFNCRQFIGPQHHHHHHHHHHHHDGHMVDDMLSADDVSCSSSQVSAKSEKNMADFDGEESGCEEELVQINSHAELTSHLQQHLPNLASIYHEHLSQGPVVHKHQFNSNAVTDINLDNVCKKGNTLLWDIVQDEDAVNLSEGLINEAEKLLCSLVCWFTDRQIRMRFIEGCLENLGNNRSVVISLRLLPKLFGTFQQFGSSYDTHWITMWAEKELNMMKLFFDNLVYYIQTVREGRQKHALYSHSAEVQVRLQFLTCVFSTLGSPDHFRLSLEQVDILWHCLVEDSECYDDALHWFLNQVRSKDQHAMGMETYKHLFLEKMPQLKPETISMTGLNLFQHLCNLARLATSAYDGCSNSELCGMDQFWGIALRAQSGDVSRAAIQYINSYYINGKTGLEKEQEFISKCMESLMIASSSLEQESHSSLMVIERGLLMLKTHLEAFRRRFAYHLRQWQIEGTGISSHLKALSDKQSLPLRVVCQPAGLPDKMTIEMYPSDQVADLRAEVTHWYENLQKEQINQQAQLQEFGQSNRKGEFPGGLMGPVRMISSGHELTTDYDEKALHELGFKDMQMVFVSLGAPRRERKGEGVQLPASCLPPPQKDNIPMLLLLQEPHLTTLFDLLEMLASFKPPSGKVAVDDSESLRCEELHLHAENLSRRVWELLMLLPTCPNMLMAFQNISDEQSNDGFNWKELLKIKSAHKLLYALEIIEALGKPNRRIRRESTGSYSDLYPDSDDSSEDQVENSKNSWSCKFVAAGGLQQLLEIFNSGILEPKEQESWTVWQLDCLACLLKLICQFAVDPSDLDLAYHDVFAWSGIAESHRKRTWPGKSRKAAGDHAKGLHIPRLTEVFLVLVQGTSLIQRLMSVAYTYDNLAPRVLKAQSDHRSRHEVSHYSMWLLVSWAHCCSLVKSSLADSDHLQDWLKKLTLLIPETAVRHESCSGLYKLSLSGLDGGDSINRSFLLLAASTLLKFLPDAQALKPIRIDDYEEEPILKPGCKEYFWLLCKLVDNIHIKDASQTTLLDLDALARHLADCIRSREILDHQDGNVEDDGLTGLLRLATSVVKHKPPFKFSREGQEFLRDIFNLLFLLPSLKDRQQPKCKSHSSRAAAYDLLVEMVKGSVENYRLIHNWVMAQHMQSHAPYKWDYWPHEDVRAECRFVGLTNLGATCYLASTIQQLYMIPEARQAVFTAKYSEDMKHKTTLLELQKMFTYLMESECKAYNPRPFCKTYTMDKQPLNTGEQKDMTEFFTDLITKIEEMSPELKNTVKSLFGGVITNNVVSLDCEHVSQTAEEFYTVRCQVADMKNIYESLDEVTIKDTLEGDNMYTCSHCGKKVRAEKRACFKKLPRILSFNTMRYTFNMVTMMKEKVNTHFSFPLRLDMTPYTEDFLMGKSERKEGFKEVSDHSKDSESYEYDLIGVTVHTGTADGGHYYSFIRDIVNPHAYKNNKWYLFNDAEVKPFDSAQLASECFGGEMTTKTYDSVTDKFMDFSFEKTHSAYMLFYKRMEPEEENGREYKFDVSSELLEWIWHDNMQFLQDKNIFEHTYFGFMWQLCSCIPSTLPDPKAVSLMTAKLSTSFVLETFIHSKEKPTMLQWIELLTKQFNNSQAACEWFLDRMADDDWWPMQILIKCPNQIVRQMFQRLCIHVIQRLRPVHAHLYLQPGMEDGSDDMDTSVEDIGGRSCVTRFVRTLLLIMEHGVKPHSKHLTEYFAFLYEFAKMGEEESQFLLSLQAISTMVHFYMGTKGPENPQVEVLSEEEGEEEEEEEDILSLAEEKYRPAALEKMIALVALLVEQSRSERHLTLSQTDMAALTGGKGFPFLFQHIRDGINIRQTCNLIFSLCRYNNRLAEHIVSMLFTSIAKLTPEAANPFFKLLTMLMEFAGGPPGMPPFASYILQRIWEVIEYNPSQCLDWLAVQTPRNKLAHSWVLQNMENWVERFLLAHNYPRVRTSAAYLLVSLIPSNSFRQMFRSTRSLHIPTRDLPLSPDTTVVLHQVYNVLLGLLSRAKLYVDAAVHGTTKLVPYFSFMTYCLISKTEKLMFSTYFMDLWNLFQPKLSEPAIATNHNKQALLSFWYNVCADCPENIRLIVQNPVVTKNIAFNYILADHDDQDVVLFNRGMLPAYYGILRLCCEQSPAFTRQLASHQNIQWAFKNLTPHASQYPGAVEELFNLMQLFIAQRPDMREEELEDIKQFKKTTISCYLRCQALIQWQERIEFAHKLLTLLNSYSPPELRNACIDVLKELVLLSPHDFLHTLVPFLQHNHCTYHHSNIPMSLGPYFPCRENIKLIGGKSNIRPPRPELNMCLLPTMVETSKGKDDVYDRMLLDYFFSYHQFIHLLCRVAINCEKFTETLVKLSVLVAYEGLPLHLALFPKLWTELCQTQSAMSKNCIKLLCEDPVFAEYIKCILMDERTFLNNNIVYTFMTHFLLKVQSQVFSEANCANLISTLITNLISQYQNLQSDFSNRVEISKASASLNGDLRALALLLSVHTPKQLNPALIPTLQELLSKCRTCLQQRNSLQEQEAKERKTKDDEGATPIKRRRVSSDEEHTVDSCISDMKTETREVLTPTSTSDNETRDSSIIDPGTEQDLPSPENSSVKEYRMEVPSSFSEDMSNIRSQHAEEQSNNGRYDDCKEFKDLHCSKDSTLAEEESEFPSTSISAVLSDLADLRSCDGQALPSQDPEVALSLSCGHSRGLFSHMQQHDILDTLCRTIESTIHVVTRISGKGNQAAS>sp|O94874|UFL1_HUMAN E3 UFM1-protein ligase 1 OS=Homo sapiens OX=9606GN=UFL1 PE=1 SV=2MADAWEEIRRLAADFQRAQFAEATQRLSERNCIEIVNKLIAQKQLEVVHTLDGKEYITPAQISKEMRDELHVRGGRVNIVDLQQVINVDLIHIENRIGDIIKSEKHVQLVLGQLIDENYLDRLAEEVNDKLQESGQVTISELCKTYDLPGNFLTQALTQRLGRIISGHIDLDNRGVIFTEAFVARHKARIRGLFSAITRPTAVNSLISKYGFQEQLLYSVLEELVNSGRLRGTVVGGRQDKAVFVPDIYSRTQSTWVDSFFRQNGYLEFDALSRLGIPDAVSYIKKRYKTTQLLFLKAACVGQGLVDQVEASVEEAISSGTWVDIAPLLPTSLSVEDAAILLQQVMRAFSKQASTVVFSDTVVVSEKFINDCTELFRELMHQKAEKEMKNNPVHLITEEDLKQISTLESVSTSKKDKKDERRRKATEGSGSMRGGGGGNAREYKIKKVKKKGRKDDDSDDESQSSHTGKKKPEISFMFQDEIEDFLRKHIQDAPEEFISELAEYLIKPLNKTYLEVVRSVFMSSTTSASGTGRKRTIKDLQEEVSNLYNNIRLFEKGMKFFADDTQAALTKHLLKSVCTDITNLIFNFLASDLMMAVDDPAAITSEIRKKILSKLSEETKVALTKLHNSLNEKSIEDFISCLDSAAEACDIMVKRGDKKRERQILFQHRQALAEQLKVTEDPALILHLTSVLLFQFSTHSMLHAPGRCVPQIIAFLNSKIPEDQHALLVKYQGLVVKQLVSQSKKTGQGDYPLNNELDKEQEDVASTTRKELQELSSSIKDLVLKSRKSSVTEE>sp|O94874-2|UFL1_HUMAN Isoform 2 of E3 UFM1-protein ligase 1 OS=Homosapiens OX=9606 GN=UFL1MRDELHVRGGRVNIVDLQQVINVDLIHIENRIGDIIKSEKHVQLVLGQLIDENYLDRLAEEVNDKLQESGQVTISELCKTYDLPGNFLTQALTQRLGRIISGHIDLDNRGVIFTEAFVARHKARIRGLFSAITRPTAVNSLISKYGFQEQLLYSVLEELVNSGRLRGTVVGGRQDKAVFVPDIYSRTQSTWVDSFFRQNGYLEFDALSRLGIPDAVSYIKKRYKTTQLLFLKAACVGQGLVDQVEASVEEAISSGTWVDIAPLLPTSLSVEDAAILLQQVMRAFSKQASTVVFSDTVVVSEKFINDCTELFRELMHQKAEKEMKNNPVHLITEEDLKQISTLESVSTSKKDKKDERRRKATEGSGSMRGGGGGNAREYKIKKVKKKGRKDDDSDDESQSSHTGKKKPEISFMFQDEIEDFLRKHIQDAPEEFISELAEYLIKPLNKTYLEVVRSVFMSSTTSASGTGRKRTIKDLQEEVSNLYNNIRLFEKGMKFFADDTQAALTKHLLKSVCTDITNLIFNFLASDLMMAVDDPAAITSEIRKKILSKLSEETKVALTKLHNSLNEKSIEDFISCLDSAAEACDIMVKRGDKKRERQILFQHRQALAEQLKVTEDPALILHLTSVLLFQFSTHSMLHAPGRCVPQIIAFLNSKIPEDQHALLVKYQGLVVKQLVSQSKKTGQGDYPLNNELDKEQEDVASTTRKELQELSSSIKDLVLKSRKSSVTEE>sp|O94874-3|UFL1_HUMAN Isoform 3 of E3 UFM1-protein ligase 1 OS=Homosapiens OX=9606 GN=UFL1MADAWEEIRRLAADFQRAQFAEATQRLSERNCIEIVNKLIAQKQLEVVHTLDGKEYITPAQISKEMRDELHVRGGRVNIVDLQQVINVDLIHIENRIGDIIKSEKHVQLVLGQLIDENYLDRLAEEVNDKLQESGQVTISELCKTYDLPGNFLTQALTQRLGRIISGHIDLDNRGVIFTEAFVARHKARIRGLFSAITRPTAVNSLISKYGFQEQLLYSVLEELVNSGRLRGTVVGGRQDKAVFVPDIYSRTQSTWVDSFFRQNGYLEFDALSRLGIPDAVSYIKKRYKTTQLLFLKAACVGQGLVDQVEASVEEAISSGTWVDIAPLLPTSLSVEDAAILLQQVMRAFSKQASTVVFSDTVVVSEKFINDCTELFRELMHQKAEKEMKNNPVHLITEEDLKQISTLESVSTSKKDKKDERRRKATEGSGSMRGGGGGNAREYKIKKVKKKGRKDDDSDDESQSSHTGKKKPEISFMFQDEIEDFLRKHIQDAPEEFISELAEYLIKQV>sp|Q8N2K1|UB2J2_HUMAN Ubiquitin-conjugating enzyme E2 J2 OS=Homo sapiensOX=9606 GN=UBE2J2 PE=1 SV=3MSSTSSKRAPTTATQRLKQDYLRIKKDPVPYICAEPLPSNILEWHYVVRGPEMTPYEGGYYHGKLIFPREFPFKPPSIYMITPNGRFKCNTRLCLSITDFHPDTWNPAWSVSTILTGLLSFMVEKGPTLGSIETSDFTKRQLAVQSLAFNLKDKVFCELFPEVVEEIKQKQKAQDELSSRPQTLPLPDVVPDGETHLVQNGIQLLNGHAPGAVPNLAGLQQANRHHGLLGGALANLFVIVGFAAFAYTVKYVLRSIAQE>sp|Q8N2K1-2|UB2J2_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 J2OS=Homo sapiens OX=9606 GN=UBE2J2MWPQDIAGRHYVVRGPEMTPYEGGYYHGKLIFPREFPFKPPSIYMITPNGRFKCNTRLCLSITDFHPDTWNPAWSVSTILTGLLSFMVEKGPTLGSIETSDFTKRQLAVQSLAFNLKDKVFCELFPEVVEEIKQKQKAQDELSSRPQTLPLPDVVPDGETHLVQNGIQLLNGHAPGAVPNLAGLQQANRHHGLLGGALANLFVIVGFAAFAYTVKYVLRSIAQE>sp|Q8N2K1-3|UB2J2_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 J2OS=Homo sapiens OX=9606 GN=UBE2J2MSSTSSKRAPTTATQRLKQDYLRIKKDPVPYICAEPLPSNILEWFKRFSWLSLLSSWDYRHYVVRGPEMTPYEGGYYHGKLIFPREFPFKPPSIYMITPNGRFKCNTRLCLSITDFHPDTWNPAWSVSTILTGLLSFMVEKGPTLGSIETSDFTKRQLAVQSLAFNLKDKVFCELFPEVVEEIKQKQKAQDELSSRPQTLPLPDVVPDGETHLVQNGIQLLNGHAPGAVPNLAGLQQANRHHGLLGGALANLFVIVGFAAFAYTVKYVLRSIAQE>sp|Q9UHD9|UBQL2_HUMAN Ubiquilin-2 OS=Homo sapiens OX=9606 GN=UBQLN2 PE=1SV=2MAENGESSGPPRPSRGPAAAQGSAAAPAEPKIIKVTVKTPKEKEEFAVPENSSVQQFKEAISKRFKSQTDQLVLIFAGKILKDQDTLIQHGIHDGLTVHLVIKSQNRPQGQSTQPSNAAGTNTTSASTPRSNSTPISTNSNPFGLGSLGGLAGLSSLGLSSTNFSELQSQMQQQLMASPEMMIQIMENPFVQSMLSNPDLMRQLIMANPQMQQLIQRNPEISHLLNNPDIMRQTLEIARNPAMMQEMMRNQDLALSNLESIPGGYNALRRMYTDIQEPMLNAAQEQFGGNPFASVGSSSSSGEGTQPSRTENRDPLPNPWAPPPATQSSATTSTTTSTGSGSGNSSSNATGNTVAAANYVASIFSTPGMQSLLQQITENPQLIQNMLSAPYMRSMMQSLSQNPDLAAQMMLNSPLFTANPQLQEQMRPQLPAFLQQMQNPDTLSAMSNPRAMQALMQIQQGLQTLATEAPGLIPSFTPGVGVGVLGTAIGPVGPVTPIGPIGPIVPFTPIGPIGPIGPTGPAAPPGSTGSGGPTGPTVSSAAPSETTSPTSESGPNQQFIQQMVQALAGANAPQLPNPEVRFQQQLEQLNAMGFLNREANLQALIATGGDINAAIERLLGSQPS>sp|Q53H54|TYW2_HUMAN tRNA wybutosine-synthesizing protein 2 homologOS=Homo sapiens OX=9606 GN=TRMT12 PE=1 SV=1MRENVVVSNMERESGKPVAVVAVVTEPWFTQRYREYLQRQKLFDTQHRVEKMPDGSVALPVLGETLPEQHLQELRNRVAPGSPCMLTQLPDPVPSKRAQGCSPAQKLCLEVSRWVEGRGVKWSAELEADLPRSWQRHGNLLLLSEDCFQAKQWKNLGPELWETVALALGVQRLAKRGRVSPDGTRTPAVTLLLGDHGWVEHVDNGIRYKFDVTQCMFSFGNITEKLRVASLSCAGEVLVDLYAGIGYFTLPFLVHAGAAFVHACEWNPHAVVALRNNLEINGVADRCQIHFGDNRKLKLSNIADRVILGLIPSSEEGWPIACQVLRQDAGGILHIHQNVESFPGKNLQALGVSKVEKEHWLYPQQITTNQWKNGATRDSRGKMLSPATKPEWQRWAESAETRIATLLQQVHGKPWKTQILHIQPVKSYAPHVDHIVLDLECCPCPSVG>sp|Q9H321|VCX3B_HUMAN Variable charge X-linked protein 3B OS=Homosapiens OX=9606 GN=VCX3B PE=2 SV=4MSPKPRASGPPAKAKEAGKRKSSSQPSPSDPKKKTTKVAKKGKAVRRGRRGKKGAATKMAAVTAPEAESGPAAPGPSDQPSQELPQHELPPEEPVSEGTQHDPLSQESELEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEMEEPLSQESQVEEPLSQESEMEEPLSQESEMEELPSV>sp|Q9H321-2|VCX3B_HUMAN Isoform 2 of Variable charge X-linked protein 3BOS=Homo sapiens OX=9606 GN=VCX3BMSPKPRASGPPAKAKEAGKRKSSSQPSPSDPKKKTTKVAKKGKAVRRGRRGKKGAATKMAAVTAPEAESGPAAPGPSDQPSQELPQHELPPEEPVSEGTQHDPLSQESELEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEMEEPLSQESQVEEPLSQESEMEEPLSQESEMEELPSV>sp|P12018|VPREB_HUMAN Immunoglobulin iota chain OS=Homo sapiens OX=9606GN=VPREB1 PE=1 SV=2MSWAPVLLMLFVYCTGCGPQPVLHQPPAMSSALGTTIRLTCTLRNDHDIGVYSVYWYQQRPGHPPRFLLRYFSQSDKSQGPQVPPRFSGSKDVARNRGYLSISELQPEDEAMYYCAMGARSSEKEEREREWEEEMEPTAARTRVP>sp|Q9P253|VPS18_HUMAN Vacuolar protein sorting-associated protein 18homolog OS=Homo sapiens OX=9606 GN=VPS18 PE=1 SV=2MASILDEYENSLSRSAVLQPGCPSVGIPHSGYVNAQLEKEVPIFTKQRIDFTPSERITSLVVSSNQLCMSLGKDTLLRIDLGKANEPNHVELGRKDDAKVHKMFLDHTGSHLLIALSSTEVLYVNRNGQKVRPLARWKGQLVESVGWNKALGTESSTGPILVGTAQGHIFEAELSASEGGLFGPAPDLYFRPLYVLNEEGGPAPVCSLEAERGPDGRSFVIATTRQRLFQFIGRAAEGAEAQGFSGLFAAYTDHPPPFREFPSNLGYSELAFYTPKLRSAPRAFAWMMGDGVLYGALDCGRPDSLLSEERVWEYPEGVGPGASPPLAIVLTQFHFLLLLADRVEAVCTLTGQVVLRDHFLEKFGPLKHMVKDSSTGQLWAYTERAVFRYHVQREARDVWRTYLDMNRFDLAKEYCRERPDCLDTVLAREADFCFRQRRYLESARCYALTQSYFEEIALKFLEARQEEALAEFLQRKLASLKPAERTQATLLTTWLTELYLSRLGALQGDPEALTLYRETKECFRTFLSSPRHKEWLFASRASIHELLASHGDTEHMVYFAVIMQDYERVVAYHCQHEAYEEALAVLARHRDPQLFYKFSPILIRHIPRQLVDAWIEMGSRLDARQLIPALVNYSQGGEVQQVSQAIRYMEFCVNVLGETEQAIHNYLLSLYARGRPDSLLAYLEQAGASPHRVHYDLKYALRLCAEHGHHRACVHVYKVLELYEEAVDLALQVDVDLAKQCADLPEEDEELRKKLWLKIARHVVQEEEDVQTAMACLASCPLLKIEDVLPFFPDFVTIDHFKEAICSSLKAYNHHIQELQREMEEATASAQRIRRDLQELRGRYGTVEPQDKCATCDFPLLNRPFYLFLCGHMFHADCLLQAVRPGLPAYKQARLEELQRKLGAAPPPAKGSARAKEAEGGAATAGPSREQLKADLDELVAAECVYCGELMIRSIDRPFIDPQRYEEEQLSWL>sp|Q3ZAQ7|VMA21_HUMAN Vacuolar ATPase assembly integral membrane proteinVMA21 OS=Homo sapiens OX=9606 GN=VMA21 PE=1 SV=1MERPDKAALNALQPPEFRNESSLASTLKTLLFFTALMITVPIGLYFTTKSYIFEGALGMSNRDSYFYAAIVAVVAVHVVLALFVYVAWNEGSRQWREGKQD>sp|Q3ZAQ7-2|VMA21_HUMAN Isoform 2 of Vacuolar ATPase assembly integralmembrane protein VMA21 OS=Homo sapiens OX=9606 GN=VMA21MLGSPCGPQLSDRDADEDQCSREFRGRRSRRPPRRTMLRGKSRLNVEWLGYSPGLLLEHRPLLAGRTPRSHRRNESSLASTLKTLLFFTALMITVPIGLYFTTKSYIFEGALGMSNRDSYFYAAIVAVVAVHVVLALFVYVAWNEGSRQWREGKQD>sp|P63122|VPK8_HUMAN Endogenous retrovirus group K member 8 Pro proteinOS=Homo sapiens OX=9606 GN=ERVK-8 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVIGLVGIGTASEVYQSMEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPLYSPTSQKIMTKRGYIPGKGLGKNEDGIKIPFEAKINQKREGIGYPF>sp|Q86VN1|VPS36_HUMAN Vacuolar protein-sorting-associated protein 36OS=Homo sapiens OX=9606 GN=VPS36 PE=1 SV=1MDRFVWTSGLLEINETLVIQQRGVRIYDGEEKIKFDAGTLLLSTHRLIWRDQKNHECCMAILLSQIVFIEEQAAGIGKSAKIVVHLHPAPPNKEPGPFQSSKNSYIKLSFKEHGQIEFYRRLSEEMTQRRWENMPVSQSLQTNRGPQPGRIRAVGIVGIERKLEEKRKETDKNISEAFEDLSKLMIKAKEMVELSKSIANKIKDKQGDITEDETIRFKSYLLSMGIANPVTRETYGSGTQYHMQLAKQLAGILQVPLEERGGIMSLTEVYCLVNRARGMELLSPEDLVNACKMLEALKLPLRLRVFDSGVMVIELQSHKEEEMVASALETVSEKGSLTSEEFAKLVGMSVLLAKERLLLAEKMGHLCRDDSVEGLRFYPNLFMTQS>sp|Q86VN1-2|VPS36_HUMAN Isoform 2 of Vacuolar protein-sorting-associatedprotein 36 OS=Homo sapiens OX=9606 GN=VPS36MAILLSQIVFIEEQAAGIGKSAKIVVHLHPAPPNKEPGPFQSSKNSYIKLSFKEHGQIEFYRRLSEEMTQRRWENMPVSQSLQTNRGPQPGRIRAVGIVGIERKLEEKRKETDKNISEAFEDLSKLMIKAKEMVELSKSIANKIKDKQGDITEDETIRFKSYLLSMGIANPVTRETYGSGTQYHMQLAKQLAGILQVPLEERGGIMSLTEVYCLVNRARGMELLSPEDLVNACKMLEALKLPLRLRVFDSGVMVIELQSHKEEEMVASALETVSEKGSLTSEEFAKLVGMSVLLAKERLLLAEKMGHLCRDDSVEGLRFYPNLFMTQS>sp|Q86XT2|VP37D_HUMAN Vacuolar protein sorting-associated protein 37DOS=Homo sapiens OX=9606 GN=VPS37D PE=1 SV=2MYRARAARAGPEPGSPGRFGILSTGQLRDLLQDEPKLDRIVRLSRKFQGLQLEREACLASNYALAKENLALRPRLEMGRAALAIKYQELREVAENCADKLQRLEESMHRWSPHCALGWLQAELEEAEQEAEEQMEQLLLGEQSLEAFLPAFQRGRALAHLRRTQAEKLQELLRRRERSAQPAPTSAADPPKSFPAAAVLPTGAARGPPAVPRSLPPLDSRPVPPLKGSPGCPLGPAPLLSPRPSQPEPPHR>sp|Q9Y6W5|WASF2_HUMAN Wiskott-Aldrich syndrome protein family member 2OS=Homo sapiens OX=9606 GN=WASF2 PE=1 SV=3MPLVTRNIEPRHLCRQTLPSVRSELECVTNITLANVIRQLGSLSKYAEDIFGELFTQANTFASRVSSLAERVDRLQVKVTQLDPKEEEVSLQGINTRKAFRSSTIQDQKLFDRNSLPVPVLETYNTCDTPPPLNNLTPYRDDGKEALKFYTDPSYFFDLWKEKMLQDTKDIMKEKRKHRKEKKDNPNRGNVNPRKIKTRKEEWEKMKMGQEFVESKEKLGTSGYPPTLVYQNGSIGCVENVDASSYPPPPQSDSASSPSPSFSEDNLPPPPAEFSYPVDNQRGSGLAGPKRSSVVSPSHPPPAPPLGSPPGPKPGFAPPPAPPPPPPPMIGIPPPPPPVGFGSPGTPPPPSPPSFPPHPDFAAPPPPPPPPAADYPTLPPPPLSQPTGGAPPPPPPPPPPGPPPPPFTGADGQPAIPPPLSDTTKPKSSLPAVSDARSDLLSAIRQGFQLRRVEEQREQEKRDVVGNDVATILSRRIAVEYSDSEDDSSEFDEDDWSD>sp|Q9Y6W5-2|WASF2_HUMAN Isoform 2 of Wiskott-Aldrich syndrome proteinfamily member 2 OS=Homo sapiens OX=9606 GN=WASF2MPLVTRNIEPRHLCRQTLPSVRSELECVTNITLANVIRQLGSLSKYAEDIFGELFTQANTFASRVSSLAERVDRLQVKVTQLDPKEEEVSLQGINTRKAFRSSTIQDQKLFDRNSLPVPVLETYNTCDTPPPLNNLTPYRDDGKEALKFYTDPSYFFDLWKEKMLQDTKDIMKEKRKHRKEKKDNPNRGNVNPRKIKTRKEEWEKMKMGQEFVESKEKLGTSGYPPTLVYQNGSIGCVENVDASSYPPPPQSDSASSPSPSFSEDNLPPPPAEFRFSAAQG>sp|Q9Y548|YIPF1_HUMAN Protein YIPF1 OS=Homo sapiens OX=9606 GN=YIPF1PE=1 SV=1MAAVDDLQFEEFGNAATSLTANPDATTVNIEDPGETPKHQPGSPRGSGREEDDELLGNDDSDKTELLAGQKKSSPFWTFEYYQTFFDVDTYQVFDRIKGSLLPIPGKNFVRLYIRSNPDLYGPFWICATLVFAIAISGNLSNFLIHLGEKTYHYVPEFRKVSIAATIIYAYAWLVPLALWGFLMWRNSKVMNIVSYSFLEIVCVYGYSLFIYIPTAILWIIPQKAVRWILVMIALGISGSLLAMTFWPAVREDNRRVALATIVTIVLLHMLLSVGCLAYFFDAPEMDHLPTTTATPNQTVAAAKSS>sp|Q9Y548-2|YIPF1_HUMAN Isoform 2 of Protein YIPF1 OS=Homo sapiensOX=9606 GN=YIPF1MWRNSKVMNIVSYSFLEIVCVYGYSLFIYIPTAILWIIPQKAVRWILVMIALGISGSLLAMTFWPAVREDNRRVALATIVTIVLLHMLLSVGCLAYFFDAPEMDHLPTTTATPNQTVAAAKSS>sp|Q8N976|YG039_HUMAN Putative uncharacterized protein FLJ38264 OS=Homosapiens OX=9606 PE=5 SV=1MISAHCSNLHFLGSSESPTLASQVGEITGTHHHTRLIFVFLVETGFHHVGHAGLELLTSSDPPTLASRSAGITGMSHRARPHGISRGEQVTLGLPLELLECVSWPLCGSPLRRAQIVSTPPSPLAALRVPVGAEGWGGTEQ>sp|Q9BZS9|YG041_HUMAN Putative uncharacterized protein PNAS-138 OS=Homosapiens OX=9606 GN=PNAS-138 PE=5 SV=1MPYDQDSFSTLLGFLQASRKYSEFTLKCPICIYVPCQCFAVGFLKQSDQ>sp|Q86UZ6|ZBT46_HUMAN Zinc finger and BTB domain-containing protein 46OS=Homo sapiens OX=9606 GN=ZBTB46 PE=1 SV=2MNNRKEDMEITSHYRHLLRELNEQRQHGVLCDVCVVVEGKVFKAHKNVLLGSSRYFKTLYCQVQKTSEQATVTHLDIVTAQGFKAIIDFMYSAHLALTSRNVIEVMSAASFLQMTDIVQACHDFIKAALDISIKSDASDELAEFEIGASSSSSTEALISAVMAGRSISPWLARRTSPANSSGDSAIASCHDGGSSYGKEDQEPKADGPDDVSSQPLWPGDVGYGPLRIKEEQVSPSQYGGSELPSAKDGAVQNSFSEQSAGDAWQPTGRRKNRKNKETVRHITQQVEDDSRASSPVPSFLPTSGWPFSSRDSNADLSVTEASSSDSRGERAELYAQVEEGLLGGEASYLGPPLTPEKDDALHQATAVANLRAALMSKNSLLSLKADVLGDDGSLLFEYLPRGAHSLSLNEFTVIRKKFKCPYCSFSAMHQCILKRHMRSHTGERPYPCEICGKKFTRREHMKRHTLVHSKDKKYVCKVCSRVFMSAASVGIRHGSRRHGVCTDCAGRGMAGPLDHGGGGGEGSPEALFPGDGPYLEDPEDPRGEAEELGEDDEGLAPEDALLADDKDEEDSPRPRSPPGGPDKDFAWLS>sp|Q8N5A5|ZGPAT_HUMAN Zinc finger CCCH-type with G patch domain-containing protein OS=Homo sapiens OX=9606 GN=ZGPAT PE=1 SV=3MDEESLESALQTYRAQLQQVELALGAGLDSSEQADLRQLQGDLKELIELTEASLVSVRKSSLLAALDEERPGRQEDAEYQAFREAITEAVEAPAAARGSGSETVPKAEAGPESAAGGQEEEEGEDEEELSGTKVSAPYYSSWGTLEYHNAMVVGTEEAEDGSAGVRVLYLYPTHKSLKPCPFFLEGKCRFKENCRFSHGQVVSLDELRPFQDPDLSSLQAGSACLAKHQDGLWHAARITDVDNGYYTVKFDSLLLREAVVEGDGILPPLRTEATESDSDSDGTGDSSYARVVGSDAVDSAQSSALCPSLAVVGSDAVDSGTCSSAFAGWEVHTRGIGSRLLTKMGYEFGKGLGRHAEGRVEPIHAVVLPRGKSLDQCVETLQKQTRVGKAGTNKPPRCRGRGARPGGRPAPRNVFDFLNEKLQGQAPGALEAGAAPAGRRSKDMYHASKSAKRALSLRLFQTEEKIERTQRDIRSIQEALARNAGRHSVASAQLQEKLAGAQRQLGQLRAQEAGLQQEQRKADTHKKMTEF>sp|Q8N5A5-2|ZGPAT_HUMAN Isoform 2 of Zinc finger CCCH-type with G patchdomain-containing protein OS=Homo sapiens OX=9606 GN=ZGPATMDEESLESALQTYRAQLQQVELALGAGLDSSEQADLRQLQGDLKELIELTEASLVSVRKSSLLAALDEERPGRQEDAEYQAFREAITEAVEAPAAARGSGSETVPKAEAGPESAAGGQEEEEGEDEEELSGTKVSAPYYSSWGTLEYHNAMVVGTEEAEDGSAGVRVLYLYPTHKSLKPCPFFLEGKCRFKENCRFSHGQVVSLDELRPFQDPDLSSLQAGSACLAKHQDGLWHAARITDVDNGYYTVKFDSLLLREAVVEGDGILPPLRTEATESDSDSDGTGDSSYARVVGSDAVDSGTCSSAFAGWEVHTRGIGSRLLTKMGYEFGKGLGRHAEGRVEPIHAVVLPRGKSLDQCVETLQKQTRVGKAGTNKPPRCRGRGARPGGRPAPRNVFDFLNEKLQGQAPGALEAGAAPAGRRSKDMYHASKSAKRALSLRLFQTEEKIERTQRDIRSIQEALARNAGRHSVASAQLQEKLAGAQRQLGQLRAQEAGLQQEQRKADTHKKMTEF>sp|Q8N5A5-3|ZGPAT_HUMAN Isoform 3 of Zinc finger CCCH-type with G patchdomain-containing protein OS=Homo sapiens OX=9606 GN=ZGPATMDEESLESALQTYRAQLQQVELALGAGLDSSEQADLRQLQGDLKELIELTEASLVSVRKSSLLAALDEERPGRQEDAEYQAFREAITEAVEAPAAARGSGSETVPKAEAGPESAAGGQEEEEGEDEEELSGTKVSAPYYSSWGTLEYHNAMVVGTEEAEDGSAGVRVLYLYPTHKSLKPCPFFLEGKCRFKENCRFSHGQVVSLDELRPFQDPDLSSLQAGSACLAKHQDGLWHAARITDVDNGYYTVKFDSLLLREAVVEGDGILPPLRTEATESDSDSDVVGSDAVDSGTCSSAFAGWEVHTRGIGSRLLTKMGYEFGKGLGRHAEGRVEPIHAVVLPRGKSLDQCVETLQKQTRVGKAGTNKPPRCRGRGARPGGRPAPRNVFDFLNEKLQGQAPGALEAGAAPAGRRSKDMYHASKSAKRALSLRLFQTEEKIERTQRDIRSIQEALARNAGRHSVASAQLQEKLAGAQRQLGQLRAQEAGLQQEQRKADTHKKMTEF>sp|Q8N5A5-4|ZGPAT_HUMAN Isoform 4 of Zinc finger CCCH-type with G patchdomain-containing protein OS=Homo sapiens OX=9606 GN=ZGPATMGYEFGKGLGRHAEGRVEPIHAVVLPRGKSLDQCVETLQKQTRVGKAGTNKPPRCRGRGARPGGRPAPRNVFDFLNEKLQGQAPGALEAGAAPAGRRSKDMYHASKSAKRALSLRLFQTEEKIERTQRDIRSIQEALARNAGRHSVASAQLQEKLAGAQRQLGQLRAQEAGLQQEQRKADTHKKMTEF>sp|Q6ZRU5|YQ032_HUMAN Putative uncharacterized protein FLJ46089 OS=Homosapiens OX=9606 PE=5 SV=2MRCVTRTRNWWRRAARMPRAGSSAWWVAVCKQVCTRVGTYAVCWCSWNTGRFTGCPSWKDFWKPVGPALHVFNVKCEAQRGLKLTQPFTVACKIDPVLCKSGLGFPPQLFTGCVYLSTYTYPWQAQAECVRCPRDSNRCKRITPSACL>sp|Q5T0B9|ZN362_HUMAN Zinc finger protein 362 OS=Homo sapiens OX=9606GN=ZNF362 PE=1 SV=1MSRSSPSGKGHSRMAEPRFNNPYFWPPPPTMPSQLDNLVLINKIKEQLMAEKIRPPHLPPTSASSQQPLLVPPAPAESSQAVMSLPKLQQVPGLHPQAVPQPDVALHARPATSTVTGLGLSTRTPSVSTSESSAGAGTGTGTSTPSTPTTTSQSRLIASSPTLISGITSPPLLDSIKTIQGHGLLGPPKSERGRKKIKAENPGGPPVLVVPYPILASGETAKEGKTYRCKVCPLTFFTKSEMQIHSKSHTEAKPHKCPHCSKSFANASYLAQHLRIHLGVKPYHCSYCDKSFRQLSHLQQHTRIHTGDRPYKCPHPGCEKAFTQLSNLQSHQRQHNKDKPYKCPNCYRAYSDSASLQIHLSAHAIKHAKAYCCSMCGRAYTSETYLMKHMSKHTVVEHLVSHHSPQRTESPGIPVRISLI>sp|Q6ZSR6|YP007_HUMAN Putative uncharacterized protein FLJ45256 OS=Homosapiens OX=9606 PE=2 SV=3MLVETGFCRVGQAGLELLSSSDKAAGLDLPKCWDYRHEPPRLAPLLIFNPHPSTVLSCNCEYNSFFEFCDSLQQIVIPERVLGTPRHIFPLPLLFSHFLWSKLKEAPACLLQGSSEHTEIICDLISSSKQFIKKFLSNKPSALHGGDADENDFLQLITRLQKLLFKSLSMYVCVHIHQHTHACPQLSCLHQNQDEELFYCQN>sp|Q5VV52|ZN691_HUMAN Zinc finger protein 691 OS=Homo sapiens OX=9606GN=ZNF691 PE=1 SV=2MSLCSPTHSAEMSLFLQGPEEMLPLSSEGSEMGSEKEQSPEPHLPEEGEGGKPWRVDDSEGSWIPPGEKEHGQESLSDELQETHPKKPWQKVTVRARELGDPIAHPRHEADEKPFICAQCGKTFNNTSNLRTHQRIHTGEKPYKCSECGKSFSRSSNRIRHERIHLEEKHYKCPKCQESFRRRSDLTTHQQDHLGKRPYRCDICGKSFSQSATLAVHHRTHLEPAPYICCECGKSFSNSSSFGVHHRTHTGERPYECTECGRTFSDISNFGAHQRTHRGEKPYRCTVCGKHFSRSSNLIRHQKTHLGEQAGKDSS>sp|Q5VV52-3|ZN691_HUMAN Isoform 2 of Zinc finger protein 691 OS=Homosapiens OX=9606 GN=ZNF691MGSEKEQSPEPHLPEEGEGGKPWRVDDSEGSWIPPGEKEHGQESLSDELQETHPKKPWQKVTVRARELGDPIAHPRHEADEKPFICAQCGKTFNNTSNLRTHQRIHTGEKPYKCSECGKSFSRSSNRIRHERIHLEEKHYKCPKCQESFRRRSDLTTHQQDHLGKRPYRCDICGKSFSQSATLAVHHRTHLEPAPYICCECGKSFSNSSSFGVHHRTHTGERPYECTECGRTFSDISNFGAHQRTHRGEKPYRCTVCGKHFSRSSNLIRHQKTHLGEQAGKDSS>sp|Q5JVG2|ZN484_HUMAN Zinc finger protein 484 OS=Homo sapiens OX=9606GN=ZNF484 PE=1 SV=1MTKSLESVSFKDVTVDFSRDEWQQLDLAQKSLYREVMLENYFNLISVGCQVPKPEVIFSLEQEEPCMLDGEIPSQSRPDGDIGFGPLQQRMSEEVSFQSEININLFTRDDPYSILEELWKDDEHTRKCGENQNKPLSRVVFINKKTLANDSIFEYKDIGEIVHVNTHLVSSRKRPHNCNSCGKNLEPIITLYNRNNATENSDKTIGDGDIFTHLNSHTEVTACECNQCGKPLHHKQALIQQQKIHTRESLYLFSDYVNVFSPKSHAFAHESICAEEKQHECHECEAVFTQKSQLDGSQRVYAGICTEYEKDFSLKSNRQKTPYEGNYYKCSDYGRAFIQKSDLFRCQRIHSGEKPYEYSECEKNLPQNSNLNIHKKIHTGGKHFECTECGKAFTRKSTLSMHQKIHTGEKPYVCTECGKAFIRKSHFITHERIHTGEKPYECSDCGKSFIKKSQLHVHQRIHTGENPFICSECGKVFTHKTNLIIHQKIHTGERPYICTVCGKAFTDRSNLIKHQKIHTGEKPYKCSDCGKSFTWKSRLRIHQKCHTGERHYECSECGKAFIQKSTLSMHQRIHRGEKPYVCTECGKAFFHKSHFITHERIHTGEKPYECSICGKSFTKKSQLHVHQQIHTGEKPYRCAECGKAFTDRSNLFTHQKIHTGEKPYKCSDCGKAFTRKSGLHIHQQSHTGERHYECSECGKAFARKSTLIMHQRIHTGEKPYICNECGKSFIQKSHLNRHRRIHTGEKPYECSDCGKSFIKKSQLHEHHRIHTGEKPYICAECGKAFTIRSNLIKHQKIHTKQKPYKCSDLGKALNWKPQLSMPQKSDNGEVECSMPQLWCGDSEGDQGQLSSI>sp|Q5JVG2-2|ZN484_HUMAN Isoform 2 of Zinc finger protein 484 OS=Homosapiens OX=9606 GN=ZNF484MLENYFNLISVGCQVPKPEVIFSLEQEEPCMLDGEIPSQSRPDGDIGFGPLQQRMSEEVSFQSEININLFTRDDPYSILEELWKDDEHTRKCGENQNKPLSRVVFINKKTLANDSIFEYKDIGEIVHVNTHLVSSRKRPHNCNSCGKNLEPIITLYNRNNATENSDKTIGDGDIFTHLNSHTEVTACECNQCGKPLHHKQALIQQQKIHTRESLYLFSDYVNVFSPKSHAFAHESICAEEKQHECHECEAVFTQKSQLDGSQRVYAGICTEYEKDFSLKSNRQKTPYEGNYYKCSDYGRAFIQKSDLFRCQRIHSGEKPYEYSECEKNLPQNSNLNIHKKIHTGGKHFECTECGKAFTRKSTLSMHQKIHTGEKPYVCTECGKAFIRKSHFITHERIHTGEKPYECSDCGKSFIKKSQLHVHQRIHTGENPFICSECGKVFTHKTNLIIHQKIHTGERPYICTVCGKAFTDRSNLIKHQKIHTGEKPYKCSDCGKSFTWKSRLRIHQKCHTGERHYECSECGKAFIQKSTLSMHQRIHRGEKPYVCTECGKAFFHKSHFITHERIHTGEKPYECSICGKSFTKKSQLHVHQQIHTGEKPYRCAECGKAFTDRSNLFTHQKIHTGEKPYKCSDCGKAFTRKSGLHIHQQSHTGERHYECSECGKAFARKSTLIMHQRIHTGEKPYICNECGKSFIQKSHLNRHRRIHTGEKPYECSDCGKSFIKKSQLHEHHRIHTGEKPYICAECGKAFTIRSNLIKHQKIHTKQKPYKCSDLGKALNWKPQLSMPQKSDNGEVECSMPQLWCGDSEGDQGQLSSI>sp|Q5JVG2-3|ZN484_HUMAN Isoform 3 of Zinc finger protein 484 OS=Homosapiens OX=9606 GN=ZNF484MSVLSLPESVSFKDVTVDFSRDEWQQLDLAQKSLYREVMLENYFNLISVGCQVPKPEVIFSLEQEEPCMLDGEIPSQSRPDGDIGFGPLQQRMSEEVSFQSEININLFTRDDPYSILEELWKDDEHTRKCGENQNKPLSRVVFINKKTLANDSIFEYKDIGEIVHVNTHLVSSRKRPHNCNSCGKNLEPIITLYNRNNATENSDKTIGDGDIFTHLNSHTEVTACECNQCGKPLHHKQALIQQQKIHTRESLYLFSDYVNVFSPKSHAFAHESICAEEKQHECHECEAVFTQKSQLDGSQRVYAGICTEYEKDFSLKSNRQKTPYEGNYYKCSDYGRAFIQKSDLFRCQRIHSGEKPYEYSECEKNLPQNSNLNIHKKIHTGGKHFECTECGKAFTRKSTLSMHQKIHTGEKPYVCTECGKAFIRKSHFITHERIHTGEKPYECSDCGKSFIKKSQLHVHQRIHTGENPFICSECGKVFTHKTNLIIHQKIHTGERPYICTVCGKAFTDRSNLIKHQKIHTGEKPYKCSDCGKSFTWKSRLRIHQKCHTGERHYECSECGKAFIQKSTLSMHQRIHRGEKPYVCTECGKAFFHKSHFITHERIHTGEKPYECSICGKSFTKKSQLHVHQQIHTGEKPYRCAECGKAFTDRSNLFTHQKIHTGEKPYKCSDCGKAFTRKSGLHIHQQSHTGERHYECSECGKAFARKSTLIMHQRIHTGEKPYICNECGKSFIQKSHLNRHRRIHTGEKPYECSDCGKSFIKKSQLHEHHRIHTGEKPYICAECGKAFTIRSNLIKHQKIHTKQKPYKCSDLGKALNWKPQLSMPQKSDNGEVECSMPQLWCGDSEGDQGQLSSI>sp|P28065|PSB9_HUMAN Proteasome subunit beta type-9 OS=Homo sapiensOX=9606 GN=PSMB9 PE=1 SV=2MLRAGAPTGDLPRAGEVHTGTTIMAVEFDGGVVMGSDSRVSAGEAVVNRVFDKLSPLHERIYCALSGSAADAQAVADMAAYQLELHGIELEEPPLVLAAANVVRNISYKYREDLSAHLMVAGWDQREGGQVYGTLGGMLTRQPFAIGGSGSTFIYGYVDAAYKPGMSPEECRRFTTDAIALAMSRDGSSGGVIYLVTITAAGVDHRVILGNELPKFYDE>sp|P28065-2|PSB9_HUMAN Isoform LMP2.S of Proteasome subunit beta type-9OS=Homo sapiens OX=9606 GN=PSMB9MLRAGEVHTGTTIMAVEFDGGVVMGSDSRVSAGEAVVNRVFDKLSPLHERIYCALSGSAADAQAVADMAAYQLELHGIELEEPPLVLAAANVVRNISYKYREDLSAHLMVAGWDQREGGQVYGTLGGMLTRQPFAIGGSGSTFIYGYVDAAYKPGMSPEECRRFTTDAIALAMSRDGSSGGVIYLVTITAAGVDHRVILGNELPKFYDE>sp|P43351|RAD52_HUMAN DNA repair protein RAD52 homolog OS=Homo sapiensOX=9606 GN=RAD52 PE=1 SV=1MSGTEEAILGGRDSHPAAGGGSVLCFGQCQYTAEEYQAIQKALRQRLGPEYISSRMAGGGQKVCYIEGHRVINLANEMFGYNGWAHSITQQNVDFVDLNNGKFYVGVCAFVRVQLKDGSYHEDVGYGVSEGLKSKALSLEKARKEAVTDGLKRALRSFGNALGNCILDKDYLRSLNKLPRQLPLEVDLTKAKRQDLEPSVEEARYNSCRPNMALGHPQLQQVTSPSRPSHAVIPADQDCSSRSLSSSAVESEATHQRKLRQKQLQQQFRERMEKQQVRVSTPSAEKSEAAPPAPPVTHSTPVTVSEPLLEKDFLAGVTQELIKTLEDNSEKWAVTPDAGDGVVKPSSRADPAQTSDTLALNNQMVTQNRTPHSVCHQKPQAKSGSWDLQTYSADQRTTGNWESHRKSQDMKKRKYDPS>sp|P43351-2|RAD52_HUMAN Isoform beta of DNA repair protein RAD52 homologOS=Homo sapiens OX=9606 GN=RAD52MSGTEEAILGGRDSHPAAGGGSVLCFGQCQYTAEEYQAIQKALRQRLGPEYISSRMAGGGQKVCYIEGHRVINLANEMFGYNGWAHSITQQNVDFVDLNNGKFYVGVCAFVRVQLKDGSYHEDVGYGVSEGLKSKALSLEKARKEAVTDGLKRALRLPLLGVSGRILYSLFSVHSVMCAGGLPTPTASAQTAPSSPCSSAVLRYAQEFWECTWKLYSGQRLPEITK>sp|P43351-3|RAD52_HUMAN Isoform gamma of DNA repair protein RAD52homolog OS=Homo sapiens OX=9606 GN=RAD52MSGTEEAILGGRDSHPAAGGGSVLCFGQCQYTAEEYQAIQKALRQRLGPEYISSRMAGGGQKVCYIEGHRVINLANEMFGYNGWAHSITQQNVDFVDLNNGKFYVGVCAFVRVQLKVRGWSRPAARKDQWVVGEGWFIS>sp|P43351-4|RAD52_HUMAN Isoform delta of DNA repair protein RAD52homolog OS=Homo sapiens OX=9606 GN=RAD52MSGTEEAILGGRDSHPAAGGGSVLCFGQCQYTAEEYQAIQKALRQRLGPEYISSRMAGGGQKVCYIEGHRVINLANEMFGYNGWAHSITQQNVGEYALQQWGLLHCPAPAESLLWVRR>sp|Q9BWF3|RBM4_HUMAN RNA-binding protein 4 OS=Homo sapiens OX=9606GN=RBM4 PE=1 SV=1MVKLFIGNLPREATEQEIRSLFEQYGKVLECDIIKNYGFVHIEDKTAAEDAIRNLHHYKLHGVNINVEASKNKSKTSTKLHVGNISPTCTNKELRAKFEEYGPVIECDIVKDYAFVHMERAEDAVEAIRGLDNTEFQGKRMHVQLSTSRLRTAPGMGDQSGCYRCGKEGHWSKECPIDRSGRVADLTEQYNEQYGAVRTPYTMSYGDSLYYNNAYGALDAYYKRCRAARSYEAVAAAAASVYNYAEQTLSQLPQVQNTAMASHLTSTSLDPYDRHLLPTSGAAATAAAAAAAAAAVTAASTSYYGRDRSPLRRATAPVPTVGEGYGYGHESELSQASAAARNSLYDMARYEREQYADRARYSAF>sp|Q9BWF3-2|RBM4_HUMAN Isoform 2 of RNA-binding protein 4 OS=Homosapiens OX=9606 GN=RBM4MVKLFIGNLPREATEQEIRSLFEQYGKVLECDIIKNYGFVHIEDKTAAEDAIRNLHHYKLHGVNINVEASKNKSKTSTKLHVGNISPTCTNKELRAKFEEYGPVIECDIVKDYAFVHMERAEDAVEAIRGLDNTEFQGEPPSLGRGLNTRLCAENGWISKRRGLVKITAVGWLVMKK>sp|Q9BWF3-3|RBM4_HUMAN Isoform 3 of RNA-binding protein 4 OS=Homosapiens OX=9606 GN=RBM4MVKLFIGNLPREATEQEIRSLFEQYGKVLECDIIKNYGFVHIEDKTAAEDAIRNLHHYKLHGVNINVEASKNKSKTSTKLHVGNISPTCTNKELRAKFEEYGPVIECDIVKDYAFVHMERAEDAVEAIRGLDNTEFQGGMCVG>sp|Q9BWF3-4|RBM4_HUMAN Isoform 4 of RNA-binding protein 4 OS=Homosapiens OX=9606 GN=RBM4MVKLFIGNLPREATEQEIRSLFEQYGKVLECDIIKNYGFVHIEDKTAAEDAIRNLHHYKLHGVNINVEASKNKSKTSTKLHVGNISPTCTNKELRAKFEEYGPVIECDIVKDYAFVHMERAEDAVEAIRGLDNTEFQGKITPVTEGYCCCNKGHTYIFKNCNLILESRKSRRC>sp|Q9Y388|RBMX2_HUMAN RNA-binding motif protein, X-linked 2 OS=Homosapiens OX=9606 GN=RBMX2 PE=1 SV=2MNPLTKVKLINELNEREVQLGVADKVSWHSEYKDSAWIFLGGLPYELTEGDIICVFSQYGEIVNINLVRDKKTGKSKGFCFLCYEDQRSTILAVDNFNGIKIKGRTIRVDHVSNYRAPKDSEEIDDVTRQLQEKGCGARTPSPSLSESSEDEKPTKKHKKDKKEKKKKKKEKEKADREVQAEQPSSSSPRRKTVKEKDDTGPKKHSSKNSERAQKSEPREGQKLPKSRTAYSGGAEDLERELKKEKPKHEHKSSSRREAREEKTRIRDRGRSSDAHSSWYNGRSEGRSYRSRSRSRDKSHRHKRARRSRERESSNPSDRWRH>sp|Q7Z6E9|RBBP6_HUMAN E3 ubiquitin-protein ligase RBBP6 OS=Homo sapiensOX=9606 GN=RBBP6 PE=1 SV=1MSCVHYKFSSKLNYDTVTFDGLHISLCDLKKQIMGREKLKAADCDLQITNAQTKEEYTDDNALIPKNSSVIVRRIPIGGVKSTSKTYVISRTEPAMATTKAIDDSSASISLAQLTKTANLAEANASEEDKIKAMMSQSGHEYDPINYMKKPLGPPPPSYTCFRCGKPGHYIKNCPTNGDKNFESGPRIKKSTGIPRSFMMEVKDPNMKGAMLTNTGKYAIPTIDAEAYAIGKKEKPPFLPEEPSSSSEEDDPIPDELLCLICKDIMTDAVVIPCCGNSYCDECIRTALLESDEHTCPTCHQNDVSPDALIANKFLRQAVNNFKNETGYTKRLRKQLPPPPPPIPPPRPLIQRNLQPLMRSPISRQQDPLMIPVTSSSTHPAPSISSLTSNQSSLAPPVSGNPSSAPAPVPDITATVSISVHSEKSDGPFRDSDNKILPAAALASEHSKGTSSIAITALMEEKGYQVPVLGTPSLLGQSLLHGQLIPTTGPVRINTARPGGGRPGWEHSNKLGYLVSPPQQIRRGERSCYRSINRGRHHSERSQRTQGPSLPATPVFVPVPPPPLYPPPPHTLPLPPGVPPPQFSPQFPPGQPPPAGYSVPPPGFPPAPANLSTPWVSSGVQTAHSNTIPTTQAPPLSREEFYREQRRLKEEEKKKSKLDEFTNDFAKELMEYKKIQKERRRSFSRSKSPYSGSSYSRSSYTYSKSRSGSTRSRSYSRSFSRSHSRSYSRSPPYPRRGRGKSRNYRSRSRSHGYHRSRSRSPPYRRYHSRSRSPQAFRGQSPNKRNVPQGETEREYFNRYREVPPPYDMKAYYGRSVDFRDPFEKERYREWERKYREWYEKYYKGYAAGAQPRPSANRENFSPERFLPLNIRNSPFTRGRREDYVGGQSHRSRNIGSNYPEKLSARDGHNQKDNTKSKEKESENAPGDGKGNKHKKHRKRRKGEESEGFLNPELLETSRKSREPTGVEENKTDSLFVLPSRDDATPVRDEPMDAESITFKSVSEKDKRERDKPKAKGDKTKRKNDGSAVSKKENIVKPAKGPQEKVDGERERSPRSEPPIKKAKEETPKTDNTKSSSSSQKDEKITGTPRKAHSKSAKEHQETKPVKEEKVKKDYSKDVKSEKLTTKEEKAKKPNEKNKPLDNKGEKRKRKTEEKGVDKDFESSSMKISKLEVTEIVKPSPKRKMEPDTEKMDRTPEKDKISLSAPAKKIKLNRETGKKIGSTENISNTKEPSEKLESTSSKVKQEKVKGKVRRKVTGTEGSSSTLVDYTSTSSTGGSPVRKSEEKTDTKRTVIKTMEEYNNDNTAPAEDVIIMIQVPQSKWDKDDFESEEEDVKSTQPISSVGKPASVIKNVSTKPSNIVKYPEKESEPSEKIQKFTKDVSHEIIQHEVKSSKNSASSEKGKTKDRDYSVLEKENPEKRKNSTQPEKESNLDRLNEQGNFKSLSQSSKEARTSDKHDSTRASSNKDFTPNRDKKTDYDTREYSSSKRRDEKNELTRRKDSPSRNKDSASGQKNKPREERDLPKKGTGDSKKSNSSPSRDRKPHDHKATYDTKRPNEETKSVDKNPCKDREKHVLEARNNKESSGNKLLYILNPPETQVEKEQITGQIDKSTVKPKPQLSHSSRLSSDLTRETDEAAFEPDYNESDSESNVSVKEEESSGNISKDLKDKIVEKAKESLDTAAVVQVGISRNQSHSSPSVSPSRSHSPSGSQTRSHSSSASSAESQDSKKKKKKKEKKKHKKHKKHKKHKKHAGTEVELEKSQKHKHKKKKSKKNKDKEKEKEKDDQKVKSVTV>sp|Q7Z6E9-2|RBBP6_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RBBP6OS=Homo sapiens OX=9606 GN=RBBP6MSCVHYKFSSKLNYDTVTFDGLHISLCDLKKQIMGREKLKAADCDLQITNAQTKEEYTDDNALIPKNSSVIVRRIPIGGVKSTSKTYVISRTEPAMATTKAIDDSSASISLAQLTKTANLAEANASEEDKIKAMMSQSGHEYDPINYMKKPLGPPPPSYTCFRCGKPGHYIKNCPTNGDKNFESGPRIKKSTGIPRSFMMEVKDPNMKGAMLTNTGKYAIPTIDAEAYAIGKKEKPPFLPEEPSSSSEEDDPIPDELLCLICKDIMTDAVVIPCCGNSYCDECIRTALLESDEHTCPTCHQNDVSPDALIANKFLRQAVNNFKNETGYTKRLRKQLPPPPPPIPPPRPLIQRNLQPLMRSPISRQQDPLMIPVTSSSTHPAPSISSLTSNQSSLAPPVSGNPSSAPAPVPDITATVSISVHSEKSDGPFRDSDNKILPAAALASEHSKGTSSIAITALMEEKGYQVPVLGTPSLLGQSLLHGQLIPTTGPVRINTARPGGGRPGWEHSNKLGYLVSPPQQIRRGERSCYRSINRGRHHSERSQRTQGPSLPATPVFVPVPPPPLYPPPPHTLPLPPGVPPPQFSPQFPPGQPPPAGYSVPPPGFPPAPANLSTPWVSSGVQTAHSNTIPTTQAPPLSREEFYREQRRLKEESKSPYSGSSYSRSSYTYSKSRSGSTRSRSYSRSFSRSHSRSYSRSPPYPRRGRGKSRNYRSRSRSHGYHRSRSRSPPYRRYHSRSRSPQAFRGQSPNKRNVPQGETEREYFNRYREVPPPYDMKAYYGRSVDFRDPFEKERYREWERKYREWYEKYYKGYAAGAQPRPSANRENFSPERFLPLNIRNSPFTRGRREDYVGGQSHRSRNIGSNYPEKLSARDGHNQKDNTKSKEKESENAPGDGKGNKHKKHRKRRKGEESEGFLNPELLETSRKSREPTGVEENKTDSLFVLPSRDDATPVRDEPMDAESITFKSVSEKDKRERDKPKAKGDKTKRKNDGSAVSKKENIVKPAKGPQEKVDGERERSPRSEPPIKKAKEETPKTDNTKSSSSSQKDEKITGTPRKAHSKSAKEHQETKPVKEEKVKKDYSKDVKSEKLTTKEEKAKKPNEKNKPLDNKGEKRKRKTEEKGVDKDFESSSMKISKLEVTEIVKPSPKRKMEPDTEKMDRTPEKDKISLSAPAKKIKLNRETGKKIGSTENISNTKEPSEKLESTSSKVKQEKVKGKVRRKVTGTEGSSSTLVDYTSTSSTGGSPVRKSEEKTDTKRTVIKTMEEYNNDNTAPAEDVIIMIQVPQSKWDKDDFESEEEDVKSTQPISSVGKPASVIKNVSTKPSNIVKYPEKESEPSEKIQKFTKDVSHEIIQHEVKSSKNSASSEKGKTKDRDYSVLEKENPEKRKNSTQPEKESNLDRLNEQGNFKSLSQSSKEARTSDKHDSTRASSNKDFTPNRDKKTDYDTREYSSSKRRDEKNELTRRKDSPSRNKDSASGQKNKPREERDLPKKGTGDSKKSNSSPSRDRKPHDHKATYDTKRPNEETKSVDKNPCKDREKHVLEARNNKESSGNKLLYILNPPETQVEKEQITGQIDKSTVKPKPQLSHSSRLSSDLTRETDEAAFEPDYNESDSESNVSVKEEESSGNISKDLKDKIVEKAKESLDTAAVVQVGISRNQSHSSPSVSPSRSHSPSGSQTRSHSSSASSAESQDSKKKKKKKEKKKHKKHKKHKKHKKHAGTEVELEKSQKHKHKKKKSKKNKDKEKEKEKDDQKVKSVTV>sp|Q7Z6E9-3|RBBP6_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RBBP6OS=Homo sapiens OX=9606 GN=RBBP6MSCVHYKFSSKLNYDTVTFDGLHISLCDLKKQIMGREKLKAADCDLQITNAQTKEEYTDDNALIPKNSSVIVRRIPIGGVKSTSKTYVISRTEPAMATTKAVCKNTISHFFYTLLLPL>sp|Q7Z6E9-4|RBBP6_HUMAN Isoform 4 of E3 ubiquitin-protein ligase RBBP6OS=Homo sapiens OX=9606 GN=RBBP6MSCVHYKFSSKLNYDTVTFDGLHISLCDLKKQIMGREKLKAADCDLQITNAQTKEEYTDDNALIPKNSSVIVRRIPIGGVKSTSKTYVISRTEPAMATTKAIDDSSASISLAQLTKTANLAEANASEEDKIKAMMSQSGHEYDPINYMKKPLGPPPPSYTCFRCGKPGHYIKNCPTNGDKNFESGPRIKKSTGIPRSFMMEVKDPNMKGAMLTNTGKYAIPTIDAEAYAIGKKEKPPFLPEEPSSSSEEDDPIPDELLCLICKDIMTDAVVIPCCGNSYCDECIRTALLESDEHTCPTCHQNDVSPDALIANKFLRQAVNNFKNETGYTKRLRKQLPPPPPPIPPPRPLIQRNLQPLMRSPISRQQDPLMIPVTSSSTHPAPSISSLTSNQSSLAPPVSGNPSSAPAPVPDITATVSISVHSEKSDGPFRTSSTGGSPVRKSEEKTDTKRTVIKTMEEYNNDNTAPAEDVIIMIQVPQSKWDKDDFESEEEDVKSTQPISSVGKPASVIKNVSTKPSNIVKYPEKESEPSEKIQKFTKDVSHEIIQHEVKSSKNSASSEKGKTKDRDYSVLEKENPEKRKNSTQPEKESNLDRLNEQGNFKSLSQSSKEARTSDKHDSTRASSNKDFTPNRDKKTDYDTREYSSSKRRDEKNELTRRKDSPSRNKDSASGQKNKPREERDLPKKGTGDSKKSNSSPSRDRKPHDHKATYDTKRPNEETKSVDKNPCKDREKHVLEARNNKESSGNKLLYILNPPETQVEKEQITGQIDKSTVKPKPQLSHSSRLSSDLTRETDEAAFEPDYNESDSESNVSVKEEESSGNISKDLKDKIVEKAKESLDTAAVVQVGISRNQSHSSPSVSPSRSHSPSGSQTRSHSSSASSAESQDSKKKKKKKEKKKHKKHKKHKKHKKHAGTEVELEKSQKHKHKKKKSKKNKDKEKEKEKDDQKVKSVTV>sp|Q86UN2|R4RL1_HUMAN Reticulon-4 receptor-like 1 OS=Homo sapiensOX=9606 GN=RTN4RL1 PE=1 SV=1MLRKGCCVELLLLLVAAELPLGGGCPRDCVCYPAPMTVSCQAHNFAAIPEGIPVDSERVFLQNNRIGLLQPGHFSPAMVTLWIYSNNITYIHPSTFEGFVHLEELDLGDNRQLRTLAPETFQGLVKLHALYLYKCGLSALPAGVFGGLHSLQYLYLQDNHIEYLQDDIFVDLVNLSHLFLHGNKLWSLGPGTFRGLVNLDRLLLHENQLQWVHHKAFHDLRRLTTLFLFNNSLSELQGECLAPLGALEFLRLNGNPWDCGCRARSLWEWLQRFRGSSSAVPCVSPGLRHGQDLKLLRAEDFRNCTGPASPHQIKSHTLTTTDRAARKEHHSPHGPTRSKGHPHGPRPGHRKPGKNCTNPRNRNQISKAGAGKQAPELPDYAPDYQHKFSFDIMPTARPKRKGKCARRTPIRAPSGVQQASSASSLGASLLAWTLGLAVTLR>sp|Q9BUV8|RCAF1_HUMAN Respirasome Complex Assembly Factor 1 OS=Homosapiens OX=9606 GN=RAB5IF PE=1 SV=1MSGGRRKEEPPQPQLANGALKVSVWSKVLRSDAAWEDKDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGFCLINAGVLYLYFSNYLQIDEEEYGGTWELTKEGFMTSFALFMVCVADSFTTGHLDHLLHCHPL>sp|Q9BUV8-2|RCAF1_HUMAN Isoform 2 of Respirasome Complex Assembly Factor1 OS=Homo sapiens OX=9606 GN=RAB5IFMSGGRRKEEPPQPQLANGALKVSVWSKVLRSDAAWEDKDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGFCLINAGVLYLYFSNYLQIDEEEYGGTWELTKEGFMTSFALFMVIWIIFYTAIHYD>sp|Q9BUV8-3|RCAF1_HUMAN Isoform 3 of Respirasome Complex Assembly Factor1 OS=Homo sapiens OX=9606 GN=RAB5IFMSGGRRKEEPPQPQLANGALKVSVWSKVLRSDAAWEDKDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGFCLINAGVLYLYFSNYLQIDEEEYGGTWELTKEGFMTSFALFMVILDHLLHCHPL>sp|Q9BUV8-4|RCAF1_HUMAN Isoform 4 of Respirasome Complex Assembly Factor1 OS=Homo sapiens OX=9606 GN=RAB5IFMSGGRRKEEPPQPQLANGALKVSVWSKVLRSDAAWEDKDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGKGHCCSGAVCVCDD>sp|Q9BUV8-5|RCAF1_HUMAN Isoform 5 of Respirasome Complex Assembly Factor1 OS=Homo sapiens OX=9606 GN=RAB5IFMSGGRRKEEPPQPQLANGALKVSVWSKVLRSDAAWEDKDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGSFGSSFTLPSIMTDGVQLPSAPYPVQRTLLITAQELDRWGTPAPWNLEDPCFLDRESVCWASVFSARVVT>sp|O00559|RCAS1_HUMAN Receptor-binding cancer antigen expressed on SiSocells OS=Homo sapiens OX=9606 GN=EBAG9 PE=1 SV=1MAITQFRLFKFCTCLATVFSFLKRLICRSGRGRKLSGDQITLPTTVDYSSVPKQTDVEEWTSWDEDAPTSVKIEGGNGNVATQQNSLEQLEPDYFKDMTPTIRKTQKIVIKKREPLNFGIPDGSTGFSSRLAATQDLPFIHQSSELGDLDTWQENTNAWEEEEDAAWQAEEVLRQQKLADREKRAAEQQRKKMEKEAQRLMKKEQNKIGVKLS>sp|O00559-2|RCAS1_HUMAN Isoform 2 of Receptor-binding cancer antigenexpressed on SiSo cells OS=Homo sapiens OX=9606 GN=EBAG9MAITQFRLFKFCTCLATVFSFLKRLICRSGRGRKLSGDQITLPTTVDYSSVPKQTDVEEWTSWDEDAPTSVKIEGGNGNVATQQNSLEQLEPDYFKDMTPTIRKTQKIVIKKREPLNFGIPDGSTGFSSRLAATQDLPFIHQSSELGDLDTWQENTNAWEEEEDAAWQAEEVLRSRTNVCLLCSLLFHHPTPTSTPYINQSVKIERVSLGQWSYGKSKEQQKLADREKRAAEQQRKKMEKEAQRLMKKEQNKIGVKLS>sp|P78563|RED1_HUMAN Double-stranded RNA-specific editase 1 OS=Homosapiens OX=9606 GN=ADARB1 PE=1 SV=1MDIEDEENMSSSSTDVKENRNLDNVSPKDGSTPGPGEGSQLSNGGGGGPGRKRPLEEGSNGHSKYRLKKRRKTPGPVLPKNALMQLNEIKPGLQYTLLSQTGPVHAPLFVMSVEVNGQVFEGSGPTKKKAKLHAAEKALRSFVQFPNASEAHLAMGRTLSVNTDFTSDQADFPDTLFNGFETPDKAEPPFYVGSNGDDSFSSSGDLSLSASPVPASLAQPPLPVLPPFPPPSGKNPVMILNELRPGLKYDFLSESGESHAKSFVMSVVVDGQFFEGSGRNKKLAKARAAQSALAAIFNLHLDQTPSRQPIPSEGLQLHLPQVLADAVSRLVLGKFGDLTDNFSSPHARRKVLAGVVMTTGTDVKDAKVISVSTGTKCINGEYMSDRGLALNDCHAEIISRRSLLRFLYTQLELYLNNKDDQKRSIFQKSERGGFRLKENVQFHLYISTSPCGDARIFSPHEPILEGSRSYTQAGVQWCNHGSLQPRPPGLLSDPSTSTFQGAGTTEPADRHPNRKARGQLRTKIESGEGTIPVRSNASIQTWDGVLQGERLLTMSCSDKIARWNVVGIQGSLLSIFVEPIYFSSIILGSLYHGDHLSRAMYQRISNIEDLPPLYTLNKPLLSGISNAEARQPGKAPNFSVNWTVGDSAIEVINATTGKDELGRASRLCKHALYCRWMRVHGKVPSHLLRSKITKPNVYHESKLAAKEYQAAKARLFTAFIKAGLGAWVEKPTEQDQFSLTP>sp|P78563-2|RED1_HUMAN Isoform 2 of Double-stranded RNA-specific editase1 OS=Homo sapiens OX=9606 GN=ADARB1MDIEDEENMSSSSTDVKENRNLDNVSPKDGSTPGPGEGSQLSNGGGGGPGRKRPLEEGSNGHSKYRLKKRRKTPGPVLPKNALMQLNEIKPGLQYTLLSQTGPVHAPLFVMSVEVNGQVFEGSGPTKKKAKLHAAEKALRSFVQFPNASEAHLAMGRTLSVNTDFTSDQADFPDTLFNGFETPDKAEPPFYVGSNGDDSFSSSGDLSLSASPVPASLAQPPLPVLPPFPPPSGKNPVMILNELRPGLKYDFLSESGESHAKSFVMSVVVDGQFFEGSGRNKKLAKARAAQSALAAIFNLHLDQTPSRQPIPSEGLQLHLPQVLADAVSRLVLGKFGDLTDNFSSPHARRKVLAGVVMTTGTDVKDAKVISVSTGTKCINGEYMSDRGLALNDCHAEIISRRSLLRFLYTQLELYLNNKDDQKRSIFQKSERGGFRLKENVQFHLYISTSPCGDARIFSPHEPILEEPADRHPNRKARGQLRTKIESGEGTIPVRSNASIQTWDGVLQGERLLTMSCSDKIARWNVVGIQGSLLSIFVEPIYFSSIILGSLYHGDHLSRAMYQRISNIEDLPPLYTLNKPLLSGISNAEARQPGKAPNFSVNWTVGDSAIEVINATTGKDELGRASRLCKHALYCRWMRVHGKVPSHLLRSKITKPNVYHESKLAAKEYQAAKARLFTAFIKAGLGAWVEKPTEQDQFSLTP>sp|P78563-3|RED1_HUMAN Isoform 3 of Double-stranded RNA-specific editase1 OS=Homo sapiens OX=9606 GN=ADARB1MDIEDEENMSSSSTDVKENRNLDNVSPKDGSTPGPGEGSQLSNGGGGGPGRKRPLEEGSNGHSKYRLKKRRKTPGPVLPKNALMQLNEIKPGLQYTLLSQTGPVHAPLFVMSVEVNGQVFEGSGPTKKKAKLHAAEKALRSFVQFPNASEAHLAMGRTLSVNTDFTSDQADFPDTLFNGFETPDKAEPPFYVGSNGDDSFSSSGDLSLSASPVPASLAQPPLPVLPPFPPPSGKNPVMILNELRPGLKYDFLSESGESHAKSFVMSVVVDGQFFEGSGRNKKLAKARAAQSALAAIFNLHLDQTPSRQPIPSEGLQLHLPQVLADAVSRLVLGKFGDLTDNFSSPHARRKVLAGVVMTTGTDVKDAKVISVSTGTKCINGEYMSDRGLALNDCHAEIISRRSLLRFLYTQLELYLNNKDDQKRSIFQKSERGGFRLKENVQFHLYISTSPCGDARIFSPHEPILEGSRSYTQAGVQWCNHGSLQPRPPGLLSDPSTSTFQGAGTTEPADRHPNRKARGQLRTKIESGEGTIPVRSNASIQTWDGVLQGERLLTMSCSDKIARWNVVGIQGSLLSIFVEPIYFSSIILGSLYHGDHLSRAMYQRISNIEDLPPLYTLNKPLLSGISNAEARQPGKAPNFSVNWTVGDSAIEVINATTGKDELGRASRLCKHALYCRWMRVHGKVPSHLLRSKITKPNVYHESKLAAKEYQAAKVH>sp|P78563-4|RED1_HUMAN Isoform 4 of Double-stranded RNA-specific editase1 OS=Homo sapiens OX=9606 GN=ADARB1MKIPRMKTPCQPDRNSLRQSRNPQKYFAMDIEDEENMSSSSTDVKENRNLDNVSPKDGSTPGPGEGSQLSNGGGGGPGRKRPLEEGSNGHSKYRLKKRRKTPGPVLPKNALMQLNEIKPGLQYTLLSQTGPVHAPLFVMSVEVNGQVFEGSGPTKKKAKLHAAEKALRSFVQFPNASEAHLAMGRTLSVNTDFTSDQADFPDTLFNGFETPDKAEPPFYVGSNGDDSFSSSGDLSLSASPVPASLAQPPLPVLPPFPPPSGKNPVMILNELRPGLKYDFLSESGESHAKSFVMSVVVDGQFFEGSGRNKKLAKARAAQSALAAIFNLHLDQTPSRQPIPSEGLQLHLPQVLADAVSRLVLGKFGDLTDNFSSPHARRKVLAGVVMTTGTDVKDAKVISVSTGTKCINGEYMSDRGLALNDCHAEIISRRSLLRFLYTQLELYLNNKDDQKRSIFQKSERGGFRLKENVQFHLYISTSPCGDARIFSPHEPILEEPADRHPNRKARGQLRTKIESGEGTIPVRSNASIQTWDGVLQGERLLTMSCSDKIARWNVVGIQGSLLSIFVEPIYFSSIILGSLYHGDHLSRAMYQRISNIEDLPPLYTLNKPLLSGISNAEARQPGKAPNFSVNWTVGDSAIEVINATTGKDELGRASRLCKHALYCRWMRVHGKVPSHLLRSKITKPNVYHESKLAAKEYQAAKARLFTAFIKAGLGAWVEKPTEQDQFSLTP>sp|P78563-5|RED1_HUMAN Isoform 5 of Double-stranded RNA-specific editase1 OS=Homo sapiens OX=9606 GN=ADARB1MASSTTPPLHMGTFFSVMGRRYKRRRKKRSERKDRNSLRQSRNPQKYFAMDIEDEENMSSSSTDVKENRNLDNVSPKDGSTPGPGEGSQLSNGGGGGPGRKRPLEEGSNGHSKYRLKKRRKTPGPVLPKNALMQLNEIKPGLQYTLLSQTGPVHAPLFVMSVEVNGQVFEGSGPTKKKAKLHAAEKALRSFVQFPNASEAHLAMGRTLSVNTDFTSDQADFPDTLFNGFETPDKAEPPFYVGSNGDDSFSSSGDLSLSASPVPASLAQPPLPVLPPFPPPSGKNPVMILNELRPGLKYDFLSESGESHAKSFVMSVVVDGQFFEGSGRNKKLAKARAAQSALAAIFNLHLDQTPSRQPIPSEGLQLHLPQVLADAVSRLVLGKFGDLTDNFSSPHARRKVLAGVVMTTGTDVKDAKVISVSTGTKCINGEYMSDRGLALNDCHAEIISRRSLLRFLYTQLELYLNNKDDQKRSIFQKSERGGFRLKENVQFHLYISTSPCGDARIFSPHEPILEGSRSYTQAGVQWCNHGSLQPRPPGLLSDPSTSTFQGAGTTEPADRHPNRKARGQLRTKIESGEGTIPVRSNASIQTWDGVLQGERLLTMSCSDKIARWNVVGIQGSLLSIFVEPIYFSSIILGSLYHGDHLSRAMYQRISNIEDLPPLYTLNKPLLSGISNAEARQPGKAPNFSVNWTVGDSAIEVINATTGKDELGRASRLCKHALYCRWMRVHGKVPSHLLRSKITKPNVYHESKLAAKEYQAAKARLFTAFIKAGLGAWVEKPTEQDQFSLTP>sp|P78563-6|RED1_HUMAN Isoform 6 of Double-stranded RNA-specific editase1 OS=Homo sapiens OX=9606 GN=ADARB1MDIEDEENMSSSSTDVKENRNLDNVSPKDGSTPGPGEGSQLSNGGGGGPGRKRPLEEGSNGHSKYRLKKRRKTPGPVLPKNALMQLNEIKPGLQYTLLSQTGPVHAPLFVMSVEVNGQVFEGSGPTKKKAKLHAAEKALRSFVQFPNASEAHLAMGRTLSVNTDFTSDQADFPDTLFNGFETPDKAEPPFYVGSNGDDSFSSSGDLSLSASPVPASLAQPPLPVLPPFPPPSGKNPVMILNELRPGLKYDFLSESGESHAKSFVMSVVVDGQFFEGSGRNKKLAKARAAQSALAAIFNLHLDQTPSRQPIPSEGLQLHLPQVLADAVSRLVLGKFGDLTDNFSSPHARRKVLAGVVMTTGTDVKDAKVISVSTGTKCINGEYMSDRGLALNDCHAEIISRRSLLRFLYTQLELYLNNKDDQKRSIFQKSERGGFRLKENVQFHLYISTSPCGDARIFSPHEPILEEPADRHPNRKARGQLRTKIESGEGTIPVRSNASIQTWDGVLQGERLLTMSCSDKIARWNVVGIQGSLLSIFVEPIYFSSIILGSLYHGDHLSRAMYQRISNIEDLPPLYTLNKPLLSGISNAEARQPGKAPNFSVNWTVGDSAIEVINATTGKDELGRASRLCKHALYCRWMRVHGKVPSHLLRSKITKPNVYHESKLAAKEYQAAKVH>sp|Q96HR9|REEP6_HUMAN Receptor expression-enhancing protein 6 OS=Homosapiens OX=9606 GN=REEP6 PE=1 SV=2MDGLRQRVEHFLEQRNLVTEVLGALEAKTGVEKRYLAAGAVTLLSLYLLFGYGASLLCNLIGFVYPAYASIKAIESPSKDDDTVWLTYWVVYALFGLAEFFSDLLLSWFPFYYVGKCAFLLFCMAPRPWNGALMLYQRVVRPLFLRHHGAVDRIMNDLSGRALDAAAGITRNVLQVLARSRAGITPVAVAGPSTPLEADLKPSQTPQPKDK>sp|Q96HR9-2|REEP6_HUMAN Isoform 2 of Receptor expression-enhancingprotein 6 OS=Homo sapiens OX=9606 GN=REEP6MDGLRQRVEHFLEQRNLVTEVLGALEAKTGVEKRYLAAGAVTLLSLYLLFGYGASLLCNLIGFVYPAYASIKAIESPSKDDDTVWLTYWVVYALFGLAEFFSDLLLSWFPFYYVGKCAFLLFCMAPRPWNGALMLYQRVVRPLFLRHHGAVDRIMNDLSGRALDAAAGITRNVKPSQTPQPKDK>sp|Q9H310|RHBG_HUMAN Ammonium transporter Rh type B OS=Homo sapiensOX=9606 GN=RHBG PE=1 SV=2MAGSPSRAAGRRLQLPLLCLFLQGATAVLFAVFVRYNHKTDAALWHRSNHSNADNEFYFRYPSFQDVHAMVFVGFGFLMVFLQRYGFSSVGFTFLLAAFALQWSTLVQGFLHSFHGGHIHVGVESMINADFCAGAVLISFGAVLGKTGPTQLLLMALLEVVLFGINEFVLLHLLGVRDAGGSMTIHTFGAYFGLVLSRVLYRPQLEKSKHRQGSVYHSDLFAMIGTIFLWIFWPSFNAALTALGAGQHRTALNTYYSLAASTLGTFALSALVGEDGRLDMVHIQNAALAGGVVVGTSSEMMLTPFGALAAGFLAGTVSTLGYKFFTPILESKFKVQDTCGVHNLHGMPGVLGALLGVLVAGLATHEAYGDGLESVFPLIAEGQRSATSQAMHQLFGLFVTLMFASVGGGLGGLLLKLPFLDSPPRLPALRGPSSLAGAWRA>sp|Q9H310-2|RHBG_HUMAN Isoform 2 of Ammonium transporter Rh type BOS=Homo sapiens OX=9606 GN=RHBGMNFTFATQKSLTLLPRLECNGAISAHCNLHLPGFQDVHAMVFVGFGFLMVFLQRYGFSSVGFTFLLAAFALQWSTLVQGFLHSFHGGHIHVGVESMINADFCAGAVLISFGAVLGKTGPTQLLLMALLEVVLFGINEFVLLHLLGVRDAGGSMTIHTFGAYFGLVLSRVLYRPQLEKSKHRQGSVYHSDLFAMIGTIFLWIFWPSFNAALTALGAGQHRTALNTYYSLAASTLGTFALSALVGEDGRLDMVHIQNAALAGGVVVGTSSEMMLTPFGALAAGFLAGTVSTLGYKFFTPILESKFKVQDTCGVHNLHGMPGVLGALLGVLVAGLATHEAYGDGLESVFPLIAEGQRSATSQAMHQLFGLFVTLMFASVGGGLGGLLLKLPFLDSPPRLPALRGPSSLAGAWRA>sp|Q9H310-3|RHBG_HUMAN Isoform 3 of Ammonium transporter Rh type BOS=Homo sapiens OX=9606 GN=RHBGMVFVGFGFLMVFLQRYGFSSVGFTFLLAAFALQWSTLVQGFLHSFHGGHIHVGVESMINADFCAGAVLISFGAVLGKTGPTQLLLMALLEVVLFGINEFVLLHLLGVRVWGGMESGVGGGQGQPLSQERGGGGGVLPLTPPPQVRDAGGSMTIHTFGAYFGLVLSRVLYRPQLEKSKHRQGSVYHSDLFAMIGTIFLWIFWPSFNAALTALGAGQHRTALNTYYSLAASTLGTFALSALVGEDGRLDMVHIQNAALAGGVVVGTSSEMMLTPFGALAAGFLAGTVSTLGYKFFTPILESKFKVQDTCGVHNLHGMPGVLGALLGVLVAGLATHEAYGDGLESVFPLIAEGQRSATSQAMHQLFGLFVTLMFASVGGGLGGLLLKLPFLDSPPRLPALRGPSSLAGAWRA>sp|Q9H310-4|RHBG_HUMAN Isoform 4 of Ammonium transporter Rh type BOS=Homo sapiens OX=9606 GN=RHBGMVFVGFGFLMVFLQRYGFSSVGFTFLLAAFALQWSTLVQGFLHSFHGGHIHVGVESMINADFCAGAVLISFGAVLGKTGPTQLLLMALLEVVLFGINEFVLLHLLGVRDAGGSMTIHTFGAYFGLVLSRVLYRPQLEKSKHRQGSVYHSDLFAMIGTIFLWIFWPSFNAALTALGAGQHRTALNTYYSLAASTLGTFALSALVGEDGRLDMVHIQNAALAGGVVVGTSSEMMLTPFGALAAGFLAGTVSTLGYKFFTPILESKFKVQDTCGVHNLHGMPGVLGALLGVLVAGLATHEAYGDGLESVFPLIAEGQRSATSQAMHQLFGLFVTLMFASVGGGLGGLLLKLPFLDSPPRLPALRGPSSLAGAWRA>sp|Q9H310-5|RHBG_HUMAN Isoform 5 of Ammonium transporter Rh type BOS=Homo sapiens OX=9606 GN=RHBGMVFVGFGFLMVFLQRYGFSSVGFTFLLAAFALQWSTLVQGFLHSFHGGHIHVGVESMINADFCAGAVLISFGAVLGKTGPTQLLLMALLEVVLFGINEFVLLHLLGVRDAGGSMTIHTFGAYFGLVLSRVLYRPQLEKSKHRQGSVYHSDLFAMIGTIFLWIFWPSFNAALTALGAGQHRTALNTYYSLAASTLGTFALSALVGEDGRLDMVHIQNAALAGGVVVGTSSEMMLTPFGALAAGFLAGTVSTLGYKFFTPILESKFKVQDTCGVHNLHGMPGVLGALLGVLVAGLATHEAYGDG>sp|Q6P5S7|RNK_HUMAN Ribonuclease kappa OS=Homo sapiens OX=9606 GN=RNASEKPE=1 SV=2MGWLRPGPRPLCPPARASWAFSHRFPSPLAPRRSPTPFFMASLLCCGPKLAACGIVLSAWGVIMLIMLGIFFNVHSAVLIEDVPFTEKDFENGPQNIYNLYEQVSYNCFIAAGLYLLLGGFSFCQVRLNKRKEYMVR>sp|Q6P5S7-2|RNK_HUMAN Isoform 2 of Ribonuclease kappa OS=Homo sapiensOX=9606 GN=RNASEKMVEAGATPPLPPCEGILGFLPPLSEPACTSAIPDSLLYGVAPVLWAEAGRLRHRPQRLGSDHIMLGIFFNVHSAVLIEDVPFTEKDFENGPQNIYNLYEQVSYNCFIAAGLYLLLGGFSFCQVRLNKRKEYMVR>sp|Q5VYX0|RNLS_HUMAN Renalase OS=Homo sapiens OX=9606 GN=RNLS PE=1 SV=1MAQVLIVGAGMTGSLCAALLRRQTSGPLYLAVWDKAEDSGGRMTTACSPHNPQCTADLGAQYITCTPHYAKKHQRFYDELLAYGVLRPLSSPIEGMVMKEGDCNFVAPQGISSIIKHYLKESGAEVYFRHRVTQINLRDDKWEVSKQTGSPEQFDLIVLTMPVPEILQLQGDITTLISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVTNAAANCPGQMTLHHKPFLACGGDGFTQSNFDGCITSALCVLEALKNYI>sp|Q5VYX0-2|RNLS_HUMAN Isoform 2 of Renalase OS=Homo sapiens OX=9606GN=RNLSMAQVLIVGAGMTGSLCAALLRRQTSGPLYLAVWDKAEDSGGRMTTACSPHNPQCTADLGAQYITCTPHYAKKHQRFYDELLAYGVLRPLSSPIEGMVMKEGDCNFVAPQGISSIIKHYLKESGAEVYFRHRVTQINLRDDKWEVSKQTGSPEQFDLIVLTMPVPEILQLQGDITTLISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVPSAGVILGCAKSPWMMAIGFPI>sp|A6NIZ1|RP1BL_HUMAN Ras-related protein Rap-1b-like protein OS=Homosapiens OX=9606 PE=2 SV=1MREYKLVVLGSRGVGKSALTVQFVQGIFVEKYDPTIEDSYREQVEVDAQQCMLEILDTAGTEQFTAMRDLYMKNGQGFALVYSITAQSTFNDLQDLREQILRVKDTDDVPMILVGNKCDLEDERVVGKEQGQNLARQWNNCAFLESSAKSKINVNEIFYDLVRQINRKTPVPGKARKKSSCQLL>sp|Q9H777|RNZ1_HUMAN Zinc phosphodiesterase ELAC protein 1 OS=Homosapiens OX=9606 GN=ELAC1 PE=1 SV=2MSMDVTFLGTGAAYPSPTRGASAVVLRCEGECWLFDCGEGTQTQLMKSQLKAGRITKIFITHLHGDHFFGLPGLLCTISLQSGSMVSKQPIEIYGPVGLRDFIWRTMELSHTELVFHYVVHELVPTADQCPAEELKEFAHVNRADSPPKEEQGRTILLDSEENSYLLFDDEQFVVKAFRLFHRIPSFGFSVVEKKRPGKLNAQKLKDLGVPPGPAYGKLKNGISVVLENGVTISPQDVLKKPIVGRKICILGDCSGVVGDGGVKLCFEADLLIHEATLDDAQMDKAKEHGHSTPQMAATFAKLCRAKRLVLTHFSQRYKPVALAREGETDGIAELKKQAESVLDLQEVTLAEDFMVISIPIKK>sp|Q8IWN7|RP1L1_HUMAN Retinitis pigmentosa 1-like 1 protein OS=Homosapiens OX=9606 GN=RP1L1 PE=1 SV=5MNSTPRNAQAPSHRECFLPSVARTPSVTKVTPAKKITFLKRGDPRFAGVRLAVHQRAFKTFSALMDELSQRVPLSFGVRSVTTPRGLHSLSALEQLEDGGCYLCSDKKPPKTPSGPGRPQERNPTAQQLRDVEGQREAPGTSSSRKSLKTPRRILLIKNMDPRLQQTVVLSHRNTRNLAAFLGKASDLLRFPVKQLYTTSGKKVDSLQALLHSPSVLVCAGHEAFRTPAMKNARRSEAETLSGLTSRNKNGSWGPKTKPSVIHSRSPPGSTPRLPERPGPSNPPVGPAPGRHPQDTPAQSGPLVAGDDMKKKVRMNEDGSLSVEMKVRFHLVGEDTLLWSRRMGRASALTAASGEDPVLGEVDPLCCVWEGYPWGFSEPGVWGPRPCRVGCREVFGRGGQPGPKYEIWTNPLHASQGERVAARKRWGLAQHVRCSGLWGHGTAGRERCSQDSASPASSTGLPEGSEPESSCCPRTPEDGVDSASPSAQIGAERKAGGSLGEDPGLCIDGAGLGGPEQGGRLTPRARSEEGASSDSSASTGSHEGSSEWGGRPQGCPGKARAETSQQEASEGGDPASPALSLSSLRSDDLQAETQGQGTEQATGAAVTREPLVLGLSCSWDSEGASSTPSTCTSSQQGQRRHRSRASAMSSPSSPGLGRVAPRGHPRHSHYRKDTHSPLDSSVTKQVPRPPERRRACQDGSVPRYSGSSSSTRTQASGNLRPPSSGSLPSQDLLGTSSATVTPAVHSDFVSGVSPHNAPSAGWAGDAGSRTCSPAPIPPHTSDSCSKSGAASLGEEARDTPQPSSPLVLQVGRPEQGAVGPHRSHCCSQPGTQPAQEAQRGPSPEASWLCGRYCPTPPRGRPCPQRRSSSCGSTGSSHQSTARGPGGSPQEGTRQPGPTPSPGPNSGASRRSSASQGAGSRGLSEEKTLRSGGGPQGQEEASGVSPSSLPRSSPEAVVREWLDNIPEEPILMTYELADETTGAAGGGLRGPEVDPGDDHSLEGLGEPAQAGQQSLEGDPGQDPEPEGALLGSSDTGPQSGEGVPQGAAPEGVSEAPAEAGADREAPAGCRVSLRALPGRVSASTQIMRALMGSKQGRPSSVPEVSRPMARRLSCSAGALITCLASLQLFEEDLGSPASKVRFKDSPRYQELLSISKDLWPGCDVGEDQLDSGLWELTWSQALPDLGSHAMTENFTPTSSSGVDISSGSGGSGESSVPCAMDGTLVTQGTELPLKTSNQRPDSRTYESPGDLENQQQCCFPTFLNARACACATNEDEAERDSEEQRASSNLEQLAENTVQEEVQLEETKEGTEGEGLQEEAVQLEETKTEEGLQEEGVQLEETKETEGEGQQEEEAQLEEIEETGGEGLQEEGVQLEEVKEGPEGGLQGEALEEGLKEEGLPEEGSVHGQELSEASSPDGKGSQEDDPVQEEEAGRASASAEPCPAEGTEEPTEPPSHLSETDPSASERQSGSQLEPGLEKPPGATMMGQEHTQAQPTQGAAERSSSVACSAALDCDPIWVSVLLKKTEKAFLAHLASAVAELRARWGLQDNDLLDQMAAELQQDVAQRLQDSTKRELQKLQGRAGRMVLEPPREALTGELLLQTQQRRHRLRGLRNLSAFSERTLGLGPLSFTLEDEPALSTALGSQLGEEAEGEEFCPCEACVRKKVSPMSPKATMGATRGPIKEAFDLQQILQRKRGEHTDGEAAEVAPGKTHTDPTSTRTVQGAEGGLGPGLSQGPGVDEGEDGEGSQRLNRDKDPKLGEAEGDAMAQEREGKTHNSETSAGSELGEAEQEGEGISERGETGGQGSGHEDNLQGEAAAGGDQDPGQSDGAEGIEAPEAEGEAQPESEGVEAPEAEGDAQEAEGEAQPESEDVEAPEAEGEAQPESEDVETPEAEWEVQPESEGAEAPEAEKEAQPETESVEALETEGEDEPESEGAEAQEAEEAAQEAEGQTQPESEVIESQEAEEEAQPESEDVEALEVEVETQEAEGEAQPESEDVEAPEAEGEMQEAEEEAQPESDGVEAQPKSEGEEAQEVEGETQKTEGDAQPESDGVEAPEAEEEAQEAEGEVQEAEGEAHPESEDVDAQEAEGEAQPESEGVEAPEAEGEAQKAEGIEAPETEGEAQPESEGIEAPEAEGEAQPESEGVEAQDAEGEAQPESEGIEAQEAEEEAQPELEGVEAPEAEGEAQPESEGIEAPEAEGEAQPELEGVEAPEAEEEAQPEPEGVETPEAEGEAQPESEGETQGEKKGSPQVSLGDGQSEEASESSSPVPEDRPTPPPSPGGDTPHQRPGSQTGPSSSRASSWGNCWQKDSENDHVLGDTRSPDAKSTGTPHAERKATRMYPESSTSEQEEAPLGSRTPEQGASEGYDLQEDQALGSLAPTEAVGRADGFGQDDLDF>sp|Q8IWN7-2|RP1L1_HUMAN Isoform 2 of Retinitis pigmentosa 1-like 1protein OS=Homo sapiens OX=9606 GN=RP1L1MNSTPRNAQAPSHRECFLPSVARTPSVTKVTPAKKITFLKRGDPRFAGVRLAVHQRAFKTFSALMDELSQRVPLSFGVRSVTTPRGLHSLSALEQLEDGGCYLCSDKKPPKTPSGPGRPQERNPTAQQLRDVEGQREAPGTSSSRKSLKTPRRILLIKNMDPRLQQTVVLSHRNTRNLAAFLGKASDLLRFPVKQLYTTSGKKVLPDMKFHQRSAEWRMEVD>sp|Q8N5U6|RNF10_HUMAN RING finger protein 10 OS=Homo sapiens OX=9606GN=RNF10 PE=1 SV=2MPLSSPNAAATASDMDKNSGSNSSSASSGSSKGQQPPRSASAGPAGESKPKSDGKNSSGSKRYNRKRELSYPKNESFNNQSRRSSSQKSKTFNKMPPQRGGGSSKLFSSSFNGGRRDEVAEAQRAEFSPAQFSGPKKINLNHLLNFTFEPRGQTGHFEGSGHGSWGKRNKWGHKPFNKELFLQANCQFVVSEDQDYTAHFADPDTLVNWDFVEQVRICSHEVPSCPICLYPPTAAKITRCGHIFCWACILHYLSLSEKTWSKCPICYSSVHKKDLKSVVATESHQYVVGDTITMQLMKREKGVLVALPKSKWMNVDHPIHLGDEQHSQYSKLLLASKEQVLHRVVLEEKVALEQQLAEEKHTPESCFIEAAIQELKTREEALSGLAGSRREVTGVVAALEQLVLMAPLAKESVFQPRKGVLEYLSAFDEETTEVCSLDTPSRPLALPLVEEEEAVSEPEPEGLPEACDDLELADDNLKEGTICTESSQQEPITKSGFTRLSSSPCYYFYQAEDGQHMFLHPVNVRCLVREYGSLERSPEKISATVVEIAGYSMSEDVRQRHRYLSHLPLTCEFSICELALQPPVVSKETLEMFSDDIEKRKRQRQKKAREERRRERRIEIEENKKQGKYPEVHIPLENLQQFPAFNSYTCSSDSALGPTSTEGHGALSISPLSRSPGSHADFLLTPLSPTASQGSPSFCVGSLEEDSPFPSFAQMLRVGKAKADVWPKTAPKKDENSLVPPAPVDSDGESDNSDRVPVPSFQNSFSQAIEAAFMKLDTPATSDPLSEEKGGKKRKKQKQKLLFSTSVVHTK>sp|Q8N5U6-2|RNF10_HUMAN Isoform 2 of RING finger protein 10 OS=Homosapiens OX=9606 GN=RNF10MPLSSPNAAATASDMDKNSGSNSSSASSGSSKGQQPPRSASAGPAGESKPKSDGKNSSGSKRYNRKRELSYPKNESFNNQSRRSSSQKSKTFNKMPPQRGGGSSKLFSSSFNGGRRDEVAEAQRAEFSPAQFSGPKKINLNHLLNFTFEPRGQTGHFEGSGHGSWGKRNKWGHKPFNKELFLQANCQFVVSEDQDYTAHFADPDTLVNWDFVEQVRICSHEVPSCPICLYPPTAAKITRCGHIFCWACILHYLSLSEKTWSKCPICYSSVHKKDLKSVVATESHQYVVGDTITMQLMKREKGVLVALPKSKWMNVDHPIHLGDEQHSQYSKLLLASKEQVLHRVVLEEKVALEQQLAEEKHTPESCFIEAAIQELKTREEALSGLAGSRREVTGVVAALEQLVLMAPLAKESVFQPRKSLLQQGVLEYLSAFDEETTEVCSLDTPSRPLALPLVEEEEAVSEPEPEGLPEACDDLELADDNLKEGTICTESSQQEPITKSGFTRLSSSPCYYFYQAEDGQHMFLHPVNVRCLVREYGSLERSPEKISATVVEIAGYSMSEDVRQRHRYLSHLPLTCEFSICELALQPPVVSKETLEMFSDDIEKRKRQRQKKAREERRRERRIEIEENKKQGKYPEVHIPLENLQQFPAFNSYTCSSDSALGPTSTEGHGALSISPLSRSPGSHADFLLTPLSPTASQGSPSFCVGSLEEDSPFPSFAQMLRVGKAKADVWPKTAPKKDENSLVPPAPVDSDGESDNSDRVPVPSFQNSFSQAIEAAFMKLDTPATSDPLSEEKGGKKRKKQKQKLLFSTSVVHTK>sp|P49247|RPIA_HUMAN Ribose-5-phosphate isomerase OS=Homo sapiensOX=9606 GN=RPIA PE=1 SV=3MQRPGPFSTLYGRVLAPLPGRAGGAASGGGGNSWDLPGSHVRLPGRAQSGTRGGAGNTSTSCGDSNSICPAPSTMSKAEEAKKLAGRAAVENHVRNNQVLGIGSGSTIVHAVQRIAERVKQENLNLVCIPTSFQARQLILQYGLTLSDLDRHPEIDLAIDGADEVDADLNLIKGGGGCLTQEKIVAGYASRFIVIADFRKDSKNLGDQWHKGIPIEVIPMAYVPVSRAVSQKFGGVVELRMAVNKAGPVVTDNGNFILDWKFDRVHKWSEVNTAIKMIPGVVDTGLFINMAERVYFGMQDGSVNMREKPFC>sp|P56715|RP1_HUMAN Oxygen-regulated protein 1 OS=Homo sapiens OX=9606GN=RP1 PE=1 SV=1MSDTPSTGFSIIHPTSSEGQVPPPRHLSLTHPVVAKRISFYKSGDPQFGGVRVVVNPRSFKSFDALLDNLSRKVPLPFGVRNISTPRGRHSITRLEELEDGESYLCSHGRKVQPVDLDKARRRPRPWLSSRAISAHSPPHPVAVAAPGMPRPPRSLVVFRNGDPKTRRAVLLSRRVTQSFEAFLQHLTEVMQRPVVKLYATDGRRVPSLQAVILSSGAVVAAGREPFKPGNYDIQKYLLPARLPGISQRVYPKGNAKSESRKISTHMSSSSRSQIYSVSSEKTHNNDCYLDYSFVPEKYLALEKNDSQNLPIYPSEDDIEKSIIFNQDGTMTVEMKVRFRIKEEETIKWTTTVSKTGPSNNDEKSEMSFPGRTESRSSGLKLAACSFSADVSPMERSSNQEGSLAEEINIQMTDQVAETCSSASWENATVDTDIIQGTQDQAKHRFYRPPTPGLRRVRQKKSVIGSVTLVSETEVQEKMIGQFSYSEERESGENKSEYHMFTHSCSKMSSVSNKPVLVQINNNDQMEESSLERKKENSLLKSSAISAGVIEITSQKMLEMSHNNGLPSTISNNSIVEEDVVDCVVLDNKTGIKNFKTYGNTNDRFSPISADATHFSSNNSGTDKNISEAPASEASSTVTARIDRLINEFAQCGLTKLPKNEKKILSSVASKKKKKSRQQAINSRYQDGQLATKGILNKNERINTKGRITKEMIVQDSDSPLKGGILCEEDLQKSDTVIESNTFCSKSNLNSTISKNFHRNKLNTTQNSKVQGLLTKRKSRSLNKISLGAPKKREIGQRDKVFPHNESKYCKSTFENKSLFHVFNILEQKPKDFYAPQSQAEVASGYLRGMAKKSLVSKVTDSHITLKSQKKRKGDKVKASAILSKQHATTRANSLASLKKPDFPEAIAHHSIQNYIQSWLQNINPYPTLKPIKSAPVCRNETSVVNCSNNSFSGNDPHTNSGKISNFVMESNKHITKIAGLTGDNLCKEGDKSFIANDTGEEDLHETQVGSLNDAYLVPLHEHCTLSQSAINDHNTKSHIAAEKSGPEKKLVYQEINLARKRQSVEAAIQVDPIEEETPKDLLPVLMLHQLQASVPGIHKTQNGVVQMPGSLAGVPFHSAICNSSTNLLLAWLLVLNLKGSMNSFCQVDAHKATNKSSETLALLEILKHIAITEEADDLKAAVANLVESTTSHFGLSEKEQDMVPIDLSANCSTVNIQSVPKCSENERTQGISSLDGGCSASEACAPEVCVLEVTCSPCEMCTVNKAYSPKETCNPSDTFFPSDGYGVDQTSMNKACFLGEVCSLTDTVFSDKACAQKENHTYEGACPIDETYVPVNVCNTIDFLNSKENTYTDNLDSTEELERGDDIQKDLNILTDPEYKNGFNTLVSHQNVSNLSSCGLCLSEKEAELDKKHSSLDDFENCSLRKFQDENAYTSFDMEEPRTSEEPGSITNSMTSSERNISELESFEELENHDTDIFNTVVNGGEQATEELIQEEVEASKTLELIDISSKNIMEEKRMNGIIYEIISKRLATPPSLDFCYDSKQNSEKETNEGETKMVKMMVKTMETGSYSESSPDLKKCIKSPVTSDWSDYRPDSDSEQPYKTSSDDPNDSGELTQEKEYNIGFVKRAIEKLYGKADIIKPSFFPGSTRKSQVCPYNSVEFQCSRKASLYDSEGQSFGSSEQVSSSSSMLQEFQEERQDKCDVSAVRDNYCRGDIVEPGTKQNDDSRILTDIEEGVLIDKGKWLLKENHLLRMSSENPGMCGNADTTSVDTLLDNNSSEVPYSHFGNLAPGPTMDELSSSELEELTQPLELKCNYFNMPHGSDSEPFHEDLLDVRNETCAKERIANHHTEEKGSHQSERVCTSVTHSFISAGNKVYPVSDDAIKNQPLPGSNMIHGTLQEADSLDKLYALCGQHCPILTVIIQPMNEEDRGFAYRKESDIENFLGFYLWMKIHPYLLQTDKNVFREENNKASMRQNLIDNAIGDIFDQFYFSNTFDLMGKRRKQKRINFLGLEEEGNLKKFQPDLKERFCMNFLHTSLLVVGNVDSNTQDLSGQTNEIFKAVDENNNLLNNRFQGSRTNLNQVVRENINCHYFFEMLGQACLLDICQVETSLNISNRNILELCMFEGENLFIWEEEDILNLTDLESSREQEDL>sp|Q9BQ52|RNZ2_HUMAN Zinc phosphodiesterase ELAC protein 2 OS=Homosapiens OX=9606 GN=ELAC2 PE=1 SV=2MWALCSLLRSAAGRTMSQGRTISQAPARRERPRKDPLRHLRTREKRGPSGCSGGPNTVYLQVVAAGSRDSGAALYVFSEFNRYLFNCGEGVQRLMQEHKLKVARLDNIFLTRMHWSNVGGLSGMILTLKETGLPKCVLSGPPQLEKYLEAIKIFSGPLKGIELAVRPHSAPEYEDETMTVYQIPIHSEQRRGKHQPWQSPERPLSRLSPERSSDSESNENEPHLPHGVSQRRGVRDSSLVVAFICKLHLKRGNFLVLKAKEMGLPVGTAAIAPIIAAVKDGKSITHEGREILAEELCTPPDPGAAFVVVECPDESFIQPICENATFQRYQGKADAPVALVVHMAPASVLVDSRYQQWMERFGPDTQHLVLNENCASVHNLRSHKIQTQLNLIHPDIFPLLTSFRCKKEGPTLSVPMVQGECLLKYQLRPRREWQRDAIITCNPEEFIVEALQLPNFQQSVQEYRRSAQDGPAPAEKRSQYPEIIFLGTGSAIPMKIRNVSATLVNISPDTSLLLDCGEGTFGQLCRHYGDQVDRVLGTLAAVFVSHLHADHHTGLPSILLQRERALASLGKPLHPLLVVAPNQLKAWLQQYHNQCQEVLHHISMIPAKCLQEGAEISSPAVERLISSLLRTCDLEEFQTCLVRHCKHAFGCALVHTSGWKVVYSGDTMPCEALVRMGKDATLLIHEATLEDGLEEEAVEKTHSTTSQAISVGMRMNAEFIMLNHFSQRYAKVPLFSPNFSEKVGVAFDHMKVCFGDFPTMPKLIPPLKALFAGDIEEMEERREKRELRQVRAALLSRELAGGLEDGEPQQKRAHTEEPQAKKVRAQ>sp|Q9BQ52-2|RNZ2_HUMAN Isoform 2 of Zinc phosphodiesterase ELAC protein2 OS=Homo sapiens OX=9606 GN=ELAC2MQEHKLKVARLDNIFLTRMHWSNVGGLSGMILTLKETGLPKCVLSGPPQLEKYLEAIKIFSGPLKGIELAVRPHSAPEYEDETMTVYQIPIHSEQRRGKHQPWQSPERPLSRLSPERSSDSESNENEPHLPHGVSQRRGVRDSSLVVAFICKLHLKRGNFLVLKAKEMGLPVGTAAIAPIIAAVKDGKSITHEGREILAEELCTPPDPGAAFVVVECPDESFIQPICENATFQRYQGKADAPVALVVHMAPASVLVDSRYQQWMERFGPDTQHLVLNENCASVHNLRSHKIQTQLNLIHPDIFPLLTSFRCKKEGPTLSVPMVQGECLLKYQLRPRREWQRDAIITCNPEEFIVEALQLPNFQQSVQEYRRSAQDGPAPAEKRSQYPEIIFLGTGSAIPMKIRNVSATLVNISPDTSLLLDCGEGTFGQLCRHYGDQVDRVLGTLAAVFVSHLHADHHTVSVGLDHKAGAWRRHCHVELALWLRLFLRFQTCPELLLLISG>sp|Q9BQ52-3|RNZ2_HUMAN Isoform 3 of Zinc phosphodiesterase ELAC protein2 OS=Homo sapiens OX=9606 GN=ELAC2MRTVPQFTTFAATRFKPSSTSSTRTSSPCSPVSAKEGPTLSVPMVQGECLLKYQLRPRREWQRDAIITCNPEEFIVEALQLPNFQQSVQEYRRSAQDGPAPAEKRSQYPEIIFLGTGSAIPMKIRNVSATLVNISPDTSLLLDCGEGTFGQLCRHYGDQVDRVLGTLAAVFVSHLHADHHTGLPSILLQRERALASLGKPLHPLLVVAPNQLKAWLQQYHNQCQEVLHHISMIPAKCLQEGAEISSPAVERLISSLLRTCDLEEFQTCLVRHCKHAFGCALVHTSGWKVVYSGDTMPCEALVRMGKDATLLIHEATLEDGLEEEAVEKTHSTTSQAISVGMRMNAEFIMLNHFSQRYAKVPLFSPNFSEKVGVAFDHMKVCFGDFPTMPKLIPPLKALFAGDIEEMEERREKRELRQVRAALLSRELAGGLEDGEPQQKRAHTEEPQAKKVRAQ>sp|Q9BQ52-4|RNZ2_HUMAN Isoform 4 of Zinc phosphodiesterase ELAC protein2 OS=Homo sapiens OX=9606 GN=ELAC2MWALCSLLRSAAGRTMSQGRTISQAPARRERPRKDPLRHLRTREKRGPSGCSGGPNTVYLQVVAAGSRDSGAALYVFSEFNRYLFNCGEGVQRLMQEHKLKVARLDNIFLTRMHWSNVGGLSGMILTLKETGLPKCVLSGPPQLEKYLEAIKIFSGPLKGIELAVRPHSAPEYEDETMTVYQIPIHSVSQRRGVRDSSLVVAFICKLHLKRGNFLVLKAKEMGLPVGTAAIAPIIAAVKDGKSITHEGREILAEELCTPPDPGAAFVVVECPDESFIQPICENATFQRYQGKADAPVALVVHMAPASVLVDSRYQQWMERFGPDTQHLVLNENCASVHNLRSHKIQTQLNLIHPDIFPLLTSFRCKKEGPTLSVPMVQGECLLKYQLRPRREWQRDAIITCNPEEFIVEALQLPNFQQSVQEYRRSAQDGPAPAEKRSQYPEIIFLGTGSAIPMKIRNVSATLVNISPDTSLLLDCGEGTFGQLCRHYGDQVDRVLGTLAAVFVSHLHADHHTGLPSILLQRERALASLGKPLHPLLVVAPNQLKAWLQQYHNQCQEVLHHISMIPAKCLQEGAEISSPAVERLISSLLRTCDLEEFQTCLVRHCKHAFGCALVHTSGWKVVYSGDTMPCEALVRMGKDATLLIHEATLEDGLEEEAVEKTHSTTSQAISVGMRMNAEFIMLNHFSQRYAKVPLFSPNFSEKVGVAFDHMKVCFGDFPTMPKLIPPLKALFAGDIEEMEERREKRELRQVRAALLSRELAGGLEDGEPQQKRAHTEEPQAKKVRAQ>sp|Q9Y3C5|RNF11_HUMAN RING finger protein 11 OS=Homo sapiens OX=9606GN=RNF11 PE=1 SV=1MGNCLKSPTSDDISLLHESQSDRASFGEGTEPDQEPPPPYQEQVPVPVYHPTPSQTRLATQLTEEEQIRIAQRIGLIQHLPKGVYDPGRDGSEKKIRECVICMMDFVYGDPIRFLPCMHIYHLDCIDDWLMRSFTCPSCMEPVDAALLSSYETN>sp|Q9NVW2|RNF12_HUMAN E3 ubiquitin-protein ligase RLIM OS=Homo sapiensOX=9606 GN=RLIM PE=1 SV=3MENSDSNDKGSGDQSAAQRRSQMDRLDREEAFYQFVNNLSEEDYRLMRDNNLLGTPGESTEEELLRRLQQIKEGPPPQNSDENRGGDSSDDVSNGDSIIDWLNSVRQTGNTTRSGQRGNQSWRAVSRTNPNSGDFRFSLEINVNRNNGSQNSENENEPSARRSSGENVENNSQRQVENPRSESTSARPSRSERNSTEALTEVPPTRGQRRARSRSPDHRRTRARAERSRSPLHPMSEIPRRSHHSISSQTFEHPLVNETEGSSRTRHHVTLRQQISGPELLSRGLFAASGTRNASQGAGSSDTAASGESTGSGQRPPTIVLDLQVRRVRPGEYRQRDSIASRTRSRSQTPNNTVTYESERGGFRRTFSRSERAGVRTYVSTIRIPIRRILNTGLSETTSVAIQTMLRQIMTGFGELSYFMYSDSDSEPTGSVSNRNMERAESRSGRGGSGGGSSSGSSSSSSSSSSSSSSSSSSSSPSSSSGGESSETSSDLFEGSNEGSSSSGSSGARREGRHRAPVTFDESGSLPFLSLAQFFLLNEDDDDQPRGLTKEQIDNLAMRSFGENDALKTCSVCITEYTEGNKLRKLPCSHEYHVHCIDRWLSENSTCPICRRAVLASGNRESVV>sp|Q9NVW2-2|RNF12_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RLIMOS=Homo sapiens OX=9606 GN=RLIMMLTRNNGSQNSENENEPSARRSSGENVENNSQRQVENPRSESTSARPSRSERNSTEALTEVPPTRGQRRARSRSPDHRRTRARAERSRSPLHPMSEIPRRSHHSISSQTFEHPLVNETEGSSRTRHHVTLRQQISGPELLSRGLFAASGTRNASQGAGSSDTAASGESTGSGQRPPTIVLDLQVRRVRPGEYRQRDSIASRTRSRSQTPNNTVTYESERGGFRRTFSRSERAGVRTYVSTIRIPIRRILNTGLSETTSVAIQTMLRQIMTGFGELSYFMYSDSDSEPTGSVSNRNMERAESRSGRGGSGGGSSSGSSSSSSSSSSSSSSSSSSSSPSSSSGGESSETSSDLFEGSNEGSSSSGSSGARREGRHRAPVTFDESGSLPFLSLAQFFLLNEDDDDQPRGLTKEQIDNLAMRSFGENDALKTCSVCITEYTEGNKLRKLPCSHEYHVHCIDRWLSENSTCPICRRAVLASGNRESVV>sp|Q96CC6|RHDF1_HUMAN Inactive rhomboid protein 1 OS=Homo sapiensOX=9606 GN=RHBDF1 PE=1 SV=2MSEARRDSTSSLQRKKPPWLKLDIPSAVPLTAEEPSFLQPLRRQAFLRSVSMPAETAHISSPHHELRRPVLQRQTSITQTIRRGTADWFGVSKDSDSTQKWQRKSIRHCSQRYGKLKPQVLRELDLPSQDNVSLTSTETPPPLYVGPCQLGMQKIIDPLARGRAFRVADDTAEGLSAPHTPVTPGAASLCSFSSSRSGFHRLPRRRKRESVAKMSFRAAAALMKGRSVRDGTFRRAQRRSFTPASFLEEDTTDFPDELDTSFFAREGILHEELSTYPDEVFESPSEAALKDWEKAPEQADLTGGALDRSELERSHLMLPLERGWRKQKEGAAAPQPKVRLRQEVVSTAGPRRGQRIAVPVRKLFAREKRPYGLGMVGRLTNRTYRKRIDSFVKRQIEDMDDHRPFFTYWLTFVHSLVTILAVCIYGIAPVGFSQHETVDSVLRNRGVYENVKYVQQENFWIGPSSEALIHLGAKFSPCMRQDPQVHSFIRSAREREKHSACCVRNDRSGCVQTSEEECSSTLAVWVKWPIHPSAPELAGHKRQFGSVCHQDPRVCDEPSSEDPHEWPEDITKWPICTKNSAGNHTNHPHMDCVITGRPCCIGTKGRCEITSREYCDFMRGYFHEEATLCSQVHCMDDVCGLLPFLNPEVPDQFYRLWLSLFLHAGILHCLVSICFQMTVLRDLEKLAGWHRIAIIYLLSGVTGNLASAIFLPYRAEVGPAGSQFGILACLFVELFQSWQILARPWRAFFKLLAVVLFLFTFGLLPWIDNFAHISGFISGLFLSFAFLPYISFGKFDLYRKRCQIIIFQVVFLGLLAGLVVLFYVYPVRCEWCEFLTCIPFTDKFCEKYELDAQLH>sp|Q9UGC7|RF1ML_HUMAN Peptide chain release factor 1-like, mitochondrialOS=Homo sapiens OX=9606 GN=MTRF1L PE=1 SV=1MRSRVLWGAARWLWPRRAVGPARRPLSSGSPPLEELFTRGGPLRTFLERQAGSEAHLKVRRPELLAVIKLLNEKERELRETEHLLHDENEDLRKLAENEITLCQKEITQLKHQIILLLVPSEETDENDLILEVTAGVGGQEAMLFTSEIFDMYQQYAAFKRWHFETLEYFPSELGGLRHASASIGGSEAYRHMKFEGGVHRVQRVPKTEKQGRVHTSTMTVAILPQPTEINLVINPKDLRIDTKRASGAGGQHVNTTDSAVRIVHLPTGVVSECQQERSQLKNKELAMTKLRAKLYSMHLEEEINKRQNARKIQIGSKGRSEKIRTYNFPQNRVTDHRINKTLHDLETFMQGDYLLDELVQSLKEYADYESLVEIISQKV>sp|Q9UGC7-2|RF1ML_HUMAN Isoform 2 of Peptide chain release factor 1-like, mitochondrial OS=Homo sapiens OX=9606 GN=MTRF1LMRSRVLWGAARWLWPRRAVGPARRPLSSGSPPLEELFTRGGPLRTFLERQAGSEAHLKVRRPELLAVIKLLNEKERELRETEHLLHDENEDLRKLAENEITLCQKEITQLKHQIILLLVPSEETDENDLILEVTAGVGGQEAMLFTSEIFDMYQQYAAFKRWHFETLEYFPSELGGLRHASASIGGSEAYRHMKFEGGVHRVQRVPKTEKQGRVHTSTMTVAILPQPTEINLVINPKDLRIDTKRASGAGGQHVNTTDSAVRIVHLPTDWK>sp|Q9UGC7-3|RF1ML_HUMAN Isoform 3 of Peptide chain release factor 1-like, mitochondrial OS=Homo sapiens OX=9606 GN=MTRF1LMLFTSEIFDMYQQYAAFKRWHFETLEYFPSELGGLRHASASIGGSEAYRHMKFEGGVHRVQRVPKTEKQGRVHTSTMTVAILPQPTEINLVINPKDLRIDTKRASGAGGQHVNTTDSAVRIVHLPTGVVSECQQERSQLKNKELAMTKLRAKLYSMHLEEEINKRQNARKIQIGSKGRSEKIRTYNFPQNRVTDHRINKTLHDLETFMQGDYLLDELVQSLKEYADYESLVEIISQKV>sp|Q9UGC7-4|RF1ML_HUMAN Isoform 4 of Peptide chain release factor 1-like, mitochondrial OS=Homo sapiens OX=9606 GN=MTRF1LMRSRVLWGAARWLWPRRAVGPARRPLSSGSPPLEELFTRGGPLRTFLERQAGSEAHLKVRRPELLAVIKLLNEKERELRETEHLLHDENEDLRKLAENEITLCQKEITQLKHQIILLLVPSEETDENDLILEVTAGVGGGLRHASASIGGSEAYRHMKFEGGVHRVQRVPKTEKQGRVHTSTMTVAILPQPTEINLVINPKDLRIDTKRASGAGGQHVNTTDSAVRIVHLPTDWK>sp|Q15669|RHOH_HUMAN Rho-related GTP-binding protein RhoH OS=Homosapiens OX=9606 GN=RHOH PE=1 SV=1MLSSIKCVLVGDSAVGKTSLLVRFTSETFPEAYKPTVYENTGVDVFMDGIQISLGLWDTAGNDAFRSIRPLSYQQADVVLMCYSVANHNSFLNLKNKWIGEIRSNLPCTPVLVVATQTDQREMGPHRASCVNAMEGKKLAQDVRAKGYLECSALSNRGVQQVFECAVRTAVNQARRRNRRRLFSINECKIF>sp|Q9H4E5|RHOJ_HUMAN Rho-related GTP-binding protein RhoJ OS=Homosapiens OX=9606 GN=RHOJ PE=1 SV=1MNCKEGTDSSCGCRGNDEKKMLKCVVVGDGAVGKTCLLMSYANDAFPEEYVPTVFDHYAVTVTVGGKQHLLGLYDTAGQEDYNQLRPLSYPNTDVFLICFSVVNPASYHNVQEEWVPELKDCMPHVPYVLIGTQIDLRDDPKTLARLLYMKEKPLTYEHGVKLAKAIGAQCYLECSALTQKGLKAVFDEAILTIFHPKKKKKRCSEGHSCCSII>sp|Q9H4E5-2|RHOJ_HUMAN Isoform 2 of Rho-related GTP-binding protein RhoJOS=Homo sapiens OX=9606 GN=RHOJMNCKEGTDSSCGCRGNDEKKMLKCVVVGDGAVGKTCLLMSYANDAFPEEYVPTVFDHYAVTVTVGGKQHLLGLYDTAGQEDYNQLRPLSYPNTDVFLICFSVVNPASYHNVQIDLRDDPKTLARLLYMKEKPLTYEHGVKLAKAIGAQCYLECSALTQKGLKAVFDEAILTIFHPKKKKKRCSEGHSCCSII>sp|P46063|RECQ1_HUMAN ATP-dependent DNA helicase Q1 OS=Homo sapiensOX=9606 GN=RECQL PE=1 SV=3MASVSALTEELDSITSELHAVEIQIQELTERQQELIQKKKVLTKKIKQCLEDSDAGASNEYDSSPAAWNKEDFPWSGKVKDILQNVFKLEKFRPLQLETINVTMAGKEVFLVMPTGGGKSLCYQLPALCSDGFTLVICPLISLMEDQLMVLKQLGISATMLNASSSKEHVKWVHAEMVNKNSELKLIYVTPEKIAKSKMFMSRLEKAYEARRFTRIAVDEVHCCSQWGHDFRPDYKALGILKRQFPNASLIGLTATATNHVLTDAQKILCIEKCFTFTASFNRPNLYYEVRQKPSNTEDFIEDIVKLINGRYKGQSGIIYCFSQKDSEQVTVSLQNLGIHAGAYHANLEPEDKTTVHRKWSANEIQVVVATVAFGMGIDKPDVRFVIHHSMSKSMENYYQESGRAGRDDMKADCILYYGFGDIFRISSMVVMENVGQQKLYEMVSYCQNISKCRRVLMAQHFDEVWNSEACNKMCDNCCKDSAFERKNITEYCRDLIKILKQAEELNEKLTPLKLIDSWMGKGAAKLRVAGVVAPTLPREDLEKIIAHFLIQQYLKEDYSFTAYATISYLKIGPKANLLNNEAHAITMQVTKSTQNSFRAESSQTCHSEQGDKKMEEKNSGNFQKKAANMLQQSGSKNTGAKKRKIDDA>sp|Q13278|RIG_HUMAN Putative protein RIG OS=Homo sapiens OX=9606 GN=RIGPE=5 SV=1MPFFSSCLCPSHYSGPSLPSSTSSSLPTGPENQLGFVLLQAMVHHANSSCVRNAFWLQITEKLTPALSIIISVVYLRCPEMVENRIGFLLNVKDSKTLSVVGPHPKPCIL>sp|Q9BRR9|RHG09_HUMAN Rho GTPase-activating protein 9 OS=Homo sapiensOX=9606 GN=ARHGAP9 PE=1 SV=2MLSSRWWPSSWGILGLGPRSPPRGSQLCALYAFTYTGADGQQVSLAEGDRFLLLRKTNSDWWLARRLEAPSTSRPIFVPAAYMIEESIPSQSPTTVIPGQLLWTPGPKLFHGSLEELSQALPSRAQASSEQPPPLPRKMCRSVSTDNLSPSLLKPFQEGPSGRSLSQEDLPSEASASTAGPQPLMSEPPVYCNLVDLRRCPRSPPPGPACPLLQRLDAWEQHLDPNSGRCFYINSLTGCKSWKPPRRSRSETNPGSMEGTQTLKRNNDVLQPQAKGFRSDTGTPEPLDPQGSLSLSQRTSQLDPPALQAPRPLPQLLDDPHEVEKSGLLNMTKIAQGGRKLRKNWGPSWVVLTGNSLVFYREPPPTAPSSGWGPAGSRPESSVDLRGAALAHGRHLSSRRNVLHIRTIPGHEFLLQSDHETELRAWHRALRTVIERLVRWVEARREAPTGRDQGSGDRENPLELRLSGSGPAELSAGEDEEEESELVSKPLLRLSSRRSSIRGPEGTEQNRVRNKLKRLIAKRPPLQSLQERGLLRDQVFGCQLESLCQREGDTVPSFLRLCIAAVDKRGLDVDGIYRVSGNLAVVQKLRFLVDRERAVTSDGRYVFPEQPGQEGRLDLDSTEWDDIHVVTGALKLFLRELPQPLVPPLLLPHFRAALALSESEQCLSQIQELIGSMPKPNHDTLRYLLEHLCRVIAHSDKNRMTPHNLGIVFGPTLFRPEQETSDPAAHALYPGQLVQLMLTNFTSLFP>sp|Q9BRR9-2|RHG09_HUMAN Isoform 2 of Rho GTPase-activating protein 9OS=Homo sapiens OX=9606 GN=ARHGAP9MLSSRWWPSSWGILGLGPRSPPRGSQLCALYAFTYTGADGQQVSLAEGDRFLLLRKTNSDWWLARRLEAPSTSRPIFVPAAYMIEESIPSQSPTTVIPGQLLWTPGPKLFHGSLEELSQALPSRAQASSEQPPPLPRKMCRSVSTDNLSPSLLKPFQEGPSGRSLSQEDLPSEASASTAGPQPLMSEPPVYCNLVDLRRCPRSPPPGPACPLLQRLDAWEQHLDPNSGRCFYINSLTGCKSWKPPRRSRSETNPGSMEGTQTLKRNNDVLQPQAKGFRSDTGTPEPLDPQGSLSLSQRTSQLDPPALQAPRPLPQLLDDPHEVEKSGLLNMTKIAQGGRKLRKNWGPSWVVLTGNSLVFYREPPPTAPSSGWGPAGSRPESSVDLRGAALAHGRHLSSRRNVLHIRTIPGHEFLLQSDHETELRAWHRALRTVIERLDRENPLELRLSGSGPAELSAGEDEEEESELVSKPLLRLSSRRSSIRGPEGTEQNRVRNKLKRLIAKRPPLQSLQERGLLRDQVFGCQLESLCQREGDTVPSFLRLCIAAVDKRGLDVDGIYRVSGNLAVVQKLRFLVDRERAVTSDGRYVFPEQPGQEGRLDLDSTEWDDIHVVTGALKLFLRELPQPLVPPLLLPHFRAALALSESEQCLSQIQELIGSMPKPNHDTLRYLLEHLCRVIAHSDKNRMTPHNLGIVFGPTLFRPEQETSDPAAHALYPGQLVQLMLTNFTSLFP>sp|Q9BRR9-3|RHG09_HUMAN Isoform 3 of Rho GTPase-activating protein 9OS=Homo sapiens OX=9606 GN=ARHGAP9MSEPPVYCNLVDLRRCPRSPPPGPACPLLQRLDAWEQHLDPNSGRCFYINSLTGCKSWKPPRRSRSETNPGSMEGTQTLKRNNDVLQPQAKGFRSDTGTPEPLDPQGSLSLSQRTSQLDPPALQAPRPLPQLLDDPHEVEKSGLLNMTKIAQGGRKLRKNWGPSWVVLTGNSLVFYREPPPTAPSSGWGPAGSRPESSVDLRGAALAHGRHLSSRRNVLHIRTIPGHEFLLQSDHETELRAWHRALRTVIERLVRWVEARREAPTGRDQGSGDRENPLELRLSGSGPAELSAGEDEEEESELVSKPLLRLSSRRSSIRGPEGTEQNRVRNKLKRLIAKRPPLQSLQERGLLRDQVFGCQLESLCQREGDTVPSFLRLCIAAVDKRGLDVDGIYRVSGNLAVVQKLRFLVDRERAVTSDGRYVFPEQPGQEGRLDLDSTEWDDIHVVTGALKLFLRELPQPLVPPLLLPHFRAALALSESEQCLSQIQELIGSMPKPNHDTLRYLLEHLCRVIAHSDKNRMTPHNLGIVFGPTLFRPEQETSDPAAHALYPGQLVQLMLTNFTSLFP>sp|Q9BRR9-4|RHG09_HUMAN Isoform 4 of Rho GTPase-activating protein 9OS=Homo sapiens OX=9606 GN=ARHGAP9MSEPPVYCNLVDLRRCPRSPPPGPACPLLQRLDAWEQHLDPNSGRCFYINSLTGCKSWKPPRRSRSETNPGSMEGTQTLKRNNDVLQPQAKGFRSDTGTPEPLDPQGSLSLSQRTSQLDPPALQAPRPLPQLLDDPHEVEKSGLLNMTKIAQGGRKLRKNWGPSWVVLTGNSLVFYREPPPTAPSSGWGPAGSRPESSVDLRGAALAHGRHLSSRRNVLHIRTIPGHEFLLQSDHETELRAWHRALRTVIERLDRENPLELRLSGSGPAELSAGEDEEEESELVSKPLLRLSSRRSSIRGPEGTEQNRVRNKLKRLIAKRPPLQSLQERGLLRDQVFGCQLESLCQREGDTVPSFLRLCIAAVDKRGLDVDGIYRVSGNLAVVQKLRFLVDRERAVTSDGRYVFPEQPGQEGRLDLDSTEWDDIHVVTGALKLFLRELPQPLVPPLLLPHFRAALALSESEQCLSQIQELIGSMPKPNHDTLRYLLEHLCRVIAHSDKNRMTPHNLGIVFGPTLFRPEQETSDPAAHALYPGQLVQLMLTNFTSLFP>sp|Q9BRR9-5|RHG09_HUMAN Isoform 5 of Rho GTPase-activating protein 9OS=Homo sapiens OX=9606 GN=ARHGAP9MLSSRWWPSSWGILGLGPRSPPRGSQLCALYAFTYTGADGQQVSLAEGDRFLLLRKTNSDWWLARRLEAPSTSRPIFVPAAYMIEESIPSQSPTTVIPGQLLWTPGPKLFHGSLEELSQALPSRAQASSEQPPPLPRKMCRSVSTDNLSPSLLKPFQEGPSGRSLSQEDLPSEASASTAGPQPLMSEPPVYCNLVDLRRCPRSPPPGPACPLLQRLDAWEQHLDPNSGRCFYINSLTGCKSWKPPRRSRSETNPGSMEGTQTLKRNNDVLQPQAKGFRSDTGTPEPLDPQGSLSLSQRTSQLDPPALQAPRPLPQLLDDPHEVEKSGLLNMTKIAQGGRKLRKNWGPSWVVLTGNSLVFYREPPPTAPSSGWGPAGSRPESSVDLRGAALAHGRHLSSRRNVLHIRTIPGHEFLLQSDHETELRAWHRALRTVIERLDRENPLELRLSGSGPAELSAGEDEEEESELVSKPLLRLSSRRSSIRGPEGTEQNRVRNKLKRLIAKRPPLQSLQERGLLRDQVFGCQLESLCQREGDTVPSFLRLCIAAVDKRGLDVDGIYRVSGNLAVVQKLRFLVDRERAVTSDGRYVFPEQPGQEGRLDLDSTEWDDIHVVTGALKLFLRELPQPLVPPLLLPHFRAALG>sp|Q14CB8|RHG19_HUMAN Rho GTPase-activating protein 19 OS=Homo sapiensOX=9606 GN=ARHGAP19 PE=1 SV=1MATEAQSEGEVPARESGRSDAICSFVICNDSSLRGQPIIFNPDFFVEKLRHEKPEIFTELVVSNITRLIDLPGTELAQLMGEVDLKLPGGAGPASGFFRSLMSLKRKEKGVIFGSPLTEEGIAQIYQLIEYLHKNLRVEGLFRVPGNSVRQQILRDALNNGTDIDLESGEFHSNDVATLLKMFLGELPEPLLTHKHFNAHLKIADLMQFDDKGNKTNIPDKDRQIEALQLLFLILPPPNRNLLKLLLDLLYQTAKKQDKNKMSAYNLALMFAPHVLWPKNVTANDLQENITKLNSGMAFMIKHSQKLFKAPAYIRECARLHYLGSRTQASKDDLDLIASCHTKSFQLAKSQKRNRVDSCPHQEETQHHTEEALRELFQHVHDMPESAKKKQLIRQFNKQSLTQTPGREPSTSQVQKRARSRSFSGLIKRKVLGNQMMSEKKKKNPTPESVAIGELKGTSKENRNLLFSGSPAVTMTPTRLKWSEGKKEGKKGFL>sp|Q14CB8-2|RHG19_HUMAN Isoform 2 of Rho GTPase-activating protein 19OS=Homo sapiens OX=9606 GN=ARHGAP19MATEAQSEGEVPARESGRSDAICSFVICNDSSLRGQPIIFNPDFFVEKLRHEKPEIFTELVVSNITRLIDLPGTELAQLMGEVDLKLPGGAGPASGFFRSLMSLKRKEKGVIFGSPLTEEGIAQIYQLIEYLHKNLRVEGLFRVPGNSVRQQILRDALNNGTDIDLESGEFHSNDVATLLKMFLGELPEPLLTHKHFNAHLKIADLMQFDDKGNKTNIPDKDRQIEALQLLFLILPPPNRNLLKLLLDLLYQTAKKQDKNKMSAYNLALMFAPHVLWPKNVTANDLQENITKLNSGMAFMIKHSQKLFKAPAYIRECARLHYLGSRTQASKDDLDLIASCHTKSFQLAKSQKRNRVDSCPHQEETQHHTEEALRELFQHVHDMPESAKKKQLIRQFNKQSLTQTPGREPSTSQVQKRARSRSFSGLIKRKVLGNQMMSEKKKKNPTPESVAIGELKGTSKENRNLLFSGSPAVTMTPTRLKWSEGKKEGKKGNSMATTSLGSIRMTLRGSSSCGCCS>sp|Q14CB8-3|RHG19_HUMAN Isoform 3 of Rho GTPase-activating protein 19OS=Homo sapiens OX=9606 GN=ARHGAP19MPHQKLSALIDAICSFVICNDSSLRGQPIIFNPDFFVEKLRHEKPEIFTELVVSNITRLIDLPGTELAQLMGEVDLKLPGGAGPASGFFRSLMSLKRKEKGVIFGSPLTEEGIAQIYQLIEYLHKNLRVEGLFRVPGNSVRQQILRDALNNGTDIDLESGEFHSNDVATLLKMFLGELPEPLLTHKHFNAHLKIADLMQFDDKGNKTNIPDKDRQIEALQLLFLILPPPNRNLLKLLLDLLYQTAKKQDKNKMSAYNLALMFAPHVLWPKNVTANDLQENITKLNSGMAFMIKHSQKLFKAPAYIRECARLHYLGSRTQASKDDLDLIASCHTKSFQLAKSQKRNRVDSCPHQEETQHHTEEALRELFQHVHDMPESAKKKQLIRQFNKQSLTQTPGREPSTSQVQKRARSRSFSGLIKRKVLGNQMMSEKKKKNPTPESVAIGELKGTSKENRNLLFSGSPAVTMTPTRLKWSEGKKEGKKGFL>sp|Q14CB8-4|RHG19_HUMAN Isoform 4 of Rho GTPase-activating protein 19OS=Homo sapiens OX=9606 GN=ARHGAP19MPESAKKKQLIRQFNKQSLTQTPGREPSTSQVQKRARSRSFSGLIKRKVLGNQMMSEKKKKNPTPESVAIGELKGTSKENRNLLFSGSPAVTMTPTRLKWSEGKKEGKKGFL>sp|Q14CB8-5|RHG19_HUMAN Isoform 5 of Rho GTPase-activating protein 19OS=Homo sapiens OX=9606 GN=ARHGAP19MATEAQSEGEVPARESGRSDAICSFVICNDSSLRGQPIIFNPDFFVEKLRHEKPEIFTELVVSNITRLIDLPGTELAQLMGEVDLKLPGGAGPASGFFRSLMSLKRKEKGVIFGSPLTEEGIAQIYQLIEYLHKNLRVEGLFRVPGNSVRQQILRDALNNGTDIDLESGEFHSNDVATLLKMFLGELPEPLLTHKHFNAHLKIADLMQFDDKGNKTNIPDKDRQIEALQLLFLILPPPNRNLLKLLLDLLYQTAKKQDKNKMSAYNLALMFAPHVLWPKNGLVLLPTLEESNTITTHCSLI>sp|Q14CB8-6|RHG19_HUMAN Isoform 6 of Rho GTPase-activating protein 19OS=Homo sapiens OX=9606 GN=ARHGAP19MATEAQSEGEVPARESGRSDAICSFVICNDSSLRGQPIIFNPDFFVEKLRHEKPEIFTELVVSNITRLIDLPGTELAQLMGEVDLKLPGGAGPASGFFRSLMSLKRKEKGVIFGSPLTEEGIAQIYQLIEYLHKNLRVEGLFRVPGNSVRQQILRDALNNGTDIDLESGEFHSNDVATLLKMFLGELPEPLLTHKHFNAHLKIADLMQFDDKGNKTNIPDKDRQIEALQLLFLILPPPNRNLLKLLLDLLYQTAKKQDKNKMSAYNLALMFAPHVLWPKNAPAYIRECARLHYLGSRTQASKDDLDLIASCHTKSFQLAKSQKRNRVDSCPHQEETQHHTEEALRELFQHVHDMPESAKKKQLIRQFNKQSLTQTPGREPSTSQVQKRARSRSFSGLIKRKVLGNQMMSEKKKKNPTPESVAIGELKGTSKENRNLLFSGSPAVTMTPTRLKWSEGKKEGKKGFL>sp|Q14CB8-7|RHG19_HUMAN Isoform 7 of Rho GTPase-activating protein 19OS=Homo sapiens OX=9606 GN=ARHGAP19MATEAQSEGEVPARESGRSDAICSFVICNDSSLRGQPIIFNPDFFVEKLRHEKPEIFTELVVSNITRLIDLPGTELAQLMGEVDLKLPGGAGPASGFFRSLMSLKRKEKGVIFGSPLTEEGIAQIYQLIEYLHKNLRVEGLFRVPGNSVRQQILRDALNNGTDIDLESGEFHSNDVATLLKMFLGELPEPLLTHKHFNAHLKIADLMQFDDKGNKTNIPDKDRQIEALQLLFLILPPPNRNLLKLLLDLLYQTAKKQDKNKMSAYNLALMFAPHVLWPKNVTANDLQENITKLNSGMAFMIKHSQKLFKAPAYIRECARLHYLGSRTQASKLAKSQKRNRVDSCPHQEETQHHTEEALRELFQHVHDMPESAKKKQLIRQFNKQSLTQTPGREPSTSQVQKRARSRSFSGLIKRKVLGNQMMSEKKKKNPTPESVAIGELKGTSKENRNLLFSGSPAVTMTPTRLKWSEGKKEGKKGFL>sp|P07949|RET_HUMAN Proto-oncogene tyrosine-protein kinase receptor RetOS=Homo sapiens OX=9606 GN=RET PE=1 SV=3MAKATSGAAGLRLLLLLLLPLLGKVALGLYFSRDAYWEKLYVDQAAGTPLLYVHALRDAPEEVPSFRLGQHLYGTYRTRLHENNWICIQEDTGLLYLNRSLDHSSWEKLSVRNRGFPLLTVYLKVFLSPTSLREGECQWPGCARVYFSFFNTSFPACSSLKPRELCFPETRPSFRIRENRPPGTFHQFRLLPVQFLCPNISVAYRLLEGEGLPFRCAPDSLEVSTRWALDREQREKYELVAVCTVHAGAREEVVMVPFPVTVYDEDDSAPTFPAGVDTASAVVEFKRKEDTVVATLRVFDADVVPASGELVRRYTSTLLPGDTWAQQTFRVEHWPNETSVQANGSFVRATVHDYRLVLNRNLSISENRTMQLAVLVNDSDFQGPGAGVLLLHFNVSVLPVSLHLPSTYSLSVSRRARRFAQIGKVCVENCQAFSGINVQYKLHSSGANCSTLGVVTSAEDTSGILFVNDTKALRRPKCAELHYMVVATDQQTSRQAQAQLLVTVEGSYVAEEAGCPLSCAVSKRRLECEECGGLGSPTGRCEWRQGDGKGITRNFSTCSPSTKTCPDGHCDVVETQDINICPQDCLRGSIVGGHEPGEPRGIKAGYGTCNCFPEEEKCFCEPEDIQDPLCDELCRTVIAAAVLFSFIVSVLLSAFCIHCYHKFAHKPPISSAEMTFRRPAQAFPVSYSSSGARRPSLDSMENQVSVDAFKILEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPGESPVPLTRADGTNTGFPRYPNDSVYANWMLSPSAAKLMDTFDS>sp|P07949-2|RET_HUMAN Isoform 2 of Proto-oncogene tyrosine-proteinkinase receptor Ret OS=Homo sapiens OX=9606 GN=RETMAKATSGAAGLRLLLLLLLPLLGKVALGLYFSRDAYWEKLYVDQAAGTPLLYVHALRDAPEEVPSFRLGQHLYGTYRTRLHENNWICIQEDTGLLYLNRSLDHSSWEKLSVRNRGFPLLTVYLKVFLSPTSLREGECQWPGCARVYFSFFNTSFPACSSLKPRELCFPETRPSFRIRENRPPGTFHQFRLLPVQFLCPNISVAYRLLEGEGLPFRCAPDSLEVSTRWALDREQREKYELVAVCTVHAGAREEVVMVPFPVTVYDEDDSAPTFPAGVDTASAVVEFKRKEDTVVATLRVFDADVVPASGELVRRYTSTLLPGDTWAQQTFRVEHWPNETSVQANGSFVRATVHDYRLVLNRNLSISENRTMQLAVLVNDSDFQGPGAGVLLLHFNVSVLPVSLHLPSTYSLSVSRRARRFAQIGKVCVENCQAFSGINVQYKLHSSGANCSTLGVVTSAEDTSGILFVNDTKALRRPKCAELHYMVVATDQQTSRQAQAQLLVTVEGSYVAEEAGCPLSCAVSKRRLECEECGGLGSPTGRCEWRQGDGKGITRNFSTCSPSTKTCPDGHCDVVETQDINICPQDCLRGSIVGGHEPGEPRGIKAGYGTCNCFPEEEKCFCEPEDIQDPLCDELCRTVIAAAVLFSFIVSVLLSAFCIHCYHKFAHKPPISSAEMTFRRPAQAFPVSYSSSGARRPSLDSMENQVSVDAFKILEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGRISHAFTRF>sp|Q8TCX5|RHPN1_HUMAN Rhophilin-1 OS=Homo sapiens OX=9606 GN=RHPN1 PE=1SV=2MILEERPDGAGAGEESPRLQGCDSLTQIQCGQLQSRRAQIHQQIDKELQMRTGAENLYRATSNNRVRETVALELSYVNSNLQLLKEELEELSGGVDPGRHGSEAVTVPMIPLGLKETKELDWSTPLKELISVHFGEDGASYEAEIRELEALRQAMRTPSRNESGLELLTAYYNQLCFLDARFLTPARSLGLFFHWYDSLTGVPAQQRALAFEKGSVLFNIGALHTQIGARQDRSCTEGARRAMEAFQRAAGAFSLLRENFSHAPSPDMSAASLCALEQLMMAQAQECVFEGLSPPASMAPQDCLAQLRLAQEAAQVAAEYRLVHRTMAQPPVHDYVPVSWTALVHVKAEYFRSLAHYHVAMALCDGSPATEGELPTHEQVFLQPPTSSKPRGPVLPQELEERRQLGKAHLKRAILGQEEALRLHALCRVLREVDLLRAVISQTLQRSLAKYAELDREDDFCEAAEAPDIQPKTHQKPEARMPRLSQGKGPDIFHRLGPLSVFSAKNRWRLVGPVHLTRGEGGFGLTLRGDSPVLIAAVIPGSQAAAAGLKEGDYIVSVNGQPCRWWRHAEVVTELKAAGEAGASLQVVSLLPSSRLPSLGDRRPVLLGPRGLLRSQREHGCKTPASTWASPRPLLNWSRKAQQGKTGGCPQPCAPVKPAPPSSLKHPGWP>sp|Q9C0H5|RHG39_HUMAN Rho GTPase-activating protein 39 OS=Homo sapiensOX=9606 GN=ARHGAP39 PE=1 SV=2MSQTQDYECRSHNVDLPESRIPGSNTRLEWVEIIEPRTRERMYANLVTGECVWDPPAGVRIKRTSENQWWELFDPNTSRFYYYNASTQRTVWHRPQGCDIIPLAKLQTLKQNTESPRASAESSPGRGSSVSREGSTSSSLEPEPDTEKAQELPARAGRPAAFGTVKEDSGSSSPPGVFLEKDYEIYRDYSADGQLLHYRTSSLRWNSGAKERMLIKVADREPSFLAAQGNGYAPDGPPGVRSRRPSGSQHSPSLQTFAPEADGTIFFPERRPSPFLKRAELPGSSSPLLAQPRKPSGDSQPSSPRYGYEPPLYEEPPVEYQAPIYDEPPMDVQFEAGGGYQAGSPQRSPGRKPRPFLQPNKQGPPSPCQQLVLTKQKCPERFLSLEYSPAGKEYVRQLVYVEQAGSSPKLRAGPRHKYAPNPGGGSYSLQPSPCLLRDQRLGVKSGDYSTMEGPELRHSQPPTPLPQAQEDAMSWSSQQDTLSSTGYSPGTRKRKSRKPSLCQATSATPTEGPGDLLVEQPLAEEQPPCGTSLAPVKRAEGEAEGARGAAEPFLAQARLAWEAQQAHFHMKQRSSWDSQQDGSGYESDGALPLPMPGPVVRAFSEDEALAQQENRHWRRGTFEKLGFPQILLEKSVSVQTNLASPEPYLHPSQSEDLAACAQFESSRQSRSGVPSSSCVFPTFTLRKPSSETDIENWASKHFNKHTQGLFRRKVSIANMLAWSSESIKKPMIVTSDRHVKKEACELFKLIQMYMGDRRAKADPLHVALEVATKGWSVQGLRDELYIQLCRQTTENFRLESLARGWELMAICLAFFPPTPKFHSYLEGYIYRHMDPVNDTKGVAISTYAKYCYHKLQKAALTGAKKGLKKPNVEEIRHAKNAVFSPSMFGSALQEVMGMQRERYPERQLPWVQTRLSEEVLALNGDQTEGIFRVPGDIDEVNALKLQVDQWKVPTGLEDPHVPASLLKLWYRELEEPLIPHEFYEQCIAHYDSPEAAVAVVHALPRINRMVLCYLIRFLQVFVQPANVAVTKMDVSNLAMVMAPNCLRCQSDDPRVIFENTRKEMSFLRVLIQHLDTSFMEGVL>sp|Q9C0H5-2|RHG39_HUMAN Isoform 2 of Rho GTPase-activating protein 39OS=Homo sapiens OX=9606 GN=ARHGAP39MSQTQDYECRSHNVDLPESRIPGSNTRLEWVEIIEPRTRERMYANLVTGECVWDPPAGVRIKRTSENQWWELFDPNTSRFYYYNASTQRTVWHRPQGCDIIPLAKLQTLKQNTESPRASAESSPGRGSSVSREGSTSSSLEPEPDTEKAQELPARAGRPAAFGTVKEDSGSSSPPGVFLEKDYEIYRDYSADGQLLHYRTSSLRWNSGAKERMLIKVADREPSFLAAQGNGYAPDGPPGVRSRRPSGSQHSPSLQTFAPEADGTIFFPERRPSPFLKRAELPGSSSPLLAQPRKPSGDSQPSSPRYGYEPPLYEEPPVEYQAPIYDEPPMDVQFEAGGGYQAGSPQRSPGRKPRPFLQPNKQGPPSPCQQLVLTKQKCPERFLSLEYSPAGKEYVRQLVYVEQAGSSPKLRAGPRHKYAPNPGGGSYSLQPSPCLLRDQRLGVKSGDYSTMEGPELRHSQPPTPLPQAQEDAMSWSSQQDTLSSTGYSPGTRKRKSRKPSLCQATSATPTEGPGDLLVEQPLAEEQPPCGTSLAPVKRAEGEAEGARGAAEPFLAQARLAWEAQQAHFHMKQRSSWDSQQDGSGYESDGALPLPMPGPVVRAFSEDEALAQQENRHWRRGTFEKLGFPQILLEKSVSVQTNLASPEPYLHPSQSEDLAACAQFESSRQSRSGVPSSSCVFPTFTLRKPSSETDIENWASKHFNKHTQGLFRRKVSIANMLAWSSESIKKPMIVTSDRHVKKEACELFKLIQMYMGDRRAKADPLHVALEVATKGWSVQGLRDELYIQLCRQTTENFRLESLARGWELMAICLAFFPPTPKFHSYLEGYIYRHMDPVNDTKVTQHIKELLERNTKKKSKLRKKPKPYVEEPDGVAISTYAKYCYHKLQKAALTGAKKGLKKPNVEEIRHAKNAVFSPSMFGSALQEVMGMQRERYPERQLPWVQTRLSEEVLALNGDQTEGIFRVPGDIDEVNALKLQVDQWKVPTGLEDPHVPASLLKLWYRELEEPLIPHEFYEQCIAHYDSPEAAVAVVHALPRINRMVLCYLIRFLQVFVQPANVAVTKMDVSNLAMVMAPNCLRCQSDDPRVIFENTRKEMSFLRVLIQHLDTSFMEGVL>sp|Q2M5E4|RGS21_HUMAN Regulator of G-protein signaling 21 OS=Homosapiens OX=9606 GN=RGS21 PE=2 SV=1MPVKCCFYRSPTAETMTWSENMDTLLANQAGLDAFRIFLKSEFSEENVEFWLACEDFKKTKNADKIASKAKMIYSEFIEADAPKEINIDFGTRDLISKNIAEPTLKCFDEAQKLIYCLMAKDSFPRFLKSEIYKKLVNSQQVPNHKKWLPFL>sp|Q7Z6I6|RHG30_HUMAN Rho GTPase-activating protein 30 OS=Homo sapiensOX=9606 GN=ARHGAP30 PE=1 SV=3MKSRQKGKKKGSAKERVFGCDLQEHLQHSGQEVPQVLKSCAEFVEEYGVVDGIYRLSGVSSNIQKLRQEFESERKPDLRRDVYLQDIHCVSSLCKAYFRELPDPLLTYRLYDKFAEAVGVQLEPERLVKILEVLRELPVPNYRTLEFLMRHLVHMASFSAQTNMHARNLAIVWAPNLLRSKDIEASGFNGTAAFMEVRVQSIVVEFILTHVDQLFGGAALSGGEVESGWRSLPGTRASGSPEDLMPRPLPYHLPSILQAGDGPPQMRPYHTIIEIAEHKRKGSLKVRKWRSIFNLGRSGHETKRKLPRGAEDREDKSNKGTLRPAKSMDSLSAAAGASDEPEGLVGPSSPRPSPLLPESLENDSIEAAEGEQEPEAEALGGTNSEPGTPRAGRSAIRAGGSSRAERCAGVHISDPYNVNLPLHITSILSVPPNIISNVSLARLTRGLECPALQHRPSPASGPGPGPGLGPGPPDEKLEASPASSPLADSGPDDLAPALEDSLSQEVQDSFSFLEDSSSSEPEWVGAEDGEVAQAEAAGAAFSPGEDDPGMGYLEELLGVGPQVEEFSVEPPLDDLSLDEAQFVLAPSCCSLDSAGPRPEVEEENGEEVFLSAYDDLSPLLGPKPPIWKGSGSLEGEAAGCGRQALGQGGEEQACWEVGEDKQAEPGGRLDIREEAEGSPETKVEAGKASEDRGEAGGSQETKVRLREGSREETEAKEEKSKGQKKADSMEAKGVEEPGGDEYTDEKEKEIEREEDEQREEAQVEAGRDLEQGAQEDQVAEEKWEVVQKQEAEGVREDEDKGQREKGYHEARKDQGDGEDSRSPEAATEGGAGEVSKERESGDGEAEGDQRAGGYYLEEDTLSEGSGVASLEVDCAKEGNPHSSEMEEVAPQPPQPEEMEPEGQPSPDGCLCPCSLGLGGVGMRLASTLVQVQQVRSVPVVPPKPQFAKMPSAMCSKIHVAPANPCPRPGRLDGTPGERAWGSRASRSSWRNGGSLSFDAAVALARDRQRTEAQGVRRTQTCTEGGDYCLIPRTSPCSMISAHSPRPLSCLELPSEGAEGSGSRSRLSLPPREPQVPDPLLSSQRRSYAFETQANPGKGEGL>sp|Q7Z6I6-2|RHG30_HUMAN Isoform 2 of Rho GTPase-activating protein 30OS=Homo sapiens OX=9606 GN=ARHGAP30MKSRQKGKKKGSAKERVFGCDLQEHLQHSGQEVPQVLKSCAEFVEEYGVVDGIYRLSGVSSNIQKLRQEFESERKPDLRRDVYLQDIHCVSSLCKAYFRELPDPLLTYRLYDKFAEAVGVQLEPERLVKILEVLRELPVPNYRTLEFLMRHLVHMASFSAQTNMHARNLAIVWAPNLLRSKDIEASGFNGTAAFMEVRVQSIVVEFILTHVDQLFGGAALSGGEVESGWRSLPGTRASGSPEDLMPRPLPYHLPSILQAGDGPPQMRPYHTIIEIAEHKRKGSLKVRKWRSIFNLGRSGHETKRKLPRGAEDREDKSNKGTLRPAKSMDSLSAAAGASDEPEGLVGPSSPRPSPLLPESLENDSIEAAEGEQEPEAEALGGTNSEPGTPRAGRSAIRAGGSSRAERCAGVHISDPYNVNLPLHITSILSVPPNIISNVSLARLTRGLECPALQHRPSPASGPGPGPGLGPGPPDEKLEASPASSPLADSGPDDLAPALEDSLSQEVQDSFSFLEDSSSSEPEWVGAEDGEVAQAEAAGAAFSPGEDDPGMGYLEELLGVGPQVEEFSVEPPLDDLSLDEAQFVLAPSCCSLDSAGPRPEVEEENGEEVFLSAYDDLSPLLGPKPPIWKGSGSLEGEAAGCGRQALGQGGEEQACWEVGEDKQAEPGGRLDIREEAEGSPQPPQPEEMEPEGQPSPDGCLCPCSLGLGGVGMRLASTLVQVQQVRSVPVVPPKPQFAKMPSAMCSKIHVAPANPCPRPGRLDGTPGERAWGSRASRSSWRNGGSLSFDAAVALARDRQRTEAQGVRRTQTCTEGGDYCLIPRTSPCSMISAHSPRPLSCLELPSEGAEGSGSRSRLSLPPREPQVPDPLLSSQRRSYAFETQANPGKGEGL>sp|Q7Z6I6-3|RHG30_HUMAN Isoform 3 of Rho GTPase-activating protein 30OS=Homo sapiens OX=9606 GN=ARHGAP30MRHLVHMASFSAQTNMHARNLAIVWAPNLLRSKDIEASGFNGTAAFMEVRVQSIVVEFILTHVDQLFGGAALSGGEVESGWRSLPGTRASGSPEDLMPRPLPYHLPSILQAGDGPPQMRPYHTIIEIAEHKRKGSLKVRKWRSIFNLGRSGHETKRKLPRGAEDREDKSNKGTLRPAKSMDSLSAAAGASDEPEGLVGPSSPRPSPLLPESLENDSIEAAEGEQEPEAEALGGTNSEPGTPRAGRSAIRAGGSSRAERCAGVHISDPYNVNLPLHITSILSVPPNIISNVSLARLTRGLECPALQHRPSPASGPGPGPGLGPGPPDEKLEASPASSPLADSGPDDLAPALEDSLSQEVQDSFSFLEDSSSSEPEWVGAEDGEVAQAEAAGAAFSPGEDDPGMGYLEELLGVGPQVEEFSVEPPLDDLSLDEAQFVLAPSCCSLDSAGPRPEVEEENGEEVFLSAYDDLSPLLGPKPPIWKGSGSLEGEAAGCGRQALGQGGEEQACWEVGEDKQAEPGGRLDIREEAEGSPETKVEAGKASEDRGEAGGSQETKVRLREGSREETEAKEEKSKGQKKADSMEAKGVEEPGGDEYTDEKEKEIEREEDEQREEAQVEAGRDLEQGAQEDQVAEEKWEVVQKQEAEGVREDEDKGQREKGYHEARKDQGDGEDSRSPEAATEGGAGEVSKERESGDGEAEGDQRAGGYYLEEDTLSEGSGVASLEVDCAKEGNPHSSEMEEVAPQPPQPEEMEPEGQPSPDGCLCPCSLGLGGVGMRLASTLVQVQQVRSVPVVPPKPQFAKMPSAMCSKIHVAPANPCPRPGRLDGTPGERAWGSRASRSSWRNGGSLSFDAAVALARDRQRTEAQGVRRTQTCTEGGDYCLIPRTSPCSMISAHSPRPLSCLELPSEGAEGSGSRSRLSLPPREPQVPDPLLSSQRRSYAFETQANPGKGEGL>sp|Q7Z6I6-4|RHG30_HUMAN Isoform 4 of Rho GTPase-activating protein 30OS=Homo sapiens OX=9606 GN=ARHGAP30MKSRQKGKKKGSAKERVFGCDLQEHLQHSGQEVPQVLKSCAEFVEEYGVVDGIYRLSGVSSNIQKLRQEFESERKPDLRRDVYLQDIHCVSSLCKAYFRELPDPLLTYRLYDKFAEAVGVQLEPERLVKILEVLRELPVPNYRTLEFLMRHLVHMASFSAQTNMHARNLAIVWAPNLLRSKDIEASGFNGTAAFMEVRVQSIVVEFILTHVDQLFGGAALSGQCPPCPPHIPLLGSQVSYSEP>sp|P50120|RET2_HUMAN Retinol-binding protein 2 OS=Homo sapiens OX=9606GN=RBP2 PE=1 SV=3MTRDQNGTWEMESNENFEGYMKALDIDFATRKIAVRLTQTKVIDQDGDNFKTKTTSTFRNYDVDFTVGVEFDEYTKSLDNRHVKALVTWEGDVLVCVQKGEKENRGWKQWIEGDKLYLELTCGDQVCRQVFKKK>sp|P48380|RFX3_HUMAN Transcription factor RFX3 OS=Homo sapiens OX=9606GN=RFX3 PE=1 SV=2MQTSETGSDTGSTVTLQTSVASQAAVPTQVVQQVPVQQQVQQVQTVQQVQHVYPAQVQYVEGSDTVYTNGAIRTTTYPYTETQMYSQNTGGNYFDTQGSSAQVTTVVSSHSMVGTGGIQMGVTGGQLISSSGGTYLIGNSMENSGHSVTHTTRASPATIEMAIETLQKSDGLSTHRSSLLNSHLQWLLDNYETAEGVSLPRSTLYNHYLRHCQEHKLDPVNAASFGKLIRSIFMGLRTRRLGTRGNSKYHYYGIRVKPDSPLNRLQEDMQYMAMRQQPMQQKQRYKPMQKVDGVADGFTGSGQQTGTSVEQTVIAQSQHHQQFLDASRALPEFGEVEISSLPDGTTFEDIKSLQSLYREHCEAILDVVVNLQFSLIEKLWQTFWRYSPSTPTDGTTITESSNLSEIESRLPKAKLITLCKHESILKWMCNCDHGMYQALVEILIPDVLRPIPSALTQAIRNFAKSLEGWLSNAMNNIPQRMIQTKVAAVSAFAQTLRRYTSLNHLAQAARAVLQNTSQINQMLSDLNRVDFANVQEQASWVCQCDDNMVQRLETDFKMTLQQQSTLEQWAAWLDNVMMQALKPYEGRPSFPKAARQFLLKWSFYSSMVIRDLTLRSAASFGSFHLIRLLYDEYMFYLVEHRVAQATGETPIAVMGEFGDLNAVSPGNLDKDEGSEVESEMDEELDDSSEPQAKREKTELSQAFPVGCMQPVLETGVQPSLLNPIHSEHIVTSTQTIRQCSATGNTYTAV>sp|P48380-2|RFX3_HUMAN Isoform 2 of Transcription factor RFX3 OS=Homosapiens OX=9606 GN=RFX3MQTSETGSDTGSTVTLQTSVASQAAVPTQVVQQVPVQQQVQQVQTVQQVQHVYPAQVQYVEGSDTVYTNGAIRTTTYPYTETQMYSQNTGGNYFDTQGSSAQVTTVVSSHSMVGTGGIQMGVTGGQLISSSGGTYLIGNSMENSGHSVTHTTRASPATIEMAIETLQKSDGLSTHRSSLLNSHLQWLLDNYETAEGVSLPRSTLYNHYLRHCQEHKLDPVNAASFGKLIRSIFMGLRTRRLGTRGNSKYHYYGIRVKPDSPLNRLQEDMQYMAMRQQPMQQKQRYKPMQKVDGVADGFTGSGQQTGTSVEQTVIAQSQHHQQFLDASRALPEFGEVEISSLPDGTTFEDIKSLQSLYREHCEAILDVVVNLQFSLIEKLWQTFWRYSPSTPTDGTTITESSNLSEIESRLPKAKLITLCKHESILKWMCNCDHGMYQALVEILIPDVLRPIPSALTQAIRNFAKSLEGWLSNAMNNIPQRMIQTKVAAVSAFAQTLRRYTSLNHLAQAARAVLQNTSQINQMLSDLNRVDFANVQEQASWVCQCDDNMVQRLETDFKMTLQQQSTLEQWAAWLDNVMMQALKPYEGRPSFPKAARQFLLKWSFYSSMVIRDLTLRSAASFGSFHLIRLLYDEYMFYLVEHRVAQATGETPIAVMGEVREAERAVTHWVIKNKPELHFSLNTLLIKTMVPNQVSLRARRDCGVIARVP>sp|P48380-3|RFX3_HUMAN Isoform 3 of Transcription factor RFX3 OS=Homosapiens OX=9606 GN=RFX3MQTSETGSDTGSTVTLQTSVASQAAVPTQVVQQVPVQQQVQQVQTVQQVQHVYPAQVQYVEGSDTVYTNGAIRTTTYPYTETQMYSQNTGGNYFDTQGSSAQVTTVVSSHSMVGTGGIQMGVTGGQLISSSGGTYLIGNSMENSGHSVTHTTRASPATIEMAIETLQKSDGLSTHRSSLLNSHLQWLLDNYETAEGVSLPRSTLYNHYLRHCQEHKLDPVNAASFGKLIRSIFMGLRTRRLGTRGNSKYHYYGIRVKPDSPLNRLQEDMQYMAMRQQPMQQKQRYKPMQKVDGVADGFTGSGQQTGTSVEQTVIAQSQHHQQFLDASRALPEFGEVEISSLPDGTTFEDIKSLQSLYREHCEAILDVVVNLQFSLIEKLWQTFWRYSPSTPTDGTTITESRSESTSFPIHFHG>sp|Q8NC24|RELL2_HUMAN RELT-like protein 2 OS=Homo sapiens OX=9606GN=RELL2 PE=1 SV=1MSEPQPDLEPPQHGLYMLFLLVLVFFLMGLVGFMICHVLKKKGYRCRTSRGSEPDDAQLQPPEDDDMNEDTVERIVRCIIQNEANAEALKEMLGDSEGEGTVQLSSVDATSSLQDGAPSHHHTVHLGSAAPCLHCSRSKRPPLVRQGRSKEGKSRPRTGETTVFSVGRFRVTHIEKRYGLHEHRDGSPTDRSWGSGGGQDPGGGQGSGGGQPKAGMPAMERLPPERPQPQVLASPPVQNGGLRDSSLTPRALEGNPRASAEPTLRAGGRGPSPGLPTQEANGQPSKPDTSDHQVSLPQGAGSM>sp|Q6ZNA4|RN111_HUMAN E3 ubiquitin-protein ligase Arkadia OS=Homosapiens OX=9606 GN=RNF111 PE=1 SV=3MSQWTPEYNELYTLKVDMKSEIPSDAPKTQESLKGILLHPEPIGAAKSFPAGVEMINSKVGNEFSHLCDDSQKQEKEMNGNQQEQEKSLVVRKKRKSQQAGPSYVQNCVKENQGILGLRQHLGTPSDEDNDSSFSDCLSSPSSSLHFGDSDTVTSDEDKEVSVRHSQTILNAKSRSHSARSHKWPRTETESVSGLLMKRPCLHGSSLRRLPCRKRFVKNNSSQRTQKQKERILMQRKKREVLARRKYALLPSSSSSSENDLSSESSSSSSTEGEEDLFVSASENHQNNPAVPSGSIDEDVVVIEASSTPQVTANEEINVTSTDSEVEIVTVGESYRSRSTLGHSRSHWSQGSSSHASRPQEPRNRSRISTVIQPLRQNAAEVVDLTVDEDEPTVVPTTSARMESQATSASINNSNPSTSEQASDTASAVTSSQPSTVSETSATLTSNSTTGTSIGDDSRRTTSSAVTETGPPAMPRLPSCCPQHSPCGGSSQNHHALGHPHTSCFQQHGHHFQHHHHHHHTPHPAVPVSPSFSDPACPVERPPQVQAPCGANSSSGTSYHEQQALPVDLSNSGIRSHGSGSFHGASAFDPCCPVSSSRAAIFGHQAAAAAPSQPLSSIDGYGSSMVAQPQPQPPPQPSLSSCRHYMPPPYASLTRPLHHQASACPHSHGNPPPQTQPPPQVDYVIPHPVHAFHSQISSHATSHPVAPPPPTHLASTAAPIPQHLPPTHQPISHHIPATAPPAQRLHPHEVMQRMEVQRRRMMQHPTRAHERPPPHPHRMHPNYGHGHHIHVPQTMSSHPRQAPERSAWELGIEAGVTAATYTPGALHPHLAHYHAPPRLHHLQLGALPLMVPDMAGYPHIRYISSGLDGTSFRGPFRGNFEELIHLEERLGNVNRGASQGTIERCTYPHKYKKVTTDWFSQRKLHCKQDGEEGTEEDTEEKCTICLSILEEGEDVRRLPCMHLFHQVCVDQWLITNKKCPICRVDIEAQLPSES>sp|Q6ZNA4-2|RN111_HUMAN Isoform 2 of E3 ubiquitin-protein ligase ArkadiaOS=Homo sapiens OX=9606 GN=RNF111MSQWTPEYNELYTLKVDMKSEIPSDAPKTQESLKGILLHPEPIGAAKSFPAGVEMINSKVGNEFSHLCDDSQKQEKEMNGNQQEQEKSLVVRKKRKSQQAGPSYVQNCVKENQGILGLRQHLGTPSDEDNDSSFSDCLSSPSSSLHFGDSDTVTSDEDKEVSVRHSQTILNAKSRSHSARSHKWPRTETESVSGLLMKRPCLHGSSLRRLPCRKRFVKNNSSQRTQKQKERILMQRKKREVLARRKYALLPSSSSSSENDLSSESSSSSSTEGEEDLFVSASENHQNNPAVPSGSIDEDVVVIEASSTPQVTANEEINVTSTDSEVEIVTVGESYRSRSTLGHSRSHWSQGSSSHASRPQEPRNRSRISTVIQPLRQNAAEVVDLTVDEDEPTVVPTTSARMESQATSASINNSNPSTSEQASDTASAVTSSQPSTVSETSATLTSNSTTGTSIGDDSRRTTSSAVTETGPPAMPRLPSCCPQHSPCGGSSQNHHALGHPHTSCFQQHGHHFQHHHHHHHTPHPAVPVSPSFSDPACPVERPPQVQAPCGANSSSGTSYHEQQALPVDLSNSGIRSHGSGSFHGASAFDPCCPVSSSRAAIFGHQAAAAAPSQPLSSIDGYGSSMVAQPQPQPPPQPSLSSCRHYMPPPYASLTRPLHHQASACPHSHGNPPPQTQPPPQVDYVIPHPVHAFHSQISSHATSHPVAPPPPTHLASTAAPIPQHLPPTHQPISHHIPATAPPAQRLHPHEVMQRMEVQRRRMMQHPTRAHERPPPHPHRMHPNYGHGHHIHVPQTMSSHPRQAPERSAWELGIEAGVTAATYTPGALHPHLAHYHAPPRLHHLQLGALPLMVPDMAGYPHIRYISSGLDGTSFRGPFRGNFEELIHLEERLGNVNRGASQGTIERCTYPHKYKKRKLHCKQDGEEGTEEDTEEKCTICLSILEEGEDVRRLPCMHLFHQVCVDQWLITNKKCPICRVDIEAQLPSES>sp|Q6ZNA4-3|RN111_HUMAN Isoform 3 of E3 ubiquitin-protein ligase ArkadiaOS=Homo sapiens OX=9606 GN=RNF111MSQWTPEYNELYTLKVDMKSEIPSDAPKTQESLKGILLHPEPIGAAKSFPAGVEMINSKVGNEFSHLCDDSQKQEKEMNGNQQEQEKSLVVRKKRKSQQAGPSYVQNCVKENQGILGLRQHLGTPSDEDNDSSFSDCLSSPSSSLHFGDSDTVTSDEDKEVSVRHSQTILNAKSRSHSARSHKWPRTETESVSGLLMKRPCLHGSSLRRLPCRKRFVKNNSSQRTQKQKERILMQRKKREVLARRKYALLPSSSSSSENDLSSESSSSSSTEGEEDLFVSASENHQNNPAVPSGSIDEDVVVIEASSTPQVTANEEINVTSTDSEVEIVTVGESYRSRSTLGHSRSHWSQGSSSHASRPQEPRNRSRISTVIQPLRQNAAEVVDLTVDEDEPTVVPTTSARMESQATSASINNSNPSTSEQASDTASAVTSSQPSTVSETSATLTSNSTTGTSIGDDSRRTTSSAVTETGPPAMPRLPSCCPQHSPCGGSSQNHHALGHPHTSCFQQHGHHFQHHHHHHHTPHPAVPVSPSFSDPACPVERPPQVQAPCGANSSSGTSYHEQQALPVDLSNSGIRSHGSGSFHGASAFDPCCPVSSSRAAIFGHQAAAAAPSQPLSSIDGYGSSMVAQPQPQPPPQPSLSSCRHYMPPPYASLTRPLHHQASACPHSHGNPPPQTQPPPQVDYVIPHPVHAFHSQISSHATSHPVAPPPPTHLASTAAPIPQHLPPTHQPISHHIPATAPPAQRLHPHEVMQRMEVQRRRMMQHPTGLFVFCVSRRAHERPPPHPHRMHPNYGHGHHIHVPQTMSSHPRQAPERSAWELGIEAGVTAATYTPGALHPHLAHYHAPPRLHHLQLGALPLMVPDMAGYPHIRYISSGLDGTSFRGPFRGNFEELIHLEERLGNVNRGASQGTIERCTYPHKYKKVTTDWFSQRKLHCKQDGEEGTEEDTEEKCTICLSILEEGEDVRRLPCMHLFHQVCVDQWLITNKKCPICRVDIEAQLPSES>sp|Q6ZNA4-4|RN111_HUMAN Isoform 4 of E3 ubiquitin-protein ligase ArkadiaOS=Homo sapiens OX=9606 GN=RNF111MSQWTPEYNELYTLKVDMKSEIPSDAPKTQESLKGILLHPEPIGAAKSFPAGVEMINSKVGNEFSHLCDDSQKQEKEMNGNQQEQEKSLVVRKKRKSQQAGPSYVQNCVKENQGILGLRQHLGTPSDEDNDSSFSDCLSSPSSSLHFGDSDTVTSDEDKEVSVRHSQTILNAKSRSHSARSHKWPRTETESVSGLLMKRPCLHGSSLRRLPCRKRFVKNNSSQRTQKQKERILMQRKKREVLARRKYALLPSSSSSSENDLSSESSSSSSTEGEEDLFVSASENHQNNPAVPSGSIDEDVVVIEASSTPQVTANEEINVTSTDSEVEIVTVGESYRSRSTLGHSRSHWSQGSSSHASRPQEPRNRSRISTVIQPLRQNAAEVVDLTVDEDEPTVVPTTSARMESQATSASINNSNPSTSEQASDTASAVTSSQPSTVSETSATLTSNSTTGTSIGDDSRRTTSSAVTETGPPAMPRLPSCCPQHSPCGGSSQNHHALGHPHTSCFQQHGHHFQHHHHHHHTPHPAVPVSPSFSDPACPVERPPQVQAPCGANSSSGTSYHEQQALPVDLSNSGIRSHGSGSFHGASAFDPCCPVSSSRAAIFGHQAAAAAPSQPLSSIDGYGSSMVAQPQPQPPPQPSLSSCRHYMPPPYASLTRPLHHQASACPHSHGNPPPQTQPPPQVDYVIPHPVHAFHSQISSHATSHPVAPPPPTHLASTAAPIPQHLPPTHQPISHHIPATAPPAQRLHPHEVMQRMEVQRRRMMQHPTGLFVFCVSRRAHERPPPHPHRMHPNYGHGHHIHVPQTMSSHPRQAPERSAWELGIEAGVTAATYTPGALHPHLAHYHAPPRLHHLQLGALPLMVPDMAGYPHIRYISSGLDGTSFRGPFRGNFEELIHLEERLGNVNRGASQGTIERCTYPHKYKKRKLHCKQDGEEGTEEDTEEKCTICLSILEEGEDVRRLPCMHLFHQVCVDQWLITNKKCPICRVDIEAQLPSES>sp|O15211|RGL2_HUMAN Ral guanine nucleotide dissociation stimulator-like2 OS=Homo sapiens OX=9606 GN=RGL2 PE=1 SV=1MLPRPLRLLLDTSPPGGVVLSSFRSRDPEEGGGPGGLVVGGGQEEEEEEEEEAPVSVWDEEEDGAVFTVTSRQYRPLDPLVPMPPPRSSRRLRAGTLEALVRHLLDTRTSGTDVSFMSAFLATHRAFTSTPALLGLMADRLEALESHPTDELERTTEVAISVLSTWLASHPEDFGSEAKGQLDRLESFLLQTGYAAGKGVGGGSADLIRNLRSRVDPQAPDLPKPLALPGDPPADPTDVLVFLADHLAEQLTLLDAELFLNLIPSQCLGGLWGHRDRPGHSHLCPSVRATVTQFNKVAGAVVSSVLGATSTGEGPGEVTIRPLRPPQRARLLEKWIRVAEECRLLRNFSSVYAVVSALQSSPIHRLRAAWGEATRDSLRVFSSLCQIFSEEDNYSQSRELLVQEVKLQSPLEPHSKKAPRSGSRGGGVVPYLGTFLKDLVMLDAASKDELENGYINFDKRRKEFAVLSELRRLQNECRGYNLQPDHDIQRWLQGLRPLTEAQSHRVSCEVEPPGSSDPPAPRVLRPTLVISQWTEVLGSVGVPTPLVSCDRPSTGGDEAPTTPAPLLTRLAQHMKWPSVSSLDSALESSPSLHSPADPSHLSPPASSPRPSRGHRRSASCGSPLSGGAEEASGGTGYGGEGSGPGASDCRIIRVQMELGEDGSVYKSILVTSQDKAPSVISRVLKKNNRDSAVASEYELVQLLPGERELTIPASANVFYAMDGASHDFLLRQRRRSSTATPGVTSGPSASGTPPSEGGGGSFPRIKATGRKIARALF>sp|O15211-2|RGL2_HUMAN Isoform 2 of Ral guanine nucleotide dissociationstimulator-like 2 OS=Homo sapiens OX=9606 GN=RGL2MPPPRSSRRLRAGTLEALVRHLLDTRTSGTDVSFMSAFLATHRAFTSTPALLGLMADRLEALESHPTDELERTTEVAISVLSTWLASHPEDFGSEAKGQLDRLESFLLQTGYAAGKGVGGGSADLIRNLRSRVDPQAPDLPKPLALPGDPPADPTDVLVFLADHLAEQLTLLDAELFLNLIPSQCLGGLWGHRDRPGHSHLCPSVRATVTQFNKVAGAVVSSVLGATSTGEGPGEVTIRPLRPPQRARLLEKWIRVAEECRLLRNFSSVYAVVSALQSSPIHRLRAAWGEATRDSLRVFSSLCQIFSEEDNYSQSRELLVQEVKLQSPLEPHSKKAPRSGSRGGGVVPYLGTFLKDLVMLDAASKDELENGYINFDKRRKVSGVSGLDAGLPYPCSRKGRGKSQGSLSFGSCSLRAPSQEFAVLSELRRLQNECRGYNLQPDHDIQRWLQGLRPLTEAQS>sp|Q15493|RGN_HUMAN Regucalcin OS=Homo sapiens OX=9606 GN=RGN PE=1 SV=1MSSIKIECVLPENCRCGESPVWEEVSNSLLFVDIPAKKVCRWDSFTKQVQRVTMDAPVSSVALRQSGGYVATIGTKFCALNWKEQSAVVLATVDNDKKNNRFNDGKVDPAGRYFAGTMAEETAPAVLERHQGALYSLFPDHHVKKYFDQVDISNGLDWSLDHKIFYYIDSLSYSVDAFDYDLQTGQISNRRSVYKLEKEEQIPDGMCIDAEGKLWVACYNGGRVIRLDPVTGKRLQTVKLPVDKTTSCCFGGKNYSEMYVTCARDGMDPEGLLRQPEAGGIFKITGLGVKGIAPYSYAG>sp|Q15493-2|RGN_HUMAN Isoform 2 of Regucalcin OS=Homo sapiens OX=9606GN=RGNMSSIKIECVLPENCRCGESPVWEEVSNSLLFVDIPAKKVCRWDSFTKQVQRVTMDAPVSSVALRQSGGYVATIGTKFCALNWKEQSAVVLATVDNDKKNNRFNDGKVDPAGRYFAANRRSVYKLEKEEQIPDGMCIDAEGKLWVACYNGGRVIRLDPVTGKRLQTVKLPVDKTTSCCFGGKNYSEMYVTCARDGMDPEGLLRQPEAGGIFKITGLGVKGIAPYSYAG>sp|P35249|RFC4_HUMAN Replication factor C subunit 4 OS=Homo sapiensOX=9606 GN=RFC4 PE=1 SV=2MQAFLKGTSISTKPPLTKDRGVAASAGSSGENKKAKPVPWVEKYRPKCVDEVAFQEEVVAVLKKSLEGADLPNLLFYGPPGTGKTSTILAAARELFGPELFRLRVLELNASDERGIQVVREKVKNFAQLTVSGSRSDGKPCPPFKIVILDEADSMTSAAQAALRRTMEKESKTTRFCLICNYVSRIIEPLTSRCSKFRFKPLSDKIQQQRLLDIAKKENVKISDEGIAYLVKVSEGDLRKAITFLQSATRLTGGKEITEKVITDIAGVIPAEKIDGVFAACQSGSFDKLEAVVKDLIDEGHAATQLVNQLHDVVVENNLSDKQKSIITEKLAEVDKCLADGADEHLQLISLCATVMQQLSQNC>sp|P35249-2|RFC4_HUMAN Isoform 2 of Replication factor C subunit 4OS=Homo sapiens OX=9606 GN=RFC4MQAFLKGTSISTKPPLTKDRGVAASAGSSGENKKAKPVPWVEKYRPKCVDEVAFQEEVVAVLKKSLEGADLPNLLFYGPPGTGKTSTILAAARELFGPELFRLRVLELNASDERGIQVVREKVKNFAQLTVSGSRSDGKPCPPFKIVILDEADSMTSAAQAALRRTMEKESKTTRFCLICNYVSRIIEPLTSRCSKFRFKPLSDKIQQQRLLDIAKKENVKISDEGIAYLVKVSEGDLRKAITFLQSATRLTGGKEITEKVITDIAGVRVLDILNFFLVGFFVAFRKFSSNKYWVFSKCQVLH>sp|P46779|RL28_HUMAN 60S ribosomal protein L28 OS=Homo sapiens OX=9606GN=RPL28 PE=1 SV=3MSAHLQWMVVRNCSSFLIKRNKQTYSTEPNNLKARNSFRYNGLIHRKTVGVEPAADGKGVVVVIKRRSGQRKPATSYVRTTINKNARATLSSIRHMIRKNKYRPDLRMAAIRRASAILRSQKPVMVKRKRTRPTKSS>sp|P46779-2|RL28_HUMAN Isoform 2 of 60S ribosomal protein L28 OS=Homosapiens OX=9606 GN=RPL28MSAHLQWMVVRNCSSFLIKRNKQTYSTEPNNLKARNSFRYNGLIHRKTVGVEPAADGKGVVVVIKRRSGQRKPATSYVRTTINKNARATLSSIRHMIRKNKYRPDLRMVSWGLGIRLGETGQCCGEGPPTTGCNMGWRGMDSCFQPTPHTQHWPRGRLVECMG>sp|P46779-3|RL28_HUMAN Isoform 3 of 60S ribosomal protein L28 OS=Homosapiens OX=9606 GN=RPL28MSAHLQWMVVRNCSSFLIKRNKQTYSTEPNNLKARNSFRYNGLIHRKTVGVEPAADGKGVVVVIKRRSGQRKPATSYVRTTINKNARATLSSIRHMIRKNKYRPDLRMDMLASTGSGLCCSVAVQPWASSSTSLCLRTLICNMRVDRPYYSGLMRRLNVQNLLDCAHKS>sp|P46779-4|RL28_HUMAN Isoform 4 of 60S ribosomal protein L28 OS=Homosapiens OX=9606 GN=RPL28MSAHLQWMVVRNCSSFLIKRNKQTYSTEPNNLKARNSFRYNGLIHRKTVGVEPAADGKGVVVVIKRRSE>sp|P46779-5|RL28_HUMAN Isoform 5 of 60S ribosomal protein L28 OS=Homosapiens OX=9606 GN=RPL28MSAHLQWMVVRNCSSFLIKRNKQTYSTEPNNLKARNSFRYNGLIHRKTVGVEPAADGKGVVVVIKRRSGEFCLVWARERPLSRVWEL>sp|P40879|S26A3_HUMAN Chloride anion exchanger OS=Homo sapiens OX=9606GN=SLC26A3 PE=1 SV=1MIEPFGNQYIVARPVYSTNAFEENHKKTGRHHKTFLDHLKVCCSCSPQKAKRIVLSLFPIASWLPAYRLKEWLLSDIVSGISTGIVAVLQGLAFALLVDIPPVYGLYASFFPAIIYLFFGTSRHISVGPFPILSMMVGLAVSGAVSKAVPDRNATTLGLPNNSNNSSLLDDERVRVAAAASVTVLSGIIQLAFGILRIGFVVIYLSESLISGFTTAAAVHVLVSQLKFIFQLTVPSHTDPVSIFKVLYSVFSQIEKTNIADLVTALIVLLVVSIVKEINQRFKDKLPVPIPIEFIMTVIAAGVSYGCDFKNRFKVAVVGDMNPGFQPPITPDVETFQNTVGDCFGIAMVAFAVAFSVASVYSLKYDYPLDGNQELIALGLGNIVCGVFRGFAGSTALSRSAVQESTGGKTQIAGLIGAIIVLIVVLAIGFLLAPLQKSVLAALALGNLKGMLMQFAEIGRLWRKDKYDCLIWIMTFIFTIVLGLGLGLAASVAFQLLTIVFRTQFPKCSTLANIGRTNIYKNKKDYYDMYEPEGVKIFRCPSPIYFANIGFFRRKLIDAVGFSPLRILRKRNKALRKIRKLQKQGLLQVTPKGFICTVDTIKDSDEELDNNQIEVLDQPINTTDLPFHIDWNDDLPLNIEVPKISLHSLILDFSAVSFLDVSSVRGLKSILQEFIRIKVDVYIVGTDDDFIEKLNRYEFFDGEVKSSIFFLTIHDAVLHILMKKDYSTSKFNPSQEKDGKIDFTINTNGGLRNRVYEVPVETKF>sp|Q08AI6|S38AB_HUMAN Putative sodium-coupled neutral amino acidtransporter 11 OS=Homo sapiens OX=9606 GN=SLC38A11 PE=1 SV=1MKQAGFPLGILLLFWVSYVTDFSLVLLIKGGALSGTDTYQSLVNKTFGFPGYLLLSVLQFLYPFIAMISYNIIAGDTLSKVFQRIPGVDPENVFIGRHFIIGLSTVTFTLPLSLYRNIAKLGKVSLISTGLTTLILGIVMARAISLGPHIPKTEDAWVFAKPNAIQAVGVMSFAFICHHNSFLVYSSLEEPTVAKWSRLIHMSIVISVFICIFFATCGYLTFTGFTQGDLFENYCRNDDLVTFGRFCYGVTVILTYPMECFVTREVIANVFFGGNLSSVFHIVVTVMVITVATLVSLLIDCLGIVLELNGVLCATPLIFIIPSACYLKLSEEPRTHSDKIMSCVMLPIGAVVMVFGFVMAITNTQDCTHGQEMFYCFPDNFSLTNTSESHVQQTTQLSTLNISIFQ>sp|Q08AI6-2|S38AB_HUMAN Isoform 2 of Putative sodium-coupled neutralamino acid transporter 11 OS=Homo sapiens OX=9606 GN=SLC38A11MKQAGFPLGILLLFWVSYVTDFSLVLLIKGGALSGTDTYQSLVNKTFGFPGYLLLSVLQFLYPFIVDPENVFIGRHFIIGLSTVTFTLPLSLYRNIAKLGKVSLISTGLTTLILGIVMARAISLGPHIPKTEDAWVFAKPNAIQAVGVMSFAFICHHNSFLVYSSLEEPTVAKWSRLIHMSIVISVFICIFFATCGYLTFTGFTQGDLFENYCRNDDLVTFGRFCYGVTVILTYPMECFVTREVIANVFFGGNLSSVFHIVVTVMVITVATLVSLLIDCLGIVLELNGVLCATPLIFIIPSACYLKLSEEPRTHSDKIMSCVMLPIGAVVMVFGFVMAITNTQDCTHGQEMFYCFPDNFSLTNTSESHVQQTTQLSTLNISIFQ>sp|P58743|S26A5_HUMAN Prestin OS=Homo sapiens OX=9606 GN=SLC26A5 PE=1SV=1MDHAEENEILAATQRYYVERPIFSHPVLQERLHTKDKVPDSIADKLKQAFTCTPKKIRNIIYMFLPITKWLPAYKFKEYVLGDLVSGISTGVLQLPQGLAFAMLAAVPPIFGLYSSFYPVIMYCFLGTSRHISIGPFAVISLMIGGVAVRLVPDDIVIPGGVNATNGTEARDALRVKVAMSVTLLSGIIQFCLGVCRFGFVAIYLTEPLVRGFTTAAAVHVFTSMLKYLFGVKTKRYSGIFSVVYSTVAVLQNVKNLNVCSLGVGLMVFGLLLGGKEFNERFKEKLPAPIPLEFFAVVMGTGISAGFNLKESYNVDVVGTLPLGLLPPANPDTSLFHLVYVDAIAIAIVGFSVTISMAKTLANKHGYQVDGNQELIALGLCNSIGSLFQTFSISCSLSRSLVQEGTGGKTQLAGCLASLMILLVILATGFLFESLPQAVLSAIVIVNLKGMFMQFSDLPFFWRTSKIELTIWLTTFVSSLFLGLDYGLITAVIIALLTVIYRTQSPSYKVLGKLPETDVYIDIDAYEEVKEIPGIKIFQINAPIYYANSDLYSNALKRKTGVNPAVIMGARRKAMRKYAKEVGNANMANATVVKADAEVDGEDATKPEEEDGEVKYPPIVIKSTFPEEMQRFMPPGDNVHTVILDFTQVNFIDSVGVKTLAGIVKEYGDVGIYVYLAGCSAQVVNDLTRNRFFENPALWELLFHSIHDAVLGSQLREALAEQEASAPPSQEDLEPNATPATPEA>sp|P58743-2|S26A5_HUMAN Isoform 2 of Prestin OS=Homo sapiens OX=9606GN=SLC26A5MDHAEENEILAATQRYYVERPIFSHPVLQERLHTKDKVPDSIADKLKQAFTCTPKKIRNIIYMFLPITKWLPAYKFKEYVLGDLVSGISTGVLQLPQGLAFAMLAAVPPIFGLYSSFYPVIMYCFLGTSRHISIGPFAVISLMIGGVAVRLVPDDIVIPGGVNATNGTEARDALRVKVAMSVTLLSGIIQFCLGVCRFGFVAIYLTEPLVRGFTTAAAVHVFTSMLKYLFGVKTKRYSGIFSVVYSTVAVLQNVKNLNVCSLGVGLMVFGLLLGGKEFNERFKEKLPAPIPLEFFAVVMGTGISAGFNLKESYNVDVVGTLPLGLLPPANPDTSLFHLVYVDAIAIAIVGFSVTISMAKTLANKHGYQVDGNQELIALGLCNSIGSLFQTFSISCSLSRSLVQEGTGGKTQLAGCLASLMILLVILATGFLFESLPQAVLSAIVIVNLKGMFMQFSDLPFFWRTSKIELTIWLTTFVSSLFLGLDYGLITAVIIALLTVIYRTQSPSYKVLGKLPETDVYIDIDAYEEVKEIPGIKIFQINAPIYYANSDLYSNALKRKTGVNPAVIMGARRKAMRKYAKEVGNANMANATVVKADAEVDGEDATKPEEEDGEVKYPPIVIKSTFPEEMQRFMPPGDNVHTVILDFTQVNFIDSVGVKTLAGIVKEYGDVGIYVYLAGCSAFIQR>sp|P58743-3|S26A5_HUMAN Isoform 3 of Prestin OS=Homo sapiens OX=9606GN=SLC26A5MDHAEENEILAATQRYYVERPIFSHPVLQERLHTKDKVPDSIADKLKQAFTCTPKKIRNIIYMFLPITKWLPAYKFKEYVLGDLVSGISTGVLQLPQGLAFAMLAAVPPIFGLYSSFYPVIMYCFLGTSRHISIGPFAVISLMIGGVAVRLVPDDIVIPGGVNATNGTEARDALRVKVAMSVTLLSGIIQFCLGVCRFGFVAIYLTEPLVRGFTTAAAVHVFTSMLKYLFGVKTKRYSGIFSVVYSTVAVLQNVKNLNVCSLGVGLMVFGLLLGGKEFNERFKEKLPAPIPLEFFAVVMGTGISAGFNLKESYNVDVVGTLPLGLLPPANPDTSLFHLVYVDAIAIAIVGFSVTISMAKTLANKHGYQVDGNQELIALGLCNSIGSLFQTFSISCSLSRSLVQEGTGGKTQLAGCLASLMILLVILATGFLFESLPQAVLSAIVIVNLKGMFMQFSDLPFFWRTSKIELTIWLTTFVSSLFLGLDYGLITAVIIALLTVIYRTQSFHTEMTRRWRP>sp|P58743-4|S26A5_HUMAN Isoform 4 of Prestin OS=Homo sapiens OX=9606GN=SLC26A5MDHAEENEILAATQRYYVERPIFSHPVLQERLHTKDKVPDSIADKLKQAFTCTPKKIRNIIYMFLPITKWLPAYKFKEYVLGDLVSGISTGVLQLPQGLAFAMLAAVPPIFGLYSSFYPVIMYCFLGTSRHISIGPFAVISLMIGGVAVRLVPDDIVIPGGVNATNGTEARDALRVKVAMSVTLLSGIIQFCLGVCRFGFVAIYLTEPLVRGFTTAAAVHVFTSMLKYLFGVKTKRYSGIFSVVYSTVAVLQNVKNLNVCSLGVGLMVFGLLLGGKEFNERFKEKLPAPIPLEFFAVVMGTGISAGFNLKESYNVDVVGTLPLGFHTEMTRRWRP>sp|P58743-5|S26A5_HUMAN Isoform 5 of Prestin OS=Homo sapiens OX=9606GN=SLC26A5MDHAEENEILAATQRYYVERPIFSHPVLQERLHTKDKVPDSIADKLKQAFTCTPKKIRNIIYMFLPITKWLPAYKFKEYVLGDLVSGISTGVLQLPQGLAFAMLAAVPPIFGLYSSFYPVIMYCFLGTSRHISIGPFAVISLMIGGVAVRLVPDDIVIPGGVNATNGTEARDALRVKVAMSVTLLSGIIQFCLGVCRFGFVAIYLTEPLVRGFTTAAAVHVFTSMLKYLFGVKTKRYSGIFSVVYSTVAVLQNVKNLNVCSLGVGLMVFGLLLGGKEFNERFKEKLPAPIPLEFFAVVMGTGISAGFNLKESYNVDVVGTLPLGLLPPANPDTSLFHLVYVDAIAIAIVGFSVTISMAKTLANKHGYQVDGNQELIALGLCNSIGSLFQTFSISCSLSRSLVQEGTGGKTQLAGCLASLMILLVILATGFLFESLPQTIWLTTFVSSLFLGLDYGLITAVIIALLTVIYRTQSPSYKVLGKLPETDVYIDIDAYEEVKEIPGIKIFQINAPIYYANSDLYSNALKRKTGVNPAVIMGARRKAMRKYAKEVGNANMANATVVKADAEVDGEDATKPEEEDGEVKYPPIVIKSTFPEEMQRFMPPGDNVHTVILDFTQVNFIDSVGVKTLAGIVKEYGDVGIYVYLAGCSAQVVNDLTRNRFFENPALWELLFHSIHDAVLGSQLREALAEQEASAPPSQEDLEPNATPATPEA>sp|P58743-6|S26A5_HUMAN Isoform 6 of Prestin OS=Homo sapiens OX=9606GN=SLC26A5MDHAEENEILAATQRYYVERPIFSHPVLQERLHTKDKVPDSIADKLKQAFTCTPKKIRNIIYMFLPITKWLPAYKFKEYVLGDLVSGISTGVLQLPQGLAFAMLAAVPPIFGLYSSFYPVIMYCFLGTSRHISIGPFAVISLMIGGVAVRLVPDDIVIPGGVNATNGTEARDALRVKVAMSVTLLSGIIQFCLGVCRFGFVAIYLTEPLVRGFTTAAAVHVFTSMLKYLFGVKTKRYSGIFSVVYSTVAVLQNVKNLNVCSLGVGLMVFGLLLGGKEFNERFKEKLPAPIPLEFFAVVMGTGISAGFNLKESYNVDVVGTLPLGLLPPANPDTSLFHLVYVDAIAIAIVGFSVTISMAKTLANKHGYQVDGNQELIALGLCNSIGSLFQTFSISCSLSRSLVQEGTGGKTQLAGCLASLMILLVILATGFLFESLPQTIWLTTFVSSLFLGLDYGLITAVIIALLTVIYRTQSPSYKVLGKLPETDVYIDIDAYEEVKEIPGIKIFQINAPIYYANSDLYSNALKRKTGVNPAVIMGARRKAMRKYAKEVGNANMANATVVKATQDAEVDGEDATKPEEEDGEVKYPPIVIKSTFPEEMQRFMPPGDNVHTVILDFTQVNFIDSVGVKTLAGIVKEYGDVGIYVYLAGCSAQVVNDLTRNRFFENPALWELLFHSIHDAVLGSQLREALAEQEASAPPSQEDLEPNATPATPEA>sp|L0R6Q1|S35U4_HUMAN SLC35A4 upstream open reading frame proteinOS=Homo sapiens OX=9606 GN=SLC35A4 PE=3 SV=1MADDKDSLPKLKDLAFLKNQLESLQRRVEDEVNSGVGQDGSLLSSPFLKGFLAGYVVAKLRASAVLGFAVGTCTGIYAAQAYAVPNVEKTLRDYLQLLRKGPD>sp|Q9NSN8|SNTG1_HUMAN Gamma-1-syntrophin OS=Homo sapiens OX=9606GN=SNTG1 PE=1 SV=1MDFRTACEETKTGICLLQDGNQEPFKVRLHLAKDILMIQEQDVICVSGEPFYSGERTVTIRRQTVGGFGLSIKGGAEHNIPVVVSKISKEQRAELSGLLFIGDAILQINGINVRKCRHEEVVQVLRNAGEEVTLTVSFLKRAPAFLKLPLNEDCACAPSDQSSGTSSPLCDSGLHLNYHPNNTDTLSCSSWPTSPGLRWEKRWCDLRLIPLLHSRFSQYVPGTDLSRQNAFQVIAVDGVCTGIIQCLSAEDCVDWLQAIATNISNLTKHNIKKINRNFPVNQQIVYMGWCEAREQDPLQDRVYSPTFLALRGSCLYKFLAPPVTTWDWTRAEKTFSVYEIMCKILKDSDLLDRRKQCFTVQSESGEDLYFSVELESDLAQWERAFQTATFLEVERIQCKTYACVLESHLMGLTIDFSTGFICFDAATKAVLWRYKFSQLKGSSDDGKSKIKFLFQNPDTKQIEAKELEFSNLFAVLHCIHSFFAAKVACLDPLFLGNQATASTAASSATTSKAKYTT>sp|Q9NSN8-2|SNTG1_HUMAN Isoform 2 of Gamma-1-syntrophin OS=Homo sapiensOX=9606 GN=SNTG1MDFRTACEETKTGICLLQDGNQEPFKVRLHLAKDILMIQEQDVICVSGEPFYSGERTVTIRRQTVGGFGLSIKGGAEHNIPVVVSKISKEQRAELSGLLFIGDAILQINGINVRKCRHEEVVQVLRNAGEEVTLTVSFLKRAPAFLKLPLNEDCACAPSDQSSGTSSPLCDSGLHLNYHPNNTDTLSCSSWPTSPGLRWEKRWCDLRLIPLLHSRFSQYVPGTDLSRQNAFQVIAVDGVCTGIIQCLSAEDCVDWLQAIATNISNLTKHNIKKINRNFPVNQQIVYMGWCEAREQDPLQDRVYSPTFLALRGSCLYKFLAPPVTTWDWTRAEKTFSVYEIMCKILKDSDLLDRRKQCFTVQSESGEDLYFSVELESDLAQWERAFQTATFLEVERIQCKTYACVLESHLMGLTIDFSTGFICFDAATKELEFSNLFAVLHCIHSFFAAKVACLDPLFLGNQATASTAASSATTSKAKYTT>sp|A6NER0|TBC3F_HUMAN TBC1 domain family member 3F OS=Homo sapiensOX=9606 GN=TBC1D3F PE=1 SV=3MDVVEVAGSWWAQEREDIIMKYEKGHRAGLPEDKGPKPFRSYNNNVDHLGIVHETELPPLTAREAKQIRREISRKSKWVDMLGDWEKYKSSRKLIDRAYKGMPMNIRGPMWSVLLNIEEMKLKNPGRYQIMKEKGKRSSEHIQRIDRDVSGTLRKHIFFRDRYGTKQRELLHILLAYEEYNPEVGYCRDLSHIAALFLLYLPEEDAFWALVQLLASERHSLQGFHSPNGGTVQGLQDQQEHVVATSQPKTMGHQDKKDLCGQCSPLGCLIRILIDGISLGLTLRLWDVYLVEGEQALMPITRIAFKVQQKRLTKTSRCGPWARFCNRFVDTWARDEDTVLKHLRASMKKLTRKKGDVPPPAKPEQGSSASRPVPASRGGKTLCKGDRQAPPGPPARFPRPIWSASPPRAPRSSTPCPGGAVREDTYPVGTQGVPSPALAQGGPQGSWRFLQWNSMPRLPTDLDVEGPWFRHYDFRQSCWVRAISQEDQLAPCWQAEHPAERVRSAFAAPSTDSDQGTPFRARDEQQCAPTSGPCLCGLHLESSQFPPGF>sp|Q9BRG2|SH23A_HUMAN SH2 domain-containing protein 3A OS=Homo sapiensOX=9606 GN=SH2D3A PE=1 SV=1MQVPQDGEDLAGQPWYHGLLSRQKAEALLQQNGDFLVRASGSRGGNPVISCRWRGSALHFEVFRVALRPRPGRPTALFQLEDEQFPSIPALVHSYMTGRRPLSQATGAVVSRPVTWQGPLRRSFSEDTLMDGPARIEPLRARKWSNSQPADLAHMGRSREDPAGMEASTMPISALPRTSSDPVLLKAPAPLGTVADSLRASDGQLQAKAPTKPPRTPSFELPDASERPPTYCELVPRVPSVQGTSPSQSCPEPEAPWWEAEEDEEEENRCFTRPQAEISFCPHDAPSCLLGPQNRPLEPQVLHTLRGLFLEHHPGSTALHLLLVDCQATGLLGVTRDQRGNMGVSSGLELLTLPHGHHLRLELLERHQTLALAGALAVLGCSGPLEERAAALRGLVELALALRPGAAGDLPGLAAVMGALLMPQVSRLEHTWRQLRRSHTEAALAFEQELKPLMRALDEGAGPCDPGEVALPHVAPMVRLLEGEEVAGPLDESCERLLRTLHGARHMVRDAPKFRKVAAQRLRGFRPNPELREALTTGFVRRLLWGSRGAGAPRAERFEKFQRVLGVLSQRLEPDR>sp|Q9BRG2-2|SH23A_HUMAN Isoform 2 of SH2 domain-containing protein 3AOS=Homo sapiens OX=9606 GN=SH2D3AMEKTLLANLGTTASCPARARKWSNSQPADLAHMGRSREDPAGMEASTMPISALPRTSSDPVLLKAPAPLGTVADSLRASDGQLQAKAPTKPPRTPSFELPDASERPPTYCELVPRVPSVQGTSPSQSCPEPEAPWWEAEEDEEEENRCFTRPQAEISFCPHDAPSCLLGPQNRPLEPQVLHTLRGLFLEHHPGSTALHLLLVDCQATGLLGVTRDQRGNMGVSSGLELLTLPHGHHLRLELLERHQTLALAGALAVLGCSGPLEERAAALRGLVELALALRPGAAGDLPGLAAVMGALLMPQVRGEQGLEEAGVRVTGKTGEEACSDLFSQVSRLEHTWRQLRRSHTEAALAFEQELKPLMRALDEGAGPCDPGEVALPHVAPMVRLLEGEEVAGPLDESCERLLRTLHGARHMVRDAPKFRKVAAQRLRGFRPNPELREALTTGFVRRLLWGSRGAGAPRAERFEKFQRVLGVLSQRLEPDR>sp|O14492|SH2B2_HUMAN SH2B adapter protein 2 OS=Homo sapiens OX=9606GN=SH2B2 PE=1 SV=2MNGAGPGPAAAAPVPVPVPVPDWRQFCELHAQAAAVDFAHKFCRFLRDNPAYDTPDAGASFSRHFAANFLDVFGEEVRRVLVAGPTTRGAAVSAEAMEPELADTSALKAAPYGHSRSSEDVSTHAATKARVRKGFSLRNMSLCVVDGVRDMWHRRASPEPDAAAAPRTAEPRDKWTRRLRLSRTLAAKVELVDIQREGALRFMVADDAAAGSGGSAQWQKCRLLLRRAVAEERFRLEFFVPPKASRPKVSIPLSAIIEVRTTMPLEMPEKDNTFVLKVENGAEYILETIDSLQKHSWVADIQGCVDPGDSEEDTELSCTRGGCLASRVASCSCELLTDAVDLPRPPETTAVGAVVTAPHSRGRDAVRESLIHVPLETFLQTLESPGGSGSDSNNTGEQGAETDPEAEPELELSDYPWFHGTLSRVKAAQLVLAGGPRNHGLFVIRQSETRPGEYVLTFNFQGKAKHLRLSLNGHGQCHVQHLWFQSVLDMLRHFHTHPIPLESGGSADITLRSYVRAQDPPPEPGPTPPAAPASPACWSDSPGQHYFSSLAAAACPPASPSDAAGASSSSASSSSAASGPAPPRPVEGQLSARSRSNSAERLLEAVAATAAEEPPEAAPGRARAVENQYSFY>sp|O14492-2|SH2B2_HUMAN Isoform 2 of SH2B adapter protein 2 OS=Homosapiens OX=9606 GN=SH2B2MDPSYCPAHGFPSQDPLWPLSSQQWSSAHYSEPAAGGCDGTEAMNGAGPGPAAAAPVPVPVPVPDWRQFCELHAQAAAVDFAHKFCRFLRDNPAYDTPDAGASFSRHFAANFLDVFGEEVRRVLVAGPTTRGAAVSAEAMEPELADTSALKAAPYGHSRSSEDVSTHAATKARVRKGFSLRNMSLCVVDGVRDMWHRRASPEPDAAAAPRTAEPRDKWTRRLRLSRTLAAKVELVDIQREGALRFMVADDAAAGSGGSAQWQKCRLLLRRAVAEERFRLEFFVPPKASRPKVSIPLSAIIEVRTTMPLEMPEKDNTFVLKVENGAEYILETIDSLQKHSWVADIQGCVDPGDSEEDTELSCTRGGCLASRVASCSCELLTDAVDLPRPPETTAVGAVVTAPHSRGRDAVRESLIHVPLETFLQTLESPGGSGSDSNNTGEQGAETDPEAEPELELSDYPWFHGTLSRVKAAQLVLAGGPRNHGLFVIRQSETRPGEYVLTFNFQGKAKHLRLSLNGHGQCHVQHLWFQSVLDMLRHFHTHPIPLESGGSADITLRSYVRAQDPPPEPGPTPPAAPASPACWSDSPGQHYFSSLAAAACPPASPSDAAGASSSSASSSSAASGPAPPRPVEGQLSARSRSNSAERLLEAVAATAAEEPPEAAPGRARAVENQYSFY>sp|P41225|SOX3_HUMAN Transcription factor SOX-3 OS=Homo sapiens OX=9606GN=SOX3 PE=1 SV=2MRPVRENSSGARSPRVPADLARSILISLPFPPDSLAHRPPSSAPTESQGLFTVAAPAPGAPSPPATLAHLLPAPAMYSLLETELKNPVGTPTQAAGTGGPAAPGGAGKSSANAAGGANSGGGSSGGASGGGGGTDQDRVKRPMNAFMVWSRGQRRKMALENPKMHNSEISKRLGADWKLLTDAEKRPFIDEAKRLRAVHMKEYPDYKYRPRRKTKTLLKKDKYSLPSGLLPPGAAAAAAAAAAAAAAASSPVGVGQRLDTYTHVNGWANGAYSLVQEQLGYAQPPSMSSPPPPPALPPMHRYDMAGLQYSPMMPPGAQSYMNVAAAAAAASGYGGMAPSATAAAAAAYGQQPATAAAAAAAAAAMSLGPMGSVVKSEPSSPPPAIASHSQRACLGDLRDMISMYLPPGGDAADAASPLPGGRLHGVHQHYQGAGTAVNGTVPLTHI>sp|Q969T3|SNX21_HUMAN Sorting nexin-21 OS=Homo sapiens OX=9606 GN=SNX21PE=1 SV=1MHRGTQEGAMASRLLHRLRHALAGDGPGEAAASPEAEQFPESSELEDDDAEGLSSRLSGTLSFTSAEDDEDDEDEDDEEAGPDQLPLGDGTSGEDAERSPPPDGQWGSQLLARQLQDFWKKSRNTLAPQRLLFEVTSANVVKDPPSKYVLYTLAVIGPGPPDCQPAQISRRYSDFERLHRNLQRQFRGPMAAISFPRKRLRRNFTAETIARRSRAFEQFLGHLQAVPELRHAPDLQDFFVLPELRRAQSLTCTGLYREALALWANAWQLQAQLGTPSGPDRPLLTLAGLAVCHQELEDPGEARACCEKALQLLGDKSLHPLLAPFLEAHVRLSWRLGLDKRQSEARLQALQEAGLTPTPPPSLKELLIKEVLD>sp|Q969T3-2|SNX21_HUMAN Isoform 2 of Sorting nexin-21 OS=Homo sapiensOX=9606 GN=SNX21MHRGTQEGAMASRLLHRLRHALAGDGPGEAAASPEAEQFPESSELEDDDAEGLSSRLSGTLSFTSAEDDEDDEDEDDEEAGPDQLPLGDGTSGEDAERSPPPDGQWGSQLLARQLQDFWKKSRNTLAPQRLLFEVTSANVVKDPPSKYVLYTLAVIGPGPPDCQPAQISRRYSDFERLHRNLQRQFRGPMAAISFPQSH>sp|Q969T3-3|SNX21_HUMAN Isoform 3 of Sorting nexin-21 OS=Homo sapiensOX=9606 GN=SNX21MHRGTQEGAMASRLLHRLRHALAGDGPGEAAASPEAEQFPESSELEDDDAEGLSSRLSGTLSFTSAEDDEDDEDEDDEEAGPDQLPLGDGTSGEDAERSPPPDGQWGSQLLARQLQDFWKKSRNTLAPQRLLFEVTSANVVKDPPSKYVTNLSSTPSP>sp|O75159|SOCS5_HUMAN Suppressor of cytokine signaling 5 OS=Homo sapiensOX=9606 GN=SOCS5 PE=1 SV=1MDKVGKMWNNFKYRCQNLFGHEGGSRSENVDMNSNRCLSVKEKNISIGDSTPQQQSSPLRENIALQLGLSPSKNSSRRNQNCATEIPQIVEISIEKDNDSCVTPGTRLARRDSYSRHAPWGGKKKHSCSTKTQSSLDADKKFGRTRSGLQRRERRYGVSSVHDMDSVSSRTVGSRSLRQRLQDTVGLCFPMRTYSKQSKPLFSNKRKIHLSELMLEKCPFPAGSDLAQKWHLIKQHTAPVSPHSTFFDTFDPSLVSTEDEEDRLRERRRLSIEEGVDPPPNAQIHTFEATAQVNPLYKLGPKLAPGMTEISGDSSAIPQANCDSEEDTTTLCLQSRRQKQRQISGDSHTHVSRQGAWKVHTQIDYIHCLVPDLLQITGNPCYWGVMDRYEAEALLEGKPEGTFLLRDSAQEDYLFSVSFRRYNRSLHARIEQWNHNFSFDAHDPCVFHSSTVTGLLEHYKDPSSCMFFEPLLTISLNRTFPFSLQYICRAVICRCTTYDGIDGLPLPSMLQDFLKEYHYKQKVRVRWLEREPVKAK>sp|Q15506|SP17_HUMAN Sperm surface protein Sp17 OS=Homo sapiens OX=9606GN=SPA17 PE=1 SV=1MSIPFSNTHYRIPQGFGNLLEGLTREILREQPDNIPAFAAAYFESLLEKREKTNFDPAEWGSKVEDRFYNNHAFEEQEPPEKSDPKQEESQISGKEEETSVTILDSSEEDKEKEEVAAVKIQAAFRGHIAREEAKKMKTNSLQNEEKEENK>sp|Q16613|SNAT_HUMAN Serotonin N-acetyltransferase OS=Homo sapiensOX=9606 GN=AANAT PE=1 SV=1MSTQSTHPLKPEAPRLPPGIPESPSCQRRHTLPASEFRCLTPEDAVSAFEIEREAFISVLGVCPLYLDEIRHFLTLCPELSLGWFEEGCLVAFIIGSLWDKERLMQESLTLHRSGGHIAHLHVLAVHRAFRQQGRGPILLWRYLHHLGSQPAVRRAALMCEDALVPFYERFSFHAVGPCAITVGSLTFMELHCSLRGHPFLRRNSGC>sp|Q16613-2|SNAT_HUMAN Isoform 2 of Serotonin N-acetyltransferaseOS=Homo sapiens OX=9606 GN=AANATMEPQSMKGQKRPFGGPWRLKVLGGPPWLRRTLPKLGRPKEAPVARMSTQSTHPLKPEAPRLPPGIPESPSCQRRHTLPASEFRCLTPEDAVSAFEIEREAFISVLGVCPLYLDEIRHFLTLCPELSLGWFEEGCLVAFIIGSLWDKERLMQESLTLHRSGGHIAHLHVLAVHRAFRQQGRGPILLWRYLHHLGSQPAVRRAALMCEDALVPFYERFSFHAVGPCAITVGSLTFMELHCSLRGHPFLRRNSGC>sp|P0C7V6|SP202_HUMAN Putative transcription factor SPT20 homolog-like 2OS=Homo sapiens OX=9606 GN=SUPT20HL2 PE=5 SV=1MDRDLEQALDRTENITEIAQQRRPRRRYSPRAGKTLQEKLYDIYVEECGKEPEDPQELRSNVNLLEKLVRRESLPCLLVNLYPGNQGYSVMLQREDGSFAETIRLPYEERALLDYLDAEELPPALGDVLDKASVNIFHSGCVIVEVRDYRQSSNMQPPGYQSRHILLRPTMQTLAPEVKTMTRDGEKWSQEDKFPLESQLILATAEPLCLDPSVAVACTANRLLYNKQKMNTDPMEQCLQRYSWPSVKPQQEQSDCPPPPELRVSTSGQKEERKVGQPCELNITKAGSCVDTWKGRPCDLAVPSEVDVEKLAKGYQSVTAADPQLPVWPAQEVEDPFRHAWEAGCQAWDTKPNIMQSFNDPLLCGKIRPRKKARQKSQKSPWQPFPDDHSACLRPGSETDAGRAVSQAQESVQSKVKGPGKMSHSSSGPASVSQLSSWKTPEQPDPVWVQSSVSGKGEKHPPPRTQLPSSSGKISSGNSFPPQQAGSPLKRPFPAAAPAVAAAAPAPAPAPAAAPALAAAAVAAAAGGAAPSHSQKPSVPLIKASRRRPAAGRPTRFVKIAPAIQVRTGSTGLKATNVEGPVRGAQVLGCSFKPVQAPGSGAPAPAGISGSGLQSSGGPLPDARPGAVQASSPAPLQFFLNTPEGLRPLTLQVPQGWAVLTGPQQQSHQLVSLQQLQQPTAAHPPQPGPQGSTLGLSTQGQAFPAQQLLNVNLTGAGSGLQPQPQAAVLSLLGSAQVPQQGVQLPFVLGQQPQPLLLLQPQPQPQQIQLQTQPLRVLQQPVFLATGAVQIVQPHPGVQAGSQLVGQRKGGKPTPPAP>sp|Q8WVK7|SKA2_HUMAN Spindle and kinetochore-associated protein 2OS=Homo sapiens OX=9606 GN=SKA2 PE=1 SV=1MEAEVDKLELMFQKAESDLDYIQYRLEYEIKTNHPDSASEKNPVTLLKELSVIKSRYQTLYARFKPVAVEQKESKSRICATVKKTMNMIQKLQKQTDLELSPLTKEEKTAAEQFKFHMPDL>sp|Q8WVK7-2|SKA2_HUMAN Isoform 2 of Spindle and kinetochore-associatedprotein 2 OS=Homo sapiens OX=9606 GN=SKA2MASEVGHNLESPETPGGGGWTRVEFPPPAPKGAATVWCLNRLGSRKLSLIWITFNTGWNMKSRLIILIQQVSCHH>sp|Q16586|SGCA_HUMAN Alpha-sarcoglycan OS=Homo sapiens OX=9606 GN=SGCAPE=1 SV=1MAETLFWTPLLVVLLAGLGDTEAQQTTLHPLVGRVFVHTLDHETFLSLPEHVAVPPAVHITYHAHLQGHPDLPRWLRYTQRSPHHPGFLYGSATPEDRGLQVIEVTAYNRDSFDTTRQRLVLEIGDPEGPLLPYQAEFLVRSHDAEEVLPSTPASRFLSALGGLWEPGELQLLNVTSALDRGGRVPLPIEGRKEGVYIKVGSASPFSTCLKMVASPDSHARCAQGQPPLLSCYDTLAPHFRVDWCNVTLVDKSVPEPADEVPTPGDGILEHDPFFCPPTEAPDRDFLVDALVTLLVPLLVALLLTLLLAYVMCCRREGRLKRDLATSDIQMVHHCTIHGNTEELRQMAASREVPRPLSTLPMFNVHTGERLPPRVDSAQVPLILDQH>sp|Q16586-2|SGCA_HUMAN Isoform SGCA-2 of Alpha-sarcoglycan OS=Homosapiens OX=9606 GN=SGCAMAETLFWTPLLVVLLAGLGDTEAQQTTLHPLVGRVFVHTLDHETFLSLPEHVAVPPAVHITYHAHLQGHPDLPRWLRYTQRSPHHPGFLYGSATPEDRGLQVIEVTAYNRDSFDTTRQRLVLEIGDPEGPLLPYQAEFLVRSHDAEEVLPSTPASRFLSALGGLWEPGELQLLNVTSALDRGGRVPLPIEGRKEGLKRDLATSDIQMVHHCTIHGNTEELRQMAASREVPRPLSTLPMFNVHTGERLPPRVDSAQVPLILDQH>sp|Q13103|SPP24_HUMAN Secreted phosphoprotein 24 OS=Homo sapiens OX=9606GN=SPP2 PE=1 SV=1MISRMEKMTMMMKILIMFALGMNYWSCSGFPVYDYDPSSLRDALSASVVKVNSQSLSPYLFRAFRSSLKRVEVLDENNLVMNLEFSIRETTCRKDSGEDPATCAFQRDYYVSTAVCRSTVKVSAQQVQGVHARCSWSSSTSESYSSEEMIFGDMLGSHKWRNNYLFGLISDESISEQFYDRSLGIMRRVLPPGNRRYPNHRHRARINTDFE>sp|Q9NY87|SPNXC_HUMAN Sperm protein associated with the nucleus on the Xchromosome C OS=Homo sapiens OX=9606 GN=SPANXC PE=1 SV=2MDKQSSAGGVKRSVPCDSNEANEMMPETSSGYSDPQPAPKKLKTSESSTILVVRYRRNVKRTSPEELVNDHARENRINPLQMEEEEFMEIMVEIPAK>sp|Q14159|SPIDR_HUMAN DNA repair-scaffolding protein OS=Homo sapiensOX=9606 GN=SPIDR PE=1 SV=2MPRGSRARGSKRKRSWNTECPSFPGERPLQVRRAGLRTAGAAASLSEAWLRCGEGFQNTSGNPSLTAEEKTITEKHLELCPRPKQETTTSKSTSGLTDITWSSSGSDLSDEDKTLSQLQRDELQFIDWEIDSDRAEASDCDEFEDDEGAVEISDCASCASNQSLTSDEKLSELPKPSSIEILEYSSDSEKEDDLENVLLIDSESPHKYHVQFASDARQIMERLIDPRTKSTETILHTPQKPTAKFPRTPENSAKKKLLRGGLAERLNGLQNRERSAISLWRHQCISYQKTLSGRKSGVLTVKILELHEECAMQVAMCEQLLGSPATSSSQSVAPRPGAGLKVLFTKETAGYLRGRPQDTVRIFPPWQKLIIPSGSCPVILNTYFCEKVVAKEDSEKTCEVYCPDIPLPRRSISLAQMFVIKGLTNNSPEIQVVCSGVATTGTAWTHGHKEAKQRIPTSTPLRDSLLDVVESQGAASWPGAGVRVVVQRVYSLPSRDSTRGQQGASSGHTDPAGTRACLLVQDACGMFGEVHLEFTMSKARQLEGKSCSLVGMKVLQKVTRGRTAGIFSLIDTLWPPAIPLKTPGRDQPCEEIKTHLPPPALCYILTAHPNLGQIDIIDEDPIYKLYQPPVTRCLRDILQMNDLGTRCSFYATVIYQKPQLKSLLLLEQREIWLLVTDVTLQTKEERDPRLPKTLLVYVAPLCVLGSEVLEALAGAAPHSLFFKDALRDQGRIVCAERTVLLLQKPLLSVVSGASSCELPGPVMLDSLDSATPVNSICSVQGTVVGVDESTAFSWPVCDMCGNGRLEQRPEDRGAFSCGDCSRVVTSPVLKRHLQVFLDCRSRPQCRVKVKLLQRSISSLLRFAAGEDGSYEVKSVLGKEVGLLNCFVQSVTAHPTSCIGLEEIELLSAGGASAEH>sp|Q14159-2|SPIDR_HUMAN Isoform 2 of DNA repair-scaffolding proteinOS=Homo sapiens OX=9606 GN=SPIDRMAQVWRRVSEHFWESETTTSKSTSGLTDITWSSSGSDLSDEDKTLSQLQRDELQFIDWEIDSDRAEASDCDEFEDDEGAVEISDCASCASNQSLTSDEKLSELPKPSSIEILEYSSDSEKEDDLENVLLIDSESPHKYHVQFASDARQIMERLIDPRTKSTETILHTPQKPTAKFPRTPENSAKKKLLRGGLAERLNGLQNRERSAISLWRHQCISYQKTLSGRKSGVLTVKILELHEECAMQVAMCEQLLGSPATSSSQSVAPRPGAGLKVLFTKETAGYLRGRPQDTVRIFPPWQKLIIPSGSCPVILNTYFCEKVVAKEDSEKTCEVYCPDIPLPRRSISLAQMFVIKGLTNNSPEIQVVCSGVATTGTAWTHGHKEAKQRIPTSTPLRDSLLDVVESQGAASWPGAGVRVVVQRVYSLPSRDSTRGQQGASSGHTDPAGTRACLLVQDACGMFGEVHLEFTMSKARQLEGKSCSLVGMKVLQKVTRGRTAGIFSLIDTLWPPAIPLKTPGRDQPCEEIKTHLPPPALCYILTAHPNLGQIDIIDEDPIYKLYQPPVTRCLRDILQMNDLGTRCSFYATVIYQKPQLKSLLLLEQREIWLLVTDVTLQTKEERDPRLPKTLLVYVAPLCVLGSEVLEALAGAAPHSLFFKDALRDQGRIVCAERTVLLLQKPLLSVVSGASSCELPGPVMLDSLDSATPVNSICSVQGTVVGVDESTAFSWPVCDMCGNGRLEQRPEDRGAFSCGDCSRVVTSPVLKRHLQVFLDCRSRPQCRVKVKLLQRSISSLLRFAAGEDGSYEVKSVLGKEVGLLNCFVQSVTAHPTSCIGLEEIELLSAGGASAEH>sp|Q14159-3|SPIDR_HUMAN Isoform 3 of DNA repair-scaffolding proteinOS=Homo sapiens OX=9606 GN=SPIDRMAQSLTAEEKTITEKHLELCPRPKQETTTSKSTSGLTDITWSSSGSDLSDEDKTLSQLQRDELQFIDWEIDSDRAEASDCDEFEDDEGAVEISDCASCASNQSLTSDEKLSELPKPSSIEILEYSSDSEKEDDLENVLLIDSESPHKYHVQFASDARQIMERLIDPRTKSTETILHTPQKPTAKFPRTPENSAKKKLLRGGLAERLNGLQNRERSAISLWRHQCISYQKTLSGRKSGVLTVKILELHEECAMQVAMCEQLLGSPATSSSQSVAPRPGAGLKVLFTKETAGYLRGRPQDTVRIFPPWQKLIIPSGSCPVILNTYFCEKVVAKEDSEKTCEVYCPDIPLPRRSISLAQMFVIKGLTNNSPEIQVVCSGVATTGTAWTHGHKEAKQRIPTSTPLRDSLLDVVESQGAASWPGAGVRVVVQRVYSLPSRDSTRGQQGASSGHTDPAGTRACLLVQDACGMFGEVHLEFTMSKARQLEGKSCSLVGMKVLQKVTRGRTAGIFSLIDTLWPPAIPLKTPGRDQPCEEIKTHLPPPALCYILTAHPNLGQIDIIDEDPIYKLYQPPVTRCLRDILQMNDLGTRCSFYATVIYQKPQLKSLLLLEQREIWLLVTDVTLQTKEERDPRLPKTLLVYVAPLCVLGSEVLEALAGAAPHSLFFKDALRDQGRIVCAERTVLLLQKPLLSVVSGASSCELPGPVMLDSLDSATPVNSICSVQGTVVGVDESTAFSWPVCDMCGNGRLEQRPEDRGAFSCGDCSRVVTSPVLKRHLQVFLDCRSRPQCRVKVKVGARPEHARTPSSLQHSEELRSEECPRKGSGVVKLFCPVRNRPPDQLHWIGGNRASECRRGLCRTLAVAAGSVNFAMWLQGWWWWW>sp|Q9BT56|SPXN_HUMAN Spexin OS=Homo sapiens OX=9606 GN=SPX PE=1 SV=1MKGLRSLAATTLALFLVFVFLGNSSCAPQRLLERRNWTPQAMLYLKGAQGRRFISDQSRRKDLSDRPLPERRSPNPQLLTIPEAATILLASLQKSPEDEEKNFDQTRFLEDSLLNW>sp|Q8N0Z3|SPICE_HUMAN Spindle and centriole-associated protein 1 OS=Homosapiens OX=9606 GN=SPICE1 PE=1 SV=1MSFVRVNRCGPRVGVRKTPKVKKKKTSVKQEWDNTVTDLTVHRATPEDLVRRHEIHKSKNRALVHWELQEKALKRKWRKQKPETLNLEKRRLSIMKEILSDQYQMQDVLEKSDHLIAAAKELFPRRRTGFPNVTVAPDSSQGPIVVNQDPITQSIFNESVIEPQALNDVDGEEEGTVNSQSGESENENELDNSLNSQSNTNTDRFLQQLTEENFELISKLWTDIQQKIATQSQITPPGTPSSALSSGEQRAALNATNAVKRLQTRLQPEESTETLDSSYVVGHVLNSRKQKQLLNKVKRKPNLHALSKPKKNISSGSTTSADLPNRTNSNLDVLKHMIHEVEHEMEEYERWTGREVKGLQSSQGLTGFTLSLVSSLCRLVRYLKESEIQLRKEVETRQQLEQVLGDHRELIDALTAEILRLREENAATQARLQQYMVTTDEQLISLTHAIKNCPVINNRQEIQASESGATGRRVMDSPERPVVNANVSVPLMFREEVAEFPQEELPVKLSQVPDPPDNMNLAKNFPAHIFEPAVLLTPPRQKSNLKFSPLQDVLRRTVQTRPAPRLPPTVEIIEKEQNWEEKTLPIDTDIQNSSEENRLFTQRWRVSHMGEDLENKTQAPFVNLSQPLCNSHSNTQQSRSPTFSEELPVLGDGQQLRTNESLIQRKDIMTRIADLTLQNSAIKAHMNNIIEPRGEQGDGLRELNKQESASDMTSTFPVAQSLTPGSMEERIAELNRQSMEARGKLLQLIEQQKLVGLNLSPPMSPVQLPLRAWTEGAKRTIEVSIPGAEAPESSKCSTVSPVSGINTRRSSGATGNSCSPLNATSGSGRFTPLNPRAKIEKQNEEGWFALSTHVS>sp|P35270|SPRE_HUMAN Sepiapterin reductase OS=Homo sapiens OX=9606GN=SPR PE=1 SV=1MEGGLGRAVCLLTGASRGFGRTLAPLLASLLSPGSVLVLSARNDEALRQLEAELGAERSGLRVVRVPADLGAEAGLQQLLGALRELPRPKGLQRLLLINNAGSLGDVSKGFVDLSDSTQVNNYWALNLTSMLCLTSSVLKAFPDSPGLNRTVVNISSLCALQPFKGWALYCAGKAARDMLFQVLALEEPNVRVLNYAPGPLDTDMQQLARETSVDPDMRKGLQELKAKGKLVDCKVSAQKLLSLLEKDEFKSGAHVDFYDK>sp|Q9BTF0|THUM2_HUMAN THUMP domain-containing protein 2 OS=Homo sapiensOX=9606 GN=THUMPD2 PE=1 SV=2MSEARGEPGSGPEAGARFFCTAGRGLEPFVMREVRARLAATQVEYISGKVFFTTCSDLNMLKKLKSAERLFLLIKKQFPLIISSVSKGKIFNEMQRLINEDPGSWLNAISIWKNLLELDAKKEKLSQRDDNQLKRKVGENEIIAKKLKIEQMQKIEENRDCQLEKQIKEETLEQRDFTTKSEKFQEEEFQNDIEKAIDTHNQNDLTFRVSCRCSGTIGKAFTAQEVGKVIGIAIMKHFGWKADLRNPQLEIFIHLNDIYSVVGIPVFRVSLASRAYIKTAGLRSTIAWAMASLADIKAGAFVLDPMCGLGTILLEAAKEWPDVYYVGADVSDSQLLGTWDNLKAAGLEDKIELLKISVIELPLPSESVDIIISDIPFGKKFKLGKDIKSILQEMERVLHVGGTIVLLLSEDHHRRLTDCKESNIPFNSKDSHTDEPGIKKCLNPEEKTGAFKTASTSFEASNHKFLDRMSPFGSLVPVECYKVSLGKTDAFICKYKKSHSSGL>sp|Q9BTF0-2|THUM2_HUMAN Isoform 2 of THUMP domain-containing protein 2OS=Homo sapiens OX=9606 GN=THUMPD2MSEARGEPGSGPEAGARFFCTAGRGLEPFVMREVRARLAATQVEYISGKVFFTTCSDLNMLKKLKSAERLFLLIKKQFPLIISSVSKGKIFNEMQRLINEDPGSWLNAISIWKNLLELDAKKEKLSQRDDNQLKRKVGENEIIAKKLKIEQMQKIEENRDCQLEKQIKEETLEQRDFTTKSEKFQEEEFQNDIEKAIDTHNQNDLTFRVSCRCSGTIGKAFTAQEVGKVIGIAIMKHFGWKADLRNPQLEIFIHLNDIYSVVGIPVFRVSLASRAYIKTAGLRSTIAWAMASLADIKVPYGSD>sp|Q7Z6L1|TCPR1_HUMAN Tectonin beta-propeller repeat-containing protein1 OS=Homo sapiens OX=9606 GN=TECPR1 PE=1 SV=1MPNSVLWAVDLFGRVYTLSTAGQYWEMCKDSQLEFKRVSATTQCCWGIACDNQVYVYVCASDVPIRRREEAYENQRWNPMGGFCEKLLLSDRWGWSDVSGLQHRPLDRVALPSPHWEWESDWYVDENFGGEPTEKGGWTYAIDFPATYTKDKKWNSCVRRRKWIRYRRYKSRDIWAKIPSKDDPKELPDPFNDLSVGGWEITEEPVGRLSVWAVSLQGKVWYREDVSHSNPEGSSWSLLDTPGEVVQISCGPHDLLWATLWEGQALVREGINRSNPKGSSWSIVEPPGSENGVMHISVGVSVVWAVTKDWKVWFRRGVNSHNPCGTSWIEMVGEMTMVNVGMNDQVWGIGCEDRAVYFRQGVTPSELSGKTWKAIIAARECDRSHSGSSSSLLSAGCFFGDEVRGSGESAPSDTDASSEVERPGPGQILPAEPLDDSKNATGNSASGLGAGRTAEDTVEDACPAEGSREARPNTHPGPAPTPAELPWTNIDLKEAKKVPSHSAAGFPETTSLSSLGLLPLGLEEPYGVDDHPLWAWVSGGGCVVEACAMPRWFTVQAGLSSSVHMLSLSITPAQTAAWRKQIFQQLTERTKRELENFRHYEQAVEQSVWVKTGALQWWCDWKPHKWVDVRLALEQFTGHDGVRDSILFIYYVVHEEKKYIHIFLNEVVALVPVLNETKHSFALYTPERTRQRWPVRLAAATEQDMNDWLALLSLSCCESRKVQGRPSPQAIWSITCKGDIFVSEPSPDLEAHEHPLPCDQMFWRQMGGHLRMVEANSRGVVWGIGYDHTAWVYTGGYGGGCFQGLASSTSNIYTQSDVKCVHIYENQRWNPVTGYTSRGLPTDRYMWSDASGLQECTKAGTKPPSLQWAWVSDWFVDFSVPGGTDQEGWQYASDFPASYHGSKTMKDFVRRRCWARKCKLVTSGPWLEVPPIALRDVSIIPESPGAEGSGHSIALWAVSDKGDVLCRLGVSELNPAGSSWLHVGTDQPFASISIGACYQVWAVARDGSAFYRGSVYPSQPAGDCWYHIPSPPRQRLKQVSAGQTSVYALDENGNLWYRQGITPSYPQGSSWEHVSNNVCRVSVGPLDQVWVIANKVQGSHSLSRGTVCHRTGVQPHEPKGHGWDYGIGGGWDHISVRANATRAPRSSSQEQEPSAPPEAHGPVCC>sp|Q7Z6L1-2|TCPR1_HUMAN Isoform 2 of Tectonin beta-propeller repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=TECPR1MPNSVLWAVDLFGRVYTLSTAGQYWEMCKDSQLEFKRVSATTQCCWGIACDNQVYVYVCASDVPIRRREEAYENQRWNPMGGFCEKLLLSDRWGWSDVSGLQHRPLDRVALPSPHWEWESDWYVDENFGGEPTEKGGWTYAIDFPATYTKDKKWNSCVRRRKWIRYRRYKSRDIWAKIPSKDDPKELPDPFNDLSVGGWEITEEPVGRLSVWAVSLQGKVWYREDVSHSNPEGSSWSLLDTPGEVVQISCGPHDLLWATLWEGQALVREGINRSNPKGSSWSIVEPPGSENGVMHISVGVSVVWAVTKDWKVWFRRGVNSHNPCGTSWIEMVGEMTMVNVGMNDQVWGIGCEDRAVYFRQGVTPSELSGKTWKAIIAARECDRSHSGSSSSLLSAGCFFGDEVRGSGESAPSDTDASSEVERPGPGQILPAEPLDDSKNATGNSASGLGAGRTAEDTVEDACPAEGSREARPNTHPGPAPTPAELPWTNIDLKEAKKVPSHSAAGFPETTSLSSLGLLPLGLEEPYGVDDHPLWAWVSGGGCVVEACAMPRWFTVQAGGLSSSVHMLSLSITPAQTAAWRKQIFQQLTERTKRELENFRHYEQAVEQSVWVKTGALQWWCDWKPHKWVDVRLALEQFTGHDGVRDSILFIYYVVHEEKKYIHIFLNEVVALVPVLNETKHSFALYTPERTRQRWPVRLAAATEQDMNDWLALLSLSCCESRKVQGRPSPQAIWSITCKGDIFVSEPSPDLEAHEHPLPCDQMFWRQMGGHLRMVEANSRGVVWGIGYDHTAWVYTGGYGGGCFQGLASSTSNIYTQSDVKCVHIYENQRWNPVTGYTSRGLPTDRYMWSDASGLQECTKAGTKPPSLQWAWVSDWFVDFSVPGGTDQEGWQYASDFPASYHGSKTMKDFVRRRCWARKCKLVTSGPWLEVPPIALRDVSIIPESPGAEGSGHSIALWAVSDKGDVLCRLGVSELNPAGSSWLHVGTDQPFASISIGACYQVWAVARDGSAFYRGSVYPSQPAGDCWYHIPSPPRQRLKQVSAGQTSVYALDENGNLWYRQGITPSYPQGSSWEHVSNNVCRVSVGPLDQVWVIANKVQGSHSLSRGTVCHRTGVQPHEPKGHGWDYGIGGGWDHISVRANATRAPRSSSQEQEPSAPPEAHGPVCC>sp|Q7Z6L1-3|TCPR1_HUMAN Isoform 3 of Tectonin beta-propeller repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=TECPR1MGGFCEKLLLSDRWGWSDVSGLQHRPLDRVALPSPHWEWESDWYVDENFGGEPTEKGGWTYAIDFPATYTKDKKWNSCVRRRKWIRYRRYKSRDIWAKIPSKDDPKELPDPFNDLSVGGWEITEEPVGRLSVWAVSLQGKVLCPCLASQVWYREDVSHSNPEGSSWSLLDTPGEVVQISCGPHDLLWATLWEGQALVREGINRSNPKGSSWSIVEPPGSENGVMHISVGVSVVWAVTKDWKVWFRRGVNSHNPCGTSWIEMVGEMTMVNVGMNDQVWGIGCEDRAVYFRQGVTPSELSGKTWKAIIAARECDRSHSGSSSSLLSAGCFFGDEVRGSGESAPSDTDASSEVERPGPGQILPAEPLDDSKNATGNSASGLGAGRTAEDTVEDACPAEGSREARPNTHPGPAPTPAELPWTNIDLKEAKKVPSHSAAGFPETTSLSSLGLLPLGLEEPYGVDDHPLWAWVSGGGCVVEACAMPRWFTVQAGLSSSVHMLSLSITPAQTAAWRKQIFQQLTERTKRELENFRHYEQAVEQSVWVKTGALQWWCDWKPHKWVDVRLALEQFTGHDGVRDSILFIYYVVHEEKKYIHIFLNEVVALVPVLNETKHSFALYTPERTRQRWPVRLAAATEQDMNDWLALLSLSCCESRKVQGRPSPQAIWSITCKGDIFVSEPSPDLEAHEHPLPCDQMFWRQMGGHLRMVEANSRGVVWGIGYDHTAWVYTGGYGGGCFQGLASSTSNIYTQSDVKCVHIYENQRWNPVTGYTSSRDRISPCW>sp|Q7Z6L1-4|TCPR1_HUMAN Isoform 4 of Tectonin beta-propeller repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=TECPR1MPNSVLWAVDLFGRVYTLSTAGQYWEMCKDSQLEFKRVSATTQCCWGIACDNQVYVYVCASDVPIRRREEAYENQRWNPMGGFCEKLLLSDRWGWSDVSGLQHRPLDRVALPSPHWEWESDWYVDENFGGEPTEKGGWTYAIDFPATYTKDKKWNSCVRRRKWIRYRRYKSRDIWAKIPSKDDPKELPDPFNDLSVGGWEITEEPVGRLSVWAVSLQGKVWYREDVSHSNPEGSSWSLLDTPGEVVQISCGPHDLLWATLWEGQALVREGINRSNPKGSSWSIVEPPGSENGVMHISVGVSVVWAVTKDWKVWFRRGVNSHNPCGTSWIEMVGEMTMVNVGMNDQVWGIGCEDRAVYFRQGVTPSELSGKTWKAIIAARECDRSHSGSSSSLLSAGCFFGDEVRGSGESAPSDTDASSEVERPGPGQILPAEPLDDSKNATGNSASGLGAGRTAEDTVEDACPAEGSREARPNTHPGPAPTPAELPWTNIDLKEAKKVPSHSAAGFPETTSLSSLGLLPLGLEEPYGVDDHPLWAWVSGGGCVVEACAMPRWFTVQAAGLSSSVHMLSLSITPAQTAAWRKQIFQQLTERTKRELENFRHYEQAVEQSVWVKTGALQWWCDWKPHKWVDVRLALEQFTGHDGVRDSILFIYYVVHEEKKYIHIFLNEVVALVPVLNETKHSFALYTPERTRQRWPVRLAAATEQDMNDWLALLSLSCCESRKVQGRPSPQAIWSITCKGDIFVSEPSPDLEAHEHPLPCDQMFWRQMGGHLRMVEANSRGVVWGIGYDHTAWVYTGGYGGGCFQGLASSTSNIYTQSDVKCVHIYENQRWNPVTGYTSSRGLPTDRYMWSDASGLQECTKAGTKPPSLQWAWVSDWFVDFSVPGGTDQEGWQYASDFPASYHGSKTMKDFVRRRCWARKCKLVTSGPWLEVPPIALRDVSIIPESPGAEGSGHSIALWAVSDKGDVLCRLGVSELNPAGSSWLHVGTDQPFASISIGACYQVWAVARDGSAFYRGSVYPSQPAGDCWYHIPSPPRQRLKQVSAGQTSVYALDENGNLWYRQGITPSYPQGSSWEHVSNNVCRVSVGPLDQVWVIANKVQGSHSLSRGTVCHRTGVQPHEPKGHGWDYGIGGGWDHISVRANATRAPRSSSQEQEPSAPPEAHGPVCC>sp|Q6B0B8|TIGD3_HUMAN Tigger transposable element-derived protein 3OS=Homo sapiens OX=9606 GN=TIGD3 PE=1 SV=1MELSSKKKLHALSLAEKIQVLELLDESKMSQSEVARRFQVSQPQISRICKNKEKLLADWCSGTANRERKRKRESKYSGIDEALLCWYHIARAKAWDVTGPMLLHKAKELADIMGQDFVPSIGWLVRWKRRNNVGFGARHVLAPSFPPEPPPPGLTSQAQLPLSLKDFSPEDVFGCAELPLLYRAVPGSFGACDQVQVLLCANSRGTEKRRVLLGGLQAAPRCFFGIRSEALPASYHPDLGIPWLEWLAQFDRDMGQQGRQVALLLAARVVEELAGLPGLYHVKLLPLAASSTTPPLPSSVVRAFKAHYRHRLLGKLAAIQSERDGTSLAEAGAGITVLDALHVASAAWAKVPPQLIFSSFIQEGLAPGKTPPSSHKTSEMPPVPGGLSLEEFSRFVDLEGEEPRSGVCKEEIGTEDEKGDREGAFEPLPTKADALRALGTLRRWFECNSTSPELFEKFYDCEEEVERLCCL>sp|Q8N6G2|TEX26_HUMAN Testis-expressed protein 26 OS=Homo sapiensOX=9606 GN=TEX26 PE=2 SV=1MEQPGPRAPDPSLCHHNLQPTDDPNWDSYATTMRTAFTPKTGAVPALIRQNGIRRLGYTYSLSDPILNQTQYSDEYTWKSHSKEDLIKTETSRGIKSHKSHLNEDIFLWTLPHCQQTGTLKNCLPWKIPASMKEVNKALSNQFISLTKRDFVDRSKAQKIKKSSHLSLEWKKLLPQPPDTEFRRNYQIPAKIPELQDFSFKYGCYSSLPVASQGLVPSVLHSYLRNQEHTKKQTTYQSDYDKTYPDFLMLLNSFTSSQVKEYLQSLSYKDRQIIDRFIRTHCDTNKKKK>sp|Q96MW7|TIGD1_HUMAN Tigger transposable element-derived protein 1OS=Homo sapiens OX=9606 GN=TIGD1 PE=1 SV=1MASKCSSERKSRTSLTLNQKLEMIKLSEEGMSKAEIGRRLGLLRQTVSQVVNAKEKFLKEVKSATPMNTRMIRKRNSLIADMEKVLVVWIEDQTSRNIPLSQSLIQNKALTLFNSMKAERGVEAAEEKFEASRGWFMRFKERSHFHNIKAQGEAASADVEAAASYPEALAKIIDEGGYTKQQIFNVDETAFYWKKMPSRTFIAREEKSVPGFKASKDRLTLLLGANAAGDFKLKPMLIYHSENPRALKNYTKSTLPVLYKWNSKARMTAHLFTAWFTEYFKPTVETYCSEKKIPFKILLLIDNAPSHPRALMEIYEEINVIFMPANTTSILQPMDQGVISTFKSYYLRNTFHKALAAMDSDVSDGSGQSKLKTFWKGFTILDAIKNIRDSWEEVKLSTLTGVWKKLIPTLIDDYEGFKTSVEEVSADVVEIAKELELEVEPEDVTELLQSHDKTLTDEELFLMDAQRKWFLEMESTPGEDAVNIVEMTTKDLEYYINLVDKAAAGFERIDSNFERSSTVGKMLSNSIACYREIFHERKSQLMRKASPMSYFRKLPQPPQPSAATTLTSQQPSTSRQDPPPAKRVRLTEGSD>sp|Q9NQ88|TIGAR_HUMAN Fructose-2,6-bisphosphatase TIGAR OS=Homo sapiensOX=9606 GN=TIGAR PE=1 SV=1MARFALTVVRHGETRFNKEKIIQGQGVDEPLSETGFKQAAAAGIFLNNVKFTHAFSSDLMRTKQTMHGILERSKFCKDMTVKYDSRLRERKYGVVEGKALSELRAMAKAAREECPVFTPPGGETLDQVKMRGIDFFEFLCQLILKEADQKEQFSQGSPSNCLETSLAEIFPLGKNHSSKVNSDSGIPGLAASVLVVSHGAYMRSLFDYFLTDLKCSLPATLSRSELMSVTPNTGMSLFIINFEEGREVKPTVQCICMNLQDHLNGLTETR>sp|P32780|TF2H1_HUMAN General transcription factor IIH subunit 1 OS=Homosapiens OX=9606 GN=GTF2H1 PE=1 SV=1MATSSEEVLLIVKKVRQKKQDGALYLMAERIAWAPEGKDRFTISHMYADIKCQKISPEGKAKIQLQLVLHAGDTTNFHFSNESTAVKERDAVKDLLQQLLPKFKRKANKELEEKNRMLQEDPVLFQLYKDLVVSQVISAEEFWANRLNVNATDSSSTSNHKQDVGISAAFLADVRPQTDGCNGLRYNLTSDIIESIFRTYPAVKMKYAENVPHNMTEKEFWTRFFQSHYFHRDRLNTGSKDLFAECAKIDEKGLKTMVSLGVKNPLLDLTALEDKPLDEGYGISSVPSASNSKSIKENSNAAIIKRFNHHSAMVLAAGLRKQEAQNEQTSEPSNMDGNSGDADCFQPAVKRAKLQESIEYEDLGKNNSVKTIALNLKKSDRYYHGPTPIQSLQYATSQDIINSFQSIRQEMEAYTPKLTQVLSSSAASSTITALSPGGALMQGGTQQAINQMVPNDIQSELKHLYVAVGELLRHFWSCFPVNTPFLEEKVVKMKSNLERFQVTKLCPFQEKIRRQYLSTNLVSHIEEMLQTAYNKLHTWQSRRLMKKT>sp|P32780-2|TF2H1_HUMAN Isoform 2 of General transcription factor IIHsubunit 1 OS=Homo sapiens OX=9606 GN=GTF2H1MLQEDPVLFQLYKDLVVSQVISAEEFWANRLNVNATDSSSTSNHKQDVGISAAFLADVRPQTDGCNGLRYNLTSDIIESIFRTYPAVKMKYAENVPHNMTEKEFWTRFFQSHYFHRDRLNTGSKDLFAECAKIDEKGLKTMVSLGVKNPLLDLTALEDKPLDEGYGISSVPSASNSKSIKENSNAAIIKRFNHHSAMVLAAGLRKQEAQNEQTSEPSNMDGNSGDADCFQPAVKRAKLQESIEYEDLGKNNSVKTIALNLKKSDRYYHGPTPIQSLQYATSQDIINSFQSIRQEMEAYTPKLTQVLSSSAASSTITALSPGGALMQGGTQQAINQMVPNDIQSELKHLYVAVGELLRHFWSCFPVNTPFLEEKVVKMKSNLERFQVTKLCPFQEKIRRQYLSTNLVSHIEEMLQTAYNKLHTWQSRRLMKKT>sp|A6NCN8|TEX52_HUMAN Testis-expressed protein 52 OS=Homo sapiensOX=9606 GN=TEX52 PE=4 SV=2MASNRQRSLRGPSHPSHMEEPFLQMVQASESLPPSQTWAQREFFLPSESWEFPGFTRQAYHQLALKLPPCTDMKSKVRQRLIHPWKGGAQHTWGFHTWLDVCRLPATFPTQPDRPYDSNVWRWLTDSNAHRCPPTEHPIPPPSWMGQNSFLTFIHCYPTFVDMKRKKQVIFRTVKELKEVEKLKLRSEARAPPLDAQGNIQPPASFKKYRHISAGGRFEPQGLQLMPNPFPNNFARSWPCPNPLPHYQEKVLKLALLPSAPLSQDLIRDFQTLIKDRTALPLHHLSKAQASKSPARKRKRRPGHF>sp|P28347|TEAD1_HUMAN Transcriptional enhancer factor TEF-1 OS=Homosapiens OX=9606 GN=TEAD1 PE=1 SV=2MEPSSWSGSESPAENMERMSDSADKPIDNDAEGVWSPDIEQSFQEALAIYPPCGRRKIILSDEGKMYGRNELIARYIKLRTGKTRTRKQVSSHIQVLARRKSRDFHSKLKDQTAKDKALQHMAAMSSAQIVSATAIHNKLGLPGIPRPTFPGAPGFWPGMIQTGQPGSSQDVKPFVQQAYPIQPAVTAPIPGFEPASAPAPSVPAWQGRSIGTTKLRLVEFSAFLEQQRDPDSYNKHLFVHIGHANHSYSDPLLESVDIRQIYDKFPEKKGGLKELFGKGPQNAFFLVKFWADLNCNIQDDAGAFYGVTSQYESSENMTVTCSTKVCSFGKQVVEKVETEYARFENGRFVYRINRSPMCEYMINFIHKLKHLPEKYMMNSVLENFTILLVVTNRDTQETLLCMACVFEVSNSEHGAQHHIYRLVKD>sp|P28347-2|TEAD1_HUMAN Isoform 2 of Transcriptional enhancer factorTEF-1 OS=Homo sapiens OX=9606 GN=TEAD1MERMSDSADKPIDNDAEGVWSPDIEQSFQEALAIYPPCGRRKIILSDEGKMYGRNELIARYIKLRTGKTRTRKQVSSHIQVLARRKSRDFHSKLKVTSMDQTAKDKALQHMAAMSSAQIVSATAIHNKLGLPGIPRPTFPGAPGFWPGMIQTGQPGSSQDVKPFVQQAYPIQPAVTAPIPGFEPASAPAPSVPAWQGRSIGTTKLRLVEFSAFLEQQRDPDSADLNCNIQDDAGAFYGVTSQYESSENMTVTCSTKVCSFGKQVVEKVETEYARFENGRFVYRINRSPMCEYMINFIHKLKHLPEKYMMNSVLENFTILLVVTNRDTQETLLCMACVFEVSNSEHGAQHHIYRLVKD>sp|P61812|TGFB2_HUMAN Transforming growth factor beta-2 proproteinOS=Homo sapiens OX=9606 GN=TGFB2 PE=1 SV=1MHYCVLSAFLILHLVTVALSLSTCSTLDMDQFMRKRIEAIRGQILSKLKLTSPPEDYPEPEEVPPEVISIYNSTRDLLQEKASRRAAACERERSDEEYYAKEVYKIDMPPFFPSENAIPPTFYRPYFRIVRFDVSAMEKNASNLVKAEFRVFRLQNPKARVPEQRIELYQILKSKDLTSPTQRYIDSKVVKTRAEGEWLSFDVTDAVHEWLHHKDRNLGFKISLHCPCCTFVPSNNYIIPNKSEELEARFAGIDGTSTYTSGDQKTIKSTRKKNSGKTPHLLLMLLPSYRLESQQTNRRKKRALDAAYCFRNVQDNCCLRPLYIDFKRDLGWKWIHEPKGYNANFCAGACPYLWSSDTQHSRVLSLYNTINPEASASPCCVSQDLEPLTILYYIGKTPKIEQLSNMIVKSCKCS>sp|P61812-2|TGFB2_HUMAN Isoform B of Transforming growth factor beta-2proprotein OS=Homo sapiens OX=9606 GN=TGFB2MHYCVLSAFLILHLVTVALSLSTCSTLDMDQFMRKRIEAIRGQILSKLKLTSPPEDYPEPEEVPPEVISIYNSTRDLLQEKASRRAAACERERSDEEYYAKEVYKIDMPPFFPSETVCPVVTTPSGSVGSLCSRQSQVLCGYLDAIPPTFYRPYFRIVRFDVSAMEKNASNLVKAEFRVFRLQNPKARVPEQRIELYQILKSKDLTSPTQRYIDSKVVKTRAEGEWLSFDVTDAVHEWLHHKDRNLGFKISLHCPCCTFVPSNNYIIPNKSEELEARFAGIDGTSTYTSGDQKTIKSTRKKNSGKTPHLLLMLLPSYRLESQQTNRRKKRALDAAYCFRNVQDNCCLRPLYIDFKRDLGWKWIHEPKGYNANFCAGACPYLWSSDTQHSRVLSLYNTINPEASASPCCVSQDLEPLTILYYIGKTPKIEQLSNMIVKSCKCS>sp|Q9NRH3|TBG2_HUMAN Tubulin gamma-2 chain OS=Homo sapiens OX=9606GN=TUBG2 PE=2 SV=1MPREIITLQLGQCGNQIGFEFWKQLCAEHGISPEGIVEEFATEGTDRKDVFFYQADDEHYIPRAVLLDLEPRVIHSILNSPYAKLYNPENIYLSEHGGGAGNNWASGFSQGEKIHEDIFDIIDREADGSDSLEGFVLCHSIAGGTGSGLGSYLLERLNDRYPKKLVQTYSVFPYQDEMSDVVVQPYNSLLTLKRLTQNADCVVVLDNTALNRIATDRLHIQNPSFSQINQLVSTIMSASTTTLRYPGYMNNDLIGLIASLIPTPRLHFLMTGYTPLTTDQSVASVRKTTVLDVMRRLLQPKNVMVSTGRDRQTNHCYIAILNIIQGEVDPTQVHKSLQRIRERKLANFIPWGPASIQVALSRKSPYLPSAHRVSGLMMANHTSISSLFESSCQQFDKLRKRDAFLEQFRKEDMFKDNFDEMDRSREVVQELIDEYHAATQPDYISWGTQEQ>sp|Q9UDY6|TRI10_HUMAN Tripartite motif-containing protein 10 OS=Homosapiens OX=9606 GN=TRIM10 PE=1 SV=3MASAASVTSLADEVNCPICQGTLREPVTIDCGHNFCRACLTRYCEIPGPDLEESPTCPLCKEPFRPGSFRPNWQLANVVENIERLQLVSTLGLGEEDVCQEHGEKIYFFCEDDEMQLCVVCREAGEHATHTMRFLEDAAAPYREQIHKCLKCLRKEREEIQEIQSRENKRMQVLLTQVSTKRQQVISEFAHLRKFLEEQQSILLAQLESQDGDILRQRDEFDLLVAGEICRFSALIEELEEKNERPARELLTDIRSTLIRCETRKCRKPVAVSPELGQRIRDFPQQALPLQREMKMFLEKLCFELDYEPAHISLDPQTSHPKLLLSEDHQRAQFSYKWQNSPDNPQRFDRATCVLAHTGITGGRHTWVVSIDLAHGGSCTVGVVSEDVQRKGELRLRPEEGVWAVRLAWGFVSALGSFPTRLTLKEQPRQVRVSLDYEVGWVTFTNAVTREPIYTFTASFTRKVIPFFGLWGRGSSFSLSS>sp|Q9UDY6-2|TRI10_HUMAN Isoform Beta of Tripartite motif-containingprotein 10 OS=Homo sapiens OX=9606 GN=TRIM10MASAASVTSLADEVNCPICQGTLREPVTIDCGHNFCRACLTRYCEIPGPDLEESPTCPLCKEPFRPGSFRPNWQLANVVENIERLQLVSTLGLGEEDVCQEHGEKIYFFCEDDEMQLCVVCREAGEHATHTMRFLEDAAAPYREQIHKCLKCLRKEREEIQEIQSRENKRMQVLLTQVSTKRQQVISEFAHLRKFLEEQQSILLAQLESQDGDILRQRDEFDLLVAGEICRFSALIEELEEKNERPARELLTDIRSTLIRCETRKCRKPVAVSPELGQRIRDFPQQALPLQREMKMFLEKLCFELDYEPAHISLDPQTSHPKLLLSEDHQRAQFSYKWQNSPDNPQRFDRATCVLAHTGITGGRHTWVWMARVPGDSGCCQFCSPPSVLGTEVAA>sp|A0JD37|TRDV3_HUMAN T cell receptor delta variable 3 OS=Homo sapiensOX=9606 GN=TRDV3 PE=1 SV=1MILTVGFSFLFFYRGTLCDKVTQSSPDQTVASGSEVVLLCTYDTVYSNPDLFWYRIRPDYSFQFVFYGDNSRSEGADFTQGRFSVKHILTQKAFHLVISPVRTEDSATYYCAF>sp|Q96Q05|TPPC9_HUMAN Trafficking protein particle complex subunit 9OS=Homo sapiens OX=9606 GN=TRAPPC9 PE=1 SV=2MSVPDYMQCAEDHQTLLVVVQPVGIVSEENFFRIYKRICSVSQISVRDSQRVLYIRYRHHYPPENNEWGDFQTHRKVVGLITITDCFSAKDWPQTFEKFHVQKEIYGSTLYDSRLFVFGLQGEIVEQPRTDVAFYPNYEDCQTVEKRIEDFIESLFIVLESKRLDRATDKSGDKIPLLCVPFEKKDFVGLDTDSRHYKKRCQGRMRKHVGDLCLQAGMLQDSLVHYHMSVELLRSVNDFLWLGAALEGLCSASVIYHYPGGTGGKSGARRFQGSTLPAEAANRHRPGAQEVLIDPGALTTNGINPDTSTEIGRAKNCLSPEDIIDKYKEAISYYSKYKNAGVIELEACIKAVRVLAIQKRSMEASEFLQNAVYINLRQLSEEEKIQRYSILSELYELIGFHRKSAFFKRVAAMQCVAPSIAEPGWRACYKLLLETLPGYSLSLDPKDFSRGTHRGWAAVQMRLLHELVYASRRMGNPALSVRHLSFLLQTMLDFLSDQEKKDVAQSLENYTSKCPGTMEPIALPGGLTLPPVPFTKLPIVRHVKLLNLPASLRPHKMKSLLGQNVSTKSPFIYSPIIAHNRGEERNKKIDFQWVQGDVCEVQLMVYNPMPFELRVENMGLLTSGVEFESLPAALSLPAESGLYPVTLVGVPQTTGTITVNGYHTTVFGVFSDCLLDNLPGIKTSGSTVEVIPALPRLQISTSLPRSAHSLQPSSGDEISTNVSVQLYNGESQQLIIKLENIGMEPLEKLEVTSKVLTTKEKLYGDFLSWKLEETLAQFPLQPGKVATFTINIKVKLDFSCQENLLQDLSDDGISVSGFPLSSPFRQVVRPRVEGKPVNPPESNKAGDYSHVKTLEAVLNFKYSGGPGHTEGYYRNLSLGLHVEVEPSVFFTRVSTLPATSTRQCHLLLDVFNSTEHELTVSTRSSEALILHAGECQRMAIQVDKFNFESFPESPGEKGQFANPKQLEEERREARGLEIHSKLGICWRIPSLKRSGEASVEGLLNQLVLEHLQLAPLQWDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYLDAVQPSGQSACLGALLFLYTGDFFLHIRFHEDSTSKELPPSWFCLPSVHVCALEAQA>sp|Q96Q05-2|TPPC9_HUMAN Isoform 2 of Trafficking protein particlecomplex subunit 9 OS=Homo sapiens OX=9606 GN=TRAPPC9MVPAGDQDRAPHRGKPAQAGARTSRASRALRSWRRSQAARATVTHPRGGHDRGSHGGYREGHRGCRRDPQWASAGPPPLSFTEEVKFELRALKDWDFKMSVPDYMQCAEDHQTLLVVVQPVGIVSEENFFRIYKRICSVSQISVRDSQRVLYIRYRHHYPPENNEWGDFQTHRKVVGLITITDCFSAKDWPQTFEKFHVQKEIYGSTLYDSRLFVFGLQGEIVEQPRTDVAFYPNYEDCQTVEKRIEDFIESLFIVLESKRLDRATDKSGDKIPLLCVPFEKKDFVGLDTDSRHYKKRCQGRMRKHVGDLCLQAGMLQDSLVHYHMSVELLRSVNDFLWLGAALEGLCSASVIYHYPGGTGGKSGARRFQGSTLPAEAANRHRPGAQEVLIDPGALTTNGINPDTSTEIGRAKNCLSPEDIIDKYKEAISYYSKYKNAGVIELEACIKAVRVLAIQKRSMEASEFLQNAVYINLRQLSEEEKIQRYSILSELYELIGFHRKSAFFKRVAAMQCVAPSIAEPGWRACYKLLLETLPGYSLSLDPKDFSRGTHRGWAAVQMRLLHELVYASRRMGNPALSVRHLSFLLQTMLDFLSDQEKKDVAQSLENYTSKCPGTMEPIALPGGLTLPPVPFTKLPIVRHVKLLNLPASLRPHKMKSLLGQNVSTKSPFIYSPIIAHNRGEERNKKIDFQWVQGDVCEVQLMVYNPMPFELRVENMGLLTSGVEFESLPAALSLPAESGLYPVTLVGVPQTTGTITVNGYHTTVFGVFSDCLLDNLPGIKTSGSTVEVIPALPRLQISTSLPRSAHSLQPSSGDEISTNVSVQLYNGESQQLIIKLENIGMEPLEKLEVTSKVLTTKEKLYGDFLSWKLEETLAQFPLQPGKVATFTINIKVKLDFSCQENLLQDLSDDGISVSGFPLSSPFRQVVRPRVEGKPVNPPESNKAGDYSHVKTLEAVLNFKYSGGPGHTEGYYRNLSLGLHVEVEPSVFFTRVSTLPATSTRQCHLLLDVFNSTEHELTVSTRSSEALILHAGECQRMAIQVDKFNFESFPESPGEKGQFANPKQLEEERREARGLEIHSKLGICWRIPSLKRSGEASVEGLLNQLVLEHLQLAPLQWDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYLDAVQPSGQSACLGALLFLYTGDFFLHIRFHEDSTSKELPPSWFCLPSVHVCALEAQA>sp|Q96Q05-3|TPPC9_HUMAN Isoform 3 of Trafficking protein particlecomplex subunit 9 OS=Homo sapiens OX=9606 GN=TRAPPC9MSVPDYMQCAEDHQTLLVVVQPVGIVSEENFFRIYKRICSVSQISVRDSQRVLYIRYRHHYPPENNEWGDFQTHRKVVGLITITDCFSAKDWPQTFEKFHVQKEIYGSTLYDSRLFVFGLQGEIVEQPRTDVAFYPNYEDCQTVEKRIEDFIESLFIVLESKRLDRATDKSGDKIPLLCVPFEKKDFVGLDTDSRHYKKRCQGRMRKHVGDLCLQAGMLQDSLVHYHMSVELLRSVNDFLWLGAALEGLCSASVIYHYPGGTGGKSGARRFQGSTLPAEAANRHRPGALTTNGINPDTSTEIGRAKNCLSPEDIIDKYKEAISYYSKYKNAGVIELEACIKAVRVLAIQKRSMEASEFLQNAVYINLRQLSEEEKIQRYSILSELYELIGFHRKSAFFKRVAAMQCVAPSIAEPGWRACYKLLLETLPGYSLSLDPKDFSRGTHRGWAAVQMRLLHELVYASRRMGNPALSVRHLSFLLQTMLDFLSDQEKKDVAQSLENYTSKCPGTMEPIALPGGLTLPPVPFTKLPIVRHVKLLNLPASLRPHKMKSLLGQNVSTKSPFIYSPIIAHNRGEERNKKIDFQWVQGDVCEVQLMVYNPMPFELRVENMGLLTSGVEFESLPAALSLPAESGLYPVTLVGVPQTTGTITVNGYHTTVFGVFSDCLLDNLPGIKTSGSTVEVIPALPRLQISTSLPRSAHSLQPSSGDEISTNVSVQLYNGESQQLIIKLENIGMEPLEKLEVTSKVLTTKEKLYGDFLSWKLEETLAQFPLQPGKVATFTINIKVKLDFSCQENLLQDLSDDGISVSGFPLSSPFRQVVRPRVEGKPVNPPESNKAGDYSHVKTLEAVLNFKYSGGPGHTEGYYRNLSLGLHVEVEPSVFFTRVSTLPATSTRQCHLLLDVFNSTEHELTVSTRSSEALILHAGECQRMAIQVDKFNFESFPESPGEKGQFANPKQLEEERREARGLEIHSKLGICWRIPSLKRSGEASVEGLLNQLVLEHLQLAPLQWDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYLDAVQPSGQSACLGALLFLYTGDFFLHIRFHEDSTSKELPPSWFCLPSVHVCALEAQA>sp|O14817|TSN4_HUMAN Tetraspanin-4 OS=Homo sapiens OX=9606 GN=TSPAN4PE=1 SV=1MARACLQAVKYLMFAFNLLFWLGGCGVLGVGIWLAATQGSFATLSSSFPSLSAANLLIITGAFVMAIGFVGCLGAIKENKCLLLTFFLLLLLVFLLEATIAILFFAYTDKIDRYAQQDLKKGLHLYGTQGNVGLTNAWSIIQTDFRCCGVSNYTDWFEVYNATRVPDSCCLEFSESCGLHAPGTWWKAPCYETVKVWLQENLLAVGIFGLCTALVQILGLTFAMTMYCQVVKADTYCA>sp|Q969D9|TSLP_HUMAN Thymic stromal lymphopoietin OS=Homo sapiensOX=9606 GN=TSLP PE=1 SV=1MFPFALLYVLSVSFRKIFILQLVGLVLTYDFTNCDFEKIKAAYLSTISKDLITYMSGTKSTEFNNTVSCSNRPHCLTEIQSLTFNPTAGCASLAKEMFAMKTKAALAIWCPGYSETQINATQAMKKRRKRKVTTNKCLEQVSQLQGLWRRFNRPLLKQQ>sp|Q969D9-2|TSLP_HUMAN Isoform 2 of Thymic stromal lymphopoietin OS=Homosapiens OX=9606 GN=TSLPMFAMKTKAALAIWCPGYSETQINATQAMKKRRKRKVTTNKCLEQVSQLQGLWRRFNRPLLKQQ>sp|A2A3L6|TTC24_HUMAN Tetratricopeptide repeat protein 24 OS=Homosapiens OX=9606 GN=TTC24 PE=4 SV=1MSSPNPEDVPRRPEPEPSSSNKKKKKRKWLRQEASIQALTRAGHGALQAGQNHEALNNFQRAFLLASKAPQTRDTPVLQACAFNLGAAYVETGDPARGLELLLRAHPEEKAQGRRHGDQCFNVALAYHALGELPQALAWYHRALGHYQPQGDQGEAWAKMGACYQALGQPELAAHCLQEASQAYAQERQLRAAALALGAAAGCMLKSGRHRVGEVVQVLEKSRRLAERSTERRLLGHLYNDLGLGYSQLQLFPLAVEAFLQALPLCWVPGEQATVLRNLGMAHNALGNYQEAREFHQKAADLHGSVGQRWEQGRSFGSLAFALSQLGDHKAARDNYLHALQAARDSGDMKGQWQACEGLGAAAARLGQYDQALKYYKEALAQCQKEPDSVRERLVAKLADTVRTRLAQVGLVQTHTLTSAPGRLQAPGGASQAEGTPAKAGSSTAGVQHRSSSGWEDEEFEEGHQKKKEERSANVPVRAGPGRPELCFLPGTVNHSHHLASSCPTFTKHTPCRGTVLGKASIYSPGPRAHLPFVGPGPPRAEYPSILVPNGPQANRSSRWPRESLSRSRQRRPMESGICTIV>sp|O14795|UN13B_HUMAN Protein unc-13 homolog B OS=Homo sapiens OX=9606GN=UNC13B PE=1 SV=2MSLLCVRVKRAKFQGSPDKFNTYVTLKVQNVKSTTVAVRGDQPSWEQDFMFEISRLDLGLSVEVWNKGLIWDTMVGTVWIALKTIRQSDEEGPGEWSTLEAETLMKDDEICGTRNPTPHKILLDTRFELPFDIPEEEARYWTYKWEQINALGADNEYSSQEESQRKPLPTAAAQCSFEDPDSAVDDRDSDYRSETSNSFPPPYHTASQPNASVHQFPVPVRSPQQLLLQGSSRDSCNDSMQSYDLDYPERRAISPTSSSRYGSSCNVSQGSSQLSELDQYHEQDDDHRETDSIHSCHSSHSLSRDGQAGFGEQEKPLEVTGQAEKEAACEPKEMKEDATTHPPPDLVLQKDHFLGPQESFPEENASSPFTQARAHWIRAVTKVRLQLQEIPDDGDPSLPQWLPEGPAGGLYGIDSMPDLRRKKPLPLVSDLSLVQSRKAGITSAMATRTSLKDEELKSHVYKKTLQALIYPISCTTPHNFEVWTATTPTYCYECEGLLWGIARQGMRCSECGVKCHEKCQDLLNADCLQRAAEKSCKHGAEDRTQNIIMAMKDRMKIRERNKPEIFEVIRDVFTVNKAAHVQQMKTVKQSVLDGTSKWSAKITITVVCAQGLQAKDKTGSSDPYVTVQVSKTKKRTKTIFGNLNPVWEEKFHFECHNSSDRIKVRVWDEDDDIKSRVKQRLKRESDDFLGQTIIEVRTLSGEMDVWYNLEKRTDKSAVSGAIRLQISVEIKGEEKVAPYHVQYTCLHENLFHYLTDIQGSGGVRIPEARGDDAWKVYFDETAQEIVDEFAMRYGIESIYQAMTHFACLSSKYMCPGVPAVMSTLLANINAYYAHTTASTNVSASDRFAASNFGKERFVKLLDQLHNSLRIDLSTYRNNFPAGSPERLQDLKSTVDLLTSITFFRMKVQELQSPPRASQVVKDCVKACLNSTYEYIFNNCHDLYSRQYQLKQELPPEEQGPSIRNLDFWPKLITLIVSIIEEDKNSYTPVLNQFPQELNVGKVSAEVMWHLFAQDMKYALEEHEKDHLCKSADYMNLHFKVKWLHNEYVRDLPVLQGQVPEYPAWFEQFVLQWLDENEDVSLEFLRGALERDKKDGFQQTSEHALFSCSVVDVFTQLNQSFEIIRKLECPDPSILAHYMRRFAKTIGKVLMQYADILSKDFPAYCTKEKLPCILMNNVQQLRVQLEKMFEAMGGKELDLEAADSLKELQVKLNTVLDELSMVFGNSFQVRIDECVRQMADILGQVRGTGNASPDARASAAQDADSVLRPLMDFLDGNLTLFATVCEKTVLKRVLKELWRVVMNTMERMIVLPPLTDQTGTQLIFTAAKELSHLSKLKDHMVREETRNLTPKQCAVLDLALDTIKQYFHAGGNGLKKTFLEKSPDLQSLRYALSLYTQTTDTLIKTFVRSQTTQGSGVDDPVGEVSIQVDLFTHPGTGEHKVTVKVVAANDLKWQTAGMFRPFVEVTMVGPHQSDKKRKFTTKSKSNNWAPKYNETFHFLLGNEEGPESYELQICVKDYCFAREDRVLGLAVMPLRDVTAKGSCACWCPLGRKIHMDETGLTILRILSQRSNDEVAREFVKLKSESRSTEEGS>sp|O14795-2|UN13B_HUMAN Isoform 2 of Protein unc-13 homolog B OS=Homosapiens OX=9606 GN=UNC13BMSLLCVRVKRAKFQGSPDKFNTYVTLKVQNVKSTTVAVRGDQPSWEQDFMFEISRLDLGLSVEVWNKGLIWDTMVGTVWIALKTIRQSDEEGPGEWSTLEAETLMKDDEICGTRNPTPHKILLDTRFELPFDIPEEEARYWTYKWEQINALGADNEYSSQEESQRKPLPTAAAQCSFEDPDSAVDDRDSDYRSETSNSFPPPYHTASQPNASVHQFPVPVRSPQQLLLQGSSRDSCNDSMQSYDLDYPERRAISPTSSSRYGSSCNVSQGSSQLSELDQYHEQDDDHRETDSIHSCHSSHSLSRDGQAGFGEQEKPLEVTGQAEKEAACEPKEMKEDATTHPPPDLVLQKDHFLGPQESFPEENASSPFTQARAHWIRAVTKVRLQLQEIPDDGDPSLPQWLPEGPAGGLYGIDSMPDLRRKKPLPLVSDLSLVQSRKAGITSAMATRTSLKDEELKSHVYKKTLQALIYPISCTTPHNFEVWTATTPTYCYECEGLLWGIARQGMRCSECGVKCHEKCQDLLNADCLQRAAEKSCKHGAEDRTQNIIMAMKDRMKIRERNKPEIFEVIRDVFTVNKAAHVQQMKTVKQSVLDGTSKWSAKITITVVCAQGLQAKDKTGSSDPYVTVQVSKTKKRTKTIFGNLNPVWEEKFHFECHNSSDRIKVRVWDEDDDIKSRVKQRLKRESDDFLGQTIIEVRTLSGEMDVWYNLEKRTDKSAVSGAIRLQISVEIKGEEKVAPYHVQYTCLHENLFHYLTDIQGSGGVRIPEARGDDAWKVYFDETAQEIVDEFAMRYGIESIYQAMTHFACLSSKYMCPGVPAVMSTLLANINAYYAHTTASTNVSASDRFAASNFGKERFVKLLDQLHNSLRIDLSTYRNNFPAGSPERLQDLKSTVDLLTSITFFRMKVQELQSPPRASQVVKDCVKACLNSTYEYIFNNCHDLYSRQYQLKQELPPEEQGPSIRNLDFWPKLITLIVSIIEEDKNSYTPVLNQFPQELNVGKVSAEVMWHLFAQDMKYALEEHEKDHLCKSADYMNLHFKVKWLHNEYVRDLPVLQGQVPEYPAWFEQFVLQWLDENEDVSLEFLRGALERDKKDGFQQTSEHALFSCSVVDVFTQLNQSFEIIRKLECPDPSILAHYMRRFAKTIGKVLMQYADILSKDFPAYCTKEKLPCILMNNVQQLRVQLEKMFEAMGGKELDLEAADSLKELQVKLNTVLDELSMVFGNSFQVRIDECVRQMADILGQVRGTGNASPDARASAAQDADSVLRPLMDFLDGNLTLFATVCEKTVLKRVLKELWRVVMNTMERMIVLPPLTDQTGTQLIFTAAKELSHLSKLKDHMVREETRNLTPKQCAVLDLALDTIKQYFHAGGNGLKKTFLEKSPDLQSLRYALSLYTQTTDTLIKTFVRSQTTQVHDGKGIRFTANEDIRPEKGSGVDDPVGEVSIQVDLFTHPGTGEHKVTVKVVAANDLKWQTAGMFRPFVEVTMVGPHQSDKKRKFTTKSKSNNWAPKYNETFHFLLGNEEGPESYELQICVKDYCFAREDRVLGLAVMPLRDVTAKGSCACWCPLGRKIHMDETGLTILRILSQRSNDEVAREFVKLKSESRSTEEGS>sp|Q96SJ8|TSN18_HUMAN Tetraspanin-18 OS=Homo sapiens OX=9606 GN=TSPAN18PE=2 SV=1MEGDCLSCMKYLMFVFNFFIFLGGACLLAIGIWVMVDPTGFREIVAANPLLLTGAYILLAMGGLLFLLGFLGCCGAVRENKCLLLFFFLFILIIFLAELSAAILAFIFRENLTREFFTKELTKHYQGNNDTDVFSATWNSVMITFGCCGVNGPEDFKFASVFRLLTLDSEEVPEACCRREPQSRDGVLLSREECLLGRSLFLNKQGCYTVILNTFETYVYLAGALAIGVLAIELFAMIFAMCLFRGIQ>sp|B1AH88|TSPOB_HUMAN Putative peripheral benzodiazepine receptor-related protein OS=Homo sapiens OX=9606 GN=TSPO PE=5 SV=1MAPHLLWCPTNGLGLGGSPAGQWGGGSHYRGLVPGEPAGRPPALPLPGLAGLHDHTQLLRMAGQPWLAWGTAAARVSARPTRDCSCTSRCHHACDVVAVTLS>sp|Q9BY64|UDB28_HUMAN UDP-glucuronosyltransferase 2B28 OS=Homo sapiensOX=9606 GN=UGT2B28 PE=1 SV=1MALKWTSVLLLIHLGCYFSSGSCGKVLVWTGEYSHWMNMKTILKELVQRGHEVTVLASSASILFDPNDAFTLKLEVYPTSLTKTEFENIIMQQVKRWSDIQKDSFWLYFSQEQEILWEFHDIFRNFCKDVVSNKKVMKKLQESRFDIIFADAFFPCGELLAALLNIPFVYSLCFTPGYTIERHSGGLIFPPSYIPVVMSKLSDQMTFMERVKNMIYVLYFDFWFQMCDMKKWDQFYSEVLGRPTTLFETMGKADIWLMRNSWSFQFPHPFLPNIDFVGGLHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSVISNMTAERANVIATALAKIPQKVLWRFDGNKPDALGLNTRLYKWIPQNDLLGLPKTRAFITHGGANGIYEAIYHGIPMVGIPLFWDQPDNIAHMKAKGAAVRLDFHTMSSTDLLNALKTVINDPSYKENVMKLSIIQHDQPVKPLHRAVFWIEFVMCHKGAKHLRVAARDLTWFQYHSLDVIGFLLACVATVIFVVTKFCLFCFWKFARKGKKGKRD>sp|Q9BY64-2|UDB28_HUMAN Isoform 2 of UDP-glucuronosyltransferase 2B28OS=Homo sapiens OX=9606 GN=UGT2B28MALKWTSVLLLIHLGCYFSSGSCGKVLVWTGEYSHWMNMKTILKELVQRGHEVTVLASSASILFDPNDAFTLKLEVYPTSLTKTEFENIIMQQVKRWSDIQKDSFWLYFSQEQEILWEFHDIFRNFCKDVVSNKKVMKKLQESRFDIIFADAFFPCGELLAALLNIPFVYSLCFTPGYTIERHSGGLIFPPSYIPVVMSKLSDQMTFMERVKNMIYVLYFDFWFQMCDMKKWDQFYSEVLGRPTTLFETMGKADIWLMRNSWSFQFPHPFLPNIDFVGGLHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSVISNMTAERANVIATALAKIPQKI>sp|Q2TAA8|TXIP1_HUMAN Translin-associated factor X-interacting protein 1OS=Homo sapiens OX=9606 GN=TSNAXIP1 PE=1 SV=1MGGHLSPWPTYTSGQTILQNRKPCSDDYRKRVGSCQQHPFRTAKPQYLEELENYLRKELLLLDLGTDSTQELRLQPYREIFEFFIEDFKTYKPLLSSIKNAYEGMLAHQREKIRALEPLKAKLVTVNEDCNERILAMRAEEKYEISLLKKEKMNLLKLIDKKNEEKISLQSEVTKLRKNLAEEYLHYLSERDACKILIADLNELRYQREDMSLAQSPGIWGEDPVKLTLALKMTRQDLTRTQMELNNMKANFGDVVPRRDFEMQEKTNKDLQEQLDTLRASYEEVRKEHEILMQLHMSTLKERDQFFSELQEIQRTSTPRPDWTKCKDVVAGGPERWQMLAEGKNSDQLVDVLLEEIGSGLLREKDFFPGLGYGEAIPAFLRFDGLVENKKPSKKDVVNLLKDAWKERLAEEQKETFPDFFFNFLEHRFGPSDAMAWAYTIFENIKIFHSNEVMSQFYAVLMGKRSENVYVTQKETVAQLLKEMTNADSQNEGLLTMEQFNTVLKSTFPLKTEEQIQELMEAGGWHPSSSNADLLNYRSLFMEDEEGQSEPFVQKLWEQYMDEKDEYLQQLKQELGIELHEEVTLPKLRGGLMTIDPSLDKQTVNTYMSQAFQLPESEMPEEGDEKEEAVVEILQTALERLQVIDIRRVGPREPEPAS>sp|Q2TAA8-2|TXIP1_HUMAN Isoform 2 of Translin-associated factor X-interacting protein 1 OS=Homo sapiens OX=9606 GN=TSNAXIP1MQLHMSTLKERDQFFSELQEIQRTSTPRPDWTKCKDVVAGGPERWQMLAEGKNSDQLVDVLLEEIGSGLLREKDFFPGLGYGEAIPAFLRFDGLVENKKPSKKDVVNLLKDAWKERLAEEQKETFPDFFFNFLEHRFGPSDAMAWAYTIFENIKIFHSNEVMSQFYAVLMGKRSENVYVTQKETVAQLLKEMTNADSQNEGLLTMEQFNTVLKSTFPLKTEEQIQELMEAGGWHPSSSNADLLNYRSLFMEDEEGQSEPFVQKLWEQYMDEKDEYLQQLKQELGIELHEEVTLPKLRGGLMTIDPSLDKQTVNTYMSQAFQLPESEMPEEGDEKEEAVVEILQTALERLQVIDIRRVGPREPEPAS>sp|Q9HBJ7|UBP29_HUMAN Ubiquitin carboxyl-terminal hydrolase 29 OS=Homosapiens OX=9606 GN=USP29 PE=2 SV=1MISLKVCGFIQIWSQKTGMTKLKEALIETVQRQKEIKLVVTFKSGKFIRIFQLSNNIRSVVLRHCKKRQSHLRLTLKNNVFLFIDKLSYRDAKQLNMFLDIIHQNKSQQPMKSDDDWSVFESRNMLKEIDKTSFYSICNKPSYQKMPLFMSKSPTHVKKGILENQGGKGQNTLSSDVQTNEDILKEDNPVPNKKYKTDSLKYIQSNRKNPSSLEDLEKDRDLKLGPSFNTNCNGNPNLDETVLATQTLNAKNGLTSPLEPEHSQGDPRCNKAQVPLDSHSQQLQQGFPNLGNTCYMNAVLQSLFAIPSFADDLLTQGVPWEYIPFEALIMTLTQLLALKDFCSTKIKRELLGNVKKVISAVAEIFSGNMQNDAHEFLGQCLDQLKEDMEKLNATLNTGKECGDENSSPQMHVGSAATKVFVCPVVANFEFELQLSLICKACGHAVLKVEPNNYLSINLHQETKPLPLSIQNSLDLFFKEEELEYNCQMCKQKSCVARHTFSRLSRVLIIHLKRYSFNNAWLLVKNNEQVYIPKSLSLSSYCNESTKPPLPLSSSAPVGKCEVLEVSQEMISEINSPLTPSMKLTSESSDSLVLPVEPDKNADLQRFQRDCGDASQEQHQRDLENGSALESELVHFRDRAIGEKELPVADSLMDQGDISLPVMYEDGGKLISSPDTRLVEVHLQEVPQHPELQKYEKTNTFVEFNFDSVTESTNGFYDCKENRIPEGSQGMAEQLQQCIEESIIDEFLQQAPPPGVRKLDAQEHTEETLNQSTELRLQKADLNHLGALGSDNPGNKNILDAENTRGEAKELTRNVKMGDPLQAYRLISVVSHIGSSPNSGHYISDVYDFQKQAWFTYNDLCVSEISETKMQEARLHSGYIFFYMHNGIFEELLRKAENSRLPSTQAGVIPQGEYEGDSLYRPA>sp|A0A075B6L2|TVG11_HUMAN Probable non-functional T cell receptor gammavariable 11 OS=Homo sapiens OX=9606 GN=TRGV11 PE=1 SV=2MPLVVAVIFFSLWVFALGQLEQPEISISRPANKSAHISWKASIQGFSSKIIHWYWQKPNKGLEYLLHVFLTISAQDCSGGKTKKLEVSKNAHTSTSTLKIKFLEKEDEVVYHCACWIRH>sp|Q8TEY7|UBP33_HUMAN Ubiquitin carboxyl-terminal hydrolase 33 OS=Homosapiens OX=9606 GN=USP33 PE=1 SV=2MTGSNSHITILTLKVLPHFESLGKQEKIPNKMSAFRNHCPHLDSVGEITKEDLIQKSLGTCQDCKVQGPNLWACLENRCSYVGCGESQVDHSTIHSQETKHYLTVNLTTLRVWCYACSKEVFLDRKLGTQPSLPHVRQPHQIQENSVQDFKIPSNTTLKTPLVAVFDDLDIEADEEDELRARGLTGLKNIGNTCYMNAALQALSNCPPLTQFFLDCGGLARTDKKPAICKSYLKLMTELWHKSRPGSVVPTTLFQGIKTVNPTFRGYSQQDAQEFLRCLMDLLHEELKEQVMEVEEDPQTITTEETMEEDKSQSDVDFQSCESCSNSDRAENENGSRCFSEDNNETTMLIQDDENNSEMSKDWQKEKMCNKINKVNSEGEFDKDRDSISETVDLNNQETVKVQIHSRASEYITDVHSNDLSTPQILPSNEGVNPRLSASPPKSGNLWPGLAPPHKKAQSASPKRKKQHKKYRSVISDIFDGTIISSVQCLTCDRVSVTLETFQDLSLPIPGKEDLAKLHSSSHPTSIVKAGSCGEAYAPQGWIAFFMEYVKRFVVSCVPSWFWGPVVTLQDCLAAFFARDELKGDNMYSCEKCKKLRNGVKFCKVQNFPEILCIHLKRFRHELMFSTKISTHVSFPLEGLDLQPFLAKDSPAQIVTYDLLSVICHHGTASSGHYIAYCRNNLNNLWYEFDDQSVTEVSESTVQNAEAYVLFYRKSSEEAQKERRRISNLLNIMEPSLLQFYISRQWLNKFKTFAEPGPISNNDFLCIHGGVPPRKAGYIEDLVLMLPQNIWDNLYSRYGGGPAVNHLYICHTCQIEAEKIEKRRKTELEIFIRLNRAFQKEDSPATFYCISMQWFREWESFVKGKDGDPPGPIDNTKIAVTKCGNVMLRQGADSGQISEETWNFLQSIYGGGPEVILRPPVVHVDPDILQAEEKIEVETRSL>sp|Q8TEY7-2|UBP33_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 33 OS=Homo sapiens OX=9606 GN=USP33MSAFRNHCPHLDSVGEITKEDLIQKSLGTCQDCKVQGPNLWACLENRCSYVGCGESQVDHSTIHSQETKHYLTVNLTTLRVWCYACSKEVFLDRKLGTQPSLPHVRQPHQIQENSVQDFKIPSNTTLKTPLVAVFDDLDIEADEEDELRARGLTGLKNIGNTCYMNAALQALSNCPPLTQFFLDCGGLARTDKKPAICKSYLKLMTELWHKSRPGSVVPTTLFQGIKTVNPTFRGYSQQDAQEFLRCLMDLLHEELKEQVMEVEEDPQTITTEETMEEDKSQSDVDFQSCESCSNSDRAENENGSRCFSEDNNETTMLIQDDENNSEMSKDWQKEKMCNKINKVNSEGEFDKDRDSISETVDLNNQETVKVQIHSRASEYITDVHSNDLSTPQILPSNEGVNPRLSASPPKSGNLWPGLAPPHKKAQSASPKRKKQHKKYRSVISDIFDGTIISSVQCLTCDRVSVTLETFQDLSLPIPGKEDLAKLHSSSHPTSIVKAGSCGEAYAPQGWIAFFMEYVKRFVVSCVPSWFWGPVVTLQDCLAAFFARDELKGDNMYSCEKCKKLRNGVKFCKVQNFPEILCIHLKRFRHELMFSTKISTHVSFPLEGLDLQPFLAKDSPAQIVTYDLLSVICHHGTASSGHYIAYCRNNLNNLWYEFDDQSVTEVSESTVQNAEAYVLFYRKSSEEAQKERRRISNLLNIMEPSLLQFYISRQWLNKFKTFAEPGPISNNDFLCIHGGVPPRKAGYIEDLVLMLPQNIWDNLYSRYGGGPAVNHLYICHTCQIEAEKIEKRRKTELEIFIRLNRAFQKEDSPATFYCISMQWFREWESFVKGKDGDPPGPIDNTKIAVTKCGNVMLRQGADSGQISEETWNFLQSIYGGGPEVILRPPVVHVDPDILQAEEKIEVETRSL>sp|Q8TEY7-3|UBP33_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 33 OS=Homo sapiens OX=9606 GN=USP33MTGSNSHITILTLKVLPHFESLGKQEKIPNKMSAFRNHCPHLDSVGEITKEDLIQKSLGTCQDCKVQGPNLWACLENRCSYVGCGESQVDHSTIHSQETKHYLTVNLTTLRVWCYACSKEVFLDRKLGTQPSLPHVRQPHQIQENSVQDFKIPSNTTLKTPLVAVFDDLDIEADEEDELRARGLTGLKNIGNTCYMNAALQALSNCPPLTQFFLDCGGLARTDKKPAICKSYLKLMTELWHKSRPGSVVPTTLFQGIKTVNPTFRGYSQQDAQEFLRCLMDLLHEELKEQVMEVEEDPQTITTEETMEEDKSQSDVDFQSCESCSNSDRAENENGSRCFSEDNNETTMLIQDDENNSEMSKDWQKEKMCNKINKVNSEGEFDKDRDSISETVDLNNQETVKVQIHSRASEYITDVHSNDLSTPQILPSNEGVNPRLSASPPKSGNLWPGLAPPHKKAQSASPKRKKQHKKYRSVISDIFDGTIISSVQCLTCDRVSVTLETFQDLSLPIPGKEDLAKLHSSSHPTSIVKAGSCGEAYAPQGWIAFFMEYVKSWFWGPVVTLQDCLAAFFARDELKGDNMYSCEKCKKLRNGVKFCKVQNFPEILCIHLKRFRHELMFSTKISTHVSFPLEGLDLQPFLAKDSPAQIVTYDLLSVICHHGTASSGHYIAYCRNNLNNLWYEFDDQSVTEVSESTVQNAEAYVLFYRKSSEEAQKERRRISNLLNIMEPSLLQFYISRQWLNKFKTFAEPGPISNNDFLCIHGGVPPRKAGYIEDLVLMLPQNIWDNLYSRYGGGPAVNHLYICHTCQIEAEKIEKRRKTELEIFIRVKK>sp|P40126|TYRP2_HUMAN L-dopachrome tautomerase OS=Homo sapiens OX=9606GN=DCT PE=1 SV=1MSPLWWGFLLSCLGCKILPGAQGQFPRVCMTVDSLVNKECCPRLGAESANVCGSQQGRGQCTEVRADTRPWSGPYILRNQDDRELWPRKFFHRTCKCTGNFAGYNCGDCKFGWTGPNCERKKPPVIRQNIHSLSPQEREQFLGALDLAKKRVHPDYVITTQHWLGLLGPNGTQPQFANCSVYDFFVWLHYYSVRDTLLGPGRPYRAIDFSHQGPAFVTWHRYHLLCLERDLQRLIGNESFALPYWNFATGRNECDVCTDQLFGAARPDDPTLISRNSRFSSWETVCDSLDDYNHLVTLCNGTYEGLLRRNQMGRNSMKLPTLKDIRDCLSLQKFDNPPFFQNSTFSFRNALEGFDKADGTLDSQVMSLHNLVHSFLNGTNALPHSAANDPIFVVLHSFTDAIFDEWMKRFNPPADAWPQELAPIGHNRMYNMVPFFPPVTNEELFLTSDQLGYSYAIDLPVSVEETPGWPTTLLVVMGTLVALVGLFVLLAFLQYRRLRKGYTPLMETHLSSKRYTEEA>sp|P40126-2|TYRP2_HUMAN Isoform 2 of L-dopachrome tautomerase OS=Homosapiens OX=9606 GN=DCTMSPLWWGFLLSCLGCKILPGAQGQFPRVCMTVDSLVNKECCPRLGAESANVCGSQQGRGQCTEVRADTRPWSGPYILRNQDDRELWPRKFFHRTCKCTGNFAGYNCGDCKFGWTGPNCERKKPPVIRQNIHSLSPQEREQFLGALDLAKKRVHPDYVITTQHWLGLLGPNGTQPQFANCSVYDFFVWLHYYSVRDTLLGPGRPYRAIDFSHQGPAFVTWHRYHLLCLERDLQRLIGNESFALPYWNFATGRNECDVCTDQLFGAARPDDPTLISRNSRFSSWETVCDSLDDYNHLVTLCNGTYEGLLRRNQMGRNSMKLPTLKDIRDCLSLQKFDNPPFFQNSTFSFRNALEGFDKADGTLDSQVMSLHNLVHSFLNGTNALPHSAANDPIFVVISNRLLYNATTNILEHVRKEKATKELPSLHVLVLHSFTDAIFDEWMKRFNPPADAWPQELAPIGHNRMYNMVPFFPPVTNEELFLTSDQLGYSYAIDLPVSVEETPGWPTTLLVVMGTLVALVGLFVLLAFLQYRRLRKGYTPLMETHLSSKRYTEEA>sp|A0A0B4J264|TV381_HUMAN T cell receptor alpha variable 38-1 OS=Homosapiens OX=9606 GN=TRAV38-1 PE=3 SV=1MTRVSLLWAVVVSTCLESGMAQTVTQSQPEMSVQEAETVTLSCTYDTSENNYYLFWYKQPPSRQMILVIRQEAYKQQNATENRFSVNFQKAAKSFSLKISDSQLGDTAMYFCAFMK>sp|Q9BV40|VAMP8_HUMAN Vesicle-associated membrane protein 8 OS=Homosapiens OX=9606 GN=VAMP8 PE=1 SV=1MEEASEGGGNDRVRNLQSEVEGVKNIMTQNVERILARGENLEHLRNKTEDLEATSEHFKTTSQKVARKFWWKNVKMIVLICVIVFIIILFIVLFATGAFS>sp|P51809|VAMP7_HUMAN Vesicle-associated membrane protein 7 OS=Homosapiens OX=9606 GN=VAMP7 PE=1 SV=3MAILFAVVARGTTILAKHAWCGGNFLEVTEQILAKIPSENNKLTYSHGNYLFHYICQDRIVYLCITDDDFERSRAFNFLNEIKKRFQTTYGSRAQTALPYAMNSEFSSVLAAQLKHHSENKGLDKVMETQAQVDELKGIMVRNIDLVAQRGERLELLIDKTENLVDSSVTFKTTSRNLARAMCMKNLKLTIIIIIVSIVFIYIIVSPLCGGFTWPSCVKK>sp|P51809-2|VAMP7_HUMAN Isoform 2 of Vesicle-associated membrane protein7 OS=Homo sapiens OX=9606 GN=VAMP7MAILFAVVARGTTILAKHAWCGGNFLEVTEQILAKIPSENNKLTYSHGNYLFHYICQDRIVYLCITDDDFERSRAFNFLNEIKKRFQTTYGSRAQTALPYAMNSEFSSVLAAQLKHHSENKGLDKVMETQAQVDELKGIMVRNIVCHLQNYQQKSCSSHVYEEPQAHYYHHHRINCVHLYHCFTSLWWIYMAKLCEEIGKKKLPLTKDMREQGVKSNPCDSSLSHTDRWYLPVSSTLFSLFKILFHASRFIFVLSTSLFL>sp|P51809-3|VAMP7_HUMAN Isoform 3 of Vesicle-associated membrane protein7 OS=Homo sapiens OX=9606 GN=VAMP7MAILFAVVARGTTILAKHAWCGGNFLEDFERSRAFNFLNEIKKRFQTTYGSRAQTALPYAMNSEFSSVLAAQLKHHSENKGLDKVMETQAQVDELKGIMVRNIDLVAQRGERLELLIDKTENLVDSSVTFKTTSRNLARAMCMKNLKLTIIIIIVSIVFIYIIVSPLCGGFTWPSCVKK>sp|Q8TAA9|VANG1_HUMAN Vang-like protein 1 OS=Homo sapiens OX=9606GN=VANGL1 PE=1 SV=1MDTESTYSGYSYYSSHSKKSHRQGERTRERHKSPRNKDGRGSEKSVTIQPPTGEPLLGNDSTRTEEVQDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTICEGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIVLLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMIAAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHSMESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDPKSHKFVLRLQSETSV>sp|Q8TAA9-2|VANG1_HUMAN Isoform 2 of Vang-like protein 1 OS=Homo sapiensOX=9606 GN=VANGL1MDTESTYSGYSYYSSHSKKSHRQGERTRERHKSPRNKDGRGSEKSVTIQPPTGEPLLGNDSTRTEEDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTICEGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIVLLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMIAAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHSMESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDPKSHKFVLRLQSETSV>sp|Q8NBZ7|UXS1_HUMAN UDP-glucuronic acid decarboxylase 1 OS=Homo sapiensOX=9606 GN=UXS1 PE=1 SV=1MVSKALLRLVSAVNRRRMKLLLGIALLAYVASVWGNFVNMRSIQENGELKIESKIEEMVEPLREKIRDLEKSFTQKYPPVKFLSEKDRKRILITGGAGFVGSHLTDKLMMDGHEVTVVDNFFTGRKRNVEHWIGHENFELINHDVVEPLYIEVDQIYHLASPASPPNYMYNPIKTLKTNTIGTLNMLGLAKRVGARLLLASTSEVYGDPEVHPQSEDYWGHVNPIGPRACYDEGKRVAETMCYAYMKQEGVEVRVARIFNTFGPRMHMNDGRVVSNFILQALQGEPLTVYGSGSQTRAFQYVSDLVNGLVALMNSNVSSPVNLGNPEEHTILEFAQLIKNLVGSGSEIQFLSEAQDDPQKRKPDIKKAKLMLGWEPVVPLEEGLNKAIHYFRKELEYQANNQYIPKPKPARIKKGRTRHS>sp|Q8NBZ7-2|UXS1_HUMAN Isoform 2 of UDP-glucuronic acid decarboxylase 1OS=Homo sapiens OX=9606 GN=UXS1MVSKALLRLVSAVNRRRMKLLLGIALLAYVASVWGNFVNMSFLLNRSIQENGELKIESKIEEMVEPLREKIRDLEKSFTQKYPPVKFLSEKDRKRILITGGAGFVGSHLTDKLMMDGHEVTVVDNFFTGRKRNVEHWIGHENFELINHDVVEPLYIEVDQIYHLASPASPPNYMYNPIKTLKTNTIGTLNMLGLAKRVGARLLLASTSEVYGDPEVHPQSEDYWGHVNPIGPRACYDEGKRVAETMCYAYMKQEGVEVRVARIFNTFGPRMHMNDGRVVSNFILQALQGEPLTVYGSGSQTRAFQYVSDLVNGLVALMNSNVSSPVNLGNPEEHTILEFAQLIKNLVGSGSEIQFLSEAQDDPQKRKPDIKKAKLMLGWEPVVPLEEGLNKAIHYFRKELEYQANNQYIPKPKPARIKKGRTRHS>sp|Q8NBZ7-3|UXS1_HUMAN Isoform 3 of UDP-glucuronic acid decarboxylase 1OS=Homo sapiens OX=9606 GN=UXS1MYNPIKTLKTNTIGTLNMLGLAKRVGARLLLASTSEVYGDPEVHPQSEDYWGHVNPIGPRACYDEGKRVAETMCYAYMKQEGVEVRVARIFNTFGPRMHMNDGRVVSNFILQALQGEPLTVYGSGSQTRAFQYVSDLVNGLVALMNSNVSSPVNLGNPEEHTILEFAQLIKNLVGSGSEIQFLSEAQDDPQKRKPDIKKAKLMLGWEPVVPLEEGLNKAIHYFRKELEYQANNQYIPKPKPARIKKGRTRHS>sp|Q16572|VACHT_HUMAN Vesicular acetylcholine transporter OS=Homosapiens OX=9606 GN=SLC18A3 PE=1 SV=2MESAEPAGQARAAATKLSEAVGAALQEPRRQRRLVLVIVCVALLLDNMLYMVIVPIVPDYIAHMRGGGEGPTRTPEVWEPTLPLPTPANASAYTANTSASPTAAWPAGSALRPRYPTESEDVKIGVLFASKAILQLLVNPLSGPFIDRMSYDVPLLIGLGVMFASTVLFAFAEDYATLFAARSLQGLGSAFADTSGIAMIADKYPEEPERSRALGVALAFISFGSLVAPPFGGILYEFAGKRVPFLVLAAVSLFDALLLLAVAKPFSAAARARANLPVGTPIHRLMLDPYIAVVAGALTTCNIPLAFLEPTIATWMKHTMAASEWEMGMAWLPAFVPHVLGVYLTVRLAARYPHLQWLYGALGLAVIGASSCIVPACRSFAPLVVSLCGLCFGIALVDTALLPTLAFLVDVRHVSVYGSVYAIADISYSVAYALGPIVAGHIVHSLGFEQLSLGMGLANLLYAPVLLLLRNVGLLTRSRSERDVLLDEPPQGLYDAVRLRERPVSGQDGEPRSPPGPFDACEDDYNYYYTRS>sp|O14599|VCY2_HUMAN Testis-specific basic protein Y 2 OS=Homo sapiensOX=9606 GN=BPY2 PE=1 SV=2MMTLVPRARTRAGQDHYSHPCPRFSQVLLTEGIMTYCLTKNLSDVNILHRLLKNGNVRNTLLQSKVGLLTYYVKLYPGEVTLLTRPSIQMRLCCITGSVSRPRSQK>sp|Q9BQY6|WFDC6_HUMAN WAP four-disulfide core domain protein 6 OS=Homosapiens OX=9606 GN=WFDC6 PE=1 SV=1MGLSGLLPILVPFILLGDIQEPGHAEGILGKPCPKIKVECEVEEIDQCTKPRDCPENMKCCPFSRGKKCLDFRKIYAVCHRRLAPAWPPYHTGGTIKKTKICSEFIYGGSQGNNNNFQTEAICLVTCKKYH>sp|Q9BQY6-2|WFDC6_HUMAN Isoform 2 of WAP four-disulfide core domainprotein 6 OS=Homo sapiens OX=9606 GN=WFDC6MGLSGLLPILVPFILLGDIQEPGHAEGILGKPCPKIKVECEVEEIDQCTKPRDCPENMKCCPFSRGKKCLDFRKVSLTLYHKEELE>sp|Q1A5X7|WHAL1_HUMAN Putative WASP homolog-associated protein withactin, membranes and microtubules-like protein 1 OS=Homo sapiens OX=9606GN=WHAMMP3 PE=5 SV=1MMILVFWSNYPYEPVCLASHRNNMEASVPKYKKHLPQLGMQKEMEQDVKRFGQAAWATAIPRLEKLKLMLAQETLQLMRAKELCLNHKRAEIQGKMEDLPEQEKNINVVDELAIQFYEIQLELYEVKFEILKNKEILLTTQLDSLERLIKDEI>sp|Q1A5X7-2|WHAL1_HUMAN Isoform 1 of Putative WASP homolog-associatedprotein with actin, membranes and microtubules-like protein 1 OS=Homosapiens OX=9606 GN=WHAMMP3MQKEMEQDVKRFGQAAWATAIPRLEKLKLMLAQETLQLMRAKELCLNHKRAEIQGKMEDLPEQEKNINVVDELAIQFYEIQLELYEVKFEILKNKEILLTTQLDSLERLIKEKQDEVVYYDPCESPEELSH>sp|Q8IUB3|WF10B_HUMAN Protein WFDC10B OS=Homo sapiens OX=9606 GN=WFDC10BPE=1 SV=2MAPQTLLLVLVLCVLLLQAQGGYRDKMRMQRIKVCEKRPSIDLCIHHCSYFQKCETNKICCSAFCGNICMSIL>sp|Q8IUB3-2|WF10B_HUMAN Isoform 2 of Protein WFDC10B OS=Homo sapiensOX=9606 GN=WFDC10BMVSCERRASKSVGQILLWDFGYTCRLSHRRRNSTEILSRNLPALYTGIKVCEKRPSIDLCIHHCSYFQKCETNKICCSAFCGNICMSIL>sp|O14609|XKRY_HUMAN Testis-specific XK-related protein, Y-linkedOS=Homo sapiens OX=9606 GN=XKRY PE=2 SV=1MFIFNSIADDIFPLISCVGAIHCNILAIRTGNDFAAIKLQVIKLIYLMIWHSLVIISPVVTLAFFPASLKQGSLHFLLIIYFVLLLTPWLEFSKSGTHLPSNTKIIPAWWVSMDAYLNHASICCHQFSCLSAVKLQLSNEELIRDTRWDIQSYTTDFSF>sp|Q9H267|VP33B_HUMAN Vacuolar protein sorting-associated protein 33BOS=Homo sapiens OX=9606 GN=VPS33B PE=1 SV=2MAFPHRPDAPELPDFSMLKRLARDQLIYLLEQLPGKKDLFIEADLMSPLDRIANVSILKQHEVDKLYKVENKPALSSNEQLCFLVRPRIKNMRYIASLVNADKLAGRTRKYKVIFSPQKFYACEMVLEEEGIYGDVSCDEWAFSLLPLDVDLLSMELPEFFRDYFLEGDQRWINTVAQALHLLSTLYGPFPNCYGIGRCAKMAYELWRNLEEEEDGETKGRRPEIGHIFLLDRDVDFVTALCSQVVYEGLVDDTFRIKCGSVDFGPEVTSSDKSLKVLLNAEDKVFNEIRNEHFSNVFGFLSQKARNLQAQYDRRRGMDIKQMKNFVSQELKGLKQEHRLLSLHIGACESIMKKKTKQDFQELIKTEHALLEGFNIRESTSYIEEHIDRQVSPIESLRLMCLLSITENGLIPKDYRSLKTQYLQSYGPEHLLTFSNLRRAGLLTEQAPGDTLTAVESKVSKLVTDKAAGKITDAFSSLAKRSNFRAISKKLNLIPRVDGEYDLKVPRDMAYVFGGAYVPLSCRIIEQVLERRSWQGLDEVVRLLNCSDFAFTDMTKEDKASSESLRLILVVFLGGCTFSEISALRFLGREKGYRFIFLTTAVTNSARLMEAMSEVKA>sp|Q9H267-2|VP33B_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 33B OS=Homo sapiens OX=9606 GN=VPS33BMRYIASLVNADKLAGRTRKYKVIFSPQKFYACEMVLEEEGIYGDVSCDEWAFSLLPLDVDLLSMELPEFFRDYFLEGDQRWINTVAQALHLLSTLYGPFPNCYGIGRCAKMAYELWRNLEEEEDGETKGRRPEIGHIFLLDRDVDFVTALCSQVVYEGLVDDTFRIKCGSVDFGPEVTSSDKSLKVLLNAEDKVFNEIRNEHFSNVFGFLSQKARNLQAQYDRRRGMDIKQMKNFVSQELKGLKQEHRLLSLHIGACESIMKKKTKQDFQELIKTEHALLEGFNIRESTSYIEEHIDRQVSPIESLRLMCLLSITENGLIPKDYRSLKTQYLQSYGPEHLLTFSNLRRAGLLTEQAPGDTLTAVESKVSKLVTDKAAGKITDAFSSLAKRSNFRAISKKLNLIPRVDGEYDLKVPRDMAYVFGGAYVPLSCRIIEQVLERRSWQGLDEVVRLLNCSDFAFTDMTKEDKASSESLRLILVVFLGGCTFSEISALRFLGREKGYRFIFLTTAVTNSARLMEAMSEVKA>sp|Q96RL7|VP13A_HUMAN Vacuolar protein sorting-associated protein 13AOS=Homo sapiens OX=9606 GN=VPS13A PE=1 SV=2MVFESVVVDVLNRFLGDYVVDLDTSQLSLGIWKGAVALKNLQIKENALSQLDVPFKVKVGHIGNLKLIIPWKNLYTQPVEAVLEEIYLLIVPSSRIKYDPLKEEKQLMEAKQQELKRIEEAKQKVVDQEQHLPEKQDTFAEKLVTQIIKNLQVKISSIHIRYEDDITNRDKPLSFGISLQNLSMQTTDQYWVPCLHDETEKLVRKLIRLDNLFAYWNVKSQMFYLSDYDNSLDDLKNGIVNENIVPEGYDFVFRPISANAKLVMNRRSDFDFSAPKINLEIELHNIAIEFNKPQYFSIMELLESVDMMAQNLPYRKFKPDVPLHHHAREWWAYAIHGVLEVNVCPRLWMWSWKHIRKHRQKVKQYKELYKKKLTSKKPPGELLVSLEELEKTLDVFNITIARQTAEVEVKKAGYKIYKEGVKDPEDNKGWFSWLWSWSEQNTNEQQPDVQPETLEEMLTPEEKALLYEAIGYSETAVDPTLLKTFEALKFFVHLKSMSIVLRENHQKPELVDIVIEEFSTLIVQRPGAQAIKFETKIDSFHITGLPDNSEKPRLLSSLDDAMSLFQITFEINPLDETVSQRCIIEAEPLEIIYDARTVNSIVEFFRPPKEVHLAQLTAATLTKLEEFRSKTATGLLYIIETQKVLDLKINLKASYIIVPQDGIFSPTSNLLLLDLGHLKVTSKSRSELPDVKQGEANLKEIMDRAYDSFDIQLTSVQLLYSRVGDNWREARKLSVSTQHILVPMHFNLELSKAMVFMDVRMPKFKIYGKLPLISLRISDKKLQGIMELIESIPKPEPVTEVSAPVKSFQIQTSTSLGTSQISQKIIPLLELPSVSEDDSEEEFFDAPCSPLEEPLQFPTGVKSIRTRKLQKQDCSVNMTTFKIRFEVPKVLIEFYHLVGDCELSVVEILVLGLGAEIEIRTYDLKANAFLKEFCLKCPEYLDENKKPVYLVTTLDNTMEDLLTLEYVKAEKNVPDLKSTYNNVLQLIKVNFSSLDIHLHTEALLNTINYLHNILPQSEEKSAPVSTTETEDKGDVIKKLALKLSTNEDIITLQILAELSCLQIFIQDQKCNISEIKIEGLDSEMIMRPSETEINAKLRNIIVLDSDITAIYKKAVYITGKEVFSFKMVSYMDATAGSAYTDMNVVDIQVNLIVGCIEVVFVTKFLYSILAFIDNFQAAKQALAEATVQAAGMAATGVKELAQRSSRMALDINIKAPVVVIPQSPVSENVFVADFGLITMTNTFHMITESQSSPPPVIDLITIKLSEMRLYRSRFINDAYQEVLDLLLPLNLEVVVERNLCWEWYQEVPCFNVNAQLKPMEFILSQEDITTIFKTLHGNIWYEKDGSASPAVTKDQYSATSGVTTNASHHSGGATVVTAAVVEVHSRALLVKTTLNISFKTDDLTMVLYSPGPKQASFTDVRDPSLKLAEFKLENIISTLKMYTDGSTFSSFSLKNCILDDKRPHVKKATPRMIGLTVGFDKKDMMDIKYRKVRDGCVTDAVFQEMYICASVEFLQTVANVFLEAYTTGTAVETSVQTWTAKEEVPTQESVKWEINVIIKNPEIVFVADMTKNDAPALVITTQCEICYKGNLENSTMTAAIKDLQVRACPFLPVKRKGKITTVLQPCDLFYQTTQKGTDPQVIDMSVKSLTLKVSPVIINTMITITSALYTTKETIPEETASSTAHLWEKKDTKTLKMWFLEESNETEKIAPTTELVPKGEMIKMNIDSIFIVLEAGIGHRTVPMLLAKSRFSGEGKNWSSLINLHCQLELEVHYYNEMFGVWEPLLEPLEIDQTEDFRPWNLGIKMKKKAKMAIVESDPEEENYKVPEYKTVISFHSKDQLNITLSKCGLVMLNNLVKAFTEAATGSSADFVKDLAPFMILNSLGLTISVSPSDSFSVLNIPMAKSYVLKNGESLSMDYIRTKDNDHFNAMTSLSSKLFFILLTPVNHSTADKIPLTKVGRRLYTVRHRESGVERSIVCQIDTVEGSKKVTIRSPVQIRNHFSVPLSVYEGDTLLGTASPENEFNIPLGSYRSFIFLKPEDENYQMCEGIDFEEIIKNDGALLKKKCRSKNPSKESFLINIVPEKDNLTSLSVYSEDGWDLPYIMHLWPPILLRNLLPYKIAYYIEGIENSVFTLSEGHSAQICTAQLGKARLHLKLLDYLNHDWKSEYHIKPNQQDISFVSFTCVTEMEKTDLDIAVHMTYNTGQTVVAFHSPYWMVNKTGRMLQYKADGIHRKHPPNYKKPVLFSFQPNHFFNNNKVQLMVTDSELSNQFSIDTVGSHGAVKCKGLKMDYQVGVTIDLSSFNITRIVTFTPFYMIKNKSKYHISVAEEGNDKWLSLDLEQCIPFWPEYASSKLLIQVERSEDPPKRIYFNKQENCILLRLDNELGGIIAEVNLAEHSTVITFLDYHDGAATFLLINHTKNELVQYNQSSLSEIEDSLPPGKAVFYTWADPVGSRRLKWRCRKSHGEVTQKDDMMMPIDLGEKTIYLVSFFEGLQRIILFTEDPRVFKVTYESEKAELAEQEIAVALQDVGISLVNNYTKQEVAYIGITSSDVVWETKPKKKARWKPMSVKHTEKLEREFKEYTESSPSEDKVIQLDTNVPVRLTPTGHNMKILQPHVIALRRNYLPALKVEYNTSAHQSSFRIQIYRIQIQNQIHGAVFPFVFYPVKPPKSVTMDSAPKPFTDVSIVMRSAGHSQISRIKYFKVLIQEMDLRLDLGFIYALTDLMTEAEVTENTEVELFHKDIEAFKEEYKTASLVDQSQVSLYEYFHISPIKLHLSVSLSSGREEAKDSKQNGGLIPVHSLNLLLKSIGATLTDVQDVVFKLAFFELNYQFHTTSDLQSEVIRHYSKQAIKQMYVLILGLDVLGNPFGLIREFSEGVEAFFYEPYQGAIQGPEEFVEGMALGLKALVGGAVGGLAGAASKITGAMAKGVAAMTMDEDYQQKRREAMNKQPAGFREGITRGGKGLVSGFVSGITGIVTKPIKGAQKGGAAGFFKGVGKGLVGAVARPTGGIIDMASSTFQGIKRATETSEVESLRPPRFFNEDGVIRPYRLRDGTGNQMLQVMENGRFAKYKYFTHVMINKTDMLMITRRGVLFVTKGTFGQLTCEWQYSFDEFTKEPFIVHGRRLRIEAKERVKSVFHAREFGKIINFKTPEDARWILTKLQEAREPSPSL>sp|Q96RL7-2|VP13A_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 13A OS=Homo sapiens OX=9606 GN=VPS13AMVFESVVVDVLNRFLGDYVVDLDTSQLSLGIWKGAVALKNLQIKENALSQLDVPFKVKVGHIGNLKLIIPWKNLYTQPVEAVLEEIYLLIVPSSRIKYDPLKEEKQLMEAKQQELKRIEEAKQKVVDQEQHLPEKQDTFAEKLVTQIIKNLQVKISSIHIRYEDDITNRDKPLSFGISLQNLSMQTTDQYWVPCLHDETEKLVRKLIRLDNLFAYWNVKSQMFYLSDYDNSLDDLKNGIVNENIVPEGYDFVFRPISANAKLVMNRRSDFDFSAPKINLEIELHNIAIEFNKPQYFSIMELLESVDMMAQNLPYRKFKPDVPLHHHAREWWAYAIHGVLEVNVCPRLWMWSWKHIRKHRQKVKQYKELYKKKLTSKKPPGELLVSLEELEKTLDVFNITIARQTAEVEVKKAGYKIYKEGVKDPEDNKGWFSWLWSWSEQNTNEQQPDVQPETLEEMLTPEEKALLYEAIGYSETAVDPTLLKTFEALKFFVHLKSMSIVLRENHQKPELVDIVIEEFSTLIVQRPGAQAIKFETKIDSFHITGLPDNSEKPRLLSSLDDAMSLFQITFEINPLDETVSQRCIIEAEPLEIIYDARTVNSIVEFFRPPKEVHLAQLTAATLTKLEEFRSKTATGLLYIIETQKVLDLKINLKASYIIVPQDGIFSPTSNLLLLDLGHLKVTSKSRSELPDVKQGEANLKEIMDRAYDSFDIQLTSVQLLYSRVGDNWREARKLSVSTQHILVPMHFNLELSKAMVFMDVRMPKFKIYGKLPLISLRISDKKLQGIMELIESIPKPEPVTEVSAPVKSFQIQTSTSLGTSQISQKIIPLLELPSVSEDDSEEEFFDAPCSPLEEPLQFPTGVKSIRTRKLQKQDCSVNMTTFKIRFEVPKVLIEFYHLVGDCELSVVEILVLGLGAEIEIRTYDLKANAFLKEFCLKCPEYLDENKKPVYLVTTLDNTMEDLLTLEYVKAEKNVPDLKSTYNNVLQLIKVNFSSLDIHLHTEALLNTINYLHNILPQSEEKSAPVSTTETEDKGDVIKKLALKLSTNEDIITLQILAELSCLQIFIQDQKCNISEIKIEGLDSEMIMRPSETEINAKLRNIIVLDSDITAIYKKAVYITGKEVFSFKMVSYMDATAGSAYTDMNVVDIQVNLIVGCIEVVFVTKFLYSILAFIDNFQAAKQALAEATVQAAGMAATGVKELAQRSSRMALDINIKAPVVVIPQSPVSENVFVADFGLITMTNTFHMITESQSSPPPVIDLITIKLSEMRLYRSRFINDAYQEVLDLLLPLNLEVVVERNLCWEWYQEVPCFNVNAQLKPMEFILSQEDITTIFKTLHGNIWYEKDGSASPAVTKDQYSATSGVTTNASHHSGGATVVTAAVVEVHSRALLVKTTLNISFKTDDLTMVLYSPGPKQASFTDVRDPSLKLAEFKLENIISTLKMYTDGSTFSSFSLKNCILDDKRPHVKKATPRMIGLTVGFDKKDMMDIKYRKVRDGCVTDAVFQEMYICASVEFLQTVANVFLEAYTTGTAVETSVQTWTAKEEVPTQESVKWEINVIIKNPEIVFVADMTKNDAPALVITTQCEICYKGNLENSTMTAAIKDLQVRACPFLPVKRKGKITTVLQPCDLFYQTTQKGTDPQVIDMSVKSLTLKVSPVIINTMITITSALYTTKETIPEETASSTAHLWEKKDTKTLKMWFLEESNETEKIAPTTELVPKGEMIKMNIDSIFIVLEAGIGHRTVPMLLAKSRFSGEGKNWSSLINLHCQLELEVHYYNEMFGVWEPLLEPLEIDQTEDFRPWNLGIKMKKKAKMAIVESDPEEENYKVPEYKTVISFHSKDQLNITLSKCGLVMLNNLVKAFTEAATGSSADFVKDLAPFMILNSLGLTISVSPSDSFSVLNIPMAKSYVLKNGESLSMDYIRTKDNDHFNAMTSLSSKLFFILLTPVNHSTADKIPLTKVGRRLYTVRHRESGVERSIVCQIDTVEGSKKVTIRSPVQIRNHFSVPLSVYEGDTLLGTASPENEFNIPLGSYRSFIFLKPEDENYQMCEGIDFEEIIKNDGALLKKKCRSKNPSKESFLINIVPEKDNLTSLSVYSEDGWDLPYIMHLWPPILLRNLLPYKIAYYIEGIENSVFTLSEGHSAQICTAQLGKARLHLKLLDYLNHDWKSEYHIKPNQQDISFVSFTCVTEMEKTDLDIAVHMTYNTGQTVVAFHSPYWMVNKTGRMLQYKADGIHRKHPPNYKKPVLFSFQPNHFFNNNKVQLMVTDSELSNQFSIDTVGSHGAVKCKGLKMDYQVGVTIDLSSFNITRIVTFTPFYMIKNKSKYHISVAEEGNDKWLSLDLEQCIPFWPEYASSKLLIQVERSEDPPKRIYFNKQENCILLRLDNELGGIIAEVNLAEHSTVITFLDYHDGAATFLLINHTKNELVQYNQSSLSEIEDSLPPGKAVFYTWADPVGSRRLKWRCRKSHGEVTQKDDMMMPIDLGEKTIYLVSFFEGLQRIILFTEDPRVFKVTYESEKAELAEQEIAVALQDVGISLVNNYTKQEVAYIGITSSDVVWETKPKKKARWKPMSVKHTEKLEREFKEYTESSPSEDKVIQLDTNVPVRLTPTGHNMKILQPHVIALRRNYLPALKVEYNTSAHQSSFRIQIYRIQIQNQIHGAVFPFVFYPVKPPKSVTMDSAPKPFTDVSIVMRSAGHSQISRIKYFKVLIQEMDLRLDLGFIYALTDLMTEAEVTENTEVELFHKDIEAFKEEYKTASLVDQSQVSLYEYFHISPIKLHLSVSLSSGREEAKDSKQNGGLIPVHSLNLLLKSIGATLTDVQDVVFKLAFFELNYQFHTTSDLQSEVIRHYSKQAIKQMYVLILGLDVLGNPFGLIREFSEGVEAFFYEPYQGAIQGPEEFVEGMALGLKALVGGAVGGLAGAASKITGAMAKGVAAMTMDEDYQQKRREAMNKQPAGFREGITRGGKGLVSGFVSGITGIVTKPIKGAQKGGAAGFFKGVGKGLVGAVARPTGGIIDMASSTFQGIKRATETSEVESLRPPRFFNEDGVIRPYRLRDGTGNQMLQKIQFYREWIMTHSSSSDDDDDDDDDDESDLNH>sp|Q96RL7-3|VP13A_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 13A OS=Homo sapiens OX=9606 GN=VPS13AMVFESVVVDVLNRFLGDYVVDLDTSQLSLGIWKGAVALKNLQIKENALSQLDVPFKVKVGHIGNLKLIIPWKNLYTQPVEAVLEEIYLLIVPSSRIKYDPLKEEKQLMEAKQQELKRIEEAKQKVVDQEQHLPEKQDTFAEKLVTQIIKNLQVKISSIHIRYEDDITNRDKPLSFGISLQNLSMQTTDQYWVPCLHDETEKLVRKLIRLDNLFAYWNVKSQMFYLSDYDNSLDDLKNGIVNENIVPEGYDFVFRPISANAKLVMNRRSDFDFSAPKINLEIELHNIAIEFNKPQYFSIMELLESVDMMAQNLPYRKFKPDVPLHHHAREWWAYAIHGVLEVNVCPRLWMWSWKHIRKHRQKVKQYKELYKKKLTSKKPPGELLVSLEELEKTLDVFNITIARQTAEVEVKKAGYKIYKEGVKDPEDNKGWFSWLWSWSEQNTNEQQPDVQPETLEEMLTPEEKALLYEAIGYSETAVDPTLLKTFEALKFFVHLKSMSIVLRENHQKPELVDIVIEEFSTLIVQRPGAQAIKFETKIDSFHITGLPDNSEKPRLLSSLDDAMSLFQITFEINPLDETVSQRCIIEAEPLEIIYDARTVNSIVEFFRPPKEVHLAQLTAATLTKLEEFRSKTATGLLYIIETQKVLDLKINLKASYIIVPQDGIFSPTSNLLLLDLGHLKVTSKSRSELPDVKQGEANLKEIMDRAYDSFDIQLTSVQLLYSRVGDNWREARKLSVSTQHILVPMHFNLELSKAMVFMDVRMPKFKIYGKLPLISLRISDKKLQGIMELIESIPKPEPVTEVSAPVKSFQIQTSTSLGTSQISQKIIPLLELPSVSEDDSEEEFFDAPCSPLEEPLQFPTGVKSIRTRKLQKQDCSVNMTTFKIRFEVPKVLIEFYHLVGDCELSVVEILVLGLGAEIEIRTYDLKANAFLKEFCLKCPEYLDENKKPVYLVTTLDNTMEDLLTLEYVKAEKNVPDLKSTYNNVLQLIKVNFSSLDIHLHTEALLNTINYLHNILPQSEEKSAPVSTTETEDKGDVIKKLGLDSEMIMRPSETEINAKLRNIIVLDSDITAIYKKAVYITGKEVFSFKMVSYMDATAGSAYTDMNVVDIQVNLIVGCIEVVFVTKFLYSILAFIDNFQAAKQALAEATVQAAGMAATGVKELAQRSSRMALDINIKAPVVVIPQSPVSENVFVADFGLITMTNTFHMITESQSSPPPVIDLITIKLSEMRLYRSRFINDAYQEVLDLLLPLNLEVVVERNLCWEWYQEVPCFNVNAQLKPMEFILSQEDITTIFKTLHGNIWYEKDGSASPAVTKDQYSATSGVTTNASHHSGGATVVTAAVVEVHSRALLVKTTLNISFKTDDLTMVLYSPGPKQASFTDVRDPSLKLAEFKLENIISTLKMYTDGSTFSSFSLKNCILDDKRPHVKKATPRMIGLTVGFDKKDMMDIKYRKVRDGCVTDAVFQEMYICASVEFLQTVANVFLEAYTTGTAVETSVQTWTAKEEVPTQESVKWEINVIIKNPEIVFVADMTKNDAPALVITTQCEICYKGNLENSTMTAAIKDLQVRACPFLPVKRKGKITTVLQPCDLFYQTTQKGTDPQVIDMSVKSLTLKVSPVIINTMITITSALYTTKETIPEETASSTAHLWEKKDTKTLKMWFLEESNETEKIAPTTELVPKGEMIKMNIDSIFIVLEAGIGHRTVPMLLAKSRFSGEGKNWSSLINLHCQLELEVHYYNEMFGVWEPLLEPLEIDQTEDFRPWNLGIKMKKKAKMAIVESDPEEENYKVPEYKTVISFHSKDQLNITLSKCGLVMLNNLVKAFTEAATGSSADFVKDLAPFMILNSLGLTISVSPSDSFSVLNIPMAKSYVLKNGESLSMDYIRTKDNDHFNAMTSLSSKLFFILLTPVNHSTADKIPLTKVGRRLYTVRHRESGVERSIVCQIDTVEGSKKVTIRSPVQIRNHFSVPLSVYEGDTLLGTASPENEFNIPLGSYRSFIFLKPEDENYQMCEGIDFEEIIKNDGALLKKKCRSKNPSKESFLINIVPEKDNLTSLSVYSEDGWDLPYIMHLWPPILLRNLLPYKIAYYIEGIENSVFTLSEGHSAQICTAQLGKARLHLKLLDYLNHDWKSEYHIKPNQQDISFVSFTCVTEMEKTDLDIAVHMTYNTGQTVVAFHSPYWMVNKTGRMLQYKADGIHRKHPPNYKKPVLFSFQPNHFFNNNKVQLMVTDSELSNQFSIDTVGSHGAVKCKGLKMDYQVGVTIDLSSFNITRIVTFTPFYMIKNKSKYHISVAEEGNDKWLSLDLEQCIPFWPEYASSKLLIQVERSEDPPKRIYFNKQENCILLRLDNELGGIIAEVNLAEHSTVITFLDYHDGAATFLLINHTKNELVQYNQSSLSEIEDSLPPGKAVFYTWADPVGSRRLKWRCRKSHGEVTQKDDMMMPIDLGEKTIYLVSFFEGLQRIILFTEDPRVFKVTYESEKAELAEQEIAVALQDVGISLVNNYTKQEVAYIGITSSDVVWETKPKKKARWKPMSVKHTEKLEREFKEYTESSPSEDKVIQLDTNVPVRLTPTGHNMKILQPHVIALRRNYLPALKVEYNTSAHQSSFRIQIYRIQIQNQIHGAVFPFVFYPVKPPKSVTMDSAPKPFTDVSIVMRSAGHSQISRIKYFKVLIQEMDLRLDLGFIYALTDLMTEAEVTENTEVELFHKDIEAFKEEYKTASLVDQSQVSLYEYFHISPIKLHLSVSLSSGREEAKDSKQNGGLIPVHSLNLLLKSIGATLTDVQDVVFKLAFFELNYQFHTTSDLQSEVIRHYSKQAIKQMYVLILGLDVLGNPFGLIREFSEGVEAFFYEPYQGAIQGPEEFVEGMALGLKALVGGAVGGLAGAASKITGAMAKGVAAMTMDEDYQQKRREAMNKQPAGFREGITRGGKGLVSGFVSGITGIVTKPIKGAQKGGAAGFFKGVGKGLVGAVARPTGGIIDMASSTFQGIKRATETSEVESLRPPRFFNEDGVIRPYRLRDGTGNQMLQVMENGRFAKYKYFTHVMINKTDMLMITRRGVLFVTKGTFGQLTCEWQYSFDEFTKEPFIVHGRRLRIEAKERVKSVFHAREFGKIINFKTPEDARWILTKLQEAREPSPSL>sp|Q96RL7-4|VP13A_HUMAN Isoform 4 of Vacuolar protein sorting-associatedprotein 13A OS=Homo sapiens OX=9606 GN=VPS13AMVFESVVVDVLNRFLGDYVVDLDTSQLSLGIWKGAVALKNLQIKENALSQLDVPFKVKVGHIGNLKLIIPWKNLYTQPVEAVLEEIYLLIVPSSRIKYDPLKEEKQLMEAKQQELKRIEEAKQKVVDQEQHLPEKQDTFAEKLVTQIIKNLQVKISSIHIRYEDDITNRDKPLSFGISLQNLSMQTTDQYWVPCLHDETEKLVRKLIRLDNLFAYWNVKSQMFYLSDYDNSLDDLKNGIVNENIVPEGYDFVFRPISANAKLVMNRRSDFDFSAPKINLEIELHNIAIEFNKPQYFSIMELLESVDMMAQNLPYRKFKPDVPLHHHAREWWAYAIHGVLEVNVCPRLWMWSWKHIRKHRQKVKQYKELYKKKLTSKKPPGELLVSLEELEKTLDVFNITIARQTAEVEVKKAGYKIYKEGVKDPEDNKGWFSWLWSWSEQNTNEQQPDVQPETLEEMLTPEEKALLYEAIGYSETAVDPTLLKTFEALKFFVHLKSMSIVLRENHQKPELVDIVIEEFSTLIVQRPGAQAIKFETKIDSFHITGLPDNSEKPRLLSSLDDAMSLFQITFEINPLDETVSQRCIIEAEPLEIIYDARTVNSIVEFFRPPKEVHLAQLTAATLTKLEEFRSKTATGLLYIIETQKVLDLKINLKASYIIVPQDGIFSPTSNLLLLDLGHLKVTSKSRSELPDVKQGEANLKEIMDRAYDSFDIQLTSVQLLYSRVGDNWREARKLSVSTQHILVPMHFNLELSKAMVFMDVRMPKFKIYGKLPLISLRISDKKLQGIMELIESIPKPEPVTEVSAPVKSFQIQTSTSLGTSQISQKIIPLLELPSVSEDDSEEEFFDAPCSPLEEPLQFPTGVKSIRTRKLQKQDCSVNMTTFKIRFEVPKVLIEFYHLVGDCELSVVEILVLGLGAEIEIRTYDLKANAFLKEFCLKCPEYLDENKKPVYLVTTLDNTMEDLLTLEYVKAEKNVPDLKSTYNNVLQLIKVNFSSLDIHLHTEALLNTINYLHNILPQSEEKSAPVSTTETEDKGDVIKKLALKLSTNEDIITLQILAELSCLQIFIQDQKCNISEIKIEGLDSEMIMRPSETEINAKLRNIIVLDSDITAIYKKAVYITGKEVFSFKMVSYMDATAGSAYTDMNVVDIQVNLIVGCIEVVFVTKFLYSILAFIDNFQAAKQALAEATVQAAGMAATGVKELAQRSSRMALDINIKAPVVVIPQSPVSENVFVADFGLITMTNTFHMITESQSSPPPVIDLITIKLSEMRLYRSRFINDAYQEVLDLLLPLNLEVVVERNLCWEWYQEVPCFNVNAQLKPMEFILSQEDITTIFKTLHGNIWYEKDGSASPAVTKDQYSATSGVTTNASHHSGGATVVTAAVVEVHSRALLVKTTLNISFKTDDLTMVLYSPGPKQASFTDVRDPSLKLAEFKLENIISTLKMYTDGSTFSSFSLKNCILDDKRPHVKKATPRMIGLTVGFDKKDMMDIKYRKVRDGCVTDAVFQEMYICASVEFLQTVANVFLEAYTTGTAVETSVQTWTAKEEVPTQESVKWEINVIIKNPEIVFVADMTKNDAPALVITTQCEICYKGNLENSTMTAAIKDLQVRACPFLPVKRKGKITTVLQPCDLFYQTTQKGTDPQVIDMSVKSLTLKVSPVIINTMITITSALYTTKETIPEETASSTAHLWEKKDTKTLKMWFLEESNETEKIAPTTELVPKGEMIKMNIDSIFIVLEAGIGHRTVPMLLAKSRFSGEGKNWSSLINLHCQLELEVHYYNEMFGVWEPLLEPLEIDQTEDFRPWNLGIKMKKKAKMAIVESDPEEENYKVPEYKTVISFHSKDQLNITLSKCGLVMLNNLVKAFTEAATGSSADFVKDLAPFMILNSLGLTISVSPSDSFSVLNIPMAKSYVLKNGESLSMDYIRTKDNDHFNAMTSLSSKLFFILLTPVNHSTADKIPLTKVGRRLYTVRHRESGVERSIVCQIDTVEGSKKVTIRSPVQIRNHFSVPLSVYEGDTLLGTASPENEFNIPLGSYRSFIFLKPEDENYQMCEGIDFEEIIKNDGALLKKKCRSKNPSKESFLINIVPEKDNLTSLSVYSEDGWDLPYIMHLWPPILLRNLLPYKIAYYIEGIENSVFTLSEGHSAQICTAQLGKARLHLKLLDYLNHDWKSEYHIKPNQQDISFVSFTCVTEMEKTDLDIAVHMTYNTGQTVVAFHSPYWMVNKTGRMLQYKADGIHRKHPPNYKKPVLFSFQPNHFFNNNKVQLMVTDSELSNQFSIDTVGSHGAVKCKGLKMDYQVGVTIDLSSFNITRIVTFTPFYMIKNKSKYHISVAEEGNDKWLSLDLEQCIPFWPEYASSKLLIQVERSEDPPKRIYFNKQENCILLRLDNELGGIIAEVNLAEHSTVITFLDYHDGAATFLLINHTKNELVQYNQSSLSEIEDSLPPGKAVFYTWADPVGSRRLKWRCRKSHGEVTQKDDMMMPIDLGEKTIYLVSFFEGLQRIILFTEDPRVFKVTYESEKAELAEQEIAVALQDVGISLVNNYTKQEVAYIGITSSDVVWETKPKKKARWKPMSVKHTEKLEREFKEYTESSPSEDKVIQLDTNVPVRLTPTGHNMKILQPHVIALRRNYLPALKVEYNTSAHQSSFRIQIYRIQIQNQIHGAVFPFVFYPVKPPKSVTMDSAPKPFTDVSIVMRSAGHSQISRIKYFKVLIQEMDLRLDLGFIYALTDLMTEAEVTENTEVELFHKDIEAFKEEYKTASLVDQSQVSLYEYFHISPIKLHLSVSLSSGREEAKDSKQNGGLIPVHSLNLLLKSIGATLTDVQDVVFKLAFFELNYQFHTTSDLQSEVIRHYSKQAIKQMYVLILGLDVLGNPFGLIREFSEGVEAFFYEPYQGAIQGPEEFVEGMALGLKALVGGAVGGLAGAASKITGAMAKGVAAMTMDEDYQQKRREAMNKQPAGFREGITRGGKGLVSGFVSGITGIVTKPIKGAQKGGAAGFFKGVGKGLVGAVARPTGGIIDMASSTFQGIKRATETSEVESLRPPRFFNEDGVIRPYRLRDGTGNQMLQASKSLI>sp|Q6ICG8|WBP2L_HUMAN Postacrosomal sheath WW domain-binding proteinOS=Homo sapiens OX=9606 GN=WBP2NL PE=1 SV=1MAVNQSHTENRRGALIPNGESLLKRSPNVELSFPQRSEGSNVFSGRKTGTLFLTSYRVIFITSCSISDPMLSFMMPFDLMTNLTVEQPVFAANFIKGTIQAAPYGGWEGQATFKLVFRNGDAIEFAQLMVKAASAAARGFPLRTLNDWFSSMGIYVITGEGNMCTPQMPCSVIVYGAPPAGYGAPPPGYGAPPAGYGAQPVGNEGPPVGYRASPVRYGAPPLGYGAPPAGYGAPPLGYGAPPLGYGTPPLGYGAPPLGYGAPPAGNEGPPAGYRASPAGSGARPQESTAAQAPENEASLPSASSSQVHS>sp|Q8N1Y9|YI025_HUMAN Putative uncharacterized protein FLJ37218 OS=Homosapiens OX=9606 PE=5 SV=2MAKWVPALLLRRVPLFSLRFRPASSTFLPVLAATEPAVSVPSGDLSMPVKTRAEGEDDGFGEAGDPRRLLERPWRFRGCLPGKGNRDVGFEGTEGPTSTRPEWVWSCRCCLGCRASTRERVTSPVRAAGPQPRFTDRETEAAAGTLAHMGFAPPTSFSHFTDQELRDCSSLECLGVVEGDPHVLCSTLSLSRPSPSATLTLLLASSCLLAPAPPSFILLLFTLIAPDLPHS>sp|O95619|YETS4_HUMAN YEATS domain-containing protein 4 OS=Homo sapiensOX=9606 GN=YEATS4 PE=1 SV=1MFKRMAEFGPDSGGRVKGVTIVKPIVYGNVARYFGKKREEDGHTHQWTVYVKPYRNEDMSAYVKKIQFKLHESYGNPLRVVTKPPYEITETGWGEFEIIIKIFFIDPNERPVTLYHLLKLFQSDTNAMLGKKTVVSEFYDEMIFQDPTAMMQQLLTTSRQLTLGAYKHETEFAELEVKTREKLEAAKKKTSFEIAELKERLKASRETINCLKNEIRKLEEDDQAKDI>sp|Q6ZMW2|ZN782_HUMAN Zinc finger protein 782 OS=Homo sapiens OX=9606GN=ZNF782 PE=2 SV=1MNTFQASVSFQDVTVEFSQEEWQHMGPVERTLYRDVMLENYSHLVSVGYCFTKPELIFTLEQGEDPWLLEKEKGFLSRNSPEDSQPDEISEKSPENQGKHLLQVLFTNKLLTTEQEISGKPHNRDINIFRARMMPCKCDIAGSACQGLSLMAPHCQYSKEKAHERNVCDKWLISIKDGRTNTQEKSFAYSKIVKTLHHKEEVIQHQTIQTLGQDFEYNESRKAFLEKAALVTSNSTHPKGKSYNFNKFGENKYDKSTFIIPQNMNPEKSHYEFNDTGNCFCRITHKTLTGGKSFSQKSHIREHHRVHIGVKPFEYGKSFNRNSTLPVHQRTHATDKYSDYHPCTETFSYQSTFSVHQKVHIRAKPYEYNECGKSCSMNSHLIWPQKSHTGEKPYECPECGKAFSEKSRLRKHQRTHTGEKPYKCDGCDKAFSAKSGLRIHQRTHTGEKPFECHECGKSFNYKSILIVHQRTHTGEKPFECNECGKSFSHMSGLRNHRRTHTGERPYKCDECGKAFKLKSGLRKHHRTHTGEKPYKCNQCGKAFGQKSQLRGHHRIHTGEKPYKCNHCGEAFSQKSNLRVHHRTHTGEKPYQCEECGKTFRQKSNLRGHQRTHTGEKPYECNECGKAFSEKSVLRKHQRTHTGEKPYNCNQCGEAFSQKSNLRVHQRTHTGEKPYKCDKCGRTFSQKSSLREHQKAHPGD>sp|Q14929|ZN169_HUMAN Zinc finger protein 169 OS=Homo sapiens OX=9606GN=ZNF169 PE=1 SV=3MSPGLLTTRKEALMAFRDVAVAFTQKEWKLLSSAQRTLYREVMLENYSHLVSLGIAFSKPKLIEQLEQGDEPWREENEHLLDLCPEPRTEFQPSFPHLVAFSSSQLLRQYALSGHPTQIFPSSSAGGDFQLEAPRCSSEKGESGETEGPDSSLRKRPSRISRTFFSPHQGDPVEWVEGNREGGTDLRLAQRMSLGGSDTMLKGADTSESGAVIRGNYRLGLSKKSSLFSHQKHHVCPECGRGFCQRSDLIKHQRTHTGEKPYLCPECGRRFSQKASLSIHQRKHSGEKPYVCRECGRHFRYTSSLTNHKRIHSGERPFVCQECGRGFRQKIALLLHQRTHLEEKPFVCPECGRGFCQKASLLQHQSSHTGERPFLCLECGRSFRQQSLLLSHQVTHSGEKPYVCAECGHSFRQKVTLIRHQRTHTGEKPYLCPQCGRGFSQKVTLIGHQRTHTGEKPYLCPDCGRGFGQKVTLIRHQRTHTGEKPYLCPKCGRAFGFKSLLTRHQRTHSEEELYVDRVCGQGLGQKSHLISDQRTHSGEKPCICDECGRGFGFKSALIRHQRTHSGEKPYVCRECGRGFSQKSHLHRHRRTKSGHQLLPQEVF>sp|Q9NPG8|ZDHC4_HUMAN Palmitoyltransferase ZDHHC4 OS=Homo sapiensOX=9606 GN=ZDHHC4 PE=1 SV=1MDFLVLFLFYLASVLMGLVLICVCSKTHSLKGLARGGAQIFSCIIPECLQRAVHGLLHYLFHTRNHTFIVLHLVLQGMVYTEYTWEVFGYCQELELSLHYLLLPYLLLGVNLFFFTLTCGTNPGIITKANELLFLHVYEFDEVMFPKNVRCSTCDLRKPARSKHCSVCNWCVHRFDHHCVWVNNCIGAWNIRYFLIYVLTLTASAATVAIVSTTFLVHLVVMSDLYQETYIDDLGHLHVMDTVFLIQYLFLTFPRIVFMLGFVVVLSFLLGGYLLFVLYLAATNQTTNEWYRGDWAWCQRCPLVAWPPSAEPQVHRNIHSHGLRSNLQEIFLPAFPCHERKKQE>sp|Q9H6S0|YTDC2_HUMAN 3'-5' RNA helicase YTHDC2 OS=Homo sapiens OX=9606GN=YTHDC2 PE=1 SV=2MSRPSSVSPRQPAPGGGGGGGPSPCGPGGGGRAKGLKDIRIDEEVKIAVNIALERFRYGDQREMEFPSSLTSTERAFIHRLSQSLGLVSKSKGKGANRYLTVKKKDGSETAHAMMTCNLTHNTKHAVRSLIQRFPVTNKERTELLPKTERGNVFAVEAENREMSKTSGRLNNGIPQIPVKRGESEFDSFRQSLPVFEKQEEIVKIIKENKVVLIVGETGSGKTTQIPQFLLDDCFKNGIPCRIFCTQPRRLAAIAVAERVAAERRERIGQTIGYQIRLESRVSPKTLLTFCTNGVLLRTLMAGDSTLSTVTHVIVDEVHERDRFSDFLLTKLRDLLQKHPTLKLILSSAALDVNLFIRYFGSCPVIYIQGRPFEVKEMFLEDILRTTGYTNKEMLKYKKEKQQEEKQQTTLTEWYSAQENSFKPESQRQRTVLNVTDEYDLLDDGGDAVFSQLTEKDVNCLEPWLIKEMDACLSDIWLHKDIDAFAQVFHLILTENVSVDYRHSETSATALMVAAGRGFASQVEQLISMGANVHSKASNGWMALDWAKHFGQTEIVDLLESYSATLEFGNLDESSLVQTNGSDLSAEDRELLKAYHHSFDDEKVDLDLIMHLLYNICHSCDAGAVLIFLPGYDEIVGLRDRILFDDKRFADSTHRYQVFMLHSNMQTSDQKKVLKNPPAGVRKIILSTNIAETSITVNDVVFVIDSGKVKEKSFDALNFVTMLKMVWISKASAIQRKGRAGRCRPGICFRLFSRLRFQNMLEFQTPELLRMPLQELCLHTKLLAPVNCPIADFLMKAPEPPPALIVRNAVQMLKTIDAMDTWEDLTELGYHLADLPVEPHLGKMVLCAVVLKCLDPILTIACTLAYRDPFVLPTQASQKRAAMLCRKRFTAGAFSDHMALLRAFQAWQKARSDGWERAFCEKNFLSQATMEIIIGMRTQLLGQLRASGFVRARGGGDIRDVNTNSENWAVVKAALVAGMYPNLVHVDRENLVLTGPKEKKVRFHPASVLSQPQYKKIPPANGQAAAIKALPTDWLIYDEMTRAHRIANIRCCSAVTPVTILVFCGPARLASNALQEPSSFRVDGIPNDSSDSEMEDKTTANLAALKLDEWLHFTLEPEAASLLLQLRQKWHSLFLRRMRAPSKPWSQVDEATIRAIIAVLSTEEQSAGLQQPSGIGQRPRPMSSEELPLASSWRSNNSRKSSADTEFSDECTTAERVLMKSPSPALHPPQKYKDRGILHPKRGTEDRSDQSSLKSTDSSSYPSPCASPSPPSSGKGSKSPSPRPNMPVRYFIMKSSNLRNLEISQQKGIWSTTPSNERKLNRAFWESSIVYLVFSVQGSGHFQGFSRMSSEIGREKSQDWGSAGLGGVFKVEWIRKESLPFQFAHHLLNPWNDNKKVQISRDGQELEPLVGEQLLQLWERLPLGEKNTTD>sp|P59817|Z280A_HUMAN Zinc finger protein 280A OS=Homo sapiens OX=9606GN=ZNF280A PE=1 SV=3MGDIFLCKKVESPKKNLRESKQREEDDEDPDLIYVGVEHVHRDAEVLFVGMISNSKPVVSNILNRVTPGSKSRRKKGHFRQYPAHVSQPANHVTSMAKAIMPVSLSEGRSTDSPVTMKSSSEPGYKMSSPQVVSPNYSDSLPPGTQCLVGAMVSGGGRNESSPDSKRLSTSDINSRDSKRVKLRDGIPGVPSLAVVPSDMSSTISTNTPSQGICNSSNHVQNGVTFPWPDANGKAHFNLTDPERANESGLAMTDISSLASQNKTFDPKKENPIVLLSNFYYGQHKGDGQPEQKTHTTFKCLSCVKVLKNIKFMNHMKHHLEFEKQRNDSWEDHTTCQHCHRQFPTPFQLQCHIDSVHIAMGPSAVCKICELSFETDQVLLQHMKDHHKPGEMPYVCQVCHYRSSVFADVETHFRTCHENTKNLLCLFCLKLFKTAIPYMNHCWRHSRRRVLQCSKCRLQFLTLKEEIEHKTKDHQTFKKPEQLQGFPRETKVIIQTSVQPGSSGMASVIVSNTDPQSSPVKTKKKTAMNTRDSRLPCSKDSS>sp|Q9H898|ZMAT4_HUMAN Zinc finger matrin-type protein 4 OS=Homo sapiensOX=9606 GN=ZMAT4 PE=1 SV=1MKSSDIDQDLFTDSYCKVCSAQLISESQRVAHYESRKHASKVRLYYMLHPRDGGCPAKRLRSENGSDADMVDKNKCCTLCNMSFTSAVVADSHYQGKIHAKRLKLLLGEKTPLKTTATPLSPLKPPRMDTAPVVASPYQRRDSDRYCGLCAAWFNNPLMAQQHYDGKKHKKNAARVALLEQLGTTLDMGELRGLRRNYRCTICSVSLNSIEQYHAHLKGSKHQTNLKNK>sp|Q9H898-2|ZMAT4_HUMAN Isoform 2 of Zinc finger matrin-type protein 4OS=Homo sapiens OX=9606 GN=ZMAT4MKSSDIDQDLFTDSYCKVCSAQLISESQRVAHYESRKHASKVRLYYMLHPRDGGCPAKRLRSENGSDADMVDKNKCCTLCNMSFTSAVVADSHYQGKIHAKRLKLLLGEKTPLKTTGLRRNYRCTICSVSLNSIEQYHAHLKGSKHQTNLKNK>sp|Q96JL9|ZN333_HUMAN Zinc finger protein 333 OS=Homo sapiens OX=9606GN=ZNF333 PE=1 SV=3MESVTFEDVAVEFIQEWALLDSARRSLCKYRMLDQCRTLASRGTPPCKPSCVSQLGQRAEPKATERGILRATGVAWESQLKPEELPSMQDLLEEASSRDMQMGPGLFLRMQLVPSIEERETPLTREDRPALQEPPWSLGCTGLKAAMQIQRVVIPVPTLGHRNPWVARDSAVPARDPAWLQEDKVEEEAMAPGLPTACSQEPVTFADVAVVFTPEEWVFLDSTQRSLYRDVMLENYRNLASVADQLCKPNALSYLEERGEQWTTDRGVLSDTCAEPQCQPQEAIPSQDTFTEILSIDVKGEQPQPGEKLYKYNELEKPFNSIEPLFQYQRIHAGEASCECQEIRNSFFQSAHLIVPEKIRSGDKSYACNKCEKSFRYSSDLIRHEKTHTAEKCFDCQECGQAFKYSSNLRRHMRTHTGEKPFECSQCGKTFTRNFNLILHQRNHTGEKPYECKDCGKAFNQPSSLRSHVRTHTGEKPFECSQCGKAFREHSSLKTHLRTHTREKPYECNQCGKPFRTSTHLNVHKRIHTGEKLYECATCGQVLSRLSTLKSHMRTHTGEKPYVCQECGRAFSEPSSLRKHARTHSGKKPYACQECGRAFGQSSHLIVHVRTHSAGRPYQCNQCEKAFRHSSSLTVHKRTHVGRETIRNGSLPLSMSHPYCGPLAN>sp|Q96JL9-2|ZN333_HUMAN Isoform 2 of Zinc finger protein 333 OS=Homosapiens OX=9606 GN=ZNF333MESVTFEDVAVEFIQEWALLDSARRSLCKYRMLDQCRTLASRGTPPCKPSCVSQLGQRAEPKATERGILRATGVAWESQLKPEELPSMQDLLEEASSRDMQMGPGLFLRMQLVPSIEERETPLTREDRPALQEPPWSLGCTLPLLSLLLPSCPEPPLVLLDSSSAPDRHLGSTLDTEARGIP>sp|Q96JL9-3|ZN333_HUMAN Isoform 3 of Zinc finger protein 333 OS=Homosapiens OX=9606 GN=ZNF333MESVTFEDVAVEFIQEWALLDSARRSLCKYRMLDQCRTLASRGTPPCKPSCVSQLGQRAEPKATERGILRATGVAWESQLKPEELPSMQDLLEEASSRDMQMGPGLFLRMQLVPSIEERETPLTREDRPALQEPPWSLGCTGLKAAMQIQRVVIPVPTLGHRNPWVARDSAVPARDPAWLQEDKVEEEAMAPGLPTACSQEPVTFADVAVVFTPEEWVFLDSTQRSLYRDVMLENYRNLASVADQLCKPNALSYLEERGEQWTTDRGVLSDTCAEPQCQPQEAIPSQDTFTEILSIDVKGPPN>sp|Q8N6K4|YP021_HUMAN Putative uncharacterized protein MGC34800 OS=Homosapiens OX=9606 PE=2 SV=1MGDLPWAPPEAQAPSTAGAGDVAEHQVAPARFLQGAWRQAAGWLCRETGAAPGSAQAGPPETAHAADPQPRGPQAPPRLPPSLSPERVHPGQPAAPAEPAPGAPALRSGPSQPRGLRLPVPVPACAGSSAPGSPAALPDSYPWPPPARNRPATLPPTSRVSPLAAFLASAPQR>sp|Q9H091|ZMY15_HUMAN Zinc finger MYND domain-containing protein 15OS=Homo sapiens OX=9606 GN=ZMYND15 PE=2 SV=2MEFVSGYRDEFLDFTALLFGWFRKFVAERGAVGTSLEGRCRQLEAQIRRLPQDPALWVLHVLPNHSVGISLGQGAEPGPGPGLGTAWLLGDNPPLHLRDLSPYISFVSLEDGEEGEEEEEEDEEEEKREDGGAGSTEKVEPEEDRELAPTSRESPQETNPPGESEEAAREAGGGKDGCREDRVENETRPQKRKGQRSEAAPLHVSCLLLVTDEHGTILGIDLLVDGAQGTASWGSGTKDLAPWAYALLCHSMACPMGSGDPRKPRQLTVGDARLHRELESLVPRLGVKLAKTPMRTWGPRPGFTFASLRARTCHVCHRHSFEAKLTPCPQCSAVLYCGEACLRADWQRCPDDVSHRFWCPRLAAFMERAGELATLPFTYTAEVTSETFNKEAFLASRGLTRGYWTQLSMLIPGPGFSRHPRGNTPSLSLLRGGDPYQLLQGDGTALMPPVPPHPPRGVFGSWQDYYTWRGLSLDSPIAVLLTYPLTVYYVITHLVPQSFPELNIQNKQSLKIHVVEAGKEFDLVMVFWELLVLLPHVALELQFVGDGLPPESDEQHFTLQRDSLEVSVRPGSGISARPSSGTKEKGGRRDLQIKVSARPYHLFQGPKPDLVIGFNSGFALKDTWLRSLPRLQSLRVPAFFTESSEYSCVMDGQTMAVATGGGTSPPQPNPFRSPFRLRAADNCMSWYCNAFIFHLVYKPAQGSGARPAPGPPPPSPTPSAPPAPTRRRRGEKKPGRGARRRK>sp|Q9H091-2|ZMY15_HUMAN Isoform 2 of Zinc finger MYND domain-containingprotein 15 OS=Homo sapiens OX=9606 GN=ZMYND15MEFVSGYRDEFLDFTALLFGWFRKFVAERGAVGTSLEGRCRQLEAQIRRLPQDPALWVLHVLPNHSVGISLGQGAEPGPGPGLGTAWLLGDNPPLHLRDLSPYISFVSLEDGEEGEEEEEEDEEEEKREDGGAGSTEKVEPEEDRELAPTSRESPQETNPPGESEEAAREAGGGKDGCREDRVENETRPQKRKGQRSEAAPLHVSCLLLVTDEHGTILGIDLLVDGAQGTASWGSGTKDLAPWAYALLCHSMACPMGSGDPRKPRQLTVGDARLHRELESLVPRLGVKLAKTPMRTWGPRPGFTFASLRARTCHVCHRHSFEAKLTPCPQCSAVLYCGEACLRADWQRCPDDVSHRFWCPRLAAFMERAGELATLPFTYTAEVTSETFNKEAFLASRGLTRGYWTQLSMLIPGPGFSRHPRGNTPSLSLLRGGDPYQLLQGDGTALMPPVPPHPPRGVFVPELNIQNKQSLKIHVVEAGKEFDLVMVFWELLVLLPHVALELQFVGDGLPPESDEQHFTLQRDSLEVSVRPGSGISARPSSGTKEKGGRRDLQIKVSARPYHLFQGPKPDLVIGFNSGFALKDTWLRSLPRLQSLRVPAFFTESSEYSCVMDGQTMAVATGGGTSPPQPNPFRSPFRLRAADNCMSWYCNAFIFHLVYKPAQGSGARPAPGPPPPSPTPSAPPAPTRRRRGEKKPGRGARRRK>sp|Q9H091-3|ZMY15_HUMAN Isoform 3 of Zinc finger MYND domain-containingprotein 15 OS=Homo sapiens OX=9606 GN=ZMYND15MEFVSGYRDEFLDFTALLFGWFRKFVAERGAVGTSLEGRCRQLEAQIRRLPQDPALWVLHVLPNHSVGISLGQGAEPGPGPGLGTAWLLGDNPPLHLRDLSPYISFVSLEDGEEGEEEEEEDEEEEKREDGGAGSTEKVEPEEDRELAPTSRESPQETNPPGESEEAAREAGGGKDGCREDRVENETRPQKRKGQRSEAAPLHVSCLLLVTDEHGTILGIDLLVDGAQGTASWGSGTKDLAPWAYALLCHSMACPMGSGDPRKPRQLTVGDARLHRELESLVPRLGVKLAKTPMRTWGPRPGFTFASLRARTCHVCHRHSFEAKLTPCPQCSAVLYCGEACLRADWQRCPDDVSHRFWCPRLAAFMERAGELATLPFTYTAEVTSETFNKEAFLASRGLTRGYWTQLSMLIPGPGFSRHPRGNTPSLSLLRGGDPYQLLQGDGTALMPPVPPHPPRGVFGSWQDYYTWRGLSLDSPIAVLLTYPLTVYYVITHLVPQSFPELNIQNKQSLKIHVVEAGKEFDLVMVFWELLVLLPHVALELQFVGDGLPPESDEQHFTLQRDSLEVSVRPGSGISARPSSGTKEKGGRRDLQIKVSARPYHLFQGPKPDLVIASPSSLSAGFNSGFALKDTWLRSLPRLQSLRVPAFFTESSEYSCVMDGQTMAVATGGGTSPPQPNPFRSPFRLRAADNCMSWYCNAFIFHLVYKPAQGSGARPAPGPPPPSPTPSAPPAPTRRRRGEKKPGRGARRRK>sp|Q8N4Q0|PTGR3_HUMAN Prostaglandin reductase 3 OS=Homo sapiens OX=9606GN=ZADH2 PE=1 SV=1MLRLVPTGARAIVDMSYARHFLDFQGSAIPQAMQKLVVTRLSPNFREAVTLSRDCPVPLPGDGDLLVRNRFVGVNASDINYSAGRYDPSVKPPFDIGFEGIGEVVALGLSASARYTVGQAVAYMAPGSFAEYTVVPASIATPVPSVKPEYLTLLVSGTTAYISLKELGGLSEGKKVLVTAAAGGTGQFAMQLSKKAKCHVIGTCSSDEKSAFLKSLGCDRPINYKTEPVGTVLKQEYPEGVDVVYESVGGAMFDLAVDALATKGRLIVIGFISGYQTPTGLSPVKAGTLPAKLLKKSASVQGFFLNHYLSKYQAAMSHLLEMCVSGDLVCEVDLGDLSPEGRFTGLESIFRAVNYMYMGKNTGKIVVELPHSVNSKL>sp|Q8N4Q0-2|PTGR3_HUMAN Isoform 2 of Prostaglandin reductase 3 OS=Homosapiens OX=9606 GN=ZADH2MAPGSFAEYTVVPASIATPVPSVKPEYLTLLVSGTTAYISLKELGGLSEGKKVLVTAAAGGTGQFAMQLSKKAKCHVIGTCSSDEKSAFLKSLGCDRPINYKTEPVGTVLKQEYPEGVDVVYESVGGAMFDLAVDALATKGRLIVIGFISGYQTPTGLSPVKAGTLPAKLLKKSASVQGFFLNHYLSKYQAAMSHLLEMCVSGDLVCEVDLGDLSPEGRFTGLESIFRAVNYMYMGKNTGKIVVELPHSVNSKL>sp|Q6NUJ5|PWP2B_HUMAN PWWP domain-containing protein 2B OS=Homo sapiensOX=9606 GN=PWWP2B PE=1 SV=3MEPRAGCRLPVRVEQVVNGALVVTVSCGERSFAGILLDCTKKSGLFGLPPLAPLPQVDESPVNDSHGRAPEEGDAEVMQLGSSSPPPARGVQPPETTRPEPPPPLVPPLPAGSLPPYPPYFEGAPFPHPLWLRDTYKLWVPQPPPRTIKRTRRRLSRNRDPGRLILSTIRLRPRQVLCEKCKSTLSPPEASPGPPAAPRARRRLGSGPDRELRKPEEPENGEPTAAATARRSKRERREEDRAPAEQVPRSPVIKISYSTPQGKGEVVKIPSRVHGSLEPFRPQQAPQDDGSQDPEVLDRESRDRPSCAPSASIPKLKLTRPVPAGADLPPPKIRLKPHRLGDSEHEPVYRAELVGELNGYLRDSSPAPCADGPAGGLADLSSGSSGEDDDFKSCPQGPQGREGLAFLVSCPEGRADCASESACSSDSLDEARSSGSEGTPADTGDLSPGHGASAPSVSREARQTVPPLTVRLHTQSVSECITEDGRTVAVGDIVWGKIHGFPWWPARVLDISLGQKEDGEPSWREAKVSWFGSPTTSFLSISKLSPFSEFFKLRFNRKKKGMYRKAITEAANAARHVAPEIRELLTQFET>sp|Q6NUJ5-2|PWP2B_HUMAN Isoform 2 of PWWP domain-containing protein 2BOS=Homo sapiens OX=9606 GN=PWWP2BMEPRAGCRLPVRVEQVVNGALVVTVSCGERSFAGILLDCTKKSGLFGLPPLAPLPQVDESPVNDSHGRAPEEGDAEVMQLGSSSPPPARGVQPPETTRPEPPPPLVPPLPAGSLPPYPPYFEGAPFPHPLWLRDTYKLWVPQPPPRTIKRTRRRLSRNRDPGRLILSTIRLRPRQVLCEKCKSTLSPPEASPGPPAAPRARRRLGSGPDRELRKPEEPENGEPTAAATARRSKRERREEDRAPAEQVPRSPVIKISYSTPQGKGEVVKIPSRVHGSLEPFRPQQAPQDDGSQDPEVLDRESRDRPSCAPSASIPKLKLTRPVPAGADLPPPKIRLKPHRLGDSEHEPVYRAELVGELNGYLRDSSPAPCADGPAGGLADLSSGSSGEDDDFKSCPQGPQGREGLAFLVSCPEGRADCASESACSSDSLDEARSSGSEGTPADTGDLSPGHGASAPSVSREARQTVPPLTVRLHTQSVSECITEDGRTVAVGDIVWGHRR>sp|Q8NEY8|PPHLN_HUMAN Periphilin-1 OS=Homo sapiens OX=9606 GN=PPHLN1PE=1 SV=2MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDDHSASRQPEYRDMRDGFRRKSFYSSHYARERSPYKRDNTFFRESPVGRKDSPHSRSGSSVSSRSYSPERSKSYSFHQSQHRKSVRPGASYKRQNEGNPERDKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVYRQDCETFGMVVKMLIEKDPSLEKSIQFALRQNLHEIESAGQTWQQVPPVRNTEMDHDGTPENEGEETAQSAPQPPQAPQPLQPRKKRVRRTTQLRRTTGAPDITWGMLKKTTQEAERILLRTQTPFTPENLFLAMLSVVHCNSRKDVKPENKQ>sp|Q8NEY8-2|PPHLN_HUMAN Isoform 2 of Periphilin-1 OS=Homo sapiensOX=9606 GN=PPHLN1MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDDHSASRQPEYRDMRDGFRRKSFYSSHYARERSPYKRDNTFFRESPVGRKDSPHSRSGSSVSSRSYSPERSKSYSFHQSQHRKSVRPGASYKRQNEGNPERDKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVYRQDCETFGMVVKMLIEKDPSLEKSIQFALRQNLHEIGERCVEELKHFIAEYDTSTQDFGEPF>sp|Q8NEY8-3|PPHLN_HUMAN Isoform 3 of Periphilin-1 OS=Homo sapiensOX=9606 GN=PPHLN1MWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRDMRDGFRRKSFYSSHYARERSPYKRDNTFFRESPVGRKDSPHSRSGSSVSSRSYSPERSKSYSFHQSQHRKSVRPGASYKRQNEGNPERDKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVYRQDCETFGMVVKMLIEKDPSLEKSIQFALRQNLHEIESAGQTWQQVPPVRNTEMDHDGTPENEGEETAQSALFGFQHDASNHTIVGLGPNQVPEMKETTLQAPQPPQAPQPLQPRKKRVRRTTQLRRTTGAPDITWGMLKKTTQEAERILLRTQTPFTPENLFLAMLSVVHCNSRKDVKPENKQ>sp|Q8NEY8-5|PPHLN_HUMAN Isoform 5 of Periphilin-1 OS=Homo sapiensOX=9606 GN=PPHLN1MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRDMRDGFRRKSFYSSHYARERSPYKRDNTFFRESPVGRKDSPHSRSGSSVSSRSYSPERSKSYSFHQSQHRKSVRPGASYKRQNEGNPERDKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVRV>sp|Q8NEY8-6|PPHLN_HUMAN Isoform 6 of Periphilin-1 OS=Homo sapiensOX=9606 GN=PPHLN1MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRDMRDGFRRKSFYSSHYARERSPYKRDNTFFRESPVGRKDSPHSRSGSSVSSRSYSPERSKSYSFHQSQHRKSVRPGASYKRQNEGNPERDKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVYRQDCETFGMVVKMLIEKDPSLEKSIQFALRQNLHEIGERCVEELKHFIAEYDTSTQDFGEPF>sp|Q8NEY8-7|PPHLN_HUMAN Isoform 7 of Periphilin-1 OS=Homo sapiensOX=9606 GN=PPHLN1MFSYIDKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVRV>sp|Q8NEY8-8|PPHLN_HUMAN Isoform 8 of Periphilin-1 OS=Homo sapiensOX=9606 GN=PPHLN1MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDDHSASRQPEYRDMRDGFRRKSFYSSHYARERSPYKRDNTFFRESPVGRKDSPHSRSGSSVSSRSYSPERSKSYSFHQSQHRKSVRPGASYKRQNEGNPERDKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVYRQDCETFGMVVKMLIEKDPSLEKSIQFALRQNLHEIGERCVEELKHFIAEYDTSTQDFGEPF>sp|Q8NEY8-9|PPHLN_HUMAN Isoform 9 of Periphilin-1 OS=Homo sapiensOX=9606 GN=PPHLN1MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDDHSASRQPEYRDMRDGFRRKSFYSSHYARERSPYKRDNTFFRESPVGRKDSPHSRSGSSVSSRSYSPERSKSYSFHQSQHRNKERPVQSLKTSRDTSPSSGSAVSSSKVLDKPSRLTEKELAEAASKWAAEKLEKSDESNLPEISEYEAGSTAPLFTDQPEEPESNTTHGIELFEDSQLTTRSKAIASKTKEIEQVYRQDCETFGMVVKMLIEKDPSLEKSIQFALRQNLHEIGERCVEELKHFIAEYDTSTQDFGEPF>sp|P01111|RASN_HUMAN GTPase NRas OS=Homo sapiens OX=9606 GN=NRAS PE=1SV=1MTEYKLVVVGAGGVGKSALTIQLIQNHFVDEYDPTIEDSYRKQVVIDGETCLLDILDTAGQEEYSAMRDQYMRTGEGFLCVFAINNSKSFADINLYREQIKRVKDSDDVPMVLVGNKCDLPTRTVDTKQAHELAKSYGIPFIETSAKTRQGVEDAFYTLVREIRQYRMKKLNSSDDGTQGCMGLPCVVM>sp|Q9HCJ3|RAVR2_HUMAN Ribonucleoprotein PTB-binding 2 OS=Homo sapiensOX=9606 GN=RAVER2 PE=1 SV=2MAAAAGDGGGEGGAGLGSAAGLGPGPGLRGQGPSAEAHEGAPDPMPAALHPEEVAARLQRMQRELSNRRKILVKNLPQDSNCQEVHDLLKDYDLKYCYVDRNKRTAFVTLLNGEQAQNAIQMFHQYSFRGKDLIVQLQPTDALLCITNVPISFTSEEFEELVRAYGNIERCFLVYSEVTGHSKGYGFVEYMKKDFAAKARLELLGRQLGASALFAQWMDVNLLASELIHSKCLCIDKLPSDYRDSEELLQIFSSVHKPVFCQLAQDEGSYVGGFAVVEYSTAEQAEEVQQAADGMTIKGSKVQVSFCAPGAPGRSTLAALIAAQRVMHSNQKGLLPEPNPVQIMKSLNNPAMLQVLLQPQLCGRAVKPAVLGTPHSLPHLMNPSISPAFLHLNKAHQSSVMGNTSNLFLQNLSHIPLAQQQLMKFENIHTNNKPGLLGEPPAVVLQTALGIGSVLPLKKELGHHHGEAHKTSSLIPTQTTITAGMGMLPFFPNQHIAGQAGPGHSNTQEKQPATVGMAEGNFSGSQPYLQSFPNLAAGSLLVGHHKQQQSQPKGTEISSGAASKNQTSLLGEPPKEIRLSKNPYLNLASVLPSVCLSSPASKTTLHKTGIASSILDAISQGSESQHALEKCIAYSPPFGDYAQVSSLRNEKRGSSYLISAPEGGSVECVDQHSQGTGAYYMETYLKKKRVY>sp|Q9HCJ3-2|RAVR2_HUMAN Isoform 2 of Ribonucleoprotein PTB-binding 2OS=Homo sapiens OX=9606 GN=RAVER2MAAAAGDGGGEGGAGLGSAAGLGPGPGLRGQGPSAEAHEGAPDPMPAALHPEEVAARLQRMQRELSNRRKILVKNLPQDSNCQEVHDLLKDYDLKYCYVDRNKRTAFVTLLNGEQAQNAIQMFHQYSFRGKDLIVQLQPTDALLCITNVPISFTSEEFEELVRAYGNIERCFLVYSEVTGHSKGYGFVEYMKKDFAAKARLELLGRQLGASALFAQWMDVNLLASELIHSKCLCIDKLPSDYRDSEELLQIFSSVHKPVFCQLAQDEGSYVGGFAVVEYSTAEQAEEVQQAADGMTIKGSKVQVSFCAPGAPGRSTLAALIAAQRVMHSNQKGLLPEPNPVQIMKSLNNPAMLQVLLQPQLCGRAVKPAVLGTPHSLPHLMNPSISPAFLHLNKAHQNLSHIPLAQQQLMKFENIHTNNKPGLLGEPPAVVLQTALGIGSVLPLKKELGHHHGEAHKTSSLIPTQTTITAGMGMLPFFPNQHIAGQAGPGHSNTQEKQPATVGMAEGNFSGSQPYLQSFPNLAAGSLLVGHHKQQQSQPKGTEISSGAASKNQTSLLGEPPKEIRLSKNPYLNLASVLPSVCLSSPASKTTLHKTGIASSILDAISQGSESQHALEKCIAYSPPFGDYAQVSSLRNEKRGSSYLISAPEGGSVECVDQHSQGTGAYYMETYLKKKRVY>sp|O95755|RAB36_HUMAN Ras-related protein Rab-36 OS=Homo sapiens OX=9606GN=RAB36 PE=1 SV=2MVIAGASWMLGRAAASPTQTPPTTSTIRVARRSRVALVAMVIAAAGSGGPGRAEPQLSQPSLDCGRMRSSLTPLGPPVSRDRVIASFPKWYTPEACLQLREHFHGQVSAACQRRNTGTVGLKLSKVVVVGDLYVGKTSLIHRFCKNVFDRDYKATIGVDFEIERFEIAGIPYSLQIWDTAGQEKFKCIASAYYRGAQVIITAFDLTDVQTLEHTRQWLEDALRENEAGSCFIFLVGTKKDLLSGAACEQAEADAVHLAREMQAEYWSVSAKTGENVKAFFSRVAALAFEQSVLQDLERQSSARLQVGNGDLIQMEGSPPETQESKRPSSLGCC>sp|O95755-2|RAB36_HUMAN Isoform 2 of Ras-related protein Rab-36 OS=Homosapiens OX=9606 GN=RAB36MVIAGASWMLGRAAASPTQTPPTTSTIRVARRSRVALVAMVIAAAGSGGPGRAEPQLSQPSLDCGRMRSSLTPLGPPVSRDRVIASFPKWYTPEACLQLREHFHGQVSAACQRRNTGTVGFCKNVFDRDYKATIGVDFEIERFEIAGIPYSLQIWDTAGQEKFKCIASAYYRGAQVIITAFDLTDVQTLEHTRQWLEDALRENEAGSCFIFLVGTKKDLLSGAACEQAEADAVHLAREMQAEYWSVSAKTGENVKAFFSRVAALAFEQSVLQDLERQSSARLQVGNGDLIQMEGSPPETQESKRPSSLGCC>sp|P61019|RAB2A_HUMAN Ras-related protein Rab-2A OS=Homo sapiens OX=9606GN=RAB2A PE=1 SV=1MAYAYLFKYIIIGDTGVGKSCLLLQFTDKRFQPVHDLTIGVEFGARMITIDGKQIKLQIWDTAGQESFRSITRSYYRGAAGALLVYDITRRDTFNHLTTWLEDARQHSNSNMVIMLIGNKSDLESRREVKKEEGEAFAREHGLIFMETSAKTASNVEEAFINTAKEIYEKIQEGVFDINNEANGIKIGPQHAATNATHAGNQGGQQAGGGCC>sp|P61019-2|RAB2A_HUMAN Isoform 2 of Ras-related protein Rab-2A OS=Homosapiens OX=9606 GN=RAB2AMAYAYLFKYIIIGDTGVEFGARMITIDGKQIKLQIWDTAGQESFRSITRSYYRGAAGALLVYDITRRDTFNHLTTWLEDARQHSNSNMVIMLIGNKSDLESRREVKKEEGEAFAREHGLIFMETSAKTASNVEEAFINTAKEIYEKIQEGVFDINNEANGIKIGPQHAATNATHAGNQGGQQAGGGCC>sp|Q13123|RED_HUMAN Protein Red OS=Homo sapiens OX=9606 GN=IK PE=1 SV=3MPERDSEPFSNPLAPDGHDVDDPHSFHQSKLTNEDFRKLLMTPRAAPTSAPPSKSRHHEMPREYNEDEDPAARRRKKKSYYAKLRQQEIERERELAEKYRDRAKERRDGVNKDYEETELISTTANYRAVGPTAEADKSAAEKRRQLIQESKFLGGDMEHTHLVKGLDFALLQKVRAEIASKEKEEEELMEKPQKETKKDEDPENKIEFKTRLGRNVYRMLFKSKAYERNELFLPGRMAYVVDLDDEYADTDIPTTLIRSKADCPTMEAQTTLTTNDIVISKLTQILSYLRQGTRNKKLKKKDKGKLEEKKPPEADMNIFEDIGDYVPSTTKTPRDKERERYRERERDRERDRDRDRERERERDRERERERDREREEEKKRHSYFEKPKVDDEPMDVDKGPGSTKELIKSINEKFAGSAGWEGTESLKKPEDKKQLGDFFGMSNSYAECYPATMDDMAVDSDEEVDYSKMDQGNKKGPLGRWDFDTQEEYSEYMNNKEALPKAAFQYGIKMSEGRKTRRFKETNDKAELDRQWKKISAIIEKRKKMEADGVEVKRPKY>sp|P05451|REG1A_HUMAN Lithostathine-1-alpha OS=Homo sapiens OX=9606GN=REG1A PE=1 SV=3MAQTSSYFMLISCLMFLSQSQGQEAQTELPQARISCPEGTNAYRSYCYYFNEDRETWVDADLYCQNMNSGNLVSVLTQAEGAFVASLIKESGTDDFNVWIGLHDPKKNRRWHWSSGSLVSYKSWGIGAPSSVNPGYCVSLTSSTGFQKWKDVPCEDKFSFVCKFKN>sp|P04090|REL2_HUMAN Prorelaxin H2 OS=Homo sapiens OX=9606 GN=RLN2 PE=1SV=1MPRLFFFHLLGVCLLLNQFSRAVADSWMEEVIKLCGRELVRAQIAICGMSTWSKRSLSQEDAPQTPRPVAEIVPSFINKDTETINMMSEFVANLPQELKLTLSEMQPALPQLQQHVPVLKDSSLLFEEFKKLIRNRQSEAADSSPSELKYLGLDTHSRKKRQLYSALANKCCHVGCTKRSLARFC>sp|P04090-2|REL2_HUMAN Isoform 2 of Prorelaxin H2 OS=Homo sapiensOX=9606 GN=RLN2MPRLFFFHLLGVCLLLNQFSRAVADSWMEEVIKLCGRELVRAQIAICGMSTWSKRSLSQEDAPQTPRPVAGDFIQTVSLGISPDGGKALRTGSCFTREFLGALSKLCHPSSTKIQKP>sp|O60673|REV3L_HUMAN DNA polymerase zeta catalytic subunit OS=Homosapiens OX=9606 GN=REV3L PE=1 SV=2MFSVRIVTADYYMASPLQGLDTCQSPLTQAPVKKVPVVRVFGATPAGQKTCLHLHGIFPYLYVPYDGYGQQPESYLSQMAFSIDRALNVALGNPSSTAQHVFKVSLVSGMPFYGYHEKERHFMKIYLYNPTMVKRICELLQSGAIMNKFYQPHEAHIPYLLQLFIDYNLYGMNLINLAAVKFRKARRKSNTLHATGSCKNHLSGNSLADTLFRWEQDEIPSSLILEGVEPQSTCELEVDAVAADILNRLDIEAQIGGNPGLQAIWEDEKQRRRNRNETSQMSQPESQDHRFVPATESEKKFQKRLQEILKQNDFSVTLSGSVDYSDGSQEFSAELTLHSEVLSPEMLQCTPANMVEVHKDKESSKGHTRHKVEEALINEEAILNLMENSQTFQPLTQRLSESPVFMDSSPDEALVHLLAGLESDGYRGERNRMPSPCRSFGNNKYPQNSDDEENEPQIEKEEMELSLVMSQRWDSNIEEHCAKKRSLCRNTHRSSTEDDDSSSGEEMEWSDNSLLLASLSIPQLDGTADENSDNPLNNENSRTHSSVIATSKLSVKPSIFHKDAATLEPSSSAKITFQCKHTSALSSHVLNKEDLIEDLSQTNKNTEKGLDNSVTSFTNESTYSMKYPGSLSSTVHSENSHKENSKKEILPVSSCESSIFDYEEDIPSVTRQVPSRKYTNIRKIEKDSPFIHMHRHPNENTLGKNSFNFSDLNHSKNKVSSEGNEKGNSTALSSLFPSSFTENCELLSCSGENRTMVHSLNSTADESGLNKLKIRYEEFQEHKTEKPSLSQQAAHYMFFPSVVLSNCLTRPQKLSPVTYKLQPGNKPSRLKLNKRKLAGHQETSTKSSETGSTKDNFIQNNPCNSNPEKDNALASDLTKTTRGAFENKTPTDGFIDCHFGDGTLETEQSFGLYGNKYTLRAKRKVNYETEDSESSFVTHNSKISLPHPMEIGESLDGTLKSRKRRKMSKKLPPVIIKYIIINRFRGRKNMLVKLGKIDSKEKQVILTEEKMELYKKLAPLKDFWPKVPDSPATKYPIYPLTPKKSHRRKSKHKSAKKKTGKQQRTNNENIKRTLSFRKKRSHAILSPPSPSYNAETEDCDLNYSDVMSKLGFLSERSTSPINSSPPRCWSPTDPRAEEIMAAAEKEAMLFKGPNVYKKTVNSRIGKTSRARAQIKKSKAKLANPSIVTKKRNKRNQTNKLVDDGKKKPRAKQKTNEKGTSRKHTTLKDEKIKSQSGAEVKFVLKHQNVSEFASSSGGSQLLFKQKDMPLMGSAVDHPLSASLPTGINAQQKLSGCFSSFLESKKSVDLQTFPSSRDDLHPSVVCNSIGPGVSKINVQRPHNQSAMFTLKESTLIQKNIFDLSNHLSQVAQNTQISSGMSSKIEDNANNIQRNYLSSIGKLSEYRNSLESKLDQAYTPNFLHCKDSQQQIVCIAEQSKHSETCSPGNTASEESQMPNNCFVTSLRSPIKQIAWEQKQRGFILDMSNFKPERVKPRSLSEAISQTKALSQCKNRNVSTPSAFGEGQSGLAVLKELLQKRQQKAQNANTTQDPLSNKHQPNKNISGSLEHNKANKRTRSVTSPRKPRTPRSTKQKEKIPKLLKVDSLNLQNSSQLDNSVSDDSPIFFSDPGFESCYSLEDSLSPEHNYNFDINTIGQTGFCSFYSGSQFVPADQNLPQKFLSDAVQDLFPGQAIEKNEFLSHDNQKCDEDKHHTTDSASWIRSGTLSPEIFEKSTIDSNENRRHNQWKNSFHPLTTRSNSIMDSFCVQQAEDCLSEKSRLNRSSVSKEVFLSLPQPNNSDWIQGHTRKEMGQSLDSANTSFTAILSSPDGELVDVACEDLELYVSRNNDMLTPTPDSSPRSTSSPSQSKNGSFTPRTANILKPLMSPPSREEIMATLLDHDLSETIYQEPFCSNPSDVPEKPREIGGRLLMVETRLANDLAEFEGDFSLEGLRLWKTAFSAMTQNPRPGSPLRSGQGVVNKGSSNSPKMVEDKKIVIMPCKCAPSRQLVQVWLQAKEEYERSKKLPKTKPTGVVKSAENFSSSVNPDDKPVVPPKMDVSPCILPTTAHTKEDVDNSQIALQAPTTGCSQTASESQMLPPVASASDPEKDEDDDDNYYISYSSPDSPVIPPWQQPISPDSKALNGDDRPSSPVEELPSLAFENFLKPIKDGIQKSPCSEPQEPLVISPINTRARTGKCESLCFHSTPIIQRKLLERLPEAPGLSPLSTEPKTQKLSNKKGSNTDTLRRVLLTQAKNQFAAVNTPQKETSQIDGPSLNNTYGFKVSIQNLQEAKALHEIQNLTLISVELHARTRRDLEPDPEFDPICALFYCISSDTPLPDTEKTELTGVIVIDKDKTVFSQDIRYQTPLLIRSGITGLEVTYAADEKALFHEIANIIKRYDPDILLGYEIQMHSWGYLLQRAAALSIDLCRMISRVPDDKIENRFAAERDEYGSYTMSEINIVGRITLNLWRIMRNEVALTNYTFENVSFHVLHQRFPLFTFRVLSDWFDNKTDLYRWKMVDHYVSRVRGNLQMLEQLDLIGKTSEMARLFGIQFLHVLTRGSQYRVESMMLRIAKPMNYIPVTPSVQQRSQMRAPQCVPLIMEPESRFYSNSVLVLDFQSLYPSIVIAYNYCFSTCLGHVENLGKYDEFKFGCTSLRVPPDLLYQVRHDITVSPNGVAFVKPSVRKGVLPRMLEEILKTRFMVKQSMKAYKQDRALSRMLDARQLGLKLIANVTFGYTSANFSGRMPCIEVGDSIVHKARETLERAIKLVNDTKKWGARVVYGDTDSMFVLLKGATKEQSFKIGQEIAEAVTATNPKPVKLKFEKVYLPCVLQTKKRYVGYMYETLDQKDPVFDAKGIETVRRDSCPAVSKILERSLKLLFETRDISLIKQYVQRQCMKLLEGKASIQDFIFAKEYRGSFSYKPGACVPALELTRKMLTYDRRSEPQVGERVPYVIIYGTPGVPLIQLVRRPVEVLQDPTLRLNATYYITKQILPPLARIFSLIGIDVFSWYHELPRIHKATSSSRSEPEGRKGTISQYFTTLHCPVCDDLTQHGICSKCRSQPQHVAVILNQEIRELERQQEQLVKICKNCTGCFDRHIPCVSLNCPVLFKLSRVNRELSKAPYLRQLLDQF>sp|O60673-2|REV3L_HUMAN Isoform 2 of DNA polymerase zeta catalyticsubunit OS=Homo sapiens OX=9606 GN=REV3LMAFSIDRALNVALGNPSSTAQHVFKVSLVSGMPFYGYHEKERHFMKIYLYNPTMVKRICELLQSGAIMNKFYQPHEAHIPYLLQLFIDYNLYGMNLINLAAVKFRKARRKSNTLHATGSCKNHLSGNSLADTLFRWEQDEIPSSLILEGVEPQSTCELEVDAVAADILNRLDIEAQIGGNPGLQAIWEDEKQRRRNRNETSQMSQPESQDHRFVPATESEKKFQKRLQEILKQNDFSVTLSGSVDYSDGSQEFSAELTLHSEVLSPEMLQCTPANMVEVHKDKESSKGHTRHKVEEALINEEAILNLMENSQTFQPLTQRLSESPVFMDSSPDEALVHLLAGLESDGYRGERNRMPSPCRSFGNNKYPQNSDDEENEPQIEKEEMELSLVMSQRWDSNIEEHCAKKRSLCRNTHRSSTEDDDSSSGEEMEWSDNSLLLASLSIPQLDGTADENSDNPLNNENSRTHSSVIATSKLSVKPSIFHKDAATLEPSSSAKITFQCKHTSALSSHVLNKEDLIEDLSQTNKNTEKGLDNSVTSFTNESTYSMKYPGSLSSTVHSENSHKENSKKEILPVSSCESSIFDYEEDIPSVTRQVPSRKYTNIRKIEKDSPFIHMHRHPNENTLGKNSFNFSDLNHSKNKVSSEGNEKGNSTALSSLFPSSFTENCELLSCSGENRTMVHSLNSTADESGLNKLKIRYEEFQEHKTEKPSLSQQAAHYMFFPSVVLSNCLTRPQKLSPVTYKLQPGNKPSRLKLNKRKLAGHQETSTKSSETGSTKDNFIQNNPCNSNPEKDNALASDLTKTTRGAFENKTPTDGFIDCHFGDGTLETEQSFGLYGNKYTLRAKRKVNYETEDSESSFVTHNSKISLPHPMEIGESLDGTLKSRKRRKMSKKLPPVIIKYIIINRFRGRKNMLVKLGKIDSKEKQVILTEEKMELYKKLAPLKDFWPKVPDSPATKYPIYPLTPKKSHRRKSKHKSAKKKTGKQQRTNNENIKRTLSFRKKRSHAILSPPSPSYNAETEDCDLNYSDVMSKLGFLSERSTSPINSSPPRCWSPTDPRAEEIMAAAEKEAMLFKGPNVYKKTVNSRIGKTSRARAQIKKSKAKLANPSIVTKKRNKRNQTNKLVDDGKKKPRAKQKTNEKGTSRKHTTLKDEKIKSQSGAEVKFVLKHQNVSEFASSSGGSQLLFKQKDMPLMGSAVDHPLSASLPTGINAQQKLSGCFSSFLESKKSVDLQTFPSSRDDLHPSVVCNSIGPGVSKINVQRPHNQSAMFTLKESTLIQKNIFDLSNHLSQVAQNTQISSGMSSKIEDNANNIQRNYLSSIGKLSEYRNSLESKLDQAYTPNFLHCKDSQQQIVCIAEQSKHSETCSPGNTASEESQMPNNCFVTSLRSPIKQIAWEQKQRGFILDMSNFKPERVKPRSLSEAISQTKALSQCKNRNVSTPSAFGEGQSGLAVLKELLQKRQQKAQNANTTQDPLSNKHQPNKNISGSLEHNKANKRTRSVTSPRKPRTPRSTKQKEKIPKLLKVDSLNLQNSSQLDNSVSDDSPIFFSDPGFESCYSLEDSLSPEHNYNFDINTIGQTGFCSFYSGSQFVPADQNLPQKFLSDAVQDLFPGQAIEKNEFLSHDNQKCDEDKHHTTDSASWIRSGTLSPEIFEKSTIDSNENRRHNQWKNSFHPLTTRSNSIMDSFCVQQAEDCLSEKSRLNRSSVSKEVFLSLPQPNNSDWIQGHTRKEMGQSLDSANTSFTAILSSPDGELVDVACEDLELYVSRNNDMLTPTPDSSPRSTSSPSQSKNGSFTPRTANILKPLMSPPSREEIMATLLDHDLSETIYQEPFCSNPSDVPEKPREIGGRLLMVETRLANDLAEFEGDFSLEGLRLWKTAFSAMTQNPRPGSPLRSGQGVVNKGSSNSPKMVEDKKIVIMPCKCAPSRQLVQVWLQAKEEYERSKKLPKTKPTGVVKSAENFSSSVNPDDKPVVPPKMDVSPCILPTTAHTKEDVDNSQIALQAPTTGCSQTASESQMLPPVASASDPEKDEDDDDNYYISYSSPDSPVIPPWQQPISPDSKALNGDDRPSSPVEELPSLAFENFLKPIKDGIQKSPCSEPQEPLVISPINTRARTGKCESLCFHSTPIIQRKLLERLPEAPGLSPLSTEPKTQKLSNKKGSNTDTLRRVLLTQAKNQFAAVNTPQKETSQIDGPSLNNTYGFKVSIQNLQEAKALHEIQNLTLISVELHARTRRDLEPDPEFDPICALFYCISSDTPLPDTEKTELTGVIVIDKDKTVFSQDIRYQTPLLIRSGITGLEVTYAADEKALFHEIANIIKRYDPDILLGYEIQMHSWGYLLQRAAALSIDLCRMISRVPDDKIENRFAAERDEYGSYTMSEINIVGRITLNLWRIMRNEVALTNYTFENVSFHVLHQRFPLFTFRVLSDWFDNKTDLYRWKMVDHYVSRVRGNLQMLEQLDLIGKTSEMARLFGIQFLHVLTRGSQYRVESMMLRIAKPMNYIPVTPSVQQRSQMRAPQCVPLIMEPESRFYSNSVLVLDFQSLYPSIVIAYNYCFSTCLGHVENLGKYDEFKFGCTSLRVPPDLLYQVRHDITVSPNGVAFVKPSVRKGVLPRMLEEILKTRFMVKQSMKAYKQDRALSRMLDARQLGLKLIANVTFGYTSANFSGRMPCIEVGDSIVHKARETLERAIKLVNDTKKWGARVVYGDTDSMFVLLKGATKEQSFKIGQEIAEAVTATNPKPVKLKFEKVYLPCVLQTKKRYVGYMYETLDQKDPVFDAKGIETVRRDSCPAVSKILERSLKLLFETRDISLIKQYVQRQCMKLLEGKASIQDFIFAKEYRGSFSYKPGACVPALELTRKMLTYDRRSEPQVGERVPYVIIYGTPGVPLIQLVRRPVEVLQDPTLRLNATYYITKQILPPLARIFSLIGIDVFSWYHELPRIHKATSSSRSEPEGRKGTISQYFTTLHCPVCDDLTQHGICSKCRSQPQHVAVILNQEIRELERQQEQLVKICKNCTGCFDRHIPCVSLNCPVLFKLSRVNRELSKAPYLRQLLDQF>sp|P49758|RGS6_HUMAN Regulator of G-protein signaling 6 OS=Homo sapiensOX=9606 GN=RGS6 PE=1 SV=5MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKGKSLAGKRLTGLMQSS>sp|P49758-2|RGS6_HUMAN Isoform 2 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVLYSNTPLAKRP>sp|P49758-3|RGS6_HUMAN Isoform 3 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVGKSLAGKRLTGLMQSS>sp|P49758-5|RGS6_HUMAN Isoform 5 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKKVSKVVELP>sp|P49758-6|RGS6_HUMAN Isoform 6 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKKVSKVVELP>sp|P49758-7|RGS6_HUMAN Isoform 7 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKGKSLAGKRLTGLMQSS>sp|P49758-8|RGS6_HUMAN Isoform 8 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKLYSNTPLAKRP>sp|P49758-9|RGS6_HUMAN Isoform 9 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVGKSLAGKRLTGLMQSS>sp|P49758-10|RGS6_HUMAN Isoform 10 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVLYSNTPLAKRP>sp|P49758-11|RGS6_HUMAN Isoform 11 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKLYSNTPLAKRP>sp|P49758-12|RGS6_HUMAN Isoform 12 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVLYSNTPLAKRP>sp|P49758-13|RGS6_HUMAN Isoform 13 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVG>sp|P49758-14|RGS6_HUMAN Isoform 14 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVLLF>sp|P49758-15|RGS6_HUMAN Isoform 15 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKPESEQGRRTSLEKFTRSVCLQLLF>sp|P49758-16|RGS6_HUMAN Isoform 16 of Regulator of G-protein signaling 6OS=Homo sapiens OX=9606 GN=RGS6MAQGSGDQRAVGVADPEESSPNMIVYCKIEDIITKMQDDKTGGVPIRTVKSFLSKIPSVVTGTDIVQWLMKNLSIEDPVEAIHLGSLIAAQGYIFPISDHVLTMKDDGTFYRFQAPYFWPSNCWEPENTDYAIYLCKRTMQNKARLELADYEAENLARLQRAFARKWEFIFMQAEAQVKIDRKKDKTERKILDSQERAFWDVHRPVPGCVNTTEMDIRKCRRLKNPQKVKKSVYGVTEESQAQSPVHVLSQPIRKTTKEDIRKQITFLNAQIDRHCLKMSKVAESLIAYTEQYVEYDPLITPAEPSNPWISDDVALWDIEMSKEPSQQRVKRWGFSFDEILKDQVGRDQFLRFLESEFSSENLRFWLAVQDLKKQPLQDVAKRVEEIWQEFLAPGAPSAINLDSHSYEITSQNVKDGGRYTFEDAQEHIYKLMKSDSYARFLRSNAYQDLLLAKKKVWLL>sp|Q8N264|RHG24_HUMAN Rho GTPase-activating protein 24 OS=Homo sapiensOX=9606 GN=ARHGAP24 PE=1 SV=2MEENNDSTENPQQGQGRQNAIKCGWLRKQGGFVKTWHTRWFVLKGDQLYYFKDEDETKPLGTIFLPGNKVSEHPCNEENPGKFLFEVVPGGDRDRMTANHESYLLMASTQNDMEDWVKSIRRVIWGPFGGGIFGQKLEDTVRYEKRYGNRLAPMLVEQCVDFIRQRGLKEEGLFRLPGQANLVKELQDAFDCGEKPSFDSNTDVHTVASLLKLYLRELPEPVIPYAKYEDFLSCAKLLSKEEEAGVKELAKQVKSLPVVNYNLLKYICRFLDEVQSYSGVNKMSVQNLATVFGPNILRPKVEDPLTIMEGTVVVQQLMSVMISKHDCLFPKDAELQSKPQDGVSNNNEIQKKATMGQLQNKENNNTKDSPSRQCSWDKSESPQRSSMNNGSPTALSGSKTNSPKNSVHKLDVSRSPPLMVKKNPAFNKGSGIVTNGSFSSSNAEGLEKTQTTPNGSLQARRSSSLKVSGTKMGTHSVQNGTVRMGILNSDTLGNPTNVRNMSWLPNGYVTLRDNKQKEQAGELGQHNRLSTYDNVHQQFSMMNLDDKQSIDSATWSTSSCEISLPENSNSCRSSTTTCPEQDFFGGNFEDPVLDGPPQDDLSHPRDYESKSDHRSVGGRSSRATSSSDNSETFVGNSSSNHSALHSLVSSLKQEMTKQKIEYESRIKSLEQRNLTLETEMMSLHDELDQERKKFTMIEIKMRNAERAKEDAEKRNDMLQKEMEQFFSTFGELTVEPRRTERGNTIWIQ>sp|Q8N264-2|RHG24_HUMAN Isoform 2 of Rho GTPase-activating protein 24OS=Homo sapiens OX=9606 GN=ARHGAP24MPEDRNSGGCPAGALASTPFIPKTTYRRIKRCFSFRKGIFGQKLEDTVRYEKRYGNRLAPMLVEQCVDFIRQRGLKEEGLFRLPGQANLVKELQDAFDCGEKPSFDSNTDVHTVASLLKLYLRELPEPVIPYAKYEDFLSCAKLLSKEEEAGVKELAKQVKSLPVVNYNLLKYICRFLDEVQSYSGVNKMSVQNLATVFGPNILRPKVEDPLTIMEGTVVVQQLMSVMISKHDCLFPKDAELQSKPQDGVSNNNEIQKKATMGQLQNKENNNTKDSPSRQCSWDKSESPQRSSMNNGSPTALSGSKTNSPKNSVHKLDVSRSPPLMVKKNPAFNKGSGIVTNGSFSSSNAEGLEKTQTTPNGSLQARRSSSLKVSGTKMGTHSVQNGTVRMGILNSDTLGNPTNVRNMSWLPNGYVTLRDNKQKEQAGELGQHNRLSTYDNVHQQFSMMNLDDKQSIDSATWSTSSCEISLPENSNSCRSSTTTCPEQDFFGGNFEDPVLDGPPQDDLSHPRDYESKSDHRSVGGRSSRATSSSDNSETFVGNSSSNHSALHSLVSSLKQEMTKQKIEYESRIKSLEQRNLTLETEMMSLHDELDQERKKFTMIEIKMRNAERAKEDAEKRNDMLQKEMEQFFSTFGELTVEPRRTERGNTIWIQ>sp|Q8N264-3|RHG24_HUMAN Isoform 3 of Rho GTPase-activating protein 24OS=Homo sapiens OX=9606 GN=ARHGAP24MTANHESYLLMASTQNDMEDWVKSIRRVIWGPFGGGIFGQKLEDTVRYEKRYGNRLAPMLVEQCVDFIRQRGLKEEGLFRLPGQANLVKELQDAFDCGEKPSFDSNTDVHTVASLLKLYLRELPEPVIPYAKYEDFLSCAKLLSKEEEAGVKELAKQVKSLPVVNYNLLKYICRFLDEVQSYSGVNKMSVQNLATVFGPNILRPKVEDPLTIMEGTVVVQQLMSVMISKHDCLFPKDAELQSKPQDGVSNNNEIQKKATMGQLQNKENNNTKDSPSRQCSWDKSESPQRSSMNNGSPTALSGSKTNSPKNSVHKLDVSRSPPLMVKKNPAFNKGSGIVTNGSFSSSNAEGLEKTQTTPNGSLQARRSSSLKVSGTKMGTHSVQNGTVRMGILNSDTLGNPTNVRNMSWLPNGYVTLRDNKQKEQAGELGQHNRLSTYDNVHQQFSMMNLDDKQSIDSATWSTSSCEISLPENSNSCRSSTTTCPEQDFFGGNFEDPVLDGPPQDDLSHPRDYESKSDHRSVGGRSSRATSSSDNSETFVGNSSSNHSALHSLVSSLKQEMTKQKIEYESRIKSLEQRNLTLETEMMSLHDELDQERKKFTMIEIKMRNAERAKEDAEKRNDMLQKEMEQFFSTFGELTVEPRRTERGNTIWIQ>sp|Q8N264-4|RHG24_HUMAN Isoform 4 of Rho GTPase-activating protein 24OS=Homo sapiens OX=9606 GN=ARHGAP24MEENNDSTENPQQGQGRQNAIKCGWLRKQGGFVKTWHTRWFVLKGDQLYYFKDEDETKPLGTIFLPGNKVSEHPCNEENPGKFLFEVVPGGDRDRMTANHESYLLMASTQNDMEDWVKSIRRVIWGPFGGGIFGQKLEDTVRYEKRYGNRLAPMLVEQCVDFIRQRGLKEEGLFRLPGQANLVKELQDAFDCGEKPSFDSNTDVHTVASLLKLYLRELPEPVIPYAKYEDFLSCAKLLSKEEEAVS>sp|Q8N264-5|RHG24_HUMAN Isoform 5 of Rho GTPase-activating protein 24OS=Homo sapiens OX=9606 GN=ARHGAP24MWLRKKDWQIFNEQFLKKEHAVGFCFSKCVLVEFSLKCFKKIKSSYWNNDALAFLGKKFLREKNKMTKKQTRNRQNKFPPKPALRSSPVHRVQHFPLLWKVKEPHYHLFFFAFSYCWSWEPFPSEQQPCPASVLSSQQGKSISLIMEENNDSTENPQQGQGRQNAIKCGWLRKQGGFVKTWHTRWFVLKGDQLYYFKDEDETKPLGTIFLPGNKVSEHPCNEENPGKFLFEVVPGKIFS>sp|O95153|RIMB1_HUMAN Peripheral-type benzodiazepine receptor-associatedprotein 1 OS=Homo sapiens OX=9606 GN=TSPOAP1 PE=1 SV=2MEQLTTLPRPGDPGAMEPWALPTWHSWTPGRGGEPSSAAPSIADTPPAALQLQELRSEESSKPKGDGSSRPVGGTDPEGAEACLPSLGQQASSSGPACQRPEDEEVEAFLKAKLNMSFGDRPNLELLRALGELRQRCAILKEENQMLRKSSFPETEEKVRRLKRKNAELAVIAKRLEERARKLQETNLRVVSAPLPRPGTSLELCRKALARQRARDLSETASALLAKDKQIAALQRECRELQARLTLVGKEGPQWLHVRDFDRLLRESQREVLRLQRQIALRNQRETLPLPPSWPPGPALQARAGAPAPGAPGEATPQEDADNLPVILGEPEKEQRVQQLESELSKKRKKCESLEQEARKKQRRCEELELQLRQAQNENARLVEENSRLSGRATEKEQVEWENAELRGQLLGVTQERDSALRKSQGLQSKLESLEQVLKHMREVAQRRQQLEVEHEQARLSLREKQEEVRRLQQAQAEAQREHEGAVQLLESTLDSMQARVRELEEQCRSQTEQFSLLAQELQAFRLHPGPLDLLTSALDCGSLGDCPPPPCCCSIPQPCRGSGPKDLDLPPGSPGRCTPKSSEPAPATLTGVPRRTAKKAESLSNSSHSESIHNSPKSCPTPEVDTASEVEELEADSVSLLPAAPEGSRGGARIQVFLARYSYNPFEGPNENPEAELPLTAGEYIYIYGNMDEDGFFEGELMDGRRGLVPSNFVERVSDDDLLTSLPPELADLSHSSGPELSFLSVGGGGSSSGGQSSVGRSQPRPEEEDAGDELSLSPSPEGLGEPPAVPYPRRLVVLKQLAHSVVLAWEPPPEQVELHGFHICVNGELRQALGPGAPPKAVLENLDLWAGPLHISVQALTSRGSSDPLRCCLAVGARAGVVPSQLRVHRLTATSAEITWVPGNSNLAHAIYLNGEECPPASPSTYWATFCHLRPGTPYQAQVEAQLPPQGPWEPGWERLEQRAATLQFTTLPAGPPDAPLDVQIEPGPSPGILIISWLPVTIDAAGTSNGVRVTGYAIYADGQKIMEVASPTAGSVLVELSQLQLLQVCREVVVRTMSPHGESADSIPAPITPALAPASLPARVSCPSPHPSPEARAPLASASPGPGDPSSPLQHPAPLGTQEPPGAPPASPSREMAKGSHEDPPAPCSQEEAGAAVLGTSEERTASTSTLGEKDPGPAAPSLAKQEAEWTAGEACPASSSTQGARAQQAPNTEMCQGGDPGSGLRPRAEKEDTAELGVHLVNSLVDHGRNSDLSDIQEEEEEEEEEEEEELGSRTCSFQKQVAGNSIRENGAKSQPDPFCETDSDEEILEQILELPLQQFCSKKLFSIPEEEEEEEEDEEEEKSGAGCSSRDPGPPEPALLGLGCDSGQPRRPGQCPLSPESSRAGDCLEDMPGLVGGSSRRRGGGSPEKPPSRRRPPDPREHCSRLLSNNGPQASGRLGPTRERGGLPVIEGPRTGLEASGRGRLGPSRRCSRGRALEPGLASCLSPKCLEISIEYDSEDEQEAGSGGISITSSCYPGDGEAWGTATVGRPRGPPKANSGPKPYPRLPAWEKGEPERRGRSATGRAKEPLSRATETGEARGQDGSGRRGPQKRGVRVLRPSTAELVPARSPSETLAYQHLPVRIFVALFDYDPVSMSPNPDAGEEELPFREGQILKVFGDKDADGFYQGEGGGRTGYIPCNMVAEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAESEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQESSPNMDVEAELPFRAGDVITVFGGMDDDGFYYGELNGQRGLVPSNFLEGPGPEAGGLDREPRTPQAESQRTRRRRVQC>sp|O95153-2|RIMB1_HUMAN Isoform 2 of Peripheral-type benzodiazepinereceptor-associated protein 1 OS=Homo sapiens OX=9606 GN=TSPOAP1MEQLTTLPRPGDPGAMEPWALPTWHSWTPGRGGEPSSAAPSIADTPPAALQLQELRSEESSKPKGDGSSRPVGGTDPEGAEACLPSLGQQASSSGPACQRPEDEEVEAFLKAKLNMSFGDRPNLELLRALGELRQRCAILKEENQMLRKSSFPETEEKVRRLKRKNAELAVIAKRLEERARKLQETNLRVEGPQWLHVRDFDRLLRESQREVLRLQRQIALRNQRETLPLPPSWPPGPALQARAGAPAPGAPGEATPQEDADNLPVILGEPEKEQRVQQLESELSKKRKKCESLEQEARKKQRRCEELELQLRQAQNENARLVEENSRLSGRATEKEQVEWENAELRGQLLGVTQERDSALRKSQGLQSKLESLEQVLKHMREVAQRRQQLEVEHEQARLSLREKQEEVRRLQQAQAEAQREHEGAVQLLESTLDSMQARVRELEEQCRSQTEQFSLLAQELQAFRLHPGPLDLLTSALDCGSLGDCPPPPCCCSIPQPCRGSGPKDLDLPPGSPGRCTPKSSEPAPATLTGVPRRTAKKAESLSNSSHSESIHNSPKSCPTPEVDTASEVEELEADSVSLLPAAPEGSRGGARIQVFLARYSYNPFEGPNENPEAELPLTAGEYIYIYGNMDEDGFFEGELMDGRRGLVPSNFVERVSDDDLLTSLPPELADLSHSSGPELSFLSVGGGGSSSGGQSSVGRSQPRPEEEDAGDELSLSPSPEGLGEPPAVPYPRRLVVLKQLAHSVVLAWEPPPEQVELHGFHICVNGELRQALGPGAPPKAVLENLDLWAGPLHISVQALTSRGSSDPLRCCLAVGARAGVVPSQLRVHRLTATSAEITWVPGNSNLAHAIYLNGEECPPASPSTYWATFCHLRPGTPYQAQVEAQLPPQGPWEPGWERLEQRAATLQFTTLPAGPPDAPLDVQIEPGPSPGILIISWLPVTIDAAGTSNGVRVTGYAIYADGQKIMEVASPTAGSVLVELSQLQLLQVCREVVVRTMSPHGESADSIPAPITPALAPASLPARVSCPSPHPSPEARAPLASASPGPGDPSSPLQHPAPLGTQEPPGAPPASPSREMAKGSHEDPPAPCSQEEAGAAVLGTSEERTASTSTLGEKDPGPAAPSLAKQEAEWTAGEACPASSSTQGARAQQAPNTEMCQGGDPGSGLRPRAEKEDTAELGVHLVNSLVDHGRNSDLSDIQEEEEEEEEEEEEELGSRTCSFQKQVAGNSIRENGAKSQPDPFCETDSDEEILEQILELPLQQFCSKKLFSIPEEEEEEEEDEEEEKSGAGCSSRDPGPPEPALLGLGCDSGQPRRPGQCPLSPESSRAGDCLEDMPGLVGGSSRRRGGGSPEKPPSRRRPPDPREHCSRLLSNNGPQASGRLGPTRERGGLPVIEGPRTGLEASGRGRLGPSRRCSRGRALEPGLASCLSPKCLEISIEYDSEDEQEAGSGGISITSSCYPGDGEAWGTATVGRPRGPPKANSGPKPYPRLPAWEKGEPERRGRSATGRAKEPLSRATETGEARGQDGSGRRGPQKRGVRVLRPSTAELVPARSPSETLAYQHLPVRIFVALFDYDPVSMSPNPDAGEEELPFREGQILKVFGDKDADGFYQGEGGGRTGYIPCNMVAEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAESEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQESSPNMDVEAELPFRAGDVITVFGGMDDDGFYYGELNGQRGLVPSNFLEGPGPEAGGLDREPRTPQAESQRTRRRRVQC>sp|O95153-3|RIMB1_HUMAN Isoform 3 of Peripheral-type benzodiazepinereceptor-associated protein 1 OS=Homo sapiens OX=9606 GN=TSPOAP1MEQLTTLPRPGDPGAMEPWALPTWHSWTPGRGGEPSSAAPSIADTPPAALQLQELRSEESSKPKGDGSSRPVGGTDPEGAEACLPSLGQQASSSGPACQRPEDEEVEAFLKAKLNMSFGDRPNLELLRALGELRQRCAILKEENQMLRKSSFPETEEKVRRLKRKNAELAVIAKRLEERARKLQETNLRVVSAPLPRPGTSLELCRKALARQRARDLSETASALLAKDKQIAALQRECRELQARLTLVGKEGPQWLHVRDFDRLLRESQREVLRLQRQIALRNQRETLPLPPSWPPGPALQARAGAPAPGAPGEATPQEDADNLPVILGEPEKEQRVQQLESELSKKRKKCESLEQEARKKQRRCEELELQLRQAQNENARLVEENSRLSGRATEKEQVEWENAELRGQLLGVTQERDSALRKSQGLQSKLESLEQVLKHMREVAQRRQQLEVEHEQARLSLREKQEEVRRLQQAQAEAQREHEGAVQLLESTLDSMQARVRELEEQCRSQTEQFSLLAQELQAFRLHPGPLDLLTSALDCGSLGDCPPPPCCCSIPQPCRGSGPKDLDLPPGSPGRCTPKSSEPAPATLTGVPRRTAKKAESLSNSSHSESIHNSPKSCPTPEVDTASEVEELEADSVSLLPAAPEGSRGGARIQVFLARYSYNPFEGPNENPEAELPLTAGEYIYIYGNMDEDGFFEGELMDGRRGLVPSNFVERVSDDDLLTSLPPELADLSHSSGPELSFLSVGGGGSSSGGQSSVGRSQPRPEEEDAGDELSLSPSPEGLGEPPAVPYPRRLVVLKQLAHSVVLAWEPPPEQVELHGFHICVNGELRQALGPGAPPKAVLENLDLWAGPLHISVQALTSRGSSDPLRCCLAVGARAGVVPSQLRVHRLTATSAEITWVPGNSNLAHAIYLNGEECPPASPSTYWATFCHLRPGTPYQAQVEAQLPPQGPWEPGWERLEQRAATLQFTTLPAGPPDAPLDVQIEPGPSPGILIISWLPVTIDAAGTSNGVRVTGYAIYADGQKIMEVASPTAGSVLVELSQLQLLQVCREVVVRTMSPHGESADSIPAPITPALAPASLPARVSCPSPHPSPEARAPLASASPGPGDPSSPLQHPAPLGTQEPPGAPPASPSREMAKGSHEDPPAPCSQEEAGAAVLGTSEERTASTSTLGEKDPGPAAPSLAKQEAEWTAGEACPASSSTQGARAQQAPNTEMCQGGDPGSGLRPRAEKEDTAELGVHLVNSLVDHGRNSDLSDIQEEEEEEEEEEEEELGSRTCSFQKQVAGNSIRENGAKSQPDPFCETDSDEEILEQILELPLQQFCSKKLFSIPEEEEEEEEDEEEEKSGAGCSSRDPGPPEPALLGLGCDSGQPRRPGQCPLSPESSRAGDCLEDMPGLVGGSSRRRGGGSPEKPPSRRRPPDPREHCSRLLSNNGPQASGRLGPTRERGGLPVIEGPRTGLEASGRGRLGPSRRCSRGRALEPGLASCLSPKCLEISIEYDSEDEQEAGSGGISITSSCYPGDGEAWGTATVGRPRGPPKANSGPKPYPRLPAWEKGEPERRGRSATGRAKEPLSRATETGEARGQDGSGRRGPQKRGVRVLRPSTAELVPARSPSETLAYQHLPVRIFVALFDYDPVSMSPNPDAGEEELPFREGQILKVFGDKDADGFYQGEGGGRTGYIPCNMVAEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAESEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQESSPNMDVEAELPFRAGDVITVFGGMDDDGFYYGELNGQRGLVPSNFLEGPGPEAGGLDREPRTPQAESQDWGCTTQGSPGPPGGPCTPSSGSAPRIERGEPQGRSEKVWGFFSKGKQLLRRLGSGKKE>sp|O15258|RER1_HUMAN Protein RER1 OS=Homo sapiens OX=9606 GN=RER1 PE=1SV=1MSEGDSVGESVHGKPSVVYRFFTRLGQIYQSWLDKSTPYTAVRWVVTLGLSFVYMIRVYLLQGWYIVTYALGIYHLNLFIAFLSPKVDPSLMEDSDDGPSLPTKQNEEFRPFIRRLPEFKFWHAATKGILVAMVCTFFDAFNVPVFWPILVMYFIMLFCITMKRQIKHMIKYRYIPFTHGKRRYRGKEDAGKAFAS>sp|Q52LW3|RHG29_HUMAN Rho GTPase-activating protein 29 OS=Homo sapiensOX=9606 GN=ARHGAP29 PE=1 SV=2MIAHKQKKTKKKRAWASGQLSTDITTSEMGLKSLSSNSIFDPDYIKELVNDIRKFSHMLLYLKEAIFSDCFKEVIHIRLEELLRVLKSIMNKHQNLNSVDLQNAAEMLTAKVKAVNFTEVNEENKNDLFQEVFSSIETLAFTFGNILTNFLMGDVGNDSLLRLPVSRETKSFENVSVESVDSSSEKGNFSPLELDNVLLKNTDSIELALSYAKTWSKYTKNIVSWVEKKLNLELESTRNMVKLAEATRTNIGIQEFMPLQSLFTNALLNDIESSHLLQQTIAALQANKFVQPLLGRKNEMEKQRKEIKELWKQEQNKMLEAENALKKAKLLCMQRQDEYEKAKSSMFRAEEEHLSSSGGLAKNLNKQLEKKRRLEEEALQKVEEANELYKVCVTNVEERRNDLENTKREILAQLRTLVFQCDLTLKAVTVNLFHMQHLQAASLADSLQSLCDSAKLYDPGQEYSEFVKATNSTEEEKVDGNVNKHLNSSQPSGFGPANSLEDVVRLPDSSNKIEEDRCSNSADITGPSFIRSWTFGMFSDSESTGGSSESRSLDSESISPGDFHRKLPRTPSSGTMSSADDLDEREPPSPSETGPNSLGTFKKTLMSKAALTHKFRKLRSPTKCRDCEGIVVFQGVECEECLLVCHRKCLENLVIICGHQKLPGKIHLFGAEFTQVAKKEPDGIPFILKICASEIENRALCLQGIYRVCGNKIKTEKLCQALENGMHLVDISEFSSHDICDVLKLYLRQLPEPFILFRLYKEFIDLAKEIQHVNEEQETKKNSLEDKKWPNMCIEINRILLKSKDLLRQLPASNFNSLHFLIVHLKRVVDHAEENKMNSKNLGVIFGPSLIRPRPTTAPITISSLAEYSNQARLVEFLITYSQKIFDGSLQPQDVMCSIGVVDQGCFPKPLLSPEERDIERSMKSLFFSSKEDIHTSESESKIFERATSFEESERKQNALGKCDACLSDKAQLLLDQEAESASQKIEDGKTPKPLSLKSDRSTNNVERHTPRTKIRPVSLPVDRLLLASPPNERNGRNMGNVNLDKFCKNPAFEGVNRKDAATTVCSKFNGFDQQTLQKIQDKQYEQNSLTAKTTMIMPSALQEKGVTTSLQISGDHSINATQPSKPYAEPVRSVREASERRSSDSYPLAPVRAPRTLQPQHWTTFYKPHAPIISIRGNEEKPASPSAAVPPGTDHDPHGLVVKSMPDPDKASACPGQATGQPKEDSEELGLPDVNPMCQRPRLKRMQQFEDLEGEIPQFV>sp|Q52LW3-2|RHG29_HUMAN Isoform 2 of Rho GTPase-activating protein 29OS=Homo sapiens OX=9606 GN=ARHGAP29MIAHKQKKTKKKRAWASGQLSTDITTSEMGLKSLSSNSIFDPDYIKELVNDIRKFSHMLLYLKEAIFSDCFKEVIHIRLEELLRVLKSIMNKHQNLNSVDLQNAAEMLTAKVKAVNFTEVNEENKNDLFQEVFSSIETLAFTFGNILTNFLMGDVGNDSLLRLPVSRETKSFENVSVESVDSSSEKGNFSPLELDNVLLKNTDSIELALSYAKTWSKYTKNIVSWVEKKLNLELESTRNMVKLAEATRTNIGIQEFMPLQSLFTNALLNDIESSHLLQQTIAALQANKFVQPLLGRKNEMEKQRKEIKELWKQEQNKMLEAENALKKAKLLCMQRQDEYEKAKSSMFRAEEEHLSSSGGLAKNLNKQLEKKRRLEEEALQKVTIFFFFICKLN>sp|A5PLK6|RGSL_HUMAN Regulator of G-protein signaling protein-likeOS=Homo sapiens OX=9606 GN=RGSL1 PE=2 SV=1MSSAEIIGSTNLIILLEDEVFADFFNTFLSLPVFGQTPFYTVENSQWSLWPEIPCNLIAKYKGLLTWLEKCRLPFFCKTNLCFHYILCQEFISFIKSPEGGEELVDFWILAENILSIDEMDLEVRDYYLSLLLMLRATHLQEGSRVVTLCNMNIKSLLNLSIWHPNQSTTRREILSHMQKVALFKLQSYWLPNFYTHTKMTMAKEEACHGLMQEYETRLYSVCYTHIGGLPLNMSIKKCHHFQKRYSSRKAKRKMWQLVDPDSWSLEMDLKPDAIGMPLQETCPQEKVVIQMPSLKMASSKETRISSLEKDMHYAKISSMENKAKSHLHMEAPFETKVSTHLRTVIPIVNHSSKMTIQKAIKQSFSLGYIHLALCADACAGNPFRDHLKKLNLKVEIQLLDLWQDLQHFLSVLLNNKKNGNAIFRHLLGDRICELYLNEQIGPCLPLKSQTIQGLKELLPSGDVIPWIPKAQKEICKMLSPWYDEFLDEEDYWFLLFTTQNRFISSRQHKREFIGKEENILLYKRIQQSLELSQALADMKEMDYRQWRKIATEDLKQGGSLQVELTSPVFLTDITKMSFEELCYKNPKMAIQKISDDYKIYCEKAPKIDFKMEIIKETKTVSRSNRKMSLLKRTLVRKPSMRPRNLTEVLLNTQHLEFFREFLKERKAKIPLQFLTAVQKISIETNEKICKSLIENVIKTFFQGQLSPEEMLQCDAPIIKEIASMRHVTTSTLLTLQGHVMKSIEEKWFKDYQDLFPPHHQEVEVQSEVQISSRKPSKIVSTYLQESQKKGWMRMISFIRSFCKYRRFMLNPSKRQEFEDYLHQEMQNSKENFTTAHNTSGRSAPPSTNVRSADQENGEITLVKRRIFGHRIITVNFAINDLYFFSEMEKFNDLVSSAHMLQVNRAYNENDVILMRSKMNIIQKLFLNSDIPPKLRVNVPEFQKDAILAAITEGYLDRSVFHGAIMSVFPVVMYFWKRFCFWKATRSYLQYRGKKFKDRKSPPKSTDKYPFSSGGDNAILRFTLLRGIEWLQPQREAISSVQNSSSSKLTQPRLVVSAMQLHPVQGQKLSYIKKEK>sp|A5PLK6-2|RGSL_HUMAN Isoform 2 of Regulator of G-protein signalingprotein-like OS=Homo sapiens OX=9606 GN=RGSL1MLSPWYDEFLDEEDYWFLLFTTQNRFISSRQHKREFIGKEENILLYKRIQQSLELSQALADMKEMDYRQWRKIATEDLKQGGSLQVELTSPVFLTDITKMSFEELCYKNPKMAIQKISDDYKIYCEKAPKIDFKMEIIKETKTVSRSNRKMSLLKRTLVRKPSMRPRNLTEVLLNTQHLEFFREFLKERKAKIPLQFLTAVQKISIETNEKICKSLIENVIKTFFQGQLSPEEMLQCDAPIIKEIASMRHVTTSTLLTLQGHVMKSIEEKWFKDYQDLFPPHHQEVEVQSEVQISSRKPSKIVSTYLQESQKKGWMRMISFIRSFCKYRRFMLNPSKRQEFEDYLHQEMQNSKENFTTAHNTSGRSAPPSTNVRSADQENGEITLVKRRIFGHRIITVNFAINDLYFFSEMEKFNDLVSSAHMLQVNRAYNENDVILMRSKMNIIQKLFLNSDIPPKLRVNVPEFQKDAILAAITEGYLDRSVFHGAIMSVFPVVMYFWKRFCFWKATRSYLQYRGKKFKDRKSPPKSTDKYPFSSGGDNAILRFTLLRGIEWLQPQREAISSVQNSSSSKLTQPRLVVSAMQLHPVQGQKLSYIKKEK>sp|A5PLK6-3|RGSL_HUMAN Isoform 3 of Regulator of G-protein signalingprotein-like OS=Homo sapiens OX=9606 GN=RGSL1MSFEELCYKNPKMAIQKISDDYKIYCEKAPKIDFKMEIIKETKTVSRSNRKMSLLKRTLVRKPSMRPRNLTEVLLNTQHLEFFREFLKERKAKIPLQFLTAVQKISIETNEKICKSLIENVIKTFFQGQLSPEEMLQCDAPIIKEIASMRHVTTSTLLTLQGHVMKSIEEKWFKDYQDLFPPHHQEVEVQSEVQISSRKPSKIVSTYLQESQKKGWMRMISFIRSFCKYRRFMLNPSKRQEFEDYLHQEMQNSKENFTTAHNTSGRSAPPSTNVRSADQENGEITLVKRRIFGHRIITVNFAINDLYFFSEMEKFNDLVSSAHMLQVNRAYNENDVILMRSKMNIIQKLFLNSDIPPKLRVNVPEFQKDAILAAITEGYLDRSVFHGAIMSVFPVVMYFWKRFCFWKATRSYLQYRGKKFKDRKSPPKSTDKYPFSSGGDNAILRFTLLRGIEWLQPQREAISSVQNSSSSKLTQPRLVVSAMQLHPVQGQKLSYIKKEK>sp|A5PLK6-4|RGSL_HUMAN Isoform 4 of Regulator of G-protein signalingprotein-like OS=Homo sapiens OX=9606 GN=RGSL1MSFEELCYKNPKMAIQKISDDYKIYCEKAPKIDFKMEIIKETKTVSRSNRKMSLLKRTLVRKPSMRPRNLTEVLLNTQHLEFFREFLKERKAKIPLQFLTAVQKISIETNEKICKSLIENVIKTFFQGQLSPEEMLQCDAPIIKEIASMRHVTTSTLLTLQGHVMKSIEEKWFKDYQDLFPPHHQEVEVQSEVQISSRKPSKIVSTYLQESQKKGWMRMISFIRSFCKYRRFMLNPSKRQEFEDYLHQEMQNSKENFTTAHNTSGRSAPPSTNVRSADQENGEITLVKRRIFGHRIITVNFAINDLYFFSEMEKFNDLVSSAHMLQVNRAYNENDVILMRSKMNIIQKLFLNSDIPPKLRVNVPEFQKDAILAAITEGYLDRSVFHGAIMSVFPVVMYFWKR>sp|A5PLK6-5|RGSL_HUMAN Isoform 5 of Regulator of G-protein signalingprotein-like OS=Homo sapiens OX=9606 GN=RGSL1MLSPWYDEFLDEEDYWFLLFTTQNRFISSRQHKREFIGKEENILLYKRIQQSLELSQALADMKEMDYRQWRKIATEDLKQGGSLQVELTSPVFLTDITKMSFEELCYKNPKMAIQKISDDYKIYCEKAPKIDFKMEIIKETKTVSRSNRKMSLLKRTLVRKPSMRPRNLTEVLLNTQHLEFFREFLKERKAKIPLQFLTAVQKISIETNEKICKSLIENVIKTFFQGQLSPEEMLQCDAPIIKEIASMRHVTTSTLLTLQGHVMKSIEEKWFKDYQDLFPPHHQEVEVQSEVQISSRKPSKIVSTYLQESQKKGWMRMISFIRSFCKYRRFMLNPSKRQEFEDYLHQEMQNSKENFTTAHNTSGRSAPPSTNVRSADQENGEITLVKRRIFGHRIITVNFAINDLYFFSEMEKFNDLVSSAHMLQVNRAYNENDVILMRSKMNIIQKLFLNSDIPPKLRVLFLEGNPLLLTV>sp|A5PLK6-6|RGSL_HUMAN Isoform 6 of Regulator of G-protein signalingprotein-like OS=Homo sapiens OX=9606 GN=RGSL1MSSAEIIGSTNLIILLEDEVFADFFNTFLSLPVFGQTPFYTVENSQWSLWPEIPCNLIAKYKGLLTWLEKCRLPFFCKTNLCFHYILCQEFISFIKSPEGAKMMRWKKADQWLLQKCIGGVRGMWRFYSYLTGSAGEELVDFWILAENILSIDEMDLEVRDYYLSLLLMLRATHLQEGSRVVTLCNMNIKSLLNLSIWHPNQSTTRREILSHMQKVALFKLQSYWLPNFYTHTKMTMAKEEACHGLMQEYETRLYSVCYTHIGGLPLNMSIKKCHHFQKRYSSRKAKRKMWQLVDPDSWSLEMDLKPDAIGMPLQETCPQEKVVIQMPSLKMASSKETRISSLEKDMHYAKISSMENKAKSHLHMEAPFETKVSTHLRTVIPIVNHSSKMTIQKAIKQSFSLGYIHLALCADACAGNPFRDHLKKLNLKVEIQLLDLWQDLQHFLSVLLNNKKNGNAIFRHLLGDRICELYLNEQIGPCLPLKSQTIQGLKELLPSGDVIPWIPKAQKEICKMLSPWYDEFLDEEDYWFLLFTVGRTLG>sp|Q9P260|RELCH_HUMAN RAB11-binding protein RELCH OS=Homo sapiensOX=9606 GN=RELCH PE=1 SV=2MAAMAPGGSGSGGGVNPFLSDSDEDDDEVAATEERRAVLRLGAGSGLDPGSAGSLSPQDPVALGSSARPGLPGEASAAAVALGGTGETPARLSIDAIAAQLLRDQYLLTALELHTELLESGRELPRLRDYFSNPGNFERQSGTPPGMGAPGVPGAAGVGGAGGREPSTASGGGQLNRAGSISTLDSLDFARYSDDGNRETDEKVAVLEFELRKAKETIQALRANLTKAAEHEVPLQERKNYKSSPEIQEPIKPLEKRALNFLVNEFLLKNNYKLTSITFSDENDDQDFELWDDVGLNIPKPPDLLQLYRDFGNHQVTGKDLVDVASGVEEDELEALTPIISNLPPTLETPQPAENSMLVQKLEDKISLLNSEKWSLMEQIRRLKSEMDFLKNEHFAIPAVCDSVQPPLDQLPHKDSEDSGQHPDVNSSDKGKNTDIHLSISDEADSTIPKENSPNSFPRREREGMPPSSLSSKKTVHFDKPNRKLSPAFHQALLSFCRMSADSRLGYEVSRIADSEKSVMLMLGRCLPHIVPNVLLAKREELIPLILCTACLHPEPKERDQLLHILFNLIKRPDDEQRQMILTGCVAFARHVGPTRVEAELLPQCWEQINHKYPERRLLVAESCGALAPYLPKEIRSSLVLSMLQQMLMEDKADLVREAVIKSLGIIMGYIDDPDKYHQGFELLLSALGDPSERVVSATHQVFLPAYAAWTTELGNLQSHLILTLLNKIEKLLREGEHGLDEHKLHMYLSALQSLIPSLFALVLQNAPFSSKAKLHGEVPQIEVTRFPRPMSPLQDVSTIIGSREQLAVLLQLYDYQLEQEGTTGWESLLWVVNQLLPQLIEIVGKINVTSTACVHEFSRFFWRLCRTFGKIFTNTKVKPQFQEILRLSEENIDSSAGNGVLTKATVPIYATGVLTCYIQEEDRKLLVGFLEDVMTLLSLSHAPLDSLKASFVELGANPAYHELLLTVLWYGVVHTSALVRCTAARMFELTLRGMSEALVDKRVAPALVTLSSDPEFSVRIATIPAFGTIMETVIQRELLERVKMQLASFLEDPQYQDQHSLHTEIIKTFGRVGPNAEPRFRDEFVIPHLHKLALVNNLQIVDSKRLDIATHLFEAYSALSCCFISEDLMVNHFLPGLRCLRTDMEHLSPEHEVILSSMIKECEQKVENKTVQEPQGSMSIAASLVSEDTKTKFLNKMGQLTTSGAMLANVFQRKK>sp|Q9P260-2|RELCH_HUMAN Isoform 2 of RAB11-binding protein RELCH OS=Homosapiens OX=9606 GN=RELCHMAAMAPGGSGSGGGVNPFLSDSDEDDDEVAATEERRAVLRLGAGSGLDPGSAGSLSPQDPVALGSSARPGLPGEASAAAVALGGTGETPARLSIDAIAAQLLRDQYLLTALELHTELLESGRELPRLRDYFSNPGNFERQSGTPPGMGAPGVPGAAGVGGAGGREPSTASGGGQLNRAGSISTLDSLDFARYSDDGNRETDEKVAVLEFELRKAKETIQALRANLTKAAEHEVPLQERKNYKSSPEIQEPIKPLEKRALNFLVNEFLLKNNYKLTSITFSDENDDQDFELWDDVGLNIPKPPDLLQLYRDFGNHQVTGKDLVDVASGVEEDELEALTPIISNLPPTLETPQPAENSMLVQKLEDKISLLNSEKWSLMEQIRRLKSEMDFLKNEHFAIPAVCDSVQPPLDQLPHKDSEDSGQHPDVNSSDKGKNTDIHLSISDEADSTIPKENSPNSFPRREREGMPPSSLSSKKTVHFDKPNRKLSPAFHQALLSFCRMSADSRLGYEVSRIADSEKSVMLMLGRCLPHIVPNVLLAKREELIPLILCTACLHPEPKERDQLLHILFNLIKRPDDEQRQMILTGCVAFARHVGPTRVEAELLPQCWEQINHKYPERRLLVAESCGALAPYLPKEIRSSLVLSMLQQMLMEDKADLVREAVIKSLGIIMGYIDDPDKYHQGFELLLSALGDPSERVVSATHQVFLPAYAAWTTELGNLQSHLILTLLNKIEKLLREGEHGLDEHKLHMYLSALQSLIPSLFALVLQNAPFSSKAKLHGEVPQIEVTRFPRPMSPLQDVSTIIGSREQLAVLLQLYDYQLEQEGTTGWESLLWVVNQLLPQLIEIVGKINVTSTACVHEFSRFFWRLCRTFGKIFTNTKVKPQFQEILRLSEENIDSSAGNGVLTKATVPIYATGVLTCYIQIKEYLHIHNEISWEWDPSLNTKCVSYTHYTHSLKEEDRKLLVGFLEDVMTLLSLSHAPLDSLKASFVELGANPAYHELLLTVLWYGVVHTSALVRCTAARMFELLVKGVNETLVAQRVVPALITLSSDPEISVRIATIPAFGTIMETVIQRELLERVKMQLASFLEDPQYQDQHSLHTEIIKTFGRVGPNAEPRFRDEFVIPHLHKLALVNNLQIVDSKRLDIATHLFEAYSALSCCFISEDLMVNHFLPGLRCLRTDMEHLSPEHEVILSSMIKECEQKVENKTVQEPQGSMSIAASLVSEDTKTKFLNKMGQLTTSGAMLANVFQRKK>sp|O14593|RFXK_HUMAN DNA-binding protein RFXANK OS=Homo sapiens OX=9606GN=RFXANK PE=1 SV=2MELTQPAEDLIQTQQTPASELGDPEDPGEEAADGSDTVVLSLFPCTPEPVNPEPDASVSSPQAGSSLKHSTTLTNRQRGNEVSALPATLDSLSIHQLAAQGELDQLKEHLRKGDNLVNKPDERGFTPLIWASAFGEIETVRFLLEWGADPHILAKERESALSLASTGGYTDIVGLLLERDVDINIYDWNGGTPLLYAVRGNHVKCVEALLARGADLTTEADSGYTPMDLAVALGYRKVQQVIENHILKLFQSNLVPADPE>sp|O14593-2|RFXK_HUMAN Isoform 2 of DNA-binding protein RFXANK OS=Homosapiens OX=9606 GN=RFXANKMELTQPAEDLIQTQQTPASELGDPEDPGEEAADGSDTVVLSLFPCTPEPVNPEPDASVSSPQGSSLKHSTTLTNRQRGNEVSALPATLDCDNLVNKPDERGFTPLIWASAFGEIETVRFLLEWGADPHILAKEREVGLLLERDVDINIYDWNGGTPLLYAVRGNHVKCVEALLARGADLTTEADSGYTPMDLAVALGYRKVQQVIENHILKLFQSNLVPADPE>sp|O14593-3|RFXK_HUMAN Isoform 3 of DNA-binding protein RFXANK OS=Homosapiens OX=9606 GN=RFXANKMELTQPAEDLIQTQQTPASELGDPEDPGEEAADGSDTVVLSLFPCTPEPVNPEPDASVSSPQAGSSLKHSTTLTNRQRGNEVSALPATLDCDNLVNKPDERGFTPLIWASAFGEIETVRFLLEWGADPHILAKERESALSLASTGGYTDIVGLLLERDVDINIYDWNGGTPLLYAVRGNHVKCVEALLARGADLTTEADSGYTPMDLAVALGYRKVQQVIENHILKLFQSNLVPADPE>sp|O14730|RIOK3_HUMAN Serine/threonine-protein kinase RIO3 OS=Homosapiens OX=9606 GN=RIOK3 PE=1 SV=2MDLVGVASPEPGTAAAWGPSKCPWAIPQNTISCSLADVMSEQLAKELQLEEEAAVFPEVAVAEGPFITGENIDTSSDLMLAQMLQMEYDREYDAQLRREEKKFNGDSKVSISFENYRKVHPYEDSDSSEDEVDWQDTRDDPYRPAKPVPTPKKGFIGKGKDITTKHDEVVCGRKNTARMENFAPEFQVGDGIGMDLKLSNHVFNALKQHAYSEERRSARLHEKKEHSTAEKAVDPKTRLLMYKMVNSGMLETITGCISTGKESVVFHAYGGSMEDEKEDSKVIPTECAIKVFKTTLNEFKNRDKYIKDDFRFKDRFSKLNPRKIIRMWAEKEMHNLARMQRAGIPCPTVVLLKKHILVMSFIGHDQVPAPKLKEVKLNSEEMKEAYYQTLHLMRQLYHECTLVHADLSEYNMLWHAGKVWLIDVSQSVEPTHPHGLEFLFRDCRNVSQFFQKGGVKEALSERELFNAVSGLNITADNEADFLAEIEALEKMNEDHVQKNGRKAASFLKDDGDPPLLYDE>sp|O14730-2|RIOK3_HUMAN Isoform 2 of Serine/threonine-protein kinaseRIO3 OS=Homo sapiens OX=9606 GN=RIOK3MDLVGVASPEPGTAAAWGPSKCPWAIPQNTISCSLADVMSEQLAKELQLEEEAAVFPEVAVAEGPFITGENIDTSSDLMLAQMLQMEYDREYDAQLRREEKKFNGDSKVSISFENYRKVHPYEDSDSSEDEVDWQDTRDDPYRPAKPVPTPKKGFIGKGKDITTKHDEVVCGRKNTARMENFAPEFQVGDGIGMDLKLSNHVFNALKQHAYSEERRSARLHEKKEHSTAEKAVDPKTRLLMYKMVNSGMLETITGCISTGKESVVFHAYGGSMEDEKEDSKVIPTECAIKVFKTTLNEFKNRDKYIKDDFRFKDRFSKLNPRKIIRMWAEKEMHNLARMQRAGIPCPTVVLLKKHILVMSFIGHDQVPAPKLKEVKLNSEEMKEAYYQTLHLMRQLYHECTLVHADLSEYNMLWHAGKVWLIDVSQSVEPTHPHGLEFLFRDCRNVSQKGGVKEALSERELFNAVSGLNITADNEADFLAEIEALEKMNEDHVQKNGRKAASFLKDDGDPPLLYDE>sp|Q6ZVN8|RGMC_HUMAN Hemojuvelin OS=Homo sapiens OX=9606 GN=HJV PE=1SV=1MGEPGQSPSPRSSHGSPPTLSTLTLLLLLCGHAHSQCKILRCNAEYVSSTLSLRGGGSSGALRGGGGGGRGGGVGSGGLCRALRSYALCTRRTARTCRGDLAFHSAVHGIEDLMIQHNCSRQGPTAPPPPRGPALPGAGSGLPAPDPCDYEGRFSRLHGRPPGFLHCASFGDPHVRSFHHHFHTCRVQGAWPLLDNDFLFVQATSSPMALGANATATRKLTIIFKNMQECIDQKVYQAEVDNLPVAFEDGSINGGDRPGGSSLSIQTANPGNHVEIQAAYIGTTIIIRQTAGQLSFSIKVAEDVAMAFSAEQDLQLCVGGCPPSQRLSRSERNRRGAITIDTARRLCKEGLPVEDAYFHSCVFDVLISGDPNFTVAAQAALEDARAFLPDLEKLHLFPSDAGVPLSSATLLAPLLSGLFVLWLCIQ>sp|Q6ZVN8-2|RGMC_HUMAN Isoform b of Hemojuvelin OS=Homo sapiens OX=9606GN=HJVMIQHNCSRQGPTAPPPPRGPALPGAGSGLPAPDPCDYEGRFSRLHGRPPGFLHCASFGDPHVRSFHHHFHTCRVQGAWPLLDNDFLFVQATSSPMALGANATATRKLTIIFKNMQECIDQKVYQAEVDNLPVAFEDGSINGGDRPGGSSLSIQTANPGNHVEIQAAYIGTTIIIRQTAGQLSFSIKVAEDVAMAFSAEQDLQLCVGGCPPSQRLSRSERNRRGAITIDTARRLCKEGLPVEDAYFHSCVFDVLISGDPNFTVAAQAALEDARAFLPDLEKLHLFPSDAGVPLSSATLLAPLLSGLFVLWLCIQ>sp|Q6ZVN8-3|RGMC_HUMAN Isoform c of Hemojuvelin OS=Homo sapiens OX=9606GN=HJVMQECIDQKVYQAEVDNLPVAFEDGSINGGDRPGGSSLSIQTANPGNHVEIQAAYIGTTIIIRQTAGQLSFSIKVAEDVAMAFSAEQDLQLCVGGCPPSQRLSRSERNRRGAITIDTARRLCKEGLPVEDAYFHSCVFDVLISGDPNFTVAAQAALEDARAFLPDLEKLHLFPSDAGVPLSSATLLAPLLSGLFVLWLCIQ>sp|O43353|RIPK2_HUMAN Receptor-interacting serine/threonine-proteinkinase 2 OS=Homo sapiens OX=9606 GN=RIPK2 PE=1 SV=2MNGEAICSALPTIPYHKLADLRYLSRGASGTVSSARHADWRVQVAVKHLHIHTPLLDSERKDVLREAEILHKARFSYILPILGICNEPEFLGIVTEYMPNGSLNELLHRKTEYPDVAWPLRFRILHEIALGVNYLHNMTPPLLHHDLKTQNILLDNEFHVKIADFGLSKWRMMSLSQSRSSKSAPEGGTIIYMPPENYEPGQKSRASIKHDIYSYAVITWEVLSRKQPFEDVTNPLQIMYSVSQGHRPVINEESLPYDIPHRARMISLIESGWAQNPDERPSFLKCLIELEPVLRTFEEITFLEAVIQLKKTKLQSVSSAIHLCDKKKMELSLNIPVNHGPQEESCGSSQLHENSGSPETSRSLPAPQDNDFLSRKAQDCYFMKLHHCPGNHSWDSTISGSQRAAFCDHKTTPCSSAIINPLSTAGNSERLQPGIAQQWIQSKREDIVNQMTEACLNQSLDALLSRDLIMKEDYELVSTKPTRTSKVRQLLDTTDIQGEEFAKVIVQKLKDNKQMGLQPYPEILVVSRSPSLNLLQNKSM>sp|O43353-2|RIPK2_HUMAN Isoform 2 of Receptor-interactingserine/threonine-protein kinase 2 OS=Homo sapiens OX=9606 GN=RIPK2MTPPLLHHDLKTQNILLDNEFHVKIADFGLSKWRMMSLSQSRSSKSAPEGGTIIYMPPENYEPGQKSRASIKHDIYSYAVITWEVLSRKQPFEDVTNPLQIMYSVSQGHRPVINEESLPYDIPHRARMISLIESGWAQNPDERPSFLKCLIELEPVLRTFEEITFLEAVIQLKKTKLQSVSSAIHLCDKKKMELSLNIPVNHGPQEESCGSSQLHENSGSPETSRSLPAPQDNDFLSRKAQDCYFMKLHHCPGNHSWDSTISGSQRAAFCDHKTTPCSSAIINPLSTAGNSERLQPGIAQQWIQSKREDIVNQMTEACLNQSLDALLSRDLIMKEDYELVSTKPTRTSKVRQLLDTTDIQGEEFAKVIVQKLKDNKQMGLQPYPEILVVSRSPSLNLLQNKSM>sp|P57078|RIPK4_HUMAN Receptor-interacting serine/threonine-proteinkinase 4 OS=Homo sapiens OX=9606 GN=RIPK4 PE=1 SV=1MEGDGGTPWALALLRTFDAGEFTGWEKVGSGGFGQVYKVRHVHWKTWLAIKCSPSLHVDDRERMELLEEAKKMEMAKFRYILPVYGICREPVGLVMEYMETGSLEKLLASEPLPWDLRFRIIHETAVGMNFLHCMAPPLLHLDLKPANILLDAHYHVKISDFGLAKCNGLSHSHDLSMDGLFGTIAYLPPERIREKSRLFDTKHDVYSFAIVIWGVLTQKKPFADEKNILHIMVKVVKGHRPELPPVCRARPRACSHLIRLMQRCWQGDPRVRPTFQGNGLNGELIRQVLAALLPVTGRWRSPGEGFRLESEVIIRVTCPLSSPQEITSETEDLCEKPDDEVKETAHDLDVKSPPEPRSEVVPARLKRASAPTFDNDYSLSELLSQLDSGVSQAVEGPEELSRSSSESKLPSSGSGKRLSGVSSVDSAFSSRGSLSLSFEREPSTSDLGTTDVQKKKLVDAIVSGDTSKLMKILQPQDVDLALDSGASLLHLAVEAGQEECAKWLLLNNANPNLSNRRGSTPLHMAVERRVRGVVELLLARKISVNAKDEDQWTALHFAAQNGDESSTRLLLEKNASVNEVDFEGRTPMHVACQHGQENIVRILLRRGVDVSLQGKDAWLPLHYAAWQGHLPIVKLLAKQPGVSVNAQTLDGRTPLHLAAQRGHYRVARILIDLCSDVNVCSLLAQTPLHVAAETGHTSTARLLLHRGAGKEAMTSDGYTALHLAARNGHLATVKLLVEEKADVLARGPLNQTALHLAAAHGHSEVVEELVSADVIDLFDEQGLSALHLAAQGRHAQTVETLLRHGAHINLQSLKFQGGHGPAATLLRRSKT>sp|P57078-2|RIPK4_HUMAN Isoform 2 of Receptor-interactingserine/threonine-protein kinase 4 OS=Homo sapiens OX=9606 GN=RIPK4MEGDGGTPWALALLRTFDAGEFTGWEKVGSGGFGQVYKVRHVHWKTWLAIKCSPSLHVDDRERMELLEEAKKMEMAKFRYILPVYGICREPVGLVMEYMETGSLEKLLASEPLPWDLRFRIIHETAVGMNFLHCMAPPLLHLDLKPANILLDAHYHVKISDFGLAKCNGLSHSHDLSMDGLFGTIAYLPPERIREKSRLFDTKHDVYSFAIVIWGVLTQKKPFADEKNILHIMVKVVKGHRPELPPVCRARPRACSHLIRLMQRCWQGDPRVRPTFQEITSETEDLCEKPDDEVKETAHDLDVKSPPEPRSEVVPARLKRASAPTFDNDYSLSELLSQLDSGVSQAVEGPEELSRSSSESKLPSSGSGKRLSGVSSVDSAFSSRGSLSLSFEREPSTSDLGTTDVQKKKLVDAIVSGDTSKLMKILQPQDVDLALDSGASLLHLAVEAGQEECAKWLLLNNANPNLSNRRGSTPLHMAVERRVRGVVELLLARKISVNAKDEDQWTALHFAAQNGDESSTRLLLEKNASVNEVDFEGRTPMHVACQHGQENIVRILLRRGVDVSLQGKDAWLPLHYAAWQGHLPIVKLLAKQPGVSVNAQTLDGRTPLHLAAQRGHYRVARILIDLCSDVNVCSLLAQTPLHVAAETGHTSTARLLLHRGAGKEAMTSDGYTALHLAARNGHLATVKLLVEEKADVLARGPLNQTALHLAAAHGHSEVVEELVSADVIDLFDEQGLSALHLAAQGRHAQTVETLLRHGAHINLQSLKFQGGHGPAATLLRRSKT>sp|P61513|RL37A_HUMAN 60S ribosomal protein L37a OS=Homo sapiens OX=9606GN=RPL37A PE=1 SV=2MAKRTKKVGIVGKYGTRYGASLRKMVKKIEISQHAKYTCSFCGKTKMKRRAVGIWHCGSCMKTVAGGAWTYNTTSAVTVKSAIRRLKELKDQ>sp|P46777|RL5_HUMAN 60S ribosomal protein L5 OS=Homo sapiens OX=9606GN=RPL5 PE=1 SV=3MGFVKVVKNKAYFKRYQVKFRRRREGKTDYYARKRLVIQDKNKYNTPKYRMIVRVTNRDIICQIAYARIEGDMIVCAAYAHELPKYGVKVGLTNYAAAYCTGLLLARRLLNRFGMDKIYEGQVEVTGDEYNVESIDGQPGAFTCYLDAGLARTTTGNKVFGALKGAVDGGLSIPHSTKRFPGYDSESKEFNAEVHRKHIMGQNVADYMRYLMEEDEDAYKKQFSQYIKNSVTPDMMEEMYKKAHAAIRENPVYEKKPKKEVKKKRWNRPKMSLAQKKDRVAQKKASFLRAQERAAES>sp|Q86VE9|SERC5_HUMAN Serine incorporator 5 OS=Homo sapiens OX=9606GN=SERINC5 PE=2 SV=1MSAQCCAGQLACCCGSAGCSLCCDCCPRIRQSLSTRFMYALYFILVVVLCCIMMSTTVAHKMKEHIPFFEDMCKGIKAGDTCEKLVGYSAVYRVCFGMACFFFIFCLLTLKINNSKSCRAHIHNGFWFFKLLLLGAMCSGAFFIPDQDTFLNAWRYVGAVGGFLFIGIQLLLLVEFAHKWNKNWTAGTASNKLWYASLALVTLIMYSIATGGLVLMAVFYTQKDSCMENKILLGVNGGLCLLISLVAISPWVQNRQPHSGLLQSGVISCYVTYLTFSALSSKPAEVVLDEHGKNVTICVPDFGQDLYRDENLVTILGTSLLIGCILYSCLTSTTRSSSDALQGRYAAPELEIARCCFCFSPGGEDTEEQQPGKEGPRVIYDEKKGTVYIYSYFHFVFFLASLYVMMTVTNWFNHVRSAFHLLP>sp|Q86VE9-2|SERC5_HUMAN Isoform 2 of Serine incorporator 5 OS=Homosapiens OX=9606 GN=SERINC5MSAQCCAGQLACCCGSAGCSLCCDCCPRIRQSLSTRFMYALYFILVVVLCCIMMSTTVAHKMKEHIPFFEDMCKGIKAGDTCEKLVGYSAVYRVCFGMACFFFIFCLLTLKINNSKSCRAHIHNGFWFFKLLLLGAMCSGAFFIPDQDTFLNAWRYVGAVGGFLFIGIQLLLLVEFAHKWNKNWTAGTASNKLWYASLALVTLIMYSIATGGLVLMAVFYTQKDSCMENKILLGVNGGLCLLISLVAISPWVQNRQPHSGLLQSGVISCYVTYLTFSALSSKPAEVVLDEHGKNVTICVPDFGQDLYRDENLVTILGTSLLIGCILYSCLTSTTRSSSDALQGRYAAPELEIARCCFCFSPGGEDTEEQQPGKEGPRVIYDEKKGTVYIYSYFHFVFFLASLYVMMTVTNWFKSAFHLLP>sp|Q86VE9-3|SERC5_HUMAN Isoform 3 of Serine incorporator 5 OS=Homosapiens OX=9606 GN=SERINC5MSAQCCAGQLACCCGSAGCSLCCDCCPRIRQSLSTRFMYALYFILVVVLCCIMMSTTVAHKMKEHIPFFEDMCKGIKAGDTCEKLVGYSAVYRVCFGMACFFFIFCLLTLKINNSKSCRAHIHNGFWFFKLLLLGAMCSGAFFIPDQDTFLNAWRYVGAVGGFLFIGIQLLLLVEFAHKWNKNWTAGTASNKLWYASLALVTLIMYSIATGGLVLMAVFYTQKDSCMENKILLGVNGGLCLLISLVAISPWVQNRQPHSGLLQSGVISCYVTYLTFSALSSKPAEVVLDEHGKNVTICVPDFGQDLYRDENLVTILGTSLLIGCILYSCLTSTTRSSSDALQGRYAAPELEIARCCFCFSPGGEDTEEQQPGKEGPRVIYDEKKGTVYIYSYFHFVFFLASLYVMMTVTNWFKNYQC>sp|Q86VE9-4|SERC5_HUMAN Isoform 4 of Serine incorporator 5 OS=Homosapiens OX=9606 GN=SERINC5MSAQCCAGQLACCCGSAGCSLCCDCCPRIRQSLSTRFMYALYFILVVVLCCIMMSTTVAHKMKEHIPFFEDMCKGIKAGDTCEKLVGYSAVYRVCFGMACFFFIFCLLTLKINNSKSCRAHIHNGFWFFKLLLLGAMCSGAFFIPDQDTFLNAWRYVGAVGGFLFIGIQLLLLVEFAHKWNKNWTAGTASNKLWYASLALVTLIMYSIATGGLVLMAVFYTQKDSCMENKILLGVNGGLCLLISLVAISPWVQNRQPHSGLLQSGVISCYVTYLTFSALSSKPAEVVLDEHGKNVTICVPDFGQDLYRDENLVTILGTSLLIGCILYSCLTSTTRSSSDALQGRYAAPELEIARCCFCFSPGGEDTEEQQPGKEGPRVIYDEKKGTVYIYSYFHFVFFLASLYVMMTVTNWFNYESANIESFFSGSWSIFWVKMASCWICVLLYLCTLVAPLCCPTREFSV>sp|P23526|SAHH_HUMAN Adenosylhomocysteinase OS=Homo sapiens OX=9606GN=AHCY PE=1 SV=4MSDKLPYKVADIGLAAWGRKALDIAENEMPGLMRMRERYSASKPLKGARIAGCLHMTVETAVLIETLVTLGAEVQWSSCNIFSTQDHAAAAIAKAGIPVYAWKGETDEEYLWCIEQTLYFKDGPLNMILDDGGDLTNLIHTKYPQLLPGIRGISEETTTGVHNLYKMMANGILKVPAINVNDSVTKSKFDNLYGCRESLIDGIKRATDVMIAGKVAVVAGYGDVGKGCAQALRGFGARVIITEIDPINALQAAMEGYEVTTMDEACQEGNIFVTTTGCIDIILGRHFEQMKDDAIVCNIGHFDVEIDVKWLNENAVEKVNIKPQVDRYRLKNGRRIILLAEGRLVNLGCAMGHPSFVMSNSFTNQVMAQIELWTHPDKYPVGVHFLPKKLDEAVAEAHLGKLNVKLTKLTEKQAQYLGMSCDGPFKPDHYRY>sp|P23526-2|SAHH_HUMAN Isoform 2 of Adenosylhomocysteinase OS=Homosapiens OX=9606 GN=AHCYMPGLMRMRERYSASKPLKGARIAGCLHMTVETAVLIETLVTLGAEVQWSSCNIFSTQDHAAAAIAKAGIPVYAWKGETDEEYLWCIEQTLYFKDGPLNMILDDGGDLTNLIHTKYPQLLPGIRGISEETTTGVHNLYKMMANGILKVPAINVNDSVTKSKFDNLYGCRESLIDGIKRATDVMIAGKVAVVAGYGDVGKGCAQALRGFGARVIITEIDPINALQAAMEGYEVTTMDEACQEGNIFVTTTGCIDIILGRHFEQMKDDAIVCNIGHFDVEIDVKWLNENAVEKVNIKPQVDRYRLKNGRRIILLAEGRLVNLGCAMGHPSFVMSNSFTNQVMAQIELWTHPDKYPVGVHFLPKKLDEAVAEAHLGKLNVKLTKLTEKQAQYLGMSCDGPFKPDHYRY>sp|Q92911|SC5A5_HUMAN Sodium/iodide cotransporter OS=Homo sapiensOX=9606 GN=SLC5A5 PE=1 SV=1MEAVETGERPTFGAWDYGVFALMLLVSTGIGLWVGLARGGQRSAEDFFTGGRRLAALPVGLSLSASFMSAVQVLGVPSEAYRYGLKFLWMCLGQLLNSVLTALLFMPVFYRLGLTSTYEYLEMRFSRAVRLCGTLQYIVATMLYTGIVIYAPALILNQVTGLDIWASLLSTGIICTFYTAVGGMKAVVWTDVFQVVVMLSGFWVVLARGVMLVGGPRQVLTLAQNHSRINLMDFNPDPRSRYTFWTFVVGGTLVWLSMYGVNQAQVQRYVACRTEKQAKLALLINQVGLFLIVSSAACCGIVMFVFYTDCDPLLLGRISAPDQYMPLLVLDIFEDLPGVPGLFLACAYSGTLSTASTSINAMAAVTVEDLIKPRLRSLAPRKLVIISKGLSLIYGSACLTVAALSSLLGGGVLQGSFTVMGVISGPLLGAFILGMFLPACNTPGVLAGLGAGLALSLWVALGATLYPPSEQTMRVLPSSAARCVALSVNASGLLDPALLPANDSSRAPSSGMDASRPALADSFYAISYLYYGALGTLTTVLCGALISCLTGPTKRSTLAPGLLWWDLARQTASVAPKEEVAILDDNLVKGPEELPTGNKKPPGFLPTNEDRLFFLGQKELEGAGSWTPCVGHDGGRDQQETNL>sp|Q9Y617|SERC_HUMAN Phosphoserine aminotransferase OS=Homo sapiensOX=9606 GN=PSAT1 PE=1 SV=2MDAPRQVVNFGPGPAKLPHSVLLEIQKELLDYKGVGISVLEMSHRSSDFAKIINNTENLVRELLAVPDNYKVIFLQGGGCGQFSAVPLNLIGLKAGRCADYVVTGAWSAKAAEEAKKFGTINIVHPKLGSYTKIPDPSTWNLNPDASYVYYCANETVHGVEFDFIPDVKGAVLVCDMSSNFLSKPVDVSKFGVIFAGAQKNVGSAGVTVVIVRDDLLGFALRECPSVLEYKVQAGNSSLYNTPPCFSIYVMGLVLEWIKNNGGAAAMEKLSSIKSQTIYEIIDNSQGFYVCPVEPQNRSKMNIPFRIGNAKGDDALEKRFLDKALELNMLSLKGHRSVGGIRASLYNAVTIEDVQKLAAFMKKFLEMHQL>sp|Q9Y617-2|SERC_HUMAN Isoform 2 of Phosphoserine aminotransferaseOS=Homo sapiens OX=9606 GN=PSAT1MDAPRQVVNFGPGPAKLPHSVLLEIQKELLDYKGVGISVLEMSHRSSDFAKIINNTENLVRELLAVPDNYKVIFLQGGGCGQFSAVPLNLIGLKAGRCADYVVTGAWSAKAAEEAKKFGTINIVHPKLGSYTKIPDPSTWNLNPDASYVYYCANETVHGVEFDFIPDVKGAVLVCDMSSNFLSKPVDVSKFGVIFAGAQKNVGSAGVTVVIVRDDLLGFALRECPSVLEYKVQAGNSSLYNTPPCFSIYVMGLVLEWIKNNGGAAAMEKLSSIKSQTIYEIIDNSQGFYVSVGGIRASLYNAVTIEDVQKLAAFMKKFLEMHQL>sp|Q5T1Q4|S35F1_HUMAN Solute carrier family 35 member F1 OS=Homo sapiensOX=9606 GN=SLC35F1 PE=1 SV=2MIPPEQPQQQLQPPSPAPPNHVVTTIENLPAEGSGGGGSLSASSRAGVRQRIRKVLNREMLISVALGQVLSLLICGIGLTSKYLSEDFHANTPVFQSFLNYILLFLVYTTTLAVRQGEENLLAILRRRWWKYMILGLIDLEANYLVVKAYQYTTLTSIQLLDCFVIPVVILLSWFFLLIRYKAVHFIGIVVCILGMGCMVGADVLVGRHQGAGENKLVGDLLVLGGATLYGISNVWEEYIIRTLSRVEFLGMIGLFGAFFSGIQLAIMEHKELLKVPWDWQIGLLYVGFSACMFGLYSFMPVVIKKTSATSVNLSLLTADLYSLFCGLFLFHYKFSGLYLLSFFTILIGLVLYSSTSTYIAQDPRVYKQFRNPSGPVVDLPTTAQVEPSVTYTSLGQETEEEPHVRVA>sp|Q5T1Q4-2|S35F1_HUMAN Isoform 2 of Solute carrier family 35 member F1OS=Homo sapiens OX=9606 GN=SLC35F1MLISVALGQVLSLLICGIGLTSKYLSEDFHANTPVFQSFLNYILLFLVYTTTLAVRQGEENLLAILRRRWWKYMILGLIDLEANYLVVKAYQYTTLTSIQLLDCFVIPVVILLSWFFLLIRYKAVHFIGIVVCILGMGCMVGADVLVGRHQGAGENKLVGDLLVLGGATLYGISNVWEEYIIRTLSRVEFLGMIGLFGAFFSGIQLAIMEHKELLKVPWDWQIGLLYVGFSACMFGLYSFMPVVIKKTSATSVNLSLLTADLYSLFCGLFLFHYKFSGLYLLSFFTILIGLVLYSSTSTYIAQDPRVYKQFRNPSGPVVDLPTTAQVEPSVTYTSLGQETEEEPHVRVA>sp|Q99624|S38A3_HUMAN Sodium-coupled neutral amino acid transporter 3OS=Homo sapiens OX=9606 GN=SLC38A3 PE=1 SV=1MEAPLQTEMVELVPNGKHSEGLLPVITPMAGNQRVEDPARSCMEGKSFLQKSPSKEPHFTDFEGKTSFGMSVFNLSNAIMGSGILGLAYAMANTGIILFLFLLTAVALLSSYSIHLLLKSSGVVGIRAYEQLGYRAFGTPGKLAAALAITLQNIGAMSSYLYIIKSELPLVIQTFLNLEEKTSDWYMNGNYLVILVSVTIILPLALMRQLGYLGYSSGFSLSCMVFFLIAVIYKKFHVPCPLPPNFNNTTGNFSHVEIVKEKVQLQVEPEASAFCTPSYFTLNSQTAYTIPIMAFAFVCHPEVLPIYTELKDPSKKKMQHISNLSIAVMYIMYFLAALFGYLTFYNGVESELLHTYSKVDPFDVLILCVRVAVLTAVTLTVPIVLFPVRRAIQQMLFPNQEFSWLRHVLIAVGLLTCINLLVIFAPNILGIFGVIGATSAPFLIFIFPAIFYFRIMPTEKEPARSTPKILALCFAMLGFLLMTMSLSFIIIDWASGTSRHGGNH>sp|Q15464|SHB_HUMAN SH2 domain-containing adapter protein B OS=Homosapiens OX=9606 GN=SHB PE=1 SV=2MAKWLNKYFSLGNSKTKSPPQPPRPDYREQRRRGERPSQPPQAVPQASSAASASCGPATASCFSASSGSLPDDSGSTSDLIRAYRAQKERDFEDPYNGPGSSLRKLRAMCRLDYCGGSGEPGGVQRAFSASSASGAAGCCCASSGAGAAASSSSSSGSPHLYRSSSERRPATPAEVRYISPKHRLIKVESAAGGGAGDPLGGACAGGRTWSPTACGGKKLLNKCAASAAEESGAGKKDKVTIADDYSDPFDAKNDLKSKAGKGESAGYMEPYEAQRIMTEFQRQESVRSQHKGIQLYDTPYEPEGQSVDSDSESTVSPRLRESKLPQDDDRPADEYDQPWEWNRVTIPALAAQFNGNEKRQSSPSPSRDRRRQLRAPGGGFKPIKHGSPEFCGILGERVDPAVPLEKQIWYHGAISRGDAENLLRLCKECSYLVRNSQTSKHDYSLSLRSNQGFMHMKLAKTKEKYVLGQNSPPFDSVPEVIHYYTTRKLPIKGAEHLSLLYPVAVRTL>sp|Q15464-2|SHB_HUMAN Isoform 2 of SH2 domain-containing adapter proteinB OS=Homo sapiens OX=9606 GN=SHBMAKWLNKYFSLGNSKTKSPPQPPRPDYREQRRRGERPSQPPQAVPQASSAASASCGPATASCFSASSGSLPDDSGSTSDLIRAYRAQKERDFEDPYNGPGSSLRKLRAMCRLDYCGGSGEPGGVQRAFSASSASGAAGCCCASSGAGAAASSSSSSGSPHLYRSSSERRPATPAEVRYISPKHRLIKVESAAGGGAGDPLGGACAGGRTWSPTACGGKKLLNKCAASAAEESGAGKKDKVTIADDYSDPFDAKNDLKSKAGKGESAGYMEPYEAQRIMTGLQEAWRHSPSGCFPVGP>sp|Q86WD7|SPA9_HUMAN Serpin A9 OS=Homo sapiens OX=9606 GN=SERPINA9 PE=1SV=3MASYLYGVLFAVGLCAPIYCVSPANAPSAYPRPSSTKSTPASQVYSLNTDFAFRLYRRLVLETPSQNIFFSPVSVSTSLAMLSLGAHSVTKTQILQGLGFNLTHTPESAIHQGFQHLVHSLTVPSKDLTLKMGSALFVKKELQLQANFLGNVKRLYEAEVFSTDFSNPSIAQARINSHVKKKTQGKVVDIIQGLDLLTAMVLVNHIFFKAKWEKPFHPEYTRKNFPFLVGEQVTVHVPMMHQKEQFAFGVDTELNCFVLQMDYKGDAVAFFVLPSKGKMRQLEQALSARTLRKWSHSLQKRWIEVFIPRFSISASYNLETILPKMGIQNVFDKNADFSGIAKRDSLQVSKATHKAVLDVSEEGTEATAATTTKFIVRSKDGPSYFTVSFNRTFLMMITNKATDGILFLGKVENPTKS>sp|Q86WD7-2|SPA9_HUMAN Isoform 2 of Serpin A9 OS=Homo sapiens OX=9606GN=SERPINA9MQGQGRRRGTCKDIFCSKMASYLYGVLFAVGLCAPIYCVSPANAPSAYPRPSSTKSTPASQVYSLNTDFAFRLYRRLVLETPSQNIFFSPARINSHVKKKTQGKVVDIIQGLDLLTAMVLVNHIFFKAKWEKPFHPEYTRKNFPFLVGEQVTVHVPMMHQKEQFAFGVDTELNCFVLQMDYKGDAVAFFVLPSKGKMRQLEQALSARTLRKWSHSLQKRWIEVFIPRFSISASYNLETILPKMGIQNVFDKNADFSGIAKRDSLQVSKATHKAVLDVSEEGTEATAATTTKFIVRSKDGPSYFTVSFNRTFLMMITNKATDGILFLGKVENPTKS>sp|Q86WD7-3|SPA9_HUMAN Isoform 3 of Serpin A9 OS=Homo sapiens OX=9606GN=SERPINA9MRSAGGRGEIKVRRELQPSKQVSGLTNHARTGQEKRNLQRHILFQNGILPLWSTLCCWPLCSNLLCVPGQCPQCIPPPFLHKEHPCLTGVFPQHRLCLPPIPQAGFGDPESEHLLLPCECLHFPGHALPWGPLSHQDPDSPGPGLQPHTHTRVCHPPGLPAPGSLTDCSQQRPDLEDGKCPLRQEGAAAAGKFLGQCQEAV>sp|Q86WD7-4|SPA9_HUMAN Isoform 4 of Serpin A9 OS=Homo sapiens OX=9606GN=SERPINA9MRSAGGRGEIKVRRELQPSKQVSGLTNHARTGQEKRNLQRLVLETPSQNIFFSPVSVSTSLAMLSLGAHSVTKTQILQGLGFNLTHTPESAIHQGFQHLVHSLTVPSKDLTLKMGSALFVKKELQLQANFLGNVKRLYEAEVFSTDFSNPSIAQARINSHVKKKTQGKVVDIIQGLDLLTAMVLVNHIFFKAKWEKPFHPEYTRKNFPFLVGEQVTVHVPMMHQKEQFAFGVDTELNCFVLQMDYKGDAVAFFVLPSKGKMRQLEQALSARTLRKWSHSLQKRWIEVFIPRFSISASYNLETILPKMGIQNVFDKNADFSGIAKRDSLQVSKVS>sp|Q86WD7-5|SPA9_HUMAN Isoform 5 of Serpin A9 OS=Homo sapiens OX=9606GN=SERPINA9MGSALFVKKELQLQANFLGNVKRLYEAEVFSTDFSNPSIAQARINSHVKKKTQGKVVDIIQGLDLLTAMVLVNHIFFKAKWEKPFHPEYTRKNFPFLVGEQVTVHVPMMHQKEQFAFGVDTELNCFVLQMDYKGDAVAFFVLPSKGKMRQLEQALSARTLRKWSHSLQKRWIEVFIPRFSISASYNLETILPKMGIQNVFDKNADFSGIAKRDSLQVSKATHKAVLDVSEEGTEATAATTTKFIVRSKDGPSYFTVSFNRTFLMMITNKATDGILFLGKVENPTKS>sp|Q86WD7-6|SPA9_HUMAN Isoform 6 of Serpin A9 OS=Homo sapiens OX=9606GN=SERPINA9MLSLGAHSVTKTQILQGLGFNLTHTPESAIHQGFQHLVHSLTVPSKDLTLKMGSALFVKKELQLQANFLGNVKRLYEAEVFSTDFSNPSIAQARINSHVKKKTQGKVVDIIQGLDLLTAMVLVNHIFFKAKWEKPFHPEYTRKNFPFLVGEQVTVHVPMMHQKEQFAFGVDTELNCFVLQMDYKGDAVAFFVLPSKGKMRQLEQALSARTLRKWSHSLQKRWIEVFIPRFSISASYNLETILPKMGIQNVFDKNADFSGIAKRDSLQVSKATHKAVLDVSEEGTEATAATTTKFIVRSKDGPSYFTVSFNRTFLMMITNKATDGILFLGKVENPTKS>sp|Q86WD7-7|SPA9_HUMAN Isoform 7 of Serpin A9 OS=Homo sapiens OX=9606GN=SERPINA9MQGQGRRRGTCKDIFCSKMASYLYGVLFAVGLCAPIYCVSPANAPSAYPRPSSTKSTPASQVYSLNTDFAFRLYRRLVLETPSQNIFFSPVSVSTSLAMLSLGAHSVTKTQILQGLGFNLTHTPESAIHQGFQHLVHSLTVPSKDLTLKMGSALFVKKELQLQANFLGNVKRLYEAEVFSTDFSNPSIAQARINSHVKKKTQGKVVDIIQGLDLLTAMVLVNHIFFKAKWEKPFHPEYTRKNFPFLVGEQVTVHVPMMHQKEQFAFGVDTELNCFVLQMDYKGDAVAFFVLPSKGKMRQLEQALSARTLRKWSHSLQKRWIEVFIPRFSISASYNLETILPKMGIQNVFDKNADFSGIAKRDSLQVSKATHKAVLDVSEEGTEATAATTTKFIVRSKDGPSYFTVSFNRTFLMMITNKATDGILFLGKVENPTKS>sp|O43760|SNG2_HUMAN Synaptogyrin-2 OS=Homo sapiens OX=9606 GN=SYNGR2PE=1 SV=1MESGAYGAAKAGGSFDLRRFLTQPQVVARAVCLVFALIVFSCIYGEGYSNAHESKQMYCVFNRNEDACRYGSAIGVLAFLASAFFLVVDAYFPQISNATDRKYLVIGDLLFSALWTFLWFVGFCFLTNQWAVTNPKDVLVGADSVRAAITFSFFSIFSWGVLASLAYQRYKAGVDDFIQNYVDPTPDPNTAYASYPGASVDNYQQPPFTQNAETTEGYQPPPVY>sp|O43760-2|SNG2_HUMAN Isoform 2 of Synaptogyrin-2 OS=Homo sapiensOX=9606 GN=SYNGR2MESGAYGAAKAGGSFDLRRFLTQPQVVARAVCLVFALIVFSCIYGEGYSNAHESKQMYCVFNRNEDACRYGSAIGVLAFLASAFFLVVDAYFPQISNATDRKYLVIGDLLFSALWTFLWFVGFCFLTNQWAVTNPKDVLVGADSVRAAITFSFFSIFSWVGWPGAGSWVKGGGGWGPPPTCTLLCSPCRVCWPPWPTSATRLAWTTSSRITLTPLRTPTLPTPPTQVHLWTTTNSHPSPRTRRPPRATSRPLCTERRLAWEGGQRGPSPLPWTFP>sp|Q5VUG0|SMBT2_HUMAN Scm-like with four MBT domains protein 2 OS=Homosapiens OX=9606 GN=SFMBT2 PE=1 SV=1MESTLSASNMQDPSSSPLEKCLGSANGNGDLDSEEGSSLEETGFNWGEYLEETGASAAPHTSFKHVEISIQSNFQPGMKLEVANKNNPDTYWVATIITTCGQLLLLRYCGYGEDRRADFWCDVVIADLHPVGWCTQNNKVLMPPDAIKEKYTDWTEFLIRDLTGSRTAPANLLEGPLRGKGPIDLITVGSLIELQDSQNPFQYWIVSVIENVGGRLRLRYVGLEDTESYDQWLFYLDYRLRPVGWCQENKYRMDPPSEIYPLKMASEWKCTLEKSLIDAAKFPLPMEVFKDHADLRSHFFTVGMKLETVNMCEPFYISPASVTKVFNNHFFQVTIDDLRPEPSKLSMLCHADSLGILPVQWCLKNGVSLTPPKGYSGQDFDWADYHKQHGAQEAPPFCFRNTSFSRGFTKNMKLEAVNPRNPGELCVASVVSVKGRLMWLHLEGLQTPVPEVIVDVESMDIFPVGWCEANSYPLTAPHKTVSQKKRKIAVVQPEKQLPPTVPVKKIPHDLCLFPHLDTTGTVNGKYCCPQLFINHRCFSGPYLNKGRIAELPQSVGPGKCVLVLKEVLSMIINAAYKPGRVLRELQLVEDPHWNFQEETLKAKYRGKTYRAVVKIVRTSDQVANFCRRVCAKLECCPNLFSPVLISENCPENCSIHTKTKYTYYYGKRKKISKPPIGESNPDSGHPKPARRRKRRKSIFVQKKRRSSAVDFTAGSGEESEEEDADAMDDDTASEETGSELRDDQTDTSSAEVPSARPRRAVTLRSGSEPVRRPPPERTRRGRGAPAASSAEEGEKCPPTKPEGTEDTKQEEEERLVLESNPLEWTVTDVVRFIKLTDCAPLAKIFQEQDIDGQALLLLTLPTVQECMELKLGPAIKLCHQIERVKVAFYAQYAN>sp|P0DUD4|SPD15_HUMAN Putative speedy protein E15 OS=Homo sapiensOX=9606 GN=SPDYE15 PE=5 SV=1MGQILGKIMMSHQPQPQEERSPQRSTSGYPLQEVVDDEVLGPSAPGVDPSPPRRSLGWKRKRECLDESDDEPEKELAPEPEETWVAETLCGLKMKAKRRRVSLVLPEYYEAFNRLLEDPVIKRLLAWDKDLRVSDKYLLAMVIAYFSRAGLPSWQYQRIHFFLALYLANDMEEDDEAPKQNIFYFLYEETRSHIPLLSELWFQLCRYMNPRARKNCSQIALFRKYRFHFFCSMRCRAWVSLEELEEIQAYDPEHWVWARDRAHLS>sp|Q13326|SGCG_HUMAN Gamma-sarcoglycan OS=Homo sapiens OX=9606 GN=SGCGPE=1 SV=4MVREQYTTATEGICIERPENQYVYKIGIYGWRKRCLYLFVLLLLIILVVNLALTIWILKVMWFSPAGMGHLCVTKDGLRLEGESEFLFPLYAKEIHSRVDSSLLLQSTQNVTVNARNSEGEVTGRLKVGPKMVEVQNQQFQINSNDGKPLFTVDEKEVVVGTDKLRVTGPEGALFEHSVETPLVRADPFQDLRLESPTRSLSMDAPRGVHIQAHAGKIEALSQMDILFHSSDGMLVLDAETVCLPKLVQGTWGPSGSSQSLYEICVCPDGKLYLSVAGVSTTCQEHNHICL>sp|Q8N661|TM86B_HUMAN Lysoplasmalogenase OS=Homo sapiens OX=9606GN=TMEM86B PE=1 SV=2MDAGKAGQTLKTHCSAQRPDVCRWLSPFILSCCVYFCLWIPEDQLSWFAALVKCLPVLCLAGFLWVMSPSGGYTQLLQGALVCSAVGDACLIWPAAFVPGMAAFATAHLLYVWAFGFSPLQPGLLLLIILAPGPYLSLVLQHLEPDMVLPVAAYGLILMAMLWRGLAQGGSAGWGALLFTLSDGVLAWDTFAQPLPHAHLVIMTTYYAAQLLITLSALRSPVPKTD>sp|H3BQB6|STMD1_HUMAN Stathmin domain-containing protein 1 OS=Homosapiens OX=9606 GN=STMND1 PE=2 SV=1MGCGPSQPAEDRRRVRAPKKGWKEEFKADVSVPHTGENCSPRMEAALTKNTVDIAEGLEQVQMGSLPGTISENSPSPSERNRRVNSDLVTNGLINKPQSLESRERQKSSDILEELIVQGIIQSHSKVFRNGESYDVTLTTTEKPLRKPPSRLKKLKIKKQVKDFTMKDIEEKMEAAEERRKTKEEEIRKRLRSDRLLPSANHSDSAELDGAEVAFAKGLQRVRSAGFEPSDLQGGKPLKRKKSKCDATLIDRNESDESFGVVESDMSYNQADDIVY>sp|O75897|ST1C4_HUMAN Sulfotransferase 1C4 OS=Homo sapiens OX=9606GN=SULT1C4 PE=1 SV=2MALHDMEDFTFDGTKRLSVNYVKGILQPTDTCDIWDKIWNFQAKPDDLLISTYPKAGTTWTQEIVELIQNEGDVEKSKRAPTHQRFPFLEMKIPSLGSGLEQAHAMPSPRILKTHLPFHLLPPSLLEKNCKIIYVARNPKDNMVSYYHFQRMNKALPAPGTWEEYFETFLAGKVCWGSWHEHVKGWWEAKDKHRILYLFYEDMKKNPKHEIQKLAEFIGKKLDDKVLDKIVHYTSFDVMKQNPMANYSSIPAEIMDHSISPFMRKGAVGDWKKHFTVAQNERFDEDYKKKMTDTRLTFHFQF>sp|O75897-2|ST1C4_HUMAN Isoform 2 of Sulfotransferase 1C4 OS=Homosapiens OX=9606 GN=SULT1C4MALHDMEDFTFDGTKRLSVNYVKGILQPTDTCDIWDKIWNFQAKPDDLLISTYPKAGTTWTQEIVELIQNEGDVEKSKRAPTHQRFPFLEMKIPSLGSVCWGSWHEHVKGWWEAKDKHRILYLFYEDMKKNPKHEIQKLAEFIGKKLDDKVLDKIVHYTSFDVMKQNPMANYSSIPAEIMDHSISPFMRKGAVGDWKKHFTVAQNERFDEDYKKKMTDTRLTFHFQF>sp|Q9Y3B3|TMED7_HUMAN Transmembrane emp24 domain-containing protein 7OS=Homo sapiens OX=9606 GN=TMED7 PE=1 SV=2MPRPGSAQRWAAVAGRWGCRLLALLLLVPGPGGASEITFELPDNAKQCFYEDIAQGTKCTLEFQVITGGHYDVDCRLEDPDGKVLYKEMKKQYDSFTFTASKNGTYKFCFSNEFSTFTHKTVYFDFQVGEDPPLFPSENRVSALTQMESACVSIHEALKSVIDYQTHFRLREAQGRSRAEDLNTRVAYWSVGEALILLVVSIGQVFLLKSFFSDKRTTTTRVGS>sp|Q9Y3B3-2|TMED7_HUMAN Isoform 2 of Transmembrane emp24 domain-containing protein 7 OS=Homo sapiens OX=9606 GN=TMED7MPRPGSAQRWAAVAGRWGCRLLALLLLVPGPGGASEITFELPDNAKQCFYEDIAQGTKCTLEFQVITGGHYDVDCRLEDPDGKVLYKEMKKQYDSFTFTASKNGTYKFCFSNEFSTFTHKTVYFDFQVGEDPPLFPSENRVSALTQMESACVSIHEALKSVIDYQTHFRLREAQGRSRAEDLNTRVAY>sp|Q9UBS9|SUCO_HUMAN SUN domain-containing ossification factor OS=Homosapiens OX=9606 GN=SUCO PE=1 SV=1MKKHRRALALVSCLFLCSLVWLPSWRVCCKESSSASASSYYSQDDNCALENEDVQFQKKDEREGPINAESLGKSGSNLPISPKEHKLKDDSIVDVQNTESKKLSPPVVETLPTVDLHEESSNAVVDSETVENISSSSTSEITPISKLDEIEKSGTIPIAKPSETEQSETDCDVGEALDASAPIEQPSFVSPPDSLVGQHIENVSSSHGKGKITKSEFESKVSASEQGGGDPKSALNASDNLKNESSDYTKPGDIDPTSVASPKDPEDIPTFDEWKKKVMEVEKEKSQSMHASSNGGSHATKKVQKNRNNYASVECGAKILAANPEAKSTSAILIENMDLYMLNPCSTKIWFVIELCEPIQVKQLDIANYELFSSTPKDFLVSISDRYPTNKWIKLGTFHGRDERNVQSFPLDEQMYAKYVKMFIKYIKVELLSHFGSEHFCPLSLIRVFGTSMVEEYEEIADSQYHSERQELFDEDYDYPLDYNTGEDKSSKNLLGSATNAILNMVNIAANILGAKTEDLTEGNKSISENATATAAPKMPESTPVSTPVPSPEYVTTEVHTHDMEPSTPDTPKESPIVQLVQEEEEEASPSTVTLLGSGEQEDESSPWFESETQIFCSELTTICCISSFSEYIYKWCSVRVALYRQRSRTALSKGKDYLVLAQPPLLLPAESVDVSVLQPLSGELENTNIEREAETVVLGDLSSSMHQDDLVNHTVDAVELEPSHSQTLSQSLLLDITPEINPLPKIEVSESVEYEAGHIPSPVIPQESSVEIDNETEQKSESFSSIEKPSITYETNKVNELMDNIIKEDVNSMQIFTKLSETIVPPINTATVPDNEDGEAKMNIADTAKQTLISVVDSSSLPEVKEEEQSPEDALLRGLQRTATDFYAELQNSTDLGYANGNLVHGSNQKESVFMRLNNRIKALEVNMSLSGRYLEELSQRYRKQMEEMQKAFNKTIVKLQNTSRIAEEQDQRQTEAIQLLQAQLTNMTQLVSNLSATVAELKREVSDRQSYLVISLVLCVVLGLMLCMQRCRNTSQFDGDYISKLPKSNQYPSPKRCFSSYDDMNLKRRTSFPLMRSKSLQLTGKEVDPNDLYIVEPLKFSPEKKKKRCKYKIEKIETIKPEEPLHPIANGDIKGRKPFTNQRDFSNMGEVYHSSYKGPPSEGSSETSSQSEESYFCGISACTSLCNGQSQKTKTEKRALKRRRSKVQDQGKLIKTLIQTKSGSLPSLHDIIKGNKEITVGTFGVTAVSGHI>sp|Q9UBS9-2|SUCO_HUMAN Isoform 2 of SUN domain-containing ossificationfactor OS=Homo sapiens OX=9606 GN=SUCOMRGFLARPFLSTNQHLAQWGSPLPQGKGLVQLPSQHTRHSRPFHELCSKEENSATVPKLISLVVSSETIDFSNKTMDSRRDWEREKRILEGKLQLPKALARTQRARDEGRAWTSRWLQRRRSPESCEAPLSAPLWGPQRGLPGREPLRSRSASAIALRTIGHILALLLRLLHLGLGSGGCREDVPPSGRGKKEEKMKKHRRALALVSCLFLCSLVWLPSWRVCCKESSSASASSYYSQDDNCALENEDVQFQKKNTESKKLSPPVVETLPTVDLHEESSNAVVDSETVENISSSSTSEITPISKLDEIEKSGTIPIAKPSETEQSETDCDVGEALDASAPIEQPSFVSPPDSLVGQHIENVSSSHGKGKITKSEFESKVSASEQGGGDPKSALNASDNLKNESSDYTKPGDIDPTSVASPKDPEDIPTFDEWKKKVMEVEKEKSQSMHASSNGGSHATKKVQKNRNNYASVECGAKILAANPEAKSTSAILIENMDLYMLNPCSTKIWFVIELCEPIQVKQLDIANYELFSSTPKDFLVSISDRYPTNKWIKLGTFHGRDERNVQSFPLDEQMYAKYVKVELLSHFGSEHFCPLSLIRVFGTSMVEEYEEIADSQYHSERQELFDEDYDYPLDYNTGEDKSSKNLLGSATNAILNMVNIAANILGAKTEDLTEGNKSISENATATAAPKMPESTPVSTPVPSPEYVTTEVHTHDMEPSTPDTPKESPIVQLVQEEEEEASPSTVTLLGSGEQEDESSPWFESETQIFCSELTTICCISSFSEYIYKWCSVRVALYRQRSRTALSKGKDYLVLAQPPLLLPAESVDVSVLQPLSGELENTNIEREAETVVLGDLSSSMHQDDLVNHTVDAVELEPSHSQTLSQSLLLDITPEINPLPKIEVSESVEYEAGHIPSPVIPQESSVEIDNETEQKSESFSSIEKPSITYETNKVNELMDNIIKEDVNSMQIFTKLSETIVPPINTATVPDNEDGEAKMNIADTAKQTLISVVDSSSLPEVKEEEQSPEDALLRGLQRTATDFYAELQNSTDLGYANGNLVHGSNQKESVFMRLNNRIKALEVNMSLSGRYLEELSQRYRKQMEEMQKAFNKTIVKLQNTSRIAEEQDQRQTEAIQLLQAQLTNMTQLVSNLSATVAELKREVSDRQSYLVISLVLCVVLGLMLCMQRCRNTSQFDGDYISKLPKSNQYPSPKRCFSSYDDMNLKRRTSFPLMRSKSLQLTGKEVDPNDLYIVEPLKFSPEKKKKRCKYKIEKIETIKPEEPLHPIANGDIKGRKPFTNQRDFSNMGEVYHSSYKGPPSEGSSETSSQSEESYFCGISACTSLCNGQSQKTKTEKRALKRRRSKVQDQGKLIKTLIQTKSGSLPSLHDIIKGNKEITVGTFGVTAVSGHI>sp|Q8IWU5|SULF2_HUMAN Extracellular sulfatase Sulf-2 OS=Homo sapiensOX=9606 GN=SULF2 PE=1 SV=1MGPPSLVLCLLSATVFSLLGGSSAFLSHHRLKGRFQRDRRNIRPNIILVLTDDQDVELGSMQVMNKTRRIMEQGGAHFINAFVTTPMCCPSRSSILTGKYVHNHNTYTNNENCSSPSWQAQHESRTFAVYLNSTGYRTAFFGKYLNEYNGSYVPPGWKEWVGLLKNSRFYNYTLCRNGVKEKHGSDYSKDYLTDLITNDSVSFFRTSKKMYPHRPVLMVISHAAPHGPEDSAPQYSRLFPNASQHITPSYNYAPNPDKHWIMRYTGPMKPIHMEFTNMLQRKRLQTLMSVDDSMETIYNMLVETGELDNTYIVYTADHGYHIGQFGLVKGKSMPYEFDIRVPFYVRGPNVEAGCLNPHIVLNIDLAPTILDIAGLDIPADMDGKSILKLLDTERPVNRFHLKKKMRVWRDSFLVERGKLLHKRDNDKVDAQEENFLPKYQRVKDLCQRAEYQTACEQLGQKWQCVEDATGKLKLHKCKGPMRLGGSRALSNLVPKYYGQGSEACTCDSGDYKLSLAGRRKKLFKKKYKASYVRSRSIRSVAIEVDGRVYHVGLGDAAQPRNLTKRHWPGAPEDQDDKDGGDFSGTGGLPDYSAANPIKVTHRCYILENDTVQCDLDLYKSLQAWKDHKLHIDHEIETLQNKIKNLREVRGHLKKKRPEECDCHKISYHTQHKGRLKHRGSSLHPFRKGLQEKDKVWLLREQKRKKKLRKLLKRLQNNDTCSMPGLTCFTHDNQHWQTAPFWTLGPFCACTSANNNTYWCMRTINETHNFLFCEFATGFLEYFDLNTDPYQLMNAVNTLDRDVLNQLHVQLMELRSCKGYKQCNPRTRNMDLGLKDGGSYEQYRQFQRRKWPEMKRPSSKSLGQLWEGWEG>sp|Q8IWU5-2|SULF2_HUMAN Isoform 2 of Extracellular sulfatase Sulf-2OS=Homo sapiens OX=9606 GN=SULF2MGPPSLVLCLLSATVFSLLGGSSAFLSHHRLKGRFQRDRRNIRPNIILVLTDDQDVELGSMQVMNKTRRIMEQGGAHFINAFVTTPMCCPSRSSILTGKYVHNHNTYTNNENCSSPSWQAQHESRTFAVYLNSTGYRTAFFGKYLNEYNGSYVPPGWKEWVGLLKNSRFYNYTLCRNGVKEKHGSDYSKDYLTDLITNDSVSFFRTSKKMYPHRPVLMVISHAAPHGPEDSAPQYSRLFPNASQHITPSYNYAPNPDKHWIMRYTGPMKPIHMEFTNMLQRKRLQTLMSVDDSMETIYNMLVETGELDNTYIVYTADHGYHIGQFGLVKGKSMPYEFDIRVPFYVRGPNVEAGCLNPHIVLNIDLAPTILDIAGLDIPADMDGKSILKLLDTERPVNRFHLKKKMRVWRDSFLVERGKLLHKRDNDKVDAQEENFLPKYQRVKDLCQRAEYQTACEQLGQKWQCVEDATGKLKLHKCKGPMRLGGSRALSNLVPKYYGQGSEACTCDSGDYKLSLAGRRKKLFKKKYKASYVRSRSIRSVAIEVDGRVYHVGLGDAAQPRNLTKRHWPGAPEDQDDKDGGDFSGTGGLPDYSAANPIKVTHRCYILENDTVQCDLDLYKSLQAWKDHKLHIDHEIETLQNKIKNLREVRGHLKKKRPEECDCHKISYHTQHKGRLKHRGSSLHPFRKGLQEKDKVWLLREQKRKKKLRKLLKRLQNNDTCSMPGLTCFTHDNQHWQTAPFWTLGPFCACTSANNNTYWCMRTINETHNFLFCEFATGFLEYFDLNTDPYQLMNAVNTLDRDVLNQLHVQLMELRSCKGYKQCNPRTRNMDLDGGSYEQYRQFQRRKWPEMKRPSSKSLGQLWEGWEG>sp|Q8TDW4|ST7L_HUMAN Suppressor of tumorigenicity 7 protein-like OS=Homosapiens OX=9606 GN=ST7L PE=2 SV=1MADRGGVGEAAAVGASPASVPGLNPTLGWRERLRAGLAGTGASLWFVAGLGLLYALRIPLRLCENLAAVTVFLNSLTPKFYVALTGTSSLISGLIFIFEWWYFHKHGTSFIEQVSVSHLQPLMGGTESSISEPGSPSRNRENETSRQNLSECKVWRNPLNLFRGAEYRRYTWVTGKEPLTYYDMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLQHWKRIEGALNLLQCTWEGTFRMIPYPLEKGHLFYPYPSCTETADRELLPTFHHVSVYPKKELPLFIHFTAGFCSSTAMIAILTHQFPEIMGIFAKAVLGLWCPQPWASSGFEENTQDLKSEDLGLSSG>sp|Q8TDW4-2|ST7L_HUMAN Isoform 2 of Suppressor of tumorigenicity 7protein-like OS=Homo sapiens OX=9606 GN=ST7LMADRGGVGEAAAVGASPASVPGLNPTLGWRERLRAGLAGTGASLWFVAGLGLLYALRIPLRLCENLAAVTVFLNSLTPKFYVALTGTSSLISGLIFIFEWWYFHKHGTSFIEQVSVSHLQPLMGGTESSISEPGSPSRNRENETSRQNLSECKVWRNPLNLFRGAEYRRYTWVTGKEPLTYYDMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLQHWKRIEGALNLLQCTWEGTFHHVSVYPKKELPLFIHFTAGFCSSTAMIAILTHQFPEIMGIFAKAVLGLWCPQPWASSGFEENTQDLKSEDLGLSSG>sp|Q8TDW4-3|ST7L_HUMAN Isoform 3 of Suppressor of tumorigenicity 7protein-like OS=Homo sapiens OX=9606 GN=ST7LMADRGGVGEAAAVGASPASVPGLNPTLGWRERLRAGLAGTGASLWFVAGLGLLYALRIPLRLCENLAAGTSSLISGLIFIFEWWYFHKHGTSFIEQVSVSHLQPLMGGTESSISEPGSPSRNRENETSRQNLSECKVWRNPLNLFRGAEYRRYTWVTGKEPLTYYDMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLQHWKRIEGALNLLQCTWEGTFRMIPYPLEKGHLFYPYPSCTETADRELLPTFHHVSVYPKKELPLFIHFTAGFCSSTAMIAILTHQFPEIMGIFAKAVLGLWCPQPWASSGFEENTQDLKSEDLGLSSG>sp|Q8TDW4-4|ST7L_HUMAN Isoform 4 of Suppressor of tumorigenicity 7protein-like OS=Homo sapiens OX=9606 GN=ST7LMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLQHWKRIEGALNLLQCTWEGTFRMIPYPLEKGHLFYPYPSCTETADRELLPTFHHVSVYPKKELPLFIHFTAGFCSSTAMIAILTHQFPEIMGIFAKAVLGLWCPQPWASSGFEENTQDLKSEDLGLSSG>sp|Q8TDW4-5|ST7L_HUMAN Isoform 5 of Suppressor of tumorigenicity 7protein-like OS=Homo sapiens OX=9606 GN=ST7LMADRGGVGEAAAVGASPASVPGLNPTLGWRERLRAGLAGTGASLWFVAGLGLLYALRIPLRLCENLAAVTVFLNSLTPKFYVALTGTSSLISGLIFIFEWWYFHKHGTSFIEQVSVSHLQPLMGGTESSISEPGSPSRNRENETSRQNLSECKVWRNPLNLFRGAEYRRYTWVTGKEPLTYYDMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLQHWKRIEGALNLLQCTWEGTFRMIPYPLEKGHLFYPYPSCTETADRELLPTFHHVSVYPKKELPLFIHFTAGFCSSTAMIAILTHQFPEIMGIFAKAVSMISRTCVDYL>sp|Q8TDW4-6|ST7L_HUMAN Isoform 6 of Suppressor of tumorigenicity 7protein-like OS=Homo sapiens OX=9606 GN=ST7LMADRGGVGEAAAVGASPASVPGLNPTLGWRERLRAGLAGTGASLWFVAGLGLLYALRIPLRLCENLAAGTSSLISGLIFIFEWWYFHKHGTSFIEQVSVSHLQPLMGGTESSISEPGSPSRNRENETSRQNLSECKVWRNPLNLFRGAEYRRYTWVTGKEPLTYYDMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLQHWKRIEGALNLLQCTWEGTFRMIPYPLEKGHLFYPYPSCTETADRELLPTFHHVSVYPKKELPLFIHFTAGFCSSTAMIAILTHQFPEIMGIFAKAVSMISRTCVDYL>sp|Q8TDW4-7|ST7L_HUMAN Isoform 7 of Suppressor of tumorigenicity 7protein-like OS=Homo sapiens OX=9606 GN=ST7LMADRGGVGEAAAVGASPASVPGLNPTLGWRERLRAGLAGTGASLWFVAGLGLLYALRIPLRLCENLAAVTVFLNSLTPKFYVALTGTSSLISGLIFIFEWWYFHKHGTSFIEQVSVSHLQPLMGGTESSISEPGSPSRNRENETSRQNLSECKVWRNPLNLFRGAEYRRYTWVTGKEPLTYYDMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLQHWKRIEGALNLLQCTWEGTFRMIPYPLEKGHLFYPYPSCTETADRELLPTFHHVSVYPKKELPLFIHFTAGFCSSTAMIAILTHQFPEIMGIFAKAVVGVKTQKENAD>sp|Q8TDW4-8|ST7L_HUMAN Isoform 8 of Suppressor of tumorigenicity 7protein-like OS=Homo sapiens OX=9606 GN=ST7LMGGTESSISEPGSPSRNRENETSRQNLSECKVWRNPLNLFRGAEYRRYTWVTGKEPLTYYDMNLSAQDHQTFFTCDTDFLRPSDTVMQKAWRERNPPARIKAAYQALELNNDCATAYVLLAEEEATTIVDAERLFKQALKAGETIYRQSQQCQHQSPQHEAQLRRDTNVLVYIKRRLAMCARKLGRIREAVKIMRDLMKEFPPLTMLNIHENLLESLLELQAYPDVQAVLAKYDDISLPKSAAICYTAALLKTRTVSEKFSPETASRRGLSTAEINAVEAIHRAVEFNPHVPKVEIYPFSPQLNIKAVDNSAISKYPANIY>sp|Q05952|STP2_HUMAN Nuclear transition protein 2 OS=Homo sapiensOX=9606 GN=TNP2 PE=1 SV=1MDTQTHSLPITHTQLHSNSQPQSRTCTRHCQTFSQSCRQSHRGSRSQSSSQSPASHRNPTGAHSSSGHQSQSPNTSPPPKRHKKTMNSHHSPMRPTILHCRCPKNRKNLEGKLKKKKMAKRIQQVYKTKTRSSGWKSN>sp|Q9Y2H1|ST38L_HUMAN Serine/threonine-protein kinase 38-like OS=Homosapiens OX=9606 GN=STK38L PE=1 SV=3MAMTAGTTTTFPMSNHTRERVTVAKLTLENFYSNLILQHEERETRQKKLEVAMEEEGLADEEKKLRRSQHARKETEFLRLKRTRLGLDDFESLKVIGRGAFGEVRLVQKKDTGHIYAMKILRKSDMLEKEQVAHIRAERDILVEADGAWVVKMFYSFQDKRNLYLIMEFLPGGDMMTLLMKKDTLTEEETQFYISETVLAIDAIHQLGFIHRDIKPDNLLLDAKGHVKLSDFGLCTGLKKAHRTEFYRNLTHNPPSDFSFQNMNSKRKAETWKKNRRQLAYSTVGTPDYIAPEVFMQTGYNKLCDWWSLGVIMYEMLIGYPPFCSETPQETYRKVMNWKETLVFPPEVPISEKAKDLILRFCIDSENRIGNSGVEEIKGHPFFEGVDWEHIRERPAAIPIEIKSIDDTSNFDDFPESDILQPVPNTTEPDYKSKDWVFLNYTYKRFEGLTQRGSIPTYMKAGKL>sp|Q9Y2H1-2|ST38L_HUMAN Isoform 2 of Serine/threonine-protein kinase 38-like OS=Homo sapiens OX=9606 GN=STK38LMEEEGLADEEVRLVQKKDTGHIYAMKILRKSDMLEKEQVAHIRAERDILVEADGAWVVKMFYSFQDKRNLYLIMEFLPGGDMMTLLMKKDTLTEEETQFYISETVLAIDAIHQLGFIHRDIKPDNLLLDAKGHVKLSDFGLCTGLKKAHRTEFYRNLTHNPPSDFSFQNMNSKRKAETWKKNRRQLAYSTVGTPDYIAPEVFMQTGYNKLCDWWSLGVIMYEMLIGYPPFCSETPQETYRKVMNWKETLVFPPEVPISEKAKDLILRFCIDSENRIGNSGVEEIKGHPFFEGVDWEHIRERPAAIPIEIKSIDDTSNFDDFPESDILQPVPNTTEPDYKSKDWVFLNYTYKRFEGLTQRGSIPTYMKAGKL>sp|Q3ZCQ8|TIM50_HUMAN Mitochondrial import inner membrane translocasesubunit TIM50 OS=Homo sapiens OX=9606 GN=TIMM50 PE=1 SV=2MAASAAVFSRLRSGLRLGSRGLCTRLATPPRRAPDQAAEIGSRGSTKAQGPQQQPGSEGPSYAKKVALWLAGLLGAGGTVSVVYIFGNNPVDENGAKIPDEFDNDPILVQQLRRTYKYFKDYRQMIIEPTSPCLLPDPLQEPYYQPPYTLVLELTGVLLHPEWSLATGWRFKKRPGIETLFQQLAPLYEIVIFTSETGMTAFPLIDSVDPHGFISYRLFRDATRYMDGHHVKDISCLNRDPARVVVVDCKKEAFRLQPYNGVALRPWDGNSDDRVLLDLSAFLKTIALNGVEDVRTVLEHYALEDDPLAAFKQRQSRLEQEEQQRLAELSKSNKQNLFLGSLTSRLWPRSKQP>sp|Q3ZCQ8-2|TIM50_HUMAN Isoform 2 of Mitochondrial import inner membranetranslocase subunit TIM50 OS=Homo sapiens OX=9606 GN=TIMM50MASALSLGNKCDPFLRCVLCRGGGALQGPRGRGPDDFESQLSPPGSARRLVRSKRACGNPPDAFGLSRASVHPPLPRVSIGCSSGPGRAKRERVGGAAWRQRKMAASAAVFSRLRSGLRLGSRGLCTRLATPPRRAPDQAAEIGSRGSTKAQGPQQQPGSEGPSYAKKVALWLAGLLGAGGTVSVVYIFGNNPVDENGAKIPDEFDNDPILVQQLRRTYKYFKDYRQMIIEPTSPCLLPDPLQEPYYQPPYTLVLELTGVLLHPEWSLATGWRFKKRPGIETLFQQLAPLYEIVIFTSETGMTAFPLIDSVDPHGFISYRLFRDATRYMDGHHVKDISCLNRDPARVVVVDCKKEAFRLQPYNGVALRPWDGNSDDRVLLDLSAFLKTIALNGVEDVRTVLEHYALEDDPLAAFKQRQSRLEQEEQQRLAELSKSNKQNLFLGSLTSRLWPRSKQP>sp|Q3ZCQ8-3|TIM50_HUMAN Isoform 3 of Mitochondrial import inner membranetranslocase subunit TIM50 OS=Homo sapiens OX=9606 GN=TIMM50MVPRFLMSSTMMIIEPTSPCLLPDPLQEPYYQPPYTLVLELTGVLLHPEWSLATGWRFKKRPGIETLFQQLAPLYEIVIFTSETGMTAFPLIDSVDPHGFISYRLFRDATRYMDGHHVKDISCLNRDPARVVVVDCKKEAFRLQPYNGVALRPWDGNSDDRVLLDLSAFLKTIALNGVEDVRTVLEHYALEDDPLAAFKQRQSRLEQEEQQRLAELSKSNKQNLFLGSLTSRLWPRSKQP>sp|Q5TH74|STPG1_HUMAN O(6)-methylguanine-induced apoptosis 2 OS=Homosapiens OX=9606 GN=STPG1 PE=1 SV=1MDNSAQKNERTGKHPRRASEVQKGFTAAYPTQSSIPFKSQASVIPESEKKGFNSQAKRFPHKKNDIPGPGFYNVIHQSPVSNSVSLSKKGTCMFPSMCARLDTIISKYPAANAYTIPSDFISKRDFSNSCSSMFQLPSFMKALKFETPAPNYYNASVSCCKQRNNVCTRAGFMSKTQRGSFAFADKGPPPGHYDINESLVKQSPNTLMSCFKSKTNRGLKLTSTGPGPGYYNPSDCTKVPKKTLFPKNPILNFSAQPSPLPPKPPFPGPGQYEIVDYLGPRKHFISSASFVSNTSRWTAAPPQPGLPGPATYKPELPGKQSFLYNEDKKWIPVL>sp|Q5TH74-2|STPG1_HUMAN Isoform 2 of O(6)-methylguanine-inducedapoptosis 2 OS=Homo sapiens OX=9606 GN=STPG1MFPSMCARLDTIISKYPAANAYTIPSDFISKRDFSNSCSSMFQLPSFMKALKFETPAPNYYNASVSCCKQRNNVCTRAGFMSKTQRGSFAFADKGPPPGHYDINESLVKQSPNTLMSCFKSKTNRGLKLTSTGPGPGYYNPSDCTKVPKKTLFPKNPILNFSAQPSPLPPKPPFPGPGQYEIVDYLGPRKHFISSASFVSNTSRWTAAPPQPGLPGPATYKPELPGKQSFLYNEDKKWIPVL>sp|Q5TH74-3|STPG1_HUMAN Isoform 3 of O(6)-methylguanine-inducedapoptosis 2 OS=Homo sapiens OX=9606 GN=STPG1MNALANIPDVPVKYRKNDIPGPGFYNVIHQSPVSNSVSLSKKGTCMFPSMCARLDTIISKYPAANAYTIPSDFISKRDFSNSCSSMFQLPSFMKALKFETPAPNYYNASVSCCKQRNNVCTRAGFMSKTQRGSFAFADKGPPPGHYDINESLVKQSPNTLMSCFKSKTNRGLKLTSTGPGPGYYNPSDCTKVPKKTLFPKNPILNFSAQPSPLPPKPPFPGPGQYEIVDYLGPRKHFISSASFVSNTSRWTAAPPQPGLPGPATYKPELPGKQSFLYNEDKKWIPVL>sp|Q6ZVD7|STOX1_HUMAN Storkhead-box protein 1 OS=Homo sapiens OX=9606GN=STOX1 PE=1 SV=2MARPVQLAPGSLALVLCRLEAQKAAGAAEEPGGRAVFRAFRRANARCFWNARLARAASRLAFQGWLRRGVLLVRAPPACLQVLRDAWRRRALRPPRGFRIRAVGDVFPVQMNPITQSQFVPLGEVLCCAISDMNTAQIVVTQESLLERLMKHYPGIAIPSEDILYTTLGTLIKERKIYHTGEGYFIVTPQTYFITNTTTQENKRMLPSDESRLMPASMTYLVSMESCAESAQENAAPISHCQSCQCFRDMHTQDVQEAPVAAEVTRKSHRGLGESVSWVQNGAVSVSAEHHICESTKPLPYTRDKEKGKKFGFSLLWRSLSRKEKPKTEHSSFSAQFPPEEWPVRDEDDLDNIPRDVEHEIIKRINPILTVDNLIKHTVLMQKYEEQKKYNSQGTSTDMLTIGHKYPSKEGVKKRQGLSAKPQGQGHSRRDRHKARNQGSEFQPGSIRLEKHPKLPATQPIPRIKSPNEMVGQKPLGEITTVLGSHLIYKKRISNPFQGLSHRGSTISKGHKIQKTSDLKPSQTGPKEKPFQKPRSLDSSRIFDGKAKEPYAEQPNDKMEAESIYINDPTVKPINDDFRGHLFSHPQQSMLQNDGKCCPFMESMLRYEVYGGENEVIPEVLRKSHSHFDKLGETKQTPHSLPSRGASFSDRTPSACRLVDNTIHQFQNLGLLDYPVGVNPLRQAARQDKDSEELLRKGFVQDAETTSLENEQLSNDDQALYQNEVEDDDGACSSLYLEEDDISENDDLRQMLPGHSQYSFTGGSQGNHLGKQKVIERSLTEYNSTMERVESQVLKRNECYKPTGLHATPGESQEPNLSAESCGLNSGAQFGFNYEEEPSVAKCVQASAPADERIFDYYSARKASFEAEVIQDTIGDTGKKPASWSQSPQNQEMRKHFPQKFQLFNTSHMPVLAQDVQYEHSHLEGTENHSMAGDSGIDSPRTQSLGSNNSVILDGLKRRQNFLQNVEGTKSSQPLTSNSLLPLTPVINV>sp|Q6ZVD7-2|STOX1_HUMAN Isoform B of Storkhead-box protein 1 OS=Homosapiens OX=9606 GN=STOX1MARPVQLAPGSLALVLCRLEAQKAAGAAEEPGGRAVFRAFRRANARCFWNARLARAASRLAFQGWLRRGVLLVRAPPACLQVLRDAWRRRALRPPRGFRIRAVGDVFPVQMNPITQSQFVPLGEVLCCAISDMNTAQIVVTQESLLERLMKHYPGIAIPSEDILYTTLGTLIKERKIYHTGEGYFIVTPQTYFITNTTTQENKRMLPSDESRLMPASMTYLDTESGI>sp|Q6ZVD7-3|STOX1_HUMAN Isoform C of Storkhead-box protein 1 OS=Homosapiens OX=9606 GN=STOX1MARPVQLAPGSLALVLCRLEAQKAAGAAEEPGGRAVFRAFRRANARCFWNARLARAASRLAFQGWLRRGVLLVRAPPACLQVLRDAWRRRALRPPRGFRIRAVGDVFPVQMNPITQSQFVPLGEVLCCAISDMNTAQIVVTQESLLERLMKHYPGHRVWDLIIQSFWMD>sp|Q9UEW8|STK39_HUMAN STE20/SPS1-related proline-alanine-rich proteinkinase OS=Homo sapiens OX=9606 GN=STK39 PE=1 SV=3MAEPSGSPVHVQLPQQAAPVTAAAAAAPAAATAAPAPAAPAAPAPAPAPAAQAVGWPICRDAYELQEVIGSGATAVVQAALCKPRQERVAIKRINLEKCQTSMDELLKEIQAMSQCSHPNVVTYYTSFVVKDELWLVMKLLSGGSMLDIIKYIVNRGEHKNGVLEEAIIATILKEVLEGLDYLHRNGQIHRDLKAGNILLGEDGSVQIADFGVSAFLATGGDVTRNKVRKTFVGTPCWMAPEVMEQVRGYDFKADMWSFGITAIELATGAAPYHKYPPMKVLMLTLQNDPPTLETGVEDKEMMKKYGKSFRKLLSLCLQKDPSKRPTAAELLKCKFFQKAKNREYLIEKLLTRTPDIAQRAKKVRRVPGSSGHLHKTEDGDWEWSDDEMDEKSEEGKAAFSQEKSRRVKEENPEIAVSASTIPEQIQSLSVHDSQGPPNANEDYREASSCAVNLVLRLRNSRKELNDIRFEFTPGRDTADGVSQELFSAGLVDGHDVVIVAANLQKIVDDPKALKTLTFKLASGCDGSEIPDEVKLIGFAQLSVS>sp|Q9UEW8-2|STK39_HUMAN Isoform 2 of STE20/SPS1-related proline-alanine-rich protein kinase OS=Homo sapiens OX=9606 GN=STK39MAEPSGSPVHVQLPQQAAPVTAAAAAAPAPAAQAVGWPICRDAYELQEVIGSGATAVVQAALCKPRQERVAIKRINLEKCQTSMDELLKEIQAMSQCSHPNVVTYYTSFVVKDELWLVMKLLSGGSMLDIIKYIVNRGEHKNGVLEEAIIATILKEVLEGLDYLHRNGQIHRDLKAGNILLGEDGSVQIADFGVSAFLATGGDVTRNKVRKTFVGTPCWMAPEVMEQVRGYDFKADMWSFGITAIELATGAAPYHKYPPMKVLMLTLQNDPPTLETGVEDKEMMKKYGKSFRKLLSLCLQKDPSKRPTAAELLKCKFFQKAKNREYLIEKLLTRTPDIAQRAKKVRRVPGSSGHLHKTEDGDWEWSDDEMDEKSEEGKAAFSQEKSRRVKEENPEIAVSASTIPEQIQSLSVHDSQGPPNANEDYREASSCAVNLVLRLRNSRKELNDIRFEFTPGRDTADGVSQELFSAGLVDGHDVVIVAANLQKIVDDPKALKTLTFKLASGCDGSEIPDEVKLIGFAQLSVS>sp|Q8TDR2|STK35_HUMAN Serine/threonine-protein kinase 35 OS=Homo sapiensOX=9606 GN=STK35 PE=1 SV=2MGHQESPLARAPAGGAAYVKRLCKGLSWREHVESHGSLGAQASPASAAAAEGSATRRARAATSRAARSRRQPGPGADHPQAGAPGGKRAARKWRCAGQVTIQGPAPPRPRAGRRDEAGGARAAPLLLPPPPAAMETGKDGARRGTQSPERKRRSPVPRAPSTKLRPAAAARAMDPVAAEAPGEAFLARRRPEGGGGSARPRYSLLAEIGRGSYGVVYEAVAGRSGARVAVKKIRCDAPENVELALAEFWALTSLKRRHQNVVQFEECVLQRNGLAQRMSHGNKSSQLYLRLVETSLKGERILGYAEEPCYLWFVMEFCEGGDLNQYVLSRRPDPATNKSFMLQLTSAIAFLHKNHIVHRDLKPDNILITERSGTPILKVADFGLSKVCAGLAPRGKEGNQDNKNVNVNKYWLSSACGSDFYMAPEVWEGHYTAKADIFALGIIIWAMIERITFIDSETKKELLGTYIKQGTEIVPVGEALLENPKMELHIPQKRRTSMSEGIKQLLKDMLAANPQDRPDAFELETRMDQVTCAA>sp|Q8TAQ9|SUN3_HUMAN SUN domain-containing protein 3 OS=Homo sapiensOX=9606 GN=SUN3 PE=1 SV=4MSGKTKARRAAMFFRRCSEDASGSASGNALLSEDENPDANGVTRSWKIILSTMLTLTFLLVGLLNHQWLKETDVPQKSRQLYAIIAEYGSRLYKYQARLRMPKEQLELLKKESQNLENNFRQILFLIEQIDVLKALLRDMKDGMDNNHNWNTHGDPVEDPDHTEEVSNLVNYVLKKLREDQVEMADYALKSAGASIIEAGTSESYKNNKAKLYWHGIGFLNHEMPPDIILQPDVYPGKCWAFPGSQGHTLIKLATKIIPTAVTMEHISEKVSPSGNISSAPKEFSVYGITKKCEGEEIFLGQFIYNKTGTTVQTFELQHAVSEYLLCVKLNIFSNWGHPKYTCLYRFRVHGTPGKHI>sp|Q8TAQ9-2|SUN3_HUMAN Isoform 2 of SUN domain-containing protein 3OS=Homo sapiens OX=9606 GN=SUN3MPKEQLELLKKESQNLENNFRQILFLIEQIDVLKALLRDMKDGMDNNHNWNTHGDPVEDPDHTEEVSNLVNYVLKKLREDQVEMADYALKSAGASIIEAGTSESYKNNKAKLYWHGIGFLNHEMPPDIILQPDVYPGKCWAFPGSQGHTLIKLATKIIPTAVTMEHISEKVSPSGNISSAPKEFSVYVQRYMCRFVIQAGITKKCEGEEIFLGQFIYNKTGTTVQTFELQHAVSEYLLCVKLNIFSNWGHPKYTCLYRFRVHGTPGKHI>sp|Q8TAQ9-3|SUN3_HUMAN Isoform 3 of SUN domain-containing protein 3OS=Homo sapiens OX=9606 GN=SUN3MEDYSKYNAYTDFSSCRLECSGAILAHCNLHLLGSSISPASASRVAGTTGLLNHQWLKETDVPQKSRQLYAIIAEYGSRLYKYQARLRMPKEQLELLKKESQNLENNFRQILFLIEQIDVLKALLRDMKDGMDNNHNWNTHGDPVEDPDHTEEVSNLVNYVLKKLREDQVEMADYALKSAGASIIEAGTSESYKNNKAKLYWHGIGFLNHEMPPDIILQPDVYPGKCWAFPGSQGHTLIKLATKIIPTAVTMEHISEKVSPSGNISSAPKEFSVYGITKKCEGEEIFLGQFIYNKTGTTVQTFELQHAVSEYLLCVKLNIFSNWGHPKYTCLYRFRVHGTPGKHI>sp|Q04837|SSBP_HUMAN Single-stranded DNA-binding protein, mitochondrialOS=Homo sapiens OX=9606 GN=SSBP1 PE=1 SV=1MFRRPVLQVLRQFVRHESETTTSLVLERSLNRVHLLGRVGQDPVLRQVEGKNPVTIFSLATNEMWRSGDSEVYQLGDVSQKTTWHRISVFRPGLRDVAYQYVKKGSRIYLEGKIDYGEYMDKNNVRRQATTIIADNIIFLSDQTKEKE>sp|P49842|STK19_HUMAN Serine/threonine-protein kinase 19 OS=Homo sapiensOX=9606 GN=STK19 PE=1 SV=2MQKWFSAFDDAIIQRQWRANPSRGGGGVSFTKEVDTNVATGAPPRRQRVPGRACPWREPIRGRRGARPGGGDAGGTPGETVRHCSAPEDPIFRFSSLHSYPFPGTIKSRDMSWKRHHLIPETFGVKRRRKRGPVESDPLRGEPGSARAAVSELMQLFPRGLFEDALPPIVLRSQVYSLVPDRTVADRQLKELQEQGEIRIVQLGFDLDAHGIIFTEDYRTRVCDCVLKACDGRPYAGAVQKFLASVLPACGDLSFQQDQMTQTFGFRDSEITHLVNAGVLTVRDAGSWWLAVPGAGRFIKYFVKGRQAVLSMVRKAKYRELLLSELLGRRAPVVVRLGLTYHVHDLIGAQLVDCISTTSGTLLRLPET>sp|P49842-2|STK19_HUMAN Isoform 2 of Serine/threonine-protein kinase 19OS=Homo sapiens OX=9606 GN=STK19MQKWFSAFDDAIIQRQWRANPSRGGGGVSFTKEVDTNVATGAPPRRQRVPGRACPWREPIRGRRGARPGGGDAGGTPGETVRHCSAPEDPIFRFSSLHSYPFPGTIKSRDMSWKRHHLIPETFGVKRRRKRGPVESDPLRGEPGSARAAVSELMQLFPRGLFEDALPPIVLRSQVYSLVPDRTVADRQLKELQEQGEIRIVQLGFDLDAHGIIFTEDYRTRVLKACDGRPYAGAVQKFLASVLPACGDLSFQQDQMTQTFGFRDSEITHLVNAGVLTVRDAGSWWLAVPGAGRFIKYFVKGRQAVLSMVRKAKYRELLLSELLGRRAPVVVRLGLTYHVHDLIGAQLVDCISTTSGTLLRLPET>sp|P49842-3|STK19_HUMAN Isoform 3 of Serine/threonine-protein kinase 19OS=Homo sapiens OX=9606 GN=STK19MSWKRHHLIPETFGVKRRRKRGPVESDPLRGEPGSARAAVSELMQLFPRGLFEDALPPIVLRSQVYSLVPDRTVADRQLKELQEQGEIRIVQLGFDLDAHGIIFTEDYRTRVCDCVLKACDGRPYAGAVQKFLASVLPACGDLSFQQDQMTQTFGFRDSEITHLVNAGVLTVRDAGSWWLAVPGAGRFIKYFVKGRQAVLSMVRKAKYRELLLSELLGRRAPVVVRLGLTYHVHDLIGAQLVDCISTTSGTLLRLPET>sp|P49842-4|STK19_HUMAN Isoform 4 of Serine/threonine-protein kinase 19OS=Homo sapiens OX=9606 GN=STK19MSWKRHHLIPETFGVKRRRKRGPVESDPLRGEPGSARAAVSELMQLFPRGLFEDALPPIVLRSQVYSLVPDRTVADRQLKELQEQGEIRIVQLGFDLDAHGIIFTEDYRTRVLKACDGRPYAGAVQKFLASVLPACGDLSFQQDQMTQTFGFRDSEITHLVNAGVLTVRDAGSWWLAVPGAGRFIKYFVKGRQAVLSMVRKAKYRELLLSELLGRRAPVVVRLGLTYHVHDLIGAQLVDCISTTSGTLLRLPET>sp|Q99469|STAC_HUMAN SH3 and cysteine-rich domain-containing proteinOS=Homo sapiens OX=9606 GN=STAC PE=1 SV=1MIPPSSPREDGVDGLPKEAVGAEQPPSPASTSSQESKLQKLKRSLSFKTKSLRSKSADNFFQRTNSEDMKLQAHMVAEISPSSSPLPAPGSLTSTPARAGLHPGGKAHAFQEYIFKKPTFCDVCNHMIVGTNAKHGLRCKACKMSIHHKCTDGLAPQRCMGKLPKGFRRYYSSPLLIHEQFGCIKEVMPIACGNKVDPVYETLRFGTSLAQRTKKGSSGSGSDSPHRTSTSDLVEVPEEANGPGGGYDLRKRSNSVFTYPENGTDDFRDPAKNINHQGSLSKDPLQMNTYVALYKFVPQENEDLEMRPGDIITLLEDSNEDWWKGKIQDRIGFFPANFVQRLQQNEKIFRCVRTFIGCKEQGQITLKENQICVSSEEEQDGFIRVLSGKKKGLIPLDVLENI>sp|Q9UJ98|STAG3_HUMAN Cohesin subunit SA-3 OS=Homo sapiens OX=9606GN=STAG3 PE=1 SV=2MSSPLQRAVGDTKRALSASSSSSASLPFDDRDSNHTSEGNGDSLLADEDTDFEDSLNRNVKKRAAKRPPKTTPVAKHPKKGSRVVHRHSRKQSEPPANDLFNAVKAAKSDMQSLVDEWLDSYKQDQDAGFLELVNFFIQSCGCKGIVTPEMFKKMSNSEIIQHLTEQFNEDSGDYPLIAPGPSWKKFQGSFCEFVRTLVCQCQYSLLYDGFPMDDLISLLTGLSDSQVRAFRHTSTLAAMKLMTSLVKVALQLSVHQDNNQRQYEAERNKGPGQRAPERLESLLEKRKELQEHQEEIEGMMNALFRGVFVHRYRDVLPEIRAICIEEIGCWMQSYSTSFLTDSYLKYIGWTLHDKHREVRLKCVKALKGLYGNRDLTTRLELFTSRFKDRMVSMVMDREYDVAVEAVRLLILILKNMEGVLTDADCESVYPVVYASHRGLASAAGEFLYWKLFYPECEIRMMGGREQRQSPGAQRTFFQLLLSFFVESELHDHAAYLVDSLWDCAGARLKDWEGLTSLLLEKDQNLGDVQESTLIEILVSSARQASEGHPPVGRVTGRKGLTSKERKTQADDRVKLTEHLIPLLPQLLAKFSADAEKVTPLLQLLSCFDLHIYCTGRLEKHLELFLQQLQEVVVKHAEPAVLEAGAHALYLLCNPEFTFFSRADFARSQLVDLLTDRFQQELEELLQSSFLDEDEVYNLAATLKRLSAFYNTHDLTRWELYEPCCQLLQKAVDTGEVPHQVILPALTLVYFSILWTLTHISKSDASQKQLSSLRDRMVAFCELCQSCLSDVDTEIQEQAFVLLSDLLLIFSPQMIVGGRDFLRPLVFFPEATLQSELASFLMDHVFIQPGDLGSGDSQEDHLQIERLHQRRRLLAGFCKLLLYGVLEMDAASDVFKHYNKFYNDYGDIIKETLTRARQIDRSHCSRILLLSLKQLYTELLQEHGPQGLNELPAFIEMRDLARRFALSFGPQQLQNRDLVVMLHKEGIQFSLSELPPAGSSNQPPNLAFLELLSEFSPRLFHQDKQLLLSYLEKCLQHVSQAPGHPWGPVTTYCHSLSPVENTAETSPQVLPSSKRRRVEGPAKPNREDVSSSQEESLQLNSIPPTPTLTSTAVKSRQPLWGLKEMEEEDGSELDFAQGQPVAGTERSRFLGPQYFQTPHNPSGPGLGNQLMRLSLMEEDEEEELEIQDESNEERQDTDMQASSYSSTSERGLDLLDSTELDIEDF>sp|Q9UJ98-2|STAG3_HUMAN Isoform 2 of Cohesin subunit SA-3 OS=Homosapiens OX=9606 GN=STAG3MSSPLQRAVGDTKRALSASSSSSASLPFDDRDSNHTSEGNGDSLLADEDTDFEDSLNRNVKKRAAKRPPKTTPVAKHPKKGSRVVHRHSRKQSEPPANDLFNAVKAAKSDMQSLVDEWLDSYKQDQDAGFLELVNFFIQSCGCKGIVTPEMFKKMSNSEIIQHLTEQFNEMDDLISLLTGLSDSQVRAFRHTSTLAAMKLMTSLVKVALQLSVHQDNNQRQYEAERNKGPGQRAPERLESLLEKRKELQEHQEEIEGMMNALFRGVFVHRYRDVLPEIRAICIEEIGCWMQSYSTSFLTDSYLKYIGWTLHDKHREVRLKCVKALKGLYGNRDLTTRLELFTSRFKDRMVSMVMDREYDVAVEAVRLLILILKNMEGVLTDADCESVYPVVYASHRGLASAAGEFLYWKLFYPECEIRMMGGREQRQSPGAQRTFFQLLLSFFVESELHDHAAYLVDSLWDCAGARLKDWEGLTSLLLEKDQNLGDVQESTLIEILVSSARQASEGHPPVGRVTGRKGLTSKERKTQADDRVKLTEHLIPLLPQLLAKFSADAEKVTPLLQLLSCFDLHIYCTGRLEKHLELFLQQLQEVVVKHAEPAVLEAGAHALYLLCNPEFTFFSRADFARSQLVDLLTDRFQQELEELLQSSFLDEDEVYNLAATLKRLSAFYNTHDLTRWELYEPCCQLLQKAVDTGEVPHQVILPALTLVYFSILWTLTHSLSPVENTAETSPQVLPSSKRRRVEGPAKPNREDVSSSQEESLQLNSIPPTPTLTSTAVKSRQPLWGLKEMEEEDGSELDFAQGQPVAGTERSRFLGPQYFQTPHNPSGPGLGNQLMRLSLMEEDEEEELEIQDESNEERQDTDMQASSYSSTSERGLDLLDSTELDIEDF>sp|Q9UJ98-3|STAG3_HUMAN Isoform 3 of Cohesin subunit SA-3 OS=Homosapiens OX=9606 GN=STAG3MSSPLQRAVGDTKRALSASSSSSASLPFDDRDSNHTSEGNGDSLLADEDTDFEDSLNRNVKKRAAKRPPKTTPVAKHPKKGSRVVHRHSRKQSEPPANDLFNAVKAAKSDMQDSGDYPLIAPGPSWKKFQGSFCEFVRTLVCQCQYSLLYDGFPMDDLISLLTGLSDSQVRAFRHTSTLAAMKLMTSLVKVALQLSVHQDNNQRQYEAERNKGPGQRAPERLESLLEKRKELQEHQEEIEGMMNALFRGVFVHRYRDVLPEIRAICIEEIGCWMQSYSTSFLTDSYLKYIGWTLHDKHREVRLKCVKALKGLYGNRDLTTRLELFTSRFKDRMVSMVMDREYDVAVEAVRLLILILKNMEGVLTDADCESVYPVVYASHRGLASAAGEFLYWKLFYPECEIRMMGGREQRQSPGAQRTFFQLLLSFFVESELHDHAAYLVDSLWDCAGARLKDWEGLTSLLLEKDQNLGDVQESTLIEILVSSARQASEGHPPVGRVTGRKGLTSKERKTQADDRVKLTEHLIPLLPQLLAKFSADAEKVTPLLQLLSCFDLHIYCTGRLEKHLELFLQQLQEVVVKHAEPAVLEAGAHALYLLCNPEFTFFSRADFARSQLVDLLTDRFQQELEELLQSSFLDEDEVYNLAATLKRLSAFYNTHDLTRWELYEPCCQLLQKAVDTGEVPHQVILPALTLVYFSILWTLTHISKSDASQKQLSSLRDRMVAFCELCQSCLSDVDTEIQEQAFVLLSDLLLIFSPQMIVGGRDFLRPLVFFPEATLQSELASFLMDHVFIQPGDLGSGDSQEDHLQIERLHQRRRLLAGFCKLLLYGVLEMDAASDVFKHYNKFYNDYGDIIKETLTRARQIDRSHCSRILLLSLKQLYTELLQEHGPQGLNELPAFIEMRDLARRFALSFGPQQLQNRDLVVMLHKEGIQFSLSELPPAGSSNQPPNLAFLELLSEFSPRLFHQDKQLLLSYLEKCLQHVSQAPGHPWGPVTTYCHSLSPVENTAETSPQVLPSSKRRRVEGPAKPNREDVSSSQEESLQLNSIPPTPTLTSTAVKSRQPLWGLKEMEEEDGSELDFAQGQPVAGTERSRFLGPQYFQTPHNPSGPGLGNQLMRLSLMEEDEEEELEIQDESNEERQDTDMQASSYSSTSERGLDLLDSTELDIEDF>sp|P14410|SUIS_HUMAN Sucrase-isomaltase, intestinal OS=Homo sapiensOX=9606 GN=SI PE=1 SV=6MARKKFSGLEISLIVLFVIVTIIAIALIVVLATKTPAVDEISDSTSTPATTRVTTNPSDSGKCPNVLNDPVNVRINCIPEQFPTEGICAQRGCCWRPWNDSLIPWCFFVDNHGYNVQDMTTTSIGVEAKLNRIPSPTLFGNDINSVLFTTQNQTPNRFRFKITDPNNRRYEVPHQYVKEFTGPTVSDTLYDVKVAQNPFSIQVIRKSNGKTLFDTSIGPLVYSDQYLQISTRLPSDYIYGIGEQVHKRFRHDLSWKTWPIFTRDQLPGDNNNNLYGHQTFFMCIEDTSGKSFGVFLMNSNAMEIFIQPTPIVTYRVTGGILDFYILLGDTPEQVVQQYQQLVGLPAMPAYWNLGFQLSRWNYKSLDVVKEVVRRNREAGIPFDTQVTDIDYMEDKKDFTYDQVAFNGLPQFVQDLHDHGQKYVIILDPAISIGRRANGTTYATYERGNTQHVWINESDGSTPIIGEVWPGLTVYPDFTNPNCIDWWANECSIFHQEVQYDGLWIDMNEVSSFIQGSTKGCNVNKLNYPPFTPDILDKLMYSKTICMDAVQNWGKQYDVHSLYGYSMAIATEQAVQKVFPNKRSFILTRSTFAGSGRHAAHWLGDNTASWEQMEWSITGMLEFSLFGIPLVGADICGFVAETTEELCRRWMQLGAFYPFSRNHNSDGYEHQDPAFFGQNSLLVKSSRQYLTIRYTLLPFLYTLFYKAHVFGETVARPVLHEFYEDTNSWIEDTEFLWGPALLITPVLKQGADTVSAYIPDAIWYDYESGAKRPWRKQRVDMYLPADKIGLHLRGGYIIPIQEPDVTTTASRKNPLGLIVALGENNTAKGDFFWDDGETKDTIQNGNYILYTFSVSNNTLDIVCTHSSYQEGTTLAFQTVKILGLTDSVTEVRVAENNQPMNAHSNFTYDASNQVLLIADLKLNLGRNFSVQWNQIFSENERFNCYPDADLATEQKCTQRGCVWRTGSSLSKAPECYFPRQDNSYSVNSARYSSMGITADLQLNTANARIKLPSDPISTLRVEVKYHKNDMLQFKIYDPQKKRYEVPVPLNIPTTPISTYEDRLYDVEIKENPFGIQIRRRSSGRVIWDSWLPGFAFNDQFIQISTRLPSEYIYGFGEVEHTAFKRDLNWNTWGMFTRDQPPGYKLNSYGFHPYYMALEEEGNAHGVFLLNSNAMDVTFQPTPALTYRTVGGILDFYMFLGPTPEVATKQYHEVIGHPVMPAYWALGFQLCRYGYANTSEVRELYDAMVAANIPYDVQYTDIDYMERQLDFTIGEAFQDLPQFVDKIRGEGMRYIIILDPAISGNETKTYPAFERGQQNDVFVKWPNTNDICWAKVWPDLPNITIDKTLTEDEAVNASRAHVAFPDFFRTSTAEWWAREIVDFYNEKMKFDGLWIDMNEPSSFVNGTTTNQCRNDELNYPPYFPELTKRTDGLHFRTICMEAEQILSDGTSVLHYDVHNLYGWSQMKPTHDALQKTTGKRGIVISRSTYPTSGRWGGHWLGDNYARWDNMDKSIIGMMEFSLFGMSYTGADICGFFNNSEYHLCTRWMQLGAFYPYSRNHNIANTRRQDPASWNETFAEMSRNILNIRYTLLPYFYTQMHEIHANGGTVIRPLLHEFFDEKPTWDIFKQFLWGPAFMVTPVLEPYVQTVNAYVPNARWFDYHTGKDIGVRGQFQTFNASYDTINLHVRGGHILPCQEPAQNTFYSRQKHMKLIVAADDNQMAQGSLFWDDGESIDTYERDLYLSVQFNLNQTTLTSTILKRGYINKSETRLGSLHVWGKGTTPVNAVTLTYNGNKNSLPFNEDTTNMILRIDLTTHNVTLEEPIEINWS>sp|P59095|STAR6_HUMAN StAR-related lipid transfer protein 6 OS=Homosapiens OX=9606 GN=STARD6 PE=1 SV=1MDFKAIAQQTAQEVLGYNRDTSGWKVVKTSKKITVSSKASRKFHGNLYRVEGIIPESPAKLSDFLYQTGDRITWDKSLQVYNMVHRIDSDTFICHTITQSFAVGSISPRDFIDLVYIKRYEGNMNIISSKSVDFPEYPPSSNYIRGYNHPCGFVCSPMEENPAYSKLVMFVQTEMRGKLSPSIIEKTMPSNLVNFILNAKDGIKAHRTPSRRGFHHNSHS>sp|Q14849|STAR3_HUMAN StAR-related lipid transfer protein 3 OS=Homosapiens OX=9606 GN=STARD3 PE=1 SV=2MSKLPRELTRDLERSLPAVASLGSSLSHSQSLSSHLLPPPEKRRAISDVRRTFCLFVTFDLLFISLLWIIELNTNTGIRKNLEQEIIQYNFKTSFFDIFVLAFFRFSGLLLGYAVLRLRHWWVIAVTTLVSSAFLIVKVILSELLSKGAFGYLLPIVSFVLAWLETWFLDFKVLPQEAEEERWYLAAQVAVARGPLLFSGALSEGQFYSPPESFAGSDNESDEEVAGKKSFSAQEREYIRQGKEATAVVDQILAQEENWKFEKNNEYGDTVYTIEVPFHGKTFILKTFLPCPAELVYQEVILQPERMVLWNKTVTACQILQRVEDNTLISYDVSAGAAGGVVSPRDFVNVRRIERRRDRYLSSGIATSHSAKPPTHKYVRGENGPGGFIVLKSASNPRVCTFVWILNTDLKGRLPRYLIHQSLAATMFEFAFHLRQRISELGARA>sp|Q14849-2|STAR3_HUMAN Isoform 2 of StAR-related lipid transfer protein3 OS=Homo sapiens OX=9606 GN=STARD3MSKLPRELTRDLERSLPAVASLGSSLSHSQSLSSHLLPPPEKRRAISDVRRTFCLFVTFDLLFISLLWIIELNTNTGIRKNLEQEIIQYNFKTSFFDIFVLAFFRFSGLLLGYAVLRLRHWWVIALLSKGAFGYLLPIVSFVLAWLETWFLDFKVLPQEAEEERWYLAAQVAVARGPLLFSGALSEGQFYSPPESFAGSDNESDEEVAGKKSFSAQEREYIRQGKEATAVVDQILAQEENWKFEKNNEYGDTVYTIEVPFHGKTFILKTFLPCPAELVYQEVILQPERMVLWNKTVTACQILQRVEDNTLISYDVSAGAAGGVVSPRDFVNVRRIERRRDRYLSSGIATSHSAKPPTHKYVRGENGPGGFIVLKSASNPRVCTFVWILNTDLKGRLPRYLIHQSLAATMFEFAFHLRQRISELGARA>sp|Q14849-3|STAR3_HUMAN Isoform 3 of StAR-related lipid transfer protein3 OS=Homo sapiens OX=9606 GN=STARD3MSKLPRELTRDLERSLPAVASLGSSLSHSQSLSSHLLPPPEKRRAISDVRRTFCLFVTFDLLFISLLWIIELNTNTGIRKNLEQEIIQYNFKTSFFDIFVLAFFRFSGLLLGYAVLRLRHWSRRWCPVHSSLSRSSSLSCSAKGHLATCSPSSLLSSPGWRPGSLTSKSYPRKLKRSDSAPPGYLAAQVAVARGPLLFSGALSEGQFYSPPESFAGSDNESDEEVAGKKSFSAQEREYIRQGKEATAVVDQILAQEENWKFEKNNEYGDTVYTIEVPFHGKTFILKTFLPCPAELVYQEVILQPERMVLWNKTVTACQILQRVEDNTLISYDVSAGAAGGVVSPRDFVNVRRIERRRDRYLSSGIATSHSAKPPTHKYVRGENGPGGFIVLKSASNPRVCTFVWILNTDLKGRLPRYLIHQSLAATMFEFAFHLRQRISELGARA>sp|Q96DR4|STAR4_HUMAN StAR-related lipid transfer protein 4 OS=Homosapiens OX=9606 GN=STARD4 PE=1 SV=1MEGLSDVASFATKLKNTLIQYHSIEEDKWRVAKKTKDVTVWRKPSEEFNGYLYKAQGVIDDLVYSIIDHIRPGPCRLDWDSLMTSLDILENFEENCCVMRYTTAGQLWNIISPREFVDFSYTVGYKEGLLSCGISLDWDEKRPEFVRGYNHPCGWFCVPLKDNPNQSLLTGYIQTDLRGMIPQSAVDTAMASTLTNFYGDLRKAL>sp|Q96DR4-2|STAR4_HUMAN Isoform 2 of StAR-related lipid transfer protein4 OS=Homo sapiens OX=9606 GN=STARD4MEGLSDVASFATKLKNTLIQYHSIEEDKWRVAKKTKDVTVWRKPSEEFNGYLYKAQGVIDDLVYSIIDHIRPGPCRLDWDSLMTSLDILENFEENCCVMRYTTAGQLWNIISPREFVDFSYTVGYKEGLLSCGNNLNMLCFFSVWFKYLCFLGWMSLSL>sp|P46977|STT3A_HUMAN Dolichyl-diphosphooligosaccharide--proteinglycosyltransferase subunit STT3A OS=Homo sapiens OX=9606 GN=STT3A PE=1SV=2MTKFGFLRLSYEKQDTLLKLLILSMAAVLSFSTRLFAVLRFESVIHEFDPYFNYRTTRFLAEEGFYKFHNWFDDRAWYPLGRIIGGTIYPGLMITSAAIYHVLHFFHITIDIRNVCVFLAPLFSSFTTIVTYHLTKELKDAGAGLLAAAMIAVVPGYISRSVAGSYDNEGIAIFCMLLTYYMWIKAVKTGSICWAAKCALAYFYMVSSWGGYVFLINLIPLHVLVLMLTGRFSHRIYVAYCTVYCLGTILSMQISFVGFQPVLSSEHMAAFGVFGLCQIHAFVDYLRSKLNPQQFEVLFRSVISLVGFVLLTVGALLMLTGKISPWTGRFYSLLDPSYAKNNIPIIASVSEHQPTTWSSYYFDLQLLVFMFPVGLYYCFSNLSDARIFIIMYGVTSMYFSAVMVRLMLVLAPVMCILSGIGVSQVLSTYMKNLDISRPDKKSKKQQDSTYPIKNEVASGMILVMAFFLITYTFHSTWVTSEAYSSPSIVLSARGGDGSRIIFDDFREAYYWLRHNTPEDAKVMSWWDYGYQITAMANRTILVDNNTWNNTHISRVGQAMASTEEKAYEIMRELDVSYVLVIFGGLTGYSSDDINKFLWMVRIGGSTDTGKHIKENDYYTPTGEFRVDREGSPVLLNCLMYKMCYYRFGQVYTEAKRPPGFDRVRNAEIGNKDFELDVLEEAYTTEHWLVRIYKVKDLDNRGLSRT>sp|P46977-2|STT3A_HUMAN Isoform 2 of Dolichyl-diphosphooligosaccharide--protein glycosyltransferase subunit STT3A OS=Homo sapiens OX=9606GN=STT3AMITSAAIYHVLHFFHITIDIRNVCVFLAPLFSSFTTIVTYHLTKELKDAGAGLLAAAMIAVVPGYISRSVAGSYDNEGIAIFCMLLTYYMWIKAVKTGSICWAAKCALAYFYMVSSWGGYVFLINLIPLHVLVLMLTGRFSHRIYVAYCTVYCLGTILSMQISFVGFQPVLSSEHMAAFGVFGLCQIHAFVDYLRSKLNPQQFEVLFRSVISLVGFVLLTVGALLMLTGKISPWTGRFYSLLDPSYAKNNIPIIASVSEHQPTTWSSYYFDLQLLVFMFPVGLYYCFSNLSDARIFIIMYGVTSMYFSAVMVRLMLVLAPVMCILSGIGVSQVLSTYMKNLDISRPDKKSKKQQDSTYPIKNEVASGMILVMAFFLITYTFHSTWVTSEAYSSPSIVLSARGGDGSRIIFDDFREAYYWLRHNTPEDAKVMSWWDYGYQITAMANRTILVDNNTWNNTHISRVGQAMASTEEKAYEIMRELDVSYVLVIFGGLTGYSSDDINKFLWMVRIGGSTDTGKHIKENDYYTPTGEFRVDREGSPVLLNCLMYKMCYYRFGQVYTEAKRPPGFDRVRNAEIGNKDFELDVLEEAYTTEHWLVRIYKVKDLDNRGLSRT>sp|P02808|STAT_HUMAN Statherin OS=Homo sapiens OX=9606 GN=STATH PE=1SV=2MKFLVFAFILALMVSMIGADSSEEKFLRRIGRFGYGYGPYQPVPEQPLYPQPYQPQYQQYTF>sp|P02808-2|STAT_HUMAN Isoform 2 of Statherin OS=Homo sapiens OX=9606GN=STATHMKFLVFAFILALMVSMIGADSSEEYGYGPYQPVPEQPLYPQPYQPQYQQYTF>sp|Q01082|SPTB2_HUMAN Spectrin beta chain, non-erythrocytic 1 OS=Homosapiens OX=9606 GN=SPTBN1 PE=1 SV=2MTTTVATDYDNIEIQQQYSDVNNRWDVDDWDNENSSARLFERSRIKALADEREAVQKKTFTKWVNSHLARVSCRITDLYTDLRDGRMLIKLLEVLSGERLPKPTKGRMRIHCLENVDKALQFLKEQRVHLENMGSHDIVDGNHRLTLGLIWTIILRFQIQDISVETEDNKEKKSAKDALLLWCQMKTAGYPNVNIHNFTTSWRDGMAFNALIHKHRPDLIDFDKLKKSNAHYNLQNAFNLAEQHLGLTKLLDPEDISVDHPDEKSIITYVVTYYHYFSKMKALAVEGKRIGKVLDNAIETEKMIEKYESLASDLLEWIEQTIIILNNRKFANSLVGVQQQLQAFNTYRTVEKPPKFTEKGNLEVLLFTIQSKMRANNQKVYMPREGKLISDINKAWERLEKAEHERELALRNELIRQEKLEQLARRFDRKAAMRETWLSENQRLVSQDNFGFDLPAVEAATKKHEAIETDIAAYEERVQAVVAVARELEAENYHDIKRITARKDNVIRLWEYLLELLRARRQRLEMNLGLQKIFQEMLYIMDWMDEMKVLVLSQDYGKHLLGVEDLLQKHTLVEADIGIQAERVRGVNASAQKFATDGEGYKPCDPQVIRDRVAHMEFCYQELCQLAAERRARLEESRRLWKFFWEMAEEEGWIREKEKILSSDDYGKDLTSVMRLLSKHRAFEDEMSGRSGHFEQAIKEGEDMIAEEHFGSEKIRERIIYIREQWANLEQLSAIRKKRLEEASLLHQFQADADDIDAWMLDILKIVSSSDVGHDEYSTQSLVKKHKDVAEEIANYRPTLDTLHEQASALPQEHAESPDVRGRLSGIEERYKEVAELTRLRKQALQDTLALYKMFSEADACELWIDEKEQWLNNMQIPEKLEDLEVIQHRFESLEPEMNNQASRVAVVNQIARQLMHSGHPSEKEIKAQQDKLNTRWSQFRELVDRKKDALLSALSIQNYHLECNETKSWIREKTKVIESTQDLGNDLAGVMALQRKLTGMERDLVAIEAKLSDLQKEAEKLESEHPDQAQAILSRLAEISDVWEEMKTTLKNREASLGEASKLQQFLRDLDDFQSWLSRTQTAIASEDMPNTLTEAEKLLTQHENIKNEIDNYEEDYQKMRDMGEMVTQGQTDAQYMFLRQRLQALDTGWNELHKMWENRQNLLSQSHAYQQFLRDTKQAEAFLNNQEYVLAHTEMPTTLEGAEAAIKKQEDFMTTMDANEEKINAVVETGRRLVSDGNINSDRIQEKVDSIDDRHRKNRETASELLMRLKDNRDLQKFLQDCQELSLWINEKMLTAQDMSYDEARNLHSKWLKHQAFMAELASNKEWLDKIEKEGMQLISEKPETEAVVKEKLTGLHKMWEVLESTTQTKAQRLFDANKAELFTQSCADLDKWLHGLESQIQSDDYGKDLTSVNILLKKQQMLENQMEVRKKEIEELQSQAQALSQEGKSTDEVDSKRLTVQTKFMELLEPLNERKHNLLASKEIHQFNRDVEDEILWVGERMPLATSTDHGHNLQTVQLLIKKNQTLQKEIQGHQPRIDDIFERSQNIVTDSSSLSAEAIRQRLADLKQLWGLLIEETEKRHRRLEEAHRAQQYYFDAAEAEAWMSEQELYMMSEEKAKDEQSAVSMLKKHQILEQAVEDYAETVHQLSKTSRALVADSHPESERISMRQSKVDKLYAGLKDLAEERRGKLDERHRLFQLNREVDDLEQWIAEREVVAGSHELGQDYEHVTMLQERFREFARDTGNIGQERVDTVNHLADELINSGHSDAATIAEWKDGLNEAWADLLELIDTRTQILAASYELHKFYHDAKEIFGRIQDKHKKLPEELGRDQNTVETLQRMHTTFEHDIQALGTQVRQLQEDAARLQAAYAGDKADDIQKRENEVLEAWKSLLDACESRRVRLVDTGDKFRFFSMVRDLMLWMEDVIRQIEAQEKPRDVSSVELLMNNHQGIKAEIDARNDSFTTCIELGKSLLARKHYASEEIKEKLLQLTEKRKEMIDKWEDRWEWLRLILEVHQFSRDASVAEAWLLGQEPYLSSREIGQSVDEVEKLIKRHEAFEKSAATWDERFSALERLTTLELLEVRRQQEEEERKRRPPSPEPSTKVSEEAESQQQWDTSKGEQVSQNGLPAEQGSPRMAETVDTSEMVNGATEQRTSSKESSPIPSPTSDRKAKTALPAQSAATLPARTQETPSAQMEGFLNRKHEWEAHNKKASSRSWHNVYCVINNQEMGFYKDAKTAASGIPYHSEVPVSLKEAVCEVALDYKKKKHVFKLRLNDGNEYLFQAKDDEEMNTWIQAISSAISSDKHEVSASTQSTPASSRAQTLPTSVVTITSESSPGKREKDKEKDKEKRFSLFGKKK>sp|Q01082-2|SPTB2_HUMAN Isoform Short of Spectrin beta chain, non-erythrocytic 1 OS=Homo sapiens OX=9606 GN=SPTBN1MTTTVATDYDNIEIQQQYSDVNNRWDVDDWDNENSSARLFERSRIKALADEREAVQKKTFTKWVNSHLARVSCRITDLYTDLRDGRMLIKLLEVLSGERLPKPTKGRMRIHCLENVDKALQFLKEQRVHLENMGSHDIVDGNHRLTLGLIWTIILRFQIQDISVETEDNKEKKSAKDALLLWCQMKTAGYPNVNIHNFTTSWRDGMAFNALIHKHRPDLIDFDKLKKSNAHYNLQNAFNLAEQHLGLTKLLDPEDISVDHPDEKSIITYVVTYYHYFSKMKALAVEGKRIGKVLDNAIETEKMIEKYESLASDLLEWIEQTIIILNNRKFANSLVGVQQQLQAFNTYRTVEKPPKFTEKGNLEVLLFTIQSKMRANNQKVYMPREGKLISDINKAWERLEKAEHERELALRNELIRQEKLEQLARRFDRKAAMRETWLSENQRLVSQDNFGFDLPAVEAATKKHEAIETDIAAYEERVQAVVAVARELEAENYHDIKRITARKDNVIRLWEYLLELLRARRQRLEMNLGLQKIFQEMLYIMDWMDEMKVLVLSQDYGKHLLGVEDLLQKHTLVEADIGIQAERVRGVNASAQKFATDGEGYKPCDPQVIRDRVAHMEFCYQELCQLAAERRARLEESRRLWKFFWEMAEEEGWIREKEKILSSDDYGKDLTSVMRLLSKHRAFEDEMSGRSGHFEQAIKEGEDMIAEEHFGSEKIRERIIYIREQWANLEQLSAIRKKRLEEASLLHQFQADADDIDAWMLDILKIVSSSDVGHDEYSTQSLVKKHKDVAEEIANYRPTLDTLHEQASALPQEHAESPDVRGRLSGIEERYKEVAELTRLRKQALQDTLALYKMFSEADACELWIDEKEQWLNNMQIPEKLEDLEVIQHRFESLEPEMNNQASRVAVVNQIARQLMHSGHPSEKEIKAQQDKLNTRWSQFRELVDRKKDALLSALSIQNYHLECNETKSWIREKTKVIESTQDLGNDLAGVMALQRKLTGMERDLVAIEAKLSDLQKEAEKLESEHPDQAQAILSRLAEISDVWEEMKTTLKNREASLGEASKLQQFLRDLDDFQSWLSRTQTAIASEDMPNTLTEAEKLLTQHENIKNEIDNYEEDYQKMRDMGEMVTQGQTDAQYMFLRQRLQALDTGWNELHKMWENRQNLLSQSHAYQQFLRDTKQAEAFLNNQEYVLAHTEMPTTLEGAEAAIKKQEDFMTTMDANEEKINAVVETGRRLVSDGNINSDRIQEKVDSIDDRHRKNRETASELLMRLKDNRDLQKFLQDCQELSLWINEKMLTAQDMSYDEARNLHSKWLKHQAFMAELASNKEWLDKIEKEGMQLISEKPETEAVVKEKLTGLHKMWEVLESTTQTKAQRLFDANKAELFTQSCADLDKWLHGLESQIQSDDYGKDLTSVNILLKKQQMLENQMEVRKKEIEELQSQAQALSQEGKSTDEVDSKRLTVQTKFMELLEPLNERKHNLLASKEIHQFNRDVEDEILWVGERMPLATSTDHGHNLQTVQLLIKKNQTLQKEIQGHQPRIDDIFERSQNIVTDSSSLSAEAIRQRLADLKQLWGLLIEETEKRHRRLEEAHRAQQYYFDAAEAEAWMSEQELYMMSEEKAKDEQSAVSMLKKHQILEQAVEDYAETVHQLSKTSRALVADSHPESERISMRQSKVDKLYAGLKDLAEERRGKLDERHRLFQLNREVDDLEQWIAEREVVAGSHELGQDYEHVTMLQERFREFARDTGNIGQERVDTVNHLADELINSGHSDAATIAEWKDGLNEAWADLLELIDTRTQILAASYELHKFYHDAKEIFGRIQDKHKKLPEELGRDQNTVETLQRMHTTFEHDIQALGTQVRQLQEDAARLQAAYAGDKADDIQKRENEVLEAWKSLLDACESRRVRLVDTGDKFRFFSMVRDLMLWMEDVIRQIEAQEKPRDVSSVELLMNNHQGIKAEIDARNDSFTTCIELGKSLLARKHYASEEIKEKLLQLTEKRKEMIDKWEDRWEWLRLILEVHQFSRDASVAEAWLLGQEPYLSSREIGQSVDEVEKLIKRHEAFEKSAATWDERFSALERLTTLELLEVRRQQEEEERKRRPPSPEPSTKVSEEAESQQQWDTSKGEQVSQNGLPAEQGSPRVSYRSQTYQNYKNFNSRRTASDQPWSGL>sp|Q01082-3|SPTB2_HUMAN Isoform 2 of Spectrin beta chain, non-erythrocytic 1 OS=Homo sapiens OX=9606 GN=SPTBN1MELQRTSSISGPLSPAYTGQVPYNYNQLEGRFKQLQDEREAVQKKTFTKWVNSHLARVSCRITDLYTDLRDGRMLIKLLEVLSGERLPKPTKGRMRIHCLENVDKALQFLKEQRVHLENMGSHDIVDGNHRLTLGLIWTIILRFQIQDISVETEDNKEKKSAKDALLLWCQMKTAGYPNVNIHNFTTSWRDGMAFNALIHKHRPDLIDFDKLKKSNAHYNLQNAFNLAEQHLGLTKLLDPEDISVDHPDEKSIITYVVTYYHYFSKMKALAVEGKRIGKVLDNAIETEKMIEKYESLASDLLEWIEQTIIILNNRKFANSLVGVQQQLQAFNTYRTVEKPPKFTEKGNLEVLLFTIQSKMRANNQKVYMPREGKLISDINKAWERLEKAEHERELALRNELIRQEKLEQLARRFDRKAAMRETWLSENQRLVSQDNFGFDLPAVEAATKKHEAIETDIAAYEERVQAVVAVARELEAENYHDIKRITARKDNVIRLWEYLLELLRARRQRLEMNLGLQKIFQEMLYIMDWMDEMKVLVLSQDYGKHLLGVEDLLQKHTLVEADIGIQAERVRGVNASAQKFATDGEGYKPCDPQVIRDRVAHMEFCYQELCQLAAERRARLEESRRLWKFFWEMAEEEGWIREKEKILSSDDYGKDLTSVMRLLSKHRAFEDEMSGRSGHFEQAIKEGEDMIAEEHFGSEKIRERIIYIREQWANLEQLSAIRKKRLEEASLLHQFQADADDIDAWMLDILKIVSSSDVGHDEYSTQSLVKKHKDVAEEIANYRPTLDTLHEQASALPQEHAESPDVRGRLSGIEERYKEVAELTRLRKQALQDTLALYKMFSEADACELWIDEKEQWLNNMQIPEKLEDLEVIQHRFESLEPEMNNQASRVAVVNQIARQLMHSGHPSEKEIKAQQDKLNTRWSQFRELVDRKKDALLSALSIQNYHLECNETKSWIREKTKVIESTQDLGNDLAGVMALQRKLTGMERDLVAIEAKLSDLQKEAEKLESEHPDQAQAILSRLAEISDVWEEMKTTLKNREASLGEASKLQQFLRDLDDFQSWLSRTQTAIASEDMPNTLTEAEKLLTQHENIKNEIDNYEEDYQKMRDMGEMVTQGQTDAQYMFLRQRLQALDTGWNELHKMWENRQNLLSQSHAYQQFLRDTKQAEAFLNNQEYVLAHTEMPTTLEGAEAAIKKQEDFMTTMDANEEKINAVVETGRRLVSDGNINSDRIQEKVDSIDDRHRKNRETASELLMRLKDNRDLQKFLQDCQELSLWINEKMLTAQDMSYDEARNLHSKWLKHQAFMAELASNKEWLDKIEKEGMQLISEKPETEAVVKEKLTGLHKMWEVLESTTQTKAQRLFDANKAELFTQSCADLDKWLHGLESQIQSDDYGKDLTSVNILLKKQQMLENQMEVRKKEIEELQSQAQALSQEGKSTDEVDSKRLTVQTKFMELLEPLNERKHNLLASKEIHQFNRDVEDEILWVGERMPLATSTDHGHNLQTVQLLIKKNQTLQKEIQGHQPRIDDIFERSQNIVTDSSSLSAEAIRQRLADLKQLWGLLIEETEKRHRRLEEAHRAQQYYFDAAEAEAWMSEQELYMMSEEKAKDEQSAVSMLKKHQILEQAVEDYAETVHQLSKTSRALVADSHPESERISMRQSKVDKLYAGLKDLAEERRGKLDERHRLFQLNREVDDLEQWIAEREVVAGSHELGQDYEHVTMLQERFREFARDTGNIGQERVDTVNHLADELINSGHSDAATIAEWKDGLNEAWADLLELIDTRTQILAASYELHKFYHDAKEIFGRIQDKHKKLPEELGRDQNTVETLQRMHTTFEHDIQALGTQVRQLQEDAARLQAAYAGDKADDIQKRENEVLEAWKSLLDACESRRVRLVDTGDKFRFFSMVRDLMLWMEDVIRQIEAQEKPRDVSSVELLMNNHQGIKAEIDARNDSFTTCIELGKSLLARKHYASEEIKEKLLQLTEKRKEMIDKWEDRWEWLRLILEVHQFSRDASVAEAWLLGQEPYLSSREIGQSVDEVEKLIKRHEAFEKSAATWDERFSALERLTTLELLEVRRQQEEEERKRRPPSPEPSTKVSEEAESQQQWDTSKGEQVSQNGLPAEQGSPRVSYRSQTYQNYKNFNSRRTASDQPWSGL>sp|Q9NRC6|SPTN5_HUMAN Spectrin beta chain, non-erythrocytic 5 OS=Homosapiens OX=9606 GN=SPTBN5 PE=1 SV=2MAGQPHSPRELLGAAGHRSRRPSTELRVPPSPSLTMDSQYETGHIRKLQARHMQMQEKTFTKWINNVFQCGQAGIKIRNLYTELADGIHLLRLLELISGEALPPPSRGRLRVHFLENSSRALAFLRAKVPVPLIGPENIVDGDQTLILGLIWVIILRFQISHISLDKEEFGASAALLSTKEALLVWCQRKTASYTNVNITDFSRSWSDGLGFNALIHAHRPDLLDYGSLRPDRPLHNLAFAFLVAEQELGIAQLLDPEDVAAAQPDERSIMTYVSLYYHYCSRLHQGQTVQRRLTKILLQLQETELLQTQYEQLVADLLRWIAEKQMQLEARDFPDSLPAMRQLLAAFTIFRTQEKPPRLQQRGAAEALLFRLQTALQAQNRRPFLPHEGLGLAELSQCWAGLEWAEAARSQALQQRLLQLQRLETLARRFQHKAALRESFLKDAEQVLDQARAPPASLATVEAAVQRLGMLEAGILPQEGRFQALAEIADILRQEQYHSWADVARRQEEVTVRWQRLLQHLQGQRKQVADMQAVLSLLQEVEAASHQLEELQEPARSTACGQQLAEVVELLQRHDLLEAQVSAHGAHVSHLAQQTAELDSSLGTSVEVLQAKARTLAQLQQSLVALVRARRALLEQTLQRAEFLRNCEEEEAWLKECGQRVGNAALGRDLSQIAGALQKHKALEAEVHRHQAVCVDLVRRGRDLSARRPPTQPDPGERAEAVQGGWQLLQTRVVGRGARLQTALLVLQYFADAAEAASWLRERRSSLERASCGQDQAAAETLLRRHVRLERVLRAFAAELRRLEEQGRAASARASLFTVNSALSPPGESLRNPGPWSEASCHPGPGDAWKMALPAEPDPDFDPNTILQTQDHLSQDYESLRALAQLRRARLEEAMALFGFCSSCGELQLWLEKQTVLLQRVQPQADTLEVMQLKYENFLTALAVGKGLWAEVSSSAEQLRQRYPGNSTQIQRQQEELSQRWGQLEALKREKAVQLAHSVEVCSFLQECGPTQVQLRDVLLQLEALQPGSSEDTCHALQLAQKKTLVLERRVHFLQSVVVKVEEPGYAESQPLQGQVETLQGLLKQVQEQVAQRARRQAETQARQSFLQESQQLLLWAESVQAQLRSKEVSVDVASAQRLLREHQDLLEEIHLWQERLQQLDAQSQPMAALDCPDSQEVPNTLRVLGQQGQELKVLWEQRQQWLQEGLELQKFGREVDGFTATCANHQAWLHLDNLGEDVREALSLLQQHREFGRLLSTLGPRAEALRAHGEKLVQSQHPAAHTVREQLQSIQAQWTRLQGRSEQRRRQLLASLQLQEWKQDVAELMQWMEEKGLMAAHEPSGARRNILQTLKRHEAAESELLATRRHVEALQQVGRELLSRRPCGQEDIQTRLQGLRSKWEALNRKMTERGDELQQAGQQEQLLRQLQDAKEQLEQLEGALQSSETGQDLRSSQRLQKRHQQLESESRTLAAKMAALASMAHGMAASPAILEETQKHLRRLELLQGHLAIRGLQLQASVELHQFCHLSNMELSWVAEHMPHGSPTSYTECLNGAQSLHRKHKELQVEVKAHQGQVQRVLSSGRSLAASGHPQAQHIVEQCQELEGHWAELERACEARAQCLQQAVTFQQYFLDVSELEGWVEEKRPLVSSRDYGRDEAATLRLINKHQALQEELAIYWSSMEELDQTAQTLTGPEVPEQQRVVQERLREQLRALQELAATRDRELEGTLRLHEFLREAEDLQGWLASQKQAAKGGESLGEDPEHALHLCTKFAKFQHQVEMGSQRVAACRLLAESLLERGHSAGPMVRQRQQDLQTAWSELWELTQARGHALRDTETTLRVHRDLLEVLTQVQEKATSLPNNVARDLCGLEAQLRSHQGLERELVGTERQLQELLETAGRVQKLCPGPQAHAVQQRQQAVTQAWAVLQRRMEQRRAQLERARLLARFRTAVRDYASWAARVRQDLQVEESSQEPSSGPLKLSAHQWLRAELEAREKLWQQATQLGQQALLAAGTPTKEVQEELRALQDQRDQVYQTWARKQERLQAEQQEQLFLRECGRLEEILAAQEVSLKTSALGSSVEEVEQLIRKHEVFLKVLTAQDKKEAALRERLKTLRRPRVRDRLPILLQRRMRVKELAESRGHALHASLLMASFTQAATQAEDWIQAWAQQLKEPVPPGDLRDKLKPLLKHQAFEAEVQAHEEVMTSVAKKGEALLAQSHPRAGEVSQRLQGLRKHWEDLRQAMALRGQELEDRRNFLEFLQRVDLAEAWIQEKEVKMNVGDLGQDLEHCLQLRRRLREFRGNSAGDTVGDACIRSISDLSLQLKNRDPEEVKIICQRRSQLNNRWASFHGNLLRYQQQLEGALEIHVLSRELDNVTKRIQEKEALIQALDCGKDLESVQRLLRKHEELEREVHPIQAQVESLEREVGRLCQRSPEAAHGLRHRQQEVAESWWQLRSRAQKRREALDALHQAQKLQAMLQELLVSAQRLRAQMDTSPAPRSPVEARRMLEEHQECKAELDSWTDSISLARSTGQQLLTAGHPFSSDIRQVLAGLEQELSSLEGAWQEHQLQLQQALELQLFLSSVEKMERWLCSKEDSLASEGLWDPLAPMEPLLWKHKMLEWDLEVQAGKISALEATARGLHQGGHPEAQSALGRCQAMLLRKEALFRQAGTRRHRLEELRQLQAFLQDSQEVAAWLREKNLVALEEGLLDTAMLPAQLQKQQNFQAELDASMHQQQELQREGQRLLQGGHPASEAIQERLEELGALWGELQDNSQKKVAKLQKACEALRLRRSMEELENWLEPIEVELRAPTVGQALPGVGELLGTQRELEAAVDKKARQAEALLGQAQAFVREGHCLAQDVEEQARRLLQRFKSLREPLQERRTALEARSLLLKFFRDADEEMAWVQEKLPLAAAQDYGQSLSAVRHLQEQHQNLESEMSSHEALTRVVLGTGYKLVQAGHFAAHEVAARVQQLEKAMAHLRAEAARRRLLLQQAQEAQQFLTELLEAGSWLAERGHVLDSEDMGHSAEATQALLRRLEATKRDLEAFSPRIERLQQTAALLESRKNPESPKVLAQLQAVREAHAELLRRAEARGHGLQEQLQLHQLERETLLLDAWLTTKAATAESQDYGQDLEGVKVLEEKFDAFRKEVQSLGQAKVYALRKLAGTLERGAPRRYPHIQAQRSRIEAAWERLDQAIKARTENLAAAHEVHSFQQAAAELQGRMQEKTALMKGEDGGHSLSSVRTLQQQHRRLERELEAMEKEVARLQTEACRLGQLHPAAPGGLAKVQEAWATLQAKAQERGQWLAQAAQGHAFLGRCQELLAWAQERQELASSEELAEDVAGAEQLLGQHEELGQEIRECRLQAQDLRQEGQQLVDNSHFMSAEVTECLQELEGRLQELEEAWALRWQRCAESWGLQKLRQRLEQAEAWLACWEGLLLKPDYGHSVSDVELLLHRHQDLEKLLAAQEEKFAQMQKTEMEQELLLQPQELKPGRAGSSLTSFQWRPSGHQGLGAQLAETRDPQDAKGTPTMEGSLEFKQHLLPGGRQPSSSSWDSCRGNLQGSSLSLFLDERMAAEKVASIALLDLTGARCERLRGRHGRKHTFSLRLTSGAEILFAAPSEEQAESWWRALGSTAAQSLSPKLKAKPVSSLNECTTKDARPGCLLRSDP>sp|O95149|SPN1_HUMAN Snurportin-1 OS=Homo sapiens OX=9606 GN=SNUPN PE=1SV=1MEELSQALASSFSVSQDLNSTAAPHPRLSQYKSKYSSLEQSERRRRLLELQKSKRLDYVNHARRLAEDDWTGMESEEENKKDDEEMDIDTVKKLPKHYANQLMLSEWLIDVPSDLGQEWIVVVCPVGKRALIVASRGSTSAYTKSGYCVNRFSSLLPGGNRRNSTAKDYTILDCIYNEVNQTYYVLDVMCWRGHPFYDCQTDFRFYWMHSKLPEEEGLGEKTKLNPFKFVGLKNFPCTPESLCDVLSMDFPFEVDGLLFYHKQTHYSPGSTPLVGWLRPYMVSDVLGVAVPAGPLTTKPDYAGHQLQQIMEHKKSQKEGMKEKLTHKASENGHYELEHLSTPKLKGSSHSPDHPGCLMEN>sp|Q7L1I2|SV2B_HUMAN Synaptic vesicle glycoprotein 2B OS=Homo sapiensOX=9606 GN=SV2B PE=1 SV=1MDDYKYQDNYGGYAPSDGYYRGNESNPEEDAQSDVTEGHDEEDEIYEGEYQGIPHPDDVKAKQAKMAPSRMDSLRGQTDLMAERLEDEEQLAHQYETIMDECGHGRFQWILFFVLGLALMADGVEVFVVSFALPSAEKDMCLSSSKKGMLGMIVYLGMMAGAFILGGLADKLGRKRVLSMSLAVNASFASLSSFVQGYGAFLFCRLISGIGIGGALPIVFAYFSEFLSREKRGEHLSWLGIFWMTGGLYASAMAWSIIPHYGWGFSMGTNYHFHSWRVFVIVCALPCTVSMVALKFMPESPRFLLEMGKHDEAWMILKQVHDTNMRAKGTPEKVFTVSNIKTPKQMDEFIEIQSSTGTWYQRWLVRFKTIFKQVWDNALYCVMGPYRMNTLILAVVWFAMAFSYYGLTVWFPDMIRYFQDEEYKSKMKVFFGEHVYGATINFTMENQIHQHGKLVNDKFTRMYFKHVLFEDTFFDECYFEDVTSTDTYFKNCTIESTIFYNTDLYEHKFINCRFINSTFLEQKEGCHMDLEQDNDFLIYLVSFLGSLSVLPGNIISALLMDRIGRLKMIGGSMLISAVCCFFLFFGNSESAMIGWQCLFCGTSIAAWNALDVITVELYPTNQRATAFGILNGLCKFGAILGNTIFASFVGITKVVPILLAAASLVGGGLIALRLPETREQVLM>sp|Q7L1I2-2|SV2B_HUMAN Isoform 2 of Synaptic vesicle glycoprotein 2BOS=Homo sapiens OX=9606 GN=SV2BMIVYLGMMAGAFILGGLADKLGRKRVLSMSLAVNASFASLSSFVQGYGAFLFCRLISGIGIGGALPIVFAYFSEFLSREKRGEHLSWLGIFWMTGGLYASAMAWSIIPHYGWGFSMGTNYHFHSWRVFVIVCALPCTVSMVALKFMPESPRFLLEMGKHDEAWMILKQVHDTNMRAKGTPEKVFTVSNIKTPKQMDEFIEIQSSTGTWYQRWLVRFKTIFKQVWDNALYCVMGPYRMNTLILAVVWFAMAFSYYGLTVWFPDMIRYFQDEEYKSKMKVFFGEHVYGATINFTMENQIHQHGKLVNDKFTRMYFKHVLFEDTFFDECYFEDVTSTDTYFKNCTIESTIFYNTDLYEHKFINCRFINSTFLEQKEGCHMDLEQDNDFLIYLVSFLGSLSVLPGNIISALLMDRIGRLKMIGGSMLISAVCCFFLFFGNSESAMIGWQCLFCGTSIAAWNALDVITVELYPTNQRATAFGILNGLCKFGAILGNTIFASFVGITKVVPILLAAASLVGGGLIALRLPETREQVLM>sp|Q6ZMD2|SPNS3_HUMAN Protein spinster homolog 3 OS=Homo sapiens OX=9606GN=SPNS3 PE=1 SV=2MAGGMSAECPEPGPGGLQGQSPGPGRQCPPPITPTSWSLPPWRAYVAAAVLCYINLLNYMNWFIIAGVLLDIQEVFQISDNHAGLLQTVFVSCLLLSAPVFGYLGDRHSRKATMSFGILLWSGAGLSSSFISPRYSWLFFLSRGIVGTGSASYSTIAPTVLGDLFVRDQRTRVLAVFYIFIPVGSGLGYVLGSAVTMLTGNWRWALRVMPCLEAVALILLILLVPDPPRGAAETQGEGAVGGFRSSWCEDVRYLGKNWSFVWSTLGVTAMAFVTGALGFWAPKFLLEARVVHGLQPPCFQEPCSNPDSLIFGALTIMTGVIGVILGAEAARRYKKVIPGAEPLICASSLLATAPCLYLALVLAPTTLLASYVFLGLGELLLSCNWAVVADILLSVVVPRCRGTAEALQITVGHILGDAGSPYLTGLISSVLRARRPDSYLQRFRSLQQSFLCCAFVIALGGGCFLLTALYLERDETRAWQPVTGTPDSNDVDSNDLERQGLLSGAGASTEEP>sp|Q6ZMD2-2|SPNS3_HUMAN Isoform 2 of Protein spinster homolog 3 OS=Homosapiens OX=9606 GN=SPNS3MLVCFRLYSWLFFLSRGIVGTGSASYSTIAPTVLGDLFVRDQRTRVLAVFYIFIPVGSGLGYVLGSAVTMLTGNWRWALRVMPCLEAVALILLILLVPDPPRGAAETQGEGAVGGFRSSWCEDVRYLGKNWSFVWSTLGVTAMAFVTGALGFWAPKFLLEARVVHGLQPPCFQEPCSNPDSLIFGALTIMTGVIGVILGAEAARRYKKVIPGAEPLICASSLLATAPCLYLALVLAPTTLLASYVFLGLGELLLSCNWAVVADILLSVVVPRCRGTAEALQITVGHILGDAGSPYLTGLISSVLRARRPDSYLQRFRSLQQSFLCCAFVIALGGGCFLLTALYLERDETRAWQPVTGTPDSNDVDSNDLERQGLLSGAGASTEEP>sp|Q6ZMY3|SPOC1_HUMAN SPOC domain-containing protein 1 OS=Homo sapiensOX=9606 GN=SPOCD1 PE=2 SV=1MSQAGDVEGPSTGDPVLSPQHNCELLQNMEGASSMPGLSPDGPGASSGPGVRAGSRRKIPRKEALRGGSSRAAGAAEVRPGVLELLAVVQSRGSMLAPGLHMQLPSVPTQGRALTSKRLQVSLCDILDDSCPRKLCSRSAGLPERALACRERLAGVEEVSCLRPREARDGGMSSPGCDRRSPTLSKEEPPGRPLTSSPDPVPVRVRKKWRRQGAHSECEEGAGDFLWLDQSPRGDNLLSVGDPPQVADLESLGGPCRPPSPKDTGSGPGEPGGSGAGCASGTEKFGYLPATGDGPQPGSPCGPVGFPVPSGGESLSSAAQAPPQSAALCLGASAQASAEQQEAVCVVRTGSDEGQAPAQDQEELEAKAQPASRGRLEQGLAAPADTCASSREPLGGLSSSLDTEASRACSGPFMEQRRSKGTKNLKKGPVPCAQDRGTDRSSDNSHQDRPEEPSPGGCPRLEEVKIPHGVKLVCYLGSGPVIQLLGAISHGQAGGQLPPKLEVLEDLMEVSSPSPAQRLRRKKRPMVQGPAGCQVFQPSPSGGTAGDPGGLSDPFYPPRSGSLALGDPSSDPACSQSGPMEAEEDSLPEQPEDSAQLQQEKPSLYIGVRGTVVRSMQEVLWTRLRELPDPVLSEEVVEGIAAGIEAALWDLTQGTNGRYKTKYRSLLFNLRDPRNLDLFLKVVHGDVTPYDLVRMSSMQLAPQELARWRDQEEKRGLNIIEQQQKEPCRLPASKMTHKGEVEIQRDMDQTLTLEDLVGPQMFMDCSPQALPIASEDTTGQHDHHFLDPNCHICKDWEPSNELLGSFEAAKSCGDNIFQKALSQTPMPAPEMPKTRELSPTEPQDRVPPSGLHVPAAPTKALPCLPPWEGVLDMFSIKRFRARAQLVSGHSCRLVQALPTVIRSAGCIPSNIVWDLLASICPAKAKDVCVVRLCPHGARDTQNCRLLYSYLNDRQRHGLASVEHMGMVLLPLPAFQPLPTRLRPLGGPGLWALPVSPLLSPGLEVTHSSLLLAVLLPKEGLPDTAGSSPWLGKVQKMVSFNSKVEKRYYQPDDRRPNVPLKGTPPPGGAWQQSQGRGSIAPRGISAWQRPPRGRGRLWPEPENWQHPGRGQWPPEPGLRQSQHPYSVAPAGHGFGRGQHFHRDSCPHQALLRHLESLATMSHQLQALLCPQTKSSIPRPLQRLSSALAAPEPPGPARDSSLGPTDEAGSECPFPRKA>sp|Q6ZMY3-2|SPOC1_HUMAN Isoform 2 of SPOC domain-containing protein 1OS=Homo sapiens OX=9606 GN=SPOCD1MSQAGDVEGPSTGDPVLSPQHNCELLQNMEGASSMPGLSPDGPGASSGPGVRAGSRRKIPRKEALRGGSSRAAGAAEVRPGVLELLAVVQSRGSMLAPGLHMQLPSVPTQGRALTSKRLQVSLCDILDDSCPRKLCSRSAGLPERALACRERLAGVEEVSCLRPREARDGGMSSPGCDRRSPTLSKEEPPGRPLTSSPDPVPVRVRKKWRRQGAHSECEEGAGDFLWLDQSPRGDNLLSVGDPPQVADLESLGGPCRPPSPKDTGSGPGEPGGSGAGCASGTEKFGYLPATGDGPQPGSPCGPVGFPVPSGGESLSSAAQAPPQSAALCLGASAQASAEQQEAVCVVRTGSDEGQAPAQDQEELEAKAQPASRGRLEQGLAAPADTCASSREPLGGLSSSLDTEASRACSGPFMEQRRSKGTKNLKKGPVPCAQDRGTDRSSDNSHQDRPEEPSPGGCPRLEEVKIPHGVKLVCYLGSGPVIQLLGAISHGQAGGQLPPKLEVLEDLMEVSSPSPAQRLRRKKRPMVQGPAGCQVFQPSPSGGTAGDPGGLSDPFYPPRSGSLALGDPSSDPACSQSGPMEAEEDSLPEQPEDSAQLQQEKPSLYIGVRGTVVRSMQEVLWTRLRELPDPVLSEEVVEGIAAGIEAALWDLTQGTNGRYKTKYRSLLFNLRDPRNLDLFLKVVHGDVTPYDLVRMSSMQLAPQELARWRDQEEKRGLNIIEQQQKEPCRLPASKMTHKGEVEIQRDMDQTLTLEDLVGPQMFMDCSPQALPIASEDTTGQHDHHFLDPNCHICKDWEPSNELLGSFEAAKSCGDNIFQKALSQTPMPAPEMPKTRELSPTEPQDRVPPSGLHVPAAPTKALPCLPPWEGVLDMFSIKRFRARAQLVSGHSCRLVQALPTVIRSAGCIPSNIVWDLLASICPAKAKDVCVVRLCPHGARDTQNCRLLYSYLNDRQRHGLASVEHMGMVLLPLPAFQPLPTRLRPLGGPGLEVTHSSLLLAVLLPKEGLPDTAGSSPWLGKVQKMVSFNSKVEKRYYQPDDRRPNVPLKGTPPPGGAWQQSQGRGSIAPRGISAWQRPPRGRGRLWPEPENWQHPGRGQWPPEPGLRQSQHPYSVAPAGHGFGRGQHFHRDSCPHQALLRHLESLATMSHQLQALLCPQTKSSIPRPLQRLSSALAAPEPPGPARDSSLGPTDEAGSECPFPRKA>sp|Q6ZMY3-3|SPOC1_HUMAN Isoform 3 of SPOC domain-containing protein 1OS=Homo sapiens OX=9606 GN=SPOCD1MEVSSPSPAQRLRRKKRPMVQGPAGCQVFQPSPSGGTAGDPGGLSDPFYPPRSGSLALGDPSSDPACSQSGPMEAEEDSLPEQPEDSAQLQQEKPSLYIGVRGTVVRSMQEVLWTRLRELPDPVLSEEVVEGIAAGIEAALWDLTQGTNGRYKTKYRSLLFNLRDPRNLDLFLKVVHGDVTPYDLVRMSSMQLAPQELARWRDQEEKRGLNIIEQQQKEPCRLPASKMTHKGEVEIQRDMDQTLTLEDLVGPQMFMDCSPQALPIASEDTTGQHDHHFLDPNCHICKDWEPSNELLGSFEAAKSCGDNIFQKALSQTPMPAPEMPKTRELSPTEPQDRVPPSGLHVPAAPTKALPCLPPWEGVLDMFSIKRFRARAQLVSGHSCRLVQALPTVIRSAGCIPSNIVWDLLASICPAKAKDVCVVRLCPHGARDTQNCRLLYSYLNDRQRHGLASVEHMGMVLLPLPAFQPLPTRLRPLGGPGLEVTHSSLLLAVLLPKEGLPDTAGSSPWLGKVQKMVSFNSKVEKRYYQPDDRRPNVPLKGTPPPGGAWQQSQGRGSIAPRGISAWQRPPRGRGRLWPEPENWQHPGRGQWPPEPGLRQSQHPYSVAPAGHGFGRGQHFHRDSCPHQALLRHLESLATMSHQLQALLCPQTKSSIPRPLQRLSSALAAPEPPGPARDSSLGPTDEAGSECPFPRKA>sp|Q6ZMY3-4|SPOC1_HUMAN Isoform 4 of SPOC domain-containing protein 1OS=Homo sapiens OX=9606 GN=SPOCD1MLGWGSSFSVWCSPAPCPHQDLFLKVVHGDVTPYDLVRMSSMQLAPQELARWRDQEEKRGLNIIEQQQKEPCRLPASKMTHKGEVEIQRDMDQTLTLEDLVVKLEPDLVLGRAHAWGSHASPHQQCGLGHVT>sp|Q6ZMY3-5|SPOC1_HUMAN Isoform 5 of SPOC domain-containing protein 1OS=Homo sapiens OX=9606 GN=SPOCD1MSQAGDVEGPSTGDPVLSPQHNCELLQNMEGASSMPGLSPDGPGASSGPGVRAGSRRKIPRKEALRGGSSRAAGAAEVRPGVLELLAVVQSRGSMLAPGLHMQLPSVPTQGRALTSKRLQVSLCDILDDSCPRKLCSRSAGLPERALACRERLAGVEEVSCLRPREARDGGMSSPGCDRRSPTLSKEEPPGRPLTSSPDPVPVRVRKKWRRQGAHSECEEGAGDFLWLDQSPRGDNLLSVGDPPQVADLESLGGPCRPPSPKDTGSGPGEPGGSGAGCASGTEKFGYLPATGDGPQPGSPCGPVGFPVPSGGESLSSAAQAPPQSAALCLGASAQASAEQQEAVCVVRTGSDEGQAPAQDQEELEAKAQPASRGRLEQGLAAPADTCASSREPLGGLSSSLDTEASRACSGPFMEQRRSKGTKNLKKGPVPCAQDRGTDRSSDNSHQDRPEEPSPGGCPRLEEVKIPHGVKLVCYVFQPSPSGGTAGDPGGLSDPFYPPRSGSLALGDPSSDPACSQSGPMEAEEDSLPEQPEDSAFGSSRTQC>sp|P0DJJ0|SRG2C_HUMAN SLIT-ROBO Rho GTPase-activating protein 2C OS=Homosapiens OX=9606 GN=SRGAP2C PE=1 SV=1MTSPAKFKKDKEIIAEYDTQVKEIRAQLTEQMKCLDQQCELRVQLLQDLQDFFRKKAEIEMDYSRNLEKLAEHFLAKTRSTKDQQFKKDQNVLSPVNCWNLLLNQVKWESRDHTTLSDIYLNNIIPRFVQVSEDSGRLFKKSKEVGQQLQDDLMKVLNELYSVMKTYHMYNADSISAQSKLKEAEKQEEKQIGKSVKQEDRQTPCSPDSTANVRIEEKHVRRSSVKKIEKMKEKHQAKYTENKLKAIKAQNEYLLALEATNASVFKYYIHDLSDLIDQCCDLGYHASLNRALRTFLSAELNLEQSKHEGLDAIENAVENLDATSDKQRLMEMYNNVFCPPMKFEFQPHMGDMASQLCAQQPVQSELVQRCQQLQSRLSTLKIENEEVKKTMEATLQTIQDIVTVEDFDVSDCFQYSNSMESVKSTVSETFMSKPSIAKRRANQQETEQFYFTVRECYGF>sp|P17947|SPI1_HUMAN Transcription factor PU.1 OS=Homo sapiens OX=9606GN=SPI1 PE=1 SV=2MLQACKMEGFPLVPPPSEDLVPYDTDLYQRQTHEYYPYLSSDGESHSDHYWDFHPHHVHSEFESFAENNFTELQSVQPPQLQQLYRHMELEQMHVLDTPMVPPHPSLGHQVSYLPRMCLQYPSLSPAQPSSDEEEGERQSPPLEVSDGEADGLEPGPGLLPGETGSKKKIRLYQFLLDLLRSGDMKDSIWWVDKDKGTFQFSSKHKEALAHRWGIQKGNRKKMTYQKMARALRNYGKTGEVKKVKKKLTYQFSGEVLGRGGLAERRHPPH>sp|P17947-2|SPI1_HUMAN Isoform 2 of Transcription factor PU.1 OS=Homosapiens OX=9606 GN=SPI1MLQACKMEGFPLVPPQPSEDLVPYDTDLYQRQTHEYYPYLSSDGESHSDHYWDFHPHHVHSEFESFAENNFTELQSVQPPQLQQLYRHMELEQMHVLDTPMVPPHPSLGHQVSYLPRMCLQYPSLSPAQPSSDEEEGERQSPPLEVSDGEADGLEPGPGLLPGETGSKKKIRLYQFLLDLLRSGDMKDSIWWVDKDKGTFQFSSKHKEALAHRWGIQKGNRKKMTYQKMARALRNYGKTGEVKKVKKKLTYQFSGEVLGRGGLAERRHPPH>sp|Q16560|U1SBP_HUMAN U11/U12 small nuclear ribonucleoprotein 35 kDaprotein OS=Homo sapiens OX=9606 GN=SNRNP35 PE=1 SV=1MNDWMPIAKEYDPLKAGSIDGTDEDPHDRAVWRAMLARYVPNKGVIGDPLLTLFVARLNLQTKEDKLKEVFSRYGDIRRLRLVRDLVTGFSKGYAFIEYKEERAVIKAYRDADGLVIDQHEIFVDYELERTLKGWIPRRLGGGLGGKKESGQLRFGGRDRPFRKPINLPVVKNDLYREGKRERRERSRSRERHWDSRTRDRDHDRGREKRWQEREPTRVWPDNDWERERDFRDDRIKGREKKERGK>sp|Q16560-2|U1SBP_HUMAN Isoform 2 of U11/U12 small nuclearribonucleoprotein 35 kDa protein OS=Homo sapiens OX=9606 GN=SNRNP35MKPANMNDWMPIAKEYDPLKAGSIDGTDEDPHDRAVWRAMLARYVPNKGVIGDPLLTLFVARLNLQTKEDKLKEVFSRYGDIRRLRLVRDLVTGFSKGYAFIEYKEERAVIKAYRDADGLVIDQHEIFVDYELERTLKGWIPRRLGGGLGGKKESGQLRFGGRDRPFRKPINLPVVKNDLYREGKRERRERSRSRERHWDSRTRDRDHDRGREKRWQEREPTRVWPDNDWERERDFRDDRIKGREKKERGK>sp|Q5JPH6|SYEM_HUMAN Probable glutamate--tRNA ligase, mitochondrialOS=Homo sapiens OX=9606 GN=EARS2 PE=1 SV=2MAALLRRLLQRERPSAASGRPVGRREANLGTDAGVAVRVRFAPSPTGFLHLGGLRTALYNYIFAKKYQGSFILRLEDTDQTRVVPGAAENIEDMLEWAGIPPDESPRRGGPAGPYQQSQRLELYAQATEALLKTGAAYPCFCSPQRLELLKKEALRNHQTPRYDNRCRNMSQEQVAQKLAKDPKPAIRFRLEQVVPAFQDLVYGWNRHEVASVEGDPVIMKSDGFPTYHLACVVDDHHMGISHVLRGSEWLVSTAKHLLLYQALGWQPPHFAHLPLLLNRDGSKLSKRQGDVFLEHFAADGFLPDSLLDIITNCGSGFAENQMGRTLPELITQFNLTQVTCHSALLDLEKLPEFNRLHLQRLVSNESQRRQLVGKLQVLVEEAFGCQLQNRDVLNPVYVERILLLRQGHICRLQDLVSPVYSYLWTRPAVGRAQLDAISEKVDVIAKRVLGLLERSSMSLTQDMLNGELKKLSEGLEGTKYSNVMKLLRMALSGQQQGPPVAEMMLALGPKEVRERIQKVVSS>sp|Q5JPH6-2|SYEM_HUMAN Isoform 2 of Probable glutamate--tRNA ligase,mitochondrial OS=Homo sapiens OX=9606 GN=EARS2MAALLRRLLQRERPSAASGRPVGRREANLGTDAGVAVRVRFAPSPTGFLHLGGLRTALYNYIFAKKYQGSFILRLEDTDQTRVVPGAAENIEDMLEWAGIPPDESPRRGGPAGPYQQSQRLELYAQATEALLKTGAAYPCFCSPQRLELLKKEALRNHQTPRYDNRCRNMSQEQVAQKLAKDPKPAIRFRLEQVVPAFQDLVYGWNRHEVASVEGDPVIMKSDGFPTYHLACVVDDHHMGISHVLRGSEWLVSTAKHLLLYQALGWQPPHFAHLPLLLNRDGSKLSKRQGDVFLEHFAADGFLPDSLLDIITNCGSGFAENQMGRTLPELITQFNLTQVTCHSALLDLEKLPEFNRLHLQRLVSNESQRRQLVGKLQVLVEEAFGCQLQNRDVLNPVYVERILLLRQGHICRLQDLVSPVYSYLWTRPAVGRAQLDAISEKVDVIAKRVLGLLERSSMSLTQDMLNGELKKLSEGLEGTKYSNVMKLLRMALSGQQVRQGHGLDCSLEPLIDPLNLHFLAGTELNIEYTKVNET>sp|P49588|SYAC_HUMAN Alanine--tRNA ligase, cytoplasmic OS=Homo sapiensOX=9606 GN=AARS1 PE=1 SV=2MDSTLTASEIRQRFIDFFKRNEHTYVHSSATIPLDDPTLLFANAGMNQFKPIFLNTIDPSHPMAKLSRAANTQKCIRAGGKHNDLDDVGKDVYHHTFFEMLGSWSFGDYFKELACKMALELLTQEFGIPIERLYVTYFGGDEAAGLEADLECKQIWQNLGLDDTKILPGNMKDNFWEMGDTGPCGPCSEIHYDRIGGRDAAHLVNQDDPNVLEIWNLVFIQYNREADGILKPLPKKSIDTGMGLERLVSVLQNKMSNYDTDLFVPYFEAIQKGTGARPYTGKVGAEDADGIDMAYRVLADHARTITVALADGGRPDNTGRGYVLRRILRRAVRYAHEKLNASRGFFATLVDVVVQSLGDAFPELKKDPDMVKDIINEEEVQFLKTLSRGRRILDRKIQSLGDSKTIPGDTAWLLYDTYGFPVDLTGLIAEEKGLVVDMDGFEEERKLAQLKSQGKGAGGEDLIMLDIYAIEELRARGLEVTDDSPKYNYHLDSSGSYVFENTVATVMALRREKMFVEEVSTGQECGVVLDKTCFYAEQGGQIYDEGYLVKVDDSSEDKTEFTVKNAQVRGGYVLHIGTIYGDLKVGDQVWLFIDEPRRRPIMSNHTATHILNFALRSVLGEADQKGSLVAPDRLRFDFTAKGAMSTQQIKKAEEIANEMIEAAKAVYTQDCPLAAAKAIQGLRAVFDETYPDPVRVVSIGVPVSELLDDPSGPAGSLTSVEFCGGTHLRNSSHAGAFVIVTEEAIAKGIRRIVAVTGAEAQKALRKAESLKKCLSVMEAKVKAQTAPNKDVQREIADLGEALATAVIPQWQKDELRETLKSLKKVMDDLDRASKADVQKRVLEKTKQFIDSNPNQPLVILEMESGASAKALNEALKLFKMHSPQTSAMLFTVDNEAGKITCLCQVPQNAANRGLKASEWVQQVSGLMDGKGGGKDVSAQATGKNVGCLQEALQLATSFAQLRLGDVKN>sp|P49588-2|SYAC_HUMAN Isoform 2 of Alanine--tRNA ligase, cytoplasmicOS=Homo sapiens OX=9606 GN=AARS1MDSTLTASEIRQRFIDFFKRNEHTYVHSSATIPLDDPTLLFANAGMNQFKPIFLNTIDPSHPMAKLSRAANTQKCIRAGGKHNDLDDVGKDVYHHTFFEMLGSWSFGDYFKELACKMALELLTQEFGIPIERLYVTYFGGDEAAGLEADLECKQIWQNLGTYLYSFVRLDDTKILPGNMKDNFWEMGDTGPCGPCSEIHYDRIGGRDAAHLVNQDDPNVLEIWNLVFIQYNREADGILKPLPKKSIDTGMGLERLVSVLQNKMSNYDTDLFVPYFEAIQKGTGARPYTGKVGAEDADGIDMAYRVLADHARTITVALADGGRPDNTGRGYVLRRILRRAVRYAHEKLNASRGFFATLVDVVVQSLGDAFPELKKDPDMVKDIINEEEVQFLKTLSRGRRILDRKIQSLGDSKTIPGDTAWLLYDTYGFPVDLTGLIAEEKGLVVDMDGFEEERKLAQLKSQGKGAGGEDLIMLDIYAIEELRARGLEVTDDSPKYNYHLDSSGSYVFENTVATVMALRREKMFVEEVSTGQECGVVLDKTCFYAEQGGQIYDEGYLVKVDDSSEDKTEFTVKNAQVRGGYVLHIGTIYGDLKVGDQVWLFIDEPRRRPIMSNHTATHILNFALRSVLGEADQKGSLVAPDRLRFDFTAKGAMSTQQIKKAEEIANEMIEAAKAVYTQDCPLAAAKAIQGLRAVFDETYPDPVRVVSIGVPVSELLDDPSGPAGSLTSVEFCGGTHLRNSSHAGAFVIVTEEAIAKGIRRIVAVTGAEAQKALRKAESLKKCLSVMEAKVKAQTAPNKDVQREIADLGEALATAVIPQWQKDELRETLKSLKKVMDDLDRASKADVQKRVLEKTKQFIDSNPNQPLVILEMESGASAKATQGPGSPPLGLISSLALNEALKLFKMHSPQTSAMLFTVDNEAGKITCLCQVPQNAANRGLKASEWVQQVSGLMDGKGGGKDVSAQATGKNVGCLQEALQLATSFAQLRLGDVKN>sp|Q9BXU2|TX13B_HUMAN Testis-expressed protein 13B OS=Homo sapiensOX=9606 GN=TEX13B PE=1 SV=1MALRPEDPSSGFRHGNVVAFIIEKMARHTKGPEFYFENISLSWEEVEDKLRAILEDSEVPSEVKEACTWGSLALGVRFAHRQGQLQNRRVQWLQGFAKLHRSAALVLASNLTELKEQQEMECNEATFQLQLTETSLAEVQRERDMLRWKLFHAELAPPQGQGQATVFPGLATAGGDWTEGAGEQEKEAVAAAGAAGGKGEERYAEAGPAPAEVLQGLGGGFRQPLGAIVAGKLHLCGAEGERSQVSTNSHVCLLWAWVHSLTGASSCPAPYLIHILIPMPFVRLLSHTQYTPFTSKGHRTGSNSDAFQLGGL>sp|A0A0J9YWL9|TX13C_HUMAN Putative testis-expressed protein 13C OS=Homosapiens OX=9606 GN=TEX13C PE=5 SV=1MAMNFGDHASGFRHDDVIRFINNEVLRNGGSPAFYTAFRSRPWNEVEDRLRAIVADPRVPRAIKRACTWSALALSVQVAARQQEELLYQVWWLQGHVEECQATSWALTSQLQQLRLEHEEVATQLHLTQAALQQVLNERDGLCGRLLEVERSMQVYPMPQDFVPGPEAGQYGPVAGTLNAEQSEAVATEAQGMPHSEAQVAAPTAVYYMPEPQSGRVQGMQPLLLMQAPHPVPFHMPSPMGLPYSTPLPPPVVMESAAAIAPQMPPAGIYPPGLWATVGSQEETAPPWDQKCHGQDGYPENFQGVYHPGDNRSCNQKEGSECPQGMTSQGDSSSHSLKKDPVMQEGTAPPEFSRSHSLEKKPVMPKEMVPLGDSNSHSLKKDPVVPKEIVPIGDSNSHSLTKNPVVHKEMVSLGDSNSHSMKKDPVMPQKMVPLGDSNSHSLKKDPMMCQEMVPLGDSNSHSLKKDPVVAQGTAPLMYSRRHSQKKVPMMPKEMVPLGESHSHSLKKDLVVPKELVPLGDSKSHRMKKDPVMPQKMVPLGDSRSHSLKKDPVMPQNMIPLEDSNSHSLKKDPVMPQNMIPLEDSNSHSLKKDPMMHQEMVPLGDSNSHSLKKDPVVPQDTAPLMFSRRHSLKKVPVMPKEMVPLGDSHSLKKDPVMPQNMVPLEDSNSHSLKKDPVVPQGTAPLMFSRRHSLKKVPVMPKEMVPLGDSNSHSLKKDPVVPQGTAPLMFSRRHSLKKVPVMPKEMVPLGDSHSLKKDPVMPQNMVPLEDSNSHSLKKDPVVPQGTAPLTFSRRHSLKKVPVVPQGTASLGFSRIHSLKKELVMPEEMVPLGDSNSHSMKKDLVMPKEMVPLGDSNSHSLKKDPVVHQEVVSLGDSNSHSLKKHPVIPQGTASLRFSKSHSQKEDQERPQVTPLEDSKSHGVKNSPWKHQPQGQKVKEQKRKKASESQQQKPASCSSPVNWACPWCNAMNFPRNKVCSKCKRVRMPVENGSVDPA>sp|A0A0J9YY54|TX13D_HUMAN Testis-expressed protein 13D OS=Homo sapiensOX=9606 GN=TEX13D PE=3 SV=1MAMNFGDHASGFRHNDVIRFINNEVLMDGSGPAFYVAFRSRPWNEVEDSLQAIVADSQVPRAIKRACTWSALALSVRVATRQREELLHHVRRLQRHAEERQATSWALTSQLQQLRLEHEVAATQLHLAQAALQQALNERDGLYGRLLQIERFPQAAPLAHEIMSGPQAEQNGAAACPLATEQQSDMVAMGTHANAQMPTPTDVLYVPGPLSPWAQGMQPPLPVPHPFPHPPPFPMKFPSLPPLPPAVVTGAEAAAVPLQMPPTEIHPPCPWPAVGFQEEMAPLWYQRSYIQEEDSKILQGSFPLGDSRSHSQGEGSERSQRMPLPGDSGCHNPLSESPQGTAPLGSSGCHSQEEGTEGPQGMDPLGNRERQNQKEGPKRARRMHTLVFRRSHKSEGPEGPQGTVPQGDSRSYSQEGCSDRAQEMATLVFIRRCKPEGPKRPQWTVPLGDSRSHIKEEGPEGPQRIVLQGDNRSYSQEGSPERAQGMATLVFSRSCKPEEGPERPQDTPLGDSRSHIKEEGPEGPQRIVLQGDNRSYSQEGSPERAQGMATLVFSRSCKPEEGPERPQDTPLGDSRSHIKEEGPEGPQRIVLQGDNRSYSQEGSRERAQGMATLVFSRSCKPEEGPERPQGTPLGDSRSHGVRESPKKWQPQRQKAKKPKVNKVSGSQQQEKPASFPVPVNWKCPWCKAINFSWRTACYKCKKACVPFESGGQTQ>sp|Q8IWF7|U2D2L_HUMAN Putative ubiquitin-conjugating enzyme E2 D2-likeprotein OS=Homo sapiens OX=9606 GN=UBE2DNL PE=5 SV=1MALKLIHKEFLELARDPQPHCSAGPVWDDMLHWQATITRPNDSSYLGGVFFLKFPSDYLFKPPKIKFTNGIYHQR>sp|P68543|UBX2A_HUMAN UBX domain-containing protein 2A OS=Homo sapiensOX=9606 GN=UBXN2A PE=1 SV=1MKDVDNLKSIKEEWVCETGSDNQPLGNNQQSNCEYFVDSLFEEAQKVSSKCVSPAEQKKQVDVNIKLWKNGFTVNDDFRSYSDGASQQFLNSIKKGELPSELQGIFDKEEVDVKVEDKKNEICLSTKPVFQPFSGQGHRLGSATPKIVSKAKNIEVENKNNLSAVPLNNLEPITNIQIWLANGKRIVQKFNITHRVSHIKDFIEKYQGSQRSPPFSLATALPVLRLLDETLTLEEADLQNAVIIQRLQKTASFRELSEH>sp|P68543-2|UBX2A_HUMAN Isoform 2 of UBX domain-containing protein 2AOS=Homo sapiens OX=9606 GN=UBXN2AMKDVDNLKSIKEEWVCETGSDNQPLGNNQQSNCEYFVDSLFEEAQKVSSKCVSPAEQKKQVDVNIKLWKNGFTVNDDFRSYSDGASQQFLNSIKKGELPSELQGIFDKEEVDVKVEDKKNEICLSTKPVFQPFSGQGHRLGRVSHIKDFIEKYQGSQRSPPFSLATALPVLRLLDETLTLEEADLQNAVIIQRLQKTASFRELSEH>sp|A1L167|U2QL1_HUMAN Ubiquitin-conjugating enzyme E2Q-like protein 1OS=Homo sapiens OX=9606 GN=UBE2QL1 PE=1 SV=2MKELQDIARLSDRFISVELVDESLFDWNVKLHQVDKDSVLWQDMKETNTEFILLNLTFPDNFPFSPPFMRVLSPRLENGYVLDGGAICMELLTPRGWSSAYTVEAVMRQFAASLVKGQGRICRKAGKSKKSFSRKEAEATFKSLVKTHEKYGWVTPPVSDG>sp|Q15046|SYK_HUMAN Lysine--tRNA ligase OS=Homo sapiens OX=9606 GN=KARS1PE=1 SV=3MAAVQAAEVKVDGSEPKLSKNELKRRLKAEKKVAEKEAKQKELSEKQLSQATAAATNHTTDNGVGPEEESVDPNQYYKIRSQAIHQLKVNGEDPYPHKFHVDISLTDFIQKYSHLQPGDHLTDITLKVAGRIHAKRASGGKLIFYDLRGEGVKLQVMANSRNYKSEEEFIHINNKLRRGDIIGVQGNPGKTKKGELSIIPYEITLLSPCLHMLPHLHFGLKDKETRYRQRYLDLILNDFVRQKFIIRSKIITYIRSFLDELGFLEIETPMMNIIPGGAVAKPFITYHNELDMNLYMRIAPELYHKMLVVGGIDRVYEIGRQFRNEGIDLTHNPEFTTCEFYMAYADYHDLMEITEKMVSGMVKHITGSYKVTYHPDGPEGQAYDVDFTPPFRRINMVEELEKALGMKLPETNLFETEETRKILDDICVAKAVECPPPRTTARLLDKLVGEFLEVTCINPTFICDHPQIMSPLAKWHRSKEGLTERFELFVMKKEICNAYTELNDPMRQRQLFEEQAKAKAAGDDEAMFIDENFCTALEYGLPPTAGWGMGIDRVAMFLTDSNNIKEVLLFPAMKPEDKKENVATTDTLESTTVGTSV>sp|Q15046-2|SYK_HUMAN Isoform Mitochondrial of Lysine--tRNA ligaseOS=Homo sapiens OX=9606 GN=KARS1MLTQAAVRLVRGSLRKTSWAEWGHRELRLGQLAPFTAPHKDKSFSDQRSELKRRLKAEKKVAEKEAKQKELSEKQLSQATAAATNHTTDNGVGPEEESVDPNQYYKIRSQAIHQLKVNGEDPYPHKFHVDISLTDFIQKYSHLQPGDHLTDITLKVAGRIHAKRASGGKLIFYDLRGEGVKLQVMANSRNYKSEEEFIHINNKLRRGDIIGVQGNPGKTKKGELSIIPYEITLLSPCLHMLPHLHFGLKDKETRYRQRYLDLILNDFVRQKFIIRSKIITYIRSFLDELGFLEIETPMMNIIPGGAVAKPFITYHNELDMNLYMRIAPELYHKMLVVGGIDRVYEIGRQFRNEGIDLTHNPEFTTCEFYMAYADYHDLMEITEKMVSGMVKHITGSYKVTYHPDGPEGQAYDVDFTPPFRRINMVEELEKALGMKLPETNLFETEETRKILDDICVAKAVECPPPRTTARLLDKLVGEFLEVTCINPTFICDHPQIMSPLAKWHRSKEGLTERFELFVMKKEICNAYTELNDPMRQRQLFEEQAKAKAAGDDEAMFIDENFCTALEYGLPPTAGWGMGIDRVAMFLTDSNNIKEVLLFPAMKPEDKKENVATTDTLESTTVGTSV>sp|Q8N434|SVOPL_HUMAN Putative transporter SVOPL OS=Homo sapiens OX=9606GN=SVOPL PE=1 SV=2MATKPTEPVTILSLRKLSLGTAEPQVKEPKTFTVEDAVETIGFGRFHIALFLIMGSTGVVEAMEIMLIAVVSPVIRCEWQLENWQVALVTTMVFFGYMVFSILFGLLADRYGRWKILLISFLWGAYFSLLTSFAPSYIWFVFLRTMVGCGVSGHSQGLIIKTEFLPTKYRGYMLPLSQVFWLAGSLLIIGLASVIIPTIGWRWLIRVASIPGIILIVAFKFIPESARFNVSTGNTRAALATLERVAKMNRSVMPEGKLVEPVLEKRGRFADLLDAKYLRTTLQIWVIWLGISFAYYGVILASAELLERDLVCGSKSDSAVVVTGGDSGESQSPCYCHMFAPSDYRTMIISTIGEIALNPLNILGINFLGRRLSLSITMGCTALFFLLLNICTSSAGLIGFLFMLRALVAANFNTVYIYTAEVYPTTMRALGMGTSGSLCRIGAMVAPFISQVLMSASILGALCLFSSVCVVCAISAFTLPIETKGRALQQIK>sp|Q8N434-2|SVOPL_HUMAN Isoform 2 of Putative transporter SVOPL OS=Homosapiens OX=9606 GN=SVOPLMAAGRLIIKTEFLPTKYRGYMLPLSQVFWLAGSLLIIGLASVIIPTIGWRWLIRVASIPGIILIVAFKFIPESARFNVSTGNTRAALATLERVAKMNRSVMPEGKLVEPVLEKRGRFADLLDAKYLRTTLQIWVIWLGISFAYYGVILASAELLERDLVCGSKSDSAVVVTGGDSGESQSPCYCHMFAPSDYRTMIISTIGEIALNPLNILGINFLGRRLSLSITMGCTALFFLLLNICTSSAGLIGFLFMLRALVAANFNTVYIYTAEVYPTTMRALGMGTSGSLCRIGAMVAPFISQVLMSASILGALCLFSSVCVVCAISAFTLPIETKGRALQQIK>sp|Q53LP3|SWAHC_HUMAN Ankyrin repeat domain-containing protein SOWAHCOS=Homo sapiens OX=9606 GN=SOWAHC PE=1 SV=1MEGPAEWGPEAALGPEAVLRFLAERGGRALHAELVQHFRGALGGEPEQRARARAHFKELVNAVATVRVDPADGAKYVHLKKRFCEGPSEPSGDPPRIQVTAEPEAPDGPAGPEARDRLPDAAAPESLPGQGRELGEGEPPAPAHWPPLSAGARRKNSRRDVQPLPRTPAPGPSEDLELPPHGCEEADRGSSLVGATAQRPARQNLRDLVMGSSPQLKRSVCPGGSSPGSSSGGGRGRGGGDSDSASVASSSAEEESSGGGSVTLDPLEHAWMLSASDGKWDSLEGLLTCEPGLLVKRDFITGFTCLHWAAKHGRQELLAMLVNFANKHQLPVNIDARTSGGYTALHLAAMHGHVEVVKLLVGAYDADVDIRDYSGKKASQYLSRSIAEEIKNLVGALDEGDGESAAGSGGGRWRLSKVLPSHLITYKLSHALEDGGDHHHHHHSAEGWVGGKAKDPGRKASGSSSGRIKPRLNKIRFRTQIVHTTPSFRDPEQPLEGRGEEGVGEERPVKGHSPFTLRPKSNVFG>sp|B2RXF0|T229A_HUMAN Transmembrane protein 229A OS=Homo sapiens OX=9606GN=TMEM229A PE=2 SV=2MAGSDVDSEGPARRGGAARRPGAPGGPGSEAAAGCPEPLSTAEAPAESATLPAWMRLYFYGMHGITLDVLVSSARRFARSPDLRMLGFSSPYRCLLHSLTHFALEKVYLQQRRCPNAFVFNFLLYPSAHVGLQTLAGQALLLSLGGGAGVAVAPGALDLALQYVLALYHCQVFLKRFLRLRYGRQRRRQQQQQQQQQQQQRRGALPVPPGARVPTAAGARRRRPRGPRGAGGAPSQGLPDLPRFLFFGMHGFLDEIFFTFFFNVLGQGDGTTSGHTSLWSFFMYGSCSFVVEKLYFHLHYSRGWGTWKRVPIYVIFIYVWELSWGLGLRTCGACSWDYSHYPLNFMGLITLMYLPGWIFLSVYQDLISNVLWRVQYVPAN>sp|Q15714|T22D1_HUMAN TSC22 domain family protein 1 OS=Homo sapiensOX=9606 GN=TSC22D1 PE=1 SV=3MHQPPESTAAAAAAADISARKMAHPAMFPRRGSGSGSASALNAAGTGVGSNATSSEDFPPPSLLQPPPPAASSTSGPQPPPPQSLNLLSQAQLQAQPLAPGGTQMKKKSGFQITSVTPAQISASISSNNSIAEDTESYDDLDESHTEDLSSSEILDVSLSRATDLGEPERSSSEETLNNFQEAETPGAVSPNQPHLPQPHLPHLPQQNVVINGNAHPHHLHHHHQIHHGHHLQHGHHHPSHVAVASASITGGPPSSPVSRKLSTTGSSDSITPVAPTSAVSSSGSPASVMTNMRAPSTTGGIGINSVTGTSTVNNVNITAVGSFNPNVTSSMLGNVNISTSNIPSAAGVSVGPGVTSGVNVNILSGMGNGTISSSAAVSSVPNAAAGMTGGSVSSQQQQPTVNTSRFRVVKLDSSSEPFKKGRWTCTEFYEKENAVPATEGVLINKVVETVKQNPIEVTSERESTSGSSVSSSVSTLSHYTESVGSGEMGAPTVVVQQQQQQQQQQQQQPALQGVTLQQMDFGSTGPQSIPAVSIPQSISQSQISQVQLQSQELSYQQKQGLQPVPLQATMSAATGIQPSPVNVVGVTSALGQQPSISSLAQPQLPYSQAAPPVQTPLPGAPPPQQLQYGQQQPMVSTQMAPGHVKSVTQNPASEYVQQQPILQTAMSSGQPSSAGVGAGTTVIPVAQPQGIQLPVQPTAVPAQPAGASVQPVGQAPAAVSAVPTGSQIANIGQQANIPTAVQQPSTQVPPSVIQQGAPPSSQVVPPAQTGIIHQGVQTSAPSLPQQLVIASQSSLLTVPPQPQGVEPVAQGIVSQQLPAVSSLPSASSISVTSQVSSTGPSGMPSAPTNLVPPQNIAQTPATQNGNLVQSVSQPPLIATNTNLPLAQQIPLSSTQFSAQSLAQAIGSQIEDARRAAEPSLVGLPQTISGDSGGMSAVSDGSSSSLAASASLFPLKVLPLTTPLVDGEDESSSGASVVAIDNKIEQAMDLVKSHLMYAVREEVEVLKEQIKELIEKNSQLEQENNLLKTLASPEQLAQFQAQLQTGSPPATTQPQGTTQPPAQPASQGSGPTA>sp|Q15714-2|T22D1_HUMAN Isoform 2 of TSC22 domain family protein 1OS=Homo sapiens OX=9606 GN=TSC22D1MKSQWCRPVAMDLGVYQLRHFSISFLSSLLGTENASVRLDNSSSGASVVAIDNKIEQAMDLVKSHLMYAVREEVEVLKEQIKELIEKNSQLEQENNLLKTLASPEQLAQFQAQLQTGSPPATTQPQGTTQPPAQPASQGSGPTA>sp|Q15714-3|T22D1_HUMAN Isoform 3 of TSC22 domain family protein 1OS=Homo sapiens OX=9606 GN=TSC22D1MGAPTVVVQQQQQQQQQQQQQPALQGVTLQQMDFGSTGPQSIPAVSIPQSISQSQISQVQLQSQELSYQQKQGLQPVPLQATMSAATGIQPSPVNVVGVTSALGQQPSISSLAQPQLPYSQAAPPVQTPLPGAPPPQQLQYGQQQPMVSTQMAPGHVKSVTQNPASEYVQQQPILQTAMSSGQPSSAGVGAGTTVIPVAQPQGIQLPVQPTAVPAQPAGASVQPVGQAPAAVSAVPTGSQIANIGQQANIPTAVQQPSTQVPPSVIQQGAPPSSQVVPPAQTGIIHQGVQTSAPSLPQQLVIASQSSLLTVPPQPQGVEPVAQGIVSQQLPAVSSLPSASSISVTSQVSSTGPSGMPSAPTNLVPPQNIAQTPATQNGNLVQSVSQPPLIATNTNLPLAQQIPLSSTQFSAQSLAQAIGSQIEDARRAAEPSLVGLPQTISGDSGGMSAVSDGSSSSLAASASLFPLKVLPLTTPLVDGEDESSSGASVVAIDNKIEQAMDLVKSHLMYAVREEVEVLKEQIKELIEKNSQLEQENNLLKTLASPEQLAQFQAQLQTGSPPATTQPQGTTQPPAQPASQGSGPTA>sp|Q15714-4|T22D1_HUMAN Isoform 4 of TSC22 domain family protein 1OS=Homo sapiens OX=9606 GN=TSC22D1MHQPPESTAAAAAAADISARKMAHPAMFPRRGSGSGSASALNAAGTGVGSNATSSEDFPPPSLLQPPPPAASSTSGPQPPPPQSLNLLSQAQLQAQPLAPGGTQMKKKSGFQITSVTPAQISASISSNNSIAEDTESYDDLDESHTEDLSSSEILDVSLSRATDLGEPERSSSEETLNNFQEAETPGAVSPNQPHLPQPHLPHLPQQNVVINGNAHPHHLHHHHQIHHGHHLQHGHHHPSHVAVASASITGGPPSSPVSRKLSTTGSSDSITPVAPTSAVSSSGSPASVMTNMRAPSTTGGIGINSVTGTSTVNNVNITAVGSFNPNVTSSMLGNVNISTSNIPSAAGVSVGPGVTSGVNVNILSGMGNGTISSSAAVSSVPNAAAGMTGGSVSSQQQQPTVNTSRFRVVKLDSSSEPFKKGRWTCTEFYEKENAVPATEGVLINKVVETVKQNPIEVTSERESTSGSSVSSSVSTLSHYTESVGSGEMGAPTVVVQQQQQQQQQQQQQPALQGVTLQQMDFGSTGPQSIPAVSIPQSISQSQISQVQLQSQELSYLTMKVVLLIVYLCM>sp|B4DZS4|T11X1_HUMAN T-complex protein 11 X-linked protein 1 OS=Homosapiens OX=9606 GN=TCP11X1 PE=2 SV=1MPKTEETVLQNDPSVAENGAPEPKTPGQSQKSKSFCLDDQSPDLIETVNEVSKLSISHEIVVNQDFYVEETILPPNSVEGRFAEAMYNAFWNHLKEQLLSTPPDFTCALELLKDVKETLLSLLLPWQNRLRNEIEEALDTDLLKQEAEHGALDVPHLSNYILNLMALLCAPVRDEAIQKLETIRDPVQLLRGILRVLGLMKMDMVNYTIQSFRPYLQEHSIQYEQAKFQELLDKQPSLLDYTTKWLTKAATDITTLCPSSPDSPSSSCSMACSLPSGADSADGQNPAPGTGIPVAPVNCPGLSLASGQKLLW>sp|Q5VZQ5|TEX36_HUMAN Testis-expressed protein 36 OS=Homo sapiensOX=9606 GN=TEX36 PE=2 SV=1MTKGRRFNPPSDKDGRWFPHIGLTQKTPESITSATSKEPQSPHLPRQAEGKLPPIYKVREKQAVNNQFPFSVHDNRHSLENSGCYLDSGLGRKKISPDKRQHVSRNFNLWACDYVPSCLDGFSNNQISYVYKEAMVVSSFRRFPRCYKEIWNAFTFLPERSYTEVLKKKPKVRFTVDKKVVSSLES>sp|Q502W6|VWA3B_HUMAN von Willebrand factor A domain-containing protein3B OS=Homo sapiens OX=9606 GN=VWA3B PE=1 SV=3MEKSGPSSTISEQQLQRQEGWINTKTDLAEQSLISSEKWLQLHGLKSNKLTLKQILSQIGFPHCEDYVASLGRPVASRYADGLFPQLYRAEDGRVYNLTAKSELIYQFVEHLTQAVESYKQRMDWLTSKSRQIFGVILEQCVTIVLDFGGILEGELDLCREALTMVLQEQVAHITEFNIIRVSQEPVKWQENATPVTEQSIATAISWVEKLTVELTVSEAGRLDALLEAGRDKTIESIYYFVVGDVPEESKELLLQRALEIPCPVYTVSFNARGEGTIAFLKDLSAKTHSRFHAFAERTECVEFPAFSTKDGDNVMTWNSRKLKGKLPPGAGVREDVFLVWQEMEEACSTLAQIQRLVAEPPKPDVATVDCESETTSVEIASNPEDTWDSKTWLQKYGLKAQKLSLYDVLADCSFRHADGVVDIKAKPENESVQTSAETNKKTVHAKYCSRFVHAPWKDGSLVHVNITKEKCKWYSERIHTALARIRRRIKWLQDGSQSLFGRLHNDCIYILIDTSHSMKSKLDLVKDKIIQFIQEQLKYKSKFNFVKFDGQAVAWREQLAEVNEDNLEQAQSWIRDIKIGSSTNTLSALKTAFADKETQAIYLLTDGRPDQPPETVIDQVKRFQEIPIYTISFNYNDEIANRFLKEVAALTGGEFHFYNFGCKDPTPPEAVQNEDLTLLVKEMEQGHSDLEKMQDLYSESLIMDWWYNAEKDGDSKHQKEICSMISTPEKCAKPQSDVDSTQTSSLNMLKGPWGLSDQKVQKKKVLHAESTKTSLLRSQMSSLRSSACSERKDGLSNASSRRTALSDKEMSILLAEEWLDDKSSEKVTREGSQVYDHDSSDVSSENWLKTYGLVAKKLTLMDALSVAAVPHSSTYVPVLDKHVVSKVFDEVFPLAHVCNDTNKMTLINPQGAKLNIYKRKVEQAIQSYEKRLNKIVWRALSQEEKEKLDANKPIQYLENKTVLNQALERLNWPISLKELSMLESEILAGKMYIQQAMELQEAAKKNYANKAPGEQQKLQGNPTKKTKSKRPDPLKGQKVIARCDENGFYFPGVVKKCVSRTQALVGFSYGDTKVVSTSFITPVGGAMPCPLLQVGDYVFAKIVIPKGFDFYVPAIVIALPNKHVATEKFYTVLKCNNRREFCPRSALIKISQNKYALSCSHIKSPPIPEDPEVEDVEARNSAFLFWPLKEADTQDSREPRREKPRRKKRPAKQPLQQAAPSDSDGSSHGISSHGSCQGTHPEPRTAHLHFPAAGRLGLSSHAIIATPPPRAALPCTLQATHSSKGLRSVPETL>sp|Q502W6-2|VWA3B_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 3B OS=Homo sapiens OX=9606 GN=VWA3BMEKSGPSSTISEQQLQRQEGWINTKTDLAEQSLISSEKWLQLHGLKSNKLTLKQILSQIGFPHCEDYVASLGRPVASRYADGLFPQLYRAEDGRVYNLTAKSELIYQFVEHLTQAVESYKQRMDWLTSKSRQIFGVILEQCVTIVLDFGGILEGELDLCREALTMVLQEQVAHITEFNIIRVSQEPVKWQENATPVTEQSIATAISWVEKLTVELTVSEAGRLDALLEAGRDKTIESIYYFVVGDVPEESKELLLQRALEIPCPVYTVSFNARGEGTIAFLKDLSAKTHSRFHAFAERTECVEFPAFSTKDGDNVMTWNSRKLKGKLPPGAGVREDVFLVWQEMEEACSTLAQIQRLVAEPPKPDVATVDCESETTSVEIASNPEDTWDSKTWLQKYGLKAQKLSLYDVLADCSFRHADGVVDIKAKPENESVQTSAETNKKTVHAKYCSRFVHAPWKDGSLVHVNITKEKCKWYSERIHTALARIRRRIKWLQDGSQSLFGRLHNDCIYILIDTSHSMKSKLDLVKDKIIQFIQEQLKYKSKFNFVKFDGQAVAWREQLAEVNEDNLEQAQSWIRDIKIGSSTNTLSALKTAFADKETQAIYLLTDGRPDQGTSSHLLLTAAV>sp|Q502W6-3|VWA3B_HUMAN Isoform 3 of von Willebrand factor A domain-containing protein 3B OS=Homo sapiens OX=9606 GN=VWA3BMATKGMRLKSTKEVFPLAHVCNDTNKMTLINPQGAKLNIYKRKVEQAIQSYEKRLNKIVWRALSQEEKEKLDANKPIQYLENKTVLNQALERLNWPISLKELSMLESEILAGKMYIQQAMELQEAAKKNYANKAPGEQQKLQGNPTKKTKSKRPDPLKGQKVIARCDENGFYFPGVVKKCVSRTQALVGFSYGDTKVVSTSFITPVGGAMPCPLLQVGDYVFAKIVIPKGFDFYVPAIVIALPNKHVATEKFYTVLKCNNRREFCPRSALIKISQNKYALSCSHIKSPPIPEDPEVEDVEARNSAFLFWPLKEADTQDSREPRREKPRRKKRPAKQPLQQAAPSDSDGSSHGISSHGSCQGTHPEPRTAHLHFPAAGRLGLSSHAIIATPPPRAALPCTLQATHSSKGLRSVPETL>sp|Q502W6-4|VWA3B_HUMAN Isoform 4 of von Willebrand factor A domain-containing protein 3B OS=Homo sapiens OX=9606 GN=VWA3BMATKGMRLKSTKEVFPLAHVCNDTNKMTLINPQGAKLNIYKRKVEQAIQSYEKRLNKIVWRALSQEEKEKLDANKPIQYLENKTVLNQALERLNWPISLKELSMLESEILAGKMYIQQAMELQEAAKKNYANKAPGEQQKLQGNPTKKTKSKRPDPLKGQKVIARCDENGFYFPGVVKKCVSRTQALVGFSYGDTKVVSTSFITPVGGAMPCPLLQVGDYVFAKIVIPKGFDFYVPAIVIALPNKHVATEKFYTVLKCNNRREFCPRSALIKISQNKYALSCSHIKSPPIPEDPEVEDVEARNSAFLFWPLKEADTQDSREPRREKPRRKKRPAKQPLQQAAPSDSDGSSHGISSHGPPPLPRGRASRTQQPRHHCHTSTSSSPALYSPSHPQQQRAEERP>sp|Q502W6-5|VWA3B_HUMAN Isoform 5 of von Willebrand factor A domain-containing protein 3B OS=Homo sapiens OX=9606 GN=VWA3BMCIIPPETVIDQVKRFQEIPIYTISFNYNDEIANRFLKEVAALTGGEFHFYNFGCKDPTPPEAVQNEDLTLLVKEMEQGHSDLEKMQDLYSESLIMDWWYNAEKDGDSKHQKEICSMISTPEKCAKPQSDVDSTQTSSLNMLKGPWGLSDQKVQKKKVLHAESTKTSLLRSQMSSLRSSACSERKDGLSNASSRRTALSDKEMSILLAEEWLDDKSSEKVTREGSQVYDHDSSDVSSENWLKTYGLVAKKLTLMDALSVAAVPHSSTYVPVLDKHVVSKVFDEVFPLAHVCNDTNKMTLINPQGAKLNIYKRKVEQAIQSYEKRLNKIVWRALSQEEKEKLDANKPIQYLENKTVLNQALERLNWPISLKELSMLESEILAGKMYIQQAMELQEAAKKNYANKAPGEQQKLQGNPTKKTKSKRPDPLKGQKVIARCDENGFYFPGVVKKCVSRTQALVGFSYGDTKVVSTSFITPVGGAMPCPLLQVGDYVFAKIVIPKGFDFYVPAIVIALPNKHVATEKFYTVLKCNNRREFCPRSALIKISQNKYALSCSHIKSPPIPEDPEVEDVEARNSAFLFWPLKEADTQDSREPRREKPRRKKRPAKQPLQQAAPSDSDGSSHGISSHGSCQGTHPEPRTAHLHFPAAGRLGLSSHAIIATPPPRAALPCTLQATHSSKGLRSVPETL>sp|Q502W6-6|VWA3B_HUMAN Isoform 6 of von Willebrand factor A domain-containing protein 3B OS=Homo sapiens OX=9606 GN=VWA3BMEKSGPSSTISEQQLQRQEGWINTKTDLAEQSLISSEKWLQLHGLKSNKLTLKQILSQIGFPHCEDYVASLGRPVASRYADGLFPQLYRAEDGRVYNLTAKSELIYQFVEHLTQAVESYKQRMDWLTSKSRQIFGVILEQCVTIVLDFGGILEGELDLCREALTMVLQEQVAHITEFNIIRVSQEPVKWQENATPVTEQSIATAISWVEKLTVELTVSEAGRLDALLEAGRDKTIESIYYFVVGDVPEESKELLLQRALEIPCPVYTVSFNARGEGTIAFLKDLSAKTHSRFHAFAERTECVEFPAFSTKDGDNVMTWNSRKLKGKLPPGAGVREDVFLVWQEMEEACSTLAQIQRLVAEPPKPDVATVDCESETTSVEIASNPEDTWDSKTWLQKYGLKAQKLSLYDVLADCSFRHADGVVDIKAKPENESVQTSAETNKKTVHAKYCSRFVHAPWKDGSLVHVNITKEKCKWYSERIHTALARIRRRIKWLQDGSQSLFGRLHNDCIYILIDTSHSMKSKLDLVKDKIIQFIQEQLKYKSKFNFVKFDGQAVAWREQLAEVNEDNLEQAQSWIRDIKIGSSTNTLSALKTAFADKETQAIYLLTDGRPDQPPETVIDQVKRFQEIPIYTISFNYNDEIANRFLKEVAALTGGEFHFYNFGCKDPTPPEAVQNEDLTLLVKEMEQGHSDLEKMQDLYSESLIMDWWYNAEKDGDSKHQKEICSMISTPEKCAKPQSDVDSTQTSSLNMLKGPWGLSDQKVQKKKVLHAESTKTSLLRSQMSSLRSSACSERKDGLSNASSRRTALSDKEMSILLAEEWLDDKSSEKVTREGSQVYDHDSSDVSSENWLKTYGLVAKKLTLMDALSVAAVPHSSTYVPVLDKHVVSKVFDEVFPLAHVCNDTNKMTLINPQGAKLNIYKRKVEQAIQSYEKRLNKIVWRALSQEEKEKLDANKPIQYLENKTVLNQALERLNWPISLKELSMLESEILAGKMYIQQAMELQEAAKKNYANKAPGEQQKLQGNPTKKTKSKRPDPLKGQKVIARCDENGFYFPGVVKKCVSRTQALVGFSYGDTKVVSTSFITPVGGAMPCPLLQVGDYVFAKIVIPKGFDFYVPAIVIALPNKHVATEKFYTVLKCNNRREFCPRSALIKISQNKYALSCSHIKSPPIPEDPEVEDVEARNSAFLFWPLKEADTQDSREPRREKPRRKKRPAKQPLQQAAPSDSDGSSHGISSHGSCQGTHPEPRVWVMGGEHNIAYLRNTLKSLSRIVHLTSSFRFWACLGSSAAKTLTSLSNAELCFPRQPTSTSPRPGV>sp|Q502W6-7|VWA3B_HUMAN Isoform 7 of von Willebrand factor A domain-containing protein 3B OS=Homo sapiens OX=9606 GN=VWA3BMISTPEKCAKPQSDVDSTQTSSLNMLKGPWGLSDQKVQKKKVLHAESTKTSLLRSQMSSLRSSACSERKDGLSNASSRRTALSDKEMSILLAEEWLDDKSSEKVTREGSQVYDHDSSDVSSENWLKTYGLVAKKLTLMDALSVAAVPHSSTYVPVLDKHVVSKVFDEVFPLAHVCNDTNKMTLINPQGAKLNIYKRKVEQAIQSYEKRLNKIVWRALSQEEKEKLDANKPIQYLENKTVLNQALERLNWPISLKELSMLESEILAGKMYIQQAMELQEAAKKNYANKAPGEQQKLQGNPTKKTKSKRPDPLKGQKVIARCDENGFYFPGVVKKCVSRTQALVGFSYGDTKVVSTSFITPVGGAMPCPLLQVGDYVFAKIVIPKGFDFYVPAIVIALPNKHVATEKFYTVLKCNNRREFCPRSALIKISQNKYALSCSHIKSPPIPEDPEVEDVEARNSAFLFWPLKEADTQDSREPRREKPRRKKRPAKQPLQQAAPSDSDGSSHGISSHGSCQGTHPEPRTAHLHFPAAGRLGLSSHAIIATPPPRAALPCTLQATHSSKGLRSVPETL>sp|Q502W6-8|VWA3B_HUMAN Isoform 8 of von Willebrand factor A domain-containing protein 3B OS=Homo sapiens OX=9606 GN=VWA3BMEKSGPSSTISEQQLQRQEGWINTKTDLAEQSLISSEKWLQLHGLKSNKLTLKQILSQIGFPHCEDYVASLGRPVASRYADGLFPQLYRAEDGRVYNLTAKSELIYQFVEHLTQAVESYKQRMDWLTSKSRQIFGVILEQCVTIVLDFGGILEGELDLCREALTMVLQEQVAHITEFNIIRVSQEPVKWQENATPVTEQSIATAISWVEKLTVELTVSEAGRLDALLEAGRDKTIESIYYFVVGDVPEESKELLLQRALEIPCPVYTVSFNARGEGTIAFLKDLSAKTHSRFHAFAERTECVEFPAFSTKDGDNVMTWNSRKLKGKLPPGAGVREDVFLVWQEMEEACSTLAQIQRLVAEPPKPDVATVDCESETTSVEIASNPEDTWDSKTWLQKYGLKAQKLSLYDVLADCSFRHADGVVDIKAKPENESVQTSAETNKKTVHAKYCSRFVHAPWKDGSLVHVNITKEKCKWYSERIHTALARIRRRIKWLQDGSQSLFGRLHNDCIYILIDTSHSMKSKLDLVKDKIIQFIQEQLKYKSKFNFVKFDGQAVAWREQLAEVNEDNLEQAQSWIRDIKIGSSTNTLSALKTAFADKETQAIYLLTDGRPDQPPETVIDQVKRFQEIPIYTISFNYNDEIANRFLKEVAALTGGEFHFYNFGCKDPTPPEAVQNEDLTLLVKEMEQGHSDLEKMQDLYSESLIMDWWYNAEKDGDSKHQKEICSMISTPEKCAKPQSDVDSTQTSSLNMLKGPWGLSDQKVQKKKVLHAESTKTSLLRSQMSSLRSSACSERKDGLSNASSRRTALSDKEMSILLAEEWLDDKSSEKVTREGSQVYDHDSSDVSSENWLKTYGLVAKKLTLMDALSVAAVPHSSTYVPVLDKHVVSKVFDEVFPLAHVCNDTNKMTLINPQGAKLNIYKRKVEQAIQSYEKRLNKIVWRALSQEEKEKLDANKPIQYLENKTVLNQALERLNWPISLKELSMLESEILAGKMYIQQAMELQEAAKKNYANKAPGEQQKLQGNPTKKTKSKRPDPLKGQKVIARCDENGFYFPGSFFFFNFVRLLLNNLILGTRSFNLCFC>sp|Q8WY91|THAP4_HUMAN Peroxynitrite isomerase THAP4 OS=Homo sapiensOX=9606 GN=THAP4 PE=1 SV=2MVICCAAVNCSNRQGKGEKRAVSFHRFPLKDSKRLIQWLKAVQRDNWTPTKYSFLCSEHFTKDSFSKRLEDQHRLLKPTAVPSIFHLTEKKRGAGGHGRTRRKDASKATGGVRGHSSAATSRGAAGWSPSSSGNPMAKPESRRLKQAALQGEATPRAAQEAASQEQAQQALERTPGDGLATMVAGSQGKAEASATDAGDESATSSIEGGVTDKSGISMDDFTPPGSGACKFIGSLHSYSFSSKHTRERPSVPREPIDRKRLKKDVEPSCSGSSLGPDKGLAQSPPSSSLTATPQKPSQSPSAPPADVTPKPATEAVQSEHSDASPMSINEVILSASGACKLIDSLHSYCFSSRQNKSQVCCLREQVEKKNGELKSLRQRVSRSDSQVRKLQEKLDELRRVSVPYPSSLLSPSREPPKMNPVVEPLSWMLGTWLSDPPGAGTYPTLQPFQYLEEVHISHVGQPMLNFSFNSFHPDTRKPMHRECGFIRLKPDTNKVAFVSAQNTGVVEVEEGEVNGQELCIASHSIARISFAKEPHVEQITRKFRLNSEGKLEQTVSMATTTQPMTQHLHVTYKKVTP>sp|Q8WY91-2|THAP4_HUMAN Isoform 2 of Peroxynitrite isomerase THAP4OS=Homo sapiens OX=9606 GN=THAP4MEPPKMNPVVEPLSWMLGTWLSDPPGAGTYPTLQPFQYLEEVHISHVGQPMLNFSFNSFHPDTRKPMHRECGFIRLKPDTNKVAFVSAQNTGVVEVEEGEVNGQELCIASHSIARISFAKEPHVEQITRKFRLNSEGKLEQTVSMATTTQPMTQHLHVTYKKVTP>sp|Q99593|TBX5_HUMAN T-box transcription factor TBX5 OS=Homo sapiensOX=9606 GN=TBX5 PE=1 SV=2MADADEGFGLAHTPLEPDAKDLPCDSKPESALGAPSKSPSSPQAAFTQQGMEGIKVFLHERELWLKFHEVGTEMIITKAGRRMFPSYKVKVTGLNPKTKYILLMDIVPADDHRYKFADNKWSVTGKAEPAMPGRLYVHPDSPATGAHWMRQLVSFQKLKLTNNHLDPFGHIILNSMHKYQPRLHIVKADENNGFGSKNTAFCTHVFPETAFIAVTSYQNHKITQLKIENNPFAKGFRGSDDMELHRMSRMQSKEYPVVPRSTVRQKVASNHSPFSSESRALSTSSNLGSQYQCENGVSGPSQDLLPPPNPYPLPQEHSQIYHCTKRKEEECSTTDHPYKKPYMETSPSEEDSFYRSSYPQQQGLGASYRTESAQRQACMYASSAPPSEPVPSLEDISCNTWPSMPSYSSCTVTTVQPMDRLPYQHFSAHFTSGPLVPRLAGMANHGSPQLGEGMFQHQTSVAHQPVVRQCGPQTGLQSPGTLQPPEFLYSHGVPRTLSPHQYHSVHGVGMVPEWSDNS>sp|Q99593-2|TBX5_HUMAN Isoform 2 of T-box transcription factor TBX5OS=Homo sapiens OX=9606 GN=TBX5MADADEGFGLAHTPLEPDAKDLPCDSKPESALGAPSKSPSSPQAAFTQQGMEGIKVFLHERELWLKFHEVGTEMIITKAGRRMFPSYKVKVTGLNPKTKYILLMDIVPADDHRYKFADNKWSVTGKAEPAMPGRLYVHPDSPATGAHWMRQLVSFQKLKLTNNHLDPFGHIILNSMHKYQPRLHIVKADENNGFGSKNTAFCTHVFPETAFIAVTSYQNHKITQLKIENNPFAKGFRGSDDMELHRMSRMQSKEYPVVPRSTVRQKVASNHSPFSSESRALSTSSNLGSQYQCENGVSGPSQDLLPPPNPYPLPQEHSQIYHCTKRKGECDHPWSICFLSYLFLSLGWG>sp|Q99593-3|TBX5_HUMAN Isoform 3 of T-box transcription factor TBX5OS=Homo sapiens OX=9606 GN=TBX5MEGIKVFLHERELWLKFHEVGTEMIITKAGRRMFPSYKVKVTGLNPKTKYILLMDIVPADDHRYKFADNKWSVTGKAEPAMPGRLYVHPDSPATGAHWMRQLVSFQKLKLTNNHLDPFGHIILNSMHKYQPRLHIVKADENNGFGSKNTAFCTHVFPETAFIAVTSYQNHKITQLKIENNPFAKGFRGSDDMELHRMSRMQSKEYPVVPRSTVRQKVASNHSPFSSESRALSTSSNLGSQYQCENGVSGPSQDLLPPPNPYPLPQEHSQIYHCTKRKEEECSTTDHPYKKPYMETSPSEEDSFYRSSYPQQQGLGASYRTESAQRQACMYASSAPPSEPVPSLEDISCNTWPSMPSYSSCTVTTVQPMDRLPYQHFSAHFTSGPLVPRLAGMANHGSPQLGEGMFQHQTSVAHQPVVRQCGPQTGLQSPGTLQPPEFLYSHGVPRTLSPHQYHSVHGVGMVPEWSDNS>sp|O75436|VP26A_HUMAN Vacuolar protein sorting-associated protein 26AOS=Homo sapiens OX=9606 GN=VPS26A PE=1 SV=2MSFLGGFFGPICEIDIVLNDGETRKMAEMKTEDGKVEKHYLFYDGESVSGKVNLAFKQPGKRLEHQGIRIEFVGQIELFNDKSNTHEFVNLVKELALPGELTQSRSYDFEFMQVEKPYESYIGANVRLRYFLKVTIVRRLTDLVKEYDLIVHQLATYPDVNNSIKMEVGIEDCLHIEFEYNKSKYHLKDVIVGKIYFLLVRIKIQHMELQLIKKEITGIGPSTTTETETIAKYEIMDGAPVKGESIPIRLFLAGYDPTPTMRDVNKKFSVRYFLNLVLVDEEDRRYFKQQEIILWRKAPEKLRKQRTNFHQRFESPESQASAEQPEM>sp|O75436-2|VP26A_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 26A OS=Homo sapiens OX=9606 GN=VPS26AMSFLGGFFGPICEIDIVLNDGETRKMAEMKTEDGKVEKHYLFYDGESVSGKVNLAFKQPGKRLEHQGIRIEFVGQIELFNDKSNTHEFVNLVKELALPGELTQSRSYDFEFMQVEKPYESYIGANVRLRYFLKVTIVRRLTDLVKEYDLIVHQLATYPDVNNSIKMEVGIEDCLHIEFEYNKSKYHLKDVIVGKIYFLLVRIKIQHMELQLIKKEITGIGPSTTTETETIAKYEIMDGAPVKGDNFMEKSS>sp|O43247|TEX33_HUMAN Testis-expressed protein 33 OS=Homo sapiensOX=9606 GN=TEX33 PE=1 SV=2MELGHGAGTTTFTRAHLNDKEGQQDLDPWKAAYSSLDTSKFKNQGLSSPQPLPLGASAQGSSLGQCHLKEIPPPPPTAASRDSLGMDPQSRSLKNAGSRSSSRENRATSGEGAQPCQGTDDGPSLGAQDQRSTPTNQKGSIIPNNIRHKFGSNVVDQLVSEEQAQKAIDEVFEGQKRASSWPSRTQNPVEISSVFSDYYDLGYNMRSNLFRGAAEETKSLMKASYTPEVIEKSVRDLEHWHGRKTDDLGRWHQKNAMNLNLQKALEEKYGENSKSKSSKY>sp|O43247-2|TEX33_HUMAN Isoform 2 of Testis-expressed protein 33 OS=Homosapiens OX=9606 GN=TEX33MDPQSRSLKNAGSRSSSRENRATSGEGAQPCQGTDDGPSLGAQDQRSTPTNQKGSIIPNNIRHKFGSNVVDQLVSEEQAQKAIDEVFEGQKRASSWPSRTQNPVEISSVFSDYYDLGYNMRSNLFRGAAEETKSLMKASYTPEVIEKSVRDLEHWHGRKTDDLGRWHQKNAMNLNLQKALEEKYGENSKSKSSKY>sp|P0DJG4|THEGL_HUMAN Testicular haploid expressed gene protein-likeOS=Homo sapiens OX=9606 GN=THEGL PE=2 SV=1MENQEFLSSSAPSEVTDGQVSTEISTCSEVFQKPIVLRILDTHRELEESEDPEKHENPEEPEEVREQDQRDESEECDEPHESYEPHAPYAPHKPRDSYAPYELHGPHAAPKLLKAREPRQLRHTREPRKSREAKETELLPSAAVMISPSLITRAPPRPQLSFLGANPVSCDFVRKCFSSRKRTPNLSKPKKQWGTPDRKLFWGNQDPIRPVSQGALKAQLTKRLENLAQPKEVSCHYVPNRAQYYHSCGRESVIWEITPPALFRQPSKRIQRLSQPNGFKRQCLLNRPFSDNSARDSLRISDPSPRILQLSVAKGTDPNYHPSKKMQTKISLSTLSAIATPRIIELAHPRIKLEGLCYERQRSELPIRPVPPAAMIAKPSPRTIALAKSKSVHQDYLPDRDAHWPVSYATTHSKASPRIQELANPNKRAPVRIVYYDPDVFKTKPAALKAQCSQRIWELSQPLTR>sp|P36402|TCF7_HUMAN Transcription factor 7 OS=Homo sapiens OX=9606GN=TCF7 PE=1 SV=3MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTETNWPRELKDGNGQESLSMSSSSSPA>sp|P36402-2|TCF7_HUMAN Isoform 4S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTETNWPRELKDGNGQESLSMSSSSSPA>sp|P36402-3|TCF7_HUMAN Isoform 1L of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDPGSPKKCRARFGLNQQTDWCGPCRRKKKCIRYLPGEGRCPSPVPSDDSALGCPGSPAPQDSPSYHLLPRFPTELLTSPAERHLHPQVSPLLSASQPQGPHRPPAAPCRAHRYSNRNLRDRWPSRHRTPGRLQEPTP>sp|P36402-4|TCF7_HUMAN Isoform 1S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDPGSPKKCRARFGLNQQTDWCGPCRRKKKCIRYLPGEGRCPSPVPSDDSALGCPGSPAPQDSPSYHLLPRFPTELLTSPAERHLHPQVSPLLSASQPQGPHRPPAAPCRAHRYSNRNLRDRWPSRHRTPGRLQEPTP>sp|P36402-9|TCF7_HUMAN Isoform 5L of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDNSLHYS>sp|P36402-10|TCF7_HUMAN Isoform 5S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDNSLHYS>sp|P36402-11|TCF7_HUMAN Isoform 6L of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDPGSPKKCRARFGLNQQTDWCGPCRKKKCIRYLPGEGRCPSPVPSDDSALGCPGSPAPQDSPSYHLLPRFPTELLTSPAERHLHPQVSPLLSASQPQGPHRPPAAPCRAHRYSNRNLRDRWPSRHRTPGRLQEPTP>sp|P36402-12|TCF7_HUMAN Isoform 6S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDPGSPKKCRARFGLNQQTDWCGPCRKKKCIRYLPGEGRCPSPVPSDDSALGCPGSPAPQDSPSYHLLPRFPTELLTSPAERHLHPQVSPLLSASQPQGPHRPPAAPCRAHRYSNRNLRDRWPSRHRTPGRLQEPTP>sp|P36402-13|TCF7_HUMAN Isoform 7L of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDGIPACTILSP>sp|P36402-14|TCF7_HUMAN Isoform 7S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDGIPACTILSP>sp|P36402-15|TCF7_HUMAN Isoform 8L of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTQLEDWDGWARKP>sp|P36402-16|TCF7_HUMAN Isoform 8S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTQLEDWDGWARKP>sp|P36402-5|TCF7_HUMAN Isoform 2L of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTGGKRNAFGTYPEKAAAPAPFLPMTVL>sp|P36402-6|TCF7_HUMAN Isoform 2S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTGGKRNAFGTYPEKAAAPAPFLPMTVL>sp|P36402-7|TCF7_HUMAN Isoform 3L of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MPQLDSGGGGAGGGDDLGAPDELLAFQDEGEEQDDKSRDSAAGPERDLAELKSSLVNESEGAAGGAGIPGVPGAGAGARGEAEALGREHAAQRLFPDKLPEPLEDGLKAPECTSGMYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDPGSPKKCRARFGLNQQTDWCGPCR>sp|P36402-8|TCF7_HUMAN Isoform 3S of Transcription factor 7 OS=Homosapiens OX=9606 GN=TCF7MYKETVYSAFNLLMHYPPPSGAGQHPQPQPPLHKANQPPHGVPQLSLYEHFNSPHPTPAPADISQKQVHRPLQTPDLSGFYSLTSGSMGQLPHTVSWFTHPSLMLGSGVPGHPAAIPHPAIVPPSGKQELQPFDRNLKTQAESKAEKEAKKPTIKKPLNAFMLYMKEMRAKVIAECTLKESAAINQILGRRWHALSREEQAKYYELARKERQLHMQLYPGWSARDNYGKKKRRSREKHQESTTDPGSPKKCRARFGLNQQTDWCGPCR>sp|Q587J7|TDR12_HUMAN Putative ATP-dependent RNA helicase TDRD12 OS=Homosapiens OX=9606 GN=TDRD12 PE=2 SV=2MLQLLVLKIEDPGCFWVIIKGCSPFLDHDVDYQKLNSAMNDFYNSTCQDIEIKPLTLEEGQVCVVYCEELKCWCRAIVKSITSSADQYLAECFLVDFAKNIPVKSKNIRVVVESFMQLPYRAKKFSLYCTKPVTLHIDFCRDSTDIVPAKKWDNAAIQYFQNLLKATTQVEARLCAVEEDTFEVYLYVTIKDEKVCVNDDLVAKNYACYMSPTKNKNLDYLEKPRLNIKSAPSFNKLNPALTLWPMFLQGKDVQGMEDSHGVNFPAQSLQHTWCKGIVGDLRPTATAQDKAVKCNMDSLRDSPKDKSEKKHHCISLKDTNKRVESSVYWPAKRGITIYADPDVPEASALSQKSNEKPLRLTEKKEYDEKNSCVKLLQFLNPDPLRADGISDLQQLQKLKGLQPPVVVLRNKIKPCLTIDSSPLSADLKKALQRNKFPGPSHTESYSWPPIARGCDVVVISHCESNPLLYLLPVLTVLQTGACYKSLPSRNGPLAVIVCPGWKKAQFIFELLGEYSMSSRPLHPVLLTIGLHKEEAKNTKLPRGCDVIVTTPYSLLRLLACQSLLFLRLCHLILDEVEVLFLEANEQMFAILDNFKKNIEVEERESAPHQIVAVGVHWNKHIEHLIKEFMNDPYIVITAMEEAALYGNVQQVVHLCLECEKTSSLLQALDFIPSQAQKTLIFTCSVAETEIVCKVVESSSIFCLKMHKEMIFNLQNVLEQWKKKLSSGSQIILALTDDCVPLLAITDATCVIHFSFPASPKVFGGRLYCMSDHFHAEQGSPAEQGDKKAKSVLLLTEKDASHAVGVLRYLERADAKVPAELYEFTAGVLEAKEDKKAGRPLCPYLKAFGFCKDKRICPDRHRINPETDLPRKLSSQALPSFGYIKIIPFYILNATNYFGRIVDKHMDLYATLNAEMNEYFKDSNKTTVEKVEKFGLYGLAEKTLFHRVQVLEVNQKEDAWALDDILVEFIDEGRTGLVTRDQLLHLPEHFHTLPPQAVEFIVCRVKPADNEIEWNPKVTRYIHHKIVGKLHDAKVILALGNTVWIDPMVHITNLSSLKTSVIDYNVRAEILSMGMGIDNPEHIEQLKKLREDAKIPACEESLSQTPPRVTGTSPAQDQDHPSEEQGGQGTPPAEDAACLQSPQPEDTGAEGGAESKTSSENQKPGGYLVFKRWLSSNR>sp|Q587J7-2|TDR12_HUMAN Isoform 2 of Putative ATP-dependent RNA helicaseTDRD12 OS=Homo sapiens OX=9606 GN=TDRD12MLQLLVLKIEDPGCFWVIIKGCSPFLDHDVDYQKLNSAMNDFYNSTCQDIEIKPLTLEEGQVCVVYCEELKCWCRAIVKSITSSADQYLAECFLVDFAKNIPVKSKNIRVVVESFMQLPYRAKKFSLYCTKPVTLHIDFCRDSTDIVPAKKWDNAAIQYFQNLLKATTQVEARLCAVEEDTFEVYLYVTIKDEKVCVNDDLVAKNYACYMSPTKNKNLDYLEKPRLNIKSAPSFNKLNPALTLWPMFLQGKDVQGMEDSHGVNFPAQSLQHTWCKGIVGDLRPTATAQDKAVKCNMDSLRDSPKDKSEKKHHCISLKDTNKRVESSVYWPAKRGITIYADPDVPEASALSQKSNEKPLRLTEKKEYDEKNSCVKLLQFLNPDPLRADGISDLQQT>sp|Q8WW24|TEKT4_HUMAN Tektin-4 OS=Homo sapiens OX=9606 GN=TEKT4 PE=1SV=1MAQTVPPCELPCKEYDVARNTGAYTSSGLATASFRTSKYLLEEWFQNCYARYHQAFADRDQSERQRHESQQLATETQALAQRTQQDSTRTVGERLQDTHSWKSELQREMEALAAETNLLLAQKQRLERALDATEVPFSITTDNLQCRERREHPNLVRDHVETELLKEAELIRNIQELLKRTIMQAVSQIRLNREHKETCEMDWSDKMEAYNIDETCGRHHSQSTEVQAHPYSTTFQESASTPETRAKFTQDNLCRAQRERLASANLRVLVDCILRDTSEDLRLQCDAVNLAFGRRCEELEDARYKLHHHLHKTLREITDQEHNVAALKQAIKDKEAPLHVAQTRLYLRSHRPNMELCRDAAQFRLLSEVEELNMSLTALREKLLEAEQSLRNLEDIHMSLEKDIAAMTNSLFIDRQKCMAHRTRYPTILQLAGYQ>sp|Q9BXF9|TEKT3_HUMAN Tektin-3 OS=Homo sapiens OX=9606 GN=TEKT3 PE=1SV=1MERVGCTLTTTYAHPRPTPTNFLPAISTMASSYRDRFPHSNLTHSLSLPWRPSTYYKVASNSPSVAPYCTRSQRVSENTMLPFVSNRTTFFTRYTPDDWYRSNLTNYQESNTSRHNSEKLRVDTSRLIQDKYQQTRKTQADTTQNLGERVNDIGFWKSEIIHELDEMIGETNALTDVKKRLERALMETEAPLQVARECLFHREKRMGIDLVHDEVEAQLLTEVDTILCCQERMKLHLDKAIAQLAANRASQHELEKDLSDKQTAYRIDDKCHHLRNTSDGVGYFRGVERVDATVSVPESWAKFTDDNILRSQSERAASAKLRDDIENLLVVTANEMWNQFNKVNLSFTNRIAETADAKNKIQTHLAKTLQEIFQTEMTIESIKKAIKDKTAFLKVAQTRLDERTRRPNIELCRDMAQLRLVNEVHEVDDTIQTLQQRLRDAEDTLQSLVHIKATLEYDLAVKANSLYIDQEKCMSMRKSYPNTLRLVGFC>sp|Q8N1B4|VPS52_HUMAN Vacuolar protein sorting-associated protein 52homolog OS=Homo sapiens OX=9606 GN=VPS52 PE=1 SV=1MAAAATMAAAARELVLRAGTSDMEEEEGPLAGGPGLQEPLQLGELDITSDEFILDEVDVHIQANLEDELVKEALKTGVDLRHYSKQVELELQQIEQKSIRDYIQESENIASLHNQITACDAVLERMEQMLGAFQSDLSSISSEIRTLQEQSGAMNIRLRNRQAVRGKLGELVDGLVVPSALVTAILEAPVTEPRFLEQLQELDAKAAAVREQEARGTAACADVRGVLDRLRVKAVTKIREFILQKIYSFRKPMTNYQIPQTALLKYRFFYQFLLGNERATAKEIRDEYVETLSKIYLSYYRSYLGRLMKVQYEEVAEKDDLMGVEDTAKKGFFSKPSLRSRNTIFTLGTRGSVISPTELEAPILVPHTAQRGEQRYPFEALFRSQHYALLDNSCREYLFICEFFVVSGPAAHDLFHAVMGRTLSMTLKHLDSYLADCYDAIAVFLCIHIVLRFRNIAAKRDVPALDRYWEQVLALLWPRFELILEMNVQSVRSTDPQRLGGLDTRPHYITRRYAEFSSALVSINQTIPNERTMQLLGQLQVEVENFVLRVAAEFSSRKEQLVFLINNYDMMLGVLMERAADDSKEVESFQQLLNARTQEFIEELLSPPFGGLVAFVKEAEALIERGQAERLRGEEARVTQLIRGFGSSWKSSVESLSQDVMRSFTNFRNGTSIIQGALTQLIQLYHRFHRVLSQPQLRALPARAELINIHHLMVELKKHKPNF>sp|Q8N1B4-2|VPS52_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 52 homolog OS=Homo sapiens OX=9606 GN=VPS52MEQMLGAFQSDLSSISSEIRTLQEQSGAMNIRLRNRQAVRGKLGELVDGLVVPSALVTAILEAPVTEPRFLEQLQELDAKAAAVREQEARGTAACADVRGVLDRLRVKAVTKIREFILQKIYSFRKPMTNYQIPQTALLKYRFFYQFLLGNERATAKEIRDEYVETLSKIYLSYYRSYLGRLMKVQYEEVAEKDDLMGVEDTAKKGFFSKPSLRSRNTIFTLGTRGSVISPTELEAPILVPHTAQRGEQRYPFEALFRSQHYALLDNSCREYLFICEFFVVSGPAAHDLFHAVMGRTLSMTLKHLDSYLADCYDAIAVFLCIHIVLRFRNIAAKRDVPALDRYWEQVLALLWPRFELILEMNVQSVRSTDPQRLGGLDTRPHYITRRYAEFSSALVSINQTIPNERTMQLLGQLQVEVENFVLRVAAEFSSRKEQLVFLINNYDMMLGVLMERAADDSKEVESFQQLLNARTQEFIEELLSPPFGGLVAFVKEAEALIERGQAERLRGEEARVTQLIRGFGSSWKSSVESLSQDVMRSFTNFRNGTSIIQGALTQLIQLYHRFHRVLSQPQLRALPARAELINIHHLMVELKKHKPNF>sp|Q15561|TEAD4_HUMAN Transcriptional enhancer factor TEF-3 OS=Homosapiens OX=9606 GN=TEAD4 PE=1 SV=3MEGTAGTITSNEWSSPTSPEGSTASGGSQALDKPIDNDAEGVWSPDIEQSFQEALAIYPPCGRRKIILSDEGKMYGRNELIARYIKLRTGKTRTRKQVSSHIQVLARRKAREIQAKLKDQAAKDKALQSMAAMSSAQIISATAFHSSMALARGPGRPAVSGFWQGALPGQAGTSHDVKPFSQQTYAVQPPLPLPGFESPAGPAPSPSAPPAPPWQGRSVASSKLWMLEFSAFLEQQQDPDTYNKHLFVHIGQSSPSYSDPYLEAVDIRQIYDKFPEKKGGLKDLFERGPSNAFFLVKFWADLNTNIEDEGSSFYGVSSQYESPENMIITCSTKVCSFGKQVVEKVETEYARYENGHYSYRIHRSPLCEYMINFIHKLKHLPEKYMMNSVLENFTILQVVTNRDTQETLLCIAYVFEVSASEHGAQHHIYRLVKE>sp|Q15561-2|TEAD4_HUMAN Isoform 2 of Transcriptional enhancer factorTEF-3 OS=Homo sapiens OX=9606 GN=TEAD4MAAMSSAQIISATAFHSSMALARGPGRPAVSGFWQGALPGQAGTSHDVKPFSQQTYAVQPPLPLPGFESPAGPAPSPSAPPAPPWQGRSVASSKLWMLEFSAFLEQQQDPDTYNKHLFVHIGQSSPSYSDPYLEAVDIRQIYDKFPEKKGGLKDLFERGPSNAFFLVKFWADLNTNIEDEGSSFYGVSSQYESPENMIITCSTKVCSFGKQVVEKVETEYARYENGHYSYRIHRSPLCEYMINFIHKLKHLPEKYMMNSVLENFTILQVVTNRDTQETLLCIAYVFEVSASEHGAQHHIYRLVKE>sp|Q15561-3|TEAD4_HUMAN Isoform 3 of Transcriptional enhancer factorTEF-3 OS=Homo sapiens OX=9606 GN=TEAD4MEGTAGTITSNEWSSPTSPEGSTASGGSQALDKPIDNDAEGVWSPDIEQSFQEALAIYPPCGRRKIILSDEGKMYGRNELIARYIKLRTGKTRTRKQVSSHIQVLARRKAREIQAKLKFWQGALPGQAGTSHDVKPFSQQTYAVQPPLPLPGFESPAGPAPSPSAPPAPPWQGRSVASSKLWMLEFSAFLEQQQDPDTYNKHLFVHIGQSSPSYSDPYLEAVDIRQIYDKFPEKKGGLKDLFERGPSNAFFLVKFWADLNTNIEDEGSSFYGVSSQYESPENMIITCSTKVCSFGKQVVEKVETEYARYENGHYSYRIHRSPLCEYMINFIHKLKHLPEKYMMNSVLENFTILQVVTNRDTQETLLCIAYVFEVSASEHGAQHHIYRLVKE>sp|Q92734|TFG_HUMAN Protein TFG OS=Homo sapiens OX=9606 GN=TFG PE=1 SV=2MNGQLDLSGKLIIKAQLGEDIRRIPIHNEDITYDELVLMMQRVFRGKLLSNDEVTIKYKDEDGDLITIFDSSDLSFAIQCSRILKLTLFVNGQPRPLESSQVKYLRRELIELRNKVNRLLDSLEPPGEPGPSTNIPENDTVDGREEKSASDSSGKQSTQVMAASMSAFDPLKNQDEINKNVMSAFGLTDDQVSGPPSAPAEDRSGTPDSIASSSSAAHPPGVQPQQPPYTGAQTQAGQIEGQMYQQYQQQAGYGAQQPQAPPQQPQQYGIQYSASYSQQTGPQQPQQFQGYGQQPTSQAPAPAFSGQPQQLPAQPPQQYQASNYPAQTYTAQTSQPTNYTVAPASQPGMAPSQPGAYQPRPGFTSLPGSTMTPPPSGPNPYARNRPPFGQGYTQPGPGYR>sp|Q92734-2|TFG_HUMAN Isoform 2 of Protein TFG OS=Homo sapiens OX=9606GN=TFGMNGQLDLSGKLIIKAQLGEDIRRIPIHNEDITYDELVLMMQRVFRGKLLSNDEVTIKYKDEDGDLITIFDSSDLSFAIQCSRILKLTLFVNGQPRPLESSQVKYLRRELIELRNKVNRLLDSLEPPGEPGPSTNIPENDTVDGREEKSASDSSGKQSTQVMAASMSAFDPLKNQDEINKNVMSAFGLTDDQVSGPPSAPAEDRSGTPDSIASSSSAAHPPGVQPQQPPYTGAQTQAGQMYQQYQQQAGYGAQQPQAPPQQPQQYGIQYSASYSQQTGPQQPQQFQGYGQQPTSQAPAPAFSGQPQQLPAQPPQQYQASNYPAQTYTAQTSQPTNYTVAPASQPGMAPSQPGAYQPRPGFTSLPGSTMTPPPSGPNPYARNRPPFGQGYTQPGPGYR>sp|Q92734-3|TFG_HUMAN Isoform 3 of Protein TFG OS=Homo sapiens OX=9606GN=TFGMNGQLDLSGKLIIKAQLGEDIRRIPIHNEDITYDELVLMMQRVFRGKLLSNDEVTIKYKDEDGDLITIFDSSDLSFAIQCSRILKLTLFVNGQPRPLESSQVKYLRRELIELRNKVNRLLDSLEPPGEPGPSTNIPENDTVDGREEKSASDSSGKQSTQVMAASMSAFDPLKNQDEINKNVMSAFGLTDDQVSGPPSAPAEDRSGTPDSIASSSSAAHPPGVQPQQPPYTGAQTQAGQIEGQMYQQYQQQAGYGAQQPQAPPQQPQQYGIQYSGFQSMERFHCK>sp|Q92734-4|TFG_HUMAN Isoform 4 of Protein TFG OS=Homo sapiens OX=9606GN=TFGMNGQLDLSGKLIIKAQLGEDIRRIPIHNEDITYDELVLMMQRVFRGKLLSNDEVTIKYKDEDGDLITIFDSSDLSFAIQCSRILKLTLFVNGQPRPLESSQVKYLRRELIELRNKVNRLLDSLEPPGEPGPSTNIPENDTVDGREEKSASDSSGKQSTQVMAASMSAFDPLKNQDEINKNVMSAFGLTDDQVSGPPSAPAEDRSGTPDSIASSSSAAHPPGVQPQQPPYTGAQTQAGQMYQQYQQQAGYGAQQPQAPPQQPQQYGIQYSGFQSMERFHCK>sp|P04155|TFF1_HUMAN Trefoil factor 1 OS=Homo sapiens OX=9606 GN=TFF1PE=1 SV=1MATMENKVICALVLVSMLALGTLAEAQTETCTVAPRERQNCGFPGVTPSQCANKGCCFDDTVRGVPWCFYPNTIDVPPEEECEF>sp|Q92752|TENR_HUMAN Tenascin-R OS=Homo sapiens OX=9606 GN=TNR PE=1 SV=3MGADGETVVLKNMLIGINLILLGSMIKPSECQLEVTTERVQRQSVEEEGGIANYNTSSKEQPVVFNHVYNINVPLDNLCSSGLEASAEQEVSAEDETLAEYMGQTSDHESQVTFTHRINFPKKACPCASSAQVLQELLSRIEMLEREVSVLRDQCNANCCQESAATGQLDYIPHCSGHGNFSFESCGCICNEGWFGKNCSEPYCPLGCSSRGVCVDGQCICDSEYSGDDCSELRCPTDCSSRGLCVDGECVCEEPYTGEDCRELRCPGDCSGKGRCANGTCLCEEGYVGEDCGQRQCLNACSGRGQCEEGLCVCEEGYQGPDCSAVAPPEDLRVAGISDRSIELEWDGPMAVTEYVISYQPTALGGLQLQQRVPGDWSGVTITELEPGLTYNISVYAVISNILSLPITAKVATHLSTPQGLQFKTITETTVEVQWEPFSFSFDGWEISFIPKNNEGGVIAQVPSDVTSFNQTGLKPGEEYIVNVVALKEQARSPPTSASVSTVIDGPTQILVRDVSDTVAFVEWIPPRAKVDFILLKYGLVGGEGGRTTFRLQPPLSQYSVQALRPGSRYEVSVSAVRGTNESDSATTQFTTEIDAPKNLRVGSRTATSLDLEWDNSEAEVQEYKVVYSTLAGEQYHEVLVPRGIGPTTRATLTDLVPGTEYGVGISAVMNSQQSVPATMNARTELDSPRDLMVTASSETSISLIWTKASGPIDHYRITFTPSSGIASEVTVPKDRTSYTLTDLEPGAEYIISVTAERGRQQSLESTVDAFTGFRPISHLHFSHVTSSSVNITWSDPSPPADRLILNYSPRDEEEEMMEVSLDATKRHAVLMGLQPATEYIVNLVAVHGTVTSEPIVGSITTGIDPPKDITISNVTKDSVMVSWSPPVASFDYYRVSYRPTQVGRLDSSVVPNTVTEFTITRLNPATEYEISLNSVRGREESERICTLVHTAMDNPVDLIATNITPTEALLQWKAPVGEVENYVIVLTHFAVAGETILVDGVSEEFRLVDLLPSTHYTATMYATNGPLTSGTISTNFSTLLDPPANLTASEVTRQSALISWQPPRAEIENYVLTYKSTDGSRKELIVDAEDTWIRLEGLLENTDYTVLLQAAQDTTWSSITSTAFTTGGRVFPHPQDCAQHLMNGDTLSGVYPIFLNGELSQKLQVYCDMTTDGGGWIVFQRRQNGQTDFFRKWADYRVGFGNVEDEFWLGLDNIHRITSQGRYELRVDMRDGQEAAFASYDRFSVEDSRNLYKLRIGSYNGTAGDSLSYHQGRPFSTEDRDNDVAVTNCAMSYKGAWWYKNCHRTNLNGKYGESRHSQGINWYHWKGHEFSIPFVEMKMRPYNHRLMAGRKRQSLQF>sp|Q92752-2|TENR_HUMAN Isoform 2 of Tenascin-R OS=Homo sapiens OX=9606GN=TNRMGADGETVVLKNMLIGINLILLGSMIKPSECQLEVTTERVQRQSVEEEGGIANYNTSSKEQPVVFNHVYNINVPLDNLCSSGLEASAEQEVSAEDETLAEYMGQTSDHESQVTFTHRINFPKKACPCASSAQVLQELLSRIEMLEREVSVLRDQCNANCCQESAATGQLDYIPHCSGHGNFSFESCGCICNEGWFGKNCSEPYCPLGCSSRGVCVDGQCICDSEYSGDDCSELRCPTDCSSRGLCVDGECVCEEPYTGEDCRELRCPGDCSGKGRCANGTCLCEEGYVGEDCGQRQCLNACSGRGQCEEGLCVCEEGYQGPDCSAVAPPEDLRVAGISDRSIELEWDGPMAVTEYVISYQPTALGGLQLQQRVPGDWSGVTITELEPGLTYNISVYAVISNILSLPITAKVATHLSTPQGLQFKTITETTVEVQWEPFSFSFDGWEISFIPKNNEGGVIAQVPSDVTSFNQTGLKPGEEYIVNVVALKEQARSPPTSASVSTVIDGPTQILVRDVSDTVAFVEWIPPRAKVDFILLKYGLVGGEGGRTTFRLQPPLSQYSVQALRPGSRYEVSVSAVRGTNESDSATTQFTTEIDAPKNLRVGSRTATSLDLEWDNSEAEVQEYKVVYSTLAGEQYHEVLVPRGIGPTTRATLTDLVPGTEYGVGISAVMNSQQSVPATMNARTELDSPRDLMVTASSETSISLIWTKASGPIDHYRITFTPSSGIASEVTVPKDRTSYTLTDLEPGAEYIISVTAERGRQQSLESTVDAFTGIDPPKDITISNVTKDSVMVSWSPPVASFDYYRVSYRPTQVGRLDSSVVPNTVTEFTITRLNPATEYEISLNSVRGREESERICTLVHTAMDNPVDLIATNITPTEALLQWKAPVGEVENYVIVLTHFAVAGETILVDGVSEEFRLVDLLPSTHYTATMYATNGPLTSGTISTNFSTLLDPPANLTASEVTRQSALISWQPPRAEIENYVLTYKSTDGSRKELIVDAEDTWIRLEGLLENTDYTVLLQAAQDTTWSSITSTAFTTGGRVFPHPQDCAQHLMNGDTLSGVYPIFLNGELSQKLQVYCDMTTDGGGWIVFQRRQNGQTDFFRKWADYRVGFGNVEDEFWLGLDNIHRITSQGRYELRVDMRDGQEAAFASYDRFSVEDSRNLYKLRIGSYNGTAGDSLSYHQGRPFSTEDRDNDVAVTNCAMSYKGAWWYKNCHRTNLNGKYGESRHSQGINWYHWKGHEFSIPFVEMKMRPYNHRLMAGRKRQSLQF>sp|Q9BQ65|USB1_HUMAN U6 snRNA phosphodiesterase OS=Homo sapiens OX=9606GN=USB1 PE=1 SV=1MSAAPLVGYSSSGSEDESEDGMRTRPGDGSHRRGQSPLPRQRFPVPDSVLNMFPGTEEGPEDDSTKHGGRVRTFPHERGNWATHVYVPYEAKEEFLDLLDVLLPHAQTYVPRLVRMKVFHLSLSQSVVLRHHWILPFVQALKARMTSFHRFFFTANQVKIYTNQEKTRTFIGLEVTSGHAQFLDLVSEVDRVMEEFNLTTFYQDPSFHLSLAWCVGDARLQLEGQCLQELQAIVDGFEDAEVLLRVHTEQVRCKSGNKFFSMPLK>sp|Q9BQ65-2|USB1_HUMAN Isoform 2 of U6 snRNA phosphodiesterase OS=Homosapiens OX=9606 GN=USB1MSAAPLVGYSSSGSEDESEDGMRTRPGDGSHRRGQSPLPRQRFPVPDSVLNMFPGTEEGPEDDSTKHGGRVRTFPHERGNWATHVYVPYEAKEEFLDLLDVLLPHAQTYVPRLVRMKVFHLSLSQSVVLRHHWILPFVQALKARMTSFHRTFIGLEVTSGHAQFLDLVSEVDRVMEEFNLTTFYQDPSFHLSLAWCVGDARLQLEGQCLQELQAIVDGFEDAEVLLRVHTEQVRCKSGNKFFSMPLK>sp|Q9BQ65-3|USB1_HUMAN Isoform 3 of U6 snRNA phosphodiesterase OS=Homosapiens OX=9606 GN=USB1MSAAPLVGYSSSGSEDESEDGMRTRPGDGSHRRGQSPLPRQRFPVPDSVLNMFPGTEEGPEDDSTKHGGRVRTFPHERGNWATHVYVPYEAKEEFLDLLDVLLPHAQTYVPRLVRMKVFHLSLSQSVVLRHHWILPFVQALKARMTSFHSPHPGPHCLIGTKDAPVTQEIPKDLGALRQEPGSQTR>sp|O60763|USO1_HUMAN General vesicular transport factor p115 OS=Homosapiens OX=9606 GN=USO1 PE=1 SV=2MNFLRGVMGGQSAGPQHTEAETIQKLCDRVASSTLLDDRRNAVRALKSLSKKYRLEVGIQAMEHLIHVLQTDRSDSEIIGYALDTLYNIISNEEEEEVEENSTRQSEDLGSQFTEIFIKQQENVTLLLSLLEEFDFHVRWPGVKLLTSLLKQLGPQVQQIILVSPMGVSRLMDLLADSREVIRNDGVLLLQALTRSNGAIQKIVAFENAFERLLDIISEEGNSDGGIVVEDCLILLQNLLKNNNSNQNFFKEGSYIQRMKPWFEVGDENSGWSAQKVTNLHLMLQLVRVLVSPTNPPGATSSCQKAMFQCGLLQQLCTILMATGVPADILTETINTVSEVIRGCQVNQDYFASVNAPSNPPRPAIVVLLMSMVNERQPFVLRCAVLYCFQCFLYKNQKGQGEIVSTLLPSTIDATGNSVSAGQLLCGGLFSTDSLSNWCAAVALAHALQENATQKEQLLRVQLATSIGNPPVSLLQQCTNILSQGSKIQTRVGLLMLLCTWLSNCPIAVTHFLHNSANVPFLTGQIAENLGEEEQLVQGLCALLLGISIYFNDNSLESYMKEKLKQLIEKRIGKENFIEKLGFISKHELYSRASQKPQPNFPSPEYMIFDHEFTKLVKELEGVITKAIYKSSEEDKKEEEVKKTLEQHDNIVTHYKNMIREQDLQLEELRQQVSTLKCQNEQLQTAVTQQVSQIQQHKDQYNLLKIQLGKDNQHQGSYSEGAQMNGIQPEEIGRLREEIEELKRNQELLQSQLTEKDSMIENMKSSQTSGTNEQSSAIVSARDSEQVAELKQELATLKSQLNSQSVEITKLQTEKQELLQKTEAFAKSVEVQGETETIIATKTTDVEGRLSALLQETKELKNEIKALSEERTAIKEQLDSSNSTIAILQTEKDKLELEITDSKKEQDDLLVLLADQDQKILSLKNKLKDLGHPVEEEDELESGDQEDEDDESEDPGKDLDHI>sp|O60763-2|USO1_HUMAN Isoform 2 of General vesicular transport factorp115 OS=Homo sapiens OX=9606 GN=USO1MNFLRGVMGGQSAGPQHTEAETIQKLCDRVASSTLLDDRRNAVRALKSLSKKYRLEVGIQAMEHLIHVLQTDRSDSEIIGYALDTLYNIISNEEEEEVDDVEEENSTRQSEDLGSQFTEIFIKQQENVTLLLSLLEEFDFHVRWPGVKLLTSLLKQLGPQVQQIILVSPMGVSRLMDLLADSREVIRNDGVLLLQALTRSNGAIQKIVAFENAFERLLDIISEEGNSDGGIVVEDCLILLQNLLKNNNSNQNFFKEGSYIQRMKPWFEVGDENSGWSAQKVTNLHLMLQLVRVLVSPTNPPGATSSCQKAMFQCGLLQQLCTILMATGVPADILTETINTVSEVIRGCQVNQDYFASVNAPSNPPRPAIVVLLMSMVNERQPFVLRCAVLYCFQCFLYKNQKGQGEIVSTLLPSTIDATGNSVSAGQLLCGGLFSTDSLSNWCAAVALAHALQENATQKEQLLRVQLATSIGNPPVSLLQQCTNILSQGDKIDRRGSKIQTRVGLLMLLCTWLSNCPIAVTHFLHNSANVPFLTGQIAENLGEEEQLVQGLCALLLGISIYFNDNSLESYMKEKLKQLIEKRIGKENFIEKLGFISKHELYSRASQKPQPNFPSPEYMIFDHEFTKLVKELEGVITKAIYKSSEEDKKEEEVKKTLEQHDNIVTHYKNMIREQDLQLEELRQQVSTLKCQNEQLQTAVTQQVSQIQQHKDQYNLLKIQLGKDNQHQGSYSEGAQMNGIQPEEIGRLREEIEELKRNQELLQSQLTEKDSMIENMKSSQTSGTNEQSSAIVSARDSEQVAELKQELATLKSQLNSQSVEITKLQTEKQELLQKTEAFAKSVEVQGETETIIATKTTDVEGRLSALLQETKELKNEIKALSEERTAIKEQLDSSNSTIAILQTEKDKLELEITDSKKEQDDLLVLLADQDQKILSLKNKLKDLGHPVEEEDELESGDQEDEDDESEDPGKDLDHI>sp|Q9P2U8|VGLU2_HUMAN Vesicular glutamate transporter 2 OS=Homo sapiensOX=9606 GN=SLC17A6 PE=2 SV=1MESVKQRILAPGKEGLKNFAGKSLGQIYRVLEKKQDTGETIELTEDGKPLEVPERKAPLCDCTCFGLPRRYIIAIMSGLGFCISFGIRCNLGVAIVDMVNNSTIHRGGKVIKEKAKFNWDPETVGMIHGSFFWGYIITQIPGGYIASRLAANRVFGAAILLTSTLNMLIPSAARVHYGCVIFVRILQGLVEGVTYPACHGIWSKWAPPLERSRLATTSFCGSYAGAVIAMPLAGILVQYTGWSSVFYVYGSFGMVWYMFWLLVSYESPAKHPTITDEERRYIEESIGESANLLGAMEKFKTPWRKFFTSMPVYAIIVANFCRSWTFYLLLISQPAYFEEVFGFEISKVGMLSAVPHLVMTIIVPIGGQIADFLRSKQILSTTTVRKIMNCGGFGMEATLLLVVGYSHTRGVAISFLVLAVGFSGFAISGFNVNHLDIAPRYASILMGISNGVGTLSGMVCPIIVGAMTKNKSREEWQYVFLIAALVHYGGVIFYAIFASGEKQPWADPEETSEEKCGFIHEDELDEETGDITQNYINYGTTKSYGATTQANGGWPSGWEKKEEFVQGEVQDSHSYKDRVDYS>sp|Q8NDX2|VGLU3_HUMAN Vesicular glutamate transporter 3 OS=Homo sapiensOX=9606 GN=SLC17A8 PE=1 SV=1MPFKAFDTFKEKILKPGKEGVKNAVGDSLGILQRKIDGTTEEEDNIELNEEGRPVQTSRPSPPLCDCHCCGLPKRYIIAIMSGLGFCISFGIRCNLGVAIVEMVNNSTVYVDGKPEIQTAQFNWDPETVGLIHGSFFWGYIMTQIPGGFISNKFAANRVFGAAIFLTSTLNMFIPSAARVHYGCVMCVRILQGLVEGVTYPACHGMWSKWAPPLERSRLATTSFCGSYAGAVVAMPLAGVLVQYIGWSSVFYIYGMFGIIWYMFWLLQAYECPAAHPTISNEEKTYIETSIGEGANVVSLSKFSTPWKRFFTSLPVYAIIVANFCRSWTFYLLLISQPAYFEEVFGFAISKVGLLSAVPHMVMTIVVPIGGQLADYLRSRQILTTTAVRKIMNCGGFGMEATLLLVVGFSHTKGVAISFLVLAVGFSGFAISGFNVNHLDIAPRYASILMGISNGVGTLSGMVCPLIVGAMTRHKTREEWQNVFLIAALVHYSGVIFYGVFASGEKQEWADPENLSEEKCGIIDQDELAEEIELNHESFASPKKKMSYGATSQNCEVQKKEWKGQRGATLDEEELTSYQNEERNFSTIS>sp|Q8NDX2-2|VGLU3_HUMAN Isoform 2 of Vesicular glutamate transporter 3OS=Homo sapiens OX=9606 GN=SLC17A8MPFKAFDTFKEKILKPGKEGVKNAVGDSLGILQRKIDGTTEEEDNIELNEEGRPVQTSRPSPPLCDCHCCGLPKRYIIAIMSGLGFCISFGIRCNLGVAIVEMVNNSTVYVDGKPEIQTAQFNWDPETVGLIHGSFFWGYIMTQIPGGFISNKFAANRVFGAAIFLTSTLNMFIPSAARVHYGCVMCVRILQGLVEGVTYPACHGMWSKWAPPLERSRLATTSFCGSYAGAVVAMPLAGVLVQYIGWSSVFYIYGMFGIIWYMFWLLQAYECPAAHPTISNEEKTYIETSIGEGANVVSLSVGLLSAVPHMVMTIVVPIGGQLADYLRSRQILTTTAVRKIMNCGGFGMEATLLLVVGFSHTKGVAISFLVLAVGFSGFAISGFNVNHLDIAPRYASILMGISNGVGTLSGMVCPLIVGAMTRHKTREEWQNVFLIAALVHYSGVIFYGVFASGEKQEWADPENLSEEKCGIIDQDELAEEIELNHESFASPKKKMSYGATSQNCEVQKKEWKGQRGATLDEEELTSYQNEERNFSTIS>sp|Q5MNZ6|WIPI3_HUMAN WD repeat domain phosphoinositide-interactingprotein 3 OS=Homo sapiens OX=9606 GN=WDR45B PE=1 SV=2MNLLPCNPHGNGLLYAGFNQDHGCFACGMENGFRVYNTDPLKEKEKQEFLEGGVGHVEMLFRCNYLALVGGGKKPKYPPNKVMIWDDLKKKTVIEIEFSTEVKAVKLRRDRIVVVLDSMIKVFTFTHNPHQLHVFETCYNPKGLCVLCPNSNNSLLAFPGTHTGHVQLVDLASTEKPPVDIPAHEGVLSCIALNLQGTRIATASEKGTLIRIFDTSSGHLIQELRRGSQAANIYCINFNQDASLICVSSDHGTVHIFAAEDPKRNKQSSLASASFLPKYFSSKWSFSKFQVPSGSPCICAFGTEPNAVIAICADGSYYKFLFNPKGECIRDVYAQFLEMTDDKL>sp|Q2TBF2|WSCD2_HUMAN WSC domain-containing protein 2 OS=Homo sapiensOX=9606 GN=WSCD2 PE=2 SV=2MAKLWFKFQRYFRRKPVRFFTFLALYLTAGSLVFLHSGFVGQPAVSGNQANPAAAGGPAEGAELSFLGDMHLGRGFRDTGEASSIARRYGPWFKGKDGNERAKLGDYGGAWSRALKGRVVREKEEERAKYIGCYLDDTQSRALRGVSFFDYKKMTIFRCQDNCAERGYLYGGLEFGAECYCGHKIQATNVSEAECDMECKGERGSVCGGANRLSVYRLQLAQESARRYGSAVFRGCFRRPDNLSLALPVTAAMLNMSVDKCVDFCTEKEYPLAALAGTACHCGFPTTRFPLHDREDEQLCAQKCSAEEFESCGTPSYFIVYQTQVQDNRCMDRRFLPGKSKQLIALASFPGAGNTWARHLIELATGFYTGSYYFDGSLYNKGFKGERDHWRSGRTICIKTHESGQKEIEAFDAAILLIRNPYKALMAEFNRKYGGHIGFAAHAHWKGKEWPEFVRNYAPWWATHTLDWLKFGKKVLVVHFEDLKQDLFVQLGRMVSLLGVAVREDRLLCVESQKDGNFKRSGLRKLEYDPYTADMQKTISAYIKMVDAALKGRNLTGVPDDYYPR>sp|Q2TBF2-2|WSCD2_HUMAN Isoform 2 of WSC domain-containing protein 2OS=Homo sapiens OX=9606 GN=WSCD2MAKLWFKFQRYFRRKPVRFFTFLALYLTAGSLVFLHSGFVGQPAVSGNQANPAAAGGPAEGAELSFLGDMHLGRGFRDTGEASSIARRYGPWFKGKDGNERAKLGDYGGAWSRALKGRVVREKEEERAKYIGCYLDDTQSRALRGVSFFDYKKMTIFRCQDNCAERGYLYGGLEFGAECYCGHKIQATNVSEAECDMECKGERGSVCGGANRLSVYRLQLAQESARRYGSAVFRGCFRRPDNLSLALPVTAAMLNMSVDKCVDFCTEKEYPLAALAGTACHCGFPTTRFPLHDREDEQLCAQKCSAEEFESCGTPSYFIVYQTQVQDNRCMDRRFLPGKSKQLIALASFPGAGNTWARHLIELATGFYTGSYYFDGSLYNKGFKGERDHWRSGRTICIKTHESGQKEIEAFDAAILLIRNPYKALMAEFNRKYGGHIGFAAHAHWKGKGAVPGSLQILFRSICTASVGEWPEFVRNYAPWWATHTLDWLKFGKKVLVVHFEDLKQDLFVQLGRMVSLLGVAVREDRLLCVESQKDGNFKRSGLRKLEYDPYTADMQKTISAYIKMVDAALKGRNLTGVPDDYYPR>sp|A8MWP4|YU008_HUMAN Putative uncharacterized protein ENSP00000401716OS=Homo sapiens OX=9606 PE=5 SV=1MQRPHRRQSQMDAASTRAPPRPSAPQQGRRQPSMPGSAQCHHRPDPHPPAPGKKKSSPVGRFFPASAMAPPWLPGIVSAAQLKPVLSDLPPHCTRAQCQPLTQRPHSLHLQDSRNASSLPHKGWRCNFPLQGPAGLTHKSACVGRMGHCCGSAGNVPELSPRPASPRGQQVTQDGPLQTPELPSECNVGPVMSRQPFPEQSQQGECAIDPRGPPRLELSWGEDPLSGV>sp|O75191|XYLB_HUMAN Xylulose kinase OS=Homo sapiens OX=9606 GN=XYLBPE=1 SV=3MAEHAPRRCCLGWDFSTQQVKVVAVDAELNVFYEESVHFDRDLPEFGTQGGVHVHKDGLTVTSPVLMWVQALDIILEKMKASGFDFSQVLALSGAGQQHGSIYWKAGAQQALTSLSPDLRLHQQLQDCFSISDCPVWMDSSTTAQCRQLEAAVGGAQALSCLTGSRAYERFTGNQIAKIYQQNPEAYSHTERISLVSSFAASLFLGSYSPIDYSDGSGMNLLQIQDKVWSQACLGACAPHLEEKLSPPVPSCSVVGAISSYYVQRYGFPPGCKVVAFTGDNPASLAGMRLEEGDIAVSLGTSDTLFLWLQEPMPALEGHIFCNPVDSQHYMALLCFKNGSLMREKIRNESVSRSWSDFSKALQSTEMGNGGNLGFYFDVMEITPEIIGRHRFNTENHKVAAFPGDVEVRALIEGQFMAKRIHAEGLGYRVMSKTKILATGGASHNREILQVLADVFDAPVYVIDTANSACVGSAYRAFHGLAGGTDVPFSEVVKLAPNPRLAATPSPGASQVYEALLPQYAKLEQRILSQTRGPPE>sp|O75191-2|XYLB_HUMAN Isoform 2 of Xylulose kinase OS=Homo sapiensOX=9606 GN=XYLBMDSSTTAQCRQLEAAVGGAQALSCLTGSRAYERFTGNQIAKIYQQNPEAYSHTERISLVSSFAASLFLGSYSPIDYSDGSGMNLLQIQDKVWSQACLGACAPHLEEKLSPPVPSCSVVGAISSYYVQRYGFPPGCKVVAFTGDNPASLAGMRLEEGDIAVSLGTSDTLFLWLQEPMPALEGHIFCNPVDSQHYMALLCFKNGSLMREKIRNESVSRSWSDFSKALQSTEMGNGGNLGFYFDVMEITPEIIGRHRFNTENHKVAAFPGDVEVRALIEGQFMAKRIHAEGLGYRVMSKTKILATGGASHNREILQVLADVFDAPVYVIDTANSACVGSAYRAFHGLAGGTDVPFSEVVKLAPNPRLAATPSPGASQVYEALLPQYAKLEQRILSQTRGPPE>sp|Q9UK41|VPS28_HUMAN Vacuolar protein sorting-associated protein 28homolog OS=Homo sapiens OX=9606 GN=VPS28 PE=1 SV=1MFHGIPATPGIGAPGNKPELYEEVKLYKNAREREKYDNMAELFAVVKTMQALEKAYIKDCVSPSEYTAACSRLLVQYKAAFRQVQGSEISSIDEFCRKFRLDCPLAMERIKEDRPITIKDDKGNLNRCIADVVSLFITVMDKLRLEIRAMDEIQPDLRELMETMHRMSHLPPDFEGRQTVSQWLQTLSGMSASDELDDSQVRQMLFDLESAYNAFNRFLHA>sp|Q9UK41-2|VPS28_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 28 homolog OS=Homo sapiens OX=9606 GN=VPS28MFHGIPATPGIGAPGNKPELYEEVKLYKNAREREKYDNMAELFAVVKTMQALEKAYIKDCVSPSEYTAACSRLLVQYKAAFRQVQGSEISSIDEFCRKFRLDCPLAMERIKEDRPITIKDDKGNLNRCIADVVSLFITVMDKLRLEIRAMDEIQPDLRELMETMHRMSHLPPDFEGRQTVSQWWVSLPARQSPAVPETLPARRSPAVPLRPSAPTCPVLHSQAADPERHVGVR>sp|Q9GZV5|WWTR1_HUMAN WW domain-containing transcription regulatorprotein 1 OS=Homo sapiens OX=9606 GN=WWTR1 PE=1 SV=1MNPASAPPPLPPPGQQVIHVTQDLDTDLEALFNSVMNPKPSSWRKKILPESFFKEPDSGSHSRQSSTDSSGGHPGPRLAGGAQHVRSHSSPASLQLGTGAGAAGSPAQQHAHLRQQSYDVTDELPLPPGWEMTFTATGQRYFLNHIEKITTWQDPRKAMNQPLNHMNLHPAVSSTPVPQRSMAVSQPNLVMNHQHQQQMAPSTLSQQNHPTQNPPAGLMSMPNALTTQQQQQQKLRLQRIQMERERIRMRQEELMRQEAALCRQLPMEAETLAPVQAAVNPPTMTPDMRSITNNSSDPFLNGGPYHSREQSTDSGLGLGCYSVPTTPEDFLSNVDEMDTGENAGQTPMNINPQQTRFPDFLDCLPGTNVDLGTLESEDLIPLFNDVESALNKSEPFLTWL>sp|P08670|VIME_HUMAN Vimentin OS=Homo sapiens OX=9606 GN=VIM PE=1 SV=4MSTRSVSSSSYRRMFGGPGTASRPSSSRSYVTTSTRTYSLGSALRPSTSRSLYASSPGGVYATRSSAVRLRSSVPGVRLLQDSVDFSLADAINTEFKNTRTNEKVELQELNDRFANYIDKVRFLEQQNKILLAELEQLKGQGKSRLGDLYEEEMRELRRQVDQLTNDKARVEVERDNLAEDIMRLREKLQEEMLQREEAENTLQSFRQDVDNASLARLDLERKVESLQEEIAFLKKLHEEEIQELQAQIQEQHVQIDVDVSKPDLTAALRDVRQQYESVAAKNLQEAEEWYKSKFADLSEAANRNNDALRQAKQESTEYRRQVQSLTCEVDALKGTNESLERQMREMEENFAVEAANYQDTIGRLQDEIQNMKEEMARHLREYQDLLNVKMALDIEIATYRKLLEGEESRISLPLPNFSSLNLRETNLDSLPLVDTHSKRTLLIKTVETRDGQVINETSQHHDDLE>sp|Q5JPB2|ZN831_HUMAN Zinc finger protein 831 OS=Homo sapiens OX=9606GN=ZNF831 PE=2 SV=4MEVPEPTCPAPPARDQPAPTPGPPGAPGGQASPHLTLGPVLLPPEQGLAPPTVFLKALPIPLYHTVPPGGLQPRAPLVTGSLDGGNVPFILSPVLQPEGPGPTQVGKPAAPTLTVNIVGTLPVLSPGLGPTLGSPGKVRNAGKYLCPHCGRDCLKPSVLEKHIRSHTGERPFPCATCGIAFKTQSNLYKHRRTQTHLNNSRLSSESEGAGGGLLEEGDKAGEPPRPEGRGESRCQGMHEGASERPLSPGAHVPLLAKNLDVRTEAAPCPGSAFADREAPWDSAPMASPGLPAASTQPWRKLPEQKSPTAGKPCALQRQQATAAEKPWDAKAPEGRLRKCESTDSGYLSRSDSAEQPHAPCSPLHSLSEHSAESEGEGGPGPGPGVAGAEPGAREAGLELEKKRLEERIAQLISHNQAVVDDAQLDNVRPRKTGLSKQGSIDLPTPYTYKDSFHFDIRALEPGRRRAPGPVRSTWTPPDKSRPLFFHSVPTQLSTTVECVPVTRSNSLPFVEGSRTWLEPREPRDPWSRTQKPLSPRPGPARLGCRSGLSSTDVPSGHPRALVRQAAVEDLPGTPIGDALVPAEDTDAKRTAAREAMAGKGRAGGRKCGQRRLKMFSQEKWQVYGDETFKRIYQKMKASPHGGKKAREVGMGSGAELGFPLQKEAAGSSGTVPTQDRRTPVHEDISAGATPEPWGNPPALEASLVTEPTKHGETVARRGDSDRPRVEEAVSSPALGGRDSPCSGSRSPLVSPNGRLELGWQMPPAPGPLKGGDVEAPRPVWPDPKLEGGARGVGDVQETCLWAQTVLRWPSRGSGEDKLPSERKKLKVEDLHSWKQPEPVSAETPGGPTQPASLSSQKQDADPGEVPGGSKESARQVGEPLESSGASLAAASVALKRVGPRDKATPLHPAAPAPAEHPSLATPPQAPRVLSALADNAFSPKYLLRLPQAETPLPLPIPWGPRHSQDSLCSSGWPEERASFVGSGLGTPLSPSPASGPSPGEADSILEDPSCSRPQDGRKGAQLGGDKGDRMATSRPAARELPISAPGAPREATSSPPTPTCEAHLVQDMEGDSHRIHRLCMGSTLARARLSGDVLNPWVPNWELGEPPGNAPEDPSSGPLVGPDPCSPLQPGSFLTALTRPQGVPPGWPELALSSHSGTSRSHSTRSPHSTQNPFPSLKAEPRLTWCCLSRSVPLPAEQKAKAASVYLAVHFPGSSLRDEGPNGPPGSNGGWTWTSPGEGGPAQMSKFSYPTVPGVMPQHQVSEPEWKKGLPWRAKMSRGNSKQRKLKINPKRYKGNFLQSCVQLRASRLRTPTWVRRRSRHPPALEGLKPCRTPGQTSSEIAGLNLQEEPSCATSESPPCCGKEEKKEGDCRQTLGTLSLGTSSRIVREMDKRTVKDISPSAGEHGDCTTHSTAATSGLSLQSDTCLAVVNDVPLPPGKGLDLGLLETQLLASQDSVSTDPKPYIFSDAQRPSSFGSKGTFPHHDIATSVAAVCISLPVRTDHIAQEIHSAESRDHSQTAGRTLTSSSPDSKVTEEGRAQTLLPGRPSSGQRISDSVPLESTEKTHLEIPASGPSSASSHHKEGRHKTFFPSRGQYGCGEMTVPCPSLGSDGRKRQVSGLITRKDSVVPSKPEQPIEIPEAPSKSLKKRSLEGMRKQTRVEFSDTSSDDEDRLVIEI>sp|Q6DD87|ZN787_HUMAN Zinc finger protein 787 OS=Homo sapiens OX=9606GN=ZNF787 PE=1 SV=4MELREEAWSPGPLDSEDQQMASHENPVDILIMDDDDVPSWPPTKLSPPQSAPPAGPPPRPRPPAPYICNECGKSFSHWSKLTRHQRTHTGERPNACADCGKTFSQSSHLVQHRRIHTGEKPYACLECGKRFSWSSNLMQHQRIHTGEKPYTCPDCGRSFTQSKSLAKHRRSHSGLKPFVCPRCGRGFSQPKSLARHLRLHPELSGPGVAAKVLAASVRRAKGPEEAVAADGEIAIPVGDGEGIIVVGAPGEGAAAAAAMAGAGAKAAGPRSRRAPAPKPYVCLECGKGFGHGAGLLAHQRAQHGDGLGAAGGEEPAHICVECGEGFVQGAALRRHKKIHAVGAPSVCSSCGQSYYRAGGEEEDDDDEAAGGRCPECRGGEGR>sp|Q9HCZ1|ZN334_HUMAN Zinc finger protein 334 OS=Homo sapiens OX=9606GN=ZNF334 PE=1 SV=2MKMKKFQIPVSFQDLTVNFTQEEWQQLDPAQRLLYRDVMLENYSNLVSVGYHVSKPDVIFKLEQGEEPWIVEEFSNQNYPDIDDALEKNKEIQDKHLTQTVFFSNKTLITERENVFGKTLNLGMNSVPSRKMPYKCNPGGNSLKTNSEVIVAKKSKENRKIPDGYSGFGKHEKSHLGMKKYRYNPMRKASNQNENLILHQNIQILKQPFDYNKCGKTFFKRAILITQKGRQTERKPNECNECRKTFSKRSTLIVHQRIHTGEKPYVCSDCRKTFRVKTSLTRHRRIHTGERPYECSECRKTFIDKSALIVHQKIHGGEKSYECNECGKTFFRKSALAEHFRSHTGEKPYECKECGNAFSKKSYLVVHQRTHRGEKPNECKECGKTFFCQSALTAHQRIHTGEKPYECSECEKTFFCQSALNVHRRSHTGEKPYECSQCGKFLCTKSALIAHQITHRGKKSYECNECGKFFCHKSTLTIHQRTHTGEKHGVFNKCGRISIVKSNCSQCKRMNTKENLYECSEHGHAVSKNSHLIVHQRTIWERPYECNECGRTYCRKSALTHHQRTHTGQRPYECNECGKTFCQKFSFVEHQRTHTGEKPYECNECGKSFCHKSAFRVHRRIHTGEKPYECNQCGKTYRRLWTLTEHQKIHTGEKPYECNKCEKTFRHKSNFLLHQKSHKE>sp|Q8N823|ZN611_HUMAN Zinc finger protein 611 OS=Homo sapiens OX=9606GN=ZNF611 PE=1 SV=2MLREEAAQKRKGKEPGMALPQGRLTFRDVAIEFSLAEWKCLNPSQRALYREVMLENYRNLEAVDISSKCMMKEVLSTGQGNTEVIHTGTLQRHESHHIGDFCFQEIEKEIHDIEFQCQEDERNGLEAPMTKIKKLTGSTDQHDHRHAGNKPIKDQLGSSFYSHLPELHIFQIKGEIGNQLEKSTNDAPSVSTFQRISCRPQTQISNNYGNNPLNSSLLPQKQEVHMREKSFQCNKSGKAFNCSSLLRKHQIPHLGDKQYKCDVCGKLFNHEQYLACHDRCHTVEKPYKCKECGKTFSQESSLTCHRRLHTGVKRYNCNECGKIFGQNSALLIDKAIDTGENPYKCNECDKAFNQQSQLSHHRIHTGEKPYKCEECDKVFSRKSTIETHKRIHTGEKPYRCKVCDTAFTWHSQLARHRRIHTAKKTYKCNECGKTFSHKSSLVCHHRLHGGEKSYKCKVCDKAFVWSSQLAKHTRIDCGEKPYKCNECGKTFGQNSDLLIHKSIHTGEQPYKCDECEKVFSRKSSLETHKIGHTGEKPYKCKVCDKAFACHSYLAKHTRIHSGEKPYKCNECSKTFSHRSYLVCHHRVHSGEKPYKCNECSKTFSRRSSLHCHRRLHSGEKPYKCNECGNTFRHCSSLIYHRRLHTGEKSYKCTICDKAFVRNSLLSRHTRIHTAEKPYKCNECGKAFNQQSHLSRHHRIHTGEKP>sp|Q8N823-2|ZN611_HUMAN Isoform 2 of Zinc finger protein 611 OS=Homosapiens OX=9606 GN=ZNF611MMKEVLSTGQGNTEVIHTGTLQRHESHHIGDFCFQEIEKEIHDIEFQCQEDERNGLEAPMTKIKKLTGSTDQHDHRHAGNKPIKDQLGSSFYSHLPELHIFQIKGEIGNQLEKSTNDAPSVSTFQRISCRPQTQISNNYGNNPLNSSLLPQKQEVHMREKSFQCNKSGKAFNCSSLLRKHQIPHLGDKQYKCDVCGKLFNHEQYLACHDRCHTVEKPYKCKECGKTFSQESSLTCHRRLHTGVKRYNCNECGKIFGQNSALLIDKAIDTGENPYKCNECDKAFNQQSQLSHHRIHTGEKPYKCEECDKVFSRKSTIETHKRIHTGEKPYRCKVCDTAFTWHSQLARHRRIHTAKKTYKCNECGKTFSHKSSLVCHHRLHGGEKSYKCKVCDKAFVWSSQLAKHTRIDCGEKPYKCNECGKTFGQNSDLLIHKSIHTGEQPYKCDECEKVFSRKSSLETHKIGHTGEKPYKCKVCDKAFACHSYLAKHTRIHSGEKPYKCNECSKTFSHRSYLVCHHRVHSGEKPYKCNECSKTFSRRSSLHCHRRLHSGEKPYKCNECGNTFRHCSSLIYHRRLHTGEKSYKCTICDKAFVRNSLLSRHTRIHTAEKPYKCNECGKAFNQQSHLSRHHRIHTGEKP>sp|Q5SXM1|ZN678_HUMAN Zinc finger protein 678 OS=Homo sapiens OX=9606GN=ZNF678 PE=2 SV=1MGTISLCIGVCAFEGANTSTSFYKLVYTAILSYSIQDLLPEQDMKDLCQKVTLTRHRSWGLDNLHLVKDWRTVNEGKGQKEYCNRLTQCSSTKSKIFQCIECGRNFSWRSILTEHKRIHTGEKPYKCEECGKVFNRCSNLTKHKRIHTGEKPYKCDECGKVFNWWSQLTNHKKIHTGEKPYKCDECDKVFNWWSQLTSHKKIHSGEKPYPCEECGKAFTQFSNLTQHKRIHTGEKPYKCKECCKAFNKFSNLTQHKRIHTGEKPYKCEECGNVFNECSHLTRHRRIHTGEKPYKCEECGKAFTQFASLTRHKRIHTGEKPYQCEECGKTFNRCSHLSSHKRIHTGEKPYKCEECGRTFTQFSNLTQHKRIHTGEKPYKCKECGKAFNKFSSLTQHRRIHTGVKPYKCEECGKVFKQCSHLTSHKRIHTGEKPYKCKECGKAFYQSSILSKHKRIHTEEKPYKCEECGKAFNQFSSLTRHKRIHTGEKRYKCKECGKGFYQSSIHSKYKRIYTGEEPDKCKKCGSL>sp|Q8NGN8|OR4A4_HUMAN Putative olfactory receptor 4A4 OS=Homo sapiensOX=9606 GN=OR4A4P PE=5 SV=1MEPRKNVTDFVLLGFTQNPKEQKVLFVMFLLFYILTMVGNLLIVVTVTVSETLGSPMSFFLAGLTFIDIIYSSSISPRLISDLFFGNNSISFQSFMAQLFIEHLFGGSEVFLLLVMAYDRYVAICKPLHYLVIMRQWVCVLLLVVSWVGGFLQSVFQLSIIYGLPFCGPNVIDHFFCDMYPLLKLACTDTHVIGLLVVANGGLSCTIAFLLLLISYGVILHSLKKLSQKGRQKAHSTCSSHITVVVFFFVPCIFMCARPARTFSIDKSVSVFYTVITPMLNPLIYTLRNSEMTSAMKKL>sp|Q9H6K4|OPA3_HUMAN Optic atrophy 3 protein OS=Homo sapiens OX=9606GN=OPA3 PE=1 SV=1MVVGAFPMAKLLYLGIRQVSKPLANRIKEAARRSEFFKTYICLPPAQLYHWVEMRTKMRIMGFRGTVIKPLNEEAAAELGAELLGEATIFIVGGGCLVLEYWRHQAQQRHKEEEQRAAWNALRDEVGHLALALEALQAQVQAAPPQGALEELRTELQEVRAQLCNPGRSASHAVPASKK>sp|Q9H6K4-2|OPA3_HUMAN Isoform 2 of Optic atrophy 3 protein OS=Homosapiens OX=9606 GN=OPA3MVVGAFPMAKLLYLGIRQVSKPLANRIKEAARRSEFFKTYICLPPAQLYHWLEMRTKMRIMGFNAAAIKPLNEGAAAELGAELLGEGIIFITACSCLMLEYWRHQLQQRRKEKERRVAREALRGEVGHLGLALEELQAQVQATSTQLALEELRAQLQEVRAHLCLRDPPPAPPVAPASEK>sp|Q06710|PAX8_HUMAN Paired box protein Pax-8 OS=Homo sapiens OX=9606GN=PAX8 PE=1 SV=2MPHNSIRSGHGGLNQLGGAFVNGRPLPEVVRQRIVDLAHQGVRPCDISRQLRVSHGCVSKILGRYYETGSIRPGVIGGSKPKVATPKVVEKIGDYKRQNPTMFAWEIRDRLLAEGVCDNDTVPSVSSINRIIRTKVQQPFNLPMDSCVATKSLSPGHTLIPSSAVTPPESPQSDSLGSTYSINGLLGIAQPGSDKRKMDDSDQDSCRLSIDSQSSSSGPRKHLRTDAFSQHHLEPLECPFERQHYPEAYASPSHTKGEQGLYPLPLLNSTLDDGKATLTPSNTPLGRNLSTHQTYPVVADPHSPFAIKQETPEVSSSSSTPSSLSSSAFLDLQQVGSGVPPFNAFPHAASVYGQFTGQALLSGREMVGPTLPGYPPHIPTSGQGSYASSAIAGMVAGSEYSGNAYGHTPYSSYSEAWRFPNSSLLSSPYYYSSTSRPSAPPTTATAFDHL>sp|Q06710-2|PAX8_HUMAN Isoform 2 of Paired box protein Pax-8 OS=Homosapiens OX=9606 GN=PAX8MPHNSIRSGHGGLNQLGGAFVNGRPLPEVVRQRIVDLAHQGVRPCDISRQLRVSHGCVSKILGRYYETGSIRPGVIGGSKPKVATPKVVEKIGDYKRQNPTMFAWEIRDRLLAEGVCDNDTVPSVSSINRIIRTKVQQPFNLPMDSCVATKSLSPGHTLIPSSAVTPPESPQSDSLGSTYSINGLLGIAQPGSDKRKMDDSDQDSCRLSIDSQSSSSGPRKHLRTDAFSQHHLEPLECPFERQHYPEAYASPSHTKGEQGLYPLPLLNSTLDDGKATLTPSNTPLGRNLSTHQTYPVVAGREMVGPTLPGYPPHIPTSGQGSYASSAIAGMVAGSEYSGNAYGHTPYSSYSEAWRFPNSSLLSSPYYYSSTSRPSAPPTTATAFDHL>sp|Q06710-3|PAX8_HUMAN Isoform 3 of Paired box protein Pax-8 OS=Homosapiens OX=9606 GN=PAX8MPHNSIRSGHGGLNQLGGAFVNGRPLPEVVRQRIVDLAHQGVRPCDISRQLRVSHGCVSKILGRYYETGSIRPGVIGGSKPKVATPKVVEKIGDYKRQNPTMFAWEIRDRLLAEGVCDNDTVPSVSSINRIIRTKVQQPFNLPMDSCVATKSLSPGHTLIPSSAVTPPESPQSDSLGSTYSINGLLGIAQPGSDKRKMDDSDQDSCRLSIDSQSSSSGPRKHLRTDAFSQHHLEPLECPFERQHYPEAYASPSHTKGEQGLYPLPLLNSTLDDGKATLTPSNTPLGRNLSTHQTYPVVAAPPFWICSKSAPGSRPSMPFPMLPPCTGSSRARPSSQGERWWGPRCPDTHPTSPPADRAAMPPLPSQAWWQEVNTLAMPMATPPTPPTARPGASPTPAC>sp|Q06710-4|PAX8_HUMAN Isoform 4 of Paired box protein Pax-8 OS=Homosapiens OX=9606 GN=PAX8MPHNSIRSGHGGLNQLGGAFVNGRPLPEVVRQRIVDLAHQGVRPCDISRQLRVSHGCVSKILGRYYETGSIRPGVIGGSKPKVATPKVVEKIGDYKRQNPTMFAWEIRDRLLAEGVCDNDTVPSVSSINRIIRTKVQQPFNLPMDSCVATKSLSPGHTLIPSSAVTPPESPQSDSLGSTYSINGLLGIAQPGSDKRKMDDSDQDSCRLSIDSQSSSSGPRKHLRTDAFSQHHLEPLECPFERQHYPEAYASPSHTKGEQGERWWGPRCPDTHPTSPPADRAAMPPLPSQAWWQEVNTLAMPMATPPTPPTARPGASPTPAC>sp|Q06710-5|PAX8_HUMAN Isoform 5 of Paired box protein Pax-8 OS=Homosapiens OX=9606 GN=PAX8MPHNSIRSGHGGLNQLGGAFVNGRPLPEVVRQRIVDLAHQGVRPCDISRQLRVSHGCVSKILGRYYETGSIRPGVIGGSKPKVATPKVVEKIGDYKRQNPTMFAWEIRDRLLAEGVCDNDTVPSVSSINRIIRTKVQQPFNLPMDSCVATKSLSPGHTLIPSSAVTPPESPQSDSLGSTYSINGLLGIAQPGSDKRKMDDSDQDSCRLSIDSQSSSSGPRKHLRTDAFSQHHLEPLECPFERQHYPEAYASPSHTKGEQEVNTLAMPMATPPTPPTARPGASPTPAC>sp|Q8NGI4|OR4DB_HUMAN Olfactory receptor 4D11 OS=Homo sapiens OX=9606GN=OR4D11 PE=3 SV=1MELGNVTRVKEFIFLGLTQSQDQSLVLFLFLCLVYMTTLLGNLLIMVTVTCESRLHTPMYFLLRNLAILDICFSSTTAPKVLLDLLSKKKTISYTSCMTQIFLFHLLGGADIFSLSVMAFDCYMAISKPLHYVTIMSRGQCTALISASWMGGFVHSIVQISLLLPLPFCGPNVLDTFYCDVPQVLKLTCTDTFALEFLMISNNGLVTTLWFIFLLVSYTVILMTLRSQAGGGRRKAISTCTSHITVVTLHFVPCIYVYARPFTALPTEKAISVTFTVISPLLNPLIYTLRNQEMKSAMRRLKRRLVPSERE>sp|Q8TEZ7|PAQR8_HUMAN Membrane progestin receptor beta OS=Homo sapiensOX=9606 GN=PAQR8 PE=1 SV=1MTTAILERLSTLSVSGQQLRRLPKILEDGLPKMPCTVPETDVPQLFREPYIRTGYRPTGHEWRYYFFSLFQKHNEVVNVWTHLLAALAVLLRFWAFAEAEALPWASTHSLPLLLFILSSITYLTCSLLAHLLQSKSELSHYTFYFVDYVGVSVYQYGSALAHFFYSSDQAWYDRFWLFFLPAAAFCGWLSCAGCCYAKYRYRRPYPVMRKICQVVPAGLAFILDISPVAHRVALCHLAGCQEQAAWYHTLQILFFLVSAYFFSCPVPEKYFPGSCDIVGHGHQIFHAFLSICTLSQLEAILLDYQGRQEIFLQRHGPLSVHMACLSFFFLAACSAATAALLRHKVKARLTKKDS>sp|Q8NGX6|O10R2_HUMAN Olfactory receptor 10R2 OS=Homo sapiens OX=9606GN=OR10R2 PE=3 SV=3MPQILIFTYLNMFYFFPPLQILAENLTMVTEFLLLGFSSLGEIQLALFVVFLFLYLVILSGNVTIISVIHLDKSLHTPMYFFLGILSTSETFYTFVILPKMLINLLSVARTISFNCCALQMFFFLGFAITNCLLLGVMGYDRYAAICHPLHYPTLMSWQVCGKLAAACAIGGFLASLTVVNLVFSLPFCSANKVNHYFCDISAVILLACTNTDVNEFVIFICGVLVLVVPFLFICVSYLCILRTILKIPSAEGRRKAFSTCASHLSVVIVHYGCASFIYLRPTANYVSNKDRLVTVTYTIVTPLLNPMVYSLRNKDVQLAIRKVLGKKGSLKLYN>sp|P56373|P2RX3_HUMAN P2X purinoceptor 3 OS=Homo sapiens OX=9606GN=P2RX3 PE=1 SV=2MNCISDFFTYETTKSVVVKSWTIGIINRVVQLLIISYFVGWVFLHEKAYQVRDTAIESSVVTKVKGSGLYANRVMDVSDYVTPPQGTSVFVIITKMIVTENQMQGFCPESEEKYRCVSDSQCGPERLPGGGILTGRCVNYSSVLRTCEIQGWCPTEVDTVETPIMMEAENFTIFIKNSIRFPLFNFEKGNLLPNLTARDMKTCRFHPDKDPFCPILRVGDVVKFAGQDFAKLARTGGVLGIKIGWVCDLDKAWDQCIPKYSFTRLDSVSEKSSVSPGYNFRFAKYYKMENGSEYRTLLKAFGIRFDVLVYGNAGKFNIIPTIISSVAAFTSVGVGTVLCDIILLNFLKGADQYKAKKFEEVNETTLKIAALTNPVYPSDQTTAEKQSTDSGAFSIGH>sp|Q96QU1|PCD15_HUMAN Protocadherin-15 OS=Homo sapiens OX=9606 GN=PCDH15PE=1 SV=2MFRQFYLWTCLASGIILGSLFEICLGQYDDDCKLARGGPPATIVAIDEESRNGTILVDNMLIKGTAGGPDPTIELSLKDNVDYWVLMDPVKQMLFLNSTGRVLDRDPPMNIHSIVVQVQCINKKVGTIIYHEVRIVVRDRNDNSPTFKHESYYATVNELTPVGTTIFTGFSGDNGATDIDDGPNGQIEYVIQYNPDDPTSNDTFEIPLMLTGNIVLRKRLNYEDKTRYFVIIQANDRAQNLNERRTTTTTLTVDVLDGDDLGPMFLPCVLVPNTRDCRPLTYQAAIPELRTPEELNPIIVTPPIQAIDQDRNIQPPSDRPGILYSILVGTPEDYPRFFHMHPRTAELSLLEPVNRDFHQKFDLVIKAEQDNGHPLPAFAGLHIEILDENNQSPYFTMPSYQGYILESAPVGATISDSLNLTSPLRIVALDKDIEDTKDPELHLFLNDYTSVFTVTQTGITRYLTLLQPVDREEQQTYTFSITAFDGVQESEPVIVNIQVMDANDNTPTFPEISYDVYVYTDMRPGDSVIQLTAVDADEGSNGEITYEILVGAQGDFIINKTTGLITIAPGVEMIVGRTYALTVQAADNAPPAERRNSICTVYIEVLPPNNQSPPRFPQLMYSLEISEAMRVGAVLLNLQATDREGDSITYAIENGDPQRVFNLSETTGILTLGKALDRESTDRYILIITASDGRPDGTSTATVNIVVTDVNDNAPVFDPYLPRNLSVVEEEANAFVGQVKATDPDAGINGQVHYSLGNFNNLFRITSNGSIYTAVKLNREVRDYYELVVVATDGAVHPRHSTLTLAIKVLDIDDNSPVFTNSTYTVLVEENLPAGTTILQIEAKDVDLGANVSYRIRSPEVKHFFALHPFTGELSLLRSLDYEAFPDQEASITFLVEAFDIYGTMPPGIATVTVIVKDMNDYPPVFSKRIYKGMVAPDAVKGTPITTVYAEDADPPGLPASRVRYRVDDVQFPYPASIFEVEEDSGRVITRVNLNEEPTTIFKLVVVAFDDGEPVMSSSATVKILVLHPGEIPRFTQEEYRPPPVSELATKGTMVGVISAAAINQSIVYSIVSGNEEDTFGINNITGVIYVNGPLDYETRTSYVLRVQADSLEVVLANLRVPSKSNTAKVYIEIQDENNHPPVFQKKFYIGGVSEDARMFTSVLRVKATDKDTGNYSVMAYRLIIPPIKEGKEGFVVETYTGLIKTAMLFHNMRRSYFKFQVIATDDYGKGLSGKADVLVSVVNQLDMQVIVSNVPPTLVEKKIEDLTEILDRYVQEQIPGAKVVVESIGARRHGDAFSLEDYTKCDLTVYAIDPQTNRAIDRNELFKFLDGKLLDINKDFQPYYGEGGRILEIRTPEAVTSIKKRGESLGYTEGALLALAFIIILCCIPAILVVLVSYRQFKVRQAECTKTARIQAALPAAKPAVPAPAPVAAPPPPPPPPPGAHLYEELGDSSILFLLYHFQQSRGNNSVSEDRKHQQVVMPFSSNTIEAHKSAHVDGSLKSNKLKSARKFTFLSDEDDLSAHNPLYKENISQVSTNSDISQRTDFVDPFSPKIQAKSKSLRGPREKIQRLWSQSVSLPRRLMRKVPNRPEIIDLQQWQGTRQKAENENTGICTNKRGSSNPLLTTEEANLTEKEEIRQGETLMIEGTEQLKSLSSDSSFCFPRPHFSFSTLPTVSRTVELKSEPNVISSPAECSLELSPSRPCVLHSSLSRRETPICMLPIETERNIFENFAHPPNISPSACPLPPPPPISPPSPPPAPAPLAPPPDISPFSLFCPPPSPPSIPLPLPPPTFFPLSVSTSGPPTPPLLPPFPTPLPPPPPSIPCPPPPSASFLSTECVCITGVKCTTNLMPAEKIKSSMTQLSTTTVCKTDPQREPKGILRHVKNLAELEKSVANMYSQIEKNYLRTNVSELQTMCPSEVTNMEITSEQNKGSLNNIVEGTEKQSHSQSTSL>sp|Q96QU1-2|PCD15_HUMAN Isoform 2 of Protocadherin-15 OS=Homo sapiensOX=9606 GN=PCDH15MTFSHSGNTAKVYIEIQDENNHPPVFQKKFYIGGVSEDARMFTSVLRVKATDKDTGNYSVMAYRLIIPPIKEGKEGFVVETYTGLIKTAMLFHNMRRSYFKFQVIATDDYGKGLSGKADVLVSVVNQLDMQVIVSNVPPTLVEKKIEDLTEILDRYVQEQIPGAKVVVESIGARRHGDAFSLEDYTKCDLTVYAIDPQTNRAIDRNELFKFLDGKLLDINKDFQPYYGEGGRILEIRTPEAVTSIKKRGESLGYTEGALLALAFIIILCCIPAILVVLVSYRQFKVRQAECTKTARIQAALPAAKPAVPAPAPVAAPPPPPPPPPGAHLYEELGDSSILFLLYHFQQSRGNNSVSEDRKHQQVVMPFSSNTIEAHKSAHVDGSLKSNKLKSARKFTFLSDEDDLSAHNPLYKENISQVSTNSDISQRTDFVDPFSPKIQAKSKSLRGPREKIQRLWSQSVSLPRRLMRKVPNRPEIIDLQQWQGTRQKAENENTGICTNKRGSSNPLLTTEEANLTEKEEIRQGETLMIEGTEQLKSLSSDSSFCFPRPHFSFSTLPTVSRTVELKSEPNVISSPAECSLELSPSRPCVLHSSLSRRETPICMLPIETERNIFENFAHPPNISPSACPLPPPPPISPPSPPPAPAPLAPPPDISPFSLFCPPPSPPSIPLPLPPPTFFPLSVSTSGPPTPPLLPPFPTPLPPPPPSIPCPPPPSASFLSTECVCITGVKCTTNLMPAEKIKSSMTQLSTTTVCKTDPQREPKGILRHVKNLAELEKSVANMYSQIEKNYLRTNVSELQTMCPSEVTNMEITSEQNKGSLNNIVEGTEKQSHSQSTSL>sp|Q96QU1-3|PCD15_HUMAN Isoform 3 of Protocadherin-15 OS=Homo sapiensOX=9606 GN=PCDH15MFRQFYLWTCLASGIILGSLFEICLGQYDDDCKLARGGPPATIVAIDEESRNGTILVDNMLIKGTAGGPDPTIELSLKDNVDYWVLMDPVKQMLFLNSTGRVLDRDPPMNIHSIVVQVQCINKKVGTIIYHEVRIVVRDRNDNSPTFKHESYYATVNELTPVGTTIFTGFSGDNGATDIDDGPNGQIEYVIQYNPDDPTSNDTFEIPLMLTGNIVLRKRLNYEDKTRYFVIIQANDRAQNLNERRTTTTTLTVDVLDGDDLGPMFLPCVLVPNTRDCRPLTYQAAIPELRTPEELNPIIVTPPIQAIDQDRNIQPPSDRPGILYSILVGTPEDYPRFFHMHPRTAELSLLEPVNRDFHQKFDLVIKAEQDNGHPLPAFAGLHIEILDENNQSPYFTMPSYQGYILESAPVGATISDSLNLTSPLRIVALDKDIEDTKDPELHLFLNDYTSVFTVTQTGITRYLTLLQPVDREEQQTYTFSITAFDGVQESEPVIVNIQVMDANDNTPTFPEISYDVYVYTDMRPGDSVIQLTAVDADEGSNGEITYEILVGAQGDFIINKTTGLITIAPGVEMIVGRTYALTVQAADNAPPAERRNSICTVYIEVLPPNNQSPPRFPQLMYSLEISEAMRVGAVLLNLQATDREGDSITYAIENGDPQRVFNLSETTGILTLGKALDRESTDRYILIITASDGRPDGTSTATVNIVVTDVNDNAPVFDPYLPRNLSVVEEEANAFVGQVKATDPDAGINGQVHYSLGNFNNLFRITSNGSIYTAVKLNREVRDYYELVVVATDGAVHPRHSTLTLAIKVLDIDDNSPVFTNSTYTVLVEENLPAGTTILQIEAKDVDLGANVSYRIRSPEVKHFFALHPFTGELSLLRSLDYEAFPDQEASITFLVEAFDIYGTMPPGIATVTVIVKDMNDYPPVFSKRIYKGMVAPDAVKGTPITTVYAEDADPPVSRRH>sp|Q96QU1-4|PCD15_HUMAN Isoform 4 of Protocadherin-15 OS=Homo sapiensOX=9606 GN=PCDH15MFRQFYLWTCLASGIILGSLFEICLGQYDDDCKLARGGPPATIVAIDEESRNGTILVDNMLIKGTAGGPDPTIELSLKDNVDYWVLMDPVKQMLFLNSTGRVLDRDPPMNIHSIVVQVQCINKKVGTIIYHEVRIVVRDRNDNSPTFKHESYYATVNELTPVGTTIFTGFSGDNGATDIDDGPNGQIEYVIQYNPDDPTSNDTFEIPLMLTGNIVLRKRLNYEDKTRYFVIIQANDRAQNLNERRTTTTTLTVDVLDGDDLGPMFLPCVLVPNTRDCRPLTYQAAIPELRTPEELNPIIVTPPIQAIDQDRNIQPPSDRPGILYSILVGTPEDYPRFFHMHPRTAELSLLEPVNRDFHQKFDLVIKAEQDNGHPLPAFAGLHIEILDENNQSPYFTMPSYQGYILESAPVGATISDSLNLTSPLRIVALDKDIEDVPPSGVPTKDPELHLFLNDYTSVFTVTQTGITRYLTLLQPVDREEQQTYTFSITAFDGVQESEPVIVNIQVMDANDNTPTFPEISYDVYVYTDMRPGDSVIQLTAVDADEGSNGEITYEILVGAQGDFIINKTTGLITIAPGVEMIVGRTYALTVQAADNAPPAERRNSICTVYIEVLPPNNQSPPRFPQLMYSLEISEAMRVGAVLLNLQATDREGDSITYAIENGDPQRVFNLSETTGILTLGKALDRESTDRYILIITASDGRPDGTSTATVNIVVTDVNDNAPVFDPYLPRNLSVVEEEANAFVGQVKATDPDAGINGQVHYSLGNFNNLFRITSNGSIYTAVKLNREVRDYYELVVVATDGAVHPRHSTLTLAIKVLDIDDNSPVFTNSTYTVLVEENLPAGTTILQIEAKDVDLGANVSYRIRSPEVKHFFALHPFTGELSLLRSLDYEAFPDQEASITFLVEAFDIYGTMPPGIATVTVIVKDMNDYPPVFSKRIYKGMVAPDAVKGTPITTVYAEDADPPGLPASRVRYRVDDVQFPYPASIFEVEEDSGRVITRVNLNEEPTTIFKLVVVAFDDGEPVMSSSATVKILVLHPGEIPRFTQEEYRPPPVSELATKGTMVGVISAAAINQSIVYSIVSGNEEDTFGINNITGVIYVNGPLDYETRTSYVLRVQADSLEVVLANLRVPSKSNTAKVYIEIQDENNHPPVFQKKFYIGGVSEDARMFTSVLRVKATDKDTGNYSVMAYRLIIPPIKEGKEGFVVETYTGLIKTAMLFHNMRRSYFKFQVIATDDYGKGLSGKADVLVSVVNQLDMQVIVSNVPPTLVEKKIEDLTEILDRYVQEQIPGAKVVVESIGARRHGDAFSLEDYTKCDLTVYAIDPQTNRAIDRNELFKFLDGKLLDINKDFQPYYGEGGRILEIRTPEAVTSIKKRGESLGYTEGALLALAFIIILCCIPAILVVLVSYRQFKVRQAECTKTARIQAALPAAKPAVPAPAPVAAPPPPPPPPPGAHLYEELGDSSMYEMPQYGSRRRLLPPAGQEEYGEVVGEAEEEYEEEEEEPKKIKKPKVEIREPSEEEEVVVTIEKPPAAEPTYTTWKRARIFPMIFKKVRGLADKRGIVDLEGEEWQRRLEEEDKDYLKLTLDQEEATESTVESEEESSSDYTEYSEEESEFSESETTEEESESETPSEEEESSTPESEESESTESEGEKARKNIVLARRRPMVEEVKEVKGRKEEPQEEQKEPKMEEEEHSEEEESGPAPVEESTDPEAQDIPEEGSAESASVEGGVESEEESESGSSSSSSESQSGGPWGYQVPAYDRSKNANQKKSPGANSEGYNTAL>sp|Q96QU1-6|PCD15_HUMAN Isoform 5 of Protocadherin-15 OS=Homo sapiensOX=9606 GN=PCDH15MFRQFYLWTCLASGIILGSLFEICLGQYDDDCKLARGGPPATIVAIDEESRNGTILVDNMLIKGTAGGPDPTIELSLKDNVDYWVLMDPVKQMLFLNSTGRVLDRDPPMNIHSIVVQVQCINKKVGTIIYHEVRIVVRDRNDNSPTFKHESYYATVNELTPVGTTIFTGFSGDNGATDIDDGPNGQIEYVIQYNPDDPTSNDTFEIPLMLTGNIVLRKRLNYEDKTRYFVIIQANDRAQNLNERRTTTTTLTVDVLDGDDLGPMFLPCVLVPNTRDCRPLTYQAAIPELRTPEELNPIIVTPPIQAIDQDRNIQPPSDRPGILYSILVGTPEDYPRFFHMHPRTAELSLLEPVNRDFHQKFDLVIKAEQDNGHPLPAFAGLHIEILDENNQSPYFTMPSYQGYILESAPVGATISDSLNLTSPLRIVALDKDIEDTKDPELHLFLNDYTSVFTVTQTGITRYLTLLQPVDREEQQTYTFSITAFDGVQESEPVIVNIQVMDANDNTPTFPEISYDVYVYTDMRPGDSVIQLTAVDADEGSNGEITYEILVGAQGDFIINKTTGLITIAPGVEMIVGRTYALTVQAADNAPPAERRNSICTVYIEVLPPNNQSPPRFPQLMYSLEISEAMRVGAVLLNLQATDREGDSITYAIENGDPQRVFNLSETTGILTLGKALDRESTDRYILIITASDGRPDGTSTATVNIVVTDVNDNAPVFDPYLPRNLSVVEEEANAFVGQVKATDPDAGINGQVHYSLGNFNNLFRITSNGSIYTAVKLNREVRDYYELVVVATDGAVHPRHSTLTLAIKVLDIDDNSPVFTNSTYTVLVEENLPAGTTILQIEAKDVDLGANVSYRIRSPEVKHFFALHPFTGELSLLRSLDYEAFPDQEASITFLVEAFDIYGTMPPGIATVTVIVKDMNDYPPVFSKRIYKGMVAPDAVKGTPITTVYAEDADPPGLPASRVRYRVDDVQFPYPASIFEVEEDSGRVITRVNLNEEPTTIFKLVVVAFDDGEPVMSSSATVKILVLHPGEIPRFTQEEYRPPPVSELATKGTMVGVISAAAINQSIVYSIVSGNEEDTFGINNITGVIYVNGPLDYETRTSYVLRVQADSLEVVLANLRVPSKSNTAKVYIEIQDENNHPPVFQKKFYIGGVSEDARMFTSVLRVKATDKDTGNYSVMAYRLIIPPIKEGKEGFVVETYTGLIKTAMLFHNMRRSYFKFQVIATDDYGKGLSGKADVLVSVVNQLDMQVIVSNVPPTLVEKKIEDLTEILDRYVQEQIPGAKVVVESIGARRHGDAFSLEDYTKCDLTVYAIDPQTNRAIDRNELFKFLDGKLLDINKDFQPYYGEGGRILEIRTPEAVTSIKKRGESLGYTEGALLALAFIIILCCIPAILVVLVSYRQFKVRQAECTKTARIQAALPAAKPAVPAPAPVAAPPPPPPPPPGAHLYEELGDSSMYEMPQYGSRRRLLPPAGQEEYGEVVGEAEEEYEEEEWARKRMIKLVVDREYETSSTGEDSAPECQRNRLHHPSIHSNINGNIYIAQNGSVVRTRRACLTDNLKVASPVRLGGPFKKLDKLAVTHEENVPLNTLSKGPFSTEKMNARPTLVTFAPCPVGTDNTAVKPLRNRLKSTVEQESMIDSKNIKEALEFHSDHTQSDDEELWMGPWNNLHIPMTKL>sp|Q8NGH6|O52L2_HUMAN Putative olfactory receptor 52L2 OS=Homo sapiensOX=9606 GN=OR52L2P PE=5 SV=3MNLDSFFSFLLKSLIMALSNSSWRLPQPSFFLVGIPGLEESQHWIALPLGILYLLALVGNVTILFIIWMDPSLHQSMYLFLSMLAAIDLVVASSTAPKALAVLLVRAQEIGYTVCLIQMFFTHAFSSMESGVLVAMALDRYVAICHPLHHSTILHPGVIGHIGMVVLVRGLLLLIPFLILLRKLIFCQATIIGHAYCEHMAVVKLACSETTVNRAYGLTVALLVVGLDVLAIGVSYAHILQAVLKVPGNEARLKAFSTCGSHVCVILVFYIPGMFSFLTHRFGHHVPHHVHVLLAILYRLVPPALNPLVYRVKTQKIHQ>sp|Q8NGG3|OR5T3_HUMAN Olfactory receptor 5T3 OS=Homo sapiens OX=9606GN=OR5T3 PE=3 SV=3MDSTFTGYNLYNLQVKTEMDKLSSGLDIYRNPLKNKTEVTMFILTGFTDDFELQVFLFLLFFAIYLFTLIGNLGLVVLVIEDSWLHNPMYYFLSVLSFLDACYSTVVTPKMLVNFLAKNKSISFIGCATQMLLFVTFGTTECFLLAAMAYDHYVAIYNPLLYSVSMSPRVYVPLITASYVAGILHATIHIVATFSLSFCGSNEIRHVFCDMPPLLAISCSDTHTNQLLLFYFVGSIEIVTILIVLISCDFILLSILKMHSAKGRQKAFSTCGSHLTGVTIYHGTILVSYMRPSSSYASDHDIIVSIFYTIVIPKLNPIIYSLRNKEVKKAVKKMLKLVYK>sp|Q86UW2|OSTB_HUMAN Organic solute transporter subunit beta OS=Homosapiens OX=9606 GN=SLC51B PE=1 SV=2MEHSEGAPGDPAGTVVPQELLEEMLWFFRVEDASPWNHSILALAAVVVIISMVLLGRSIQASRKEKMQPPEKETPEVLHLDEAKDHNSLNNLRETLLSEKPNLAQVELELKERDVLSVFLPDVPETES>sp|Q8NH57|O52P1_HUMAN Putative olfactory receptor 52P1 OS=Homo sapiensOX=9606 GN=OR52P1P PE=5 SV=2MESPNHTDVDPSVFFLLGIPGLEQFHLWLSLPVCGLGTATIVGNITILVVVATEPVLHKPVYLFLCMLSTIDLAASVSTVPKLLAIFWCGAGHISASACLAQMFFIHAFCMMESTVLLAMAFDRYVAICHPLRYATILTDTIIAHIGVAAVVRGSLLMLPCPFLIGRLNFCQSHVILHTYCEHMAVVKLACGDTRPNRVYGLTAALLVIGVDLFCIGLSYALSAQAVLRLSSHEARSKALGTCGSHVCVILISYTPALFSFFTHRFGHHVPVHIHILLANVYLLLPPALNPVVYGVKTKQIRKRVVRVFQSGQGMGIKASE>sp|Q8NHW6|OTOSP_HUMAN Otospiralin OS=Homo sapiens OX=9606 GN=OTOS PE=1SV=1MQACMVPGLALCLLLGPLAGAKPVQEEGDPYAELPAMPYWPFSTSDFWNYVQHFQALGAYPQIEDMARTFFAHFPLGSTLGFHVPYQED>sp|Q8NGX3|O10T2_HUMAN Olfactory receptor 10T2 OS=Homo sapiens OX=9606GN=OR10T2 PE=3 SV=1MRGFNKTTVVTQFILVGFSSLGELQLLLFVIFLLLYLTILVANVTIMAVIRFSWTLHTPMYGFLFILSFSESCYTFVIIPQLLVHLLSDTKTISFMACATQLFFFLGFACTNCLLIAVMGYDRYVAICHPLRYTLIINKRLGLELISLSGATGFFIALVATNLICDMRFCGPNRVNHYFCDMAPVIKLACTDTHVKELALFSLSILVIMVPFLLILISYGFIVNTILKIPSAEGKKAFVTCASHLTVVFVHYGCASIIYLRPKSKSASDKDQLVAVTYTVVTPLLNPLVYSLRNKEVKTALKRVLGMPVATKMS>sp|Q8NGF3|O51D1_HUMAN Olfactory receptor 51D1 OS=Homo sapiens OX=9606GN=OR51D1 PE=2 SV=1MQKPQLLVPIIATSNGNLVHAAYFLLVGIPGLGPTIHFWLAFPLCFMYALATLGNLTIVLIIRVERRLHEPMYLFLAMLSTIDLVLSSITMPKMASLFLMGIQEIEFNICLAQMFLIHALSAVESAVLLAMAFDRFVAICHPLRHASVLTGCTVAKIGLSALTRGFVFFFPLPFILKWLSYCQTHTVTHSFCLHQDIMKLSCTDTRVNVVYGLFIILSVMGVDSLFIGFSYILILWAVLELSSRRAALKAFNTCISHLCAVLVFYVPLIGLSVVHRLGGPTSLLHVVMANTYLLLPPVVNPLVYGAKTKEICSRVLCMFSQGGK>sp|P42785|PCP_HUMAN Lysosomal Pro-X carboxypeptidase OS=Homo sapiensOX=9606 GN=PRCP PE=1 SV=1MGRRALLLLLLSFLAPWATIALRPALRALGSLHLPTNPTSLPAVAKNYSVLYFQQKVDHFGFNTVKTFNQRYLVADKYWKKNGGSILFYTGNEGDIIWFCNNTGFMWDVAEELKAMLVFAEHRYYGESLPFGDNSFKDSRHLNFLTSEQALADFAELIKHLKRTIPGAENQPVIAIGGSYGGMLAAWFRMKYPHMVVGALAASAPIWQFEDLVPCGVFMKIVTTDFRKSGPHCSESIHRSWDAINRLSNTGSGLQWLTGALHLCSPLTSQDIQHLKDWISETWVNLAMVDYPYASNFLQPLPAWPIKVVCQYLKNPNVSDSLLLQNIFQALNVYYNYSGQVKCLNISETATSSLGTLGWSYQACTEVVMPFCTNGVDDMFEPHSWNLKELSDDCFQQWGVRPRPSWITTMYGGKNISSHTNIVFSNGELDPWSGGGVTKDITDTLVAVTISEGAHHLDLRTKNALDPMSVLLARSLEVRHMKNWIRDFYDSAGKQH>sp|P42785-2|PCP_HUMAN Isoform 2 of Lysosomal Pro-X carboxypeptidaseOS=Homo sapiens OX=9606 GN=PRCPMGRRALLLLLLSFLAPWATIALRPALRALGSLHLPTNPTSLPAVAKNYSVLYFQQKALAAGQLHICIIQLNHYKTPLVDHFGFNTVKTFNQRYLVADKYWKKNGGSILFYTGNEGDIIWFCNNTGFMWDVAEELKAMLVFAEHRYYGESLPFGDNSFKDSRHLNFLTSEQALADFAELIKHLKRTIPGAENQPVIAIGGSYGGMLAAWFRMKYPHMVVGALAASAPIWQFEDLVPCGVFMKIVTTDFRKSGPHCSESIHRSWDAINRLSNTGSGLQWLTGALHLCSPLTSQDIQHLKDWISETWVNLAMVDYPYASNFLQPLPAWPIKVVCQYLKNPNVSDSLLLQNIFQALNVYYNYSGQVKCLNISETATSSLGTLGWSYQACTEVVMPFCTNGVDDMFEPHSWNLKELSDDCFQQWGVRPRPSWITTMYGGKNISSHTNIVFSNGELDPWSGGGVTKDITDTLVAVTISEGAHHLDLRTKNALDPMSVLLARSLEVRHMKNWIRDFYDSAGKQH>sp|Q99571|P2RX4_HUMAN P2X purinoceptor 4 OS=Homo sapiens OX=9606GN=P2RX4 PE=1 SV=2MAGCCAALAAFLFEYDTPRIVLIRSRKVGLMNRAVQLLILAYVIGWVFVWEKGYQETDSVVSSVTTKVKGVAVTNTSKLGFRIWDVADYVIPAQEENSLFVMTNVILTMNQTQGLCPEIPDATTVCKSDASCTAGSAGTHSNGVSTGRCVAFNGSVKTCEVAAWCPVEDDTHVPQPAFLKAAENFTLLVKNNIWYPKFNFSKRNILPNITTTYLKSCIYDAKTDPFCPIFRLGKIVENAGHSFQDMAVEGGIMGIQVNWDCNLDRAASLCLPRYSFRRLDTRDVEHNVSPGYNFRFAKYYRDLAGNEQRTLIKAYGIRFDIIVFGKAGKFDIIPTMINIGSGLALLGMATVLCDIIVLYCMKKRLYYREKKYKYVEDYEQGLASELDQ>sp|Q99571-2|P2RX4_HUMAN Isoform 2 of P2X purinoceptor 4 OS=Homo sapiensOX=9606 GN=P2RX4MAGCCAALAAFLFEYDTPRIVLIRSRKVGLMNRAVQLLILAYVIGCYHPHLAEVEMESPRRWVFVWEKGYQETDSVVSSVTTKVKGVAVTNTSKLGFRIWDVADYVIPAQEENSLFVMTNVILTMNQTQGLCPEIPDATTVCKSDASCTAGSAGTHSNGVSTGRCVAFNGSVKTCEVAAWCPVEDDTHVPQPAFLKAAENFTLLVKNNIWYPKFNFSKRNILPNITTTYLKSCIYDAKTDPFCPIFRLGKIVENAGHSFQDMAVEGGIMGIQVNWDCNLDRAASLCLPRYSFRRLDTRDVEHNVSPGYNFRFAKYYRDLAGNEQRTLIKAYGIRFDIIVFGKAGKFDIIPTMINIGSGLALLGMATVLCDIIVLYCMKKRLYYREKKYKYVEDYEQGLASELDQ>sp|Q99571-3|P2RX4_HUMAN Isoform 3 of P2X purinoceptor 4 OS=Homo sapiensOX=9606 GN=P2RX4MAGCCAALAAFLFEYDTPRIVLIRSRKVGLMNRAVQLLILAYVIGWVFVWEKGYQETDSVVSSVTTKVKGVAVTNTSKLGFRIWDVADYVIPAQEENSLFVMTNVILTMNQTQGLCPEIPDATTVCKSDASCTAGSAGTHSNGVSTGRPAFLKAAENFTLLVKNNIWYPKFNFSKRNILPNITTTYLKSCIYDAKTDPFCPIFRLGKIVENAGHSFQDMAVEGGIMGIQVNWDCNLDRAASLCLPRYSFRRLDTRDVEHNVSPGYNFRFAKYYRDLAGNEQRTLIKAYGIRFDIIVFGKAGKFDIIPTMINIGSGLALLGMATVLCDIIVLYCMKKRLYYREKKYKYVEDYEQGLASELDQ>sp|Q08499|PDE4D_HUMAN cAMP-specific 3',5'-cyclic phosphodiesterase 4DOS=Homo sapiens OX=9606 GN=PDE4D PE=1 SV=2MEAEGSSAPARAGSGEGSDSAGGATLKAPKHLWRHEQHHQYPLRQPQFRLLHPHHHLPPPPPPSPQPQPQCPLQPPPPPPLPPPPPPPGAARGRYASSGATGRVRHRGYSDTERYLYCRAMDRTSYAVETGHRPGLKKSRMSWPSSFQGLRRFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-2|PDE4D_HUMAN Isoform 3 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMMHVNNFPFRRHSWICFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-3|PDE4D_HUMAN Isoform 10 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-4|PDE4D_HUMAN Isoform 1 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMKEQPSCAGTGHPMAGYGRMAPFELASGPVKRLRTESPFPCLFAEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-5|PDE4D_HUMAN Isoform 2 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-6|PDE4D_HUMAN Isoform 5 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMAQQTSPDTLTVPEVDNPHCPNPWLNEDLVKSLRENLLQHEKSKTARKSVSPKLSPVISPRNSPRLLRRMLLSSNIPKQRRFTVAHTCFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-7|PDE4D_HUMAN Isoform N3 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMAQQTSPDTLTVPEVDNPHCPNPWLNEDLVKSLRENLLQHEKSKTARKSVSPKLSPVISPRNSPRLLRRMLLSSNIPKQRRFTVAHTCFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITGLYNGIIAFL>sp|Q08499-8|PDE4D_HUMAN Isoform 6 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMPEANYLLSVSWGYIKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-9|PDE4D_HUMAN Isoform 8 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMAFVWDPLGATVPGPSTRAKSRLRFSKSYSFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-10|PDE4D_HUMAN Isoform 9 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMSIIMKPRSRSTSSLRTAEAVCFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-11|PDE4D_HUMAN Isoform 7 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMKRNTCDLLSRSKSASEETLHSSNEEEDPFRGMEPYLVRRLSCRNIQLPPLAFRQLEQADLKSESENIQRPTSLPLKILPLIAITSAESSGFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITEEAYQKLASETLEELDWCLDQLETLQTRHSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEFISNTFLDKQHEVEIPSPTQKEKEKKKRPMSQISGVKKLMHSSSLTNSSIPRFGVKTEQEDVLAKELEDVNKWGLHVFRIAELSGNRPLTVIMHTIFQERDLLKTFKIPVDTLITYLMTLEDHYHADVAYHNNIHAADVVQSTHVLLSTPALEAVFTDLEILAAIFASAIHDVDHPGVSNQFLINTNSELALMYNDSSVLENHHLAVGFKLLQEENCDIFQNLTKKQRQSLRKMVIDIVLATDMSKHMNLLADLKTMVETKKVTSSGVLLLDNYSDRIQVLQNMVHCADLSNPTKPLQLYRQWTDRIMEEFFRQGDRERERGMEISPMCDKHNASVEKSQVGFIDYIVHPLWETWADLVHPDAQDILDTLEDNREWYQSTIPQSPSPAPDDPEEGRQGQTEKFQFELTLEEDGESDTEKDSGSQVEEDTSCSDSKTLCTQDSESTEIPLDEQVEEEAVGEEEESQPEACVIDDRSPDT>sp|Q08499-12|PDE4D_HUMAN Isoform 12 of cAMP-specific 3',5'-cyclicphosphodiesterase 4D OS=Homo sapiens OX=9606 GN=PDE4DMAQQTSPDTLTVPEVDNPHCPNPWLNEDLVKSLRENLLQHEKSKTARKSVSPKLSPVISPRNSPRLLRRMLLSSNIPKQRRFTVAHTCFDVDNGTSAGRSPLDPMTSPGSGLILQANFVHSQRRESFLYRSDSDYDLSPKSMSRNSSIASDIHGDDLIVTPFAQVLASLRTVRNNFAALTNLQDRAPSKRSPMCNQPSINKATITGSWMELNPYTLLDM>sp|Q8TCG2|P4K2B_HUMAN Phosphatidylinositol 4-kinase type 2-beta OS=Homosapiens OX=9606 GN=PI4K2B PE=1 SV=1MEDPSEPDRLASADGGSPEEEEDGEREPLLPRIAWAHPRRGAPGSAVRLLDAAGEEGEAGDEELPLPPGDVGVSRSSSAELDRSRPAVSVTIGTSEMNAFLDDPEFADIMLRAEQAIEVGIFPERISQGSSGSYFVKDPKRKIIGVFKPKSEEPYGQLNPKWTKYVHKVCCPCCFGRGCLIPNQGYLSEAGAYLVDNKLHLSIVPKTKVVWLVSETFNYNAIDRAKSRGKKYALEKVPKVGRKFHRIGLPPKIGSFQLFVEGYKEAEYWLRKFEADPLPENIRKQFQSQFERLVILDYIIRNTDRGNDNWLVRYEKQKCEKEIDHKESKWIDDEEFLIKIAAIDNGLAFPFKHPDEWRAYPFHWAWLPQAKVPFSEEIRNLILPYISDMNFVQDLCEDLYELFKTDKGFDKATFESQMSVMRGQILNLTQALRDGKSPFQLVQIPCVIVERSQGGSQGRIVHLSNSFTQTVNCRKPFFSSW>sp|P16499|PDE6A_HUMAN Rod cGMP-specific 3',5'-cyclic phosphodiesterasesubunit alpha OS=Homo sapiens OX=9606 GN=PDE6A PE=1 SV=4MGEVTAEEVEKFLDSNIGFAKQYYNLHYRAKLISDLLGAKEAAVDFSNYHSPSSMEESEIIFDLLRDFQENLQTEKCIFNVMKKLCFLLQADRMSLFMYRTRNGIAELATRLFNVHKDAVLEDCLVMPDQEIVFPLDMGIVGHVAHSKKIANVPNTEEDEHFCDFVDILTEYKTKNILASPIMNGKDVVAIIMAVNKVDGSHFTKRDEEILLKYLNFANLIMKVYHLSYLHNCETRRGQILLWSGSKVFEELTDIERQFHKALYTVRAFLNCDRYSVGLLDMTKQKEFFDVWPVLMGEVPPYSGPRTPDGREINFYKVIDYILHGKEDIKVIPNPPPDHWALVSGLPAYVAQNGLICNIMNAPAEDFFAFQKEPLDESGWMIKNVLSMPIVNKKEEIVGVATFYNRKDGKPFDEMDETLMESLTQFLGWSVLNPDTYESMNKLENRKDIFQDIVKYHVKCDNEEIQKILKTREVYGKEPWECEEEELAEILQAELPDADKYEINKFHFSDLPLTELELVKCGIQMYYELKVVDKFHIPQEALVRFMYSLSKGYRKITYHNWRHGFNVGQTMFSLLVTGKLKRYFTDLEALAMVTAAFCHDIDHRGTNNLYQMKSQNPLAKLHGSSILERHHLEFGKTLLRDESLNIFQNLNRRQHEHAIHMMDIAIIATDLALYFKKRTMFQKIVDQSKTYESEQEWTQYMMLEQTRKEIVMAMMMTACDLSAITKPWEVQSQVALLVAAEFWEQGDLERTVLQQNPIPMMDRNKADELPKLQVGFIDFVCTFVYKEFSRFHEEITPMLDGITNNRKEWKALADEYDAKMKVQEEKKQKQQSAKSAAAGNQPGGNPSPGGATTSKSCCIQ>sp|Q07343|PDE4B_HUMAN cAMP-specific 3',5'-cyclic phosphodiesterase 4BOS=Homo sapiens OX=9606 GN=PDE4B PE=1 SV=1MKKSRSVMTVMADDNVKDYFECSLSKSYSSSSNTLGIDLWRGRRCCSGNLQLPPLSQRQSERARTPEGDGISRPTTLPLTTLPSIAITTVSQECFDVENGPSPGRSPLDPQASSSAGLVLHATFPGHSQRRESFLYRSDSDYDLSPKAMSRNSSLPSEQHGDDLIVTPFAQVLASLRSVRNNFTILTNLHGTSNKRSPAASQPPVSRVNPQEESYQKLAMETLEELDWCLDQLETIQTYRSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEYISNTFLDKQNDVEIPSPTQKDREKKKKQQLMTQISGVKKLMHSSSLNNTSISRFGVNTENEDHLAKELEDLNKWGLNIFNVAGYSHNRPLTCIMYAIFQERDLLKTFRISSDTFITYMMTLEDHYHSDVAYHNSLHAADVAQSTHVLLSTPALDAVFTDLEILAAIFAAAIHDVDHPGVSNQFLINTNSELALMYNDESVLENHHLAVGFKLLQEEHCDIFMNLTKKQRQTLRKMVIDMVLATDMSKHMSLLADLKTMVETKKVTSSGVLLLDNYTDRIQVLRNMVHCADLSNPTKSLELYRQWTDRIMEEFFQQGDKERERGMEISPMCDKHTASVEKSQVGFIDYIVHPLWETWADLVQPDAQDILDTLEDNRNWYQSMIPQSPSPPLDEQNRDCQGLMEKFQFELTLDEEDSEGPEKEGEGHSYFSSTKTLCVIDPENRDSLGETDIDIATEDKSPVDT>sp|Q07343-2|PDE4B_HUMAN Isoform PDE4B2 of cAMP-specific 3',5'-cyclicphosphodiesterase 4B OS=Homo sapiens OX=9606 GN=PDE4BMKEHGGTFSSTGISGGSGDSAMDSLQPLQPNYMPVCLFAEESYQKLAMETLEELDWCLDQLETIQTYRSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEYISNTFLDKQNDVEIPSPTQKDREKKKKQQLMTQISGVKKLMHSSSLNNTSISRFGVNTENEDHLAKELEDLNKWGLNIFNVAGYSHNRPLTCIMYAIFQERDLLKTFRISSDTFITYMMTLEDHYHSDVAYHNSLHAADVAQSTHVLLSTPALDAVFTDLEILAAIFAAAIHDVDHPGVSNQFLINTNSELALMYNDESVLENHHLAVGFKLLQEEHCDIFMNLTKKQRQTLRKMVIDMVLATDMSKHMSLLADLKTMVETKKVTSSGVLLLDNYTDRIQVLRNMVHCADLSNPTKSLELYRQWTDRIMEEFFQQGDKERERGMEISPMCDKHTASVEKSQVGFIDYIVHPLWETWADLVQPDAQDILDTLEDNRNWYQSMIPQSPSPPLDEQNRDCQGLMEKFQFELTLDEEDSEGPEKEGEGHSYFSSTKTLCVIDPENRDSLGETDIDIATEDKSPVDT>sp|Q07343-3|PDE4B_HUMAN Isoform PDE4B3 of cAMP-specific 3',5'-cyclicphosphodiesterase 4B OS=Homo sapiens OX=9606 GN=PDE4BMTAKDSSKELTASEPEVCIKTFKEQMHLELELPRLPGNRPTSPKISPRSSPRNSPCFFRKLLVNKSIRQRRRFTVAHTCFDVENGPSPGRSPLDPQASSSAGLVLHATFPGHSQRRESFLYRSDSDYDLSPKAMSRNSSLPSEQHGDDLIVTPFAQVLASLRSVRNNFTILTNLHGTSNKRSPAASQPPVSRVNPQEESYQKLAMETLEELDWCLDQLETIQTYRSVSEMASNKFKRMLNRELTHLSEMSRSGNQVSEYISNTFLDKQNDVEIPSPTQKDREKKKKQQLMTQISGVKKLMHSSSLNNTSISRFGVNTENEDHLAKELEDLNKWGLNIFNVAGYSHNRPLTCIMYAIFQERDLLKTFRISSDTFITYMMTLEDHYHSDVAYHNSLHAADVAQSTHVLLSTPALDAVFTDLEILAAIFAAAIHDVDHPGVSNQFLINTNSELALMYNDESVLENHHLAVGFKLLQEEHCDIFMNLTKKQRQTLRKMVIDMVLATDMSKHMSLLADLKTMVETKKVTSSGVLLLDNYTDRIQVLRNMVHCADLSNPTKSLELYRQWTDRIMEEFFQQGDKERERGMEISPMCDKHTASVEKSQVGFIDYIVHPLWETWADLVQPDAQDILDTLEDNRNWYQSMIPQSPSPPLDEQNRDCQGLMEKFQFELTLDEEDSEGPEKEGEGHSYFSSTKTLCVIDPENRDSLGETDIDIATEDKSPVDT>sp|Q07343-4|PDE4B_HUMAN Isoform PDE4B5 of cAMP-specific 3',5'-cyclicphosphodiesterase 4B OS=Homo sapiens OX=9606 GN=PDE4BMPEANYLLSVSWGYIKFKRMLNRELTHLSEMSRSGNQVSEYISNTFLDKQNDVEIPSPTQKDREKKKKQQLMTQISGVKKLMHSSSLNNTSISRFGVNTENEDHLAKELEDLNKWGLNIFNVAGYSHNRPLTCIMYAIFQERDLLKTFRISSDTFITYMMTLEDHYHSDVAYHNSLHAADVAQSTHVLLSTPALDAVFTDLEILAAIFAAAIHDVDHPGVSNQFLINTNSELALMYNDESVLENHHLAVGFKLLQEEHCDIFMNLTKKQRQTLRKMVIDMVLATDMSKHMSLLADLKTMVETKKVTSSGVLLLDNYTDRIQVLRNMVHCADLSNPTKSLELYRQWTDRIMEEFFQQGDKERERGMEISPMCDKHTASVEKSQVGFIDYIVHPLWETWADLVQPDAQDILDTLEDNRNWYQSMIPQSPSPPLDEQNRDCQGLMEKFQFELTLDEEDSEGPEKEGEGHSYFSSTKTLCVIDPENRDSLGETDIDIATEDKSPVDT>sp|Q86XP0|PA24D_HUMAN Cytosolic phospholipase A2 delta OS=Homo sapiensOX=9606 GN=PLA2G4D PE=1 SV=2MESLSPGGPPGHPYQGEASTCWQLTVRVLEARNLRWADLLSEADPYVILQLSTAPGMKFKTKTLTDTSHPVWNEAFRFLIQSQVKNVLELSIYDEDSVTEDDICFKVLYDISEVLPGKLLRKTFSQSPQGEEELDVEFLMEETSDRPENLITNKVIVARELSCLDVHLDSTGSTAVVADQDKLELELVLKGSYEDTQTSFLGTASAFRFHYMAALETELSGRLRSSRSNGWNGDNSAGYLTVPLRPLTIGKEVTMDVPAPNAPGVRLQLKAEGCPEELAVHLGFNLCAEEQAFLSRRKQVVAKALKQALQLDRDLQEDEVPVVGIMATGGGARAMTSLYGHLLALQKLGLLDCVTYFSGISGSTWTMAHLYGDPEWSQRDLEGPIRYAREHLAKSKLEVFSPERLASYRRELELRAEQGHPTTFVDLWALVLESMLHGQVMDQKLSGQRAALERGQNPLPLYLSLNVKENNLETLDFKEWVEFSPYEVGFLKYGAFVPPELFGSEFFMGRLMRRIPEPRICFLEAIWSNIFSLNLLDAWYDLTSSGESWKQHIKDKTRSLEKEPLTTSGTSSRLEASWLQPGTALAQAFKGFLTGRPLHQRSPNFLQGLQLHQDYCSHKDFSTWADYQLDSMPSQLTPKEPRLCLVDAAYFINTSSPSMFRPGRRLDLILSFDYSLSAPFEALQQTELYCRARGLPFPRVEPSPQDQHQPRECHLFSDPACPEAPILLHFPLVNASFKDHSAPGVQRSPAELQGGQVDLTGATCPYTLSNMTYKEEDFERLLRLSDYNVQTSQGAILQALRTALKHRTLEARPPRAQT>sp|Q86XP0-2|PA24D_HUMAN Isoform 2 of Cytosolic phospholipase A2 deltaOS=Homo sapiens OX=9606 GN=PLA2G4DMESLSPGGPPGHPYQGEASTCWQLTVRVLEARNLRWADLLSEADPYVILQLSTAPGMKFKTKTLTDTSHPVWNEAFRFLIQSQVKNVLELSIYDEDSVTEDDICFKVLYDISEVLPGKLLRKTFSQSPQGEEELDVEFLMEETSDRPENLITNKVIVARELSCLDVHLDSTGSTAVVADQDKLELELVLKGSYEDTQTSFLGTASAFRFHYMAALETELSGRLRSSRSNGWNGDNSAGYLTVPLRPLTIGKEVTMDVPAPNAPGVRLQLKAEGCPEELAVHLGFNLCAEEQAFLSRRKQVVAKALKQALQLDRDLQEDEVPVVGIMATGGGARAMTSLYGHLLALQKLGLLDCVTYFSGISGSTWTMAHLYGDPEWSQRDLEGPIRYAREHLAKSKLEVFSPERLASYRRELELRAEQGHPTTFVDLWALVLESMLHGQVMDQKLSGQRAALERGQNPLPLYLSLNVKENNLETLDFKEWVEFSPYEVGFLKYGAFVPPELFGSEFFMGRLMRRIPEPRICFLEAIWSNIFSLNLLDAWYDLTSSGESWKQHIKDKTRSLEKEPLTTSGTSSRLEASWLQPGTALAQAFKGFLTGRPLHQRSPNFLQGLQLHQDYCSHKDFSTWADYQLDSMPSQLTPKEPRLCLVDAAYFINTSSPSMFRPGRRLDLILSFDYSLSAPFEVPWSPQGNPSAQPGQAPEASSRATEPLPHTAGVPKGRRGVRP>sp|P05120|PAI2_HUMAN Plasminogen activator inhibitor 2 OS=Homo sapiensOX=9606 GN=SERPINB2 PE=1 SV=2MEDLCVANTLFALNLFKHLAKASPTQNLFLSPWSISSTMAMVYMGSRGSTEDQMAKVLQFNEVGANAVTPMTPENFTSCGFMQQIQKGSYPDAILQAQAADKIHSSFRSLSSAINASTGNYLLESVNKLFGEKSASFREEYIRLCQKYYSSEPQAVDFLECAEEARKKINSWVKTQTKGKIPNLLPEGSVDGDTRMVLVNAVYFKGKWKTPFEKKLNGLYPFRVNSAQRTPVQMMYLREKLNIGYIEDLKAQILELPYAGDVSMFLLLPDEIADVSTGLELLESEITYDKLNKWTSKDKMAEDEVEVYIPQFKLEEHYELRSILRSMGMEDAFNKGRANFSGMSERNDLFLSEVFHQAMVDVNEEGTEAAAGTGGVMTGRTGHGGPQFVADHPFLFLIMHKITNCILFFGRFSSP>sp|Q9BYU1|PBX4_HUMAN Pre-B-cell leukemia transcription factor 4 OS=Homosapiens OX=9606 GN=PBX4 PE=1 SV=2MAAPPRPAPSPPAPRRLDTSDVLQQIMAITDQSLDEAQARKHALNCHRMKPALFSVLCEIKEKTVVSIRGIQDEDPPDAQLLRLDNMLLAEGVCRPEKRGRGGAVARAGTATPGGCPNDNSIEHSDYRAKLSQIRQIYHSELEKYEQACREFTTHVTNLLQEQSRMRPVSPKEIERMVGAIHGKFSAIQMQLKQSTCEAVMTLRSRLLDARRKRRNFSKQATEVLNEYFYSHLNNPYPSEEAKEELARKGGLTISQVSNWFGNKRIRYKKNMGKFQEEATIYTGKTAVDTTEVGVPGNHASCLSTPSSGSSGPFPLPSAGDAFLTLRTLASLQPPPGGGCLQSQAQGSWQGATPQPATASPAGDPGSINSSTSN>sp|Q9ULR5|PAI2B_HUMAN Polyadenylate-binding protein-interacting protein2B OS=Homo sapiens OX=9606 GN=PAIP2B PE=1 SV=2MNGSNMANTSPSVKSKEDQGLSGHDEKENPFAEYMWMENEEDFNRQVEEELQEQDFLDRCFQEMLDEEDQDWFIPSRDLPQAMGQLQQQLNGLSVSEGHDSEDILSKSNLNPDAKEFIPGEKY>sp|Q9BPZ3|PAIP2_HUMAN Polyadenylate-binding protein-interacting protein2 OS=Homo sapiens OX=9606 GN=PAIP2 PE=1 SV=1MKDPSRSSTSPSIINEDVIINGHSHEDDNPFAEYMWMENEEEFNRQIEEELWEEEFIERCFQEMLEEEEEHEWFIPARDLPQTMDQIQDQFNDLVISDGSSLEDLVVKSNLNPNAKEFVPGVKYGNI>sp|Q6ZMV5|P4R3C_HUMAN Protein PPP4R3C OS=Homo sapiens OX=9606 GN=PPP4R3CPE=2 SV=3MAGLRYSVKVYVLNEDEEWNNLGTGQVSSTYDEQFQGMSLLVRSDSDGSVILRSQIPPDRPYGKYQETLIVWYEAENQGLVLKFQDPAGCQDIWKEICQAQGKDPSIQTTVNISDEPEEDFNEMSVISNMVVLPDCELNTLDQIADIVTSVFSSPVTDRERLAEILKNEAYIPKLLQLFHTCENLENTEGLHHLYEIIKGILFLNEACLFEIMFSDECIMDVVGCLEYDPALDQPKRHRDFLTNDAKFKEVIPITNSELRQKIHQTYRLQYIYDILLPVPSIFEDNFLSTLTTFIFSNKAEIVSMLQKDHKFLYEVFAQLKDETTHDDRRCELLFFFKELCSFSQALQPQSKDALFETLIQLGVLPALKIVMIRDDLQVRSAAAVICAYLVEYSPSRIREFIISEAHVCKDSDLFINVIIKQMICDTDPELGGAVHLMVVLHTLLDPRNMLTTPEKSERSEFLHFFYKHCMHKFTAPLLAATSEHNCEEDDIAGYDKSKNCPNDNQTAQLLALILELLTFCIQHHTFYIRSYILNKDLLRKALILMNSKHTHLILCVLRFMRRMICLNDEAYNNYIIKGNLFEPVVNALLDNGTRYNMLNSAILELFEYIRVENIKPLVSHIVEKFYNTLESIEYVQTFKGLKIKYEKERDRQSQIQKNLHSVLQNIVVFRGTIEEIGLEEEICFMEDAGEVVMPPLEDDDEFMETKRTQEGEAVMPPLEDDDKFTETKRTHQEGEAVMPPLEDDDEFMETKRNQEHEGKVDSPKRTSSGDFKFSSSYSACAAIGTGSPSGSSVVRLVDHPDDEEEKEEDEEEKEEDKEDETSPKKKPHLSS>sp|Q6ZMV5-2|P4R3C_HUMAN Isoform 2 of Protein PPP4R3C OS=Homo sapiensOX=9606 GN=PPP4R3CMAGLRYSVKVYVLNEDEEWNNLGTGQVSSTYDEQFQGMSLLVRSDSDGSVILRSQIPPDRPYGKYQETLIVWYEAENQGLVLKFQDPAGCQDIWKEICQAQGKDPSIQTTVNISDEPEEDFNEMSVISNMVVLPDCELNTLDQIADIVTSVFSSPVTDRERLAEILKNEAYIPKLLQLFHTCENLENTEGLHHLYEIIKGILFLNEACLFEIMFSDECIMDVVGCLEYDPALDQPKRHRDFLTNDAKFKEVIPITNSELRQKIHQTYRLQYIYDILLPVPSIFEDNFLSTLTTFIFSNKAEIVSMLQKDHKFLYEVFAQLKDETTHDDRRCELLFFFKELCSFSQALQPQSKDALFETLIQLGVLPALKIVMIRDDLQVRSAAAVICAYLVEYSPSRIREFIISEAHVCKDSDLFINVIIKQMICDTDPELGGAVHLMVVLHTLLDPRNMLTTPEKSERSEFLHFFYKHCMHKFTAPLLAATSEHNCEEDDIAGYDKSKNCPNDNQTAQLLALILELLTFCIQHHTFYIRSYILNKDLLRKALILMNSKHTHLILCVLRFMRRMICLNDEAYNNYIIKGNLFEPVVNALLDNGTRYNMLNSAILELFEYIRVENIKPLVSHIVEKFYNTLESIEYVQTFKGLKIKYEKERDRQSQIQKNLHSVLQNIVVFRGTIEEIGLEEEICFMEDAGEVVMPPLEDDDEFMETKRTQEGEAVMPPLEDDDKFTETKRTHQDEEEKEEDKEDETSPKKKPHLSS>sp|Q13177|PAK2_HUMAN Serine/threonine-protein kinase PAK 2 OS=Homosapiens OX=9606 GN=PAK2 PE=1 SV=3MSDNGELEDKPPAPPVRMSSTIFSTGGKDPLSANHSLKPLPSVPEEKKPRHKIISIFSGTEKGSKKKEKERPEISPPSDFEHTIHVGFDAVTGEFTGMPEQWARLLQTSNITKLEQKKNPQAVLDVLKFYDSNTVKQKYLSFTPPEKDGFPSGTPALNAKGTEAPAVVTEEEDDDEETAPPVIAPRPDHTKSIYTRSVIDPVPAPVGDSHVDGAAKSLDKQKKKTKMTDEEIMEKLRTIVSIGDPKKKYTRYEKIGQGASGTVFTATDVALGQEVAIKQINLQKQPKKELIINEILVMKELKNPNIVNFLDSYLVGDELFVVMEYLAGGSLTDVVTETCMDEAQIAAVCRECLQALEFLHANQVIHRDIKSDNVLLGMEGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMVEGEPPYLNENPLRALYLIATNGTPELQNPEKLSPIFRDFLNRCLEMDVEKRGSAKELLQHPFLKLAKPLSSLTPLIMAAKEAMKSNR>sp|P29122|PCSK6_HUMAN Proprotein convertase subtilisin/kexin type 6OS=Homo sapiens OX=9606 GN=PCSK6 PE=1 SV=1MPPRAPPAPGPRPPPRAAAATDTAAGAGGAGGAGGAGGPGFRPLAPRPWRWLLLLALPAACSAPPPRPVYTNHWAVQVLGGPAEADRVAAAHGYLNLGQIGNLEDYYHFYHSKTFKRSTLSSRGPHTFLRMDPQVKWLQQQEVKRRVKRQVRSDPQALYFNDPIWSNMWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKVSHFYGFGLVDAEALVVEAKKWTAVPSQHMCVAASDKRPRSIPLVQVLRTTALTSACAEHSDQRVVYLEHVVVRTSISHPRRGDLQIYLVSPSGTKSQLLAKRLLDLSNEGFTNWEFMTVHCWGEKAEGQWTLEIQDLPSQVRNPEKQGKLKEWSLILYGTAEHPYHTFSAHQSRSRMLELSAPELEPPKAALSPSQVEVPEDEEDYTAQSTPGSANILQTSVCHPECGDKGCDGPNADQCLNCVHFSLGSVKTSRKCVSVCPLGYFGDTAARRCRRCHKGCETCSSRAATQCLSCRRGFYHHQEMNTCVTLCPAGFYADESQKNCLKCHPSCKKCVDEPEKCTVCKEGFSLARGSCIPDCEPGTYFDSELIRCGECHHTCGTCVGPGREECIHCAKNFHFHDWKCVPACGEGFYPEEMPGLPHKVCRRCDENCLSCAGSSRNCSRCKTGFTQLGTSCITNHTCSNADETFCEMVKSNRLCERKLFIQFCCRTCLLAG>sp|P29122-2|PCSK6_HUMAN Isoform PACE4A-II of Proprotein convertasesubtilisin/kexin type 6 OS=Homo sapiens OX=9606 GN=PCSK6MPPRAPPAPGPRPPPRAAAATDTAAGAGGAGGAGGAGGPGFRPLAPRPWRWLLLLALPAACSAPPPRPVYTNHWAVQVLGGPAEADRVAAAHGYLNLGQIGNLEDYYHFYHSKTFKRSTLSSRGPHTFLRMDPQVKWLQQQEVKRRVKRQVRSDPQALYFNDPIWSNMWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKVSHFYGFGLVDAEALVVEAKKWTAVPSQHMCVAASDKRPRSIPLVQVLRTTALTSACAEHSDQRVVYLEHVVVRTSISHPRRGDLQIYLVSPSGTKSQLLAKRLLDLSNEGFTNWEFMTVHCWGEKAEGQWTLEIQDLPSQVRNPEKQGKLKEWSLILYGTAEHPYHTFSAHQSRSRMLELSAPELEPPKAALSPSQVEVPEDEEDYTGVCHPECGDKGCDGPNADQCLNCVHFSLGSVKTSRKCVSVCPLGYFGDTAARRCRRCHKGCETCSSRAATQCLSCRRGFYHHQEMNTCVTLCPAGFYADESQKNCLKCHPSCKKCVDEPEKCTVCKEGFSLARGSCIPDCEPGTYFDSELIRCGECHHTCGTCVGPGREECIHCAKNFHFHDWKCVPACGEGFYPEEMPGLPHKVCRRCDENCLSCAGSSRNCSRCKTGFTQLGTSCITNHTCSNADETFCEMVKSNRLCERKLFIQFCCRTCLLAG>sp|P29122-3|PCSK6_HUMAN Isoform PACE4B of Proprotein convertasesubtilisin/kexin type 6 OS=Homo sapiens OX=9606 GN=PCSK6MPPRAPPAPGPRPPPRAAAATDTAAGAGGAGGAGGAGGPGFRPLAPRPWRWLLLLALPAACSAPPPRPVYTNHWAVQVLGGPAEADRVAAAHGYLNLGQIGNLEDYYHFYHSKTFKRSTLSSRGPHTFLRMDPQVKWLQQQEVKRRVKRQVRSDPQALYFNDPIWSNMWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKGAAVAFWWTIGWPWNV>sp|P29122-4|PCSK6_HUMAN Isoform PACE4C of Proprotein convertasesubtilisin/kexin type 6 OS=Homo sapiens OX=9606 GN=PCSK6MPPRAPPAPGPRPPPRAAAATDTAAGAGGAGGAGGAGGPGFRPLAPRPWRWLLLLALPAACSAPPPRPVYTNHWAVQVLGGPAEADRVAAAHGYLNLGQIGNLEDYYHFYHSKTFKRSTLSSRGPHTFLRMDPQVKWLQQQEVKRRVKRQVRSDPQALYFNDPIWSNMWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKVSHFYGFGLVDAEALVVEAKKWTAVPSQHMCVAASDKRPRSIPLVQVLRTTALTSACAEHSDQRVVYLEHVVVRTSISHPRRGDLQIYLVSPSGTKSQLLAKRLLDLSNEGFTNWEFMTVHCWGEKAEGQWTLEIQDLPSQVRNPEKQGDLETPVANQLTTEEREPGLKHVFRWQIEQELW>sp|P29122-5|PCSK6_HUMAN Isoform PACE4CS of Proprotein convertasesubtilisin/kexin type 6 OS=Homo sapiens OX=9606 GN=PCSK6MPPRAPPAPGPRPPPRAAAATDTAAGAGGAGGAGGAGGPGFRPLAPRPWRWLLLLALPAACSAPPPRPVYTNHWAVQVLGGPAEADRVAAAHGYLNLGQIGNLEDYYHFYHSKTFKRSTLSSRGPHTFLRMDPQVKWLQQQEVKRRVKRQVRSDPQALYFNDPIWSNMWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKVSHFYGFGLVDAEALVVEAKKWTAVPSQHMCVAASDKRPRSIPLVQVLRTTALTSACAEHSDQRVVYLEHVVVRTSISHPRRGDLQIYLVSPSGTKSQLLAKRLLDLSNEGFTNWEFMTVHCWGEKAEGQWTLEIQDLPSQVRNPEKQGNLD>sp|P29122-6|PCSK6_HUMAN Isoform PACE4D of Proprotein convertasesubtilisin/kexin type 6 OS=Homo sapiens OX=9606 GN=PCSK6MWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKVSHFYGFGLVDAEALVVEAKKWTAVPSQHMCVAASDKRPRSIPLVQVLRTTALTSACAEHSDQRVVYLEHVVVRTSISHPRRGDLQIYLVSPSGTKSQLLAKRLLDLSNEGFTNWEFMTVHCWGEKAEGQWTLEIQDLPSQVRNPEKQGDLETPVANQLTTEERFVSTPSILFHWSVYLSWSQYHIVLITVAL>sp|P29122-7|PCSK6_HUMAN Isoform PACE4E-I of Proprotein convertasesubtilisin/kexin type 6 OS=Homo sapiens OX=9606 GN=PCSK6MPPRAPPAPGPRPPPRAAAATDTAAGAGGAGGAGGAGGPGFRPLAPRPWRWLLLLALPAACSAPPPRPVYTNHWAVQVLGGPAEADRVAAAHGYLNLGQIGNLEDYYHFYHSKTFKRSTLSSRGPHTFLRMDPQVKWLQQQEVKRRVKRQVRSDPQALYFNDPIWSNMWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKVSHFYGFGLVDAEALVVEAKKWTAVPSQHMCVAASDKRPRSIPLVQVLRTTALTSACAEHSDQRVVYLEHVVVRTSISHPRRGDLQIYLVSPSGTKSQLLAKRLLDLSNEGFTNWEFMTVHCWGEKAEGQWTLEIQDLPSQVRNPEKQGKLKEWSLILYGTAEHPYHTFSAHQSRSRMLELSAPELEPPKAALSPSQVEVPEDEEDYTAQSTPGSANILQTSVCHPECGDKGCDGPNADQCLNCVHFSLGSVKTSRKCVSVCPLGYFGDTAARRCRRCHKGCETCSSRAATQCLSCRRGFYHHQEMNTCVTLCPAGFYADESQKNCLKCHPSCKKCVDEPEKCTVCKEGFSLARGSCIPDCEPGTYFDSELIRCGECHHTCGTCVGPGREECIHCAKNFHFHDWKCVPACGEGFYPEEMPGLPHKVCRRYGPPGGERQATVSSKGVPGGQSLSASSPGAGEGMLHHPTVDRSPFTELLRGLRPFVHWMHICWVPAVGRHRAAAG>sp|P29122-8|PCSK6_HUMAN Isoform PACE4E-II of Proprotein convertasesubtilisin/kexin type 6 OS=Homo sapiens OX=9606 GN=PCSK6MPPRAPPAPGPRPPPRAAAATDTAAGAGGAGGAGGAGGPGFRPLAPRPWRWLLLLALPAACSAPPPRPVYTNHWAVQVLGGPAEADRVAAAHGYLNLGQIGNLEDYYHFYHSKTFKRSTLSSRGPHTFLRMDPQVKWLQQQEVKRRVKRQVRSDPQALYFNDPIWSNMWYLHCGDKNSRCRSEMNVQAAWKRGYTGKNVVVTILDDGIERNHPDLAPNYDSYASYDVNGNDYDPSPRYDASNENKHGTRCAGEVAASANNSYCIVGIAYNAKIGGIRMLDGDVTDVVEAKSLGIRPNYIDIYSASWGPDDDGKTVDGPGRLAKQAFEYGIKKGRQGLGSIFVWASGNGGREGDYCSCDGYTNSIYTISVSSATENGYKPWYLEECASTLATTYSSGAFYERKIVTTDLRQRCTDGHTGTSVSAPMVAGIIALALEANSQLTWRDVQHLLVKTSRPAHLKASDWKVNGAGHKVSHFYGFGLVDAEALVVEAKKWTAVPSQHMCVAASDKRPRSIPLVQVLRTTALTSACAEHSDQRVVYLEHVVVRTSISHPRRGDLQIYLVSPSGTKSQLLAKRLLDLSNEGFTNWEFMTVHCWGEKAEGQWTLEIQDLPSQVRNPEKQGKLKEWSLILYGTAEHPYHTFSAHQSRSRMLELSAPELEPPKAALSPSQVEVPEDEEDYTGVCHPECGDKGCDGPNADQCLNCVHFSLGSVKTSRKCVSVCPLGYFGDTAARRCRRCHKGCETCSSRAATQCLSCRRGFYHHQEMNTCVTLCPAGFYADESQKNCLKCHPSCKKCVDEPEKCTVCKEGFSLARGSCIPDCEPGTYFDSELIRCGECHHTCGTCVGPGREECIHCAKNFHFHDWKCVPACGEGFYPEEMPGLPHKVCRRYGPPGGERQATVSSKGVPGGQSLSASSPGAGEGMLHHPTVDRSPFTELLRGLRPFVHWMHICWVPAVGRHRAAAG>sp|Q99447|PCY2_HUMAN Ethanolamine-phosphate cytidylyltransferase OS=Homosapiens OX=9606 GN=PCYT2 PE=1 SV=1MIRNGRGAAGGAEQPGPGGRRAVRVWCDGCYDMVHYGHSNQLRQARAMGDYLIVGVHTDEEIAKHKGPPVFTQEERYKMVQAIKWVDEVVPAAPYVTTLETLDKYNCDFCVHGNDITLTVDGRDTYEEVKQAGRYRECKRTQGVSTTDLVGRMLLVTKAHHSSQEMSSEYREYADSFGKCPGGRNPWTGVSQFLQTSQKIIQFASGKEPQPGETVIYVAGAFDLFHIGHVDFLEKVHRLAERPYIIAGLHFDQEVNHYKGKNYPIMNLHERTLSVLACRYVSEVVIGAPYAVTAELLSHFKVDLVCHGKTEIIPDRDGSDPYQEPKRRGIFRQIDSGSNLTTDLIVQRIITNRLEYEARNQKKEAKELAFLEAARQQAAQPLGERDGDF>sp|Q99447-2|PCY2_HUMAN Isoform 2 of Ethanolamine-phosphatecytidylyltransferase OS=Homo sapiens OX=9606 GN=PCYT2MVQAIKWVDEVVPAAPYVTTLETLDKYNCDFCVHGNDITLTVDGRDTYEEVKQAGRYRECKRTQGVSTTDLVGRMLLVTKAHHSSQEMSSEYREYADSFGKCPGGRNPWTGVSQFLQTSQKIIQFASGKEPQPGETVIYVAGAFDLFHIGHVDFLEKVHRLAERPYIIAGLHFDQEVNHYKGKNYPIMNLHERTLSVLACRYVSEVVIGAPYAVTAELLSHFKVDLVCHGKTEIIPDRDGSDPYQEPKRRGIFRQIDSGSNLTTDLIVQRIITNRLEYEARNQKKEAKELAFLEAARQQAAQPLGERDGDF>sp|Q99447-3|PCY2_HUMAN Isoform 3 of Ethanolamine-phosphatecytidylyltransferase OS=Homo sapiens OX=9606 GN=PCYT2MIRNGRGAAGGAEQPGPGGRRAVRVWCDGCYDMVHYGHSNQLRQARAMGDYLIVGVHTDEEIAKHKGPPVFTQEERYKMVQAIKWVDEVVPAAPYVTTLETLDKYNCDFCVHGNDITLTVDGRDTYEEVKQAGRYRECKRTQGVSTTDLVGRMLLVTKAHHSSQEMSSEYREYADSFGKPPHPIPAGDILSSEGCSQCPGGRNPWTGVSQFLQTSQKIIQFASGKEPQPGETVIYVAGAFDLFHIGHVDFLEKVHRLAERPYIIAGLHFDQEVNHYKGKNYPIMNLHERTLSVLACRYVSEVVIGAPYAVTAELLSHFKVDLVCHGKTEIIPDRDGSDPYQEPKRRGIFRQIDSGSNLTTDLIVQRIITNRLEYEARNQKKEAKELAFLEAARQQAAQPLGERDGDF>sp|Q99447-4|PCY2_HUMAN Isoform 4 of Ethanolamine-phosphatecytidylyltransferase OS=Homo sapiens OX=9606 GN=PCYT2MVHYGHSNQLRQARAMGDYLIVGVHTDEEIAKHKGPPVFTQEERYKMVQAIKWVDEVVPAAPYVTTLETLDKYNCDFCVHGNDITLTVDGRDTYEEVKQAGRYRECKRTQGVSTTDLVGRMLLVTKAHHSSQEMSSEYREYADSFGKCPGGRNPWTGVSQFLQTSQKIIQFASGKEPQPGETVIYVAGAFDLFHIGHVDFLEKVHRLAERPYIIAGLHFDQEVNHYKGKNYPIMNLHERTLSVLACRYVSEVVIGAPYAVTAELLSHFKVDLVCHGKTEIIPDRDGSDPYQEPKRRGIFRQIDSGSNLTTDLIVQRIITNRLEYEARNQKKEAKELAFLEAARQQAAQPLGERDGDF>sp|Q9Y536|PAL4A_HUMAN Peptidyl-prolyl cis-trans isomerase A-like 4AOS=Homo sapiens OX=9606 GN=PPIAL4A PE=2 SV=1MVNSVVFFDITVDGKPLGRISIKLFADKILKTAENFRALSTGEKGFRYKGSCFHRIIPGFMCQGGDFTRHNGTGDKSIYGEKFDDENLIRKHTGSGILSMANAGPNTNGSQFFICAAKTEWLDGKHVAFGKVKERVNIVEAMEHFGYRNSKTSKKITIADCGQF>sp|Q9NP74|PALMD_HUMAN Palmdelphin OS=Homo sapiens OX=9606 GN=PALMD PE=1SV=1MEEAELVKGRLQAITDKRKIQEEISQKRLKIEEDKLKHQHLKKKALREKWLLDGISSGKEQEEMKKQNQQDQHQIQVLEQSILRLEKEIQDLEKAELQISTKEEAILKKLKSIERTTEDIIRSVKVEREERAEESIEDIYANIPDLPKSYIPSRLRKEINEEKEDDEQNRKALYAMEIKVEKDLKTGESTVLSSIPLPSDDFKGTGIKVYDDGQKSVYAVSSNHSAAYNGTDGLAPVEVEELLRQASERNSKSPTEYHEPVYANPFYRPTTPQRETVTPGPNFQERIKIKTNGLGIGVNESIHNMGNGLSEERGNNFNHISPIPPVPHPRSVIQQAEEKLHTPQKRLMTPWEESNVMQDKDAPSPKPRLSPRETIFGKSEHQNSSPTCQEDEEDVRYNIVHSLPPDINDTEPVTMIFMGYQQAEDSEEDKKFLTGYDGIIHAELVVIDDEEEEDEGEAEKPSYHPIAPHSQVYQPAKPTPLPRKRSEASPHENTNHKSPHKNSISLKEQEESLGSPVHHSPFDAQTTGDGTEDPSLTALRMRMAKLGKKVI>sp|Q9NP74-2|PALMD_HUMAN Isoform 2 of Palmdelphin OS=Homo sapiens OX=9606GN=PALMDMASRWNQQRKRTGRDEEAKSTKEEAILKKLKSIERTTEDIIRSVKVEREERAEESIEDIYANIPDLPKSYIPSRLRKEINEEKEDDEQNRKALYAMEIKVEKDLKTGESTVLSSIPLPSDDFKGTGIKVYDDGQKSVYAVSSNHSAAYNGTDGLAPVEVEELLRQASERNSKSPTEYHEPVYANPFYRPTTPQRETVTPGPNFQERIKIKTNGLGIGVNESIHNMGNGLSEERGNNFNHISPIPPVPHPRSVIQQAEEKLHTPQKRLMTPWEESNVMQDKDAPSPKPRLSPRETIFGKSEHQNSSPTCQEDEEDVRYNIVHSLPPDINDTEPVTMIFMGYQQAEDSEEDKKFLTGYDGIIHAELVVIDDEEEEDEGEAEKPSYHPIAPHSQVYQPAKPTPLPRKRSEASPHENTNHKSPHKNSISLKEQEESLGSPVHHSPFDAQTTGDGTEDPSLTALRMRMAKLGKKVI>sp|Q9NP74-3|PALMD_HUMAN Isoform 3 of Palmdelphin OS=Homo sapiens OX=9606GN=PALMDMEIKVEKDLKTGESTVLSSIPLPSDDFKGTGIKVYDDGQKSVYAVSSNHSAAYNGTDGLAPVEVEELLRQASERNSKSPTEYHEPVYANPFYRPTTPQRETVTPGPNFQERIKIKTNGLGIGVNESIHNMGNGLSEERGNNFNHISPIPPVPHPRSVIQQAEEKLHTPQKRLMTPWEESNVMQDKDAPSPKPRLSPRETIFGKSEHQNSSPTCQEDEEDVRYNIVHSLPPDINDTEPVTMIFMGYQQAEDSEEDKKFLTGYDGIIHAELVVIDDEEEEDEGEAEKPSYHPIAPHSQVYQPAKPTPLPRKRSEASPHENTNHKSPHKNSISLKEQEESLGSPVHHSPFDAQTTGDGTEDPSLTALRMRMAKLGKKVI>sp|P53609|PGTB1_HUMAN Geranylgeranyl transferase type-1 subunit betaOS=Homo sapiens OX=9606 GN=PGGT1B PE=1 SV=2MAATEDERLAGSGEGERLDFLRDRHVRFFQRCLQVLPERYSSLETSRLTIAFFALSGLDMLDSLDVVNKDDIIEWIYSLQVLPTEDRSNLNRCGFRGSSYLGIPFNPSKAPGTAHPYDSGHIAMTYTGLSCLVILGDDLSRVNKEACLAGLRALQLEDGSFCAVPEGSENDMRFVYCASCICYMLNNWSGMDMKKAITYIRRSMSYDNGLAQGAGLESHGGSTFCGIASLCLMGKLEEVFSEKELNRIKRWCIMRQQNGYHGRPNKPVDTCYSFWVGATLKLLKIFQYTNFEKNRNYILSTQDRLVGGFAKWPDSHPDALHAYFGICGLSLMEESGICKVHPALNVSTRTSERLLDLHQSWKTKDSKQCSENVHIST>sp|P53609-2|PGTB1_HUMAN Isoform 2 of Geranylgeranyl transferase type-1subunit beta OS=Homo sapiens OX=9606 GN=PGGT1BMAATEDERLAGSGEGERLDFLRDRHVRFFQRCLQVLPERYSSLETSRLTIAFFALSGLDMLDSLDVVNKDDIIEWIYSLQVLPTEDRSNLNRCGFRGSSYLGIPFNPSKAPGTAHPYDSGHIAMTYTGLSCLVILGDDLSRVNKEACLAGLRALQLEDGSFCAVPEGSENDMRFVYCASCICYMLNNWSGMDMKKAITYIRRSMLLKIFQYTNFEKNRNYILSTQDRLVGGFAKWPDSHPDALHAYFGICGLSLMEESGICKVHPALNVSTRTSERLLDLHQSWKTKDSKQCSENVHIST>sp|Q9HCN3|PGAP6_HUMAN Post-GPI attachment to proteins factor 6 OS=Homosapiens OX=9606 GN=PGAP6 PE=1 SV=3MGRAGTGTGGEAVAAVVAGPLLLLLLARPPPASAGYSGKSEVGLVSEHFSQAPQRLSFYSWYGSARLFRFRVPPDAVLLRWLLQVSRESGAACTDAEITVHFRSGAPPVINPLGTSFPDDTAVQPSFQVGVPLSTTPRSNASVNVSHPAPGDWFVAAHLPPSSQKIELKGLAPTCAYVFQPELLVTRVVEISIMEPDVPLPQTLLSHPSYLKVFVPDYTRELLLELRDCVSNGSLGCPVRLTVGPVTLPSNFQKVLTCTGAPWPCRLLLPSPPWDRWLQVTAESLVGPLGTVAFSAVAALTACRPRSVTIQPLLQSSQNQSFNASSGLLSPSPDHQDLGRSGRVDRSPFCLTNYPVTREDMDVVSVHFQPLDRVSVRVCSDTPSVMRLRLNTGMDSGGSLTISLRANKTEMRNETVVVACVNAASPFLGFNTSLNCTTAFFQGYPLSLSAWSRRANLIIPYPETDNWYLSLQLMCPENAEDCEQAVVHVETTLYLVPCLNDCGPYGQCLLLRRHSYLYASCSCKAGWRGWSCTDNSTAQTVAQQRAATLLLTLSNLMFLAPIAVSVRRFFLVEASVYAYTMFFSTFYHACDQPGEAVLCILSYDTLQYCDFLGSGAAIWVTILCMARLKTVLKYVLFLLGTLVIAMSLQLDRRGMWNMLGPCLFAFVIMASMWAYRCGHRRQCYPTSWQRWAFYLLPGVSMASVGIAIYTSMMTSDNYYYTHSIWHILLAGSAALLLPPPDQPAEPWACSQKFPCHYQICKNDREELYAVT>sp|Q8N328|PGBD3_HUMAN PiggyBac transposable element-derived protein 3OS=Homo sapiens OX=9606 GN=PGBD3 PE=1 SV=3MPRTLSLHEITDLLETDDSIEASAIVIQPPENATAPVSDEESGDEEGGTINNLPGSLLHTAAYLIQDGSDAESDSDDPSYAPKDDSPDEVPSTFTVQQPPPSRRRKMTKILCKWKKADLTVQPVAGRVTAPPNDFFTVMRTPTEILELFLDDEVIELIVKYSNLYACSKGVHLGLTSSEFKCFLGIIFLSGYVSVPRRRMFWEQRTDVHNVLVSAAMRRDRFETIFSNLHVADNANLDPVDKFSKLRPLISKLNERCMKFVPNETYFSFDEFMVPYFGRHGCKQFIRGKPIRFGYKFWCGATCLGYICWFQPYQGKNPNTKHEEYGVGASLVLQFSEALTEAHPGQYHFVFNNFFTSIALLDKLSSMGHQATGTVRKDHIDRVPLESDVALKKKERGTFDYRIDGKGNIVCRWNDNSVVTVASSGAGIHPLCLVSRYSQKLKKKIQVQQPNMIKVYNQFMGGVDRADENIDKYRASIRGKKWYSSPLLFCFELVLQNAWQLHKTYDEKPVDFLEFRRRVVCHYLETHGHPPEPGQKGRPQKRNIDSRYDGINHVIVKQGKQTRCAECHKNTTFRCEKCDVALHVKCSVEYHTE>sp|Q75T13|PGAP1_HUMAN GPI inositol-deacylase OS=Homo sapiens OX=9606GN=PGAP1 PE=1 SV=1MFLHSVNLWNLAFYVFMVFLATLGLWDVFFGFEENKCSMSYMFEYPEYQKIELPKKLAKRYPAYELYLYGEGSYAEEHKILPLTGIPVLFLPGNAGSYKQVRSIGSIALRKAEDIDFKYHFDFFSVNFNEELVALYGGSLQKQTKFVHECIKTILKLYKGQEFAPKSVAIIGHSMGGLVARALLTLKNFKHDLINLLITQATPHVAPVMPLDRFITDFYTTVNNYWILNARHINLTTLSVAGGFRDYQVRSGLTFLPKLSHHTSALSVVSSAVPKTWVSTDHLSIVWCKQLQLTTVRAFFDLIDADTKQITQNSKKKLSVLYHHFIRHPSKHFEENPAIISDLTGTSMWVLVKVSKWTYVAYNESEKIYFTFPLENHRKIYTHVYCQSTMLDTNSWIFACINSTSMCLQGVDLSWKAELLPTIKYLTLRLQDYPSLSHLVVYVPSVRGSKFVVDCEFFKKEKRYIQLPVTHLFSFGLSSRKVVLNTNGLYYNLELLNFGQIYQAFKINVVSKCSAVKEEITSIYRLHIPWSYEDSLTIAQAPSSTEISLKLHIAQPENNTHVALFKMYTSSDCRYEVTVKTSFSQILGQVVRFHGGALPAYVVSNILLAYRGQLYSLFSTGCCLEYATMLDKEAKPYKVDPFVIIIKFLLGYKWFKELWDVLLLPELDAVILTCQSMCFPLISLILFLFGTCTAYWSGLLSSASVRLLSSLWLALKRPSELPKDIKMISPDLPFLTIVLIIVSWTTCGALAILLSYLYYVFKVVHLQASLTTFKNSQPVNPKHSRRSEKKSNHHKDSSIHHLRLSANDAEDSLRMHSTVINLLTWIVLLSMPSLIYWLKNLRYYFKLNPDPCKPLAFILIPTMAILGNTYTVSIKSSKLLKTTSQFPLPLAVGVIAFGSAHLYRLPCFVFIPLLLHALCNFM>sp|Q75T13-2|PGAP1_HUMAN Isoform 2 of GPI inositol-deacylase OS=Homosapiens OX=9606 GN=PGAP1MGGLVARALLTLKNFKHDLINLLITQATPHVAPVMPLDRFITDFYTTVNNYWILNARHINLTTLSVAGGFRDYQVRSGLTFLPKLSHHTSALSVVSSAVPKTWVSTDHLSIVWCKQLQLTTVRAFFDLIDADTKQITQNSKKKLSVLYHHFIRHPSKHFEENPAIISDLTGTSMWVLVKVSKWTYVAYNESEKIYFTFPLENHRKIYTHVYCQSTMLDTNSWIFACINSTSMCLQGVDLSWKAELLPTIKYLTLRLQDYPSLSHLVVYVPSVRGSKFVVDCEFFKKEKRYIQLPVTHLFSFGLSSRKVVLNTNGLYYNLELLNFGQIYQAFKINVVSKCSAVKEEITSIYRLHIPWSYEDSLTIAQAPSSTEISLKLHIAQPENNTHVALFKMYTSSDCRYEVTVKTSFSQILGQVVRFHGGALPAYVVSNILLAYRGQLYSLFSTGCCLEYATMLDKEAKPYKVDPFVIIIKFLLGYKWFKELWDVLLLPELDAVILTCQSMCFPLISLILFLFGTCTAYWSGLLSSASVRLLSSLWLALKRPSELPKDIKMISPDLPFLTIVLIIVSWTTCGALAILLSYLYYVFKVVHLQASLTTFKNSQPVNPKHSRRSEKKSNHHKDSSIHHLRLSANDAEDSLRMHSTVINLLTWIVLLSMPSLIYWLKNLRYYFKLNPDPCKPLAFILIPTMAILGNTYTVSIKSSKLLKTTSQFPLPLAVGVIAFGSAHLYRLPCFVFIPLLLHALCNFM>sp|Q75T13-3|PGAP1_HUMAN Isoform 3 of GPI inositol-deacylase OS=Homosapiens OX=9606 GN=PGAP1MFLHSVNLWNLAFYVFMVFLATLGLWDVFFGFEENKCSMSYMFEYPEYQKIELPKKLAKRYPAYELYLYGEGSYAEEHKILPLTGIPVLFLPGNAGSYKQVRSIGSIALRKAEDIDFKYHFDFFSVNFNEELVALYGGSLQKQTKFVHECIKTILKLYKGQEFAPKSVAIIGHSMGGLVARALLTLKNFKHDLINLLITQATPHVAPVMPLDRFITDFYTTVNNYWILNARHINLTTLSVAGGFRDYQVRSGLTFLPKLSHHTSALSVVSSAVPKTWVSTDHLSIVWCKQLQLTTVRAFFDLIDADTKQITQNSKKKLSVLYHHFIRHPSKHFEENPAIISDLTGTSMWVLVKVSKWTYVAYNESEKIYFTFPLENHRKIYTHVYCQSTMLDTNSWIFACINSTSMCLQGVDLSWKAELLPTIKYLTLRLQDYPSLSHLVVYVPSVRGSKFVVDCEFFKKEKRYIQLPVTHLFSFGLSSRKVVLNTNGLYYNLELLNFGQIYQAFKINVVSKCSAVKEEITSIYRLHIPWSYEDSLTIAQAPSSTEISLKLHIAQPENNTHVALFKMYTSSDCRYEVTVKTSFSQILGQVVA>sp|Q75T13-4|PGAP1_HUMAN Isoform 4 of GPI inositol-deacylase OS=Homosapiens OX=9606 GN=PGAP1MFLHSVNLWNLAFYVFMVFLATLGLWDVFFGFEENKCSMSYMFEYPEYQSSAVPKTWVSTDHLSIVWCKQLQLTTVRAFFDLIDADTKQITQNSKKKLSVLYHHFIRHPSKHFEENPAIISDLTGTSMWVLVKVSKWTYVAYNESEKIYFTFPLENHRKIYTHVYCQSTMLDTNSWIFACINSTSMCLQGVDLSWKAELLPTIKYLTLRLQDYPSLSHLVVYVPSVRGSKFVVDCEFFKKEKRYIQLPVTHLFSFGLSSRKVVLNTNGLYYNLELLNFGQIYQAFKINVVSKCSAVKEEITSIYRLHIPWSYEDSLTIAQAPSSTEISLKLHIAQPENNTHVALFKMYTSSDCRYEVTVKTSFSQILGQVVRFHGGALPAYVVSNILLAYRGQLYSLFSTGCCLEYATMLDKEAKPYKVDPFVIIIKFLLG>sp|P20142|PEPC_HUMAN Gastricsin OS=Homo sapiens OX=9606 GN=PGC PE=1 SV=1MKWMVVVLVCLQLLEAAVVKVPLKKFKSIRETMKEKGLLGEFLRTHKYDPAWKYRFGDLSVTYEPMAYMDAAYFGEISIGTPPQNFLVLFDTGSSNLWVPSVYCQSQACTSHSRFNPSESSTYSTNGQTFSLQYGSGSLTGFFGYDTLTVQSIQVPNQEFGLSENEPGTNFVYAQFDGIMGLAYPALSVDEATTAMQGMVQEGALTSPVFSVYLSNQQGSSGGAVVFGGVDSSLYTGQIYWAPVTQELYWQIGIEEFLIGGQASGWCSEGCQAIVDTGTSLLTVPQQYMSALLQATGAQEDEYGQFLVNCNSIQNLPSLTFIINGVEFPLPPSSYILSNNGYCTVGVEPTYLSSQNGQPLWILGDVFLRSYYSVYDLGNNRVGFATAA>sp|P20142-2|PEPC_HUMAN Isoform 2 of Gastricsin OS=Homo sapiens OX=9606GN=PGCMKWMVVVLVCLQLLEAAVVKVPLKKFKSIRETMKEKGLLGEFLRTHKYDPAWKYRFGDLSVTYEPMAYMDAAYFGEISIGTPPQNFLVLFDTGSSNLWVPSVYCQSQACTSHSRFNPSESSTYSTNGQTFSLQYGSGSLTGFFGYDTLTVQSIQVPNQEFGLSENEPGTNFVYAQFDGIMGLAYPALSVDEATTAMQGMVQEGALTSPVFSVYLSNLVLESSGLGPLLTPSRAAPPSSTLQLPEKPLEQTWNILTPFTKTLPVSNLSRKVTSWAGVGIPVTCLPEAGSGGERRAECGLGVPTTRGPPRSQHHSGA>sp|Q15198|PGFRL_HUMAN Platelet-derived growth factor receptor-likeprotein OS=Homo sapiens OX=9606 GN=PDGFRL PE=1 SV=1MKVWLLLGLLLVHEALEDVTGQHLPKNKRPKEPGENRIKPTNKKVKPKIPKMKDRDSANSAPKTQSIMMQVLDKGRFQKPAATLSLLAGQTVELRCKGSRIGWSYPAYLDTFKDSRLSVKQNERYGQLTLVNSTSADTGEFSCWVQLCSGYICRKDEAKTGSTYIFFTEKGELFVPSPSYFDVVYLNPDRQAVVPCRVTVLSAKVTLHREFPAKEIPANGTDIVYDMKRGFVYLQPHSEHQGVVYCRAEAGGRSQISVKYQLLYVAVPSGPPSTTILASSNKVKSGDDISVLCTVLGEPDVEVEFTWIFPGQKDERPVTIQDTWRLIHRGLGHTTRISQSVITVEDFETIDAGYYICTAQNLQGQTTVATTVEFS>sp|Q8IXK0|PHC2_HUMAN Polyhomeotic-like protein 2 OS=Homo sapiens OX=9606GN=PHC2 PE=1 SV=1MENELPVPHTSSSACATSSTSGASSSSGCNNSSSGGSGRPTGPQISVYSGIPDRQTVQVIQQALHRQPSTAAQYLQQMYAAQQQHLMLQTAALQQQHLSSAQLQSLAAVQQASLVSNRQGSTSGSNVSAQAPAQSSSINLAASPAAAQLLNRAQSVNSAAASGIAQQAVLLGNTSSPALTASQAQMYLRAQMLIFTPTATVATVQPELGTGSPARPPTPAQVQNLTLRTQQTPAAAASGPTPTQPVLPSLALKPTPGGSQPLPTPAQSRNTAQASPAGAKPGIADSVMEPHKKGDGNSSVPGSMEGRAGLSRTVPAVAAHPLIAPAYAQLQPHQLLPQPSSKHLQPQFVIQQQPQPQQQQPPPQQSRPVLQAEPHPQLASVSPSVALQPSSEAHAMPLGPVTPALPLQCPTANLHKPGGSQQCHPPTPDTGPQNGHPEGVPHTPQRRFQHTSAVILQLQPASPPQQCVPDDWKEVAPGEKSVPETRSGPSPHQQAIVTAMPGGLPVPTSPNIQPSPAHETGQGIVHALTDLSSPGMTSGNGNSASSIAGTAPQNGENKPPQAIVKPQILTHVIEGFVIQEGAEPFPVGRSSLLVGNLKKKYAQGFLPEKLPQQDHTTTTDSEMEEPYLQESKEEGAPLKLKCELCGRVDFAYKFKRSKRFCSMACAKRYNVGCTKRVGLFHSDRSKLQKAGAATHNRRRASKASLPPLTKDTKKQPTGTVPLSVTAALQLTHSQEDSSRCSDNSSYEEPLSPISASSSTSRRRQGQRDLELPDMHMRDLVGMGHHFLPSEPTKWNVEDVYEFIRSLPGCQEIAEEFRAQEIDGQALLLLKEDHLMSAMNIKLGPALKIYARISMLKDS>sp|Q8IXK0-2|PHC2_HUMAN Isoform 2 of Polyhomeotic-like protein 2 OS=Homosapiens OX=9606 GN=PHC2MTSGNGNSASSIAGTAPQNGENKPPQAIVKPQILTHVIEGFVIQEGAEPFPVGRSSLLVGNLKKKYAQGFLPEKLPQQDHTTTTDSEMEEPYLQESKEEGAPLKLKCELCGRVDFAYKFKRSKRFCSMACAKRYNVGCTKRVGLFHSDRSKLQKAGAATHNRRRASKASLPPLTKDTKKQPTGTVPLSVTAALQLTHSQEDSSRCSDNSSYEEPLSPISASSSTSRRRQGQRDLELPDMHMRDLVGMGHHFLPSEPTKWNVEDVYEFIRSLPGCQEIAEEFRAQEIDGQALLLLKEDHLMSAMNIKLGPALKIYARISMLKDS>sp|Q8IXK0-3|PHC2_HUMAN Isoform 3 of Polyhomeotic-like protein 2 OS=Homosapiens OX=9606 GN=PHC2MVGRSSLLVGNLKKKYAQGFLPEKLPQQDHTTTTDSEMEEPYLQESKEEGAPLKLKCELCGRVDFAYKFKRSKRFCSMACAKRYNVGCTKRVGLFHSDRSKLQKAGAATHNRRRASKASLPPLTKDTKKQPTGTVPLSVTAALQLTHSQEDSSRCSDNSSYEEPLSPISASSSTSRRRQGQRDLELPDMHMRDLVGMGHHFLPSEPTKWNVEDVYEFIRSLPGLPSSFPKGHETSIYSLSKHLRHSRFPQSPSGSCLWPVLRPRPHL>sp|Q8IXK0-4|PHC2_HUMAN Isoform 4 of Polyhomeotic-like protein 2 OS=Homosapiens OX=9606 GN=PHC2MENELPVPHTSSSACATSSTSGASSSSGCNNSSSGGSGRPTGPQISVYSGIPDRQTVQVIQQALHRQPSTAAQYLQQMYAAQQQHLMLQTAALQQQHLSSAQLQSLAAVQQASLVSNRQGSTSGSNVSAQAPAQSSSINLAASPAAAQLLNRAQSVNSAAASGIAQQAVLLGNTSSPALTASQAQMYLRAQMVQNLTLRTQQTPAAAASGPTPTQPVLPSLALKPTPGGSQPLPTPAQSRNTAQASPAGAKPGIADSVMEPHKKGDGNSSVPGSMEGRAGLSRTVPAVAAHPLIAPAYAQLQPHQLLPQPSSKHLQPQFVIQQQPQPQQQQPPPQQSRPVLQAEPHPQLASVSPSVALQPSSEAHAMPLGPVTPALPLQCPTANLHKPGGSQQCHPPTPDTGPQNGHPEGVPHTPQRRFQHTSAVILQLQPASPPQQCVPDDWKEVAPGEKSVPETRSGPSPHQQAIVTAMPGGLPVPTSPNIQPSPAHETGQGIVHALTDLSSPGMTSGNGNSASSIAGTAPQNGENKPPQAIVKPQILTHVIEGFVIQEGAEPFPVGRSSLLVGNLKKKYAQGFLPEKLPQQDHTTTTDSEMEEPYLQESKEEGAPLKLKCELCGRVDFAYKFKRSKRFCSMACAKRYNVGCTKRVGLFHSDRSKLQKAGAATHNRRRASKASLPPLTKDTKKQPTGTVPLSVTAALQLTHSQEDSSRCSDNSSYEEPLSPISASSSTSRRRQGQRDLELPDMHMRDLVGMGHHFLPSEPTKWNVEDVYEFIRSLPGCQEIAEEFRAQEIDGQALLLLKEDHLMSAMNIKLGPALKIYARISMLKDS>sp|Q8IXK0-5|PHC2_HUMAN Isoform 5 of Polyhomeotic-like protein 2 OS=Homosapiens OX=9606 GN=PHC2MENELPVPHTSSSACATSSTSGASSSSGCNNSSSGGSGRPTGPQISVYSGIPDRQTVQVIQQALHRQPSTAAQYLQQMYAAQQQHLMLQTAALQQQHLSSAQLQSLAAVQQASLVSNRQGSTSGSNVSAQAPAQSSSINLAASPAAAQLLNRAQSVNSAAASGIAQQAVLLGNTSSPALTASQAQMYLRAQMLIFTPTATVATVQPELGTGSPARPPTPAQVQNLTLRTQQTPAAAASGPTPTQPVLPSLALKPTPGGSQPLPTPAQSRNTAQASPAGAKPGIADSVMEPHKKGDGNSSVPGSMEGRAGLSRTVPAVAAHPLIAPAYAQLQPHQLLPQPSSKHLQPQFVIQQQPQPQQQQPPPQQSRPVLQAEPHPQLASVSPSVALQPSSEAHAMPLGPVTPALPLQCPTANLHKPGGSQQCHPPTPDTGPQNGHPEGVPHTPQRRFQHTSAVILQLQPASPVPQQCVPDDWKEVAPGEKSVPETRSGPSPHQQAIVTAMPGGLPVPTSPNIQPSPAHETGQGIVHALTDLSSPGMTSGNGNSASSIAGTAPQNGENKPPQAIVKPQILTHVIEGFVIQEGAEPFPVGRSSLLVGNLKKKYAQGFLPEKLPQQDHTTTTDSEMEEPYLQESKEEGAPLKLKCELCGRVDFAYKFKRSKRFCSMACAKRYNVGCTKRVGLFHSDRSKLQKAGAATHNRRRASKASLPPLTKDTKKQPTGTVPLSVTAALQLTHSQEDSSRCSDNSSYEEPLSPISASSSTSRRRQGQRDLELPDMHMRDLVGMGHHFLPSEPTKWNVEDVYEFIRSLPGCQEIAEEFRAQEIDGQALLLLKEDHLMSAMNIKLGPALKIYARISMLKDS>sp|Q01813|PFKAP_HUMAN ATP-dependent 6-phosphofructokinase, platelet typeOS=Homo sapiens OX=9606 GN=PFKP PE=1 SV=2MDADDSRAPKGSLRKFLEHLSGAGKAIGVLTSGGDAQGMNAAVRAVVRMGIYVGAKVYFIYEGYQGMVDGGSNIAEADWESVSSILQVGGTIIGSARCQAFRTREGRLKAACNLLQRGITNLCVIGGDGSLTGANLFRKEWSGLLEELARNGQIDKEAVQKYAYLNVVGMVGSIDNDFCGTDMTIGTDSALHRIIEVVDAIMTTAQSHQRTFVLEVMGRHCGYLALVSALACGADWVFLPESPPEEGWEEQMCVKLSENRARKKRLNIIIVAEGAIDTQNKPITSEKIKELVVTQLGYDTRVTILGHVQRGGTPSAFDRILASRMGVEAVIALLEATPDTPACVVSLNGNHAVRLPLMECVQMTQDVQKAMDERRFQDAVRLRGRSFAGNLNTYKRLAIKLPDDQIPKTNCNVAVINVGAPAAGMNAAVRSAVRVGIADGHRMLAIYDGFDGFAKGQIKEIGWTDVGGWTGQGGSILGTKRVLPGKYLEEIATQMRTHSINALLIIGGFEAYLGLLELSAAREKHEEFCVPMVMVPATVSNNVPGSDFSIGADTALNTITDTCDRIKQSASGTKRRVFIIETMGGYCGYLANMGGLAAGADAAYIFEEPFDIRDLQSNVEHLTEKMKTTIQRGLVLRNESCSENYTTDFIYQLYSEEGKGVFDCRKNVLGHMQQGGAPSPFDRNFGTKISARAMEWITAKLKEARGRGKKFTTDDSICVLGISKRNVIFQPVAELKKQTDFEHRIPKEQWWLKLRPLMKILAKYKASYDVSDSGQLEHVQPWSV>sp|Q01813-2|PFKAP_HUMAN Isoform 2 of ATP-dependent 6-phosphofructokinase, platelet type OS=Homo sapiens OX=9606 GN=PFKPMCGYERCRPCRGAHGYLRGGQGVLHLRGLPGHGGRRLKHRRGRLGECLQHPASGAVRGDWREKPGCWSHRFPCPGRHALVGGTIIGSARCQAFRTREGRLKAACNLLQRGITNLCVIGGDGSLTGANLFRKEWSGLLEELARNGQIDKEAVQKYAYLNVVGMVGSIDNDFCGTDMTIGTDSALHRIIEVVDAIMTTAQSHQRTFVLEVMGRHCGYLALVSALACGADWVFLPESPPEEGWEEQMCVKLSENRARKKRLNIIIVAEGAIDTQNKPITSEKIKELVVTQLGYDTRVTILGHVQRGGTPSAFDRILASRMGVEAVIALLEATPDTPACVVSLNGNHAVRLPLMECVQMTQDVQKAMDERRFQDAVRLRGRSFAGNLNTYKRLAIKLPDDQIPKTNCNVAVINVGAPAAGMNAAVRSAVRVGIADGHRMLAIYDGFDGFAKGQIKEIGWTDVGGWTGQGGSILGTKRVLPGKYLEEIATQMRTHSINALLIIGGFEAYLGLLELSAAREKHEEFCVPMVMVPATVSNNVPGSDFSIGADTALNTITDTCDRIKQSASGTKRRVFIIETMGGYCGYLANMGGLAAGADAAYIFEEPFDIRDLQSNVEHLTEKMKTTIQRGLVLRNESCSENYTTDFIYQLYSEEGKGVFDCRKNVLGHMQQGGAPSPFDRNFGTKISARAMEWITAKLKEARGRGKKFTTDDSICVLGISKRNVIFQPVAELKKQTDFEHRIPKEQWWLKLRPLMKILAKYKASYDVSDSGQLEHVQPWSV>sp|Q9H4I0|RD21L_HUMAN Double-strand-break repair protein rad21-likeprotein 1 OS=Homo sapiens OX=9606 GN=RAD21L1 PE=2 SV=3MFYTHVLMSKRGPLAKIWLAAHWEKKLTKAHVFECNLEITIEKILSPKVKIALRTSGHLLLGVVRIYNRKAKYLLADCSEAFLKMKMTFCPGLVDLPKENFEASYNAITLPEEFHDFDTQNMNAIDVSEHFTQNQSRPEEITLRENFDNDLIFQAESFGEESEILRRHSFFDDNILLNSSGPLIEHSSGSLTGERSLFYDSGDGFGDEGAAGEMIDNLLQDDQNILLEDMHLNREISLPSEPPNSLAVEPDNSECICVPENEKMNETILLSTEEEGFTLDPIDISDIAEKRKGKKRRLLIDPIKELSSKVIHKQLTSFADTLMVLELAPPTQRLMMWKKRGGVHTLLSTAAQDLIHAELKMLFTKCFLSSGFKLGRKMIQKESVREEVGNQNIVETSMMQEPNYQQELSKPQTWKDVIGGSQHSSHEDTNKNINSEQDIVEMVSLAAEESSLMNDLFAQEIEYSPVELESLSNEENIETERWNGRILQMLNRLRESNKMGMQSFSLMKLCRNSDRKQAAAKFYSFLVLKKQLAIELSQSAPYADIIATMGPMFYNI>sp|Q9H4I0-2|RD21L_HUMAN Isoform 2 of Double-strand-break repair proteinrad21-like protein 1 OS=Homo sapiens OX=9606 GN=RAD21L1MFYTHVLMSKRGPLAKIWLAAHWEKKLTKAHVFECNLEITIEKILSPKVKIALRTSGHLLLGVVRIYNRKAKYLLADCSEAFLKMKMTFCPGLVDLPKENFEASYNAITLPEEFHDFDTQNMNAIDVSEHFTQNQSRPEEITLRENFDNDLIFQAESFGEESEILRRHSFFDDNILLNSSGPLIEHSSGSLTGERSLFYDSGDGFGDEGAAGEMIDNLLQDDQNILLEDMHLNREISLPSEPPNSLAVEPDNSECICVPENEKMNETILLSTEEEGFTLDPIDISDIAEKRKGKKRRLLIDPIKELSSKVIHKQLTSFADTLMVLELAPPTQRLMMWKKRGGVHTLLSTAAQDLIHAELKMLFTKCFLSSGFKLGRKMIQKESVREEVGNQNIVETSMMQEPNYQQELSKPQTWKDVIGGSQHSSHEDTNKNINSEESLSNEENIETERWNGRILQMLNRLRVADQGQAAAAATAEALRQAGPEWCEPAGLRRASGLSPRDTAHPTPYSDPQPHGHVPARK>sp|Q13113|PDZ1I_HUMAN PDZK1-interacting protein 1 OS=Homo sapiensOX=9606 GN=PDZK1IP1 PE=1 SV=1MSALSLLILGLLTAVPPASCQQGLGNLQPWMQGLIAVAVFLVLVAIAFAVNHFWCQEEPEPAHMILTVGNKADGVLVGTDGRYSSMAASFRSSEHENAYENVPEEEGKVRSTPM>sp|Q16654|PDK4_HUMAN [Pyruvate dehydrogenase (acetyl-transferring)]kinase isozyme 4, mitochondrial OS=Homo sapiens OX=9606 GN=PDK4 PE=1 SV=1MKAARFVLRSAGSLNGAGLVPREVEHFSRYSPSPLSMKQLLDFGSENACERTSFAFLRQELPVRLANILKEIDILPTQLVNTSSVQLVKSWYIQSLMDLVEFHEKSPDDQKALSDFVDTLIKVRNRHHNVVPTMAQGIIEYKDACTVDPVTNQNLQYFLDRFYMNRISTRMLMNQHILIFSDSQTGNPSHIGSIDPNCDVVAVVQDAFECSRMLCDQYYLSSPELKLTQVNGKFPDQPIHIVYVPSHLHHMLFELFKNAMRATVEHQENQPSLTPIEVIVVLGKEDLTIKISDRGGGVPLRIIDRLFSYTYSTAPTPVMDNSRNAPLAGFGYGLPISRLYAKYFQGDLNLYSLSGYGTDAIIYLKALSSESIEKLPVFNKSAFKHYQMSSEADDWCIPSREPKNLAKEVAM>sp|Q29RF7|PDS5A_HUMAN Sister chromatid cohesion protein PDS5 homolog AOS=Homo sapiens OX=9606 GN=PDS5A PE=1 SV=1MDFTAQPKPATALCGVVSADGKIAYPPGVKEITDKITTDEMIKRLKMVVKTFMDMDQDSEDEKQQYLPLALHLASEFFLRNPNKDVRLLVACCLADIFRIYAPEAPYTSHDKLKDIFLFITRQLKGLEDTKSPQFNRYFYLLENLAWVKSYNICFELEDCNEIFIQLFRTLFSVINNSHNKKVQMHMLDLMSSIIMEGDGVTQELLDSILINLIPAHKNLNKQSFDLAKVLLKRTVQTIEACIANFFNQVLVLGRSSVSDLSEHVFDLIQELFAIDPHLLLSVMPQLEFKLKSNDGEERLAVVRLLAKLFGSKDSDLATQNRPLWQCFLGRFNDIHVPVRLESVKFASHCLMNHPDLAKDLTEYLKVRSHDPEEAIRHDVIVTIITAAKRDLALVNDQLLGFVRERTLDKRWRVRKEAMMGLAQLYKKYCLHGEAGKEAAEKVSWIKDKLLHIYYQNSIDDKLLVEKIFAQYLVPHNLETEERMKCLYYLYASLDPNAVKALNEMWKCQNMLRSHVRELLDLHKQPTSEANCSAMFGKLMTIAKNLPDPGKAQDFVKKFNQVLGDDEKLRSQLELLISPTCSCKQADICVREIARKLANPKQPTNPFLEMVKFLLERIAPVHIDSEAISALVKLMNKSIEGTADDEEEGVSPDTAIRSGLELLKVLSFTHPTSFHSAETYESLLQCLRMEDDKVAEAAIQIFRNTGHKIETDLPQIRSTLIPILHQKAKRGTPHQAKQAVHCIHAIFTNKEVQLAQIFEPLSRSLNADVPEQLITPLVSLGHISMLAPDQFASPMKSVVANFIVKDLLMNDRSTGEKNGKLWSPDEEVSPEVLAKVQAIKLLVRWLLGMKNNQSKSANSTLRLLSAMLVSEGDLTEQKRISKSDMSRLRLAAGSAIMKLAQEPCYHEIITPEQFQLCALVINDECYQVRQIFAQKLHKALVKLLLPLEYMAIFALCAKDPVKERRAHARQCLLKNISIRREYIKQNPMATEKLLSLLPEYVVPYMIHLLAHDPDFTRSQDVDQLRDIKECLWFMLEVLMTKNENNSHAFMKKMAENIKLTRDAQSPDESKTNEKLYTVCDVALCVINSKSALCNADSPKDPVLPMKFFTQPEKDFCNDKSYISEETRVLLLTGKPKPAGVLGAVNKPLSATGRKPYVRSTGTETGSNINVNSELNPSTGNRSREQSSEAAETGVSENEENPVRIISVTPVKNIDPVKNKEINSDQATQGNISSDRGKKRTVTAAGAENIQQKTDEKVDESGPPAPSKPRRGRRPKSESQGNATKNDDLNKPINKGRKRAAVGQESPGGLEAGNAKAPKLQDLAKKAAPAERQIDLQR>sp|Q29RF7-3|PDS5A_HUMAN Isoform 2 of Sister chromatid cohesion proteinPDS5 homolog A OS=Homo sapiens OX=9606 GN=PDS5AMDFTAQPKPATALCGVVSADGKIAYPPGVKEITDKITTDEMIKRLKMVVKTFMDMDQDSEDEKQQYLPLALHLASEFFLRNPNKDVRLLVACCLADIFRIYAPEAPYTSHDKLKDIFLFITRQLKGLEDTKSPQFNRYFYLLENLAWVKSYNICFELEDCNEIFIQLFRTLFSVINNSHNKKVQMHMLDLMSSIIMEGDGVTQELLDSILINLIPAHKNLNKQSFDLAKVLLKRTVQTIEACIANFFNQVLVLGRSSVSDLSEHVFDLIQELFAIDPHLLLSVMPQLEFKLKSNDGEERLAVVRLLAKLFGSKDSDLATQNRPLWQCFLGRFNDIHVPVRLESVKFASHCLMNHPDLAKDLTEYLKVRSHDPEEAIRHDVIVTIITAAKRDLALVNDQLLGFVRERTLDKRWRVRKEAMMGLAQLYKKYCLHGEAGKEAAEKVSWIKDKLLHIYYQNSIDDKLLVEKIFAQYLVPHNLETEERMKCLYYLYASLDPNAVKALNEMWKCQNMLRSHVRELLDLHKQPTSEANCSAMFGKLMTIAKNLPDPGKAQDFVKKFNQVLGDDEKLRSQLELLISPTCSCKQADICVVSKSYFTLFL>sp|P43116|PE2R2_HUMAN Prostaglandin E2 receptor EP2 subtype OS=Homosapiens OX=9606 GN=PTGER2 PE=1 SV=2MGNASNDSQSEDCETRQWLPPGESPAISSVMFSAGVLGNLIALALLARRWRGDVGCSAGRRSSLSLFHVLVTELVFTDLLGTCLISPVVLASYARNQTLVALAPESRACTYFAFAMTFFSLATMLMLFAMALERYLSIGHPYFYQRRVSRSGGLAVLPVIYAVSLLFCSLPLLDYGQYVQYCPGTWCFIRHGRTAYLQLYATLLLLLIVSVLACNFSVILNLIRMHRRSRRSRCGPSLGSGRGGPGARRRGERVSMAEETDHLILLAIMTITFAVCSLPFTIFAYMNETSSRKEKWDLQALRFLSINSIIDPWVFAILRPPVLRLMRSVLCCRISLRTQDATQTSCSTQSDASKQADL>sp|Q9NWW9|PLAT2_HUMAN Phospholipase A and acyltransferase 2 OS=Homosapiens OX=9606 GN=PLAAT2 PE=1 SV=1MALARPRPRLGDLIEISRFGYAHWAIYVGDGYVVHLAPASEIAGAGAASVLSALTNKAIVKKELLSVVAGGDNYRVNNKHDDRYTPLPSNKIVKRAEELVGQELPYSLTSDNCEHFVNHLRYGVSRSDQVTGAVTTVGVAAGLLAAASLVGILLARSKRERQ>sp|Q9UL19|PLAT4_HUMAN Phospholipase A and acyltransferase 4 OS=Homosapiens OX=9606 GN=PLAAT4 PE=1 SV=1MASPHQEPKPGDLIEIFRLGYEHWALYIGDGYVIHLAPPSEYPGAGSSSVFSVLSNSAEVKRERLEDVVGGCCYRVNNSLDHEYQPRPVEVIISSAKEMVGQKMKYSIVSRNCEHFVTQLRYGKSRCKQVEKAKVEVGVATALGILVVAGCSFAIRRYQKKATA>sp|Q9UL19-2|PLAT4_HUMAN Isoform 2 of Phospholipase A and acyltransferase4 OS=Homo sapiens OX=9606 GN=PLAAT4MASPHQEPKPGDLIEIFRLGYEHWALYIGDGYVIHLAPPSEYPGAGSSSVFSVLSNSAEVKRERLEDVVGGCCYRVNNSLDHEYQPRPVEVIISSAKEMVGQKMKYSIVSRNCEHFVTQLRYGKSRCKQVRTSLDNPSPSAWGWTHGAVQPGDHCE>sp|P00491|PNPH_HUMAN Purine nucleoside phosphorylase OS=Homo sapiensOX=9606 GN=PNP PE=1 SV=2MENGYTYEDYKNTAEWLLSHTKHRPQVAIICGSGLGGLTDKLTQAQIFDYGEIPNFPRSTVPGHAGRLVFGFLNGRACVMMQGRFHMYEGYPLWKVTFPVRVFHLLGVDTLVVTNAAGGLNPKFEVGDIMLIRDHINLPGFSGQNPLRGPNDERFGDRFPAMSDAYDRTMRQRALSTWKQMGEQRELQEGTYVMVAGPSFETVAECRVLQKLGADAVGMSTVPEVIVARHCGLRVFGFSLITNKVIMDYESLEKANHEEVLAAGKQAAQKLEQFVSILMASIPLPDKAS>sp|Q9Y237|PIN4_HUMAN Peptidyl-prolyl cis-trans isomerase NIMA-interacting 4 OS=Homo sapiens OX=9606 GN=PIN4 PE=1 SV=1MPPKGKSGSGKAGKGGAASGSDSADKKAQGPKGGGNAVKVRHILCEKHGKIMEAMEKLKSGMRFNEVAAQYSEDKARQGGDLGWMTRGSMVGPFQEAAFALPVSGMDKPVFTDPPVKTKFGYHIIMVEGRK>sp|Q9Y237-2|PIN4_HUMAN Isoform 2 of Peptidyl-prolyl cis-trans isomeraseNIMA-interacting 4 OS=Homo sapiens OX=9606 GN=PIN4MPMAGLLKGLVRQLERFSVQQQASKMPPKGKSGSGKAGKGGAASGSDSADKKAQGPKGGGNAVKVRHILCEKHGKIMEAMEKLKSGMRFNEVAAQYSEDKARQGGDLGWMTRGSMVGPFQEAAFALPVSGMDKPVFTDPPVKTKFGYHIIMVEGRK>sp|Q9Y237-3|PIN4_HUMAN Isoform 3 of Peptidyl-prolyl cis-trans isomeraseNIMA-interacting 4 OS=Homo sapiens OX=9606 GN=PIN4MPMAGLLKGLVRQLERFSVQQQASKMPPKGKSGSGKAGKGGAASGSDSADKKAQGPKGGGNAVKVRHILCEKHGKIMEAMEKLKSGMRFNEVAAQYSEDKARQGIPSLQQHAGHHRDLRSTLISLVSYLQTTP>sp|A0A0A6YYL3|POTEB_HUMAN POTE ankyrin domain family member B OS=Homosapiens OX=9606 GN=POTEB PE=1 SV=1MVAEVCSMPAASAVKKPFDLRSKMGKWCHHRFPCCRGSGTSNVGTSGDHDDSFMKTLRSKMGKWCCHCFPCCRGSGKSNVGTWGDYDDSAFMEPRYHVRREDLDKLHRAAWWGKVPRKDLIVMLRDTDMNKRDKQKRTALHLASANGNSEVVQLLLDRRCQLNVLDNKKRTALIKAVQCQEDECVLMLLEHGADGNIQDEYGNTALHYAIYNEDKLMAKALLLYGADIESKNKCGLTPLLLGVHEQKQEVVKFLIKKKANLNALDRYGRTALILAVCCGSASIVNLLLEQNVDVSSQDLSGQTAREYAVSSHHHVICELLSDYKEKQMLKISSENSNPEQDLKLTSEEESQRLKVSENSQPEKMSQEPEINKDCDREVEEEIKKHGSNPVGLPENLTNGASAGNGDDGLIPQRKSRKPENQQFPDTENEEYHSDEQNDTQKQLSEEQNTGISQDEILTNKQKQIEVAEKEMNSELSLSHKKEEDLLRENSMLREEIAKLRLELDETKHQNQLRENKILEEIESVKEKLLKTIQLNEEALTKTSI>sp|O15428|PINL_HUMAN Putative PIN1-like protein OS=Homo sapiens OX=9606GN=PIN1P1 PE=5 SV=1MADEEKLPPGWEKRMSRPSGRGYYFNHITNPSQWERPSGNSSSGGKIWQGEPARVRRSHLLVKPVKAALDLAAGNHPDQGGGPGADQRLHPEDQGRREGL>sp|Q63HM9|PLCX3_HUMAN PI-PLC X domain-containing protein 3 OS=Homosapiens OX=9606 GN=PLCXD3 PE=1 SV=2MASSQGKNELKLADWMATLPESMHSIPLTNLAIPGSHDSFSFYIDEASPVGPEQPETVQNFVSVFGTVAKKLMRKWLATQTMNFTGQLGAGIRYFDLRISTKPRDPDNELYFAHGLFSAKVNEGLEEINAFLTDHHKEVVFLDFNHFYGMQKYHHEKLVQMLKDIYGNKMCPAIFAQEVSLKYLWEKDYQVLVFYHSPVALEVPFLWPGQMMPAPWANTTDPEKLIQFLQASITERRKKGSFFISQVVLTPKASTVVKGVASGLRETITERALPAMMQWVRTQKPGESGINIVTADFVELGDFISTVIKLNYVFDEGEANT>sp|P13797|PLST_HUMAN Plastin-3 OS=Homo sapiens OX=9606 GN=PLS3 PE=1 SV=4MDEMATTQISKDELDELKEAFAKVDLNSNGFICDYELHELFKEANMPLPGYKVREIIQKLMLDGDRNKDGKISFDEFVYIFQEVKSSDIAKTFRKAINRKEGICALGGTSELSSEGTQHSYSEEEKYAFVNWINKALENDPDCRHVIPMNPNTDDLFKAVGDGIVLCKMINLSVPDTIDERAINKKKLTPFIIQENLNLALNSASAIGCHVVNIGAEDLRAGKPHLVLGLLWQIIKIGLFADIELSRNEALAALLRDGETLEELMKLSPEELLLRWANFHLENSGWQKINNFSADIKDSKAYFHLLNQIAPKGQKEGEPRIDINMSGFNETDDLKRAESMLQQADKLGCRQFVTPADVVSGNPKLNLAFVANLFNKYPALTKPENQDIDWTLLEGETREERTFRNWMNSLGVNPHVNHLYADLQDALVILQLYERIKVPVDWSKVNKPPYPKLGANMKKLENCNYAVELGKHPAKFSLVGIGGQDLNDGNQTLTLALVWQLMRRYTLNVLEDLGDGQKANDDIIVNWVNRTLSEAGKSTSIQSFKDKTISSSLAVVDLIDAIQPGCINYDLVKSGNLTEDDKHNNAKYAVSMARRIGARVYALPEDLVEVKPKMVMTVFACLMGRGMKRV>sp|P13797-2|PLST_HUMAN Isoform 2 of Plastin-3 OS=Homo sapiens OX=9606GN=PLS3MEDLNSNGFICDYELHELFKEANMPLPGYKVREIIQKLMLDGDRNKDGKISFDEFVYIFQEVKSSDIAKTFRKAINRKEGICALGGTSELSSEGTQHSYSEEEKYAFVNWINKALENDPDCRHVIPMNPNTDDLFKAVGDGIVLCKMINLSVPDTIDERAINKKKLTPFIIQENLNLALNSASAIGCHVVNIGAEDLRAGKPHLVLGLLWQIIKIGLFADIELSRNEALAALLRDGETLEELMKLSPEELLLRWANFHLENSGWQKINNFSADIKLIDFSNSVKDSKAYFHLLNQIAPKGQKEGEPRIDINMSGFNETDDLKRAESMLQQADKLGCRQFVTPADVVSGNPKLNLAFVANLFNKYPALTKPENQDIDWTLLEGETREERTFRNWMNSLGVNPHVNHLYADLQDALVILQLYERIKVPVDWSKVNKPPYPKLGANMKKLENCNYAVELGKHPAKFSLVGIGGQDLNDGNQTLTLALVWQLMRRYTLNVLEDLGDGQKANDDIIVNWVNRTLSEAGKSTSIQSFKDKTISSSLAVVDLIDAIQPGCINYDLVKSGNLTEDDKHNNAKYAVSMARRIGARVYALPEDLVEVKPKMVMTVFACLMGRGMKRV>sp|P13797-3|PLST_HUMAN Isoform 3 of Plastin-3 OS=Homo sapiens OX=9606GN=PLS3MPLPGYKVREIIQKLMLDGDRNKDGKISFDEFVYIFQEVKSSDIAKTFRKAINRKEGICALGGTSELSSEGTQHSYSEEEKYAFVNWINKALENDPDCRHVIPMNPNTDDLFKAVGDGIVLCKMINLSVPDTIDERAINKKKLTPFIIQENLNLALNSASAIGCHVVNIGAEDLRAGKPHLVLGLLWQIIKIGLFADIELSRNEALAALLRDGETLEELMKLSPEELLLRWANFHLENSGWQKINNFSADIKDSKAYFHLLNQIAPKGQKEGEPRIDINMSGFNETDDLKRAESMLQQADKLGCRQFVTPADVVSGNPKLNLAFVANLFNKYPALTKPENQDIDWTLLEGETREERTFRNWMNSLGVNPHVNHLYADLQDALVILQLYERIKVPVDWSKVNKPPYPKLGANMKKLENCNYAVELGKHPAKFSLVGIGGQDLNDGNQTLTLALVWQLMRRYTLNVLEDLGDGQKANDDIIVNWVNRTLSEAGKSTSIQSFKDKTISSSLAVVDLIDAIQPGCINYDLVKSGNLTEDDKHNNAKYAVSMARRIGARVYALPEDLVEVKPKMVMTVFACLMGRGMKRV>sp|Q8NBV4|PLPP7_HUMAN Inactive phospholipid phosphatase 7 OS=Homosapiens OX=9606 GN=PLPP7 PE=2 SV=1MPASQSRARARDRNNVLNRAEFLSLNQPPKGGPEPRSSGRKASGPSAQPPPAGDGARERRQSQQLPEEDCMQLNPSFKGIAFNSLLAIDICMSKRLGVCAGRAASWASARSMVKLIGITGHGIPWIGGTILCLVKSSTLAGQEVLMNLLLALLLDIMTVAGVQKLIKRRGPYETSPSLLDYLTMDIYAFPAGHASRAAMVSKFFLSHLVLAVPLRVLLVLWALCVGLSRVMIGRHHVTDVLSGFVIGYLQFRLVELVWMPSSTCQMLISAW>sp|Q96QC0|PP1RA_HUMAN Serine/threonine-protein phosphatase 1 regulatorysubunit 10 OS=Homo sapiens OX=9606 GN=PPP1R10 PE=1 SV=1MGSGPIDPKELLKGLDSFLNRDGEVKSVDGISKIFSLMKEARKMVSRCTYLNILLQTRSPEILVKFIDVGGYKLLNNWLTYSKTTNNIPLLQQILLTLQHLPLTVDHLKQNNTAKLVKQLSKSSEDEELRKLASVLVSDWMAVIRSQSSTQPAEKDKKKRKDEGKSRTTLPERPLTEVKAETRAEEAPEKKREKPKSLRTTAPSHAKFRSTGLELETPSLVPVKKNASTVVVSDKYNLKPIPLKRQSNVAAPGDATPPAEKKYKPLNTTPNATKEIKVKIIPPQPMEGLGFLDALNSAPVPGIKIKKKKKVLSPTAAKPSPFEGKTSTEPSTAKPSSPEPAPPSEAMDADRPGTPVPPVEVPELMDTASLEPGALDAKPVESPGDPNQLTRKGRKRKSVTWPEEGKLREYFYFELDETERVNVNKIKDFGEAAKREILSDRHAFETARRLSHDNMEEKVPWVCPRPLVLPSPLVTPGSNSQERYIQAEREKGILQELFLNKESPHEPDPEPYEPIPPKLIPLDEECSMDETPYVETLEPGGSGGSPDGAGGSKLPPVLANLMGSMGAGKGPQGPGGGGINVQEILTSIMGSPNSHPSEELLKQPDYSDKIKQMLVPHGLLGPGPIANGFPPGGPGGPKGMQHFPPGPGGPMPGPHGGPGGPVGPRLLGPPPPPRGGDPFWDGPGDPMRGGPMRGGPGPGPGPYHRGRGGRGGNEPPPPPPPFRGARGGRSGGGPPNGRGGPGGGMVGGGGHRPHEGPGGGMGNSSGHRPHEGPGGGMGSGHRPHEGPGGSMGGGGGHRPHEGPGGGISGGSGHRPHEGPGGGMGAGGGHRPHEGPGGSMGGSGGHRPHEGPGHGGPHGHRPHDVPGHRGHDHRGPPPHEHRGHDGPGHGGGGHRGHDGGHSHGGDMSNRPVCRHFMMKGNCRYENNCAFYHPGVNGPPLP>sp|Q8NE79|POPD1_HUMAN Blood vessel epicardial substance OS=Homo sapiensOX=9606 GN=BVES PE=1 SV=1MNYTESSPLRESTAIGFTPELESIIPVPSNKTTCENWREIHHLVFHVANICFAVGLVIPTTLHLHMIFLRGMLTLGCTLYIVWATLYRCALDIMIWNSVFLGVNILHLSYLLYKKRPVKIEKELSGMYRRLFEPLRVPPDLFRRLTGQFCMIQTLKKGQTYAAEDKTSVDDRLSILLKGKMKVSYRGHFLHNIYPCAFIDSPEFRSTQMHKGEKFQVTIIADDNCRFLCWSRERLTYFLESEPFLYEIFRYLIGKDITNKLYSLNDPTLNDKKAKKLEHQLSLCTQISMLEMRNSIASSSDSDDGLHQFLRGTSSMSSLHVSSPHQRASAKMKPIEEGAEDDDDVFEPASPNTLKVHQLP>sp|P51817|PRKX_HUMAN cAMP-dependent protein kinase catalytic subunitPRKX OS=Homo sapiens OX=9606 GN=PRKX PE=1 SV=1MEAPGLAQAAAAESDSRKVAEETPDGAPALCPSPEALSPEPPVYSLQDFDTLATVGTGTFGRVHLVKEKTAKHFFALKVMSIPDVIRLKQEQHVHNEKSVLKEVSHPFLIRLFWTWHDERFLYMLMEYVPGGELFSYLRNRGRFSSTTGLFYSAEIICAIEYLHSKEIVYRDLKPENILLDRDGHIKLTDFGFAKKLVDRTWTLCGTPEYLAPEVIQSKGHGRAVDWWALGILIFEMLSGFPPFFDDNPFGIYQKILAGKIDFPRHLDFHVKDLIKKLLVVDRTRRLGNMKNGANDVKHHRWFRSVDWEAVPQRKLKPPIVPKIAGDGDTSNFETYPENDWDTAAPVPQKDLEIFKNF>sp|P16471|PRLR_HUMAN Prolactin receptor OS=Homo sapiens OX=9606 GN=PRLRPE=1 SV=1MKENVASATVFTLLLFLNTCLLNGQLPPGKPEIFKCRSPNKETFTCWWRPGTDGGLPTNYSLTYHREGETLMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSDFTMNDTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEKGKSEELLSALGCQDFPPTSDYEDLLVEYLEVDDSEDQHLMSVHSKEHPSQGMKPTYLDPDTDSGRGSCDSPSLLSEKCEEPQANPSTFYDPEVIEKPENPETTHTWDPQCISMEGKIPYFHAGGSKCSTWPLPQPSQHNPRSSYHNITDVCELAVGPAGAPATLLNEAGKDALKSSQTIKSREEGKATQQREVESFHSETDQDTPWLLPQEKTPFGSAKPLDYVEIHKVNKDGALSLLPKQRENSGKPKKPGTPENNKEYAKVSGVMDNNILVLVPDPHAKNVACFEESAKEAPPSLEQNQAEKALANFTATSSKCRLQLGGLDYLDPACFTHSFH>sp|P16471-2|PRLR_HUMAN Isoform 2 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMKENVASATVFTLLLFLNTCLLNVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSDFTMNDTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEKGKSEELLSALGCQDFPPTSDYEDLLVEYLEVDDSEDQHLMSVHSKEHPSQGMKPTYLDPDTDSGRGSCDSPSLLSEKCEEPQANPSTFYDPEVIEKPENPETTHTWDPQCISMEGKIPYFHAGGSKCSTWPLPQPSQHNPRSSYHNITDVCELAVGPAGAPATLLNEAGKDALKSSQTIKSREEGKATQQREVESFHSETDQDTPWLLPQEKTPFGSAKPLDYVEIHKVNKDGALSLLPKQRENSGKPKKPGTPENNKEYAKVSGVMDNNILVLVPDPHAKNVACFEESAKEAPPSLEQNQAEKALANFTATSSKCRLQLGGLDYLDPACFTHSFH>sp|P16471-3|PRLR_HUMAN Isoform 3 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMKENVASATVFTLLLFLNTCLLNGQLPPGKPEIFKCRSPNKETFTCWWRPGTDGGLPTNYSLTYHREGETLMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSAW>sp|P16471-4|PRLR_HUMAN Isoform 4 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMKENVASATVFTLLLFLNTCLLNGQLPPGKPEIFKCRSPNKETFTCWWRPGTDGGLPTNYSLTYHREGETLMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSDFTMNDTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEKGKSEELLSALGCQDFPPTSDYEDLLVEYLEVDDSEDQHLMSVHSKEHPSQGDPLMLGASHYKNLKSYRPRKISSQGRLAVFTKATLTTVQ>sp|P16471-5|PRLR_HUMAN Isoform 5 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMKENVASATVFTLLLFLNTCLLNGQLPPGKPEIFKCRSPNKETFTCWWRPGTDGGLPTNYSLTYHREGETLMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSDFTMNDTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEKGKSEELLSALGCQDFPPTSDYEDLLVEYLEVDDSEDQHLMSVHSKEHPSQEREQRQAQEARDS>sp|P16471-6|PRLR_HUMAN Isoform 6 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMKENVASATVFTLLLFLNTCLLNGQLPPGKPEIFKCRSPNKETFTCWWRPGTDGGLPTNYSLTYHREGETLMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSDFTMNDTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEVTP>sp|P16471-7|PRLR_HUMAN Isoform 7 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMKENVASATVFTLLLFLNTCLLNGQLPPGKPEIFKCRSPNKETFTCWWRPGTDGGLPTNYSLTYHREGETLMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSGDPLMLGASHYKNLKSYRPRKISSQGRLAVFTKATLTTVQ>sp|P16471-8|PRLR_HUMAN Isoform 8 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSDFTMNDTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEVTP>sp|P16471-9|PRLR_HUMAN Isoform 9 of Prolactin receptor OS=Homo sapiensOX=9606 GN=PRLRMKENVASATVFTLLLFLNTCLLNGQLPPGKPEIFKCRSPNKETFTCWWRPGTDGGLPTNYSLTYHREGETLMHECPDYITGGPNSCHFGKQYTSMWRTYIMMVNATNQMGSSFSDELYVDVTYIVQPDPPLELAVEVKQPEDRKPYLWIKWSPPTLIDLKTGWFTLLYEIRLKPEKAAEWEIHFAGQQTEFKILSLHPGQKYLVQVRCKPDHGYWSAWSPATFIQIPSDFTMNDTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEDRLCTPGRCCVSTGLTDLDYSCST>sp|Q3SYG4|PTHB1_HUMAN Protein PTHB1 OS=Homo sapiens OX=9606 GN=BBS9 PE=1SV=1MSLFKARDWWSTILGDKEEFDQGCLCLANVDNSGNGQDKIIVGSFMGYLRIFSPHPAKTGDGAQAEDLLLEVDLRDPVLQVEVGKFVSGTEMLHLAVLHSRKLCVYSVSGTLGNVEHGNQCQMKLMYEHNLQRTACNMTYGSFGGVKGRDLICIQSMDGMLMVFEQESYAFGRFLPGFLLPGPLAYSSRTDSFLTVSSCQQVESYKYQVLAFATDADKRQETEQQKLGSGKRLVVDWTLNIGEQALDICIVSFNQSASSVFVLGERNFFCLKDNGQIRFMKKLDWSPSCFLPYCSVSEGTINTLIGNHNNMLHIYQDVTLKWATQLPHIPVAVRVGCLHDLKGVIVTLSDDGHLQCSYLGTDPSLFQAPNVQSRELNYDELDVEMKELQKIIKDVNKSQGVWPMTEREDDLNVSVVVSPNFDSVSQATDVEVGTDLVPSVTVKVTLQNRVILQKAKLSVYVQPPLELTCDQFTFEFMTPDLTRTVSFSVYLKRSYTPSELEGNAVVSYSRPTDRNPDGIPRVIQCKFRLPLKLICLPGQPSKTASHKITIDTNKSPVSLLSLFPGFASQSDDDQVNVMGFHFLGGARITVLASKTSQRYRIQSEQFEDLWLITNELILRLQEYFEKQGVKDFACSFSGSIPLQEYFELIDHHFELRINGEKLEELLSERAVQFRAIQRRLLARFKDKTPAPLQHLDTLLDGTYKQVIALADAVEENQGNLFQSFTRLKSATHLVILLIALWQKLSADQVAILEAAFLPLQEDTQELGWEETVDAAISHLLKTCLSKSSKEQALNLNSQLNIPKDTSQLKKHITLLCDRLSKGGRLCLSTDAAAPQTMVMPGGCTTIPESDLEERSVEQDSTELFTNHRHLTAETPRPEVSPLQGVSE>sp|Q3SYG4-2|PTHB1_HUMAN Isoform 2 of Protein PTHB1 OS=Homo sapiensOX=9606 GN=BBS9MSLFKARDWWSTILGDKEEFDQGCLCLANVDNSGNGQDKIIVGSFMGYLRIFSPHPAKTGDGAQAEDLLLEVDLRDPVLQVEVGKFVSGTEMLHLAVLHSRKLCVYSVSGTLGNVEHGNQCQMKLMYEHNLQRTACNMTYGSFGGVKGRDLICIQSMDGMLMVFEQESYAFGRFLPGFLLPGPLAYSSRTDSFLTVSSCQQVESYKYQVLAFATDADKRQETEQQKLGSGKRLVVDWTLNIGEQALDICIVSFNQSASSVFVLGERNFFCLKDNGQIRFMKKLDWSPSCFLPYCSVSEGTINTLIGNHNNMLHIYQDVTLKWATQLPHIPVAVRVGCLHDLKGVIVTLSDDGHLQCSYLGTDPSLFQAPNVQSRELNYDELDVEMKELQKIIKDVNKSQGVWPMTEREDDLNVSVVVSPNFDSVSQATDVEVGTDLVPSVTVKVTLQNRVILQKAKLSVYVQPPLELTCDQFTFEFMSIPRVIQCKFRLPLKLICLPGQPSKTASHKITIDTNKSPVSLLSLFPGFASQSDDDQVNVMGFHFLGGARITVLASKTSQRYRIQSEQFEDLWLITNELILRLQEYFEKQGVKDFACSFSGSIPLQEYFELIDHHFELRINGEKLEELLSERAVQFRAIQRRLLARFKDKTPAPLQHLDTLLDGTYKQVIALADAVEENQGNLFQSFTRLKSATHLVILLIALWQKLSADQVAILEAAFLPLQEDTQELGWEETVDAAISHLLKTCLSKSSKEQALNLNSQLNIPKDTSQLKKHITLLCDRLSKGGRLCLSTDAAAPQTMVMPGGCTTIPESDLEERSVEQDSTELFTNHRHLTAETPRPEVSPLQGVSE>sp|Q3SYG4-3|PTHB1_HUMAN Isoform 3 of Protein PTHB1 OS=Homo sapiensOX=9606 GN=BBS9MSLFKARDWWSTILGDKEEFDQGCLCLANVDNSGNGQDKIIVGSFMGYLRIFSPHPAKTGDGAQAEDLLLEVDLRDPVLQVEVGKFVSGTEMLHLAVLHSRKLCVYSVSGTLGNVEHGNQCQMKLMYEHNLQRTACNMTYGSFGGVKGRDLICIQSMDGMLMVFEQESYAFGRFLPGFLLPGPLAYSSRTDSFLTVSSCQQVESYKYQVLAFATDADKRQETEQQKLGSGKRLVVDWTLNIGEQALDICIVSFNQSASSVFVLGERNFFCLKDNGQIRFMKKLDWSPSCFLPYCSVSEGTINTLIGNHNNMLHIYQDVTLKWATQLPHIPVAVRVGCLHDLKGVIVTLSDDGHLQCSYLGTDPSLFQAPNVQSRELNYDELDVEMKELQKIIKDVNKSQGVWPMTEREDDLNVSVVVSPNFDSVSQATDVEVGTDLVPSVTVKVTLQNRVILQKAKLSVYVQPPLELTCDQFTFEFMTPDLTRTVSFSVYLKRSYTPSELEGNAVVSYSRPTDRNPDGIPRVIQCKFRLPLKLICLPGQPSKTASHKITIDTNKSPVSLLSLFPGFASQSDDDQVNVMGFHFLGGARITVLASKTSQRYRIQSEQFEDLWLITNELILRLQEYFEKQGVKDFACSFSGSIPLQEYFELIDHHFELRINGEKLEELLSERAVQFRAIQRRLLARFKDKTPAPLQHLDTLLDGTYKQVIALADAVEENQGNLFQSFTRLKSATHLVILLIALWQKLSADQVAILEAAFLPLQEDTQELGWEETVDAAISHLLKTCLSKSSKEQALNLNSQLNIPKDTSQLKKHITLLCDRLSKGGRLCLSTDAAAPQTMVMPGGCTTIPESDLEERSVEQDSTELFTNHRHLTAETPRPGKRLDGLHKR>sp|Q3SYG4-4|PTHB1_HUMAN Isoform 4 of Protein PTHB1 OS=Homo sapiensOX=9606 GN=BBS9MSLFKARDWWSTILGDKEEFDQGCLCLANVDNSGNGQDKIIVGSFMGYLRIFSPHPAKTGDGAQAEDLLLEVDLRDPVLQVEVGKFVSGTEMLHLAVLHSRKLCVYSVSGTLGNVEHGNQCQMKLMYEHNLQRTACNMTYGSFGGVKGRDLICIQSMDGMLMVFEQESYAFGRFLPGFLLPGPLAYSSRTDSFLTVSSCQQVESYKYQVLAFATDADKRQETEQQKLGSGKRLVVDWTLNIGEQALDICIVSFNQSASSVFVLGERNFFCLKDNGQIRFMKKLDWSPSCFLPYCSVSEGTINTLIGNHNNMLHIYQDVTLKWATQLPHIPVAVRVGCLHDLKGVIVTLSDDGHLQCSYLGTDPSLFQAPNVQSRELNYDELDVEMKELQKIIKDVNKSQGVWPMTEREDDLNVSVVVSPNFDSVSQATDVEVGTDLVPSVTVKVTLQNRVILQKAKLSVYVQPPLELTCDQFTFEFMNRNPDGIPRVIQCKFRLPLKLICLPGQPSKTASHKITIDTNKSPVSLLSLFPGFASQSDDDQVNVMGFHFLGGARITVLASKTSQRYRIQSEQFEDLWLITNELILRLQEYFEKQGVKDFACSFSGSIPLQEYFELIDHHFELRINGEKLEELLSERAVQFRAIQRRLLARFKDKTPAPLQHLDTLLDGTYKQVIALADAVEENQGNLFQSFTRLKSATHLVILLIALWQKLSADQVAILEAAFLPLQEDTQELGWEETVDAAISHLLKTCLSKSSKEQALNLNSQLNIPKDTSQLKKHITLLCDRLSKGGRLCLSTDAAAPQTMVMPGGCTTIPESDLEERSVEQDSTELFTNHRHLTAETPRPEVSPLQGVSE>sp|Q3SYG4-5|PTHB1_HUMAN Isoform 5 of Protein PTHB1 OS=Homo sapiensOX=9606 GN=BBS9MGYLRIFSPHPAKTGDGAQAEDLLLEVDLRDPVLQVEVGKFVSGTEMLHLAVLHSRKLCVYSVSGTLGNVEHGNQCQMKLMYEHNLQRTACNMTYGSFGGVKGRDLICIQSMDGMLMVFEQESYAFGRFLPGFLLPGPLAYSSRTDSFLTVSSCQQVESYKYQVLAFATDADKRQETEQQKLGSGKRLVVDWTLNIGEQALDICIVSFNQSASSVFVLGERNFFCLKDNGQIRFMKKLDWSPSCFLPYCSVSEGTINTLIGNHNNMLHIYQDVTLKWATQLPHIPVAVRVGCLQFSLWKHLLPRSSTLEK>sp|Q3SYG4-6|PTHB1_HUMAN Isoform 6 of Protein PTHB1 OS=Homo sapiensOX=9606 GN=BBS9MSLFKARDWWSTILGDKEEFDQGCLCLANVDNSGNGQDKIIVGSFMGYLRIFSPHPAKTGDGAQAEDLLLEVDLRDPVLQVEVGKFVSGTEMLHLAVLHSRKLCVYSVSGTLGNVEHGNQCQMKLMYEHNLQRTACNMTYGSFGGVKGRDLICIQSMDGMLMVFEQESYAFGRFLPGFLLPGPLAYSSRTDSFLTVSSCQQVESYKYQVLAFATDADKRQETEQQKLGSGKRLVVDWTLNIGEQALDICIVSFNQSASSVFVLGERNFFCLKDNGQIRFMKKLDWSPSCFLPYCSVSEGTINTLIGNHNNMLHIYQDVTLKWATQLPHIPVAVRVGCLHDLKGVIVTLSDDGHLQCSYLGTDPSLFQAPNVQSRELNYDELDVEMKELQKIIKDVNKSQGVWPMTEREDDLNVSVVVSPNFDSVSQATDVEVGTDLVPSVTVKVTLQNRVILQKAKLSVYVQPPLELTCDQFTFEFMIFSS>sp|Q3SYG4-7|PTHB1_HUMAN Isoform 7 of Protein PTHB1 OS=Homo sapiensOX=9606 GN=BBS9MSLFKARDWWSTILGDKEEFDQGCLCLANVDNSGNGQDKIIVGSFMGYLRIFSPHPAKTGDGAQAEDLLLEVDLRDPVLQVEVGKFVSGTEMLHLAVLHSRKLCVYSVSGTLGNVEHGNQCQMKLMYEHNLQRTACNMTYGSFGGVKGRDLICIQSMDGMLMVFEQESYAFGRFLPGFLLPGPLAYSSRTDSFLTVSSCQQVESYKYQVLAFATDADKRQETEQQKLGSGKRLVVDWTLNIGEQALDICIVSFNQSASSVFVLGERNFFCLKDNGQIRFMKKLDWSPSCFLPYCSVSEGTINTLIGNHNNMLHIYQDVTLKWATQLPHIPVAVRVGCLHDLKGVIVTLSDDGHLQCSYLGTDPSLFQAPNVQSRELNYDELDVEMKELQKIIKDVNKSQGVWPMTEREDDLNVSVVVSPNFDSVSQATDVEVGTDLVPSVTVKVTLQNRVILQKAKLSVYVQPPLELTCDQFTFEFMTPDLTRTVSFSVYLKRSYTPSELEGNAVVSYSRPTGIPRVIQCKFRLPLKLICLPGQPSKTASHKITIDTNKSPVSLLSLFPGFASQSDDDQVNVMGFHFLGGARITVLASKTSQRYRIQSEQFEDLWLITNELILRLQEYFEKQGVKDFACSFSGSIPLQEYFELIDHHFELRINGEKLEELLSERAVQFRAIQRRLLARFKDKTPAPLQHLDTLLDGTYKQVIALADAVEENQGNLFQSFTRLKSATHLVILLIALWQKLSADQVAILEAAFLPLQEDTQELGWEETVDAAISHLLKTCLSKSSKEQALNLNSQLNIPKDTSQLKKHITLLCDRLSKGGRLCLSTDAAAPQTMVMPGGCTTIPESDLEERSVEQDSTELFTNHRHLTAETPRPEVSPLQGVSE>sp|Q96PK6|RBM14_HUMAN RNA-binding protein 14 OS=Homo sapiens OX=9606GN=RBM14 PE=1 SV=2MKIFVGNVDGADTTPEELAALFAPYGTVMSCAVMKQFAFVHMRENAGALRAIEALHGHELRPGRALVVEMSRPRPLNTWKIFVGNVSAACTSQELRSLFERRGRVIECDVVKDYAFVHMEKEADAKAAIAQLNGKEVKGKRINVELSTKGQKKGPGLAVQSGDKTKKPGAGDTAFPGTGGFSATFDYQQAFGNSTGGFDGQARQPTPPFFGRDRSPLRRSPPRASYVAPLTAQPATYRAQPSVSLGAAYRAQPSASLGVGYRTQPMTAQAASYRAQPSVSLGAPYRGQLASPSSQSAAASSLGPYGGAQPSASALSSYGGQAAAASSLNSYGAQGSSLASYGNQPSSYGAQAASSYGVRAAASSYNTQGAASSLGSYGAQAASYGAQSAASSLAYGAQAASYNAQPSASYNAQSAPYAAQQAASYSSQPAAYVAQPATAAAYASQPAAYAAQATTPMAGSYGAQPVVQTQLNSYGAQASMGLSGSYGAQSAAAATGSYGAAAAYGAQPSATLAAPYRTQSSASLAASYAAQQHPQAAASYRGQPGNAYDGAGQPSAAYLSMSQGAVANANSTPPPYERTRLSPPRASYDDPYKKAVAMSKRYGSDRRLAELSDYRRLSESQLSFRRSPTKSSLDYRRLPDAHSDYARYSGSYNDYLRAAQMHSGYQRRM>sp|Q96PK6-2|RBM14_HUMAN Isoform 2 of RNA-binding protein 14 OS=Homosapiens OX=9606 GN=RBM14MKIFVGNVDGADTTPEELAALFAPYGTVMSCAVMKQFAFVHMRENAGALRAIEALHGHELRPGRALVVEMSRPRPLNTWKIFVGNVSAACTSQELRSLFERRGRVIECDVVKDYAFVHMEKEADAKAAIAQLNGKEVKGKRINVELSTKGMVPTGV>sp|Q96PK6-3|RBM14_HUMAN Isoform 3 of RNA-binding protein 14 OS=Homosapiens OX=9606 GN=RBM14MKIFVGNVDGADTTPEELAALFAPYGTVMSCAVMKQFAFVHMRENAGALRAIEALHGHELRPGRALVVEMSRPRPLNTWKIFVGNVSAACTSQELRSLFERRGRVIECDVVKGGMCVG>sp|Q96PK6-4|RBM14_HUMAN Isoform 4 of RNA-binding protein 14 OS=Homosapiens OX=9606 GN=RBM14MKIFVGNVDGADTTPEELAALFAPYGTVMSCAVMKQFAFVHMRENAGALRAIEALHGHELRPGRALVVEMSRPRPLNTWKIFVGNVSAACTSQELRSLFERRGRVIECDVVKGMVPTGV>sp|Q96PK6-5|RBM14_HUMAN Isoform 5 of RNA-binding protein 14 OS=Homosapiens OX=9606 GN=RBM14MKIFVGNVDGADTTPEELAALFAPYGTVMSCAVMKQFAFVHMRENAGALRAIEALHGHELRPGRALVVEMSRPRPLNTWKIFVGNVSAACTSQELRSLFERRGRVIECDVVKGKRMHVQLSTSRLRTAPGMGDQSGCYRCGKEGHWSKECPIDRSGRVADLTEQYNEQYGAVRTPYTMSYGDSLYYNNAYGALDAYYKRCRAARSYEAVAAAAASVYNYAEQTLSQLPQVQNTAMASHLTSTSLDPYDRHLLPTSGAAATAAAAAAAAAAVTAASTSYYGRDRSPLRRATAPVPTVGEGYGYGHESELSQASAAARNSLYDMARYEREQYADRARYSAF>sp|Q02833|RASF7_HUMAN Ras association domain-containing protein 7OS=Homo sapiens OX=9606 GN=RASSF7 PE=1 SV=1MLLGLAAMELKVWVDGIQRVVCGVSEQTTCQEVVIALAQAIGQTGRFVLVQRLREKERQLLPQECPVGAQATCGQFASDVQFVLRRTGPSLAGRPSSDSCPPPERCLIRASLPVKPRAALGCEPRKTLTPEPAPSLSRPGPAAPVTPTPGCCTDLRGLELRVQRNAEELGHEAFWEQELRREQAREREGQARLQALSAATAEHAARLQALDAQARALEAELQLAAEAPGPPSPMASATERLHQDLAVQERQSAEVQGSLALVSRALEAAERALQAQAQELEELNRELRQCNLQQFIQQTGAALPPPPRPDRGPPGTQGPLPPAREESLLGAPSESHAGAQPRPRGGPHDAELLEVAAAPAPEWCPLAAQPQAL>sp|Q02833-2|RASF7_HUMAN Isoform 2 of Ras association domain-containingprotein 7 OS=Homo sapiens OX=9606 GN=RASSF7MLLGLAAMELKVWVDGIQRVVCGVSEQTTCQEVVIALAQAIGQTGRFVLVQRLREKERQLLPQECPVGAQATCGQFASDVQFVLRRTGPSLAGRPSSDSCPPPERCLIRASLPVKPRAALGCEPRKTLTPEPAPSLSRPGPAAPVTPTPGCCTDLRGLELRVQRNAEELGHEAFWEQELRREQAREREGQARLQALSAATAEHAARLQALDAQARALEAELQLAAEAPGPPSPMASATERLHQDLAVQERQSAEVQGSLALVSRALEAAERALQAQAQELEELNRELRQCNLQQFIQQTGAALPPPPRPDRGPPGTQVGVVLGGGWEVRTWPSPTPS>sp|Q02833-3|RASF7_HUMAN Isoform 3 of Ras association domain-containingprotein 7 OS=Homo sapiens OX=9606 GN=RASSF7MLLGLAAMELKVWVDGIQRVVCGVSEQTTCQEVVIALAQAIGQTGRFVLVQRLREKERQLLPQECPVGAQATCGQFASDVQFVLRRTGPSLAGRPSSDSCPPPERCLIRASLPVKPRAALGCEPRKTLTPEPAPSLSRPGPAAPVTPTPGCCTDLRGLELRVQRNAEELGHEAFWEQELRREQAREREGQARLQALSAATAEHAARLQALDAQARALEAELQLAAEAPGPPSPMASATERLHQDLAVQERQSAEVQGSLALVSRALEAAERALQAQAQELEELNRELRQCNLQQFIQQTGAALPPPPRPDRGPPGTQWPP>sp|Q15286|RAB35_HUMAN Ras-related protein Rab-35 OS=Homo sapiens OX=9606GN=RAB35 PE=1 SV=1MARDYDHLFKLLIIGDSGVGKSSLLLRFADNTFSGSYITTIGVDFKIRTVEINGEKVKLQIWDTAGQERFRTITSTYYRGTHGVIVVYDVTSAESFVNVKRWLHEINQNCDDVCRILVGNKNDDPERKVVETEDAYKFAGQMGIQLFETSAKENVNVEEMFNCITELVLRAKKDNLAKQQQQQQNDVVKLTKNSKRKKRCC>sp|Q15286-2|RAB35_HUMAN Isoform 2 of Ras-related protein Rab-35 OS=Homosapiens OX=9606 GN=RAB35MARDYDHLFKLLIIGDSGVGKSSLLLRFADNTFSGSYITTIGVDFKIRTVEINGEKVKLQIWDTAGQERFRTITSTYYRGTHGVIVVYDVTSAESFVNVKRWLHEINQNCDDVCRILDVQLHHGAGPPSKERQPGKTAAATTERCGEAHEEQ>sp|Q9ULI2|RIMKB_HUMAN Beta-citrylglutamate synthase B OS=Homo sapiensOX=9606 GN=RIMKLB PE=2 SV=2MCSSVAAKLWFLTDRRIREDYPQKEILRALKAKCCEEELDFRAVVMDEVVLTIEQGNLGLRINGELITAYPQVVVVRVPTPWVQSDSDITVLRHLEKMGCRLMNRPQAILNCVNKFWTFQELAGHGVPLPDTFSYGGHENFAKMIDEAEVLEFPMVVKNTRGHRGKAVFLARDKHHLADLSHLIRHEAPYLFQKYVKESHGRDVRVIVVGGRVVGTMLRCSTDGRMQSNCSLGGVGMMCSLSEQGKQLAIQVSNILGMDVCGIDLLMKDDGSFCVCEANANVGFIAFDKACNLDVAGIIADYAASLLPSGRLTRRMSLLSVVSTASETSEPELGPPASTAVDNMSASSSSVDSDPESTERELLTKLPGGLFNMNQLLANEIKLLVD>sp|Q9ULI2-2|RIMKB_HUMAN Isoform 2 of Beta-citrylglutamate synthase BOS=Homo sapiens OX=9606 GN=RIMKLBMCSSVAAKLWFLTDRRIREDYPQKEILRALKAKCCEEELDFRAVVMDEVVLTIEQGNLGLRINGELITAYPQVVVVRVPTPWVQSDSDITVLRHLEKMGCRLMNRPQAILNCVNKFWTFQELAGHGVPLPDTFSYGGHENFAKMIDEAEVLEFPMVVKNTRGHRGKAVFLARDKHHLADLSHLIRHEAPYLFQKYVKESHGRDVRVIVVGGRVVGTMLRCSTDGRMQSNCSLGGVGMMCSLSEQGKQLAIQVSNILGMDVCGIDLLMKDDGSFCVCEANANPFQEPKKQIQTNKKIPREKTFLLPPS>sp|P0DJD4|RBY1C_HUMAN RNA-binding motif protein, Y chromosome, family 1member C OS=Homo sapiens OX=9606 GN=RBMY1C PE=1 SV=1MVEADHPGKLFIGGLNRETNEKMLKAVFGKHGPISEVLLIKDRTSKSRGFAFITFENPADAKNAAKDMNGKSLHGKAIKVEQAQKPSFQSGGRRRPPASSRNRSPSGSLRSARGSRGGTRGWLPSHEGHLDDGGYTPDLKMSYSRGLIPVKRGPSSRSGGPPPKKSAPSAVARSNSWMGSQGPMSQRRENYGVPPRRATISSWRNDRMSTRHDGYATNDGNHPSCQETRDYAPPSRGYAYRDNGHSNRDEHSSRGYRNHRSSRETRDYAPPSRGHAYRDYGHSRRDESYSRGYRNRRSSRETREYAPPSRGHGYRDYGHSRRHESYSRGYRNHPSSRETRDYAPPHRDYAYRDYGHSSWDEHSSRGYSYHDGYGEALGRDHSEHLSGSSYRDALQRYGTSHGAPPARGPRMSYGGSTCHAYSNTRDRYGRSWESYSSCGDFHYCDREHVCRKDQRNPPSLGRVLPDPREACGSSSYVASIVDGGESRSEKGDSSRY>sp|Q9BRK0|REEP2_HUMAN Receptor expression-enhancing protein 2 OS=Homosapiens OX=9606 GN=REEP2 PE=1 SV=2MVSWIISRLVVLIFGTLYPAYSSYKAVKTKNVKEYVKWMMYWIVFAFFTTAETLTDIVLSWFPFYFELKIAFVIWLLSPYTKGSSVLYRKFVHPTLSNKEKEIDEYITQARDKSYETMMRVGKRGLNLAANAAVTAAAKGVLSEKLRSFSMQDLTLIRDEDALPLQRPDGRLRPSPGSLLDTIEDLGDDPALSLRSSTNPADSRTEASEDDMGDKAPKRAKPIKKAPKAEPLASKTLKTRPKKKTSGGGDSA>sp|Q9BRK0-2|REEP2_HUMAN Isoform 2 of Receptor expression-enhancingprotein 2 OS=Homo sapiens OX=9606 GN=REEP2MVSWIISRLVVLIFGTLYPAYSSYKAVKTKNVKEYVKWMMYWIVFAFFTTAETLTDIVLSWFPFYFELKIAFVIWLLSPYTKGSSVLYRKFVHPTLSNKEKEIDEYITQARDKSYETMMRVGKRGLNLAANAAVTAAAKGQGVLSEKLRSFSMQDLTLIRDEDALPLQRPDGRLRPSPGSLLDTIEDLGDDPALSLRSSTNPADSRTEASEDDMGDKAPKRAKPIKKAPKAEPLASKTLKTRPKKKTSGGGDSA>sp|P04808|REL1_HUMAN Prorelaxin H1 OS=Homo sapiens OX=9606 GN=RLN1 PE=1SV=1MPRLFLFHLLEFCLLLNQFSRAVAAKWKDDVIKLCGRELVRAQIAICGMSTWSKRSLSQEDAPQTPRPVAEIVPSFINKDTETIIIMLEFIANLPPELKAALSERQPSLPELQQYVPALKDSNLSFEEFKKLIRNRQSEAADSNPSELKYLGLDTHSQKKRRPYVALFEKCCLIGCTKRSLAKYC>sp|P04808-2|REL1_HUMAN Isoform 2 of Prorelaxin H1 OS=Homo sapiensOX=9606 GN=RLN1MPRLFLFHLLEFCLLLNQFSRAVAAKWKDDVIKLCGRELVRAQIAICGMSTWSKRSLSQEDAPQTPRPVAGDFIQTVSLGISPDGGKALRTGSCFTREFLGALSKLYHPSSTKIQKL>sp|O94762|RECQ5_HUMAN ATP-dependent DNA helicase Q5 OS=Homo sapiensOX=9606 GN=RECQL5 PE=1 SV=2MSSHHTTFPFDPERRVRSTLKKVFGFDSFKTPLQESATMAVVKGNKDVFVCMPTGAGKSLCYQLPALLAKGITIVVSPLIALIQDQVDHLLTLKVRVSSLNSKLSAQERKELLADLEREKPQTKILYITPEMAASSSFQPTLNSLVSRHLLSYLVVDEAHCVSQWGHDFRPDYLRLGALRSRLGHAPCVALTATATPQVQEDVFAALHLKKPVAIFKTPCFRANLFYDVQFKELISDPYGNLKDFCLKALGQEADKGLSGCGIVYCRTREACEQLAIELSCRGVNAKAYHAGLKASERTLVQNDWMEEKVPVIVATISFGMGVDKANVRFVAHWNIAKSMAGYYQESGRAGRDGKPSWCRLYYSRNDRDQVSFLIRKEVAKLQEKRGNKASDKATIMAFDALVTFCEELGCRHAAIAKYFGDALPACAKGCDHCQNPTAVRRRLEALERSSSWSKTCIGPSQGNGFDPELYEGGRKGYGDFSRYDEGSGGSGDEGRDEAHKREWNLFYQKQMQLRKGKDPKIEEFVPPDENCPLKEASSRRIPRLTVKAREHCLRLLEEALSSNRQSTRTADEADLRAKAVELEHETFRNAKVANLYKASVLKKVADIHRASKDGQPYDMGGSAKSCSAQAEPPEPNEYDIPPASHVYSLKPKRVGAGFPKGSCPFQTATELMETTRIREQAPQPERGGEHEPPSRPCGLLDEDGSEPLPGPRGEVPGGSAHYGGPSPEKKAKSSSGGSSLAKGRASKKQQLLATAAHKDSQSIARFFCRRVESPALLASAPEAEGACPSCEGVQGPPMAPEKYTGEEDGAGGHSPAPPQTEECLRERPSTCPPRDQGTPEVQPTPAKDTWKGKRPRSQQENPESQPQKRPRPSAKPSVVAEVKGSVSASEQGTLNPTAQDPFQLSAPGVSLKEAANVVVKCLTPFYKEGKFASKELFKGFARHLSHLLTQKTSPGRSVKEEAQNLIRHFFHGRARCESEADWHGLCGPQR>sp|O94762-2|RECQ5_HUMAN Isoform Alpha of ATP-dependent DNA helicase Q5OS=Homo sapiens OX=9606 GN=RECQL5MSSHHTTFPFDPERRVRSTLKKVFGFDSFKTPLQESATMAVVKGNKDVFVCMPTGAGKSLCYQLPALLAKGITIVVSPLIALIQDQVDHLLTLKVRVSSLNSKLSAQERKELLADLEREKPQTKILYITPEMAASSSFQPTLNSLVSRHLLSYLVVDEAHCVSQWGHDFRPDYLRLGALRSRLGHAPCVALTATATPQVQEDVFAALHLKKPVAIFKTPCFRANLFYDVQFKELISDPYGNLKDFCLKALGQEADKGLSGCGIVYCRTREACEQLAIELSCRGVNAKAYHAGLKASERTLVQNDWMEEKVPVIVATISFGMGVDKANVRFVAHWNIAKSMAGYYQESGRAGRDGKPSWCRLYYSRNDRDQVSFLIRKEVAKLQEKRGNKASDKATIMAFDALVTFCEELG>sp|O94762-3|RECQ5_HUMAN Isoform Gamma of ATP-dependent DNA helicase Q5OS=Homo sapiens OX=9606 GN=RECQL5MSSHHTTFPFDPERRVRSTLKKVFGFDSFKTPLQESATMAVVKGNKDVFVCMPTGAGKSLCYQLPALLAKGITIVVSPLIALIQDQVDHLLTLKVRVSSLNSKLSAQERKELLADLEREKPQTKILYITPEMAASSSFQPTLNSLVSRHLLSYLVVDEAHCVSQWGHDFRPDYLRLGALRSRLGHAPCVALTATATPQVQEDVFAALHLKKPVAIFKTPCFRANLFYDVQFKELISDPYGNLKDFCLKALGQEADKGLSGCGIVYCRTREACEQLAIELSCRGVNAKAYHAGLKASERTLVQNDWMEEKVPVIVATISFGMGVDKANVRFVAHWNIAKSMAGYYQESGRAGRDGKPSWCRLYYSRNDRDQVSFLIRKEVAKLQEKRGNKASDKATIMAFDALVTFCEELGRWGRGHGKSLRAAWCSQVVSRHAEL>sp|O94762-4|RECQ5_HUMAN Isoform 4 of ATP-dependent DNA helicase Q5OS=Homo sapiens OX=9606 GN=RECQL5MSSHHTTFPFDPERRVRSTLKKVFGFDSFKTPLQESATMAVVKGITIVVSPLIALIQDQVDHLLTLKVRVSSLNSKLSAQERKELLADLEREKPQTKILYITPEMAASSSFQPTLNSLVSRHLLSYLVVDEAHCVSQWGHDFRPDYLRLGALRSRLGHAPCVALTATATPQVQEDVFAALHLKKPVAIFKTPCFRANLFYDVQFKELISDPYGNLKDFCLKALGQEADKGLSGCGIVYCRTREACEQLAIELSCRGVNAKAYHAGLKASERTLVQNDWMEEKVPVIVATISFGMGVDKANVRFVAHWNIAKSMAGYYQESGRAGRDGKPSWCRLYYSRNDRDQVSFLIRKEVAKLQEKRGNKASDKATIMAFDALVTFCEELGCRHAAIAKYFGDALPACAKGCDHCQNPTAVRRRLEALERSSSWSKTCIGPSQGNGFDPELYEGGRKGYGDFSRYDEGSGGSGDEGRDEAHKREWNLFYQKQMQLRKGKDPKIEEFVPPDENCPLKEASSRRIPRLTVKAREHCLRLLEEALSSNRQSTRTADEADLRAKAVELEHETFRNAKVANLYKASVLKKVADIHRASKDGQPYDMGGSAKSCSAQAEPPEPNEYDIPPASHVYSLKPKRVGAGFPKGSCPFQTATELMETTRIREQAPQPERGGEHEPPSRPCGLLDEDGSEPLPGPRGEVPGGSAHYGGPSPEKKAKSSSGGSSLAKGRASKKQQLLATAAHKDSQSIARFFCRRVESPALLASAPEAEGACPSCEGVQGPPMAPEKYTGEEDGAGGHSPAPPQTEECLRERPSTCPPRDQGTPEVQPTPAKDTWKGKRPRSQQENPESQPQKRPRPSAKPSVVAEVKGSVSASEQGTLNPTAQDPFQLSAPGVSLKEAANVVVKCLTPFYKEGKFASKELFKGFARHLSHLLTQKTSPGRSVKEEAQNLIRHFFHGRARCESEADWHGLCGPQR>sp|Q9Y225|RNF24_HUMAN RING finger protein 24 OS=Homo sapiens OX=9606GN=RNF24 PE=1 SV=1MSSDFPHYNFRMPNIGFQNLPLNIYIVVFGTAIFVFILSLLFCCYLIRLRHQAHKEFYAYKQVILKEKVKELNLHELCAVCLEDFKPRDELGICPCKHAFHRKCLIKWLEVRKVCPLCNMPVLQLAQLHSKQDRGPPQGPLPGAENIV>sp|Q9Y225-2|RNF24_HUMAN Isoform 2 of RING finger protein 24 OS=Homosapiens OX=9606 GN=RNF24MLNKSGESRYPALFPVLGGSSMSSDFPHYNFRMPNIGFQNLPLNIYIVVFGTAIFVFILSLLFCCYLIRLRHQAHKEFYAYKQVILKEKVKELNLHELCAVCLEDFKPRDELGICPCKHAFHRKCLIKWLEVRKVCPLCNMPVLQLAQLHSKQDRGPPQGPLPGAENIV>sp|Q96BH1|RNF25_HUMAN E3 ubiquitin-protein ligase RNF25 OS=Homo sapiensOX=9606 GN=RNF25 PE=1 SV=1MAASASAAAGEEDWVLPSEVEVLESIYLDELQVIKGNGRTSPWEIYITLHPATAEDQDSQYVCFTLVLQVPAEYPHEVPQISIRNPRGLSDEQIHTILQVLGHVAKAGLGTAMLYELIEKGKEILTDNNIPHGQCVICLYGFQEKEAFTKTPCYHYFHCHCLARYIQHMEQELKAQGQEQEQERQHATTKQKAVGVQCPVCREPLVYDLASLKAAPEPQQPMELYQPSAESLRQQEERKRLYQRQQERGGIIDLEAERNRYFISLQQPPAPAEPESAVDVSKGSQPPSTLAAELSTSPAVQSTLPPPLPVATQHICEKIPGTRSNQQRLGETQKAMLDPPKPSRGPWRQPERRHPKGGECHAPKGTRDTQELPPPEGPLKEPMDLKPEPHSQGVEGPPQEKGPGSWQGPPPRRTRDCVRWERSKGRTPGSSYPRLPRGQGAYRPGTRRESLGLESKDGS>sp|Q9BY78|RNF26_HUMAN E3 ubiquitin-protein ligase RNF26 OS=Homo sapiensOX=9606 GN=RNF26 PE=1 SV=1MEAVYLVVNGLGLVLDVLTLVLDLNFLLVSSLLASLAWLLAFVYNLPHTVLTSLLHLGRGVLLSLLALIEAVVRFTCGGLQALCTLLYSCCSGLESLKLLGHLASHGALRSREILHRGVLNVVSSGHALLRQACDICAIAMSLVAYVINSLVNICLIGTQNLFSLVLALWDAVTGPLWRMTDVVAAFLAHISSSAVAMAILLWTPCQLALELLASAARLLASFVLVNLTGLVLLACVLAVTVTVLHPDFTLRLATQALSQLHARPSYHRLREDVMRLSRLALGSEAWRRVWSRSLQLASWPNRGGAPGAPQGDPMRVFSVRTRRQDTLPEAGRRSEAEEEEARTIRVTPVRGRERLNEEEPPGGQDPWKLLKEQEERKKCVICQDQSKTVLLLPCRHLCLCQACTEILMRHPVYHRNCPLCRRGILQTLNVYL>sp|Q96EP0|RNF31_HUMAN E3 ubiquitin-protein ligase RNF31 OS=Homo sapiensOX=9606 GN=RNF31 PE=1 SV=1MPGEEEERAFLVAREELASALRRDSGQAFSLEQLRPLLASSLPLAARYLQLDAARLVRCNAHGEPRNYLNTLSTALNILEKYGRNLLSPQRPRYWRGVKFNNPVFRSTVDAVQGGRDVLRLYGYTEEQPDGLSFPEGQEEPDEHQVATVTLEVLLLRTELSLLLQNTHPRQQALEQLLEDKVEDDMLQLSEFDPLLREIAPGPLTTPSVPGSTPGPCFLCGSAPGTLHCPSCKQALCPACDHLFHGHPSRAHHLRQTLPGVLQGTHLSPSLPASAQPRPQSTSLLALGDSSLSSPNPASAHLPWHCAACAMLNEPWAVLCVACDRPRGCKGLGLGTEGPQGTGGLEPDLARGRWACQSCTFENEAAAVLCSICERPRLAQPPSLVVDSRDAGICLQPLQQGDALLASAQSQVWYCIHCTFCNSSPGWVCVMCNRTSSPIPAQHAPRPYASSLEKGPPKPGPPRRLSAPLPSSCGDPEKQRQDKMREEGLQLVSMIREGEAAGACPEEIFSALQYSGTEVPLQWLRSELPYVLEMVAELAGQQDPGLGAFSCQEARRAWLDRHGNLDEAVEECVRTRRRKVQELQSLGFGPEEGSLQALFQHGGDVSRALTELQRQRLEPFRQRLWDSGPEPTPSWDGPDKQSLVRRLLAVYALPSWGRAELALSLLQETPRNYELGDVVEAVRHSQDRAFLRRLLAQECAVCGWALPHNRMQALTSCECTICPDCFRQHFTIALKEKHITDMVCPACGRPDLTDDTQLLSYFSTLDIQLRESLEPDAYALFHKKLTEGVLMRDPKFLWCAQCSFGFIYEREQLEATCPQCHQTFCVRCKRQWEEQHRGRSCEDFQNWKRMNDPEYQAQGLAMYLQENGIDCPKCKFSYALARGGCMHFHCTQCRHQFCSGCYNAFYAKNKCPEPNCRVKKSLHGHHPRDCLFYLRDWTALRLQKLLQDNNVMFNTEPPAGARAVPGGGCRVIEQKEVPNGLRDEACGKETPAGYAGLCQAHYKEYLVSLINAHSLDPATLYEVEELETATERYLHVRPQPLAGEDPPAYQARLLQKLTEEVPLGQSIPRRRK>sp|Q96EP0-2|RNF31_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF31OS=Homo sapiens OX=9606 GN=RNF31MPGEEEERAFLVAREELASALRRDSGQAFSLEQLRPLLASSLPLAARYLQLDAARLVRCNAHGEPRNYLNTLPTPSWDGPDKQSLVRRLLAVYALPSWGRAELALSLLQETPRNYELGDVVEAVRHSQDRAFLRRLLAQECAVCGWALPHNRMQALTSCECTICPDCFRQHFTIALKEKHITDMVCPACGRPDLTDDTQLLSYFSTLDIQLRESLEPDAYALFHKKLTEGVLMRDPKFLWCAQCSFGFIYEREQLEATCPQCHQTFCVRCKRQWEDFQNWKRMNDPEYQAQGLAMYLQENGIDCPKCKFSYALARGGCMHFHCTQCRHQFCSGCYNAFYAKNKCPEPNCRVKKSLHGHHPRDCLFYLRDWTALRLQKLLQDNNVMFNTEPPAGARAVPGGGCRVIEQKEVPNGLRDEACGKETPAGYAGLCQAHYKEYLVSLINAHSLDPATLYEVEELETATERYLHVRPQPLAGEDPPAYQARLLQKLTEEVPLGQSIPRRRK>sp|Q96EP0-3|RNF31_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNF31OS=Homo sapiens OX=9606 GN=RNF31MDLCTRAGEPSLTQNTHPRQQALEQLLEDKVEDDMLQLSEFDPLLREIAPGPLTTPSVPGSTPGPCFLCGSAPGTLHCPSCKQALCPACDHLFHGHPSRAHHLRQTLPGVLQGTHLSPSLPASAQPRPQSTSLLALGDSSLSSPNPASAHLPWHCAACAMLNEPWAVLCVACDRPRGCKGLGLGTEGPQGTGGLEPDLARGRWACQSCTFENEAAAVLCSICERPRLAQPPSLVVDSRDAGICLQPLQQGDALLASAQSQVWYCIHCTFCNSSPGWVCVMCNRTSSPIPAQHAPRPYASSLEKGPPKPGPPRRLSAPLPSSCGDPEKQRQDKMREEGLQLVSMIREGEAAGACPEEIFSALQYSGTEVPLQWLRSELPYVLEMVAELAGQQDPGLGAFSCQEARRAWLDRHGNLDEAVEECVRTRRRKVQELQSLGFGPEEGSLQALFQHGGDVSRALTELQRQRLEPFRQRLWDSGPEPTPSWDGPDKQSLVRRLLAVYALPSWGRAELALSLLQETPRNYELGDVVEAVRHSQDRAFLRRLLAQECAVCGWALPHNRMQALTSCECTICPDCFRQHFTIALKEKHITDMVCPACGRPDLTDDTQLLSYFSTLDIQLRESLEPDAYALFHKKLTEGVLMRDPKFLWCAQCSFGFIYEREQLEATCPQCHQTFCVRCKRQWEEQHRGRSCEDFQNWKRMNDPEYQAQGLAMYLQENGIDCPKCKFSYALARGGCMHFHCTQCRHQFCSGCYNAFYAKNKCPEPNCRVKKSLHGHHPRDCLFYLRDWTALRLQKLLQDNNVMFNTEPPAGARAVPGGGCRVIEQKEVPNGLRDEACGKETPAGYAGLCQAHYKEYLVSLINAHSLDPATLYEVEELETATERYLHVRPQPLAGEDPPAYQARLLQKLTEEVPLGQSIPRRRK>sp|Q7L0Q8|RHOU_HUMAN Rho-related GTP-binding protein RhoU OS=Homosapiens OX=9606 GN=RHOU PE=1 SV=1MPPQQGDPAFPDRCEAPPVPPRRERGGRGGRGPGEPGGRGRAGGAEGRGVKCVLVGDGAVGKTSLVVSYTTNGYPTEYIPTAFDNFSAVVSVDGRPVRLQLCDTAGQDEFDKLRPLCYTNTDIFLLCFSVVSPSSFQNVSEKWVPEIRCHCPKAPIILVGTQSDLREDVKVLIELDKCKEKPVPEEAAKLCAEEIKAASYIECSALTQKNLKEVFDAAIVAGIQYSDTQQQPKKSKSRTPDKMKNLSKSWWKKYCCFV>sp|Q7L0Q8-2|RHOU_HUMAN Isoform 2 of Rho-related GTP-binding protein RhoUOS=Homo sapiens OX=9606 GN=RHOUMTNIGVSYTTNGYPTEYIPTAFDNFSAVVSVDGRPVRLQLCDTAGQDEFDKLRPLCYTNTDIFLLCFSVVSPSSFQNVSEKWVPEIRCHCPKAPIILVGTQSDLREDVKVLIELDKCKEKPVPEEAAKLCAEEIKAASYIECSALTQKNLKEVFDAAIVAGIQYSDTQQQPKKSKSRTPDKMKNLSKSWWKKYCCFV>sp|Q07960|RHG01_HUMAN Rho GTPase-activating protein 1 OS=Homo sapiensOX=9606 GN=ARHGAP1 PE=1 SV=1MDPLSELQDDLTLDDTSEALNQLKLASIDEKNWPSDEMPDFPKSDDSKSSSPELVTHLKWDDPYYDIARHQIVEVAGDDKYGRKIIVFSACRMPPSHQLDHSKLLGYLKHTLDQYVESDYTLLYLHHGLTSDNKPSLSWLRDAYREFDRKYKKNIKALYIVHPTMFIKTLLILFKPLISFKFGQKIFYVNYLSELSEHVKLEQLGIPRQVLKYDDFLKSTQKSPATAPKPMPPRPPLPNQQFGVSLQHLQEKNPEQEPIPIVLRETVAYLQAHALTTEGIFRRSANTQVVREVQQKYNMGLPVDFDQYNELHLPAVILKTFLRELPEPLLTFDLYPHVVGFLNIDESQRVPATLQVLQTLPEENYQVLRFLTAFLVQISAHSDQNKMTNTNLAVVFGPNLLWAKDAAITLKAINPINTFTKFLLDHQGELFPSPDPSGL>sp|Q9BWE0|REPI1_HUMAN Replication initiator 1 OS=Homo sapiens OX=9606GN=REPIN1 PE=1 SV=1MLERRCRGPLAMGLAQPRLLSGPSQESPQTLGKESRGLRQQGTSVAQSGAQAPGRAHRCAHCRRHFPGWVALWLHTRRCQARLPLPCPECGRRFRHAPFLALHRQVHAAATPDLGFACHLCGQSFRGWVALVLHLRAHSAAKRPIACPKCERRFWRRKQLRAHLRRCHPPAPEARPFICGNCGRSFAQWDQLVAHKRVHVAEALEEAAAKALGPRPRGRPAVTAPRPGGDAVDRPFQCACCGKRFRHKPNLIAHRRVHTGERPHQCPECGKRFTNKPYLTSHRRIHTGEKPYPCKECGRRFRHKPNLLSHSKIHKRSEGSAQAAPGPGSPQLPAGPQESAAEPTPAVPLKPAQEPPPGAPPEHPQDPIEAPPSLYSCDDCGRSFRLERFLRAHQRQHTGERPFTCAECGKNFGKKTHLVAHSRVHSGERPFACEECGRRFSQGSHLAAHRRDHAPDRPFVCPDCGKAFRHKPYLAAHRRIHTGEKPYVCPDCGKAFSQKSNLVSHRRIHTGERPYACPDCDRSFSQKSNLITHRKSHIRDGAFCCAICGQTFDDEERLLAHQKKHDV>sp|Q9BWE0-4|REPI1_HUMAN Isoform 2 of Replication initiator 1 OS=Homosapiens OX=9606 GN=REPIN1MGIGVSLLLQFSLTPGGYRSVGRSRRCSRGSIPRNIPKRSWKKPHPQLCSLQAEEEPMLERRCRGPLAMGLAQPRLLSGPSQESPQTLGKESRGLRQQGTSVAQSGAQAPGRAHRCAHCRRHFPGWVALWLHTRRCQARLPLPCPECGRRFRHAPFLALHRQVHAAATPDLGFACHLCGQSFRGWVALVLHLRAHSAAKRPIACPKCERRFWRRKQLRAHLRRCHPPAPEARPFICGNCGRSFAQWDQLVAHKRVHVAEALEEAAAKALGPRPRGRPAVTAPRPGGDAVDRPFQCACCGKRFRHKPNLIAHRRVHTGERPHQCPECGKRFTNKPYLTSHRRIHTGEKPYPCKECGRRFRHKPNLLSHSKIHKRSEGSAQAAPGPGSPQLPAGPQESAAEPTPAVPLKPAQEPPPGAPPEHPQDPIEAPPSLYSCDDCGRSFRLERFLRAHQRQHTGERPFTCAECGKNFGKKTHLVAHSRVHSGERPFACEECGRRFSQGSHLAAHRRDHAPDRPFVCPDCGKAFRHKPYLAAHRRIHTGEKPYVCPDCGKAFSQKSNLVSHRRIHTGERPYACPDCDRSFSQKSNLITHRKSHIRDGAFCCAICGQTFDDEERLLAHQKKHDV>sp|P0DJD0|RGPD1_HUMAN RANBP2-like and GRIP domain-containing protein 1OS=Homo sapiens OX=9606 GN=RGPD1 PE=2 SV=1MNVMGFNTDRLAWTRNKLRGFYFAKLYYEAKEYDLAKKYVCTYLSVQERDPRAHRFLGLLYELEENTEKAVECYRRSLELNPPQKDLVLKIAELLCKNDVTDGRAKYWVERAAKLFPGSPAIYKLKEHLLDCEGEDGWNKLFDWIQSELYVRPDDVHMNIRLVELYRSNKRLKDAVARCHEAERNIALRSSLEWNSCVVQTLKEYLESLQCLESDKSDWRATNTDLLLAYANLMLLTLSTRDVQESRELLESFDSALQSAKSSLGGNDELSATFLEMKGHFYMHAGSLLLKMGQHGNNVQWQALSELAALCYVIAFQVPRPKIKLIKGEAGQNLLEMMACDRLSQSGHMLLNLSRGKQDFLKEVVETFANKSGQSVLYNALFSSQSSKDTSFLGSDDIGNIDVQEPELEDLARYDVGAIQAHNGSLQHLTWLGLQWNSLPALPGIRKWLKQLFHHLPQETSRLETNAPESICILDLEVFLLGVVYTSHLQLKEKCNSHHSSYQPLCLPLPVCKRLCTERQKSWWDAVCTLIHRKAVPGNSAELRLVVQHEINTLRAQEKHGLQPALLVHWAKCLQKMGRGLNSSYDQQEYIGRSVHYWKKVLPLLKIIKKNSIPEPIDPLFKHFHSVDIQASEIVEYEEDAHITFAILDAVHGNIEDAVTAFESIKSVVSYWNLALIFHRKAEDIENDAVFPEEQEECKNYLRKTRDYLIKIIDDSDSNLSVVKKLPVPLESVKEMLKSVMQELEDYSEGGPLYKNGSLRNADSEIKHSTPSPTKYSLSPSKSYKYSPKTPPRWAEDQNSLRKMICQEVKAITKLNSSKSASRHRWPTENYGPDSVPDGYQGSQTFHGAPLTVATTGPSVYYSQSPAYNSQYLLRPAANVTPTKGSSNTEFKSTKEGFSIAVSADGFKFGISEPGNQEKKSEKPLENDTGFQAQDISGQKNGRGVIFGQTSSTFTFADVAKSTSGEGFQFGKKDPNFKGFSGAGEKLFSSQCGKMANKANTSGDFEKDDDACKTEDSDDIHFEPVVQMPEKVELVTGEEGEKVLYSQGVKLFRFDAEISQWKERGLGNLKILKNEVNGKPRMLMRRDQVLKVCANHWITTTMNLKPLSGSDRAWMWLASDFSDGDAKLERLAAQFKTPELAEEFKQKFEECQRLLLDIPLQTPHKLVDTGRAAKLIQRAEEMKSGLKDFKTFLTNDQTKVTEEENKGSGTGAAGASDTTIKPNPENTGPTLEWDNYDLREDALDDNVSSSSVHDSPLASSPVRKNIFRFDESTTGFNFSFKSALSLSKSPAKLNQSGTSVGTDEESDVTQEEERDGQYFEPVVPLPDLVEVSSGEENEQVVFSHRAELYRYDKDVGQWKERGIGDIKILQNYDNKQVRIVMRRDQVLKLCANHRITPDMSLQNMKGTERVWVWTACDFADGERKVEHLAVRFKLQDVADSFKKIFDEAKTAQEKDSLITPHVSRSSTPRESPCGKIAVAVLEETTRERTDVIQGDDVADAASEVEVSSTSETTTKAVVSPPKFVFGSESVKRIFSSEKSNPFAFGNSSATGSLFGFSFNAPLKSNDSETSSVAQSGSESKVEPKKCELSKNSDIEQSSDSKVKNLSASFPMEESSINYTFKTPEKEPPLWHAEFTKEELVQKLSSTTKSADQLNGLLRETEATSAVLMEQIKLLKSEIRRLERNQEESAANVEHLKNVLLQFIFLKPGSERESLLPVINTMLQLSPEEKGKLAAVAQGLQETSIPKKK>sp|P98171|RHG04_HUMAN Rho GTPase-activating protein 4 OS=Homo sapiensOX=9606 GN=ARHGAP4 PE=1 SV=2MAAHGKLRRERGLQAEYETQVKEMRWQLSEQLRCLELQGELRRELLQELAEFMRRRAEVELEYSRGLEKLAERFSSRGGRLGSSREHQSFRKEPSLLSPLHCWAVLLQHTRQQSRESAALSEVLAGPLAQRLSHIAEDVGRLVKKSRDLEQQLQDELLEVVSELQTAKKTYQAYHMESVNAEAKLREAERQEEKRAGRSVPTTTAGATEAGPLRKSSLKKGGRLVEKRQAKFMEHKLKCTKARNEYLLSLASVNAAVSNYYLHDVLDLMDCCDTGFHLALGQVLRSYTAAESRTQASQVQGLGSLEEAVEALDPPGDKAKVLEVHATVFCPPLRFDYHPHDGDEVAEICVEMELRDEILPRAQNIQSRLDRQTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKHEKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRVSEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNHLAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNEPELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGESGSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPPSSRLGRNKGFSRGPGAPASPSASHPQGLDTTPKPH>sp|P98171-2|RHG04_HUMAN Isoform 2 of Rho GTPase-activating protein 4OS=Homo sapiens OX=9606 GN=ARHGAP4MAAHGKLRRERGLQAEYETQVKEMRWQLSEQLRCLELQGELRRELLQELAEFMRRRAEVELEYSRGLEKLAERFSSRGGRLGSSREHQSFRKEPSLLSPLHCWAVLLQHTRQQSRESAALSEVLAGPLAQRLSHIAEDVGRLVKKSRDLEQQLQDELLEVVSELQTAKKTYQAYHMESVNAEAKLREAERQEEKRAGRSVPTTTAGATEAGPLRKSSLKKGGRLVEKLWPPQRPVAASSCAPVCWLQAGFLVHPPWWGAMCAPSTHQRQAKFMEHKLKCTKARNEYLLSLASVNAAVSNYYLHDVLDLMDCCDTGFHLALGQVLRSYTAAESRTQASQVQGLGSLEEAVEALDPPGDKAKVLEVHATVFCPPLRFDYHPHDGDEVAEICVEMELRDEILPRAQNIQSRLDRQTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKHEKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRVSEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNHLAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNEPELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGESGSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPPSSRLGRNKGFSRGPGAPASPSASHPQGLDTTPKPH>sp|Q7Z3J3|RGPD4_HUMAN RanBP2-like and GRIP domain-containing protein 4OS=Homo sapiens OX=9606 GN=RGPD4 PE=2 SV=3MSCSKAYGERYVASVQGSAPSPRKKSTRGFYFAKLYYEAKEYDLAKKYICTYINVREMDPRAHRFLGLLYELEENTEKAVECYRRSVELNPTQKDLVLKIAELLCKNDVTDGRAKYWVERAAKLFPGSPAIYKLKEQLLDCEGEDGWNKLFDLIQSELYVRPDDVHVNIRLVELYRSTKRLKDAVARCHEAERNIALRSSLEWNSCVVQTLKEYLESLQCLESDKSDWRATNTDLLLAYANLMLLTLSTRDVQESRELLESFDSALQSAKSSLGGNDELSATFLEMKGHFYMHAGSLLLKMGQHGNNVQWRALSELAALCYLIAFQVPRPKIKLIKGEAGQNLLEMMACDRLSQSGHMLLNLSRGKQDFLKVVVETFANKSGQSALYDALFSSQSPKDTSFLGSDDIGNIDVQEPELEDLARYDVGAIRAHNGSLQHLTWLGLQWNSLPALPGIRKWLKQLFHHLPQETSRLETNAPESICILDLEVFLLGVVYTSHLQLKEKCNSHHSSYQPLCLPLPVCKQLCTERQKSWWDAVCTLIHRKAVPGNSAKLRLLVQHEINTLRAQEKHGLQPALLVHWAKCLQKMGSGLNSFYDQREYIGRSVHYWKKVLPLLKIIKKKNSIPEPIDPLFKHFHSVDIQASEIVEYEEDAHVTFAILDAVNGNIEDAMTAFESIKSVVSYWNLALIFHRKAEDIANDALSPEEQEECKNYLRKTRGYLIKILDDSDSNLSVVKKLPVPLESVKEMLKSVMQELENYSEGDPLYKNGSLRNADSEIKHSTPSPTKYSLSPSKSYKYSPKTPPRWAEDQNSLLKMIRQEVKAIKEEMQELKLNSSKSASHHRWPTENYGPDSVPDGYQGSQTFHGAPLTVATTGPSVYYSQSPAYNSQYLLRPAANVTPTKGSSNTEFKSTKEGFSIPVSADGFKFGISEPGNQEKESEKPLENDTGFQAQDISGQKNGRGVIFGQTSSTFTFADVAKSTSGEGFQFGKKDPNFKGFSGAGEKLFSSQCGKMANKANTSGDFEKDDDAYKTEDSDDIHFEPVVQMPEKVELVIGEEGEKVLYSQGVKLFRFDAEVRQWKERGLGNLKILKNEVNGKPRMLMRREQVLKVCANHWITTTMNLKPLSGSDRAWMWSASDFSDGDAKLERLAAKFKTPELAEEFKQKFEECQQLLLDIPLQTPHKLVDTGRAAKLIQRAEEMKSGLKDFKTFLTNDQTKVTEEENKGSGTGAAGASDTTIKPNPENTGPTLEWDNCDLREDALDDSVSSSSVHASPLASSPVRKNLFHFGESTTGSNFSFKSALSPSKSPAKLNQSGTSVGTDEESDVTQEEERDGQYFEPVVPLPDLVEVSSGEENEKVVFSHRAELYRYDKDVGQWKERGIGDIKILQNYDNKQVRIVMRRDQVLKLCANHTITPDMSLQNMKGTERVWVWTACDFADGERKVEHLAVRFKLQDVADSFKKIFDEAKTAQEKDSLITPHVSRSSTPRESPCGKIAVAVLEETTRERTDVIQGDDVADAASEVEVSSTSETTTKAVVSPPKFVFGSESVKRIFSSEKSKPFAFGNSSATGSLFGFSFNASLKSNNSETSSVAQSGSESKVEPKKCELSKNSDIEQSSDSKVKNLSASFPMEESSINYTFKTPEKEPPLWHAEFTKEELVQKLSSTTKSADHLNGLLREAEATSAVLMEQIKLLKSEIRRLERNQEQEESAANVEHLKNVLLQFIFLKPGSERERLLPVINTMLQLSPEEKGKLAAVAQGEE>sp|Q7Z3J3-2|RGPD4_HUMAN Isoform 2 of RanBP2-like and GRIP domain-containing protein 4 OS=Homo sapiens OX=9606 GN=RGPD4MDPRAHRFLGLLYELEENTEKAVECYRRSVELNPTQKDLVLKIAELLCKNDVTDGRAKYWVERAAKLFPGSPAIYKLKEQLLDCEGEDGWNKLFDLIQSELYVRPDDVHVNIRLVELYRSTKRLKDAVARCHEAERNIALRSSLEWNSCVVQTLK>sp|Q96L33|RHOV_HUMAN Rho-related GTP-binding protein RhoV OS=Homosapiens OX=9606 GN=RHOV PE=1 SV=1MPPRELSEAEPPPLRAPTPPPRRRSAPPELGIKCVLVGDGAVGKSSLIVSYTCNGYPARYRPTALDTFSVQVLVDGAPVRIELWDTAGQEDFDRLRSLCYPDTDVFLACFSVVQPSSFQNITEKWLPEIRTHNPQAPVLLVGTQADLRDDVNVLIQLDQGGREGPVPQPQAQGLAEKIRACCYLECSALTQKNLKEVFDSAILSAIEHKARLEKKLNAKGVRTLSRCRWKKFFCFV>sp|O14715|RGPD8_HUMAN RANBP2-like and GRIP domain-containing protein 8OS=Homo sapiens OX=9606 GN=RGPD8 PE=1 SV=2MRRSKADVERYVASVLGLTPSPRQKSMKGFYFAKLYYEAKEYDLAKKYICTYINVQERDPKAHRFLGLLYELEENTEKAVECYRRSVELNPTQKDLVLKIAELLCKNDVTDGRAKYWVERAAKLFPGSPAIYKLKEQLLDCEGEDGWNKLFDLIQSELYVRPDDVHVNIRLVELYRSTKRLKDAVAHCHEAERNIALRSSLEWNSCVVQTLKEYLESLQCLESDKSDWRATNTDLLLAYANLMLLTLSTRDVQENRELLESFDSALQSAKSSLGGNDELSATFLEMKGHFYMYAGSLLLKMGQHGNNVQWRALSELAALCYLIAFQVPRPKIKLREGKAGQNLLEMMACDRLSQSGHMLLSLSRGKQDFLKEVVETFANKIGQSALYDALFSSQSPKDTSFLGSDDIGKIDVQEPELEDLARYDVGAIRAHNGSLQHLTWLGLQWNSLPALPGIRKWLKQLFHRLPHETSRLETNAPESICILDLEVFLLGVVYTSHLQLKEKCNSHHSSYQPLCLPFPVCKQLCTERQKSWWDAVCTLIHRKAVPGNLAKLRLLVQHEINTLRAQEKHGLQPALLVHWAKYLQKTGSGLNSFYGQLEYIGRSVHYWKKVLPLLKIIKKNSIPEPIDPLFKHFHSVDIQASEIVEYEEDAHITFAILDAVNGNIEDAVTAFESIKSVVSYWNLALIFHRKAEDIENDALSPEEQEECRNYLTKTRDYLIKIIDDGDSNLSVVKKLPVPLESVKQMLNSVMQELEDYSEGGPLYKNGSLRNADSEIKHSTPSPTKYSLSPSKSYKYSPETPPRWTEDRNSLLNMICQQVEAIKKEMQELKLNSSKSASRHRWPTENYGPDSVPDGYQGSQTFHGAPLTVATTGPSVYYSQSPAYNSQYLLRPAANVTPTKGSSNTEFKSTKEGFSIPVSADGFKFGISEPGNQEKKREKPLENDTGLQAQDIRGRKKGRGVIFGQTSSTFTFADVAKSTSGEGFQFGKKDLNFKGFSGAGEKLFSSRYGKMANKANTSGDFEKDDDAYKTEDSDDIHFEPVVQMPEKVELVTGEEGEKVLYSQGVKLFRFDAEVRQWKERGLGNLKILKNEVNGKLRMLMRREQVLKVCANHWITTTMNLKPLSGSDRAWMWSASDFSDGDAKLERLAAKFKTPELAEEFKQKFEECQRLLLDIPLQTPHKLVDTGRAAKLIQRAEEMKSGLKDFKTFLTNDQTKVTEEENKGSGTGVAGASDTTIKPNAENTGPTLEWDNYDLREDALDDSVSSSSVHASPLASSPVRKNLFRFDESTTGSNFSFKSALSLSKSPAKLNQSGTSVGTDEESVVTQEEERDGQYFEPVVPLPDLVEVSSGEENEQVVFSHRAEIYRYDKDVGQWKERGIGDIKILQNYDNKQVRIVMRRDQVLKLCANHRITPDMSLQNMKGTERVWVWTACDFADGERKVEHLAVRFKLQDVADSFKKIFDEAKTAQEKDSLITPHVSRSSTPRESPCGKIAVAVLEEITRERTDVIQGDDVADAASEVEVSSTSETTTKAVVSPPKFVFVSESVKRIFSSEKSKPFAFGNSSATGSLFGFSFNAPLKSNNSETSSVAQSGSESKVEPKKCELSKNSDIEQSSDSKVKNLSASFPTEESSINYTFKTPEKEPPLWHAEFTKEELVQKLRSTTKSADHLNGLLREIEATNAVLMEQIKLLKSEIRRLERNQEREKSAANLEYLKNVLLQFIFLKPGSERERLLPVINTMLQLSPEEKGKLAAVAQDEEENPSRSSG>sp|Q5JS13|RGPS1_HUMAN Ras-specific guanine nucleotide-releasing factorRalGPS1 OS=Homo sapiens OX=9606 GN=RALGPS1 PE=1 SV=1MYKRNGLMASVLVTSATPQGSSSSDSLEGQSCDYASKSYDAVVFDVLKVTPEEFASQITLMDIPVFKAIQPEELASCGWSKKEKHSLAPNVVAFTRRFNQVSFWVVREILTAQTLKIRAEILSHFVKIAKKLLELNNLHSLMSVVSALQSAPIFRLTKTWALLNRKDKTTFEKLDYLMSKEDNYKRTREYIRSLKMVPSIPYLGIYLLDLIYIDSAYPASGSIMENEQRSNQMNNILRIIADLQVSCSYDHLTTLPHVQKYLKSVRYIEELQKFVEDDNYKLSLRIEPGSSSPRLVSSKEDLAGPSAGSGSARFSRRPTCPDTSVAGSLPTPPVPRHRKSHSLGNNMMCQLSVVESKSATFPSEKARHLLDDSVLESRSPRRGLALTSSSAVTNGLSLGSSESSEFSEEMSSGLESPTGPCICSLGNSAAVPTMEGPLRRKTLLKEGRKPALSSWTRYWVILSGSTLLYYGAKSLRGTDRKHYKSTPGKKVSIVGWMVQLPDDPEHPDIFQLNNPDKGNVYKFQTGSRFHAILWHKHLDDACKSNRPQVPANLMSFE>sp|Q5JS13-2|RGPS1_HUMAN Isoform 2 of Ras-specific guanine nucleotide-releasing factor RalGPS1 OS=Homo sapiens OX=9606 GN=RALGPS1MYKRNGLMASVLVTSATPQGSSSSDSLEGQSCDYASKSYDAVVFDVLKVTPEEFASQITLMDIPVFKAIQPEELASCGWSKKEKHSLAPNVVAFTRRFNQVSFWVVREILTAQTLKIRAEILSHFVKIAKKLLELNNLHSLMSVVSALQSAPIFRLTKTWALLNRKDKTTFEKLDYLMSKEDNYKRTREYIRSLKMVPSIPYLGIYLLDLIYIDSAYPASGSIMENEQRSNQMNNILRIIADLQVSCSYDHLTTLPHVQKYLKSVRYIEELQKFVEDDNYKLSLRIEPGSSSPRLVSSKEDLAGPSAGSGSARFSRRPTCPDTSVAGSLPTPPVPRHRKSHSLGNNRGRLYATLGPNWRVPVRNSPRTRSCVYSPTGPCICSLGNSAAVPTMEGPLRRKTLLKEGRKPALSSWTRYWVILSGSTLLYYGAKSLRGTDRKHVSIVGWMVQLPDDPEHPDIFQLNNPDKGNVYKFQTGSRFHAILWHKHLDDACKSNRPQEAGAAPGPTGTDSHEVDHLEGGAGKEAGPCA>sp|Q5JS13-3|RGPS1_HUMAN Isoform 3 of Ras-specific guanine nucleotide-releasing factor RalGPS1 OS=Homo sapiens OX=9606 GN=RALGPS1MYKRNGLMASVLVTSATPQGSSSSDSLEGQSCDYASKSYDAVVFDVLKVTPEEFASQITLMDIPVFKAIQPEELASCGWSKKEKHSLAPNVVAFTRRFNQVSFWVVREILTAQTLKIRAEILSHFVKIAKKLLELNNLHSLMSVVSALQSAPIFRLTKTWALLNRKDKTTFEKLDYLMSKEDNYKRTREYIRSLKMVPSIPYLGIYLLDLIYIDSAYPASGSIMENEQRSNQMNNILRIIADLQVSCSYDHLTTLPHVQKYLKSVRYIEELQKFVEDDNYKLSLRIEPGSSSPRLVSSKEDLAVSHLSSLSHQGQAEEARLKPTSGQHPAWMWPSSSRVPAAPPASAAPRSPWPRNLRNDQGQPGAVALTCNPSTLGSRSRRIT>sp|Q5JS13-4|RGPS1_HUMAN Isoform 4 of Ras-specific guanine nucleotide-releasing factor RalGPS1 OS=Homo sapiens OX=9606 GN=RALGPS1MYKRNGLMASVLVTSATPQGSSSSDSLEGQSCDYASKSYDAVVFDVLKVTPEEFASQITLMDIPVFKAIQPEELASCGWSKKEKHSLAPNVVAFTRRFNQVSFWVVREILTAQTLKIRAEILSHFVKIAKKLLELNNLHSLMSVVSALQSAPIFRLTKTWALLNRKDKTTFEKLDYLMSKEDNYKRTREYIRSLKMVPSIPYLGIYLLDLIYIDSAYPASGSIMENEQRSNQMNNILRIIADLQVSCSYDHLTTLPHVQKYLKSVRYIEELQKFVEDDNYKLSLRIEPGSSSPRLVSSKEDLAAM>sp|Q5JS13-5|RGPS1_HUMAN Isoform 5 of Ras-specific guanine nucleotide-releasing factor RalGPS1 OS=Homo sapiens OX=9606 GN=RALGPS1MYKRNGLMASVLVTSATPQGSSSSDSLEGQSCDYASKSYDAVVFDVLKVTPEEFASQITLMDIPVFKAIQPEELASCGWSKKEKHSLAPNVVAFTRRFNQVSFWVVREILTAQTLKIRAEILSHFVKIAKKLLELNNLHSLMSVVSALQSAPIFRLTKTWALLNRKDKTTFEKLDYLMSKEDNYKRTREYIRSLKMVPSIPYLGRSLNWLIFF>sp|Q5JS13-6|RGPS1_HUMAN Isoform 6 of Ras-specific guanine nucleotide-releasing factor RalGPS1 OS=Homo sapiens OX=9606 GN=RALGPS1MYKRNGLMASVLVTSATPQGSSSSDSLEGQSCDYASKSYDAVVFDVLKVTPEEFASQITLMDIPVFKAIQPEKGWPARMEDSLQKSTVSSRPHDTLQFRKTLPVGPGT>sp|Q5JS13-7|RGPS1_HUMAN Isoform 7 of Ras-specific guanine nucleotide-releasing factor RalGPS1 OS=Homo sapiens OX=9606 GN=RALGPS1MYKRNGLMASVLVTSATPQGSSSSDSLEGQSCDYASKSYDAVVFDVLKVTPEEFASQITLMDIPVFKAIQPEELASCGWSKKEKHSLAPNVVAFTRRFNQVSFWVVREILTAQTLKIRAEILSHFVKIAKKLLELNNLHSLMSVVSALQSAPIFRLTKTWALLNRKDKTTFEKLDYLMSKEDNYKRTREYIRSLKMVPSIPYLGIYLLDLIYIDSAYPASGSIMENEQRSNQMNNILRIIADLQVSCSYDHLTTLPHVQKYLKSVRYIEELQKFVEDDNYKLSLRIEPGSSSPRLVSSKEDLAGPSAGSGSARFSRRPTCPDTSVAGSLPTPPVPRHRKSHSLGNNRGRLYATLGPNWRVPVRNSPRTRSCVYSPTGPCICSLGNSAAVPTMEGPLRRKTLLKEGRKPALSSWTRYWVILSGSTLLYYGAKSLRGTDRKHYKSTPGKKVSIVGWMVQLPDDPEHPDIFQLNNPDKGNVYKFQTGSRFHAILWHKHLDDACKSNRPQEAGAAPGPTGTDSHEVDHLEGGAGKEAGPCA>sp|Q96D71|REPS1_HUMAN RalBP1-associated Eps domain-containing protein 1OS=Homo sapiens OX=9606 GN=REPS1 PE=1 SV=3MEGLTLSDAEQKYYSDLFSYCDIESTKKVVVNGRVLELFRAAQLPNDVVLQIMELCGATRLGYFGRSQFYIALKLVAVAQSGFPLRVESINTVKDLPLPRFVASKNEQESRHAASYSSDSENQGSYSGVIPPPPGRGQVKKGSVSHDTVQPRTSADAQEPASPVVSPQQSPPTSPHTWRKHSRHPSGGNSERPLAGPGPFWSPFGEAQSGSSAGDAVWSGHSPPPPQENWVSFADTPPTSTLLTMHPASVQDQTTVRTVASATTAIEIRRQSSSYDDPWKITDEQRQYYVNQFKTIQPDLNGFIPGSAAKEFFTKSKLPILELSHIWELSDFDKDGALTLDEFCAAFHLVVARKNGYDLPEKLPESLMPKLIDLEDSADVGDQPGEVGYSGSPAEAPPSKSPSMPSLNQTWPELNQSSEQWETFSERSSSSQTLTQFDSNIAPADPDTAIVHPVPIRMTPSKIHMQEMELKRTGSDHTNPTSPLLVKPSDLLEENKINSSVKFASGNTVADGYSSSDSFTSDPEQIGSNVTRQRSHSGTSPDNTAPPPPPPRPQPSHSRSSSLDMNRTFTVTTGQQQAGVVAHPPAVPPRPQPSQAPGPAVHRPVDADGLITHTSTSPQQIPEQPNFADFSQFEVFAASNVNDEQDDEAEKHPEVLPAEKASDPASSLRVAKTDSKTEEKTAASAPANVSKGTTPLAPPPKPVRRRLKSEDELRPEVDEHTQKTGVLAAVLASQPSIPRSVGKDKKAIQASIRRNKETNTVLARLNSELQQQLKDVLEERISLEVQLEQLRPFSHL>sp|Q96D71-2|REPS1_HUMAN Isoform 2 of RalBP1-associated Eps domain-containing protein 1 OS=Homo sapiens OX=9606 GN=REPS1MEGLTLSDAEQKYYSDLFSYCDIESTKKVVVNGRVLELFRAAQLPNDVVLQIMELCGATRLGYFGRSQFYIALKLVAVAQSGFPLRVESINTVKDLPLPRFVASKNEQESRHAASYSSDSENQGSYSGVIPPPPGRGQVKKGSVSHDTVQPRTSADAQEPASPVVSPQQSPPTSPHTWRKHSRHPSGGNSERPLAGPGPFWSPFGEAQSGSSAGDAVWSGHSPPPPQENWVSFADTPPTSTLLTMHPASVQDQTTVRTVASATTAIEIRRQSSSYDDPWKITDEQRQYYVNQFKTIQPDLNGFIPGSAAKEFFTKSKLPILELSHIWELSDFDKDGALTLDEFCAAFHLVVARKNGYDLPEKLPESLMPKLIDLEDSADVGDQPGEVGYSGSPAEAPPSKSPSMPSLNQTWPELNQSSEDTAIVHPVPIRMTPSKIHMQEMELKRTGSDHTNPTSPLLVKPSDLLEENKINSSVKFASGNTVGQQQAGVVAHPPAVPPRPQPSQAPGPAVHRPVDADGLITHTSTSPQQIPEQPNFADFSQFEVFAASNVNDEQDDEAEKHPEVLPAEKASDPASSLRVAKTDSKTEEKTAASAPANVSKGTTPLAPPPKPVRRRLKSEDELRPEVDEHTQKTGVLAAVLASQPSIPRSVGKDKKAIQASIRRNKETNTVLARLNSELQQQLKDVLEERISLEVQLEQLRPFSHL>sp|Q96D71-3|REPS1_HUMAN Isoform 3 of RalBP1-associated Eps domain-containing protein 1 OS=Homo sapiens OX=9606 GN=REPS1MEGLTLSDAEQKYYSDLFSYCDIESTKKVVVNGRVLELFRAAQLPNDVVLQIMELCGATRLGYFGRSQFYIALKLVAVAQSGFPLRVESINTVKDLPLPRFVASKNEQESRHAASYSSDSENQGSYSGVIPPPPGRGQVKKGSVSHDTVQPRTSADAQEPASPVVSPQQSPPTSPHTWRKHSRHPSGGNSERPLAGPGPFWSPFGEAQSGSSAGDAVWSGHSPPPPQENWVSFADTPPTSTLLTMHPASVQDQTTVRTVASATTAIEIRRQSSSYDDPWKITDEQRQYYVNQFKTIQPDLNGFIPGSAAKEFFTKSKLPILELSHIWELSDFDKDGALTLDEFCAAFHLVVARKNGYDLPEKLPESLMPKLIDLEDSADVGDQPGEVGYSGSPAEAPPSKSPSMPSLNQTWPELNQSSEQWETFSERSSSSQTLTQFDSNIAPADPDTAIVHPVPIRMTPSKIHMQEMELKRTGSDHTNPTSPLLVKPSDLLEENKINSSVKFASGNTVDGYSSSDSFTSDPEQIGSNVTRQRSHSGTSPDNTAPPPPPPRPQPSHSRSSSLDMNRTFTVTTGQQQAGVVAHPPAVPPRPQPSQAPGPAVHRPVDADGLITHTSTSPQQIPEQPNFADFSQFEVFAASNVNDEQDDEAEKHPEVLPAEKASDPASSLRVAKTDSKTEEKTAASAPANVSKGTTPLAPPPKPVRRRLKSEDELRPEVDEHTQKTGVLAAVLASQPSIPRSVGKDKKAIQASIRRNKETNTVLARLNSELQQQLKDVLEERISLEVQLEQLRPFSHL>sp|Q96D71-4|REPS1_HUMAN Isoform 4 of RalBP1-associated Eps domain-containing protein 1 OS=Homo sapiens OX=9606 GN=REPS1MEGLTLSDAEQKYYSDLFSYCDIESTKKVVVNGRVLELFRAAQLPNDVVLQIMELCGATRLGYFGRSQFYIALKLVAVAQSGFPLRVESINTVKDLPLPRFVASKNEQESRHAASYSSDSENQGSYSGVIPPPPGRGQVKKGSVSHDTVQPRTSADAQEPASPVVSPQQSPPTSPHTWRKHSRHPSGGNSERPLAGPGPFWSPFGEAQSGSSAGDAVWSGHSPPPPQENWVSFADTPPTSTLLTMHPASVQDQTTVRTVASATTAIEIRRQSSSYDDPWKITDEQRQYYVNQFKTIQPDLNGFIPGSAAKEFFTKSKLPILELSHIWELSDFDKDGALTLDEFCAAFHLVVARKNGYDLPEKLPESLMPKLIDLEDSADVGDQPGEVGYSGSPAEAPPSKSPSMPSLNQTWPELNQSSEDTAIVHPVPIRMTPSKIHMQEMELKRTGSDHTNPTSPLLVKPSDLLEENKINSSVKFASGNTVADGYSSSDSFTSDPEQIGSNVTRQRSHSGTSPDNTAPPPPPPRPQPSHSRSSSLDMNRTFTVTTGQQQAGVVAHPPAVPPRPQPSQAPGPAVHRPVDADGLITHTSTSPQQIPEQPNFADFSQFEVFAASNVNDEQDDEAEKHPEVLPAEKASDPASSLRVAKTDSKTEEKTAASAPANVSKGTTPLAPPPKPVRRRLKSEDELRPEVDEHTQKTGVLAAVLASQPSIPRSVGKDKKAIQASIRRNKETNTVLARLNSELQQQLKDVLEERISLEVQLEQLRPFSHL>sp|Q8NFH8|REPS2_HUMAN RalBP1-associated Eps domain-containing protein 2OS=Homo sapiens OX=9606 GN=REPS2 PE=1 SV=2MEAAAAAAAAAAAAAAAGGGCGSGPPPLLLSEGEQQCYSELFARCAGAAGGGPGSGPPEAARVAPGTATAAAGPVADLFRASQLPAETLHQITELCGAKRVGYFGPTQFYIALKLIAAAQSGLPVRIESIKCELPLPRFMMSKNDGEIRFGNPAELHGTKVQIPYLTTEKNSFKRMDDEDKQQETQSPTMSPLASPPSSPPHYQRVPLSHGYSKLRSSAEQMHPAPYEARQPLVQPEGSSSGGPGTKPLRHQASLIRSFSVERELQDNSSYPDEPWRITEEQREYYVNQFRSLQPDPSSFISGSVAKNFFTKSKLSIPELSYIWELSDADCDGALTLPEFCAAFHLIVARKNGYPLPEGLPPTLQPEYLQAAFPKPKWDCQLFDSYSESLPANQQPRDLNRMEKTSVKDMADLPVPNQDVTSDDKQALKSTINEALPKDVSEDPATPKDSNSLKARPRSRSYSSTSIEEAMKRGEDPPTPPPRPQKTHSRASSLDLNKVFQPSVPATKSGLLPPPPALPPRPCPSQSEQVSEAELLPQLSRAPSQAAESSPAKKDVLYSQPPSKPIRRKFRPENQATENQEPSTAASGPASAATMKPHPTVQKQSSKQKKAIQTAIRKNKEANAVLARLNSELQQQLKEVHQERIALENQLEQLRPVTVL>sp|Q8NFH8-4|REPS2_HUMAN Isoform 2 of RalBP1-associated Eps domain-containing protein 2 OS=Homo sapiens OX=9606 GN=REPS2MEAAAAAAAAAAAAAAAGGGCGSGPPPLLLSEGEQQCYSELFARCAGAAGGGPGSGPPEAARVAPGTATAAAGPVADLFRASQLPAETLHQITELCGAKRVGYFGPTQFYIALKLIAAAQSGLPVRIESIKCELPLPRFMMSKNDGEIRFGNPAELHGTKVQIPYLTTEKNSFKRMDDEDKQETQSPTMSPLASPPSSPPHYQRVPLSHGYSKLRSSAEQMHPAPYEARQPLVQPEGSSSGGPGTKPLRHQASLIRSFSVERELQDNSSYPDEPWRITEEQREYYVNQFRSLQPDPSSFISGSVAKNFFTKSKLSIPELSYIWELSDADCDGALTLPEFCAAFHLIVARKNGYPLPEGLPPTLQPEYLQAAFPKPKWDCQLFDSYSESLPANQQPRDLNRMEKTSVKDMADLPVPNQDVTSDDKQALKSTINEALPKDVSEDPATPKDSNSLKARPRSRSYSSTSIEEAMKRGEDPPTPPPRPQKTHSRASSLDLNKVFQPSVPATKSGLLPPPPALPPRPCPSQSEQVSEAELLPQLSRAPSQAAESSPAKKDVLYSQPPSKPIRRKFRPENQATENQEPSTAASGPASAATMKPHPTVQKQSSKQKKAIQTAIRKNKEANAVLARLNSELQQQLKEVHQERIALENQLEQLRPVTVL>sp|Q86X27|RGPS2_HUMAN Ras-specific guanine nucleotide-releasing factorRalGPS2 OS=Homo sapiens OX=9606 GN=RALGPS2 PE=1 SV=1MDLMNGQASSVNIAATASEKSSSSESLSDKGSELKKSFDAVVFDVLKVTPEEYAGQITLMDVPVFKAIQPDELSSCGWNKKEKYSSAPNAVAFTRRFNHVSFWVVREILHAQTLKIRAEVLSHYIKTAKKLYELNNLHALMAVVSGLQSAPIFRLTKTWALLSRKDKTTFEKLEYVMSKEDNYKRLRDYISSLKMTPCIPYLGIYLSDLTYIDSAYPSTGSILENEQRSNLMNNILRIISDLQQSCEYDIPMLPHVQKYLNSVQYIEELQKFVEDDNYKLSLKIEPGTSTPRSAASREDLVGPEVGASPQSGRKSVAAEGALLPQTPPSPRNLIPHGHRKCHSLGYNFIHKMNTAEFKSATFPNAGPRHLLDDSVMEPHAPSRGQAESSTLSSGISIGSSDGSELSEETSWPAFERNRLYHSLGPVTRVARNGYRSHMKASSSAESEDLAVHLYPGAVTIQGVLRRKTLLKEGKKPTVASWTKYWAALCGTQLFYYAAKSLKATERKHFKSTSNKNVSVIGWMVMMADDPEHPDLFLLTDSEKGNSYKFQAGNRMNAMLWFKHLSAACQSNKQQVPTNLMTFE>sp|Q86X27-2|RGPS2_HUMAN Isoform 2 of Ras-specific guanine nucleotide-releasing factor RalGPS2 OS=Homo sapiens OX=9606 GN=RALGPS2MDLMNGQASSVNIAATASEKSSSSESLSDKGSELKKSFDAVVFDVLKVTPEEYAGQITLMDVPVFKAIQPDELSSCGWNKKEKYSSAPNAVAFTRRFNHVSFWVVREILHAQTLKIRAEVLSHYIKTAKKLYELNNLHALMAVVSGLQSAPIFRLTKTWALLSRKDKTTFEKLEYVMSKEDNYKRLRDYISSLKMTPCIPYLGIYLSDLTYIDSAYPSTGSILENEQRSNLMNNILRIISDLQQSCEYDIPMLPHVQKYLNSVQYIEELQKFVEDDNYK>sp|Q86X27-3|RGPS2_HUMAN Isoform 3 of Ras-specific guanine nucleotide-releasing factor RalGPS2 OS=Homo sapiens OX=9606 GN=RALGPS2MDLMNGQASSVNIAATASEKSSSSESLSDKGSELKKSFDAVVFDVLKVTPEEYAGQITLMDVPVFKAIQPDELSSCGWNKKEKYSSAPNAVAFTRRFNHVSFWVVREILHAQTLKIRAEVLSHYIKTAKKLYELNNLHALMAVVSGLQSAPIFRLTKTWALLSRKDKTTFEKLEYVMSKEDNYKRLRDYISSLKMTPCIPYLGIYLSDLTYIDSAYPSTGSILENEQRSNLMNNILRIISDLQQSCEYDIPMLPHVQKYLNSVQYIEELQKFVEDDNYKLSLKIEPGTSTPRSAASREDLVGPEVGASPQSGRKSVAAEGALLPQTPPSPRNLIPHGHRKCHSLGYNFIHKMNTAEFKSATFPNAGPRHLLDDSVMEPHAPSRGQAESSTLSSGISIGSSDGSELSEETSWPAFESSAESEDLAVHLYPGAVTIQGVLRRKTLLKEGKKPTVASWTKYWAALCGTQLFYYAAKSLKATERKHFKSTSNKNVSVIGWMVMMADDPEHPDLFLLTDSEKGNSYKFQAGNRMNAMLWFKHLSAACQSNKQQVPTNLMTFE>sp|P47804|RGR_HUMAN RPE-retinal G protein-coupled receptor OS=Homosapiens OX=9606 GN=RGR PE=1 SV=1MAETSALPTGFGELEVLAVGMVLLVEALSGLSLNTLTIFSFCKTPELRTPCHLLVLSLALADSGISLNALVAATSSLLRRWPYGSDGCQAHGFQGFVTALASICSSAAIAWGRYHHYCTRSQLAWNSAVSLVLFVWLSSAFWAALPLLGWGHYDYEPLGTCCTLDYSKGDRNFTSFLFTMSFFNFAMPLFITITSYSLMEQKLGKSGHLQVNTTLPARTLLLGWGPYAILYLYAVIADVTSISPKLQMVPALIAKMVPTINAINYALGNEMVCRGIWQCLSPQKREKDRTK>sp|P47804-2|RGR_HUMAN Isoform 2 of RPE-retinal G protein-coupledreceptor OS=Homo sapiens OX=9606 GN=RGRMAETSALPTGFGELEVLAVGMVLLVEALSGLSLNTLTIFSFCKTPELRTPCHLLVLSLALADSGISLNALVAATSSLLRVSHRRWPYGSDGCQAHGFQGFVTALASICSSAAIAWGRYHHYCTRSQLAWNSAVSLVLFVWLSSAFWAALPLLGWGHYDYEPLGTCCTLDYSKGDRNFTSFLFTMSFFNFAMPLFITITSYSLMEQKLGKSGHLQVNTTLPARTLLLGWGPYAILYLYAVIADVTSISPKLQMVPALIAKMVPTINAINYALGNEMVCRGIWQCLSPQKREKDRTK>sp|P47804-3|RGR_HUMAN Isoform 3 of RPE-retinal G protein-coupledreceptor OS=Homo sapiens OX=9606 GN=RGRMAETSALPTGFGELEVLAVGMVLLVEALSGLSLNTLTIFSFCKTPELRTPCHLLVLSLALADSGISLNALVAATSSLLRRWPYGSDGCQAHGFQGFVTALASICSSAAIAWGRYHHYCTRSQLAWNSAVSLVLFVWLSSAFWAALPLLGWGHYDYEPLGTCCTLDYSKGDRNFTSFLFTMSFFNFAMPLFITITSYSLMEQKLGKSGHLQVPALIAKMVPTINAINYALGNEMVCRGIWQCLSPQKREKDRTK>sp|Q7L0R7|RNF44_HUMAN RING finger protein 44 OS=Homo sapiens OX=9606GN=RNF44 PE=1 SV=1MRPWALAVTRWPPSAPVGQRRFSAGPGSTPGQLWGSPGLEGPLASPPARDERLPSQQPPSRPPHLPVEERRASAPAGGSPRMLHPATQQSPFMVDLHEQVHQGPVPLSYTVTTVTTQGFPLPTGQHIPGCSAQQLPACSVMFSGQHYPLCCLPPPLIQACTMQQLPVPYQAYPHLISSDHYILHPPPPAPPPQPTHMAPLGQFVSLQTQHPRMPLQRLDNDVDLRGDQPSLGSFTYSTSAPGPALSPSVPLHYLPHDPLHQELSFGVPYSHMMPRRLSTQRYRLQQPLPPPPPPPPPPPYYPSFLPYFLSMLPMSPTAMGPTISLDLDVDDVEMENYEALLNLAERLGDAKPRGLTKADIEQLPSYRFNPDSHQSEQTLCVVCFSDFEARQLLRVLPCNHEFHTKCVDKWLKANRTCPICRADASEVPREAE>sp|Q7L0R7-2|RNF44_HUMAN Isoform 2 of RING finger protein 44 OS=Homosapiens OX=9606 GN=RNF44MLHPATQQSPFMVDLHEQVHQGPVPLSYTVTTVTTQGFPLPTGQHIPGCSAQQLPACSVMFSGQHYPLCCLPPPLIQACTMQQLPVPYQAYPHLISSDHYILHPPPPAPPPQPTHMAPLGQFVSLQTQHPRMPLQRLDNDVDLRGDQPSLGSFTYSTSAPGPALSPSVPLHYLPHDPLHQELSFGVPYSHMMPRRLSTQRYRLQQPLPPPPPPPPPPPYYPSFLPYFLSMLPMSPTAMGPTISLDLDVDDVEMENYEALLNLAERLGDAKPRGLTKADIEQLPSYRFNPDSHQSEQTLCVVCFSDFEARQLLRVLPCNHEFHTKCVDKWLKANRTCPICRADASEVPREAE>sp|Q96QB1|RHG07_HUMAN Rho GTPase-activating protein 7 OS=Homo sapiensOX=9606 GN=DLC1 PE=1 SV=4MSVAIRKRSWEEHVTHWMGQPFNSDDRNTACHHGLVADSLQASMEKDATLNVDRKEKCVSLPDCCHGSELRDFPGRPMGHLSKDVDENDSHEGEDQFLSLEASTETLVHVSDEDNNADLCLTDDKQVLNTQGQKTSGQHMIQGAGSLEKALPIIQSNQVSSNSWGIAGETELALVKESGERKVTDSISKSLELCNEISLSEIKDAPKVNAVDTLNVKDIAPEKQLLNSAVIAQQRRKPDPPKDENERSTCNVVQNEFLDTPCTNRGLPLLKTDFGSCLLQPPSCPNGMSAENGLEKSGFSQHQNKSPPKVKAEDGMQCLQLKETLATQEPTDNQVRLRKRKEIREDRDRARLDSMVLLIMKLDQLDQDIENALSTSSSPSGTPTNLRRHVPDLESGSESGADTISVNQTRVNLSSDTESTDLPSSTPVANSGTKPKTTAIQGISEKEKAEIEAKEACDWLRATGFPQYAQLYEDFLFPIDISLVKREHDFLDRDAIEALCRRLNTLNKCAVMKLEISPHRKRSDDSDEDEPCAISGKWTFQRDSKRWSRLEEFDVFSPKQDLVPGSPDDSHPKDGPSPGGTLMDLSERQEVSSVRSLSSTGSLPSHAPPSEDAATPRTNSVISVCSSSNLAGNDDSFGSLPSPKELSSFSFSMKGHEKTAKSKTRSLLKRMESLKLKSSHHSKHKAPSKLGLIISGPILQEGMDEEKLKQLNCVEISALNGNRINVPMVRKRSVSNSTQTSSSSSQSETSSAVSTPSPVTRTRSLSACNKRVGMYLEGFDPFNQSTFNNVVEQNFKNRESYPEDTVFYIPEDHKPGTFPKALTNGSFSPSGNNGSVNWRTGSFHGPGHISLRRENSSDSPKELKRRNSSSSMSSRLSIYDNVPGSILYSSSGDLADLENEDIFPELDDILYHVKGMQRIVNQWSEKFSDEGDSDSALDSVSPCPSSPKQIHLDVDNDRTTPSDLDSTGNSLNEPEEPSEIPERRDSGVGASLTRSNRHRLRWHSFQSSHRPSLNSVSLQINCQSVAQMNLLQKYSLLKLTALLEKYTPSNKHGFSWAVPKFMKRIKVPDYKDRSVFGVPLTVNVQRTGQPLPQSIQQAMRYLRNHCLDQVGLFRKSGVKSRIQALRQMNEGAIDCVNYEGQSAYDVADMLKQYFRDLPEPLMTNKLSETFLQIYQYVPKDQRLQAIKAAIMLLPDENREVLQTLLYFLSDVTAAVKENQMTPTNLAVCLAPSLFHLNTLKRENSSPRVMQRKQSLGKPDQKDLNENLAATQGLAHMIAECKKLFQVPEEMSRCRNSYTEQELKPLTLEALGHLGNDDSADYQHFLQDCVDGLFKEVKEKFKGWVSYSTSEQAELSYKKVSEGPPLRLWRSVIEVPAVPEEILKRLLKEQHLWDVDLLDSKVIEILDSQTEIYQYVQNSMAPHPARDYVVLRTWRTNLPKGACALLLTSVDHDRAPVVGVRVNVLLSRYLIEPCGPGKSKLTYMCRVDLRGHMPEWYTKSFGHLCAAEVVKIRDSFSNQNTETKDTKSR>sp|Q96QB1-1|RHG07_HUMAN Isoform 1 of Rho GTPase-activating protein 7OS=Homo sapiens OX=9606 GN=DLC1MCRKKPDTMILTQIEAKEACDWLRATGFPQYAQLYEDFLFPIDISLVKREHDFLDRDAIEALCRRLNTLNKCAVMKLEISPHRKRSDDSDEDEPCAISGKWTFQRDSKRWSRLEEFDVFSPKQDLVPGSPDDSHPKDGPSPGGTLMDLSERQEVSSVRSLSSTGSLPSHAPPSEDAATPRTNSVISVCSSSNLAGNDDSFGSLPSPKELSSFSFSMKGHEKTAKSKTRSLLKRMESLKLKSSHHSKHKAPSKLGLIISGPILQEGMDEEKLKQLNCVEISALNGNRINVPMVRKRSVSNSTQTSSSSSQSETSSAVSTPSPVTRTRSLSACNKRVGMYLEGFDPFNQSTFNNVVEQNFKNRESYPEDTVFYIPEDHKPGTFPKALTNGSFSPSGNNGSVNWRTGSFHGPGHISLRRENSSDSPKELKRRNSSSSMSSRLSIYDNVPGSILYSSSGDLADLENEDIFPELDDILYHVKGMQRIVNQWSEKFSDEGDSDSALDSVSPCPSSPKQIHLDVDNDRTTPSDLDSTGNSLNEPEEPSEIPERRDSGVGASLTRSNRHRLRWHSFQSSHRPSLNSVSLQINCQSVAQMNLLQKYSLLKLTALLEKYTPSNKHGFSWAVPKFMKRIKVPDYKDRSVFGVPLTVNVQRTGQPLPQSIQQAMRYLRNHCLDQVGLFRKSGVKSRIQALRQMNEGAIDCVNYEGQSAYDVADMLKQYFRDLPEPLMTNKLSETFLQIYQYVPKDQRLQAIKAAIMLLPDENREVLQTLLYFLSDVTAAVKENQMTPTNLAVCLAPSLFHLNTLKRENSSPRVMQRKQSLGKPDQKDLNENLAATQGLAHMIAECKKLFQVPEEMSRCRNSYTEQELKPLTLEALGHLGNDDSADYQHFLQDCVDGLFKEVKEKFKGWVSYSTSEQAELSYKKVSEGPPLRLWRSVIEVPAVPEEILKRLLKEQHLWDVDLLDSKVIEILDSQTEIYQYVQNSMAPHPARDYVVLRTWRTNLPKGACALLLTSVDHDRAPVVGVRVNVLLSRYLIEPCGPGKSKLTYMCRVDLRGHMPEWYTKSFGHLCAAEVVKIRDSFSNQNTETKDTKSR>sp|Q96QB1-3|RHG07_HUMAN Isoform 3 of Rho GTPase-activating protein 7OS=Homo sapiens OX=9606 GN=DLC1MSVAIRKRSWEEHVTHWMGQPFNSDDRNTACHHGLVADSLQASMEKDATLNVDRKEKCVSLPDCCHGSELRDFPGRPMGHLSKDVDENDSHEGEDQFLSLEASTETLVHVSDEDNNADLCLTDDKQVLNTQGQKTSGQHMIQGAGSLEKALPIIQSNQVSSNSWGIAGETELALVKESGERKVTDSISKSLELCNEISLSEIKDAPKVNAVDTLNVKDIAPEKQLLNSAVIAQQRRKPDPPKDENERSTCNVVQNEFLDTPCTNRGLPLLKTDFGSCLLQPPSCPNGMSAENGLEKSGFSQHQNKSPPKVKAEDGMQCLQLKETLATQEPTDNQVRLRKRKEIREDRDRARLDSMVLLIMKLDQLDQDIENALSTSSSPSGTPTNLRRHVPDLESGSESGADTISVNQTRVNLSSDTESTDLPSSTPVANSGTKPKTTAIQGISEKEKAAVKSVKLEVDEDKSTKGSNFSNSEVAIGLSPYTFPQKRLFHVAGEENIT>sp|Q96QB1-4|RHG07_HUMAN Isoform 4 of Rho GTPase-activating protein 7OS=Homo sapiens OX=9606 GN=DLC1MKLEISPHRKRSDDSDEDEPCAISGKWTFQRDSKRWSRLEEFDVFSPKQDLVPGSPDDSHPKDGPSPGGTLMDLSERQEVSSVRSLSSTGSLPSHAPPSEDAATPRTNSVISVCSSSNLAGNDDSFGSLPSPKELSSFSFSMKGHEKTAKSKTRSLLKRMESLKLKSSHHSKHKAPSKLGLIISGPILQEGMDEEKLKQLNCVEISALNGNRINVPMVRKRSVSNSTQTSSSSSQSETSSAVSTPSPVTRTRSLSACNKRVGMYLEGFDPFNQSTFNNVVEQNFKNRESYPEDTVFYIPEDHKPGTFPKALTNGSFSPSGNNGSVNWRTGSFHGPGHISLRRENSSDSPKELKRRNSSSSMSSRLSIYDNVPGSILYSSSGDLADLENEDIFPELDDILYHVKGMQRIVNQWSEKFSDEGDSDSALDSVSPCPSSPKQIHLDVDNDRTTPSDLDSTGNSLNEPEEPSEIPERRDSGVGASLTRSNRHRLRWHSFQSSHRPSLNSVSLQINCQSVAQMNLLQKYSLLKLTALLEKYTPSNKHGFSWAVPKFMKRIKVPDYKDRSVFGVPLTVNVQRTGQPLPQSIQQAMRYLRNHCLDQVGLFRKSGVKSRIQALRQMNEGAIDCVNYEGQSAYDVADMLKQYFRDLPEPLMTNKLSETFLQIYQYVPKDQRLQAIKAAIMLLPDENREVLQTLLYFLSDVTAAVKENQMTPTNLAVCLAPSLFHLNTLKRENSSPRVMQRKQSLGKPDQKDLNENLAATQGLAHMIAECKKLFQVPEEMSRCRNSYTEQELKPLTLEALGHLGNDDSADYQHFLQDCVDGLFKEVKEKFKGWVSYSTSEQAELSYKKVSEGPPLRLWRSVIEVPAVPEEILKRLLKEQHLWDVDLLDSKVIEILDSQTEIYQYVQNSMAPHPARDYVVLRTWRTNLPKGACALLLTSVDHDRAPVVGVRVNVLLSRYLIEPCGPGKSKLTYMCRVDLRGHMPEWYTKSFGHLCAAEVVKIRDSFSNQNTETKDTKSR>sp|Q96QB1-5|RHG07_HUMAN Isoform 5 of Rho GTPase-activating protein 7OS=Homo sapiens OX=9606 GN=DLC1MSVAIRKRSWEEHVTHWMGQPFNSDDRNTACHHGLVADSLQASMEKDATLNVDRKEKCVSLPDCCHGSELRDFPGRPMGHLSKDVDENDSHEGEDQFLSLEASTETLVHVSDEDNNADLCLTDDKQVLNTQGQKTSGQHMIQGAGSLEKALPIIQSNQVSSNSWGIAGETELALVKESGERKVTDSISKSLELCNEISLSEIKDAPKVNAVDTLNVKDIAPEKQLLNSAVIAQQRRKPDPPKDENERSTCNVVQNEFLDTPCTNRGLPLLKTDFGSCLLQPPSCPNGMSAENGLEKSGFSQHQNKSPPKVKAEDGMQCLQLKETLATQEPTDNQVRLRKRKEIREDRDRARLDSMVLLIMKLDQLDQDIENALSTSSSPSGTPTNLRRHVPDLESGSESGADTISVNQTRVNLSSDTESTDLPSSTPVANSGTKPKTTAIQGISEKEKAGKLTFWFCFLANLF>sp|Q96QB1-6|RHG07_HUMAN Isoform 6 of Rho GTPase-activating protein 7OS=Homo sapiens OX=9606 GN=DLC1MGDPKAHVMARPLRAPLRRSFSDHIRDSTARALDVIWKNTRDRRLAEIEAKEACDWLRATGFPQYAQLYEDFLFPIDISLVKREHDFLDRDAIEALCRRLNTLNKCAVMKLEISPHRKRSDDSDEDEPCAISGKWTFQRDSKRWSRLEEFDVFSPKQDLVPGSPDDSHPKDGPSPGGTLMDLSERQEVSSVRSLSSTGSLPSHAPPSEDAATPRTNSVISVCSSSNLAGNDDSFGSLPSPKELSSFSFSMKGHEKTAKSKTRSLLKRMESLKLKSSHHSKHKAPSKLGLIISGPILQEGMDEEKLKQLNCVEISALNGNRINVPMVRKRSVSNSTQTSSSSSQSETSSAVSTPSPVTRTRSLSACNKRVGMYLEGFDPFNQSTFNNVVEQNFKNRESYPEDTVFYIPEDHKPGTFPKALTNGSFSPSGNNGSVNWRTGSFHGPGHISLRRENSSDSPKELKRRNSSSSMSSRLSIYDNVPGSILYSSSGDLADLENEDIFPELDDILYHVKGMQRIVNQWSEKFSDEGDSDSALDSVSPCPSSPKQIHLDVDNDRTTPSDLDSTGNSLNEPEEPSEIPERRDSGVGASLTRSNRHRLRWHSFQSSHRPSLNSVSLQINCQSVAQMNLLQKYSLLKLTALLEKYTPSNKHGFSWAVPKFMKRIKVPDYKDRSVFGVPLTVNVQRTGQPLPQSIQQAMRYLRNHCLDQVGLFRKSGVKSRIQALRQMNEGAIDCVNYEGQSAYDVADMLKQYFRDLPEPLMTNKLSETFLQIYQYVPKDQRLQAIKAAIMLLPDENREVLQTLLYFLSDVTAAVKENQMTPTNLAVCLAPSLFHLNTLKRENSSPRVMQRKQSLGKPDQKDLNENLAATQGLAHMIAECKKLFQVPEEMSRCRNSYTEQELKPLTLEALGHLGNDDSADYQHFLQDCVDGLFKEVKEKFKGWVSYSTSEQAELSYKKVSEGPPLRLWRSVIEVPAVPEEILKRLLKEQHLWDVDLLDSKVIEILDSQTEIYQYVQNSMAPHPARDYVVLRTWRTNLPKGACALLLTSVDHDRAPVVGVRVNVLLSRYLIEPCGPGKSKLTYMCRVDLRGHMPEWYTKSFGHLCAAEVVKIRDSFSNQNTETKDTKSR>sp|A6NJZ7|RIM3C_HUMAN RIMS-binding protein 3C OS=Homo sapiens OX=9606GN=RIMBP3C PE=1 SV=3MAKDSPSPLGASPKKPGCSSPAAAVLENQRRELEKLRAELEAERAGWRAERRRFAARERQLREEAERERRQLADRLRSKWEAQRSRELRQLQEEMQREREAEIRQLLRWKEAEQRQLQQLLHRERDGVVRQARELQRQLAEELVNRGHCSRPGASEVSAAQCRCRLQEVLAQLRWQTDGEQAARIRYLQAALEVERQLFLKYILAHFRGHPALSGSPDPQAVHSLEEPLPQTSSGSCHAPKPACQLGSLDSLSAEVGVRSRSLGLVSSACSSSPDGLLSTHASSLDCFAPACSRSLDSTRSLPKASKSEERPSSPDTSTPGSRRLSPPPSPLPPPPPPSAHRKLSNPRGGEGSESQPCEVLTPSPPGLGHHELIKLNWLLAKALWVLARRCYTLQEENKQLRRAGCPYQADEKVKRLKVKRAELTGLARRLADRARELQETNLRAVSAPIPGESCAGLELCQVFARQRARDLSEQASAPLAKDKQIEELRQECHLLQARVASGPCSDLHTGRGGPCTQWLNVRDLDRLQRESQREVLRLQRQLMLQQGNGGAWPEAGGQSATCEEVRRQMLALERELDQRRRECQELGTQAAPARRRGEEAETQLQAALLKNAWLAEENGRLQAKTDWVRKVEAENSEVRGHLGRACQERDASGLIAEQLLQQAARGQDRQQQLQRDPQKALCDLHPSWKEIQALQCRPGHPPEQPWETSQMPESQVKGSRRPKFHARPEDYAVSQPNRDIQEKREASLEESPVALGESASVPQVSETVPASQPLSKKTSSQSNSSSEGSMWATVPSSPTLDRDTASEVDDLEPDSVSLALEMGGSAAPAAPKLKIFMAQYNYNPFEGPNDHPEGELPLTAGDYIYIFGDMDEDGFYEGELDDGRRGLVPSNFVEQIPDSYIPGCLPAKSPDLGPSQLPAGQDEALEEDSLLSGKAQGMVDRGLCQMVRVGSKTEVATEILDTKTEACQLGLLQSMGKQGLSRPLLGTKGVLRMAPMQLHLQNVTATSANITWVYSSHRHPHVVYLDDREHALTPAGVSCYTFQGLCPGTHYRVRVEVRLPWDLLQVYWGTMSSTVTFDTLLAGPPYPPLDVLVERHASPGVLVVSWLPVTIDSAGSSNGVQVTGYAVYADGLKVCEVADATAGSTVLEFSQLQVPLTWQKVSVRTMSLCGESLDSVPAQIPEDFFMCHRWPETPPFSYTCGDPSTYRVTFPVCPQKLSLAPPSAKASPHNPGSCGEPQAKFLEAFFEEPPRRQSPVSNLGSEGECPSSGAGSQAQELAEAWEGCRKDLLFQKSPQNHRPPSVSDQPGEKENCYQHMGTSKSPAPGFIHLRTECGPRKEPCQEKAALERVLRQKQDAQGFTPPQLGASQQYASDFHNVLKEEQEALCLDLRGTERREERREPEPHSRQGQALGVKRGCQLHEPSSALCPAPSAKVIKMPRGGPQQLGTGANTPARVFVALSDYNPLVMSANLKAAEEELVFQKRQLLRVWGSQDTHDFYLSECNRQVGNIPGRLVAEMEVGTEQTDRRWRSPAQGHLPSVAHLEDFQGLIIPQGSSLVLQGNSKRLPLWTPKIMIAALDYDPGDGQMGGQGKGRLALRAGDVVMVYGPMDDQGFYYGELGGHRGLVPAHLLDHMSLHGH>sp|Q96NA2|RILP_HUMAN Rab-interacting lysosomal protein OS=Homo sapiensOX=9606 GN=RILP PE=1 SV=1MEPRRAAPGVPGWGSREAAGSASAAELVYHLAGALGTELQDLARRFGPEAAAGLVPLVVRALELLEQAAVGPAPDSLQVSAQPAEQELRRLREENERLRRELRAGPQEERALLRQLKEVTDRQRDELRAHNRDLRQRGQETEALQEQLQRLLLVNAELRHKLAAMQTQLRAAQDRERERQQPGEAATPQAKERARGQAGRPGHQHGQEPEWATAGAGAPGNPEDPAEAAQQLGRPSEAGQCRFSREEFEQILQERNELKAKVFLLKEELAYFQRELLTDHRVPGLLLEAMKVAVRKQRKKIKAKMLGTPEEAESSEDEAGPWILLSDDKGDHPPPPESKIQSFFGLWYRGKAESSEDETSSPAPSKLGGEEEAQPQSPAPDPPCSALHEHLCLGASAAPEA>sp|Q96NA2-2|RILP_HUMAN Isoform 2 of Rab-interacting lysosomal proteinOS=Homo sapiens OX=9606 GN=RILPMGAAGAGAPGNPEDPAEAAQQLGRPSEAGQCRFSREEFEQILQERNELKAKVFLLKEELAYFQRELLTDHRVPGLLLEAMKVAVRKQRKKIKAKMLGTPEEAESSEDEAGPWILLSDDKGDHPPPPESKIQSFFGLWYRGKAESSEDETSSPAPSKLGGEEEAQPQSPAPDPPCSALHEHLCLGASAAPEA>sp|Q96KN7|RPGR1_HUMAN X-linked retinitis pigmentosa GTPase regulator-interacting protein 1 OS=Homo sapiens OX=9606 GN=RPGRIP1 PE=1 SV=2MSHLVDPTSGDLPVRDIDAIPLVLPASKGKNMKTQPPLSRMNREELEDSFFRLREDHMLVKELSWKQQDEIKRLRTTLLRLTAAGRDLRVAEEAAPLSETARRGQKAGWRQRLSMHQRPQMHRLQGHFHCVGPASPRRAQPRVQVGHRQLHTAGAPVPEKPKRGPRDRLSYTAPPSFKEHATNENRGEVASKPSELVSGSNSIISFSSVISMAKPIGLCMPNSAHIMASNTMQVEEPPKSPEKMWPKDENFEQRSSLECAQKAAELRASIKEKVELIRLKKLLHERNASLVMTKAQLTEVQEAYETLLQKNQGILSAAHEALLKQVNELRAELKEESKKAVSLKSQLEDVSILQMTLKEFQERVEDLEKERKLLNDNYDKLLESMLDSSDSSSQPHWSNELIAEQLQQQVSQLQDQLDAELEDKRKVLLELSREKAQNEDLKLEVTNILQKHKQEVELLQNAATISQPPDRQSEPATHPAVLQENTQIEPSEPKNQEEKKLSQVLNELQVSHAETTLELEKTRDMLILQRKINVCYQEELEAMMTKADNDNRDHKEKLERLTRLLDLKNNRIKQLEGILRSHDLPTSEQLKDVAYGTRPLSLCLETLPAHGDEDKVDISLLHQGENLFELHIHQAFLTSAALAQAGDTQPTTFCTYSFYDFETHCTPLSVGPQPLYDFTSQYVMETDSLFLHYLQEASARLDIHQAMASEHSTLAAGWICFDRVLETVEKVHGLATLIGAGGEEFGVLEYWMRLRFPIKPSLQACNKRKKAQVYLSTDVLGGRKAQEEEFRSESWEPQNELWIEITKCCGLRSRWLGTQPSPYAVYRFFTFSDHDTAIIPASNNPYFRDQARFPVLVTSDLDHYLRREALSIHVFDDEDLEPGSYLGRARVPLLPLAKNESIKGDFNLTDPAEKPNGSIQVQLDWKFPYIPPESFLKPEAQTKGKDTKDSSKISSEEEKASFPSQDQMASPEVPIEAGQYRSKRKPPHGGERKEKEHQVVSYSRRKHGKRIGVQGKNRMEYLSLNILNGNTPEQVNYTEWKFSETNSFIGDGFKNQHEEEEMTLSHSALKQKEPLHPVNDKESSEQGSEVSEAQTTDSDDVIVPPMSQKYPKADSEKMCIEIVSLAFYPEAEVMSDENIKQVYVEYKFYDLPLSETETPVSLRKPRAGEEIHFHFSKVIDLDPQEQQGRRRFLFDMLNGQDPDQGHLKFTVVSDPLDEEKKECEEVGYAYLQLWQILESGRDILEQELDIVSPEDLATPIGRLKVSLQAAAVLHAIYKEMTEDLFS>sp|Q96KN7-2|RPGR1_HUMAN Isoform 2 of X-linked retinitis pigmentosaGTPase regulator-interacting protein 1 OS=Homo sapiens OX=9606 GN=RPGRIP1MTFQHLGENLFELHIHQAFLTSAALAQAGDTQPTTFCTYSFYDFETHCTPLSVGPQPLYDFTSQYVMETDSLFLHYLQEASARLDIHQAMASEHSTLAAGWICFDRVLETVEKVHGLATLIGAGGEEFGVLEYWMRLRFPIKPSLQACNKRKKAQVYLSTDVLGGRKAQEEEFRSESWEPQNELWIEITKCCGLRSRWLGTQPSPYAVYRFFTFSDHDTAIIPASNNPYFRDQARFPVLVTSDLDHYLRREALSIHVFDDEDLEPGSYLGRARVPLLPLAKNESIKGDFNLTDPAEKPNGSIQVQLDWKFPYIPPESFLKPEAQTKGKDTKDSSKISSEEEKASFPSQDQMASPEVPIEAGQYRSKRKPPHGGERKEKEHQVVSYSRRKHGKRIGVQGKNRMEYLSLNILNGNTPEQVNYTEWKFSETNSFIGDGFKNQHEEEEMTLSHSALKQKEPLHPVNDKESSEQGSEVSEAQTTDSDDVIVPPMSQKYPKADSEKMCIEIVSLAFYPEAEVMSDENIKQVYVEYKFYDLPLSETETPVSLRKPRAGEEIHFHFSKVIDLDPQEQQGRRRFLFDMLNGQDPDQGHLKFTVVSDPLDEEKKECEEVGYAYLQLWQILESGRDILEQELDIVSPEDLATPIGRLKVSLQAAAVLHAIYKEMTEDLFS>sp|Q96KN7-3|RPGR1_HUMAN Isoform 3 of X-linked retinitis pigmentosaGTPase regulator-interacting protein 1 OS=Homo sapiens OX=9606 GN=RPGRIP1MLLMAPDRCRYVWKHCQPMEMRIKWIFLCCIRPLYDFTSQYVMETDSLFLHYLQEASARLDIHQAMASEHSTLAAGWICFDRVLETVEKVHGLATLIGAGGEEFGVLEYWMRLRFPIKPSLQACNKRKKAQVYLSTDVLGGRKAQEEEFRSESWEPQNELWIEITKCCGLRSRWLGTQPSPYAVYRFFTFSDHDTAIIPASNNPYFRDQARFPVLVTSDLDHYLRREALSIHVFDDEDLEPGSYLGRARVPLLPLAKNESIKGDFNLTDPAEKPNGSIQVQLDWKFPYIPPESFLKPEAQTKGKDTKDSSKISSEEEKASFPSQDQMASPEVPIEAGQYRSKRKPPHGGERKEKEHQVVSYSRRKHGKRIGVQGKNRMEYLSLNILNGNTPEQVNYTEWKFSETNSFIGDGFKNQHEEEEMTLSHSALKQKEPLHPVNDKESSEQGSEVSEAQTTDSDDVIVPPMSQKYPKADSEKMCIEIVSLAFYPEAEVMSDENIKQVYVEYKFYDLPLSETETPVSLRKPRAGEEIHFHFSKVIDLDPQEQQGRRRFLFDMLNGQDPDQGHLKFTVVSDPLDEEKKECEEVGYAYLQLWQILESGRDILEQELDIVSPEDLATPIGRLKVSLQAAAVLHAIYKEMTEDLFS>sp|Q96KN7-4|RPGR1_HUMAN Isoform 4 of X-linked retinitis pigmentosaGTPase regulator-interacting protein 1 OS=Homo sapiens OX=9606 GN=RPGRIP1MLKLDNKDVISHPLGYPSESLLSIASMLDSSDSSSQPHWSNELIAEQLQQQVSQLQDQLDAELEDKRKVLLELSREKAQNEDLKLEVTNILQKHKQEVELLQNAATISQPPDRQSEPATHPAVLQENTQIEPSEPKNQEEKKLSQVLNELQVSHAETTLELEKTRDMLILQRKINVCYQEELEAMMTKADNDNRDHKEKLERLTRLLDLKNNRIKQLEGILRSHDLPTSGDFNLTDPAEKPNGSIQVQLDWKFPYIPPESFLKPEAQTKGKDTKDSSKISSEEEKASFPSQDQMASPEVPIEAGQYRSKRKPPHGGERKEKEHQVVSYSRRKHGKRIGVQGKNRMEYLSLNILNGNTPEQVNYTEWKFSETNSFIGDGFKNQHEEEEMTLSHSALKQKEPLHPVNDKESSEQGSEVSEAQTTDSDDVIVPPMSQKYPKADSEKMCIEIVSLAFYPEAEVMSDENIKQVYVEYKFYDLPLSETETPVSLRKPRAGEEIHFHFSKVIDLDPQEQQGRRRFLFDMLNGQDPDQGHLKFTVVSDPLDEEKKECEEVGYAYLQLWQILESGRDILEQELDIVSPEDLATPIGRLKVSLQAAAVLHAIYKEMTEDLFS>sp|Q96KN7-5|RPGR1_HUMAN Isoform 5 of X-linked retinitis pigmentosaGTPase regulator-interacting protein 1 OS=Homo sapiens OX=9606 GN=RPGRIP1MLDSSDSSSQPHWSNELIAEQLQQQVSQLQDQLDAELEDKRKVLLELSREKAQNEDLKLEVTNILQKHKQEVELLQNAATISQPPDRQSEPATHPAVLQENTQIEPSEPKNQEEKKLSQVLNELQVSHAETTLELEKTRDMLILQRKINVCYQEELEAMMTKADNDNRDHKEKLERLTRLLDLKNNRIKQLEGILRSHDLPTSEQLKDVAYGTRPLSLCLETLPAHGDEDKVDISLLHQGENLFELHIHQAFLTSAALAQAGDTQPTTFCTYSFYDFETHCTPLSVGPQPLYDFTSQYVMETDSLFLHYLQEASARLDIHQAMASEHSTLAAGWICFDRVLETVEKVHGLATLIGAGGEEFGVLEYWMRLRFPIKPSLQACNKRKKAQVYLSTDVLGGRKAQEEEFRSESWEPQNELWIEITKCCGLRSRWLGTQPSPYAVYRFFTFSDHDTAIIPASNNPYFRDQARFPVLVTSDLDHYLRREALSIHVFDDEDLEPGSYLGRARVPLLPLAKNESIKGDFNLTDPAEKPNGSIQVQLDWKFPYIPPESFLKPEAQTKGKDTKDSSKISSEEEKASFPSQDQMASPEVPIEAGQYRSKRKPPHGGERKEKEHQVVSYSRRKHGKRIGVQGKNRMEYLSLNILNGNTPEQVNYTEWKFSETNSFIGDGFKNQHEEEEMTLSHSALKQKEPLHPVNDKESSEQGSEVSEAQTTDSDDVIVPPMSQKYPKADSEKMCIEIVSLAFYPEAEVMSDENIKQVYVEYKFYDLPLSETETPVSLRKPRAGEEIHFHFSKVIDLDPQEQQGRRRFLFDMLNGQDPDQGHLKFTVVSDPLDEEKKECEEVGYAYLQLWQILESGRDILEQELDIVSPEDLATPIGRLKVSLQAAAVLHAIYKEMTEDLFS>sp|Q96KN7-6|RPGR1_HUMAN Isoform 6 of X-linked retinitis pigmentosaGTPase regulator-interacting protein 1 OS=Homo sapiens OX=9606 GN=RPGRIP1MLDSSDSSSQPHWSNELIAEQLQQQVSQLQDQLDAELEDKRKVLLELSREKAQNEDLKLEVTNILQKHKQEVELLQNAATISQPPDRQSEPATHPAVLQENTQIEPSEPKNQEEKKLSQVLNELQVSHAETTLELEKTRDMLILQRKINVCYQEELEAMMTKADNDNRDHKEKLERLTRLLDLKNNRIKQLEGILRSHDLPTSEQLKDVAYGTRPLSLCLETLPAHGDEDKVDISLLHQGENLFELHIHQAFLTSAALAQAGDTQPTTFCTYSFYDFETHCTPLSVGPQPLYDFTSQYVMETDSLFLHYLQEASARLDIHQAMASEHSTLAAGWICFDRVLETVEKVHGLATLIGAGGEEFGVLEYWMRLRFPIKPSLQACNKRKKAQVYLSTDVLGGRKAQEEEFRSESWEPQNELWIEITKCCGLRSRWLGTQPSPYAVYRFFTFSDHDTAIIPASNNPYFRDQARFPVLVTSDLDHYLRREALSIHVFDDEDLEPGSYLGRARVPLLPLAKNESIKGDFNLTDPAEKPNGSIQVQLDWKFPYIPPESFLKPEAQTKGKDTKDSSKISSEEEKASFPSQ>sp|P09455|RET1_HUMAN Retinol-binding protein 1 OS=Homo sapiens OX=9606GN=RBP1 PE=1 SV=2MPVDFTGYWKMLVNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGRGWTQWIEGDELHLEMRVEGVVCKQVFKKVQ>sp|P09455-2|RET1_HUMAN Isoform 2 of Retinol-binding protein 1 OS=Homosapiens OX=9606 GN=RBP1MDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMSETGFSS>sp|P09455-3|RET1_HUMAN Isoform 3 of Retinol-binding protein 1 OS=Homosapiens OX=9606 GN=RBP1MDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMAGVQSRDLSSL>sp|Q6ZRI8|RHG36_HUMAN Rho GTPase-activating protein 36 OS=Homo sapiensOX=9606 GN=ARHGAP36 PE=2 SV=1MGGCIPFLKAARALCPRIMPPLLLLSAFIFLVSVLGGAPGHNPDRRTKMVSIHSLSELERLKLQETAYHELVARHFLSEFKPDRALPIDRPNTLDKWFLILRGQQRAVSHKTFGISLEEVLVNEFTRRKHLELTATMQVEEATGQAAGRRRGNVVRRVFGRIRRFFSRRRNEPTLPREFTRRGRRGAVSVDSLAELEDGALLLQTLQLSKISFPIGQRLLGSKRKMSLNPIAKQIPQVVEACCQFIEKHGLSAVGIFTLEYSVQRVRQLREEFDQGLDVVLDDNQNVHDVAALLKEFFRDMKDSLLPDDLYMSFLLTATLKPQDQLSALQLLVYLMPPCHSDTLERLLKALHKITENCEDSIGIDGQLVPGNRMTSTNLALVFGSALLKKGKFGKRESRKTKLGIDHYVASVNVVRAMIDNWDVLFQVPPHIQRQVAKRVWKSSPEALDFIRRRNLRKIQSARIKMEEDALLSDPVETSAEARAAVLAQSKPSDEGSSEEPAVPSGTARSHDDEEGAGNPPIPEQDRPLLRVPREKEAKTGVSYFFP>sp|Q6ZRI8-2|RHG36_HUMAN Isoform 2 of Rho GTPase-activating protein 36OS=Homo sapiens OX=9606 GN=ARHGAP36MSVLGGAPGHNPDRRTKMVSIHSLSELERLKLQETAYHELVARHFLSEFKPDRALPIDRPNTLDKWFLILRGQQRAVSHKTFGISLEEVLVNEFTRRKHLELTATMQVEEATGQAAGRRRGNVVRRVFGRIRRFFSRRRNEPTLPREFTRRGRRGAVSVDSLAELEDGALLLQTLQLSKISFPIGQRLLGSKRKMSLNPIAKQIPQVVEACCQFIEKHGLSAVGIFTLEYSVQRVRQLREEFDQGLDVVLDDNQNVHDVAALLKEFFRDMKDSLLPDDLYMSFLLTATLKPQDQLSALQLLVYLMPPCHSDTLERLLKALHKITENCEDSIGIDGQLVPGNRMTSTNLALVFGSALLKKGKFGKRESRKTKLGIDHYVASVNVVRAMIDNWDVLFQVPPHIQRQVAKRVWKSSPEALDFIRRRNLRKIQSARIKMEEDALLSDPVETSAEARAAVLAQSKPSDEGSSEEPAVPSGTARSHDDEEGAGNPPIPEQDRPLLRVPREKEAKTGVSYFFP>sp|Q6ZRI8-3|RHG36_HUMAN Isoform 3 of Rho GTPase-activating protein 36OS=Homo sapiens OX=9606 GN=ARHGAP36MQVEEATGQAAGRRRGNVVRRVFGRIRRFFSRRRNEPTLPREFTRRGRRGAVSVDSLAELEDGALLLQTLQLSKISFPIGQRLLGSKRKMSLNPIAKQIPQVVEACCQFIEKHGLSAVGIFTLEYSVQRVRQLREEFDQGLDVVLDDNQNVHDVAALLKEFFRDMKDSLLPDDLYMSFLLTATLKPQDQLSALQLLVYLMPPCHSDTLERLLKALHKITENCEDSIGIDGQLVPGNRMTSTNLALVFGSALLKKGKFGKRESRKTKLGIDHYVASVNVVRAMIDNWDVLFQVPPHIQRQVAKRVWKSSPEALDFIRRRNLRKIQSARIKMEEDALLSDPVETSAEARAAVLAQSKPSDEGSSEEPAVPSGTARSHDDEEGAGNPPIPEQDRPLLRVPREKEAKTGVSYFFP>sp|Q6ZRI8-4|RHG36_HUMAN Isoform 4 of Rho GTPase-activating protein 36OS=Homo sapiens OX=9606 GN=ARHGAP36MAWILDCLFASAFEPRPRRVSVLGGAPGHNPDRRTKMVSIHSLSELERLKLQETAYHELVARHFLSEFKPDRALPIDRPNTLDKWFLILRGQQRAVSHKTFGISLEEVLVNEFTRRKHLELTATMQVEEATGQAAGRRRGNVVRRVFGRIRRFFSRRRNEPTLPREFTRRGRRGAVSVDSLAELEDGALLLQTLQLSKISFPIGQRLLGSKRKMSLNPIAKQIPQVVEACCQFIEKHGLSAVGIFTLEYSVQRVRQLREEFDQGLDVVLDDNQNVHDVAALLKEFFRDMKDSLLPDDLYMSFLLTATLKPQDQLSALQLLVYLMPPCHSDTLERLLKALHKITENCEDSIGIDGQLVPGNRMTSTNLALVFGSALLKKGKFGKRESRKTKLGIDHYVASVNVVRAMIDNWDVLFQVPPHIQRQVAKRVWKSSPEALDFIRRRNLRKIQSARIKMEEDALLSDPVETSAEARAAVLAQSKPSDEGSSEEPAVPSGTARSHDDEEGAGNPPIPEQDRPLLRVPREKEAKTGVSYFFP>sp|Q6ZRI8-5|RHG36_HUMAN Isoform 5 of Rho GTPase-activating protein 36OS=Homo sapiens OX=9606 GN=ARHGAP36MVSIHSLSELERLKLQETAYHELVARHFLSEFKPDRALPIDRPNTLDKWFLILRGQQRAVSHKTFGISLEEVLVNEFTRRKHLELTATMQVEEATGQAAGRRRGNVVRRVFGRIRRFFSRRRNEPTLPREFTRRGRRGAVSVDSLAELEDGALLLQTLQLSKISFPIGQRLLGSKRKMSLNPIAKQIPQVVEACCQFIEKHGLSAVGIFTLEYSVQRVRQLREEFDQGLDVVLDDNQNVHDVAALLKEFFRDMKDSLLPDDLYMSFLLTATLKPQDQLSALQLLVYLMPPCHSDTLERLLKALHKITENCEDSIGIDGQLVPGNRMTSTNLALVFGSALLKKGKFGKRESRKTKLGIDHYVASVNVVRAMIDNWDVLFQVPPHIQRQVAKRVWKSSPEALDFIRRRNLRKIQSARIKMEEDALLSDPVETSAEARAAVLAQSKPSDEGSSEEPAVPSGTARSHDDEEGAGNPPIPEQDRPLLRVPREKEAKTGVSYFFP>sp|Q8N1G1|REXO1_HUMAN RNA exonuclease 1 homolog OS=Homo sapiens OX=9606GN=REXO1 PE=1 SV=3MLRSTGFFRAIDCPYWSGAPGGPCRRPYCHFRHRGARGSGAPGDGGEAPPAAGLGYDPYNPELPKPPAQRENGTLGLGEEPRPDVLELELVNQAIEAVRSEVELEQRRYRELLETTREHRSAEAPALAPRGPNASPTVGPDEDAFPLAFDYSPGSHGLLSPDAGYQPTPLAAPAEPGSKYSLASLDRGQGRGGGGGGALEYVPKAVSQPRRHSRPVPSGKYVVDNSRPPTDLEYDPLSNYSARHLSRASSRDERAAKRPRGSRGSEPYTPAPKKLCDPFGSCDARFSDSEDEAATVPGNEPTTASTPKARADPEIKATGQPPSKEGLEAEGGGLRETKETAVQCDVGDLQPPPAKPASPAQVQSSQDGGCPKEGKPKKKKTGAPPAPSCKDGAQGKDKTKDKGRGRPVEKPRADKKGPQASSPRRKAERPEGTKKKPSSATPVATSGKGRPDRPARRPSPTSGDSRPAAGRGPPRPLQLPDRKSTKAPSGKLVERKARSLDEGASQDAPKLKKRALSHADLFGDESEDEAAGPGVPSVWPSALPSLSSDSDSDSDSSLGFPEAQGPPKRLKASPPPSPAPSSSSSSSSSTSSAGADVDYSALEKEVDFDSDPMEECLRIFNESTSVKTEDRGRLARQPPKEEKSEEKGLSGLTTLFPGQKRRISHLSKQGQEVEPPRRGPAVPPARPPTAQEVCYLRAQQAQRASASLLQAPARLAEKSPSVHISAPGEKRRIAHIPNPRLAAAPTGAKRTLAASGSQSSNGPEPGGQQLKTRTLSGMASKTTTTIIPKRIAHSPSLQSLKKPIIPKEFGGKVPTVIRQRYLNLFIEECLKFCTSNQEAIEKALNEEKVAYDRSPSKNIYLNVAVNTLKKLRGLAPSAVPGLSKTSGRRVVSHEVVLGGRLAAKTSFSLSRPSSPRVEDLKGAALYSRLREYLLTQDQLKENGYPFPHPERPGGAIIFTAEEKRPKDSSCRTCCRCGTEYLVSSSGRCIRDEECYYHWGRLRRNRVAGGWETQYMCCSAAAGSVGCQVAKQHVQDGRKERLEGFVKTFEKELSGDTHPGIYALDCEMSYTTYGLELTRVTVVDTDVHVVYDTFVKPDNEIVDYNTRFSGVTEADLADTSVTLRDVQAVLLSMFSADTILIGHSLESDLLALKVIHSTVVDTSVLFPHRLGLPYKRSLRNLMADYLRQIIQDNVDGHSSSEDAGACMHLVIWKVREDAKTKR>sp|Q86X10|RLGPB_HUMAN Ral GTPase-activating protein subunit beta OS=Homosapiens OX=9606 GN=RALGAPB PE=1 SV=1MYSEWRSLHLVIQNDQGHTSVLHSYPESVGREVANAVVRPLGQVLGTPSVAGSENLLKTDKEVKWTMEVICYGLTLPLDGETVKYCVDVYTDWIMALVLPKDSIPLPVIKEPNQYVQTILKHLQNLFVPRQEQGSSQIRLCLQVLRAIQKLARESSLMARETWEVLLLFLLQINDILLAPPTVQGGIAENLAEKLIGVLFEVWLLACTRCFPTPPYWKTAKEMVANWRHHPAVVEQWSKVICALTSRLLRFTYGPSFPAFKVPDEDASLIPPEMDNECVAQTWFRFLHMLSNPVDLSNPAIISSTPKFQEQFLNVSGMPQELNQYPCLKHLPQIFFRAMRGISCLVDAFLGISRPRSDSAPPTPVNRLSMPQSAAVSTTPPHNRRHRAVTVNKATMKTSTVSTAHASKVQHQTSSTSPLSSPNQTSSEPRPLPAPRRPKVNSILNLFGSWLFDAAFVHCKLHNGINRDSSMTAITTQASMEFRRKGSQMSTDTMVSNPMFDASEFPDNYEAGRAEACGTLCRIFCSKKTGEEILPAYLSRFYMLLIQGLQINDYVCHPVLASVILNSPPLFCCDLKGIDVVVPYFISALETILPDRELSKFKSYVNPTELRRSSINILLSLLPLPHHFGTVKSEVVLEGKFSNDDSSSYDKPITFLSLKLRLVNILIGALQTETDPNNTQMILGAMLNIVQDSALLEAIGCQMEMGGGENNLKSHSRTNSGISSASGGSTEPTTPDSERPAQALLRDYALNTDSAAGLLIRSIHLVTQRLNSQWRQDMSISLAALELLSGLAKVKVMVDSGDRKRAISSVCTYIVYQCSRPAPLHSRDLHSMIVAAFQCLCVWLTEHPDMLDEKDCLKEVLEIVELGISGSKSKNNEQEVKYKGDKEPNPASMRVKDAAEATLTCIMQLLGAFPSPSGPASPCSLVNETTLIKYSRLPTINKHSFRYFVLDNSVILAMLEQPLGNEQNDFFPSVTVLVRGMSGRLAWAQQLCLLPRGAKANQKLFVPEPRPVPKNDVGFKYSVKHRPFPEEVDKIPFVKADLSIPDLHEIVTEELEERHEKLRSGMAQQIAYEIHLEQQSEEELQKRSFPDPVTDCKPPPPAQEFQTARLFLSHFGFLSLEALKEPANSRLPPHLIALDSTIPGFFDDIGYLDLLPCRPFDTVFIFYMKPGQKTNQEILKNVESSRTVQPHFLEFLLSLGWSVDVGRHPGWTGHVSTSWSINCCDDGEGSQQEVISSEDIGASIFNGQKKVLYYADALTEIAFVVPSPVESLTDSLESNISDQDSDSNMDLMPGILKQPSLTLELFPNHTDNLNSSQRLSPSSRMRKLPQGRPVPPLGPETRVSVVWVERYDDIENFPLSELMTEISTGVETTANSSTSLRSTTLEKEVPVIFIHPLNTGLFRIKIQGATGKFNMVIPLVDGMIVSRRALGFLVRQTVINICRRKRLESDSYSPPHVRRKQKITDIVNKYRNKQLEPEFYTSLFQEVGLKNCSS>sp|Q86X10-2|RLGPB_HUMAN Isoform 2 of Ral GTPase-activating proteinsubunit beta OS=Homo sapiens OX=9606 GN=RALGAPBMVANWRHHPAVVEQWSKVICALTSRLLRFTYGPSFPAFKVPDEDASLIPPEMDNECVAQTWFRFLHMLSNPVDLSNPAIISSTPKFQEQFLNVSGMPQELNQYPCLKHLPQIFFRAMRGISCLVDAFLGISRPRSDSAPPTPVNRLSMPQSAAVSTTPPHNRRHRAVTVNKATMKTSTVSTAHASKVQHQTSSTSPLSSPNQTSSEPRPLPAPRRPKVNSILNLFGSWLFDAAFVHCKLHNGINRDSSMTAITTQASMEFRRKGSQMSTDTMVSNPMFDASEFPDNYEAGRAEACGTLCRIFCSKKTGEEILPAYLSRFYMLLIQGLQINDYVCHPVLASVILNSPPLFCCDLKGIDVVVPYFISALETILPDRELSKFKSYVNPTELRRSSINILLSLLPLPHHFGTVKSEVVLEGKFSNDDSSSYDKPITFLSLKLRLVNILIGALQTETDPNNTQMILGAMLNIVQDSALLEAIGCQMEMGGGENNLKSHSRTNSGISSASGGSTEPTTPDSERPAQALLRDYALNTDSAAGLLIRSIHLVTQRLNSQWRQDMSISLAALELLSGLAKVKVMVDSGDRKRAISSVCTYIVYQCSRPAPLHSRDLHSMIVAAFQCLCVWLTEHPDMLDEKDCLKEVLEIVELGISGSKSKNNEQEVKYKGDKEPNPASMRVKDAAEATLTCIMQLLGAFPSPSGPASPCSLVNETTLIKYSRLPTINKHSFRYFVLDNSVILAMLEQPLGNEQNDFFPSVTVLVRGMSGRLAWAQQLCLLPRGAKANQKLFVPEPRPVPKNDVGFKYSVKHRPFPEEVDKIPFVKADLSIPDLHEIVTEELEERHEKLRSGMAQQIAYEIHLEQQSEEELQKRSFPDPVTDCKPPPPAQEFQTARLFLSHFGFLSLEALKEPANSRLPPHLIALDSTIPGFFDDIGYLDLLPCRPFDTVFIFYMKPGQKTNQEILKNVESSRTVQPHFLEFLLSLGWSVDVGRHPGWTGHVSTSWSINCCDDGEGSQQEEVISSEDIGASIFNGQKKVLYYADALTEIAFVVPSPVESLTDSLESNISDQDSDSNMDLMPGILKQPSLTLELFPNHTDNLNSSQRLSPSSRMRKLPQGRPVPPLGPETRVSVVWVERYDDIENFPLSELMTEISTGVETTANSSTSLRSTTLEKEVPVIFIHPLNTGLFRIKIQGATGKFNMVIPLVDGMIVSRRALGFLVRQTVINICRRKRLESDSYSPPHVRRKQKITDIVNKYRNKQLEPEFYTSLFQEVGLKNCSS>sp|Q86X10-3|RLGPB_HUMAN Isoform 3 of Ral GTPase-activating proteinsubunit beta OS=Homo sapiens OX=9606 GN=RALGAPBMYSEWRSLHLVIQNDQGHTSVLHSYPESVGREVANAVVRPLGQVLGTPSVAGSENLLKTDKEVKWTMEVICYGLTLPLDGETVKYCVDVYTDWIMALVLPKDSIPLPVIKEPNQYVQTILKHLQNLFVPRQEQGSSQIRLCLQVLRAIQKLARESSLMARETWEVLLLFLLQINDILLAPPTVQGGIAENLAEKLIGVLFEVWLLACTRCFPTPPYWKTAKEMVANWRHHPAVVEQWSKVICALTSRLLRFTYGPSFPAFKVPDEDASLIPPEMDNECVAQTWFRFLHMLSNPVDLSNPAIISSTPKFQEQFLNVSGMPQELNQYPCLKHLPQIFFRAMRGISCLVDAFLGISRPRSDSAPPTPVNRLSMPQSAAVSTTPPHNRRHRAVTVNKATMKTSTVSTAHASKVQHQTSSTSPLSSPNQTSSEPRPLPAPRRPKVNSILNLFGSWLFDAAFVHCKLHNGINRDSSMTAITTQASMEFRRKGSQMSTDTMVSNPMFDASEFPDNYEAGRAEACGTLCRIFCSKKTGEEILPAYLSRFYMLLIQGLQINDYVCHPVLASVILNSPPLFCCDLKGIDVVVPYFISALETILPDRELSKFKSYVNPTELRRSSINILLSLLPLPHHFGTVKSEVVLEGKFSNDDSSSYDKPITFLSLKLRLVNILIGALQTETDPNNTQMILGAMLNIVQDSALLEAIGCQMEMGGGENNLKSHSRTNSGISSASGGSTEPTTPDSERPAQALLRDYDSAAGLLIRSIHLVTQRLNSQWRQDMSISLAALELLSGLAKVKVMVDSGDRKRAISSVCTYIVYQCSRPAPLHSRDLHSMIVAAFQCLCVWLTEHPDMLDEKDCLKEVLEIVELGISGSKSKNNEQEVKYKGDKEPNPASMRVKDAAEATLTCIMQLLGAFPSPSGPASPCSLVNETTLIKYSRLPTINKHSFRYFVLDNSVILAMLEQPLGNEQNDFFPSVTVLVRGMSGRLAWAQQLCLLPRGAKANQKLFVPEPRPVPKNDVGFKYSVKHRPFPEEVDKIPFVKADLSIPDLHEIVTEELEERHEKLRSGMAQQIAYEIHLEQQSEEELQKRSFPDPVTDCKPPPPAQEFQTARLFLSHFGFLSLEALKEPANSRLPPHLIALDSTIPGFFDDIGYLDLLPCRPFDTVFIFYMKPGQKTNQEILKNVESSRTVQPHFLEFLLSLGWSVDVGRHPGWTGHVSTSWSINCCDDGEGSQQEEVISSEDIGASIFNGQKKVLYYADALTEIAFVVPSPVESLTDSLESNISDQDSDSNMDLMPGILKQPSLTLELFPNHTDNLNSSQRLSPSSRMRKLPQGRPVPPLGPETRVSVVWVERYDDIENFPLSELMTEISTGVETTANSSTSLRSTTLEKEVPVIFIHPLNTGLFRIKIQGATGKFNMVIPLVDGMIVSRRALGFLVRQTVINICRRKRLESDSYSPPHVRRKQKITDIVNKYRNKQLEPEFYTSLFQEVGLKNCSS>sp|Q86X10-4|RLGPB_HUMAN Isoform 4 of Ral GTPase-activating proteinsubunit beta OS=Homo sapiens OX=9606 GN=RALGAPBMYSEWRSLHLVIQNDQGHTSVLHSYPESVGREVANAVVRPLGQVLGTPSVAGSENLLKTDKEVKWTMEVICYGLTLPLDGETVKYCVDVYTDWIMALVLPKDSIPLPVIKEPNQYVQTILKHLQNLFVPRQEQGSSQIRLCLQVLRAIQKLARESSLMARETWEVLLLFLLQINDILLAPPTVQGGIAENLAEKLIGVLFEVWLLACTRCFPTPPYWKTAKEMVANWRHHPAVVEQWSKVICALTSRLLRFTYGPSFPAFKVPDEDASLIPPEMDNECVAQTWFRFLHMLSNPVDLSNPAIISSTPKFQEQFLNVSGMPQELNQYPCLKHLPQIFFRAMRGISCLVDAFLGISRPRSDSAPPTPVNRLSMPQSAAVSTTPPHNRRHRAVTVNKATMKTSTVSTAHASKVQHQTSSTSPLSSPNQTSSEPRPLPAPRRPKVNSILNLFGSWLFDAAFVHCKLHNGINRDSSMTAITTQASMEFRRKGSQMSTDTMVSNPMFDASEFPDNYEAGRAEACGTLCRIFCSKKTGEEILPAYLSRFYMLLIQGLQINDYVCHPVLASVILNSPPLFCCDLKGIDVVVPYFISALETILPDRELSKFKSYVNPTELRRSSINILLSLLPLPHHFGTVKSEVVLEGKFSNDDSSSYDKPITFLSLKLRLVNILIGALQTETDPNNTQMILGAMLNIVQDSALLEAIGCQMEMGGGENNLKSHSRTNSGISSASGGSTEPTTPDSERPAQALLRDYALNTDSAAGLLIRSIHLVTQRLNSQWRQDMSISLAALELLSGLAKVKVMVDSGDRKRAISSVCTYIVYQCSRPAPLHSRDLHSMIVAAFQCLCVWLTEHPDMLDEKDCLKEVLEIVELGISGSKSKNNEQEVKYKGDKEPNPASMRVKDAAEATLTCIMQLLGAFPSPSGPASPCSLVNETTLIKYSRLPTINKQLEPEFYTSLFQEVGLKNCSS>sp|P82912|RT11_HUMAN 28S ribosomal protein S11, mitochondrial OS=Homosapiens OX=9606 GN=MRPS11 PE=1 SV=2MQAVRNAGSRFLRSWTWPQTAGRVVARTPAGTICTGARQLQDAAAKQKVEQNAAPSHTKFSIYPPIPGEESSLRWAGKKFEEIPIAHIKASHNNTQIQVVSASNEPLAFASCGTEGFRNAKKGTGIAAQTAGIAAAARAKQKGVIHIRVVVKGLGPGRLSAMHGLIMGGLEVISITDNTPIPHNGCRPRKARKL>sp|P82912-2|RT11_HUMAN Isoform 2 of 28S ribosomal protein S11,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS11MQAVRNAGSRFLRSWTWPQTAGVVARTPAGTICTGARQLQDAAAKQKVEQNAAPSHTKFSIYPPIPGEESSLRWAGKKFEEIPIAHIKASHNNTQIQVVSASNEPLAFASCGTEGFRNAKKGTGIAAQTAGIAAAARAKQKGVIHIRVVVKGLGPGRLSAMHGLIMGGLEVISITDNTPIPHNGCRPRKARKL>sp|P82912-3|RT11_HUMAN Isoform 3 of 28S ribosomal protein S11,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS11MQAVRNAGSRFLRSWTWPQTAGRVVARTPAGTICTGARQLQDAAAKQKVEQNAAPSHTKFSTQIQVVSASNEPLAFASCGTEGFRNAKKGTGIAAQTAGIAAAARAKQKGVIHIRVVVKGLGPGRLSAMHGLIMGGLEVISITDNTPIPHNGCRPRKARKL>sp|Q9BYT1|S17A9_HUMAN Solute carrier family 17 member 9 OS=Homo sapiensOX=9606 GN=SLC17A9 PE=1 SV=2MQPPPDEARRDMAGDTQWSRPECQAWTGTLLLGTCLLYCARSSMPICTVSMSQDFGWNKKEAGIVLSSFFWGYCLTQVVGGHLGDRIGGEKVILLSASAWGSITAVTPLLAHLSSAHLAFMTFSRILMGLLQGVYFPALTSLLSQKVRESERAFTYSIVGAGSQFGTLLTGAVGSLLLEWYGWQSIFYFSGGLTLLWVWYVYRYLLSEKDLILALGVLAQSRPVSRHNRVPWRRLFRKPAVWAAVVSQLSAACSFFILLSWLPTFFEETFPDAKGWIFNVVPWLVAIPASLFSGFLSDHLINQGYRAITVRKLMQGMGLGLSSVFALCLGHTSSFCESVVFASASIGLQTFNHSGISVNIQDLAPSCAGFLFGVANTAGALAGVVGVCLGGYLMETTGSWTCLFNLVAIISNLGLCTFLVFGQAQRVDLSSTHEDL>sp|Q9BYT1-2|S17A9_HUMAN Isoform 2 of Solute carrier family 17 member 9OS=Homo sapiens OX=9606 GN=SLC17A9MTLTSRRQDSQEARPECQAWTGTLLLGTCLLYCARSSMPICTVSMSQDFGWNKKEAGIVLSSFFWGYCLTQVVGGHLGDRIGGEKVILLSASAWGSITAVTPLLAHLSSAHLAFMTFSRILMGLLQGVYFPALTSLLSQKVRESERAFTYSIVGAGSQFGTLLTGAVGSLLLEWYGWQSIFYFSGGLTLLWVWYVYRYLLSEKDLILALGVLAQSRPVSRHNRVPWRRLFRKPAVWAAVVSQLSAACSFFILLSWLPTFFEETFPDAKGWIFNVVPWLVAIPASLFSGFLSDHLINQGYRAITVRKLMQGMGLGLSSVFALCLGHTSSFCESVVFASASIGLQTFNHSGISVNIQDLAPSCAGFLFGVANTAGALAGVVGVCLGGYLMETTGSWTCLFNLVAIISNLGLCTFLVFGQAQRVDLSSTHEDL>sp|Q9BYT1-3|S17A9_HUMAN Isoform 3 of Solute carrier family 17 member 9OS=Homo sapiens OX=9606 GN=SLC17A9MQPPPDEARRDMAGDTQWSRPECQAWTGTLLLGTCLLYCARSSMPICTVSMSQDFGWNKKEAGIVLSSFFWGYCLTQVVGGHLGDRIGGEKVILLSASAWGSITAVTPLLAHLSSAHLAFMTFSRILMGLLQGVYFPALTSLLSQKVRESERAFTYSIVGAGSQFGTLLTGAVGSLLLEWYGWQSIFYFSGGLTLLWVWYVYRYLLSEKGNAGRAG>sp|O15235|RT12_HUMAN 28S ribosomal protein S12, mitochondrial OS=Homosapiens OX=9606 GN=MRPS12 PE=1 SV=1MSWSGLLHGLNTSLTCGPALVPRLWATCSMATLNQMHRLGPPKRPPRKLGPTEGRPQLKGVVLCTFTRKPKKPNSANRKCCRVRLSTGREAVCFIPGEGHTLQEHQIVLVEGGRTQDLPGVKLTVVRGKYDCGHVQKK>sp|P41440|S19A1_HUMAN Reduced folate transporter OS=Homo sapiens OX=9606GN=SLC19A1 PE=1 SV=3MVPSSPAVEKQVPVEPGPDPELRSWRHLVCYLCFYGFMAQIRPGESFITPYLLGPDKNFTREQVTNEITPVLSYSYLAVLVPVFLLTDYLRYTPVLLLQGLSFVSVWLLLLLGHSVAHMQLMELFYSVTMAARIAYSSYIFSLVRPARYQRVAGYSRAAVLLGVFTSSVLGQLLVTVGRVSFSTLNYISLAFLTFSVVLALFLKRPKRSLFFNRDDRGRCETSASELERMNPGPGGKLGHALRVACGDSVLARMLRELGDSLRRPQLRLWSLWWVFNSAGYYLVVYYVHILWNEVDPTTNSARVYNGAADAASTLLGAITSFAAGFVKIRWARWSKLLIAGVTATQAGLVFLLAHTRHPSSIWLCYAAFVLFRGSYQFLVPIATFQIASSLSKELCALVFGVNTFFATIVKTIITFIVSDVRGLGLPVRKQFQLYSVYFLILSIIYFLGAMLDGLRHCQRGHHPRQPPAQGLRSAAEEKAAQALSVQDKGLGGLQPAQSPPLSPEDSLGAVGPASLEQRQSDPYLAQAPAPQAAEFLSPVTTPSPCTLCSAQASGPEAADETCPQLAVHPPGVSKLGLQCLPSDGVQNVNQ>sp|P41440-2|S19A1_HUMAN Isoform 2 of Reduced folate transporter OS=Homosapiens OX=9606 GN=SLC19A1MRPQPAEPAPGGRGNEACSIHSEVTNEITPVLSYSYLAVLVPVFLLTDYLRYTPVLLLQGLSFVSVWLLLLLGHSVAHMQLMELFYSVTMAARIAYSSYIFSLVRPARYQRVAGYSRAAVLLGVFTSSVLGQLLVTVGRVSFSTLNYISLAFLTFSVVLALFLKRPKRSLFFNRDDRGRCETSASELERMNPGPGGKLGHALRVACGDSVLARMLRELGDSLRRPQLRLWSLWWVFNSAGYYLVVYYVHILWNEVDPTTNSARVYNGAADAASTLLGAITSFAAGFVKIRWARWSKLLIAGVTATQAGLVFLLAHTRHPSSIWLCYAAFVLFRGSYQFLVPIATFQIASSLSKELCALVFGVNTFFATIVKTIITFIVSDVRGLGLPVRKQFQLYSVYFLILSIIYFLGAMLDGLRHCQRGHHPRQPPAQGLRSAAEEKAAQALSVQDKGLGGLQPAQSPPLSPEDSLGAVGPASLEQRQSDPYLAQAPAPQAAEFLSPVTTPSPCTLCSAQASGPEAADETCPQLAVHPPGVSKLGLQCLPSDGVQNVNQ>sp|P41440-3|S19A1_HUMAN Isoform 3 of Reduced folate transporter OS=Homosapiens OX=9606 GN=SLC19A1MVPSSPAVEKQVPVEPGPDPELRSWRHLVCYLCFYGFMAQIRPGESFITPYLLGPDKNFTREQVTNEITPVLSYSYLAVLVPVFLLTDYLRYTPVLLLQGLSFVSVWLLLLLGHSVAHMQLMELFYSVTMAARIAYSSYIFSLVRPARYQRVAGYSRAAVLLGVFTSSVLGQLLVTVGRVSFSTLNYISLAFLTFSVVLALFLKRPKRSLFFNRDDRGRCETSASELERMNPGPGGKLGHALRVACGDSVLARMLRELGDSLRRPQLRLWSLWWVFNSAGYYLVVYYVHILWNEVDPTTNSARVYNGAADAASTLLGAITSFAAGFVKIRWARWSKLLIAGVTATQAGLVFLLAHTRHPSSIWLCYAAFVLFRGSYQFLVPIATFQIASSLSKELCALVFGVNTFFATIVKTIITFIVSDVRGLGLPVRKQNEELHVASLSLWKSHLRLAADTLSSEGSSGSGPRSWFLSPTLRAALHGPVCPSEVCPS>sp|Q8WXA3|RUFY2_HUMAN RUN and FYVE domain-containing protein 2 OS=Homosapiens OX=9606 GN=RUFY2 PE=1 SV=3MATKDPTAVERANLLNMAKLSIKGLIESALSFGRTLDSDYPPLQQFFVVMEHCLKHGLKVRKSFLSYNKTIWGPLELVEKLYPEAEEIGASVRDLPGLKTPLGRARAWLRLALMQKKMADYLRCLIIQRDLLSEFYEYHALMMEEEGAVIVGLLVGLNVIDANLCVKGEDLDSQVGVIDFSMYLKNEEDIGNKERNVQIAAILDQKNYVEELNRQLNSTVSSLHSRVDSLEKSNTKLIEELAIAKNNIIKLQEENHQLRSENKLILMKTQQHLEVTKVDVETELQTYKHSRQGLDEMYNEARRQLRDESQLRQDVENELAVQVSMKHEIELAMKLLEKDIHEKQDTLIGLRQQLEEVKAINIEMYQKLQGSEDGLKEKNEIIARLEEKTNKITAAMRQLEQRLQQAEKAQMEAEDEDEKYLQECLSKSDSLQKQISQKEKQLVQLETDLKIEKEWRQTLQEDLQKEKDALSHLRNETQQIISLKKEFLNLQDENQQLKKIYHEQEQALQELGNKLSESKLKIEDIKEANKALQGLVWLKDKEATHCKLCEKEFSLSKRKHHCRNCGEIFCNACSDNELPLPSSPKPVRVCDSCHALLIQRCSSNLP>sp|Q8WXA3-1|RUFY2_HUMAN Isoform 5 of RUN and FYVE domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RUFY2MGGDCLGLGGSRGRHGNAPPPLFRPVPARVLRHSGRGLEVPRRPGARTGPATKDPTAVERANLLNMAKLSIKGLIESALSFGRTLDSDYPPLQQFFVVMEHCLKHGLKVRKSFLSYNKTIWGPLELVEKLYPEAEEIGASVRDLPGLKTPLGRARAWLRLALMQKKMADYLRCLIIQRDLLSEFYEYHALMMEEEGAVIVGLLVGLNVIDANLCVKGEDLDSQVGVIDFSMYLKNEEDIGNKERNVQIAAILDQKNYVEELNRQLNSTVSSLHSRVDSLEKSNTKLIEELAIAKNNIIKLQEENHQLRSENKLILMKTQQHLEVTKVDVETELQTYKHSRQGLDEMYNEARRQLRDESQLRQDVENELAVQVSMKHEIELAMKLLEKDIHEKQDTLIGLRQQLEEVKAINIEMYQKLQGSEDGLKEKNEIIARLEEKTNKITAAMRQLEQRLQQAEKAQMEAEDEDEKYLQECLSKSDSLQKQISQKEKQLVQLETDLKIEKEWRQTLQEDLQKEKDALSHLRNETQQIISLKKEFLNLQDENQQLKKIYHEQEQALQELGNKLSESKLKIEDIKEANKALQGLVWLKDKEATHCKLCEKEFSLSKRKHHCRNCGEIFCNACSDNELPLPSSPKPVRVCDSCHALLIQRCSSNLP>sp|Q8WXA3-3|RUFY2_HUMAN Isoform 2 of RUN and FYVE domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RUFY2MTFQVWGWRREDASQVLAWVPDAEGGRRGMLTRRSLATKDPTAVERANLLNMAKLSIKGLIESALSFGRTLDSDYPPLQQFFVVMEHCLKHGLKVRKSFLSYNKTIWGPLELVEKLYPEAEEIGASVRDLPGLKTPLGRARAWLRLALMQKKMADYLRCLIIQRDLLSEFYEYHALMMEEEGAVIVGLLVGLNVIDANLCVKGEDLDSQVGVIDFSMYLKNEEDIGNKERNVQIAAILDQKNYVEELNRQLNSTVSSLHSRVDSLEKSNTKLIEELAIAKNNIIKLQEENHQLRSENKLILMKTQQHLEVTKVDVETELQTYKHSRQGLDEMYNEARRQLRDESQLRQDVENELAVQVSMKHEIELAMKLLEKDIHEKQDTLIGLRQQLEEVKAINIEMYQKLQGSEDGLKEKNEIIARLEEKTNKITAAMRQLEQRLQQAEKAQMEAEDEDEKYLQECLSKSDSLQKQISQKEKQLVQLETDLKIEKEWRQTLQEDLQKEKDALSHLRNETQQIISLKKEFLNLQDENQQLKKIYHEQEQALQELGNKLSESKLKIEDIKEANKALQGLVWLKDKEATHCKLCEKEFSLSKRKHHCRNCGEIFCNACSDNELPLPSSPKPVRVCDSCHALLIQRCSSNLP>sp|Q8WXA3-4|RUFY2_HUMAN Isoform 3 of RUN and FYVE domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RUFY2MATKDPTAVERANLLNMAKLSIKGLIESALSFGRTLDSDYPPLQQFFVVMEHCLKHGLKVRKSFLSYNKTIWGPLELVEKLYPEAEEIGASVRDLPGLNEFYEYHALMMEEEGAVIVGLLVGLNVIDANLCVKGEDLDSQVGVIDFSMYLKNEEDIGNKERNVQIAAILDQKNYVEELNRQLNSTVSSLHSRVDSLEKSNTKLIEELAIAKNNIIKLQEENHQLRSENKLILMKTQQHLEVTKVDVETELQTYKHSRQGLDEMYNEARRQLRDESQLRQDVENELAVQVSMKHEIELAMKLLEKDIHEKQDTLIGLRQQLEEVKAINIEMYQKLQGSEDGLKEKNEIIARLEEKTNKITAAMRQLEQSDNDLLTQTRTIAMSLVKCASSDTQDQYKLVKDISF>sp|Q8WXA3-5|RUFY2_HUMAN Isoform 4 of RUN and FYVE domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RUFY2MVRKSFLSYNKTIWGPLELVEKLYPEAEEIGASVRDLPGLKTPLGRARAWLRLALMQKKMADYLRCLIIQRDLLSEFYEYHALMMEEEGAVIVGLLVGLNVIDANLCVKGEDLDSQVGVIDFSMYLKNEEDIGNKERNVQIAAILDQKNYVEELNRQLNSTVSSLHSRVDSLEKSNTKLIEELAIAKNNIIKLQEENHQLRSENKLILMKTQQHLEVTKVDVETELQTYKHSRQGLDEMYNEARRQLRDESQLRQDVENELAVQVSMKHEIELAMKLLEKDIHEKQDTLIGLRQQLEEVKAINIEMYQKLQGSEDGLKEKNEIIARLEEKTNKITAAMRQLEQSDNDLLTQTRTIAMSLVKCASSDTQDQYKLVKDISF>sp|O60783|RT14_HUMAN 28S ribosomal protein S14, mitochondrial OS=Homosapiens OX=9606 GN=MRPS14 PE=1 SV=1MAAFMLGSLLRTFKQMVPSSASGQVRSHYVDWRMWRDVKRRKMAYEYADERLRINSLRKNTILPKILQDVADEEIAALPRDSCPVRIRNRCVMTSRPRGVKRRWRLSRIVFRHLADHGQLSGIQRATW>sp|Q7L099|RUFY3_HUMAN Protein RUFY3 OS=Homo sapiens OX=9606 GN=RUFY3PE=1 SV=1MSALTPPTDMPTPTTDKITQAAMETIYLCKFRVSMDGEWLCLRELDDISLTPDPEPTHEDPNYLMANERMNLMNMAKLSIKGLIESALNLGRTLDSDYAPLQQFFVVMEHCLKHGLKAKKTFLGQNKSFWGPLELVEKLVPEAAEITASVKDLPGLKTPVGRGRAWLRLALMQKKLSEYMKALINKKELLSEFYEPNALMMEEEGAIIAGLLVGLNVIDANFCMKGEDLDSQVGVIDFSMYLKDGNSSKGTEGDGQITAILDQKNYVEELNRHLNATVNNLQAKVDALEKSNTKLTEELAVANNRIITLQEEMERVKEESSYILESNRKGPKQDRTAEGQALSEARKHLKEETQLRLDVEKELEMQISMRQEMELAMKMLEKDVCEKQDALVSLRQQLDDLRALKHELAFKLQSSDLGVKQKSELNSRLEEKTNQMAATIKQLEQSEKDLVKQAKTLNSAANKLIPKHH>sp|Q7L099-2|RUFY3_HUMAN Isoform 2 of Protein RUFY3 OS=Homo sapiensOX=9606 GN=RUFY3MAETPPPPTAGAESCSEEPARGGEWRPEEPRRAPAGGTDREGEAGPPPASPAGQSEPDSPVAAPFFLLYPGDGGAGFGVRPPPQQQRSWRTPPSPGSPLPFLLLSYPSGGGGSSGSGKHHPNYLMANERMNLMNMAKLSIKGLIESALNLGRTLDSDYAPLQQFFVVMEHCLKHGLKAKKTFLGQNKSFWGPLELVEKLVPEAAEITASVKDLPGLKTPVGRGRAWLRLALMQKKLSEYMKALINKKELLSEFYEPNALMMEEEGAIIAGLLVGLNVIDANFCMKGEDLDSQVGVIDFSMYLKDGNSSKGTEGDGQITAILDQKNYVEELNRHLNATVNNLQAKVDALEKSNTKLTEELAVANNRIITLQEEMERVKEESSYILESNRKGPKQDRTAEGQALSEARKHLKEETQLRLDVEKELEMQISMRQEMELAMKMLEKDVCEKQDALVSLRQQLDDLRALKHELAFKLQSSDLGVKQKSELNSRLEEKTNQMAATIKQLEQR>sp|Q7L099-3|RUFY3_HUMAN Isoform 3 of Protein RUFY3 OS=Homo sapiensOX=9606 GN=RUFY3MSALTPPTDMPTPTTDKITQAAMETIYLCKFRVSMDGEWLCLRELDDISLTPDPEPTHEDPNYLMANERMNLMNMAKLSIKGLIESALNLGRTLDSDYAPLQQFFVVMEHCLKHGLKAKKTFLGQNKSFWGPLELVEKLVPEAAEITASVKDLPGLKTPVGRGRAWLRLALMQKKLSEYMKALINKKELLSEFYEPNALMMEEEGAIIAGLLVGLNVIDANFCMKGEDLDSQVGVIDFSMYLKDGNSSKGTEGDGQITAILDQKNYVEELNRHLNATVNNLQAKVDALEKSNTKLTEELAVANNRIITLQEEMERVKEESSYILESNRKGPKQDRTAEGQALSEARKHLKEETQLRLDVEKELEMQISMRQEMELAMKMLEKDVCEKQDALVSLRQQLDDLRALKHELAFKLQSSDLGVKQKSELNSRLEEKTNQMAATIKQLEQRLRQAERSRQSAELDNRLFKQDFGDKINSLQLEVEELTRQRNQLELELKQEKERRLQNDRSIPGRGSQKSESKMDGKHKMQEENVKLKKPLEESHRLQPHPMDEQDQLLLSEKPQLCQLCQEDGSLTKNVCKNCSGTFCDACSTNELPLPSSIKLERVCNPCHKHLMKQYSTSPS>sp|Q7L099-4|RUFY3_HUMAN Isoform 4 of Protein RUFY3 OS=Homo sapiensOX=9606 GN=RUFY3MRDDTEDPNYLMANERMNLMNMAKLSIKGLIESALNLGRTLDSDYAPLQQFFVVMEHCLKHGLKAKKTFLGQNKSFWGPLELVEKLVPEAAEITASVKDLPGLKTPVGRGRAWLRLALMQKKLSEYMKALINKKELLSEFYEPNALMMEEEGAIIAGLLVGLNVIDANFCMKGEDLDSQVGVIDFSMYLKDGNSSKGTEGDGQITAILDQKNYVEELNRHLNATVNNLQAKVDALEKSNTKLTEELAVANNRIITLQEEMERVKEESSYILESNRKGPKQDRTAEGQALSEARKHLKEETQLRLDVEKELEMQISMRQEMELAMKMLEKDVCEKQDALVSLRQQLDDLRALKHELAFKLQSSDLGVKQKSELNSRLEEKTNQMAATIKQLEQRLRQAERSRQSAELDNRLFKQDFGDKINSLQLEVEELTRQRNQLELELKQEKERRLQNDRSIPGRGSQKSESKMDGKHKMQEENVKLKKPLEESHRLQPHPMDEQDQLLLSEKPQLCQLCQEDGSLTKNVCKNCSGTFCDACSTNELPLPSSIKLERVCNPCHKHLMKQYSTSPS>sp|O60779|S19A2_HUMAN Thiamine transporter 1 OS=Homo sapiens OX=9606GN=SLC19A2 PE=1 SV=2MDVPGPVSRRAAAAAATVLLRTARVRRECWFLPTALLCAYGFFASLRPSEPFLTPYLLGPDKNLTEREVFNEIYPVWTYSYLVLLFPVFLATDYLRYKPVVLLQGLSLIVTWFMLLYAQGLLAIQFLEFFYGIATATEIAYYSYIYSVVDLGMYQKVTSYCRSATLVGFTVGSVLGQILVSVAGWSLFSLNVISLTCVSVAFAVAWFLPMPQKSLFFHHIPSTCQRVNGIKVQNGGIVTDTPASNHLPGWEDIESKIPLNMEEPPVEEPEPKPDRLLVLKVLWNDFLMCYSSRPLLCWSVWWALSTCGYFQVVNYTQGLWEKVMPSRYAAIYNGGVEAVSTLLGAVAVFAVGYIKISWSTWGEMTLSLFSLLIAAAVYIMDTVGNIWVCYASYVVFRIIYMLLITIATFQIAANLSMERYALVFGVNTFIALALQTLLTLIVVDASGLGLEITTQFLIYASYFALIAVVFLASGAVSVMKKCRKLEDPQSSSQVTTS>sp|O60779-2|S19A2_HUMAN Isoform 2 of Thiamine transporter 1 OS=Homosapiens OX=9606 GN=SLC19A2MDVPGPVSRRAAAAAATVLLRTARVRRECWFLPTALLCAYGFFASLRPSEPFLTPYLLGPDKNLTEREEPKPDRLLVLKVLWNDFLMCYSSRPLLCWSVWWALSTCGYFQVVNYTQGLWEKVMPSRYAAIYNGGVEAVSTLLGAVAVFAVGYIKISWSTWGEMTLSLFSLLIAAAVYIMDTVGNIWVCYASYVVFRIIYMLLITIATFQIAANLSMERYALVFGVNTFIALALQTLLTLIVVDASGLGLEITTQFLIYASYFALIAVVFLASGAVSVMKKCRKLEDPQSSSQVTTS>sp|Q6ZNE9|RUFY4_HUMAN RUN and FYVE domain-containing protein 4 OS=Homosapiens OX=9606 GN=RUFY4 PE=1 SV=2MAEEGAILKVTKDLRAAVSAILQGYGDGQGPVTDTSAELHRLCGCLELLLQFDQKEQKSFLGPRKDYWDFLCTALRRQRGNMEPIHFVRSQDKLKTPLGKGRAFIRFCLARGQLAEALQLCLLNSELTREWYGPRSPLLCPERQEDILDSLYALNGVAFELDLQQPDLDGAWPMFSESRCSSSTQTQGRRPRKNKDAPKKIPAAYGGPENVQIEDSHTSQAICLQDAPSGQQLAGLPRSQQQRHLPFFLEKKGESSRKHRYPQSMWEPEGKELQLDQEERAPWIEIFLGNSTPSTQGQGKGAMGTQKEVIGMEAEVTGVLLVAEGQRTTEGTHKKEAEWSHVQRLLMPSPRGAVEGAVSGSRQGSGGSSILGEPWVLQGHATKEDSTVENPQVQTEVTLVARREEQAEVSLQDEIKSLRLGLRKAEEQAQRQEQLLREQEGELQALREQLSRCQEERAELQAQLEQKQQEAERRDAMYQEELGGQRDLVQAMKRRVLELIQEKDRLWQRLQHLSSMAPECCVACSKIFGRFSRRYPCRLCGGLLCHACSMDYKKRDRCCPPCAQGREAQVT>sp|Q6ZNE9-3|RUFY4_HUMAN Isoform 2 of RUN and FYVE domain-containingprotein 4 OS=Homo sapiens OX=9606 GN=RUFY4MAEEGAILKVTKDLRAAVSAILQGYGDGQGPVTDTSAELHRLCGCLELLLQFDQKEQKSFLGPRKDYWDFLCTALRRQRGNMEPIHFVRSQDKGMVWTPEPSALPRTPRRHPGLSLCSQWGGLRVGPPAARPGWSLAHVLRVTLLQFHPNPGKETQKKQRCPKEDPSRIWRA>sp|Q9BZV2|S19A3_HUMAN Thiamine transporter 2 OS=Homo sapiens OX=9606GN=SLC19A3 PE=1 SV=1MDCYRTSLSSSWIYPTVILCLFGFFSMMRPSEPFLIPYLSGPDKNLTSAEITNEIFPVWTYSYLVLLLPVFVLTDYVRYKPVIILQGISFIITWLLLLFGQGVKTMQVVEFFYGMVTAAEVAYYAYIYSVVSPEHYQRVSGYCRSVTLAAYTAGSVLAQLLVSLANMSYFYLNVISLASVSVAFLFSLFLPMPKKSMFFHAKPSREIKKSSSVNPVLEETHEGEAPGCEEQKPTSEILSTSGKLNKGQLNSLKPSNVTVDVFVQWFQDLKECYSSKRLFYWSLWWAFATAGFNQVLNYVQILWDYKAPSQDSSIYNGAVEAIATFGGAVAAFAVGYVKVNWDLLGELALVVFSVVNAGSLFLMHYTANIWACYAGYLIFKSSYMLLITIAVFQIAVNLNVERYALVFGINTFIALVIQTIMTVIVVDQRGLNLPVSIQFLVYGSYFAVIAGIFLMRSMYITYSTKSQKDVQSPAPSENPDVSHPEEESNIIMSTKL>sp|P82914|RT15_HUMAN 28S ribosomal protein S15, mitochondrial OS=Homosapiens OX=9606 GN=MRPS15 PE=1 SV=1MLRVAWRTLSLIRTRAVTQVLVPGLPGGGSAKFPFNQWGLQPRSLLLQAARGYVVRKPAQSRLDDDPPPSTLLKDYQNVPGIEKVDDVVKRLLSLEMANKKEMLKIKQEQFMKKIVANPEDTRSLEARIIALSVKIRSYEEHLEKHRKDKAHKRYLLMSIDQRKKMLKNLRNTNYDVFEKICWGLGIEYTFPPLYYRRAHRRFVTKKALCIRVFQETQKLKKRRRALKAAAAAQKQAKRRNPDSPAKAIPKTLKDSQ>sp|Q86SG5|S1A7A_HUMAN Protein S100-A7A OS=Homo sapiens OX=9606GN=S100A7A PE=1 SV=3MSNTQAERSIIGMIDMFHKYTGRDGKIEKPSLLTMMKENFPNFLSACDKKGIHYLATVFEKKDKNEDKKIDFSEFLSLLGDIAADYHKQSHGAAPCSGGSQ>sp|Q5SY68|S1A7B_HUMAN Protein S100-A7-like 2 OS=Homo sapiens OX=9606GN=S100A7L2 PE=1 SV=1MNIPLGEKVMLDIVAMFRQYSGDDGRMDMPGLVNLMKENFPNFLSGCEKSDMDYLSNALEKKDDNKDKKVNYSEFLSLLGDITIDHHKIMHGVAPCSGGSQ>sp|Q9Y3D3|RT16_HUMAN 28S ribosomal protein S16, mitochondrial OS=Homosapiens OX=9606 GN=MRPS16 PE=1 SV=1MVHLTTLLCKAYRGGHLTIRLALGGCTNRPFYRIVAAHNKCPRDGRFVEQLGSYDPLPNSHGEKLVALNLDRIRHWIGCGAHLSKPMEKLLGLAGFFPLHPMMITNAERLRRKRAREVLLASQKTDAEATDTEATET>sp|Q9Y3D3-2|RT16_HUMAN Isoform 2 of 28S ribosomal protein S16,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS16MVHLTTLLCKAYRGGHLTIRLALGGCTNRPFYRIVAAHNKCPRDGRFVEQLGSYDPLPNSHGEKLVALNLDRIRHWIGCGAHLSKPMEKLLGKTDARFPEQGEERPEQHHFPEDLAPARGRGL>sp|Q9Y3D5|RT18C_HUMAN 28S ribosomal protein S18c, mitochondrial OS=Homosapiens OX=9606 GN=MRPS18C PE=1 SV=1MAAVVAVCGGLGRKKLTHLVTAAVSLTHPGTHTVLWRRGCSQQVSSNEDLPISMENPYKEPLKKCILCGKHVDYKNVQLLSQFVSPFTGCIYGRHITGLCGKKQKEITKAIKRAQIMGFMPVTYKDPAYLKDPKVCNIRYRE>sp|O95136|S1PR2_HUMAN Sphingosine 1-phosphate receptor 2 OS=Homo sapiensOX=9606 GN=S1PR2 PE=1 SV=2MGSLYSEYLNPNKVQEHYNYTKETLETQETTSRQVASAFIVILCCAIVVENLLVLIAVARNSKFHSAMYLFLGNLAASDLLAGVAFVANTLLSGSVTLRLTPVQWFAREGSAFITLSASVFSLLAIAIERHVAIAKVKLYGSDKSCRMLLLIGASWLISLVLGGLPILGWNCLGHLEACSTVLPLYAKHYVLCVVTIFSIILLAIVALYVRIYCVVRSSHADMAAPQTLALLKTVTIVLGVFIVCWLPAFSILLLDYACPVHSCPILYKAHYFFAVSTLNSLLNPVIYTWRSRDLRREVLRPLQCWRPGVGVQGRRRGGTPGHHLLPLRSSSSLERGMHMPTSPTFLEGNTVV>sp|Q9UHP6|RSP14_HUMAN Radial spoke head 14 homolog OS=Homo sapiensOX=9606 GN=RSPH14 PE=1 SV=1MAHSQNSLELPININATQITTAYGHRALPKLKEELQSEDLQTRQKALMALCDLMHDPECIYKAMNIGCMENLKALLKDSNSMVRIKTTEVLHITASHSVGRYAFLEHDIVLALSFLLNDPSPVCRGNLYKAYMQLVQVPRGAQEIISKGLISSLVWKLQVEVEEEEFQEFILDTLVLCLQEDATEALGSNVVLVLKQKLLSANQNIRSKAARALLNVSISREGKKQVCHFDVIPILVHLLKDPVEHVKSNAAGALMFATVITEGKYAALEAQAIGLLLELLHSPMTIARLNATKALTMLAEAPEGRKALQTHVPTFRAMEVETYEKPQVAEALQRAARIAISVIEFKP>sp|Q99500|S1PR3_HUMAN Sphingosine 1-phosphate receptor 3 OS=Homo sapiensOX=9606 GN=S1PR3 PE=1 SV=2MATALPPRLQPVRGNETLREHYQYVGKLAGRLKEASEGSTLTTVLFLVICSFIVLENLMVLIAIWKNNKFHNRMYFFIGNLALCDLLAGIAYKVNILMSGKKTFSLSPTVWFLREGSMFVALGASTCSLLAIAIERHLTMIKMRPYDANKRHRVFLLIGMCWLIAFTLGALPILGWNCLHNLPDCSTILPLYSKKYIAFCISIFTAILVTIVILYARIYFLVKSSSRKVANHNNSERSMALLRTVVIVVSVFIACWSPLFILFLIDVACRVQACPILFKAQWFIVLAVLNSAMNPVIYTLASKEMRRAFFRLVCNCLVRGRGARASPIQPALDPSRSKSSSSNNSSHSPKVKEDLPHTAPSSCIMDKNAALQNGIFCN>sp|Q01196|RUNX1_HUMAN Runt-related transcription factor 1 OS=Homosapiens OX=9606 GN=RUNX1 PE=1 SV=3MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQSYQYLGSIASPSVHPATPISPGRASGMTTLSAELSSRLSTAPDLTAFSDPRQFPALPSISDPRMHYPGAFTYSPTPVTSGIGIGMSAMGSATRYHTYLPPPYPGSSQAQGGPFQASSPSYHLYYGASAGSYQFSMVGGERSPPRILPPCTNASTGSALLNPSLPNQSDVVEAEGSHSNSPTNMAPSARLEEAVWRPY>sp|Q01196-2|RUNX1_HUMAN Isoform AML-1A of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQSYQYLGSIASPSVHPATPISPGRASGMTTLSAELSSRLSTAPDLTAFSDPRQFPALPSISDPRMHYPGAFTYSPTPVTSGIGIGMSAMGSATRYHTYLPPPYPGSSQAQGGPFQASSPSYHLYYGASAGSYQFSMVGGERSPPRILPPCTNASTGSALLNPSLPNQSDVVEAEGSHSNSPTNMGGASCSRQARRDPGPWARTPSWGRGRPTDRISL>sp|Q01196-3|RUNX1_HUMAN Isoform AML-1C of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQEEDTAPWRC>sp|Q01196-4|RUNX1_HUMAN Isoform AML-1E of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQS>sp|Q01196-5|RUNX1_HUMAN Isoform AML-1FA of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRSKCIHLGLVHPPGWYTLQAGILRDHVSDSLGSTFPPGGWQAPVKPKS>sp|Q01196-6|RUNX1_HUMAN Isoform AML-1FB of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRNSLTWPRYPHI>sp|Q01196-7|RUNX1_HUMAN Isoform AML-1FC of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQSYQYLGSIASPSVHPATPI>sp|Q01196-8|RUNX1_HUMAN Isoform AML-1G of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MASDSIFESFPSYPQCFMRECILGMNPSRDVHDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQSYQYLGSIASPSVHPATPISPGRASGMTTLSAELSSRLSTAPDLTAFSDPRQFPALPSISDPRMHYPGAFTYSPTPVTSGIGIGMSAMGSATRYHTYLPPPYPGSSQAQGGPFQASSPSYHLYYGASAGSYQFSMVGGERSPPRILPPCTNASTGSALLNPSLPNQSDVVEAEGSHSNSPTNMAPSARLEEAVWRPY>sp|Q01196-9|RUNX1_HUMAN Isoform AML-1H of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MNPSRDVHDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQSYQYLGSIASPSVHPATPISPGRASGMTTLSAELSSRLSTAPDLTAFSDPRQFPALPSISDPRMHYPGAFTYSPTPVTSGIGIGMSAMGSATRYHTYLPPPYPGSSQAQGGPFQASSPSYHLYYGASAGSYQFSMVGGERSPPRILPPCTNASTGSALLNPSLPNQSDVVEAEGSHSNSPTNMAPSARLEEAVWRPY>sp|Q01196-10|RUNX1_HUMAN Isoform AML-1I of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MPAAPRGPAQGEAAARTRSRDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNFLCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQSYQYLGSIASPSVHPATPISPGRASGMTTLSAELSSRLSTAPDLTAFSDPRQFPALPSISDPRMHYPGAFTYSPTPVTSGIGIGMSAMGSATRYHTYLPPPYPGSSQAQGGPFQASSPSYHLYYGASAGSYQFSMVGGERSPPRILPPCTNASTGSALLNPSLPNQSDVVEAEGSHSNSPTNMAPSARLEEAVWRPY>sp|Q01196-11|RUNX1_HUMAN Isoform AML-1L of Runt-related transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=RUNX1MAGNDENYSAELRNATAAMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRRHRQKLDDQTKPGSLSFSERLSELEQLRRTAMRVSPHHPAPTPNPRASLNHSTAFNPQPQSQMQDTRQIQPSPPWSYDQSYQYLGSIASPSVHPATPISPGRASGMTTLSAELSSRLSTAPDLTAFSDPRQFPALPSISDPRMHYPGAFTYSPTPVTSGIGIGMSAMGSATRYHTYLPPPYPGSSQAQGGPFQASSPSYHLYYGASAGSYQFSMVGGERSPPRILPPCTNASTGSALLNPSLPNQSDVVEAEGSHSNSPTNMAPSARLEEAVWRPY>sp|Q13950|RUNX2_HUMAN Runt-related transcription factor 2 OS=Homosapiens OX=9606 GN=RUNX2 PE=1 SV=2MASNSLFSTVTPCQQNFFWDPSTSRRFSPPSSSLQPGKMSDVSPVVAAQQQQQQQQQQQQQQQQQQQQQQQEAAAAAAAAAAAAAAAAAVPRLRPPHDNRTMVEIIADHPAELVRTDSPNFLCSVLPSHWRCNKTLPVAFKVVALGEVPDGTVVTVMAGNDENYSAELRNASAVMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKVTVDGPREPRRHRQKLDDSKPSLFSDRLSDLGRIPHPSMRVGVPPQNPRPSLNSAPSPFNPQGQSQITDPRQAQSSPPWSYDQSYPSYLSQMTSPSIHSTTPLSSTRGTGLPAITDVPRRISDDDTATSDFCLWPSTLSKKSQAGASELGPFSDPRQFPSISSLTESRFSNPRMHYPATFTYTPPVTSGMSLGMSATTHYHTYLPPPYPGSSQSQSGPFQTSSTPYLYYGTSSGSYQFPMVPGGDRSPSRMLPPCTTTSNGSTLLNPNLPNQNDGVDADGSHSSSPTVLNSSGRMDESVWRPY>sp|Q13950-2|RUNX2_HUMAN Isoform 2 of Runt-related transcription factor 2OS=Homo sapiens OX=9606 GN=RUNX2MRIPVDPSTSRRFSPPSSSLQPGKMSDVSPVVAAQQQQQQQQQQQQQQQQQQQQQQQEAAAAAAAAAAAAAAAAAVPRLRPPHDNRTMVEIIADHPAELVRTDSPNFLCSVLPSHWRCNKTLPVAFKVVALGEVPDGTVVTVMAGNDENYSAELRNASAVMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKVTVDGPREPRRHRQKLDDSKPSLFSDRLSDLGRIPHPSMRVGVPPQNPRPSLNSAPSPFNPQGQSQITDPRQAQSSPPWSYDQSYPSYLSQMTSPSIHSTTPLSSTRGTGLPAITDVPRRISDDDTATSDFCLWPSTLSKKSQAGASELGPFSDPRQFPSISSLTESRFSNPRMHYPATFTYTPPVTSGMSLGMSATTHYHTYLPPPYPGSSQSQSGPFQTSSTPYLYYGTSSGSYQFPMVPGGDRSPSRMLPPCTTTSNGSTLLNPNLPNQNDGVDADGSHSSSPTVLNSSGRMDESVWRPY>sp|Q13950-3|RUNX2_HUMAN Isoform 3 of Runt-related transcription factor 2OS=Homo sapiens OX=9606 GN=RUNX2MASNSLFSTVTPCQQNFFWDPSTSRRFSPPSSSLQPGKMSDVSPVVAAQQQQQQQQQQQQQQQQQQQQQQQEAAAAAAAAAAAAAAAAAVPRLRPPHDNRTMVEIIADHPAELVRTDSPNFLCSVLPSHWRCNKTLPVAFKVVALGEVPDGTVVTVMAGNDENYSAELRNASAVMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPPQVATYHRAIKVTVDGPREPRRHRQKLDDSKPSLFSDRLSDLGRIPHPSMRVGVPPQNPRPSLNSAPSPFNPQGQSQITDPRQAQSSPPWSYDQSYPSYLSQMTSPSIHSTTPLSSTRGTGLPAITDVPRRISGASELGPFSDPRQFPSISSLTESRFSNPRMHYPATFTYTPPVTSGMSLGMSATTHYHTYLPPPYPGSSQSQSGPFQTSSTPYLYYGTSSGSYQFPMVPGGDRSPSRMLPPCTTTSNGSTLLNPNLPNQNDGVDADGSHSSSPTVLNSSGRMDESVWRPY>sp|P82650|RT22_HUMAN 28S ribosomal protein S22, mitochondrial OS=Homosapiens OX=9606 GN=MRPS22 PE=1 SV=1MAPLGTTVLLWSLLRSSPGVERVCFRARIQPWHGGLLQPLPCSFEMGLPRRRFSSEAAESGSPETKKPTFMDEEVQSILTKMTGLNLQKTFKPAIQELKPPTYKLMTQAQLEEATRQAVEAAKVRLKMPPVLEERVPINDVLAEDKILEGTETTKYVFTDISYSIPHRERFIVVREPSGTLRKASWEERDRMIQVYFPKEGRKILTPIIFKEENLRTMYSQDRHVDVLNLCFAQFEPDSTEYIKVHHKTYEDIDKRGKYDLLRSTRYFGGMVWYFVNNKKIDGLLIDQIQRDLIDDATNLVQLYHVLHPDGQSAQGAKDQAAEGINLIKVFAKTEAQKGAYIELTLQTYQEALSRHSAAS>sp|P82650-2|RT22_HUMAN Isoform 2 of 28S ribosomal protein S22,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS22MAPLGTTVLLWSLLRSSPGVERVCFRARIQPWHGGLLQPLPCSFEMGLPRRRFSSEAESGSPETKKPTFMDEEVQSILTKMTGLNLQKTFKPAIQELKPPTYKLMTQAQLEEATRQAVEAAKVRLKMPPVLEERVPINDVLAEDKILEGTETTKYVFTDISYSIPHRC>sp|Q8WUM9|S20A1_HUMAN Sodium-dependent phosphate transporter 1 OS=Homosapiens OX=9606 GN=SLC20A1 PE=1 SV=1MATLITSTTAATAASGPLVDYLWMLILGFIIAFVLAFSVGANDVANSFGTAVGSGVVTLKQACILASIFETVGSVLLGAKVSETIRKGLIDVEMYNSTQGLLMAGSVSAMFGSAVWQLVASFLKLPISGTHCIVGATIGFSLVAKGQEGVKWSELIKIVMSWFVSPLLSGIMSGILFFLVRAFILHKADPVPNGLRALPVFYACTVGINLFSIMYTGAPLLGFDKLPLWGTILISVGCAVFCALIVWFFVCPRMKRKIEREIKCSPSESPLMEKKNSLKEDHEETKLSVGDIENKHPVSEVGPATVPLQAVVEERTVSFKLGDLEEAPERERLPSVDLKEETSIDSTVNGAVQLPNGNLVQFSQAVSNQINSSGHYQYHTVHKDSGLYKELLHKLHLAKVGDCMGDSGDKPLRRNNSYTSYTMAICGMPLDSFRAKEGEQKGEEMEKLTWPNADSKKRIRMDSYTSYCNAVSDLHSASEIDMSVKAEMGLGDRKGSNGSLEEWYDQDKPEVSLLFQFLQILTACFGSFAHGGNDVSNAIGPLVALYLVYDTGDVSSKVATPIWLLLYGGVGICVGLWVWGRRVIQTMGKDLTPITPSSGFSIELASALTVVIASNIGLPISTTHCKVGSVVSVGWLRSKKAVDWRLFRNIFMAWFVTVPISGVISAAIMAIFRYVILRM>sp|Q13761|RUNX3_HUMAN Runt-related transcription factor 3 OS=Homosapiens OX=9606 GN=RUNX3 PE=1 SV=2MRIPVDPSTSRRFTPPSPAFPCGGGGGKMGENSGALSAQAAVGPGGRARPEVRSMVDVLADHAGELVRTDSPNFLCSVLPSHWRCNKTLPVAFKVVALGDVPDGTVVTVMAGNDENYSAELRNASAVMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPTQVATYHRAIKVTVDGPREPRRHRQKLEDQTKPFPDRFGDLERLRMRVTPSTPSPRGSLSTTSHFSSQPQTPIQGTSELNPFSDPRQFDRSFPTLPTLTESRFPDPRMHYPGAMSAAFPYSATPSGTSISSLSVAGMPATSRFHHTYLPPPYPGAPQNQSGPFQANPSPYHLYYGTSSGSYQFSMVAGSSSGGDRSPTRMLASCTSSAASVAAGNLMNPSLGGQSDGVEADGSHSNSPTALSTPGRMDEAVWRPY>sp|Q13761-2|RUNX3_HUMAN Isoform 2 of Runt-related transcription factor 3OS=Homo sapiens OX=9606 GN=RUNX3MASNSIFDSFPTYSPTFIRDPSTSRRFTPPSPAFPCGGGGGKMGENSGALSAQAAVGPGGRARPEVRSMVDVLADHAGELVRTDSPNFLCSVLPSHWRCNKTLPVAFKVVALGDVPDGTVVTVMAGNDENYSAELRNASAVMKNQVARFNDLRFVGRSGRGKSFTLTITVFTNPTQVATYHRAIKVTVDGPREPRRHRQKLEDQTKPFPDRFGDLERLRMRVTPSTPSPRGSLSTTSHFSSQPQTPIQGTSELNPFSDPRQFDRSFPTLPTLTESRFPDPRMHYPGAMSAAFPYSATPSGTSISSLSVAGMPATSRFHHTYLPPPYPGAPQNQSGPFQANPSPYHLYYGTSSGSYQFSMVAGSSSGGDRSPTRMLASCTSSAASVAAGNLMNPSLGGQSDGVEADGSHSNSPTALSTPGRMDEAVWRPY>sp|Q8WYR4|RSPH1_HUMAN Radial spoke head 1 homolog OS=Homo sapiensOX=9606 GN=RSPH1 PE=1 SV=1MSDLGSEELEEEGENDIGEYEGGRNEAGERHGRGRARLPNGDTYEGSYEFGKRHGQGIYKFKNGARYIGEYVRNKKHGQGTFIYPDGSRYEGEWANDLRHGHGVYYYINNDTYTGEWFAHQRHGQGTYLYAETGSKYVGTWVNGQQEGTAELIHLNHRYQGKFLNKNPVGPGKYVFDVGCEQHGEYRLTDMERGEEEEEEELVTVVPKWKATQITELALWTPTLPKKPTSTDGPGQDAPGAESAGEPGEEAQALLEGFEGEMDMRPGDEDADVLREESREYDQEEFRYDMDEGNINSEEEETRQSDLQD>sp|Q8WYR4-2|RSPH1_HUMAN Isoform 2 of Radial spoke head 1 homolog OS=Homosapiens OX=9606 GN=RSPH1MSDLGSEELEEEGENDIGGIYKFKNGARYIGEYVRNKKHGQGTFIYPDGSRYEGEWANDLRHGHGVYYYINNDTYTGEWFAHQRHGQGTYLYAETGSKYVGTWVNGQQEGTAELIHLNHRYQGKFLNKNPVGPGKYVFDVGCEQHGEYRLTDMERGEEEEEEELVTVVPKWKATQITELALWTPTLPKKPTSTDGPGQDAPGAESAGEPGEEAQALLEGFEGEMDMRPGDEDADVLREESREYDQEEFRYDMDEGNINSEEEETRQSDLQD>sp|Q08357|S20A2_HUMAN Sodium-dependent phosphate transporter 2 OS=Homosapiens OX=9606 GN=SLC20A2 PE=1 SV=1MAMDEYLWMVILGFIIAFILAFSVGANDVANSFGTAVGSGVVTLRQACILASIFETTGSVLLGAKVGETIRKGIIDVNLYNETVETLMAGEVSAMVGSAVWQLIASFLRLPISGTHCIVGSTIGFSLVAIGTKGVQWMELVKIVASWFISPLLSGFMSGLLFVLIRIFILKKEDPVPNGLRALPVFYAATIAINVFSIMYTGAPVLGLVLPMWAIALISFGVALLFAFFVWLFVCPWMRRKITGKLQKEGALSRVSDESLSKVQEAESPVFKELPGAKANDDSTIPLTGAAGETLGTSEGTSAGSHPRAAYGRALSMTHGSVKSPISNGTFGFDGHTRSDGHVYHTVHKDSGLYKDLLHKIHIDRGPEEKPAQESNYRLLRRNNSYTCYTAAICGLPVHATFRAADSSAPEDSEKLVGDTVSYSKKRLRYDSYSSYCNAVAEAEIEAEEGGVEMKLASELADPDQPREDPAEEEKEEKDAPEVHLLFHFLQVLTACFGSFAHGGNDVSNAIGPLVALWLIYKQGGVTQEAATPVWLLFYGGVGICTGLWVWGRRVIQTMGKDLTPITPSSGFTIELASAFTVVIASNIGLPVSTTHCKVGSVVAVGWIRSRKAVDWRLFRNIFVAWFVTVPVAGLFSAAVMALLMYGILPYV>sp|Q96EL2|RT24_HUMAN 28S ribosomal protein S24, mitochondrial OS=Homosapiens OX=9606 GN=MRPS24 PE=1 SV=1MAASVCSGLLGPRVLSWSRELPCAWRALHTSPVCAKNRAARVRVSKGDKPVTYEEAHAPHYIAHRKGWLSLHTGNLDGEDHAAERTVEDVFLRKFMWGTFPGCLADQLVLKRRGNQLEICAVVLRQLSPHKYYFLVGYSETLLSYFYKCPVRLHLQTVPSKVVYKYL>sp|Q9H1X1|RSPH9_HUMAN Radial spoke head protein 9 homolog OS=Homosapiens OX=9606 GN=RSPH9 PE=1 SV=1MDADSLLLSLELASGSGQGLSPDRRASLLTSLMLVKRDYRYDRVLFWGRILGLVADYYIAQGLSEDQLAPRKTLYSLNCTEWSLLPPATEEMVAQSSVVKGRFMGDPSYEYEHTELQKVNEGEKVFEEEIVVQIKEETRLVSVIDQIDKAVAIIPRGALFKTPFGPTHVNRTFEGLSLSEAKKLSSYFHFREPVELKNKTLLEKADLDPSLDFMDSLEHDIPKGSWSIQMERGNALVVLRSLLWPGLTFYHAPRTKNYGYVYVGTGEKNMDLPFML>sp|Q9H1X1-2|RSPH9_HUMAN Isoform 2 of Radial spoke head protein 9 homologOS=Homo sapiens OX=9606 GN=RSPH9MDADSLLLSLELASGSGQGLSPDRRASLLTSLMLVKRDYRYDRVLFWGRILGLVADYYIAQGLSEDQLAPRKTLYSLNCTEWSLLPPATEEMVAQSSVVKGRFMGDPSYEYEHTELQKVNEGEKVFEEEIVIDKAVAIIPRGALFKTPFGPTHVNRTFEGLSLSEAKKLSSYFHFREPVELKNKTLLEKADLDPSLDFMDSLEHDIPKGSEAVVQGDFTWLLSRCGFGWPCSWDSCSVSMRVLEHPDGEGQCPGGAAQPALAGPHLLPCSPHQELWLRLRGHWREEHGLALHAIEWEPAWMFLNRV>sp|O15245|S22A1_HUMAN Solute carrier family 22 member 1 OS=Homo sapiensOX=9606 GN=SLC22A1 PE=1 SV=2MPTVDDILEQVGESGWFQKQAFLILCLLSAAFAPICVGIVFLGFTPDHHCQSPGVAELSQRCGWSPAEELNYTVPGLGPAGEAFLGQCRRYEVDWNQSALSCVDPLASLATNRSHLPLGPCQDGWVYDTPGSSIVTEFNLVCADSWKLDLFQSCLNAGFLFGSLGVGYFADRFGRKLCLLGTVLVNAVSGVLMAFSPNYMSMLLFRLLQGLVSKGNWMAGYTLITEFVGSGSRRTVAIMYQMAFTVGLVALTGLAYALPHWRWLQLAVSLPTFLFLLYYWCVPESPRWLLSQKRNTEAIKIMDHIAQKNGKLPPADLKMLSLEEDVTEKLSPSFADLFRTPRLRKRTFILMYLWFTDSVLYQGLILHMGATSGNLYLDFLYSALVEIPGAFIALITIDRVGRIYPMAMSNLLAGAACLVMIFISPDLHWLNIIIMCVGRMGITIAIQMICLVNAELYPTFVRNLGVMVCSSLCDIGGIITPFIVFRLREVWQALPLILFAVLGLLAAGVTLLLPETKGVALPETMKDAENLGRKAKPKENTIYLKVQTSEPSGT>sp|O15245-2|S22A1_HUMAN Isoform 2 of Solute carrier family 22 member 1OS=Homo sapiens OX=9606 GN=SLC22A1MPTVDDILEQVGESGWFQKQAFLILCLLSAAFAPICVGIVFLGFTPDHHCQSPGVAELSQRCGWSPAEELNYTVPGLGPAGEAFLGQCRRYEVDWNQSALSCVDPLASLATNRSHLPLGPCQDGWVYDTPGSSIVTEFNLVCADSWKLDLFQSCLNAGFLFGSLGVGYFADRFGRKLCLLGTVLVNAVSGVLMAFSPNYMSMLLFRLLQGLVSKGNWMAGYTLITEFVGSGSRRTVAIMYQMAFTVGLVALTGLAYALPHWRWLQLAVSLPTFLFLLYYWCVPESPRWLLSQKRNTEAIKIMDHIAQKNGKLPPADLKMLSLEEDVTEKLSPSFADLFRTPRLRKRTFILMYLWFTDSVLYQGLILHMGATSGNLYLDFLYSALVEIPGAFIALITIDRVGRIYPMAMSNLLAGAACLVMIFISPDLHWLNIIIMCVGRMGITIAIQMICLVNAELYPTFVSGVGPACRGSDATSSRDQGGRFARDHEGRREPWEKSKAQRKHDLP>sp|O15245-3|S22A1_HUMAN Isoform 3 of Solute carrier family 22 member 1OS=Homo sapiens OX=9606 GN=SLC22A1MPTVDDILEQVGESGWFQKQAFLILCLLSAAFAPICVGIVFLGFTPDHHCQSPGVAELSQRCGWSPAEELNYTVPGLGPAGEAFLGQCRRYEVDWNQSALSCVDPLASLATNRSHLPLGPCQDGWVYDTPGSSIVTEFNLVCADSWKLDLFQSCLNAGFLFGSLGVGYFADRFGRKLCLLGTVLVNAVSGVLMAFSPNYMSMLLFRLLQGLVSKGNWMAGYTLITEFVGSGSRRTVAIMYQMAFTVGLVALTGLAYALPHWRWLQLAVSLPTFLFLLYYWCVPESPRWLLSQKRNTEAIKIMDHIAQKNGKLPPADLKMLSLEEDVTEKLSPSFADLFRTPRLRKRTFILMYLWFTDSVLYQGLILHMGATSGNLYLDFLYSALVEIPGAFIALITIDRVGRIYPMAMSNLLAGAACLVMIFISPDLHWLNIIIMCVGRMGITIAIQMICLVNAELYPTFVRKAKPKENTIYLKVQTSEPSGT>sp|O15245-4|S22A1_HUMAN Isoform 4 of Solute carrier family 22 member 1OS=Homo sapiens OX=9606 GN=SLC22A1MPTVDDILEQVGESGWFQKQAFLILCLLSAAFAPICVGIVFLGFTPDHHCQSPGVAELSQRCGWSPAEELNYTVPGLGPAGEAFLGQCRRYEVDWNQSALSCVDPLASLATNRSHLPLGPCQDGWVYDTPGSSIVTEFNLVCADSWKLDLFQSCLNAGFLFGSLGVGYFADRFGRKLCLLGTVLVNAVSGVLMAFSPNYMSMLLFRLLQGLVSKGNWMAGYTLITEFVGSGSRRTVAIMYQMAFTVGLVALTGLAYALPHWRWLQLAVSLPTFLFLLYYWCVPESPRWLLSQKRNTEAIKIMDHIAQKNGKLPPADLKMLSLEEDVTEKLSPSFADLFRTPRLRKRTFILMYL>sp|P82663|RT25_HUMAN 28S ribosomal protein S25, mitochondrial OS=Homosapiens OX=9606 GN=MRPS25 PE=1 SV=1MPMKGRFPIRRTLQYLSQGNVVFKDSVKVMTVNYNTHGELGEGARKFVFFNIPQIQYKNPWVQIMMFKNMTPSPFLRFYLDSGEQVLVDVETKSNKEIMEHIRKILGKNEETLREEEEEKKQLSHPANFGPRKYCLRECICEVEGQVPCPSLVPLPKEMRGKYKAALKADAQD>sp|P82663-2|RT25_HUMAN Isoform 2 of 28S ribosomal protein S25,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS25MPMKGRFPIRRTLQYLSQGNVVFKDSVKVMTVNYNTHGELGEGARKFVFFNIPQIQYKNPWVQIMMFKNMTPSPFLRFYLDSGEQVLVDVETKSNKEIMEHIRKILGKNEHYLAAPSKPVSSAVVPVTQEAEAGGSLEPRRLRLE>sp|P82663-3|RT25_HUMAN Isoform 3 of 28S ribosomal protein S25,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS25MPMKGRFPIRRTLQYLSQGNVVFKDSVKVMTVNYNTHGELGEGARKFVFFNIPQIQYKNPWVQIMMFKNMTPSPFLRFYLGKPSGKRRRRKSSFLTQPTSALESTACGSASVKWKGRCPAPAWCHYPRR>sp|O15244|S22A2_HUMAN Solute carrier family 22 member 2 OS=Homo sapiensOX=9606 GN=SLC22A2 PE=1 SV=2MPTTVDDVLEHGGEFHFFQKQMFFLLALLSATFAPIYVGIVFLGFTPDHRCRSPGVAELSLRCGWSPAEELNYTVPGPGPAGEASPRQCRRYEVDWNQSTFDCVDPLASLDTNRSRLPLGPCRDGWVYETPGSSIVTEFNLVCANSWMLDLFQSSVNVGFFIGSMSIGYIADRFGRKLCLLTTVLINAAAGVLMAISPTYTWMLIFRLIQGLVSKAGWLIGYILITEFVGRRYRRTVGIFYQVAYTVGLLVLAGVAYALPHWRWLQFTVSLPNFFFLLYYWCIPESPRWLISQNKNAEAMRIIKHIAKKNGKSLPASLQRLRLEEETGKKLNPSFLDLVRTPQIRKHTMILMYNWFTSSVLYQGLIMHMGLAGDNIYLDFFYSALVEFPAAFMIILTIDRIGRRYPWAASNMVAGAACLASVFIPGDLQWLKIIISCLGRMGITMAYEIVCLVNAELYPTFIRNLGVHICSSMCDIGGIITPFLVYRLTNIWLELPLMVFGVLGLVAGGLVLLLPETKGKALPETIEEAENMQRPRKNKEKMIYLQVQKLDIPLN>sp|O15244-2|S22A2_HUMAN Isoform 2 of Solute carrier family 22 member 2OS=Homo sapiens OX=9606 GN=SLC22A2MPTTVDDVLEHGGEFHFFQKQMFFLLALLSATFAPIYVGIVFLGFTPDHRCRSPGVAELSLRCGWSPAEELNYTVPGPGPAGEASPRQCRRYEVDWNQSTFDCVDPLASLDTNRSRLPLGPCRDGWVYETPGSSIVTEFNLVCANSWMLDLFQSSVNVGFFIGSMSIGYIADRFGRKLCLLTTVLINAAAGVLMAISPTYTWMLIFRLIQGLVSKAGWLIGYILITEFVGRRYRRTVGIFYQVAYTVGLLVLAGVAYALPHWRWLQFTVSLPNFFFLLYYWCIPESPRWLISQNKNAEAMRIIKHIAKKNGKSLPASLQRLRLEEETGKKLNPSFLDLVRTPQIRKHTMILMYNWFTSSVLYQGLIMHMGLAGDNIYLDFFYSALVEFPAAFMIILTIDRIGRRYPWAASNMVAGAACLASVFIPGGKFQVKLESYLQDPGERECHGPLIGKPCNLSSKSIWKDKLEGSIWDPSEQIHMASLL>sp|O15244-3|S22A2_HUMAN Isoform 3 of Solute carrier family 22 member 2OS=Homo sapiens OX=9606 GN=SLC22A2MPTTVDDVLEHGGEFHFFQKQMFFLLALLSATFAPIYVGIVFLGFTPDHRCRSPGVAELSLRCGWSPAEELNYTVPGPGPAGEASPRQCRRYEVDWNQSTFDCVDPLASLDTNRSRLPLGPCRDGWVYETPGSSIVTEFNLVCANSWMLDLFQSSVNVGFFIGSMSIGYIADRFGRKLCLLTTVLINAAAGVLMAISPTYTWMLIFRLIQGLVSKAGWLIGYILSKNVCACNCENKATSLPK>sp|O75751|S22A3_HUMAN Solute carrier family 22 member 3 OS=Homo sapiensOX=9606 GN=SLC22A3 PE=1 SV=1MPSFDEALQRVGEFGRFQRRVFLLLCLTGVTFAFLFVGVVFLGTQPDHYWCRGPSAAALAERCGWSPEEEWNRTAPASRGPEPPERRGRCQRYLLEAANDSASATSALSCADPLAAFPNRSAPLVPCRGGWRYAQAHSTIVSEFDLVCVNAWMLDLTQAILNLGFLTGAFTLGYAADRYGRIVIYLLSCLGVGVTGVVVAFAPNFPVFVIFRFLQGVFGKGTWMTCYVIVTEIVGSKQRRIVGIVIQMFFTLGIIILPGIAYFIPNWQGIQLAITLPSFLFLLYYWVVPESPRWLITRKKGDKALQILRRIAKCNGKYLSSNYSEITVTDEEVSNPSFLDLVRTPQMRKCTLILMFAWFTSAVVYQGLVMRLGIIGGNLYIDFFISGVVELPGALLILLTIERLGRRLPFAASNIVAGVACLVTAFLPEGIAWLRTTVATLGRLGITMAFEIVYLVNSELYPTTLRNFGVSLCSGLCDFGGIIAPFLLFRLAAVWLELPLIIFGILASICGGLVMLLPETKGIALPETVDDVEKLGSPHSCKCGRNKKTPVSRSHL>sp|Q9H015|S22A4_HUMAN Solute carrier family 22 member 4 OS=Homo sapiensOX=9606 GN=SLC22A4 PE=1 SV=3MRDYDEVIAFLGEWGPFQRLIFFLLSASIIPNGFNGMSVVFLAGTPEHRCRVPDAANLSSAWRNNSVPLRLRDGREVPHSCSRYRLATIANFSALGLEPGRDVDLGQLEQESCLDGWEFSQDVYLSTVVTEWNLVCEDNWKVPLTTSLFFVGVLLGSFVSGQLSDRFGRKNVLFATMAVQTGFSFLQIFSISWEMFTVLFVIVGMGQISNYVVAFILGTEILGKSVRIIFSTLGVCTFFAVGYMLLPLFAYFIRDWRMLLLALTVPGVLCVPLWWFIPESPRWLISQRRFREAEDIIQKAAKMNNIAVPAVIFDSVEELNPLKQQKAFILDLFRTRNIAIMTIMSLLLWMLTSVGYFALSLDAPNLHGDAYLNCFLSALIEIPAYITAWLLLRTLPRRYIIAAVLFWGGGVLLFIQLVPVDYYFLSIGLVMLGKFGITSAFSMLYVFTAELYPTLVRNMAVGVTSTASRVGSIIAPYFVYLGAYNRMLPYIVMGSLTVLIGILTLFFPESLGMTLPETLEQMQKVKWFRSGKKTRDSMETEENPKVLITAF>sp|O76082|S22A5_HUMAN Solute carrier family 22 member 5 OS=Homo sapiensOX=9606 GN=SLC22A5 PE=1 SV=1MRDYDEVTAFLGEWGPFQRLIFFLLSASIIPNGFTGLSSVFLIATPEHRCRVPDAANLSSAWRNHTVPLRLRDGREVPHSCRRYRLATIANFSALGLEPGRDVDLGQLEQESCLDGWEFSQDVYLSTIVTEWNLVCEDDWKAPLTISLFFVGVLLGSFISGQLSDRFGRKNVLFVTMGMQTGFSFLQIFSKNFEMFVVLFVLVGMGQISNYVAAFVLGTEILGKSVRIIFSTLGVCIFYAFGYMVLPLFAYFIRDWRMLLVALTMPGVLCVALWWFIPESPRWLISQGRFEEAEVIIRKAAKANGIVVPSTIFDPSELQDLSSKKQQSHNILDLLRTWNIRMVTIMSIMLWMTISVGYFGLSLDTPNLHGDIFVNCFLSAMVEVPAYVLAWLLLQYLPRRYSMATALFLGGSVLLFMQLVPPDLYYLATVLVMVGKFGVTAAFSMVYVYTAELYPTVVRNMGVGVSSTASRLGSILSPYFVYLGAYDRFLPYILMGSLTILTAILTLFLPESFGTPLPDTIDQMLRVKGMKHRKTPSHTRMLKDGQERPTILKSTAF>sp|O76082-2|S22A5_HUMAN Isoform 2 of Solute carrier family 22 member 5OS=Homo sapiens OX=9606 GN=SLC22A5MWILLFQLSSALCFRMTISVGYFGLSLDTPNLHGDIFVNCFLSAMVEVPAYVLAWLLLQYLPRRYSMATALFLGGSVLLFMQLVPPDLYYLATVLVMVGKFGVTAAFSMVYVYTAELYPTVVRNMGVGVSSTASRLGSILSPYFVYLGAYDRFLPYILMGSLTILTAILTLFLPESFGTPLPDTIDQMLRVKGMKHRKTPSHTRMLKDGQERPTILKSTAF>sp|O76082-3|S22A5_HUMAN Isoform 3 of Solute carrier family 22 member 5OS=Homo sapiens OX=9606 GN=SLC22A5MRDYDEVTAFLGEWGPFQRLIFFLLSASIIPNGFTGLSSVFLIATPEHRCRVPDAANLSSAWRNHTVPLRLRDGREVPHSCRRYRLATIANFSALGLEPGRDVDLGQLEQESCLDGWEFSQDVYLSTIVTEQDSGAYNAMKNRMGKKPALCLPAQWNLVCEDDWKAPLTISLFFVGVLLGSFISGQLSDRFGRKNVLFVTMGMQTGFSFLQIFSKNFEMFVVLFVLVGMGQISNYVAAFVLGTEILGKSVRIIFSTLGVCIFYAFGYMVLPLFAYFIRDWRMLLVALTMPGVLCVALWWFIPESPRWLISQGRFEEAEVIIRKAAKANGIVVPSTIFDPSELQDLSSKKQQSHNILDLLRTWNIRMVTIMSIMLWMTISVGYFGLSLDTPNLHGDIFVNCFLSAMVEVPAYVLAWLLLQYLPRRYSMATALFLGGSVLLFMQLVPPDLYYLATVLVMVGKFGVTAAFSMVYVYTAELYPTVVRNMGVGVSSTASRLGSILSPYFVYLGAYDRFLPYILMGSLTILTAILTLFLPESFGTPLPDTIDQMLRVKGMKHRKTPSHTRMLKDGQERPTILKSTAF>sp|Q4U2R8|S22A6_HUMAN Solute carrier family 22 member 6 OS=Homo sapiensOX=9606 GN=SLC22A6 PE=1 SV=1MAFNDLLQQVGGVGRFQQIQVTLVVLPLLLMASHNTLQNFTAAIPTHHCRPPADANLSKNGGLEVWLPRDRQGQPESCLRFTSPQWGLPFLNGTEANGTGATEPCTDGWIYDNSTFPSTIVTEWDLVCSHRALRQLAQSLYMVGVLLGAMVFGYLADRLGRRKVLILNYLQTAVSGTCAAFAPNFPIYCAFRLLSGMALAGISLNCMTLNVEWMPIHTRACVGTLIGYVYSLGQFLLAGVAYAVPHWRHLQLLVSAPFFAFFIYSWFFIESARWHSSSGRLDLTLRALQRVARINGKREEGAKLSMEVLRASLQKELTMGKGQASAMELLRCPTLRHLFLCLSMLWFATSFAYYGLVMDLQGFGVSIYLIQVIFGAVDLPAKLVGFLVINSLGRRPAQMAALLLAGICILLNGVIPQDQSIVRTSLAVLGKGCLAASFNCIFLYTGELYPTMIRQTGMGMGSTMARVGSIVSPLVSMTAELYPSMPLFIYGAVPVAASAVTVLLPETLGQPLPDTVQDLESRWAPTQKEAGIYPRKGKQTRQQQEHQKYMVPLQASAQEKNGL>sp|Q4U2R8-2|S22A6_HUMAN Isoform 2 of Solute carrier family 22 member 6OS=Homo sapiens OX=9606 GN=SLC22A6MAFNDLLQQVGGVGRFQQIQVTLVVLPLLLMASHNTLQNFTAAIPTHHCRPPADANLSKNGGLEVWLPRDRQGQPESCLRFTSPQWGLPFLNGTEANGTGATEPCTDGWIYDNSTFPSTIVTEWDLVCSHRALRQLAQSLYMVGVLLGAMVFGYLADRLGRRKVLILNYLQTAVSGTCAAFAPNFPIYCAFRLLSGMALAGISLNCMTLNVEWMPIHTRACVGTLIGYVYSLGQFLLAGVAYAVPHWRHLQLLVSAPFFAFFIYSWFFIESARWHSSSGRLDLTLRALQRVARINGKREEGAKLSMEVLRASLQKELTMGKGQASAMELLRCPTLRHLFLCLSMLWFATSFAYYGLVMDLQGFGVSIYLIQVIFGAVDLPAKLVGFLVINSLGRRPAQMAALLLAGICILLNGVIPQDQSIVRTSLAVLGKGCLAASFNCIFLYTGELYPTMIRQTGMGMGSTMARVGSIVSPLVSMTAELYPSMPLFIYGAVPVAASAVTVLLPETLGQPLPDTVQDLESRKGKQTRQQQEHQKYMVPLQASAQEKNGL>sp|Q4U2R8-3|S22A6_HUMAN Isoform 3 of Solute carrier family 22 member 6OS=Homo sapiens OX=9606 GN=SLC22A6MAFNDLLQQVGGVGRFQQIQVTLVVLPLLLMASHNTLQNFTAAIPTHHCRPPADANLSKNGGLEVWLPRDRQGQPESCLRFTSPQWGLPFLNGTEANGTGATEPCTDGWIYDNSTFPSTIVTEWDLVCSHRALRQLAQSLYMVGVLLGAMVFGYLADRLGRRKVLILNYLQTAVSGTCAAFAPNFPIYCAFRLLSGMALAGISLNCMTLNVEWMPIHTRACVGTLIGYVYSLGQFLLAGVAYAVPHWRHLQLLVSAPFFAFFIYSWFFIESARWHSSSGRLDLTLRALQRVARINGKREEGAKLSMEVLRASLQKELTMGKGQASAMELLRCPTLRHLFLCLSMLWFATSFAYYGLVMDLQGFGVSIYLIQVIFGAVDLPAKLVGFLVINSLGRRPAQMAALLLAGICILLNGVIPQDQSIVRTSLAVLGKGCLAASFNCIFLYTGELYPTMIRAVTVLLPETLGQPLPDTVQDLESRKGKQTRQQQEHQKYMVPLQASAQEKNGL>sp|Q4U2R8-4|S22A6_HUMAN Isoform 4 of Solute carrier family 22 member 6OS=Homo sapiens OX=9606 GN=SLC22A6MAFNDLLQQVGGVGRFQQIQVTLVVLPLLLMASHNTLQNFTAAIPTHHCRPPADANLSKNGGLEVWLPRDRQGQPESCLRFTSPQWGLPFLNGTEANGTGATEPCTDGWIYDNSTFPSTIVTEWDLVCSHRALRQLAQSLYMVGVLLGAMVFGYLADRLGRRKVLILNYLQTAVSGTCAAFAPNFPIYCAFRLLSGMALAGISLNCMTLNVEWMPIHTRACVGTLIGYVYSLGQFLLAGVAYAVPHWRHLQLLVSAPFFAFFIYSWFFIESARWHSSSGRLDLTLRALQRVARINGKREEGAKLSMEVLRASLQKELTMGKGQASAMELLRCPTLRHLFLCLSMLWFATSFAYYGLVMDLQGFGVSIYLIQVIFGAVDLPAKLVGFLVINSLGRRPAQMAALLLAGICILLNGVIPQDQSIVRTSLAVLGKGCLAASFNCIFLYTGELYPTMIRAVTVLLPETLGQPLPDTVQDLESRWAPTQKEAGIYPRKGKQTRQQQEHQKYMVPLQASAQEKNGL>sp|Q9Y694|S22A7_HUMAN Solute carrier family 22 member 7 OS=Homo sapiensOX=9606 GN=SLC22A7 PE=1 SV=1MGFEELLEQVGGFGPFQLRNVALLALPRVLLPLHFLLPIFLAAVPAHRCALPGAPANFSHQDVWLEAHLPREPDGTLSSCLRFAYPQALPNTTLGEERQSRGELEDEPATVPCSQGWEYDHSEFSSTIATESQWDLVCEQKGLNRAASTFFFAGVLVGAVAFGYLSDRFGRRRLLLVAYVSTLVLGLASAASVSYVMFAITRTLTGSALAGFTIIVMPLELEWLDVEHRTVAGVLSSTFWTGGVMLLALVGYLIRDWRWLLLAVTLPCAPGILSLWWVPESARWLLTQGHVKEAHRYLLHCARLNGRPVCEDSFSQEAVSKVAAGERVVRRPSYLDLFRTPRLRHISLCCVVVWFGVNFSYYGLSLDVSGLGLNVYQTQLLFGAVELPSKLLVYLSVRYAGRRLTQAGTLLGTALAFGTRLLVSSDMKSWSTVLAVMGKAFSEAAFTTAYLFTSELYPTVLRQTGMGLTALVGRLGGSLAPLAALLDGVWLSLPKLTYGGIALLAAGTALLLPETRQAQLPETIQDVERKSAPTSLQEEEMPMKQVQN>sp|Q9Y694-2|S22A7_HUMAN Isoform 2 of Solute carrier family 22 member 7OS=Homo sapiens OX=9606 GN=SLC22A7MGFEELLEQVGGFGPFQLRNVALLALPRVLLPLHFLLPIFLAAVPAHRCALPGAPANFSHQDVWLEAHLPREPDGTLSSCLRFAYPQALPNTTLGEERQSRGELEDEPATVPCSQGWEYDHSEFSSTIATEWDLVCEQKGLNRAASTFFFAGVLVGAVAFGYLSDRFGRRRLLLVAYVSTLVLGLASAASVSYVMFAITRTLTGSALAGFTIIVMPLELEWLDVEHRTVAGVLSSTFWTGGVMLLALVGYLIRDWRWLLLAVTLPCAPGILSLWWVPESARWLLTQGHVKEAHRYLLHCARLNGRPVCEDSFSQEAVSKVAAGERVVRRPSYLDLFRTPRLRHISLCCVVVWFGVNFSYYGLSLDVSGLGLNVYQTQLLFGAVELPSKLLVYLSVRYAGRRLTQAGTLLGTALAFGTRLLVSSDMKSWSTVLAVMGKAFSEAAFTTAYLFTSELYPTVLRQTGMGLTALVGRLGGSLAPLAALLDGVWLSLPKLTYGGIALLAAGTALLLPETRQAQLPETIQDVERKSAPTSLQEEEMPMKQVQN>sp|Q9Y694-3|S22A7_HUMAN Isoform 3 of Solute carrier family 22 member 7OS=Homo sapiens OX=9606 GN=SLC22A7MGFEELLEQVGGFGPFQLRNVALLALPRVLLPLHFLLPIFLAAVPAHRCALPGAPANFSHQDVWLEAHLPREPDGTLSSCLRFAYPQALPNTTLGEERQSRGELEDEPATVPCSQGWEYDHSEFSSTIATEWDLVCEQKGLNRAASTFFFAGVLVGAVAFGYLSDRFGRRRLLLVAYVSTLVLGLASAASVSYVMFAITRTLTGSALAGFTIIVMPLELEWLDVEHRTVAGVLSSTFWTGGVMLLALVGYLIRDWRWLLLAVTLPCAPGILSLWWVPESARWLLTQGHVKEAHRYLLHCARLNGRPVCEDSFSQEAVSKVAAGERVVRRPSYLDLFRTPRLRHISLCCVVVWFGVNFSYYGLSLDVSGLGLNVYQTQLLFGAVELPSKLLVYLSVRYAGRRLTQAGTLLGTALAFGTRLLVSSDMKSWSTVLAVMGKAFSEAAFTTAYLFTSELYPTVLRQTGMGLTALVGRLGGSLAPLAALLDGVWLSLPKLTYGGIALLAAGTALLLPETRQAQLPETIQDVERKRCVHRTVSVYV>sp|Q9Y694-4|S22A7_HUMAN Isoform 4 of Solute carrier family 22 member 7OS=Homo sapiens OX=9606 GN=SLC22A7MLQPHLLPYQAVSKVAAGERVVRRPSYLDLFRTPRLRHISLCCVVVWFGVNFSYYGLSLDVSGLGLNVYQTQLLFGAVELPSKLLVYLSVRYAGRRLTQAGTLLGTALAFGTRLLVSSDMKSWSTVLAVMGKAFSEAAFTTAYLFTSELYPTVLRQTGMGLTALVGRLGGSLAPLAALLDGVWLSLPKLTYGGIALLAAGTALLLPETRQAQLPETIQDVERKSAPTSLQEEEMPMKQVQN>sp|Q8TCC7|S22A8_HUMAN Solute carrier family 22 member 8 OS=Homo sapiensOX=9606 GN=SLC22A8 PE=1 SV=1MTFSEILDRVGSMGHFQFLHVAILGLPILNMANHNLLQIFTAATPVHHCRPPHNASTGPWVLPMGPNGKPERCLRFVHPPNASLPNDTQRAMEPCLDGWVYNSTKDSIVTEWDLVCNSNKLKEMAQSIFMAGILIGGLVLGDLSDRFGRRPILTCSYLLLAASGSGAAFSPTFPIYMVFRFLCGFGISGITLSTVILNVEWVPTRMRAIMSTALGYCYTFGQFILPGLAYAIPQWRWLQLTVSIPFFVFFLSSWWTPESIRWLVLSGKSSKALKILRRVAVFNGKKEEGERLSLEELKLNLQKEISLAKAKYTASDLFRIPMLRRMTFCLSLAWFATGFAYYSLAMGVEEFGVNLYILQIIFGGVDVPAKFITILSLSYLGRHTTQAAALLLAGGAILALTFVPLDLQTVRTVLAVFGKGCLSSSFSCLFLYTSELYPTVIRQTGMGVSNLWTRVGSMVSPLVKITGEVQPFIPNIIYGITALLGGSAALFLPETLNQPLPETIEDLENWSLRAKKPKQEPEVEKASQRIPLQPHGPGLGSS>sp|Q8TCC7-2|S22A8_HUMAN Isoform 2 of Solute carrier family 22 member 8OS=Homo sapiens OX=9606 GN=SLC22A8MTFSEILDRVGSMGHFQFLHVAILGLPILNMANHNLLQIFTAATPVHHCRPPHNASTGPWVLPMGPNGKPERCLRFVHPPNASLPNDTQRAMEPCLDGWVYNSTKDSIVTEWDLVCNSNKLKEMAQSIFMAGILIGGLVLGDLSDRFGRRPILTCSYLLLAASGSGAAFSPTFPIYMVFRFLCGFGISGITLSTVILNVEWVPTRMRAIMSTALGYCYTFGQFILPGLAYAIPQWRWLQLTVSIPFFVFFLSSWWTPESIRWLVLSGKSSKALKILRRVAVFNGKKEEGERLSLEELKLNLQKEISLAKAKYTASDLFRIPMLRRMTFCLSLAWFATGFAYYSLAMGVEEFGVNLYILQIIFGGVDVPAKFITILSLSYLGRHTTQAAALLLAGGAILALTFVPLDLQTVRTVLAVFGKGCLSSSFSCLFLYTSELYPTVIRQTGMGVSNLWTRVGSMVSPLVKITGEVQPFIPNIIYGITALLGGSAALFLPETLNQPLPETIEDLENWSVTASGPPRSLRAKKPKQEPEVEKASQRIPLQPHGPGLGSS>sp|Q8TCC7-5|S22A8_HUMAN Isoform 5 of Solute carrier family 22 member 8OS=Homo sapiens OX=9606 GN=SLC22A8MAQSIFMAGILIGGLVLGDLSDRFGRRPILTCSYLLLAASGSGAAFSPTFPIYMVFRFLCGFGISGITLSTVILNVEWVPTRMRAIMSTALGYCYTFGQFILPGLAYAIPQWRWLQLTVSIPFFVFFLSSWWTPESIRWLVLSGKSSKALKILRRVAVFNGKKEEGERLSLEELKLNLQKEISLAKAKYTASDLFRIPMLRRMTFCLSLAWFATGFAYYSLAMGVEEFGVNLYILQIIFGGVDVPAKFITILSLSYLGRHTTQAAALLLAGGAILALTFVPLDLQTVRTVLAVFGKGCLSSSFSCLFLYTSELYPTVIRQTGMGVSNLWTRVGSMVSPLVKITGEVQPFIPNIIYGITALLGGSAALFLPETLNQPLPETIEDLENWSLRAKKPKQEPEVEKASQRIPLQPHGPGLGSS>sp|Q8TCC7-3|S22A8_HUMAN Isoform 3 of Solute carrier family 22 member 8OS=Homo sapiens OX=9606 GN=SLC22A8MGVEEFGVNLYILQIIFGGVDVPAKFITILSLSYLGRHTTQAAALLLAGGAILALTFVPLGERLGLPQNPLEEAARLGARDFTAGSASKSLCYLEQVPALSGAQGLSSRK>sp|Q8TCC7-4|S22A8_HUMAN Isoform 4 of Solute carrier family 22 member 8OS=Homo sapiens OX=9606 GN=SLC22A8MEPCLDGWVYNSTKDSIVTEWDLVCNSNKLKEMAQSIFMAGILIGGLVLGDLSDRFGRRPILTCSYLLLAASGSGAAFSPTFPIYMVFRFLCGFGISGITLSTVILNVEWVPTRMRAIMSTALGYCYTFGQFILPGLAYAIPQWRWLQLTVSIPFFVFFLSSWWTPESIRWLVLSGKSSKALKILRRVAVFNGKKEEGERLSLEELKLNLQKEISLAKAKYTASDLFRIPMLRRMTFCLSLAWFATGFAYYSLAMGVEEFGVNLYILQIIFGGVDVPAKFITILSLSYLGRHTTQAAALLLAGGAILALTFVPLDLQTVRTVLAVFGKGCLSSSFSCLFLYTSELYPTVIRQTGMGVSNLWTRVGSMVSPLVKITGEVQPFIPNIIYGITALLGGSAALFLPETLNQPLPETIEDLENWSLRAKKPKQEPEVEKASQRIPLQPHGPGLGSS>sp|Q9Y2B1|RXLT1_HUMAN Ribitol-5-phosphate xylosyltransferase 1 OS=Homosapiens OX=9606 GN=RXYLT1 PE=1 SV=1MRLTRKRLCSFLIALYCLFSLYAAYHVFFGRRRQAPAGSPRGLRKGAAPARERRGREQSTLESEEWNPWEGDEKNEQQHRFKTSLQILDKSTKGKTDLSVQIWGKAAIGLYLWEHIFEGLLDPSDVTAQWREGKSIVGRTQYSFITGPAVIPGYFSVDVNNVVLILNGREKAKIFYATQWLLYAQNLVQIQKLQHLAVVLLGNEHCDNEWINPFLKRNGGFVELLFIIYDSPWINDVDVFQWPLGVATYRNFPVVEASWSMLHDERPYLCNFLGTIYENSSRQALMNILKKDGNDKLCWVSAREHWQPQETNESLKNYQDALLQSDLTLCPVGVNTECYRIYEACSYGSIPVVEDVMTAGNCGNTSVHHGAPLQLLKSMGAPFIFIKNWKELPAVLEKEKTIILQEKIERRKMLLQWYQHFKTELKMKFTNILESSFLMNNKS>sp|Q8IVM8|S22A9_HUMAN Solute carrier family 22 member 9 OS=Homo sapiensOX=9606 GN=SLC22A9 PE=1 SV=1MAFQDLLGHAGDLWRFQILQTVFLSIFAVATYLHFMLENFTAFIPGHRCWVHILDNDTVSDNDTGALSQDALLRISIPLDSNMRPEKCRRFVHPQWQLLHLNGTFPNTSDADMEPCVDGWVYDRISFSSTIVTEWDLVCDSQSLTSVAKFVFMAGMMVGGILGGHLSDRFGRRFVLRWCYLQVAIVGTCAALAPTFLIYCSLRFLSGIAAMSLITNTIMLIAEWATHRFQAMGITLGMCPSGIAFMTLAGLAFAIRDWHILQLVVSVPYFVIFLTSSWLLESARWLIINNKPEEGLKELRKAAHRSGMKNARDTLTLEILKSTMKKELEAAQKKKPSLCEMLHMPNICKRISLLSFTRFANFMAYFGLNLHVQHLGNNVFLLQTLFGAVILLANCVAPWALKYMNRRASQMLLMFLLAICLLAIIFVPQEMQTLREVLATLGLGASALANTLAFAHGNEVIPTIIRARAMGINATFANIAGALAPLMMILSVYSPPLPWIIYGVFPFISGFAFLLLPETRNKPLFDTIQDEKNERKDPREPKQEDPRVEVTQF>sp|Q8IVM8-2|S22A9_HUMAN Isoform 2 of Solute carrier family 22 member 9OS=Homo sapiens OX=9606 GN=SLC22A9MAFQDLLGHAGDLWRFQILQTVFLSIFAVATYLHFMLENFTAFIPGHRCWVHILDNDTVSDNDTGALSQDALLRISIPLDSNMRPEKCRRFVHPQWQLLHLNGTFPNTSDADMEPCVDGWVYDRISFSSTIVTEWDLVCDSQSLTSVAKFVFMAGMMVGGILGGHLSDSSRVGNTQIPGHGNYIGNVPFWYCIYDPGRPGFCHSRLAYPPAGGVCTILCDLSDLKLAARVCSVAHYQQ>sp|Q63ZE4|S22AA_HUMAN Solute carrier family 22 member 10 OS=Homo sapiensOX=9606 GN=SLC22A10 PE=2 SV=2MAFEELLSQVGGLGRFQMLHLVFILPSLMLLIPHILLENFAAAIPGHRCWVHMLDNNTGSGNETGILSEDALLRISIPLDSNLRPEKCRRFVHPQWQLLHLNGTIHSTSEADTEPCVDGWVYDQSYFPSTIVTKWDLVCDYQSLKSVVQFLLLTGMLVGGIIGGHVSDRFGRRFILRWCLLQLAITDTCAAFAPTFPVYCVLRFLAGFSSMIIISNNSLPITEWIRPNSKALVVILSSGALSIGQIILGGLAYVFRDWQTLHVVASVPFFVFFLLSRWLVESARWLIITNKLDEGLKALRKVARTNGIKNAEETLNIEVVRSTMQEELDAAQTKTTVCDLFRNPSMRKRICILVFLRFANTIPFYGTMVNLQHVGSNIFLLQVLYGAVALIVRCLALLTLNHMGRRISQILFMFLVGLSILANTFVPKEMQTLRVALACLGIGCSAATFSSVAVHFIELIPTVLRARASGIDLTASRIGAALAPLLMTLTVFFTTLPWIIYGIFPIIGGLIVFLLPETKNLPLPDTIKDVENQKKNLKEKA>sp|Q63ZE4-2|S22AA_HUMAN Isoform 2 of Solute carrier family 22 member 10OS=Homo sapiens OX=9606 GN=SLC22A10MLVGGIIGGHVSDRFGRRFILRWCLLQLAITDTCAAFAPTFPVYCVLRFLAGFSSMIIISNNSLPITEWIRPNSKALVVILSSGALSIGQIILGGLAYVFRDWQTLHVVASVPFFVFFLLSRWLVESARWLIITNKLDEGLKALRKVARTNGIKNAEETLNIEVVRSTMQEELDAAQTKTTVCDLFRNPSMRKRICILVFLRFANTIPFYGTMVNLQHVGSNIFLLQKCRPCVWLWHVWESAVLLLLFPVLLFTSLNSSPLFSGQELQE>sp|Q9NSA0|S22AB_HUMAN Solute carrier family 22 member 11 OS=Homo sapiensOX=9606 GN=SLC22A11 PE=1 SV=1MAFSKLLEQAGGVGLFQTLQVLTFILPCLMIPSQMLLENFSAAIPGHRCWTHMLDNGSAVSTNMTPKALLTISIPPGPNQGPHQCRRFRQPQWQLLDPNATATSWSEADTEPCVDGWVYDRSVFTSTIVAKWDLVCSSQGLKPLSQSIFMSGILVGSFIWGLLSYRFGRKPMLSWCCLQLAVAGTSTIFAPTFVIYCGLRFVAAFGMAGIFLSSLTLMVEWTTTSRRAVTMTVVGCAFSAGQAALGGLAFALRDWRTLQLAASVPFFAISLISWWLPESARWLIIKGKPDQALQELRKVARINGHKEAKNLTIEVLMSSVKEEVASAKEPRSVLDLFCVPVLRWRSCAMLVVNFSLLISYYGLVFDLQSLGRDIFLLQALFGAVDFLGRATTALLLSFLGRRTIQAGSQAMAGLAILANMLVPQDLQTLRVVFAVLGKGCFGISLTCLTIYKAELFPTPVRMTADGILHTVGRLGAMMGPLILMSRQALPLLPPLLYGVISIASSLVVLFFLPETQGLPLPDTIQDLESQKSTAAQGNRQEAVTVESTSL>sp|Q9NSA0-2|S22AB_HUMAN Isoform 2 of Solute carrier family 22 member 11OS=Homo sapiens OX=9606 GN=SLC22A11MAFSKLLEQAGGVGLFQTLQVLTFILPCLMIPSQMLLENFSAAIPGHRCWTHMLDNGSAVSTNMTPKALLTISIPPGPNQGPHQCRRFRQPQWQLLDPNATATSWSEADTEPCVDGWVYDRSVFTSTIVAKWDLVCSSQGLKPLSQSIFMSGILVGSFIWGLLSYRFGRKPMLSWCCLQLAVAGTSTIFAPTFVIYCGLRFVAAFGMAGIFLSSLTLMVEWTTTSRRAVTMTVVGCAFSAGQAALGGLAFALRDWRTLQLAASVPFFAISLISWWLPESARWLIIKGKPDQALQELRKVARINGHKEAKNLTIEVLMSSVKEEVASAKEPRSVLDLFCVPVLRWRSCAMLVVKMTADGILHTVGRLGAMMGPLILMSRQALPLLPPLLYGVISIASSLVVLFFLPETQGLPLPDTIQDLESQKSTAAQGNRQEAVTVESTSL>sp|Q96S37|S22AC_HUMAN Solute carrier family 22 member 12 OS=Homo sapiensOX=9606 GN=SLC22A12 PE=1 SV=1MAFSELLDLVGGLGRFQVLQTMALMVSIMWLCTQSMLENFSAAVPSHRCWAPLLDNSTAQASILGSLSPEALLAISIPPGPNQRPHQCRRFRQPQWQLLDPNATATSWSEADTEPCVDGWVYDRSIFTSTIVAKWNLVCDSHALKPMAQSIYLAGILVGAAACGPASDRFGRRLVLTWSYLQMAVMGTAAAFAPAFPVYCLFRFLLAFAVAGVMMNTGTLLMEWTAARARPLVMTLNSLGFSFGHGLTAAVAYGVRDWTLLQLVVSVPFFLCFLYSWWLAESARWLLTTGRLDWGLQELWRVAAINGKGAVQDTLTPEVLLSAMREELSMGQPPASLGTLLRMPGLRFRTCISTLCWFAFGFTFFGLALDLQALGSNIFLLQMFIGVVDIPAKMGALLLLSHLGRRPTLAASLLLAGLCILANTLVPHEMGALRSALAVLGLGGVGAAFTCITIYSSELFPTVLRMTAVGLGQMAARGGAILGPLVRLLGVHGPWLPLLVYGTVPVLSGLAALLLPETQSLPLPDTIQDVQNQAVKKATHGTLGNSVLKSTQF>sp|Q96S37-2|S22AC_HUMAN Isoform 2 of Solute carrier family 22 member 12OS=Homo sapiens OX=9606 GN=SLC22A12MAFSELLDLVGGLGRFQVLQTMALMVSIMWLCTQSMLENFSAAVPSHRCWAPLLDNSTAQASILGSLSPEALLAISIPPGPNQRPHQCRRFRQPQWQLLDPNATATSWSEADTEPCVDGWVYDRSIFTSTIVAKWNLVCDSHALKPMAQSIYLAGILVGAAACGPASDRWLAESARWLLTTGRLDWGLQELWRVAAINGKGAVQDTLTPEVLLSAMREELSMGQPPASLGTLLRMPGLRFRTCISTLCWFAFGFTFFGLALDLQALGSNIFLLQMFIGVVDIPAKMGALLLLSHLGRRPTLAASLLLAGLCILANTLVPHEMGALRSALAVLGLGGVGAAFTCITIYSSELFPTVLRMTAVGLGQMAARGGAILGPLVRLLGVHGPWLPLLVYGTVPVLSGLAALLLPETQSLPLPDTIQDVQNQAVKKATHGTLGNSVLKSTQF>sp|Q96S37-3|S22AC_HUMAN Isoform 3 of Solute carrier family 22 member 12OS=Homo sapiens OX=9606 GN=SLC22A12MEWTAARARPLVMTLNSLGFSFGHGLTAAVAYGVRDWTLLQLVVSVPFFLCFLYSWWLAESARWLLTTGRLDWGLQELWRVAAINGKGAVQDTLTPEVLLSAMREELSMGQPPASLGTLLRMPGLRFRTCISTLCWFAFGFTFFGLALDLQALGSNIFLLQMFIGVVDIPAKMGALLLLSHLGRRPTLAASLLLAGLCILANTLVPHEMGALRSALAVLGLGGVGAAFTCITIYSSELFPTVLRMTAVGLGQMAARGGAILGPLVRLLGVHGPWLPLLVYGTVPVLSGLAALLLPETQSLPLPDTIQDVQNQAVKKATHGTLGNSVLKSTQF>sp|Q96S37-4|S22AC_HUMAN Isoform 4 of Solute carrier family 22 member 12OS=Homo sapiens OX=9606 GN=SLC22A12MAFSELLDLVGGLGRFQVLQTMALMVSIMWLCTQSMLENFSAAVPSHRCWAPLLDNSTAQASILGSLSPEALLAISIPPGPNQRPHQCRRFRQPQWQLLDPNATATSWSEADTEPCVDGWVYDRSIFTSTIVAKWNLVCDSHALKPMAQSIYLAGILVGAAACGPASDRFGRRLVLTWSYLQMAVMVMEWTAARARPLVMTLNSLGFSFGHGLTAAVAYGVRDWTLLQLVVSVPFFLCFLYSWWLAESARWLLTTGRLDWGLQELWRVAAINGKGAVQDTLTPEVLLSAMREELSMGQPPASLGTLLRMPGLRFRTCISTLCWFAFGFTFFGLALDLQALGSNIFLLQMFIGVVDIPAKMGALLLLSHLGRRPTLAASLLLAGLCILANTLVPHEMGALRSALAVLGLGGVGAAFTCITIYSSELFPTVLRMTAVGLGQMAARGGAILGPLVRLLGVHGPWLPLLVYGTVPVLSGLAALLLPETQSLPLPDTIQDVQNQAVKKATHGTLGNSVLKSTQF>sp|Q9Y226|S22AD_HUMAN Solute carrier family 22 member 13 OS=Homo sapiensOX=9606 GN=SLC22A13 PE=2 SV=2MAQFVQVLAEIGDFGRFQIQLLILLCVLNFLSPFYFFAHVFMVLDEPHHCAVAWVKNHTFNLSAAEQLVLSVPLDTAGHPEPCLMFRPPPANASLQDILSHRFNETQPCDMGWEYPENRLPSLKNEFNLVCDRKHLKDTTQSVFMAGLLVGTLMFGPLCDRIGRKATILAQLLLFTLIGLATAFVPSFELYMALRFAVATAVAGLSFSNVTLLTEWVGPSWRTQAVVLAQCNFSLGQMVLAGLAYGFRNWRLLQITGTAPGLLLFFYFWALPESARWLLTRGRMDEAIQLIQKAASVNRRKLSPELMNQLVPEKTGPSGNALDLFRHPQLRKVTLIIFCVWFVDSLGYYGLSLQVGDFGLDVYLTQLIFGAVEVPARCSSIFMMQRFGRKWSQLGTLVLGGLMCIIIIFIPADLPVVVTMLAVVGKMATAAAFTISYVYSAELFPTILRQTGMGLVGIFSRIGGILTPLVILLGEYHAALPMLIYGSLPIVAGLLCTLLPETHGQGLKDTLQDLELGPHPRSPKSVPSEKETEAKGRTSSPGVAFVSSTYF>sp|Q9Y226-2|S22AD_HUMAN Isoform 2 of Solute carrier family 22 member 13OS=Homo sapiens OX=9606 GN=SLC22A13MAQFVQVLAEIGDFGRFQIQLLILLCVLNFLSPFYFFAHVFMVLDEPHHCAVAWVKNHTFNLSAAEQLVLSVPLDTAGHPEPCLMFRPPPANASLQDILSHRFNETQPCDMGWEYPENRLPSLKNEFNLVCDRKHLKDTTQSVFMAGLLVGTLMFGPLCDRIGRKATILAQLLLFTLIGLATAFVPSFELYMALRFAVATAVAGLSFSNVTLLTEWVGPSWRTQAVVLAQCNFSLGQMVLAGLAYGFRNWRLLQITGTAPGLLLFFYFWALPESARWLLTRGRMDEAIQLIQKAASVNRRKLSPELMNQLVPEKTGPSGNALDLFRHPQLRKVTLIIFCVWFVDSLGYYGLSLQVGDFGLDVYLTQLIFGAVEVPARCSSIFMMQRFGRKWSQLGTLVLGGLMCIIIIFIPADLPVVVTMLAVVGKMATAAAFTISYVYSAELFPTILRQAWGWWASSHGSGASSHHL>sp|P19793|RXRA_HUMAN Retinoic acid receptor RXR-alpha OS=Homo sapiensOX=9606 GN=RXRA PE=1 SV=1MDTKHFLPLDFSTQVNSSLTSPTGRGSMAAPSLHPSLGPGIGSPGQLHSPISTLSSPINGMGPPFSVISSPMGPHSMSVPTTPTLGFSTGSPQLSSPMNPVSSSEDIKPPLGLNGVLKVPAHPSGNMASFTKHICAICGDRSSGKHYGVYSCEGCKGFFKRTVRKDLTYTCRDNKDCLIDKRQRNRCQYCRYQKCLAMGMKREAVQEERQRGKDRNENEVESTSSANEDMPVERILEAELAVEPKTETYVEANMGLNPSSPNDPVTNICQAADKQLFTLVEWAKRIPHFSELPLDDQVILLRAGWNELLIASFSHRSIAVKDGILLATGLHVHRNSAHSAGVGAIFDRVLTELVSKMRDMQMDKTELGCLRAIVLFNPDSKGLSNPAEVEALREKVYASLEAYCKHKYPEQPGRFAKLLLRLPALRSIGLKCLEHLFFFKLIGDTPIDTFLMEMLEAPHQMT>sp|P19793-2|RXRA_HUMAN Isoform 2 of Retinoic acid receptor RXR-alphaOS=Homo sapiens OX=9606 GN=RXRAMNPVSSSEDIKPPLGLNGVLKVPAHPSGNMASFTKHICAICGDRSSGKHYGVYSCEGCKGFFKRTVRKDLTYTCRDNKDCLIDKRQRNRCQYCRYQKCLAMGMKREAVQEERQRGKDRNENEVESTSSANEDMPVERILEAELAVEPKTETYVEANMGLNPSSPNDPVTNICQAADKQLFTLVEWAKRIPHFSELPLDDQVILLRAGWNELLIASFSHRSIAVKDGILLATGLHVHRNSAHSAGVGAIFDRVLTELVSKMRDMQMDKTELGCLRAIVLFNPDSKGLSNPAEVEALREKVYASLEAYCKHKYPEQPGRFAKLLLRLPALRSIGLKCLEHLFFFKLIGDTPIDTFLMEMLEAPHQMT>sp|Q9Y267|S22AE_HUMAN Solute carrier family 22 member 14 OS=Homo sapiensOX=9606 GN=SLC22A14 PE=1 SV=4MAGEENFKEELRSQDASRNLNQHEVAGHPHSWSLEMLLRRLRAVHTKQDDKFANLLDAVGEFGTFQQRLVALTFIPSIMSAFFMFADHFVFTAQKPYCNTSWILAVGPHLSKAEQLNLTIPQAPNGSFLTCFMYLPVPWNLDSIIQFGLNDTDTCQDGWIYPDAKKRSLINEFDLVCGMETKKDTAQIMFMAGLPIGSLIFRLITDKMGRYPAILLSLLGLIIFGFGTAFMNSFHLYLFFRFGISQSVVGYAISSISLATEWLVGEHRAHAIILGHCFFAVGAVLLTGIAYSLPHWQLLFLVGGILVIPFISYIWILPESPRWLMMKGKVKEAKQVLCYAASVNKKTIPSNLLDELQLPRKKVTRASVLDFCKNRQLCKVTLVMSCVWFTVSYTYFTLSLRMRELGVSVHFRHVVPSIMEVPARLCCIFLLQQIGRKWSLAVTLLQAIIWCLLLLFLPEGEDGLRLKWPRCPATELKSMTILVLMLREFSLAATVTVFFLYTAELLPTVLRATGLGLVSLASVAGAILSLTIISQTPSLLPIFLCCVLAIVAFSLSSLLPETRDQPLSESLNHSSQIRNKVKDMKTKETSSDDV>sp|P28702|RXRB_HUMAN Retinoic acid receptor RXR-beta OS=Homo sapiensOX=9606 GN=RXRB PE=1 SV=2MSWAARPPFLPQRHAAGQCGPVGVRKEMHCGVASRWRRRRPWLDPAAAAAAAVAGGEQQTPEPEPGEAGRDGMGDSGRDSRSPDSSSPNPLPQGVPPPSPPGPPLPPSTAPSLGGSGAPPPPPMPPPPLGSPFPVISSSMGSPGLPPPAPPGFSGPVSSPQINSTVSLPGGGSGPPEDVKPPVLGVRGLHCPPPPGGPGAGKRLCAICGDRSSGKHYGVYSCEGCKGFFKRTIRKDLTYSCRDNKDCTVDKRQRNRCQYCRYQKCLATGMKREAVQEERQRGKDKDGDGEGAGGAPEEMPVDRILEAELAVEQKSDQGVEGPGGTGGSGSSPNDPVTNICQAADKQLFTLVEWAKRIPHFSSLPLDDQVILLRAGWNELLIASFSHRSIDVRDGILLATGLHVHRNSAHSAGVGAIFDRVLTELVSKMRDMRMDKTELGCLRAIILFNPDAKGLSNPSEVEVLREKVYASLETYCKQKYPEQQGRFAKLLLRLPALRSIGLKCLEHLFFFKLIGDTPIDTFLMEMLEAPHQLA>sp|P28702-3|RXRB_HUMAN Isoform 2 of Retinoic acid receptor RXR-betaOS=Homo sapiens OX=9606 GN=RXRBMSWAARPPFLPQRHAAGQCGPVGVRKEMHCGVASRWRRRRPWLDPAAAAAAAVAGGEQQTPEPEPGEAGRDGMGDSGRDSRSPDSSSPNPLPQGVPPPSPPGPPLPPSTAPSLGGSGAPPPPPMPPPPLGSPFPVISSSMGSPGLPPPAPPGFSGPVSSPQINSTVSLPGGGSGPPEDVKPPVLGVRGLHCPPPPGGPGAGKRLCAICGDRSSGKHYGVYSCEGCKGFFKRTIRKDLTYSCRDNKDCTVDKRQRNRCQYCRYQKCLATGMKREAVQEERQRGKDKDGDGEGAGGAPEEMPVDRILEAELAVEQKSDQGVEGPGGTGGSGSSPNDPVTNICQAADKQLFTLVEWAKRIPHFSSLPLDDQVILLRAGWNELLIASFSHRSIDVRDGILLATGLHVHRNSAHSAGVGAIFDRSLSRVLTELVSKMRDMRMDKTELGCLRAIILFNPDAKGLSNPSEVEVLREKVYASLETYCKQKYPEQQGRFAKLLLRLPALRSIGLKCLEHLFFFKLIGDTPIDTFLMEMLEAPHQLA>sp|Q86VW1|S22AG_HUMAN Solute carrier family 22 member 16 OS=Homo sapiensOX=9606 GN=SLC22A16 PE=1 SV=1MGSRHFEGIYDHVGHFGRFQRVLYFICAFQNISCGIHYLASVFMGVTPHHVCRPPGNVSQVVFHNHSNWSLEDTGALLSSGQKDYVTVQLQNGEIWELSRCSRNKRENTSSLGYEYTGSKKEFPCVDGYIYDQNTWKSTAVTQWNLVCDRKWLAMLIQPLFMFGVLLGSVTFGYFSDRLGRRVVLWATSSSMFLFGIAAAFAVDYYTFMAARFFLAMVASGYLVVGFVYVMEFIGMKSRTWASVHLHSFFAVGTLLVALTGYLVRTWWLYQMILSTVTVPFILCCWVLPETPFWLLSEGRYEEAQKIVDIMAKWNRASSCKLSELLSLDLQGPVSNSPTEVQKHNLSYLFYNWSITKRTLTVWLIWFTGSLGFYSFSLNSVNLGGNEYLNLFLLGVVEIPAYTFVCIAMDKVGRRTVLAYSLFCSALACGVVMVIPQKHYILGVVTAMVGKFAIGAAFGLIYLYTAELYPTIVRSLAVGSGSMVCRLASILAPFSVDLSSIWIFIPQLFVGTMALLSGVLTLKLPETLGKRLATTWEEAAKLESENESKSSKLLLTTNNSGLEKTEAITPRDSGLGE>sp|Q86VW1-2|S22AG_HUMAN Isoform 2 of Solute carrier family 22 member 16OS=Homo sapiens OX=9606 GN=SLC22A16MRTLHAVSHPYSNSMRFQRVLYFICAFQNISCGIHYLASVFMGVTPHHVCRPPGNLQNGEIWELSRCSRNKRENTSSLGYEYTGSKKEFPCVDGYIYDQNTWKSTAVTQWNLVCDRKWLAMLIQPLFMFGVLLGSVTFGYFSDRLGRRVVLWATSSSMFLFGIAAAFAVDYYTFMAARFFLAMVASGYLVVGFVYVMEFIGMKSRTWASVHLHSFFAVGTLLVALTGYLVRTWWLYQMILSTVTVPFILCCWVLPETPFWLLSEGRYEEAQKIVDIMAKWNRASSCKLSELLSLDLQGPVSNSPTEVQKHNLSYLFYNWSITKRTLTVWLIWFTGSLGFYSFSLNSVNLGGNEYLNLFLLGVVEIPAYTFVCIAMDKVGRRTVLAYSLFCSALACGVVMVIPQKHYILGVVTAMVGKFAIGAAFGLIYLYTAELYPTIVRSLAVGSGSMVCRLASILAPFSVDLSSIWIFIPQLFVGTMALLSGVLTLKLPETLGKRLATTWEEAAKLESENESKSSKLLLTTNNSGLEKTEAITPRDSGLGE>sp|Q86VW1-3|S22AG_HUMAN Isoform 3 of Solute carrier family 22 member 16OS=Homo sapiens OX=9606 GN=SLC22A16MGSRHFEGIYDHVGHFGRFQRVLYFICAFQNISCGIHYLASVFMGVTPHHVCRPPGNVSQVVFHNHSNWSLEDTGALLSSGQKDYVTVQLQNGEIWELSRCSRNKRENTSSLGYEYTGSKKEFPCVDGYIYDQNTWKSTAVTQWNLVCDRKWLAMLIQPLFMFGVLLGSVTFGYFSDRLGRRVVLWATSSSMFLFGIAAAFAVDYYTFMAARFFLAMVASGYLVVGFVYVMEFIGMKSRTWASVHLHSFFAVGTLLVALTGYLVRTWWLYQMILSTVTVPFILCCWVLPETPFWLLSEGRYEEAQKIVDIMAKWNRASSCKLSELLSLDLQGPVSNSPTEVQKHNLSYLFYNWSITKRTLTVWLIWFTGSLGFYSFSLNSVNLGGNEYLNLFLLGVVEIPAYTFVCIAMDKVGRRTVLAYSLFCSALACGVVMVIPQKHYILGVVTAMVGKFAIGAAFGLIYLYTAELYPTIVRSLAVGSGSMVCRLASILAPFSVDLSSIWIFIPQLLGQHLQE>sp|Q9Y265|RUVB1_HUMAN RuvB-like 1 OS=Homo sapiens OX=9606 GN=RUVBL1 PE=1SV=1MKIEEVKSTTKTQRIASHSHVKGLGLDESGLAKQAASGLVGQENAREACGVIVELIKSKKMAGRAVLLAGPPGTGKTALALAIAQELGSKVPFCPMVGSEVYSTEIKKTEVLMENFRRAIGLRIKETKEVYEGEVTELTPCETENPMGGYGKTISHVIIGLKTAKGTKQLKLDPSIFESLQKERVEAGDVIYIEANSGAVKRQGRCDTYATEFDLEAEEYVPLPKGDVHKKKEIIQDVTLHDLDVANARPQGGQDILSMMGQLMKPKKTEITDKLRGEINKVVNKYIDQGIAELVPGVLFVDEVHMLDIECFTYLHRALESSIAPIVIFASNRGNCVIRGTEDITSPHGIPLDLLDRVMIIRTMLYTPQEMKQIIKIRAQTEGINISEEALNHLGEIGTKTTLRYSVQLLTPANLLAKINGKDSIEKEHVEEISELFYDAKSSAKILADQQDKYMK>sp|Q9Y265-2|RUVB1_HUMAN Isoform 2 of RuvB-like 1 OS=Homo sapiens OX=9606GN=RUVBL1MKIEEVKSTTKTQRIASHSHVKGLGLDESGLAKQAASGLVGQENAREACGVIVELIKSKKMAGRAVLLAGPPGTGKTALALAIAQELGSKVPFCPMVGSEVYSTEIKKTEVLMENFRRAIGLRIKETKEVYEGEVTELTPCETENPMGGYGKTISHVIIGLKTAKGTKQLKLDPSIFESLQKERVEAGDVIYIEANSGAVKRQGRCDTYATEFDLEAEEYVPLPKGDVHKKKEIIQDVTLHDLDVANARPQGGQDILSMMGQLMKPKKTEITDKLRGEINKVVNKYIDQGIAELVPGVLFVDEVHMLDIECFTYLHRALESSIAPIVIFASNRGNCVIRGTEDITSPHGIPLDLLDRVMIIRTMLYTPQEMKQVLSAAADPGQLAC>sp|Q9Y2V3|RX_HUMAN Retinal homeobox protein Rx OS=Homo sapiens OX=9606GN=RAX PE=1 SV=2MHLPGCAPAMADGSFSLAGHLLRSPGGSTSRLHSIEAILGFTKDDGILGTFPAERGARGAKERDRRLGARPACPKAPEEGSEPSPPPAPAPAPEYEAPRPYCPKEPGEARPSPGLPVGPATGEAKLSEEEQPKKKHRRNRTTFTTYQLHELERAFEKSHYPDVYSREELAGKVNLPEVRVQVWFQNRRAKWRRQEKLEVSSMKLQDSPLLSFSRSPPSATLSPLGAGPGSGGGPAGGALPLESWLGPPLPGGGATALQSLPGFGPPAQSLPASYTPPPPPPPFLNSPPLGPGLQPLAPPPPSYPCGPGFGDKFPLDEADPRNSSIAALRLKAKEHIQAIGKPWQAL>sp|Q9Y2V3-2|RX_HUMAN Isoform 2 of Retinal homeobox protein Rx OS=Homosapiens OX=9606 GN=RAXMHLPGCAPAMADGSFSLAGHLLRSPGGSTSRLHSIEAILGFTKDDGILGTFPAERGARGAKERDRRLGARPACPKAPEEGSEPSPPPAPAPAPEYEGVVPEPTG>sp|P61587|RND3_HUMAN Rho-related GTP-binding protein RhoE OS=Homosapiens OX=9606 GN=RND3 PE=1 SV=1MKERRASQKLSSKSIMDPNQNVKCKIVVVGDSQCGKTALLHVFAKDCFPENYVPTVFENYTASFEIDTQRIELSLWDTSGSPYYDNVRPLSYPDSDAVLICFDISRPETLDSVLKKWKGEIQEFCPNTKMLLVGCKSDLRTDVSTLVELSNHRQTPVSYDQGANMAKQIGAATYIECSALQSENSVRDIFHVATLACVNKTNKNVKRNKSQRATKRISHMPSRPELSAVATDLRKDKAKSCTVM>sp|Q96ER3|SAAL1_HUMAN Protein SAAL1 OS=Homo sapiens OX=9606 GN=SAAL1PE=1 SV=2MDRNPSPPPPGRDKEEEEEVAGGDCIGSTVYSKHWLFGVLSGLIQIVSPENTKSSSDDEEQLTELDEEMENEICRVWDMSMDEDVALFLQEFNAPDIFMGVLAKSKCPRLREICVGILGNMACFQEICVSISSDKNLGQVLLHCLYDSDPPTLLETSRLLLTCLSQAEVASVWVERIQEHPAIYDSICFIMSSSTNVDLLVKVGEVVDKLFDLDEKLMLEWVRNGAAQPLDQPQEESEEQPVFRLVPCILEAAKQVRSENPEWLDVYMHILQLLTTVDDGIQAIVHCPDTGKDIWNLLFDLVCHEFCQSDDPPIILQEQKTVLASVFSVLSAIYASQTEQEYLKIEKVDLPLIDSLIRVLQNMEQCQKKPENSAESNTEETKRTDLTQDDFHLKILKDILCEFLSNIFQALTKETVAQGVKEGQLSKQKCSSAFQNLLPFYSPVVEDFIKILREVDKALADDLEKNFPSLKVQT>sp|Q96AT9|RPE_HUMAN Ribulose-phosphate 3-epimerase OS=Homo sapiensOX=9606 GN=RPE PE=1 SV=1MASGCKIGPSILNSDLANLGAECLRMLDSGADYLHLDVMDGHFVPNITFGHPVVESLRKQLGQDPFFDMHMMVSKPEQWVKPMAVAGANQYTFHLEATENPGALIKDIRENGMKVGLAIKPGTSVEYLAPWANQIDMALVMTVEPGFGGQKFMEDMMPKVHWLRTQFPSLDIEVDGGVGPDTVHKCAEAGANMIVSGSAIMRSEDPRSVINLLRNVCSEAAQKRSLDR>sp|Q96AT9-2|RPE_HUMAN Isoform 2 of Ribulose-phosphate 3-epimeraseOS=Homo sapiens OX=9606 GN=RPEMASGCKIGPSILNSDLANLGAECLRMLDSGADYLHLDVMDGHMHMMVSKPEQWVKPMAVAGANQYTFHLEATENPGALIKDIRENGMKSCSVTQAEVQWHSQGPLQVGLAIKPGTSVEYLAPWANQIDMALVMTVEPGFGGQKFMEDMMPKVHWLRTQFPSLDIEVDGGVGPDTVHKCAEAGANMIVSGSAIMRSEDPRSVINLLRNVCSEAAQKRSLDR>sp|Q96AT9-3|RPE_HUMAN Isoform 3 of Ribulose-phosphate 3-epimeraseOS=Homo sapiens OX=9606 GN=RPEMHMMVSKPEQWVKPMAVAGANQYTFHLEATENPGALIKDIRENGMKSCSVTQAEVQWHSQGPLQVGLAIKPGTSVEYLAPWANQIDMALVMTVEPGFGGQKFMEDMMPKVHWLRTQFPSLDIEVDGGVGPDTVHKCAEAGANMIVSGSAIMRSEDPRSVINLLRNVCSEAAQKRSLDR>sp|Q96AT9-4|RPE_HUMAN Isoform 4 of Ribulose-phosphate 3-epimeraseOS=Homo sapiens OX=9606 GN=RPEMASGCKIGPSILNSDLANLGAECLRMLDSGADYLHLDVMDGHFVPNITFGHPVVESLRKQLGQDPFFDMHMMVSKPEQWVKPMAVAGANQYTFHLEATENPGALIKDIRENGMKVGLAIKPGTSVEYLAPWANQIDMALVMTVEPGFGGQKFMEDMMPKAGANMIVSGSAIMRSEDPRSVINLLRNVCSEAAQKRSLDR>sp|Q96AT9-5|RPE_HUMAN Isoform 5 of Ribulose-phosphate 3-epimeraseOS=Homo sapiens OX=9606 GN=RPEMHMMVSKPEQWVKPMAVAGANQYTFHLEATENPGALIKDIRENGMKVGLAIKPGTSVEYLAPWANQIDMALVMTVEPGFGGQKFMEDMMPKVHWLRTQFPSLDIEVDGGVGPDTVHKCAEAGANMIVSGSAIMRSEDPRSVINLLRNVCSEAAQKRSLDR>sp|Q9H9A7|RMI1_HUMAN RecQ-mediated genome instability protein 1 OS=Homosapiens OX=9606 GN=RMI1 PE=1 SV=3MNVTSIALRAETWLLAAWHVKVPPMWLEACINWIQEENNNVNLSQAQMNKQVFEQWLLTDLRDLEHPLLPDGILEIPKGELNGFYALQINSLVDVSQPAYSQIQKLRGKNTTNDLVTAEAQVTPKPWEAKPSRMLMLQLTDGIVQIQGMEYQPIPILHSDLPPGTKILIYGNISFRLGVLLLKPENVKVLGGEVDALLEEYAQEKVLARLIGEPDLVVSVIPNNSNENIPRVTDVLDPALGPSDEELLASLDENDELTANNDTSSERCFTTGSSSNTIPTRQSSFEPEFVISPRPKEEPSNLSIHVMDGELDDFSLEEALLLEETVQKEQMETKELQPLTFNRNADRSIERFSHNPNTTNNFSLTCKNGNNNWSEKNVSEQMTNEDKSFGCPSVRDQNRSIFSVHCNVPLAHDFTNKEKNLETDNKIKQTSSSDSHSLNNKILNREVVNYVQKRNSQISNENDCNLQSCSLRSSENSINLSIAMDLYSPPFVYLSVLMASKPKEVTTVKVKAFIVTLTGNLSSSGGIWSITAKVSDGTAYLDVDFVDEILTSLIGFSVPEMKQSKKDPLQYQKFLEGLQKCQRDLIDLCCLMTISFNPSLSKAMVLALQDVNMEHLENLKKRLNK>sp|Q9NWS8|RMND1_HUMAN Required for meiotic nuclear division protein 1homolog OS=Homo sapiens OX=9606 GN=RMND1 PE=1 SV=2MPATLLRAVARSHHILSKAHQCRRIGHLMLKPLKEFENTTCSTLTIRQSLDLFLPDKTASGLNKSQILEMNQKKSDTSMLSPLNAARCQDEKAHLPTMKSFGTHRRVTHKPNLLGSKWFIKILKRHFSSVSTETFVPKQDFPQVKRPLKASRTRQPSRTNLPVLSVNEDLMHCTAFATADEYHLGNLSQDLASHGYVEVTSLPRDAANILVMGVENSAKEGDPGTIFFFREGAAVFWNVKDKTMKHVMKVLEKHEIQPYEIALVHWENEELNYIKIEGQSKLHRGEIKLNSELDLDDAILEKFAFSNALCLSVKLAIWEASLDKFIESIQSIPEALKAGKKVKLSHEEVMQKIGELFALRHRINLSSDFLITPDFYWDRENLEGLYDKTCQFLSIGRRVKVMNEKLQHCMELTDLMRNHLNEKRALRLEWMIVILITIEVMFELGRVFF>sp|Q9NWS8-2|RMND1_HUMAN Isoform 2 of Required for meiotic nucleardivision protein 1 homolog OS=Homo sapiens OX=9606 GN=RMND1MGVENSAKEGDPGTIFFFREGAAVFWNVKDKTMKHVMKVLEKHEIQPYEIALVHWENEELNYIKIEGQSKLHRGEIKLNSELDLDDAILEKFAFSNALCLSVKLAIWEASLDKFIESIQSIPEALKAGKKVKLSHEEVMQKIGELFALRHRINLSSDFLITPDFYWDRENLEGLYDKTCQFLSIGRRVKVMNEKLQHCMELTDLMRNHLNEKRALRLEWMIVILITIEVMFELGRVFF>sp|Q9NWS8-3|RMND1_HUMAN Isoform 3 of Required for meiotic nucleardivision protein 1 homolog OS=Homo sapiens OX=9606 GN=RMND1MPATLLRAVARSHHILSKAHQCRRIGHLMLKPLKEFENTTCSTLTIRQSLDLFLPDKTASGLNKSQILEMNQKKSDTSMLSPLNAARCQDEKAHLPTMKSFGTHRRVTHKPNLLGSKWFIKILKRHFSSVSTETFVPKQDFPQVKRPLKASRTRQPSRTNLPVLSVNEDLMHCTAFATADEYHLGNLSQDLASHGYVEVTSLPRGTSS>sp|O95398|RPGF3_HUMAN Rap guanine nucleotide exchange factor 3 OS=Homosapiens OX=9606 GN=RAPGEF3 PE=1 SV=6MKVGWPGESCWQVGLAVEDSPALGAPRVGALPDVVPEGTLLNMVLRRMHRPRSCSYQLLLEHQRPSCIQGLRWTPLTNSEESLDFSESLEQASTERVLRAGRQLHRHLLATCPNLIRDRKYHLRLYRQCCSGRELVDGILALGLGVHSRSQVVGICQVLLDEGALCHVKHDWAFQDRDAQFYRFPGPEPEPVRTHEMEEELAEAVALLSQRGPDALLTVALRKPPGQRTDEELDLIFEELLHIKAVAHLSNSVKRELAAVLLFEPHSKAGTVLFSQGDKGTSWYIIWKGSVNVVTHGKGLVTTLHEGDDFGQLALVNDAPRAATIILREDNCHFLRVDKQDFNRIIKDVEAKTMRLEEHGKVVLVLERASQGAGPSRPPTPGRNRYTVMSGTPEKILELLLEAMGPDSSAHDPTETFLSDFLLTHRVFMPSAQLCAALLHHFHVEPAGGSEQERSTYVCNKRQQILRLVSQWVALYGSMLHTDPVATSFLQKLSDLVGRDTRLSNLLREQWPERRRCHRLENGCGNASPQMKARNLPVWLPNQDEPLPGSSCAIQVGDKVPYDICRPDHSVLTLQLPVTASVREVMAALAQEDGWTKGQVLVKVNSAGDAIGLQPDARGVATSLGLNERLFVVNPQEVHELIPHPDQLGPTVGSAEGLDLVSAKDLAGQLTDHDWSLFNSIHQVELIHYVLGPQHLRDVTTANLERFMRRFNELQYWVATELCLCPVPGPRAQLLRKFIKLAAHLKEQKNLNSFFAVMFGLSNSAISRLAHTWERLPHKVRKLYSALERLLDPSWNHRVYRLALAKLSPPVIPFMPLLLKDMTFIHEGNHTLVENLINFEKMRMMARAARMLHHCRSHNPVPLSPLRSRVSHLHEDSQVARISTCSEQSLSTRSPASTWAYVQQLKVIDNQRELSRLSRELEP>sp|O95398-2|RPGF3_HUMAN Isoform 2 of Rap guanine nucleotide exchangefactor 3 OS=Homo sapiens OX=9606 GN=RAPGEF3MKVGWPGESCWQVGLAVEDSPALGAPRVGALPDVVPEGTLLNMVLRRMHRPRSCSYQLLLEHQRPSCIQGLRWTPLTNSEESLDFSESLEQASTERVLRAGRQLHRHLLATCPNLIRDRKYHLRLYRQCCSGRELVDGILALGLGVHSRSQVVGICQVLLDEGALCHVKHDWAFQDRDAQFYRFPGPEPEPVRTHEMEEELAEAVALLSQRGPDALLTVALRKPPGQRTDEELDLIFEELLHIKAVAHLSNSVKRELAAVLLFEPHSKAGTVLFSQGDKGTSWYIIWKGSVNVVTHGKGLVTTLHEGDDFGQLALVNDAPRAATIILREDNCHFLRVDKQDFNRIIKDVEAKTMRLEEHGKVVLVLERASQGAGPSRPPTPGRNRYTVMSGTPEKILELLLEAMGPDSSAHDPTETFLSDFLLTHRVFMPSAQLCAALLHHFHVEPAGGSEQERSTYVCNKRQQILRLVSQWVALYGSMLHTDPVATSFLQKLSDLVGRDTRLSNLLREQWPERRRCHRLENGCGNASPQMKVSAWPQFLSSAPPGLQAPPSPPDPEGLCGRGKLSSHRHTLGSLIGVHGALAACGALGQAVPGGAEA>sp|O95398-3|RPGF3_HUMAN Isoform 3 of Rap guanine nucleotide exchangefactor 3 OS=Homo sapiens OX=9606 GN=RAPGEF3MVLRRMHRPRSCSYQLLLEHQRPSCIQGLRWTPLTNSEESLDFSESLEQASTERVLRAGRQLHRHLLATCPNLIRDRKYHLRLYRQCCSGRELVDGILALGLGVHSRSQVVGICQVLLDEGALCHVKHDWAFQDRDAQFYRFPGPEPEPVRTHEMEEELAEAVALLSQRGPDALLTVALRKPPGQRTDEELDLIFEELLHIKAVAHLSNSVKRELAAVLLFEPHSKAGTVLFSQGDKGTSWYIIWKGSVNVVTHGKGLVTTLHEGDDFGQLALVNDAPRAATIILREDNCHFLRVDKQDFNRIIKDVEAKTMRLEEHGKVVLVLERASQGAGPSRPPTPGRNRYTVMSGTPEKILELLLEAMGPDSSAHDPTETFLSDFLLTHRVFMPSAQLCAALLHHFHVEPAGGSEQERSTYVCNKRQQILRLVSQWVALYGSMLHTDPVATSFLQKLSDLVGRDTRLSNLLREQWPERRRCHRLENGCGNASPQMKARNLPVWLPNQDEPLPGSSCAIQVGDKVPYDICRPDHSVLTLQLPVTASVREVMAALAQEDGWTKGQVLVKVNSAGDAIGLQPDARGVATSLGLNERLFVVNPQEVHELIPHPDQLGPTVGSAEGLDLVSAKDLAGQLTDHDWSLFNSIHQVELIHYVLGPQHLRDVTTANLERFMRRFNELQYWVATELCLCPVPGPRAQLLRKFIKLAAHLKEQKNLNSFFAVMFGLSNSAISRLAHTWERLPHKVRKLYSALERLLDPSWNHRVYRLALAKLSPPVIPFMPLLLKDMTFIHEGNHTLVENLINFEKMRMMARAARMLHHCRSHNPVPLSPLRSRVSHLHEDSQVARISTCSEQSLSTRSPASTWAYVQQLKVIDNQRELSRLSRELEP>sp|Q13905|RPGF1_HUMAN Rap guanine nucleotide exchange factor 1 OS=Homosapiens OX=9606 GN=RAPGEF1 PE=1 SV=3MDTDSQRSHLSSFTMKLMDKFHSPKIKRTPSKKGKPAEVSVKIPEKPVNKEATDRFLPEGYPLPLDLEQQAVEFMSTSAVASRSQRQKNLSWLEEKEKEVVSALRYFKTIVDKMAIDKKVLEMLPGSASKVLEAILPLVQNDPRIQHSSALSSCYSRVYQSLANLIRWSDQVMLEGVNSEDKEMVTTVKGVIKAVLDGVKELVRLTIEKQGRPSPTSPVKPSSPASKPDGPAELPLTDREVEILNKTTGMSQSTELLPDATDEEVAPPKPPLPGIRVVDNSPPPALPPKKRQSAPSPTRVAVVAPMSRATSGSSLPVGINRQDFDVDCYAQRRLSGGSHSYGGESPRLSPCSSIGKLSKSDEQLSSLDRDSGQCSRNTSCETLDHYDPDYEFLQQDLSNADQIPQQTAWNLSPLPESLGESGSPFLGPPFQLPLGGHPQPDGPLAPGQQTDTPPALPEKKRRSAASQTADGSGCRVSYERHPSQYDNISGEDLQSTAPIPSVPYAPFAAILPFQHGGSSAPVEFVGDFTAPESTGDPEKPPPLPEKKNKHMLAYMQLLEDYSEPQPSMFYQTPQNEHIYQQKNKLLMEVYGFSDSFSGVDSVQELAPPPALPPKQRQLEPPAGKDGHPRDPSAVSGVPGKDSRDGSERAPKSPDALESAQSEEEVDELSLIDHNEIMSRLTLKQEGDDGPDVRGGSGDILLVHATETDRKDLVLYCEAFLTTYRTFISPEELIKKLQYRYEKFSPFADTFKKRVSKNTFFVLVRVVDELCLVELTEEILKLLMELVFRLVCNGELSLARVLRKNILDKVDQKKLLRCATSSQPLAARGVAARPGTLHDFHSHEIAEQLTLLDAELFYKIEIPEVLLWAKEQNEEKSPNLTQFTEHFNNMSYWVRSIIMLQEKAQDRERLLLKFIKIMKHLRKLNNFNSYLAILSALDSAPIRRLEWQKQTSEGLAEYCTLIDSSSSFRAYRAALSEVEPPCIPYLGLILQDLTFVHLGNPDYIDGKVNFSKRWQQFNILDSMRCFQQAHYDMRRNDDIINFFNDFSDHLAEEALWELSLKIKPRNITRRKTDREEKT>sp|Q13905-2|RPGF1_HUMAN Isoform Short of Rap guanine nucleotide exchangefactor 1 OS=Homo sapiens OX=9606 GN=RAPGEF1MDTDSQRSHLSSFTMKLMDKFHSPKIKRTPSKKGKPAEVSVKIPEKPVNNLSWLEEKEKEVVSALRYFKTIVDKMAIDKKVLEMLPGSASKVLEAILPLVQNDPRIQHSSALSSCYSRVYQSLANLIRWSDQVMLEGVNSEDKEMVTTVKGVIKAVLDGVKELVRLTIEKQGRPSPTSPVKPSSPASKPDGPAELPLTDREVEILNKTTGMSQSTELLPDATDEEVAPPKPPLPGIRVVDNSPPPALPPKKRQSAPSPTRVAVVAPMSRATSGSSLPVGINRQDFDVDCYAQRRLSGGSHSYGGESPRLSPCSSIGKLSKSDEQLSSLDRDSGQCSRNTSCETLDHYDPDYEFLQQDLSNADQIPQQTAWNLSPLPESLGESGSPFLGPPFQLPLGGHPQPDGPLAPGQQTDTPPALPEKKRRSAASQTADGSGCRVSYERHPSQYDNISGEDLQSTAPIPSVPYAPFAAILPFQHGGSSAPVEFVGDFTAPESTGDPEKPPPLPEKKNKHMLAYMQLLEDYSEPQPSMFYQTPQNEHIYQQKNKLLMEVYGFSDSFSGVDSVQELAPPPALPPKQRQLEPPAGKDGHPRDPSAVSGVPGKDSRDGSERAPKSPDALESAQSEEEVDELSLIDHNEIMSRLTLKQEGDDGPDVRGGSGDILLVHATETDRKDLVLYCEAFLTTYRTFISPEELIKKLQYRYEKFSPFADTFKKRVSKNTFFVLVRVVDELCLVELTEEILKLLMELVFRLVCNGELSLARVLRKNILDKVDQKKLLRCATSSQPLAARGVAARPGTLHDFHSHEIAEQLTLLDAELFYKIEIPEVLLWAKEQNEEKSPNLTQFTEHFNNMSYWVRSIIMLQEKAQDRERLLLKFIKIMKHLRKLNNFNSYLAILSALDSAPIRRLEWQKQTSEGLAEYCTLIDSSSSFRAYRAALSEVEPPCIPYLGLILQDLTFVHLGNPDYIDGKVNFSKRWQQFNILDSMRCFQQAHYDMRRNDDIINFFNDFSDHLAEEALWELSLKIKPRNITRRKTDREEKT>sp|Q13905-3|RPGF1_HUMAN Isoform 3 of Rap guanine nucleotide exchangefactor 1 OS=Homo sapiens OX=9606 GN=RAPGEF1MGNAIEKQKPLKRSHLYPWKQDSQRSHLSSFTMKLMDKFHSPKIKRTPSKKGKPAEVSVKIPEKPVNKEATDRFLPEGYPLPLDLEQQAVEFMSTSAVASRSQRQKNLSWLEEKEKEVVSALRYFKTIVDKMAIDKKVLEMLPGSASKVLEAILPLVQNDPRIQHSSALSSCYSRVYQSLANLIRWSDQVMLEGVNSEDKEMVTTVKGVIKAVLDGVKELVRLTIEKQGRPSPTSPVKPSSPASKPDGPAELPLTDREVEILNKTTGMSQSTELLPDATDEEVAPPKPPLPGIRVVDNSPPPALPPKKRQSAPSPTRVAVVAPMSRATSGSSLPVGINRQDFDVDCYAQRRLSGGSHSYGGESPRLSPCSSIGKLSKSDEQLSSLDRDSGQCSRNTSCETLDHYDPDYEFLQQDLSNADQIPQQTAWNLSPLPESLGESGSPFLGPPFQLPLGGHPQPDGPLAPGQQTDTPPALPEKKRRSAASQTADGSGCRVSYERHPSQYDNISGEDLQSTAPIPSVPYAPFAAILPFQHGGSSAPVEFVGDFTAPESTGDPEKPPPLPEKKNKHMLAYMQLLEDYSEPQPSMFYQTPQNEHIYQQKNKLLMEVYGFSDSFSGVDSVQELAPPPALPPKQRQLEPPAGKDGHPRDPSAVSGVPGKDSRDGSERAPKSPDALESAQSEEEVDELSLIDHNEIMSRLTLKQEGDDGPDVRGGSGDILLVHATETDRKDLVLYCEAFLTTYRTFISPEELIKKLQYRYEKFSPFADTFKKRVSKNTFFVLVRVVDELCLVELTEEILKLLMELVFRLVCNGELSLARVLRKNILDKVDQKKLLRCATSSQPLAARGVAARPGTLHDFHSHEIAEQLTLLDAELFYKIEIPEVLLWAKEQNEEKSPNLTQFTEHFNNMSYWVRSIIMLQEKAQDRERLLLKFIKIMKHLRKLNNFNSYLAILSALDSAPIRRLEWQKQTSEGLAEYCTLIDSSSSFRAYRAALSEVEPPCIPYLGLILQDLTFVHLGNPDYIDGKVNFSKRWQQFNILDSMRCFQQAHYDMRRNDDIINFFNDFSDHLAEEALWELSLKIKPRNITRRKTDREEKT>sp|Q13905-4|RPGF1_HUMAN Isoform 4 of Rap guanine nucleotide exchangefactor 1 OS=Homo sapiens OX=9606 GN=RAPGEF1MSGGLGLRRSPEMSGKIEKADSQRSHLSSFTMKLMDKFHSPKIKRTPSKKGKPAEVSVKIPEKPVNKEATDRFLPEGYPLPLDLEQQAVEFMSTSAVASRSQRQKNLSWLEEKEKEVVSALRYFKTIVDKMAIDKKVLEMLPGSASKVLEAILPLVQNDPRIQHSSALSSCYSRVYQSLANLIRWSDQVMLEGVNSEDKEMVTTVKGVIKAVLDGVKELVRLTIEKQGRPSPTSPVKPSSPASKPDGPAELPLTDREVEILNKTTGMSQSTELLPDATDEEVAPPKPPLPGIRVVDNSPPPALPPKKRQSAPSPTRVAVVAPMSRATSGSSLPVGINRQDFDVDCYAQRRLSGGSHSYGGESPRLSPCSSIGKLSKSDEQLSSLDRDSGQCSRNTSCETLDHYDPDYEFLQQDLSNADQIPQQTAWNLSPLPESLGESGSPFLGPPFQLPLGGHPQPDGPLAPGQQTDTPPALPEKKRRSAASQTADGSGCRVSYERHPSQYDNISGEDLQSTAPIPSVPYAPFAAILPFQHGGSSAPVEFVGDFTAPESTGDPEKPPPLPEKKNKHMLAYMQLLEDYSEPQPSMFYQTPQNEHIYQQKNKLLMEVYGFSDSFSGVDSVQELAPPPALPPKQRQLEPPAGKDGHPRDPSAVSGVPGKDSRDGSERAPKSPDALESAQSEEEVDELSLIDHNEIMSRLTLKQEGDDGPDVRGGSGDILLVHATETDRKDLVLYCEAFLTTYRTFISPEELIKKLQYRYEKFSPFADTFKKRVSKNTFFVLVRVVDELCLVELTEEILKLLMELVFRLVCNGELSLARVLRKNILDKVDQKKLLRCATSSQPLAARGVAARPGTLHDFHSHEIAEQLTLLDAELFYKIEIPEVLLWAKEQNEEKSPNLTQFTEHFNNMSYWVRSIIMLQEKAQDRERLLLKFIKIMKHLRKLNNFNSYLAILSALDSAPIRRLEWQKQTSEGLAEYCTLIDSSSSFRAYRAALSEVEPPCIPYLGLILQDLTFVHLGNPDYIDGKVNFSKRWQQFNILDSMRCFQQAHYDMRRNDDIINFFNDFSDHLAEEALWELSLKIKPRNITRRKTDREEKT>sp|Q8WZA2|RPGF4_HUMAN Rap guanine nucleotide exchange factor 4 OS=Homosapiens OX=9606 GN=RAPGEF4 PE=1 SV=1MVAAHAAHSSSSAEWIACLDKRPLERSSEDVDIIFTRLKEVKAFEKFHPNLLHQICLCGYYENLEKGITLFRQGDIGTNWYAVLAGSLDVKVSETSSHQDAVTICTLGIGTAFGESILDNTPRHATIVTRESSELLRIEQKDFKALWEKYRQYMAGLLAPPYGVMETGSNNDRIPDKENTPLIEPHVPLRPANTITKVPSEKILRAGKILRNAILSRAPHMIRDRKYHLKTYRQCCVGTELVDWMMQQTPCVHSRTQAVGMWQVLLEDGVLNHVDQEHHFQDKYLFYRFLDDEHEDAPLPTEEEKKECDEELQDTMLLLSQMGPDAHMRMILRKPPGQRTVDDLEIIYEELLHIKALSHLSTTVKRELAGVLIFESHAKGGTVLFNQGEEGTSWYIILKGSVNVVIYGKGVVCTLHEGDDFGKLALVNDAPRAASIVLREDNCHFLRVDKEDFNRILRDVEANTVRLKEHDQDVLVLEKVPAGNRASNQGNSQPQQKYTVMSGTPEKILEHFLETIRLEATLNEATDSVLNDFIMMHCVFMPNTQLCPALVAHYHAQPSQGTEQEKMDYALNNKRRVIRLVLQWAAMYGDLLQEDDVSMAFLEEFYVSVSDDARMIAALKEQLPELEKIVKQISEDAKAPQKKHKVLLQQFNTGDERAQKRQPIRGSDEVLFKVYCMDHTYTTIRVPVATSVKEVISAVADKLGSGEGLIIVKMSSGGEKVVLKPNDVSVFTTLTINGRLFACPREQFDSLTPLPEQEGPTVGTVGTFELMSSKDLAYQMTIYDWELFNCVHELELIYHTFGRHNFKKTTANLDLFLRRFNEIQFWVVTEICLCSQLSKRVQLLKKFIKIAAHCKEYKNLNSFFAIVMGLSNVAVSRLALTWEKLPSKFKKFYAEFESLMDPSRNHRAYRLTVAKLEPPLIPFMPLLIKDMTFTHEGNKTFIDNLVNFEKMRMIANTARTVRYYRSQPFNPDAAQANKNHQDVRSYVRQLNVIDNQRTLSQMSHRLEPRRP>sp|Q8WZA2-2|RPGF4_HUMAN Isoform 2 of Rap guanine nucleotide exchangefactor 4 OS=Homo sapiens OX=9606 GN=RAPGEF4MLLLSQMGPDAHMRMILRKPPGQRTVDDLEIIYEELLHIKALSHLSTTVKRELAGVLIFESHAKGGTVLFNQGEEGTSWYIILKGSVNVVIYGKGVVCTLHEGDDFGKLALVNDAPRAASIVLREDNCHFLRVDKEDFNRILRDVEANTVRLKEHDQDVLVLEKVPAGNRASNQGNSQPQQKYTVMSGTPEKILEHFLETIRLEATLNEATDSVLNDFIMMHCVFMPNTQLCPALVAHYHAQPSQGTEQEKMDYALNNKRRVIRLVLQWAAMYGDLLQEDDVSMAFLEEFYVSVSDDARMIAALKEQLPELEKIVKQISEDAKAPQKKHKVLLQQFNTGDERAQKRQPIRGSDEVLFKVYCMDHTYTTIRVPVATSVKEVISAVADKLGSGEGLIIVKMSSGGEKVVLKPNDVSVFTTLTINGRLFACPREQFDSLTPLPEQEGPTVGTVGTFELMSSKDLAYQMTIYDWELFNCVHELELIYHTFGRHNFKKTTANLDLFLRRFNEIQFWVVTEICLCSQLSKRVQLLKKFIKIAAHCKEYKNLNSFFAIVMGLSNVAVSRLALTWEKLPSKFKKFYAEFESLMDPSRNHRAYRLTVAKLEPPLIPFMPLLIKDMTFTHEGNKTFIDNLVNFEKMRMIANTARTVRYYRSQPFNPDAAQANKNHQDVRSYVRQLNVIDNQRTLSQMSHRLEPRRP>sp|Q8WZA2-3|RPGF4_HUMAN Isoform 3 of Rap guanine nucleotide exchangefactor 4 OS=Homo sapiens OX=9606 GN=RAPGEF4MLYKKYRQYMAGLLAPPYGVMETGSNNDRIPDKENTPLIEPHVPLRPANTITKVPSEKILRAGKILRNAILSRAPHMIRDRKYHLKTYRQCCVGTELVDWMMQQTPCVHSRTQAVGMWQVLLEDGVLNHVDQEHHFQDKYLFYRFLDDEHEDAPLPTEEEKKECDEELQDTMLLLSQMGPDAHMRMILRKPPGQRTVDDLEIIYEELLHIKALSHLSTTVKRELAGVLIFESHAKGGTVLFNQGEEGTSWYIILKGSVNVVIYGKGVVCTLHEGDDFGKLALVNDAPRAASIVLREDNCHFLRVDKEDFNRILRDVEANTVRLKEHDQDVLVLEKVPAGNRASNQGNSQPQQKYTVMSGTPEKILEHFLETIRLEATLNEATDSVLNDFIMMHCVFMPNTQLCPALVAHYHAQPSQGTEQEKMDYALNNKRRVIRLVLQWAAMYGDLLQEDDVSMAFLEEFYVSVSDDARMIAALKEQLPELEKIVKQISEDAKAPQKKHKVLLQQFNTGDERAQKRQPIRGSDEVLFKVYCMDHTYTTIRVPVATSVKEVISAVADKLGSGEGLIIVKMSSGGEKVVLKPNDVSVFTTLTINGRLFACPREQFDSLTPLPEQEGPTVGTVGTFELMSSKDLAYQMTIYDWELFNCVHELELIYHTFGRHNFKKTTANLDLFLRRFNEIQFWVVTEICLCSQLSKRVQLLKKFIKIAAHCKEYKNLNSFFAIVMGLSNVAVSRLALTWEKLPSKFKKFYAEFESLMDPSRNHRAYRLTVAKLEPPLIPFMPLLIKDMTFTHEGNKTFIDNLVNFEKMRMIANTARTVRYYRSQPFNPDAAQANKNHQDVRSYVRQLNVIDNQRTLSQMSHRLEPRRP>sp|Q8WZA2-4|RPGF4_HUMAN Isoform 4 of Rap guanine nucleotide exchangefactor 4 OS=Homo sapiens OX=9606 GN=RAPGEF4MAGLLAPPYGVMETGSNNDRIPDKENTPLIEPHVPLRPANTITKVPSEKILRAGKILRNAILSRAPHMIRDRKYHLKTYRQCCVGTELVDWMMQQTPCVHSRTQAVGMWQVLLEDGVLNHVDQEHHFQDKYLFYRFLDDEHEDAPLPTEEEKKECDEELQDTMLLLSQMGPDAHMRMILRKPPGQRTVDDLEIIYEELLHIKALSHLSTTVKRELAGVLIFESHAKGGTVLFNQGEEGTSWYIILKGSVNVVIYGKGVVCTLHEGDDFGKLALVNDAPRAASIVLREDNCHFLRVDKEDFNRILRDVEANTVRLKEHDQDVLVLEKVPAGNRASNQGNSQPQQKYTVMSGTPEKILEHFLETIRLEATLNEATDSVLNDFIMMHCVFMPNTQLCPALVAHYHAQPSQGTEQEKMDYALNNKRRVIRLVLQWAAMYGDLLQEDDVSMAFLEEFYVSVSDDARMIAALKEQLPELEKIVKQISEDAKAPQKKHKVLLQQFNTGDERAQKRQPIRGSDEVLFKVYCMDHTYTTIRVPVATSVKEVISAVADKLGSGEGLIIVKMSSGGEKVVLKPNDVSVFTTLTINGRLFACPREQFDSLTPLPEQEGPTVGTVGTFELMSSKDLAYQMTIYDWELFNCVHELELIYHTFGRHNFKKTTANLDLFLRRFNEIQFWVVTEICLCSQLSKRVQLLKKFIKIAAHCKEYKNLNSFFAIVMGLSNVAVSRLALTWEKLPSKFKKFYAEFESLMDPSRNHRAYRLTVAKLEPPLIPFMPLLIKDMTFTHEGNKTFIDNLVNFEKMRMIANTARTVRYYRSQPFNPDAAQANKNHQDVRSYVRQLNVIDNQRTLSQMSHRLEPRRP>sp|Q8WZA2-5|RPGF4_HUMAN Isoform 5 of Rap guanine nucleotide exchangefactor 4 OS=Homo sapiens OX=9606 GN=RAPGEF4MAGLLAPPYGVMETGSNNDRIPDKENVPSEKILRAGKILRNAILSRAPHMIRDRKYHLKTYRQCCVGTELVDWMMQQTPCVHSRTQAVGMWQVLLEDGVLNHVDQEHHFQDKYLFYRFLDDEHEDAPLPTEEEKKECDEELQDTMLLLSQMGPDAHMRMILRKPPGQRTVDDLEIIYEELLHIKALSHLSTTVKRELAGVLIFESHAKGGTVLFNQGEEGTSWYIILKGSVNVVIYGKGVVCTLHEGDDFGKLALVNDAPRAASIVLREDNCHFLRVDKEDFNRILRDVEANTVRLKEHDQDVLVLEKVPAGNRASNQGNSQPQQKYTVMSGTPEKILEHFLETIRLEATLNEATDSVLNDFIMMHCVFMPNTQLCPALVAHYHAQPSQGTEQEKMDYALNNKRRVIRLVLQWAAMYGDLLQEDDVSMAFLEEFYVSVSDDARMIAALKEQLPELEKIVKQISEDAKAPQKKHKVLLQQFNTGDERAQKRQPIRGSDEVLFKVYCMDHTYTTIRVPVATSVKEVISAVADKLGSGEGLIIVKMSSGGEKVVLKPNDVSVFTTLTINGRLFACPREQFDSLTPLPEQEGPTVGTVGTFELMSSKDLAYQMTIYDWELFNCVHELELIYHTFGRHNFKKTTANLDLFLRRFNEIQFWVVTEICLCSQLSKRVQLLKKFIKIAAHCKEYKNLNSFFAIVMGLSNVAVSRLALTWEKLPSKFKKFYAEFESLMDPSRNHRAYRLTVAKLEPPLIPFMPLLIKDMTFTHEGNKTFIDNLVNFEKMRMIANTARTVRYYRSQPFNPDAAQANKNHQDVRSYVRQLNVIDNQRTLSQMSHRLEPRRP>sp|Q6P1L8|RM14_HUMAN 39S ribosomal protein L14, mitochondrial OS=Homosapiens OX=9606 GN=MRPL14 PE=1 SV=1MAFFTGLWGPFTCVSRVLSHHCFSTTGSLSAIQKMTRVRVVDNSALGNSPYHRAPRCIHVYKKNGVGKVGDQILLAIKGQKKKALIVGHCMPGPRMTPRFDSNNVVLIEDNGNPVGTRIKTPIPTSLRKREGEYSKVLAIAQNFV>sp|P24928|RPB1_HUMAN DNA-directed RNA polymerase II subunit RPB1 OS=Homosapiens OX=9606 GN=POLR2A PE=1 SV=2MHGGGPPSGDSACPLRTIKRVQFGVLSPDELKRMSVTEGGIKYPETTEGGRPKLGGLMDPRQGVIERTGRCQTCAGNMTECPGHFGHIELAKPVFHVGFLVKTMKVLRCVCFFCSKLLVDSNNPKIKDILAKSKGQPKKRLTHVYDLCKGKNICEGGEEMDNKFGVEQPEGDEDLTKEKGHGGCGRYQPRIRRSGLELYAEWKHVNEDSQEKKILLSPERVHEIFKRISDEECFVLGMEPRYARPEWMIVTVLPVPPLSVRPAVVMQGSARNQDDLTHKLADIVKINNQLRRNEQNGAAAHVIAEDVKLLQFHVATMVDNELPGLPRAMQKSGRPLKSLKQRLKGKEGRVRGNLMGKRVDFSARTVITPDPNLSIDQVGVPRSIAANMTFAEIVTPFNIDRLQELVRRGNSQYPGAKYIIRDNGDRIDLRFHPKPSDLHLQTGYKVERHMCDGDIVIFNRQPTLHKMSMMGHRVRILPWSTFRLNLSVTTPYNADFDGDEMNLHLPQSLETRAEIQELAMVPRMIVTPQSNRPVMGIVQDTLTAVRKFTKRDVFLERGEVMNLLMFLSTWDGKVPQPAILKPRPLWTGKQIFSLIIPGHINCIRTHSTHPDDEDSGPYKHISPGDTKVVVENGELIMGILCKKSLGTSAGSLVHISYLEMGHDITRLFYSNIQTVINNWLLIEGHTIGIGDSIADSKTYQDIQNTIKKAKQDVIEVIEKAHNNELEPTPGNTLRQTFENQVNRILNDARDKTGSSAQKSLSEYNNFKSMVVSGAKGSKINISQVIAVVGQQNVEGKRIPFGFKHRTLPHFIKDDYGPESRGFVENSYLAGLTPTEFFFHAMGGREGLIDTAVKTAETGYIQRRLIKSMESVMVKYDATVRNSINQVVQLRYGEDGLAGESVEFQNLATLKPSNKAFEKKFRFDYTNERALRRTLQEDLVKDVLSNAHIQNELEREFERMREDREVLRVIFPTGDSKVVLPCNLLRMIWNAQKIFHINPRLPSDLHPIKVVEGVKELSKKLVIVNGDDPLSRQAQENATLLFNIHLRSTLCSRRMAEEFRLSGEAFDWLLGEIESKFNQAIAHPGEMVGALAAQSLGEPATQMTLNTFHYAGVSAKNVTLGVPRLKELINISKKPKTPSLTVFLLGQSARDAERAKDILCRLEHTTLRKVTANTAIYYDPNPQSTVVAEDQEWVNVYYEMPDFDVARISPWLLRVELDRKHMTDRKLTMEQIAEKINAGFGDDLNCIFNDDNAEKLVLRIRIMNSDENKMQEEEEVVDKMDDDVFLRCIESNMLTDMTLQGIEQISKVYMHLPQTDNKKKIIITEDGEFKALQEWILETDGVSLMRVLSEKDVDPVRTTSNDIVEIFTVLGIEAVRKALERELYHVISFDGSYVNYRHLALLCDTMTCRGHLMAITRHGVNRQDTGPLMKCSFEETVDVLMEAAAHGESDPMKGVSENIMLGQLAPAGTGCFDLLLDAEKCKYGMEIPTNIPGLGAAGPTGMFFGSAPSPMGGISPAMTPWNQGATPAYGAWSPSVGSGMTPGAAGFSPSAASDASGFSPGYSPAWSPTPGSPGSPGPSSPYIPSPGGAMSPSYSPTSPAYEPRSPGGYTPQSPSYSPTSPSYSPTSPSYSPTSPNYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPSYSPTSPNYSPTSPNYTPTSPSYSPTSPSYSPTSPNYTPTSPNYSPTSPSYSPTSPSYSPTSPSYSPSSPRYTPQSPTYTPSSPSYSPSSPSYSPASPKYTPTSPSYSPSSPEYTPTSPKYSPTSPKYSPTSPKYSPTSPTYSPTTPKYSPTSPTYSPTSPVYTPTSPKYSPTSPTYSPTSPKYSPTSPTYSPTSPKGSTYSPTSPGYSPTSPTYSLTSPAISPDDSDEEN>sp|P24928-2|RPB1_HUMAN Isoform 2 of DNA-directed RNA polymerase IIsubunit RPB1 OS=Homo sapiens OX=9606 GN=POLR2AMHGGGPPSGDSACPLRTIKRVQFGVLSPDELKRMSVTEGGIKYPETTEGGRPKLGGLMDPRQGVIERTGRCQTCAGNMTECPGHFGHIELAKPVFHVGFLVKTMKVLRCVCFFCSKLLVDSNNPKIKDILAKSKGQPKKRLTHVYDLCKGKNICEGGEEMDNKFGVEQPEGDEDLTKEKGHGGCGRYQPRIRRSGLELYAEWKHVNEDSQEKKILLSPERVHEIFKRISDEECFVLGMEPRYARPEWMIVTVLPVPPLSVRPAVVMQGSARNQDDLTHKLADIVKINNQLRRNEQNGAAAHVIAEDVKLLQFHVATMVDNELPGLPRAMQKSGRPLKSLKQRLKGKEGRVRGNLMGKRVDFSARTVITPDPNLSIDQVGVPRSIAANMTFAEIVTPFNIDRLQELVRRGNSQYPGAKYIIRDNGDRIDLRFHPKPSDLHLQTGYKVERHMCDGDIVIFNRQPTLHKMSMMGHRVRILPWSTFRLNLSVTTPYNADFDGDEMNLHLPQSLETRAEIQELAMVPRMIVTPQSNRPVMGIVQDTLTAVRKFTKRDVFLERVCGPNGNLA>sp|Q2M238|RN3P1_HUMAN Putative RRN3-like protein RRN3P1 OS=Homo sapiensOX=9606 GN=RRN3P1 PE=5 SV=1MGFAEAFLEHLWKNLQDPSNPAIIRQAAGNYIGSFLARAKFISLITVKPCLDLLVNWLHIYLNNQDSGTKAFCDVALHGPFYSACQAVFYTFVFRHKQLLSGNLKEGLQYPQSLNFERIVMSQLNPLKICLPSVVNFFAAITKMKTCGYGWW>sp|P04844|RPN2_HUMAN Dolichyl-diphosphooligosaccharide--proteinglycosyltransferase subunit 2 OS=Homo sapiens OX=9606 GN=RPN2 PE=1 SV=3MAPPGSSTVFLLALTIIASTWALTPTHYLTKHDVERLKASLDRPFTNLESAFYSIVGLSSLGAQVPDAKKACTYIRSNLDPSNVDSLFYAAQASQALSGCEISISNETKDLLLAAVSEDSSVTQIYHAVAALSGFGLPLASQEALSALTARLSKEETVLATVQALQTASHLSQQADLRSIVEEIEDLVARLDELGGVYLQFEEGLETTALFVAATYKLMDHVGTEPSIKEDQVIQLMNAIFSKKNFESLSEAFSVASAAAVLSHNRYHVPVVVVPEGSASDTHEQAILRLQVTNVLSQPLTQATVKLEHAKSVASRATVLQKTSFTPVGDVFELNFMNVKFSSGYYDFLVEVEGDNRYIANTVELRVKISTEVGITNVDLSTVDKDQSIAPKTTRVTYPAKAKGTFIADSHQNFALFFQLVDVNTGAELTPHQTFVRLHNQKTGQEVVFVAEPDNKNVYKFELDTSERKIEFDSASGTYTLYLIIGDATLKNPILWNVADVVIKFPEEEAPSTVLSQNLFTPKQEIQHLFREPEKRPPTVVSNTFTALILSPLLLLFALWIRIGANVSNFTFAPSTIIFHLGHAAMLGLMYVYWTQLNMFQTLKYLAILGSVTFLAGNRMLAQQAVKRTAH>sp|P04844-2|RPN2_HUMAN Isoform 2 of Dolichyl-diphosphooligosaccharide--protein glycosyltransferase subunit 2 OS=Homo sapiens OX=9606 GN=RPN2MAPPGSSTVFLLALTIIASTWALTPTHYLTKHDVERLKASLDRPFTNLESAFYSIVGLSSLGAQVPDAKISISNETKDLLLAAVSEDSSVTQIYHAVAALSGFGLPLASQEALSALTARLSKEETVLATVQALQTASHLSQQADLRSIVEEIEDLVARLDELGGVYLQFEEGLETTALFVAATYKLMDHVGTEPSIKEDQVIQLMNAIFSKKNFESLSEAFSVASAAAVLSHNRYHVPVVVVPEGSASDTHEQAILRLQVTNVLSQPLTQATVKLEHAKSVASRATVLQKTSFTPVGDVFELNFMNVKFSSGYYDFLVEVEGDNRYIANTVELRVKISTEVGITNVDLSTVDKDQSIAPKTTRVTYPAKAKGTFIADSHQNFALFFQLVDVNTGAELTPHQTFVRLHNQKTGQEVVFVAEPDNKNVYKFELDTSERKIEFDSASGTYTLYLIIGDATLKNPILWNVADVVIKFPEEEAPSTVLSQNLFTPKQEIQHLFREPEKRPPTVVSNTFTALILSPLLLLFALWIRIGANVSNFTFAPSTIIFHLGHAAMLGLMYVYWTQLNMFQTLKYLAILGSVTFLAGNRMLAQQAVKRIAAEQSSRLAKYRTLRTAH>sp|P49406|RM19_HUMAN 39S ribosomal protein L19, mitochondrial OS=Homosapiens OX=9606 GN=MRPL19 PE=1 SV=2MAACIAAGHWAAMGLGRSFQAARTLLPPPASIACRVHAGPVRQQSTGPSEPGAFQPPPKPVIVDKHRPVEPERRFLSPEFIPRRGRTDPLKFQIERKDMLERRKVLHIPEFYVGSILRVTTADPYASGKISQFLGICIQRSGRGLGATFILRNVIEGQGVEICFELYNPRVQEIQVVKLEKRLDDSLLYLRDALPEYSTFDVNMKPVVQEPNQKVPVNELKVKMKPKPWSKRWERPNFNIKGIRFDLCLTEQQMKEAQKWNQPWLEFDMMREYDTSKIEAAIWKEIEASKRS>sp|Q9NRX2|RM17_HUMAN 39S ribosomal protein L17, mitochondrial OS=Homosapiens OX=9606 GN=MRPL17 PE=1 SV=1MRLSVAAAISHGRVFRRMGLGPESRIHLLRNLLTGLVRHERIEAPWARVDEMRGYAEKLIDYGKLGDTNERAMRMADFWLTEKDLIPKLFQVLAPRYKDQTGGYTRMLQIPNRSLDRAKMAVIEYKGNCLPPLPLPRRDSHLTLLNQLLQGLRQDLRQSQEASNHSSHTAQTPGI>sp|Q9NWU5|RM22_HUMAN 39S ribosomal protein L22, mitochondrial OS=Homosapiens OX=9606 GN=MRPL22 PE=1 SV=1MAAAVLGQLGALWIHNLRSRGKLALGVLPQSYIHTSASLDISRKWEKKNKIVYPPQLPGEPRRPAEIYHCRRQIKYSKDKMWYLAKLIRGMSIDQALAQLEFNDKKGAKIIKEVLLEAQDMAVRDHNVEFRSNLYIAESTSGRGQCLKRIRYHGRGRFGIMEKVYCHYFVKLVEGPPPPPEPPKTAVAHAKEYIQQLRSRTIVHTL>sp|Q9NWU5-2|RM22_HUMAN Isoform 2 of 39S ribosomal protein L22,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL22MIRGMSIDQALAQLEFNDKKGAKIIKEVLLEAQDMAVRDHNVEFRSNLYIAESTSGRGQCLKRIRYHGRGRFGIMEKVYCHYFVKLVEGPPPPPEPPKTAVAHAKEYIQQLRSRTIVHTL>sp|Q9NWU5-3|RM22_HUMAN Isoform 3 of 39S ribosomal protein L22,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL22MWYLAKLIRGMSIDQALAQLEFNDKKGAKIIKEVLLEAQDMAVRDHNVEFRSNLYIAESTSGRGQCLKRIRYHGRGRFGIMEKVYCHYFVKLVEGPPPPPEPPKTAVAHAKEYIQQLRSRTIVHTL>sp|P62487|RPB7_HUMAN DNA-directed RNA polymerase II subunit RPB7 OS=Homosapiens OX=9606 GN=POLR2G PE=1 SV=1MFYHISLEHEILLHPRYFGPNLLNTVKQKLFTEVEGTCTGKYGFVIAVTTIDNIGAGVIQPGRGFVLYPVKYKAIVFRPFKGEVVDAVVTQVNKVGLFTEIGPMSCFISRHSIPSEMEFDPNSNPPCYKTMDEDIVIQQDDEIRLKIVGTRVDKNDIFAIGSLMDDYLGLVS>sp|Q9ULF5|S39AA_HUMAN Zinc transporter ZIP10 OS=Homo sapiens OX=9606GN=SLC39A10 PE=1 SV=2MKVHMHTKFCLICLLTFIFHHCNHCHEEHDHGPEALHRQHRGMTELEPSKFSKQAAENEKKYYIEKLFERYGENGRLSFFGLEKLLTNLGLGERKVVEINHEDLGHDHVSHLDILAVQEGKHFHSHNHQHSHNHLNSENQTVTSVSTKRNHKCDPEKETVEVSVKSDDKHMHDHNHRLRHHHRLHHHLDHNNTHHFHNDSITPSERGEPSNEPSTETNKTQEQSDVKLPKGKRKKKGRKSNENSEVITPGFPPNHDQGEQYEHNRVHKPDRVHNPGHSHVHLPERNGHDPGRGHQDLDPDNEGELRHTRKREAPHVKNNAIISLRKDLNEDDHHHECLNVTQLLKYYGHGANSPISTDLFTYLCPALLYQIDSRLCIEHFDKLLVEDINKDKNLVPEDEANIGASAWICGIISITVISLLSLLGVILVPIINQGCFKFLLTFLVALAVGTMSGDALLHLLPHSQGGHDHSHQHAHGHGHSHGHESNKFLEEYDAVLKGLVALGGIYLLFIIEHCIRMFKHYKQQRGKQKWFMKQNTEESTIGRKLSDHKLNNTPDSDWLQLKPLAGTDDSVVSEDRLNETELTDLEGQQESPPKNYLCIEEEKIIDHSHSDGLHTIHEHDLHAAAHNHHGENKTVLRKHNHQWHHKHSHHSHGPCHSGSDLKETGIANIAWMVIMGDGIHNFSDGLAIGAAFSAGLTGGISTSIAVFCHELPHELGDFAVLLKAGMTVKQAIVYNLLSAMMAYIGMLIGTAVGQYANNITLWIFAVTAGMFLYVALVDMLPEMLHGDGDNEEHGFCPVGQFILQNLGLLFGFAIMLVIALYEDKIVFDIQF>sp|Q9ULF5-2|S39AA_HUMAN Isoform 2 of Zinc transporter ZIP10 OS=Homosapiens OX=9606 GN=SLC39A10MSGDALLHLLPHSQGGHDHSHQHAHGHGHSHGHESNKFLEEYDAVLKGLVALGGIYLLFIIEHCIRMFKHYKQQRGKQKWFMKQNTEESTIGRKLSDHKLNNTPDSDWLQLKPLAGTDDSVVSEDRLNETELTDLEGQQESPPKNYLCIEEEKIIDHSHSDGLHTIHEHDLHAAAHNHHGENKTVLRKHNHQWHHKHSHHSHGPCHSGSDLKETGIANIAWMVIMGDGIHNFSDGLAIGAAFSAGLTGGISTSIAVFCHELPHELGDFAVLLKAGMTVKQAIVYNLLSAMMAYIGMLIGTAVGQYANNITLWIFAVTAGMFLYVALVDMLPEMLHGDGDNEEHGFCPVGQFILQNLGLLFGFAIMLVIALYEDKIVFDIQF>sp|Q9NRP4|SDHF3_HUMAN Succinate dehydrogenase assembly factor 3,mitochondrial OS=Homo sapiens OX=9606 GN=SDHAF3 PE=1 SV=1MPGRHVSRVRALYKRVLQLHRVLPPDLKSLGDQYVKDEFRRHKTVGSDEAQRFLQEWEVYATALLQQANENRQNSTGKACFGTFLPEEKLNDFRDEQIGQLQELMQEATKPNRQFSISESMKPKF>sp|Q9NRR4|RNC_HUMAN Ribonuclease 3 OS=Homo sapiens OX=9606 GN=DROSHAPE=1 SV=2MMQGNTCHRMSFHPGRGCPRGRGGHGARPSAPSFRPQNLRLLHPQQPPVQYQYEPPSAPSTTFSNSPAPNFLPPRPDFVPFPPPMPPSAQGPLPPCPIRPPFPNHQMRHPFPVPPCFPPMPPPMPCPNNPPVPGAPPGQGTFPFMMPPPSMPHPPPPPVMPQQVNYQYPPGYSHHNFPPPSFNSFQNNPSSFLPSANNSSSPHFRHLPPYPLPKAPSERRSPERLKHYDDHRHRDHSHGRGERHRSLDRRERGRSPDRRRQDSRYRSDYDRGRTPSRHRSYERSRERERERHRHRDNRRSPSLERSYKKEYKRSGRSYGLSVVPEPAGCTPELPGEIIKNTDSWAPPLEIVNHRSPSREKKRARWEEEKDRWSDNQSSGKDKNYTSIKEKEPEETMPDKNEEEEEELLKPVWIRCTHSENYYSSDPMDQVGDSTVVGTSRLRDLYDKFEEELGSRQEKAKAARPPWEPPKTKLDEDLESSSESECESDEDSTCSSSSDSEVFDVIAEIKRKKAHPDRLHDELWYNDPGQMNDGPLCKCSAKARRTGIRHSIYPGEEAIKPCRPMTNNAGRLFHYRITVSPPTNFLTDRPTVIEYDDHEYIFEGFSMFAHAPLTNIPLCKVIRFNIDYTIHFIEEMMPENFCVKGLELFSLFLFRDILELYDWNLKGPLFEDSPPCCPRFHFMPRFVRFLPDGGKEVLSMHQILLYLLRCSKALVPEEEIANMLQWEELEWQKYAEECKGMIVTNPGTKPSSVRIDQLDREQFNPDVITFPIIVHFGIRPAQLSYAGDPQYQKLWKSYVKLRHLLANSPKVKQTDKQKLAQREEALQKIRQKNTMRREVTVELSSQGFWKTGIRSDVCQHAMMLPVLTHHIRYHQCLMHLDKLIGYTFQDRCLLQLAMTHPSHHLNFGMNPDHARNSLSNCGIRQPKYGDRKVHHMHMRKKGINTLINIMSRLGQDDPTPSRINHNERLEFLGDAVVEFLTSVHLYYLFPSLEEGGLATYRTAIVQNQHLAMLAKKLELDRFMLYAHGPDLCRESDLRHAMANCFEALIGAVYLEGSLEEAKQLFGRLLFNDPDLREVWLNYPLHPLQLQEPNTDRQLIETSPVLQKLTEFEEAIGVIFTHVRLLARAFTLRTVGFNHLTLGHNQRMEFLGDSIMQLVATEYLFIHFPDHHEGHLTLLRSSLVNNRTQAKVAEELGMQEYAITNDKTKRPVALRTKTLADLLESFIAALYIDKDLEYVHTFMNVCFFPRLKEFILNQDWNDPKSQLQQCCLTLRTEGKEPDIPLYKTLQTVGPSHARTYTVAVYFKGERIGCGKGPSIQQAEMGAAMDALEKYNFPQMAHQKRFIERKYRQELKEMRWEREHQEREPDETEDIKK>sp|Q9NRR4-2|RNC_HUMAN Isoform 2 of Ribonuclease 3 OS=Homo sapiensOX=9606 GN=DROSHAMMQGNTCHRMSFHPGRGCPRGRGGHGARPSAPSFRPQNLRLLHPQQPPVQYQYEPPSAPSTTFSNSPAPNFLPPRPDFVPFPPPMPPSAQGPLPPCPIRPPFPNHQMRHPFPVPPCFPPMPPPMPCPNNPPVPGAPPGQGTFPFMMPPPSMPHPPPPPVMPQQVNYQYPPGYSHHNFPPPSFNSFQNNPSSFLPSANNSSSPHFRHLPPYPLPKAPSERRSPERLKHYDDHRHRDHSHGRGERHRSLDRRERGRSPDRRRQDSRYRSDYDRGRTPSRHRSYERSSRSPSREKKRARWEEEKDRWSDNQSSGKDKNYTSIKEKEPEETMPDKNEEEEEELLKPVWIRCTHSENYYSSDPMDQVGDSTVVGTSRLRDLYDKFEEELGSRQEKAKAARPPWEPPKTKLDEDLESSSESECESDEDSTCSSSSDSEVFDVIAEIKRKKAHPDRLHDELWYNDPGQMNDGPLCKCSAKARRTGIRHSIYPGEEAIKPCRPMTNNAGRLFHYRITVSPPTNFLTDRPTVIEYDDHEYIFEGFSMFAHAPLTNIPLCKVIRFNIDYTIHFIEEMMPENFCVKGLELFSLFLFRDILELYDWNLKGPLFEDSPPCCPRFHFMPRFVRFLPDGGKEVLSMHQILLYLLRCSKALVPEEEIANMLQWEELEWQKYAEECKGMIVTNPGTKPSSVRIDQLDREQFNPDVITFPIIVHFGIRPAQLSYAGDPQYQKLWKSYVKLRHLLANSPKVKQTDKQKLAQREEALQKIRQKNTMRREVTVELSSQGFWKTGIRSDVCQHAMMLPVLTHHIRYHQCLMHLDKLIGYTFQDRCLLQLAMTHPSHHLNFGMNPDHARNSLSNCGIRQPKYGDRKVHHMHMRKKGINTLINIMSRLGQDDPTPSRINHNERLEFLGDAVVEFLTSVHLYYLFPSLEEGGLATYRTAIVQNQHLAMLAKKLELDRFMLYAHGPDLCRESDLRHAMANCFEALIGAVYLEGSLEEAKQLFGRLLFNDPDLREVWLNYPLHPLQLQEPNTDRQLIETSPVLQKLTEFEEAIGVIFTHVRLLARAFTLRTVGFNHLTLGHNQRMEFLGDSIMQLVATEYLFIHFPDHHEGHLTLLRSSLVNNRTQAKVAEELGMQEYAITNDKTKRPVALRTKTLADLLESFIAALYIDKDLEYVHTFMNVCFFPRLKEFILNQDWNDPKSQLQQCCLTLRTEGKEPDIPLYKTLQTVGPSHARTYTVAVYFKGERIGCGKGPSIQQAEMGAAMDALEKYNFPQMAHQKRFIERKYRQELKEMRWEREHQEREPDETEDIKK>sp|Q9NRR4-3|RNC_HUMAN Isoform 3 of Ribonuclease 3 OS=Homo sapiensOX=9606 GN=DROSHAMMQGNTCHRMSFHPGRGCPRGRGGHGARPSAPSFRPQNLRLLHPQQPPVQYQYEPPSAPSTTFSNSPAPNFLPPRPDFVPFPPPMPPSAQGPLPPCPIRPPFPNHQMRHPFPVPPCFPPMPPPMPCPNNPPVPGAPPGQGTFPFMMPPPSMPHPPPPPVMPQQVNYQYPPGYSHHNFPPPSFNSFQNNPSSFLPSANNSSSPHFRHLPPYPLPKAPSERRSPERLKHYDDHRHRDHSHGRGERHRSLDRRERGRSPDRRRQDSRYRSDYDRGRTPSRHRSYERSRERERERHRHRDNRRSPSLERSYKKEYKRSGSRSPSREKKRARWEEEKDRWSDNQSSGKDKNYTSIKEKEPEETMPDKNEEEEEELLKPVWIRCTHSENYYSSDPMDQVGDSTVVGTSRLRDLYDKFEEELGSRQEKAKAARPPWEPPKTKLDEDLESSSESECESDEDSTCSSSSDSEVFDVIAEIKRKKAHPDRLHDELWYNDPGQMNDGPLCKCSAKARRTGIRHSIYPGEEAIKPCRPMTNNAGRLFHYRITVSPPTNFLTDRPTVIEYDDHEYIFEGFSMFAHAPLTNIPLCKVIRFNIDYTIHFIEEMMPENFCVKGLELFSLFLFRDILELYDWNLKGPLFEDSPPCCPRFHFMPRFVRFLPDGGKEVLSMHQILLYLLRCSKALVPEEEIANMLQWEELEWQKYAEECKGMIVTNPGTKPSSVRIDQLDREQFNPDVITFPIIVHFGIRPAQLSYAGDPQYQKLWKSYVKLRHLLANSPKVKQTDKQKLAQREEALQKIRQKNTMRREVTVELSSQGFWKTGIRSDVCQHAMMLPVLTHHIRYHQCLMHLDKLIGYTFQDRCLLQLAMTHPSHHLNFGMNPDHARNSLSNCGIRQPKYGDRKVHHMHMRKKGINTLINIMSRLGQDDPTPSRINHNERLEFLGDAVVEFLTSVHLYYLFPSLEEGGLATYRTAIVQNQHLAMLAKKLELDRFMLYAHGPDLCRESDLRHAMANCFEALIGAVYLEGSLEEAKQLFGRLLFNDPDLREVWLNYPLHPLQLQEPNTDRQLIETSPVLQKLTEFEEAIGVIFTHVRLLARAFTLRTVGFNHLTLGHNQRMEFLGDSIMQLVATEYLFIHFPDHHEGHLTLLRSSLVNNRTQAKVAEELGMQVWSIYLLSNCDCCLLRPSLVFLQTMNEVCSLK>sp|Q9NRR4-4|RNC_HUMAN Isoform 4 of Ribonuclease 3 OS=Homo sapiensOX=9606 GN=DROSHAMMQGNTCHRMSFHPGRGCPRGRGGHGARPSAPSFRPQNLRLLHPQQPPVQYQYEPPSAPSTTFSNSPAPNFLPPRPDFVPFPPPMPPSAQGPLPPCPIRPPFPNHQMRHPFPVPPCFPPMPPPMPCPNNPPVPGAPPGQGTFPFMMPPPSMPHPPPPPVMPQQVNYQYPPGYSHHNFPPPSFNSFQNNPSSFLPSANNSSSPHFRHLPPYPLPKAPSERRSPERLKHYDDHRHRDHSHGRGERHRSLDRRERGRSPDRRRQDSRYRSDYDRGRTPSRHRSYERSRERERERHRHRDNRRSPSLERSYKKEYKRSGSRSPSREKKRARWEEEKDRWSDNQSSGKDKNYTSIKEKEPEETMPDKNEEEEEELLKPVWIRCTHSENYYSSDPMDQVGDSTVVGTSRLRDLYDKFEEELGSRQEKAKAARPPWEPPKTKLDEDLESSSESECESDEDSTCSSSSDSEVFDVIAEIKRKKAHPDRLHDELWYNDPGQMNDGPLCKCSAKARRTGIRHSIYPGEEAIKPCRPMTNNAGRLFHYRITVSPPTNFLTDRPTVIEYDDHEYIFEGFSMFAHAPLTNIPLCKVIRFNIDYTIHFIEEMMPENFCVKGLELFSLFLFRDILELYDWNLKGPLFEDSPPCCPRFHFMPRFVRFLPDGGKEVLSMHQILLYLLRCSKALVPEEEIANMLQWEELEWQKYAEECKGMIVTNPGTKPSSVRIDQLDREQFNPDVITFPIIVHFGIRPAQLSYAGDPQYQKLWKSYVKLRHLLANSPKVKQTDKQKLAQREEALQKIRQKNTMRREVTVELSSQGFWKTGIRSDVCQHAMMLPVLTHHIRYHQCLMHLDKLIGYTFQDRCLLQLAMTHPSHHLNFGMNPDHARNSLSNCGIRQPKYGDRKVHHMHMRKKGINTLINIMSRLGQDDPTPSRINHNERLEFLGDAVVEFLTSVHLYYLFPSLEEGGLATYRTAIVQNQHLAMLAKKLELDRFMLYAHGPDLCRESDLRHAMANCFEALIGAVYLEGSLEEAKQLFGRLLFNDPDLREVWLNYPLHPLQLQEPNTDRQLIETSPVLQKLTEFEEAIGVIFTHVRLLARAFTLRTVGFNHLTLGHNQRMEFLGDSIMQLVATEYLFIHFPDHHEGHLTLLRSSLVNNRTQAKVAEELGMQEYAITNDKTKRPVALRTKTLADLLESFIAALYIDKDLEYVHTFMNVCFFPRLKEFILNQDWNDPKSQLQQCCLTLRTEGKEPDIPLYKTLQTVGPSHARTYTVAVYFKGERIGCGKGPSIQQAEMGAAMDALEKYNFPQMAHQKRFIERKYRQELKEMRWEREHQEREPDETEDIKK>sp|O00237|RN103_HUMAN E3 ubiquitin-protein ligase RNF103 OS=Homo sapiensOX=9606 GN=RNF103 PE=1 SV=1MWLKLFFLLLYFLVLFVLARFFEAIVWYETGIFATQLVDPVALSFKKLKTILECRGLGYSGLPEKKDVRELVEKSGDLMEGELYSALKEEEASESVSSTNFSGEMHFYELVEDTKDGIWLVQVIANDRSPLVGKIHWEKMVKKVSRFGIRTGTFNCSSDPRYCRRRGWVRSTLIMSVPQTSTSKGKVMLKEYSGRKIEVEHIFKWITAHAASRIKTIYNAEHLKEEWNKSDQYWLKIYLFANLDQPPAFFSALSIKFTGRVEFIFVNVENWDNKSYMTDIGIYNMPSYILRTPEGIYRYGNHTGEFISLQAMDSFLRSLQPEVNDLFVLSLVLVNLMAWMDLFITQGATIKRFVVLISTLGTYNSLLIISWLPVLGFLQLPYLDSFYEYSLKLLRYSNTTTLASWVRADWMFYSSHPALFLSTYLGHGLLIDYFEKKRRRNNNNDEVNANNLEWLSSLWDWYTSYLFHPIASFQNFPVESDWDEDPDLFLERLAFPDLWLHPLIPTDYIKNLPMWRFKCLGVQSEEEMSEGSQDTENDSESENTDTLSSEKEVFEDKQSVLHNSPGTASHCDAEACSCANKYCQTSPCERKGRSYGSYNTNEDMEPDWLTWPADMLHCTECVVCLENFENGCLLMGLPCGHVFHQNCIVMWLAGGRHCCPVCRWPSYKKKQPYAQHQPLSNDVPS>sp|Q9Y2P5|S27A5_HUMAN Bile acyl-CoA synthetase OS=Homo sapiens OX=9606GN=SLC27A5 PE=1 SV=1MGVRQQLALLLLLLLLLWGLGQPVWPVAVALTLRWLLGDPTCCVLLGLAMLARPWLGPWVPHGLSLAAAALALTLLPARLPPGLRWLPADVIFLAKILHLGLKIRGCLSRQPPDTFVDAFERRARAQPGRALLVWTGPGAGSVTFGELDARACQAAWALKAELGDPASLCAGEPTALLVLASQAVPALCMWLGLAKLGCPTAWINPHGRGMPLAHSVLSSGARVLVVDPDLRESLEEILPKLQAENIRCFYLSHTSPTPGVGALGAALDAAPSHPVPADLRAGITWRSPALFIYTSGTTGLPKPAILTHERVLQMSKMLSLSGATADDVVYTVLPLYHVMGLVVGILGCLDLGATCVLAPKFSTSCFWDDCRQHGVTVILYVGELLRYLCNIPQQPEDRTHTVRLAMGNGLRADVWETFQQRFGPIRIWEVYGSTEGNMGLVNYVGRCGALGKMSCLLRMLSPFELVQFDMEAAEPVRDNQGFCIPVGLGEPGLLLTKVVSQQPFVGYRGPRELSERKLVRNVRQSGDVYYNTGDVLAMDREGFLYFRDRLGDTFRWKGENVSTHEVEGVLSQVDFLQQVNVYGVCVPGCEGKVGMAAVQLAPGQTFDGEKLYQHVRAWLPAYATPHFIRIQDAMEVTSTFKLMKTRLVREGFNVGIVVDPLFVLDNRAQSFRPLTAEMYQAVCEGTWRL>sp|Q9Y2P5-2|S27A5_HUMAN Isoform 2 of Bile acyl-CoA synthetase OS=Homosapiens OX=9606 GN=SLC27A5MGVRQQLALLLLLLLLLWGLGQPVWPVAVALTLRWLLGDPTCCVLLGLAMLARPWLGPWVPHGLSLAAAALALTLLPARLPPGLRWLPADVIFLAKILHLGLKIRGCLSRQPPDTFVDAFERRARAQPGRALLVWTGPGAGSVTFDLRESLEEILPKLQAENIRCFYLSHTSPTPGVGALGAALDAAPSHPVPADLRAGITWRSPALFIYTSGTTGLPKPAILTHERVLQMSKMLSLSGATADDVVYTVLPLYHVMGLVVGILGCLDLGATCVLAPKFSTSCFWDDCRQHGVTVILYVGELLRYLCNIPQQPEDRTHTVRLAMGNGLRADVWETFQQRFGPIRIWEVYGSTEGNMGLVNYVGRCGALGKMSCLLRMLSPFELVQFDMEAAEPVRDNQGFCIPVGLGEPGLLLTKVVSQQPFVGYRGPRELSERKLVRNVRQSGDVYYNTGDVLAMDREGFLYFRDRLGDTFRWKGENVSTHEVEGVLSQVDFLQQVNVYGVCVPGCEGKVGMAAVQLAPGQTFDGEKLYQHVRAWLPAYATPHFIRIQDAMEVTSTFKLMKTRLVREGFNVGIVVDPLFVLDNRAQSFRPLTAEMYQAVCEGTWRL>sp|Q8IXM3|RM41_HUMAN 39S ribosomal protein L41, mitochondrial OS=Homosapiens OX=9606 GN=MRPL41 PE=1 SV=1MGVLAAAARCLVRGADRMSKWTSKRGPRSFRGRKGRGAKGIGFLTSGWRFVQIKEMVPEFVVPDLTGFKLKPYVSYLAPESEETPLTAAQLFSEAVAPAIEKDFKDGTFDPDNLEKYGFEPTQEGKLFQLYPRNFLR>sp|O75792|RNH2A_HUMAN Ribonuclease H2 subunit A OS=Homo sapiens OX=9606GN=RNASEH2A PE=1 SV=2MDLSELERDNTGRCRLSSPVPAVCRKEPCVLGVDEAGRGPVLGPMVYAICYCPLPRLADLEALKVADSKTLLESERERLFAKMEDTDFVGWALDVLSPNLISTSMLGRVKYNLNSLSHDTATGLIQYALDQGVNVTQVFVDTVGMPETYQARLQQSFPGIEVTVKAKADALYPVVSAASICAKVARDQAVKKWQFVEKLQDLDTDYGSGYPNDPKTKAWLKEHVEPVFGFPQFVRFSWRTAQTILEKEAEDVIWEDSASENQEGLRKITSYFLNEGSQARPRSSHRYFLERGLESATSL>sp|Q8IYW5|RN168_HUMAN E3 ubiquitin-protein ligase RNF168 OS=Homo sapiensOX=9606 GN=RNF168 PE=1 SV=1MALPKDAIPSLSECQCGICMEILVEPVTLPCNHTLCKPCFQSTVEKASLCCPFCRRRVSSWTRYHTRRNSLVNVELWTIIQKHYPRECKLRASGQESEEVADDYQPVRLLSKPGELRREYEEEISKVAAERRASEEEENKASEEYIQRLLAEEEEEEKRQAEKRRRAMEEQLKSDEELARKLSIDINNFCEGSISASPLNSRKSDPVTPKSEKKSKNKQRNTGDIQKYLTPKSQFGSASHSEAVQEVRKDSVSKDIDSSDRKSPTGQDTEIEDMPTLSPQISLGVGEQGADSSIESPMPWLCACGAEWYHEGNVKTRPSNHGKELCVLSHERPKTRVPYSKETAVMPCGRTESGCAPTSGVTQTNGNNTGETENEESCLLISKEISKRKNQESSFEAVKDPCFSAKRRKVSPESSPDQEETEINFTQKLIDLEHLLFERHKQEEQDRLLALQLQKEVDKEQMVPNRQKGSPDEYHLRATSSPPDKVLNGQRKNPKDGNFKRQTHTKHPTPERGSRDKNRQVSLKMQLKQSVNRRKMPNSTRDHCKVSKSAHSLQPSISQKSVFQMFQRCTK>sp|Q9UQD0|SCN8A_HUMAN Sodium channel protein type 8 subunit alphaOS=Homo sapiens OX=9606 GN=SCN8A PE=1 SV=1MAARLLAPPGPDSFKPFTPESLANIERRIAESKLKKPPKADGSHREDDEDSKPKPNSDLEAGKSLPFIYGDIPQGLVAVPLEDFDPYYLTQKTFVVLNRGKTLFRFSATPALYILSPFNLIRRIAIKILIHSVFSMIIMCTILTNCVFMTFSNPPDWSKNVEYTFTGIYTFESLVKIIARGFCIDGFTFLRDPWNWLDFSVIMMAYITEFVNLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCVVWPINFNESYLENGTKGFDWEEYINNKTNFYTVPGMLEPLLCGNSSDAGQCPEGYQCMKAGRNPNYGYTSFDTFSWAFLALFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFVGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFKAMLEQLKKQQEEAQAAAMATSAGTVSEDAIEEEGEEGGGSPRSSSEISKLSSKSAKERRNRRKKRKQKELSEGEEKGDPEKVFKSESEDGMRRKAFRLPDNRIGRKFSIMNQSLLSIPGSPFLSRHNSKSSIFSFRGPGRFRDPGSENEFADDEHSTVEESEGRRDSLFIPIRARERRSSYSGYSGYSQGSRSSRIFPSLRRSVKRNSTVDCNGVVSLIGGPGSHIGGRLLPEATTEVEIKKKGPGSLLVSMDQLASYGRKDRINSIMSVVTNTLVEELEESQRKCPPCWYKFANTFLIWECHPYWIKLKEIVNLIVMDPFVDLAITICIVLNTLFMAMEHHPMTPQFEHVLAVGNLVFTGIFTAEMFLKLIAMDPYYYFQEGWNIFDGFIVSLSLMELSLADVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINQDCELPRWHMHDFFHSFLIVFRVLCGEWIETMWDCMEVAGQAMCLIVFMMVMVIGNLVVLNLFLALLLSSFSADNLAATDDDGEMNNLQISVIRIKKGVAWTKLKVHAFMQAHFKQREADEVKPLDELYEKKANCIANHTGADIHRNGDFQKNGNGTTSGIGSSVEKYIIDEDHMSFINNPNLTVRVPIAVGESDFENLNTEDVSSESDPEGSKDKLDDTSSSEGSTIDIKPEVEEVPVEQPEEYLDPDACFTEGCVQRFKCCQVNIEEGLGKSWWILRKTCFLIVEHNWFETFIIFMILLSSGALAFEDIYIEQRKTIRTILEYADKVFTYIFILEMLLKWTAYGFVKFFTNAWCWLDFLIVAVSLVSLIANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKYHYCFNETSEIRFEIEDVNNKTECEKLMEGNNTEIRWKNVKINFDNVGAGYLALLQVATFKGWMDIMYAAVDSRKPDEQPKYEDNIYMYIYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPLNKIQGIVFDFVTQQAFDIVIMMLICLNMVTMMVETDTQSKQMENILYWINLVFVIFFTCECVLKMFALRHYYFTIGWNIFDFVVVILSIVGMFLADIIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIFSIFGMSNFAYVKHEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLLPILNRPPDCSLDKEHPGSGFKGDCGNPSVGIFFFVSYIIISFLIVVNMYIAIILENFSVATEESADPLSEDDFETFYEIWEKFDPDATQFIEYCKLADFADALEHPLRVPKPNTIELIAMDLPMVSGDRIHCLDILFAFTKRVLGDSGELDILRQQMEERFVASNPSKVSYEPITTTLRRKQEEVSAVVLQRAYRGHLARRGFICKKTTSNKLENGGTHREKKESTPSTASLPSYDSVTKPEKEKQQRAEEGRRERAKRQKEVRESKC>sp|Q9UQD0-2|SCN8A_HUMAN Isoform 2 of Sodium channel protein type 8subunit alpha OS=Homo sapiens OX=9606 GN=SCN8AMAARLLAPPGPDSFKPFTPESLANIERRIAESKLKKPPKADGSHREDDEDSKPKPNSDLEAGKSLPFIYGDIPQGLVAVPLEDFDPYYLTQKTFVVLNRGKTLFRFSATPALYILSPFNLIRRIAIKILIHSVFSMIIMCTILTNCVFMTFSNPPDWSKNVEYTFTGIYTFESLVKIIARGFCIDGFTFLRDPWNWLDFSVIMMAYVTEFVDLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCVVWPINFNESYLENGTKGFDWEEYINNKTNFYTVPGMLEPLLCGNSSDAGQCPEGYQCMKAGRNPNYGYTSFDTFSWAFLALFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFVGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFKAMLEQLKKQQEEAQAAAMATSAGTVSEDAIEEEGEEGGGSPRSSSEISKLSSKSAKERRNRRKKRKQKELSEGEEKGDPEKVFKSESEDGMRRKAFRLPDNRIGRKFSIMNQSLLSIPGSPFLSRHNSKSSIFSFRGPGRFRDPGSENEFADDEHSTVEESEGRRDSLFIPIRARERRSSYSGYSGYSQGSRSSRIFPSLRRSVKRNSTVDCNGVVSLIGGPGSHIGGRLLPEATTEVEIKKKGPGSLLVSMDQLASYGRKDRINSIMSVVTNTLVEELEESQRKCPPCWYKFANTFLIWECHPYWIKLKEIVNLIVMDPFVDLAITICIVLNTLFMAMEHHPMTPQFEHVLAVGNLVFTGIFTAEMFLKLIAMDPYYYFQEGWNIFDGFIVSLSLMELSLADVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINQDCELPRWHMHDFFHSFLIVFRVLCGEWIETMWDCMEVAGQAMCLIVFMMVMVIGNLVVLNLFLALLLSSFSADNLAATDDDGEMNNLQISVIRIKKGVAWTKLKVHAFMQAHFKQREADEVKPLDELYEKKANCIANHTGADIHRNGDFQKNGNGTTSGIGSSVEKYIIDEDHMSFINNPNLTVRVPIAVGESDFENLNTEDVSSESDPEGSKDKLDDTSSSEGSTIDIKPEVEEVPVEQPEEYLDPDACFTEGCVQRFKCCQVNIEEGLGKSWWILRKTCFLIVEHNWFETFIIFMILLSSGALAFEDIYIEQRKTIRTILEYADKVFTYIFILEMLLKWTAYGFVKFFTNAWCWLDFLIVAVSLVSLIANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKYHYCFNETSEIRFEIEDVNNKTECEKLMEGNNTEIRWKNVKINFDNVGAGYLALLQVATFKGWMDIMYAAVDSRKPDEQPKYEDNIYMYIYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPLNKIQGIVFDFVTQQAFDIVIMMLICLNMVTMMVETDTQSKQMENILYWINLVFVIFFTCECVLKMFALRHYYFTIGWNIFDFVVVILSIVGMFLADIIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIFSIFGMSNFAYVKHEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLLPILNRPPDCSLDKEHPGSGFKGDCGNPSVGIFFFVSYIIISFLIVVNMYIAIILENFSVATEESADPLSEDDFETFYEIWEKFDPDATQFIEYCKLADFADALEHPLRVPKPNTIELIAMDLPMVSGDRIHCLDILFAFTKRVLGDSGELDILRQQMEERFVASNPSKVSYEPITTTLRRKQEEVSAVVLQRAYRGHLARRGFICKKTTSNKLENGGTHREKKESTPSTASLPSYDSVTKPEKEKQQRAEEGRRERAKRQKEVRESKC>sp|Q9UQD0-3|SCN8A_HUMAN Isoform 3 of Sodium channel protein type 8subunit alpha OS=Homo sapiens OX=9606 GN=SCN8AMAARLLAPPGPDSFKPFTPESLANIERRIAESKLKKPPKADGSHREDDEDSKPKPNSDLEAGKSLPFIYGDIPQGLVAVPLEDFDPYYLTQKTFVVLNRGKTLFRFSATPALYILSPFNLIRRIAIKILIHSVFSMIIMCTILTNCVFMTFSNPPDWSKNVEYTFTGIYTFESLVKIIARGFCIDGFTFLRDPWNWLDFSVIMMAYITEFVNLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCVVWPINFNESYLENGTKGFDWEEYINNKTNFYTVPGMLEPLLCGNSSDAGQCPEGYQCMKAGRNPNYGYTSFDTFSWAFLALFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFVGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFKAMLEQLKKQQEEAQAAAMATSAGTVSEDAIEEEGEEGGGSPRSSSEISKLSSKSAKERRNRRKKRKQKELSEGEEKGDPEKVFKSESEDGMRRKAFRLPDNRIGRKFSIMNQSLLSIPGSPFLSRHNSKSSIFSFRGPGRFRDPGSENEFADDEHSTVEESEGRRDSLFIPIRARERRSSYSGYSGYSQGSRSSRIFPSLRRSVKRNSTVDCNGVVSLIGGPGSHIGGRLLPEVKIDKAATDDSATTEVEIKKKGPGSLLVSMDQLASYGRKDRINSIMSVVTNTLVEELEESQRKCPPCWYKFANTFLIWECHPYWIKLKEIVNLIVMDPFVDLAITICIVLNTLFMAMEHHPMTPQFEHVLAVGNLVFTGIFTAEMFLKLIAMDPYYYFQEGWNIFDGFIVSLSLMELSLADVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINQDCELPRWHMHDFFHSFLIVFRVLCGEWIETMWDCMEVAGQAMCLIVFMMVMVIGNLVVLNLFLALLLSSFSADNLAATDDDGEMNNLQISVIRIKKGVAWTKLKVHAFMQAHFKQREADEVKPLDELYEKKANCIANHTGADIHRNGDFQKNGNGTTSGIGSSVEKYIIDEDHMSFINNPNLTVRVPIAVGESDFENLNTEDVSSESDPEGSKDKLDDTSSSEGSTIDIKPEVEEVPVEQPEEYLDPDACFTEGCVQRFKCCQVNIEEGLGKSWWILRKTCFLIVEHNWFETFIIFMILLSSGALAFEDIYIEQRKTIRTILEYADKVFTYIFILEMLLKWTAYGFVKFFTNAWCWLDFLIVAVSLVSLIANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKYHYCFNETSEIRFEIEDVNNKTECEKLMEGNNTEIRWKNVKINFDNVGAGYLALLQVATFKGWMDIMYAAVDSRKPDEQPKYEDNIYMYIYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPLNKIQGIVFDFVTQQAFDIVIMMLICLNMVTMMVETDTQSKQMENILYWINLVFVIFFTCECVLKMFALRHYYFTIGWNIFDFVVVILSIVGMFLADIIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIFSIFGMSNFAYVKHEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLLPILNRPPDCSLDKEHPGSGFKGDCGNPSVGIFFFVSYIIISFLIVVNMYIAIILENFSVATEESADPLSEDDFETFYEIWEKFDPDATQFIEYCKLADFADALEHPLRVPKPNTIELIAMDLPMVSGDRIHCLDILFAFTKRVLGDSGELDILRQQMEERFVASNPSKVSYEPITTTLRRKQEEVSAVVLQRAYRGHLARRGFICKKTTSNKLENGGTHREKKESTPSTASLPSYDSVTKPEKEKQQRAEEGRRERAKRQKEVRESKC>sp|Q9UQD0-4|SCN8A_HUMAN Isoform 4 of Sodium channel protein type 8subunit alpha OS=Homo sapiens OX=9606 GN=SCN8AMAARLLAPPGPDSFKPFTPESLANIERRIAESKLKKPPKADGSHREDDEDSKPKPNSDLEAGKSLPFIYGDIPQGLVAVPLEDFDPYYLTQKTFVVLNRGKTLFRFSATPALYILSPFNLIRRIAIKILIHSVFSMIIMCTILTNCVFMTFSNPPDWSKNVEYTFTGIYTFESLVKIIARGFCIDGFTFLRDPWNWLDFSVIMMAYITEFVNLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCVVWPINFNESYLENGTKGFDWEEYINNKTNFYTVPGMLEPLLCGNSSDAGQCPEGYQCMKAGRNPNYGYTSFDTFSWAFLALFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFVGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFKAMLEQLKKQQEEAQAAAMATSAGTVSEDAIEEEGEEGGGSPRSSSEISKLSSKSAKERRNRRKKRKQKELSEGEEKGDPEKVFKSESEDGMRRKAFRLPDNRIGRKFSIMNQSLLSIPGSPFLSRHNSKSSIFSFRGPGRFRDPGSENEFADDEHSTVEESEGRRDSLFIPIRARERRSSYSGYSGYSQGSRSSRIFPSLRRSVKRNSTVDCNGVVSLIGGPGSHIGGRLLPEATTEVEIKKKGPGSLLVSMDQLASYGRKDRINSIMSVVTNTLVEELEESQRKCPPCWYKFANTFLIWECHPYWIKLKEIVNLIVMDPFVDLAITICIVLNTLFMAMEHHPMTPQFEHVLAVGNLVFTGIFTAEMFLKLIAMDPYYYFQEGWNIFDGFIVSLSLMELSLADVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINQDCELPRWHMHDFFHSFLIVFRVLCGEWIETMWDCMEVAGQAMCLIVFMMVMVIGNLVVLNLFLALLLSSFSADNLAATDDDGEMNNLQISVIRIKKGVAWTKLKVHAFMQAHFKQREADEVKPLDELYEKKANCIANHTGADIHRNGDFQKNGNGTTSGIGSSVEKYIIDEDHMSFINNPNLTVRVPIAVGESDFENLNTEDVSSESDPEGSKDKLDDTSSSEGSTIDIKPEVEEVPVEQPEEYLDPDACFTEGCVQRFKCCQVNIEEGLGKSWWILRKTCFLIVEHNWFETFIIFMILLSSGALAFEDIYIEQRKTIRTILEYADKVFTYIFILEMLLKWTAYGFVKFFTNAWCWLDFLIVAVPLNLSGLI>sp|Q9UQD0-5|SCN8A_HUMAN Isoform 5 of Sodium channel protein type 8subunit alpha OS=Homo sapiens OX=9606 GN=SCN8AMAARLLAPPGPDSFKPFTPESLANIERRIAESKLKKPPKADGSHREDDEDSKPKPNSDLEAGKSLPFIYGDIPQGLVAVPLEDFDPYYLTQKTFVVLNRGKTLFRFSATPALYILSPFNLIRRIAIKILIHSVFSMIIMCTILTNCVFMTFSNPPDWSKNVEYTFTGIYTFESLVKIIARGFCIDGFTFLRDPWNWLDFSVIMMAYITEFVNLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCVVWPINFNESYLENGTKGFDWEEYINNKTNFYTVPGMLEPLLCGNSSDAGQCPEGYQCMKAGRNPNYGYTSFDTFSWAFLALFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFVGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFKAMLEQLKKQQEEAQAAAMATSAGTVSEDAIEEEGEEGGGSPRSSSEISKLSSKSAKERRNRRKKRKQKELSEGEEKGDPEKVFKSESEDGMRRKAFRLPDNRIGRKFSIMNQSLLSIPGSPFLSRHNSKSSIFSFRGPGRFRDPGSENEFADDEHSTVEESEGRRDSLFIPIRARERRSSYSGYSGYSQGSRSSRIFPSLRRSVKRNSTVDCNGVVSLIGGPGSHIGGRLLPEATTEVEIKKKGPGSLLVSMDQLASYGRKDRINSIMSVVTNTLVEELEESQRKCPPCWYKFANTFLIWECHPYWIKLKEIVNLIVMDPFVDLAITICIVLNTLFMAMEHHPMTPQFEHVLAVGNLVFTGIFTAEMFLKLIAMDPYYYFQEGWNIFDGFIVSLSLMELSLADVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINQDCELPRWHMHDFFHSFLIVFRVLCGEWIETMWDCMEVAGQAMCLIVFMMVMVIGNLVVLNLFLALLLSSFSADNLAATDDDGEMNNLQISVIRIKKGVAWTKLKVHAFMQAHFKQREADEVKPLDELYEKKANCIANHTGADIHRNGDFQKNGNGTTSGIGSSVEKYIIDEDHMSFINNPNLTVRVPIAVGESDFENLNTEDVSSESDPEGSKDKLDDTSSSEGSTIDIKPEVEEVPVEQPEEYLDPDACFTEGCVQRFKCCQVNIEEGLGKSWWILRKTCFLIVEHNWFETFIIFMILLSSGALAFEDIYIEQRKTIRTILEYADKVFTYIFILEMLLKWTAYGFVKFFTNAWCWLDFLIVAVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKYHYCFNETSEIRFEIEDVNNKTECEKLMEGNNTEIRWKNVKINFDNVGAGYLALLQVATFKGWMDIMYAAVDSRKPDEQPKYEDNIYMYIYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPLNKIQGIVFDFVTQQAFDIVIMMLICLNMVTMMVETDTQSKQMENILYWINLVFVIFFTCECVLKMFALRHYYFTIGWNIFDFVVVILSIVGMFLADIIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIFSIFGMSNFAYVKHEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLLPILNRPPDCSLDKEHPGSGFKGDCGNPSVGIFFFVSYIIISFLIVVNMYIAIILENFSVATEESADPLSEDDFETFYEIWEKFDPDATQFIEYCKLADFADALEHPLRVPKPNTIELIAMDLPMVSGDRIHCLDILFAFTKRVLGDSGELDILRQQMEERFVASNPSKVSYEPITTTLRRKQEEVSAVVLQRAYRGHLARRGFICKKTTSNKLENGGTHREKKESTPSTASLPSYDSVTKPEKEKQQRAEEGRRERAKRQKEVRESKC>sp|Q99729|ROAA_HUMAN Heterogeneous nuclear ribonucleoprotein A/B OS=Homosapiens OX=9606 GN=HNRNPAB PE=1 SV=2MSEAGEEQPMETTGATENGHEAVPEASRGRGWTGAAAGAGGATAAPPSGNQNGAEGDQINASKNEEDAGKMFVGGLSWDTSKKDLKDYFTKFGEVVDCTIKMDPNTGRSRGFGFILFKDAASVEKVLDQKEHRLDGRVIDPKKAMAMKKDPVKKIFVGGLNPESPTEEKIREYFGEFGEIEAIELPMDPKLNKRRGFVFITFKEEEPVKKVLEKKFHTVSGSKCEIKVAQPKEVYQQQQYGSGGRGNRNRGNRGSGGGGGGGGQSQSWNQGYGNYWNQGYGYQQGYGPGYGGYDYSPYGYYGYGPGYDYSQGSTNYGKSQRRGGHQNNYKPY>sp|Q99729-2|ROAA_HUMAN Isoform 2 of Heterogeneous nuclearribonucleoprotein A/B OS=Homo sapiens OX=9606 GN=HNRNPABMSEAGEEQPMETTGATENGHEAVPEGESPAGAGTGAAAGAGGATAAPPSGNQNGAEGDQINASKNEEDAGKMFVGGLSWDTSKKDLKDYFTKFGEVVDCTIKMDPNTGRSRGFGFILFKDAASVEKVLDQKEHRLDGRVIDPKKAMAMKKDPVKKIFVGGLNPEATEEKIREYFGEFGEIEAIELPMDPKLNKRRGFVFITFKEEEPVKKVLEKKFHTVSGSKCEIKVAQPKEVYQQQQYGSGGRGNRNRGNRGSGGGGGGGGQSQSWNQGYGNYWNQGYGYQQGYGPGYGGYDYSPYGYYGYGPGYDYSQGSTNYGKSQRRGGHQNNYKPY>sp|Q99729-3|ROAA_HUMAN Isoform 3 of Heterogeneous nuclearribonucleoprotein A/B OS=Homo sapiens OX=9606 GN=HNRNPABMSEAGEEQPMETTGATENGHEAVPEGESPAGAGTGAAAGAGGATAAPPSGNQNGAEGDQINASKNEEDAGKMFVGGLSWDTSKKDLKDYFTKFGEVVDCTIKMDPNTGRSRGFGFILFKDAASVEKVLDQKEHRLDGRVIDPKKAMAMKKDPVKKIFVGGLNPEATEEKIREYFGEFGEIEAIELPMDPKLNKRRGFVFITFKEEEPVKKVLEKKFHTVSGSKCEIKVAQPKEVYQQQQYGSGGRGNRNRGNRGSGGGGGGGGQGSTNYGKSQRRGGHQNNYKPY>sp|Q99729-4|ROAA_HUMAN Isoform 4 of Heterogeneous nuclearribonucleoprotein A/B OS=Homo sapiens OX=9606 GN=HNRNPABMSEAGEEQPMETTGATENGHEAVPEGESPAGAGTGAAAGAGGATAAPPSGNQNGAEGDQINASKNEEDAGKMFVGGLSWDTSKKDLKDYFTKFGEVVDCTIKMDPNTGRSRGFGFILFKDAASVEKVLDQKEHRLDGRVIDPKKAMAMKKDPVKKIFVGGLNPESPTEEKIREYFGEFGEIEAIELPMDPKLNKRRGFVFITFKEEEPVKKVLEKKFHTVSGSKCEIKVAQPKEVYQQQQYGSGGRGNRNRGNRGSGGGGGGGGQGSTNYGKSQRRGGHQNNYKPY>sp|Q6ZSG1|RN165_HUMAN E3 ubiquitin-protein ligase RNF165 OS=Homo sapiensOX=9606 GN=RNF165 PE=1 SV=1MVLVHVGYLVLPVFGSVRNRGAPFQRSQHPHATSCRHFHLGPPQPQQLAPDFPLAHPVQSQPGLSAHMAPAHQHSGALHQSLTPLPTLQFQDVTGPSFLPQALHQQYLLQQQLLEAQHRRLVSHPRRSQERVSVHPHRLHPSFDFGQLQTPQPRYLAEGTDWDLSVDAGLSPAQFQVRPIPQHYQHYLATPRMHHFPRNSSSTQMVVHEIRNYPYPQLHFLALQGLNPSRHTSAVRESYEELLQLEDRLGNVTRGAVQNTIERFTFPHKYKKRRPQDGKGKKDEGEESDTDEKCTICLSMLEDGEDVRRLPCMHLFHQLCVDQWLAMSKKCPICRVDIETQLGADS>sp|Q6ZSG1-2|RN165_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF165OS=Homo sapiens OX=9606 GN=RNF165MHHFPRNSSSTQMVVHEIRNYPYPQLHFLALQGLNPSRHTSAVRESYEELLQLEDRLGNVTRGAVQNTIERFTFPHKYKKRRPQDGKGKKDEGEESDTDEKCTICLSMLEDGEDVRRLPCMHLFHQLCVDQWLAMSKKCPICRVDIETQLGADS>sp|Q9P0P0|RN181_HUMAN E3 ubiquitin-protein ligase RNF181 OS=Homo sapiensOX=9606 GN=RNF181 PE=1 SV=1MASYFDEHDCEPSDPEQETRTNMLLELARSLFNRMDFEDLGLVVDWDHHLPPPAAKTVVENLPRTVIRGSQAELKCPVCLLEFEEEETAIEMPCHHLFHSSCILPWLSKTNSCPLCRYELPTDDDTYEEHRRDKARKQQQQHRLENLHGAMYT>sp|P78381|S35A2_HUMAN UDP-galactose translocator OS=Homo sapiens OX=9606GN=SLC35A2 PE=1 SV=1MAAVGAGGSTAAPGPGAVSAGALEPGTASAAHRRLKYISLAVLVVQNASLILSIRYARTLPGDRFFATTAVVMAEVLKGLTCLLLLFAQKRGNVKHLVLFLHEAVLVQYVDTLKLAVPSLIYTLQNNLQYVAISNLPAATFQVTYQLKILTTALFSVLMLNRSLSRLQWASLLLLFTGVAIVQAQQAGGGGPRPLDQNPGAGLAAVVASCLSSGFAGVYFEKILKGSSGSVWLRNLQLGLFGTALGLVGLWWAEGTAVATRGFFFGYTPAVWGVVLNQAFGGLLVAVVVKYADNILKGFATSLSIVLSTVASIRLFGFHVDPLFALGAGLVIGAVYLYSLPRGAAKAIASASASASGPCVHQQPPGQPPPPQLSSHRGDLITEPFLPKLLTKVKGS>sp|P78381-2|S35A2_HUMAN Isoform 2 of UDP-galactose translocator OS=Homosapiens OX=9606 GN=SLC35A2MAAVGAGGSTAAPGPGAVSAGALEPGTASAAHRRLKYISLAVLVVQNASLILSIRYARTLPGDRFFATTAVVMAEVLKGLTCLLLLFAQKRGNVKHLVLFLHEAVLVQYVDTLKLAVPSLIYTLQNNLQYVAISNLPAATFQVTYQLKILTTALFSVLMLNRSLSRLQWASLLLLFTGVAIVQAQQAGGGGPRPLDQNPGAGLAAVVASCLSSGFAGVYFEKILKGSSGSVWLRNLQLGLFGTALGLVGLWWAEGTAVATRGFFFGYTPAVWGVVLNQAFGGLLVAVVVKYADNILKGFATSLSIVLSTVASIRLFGFHVDPLFALGAGLVIGAVYLYSLPRGAAKAIASASASASGPCVHQQPPGQPPPPQLSSHRGDLITEPFLPKSVLVK>sp|P78381-3|S35A2_HUMAN Isoform 3 of UDP-galactose translocator OS=Homosapiens OX=9606 GN=SLC35A2MAAVGAGGSTAAPGPGAVSAGALEPGTASAAHRRLKYISLAVLVVQNASLILSIRYARTLPGDRFFATTAVVMAEVLKGLTCLLLLFAQKRGNVKHLVLFLHEAVLVQYVDTLKLAVPSLIYTLQNNLQYVAISNLPAATFQPSPRCSQSHSLCLCLRLRALRSPAASRAATTTAAVFPPWRPHHGALSAKVSAGEVRAGSNGGTQGRGTGVEGVGHLQDPSRHPPGPGSSGFGRWSFLPGH>sp|P78381-4|S35A2_HUMAN Isoform 4 of UDP-galactose translocator OS=Homosapiens OX=9606 GN=SLC35A2MAAVGAGGSTAAPGPGAVSAGALEPGTASAELLLTWEEAEARGQGLPQPLPDTSVRIPAHRRLKYISLAVLVVQNASLILSIRYARTLPGDRFFATTAVVMAEVLKGLTCLLLLFAQKRGNVKHLVLFLHEAVLVQYVDTLKLAVPSLIYTLQNNLQYVAISNLPAATFQVTYQLKILTTALFSVLMLNRSLSRLQWASLLLLFTGVAIVQAQQAGGGGPRPLDQNPGAGLAAVVASCLSSGFAGVYFEKILKGSSGSVWLRNLQLGLFGTALGLVGLWWAEGTAVATRGFFFGYTPAVWGVVLNQAFGGLLVAVVVKYADNILKGFATSLSIVLSTVASIRLFGFHVDPLFALGAGLVIGAVYLYSLPRGAAKAIASASASASGPCVHQQPPGQPPPPQLSSHRGDLITEPFLPKSVLVK>sp|P78381-5|S35A2_HUMAN Isoform 5 of UDP-galactose translocator OS=Homosapiens OX=9606 GN=SLC35A2MAAVGAGGSTAAPGPGAVSAGALEPGTASAGNVKHLVLFLHEAVLVQYVDTLKLAVPSLIYTLQNNLQYVAISNLPAATFQVTYQLKILTTALFSVLMLNRSLSRLQWASLLLLFTGVAIVQAQQAGGGGPRPLDQNPGAGLAAVVASCLSSGFAGVYFEKILKGSSGSVWLRNLQLGLFGTALGLVGLWWAEGTAVATRGFFFGYTPAVWGVVLNQAFGGLLVAVVVKYADNILKGFATSLSIVLSTVASIRLFGFHVDPLFALGAGLVIGAVYLYSLPRGAAKAIASASASASGPCVHQQPPGQPPPPQLSSHRGDLITEPFLPKSVLVK>sp|Q92599|SEPT8_HUMAN Septin-8 OS=Homo sapiens OX=9606 GN=SEPTIN8 PE=1SV=4MAATDLERFSNAEPEPRSLSLGGHVGFDSLPDQLVSKSVTQGFSFNILCVGETGIGKSTLMNTLFNTTFETEEASHHEACVRLRPQTYDLQESNVQLKLTIVDAVGFGDQINKDESYRPIVDYIDAQFENYLQEELKIRRSLFDYHDTRIHVCLYFITPTGHSLKSLDLVTMKKLDSKVNIIPIIAKADTISKSELHKFKIKIMGELVSNGVQIYQFPTDDEAVAEINAVMNAHLPFAVVGSTEEVKVGNKLVRARQYPWGVVQVENENHCDFVKLREMLIRVNMEDLREQTHSRHYELYRRCKLEEMGFQDSDGDSQPFSLQETYEAKRKEFLSELQRKEEEMRQMFVNKVKETELELKEKERELHEKFEHLKRVHQEEKRKVEEKRRELEEETNAFNRRKAAVEALQSQALHATSQQPLRKDKDKKNRSDIGAHQPGMSLSSSKVMMTKASVEPLNCSSWWPAIQCCSCLVRDATWREGFL>sp|Q92599-2|SEPT8_HUMAN Isoform 2 of Septin-8 OS=Homo sapiens OX=9606GN=SEPTIN8MAATDLERFSNAEPEPRSLSLGGHVGFDSLPDQLVSKSVTQGFSFNILCVGETGIGKSTLMNTLFNTTFETEEASHHEACVRLRPQTYDLQESNVQLKLTIVDAVGFGDQINKDESYRPIVDYIDAQFENYLQEELKIRRSLFDYHDTRIHVCLYFITPTGHSLKSLDLVTMKKLDSKVNIIPIIAKADTISKSELHKFKIKIMGELVSNGVQIYQFPTDDEAVAEINAVMNAHLPFAVVGSTEEVKVGNKLVRARQYPWGVVQVENENHCDFVKLREMLIRVNMEDLREQTHSRHYELYRRCKLEEMGFQDSDGDSQPFSLQETYEAKRKEFLSELQRKEEEMRQMFVNKVKETELELKEKERELHEKFEHLKRVHQEEKRKVEEKRRELEEETNAFNRRKAAVEALQSQALHATSQQPLRKDKDKKN>sp|Q92599-3|SEPT8_HUMAN Isoform 3 of Septin-8 OS=Homo sapiens OX=9606GN=SEPTIN8MNTLFNTTFETEEASHHEACVRLRPQTYDLQESNVQLKLTIVDAVGFGDQINKDESYRPIVDYIDAQFENYLQEELKIRRSLFDYHDTRIHVCLYFITPTGHSLKSLDLVTMKKLDSKVNIIPIIAKADTISKSELHKFKIKIMGELVSNGVQIYQFPTDDEAVAEINAVMNAHLPFAVVGSTEEVKVGNKLVRARQYPWGVVQVENENHCDFVKLREMLIRVNMEDLREQTHSRHYELYRRCKLEEMGFQDSDGDSQPFSLQETYEAKRKEFLSELQRKEEEMRQMFVNKVKETELELKEKERELHEKFEHLKRVHQEEKRKVEEKRRELEEETNAFNRRKAAVEALQSQALHATSQQPLRKDKDKKN>sp|Q92599-4|SEPT8_HUMAN Isoform 4 of Septin-8 OS=Homo sapiens OX=9606GN=SEPTIN8MAATDLERFSNAEPEPRSLSLGGHVGFDSLPDQLVSKSVTQGFSFNILCVGETGIGKSTLMNTLFNTTFETEEASHHEACVRLRPQTYDLQESNVQLKLTIVDAVGFGDQINKDESYRPIVDYIDAQFENYLQEELKIRRSLFDYHDTRIHVCLYFITPTGHSLKSLDLVTMKKLDSKVNIIPIIAKADTISKSELHKFKIKIMGELVSNGVQIYQFPTDDEAVAEINAVMNAHLPFAVVGSTEEVKVGNKLVRARQYPWGVVQVENENHCDFVKLREMLIRVNMEDLREQTHSRHYELYRRCKLEEMGFQDSDGDSQPFSLQETYEAKRKEFLSELQRKEEEMRQMFVNKVKETELELKEKERELHEKFEHLKRVHQEEKRKVEEKRRELEEETNAFNRRKAAVEALQSQALHATSQQPLRKDKDKKKASGWSSIYSVTIP>sp|Q9Y2D2|S35A3_HUMAN UDP-N-acetylglucosamine transporter OS=Homosapiens OX=9606 GN=SLC35A3 PE=1 SV=1MFANLKYVSLGILVFQTTSLVLTMRYSRTLKEEGPRYLSSTAVVVAELLKIMACILLVYKDSKCSLRALNRVLHDEILNKPMETLKLAIPSGIYTLQNNLLYVALSNLDAATYQVTYQLKILTTALFSVSMLSKKLGVYQWLSLVILMTGVAFVQWPSDSQLDSKELSAGSQFVGLMAVLTACFSSGFAGVYFEKILKETKQSVWIRNIQLGFFGSIFGLMGVYIYDGELVSKNGFFQGYNRLTWIVVVLQALGGLVIAAVIKYADNILKGFATSLSIILSTLISYFWLQDFVPTSVFFLGAILVITATFLYGYDPKPAGNPTKA>sp|Q9Y2D2-2|S35A3_HUMAN Isoform 2 of UDP-N-acetylglucosamine transporterOS=Homo sapiens OX=9606 GN=SLC35A3MSSRSVLSPVVGTDAPDQHLELKKPQELKEMERLPLANEDKTMFANLKYVSLGILVFQTTSLVLTMRYSRTLKEEGPRYLSSTAVVVAELLKIMACILLVYKDSKCSLRALNRVLHDEILNKPMETLKLAIPSGIYTLQNNLLYVALSNLDAATYQVTYQLKILTTALFSVSMLSKKLGVYQWLSLVILMTGVAFVQWPSDSQLDSKELSAGSQFVGLMAVLTACFSSGFAGVYFEKILKETKQSVWIRNIQLGFFGSIFGLMGVYIYDGELVSKNGFFQGYNRLTWIVVVLQALGGLVIAAVIKYADNILKGFATSLSIILSTLISYFWLQDFVPTSVFFLGAILVITATFLYGYDPKPAGNPTKA>sp|Q9Y2D2-3|S35A3_HUMAN Isoform 3 of UDP-N-acetylglucosamine transporterOS=Homo sapiens OX=9606 GN=SLC35A3MFANLKYVSLGILVFQTTSLVLTMRYSRTLKEEGPRYLSSTAVVVAELLKIMACILLVYKDSKCSLRALNRVLHDEILNKPMETLKLAIPSGIYTLQNNLLYVALSNLDAATYQVTYQLKILTTALFSVSMLSKKLGVYQWLSLVILMTGVAFVQWPSDSQLDSKELSAGSQFVGLMAVLTACFSSGFAGVYFEKILKETKQSVWIRNIQLVSFSLEPSL>sp|Q86VL8|S47A2_HUMAN Multidrug and toxin extrusion protein 2 OS=Homosapiens OX=9606 GN=SLC47A2 PE=1 SV=1MDSLQDTVALDHGGCCPALSRLVPRGFGTEMWTLFALSGPLFLFQVLTFMIYIVSTVFCGHLGKVELASVTLAVAFVNVCGVSVGVGLSSACDTLMSQSFGSPNKKHVGVILQRGALVLLLCCLPCWALFLNTQHILLLFRQDPDVSRLTQDYVMIFIPGLPVIFLYNLLAKYLQNQGWLKGQEEESPFQTPGLSILHPSHSHLSRASFHLFQKITWPQVLSGVVGNCVNGVANYALVSVLNLGVRGSAYANIISQFAQTVFLLLYIVLKKLHLETWAGWSSQCLQDWGPFFSLAVPSMLMICVEWWAYEIGSFLMGLLSVVDLSAQAVIYEVATVTYMIPLGLSIGVCVRVGMALGAADTVQAKRSAVSGVLSIVGISLVLGTLISILKNQLGHIFTNDEDVIALVSQVLPVYSVFHVFEAICCVYGGVLRGTGKQAFGAAVNAITYYIIGLPLGILLTFVVRMRIMGLWLGMLACVFLATAAFVAYTARLDWKLAAEEAKKHSGRQQQQRAESTATRPGPEKAVLSSVATGSSPGITLTTYSRSECHVDFFRTPEEAHALSAPTSRLSVKQLVIRRGAALGAASATLMVGLTVRILATRH>sp|Q86VL8-2|S47A2_HUMAN Isoform 2 of Multidrug and toxin extrusionprotein 2 OS=Homo sapiens OX=9606 GN=SLC47A2MIYIVSTVFCGHLGKVELASVTLAVAFVNVCGVSVGVGLSSACDTLMSQSFGSPNKKHVGVILQRGALVLLLCCLPCWALFLNTQHILLLFRQDPDVSRLTQDYVMIFIPGLPVIFLYNLLAKYLQNQKITWPQVLSGVVGNCVNGVANYALVSVLNLGVRGSAYANIISQFAQTVFLLLYIVLKKLHLETWAGWSSQCLQDWGPFFSLAVPSMLMICVEWWAYEIGSFLMGLLSVVDLSAQAVIYEVATVTYMIPLGLSIGVCVRVGMALGAADTVQAKRSAVSGVLSIEMSLPW>sp|Q86VL8-3|S47A2_HUMAN Isoform 3 of Multidrug and toxin extrusionprotein 2 OS=Homo sapiens OX=9606 GN=SLC47A2MDSLQDTVALDHGGCCPALSRLVPRGFGTEMWTLFALSGPLFLFQVLTFMIYIVSTVFCGHLGKVELASVTLAVAFVNVCGVSVGVGLSSACDTLMSQSFGSPNKKHVGVILQRGALVLLLCCLPCWALFLNTQHILLLFRQDPDVSRLTQDYVMIFIPGLPVIFLYNLLAKYLQNQKITWPQVLSGVVGNCVNGVANYALVSVLNLGVRGSAYANIISQFAQTVFLLLYIVLKKLHLETWAGWSSQCLQDWGPFFSLAVPSMLMICVEWWAYEIGSFLMGLLSVVDLSAQAVIYEVATVTYMIPLGLSIGVCVRVGMALGAADTVQAKRSAVSGVLSIVGISLVLGTLISILKNQLGHIFTNDEDVIALVSQVLPVYSVFHVFEAICCVYGGVLRGTGKQAFGAAVNAITYYIIGLPLGILLTFVVRMRIMGLWLGMLACVFLATAAFVAYTARLDWKLAAEEAKKHSGRQQQQRAESTATRPGPEKAVLSSVATGSSPGITLTTYSRSECHVDFFRTPEEAHALSAPTSRLSVKQLVIRRGAALGAASATLMVGLTVRILATRH>sp|Q86VL8-4|S47A2_HUMAN Isoform 4 of Multidrug and toxin extrusionprotein 2 OS=Homo sapiens OX=9606 GN=SLC47A2MDSLQDTVALDHGGCCPALSRLVPRGFGTEMWTLFALSGPLFLFQVLTFMIYIVSTVFCGHLGKVELASVTLAVAFVNVCGVSVGVGLSSACDTLMSQSFGSPNKKHVGVILQRGALVLLLCCLPCWALFLNTQHILLLFRQDPDVSRLTQDYVMIFIPGLPVIFLYNLLAKYLQNQKITWPQVLSGVVGNCVNGVANYALVSVLNLGVRGSAYANIISQFAQTVFLLLYIVLKKLHLETWAGWSSQCLQDWGPFFSLAVPSMLMICVEWWAYEIGSFLMGLLSVVDLSAQAVIYEVATVTYMRHSHRLAYAAHVTRIPLGLSIGVCVRVGMALGAADTVQAKRSAVSGVLSIVGISLVLGTLISILKNQLGHIFTNDEDVIALVSQVLPVYSVFHVFEAICCVYGGVLRGTGKQAFGAAVNAITYYIIGLPLGILLTFVVRMRIMGLWLGMLACVFLATAAFVAYTARLDWKLAAEEAKKHSGRQQQQRAESTATRPGPEKAVLSSVATGSSPGITLTTYSRSECHVDFFRTPEEAHALSAPTSRLSVKQLVIRRGAALGAASATLMVGLTVRILATRH>sp|Q86VL8-5|S47A2_HUMAN Isoform 5 of Multidrug and toxin extrusionprotein 2 OS=Homo sapiens OX=9606 GN=SLC47A2MDSLQDTVALDHGGCCPALSRLVPRGFGTEMWTLFALSGPLFLFQVLTFMIYIVSTVFCGHLGKVELASVTLAVAFVNVCGVSVGVGLSSACDTLMSQSFGSPNKKHVGVILQRGALVLLLCCLPCWALFLNTQHILLLFRQDPDVSRLTQDYVMIFIPGLPVIFLYNLLAKYLQNQKITWPQVLSGVVGNCVNGVANYALVSVLNLGVRGSAYANIISQFAQTVFLLLYIVLKKLHLETWAGWSSQCLQDWGPFFSLAVPSMLMICVEWWAYEIGSFLMEHAQCGGSLCPGCHLGGHCDLHDSLGAQHRGLCPSGDGSGGRGYCAGQALGRLGRAQHSWHFPGPGHPDKHPEKSAGAYFYQ>sp|Q86VL8-6|S47A2_HUMAN Isoform 6 of Multidrug and toxin extrusionprotein 2 OS=Homo sapiens OX=9606 GN=SLC47A2MDSLQDTVALDHGGCCPALSRLVPRGFGTEMWTLFALSGPLFLFQVLTFMIYIVSTVFCGHLGKVELASVTLAVAFVNVCGVSVGVGLSSACDTLMSQSFGSPNKKHVGVILQRGALVLLLCCLPCWALFLNTQHILLLFRQDPDVSRLTQDYVMIFIPGLPVIFLYNLLAKYLQNQAGERLCVPASSNSSTGMAEGAGGGVPIPNPGFVHPPSISLTP>sp|Q96G79|S35A4_HUMAN Probable UDP-sugar transporter protein SLC35A4OS=Homo sapiens OX=9606 GN=SLC35A4 PE=1 SV=1MSVEDGGMPGLGRPRQARWTLMLLLSTAMYGAHAPLLALCHVDGRVPFRPSSAVLLTELTKLLLCAFSLLVGWQAWPQGPPPWRQAAPFALSALLYGANNNLVIYLQRYMDPSTYQVLSNLKIGSTAVLYCLCLRHRLSVRQGLALLLLMAAGACYAAGGLQVPGNTLPSPPPAAAASPMPLHITPLGLLLLILYCLISGLSSVYTELLMKRQRLPLALQNLFLYTFGVLLNLGLHAGGGSGPGLLEGFSGWAALVVLSQALNGLLMSAVMKHGSSITRLFVVSCSLVVNAVLSAVLLRLQLTAAFFLATLLIGLAMRLYYGSR>sp|P51168|SCNNB_HUMAN Amiloride-sensitive sodium channel subunit betaOS=Homo sapiens OX=9606 GN=SCNN1B PE=1 SV=2MHVKKYLLKGLHRLQKGPGYTYKELLVWYCDNTNTHGPKRIICEGPKKKAMWFLLTLLFAALVCWQWGIFIRTYLSWEVSVSLSVGFKTMDFPAVTICNASPFKYSKIKHLLKDLDELMEAVLERILAPELSHANATRNLNFSIWNHTPLVLIDERNPHHPMVLDLFGDNHNGLTSSSASEKICNAHGCKMAMRLCSLNRTQCTFRNFTSATQALTEWYILQATNIFAQVPQQELVEMSYPGEQMILACLFGAEPCNYRNFTSIFYPHYGNCYIFNWGMTEKALPSANPGTEFGLKLILDIGQEDYVPFLASTAGVRLMLHEQRSYPFIRDEGIYAMSGTETSIGVLVDKLQRMGEPYSPCTVNGSEVPVQNFYSDYNTTYSIQACLRSCFQDHMIRNCNCGHYLYPLPRGEKYCNNRDFPDWAHCYSDLQMSVAQRETCIGMCKESCNDTQYKMTISMADWPSEASEDWIFHVLSQERDQSTNITLSRKGIVKLNIYFQEFNYRTIEESAANNIVWLLSNLGGQFGFWMGGSVLCLIEFGEIIIDFVWITIIKLVALAKSLRQRRAQASYAGPPPTVAELVEAHTNFGFQPDTAPRSPNTGPYPSEQALPIPGTPPPNYDSLRLQPLDVIESDSEGDAI>sp|P51168-2|SCNNB_HUMAN Isoform 2 of Amiloride-sensitive sodium channelsubunit beta OS=Homo sapiens OX=9606 GN=SCNN1BMLLHINPAYLFKLLHGFPPWIMPTDGNLGDKNFQMGKPGHREGATMHVKKYLLKGLHRLQKGPGYTYKELLVWYCDNTNTHGPKRIICEGPKKKAMWFLLTLLFAALVCWQWGIFIRTYLSWEVSVSLSVGFKTMDFPAVTICNASPFKYSKIKHLLKDLDELMEAVLERILAPELSHANATRNLNFSIWNHTPLVLIDERNPHHPMVLDLFGDNHNGLTSSSASEKICNAHGCKMAMRLCSLNRTQCTFRNFTSATQALTEWYILQATNIFAQVPQQELVEMSYPGEQMILACLFGAEPCNYRNFTSIFYPHYGNCYIFNWGMTEKALPSANPGTEFGLKLILDIGQEDYVPFLASTAGVRLMLHEQRSYPFIRDEGIYAMSGTETSIGVLVDKLQRMGEPYSPCTVNGSEVPVQNFYSDYNTTYSIQACLRSCFQDHMIRNCNCGHYLYPLPRGEKYCNNRDFPDWAHCYSDLQMSVAQRETCIGMCKESCNDTQYKMTISMADWPSEASEDWIFHVLSQERDQSTNITLSRKGIVKLNIYFQEFNYRTIEESAANNIVWLLSNLGGQFGFWMGGSVLCLIEFGEIIIDFVWITIIKLVALAKSLRQRRAQASYAGPPPTVAELVEAHTNFGFQPDTAPRSPNTGPYPSEQALPIPGTPPPNYDSLRLQPLDVIESDSEGDAI>sp|Q6UXD7|S49A3_HUMAN Solute carrier family 49 member A3 OS=Homo sapiensOX=9606 GN=SLC49A3 PE=1 SV=1MAGPTEAETGLAEPRALCAQRGHRTYARRWVFLLAISLLNCSNATLWLSFAPVADVIAEDLVLSMEQINWLSLVYLVVSTPFGVAAIWILDSVGLRAATILGAWLNFAGSVLRMVPCMVVGTQNPFAFLMGGQSLCALAQSLVIFSPAKLAALWFPEHQRATANMLATMSNPLGVLVANVLSPVLVKKGEDIPLMLGVYTIPAGVVCLLSTICLWESVPPTPPSAGAASSTSEKFLDGLKLQLMWNKAYVILAVCLGGMIGISASFSALLEQILCASGHSSGFSGLCGALFITFGILGALALGPYVDRTKHFTEATKIGLCLFSLACVPFALVSQLQGQTLALAATCSLLGLFGFSVGPVAMELAVECSFPVGEGAATGMIFVLGQAEGILIMLAMTALTVRRSEPSLSTCQQGEDPLDWTVSLLLMAGLCTFFSCILAVFFHTPYRRLQAESGEPPSTRNAVGGADSGPGVDRGGAGRAGVLGPSTATPECTARGASLEDPRGPGSPHPACHRATPRAQGPAATDAPSRPGRLAGRVQASRFIDPAGSHSSFSSPWVIT>sp|Q6UXD7-2|S49A3_HUMAN Isoform 2 of Solute carrier family 49 member A3OS=Homo sapiens OX=9606 GN=SLC49A3MAGPTEAETGLAEPRALCAQRGHRTYARRWVFLLAISLLNCSNATLWLSFAPVADVIAEDLVLSMEQINWLSLVYLVVSTPFGVAAIWILDSVGLRAATILGAWLNFAGSVLRMVPCMVVGTQNPFAFLMGGQSLCALAQSLVIFSPAKLAALWFPEHQRATANMLATMSNPLGVLVANVLSPVLVKKGEDIPLMLGVYTIPAGVVCLLSTICLWESVPPTPPSAGAASSTSEKFLDGLKLLMWNKAYVILAVCLGGMIGISASFSALLEQILCASGHSSGFSGLCGALFITFGILGALALGPYVDRTKHFTEATKIGLCLFSLACVPFALVSQLQGQTLALAATCSLLGLFGFSVGPVAMELAVECSFPVGEGAATGMIFVLGQAEGILIMLAMTALTVRRSEPSLSTCQQGEDPLDWTVSLLLMAGLCTFFSCILAVFFHTPYRRLQAESGEPPSTRNAVGGADSGPGVDRGGAGRAGVLGPSTATPECTARGASLEDPRGPGSPHPACHRATPRAQGPAATDAPSRPGRLAGRVQASRFIDPAGSHSSFSSPWVIT>sp|Q6UXD7-3|S49A3_HUMAN Isoform 3 of Solute carrier family 49 member A3OS=Homo sapiens OX=9606 GN=SLC49A3MAGPTEAETGLAEPRALCAQRGHRTYARRWVFLLAISLLNCSNATINWLSLVYLVVSTPFGVAAIWILDSVGLRAALGVYTIPAGVVCLLSTICLWESVPPTPPSAGAASSTSEKFLDGLKLQLMWNKAYVILAVCLGGMIGISASFSALLEQILCASGHSSGFSGLCGALFITFGILGALALGPYVDRTKHFTEATKIGLCLFSLACVPFALVSQLQGQTLALAATCSLLGLFGFSVGPVAMELAVECSFPVGEGAATGMIFVLGQAEGILIMLAMTALTVRRSEPSLSTCQQGEDPLDWTVSLLLMAGLCTFFSCILAVFFHTPYRRLQAESGEPPSTRNAVGGADSGPGVDRGGAGRAGVLGPSTATPECTARGASLEDPRGPGSPHPACHRATPRAQGPAATDAPSRPGRLAGRVQASRFIDPAGSHSSFSSPWVIT>sp|P51172|SCNND_HUMAN Amiloride-sensitive sodium channel subunit deltaOS=Homo sapiens OX=9606 GN=SCNN1D PE=1 SV=3MRAVLSQKTTPLPRYLWPGHLSGPRRLTWSWCSDHRTPTCRELGSPHPTPCTGPARGWPRRGGGPCGFTSAGHVLCGYPLCLLSGPIQGCGTGLGDSSMAFLSRTSPVAAASFQSRQEARGSILLQSCQLPPQWLSTEAWTGEWKQPHGGALTSRSPGPVAPQRPCHLKGWQHRPTQHNAACKQGQAAAQTPPRPGPPSAPPPPPKEGHQEGLVELPASFRELLTFFCTNATIHGAIRLVCSRGNRLKTTSWGLLSLGALVALCWQLGLLFERHWHRPVLMAVSVHSERKLLPLVTLCDGNPRRPSPVLRHLELLDEFARENIDSLYNVNLSKGRAALSATVPRHEPPFHLDREIRLQRLSHSGSRVRVGFRLCNSTGGDCFYRGYTSGVAAVQDWYHFHYVDILALLPAAWEDSHGSQDGHFVLSCSYDGLDCQARQFRTFHHPTYGSCYTVDGVWTAQRPGITHGVGLVLRVEQQPHLPLLSTLAGIRVMVHGRNHTPFLGHHSFSVRPGTEATISIREDEVHRLGSPYGHCTAGGEGVEVELLHNTSYTRQACLVSCFQQLMVETCSCGYYLHPLPAGAEYCSSARHPAWGHCFYRLYQDLETHRLPCTSRCPRPCRESAFKLSTGTSRWPSAKSAGWTLATLGEQGLPHQSHRQRSSLAKINIVYQELNYRSVEEAPVYSVPQLLSAMGSLCSLWFGASVLSLLELLELLLDASALTLVLGGRRLRRAWFSWPRASPASGASSIKPEASQMPPPAGGTSDDPEPSGPHLPRVMLPGVLAGVSAEESWAGPQPLETLDT>sp|P51172-1|SCNND_HUMAN Isoform 1 of Amiloride-sensitive sodium channelsubunit delta OS=Homo sapiens OX=9606 GN=SCNN1DMAEHRSMDGRMEAATRGGSHLQAAAQTPPRPGPPSAPPPPPKEGHQEGLVELPASFRELLTFFCTNATIHGAIRLVCSRGNRLKTTSWGLLSLGALVALCWQLGLLFERHWHRPVLMAVSVHSERKLLPLVTLCDGNPRRPSPVLRHLELLDEFARENIDSLYNVNLSKGRAALSATVPRHEPPFHLDREIRLQRLSHSGSRVRVGFRLCNSTGGDCFYRGYTSGVAAVQDWYHFHYVDILALLPAAWEDSHGSQDGHFVLSCSYDGLDCQARQFRTFHHPTYGSCYTVDGVWTAQRPGITHGVGLVLRVEQQPHLPLLSTLAGIRVMVHGRNHTPFLGHHSFSVRPGTEATISIREDEVHRLGSPYGHCTAGGEGVEVELLHNTSYTRQACLVSCFQQLMVETCSCGYYLHPLPAGAEYCSSARHPAWGHCFYRLYQDLETHRLPCTSRCPRPCRESAFKLSTGTSRWPSAKSAGWTLATLGEQGLPHQSHRQRSSLAKINIVYQELNYRSVEEAPVYSVPQLLSAMGSLCSLWFGASVLSLLELLELLLDASALTLVLGGRRLRRAWFSWPRASPASGASSIKPEASQMPPPAGGTSDDPEPSGPHLPRVMLPGVLAGVSAEESWAGPQPLETLDT>sp|P51172-2|SCNND_HUMAN Isoform 2 of Amiloride-sensitive sodium channelsubunit delta OS=Homo sapiens OX=9606 GN=SCNN1DMAFLSRTSPVAAASFQSRQEARGSILLQSCQLPPQWLSTEAWTGEWKQPHGGALTSRSPGPVAPQRPCHLKGWQHRPTQHNAACKQGQAAAQTPPRPGPPSAPPPPPKEGHQEGLVELPASFRELLTFFCTNATIHGAIRLVCSRGNRLKTTSWGLLSLGALVALCWQLGLLFERHWHRPVLMAVSVHSERKLLPLVTLCDGNPRRPSPVLRHLELLDEFARENIDSLYNVNLSKGRAALSATVPRHEPPFHLDREIRLQRLSHSGSRVRVGFRLCNSTGGDCFYRGYTSGVAAVQDWYHFHYVDILALLPAAWEDSHGSQDGHFVLSCSYDGLDCQARQFRTFHHPTYGSCYTVDGVWTAQRPGITHGVGLVLRVEQQPHLPLLSTLAGIRVMVHGRNHTPFLGHHSFSVRPGTEATISIREDEVHRLGSPYGHCTAGGEGVEVELLHNTSYTRQACLVSCFQQLMVETCSCGYYLHPLPAGAEYCSSARHPAWGHCFYRLYQDLETHRLPCTSRCPRPCRESAFKLSTGTSRWPSAKSAGWTLATLGEQGLPHQSHRQRSSLAKINIVYQELNYRSVEEAPVYSVPQLLSAMGSLCSLWFGASVLSLLELLELLLDASALTLVLGGRRLRRAWFSWPRASPASGASSIKPEASQMPPPAGGTSDDPEPSGPHLPRVMLPGVLAGVSAEESWAGPQPLETLDT>sp|P78383|S35B1_HUMAN Solute carrier family 35 member B1 OS=Homo sapiensOX=9606 GN=SLC35B1 PE=1 SV=1MASSSSLVPDRLRLPLCFLGVFVCYFYYGILQEKITRGKYGEGAKQETFTFALTLVFIQCVINAVFAKILIQFFDTARVDRTRSWLYAACSISYLGAMVSSNSALQFVNYPTQVLGKSCKPIPVMLLGVTLLKKKYPLAKYLCVLLIVAGVALFMYKPKKVVGIEEHTVGYGELLLLLSLTLDGLTGVSQDHMRAHYQTGSNHMMLNINLWSTLLLGMGILFTGELWEFLSFAERYPAIIYNILLFGLTSALGQSFIFMTVVYFGPLTCSIITTTRKFFTILASVILFANPISPMQWVGTVLVFLGLGLDAKFGKGAKKTSH>sp|P78383-2|S35B1_HUMAN Isoform 2 of Solute carrier family 35 member B1OS=Homo sapiens OX=9606 GN=SLC35B1MRPLPPVGDVRLELSPPPPLLPVPVVSGSPVGSSGRLMASSSSLVPDRLRLPLCFLGVFVCYFYYGILQEKITRGKYGEGAKQETFTFALTLVFIQCVINAVFAKILIQFFDTARVDRTRSWLYAACSISYLGAMVSSNSALQFVNYPTQVLGKSCKPIPVMLLGVTLLKKKYPLAKYLCVLLIVAGVALFMYKPKKVVGIEEHTVGYGELLLLLSLTLDGLTGVSQDHMRAHYQTGSNHMMLNINLWSTLLLGMGILFTGELWEFLSFAERYPAIIYNILLFGLTSALGQSFIFMTVVYFGPLTCSIITTTRKFFTILASVILFANPISPMQWVGTVLVFLGLGLDAKFGKGAKKTSH>sp|Q8TB61|S35B2_HUMAN Adenosine 3'-phospho 5'-phosphosulfate transporter1 OS=Homo sapiens OX=9606 GN=SLC35B2 PE=1 SV=1MDARWWAVVVLAAFPSLGAGGETPEAPPESWTQLWFFRFVVNAAGYASFMVPGYLLVQYFRRKNYLETGRGLCFPLVKACVFGNEPKASDEVPLAPRTEAAETTPMWQALKLLFCATGLQVSYLTWGVLQERVMTRSYGATATSPGERFTDSQFLVLMNRVLALIVAGLSCVLCKQPRHGAPMYRYSFASLSNVLSSWCQYEALKFVSFPTQVLAKASKVIPVMLMGKLVSRRSYEHWEYLTATLISIGVSMFLLSSGPEPRSSPATTLSGLILLAGYIAFDSFTSNWQDALFAYKMSSVQMMFGVNFFSCLFTVGSLLEQGALLEGTRFMGRHSEFAAHALLLSICSACGQLFIFYTIGQFGAAVFTIIMTLRQAFAILLSCLLYGHTVTVVGGLGVAVVFAALLLRVYARGRLKQRGKKAVPVESPVQKV>sp|Q8TB61-2|S35B2_HUMAN Isoform 2 of Adenosine 3'-phospho 5'-phosphosulfate transporter 1 OS=Homo sapiens OX=9606 GN=SLC35B2MDARWWAVVVLAAFPSLGAGGETPEAPPESWTQLWFFRFVVNAAGYASFMVPGYLLVQYFRRKNYLETGRGLCFPLVKACVFGNEPKASDEVPLAPRTEAAETTPMWQALKLLFCATGLQVSYLTWGVLQERVMTRSYGATATSPGERFTDSQFLVLMNRVLALIVAGLSCVLCKQPRHGAPMYRYSFASLSNVLSSWCQYEALKFVSFPTQVLAKASKVIPVMLMGKLVSRRSYEHWEYLTATLISIGVSMFLLSSGPEPRSSPATTLSGLFTVGSLLEQGALLEGTRFMGRHSEFAAHALLLSICSACGQLFIFYTIGQFGAAVFTIIMTLRQAFAILLSCLLYGHTVTVVGGLGVAVVFAALLLRVYARGRLKQRGKKAVPVESPVQKV>sp|Q8TB61-3|S35B2_HUMAN Isoform 3 of Adenosine 3'-phospho 5'-phosphosulfate transporter 1 OS=Homo sapiens OX=9606 GN=SLC35B2MVPGYLLVQYFRRKNYLETGRGLCFPLVKACVFGNEPKASDEVPLAPRTEAAETTPMWQALKLLFCATGLQVSYLTWGVLQERVMTRSYGATATSPGERFTDSQFLVLMNRVLALIVAGLSCVLCKQPRHGAPMYRYSFASLSNVLSSWCQYEALKFVSFPTQVLAKASKVIPVMLMGKLVSRRSYEHWEYLTATLISIGVSMFLLSSGPEPRSSPATTLSGLILLAGYIAFDSFTSNWQDALFAYKMSSVQMMFGVNFFSCLFTVGSLLEQGALLEGTRFMGRHSEFAAHALLLSICSACGQLFIFYTIGQFGAAVFTIIMTLRQAFAILLSCLLYGHTVTVVGGLGVAVVFAALLLRVYARGRLKQRGKKAVPVESPVQKV>sp|Q8TB61-4|S35B2_HUMAN Isoform 4 of Adenosine 3'-phospho 5'-phosphosulfate transporter 1 OS=Homo sapiens OX=9606 GN=SLC35B2MLLAMPALWYLATSWCSTSGGRTTWRPVSYLTWGVLQERVMTRSYGATATSPGERFTDSQFLVLMNRVLALIVAGLSCVLCKQPRHGAPMYRYSFASLSNVLSSWCQYEALKFVSFPTQVLAKASKVIPVMLMGKLVSRRSYEHWEYLTATLISIGVSMFLLSSGPEPRSSPATTLSGLILLAGYIAFDSFTSNWQDALFAYKMSSVQMMFGVNFFSCLFTVGSLLEQGALLEGTRFMGRHSEFAAHALLLSICSACGQLFIFYTIGQFGAAVFTIIMTLRQAFAILLSCLLYGHTVTVVGGLGVAVVFAALLLRVYARGRLKQRGKKAVPVESPVQKV>sp|Q8TB61-5|S35B2_HUMAN Isoform 5 of Adenosine 3'-phospho 5'-phosphosulfate transporter 1 OS=Homo sapiens OX=9606 GN=SLC35B2MTRSYGATATSPGERFTDSQFLVLMNRVLALIVAGLSCVLCKQPRHGAPMYRYSFASLSNVLSSWCQYEALKFVSFPTQVLAKASKVIPVMLMGKLVSRRSYEHWEYLTATLISIGVSMFLLSSGPEPRSSPATTLSGLILLAGYIAFDSFTSNWQDALFAYKMSSVQMMFGVNFFSCLFTVGSLLEQGALLEGTRFMGRHSEFAAHALLLSICSACGQLFIFYTIGQFGAAVFTIIMTLRQAFAILLSCLLYGHTVTVVGGLGVAVVFAALLLRVYARGRLKQRGKKAVPVESPVQKV>sp|P21912|SDHB_HUMAN Succinate dehydrogenase [ubiquinone] iron-sulfursubunit, mitochondrial OS=Homo sapiens OX=9606 GN=SDHB PE=1 SV=3MAAVVALSLRRRLPATTLGGACLQASRGAQTAAATAPRIKKFAIYRWDPDKAGDKPHMQTYEVDLNKCGPMVLDALIKIKNEVDSTLTFRRSCREGICGSCAMNINGGNTLACTRRIDTNLNKVSKIYPLPHMYVIKDLVPDLSNFYAQYKSIEPYLKKKDESQEGKQQYLQSIEEREKLDGLYECILCACCSTSCPSYWWNGDKYLGPAVLMQAYRWMIDSRDDFTEERLAKLQDPFSLYRCHTIMNCTRTCPKGLNPGKAIAEIKKMMATYKEKKASV>sp|O75880|SCO1_HUMAN Protein SCO1 homolog, mitochondrial OS=Homo sapiensOX=9606 GN=SCO1 PE=1 SV=1MAMLVLVPGRVMRPLGGQLWRFLPRGLEFWGPAEGTARVLLRQFCARQAEAWRASGRPGYCLGTRPLSTARPPPPWSQKGPGDSTRPSKPGPVSWKSLAITFAIGGALLAGMKHVKKEKAEKLEKERQRHIGKPLLGGPFSLTTHTGERKTDKDYLGQWLLIYFGFTHCPDVCPEELEKMIQVVDEIDSITTLPDLTPLFISIDPERDTKEAIANYVKEFSPKLVGLTGTREEVDQVARAYRVYYSPGPKDEDEDYIVDHTIIMYLIGPDGEFLDYFGQNKRKGEIAASIATHMRPYRKKS>sp|Q9H1N7|S35B3_HUMAN Adenosine 3'-phospho 5'-phosphosulfate transporter2 OS=Homo sapiens OX=9606 GN=SLC35B3 PE=1 SV=1MDLTQQAKDIQNITVQETNKNNSESIECSKITMDLKFNNSRKYISITVPSKTQTMSPHIKSVDDVVVLGMNLSKFNKLTQFFICVAGVFVFYLIYGYLQELIFSVEGFKSCGWYLTLVQFAFYSIFGLIELQLIQDKRRRIPGKTYMIIAFLTVGTMGLSNTSLGYLNYPTQVIFKCCKLIPVMLGGVFIQGKRYNVADVSAAICMSLGLIWFTLADSTTAPNFNLTGVVLISLALCADAVIGNVQEKAMKLHNASNSEMVLYSYSIGFVYILLGLTCTSGLGPAVTFCAKNPVRTYGYAFLFSLTGYFGISFVLALIKIFGALIAVTVTTGRKAMTIVLSFIFFAKPFTFQYVWSGLLVVLGIFLNVYSKNMDKIRLPSLYDLINKSVEARKSRTLAQTV>sp|Q9H1N7-2|S35B3_HUMAN Isoform 2 of Adenosine 3'-phospho 5'-phosphosulfate transporter 2 OS=Homo sapiens OX=9606 GN=SLC35B3MDLTQQAKDIQNITVQETNKNNSESIECSKITMDLKFNNSRKYISITVPSKTQTMSPHIKSVDDVVVLGMNLSKFNKLTQFFICVAGVFVFYLIYGYLQELIFSVEGFKSCGWYLTLVQFAFYSIFGLIELQLIQDKRRRYVVCFYFLIFHLY>sp|Q9H1N7-3|S35B3_HUMAN Isoform 3 of Adenosine 3'-phospho 5'-phosphosulfate transporter 2 OS=Homo sapiens OX=9606 GN=SLC35B3MDLTQQAKDIQNITVQETNKNNSESIECSKITMDLKFNNSRKYISITVPSKTQTMSPHIKSVDDVVVLGMNLSKFNKLTQFFICVAGVFVFYLIYGYLQELIFSVEGFKSCGWYLTLVQFAFYSIFGLIELQLIQDKRRRIPGKTYMIIAFLTVGTMGLSNTSLGYLNYPTQVIFKCCKLIPVMLGGVFIQGKRYNVADVSAAICMSLGLIWFTLADSTTAPNFNLTGVVLISLALCADAVIGNVQEKAMKLHNASNSEMNITTSSYSGVFIFPNKLKIPLVL>sp|Q969S0|S35B4_HUMAN UDP-xylose and UDP-N-acetylglucosamine transporterOS=Homo sapiens OX=9606 GN=SLC35B4 PE=1 SV=1MRPALAVGLVFAGCCSNVIFLELLARKHPGCGNIVTFAQFLFIAVEGFLFEADLGRKPPAIPIRYYAIMVTMFFTVSVVNNYALNLNIAMPLHMIFRSGSLIANMILGIIILKKRYSIFKYTSIALVSVGIFICTFMSAKQVTSQSSLSENDGFQAFVWWLLGIGALTFALLMSARMGIFQETLYKRFGKHSKEALFYNHALPLPGFVFLASDIYDHAVLFNKSELYEIPVIGVTLPIMWFYLLMNIITQYVCIRGVFILTTECASLTVTLVVTLRKFVSLIFSILYFQNPFTLWHWLGTLFVFIGTLMYTEVWNNLGTTKSEPQKDSKKN>sp|Q969S0-2|S35B4_HUMAN Isoform 2 of UDP-xylose and UDP-N-acetylglucosamine transporter OS=Homo sapiens OX=9606 GN=SLC35B4MRPALAVGLVFAGCCSNVIFLELLARKHPGCGNIVTFAQFLFIAVEGFLFEADLGRKPPAIPIRYYAIMVTMFFTVSVVNNYALNLNIAMPLHMIFRSGSLIANMILGIIILKKRYSIFKYTSIALVSVGIFICTFMSAKQVTSQSSLSENDGFQAFVWWLLGIGALTFALLMSARMGIFQETLYKRFGKHSKEALFYNHALPLPGFVFLASDIYDHAVLFNKSGEFGVRQ>sp|Q969S0-3|S35B4_HUMAN Isoform 3 of UDP-xylose and UDP-N-acetylglucosamine transporter OS=Homo sapiens OX=9606 GN=SLC35B4MRPALAVGLVFAGCCSNVIFLELLARKHPGCGNIVTFAQFLFIAVEGFLFEADLGRKPPAIPIRYYAIMVTMFFTVSVVNNYALNLNIAMPLHMIFRSGSLIANMILGIIILKKRYSIFKYTSIALVSVGIFICTFMSAKQVTSQSSLSENDGFQAFVWWLLGIGALTFALLMSARMGIFQETLYKRFGKHSKEALFYNHALPLPGFVFLASDIYDHAVLFNKSELYEIPVIGVTLPIMWFYLLMNIITQTPT>sp|O43819|SCO2_HUMAN Protein SCO2 homolog, mitochondrial OS=Homo sapiensOX=9606 GN=SCO2 PE=1 SV=3MLLLTRSPTAWHRLSQLKPRVLPGTLGGQALHLRSWLLSRQGPAETGGQGQPQGPGLRTRLLITGLFGAGLGGAWLALRAEKERLQQQKRTEALRQAAVGQGDFHLLDHRGRARCKADFRGQWVLMYFGFTHCPDICPDELEKLVQVVRQLEAEPGLPPVQPVFITVDPERDDVEAMARYVQDFHPRLLGLTGSTKQVAQASHSYRVYYNAGPKDEDQDYIVDHSIAIYLLNPDGLFTDYYGRSRSAEQISDSVRRHMAAFRSVLS>sp|Q9NQQ7|S35C2_HUMAN Solute carrier family 35 member C2 OS=Homo sapiensOX=9606 GN=SLC35C2 PE=1 SV=2MGRWALDVAFLWKAVLTLGLVLLYYCFSIGITFYNKWLTKSFHFPLFMTMLHLAVIFLFSALSRALVQCSSHRARVVLSWADYLRRVAPTALATALDVGLSNWSFLYVTVSLYTMTKSSAVLFILIFSLIFKLEELRAALVLVVLLIAGGLFMFTYKSTQFNVEGFALVLGASFIGGIRWTLTQMLLQKAELGLQNPIDTMFHLQPLMFLGLFPLFAVFEGLHLSTSEKIFRFQDTGLLLRVLGSLFLGGILAFGLGFSEFLLVSRTSSLTLSIAGIFKEVCTLLLAAHLLGDQISLLNWLGFALCLSGISLHVALKALHSRGDGGPKALKGLGSSPDLELLLRSSQREEGDNEEEEYFVAQGQQ>sp|Q9NQQ7-2|S35C2_HUMAN Isoform 2 of Solute carrier family 35 member C2OS=Homo sapiens OX=9606 GN=SLC35C2MGRWALDVAFLWKAVLTLGLVLLYYCFSIGITFYNKWLTKSFHFPLFMTMLHLAVIFLFSALSRALVQCSSHRARVVLSWADYLRRVAPTALATALDVGLSNWSFLYVTVSLYTMTKSSAVLFILIFSLIFKLEELSTQFNVEGFALVLGASFIGGIRWTLTQMLLQKAELGLQNPIDTMFHLQPLMFLGLFPLFAVFEGLHLSTSEKIFRFQDTGLLLRVLGSLFLGGILAFGLGFSEFLLVSRTSSLTLSIAGIFKEVCTLLLAAHLLGDQISLLNWLGFALCLSGISLHVALKALHSRGDGGPKALKGLGSSPDLELLLRSSQREEGDNEEEEYFVAQGQQ>sp|Q9NQQ7-3|S35C2_HUMAN Isoform 3 of Solute carrier family 35 member C2OS=Homo sapiens OX=9606 GN=SLC35C2MGRVSTSHQPLRGVPAPADSGAPVLQPPRMGRWALDVAFLWKAVLTLGLVLLYYCFSIGITFYNKWLTKSFHFPLFMTMLHLAVIFLFSALSRALVQCSSHRARVVLSWADYLRRVAPTALATALDVGLSNWSFLYVTVSLYTMTKSSAVLFILIFSLIFKLEELRAALVLVVLLIAGGLFMFTYKSTQFNVEGFALVLGASFIGGIRWTLTQMLLQKAELGLQNPIDTMFHLQPLMFLGLFPLFAVFEGLHLSTSEKIFRFQDTGLLLRVLGSLFLGGILAFGLGFSEFLLVSRTSSLTLSIAGIFKEVCTLLLAAHLLGDQISLLNWLGFALCLSGISLHVALKALHSRGDGGPKALKGLGSSPDLELLLRSSQREEGDNEEEEYFVAQGQQ>sp|Q9NTN3|S35D1_HUMAN UDP-glucuronic acid/UDP-N-acetylgalactosaminetransporter OS=Homo sapiens OX=9606 GN=SLC35D1 PE=2 SV=1MAEVHRRQHARVKGEAPAKSSTLRDEEELGMASAETLTVFLKLLAAGFYGVSSFLIVVVNKSVLTNYRFPSSLCVGLGQMVATVAVLWVGKALRVVKFPDLDRNVPRKTFPLPLLYFGNQITGLFSTKKLNLPMFTVLRRFSILFTMFAEGVLLKKTFSWGIKMTVFAMIIGAFVAASSDLAFDLEGYAFILINDVLTAANGAYVKQKLDSKELGKYGLLYYNALFMILPTLAIAYFTGDAQKAVEFEGWADTLFLLQFTLSCVMGFILMYATVLCTQYNSALTTTIVGCIKNILITYIGMVFGGDYIFTWTNFIGLNISIAGSLVYSYITFTEEQLSKQSEANNKLDIKGKGAV>sp|Q9NTN3-2|S35D1_HUMAN Isoform 2 of UDP-glucuronic acid/UDP-N-acetylgalactosamine transporter OS=Homo sapiens OX=9606 GN=SLC35D1MVATVAVLWVGKALRVVKFPDLDRNVPRKTFPLPLLYFGNQITGLFSTKKLNLPMFTVLRRFSILFTMFAEGVLLKKTFSWGIKMTVFAMIIGAFVAASSDLAFDLEGYAFILINDVLTAANGAYVKQKLDSKELGKYGLLYYNALFMILPTLAIAYFTGDAQKAVEFEGWADTLFLLQFTLSCVMGFILMYATVLCTQYNSALTTTIVGCIKNILITYIGMVFGGDYIFTWTNFIGLNISCICHRGLCELRVGSATLGG>sp|Q76EJ3|S35D2_HUMAN UDP-N-acetylglucosamine/UDP-glucose/GDP-mannosetransporter OS=Homo sapiens OX=9606 GN=SLC35D2 PE=1 SV=1MTAGGQAEAEGAGGEPGAARLPSRVARLLSALFYGTCSFLIVLVNKALLTTYGFPSPIFLGIGQMAATIMILYVSKLNKIIHFPDFDKKIPVKLFPLPLLYVGNHISGLSSTSKLSLPMFTVLRKFTIPLTLLLETIILGKQYSLNIILSVFAIILGAFIAAGSDLAFNLEGYIFVFLNDIFTAANGVYTKQKMDPKELGKYGVLFYNACFMIIPTLIISVSTGDLQQATEFNQWKNVVFILQFLLSCFLGFLLMYSTVLCSYYNSALTTAVVGAIKNVSVAYIGILIGGDYIFSLLNFVGLNICMAGGLRYSFLTLSSQLKPKPVGEENICLDLKS>sp|Q76EJ3-2|S35D2_HUMAN Isoform 2 of UDP-N-acetylglucosamine/UDP-glucose/GDP-mannose transporter OS=Homo sapiens OX=9606 GN=SLC35D2MTAGGQAEAEGAGGEPGAARLPSRVARLLSALFYGTCSFLIVLVNKALLTTYGFPSPIFLGIGQMAATIMILYVSKLNKIIHFPDFDKKIPVKLFPLPLLYVGNHISGLSSTSKLSLPMFTVLRKFTIPLTLLLETIILGKQYSLNIILSVFAIILGAFIAAGFLLMYSTVLCSYYNSALTTAVVGAIKNVSVAYIGILIGGDYIFSLLNFVGLNICMAGGLRYSFLTLSSQLKPKPVGEENICLDLKS>sp|Q9H7L9|SDS3_HUMAN Sin3 histone deacetylase corepressor complexcomponent SDS3 OS=Homo sapiens OX=9606 GN=SUDS3 PE=1 SV=2MSAAGLLAPAPAQAGAPPAPEYYPEEDEELESAEDDERSCRGRESDEDTEDASETDLAKHDEEDYVEMKEQMYQDKLASLKRQLQQLQEGTLQEYQKRMKKLDQQYKERIRNAELFLQLETEQVERNYIKEKKAAVKEFEDKKVELKENLIAELEEKKKMIENEKLTMELTGDSMEVKPIMTRKLRRRPNDPVPIPDKRRKPAPAQLNYLLTDEQIMEDLRTLNKLKSPKRPASPSSPEHLPATPAESPAQRFEARIEDGKLYYDKRWYHKSQAIYLESKDNQKLSCVISSVGANEIWVRKTSDSTKMRIYLGQLQRGLFVIRRRSAA>sp|Q9UIL1|SCOC_HUMAN Short coiled-coil protein OS=Homo sapiens OX=9606GN=SCOC PE=1 SV=2MRRRVFSSQDWRASGWDGMGFFSRRTFCGRSGRSCRGQLVQVSRPEVSAGSLLLPAPQAEDHSSRILYPRPKSLLPKMMNADMDAVDAENQVELEEKTRLINQVLELQHTLEDLSARVDAVKEENLKLKSENQVLGQYIENLMSASSVFQTTDTKSKRK>sp|Q9UIL1-2|SCOC_HUMAN Isoform 2 of Short coiled-coil protein OS=Homosapiens OX=9606 GN=SCOCMDGSRKEEEEDSTFTNISLADDIDHSSRILYPRPKSLLPKMMNADMDAVDAENQVELEEKTRLINQVLELQHTLEDLSARVDAVKEENLKLKSENQVLGQYIENLMSASSVFQTTDTKSKRK>sp|Q9UIL1-3|SCOC_HUMAN Isoform 3 of Short coiled-coil protein OS=Homosapiens OX=9606 GN=SCOCMDGSRKEEEEDSTFTNISLADDIDHSSRILYPRPKSLLPKMMNADMDVDAENQVELEEKTRLINQVLELQHTLEDLSARVDAVKEENLKLKSENQVLGQYIENLMSASSVFQTTDTKSKRK>sp|Q9UIL1-4|SCOC_HUMAN Isoform 4 of Short coiled-coil protein OS=Homosapiens OX=9606 GN=SCOCMRRRVFSSQDWRASGWDGMGFFSRRTFCGRSGRSCRGQLVQVSRPEVSAGSLLLPAPQAEDHSSRILYPRPKSLLPKMMNADMDDLSARVDAVKEENLKLKSENQVLGQYIENLMSASSVFQTTDTKSKRK>sp|O76038|SEGN_HUMAN Secretagogin OS=Homo sapiens OX=9606 GN=SCGN PE=1SV=2MDSSREPTLGRLDAAGFWQVWQRFDADEKGYIEEKELDAFFLHMLMKLGTDDTVMKANLHKVKQQFMTTQDASKDGRIRMKELAGMFLSEDENFLLLFRRENPLDSSVEFMQIWRKYDADSSGFISAAELRNFLRDLFLHHKKAISEAKLEEYTGTMMKIFDRNKDGRLDLNDLARILALQENFLLQFKMDACSTEERKRDFEKIFAYYDVSKTGALEGPEVDGFVKDMMELVQPSISGVDLDKFREILLRHCDVNKDGKIQKSELALCLGLKINP>sp|O43175|SERA_HUMAN D-3-phosphoglycerate dehydrogenase OS=Homo sapiensOX=9606 GN=PHGDH PE=1 SV=4MAFANLRKVLISDSLDPCCRKILQDGGLQVVEKQNLSKEELIAELQDCEGLIVRSATKVTADVINAAEKLQVVGRAGTGVDNVDLEAATRKGILVMNTPNGNSLSAAELTCGMIMCLARQIPQATASMKDGKWERKKFMGTELNGKTLGILGLGRIGREVATRMQSFGMKTIGYDPIISPEVSASFGVQQLPLEEIWPLCDFITVHTPLLPSTTGLLNDNTFAQCKKGVRVVNCARGGIVDEGALLRALQSGQCAGAALDVFTEEPPRDRALVDHENVISCPHLGASTKEAQSRCGEEIAVQFVDMVKGKSLTGVVNAQALTSAFSPHTKPWIGLAEALGTLMRAWAGSPKGTIQVITQGTSLKNAGNCLSPAVIVGLLKEASKQADVNLVNAKLLVKEAGLNVTTSHSPAAPGEQGFGECLLAVALAGAPYQAVGLVQGTTPVLQGLNGAVFRPEVPLRRDLPLLLFRTQTSDPAMLPTMIGLLAEAGVRLLSYQTSLVSDGETWHVMGISSLLPSLEAWKQHVTEAFQFHF>sp|Q96GA7|SDSL_HUMAN Serine dehydratase-like OS=Homo sapiens OX=9606GN=SDSL PE=1 SV=1MDGPVAEHAKQEPFHVVTPLLESWALSQVAGMPVFLKCENVQPSGSFKIRGIGHFCQEMAKKGCRHLVCSSGGNAGIAAAYAARKLGIPATIVLPESTSLQVVQRLQGEGAEVQLTGKVWDEANLRAQELAKRDGWENVPPFDHPLIWKGHASLVQELKAVLRTPPGALVLAVGGGGLLAGVVAGLLEVGWQHVPIIAMETHGAHCFNAAITAGKLVTLPDITSVAKSLGAKTVAARALECMQVCKIHSEVVEDTEAVSAVQQLLDDERMLVEPACGAALAAIYSGLLRRLQAEGCLPPSLTSVVVIVCGGNNINSRELQALKTHLGQV>sp|P62070|RRAS2_HUMAN Ras-related protein R-Ras2 OS=Homo sapiens OX=9606GN=RRAS2 PE=1 SV=1MAAAGWRDGSGQEKYRLVVVGGGGVGKSALTIQFIQSYFVTDYDPTIEDSYTKQCVIDDRAARLDILDTAGQEEFGAMREQYMRTGEGFLLVFSVTDRGSFEEIYKFQRQILRVKDRDEFPMILIGNKADLDHQRQVTQEEGQQLARQLKVTYMEASAKIRMNVDQAFHELVRVIRKFQEQECPPSPEPTRKEKDKKGCHCVIF>sp|P62070-2|RRAS2_HUMAN Isoform 2 of Ras-related protein R-Ras2 OS=Homosapiens OX=9606 GN=RRAS2MREQYMRTGEGFLLVFSVTDRGSFEEIYKFQRQILRVKDRDEFPMILIGNKADLDHQRQVTQEEGQQLARQLKVTYMEASAKIRMNVDQAFHELVRVIRKFQEQECPPSPEPTRKEKDKKGCHCVIF>sp|P62070-3|RRAS2_HUMAN Isoform 3 of Ras-related protein R-Ras2 OS=Homosapiens OX=9606 GN=RRAS2MSYFVTDYDPTIEDSYTKQCVIDDRAARLDILDTAGQEEFGAMREQYMRTGEGFLLVFSVTDRGSFEEIYKFQRQILRVKDRDEFPMILIGNKADLDHQRQVTQEEGQQLARQLKVTYMEASAKIRMNVDQAFHELVRVIRKFQEQECPPSPEPTRKEKDKKGCHCVIF>sp|P62070-4|RRAS2_HUMAN Isoform 4 of Ras-related protein R-Ras2 OS=Homosapiens OX=9606 GN=RRAS2MAAAGWRDGSGQEKYRLVVVGGGGVGKSALTIQFIQFFLFLQSYFVTDYDPTIEDSYTKQCVIDDRAARLDILDTAGQEEFGAMREQYMRTGEGFLLVFSVTDRGSFEEIYKFQRQILRVKDRDEFPMILIGNKADLDHQRQVTQEEGQQLARQLKVTYMEASAKIRMNVDQAFHELVRVIRKFQEQECPPSPEPTRKEKDKKGCHCVIF>sp|A8K8P3|SFI1_HUMAN Protein SFI1 homolog OS=Homo sapiens OX=9606GN=SFI1 PE=1 SV=2MKNLLTEKCISSHNFHQKVIKQRMEKKVDSRYFKDGAVKKPYSAKTLSNKKSSASFGIRRELPSTSHLVQYRGTHTCTRQGRLRELRIRCVARKFLYLWIRMTFGRVFPSKARFYYEQRLLRKVFEEWKEEWWVFQHEWKLCVRADCHYRYYLYNLMFQTWKTYVRQQQEMRNKYIRAEVHDAKQKMRQAWKSWLIYVVVRRTKLQMQTTALEFRQRIILRVWWSTWRQRLGQVRVSRALHASALKHRALSLQVQAWSQWREQLLYVQKEKQKVVSAVKHHQHWQKRRFLKAWLEYLQVRRVKRQQNEMAERFHHVTVLQIYFCDWQQAWERRESLYAHHAQVEKLARKMALRRAFTHWKHYMLLCAEEAAQFEMAEEHHRHSQLYFCFRALKDNVTHAHLQQIRRNLAHQQHGVTLLHRFWNLWRSQIEQKKERELLPLLHAAWDHYRIALLCKCIELWLQYTQKRRYKQLLQARADGHFQQRALPAAFHTWNRLWRWRHQENVLSARATRFHRETLEKQVFSLWRQKMFQHRENRLAERMAILHAERQLLYRSWFMWHQQAAARHQEQEWQTVACAHHRHGRLKKAFCLWRESAQGLRTERTGRVRAAEFHMAQLLRWAWSQWRECLALRGAERQKLMRADLHHQHSVLHRALQAWVTYQGRVRSILREVAARESQHNRQLLRGALRRWKENTMARVDEAKKTFQASTHYRRTICSKVLVQWREAVSVQMYYRQQEDCAIWEAQKVLDRGCLRTWFQRWWDCSRRSAQQRLQLERAVQHHHRQLLLEGLARWKTHHLQCVRKRLLHRQSTQLLAQRLSRTCFRQWRQQLAARRQEQRATVRALWFWAFSLQAKVWATWLAFVLERRRKKARLQWALQAYQGQLLQEGATRLLRFAASMKASRQQLQAQQQVQAAHSLHRAVRRCATLWKQKVLGRGGKPQPLAAIAPSRKVTFEGPLLNRIAAGAGDGTLETKRPQASRPLGALGRLAAEEPHALELNTAHSARKQPRRPHFLLEPAQSQRPQKPQEHGLGMAQPAAPSLTRPFLAEAPTALVPHSPLPGALSSAPGPKQPPTASTGPELLLLPLSSFMPCGAAAPARVSAQRATPRDKPPVPSSLASVPDPHLLLPGDFSATRAGPGLSTAGSLDLEAELEEIQQQLLHYQTTKQNLWSCRRQASSLRRWLELNREEPGPEDQEVEQQVQKELEQVEMQIQLLAEELQAQRQPIGACVARIQALRQALC>sp|A8K8P3-2|SFI1_HUMAN Isoform 2 of Protein SFI1 homolog OS=Homo sapiensOX=9606 GN=SFI1MKNLLTEKCISSHNFHQKVIKQRMEKKVDSRYFKDGAVKKPYSAKTLSNKKSSASFGIRRELPSTSHLVQYRGTHTCTRQGRLRELRIRCVARKFLYLWIRMTFGRVFPSKARFYYEQRLLRKVFEEWKEEWWVFQHEWKLCVRADCHYRYYLYNLMFQTWKTYVRQQQEMRNKYIRAEVHDAKQKMRQAWKSWLIYVVVRRTKLQMQTTALEFRQRIILRVWWSTWRQRLGQVRVSRALHASALKHRALSLQVQAWSQWREQLLYVQKEKQKVVSAVKHHQHWQKRRFLKAWLEYLQVRRVKRQQNEMAERFHHVTVLQIYFCDWQQAWERRESLYAHHAQVEKLARKMALRRAFTHWKHYMLLCAEEAAQFEMAEEHHRHSQLLLHRFWNLWRSQIEQKKERELLPLLHAAWDHYRIALLCKCIELWLQYTQKRRYKQLLQARADGHFQQRALPAAFHTWNRLWRWRHQENVLSARATRFHRETLEKQVFSLWRQKMFQHRENRLAERMAILHAERQLLYRSWFMWHQQAAARHQEQEWQTVACAHHRHGRLKKAFCLWRESAQGLRTERTGRVRAAEFHMAQLLRWAWSQWRECLALRGAERQKLMRADLHHQHSVLHRALQAWVTYQGRVRSILREVAARESQHNRQLLRGALRRWKENTMARVDEAKKTFQASTHYRRTICSKVLVQWREAVSVQMYYRQQEDCAIWEAQKVLDRGCLRTWFQRWWDCSRRSAQQRLQLERAVQHHHRQLLLEGLARWKTHHLQCVRKRLLHRQSTQLLAQRLSRTCFRQWRQQLAARRQEQRATVRALWFWAFSLQAKVWATWLAFVLERRRKKARLQWALQAYQGQLLQEGATRLLRFAASMKASRQQLQAQQQVQAAHSLHRAVRRCATLWKQKVLGRGGKPQPLAAIAPSRKVTFEGPLLNRIAAGAGDGTLETKRPQASRPLGALGRLAAEEPHALELNTAHSARKQPRRPHFLLEPAQSQRPQKPQEHGLGMAQPAAPSLTRPFLAEAPTALVPHSPLPGALSSAPGPKQPPTASTGPELLLLPLSSFMPCGAAAPARVSAQRATPRDKPPVPSSLASVPDPHLLLPGDFSATRAGPGLSTAGSLDLEAELEEIQQQLLHYQTTKQNLWSCRRQASSLRRWLELNREEPGPEDQEVEQQVQKELEQVEMQIQLLAEELQAQRQPIGACVARIQALRQALC>sp|A8K8P3-3|SFI1_HUMAN Isoform 3 of Protein SFI1 homolog OS=Homo sapiensOX=9606 GN=SFI1MKNLLTEKCISSHNFHQKVIKQRMEKKVDSRFYYEQRLLRKVFEEWKEEWWVFQHEWKLCVRADCHYRYYLYNLMFQTWKTYVRQQQEMRNKYIRAEVHDAKQKMRQAWKSWLIYVVVRRTKLQMQTTALEFRQRIILRVWWSTWRQRLGQVRVSRALHASALKHRALSLQVQAWSQWREQLLYVQKEKQKVVSAVKHHQHWQKRRFLKAWLEYLQVRRVKRQQNEMAERFHHVTVLQIYFCDWQQAWERRESLYAHHAQVEKLARKMALRRAFTHWKHYMLLCAEEAAQFEMAEEHHRHSQLYFCFRALKDNVTHAHLQQIRRNLAHQQHGVTLLHRFWNLWRSQIEQKKERELLPLLHAAWDHYRIALLCKCIELWLQYTQKRRYKQLLQARADGHFQQRALPAAFHTWNRLWRWRHQENVLSARATRFHRETLEKQVFSLWRQKMFQHRENRLAERMAILHAERQLLYRSWFMWHQQAAARHQEQEWQTVACAHHRHGRLKKAFCLWRESAQGLRTERTGRVRAAEFHMAQLLRWAWSQWRECLALRGAERQKLMRADLHHQHSVLHRALQAWVTYQGRVRSILREVAARESQHNRQLLRGALRRWKENTMARVDEAKKTFQASTHYRRTICSKVLVQWREAVSVQMYYRQQEDCAIWEAQKVLDRGCLRTWFQRWWDCSRRSAQQRLQLERAVQHHHRQLLLEGLARWKTHHLQCVRKRLLHRQSTQLLAQRLSRTCFRQWRQQLAARRQEQRATVRALWFWAFSLQAKVWATWLAFVLERRRKKARLQWALQAYQGQLLQEGATRLLRFAASMKASRQQLQAQQQVQAAHSLHRAVRRCATLWKQKVLGRGGKPQPLAAIAPSRKVTFEGPLLNRIAAGAGDGTLETKRPQASRPLGALGRLAAEEPHALELNTAHSARKQPRRPHFLLEPAQSQRPQKPQEHGLGMAQPAAPSLTRPFLAEAPTALVPHSPLPGALSSAPGPKQPPTASTGPELLLLPLSSFMPCGAAAPARVSAQRATPRDKPPVPSSLASVPDPHLLLPGDFSATRAGPGLSTAGSLDLEAELEEIQQQLLHYQTTKQNLWSCRRQASSLRRWLELNREEPGPEDQEVEQQVQKELEQVEMQIQLLAEELQAQRQPIGACVARIQALRQALC>sp|A8K8P3-4|SFI1_HUMAN Isoform 4 of Protein SFI1 homolog OS=Homo sapiensOX=9606 GN=SFI1MKNLLTEKCISSHNFHQKVIKQRMEKKVDSRFYYEQRLLRKVFEEWKEEWWVFQHEWKLCVRADCHYRVWWSTWRQRLGQVRVSRALHASALKHRALSLQVQAWSQWREQLLYVQKEKQKVVSAVKHHQHWQKRRFLKAWLEYLQVRRVKRQQNEMAERFHHVTVLQIYFCDWQQAWERRESLYAHHAQVEKLARKMALRRAFTHWKHYMLLCAEEAAQFEMAEEHHRHSQLYFCFRALKDNVTHAHLQQIRRNLAHQQHGVTLLHRFWNLWRSQIEQKKERELLPLLHAAWDHYRIALLCKCIELWLQYTQKRRYKQLLQARADGHFQQRALPAAFHTWNRLWRWRHQENVLSARATRFHRETLEKQVFSLWRQKMFQHRENRLAERMAILHAERQLLYRSWFMWHQQAAARHQEQEWQTVACAHHRHGRLKKAFCLWRESAQGLRTERTGRVRAAEFHMAQLLRWAWSQWRECLALRGAERQKLMRADLHHQHSVLHRALQAWVTYQGRVRSILREVAARESQHNRQLLRGALRRWKENTMARVDEAKKTFQASTHYRRTICSKVLVQWREAVSVQMYYRQQEDCAIWEAQKVLDRGCLRTWFQRWWDCSRRSAQQRLQLERAVQHHHRQLLLEGLARWKTHHLQCVRKRLLHRQSTQLLAQRLSRTCFRQWRQQLAARRQEQRATVRALWFWAFSLQAKVWATWLAFVLERRRKKARLQWALQAYQGQLLQEGATRLLRFAASMKASRQQLQAQQQVQAAHSLHRAVRRCATLWKQKVLGRGGKPQPLAAIAPSRKVTFEGPLLNRIAAGAGDGTLETKRPQASRPLGALGRLAAEEPHALELNTAHSARKQPRRPHFLLEPAQSQRPQKPQEHGLGMAQPAAPSLTRPFLAEAPTALVPHSPLPGALSSAPGPKQPPTASTGPELLLLPLSSFMPCGAAAPARVSAQRATPRDKPPVPSSLASVPDPHLLLPGDFSATRAGPGLSTAAWTLRLNLRRSSSNYCTTRPPSRTSGPVGGKRAACAGGWS>sp|A8K8P3-5|SFI1_HUMAN Isoform 5 of Protein SFI1 homolog OS=Homo sapiensOX=9606 GN=SFI1MKNLLTEKCISSHNFHQKVIKQRMEKKVDSRYFKDGAVKKPYSAKTLSNKKSSASFGIRRELPSTSHLVQYRGTHTCTRQGRLRELRIRFYYEQRLLRKVFEEWKEEWWVFQHEWKLCVRADCHYRYYLYNLMFQTWKTYVRQQQEMRNKYIRAEVHDAKQKMRQAWKSWLIYVVVRRTKLQMQTTALEFRQRIILRVWWSTWRQRLGQVRVSRALHASALKHRALSLQVQAWSQWREQLLYVQKEKQKVVSAVKHHQHWQKRRFLKAWLEYLQVRRVKRQQNEMAERFHHVTVLQIYFCDWQQAWERRESLYAHHAQVEKLARKMALRRAFTHWKHYMLLCAEEAAQFEMAEEHHRHSQLYFCFRALKDNVTHAHLQQIRRNLAHQQHGVTLLHRFWNLWRSQIEQKKERELLPLLHAAWDHYRIALLCKCIELWLQYTQKRRYKQLLQARADGHFQQRALPAAFHTWNRLWRWRHQENVLSARATRFHRETLEKQVFSLWRQKMFQHRENRLAERMAILHAERQLLYRSWFMWHQQAAARHQEQEWQTVACAHHRHGRLKKAFCLWRESAQGLRTERTGRVRAAEFHMAQLLRWAWSQWRECLALRGAERQKLMRADLHHQHSVLHRALQAWVTYQGRVRSILREVAARESQQLQAQQQVQAAHSLHRAVRRCATLWKQKVLGRGGKPQPLAAIAPSRKVTFEGPLLNRIAAGAGDGTLETKRPQASRPLGALGRLAAEEPHALELNTAHSARKQPRRPHFLLEPAQSQRPQKPQEHGLGMAQPAAPSLTRPFLAEAPTALVPHSPLPGALSSAPGPKQPPTASTGPELLLLPLSSFMPCGAAAPARVSAQRATPRDKPPVPSSLASVPDPHLLLPGDFSATRAGPGLSTAGSLDLEAELEEIQQQLLHYQTTKQNLWSCRRQASSLRRWLELNREEPGPEDQEVEQQVQKELEQVEMQIQLLAEELQAQRQPIGACVARIQALRQALC>sp|A8K8P3-9|SFI1_HUMAN Isoform 9 of Protein SFI1 homolog OS=Homo sapiensOX=9606 GN=SFI1MKNLLTEKCISSHNFHQKVIKQRMEKKVDSRYFKDGAVKKPYSAKTLSNKKSSASFGIRRELPSTSHLVQYRGTHTCTRQGRLRELRIRFYYEQRLLRKVFEEWKEEWWVFQHEWKLCVRADCHYRYYLYNLMFQTWKTYVRQQQEMRNKYIRAEVHDAKQKMRQAWKSWLIYVVVRRTKLQMQTTALEFRQRIILRVWWSTWRQRLGQVRVSRALHASALKHRALSLQVQAWSQWREQLLYVQKEKQKVVSAVKHHQHWQKRRFLKAWLEYLQVRRVKRQQNEMAERFHHVTVLQIYFCDWQQAWERRESLYAHHAQVEKLARKMALRRAFTHWKHYMLLCAEEAAQFEMAEEHHRHSQLLLHRFWNLWRSQIEQKKERELLPLLHAAWDHYRIALLCKCIELWLQYTQKRRYKQLLQARADGHFQQRALPAAFHTWNRLWRWRHQENVLSARATRFHRETLEKQVFSLWRQKMFQHRENRLAERMAILHAERQLLYRSWFMWHQQAAARHQEQEWQTVACAHHRHGRLKKAFCLWRESAQGLRTERTGRVRAAEFHMAQLLRWAWSQWRECLALRGAERQKLMRADLHHQHSVLHRALQAWVTYQGRVRSILREVAARESQHNRQLLRGALRRWKENTMARVDEAKKTFQASTHYRRTICSKVLVQWREAVSVQMYYRQQEDCAIWEAQKVLDRGCLRTWFQRWWDCSRRSAQQRLQLERAVQHHHRQLLLEGLARWKTHHLQCVRKRLLHRQSTQLLAQRLSRTCFRQWRQQLAARRQEQRATVRALWFWAFSLQAKVWATWLAFVLERRRKKARLQWALQAYQGQLLQEGATRLLRFAASMKASRQQLQAQQQVQAAHSLHRAVRRCATLWKQKVLGRGGKPQPLAAIAPSRKVTFEGPLLNRIAAGAGDGTLETKRPQASRPLGALGRLAAEEPHALELNTAHSARKQPRRPHFLLEPAQSQRPQKPQEHGLGMAQPAAPSLTRPFLAEAPTALVPHSPLPGALSSAPGPKQPPTASTGPELLLLPLSSFMPCGAAAPARVSAQRATPRDKPPVPSSLASVPDPHLLLPGDFSATRAGPGLSTAGSLDLEAELEEIQQQLLHYQTTKQNLWSCRRQASSLRRWLELNREEPGPEDQEVEQQVQKELEQVEMQIQLLAEELQAQRQPIGACVARIQALRQALC>sp|A8K8P3-10|SFI1_HUMAN Isoform 10 of Protein SFI1 homolog OS=Homosapiens OX=9606 GN=SFI1MKNLLTEKCISSHNFHQKVIKQRMEKKVDSRFYYEQRLLRKVFEEWKEEWWVFQHEWKLCVRADCHYRYYLYNLMFQTWKTYVRQQQEMRNKYIRAEVHDAKQKMRQAWKSWLIYVVVRRTKLQMQTTALEFRQRIILRVWWSTWRQRLGQVRVSRALHASALKHRALSLQVQAWSQWREQLLYVQKEKQKVVSAVKHHQHWQKRRFLKAWLEYLQVRRVKRQQNEMAERFHHVTVLQIYFCDWQQAWERRESLYAHHAQVEKLARKMALRRAFTHWKHYMLLCAEEAAQFEMAEEHHRHSQLYFCFRALKDNVTHAHLQQIRRNLAHQQHGVTLLHRFWNLWRSQIEQKKERELLPLLHAAWDHYRIALLCKCIELWLQYTQKRRYKQLLQARADGHFQQRALPAAFHTWNRLWRWRHQENVLSARATRFHRETLEKQVFSLWRQKMFQHRENRLAERMAILHAERQLLYRSWFMWHQQAAARHQEQEWQTVACAHHRHGRLKKAFCLWRESAQGLRTERTGRVRAAEFHMAQLLRWAWSQWRECLALRGAERQKLMRADLHHQHSVLHRALQAWVTYQGRVRSILREVAARESQHNRQLLRGALRRWKENTMARVDEAKKTFQVLVQWREAVSVQMYYRQQEDCAIWEAQKVLDRGCLRTWFQRWWDCSRRSAQQRLQLERAVQHHHRQLLLEGLARWKTHHLQCVRKRLLHRQSTQLLAQRLSRTCFRQWRQQLAARRQEQRATVRALWFWAFSLQAKVWATWLAFVLERRRKKARLQWALQAYQGQLLQEGATRLLRFAASMKASRQQLQAQQQVQAAHSLHRAVRRCATLWKQKVLGRGGKPQPLAAIAPSRKVTFEGPLLNRIAAGAGDGTLETKRPQASRPLGALGRLAAEEPHALELNTAHSARKQPRRPHFLLEPAQSQRPQKPQEHGLGMAQPAAPSLTRPFLAEAPTALVPHSPLPGALSSAPGPKQPPTASTGPELLLLPLSSFMPCGAAAPARVSAQRATPRDKPPVPSSLASVPDPHLLLPGDFSATRAGPGLSTAGSLDLEAELEEIQQQLLHYQTTKQNLWSCRRQASSLRRWLELNREEPGPEDQEVEQQVQKELEQVEMQIQLLAEELQAQRQPIGACVARIQALRQALC>sp|P62316|SMD2_HUMAN Small nuclear ribonucleoprotein Sm D2 OS=Homosapiens OX=9606 GN=SNRPD2 PE=1 SV=1MSLLNKPKSEMTPEELQKREEEEFNTGPLSVLTQSVKNNTQVLINCRNNKKLLGRVKAFDRHCNMVLENVKEMWTEVPKSGKGKKKSKPVNKDRYISKMFLRGDSVIVVLRNPLIAGK>sp|P62316-2|SMD2_HUMAN Isoform 2 of Small nuclear ribonucleoprotein SmD2 OS=Homo sapiens OX=9606 GN=SNRPD2MTPEELQKREEEEFNTGPLSVLTQSVKNNTQVLINCRNNKKLLGRVKAFDRHCNMVLENVKEMWTEVPKSGKGKKKSKPVNKDRYISKMFLRGDSVIVVLRNPLIAGK>sp|Q9H633|RPP21_HUMAN Ribonuclease P protein subunit p21 OS=Homo sapiensOX=9606 GN=RPP21 PE=1 SV=1MAGPVKDREAFQRLNFLYQAAHCVLAQDPENQALARFYCYTERTIAKRLVLRRDPSVKRTLCRGCSSLLVPGLTCTQRQRRCRGQRWTVQTCLTCQRSQRFLNDPGHLLWGDRPEAQLGSQADSKPLQPLPNTAHSISDRLPEEKMQTQGSSNQ>sp|Q9H633-2|RPP21_HUMAN Isoform 2 of Ribonuclease P protein subunit p21OS=Homo sapiens OX=9606 GN=RPP21MAGPVKDREAFQRLNFLYQVSLRQGPHGDGARRPRVTAPLPQAAHCVLAQDPENQALARFYCYTERTIAKRLVLRRDPSVKRTLCRGCSSLLVPGLTCTQRQRRCRGQRWTVQTCLTCQRSQRFLNDPGHLLWGDRPEAQLGSQADSKPLQPLPNTAHSISDRLPEEKMQTQGSSNQ>sp|Q9H633-3|RPP21_HUMAN Isoform 3 of Ribonuclease P protein subunit p21OS=Homo sapiens OX=9606 GN=RPP21MAGPVKDREAFQRLNFLYQAAHCVLAQDPENQALARFYCYTERTIAKRLVLRRDPSVKRTLCRGCSSLLVPGLTCTQRQRRCRGQRWTVQTCLTCQRSQRFLNDPGHLLWGDRPEAQLGSQAGERFQTTTTLAKHSPLHFRPPS>sp|Q9H633-4|RPP21_HUMAN Isoform 4 of Ribonuclease P protein subunit p21OS=Homo sapiens OX=9606 GN=RPP21MAGPVKDREAFQRLNFLYQAAHCVLAQDPENQALARFYCYTERTIAKRLVLRRPLSSSAPRDPSVKRTLCRGCSSLLVPGLTCTQRQRRCRGQRWTVQTCLTCQRSQRFLNDPGHLLWGDRPEAQLGSQADSKPLQPLPNTAHSISDRLPEEKMQTQGSSNQ>sp|P23246|SFPQ_HUMAN Splicing factor, proline- and glutamine-richOS=Homo sapiens OX=9606 GN=SFPQ PE=1 SV=2MSRDRFRSRGGGGGGFHRRGGGGGRGGLHDFRSPPPGMGLNQNRGPMGPGPGQSGPKPPIPPPPPHQQQQQPPPQQPPPQQPPPHQPPPHPQPHQQQQPPPPPQDSSKPVVAQGPGPAPGVGSAPPASSSAPPATPPTSGAPPGSGPGPTPTPPPAVTSAPPGAPPPTPPSSGVPTTPPQAGGPPPPPAAVPGPGPGPKQGPGPGGPKGGKMPGGPKPGGGPGLSTPGGHPKPPHRGGGEPRGGRQHHPPYHQQHHQGPPPGGPGGRSEEKISDSEGFKANLSLLRRPGEKTYTQRCRLFVGNLPADITEDEFKRLFAKYGEPGEVFINKGKGFGFIKLESRALAEIAKAELDDTPMRGRQLRVRFATHAAALSVRNLSPYVSNELLEEAFSQFGPIERAVVIVDDRGRSTGKGIVEFASKPAARKAFERCSEGVFLLTTTPRPVIVEPLEQLDDEDGLPEKLAQKNPMYQKERETPPRFAQHGTFEYEYSQRWKSLDEMEKQQREQVEKNMKDAKDKLESEMEDAYHEHQANLLRQDLMRRQEELRRMEELHNQEMQKRKEMQLRQEEERRRREEEMMIRQREMEEQMRRQREESYSRMGYMDPRERDMRMGGGGAMNMGDPYGSGGQKFPPLGGGGGIGYEANPGVPPATMSGSMMGSDMRTERFGQGGAGPVGGQGPRGMGPGTPAGYGRGREEYEGPNKKPRF>sp|P23246-2|SFPQ_HUMAN Isoform Short of Splicing factor, proline- andglutamine-rich OS=Homo sapiens OX=9606 GN=SFPQMSRDRFRSRGGGGGGFHRRGGGGGRGGLHDFRSPPPGMGLNQNRGPMGPGPGQSGPKPPIPPPPPHQQQQQPPPQQPPPQQPPPHQPPPHPQPHQQQQPPPPPQDSSKPVVAQGPGPAPGVGSAPPASSSAPPATPPTSGAPPGSGPGPTPTPPPAVTSAPPGAPPPTPPSSGVPTTPPQAGGPPPPPAAVPGPGPGPKQGPGPGGPKGGKMPGGPKPGGGPGLSTPGGHPKPPHRGGGEPRGGRQHHPPYHQQHHQGPPPGGPGGRSEEKISDSEGFKANLSLLRRPGEKTYTQRCRLFVGNLPADITEDEFKRLFAKYGEPGEVFINKGKGFGFIKLESRALAEIAKAELDDTPMRGRQLRVRFATHAAALSVRNLSPYVSNELLEEAFSQFGPIERAVVIVDDRGRSTGKGIVEFASKPAARKAFERCSEGVFLLTTTPRPVIVEPLEQLDDEDGLPEKLAQKNPMYQKERETPPRFAQHGTFEYEYSQRWKSLDEMEKQQREQVEKNMKDAKDKLESEMEDAYHEHQANLLRQDLMRRQEELRRMEELHNQEMQKRKEMQLRQEEERRRREEEMMIRQREMEEQMRRQREESYSRMGYMDPRERDMRMGGGGAMNMGDPYGSGGQKFPPLGGGGGIGYEANPGVPPATMSGSMMGSDMVRMIDVG>sp|O15389|SIGL5_HUMAN Sialic acid-binding Ig-like lectin 5 OS=Homosapiens OX=9606 GN=SIGLEC5 PE=1 SV=1MLPLLLLPLLWGGSLQEKPVYELQVQKSVTVQEGLCVLVPCSFSYPWRSWYSSPPLYVYWFRDGEIPYYAEVVATNNPDRRVKPETQGRFRLLGDVQKKNCSLSIGDARMEDTGSYFFRVERGRDVKYSYQQNKLNLEVTALIEKPDIHFLEPLESGRPTRLSCSLPGSCEAGPPLTFSWTGNALSPLDPETTRSSELTLTPRPEDHGTNLTCQMKRQGAQVTTERTVQLNVSYAPQTITIFRNGIALEILQNTSYLPVLEGQALRLLCDAPSNPPAHLSWFQGSPALNATPISNTGILELRRVRSAEEGGFTCRAQHPLGFLQIFLNLSVYSLPQLLGPSCSWEAEGLHCRCSFRARPAPSLCWRLEEKPLEGNSSQGSFKVNSSSAGPWANSSLILHGGLSSDLKVSCKAWNIYGSQSGSVLLLQGRSNLGTGVVPAALGGAGVMALLCICLCLIFFLIVKARRKQAAGRPEKMDDEDPIMGTITSGSRKKPWPDSPGDQASPPGDAPPLEEQKELHYASLSFSEMKSREPKDQEAPSTTEYSEIKTSK>sp|Q9BX95|SGPP1_HUMAN Sphingosine-1-phosphate phosphatase 1 OS=Homosapiens OX=9606 GN=SGPP1 PE=1 SV=2MSLRQRLAQLVGRLQDPQKVARFQRLCGVEAPPRRSADRREDEKAEAPLAGDPRLRGRQPGAPGGPQPPGSDRNQCPAKPDGGGAPNGVRNGLAAELGPASPRRAGALRRNSLTGEEGQLARVSNWPLYCLFCFGTELGNELFYILFFPFWIWNLDPLVGRRLVVIWVLVMYLGQCTKDIIRWPRPASPPVVKLEVFYNSEYSMPSTHAMSGTAIPISMVLLTYGRWQYPLIYGLILIPCWCSLVCLSRIYMGMHSILDIIAGFLYTILILAVFYPFVDLIDNFNQTHKYAPFIIIGLHLALGIFSFTLDTWSTSRGDTAEILGSGAGIACGSHVTYNMGLVLDPSLDTLPLAGPPITVTLFGKAILRILIGMVFVLIIRDVMKKITIPLACKIFNIPCDDIRKARQHMEVELPYRYITYGMVGFSITFFVPYIFFFIGIS>sp|O43699|SIGL6_HUMAN Sialic acid-binding Ig-like lectin 6 OS=Homosapiens OX=9606 GN=SIGLEC6 PE=1 SV=2MQGAQEASASEMLPLLLPLLWAGALAQERRFQLEGPESLTVQEGLCVLVPCRLPTTLPASYYGYGYWFLEGADVPVATNDPDEEVQEETRGRFHLLWDPRRKNCSLSIRDARRRDNAAYFFRLKSKWMKYGYTSSKLSVRVMALTHRPNISIPGTLESGHPSNLTCSVPWVCEQGTPPIFSWMSAAPTSLGPRTTQSSVLTITPRPQDHSTNLTCQVTFPGAGVTMERTIQLNVSYAPQKVAISIFQGNSAAFKILQNTSSLPVLEGQALRLLCDADGNPPAHLSWFQGFPALNATPISNTGVLELPQVGSAEEGDFTCRAQHPLGSLQISLSLFVHWKPEGRAGGVLGAVWGASITTLVFLCVCFIFRVKTRRKKAAQPVQNTDDVNPVMVSGSRGHQHQFQTGIVSDHPAEAGPISEDEQELHYAVLHFHKVQPQEPKVTDTEYSEIKIHK>sp|O43699-2|SIGL6_HUMAN Isoform 2 of Sialic acid-binding Ig-like lectin6 OS=Homo sapiens OX=9606 GN=SIGLEC6MQGAQEASASEMLPLLLPLLWAGALAQERRFQLEGPESLTVQEGLCVLVPCRLPTTLPASYYGYGYWFLEGADVPVATNDPDEEVQEETRGRFHLLWDPRRKNCSLSIRDARRRDNAAYFFRLKSKWMKYGYTSSKLSVRVMALTHRPNISIPGTLESGHPSNLTCSVPWVCEQGTPPIFSWMSAAPTSLGPRTTQSSVLTITPRPQDHSTNLTCQVTFPGAGVTMERTIQLNVSYAPQKVAISIFQGNSAAFKILQNTSSLPVLEGQALRLLCDADGNPPAHLSWFQGFPALNATPISNTGVLELPQVGSAEEGDFTCRAQHPLGSLQISLSLFVHWSSAPVPDRHSFRPPC>sp|O43699-3|SIGL6_HUMAN Isoform 3 of Sialic acid-binding Ig-like lectin6 OS=Homo sapiens OX=9606 GN=SIGLEC6MQGAQEASASEMLPLLLPLLWAGALAQERRFQLEGPESLTVQEGLCVLVPCRLPTTLPASYYGYGYWFLEGADVPVATNDPDEEVQEETRGRFHLLWDPRRKNCSLSIRDARRRDNAAYFFRLKSKWMKYGYTSSKLSVRVMALTHRPNISIPGTLESGHPSNLTCSVPWVCEQGTPPIFSWMSAAPTSLGPRTTQSSVLTITPRPQDHSTNLTCQVTFPGAGVTMERTIQLNVSSFKILQNTSSLPVLEGQALRLLCDADGNPPAHLSWFQGFPALNATPISNTGVLELPQVGSAEEGDFTCRAQHPLGSLQISLSLFVHWKPEGRAGGVLGAVWGASITTLVFLCVCFIFRVKTRRKKAAQPVQNTDDVNPVMVSGSRGHQHQFQTGIVSDHPAEAGPISEDEQELHYAVLHFHKVQPQEPKVTDTEYSEIKIHK>sp|O43699-4|SIGL6_HUMAN Isoform 4 of Sialic acid-binding Ig-like lectin6 OS=Homo sapiens OX=9606 GN=SIGLEC6MQGAQEASASEMLPLLLPLLWAGALAQERRFQLEGPESLTVQEGLCVLVPCRLPTTLPASYYGYGYWFLEGADVPVATNDPDEEVQEETRGRFHLLWDPRRKNCSLSIRDARRRDNAAYFFRLKSKWMKYGYTSSKLSVRVMGTLESGHPSNLTCSVPWVCEQGTPPIFSWMSAAPTSLGPRTTQSSVLTITPRPQDHSTNLTCQVTFPGAGVTMERTIQLNVSYAPQKVAISIFQGNSAAFKILQNTSSLPVLEGQALRLLCDADGNPPAHLSWFQGFPALNATPISNTGVLELPQVGSAEEGDFTCRAQHPLGSLQISLSLFVHWSSAPVPDRHSFRPPC>sp|O43699-5|SIGL6_HUMAN Isoform 5 of Sialic acid-binding Ig-like lectin6 OS=Homo sapiens OX=9606 GN=SIGLEC6MQGAQEASASEMLPLLLPLLWAGALAQERRFQLEGPESLTVQEGLCVLVPCRLPTTLPASYYGYGYWFLEGADVPVATNDPDEEVQEETRGRFHLLWDPRRKNCSLSIRDARRRDNAAYFFRLKSKWMKYGYTSSKLSVRVMALTHRPNISIPGTLESGHPSNLTCSVPWVCEQGTPPIFSWMSAAPTSLGPRTTQSSVLTITPRPQDHSTNLTCQVTFPGAGVTMERTIQLNVSWMLRRPPLSTPDAPQKVAISIFQGNSAAFKILQNTSSLPVLEGQALRLLCDADGNPPAHLSWFQGFPALNATPISNTGVLELPQVGSAEEGDFTCRAQHPLGSLQISLSLFVHWKPEGRAGGVLGAVWGASITTLVFLCVCFIFRVISTSSRQA>sp|O43699-6|SIGL6_HUMAN Isoform 6 of Sialic acid-binding Ig-like lectin6 OS=Homo sapiens OX=9606 GN=SIGLEC6MQGAQEASASEMLPLLLPLLWAASYYGYGYWFLEGADVPVATNDPDEEVQEETRGRFHLLWDPRRKNCSLSIRDARRRDNAAYFFRLKSKWMKYGYTSSKLSVRVMALTHRPNISIPGTLESGHPSNLTCSVPWVCEQGTPPIFSWMSAAPTSLGPRTTQSSVLTITPRPQDHSTNLTCQVTFPGAGVTMERTIQLNVSSFKILQNTSSLPVLEGQALRLLCDADGNPPAHLSWFQGFPALNATPISNTGVLELPQVGSAEEGDFTCRAQHPLGSLQISLSLFVHWKPEGRAGGVLGAVWGASITTLVFLCVCFIFRVKTRRKKAAQPVQNTDDVNPVMVSGSRGHQHQFQTGIVSDHPAEAGPISEDEQELHYAVLHFHKVQPQEPKVTDTEYSEIKIHK>sp|Q6FHJ7|SFRP4_HUMAN Secreted frizzled-related protein 4 OS=Homosapiens OX=9606 GN=SFRP4 PE=1 SV=2MFLSILVALCLWLHLALGVRGAPCEAVRIPMCRHMPWNITRMPNHLHHSTQENAILAIEQYEELVDVNCSAVLRFFLCAMYAPICTLEFLHDPIKPCKSVCQRARDDCEPLMKMYNHSWPESLACDELPVYDRGVCISPEAIVTDLPEDVKWIDITPDMMVQERPLDVDCKRLSPDRCKCKKVKPTLATYLSKNYSYVIHAKIKAVQRSGCNEVTTVVDVKEIFKSSSPIPRTQVPLITNSSCQCPHILPHQDVLIMCYEWRSRMMLLENCLVEKWRDQLSKRSIQWEERLQEQRRTVQDKKKTAGRTSRSNPPKPKGKPPAPKPASPKKNIKTRSAQKRTNPKRV>sp|Q9Y286|SIGL7_HUMAN Sialic acid-binding Ig-like lectin 7 OS=Homosapiens OX=9606 GN=SIGLEC7 PE=1 SV=1MLLLLLLPLLWGRERVEGQKSNRKDYSLTMQSSVTVQEGMCVHVRCSFSYPVDSQTDSDPVHGYWFRAGNDISWKAPVATNNPAWAVQEETRDRFHLLGDPQTKNCTLSIRDARMSDAGRYFFRMEKGNIKWNYKYDQLSVNVTALTHRPNILIPGTLESGCFQNLTCSVPWACEQGTPPMISWMGTSVSPLHPSTTRSSVLTLIPQPQHHGTSLTCQVTLPGAGVTTNRTIQLNVSYPPQNLTVTVFQGEGTASTALGNSSSLSVLEGQSLRLVCAVDSNPPARLSWTWRSLTLYPSQPSNPLVLELQVHLGDEGEFTCRAQNSLGSQHVSLNLSLQQEYTGKMRPVSGVLLGAVGGAGATALVFLSFCVIFIVVRSCRKKSARPAADVGDIGMKDANTIRGSASQGNLTESWADDNPRHHGLAAHSSGEEREIQYAPLSFHKGEPQDLSGQEATNNEYSEIKIPK>sp|Q9Y286-2|SIGL7_HUMAN Isoform 2 of Sialic acid-binding Ig-like lectin7 OS=Homo sapiens OX=9606 GN=SIGLEC7MLLLLLLPLLWGRERVEGQKSNRKDYSLTMQSSVTVQEGMCVHVRCSFSYPVDSQTDSDPVHGYWFRAGNDISWKAPVATNNPAWAVQEETRDRFHLLGDPQTKNCTLSIRDARMSDAGRYFFRMEKGNIKWNYKYDQLSVNVTDPPQNLTVTVFQGEGTASTALGNSSSLSVLEGQSLRLVCAVDSNPPARLSWTWRSLTLYPSQPSNPLVLELQVHLGDEGEFTCRAQNSLGSQHVSLNLSLQQEYTGKMRPVSGVLLGAVGGAGATALVFLSFCVIFIVVRSCRKKSARPAADVGDIGMKDANTIRGSASQGNLTESWADDNPRHHGLAAHSSGEEREIQYAPLSFHKGEPQDLSGQEATNNEYSEIKIPK>sp|Q9Y286-3|SIGL7_HUMAN Isoform 3 of Sialic acid-binding Ig-like lectin7 OS=Homo sapiens OX=9606 GN=SIGLEC7MLLLLLLPLLWGRERVEGQKSNRKDYSLTMQSSVTVQEGMCVHVRCSFSYPVDSQTDSDPVHGYWFRAGNDISWKAPVATNNPAWAVQEETRDRFHLLGDPQTKNCTLSIRDARMSDAGRYFFRMEKGNIKWNYKYDQLSVNVTE>sp|Q9Y286-4|SIGL7_HUMAN Isoform 4 of Sialic acid-binding Ig-like lectin7 OS=Homo sapiens OX=9606 GN=SIGLEC7MLLLLLLPLLWGRERVEGQKSNRKDYSLTMQSSVTVQEGMCVHVRCSFSYPVDSQTDSDPVHGYWFRAGNDISWKAPVATNNPAWAVQEETRDRFHLLGDPQTKNCTLSIRDARMSDAGRYFFRMEKGNIKWNYKYDQLSVNVTG>sp|Q8IUQ4|SIAH1_HUMAN E3 ubiquitin-protein ligase SIAH1 OS=Homo sapiensOX=9606 GN=SIAH1 PE=1 SV=2MSRQTATALPTGTSKCPPSQRVPALTGTTASNNDLASLFECPVCFDYVLPPILQCQSGHLVCSNCRPKLTCCPTCRGPLGSIRNLAMEKVANSVLFPCKYASSGCEITLPHTEKADHEELCEFRPYSCPCPGASCKWQGSLDAVMPHLMHQHKSITTLQGEDIVFLATDINLPGAVDWVMMQSCFGFHFMLVLEKQEKYDGHQQFFAIVQLIGTRKQAENFAYRLELNGHRRRLTWEATPRSIHEGIATAIMNSDCLVFDTSIAQLFAENGNLGINVTISMC>sp|Q8IUQ4-2|SIAH1_HUMAN Isoform 2 of E3 ubiquitin-protein ligase SIAH1OS=Homo sapiens OX=9606 GN=SIAH1MTGKATPPSLYSWRGVLFTCLPAARTRKRKEMSRQTATALPTGTSKCPPSQRVPALTGTTASNNDLASLFECPVCFDYVLPPILQCQSGHLVCSNCRPKLTCCPTCRGPLGSIRNLAMEKVANSVLFPCKYASSGCEITLPHTEKADHEELCEFRPYSCPCPGASCKWQGSLDAVMPHLMHQHKSITTLQGEDIVFLATDINLPGAVDWVMMQSCFGFHFMLVLEKQEKYDGHQQFFAIVQLIGTRKQAENFAYRLELNGHRRRLTWEATPRSIHEGIATAIMNSDCLVFDTSIAQLFAENGNLGINVTISMC>sp|Q8IUQ4-3|SIAH1_HUMAN Isoform 3 of E3 ubiquitin-protein ligase SIAH1OS=Homo sapiens OX=9606 GN=SIAH1MSRQTATALPTGTSKCPPSQRVPALTGTTASNNDLASLFECPVCFDYVLPPILQCQSGHLVCSNCRPKLTCCPTCRGPLGSIRNLAMEKVANSVLFPCKYASSGCEITLPHTEKADHEELCEFRPYSCPCPGASCKWQGSLDAVMPHLMHQHKSITTLQGEDIVFLATDINLPGAVDWVMMQSCFGFHFMLVDLS>sp|Q8IWX5|SGPP2_HUMAN Sphingosine-1-phosphate phosphatase 2 OS=Homosapiens OX=9606 GN=SGPP2 PE=1 SV=1MAELLRSLQDSQLVARFQRRCGLFPAPDEGPRENGADPTERAARVPGVEHLPAANGKGGEAPANGLRRAAAPEAYVQKYVVKNYFYYYLFQFSAALGQEVFYITFLPFTHWNIDPYLSRRLIIIWVLVMYIGQVAKDVLKWPRPSSPPVVKLEKRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMHTVLDVLGGVLITALLIVLTYPAWTFIDCLDSASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKPAESLPVIQNIPPLTTYMLVLGLTKFAVGIVLILLVRQLVQNLSLQVLYSWFKVVTRNKEARRRLEIEVPYKFVTYTSVGICATTFVPMLHRFLGLP>sp|Q8IWX5-2|SGPP2_HUMAN Isoform 2 of Sphingosine-1-phosphate phosphatase2 OS=Homo sapiens OX=9606 GN=SGPP2MYIGQVAKDVLKWPRPSSPPVVKLEKRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMHTVLDVLGGVLITALLIVLTYPAWTFIDCLDSASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKPAESLPVIQNIPPLTTYMLVLGLTKFAVGIVLILLVRQLVQNLSLQVLYSWFKVVTRNKEARRRLEIEVPYKFVTYTSVGICATTFVPMLHRFLGLP>sp|Q9NYZ4|SIGL8_HUMAN Sialic acid-binding Ig-like lectin 8 OS=Homosapiens OX=9606 GN=SIGLEC8 PE=1 SV=2MLLLLLLLPLLWGTKGMEGDRQYGDGYLLQVQELVTVQEGLCVHVPCSFSYPQDGWTDSDPVHGYWFRAGDRPYQDAPVATNNPDREVQAETQGRFQLLGDIWSNDCSLSIRDARKRDKGSYFFRLERGSMKWSYKSQLNYKTKQLSVFVTALTHRPDILILGTLESGHSRNLTCSVPWACKQGTPPMISWIGASVSSPGPTTARSSVLTLTPKPQDHGTSLTCQVTLPGTGVTTTSTVRLDVSYPPWNLTMTVFQGDATASTALGNGSSLSVLEGQSLRLVCAVNSNPPARLSWTRGSLTLCPSRSSNPGLLELPRVHVRDEGEFTCRAQNAQGSQHISLSLSLQNEGTGTSRPVSQVTLAAVGGAGATALAFLSFCIIFIIVRSCRKKSARPAAGVGDTGMEDAKAIRGSASQGPLTESWKDGNPLKKPPPAVAPSSGEEGELHYATLSFHKVKPQDPQGQEATDSEYSEIKIHKRETAETQACLRNHNPSSKEVRG>sp|Q9NYZ4-2|SIGL8_HUMAN Isoform 2 of Sialic acid-binding Ig-like lectin8 OS=Homo sapiens OX=9606 GN=SIGLEC8MLLLLLLLPLLWGTKGMEGDRQYGDGYLLQVQELVTVQEGLCVHVPCSFSYPQDGWTDSDPVHGYWFRAGDRPYQDAPVATNNPDREVQAETQGRFQLLGDIWSNDCSLSIRDARKRDKGSYFFRLERGSMKWSYKSQLNYKTKQLSVFVTDPPWNLTMTVFQGDATASTALGNGSSLSVLEGQSLRLVCAVNSNPPARLSWTRGSLTLCPSRSSNPGLLELPRVHVRDEGEFTCRAQNAQGSQHISLSLSLQNEGTGTSRPVSQVTLAAVGGAGATALAFLSFCIIFIIVRSCRKKSARPAAGVGDTGMEDAKAIRGSASQGPLTESWKDGNPLKKPPPAVAPSSGEEGELHYATLSFHKVKPQDPQGQEATDSEYSEIKIHKRETAETQACLRNHNPSSKEVRG>sp|Q9NYZ4-3|SIGL8_HUMAN Isoform 3 of Sialic acid-binding Ig-like lectin8 OS=Homo sapiens OX=9606 GN=SIGLEC8MLLLLLLLPLLWGTKGMEGDRQYGDGYLLQVQELVTVQEGLCVHVPCSFSYPQDGWTDSDPVHGYWFRAGDRPYQDAPVATNNPDREVQAETQGRFQLLGDIWSNDCSLSIRDARKRDKGSYFFRLERGSMKWSYKSQLNYKTKQLSVFVTALTHRPDILILGTLESGHSRNLTCSVPWACKQGTPPMISWIGASVSSPGPTTARSSVLTLTPKPQDHGTSLTCQVTLPGTGVTTTSTVRLDVSYPPWNLTMTVFQGDATASTALGNGSSLSVLEGQSLRLVCAVNSNPPARLSWTRGSLTLCPSRSSNPGLLELPRVHVRDEGEFTCRAQNAQGSQHISLSLSLQNEGTGTSRPVSQVTLAAVGGAGATALAFLSFCIIFIIVRSCRKKSARPAAGVGDTGMEDAKAIRGSASQVSDVGFSTPSIQPGHL>sp|Q99717|SMAD5_HUMAN Mothers against decapentaplegic homolog 5 OS=Homosapiens OX=9606 GN=SMAD5 PE=1 SV=1MTSMASLFSFTSPAVKRLLGWKQGDEEEKWAEKAVDALVKKLKKKKGAMEELEKALSSPGQPSKCVTIPRSLDGRLQVSHRKGLPHVIYCRVWRWPDLQSHHELKPLDICEFPFGSKQKEVCINPYHYKRVESPVLPPVLVPRHNEFNPQHSLLVQFRNLSHNEPHMPQNATFPDSFHQPNNTPFPLSPNSPYPPSPASSTYPNSPASSGPGSPFQLPADTPPPAYMPPDDQMGQDNSQPMDTSNNMIPQIMPSISSRDVQPVAYEEPKHWCSIVYYELNNRVGEAFHASSTSVLVDGFTDPSNNKSRFCLGLLSNVNRNSTIENTRRHIGKGVHLYYVGGEVYAECLSDSSIFVQSRNCNFHHGFHPTTVCKIPSSCSLKIFNNQEFAQLLAQSVNHGFEAVYELTKMCTIRMSFVKGWGAEYHRQDVTSTPCWIEIHLHGPLQWLDKVLTQMGSPLNPISSVS>sp|Q9Y336|SIGL9_HUMAN Sialic acid-binding Ig-like lectin 9 OS=Homosapiens OX=9606 GN=SIGLEC9 PE=1 SV=2MLLLLLPLLWGRERAEGQTSKLLTMQSSVTVQEGLCVHVPCSFSYPSHGWIYPGPVVHGYWFREGANTDQDAPVATNNPARAVWEETRDRFHLLGDPHTKNCTLSIRDARRSDAGRYFFRMEKGSIKWNYKHHRLSVNVTALTHRPNILIPGTLESGCPQNLTCSVPWACEQGTPPMISWIGTSVSPLDPSTTRSSVLTLIPQPQDHGTSLTCQVTFPGASVTTNKTVHLNVSYPPQNLTMTVFQGDGTVSTVLGNGSSLSLPEGQSLRLVCAVDAVDSNPPARLSLSWRGLTLCPSQPSNPGVLELPWVHLRDAAEFTCRAQNPLGSQQVYLNVSLQSKATSGVTQGVVGGAGATALVFLSFCVIFVVVRSCRKKSARPAAGVGDTGIEDANAVRGSASQGPLTEPWAEDSPPDQPPPASARSSVGEGELQYASLSFQMVKPWDSRGQEATDTEYSEIKIHR>sp|Q9Y336-2|SIGL9_HUMAN Isoform 2 of Sialic acid-binding Ig-like lectin9 OS=Homo sapiens OX=9606 GN=SIGLEC9MLLLLLPLLWGRERAEGQTSKLLTMQSSVTVQEGLCVHVPCSFSYPSHGWIYPGPVVHGYWFREGANTDQDAPVATNNPARAVWEETRDRFHLLGDPHTKNCTLSIRDARRSDAGRYFFRMEKGSIKWNYKHHRLSVNVTALTHRPNILIPGTLESGCPQNLTCSVPWACEQGTPPMISWIGTSVSPLDPSTTRSSVLTLIPQPQDHGTSLTCQVTFPGASVTTNKTVHLNVSYPPQNLTMTVFQGDGTVSTVLGNGSSLSLPEGQSLRLVCAVDAVDSNPPARLSLSWRGLTLCPSQPSNPGVLELPWVHLRDAAEFTCRAQNPLGSQQVYLNVSLQSKATSGVTQGVVGGAGATALVFLSFCVIFVVVRSCRKKSARPAAGVGDTGIEDANAVRGSASQILNHFIGFPTFLGLGFEFLLNLRDLCCHPDSEFYVYHFSHFRLIKNIAGEIVWSLEGKILWLLDVSDFFHWFFLICVG>sp|O43255|SIAH2_HUMAN E3 ubiquitin-protein ligase SIAH2 OS=Homo sapiensOX=9606 GN=SIAH2 PE=1 SV=1MSRPSSTGPSANKPCSKQPPPQPQHTPSPAAPPAAATISAAGPGSSAVPAAAAVISGPGGGGGAGPVSPQHHELTSLFECPVCFDYVLPPILQCQAGHLVCNQCRQKLSCCPTCRGALTPSIRNLAMEKVASAVLFPCKYATTGCSLTLHHTEKPEHEDICEYRPYSCPCPGASCKWQGSLEAVMSHLMHAHKSITTLQGEDIVFLATDINLPGAVDWVMMQSCFGHHFMLVLEKQEKYEGHQQFFAIVLLIGTRKQAENFAYRLELNGNRRRLTWEATPRSIHDGVAAAIMNSDCLVFDTAIAHLFADNGNLGINVTISTCCP>sp|Q5T4F7|SFRP5_HUMAN Secreted frizzled-related protein 5 OS=Homosapiens OX=9606 GN=SFRP5 PE=2 SV=3MRAAAAGGGVRTAALALLLGALHWAPARCEEYDYYGWQAEPLHGRSYSKPPQCLDIPADLPLCHTVGYKRMRLPNLLEHESLAEVKQQASSWLPLLAKRCHSDTQVFLCSLFAPVCLDRPIYPCRSLCEAVRAGCAPLMEAYGFPWPEMLHCHKFPLDNDLCIAVQFGHLPATAPPVTKICAQCEMEHSADGLMEQMCSSDFVVKMRIKEIKIENGDRKLIGAQKKKKLLKPGPLKRKDTKRLVLHMKNGAGCPCPQLDSLAGSFLVMGRKVDGQLLLMAVYRWDKKNKEMKFAVKFMFSYPCSLYYPFFYGAAEPH>sp|Q7Z7L1|SLN11_HUMAN Schlafen family member 11 OS=Homo sapiens OX=9606GN=SLFN11 PE=1 SV=2MEANQCPLVVEPSYPDLVINVGEVTLGEENRKKLQKIQRDQEKERVMRAACALLNSGGGVIRMAKKVEHPVEMGLDLEQSLRELIQSSDLQAFFETKQQGRCFYIFVKSWSSGPFPEDRSVKPRLCSLSSSLYRRSETSVRSMDSREAFCFLKTKRKPKILEEGPFHKIHKGVYQELPNSDPADPNSDPADLIFQKDYLEYGEILPFPESQLVEFKQFSTKHFQEYVKRTIPEYVPAFANTGGGYLFIGVDDKSREVLGCAKENVDPDSLRRKIEQAIYKLPCVHFCQPQRPITFTLKIVNVLKRGELYGYACMIRVNPFCCAVFSEAPNSWIVEDKYVCSLTTEKWVGMMTDTDPDLLQLSEDFECQLSLSSGPPLSRPVYSKKGLEHKKELQQLLFSVPPGYLRYTPESLWRDLISEHRGLEELINKQMQPFFRGILIFSRSWAVDLNLQEKPGVICDALLIAQNSTPILYTILREQDAEGQDYCTRTAFTLKQKLVNMGGYTGKVCVRAKVLCLSPESSAEALEAAVSPMDYPASYSLAGTQHMEALLQSLVIVLLGFRSLLSDQLGCEVLNLLTAQQYEIFSRSLRKNRELFVHGLPGSGKTIMAMKIMEKIRNVFHCEAHRILYVCENQPLRNFISDRNICRAETRKTFLRENFEHIQHIVIDEAQNFRTEDGDWYGKAKSITRRAKGGPGILWIFLDYFQTSHLDCSGLPPLSDQYPREELTRIVRNADPIAKYLQKEMQVIRSNPSFNIPTGCLEVFPEAEWSQGVQGTLRIKKYLTVEQIMTCVADTCRRFFDRGYSPKDVAVLVSTAKEVEHYKYELLKAMRKKRVVQLSDACDMLGDHIVLDSVRRFSGLERSIVFGIHPRTADPAILPNVLICLASRAKQHLYIFPWGGH>sp|Q8IYM2|SLN12_HUMAN Schlafen family member 12 OS=Homo sapiens OX=9606GN=SLFN12 PE=1 SV=2MNISVDLETNYAELVLDVGRVTLGENSRKKMKDCKLRKKQNESVSRAMCALLNSGGGVIKAEIENEDYSYTKDGIGLDLENSFSNILLFVPEYLDFMQNGNYFLIFVKSWSLNTSGLRITTLSSNLYKRDITSAKVMNATAALEFLKDMKKTRGRLYLRPELLAKRPCVDIQEENNMKALAGVFFDRTELDRKEKLTFTESTHVEIKNFSTEKLLQRIKEILPQYVSAFANTDGGYLFIGLNEDKEIIGFKAEMSDLDDLEREIEKSIRKMPVHHFCMEKKKINYSCKFLGVYDKGSLCGYVCALRVERFCCAVFAKEPDSWHVKDNRVMQLTRKEWIQFMVEAEPKFSSSYEEVISQINTSLPAPHSWPLLEWQRQRHHCPGLSGRITYTPENLCRKLFLQHEGLKQLICEEMDSVRKGSLIFSRSWSVDLGLQENHKVLCDALLISQDSPPVLYTFHMVQDEEFKGYSTQTALTLKQKLAKIGGYTKKVCVMTKIFYLSPEGMTSCQYDLRSQVIYPESYYFTRRKYLLKALFKALKRLKSLRDQFSFAENLYQIIGIDCFQKNDKKMFKSCRRLT>sp|Q8IW03|SIAH3_HUMAN Seven in absentia homolog 3 OS=Homo sapiensOX=9606 GN=SIAH3 PE=1 SV=3MLFFTQCFGAVLDLIHLRFQHYKAKRVFSAAGQLVCVVNPTHNLKYVSSRRAVTQSAPEQGSFHPHHLSHHHCHHRHHHHLRHHAHPHHLHHQEAGLHANPVTPCLCMCPLFSCQWEGRLEVVVPHLRQIHRVDILQGAEIVFLATDMHLPAPADWIIMHSCLGHHFLLVLRKQERHEGHPQFFATMMLIGTPTQADCFTYRLELNRNHRRLKWEATPRSVLECVDSVITDGDCLVLNTSLAQLFSDNGSLAIGIAITATEVLPSEAEM>sp|Q68D06|SLN13_HUMAN Schlafen family member 13 OS=Homo sapiens OX=9606GN=SLFN13 PE=1 SV=1MEANHCSLGVYPSYPDLVIDVGEVTLGEENRKKLQKTQRDQERARVIRAACALLNSGGGVIQMEMANRDERPTEMGLDLEESLRKLIQYPYLQAFFETKQHGRCFYIFVKSWSGDPFLKDGSFNSRICSLSSSLYCRSGTSVLHMNSRQAFDFLKTKERQSKYNLINEGSPPSKIMKAVYQNISESNPAYEVFQTDTIEYGEILSFPESPSIEFKQFSTKHIQQYVENIIPEYISAFANTEGGYLFIGVDDKSRKVLGCAKEQVDPDSLKNVIARAISKLPIVHFCSSKPRVEYSTKIVEVFCGKELYGYLCVIKVKAFCCVVFSEAPKSWMVREKYIRPLTTEEWVEKMMDADPEFPPDFAEAFESQLSLSDSPSLCRPVYSKKGLEHKADLQQHLFPVPPGHLECTPESLWKELSLQHEGLKELIHKQMRPFSQGIVILSRSWAVDLNLQEKPGVICDALLIAQNSTPILYTILREQDAEGQDYCTRTAFTLKQKLVNMGGYTGKVCVRAKVLCLSPESSAEALEAAVSPMDYPASYSLAGTQHMEALLQSLVIVLLGFRSLLSDQLGCEVLNLLTAQQYEIFSRSLRKNRELFVHGLPGSGKTIMAMKIMEKIRNVFHCEAHRILYVCENQPLRNFISDRNICRAETRETFLREKFEHIQHIVIDEAQNFRTEDGDWYRKAKTITQREKDCPGVLWIFLDYFQTSHLGHSGLPPLSAQYPREELTRVVRNADEIAEYIQQEMQLIIENPPINIPHGYLAILSEAKWVPGVPGNTKIIKNFTLEQIVTYVADTCRCFFERGYSPKDVAVLVSTVTEVEQYQSKLLKAMRKKMVVQLSDACDMLGVHIVLDSVRRFSGLERSIVFGIHPRTADPAILPNILICLASRAKQHLYIFL>sp|Q68D06-2|SLN13_HUMAN Isoform 2 of Schlafen family member 13 OS=Homosapiens OX=9606 GN=SLFN13MEANHCSLAPKSWMVREKYIRPLTTEEWVEKMMDADPEFPPDFAEAFESQLSLSDSPSLCRPVYSKKGLEHKADLQQHLFPVPPGHLECTPESLWKELSLQHEGLKELIHKQMRPFSQGIVILSRSWAVDLNLQEKPGVICDALLIAQNSTPILYTILREQDAEGQDYCTRTAFTLKQKLVNMGGYTGKVCVRAKVLCLSPESSAEALEAAVSPMDYPASYSLAGTQHMEALLQSLVIVLLGFRSLLSDQLGCEVLNLLTAQQYEIFSRSLRKNRELFVHGLPGSGKTIMAMKIMEKIRNVFHCEAHRILYVCENQPLRNFISDRNICRAETRETFLREKFEHIQHIVIDEAQNFRTEDGDWYRKAKTITQREKDCPGVLWIFLDYFQTSHLGHSGLPPLSAQYPREELTRVVRNADEIAEYIQQEMQLIIENPPINIPHGYLAILSEAKWVPGVPGNTKIIKNFTLEQIVTYVADTCRCFFERGYSPKDVAVLVSTVTEVEQYQSKLLKAMRKKMVVQLSDACDMLGVHIVLDSVRRFSGLERSIVFGIHPRTADPAILPNILICLASRAKQHLYIFL>sp|O43541|SMAD6_HUMAN Mothers against decapentaplegic homolog 6 OS=Homosapiens OX=9606 GN=SMAD6 PE=1 SV=2MFRSKRSGLVRRLWRSRVVPDREEGGSGGGGGGDEDGSLGSRAEPAPRAREGGGCGRSEVRPVAPRRPRDAVGQRGAQGAGRRRRAGGPPRPMSEPGAGAGSSLLDVAEPGGPGWLPESDCETVTCCLFSERDAAGAPRDASDPLAGAALEPAGGGRSREARSRLLLLEQELKTVTYSLLKRLKERSLDTLLEAVESRGGVPGGCVLVPRADLRLGGQPAPPQLLLGRLFRWPDLQHAVELKPLCGCHSFAAAADGPTVCCNPYHFSRLCGPESPPPPYSRLSPRDEYKPLDLSDSTLSYTETEATNSLITAPGEFSDASMSPDATKPSHWCSVAYWEHRTRVGRLYAVYDQAVSIFYDLPQGSGFCLGQLNLEQRSESVRRTRSKIGFGILLSKEPDGVWAYNRGEHPIFVNSPTLDAPGGRALVVRKVPPGYSIKVFDFERSGLQHAPEPDAADGPYDPNSVRISFAKGWGPCYSRQFITSCPCWLEILLNNPR>sp|O43541-2|SMAD6_HUMAN Isoform B of Mothers against decapentaplegichomolog 6 OS=Homo sapiens OX=9606 GN=SMAD6MSRMGKPIETQKSPPPPYSRLSPRDEYKPLDLSDSTLSYTETEATNSLITAPGEFSDASMSPDATKPSHWCSVAYWEHRTRVGRLYAVYDQAVSIFYDLPQGSGFCLGQLNLEQRSESVRRTRSKIGFGILLSKEPDGVWAYNRGEHPIFVNSPTLDAPGGRALVVRKVPPGYSIKVFDFERSGLQHAPEPDAADGPYDPNSVRISFAKGWGPCYSRQFITSCPCWLEILLNNPR>sp|O43541-4|SMAD6_HUMAN Isoform D of Mothers against decapentaplegichomolog 6 OS=Homo sapiens OX=9606 GN=SMAD6MFRSKRSGLVRRLWRSRVVPDREEGGSGGGGGGDEDGSLGSRAEPAPRAREGGGCGRSEVRPVAPRRPRDAVGQRGAQGAGRRRRAGGPPRPMSEPGAGAGSSLLDVAEPGGPGWLPESDCETVTCCLFSERDAAGAPRDASDPLAGAALEPAGGGRSREARSRLLLLEQELKTVTYSLLKRLKERSLDTLLEAVESRGGVPGGCVLVPRADLRLGGQPAPPQLLLGRLFRWPDLQHAVELKPLCGCHSFAAAADGPTVCCNPYHFSRLCGPESPPPPYSRLSPRDEYKPLDLSDSTLSYTETEATNSLITAPGEFSAADAGIGSRGNRGLESSVPCS>sp|P21815|SIAL_HUMAN Bone sialoprotein 2 OS=Homo sapiens OX=9606 GN=IBSPPE=1 SV=4MKTALILLSILGMACAFSMKNLHRRVKIEDSEENGVFKYRPRYYLYKHAYFYPHLKRFPVQGSSDSSEENGDDSSEEEEEEEETSNEGENNEESNEDEDSEAENTTLSATTLGYGEDATPGTGYTGLAAIQLPKKAGDITNKATKEKESDEEEEEEEEGNENEESEAEVDENEQGINGTSTNSTEAENGNGSSGGDNGEEGEEESVTGANAEDTTETGRQGKGTSKTTTSPNGGFEPTTPPQVYRTTSPPFGKTTTVEYEGEYEYTGANEYDNGYEIYESENGEPRGDNYRAYEDEYSYFKGQGYDGYDGQNYYHHQ>sp|P0C7P3|SLN14_HUMAN Protein SLFN14 OS=Homo sapiens OX=9606 GN=SLFN14PE=1 SV=2MESLKTDTEMPYPEVIVDVGRVIFGEENRKKMTNSCLKRSENSRIIRAICALLNSGGGVIKAEIDDKTYSYQCHGLGQDLETSFQKLLPSGSQKYLDYMQQGHNLLIFVKSWSPDVFSLPLRICSLRSNLYRRDVTSAINLSASSALELLREKGFRAQRGRPRVKKLHPQQVLNRCIQEEEDMRILASEFFKKDKLMYKEKLNFTESTHVEFKRFTTKKVIPRIKEMLPHYVSAFANTQGGYVLIGVDDKSKEVVGCKWEKVNPDLLKKEIENCIEKLPTFHFCCEKPKVNFTTKILNVYQKDVLDGYVCVIQVEPFCCVVFAEAPDSWIMKDNSVTRLTAEQWVVMMLDTQSAPPSLVTDYNSCLISSASSARKSPGYPIKVHKFKEALQRHLFPVTQEEVQFKPESLCKKLFSDHKELEGLMKTLIHPCSQGIVIFSRSWAGDVGFRKEQNVLCDALLIAVNSPVVLYTILIDPNWPGGLEYARNTAHQLKQKLQTVGGYTGKVCIIPRLIHLSSTQSRPGEIPLRYPRSYRLADEEEMEDLLQALVVVSLSSRSLLSDQMGCEFFNLLIMEQSQLLSESLQKTRELFIYCFPGVRKTALAIKIMEKIKDLFHCKPKEILYVCESDSLKDFVTQQTTCQAVTRKTFMQGEFLKIKHIVMDETENFCSKYGNWYMKAKNITHPKAKGTGSENLHHGILWLFLDPFQIHHADVNGLPPPSAQFPRKTITSGIHCALEIAKVMKEEMKRIKENPPSNMSPDTLALFSETAYEEATCAQALPGVCETKTNLTTEQIANYVARKCHSLFQCGYLPKDIAILCRRGEDRGRYRLALLKAMELIETHRPSEVVFSPATGVWGSHIVLDSIQQFSGLERTVVFGLSPECDQSEEFHKLCFASRAIKHLYLLYEKRAAY>sp|P0C7P3-2|SLN14_HUMAN Isoform 2 of Protein SLFN14 OS=Homo sapiensOX=9606 GN=SLFN14MESLKTDTEMPYPEVIVDVGRVIFGEENRKKMTNSCLKRSENSRIIRAICALLNSGGGVIKAEIDDKTYSYQCHGLGQDLETSFQKLLPSGSQKYLDYMQQGHNLLIFVKSWSPDVFSLPLRICSLRSNLYRRDVTSAINLSASSALELLREKGFRAQRGRPRVKKLHPQQVLNRCIQEEEDMRILASEFFKKDKLMYKEKLNFTESTHVEFKRFTTKKVIPRIKEMLPHYVSAFANTQGGYVLIGVDDKSKEVVGCKWEKVNPDLLKKEIENCIEKLPTFHFCCEKPKVNFTTKILNVYQKDVLDGYVCVIQVEPFCCVVFAEAPDSWIMKDNSVTRLTAEQWVVMMLDTQSASSARKSPGYPIKVHKFKEALQRHLFPVTQEEVQFKPESLCKKLFSDHKELEGLMKTLIHPCSQGIVIFSRSWAGDVGFRKEQNVLCDALLIAVNSPVVLYTILIDPNWPGGLEYARNTAHQLKQKLQTVGGYTGKVCIIPRLIHLSSTQSRPGEIPLRYPRSYRLADEEEMEDLLQALVVVSLSSRSLLSDQMGCEFFNLLIMEQSQLLSESLQKTRELFIYCFPGVRKTALAIKIMEKIKDLFHCKPKEILYVCESDSLKDFVTQQTTCQAVTRKTFMQGEFLKIKHIVMDETENFCSKYGNWYMKAKNITHPKAKGTGSENLHHGILWLFLDPFQIHHADVNGLPPPSAQFPRKTITSGIHCALEIAKVMKEEMKRIKENPPSNMSPDTLALFSETAYEEATCAQALPGVCETKTNLTTEQIANYVARKCHSLFQCGYLPKDIAILCRRGEDRGRYRLALLKAMELIETHRPSEVVFSPATGVWGSHIVLDSIQQFSGLERTVVFGLSPECDQSEEFHKLCFASRAIKHLYLLYEKRAAY>sp|Q07889|SOS1_HUMAN Son of sevenless homolog 1 OS=Homo sapiens OX=9606GN=SOS1 PE=1 SV=1MQAQQLPYEFFSEENAPKWRGLLVPALKKVQGQVHPTLESNDDALQYVEELILQLLNMLCQAQPRSASDVEERVQKSFPHPIDKWAIADAQSAIEKRKRRNPLSLPVEKIHPLLKEVLGYKIDHQVSVYIVAVLEYISADILKLVGNYVRNIRHYEITKQDIKVAMCADKVLMDMFHQDVEDINILSLTDEEPSTSGEQTYYDLVKAFMAEIRQYIRELNLIIKVFREPFVSNSKLFSANDVENIFSRIVDIHELSVKLLGHIEDTVEMTDEGSPHPLVGSCFEDLAEELAFDPYESYARDILRPGFHDRFLSQLSKPGAALYLQSIGEGFKEAVQYVLPRLLLAPVYHCLHYFELLKQLEEKSEDQEDKECLKQAITALLNVQSGMEKICSKSLAKRRLSESACRFYSQQMKGKQLAIKKMNEIQKNIDGWEGKDIGQCCNEFIMEGTLTRVGAKHERHIFLFDGLMICCKSNHGQPRLPGASNAEYRLKEKFFMRKVQINDKDDTNEYKHAFEIILKDENSVIFSAKSAEEKNNWMAALISLQYRSTLERMLDVTMLQEEKEEQMRLPSADVYRFAEPDSEENIIFEENMQPKAGIPIIKAGTVIKLIERLTYHMYADPNFVRTFLTTYRSFCKPQELLSLIIERFEIPEPEPTEADRIAIENGDQPLSAELKRFRKEYIQPVQLRVLNVCRHWVEHHFYDFERDAYLLQRMEEFIGTVRGKAMKKWVESITKIIQRKKIARDNGPGHNITFQSSPPTVEWHISRPGHIETFDLLTLHPIEIARQLTLLESDLYRAVQPSELVGSVWTKEDKEINSPNLLKMIRHTTNLTLWFEKCIVETENLEERVAVVSRIIEILQVFQELNNFNGVLEVVSAMNSSPVYRLDHTFEQIPSRQKKILEEAHELSEDHYKKYLAKLRSINPPCVPFFGIYLTNILKTEEGNPEVLKRHGKELINFSKRRKVAEITGEIQQYQNQPYCLRVESDIKRFFENLNPMGNSMEKEFTDYLFNKSLEIEPRNPKPLPRFPKKYSYPLKSPGVRPSNPRPGTMRHPTPLQQEPRKISYSRIPESETESTASAPNSPRTPLTPPPASGASSTTDVCSVFDSDHSSPFHSSNDTVFIQVTLPHGPRSASVSSISLTKGTDEVPVPPPVPPRRRPESAPAESSPSKIMSKHLDSPPAIPPRQPTSKAYSPRYSISDRTSISDPPESPPLLPPREPVRTPDVFSSSPLHLQPPPLGKKSDHGNAFFPNSPSPFTPPPPQTPSPHGTRRHLPSPPLTQEVDLHSIAGPPVPPRQSTSQHIPKLPPKTYKREHTHPSMHRDGPPLLENAHSS>sp|Q07889-2|SOS1_HUMAN Isoform 2 of Son of sevenless homolog 1 OS=Homosapiens OX=9606 GN=SOS1MLCQAQPRSASDVEERVQKSFPHPIDKWAIADAQSAIEKRKRRNPLSLPVEKIHPLLKEVLGYKIDHQVSVYIVAVLEYISADILKLVGNYVRNIRHYEITKQDIKVAMCADKVLMDMFHQDVEDINILSLTDEEPSTSGEQTYYDLVKAFMAEIRQYIRELNLIIKVFREPFVSNSKLFSANDVENIFSRIVDIHELSVKLLGHIEDTVEMTDEGSPHPLVGSCFEDLAEELAFDPYESYARDILRPGFHDRFLSQLSKPGAALYLQSIGEGFKEAVQYVLPRLLLAPVYHCLHYFELLKFPFGDLSRLRDSV>sp|O15105|SMAD7_HUMAN Mothers against decapentaplegic homolog 7 OS=Homosapiens OX=9606 GN=SMAD7 PE=1 SV=1MFRTKRSALVRRLWRSRAPGGEDEEEGAGGGGGGGELRGEGATDSRAHGAGGGGPGRAGCCLGKAVRGAKGHHHPHPPAAGAGAAGGAEADLKALTHSVLKKLKERQLELLLQAVESRGGTRTACLLLPGRLDCRLGPGAPAGAQPAQPPSSYSLPLLLCKVFRWPDLRHSSEVKRLCCCESYGKINPELVCCNPHHLSRLCELESPPPPYSRYPMDFLKPTADCPDAVPSSAETGGTNYLAPGGLSDSQLLLEPGDRSHWCVVAYWEEKTRVGRLYCVQEPSLDIFYDLPQGNGFCLGQLNSDNKSQLVQKVRSKIGCGIQLTREVDGVWVYNRSSYPIFIKSATLDNPDSRTLLVHKVFPGFSIKAFDYEKAYSLQRPNDHEFMQQPWTGFTVQISFVKGWGQCYTRQFISSCPCWLEVIFNSR>sp|O15105-2|SMAD7_HUMAN Isoform 2 of Mothers against decapentaplegichomolog 7 OS=Homo sapiens OX=9606 GN=SMAD7MDFLKPTADCPDAVPSSAETGGTNYLAPGGLSDSQLLLEPGDRSHWCVVAYWEEKTRVGRLYCVQEPSLDIFYDLPQGNGFCLGQLNSDNKSQLVQKVRSKIGCGIQLTREVDGVWVYNRSSYPIFIKSATLDNPDSRTLLVHKVFPGFSIKAFDYEKAYSLQRPNDHEFMQQPWTGFTVQISFVKGWGQCYTRQFISSCPCWLEVIFNSR>sp|O15105-3|SMAD7_HUMAN Isoform 3 of Mothers against decapentaplegichomolog 7 OS=Homo sapiens OX=9606 GN=SMAD7MFRTKRSALVRRLWRSRAPGGEDEEEGAGGGGGGGELRGEGATDSRAHGAGGGGPGRAGCCLGKAVRGAKGHHHPHPPAAGAGAAGGAEADLKALTHSVLKKLKERQLELLLQAVESRGGTRTACLLLPGRLDCRLGPGAPAGAQPAQPPSSYSLPLLLCKVFRWPDLRHSSEVKRLCCCESYGKINPELVCCNPHHLSRLCELESPPPPYSRYPMDFLKPTDCPDAVPSSAETGGTNYLAPGGLSDSQLLLEPGDRSHWCVVAYWEEKTRVGRLYCVQEPSLDIFYDLPQGNGFCLGQLNSDNKSQLVQKVRSKIGCGIQLTREVDGVWVYNRSSYPIFIKSATLDNPDSRTLLVHKVFPGFSIKAFDYEKAYSLQRPNDHEFMQQPWTGFTVQISFVKGWGQCYTRQFISSCPCWLEVIFNSR>sp|Q07890|SOS2_HUMAN Son of sevenless homolog 2 OS=Homo sapiens OX=9606GN=SOS2 PE=1 SV=2MQQAPQPYEFFSEENSPKWRGLLVSALRKVQEQVHPTLSANEESLYYIEELIFQLLNKLCMAQPRTVQDVEERVQKTFPHPIDKWAIADAQSAIEKRKRRNPLLLPVDKIHPSLKEVLGYKVDYHVSLYIVAVLEYISADILKLAGNYVFNIRHYEISQQDIKVSMCADKVLMDMFDQDDIGLVSLCEDEPSSSGELNYYDLVRTEIAEERQYLRELNMIIKVFREAFLSDRKLFKPSDIEKIFSNISDIHELTVKLLGLIEDTVEMTDESSPHPLAGSCFEDLAEEQAFDPYETLSQDILSPEFHEHFNKLMARPAVALHFQSIADGFKEAVRYVLPRLMLVPVYHCWHYFELLKQLKACSEEQEDRECLNQAITALMNLQGSMDRIYKQYSPRRRPGDPVCPFYSHQLRSKHLAIKKMNEIQKNIDGWEGKDIGQCCNEFIMEGPLTRIGAKHERHIFLFDGLMISCKPNHGQTRLPGYSSAEYRLKEKFVMRKIQICDKEDTCEHKHAFELVSKDENSIIFAAKSAEEKNNWMAALISLHYRSTLDRMLDSVLLKEENEQPLRLPSPEVYRFVVKDSEENIVFEDNLQSRSGIPIIKGGTVVKLIERLTYHMYADPNFVRTFLTTYRSFCKPQELLSLLIERFEIPEPEPTDADKLAIEKGEQPISADLKRFRKEYVQPVQLRILNVFRHWVEHHFYDFERDLELLERLESFISSVRGKAMKKWVESIAKIIRRKKQAQANGVSHNITFESPPPPIEWHISKPGQFETFDLMTLHPIEIARQLTLLESDLYRKVQPSELVGSVWTKEDKEINSPNLLKMIRHTTNLTLWFEKCIVEAENFEERVAVLSRIIEILQVFQDLNNFNGVLEIVSAVNSVSVYRLDHTFEALQERKRKILDEAVELSQDHFKKYLVKLKSINPPCVPFFGIYLTNILKTEEGNNDFLKKKGKDLINFSKRRKVAEITGEIQQYQNQPYCLRIEPDMRRFFENLNPMGSASEKEFTDYLFNKSLEIEPRNCKQPPRFPRKSTFSLKSPGIRPNTGRHGSTSGTLRGHPTPLEREPCKISFSRIAETELESTVSAPTSPNTPSTPPVSASSDLSVFLDVDLNSSCGSNSIFAPVLLPHSKSFFSSCGSLHKLSEEPLIPPPLPPRKKFDHDASNSKGNMKSDDDPPAIPPRQPPPPKVKPRVPVPTGAFDGPLHSPPPPPPRDPLPDTPPPVPLRPPEHFINCPFNLQPPPLGHLHRDSDWLRDISTCPNSPSTPPSTPSPRVPRRCYVLSSSQNNLAHPPAPPVPPRQNSSPHLPKLPPKTYKRELSHPPLYRLPLLENAETPQ>sp|Q07890-2|SOS2_HUMAN Isoform 2 of Son of sevenless homolog 2 OS=Homosapiens OX=9606 GN=SOS2MQQAPQPYEFFSEENSPKWRGLLVSALRKVQEQVHPTLSANEESLYYIEELIFQLLNKLCMAQPRTVQDVEERVQKTFPHPIDKWAIADAQSAIEKRKRRNPLLLPVDKIHPSLKEVLGYKVDYHVSLYIVAVLEYISADILKLAGNYVFNIRHYEISQQDIKVSMCADKVLMDMFDQDDIGLVSLCEDEPSSSGELNYYDLVRTEIAEERQYLRELNMIIKVFREAFLSDRKLFKPSDIEKIFSNISDIHELTVKLLGLIEDTVEMTDESSPHPLAGSCFEDLAEEQAFDPYETLSQDILSPEFHEHFNKLMARPAVALHFQQLKACSEEQEDRECLNQAITALMNLQGSMDRIYKQYSPRRRPGDPVCPFYSHQLRSKHLAIKKMNEIQKNIDGWEGKDIGQCCNEFIMEGPLTRIGAKHERHIFLFDGLMISCKPNHGQTRLPGYSSAEYRLKEKFVMRKIQICDKEDTCEHKHAFELVSKDENSIIFAAKSAEEKNNWMAALISLHYRSTLDRMLDSVLLKEENEQPLRLPSPEVYRFVVKDSEENIVFEDNLQSRSGIPIIKGGTVVKLIERLTYHMYADPNFVRTFLTTYRSFCKPQELLSLLIERFEIPEPEPTDADKLAIEKGEQPISADLKRFRKEYVQPVQLRILNVFRHWVEHHFYDFERDLELLERLESFISSVRGKAMKKWVESIAKIIRRKKQAQANGVSHNITFESPPPPIEWHISKPGQFETFDLMTLHPIEIARQLTLLESDLYRKVQPSELVGSVWTKEDKEINSPNLLKMIRHTTNLTLWFEKCIVEAENFEERVAVLSRIIEILQVFQDLNNFNGVLEIVSAVNSVSVYRLDHTFEALQERKRKILDEAVELSQDHFKKYLVKLKSINPPCVPFFGIYLTNILKTEEGNNDFLKKKGKDLINFSKRRKVAEITGEIQQYQNQPYCLRIEPDMRRFFENLNPMGSASEKEFTDYLFNKSLEIEPRNCKQPPRFPRKSTFSLKSPGIRPNTGRHGSTSGTLRGHPTPLEREPCKISFSRIAETELESTVSAPTSPNTPSTPPVSASSDLSVFLDVDLNSSCGSNSIFAPVLLPHSKSFFSSCGSLHKLSEEPLIPPPLPPRKKFDHDASNSKGNMKSDDDPPAIPPRQPPPPKVKPRVPVPTGAFDGPLHSPPPPPPRDPLPDTPPPVPLRPPEHFINCPFNLQPPPLGHLHRDSDWLRDISTCPNSPSTPPSTPSPRVPRRCYVLSSSQNNLAHPPAPPVPPRQNSSPHLPKLPPKTYKRELSHPPLYRLPLLENAETPQ>sp|Q499Z3|SLNL1_HUMAN Schlafen-like protein 1 OS=Homo sapiens OX=9606GN=SLFNL1 PE=2 SV=2MTPMKRSVQTQVSEPFMESWGEESLPELPAEQSLTEYSDLEEAPSAHTLYVGHLNPQFSVPVLACLLRDTLERLEMPVAREHIEVVRRPRKAYALVQVTVHRDTLASLPWRLQTALEEHLILKELAARGKDLLLSEAQGPFSHREEKEEEEEDSGLSPGPSPGSGVPLPTWPTHTLPDRPQAQQLQSCQGRPSGVCSDSAIVHQQIVGKDQLFQGAFLGSETRNMEFKRGSGEYLSLAFKHHVRRYVCAFLNSEGGSLLVGVEDSGLVQGIRCSHRDEDRARLLVDSILQGFKPQIFPDAYTLTFIPVISTSETSVPLKVIRLTVHTPKAQSQPQLYQTDQGEVFLRRDGSIQGPLSASAIQEWCRQRWLVELGKLEEKMKALMMEKEQLQQQLQQHGPVSCTCCVL>sp|Q499Z3-2|SLNL1_HUMAN Isoform 2 of Schlafen-like protein 1 OS=Homosapiens OX=9606 GN=SLFNL1MTPMKRSVQTQVSEPFMESWGEESLPELPAEQSLTEYSDLEEAPSAHTLYVGHLNPQFSVPVLACLLRDTLERLEMPVAREHIEVVRRPRKAYALVQVTVHRDTLASLPWRLQTALEEHLILKELAARGKDLLLSEAQGPFSHREQIVGKDQLFQGAFLGSETRNMEFKRGSGEYLSLAFKHHVRRYVCAFLNSEGGSLLVGVEDSGLVQGIRCSHRDEDRARLLVDSILQGFKPQIFPDAYTLTFIPVISTSETSVPLKVIRLTVHTPKAQSQPQLYQTDQGEVFLRRDGSIQGPLSASAIQEWCRQRWLVELGKLEEKMKALMMEKEQLQQQLQQHGPVSCTCCVL>sp|Q499Z3-3|SLNL1_HUMAN Isoform 3 of Schlafen-like protein 1 OS=Homosapiens OX=9606 GN=SLFNL1MTPMKRSVQTQVSEPFMESWGEESLPELPAEQSLTEYSDLEEAPSAHTLYVGHLNPQFSVPVLACLLRDTLERLEMPVAREHIEVVRRPRKAYALVQVTVHRDTLASLPWRLQTALEEHLILKELAARGKDLLLSEAQGPFSHREEKEEEEEDSGLSPGPSPGSGVPLPTWPTHTLPDRPQAQQLQSCQGRPSGVCSDSAIVHQQIVGKDQLFQGAFLGSETRNMEFKRGSGEYLSLAFKHHVRRYVCAFLNSEGGSLLVGVEDSGLVQGIRCSHRDEDRARLLVDSILQGFKPQIFPDAYTLTFIPVISTSETSVPLKRWLVELGKLEEKMKALMMEKEQLQQQLQQHGPVSCTCCVL>sp|Q499Z3-4|SLNL1_HUMAN Isoform 4 of Schlafen-like protein 1 OS=Homosapiens OX=9606 GN=SLFNL1MTPMKRSVQTQVSEPFMESWGEESLPELPAEQSLTEYSDLEEAPSAHTLYVGHLNPQFSVPVLACLLRDTLERLEMPVAREHIEVVRRPRKAYALVQVTVHRDTLASLPWRLQTALEEHLILKELAARGKDLLLSEAQGPFSHREVSGTFPKQAPKPHPKGEPLSGSGLQSGDGGVSLGKQGQICKLGGCHSNDHGLRLVLPAFSGKNSLPQAQARRLCEERPRGDLLSLGPFTFQPLGLGDPRRHRGPDFLLGPTHLFN>sp|Q9BQ15|SOSB1_HUMAN SOSS complex subunit B1 OS=Homo sapiens OX=9606GN=NABP2 PE=1 SV=1MTTETFVKDIKPGLKNLNLIFIVLETGRVTKTKDGHEVRTCKVADKTGSINISVWDDVGNLIQPGDIIRLTKGYASVFKGCLTLYTGRGGDLQKIGEFCMVYSEVPNFSEPNPEYSTQQAPNKAVQNDSNPSASQPTTGPSAASPASENQNGNGLSAPPGPGGGPHPPHTPSHPPSTRITRSQPNHTPAGPPGPSSNPVSNGKETRRSSKR>sp|Q9BQ15-2|SOSB1_HUMAN Isoform 2 of SOSS complex subunit B1 OS=Homosapiens OX=9606 GN=NABP2MVYSEVPNFSEPNPEYSTQQAPNKAVQNDSNPSASQPTTGPSAASPASENQNGNGLSAPPGPGGGPHPPHTPSHPPSTRITRSQPNHTPAGPPGPSSNPVSNGKETRRSSKR>sp|O15198|SMAD9_HUMAN Mothers against decapentaplegic homolog 9 OS=Homosapiens OX=9606 GN=SMAD9 PE=1 SV=1MHSTTPISSLFSFTSPAVKRLLGWKQGDEEEKWAEKAVDSLVKKLKKKKGAMDELERALSCPGQPSKCVTIPRSLDGRLQVSHRKGLPHVIYCRVWRWPDLQSHHELKPLECCEFPFGSKQKEVCINPYHYRRVETPVLPPVLVPRHSEYNPQLSLLAKFRSASLHSEPLMPHNATYPDSFQQPPCSALPPSPSHAFSQSPCTASYPHSPGSPSEPESPYQHSVDTPPLPYHATEASETQSGQPVDATADRHVVLSIPNGDFRPVCYEEPQHWCSVAYYELNNRVGETFQASSRSVLIDGFTDPSNNRNRFCLGLLSNVNRNSTIENTRRHIGKGVHLYYVGGEVYAECVSDSSIFVQSRNCNYQHGFHPATVCKIPSGCSLKVFNNQLFAQLLAQSVHHGFEVVYELTKMCTIRMSFVKGWGAEYHRQDVTSTPCWIEIHLHGPLQWLDKVLTQMGSPHNPISSVS>sp|O15198-2|SMAD9_HUMAN Isoform B of Mothers against decapentaplegichomolog 9 OS=Homo sapiens OX=9606 GN=SMAD9MHSTTPISSLFSFTSPAVKRLLGWKQGDEEEKWAEKAVDSLVKKLKKKKGAMDELERALSCPGQPSKCVTIPRSLDGRLQVSHRKGLPHVIYCRVWRWPDLQSHHELKPLECCEFPFGSKQKEVCINPYHYRRVETPVLPPVLVPRHSEYNPQLSLLAKFRSASLHSEPLMPHNATYPDSFQQPPCSALPPSPSHAFSQSPCTASYPHSPGSPSEPESPYQHSDFRPVCYEEPQHWCSVAYYELNNRVGETFQASSRSVLIDGFTDPSNNRNRFCLGLLSNVNRNSTIENTRRHIGKGVHLYYVGGEVYAECVSDSSIFVQSRNCNYQHGFHPATVCKIPSGCSLKVFNNQLFAQLLAQSVHHGFEVVYELTKMCTIRMSFVKGWGAEYHRQDVTSTPCWIEIHLHGPLQWLDKVLTQMGSPHNPISSVS>sp|A0MZ66|SHOT1_HUMAN Shootin-1 OS=Homo sapiens OX=9606 GN=SHTN1 PE=1SV=4MNSSDEEKQLQLITSLKEQAIGEYEDLRAENQKTKEKCDKIRQERDEAVKKLEEFQKISHMVIEEVNFMQNHLEIEKTCRESAEALATKLNKENKTLKRISMLYMAKLGPDVITEEINIDDEDSTTDTDGAAETCVSVQCQKQIKELRDQIVSVQEEKKILAIELENLKSKLVEVIEEVNKVKQEKTVLNSEVLEQRKVLEKCNRVSMLAVEEYEEMQVNLELEKDLRKKAESFAQEMFIEQNKLKRQSHLLLQSSIPDQQLLKALDENAKLTQQLEEERIQHQQKVKELEEQLENETLHKEIHNLKQQLELLEEDKKELELKYQNSEEKARNLKHSVDELQKRVNQSENSVPPPPPPPPPLPPPPPNPIRSLMSMIRKRSHPSGSGAKKEKATQPETTEEVTDLKRQAVEEMMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILGTLNKSTSSRSLKSLDPENSETELERILRRRKVTAEADSSSPTGILATSESKSMPVLGSVSSVTKTALNKKTLEAEFNSPSPPTPEPGEGPRKLEGCTSSKVTFQPPSSIGCRKKYIDGEKQAEPVVVLDPVSTHEPQTKDQVAEKDPTQHKEDEGEIQPENKEDSIENVRETDSSNC>sp|A0MZ66-2|SHOT1_HUMAN Isoform 2 of Shootin-1 OS=Homo sapiens OX=9606GN=SHTN1MNSSDEEKQLQLITSLKEQAIGEYEDLRAENQKTKEKCDKIRQERDEAVKKLEEFQKISHMVIEEVNFMQNHLEIEKTCRESAEALATKLNKENKTLKRISMLYMAKLGPDVITEEINIDDEDSTTDTDGAAETCVSVQCQKQIKELRDQIVSVQEEKKILAIELENLKSKLVEVIEEVNKVKQEKTVLNSEVLEQRKVLEKCNRVSMLAVEEYEEMQVNLELEKDLRKKAESFAQEMFIEQNKLKRQSHLLLQSSIPDQQLLKALDENAKLTQQLEEERIQHQQKVKELEEQLENETLHKEIHNLKQQLELLEEDKKELELKYQNSEEKARNLKHSVDELQKRVNQSENSVPPPPPPPPPLPPPPPNPIRSLMSMIRKRSHPSGSGAKKEKATQPETTEEVTDLKRQAVEEMMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILASQ>sp|A0MZ66-3|SHOT1_HUMAN Isoform 3 of Shootin-1 OS=Homo sapiens OX=9606GN=SHTN1MNSSDEEKQLQLITSLKEQAIGEYEDLRAENQKTKEKCDKIRQERDEAVKKLEEFQKISHMVIEEVNFMQNHLEIEKTCRESAEALATKLNKENKTLKRISMLYMAKLGPDVITEEINIDDEDSTTDTDGAAETCVSVQCQKQIKELRDQIVSVQEEKKILAIELENLKSKLVEVIEEVNKVKQEKTVLNSEVLEQRKVLEKCNRVSMLAVEEYEEMQVNLELEKDLRKKAESFAQEMFIEQNKLKRQSHLLLQSSIPDQQLLKALDENAKLTQQLEEERIQHQQKVKELEEQLENETLHKEIHNLKQQLELLEEDKKELELKYQNSEEKARNLKHSVDELQKRVNQSENSVPPPPPPPPPLPPPPPNPIRSLMSMIRKRSHPSGSGAKKEKATQPETTEEVTDLKRQAVEEMMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILGTLNKSTSSRSLKSLDPENSETELERILRRRKVTAEADSSSPTGILATSESKSMPVLGSVSSVTKTALNKKTLEAEFNSPSPPTPEPGEGPRKLEGCTSSKVTFQPPSSIGCRKKYIDGEKQAEPVVVLDPVSTHEPQTKDQVAEKDPTQHKEDEGEIQPENKEDSIENFFPFHFGFEGVLPLAGVTLSTKARDPK>sp|A0MZ66-4|SHOT1_HUMAN Isoform 4 of Shootin-1 OS=Homo sapiens OX=9606GN=SHTN1MNSSDEEKQLQLITSLKEQAIGEYEDLRAENQKTKEKCDKIRQERDEAVKKLEEFQKISHMVIEEVNFMQNHLEIEKTCRESAEALATKLNKENKTLKRISMLYMAKLGPDVITEEINIDDEDSTTDTDGAAETCVSVQCQKQIKELRDQIVSVQEEKKILAIELENLKSKLVEVIEEVNKVKQEKTVLNSEVLEQRKVLEKCNRVSMLAVEEYEEMQVNLELEKDLRKKAESFAQEMFIEQNKLKRQSHLLLQSSIPDQQLLKALDENAKLTQQLEEERIQHQQKVKELEEQLENETLHKEIHNLKQQLELLEEDKKELELKYQNSEEKARNLKHSVDELQKRVNQSENSVPPPPPPPPPLPPPPPNPIRSLMSMIRKRSHPSGSGAKKEKATQPETTEEVTDLKRQAVEEMMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILGTLNKSTSSRSLKSLDPENSETELERILRRRKVTAEADSSSPTGILATSESKSMPVLGSVSSVTKTALNKKTLEAEFNSPSPPTPEPGEGPRKLEGCTSSKVTFQ>sp|A0MZ66-5|SHOT1_HUMAN Isoform 5 of Shootin-1 OS=Homo sapiens OX=9606GN=SHTN1MVIEEVNFMQNHLEIEKTCRESAEALATKLNKENKTLKRISMLYMAKLGPDVITEEINIDDEDSTTDTDGAAETCVSVQCQKQIKELRDQIVSVQEEKKILAIELENLKSKLVEVIEEVNKVKQEKTVLNSEVLEQRKVLEKCNRVSMLAVEEYEEMQVNLELEKDLRKKAESFAQEMFIEQNKLKRQSHLLLQSSIPDQQLLKALDENAKLTQQLEEERIQHQQKVKELEEQLENETLHKEIHNLKQQLELLEEDKKELELKYQNSEEKARNLKHSVDELQKRVNQSENSVPPPPPPPPPLPPPPPNPIRSLMSMIRKRSHPSGSGAKKEKATQPETTEEVTDLKRQAVEEMMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILGTLNKSTSSRSLKSLDPENSETELERILRRRKVTAEADSSSPTGILATSESKSMPVLGSVSSVTKTALNKKTLEAEFNSPSPPTPEPGEGPRKLEGCTSSKVTFQPPSSIGCRKKYIDGEKQAEPVVVLDPVSTHEPQTKDQVAEKDPTQHKEDEGEIQPENKEDSIENVRETDSSNC>sp|A0MZ66-6|SHOT1_HUMAN Isoform 6 of Shootin-1 OS=Homo sapiens OX=9606GN=SHTN1MPRILKQCDKIRQERDEAVKKLEEFQKISHMVIEEVNFMQNHLEIEKTCRESAEALATKLNKENKTLKRISMLYMAKLGPDVITEEINIDDEDSTTDTDGAAETCVSVQCQKQIKELRDQIVSVQEEKKILAIELENLKSKLVEVIEEVNKVKQEKTVLNSEVLEQRKVLEKCNRVSMLAVEEYEEMQVNLELEKDLRKKAESFAQEMFIEQNKLKRQSHLLLQSSIPDQQLLKALDENAKLTQQLEEERIQHQQKVKELEEQLENETLHKEIHNLKQQLELLEEDKKELELKYQNSEEKARNLKHSVDELQKRVNQSENSVPPPPPPPPPLPPPPPNPIRSLMSMIRKRSHPSGSGAKKEKATQPETTEEVTDLKRQAVEEMMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILGTLNKSTSSRSLKSLDPENSETELERILRRRKVTAEADSSSPTGILATSESKSMPVLGSVSSVTKTALNKKTLEAEFNSPSPPTPEPGEGPRKLEGCTSSKVTFQPPSSIGCRKKYIDGEKQAEPVVVLDPVSTHEPQTKDQVAEKDPTQHKEDEGEIQPENKEDSIENVRETDSSNC>sp|A0MZ66-7|SHOT1_HUMAN Isoform 7 of Shootin-1 OS=Homo sapiens OX=9606GN=SHTN1MMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILGTLNKSTSSRSLKSLDPENSETELERILRRRKVTAEADSSSPTGILATSESKSMPVLGSVSSVTKTALNKKTLEAEFNSPSPPTPEPGEGPRKLEGCTSSKVTFQPPSSIGCRKKYIDGEKQAEPVVVLDPVSTHEPQTKDQVAEKDPTQHKEDEGEIQPENKEDSIENVRETDSSNC>sp|A0MZ66-8|SHOT1_HUMAN Isoform 8 of Shootin-1 OS=Homo sapiens OX=9606GN=SHTN1MVIEEVNFMQNHLEIEKTCRESAEALATKLNKENKTLKRISMLYMAKLGPDVITEEINIDDEDSTTDTDGAAETCVSVQCQKQIKELRDQIVSVQEEKKILAIELENLKSKLVEVIEEVNKVKQEKTVLNSEVLEQRKVLEKCNRVSMLAVEEYEEMQVNLELEKDLRKKAESFAQEMFIEQNKLKRQSHLLLQSSIPDQQLLKALDENAKLTQQLEEERIQHQQKVKELEEQLENETLHKEIHNLKQQLELLEEDKKELELKYQNSEEKARNLKHSVDELQKRVNQSENSVPPPPPPPPPLPPPPPNPIRSLMSMIRKRSHPSGSGAKKEKATQPETTEEVTDLKRQAVEEMMDRIKKGVHLRPVNQTARPKTKPESSKGCESAVDELKGILGTLNKSTSSRSLKSLDPENSETELERILRRRKVTAEADSSSPTGILATSESKSMPVLGSVSSVTKTALNKKTLEAEFNSPSPPTPEPGEGPRKLEGCTSSKVTFQ>sp|Q9NR45|SIAS_HUMAN Sialic acid synthase OS=Homo sapiens OX=9606GN=NANS PE=1 SV=2MPLELELCPGRWVGGQHPCFIIAEIGQNHQGDLDVAKRMIRMAKECGADCAKFQKSELEFKFNRKALERPYTSKHSWGKTYGEHKRHLEFSHDQYRELQRYAEEVGIFFTASGMDEMAVEFLHELNVPFFKVGSGDTNNFPYLEKTAKKGRPMVISSGMQSMDTMKQVYQIVKPLNPNFCFLQCTSAYPLQPEDVNLRVISEYQKLFPDIPIGYSGHETGIAISVAAVALGAKVLERHITLDKTWKGSDHSASLEPGELAELVRSVRLVERALGSPTKQLLPCEMACNEKLGKSVVAKVKIPEGTILTMDMLTVKVGEPKGYPPEDIFNLVGKKVLVTVEEDDTIMEELVDNHGKKIKS>sp|Q9UPU9|SMAG1_HUMAN Protein Smaug homolog 1 OS=Homo sapiens OX=9606GN=SAMD4A PE=1 SV=3MMFRDQVGVLAGWFKGWNECEQTVALLSLLKRVSQTQARFLQLCLEHSLADCAELHVLEREANSPGIINQWQQESKDKVISLLLTHLPLLKPGNLDAKVEYMKLLPKILAHSIEHNQHIEESRQLLSYALIHPATSLEDRSALAMWLNHLEDRTSTSFGGQNRGRSDSVDYGQTHYYHQRQNSDDKLNGWQNSRDSGICINASNWQDKSMGCENGHVPLYSSSSVPTTINTIGTSTSTILSGQAHHSPLKRSVSLTPPMNVPNQPLGHGWMSHEDLRARGPQCLPSDHAPLSPQSSVASSGSGGSEHLEDQTTARNTFQEEGSGMKDVPAWLKSLRLHKYAALFSQMTYEEMMALTECQLEAQNVTKGARHKIVISIQKLKERQNLLKSLERDIIEGGSLRIPLQELHQMILTPIKAYSSPSTTPEARRREPQAPRQPSLMGPESQSPDCKDGAAATGATATPSAGASGGLQPHQLSSCDGELAVAPLPEGDLPGQFTRVMGKVCTQLLVSRPDEENISSYLQLIDKCLIHEAFTETQKKRLLSWKQQVQKLFRSFPRKTLLDISGYRQQRNRGFGQSNSLPTAGSVGGGMGRRNPRQYQIPSRNVPSARLGLLGTSGFVSSNQRNTTATPTIMKQGRQNLWFANPGGSNSMPSRTHSSVQRTRSLPVHTSPQNMLMFQQPEFQLPVTEPDINNRLESLCLSMTEHALGDGVDRTSTI>sp|Q9UPU9-2|SMAG1_HUMAN Isoform 2 of Protein Smaug homolog 1 OS=Homosapiens OX=9606 GN=SAMD4AMKLLPKILAHSIEHNQHIEESRQLLSYALIHPATSLEDRSALAMWLNHLEDRTSTSFGGQNRGRSDSVDYGQTHYYHQRQNSDDKLNGWQNSRDSGICINASNWQDKSMGCENGHVPLYSSSSVPTTINTIGTSTSTILSGQAHHSPLKRSVSLTPPMNVPNQPLGHGWMSHEDLRARGPQCLPSDHAPLSPQSSVASSGSGGSEHLEDQTTARNTFQEEGSGMKDVPAWLKSLRLHKYAALFSQMTYEEMMALTECQLEAQNVTKGARHKIVISIQKLKERQNLLKSLERDIIEGGSLRIPLQELHQMILTPIKAYSSPSTTPEARRREPQAPRQPSLMGPESQSPDCKDGAAATGATATPSAGASGGLQPHQLSSCDGELAVAPLPEGDLPGQFTRVMGKVCTQLLVSRPDEENISSYLQLIDKCLIHEAFTETQKKRLLSWKQQVQKLFRSFPRKTLLDISGYRQQRNRGFGQSNSLPTAGSVGGGMGRRNPRQYQIPSRNVPSARLGLLGTSGFVSSNQRNTTATPTIMKQGRQNLWFANPGGSNSMPSRTHSSVQRTRSLPVHTSPQNMLMFQQPEFQLPVTEPDINNRLESLCLSMTEHALGDGVDRTSTI>sp|Q9UPU9-3|SMAG1_HUMAN Isoform 3 of Protein Smaug homolog 1 OS=Homosapiens OX=9606 GN=SAMD4AMMFRDQVGVLAGWFKGWNECEQTVALLSLLKRVSQTQARFLQLCLEHSLADCAELHVLEREANSPGIINQWQQESKDKVISLLLTHLPLLKPGNLDAKVEYMKLLPKILAHSIEHNQHIEESRQLLSYALIHPATSLEDRSALAMWLNHLEDRTSTSFGGQNRGRSDSVDYGQTHYYHQRQNSDDKLNGWQNSRDSGICINASNWQDKSMGCENGHVPLYSSSSVPTTINTIGTSTSTNVPAWLKSLRLHKYAALFSQMTYEEMMALTECQLEAQNVTKGARHKIVISIQKLKERQNLLKSLERDIIEGGSLRIPLQELHQMILTPIKAYSSPSTTPEARRREPQAPRQPSLMGPESQSPDCKDGAAATGATATPSAGASGGLQPHQLSSCDGELAVAPLPEGDLPGQFTRVMGKVCTQLLVSRPDEENISSYLQLIDKCLIHEAFTETQKKRLLSWKQQVQKLFRSFPRKTLLDISGYRQQRNRGFGQSNSLPTAGSVGGGMGRRNPRQYQIPSRNVPSARLGLLGTSGFVSSNQRNTTATPTIMKQGRQNLWFANPGGSNSMPSRTHSSVQRTRSLPVHTSPQNMLMFQQPEFQLPVTEPDINNRLESLCLSMTEHALGDGVDRTSTI>sp|Q96AH0|SOSB2_HUMAN SOSS complex subunit B2 OS=Homo sapiens OX=9606GN=NABP1 PE=1 SV=1MNRVNDPLIFIRDIKPGLKNLNVVFIVLEIGRVTKTKDGHEVRSCKVADKTGSITISVWDEIGGLIQPGDIIRLTRGYASMWKGCLTLYTGRGGELQKIGEFCMVYSEVPNFSEPNPDYRGQQNKGAQSEQKNNSMNSNMGTGTFGPVGNGVHTGPESREHQFSHAGRSNGRGLINPQLQGTASNQTVMTTISNGRDPRRAFKR>sp|Q96AH0-2|SOSB2_HUMAN Isoform 2 of SOSS complex subunit B2 OS=Homosapiens OX=9606 GN=NABP1MWKGCLTLYTGRGGELQKIGEFCMVYSEVPNFSEPNPDYRGQQNKGAQSEQKNNSMNSNMGTGTFGPVGNGVHTGPESREHQFSHAGRSNGRGLINPQLQGTASNQTVMTTISNGRDPRRAFKR>sp|Q96AH0-3|SOSB2_HUMAN Isoform 3 of SOSS complex subunit B2 OS=Homosapiens OX=9606 GN=NABP1MNRVNDPLIFIRDIKPGLKNLNVVFIVLEIGRVTKTKDGHEVRSCKVADKTGSITISVWDEIGGLIQPGDIIRLTRGYASMWKGCLTLYTGRGGELQKIGDLGAVQAAAMRDSIHYYPGNDLHPDLEEPSSLGV>sp|P15907|SIAT1_HUMAN Beta-galactoside alpha-2,6-sialyltransferase 1OS=Homo sapiens OX=9606 GN=ST6GAL1 PE=1 SV=1MIHTNLKKKFSCCVLVFLLFAVICVWKEKKKGSYYDSFKLQTKEFQVLKSLGKLAMGSDSQSVSSSSTQDPHRGRQTLGSLRGLAKAKPEASFQVWNKDSSSKNLIPRLQKIWKNYLSMNKYKVSYKGPGPGIKFSAEALRCHLRDHVNVSMVEVTDFPFNTSEWEGYLPKESIRTKAGPWGRCAVVSSAGSLKSSQLGREIDDHDAVLRFNGAPTANFQQDVGTKTTIRLMNSQLVTTEKRFLKDSLYNEGILIVWDPSVYHSDIPKWYQNPDYNFFNNYKTYRKLHPNQPFYILKPQMPWELWDILQEISPEEIQPNPPSSGMLGIIIMMTLCDQVDIYEFLPSKRKTDVCYYYQKFFDSACTMGAYHPLLYEKNLVKHLNQGTDEDIYLLGKATLPGFRTIHC>sp|P15907-2|SIAT1_HUMAN Isoform 2 of Beta-galactoside alpha-2,6-sialyltransferase 1 OS=Homo sapiens OX=9606 GN=ST6GAL1MNSQLVTTEKRFLKDSLYNEGILIVWDPSVYHSDIPKWYQNPDYNFFNNYKTYRKLHPNQPFYILKPQMPWELWDILQEISPEEIQPNPPSSGMLGIIIMMTLCDQVDIYEFLPSKRKTDVCYYYQKFFDSACTMGAYHPLLYEKNLVKHLNQGTDEDIYLLGKATLPGFRTIHC>sp|O60902|SHOX2_HUMAN Short stature homeobox protein 2 OS=Homo sapiensOX=9606 GN=SHOX2 PE=1 SV=4MEELTAFVSKSFDQKVKEKKEAITYREVLESGPLRGAKEPTGCTEAGRDDRSSPAVRAAGGGGGGGGGGGGGGGGGGVGGGGAGGGAGGGRSPVRELDMGAAERSREPGSPRLTEVSPELKDRKEDAKGMEDEGQTKIKQRRSRTNFTLEQLNELERLFDETHYPDAFMREELSQRLGLSEARVQVWFQNRRAKCRKQENQLHKGVLIGAASQFEACRVAPYVNVGALRMPFQQDSHCNVTPLSFQVQAQLQLDSAVAHAHHHLHPHLAAHAPYMMFPAPPFGLPLATLAADSASAASVVAAAAAAKTTSKNSSIADLRLKAKKHAAALGL>sp|O60902-2|SHOX2_HUMAN Isoform 2 of Short stature homeobox protein 2OS=Homo sapiens OX=9606 GN=SHOX2MEELTAFVSKSFDQKVKEKKEAITYREVLESGPLRGAKEPTGCTEAGRDDRSSPAVRAAGGGGGGGGGGGGGGGGGGVGGGGAGGGAGGGRSPVRELDMGAAERSREPGSPRLTEVSPELKDRKEDAKGMEDEGQTKIKQRRSRTNFTLEQLNELERLFDETHYPDAFMREELSQRLGLSEARVQVWFQNRRAKCRKQENQLHKGVLIGAASQFEACRVAPYVNVGALRMPFQQVQAQLQLDSAVAHAHHHLHPHLAAHAPYMMFPAPPFGLPLATLAADSASAASVVAAAAAAKTTSKNSSIADLRLKAKKHAAALGL>sp|O60902-3|SHOX2_HUMAN Isoform 3 of Short stature homeobox protein 2OS=Homo sapiens OX=9606 GN=SHOX2MEELTAFVSKSFDQKVKEKKEAITYREVLESGPLRGAKEPTGCTEAGRDDRSSPAVRAAGGGGGGGGGGGGGGGGGGVGGGGAGGGAGGGRSPVRELDMGAAERSREPGSPRLTEGRRKPTKAEVQATLLLPGEAFRFLVSPELKDRKEDAKGMEDEGQTKIKQRRSRTNFTLEQLNELERLFDETHYPDAFMREELSQRLGLSEARVQVWFQNRRAKCRKQENQLHKGVLIGAASQFEACRVAPYVNVGALRMPFQQDSHCNVTPLSFQVQAQLQLDSAVAHAHHHLHPHLAAHAPYMMFPAPPFGLPLATLAADSASAASVVAAAAAAKTTSKNSSIADLRLKAKKHAAALGL>sp|Q6X4U4|SOSD1_HUMAN Sclerostin domain-containing protein 1 OS=Homosapiens OX=9606 GN=SOSTDC1 PE=1 SV=2MLPPAIHFYLLPLACILMKSCLAFKNDATEILYSHVVKPVPAHPSSNSTLNQARNGGRHFSNTGLDRNTRVQVGCRELRSTKYISDGQCTSISPLKELVCAGECLPLPVLPNWIGGGYGTKYWSRRSSQEWRCVNDKTRTQRIQLQCQDGSTRTYKITVVTACKCKRYTRQHNESSHNFESMSPAKPVQHHRERKRASKSSKHSMS>sp|Q6X4U4-2|SOSD1_HUMAN Isoform 2 of Sclerostin domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SOSTDC1MLPPAIHFYLLPLACILMKSCLAFKNDATEILYSHVVKPVPAHPSSNSTLNQARNGGRHFSNTGLDRNRTESLTRQNYFWLFPGAFLRQLQEARVQVGCRELRSTKYISDGQCTSISPLKELVCAGECLPLPVLPNWIGGGYGTKYWSRRSSQEWRCVNDKTRTQRIQLQCQDGSTRTYKITVVTACKCKRYTRQHNESSHNFESMSPAKPVQHHRERKRASKSSKHSMS>sp|Q5PRF9|SMAG2_HUMAN Protein Smaug homolog 2 OS=Homo sapiens OX=9606GN=SAMD4B PE=1 SV=1MMFRDQVGILAGWFKGWNECEQTVALLSLLKRVTRTQARFLQLCLEHSLADCNDIHLLESEANSAAIVSQWQQESKEKVVSLLLSHLPLLQPGNTEAKSEYMRLLQKVLAYSIESNAFIEESRQLLSYALIHPATTLEDRNALALWLSHLEERLASGFRSRPEPSYHSRQGSDEWGGPAELGPGEAGPGWQDKPPRENGHVPFHPSSSVPPAINSIGSNANTGLPCQIHPSPLKRSMSLIPTSPQVPGEWPSPEELGARAAFTTPDHAPLSPQSSVASSGSEQTEEQGSSRNTFQEDGSGMKDVPSWLKSLRLHKYAALFSQMSYEEMMTLTEQHLESQNVTKGARHKIALSIQKLRERQSVLKSLEKDVLEGGNLRNALQELQQIIITPIKAYSVLQATVAAATTTPTAKDGAPGEPPLPGAEPPLAHPGTDKGTEAKDPPAVENYPPPPAPAPTDGSEPAPAPVADGDIPSQFTRVMGKVCTQLLVSRPDEENITSYLQLIEKCLTHEAFTETQKKRLLSWKQQVLKLLRTFPRKAALEMQNYRQQKGWAFGSNSLPIAGSVGMGVARRTQRQFPMPPRALPPGRMGLLSPSGIGGVSPRHALTSPSLGGQGRQNLWFANPGGSNSMPSQSRSSVQRTHSLPVHSSPQAILMFPPDCPVPGPDLEINPTLESLCLSMTEHALGDGTDKTSTI>sp|O15266|SHOX_HUMAN Short stature homeobox protein OS=Homo sapiensOX=9606 GN=SHOX PE=1 SV=1MEELTAFVSKSFDQKSKDGNGGGGGGGGKKDSITYREVLESGLARSRELGTSDSSLQDITEGGGHCPVHLFKDHVDNDKEKLKEFGTARVAEGIYECKEKREDVKSEDEDGQTKLKQRRSRTNFTLEQLNELERLFDETHYPDAFMREELSQRLGLSEARVQVWFQNRRAKCRKQENQMHKGVILGTANHLDACRVAPYVNMGALRMPFQQVQAQLQLEGVAHAHPHLHPHLAAHAPYLMFPPPPFGLPIASLAESASAAAVVAAAAKSNSKNSSIADLRLKARKHAEALGL>sp|O15266-2|SHOX_HUMAN Isoform SHOXB of Short stature homeobox proteinOS=Homo sapiens OX=9606 GN=SHOXMEELTAFVSKSFDQKSKDGNGGGGGGGGKKDSITYREVLESGLARSRELGTSDSSLQDITEGGGHCPVHLFKDHVDNDKEKLKEFGTARVAEGIYECKEKREDVKSEDEDGQTKLKQRRSRTNFTLEQLNELERLFDETHYPDAFMREELSQRLGLSEARVQVWFQNRRAKCRKQENQMHKGVILGTANHLDACRVAPYVNMGALRMPFQQMEFCSCRPGWSIMA>sp|Q9BZQ2|SHP1L_HUMAN Testicular spindle-associated protein SHCBP1LOS=Homo sapiens OX=9606 GN=SHCBP1L PE=1 SV=3MASGSKASVPADSFRTISPDRRGEKSASAVSGDTAAATTLKGTAIPVRSVVASPRPVKGKAGRETARLRLQRLPAAQAEDTGEAAAAAAEEPLLPVPEDEEEAQPLPPVCVSRMRGMWRDEKVSLYCDEVLQDCKAEDADEVMGKYLSEKLKLKDKWLGVWKTNPSVFFVKYEEASIPFVGILVEVTCEPYQDSSSRFKVTVSVAEPFSSNIANIPRDLVDEILEELEHSVPLLEVYPVEGQDTDIHVIALALEVVRFFYDFLWRDWDDEESCENYTALIEERINLWCDIQDGTIPGPIAQRFKKTLEKYKNKRVELIEYQSNIKEDPSAAEAVECWKKYYEIVMLCGLLKMWEDLRLRVHGPFFPRILRRRKGKREFGKTITHIVAKMMTTEMIKDLSSDTLLQQHGDLDLALDNCYSGDTVIIFPGEYQAANLALLTDDIIIKGVGKREEIMITSEPSRDSFVVSKADNVKLMHLSLIQQGTVDGIVVVESGHMTLENCILKCEGTGVCVLTGAALTITDSEITGAQGAGVELYPGSIAILERNEIHHCNNLRTSNSSKSTLGGVNMKVLPAPKLKMTNNHIYSNKGYGVSILQPMEQFFIVAEEALNKRASSGDKKDDKMLFKVMQNLNLEMNNNKIEANVKGDIRIVTS>sp|Q9BZQ2-2|SHP1L_HUMAN Isoform 2 of Testicular spindle-associatedprotein SHCBP1L OS=Homo sapiens OX=9606 GN=SHCBP1LMGFLQLVRLDSNSRPQAEDADEVMGKYLSEKLKLKDKWLGVWKTNPSVFFVKYEEASIPFVGILVEVTCEPYQDSSSRFKVTVSVAEPFSSNIANIPRDLVDEILEELEHSVPLLEVYPVEGQDTDIHVIALALEVVRFFYDFLWRDWDDEESCENYTALIEERINLWCDIQDGTIPGPIAQRFKKTLEKYKNKRVELIEYQSNIKEDPSAAEAVECWKKYYEIVMLCGLLKMWEDLRLRVHGPFFPRILRRRKGKREFGKTITHIVAKMMTTEMIKDLSSDTLLQQHGDLDLALDNCYSGDTVIIFPGEYQAANLALLTDDIIIKGVGKREEIMITSEPSRDSFVVSKADNVKLMHLSLIQQGTVDGIVVVESGHMTLENCILKCEGTGVCVLTGAALTITDSEITGAQGAGVELYPGSIAILERNEIHHCNNLRTSNSSKSTLGGVNMKVLPAPKLKMTNNHIYSNKGYGVSILQPMEQFFIVAEEALNKRASSGDKKDDKMLFKVMQNLNLEMNNNKIEANVKGDIRIVTS>sp|Q9BZQ2-4|SHP1L_HUMAN Isoform 4 of Testicular spindle-associatedprotein SHCBP1L OS=Homo sapiens OX=9606 GN=SHCBP1LMASGSKASVPADSFRTISPDRRGEKSASAVSGDTAAATTLKGTAIPVRSVVASPRPVKGKAGRETARLRLQRLPAAQAEDTGEAAAAAAEEPLLPVPEDEEEAQPLPPVCVSRMRGMWRDEKVSLYCDEVLQDCKKMLMKLWVNTYQKN>sp|Q0VAQ4|SMAGP_HUMAN Small cell adhesion glycoprotein OS=Homo sapiensOX=9606 GN=SMAGP PE=1 SV=1MTSLLTTPSPREELMTTPILQPTEALSPEDGASTALIAVVITVVFLTLLSVVILIFFYLYKNKGSYVTYEPTEGEPSAIVQMESDLAKGSEKEEYFI>sp|A0A0B4J2F2|SIK1B_HUMAN Putative serine/threonine-protein kinase SIK1BOS=Homo sapiens OX=9606 GN=SIK1B PE=5 SV=1MVIMSEFSADPAGQGQGQQKPLRVGFYDIERTLGKGNFAVVKLARHRVTKTQVAIKIIDKTRLDSSNLEKIYREVQLMKLLNHPHIIKLYQVMETKDMLYIVTEFAKNGEMFDYLTSNGHLSENEARKKFWQILSAVEYCHDHHIVHRDLKTENLLLDGNMDIKLADFGFGNFYKSGEPLSTWCGSPPYAAPEVFEGKEYEGPQLDIWSLGVVLYVLVCGSLPFDGPNLPTLRQRVLEGRFRIPFFMSQDCESLIRRMLVVDPARRITIAQIRQHRWMRAEPCLPGPACPAFSAHSYTSNLGDYDEQALGIMQTLGVDRQRTVESLQNSSYNHFAAIYYLLLERLKEYRNAQCARPGPARQPRPRSSDLSGLEVPQEGLSTDPFRPALLCPQPQTLVQSVLQAEMDCELQSSLQWPLFFPVDASCSGVFRPRPVSPSSLLDTAISEEARQGPGLEEEQDTQESLPSSTGRRHTLAEVSTRLSPLTAPCIVVSPSTTASPAEGTSSDSCLTFSASKSPAGLSGTPATQGLLGACSPVRLASPFLGSQSATPVLQAQGGLGGAVLLPVSFQEGRRASDTSLTQGLKAFRQQLRKTTRTKGFLGLNKIKGLARQVCQVPASRASRGGLSPFHAPAQSPGLHGGAAGSREGWSLLEEVLEQQRLLQLQHHPAAAPGCSQAPQPAPAPFVIAPCDGPGAAPLPSTLLTSGLPLLPPPLLQTGASPVASAAQLLDTHLHIGTGPTALPAVPPPRLARLAPGCEPLGLLQGDCEMEDLMPCSLGTFVLVQ>sp|Q96JF0|SIAT2_HUMAN Beta-galactoside alpha-2,6-sialyltransferase 2OS=Homo sapiens OX=9606 GN=ST6GAL2 PE=1 SV=2MKPHLKQWRQRMLFGIFAWGLLFLLIFIYFTDSNPAEPVPSSLSFLETRRLLPVQGKQRAIMGAAHEPSPPGGLDARQALPRAHPAGSFHAGPGDLQKWAQSQDGFEHKEFFSSQVGRKSQSAFYPEDDDYFFAAGQPGWHSHTQGTLGFPSPGEPGPREGAFPAAQVQRRRVKKRHRRQRRSHVLEEGDDGDRLYSSMSRAFLYRLWKGNVSSKMLNPRLQKAMKDYLTANKHGVRFRGKREAGLSRAQLLCQLRSRARVRTLDGTEAPFSALGWRRLVPAVPLSQLHPRGLRSCAVVMSAGAILNSSLGEEIDSHDAVLRFNSAPTRGYEKDVGNKTTIRIINSQILTNPSHHFIDSSLYKDVILVAWDPAPYSANLNLWYKKPDYNLFTPYIQHRQRNPNQPFYILHPKFIWQLWDIIQENTKEKIQPNPPSSGFIGILIMMSMCREVHVYEYIPSVRQTELCHYHELYYDAACTLGAYHPLLYEKLLVQRLNMGTQGDLHRKGKVVLPGFQAVHCPAPSPVIPHS>sp|Q96JF0-2|SIAT2_HUMAN Isoform 2 of Beta-galactoside alpha-2,6-sialyltransferase 2 OS=Homo sapiens OX=9606 GN=ST6GAL2MKPHLKQWRQRMLFGIFAWGLLFLLIFIYFTDSNPAEPVPSSLSFLETRRLLPVQGKQRAIMGAAHEPSPPGGLDARQALPRAHPAGSFHAGPGDLQKWAQSQDGFEHKEFFSSQVGRKSQSAFYPEDDDYFFAAGQPGWHSHTQGTLGFPSPGEPGPREGAFPAAQVQRRRVKKRHRRQRRSHVLEEGDDGDRLYSSMSRAFLYRLWKGNVSSKMLNPRLQKAMKDYLTANKHGVRFRGKREAGLSRAQLLCQLRSRARVRTLDGTEAPFSALGWRRLVPAVPLSQLHPRGLRSCAVVMSAGAILNSSLGEEIDSHDAVLRFNSAPTRGYEKDVGNKTTIRIINSQILTNPSHHFIDSSLYKDVILVAWDPAPYSANLNLWYKKPDYNLFTPYIQHRQRNPNQPFYILHPKFIWQLWDIIQENTKEKIQPNPPSSGFIGSFVKIGHIRACSEPRSRDCTPAWTTE>sp|P57059|SIK1_HUMAN Serine/threonine-protein kinase SIK1 OS=Homosapiens OX=9606 GN=SIK1 PE=1 SV=2MVIMSEFSADPAGQGQGQQKPLRVGFYDIERTLGKGNFAVVKLARHRVTKTQVAIKIIDKTRLDSSNLEKIYREVQLMKLLNHPHIIKLYQVMETKDMLYIVTEFAKNGEMFDYLTSNGHLSENEARKKFWQILSAVEYCHDHHIVHRDLKTENLLLDGNMDIKLADFGFGNFYKSGEPLSTWCGSPPYAAPEVFEGKEYEGPQLDIWSLGVVLYVLVCGSLPFDGPNLPTLRQRVLEGRFRIPFFMSQDCESLIRRMLVVDPARRITIAQIRQHRWMRAEPCLPGPACPAFSAHSYTSNLGDYDEQALGIMQTLGVDRQRTVESLQNSSYNHFAAIYYLLLERLKEYRNAQCARPGPARQPRPRSSDLSGLEVPQEGLSTDPFRPALLCPQPQTLVQSVLQAEMDCELQSSLQWPLFFPVDASCSGVFRPRPVSPSSLLDTAISEEARQGPGLEEEQDTQESLPSSTGRRHTLAEVSTRLSPLTAPCIVVSPSTTASPAEGTSSDSCLTFSASKSPAGLSGTPATQGLLGACSPVRLASPFLGSQSATPVLQAQGGLGGAVLLPVSFQEGRRASDTSLTQGLKAFRQQLRKTTRTKGFLGLNKIKGLARQVCQAPASRASRGGLSPFHAPAQSPGLHGGAAGSREGWSLLEEVLEQQRLLQLQHHPAAAPGCSQAPQPAPAPFVIAPCDGPGAAPLPSTLLTSGLPLLPPPLLQTGASPVASAAQLLDTHLHIGTGPTALPAVPPPRLARLAPGCEPLGLLQGDCEMEDLMPCSLGTFVLVQ>sp|Q9BSF0|SMAKA_HUMAN Small membrane A-kinase anchor protein OS=Homosapiens OX=9606 GN=C2orf88 PE=1 SV=2MGCMKSKQTFPFPTIYEGEKQHESEEPFMPEERCLPRMASPVNVKEEVKEPPGTNTVILEYAHRLSQDILCDALQQWACNNIKYHDIPYIESEGP>sp|Q9UHJ6|SHPK_HUMAN Sedoheptulokinase OS=Homo sapiens OX=9606 GN=SHPKPE=1 SV=3MAARPITLGIDLGTTSVKAALLRAAPDDPSGFAVLASCARAARAEAAVESAVAGPQGREQDVSRILQALHECLAALPRPQLRSVVGIGVSGQMHGVVFWKTGQGCEWTEGGITPVFEPRAVSHLVTWQDGRCSSEFLASLPQPKSHLSVATGFGCATIFWLLKYRPEFLKSYDAAGTIHDYVVAMLCGLPRPLMSDQNAASWGYFNTQSQSWNVETLRSSGFPVHLLPDIAEPGSVAGRTSHMWFEIPKGTQVGVALGDLQASVYSCMAQRTDAVLNISTSVQLAASMPSGFQPAQTPDPTAPVAYFPYFNRTYLGVAASLNGGNVLATFVHMLVQWMADLGLEVEESTVYSRMIQAAVQQRDTHLTITPTVLGERHLPDQLASVTRISSSDLSLGHVTRALCRGIVQNLHSMLPIQQLQDWGVERVMGSGSALSRNDVLKQEVQRAFPLPMSFGQDVDAAVGAALVMLRRHLNQKES>sp|Q9NRY2|SOSSC_HUMAN SOSS complex subunit C OS=Homo sapiens OX=9606GN=INIP PE=1 SV=1MAANSSGQGFQNKNRVAILAELDKEKRKLLMQNQSSTNHPGASIALSRPSLNKDFRDHAEQQHIAAQQKAALQHAHAHSSGYFITQDSAFGNLILPVLPRLDPE>sp|Q9NRY2-2|SOSSC_HUMAN Isoform 2 of SOSS complex subunit C OS=Homosapiens OX=9606 GN=INIPMAANSSGQGFQNKNRVAILAELDKEKRKLLMQNQSSTNHPGARY>sp|Q11203|SIAT6_HUMAN CMP-N-acetylneuraminate-beta-1,4-galactosidealpha-2,3-sialyltransferase OS=Homo sapiens OX=9606 GN=ST3GAL3 PE=1 SV=1MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSASDGFWKSVATRVPKEPPEIRILNPYFIQEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-2|SIAT6_HUMAN Isoform A1 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSSKYSHSSSPQEKPVADSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSASDGFWKSVATRVPKEPPEIRILNPYFIQEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-3|SIAT6_HUMAN Isoform A7 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSSKYSHSSSPQEKPVADSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQVLDAQYPARERVSAEAGESSRHH>sp|Q11203-4|SIAT6_HUMAN Isoform A8 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSSKYSHSSSPQEKPVADSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLSPRTLCTVVFGLDCILESPGEPKKLLMPASHPLEILKSLSEDTAFALGFLKLPRPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSASDGFWKSVATRVPKEPPEIRILNPYFIQEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-5|SIAT6_HUMAN Isoform B1-90 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-6|SIAT6_HUMAN Isoform B1+32 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRPRL>sp|Q11203-7|SIAT6_HUMAN Isoform B3 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSASDGFWKSVATRVPKEPPEIRILNPYFIQEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-8|SIAT6_HUMAN Isoform B4 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-9|SIAT6_HUMAN Isoform B4+173 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPREKVRTFMAWLAWYG>sp|Q11203-10|SIAT6_HUMAN Isoform B5+26 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVR>sp|Q11203-11|SIAT6_HUMAN Isoform B5+173 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRAKRNGAWRQKHIQAYVLRQR>sp|Q11203-12|SIAT6_HUMAN Isoform B7 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQVLDAQYPARERVSAEAGESSRHH>sp|Q11203-13|SIAT6_HUMAN Isoform B8 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLSPRTLCTVVFGLDCILESPGEPKKLLMPASHPLEILKSLSEDTAFALGFLKLPRPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSASDGFWKSVATRVPKEPPEIRILNPYFIQEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-14|SIAT6_HUMAN Isoform B10 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSNSVVLSFDSAGQTLGSEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQECIGWLLEICGHSSAQGAP>sp|Q11203-15|SIAT6_HUMAN Isoform C1 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSASDGFWKSVATRVPKEPPEIRILNPYFIQEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-16|SIAT6_HUMAN Isoform C4 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-17|SIAT6_HUMAN Isoform C5 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVSPGRTISSERKSFCGSW>sp|Q11203-18|SIAT6_HUMAN Isoform C7 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQVLDAQYPARERVSAEAGESSRHH>sp|Q11203-19|SIAT6_HUMAN Isoform C8 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLSPRTLCTVVFGLDCILESPGEPKKLLMPASHPLEILKSLSEDTAFALGFLKLPRPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSASDGFWKSVATRVPKEPPEIRILNPYFIQEAAFTLIGLPFNNGLMGRGNIPTLGSVAVTMALHGCDEVAVAGFGYDMSTPNAPLHYYETVRMAAIKESWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-20|SIAT6_HUMAN Isoform C9 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRVHRMASGNLWPLECPRSPLRFESSTHISSRRPPSPSLACPSTMASWAGGTSLPLAVWQ>sp|Q11203-21|SIAT6_HUMAN Isoform C11 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVRLNSAPVKGFEKDVGSKTTLRITYPEGAMQRPEQYERDSLFVLAGFKWQDFKWLKYIVYKERVSWTHNIQREKEFLRKLVKARVITDLSSGI>sp|Q11203-22|SIAT6_HUMAN Isoform C12 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSKYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRPGRTISSERKSFCGSW>sp|Q11203-23|SIAT6_HUMAN Isoform D2+26 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSSKYSHSSSPQEKPVAEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVR>sp|Q11203-24|SIAT6_HUMAN Isoform D5 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSSKYSHSSSPQEKPVAEYDRLGFLLNLDSKLPAELATKYANFSEGACKPGYASALMTAIFPRFSKPAPMFLDDSFRKWARIREFVPPFGIKGQDNLIKAILSVTKEYRLTPALDSLRCRRCIIVGNGGVLANKSLGSRIDDYDIVVSPGRTISSERKSFCGSW>sp|Q11203-25|SIAT6_HUMAN Isoform E1 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSSLLN>sp|Q11203-26|SIAT6_HUMAN Isoform E3+32 of CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606GN=ST3GAL3MGLLVFVRNLLLALCLFLVLGFLYYSAWKLHLLQWEEDSSSPSQHPCSWMTPFASGLESGSSCRLLGSKVKTI>sp|Q9P270|SLAI2_HUMAN SLAIN motif-containing protein 2 OS=Homo sapiensOX=9606 GN=SLAIN2 PE=1 SV=2MEDVNSNVNADQEVRKLQELVKKLEKQNEQLRSRSGAVQGAGSLGPGSPVRAGASIPSSGAASPRGFPLGLSAKSGGGPGSGPRRTSSEELRDATSLLAAGEGGLLDEVEPLRPDELERLSGWEEEEESWLYSSPKKKLTPMQKSVSPLVWCRQVLDYPSPDVECAKKSLIHKLDQTMSALKRQNLYNNPFNSMSYTSPYSPNASSPYSSGFNSPSSTPVRPPIVKQLILPGNSGNLKSSDRNPPLSPQSSIDSELSASELDEDSIGSNYKLNDVTDVQILARMQEESLRQEYAATTSRRSSGSSCNSTRRGTFSDQELDAQSLDDEDDNMHHAVYPAVNRFSPSPRNSPRPSPKQSPRNSPRSRSPARGIEYSRVSPQPMISRLQQPRLSLQGHPTDLQTSNVKNEEKLRRSLPNLSRTSNTQVDSVKSSRSDSNFQVPNGGIPRMQPQASAIPSPGKFRSPAAPSPLALRQPVKAFSNHGSGSPGSQEITQLTQTTSSPGPPMVQSTVSANPPSNINSATLTRPAGTTAMRSGLPRPSAPSAGGIPVPRSKLAQPVRRSLPAPKTYGSMKDDSWKDGCY>sp|Q149N8|SHPRH_HUMAN E3 ubiquitin-protein ligase SHPRH OS=Homo sapiensOX=9606 GN=SHPRH PE=1 SV=2MSSRRKRAPPVRVDEEKRQQLHWNMHEDRRNEPIIISDDDEQPCPGSDTSSAHYIILSDSLKEEVAHRDKKRCSKVVSFSKPIEKEETVGIFSPLSVKLNIVISPYHFDNSWKAFLGELTLQLLPAQSLIENFSERSITLMSSESSNQFLIYVHSKGEDVEKQKKEPMSICDKGILVESSFSGEMLEDLGWLQKKRRIKLYQKPEGNHIIKVGIYLLEAGLAKLDFLSDANSRMKKFNQLMKKVMEKLHNSIIPDVLEEDEDDPESEPEGQDIDELYHFVKQTHQQETQSIQVDVQHPALIPVLRPYQREAVNWMLQQECFRSSPATESALHFLWREIVTSEGLKLYYNPYTGCIIREYPNSGPQLLGGILADEMGLGKTVEVLALILTHTRQDVKQDALTLPEGKVVNYFIPSHYFGGKLKKTEIQNIEFEPKEKVQCPPTRVMILTAVKEMNGKKGVSILSIYKYVSSIYRYDVQRNRSLLKRMLKCLIFEGLVKQIKGHGFSGTFTLGKNYKEEDICDKTKKQAVGSPRKIQKETRKSGNKDTDSEYLPSDTSDDDDDPYYYYYKSRRNRSKLRKKLVPSTKKGKSQPFINPDSQGHCPATSDSGITDVAMSKSTCISEFNQEHETEDCAESLNHADSDVPPSNTMSPFNTSDYRFECICGELDQIDRKPRVQCLKCHLWQHAKCVNYDEKNLKIKPFYCPHCLVAMEPVSTRATLIISPSSICHQWVDEINRHVRSSSLRVLVYQGVKKDGFLQPHFLAEQDIVIITYDVLRSELNYVDIPHSNSEDGRRLRNQKRYMAIPSPLVAVEWWRICLDEAQMVECPTVKAAEMAQRLSGINRWCISGTPVQRGLEDLFGLVVFLGIEPYCVKHWWVRLLYRPYCKKNPQHLYSFIAKILWRSAKKDVIDQIQIPPQTEEIHWLHFSPVERHFYHRQHEVCCQDVVVKLRKISDWALKLSSLDRRTVTSILYPLLRLRQACCHPQAVRGEFLPLQKSTMTMEELLTSLQKKCGTECEEAHRQLVCALNGLAGIHIIKGEYALAAELYREVLRSSEEHKGKLKTDSLQRLHATHNLMELLIARHPGIPPTLRDGRLEEEAKQLREHYMSKCNTEVAEAQQALYPVQQTIHELQRKIHSNSPWWLNVIHRAIEFTIDEELVQRVRNEITSNYKQQTGKLSMSEKFRDCRGLQFLLTTQMEELNKCQKLVREAVKNLEGPPSRNVIESATVCHLRPARLPLNCCVFCKADELFTEYESKLFSNTVKGQTAIFEEMIEDEEGLVDDRAPTTTRGLWAISETERSMKAILSFAKSHRFDVEFVDEGSTSMDLFEAWKKEYKLLHEYWMALRNRVSAVDELAMATERLRVRDPREPKPNPPVLHIIEPHEVEQNRIKLLNDKAVATSQLQKKLGQLLYLTNLEKSQDKTSGGVNPEPCPICARQLGKQWAVLTCGHCFCNECISIIIEQYSVGSHRSSIKCAICRQTTSHKEISYVFTSEKANQEEDIPVKGSHSTKVEAVVRTLMKIQLRDPGAKALVFSTWQDVLDIISKALTDNNMEFAQISRVKTFQENLSAFKRDPQINILLLPLHTGSNGLTIIEATHVLLVEPILNPAHELQAIGRVHRIGQTKPTIVHRFLIKATIEERMQAMLKTAERSHTNSSAKHSEASVLTVADLADLFTKETEELE>sp|Q149N8-2|SHPRH_HUMAN Isoform 2 of E3 ubiquitin-protein ligase SHPRHOS=Homo sapiens OX=9606 GN=SHPRHMSSRRKRAPPVRVDEEKRQQLHWNMHEDRRNEPIIISDDDEQPCPGEDVEKQKKEPMSICDKGILVESSFSGEMLEDLGWLQKKRRIKLYQKPEGNHIIKVGIYLLEAGLAKLDFLSDANSRMKKFNQLMKKVMEKLHNSIIPDVLEEDEDDPESEPEGQDIDELYHFVKQTHQQETQSIQVDVQHPALIPVLRPYQREAVNWMLQQECFRSSPATESALHFLWREIVTSEGLKLYYNPYTGCIIREYPNSGPQLLGGILADEMGLGKTVEVLALILTHTRQDVKQDALTLPEGKVVNYFIPSHYFGGKLKKTEIQNIEFEPKEKVQCPPTRVMILTAVKEMNGKKGVSILSIYKYVSSIYRYDVQRNRSLLKRMLKCLIFEGLVKQIKGHGFSGTFTLGKNYKEEDICDKTKKQAVGSPRKIQKETRKSGNKDTDSEYLPSDTSDDDDDPYYYYYKSRRNRSKLRKKLVPSTKKGKSQPFINPDSQGHCPATSDSGITDVAMSKSTCISEFNQEHETEDCAESLNHADSDVPPSNTMSPFNTSDYRFECICGELDQIDRKPRVQCLKCHLWQHAKCVNYDEKNLKIKPFYCPHCLVAMEPVSTRATLIISPSSICHQWVDEINRHVRSSSLRVLVYQGVKKDGFLQPHFLAEQDIVIITYDVLRSELNYVDIPHSNSEDGRRLRNQKRYMAIPSPLVAVEWWRICLDEAQMVECPTVKAAEMAQRLSGINRWCISGTPVQRGLEDLFGLVVFLGIEPYCVKHWWVRLLYRPYCKKNPQHLYSFIAKILWRSAKKDVIDQIQIPPQTEEIHWLHFSPVERHFYHRQHEVCCQDVVVKLRKISDWALKLSSLDRRTVTSILYPLLRLRQACCHPQAVRGEFLPLQKSTMTMEELLTSLQKKCGTECEEAHRQLVCALNGLAGIHIIKGRR>sp|Q149N8-4|SHPRH_HUMAN Isoform 3 of E3 ubiquitin-protein ligase SHPRHOS=Homo sapiens OX=9606 GN=SHPRHMSSRRKRAPPVRVDEEKRQQLHWNMHEDRRNEPIIISDDDEQPCPGSDTSSAHYIILSDSLKEEVAHRDKKRCSKVVSFSKPIEKEETVGIFSPLSVKLNIVISPYHFDNSWKAFLGELTLQLLPAQSLIENFSERSITLMSSESSNQFLIYVHSKGEDVEKQKKEPMSICDKGILVESSFSGEMLEDLGWLQKKRRIKLYQKPEGNHIIKVGIYLLEAGLAKLDFLSDANSRMKKFNQLMKKVMEKLHNSIIPDVLEEDEDDPESEPEGQDIDELYHFVKQTHQQETQSIQVDVQHPALIPVLRPYQREAVNWMLQQECFRSSPATESALHFLWREIVTSEGLKLYYNPYTGCIIREYPNSGPQLLGGILADEMGLGKTVEVLALILTHTRQDVKQDALTLPEGKVVNYFIPSHYFGGKLKKTEIQNIEFEPKEKVQCPPTRVMILTAVKEMNGKKGVSILSIYKYVSSIYRYDVQRNRSLLKRMLKCLIFEGLVKQIKGHGFSGTFTLGKNYKEEDICDKTKKQAVGSPRKIQKETRKSGNKDTDSEYLPSDTSDDDDDPYYYYYKSRRNRSKLRKKLVPSTKKGKSQPFINPDSQGHCPATSDSGITDVAMSKSTCISEFNQEHETEDCAESLNHADSDVPPSNTMSPFNTSDYRFECICGELDQIDRKPRVQCLKCHLWQHAKCVNYDEKNLKIKPFYCPHCLVAMEPVSTRATLIISPSSICHQWVDEINRHVRSSSLRVLVYQGVKKDGFLQPHFLAEQDIVIITYDVLRSELNYVDIPHSNSEDGRRLRNQKRYMAIPSPLVAVEWWRICLDEAQMVECPTVKAAEMAQRLSGINRWCISGTPVQRGLEDLFGLVVFLGIEPYCVKHWWVRLLYRPYCKKNPQHLYSFIAKILWRSAKKDVIDQIQIPPQTEEIHWLHFSPVERHFYHRQHEVCCQDVVVKLRKISDWALKLSSLDRRTVTSILYPLLRLRQACCHPQAVRGEFLPLQKSFEQSTFSFSTMTMEELLTSLQKKCGTECEEAHRQLVCALNGLAGIHIIKGEYALAAELYREVLRSSEEHKGKLKTDSLQRLHATHNLMELLIARHPGIPPTLRDGRLEEEAKQLREHYMSKCNTEVAEAQQALYPVQQTIHELQRKIHSNSPWWLNVIHRAIEFTIDEELVQRVRNEITSNYKQQTGKLSMSEKGLQFLLTTQMEELNKCQKLVREAVKNLEGPPSRNVIESATVCHLRPARLPLNCCVFCKADELFTEYESKLFSNTVKGQTAIFEEMIEDEEGLVDDRAPTTTRGLWAISETERSMKAILSFAKSHRFDVEFVDEGSTSMDLFEAWKKEYKLLHEYWMALRNRVSAVDELAMATERLRVRDPREPKPNPPVLHIIEPHEVEQNRIKLLNDKAVATSQLQKKLGQLLYLTNLEKSQDKTSGGVNPEPCPICARQLGKQWAVLTCGHCFCNECISIIIEQYSVGSHRSSIKCAICRQTTSHKEISYVFTSEKANQEEDIPVKGSHSTKVEAVVRTLMKIQLRDPGAKALVFSTWQDVLDIISKALTDNNMEFAQISRVKTFQENLSAFKRDPQINILLLPLHTGSNGLTIIEATHVLLVEPILNPAHELQAIGRVHRIGQTKPTIVHRFLIKATIEERMQAMLKTAERSIYI>sp|Q149N8-5|SHPRH_HUMAN Isoform 4 of E3 ubiquitin-protein ligase SHPRHOS=Homo sapiens OX=9606 GN=SHPRHMSSRRKRAPPVRVDEEKRQQLHWNMHEDRRNEPIIISDDDEQPCPGSDTSSAHYIILSDSLKEEVAHRDKKRCSKVVSFSKPIEKEETVGIFSPLSVKLNIVISPYHFDNSWKAFLGELTLQLLPAQSLIENFSERSITLMSSESSNQFLIYVHSKGEDVEKQKKEPMSICDKGILVESSFSGEMLEDLGWLQKKRRIKLYQKPEGNHIIKVGIYLLEAGLAKLDFLSDANSRMKKFNQLMKKVMEKLHNSIIPDVLEEDEDDPESEPEGQDIDELYHFVKQTHQQETQSIQVDVQHPALIPVLRPYQREAVNWMLQQECFRSSPATESALHFLWREIVTSEGLKLYYNPYTGCIIREYPNSGPQLLGGILADEMGLGKTVEVLALILTHTRQDVKQDALTLPEGKVVNYFIPSHYFGGKLKKTEIQNIEFEPKEKVQCPPYPFTFSYTCDDTDSCERNEWKKRSVHPFHL>sp|P03973|SLPI_HUMAN Antileukoproteinase OS=Homo sapiens OX=9606 GN=SLPIPE=1 SV=2MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCPGKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLNPPNFCEMDGQCKRDLKCCMGMCGKSCVSPVKA>sp|Q9H0K1|SIK2_HUMAN Serine/threonine-protein kinase SIK2 OS=Homosapiens OX=9606 GN=SIK2 PE=1 SV=1MVMADGPRHLQRGPVRVGFYDIEGTLGKGNFAVVKLGRHRITKTEVAIKIIDKSQLDAVNLEKIYREVQIMKMLDHPHIIKLYQVMETKSMLYLVTEYAKNGEIFDYLANHGRLNESEARRKFWQILSAVDYCHGRKIVHRDLKAENLLLDNNMNIKIADFGFGNFFKSGELLATWCGSPPYAAPEVFEGQQYEGPQLDIWSMGVVLYVLVCGALPFDGPTLPILRQRVLEGRFRIPYFMSEDCEHLIRRMLVLDPSKRLTIAQIKEHKWMLIEVPVQRPVLYPQEQENEPSIGEFNEQVLRLMHSLGIDQQKTIESLQNKSYNHFAAIYFLLVERLKSHRSSFPVEQRLDGRQRRPSTIAEQTVAKAQTVGLPVTMHSPNMRLLRSALLPQASNVEAFSFPASGCQAEAAFMEEECVDTPKVNGCLLDPVPPVLVRKGCQSLPSNMMETSIDEGLETEGEAEEDPAHAFEAFQSTRSGQRRHTLSEVTNQLVVMPGAGKIFSMNDSPSLDSVDSEYDMGSVQRDLNFLEDNPSLKDIMLANQPSPRMTSPFISLRPTNPAMQALSSQKREVHNRSPVSFREGRRASDTSLTQGIVAFRQHLQNLARTKGILELNKVQLLYEQIGPEADPNLAPAAPQLQDLASSCPQEEVSQQQESVSTLPASVHPQLSPRQSLETQYLQHRLQKPSLLSKAQNTCQLYCKEPPRSLEQQLQEHRLQQKRLFLQKQSQLQAYFNQMQIAESSYPQPSQQLPLPRQETPPPSQQAPPFSLTQPLSPVLEPSSEQMQYSPFLSQYQEMQLQPLPSTSGPRAAPPLPTQLQQQQPPPPPPPPPPRQPGAAPAPLQFSYQTCELPSAASPAPDYPTPCQYPVDGAQQSDLTGPDCPRSPGLQEAPSSYDPLALSELPGLFDCEMLDAVDPQHNGYVLVN>sp|Q9BQB4|SOST_HUMAN Sclerostin OS=Homo sapiens OX=9606 GN=SOST PE=1SV=1MQLPLALCLVCLLVHTAFRVVEGQGWQAFKNDATEIIPELGEYPEPPPELENNKTMNRAENGGRPPHHPFETKDVSEYSCRELHFTRYVTDGPCRSAKPVTELVCSGQCGPARLLPNAIGRGKWWRPSGPDFRCIPDRYRAQRVQLLCPGGEAPRARKVRLVASCKCKRLTRFHNQSELKDFGTEAARPQKGRKPRPRARSAKANQAELENAY>sp|Q9BQB4-2|SOST_HUMAN Isoform 2 of Sclerostin OS=Homo sapiens OX=9606GN=SOSTMQLPLALCLVCLLVHTAFRVVEGQGWQAFKNDATEIIPELGEYPEPPPELENNKTMNRAENGGWPGGRPPSRAPLSTDVSEYSCRELHFTRYVTDGPCRSAKPVTELVCSGQCGPARLLPNAIGRGKWWRPSGPDFRCIPDRYRAQRVQLLCPGGEAPRARKVRLVASCKCKRLTRFHNQSELKDFGTEAARPQKGRKPRPRARSAKANQAELENAY>sp|Q9UNP4|SIAT9_HUMAN Lactosylceramide alpha-2,3-sialyltransferaseOS=Homo sapiens OX=9606 GN=ST3GAL5 PE=1 SV=4MRTKAAGCAERRPLQPRTEAAAAPAGRAMPSEYTYVKLRSDCSRPSLQWYTRAQSKMRRPSLLLKDILKCTLLVFGVWILYILKLNYTTEECDMKKMHYVDPDHVKRAQKYAQQVLQKECRPKFAKTSMALLFEHRYSVDLLPFVQKAPKDSEAESKYDPPFGFRKFSSKVQTLLELLPEHDLPEHLKAKTCRRCVVIGSGGILHGLELGHTLNQFDVVIRLNSAPVEGYSEHVGNKTTIRMTYPEGAPLSDLEYYSNDLFVAVLFKSVDFNWLQAMVKKETLPFWVRLFFWKQVAEKIPLQPKHFRILNPVIIKETAFDILQYSEPQSRFWGRDKNVPTIGVIAVVLATHLCDEVSLAGFGYDLNQPRTPLHYFDSQCMAAMNFQTMHNVTTETKFLLKLVKEGVVKDLSGGIDREF>sp|Q9UNP4-2|SIAT9_HUMAN Isoform 2 of Lactosylceramide alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606 GN=ST3GAL5MPSEYTYVKLRSDCSRPSLQWYTRAQSKMRRPSLLLKDILKCTLLVFGVWILYILKLNYTTEECDMKKMHYVDPDHVKRAQKYAQQVLQKECRPKFAKTSMALLFEHRYSVDLLPFVQKAPKDSEAESKYDPPFGFRKFSSKVQTLLELLPEHDLPEHLKAKTCRRCVVIGSGGILHGLELGHTLNQFDVVIRLNSAPVEGYSEHVGNKTTIRMTYPEGAPLSDLEYYSNDLFVAVLFKSVDFNWLQAMVKKETLPFWVRLFFWKQVAEKIPLQPKHFRILNPVIIKETAFDILQYSEPQSRFWGRDKNVPTIGVIAVVLATHLCDEVSLAGFGYDLNQPRTPLHYFDSQCMAAMNFQTMHNVTTETKFLLKLVKEGVVKDLSGGIDREF>sp|Q9UNP4-3|SIAT9_HUMAN Isoform 3 of Lactosylceramide alpha-2,3-sialyltransferase OS=Homo sapiens OX=9606 GN=ST3GAL5MASVPMPSEYTYVKLRSDCSRPSLQWYTRAQSKMRRPSLLLKDILKCTLLVFGVWILYILKLNYTTEECDMKKMHYVDPDHVKRAQKYAQQVLQKECRPKFAKTSMALLFEHRYSVDLLPFVQKAPKDSEAESKYDPPFGFRKFSSKVQTLLELLPEHDLPEHLKAKTCRRCVVIGSGGILHGLELGHTLNQFDVVIRLNSAPVEGYSEHVGNKTTIRMTYPEGAPLSDLEYYSNDLFVAVLFKSVDFNWLQAMVKKETLPFWVRLFFWKQVAEKIPLQPKHFRILNPVIIKETAFDILQYSEPQSRFWGRDKNVPTIGVIAVVLATHLCDEVSLAGFGYDLNQPRTPLHYFDSQCMAAMNFQTMHNVTTETKFLLKLVKEGVVKDLSGGIDREF>sp|P78324|SHPS1_HUMAN Tyrosine-protein phosphatase non-receptor typesubstrate 1 OS=Homo sapiens OX=9606 GN=SIRPA PE=1 SV=2MEPAGPAPGRLGPLLCLLLAASCAWSGVAGEEELQVIQPDKSVLVAAGETATLRCTATSLIPVGPIQWFRGAGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRIGNITPADAGTYYCVKFRKGSPDDVEFKSGAGTELSVRAKPSAPVVSGPAARATPQHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPVGESVSYSIHSTAKVVLTREDVHSQVICEVAHVTLQGDPLRGTANLSETIRVPPTLEVTQQPVRAENQVNVTCQVRKFYPQRLQLTWLENGNVSRTETASTVTENKDGTYNWMSWLLVNVSAHRDDVKLTCQVEHDGQPAVSKSHDLKVSAHPKEQGSNTAAENTGSNERNIYIVVGVVCTLLVALLMAALYLVRIRQKKAQGSTSSTRLHEPEKNAREITQDTNDITYADLNLPKGKKPAPQAAEPNNHTEYASIQTSPQPASEDTLTYADLDMVHLNRTPKQPAPKPEPSFSEYASVQVPRK>sp|P78324-2|SHPS1_HUMAN Isoform 2 of Tyrosine-protein phosphatase non-receptor type substrate 1 OS=Homo sapiens OX=9606 GN=SIRPAMEPAGPAPGRLGPLLCLLLAASCAWSGVAGEEELQVIQPDKSVLVAAGETATLRCTATSLIPVGPIQWFRGAGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRIGNITPADAGTYYCVKFRKGSPDDVEFKSGAGTELSVRAKPSAPVVSGPAARATPQHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPVGESVSYSIHSTAKVVLTREDVHSQVICEVAHVTLQGDPLRGTANLSETIRVPPTLEVTQQPVRAENQVNVTCQVRKFYPQRLQLTWLENGNVSRTETASTVTENKDGTYNWMSWLLVNVSAHRDDVKLTCQVEHDGQPAVSKSHDLKVSAHPKEQGSNTAAENTGSNERNIYIVVGVVCTLLVALLMAALYLVRIRQKKAQGSTSSTRLHEPEKNAREITQVQSLDTNDITYADLNLPKGKKPAPQAAEPNNHTEYASIQTSPQPASEDTLTYADLDMVHLNRTPKQPAPKPEPSFSEYASVQVPRK>sp|P78324-4|SHPS1_HUMAN Isoform 4 of Tyrosine-protein phosphatase non-receptor type substrate 1 OS=Homo sapiens OX=9606 GN=SIRPAMEPAGPAPGRLGPLLCLLLAASCAWSGVAGEEELQVIQPDKSVLVAAGETATLRCTATSLIPVGPIQWFRGAGPGRELIYNQKEGHFPRVTTVSDLTKRNNMDFSIRIGNITPADAGTYYCVKFRKGSPDVEFKSGAGTELSVRAKPSAPVVSGPAARATPQHTVSFTCESHGFSPRDITLKWFKNGNELSDFQTNVDPVGESVSYSIHSTAKVVLTREDVHSQVICEVAHVTLQGDPLRGTANLSETIRVPPTLEVTQQPVRAENQVNVTCQVRKFYPQRLQLTWLENGNVSRTETASTVTENKDGTYNWMSWLLVNVSAHRDDVKLTCQVEHDGQPAVSKSHDLKVSAHPKEQGSNTAAENTGSNERNIYIVVGVVCTLLVALLMAALYLVRIRQKKAQGSTSSTRLHEPEKNAREITQDTNDITYADLNLPKGKKPAPQAAEPNNHTEYASIQTSPQPASEDTLTYADLDMVHLNRTPKQPAPKPEPSFSEYASVQVPRK>sp|Q9Y2K2|SIK3_HUMAN Serine/threonine-protein kinase SIK3 OS=Homosapiens OX=9606 GN=SIK3 PE=1 SV=4MAAAAASGAGGAAGAGTGGAGPAGRLLPPPAPGSPAAPAAVSPAAGQPRPPAPASRGPMPARIGYYEIDRTIGKGNFAVVKRATHLVTKAKVAIKIIDKTQLDEENLKKIFREVQIMKMLCHPHIIRLYQVMETERMIYLVTEYASGGEIFDHLVAHGRMAEKEARRKFKQIVTAVYFCHCRNIVHRDLKAENLLLDANLNIKIADFGFSNLFTPGQLLKTWCGSPPYAAPELFEGKEYDGPKVDIWSLGVVLYVLVCGALPFDGSTLQNLRARVLSGKFRIPFFMSTECEHLIRHMLVLDPNKRLSMEQICKHKWMKLGDADPNFDRLIAECQQLKEERQVDPLNEDVLLAMEDMGLDKEQTLQSLRSDAYDHYSAIYSLLCDRHKRHKTLRLGALPSMPRALAFQAPVNIQAEQAGTAMNISVPQVQLINPENQIVEPDGTLNLDSDEGEEPSPEALVRYLSMRRHTVGVADPRTEVMEDLQKLLPGFPGVNPQAPFLQVAPNVNFMHNLLPMQNLQPTGQLEYKEQSLLQPPTLQLLNGMGPLGRRASDGGANIQLHAQQLLKRPRGPSPLVTMTPAVPAVTPVDEESSDGEPDQEAVQSSTYKDSNTLHLPTERFSPVRRFSDGAASIQAFKAHLEKMGNNSSIKQLQQECEQLQKMYGGQIDERTLEKTQQQHMLYQQEQHHQILQQQIQDSICPPQPSPPLQAACENQPALLTHQLQRLRIQPSSPPPNHPNNHLFRQPSNSPPPMSSAMIQPHGAASSSQFQGLPSRSAIFQQQPENCSSPPNVALTCLGMQQPAQSQQVTIQVQEPVDMLSNMPGTAAGSSGRGISISPSAGQMQMQHRTNLMATLSYGHRPLSKQLSADSAEAHSLNVNRFSPANYDQAHLHPHLFSDQSRGSPSSYSPSTGVGFSPTQALKVPPLDQFPTFPPSAHQQPPHYTTSALQQALLSPTPPDYTRHQQVPHILQGLLSPRHSLTGHSDIRLPPTEFAQLIKRQQQQRQQQQQQQQQQEYQELFRHMNQGDAGSLAPSLGGQSMTERQALSYQNADSYHHHTSPQHLLQIRAQECVSQASSPTPPHGYAHQPALMHSESMEEDCSCEGAKDGFQDSKSSSTLTKGCHDSPLLLSTGGPGDPESLLGTVSHAQELGIHPYGHQPTAAFSKNKVPSREPVIGNCMDRSSPGQAVELPDHNGLGYPARPSVHEHHRPRALQRHHTIQNSDDAYVQLDNLPGMSLVAGKALSSARMSDAVLSQSSLMGSQQFQDGENEECGASLGGHEHPDLSDGSQHLNSSCYPSTCITDILLSYKHPEVSFSMEQAGV>sp|Q9Y2K2-6|SIK3_HUMAN Isoform 2 of Serine/threonine-protein kinase SIK3OS=Homo sapiens OX=9606 GN=SIK3MACSTPHGSNRRLPRKCHFSLPTRTPTLCTSLRSVSPLCAGSQMGLRASRPSKLTWKKWATTAASNSCSRSVSSCRRCTGGRLMKEPWRRPSSSICYTSRSSTIKFSSNKFKTLSVLLSHLHLFRLHVKISQPSLPISSRGAASSSQFQGLPSRSAIFQQQPENCSSPPNVALTCLGMQQPAQSQQVTIQVQEPVDMLSNMPGTAAGSSGRGISISPSAGQMQMQHRTNLMATLSYGHRPLSKQLSADSAEAHSAHQQPPHYTTSALQQALLSPTPPDYTRHQQVPHILQGLLSPRHSLTGHSDIRLPPTEFAQLIKRQQQQRQQQQQQQQQQEYQELFRHMNQGDAGSLAPSLGGQSMTERQALSYQNADSYHHHTSPQHLLQIRAQECVSQASSPTPPHGYAHQPALMHSESMEEDCSCEGAKDGFQDSKSSSTLTKGCHDSPLLLSTGGPGDPESLLGTVSHAQELGIHPYGHQPTAAFSKNKVPSREPVIGNCMDRSSPGQAVELPDHNGLGYPARPSVHEHHRPRALQRHHTIQNSDDAYVQLDNLPGMSLVAGKALSSARMSDAVLSQSSLMGSQQFQDGENEECGASLGGHEHPDLSDGSQHLNSSCYPSTCITDILLSYKHPEVSFSMEQAGV>sp|Q9Y2K2-7|SIK3_HUMAN Isoform 3 of Serine/threonine-protein kinase SIK3OS=Homo sapiens OX=9606 GN=SIK3MAAAAASGAGGAAGAGTGGAGPAGRLLPPPAPGSPAAPAAVSPAAGQPRPPAPASRGPMPARIGYYEIDRTIGKGNFAVVKRATHLVTKAKVAIKIIDKTQLDEENLKKIFREVQIMKMLCHPHIIRLYQVMETERMIYLVTEYASGGEIFDHLVAHGRMAEKEARRKFKQIVTAVYFCHCRNIVHRDLKAENLLLDANLNIKIADFGFSNLFTPGQLLKTWCGSPPYAAPELFEGKEYDGPKVDIWSLGVVLYVLVCGALPFDGSTLQNLRARVLSGKFRIPFFMSTECEHLIRHMLVLDPNKRLSMEQICKHKWMKLGDADPNFDRLIAECQQLKEERQVDPLNEDVLLAMEDMGLDKEQTLQSLRSDAYDHYSAIYSLLCDRHKRHKTLRLGALPSMPRALAFQAPVNIQAEQAGTAMNISVPQVQLINPENQIVEPDGTLNLDSDEGEEPSPEALVRYLSMRRHTVGVADPRTEVMEDLQKLLPGFPGVNPQAPFLQVAPNVNFMHNLLPMQNLQPTGQLEYKEQSLLQPPTLQLLNGMGPLGRRASDGGANIQLHAQQLLKRPRGPSPLVTMTPAVPAVTPVDEESSDGEPDQEAVQSSTYKDSNTLHLPTERFSPVRRFSDGAASIQAFKAHLEKMGNNSSIKQLQQECEQLQKMYGGQIDERTLEKTQQQHMLYQQEQHHQILQQQIQDSICPPQPSPPLQAACENQPALLTHQLQRLRIQPSSPPPNHPNNHLFRQPSNSPPPMSSAMIQPHGAASSSQFQGLPSRSAIFQQQPENCSSPPNVALTCLGMQQPAQSQQVTIQVQEPVDMLSNMPGTAAGSSGRGISISPSAGQMQMQHRTNLMATLSYGHRPLSKQLSADSAEAHSLNVNRFSPANYDQAHLHPHLFSDQSRGSPSSYSPSTGVGFSPTQALKVPPLDQFPTFPPSAHQQPPHYTTSALQQALLSPTPPDYTRHQQVPHILQGLLSPRHSLTGHSDIRLPPTEFAQLIKRQQQQRQQQQQQQQQQEYQELFRHMNQGDAGSLAPSLGGQSMTERQALSYQNADSYHHHTSPQHLLQIRAQECVSQASSPTPPHGYAHQPALMHSESMEEDCSCEGAKDGFQDSKSSSTLTKGCHDSPLLLSTGGPGDPESLLGTVSHAQELGIHPYGHQPTAAFSKNKVPSRGKCLLTVEVLGQSALIN>sp|Q9Y2K2-8|SIK3_HUMAN Isoform 4 of Serine/threonine-protein kinase SIK3OS=Homo sapiens OX=9606 GN=SIK3MAAAAASGAGGAAGAGTGGAGPAGRLLPPPAPGSPAAPAAVSPAAGQPRPPAPASRGPMPARIGYYEIDRTIGKGNFAVVKRATHLVTKAKVAIKIIDKTQLDEENLKKIFREVQIMKMLCHPHIIRLYQVMETERMIYLVTEYASGGEIFDHLVAHGRMAEKEARRKFKQIVTAVYFCHCRNIVHRDLKAENLLLDANLNIKIADFGFSNLFTPGQLLKTWCGSPPYAAPELFEGKEYDGPKVDIWSLGVVLYVLVCGALPFDGSTLQNLRARVLSGKFRIPFFMSTECEHLIRHMLVLDPNKRLSMEQICKHKWMKLGDADPNFDRLIAECQQLKEERQVDPLNEDVLLAMEDMGLDKEQTLQAEQAGTAMNISVPQVQLINPENQIVEPDGTLNLDSDEGEEPSPEALVRYLSMRRHTVGVADPRTEVMEDLQKLLPGFPGVNPQAPFLQVAPNVNFMHNLLPMQNLQPTGQLEYKEQSLLQPPTLQLLNGMGPLGRRASDGGANIQLHAQQLLKRPRGPSPLVTMTPAVPAVTPVDEESSDGEPDQEAVQRYLANRSKRHTLAMTNPTAEIPPDLQRQLGQQPFRSRVWPPHLVPDQHRSTYKDSNTLHLPTERFSPVRRFSDGAASIQAFKAHLEKMGNNSSIKQLQQECEQLQKMYGGQIDERTLEKTQQQHMLYQQEQHHQILQQQIQDSICPPQPSPPLQAACENQPALLTHQLQRLRIQPSSPPPNHPNNHLFRQPSNSPPPMSSAMIQPHGAASSSQFQGLPSRSAIFQQQPENCSSPPNVALTCLGMQQPAQSQQVTIQVQEPVDMLSNMPGTAAGSSGRGISISPSAGQMQMQHRTNLMATLSYGHRPLSKQLSADSAEAHSAHQQPPHYTTSALQQALLSPTPPDYTRHQQVPHILQGLLSPRHSLTGHSDIRLPPTEFAQLIKRQQQQRQQQQQQQQQQEYQELFRHMNQGDAGSLAPSLGGQSMTERQALSYQNADSYHHHTSPQHLLQIRAQECVSQASSPTPPHGYAHQPALMHSESMEEDCSCEGAKDGFQDSKSSSTLTKGCHDSPLLLSTGGPGDPESLLGTVSHAQELGIHPYGHQPTAAFSKNKVPSREPVIGNCMDRSSPGQAVELPDHNGLGYPARPSVHEHHRPRALQRHHTIQNSDDAYVQLDNLPGMSLVAGKALSSARMSDAVLSQSSLMGSQQFQDGENEECGASLGGHEHPDLSDGSQHLNSSCYPSTCITDILLSYKHPEVSFSMEQAGV>sp|Q86TU7|SETD3_HUMAN Actin-histidine N-methyltransferase OS=Homosapiens OX=9606 GN=SETD3 PE=1 SV=1MGKKSRVKTQKSGTGATATVSPKEILNLTSELLQKCSSPAPGPGKEWEEYVQIRTLVEKIRKKQKGLSVTFDGKREDYFPDLMKWASENGASVEGFEMVNFKEEGFGLRATRDIKAEELFLWVPRKLLMTVESAKNSVLGPLYSQDRILQAMGNIALAFHLLCERASPNSFWQPYIQTLPSEYDTPLYFEEDEVRYLQSTQAIHDVFSQYKNTARQYAYFYKVIQTHPHANKLPLKDSFTYEDYRWAVSSVMTRQNQIPTEDGSRVTLALIPLWDMCNHTNGLITTGYNLEDDRCECVALQDFRAGEQIYIFYGTRSNAEFVIHSGFFFDNNSHDRVKIKLGVSKSDRLYAMKAEVLARAGIPTSSVFALHFTEPPISAQLLAFLRVFCMTEEELKEHLLGDSAIDRIFTLGNSEFPVSWDNEVKLWTFLEDRASLLLKTYKTTIEEDKSVLKNHDLSVRAKMAIKLRLGEKEILEKAVKSAAVNREYYRQQMEEKAPLPKYEESNLGLLESSVGDSRLPLVLRNLEEEAGVQDALNIREAISKAKATENGLVNGENSIPNGTRSENESLNQESKRAVEDAKGSSSDSTAGVKE>sp|Q86TU7-2|SETD3_HUMAN Isoform 2 of Actin-histidine N-methyltransferaseOS=Homo sapiens OX=9606 GN=SETD3MGKKSRVKTQKSGTGATATVSPKEILNLTSELLQKCSSPAPGPGKEWEEYVQIRTLVEKIRKKQKGLSVTFDGKREDYFPDLMKWASENGASVEGFEMVNFKEEGFGLRATRDIKAEELFLWVPRKLLMTVESAKNSVLGPLYSQDRILQAMGNIALAFHLLCERASPNSFWQPYIQTLPSEYDTPLYFEEDEVRYLQSTQAIHDVFSQYKNTARQYAYFYKVIQTHPHANKLPLKDSFTYEDYRWAVSSVMTRQNQIPTEDGSRVTLALIPLWDMCNHTNGLTPEDSFALAVASA>sp|Q86TU7-3|SETD3_HUMAN Isoform 3 of Actin-histidine N-methyltransferaseOS=Homo sapiens OX=9606 GN=SETD3MGKKSRVKTQKSGTGATATVSPKEILNLTSELLQKCSSPAPGPGKEWEEYVQIRTLVEKIRKKQKGLSVTFDGKREDYFPDLMKWASENGASVEGFEMVNFKEEGFGLRATRDIKAEELFLWVPRKLLMTVESAKNSVLGPLYSQDRILQAMGNIALAFHLLCERASPNSFWQPYIQTLPSEYDTPLYFEEDEVRYLQSTQAIHDVFSQYKNTARQYAYFYKVIQTHPHANKLPLKDSFTYEDYRWAVSSVMTRQNQIPTEDGSRVTLALIPLWDMCNHTNGLV>sp|P62910|RL32_HUMAN 60S ribosomal protein L32 OS=Homo sapiens OX=9606GN=RPL32 PE=1 SV=2MAALRPLVKPKIVKKRTKKFIRHQSDRYVKIKRNWRKPRGIDNRVRRRFKGQILMPNIGYGSNKKTKHMLPSGFRKFLVHNVKELEVLLMCNKSYCAEIAHNVSSKNRKAIVERAAQLAIRVTNPNARLRSEENE>sp|Q9NZJ4|SACS_HUMAN Sacsin OS=Homo sapiens OX=9606 GN=SACS PE=1 SV=2METKENRWVPVTVLPGCVGCRTVAALASWTVRDVKERIFAETGFPVSEQRLWRGGRELSDWIKIGDLTSKNCHLFVNLQSKGLKGGGRFGQTTPPLVDFLKDILRRYPEGGQILKELIQNAEDAGATEVKFLYDETQYGTETLWSKDMAPYQGPALYVYNNAVFTPEDWHGIQEIARSRKKDDPLKVGRFGIGFNSVYHITDVPCIFSGDQIGMLDPHQTLFGPHESGQCWNLKDDSKEISELSDQFAPFVGIFGSTKETFINGNFPGTFFRFPLRLQPSQLSSNLYNKQKVLELFESFRADADTVLLFLKSVQDVSLYVREADGTEKLVFRVTSSESKALKHERPNSIKILGTAISNYCKKTPSNNITCVTYHVNIVLEEESTKDAQKTSWLVCNSVGGRGISSKLDSLADELKFVPIIGIAMPLSSRDDEAKGATSDFSGKAFCFLPLPPGEESSTGLPVHISGFFGLTDNRRSIKWRELDQWRDPAALWNEFLVMNVVPKAYATLILDSIKRLEMEKSSDFPLSVDVIYKLWPEASKVKVHWQPVLEPLFSELLQNAVIYSISCDWVRLEQVYFSELDENLEYTKTVLNYLQSSGKQIAKVPGNVDAAVQLTAASGTTPVRKVTPAWVRQVLRKCAHLGCAEEKLHLLEFVLSDQAYSELLGLELLPLQNGNFVPFSSSVSDQDVIYITSAEYPRSLFPSLEGRFILDNLKPHLVAALKEAAQTRGRPCTQLQLLNPERFARLIKEVMNTFWPGRELIVQWYPFDENRNHPSVSWLKMVWKNLYIHFSEDLTLFDEMPLIPRTILEEGQTCVELIRLRIPSLVILDDESEAQLPEFLADIVQKLGGFVLKKLDASIQHPLIKKYIHSPLPSAVLQIMEKMPLQKLCNQITSLLPTHKDALRKFLASLTDSSEKEKRIIQELAIFKRINHSSDQGISSYTKLKGCKVLHHTAKLPADLRLSISVIDSSDEATIRLANMLKIEQLKTTSCLKLVLKDIENAFYSHEEVTQLMLWVLENLSSLKNENPNVLEWLTPLKFIQISQEQMVSAGELFDPDIEVLKDLFCNEEGTYFPPSVFTSPDILHSLRQIGLKNEASLKEKDVVQVAKKIEALQVGACPDQDVLLKKAKTLLLVLNKNHTLLQSSEGKMTLKKIKWVPACKERPPNYPGSLVWKGDLCNLCAPPDMCDVGHAILIGSSLPLVESIHVNLEKALGIFTKPSLSAVLKHFKIVVDWYSSKTFSDEDYYQFQHILLEIYGFMHDHLNEGKDSFRALKFPWVWTGKKFCPLAQAVIKPIHDLDLQPYLHNVPKTMAKFHQLFKVCGSIEELTSDHISMVIQKIYLKSDQDLSEQESKQNLHLMLNIIRWLYSNQIPASPNTPVPIHHSKNPSKLIMKPIHECCYCDIKVDDLNDLLEDSVEPIILVHEDIPMKTAEWLKVPCLSTRLINPENMGFEQSGQREPLTVRIKNILEEYPSVSDIFKELLQNADDANATECSFLIDMRRNMDIRENLLDPGMAACHGPALWSFNNSQFSDSDFVNITRLGESLKRGEVDKVGKFGLGFNSVYHITDIPIIMSREFMIMFDPNINHISKHIKDKSNPGIKINWSKQQKRLRKFPNQFKPFIDVFGCQLPLTVEAPYSYNGTLFRLSFRTQQEAKVSEVSSTCYNTADIYSLVDEFSLCGHRLIIFTQSVKSMYLKYLKIEETNPSLAQDTVIIKKKSCSSKALNTPVLSVLKEAAKLMKTCSSSNKKLPSDEPKSSCILQITVEEFHHVFRRIADLQSPLFRGPDDDPAALFEMAKSGQSKKPSDELSQKTVECTTWLLCTCMDTGEALKFSLSESGRRLGLVPCGAVGVQLSEIQDQKWTVKPHIGEVFCYLPLRIKTGLPVHINGCFAVTSNRKEIWKTDTKGRWNTTFMRHVIVKAYLQVLSVLRDLATSGELMDYTYYAVWPDPDLVHDDFSVICQGFYEDIAHGKGKELTKVFSDGSTWVSMKNVRFLDDSILKRRDVGSAAFKIFLKYLKKTGSKNLCAVELPSSVKLGFEEAGCKQILLENTFSEKQFFSEVFFPNIQEIEAELRDPLMIFVLNEKVDEFSGVLRVTPCIPCSLEGHPLVLPSRLIHPEGRVAKLFDIKDGRFPYGSTQDYLNPIILIKLVQLGMAKDDILWDDMLERAVSVAEINKSDHVAACLRSSILLSLIDEKLKIRDPRAKDFAAKYQTIRFLPFLTKPAGFSLDWKGNSFKPETMFAATDLYTAEHQDIVCLLQPILNENSHSFRGCGSVSLAVKEFLGLLKKPTVDLVINQLKEVAKSVDDGITLYQENITNACYKYLHEALMQNEITKMSIIDKLKPFSFILVENAYVDSEKVSFHLNFEAAPYLYQLPNKYKNNFRELFETVGVRQSCTVEDFALVLESIDQERGTKQITEENFQLCRRIISEGIWSLIREKKQEFCEKNYGKILLPDTNLMLLPAKSLCYNDCPWIKVKDTTVKYCHADIPREVAVKLGAVPKRHKALERYASNVCFTTLGTEFGQKEKLTSRIKSILNAYPSEKEMLKELLQNADDAKATEICFVFDPRQHPVDRIFDDKWAPLQGPALCVYNNQPFTEDDVRGIQNLGKGTKEGNPYKTGQYGIGFNSVYHITDCPSFISGNDILCIFDPHARYAPGATSISPGRMFRDLDADFRTQFSDVLDLYLGTHFKLDNCTMFRFPLRNAEMAKVSEISSVPASDRMVQNLLDKLRSDGAELLMFLNHMEKISICEIDKSTGALNVLYSVKGKITDGDRLKRKQFHASVIDSVTKKRQLKDIPVQQITYTMDTEDSEGNLTTWLICNRSGFSSMEKVSKSVISAHKNQDITLFPRGGVAACITHNYKKPHRAFCFLPLSLETGLPFHVNGHFALDSARRNLWRDDNGVGVRSDWNNSLMTALIAPAYVELLIQLKKRYFPGSDPTLSVLQNTPIHVVKDTLKKFLSFFPVNRLDLQPDLYCLVKALYNCIHEDMKRLLPVVRAPNIDGSDLHSAVIITWINMSTSNKTRPFFDNLLQDELQHLKNADYNITTRKTVAENVYRLKHLLLEIGFNLVYNCDETANLYHCLIDADIPVSYVTPADIRSFLMTFSSPDTNCHIGKLPCRLQQTNLKLFHSLKLLVDYCFKDAEENEIEVEGLPLLITLDSVLQTFDAKRPKFLTTYHELIPSRKDLFMNTLYLKYSNILLNCKVAKVFDISSFADLLSSVLPREYKTKSCTKWKDNFASESWLKNAWHFISESVSVKEDQEETKPTFDIVVDTLKDWALLPGTKFTVSANQLVVPEGDVLLPLSLMHIAVFPNAQSDKVFHALMKAGCIQLALNKICSKDSAFVPLLSCHTANIESPTSILKALHYMVQTSTFRAEKLVENDFEALLMYFNCNLNHLMSQDDIKILKSLPCYKSISGRYVSIGKFGTCYVLTKSIPSAEVEKWTQSSSSAFLEEKIHLKELYEVIGCVPVDDLEVYLKHLLPKIENLSYDAKLEHLIYLKNRLSSAEELSEIKEQLFEKLESLLIIHDANSRLKQAKHFYDRTVRVFEVMLPEKLFIPNDFFKKLEQLIKPKNHVTFMTSWVEFLRNIGLKYILSQQQLLQFAKEISVRANTENWSKETLQNTVDILLHHIFQERMDLLSGNFLKELSLIPFLCPERAPAEFIRFHPQYQEVNGTLPLIKFNGAQVNPKFKQCDVLQLLWTSCPILPEKATPLSIKEQEGSDLGPQEQLEQVLNMLNVNLDPPLDKVINNCRNICNITTLDEEMVKTRAKVLRSIYEFLSAEKREFRFQLRGVAFVMVEDGWKLLKPEEVVINLEYESDFKPYLYKLPLELGTFHQLFKHLGTEDIISTKQYVEVLSRIFKNSEGKQLDPNEMRTVKRVVSGLFRSLQNDSVKVRSDLENVRDLALYLPSQDGRLVKSSILVFDDAPHYKSRIQGNIGVQMLVDLSQCYLGKDHGFHTKLIMLFPQKLRPRLLSSILEEQLDEETPKVCQFGALCSLQGRLQLLLSSEQFITGLIRIMKHENDNAFLANEEKAIRLCKALREGLKVSCFEKLQTTLRVKGFNPIPHSRSETFAFLKRFGNAVILLYIQHSDSKDINFLLALAMTLKSATDNLISDTSYLIAMLGCNDIYRIGEKLDSLGVKYDSSEPSKLELPMPGTPIPAEIHYTLLMDPMNVFYPGEYVGYLVDAEGGDIYGSYQPTYTYAIIVQEVEREDADNSSFLGKIYQIDIGYSEYKIVSSLDLYKFSRPEESSQSRDSAPSTPTSPTEFLTPGLRSIPPLFSGRESHKTSSKHQSPKKLKVNSLPEILKEVTSVVEQAWKLPESERKKIIRRLYLKWHPDKNPENHDIANEVFKHLQNEINRLEKQAFLDQNADRASRRTFSTSASRFQSDKYSFQRFYTSWNQEATSHKSERQQQNKEKCPPSAGQTYSQRFFVPPTFKSVGNPVEARRWLRQARANFSAARNDLHKNANEWVCFKCYLSTKLALIAADYAVRGKSDKDVKPTALAQKIEEYSQQLEGLTNDVHTLEAYGVDSLKTRYPDLLPFPQIPNDRFTSEVAMRVMECTACIIIKLENFMQQKV>sp|Q9NZJ4-2|SACS_HUMAN Isoform 2 of Sacsin OS=Homo sapiens OX=9606GN=SACSMNTFWPGRELIVQWYPFDENRNHPSVSWLKMVWKNLYIHFSEDLTLFDEMPLIPRTILEEGQTCVELIRLRIPSLVILDDESEAQLPEFLADIVQKLGGFVLKKLDASIQHPLIKKYIHSPLPSAVLQIMEKMPLQKLCNQITSLLPTHKDALRKFLASLTDSSEKEKRIIQELAIFKRINHSSDQGISSYTKLKGCKVLHHTAKLPADLRLSISVIDSSDEATIRLANMLKIEQLKTTSCLKLVLKDIENAFYSHEEVTQLMLWVLENLSSLKNENPNVLEWLTPLKFIQISQEQMVSAGELFDPDIEVLKDLFCNEEGTYFPPSVFTSPDILHSLRQIGLKNEASLKEKDVVQVAKKIEALQVGACPDQDVLLKKAKTLLLVLNKNHTLLQSSEGKMTLKKIKWVPACKERPPNYPGSLVWKGDLCNLCAPPDMCDVGHAILIGSSLPLVESIHVNLEKALGIFTKPSLSAVLKHFKIVVDWYSSKTFSDEDYYQFQHILLEIYGFMHDHLNEGKDSFRALKFPWVWTGKKFCPLAQAVIKPIHDLDLQPYLHNVPKTMAKFHQLFKVCGSIEELTSDHISMVIQKIYLKSDQDLSEQESKQNLHLMLNIIRWLYSNQIPASPNTPVPIHHSKNPSKLIMKPIHECCYCDIKVDDLNDLLEDSVEPIILVHEDIPMKTAEWLKVPCLSTRLINPENMGFEQSGQREPLTVRIKNILEEYPSVSDIFKELLQNADDANATECSFLIDMRRNMDIRENLLDPGMAACHGPALWSFNNSQFSDSDFVNITRLGESLKRGEVDKVGKFGLGFNSVYHITDIPIIMSREFMIMFDPNINHISKHIKDKSNPGIKINWSKQQKRLRKFPNQFKPFIDVFGCQLPLTVEAPYSYNGTLFRLSFRTQQEAKVSEVSSTCYNTADIYSLVDEFSLCGHRLIIFTQSVKSMYLKYLKIEETNPSLAQDTVIIKKKSCSSKALNTPVLSVLKEAAKLMKTCSSSNKKLPSDEPKSSCILQITVEEFHHVFRRIADLQSPLFRGPDDDPAALFEMAKSGQSKKPSDELSQKTVECTTWLLCTCMDTGEALKFSLSESGRRLGLVPCGAVGVQLSEIQDQKWTVKPHIGEVFCYLPLRIKTGLPVHINGCFAVTSNRKEIWKTDTKGRWNTTFMRHVIVKAYLQVLSVLRDLATSGELMDYTYYAVWPDPDLVHDDFSVICQGFYEDIAHGKGKELTKVFSDGSTWVSMKNVRFLDDSILKRRDVGSAAFKIFLKYLKKTGSKNLCAVELPSSVKLGFEEAGCKQILLENTFSEKQFFSEVFFPNIQEIEAELRDPLMIFVLNEKVDEFSGVLRVTPCIPCSLEGHPLVLPSRLIHPEGRVAKLFDIKDGRFPYGSTQDYLNPIILIKLVQLGMAKDDILWDDMLERAVSVAEINKSDHVAACLRSSILLSLIDEKLKIRDPRAKDFAAKYQTIRFLPFLTKPAGFSLDWKGNSFKPETMFAATDLYTAEHQDIVCLLQPILNENSHSFRGCGSVSLAVKEFLGLLKKPTVDLVINQLKEVAKSVDDGITLYQENITNACYKYLHEALMQNEITKMSIIDKLKPFSFILVENAYVDSEKVSFHLNFEAAPYLYQLPNKYKNNFRELFETVGVRQSCTVEDFALVLESIDQERGTKQITEENFQLCRRIISEGIWSLIREKKQEFCEKNYGKILLPDTNLMLLPAKSLCYNDCPWIKVKDTTVKYCHADIPREVAVKLGAVPKRHKALERYASNVCFTTLGTEFGQKEKLTSRIKSILNAYPSEKEMLKELLQNADDAKATEICFVFDPRQHPVDRIFDDKWAPLQGPALCVYNNQPFTEDDVRGIQNLGKGTKEGNPYKTGQYGIGFNSVYHITDCPSFISGNDILCIFDPHARYAPGATSISPGRMFRDLDADFRTQFSDVLDLYLGTHFKLDNCTMFRFPLRNAEMAKVSEISSVPASDRMVQNLLDKLRSDGAELLMFLNHMEKISICEIDKSTGALNVLYSVKGKITDGDRLKRKQFHASVIDSVTKKRQLKDIPVQQITYTMDTEDSEGNLTTWLICNRSGFSSMEKVSKSVISAHKNQDITLFPRGGVAACITHNYKKPHRAFCFLPLSLETGLPFHVNGHFALDSARRNLWRDDNGVGVRSDWNNSLMTALIAPAYVELLIQLKKRYFPGSDPTLSVLQNTPIHVVKDTLKKFLSFFPVNRLDLQPDLYCLVKALYNCIHEDMKRLLPVVRAPNIDGSDLHSAVIITWINMSTSNKTRPFFDNLLQDELQHLKNADYNITTRKTVAENVYRLKHLLLEIGFNLVYNCDETANLYHCLIDADIPVSYVTPADIRSFLMTFSSPDTNCHIGKLPCRLQQTNLKLFHSLKLLVDYCFKDAEENEIEVEGLPLLITLDSVLQTFDAKRPKFLTTYHELIPSRKDLFMNTLYLKYSNILLNCKVAKVFDISSFADLLSSVLPREYKTKSCTKWKDNFASESWLKNAWHFISESVSVKEDQEETKPTFDIVVDTLKDWALLPGTKFTVSANQLVVPEGDVLLPLSLMHIAVFPNAQSDKVFHALMKAGCIQLALNKICSKDSAFVPLLSCHTANIESPTSILKALHYMVQTSTFRAEKLVENDFEALLMYFNCNLNHLMSQDDIKILKSLPCYKSISGRYVSIGKFGTCYVLTKSIPSAEVEKWTQSSSSAFLEEKIHLKELYEVIGCVPVDDLEVYLKHLLPKIENLSYDAKLEHLIYLKNRLSSAEELSEIKEQLFEKLESLLIIHDANSRLKQAKHFYDRTVRVFEVMLPEKLFIPNDFFKKLEQLIKPKNHVTFMTSWVEFLRNIGLKYILSQQQLLQFAKEISVRANTENWSKETLQNTVDILLHHIFQERMDLLSGNFLKELSLIPFLCPERAPAEFIRFHPQYQEVNGTLPLIKFNGAQVNPKFKQCDVLQLLWTSCPILPEKATPLSIKEQEGSDLGPQEQLEQVLNMLNVNLDPPLDKVINNCRNICNITTLDEEMVKTRAKVLRSIYEFLSAEKREFRFQLRGVAFVMVEDGWKLLKPEEVVINLEYESDFKPYLYKLPLELGTFHQLFKHLGTEDIISTKQYVEVLSRIFKNSEGKQLDPNEMRTVKRVVSGLFRSLQNDSVKVRSDLENVRDLALYLPSQDGRLVKSSILVFDDAPHYKSRIQGNIGVQMLVDLSQCYLGKDHGFHTKLIMLFPQKLRPRLLSSILEEQLDEETPKVCQFGALCSLQGRLQLLLSSEQFITGLIRIMKHENDNAFLANEEKAIRLCKALREGLKVSCFEKLQTTLRVKGFNPIPHSRSETFAFLKRFGNAVILLYIQHSDSKDINFLLALAMTLKSATDNLISDTSYLIAMLGCNDIYRIGEKLDSLGVKYDSSEPSKLELPMPGTPIPAEIHYTLLMDPMNVFYPGEYVGYLVDAEGGDIYGSYQPTYTYAIIVQEVEREDADNSSFLGKIYQIDIGYSEYKIVSSLDLYKFSRPEESSQSRDSAPSTPTSPTEFLTPGLRSIPPLFSGRESHKTSSKHQSPKKLKVNSLPEILKEVTSVVEQAWKLPESERKKIIRRLYLKWHPDKNPENHDIANEVFKHLQNEINRLEKQAFLDQNADRASRRTFSTSASRFQSDKYSFQRFYTSWNQEATSHKSERQQQNKEKCPPSAGQTYSQRFFVPPTFKSVGNPVEARRWLRQARANFSAARNDLHKNANEWVCFKCYLSTKLALIAADYAVRGKSDKDVKPTALAQKIEEYSQQLEGLTNDVHTLEAYGVDSLKTRYPDLLPFPQIPNDRFTSEVAMRVMECTACIIIKLENFMQQKV>sp|Q9BWH6|RPAP1_HUMAN RNA polymerase II-associated protein 1 OS=Homosapiens OX=9606 GN=RPAP1 PE=1 SV=3MLSRPKPGESEVDLLHFQSQFLAAGAAPAVQLVKKGNRGGGDANSDRPPLQDHRDVVMLDNLPDLPPALVPSPPKRARPSPGHCLPEDEDPEERLRRHDQHITAVLTKIIERDTSSVAVNLPVPSGVAFPAVFLRSRDTQGKSATSGKRSIFAQEIAARRIAEAKGPSVGEVVPNVGPPEGAVTCETPTPRNQGCQLPGSSHSFQGPNLVTGKGLRDQEAEQEAQTIHEENIARLQAMAPEEILQEQQRLLAQLDPSLVAFLRSHSHTQEQTGETASEEQRPGGPSANVTKEEPLMSAFASEPRKRDKLEPEAPALALPVTPQKEWLHMDTVELEKLHWTQDLPPVRRQQTQERMQARFSLQGELLAPDVDLPTHLGLHHHGEEAERAGYSLQELFHLTRSQVSQQRALALHVLAQVISRAQAGEFGDRLAGSVLSLLLDAGFLFLLRFSLDDRVDGVIATAIRALRALLVAPGDEELLDSTFSWYHGALTFPLMPSQEDKEDEDEDEECPAGKAKRKSPEEESRPPPDLARHDVIKGLLATSLLPRLRYVLEVTYPGPAVVLDILAVLIRLARHSLESATRVLECPRLIETIVREFLPTSWSPVGAGPTPSLYKVPCATAMKLLRVLASAGRNIAARLLSSFDLRSRLCRIIAEAPQELALPPEEAEMLSTEALRLWAVAASYGQGGYLYRELYPVLMRALQVVPRELSTHPPQPLSMQRIASLLTLLTQLTLAAGSTPAETISDSAEASLSATPSLVTWTQVSGLQPLVEPCLRQTLKLLSRPEMWRAVGPVPVACLLFLGAYYQAWSQQPSSCPEDWLQDMQRLSEELLLPLLSQPTLGSLWDSLRHCSLLCNPLSCVPALEAPPSLVSLGCSGGCPRLSLAGSASPFPFLTALLSLLNTLAQIHKGLCGQLAAILAAPGLQNYFLQCVAPGAAPHLTPFSAWALRHEYHLQYLALALAQKAAALQPLPATHAALYHGMALALLSRLLPGSEYLTHELLLSCVFRLEFLPERTSGGPEAADFSDQLSLGSSRVPRCGQGTLLAQACQDLPSIRNCYLTHCSPARASLLASQALHRGELQRVPTLLLPMPTEPLLPTDWPFLPLIRLYHRASDTPSGLSPTDTMGTAMRVLQWVLVLESWRPQALWAVPPAARLARLMCVFLVDSELFRESPVQHLVAALLAQLCQPQVLPNLNLDCRLPGLTSFPDLYANFLDHFEAVSFGDHLFGALVLLPLQRRFSVTLRLALFGEHVGALRALSLPLTQLPVSLECYTVPPEDNLALLQLYFRTLVTGALRPRWCPVLYAVAVAHVNSFIFSQDPQSSDEVKAARRSMLQKTWLLADEGLRQHLLHYKLPNSTLPEGFELYSQLPPLRQHYLQRLTSTVLQNGVSET>sp|Q9BWH6-2|RPAP1_HUMAN Isoform 2 of RNA polymerase II-associatedprotein 1 OS=Homo sapiens OX=9606 GN=RPAP1MLSRPKPGESEVDLLHFQSQFLAAGAAPAVQLVKKGNRGGGDANSDRPPLQDHRDVVMLDNLPDLPPALVPSPPKRARPSPGHCLPEDEDPEERLRRHDQHITAVLTKIIERDTSSVAVNLPVPSGVAFPAVFLRSRDTQGKSATSGKRSIFAQEIAARRIAEAKGPSVGEVVPNVGPPEGAVTCETPTPRNQGCQLPGSSHSFQGPNLVTGKGLRDQEAEQEAQTIHEENIARLQAMAPEEILQEQQRLLAQLDPSLVAFLRSHSHTQEQTGETASEEQRPGGPSANVTKEEPLMSAFASEPRKRDKLEPEAPALALPVTPQKEWLHMDTVELEKLHWTQDLPPVRRQQTQERMQARFSLQGELLAPDVDLPTHLGLHHHGEEAERAGYSLQELFHLTRSQVSQQRALALHVLAQVISRAQAGEFGDRLAGSVLSLLLDAGFLFLLRFSLDDRVDGVIATAIRALRALLVAPGDEELLDSTFSWYHGALTFPLMPSQEDKEDEDEDEECPAGKAKRKSPEEESRPPPDLARHDVIKGLLATSLLPRLRYVLEVTYPGPAVVLDILAVLIRLARHSLESATRVLECPRLIETIVREFLPTSWSPVGAGPTPSLYKVPCATAMKLLRVLASAGRNIAARLLSSFDLRSRLCRIIAEAPQELALPPEEAEMLSTEALRLWAVAASYGQGGYLYRELYPVLMRALQVVPRELSTHPPQPLSMQRIASLLTLLTQLTLAAGSTPAETISDSAEASLSATPSLVTWTQVSGLQPLVEPCLRQTLKLLSRPEMWRAVGPVPVACLLFLGAYYQAWSQQPSSCPEDWLQDMQRLSEELLLPLLSQPTLGSLWDSLRHCSLLCNPLSCVPALEAPPSLVSLGCSGGCPRLSLAGSASPFPFLTALLSLLNTLAQIHKGLCGQLAAILAAPGLQNYFLQCVAPGAAPHLTPFSAWALRHEYHLQYLALALAQKAAALQPLPATHAALYHGMALALLSRLLPGSEYLTHELLLSCVFRLEFLPERTSGGPEAADFSDQLSLGSSRVPRCGQGTLLAQACQDLPSIRNCYLTHCSPARASLLASQALHRGELQRVPTLLLPMPTEPLLPTDWPFLPLIRLYHRASDTPSGLSPTDTMGTAMRVLQWVLVLESWRPQALWAVPPAARLARLMCVFLVDSELFRESPVQHLVAALLAQLCQPQVLPNLNLDCRLPGLTSFPDLYANFLDHFEAVSFGDHLFGALVLLPLQRRFSVTLRLALFGEHVGALRALSLPLTQVLSQPSRTCKGTLHWASGAVLSLEELWKTSASSSYLLGALRGLRESMKRA>sp|Q9BWH6-3|RPAP1_HUMAN Isoform 3 of RNA polymerase II-associatedprotein 1 OS=Homo sapiens OX=9606 GN=RPAP1MKLLRVLASAGRNIAARLLSSFDLRSRLCRIIAEAPQELALPPEEAEMLSTEALRLWAVAASYGQGGYLYRELYPVLMRALQVVPRELSTHPPQPLSMQRIASLLTLLTQLTLAAGSTPAETISDSAEASLSATPSLVTWTQVSGLQPLVEPCLRQTLKLLSRPEMWRAVGPVPVACLLFLGAYYQAWSQQPSSCPEDWLQDMQRLSEELLLPLLSQPTLGSLWDSLRHCSLLCNPLSCVPALEAPPSLVSLGCSGGCPRLSLAGSASPFPFLTALLSLLNTLAQIHKGLCGQLAAILAAPGLQNYFLQCVAPGAAPHLTPFSAWALRHEYHLQYLALALAQKAAALQPLPATHAALYHGMALALLSRLLPGSEYLTHELLLSCVFRLEFLPERTSGGPEAADFSDQLSLGSSRVPRCGQGTLLAQACQDLPSIRNCYLTHCSPARASLLASQALHRGELQRVPTLLLPMPTEPLLPTDWPFLPLIRLYHRASDTPSGLSPTDTMGTAMRVLQWVLVLESWRPQALWAVPPAARLARLMCVFLVDSELFRESPVQHLVAALLAQLCQPQVLPNLNLDCRLPGLTSFPDLYANFLDHFEAVSFGDHLFGALVLLPLQRRFSVTLRLALFGEHVGALRALSLPLTQLPVSLECYTVPPEDNLALLQLYFRTLVTGALRPRWCPVLYAVAVAHVNSFIFSQDPQSSDEVKAARRSMLQKTWLLADEGLRQHLLHYKLPNSTLPEGFELYSQLPPLRQHYLQRLTSTVLQNGVSET>sp|Q9Y4G8|RPGF2_HUMAN Rap guanine nucleotide exchange factor 2 OS=Homosapiens OX=9606 GN=RAPGEF2 PE=1 SV=1MKPLAIPANHGVMGQQEKHSLPADFTKLHLTDSLHPQVTHVSSSHSGCSITSDSGSSSLSDIYQATESEAGDMDLSGLPETAVDSEDDDDEEDIERASDPLMSRDIVRDCLEKDPIDRTDDDIEQLLEFMHQLPAFANMTMSVRRELCAVMVFAVVERAGTIVLNDGEELDSWSVILNGSVEVTYPDGKAEILCMGNSFGVSPTMDKEYMKGVMRTKVDDCQFVCIAQQDYCRILNQVEKNMQKVEEEGEIVMVKEHRELDRTGTRKGHIVIKGTSERLTMHLVEEHSVVDPTFIEDFLLTYRTFLSSPMEVGKKLLEWFNDPSLRDKVTRVVLLWVNNHFNDFEGDPAMTRFLEEFENNLEREKMGGHLRLLNIACAAKAKRRLMTLTKPSREAPLPFILLGGSEKGFGIFVDSVDSGSKATEAGLKRGDQILEVNGQNFENIQLSKAMEILRNNTHLSITVKTNLFVFKELLTRLSEEKRNGAPHLPKIGDIKKASRYSIPDLAVDVEQVIGLEKVNKKSKANTVGGRNKLKKILDKTRISILPQKPYNDIGIGQSQDDSIVGLRQTKHIPTALPVSGTLSSSNPDLLQSHHRILDFSATPDLPDQVLRVFKADQQSRYIMISKDTTAKEVVIQAIREFAVTATPDQYSLCEVSVTPEGVIKQRRLPDQLSKLADRIQLSGRYYLKNNMETETLCSDEDAQELLRESQISLLQLSTVEVATQLSMRNFELFRNIEPTEYIDDLFKLRSKTSCANLKRFEEVINQETFWVASEILRETNQLKRMKIIKHFIKIALHCRECKNFNSMFAIISGLNLAPVARLRTTWEKLPNKYEKLFQDLQDLFDPSRNMAKYRNVLNSQNLQPPIIPLFPVIKKDLTFLHEGNDSKVDGLVNFEKLRMIAKEIRHVGRMASVNMDPALMFRTRKKKWRSLGSLSQGSTNATVLDVAQTGGHKKRVRRSSFLNAKKLYEDAQMARKVKQYLSNLELEMDEESLQTLSLQCEPATNTLPKNPGDKKPVKSETSPVAPRAGSQQKAQSLPQPQQQPPPAHKINQGLQVPAVSLYPSRKKVPVKDLPPFGINSPQALKKILSLSEEGSLERHKKQAEDTISNASSQLSSPPTSPQSSPRKGYTLAPSGTVDNFSDSGHSEISSRSSIVSNSSFDSVPVSLHDERRQRHSVSIVETNLGMGRMERRTMIEPDQYSLGSYAPMSEGRGLYATATVISSPSTEELSQDQGDRASLDAADSGRGSWTSCSSGSHDNIQTIQHQRSWETLPFGHTHFDYSGDPAGLWASSSHMDQIMFSDHSTKYNRQNQSRESLEQAQSRASWASSTGYWGEDSEGDTGTIKRRGGKDVSIEAESSSLTSVTTEETKPVPMPAHIAVASSTTKGLIARKEGRYREPPPTPPGYIGIPITDFPEGHSHPARKPPDYNVALQRSRMVARSSDTAGPSSVQQPHGHPTSSRPVNKPQWHKPNESDPRLAPYQSQGFSTEEDEDEQVSAV>sp|Q7Z2W9|RM21_HUMAN 39S ribosomal protein L21, mitochondrial OS=Homosapiens OX=9606 GN=MRPL21 PE=1 SV=2MAASSLTVTLGRLASACSHSILRPSGPGAASLWSASRRFNSQSTSYLPGYVPKTSLSSPPWPEVVLPDPVEETRHHAEVVKKVNEMIVTGQYGRLFAVVHFASRQWKVTSEDLILIGNELDLACGERIRLEKVLLVGADNFTLLGKPLLGKDLVRVEATVIEKTESWPRIIMRFRKRKNFKKKRIVTTPQTVLRINSIEIAPCLL>sp|Q7Z2W9-2|RM21_HUMAN Isoform 2 of 39S ribosomal protein L21,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL21MIVTGQYGRLFAVVHFASRQWKVTSEDLILIGNELDLACGERIRLEKVLLVGADNFTLLGKPLLGKDLVRVEATVIEKTESWPRIIMRFRKRKNFKKKRIVTTPQTVLRINSIEIAPCLL>sp|Q9H9J2|RM44_HUMAN 39S ribosomal protein L44, mitochondrial OS=Homosapiens OX=9606 GN=MRPL44 PE=1 SV=1MASGLVRLLQQGHRCLLAPVAPKLVPPVRGVKKGFRAAFRFQKELERQRLLRCPPPPVRRSEKPNWDYHAEIQAFGHRLQENFSLDLLKTAFVNSCYIKSEEAKRQQLGIEKEAVLLNLKSNQELSEQGTSFSQTCLTQFLEDEYPDMPTEGIKNLVDFLTGEEVVCHVARNLAVEQLTLSEEFPVPPAVLQQTFFAVIGALLQSSGPERTALFIRDFLITQMTGKELFEMWKIINPMGLLVEELKKRNVSAPESRLTRQSGGTTALPLYFVGLYCDKKLIAEGPGETVLVAEEEAARVALRKLYGFTENRRPWNYSKPKETLRAEKSITAS>sp|Q9BV68|RN126_HUMAN E3 ubiquitin-protein ligase RNF126 OS=Homo sapiensOX=9606 GN=RNF126 PE=1 SV=2MAEASPHPGRYFCHCCSVEIVPRLPDYICPRCESGFIEELPEETRSTENGSAPSTAPTDQSRPPLEHVDQHLFTLPQGYGQFAFGIFDDSFEIPTFPPGAQADDGRDPESRRERDHPSRHRYGARQPRARLTTRRATGRHEGVPTLEGIIQQLVNGIITPATIPSLGPWGVLHSNPMDYAWGANGLDAIITQLLNQFENTGPPPADKEKIQALPTVPVTEEHVGSGLECPVCKDDYALGERVRQLPCNHLFHDGCIVPWLEQHDSCPVCRKSLTGQNTATNPPGLTGVSFSSSSSSSSSSSPSNENATSNS>sp|Q9H920|RN121_HUMAN RING finger protein 121 OS=Homo sapiens OX=9606GN=RNF121 PE=1 SV=1MAAVVEVEVGGGAAGERELDEVDMSDLSPEEQWRVEHARMHAKHRGHEAMHAEMVLILIATLVVAQLLLVQWKQRHPRSYNMVTLFQMWVVPLYFTVKLHWWRFLVIWILFSAVTAFVTFRATRKPLVQTTPRLVYKWFLLIYKISYATGIVGYMAVMFTLFGLNLLFKIKPEDAMDFGISLLFYGLYYGVLERDFAEMCADYMASTIGFYSESGMPTKHLSDSVCAVCGQQIFVDVSEEGIIENTYRLSCNHVFHEFCIRGWCIVGKKQTCPYCKEKVDLKRMFSNPWERPHVMYGQLLDWLRYLVAWQPVIIGVVQGINYILGLE>sp|Q9H920-2|RN121_HUMAN Isoform 2 of RING finger protein 121 OS=Homosapiens OX=9606 GN=RNF121MVTLFQMWVVPLYFTVKLHWWRFLVIWILFSAVTAFVTFRATRKPLVQTTPRLVYKWFLLIYKISYATGIVGYMAVMFTLFGLNLLFKIKPEDAMDFGISLLFYGLYYGVLERDFAEMCADYMASTIGFYSESGMPTKHLSDSVCAVCGQQIFVDVSEEGIIENTYRLSCNHVFHEFCIRGWCIVGKKQTCPYCKEKVDLKRMFSNPWERPHVMYGQLLDWLRYLVAWQPVIIGVVQGINYILGLE>sp|Q9GZN7|ROGDI_HUMAN Protein rogdi homolog OS=Homo sapiens OX=9606GN=ROGDI PE=1 SV=1MATVMAATAAERAVLEEEFRWLLHDEVHAVLKQLQDILKEASLRFTLPGSGTEGPAKQENFILGSCGTDQVKGVLTLQGDALSQADVNLKMPRNNQLLHFAFREDKQWKLQQIQDARNHVSQAIYLLTSRDQSYQFKTGAEVLKLMDAVMLQLTRARNRLTTPATLTLPEIAASGLTRMFAPALPSDLLVNVYINLNKLCLTVYQLHALQPNSTKNFRPAGGAVLHSPGAMFEWGSQRLEVSHVHKVECVIPWLNDALVYFTVSLQLCQQLKDKISVFSSYWSYRPF>sp|Q9BZX4|ROP1B_HUMAN Ropporin-1B OS=Homo sapiens OX=9606 GN=ROPN1B PE=1SV=1MAQTDKPTCIPPELPKMLKEFAKAAIRAQPQDLIQWGADYFEALSRGETPPVRERSERVALCNWAELTPELLKILHSQVAGRLIIRAEELAQMWKVVNLPTDLFNSVMNVGRFTEEIEWLKFLALACSALGVTITKTLKIVCEVLSCDHNGGLPRIPFSTFQFLYTYIAEVDGEICASHVSRMLNYIEQEVIGPDGLITVNDFTQNPRVWLE>sp|Q9BZX4-2|ROP1B_HUMAN Isoform 2 of Ropporin-1B OS=Homo sapiens OX=9606GN=ROPN1BMWKVVNLPTDLFNSVMNVGRFTEEIEWLKFLALACSALGVTITKTLKIVCEVLSCDHNGGLPRIPFSTFQFLYTYIAEVDGEICASHVSRMLNYIEQEVIGPDGLITVNDFTQNPRVWLE>sp|Q8N8N0|RN152_HUMAN E3 ubiquitin-protein ligase RNF152 OS=Homo sapiensOX=9606 GN=RNF152 PE=1 SV=1METLSQDSLLECQICFNYYSPRRRPKLLDCKHTCCSVCLQQMRTSQKDVRCPWCRGVTKLPPGFSVSQLPDDPEVLAVIAIPHTSEHTPVFIKLPSNGCYMLPLPISKERALLPGDMGCRLLPGSQQKSVTVVTIPAEQQPLQGGAPQEAVEEEQDRRGVVKSSTWSGVCTVILVACVLVFLLGIVLHNMSCISKRFTVISCG>sp|Q6XPR3|RPTN_HUMAN Repetin OS=Homo sapiens OX=9606 GN=RPTN PE=1 SV=1MAQLLNSILSVIDVFHKYAKGNGDCALLCKEELKQLLLAEFGDILQRPNDPETVETILNLLDQDRDGHIDFHEYLLLVFQLVQACYHKLDNKSHGGRTSQQERGQEGAQDCKFPGNTGRQHRQRHEEERQNSHHSQPERQDGDSHHGQPERQDRDSHHGQSEKQDRDSHHSQPERQDRDSHHNQSERQDKDFSFDQSERQSQDSSSGKKVSHKSTSGQAKWQGHIFALNRCEKPIQDSHYGQSERHTQQSETLGQASHFNQTNQQKSGSYCGQSERLGQELGCGQTDRQGQSSHYGQTDRQDQSYHYGQTDRQGQSSHYSQTDRQGQSSHYSQPDRQGQSSHYGQMDRKGQCYHYDQTNRQGQGSHYSQPNRQGQSSHYGQPDTQDQSSHYGQTDRQDQSSHYGQTERQGQSSHYSQMDRQGQGSHYGQTDRQGQSSHYGQPDRQGQNSHYGQTDRQGQSSHYGQTDRQGQSSHYSQPDKQGQSSHYGKIDRQDQSYHYGQPDGQGQSSHYGQTDRQGQSFHYGQPDRQGQSSHYSQMDRQGQSSHYGQTDRQGQSSHYGQTDRQGQSYHYGQTDRQGQSSHYIQSQTGEIQGQNKYFQGTEGTRKASYVEQSGRSGRLSQQTPGQEGYQNQGQGFQSRDSQQNGHQVWEPEEDSQHHQHKLLAQIQQERPLCHKGRDWQSCSSEQGHRQAQTRQSHGEGLSHWAEEEQGHQTWDRHSHESQEGPCGTQDRRTHKDEQNHQRRDRQTHEHEQSHQRRDRQTHEDKQNRQRRDRQTHEDEQNHQR>sp|Q9Y2L1|RRP44_HUMAN Exosome complex exonuclease RRP44 OS=Homo sapiensOX=9606 GN=DIS3 PE=1 SV=2MLKSKTFLKKTRAGGVMKIVREHYLRDDIGCGAPGCAACGGAHEGPALEPQPQDPASSVCPQPHYLLPDTNVLLHQIDVLEDPAIRNVIVLQTVLQEVRNRSAPVYKRIRDVTNNQEKHFYTFTNEHHRETYVEQEQGENANDRNDRAIRVAAKWYNEHLKKMSADNQLQVIFITNDRRNKEKAIEEGIPAFTCEEYVKSLTANPELIDRLACLSEEGNEIESGKIIFSEHLPLSKLQQGIKSGTYLQGTFRASRENYLEATVWIHGDNEENKEIILQGLKHLNRAVHEDIVAVELLPKSQWVAPSSVVLHDEGQNEEDVEKEEETERMLKTAVSEKMLKPTGRVVGIIKRNWRPYCGMLSKSDIKESRRHLFTPADKRIPRIRIETRQASTLEGRRIIVAIDGWPRNSRYPNGHFVRNLGDVGEKETETEVLLLEHDVPHQPFSQAVLSFLPKMPWSITEKDMKNREDLRHLCICSVDPPGCTDIDDALHCRELENGNLEVGVHIADVSHFIRPGNALDQESARRGTTVYLCEKRIDMVPELLSSNLCSLKCDVDRLAFSCIWEMNHNAEILKTKFTKSVINSKASLTYAEAQLRIDSANMNDDITTSLRGLNKLAKILKKRRIEKGALTLSSPEVRFHMDSETHDPIDLQTKELRETNSMVEEFMLLANISVAKKIHEEFSEHALLRKHPAPPPSNYEILVKAARSRNLEIKTDTAKSLAESLDQAESPTFPYLNTLLRILATRCMMQAVYFCSGMDNDFHHYGLASPIYTHFTSPIRRYADVIVHRLLAVAIGADCTYPELTDKHKLADICKNLNFRHKMAQYAQRASVAFHTQLFFKSKGIVSEEAYILFVRKNAIVVLIPKYGLEGTVFFEEKDKPNPQLIYDDEIPSLKIEDTVFHVFDKVKVKIMLDSSNLQHQKIRMSLVEPQIPGISIPTDTSNMDLNGPKKKKMKLGK>sp|Q9Y2L1-2|RRP44_HUMAN Isoform 2 of Exosome complex exonuclease RRP44OS=Homo sapiens OX=9606 GN=DIS3MLKSKTFLKKTRAGGVMKIVREHYLRDDIGCGAPGCAACGGAHEGPALEPQPQDPASSVCPQPHYLLPDTNVLLHQIVSAWRPGTWASVASSLRLPGSLETYVEQEQGENANDRNDRAIRVAAKWYNEHLKKMSADNQLQVIFITNDRRNKEKAIEEGIPAFTCEEYVKSLTANPELIDRLACLSEEGNEIESGKIIFSEHLPLSKLQQGIKSGTYLQGTFRASRENYLEATVWIHGDNEENKEIILQGLKHLNRAVHEDIVAVELLPKSQWVAPSSVVLHDEGQNEEDVEKEEETERMLKTAVSEKMLKPTGRVVGIIKRNWRPYCGMLSKSDIKESRRHLFTPADKRIPRIRIETRQASTLEGRRIIVAIDGWPRNSRYPNGHFVRNLGDVGEKETETEVLLLEHDVPHQPFSQAVLSFLPKMPWSITEKDMKNREDLRHLCICSVDPPGCTDIDDALHCRELENGNLEVGVHIADVSHFIRPGNALDQESARRGTTVYLCEKRIDMVPELLSSNLCSLKCDVDRLAFSCIWEMNHNAEILKTKFTKSVINSKASLTYAEAQLRIDSANMNDDITTSLRGLNKLAKILKKRRIEKGALTLSSPEVRFHMDSETHDPIDLQTKELRETNSMVEEFMLLANISVAKKIHEEFSEHALLRKHPAPPPSNYEILVKAARSRNLEIKTDTAKSLAESLDQAESPTFPYLNTLLRILATRCMMQAVYFCSGMDNDFHHYGLASPIYTHFTSPIRRYADVIVHRLLAVAIGADCTYPELTDKHKLADICKNLNFRHKMAQYAQRASVAFHTQLFFKSKGIVSEEAYILFVRKNAIVVLIPKYGLEGTVFFEEKDKPNPQLIYDDEIPSLKIEDTVFHVFDKVKVKIMLDSSNLQHQKIRMSLVEPQIPGISIPTDTSNMDLNGPKKKKMKLGK>sp|Q14684|RRP1B_HUMAN Ribosomal RNA processing protein 1 homolog BOS=Homo sapiens OX=9606 GN=RRP1B PE=1 SV=3MAPAMQPAEIQFAQRLASSEKGIRDRAVKKLRQYISVKTQRETGGFSQEELLKIWKGLFYCMWVQDEPLLQEELANTIAQLVHAVNNSAAQHLFIQTFWQTMNREWKGIDRLRLDKYYMLIRLVLRQSFEVLKRNGWEESRIKVFLDVLMKEVLCPESQSPNGVRFHFIDIYLDELSKVGGKELLADQNLKFIDPFCKIAAKTKDHTLVQTIARGVFEAIVDQSPFVPEETMEEQKTKVGDGDLSAEEIPENEVSLRRAVSKKKTALGKNHSRKDGLSDERGRDDCGTFEDTGPLLQFDYKAVADRLLEMTSRKNTPHFNRKRLSKLIKKFQDLSEGSSISQLSFAEDISADEDDQILSQGKHKKKGNKLLEKTNLEKEKGSRVFCVEEEDSESSLQKRRRKKKKKHHLQPENPGPGGAAPSLEQNRGREPEASGLKALKARVAEPGAEATSSTGEESGSEHPPAVPMHNKRKRPRKKSPRAHREMLESAVLPPEDMSQSGPSGSHPQGPRGSPTGGAQLLKRKRKLGVVPVNGSGLSTPAWPPLQQEGPPTGPAEGANSHTTLPQRRRLQKKKAGPGSLELCGLPSQKTASLKKRKKMRVMSNLVEHNGVLESEAGQPQALGSSGTCSSLKKQKLRAESDFVKFDTPFLPKPLFFRRAKSSTATHPPGPAVQLNKTPSSSKKVTFGLNRNMTAEFKKTDKSILVSPTGPSRVAFDPEQKPLHGVLKTPTSSPASSPLVAKKPLTTTPRRRPRAMDFF>sp|Q14684-2|RRP1B_HUMAN Isoform 2 of Ribosomal RNA processing protein 1homolog B OS=Homo sapiens OX=9606 GN=RRP1BMAPAMQPAEIQFAQRLASSEKGIRDRAVKKLRQYISVKTQRETGGFSQEELLQEELANTIAQLVHAVNNSAAQHLFIQTFWQTMNREWKGIDRLRLDKYYMLIRLVLRQSFEVLKRNGWEESRIKVFLDVLMKEVLCPESQSPNGVRFHFIDIYLDELSKVGGKELLADQNLKFIDPFCKIAAKTKDHTLVQTIARGVFEAIVDQSPFVPEETMEEQKTKVGDGDLSAEEIPENEVSLRRAVSKKKTALGKNHSRKDGLSDERGRDDCGTFEDTGPLLQFDYKAVADRLLEMTSRKNTPHFNRKRLSKLIKKFQDLSEGSSISQLSFAEDISADEDDQILSQGKHKKKGNKLLEKTNLEKEKGSRVFCVEEEDSESSLQKRRRKKKKKHHLQPENPGPGGAAPSLEQNRGREPEASGLKALKARVAEPGAEATSSTGEESGSEHPPAVPMHNKRKRPRKKSPRAHREMLESAVLPPEDMSQSGPSGSHPQGPRGSPTGGAQLLKRKRKLGVVPVNGSGLSTPAWPPLQQEGPPTGPAEGANSHTTLPQRRRLQKKKAGPGSLELCGLPSQKTASLKKRKKMRVMSNLVEHNGVLESEAGQPQALGSSGTCSSLKKQKLRAESDFVKFDTPFLPKPLFFRRAKSSTATHPPGPAVQLNKTPSSSKKVTFGLNRNMTAEFKKTDKSILVSPTGPSRVAFDPEQKPLHGVLKTPTSSPASSPLVAKKPLTTTPRRRPRAMDFF>sp|Q9Y3A4|RRP7A_HUMAN Ribosomal RNA-processing protein 7 homolog AOS=Homo sapiens OX=9606 GN=RRP7A PE=1 SV=2MVARRRKCAARDPEDRIPSPLGYAAIPIKFSEKQQASHYLYVRAHGVRQGTKSTWPQKRTLFVLNVPPYCTEESLSRLLSTCGLVQSVELQEKPDLAESPKESRSKFFHPKPVPGFQVAYVVFQKPSGVSAALALKGPLLVSTESHPVKSGIHKWISDYADSVPDPEALRVEVDTFMEAYDQKIAEEEAKAKEEEGVPDEEGWVKVTRRGRRPVLPRTEAASLRVLERERRKRSRKELLNFYAWQHRESKMEHLAQLRKKFEEDKQRIELLRAQRKFRPY>sp|P0DUD1|SPD8_HUMAN Putative speedy protein E8 OS=Homo sapiens OX=9606GN=SPDYE8 PE=5 SV=1MGQILGKIMMSHQPQPQEERSPQRSTSGYPLQEVVDDEVSGPSAPGVDPSPPRRSLGWKRKRECLDESDDEPEKELAPEPEETWVAETLCGLKMKAKRRRVSLVLPEYYEAFNRLLEDPVIKRLLAWDKDLRVSDKYLLAMVIAYFSRAGLPSWQYQRIHFFLALYLANDMEEDDEAPKQNIFYFLYEETRSHIPLLSELWFQLCRYMNPRARKNCSQIALFRKYRFHFFCSMRCRAWVSLEELEEIQAYDPEHWVWARDRAHLS>sp|Q15477|SKIV2_HUMAN Helicase SKI2W OS=Homo sapiens OX=9606 GN=SKIV2LPE=1 SV=3MMETERLVLPPPDPLDLPLRAVELGCTGHWELLNLPGAPESSLPHGLPPCAPDLQQEAEQLFLSSPAWLPLHGVEHSARKWQRKTDPWSLLAVLGAPVPSDLQAQRHPTTGQILGYKEVLLENTNLSATTSLSLRRPPGPASQSLWGNPTQYPFWPGGMDEPTITDLNTREEAEEEIDFEKDLLTIPPGFKKGMDFAPKDCPTPAPGLLSLSCMLEPLDLGGGDEDENEAVGQPGGPRGDTVSASPCSAPLARASSLEDLVLKEASTAVSTPEAPEPPSQEQWAIPVDATSPVGDFYRLIPQPAFQWAFEPDVFQKQAILHLERHDSVFVAAHTSAGKTVVAEYAIALAQKHMTRTIYTSPIKALSNQKFRDFRNTFGDVGLLTGDVQLHPEASCLIMTTEILRSMLYSGSDVIRDLEWVIFDEVHYINDVERGVVWEEVLIMLPDHVSIILLSATVPNALEFADWIGRLKRRQIYVISTVTRPVPLEHYLFTGNSSKTQGELFLLLDSRGAFHTKGYYAAVEAKKERMSKHAQTFGAKQPTHQGGPAQDRGVYLSLLASLRTRAQLPVVVFTFSRGRCDEQASGLTSLDLTTSSEKSEIHLFLQRCLARLRGSDRQLPQVLHMSELLNRGLGVHHSGILPILKEIVEMLFSRGLVKVLFATETFAMGVNMPARTVVFDSMRKHDGSTFRDLLPGEYVQMAGRAGRRGLDPTGTVILLCKGRVPEMADLHRMMMGKPSQLQSQFRLTYTMILNLLRVDALRVEDMMKRSFSEFPSRKDSKAHEQALAELTKRLGALEEPDMTGQLVDLPEYYSWGEELTETQHMIQRRIMESVNGLKSLSAGRVVVVKNQEHHNALGVILQVSSNSTSRVFTTLVLCDKPLSQDPQDRGPATAEVPYPDDLVGFKLFLPEGPCDHTVVKLQPGDMAAITTKVLRVNGEKILEDFSKRQQPKFKKDPPLAAVTTAVQELLRLAQAHPAGPPTLDPVNDLQLKDMSVVEGGLRARKLEELIQGAQCVHSPRFPAQYLKLRERMQIQKEMERLRFLLSDQSLLLLPEYHQRVEVLRTLGYVDEAGTVKLAGRVACAMSSHELLLTELMFDNALSTLRPEEIAALLSGLVCQSPGDAGDQLPNTLKQGIERVRAVAKRIGEVQVACGLNQTVEEFVGELNFGLVEVVYEWARGMPFSELAGLSGTPEGLVVRCIQRLAEMCRSLRGAARLVGEPVLGAKMETAATLLRRDIVFAASLYTQ>sp|Q5FBB7|SGO1_HUMAN Shugoshin 1 OS=Homo sapiens OX=9606 GN=SGO1 PE=1SV=1MAKERCLKKSFQDSLEDIKKRMKEKRNKNLAEIGKRRSFIAAPCQIITNTSTLLKNYQDNNKMLVLALENEKSKVKEAQDIILQLRKECYYLTCQLYALKGKLTSQQTVEPAQNQEICSSGMDPNSDDSSRNLFVKDLPQIPLEETELPGQGESFQIEDQIPTIPQDTLGVDFDSGEAKSTDNVLPRTVSVRSSLKKHCNSICQFDSLDDFETSHLAGKSFEFERVGFLDPLVNMHIPENVQHNACQWSKDQVNLSPKLIQPGTFTKTKEDILESKSEQTKSKQRDTQERKREEKRKANRRKSKRMSKYKENKSENKKTVPQKKMHKSVSSNDAYNFNLEEGVHLTPFRQKVSNDSNREENNESEVSLCESSGSGDDSDDLYLPTCKYIQNPTSNSDRPVTRPLAKRALKYTDEKETEGSKPTKTPTTTPPETQQSPHLSLKDITNVSLYPVVKIRRLSLSPKKNKASPAVALPKRRCTASVNYKEPTLASKLRRGDPFTDLCFLNSPIFKQKKDLRRSKKRALEVSPAKEAIFILYYVREFVSRFPDCRKCKLETHICLR>sp|Q5FBB7-2|SGO1_HUMAN Isoform 2 of Shugoshin 1 OS=Homo sapiens OX=9606GN=SGO1MAKERCLKKSFQDSLEDIKKRMKEKRNKNLAEIGKRRSFIAAPCQIITNTSTLLKNYQDNNKMLVLALENEKSKVKEAQDIILQLRKECYYLTCQLYALKGKLTSQQTVEPAQNQEICSSGMDPNSDDSSRNLFVKDLPQIPLEETELPGQGESFQIEDQIPTIPQDTLGVDFDSATPPETQQSPHLSLKDITNVSLYPVVKIRRLSLSPKKNKASPAVALPKRRCTASVNYKEPTLASKLRRGDPFTDLCFLNSPIFKQKKDLRRSKKRALEVSPAKEAIFILYYVREFVSRFPDCRKCKLETHICLR>sp|Q5FBB7-3|SGO1_HUMAN Isoform 3 of Shugoshin 1 OS=Homo sapiens OX=9606GN=SGO1MAKERCLKKSFQDSLEDIKKRMKEKRNKNLAEIGKRRSFIAAPCQIITNTSTLLKNYQDNNKMLVLALENEKSKVKEAQDIILQLRKECYYLTCQLYALKGKLTSQQTVEPAQNQEICSSGMDPNSDDSSRNLFVKDLPQIPLEETELPGQGESFQIEATPPETQQSPHLSLKDITNVSLYPVVKIRRLSLSPKKNKASPAVALPKRRCTASVNYKEPTLASKLRRGDPFTDLCFLNSPIFKQKKDLRRSKKRALEVSPAKEAIFILYYVREFVSRFPDCRKCKLETHICLR>sp|Q5FBB7-4|SGO1_HUMAN Isoform 4 of Shugoshin 1 OS=Homo sapiens OX=9606GN=SGO1MAKERCLKKSFQDSLEDIKKRMKEKRNKNLAEIGKRRSFIAAPCQIITNTSTLLKNYQDNNKMLVLALENEKSKVKEAQDIILQLRKECYYLTCQLYALKGKLTSQQTVEPAQNQEICSSGMDPNSDDSSRNLFVKDLPQIPLEETELPGQGESFQIEDQIPTIPQDTLGVDFDSATPPETQQSPHLSLKDITNVSLYPVVKIRRLSLSPKKNKASPAVALPKRRCTASVNYKEPTLASKLRRGDPFTDLCFLNSPIFKQKKDLRRSKKSMKQIQ>sp|Q5FBB7-5|SGO1_HUMAN Isoform 5 of Shugoshin 1 OS=Homo sapiens OX=9606GN=SGO1MAKERCLKKSFQDSLEDIKKRMKEKRNKNLAEIGKRRSFIAAPCQIITNTSTLLKNYQDNNKMLVLALENEKSKVKEAQDIILQLRKECYYLTCQLYALKGKLTSQQTVEPAQNQEICSSGMDPNSDDSSRNLFVKDLPQIPLEETELPGQGESFQIEATPPETQQSPHLSLKDITNVSLYPVVKIRRLSLSPKKNKASPAVALPKRRCTASVNYKEPTLASKLRRGDPFTDLCFLNSPIFKQKKDLRRSKKSMKQIQ>sp|Q5FBB7-6|SGO1_HUMAN Isoform 6 of Shugoshin 1 OS=Homo sapiens OX=9606GN=SGO1MAKERCLKKSFQDSLEDIKKRMKEKRNKNLAEIGKRRSFIAAPCQIITNTSTLLKNYQDNNKMLVLALENEKSKVKEAQDIILQLRKECYYLTCQLYALKGKLTSQQTVEPAQNQEICSSGMDPNSDDSSRNLFVKDLPQIPLEETELPGQGESFQIEDQIPTIPQDTLGVDFDSGEAKSTDNVLPRTVSVRSSLKKHCNSICQFDSLDDFETSHLAGKSFEFERVGFLDPLVNMHIPENVQHNACQWSKDQVNLSPKLIQPGTFTKTKEDILESKSEQTKSKQRDTQERKREEKRKANRRKSKRMSKYKENKSENKKTVPQKKMHKSVSSNDAYNFNLEEGVHLTPFRQKVSNDSNREENNESEVSLCESSGSGDDSDDLYLPTCKYIQNPTSNSDRPVTRPLAKRALKYTDEKETEGSKPTKTPTTTPPETQQSPHLSLKDITNVSLYPVVKIRRLSLSPKKNKASPAVALPKRRCTASVNYKEPTLASKLRRGDPFTDLCFLNSPIFKQKKDLRRSKKSMKQIQ>sp|Q5FBB7-7|SGO1_HUMAN Isoform 7 of Shugoshin 1 OS=Homo sapiens OX=9606GN=SGO1MAKERCLKKSFQDSLEDIKKRMKEKRNKNLAEIGKRRSFIAAPCQIITNTSTLLKNYQDNNKMLVLALENEKSKVKEAQDIILQLRKECYYLTCQLYALKGKLTSQQTVEPAQNQEICSSGMDPNSDDSSRNLFVKDLPQIPLEETELPGQGESFQIEDQIPTIPQDTLGVDFDSGALEVSPAKEAIFILYYVREFVSRFPDCRKCKLETHICLR>sp|Q9UPU3|SORC3_HUMAN VPS10 domain-containing receptor SorCS3 OS=Homosapiens OX=9606 GN=SORCS3 PE=1 SV=2MEAARTERPAGRPGAPLVRTGLLLLSTWVLAGAEITWDATGGPGRPAAPASRPPALSPLSPRAVASQWPEELASARRAAVLGRRAGPELLPQQGGGRGGEMQVEAGGTSPAGERRGRGIPAPAKLGGARRSRRAQPPITQERGDAWATAPADGSRGSRPLAKGSREEVKAPRAGGSAAEDLRLPSTSFALTGDSAHNQAMVHWSGHNSSVILILTKLYDFNLGSVTESSLWRSTDYGTTYEKLNDKVGLKTVLSYLYVNPTNKRKIMLLSDPEMESSILISSDEGATYQKYRLTFYIQSLLFHPKQEDWVLAYSLDQKLYSSMDFGRRWQLMHERITPNRFYWSVAGLDKEADLVHMEVRTTDGYAHYLTCRIQECAETTRSGPFARSIDISSLVVQDEYIFIQVTTSGRASYYVSYRREAFAQIKLPKYSLPKDMHIISTDENQVFAAVQEWNQNDTYNLYISDTRGIYFTLAMENIKSSRGLMGNIIIELYEVAGIKGIFLANKKVDDQVKTYITYNKGRDWRLLQAPDVDLRGSPVHCLLPFCSLHLHLQLSENPYSSGRISSKETAPGLVVATGNIGPELSYTDIGVFISSDGGNTWRQIFDEEYNVWFLDWGGALVAMKHTPLPVRHLWVSFDEGHSWDKYGFTSVPLFVDGALVEAGMETHIMTVFGHFSLRSEWQLVKVDYKSIFSRHCTKEDYQTWHLLNQGEPCVMGERKIFKKRKPGAQCALGRDHSGSVVSEPCVCANWDFECDYGYERHGESQCVPAFWYNPASPSKDCSLGQSYLNSTGYRRIVSNNCTDGLREKYTAKAQMCPGKAPRGLHVVTTDGRLVAEQGHNATFIILMEEGDLQRTNIQLDFGDGIAVSYANFSPIEDGIKHVYKSAGIFQVTAYAENNLGSDTAVLFLHVVCPVEHVHLRVPFVAIRNKEVNISAVVWPSQLGTLTYFWWFGNSTKPLITLDSSISFTFLAEGTDTITVQVAAGNALIQDTKEIAVHEYFQSQLLSFSPNLDYHNPDIPEWRKDIGNVIKRALVKVTSVPEDQILIAVFPGLPTSAELFILPPKNLTERRKGNEGDLEQIVETLFNALNQNLVQFELKPGVQVIVYVTQLTLAPLVDSSAGHSSSAMLMLLSVVFVGLAVFLIYKFKRKIPWINIYAQVQHDKEQEMIGSVSQSENAPKITLSDFTEPEELLDKELDTRVIGGIATIANSESTKEIPNCTSV>sp|P12755|SKI_HUMAN Ski oncogene OS=Homo sapiens OX=9606 GN=SKI PE=1SV=1MEAAAGGRGCFQPHPGLQKTLEQFHLSSMSSLGGPAAFSARWAQEAYKKESAKEAGAAAVPAPVPAATEPPPVLHLPAIQPPPPVLPGPFFMPSDRSTERCETVLEGETISCFVVGGEKRLCLPQILNSVLRDFSLQQINAVCDELHIYCSRCTADQLEILKVMGILPFSAPSCGLITKTDAERLCNALLYGGAYPPPCKKELAASLALGLELSERSVRVYHECFGKCKGLLVPELYSSPSAACIQCLDCRLMYPPHKFVVHSHKALENRTCHWGFDSANWRAYILLSQDYTGKEEQARLGRCLDDVKEKFDYGNKYKRRVPRVSSEPPASIRPKTDDTSSQSPAPSEKDKPSSWLRTLAGSSNKSLGCVHPRQRLSAFRPWSPAVSASEKELSPHLPALIRDSFYSYKSFETAVAPNVALAPPAQQKVVSSPPCAAAVSRAPEPLATCTQPRKRKLTVDTPGAPETLAPVAAPEEDKDSEAEVEVESREEFTSSLSSLSSPSFTSSSSAKDLGSPGARALPSAVPDAAAPADAPSGLEAELEHLRQALEGGLDTKEAKEKFLHEVVKMRVKQEEKLSAALQAKRSLHQELEFLRVAKKEKLREATEAKRNLRKEIERLRAENEKKMKEANESRLRLKRELEQARQARVCDKGCEAGRLRAKYSAQIEDLQVKLQHAEADREQLRADLLREREAREHLEKVVKELQEQLWPRARPEAAGSEGAAELEP>sp|Q9H7N4|SFR19_HUMAN Splicing factor, arginine/serine-rich 19 OS=Homosapiens OX=9606 GN=SCAF1 PE=1 SV=3MEEEDESRGKTEESGEDRGDGPPDRDPTLSPSAFILRAIQQAVGSSLQGDLPNDKDGSRCHGLRWRRCRSPRSEPRSQESGGTDTATVLDMATDSFLAGLVSVLDPPDTWVPSRLDLRPGESEDMLELVAEVRIGDRDPIPLPVPSLLPRLRAWRTGKTVSPQSNSSRPTCARHLTLGTGDGGPAPPPAPSSASSSPSPSPSSSSPSPPPPPPPPAPPAPPAPRFDIYDPFHPTDEAYSPPPAPEQKYDPFEPTGSNPSSSAGTPSPEEEEEEEEEEEEEEEDEEEEEGLSQSISRISETLAGIYDDNSLSQDFPGDESPRPDAQPTQPTPAPGTPPQVDSTRADGAMRRRVFVVGTEAEACREGKVSVEVVTAGGAALPPPLLPPGDSEIEEGEIVQPEEEPRLALSLFRPGGRAARPTPAASATPTAQPLPQPPAPRAPEGDDFLSLHAESDGEGALQVDLGEPAPAPPAADSRWGGLDLRRKILTQRRERYRQRSPSPAPAPAPAAAAGPPTRKKSRRERKRSGEAKEAASSSSGTQPAPPAPASPWDSKKHRSRDRKPGSHASSSARRRSRSRSRSRSTRRRSRSTDRRRGGSRRSRSREKRRRRRRSASPPPATSSSSSSRRERHRGKHRDGGGSKKKKKRSRSRGEKRSGDGSEKAPAPAPPPSGSTSCGDRDSRRRGAVPPSIQDLTDHDLFAIKRTITVGRLDKSDPRGPSPAPASSPKREVLYDSEGLSGEERGGKSSQKDRRRSGAASSSSSSREKGSRRKALDGGDRDRDRDRDRDRDRSSKKARPPKESAPSSGPPPKPPVSSGSGSSSSSSSCSSRKVKLQSKVAVLIREGVSSTTPAKDAASAGLGSIGVKFSRDRESRSPFLKPDERAPTEMAKAAPGSTKPKKTKVKAKAGAKKTKGTKGKTKPSKTRKKVRSGGGSGGSGGQVSLKKSKADSCSQAAGTKGAEETSWSGEERAAKVPSTPPPKAAPPPPALTPDSQTVDSSCKTPEVSFLPEEATEEAGVRGGAEEEEEEEEEEEEEEEEEEQQPATTTATSTAAAAPSTAPSAGSTAGDSGAEDGPASRVSQLPTLPPPMPWNLPAGVDCTTSGVLALTALLFKMEEANLASRAKAQELIQATNQILSHRKPPSSLGMTPAPVPTSLGLPPGPSSYLLPGSLPLGGCGSTPPTPTGLAATSDKREGSSSSEGRGDTDKYLKKLHTQERAVEEVKLAIKPYYQKKDITKEEYKDILRKAVHKICHSKSGEINPVKVSNLVRAYVQRYRYFRKHGRKPGDPPGPPRPPKEPGPPDKGGPGLPLPPL>sp|Q6P435|SMG1L_HUMAN Putative uncharacterized SMG1-like protein OS=Homosapiens OX=9606 PE=5 SV=1MSRRAPGSRLSSGGTNYSRSWNDWQPRTDSASADPGNLKYSSSRDRGGSSSYGLQPSNSAVVSRQRHDDTRVHADIQNDEKGGYSVNGGSGENTYGRKSLGQELRVNNVTSPEFTSVQHGSRALATKDMRKSQERSMSYCDESRLSNLLRRITREDDRD>sp|Q15796|SMAD2_HUMAN Mothers against decapentaplegic homolog 2 OS=Homosapiens OX=9606 GN=SMAD2 PE=1 SV=1MSSILPFTPPVVKRLLGWKKSAGGSGGAGGGEQNGQEEKWCEKAVKSLVKKLKKTGRLDELEKAITTQNCNTKCVTIPSTCSEIWGLSTPNTIDQWDTTGLYSFSEQTRSLDGRLQVSHRKGLPHVIYCRLWRWPDLHSHHELKAIENCEYAFNLKKDEVCVNPYHYQRVETPVLPPVLVPRHTEILTELPPLDDYTHSIPENTNFPAGIEPQSNYIPETPPPGYISEDGETSDQQLNQSMDTGSPAELSPTTLSPVNHSLDLQPVTYSEPAFWCSIAYYELNQRVGETFHASQPSLTVDGFTDPSNSERFCLGLLSNVNRNATVEMTRRHIGRGVRLYYIGGEVFAECLSDSAIFVQSPNCNQRYGWHPATVCKIPPGCNLKIFNNQEFAALLAQSVNQGFEAVYQLTRMCTIRMSFVKGWGAEYRRQTVTSTPCWIELHLNGPLQWLDKVLTQMGSPSVRCSSMS>sp|Q15796-2|SMAD2_HUMAN Isoform Short of Mothers against decapentaplegichomolog 2 OS=Homo sapiens OX=9606 GN=SMAD2MSSILPFTPPVVKRLLGWKKSAGGSGGAGGGEQNGQEEKWCEKAVKSLVKKLKKTGRLDELEKAITTQNCNTKCVTIPRSLDGRLQVSHRKGLPHVIYCRLWRWPDLHSHHELKAIENCEYAFNLKKDEVCVNPYHYQRVETPVLPPVLVPRHTEILTELPPLDDYTHSIPENTNFPAGIEPQSNYIPETPPPGYISEDGETSDQQLNQSMDTGSPAELSPTTLSPVNHSLDLQPVTYSEPAFWCSIAYYELNQRVGETFHASQPSLTVDGFTDPSNSERFCLGLLSNVNRNATVEMTRRHIGRGVRLYYIGGEVFAECLSDSAIFVQSPNCNQRYGWHPATVCKIPPGCNLKIFNNQEFAALLAQSVNQGFEAVYQLTRMCTIRMSFVKGWGAEYRRQTVTSTPCWIELHLNGPLQWLDKVLTQMGSPSVRCSSMS>sp|P30626|SORCN_HUMAN Sorcin OS=Homo sapiens OX=9606 GN=SRI PE=1 SV=1MAYPGHPGAGGGYYPGGYGGAPGGPAFPGQTQDPLYGYFAAVAGQDGQIDADELQRCLTQSGIAGGYKPFNLETCRLMVSMLDRDMSGTMGFNEFKELWAVLNGWRQHFISFDTDRSGTVDPQELQKALTTMGFRLSPQAVNSIAKRYSTNGKITFDDYIACCVKLRALTDSFRRRDTAQQGVVNFPYDDFIQCVMSV>sp|P30626-2|SORCN_HUMAN Isoform 2 of Sorcin OS=Homo sapiens OX=9606GN=SRIMQYGGAPGGPAFPGQTQDPLYGYFAAVAGQDGQIDADELQRCLTQSGIAGGYKPFNLETCRLMVSMLDRDMSGTMGFNEFKELWAVLNGWRQHFISFDTDRSGTVDPQELQKALTTMGFRLSPQAVNSIAKRYSTNGKITFDDYIACCVKLRALTDSFRRRDTAQQGVVNFPYDDFIQCVMSV>sp|P30626-3|SORCN_HUMAN Isoform 3 of Sorcin OS=Homo sapiens OX=9606GN=SRIMQYGGAPGGPAFPGQTQDPLYGYFAAVAGQDGQIDADELQRCLTQSGIAGGYKPFNLETCRLMVSMLDRDMSGTMGFNEFKELWAVLNGWRQHFISFDTDRSGTVDPQELQKALTTMGFRLSPQAVNSIAKRYSTNGKITFDDYIACCVKLRALTDSFRRRDTAQQGVVNFPYDDVSLRN>sp|Q86XK3|SFR1_HUMAN Swi5-dependent recombination DNA repair protein 1homolog OS=Homo sapiens OX=9606 GN=SFR1 PE=1 SV=2MAEGEKNQDFTFKMESPSDSAVVLPSTPQASANPSSPYTNSSRKQPMSATLRERLRKTRFSFNSSYNVVKRLKVESEENDQTFSEKPASSTEENCLEFQESFKHIDSEFEENTNLKNTLKNLNVCESQSLDSGSCSALQNEFVSEKLPKQRLNAEKAKLVKQVQEKEDLLRRLKLVKMYRSKNDLSQLQLLIKKWRSCSQLLLYELQSAVSEENKKLSLTQLIDHYGLDDKLLHYNRSEEEFIDV>sp|Q86XK3-2|SFR1_HUMAN Isoform 2 of Swi5-dependent recombination DNArepair protein 1 homolog OS=Homo sapiens OX=9606 GN=SFR1MKNLVVPMWEGKWKTAKRARMNYKVKLEEISGLLVDALYTNTIYYLIKVDYREVWLIRLFYNFSFLEKNQDFTFKMESPSDSAVVLPSTPQASANPSSPYTNSSRKQPMSATLRERLRKTRFSFNSSYNVVKRLKVESEENDQTFSEKPASSTEENCLEFQESFKHIDSEFEENTNLKNTLKNLNVCESQSLDSGSCSALQNEFVSEKLPKQRLNAEKAKLVKQVQEKEDLLRRLKLVKMYRSKNDLSQLQLLIKKWRSCSQLLLYELQSAVSEENKKLSLTQLIDHYGLDDKLLHYNRSEEEFIDV>sp|Q86XK3-3|SFR1_HUMAN Isoform 3 of Swi5-dependent recombination DNArepair protein 1 homolog OS=Homo sapiens OX=9606 GN=SFR1MESPSDSAVVLPSTPQASANPSSPYTNSSRKQPMSATLRERLRKTRFSFNSSYNVVKRLKVESEENDQTFSEKPASSTEENCLEFQESFKHIDSEFEENTNLKNTLKNLNVCESQSLDSGSCSALQNEFVSEKLPKQRLNAEKAKLVKQVQEKEDLLRRLKLVKMYRSKNDLSQLQLLIKKWRSCSQLLLYELQSAVSEENKKLSLTQLIDHYGLDDKLLHYNRSEEEFIDV>sp|Q562F6|SGO2_HUMAN Shugoshin 2 OS=Homo sapiens OX=9606 GN=SGO2 PE=1SV=2MECPVMETGSLFTSGIKRHLKDKRISKTTKLNVSLASKIKTKILNNSSIFKISLKHNNRALAQALSREKENSRRITTEKMLLQKEVEKLNFENTFLRLKLNNLNKKLIDIEALMNNNLITAIEMSSLSEFHQSSFLLSASKKKRISKQCKLMRLPFARVPLTSNDDEDEDKEKMQCDNNIKSKTLPDIPSSGSTTQPLSTQDNSEVLFLKENNQNVYGLDDSEHISSIVDVPPRESHSHSDQSSKTSLMSEMRNAQSIGRRWEKPSPSNVTERKKRGSSWESNNLSADTPCATVLDKQHISSPELNCNNEINGHTNETNTEMQRNKQDLPGLSSESAREPNAECMNQIEDNDDFQLQKTVYDADMDLTASEVSKIVTVSTGIKKKSNKKTNEHGMKTFRKVKDSSSEKKRERSKRQFKNSSDVDIGEKIENRTERSDVLDGKRGAEDPGFIFNNEQLAQMNEQLAQVNELKKMTLQTGFEQGDRENVLCNKKEKRITNEQEETYSLSQSSGKFHQESKFDKGQNSLTCNKSKASRQTFVIHKLEKDNLLPNQKDKVTIYENLDVTNEFHTANLSTKDNGNLCDYGTHNILDLKKYVTDIQPSEQNESNINKLRKKVNRKTEIISGMNHMYEDNDKDVVHGLKKGNFFFKTQEDKEPISENIEVSKELQIPALSTRDNENQCDYRTQNVLGLQKQITNMYPVQQNESKVNKKLRQKVNRKTEIISEVNHLDNDKSIEYTVKSHSLFLTQKDKEIIPGNLEDPSEFETPALSTKDSGNLYDSEIQNVLGVKHGHDMQPACQNDSKIGKKPRLNVCQKSEIIPETNQIYENDNKGVHDLEKDNFFSLTPKDKETISENLQVTNEFQTVDLLIKDNGNLCDYDTQNILELKKYVTDRKSAEQNESKINKLRNKVNWKTEIISEMNQIYEDNDKDAHVQESYTKDLDFKVNKSKQKLECQDIINKHYMEVNSNEKESCDQILDSYKVVKKRKKESSCKAKNILTKAKNKLASQLTESSQTSISLESDLKHITSEADSDPGNPVELCKTQKQSTTTLNKKDLPFVEEIKEGECQVKKVNKMTSKSKKRKTSIDPSPESHEVMERILDSVQGKSTVSEQADKENNLENEKMVKNKPDFYTKAFRSLSEIHSPNIQDSSFDSVREGLVPLSVSSGKNVIIKENFALECSPAFQVSDDEHEKMNKMKFKVNRRTQKSGIGDRPLQDLSNTSFVSNNTAESENKSEDLSSERTSRRRRCTPFYFKEPSLRDKMRR>sp|Q562F6-2|SGO2_HUMAN Isoform 2 of Shugoshin 2 OS=Homo sapiens OX=9606GN=SGO2MECPVMETGSLFTSGIKRHLKDKRISKTTKLNVSLASKIKTKILNNSSIFKISLKHNNRALAQALSREKENSRRITTEKMLLQKEVEKLNFENTFLRLKLNNLNKKLIDIEALMNNNLITAIEMSSLSEFHQSSFLLSASKKKRISKQCKLMRLPFARVPLTSNDDEDEDKEKMQCDNNIKSKTLPDIPSSGSTTQPLSTQDNSEVLFLKENNQNVYGLDDSEHISSIVDVPPRESHSHSDQSSKTSLMSEMRNAQSIGRRWEKPSPSNVTERKKRGSSWESNNLSADTPCATVLDKQHISSPELNCNNEINGHTNETNTEMQRNKQDLPGLSSESAREPNAECMNQIEDNDDFQLQKTVYDADMDLTASEVSKIVTVSTGIKKKSNKKTNEHGMKTFRKVKDSSSEKKRERSKRQFKNSSDVDIGEKIENRTERSDVLDGKRGAEDPGFIFNNEQLAQMNEQLAQVNELKKMTLQTGFEQGDRENVLCNKKEKRITNEQEETYSLSQSSGKFHQESKFDKGQNSLTCNKSKASRQTFVIHKLEKDNLLPNQKDKVTIYENLDVTNEFHTANLSTKDNGNLCDYGTHNILDLKKYVTDIQPSEQNESNINKLRKKVNRKTEIISGMNHMYEDNDKDVVHGLKKGNFFFKTQEDKEPISENIEVSKELQIPALSTRDNENQCDYRTQNVLGLQKQITNMYPVQQNESKVNKKLRQKVNRKTEIISEVNHLDNDKSIEYTVKSHSLFLTQKDKEIIPGNLEDPSEFETPALSTKDSGNLYDSEIQNVLGVKHGHDMQPACQNDSKIGKKPRLNVCQKSEIIPETNQIYENDNKGVHDLEKDNFFSLTPKDKETISENLQVTNEFQTVDLLIKDNGNLCDYDTQNILELKKYVTDRKSAEQNESKINKLRNKVNWKTEIISEMNQIYEDNDKDAHVQESYTKDLDFKVNKSKQKLECQDIINKHYMEVNSNEKESCDQILDSYKVVKKRKKESSCKAKNILTKAKNKLASQLTESSQTSISLESDLKHITSEADSDPGNPVELCKTQKQSTTTLNKKDLPFVEEIKEGECQVKKVNKMTSKSKKRKTSIDPSPESHEVMERILDSVQGKSTVSEQADKENNLENEKMVKNKPDFYTKAFRSLSEIHSPNIQDSSFDSVREGLVPLSVSSGKNVIIKENFALECSPAFQVSDDEHEKMNKMKFKVNRRTQKSGIGDRPLQDLSNTSFVSNNTAESENKSEDLSSERTSRRRRCTPFYFKEPSLRE>sp|Q562F6-3|SGO2_HUMAN Isoform 3 of Shugoshin 2 OS=Homo sapiens OX=9606GN=SGO2MECPVMETGSLFTSGIKRHLKDKRISKTTKLNVSLASKIKTKILNNSSIFKISLKHNNRALAQALSREKENSRRITTEKMLLQKEVEKLNFENTFLRLKLNNLNKKLIDIEALMNNNLITAIEMSSLSEFHQSSFLLSASKKKRISKQCKLMRLPFARVPLTSNDDEDEDKEKMQCDNNIKSKTLPDIPSSGSTTQPLSTQDNSEVLFLKENNQNVYGLDDSEHISSIVDVPPRGEIVLKIHFEYLY>sp|Q9UPR3|SMG5_HUMAN Protein SMG5 OS=Homo sapiens OX=9606 GN=SMG5 PE=1SV=3MSQGPPTGESSEPEAKVLHTKRLYRAVVEAVHRLDLILCNKTAYQEVFKPENISLRNKLRELCVKLMFLHPVDYGRKAEELLWRKVYYEVIQLIKTNKKHIHSRSTLECAYRTHLVAGIGFYQHLLLYIQSHYQLELQCCIDWTHVTDPLIGCKKPVSASGKEMDWAQMACHRCLVYLGDLSRYQNELAGVDTELLAERFYYQALSVAPQIGMPFNQLGTLAGSKYYNVEAMYCYLRCIQSEVSFEGAYGNLKRLYDKAAKMYHQLKKCETRKLSPGKKRCKDIKRLLVNFMYLQSLLQPKSSSVDSELTSLCQSVLEDFNLCLFYLPSSPNLSLASEDEEEYESGYAFLPDLLIFQMVIICLMCVHSLERAGSKQYSAAIAFTLALFSHLVNHVNIRLQAELEEGENPVPAFQSDGTDEPESKEPVEKEEEPDPEPPPVTPQVGEGRKSRKFSRLSCLRRRRHPPKVGDDSDLSEGFESDSSHDSARASEGSDSGSDKSLEGGGTAFDAETDSEMNSQESRSDLEDMEEEEGTRSPTLEPPRGRSEAPDSLNGPLGPSEASIASNLQAMSTQMFQTKRCFRLAPTFSNLLLQPTTNPHTSASHRPCVNGDVDKPSEPASEEGSESEGSESSGRSCRNERSIQEKLQVLMAEGLLPAVKVFLDWLRTNPDLIIVCAQSSQSLWNRLSVLLNLLPAAGELQESGLALCPEVQDLLEGCELPDLPSSLLLPEDMALRNLPPLRAAHRRFNFDTDRPLLSTLEESVVRICCIRSFGHFIARLQGSILQFNPEVGIFVSIAQSEQESLLQQAQAQFRMAQEEARRNRLMRDMAQLRLQLEVSQLEGSLQQPKAQSAMSPYLVPDTQALCHHLPVIRQLATSGRFIVIIPRTVIDGLDLLKKEHPGARDGIRYLEAEFKKGNRYIRCQKEVGKSFERHKLKRQDADAWTLYKILDSCKQLTLAQGAGEEDPSGMVTIITGLPLDNPSVLSGPMQAALQAAAHASVDIKNVLDFYKQWKEIG>sp|P84550|SKOR1_HUMAN SKI family transcriptional corepressor 1 OS=Homosapiens OX=9606 GN=SKOR1 PE=1 SV=1MALLCGLGQVTLRIWVSLPSQSENGIGFLAARAFLRSGGMEALTTQLGPGREGSSSPNSKQELQPYSGSSALKPNQVGETSLYGVPIVSLVIDGQERLCLAQISNTLLKNYSYNEIHNRRVALGITCVQCTPVQLEILRRAGAMPISSRRCGMITKREAERLCKSFLGEHKPPKLPENFAFDVVHECAWGSRGSFIPARYNSSRAKCIKCGYCSMYFSPNKFIFHSHRTPDAKYTQPDAANFNSWRRHLKLSDKSATDELSHAWEDVKAMFNGGTRKRTFSLQGGGGGGANGGSGGQGKGGAGGGGGGGPGCGAEMAPGPPPHKSLRCGEDEAAGPPGPPPPHPQRGLGLATGASGPAGPGGPGGGAGVRSYPVIPVPSKGFGLLQKLPPPLFPHPYGFPTAFGLCPKKDDPVLGAGEPKGGPGTGSGGGGAGTGGGAGGPGASHLPPGAGAGPGGGAMFWGHQPSGAAKDAAAVAAAAAAATVYPTFPMFWPAAGSLPVPSYPAAQSQAKAVAAAVAAAAAAAAAAAGSGAPEPLDGAEPAKESGLGAEERCPSALSRGPLDEDGTDEALPPPLAPLPPPPPPPARKGSYVSAFRPVVKDTESIAKLYGSAREAYGAGPARGPGPGAGSGGYVSPDFLSEGSSSYNSASPDVDTADEPEVDVESNRFPDDEDAQEETEPSAPSAGGGPDGEQPTGPPSATSSGADGPANSPDGGSPRPRRRLGPPPAGRPAFGDLAAEDLVRRPERSPPSGGGGYELREPCGPLGGPAPAKVFAPERDEHVKSAAVALGPAASYVCTPEAHEPDKEDNHSPADDLETRKSYPDQRSISQPSPANTDRGEDGLTLDVTGTHLVEKDIENLAREELQKLLLEQMELRKKLEREFQSLKDNFQDQMKRELAYREEMVQQLQIVRDTLCNELDQERKARYAIQQKLKEAHDALHHFSCKMLTPRHCTGNCSFKPPLLP>sp|P84550-2|SKOR1_HUMAN Isoform 2 of SKI family transcriptionalcorepressor 1 OS=Homo sapiens OX=9606 GN=SKOR1MIPKSLVQAAETQRGLCEPGGKGREGRSGGKGETRPRGVGTQEGKGTIPGSPREKRGERGEGDPALLPAEDLWRLPGSKDRLRSSLLPPPGPPSSDSGPGPPSSHSGKTAQGPRTLNWARKQSARTSSNLCAWSLAMATKMAEIPSSPYEPGQRGMKDTQRGDAPQRGSPEPRILQLARVGNVYLKEESSRSGRLEAKKWIPTKFLENLSVPHVDLGGNQLWSGGMEALTTQLGPGREGSSSPNSKQELQPYSGSSALKPNQVGETSLYGVPIVSLVIDGQERLCLAQISNTLLKNYSYNEIHNRRVALGITCVQCTPVQLEILRRAGAMPISSRRCGMITKREAERLCKSFLGEHKPPKLPENFAFDVVHECAWGSRGSFIPARYNSSRAKCIKCGYCSMYFSPNKFIFHSHRTPDAKYTQPDAANFNSWRRHLKLSDKSATDELSHAWEDRGLGLATGASGPAGPGGPGGGAGVRSYPVIPVPSKGFGLLQKLPPPLFPHPYGFPTAFGLCPKKDDPVLGAGEPKGGSYVSAFRPVVKDTESIAKLYGSAREAYGAGPARGPGPGAGSGGYVSPDFLSEGSSSYNSASPDVDTADEPEVDVESNRFPDDEDAQEETEPSAPSAGGGPDAGRPAFGDLAAEDLVRRPERSPPSGGGGYELREPCGPLGGPAPAKVFAPERDEHVKSAAVALGPAASYVCTPEAHEPDKEDNHSPADDLETRKSYPDQRSISQPSPANTDRGEDGLTLDVTGTHLVEKDIENLAREELQKLLLEQMELRKKLEREFQSLKDNFQDQMKRELAYREEMVQQLQIVRDTLCNELDQERKARYAIQQKLKEAHDALHHFSCKMLTPRHCTGNCSFKPPLLP>sp|P84550-3|SKOR1_HUMAN Isoform 3 of SKI family transcriptionalcorepressor 1 OS=Homo sapiens OX=9606 GN=SKOR1MALLCGLGQVTLRIWVSLPSQSENGIGSGGMEALTTQLGPGREGSSSPNSKQELQPYSGSSALKPNQVGETSLYGVPIVSLVIDGQERLCLAQISNTLLKNYSYNEIHNRRVALGITCVQCTPVQLEILRRAGAMPISSRRCGMITKREAERLCKSFLGEHKPPKLPENFAFDVVHECAWGSRGSFIPARYNSSRAKCIKCGYCSMYFSPNKFIFHSHRTPDAKYTQPDAANFNSWRRHLKLSDKSATDELSHAWEDVKAMFNGGTRCGAEMAPGPPPHKSLRCGEDEAAGPPGPPPPHPQRGLGLATGASGPAGPGGPGGGAGVRSYPVIPVPSKGFGLLQKLPPPLFPHPYGFPTAFGLCPKKDDPVLGAGEPKGGPGTGSGGGGAGTGGGAGGPGASHLPPGAGAGPGGGAMFWGHQPSGAAKDAAAVAAAAAAATVYPTFPMFWPAAGSLPVPSYPAAQSQAKAVAAAVAAAAAAAAAAAGSGAPEPLDGAEPAKESGLGAEERCPSALSRGPLDEDGTDEALPPPLAPLPPPPPPPARKGSYVSAFRPVVKDTESIAKLYGSAREAYGAGPARGPGPGAGSGGYVSPDFLSEGSSSYNSASPDVDTADEPEVDVESNRFPDDEDAQEETEPSAPSAGGGPDGEQPTGPPSATSSGADGPANSPDGGSPRPRRRLGPPPAGRPAFGDLAAEDLVRRPERSPPSGGGGYELREPCGPLGGPAPAKVFAPERDEHVKSAAVALGPAASYVCTPEAHEPDKEDNHSPADDLETRKSYPDQRSISQPSPANTDRGEDGLTLDVTGTHLVEKDIENLAREELQKLLLEQMELRKKLEREFQSLKDNFQDQMKRELAYREEMVQQLQIVRDTLCNELDQERKARYAIQQKLKEAHDALHHFSCKMLTPRHCTGNCSFKPPLLP>sp|O95470|SGPL1_HUMAN Sphingosine-1-phosphate lyase 1 OS=Homo sapiensOX=9606 GN=SGPL1 PE=1 SV=3MPSTDLLMLKAFEPYLEILEVYSTKAKNYVNGHCTKYEPWQLIAWSVVWTLLIVWGYEFVFQPESLWSRFKKKCFKLTRKMPIIGRKIQDKLNKTKDDISKNMSFLKVDKEYVKALPSQGLSSSAVLEKLKEYSSMDAFWQEGRASGTVYSGEEKLTELLVKAYGDFAWSNPLHPDIFPGLRKIEAEIVRIACSLFNGGPDSCGCVTSGGTESILMACKAYRDLAFEKGIKTPEIVAPQSAHAAFNKAASYFGMKIVRVPLTKMMEVDVRAMRRAISRNTAMLVCSTPQFPHGVIDPVPEVAKLAVKYKIPLHVDACLGGFLIVFMEKAGYPLEHPFDFRVKGVTSISADTHKYGYAPKGSSLVLYSDKKYRNYQFFVDTDWQGGIYASPTIAGSRPGGISAACWAALMHFGENGYVEATKQIIKTARFLKSELENIKGIFVFGNPQLSVIALGSRDFDIYRLSNLMTAKGWNLNQLQFPPSIHFCITLLHARKRVAIQFLKDIRESVTQIMKNPKAKTTGMGAIYGMAQTTVDRNMVAELSSVFLDSLYSTDTVTQGSQMNGSPKPH>sp|Q92673|SORL_HUMAN Sortilin-related receptor OS=Homo sapiens OX=9606GN=SORL1 PE=1 SV=2MATRSSRRESRLPFLFTLVALLPPGALCEVWTQRLHGGSAPLPQDRGFLVVQGDPRELRLWARGDARGASRADEKPLRRKRSAALQPEPIKVYGQVSLNDSHNQMVVHWAGEKSNVIVALARDSLALARPKSSDVYVSYDYGKSFKKISDKLNFGLGNRSEAVIAQFYHSPADNKRYIFADAYAQYLWITFDFCNTLQGFSIPFRAADLLLHSKASNLLLGFDRSHPNKQLWKSDDFGQTWIMIQEHVKSFSWGIDPYDKPNTIYIERHEPSGYSTVFRSTDFFQSRENQEVILEEVRDFQLRDKYMFATKVVHLLGSEQQSSVQLWVSFGRKPMRAAQFVTRHPINEYYIADASEDQVFVCVSHSNNRTNLYISEAEGLKFSLSLENVLYYSPGGAGSDTLVRYFANEPFADFHRVEGLQGVYIATLINGSMNEENMRSVITFDKGGTWEFLQAPAFTGYGEKINCELSQGCSLHLAQRLSQLLNLQLRRMPILSKESAPGLIIATGSVGKNLASKTNVYISSSAGARWREALPGPHYYTWGDHGGIITAIAQGMETNELKYSTNEGETWKTFIFSEKPVFVYGLLTEPGEKSTVFTIFGSNKENVHSWLILQVNATDALGVPCTENDYKLWSPSDERGNECLLGHKTVFKRRTPHATCFNGEDFDRPVVVSNCSCTREDYECDFGFKMSEDLSLEVCVPDPEFSGKSYSPPVPCPVGSTYRRTRGYRKISGDTCSGGDVEARLEGELVPCPLAEENEFILYAVRKSIYRYDLASGATEQLPLTGLRAAVALDFDYEHNCLYWSDLALDVIQRLCLNGSTGQEVIINSGLETVEALAFEPLSQLLYWVDAGFKKIEVANPDGDFRLTIVNSSVLDRPRALVLVPQEGVMFWTDWGDLKPGIYRSNMDGSAAYHLVSEDVKWPNGISVDDQWIYWTDAYLECIERITFSGQQRSVILDNLPHPYAIAVFKNEIYWDDWSQLSIFRASKYSGSQMEILANQLTGLMDMKIFYKGKNTGSNACVPRPCSLLCLPKANNSRSCRCPEDVSSSVLPSGDLMCDCPQGYQLKNNTCVKQENTCLRNQYRCSNGNCINSIWWCDFDNDCGDMSDERNCPTTICDLDTQFRCQESGTCIPLSYKCDLEDDCGDNSDESHCEMHQCRSDEYNCSSGMCIRSSWVCDGDNDCRDWSDEANCTAIYHTCEASNFQCRNGHCIPQRWACDGDTDCQDGSDEDPVNCEKKCNGFRCPNGTCIPSSKHCDGLRDCSDGSDEQHCEPLCTHFMDFVCKNRQQCLFHSMVCDGIIQCRDGSDEDAAFAGCSQDPEFHKVCDEFGFQCQNGVCISLIWKCDGMDDCGDYSDEANCENPTEAPNCSRYFQFRCENGHCIPNRWKCDRENDCGDWSDEKDCGDSHILPFSTPGPSTCLPNYYRCSSGTCVMDTWVCDGYRDCADGSDEEACPLLANVTAASTPTQLGRCDRFEFECHQPKTCIPNWKRCDGHQDCQDGRDEANCPTHSTLTCMSREFQCEDGEACIVLSERCDGFLDCSDESDEKACSDELTVYKVQNLQWTADFSGDVTLTWMRPKKMPSASCVYNVYYRVVGESIWKTLETHSNKTNTVLKVLKPDTTYQVKVQVQCLSKAHNTNDFVTLRTPEGLPDAPRNLQLSLPREAEGVIVGHWAPPIHTHGLIREYIVEYSRSGSKMWASQRAASNFTEIKNLLVNTLYTVRVAAVTSRGIGNWSDSKSITTIKGKVIPPPDIHIDSYGENYLSFTLTMESDIKVNGYVVNLFWAFDTHKQERRTLNFRGSILSHKVGNLTAHTSYEISAWAKTDLGDSPLAFEHVMTRGVRPPAPSLKAKAINQTAVECTWTGPRNVVYGIFYATSFLDLYRNPKSLTTSLHNKTVIVSKDEQYLFLVRVVVPYQGPSSDYVVVKMIPDSRLPPRHLHVVHTGKTSVVIKWESPYDSPDQDLLYAVAVKDLIRKTDRSYKVKSRNSTVEYTLNKLEPGGKYHIIVQLGNMSKDSSIKITTVSLSAPDALKIITENDHVLLFWKSLALKEKHFNESRGYEIHMFDSAMNITAYLGNTTDNFFKISNLKMGHNYTFTVQARCLFGNQICGEPAILLYDELGSGADASATQAARSTDVAAVVVPILFLILLSLGVGFAILYTKHRRLQSSFTAFANSHYSSRLGSAIFSSGDDLGEDDEDAPMITGFSDDVPMVIA>sp|Q92766|RREB1_HUMAN Ras-responsive element-binding protein 1 OS=Homosapiens OX=9606 GN=RREB1 PE=1 SV=3MTSSSPAGLEGSDLSSINTMMSAVMSVGKVTENGGSPQGIKSPSKPPGPNRIGRRNQETKEEKSSYNCPLCEKICTTQHQLTMHIRQHNTDTGGADHSCSICGKSLSSASSLDRHMLVHSGERPYKCTVCGQSFTTNGNMHRHMKIHEKDPNSATATAPPSPLKRRRLSSKRKLSHDAESEREDPAPAKKMVEDGQSGDLEKKADEVFHCPVCFKEFVCKYGLETHMETHSDNPLRCDICCVTFRTHRGLLRHNALVHKQLPRDAMGRPFIQNNPSIPAGFHDLGFTDFSCRKFPRISQAWCETNLRRCISEQHRFVCDTCDKAFPMLCSLALHKQTHVAADQGQEKPQATPLPGDALDQKGFLALLGLQHTKDVRPAPAEEPLPDDNQAIQLQTLKCQLPQDPGCTNLLSLSPFEAASLGGSLTVLPATKDSIKHLSLQPFQKGFIIQPDSSIVVKPISGESAIELADIQQILKMAASAPPQISLPPFSKAPAAPLQAIFKHMPPLKPKPLVTPRTVVATSTPPPLINAQQASPGCISPSLPPPPLKLLKGSVEAASNAHLLQSKSGTQPHAATRLSLQQPRAELPGQPEMKTQLEQDSIIEALLPLSMEAKIKQEITEGELKAFMTAPGGKKTPAMRKVLYPCRFCNQVFAFSGVLRAHVRSHLGISPYQCNICDYIAADKAALIRHLRTHSGERPYICKICHYPFTVKANCERHLRKKHLKATRKDIEKNIEYVSSSAAELVDAFCAPDTVCRLCGEDLKHYRALRIHMRTHCGRGLGGGHKGRKPFECKECSAAFAAKRNCIHHILKQHLHVPEQDIESYVLAADGLGPAEAPAAEASGRGEDSGCAALGDCKPLTAFLEPQNGFLHRGPTQPPPPHVSIKLEPASSFAVDFNEPLDFSQKGLALVQVKQENISFLSPSSLVPYDCSMEPIDLSIPKNFRKGDKDLATPSEAKKPEEEAGSSEQPSPCPAPGPSLPVTLGPSGILESPMAPAPAATPEPPAQPLQGPVQLAVPIYSSALVSSPPLVGSSALLSGTALLRPLRPKPPLLLPKPPVTEELPPLASIAQIISSVSSAPTLLKTKVADPGPASTGSNTTASDSLGGSVPKAATTATPAATTSPKESSEPPAPASSPEAASPTEQGPAGTSKKRGRKRGMRSRPRANSGGVDLDSSGEFASIEKMLATTDTNKFSPFLQTAEDNTQDEVAGAPADHHGPSDEEQGSPPEDKLLRAKRNSYTNCLQKITCPHCPRVFPWASSLQRHMLTHTDSQSDAETAAAAGEVLDLTSRDREQPSEGATELRQVAGDAPVEQATAETASPVHREEHGRGESHEPEEEHGTEESTGDADGAEEDASSNQSLDLDFATKLMDFKLAEGDGEAGAGGAASQEQKLACDTCGKSFKFLGTLSRHRKAHGRQEPKDEKGDGASTAEEGPQPAPEQEEKPPETPAEVVESAPGAGEAPAEKLAEETEGPSDGESAAEKRSSEKSDDDKKPKTDSPKSVASKADKRKKVCSVCNKRFWSLQDLTRHMRSHTGERPYKCQTCERTFTLKHSLVRHQRIHQKARHAKHHGKDSDKEERGEEDSENESTHSGNNAVSENEAELAPNASNHMAVTRSRKEGLASATKDCSHREEKVTAGWPSEPGQGDLNPESPAALGQDLLEPRSKRPAHPILATADGASQLVGME>sp|Q92766-2|RREB1_HUMAN Isoform 2 of Ras-responsive element-bindingprotein 1 OS=Homo sapiens OX=9606 GN=RREB1MTSSSPAGLEGSDLSSINTMMSAVMSVGKVTENGGSPQGIKSPSKPPGPNRIGRRNQETKEEKSSYNCPLCEKICTTQHQLTMHIRQHNTDTGGADHSCSICGKSLSSASSLDRHMLVHSGERPYKCTVCGQSFTTNGNMHRHMKIHEKDPNSATATAPPSPLKRRRLSSKRKLSHDAESEREDPAPAKKMVEDGQSGDLEKKADEVFHCPVCFKEFVCKYGLETHMETHSDNPLRCDICCVTFRTHRGLLRHNALVHKQLPRDAMGRPFIQNNPSIPAGFHDLGFTDFSCRKFPRISQAWCETNLRRCISEQHRFVCDTCDKAFPMLCSLALHKQTHVAADQGQEKPQATPLPGDALDQKGFLALLGLQHTKDVRPAPAEEPLPDDNQAIQLQTLKCQLPQDPGCTNLLSLSPFEAASLGGSLTVLPATKDSIKHLSLQPFQKGFIIQPDSSIVVKPISGESAIELADIQQILKMAASAPPQISLPPFSKAPAAPLQAIFKHMPPLKPKPLVTPRTVVATSTPPPLINAQQASPGCISPSLPPPPLKLLKGSVEAASNAHLLQSKSGTQPHAATRLSLQQPRAELPGQPEMKTQLEQDSIIEALLPLSMEAKIKQEITEGELKAFMTAPGGKKTPAMRKVLYPCRFCNQVFAFSGVLRAHVRSHLGISPYQCNICDYIAADKAALIRHLRTHSGERPYICKICHYPFTVKANCERHLRKKHLKATRKDIEKNIEYVSSSAAELVDAFCAPDTVCRLCGEDLKHYRALRIHMRTHCGRGLGGGHKGRKPFECKECSAAFAAKRNCIHHILKQHLHVPEQDIESYVLAADGLGPAEAPAAEASGRGEDSGCAALGDCKPLTAFLEPQNGFLHRGPTQPPPPHVSIKLEPASSFAVDFNEPLDFSQKGLALVQVKQENISFLSPSSLVPYDCSMEPIDLSIPKNFRKGDKDLATPSEAKKPEEEAGSSEQPSPCPAPGPSLPVTLGPSGILESPMAPAPAATPEPPAQPLQGPVQLAVPIYSSALVSSPPLVGSSALLSGTALLRPLRPKPPLLLPKPPVTEELPPLASIAQIISSVSSAPTLLKTKVADPGPASTGSNTTASDSLGGSVPKAATTATPAATTSPKESSEPPAPASSPEAASPTEQGPAGTSKKRGRKRGMRSRPRANSGGVDLDSSGEFASIEKMLATTDTNKFSPFLQTAEDNTQDEVAGAPADHHGPSDEEQGSPPEDKLLRAKRNSYTNCLQKITCPHCPRVFPWASSLQRHMLTHTGQKPFPCQKCDAFFSTKSNCERHQLRKHGVTTCSLRRNGLIPQSKESDVGSHDSTDSQSDAETAAAAGEVLDLTSRDREQPSEGATELRQVAGDAPVEQATAETASPVHREEHGRGESHEPEEEHGTEESTGDADGAEEDASSNQSLDLDFATKLMDFKLAEGDGEAGAGGAASQEQKLACDTCGKSFKFLGTLSRHRKAHGRQEPKDEKGDGASTAEEGPQPAPEQEEKPPETPAEVVESAPGAGEAPAEKLAEETEGPSDGESAAEKRSSEKSDDDKKPKTDSPKSVASKADKRKKVCSVCNKRFWSLQDLTRHMRSHTGERPYKCQTCERTFTLKHSLVRHQRIHQKARHAKHHGKDSDKEERGEEDSENESTHSGNNAVSENEAELAPNASNHMAVTRSRKEGLASATKDCSHREEKVTAGWPSEPGQGDLNPESPAALGQDLLEPRSKRPAHPILATADGASQLVGME>sp|Q92766-3|RREB1_HUMAN Isoform 3 of Ras-responsive element-bindingprotein 1 OS=Homo sapiens OX=9606 GN=RREB1MTSSSPAGLEGSDLSSINTMMSAVMSVGKVTENGGSPQGIKSPSKPPGPNRIGRRNQETKEEKSSYNCPLCEKICTTQHQLTMHIRQHNTDTGGADHSCSICGKSLSSASSLDRHMLVHSGERPYKCTVCGQSFTTNGNMHRHMKIHEKDPNSATATAPPSPLKRRRLSSKRKLSHDAESEREDPAPAKKMVEDGQSGDLEKKADEVFHCPVCFKEFVCKYGLETHMETHSDNPLRCDICCVTFRTHRGLLRHNALVHKQLPRDAMGRPFIQNNPSIPAGFHDLGFTDFSCRKFPRISQAWCETNLRRCISEQHRFVCDTCDKAFPMLCSLALHKQTHVAADQGQEKPQATPLPGDALDQKGFLALLGLQHTKDVRPAPAEEPLPDDNQAIQLQTLKCQLPQDPGCTNLLSLSPFEAASLGGSLTVLPATKDSIKHLSLQPFQKGFIIQPDSSIVVKPISGESAIELADIQQILKMAASAPPQISLPPFSKAPAAPLQAIFKHMPPLKPKPLVTPRTVVATSTPPPLINAQQASPGCISPSLPPPPLKLLKGSVEAASNAHLLQSKSGTQPHAATRLSLQQPRAELPGQPEMKTQLEQDSIIEALLPLSMEAKIKQEITEGELKAFMTAPGGKKTPAMRKVLYPCRFCNQVFAFSGVLRAHVRSHLGISPYQCNICDYIAADKAALIRHLRTHSGERPYICKICHYPFTVKANCERHLRKKHLKATRKDIEKNIEYVSSSAAELVDAFCAPDTVCRLCGEDLKHYRALRIHMRTHCGRGLGGGHKGRKPFECKECSAAFAAKRNCIHHILKQHLHVPEQDIESYVLAADGLGPAEAPAAEASGRGEDSGCAALGDCKPLTAFLEPQNGFLHRGPTQPPPPHVSIKLEPASSFAVDFNEPLDFSQKGLALVQVKQENISFLSPSSLVPYDCSMEPIDLSIPKNFRKGDKDLATPSEAKKPEEEAGSSEQPSPCPAPGPSLPVTLGPSGILESPMAPAPAATPEPPAQPLQGPVQLAVPIYSSALVSSPPLVGSSALLSGTALLRPLRPKPPLLLPKPPVTEELPPLASIAQIISSVSSAPTLLKTKVADPGPASTGSNTTASDSLGGSVPKAATTATPAATTSPKESSEPPAPASSPEAASPTEQGPAGTSKKRGRKRGMRSRPRANSGGVDLDSSGEFASIEKMLATTDTNKFSPFLQTAEDNTQDEVAGAPADHHGPSDEEQGSPPEDKLLRAKRNSYTNCLQKITCPHCPRVFPWASSLQRHMLTHTGQKPFPCQKCDAFFSTKSNCERHQLRKHGVTTCSLRRNGLIPQSKESDVGSHDSTGERPYKCQTCERTFTLKHSLVRHQRIHQKARHAKHHGKDSDKEERGEEDSENESTHSGNNAVSENEAELAPNASNHMAVTRSRKEGLASATKDCSHREEKVTAGWPSEPGQGDLNPESPAALGQDLLEPRSKRPAHPILATADGASQLVGME>sp|Q92766-4|RREB1_HUMAN Isoform 4 of Ras-responsive element-bindingprotein 1 OS=Homo sapiens OX=9606 GN=RREB1MLTHTGQKPFPCQKCDAFFSTKSNCERHQLRKHGVTTCSLRRNGLIPQSKESDVGSHDSTDSQSDAETAAAAGEVLDLTSRDREQPSEGATELRQVAGDAPVEQATAETASPVHREEHGRGESHEPEEEHGTEESTGDADGAEEDASSNQSLDLDFATKLMDFKLAEGDGEAGAGGAASQEQKLACDTCGKSFKFLGTLSRHRKAHGRQEPKDEKGDGASTAEEGPQPAPEQEEKPPETPAEVVESAPGAGEAPAEKLAEETEGPSDGESAAEKRSSEKSDDDKKPKTDSPKSVASKADKRKKVCSVCNKRFWSLQDLTRHMRSHTGERPYKCQTCERTFTLKHSLVRHQRIHQKARHAKHHGKDSDKEERGEEDSENESTHSGNNAVSENEAELAPNASNHMAVTRSRKEGLASATKDCSHREEKVTAGWPSEPGQGDLNPESPAALGQDLLEPRSKRPAHPILATADGASQLVGME>sp|Q92766-5|RREB1_HUMAN Isoform 5 of Ras-responsive element-bindingprotein 1 OS=Homo sapiens OX=9606 GN=RREB1MTSSSPAGLEGSDLSSINTMMSAVMSVGKVTENGGSPQGIKSPSKPPGPNRIGRRNQETKEEKSSYNCPLCEKICTTQHQLTMHIRQHNTDTGGADHSCSICGKSLSSASSLDRHMLVHSGERPYKCTVCGQSFTTNGNMHRHMKIHEKDPNSATATAPPSPLKRRRLSSKRKLSHDAESEREDPAPAKKMVEDGQSGDLEKKADEVFHCPVCFKEFVCKYGLETHMETHSDNPLRCDICCVTFRTHRGLLRHNALVHKQLPRDAMGRPFIQNNPSIPAGFHDLGFTDFSCRKFPRISQAWCETNLRRCISEQHRFVCDTCDKAFPMLCSLALHKQTHVAADQGQEKPQATPLPGDALDQKGFLALLGLQHTKDVRPAPAEEPLPDDNQAIQLQTLKCQLPQDPGCTNLLSLSPFEAASLGGSLTVLPATKDSIKHLSLQPFQKGFIIQPDSSIVVKPISGESAIELADIQQILKMAASAPPQISLPPFSKAPAAPLQAIFKHMPPLKPKPLVTPRTVVATSTPPPLINAQQASPGCISPSLPPPPLKLLKGSVEAASNAHLLQSKSGTQPHAATRLSLQQPRAELPGQPEMKTQLEQDSIIEALLPLSMEAKIKQEITEGELKAFMTAPGGKKTPAMRKVLYPCRFCNQVFAFSGVLRAHVRSHLGISPYQCNICDYIAADKAALIRHLRTHSGERPYICKICHYPFTVKANCERHLRKKHLKATRKDIEKNIEYVSSSAAELVDAFCAPDTVCRLCGEDLKHYRALRIHMRTHCGRGLGGGHKGRKPFECKECSAAFAAKRNCIHHILKQHLHVPEQDIESYVLAADGLGPAEAPAAEASGRGEDSGCAALGDCKPLTAFLEPQNGFLHRGPTQPPPPHVSIKLEPASSFAVDFNEPLDFSQKGLALVQVKQENISFLSPSSLVPYDCSMEPIDLSIPKNFRKGDKDLATPSEAKKPEEEAGSSEQPSPCPAPGPSLPVTLGPSGILESPMAPAPAATPEPPAQPLQGPVQLAVPIYSSALVSSPPLVGSSALLSGTALLRPLRPKPPLLLPKPPVTEELPPLASIAQIISSVSSAPTLLKTKVADPGPASTGSNTTASDSLGGSVPKAATTATPAATTSPKESSEPPAPASSPEAASPTEQGPAGTSKKRGRKRGMRSRPRANSGGVDLDSSGEFASIEKMLATTDTNKFSPFLQTAEDNTQDEVAGAPADHHGPSDEEQGSPPEDKLLRAKRNSYTNCLQKITCPHCPRVFPWASSLQRHMLTHTGERPYKCQTCERTFTLKHSLVRHQRIHQKARHAKHHGKDSDKEERGEEDSENESTHSGNNAVSENEAELAPNASNHMAVTRSRKEGLASATKDCSHREEKVTAGWPSEPGQGDLNPESPAALGQDLLEPRSKRPAHPILATADGASQLVGME>sp|Q92766-6|RREB1_HUMAN Isoform 6 of Ras-responsive element-bindingprotein 1 OS=Homo sapiens OX=9606 GN=RREB1MTSSSPAGLEGSDLSSINTMMSAVMSVGKVTENGGSPQGIKSPSKPPGPNRIGRRNQETKEEKSSYNCPLCEKICTTQHQLTMHIRQHNTDTGGADHSCSICGKSLSSASSLDRHMLVHSGERPYKCTVCGQSFTTNGNMHRHMKIHEKDPNSATATAPPSPLKRRRLSSKRKLSHDAESEREDPAPAKKMVEDGQSGDLEKKADEVFHCPVCFKEFVCKYGLETHMETHSDNPLRCDICCVTFRTHRGLLRHNALVHKQLPRDAMGRPFIQNNPSIPAGFHDLGFTDFSCRKFPRISQGKGHTNVRPASEPSP>sp|Q13796|SHRM2_HUMAN Protein Shroom2 OS=Homo sapiens OX=9606 GN=SHROOM2PE=1 SV=1MEGAEPRARPERLAEAETRAADGGRLVEVQLSGGAPWGFTLKGGREHGEPLVITKIEEGSKAAAVDKLLAGDEIVGINDIGLSGFRQEAICLVKGSHKTLKLVVKRRSELGWRPHSWHATKFSDSHPELAASPFTSTSGCPSWSGRHHASSSSHDLSSSWEQTNLQRTLDHFSSLGSVDSLDHPSSRLSVAKSNSSIDHLGSHSKRDSAYGSFSTSSSTPDHTLSKADTSSAENILYTVGLWEAPRQGGRQAQAAGDPQGSEEKLSCFPPRVPGDSGKGPRPEYNAEPKLAAPGRSNFGPVWYVPDKKKAPSSPPPPPPPLRSDSFAATKSHEKAQGPVFSEAAAAQHFTALAQAQPRGDRRPELTDRPWRSAHPGSLGKGSGGPGCPQEAHADGSWPPSKDGASSRLQASLSSSDVRFPQSPHSGRHPPLYSDHSPLCADSLGQEPGAASFQNDSPPQVRGLSSCDQKLGSGWQGPRPCVQGDLQAAQLWAGCWPSDTALGALESLPPPTVGQSPRHHLPQPEGPPDARETGRCYPLDKGAEGCSAGAQEPPRASRAEKASQRLAASITWADGESSRICPQETPLLHSLTQEGKRRPESSPEDSATRPPPFDAHVGKPTRRSDRFATTLRNEIQMHRAKLQKSRSTVALTAAGEAEDGTGRWRAGLGGGTQEGPLAGTYKDHLKEAQARVLRATSFKRRDLDPNPGDLYPESLEHRMGDPDTVPHFWEAGLAQPPSSTSGGPHPPRIGGRRRFTAEQKLKSYSEPEKMNEVGLTRGYSPHQHPRTSEDTVGTFADRWKFFEETSKPVPQRPAQKQALHGIPRDKPERPRTAGRTCEGTEPWSRTTSLGDSLNAHSAAEKAGTSDLPRRLGTFAEYQASWKEQRKPLEARSSGRCHSADDILDVSLDPQERPQHVHGRSRSSPSTDHYKQEASVELRRQAGDPGEPREELPSAVRAEEGQSTPRQADAQCREGSPGSQQHPPSQKAPNPPTFSELSHCRGAPELPREGRGRAGTLPRDYRYSEESTPADLGPRAQSPGSPLHARGQDSWPVSSALLSKRPAPQRPPPPKREPRRYRATDGAPADAPVGVLGRPFPTPSPASLDVYVARLSLSHSPSVFSSAQPQDTPKATVCERGSQHVSGDASRPLPEALLPPKQQHLRLQTATMETSRSPSPQFAPQKLTDKPPLLIQDEDSTRIERVMDNNTTVKMVPIKIVHSESQPEKESRQSLACPAEPPALPHGLEKDQIKTLSTSEQFYSRFCLYTRQGAEPEAPHRAQPAEPQPLGTQVPPEKDRCTSPPGLSYMKAKEKTVEDLKSEELAREIVGKDKSLADILDPSVKIKTTMDLMEGIFPKDEHLLEEAQQRRKLLPKIPSPRSTEERKEEPSVPAAVSLATNSTYYSTSAPKAELLIKMKDLQEQQEHEEDSGSDLDHDLSVKKQELIESISRKLQVLREARESLLEDVQANTVLGAEVEAIVKGVCKPSEFDKFRMFIGDLDKVVNLLLSLSGRLARVENALNNLDDGASPGDRQSLLEKQRVLIQQHEDAKELKENLDRRERIVFDILANYLSEESLADYEHFVKMKSALIIEQRELEDKIHLGEEQLKCLLDSLQPERGK>sp|Q8TF72|SHRM3_HUMAN Protein Shroom3 OS=Homo sapiens OX=9606 GN=SHROOM3PE=1 SV=2MMRTTEDFHKPSATLNSNTATKGRYIYLEAFLEGGAPWGFTLKGGLEHGEPLIISKVEEGGKADTLSSKLQAGDEVVHINEVTLSSSRKEAVSLVKGSYKTLRLVVRRDVCTDPGHADTGASNFVSPEHLTSGPQHRKAAWSGGVKLRLKHRRSEPAGRPHSWHTTKSGEKQPDASMMQISQGMIGPPWHQSYHSSSSTSDLSNYDHAYLRRSPDQCSSQGSMESLEPSGAYPPCHLSPAKSTGSIDQLSHFHNKRDSAYSSFSTSSSILEYPHPGISGRERSGSMDNTSARGGLLEGMRQADIRYVKTVYDTRRGVSAEYEVNSSALLLQGREARASANGQGYDKWSNIPRGKGVPPPSWSQQCPSSLETATDNLPPKVGAPLPPARSDSYAAFRHRERPSSWSSLDQKRLCRPQANSLGSLKSPFIEEQLHTVLEKSPENSPPVKPKHNYTQKAQPGQPLLPTSIYPVPSLEPHFAQVPQPSVSSNGMLYPALAKESGYIAPQGACNKMATIDENGNQNGSGRPGFAFCQPLEHDLLSPVEKKPEATAKYVPSKVHFCSVPENEEDASLKRHLTPPQGNSPHSNERKSTHSNKPSSHPHSLKCPQAQAWQAGEDKRSSRLSEPWEGDFQEDHNANLWRRLEREGLGQSLSGNFGKTKSAFSSLQNIPESLRRHSSLELGRGTQEGYPGGRPTCAVNTKAEDPGRKAAPDLGSHLDRQVSYPRPEGRTGASASFNSTDPSPEEPPAPSHPHTSSLGRRGPGPGSASALQGFQYGKPHCSVLEKVSKFEQREQGSQRPSVGGSGFGHNYRPHRTVSTSSTSGNDFEETKAHIRFSESAEPLGNGEQHFKNGELKLEEASRQPCGQQLSGGASDSGRGPQRPDARLLRSQSTFQLSSEPEREPEWRDRPGSPESPLLDAPFSRAYRNSIKDAQSRVLGATSFRRRDLELGAPVASRSWRPRPSSAHVGLRSPEASASASPHTPRERHSVTPAEGDLARPVPPAARRGARRRLTPEQKKRSYSEPEKMNEVGIVEEAEPAPLGPQRNGMRFPESSVADRRRLFERDGKACSTLSLSGPELKQFQQSALADYIQRKTGKRPTSAAGCSLQEPGPLRERAQSAYLQPGPAALEGSGLASASSLSSLREPSLQPRREATLLPATVAETQQAPRDRSSSFAGGRRLGERRRGDLLSGANGGTRGTQRGDETPREPSSWGARAGKSMSAEDLLERSDVLAGPVHVRSRSSPATADKRQDVLLGQDSGFGLVKDPCYLAGPGSRSLSCSERGQEEMLPLFHHLTPRWGGSGCKAIGDSSVPSECPGTLDHQRQASRTPCPRPPLAGTQGLVTDTRAAPLTPIGTPLPSAIPSGYCSQDGQTGRQPLPPYTPAMMHRSNGHTLTQPPGPRGCEGDGPEHGVEEGTRKRVSLPQWPPPSRAKWAHAAREDSLPEESSAPDFANLKHYQKQQSLPSLCSTSDPDTPLGAPSTPGRISLRISESVLRDSPPPHEDYEDEVFVRDPHPKATSSPTFEPLPPPPPPPPSQETPVYSMDDFPPPPPHTVCEAQLDSEDPEGPRPSFNKLSKVTIARERHMPGAAHVVGSQTLASRLQTSIKGSEAESTPPSFMSVHAQLAGSLGGQPAPIQTQSLSHDPVSGTQGLEKKVSPDPQKSSEDIRTEALAKEIVHQDKSLADILDPDSRLKTTMDLMEGLFPRDVNLLKENSVKRKAIQRTVSSSGCEGKRNEDKEAVSMLVNCPAYYSVSAPKAELLNKIKEMPAEVNEEEEQADVNEKKAELIGSLTHKLETLQEAKGSLLTDIKLNNALGEEVEALISELCKPNEFDKYRMFIGDLDKVVNLLLSLSGRLARVENVLSGLGEDASNEERSSLYEKRKILAGQHEDARELKENLDRRERVVLGILANYLSEEQLQDYQHFVKMKSTLLIEQRKLDDKIKLGQEQVKCLLESLPSDFIPKAGALALPPNLTSEPIPAGGCTFSGIFPTLTSPL>sp|Q8TF72-2|SHRM3_HUMAN Isoform 2 of Protein Shroom3 OS=Homo sapiensOX=9606 GN=SHROOM3MAFYSTPEYDIQLARGLLSGMFLFATRRSEPAGRPHSWHTTKSGEKQPDASMMQISQGMIGPPWHQSYHSSSSTSDLSNYDHAYLRRSPDQCSSQGSMESLEPSGAYPPCHLSPAKSTGSIDQLSHFHNKRDSAYSSFSTSSSILEYPHPGKRVKTRDLPGSQSPGRAISRKTTMPTSGGGWREKA>sp|P58511|SIM11_HUMAN Small integral membrane protein 11 OS=Homo sapiensOX=9606 GN=SMIM11 PE=1 SV=1MNWKVLEHVPLLLYILAAKTLILCLTFAGVKMYQRKRLEAKQQKLEAERKKQSEKKDN>sp|Q96EX1|SIM12_HUMAN Small integral membrane protein 12 OS=Homo sapiensOX=9606 GN=SMIM12 PE=1 SV=3MWPVFWTVVRTYAPYVTFPVAFVVGAVGYHLEWFIRGKDPQPVEEEKSISERREDRKLDELLGKDHTQVVSLKDKLEFAPKAVLNRNRPEKN>sp|Q53EL9|SEZ6_HUMAN Seizure protein 6 homolog OS=Homo sapiens OX=9606GN=SEZ6 PE=1 SV=2MRPVALLLLPSLLALLAHGLSLEAPTVGKGQAPGIEETDGELTAAPTPEQPERGVHFVTTAPTLKLLNHHPLLEEFLQEGLEKGDEELRPALPFQPDPPAPFTPSPLPRLANQDSRPVFTSPTPAMAAVPTQPQSKEGPWSPESESPMLRITAPLPPGPSMAVPTLGPGEIASTTPPSRAWTPTQEGPGDMGRPWVAEVVSQGAGIGIQGTITSSTASGDDEETTTTTTIITTTITTVQTPGPCSWNFSGPEGSLDSPTDLSSPTDVGLDCFFYISVYPGYGVEIKVQNISLREGETVTVEGLGGPDPLPLANQSFLLRGQVIRSPTHQAALRFQSLPPPAGPGTFHFHYQAYLLSCHFPRRPAYGDVTVTSLHPGGSARFHCATGYQLKGARHLTCLNATQPFWDSKEPVCIAACGGVIRNATTGRIVSPGFPGNYSNNLTCHWLLEAPEGQRLHLHFEKVSLAEDDDRLIIRNGDNVEAPPVYDSYEVEYLPIEGLLSSGKHFFVELSTDSSGAAAGMALRYEAFQQGHCYEPFVKYGNFSSSTPTYPVGTTVEFSCDPGYTLEQGSIIIECVDPHDPQWNETEPACRAVCSGEITDSAGVVLSPNWPEPYGRGQDCIWGVHVEEDKRIMLDIRVLRIGPGDVLTFYDGDDLTARVLGQYSGPRSHFKLFTSMADVTIQFQSDPGTSVLGYQQGFVIHFFEVPRNDTCPELPEIPNGWKSPSQPELVHGTVVTYQCYPGYQVVGSSVLMCQWDLTWSEDLPSCQRVTSCHDPGDVEHSRRLISSPKFPVGATVQYICDQGFVLMGSSILTCHDRQAGSPKWSDRAPKCLLEQLKPCHGLSAPENGARSPEKQLHPAGATIHFSCAPGYVLKGQASIKCVPGHPSHWSDPPPICRAASLDGFYNSRSLDVAKAPAASSTLDAAHIAAAIFLPLVAMVLLVGGVYFYFSRLQGKSSLQLPRPRPRPYNRITIESAFDNPTYETGSLSFAGDERI>sp|Q53EL9-2|SEZ6_HUMAN Isoform 2 of Seizure protein 6 homolog OS=Homosapiens OX=9606 GN=SEZ6MAAVPTQPQSKEGPWSPESESPMLRITAPLPPGPSMAVPTLGPGEIASTTPPSRAWTPTQEGPGDMGRPWVAEVVSQGAGIGIQGTITSSTASGDDEETTTTTTIITTTITTVQTPGPCSWNFSGPEGSLDSPTDLSSPTDVGLDCFFYISVYPGYGVEIKVQNISLREGETVTVEGLGGPDPLPLANQSFLLRGQVIRSPTHQAALRFQSLPPPAGPGTFHFHYQAYLLSCHFPRRPAYGDVTVTSLHPGGSARFHCATGYQLKGARHLTCLNATQPFWDSKEPVCIAACGGVIRNATTGRIVSPGFPGNYSNNLTCHWLLEAPEGQRLHLHFEKVSLAEDDDRLIIRNGDNVEAPPVYDSYEVEYLPIEGLLSSGKHFFVELSTDSSGAAAGMALRYEAFQQGHCYEPFVKYGNFSSSTPTYPVGTTVEFSCDPGYTLEQGSIIIECVDPHDPQWNETEPACRAVCSGEITDSAGVVLSPNWPEPYGRGQDCIWGVHVEEDKRIMLDIRVLRIGPGDVLTFYDGDDLTARVLGQYSGPRSHFKLFTSMADVTIQFQSDPGTSVLGYQQGFVIHFFEVPRNDTCPELPEIPNGWKSPSQPELVHGTVVTYQCYPGYQVVGSSVLMCQWDLTWSEDLPSCQRVTSCHDPGDVEHSRRLISSPKFPVGATVQYICDQGFVLMGSSILTCHDRQAGSPKWSDRAPKCLLEQLKPCHGLSAPENGARSPEKQLHPAGATIHFSCAPGYVLKGQASIKCVPGHPSHWSDPPPICRAASLDGFYNSRSLDVAKAPAASSTLDAAHIAAAIFLPLVAMVLLVGGVYFYFSRLQGKSSLQLPRPRPRPYNRITIESAFDNPTYETGSLSFAGDERI>sp|Q53EL9-3|SEZ6_HUMAN Isoform 3 of Seizure protein 6 homolog OS=Homosapiens OX=9606 GN=SEZ6MRPVALLLLPSLLALLAHGLSLEAPTVGKGQAPGIEETDGELTAAPTPEQPERGVHFVTTAPTLKLLNHHPLLEEFLQEGLEKGDEELRPALPFQPDPPAPFTPSPLPRLANQDSRPVFTSPTPAMAAVPTQPQSKEGPWSPESESPMLRITAPLPPGPSMAVPTLGPGEIASTTPPSRAWTPTQEGPGDMGRPWVAEVVSQGAGIGIQGTITSSTASGDDEETTTTTTIITTTITTVQTPGPCSWNFSGPEGSLDSPTDLSSPTDVGLDCFFYISVYPGYGVEIKVQNISLREGETVTVEGLGGPDPLPLANQSFLLRGQVIRSPTHQAALRFQSLPPPAGPGTFHFHYQAYLLSCHFPRRPAYGDVTVTSLHPGGSARFHCATGYQLKGARHLTCLNATQPFWDSKEPVCIAACGGVIRNATTGRIVSPGFPGNYSNNLTCHWLLEAPEGQRLHLHFEKVSLAEDDDRLIIRNGDNVEAPPVYDSYEVEYLPIEGLLSSGKHFFVELSTDSSGAAAGMALRYEAFQQGHCYEPFVKYGNFSSSTPTYPVGTTVEFSCDPGYTLEQGSIIIECVDPHDPQWNETEPACRAVCSGEITDSAGVVLSPNWPEPYGRGQDCIWGVHVEEDKRIMLDIRVLRIGPGDVLTFYDGDDLTARVLGQYSGPRSHFKLFTSMADVTIQFQSDPGTSVLGYQQGFVIHFFEVPRNDTCPELPEIPNGWKSPSQPELVHGTVVTYQCYPGYQVVGSSVLMCQWDLTWSEDLPSCQRVTSCHDPGDVEHSRRLISSPKFPVGATVQYICDQGFVLMGSSILTCHDRQAGSPKWSDRAPKCLLEQLKPCHGLSAPENGARSPEKQLHPAGATIHFSCAPGYVLKGQASIKCVPGHPSHWSDPPPICRAASLDGFYNSRSLDVAKAPAASSTLDAAHIAAAIFLPLVAMVLLVGGVYFYFSRLQGKSSLQLPRPRPRPYNRITIESAFDNPTYETGETREYEVSI>sp|Q53EL9-4|SEZ6_HUMAN Isoform 4 of Seizure protein 6 homolog OS=Homosapiens OX=9606 GN=SEZ6MRPVALLLLPSLLALLAHGLSLEAPTVGKGQAPGIEETDGELTAAPTPEQPERGVHFVTTAPTLKLLNHHPLLEEFLQEGLEKGDEELRPALPFQPDPPAPFTPSPLPRLANQDSRPVFTSPTPAMAAVPTQPQSKEGPWSPESESPMLRITAPLPPGPSMAVPTLGPGEIASTTPPSRAWTPTQEGPGDMGRPWVAEVVSQGAGIGIQGTITSSTASGDDEETTTTTTIITTTITTVQTPGPCSWNFSGPEGSLDSPTDLSSPTDVGLDCFFYISVYPGYGVEIKVQNISLREGETVTVEGLGGPDPLPLANQSFLLRGQVIRSPTHQAALRFQSLPPPAGPGTFHFHYQAYLLSCHFPRRPAYGDVTVTSLHPGGSARFHCATGYQLKGARHLTCLNATQPFWDSKEPVCIAACGGVIRNATTGRIVSPGFPGNYSNNLTCHWLLEAPEGQRLHLHFEKVSLAEDDDRLIIRNGDNVEAPPVYDSYEVEYPPPPPPLQPHYHRVSV>sp|O94964|SOGA1_HUMAN Protein SOGA1 OS=Homo sapiens OX=9606 GN=SOGA1PE=1 SV=2MLEMRDVYMEEDVYQLQELRQQLDQASKTCRILQYRLRKAERRSLRAAQTGQVDGELIRGLEQDVKVSKDISMRLHKELEVVEKKRARLEEENEELRQRLIETELAKQVLQTELERPREHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYYSPPVARRLGVPVVHDKEGKIIIEPGFLFTTAKPKESAEADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDDMKEITNCVRQAMRSGSLERKVKSTSSQTVGLASVGTQTIRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPCCSPKYGSPKLQRRSVSKLDSSKDRSLWNLHQGKQNGSAWARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPKYGIVQEFFRNVCGRAPSPTSSAGEEGTKKPEPLSPASYHQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAVCDCSTQSLTSCFARSSRSAIRHSPSKCRLHPSESSWGGEERALPPSE>sp|O94964-2|SOGA1_HUMAN Isoform 2 of Protein SOGA1 OS=Homo sapiensOX=9606 GN=SOGA1MEAPAAEPPVRGCGPQPAPAPAPAPERKKSHRAPSPARPKDVAGWSLAKGRRGPGPGSAVACSAAFSSRPDKKGRAVAPGARGAGVRVAGVRTGVRAKGRPRSGAGPRPPPPPPSLTDSSSEVSDCASEEARLLGLELALSSDAESAAGGPAGVRTGQPAQPAPSAQQPPRPPASPDEPSVAASSVGSSRLPLSASLAFSDLTEEMLDCGPSGLVRELEELRSENDYLKDEIEELRAEMLEMRDVYMEEDVYQLQELRQQLDQASKTCRILQYRLRKAERRSLRAAQTGQVDGELIRGLEQDVKVSKDISMRLHKELEVVEKKRARLEEENEELRQRLIETELAKQVLQTELERPREHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYYSPPVARRLGVPVVHDKEGKIIIEPGFLFTTAKPKESAEADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDDMKEITNCVRQAMRSGSLERKVKSTSSQTVGLASVGTQTIRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPCCSPKYGSPKLQRRSVSKLDSSKDRSLWNLHQGKQNGSAWARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPKYGIVQEFFRNVCGRAPSPTSSAGEEGTKKPEPLSPASYHQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAVCDCSTQSLTSCFARSSRSAIRHSPSKCRLHPSESSWGGEERALPPSE>sp|O94964-3|SOGA1_HUMAN Isoform 3 of Protein SOGA1 OS=Homo sapiensOX=9606 GN=SOGA1MWDWAPTTSLQEVNKTVLVFALTQHTDQGGRPECALSVISTNNDVSSSVLRRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYYSPPVARRLGVPVVHDKEGKIIIEPGFLFTTAKPKESAEADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDDMKEITNCVRQAMRSGSLERKVKSTSSQTVGLASVGTQTIRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPCCSPKYGSPKLQRRSVSKLDSSKDRSLWNLHQGKQNGSAWARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPKYGIVQEFFRNVCGRAPSPTSSAGEEGTKKPEPLSPASYHQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEVGGWDLSFLLVGGVSI>sp|O94964-4|SOGA1_HUMAN Isoform 4 of Protein SOGA1 OS=Homo sapiensOX=9606 GN=SOGA1MLEMRDVYMEEDVYQLQELRQQLDQASKTCRILQYRLRKAERRSLRAAQTGQVDGELIRGLEQDVKVSKDISMRLHKELEVVEKKRARLEEENEELRQRLIETELAKQVLQTELERPREHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQKLPFLLILAPPQPPPIL>sp|Q15637|SF01_HUMAN Splicing factor 1 OS=Homo sapiens OX=9606 GN=SF1PE=1 SV=4MATGANATPLDFPSKKRKRSRWNQDTMEQKTVIPGMPTVIPPGLTREQERAYIVQLQIEDLTRKLRTGDLGIPPNPEDRSPSPEPIYNSEGKRLNTREFRTRKKLEEERHNLITEMVALNPDFKPPADYKPPATRVSDKVMIPQDEYPEINFVGLLIGPRGNTLKNIEKECNAKIMIRGKGSVKEGKVGRKDGQMLPGEDEPLHALVTANTMENVKKAVEQIRNILKQGIETPEDQNDLRKMQLRELARLNGTLREDDNRILRPWQSSETRSITNTTVCTKCGGAGHIASDCKFQRPGDPQSAQDKARMDKEYLSLMAELGEAPVPASVGSTSGPATTPLASAPRPAAPANNPPPPSLMSTTQSRPPWMNSGPSESRPYHGMHGGGPGGPGGGPHSFPHPLPSLTGGHGGHPMQHNPNGPPPPWMQPPPPPMNQGPHPPGHHGPPPMDQYLGSTPVGSGVYRLHQGKGMMPPPPMGMMPPPPPPPSGQPPPPPSGPLPPWQQQQQQPPPPPPPSSSMASSTPLPWQQNTTTTTTSAGTGSIPPWQQQQAAAAASPGAPQMQGNPTMVPLPPGVQPPLPPGAPPPPPPPPPGSAGMMYAPPPPPPPPMDPSNFVTMMGMGVAGMPPFGMPPAPPPPPPQN>sp|Q15637-2|SF01_HUMAN Isoform 2 of Splicing factor 1 OS=Homo sapiensOX=9606 GN=SF1MATGANATPLDFPSKKRKRSRWNQDTMEQKTVIPGMPTVIPPGLTREQERAYIVQLQIEDLTRKLRTGDLGIPPNPEDRSPSPEPIYNSEGKRLNTREFRTRKKLEEERHNLITEMVALNPDFKPPADYKPPATRVSDKVMIPQDEYPEINFVGLLIGPRGNTLKNIEKECNAKIMIRGKGSVKEGKVGRKDGQMLPGEDEPLHALVTANTMENVKKAVEQIRNILKQGIETPEDQNDLRKMQLRELARLNGTLREDDNRILRPWQSSETRSITNTTVCTKCGGAGHIASDCKFQRPGDPQSAQDKARMDKEYLSLMAELGEAPVPASVGSTSGPATTPLASAPRPAAPANNPPPPSLMSTTQSRPPWMNSGPSESRPYHGMHGGGPGGPGGGPHSFPHPLPSLTGGHGGHPMQHNPNGPPPPWMQPPPPPMNQGPHPPGHHGPPPMDQYLGSTPVGSGVYRLHQGKGMMPPPPMGMMPPPPPPPSGQPPPPPSGPLPPWQQQQQQPPPPPPPSSSMASSTPLPWQQNTTTTTTSAGTGSIPPWQQQQAAAAASPGAPQMQGNPTMVPLPPGVQPPLPPGAPPPPPPPPPGSAGMMIPPRGGDGPSHESEDFPRPLVTLPGRQPQQRPWWTGWFGKAA>sp|Q15637-3|SF01_HUMAN Isoform 3 of Splicing factor 1 OS=Homo sapiensOX=9606 GN=SF1MATGANATPLDFPSKKRKRSRWNQDTMEQKTVIPGMPTVIPPGLTREQERAYIVQLQIEDLTRKLRTGDLGIPPNPEDRSPSPEPIYNSEGKRLNTREFRTRKKLEEERHNLITEMVALNPDFKPPADYKPPATRVSDKVMIPQDEYPEINFVGLLIGPRGNTLKNIEKECNAKIMIRGKGSVKEGKVGRKDGQMLPGEDEPLHALVTANTMENVKKAVEQIRNILKQGIETPEDQNDLRKMQLRELARLNGTLREDDNRILRPWQSSETRSITNTTVCTKCGGAGHIASDCKFQRPGDPQSAQDKARMDKEYLSLMAELGEAPVPASVGSTSGPATTPLASAPRPAAPANNPPPPSLMSTTQSRPPWMNSGPSESRPYHGMHGGGPGGPGGGPHSFPHPLPSLTGGHGGHPMQHNPNGPPPPWMQPPPPPMNQGPHPPGHHGPPPMDQYLGSTPVGSGVYRLHQGKGMMPPPPMGMMPPPPPPPSGQPPPPPSGPLPPWQQQQQQPPPPPPPSSSMASSTPLPWQQNTTTTTTSAGTGSIPPWQQQQAAAAASPGAPQMQGNPTMVPLPPGVQPPLPPGAPPPPPRSIECLLCLLSLLTQLPLPLPKPGRQDPSPRRRWPEP>sp|Q15637-4|SF01_HUMAN Isoform 4 of Splicing factor 1 OS=Homo sapiensOX=9606 GN=SF1MATGANATPLDFPSKKRKRSRWNQDTMEQKTVIPGMPTVIPPGLTREQERAYIVQLQIEDLTRKLRTGDLGIPPNPEDRSPSPEPIYNSEGKRLNTREFRTRKKLEEERHNLITEMVALNPDFKPPADYKPPATRVSDKVMIPQDEYPEINFVGLLIGPRGNTLKNIEKECNAKIMIRGKGSVKEGKVGRKDGQMLPGEDEPLHALVTANTMENVKKAVEQIRNILKQGIETPEDQNDLRKMQLRELARLNGTLREDDNRILRPWQSSETRSITNTTVCTKCGGAGHIASDCKFQRPGDPQSAQDKARMDKEYLSLMAELGEAPVPASVGSTSGPATTPLASAPRPAAPANNPPPPSLMSTTQSRPPWMNSGPSESRPYHGMHGGGPGGPGGGPHSFPHPLPSLTGGHGGHPMQHNPNGPPPPWMQPPPPPMNQGPHPPGHHGPPPMDQYLGSTPVGSGVYRLHQGKGMMPPPPMGMMPPPPPPPSGQPPPPPSGPLPPWQQQQQQPPPPPPPSSSMASSTPLPWQQRSLPAAAMARAMRVRTFRAHW>sp|Q15637-5|SF01_HUMAN Isoform 5 of Splicing factor 1 OS=Homo sapiensOX=9606 GN=SF1MATGANATPLGKLGPPGLPPLPGPKGGFEPGPPPAPGPGAGLLAPGPPPPPPVGSMGALTAAFPFAALPPPPPPPPPPPPQQPPPPPPPPSPGASYPPPQPPPPPPLYQRVSPPQPPPPQPPRKDQQPGPAGGGGDFPSKKRKRSRWNQDTMEQKTVIPGMPTVIPPGLTREQERAYIVQLQIEDLTRKLRTGDLGIPPNPEDRSPSPEPIYNSEGKRLNTREFRTRKKLEEERHNLITEMVALNPDFKPPADYKPPATRVSDKVMIPQDEYPEINFVGLLIGPRGNTLKNIEKECNAKIMIRGKGSVKEGKVGRKDGQMLPGEDEPLHALVTANTMENVKKAVEQIRNILKQGIETPEDQNDLRKMQLRELARLNGTLREDDNRILRPWQSSETRSITNTTVCTKCGGAGHIASDCKFQRPGDPQSAQDKARMDKEYLSLMAELGEAPVPASVGSTSGPATTPLASAPRPAAPANNPPPPSLMSTTQSRPPWMNSGPSESRPYHGMHGGGPGGPGGGPHSFPHPLPSLTGGHGGHPMQHNPNGPPPPWMQPPPPPMNQGPHPPGHHGPPPMDQYLGSTPVGSGVYRLHQGKGMMPPPPMGMMPPPPPPPSGQPPPPPSGPLPPWQQQQQQPPPPPPPSSSMASSTPLPWQQRSLPAAAMARAMRVRTFRAHW>sp|Q15637-6|SF01_HUMAN Isoform 6 of Splicing factor 1 OS=Homo sapiensOX=9606 GN=SF1MATGANATPLDFPSKKRKRSRWNQDTMEQKTVIPGMPTVIPPGLTREQERAYIVQLQIEDLTRKLRTGDLGIPPNPEDRSPSPEPIYNSEGKRLNTREFRTRKKLEEERHNLITEMVALNPDFKPPADYKPPATRVSDKVMIPQDEYPEINFVGLLIGPRGNTLKNIEKECNAKIMIRGKGSVKEGKVGRKDGQMLPGEDEPLHALVTANTMENVKKAVEQIRNILKQGIETPEDQNDLRKMQLRELARLNGTLREDDNRILRPWQSSETRSITNTTVCTKCGGAGHIASDCKFQRPGDPQSAQDKARMDKEYLSLMAELGEAPVPASVGSTSGPATTPLASAPRPAAPANNPPPPSLMSTTQSRPPWMNSGPSESRPYHGMHGGGPGGPGGGPHSFPHPLPSLTGGHGGHPMQHNPNGPPPPWMQPPPPPMNQGPHPPGHHGPPPMGKSVPGKYACGLWGLSPASRKRYDAATTYGHDAAAAAASQWAAPTPSLWSSSPMATTAAAASATPSAQQQYGFQYPLAMAAKIPPRGGDGPSHESEDFPRPLVTLPGRQPQQRPWWTGWFGKAA>sp|Q15637-7|SF01_HUMAN Isoform 7 of Splicing factor 1 OS=Homo sapiensOX=9606 GN=SF1MEQKTVIPGMPTVIPPGLTREQERAYIVQLQIEDLTRKLRTGDLGIPPNPEDRSPSPEPIYNSEGKRLNTREFRTRKKLEEERHNLITEMVALNPDFKPPADYKPPATRVSDKVMIPQDEYPEINFVGLLIGPRGNTLKNIEKECNAKIMIRGKGSVKEGKVGRKDGQMLPGEDEPLHALVTANTMENVKKAVEQIRNILKQGIETPEDQNDLRKMQLRELARLNGTLREDDNRILRPWQSSETRSITNTTVCTKCGGAGHIASDCKFQRPGDPQSAQDKARMDKEYLSLMAELGEAPVPASVGSTSGPATTPLASAPRPAAPANNPPPPSLMSTTQSRPPWMNSGPSESRPYHGMHGGGPGGPGGGPHSFPHPLPSLTGGHGGHPMQHNPNGPPPPWMQPPPPPMNQGPHPPGHHGPPPMDQYLGSTPVGSGVYRLHQGKGMMPPPPMGMMPPPPPPPSGQPPPPPSGPLPPWQQQQQQPPPPPPPSSSMASSTPLPWQQNTTTTTTSAGTGSIPPWQQQQAAAAASPGAPQMQGNPTMVPLPPGVQPPLPPGAPPPPPPPPPGSAGMMYAPPPPPPPPMDPSNFVTMMGMGVAGMPPFGMPPAPPPPPPQN>sp|Q8TD22|SFXN5_HUMAN Sideroflexin-5 OS=Homo sapiens OX=9606 GN=SFXN5PE=1 SV=1MADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQLWSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISAVSIAVGLNVLVQKANKFTPATRLLIQRFVPFPAVASANICNVVLMRYGELEEGIDVLDSDGNLVGSSKIAARHALLETALTRVVLPMPILVLPPIVMSMLEKTALLQARPRLLLPVQSLVCLAAFGLALPLAISLFPQMSEIETSQLEPEIAQATSSRTVVYNKGL>sp|Q8IX21|SLF2_HUMAN SMC5-SMC6 complex localization factor protein 2OS=Homo sapiens OX=9606 GN=SLF2 PE=1 SV=2MTRRCMPARPGFPSSPAPGSSPPRCHLRPGSTAHAAAGKRTESPGDRKQSIIDFFKPASKQDRHMLDSPQKSNIKYGGSRLSITGTEQFERKLSSPKESKPKRVPPEKSPIIEAFMKGVKEHHEDHGIHESRRPCLSLASKYLAKGTNIYVPSSYHLPKEMKSLKKKHRSPERRKSLFIHENNEKNDRDRGKTNADSKKQTTVAEADIFNNSSRSLSSRSSLSRHHPEESPLGAKFQLSLASYCRERELKRLRKEQMEQRINSENSFSEASSLSLKSSIERKYKPRQEQRKQNDIIPGKNNLSNVENGHLSRKRSSSDSWEPTSAGSKQNKFPEKRKRNSVDSDLKSTRESMIPKARESFLEKRPDGPHQKEKFIKHIALKTPGDVLRLEDISKEPSDETDGSSAGLAPSNSGNSGHHSTRNSDQIQVAGTKETKMQKPHLPLSQEKSAIKKASNLQKNKTASSTTKEKETKLPLLSRVPSAGSSLVPLNAKNCALPVSKKDKERSSSKECSGHSTESTKHKEHKAKTNKADSNVSSGKISGGPLRSEYGTPTKSPPAALEVVPCIPSPAAPSDKAPSEGESSGNSNAGSSALKRKLRGDFDSDEESLGYNLDSDEEEETLKSLEEIMALNFNQTPAATGKPPALSKGLRSQSSDYTGHVHPGTYTNTLERLVKEMEDTQRLDELQKQLQEDIRQGRGIKSPIRIGEEDSTDDEDGLLEEHKEFLKKFSVTIDAIPDHHPGEEIFNFLNSGKIFNQYTLDLRDSGFIGQSAVEKLILKSGKTDQIFLTTQGFLTSAYHYVQCPVPVLKWLFRMMSVHTDCIVSVQILSTLMEITIRNDTFSDSPVWPWIPSLSDVAAVFFNMGIDFRSLFPLENLQPDFNEDYLVSETQTTSRGKESEDSSYKPIFSTLPETNILNVVKFLGLCTSIHPEGYQDREIMLLILMLFKMSLEKQLKQIPLVDFQSLLINLMKNIRDWNTKVPELCLGINELSSHPHNLLWLVQLVPNWTSRGRQLRQCLSLVIISKLLDEKHEDVPNASNLQVSVLHRYLVQMKPSDLLKKMVLKKKAEQPDGIIDDSLHLELEKQAYYLTYILLHLVGEVSCSHSFSSGQRKHFVLLCGALEKHVKCDIREDARLFYRTKVKDLVARIHGKWQEIIQNCRPTQGQLHDFWVPDS>sp|Q8IX21-2|SLF2_HUMAN Isoform 2 of SMC5-SMC6 complex localizationfactor protein 2 OS=Homo sapiens OX=9606 GN=SLF2MTRRCMPARPGFPSSPAPGSSPPRCHLRPGSTAHAAAGKRTESPGDRKQSIIDFFKPASKQDRHMLDSPQKSNIKYGGSRLSITGTEQFERKLSSPKESKPKRVPPEKSPIIEAFMKGVKEHHEDHGIHESRRPCLSLASKYLAKGTNIYVPSSYHLPKEMKSLKKKHRSPERRKSLFIHENNEKNDRDRGKTNADSKKQTTVAEADIFNNSSRSLSSRSSLSRHHPEESPLGAKFQLSLASYCRERELKRLRKEQMEQRINSENSFSEASSLSLKSSIERKYKPRQEQRKQNDIIPGKNNLSNVENGHLSRKRSSSDSWEPTSAGSKQNKFPEKRKRNSVDSDLKSTRESMIPKARESFLEKRPDGPHQKEKFIKHIALKTPGDVLRLEDISKEPSDETDGSSAGLAPSNSGNSGHHSTRNSDQIQVAGTKETKMQKPHLPLSQEKSAIKKASNLQKNKTASSTTKEKETKLPLLSRVPSAGSSLVPLNAKNCALPVSKKDKERSSSKECSGHSTESTKHKEHKAKTNKADSNVSSGKISGGPLRSEYGTPTKSPPAALEVVPCIPSPAAPSDKAPSEGESSGNSNAGSSALKRKLRGDFDSDEESLGYNLDSDEEEETLKSLEEIMALNFNQTPAATGKPPALSKGLRSQSSDYTGHVHPGTYTNTLERLVKEMEDTQRLDELQKQLQEDIRQGRGIKSPIRIGEEDSTDDEDGLLEEHKEFLKKFSVTIDAIPDHHPGEEIFNFLNSGKIFNQYTLDLRDSGFIGQSAVEKLILKSGKTDQIFLTTQGFLTSAYHYVQCPVPVLKWLFRMMSVHTDCIVSVQILSTLMEITIRNDTFSDSPVWPWIPSLSDVAAVFFNMGIDFRSLFPLENLQPDFNEDYLVSETQTTSRGKESEDSSYKPIFSTLPETNILNVVKFLGLCTSIHPEGYQDREIMLLILMLFKMSLEKQLKQIPLVDFQSLLINLMKNIRDWNTKVPELCLGINELSSHPHNLLWLVQLVPNWTSRGRQLRQCLSLVIISKLLDEKHEDVPNASNLQVSVLHRYLVQMKPSDLLKKMVLKKKAEQPDGIIDDSLHLELEKQAYYLTYILLHLVGEVSCSHSFSSGQRKHFVLLCGALEKHVKCDIREDARLFYRTKVKDLVARIHGKWQEIIQNCRPTQVSFCYTISCILNSFAEWHSSYCLK>sp|Q8IX21-3|SLF2_HUMAN Isoform 3 of SMC5-SMC6 complex localizationfactor protein 2 OS=Homo sapiens OX=9606 GN=SLF2MTRRCMPARPGFPSSPAPGSSPPRCHLRPGSTAHAAAGKRTESPGDRYRAEGLRRGRVAGARV>sp|Q08AF3|SLFN5_HUMAN Schlafen family member 5 OS=Homo sapiens OX=9606GN=SLFN5 PE=1 SV=1MSLRIDVDTNFPECVVDAGKVTLGTQQRQEMDPRLREKQNEIILRAVCALLNSGGGIIKAEIENKGYNYERHGVGLDVPPIFRSHLDKMQKENHFLIFVKSWNTEAGVPLATLCSNLYHRERTSTDVMDSQEALAFLKCRTQTPTNINVSNSLGPQAAQGSVQYEGNINVSAAALFDRKRLQYLEKLNLPESTHVEFVMFSTDVSHCVKDRLPKCVSAFANTEGGYVFFGVHDETCQVIGCEKEKIDLTSLRASIDGCIKKLPVHHFCTQRPEIKYVLNFLEVHDKGALRGYVCAIKVEKFCCAVFAKVPSSWQVKDNRVRQLPTREWTAWMMEADPDLSRCPEMVLQLSLSSATPRSKPVCIHKNSECLKEQQKRYFPVFSDRVVYTPESLYKELFSQHKGLRDLINTEMRPFSQGILIFSQSWAVDLGLQEKQGVICDALLISQNNTPILYTIFSKWDAGCKGYSMIVAYSLKQKLVNKGGYTGRLCITPLVCVLNSDRKAQSVYSSYLQIYPESYNFMTPQHMEALLQSLVIVLLGFKSFLSEELGSEVLNLLTNKQYELLSKNLRKTRELFVHGLPGSGKTILALRIMEKIRNVFHCEPANILYICENQPLKKLVSFSKKNICQPVTRKTFMKNNFEHIQHIIIDDAQNFRTEDGDWYGKAKFITQTARDGPGVLWIFLDYFQTYHLSCSGLPPPSDQYPREEINRVVRNAGPIANYLQQVMQEARQNPPPNLPPGSLVMLYEPKWAQGVPGNLEIIEDLNLEEILIYVANKCRFLLRNGYSPKDIAVLFTKASEVEKYKDRLLTAMRKRKLSQLHEESDLLLQIGDASDVLTDHIVLDSVCRFSGLERNIVFGINPGVAPPAGAYNLLLCLASRAKRHLYILKASV>sp|Q08AF3-2|SLFN5_HUMAN Isoform 2 of Schlafen family member 5 OS=Homosapiens OX=9606 GN=SLFN5MSLRIDVDTNFPECVVDAGKVTLGTQQRQEMDPRLREKQNEIILRAVCALLNSGGGIIKAEIENKGYNYERHGVGLDVPPIFRSHLDKMQKENHFLIFVKSWNTEAGVPLATLCSNLYHRERTSTDVMDSQEALAFLKCRTQTPTNINVSNSLGPQAAQGSVQYEGNINVSAAALFDRKRLQYLEKLNLPESTHVEFVMFSTDVSHCVKDRLPKCVSAFANTEGGYVFFGVHDETCQVIGCEKEKIDLTSLRASIDGCIKKLPVHHFCTQRPEIKYVLNFLEVHDKGALRGYVCAIKVEKFCCAVFAKVPSSWQVKDNRVRQLPTREWTAWMMEADPG>sp|Q5VT52|RPRD2_HUMAN Regulation of nuclear pre-mRNA domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RPRD2 PE=1 SV=1MAAGGGGGSSKASSSSASSAGALESSLDRKFQSVTNTMESIQGLSSWCIENKKHHSTIVYHWMKWLRRSAYPHRLNLFYLANDVIQNCKRKNAIIFRESFADVLPEAAALVKDPSVSKSVERIFKIWEDRNVYPEEMIVALREALSTTFKTQKQLKENLNKQPNKQWKKSQTSTNPKAALKSKIVAEFRSQALIEELLLYKRSEDQIELKEKQLSTMRVDVCSTETLKCLKDKTGGKKFSKEFEEASSKLEEFVNGLDKQVKNGPSLTEALENAGIFYEAQYKEVKVVANAYKTFANRVNNLKKKLDQLKSTLPDPEESPVPSPSMDAPSPTGSESPFQGMGGEESQSPTMESEKSATPEPVTDNRDVEDMELSDVEDDGSKIIVEDRKEKPAEKSAVSTSVPTKPTENISKASSCTPVPVTMTATPPLPKPVNTSLSPSPALALPNLANVDLAKISSILSSLTSVMKNTGVSPASRPSPGTPTSPSNLTSGLKTPAPATTTSHNPLANILSKVEITPESILSALSKTQTQSAPALQGLSSLLQSVTGNPVPASEAASQSTSASPANTTVSTIKGRNLPSSAQPFIPKSFNYSPNSSTSEVSSTSASKASIGQSPGLPSTTFKLPSNSLGFTATHNTSPAAPPTEVTICQSSEVSKPKLESESTSPSLEMKIHNFLKGNPGFSGLNLNIPILSSLGSSAPSESHPSDFQRGPTSTSIDNIDGTPVRDERSGTPTQDEMMDKPTSSSVDTMSLLSKIISPGSSTPSSTRSPPPGRDESYPRELSNSVSTYRPFGLGSESPYKQPSDGMERPSSLMDSSQEKFYPDTSFQEDEDYRDFEYSGPPPSAMMNLEKKPAKSILKSSKLSDTTEYQPILSSYSHRAQEFGVKSAFPPSVRALLDSSENCDRLSSSPGLFGAFSVRGNEPGSDRSPSPSKNDSFFTPDSNHNSLSQSTTGHLSLPQKQYPDSPHPVPHRSLFSPQNTLAAPTGHPPTSGVEKVLASTISTTSTIEFKNMLKNASRKPSDDKHFGQAPSKGTPSDGVSLSNLTQPSLTATDQQQQEEHYRIETRVSSSCLDLPDSTEEKGAPIETLGYHSASNRRMSGEPIQTVESIRVPGKGNRGHGREASRVGWFDLSTSGSSFDNGPSSASELASLGGGGSGGLTGFKTAPYKERAPQFQESVGSFRSNSFNSTFEHHLPPSPLEHGTPFQREPVGPSSAPPVPPKDHGGIFSRDAPTHLPSVDLSNPFTKEAALAHAAPPPPPGEHSGIPFPTPPPPPPPGEHSSSGGSGVPFSTPPPPPPPVDHSGVVPFPAPPLAEHGVAGAVAVFPKDHSSLLQGTLAEHFGVLPGPRDHGGPTQRDLNGPGLSRVRESLTLPSHSLEHLGPPHGGGGGGGSNSSSGPPLGPSHRDTISRSGIILRSPRPDFRPREPFLSRDPFHSLKRPRPPFARGPPFFAPKRPFFPPRY>sp|Q5VT52-2|RPRD2_HUMAN Isoform 2 of Regulation of nuclear pre-mRNAdomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RPRD2MESIQGLSSWCIENKKHHSTIVYHWMKWLRRSAYPHRLNLFYLANDVIQNCKRKNAIIFRESFADVLPEAAALVKDPSVSKSVERIFKIWEDRNVYPEEMIVALREALSTTFKTQKQLKENLNKQPNKQWKKSQTSTNPKAALKSKIVAEFRSQALIEELLLYKRSEDQIELKEKQLSTMRVDVCSTETLKCLKDKTGGKKFSKEFEEASSKLEEFVNGLDKQVKNGPSLTEALENAGIFYEAQYKEVKVVANAYKTFANRVNNLKKKLDQLKSTLPDPEESPVPSPSMDAPSPTGSESPFQGMGGEESQSPTMESEKSATPEPVTDNRDVEDMELSDVEDDGSKIIVEDRKEKPAEKSAVSTSVPTKPTENISKASSCTPVPVTMTATPPLPKPVNTSLSPSPALALPNLANVDLAKISSILSSLTSVMKNTGVSPASRPSPGTPTSPSNLTSGLKTPAPATTTSHNPLANILSKVEITPESILSALSKTQTQSAPALQGLSSLLQSVTGNPVPASEAASQSTSASPANTTVSTIKGRNLPSSAQPFIPKSFNYSPNSSTSEVSSTSASKASIGQSPGLPSTTFKLPSNSLGFTATHNTSPAAPPTEVTICQSSEVSKPKLESESTSPSLEMKIHNFLKGNPGFSGLNLNIPILSSLGSSAPSESHPSDFQRGPTSTSIDNIDGTPVRDERSGTPTQDEMMDKPTSSSVDTMSLLSKIISPGSSTPSSTRSPPPGRDESYPRELSNSVSTYRPFGLGSESPYKQPSDGMERPSSLMDSSQEKFYPDTSFQEDEDYRDFEYSGPPPSAMMNLEKKPAKSILKSSKLSDTTEYQPILSSYSHRAQEFGVKSAFPPSVRALLDSSENCDRLSSSPGLFGAFSVRGNEPGSDRSPSPSKNDSFFTPDSNHNSLSQSTTGHLSLPQKQYPDSPHPVPHRSLFSPQNTLAAPTGHPPTSGVEKVLASTISTTSTIEFKNMLKNASRKPSDDKHFGQAPSKGTPSDGVSLSNLTQPSLTATDQQQQEEHYRIETRVSSSCLDLPDSTEEKGAPIETLGYHSASNRRMSGEPIQTVESIRVPGKGNRGHGREASRVGWFDLSTSGSSFDNGPSSASELASLGGGGSGGLTGFKTAPYKERAPQFQESVGSFRSNSFNSTFEHHLPPSPLEHGTPFQREPVGPSSAPPVPPKDHGGIFSRDAPTHLPSVDLSNPFTKEAALAHAAPPPPPGEHSGIPFPTPPPPPPPGEHSSSGGSGVPFSTPPPPPPPVDHSGVVPFPAPPLAEHGVAGAVAVFPKDHSSLLQGTLAEHFGVLPGPRDHGGPTQRDLNGPGLSRVRESLTLPSHSLEHLGPPHGGGGGGGSNSSSGPPLGPSHRDTISRSGIILRSPRPDFRPREPFLSRDPFHSLKRPRPPFARGPPFFAPKRPFFPPRY>sp|Q5VT52-3|RPRD2_HUMAN Isoform 3 of Regulation of nuclear pre-mRNAdomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RPRD2MAAGGGGGSSKASSSSASSAGALESSLDRKFQSVTNTMESIQGLSSWCIENKKHHSTIVYHWMKWLRRSAYPHRLNLFYLANDVIQNCKRKNAIIFRESFADVLPEAAALVKDPSVSKSVERIFKIWEDRNVYPEEMIVALREALTSTNPKAALKSKIVAEFRSQALIEELLLYKRSEDQIELKEKQLSTMRVDVCSTETLKCLKDKTGGKKFSKEFEEASSKLEEFVNGLDKQVKNGPSLTEALENAGIFYEAQYKEVKVVANAYKTFANRVNNLKKKLDQLKSTLPDPEESPVPSPSMDAPSPTGSESPFQGMGGEESQSPTMESEKSATPEPVTDNRDVEDMELSDVEDDGSKIIVEDRKEKPAEKSAVSTSVPTKPTENISKASSCTPVPVTMTATPPLPKPVNTSLSPSPALALPNLANVDLAKISSILSSLTSVMKNTGVSPASRPSPGTPTSPSNLTSGLKTPAPATTTSHNPLANILSKVEITPESILSALSKTQTQSAPALQGLSSLLQSVTGNPVPASEAASQSTSASPANTTVSTIKGRNLPSSAQPFIPKSFNYSPNSSTSEVSSTSASKASIGQSPGLPSTTFKLPSNSLGFTATHNTSPAAPPTEVTICQSSEVSKPKLESESTSPSLEMKIHNFLKGNPGFSGLNLNIPILSSLGSSAPSESHPSDFQRGPTSTSIDNIDGTPVRDERSGTPTQDEMMDKPTSSSVDTMSLLSKIISPGSSTPSSTRSPPPGRDESYPRELSNSVSTYRPFGLGSESPYKQPSDGMERPSSLMDSSQEKFYPDTSFQEDEDYRDFEYSGPPPSAMMNLEKKPAKSILKSSKLSDTTEYQPILSSYSHRAQEFGVKSAFPPSVRALLDSSENCDRLSSSPGLFGAFSVRGNEPGSDRSPSPSKNDSFFTPDSNHNSLSQSTTGHLSLPQKQYPDSPHPVPHRSLFSPQNTLAAPTGHPPTSGVEKVLASTISTTSTIEFKNMLKNASRKPSDDKHFGQAPSKGTPSDGVSLSNLTQPSLTATDQQQQEEHYRIETRVSSSCLDLPDSTEEKGAPIETLGYHSASNRRMSGEPIQTVESIRVPGKGNRGHGREASRVGWFDLSTSGSSFDNGPSSASELASLGGGGSGGLTGFKTAPYKERAPQFQESVGSFRSNSFNSTFEHHLPPSPLEHGTPFQREPVGPSSAPPVPPKDHGGIFSRDAPTHLPSVDLSNPFTKEAALAHAAPPPPPGEHSGIPFPTPPPPPPPGEHSSSGGSGVPFSTPPPPPPPVDHSGVVPFPAPPLAEHGVAGAVAVFPKDHSSLLQGTLAEHFGVLPGPRDHGGPTQRDLNGPGLSRVRESLTLPSHSLEHLGPPHGGGGGGGSNSSSGPPLGPSHRDTISRSGIILRSPRPDFRPREPFLSRDPFHSLKRPRPPFARGPPFFAPKRPFFPPRY>sp|Q5VT52-4|RPRD2_HUMAN Isoform 4 of Regulation of nuclear pre-mRNAdomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RPRD2MAAGGGGGSSKASSSSASSAGALESSLDRKFQSVTNTMESIQGLSSWCIENKKHHSTIVYHWMKWLRRSAYPHRLNLFYLANDVIQNCKRKNAIIFRESFADVLPEAAALVKDPSVSKSVERIFKIWEDRNVYPEEMIVALREALSKCLFLS>sp|Q5VT52-5|RPRD2_HUMAN Isoform 5 of Regulation of nuclear pre-mRNAdomain-containing protein 2 OS=Homo sapiens OX=9606 GN=RPRD2MAAGGGGGSSKASSSSASSAGALESSLDRKFQSVTNTMESIQGLSSWCIENKKHHSTIVYHWMKWLRRSAYPHRLNLFYLANDVIQNCKRKNAIIFRESFADVLPEAAALVKDPSVSKSVERIFKIWEDRNVYPEEMIVALREALTSTNPKAALKSKIVAEFRSQALIEELLLYKRSEDQIELKEKQLSTMRVDVCSTETLKCLKDKTGGKKFSKEFEEASSKLEEFVNGLDKQVKNGPSLTEALENAGIFYEAQYKEVKVVANAYKTFANRVNNLKKKLDQLKSTLPDPEESPVPSPSMDAPSPTGSESPFQGMGGEESQSPTMESEKSATPEPVTDNRDVEDMELSDVEDDGSKIIVEDRKEKPAEKSAVSTSVPTKPTENISKASSCTPVPVTMTATPPLPKPVNTSLSPSPALALPNLANVDLAKISSILSSLTSVMKNTGVSPASRPSPGTPTSPSNLTSGLKTPAPATTTSHNPLANILSKVEITPESILSALSKTQTQSAPALQGLSSLLQSVTGNPVPASEAASQSTSASPANTTVSTIKGRNLPSSAQPFIPKSFNYSPNSSTSEVSSTSASKASIGQSPGLPSTTFKLPSNSLGFTATHNTSPAAPPTEVTICQSSEVSKPKLESESTSPSLEMKIHNFLKGNPGFSGLNLNIPILSSLGSSAPSESHPSDFQRGPTSTSIDNIDGTPVRDERSGTPTQDEMMDKPTSSSVDTMSLLSKIISPGSSTPSSTRSPPPGRDESYPRELSNSVSTYRPFGLGSESPYKQPSDGMERPSSLMDSSQEKFYPDTSFQEDEDYRDFEYSGPPPSAMMNLEKKPAKSILKSSKLSDTTEYQPILSSYSHRAQEFGVKSAFPPSVRALLDSSENCDRLSSSPGLFGAFSVRGNEPGSDRSPSPKHPCRSHGSPTHVRRGESPGLHHFHHVDD>sp|Q9NSI2|SLX9_HUMAN Ribosome biogenesis protein SLX9 homolog OS=Homosapiens OX=9606 GN=SLX9 PE=1 SV=2MGKVRGLRARVHQAAVRPKGEAAPGPAPPAPEATPPPASAAGKDWAFINTNIFARTKIDPSALVQKLELDVRSVTSVRRGEAGSSARSVPSIRRGAEAKTVLPKKEKMKLRREQWLQKIEAIKLAEQKHREERRRRATVVVGDLHPLRDALPELLGLEAGSRRQARSRESNKPRPSELSRMSAAQRQQLLEEERTRFQELLASPAYRASPLVAIGQTLARQMQLEDGGQL>sp|Q9NSI2-2|SLX9_HUMAN Isoform B of Ribosome biogenesis protein SLX9homolog OS=Homo sapiens OX=9606 GN=SLX9MGKVRGLRARVHQAAVRPKGEAAPGPAPPAPEATPPPASAAGKDWAFINTNIFARTKIDPSALVQKLELDVRSVTSVRRGAEAKTVLPKKEKMKLRREQWLQKIEAIKLAEQKHREERRRRATVVVGDLHPLRDALPELLGLEAGSRRQARSRESNKPRPSELSRMSAAQRQQLLEEERTRFQELLASPAYRASPLVAIGQTLARQMQLEDGGQL>sp|Q13435|SF3B2_HUMAN Splicing factor 3B subunit 2 OS=Homo sapiensOX=9606 GN=SF3B2 PE=1 SV=2MATEHPEPPKAELQLPPPPPPGHYGAWAAQELQAKLAEIGAPIQGNREELVERLQSYTRQTGIVLNRPVLRGEDGDKAAPPPMSAQLPGIPMPPPPLGLPPLQPPPPPPPPPPGLGLGFPMAHPPNLGPPPPLRVGEPVALSEEERLKLAQQQAALLMQQEERAKQQGDHSLKEHELLEQQKRAAVLLEQERQQEIAKMGTPVPRPPQDMGQIGVRTPLGPRVAAPVGPVGPTPTVLPMGAPVPRPRGPPPPPGDENREMDDPSVGPKIPQALEKILQLKESRQEEMNSQQEEEEMETDARSSLGQSASETEEDTVSVSKKEKNRKRRNRKKKKKPQRVRGVSSESSGDREKDSTRSRGSDSPAADVEIEYVTEEPEIYEPNFIFFKRIFEAFKLTDDVKKEKEKEPEKLDKLENSAAPKKKGFEEEHKDSDDDSSDDEQEKKPEAPKLSKKKLRRMNRFTVAELKQLVARPDVVEMHDVTAQDPKLLVHLKATRNSVPVPRHWCFKRKYLQGKRGIEKPPFELPDFIKRTGIQEMREALQEKEEQKTMKSKMREKVRPKMGKIDIDYQKLHDAFFKWQTKPKLTIHGDLYYEGKEFETRLKEKKPGDLSDELRISLGMPVGPNAHKVPPPWLIAMQRYGPPPSYPNLKIPGLNSPIPESCSFGYHAGGWGKPPVDETGKPLYGDVFGTNAAEFQTKTEEEEIDRTPWGELEPSDEESSEEEEEEESDEDKPDETGFITPADSGLITPGGFSSVPAGMETPELIELRKKKIEEAMDGSETPQLFTVLPEKRTATVGGAMMGSTHIYDMSTVMSRKGPAPELQGVEVALAPEELELDPMAMTQKYEEHVREQQAQVEKEDFSDMVAEHAAKQKQKKRKAQPQDSRGGSKKYKEFKF>sp|Q16842|SIA4B_HUMAN CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 2 OS=Homo sapiens OX=9606 GN=ST3GAL2 PE=1 SV=1MKCSLRVWFLSVAFLLVFIMSLLFTYSHHSMATLPYLDSGALDGTHRVKLVPGYAGLQRLSKERLSGKSCACRRCMGDAGASDWFDSHFDGNISPVWTRENMDLPPDVQRWWMMLQPQFKSHNTNEVLEKLFQIVPGENPYRFRDPHQCRRCAVVGNSGNLRGSGYGQDVDGHNFIMRMNQAPTVGFEQDVGSRTTHHFMYPESAKNLPANVSFVLVPFKVLDLLWIASALSTGQIRFTYAPVKSFLRVDKEKVQIYNPAFFKYIHDRWTEHHGRYPSTGMLVLFFALHVCDEVNVYGFGADSRGNWHHYWENNRYAGEFRKTGVHDADFEAHIIDMLAKASKIEVYRGN>sp|O94991|SLIK5_HUMAN SLIT and NTRK-like protein 5 OS=Homo sapiensOX=9606 GN=SLITRK5 PE=1 SV=2MHTCCPPVTLEQDLHRKMHSWMLQTLAFAVTSLVLSCAETIDYYGEICDNACPCEEKDGILTVSCENRGIISLSEISPPRFPIYHLLLSGNLLNRLYPNEFVNYTGASILHLGSNVIQDIETGAFHGLRGLRRLHLNNNKLELLRDDTFLGLENLEYLQVDYNYISVIEPNAFGKLHLLQVLILNDNLLSSLPNNLFRFVPLTHLDLRGNRLKLLPYVGLLQHMDKVVELQLEENPWNCSCELISLKDWLDSISYSALVGDVVCETPFRLHGRDLDEVSKQELCPRRLISDYEMRPQTPLSTTGYLHTTPASVNSVATSSSAVYKPPLKPPKGTRQPNKPRVRPTSRQPSKDLGYSNYGPSIAYQTKSPVPLECPTACSCNLQISDLGLNVNCQERKIESIAELQPKPYNPKKMYLTENYIAVVRRTDFLEATGLDLLHLGNNRISMIQDRAFGDLTNLRRLYLNGNRIERLSPELFYGLQSLQYLFLQYNLIREIQSGTFDPVPNLQLLFLNNNLLQAMPSGVFSGLTLLRLNLRSNHFTSLPVSGVLDQLKSLIQIDLHDNPWDCTCDIVGMKLWVEQLKVGVLVDEVICKAPKKFAETDMRSIKSELLCPDYSDVVVSTPTPSSIQVPARTSAVTPAVRLNSTGAPASLGAGGGASSVPLSVLILSLLLVFIMSVFVAAGLFVLVMKRRKKNQSDHTSTNNSDVSSFNMQYSVYGGGGGTGGHPHAHVHHRGPALPKVKTPAGHVYEYIPHPLGHMCKNPIYRSREGNSVEDYKDLHELKVTYSSNHHLQQQQQPPPPPQQPQQQPPPQLQLQPGEEERRESHHLRSPAYSVSTIEPREDLLSPVQDADRFYRGILEPDKHCSTTPAGNSLPEYPKFPCSPAAYTFSPNYDLRRPHQYLHPGAGDSRLREPVLYSPPSAVFVEPNRNEYLELKAKLNVEPDYLEVLEKQTTFSQF>sp|O94991-2|SLIK5_HUMAN Isoform 2 of SLIT and NTRK-like protein 5OS=Homo sapiens OX=9606 GN=SLITRK5MGAGKHREGGGGDPTSLNGCADLIQRRTEISRDLDEVSKQELCPRRLISDYEMRPQTPLSTTGYLHTTPASVNSVATSSSAVYKPPLKPPKGTRQPNKPRVRPTSRQPSKDLGYSNYGPSIAYQTKSPVPLECPTACSCNLQISDLGLNVNCQERKIESIAELQPKPYNPKKMYLTENYIAVVRRTDFLEATGLDLLHLGNNRISMIQDRAFGDLTNLRRLYLNGNRIERLSPELFYGLQSLQYLFLQYNLIREIQSGTFDPVPNLQLLFLNNNLLQAMPSGVFSGLTLLRLNLRSNHFTSLPVSGVLDQLKSLIQIDLHDNPWDCTCDIVGMKLWVEQLKVGVLVDEVICKAPKKFAETDMRSIKSELLCPDYSDVVVSTPTPSSIQVPARTSAVTPAVRLNSTGAPASLGAGGGASSVPLSVLILSLLLVFIMSVFVAAGLFVLVMKRRKKNQSDHTSTNNSDVSSFNMQYSVYGGGGGTGGHPHAHVHHRGPALPKVKTPAGHVYEYIPHPLGHMCKNPIYRSREGNSVEDYKDLHELKVTYSSNHHLQQQQQPPPPPQQPQQQPPPQLQLQPGEEERRESHHLRSPAYSVSTIEPREDLLSPVQDADRFYRGILEPDKHCSTTPAGNSLPEYPKFPCSPAAYTFSPNYDLRRPHQYLHPGAGDSRLREPVLYSPPSAVFVEPNRNEYLELKAKLNVEPDYLEVLEKQTTFSQF>sp|O43173|SIA8C_HUMAN Sia-alpha-2,3-Gal-beta-1,4-GlcNAc-R:alpha 2,8-sialyltransferase OS=Homo sapiens OX=9606 GN=ST8SIA3 PE=1 SV=3MRNCKMARVASVLGLVMLSVALLILSLISYVSLKKENIFTTPKYASPGAPRMYMFHAGFRSQFALKFLDPSFVPITNSLTQELQEKPSKWKFNRTAFLHQRQEILQHVDVIKNFSLTKNSVRIGQLMHYDYSSHKYVFSISNNFRSLLPDVSPIMNKHYNICAVVGNSGILTGSQCGQEIDKSDFVFRCNFAPTEAFQRDVGRKTNLTTFNPSILEKYYNNLLTIQDRNNFFLSLKKLDGAILWIPAFFFHTSATVTRTLVDFFVEHRGQLKVQLAWPGNIMQHVNRYWKNKHLSPKRLSTGILMYTLASAICEEIHLYGFWPFGFDPNTREDLPYHYYDKKGTKFTTKWQESHQLPAEFQLLYRMHGEGLTKLTLSHCA>sp|Q15465|SHH_HUMAN Sonic hedgehog protein OS=Homo sapiens OX=9606GN=SHH PE=1 SV=1MLLLARCLLLVLVSSLLVCSGLACGPGRGFGKRRHPKKLTPLAYKQFIPNVAEKTLGASGRYEGKISRNSERFKELTPNYNPDIIFKDEENTGADRLMTQRCKDKLNALAISVMNQWPGVKLRVTEGWDEDGHHSEESLHYEGRAVDITTSDRDRSKYGMLARLAVEAGFDWVYYESKAHIHCSVKAENSVAAKSGGCFPGSATVHLEQGGTKLVKDLSPGDRVLAADDQGRLLYSDFLTFLDRDDGAKKVFYVIETREPRERLLLTAAHLLFVAPHNDSATGEPEASSGSGPPSGGALGPRALFASRVRPGQRVYVVAERDGDRRLLPAAVHSVTLSEEAAGAYAPLTAQGTILINRVLASCYAVIEEHSWAHRAFAPFRLAHALLAALAPARTDRGGDSGGGDRGGGGGRVALTAPGAADAPGAGATAGIHWYSQLLYQIGTWLLDSEALHPLGMAVKSS>sp|P08708|RS17_HUMAN 40S ribosomal protein S17 OS=Homo sapiens OX=9606GN=RPS17 PE=1 SV=2MGRVRTKTVKKAARVIIEKYYTRLGNDFHTNKRVCEEIAIIPSKKLRNKIAGYVTHLMKRIQRGPVRGISIKLQEEERERRDNYVPEVSALDQEIIEVDPDTKEMLKLLDFGSLSNLQVTQPTVGMNFKTPRGPV>sp|O15466|SIA8E_HUMAN Alpha-2,8-sialyltransferase 8E OS=Homo sapiensOX=9606 GN=ST8SIA5 PE=1 SV=2MRYADPSANRDLLGSRTLLFIFICAFALVTLLQQILYGRNYIKRYFEFYEGPFEYNSTRCLELRHEILEVKVLSMVKQSELFDRWKSLQMCKWAMNISEANQFKSTLSRCCNAPAFLFTTQKNTPLGTKLKYEVDTSGIYHINQEIFRMFPKDMPYYRSQFKKCAVVGNGGILKNSRCGREINSADFVFRCNLPPISEKYTMDVGVKTDVVTVNPSIITERFHKLEKWRRPFYRVLQVYENASVLLPAFYNTRNTDVSIRVKYVLDDFESPQAVYYFHPQYLVNVSRYWLSLGVRAKRISTGLILVTAALELCEEVHLFGFWAFPMNPSGLYITHHYYDNVKPRPGFHAMPSEIFNFLHLHSRGILRVHTGTCSCC>sp|O15466-2|SIA8E_HUMAN Isoform 2 of Alpha-2,8-sialyltransferase 8EOS=Homo sapiens OX=9606 GN=ST8SIA5MRYADPSANRDLLGSRTLLFIFICAFALVTLLQQILYGRNYIKRGLQFGWQSGDQLTNWTGLFNVTDDPAVQSGSDSSSRYFEFYEGPFEYNSTRCLELRHEILEVKVLSMVKQSELFDRWKSLQMCKWAMNISEANQFKSTLSRCCNAPAFLFTTQKNTPLGTKLKYEVDTSGIYHINQEIFRMFPKDMPYYRSQFKKCAVVGNGGILKNSRCGREINSADFVFRCNLPPISEKYTMDVGVKTDVVTVNPSIITERFHKLEKWRRPFYRVLQVYENASVLLPAFYNTRNTDVSIRVKYVLDDFESPQAVYYFHPQYLVNVSRYWLSLGVRAKRISTGLILVTAALELCEEVHLFGFWAFPMNPSGLYITHHYYDNVKPRPGFHAMPSEIFNFLHLHSRGILRVHTGTCSCC>sp|P61647|SIA8F_HUMAN Alpha-2,8-sialyltransferase 8F OS=Homo sapiensOX=9606 GN=ST8SIA6 PE=2 SV=1MRPGGALLALLASLLLLLLLRLLWCPADAPGRARILVEESREATHGTPAALRTLRSPATAVPRATNSTYLNEKSLQLTEKCKNLQYGIESFSNKTKGYSENDYLQIITDIQSCPWKRQAEEYANFRAKLASCCDAVQNFVVSQNNTPVGTNMSYEVESKKEIPIKKNIFHMFPVSQPFVDYPYNQCAVVGNGGILNKSLCGTEIDKSDFVFRCNLPPTTGDVSKDVGSKTNLVTINPSIITLKYGNLKEKKALFLEDIATYGDAFFLLPAFSFRANTGTSFKVYYTLEESKARQKVLFFHPKYLKDLALFWRTKGVTAYRLSTGLMITSVAVELCKNVKLYGFWPFSKTVEDIPVSHHYYDNKLPKHGFHQMPKEYSQILQLHMKGILKLQFSKCEVA>sp|Q5T5P2|SKT_HUMAN Sickle tail protein homolog OS=Homo sapiens OX=9606GN=KIAA1217 PE=1 SV=2MEENESQKCEPCLPYSADRRQMQEQGKGNLHVTSPEDAECRRTKERLSNGNSRGSVSKSSRNIPRRHTLGGPRSSKEILGMQTSEMDRKREAFLEHLKQKYPHHASAIMGHQERLRDQTRSPKLSHSPQPPSLGDPVEHLSETSADSLEAMSEGDAPTPFSRGSRTRASLPVVRSTNQTKERSLGVLYLQYGDETKQLRMPNEITSADTIRALFVSAFPQQLTMKMLESPSVAIYIKDESRNVYYELNDVRNIQDRSLLKVYNKDPAHAFNHTPKTMNGDMRMQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETRERMQAMEKQIASLTGLVQSALFKGPITSYSKDASSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQAFQKCSFMDVNSNSHAEPSRADSHVKDTRSGATVPPKEKKNLEFFHEDVRKSDVEYENGPQMEFQKVTTGAVRPSDPPKWERGMENSISDASRTSEYKTEIIMKENSISNMSLLRDSRNYSQETVPKASFGFSGISPLEDEINKGSKISGLQYSIPDTENQTLNYGKTKEMEKQNTDKCHVSSHTRLTESSVHDFKTEDQEVITTDFGQVVLRPKEARHANVNPNEDGESSSSSPTEENAATDNIAFMITETTVQVLSSGEVHDIVSQKGEDIQTVNIDARKEMTPRQEGTDNEDPVVCLDKKPVIIIFDEPMDIRSAYKRLSTIFEECDEELERMMMEEKIEEEEEEENGDSVVQNNNTSQMSHKKVAPGNLRTGQQVETKSQPHSLATETRNPGGQEMNRTELNKFSHVDSPNSECKGEDATDDQFESPKKKFKFKFPKKQLAALTQAIRTGTKTGKKTLQVVVYEEEEEDGTLKQHKEAKRFEIARSQPEDTPENTVRRQEQPSIESTSPISRTDEIRKNTYRTLDSLEQTIKQLENTISEMSPKALVDTSCSSNRDSVASSSHIAQEASPRPLLVPDEGPTALEPPTSIPSASRKGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQANGSAKKSGGDFKPTSPSLPASKIPALSPSSGKSSSLPSSSGDSSNLPNPPATKPSIASNPLSPQTGPPAHSASLIPSVSNGSLKFQSLTHTGKGHHLSFSPQSQNGRAPPPLSFSSSPPSPASSVSLNQGAKGTRTIHTPSLTSYKAQNGSSSKATPSTAKETS>sp|Q5T5P2-2|SKT_HUMAN Isoform 2 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MEENESQKCEPCLPYSADRRQMQEQGKGNLHVTSPEDAECRRTKERLSNGNSRGSVSKSSRNIPRRHTLGGPRSSKEILGMQTSEMDRKREAFLEHLKQKYPHHASAIMGHQERLRDQTRSPKLSHSPQPPSLGDPVEHLSETSADSLEAMSEGDAPTPFSRGSRTRASLPVVRSTNQTKERSLGVLYLQYGDETKQLRMPNEITSADTIRALFVSAFPQQLTMKMLESPSVAIYIKDESRNVYYELNDVRNIQDRSLLKVYNKDPAHAFNHTPKTMNGDMRMQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETRERMQAMEKQIASLTGLVQSALFKGPITSYSKDASSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQANGSAKKSGGDFKPTSPSLPASKIPALSPSSGKSSSLPSSSGDSSNLPNPPATKPSIASNPLSPQTGPPAHSASLIPSVSNGSLKFQSLTHTGKGHHLSFSPQSQNGRAPPPLSFSSSPPSPASSVSLNQGAKGTRTIHTPSLTSYKAQNGSSSKATPSTAKETS>sp|Q5T5P2-3|SKT_HUMAN Isoform 3 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQAFQKCSFMDVNSNSHAEPSRADSHVKDTRSGATVPPKEKKNLEFFHEDVRKSDVEYENGPQMEFQKVTTGAVRPSDPPKWERGMENSISDASRTSEYKTEIIMKENSISNMSLLRDSRNYSQETVPKASFGFSGISPLEDEINKGSKISGLQYSIPDTENQTLNYGKTKEMEKQNTDKCHVSSHTRLTESSVHDFKTEDQEVITTDFGQVVLRPKEARHANVNPNEDGESSSSSPTEENAATDNIAFMITETTVQVLSSGEVHDIVSQKGEDIQTVNIDARKEMTPRQEGTDNEDPVVCLDKKPVIIIFDEPMDIRSAYKRLSTIFEECDEELERMMMEEKIEEEEEEENGDSVVQNNNTSQMSHKKVAPGNLRTGQQVETKSQPHSLATETRNPGGQEMNRTELNKFSHVDSPNSECKGEDATDDQFESPKKKFKFKFPKKQLAALTQAIRTGTKTGKKTLQVVVYEEEEEDGTLKQHKEAKRFEIARSQPEDTPENTVRRQEQPSIESTSPISRTDEIRKNTYRTLDSLEQTIKQLENTISEMSPKALVDTSCSSNRDSVASSSHIAQEASPRPLLVPDEGPTALEPPTSIPSASRKGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQVVLP>sp|Q5T5P2-4|SKT_HUMAN Isoform 4 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQVVLP>sp|Q5T5P2-7|SKT_HUMAN Isoform 5 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MEENESQKCEPCLPYSADRRQMQEQGKGNLHVTSPEDAECRRTKERLSNGNSRGSVSKSSRNIPRRHTLGGPRSSKEILGMQTSEMDRKREAFLEHLKQKYPHHASAIMGHQERLRDQTRSPKLSHSPQPPSLGDPVEHLSETSADSLEAMSEGDAPTPFSRGSRTRASLPVVRSTNQTKERSLGVLYLQYGDETKQLRMPNEITSADTIRALFVSAFPQQLTMKMLESPSVAIYIKDESRNVYYELNDVRNIQDRSLLKVYNKDPAHAFNHTPKTMNGDMRMQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQAFQKCSFMDVNSNSHAEPSRADSHVKDTRSGATVPPKEKKGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQANGSAKKSGGDFKPTSPSLPASKIPALSPSSGKSSSLPSSSGDSSNLPNPPATKPSIASNPLSPQTGPPAHSASLIPSVSNGSLKFQSLTHTGKGHHLSFSPQSQNGRAPPPLSFSSSPPSPASSVSLNQGAKGTRTIHTPSLTSYKAQNGSSSKATPSTAKETS>sp|Q5T5P2-6|SKT_HUMAN Isoform 6 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQAFQKCSFMDVNSNSHAEPSRADSHVKDTRSGATVPPKEKKNLEFFHEDVRKSDVEYENGPQMEFQKGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQVVLP>sp|Q5T5P2-8|SKT_HUMAN Isoform 7 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQAFQKCSFMDVNSNSHAEPSRADSHVKDTRSGATVPPKEKKGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQVVLP>sp|Q5T5P2-9|SKT_HUMAN Isoform 9 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MQTSEMDRKREAFLEHLKQKYPHHASAIMGHQERLRDQTRSPKLSHSPQPPSLGDPVEHLSETSADSLEAMSEGDAPTPFSRGSRTRASLPVVRSTNQTKERSLGVLYLQYGDETKQLRMPNEITSADTIRALFVSAFPQQLTMKMLESPSVAIYIKDESRNVYYELNDVRNIQDRSLLKVYNKDPAHAFNHTPKTMNGDMRMQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETRERMQAMEKQIASLTGLVQSALFKGPITSYSKDASSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSEDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQANGSAKKSGGDFKPTSPSLPASKIPALSPSSGKSSSLPSSSGDSSNLPNPPATKPSIASNPLSPQTGPPAHSASLIPSVSNGSLKFQSLTHTGKGHHLSFSPQSQNGRAPPPLSFSSSPPSPASSVSLNQGAKGTRTIHTPSLTSYKAQNGSSSKATPSTAKETS>sp|Q5T5P2-10|SKT_HUMAN Isoform 10 of Sickle tail protein homolog OS=Homosapiens OX=9606 GN=KIAA1217MEENESQKCEPCLPYSADRRQMQEQGKGNLHVTSPEDAECRRTKERLSNGNSRGSVSKSSRNIPRRHTLGGPRSSKEILGMQTSEMDRKREAFLEHLKQKYPHHASAIMGHQERLRDQTRSPKLSHSPQPPSLGDPVEHLSETSADSLEAMSEGDAPTPFSRGSRTRASLPVVRSTNQTKERSLGVLYLQYGDETKQLRMPNEITSADTIRALFVSAFPQQLTMKMLESPSVAIYIKDESRNVYYELNDVRNIQDRSLLKVYNKDPAHAFNHTPKTMNGDMRMQRELVYARGDGPGAPRPGSTAHPPHAIPNSPPSTPVPHSMPPSPSRIPYGGTRSMVVPGNATIPRDRISSLPVSRPISPSPSAILERRDVKPDEDMSGKNIAMYRNEGFYADPYLYHEGRMSIASSHGGHPLDVPDHIIAYHRTAIRSASAYCNPSMQAEMHMEQSLYRQKSRKYPDSHLPTLGSKTPPASPHRVSDLRMIDMHAHYNAHGPPHTMQPDRASPSRQAFKKEPGTLVYIEKPRSAAGLSSLVDLGPPLMEKQVFAYSTATIPKDRETSEKMMKTTANRNHTDSAGTPHVSGGKMLSALESTVPPSQPPPVGTSAIHMSLLEMRRSVAELRLQLQQMRQLQLQNQELLRAMMKKAELEISGKVMETMKRLEDPVQRQRVLVEQERQKYLHEEEKIVKKLCELEDFVEDLKKDSTAASRLVTLKDVEDGAFLLRQVGEAVATLKGEFPTLQNKMRAILRIEVEAVRFLKEEPHKLDSLLKRVRSMTDVLTMLRRHVTDGLLKGTDAAQAAQYMAMEKATAAEVLKSQEEAAHTSGQPFHSTGAPGDAKSEVVPLSGMMVRHAQSSPVVIQPSQHSVALLNPAQNLPHVASSPAVPQEATSTLQMSQAPQSPQIPMNGSAMQSLFIEEIHSVSAKNRAVSIEKAEKKWEEKRQNLDHYNGKEFEKLLEEAQANIMKSIPNLEMPPATGPLPRGDAPVDKVELSDSPNSEQDLEKLGGKSPPPPPPPPRRSYLPGSGLTTTRSGDVVYTGRKENITAKASSEDAGPSPQTRATKYPAEEPASAWTPSPPPVTTSSSKDEEEEEEEGDKIMAELQAFQKCSFMDVNSNSHAEPSRADSHVKDTRSGATVPPKEKKNLEFFHEDVRKSDVEYENGPQMEFQKGSSGAPQTSRMPVPMSAKNRPGTLDKPGKQSKLQDPRQYRQANGSAKKSGGDFKPTSPSLPASKIPALSPSSGKSSSLPSSSGDSSNLPNPPATKPSIASNPLSPQTGPPAHSASLIPSVSNGSLKFQSLTHTGKGHHLSFSPQSQNGRAPPPLSFSSSPPSPASSVSLNQGAKGTRTIHTPSLTSYKAQNGSSSKATPSTAKETS>sp|Q92835|SHIP1_HUMAN Phosphatidylinositol 3,4,5-trisphosphate 5-phosphatase 1 OS=Homo sapiens OX=9606 GN=INPP5D PE=1 SV=2MVPCWNHGNITRSKAEELLSRTGKDGSFLVRASESISRAYALCVLYRNCVYTYRILPNEDDKFTVQASEGVSMRFFTKLDQLIEFYKKENMGLVTHLQYPVPLEEEDTGDDPEEDTVESVVSPPELPPRNIPLTASSCEAKEVPFSNENPRATETSRPSLSETLFQRLQSMDTSGLPEEHLKAIQDYLSTQLAQDSEFVKTGSSSLPHLKKLTTLLCKELYGEVIRTLPSLESLQRLFDQQLSPGLRPRPQVPGEANPINMVSKLSQLTSLLSSIEDKVKALLHEGPESPHRPSLIPPVTFEVKAESLGIPQKMQLKVDVESGKLIIKKSKDGSEDKFYSHKKILQLIKSQKFLNKLVILVETEKEKILRKEYVFADSKKREGFCQLLQQMKNKHSEQPEPDMITIFIGTWNMGNAPPPKKITSWFLSKGQGKTRDDSADYIPHDIYVIGTQEDPLSEKEWLEILKHSLQEITSVTFKTVAIHTLWNIRIVVLAKPEHENRISHICTDNVKTGIANTLGNKGAVGVSFMFNGTSLGFVNSHLTSGSEKKLRRNQNYMNILRFLALGDKKLSPFNITHRFTHLFWFGDLNYRVDLPTWEAETIIQKIKQQQYADLLSHDQLLTERREQKVFLHFEEEEITFAPTYRFERLTRDKYAYTKQKATGMKYNLPSWCDRVLWKSYPLVHVVCQSYGSTSDIMTSDHSPVFATFEAGVTSQFVSKNGPGTVDSQGQIEFLRCYATLKTKSQTKFYLEFHSSCLESFVKSQEGENEEGSEGELVVKFGETLPKLKPIISDPEYLLDQHILISIKSSDSDESYGEGCIALRLEATETQLPIYTPLTHHGELTGHFQGEIKLQTSQGKTREKLYDFVKTERDESSGPKTLKSLTSHDPMKQWEVTSRAPPCSGSSITEIINPNYMGVGPFGPPMPLHVKQTLSPDQQPTAWSYDQPPKDSPLGPCRGESPPTPPGQPPISPKKFLPSTANRGLPPRTQESRPSDLGKNAGDTLPQEDLPLTKPEMFENPLYGSLSSFPKPAPRKDQESPKMPRKEPPPCPEPGILSPSIVLTKAQEADRGEGPGKQVPAPRLRSFTCSSSAEGRAAGGDKSQGKPKTPVSSQAPVPAKRPIKPSRSEINQQTPPTPTPRPPLPVKSPAVLHLQHSKGRDYRDNTELPHHGKHRPEEGPPGPLGRTAMQ>sp|Q92835-2|SHIP1_HUMAN Isoform 2 of Phosphatidylinositol 3,4,5-trisphosphate 5-phosphatase 1 OS=Homo sapiens OX=9606 GN=INPP5DMVPCWNHGNITRSKAEELLSRTGKDGSFLVRASESISRAYALCVLYRNCVYTYRILPNEDDKFTVQASEGVSMRFFTKLDQLIEFYKKENMGLVTHLQYPVPLEEEDTGDDPEEDTESVVSPPELPPRNIPLTASSCEAKEVPFSNENPRATETSRPSLSETLFQRLQSMDTSGLPEEHLKAIQDYLSTQLAQDSEFVKTGSSSLPHLKKLTTLLCKELYGEVIRTLPSLESLQRLFDQQLSPGLRPRPQVPGEANPINMVSKLSQLTSLLSSIEDKVKALLHEGPESPHRPSLIPPVTFEVKAESLGIPQKMQLKVDVESGKLIIKKSKDGSEDKFYSHKKILQLIKSQKFLNKLVILVETEKEKILRKEYVFADSKKREGFCQLLQQMKNKHSEQPEPDMITIFIGTWNMGNAPPPKKITSWFLSKGQGKTRDDSADYIPHDIYVIGTQEDPLSEKEWLEILKHSLQEITSVTFKTVAIHTLWNIRIVVLAKPEHENRISHICTDNVKTGIANTLGNKGAVGVSFMFNGTSLGFVNSHLTSGSEKKLRRNQNYMNILRFLALGDKKLSPFNITHRFTHLFWFGDLNYRVDLPTWEAETIIQKIKQQQYADLLSHDQLLTERREQKVFLHFEEEEITFAPTYRFERLTRDKYAYTKQKATGMKYNLPSWCDRVLWKSYPLVHVVCQSYGSTSDIMTSDHSPVFATFEAGVTSQFVSKNGPGTVDSQGQIEFLRCYATLKTKSQTKFYLEFHSSCLESFVKSQEGENEEGSEGELVVKFGETLPKLKPIISDPEYLLDQHILISIKSSDSDESYGEGCIALRLEATETQLPIYTPLTHHGELTGHFQGEIKLQTSQGKTREKLYDFVKTERDESSGPKTLKSLTSHDPMKQWEVTSRAPPCSGSSITEIINPNYMGVGPFGPPMPLHVKQTLSPDQQPTAWSYDQPPKDSPLGPCRGESPPTPPGQPPISPKKFLPSTANRGLPPRTQESRPSDLGKNAGDTLPQEDLPLTKPEMFENPLYGSLSSFPKPAPRKDQESPKMPRKEPPPCPEPGILSPSIVLTKAQEADRGEGPGKQVPAPRLRSFTCSSSAEGRAAGGDKSQGKPKTPVSSQAPVPAKRPIKPSRSEINQQTPPTPTPRPPLPVKSPAVLHLQHSKGRDYRDNTELPHHGKHRPEEGPPGPLGRTAMQ>sp|Q92835-3|SHIP1_HUMAN Isoform 3 of Phosphatidylinositol 3,4,5-trisphosphate 5-phosphatase 1 OS=Homo sapiens OX=9606 GN=INPP5DMFTLSPAPREVIRTLPSLESLQRLFDQQLSPGLRPRPQVPGEANPINMVSKLSQLTSLLSSIEDKVKALLHEGPESPHRPSLIPPVTFEVKAESLGIPQKMQLKVDVESGKLIIKKSKDGSEDKFYSHKKILQLIKSQKFLNKLVILVETEKEKILRKEYVFADSKKREGFCQLLQQMKNKHSEQPEPDMITIFIGTWNMGNAPPPKKITSWFLSKGQGKTRDDSADYIPHDIYVIGTQEDPLSEKEWLEILKHSLQEITSVTFKTVAIHTLWNIRIVVLAKPEHENRISHICTDNVKTGIANTLGNKGAVGVSFMFNGTSLGFVNSHLTSGSEKKLRRNQNYMNILRFLALGDKKLSPFNITHRFTHLFWFGDLNYRVDLPTWEAETIIQKIKQQQYADLLSHDQLLTERREQKVFLHFEEEEITFAPTYRFERLTRDKYAYTKQKATGMKYNLPSWCDRVLWKSYPLVHVVCQSYGSTSDIMTSDHSPVFATFEAGVTSQFVSKNGPGTVDSQGQIEFLRCYATLKTKSQTKFYLEFHSSCLESFVKSQEGENEEGSEGELVVKFGETLPKLKPIISDPEYLLDQHILISIKSSDSDESYGEGCIALRLEATETQLPIYTPLTHHGELTGHFQGEIKLQTSQGKTREKLYDFVKTERDESSGPKTLKSLTSHDPMKQWEVTSRAPPCSGSSITEIINPNYMGVGPFGPPMPLHVKQTLSPDQQPTAWSYDQPPKDSPLGPCRGESPPTPPGQPPISPKKFLPSTANRGLPPRTQESRPSDLGKNAGDTLPQEDLPLTKPEMFENPLYGSLSSFPKPAPRKDQESPKMPRKEPPPCPEPGILSPSIVLTKAQEADRGEGPGKQVPAPRLRSFTCSSSAEGRAAGGDKSQGKPKTPVSSQAPVPAKRPIKPSRSEINQQTPPTPTPRPPLPVKSPAVLHLQHSKGRDYRDNTELPHHGKHRPEEGPPGPLGRTAMQ>sp|O15357|SHIP2_HUMAN Phosphatidylinositol 3,4,5-trisphosphate 5-phosphatase 2 OS=Homo sapiens OX=9606 GN=INPPL1 PE=1 SV=2MASACGAPGPGGALGSQAPSWYHRDLSRAAAEELLARAGRDGSFLVRDSESVAGAFALCVLYQKHVHTYRILPDGEDFLAVQTSQGVPVRRFQTLGELIGLYAQPNQGLVCALLLPVEGEREPDPPDDRDASDGEDEKPPLPPRSGSTSISAPTGPSSPLPAPETPTAPAAESAPNGLSTVSHDYLKGSYGLDLEAVRGGASHLPHLTRTLATSCRRLHSEVDKVLSGLEILSKVFDQQSSPMVTRLLQQQNLPQTGEQELESLVLKLSVLKDFLSGIQKKALKALQDMSSTAPPAPQPSTRKAKTIPVQAFEVKLDVTLGDLTKIGKSQKFTLSVDVEGGRLVLLRRQRDSQEDWTTFTHDRIRQLIKSQRVQNKLGVVFEKEKDRTQRKDFIFVSARKREAFCQLLQLMKNKHSKQDEPDMISVFIGTWNMGSVPPPKNVTSWFTSKGLGKTLDEVTVTIPHDIYVFGTQENSVGDREWLDLLRGGLKELTDLDYRPIAMQSLWNIKVAVLVKPEHENRISHVSTSSVKTGIANTLGNKGAVGVSFMFNGTSFGFVNCHLTSGNEKTARRNQNYLDILRLLSLGDRQLNAFDISLRFTHLFWFGDLNYRLDMDIQEILNYISRKEFEPLLRVDQLNLEREKHKVFLRFSEEEISFPPTYRYERGSRDTYAWHKQKPTGVRTNVPSWCDRILWKSYPETHIICNSYGCTDDIVTSDHSPVFGTFEVGVTSQFISKKGLSKTSDQAYIEFESIEAIVKTASRTKFFIEFYSTCLEEYKKSFENDAQSSDNINFLKVQWSSRQLPTLKPILADIEYLQDQHLLLTVKSMDGYESYGECVVALKSMIGSTAQQFLTFLSHRGEETGNIRGSMKVRVPTERLGTRERLYEWISIDKDEAGAKSKAPSVSRGSQEPRSGSRKPAFTEASCPLSRLFEEPEKPPPTGRPPAPPRAAPREEPLTPRLKPEGAPEPEGVAAPPPKNSFNNPAYYVLEGVPHQLLPPEPPSPARAPVPSATKNKVAITVPAPQLGHHRHPRVGEGSSSDEESGGTLPPPDFPPPPLPDSAIFLPPSLDPLPGPVVRGRGGAEARGPPPPKAHPRPPLPPGPSPASTFLGEVASGDDRSCSVLQMAKTLSEVDYAPAGPARSALLPGPLELQPPRGLPSDYGRPLSFPPPRIRESIQEDLAEEAPCLQGGRASGLGEAGMSAWLRAIGLERYEEGLVHNGWDDLEFLSDITEEDLEEAGVQDPAHKRLLLDTLQLSK>sp|O15357-2|SHIP2_HUMAN Isoform 2 of Phosphatidylinositol 3,4,5-trisphosphate 5-phosphatase 2 OS=Homo sapiens OX=9606 GN=INPPL1MVTRLLQQQNLPQTGEQELESLVLKLSVLKDFLSGIQKKALKALQDMSSTAPPAPQPSTRKAKTIPVQAFEVKLDVTLGDLTKIGKSQKFTLSVDVEGGRLVLLRRQRDSQEDWTTFTHDRIRQLIKSQRVQNKLGVVFEKEKDRTQRKDFIFVSARKREAFCQLLQLMKNKHSKQDEPDMISVFIGTWNMGSVPPPKNVTSWFTSKGLGKTLDEVTVTIPHDIYVFGTQENSVGDREWLDLLRGGLKELTDLDYRPIAMQSLWNIKVAVLVKPEHENRISHVSTSSVKTGIANTLGNKGAVGVSFMFNGTSFGFVNCHLTSGNEKTARRNQNYLDILRLLSLGDRQLNAFDISLRFTHLFWFGDLNYRLDMDIQEILNYISRKEFEPLLRVDQLNLEREKHKVFLRFSEEEISFPPTYRYERGSRDTYAWHKQKPTGVRTNVPSWCDRILWKSYPETHIICNSYGCTDDIVTSDHSPVFGTFEVGVTSQFISKKGLSKTSDQAYIEFESIEAIVKTASRTKFFIEFYSTCLEEYKKSFENDAQSSDNINFLKVQWSSRQLPTLKPILADIEYLQDQHLLLTVKSMDGYESYGECVVALKSMIGSTAQQFLTFLSHRGEETGNIRGSMKVRVPTERLGTRERLYEWISIDKDEAGAKSKAPSVSRGSQEPRSGSRKPAFTEASCPLSRLFEEPEKPPPTGRPPAPPRAAPREEPLTPRLKPEGAPEPEGVAAPPPKNSFNNPAYYVLEGVPHQLLPPEPPSPARAPVPSATKNKVAITVPAPQLGHHRHPRVGEGSSSDEESGGTLPPPDFPPPPLPDSAIFLPPSLDPLPGPVVRGRGGAEARGPPPPKAHPRPPLPPGPSPASTFLGEVASGDDRSCSVLQMAKTLSEVDYAPAGPARSALLPGPLELQPPRGLPSDYGRPLSFPPPRIRESIQEDLAEEAPCLQGGRASGLGEAGMSAWLRAIGLERYEEGLVHNGWDDLEFLSDITEEDLEEAGVQDPAHKRLLLDTLQLSK>sp|O75920|SERF1_HUMAN Small EDRK-rich factor 1 OS=Homo sapiens OX=9606GN=SERF1A PE=1 SV=1MARGNQRELARQKNMKKTQEISKGKRKEDSLTASQRKQSSGGQKSESKMSAGPHLPLKAPRENPCFPLPAAGGSRYYLAYGSITPISAFVFVVFFSVFFPSFYEDFCCWI>sp|O75920-2|SERF1_HUMAN Isoform Short of Small EDRK-rich factor 1OS=Homo sapiens OX=9606 GN=SERF1AMARGNQRELARQKNMKKTQEISKGKRKEDSLTASQRKQRDSEIMQEKQKAANEKKSMQTREK>sp|P84101|SERF2_HUMAN Small EDRK-rich factor 2 OS=Homo sapiens OX=9606GN=SERF2 PE=1 SV=1MTRGNQRELARQKNMKKQSDSVKGKRRDDGLSAAARKQRDSEIMQQKQKKANEKKEEPK>sp|P84101-2|SERF2_HUMAN Isoform 2 of Small EDRK-rich factor 2 OS=Homosapiens OX=9606 GN=SERF2MTRGNQRELARQKNMKKQSDSVKGKRRDDGLSAAARKQRVGVQQPNAELSPIHFHLILCALHPPASCPFCPLVPPSAPSSLPPGTRRSCSRSRKRQTRRRRNPSSFVASCPTLLPFACVPGASPTTLAFPPVVLTGPSTDGIPFALSLQRVPFVLPSPQVASLPLGHSRG>sp|P84101-3|SERF2_HUMAN Isoform 3 of Small EDRK-rich factor 2 OS=Homosapiens OX=9606 GN=SERF2MTRGNQRELARQKNMKKQSDSVKGKRRDDGLSAAARKQSAPSSLPPGTRRSCSRSRKRQTRRRRNPSSFVASCPTLLPFACVPGASPTTLAFPPVVLTGPSTDGIPFALSLQRVPFVLPSPQVASLPLGHSRG>sp|P84101-4|SERF2_HUMAN Isoform 4 of Small EDRK-rich factor 2 OS=Homosapiens OX=9606 GN=SERF2MKKQSDSVKGKRRDDGLSAAARKQRDSEIMQQKQKKANEKKEEPK>sp|Q8TBC3|SHKB1_HUMAN SH3KBP1-binding protein 1 OS=Homo sapiens OX=9606GN=SHKBP1 PE=1 SV=2MAAAATAAEGVPSRGPPGEVIHLNVGGKRFSTSRQTLTWIPDSFFSSLLSGRISTLKDETGAIFIDRDPTVFAPILNFLRTKELDPRGVHGSSLLHEAQFYGLTPLVRRLQLREELDRSSCGNVLFNGYLPPPVFPVKRRNRHSLVGPQQLGGRPAPVRRSNTMPPNLGNAGLLGRMLDEKTPPSPSGQPEEPGMVRLVCGHHNWIAVAYTQFLVCYRLKEASGWQLVFSSPRLDWPIERLALTARVHGGALGEHDKMVAAATGSEILLWALQAEGGGSEIGVFHLGVPVEALFFVGNQLIATSHTGRIGVWNAVTKHWQVQEVQPITSYDAAGSFLLLGCNNGSIYYVDVQKFPLRMKDNDLLVSELYRDPAEDGVTALSVYLTPKTSDSGNWIEIAYGTSSGGVRVIVQHPETVGSGPQLFQTFTVHRSPVTKIMLSEKHLISVCADNNHVRTWSVTRFRGMISTQPGSTPLASFKILALESADGHGGCSAGNDIGPYGERDDQQVFIQKVVPSASQLFVRLSSTGQRVCSVRSVDGSPTTAFTVLECEGSRRLGSRPRRYLLTGQANGSLAMWDLTTAMDGLGQAPAGGLTEQELMEQLEHCELAPPAPSAPSWGCLPSPSPRISLTSLHSASSNTSLSGHRGSPSPPQAEARRRGGGSFVERCQELVRSGPDLRRPPTPAPWPSSGLGTPLTPPKMKLNETSF>sp|Q8TBC3-2|SHKB1_HUMAN Isoform 2 of SH3KBP1-binding protein 1 OS=Homosapiens OX=9606 GN=SHKBP1MAAAATAAEGVPSRGPPGEVIHLNVGGKRFSTSRQTLTWIPDSFFSSLLSGRISTLKDETGAIFIDRDPTVFAPILNFLRTKELDPRGVHGSSLLHEAQFYGLTPLVRRLQLREELDRSSCGNVLFNGYLPPPVFPVKRRNRHSLVGPQQLGGRPAPVRRSNTMPPNLGNAGLLGRMLDEKTPPSPSGQPEEPGMVRLVCGHHNWIAVAYTQFLVCYRLKEASGWQLVFSSPRLDWPIERLALTARVHGGALGEHDKMVAAATGSEILLWALQAEGGGSEIGAHRGVECRHQALAGPGGAAHHQL>sp|P30825|SL7A1_HUMAN High affinity cationic amino acid transporter 1OS=Homo sapiens OX=9606 GN=SLC7A1 PE=1 SV=1MGCKVLLNIGQQMLRRKVVDCSREETRLSRCLNTFDLVALGVGSTLGAGVYVLAGAVARENAGPAIVISFLIAALASVLAGLCYGEFGARVPKTGSAYLYSYVTVGELWAFITGWNLILSYIIGTSSVARAWSATFDELIGRPIGEFSRTHMTLNAPGVLAENPDIFAVIIILILTGLLTLGVKESAMVNKIFTCINVLVLGFIMVSGFVKGSVKNWQLTEEDFGNTSGRLCLNNDTKEGKPGVGGFMPFGFSGVLSGAATCFYAFVGFDCIATTGEEVKNPQKAIPVGIVASLLICFIAYFGVSAALTLMMPYFCLDNNSPLPDAFKHVGWEGAKYAVAVGSLCALSASLLGSMFPMPRVIYAMAEDGLLFKFLANVNDRTKTPIIATLASGAVAAVMAFLFDLKDLVDLMSIGTLLAYSLVAACVLVLRYQPEQPNLVYQMASTSDELDPADQNELASTNDSQLGFLPEAEMFSLKTILSPKNMEPSKISGLIVNISTSLIAVLIITFCIVTVLGREALTKGALWAVFLLAGSALLCAVVTGVIWRQPESKTKLSFKVPFLPVLPILSIFVNVYLMMQLDQGTWVRFAVWMLIGFIIYFGYGLWHSEEASLDADQARTPDGNLDQCK>sp|Q9NQF3|SERHL_HUMAN Serine hydrolase-like protein OS=Homo sapiensOX=9606 GN=SERHL PE=5 SV=1MAENAAPGLISELKLAVPWGHIAAKAWGSLQGPPVLCLHGWLDNASSFDRLIPLLPQDFYYVAMDFGGHGLSSHYSPGVPYYLQTFVSEIRRVVAALKWNRFSILGHSFGGVVGGMFFCTFPEMVDKLILLDTPLFLLESDEMENLLTYKRRAIEHVLQVEASQEPSHVFSLKQLLQRQRTALTSSAGSCVRIPSGSCRPMSC>sp|Q6UWV7|SHL2A_HUMAN Protein shisa-like-2A OS=Homo sapiens OX=9606GN=SHISAL2A PE=1 SV=2MSGACTSYVSAEQEVVRGFSCPRPGGEAAAVFCCGFRDHKYCCDDPHSFFPYEHSYMWWLSIGALIGLSVAAVVLLAFIVTACVLCYLFISSKPHTKLDLGLSLQTAGPEEVSPDCQGVNTGMAAEVPKVSPLQQSYSCLNPQLESNEGQAVNSKRLLHHCFMATVTTSDIPGSPEEASVPNPDLCGPVP>sp|Q6UWV7-2|SHL2A_HUMAN Isoform 2 of Protein shisa-like-2A OS=Homosapiens OX=9606 GN=SHISAL2AMSGACTSYVSAEQEVVRGFSCPRPGGEAAAVFCCGFRDHKYCCDDPHSFFPYEHSYMWWLSIGALIGLSVAAVVLLAFIVTACVLCYLFISSKPHTKLDLGLSLQTAGPVQVATNKRNQTVLTLKGLTWRTRQAHKWPGGPVVALHGALGRKK>sp|A6NKW6|SHL2B_HUMAN Protein shisa-like-2B OS=Homo sapiens OX=9606GN=SHISAL2B PE=3 SV=2MSEASRLCSGYYSLNQSFVEPFQCPRRGEGAALQYCCGFADLKYCCSEPGSYFPYKHSYMWSLSIGALIGLGIAALVLLAFVISVCVLCYLFLYTKPQRLDTGLKLQHLEASSTQEGKSNGKTKALNSNAASNATNETYYEADDIIQEKTMDATQIHIAY>sp|P19634|SL9A1_HUMAN Sodium/hydrogen exchanger 1 OS=Homo sapiensOX=9606 GN=SLC9A1 PE=1 SV=2MVLRSGICGLSPHRIFPSLLVVVALVGLLPVLRSHGLQLSPTASTIRSSEPPRERSIGDVTTAPPEVTPESRPVNHSVTDHGMKPRKAFPVLGIDYTHVRTPFEISLWILLACLMKIGFHVIPTISSIVPESCLLIVVGLLVGGLIKGVGETPPFLQSDVFFLFLLPPIILDAGYFLPLRQFTENLGTILIFAVVGTLWNAFFLGGLMYAVCLVGGEQINNIGLLDNLLFGSIISAVDPVAVLAVFEEIHINELLHILVFGESLLNDAVTVVLYHLFEEFANYEHVGIVDIFLGFLSFFVVALGGVLVGVVYGVIAAFTSRFTSHIRVIEPLFVFLYSYMAYLSAELFHLSGIMALIASGVVMRPYVEANISHKSHTTIKYFLKMWSSVSETLIFIFLGVSTVAGSHHWNWTFVISTLLFCLIARVLGVLGLTWFINKFRIVKLTPKDQFIIAYGGLRGAIAFSLGYLLDKKHFPMCDLFLTAIITVIFFTVFVQGMTIRPLVDLLAVKKKQETKRSINEEIHTQFLDHLLTGIEDICGHYGHHHWKDKLNRFNKKYVKKCLIAGERSKEPQLIAFYHKMEMKQAIELVESGGMGKIPSAVSTVSMQNIHPKSLPSERILPALSKDKEEEIRKILRNNLQKTRQRLRSYNRHTLVADPYEEAWNQMLLRRQKARQLEQKINNYLTVPAHKLDSPTMSRARIGSDPLAYEPKEDLPVITIDPASPQSPESVDLVNEELKGKVLGLSRDPAKVAEEDEDDDGGIMMRSKETSSPGTDDVFTPAPSDSPSSQRIQRCLSDPGPHPEPGEGEPFFPKGQ>sp|P19634-2|SL9A1_HUMAN Isoform 2 of Sodium/hydrogen exchanger 1 OS=Homosapiens OX=9606 GN=SLC9A1MVLRSGICGLSPHRIFPSLLVVVALVGLLPVLRSHGLQLSPTASTIRSSEPPRERSIGDVTTAPPEVTPESRPVNHSVTDHGMKPRKAFPVLGIDYTHVRTPFEISLWILLACLMKIGFHVIPTISSIVPESCLLIVVGLLVGGLIKGVGETPPFLQSDVFFLFLLPPIILDAGYFLPLRQFTENLGTILIFAVVGTLWNAFFLGGLMYAVCLVGGEQINNIGLLDNLLFGSIISAVDPVAVLAVFEEIHINELLHILVFGESLLNDAVTVVLYHLFEEFANYEHVGIVDIFLGFLSFFVVALGGVLVGVVYGVIAAFTSRFTSHIRVIEPLFVFLYSYMAYLSAELFHLSGIMALIASGVVMRPYVEANISHKSHTTIKYFLKMWSSVSETLIFIFLGVSTVAGSHHWNWTFVISTLLFCLIARVLGVLGLTWFINKFRIVKLTPKDQFIIAYGGLRGAIAFSLGYLLDKKHFPMCDLFLTAIITVIFFTVFVQVLGQGRAGPCLGDPHRLFPWKERKACDLKCDSSPSSTTNLLCDLGRATPPFWASVSSIVK>sp|Q9NR46|SHLB2_HUMAN Endophilin-B2 OS=Homo sapiens OX=9606 GN=SH3GLB2PE=1 SV=1MDFNMKKLASDAGIFFTRAVQFTEEKFGQAEKTELDAHFENLLARADSTKNWTEKILRQTEVLLQPNPSARVEEFLYEKLDRKVPSRVTNGELLAQYMADAASELGPTTPYGKTLIKVAEAEKQLGAAERDFIHTASISFLTPLRNFLEGDWKTISKERRLLQNRRLDLDACKARLKKAKAAEAKATTVPDFQETRPRNYILSASASALWNDEVDKAEQELRVAQTEFDRQAEVTRLLLEGISSTHVNHLRCLHEFVKSQTTYYAQCYRHMLDLQKQLGRFPGTFVGTTEPASPPLSSTSPTTAAATMPVVPSVASLAPPGEASLCLEEVAPPASGTRKARVLYDYEAADSSELALLADELITVYSLPGMDPDWLIGERGNKKGKVPVTYLELLS>sp|Q9NR46-2|SHLB2_HUMAN Isoform 2 of Endophilin-B2 OS=Homo sapiensOX=9606 GN=SH3GLB2MDFNMKKLASDAGIFFTRAVQFTEEKFGQAEKTELDAHFENLLARADSTKNWTEKILRQTEVLLQPNPSARVEEFLYEKLDRKVPSRVTNGELLAQYMADAASELGPTTPYGKTLIKVAEAEKQLGAAERDFIHTASISFLTPLRNFLEGDWKTISKERRLLQNRRLDLDACKARLKKAKAAEAKATCEGDTVPDFQETRPRNYILSASASALWNDEVDKAEQELRVAQTEFDRQAEVTRLLLEGISSTHVNHLRCLHEFVKSQTTYYAQCYRHMLDLQKQLGSSQGAIFPGTFVGTTEPASPPLSSTSPTTAAATMPVVPSVASLAPPGEASLCLEEVAPPASGTRKARVLYDYEAADSSELALLADELITVYSLPGMDPDWLIGERGNKKGKVPVTYLELLS>sp|P62263|RS14_HUMAN 40S ribosomal protein S14 OS=Homo sapiens OX=9606GN=RPS14 PE=1 SV=3MAPRKGKEKKEEQVISLGPQVAEGENVFGVCHIFASFNDTFVHVTDLSGKETICRVTGGMKVKADRDESSPYAAMLAAQDVAQRCKELGITALHIKLRATGGNRTKTPGPGAQSALRALARSGMKIGRIEDVTPIPSDSTRRKGGRRGRRL>sp|Q5JNZ5|RS26L_HUMAN Putative 40S ribosomal protein S26-like 1 OS=Homosapiens OX=9606 GN=RPS26P11 PE=5 SV=1MTKKRRNNSHAKKGRGHVQPIRCTNCVRCVPTDKAIKKFVIRNIVEAAAVRDISEVSVFDAYVLPKLYVKLHYCVSCAIHSKVVRNRSREACKDRTPPPRFRPAGAAPRPPPKPM>sp|P62701|RS4X_HUMAN 40S ribosomal protein S4, X isoform OS=Homo sapiensOX=9606 GN=RPS4X PE=1 SV=2MARGPKKHLKRVAAPKHWMLDKLTGVFAPRPSTGPHKLRECLPLIIFLRNRLKYALTGDEVKKICMQRFIKIDGKVRTDITYPAGFMDVISIDKTGENFRLIYDTKGRFAVHRITPEEAKYKLCKVRKIFVGTKGIPHLVTHDARTIRYPDPLIKVNDTIQIDLETGKITDFIKFDTGNLCMVTGGANLGRIGVITNRERHPGSFDVVHVKDANGNSFATRLSNIFVIGKGNKPWISLPRGKGIRLTIAEERDKRLAAKQSSG>sp|Q9BVN2|RUSC1_HUMAN AP-4 complex accessory subunit RUSC1 OS=Homosapiens OX=9606 GN=RUSC1 PE=1 SV=3MLSPQRALLCNLNHIHLQHVSLGLHLSRRPELQEGPLSTPPPPGDTGGKESRGPCSGTLVDANSNSPAVPCRCCQEHGPGLENRQDPSQEEEGAASPSDPGCSSSLSSCSDLSPDESPVSVYLRDLPGDEDAHPQPSIIPLEQGSPLASAGPGTCSPDSFCCSPDSCSGASSSPDPGLDSNCNALTTCQDVPSPGLEEEDERAEQDLPTSELLEADDGKIDAGKTEPSWKINPIWKIDTEKTKAEWKTTENNNTGWKNNGNVNSSWKSEPEKFDSGWKTNTRITDSGSKTDAGKIDGGWRSDVSEEPVPHRTITSFHELAQKRKRGPGLPLVPQAKKDRSDWLIVFSPDTELPPSGSPGGSSAPPREVTTFKELRSRSRAPAPPVPPRDPPVGWALVPPRPPPPPVPPRRKKNRPGLQPIAEGQSEEGRAVSPAAGEEAPAAKEPGAQAGLEVRSSWSFAGVPGAQRLWMAEAQSGTGQLQEQKKGLLIAVSVSVDKIISHFGAARNLVQKAQLGDSRLSPDVGHLVLTTLCPALHALVADGLKPFRKDLITGQRRSSPWSVVEASVKPGSSTRSLGTLYSQVSRLAPLSSSRSRFHAFILGLLNTKQLELWFSSLQEDAGLLSLLYLPTGFFSLARGGCPSLSTELLLLLQPLSVLTFHLDLLFEHHHHLPLGPPQAPAPPGPPPALQQTMQAMLHFGGRLAQSLRGTSKEAASDPSDSPNLPTPGSWWEQLTQASRVYASGGTEGFPLSRWAPGRHGTAAEEGAQERPLPTDEMAPGRGLWLGRLFGVPGGPAENENGALKSRRPSSWLPPTVSVLALVKRGAPPEMPSPQELEASAPRMVQTHRAVRALCDHTAARPDQLSFRRGEVLRVITTVDEDWLRCGRDGMEGLVPVGYTSLVL>sp|Q9BVN2-2|RUSC1_HUMAN Isoform 2 of AP-4 complex accessory subunitRUSC1 OS=Homo sapiens OX=9606 GN=RUSC1MAEAQSGTGQLQEQKKGLLIAVSVSVDKIISHFGAARNLVQKAQLGDSRLSPDVGHLVLTTLCPALHALVADGLKPFRKDLITGQRRSSPWSVVEASVKPGSSTRSLGTLYSQVSRLAPLSSSRSRFHAFILGLLNTKQLELWFSSLQEDAGLLSLLYLPTGFFSLARGGCPSLSTELLLLLQPLSVLTFHLDLLFEHHHHLPLGPPQAPAPPGPPPALQQTMQAMLHFGGRLAQSLRGTSKEAASDPSDSPNLPTPGSWWEQLTQASRVYASGGTEGFPLSRWAPGRHGTAAEEGAQERPLPTDEMAPGRGLWLGRLFGVPGGPAENENGALKSRRPSSWLPPTVSVLALVKRGAPPEMPSPQELEASAPRMVQTHRAVRALCDHTAARPDQLSFRRGEVLRVITTVDEDWLRCGRDGMEGLVPVGYTSLVL>sp|Q9BVN2-3|RUSC1_HUMAN Isoform 3 of AP-4 complex accessory subunitRUSC1 OS=Homo sapiens OX=9606 GN=RUSC1MPPTCSPGLRRQDWAPGRCAGLHLPPRAPSSPALQALAGQAGVRSSWSFAGVPGAQRLWMAEAQSGTGQLQEQKKGLLIAVSVSVDKIISHFGAARNLVQKAQLGDSRLSPDVGHLVLTTLCPALHALVADGLKPFRKDLITGQRRSSPWSVVEASVKPGSSTRSLGTLYSQVSRLAPLSSSRSRFHAFILGLLNTKQLELWFSSLQEDAGLLSLLYLPTGFFSLARGGCPSLSTELLLLLQPLSVLTFHLDLLFEHHHHLPLGPPQAPAPPGPPPALQQTMQAMLHFGGRLAQSLRGTSKEAASDPSDSPNLPTPGSWWEQLTQASRVYASGGTEGFPLSRWAPGRHGTAAEEGAQERPLPTDEMAPGRGLWLGRLFGVPGGPAENENGALKSRRPSSWLPPTVSVLALVKRGAPPEMPSPQELEASAPRMVQTHRAVRALCDHTAARPDQLSFRRGEVLRVITTVDEDWLRCGRDGMEGLVPVGYTSLVL>sp|Q9BVN2-4|RUSC1_HUMAN Isoform 4 of AP-4 complex accessory subunitRUSC1 OS=Homo sapiens OX=9606 GN=RUSC1MLSPQRALLCNLNHIHLQHVSLGLHLSRRPELQEGPLSTPPPPGDTGGKESRGPCSGTLVDANSNSPAVPCRCCQEHGPGLENRQDPSQEEEGAASPSDPGCSSSLSSCSDLSPDESPVSVYLRDLPGDEDAHPQPSIIPLEQGSPLASAGPGTCSPDSFCCSPDSCSGASSSPDPGLDSNCNALTTCQDVPSPGLEEEDERAEQDLPTSELLEADDGKIDAGKTEPSWKINPIWKIDTEKTKAEWKTTENNNTGWKNNGNVNSSWKSEPEKFDSGWKTNTRITDSGSKTDAGKIDGGWRSDVSEEPVPHRTITSFHELAQKRKRGPGLPLVPQAKKDRSDWLIVFSPDTELPPSGSPGGSSAPPREVTTFKELRSRSRAPAPPVPPRDPPVGWALVPPRPPPPPVPPRRKKNRPGLQPIAEGQSEEGRAVSPAAGEEAPAAKEPGAQAGLEVRSSWSFAGVPGAQRLWMAEAQSGTGQLQEQKKGLLIAVSVSVDKIISHFGAARNLVQKAQLGDSRLSPDVGHLVLTTLCPALHALVADGLKPFRKDLITGQRRSSPWSVVEASVKPGSSTRSLGTLYSQVSRLAPLSSSRSRFHAFILGLLNTKQLELWFSSLQEDAGSWWEQLTQASRVYASGGTEGFPLSRWAPGRHGTAAEEGAQERPLPTDEMAPGRGLWLGRLFGVPGGPAENENGALKSRRPSSWLPPTVSVLALVKRGAPPEMPSPQELEASAPRMVQTHRAVRALCDHTAARPDQLSFRRGEVLRVITTVDEDWLRCGRDGMEGLVPVGYTSLVL>sp|Q9UIY3|RWD2A_HUMAN RWD domain-containing protein 2A OS=Homo sapiensOX=9606 GN=RWDD2A PE=1 SV=1MSASVKESLQLQLLEMEMLFSMFPNQGEVKLEDVNALTNIKRYLEGTREALPPKIEFVITLQIEEPKVKIDLQVTMPHSYPYVALQLFGRSSELDRHQQLLLNKGLTSYIGTFDPGELCVCAAIQWLQDNSASYFLNRKLVYEPSTQAKPVKNTFLRMWIYSHHIYQQDLRKKILDVGKRLDVTGFCMTGKPGIICVEGFKEHCEEFWHTIRYPNWKHISCKHAESVETEGNGEDLRLFHSFEELLLEAHGDYGLRNDYHMNLGQFLEFLKKHKSEHVFQILFGIESKSSDS>sp|Q9UIY3-2|RWD2A_HUMAN Isoform 2 of RWD domain-containing protein 2AOS=Homo sapiens OX=9606 GN=RWDD2AMLWYLNLFDFHFKVKIDLQVTMPHSYPYVALQLFGRSSELDRHQQLLLNKGLTSYIGTFDPGELCVCAAIQWLQDNSASYFLNRKLVYEPSTQAKPVKNTFLRMWIYSHHIYQQDLRKKILDVGKRLDVTGFCMTGKPGIICVEGFKEHCEEFWHTIRYPNWKHISCKHAESVETEGNGEDLRLFHSFEELLLEAHGDYGLRNDYHMNLGQFLEFLKKHKSEHVFQILFGIESKSSDS>sp|Q6T310|RSLBA_HUMAN Ras-like protein family member 11A OS=Homo sapiensOX=9606 GN=RASL11A PE=1 SV=1MRPLSMSGHFLLAPIPESSSDYLLPKDIKLAVLGAGRVGKSAMIVRFLTKRFIGDYEPNTGKLYSRLVYVEGDQLSLQIQDTPGGVQIQDSLPQVVDSLSKCVQWAEGFLLVYSITDYDSYLSIRPLYQHIRKVHPDSKAPVIIVGNKGDLLHARQVQTQDGIQLANELGSLFLEISTSENYEDVCDVFQHLCKEVSKMHGLSGERRRASIIPRPRSPNMQDLKRRFKQALSPKVKAPSALG>sp|Q92737|RSLAA_HUMAN Ras-like protein family member 10A OS=Homo sapiensOX=9606 GN=RASL10A PE=1 SV=1MGGSLRVAVLGAPGVGKTAIIRQFLFGDYPERHRPTDGPRLYRPAVLLDGAVYDLSIRDGDVAGPGSSPGGPEEWPDAKDWSLQDTDAFVLVYDICSPDSFDYVKALRQRIAETRPAGAPEAPILVVGNKRDRQRLRFGPRRALAALVRRGWRCGYLECSAKYNWHVLRLFRELLRCALVRARPAHPALRLQGALHPARCSLM>sp|Q92737-2|RSLAA_HUMAN Isoform 2 of Ras-like protein family member 10AOS=Homo sapiens OX=9606 GN=RASL10AMGGSLRVAVLGAPGVGKTAIIRQFLFGDYPERHRPTDGPRLYRPAVLLDGAVYDLSIRDGDVAGPGSSPGGPEEWPDAKDWSLQDTDAFVLVYDICSPDSFDYVKALRQRIAETR>sp|Q9NZ71|RTEL1_HUMAN Regulator of telomere elongation helicase 1OS=Homo sapiens OX=9606 GN=RTEL1 PE=1 SV=2MPKIVLNGVTVDFPFQPYKCQQEYMTKVLECLQQKVNGILESPTGTGKTLCLLCTTLAWREHLRDGISARKIAERAQGELFPDRALSSWGNAAAAAGDPIACYTDIPKIIYASRTHSQLTQVINELRNTSYRPKVCVLGSREQLCIHPEVKKQESNHLQIHLCRKKVASRSCHFYNNVEEKSLEQELASPILDIEDLVKSGSKHRVCPYYLSRNLKQQADIIFMPYNYLLDAKSRRAHNIDLKGTVVIFDEAHNVEKMCEESASFDLTPHDLASGLDVIDQVLEEQTKAAQQGEPHPEFSADSPSPGLNMELEDIAKLKMILLRLEGAIDAVELPGDDSGVTKPGSYIFELFAEAQITFQTKGCILDSLDQIIQHLAGRAGVFTNTAGLQKLADIIQIVFSVDPSEGSPGSPAGLGALQSYKVHIHPDAGHRRTAQRSDAWSTTAARKRGKVLSYWCFSPGHSMHELVRQGVRSLILTSGTLAPVSSFALEMQIPFPVCLENPHIIDKHQIWVGVVPRGPDGAQLSSAFDRRFSEECLSSLGKALGNIARVVPYGLLIFFPSYPVMEKSLEFWRARDLARKMEALKPLFVEPRSKGSFSETISAYYARVAAPGSTGATFLAVCRGKASEGLDFSDTNGRGVIVTGLPYPPRMDPRVVLKMQFLDEMKGQGGAGGQFLSGQEWYRQQASRAVNQAIGRVIRHRQDYGAVFLCDHRFAFADARAQLPSWVRPHVRVYDNFGHVIRDVAQFFRVAERTMPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTGRTAPDPKLTVSTAAAQQLDPQEHLNQGRPHLSPRPPPTGDPGSQPQWGSGVPRAGKQGQHAVSAYLADARRALGSAGCSQLLAALTAYKQDDDLDKVLAVLAALTTAKPEDFPLLHRFSMFVRPHHKQRFSQTCTDLTGRPYPGMEPPGPQEERLAVPPVLTHRAPQPGPSRSEKTGKTQSKISSFLRQRPAGTVGAGGEDAGPSQSSGPPHGPAASEWGL>sp|Q9NZ71-2|RTEL1_HUMAN Isoform 1 of Regulator of telomere elongationhelicase 1 OS=Homo sapiens OX=9606 GN=RTEL1MPKIVLNGVTVDFPFQPYKCQQEYMTKVLECLQQKVNGILESPTGTGKTLCLLCTTLAWREHLRDGISARKIAERAQGELFPDRALSSWGNAAAAAGDPIACYTDIPKIIYASRTHSQLTQVINELRNTSYRPKVCVLGSREQLCIHPEVKKQESNHLQIHLCRKKVASRSCHFYNNVEEKSLEQELASPILDIEDLVKSGSKHRVCPYYLSRNLKQQADIIFMPYNYLLDAKSRRAHNIDLKGTVVIFDEAHNVEKMCEESASFDLTPHDLASGLDVIDQVLEEQTKAAQQGEPHPEFSADSPSPGLNMELEDIAKLKMILLRLEGAIDAVELPGDDSGVTKPGSYIFELFAEAQITFQTKGCILDSLDQIIQHLAGRAGVFTNTAGLQKLADIIQIVFSVDPSEGSPGSPAGLGALQSYKVHIHPDAGHRRTAQRSDAWSTTAARKRGKVLSYWCFSPGHSMHELVRQGVRSLILTSGTLAPVSSFALEMQIPFPVCLENPHIIDKHQIWVGVVPRGPDGAQLSSAFDRRFSEECLSSLGKALGNIARVVPYGLLIFFPSYPVMEKSLEFWRARDLARKMEALKPLFVEPRSKGSFSETISAYYARVAAPGSTGATFLAVCRGKASEGLDFSDTNGRGVIVTGLPYPPRMDPRVVLKMQFLDEMKGQGGAGGQFLSGQEWYRQQASRAVNQAIGRVIRHRQDYGAVFLCDHRFAFADARAQLPSWVRPHVRVYDNFGHVIRDVAQFFRVAERTMPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTGRTAPDPKLTVSTAAAQQLDPQEHLNQGRPHLSPRPPPTGDPGSQPQWGSGVPRAGKQGQHAVSAYLADARRALGSAGCSQLLAALTAYKQDDDLDKVLAVLAALTTAKPEDFPLLHRFSMFVRPHHKQRFSQTCTDLTGRPYPGMEPPGPQEERLAVPPVLTHRAPQPGPSRSEKTGKTQSKISSFLRQRPAGTVGAGGEDAGPSQSSGPPHGPAASEWGEPHGRDIAGQQATGAPGGPLSAGCVCQGCGAEDVVPFQCPACDFQRCQACWQRHLQASRMCPACHTASRKQSVMQVFWPEPHKDHEGAGGARPVAAVPGVGAACPAAGAGCTRSGRNTHLPLAGRRDRGAAGVCPVPPRHLCAAAVPPRQPHDVWPVSTAPLHAVLELPGALPLLQRPLRGA>sp|Q9NZ71-4|RTEL1_HUMAN Isoform 4 of Regulator of telomere elongationhelicase 1 OS=Homo sapiens OX=9606 GN=RTEL1MPKIVLNGVTVDFPFQPYKCQQEYMTKVLECLQQKVNGILESPTGTGKTLCLLCTTLAWREHLRDGISARKIAERAQGELFPDRALSSWGNAAAAAGDPIACYTDIPKIIYASRTHSQLTQVINELRNTSYRPKVCVLGSREQLCIHPEVKKQESNHLQIHLCRKKVASRSCHFYNNVEEKSLEQELASPILDIEDLVKSGSKHRVCPYYLSRNLKQQADIIFMPYNYLLDAKSRRAHNIDLKGTVVIFDEAHNVEKMCEESASFDLTPHDLASGLDVIDQVLEEQTKAAQQGEPHPEFSADSPSPGLNMELEDIAKLKMILLRLEGAIDAVELPGDDSGVTKPGSYIFELFAEAQITFQTKGCILDSLDQIIQHLAGRAGVFTNTAGLQKLADIIQIVFSVDPSEGSPGSPAGLGALQSYKVHIHPDAGHRRTAQRSDAWSTTAARKRGKVLSYWCFSPGHSMHELVRQGVRSLILTSGTLAPVSSFALEMQIPFPVCLENPHIIDKHQIWVGVVPRGPDGAQLSSAFDRRFSEECLSSLGKALGNIARVVPYGLLIFFPSYPVMEKSLEFWRARDLARKMEALKPLFVEPRSKGSFSETISAYYARVAAPGSTGATFLAVCRGKASEGLDFSDTNGRGVIVTGLPYPPRMDPRVVLKMQFLDEMKGQGGAGGQFLSGQEWYRQQASRAVNQAIGRVIRHRQDYGAVFLCDHRFAFADARAQLPSWVRPHVRVYDNFGHVIRDVAQFFRVAERTMPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTGNFPDALDQLCGSTSLHQEERRRIPS>sp|Q9NZ71-5|RTEL1_HUMAN Isoform 5 of Regulator of telomere elongationhelicase 1 OS=Homo sapiens OX=9606 GN=RTEL1MPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTGRTAPDPKLTVSTAAAQQLDPQEHLNQGRPHLSPRPPPTGDPGSQPQWGSGVPRAGKQGQHAVSAYLADARRALGSAGCSQLLAALTAYKQDDDLDKVLAVLAALTTAKPEDFPLLHRFSMFVRPHHKQRFSQTCTDLTGRPYPGMEPPGPQEERLAVPPVLTHRAPQPGPSRSEKTGKTQSKISSFLRQRPAGTVGAGGEDAGPSQSSGPPHGPAASEWGEPHGRDIAGQQATGAPGGPLSAGCVCQGCGAEDVVPFQCPACDFQRCQACWQRHLQASRMCPACHTASRKQSVMQVFWPEPQ>sp|Q9NZ71-6|RTEL1_HUMAN Isoform 6 of Regulator of telomere elongationhelicase 1 OS=Homo sapiens OX=9606 GN=RTEL1MPKIVLNGVTVDFPFQPYKCQQEYMTKVLECLQQKVNGILESPTGTGKTLCLLCTTLAWREHLRDGISARKIAERAQGELFPDRALSSWGNAAAAAGDPIACYTDIPKIIYASRTHSQLTQVINELRNTSYRPKVCVLGSREQLCIHPEVKKQESNHLQIHLCRKKVASRSCHFYNNVEEKSLEQELASPILDIEDLVKSGSKHRVCPYYLSRNLKQQADIIFMPYNYLLDAKSRRAHNIDLKGTVVIFDEAHNVEKMCEESASFDLTPHDLASGLDVIDQVLEEQTKAAQQGEPHPEFSADSPSPGLNMELEDIAKLKMILLRLEGAIDAVELPGDDSGVTKPGSYIFELFAEAQITFQTKGCILDSLDQIIQHLAGRAGVFTNTAGLQKLADIIQIVFSVDPSEGSPGSPAGLGALQSYKVHIHPDAGHRRTAQRSDAWSTTAARKRGKVLSYWCFSPGHSMHELVRQGVRSLILTSGTLAPVSSFALEMQIPFPVCLENPHIIDKHQIWVGVVPRGPDGAQLSSAFDRRFSEECLSSLGKALGNIARVVPYGLLIFFPSYPVMEKSLEFWRARDLARKMEALKPLFVEPRSKGSFSETISAYYARVAAPGSTGATFLAVCRGKASEGLDFSDTNGRGVIVTGLPYPPRMDPRVVLKMQFLDEMKGQGGAGGQFLSGQEWYRQQASRAVNQAIGRVIRHRQDYGAVFLCDHRFAFADARAQLPSWVRPHVRVYDNFGHVIRDVAQFFRVAERTMPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTGRTAPDPKLTVSTAAAQQLDPQEHLNQGRPHLSPRPPPTGDPGSQPQWGSGVPRAGKQGQHAVSAYLADARRALGSAGCSQLLAALTAYKQDDDLDKVLAVLAALTTAKPEDFPLLHRFSMFVRPHHKQRFSQTCTDLTGRPYPGMEPPGPQEERLAVPPVLTHRAPQPGPSRSEKTGKTQSKISSFLRQRPAGTVGAGGEDAGPSQSSGPPHGPAASEWGEPHGRDIAGQQATGAPGGPLSAGCVCQGCGAEDVVPFQCPACDFQRCQACWQRHLQASRMCPACHTASRKQSVMQVFWPEPQ>sp|Q9NZ71-7|RTEL1_HUMAN Isoform 7 of Regulator of telomere elongationhelicase 1 OS=Homo sapiens OX=9606 GN=RTEL1MPKIVLNGVTVDFPFQPYKCQQEYMTKVLECLQQKVNGILESPTGTGKTLCLLCTTLAWREHLRDGISARKIAERAQGELFPDRALSSWGNAAAAAGDPIACYTDIPKIIYASRTHSQLTQVINELRNTSYRSRCRATLWVLETAPPRPTVLSPTRPKVCVLGSREQLCIHPEVKKQESNHLQIHLCRKKVASRSCHFYNNVEEKSLEQELASPILDIEDLVKSGSKHRVCPYYLSRNLKQQADIIFMPYNYLLDAKSRRAHNIDLKGTVVIFDEAHNVEKMCEESASFDLTPHDLASGLDVIDQVLEEQTKAAQQGEPHPEFSADSPSPGLNMELEDIAKLKMILLRLEGAIDAVELPGDDSGVTKPGSYIFELFAEAQITFQTKGCILDSLDQIIQHLAGRAGVFTNTAGLQKLADIIQIVFSVDPSEGSPGSPAGLGALQSYKVHIHPDAGHRRTAQRSDAWSTTAARKRGKVLSYWCFSPGHSMHELVRQGVRSLILTSGTLAPVSSFALEMQIPFPVCLENPHIIDKHQIWVGVVPRGPDGAQLSSAFDRRFSEECLSSLGKALGNIARVVPYGLLIFFPSYPVMEKSLEFWRARDLARKMEALKPLFVEPRSKGSFSETISAYYARVAAPGSTGATFLAVCRGKASEGLDFSDTNGRGVIVTGLPYPPRMDPRVVLKMQFLDEMKGQGGAGGQFLSGQEWYRQQASRAVNQAIGRVIRHRQDYGAVFLCDHRFAFADARAQLPSWVRPHVRVYDNFGHVIRDVAQFFRVAERTMPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTGRTAPDPKLTVSTAAAQQLDPQEHLNQGRPHLSPRPPPTGDPGSQPQWGSGVPRAGKQGQHAVSAYLADARRALGSAGCSQLLAALTAYKQDDDLDKVLAVLAALTTAKPEDFPLLHRFSMFVRPHHKQRFSQTCTDLTGRPYPGMEPPGPQEERLAVPPVLTHRAPQPGPSRSEKTGKTQSKISSFLRQRPAGTVGAGGEDAGPSQSSGPPHGPAASEWGL>sp|Q9NZ71-8|RTEL1_HUMAN Isoform 8 of Regulator of telomere elongationhelicase 1 OS=Homo sapiens OX=9606 GN=RTEL1MPKIVLNGVTVDFPFQPYKCQQEYMTKVLECLQQKVNGILESPTGTGKTLCLLCTTLAWREHLRDGISARKIAERAQGELFPDRALSSWGNAAAAAGDPIACYTDIPKIIYASRTHSQLTQVINELRNTSYRPKVCVLGSREQLCIHPEVKKQESNHLQIHLCRKKVASRSCHFYNNVEEKSLEQELASPILDIEDLVKSGSKHRVCPYYLSRNLKQQADIIFMPYNYLLDAKSRRAHNIDLKGTVVIFDEAHNVEKMCEESASFDLTPHDLASGLDVIDQVLEEQTKAAQQGEPHPEFSADSPSPGLNMELEDIAKLKMILLRLEGAIDAVELPGDDSGVTKPGSYIFELFAEAQITFQTKGCILDSLDQIIQHLAGRAGVFTNTAGLQKLADIIQIVFSVDPSEGSPGSPAGLGALQSYKVHIHPDAGHRRTAQRSDAWSTTAARKRGKVLSYWCFSPGHSMHELVRQGVRSLILTSGTLAPVSSFALEMQIPFPVCLENPHIIDKHQIWVGVVPRGPDGAQLSSAFDRRFSEECLSSLGKALGNIARVVPYGLLIFFPSYPVMEKSLEFWRARDLARKMEALKPLFVEPRSKGSFSETISAYYARVAAPGSTGATFLAVCRGKASEGLDFSDTNGRGVIVTGLPYPPRMDPRVVLKMQFLDEMKGQGGAGGQFLSGQEWYRQQASRAVNQAIGRVIRHRQDYGAVFLCDHRFAFADARAQLPSWVRPHVRVYDNFGHVIRDVAQFFRVAERTMPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTERRRIPS>sp|Q9NZ71-9|RTEL1_HUMAN Isoform 9 of Regulator of telomere elongationhelicase 1 OS=Homo sapiens OX=9606 GN=RTEL1MPYNYLLDAKSRRAHNIDLKGTVVIFDEAHNVEKMCEESASFDLTPHDLASGLDVIDQVLEEQTKAAQQGEPHPEFSADSPSPGLNMELEDIAKLKMILLRLEGAIDAVELPGDDSGVTKPGSYIFELFAEAQITFQTKGCILDSLDQIIQHLAGRAGVFTNTAGLQKLADIIQIVFSVDPSEGSPGSPAGLGALQSYKVHIHPDAGHRRTAQRSDAWSTTAARKRGKVLSYWCFSPGHSMHELVRQGVRSLILTSGTLAPVSSFALEMQIPFPVCLENPHIIDKHQIWVGVVPRGPDGAQLSSAFDRRFSEECLSSLGKALGNIARVVPYGLLIFFPSYPVMEKSLEFWRARDLARKMEALKPLFVEPRSKGSFSETISAYYARVAAPGSTGATFLAVCRGKASEGLDFSDTNGRGVIVTGLPYPPRMDPRVVLKMQFLDEMKGQGGAGGQFLSGQEWYRQQASRAVNQAIGRVIRHRQDYGAVFLCDHRFAFADARAQLPSWVRPHVRVYDNFGHVIRDVAQFFRVAERTMPAPAPRATAPSVRGEDAVSEAKSPGPFFSTRKAKSLDLHVPSLKQRSSGSPAAGDPESSLCVEYEQEPVPARQRPRGLLAALEHSEQRAGSPGEEQAHSCSTLSLLSEKRPAEEPRGGRKKIRLVSHPEEPVAGAQTDRAKLFMVAVKQELSQANFATFTQALQDYKGSDDFAALAACLGPLFAEDPKKHNLLQGFYQFVRPHHKQQFEEVCIQLTGRGCGYRPEHSIPRRQRAQPVLDPTGRTAPDPKLTVSTAAAQQLDPQEHLNQGRPHLSPRPPPTGDPGSQPQWGSGVPRAGKQGQHAVSAYLADARRALGSAGCSQLLAALTAYKQDDDLDKVLAVLAALTTAKPEDFPLLHRFSMFVRPHHKQRFSQTCTDLTGRPYPGMEPPGPQEERLAVPPVLTHRAPQPGPSRSEKTGKTQSKISSFLRQRPAGTVGAGGEDAGPSQSSGPPHGPAASEWGL>sp|Q6ZR62|RTL4_HUMAN Retrotransposon Gag-like protein 4 OS=Homo sapiensOX=9606 GN=RTL4 PE=1 SV=2MEKCTKSSSTMQVEPSFLQAENLILRLQMQHPTTENTAKRGQVMPALATTVMPVPYSLEHLTQFHGDPANCSEFLTQVTTYLTALQISNPANDAQIKLFFDYLSQQLESCGIISGPDKSTLLKQYENLILEFQQSFGKPTKQEINPLMNAKFDKGDNSSQQDPATFHLLAQNLICNETNQSGQFEKALADPNQDEESVTDMMDNLPDLITQCIQLDKKHSDRPELLQSETQLPLLASLIQHQALFSPTDPPPKKGPIQLREGQLPLTPAKRARQQETQLCLYCSQSGHFTRDCLAKRSRAPATTNNTAHQ>sp|Q9UKG4|S13A4_HUMAN Solute carrier family 13 member 4 OS=Homo sapiensOX=9606 GN=SLC13A4 PE=1 SV=2MGLLQGLLRVRKLLLVVCVPLLLLPLPVLHPSSEASCAYVLIVTAVYWVSEAVPLGAAALVPAFLYPFFGVLRSNEVAAEYFKNTTLLLVGVICVAAAVEKWNLHKRIALRMVLMAGAKPGMLLLCFMCCTTLLSMWLSNTSTTAMVMPIVEAVLQELVSAEDEQLVAGNSNTEEAEPISLDVKNSQPSLELIFVNEESNADLTTLMHNENLNGVPSITNPIKTANQHQGKKQHPSQEKPQVLTPSPRKQKLNRKYRSHHDQMICKCLSLSISYSATIGGLTTIIGTSTSLIFLEHFNNQYPAAEVVNFGTWFLFSFPISLIMLVVSWFWMHWLFLGCNFKETCSLSKKKKTKREQLSEKRIQEEYEKLGDISYPEMVTGFFFILMTVLWFTREPGFVPGWDSFFEKKGYRTDATVSVFLGFLLFLIPAKKPCFGKKNDGENQEHSLGTEPIITWKDFQKTMPWEIVILVGGGYALASGSKSSGLSTWIGNQMLSLSSLPPWAVTLLACILVSIVTEFVSNPATITIFLPILCSLSETLHINPLYTLIPVTMCISFAVMLPVGNPPNAIVFSYGHCQIKDMVKAGLGVNVIGLVIVMVAINTWGVSLFHLDTYPAWARVSNITDQA>sp|P82932|RT06_HUMAN 28S ribosomal protein S6, mitochondrial OS=Homosapiens OX=9606 GN=MRPS6 PE=1 SV=3MPRYELALILKAMQRPETAATLKRTIEALMDRGAIVRDLENLGERALPYRISAHSQQHNRGGYFLVDFYAPTAAVESMVEHLSRDIDVIRGNIVKHPLTQELKECEGIVPVPLAEKLYSTKKRKK>sp|Q86YT5|S13A5_HUMAN Solute carrier family 13 member 5 OS=Homo sapiensOX=9606 GN=SLC13A5 PE=1 SV=1MASALSYVSKFKSFVILFVTPLLLLPLVILMPAKFVRCAYVIILMAIYWCTEVIPLAVTSLMPVLLFPLFQILDSRQVCVQYMKDTNMLFLGGLIVAVAVERWNLHKRIALRTLLWVGAKPARLMLGFMGVTALLSMWISNTATTAMMVPIVEAILQQMEATSAATEAGLELVDKGKAKELPGSQVIFEGPTLGQQEDQERKRLCKAMTLCICYAASIGGTATLTGTGPNVVLLGQMNELFPDSKDLVNFASWFAFAFPNMLVMLLFAWLWLQFVYMRFNFKKSWGCGLESKKNEKAALKVLQEEYRKLGPLSFAEINVLICFFLLVILWFSRDPGFMPGWLTVAWVEGETKYVSDATVAIFVATLLFIVPSQKPKFNFRSQTEEERKTPFYPPPLLDWKVTQEKVPWGIVLLLGGGFALAKGSEASGLSVWMGKQMEPLHAVPPAAITLILSLLVAVFTECTSNVATTTLFLPIFASMSRSIGLNPLYIMLPCTLSASFAFMLPVATPPNAIVFTYGHLKVADMVKTGVIMNIIGVFCVFLAVNTWGRAIFDLDHFPDWANVTHIET>sp|Q86YT5-2|S13A5_HUMAN Isoform 2 of Solute carrier family 13 member 5OS=Homo sapiens OX=9606 GN=SLC13A5MASALSYVSKFKSFVILFVTPLLLLPLVILMPAKFVRCAYVIILMAIYWCTEVIPLAVTSLMPVLLFPLFQILDSRQVCVQYMKDTNMLFLGGLIVAVAVERWNLHKRIALRTLLWVGAKPARLMLGFMGVTALLSMWISNTATTAMMVPIVEAILQQMEATSAATEAGLELVDKGKAKELPGSQVIFEGPTLGQQEDQERKRLCKAMTLCICYAASIGGTATLTGTGPNVVLLGQMNELFPDSKDLVNFASWFAFAFPNMLVMLLFAWLWLQFVYMRFNFKKSWGCGLESKKNEKAALKVLQEEYRKLGPLSFAEINVLICFFLLVILWFSRDPGFMPGWLTVAWVEGETKYVSDATVAIFVATLLFIVPSQKPKFNFRSQTEEERKTPFYPPPLLDWKVTQEKVPWGIVLLLGGGFALAKGSEASGLSVWMGKQMEPLHAVPPAAITLILSLLVAVFTECTSNVATTTLFLPIFASMVKTGVIMNIIGVFCVFLAVNTWGRAIFDLDHFPDWANVTHIET>sp|Q86YT5-3|S13A5_HUMAN Isoform 3 of Solute carrier family 13 member 5OS=Homo sapiens OX=9606 GN=SLC13A5MASALSYVSKFKSFVILFVTPLLLLPLVILMPAKFVRCAYVIILMAIYWCTEVIPLAVTSLMPVLLFPLFQILDSRQVCVQYMKDTNMLFLGGLIVAVAVERWNLHKRIALRTLLWVGAKPARNTATTAMMVPIVEAILQQMEATSAATEAGLELVDKGKAKELPGSQVIFEGPTLGQQEDQERKRLCKAMTLCICYAASIGGTATLTGTGPNVVLLGQMNELFPDSKDLVNFASWFAFAFPNMLVMLLFAWLWLQFVYMRFNFKKSWGCGLESKKNEKAALKVLQEEYRKLGPLSFAEINVLICFFLLVILWFSRDPGFMPGWLTVAWVEGETKYVSDATVAIFVATLLFIVPSQKPKFNFRSQTEEERKTPFYPPPLLDWKVTQEKVPWGIVLLLGGGFALAKGSEASGLSVWMGKQMEPLHAVPPAAITLILSLLVAVFTECTSNVATTTLFLPIFASMSRSIGLNPLYIMLPCTLSASFAFMLPVATPPNAIVFTYGHLKVADMVKTGVIMNIIGVFCVFLAVNTWGRAIFDLDHFPDWANVTHIET>sp|Q86YT5-4|S13A5_HUMAN Isoform 4 of Solute carrier family 13 member 5OS=Homo sapiens OX=9606 GN=SLC13A5MASALSYVSKFKSFVILFVTPLLLLPLVILMPAKVCVQYMKDTNMLFLGGLIVAVAVERWNLHKRIALRTLLWVGAKPARLMLGFMGVTALLSMWISNTATTAMMVPIVEAILQQMEATSAATEAGLELVDKGKAKELPGSQVIFEGPTLGQQEDQERKRLCKAMTLCICYAASIGGTATLTGTGPNVVLLGQMNELFPDSKDLVNFASWFAFAFPNMLVMLLFAWLWLQFVYMRFNFKKSWGCGLESKKNEKAALKVLQEEYRKLGPLSFAEINVLICFFLLVILWFSRDPGFMPGWLTVAWVEGETKYVSDATVAIFVATLLFIVPSQKPKFNFRSQTEEERKTPFYPPPLLDWKVTQEKVPWGIVLLLGGGFALAKGSEASGLSVWMGKQMEPLHAVPPAAITLILSLLVAVFTECTSNVATTTLFLPIFASMSRSIGLNPLYIMLPCTLSASFAFMLPVATPPNAIVFTYGHLKVADMVKTGVIMNIIGVFCVFLAVNTWGRAIFDLDHFPDWANVTHIET>sp|P59025|RTP1_HUMAN Receptor-transporting protein 1 OS=Homo sapiensOX=9606 GN=RTP1 PE=2 SV=2MRIFRPWRLRCPALHLPSLSVFSLRWKLPSLTTDETMCKSVTTDEWKKVFYEKMEEAKPADSWDLIIDPNLKHNVLSPGWKQYLELHASGRFHCSWCWHTWQSPYVVILFHMFLDRAQRAGSVRMRVFKQLCYECGTARLDESSMLEENIEGLVDNLITSLREQCYGERGGQYRIHVASRQDNRRHRGEFCEACQEGIVHWKPSEKLLEEEATTYTFSRAPSPTKSQDQTGSGWNFCSIPWCLFWATVLLLIIYLQFSFRSSV>sp|Q9BQQ7|RTP3_HUMAN Receptor-transporting protein 3 OS=Homo sapiensOX=9606 GN=RTP3 PE=1 SV=1MAGDTEVWKQMFQELMREVKPWHRWTLRPDKGLLPNVLKPGWMQYQQWTFARFQCSSCSRNWASAQVLVLFHMNWSEEKSRGQVKMRVFTQRCKKCPQPLFEDPEFTQENISRILKNLVFRILKKCYRGRFQLIEEVPMIKDISLEGPHNSDNCEACLQGFCAGPIQVTSLPPSQTPRVHSIYKVEEVVKPWASGENVYSYACQNHICRNLSIFCCCVILIVIVVIVVKTAI>sp|Q14D33|RTP5_HUMAN Receptor-transporting protein 5 OS=Homo sapiensOX=9606 GN=RTP5 PE=1 SV=2MDRAGADMWASTFTLAMAERKPQDVWVLLPEHSLVPGCLDGGGVQYLLVGLSRLQCGHCPGTWDSAHVHVLFHLWWDRASHRGLVKMRIWGQRCRLCPAPGDCQVRPPGEQPFLSRLVLHILQDCYGDGPGPARHPREAYEGCCEACELGVCFLQKAPDPAWSANATKGNFPATAWGGTGTVSRGKPLSTPGDDLGKGGVVIAIPFSLVGTSNDQVPIAEGPAPPAGASLPVTGSCEALVIGQGSIFLSGDSVAMPGGKGFPVAIGDPLFHGPGLLGSSIQTFELKGFLFKGRGSLCSPVGVAQGWGPISLNNGLVPVGKHTPTVFYCVGLSASGEGSLTFPSSLTSIFTNTLSEPTDGPVATKEASITFPFIFTDVKDAVAEVAEGNGKEGGGQGLVPVGHDALPETNAGGLPSQVKGSLALPFPADVQGKDAFTDITEGKEKEGGLVTAGHDAPLEANAEGPITVSEGCITIPFAVFDVIKRKGGGHVAYGPQGNGCFSQGYYQKRQLRSRFHKARCGCRREEDERPGRACRRPHAEPYEDFWIWVSMTVCVFWLMCMCRLNPGIYPQQV>sp|Q96T23|RSF1_HUMAN Remodeling and spacing factor 1 OS=Homo sapiensOX=9606 GN=RSF1 PE=1 SV=2MATAAAAAAVMAPPGCPGSCPNFAVVCSFLERYGPLLDLPELPFPELERVLQAPPPDVGNGEVPKELVELHLKLMRKIGKSVTADRWEKYLIKICQEFNSTWAWEMEKKGYLEMSVECKLALLKYLCECQFDDNLKFKNIINEEDADTMRLQPIGRDKDGLMYWYQLDQDHNVRMYIEEQDDQDGSSWKCIVRNRNELAETLALLKAQIDPVLLKNSSQQDNSSRESPSLEDEETKKEEETPKQEEQKESEKMKSEEQPMDLENRSTANVLEETTVKKEKEDEKELVKLPVIVKLEKPLPENEEKKIIKEESDSFKENVKPIKVEVKECRADPKDTKSSMEKPVAQEPERIEFGGNIKSSHEITEKSTEETEKLKNDQQAKIPLKKREIKLSDDFDSPVKGPLCKSVTPTKEFLKDEIKQEEETCKRISTITALGHEGKQLVNGEVSDERVAPNFKTEPIETKFYETKEESYSPSKDRNIITEGNGTESLNSVITSMKTGELEKETAPLRKDADSSISVLEIHSQKAQIEEPDPPEMETSLDSSEMAKDLSSKTALSSTESCTMKGEEKSPKTKKDKRPPILECLEKLEKSKKTFLDKDAQRLSPIPEEVPKSTLESEKPGSPEAAETSPPSNIIDHCEKLASEKEVVECQSTSTVGGQSVKKVDLETLKEDSEFTKVEMDNLDNAQTSGIEEPSETKGSMQKSKFKYKLVPEEETTASENTEITSERQKEGIKLTIRISSRKKKPDSPPKVLEPENKQEKTEKEEEKTNVGRTLRRSPRISRPTAKVAEIRDQKADKKRGEGEDEVEEESTALQKTDKKEILKKSEKDTNSKVSKVKPKGKVRWTGSRTRGRWKYSSNDESEGSGSEKSSAASEEEEEKESEEAILADDDEPCKKCGLPNHPELILLCDSCDSGYHTACLRPPLMIIPDGEWFCPPCQHKLLCEKLEEQLQDLDVALKKKERAERRKERLVYVGISIENIIPPQEPDFSEDQEEKKKDSKKSKANLLERRSTRTRKCISYRFDEFDEAIDEAIEDDIKEADGGGVGRGKDISTITGHRGKDISTILDEERKENKRPQRAAAARRKKRRRLNDLDSDSNLDEEESEDEFKISDGSQDEFVVSDENPDESEEDPPSNDDSDTDFCSRRLRRHPSRPMRQSRRLRRKTPKKKYSDDDEEEESEENSRDSESDFSDDFSDDFVETRRRRSRRNQKRQINYKEDSESDGSQKSLRRGKEIRRVHKRRLSSSESEESYLSKNSEDDELAKESKRSVRKRGRSTDEYSEADEEEEEEEGKPSRKRLHRIETDEEESCDNAHGDANQPARDSQPRVLPSEQESTKKPYRIESDEEEDFENVGKVGSPLDYSLVDLPSTNGQSPGKAIENLIGKPTEKSQTPKDNSTASASLASNGTSGGQEAGAPEEEEDELLRVTDLVDYVCNSEQL>sp|Q96T23-2|RSF1_HUMAN Isoform 2 of Remodeling and spacing factor 1OS=Homo sapiens OX=9606 GN=RSF1MATAAAAAAVMAPPGCPGSCPNFAVVCSFLERYGPLLDLPELPFPELERVLQAPPPDVGNGEVPKELVELHLKLMRKIGKSVTADRWEKYLIKYLCECQFDDNLKFKNIINEEDADTMRLQPIGRDKDGLMYWYQLDQDHNVRMYIEEQDDQDGSSWKCIVRNRNELAETLALLKAQIDPVLLKNSSQQDNSSRESPSLEDEETKKEEETPKQEEQKESEKMKSEEQPMDLENRSTANVLEETTVKKEKEDEKELVKLPVIVKLEKPLPENEEKKIIKEESDSFKENVKPIKVEVKECRADPKDTKSSMEKPVAQEPERIEFGGNIKSSHEITEKSTEETEKLKNDQQAKIPLKKREIKLSDDFDSPVKGPLCKSVTPTKEFLKDEIKQEEETCKRISTITALGHEGKQLVNGEVSDERVAPNFKTEPIETKFYETKEESYSPSKDRNIITEGNGTESLNSVITSMKTGELEKETAPLRKDADSSISVLEIHSQKAQIEEPDPPEMETSLDSSEMAKDLSSKTALSSTESCTMKGEEKSPKTKKDKRPPILECLEKLEKSKKTFLDKDAQRLSPIPEEVPKSTLESEKPGSPEAAETSPPSNIIDHCEKLASEKEVVECQSTSTVGGQSVKKVDLETLKEDSEFTKVEMDNLDNAQTSGIEEPSETKGSMQKSKFKYKLVPEEETTASENTEITSERQKEGIKLTIRISSRKKKPDSPPKVLEPENKQEKTEKEEEKTNVGRTLRRSPRISRPTAKVAEIRDQKADKKRGEGEDEVEEESTALQKTDKKEILKKSEKDTNSKVSKVKPKGKVRWTGSRTRGRWKYSSNDESEGSGSEKSSAASEEEEEKESEEAILADDDEPCKKCGLPNHPELILLCDSCDSGYHTACLRPPLMIIPDGEWFCPPCQHKLLCEKLEEQLQDLDVALKKKERAERRKERLVYVGISIENIIPPQEPDFSEDQEEKKKDSKKSKANLLERRSTRTRKCISYRFDEFDEAIDEAIEDDIKEADGGGVGRGKDISTITGHRGKDISTILDEERKENKRPQRAAAARRKKRRRLNDLDSDSNLDEEESEDEFKISDGSQDEFVVSDENPDESEEDPPSNDDSDTDFCSRRLRRHPSRPMRQSRRLRRKTPKKKYSDDDEEEESEENSRDSESDFSDDFSDDFVETRRRRSRRNQKRQINYKEDSESDGSQKSLRRGKEIRRVHKRRLSSSESEESYLSKNSEDDELAKESKRSVRKRGRSTDEYSEADEEEEEEEGKPSRKRLHRIETDEEESCDNAHGDANQPARDSQPRVLPSEQESTKKPYRIESDEEEDFENVGKVGSPLDYSLVDLPSTNGQSPGKAIENLIGKPTEKSQTPKDNSTASASLASNGTSGGQEAGAPEEEEDELLRVTDLVDYVCNSEQL>sp|Q96T23-3|RSF1_HUMAN Isoform 3 of Remodeling and spacing factor 1OS=Homo sapiens OX=9606 GN=RSF1MKSEEQPMDLENRSTANVLEETTVKKEKEDEKELVKLPVIVKLEKPLPENEEKKIIKEESDSFKENVKPIKVEVKECRADPKDTKSSMEKPVAQEPERIEFGGNIKSSHEITEKSTEETEKLKNDQQAKIPLKKREIKLSDDFDSPVKGPLCKSVTPTKEFLKDEIKQEEETCKRISTITALGHEGKQLVNGEVSDERVAPNFKTEPIETKFYETKEESYSPSKDRNIITEGNGTESLNSVITSMKTGELEKETAPLRKDADSSISVLEIHSQKAQIEEPDPPEMETSLDSSEMAKDLSSKTALSSTESCTMKGEEKSPKTKKDKRPPILECLEKLEKSKKTFLDKDAQRLSPIPEEVPKSTLESEKPGSPEAAETSPPSNIIDHCEKLASEKEVVECQSTSTVGGQSVKKVDLETLKEDSEFTKVEMDNLDNAQTSGIEEPSETKGSMQKSKFKYKLVPEEETTASENTEITSERQKEGIKLTIRISSRKKKPDSPPKVLEPENKQEKTEKEEEKTNVGRTLRRSPRISRPTAKVAEIRDQKADKKRGEGEDEVEEESTALQKTDKKEILKKSEKDTNSKVSKVKPKGKVRWTGSRTRGRWKYSSNDESEGSGSEKSSAASEEEEEKESEEAILADDDEPCKKCGLPNHPELILLCDSCDSGYHTACLRPPLMIIPDGEWFCPPCQHKLLCEKLEEQLQDLDVALKKKERAERRKERLVYVGISIENIIPPQEPDFSEDQEEKKKDSKKSKANLLERRSTRTRKCISYRFDEFDEAIDEAIEDDIKEADGGGVGRGKDISTITGHRGKDISTILDEERKENKRPQRAAAARRKKRRRLNDLDSDSNLDEEESEDEFKISDGSQDEFVVSDENPDESEEDPPSNDDSDTDFCSRRLRRHPSRPMRQSRRLRRKTPKKKYSDDDEEEESEENSRDSESDFSDDFSDDFVETRRRRSRRNQKRQINYKEDSESDGSQKSLRRGKEIRRVHKRRLSSSESEESYLSKNSEDDELAKESKRSVRKRGRSTDEYSEADEEEEEEEGKPSRKRLHRIETDEEESCDNAHGDANQPARDSQPRVLPSEQESTKKPYRIESDEEEDFENVGKVGSPLDYSLVDLPSTNGQSPGKAIENLIGKPTEKSQTPKDNSTASASLASNGTSGGQEAGAPEEEEDELLRVTDLVDYVCNSEQL>sp|P46059|S15A1_HUMAN Solute carrier family 15 member 1 OS=Homo sapiensOX=9606 GN=SLC15A1 PE=1 SV=1MGMSKSHSFFGYPLSIFFIVVNEFCERFSYYGMRAILILYFTNFISWDDNLSTAIYHTFVALCYLTPILGALIADSWLGKFKTIVSLSIVYTIGQAVTSVSSINDLTDHNHDGTPDSLPVHVVLSLIGLALIALGTGGIKPCVSAFGGDQFEEGQEKQRNRFFSIFYLAINAGSLLSTIITPMLRVQQCGIHSKQACYPLAFGVPAALMAVALIVFVLGSGMYKKFKPQGNIMGKVAKCIGFAIKNRFRHRSKAFPKREHWLDWAKEKYDERLISQIKMVTRVMFLYIPLPMFWALFDQQGSRWTLQATTMSGKIGALEIQPDQMQTVNAILIVIMVPIFDAVLYPLIAKCGFNFTSLKKMAVGMVLASMAFVVAAIVQVEIDKTLPVFPKGNEVQIKVLNIGNNTMNISLPGEMVTLGPMSQTNAFMTFDVNKLTRINISSPGSPVTAVTDDFKQGQRHTLLVWAPNHYQVVKDGLNQKPEKGENGIRFVNTFNELITITMSGKVYANISSYNASTYQFFPSGIKGFTISSTEIPPQCQPNFNTFYLEFGSAYTYIVQRKNDSCPEVKVFEDISANTVNMALQIPQYFLLTCGEVVFSVTGLEFSYSQAPSNMKSVLQAGWLLTVAVGNIIVLIVAGAGQFSKQWAEYILFAALLLVVCVIFAIMARFYTYINPAEIEAQFDEDEKKNRLEKSNPYFMSGANSQKQM>sp|Q66K80|RUAS1_HUMAN Putative uncharacterized protein RUSC1-AS1 OS=Homosapiens OX=9606 GN=RUSC1-AS1 PE=5 SV=1MEPGGSENAAALWISEGGRGPGRGPGPEWTSRSLLPQSGPALQPTPYSQRKGPRETHPDALKGGGGWGWGNTQSLSGECRKGVGAGEEKDGAAVSLSTPHLLAASAGLQPAPSPLGTAVCPFSPHSSPSFSHHRTLSLFISPAPLSCPAPRAQVHRSTPMGRALLTRVLLEPLRPWACPRLPRSPPGGAQSGRGGALAQPTLRCAAAPLRAWAWRSSDPPPAFSVFCHPPRGFDIS>sp|Q66K80-2|RUAS1_HUMAN Isoform 2 of Putative uncharacterized proteinRUSC1-AS1 OS=Homo sapiens OX=9606 GN=RUSC1-AS1MEPGGSENAAALWISEGGRGPGRGPGPEWTSRSLLPQSGPALQPTPYSQRKGPRETHPDALKGGGGWGWGNTQSLSGECRKGVGAGEEKDGAAVSLSTPHLLAASAGLQPAPSPLGTAGPTTLSQAPSGSGTVLEWPVADTEPPASCICCPGCQCQFCRSHWGPQRGQGTLQSCTLKPAR>sp|Q9HCY8|S10AE_HUMAN Protein S100-A14 OS=Homo sapiens OX=9606GN=S100A14 PE=1 SV=1MGQCRSANAEDAQEFSDVERAIETLIKNFHQYSVEGGKETLTPSELRDLVTQQLPHLMPSNCGLEEKIANLGSCNDSKLEFRSFWELIGEAAKSVKLERPVRGH>sp|Q9Y666|S12A7_HUMAN Solute carrier family 12 member 7 OS=Homo sapiensOX=9606 GN=SLC12A7 PE=1 SV=3MPTNFTVVPVEAHADGGGDETAERTEAPGTPEGPEPERPSPGDGNPRENSPFLNNVEVEQESFFEGKNMALFEEEMDSNPMVSSLLNKLANYTNLSQGVVEHEEDEESRRREAKAPRMGTFIGVYLPCLQNILGVILFLRLTWIVGVAGVLESFLIVAMCCTCTMLTAISMSAIATNGVVPAGGSYYMISRSLGPEFGGAVGLCFYLGTTFAGAMYILGTIEIFLTYISPGAAIFQAEAAGGEAAAMLHNMRVYGTCTLVLMALVVFVGVKYVNKLALVFLACVVLSILAIYAGVIKSAFDPPDIPVCLLGNRTLSRRSFDACVKAYGIHNNSATSALWGLFCNGSQPSAACDEYFIQNNVTEIQGIPGAASGVFLENLWSTYAHAGAFVEKKGVPSVPVAEESRASALPYVLTDIAASFTLLVGIYFPSVTGIMAGSNRSGDLKDAQKSIPTGTILAIVTTSFIYLSCIVLFGACIEGVVLRDKFGEALQGNLVIGMLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIARDGIVPFLQVFGHGKANGEPTWALLLTVLICETGILIASLDSVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKFYHWTLSFLGMSLCLALMFICSWYYALSAMLIAGCIYKYIEYRGAEKEWGDGIRGLSLNAARYALLRVEHGPPHTKNWRPQVLVMLNLDAEQAVKHPRLLSFTSQLKAGKGLTIVGSVLEGTYLDKHMEAQRAEENIRSLMSTEKTKGFCQLVVSSSLRDGMSHLIQSAGLGGLKHNTVLMAWPASWKQEDNPFSWKNFVDTVRDTTAAHQALLVAKNVDSFPQNQERFGGGHIDVWWIVHDGGMLMLLPFLLRQHKVWRKCRMRIFTVAQVDDNSIQMKKDLQMFLYHLRISAEVEVVEMVENDISAFTYERTLMMEQRSQMLKQMQLSKNEQEREAQLIHDRNTASHTAAAARTQAPPTPDKVQMTWTREKLIAEKYRSRDTSLSGFKDLFSMKPDQSNVRRMHTAVKLNGVVLNKSQDAQLVLLNMPGPPKNRQGDENYMEFLEVLTEGLNRVLLVRGGGREVITIYS>sp|Q9Y666-2|S12A7_HUMAN Isoform 2 of Solute carrier family 12 member 7OS=Homo sapiens OX=9606 GN=SLC12A7MPTNFTVVPVEAHADGGGDETAERTEAPGTPEGPEPERPSPGDGNPRENSPFLNNVEVEQESFFEGKNMALFEEEMDSNPMVSSLLNKLANYTNLSQGVVEHEEDEESRRREAKAPRMGTFIGVYLPCLQNILGVILFLRLTWIVGVAGVLESFLIVAMCCTCTMLTAISMSAIATNGVVPAGGSYYMISRSLGPEFGGAVGLCFYLGTTFAGAMYILGTIEIFLTGTEDGVGSLGLGLAQGNRRQTHLSPSDAAQAAHGASYGSF>sp|A0AV02|S12A8_HUMAN Solute carrier family 12 member 8 OS=Homo sapiensOX=9606 GN=SLC12A8 PE=1 SV=4MTQMSQVQELFHEAAQQDALAQPQPWWKTQLFMWEPVLFGTWDGVFTSCMINIFGVVLFLRTGWLVGNTGVLLGMFLVSFVILVALVTVLSGIGVGERSSIGSGGVYSMISSVLGGQTGGTIGLLYVFGQCVAGAMYITGFAESISDLLGLGNIWAVRGISVAVLLALLGINLAGVKWIIRLQLLLLFLLAVSTLDFVVGSFTHLDPEHGFIGYSPELLQNNTLPDYSPGESFFTVFGVFFPAATGVMAGFNMGGDLREPAASIPLGSLAAVGISWFLYIIFVFLLGAICTREALRYDFLIAEKVSLMGFLFLLGLYISSLASCMGGLYGAPRILQCIAQEKVIPALACLGQGKGPNKTPVAAICLTSLVTMAFVFVGQVNVLAPIVTINFMLTYVAVDYSYFSLSMCSCSLTPVPEPVLREGAEGLHCSEHLLLEKAPSYGSEGPAQRVLEGTLLEFTKDMDQLLQLTRKLESSQPRQGEGNRTPESQKRKSKKATKQTLQDSFLLDLKSPPSFPVEISDRLPAASWEGQESCWNKQTSKSEGTQPEGTYGEQLVPELCNQSESSGEDFFLKSRLQEQDVWRRSTSFYTHMCNPWVSLLGAVGSLLIMFVIQWVYTLVNMGVAAIVYFYIGRASPGLHLGSASNFSFFRWMRSLLLPSCRSLRSPQEQIILAPSLAKVDMEMTQLTQENADFATRDRYHHSSLVNREQLMPHY>sp|A0AV02-2|S12A8_HUMAN Isoform 2 of Solute carrier family 12 member 8OS=Homo sapiens OX=9606 GN=SLC12A8MLPLERTITYRDMSSFIQVKNHFNVVNVTCVSYRSTCFRDMRRFILDALAQPQPWWKTQLFMWEPVLFGTWDGVFTSCMINIFGVVLFLRTGWLVGNTGVLLGMFLVSFVILVALVTVLSGIGVGERSSIGSGGVYSMISSVLGGQTGGTIGLLYVFGQCVAGAMYITGFAESISDLLGLGNIWAVRGISVAVLLALLGINLAGVKWIIRLQLLLLFLLAVSTLDFVVGSFTHLDPEHGFIGYSPELLQNNTLPDYSPGESFFTVFGVFFPAATGVMAGFNMGGDLREPAASIPLGSLAAVGISWFLYIIFVFLLGAICTREALRYDFLIAEKVSLMGFLFLLGLYISSLASCMGGLYGAPRILQCIAQEKVIPALACLGQGKGPNKTPVAAICLTSLVTMAFVFVGQVNVLAPIVTINFMLTYVAVDYSYFSLSMCSCSLTPVPEPVLREGAEGLHCSEHLLLEKAPSYGSEGPAQRVLEGTLLEFTKDMDQLLQLTRKLESSQPRQGEGNRTPESQKRKSKKATKQTLQDSFLLDLKSPPSFPVEISDRLPAASWEGQESCWNKQTSKSEGTQPEGTYGEQLVPELCNQSESSGEDFFLKSRLQEQDVWRRSTSFYTHMCNPWVSLLGAVGSLLIMFVIQWVYTLVNMGVAAIVYFYIGRASPGLHLGSASNFSFFRWMRSLLLPSCRSLRSPQEQIILAPSLAKVDMEMTQLTQENADFATRDRYHHSSLVNREQLMPHY>sp|A0AV02-3|S12A8_HUMAN Isoform 3 of Solute carrier family 12 member 8OS=Homo sapiens OX=9606 GN=SLC12A8MRRAAAGGLAVGQLPGEGPAGEEGAALGKAMRGGGCSPHSPSGCLSGVMAGFNMGGDLREPAASIPLGSLAAVGISWFLYIIFVFLLGAICTREALRYDFLIAEKVSLMGFLFLLGLYISSLASCMGGLYGAPRILQCIAQEKVIPALACLGQGKGPNKTPVAAICLTSLVTMAFVFVGQVNVLAPIVTINFMLTYVAVDYSYFSLSMCSCSLTPVPEPVLREGAEGLHCSEHLLLEKAPSYGSEGPAQRVLEGTLLEFTKDMDQLLQLTRKLESSQPRQGEGNRTPESQKRKSKKATKQTLQDSFLLDLKSPPSFPVEISDRLPAASWEGQESCWNKQTSKSEGTQPEGTYGEQLVPELCNQSESSGEDFFLKSRLQEQDVWRRSTSFYTHMCNPWVSLLGAVGSLLIMFVIQWVYTLVNMGVAAIVYFYIGRASPGLHLGSASNFSFFRWMRSLLLPSCRSLRSPQEQIILAPSLAKVDMEMTQLTQENADFATRDRYHHSSLVNREQLMPHY>sp|A0AV02-4|S12A8_HUMAN Isoform 4 of Solute carrier family 12 member 8OS=Homo sapiens OX=9606 GN=SLC12A8MAGFNMGGDLREPAASIPLGSLAAVGISWFLYIIFVFLLGAICTREALRYDFLIAEKVSLMGFLFLLGLYISSLASCMGGLYGAPRILQCIAQEKVIPALACLGQGKGPNKTPVAAICLTSLVTMAFVFVGQVNVLAPIVTINFMLTYVAVDYSYFSLSMCSCSLTPVPEPVLREGAEGLHCSEHLLLEKAPSYGSEGPAQRVLEGTLLEFTKDMDQLLQLTRKLESSQPRQGEGNRTPESQKRKSKKATKQTLQDSFLLDLKSPPSFPVEISDRLPAASWEGQESCWNKQTSKSEGTQPEGTYGEQLVPELCNQSESSGEGSLRSPQEQIILAPSLAKVDMEMTQLTQENADFATRDRYHHSSLVNREQLMPHY>sp|A0AV02-5|S12A8_HUMAN Isoform 5 of Solute carrier family 12 member 8OS=Homo sapiens OX=9606 GN=SLC12A8MCSCSLTPVPEPVLREGAEGLHCSEHLLLEKAPSYGSEGPAQRVLEGTLLEFTKDMDQLLQLTRKLESSQPRQGEGNRTPESQKRKSKKATKQTLQDSFLLDLKSPPSFPVEISDRLPAASWEGQESCWNKQTSKSEGTQPEGTYGEQLVPELCNQSESSGEDFFLKSRLQEQDVWRRSTSFYTHMCNPWVSLLGAVGSLLIMFVIQWVYTLVNMGVAAIVYFYIGRASPGLHLGSASNFSFFRWMRSLLLPSCRSLRSPQEQIILAPSLAKVDMEMTQLTQENADFATRDRYHHSSLVNREQLMPHY>sp|Q9NTJ5|SAC1_HUMAN Phosphatidylinositol-3-phosphatase SAC1 OS=Homosapiens OX=9606 GN=SACM1L PE=1 SV=2MATAAYEQLKLHITPEKFYVEACDDGADDVLTIDRVSTEVTLAVKKDVPPSAVTRPIFGILGTIHLVAGNYLIVITKKIKVGEFFSHVVWKATDFDVLSYKKTMLHLTDIQLQDNKTFLAMLNHVLNVDGFYFSTTYDLTHTLQRLSNTSPEFQEMSLLERADQRFVWNGHLLRELSAQPEVHRFALPVLHGFITMHSCSINGKYFDWILISRRSCFRAGVRYYVRGIDSEGHAANFVETEQIVHYNGSKASFVQTRGSIPVFWSQRPNLKYKPLPQISKVANHMDGFQRHFDSQVIIYGKQVIINLINQKGSEKPLEQTFATMVSSLGSGMMRYIAFDFHKECKNMRWDRLSILLDQVAEMQDELSYFLVDSAGQVVANQEGVFRSNCMDCLDRTNVIQSLLARRSLQAQLQRLGVLHVGQKLEEQDEFEKIYKNAWADNANACAKQYAGTGALKTDFTRTGKRTHLGLIMDGWNSMIRYYKNNFSDGFRQDSIDLFLGNYSVDELESHSPLSVPRDWKFLALPIIMVVAFSMCIICLLMAGDTWTETLAYVLFWGVASIGTFFIILYNGKDFVDAPRLVQKEKID>sp|Q9NTJ5-2|SAC1_HUMAN Isoform 2 of Phosphatidylinositol-3-phosphataseSAC1 OS=Homo sapiens OX=9606 GN=SACM1LMWKLVMMEQMTYLPLTVCPQRLPLQSRKMFLLQLSQDQYLVYWAQSIWWQLQDNKTFLAMLNHVLNVDGFYFSTTYDLTHTLQRLSNTSPEFQEMSLLERADQRFVWNGHLLRELSAQPEVHRFALPVLHGFITMHSCSINGKYFDWILISRRSCFRAGVRYYVRGIDSEGHAANFVETEQIVHYNGSKASFVQTRGSIPVFWSQRPNLKYKPLPQISKVANHMDGFQRHFDSQVIIYGKQVIINLINQKGSEKPLEQTFATMVSSLGSGMMRYIAFDFHKECKNMRWDRLSILLDQVAEMQDELSYFLVDSAGQVVANQEGVFRSNCMDCLDRTNVIQSLLARRSLQAQLQRLGVLHVGQKLEEQDEFEKIYKNAWADNANACAKQYAGTGALKTDFTRTGKRTHLGLIMDGWNSMIRYYKNNFSDGFRQDSIDLFLGNYSVDELESHSPLSVPRDWKFLALPIIMVVAFSMCIICLLMAGDTWTETLAYVLFWGVASIGTFFIILYNGKDFVDAPRLVQKEKID>sp|Q96NL6|SCLT1_HUMAN Sodium channel and clathrin linker 1 OS=Homosapiens OX=9606 GN=SCLT1 PE=1 SV=2MAAEIDFLREQNRRLNEDFRRYQMESFSKYSSVQKAVCQGEGDDTFENLVFDQSFLAPLVTEYDKHLGELNGQLKYYQKQVGEMKLQLENVIKENERLHSELKDAVEKKLEAFPLGTEVGTDIYADDETVRNLQEQLQLANQEKTQAVELWQTVSQELDRLHKLYQEHMTEAQIHVFESQKQKDQLFDFQQLTKQLHVTNENMEVTNQQFLKTVTEQSVIIEQLRKKLRQAKLELRVAVAKVEELTNVTEDLQGQMKKKEKDVVSAHGREEASDRRLQQLQSSIKQLEIRLCVTIQEANQLRTENTHLEKQTRELQAKCNELENERYEAIVRARNSMQLLEEANLQKSQALLEEKQKEEDIEKMKETVSRFVQDATIRTKKEVANTKKQCNIQISRLTEELSALQMECAEKQGQIERVIKEKKAVEEELEKIYREGRGNESDYRKLEEMHQRFLVSERSKDDLQLRLTRAENRIKQLETDSSEEISRYQEMIQKLQNVLESERENCGLVSEQRLKLQQENKQLRKETESLRKIALEAQKKAKVKISTMEHEFSIKERGFEVQLREMEDSNRNSIVELRHLLATQQKAANRWKEETKKLTESAEIRINNLKSELSRQKLHTQELLSQLEMANEKVAENEKLILEHQEKANRLQRRLSQAEERAASASQQLSVITVQRRKAASLMNLENI>sp|Q96NL6-2|SCLT1_HUMAN Isoform 2 of Sodium channel and clathrin linker1 OS=Homo sapiens OX=9606 GN=SCLT1MAAEIDFLREQNRRLNEDFRRYQMESFSKYSSVQKAVCQGEGDDTFENLVFDQSFLAPLVTEYDKHLGELNGQLKYYQKQVGEMKLQLENVIKENERLHSELKDAVEKKLEAFPLGTEVGTDIYADDETVRNLQEQLQLANQEKTQAVELWQTVSQELDRLHKLYQEHMTEAQIHVFESQKQKDQLFDFQQLTKQLHVTNENMEVTNQQFLKTVTEQSVIIEQLRKKLRSELSRQKLHTQELLSQLEMANEKVAENEKLILEHQEKANRLQRRLSQAEERAASASQQLSVITVQRRKAASLMNLENI>sp|Q96NL6-3|SCLT1_HUMAN Isoform 3 of Sodium channel and clathrin linker1 OS=Homo sapiens OX=9606 GN=SCLT1MAAEIDFLREQNRRLNEDFRRYQMESFSKYSSVQKAVCQGEGDDTFENLVFDQSFLAPLVTEYDKHLGELNGQLKYYQKQVGEMKLQLENVIKENERSELSRQKLHTQELLSQLEMANEKVAENEKLILEHQEKANRLQRRLSQAEERAASASQQLSVITVQRRKAASLMNLENI>sp|Q96NL6-4|SCLT1_HUMAN Isoform 4 of Sodium channel and clathrin linker1 OS=Homo sapiens OX=9606 GN=SCLT1MAAEIDFLREQNRRLNEDFRRYQMESFSKYSSVQKAVCQGEGDDTFENLVFDQSFLAPLVTEYDKHLGELNGQLKYYQA>sp|Q969E2|SCAM4_HUMAN Secretory carrier-associated membrane protein 4OS=Homo sapiens OX=9606 GN=SCAMP4 PE=1 SV=1MSEKENNFPPLPKFIPVKPCFYQNFSDEIPVEHQVLVKRIYRLWMFYCATLGVNLIACLAWWIGGGSGTNFGLAFVWLLLFTPCGYVCWFRPVYKAFRADSSFNFMAFFFIFGAQFVLTVIQAIGFSGWGACGWLSAIGFFQYSPGAAVVMLLPAIMFSVSAAMMAIAIMKVHRIYRGAGGSFQKAQTEWNTGTWRNPPSREAQYNNFSGNSLPEYPTVPSYPGSGQWP>sp|Q969E2-2|SCAM4_HUMAN Isoform 2 of Secretory carrier-associatedmembrane protein 4 OS=Homo sapiens OX=9606 GN=SCAMP4MSEKENNFPPLPKFIPVKPCFYQNFSDEIPVEHQVLVKRIYRLWMFYCATLGVNLIACLAWWIGGGSGTNFGLAFVWLLLFTPCGYVCWFRPVYKAFRGWLSAIGFFQYSPGAAVVMLLPAIMFSVSAAMMAIAIMKVHRIYRGAGGSFQKAQTEWNTGTWRNPPSREAQYNNFSGNSLPEYPTVPSYPGSGQWP>sp|Q969E2-3|SCAM4_HUMAN Isoform 3 of Secretory carrier-associatedmembrane protein 4 OS=Homo sapiens OX=9606 GN=SCAMP4MSEKENNFPPLPKFIPVKPCFYQNFSDEIPVEHQVLVKRIYRLWMFYCATLGVNLIACLAWWIGGGSGTNFGLAFVWLLLFTPCGYVCWFRPVYKAFRADSSFNFMAFFFIFGAQFVLTVIQAIGFSGWGAG>sp|Q6UVJ0|SAS6_HUMAN Spindle assembly abnormal protein 6 homolog OS=Homosapiens OX=9606 GN=SASS6 PE=1 SV=1MSQVLFHQLVPLQVKCKDCEERRVSIRMSIELQSVSNPVHRKDLVIRLTDDTDPFFLYNLVISEEDFQSLKFQQGLLVDFLAFPQKFIDLLQQCTQEHAKEIPRFLLQLVSPAAILDNSPAFLNVVETNPFKHLTHLSLKLLPGNDVEIKKFLAGCLKCSKEEKLSLMQSLDDATKQLDFTRKTLAEKKQELDKLRNEWASHTAALTNKHSQELTNEKEKALQAQVQYQQQHEQQKKDLEILHQQNIHQLQNRLSELEAANKDLTERKYKGDSTIRELKAKLSGVEEELQRTKQEVLSLRRENSTLDVECHEKEKHVNQLQTKVAVLEQEIKDKDQLVLRTKEAFDTIQEQKVVLEENGEKNQVQLGKLEATIKSLSAELLKANEIIKKLQGDLKTLMGKLKLKNTVTIQQEKLLAEKEEKLQKEQKELQDVGQSLRIKEQEVCKLQEQLEATVKKLEESKQLLKNNEKLITWLNKELNENQLVRKQDVLGPSTTPPAHSSSNTIRSGISPNLNVVDGRLTYPTCGIGYPVSSAFAFQNTFPHSISAKNTSHPGSGTKVQFNLQFTKPNASLGDVQSGATISMPCSTDKENGENVGLESKYLKKREDSIPLRGLSQNLFSNSDHQRDGTLGALHTSSKPTALPSASSAYFPGQLPNS>sp|Q9Y2G9|SBNO2_HUMAN Protein strawberry notch homolog 2 OS=Homo sapiensOX=9606 GN=SBNO2 PE=2 SV=3MLAVGPAMDRDYPQHEPPPAGSLLYSPPPLQSAMLHCPYWNTFSLPPYPAFSSDSRPFMSSASFLGSQPCPDTSYAPVATASSLPPKTCDFAQDSSYFEDFSNISIFSSSVDSLSDIVDTPDFLPADSLNQVSTIWDDNPAPSTHDKLFQLSRPFAGFEDFLPSHSTPLLVSYQEQSVQSQPEEEDEAEEEEAEELGHTETYADYVPSKSKIGKQHPDRVVETSTLSSVPPPDITYTLALPSDSGALSALQLEAITYACQQHEVLLPSGQRAGFLIGDGAGVGKGRTVAGVILENHLRGRKKALWFSVSNDLKYDAERDLRDIEATGIAVHALSKIKYGDTTTSEGVLFATYSALIGESQAGGQHRTRLRQILDWCGEAFEGVIVFDECHKAKNAGSTKMGKAVLDLQNKLPLARVVYASATGASEPRNMIYMSRLGIWGEGTPFRNFEEFLHAIEKRGVGAMEIVAMDMKVSGMYIARQLSFSGVTFRIEEIPLAPAFECVYNRAALLWAEALNVFQQAADWIGLESRKSLWGQFWSAHQRFFKYLCIAAKVRRLVELAREELARDKCVVIGLQSTGEARTREVLGENDGHLNCFVSAAEGVFLSLIQKHFPSTKRKRDRGAGSKRKRRPRGRGAKAPRLACETAGVIRISDDSSTESDPGLDSDFNSSPESLVDDDVVIVDAVGLPSDDRGPLCLLQRDPHGPGVLERVERLKQDLLDKVRRLGRELPVNTLDELIDQLGGPQRVAEMTGRKGRVVSRPDGTVAFESRAEQGLSIDHVNLREKQRFMSGEKLVAIISEASSSGVSLQADRRVQNQRRRVHMTLELPWSADRAIQQFGRTHRSNQVSAPEYVFLISELAGERRFASIVAKRLESLGALTHGDRRATESRDLSKYNFENKYGTRALHCVLTTILSQTENKVPVPQGYPGGVPTFFRDMKQGLLSVGIGGRESRNGCLDVEKDCSITKFLNRILGLEVHKQNALFQYFSDTFDHLIEMDKREGKYDMGILDLAPGIEEIYEESQQVFLAPGHPQDGQVVFYKISVDRGLKWEDAFAKSLALTGPYDGFYLSYKVRGNKPSCLLAEQNRGQFFTVYKPNIGRQSQLEALDSLRRKFHRVTAEEAKEPWESGYALSLTHCSHSAWNRHCRLAQEGKDCLQGLRLRHHYMLCGALLRVWGRIAAVMADVSSSSYLQIVRLKTKDRKKQVGIKIPEGCVRRVLQELRLMDADVKRRQAPALGCPAPPAPRPLALPCGPGEVLDLTYSPPAEAFPPPPHFSFPAPLSLDAGPGVVPLGTPDAQADPAALAHQGCDINFKEVLEDMLRSLHAGPPSEGALGEGAGAGGAAGGGPERQSVIQFSPPFPGAQAPL>sp|Q9Y2G9-3|SBNO2_HUMAN Isoform 2 of Protein strawberry notch homolog 2OS=Homo sapiens OX=9606 GN=SBNO2MREPLPGSASWGTPGPPSAGTMSQLQLWLQFEALNKDSSYFEDFSNISIFSSSVDSLSDIVDTPDFLPADSLNQVSTIWDDNPAPSTHDKLFQLSRPFAGFEDFLPSHSTPLLVSYQEQSVQSQPEEEDEAEEEEAEELGHTETYADYVPSKSKIGKQHPDRVVETSTLSSVPPPDITYTLALPSDSGALSALQLEAITYACQQHEVLLPSGQRAGFLIGDGAGVGKGRTVAGVILENHLRGRKKALWFSVSNDLKYDAERDLRDIEATGIAVHALSKIKYGDTTTSEGVLFATYSALIGESQAGGQHRTRLRQILDWCGEAFEGVIVFDECHKAKNAGSTKMGKAVLDLQNKLPLARVVYASATGASEPRNMIYMSRLGIWGEGTPFRNFEEFLHAIEKRGVGAMEIVAMDMKVSGMYIARQLSFSGVTFRIEEIPLAPAFECVYNRAALLWAEALNVFQQAADWIGLESRKSLWGQFWSAHQRFFKYLCIAAKVRRLVELAREELARDKCVVIGLQSTGEARTREVLGENDGHLNCFVSAAEGVFLSLIQKHFPSTKRKRDRGAGSKRKRRPRGRGAKAPRLACETAGVIRISDDSSTESDPGLDSDFNSSPESLVDDDVVIVDAVGLPSDDRGPLCLLQRDPHGPGVLERVERLKQDLLDKVRRLGRELPVNTLDELIDQLGGPQRVAEMTGRKGRVVSRPDGTVAFESRAEQGLSIDHVNLREKQRFMSGEKLVAIISEASSSGVSLQADRRVQNQRRRVHMTLELPWSADRAIQQFGRTHRSNQVSAPEYVFLISELAGERRFASIVAKRLESLGALTHGDRRATESRDLSKYNFENKYGTRALHCVLTTILSQTENKVPVPQGYPGGVPTFFRDMKQGLLSVGIGGRESRNGCLDVEKDCSITKFLNRILGLEVHKQNALFQYFSDTFDHLIEMDKREGKYDMGILDLAPGIEEIYEESQQVFLAPGHPQDGQVVFYKISVDRGLKWEDAFAKSLALTGPYDGFYLSYKVRGNKPSCLLAEQNRGQFFTVYKPNIGRQSQLEALDSLRRKFHRVTAEEAKEPWESGYALSLTHCSHSAWNRHCRLAQEGKDCLQGLRLRHHYMLCGALLRVWGRIAAVMADVSSSSYLQIVRLKTKDRKKQVGIKIPEGCVRRVLQELRLMDADVKRRQAPALGCPAPPAPRPLALPCGPGEVLDLTYSPPAEAFPPPPHFSFPAPLSLDAGPGVVPLGTPDAQADPAALAHQGCDINFKEVLEDMLRSLHAGPPSEGALGEGAGAGGAAGGGPERQSVIQFSPPFPGAQAPL>sp|Q13228|SBP1_HUMAN Methanethiol oxidase OS=Homo sapiens OX=9606GN=SELENBP1 PE=1 SV=2MATKCGNCGPGYSTPLEAMKGPREEIVYLPCIYRNTGTEAPDYLATVDVDPKSPQYCQVIHRLPMPNLKDELHHSGWNTCSSCFGDSTKSRTKLVLPSLISSRIYVVDVGSEPRAPKLHKVIEPKDIHAKCELAFLHTSHCLASGEVMISSLGDVKGNGKGGFVLLDGETFEVKGTWERPGGAAPLGYDFWYQPRHNVMISTEWAAPNVLRDGFNPADVEAGLYGSHLYVWDWQRHEIVQTLSLKDGLIPLEIRFLHNPDAAQGFVGCALSSTIQRFYKNEGGTWSVEKVIQVPPKKVKGWLLPEMPGLITDILLSLDDRFLYFSNWLHGDLRQYDISDPQRPRLTGQLFLGGSIVKGGPVQVLEDEELKSQPEPLVVKGKRVAGGPQMIQLSLDGKRLYITTSLYSAWDKQFYPDLIREGSVMLQVDVDTVKGGLKLNPNFLVDFGKEPLGPALAHELRYPGGDCSSDIWI>sp|Q13228-2|SBP1_HUMAN Isoform 2 of Methanethiol oxidase OS=Homo sapiensOX=9606 GN=SELENBP1MPNLKDELHHSGWNTCSSCFGDSTKSRTKLVLPSLISSRIYVVDVGSEPRAPKLHKVIEPKDIHAKCELAFLHTSHCLASGEVMISSLGDVKGNGKGGFVLLDGETFEVKGTWERPGGAAPLGYDFWYQPRHNVMISTEWAAPNVLRDGFNPADVEAGLYGSHLYVWDWQRHEIVQTLSLKDGLIPLEIRFLHNPDAAQGFVGCALSSTIQRFYKNEGGTWSVEKVIQVPPKKVKGWLLPEMPGLITDILLSLDDRFLYFSNWLHGDLRQYDISDPQRPRLTGQLFLGGSIVKGGPVQVLEDEELKSQPEPLVVKGKRVAGGPQMIQLSLDGKRLYITTSLYSAWDKQFYPDLIREGSVMLQVDVDTVKGGLKLNPNFLVDFGKEPLGPALAHELRYPGGDCSSDIWI>sp|Q13228-3|SBP1_HUMAN Isoform 3 of Methanethiol oxidase OS=Homo sapiensOX=9606 GN=SELENBP1MATKCGNCGPGYSTPLEAMKGPREEIVYLPCIYRNTGTEAPDYLATVDVDPKSPQYCQVIEPKDIHAKCELAFLHTSHCLASGEVMISSLGDVKGNGKGGFVLLDGETFEVKGTWERPGGAAPLGYDFWYQPRHNVMISTEWAAPNVLRDGFNPADVEAGLYGSHLYVWDWQRHEIVQTLSLKDGLIPLEIRFLHNPDAAQGFVGCALSSTIQRFYKNEGGTWSVEKVIQVPPKKVKGWLLPEMPGLITDILLSLDDRFLYFSNWLHGDLRQYDISDPQRPRLTGQLFLGGSIVKGGPVQVLEDEELKSQPEPLVVKGKRVAGGPQMIQLSLDGKRLYITTSLYSAWDKQFYPDLIREGSVMLQVDVDTVKGGLKLNPNFLVDFGKEPLGPALAHELRYPGGDCSSDIWI>sp|Q13228-4|SBP1_HUMAN Isoform 4 of Methanethiol oxidase OS=Homo sapiensOX=9606 GN=SELENBP1MRLEWGPRPAALPWPAGMCAAERAEGAFTLQSVAQPMRPIASTATKCGNCGPGYSTPLEAMKGPREEIVYLPCIYRNTGTEAPDYLATVDVDPKSPQYCQVIHRLPMPNLKDELHHSGWNTCSSCFGDSTKSRTKLVLPSLISSRIYVVDVGSEPRAPKLHKVIEPKDIHAKCELAFLHTSHCLASGEVMISSLGDVKGNGKGGFVLLDGETFEVKGTWERPGGAAPLGYDFWYQPRHNVMISTEWAAPNVLRDGFNPADVEAGLYGSHLYVWDWQRHEIVQTLSLKDGLIPLEIRFLHNPDAAQGFVGCALSSTIQRFYKNEGGTWSVEKVIQVPPKKVKGWLLPEMPGLITDILLSLDDRFLYFSNWLHGDLRQYDISDPQRPRLTGQLFLGGSIVKGGPVQVLEDEELKSQPEPLVVKGKRVAGGPQMIQLSLDGKRLYITTSLYSAWDKQFYPDLIREGSVMLQVDVDTVKGGLKLNPNFLVDFGKEPLGPALAHELRYPGGDCSSDIWI>sp|O94885|SASH1_HUMAN SAM and SH3 domain-containing protein 1 OS=Homosapiens OX=9606 GN=SASH1 PE=1 SV=3MEDAGAAGPGPEPEPEPEPEPEPAPEPEPEPKPGAGTSEAFSRLWTDVMGILDGSLGNIDDLAQQYADYYNTCFSDVCERMEELRKRRVSQDLEVEKPDASPTSLQLRSQIEESLGFCSAVSTPEVERKNPLHKSNSEDSSVGKGDWKKKNKYFWQNFRKNQKGIMRQTSKGEDVGYVASEITMSDEERIQLMMMVKEKMITIEEALARLKEYEAQHRQSAALDPADWPDGSYPTFDGSSNCNSREQSDDETEESVKFKRLHKLVNSTRRVRKKLIRVEEMKKPSTEGGEEHVFENSPVLDERSALYSGVHKKPLFFDGSPEKPPEDDSDSLTTSPSSSSLDTWGAGRKLVKTFSKGESRGLIKPPKKMGTFFSYPEEEKAQKVSRSLTEGEMKKGLGSLSHGRTCSFGGFDLTNRSLHVGSNNSDPMGKEGDFVYKEVIKSPTASRISLGKKVKSVKETMRKRMSKKYSSSVSEQDSGLDGMPGSPPPSQPDPEHLDKPKLKAGGSVESLRSSLSGQSSMSGQTVSTTDSSTSNRESVKSEDGDDEEPPYRGPFCGRARVHTDFTPSPYDTDSLKLKKGDIIDIISKPPMGTWMGLLNNKVGTFKFIYVDVLSEDEEKPKRPTRRRRKGRPPQPKSVEDLLDRINLKEHMPTFLFNGYEDLDTFKLLEEEDLDELNIRDPEHRAVLLTAVELLQEYDSNSDQSGSQEKLLVDSQGLSGCSPRDSGCYESSENLENGKTRKASLLSAKSSTEPSLKSFSRNQLGNYPTLPLMKSGDALKQGQEEGRLGGGLAPDTSKSCDPPGVTGLNKNRRSLPVSICRSCETLEGPQTVDTWPRSHSLDDLQVEPGAEQDVPTEVTEPPPQIVPEVPQKTTASSTKAQPLEQDSAVDNALLLTQSKRFSEPQKLTTKKLEGSIAASGRGLSPPQCLPRNYDAQPPGAKHGLARTPLEGHRKGHEFEGTHHPLGTKEGVDAEQRMQPKIPSQPPPVPAKKSRERLANGLHPVPMGPSGALPSPDAPCLPVKRGSPASPTSPSDCPPALAPRPLSGQAPGSPPSTRPPPWLSELPENTSLQEHGVKLGPALTRKVSCARGVDLETLTENKLHAEGIDLTEEPYSDKHGRCGIPEALVQRYAEDLDQPERDVAANMDQIRVKQLRKQHRMAIPSGGLTEICRKPVSPGCISSVSDWLISIGLPMYAGTLSTAGFSTLSQVPSLSHTCLQEAGITEERHIRKLLSAARLFKLPPGPEAM>sp|Q6KCM7|SCMC2_HUMAN Calcium-binding mitochondrial carrier proteinSCaMC-2 OS=Homo sapiens OX=9606 GN=SLC25A25 PE=1 SV=1MLCLCLYVPVIGEAQTEFQYFESKGLPAELKSIFKLSVFIPSQEFSTYRQWKQKIVQAGDKDLDGQLDFEEFVHYLQDHEKKLRLVFKSLDKKNDGRIDAQEIMQSLRDLGVKISEQQAEKILKSMDKNGTMTIDWNEWRDYHLLHPVENIPEIILYWKHSTIFDVGENLTVPDEFTVEERQTGMWWRHLVAGGGAGAVSRTCTAPLDRLKVLMQVHASRSNNMGIVGGFTQMIREGGARSLWRGNGINVLKIAPESAIKFMAYEQIKRLVGSDQETLRIHERLVAGSLAGAIAQSSIYPMEVLKTRMALRKTGQYSGMLDCARRILAREGVAAFYKGYVPNMLGIIPYAGIDLAVYETLKNAWLQHYAVNSADPGVFVLLACGTMSSTCGQLASYPLALVRTRMQAQASIEGAPEVTMSSLFKHILRTEGAFGLYRGLAPNFMKVIPAVSISYVVYENLKITLGVQSR>sp|Q6KCM7-2|SCMC2_HUMAN Isoform 2 of Calcium-binding mitochondrialcarrier protein SCaMC-2 OS=Homo sapiens OX=9606 GN=SLC25A25MVSSVLCRCVASPPPDAAATAASSSASSPASVGDPCGGAICGGPDHRLRLWRLFQTLDVNRDGGLCVNDLAVGLRRLGLHRTEGELQKIVQAGDKDLDGQLDFEEFVHYLQDHEKKLRLVFKSLDKKNDGRIDAQEIMQSLRDLGVKISEQQAEKILKSMDKNGTMTIDWNEWRDYHLLHPVENIPEIILYWKHSTIFDVGENLTVPDEFTVEERQTGMWWRHLVAGGGAGAVSRTCTAPLDRLKVLMQVHASRSNNMGIVGGFTQMIREGGARSLWRGNGINVLKIAPESAIKFMAYEQIKRLVGSDQETLRIHERLVAGSLAGAIAQSSIYPMEVLKTRMALRKTGQYSGMLDCARRILAREGVAAFYKGYVPNMLGIIPYAGIDLAVYETLKNAWLQHYAVNSADPGVFVLLACGTMSSTCGQLASYPLALVRTRMQAQASIEGAPEVTMSSLFKHILRTEGAFGLYRGLAPNFMKVIPAVSISYVVYENLKITLGVQSR>sp|Q6KCM7-3|SCMC2_HUMAN Isoform 3 of Calcium-binding mitochondrialcarrier protein SCaMC-2 OS=Homo sapiens OX=9606 GN=SLC25A25MVSSVLCRCVASPPPDAAATAASSSASSPASVGDPCGGAICGGPDHRLRLWRLFQTLDVNRDGGLCVNDLAVGLRRLGLHRTEGELQKIVQAGDKDLDGQLDFEEFVHYLQDHEKKLRLVFKSLDKKNDGRIDAQEIMQSLRDLGVKISEQQAEKILKRIRTGHFWGPVTYMDKNGTMTIDWNEWRDYHLLHPVENIPEIILYWKHSTIFDVGENLTVPDEFTVEERQTGMWWRHLVAGGGAGAVSRTCTAPLDRLKVLMQVHASRSNNMGIVGGFTQMIREGGARSLWRGNGINVLKIAPESAIKFMAYEQIKRLVGSDQETLRIHERLVAGSLAGAIAQSSIYPMEVLKTRMALRKTGQYSGMLDCARRILAREGVAAFYKGYVPNMLGIIPYAGIDLAVYETLKNAWLQHYAVNSADPGVFVLLACGTMSSTCGQLASYPLALVRTRMQAQASIEGAPEVTMSSLFKHILRTEGAFGLYRGLAPNFMKVIPAVSISYVVYENLKITLGVQSR>sp|Q6KCM7-4|SCMC2_HUMAN Isoform 4 of Calcium-binding mitochondrialcarrier protein SCaMC-2 OS=Homo sapiens OX=9606 GN=SLC25A25MLQMLWHFLASFFPRAGCHGSREGDDREVRGTPAPAWRDQMASFLGKQDGRAEATEKRPTILLVVGPAEQFPKKIVQAGDKDLDGQLDFEEFVHYLQDHEKKLRLVFKSLDKKNDGRIDAQEIMQSLRDLGVKISEQQAEKILKSMDKNGTMTIDWNEWRDYHLLHPVENIPEIILYWKHSTIFDVGENLTVPDEFTVEERQTGMWWRHLVAGGGAGAVSRTCTAPLDRLKVLMQVHASRSNNMGIVGGFTQMIREGGARSLWRGNGINVLKIAPESAIKFMAYEQIKRLVGSDQETLRIHERLVAGSLAGAIAQSSIYPMEVLKTRMALRKTGQYSGMLDCARRILAREGVAAFYKGYVPNMLGIIPYAGIDLAVYETLKNAWLQHYAVNSADPGVFVLLACGTMSSTCGQLASYPLALVRTRMQAQASIEGAPEVTMSSLFKHILRTEGAFGLYRGLAPNFMKVIPAVSISYVVYENLKITLGVQSR>sp|Q6KCM7-5|SCMC2_HUMAN Isoform 5 of Calcium-binding mitochondrialcarrier protein SCaMC-2 OS=Homo sapiens OX=9606 GN=SLC25A25MLQMLWHFLASFFPRAGCHGSREGDDREVRGTPAPAWRDQMASFLGKQDGRAEATEKRPTILLVVGPAEQFPKKIVQAGDKDLDGQLDFEEFVHYLQDHEKKLRLVFKSLDKKNDGRIDAQEIMQSLRDLGVKISEQQAEKILKRIRTGHFWGPVTYMDKNGTMTIDWNEWRDYHLLHPVENIPEIILYWKHSTIFDVGENLTVPDEFTVEERQTGMWWRHLVAGGGAGAVSRTCTAPLDRLKVLMQVHASRSNNMGIVGGFTQMIREGGARSLWRGNGINVLKIAPESAIKFMAYEQIKRLVGSDQETLRIHERLVAGSLAGAIAQSSIYPMEVLKTRMALRKTGQYSGMLDCARRILAREGVAAFYKGYVPNMLGIIPYAGIDLAVYETLKNAWLQHYAVNSADPGVFVLLACGTMSSTCGQLASYPLALVRTRMQAQASIEGAPEVTMSSLFKHILRTEGAFGLYRGLAPNFMKVIPAVSISYVVYENLKITLGVQSR>sp|Q6KCM7-6|SCMC2_HUMAN Isoform 6 of Calcium-binding mitochondrialcarrier protein SCaMC-2 OS=Homo sapiens OX=9606 GN=SLC25A25MQSLRDLGVKISEQQAEKILKSMDKNGTMTIDWNEWRDYHLLHPVENIPEIILYWKHSTIFDVGENLTVPDEFTVEERQTGMWWRHLVAGGGAGAVSRTCTAPLDRLKVLMQVHASRSNNMGIVGGFTQMIREGGARSLWRGNGINVLKIAPESAIKFMAYEQIKRLVGSDQETLRIHERLVAGSLAGAIAQSSIYPMEVLKTRMALRKTGQYSGMLDCARRILAREGVAAFYKGYVPNMLGIIPYAGIDLAVYETLKNAWLQHYAVNSADPGVFVLLACGTMSSTCGQLASYPLALVRTRMQAQASIEGAPEVTMSSLFKHILRTEGAFGLYRGLAPNFMKVIPAVSISYVVYENLKITLGVQSR>sp|Q6I9Y2|THOC7_HUMAN THO complex subunit 7 homolog OS=Homo sapiensOX=9606 GN=THOC7 PE=1 SV=3MGAVTDDEVIRKRLLIDGDGAGDDRRINLLVKSFIKWCNSGSQEEGYSQYQRMLSTLSQCEFSMGKTLLVYDMNLREMENYEKIYKEIECSIAGAHEKIAECKKQILQAKRIRKNRQEYDALAKVIQHHPDRHETLKELEALGKELEHLSHIKESVEDKLELRRKQFHVLLSTIHELQQTLENDEKLSEVEEAQEASMETDPKP>sp|P49221|TGM4_HUMAN Protein-glutamine gamma-glutamyltransferase 4OS=Homo sapiens OX=9606 GN=TGM4 PE=1 SV=2MMDASKELQVLHIDFLNQDNAVSHHTWEFQTSSPVFRRGQVFHLRLVLNQPLQSYHQLKLEFSTGPNPSIAKHTLVVLDPRTPSDHYNWQATLQNESGKEVTVAVTSSPNAILGKYQLNVKTGNHILKSEENILYLLFNPWCKEDMVFMPDEDERKEYILNDTGCHYVGAARSIKCKPWNFGQFEKNVLDCCISLLTESSLKPTDRRDPVLVCRAMCAMMSFEKGQGVLIGNWTGDYEGGTAPYKWTGSAPILQQYYNTKQAVCFGQCWVFAGILTTVLRALGIPARSVTGFDSAHDTERNLTVDTYVNENGEKITSMTHDSVWNFHVWTDAWMKRPDLPKGYDGWQAVDATPQERSQGVFCCGPSPLTAIRKGDIFIVYDTRFVFSEVNGDRLIWLVKMVNGQEELHVISMETTSIGKNISTKAVGQDRRRDITYEYKYPEGSSEERQVMDHAFLLLSSEREHRRPVKENFLHMSVQSDDVLLGNSVNFTVILKRKTAALQNVNILGSFELQLYTGKKMAKLCDLNKTSQIQGQVSEVTLTLDSKTYINSLAILDDEPVIRGFIIAEIVESKEIMASEVFTSFQYPEFSIELPNTGRIGQLLVCNCIFKNTLAIPLTDVKFSLESLGISSLQTSDHGTVQPGETIQSQIKCTPIKTGPKKFIVKLSSKQVKEINAQKIVLITK>sp|P53999|TCP4_HUMAN Activated RNA polymerase II transcriptionalcoactivator p15 OS=Homo sapiens OX=9606 GN=SUB1 PE=1 SV=3MPKSKELVSSSSSGSDSDSEVDKKLKRKKQVAPEKPVKKQKTGETSRALSSSKQSSSSRDDNMFQIGKMRYVSVRDFKGKVLIDIREYWMDPEGEMKPGRKGISLNPEQWSQLKEQISDIDDAVRKL>sp|O43548|TGM5_HUMAN Protein-glutamine gamma-glutamyltransferase 5OS=Homo sapiens OX=9606 GN=TGM5 PE=1 SV=4MAQGLEVALTDLQSSRNNVRHHTEEITVDHLLVRRGQAFNLTLYFRNRSFQPGLDNIIFVVETGPLPDLALGTRAVFSLARHHSPSPWIAWLETNGATSTEVSLCAPPTAAVGRYLLKIHIDSFQGSVTAYQLGEFILLFNPWCPEDAVYLDSEPQRQEYVMNDYGFIYQGSKNWIRPCPWNYGQFEDKIIDICLKLLDKSLHFQTDPATDCALRGSPVYVSRVVCAMINSNDDNGVLNGNWSENYTDGANPAEWTGSVAILKQWNATGCQPVRYGQCWVFAAVMCTVMRCLGIPTRVITNFDSGHDTDGNLIIDEYYDNTGRILGNKKKDTIWNFHVWNECWMARKDLPPAYGGWQVLDATPQEMSNGVYCCGPASVRAIKEGEVDLNYDTPFVFSMVNADCMSWLVQGGKEQKLHQDTSSVGNFISTKSIQSDERDDITENYKYEEGSLQERQVFLKALQKLKARSFHGSQRGAELQPSRPTSLSQDSPRSLHTPSLRPSDVVQVSLKFKLLDPPNMGQDICFVLLALNMSSQFKDLKVNLSAQSLLHDGSPLSPFWQDTAFITLSPKEAKTYPCKISYSQYSQYLSTDKLIRISALGEEKSSPEKILVNKIITLSYPSITINVLGAAVVNQPLSIQVIFSNPLSEQVEDCVLTVEGSGLFKKQQKVFLGVLKPQHQASIILETVPFKSGQRQIQANMRSNKFKDIKGYRNVYVDFAL>sp|O43548-2|TGM5_HUMAN Isoform Short of Protein-glutamine gamma-glutamyltransferase 5 OS=Homo sapiens OX=9606 GN=TGM5MAQGLEVALTDLQSSRNNVRHHTEEITVDHLLVRRGQAFNLTLYFRNRSFQPGLDNIIFVVETEDAVYLDSEPQRQEYVMNDYGFIYQGSKNWIRPCPWNYGQFEDKIIDICLKLLDKSLHFQTDPATDCALRGSPVYVSRVVCAMINSNDDNGVLNGNWSENYTDGANPAEWTGSVAILKQWNATGCQPVRYGQCWVFAAVMCTVMRCLGIPTRVITNFDSGHDTDGNLIIDEYYDNTGRILGNKKKDTIWNFHVWNECWMARKDLPPAYGGWQVLDATPQEMSNGVYCCGPASVRAIKEGEVDLNYDTPFVFSMVNADCMSWLVQGGKEQKLHQDTSSVGNFISTKSIQSDERDDITENYKYEEGSLQERQVFLKALQKLKARSFHGSQRGAELQPSRPTSLSQDSPRSLHTPSLRPSDVVQVSLKFKLLDPPNMGQDICFVLLALNMSSQFKDLKVNLSAQSLLHDGSPLSPFWQDTAFITLSPKEAKTYPCKISYSQYSQYLSTDKLIRISALGEEKSSPEKILVNKIITLSYPSITINVLGAAVVNQPLSIQVIFSNPLSEQVEDCVLTVEGSGLFKKQQKVFLGVLKPQHQASIILETVPFKSGQRQIQANMRSNKFKDIKGYRNVYVDFAL>sp|P52888|THOP1_HUMAN Thimet oligopeptidase OS=Homo sapiens OX=9606GN=THOP1 PE=1 SV=2MKPPAACAGDMADAASPCSVVNDLRWDLSAQQIEERTRELIEQTKRVYDQVGTQEFEDVSYESTLKALADVEVTYTVQRNILDFPQHVSPSKDIRTASTEADKKLSEFDVEMSMREDVYQRIVWLQEKVQKDSLRPEAARYLERLIKLGRRNGLHLPRETQENIKRIKKKLSLLCIDFNKNLNEDTTFLPFTLQELGGLPEDFLNSLEKMEDGKLKVTLKYPHYFPLLKKCHVPETRRKVEEAFNCRCKEENCAILKELVTLRAQKSRLLGFHTHADYVLEMNMAKTSQTVATFLDELAQKLKPLGEQERAVILELKRAECERRGLPFDGRIRAWDMRYYMNQVEETRYCVDQNLLKEYFPVQVVTHGLLGIYQELLGLAFHHEEGASAWHEDVRLYTARDAASGEVVGKFYLDLYPREGKYGHAACFGLQPGCLRQDGSRQIAIAAMVANFTKPTADAPSLLQHDEVETYFHEFGHVMHQLCSQAEFAMFSGTHVERDFVEAPSQMLENWVWEQEPLLRMSRHYRTGSAVPRELLEKLIESRQANTGLFNLRQIVLAKVDQALHTQTDADPAEEYARLCQEILGVPATPGTNMPATFGHLAGGYDAQYYGYLWSEVYSMDMFHTRFKQEGVLNSKVGMDYRSCILRPGGSEDASAMLRRFLGRDPKQDAFLLSKGLQVGGCEPEPQVC>sp|P52888-2|THOP1_HUMAN Isoform 2 of Thimet oligopeptidase OS=Homosapiens OX=9606 GN=THOP1MFSGTHVERDFVEAPSQMLENWVWEQEPLLRMSRHYRTGSAVPRELLEKLIESRQANTGLFNLRQIVLAKVDQALHTQTDADPAEEYARLCQEILGVPATPGTNMPATFGHLAGGYDAQYYGYLWSEVYSMDMFHTRFKQEGVLNSKFPHYEVRPLRHVSLCLPLTWCDPGSGQPPESLTRNRWLPALRAGPALPGCNIALGSLQVGMDYRSCILRPGGSEDASAMLRRFLGRDPKQDAFLLSKGLQVGGCEPEPQVC>sp|Q96PF1|TGM7_HUMAN Protein-glutamine gamma-glutamyltransferase ZOS=Homo sapiens OX=9606 GN=TGM7 PE=1 SV=1MDQVATLRLESVDLQSSRNNKEHHTQEMGVKRLTVRRGQPFYLRLSFSRPFQSQNDHITFVAETGPKPSELLGTRATFFLTRVQPGNVWSASDFTIDSNSLQVSLFTPANAVIGHYTLKIEISQGQGHSVTYPLGTFILLFNPWSPEDDVYLPSEILLQEYIMRDYGFVYKGHERFITSWPWNYGQFEEDIIDICFEILNKSLYHLKNPAKDCSQRNDVVYVCRVVSAMINSNDDNGVLQGNWGEDYSKGVSPLEWKGSVAILQQWSARGGQPVKYGQCWVFASVMCTVMRCLGVPTRVVSNFRSAHNVDRNLTIDTYYDRNAEMLSTQKRDKIWNFHVWNECWMIRKDLPPGYNGWQVLDPTPQQTSSGLFCCGPASVKAIREGDVHLAYDTPFVYAEVNADEVIWLLGDGQAQEILAHNTSSIGKEISTKMVGSDQRQSITSSYKYPEGSPEERAVFMKASRKMLGPQRASLPFLDLLESGGLRDQPAQLQLHLARIPEWGQDLQLLLRIQRVPDSTHPRGPIGLVVRFCAQALLHGGGTQKPFWRHTVRMNLDFGKETQWPLLLPYSNYRNKLTDEKLIRVSGIAEVEETGRSMLVLKDICLEPPHLSIEVSERAEVGKALRVHVTLTNTLMVALSSCTMVLEGSGLINGQIAKDLGTLVAGHTLQIQLDLYPTKAGPRQLQVLISSNEVKEIKGYKDIFVTVAGAP>sp|Q5JRA6|TGO1_HUMAN Transport and Golgi organization protein 1 homologOS=Homo sapiens OX=9606 GN=MIA3 PE=1 SV=1MAAAPGLLVWLLVLRLPWRVPGQLDPSTGRRFSEHKLCADDECSMLMYRGEALEDFTGPDCRFVNFKKGDPVYVYYKLARGWPEVWAGSVGRTFGYFPKDLIQVVHEYTKEELQVPTDETDFVCFDGGRDDFHNYNVEELLGFLELYNSAATDSEKAVEKTLQDMEKNPELSKEREPEPEPVEANSEESDSVFSENTEDLQEQFTTQKHHSHANSQANHAQGEQASFESFEEMLQDKLKVPESENNKTSNSSQVSNEQDKIDAYKLLKKEMTLDLKTKFGSTADALVSDDETTRLVTSLEDDFDEELDTEYYAVGKEDEENQEDFDELPLLTFTDGEDMKTPAKSGVEKYPTDKEQNSNEEDKVQLTVPPGIKNDDKNILTTWGDTIFSIVTGGEETRDTMDLESSSSEEEKEDDDDALVPDSKQGKPQSATDYSDPDNVDDGLFIVDIPKTNNDKEVNAEHHIKGKGRGVQESKRGLVQDKTELEDENQEGMTVHSSVHSNNLNSMPAAEKGKDTLKSAYDDTENDLKGAAIHISKGMLHEEKPGEQILEGGSESESAQKAAGNQMNDRKIQQESLGSAPLMGDDHPNASRDSVEGDALVNGAKLHTLSVEHQREELKEELVLKTQNQPRFSSPDEIDLPRELEDEVPILGRNLPWQQERDVAATASKQMSEKIRLSEGEAKEDSLDEEFFHHKAMQGTEVGQTDQTDSTGGPAFLSKVEEDDYPSEELLEDENAINAKRSKEKNPGNQGRQFDVNLQVPDRAVLGTIHPDPEIEESKQETSMILDSEKTSETAAKGVNTGGREPNTMVEKERPLADKKAQRPFERSDFSDSIKIQTPELGEVFQNKDSDYLKNDNPEEHLKTSGLAGEPEGELSKEDHENTEKYMGTESQGSAAAEPEDDSFHWTPHTSVEPGHSDKREDLLIISSFFKEQQSLQRFQKYFNVHELEALLQEMSSKLKSAQQESLPYNMEKVLDKVFRASESQILSIAEKMLDTRVAENRDLGMNENNIFEEAAVLDDIQDLIYFVRYKHSTAEETATLVMAPPLEEGLGGAMEEMQPLHEDNFSREKTAELNVQVPEEPTHLDQRVIGDTHASEVSQKPNTEKDLDPGPVTTEDTPMDAIDANKQPETAAEEPASVTPLENAILLIYSFMFYLTKSLVATLPDDVQPGPDFYGLPWKPVFITAFLGIASFAIFLWRTVLVVKDRVYQVTEQQISEKLKTIMKENTELVQKLSNYEQKIKESKKHVQETRKQNMILSDEAIKYKDKIKTLEKNQEILDDTAKNLRVMLESEREQNVKNQDLISENKKSIEKLKDVISMNASEFSEVQIALNEAKLSEEKVKSECHRVQEENARLKKKKEQLQQEIEDWSKLHAELSEQIKSFEKSQKDLEVALTHKDDNINALTNCITQLNLLECESESEGQNKGGNDSDELANGEVGGDRNEKMKNQIKQMMDVSRTQTAISVVEEDLKLLQLKLRASVSTKCNLEDQVKKLEDDRNSLQAAKAGLEDECKTLRQKVEILNELYQQKEMALQKKLSQEEYERQEREHRLSAADEKAVSAAEEVKTYKRRIEEMEDELQKTERSFKNQIATHEKKAHENWLKARAAERAIAEEKREAANLRHKLLELTQKMAMLQEEPVIVKPMPGKPNTQNPPRRGPLSQNGSFGPSPVSGGECSPPLTVEPPVRPLSATLNRRDMPRSEFGSVDGPLPHPRWSAEASGKPSPSDPGSGTATMMNSSSRGSSPTRVLDEGKVNMAPKGPPPFPGVPLMSTPMGGPVPPPIRYGPPPQLCGPFGPRPLPPPFGPGMRPPLGLREFAPGVPPGRRDLPLHPRGFLPGHAPFRPLGSLGPREYFIPGTRLPPPTHGPQEYPPPPAVRDLLPSGSRDEPPPASQSTSQDCSQALKQSP>sp|Q5JRA6-2|TGO1_HUMAN Isoform 2 of Transport and Golgi organizationprotein 1 homolog OS=Homo sapiens OX=9606 GN=MIA3MAAAPGLLVWLLVLRLPWRVPGQLDPSTGRRFSEHKLCADDECSMLMYRGEALEDFTGPDCRFVNFKKGDPVYVYYKLARGWPEVWAGSVGRTFGYFPKDLIQVVHEYTKEELQVPTDETDFVCFDGGRDDFHNYNVEELLGFLELYNSAATDSEKAVEKTLQDMEKNPELSKEREPEPEPVEANSEESDSVFSENTEDLQEQFTTQKHHSHANSQANHAQGEQASFESFEEMLQDKLKVPESENNKTSNSSQVSNEQDKIDAYKLLKKEMTLDLKTKFGSTADALVSDDETTRLVTSLEDDFDEELDTEYYAVGKEDEENQEDFDELPLLTFTDGEDMKTPAKSGVEKYPTDKEQNSNEEDKVQLTVPPGIKNDDKNILTTWGDTIFSIVTGGEETRDTMDLESSSSEEEKEDDDDALVPDSKQGKPQSATDYSDPDNVDDGLFIVDIPKTNNDKEVNAEHHIKGKGRGVQESKRGLVQDKTELEDENQEGMTVHSSVHSNNLNSMPAAEKGKDTLKSAYDDTENDLKGAAIHISKGMLHEEKPGEQILEGGSESESAQKAAGNQMNDRKIQQESLGSAPLMGDDHPNASRDSVEGDALVNGAKLHTLSVEHQREELKEELVLKTQNQPRFSSPDEIDLPRELEDEVPILGRNLPWQQERDVAATASKQMSEKIRLSEGEAKEDSLDEEFFHHKAMQGTEVGQTDQTDSTGGPAFLSKVEEDDYPSEELLEDENAINAKRSKEKNPGNQGRQFDVNLQVPDRAVLGTIHPDPEIEESKQETSMILDSEKTSETAAKGVNTGGREPNTMVEKERPLADKKAQRPFERSDFSDSIKIQTPELGEVFQNKDSDYLKNDNPEEHLKTSGLAGEPEGELSKEDHENTEKYMGTESQGSAAAEPEDDSFHWTPHTSVEPGHSDKREDLLIISSFFKEQQSLQRFQKYFNVHELEALLQEMSSKLKSAQQESLPYNMEKVLDKVFRASESQILSIAEKMLDTRVAENRDLGMNENNIFEEAAVLDDIQDLIYFVRYKHSTAEETATLVMAPPLEEGLGGAMEEMQPLHEDNFSREKTAELNVQVPEEPTHLDQRVIGDTHASEVSQKPNTEKDLDPGPVTTEDTPMDAIDANKQPETAAEEPASVTPLENAILLIYSFMFYLTKSLVATLPDDVQPGPDFYGLPWKPVFITAFLGIASFAIFLWRTVLVVKDRVYQVTEQQISEKLKTIMKENTELVQKLSNYEQKIKESKKHVQETRKQNMILSDEAIKYKDKIKTLEKNQEILDDTAKNLRVMLESEREQNVKNQDLLQQEIEDWSKLHAELSEQIKSFEKSQKDLEVALTHKDDNINALTNCITQLNLLECESESEGQNKGGNDSDELANGEVGGDRNEKMKNQIKQMMDVSRTQTAISVVEEDLKLLQLKLRASVSTKCNLEDQVKKLEDDRNSLQAAKAGLEDECKTLRQKVEILNELYQQKEMALQKKLSQEEYERQEREHRLSAADEKAVSAAEEVKTYKRRIEEMEDELQKTERSFKNQIATHEKKAHENWLKARAAERAIAEEKREAANLRHKLLELTQKMAMLQEEPVIVKPMPGKPNTQNPPRRGPLSQNGSFGPSPVSGGECSPPLTVEPPVRPLSATLNRRDMPRSEFGSVDGPLPHPRWSAEASGKPSPSDPGSGTATMMNSSSRGSSPTRVLDEGKVNMAPKGPPPFPGVPLMSTPMGGPVPPPIRYGPPPQLCGPFGPRPLPPPFGPGMRPPLGLREFAPGVPPGRRDLPLHPRGFLPGHAPFRPLGSLGPREYFIPGTRLPPPTHGPQEYPPPPAVRDLLPSGSRDEPPPASQSTSQDCSQALKQSP>sp|Q5JRA6-3|TGO1_HUMAN Isoform 3 of Transport and Golgi organizationprotein 1 homolog OS=Homo sapiens OX=9606 GN=MIA3MAAAPGLLVWLLVLRLPWRVPGQLDPSTGRRFSEHKLCADDECSMLMYRGEALEDFTGPDCRFVNFKKGDPVYVYYKLARGWPEVWAGSVGRTFGYFPKDLIQVVHEYTKEELQVPTDETDFVCFDGGRDDFHNYNVEELLGFLELYNSAATDSEKAVEKTLQDMEKNPELSKEREPEPEPVEANSEESDSVFSENTEDLQEQFTTQKHHSHANSQANHAQGEQASFESFEEMLQDKLKVPESENNKTSNSSQVSNEQDKIDAYKLLKKEMTLDLKTKFGSTADALVSDDETTRLVTSLEDDFDEELDTEYYAVGKEDEENQEDFDELPLLTFTDGEDMKTPAKSGVEKYPTDKEQNSNEEDKVQLTVPPGIKNDDKNILTTWGDTIFSIVTGGEETRDTMDLESSSSEEEKEDDDDALVPDSKQGKPQSATDYSDPDNVDDGLFIVDIPKTNNDKEVNAEHHIKGKGRGVQESKRGLVQDKTELEDENQEGFKTEPIKL>sp|Q5JRA6-4|TGO1_HUMAN Isoform 4 of Transport and Golgi organizationprotein 1 homolog OS=Homo sapiens OX=9606 GN=MIA3MDSVPATVPSIAATPGDPELVGPLSVLYAAFIAKLLELVATLPDDVQPGPDFYGLPWKPVFITAFLGIASFAIFLWRTVLVVKDRVYQVTEQQISEKLKTIMKENTELVQKLSNYEQKIKESKKHVQETRKQNMILSDEAIKYKDKIKTLEKNQEILDDTAKNLRVMLESEREQNVKNQDLISENKKSIEKLKDVISMNASEFSEVQIALNEAKLSEEKVKSECHRVQEENARLKKKKEQLQQEIEDWSKLHAELSEQIKSFEKSQKDLEVALTHKDDNINALTNCITQLNLLECESESEGQNKGGNDSDELANGEVGGDRNEKMKNQIKQMMDVSRTQTAISVVEEDLKLLQLKLRASVSTKCNLEDQVKKLEDDRNSLQAAKAGLEDECKTLRQKVEILNELYQQKEMALQKKLSQEEYERQEREHRLSAADEKAVSAAEEVKTYKRRIEEMEDELQKTERSFKNQIATHEKKAHENWLKARAAERAIAEEKREAANLRHKLLELTQKMAMLQEEPVIVKPMPGKPNTQNPPRRGPLSQNGSFGPSPVSGGECSPPLTVEPPVRPLSATLNRRDMPRSEFGSVDGPLPHPRWSAEASGKPSPSDPGSGTATMMNSSSRGSSPTRVLDEGKVNMAPKGPPPFPGVPLMSTPMGGPVPPPIRYGPPPQLCGPFGPRPLPPPFGPGMRPPLGLREFAPGVPPGRRDLPLHPRGFLPGHAPFRPLGSLGPREYFIPGTRLPPPTHGPQEYPPPPAVRDLLPSGSRDEPPPASQSTSQDCSQALKQSP>sp|P17987|TCPA_HUMAN T-complex protein 1 subunit alpha OS=Homo sapiensOX=9606 GN=TCP1 PE=1 SV=1MEGPLSVFGDRSTGETIRSQNVMAAASIANIVKSSLGPVGLDKMLVDDIGDVTITNDGATILKLLEVEHPAAKVLCELADLQDKEVGDGTTSVVIIAAELLKNADELVKQKIHPTSVISGYRLACKEAVRYINENLIVNTDELGRDCLINAAKTSMSSKIIGINGDFFANMVVDAVLAIKYTDIRGQPRYPVNSVNILKAHGRSQMESMLISGYALNCVVGSQGMPKRIVNAKIACLDFSLQKTKMKLGVQVVITDPEKLDQIRQRESDITKERIQKILATGANVILTTGGIDDMCLKYFVEAGAMAVRRVLKRDLKRIAKASGATILSTLANLEGEETFEAAMLGQAEEVVQERICDDELILIKNTKARTSASIILRGANDFMCDEMERSLHDALCVVKRVLESKSVVPGGGAVEAALSIYLENYATSMGSREQLAIAEFARSLLVIPNTLAVNAAQDSTDLVAKLRAFHNEAQVNPERKNLKWIGLDLSNGKPRDNKQAGVFEPTIVKVKSLKFATEAAITILRIDDLIKLHPESKDDKHGSYEDAVHSGALND>sp|O43493|TGON2_HUMAN Trans-Golgi network integral membrane protein 2OS=Homo sapiens OX=9606 GN=TGOLN2 PE=1 SV=4MRFVVALVLLNVAAAGAVPLLATESVKQEEAGVRPSAGNVSTHPSLSQRPGGSTKSHPEPQTPKDSPSKSSAEAQTPEDTPNKSGAEAKTQKDSSNKSGAEAKTQKGSTSKSGSEAQTTKDSTSKSHPELQTPKDSTGKSGAEAQTPEDSPNRSGAEAKTQKDSPSKSGSEAQTTKDVPNKSGADGQTPKDGSSKSGAEDQTPKDVPNKSGAEKQTPKDGSNKSGAEEQGPIDGPSKSGAEEQTSKDSPNKVVPEQPSRKDHSKPISNPSDNKELPKADTNQLADKGKLSPHAFKTESGEETDLISPPQEEVKSSEPTEDVEPKEAEDDDTGPEEGSPPKEEKEKMSGSASSENREGTLSDSTGSEKDDLYPNGSGNGSAESSHFFAYLVTAAILVAVLYIAHHNKRKIIAFVLEGKRSKVTRRPKASDYQRLDQKS>sp|O43493-3|TGON2_HUMAN Isoform TGN48 of Trans-Golgi network integralmembrane protein 2 OS=Homo sapiens OX=9606 GN=TGOLN2MRFVVALVLLNVAAAGAVPLLATESVKQEEAGVRPSAGNVSTHPSLSQRPGGSTKSHPEPQTPKDSPSKSSAEAQTPEDTPNKSGAEAKTQKDSSNKSGAEAKTQKGSTSKSGSEAQTTKDSTSKSHPELQTPKDSTGKSGAEAQTPEDSPNRSGAEAKTQKDSPSKSGSEAQTTKDVPNKSGADGQTPKDGSSKSGAEDQTPKDVPNKSGAEKQTPKDGSNKSGAEEQGPIDGPSKSGAEEQTSKDSPNKVVPEQPSRKDHSKPISNPSDNKELPKADTNQLADKGKLSPHAFKTESGEETDLISPPQEEVKSSEPTEDVEPKEAEDDDTGPEEGSPPKEEKEKMSGSASSENREGTLSDSTGSEKDDLYPNGSGNGSAESSHFFAYLVTAAILVAVLYIAHHNKRKIIAFVLEGKRSKVTRRPKASDYQRLDQKIFSPPSPNRMVYSSGKR>sp|O43493-4|TGON2_HUMAN Isoform 4 of Trans-Golgi network integralmembrane protein 2 OS=Homo sapiens OX=9606 GN=TGOLN2MRFVVALVLLNVAAAGAVPLLATESVKQEEAGVRPSAGNVSTHPSLSQRPGGSTKSHPEPQTPKDSPSKSSAEAQTPEDTPNKSGAEAKTQKDSSNKSGAEAKTQKGSTSKSGSEAQTTKDSTSKSHPELQTPKDSTGKSGAEAQTPEDSPNRSGAEAKTQKDSPSKSGSEAQTTKDVPNKSGADGQTPKDGSSKSGAEDQTPKDVPNKSGAEKQTPKDGSNKSGAEEQGPIDGPSKSGAEEQTSKDSPNKEEVKSSEPTEDVEPKEAEDDDTGPEEGSPPKEEKEKMSGSASSENREGTLSDSTGSEKDDLYPNGSGNGSAESSHFFAYLVTAAILVAVLYIAHHNKRKIIAFVLEGKRSKVTRRPKASDYQRLDQKS>sp|O43493-5|TGON2_HUMAN Isoform 5 of Trans-Golgi network integralmembrane protein 2 OS=Homo sapiens OX=9606 GN=TGOLN2MRFVVALVLLNVAAAGAVPLLATESVKQEEAGVRPSAGNVSTHPSLSQRPGGSTKSHPEPQTPKDSPSKSSAEAQTPEDTPNKSGAEAKTQKDSSNKSGAEAKTQKGSTSKSGSEAQTTKDSTSKSHPELQTPKDSTGKSGAEAQTPEDSPNRSGAEAKTQKDSPSKSGSEAQTTKDVPNKSGADGQTPKDGSSKSGAEDQTPKDVPNKSGAEKQTPKDGSNKSGAEEQGPIDGPSKSGAEEQTSKDSPNKVVPEQPSRKDHSKPISNPSDNKELPKADTNQLADKGKLSPHAFKTESGEETDLISPPQEEVKSSEPTEDVEPKEAEDDDTGPEEGSPPKEEKEKMSGSASSENREGTLSDSTGSEKDDLYPNGSGNGSAESSHFFAYLVTAAILVAVLYIAHHNKRKIIAFVLEGKRSKVTRRPKASDYQRLDQKVRKEEPGPWEG>sp|O43493-6|TGON2_HUMAN Isoform 6 of Trans-Golgi network integralmembrane protein 2 OS=Homo sapiens OX=9606 GN=TGOLN2MRFVVALVLLNVAAAGAVPLLATESVKQEEAGVRPSAGNVSTHPSLSQRPGGSTKSHPEPQTPKDSPSKSGSEAQTTKDVPNKSGADGQTPKDGSSKSGAEDQTPKDVPNKSGAEKQTPKDGSNKSGAEEQGPIDGPSKSGAEEQTSKDSPNKEEVKSSEPTEDVEPKEAEDDDTGPEEGSPPKEEKEKMSGSASSENREGTLSDSTGSEKDDLYPNGSGNGSAESSHFFAYLVTAAILVAVLYIAHHNKRKIIAFVLEGKRSKVTRRPKASDYQRLDQKS>sp|O43493-7|TGON2_HUMAN Isoform 7 of Trans-Golgi network integralmembrane protein 2 OS=Homo sapiens OX=9606 GN=TGOLN2MRFVVALVLLNVAAAGAVPLLATESVKQEEAGVRPSAGNVSTHPSLSQRPGGSTKSHPEPQTPKDSPSKSSAEAQTPEDTPNKSGAEAKTQKDSSNKSGAEAKTQKGSTSKSGSEAQTTKDSTSKSHPELQTPKDSTGKSGAEAQTPEDSPNRSGAEAKTQKDSPSKSGSEAQTTKDVPNKSGADGQTPKDGSSKSGAEDQTPKDVPNKSGAEKQTPKDGSNKSGAEEQGPIDGPSKSGAEEQTSKDSPNKVVPEQPSRKDHSKPISNPSDNKELPKADTNQLADKGKLSPHAFKTESGEETDLISPPQEEVKSSEPTEDVEPKEAEDDDTGPEEGSPPKEEKEKMSGSASSENREGTLSDSTGSEKDDLYPNGSGNGSAESSHFFAYLVTAAILVAVLYIAHHNKRKIIAFVLEGKRSKVTRRPKASDYQRLDQKYVLILNVFPAPPKRSFFP>sp|P24752|THIL_HUMAN Acetyl-CoA acetyltransferase, mitochondrial OS=Homosapiens OX=9606 GN=ACAT1 PE=1 SV=1MAVLAALLRSGARSRSPLLRRLVQEIRYVERSYVSKPTLKEVVIVSATRTPIGSFLGSLSLLPATKLGSIAIQGAIEKAGIPKEEVKEAYMGNVLQGGEGQAPTRQAVLGAGLPISTPCTTINKVCASGMKAIMMASQSLMCGHQDVMVAGGMESMSNVPYVMNRGSTPYGGVKLEDLIVKDGLTDVYNKIHMGSCAENTAKKLNIARNEQDAYAINSYTRSKAAWEAGKFGNEVIPVTVTVKGQPDVVVKEDEEYKRVDFSKVPKLKTVFQKENGTVTAANASTLNDGAAALVLMTADAAKRLNVTPLARIVAFADAAVEPIDFPIAPVYAASMVLKDVGLKKEDIAMWEVNEAFSLVVLANIKMLEIDPQKVNINGGAVSLGHPIGMSGARIVGHLTHALKQGEYGLASICNGGGGASAMLIQKL>sp|P24752-2|THIL_HUMAN Isoform 2 of Acetyl-CoA acetyltransferase,mitochondrial OS=Homo sapiens OX=9606 GN=ACAT1MAVLAALLRSGARSRSPLLRRLVQEIRYVERSYVSKPTLKEVVIVSATRTPIGSFLGSLSLLPATKLGSIAIQGAIEKAGIPKEEVKEAYMGNVLQGGEGQAPTRQAVLGAGLPISTPCTTINKVCASGMKAIMMASQSLMCGHQIKQETGSLAKICCHVRR>sp|H3BV60|TGR3L_HUMAN Transforming growth factor-beta receptor type 3-like protein OS=Homo sapiens OX=9606 GN=TGFBR3L PE=2 SV=1MGESAAATASLFQRRRRGRGGRVTFPGGLKGSARFLSFGPPFPAPPAPPFPAAPGPWLRRPLFSLKLSDTEDVFPRRAGPLEVPADSRVFVQAALARPSPRWGLALHRCSVTPSSRPAPGPALALLREGCPADTSVAFPPPPPPSPGAARPARFSFRLRPVFNASVQFLHCQLSRCRRLRGVRRAPAPLTPPPPPPPSRCLPQDEACADTGSGSAEGLAADGPHLHTLTQPIVVTVPRPPPRPPKSVPGRAVRPEPPAPAPAALEPAPVVALVLAAFVLGAALAAGLGLVCAHSAPHAPGPPARASPSGPQPRRSQ>sp|O14746|TERT_HUMAN Telomerase reverse transcriptase OS=Homo sapiensOX=9606 GN=TERT PE=1 SV=1MPRAPRCRAVRSLLRSHYREVLPLATFVRRLGPQGWRLVQRGDPAAFRALVAQCLVCVPWDARPPPAAPSFRQVSCLKELVARVLQRLCERGAKNVLAFGFALLDGARGGPPEAFTTSVRSYLPNTVTDALRGSGAWGLLLRRVGDDVLVHLLARCALFVLVAPSCAYQVCGPPLYQLGAATQARPPPHASGPRRRLGCERAWNHSVREAGVPLGLPAPGARRRGGSASRSLPLPKRPRRGAAPEPERTPVGQGSWAHPGRTRGPSDRGFCVVSPARPAEEATSLEGALSGTRHSHPSVGRQHHAGPPSTSRPPRPWDTPCPPVYAETKHFLYSSGDKEQLRPSFLLSSLRPSLTGARRLVETIFLGSRPWMPGTPRRLPRLPQRYWQMRPLFLELLGNHAQCPYGVLLKTHCPLRAAVTPAAGVCAREKPQGSVAAPEEEDTDPRRLVQLLRQHSSPWQVYGFVRACLRRLVPPGLWGSRHNERRFLRNTKKFISLGKHAKLSLQELTWKMSVRDCAWLRRSPGVGCVPAAEHRLREEILAKFLHWLMSVYVVELLRSFFYVTETTFQKNRLFFYRKSVWSKLQSIGIRQHLKRVQLRELSEAEVRQHREARPALLTSRLRFIPKPDGLRPIVNMDYVVGARTFRREKRAERLTSRVKALFSVLNYERARRPGLLGASVLGLDDIHRAWRTFVLRVRAQDPPPELYFVKVDVTGAYDTIPQDRLTEVIASIIKPQNTYCVRRYAVVQKAAHGHVRKAFKSHVSTLTDLQPYMRQFVAHLQETSPLRDAVVIEQSSSLNEASSGLFDVFLRFMCHHAVRIRGKSYVQCQGIPQGSILSTLLCSLCYGDMENKLFAGIRRDGLLLRLVDDFLLVTPHLTHAKTFLRTLVRGVPEYGCVVNLRKTVVNFPVEDEALGGTAFVQMPAHGLFPWCGLLLDTRTLEVQSDYSSYARTSIRASLTFNRGFKAGRNMRRKLFGVLRLKCHSLFLDLQVNSLQTVCTNIYKILLLQAYRFHACVLQLPFHQQVWKNPTFFLRVISDTASLCYSILKAKNAGMSLGAKGAAGPLPSEAVQWLCHQAFLLKLTRHRVTYVPLLGSLRTAQTQLSRKLPGTTLTALEAAANPALPSDFKTILD>sp|O14746-2|TERT_HUMAN Isoform 2 of Telomerase reverse transcriptaseOS=Homo sapiens OX=9606 GN=TERTMPRAPRCRAVRSLLRSHYREVLPLATFVRRLGPQGWRLVQRGDPAAFRALVAQCLVCVPWDARPPPAAPSFRQVSCLKELVARVLQRLCERGAKNVLAFGFALLDGARGGPPEAFTTSVRSYLPNTVTDALRGSGAWGLLLRRVGDDVLVHLLARCALFVLVAPSCAYQVCGPPLYQLGAATQARPPPHASGPRRRLGCERAWNHSVREAGVPLGLPAPGARRRGGSASRSLPLPKRPRRGAAPEPERTPVGQGSWAHPGRTRGPSDRGFCVVSPARPAEEATSLEGALSGTRHSHPSVGRQHHAGPPSTSRPPRPWDTPCPPVYAETKHFLYSSGDKEQLRPSFLLSSLRPSLTGARRLVETIFLGSRPWMPGTPRRLPRLPQRYWQMRPLFLELLGNHAQCPYGVLLKTHCPLRAAVTPAAGVCAREKPQGSVAAPEEEDTDPRRLVQLLRQHSSPWQVYGFVRACLRRLVPPGLWGSRHNERRFLRNTKKFISLGKHAKLSLQELTWKMSVRDCAWLRRSPGVGCVPAAEHRLREEILAKFLHWLMSVYVVELLRSFFYVTETTFQKNRLFFYRKSVWSKLQSIGIRQHLKRVQLRELSEAEVRQHREARPALLTSRLRFIPKPDGLRPIVNMDYVVGARTFRREKRAERLTSRVKALFSVLNYERARRPGLLGASVLGLDDIHRAWRTFVLRVRAQDPPPELYFVKVDVTGAYDTIPQDRLTEVIASIIKPQNTYCVRRYAVVQKAAHGHVRKAFKSHVLRPVPGDPAGLHPLHAALQPVLRRHGEQAVCGDSAGRAAPAFGG>sp|O14746-3|TERT_HUMAN Isoform 3 of Telomerase reverse transcriptaseOS=Homo sapiens OX=9606 GN=TERTMPRAPRCRAVRSLLRSHYREVLPLATFVRRLGPQGWRLVQRGDPAAFRALVAQCLVCVPWDARPPPAAPSFRQVSCLKELVARVLQRLCERGAKNVLAFGFALLDGARGGPPEAFTTSVRSYLPNTVTDALRGSGAWGLLLRRVGDDVLVHLLARCALFVLVAPSCAYQVCGPPLYQLGAATQARPPPHASGPRRRLGCERAWNHSVREAGVPLGLPAPGARRRGGSASRSLPLPKRPRRGAAPEPERTPVGQGSWAHPGRTRGPSDRGFCVVSPARPAEEATSLEGALSGTRHSHPSVGRQHHAGPPSTSRPPRPWDTPCPPVYAETKHFLYSSGDKEQLRPSFLLSSLRPSLTGARRLVETIFLGSRPWMPGTPRRLPRLPQRYWQMRPLFLELLGNHAQCPYGVLLKTHCPLRAAVTPAAGVCAREKPQGSVAAPEEEDTDPRRLVQLLRQHSSPWQVYGFVRACLRRLVPPGLWGSRHNERRFLRNTKKFISLGKHAKLSLQELTWKMSVRDCAWLRRSPGVGCVPAAEHRLREEILAKFLHWLMSVYVVELLRSFFYVTETTFQKNRLFFYRKSVWSKLQSIGIRQHLKRVQLRELSEAEVRQHREARPALLTSRLRFIPKPDGLRPIVNMDYVVGARTFRREKRAERLTSRVKALFSVLNYERARRPGLLGASVLGLDDIHRAWRTFVLRVRAQDPPPELYFVKVDVTGAYDTIPQDRLTEVIASIIKPQNTYCVRRYAVVQKAAHGHVRKAFKSHVSTLTDLQPYMRQFVAHLQETSPLRDAVVIEQSSSLNEASSGLFDVFLRFMCHHAVRIRGKSYVQCQGIPQGSILSTLLCSLCYGDMENKLFAGIRRDGLLLRLVDDFLLVTPHLTHAKTFLSYARTSIRASLTFNRGFKAGRNMRRKLFGVLRLKCHSLFLDLQVNSLQTVCTNIYKILLLQAYRFHACVLQLPFHQQVWKNPTFFLRVISDTASLCYSILKAKNAGMSLGAKGAAGPLPSEAVQWLCHQAFLLKLTRHRVTYVPLLGSLRTAQTQLSRKLPGTTLTALEAAANPALPSDFKTILD>sp|O14746-4|TERT_HUMAN Isoform 4 of Telomerase reverse transcriptaseOS=Homo sapiens OX=9606 GN=TERTMPRAPRCRAVRSLLRSHYREVLPLATFVRRLGPQGWRLVQRGDPAAFRALVAQCLVCVPWDARPPPAAPSFRQVSCLKELVARVLQRLCERGAKNVLAFGFALLDGARGGPPEAFTTSVRSYLPNTVTDALRGSGAWGLLLRRVGDDVLVHLLARCALFVLVAPSCAYQVCGPPLYQLGAATQARPPPHASGPRRRLGCERAWNHSVREAGVPLGLPAPGARRRGGSASRSLPLPKRPRRGAAPEPERTPVGQGSWAHPGRTRGPSDRGFCVVSPARPAEEATSLEGALSGTRHSHPSVGRQHHAGPPSTSRPPRPWDTPCPPVYAETKHFLYSSGDKEQLRPSFLLSSLRPSLTGARRLVETIFLGSRPWMPGTPRRLPRLPQRYWQMRPLFLELLGNHAQCPYGVLLKTHCPLRAAVTPAAGVCAREKPQGSVAAPEEEDTDPRRLVQLLRQHSSPWQVYGFVRACLRRLVPPGLWGSRHNERRFLRNTKKFISLGKHAKLSLQELTWKMSVRDCAWLRRSPGVGCVPAAEHRLREEILAKFLHWLMSVYVVELLRSFFYVTETTFQKNRLFFYRKSVWSKLQSIGIRQHLKRVQLRELSEAEVRQHREARPALLTSRLRFIPKPDGLRPIVNMDYVVGARTFRREKRAERLTSRVKALFSVLNYERARRPGLLGASVLGLDDIHRAWRTFVLRVRAQDPPPELYFVKDRLTEVIASIIKPQNTYCVRRYAVVQKAAHGHVRKAFKSHVLRPVPGDPAGLHPLHAALQPVLRRHGEQAVCGDSAGRAAPAFGG>sp|P78371|TCPB_HUMAN T-complex protein 1 subunit beta OS=Homo sapiensOX=9606 GN=CCT2 PE=1 SV=4MASLSLAPVNIFKAGADEERAETARLTSFIGAIAIGDLVKSTLGPKGMDKILLSSGRDASLMVTNDGATILKNIGVDNPAAKVLVDMSRVQDDEVGDGTTSVTVLAAELLREAESLIAKKIHPQTIIAGWREATKAAREALLSSAVDHGSDEVKFRQDLMNIAGTTLSSKLLTHHKDHFTKLAVEAVLRLKGSGNLEAIHIIKKLGGSLADSYLDEGFLLDKKIGVNQPKRIENAKILIANTGMDTDKIKIFGSRVRVDSTAKVAEIEHAEKEKMKEKVERILKHGINCFINRQLIYNYPEQLFGAAGVMAIEHADFAGVERLALVTGGEIASTFDHPELVKLGSCKLIEEVMIGEDKLIHFSGVALGEACTIVLRGATQQILDEAERSLHDALCVLAQTVKDSRTVYGGGCSEMLMAHAVTQLANRTPGKEAVAMESYAKALRMLPTIIADNAGYDSADLVAQLRAAHSEGNTTAGLDMREGTIGDMAILGITESFQVKRQVLLSAAEAAEVILRVDNIIKAAPRKRVPDHHPC>sp|P78371-2|TCPB_HUMAN Isoform 2 of T-complex protein 1 subunit betaOS=Homo sapiens OX=9606 GN=CCT2MDKILLSSGRDASLMVTNDGATILKNIGVDNPAAKVLVDMSRVQDDEVGDGTTSVTVLAAELLREAESLIAKKIHPQTIIAGWREATKAAREALLSSAVDHGSDEVKFRQDLMNIAGTTLSSKLLTHHKDHFTKLAVEAVLRLKGSGNLEAIHIIKKLGGSLADSYLDEGFLLDKKIGVNQPKRIENAKILIANTGMDTDKIKIFGSRVRVDSTAKVAEIEHAEKEKMKEKVERILKHGINCFINRQLIYNYPEQLFGAAGVMAIEHADFAGVERLALVTGGEIASTFDHPELVKLGSCKLIEEVMIGEDKLIHFSGVALGEACTIVLRGATQQILDEAERSLHDALCVLAQTVKDSRTVYGGGCSEMLMAHAVTQLANRTPGKEAVAMESYAKALRMLPTIIADNAGYDSADLVAQLRAAHSEGNTTAGLDMREGTIGDMAILGITESFQVKRQVLLSAAEAAEVILRVDNIIKAAPRKRVPDHHPC>sp|Q96F10|SAT2_HUMAN Thialysine N-epsilon-acetyltransferase OS=Homosapiens OX=9606 GN=SAT2 PE=1 SV=1MASVRIREAKEGDCGDILRLIRELAEFEKLSDQVKISEEALRADGFGDNPFYHCLVAEILPAPGKLLGPCVVGYGIYYFIYSTWKGRTIYLEDIYVMPEYRGQGIGSKIIKKVAEVALDKGCSQFRLAVLDWNQRAMDLYKALGAQDLTEAEGWHFFCFQGEATRKLAGK>sp|Q13214|SEM3B_HUMAN Semaphorin-3B OS=Homo sapiens OX=9606 GN=SEMA3BPE=1 SV=1MGRAGAAAVIPGLALLWAVGLGSAAPSPPRLRLSFQELQAWHGLQTFSLERTCCYQALLVDEERGRLFVGAENHVASLNLDNISKRAKKLAWPAPVEWREECNWAGKDIGTECMNFVKLLHAYNRTHLLACGTGAFHPTCAFVEVGHRAEEPVLRLDPGRIEDGKGKSPYDPRHRAASVLVGEELYSGVAADLMGRDFTIFRSLGQRPSLRTEPHDSRWLNEPKFVKVFWIPESENPDDDKIYFFFRETAVEAAPALGRLSVSRVGQICRNDVGGQRSLVNKWTTFLKARLVCSVPGVEGDTHFDQLQDVFLLSSRDHRTPLLYAVFSTSSSIFQGSAVCVYSMNDVRRAFLGPFAHKEGPMHQWVSYQGRVPYPRPGMCPSKTFGTFSSTKDFPDDVIQFARNHPLMYNSVLPTGGRPLFLQVGANYTFTQIAADRVAAADGHYDVLFIGTDVGTVLKVISVPKGSRPSAEGLLLEELHVFEDSAAVTSMQISSKRHQLYVASRSAVAQIALHRCAAHGRVCTECCLARDPYCAWDGVACTRFQPSAKRRFRRQDVRNGDPSTLCSGDSSRPALLEHKVFGVEGSSAFLECEPRSLQARVEWTFQRAGVTAHTQVLAEERTERTARGLLLRRLRRRDSGVYLCAAVEQGFTQPLRRLSLHVLSATQAERLARAEEAAPAAPPGPKLWYRDFLQLVEPGGGGSANSLRMCRPQPALQSLPLESRRKGRNRRTHAPEPRAERGPRSATHW>sp|Q13214-2|SEM3B_HUMAN Isoform 2 of Semaphorin-3B OS=Homo sapiensOX=9606 GN=SEMA3BMGRAGAAAVIPGLALLWAVGLGSAAPSPPRLRLSFQELQAWHGLQTFSLERTCCYQALLVDEERGRLFVGAENHVASLNLDNISKRAKKLAWPAPVEWREECNWAGKDIGTECMNFVKLLHAYNRTHLLACGTGAFHPTCAFVEVGHRAEEPVLRLDPGRIEDGKGKSPYDPRHRAASVLVGEELYSGVAADLMGRDFTIFRSLGQRPSLRTEPHDSRWLNEPKFVKVFWIPESENPDDDKIYFFFRETAVEAAPALGRLSVSRVGQICRNDVGGQRSLVNKWTTFLKARLVCSVPGVEGDTHFDQLQDVFLLSSRDHRTPLLYAVFSTSSIFQGSAVCVYSMNDVRRAFLGPFAHKEGPMHQWVSYQGRVPYPRPGMCPSKTFGTFSSTKDFPDDVIQFARNHPLMYNSVLPTGGRPLFLQVGANYTFTQIAADRVAAADGHYDVLFIGTDVGTVLKVISVPKGSRPSAEGLLLEELHVFEDSAAVTSMQISSKRHQLYVASRSAVAQIALHRCAAHGRVCTECCLARDPYCAWDGVACTRFQPSAKRRFRRQDVRNGDPSTLCSGDSSRPALLEHKVFGVEGSSAFLECEPRSLQARVEWTFQRAGVTAHTQVLAEERTERTARGLLLRRLRRRDSGVYLCAAVEQGFTQPLRRLSLHVLSATQAERLARAEEAAPAAPPGPKLWYRDFLQLVEPGGGGSANSLRMCRPQPALQSLPLESRRKGRNRRTHAPEPRAERGPRSATHW>sp|Q14563|SEM3A_HUMAN Semaphorin-3A OS=Homo sapiens OX=9606 GN=SEMA3APE=1 SV=1MGWLTRIVCLFWGVLLTARANYQNGKNNVPRLKLSYKEMLESNNVITFNGLANSSSYHTFLLDEERSRLYVGAKDHIFSFDLVNIKDFQKIVWPVSYTRRDECKWAGKDILKECANFIKVLKAYNQTHLYACGTGAFHPICTYIEIGHHPEDNIFKLENSHFENGRGKSPYDPKLLTASLLIDGELYSGTAADFMGRDFAIFRTLGHHHPIRTEQHDSRWLNDPKFISAHLISESDNPEDDKVYFFFRENAIDGEHSGKATHARIGQICKNDFGGHRSLVNKWTTFLKARLICSVPGPNGIDTHFDELQDVFLMNFKDPKNPVVYGVFTTSSNIFKGSAVCMYSMSDVRRVFLGPYAHRDGPNYQWVPYQGRVPYPRPGTCPSKTFGGFDSTKDLPDDVITFARSHPAMYNPVFPMNNRPIVIKTDVNYQFTQIVVDRVDAEDGQYDVMFIGTDVGTVLKVVSIPKETWYDLEEVLLEEMTVFREPTAISAMELSTKQQQLYIGSTAGVAQLPLHRCDIYGKACAECCLARDPYCAWDGSACSRYFPTAKRRTRRQDIRNGDPLTHCSDLHHDNHHGHSPEERIIYGVENSSTFLECSPKSQRALVYWQFQRRNEERKEEIRVDDHIIRTDQGLLLRSLQQKDSGNYLCHAVEHGFIQTLLKVTLEVIDTEHLEELLHKDDDGDGSKTKEMSNSMTPSQKVWYRDFMQLINHPNLNTMDEFCEQVWKRDRKQRRQRPGHTPGNSNKWKHLQENKKGRNRRTHEFERAPRSV>sp|Q99250|SCN2A_HUMAN Sodium channel protein type 2 subunit alphaOS=Homo sapiens OX=9606 GN=SCN2A PE=1 SV=3MAQSVLVPPGPDSFRFFTRESLAAIEQRIAEEKAKRPKQERKDEDDENGPKPNSDLEAGKSLPFIYGDIPPEMVSVPLEDLDPYYINKKTFIVLNKGKAISRFSATPALYILTPFNPIRKLAIKILVHSLFNMLIMCTILTNCVFMTMSNPPDWTKNVEYTFTGIYTFESLIKILARGFCLEDFTFLRDPWNWLDFTVITFAYVTEFVDLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCLQWPPDNSSFEINITSFFNNSLDGNGTTFNRTVSIFNWDEYIEDKSHFYFLEGQNDALLCGNSSDAGQCPEGYICVKAGRNPNYGYTSFDTFSWAFLSLFRLMTQDFWENLYQLTLRAAGKTYMIFFVLVIFLGSFYLINLILAVVAMAYEEQNQATLEEAEQKEAEFQQMLEQLKKQQEEAQAAAAAASAESRDFSGAGGIGVFSESSSVASKLSSKSEKELKNRRKKKKQKEQSGEEEKNDRVRKSESEDSIRRKGFRFSLEGSRLTYEKRFSSPHQSLLSIRGSLFSPRRNSRASLFSFRGRAKDIGSENDFADDEHSTFEDNDSRRDSLFVPHRHGERRHSNVSQASRASRVLPILPMNGKMHSAVDCNGVVSLVGGPSTLTSAGQLLPEGTTTETEIRKRRSSSYHVSMDLLEDPTSRQRAMSIASILTNTMEELEESRQKCPPCWYKFANMCLIWDCCKPWLKVKHLVNLVVMDPFVDLAITICIVLNTLFMAMEHYPMTEQFSSVLSVGNLVFTGIFTAEMFLKIIAMDPYYYFQEGWNIFDGFIVSLSLMELGLANVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKISNDCELPRWHMHDFFHSFLIVFRVLCGEWIETMWDCMEVAGQTMCLTVFMMVMVIGNLVVLNLFLALLLSSFSSDNLAATDDDNEMNNLQIAVGRMQKGIDFVKRKIREFIQKAFVRKQKALDEIKPLEDLNNKKDSCISNHTTIEIGKDLNYLKDGNGTTSGIGSSVEKYVVDESDYMSFINNPSLTVTVPIAVGESDFENLNTEEFSSESDMEESKEKLNATSSSEGSTVDIGAPAEGEQPEVEPEESLEPEACFTEDCVRKFKCCQISIEEGKGKLWWNLRKTCYKIVEHNWFETFIVFMILLSSGALAFEDIYIEQRKTIKTMLEYADKVFTYIFILEMLLKWVAYGFQVYFTNAWCWLDFLIVDVSLVSLTANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALLGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFYHCINYTTGEMFDVSVVNNYSECKALIESNQTARWKNVKVNFDNVGLGYLSLLQVATFKGWMDIMYAAVDSRNVELQPKYEDNLYMYLYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPANKFQGMVFDFVTKQVFDISIMILICLNMVTMMVETDDQSQEMTNILYWINLVFIVLFTGECVLKLISLRYYYFTIGWNIFDFVVVILSIVGMFLAELIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYAIFGMSNFAYVKREVGIDDMFNFETFGNSMICLFQITTSAGWDGLLAPILNSGPPDCDPDKDHPGSSVKGDCGNPSVGIFFFVSYIIISFLVVVNMYIAVILENFSVATEESAEPLSEDDFEMFYEVWEKFDPDATQFIEFAKLSDFADALDPPLLIAKPNKVQLIAMDLPMVSGDRIHCLDILFAFTKRVLGESGEMDALRIQMEERFMASNPSKVSYEPITTTLKRKQEEVSAIIIQRAYRRYLLKQKVKKVSSIYKKDKGKECDGTPIKEDTLIDKLNENSTPEKTDMTPSTTSPPSYDSVTKPEKEKFEKDKSEKEDKGKDIRESKK>sp|Q99250-2|SCN2A_HUMAN Isoform 2 of Sodium channel protein type 2subunit alpha OS=Homo sapiens OX=9606 GN=SCN2AMAQSVLVPPGPDSFRFFTRESLAAIEQRIAEEKAKRPKQERKDEDDENGPKPNSDLEAGKSLPFIYGDIPPEMVSVPLEDLDPYYINKKTFIVLNKGKAISRFSATPALYILTPFNPIRKLAIKILVHSLFNMLIMCTILTNCVFMTMSNPPDWTKNVEYTFTGIYTFESLIKILARGFCLEDFTFLRDPWNWLDFTVITFAYVTEFVNLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCLQWPPDNSSFEINITSFFNNSLDGNGTTFNRTVSIFNWDEYIEDKSHFYFLEGQNDALLCGNSSDAGQCPEGYICVKAGRNPNYGYTSFDTFSWAFLSLFRLMTQDFWENLYQLTLRAAGKTYMIFFVLVIFLGSFYLINLILAVVAMAYEEQNQATLEEAEQKEAEFQQMLEQLKKQQEEAQAAAAAASAESRDFSGAGGIGVFSESSSVASKLSSKSEKELKNRRKKKKQKEQSGEEEKNDRVRKSESEDSIRRKGFRFSLEGSRLTYEKRFSSPHQSLLSIRGSLFSPRRNSRASLFSFRGRAKDIGSENDFADDEHSTFEDNDSRRDSLFVPHRHGERRHSNVSQASRASRVLPILPMNGKMHSAVDCNGVVSLVGGPSTLTSAGQLLPEGTTTETEIRKRRSSSYHVSMDLLEDPTSRQRAMSIASILTNTMEELEESRQKCPPCWYKFANMCLIWDCCKPWLKVKHLVNLVVMDPFVDLAITICIVLNTLFMAMEHYPMTEQFSSVLSVGNLVFTGIFTAEMFLKIIAMDPYYYFQEGWNIFDGFIVSLSLMELGLANVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKISNDCELPRWHMHDFFHSFLIVFRVLCGEWIETMWDCMEVAGQTMCLTVFMMVMVIGNLVVLNLFLALLLSSFSSDNLAATDDDNEMNNLQIAVGRMQKGIDFVKRKIREFIQKAFVRKQKALDEIKPLEDLNNKKDSCISNHTTIEIGKDLNYLKDGNGTTSGIGSSVEKYVVDESDYMSFINNPSLTVTVPIAVGESDFENLNTEEFSSESDMEESKEKLNATSSSEGSTVDIGAPAEGEQPEVEPEESLEPEACFTEDCVRKFKCCQISIEEGKGKLWWNLRKTCYKIVEHNWFETFIVFMILLSSGALAFEDIYIEQRKTIKTMLEYADKVFTYIFILEMLLKWVAYGFQVYFTNAWCWLDFLIVDVSLVSLTANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALLGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFYHCINYTTGEMFDVSVVNNYSECKALIESNQTARWKNVKVNFDNVGLGYLSLLQVATFKGWMDIMYAAVDSRNVELQPKYEDNLYMYLYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPANKFQGMVFDFVTKQVFDISIMILICLNMVTMMVETDDQSQEMTNILYWINLVFIVLFTGECVLKLISLRYYYFTIGWNIFDFVVVILSIVGMFLAELIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYAIFGMSNFAYVKREVGIDDMFNFETFGNSMICLFQITTSAGWDGLLAPILNSGPPDCDPDKDHPGSSVKGDCGNPSVGIFFFVSYIIISFLVVVNMYIAVILENFSVATEESAEPLSEDDFEMFYEVWEKFDPDATQFIEFAKLSDFADALDPPLLIAKPNKVQLIAMDLPMVSGDRIHCLDILFAFTKRVLGESGEMDALRIQMEERFMASNPSKVSYEPITTTLKRKQEEVSAIIIQRAYRRYLLKQKVKKVSSIYKKDKGKECDGTPIKEDTLIDKLNENSTPEKTDMTPSTTSPPSYDSVTKPEKEKFEKDKSEKEDKGKDIRESKK>sp|Q9Y467|SALL2_HUMAN Sal-like protein 2 OS=Homo sapiens OX=9606GN=SALL2 PE=1 SV=4MSRRKQRKPQQLISDCEGPSASENGDASEEDHPQVCAKCCAQFTDPTEFLAHQNACSTDPPVMVIIGGQENPNNSSASSEPRPEGHNNPQVMDTEHSNPPDSGSSVPTDPTWGPERRGEESPGHFLVAATGTAAGGGGGLILASPKLGATPLPPESTPAPPPPPPPPPPPGVGSGHLNIPLILEELRVLQQRQIHQMQMTEQICRQVLLLGSLGQTVGAPASPSELPGTGTASSTKPLLPLFSPIKPVQTSKTLASSSSSSSSSSGAETPKQAFFHLYHPLGSQHPFSAGGVGRSHKPTPAPSPALPGSTDQLIASPHLAFPSTTGLLAAQCLGAARGLEATASPGLLKPKNGSGELSYGEVMGPLEKPGGRHKCRFCAKVFGSDSALQIHLRSHTGERPYKCNVCGNRFTTRGNLKVHFHRHREKYPHVQMNPHPVPEHLDYVITSSGLPYGMSVPPEKAEEEAATPGGGVERKPLVASTTALSATESLTLLSTSAGTATAPGLPAFNKFVLMKAVEPKNKADENTPPGSEGSAISGVAESSTATRMQLSKLVTSLPSWALLTNHFKSTGSFPFPYVLEPLGASPSETSKLQQLVEKIDRQGAVAVTSAASGAPTTSAPAPSSSASSGPNQCVICLRVLSCPRALRLHYGQHGGERPFKCKVCGRAFSTRGNLRAHFVGHKASPAARAQNSCPICQKKFTNAVTLQQHVRMHLGGQIPNGGTALPEGGGAAQENGSEQSTVSGAGSFPQQQSQQPSPEEELSEEEEEEDEEEEEDVTDEDSLAGRGSESGGEKAISVRGDSEEASGAEEEVGTVAAAATAGKEMDSNEKTTQQSSLPPPPPPDSLDQPQPMEQGSSGVLGGKEEGGKPERSSSPASALTPEGEATSVTLVEELSLQEAMRKEPGESSSRKACEVCGQAFPSQAALEEHQKTHPKEGPLFTCVFCRQGFLERATLKKHMLLAHHQVQPFAPHGPQNIAALSLVPGCSPSITSTGLSPFPRKDDPTIP>sp|Q9Y467-3|SALL2_HUMAN Isoform 2 of Sal-like protein 2 OS=Homo sapiensOX=9606 GN=SALL2MAHESERSSRLGVPCGEPAELGGDASEEDHPQVCAKCCAQFTDPTEFLAHQNACSTDPPVMVIIGGQENPNNSSASSEPRPEGHNNPQVMDTEHSNPPDSGSSVPTDPTWGPERRGEESPGHFLVAATEPVCGIPVKWPAHEALEFQLHLHYHSKPGPTSAVWPRNCGWEGASNNGIQGSQGEDSPPPISASCTQGSA>sp|Q6IQ49|SDE2_HUMAN Replication stress response regulator SDE2 OS=Homosapiens OX=9606 GN=SDE2 PE=1 SV=1MAEAAALVWIRGPGFGCKAVRCASGRCTVRDFIHRHCQDQNVPVENFFVKCNGALINTSDTVQHGAVYSLEPRLCGGKGGFGSMLRALGAQIEKTTNREACRDLSGRRLRDVNHEKAMAEWVKQQAEREAEKEQKRLERLQRKLVEPKHCFTSPDYQQQCHEMAERLEDSVLKGMQAASSKMVSAEISENRKRQWPTKSQTDRGASAGKRRCFWLGMEGLETAEGSNSESSDDDSEEAPSTSGMGFHAPKIGSNGVEMAAKFPSGSQRARVVNTDHGSPEQLQIPVTDSGRHILEDSCAELGESKEHMESRMVTETEETQEKKAESKEPIEEEPTGAGLNKDKETEERTDGERVAEVAPEERENVAVAKLQESQPGNAVIDKETIDLLAFTSVAELELLGLEKLKCELMALGLKCGGTLQERAARLFSVRGLAKEQIDPALFAKPLKGKKK>sp|Q6IQ49-2|SDE2_HUMAN Isoform 2 of Replication stress responseregulator SDE2 OS=Homo sapiens OX=9606 GN=SDE2MAEAAALVWIRGPGFGCKAVRCASGRCTVRDFIHRHCQDQNVPVENFFVKCNGAVYSLEPRLCGGKGGFGSMLRALGAQIEKTTNREACRDLSGRRLRDVNHEKAMAEWVKQQAEREAEKEQKRLERLQRKLVEPKHCFTSPDYQQQCHEMAERLEDSVLKGMQAASSKMVSAEISENRKRQWPTKSQTDRGASAGKRRCFWLGMEGLETAEGSNSESSDDDSEEAPSTSGMGFHAPKIGSNGVEMAAKFPSGSQRARVVNTDHGSPEQLQIPVTDSGRHILEDSCAELGESKEHMESRMVTETEETQEKKAESKEPIEEEPTGAGLNKDKETEERTDGERVAEVAPEERENVAVAKLQESQPGNAVIDKETIDLLAFTSVAELELLGLEKLKCELMALGLKCGGTLQERAARLFSVRGLAKEQIDPALFAKPLKGKKK>sp|Q6IQ49-3|SDE2_HUMAN Isoform 3 of Replication stress responseregulator SDE2 OS=Homo sapiens OX=9606 GN=SDE2MEHSLTPVTQCSMELFIVWNPDFAVEKEVLDLCSEHLVLRLRRQPIEKLVEPKHCFTSPDYQQQCHEMAERLEDSVLKGMQAASSKMVSAEISENRKRQWPTKSQTDRGASAGKRRCFWLGMEGLETAEGSNSESSDDDSEEAPSTSGMGFHAPKIGSNGVEMAAKFPSGSQRARVVNTDHGSPEQLQIPVTDSGRHILEDSCAELGESKEHMESRMVTETEETQEKKAESKEPIEEEPTGAGLNKDKETEERTDGERVAEVAPEERENVAVAKLQESQPGNAVIDKETIDLLAFTSVAELELLGLEKLKCELMALGLKCGGTLQERAARLFSVRGLAKEQIDPALFAKPLKGKKK>sp|Q13275|SEM3F_HUMAN Semaphorin-3F OS=Homo sapiens OX=9606 GN=SEMA3FPE=2 SV=2MLVAGLLLWASLLTGAWPSFPTQDHLPATPRVRLSFKELKATGTAHFFNFLLNTTDYRILLKDEDHDRMYVGSKDYVLSLDLHDINREPLIIHWAASPQRIEECVLSGKDVNGECGNFVRLIQPWNRTHLYVCGTGAYNPMCTYVNRGRRAQATPWTQTQAVRGRGSRATDGALRPMPTAPRQDYIFYLEPERLESGKGKCPYDPKLDTASALINEELYAGVYIDFMGTDAAIFRTLGKQTAMRTDQYNSRWLNDPSFIHAELIPDSAERNDDKLYFFFRERSAEAPQSPAVYARIGRICLNDDGGHCCLVNKWSTFLKARLVCSVPGEDGIETHFDELQDVFVQQTQDVRNPVIYAVFTSSGSVFRGSAVCVYSMADIRMVFNGPFAHKEGPNYQWMPFSGKMPYPRPGTCPGGTFTPSMKSTKDYPDEVINFMRSHPLMYQAVYPLQRRPLVVRTGAPYRLTTIAVDQVDAADGRYEVLFLGTDRGTVQKVIVLPKDDQELEELMLEEVEVFKDPAPVKTMTISSKRQQLYVASAVGVTHLSLHRCQAYGAACADCCLARDPYCAWDGQACSRYTASSKRRSRRQDVRHGNPIRQCRGFNSNANKNAVESVQYGVAGSAAFLECQPRSPQATVKWLFQRDPGDRRREIRAEDRFLRTEQGLLLRALQLSDRGLYSCTATENNFKHVVTRVQLHVLGRDAVHAALFPPLSMSAPPPPGAGPPTPPYQELAQLLAQPEVGLIHQYCQGYWRHVPPSPREAPGAPRSPEPQDQKKPRNRRHHPPDT>sp|Q13275-2|SEM3F_HUMAN Isoform 2 of Semaphorin-3F OS=Homo sapiensOX=9606 GN=SEMA3FMLVAGLLLWASLLTGAWPSFPTQDHLPATPRVRLSFKELKATGTAHFFNFLLNTTDYRILLKDEDHDRMYVGSKDYVLSLDLHDINREPLIIHWAASPQRIEECVLSGKDVNGECGNFVRLIQPWNRTHLYVCGTGAYNPMCTYVNRGRRAQDYIFYLEPERLESGKGKCPYDPKLDTASALINEELYAGVYIDFMGTDAAIFRTLGKQTAMRTDQYNSRWLNDPSFIHAELIPDSAERNDDKLYFFFRERSAEAPQSPAVYARIGRICLNDDGGHCCLVNKWSTFLKARLVCSVPGEDGIETHFDELQDVFVQQTQDVRNPVIYAVFTSSGSVFRGSAVCVYSMADIRMVFNGPFAHKEGPNYQWMPFSGKMPYPRPGTCPGGTFTPSMKSTKDYPDEVINFMRSHPLMYQAVYPLQRRPLVVRTGAPYRLTTIAVDQVDAADGRYEVLFLGTDRGTVQKVIVLPKDDQELEELMLEEVEVFKDPAPVKTMTISSKRQQLYVASAVGVTHLSLHRCQAYGAACADCCLARDPYCAWDGQACSRYTASSKRRSRRQDVRHGNPIRQCRGFNSNANKNAVESVQYGVAGSAAFLECQPRSPQATVKWLFQRDPGDRRREIRAEDRFLRTEQGLLLRALQLSDRGLYSCTATENNFKHVVTRVQLHVLGRDAVHAALFPPLSMSAPPPPGAGPPTPPYQELAQLLAQPEVGLIHQYCQGYWRHVPPSPREAPGAPRSPEPQDQKKPRNRRHHPPDT>sp|Q9H3S1|SEM4A_HUMAN Semaphorin-4A OS=Homo sapiens OX=9606 GN=SEMA4APE=1 SV=2MALPALGLDPWSLLGLFLFQLLQLLLPTTTAGGGGQGPMPRVRYYAGDERRALSFFHQKGLQDFDTLLLSGDGNTLYVGAREAILALDIQDPGVPRLKNMIPWPASDRKKSECAFKKKSNETQCFNFIRVLVSYNVTHLYTCGTFAFSPACTFIELQDSYLLPISEDKVMEGKGQSPFDPAHKHTAVLVDGMLYSGTMNNFLGSEPILMRTLGSQPVLKTDNFLRWLHHDASFVAAIPSTQVVYFFFEETASEFDFFERLHTSRVARVCKNDVGGEKLLQKKWTTFLKAQLLCTQPGQLPFNVIRHAVLLPADSPTAPHIYAVFTSQWQVGGTRSSAVCAFSLLDIERVFKGKYKELNKETSRWTTYRGPETNPRPGSCSVGPSSDKALTFMKDHFLMDEQVVGTPLLVKSGVEYTRLAVETAQGLDGHSHLVMYLGTTTGSLHKAVVSGDSSAHLVEEIQLFPDPEPVRNLQLAPTQGAVFVGFSGGVWRVPRANCSVYESCVDCVLARDPHCAWDPESRTCCLLSAPNLNSWKQDMERGNPEWACASGPMSRSLRPQSRPQIIKEVLAVPNSILELPCPHLSALASYYWSHGPAAVPEASSTVYNGSLLLIVQDGVGGLYQCWATENGFSYPVISYWVDSQDQTLALDPELAGIPREHVKVPLTRVSGGAALAAQQSYWPHFVTVTVLFALVLSGALIILVASPLRALRARGKVQGCETLRPGEKAPLSREQHLQSPKECRTSASDVDADNNCLGTEVA>sp|Q9H3S1-2|SEM4A_HUMAN Isoform 2 of Semaphorin-4A OS=Homo sapiensOX=9606 GN=SEMA4AMIPWPASDRKKSECAFKKKSNEELQDSYLLPISEDKVMEGKGQSPFDPAHKHTAVLVDGMLYSGTMNNFLGSEPILMRTLGSQPVLKTDNFLRWLHHDASFVAAIPSTQVVYFFFEETASEFDFFERLHTSRVARVCKNDVGGEKLLQKKWTTFLKAQLLCTQPGQLPFNVIRHAVLLPADSPTAPHIYAVFTSQWQVGGTRSSAVCAFSLLDIERVFKGKYKELNKETSRWTTYRGPETNPRPGSCSVGPSSDKALTFMKDHFLMDEQVVGTPLLVKSGVEYTRLAVETAQGLDGHSHLVMYLGTTTGSLHKAVVSGDSSAHLVEEIQLFPDPEPVRNLQLAPTQGAVFVGFSGGVWRVPRANCSVYESCVDCVLARDPHCAWDPESRTCCLLSAPNLNSWKQDMERGNPEWACASGPMSRSLRPQSRPQIIKEVLAVPNSILELPCPHLSALASYYWSHGPAAVPEASSTVYNGSLLLIVQDGVGGLYQCWATENGFSYPVISYWVDSQDQTLALDPELAGIPREHVKVPLTRVSGGAALAAQQSYWPHFVTVTVLFALVLSGALIILVASPLRALRARGKVQGCETLRPGEKAPLSREQHLQSPKECRTSASDVDADNNCLGTEVA>sp|Q13591|SEM5A_HUMAN Semaphorin-5A OS=Homo sapiens OX=9606 GN=SEMA5APE=1 SV=3MKGTCVIAWLFSSLGLWRLAHPEAQGTTQCQRTEHPVISYKEIGPWLREFRAKNAVDFSQLTFDPGQKELVVGARNYLFRLQLEDLSLIQAVEWECDEATKKACYSKGKSKEECQNYIRVLLVGGDRLFTCGTNAFTPVCTNRSLSNLTEIHDQISGMARCPYSPQHNSTALLTAGGELYAATAMDFPGRDPAIYRSLGILPPLRTAQYNSKWLNEPNFVSSYDIGNFTYFFFRENAVEHDCGKTVFSRAARVCKNDIGGRFLLEDTWTTFMKARLNCSRPGEVPFYYNELQSTFFLPELDLIYGIFTTNVNSIAASAVCVFNLSAIAQAFSGPFKYQENSRSAWLPYPNPNPHFQCGTVDQGLYVNLTERNLQDAQKFILMHEVVQPVTTVPSFMEDNSRFSHVAVDVVQGREALVHIIYLATDYGTIKKVRVPLNQTSSSCLLEEIELFPERRREPIRSLQILHSQSVLFVGLREHVVKIPLKRCQFYRTRSTCIGAQDPYCGWDVVMKKCTSLEESLSMTQWEQSISACPTRNLTVDGHFGVWSPWTPCTHTDGSAVGSCLCRTRSCDSPAPQCGGWQCEGPGMEIANCSRNGGWTPWTSWSPCSTTCGIGFQVRQRSCSNPTPRHGGRVCVGQNREERYCNEHLLCPPHMFWTGWGPWERCTAQCGGGIQARRRICENGPDCAGCNVEYQSCNTNPCPELKKTTPWTPWTPVNISDNGGHYEQRFRYTCKARLADPNLLEVGRQRIEMRYCSSDGTSGCSTDGLSGDFLRAGRYSAHTVNGAWSAWTSWSQCSRDCSRGIRNRKRVCNNPEPKYGGMPCLGPSLEYQECNILPCPVDGVWSCWSPWTKCSATCGGGHYMRTRSCSNPAPAYGGDICLGLHTEEALCNTQPCPESWSEWSDWSECEASGVQVRARQCILLFPMGSQCSGNTTESRPCVFDSNFIPEVSVARSSSVEEKRCGEFNMFHMIAVGLSSSILGCLLTLLVYTYCQRYQQQSHDATVIHPVSPAPLNTSITNHINKLDKYDSVEAIKAFNKNNLILEERNKYFNPHLTGKTYSNAYFTDLNNYDEY>sp|Q8N8I0|SAM12_HUMAN Sterile alpha motif domain-containing protein 12OS=Homo sapiens OX=9606 GN=SAMD12 PE=1 SV=2MAVEALHCGLNPRGIDHPAHAEGIKLQIEGEGVESQSIKNKNFQKVPDQKGTPKRLQAEAETAKSATVKLSKPVALWTQQDVCKWLKKHCPNQYQIYSESFKQHDITGRALLRLTDKKLERMGIAQENLRQHILQQVLQLKVREEVRNLQLLTQGTLLLPDGWMDGEIRRKTTLLLGQTGVRENLLLFLHRISIIENSIQI>sp|Q9Y512|SAM50_HUMAN Sorting and assembly machinery component 50homolog OS=Homo sapiens OX=9606 GN=SAMM50 PE=1 SV=3MGTVHARSLEPLPSSGPDFGGLGEEAEFVEVEPEAKQEILENKDVVVQHVHFDGLGRTKDDIIICEIGDVFKAKNLIEVMRKSHEAREKLLRLGIFRQVDVLIDTCQGDDALPNGLDVTFEVTELRRLTGSYNTMVGNNEGSMVLGLKLPNLLGRAEKVTFQFSYGTKETSYGLSFFKPRPGNFERNFSVNLYKVTGQFPWSSLRETDRGMSAEYSFPIWKTSHTVKWEGVWRELGCLSRTASFAVRKESGHSLKSSLSHAMVIDSRNSSILPRRGALLKVNQELAGYTGGDVSFIKEDFELQLNKQLIFDSVFSASFWGGMLVPIGDKPSSIADRFYLGGPTSIRGFSMHSIGPQSEGDYLGGEAYWAGGLHLYTPLPFRPGQGGFGELFRTHFFLNAGNLCNLNYGEGPKAHIRKLAECIRWSYGAGIVLRLGNIARLELNYCVPMGVQTGDRICDGVQFGAGIRFL>sp|Q8IVF5|TIAM2_HUMAN Rho guanine nucleotide exchange factor TIAM2OS=Homo sapiens OX=9606 GN=TIAM2 PE=2 SV=4MGNSDSQYTLQGSKNHSNTITGAKQIPCSLKIRGIHAKEEKSLHGWGHGSNGAGYKSRSLARSCLSHFKSNQPYASRLGGPTCKVSRGVAYSTHRTNAPGKDFQGISAAFSTENGFHSVGHELADNHITSRDCNGHLLNCYGRNESIASTPPGEDRKSPRVLIKTLGKLDGCLRVEFHNGGNPSKVPAEDCSEPVQLLRYSPTLASETSPVPEARRGSSADSLPSHRPSPTDSRLRSSKGSSLSSESSWYDSPWGNAGELSEAEGSFLAPGMPDPSLHASFPPGDAKKPFNQSSSLSSLRELYKDANLGSLSPSGIRLSDEYMGTHASLSNRVSFASDIDVPSRVAHGDPIQYSSFTLPCRKPKAFVEDTAKKDSLKARMRRISDWTGSLSRKKRKLQEPRSKEGSDYFDSRSDGLNTDVQGSSQASAFLWSGGSTQILSQRSESTHAIGSDPLRQNIYENFMRELEMSRTNTENIETSTETAESSSESLSSLEQLDLLFEKEQGVVRKAGWLFFKPLVTVQKERKLELVARRKWKQYWVTLKGCTLLFYETYGKNSMDQSSAPRCALFAEDSIVQSVPEHPKKENVFCLSNSFGDVYLFQATSQTDLENWVTAVHSACASLFAKKHGKEDTLRLLKNQTKNLLQKIDMDSKMKKMAELQLSVVSDPKNRKAIENQIQQWEQNLEKFHMDLFRMRCYLASLQGGELPNPKSLLAAASRPSKLALGRLGILSVSSFHALVCSRDDSALRKRTLSLTQRGRNKKGIFSSLKGLDTLARKGKEKRPSITQVDELLHIYGSTVDGVPRDNAWEIQTYVHFQDNHGVTVGIKPEHRVEDILTLACKMRQLEPSHYGLQLRKLVDDNVEYCIPAPYEYMQQQVYDEIEVFPLNVYDVQLTKTGSVCDFGFAVTAQVDERQHLSRIFISDVLPDGLAYGEGLRKGNEIMTLNGEAVSDLDLKQMEALFSEKSVGLTLIARPPDTKATLCTSWSDSDLFSRDQKSLLPPPNQSQLLEEFLDNFKKNTANDFSNVPDITTGLKRSQTDGTLDQVSHREKMEQTFRSAEQITALCRSFNDSQANGMEGPRENQDPPPRSLARHLSDADRLRKVIQELVDTEKSYVKDLSCLFELYLEPLQNETFLTQDEMESLFGSLPEMLEFQKVFLETLEDGISASSDFNTLETPSQFRKLLFSLGGSFLYYADHFKLYSGFCANHIKVQKVLERAKTDKAFKAFLDARNPTKQHSSTLESYLIKPVQRVLKYPLLLKELVSLTDQESEEHYHLTEALKAMEKVASHINEMQKIYEDYGTVFDQLVAEQSGTEKEVTELSMGELLMHSTVSWLNPFLSLGKARKDLELTVFVFKRAVILVYKENCKLKKKLPSNSRPAHNSTDLDPFKFRWLIPISALQVRLGNPAGTENNSIWELIHTKSEIEGRPETIFQLCCSDSESKTNIVKVIRSILRENFRRHIKCELPLEKTCKDRLVPLKNRVPVSAKLASSRSLKVLKNSSSNEWTGETGKGTLLDSDEGSLSSGTQSSGCPTAEGRQDSKSTSPGKYPHPGLADFADNLIKESDILSDEDDDHRQTVKQGSPTKDIEIQFQRLRISEDPDVHPEAEQQPGPESGEGQKGGEQPKLVRGHFCPIKRKANSTKRDRGTLLKAQIRHQSLDSQSENATIDLNSVLEREFSVQSLTSVVSEECFYETESHGKS>sp|Q8IVF5-2|TIAM2_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor TIAM2 OS=Homo sapiens OX=9606 GN=TIAM2MGNSDSQYTLQGSKNHSNTITGAKQIPCSLKIRGIHAKEEKSLHGWGHGSNGAGYKSRSLARSCLSHFKSNQPYASRLGGPTCKVSRGVAYSTHRTNAPGKDFQGISAAFSTENGFHSVGHELADNHITSRDCNGHLLNCYGRNESIASTPPGEDRKSPRVLIKTLGKLDGCLRVEFHNGGNPSKVPAEDCSEPVQLLRYSPTLASETSPVPEARRGSSADSLPSHRPSPTDSRLRSSKGSSLSSESSWYDSPWGNAGELSEAEGSFLAPGMPDPSLHASFPPGDAKKPFNQSSSLSSLRELYKDANLGSLSPSGIRLSDEYMGTHASLSNRVSFASDIDVPSRVAHGDPIQYSSFTLPCRKPKAFVEDTAKKDSLKARMRRISDWTGSLSRKKRKLQEPRSKEGSDYFDSRSDGLNTDVQGSSQASAFLWSGGSTQILSQRSESTHAIGSDPLRQNIYENFMRELEMSRTNTENIETSTETAESSSESLSSLEQLDLLFEKEQGVVRKAGWLFFKPLVTVQKERKLELVARRKWKQYWVTLKGCTLLFYETYGKNSMDQSSAPRCALFAEDSIVQSVPEHPKKENVFCLSNSFGDVYLFQATSQTDLENWVTAVHSACASLFAKKHGKEDTLRLLKNQTKNLLQKIDMDSKMKKMAELQLSVVSDPKNRKAIENQIQQWEQNLEKFHMDLFRMRCYLASLQGGELPNPKSLLAAASRPSKLALGRLGILSVSSFHALVCSRDDSALRKRTLSLTQRGRNKKGIFSSLKGLDTLARKGKEKRPSITQVDELLHIYGSTVDGVPRDNAWEIQTYVHFQDNHGVTVGIKPEHRVEDILTLACKMRQLEPSHYGLQLRKLVDDNVEYCIPAPYEYMQQQVYDEIEVFPLNVYDVQLTKTGSVCDFGFAVTAQVDERQHLSRIFISDVLPDGLAYGEGLRKGNEIMTLNGEAVSDLDLKQMEALFSEKSVGLTLIARPPDTKATLCTSWSDSDLFSRDQKSLLPPPNQSQLLEEFLDNFKKNTANDFSNVPDITTGLKRSQTDGTLDQVSHREKMEQTFRSAEQITALCRSFNDSQANGMEGPRENQDPPPRSLARHLSDADRLRKVIQELVDTEKSYVKDLSCLFELYLEPLQNETFLTQDEMESLFGSLPEMLEFQKVFLETLEDGISASSDFNTLETPSQFRKLLFSLGGSFLYYADHFKLYSGFCANHIKVQKVLERAKTDKAFKAFLDARNPTKQHSSTLESYLIKPVQRVLKYPLLLKELVSLTDQESEEHYHLTEALKAMEKVASHINEMQKIYEDYGTVFDQLVAEQSGTEKEQPEWSSEVMDVLDPRGKLTKGTLEEPRTLVTELSMGELLMHSTVSWLNPFLSLGKARKDLELTVFVFKRAVILVYKENCKLKKKLPSNSRPAHNSTDLDPFKFRWLIPISALQVRLGNPAGTENNSIWELIHTKSEIEGRPETIFQLCCSDSESKTNIVKVIRSILRENFRRHIKCELPLEKTCKDRLVPLKNRVPVSAKLASSRSLKVLKNSSSNEWTGETGKGTLLDSDEGSLSSGTQSSGCPTAEGRQDSKSTSPGKYPHPGLADFADNLIKESDILSDEDDDHRQTVKQGSPTKDIEIQFQRLRISEDPDVHPEAEQQPGPESGEGQKGGEQPKLVRGHFCPIKRKANSTKRDRGTLLKAQIRHQSLDSQSENATIDLNSVLEREFSVQSLTSVVSEECFYETESHGKS>sp|Q8IVF5-3|TIAM2_HUMAN Isoform 3 of Rho guanine nucleotide exchangefactor TIAM2 OS=Homo sapiens OX=9606 GN=TIAM2MEGPRENQDPPPRSLARHLSDADRLRKVIQELVDTEKSYVKDLSCLFELYLEPLQNETFLTQDEMESLFGSLPEMLEFQKVFLETLEDGISASSDFNTLETPSQFRKLLFSLGGSFLYYADHFKLYSGFCANHIKVQKVLERAKTDKAFKAFLDARNPTKQHSSTLESYLIKPVQRVLKYPLLLKELVSLTDQESEEHYHLTEALKAMEKVASHINEMQKIYEDYGTVFDQLVAEQSGTEKEVTELSMGELLMHSTVSWLNPFLSLGKARKDLELTVFVFKRAVILVYKENCKLKKKLPSNSRPAHNSTDLDPFKFRWLIPISALQVRLGNPAGTENNSIWELIHTKSEIEGRPETIFQLCCSDSESKTNIVKVIRSILRENFRRHIKCELPLEKTCKDRLVPLKNRVPVSAKLASSRSLKVLKNSSSNEWTGETGKGTLLDSDEGSLSSGTQSSGCPTAEGRQDSKSTSPGKYPHPGLADFADNLIKESDILSDEDDDHRQTVKQGSPTKDIEIQFQRLRISEDPDVHPEAEQQPGPESGEGQKGGEQPKLVRGHFCPIKRKANSTKRDRGTLLKAQIRHQSLDSQSENATIDLNSVLEREFSVQSLTSVVSEECFYETESHGKS>sp|Q8IVF5-4|TIAM2_HUMAN Isoform 4 of Rho guanine nucleotide exchangefactor TIAM2 OS=Homo sapiens OX=9606 GN=TIAM2MDLFRMRCYLASLQGGELPNPKSLLAAASRPSKLALGRLGILSVSSFHALVCSRDDSALRKRTLSLTQRGRNKKGIFSSLKGLDTLARKGKEKRPSITQVDELLHIYGSTVDGVPRDNAWEIQTYVHFQDNHGVTVGIKPEHRVEDILTLACKMRQLEPSHYGLQLRKLVDDNVEYCIPAPYEYMQQQVYDEIEVFPLNVYDVQLTKTGSVCDFGFAVTAQVDERQHLSRIFISDVLPDGLAYGEGLRKGNEIMTLNGEAVSDLDLKQMEALFSEKSVGLTLIARPPDTKATLCTSWSDSDLFSRDQKSLLPPPNQSQLLEEFLDNFKKNTANDFSNVPDITTGLKRSQTDGTLDQVSHREKMEQTFRSAEQITALCRSFNDSQANGMEGPRENQDPPPRSLARHLSDADRLRKVIQELVDTEKSYVKDLSCLFELYLEPLQNETFLTQDEMESLFGSLPEMLEFQKVFLETLEDGISASSDFNTLETPSQFRKLLFSLGGSFLYYADHFKLYSGFCANHIKVQKVLERAKTDKAFKAFLDARNPTKQHSSTLESYLIKPVQRVLKYPLLLKELVSLTDQESEEHYHLTEALKAMEKVASHINEMQKIYEDYGTVFDQLVAEQSGTEKEVTELSMGELLMHSTVSWLNPFLSLGKARKDLELTVFVFKRAVILVYKENCKLKKKLPSNSRPAHNSTDLDPFKFRWLIPISALQVRLGNPAGTENNSIWELIHTKSEIEGRPETIFQLCCSDSESKTNIVKVIRSILRENFRRHIKCELPLEKTCKDRLVPLKNRVPVSAKLASSRSLKVLKNSSSNEWTGETGKGTLLDSDEGSLSSGTQSSGCPTAEGRQDSKSTSPGKYPHPGLADFADNLIKESDILSDEDDDHRQTVKQGSPTKDIEIQFQRLRISEDPDVHPEAEQQPGPESGEGQKGGEQPKLVRGHFCPIKRKANSTKRDRGTLLKAQIRHQSLDSQSENATIDLNSVLEREFSVQSLTSVVSEECFYETESHGKS>sp|Q8IVF5-5|TIAM2_HUMAN Isoform 5 of Rho guanine nucleotide exchangefactor TIAM2 OS=Homo sapiens OX=9606 GN=TIAM2MGNSDSQYTLQGSKNHSNTITGAKQIPCSLKIRGIHAKEEKSLHGWGHGSNGAGYKSRSLARSCLSHFKSNQPYASRLGGPTCKVSRGVAYSTHRTNAPGKDFQGISAAFSTENGFHSVGHELADNHITSRDCNGHLLNCYGRNESIASTPPGEDRKSPRVLIKTLGKLDGCLRVEFHNGGNPSKVPAEDCSEPVQLLRYSPTLASETSPVPEARRGSSADSLPSHRPSPTDSRLRSSKGSSLSSESSWYDSPWGNAGELSEAEGSFLAPGMPDPSLHASFPPGDAKKPFNQSSSLSSLRELYKDANLGSLSPSGIRLSDEYMGTHASLSNRVSFASDIDVPSRVAHGDPIQYSSFTLPCRKPKAFVEDTAKKDSLKARMRRISDWTGSLSRKKRKLQEPRSKEGSDYFDSRSDGLNTDVQGSSQASAFLWSGGSTQILSQRSESTHAIGSDPLRQNIYENFMRELEMSRTNTENIETSTETAESSSESLSSLEQLDLLFEKEQGVVRKAGWLFFKPLVTVQKERKLELVARRKWKQYWVTLKGCTLLFYETYGKNSMDQSSAPRCALFAEDSIVQSVPEHPKKENVFCLSNSFGDVYLFQATSQTDLENWVTAVHSACASLFAKKHGKEDTLRLLKNQTKNLLQKIDMDSKMKKMAELQLSVVSDPKNRKAIENQIQQWEQNLEKFHMDLFRMRCYLASLQGGELPNPKSLLAAASRPSKLALGRLGILSVSSFHALVCSRDDSALRKRTLSLTQRGRNKKGIFSSLKGLDTLARKGKEKRPSITQIFDSSGSHGFSGTQLPQNSSNSSEVDELLHIYGSTVDGVPRDNAWEIQTYVHFQDNHGVTVGIKPEHRVEDILTLACKMRQLEPSHYGLQLRKLVDDNVEYCIPAPYEYMQQQVYDEIEVFPLNVYDVQLTKTGSVCDFGFAVTAQVDERQHLSRIFISDVLPDGLAYGEGLRKGNEIMTLNGEAVSDLDLKQMEALFSEKSVGLTLIARPPDTKATLCTSWSDSDLFSRDQKSLLPPPNQSQLLEEFLDNFKKNTANDFSNVPDITTGLKRSQTDGTLDQVSHREKMEQTFRSAEQITALCRSFNDSQANGMEGPRENQDPPPRSLARHLSDADRLRKVIQELVDTEKSYVKDLSCLFELYLEPLQNETFLTQDEMESLFGSLPEMLEFQKVFLETLEDGISASSDFNTLETPSQFRKLLFSLGGSFLYYADHFKLYSGFCANHIKVQKVLERAKTDKAFKAFLDARNPTKQHSSTLESYLIKPVQRVLKYPLLLKELVSLTDQESEEHYHLTEALKAMEKVASHINEMQKIYEDYGTVFDQLVAEQSGTEKEVTELSMGELLMHSTVSWLNPFLSLGKARKDLELTVFVFKRAVILVYKENCKLKKKLPSNSRPAHNSTDLDPFKFRWLIPISALQVRLGNPAGTENNSIWELIHTKSEIEGRPETIFQLCCSDSESKTNIVKVIRSILRENFRRHIKCELPLEKTCKDRLVPLKNRVPVSAKLASSRSLKVLKNSSSNEWTGETGKGTLLDSDEGSLSSGTQSSGCPTAEGRQDSKSTSPGKYPHPGLADFADNLIKESDILSDEDDDHRQTVKQGSPTKDIEIQFQRLRISEDPDVHPEAEQQPGPESGEGQKGGEQPKLVRGHFCPIKRKANSTKRDRGTLLKAQIRHQSLDSQSENATIDLNSVLEREFSVQSLTSVVSEECFYETESHGKS>sp|Q4G0G5|SC2B2_HUMAN Secretoglobin family 2B member 2 OS=Homo sapiensOX=9606 GN=SCGB2B2 PE=1 SV=1MRVTSATCALLLALICSVQLGDACLDIDKLLANVVFDVSQDLLKEELARYNPSPLTEESFLNVQQCFANVSVTERFAHSVVIKKILQSNDCIEAAF>sp|Q8NBX0|SCPDL_HUMAN Saccharopine dehydrogenase-like oxidoreductaseOS=Homo sapiens OX=9606 GN=SCCPDH PE=1 SV=1MATEQRPFHLVVFGASGFTGQFVTEEVAREQVDPERSSRLPWAVAGRSREKLQRVLEKAALKLGRPTLSSEVGIIICDIANPASLDEMAKQATVVLNCVGPYRFYGEPVIKACIENGASCIDISGEPQFLELMQLKYHEKAADKGVYIIGSSGFDSIPADLGVIYTRNKMNGTLTAVESFLTIHSGPEGLSIHDGTWKSAIYGFGDQSNLRKLRNVSNLKPVPLIGPKLKRRWPISYCRELKGYSIPFMGSDVSVVRRTQRYLYENLEESPVQYAAYVTVGGITSVIKLMFAGLFFLFFVRFGIGRQLLIKFPWFFSFGYFSKQGPTQKQIDAASFTLTFFGQGYSQGTGTDKNKPNIKICTQVKGPEAGYVATPIAMVQAAMTLLSDASHLPKAGGVFTPGAAFSKTKLIDRLNKHGIEFSVISSSEV>sp|Q8IY50|S35F3_HUMAN Putative thiamine transporter SLC35F3 OS=Homosapiens OX=9606 GN=SLC35F3 PE=2 SV=2MKKHSARVAPLSACNSPVLTLTKVEGEERPRDSPGPAEAQAPAGVEAGGRASRRCWTCSRAQLKKIFWGVAVVLCVCSSWAGSTQLAKLTFRKFDAPFTLTWFATNWNFLFFPLYYVGHVCKSTEKQSVKQRYRECCRFFGDNGLTLKVFFTKAAPFGVLWTLTNYLYLHAIKKINTTDVSVLFCCNKAFVFLLSWIVLRDRFMGVRIVAAILAIAGIVMMTYADGFHSHSVIGIALVVASASMSALYKVLFKLLLGSAKFGEAALFLSILGVFNILFITCIPIILYFTKVEYWSSFDDIPWGNLCGFSVLLLTFNIVLNFGIAVTYPTLMSLGIVLSIPVNAVIDHYTSQIVFNGVRVIAIIIIGLGFLLLLLPEEWDVWLIKLLTRLKVRKKEEPAEGAADLSSGPQSKNRRARPSFAR>sp|Q8IY50-2|S35F3_HUMAN Isoform 2 of Putative thiamine transporterSLC35F3 OS=Homo sapiens OX=9606 GN=SLC35F3MGIREFPSGAPRGKSIAVGMRRSPDVSPRRLSDISPQLRQLKYLVVDEAIKEDLKWSRSVEDLTSGPVGLTSIEERILRITGYYGYQPWAASCKREERPRDSPGPAEAQAPAGVEAGGRASRRCWTCSRAQLKKIFWGVAVVLCVCSSWAGSTQLAKLTFRKFDAPFTLTWFATNWNFLFFPLYYVGHVCKSTEKQSVKQRYRECCRFFGDNGLTLKVFFTKAAPFGVLWTLTNYLYLHAIKKINTTDVSVLFCCNKAFVFLLSWIVLRDRFMGVRIVAAILAIAGIVMMTYADGFHSHSVIGIALVVASASMSALYKVLFKLLLGSAKFGEAALFLSILGVFNILFITCIPIILYFTKVEYWSSFDDIPWGNLCGFSVLLLTFNIVLNFGIAVTYPTLMSLGIVLSIPVNAVIDHYTSQIVFNGVRVIAIIIIGLGFLLLLLPEEWDVWLIKLLTRLKVRKKEEPAEGAADLSSGPQSKNRRARPSFAR>sp|O95487|SC24B_HUMAN Protein transport protein Sec24B OS=Homo sapiensOX=9606 GN=SEC24B PE=1 SV=2MSAPAGSSHPAASARIPPKFGGAAVSGAAAPAGPGAGPAPHQQNGPAQNQMQVPSGYGLHHQNYIAPSGHYSQGPGKMTSLPLDTQCGDYYSALYTVPTQNVTPNTVNQQPGAQQLYSRGPPAPHIVGSTLGSFQGAASSASHLHTSASQPYSSFVNHYNSPAMYSASSSVASQGFPSTCGHYAMSTVSNAAYPSVSYPSLPAGDTYGQMFTSQNAPTVRPVKDNSFSGQNTAISHPSPLPPLPSQQHHQQQSLSGYSTLTWSSPGLPSTQDNLIRNHTGSLAVANNNPTITVADSLSCPVMQNVQPPKSSPVVSTVLSGSSGSSSTRTPPTANHPVEPVTSVTQPSELLQQKGVQYGEYVNNQASSAPTPLSSTSDDEEEEEEDEEAGVDSSSTTSSASPMPNSYDALEGGSYPDMLSSSASSPAPDPAPEPDPASAPAPASAPAPVVPQPSKMAKPFGYGYPTLQPGYQNATAPLISGVQPSNPVYSGFQQYPQQYPGVNQLSSSIGGLSLQSSPQPESLRPVNLTQERNILPMTPVWAPVPNLNADLKKLNCSPDSFRCTLTNIPQTQALLNKAKLPLGLLLHPFRDLTQLPVITSNTIVRCRSCRTYINPFVSFIDQRRWKCNLCYRVNDVPEEFMYNPLTRSYGEPHKRPEVQNSTVEFIASSDYMLRPPQPAVYLFVLDVSHNAVEAGYLTILCQSLLENLDKLPGDSRTRIGFMTFDSTIHFYNLQEGLSQPQMLIVSDIDDVFLPTPDSLLVNLYESKELIKDLLNALPNMFTNTRETHSALGPALQAAFKLMSPTGGRVSVFQTQLPSLGAGLLQSREDPNQRSSTKVVQHLGPATDFYKKLALDCSGQQTAVDLFLLSSQYSDLASLACMSKYSAGCIYYYPSFHYTHNPSQAEKLQKDLKRYLTRKIGFEAVMRIRCTKGLSMHTFHGNFFVRSTDLLSLANINPDAGFAVQLSIEESLTDTSLVCFQTALLYTSSKGERRIRVHTLCLPVVSSLADVYAGVDVQAAICLLANMAVDRSVSSSLSDARDALVNAVVDSLSAYGSTVSNLQHSALMAPSSLKLFPLYVLALLKQKAFRTGTSTRLDDRVYAMCQIKSQPLVHLMKMIHPNLYRIDRLTDEGAVHVNDRIVPQPPLQKLSAEKLTREGAFLMDCGSVFYIWVGKGCDNNFIEDVLGYTNFASIPQKMTHLPELDTLSSERARSFITWLRDSRPLSPILHIVKDESPAKAEFFQHLIEDRTEAAFSYYEFLLHVQQQICK>sp|O95487-2|SC24B_HUMAN Isoform 2 of Protein transport protein Sec24BOS=Homo sapiens OX=9606 GN=SEC24BMSAPAGSSHPAASARIPPKFGGAAVSGAAAPAGPGAGPAPHQQNGPAQNQMQVPSGYGLHHQNYIAPSGHYSQGPGKMTSLPLDTQCGDYYSALYTVPTQNVTPNTVNQQPGAQQLYSRGPPAPHIVGSTLGSFQGAASSASHLHTSASQPYSSFVNHYNSPAMYSASSSVASQGFPSTCGHYAMSTVSNAAYPSVSYPSLPAGDTYGQMFTSQNAPTVRPVKDNSFSGQNTAISHPSPLPPLPSQQHHQQQSLSGYSTLTWSSPGLPSTQDNLIRNHTGSLAVANNNPTITVADSLSCPVMQNVQPPKSSPVVSTVLSGSSGSSSTRTPPTANHPVEPVTSVTQPSELLQQKGVDSSSTTSSASPMPNSYDALEGGSYPDMLSSSASSPAPDPAPEPDPASAPAPASAPAPVVPQPSKMAKPFGYGYPTLQPGYQNATAPLISGVQPSNPVYSGFQQYPQQYPGVNQLSSSIGGLSLQSSPQPESLRPVNLTQERNILPMTPVWAPVPNLNADLKKLNCSPDSFRCTLTNIPQTQALLNKAKLPLGLLLHPFRDLTQLPVITSNTIVRCRSCRTYINPFVSFIDQRRWKCNLCYRVNDVPEEFMYNPLTRSYGEPHKRPEVQNSTVEFIASSDYMLRPPQPAVYLFVLDVSHNAVEAGYLTILCQSLLENLDKLPGDSRTRIGFMTFDSTIHFYNLQEGLSQPQMLIVSDIDDVFLPTPDSLLVNLYESKELIKDLLNALPNMFTNTRETHSALGPALQAAFKLMSPTGGRVSVFQTQLPSLGAGLLQSREDPNQRSSTKVVQHLGPATDFYKKLALDCSGQQTAVDLFLLSSQYSDLASLACMSKYSAGCIYYYPSFHYTHNPSQAEKLQKDLKRYLTRKIGFEAVMRIRCTKGLSMHTFHGNFFVRSTDLLSLANINPDAGFAVQLSIEESLTDTSLVCFQTALLYTSSKGERRIRVHTLCLPVVSSLADVYAGVDVQAAICLLANMAVDRSVSSSLSDARDALVNAVVDSLSAYGSTVSNLQHSALMAPSSLKLFPLYVLALLKQKAFRTGTSTRLDDRVYAMCQIKSQPLVHLMKMIHPNLYRIDRLTDEGAVHVNDRIVPQPPLQKLSAEKLTREGAFLMDCGSVFYIWVGKGCDNNFIEDVLGYTNFASIPQKMTHLPELDTLSSERARSFITWLRDSRPLSPILHIVKDESPAKAEFFQHLIEDRTEAAFSYYEFLLHVQQQICK>sp|O95487-3|SC24B_HUMAN Isoform 3 of Protein transport protein Sec24BOS=Homo sapiens OX=9606 GN=SEC24BMSAPAGSSHPAASARIPPKFGGAAVSGAAAPAGPGAGPAPHQQNETGFHHVAQASLELLDPSNLPASASQIAGSTGPAQNQMQVPSGYGLHHQNYIAPSGHYSQGPGKMTSLPLDTQCGDYYSALYTVPTQNVTPNTVNQQPGAQQLYSRGPPAPHIVGSTLGSFQGAASSASHLHTSASQPYSSFVNHYNSPAMYSASSSVASQGFPSTCGHYAMSTVSNAAYPSVSYPSLPAGDTYGQMFTSQNAPTVRPVKDNSFSGQNTAISHPSPLPPLPSQQHHQQQSLSGYSTLTWSSPGLPSTQDNLIRNHTGSLAVANNNPTITVADSLSCPVMQNVQPPKSSPVVSTVLSGSSGSSSTRTPPTANHPVEPVTSVTQPSELLQQKGVQYGEYVNNQASSAPTPLSSTSDDEEEEEEDEEAGVDSSSTTSSASPMPNSYDALEGGSYPDMLSSSASSPAPDPAPEPDPASAPAPASAPAPVVPQPSKMAKPFGYGYPTLQPGYQNATAPLISGVQPSNPVYSGFQQYPQYPGVNQLSSSIGGLSLQSSPQPESLRPVNLTQERNILPMTPVWAPVPNLNADLKKLNCSPDSFRCTLTNIPQTQALLNKAKLPLGLLLHPFRDLTQLPVITSNTIVRCRSCRTYINPFVSFIDQRRWKCNLCYRVNDVPEEFMYNPLTRSYGEPHKRPEVQNSTVEFIASSDYMLRPPQPAVYLFVLDVSHNAVEAGYLTILCQSLLENLDKLPGDSRTRIGFMTFDSTIHFYNLQEGLSQPQMLIVSDIDDVFLPTPDSLLVNLYESKELIKDLLNALPNMFTNTRETHSALGPALQAAFKLMSPTGGRVSVFQTQLPSLGAGLLQSREDPNQRSSTKVVQHLGPATDFYKKLALDCSGQQTAVDLFLLSSQYSDLASLACMSKYSAGCIYYYPSFHYTHNPSQAEKLQKDLKRYLTRKIGFEAVMRIRCTKGLSMHTFHGNFFVRSTDLLSLANINPDAGFAVQLSIEESLTDTSLVCFQTALLYTSSKGERRIRVHTLCLPVVSSLADVYAGVDVQAAICLLANMAVDRSVSSSLSDARDALVNAVVDSLSAYGSTVSNLQHSALMAPSSLKLFPLYVLALLKQKAFRTGTSTRLDDRVYAMCQIKSQPLVHLMKMIHPNLYRIDRLTDEGAVHVNDRIVPQPPLQKLSAEKLTREGAFLMDCGSVFYIWVGKGCDNNFIEDVLGYTNFASIPQKMTHLPELDTLSSERARSFITWLRDSRPLSPILHIVKDESPAKAEFFQHLIEDRTEAAFSYYEFLLHVQQQICK>sp|P57772|SELB_HUMAN Selenocysteine-specific elongation factor OS=Homosapiens OX=9606 GN=EEFSEC PE=1 SV=4MAGRRVNVNVGVLGHIDSGKTALARALSTTASTAAFDKQPQSRERGITLDLGFSCFSVPLPARLRSSLPEFQAAPEAEPEPGEPLLQVTLVDCPGHASLIRTIIGGAQIIDLMMLVIDVTKGMQTQSAECLVIGQIACQKLVVVLNKIDLLPEGKRQAAIDKMTKKMQKTLENTKFRGAPIIPVAAKPGGPEAPETEAPQGIPELIELLTSQISIPTRDPSGPFLMSVDHCFSIKGQGTVMTGTILSGSISLGDSVEIPALKVVKKVKSMQMFHMPITSAMQGDRLGICVTQFDPKLLERGLVCAPESLHTVHAALISVEKIPYFRGPLQTKAKFHITVGHETVMGRLMFFSPAPDNFDQEPILDSFNFSQEYLFQEQYLSKDLTPAVTDNDEADKKAGQATEGHCPRQQWALVEFEKPVTCPRLCLVIGSRLDADIHTNTCRLAFHGILLHGLEDRNYADSFLPRLKVYKLKHKHGLVERAMDDYSVIGRSLFKKETNIQLFVGLKVHLSTGELGIIDSAFGQSGKFKIHIPGGLSPESKKILTPALKKRARAGRGEATRQEESAERSEPSQHVVLSLTFKRYVFDTHKRMVQSP>sp|P57772-2|SELB_HUMAN Isoform 2 of Selenocysteine-specific elongationfactor OS=Homo sapiens OX=9606 GN=EEFSECMASCSTAAFDKQPQSRERGITLDLGFSCFSVPLPARLRSSLPEFQAAPEAEPEPGEPLLQVTLVDCPGHASLIRTIIGGAQIIDLMMLVIDVTKGMQTQSAECLVIGQIACQKLVVVLNKIDLLPEGKRQAAIDKMTKKMQKTLENTKFRGAPIIPVAAKPGGPEAPETEAPQGIPELIELLTSQISIPTRDPSGPFLMSVDHCFSIKGQGTVMTGTILSGSISLGDSVEIPALKVVKKVKSMQMFHMPITSAMQGDRLGICVTQFDPKLLERGLVCAPESLHTVHAALISVEKIPYFRGPLQTKAKFHITVGHETVMGRLMFFSPAPDNFDQEPILDSFNFSQEYLFQEQYLSKDLTPAVTDNDEADKKAGQATEGHCPRQQWALVEFEKPVTCPRLCLVIGSRLDADIHTNTCRLAFHGILLHGLEDRNYADSFLPRLKVYKLKHKHGLVERAMDDYSVIGRSLFKKETNIQLFVGLKVHLSTGELGIIDSAFGQSGKFKIHIPGGLSPESKKILTPALKKRARAGRGEATRQEESAERSEPSQHVVLSLTFKRYVFDTHKRMVQSP>sp|Q9BZJ4|S2539_HUMAN Solute carrier family 25 member 39 OS=Homo sapiensOX=9606 GN=SLC25A39 PE=2 SV=2MADQDPAGISPLQQMVASGTGAVVTSLFMTPLDVVKVRLQSQRPSMASELMPSSRLWSLSYTKLPSSLQSTGKCLLYCNGVLEPLYLCPNGARCATWFQDPTRFTGTMDAFVKIVRHEGTRTLWSGLPATLVMTVPATAIYFTAYDQLKAFLCGRALTSDLYAPMVAGALARLGTVTVISPLELMRTKLQAQHVSYRELGACVRTAVAQGGWRSLWLGWGPTALRDVPFSALYWFNYELVKSWLNGFRPKDQTSVGMSFVAGGISGTVAAVLTLPFDVVKTQRQVALGAMEAVRVNPLHVDSTWLLLRRIRAESGTKGLFAGFLPRIIKAAPSCAIMISTYEFGKSFFQRLNQDRLLGG>sp|Q9BZJ4-2|S2539_HUMAN Isoform 2 of Solute carrier family 25 member 39OS=Homo sapiens OX=9606 GN=SLC25A39MADQDPAGISPLQQMVASGTGAVVTSLFMTPLDVVKVRLQSQRPSMASELMPSSRLWSLSYTKWKCLLYCNGVLEPLYLCPNGARCATWFQDPTRFTGTMDAFVKIVRHEGTRTLWSGLPATLVMTVPATAIYFTAYDQLKAFLCGRALTSDLYAPMVAGALARLGTVTVISPLELMRTKLQAQHVSYRELGACVRTAVAQGGWRSLWLGWGPTALRDVPFSALYWFNYELVKSWLNGFRPKDQTSVGMSFVAGGISGTVAAVLTLPFDVVKTQRQVALGAMEAVRVNPLHVDSTWLLLRRIRAESGTKGLFAGFLPRIIKAAPSCAIMISTYEFGKSFFQRLNQDRLLGG>sp|Q8N413|S2545_HUMAN Solute carrier family 25 member 45 OS=Homo sapiensOX=9606 GN=SLC25A45 PE=2 SV=2MPVEEFVAGWISGALGLVLGHPFDTVKVRLQTQTTYRGIVDCMVKIYRHESLLGFFKGMSFPIASIAVVNSVLFGVYSNTLLVLTATSHQERRAQPPSYMHIFLAGCTGGFLQAYCLAPFDLIKVRLQNQTEPRAQPGSPPPRYQGPVHCAASIFREEGPRGLFRGAWALTLRDTPTVGIYFITYEGLCRQYTPEGQNPSSATVLVAGGFAGIASWVAATPLDMIKSRMQMDGLRRRVYQGMLDCMVSSIRQEGLGVFFRGVTINSARAFPVNAVTFLSYEYLLRWWG>sp|Q8N413-2|S2545_HUMAN Isoform 2 of Solute carrier family 25 member 45OS=Homo sapiens OX=9606 GN=SLC25A45MVKIYRHESLLGFFKGMSFPIASIAVVNSVLFGVYSNTLLVLTATSHQERRAQPPSYMHIFLAGCTGGFLQAYCLAPFDLIKVRLQNQTEPRAQPGSPPPRYQGPVHCAASIFREEGPRGLFRGAWALTLRDTPTVGIYFITYEGLCRQYTPEGQNPSSATVLVAGGFAGIASWVAATPLDMIKSRMQMDGLRRRVYQGMLDCMVSSIRQEGLGVFFRGVTINSARAFPVNAVTFLSYEYLLRWWG>sp|Q8N413-3|S2545_HUMAN Isoform 3 of Solute carrier family 25 member 45OS=Homo sapiens OX=9606 GN=SLC25A45MVKIYRHESAYCLAPFDLIKVRLQNQTEPRAQPGSPPPRYQGPVHCAASIFREEGPRGLFRGAWALTLRDTPTVGIYFITYEGLCRQYTPEGQNPSSATVLVAGGFAGIASWVAATPLDMIKSRMQMDGLRRRVYQGMLDCMVSSIRQEGLGVFFRGVTINSARAFPVNAVTFLSYEYLLRWWG>sp|Q8N413-4|S2545_HUMAN Isoform 4 of Solute carrier family 25 member 45OS=Homo sapiens OX=9606 GN=SLC25A45MPVEEFVAGWISGALGLVLGHPFDTVKLLGFFKGMSFPIASIAVVNSVLFGVYSNTLLVLTATSHQERRAQPPSYMHIFLAGCTGGFLQAYCLAPFDLIKVRLQNQTEPRAQPGSPPPRYQGPVHCAASIFREEGPRGLFRGAWALTLRDTPTVGIYFITYEGLCRQYTPEGQNPSSATVLVAGGFAGIASWVAATPLDMIKSRMQMDGLRRRVYQGMLDCMVSSIRQEGLGVFFRGVTINSARAFPVNAVTFLSYEYLLRWWG>sp|O43623|SNAI2_HUMAN Zinc finger protein SNAI2 OS=Homo sapiens OX=9606GN=SNAI2 PE=1 SV=1MPRSFLVKKHFNASKKPNYSELDTHTVIISPYLYESYSMPVIPQPEILSSGAYSPITVWTTAAPFHAQLPNGLSPLSGYSSSLGRVSPPPPSDTSSKDHSGSESPISDEEERLQSKLSDPHAIEAEKFQCNLCNKTYSTFSGLAKHKQLHCDAQSRKSFSCKYCDKEYVSLGALKMHIRTHTLPCVCKICGKAFSRPWLLQGHIRTHTGEKPFSCPHCNRAFADRSNLRAHLQTHSDVKKYQCKNCSKTFSRMSLLHKHEESGCCVAH>sp|Q8IYB5|SMAP1_HUMAN Stromal membrane-associated protein 1 OS=Homosapiens OX=9606 GN=SMAP1 PE=1 SV=2MATRSCREKAQKLNEQHQLILSKLLREEDNKYCADCEAKGPRWASWNIGVFICIRCAGIHRNLGVHISRVKSVNLDQWTAEQIQCMQDMGNTKARLLYEANLPENFRRPQTDQAVEFFIRDKYEKKKYYDKNAIAITNISSSDAPLQPLVSSPSLQAAVDKNKLEKEKEKKKEEKKREKEPEKPAKPLTAEKLQKKDQQLEPKKSTSPKKAAEPTVDLLGLDGPAVAPVTNGNTTVPPLNDDLDIFGPMISNPLPATVMPPAQGTPSAPAAATLSTVTSGDLDLFTEQTTKSEEVAKKQLSKDSILSLYGTGTIQQQSTPGVFMGPTNIPFTSQAPAAFQGFPSMGVPVPAAPGLIGNVMGQSPSMMVGMPMPNGFMGNAQTGVMPLPQNVVGPQGGMVGQMGAPQSKFGLPQAQQPQWSLSQMNQQMAGMSISSATPTAGFGQPSSTTAGWSGSSSGQTLSTQLWK>sp|Q8IYB5-2|SMAP1_HUMAN Isoform 2 of Stromal membrane-associated protein1 OS=Homo sapiens OX=9606 GN=SMAP1MATRSCREKAQKLNEQHQLILSKLLREEDNKYCADCEAKGPRWASWNIGVFICIRCAGIHRNLGVHISRVKSVNLDQWTAEQIQCMQDMGNTKARLLYEANLPENFRRPQTDQAVEFFIRDKYEKKKYYDKNAIAITNKEKEKKKEEKKREKEPEKPAKPLTAEKLQKKDQQLEPKKSTSPKKAAEPTVDLLGLDGPAVAPVTNGNTTVPPLNDDLDIFGPMISNPLPATVMPPAQGTPSAPAAATLSTVTSGDLDLFTEQTTKSEEVAKKQLSKDSILSLYGTGTIQQQSTPGVFMGPTNIPFTSQAPAAFQGFPSMGVPVPAAPGLIGNVMGQSPSMMVGMPMPNGFMGNAQTGVMPLPQNVVGPQGGMVGQMGAPQSKFGLPQAQQPQWSLSQMNQQMAGMSISSATPTAGFGQPSSTTAGWSGSSSGQTLSTQLWK>sp|Q8IYB5-3|SMAP1_HUMAN Isoform 3 of Stromal membrane-associated protein1 OS=Homo sapiens OX=9606 GN=SMAP1MATRSCREKAQKLNEQHQLILSKLLREEDNKYCADCEAKGPRWASWNIGVFICIRCAGIHRNLGVHISRVKSVNLDQWTAEQIQCMQDMGNTKARLLYEANLPENFRRPQTDQAVEFFIRDKYEKKKYYDKNAIAITNKEKEKKKEEKKREKEPEKPAKPLTAEKLQKKDQQLEPKKSTSPKKAAEPTVDLLGLDGPAVAPVTNGNTTVPPLNDDLDIFGPMISNPLPATVMPPAQGTPSAPAAATLSTVTSGDLDLFTEQTTKSEEVAKKQLSKDSILSLYGTGTIQQQSTPGVFMGPTNIPFTSQAPAAFQGFPSMGVPVPAAPGLIGNVMGQSPSMMVGMPMPNGFMGNAQTGVMPLPQNVVGPQGGMVGQMGAPQSKFGLPQAQQPQWSLSQIMQKGDAVLQHSISAIYWPMTRWLKCPLVDESADGWHEYQ>sp|Q9Y5W7|SNX14_HUMAN Sorting nexin-14 OS=Homo sapiens OX=9606 GN=SNX14PE=1 SV=3MVPWVRTMGQKLKQRLRLDVGREICRQYPLFCFLLLCLSAASLLLNRYIHILMIFWSFVAGVVTFYCSLGPDSLLPNIFFTIKYKPKQLGLQELFPQGHSCAVCGKVKCKRHRPSLLLENYQPWLDLKISSKVDASLSEVLELVLENFVYPWYRDVTDDESFVDELRITLRFFASVLIRRIHKVDIPSIITKKLLKAAMKHIEVIVKARQKVKNTEFLQQAALEEYGPELHVALRSRRDELHYLRKLTELLFPYILPPKATDCRSLTLLIREILSGSVFLPSLDFLADPDTVNHLLIIFIDDSPPEKATEPASPLVPFLQKFAEPRNKKPSVLKLELKQIREQQDLLFRFMNFLKQEGAVHVLQFCLTVEEFNDRILRPELSNDEMLSLHEELQKIYKTYCLDESIDKIRFDPFIVEEIQRIAEGPYIDVVKLQTMRCLFEAYEHVLSLLENVFTPMFCHSDEYFRQLLRGAESPTRNSKLNRGSLSLDDFRNTQKRGESFGISRIGSKIKGVFKSTTMEGAMLPNYGVAEGEDDFIEEGIVVMEDDSPVEAVSTPNTPRNLAAWKISIPYVDFFEDPSSERKEKKERIPVFCIDVERNDRRAVGHEPEHWSVYRRYLEFYVLESKLTEFHGAFPDAQLPSKRIIGPKNYEFLKSKREEFQEYLQKLLQHPELSNSQLLADFLSPNGGETQFLDKILPDVNLGKIIKSVPGKLMKEKGQHLEPFIMNFINSCESPKPKPSRPELTILSPTSENNKKLFNDLFKNNANRAENTERKQNQNYFMEVMTVEGVYDYLMYVGRVVFQVPDWLHHLLMGTRILFKNTLEMYTDYYLQCKLEQLFQEHRLVSLITLLRDAIFCENTEPRSLQDKQKGAKQTFEEMMNYIPDLLVKCIGEETKYESIRLLFDGLQQPVLNKQLTYVLLDIVIQELFPELNKVQKEVTSVTSWM>sp|Q9Y5W7-2|SNX14_HUMAN Isoform 2 of Sorting nexin-14 OS=Homo sapiensOX=9606 GN=SNX14MVPWVRTMGQKLKQRLRLDVGREICRQYPLFCFLLLCLSAASLLLNRYIHILMIFWSFVAGVVTFYCSLGPDSLLPNIFFTIKYKPKQLGLQELFPQGHSCAVCGKVKCKRHRPSLLLENYQPWLDLKISSKVDASLSEVDIPSIITKKLLKAAMKHIEVIVKARQKVKNTEFLQQAALEEYGPELHVALRSRRDELHYLRKLTELLFPYILPPKATDCRSLTLLIREILSGSVFLPSLDFLADPDTVNHLLIIFIDDSPPEKATEPASPLVPFLQKFAEPRNKKPSVLKLELKQIREQQDLLFRFMNFLKQEGAVHVLQFCLTVEEFNDRILRPELSNDEMLSLHEELQKIYKTYCLDESIDKIRFDPFIVEEIQRIAEGPYIDVVKLQTMRCLFEAYEHVLSLLENVFTPMFCHSDEYFRQLLRGAESPTRNSKLNRNTQKRGESFGISRIGSKIKGVFKSTTMEGAMLPNYGVAEGEDDFIEEGIVVMEDDSPVEAVSTPNTPRNLAAWKISIPYVDFFEDPSSERKEKKERIPVFCIDVERNDRRAVGHEPEHWSVYRRYLEFYVLESKLTEFHGAFPDAQLPSKRIIGPKNYEFLKSKREEFQEYLQKLLQHPELSNSQLLADFLSPNGGETQFLDKILPDVNLGKIIKSVPGKLMKEKGQHLEPFIMNFINSCESPKPKPSRPELTILSPTSENNKKLFNDLFKNNANRAENTERKQNQNYFMEVMTVEGVYDYLMYVGRVVFQVPDWLHHLLMGTRILFKNTLEMYTDYYLQCKLEQLFQEHRLVSLITLLRDAIFCENTEPRSLQDKQKGAKQTFEEMMNYIPDLLVKCIGEETKYESIRLLFDGLQQPVLNKQLTYVLLDIVIQELFPELNKVQKEVTSVTSWM>sp|Q9Y5W7-3|SNX14_HUMAN Isoform 3 of Sorting nexin-14 OS=Homo sapiensOX=9606 GN=SNX14MIFWSFVAGVVTFYCSLGPDSLLPNIFFTIKYKPKQLGLQELFPQGHSCAVCGKVKCKRHRPSLLLENYQPWLDLKISSKVDASLSEVLELVLENFVYPWYRDVTDDESFVDELRITLRFFASVLIRRIHKVDIPSIITKKLLKAAMKHIEVIVKARQKVKNTEFLQQAALEEYGPELHVALRSRRDELHYLRKLTELLFPYILPPKATDCRSLTLLIREILSGSVFLPSLDFLADPDTVNHLLIIFIDDSPPEKATEPASPLVPFLQKFAEPRNKKPSVLKLELKQIREQQDLLFRFMNFLKQEGAVHVLQFCLTVEEFNDRILRPELSNDEMLSLHEELQKIYKTYCLDESIDKIRFDPFIVEEIQRIAEGPYIDVVKLQTMRCLFEAYEHVLSLLENVFTPMFCHSDEYFRQLLRGAESPTRNSKLNRGSLSLDDFRNTQKRGESFGISRIGSKIKGVFKSTTMEGAMLPNYGVAEGEDDFIEEGIVVMEDDSPVEAVSTPNTPRNLAAWKISIPYVDFFEDPSSERKEKKERIPVFCIDVERNDRRAVGHEPEHWSVYRRYLEFYVLESKLTEFHGAFPDAQLPSKRIIGPKNYEFLKSKREEFQEYLQKLLQHPELSNSQLLADFLSPNGGETQFLDKILPDVNLGKIIKSVPGKLMKEKGQHLEPFIMNFINSCESPKPKPSRPELTILSPTSENNKKLFNDLFKNNANRAENTERKQNQNYFMEVMTVEGVYDYLMYVGRVVFQVPDWLHHLLMGTRILFKNTLEMYTDYYLQCKLEQLFQEHRLVSLITLLRDAIFCENTEPRSLQDKQKGAKQTFEEMMNYIPDLLVKCIGEETKYESIRLLFDGLQQPVLNKQLTYVLLDIVIQELFPELNKVQKEVTSVTSWM>sp|Q9Y5W7-4|SNX14_HUMAN Isoform 4 of Sorting nexin-14 OS=Homo sapiensOX=9606 GN=SNX14MVPWVRTMGQKLKQRLRLDVGREICRQYPLFCFLLLCLSAASLLLNRYIHILMIFWSFVAGVVTFYCSLGPDSLLPNIFFTIKYKPKQLGLQELFPQGHSCAVCGKVKCKRHRPSLLLENYQPWLDLKISSKVDASLSEVLELVLENFVYPWYRDVTDDESFVDELRITLRFFASVLIRRIHKVDIPSIITKKLLKAAMKHIEVIVKARQKVKNTEFLQQAALEEYGPELHVALRSRRDELHYLRKLTELLFPYILPPKATDCRSLTLLIREILSGSVFLPSLDFLADPDTVNHLLIIFIDDSPPEKATEPASPLVPFLQKFAEPRNKKPSVLKLELKQIREQQDLLFRFMNFLKQEGAVHVLQFCLTVEEFNDRILRPELSNDEMLSLHEELQKIYKTYCLDESIDKIRFDPFIVEEIQRIAEGPYIDVVKLQTMRCLFEAYEHVLSLLENVFTPMFCHSDEYFRQLLRGAESPTRNSKLNRNTQKRGESFGISRIGSKIKGVFKSTTMEGAMLPNYGVAEGEDDFIEEGIVVMEDDSPVEAVSTPNTPRNLAAWKISIPYVDFFEDPSSERKEKKERIPVFCIDVERNDRRAVGHEPEHWSVYRRYLEFYVLESKLTEFHGAFPDAQLPSKRIIGPKNYEFLKSKREEFQEYLQKLLQHPELSNSQLLADFLSPNGGETQFLDKILPDVNLGKIIKSVPGKLMKEKGQHLEPFIMNFINSCESPKPKPSRPELTILSPTSENNKKLFNDLFKNNANRAENTERKQNQNYFMEVMTVEGVYDYLMYVGRVVFQVPDWLHHLLMGTRILFKNTLEMYTDYYLQCKLEQLFQEHRLVSLITLLRDAIFCENTEPRSLQDKQKGAKQTFEEMMNYIPDLLVKCIGEETKYESIRLLFDGLQQPVLNKQLTYVLLDIVIQELFPELNKVQKEVTSVTSWM>sp|Q6GMV2|SMYD5_HUMAN Histone-lysine N-trimethyltransferase SMYD5OS=Homo sapiens OX=9606 GN=SMYD5 PE=1 SV=2MAASMCDVFSFCVGVAGRARVSVEVRFVSSAKGKGLFATQLIRKGETIFVERPLVAAQFLWNALYRYRACDHCLRALEKAEENAQRLTGKPGQVLPHPELCTVRKDLHQNCPHCQVMYCSAECRLAATEQYHQVLCPGPSQDDPLHPLNKLQEAWRSIHYPPETASIMLMARMVATVKQAKDKDRWIRLFSQFCNKTANEEEEIVHKLLGDKFKGQLELLRRLFTEALYEEAVSQWFTPDGFRSLFALVGTNGQGIGTSSLSQWVHACDTLELKPQDREQLDAFIDQLYKDIEAATGEFLNCEGSGLFVLQSCCNHSCVPNAETSFPENNFLLHVTALEDIKPGEEICISYLDCCQRERSRHSRHKILRENYLFVCSCPKCLAEADEPNVTSEEEEEEEEEEEGEPEDAELGDEMTDV>sp|Q07617|SPAG1_HUMAN Sperm-associated antigen 1 OS=Homo sapiens OX=9606GN=SPAG1 PE=1 SV=3MTTKDYPSLWGFGTTKTFKIPIEHLDFKYIEKCSDVKHLEKILCVLRSGEEGYYPELTEFCEKHLQALAPESRALRKDKPAATAASFTAEEWEKIDGDIKSWVSEIKKEEDKMHFHETETFPAMKDNLPPVRGSNSCLHVGKEKYSKRPTKKKTPRDYAEWDKFDVEKECLKIDEDYKEKTVIDKSHLSKIETRIDTAGLTEKEKDFLATREKEKGNEAFNSGDYEEAVMYYTRSISALPTVVAYNNRAQAEIKLQNWNSAFQDCEKVLELEPGNVKALLRRATTYKHQNKLREATEDLSKVLDVEPDNDLAKKTLSEVERDLKNSEAASETQTKGKRMVIQEIENSEDEEGKSGRKHEDGGGDKKPAEPAGAARAAQPCVMGNIQKKLTGKAEGGKRPARGAPQRGQTPEAGADKRSPRRASAAAAAGGGATGHPGGGQGAENPAGLKSQGNELFRSGQFAEAAGKYSAAIALLEPAGSEIADDLSILYSNRAACYLKEGNCSGCIQDCNRALELHPFSMKPLLRRAMAYETLEQYGKAYVDYKTVLQIDCGLQLANDSVNRLSRILMELDGPNWREKLSPIPAVPASVPLQAWHPAKEMISKQAGDSSSHRQQGITDEKTFKALKEEGNQCVNDKNYKDALSKYSECLKINNKECAIYTNRALCYLKLCQFEEAKQDCDQALQLADGNVKAFYRRALAHKGLKNYQKSLIDLNKVILLDPSIIEAKMELEEVTRLLNLKDKTAPFNKEKERRKIEIQEVNEGKEEPGRPAGEVSMGCLASEKGGKSSRSPEDPEKLPIAKPNNAYEFGQIINALSTRKDKEACAHLLAITAPKDLPMFLSNKLEGDTFLLLIQSLKNNLIEKDPSLVYQHLLYLSKAERFKMMLTLISKGQKELIEQLFEDLSDTPNNHFTLEDIQALKRQYEL>sp|Q07617-2|SPAG1_HUMAN Isoform 2 of Sperm-associated antigen 1 OS=Homosapiens OX=9606 GN=SPAG1MTTKDYPSLWGFGTTKTFKIPIEHLDFKYIEKCSDVKHLEKILCVLRSGEEGYYPELTEFCEKHLQALAPESRALRKDKPAATAASFTAEEWEKIDGDIKSWVSEIKKEEDKMHFHETETFPAMKDNLPPVRGSNSCLHVGKEKYSKRPTKKKTPRDYAEWDKFDVEKECLKIDEDYKEKTVIDKSHLSKIETRIDTAGLTEKEKDFLATREKEKGNEAFNSGDYEEAVMYYTRSISALPTVVAYNNRAQAEIKLQNWNSAFQDCEKVLELEPGNVKALLRRATTYKHQNKLREATEDLSKVLDVEPDNDLAKKTLSEVERDLKNSEAASETQTKGKRMVIQEIENSEDEEGKSGRKHEDGGGDKSKIFFLFRLCKKLPFNMMSWLNFSIRTEIRNLSVFLALPCKFTSQFRSSFS>sp|O95863|SNAI1_HUMAN Zinc finger protein SNAI1 OS=Homo sapiens OX=9606GN=SNAI1 PE=1 SV=2MPRSFLVRKPSDPNRKPNYSELQDSNPEFTFQQPYDQAHLLAAIPPPEILNPTASLPMLIWDSVLAPQAQPIAWASLRLQESPRVAELTSLSDEDSGKGSQPPSPPSPAPSSFSSTSVSSLEAEAYAAFPGLGQVPKQLAQLSEAKDLQARKAFNCKYCNKEYLSLGALKMHIRSHTLPCVCGTCGKAFSRPWLLQGHVRTHTGEKPFSCPHCSRAFADRSNLRAHLQTHSDVKKYQCQACARTFSRMSLLHKHQESGCSGCPR>sp|O95968|SG1D1_HUMAN Secretoglobin family 1D member 1 OS=Homo sapiensOX=9606 GN=SCGB1D1 PE=1 SV=1MRLSVCLLLLTLALCCYRANAVVCQALGSEITGFLLAGKPVFKFQLAKFKAPLEAVAAKMEVKKCVDTMAYEKRVLITKTLGKIAEKCDR>sp|Q5VWJ9|SNX30_HUMAN Sorting nexin-30 OS=Homo sapiens OX=9606 GN=SNX30PE=1 SV=1MAGGPPKALPSTGPHSLRDMPHPLAGSSSEEAVGGDSTPSPDLLMARSFGDKDLILPNGGTPAGTSSPASSSSLLNRLQLDDDIDGETRDLFVIVDDPKKHVCTMETYITYRITTKSTRVEFDLPEYSVRRRYQDFDWLRSKLEESQPTHLIPPLPEKFVVKGVVDRFSEEFVETRRKALDKFLKRITDHPVLSFNEHFNIFLTAKDLNAYKKQGIALLTRMGESVKHVTGGYKLRTRPLEFAAIGDYLDTFALKLGTIDRIAQRIIKEEIEYLVELREYGPVYSTWSALEGELAEPLEGVSACIGNCSTALEELTDDMTEDFLPVLREYILYSDSMKSVLKKRDQVQAEYEAKLEAVALRKEDRPKVPADVEKCQDRMECFNADLKADMERWQNNKRQDFRQLLMGMADKNIQYYEKCLMAWESIIPLLQEKQEAK>sp|Q9BTD1|SHAS3_HUMAN Putative uncharacterized protein SHANK2-AS3OS=Homo sapiens OX=9606 GN=SHANK2-AS3 PE=5 SV=2MAQLPSAQMPAPRTQPDLILVHPVLALSGRAPSILCSVPWDACELLATAMWWKTRILWGVFLISRTRPPAPMQILILTLDPSEGEVCCKKRKPGQTGRNRVRMTTATCKPGGEASGETSPGTP>sp|O95969|SG1D2_HUMAN Secretoglobin family 1D member 2 OS=Homo sapiensOX=9606 GN=SCGB1D2 PE=2 SV=1MKLSVCLLLVTLALCCYQANAEFCPALVSELLDFFFISEPLFKLSLAKFDAPPEAVAAKLGVKRCTDQMSLQKRSLIAEVLVKILKKCSV>sp|Q9NP50|SHCAF_HUMAN SIN3-HDAC complex-associated factor OS=Homosapiens OX=9606 GN=SINHCAF PE=1 SV=1MFGFHKPKMYRSIEGCCICRAKSSSSRFTDSKRYEKDFQSCFGLHETRSGDICNACVLLVKRWKKLPAGSKKNWNHVVDARAGPSLKTTLKPKKVKTLSGNRIKSNQISKLQKEFKRHNSDAHSTTSSASPAQSPCYSNQSDDGSDTEMASGSNRTPVFSFLDLTYWKRQKICCGIIYKGRFGEVLIDTHLFKPCCSNKKAAAEKPEEQGPEPLPISTQEW>sp|Q9NP50-2|SHCAF_HUMAN Isoform 2 of SIN3-HDAC complex-associated factorOS=Homo sapiens OX=9606 GN=SINHCAFMASGSNRTPVFSFLDLTYWKRQKICCGIIYKGRFGEVLIDTHLFKPCCSNKKAAAEKPEEQGPEPLPISTQEW>sp|Q96H20|SNF8_HUMAN Vacuolar-sorting protein SNF8 OS=Homo sapiensOX=9606 GN=SNF8 PE=1 SV=1MHRRGVGAGAIAKKKLAEAKYKERGTVLAEDQLAQMSKQLDMFKTNLEEFASKHKQEIRKNPEFRVQFQDMCATIGVDPLASGKGFWSEMLGVGDFYYELGVQIIEVCLALKHRNGGLITLEELHQQVLKGRGKFAQDVSQDDLIRAIKKLKALGTGFGIIPVGGTYLIQSVPAELNMDHTVVLQLAEKNGYVTVSEIKASLKWETERARQVLEHLLKEGLAWLDLQAPGEAHYWLPALFTDLYSQEITAEEAREALP>sp|Q96H20-2|SNF8_HUMAN Isoform 2 of Vacuolar-sorting protein SNF8OS=Homo sapiens OX=9606 GN=SNF8MHRRGVGAGAIAKKKLAEAKYKERGTVLAEDQLAQMSKQLDMFKTNLEEFASKHKQEIRKNPEFRVQFQDMCATIGVDPLASGKGFWSEMLGVGDFYYELGVQIIEVCLALKHRNGGLITLEELHQQVLKGRGKFAQDVSQDDLIRAIKKLKALGTGFGIIPVGGTYLIQSVPAELNMDHTVVLQLAENGYVTVSEIKASLKWETERARQVLEHLLKEGLAWLDLQAPGEAHYWLPALFTDLYSQEITAEEAREALP>sp|P0DPA3|SNH28_HUMAN Putative uncharacterized protein SNHG28 OS=Homosapiens OX=9606 GN=SNHG28 PE=5 SV=1MGMLAPGPLQGRRPRKGHKGQEDAVAPGCKASGRGSRVTHLLGYPTQNVSRSLRRKYAPPPCGGPEDVALAPCTAAAACEAGPSPVYVKVKSAEPADCAEGPVQCKNGLLVSSPHCEEPCAHSCAHPGLPPHLVHKLPLSYLQTQDTDAASRRINAPLAAGWSWLRLWLVTLASGVDFPQVSAWMRALPSPDCPGLRTTGEQMQKLLLKENKVKTRKSKRRSGEGSHLTTSILEQ>sp|P19623|SPEE_HUMAN Spermidine synthase OS=Homo sapiens OX=9606 GN=SRMPE=1 SV=1MEPGPDGPAASGPAAIREGWFRETCSLWPGQALSLQVEQLLHHRRSRYQDILVFRSKTYGNVLVLDGVIQCTERDEFSYQEMIANLPLCSHPNPRKVLIIGGGDGGVLREVVKHPSVESVVQCEIDEDVIQVSKKFLPGMAIGYSSSKLTLHVGDGFEFMKQNQDAFDVIITDSSDPMGPAESLFKESYYQLMKTALKEDGVLCCQGECQWLHLDLIKEMRQFCQSLFPVVAYAYCTIPTYPSGQIGFMLCSKNPSTNFQEPVQPLTQQQVAQMQLKYYNSDVHRAAFVLPEFARKALNDVS>sp|Q02447|SP3_HUMAN Transcription factor Sp3 OS=Homo sapiens OX=9606GN=SP3 PE=1 SV=3MTAPEKPVKQEEMAALDVDSGGGGGGGGGHGEYLQQQQQHGNGAVAAAAAAQDTQPSPLALLAATCSKIGPPSPGDDEEEAAAAAGAPAAAGATGDLASAQLGGAPNRWEVLSATPTTIKDEAGNLVQIPSAATSSGQYVLPLQNLQNQQIFSVAPGSDSSNGTVSSVQYQVIPQIQSADGQQVQIGFTGSSDNGGINQESSQIQIIPGSNQTLLASGTPSANIQNLIPQTGQVQVQGVAIGGSSFPGQTQVVANVPLGLPGNITFVPINSVDLDSLGLSGSSQTMTAGINADGHLINTGQAMDSSDNSERTGERVSPDINETNTDTDLFVPTSSSSQLPVTIDSTGILQQNTNSLTTSSGQVHSSDLQGNYIQSPVSEETQAQNIQVSTAQPVVQHLQLQESQQPTSQAQIVQGITPQTIHGVQASGQNISQQALQNLQLQLNPGTFLIQAQTVTPSGQVTWQTFQVQGVQNLQNLQIQNTAAQQITLTPVQTLTLGQVAAGGAFTSTPVSLSTGQLPNLQTVTVNSIDSAGIQLHPGENADSPADIRIKEEEPDPEEWQLSGDSTLNTNDLTHLRVQVVDEEGDQQHQEGKRLRRVACTCPNCKEGGGRGTNLGKKKQHICHIPGCGKVYGKTSHLRAHLRWHSGERPFVCNWMYCGKRFTRSDELQRHRRTHTGEKKFVCPECSKRFMRSDHLAKHIKTHQNKKGIHSSSTVLASVEAARDDTLITAGGTTLILANIQQGSVSGIGTVNTSATSNQDILTNTEIPLQLVTVSGNETME>sp|Q02447-2|SP3_HUMAN Isoform 2 of Transcription factor Sp3 OS=Homosapiens OX=9606 GN=SP3MAALDVDSGGGGGGGGGHGEYLQQQQQHGNGAVAAAAAAQDTQPSPLALLAATCSKIGPPSPGDDEEEAAAAAGAPAAAGATGDLASAQLGGAPNRWEVLSATPTTIKDEAGNLVQIPSAATSSGQYVLPLQNLQNQQIFSVAPGSDSSNGTVSSVQYQVIPQIQSADGQQVQIGFTGSSDNGGINQESSQIQIIPGSNQTLLASGTPSANIQNLIPQTGQVQVQGVAIGGSSFPGQTQVVANVPLGLPGNITFVPINSVDLDSLGLSGSSQTMTAGINADGHLINTGQAMDSSDNSERTGERVSPDINETNTDTDLFVPTSSSSQLPVTIDSTGILQQNTNSLTTSSGQVHSSDLQGNYIQSPVSEETQAQNIQVSTAQPVVQHLQLQESQQPTSQAQIVQGITPQTIHGVQASGQNISQQALQNLQLQLNPGTFLIQAQTVTPSGQVTWQTFQVQGVQNLQNLQIQNTAAQQITLTPVQTLTLGQVAAGGAFTSTPVSLSTGQLPNLQTVTVNSIDSAGIQLHPGENADSPADIRIKEEEPDPEEWQLSGDSTLNTNDLTHLRVQVVDEEGDQQHQEGKRLRRVACTCPNCKEGGGRGTNLGKKKQHICHIPGCGKVYGKTSHLRAHLRWHSGERPFVCNWMYCGKRFTRSDELQRHRRTHTGEKKFVCPECSKRFMRSDHLAKHIKTHQNKKGIHSSSTVLASVEAARDDTLITAGGTTLILANIQQGSVSGIGTVNTSATSNQDILTNTEIPLQLVTVSGNETME>sp|Q02447-3|SP3_HUMAN Isoform 3 of Transcription factor Sp3 OS=Homosapiens OX=9606 GN=SP3MTAGINADGHLINTGQAMDSSDNSERTGERVSPDINETNTDTDLFVPTSSSSQLPVTIDSTGILQQNTNSLTTSSGQVHSSDLQGNYIQSPVSEETQAQNIQVSTAQPVVQHLQLQESQQPTSQAQIVQGITPQTIHGVQASGQNISQQALQNLQLQLNPGTFLIQAQTVTPSGQVTWQTFQVQGVQNLQNLQIQNTAAQQITLTPVQTLTLGQVAAGGAFTSTPVSLSTGQLPNLQTVTVNSIDSAGIQLHPGENADSPADIRIKEEEPDPEEWQLSGDSTLNTNDLTHLRVQVVDEEGDQQHQEGKRLRRVACTCPNCKEGGGRGTNLGKKKQHICHIPGCGKVYGKTSHLRAHLRWHSGERPFVCNWMYCGKRFTRSDELQRHRRTHTGEKKFVCPECSKRFMRSDHLAKHIKTHQNKKGIHSSSTVLASVEAARDDTLITAGGTTLILANIQQGSVSGIGTVNTSATSNQDILTNTEIPLQLVTVSGNETME>sp|Q02447-4|SP3_HUMAN Isoform 4 of Transcription factor Sp3 OS=Homosapiens OX=9606 GN=SP3MDSSDNSERTGERVSPDINETNTDTDLFVPTSSSSQLPVTIDSTGILQQNTNSLTTSSGQVHSSDLQGNYIQSPVSEETQAQNIQVSTAQPVVQHLQLQESQQPTSQAQIVQGITPQTIHGVQASGQNISQQALQNLQLQLNPGTFLIQAQTVTPSGQVTWQTFQVQGVQNLQNLQIQNTAAQQITLTPVQTLTLGQVAAGGAFTSTPVSLSTGQLPNLQTVTVNSIDSAGIQLHPGENADSPADIRIKEEEPDPEEWQLSGDSTLNTNDLTHLRVQVVDEEGDQQHQEGKRLRRVACTCPNCKEGGGRGTNLGKKKQHICHIPGCGKVYGKTSHLRAHLRWHSGERPFVCNWMYCGKRFTRSDELQRHRRTHTGEKKFVCPECSKRFMRSDHLAKHIKTHQNKKGIHSSSTVLASVEAARDDTLITAGGTTLILANIQQGSVSGIGTVNTSATSNQDILTNTEIPLQLVTVSGNETME>sp|Q02447-5|SP3_HUMAN Isoform 5 of Transcription factor Sp3 OS=Homosapiens OX=9606 GN=SP3MGPPSPGDDEEEAAAAAGAPAAAGATGDLASAQLGGAPNRWEVLSATPTTIKDEAGNLVQIPSAATSSGQYVLPLQNLQNQQIFSVAPGSDSSNGTVSSVQYQVIPQIQSADGQQVQIGFTGSSDNGGINQESSQIQIIPGSNQTLLASGTPSANIQNLIPQTGQVQVQGVAIGGSSFPGQTQVVANVPLGLPGNITFVPINSVDLDSLGLSGSSQTMTAGINADGHLINTGQAMDSSDNSERTGERVSPDINETNTDTDLFVPTSSSSQLPVTIDSTGILQQNTNSLTTSSGQVHSSDLQGNYIQSPVSEETQAQNIQVSTAQPVVQHLQLQESQQPTSQAQIVQGITPQTIHGVQASGQNISQQALQNLQLQLNPGTFLIQAQTVTPSGQVTWQTFQVQGVQNLQNLQIQNTAAQQITLTPVQTLTLGQVAAGGAFTSTPVSLSTGQLPNLQTVTVNSIDSAGIQLHPGENADSPADIRIKEEEPDPEEWQLSGDSTLNTNDLTHLRVQVVDEEGDQQHQEGKRLRRVACTCPNCKEGGGRGTNLGKKKQHICHIPGCGKVYGKTSHLRAHLRWHSGERPFVCNWMYCGKRFTRSDELQRHRRTHTGEKKFVCPECSKRFMRSDHLAKHIKTHQNKKGIHSSSTVLASVEAARDDTLITAGGTTLILANIQQGSVSGIGTVNTSATSNQDILTNTEIPLQLVTVSGNETME>sp|Q02447-6|SP3_HUMAN Isoform 6 of Transcription factor Sp3 OS=Homosapiens OX=9606 GN=SP3MAALDVDSGGGGGGGGGHGEYLQQQQQHGNGAVAAAAAAQTGDLASAQLGGAPNRWEVLSATPTTIKDEAGNLVQIPSAATSSGQYVLPLQNLQNQQIFSVAPGSDSSNGTVSSVQYQVIPQIQSADGQQVQIGFTGSSDNGGINQESSQIQIIPGSNQTLLASGTPSANIQNLIPQTGQVQVQGVAIGGSSFPGQTQVVANVPLGLPGNITFVPINSVDLDSLGLSGSSQTMTAGINADGHLINTGQAMDSSDNSERTGERVSPDINETNTDTDLFVPTSSSSQLPVTIDSTGILQQNTNSLTTSSGQVHSSDLQGNYIQSPVSEETQAQNIQVSTAQPVVQHLQLQESQQPTSQAQIVQGITPQTIHGVQASGQNISQQALQNLQLQLNPGTFLIQAQTVTPSGQVTWQTFQVQGVQNLQNLQIQNTAAQQITLTPVQTLTLGQVAAGGAFTSTPVSLSTGQLPNLQTVTVNSIDSAGIQLHPGENADSPADIRIKEEEPDPEEWQLSGDSTLNTNDLTHLRVQVVDEEGDQQHQEGKRLRRVACTCPNCKEGGGRGTNLGKKKQHICHIPGCGKVYGKTSHLRAHLRWHSGERPFVCNWMYCGKRFTRSDELQRHRRTHTGEKKFVCPECSKRFMRSDHLAKHIKTHQNKKGIHSSSTVLASVEAARDDTLITAGGTTLILANIQQGSVSGIGTVNTSATSNQDILTNTEIPLQLVTVSGNETME>sp|P0DUX0|SPD10_HUMAN Speedy protein E10 OS=Homo sapiens OX=9606GN=SPDYE10 PE=3 SV=1MGQILGKIMMSHQPQPQEERSPQRSTSGYPLQEVVDDEVSGPSAPGVDPSPPRRSLGWKRKRECLDESDDEPEKELAPEPEETWVAETLCGLKMKAKRRRVSLVLPEYYEAFNRLLEDPVIKRLLAWDKDLRVSDKYLLAMVIAYFSRAGLPSWQYQRIHFFLALYLANDMEEDDEAPKQNIFYFLYEETRSHIPLLSELWFQLCRYMNPRARKNCSQIALFRKYRFHFFCSMRCRAWVSLEELEEIQAYDPEHWVWARDRAHLS>sp|Q9NRQ5|SMCO4_HUMAN Single-pass membrane and coiled-coil domain-containing protein 4 OS=Homo sapiens OX=9606 GN=SMCO4 PE=1 SV=1MRQLKGKPKKETSKDKKERKQAMQEARQQITTVVLPTLAVVVLLIVVFVYVATRPTITE>sp|Q15833|STXB2_HUMAN Syntaxin-binding protein 2 OS=Homo sapiens OX=9606GN=STXBP2 PE=1 SV=2MAPSGLKAVVGEKILSGVIRSVKKDGEWKVLIMDHPSMRILSSCCKMSDILAEGITIVEDINKRREPIPSLEAIYLLSPTEKSVQALIKDFQGTPTFTYKAAHIFFTDTCPEPLFSELGRSRLAKVVKTLKEIHLAFLPYEAQVFSLDAPHSTYNLYCPFRAEERTRQLEVLAQQIATLCATLQEYPAIRYRKGPEDTAQLAHAVLAKLNAFKADTPSLGEGPEKTRSQLLIMDRAADPVSPLLHELTFQAMAYDLLDIEQDTYRYETTGLSEAREKAVLLDEDDDLWVELRHMHIADVSKKVTELLRTFCESKRLTTDKANIKDLSQILKKMPQYQKELNKYSTHLHLADDCMKHFKGSVEKLCSVEQDLAMGSDAEGEKIKDSMKLIVPVLLDAAVPAYDKIRVLLLYILLRNGVSEENLAKLIQHANVQAHSSLIRNLEQLGGTVTNPGGSGTSSRLEPRERMEPTYQLSRWTPVIKDVMEDAVEDRLDRNLWPFVSDPAPTASSQAAVSARFGHWHKNKAGIEARAGPRLIVYVMGGVAMSEMRAAYEVTRATEGKWEVLIGSSHILTPTRFLDDLKALDKKLEDIALP>sp|Q15833-2|STXB2_HUMAN Isoform 2 of Syntaxin-binding protein 2 OS=Homosapiens OX=9606 GN=STXBP2MAPSGLKAVVGEKILSGVIRSVKKDGEWKVLIMDHPSMRILSSCCKMSDILAEGITIVEDINKRREPIPSLEAIYLLSPTEKALIKDFQGTPTFTYKAAHIFFTDTCPEPLFSELGRSRLAKVVKTLKEIHLAFLPYEAQVFSLDAPHSTYNLYCPFRAEERTRQLEVLAQQIATLCATLQEYPAIRYRKGPEDTAQLAHAVLAKLNAFKADTPSLGEGPEKTRSQLLIMDRAADPVSPLLHELTFQAMAYDLLDIEQDTYRYETTGLSEAREKAVLLDEDDDLWVELRHMHIADVSKKVTELLRTFCESKRLTTDKANIKDLSQILKKMPQYQKELNKYSTHLHLADDCMKHFKGSVEKLCSVEQDLAMGSDAEGEKIKDSMKLIVPVLLDAAVPAYDKIRVLLLYILLRNGVSEENLAKLIQHANVQAHSSLIRNLEQLGGTVTNPGGSGTSSRLEPRERMEPTYQLSRWTPVIKDVMEDAVEDRLDRNLWPFVSDPAPTASSQAAVSARFGHWHKNKAGIEARAGPRLIVYVMGGVAMSEMRAAYEVTRATEGKWEVLIGSSHILTPTRFLDDLKALDKKLEDIALP>sp|Q15833-3|STXB2_HUMAN Isoform 3 of Syntaxin-binding protein 2 OS=Homosapiens OX=9606 GN=STXBP2MAPSGLKAVVGEKILSGVIRSVKKDGEWKVLIMDHPSMRILSSCCKMSDILAEGITIVEDINKRREPIPSLEAIYLLSPTEKAQAQRVIHLPQSVQALIKDFQGTPTFTYKAAHIFFTDTCPEPLFSELGRSRLAKVVKTLKEIHLAFLPYEAQVFSLDAPHSTYNLYCPFRAEERTRQLEVLAQQIATLCATLQEYPAIRYRKGPEDTAQLAHAVLAKLNAFKADTPSLGEGPEKTRSQLLIMDRAADPVSPLLHELTFQAMAYDLLDIEQDTYRYETTGLSEAREKAVLLDEDDDLWVELRHMHIADVSKKVTELLRTFCESKRLTTDKANIKDLSQILKKMPQYQKELNKYSTHLHLADDCMKHFKGSVEKLCSVEQDLAMGSDAEGEKIKDSMKLIVPVLLDAAVPAYDKIRVLLLYILLRNGVSEENLAKLIQHANVQAHSSLIRNLEQLGGTVTNPGGSGTSSRLEPRERMEPTYQLSRWTPVIKDVMEDAVEDRLDRNLWPFVSDPAPTASSQAAVSARFGHWHKNKAGIEARAGPRLIVYVMGGVAMSEMRAAYEVTRATEGKWEVLIGSSHILTPTRFLDDLKALDKKLEDIALP>sp|Q9UNK0|STX8_HUMAN Syntaxin-8 OS=Homo sapiens OX=9606 GN=STX8 PE=1SV=2MAPDPWFSTYDSTCQIAQEIAEKIQQRNQYERKGEKAPKLTVTIRALLQNLKEKIALLKDLLLRAVSTHQITQLEGDRRQNLLDDLVTRERLLLASFKNEGAEPDLIRSSLMSEEAKRGAPNPWLFEEPEETRGLGFDEIRQQQQKIIQEQDAGLDALSSIISRQKQMGQEIGNELDEQNEIIDDLANLVENTDEKLRNETRRVNMVDRKSASCGMIMVILLLLVAIVVVAVWPTN>sp|Q86WV6|STING_HUMAN Stimulator of interferon genes protein OS=Homosapiens OX=9606 GN=STING1 PE=1 SV=1MPHSSLHPSIPCPRGHGAQKAALVLLSACLVTLWGLGEPPEHTLRYLVLHLASLQLGLLLNGVCSLAEELRHIHSRYRGSYWRTVRACLGCPLRRGALLLLSIYFYYSLPNAVGPPFTWMLALLGLSQALNILLGLKGLAPAEISAVCEKGNFNVAHGLAWSYYIGYLRLILPELQARIRTYNQHYNNLLRGAVSQRLYILLPLDCGVPDNLSMADPNIRFLDKLPQQTGDHAGIKDRVYSNSIYELLENGQRAGTCVLEYATPLQTLFAMSQYSQAGFSREDRLEQAKLFCRTLEDILADAPESQNNCRLIAYQEPADDSSFSLSQEVLRHLRQEEKEEVTVGSLKTSAVPSTSTMSQEPELLISGMEKPLPLRTDFS>sp|Q9BYN0|SRXN1_HUMAN Sulfiredoxin-1 OS=Homo sapiens OX=9606 GN=SRXN1PE=1 SV=2MGLRAGGTLGRAGAGRGAPEGPGPSGGAQGGSIHSGRIAAVHNVPLSVLIRPLPSVLDPAKVQSLVDTIREDPDSVPPIDVLWIKGAQGGDYFYSFGGCHRYAAYQQLQRETIPAKLVQSTLSDLRVYLGASTPDLQ>sp|Q969M1|TM40L_HUMAN Mitochondrial import receptor subunit TOM40BOS=Homo sapiens OX=9606 GN=TOMM40L PE=1 SV=1MGNTLGLAPMGTLPRRSPRREEPLPNPGSFDELHRLCKDVFPAQMEGVKLVVNKVLSSHFQVAHTIHMSALGLPGYHLHAAYAGDWQLSPTEVFPTVVGDMDSSGSLNAQVLLLLAERLRAKAVFQTQQAKFLTWQFDGEYRGDDYTATLTLGNPDLIGESVIMVAHFLQSLTHRLVLGGELVYHRRPGEEGAILTLAGKYSAVHWVATLNVGSGGAHASYYHRANEQVQVGVEFEANTRLQDTTFSFGYHLTLPQANMVFRGLVDSNWCVGAVLEKKMPPLPVTLALGAFLNHWRNRFHCGFSITVG>sp|Q969M1-2|TM40L_HUMAN Isoform 2 of Mitochondrial import receptorsubunit TOM40B OS=Homo sapiens OX=9606 GN=TOMM40LMGNTLGLAPMGTLPRRSPRREEPLPNPGSFDELHRLCKDVFPAQMEGVKLVVNKVLSSHFQVAHTIHMSALGLPGYHLHAAYAGDWQLSPTETQQAKFLTWQFDGEYRGDDYTATLTLGNPDLIGESVIMVAHFLQSLTHRLVLGGELVYHRRPGEEGAILTLAGKYSAVHWVATLNVGSGGAHASYYHRANEQVQVGVEFEANTRLQDTTFSFGYHLTLPQANMVFRGLVDSNWCVGAVLEKKMPPLPVTLALGAFLNHWRNRFHCGFSITVG>sp|Q9NRC1|ST7_HUMAN Suppressor of tumorigenicity 7 protein OS=Homosapiens OX=9606 GN=ST7 PE=1 SV=1MAEAATGFLEQLKSCIVWSWTYLWTVWFFIVLFLVYILRVPLKINDNLSTVSMFLNTLTPKFYVALTGTSSLISGLILIFEWWYFRKYGTSFIEQVSVSHLRPLLGGVDNNSSNNSNSSNGDSDSNRQSVSECKVWRNPLNLFRGAEYNRYTWVTGREPLTYYDMNLSAQDHQTFFTCDSDHLRPADAIMQKAWRERNPQARISAAHEALEINEIRSRVEVPLIASSTIWEIKLLPKCATAYILLAEEEATTIAEAEKLFKQALKAGDGCYRRSQQLQHHGSQYEAQHRRDTNVLVYIKRRLAMCARRLGRTREAVKMMRDLMKEFPLLSMFNIHENLLEALLELQAYADVQAVLAKYDDISLPKSATICYTAALLKARAVSDKFSPEAASRRGLSTAEMNAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLAHWKRVEGALNLLHCTWEGTFRMIPYPLEKGHLFYPYPICTETADRELLPSFHEVSVYPKKELPFFILFTAGLCSFTAMLALLTHQFPELMGVFAKAMIDIFCSAEFRDWNCKSIFMRVEDELEIPPAPQSQHFQN>sp|Q9NRC1-2|ST7_HUMAN Isoform 2 of Suppressor of tumorigenicity 7protein OS=Homo sapiens OX=9606 GN=ST7MAEAATGFLEQLKSCIVWSWTYLWTVWFFIVLFLVYILRVPLKINDNLSTVSMFLNTLTPKFYVALTGTSSLISGLILIFEWWYFRKYGTSFIEQVSVSHLRPLLGGVDNNSSNNSNSSNGDSDSNRQSVSECKVWRNPLNLFRGAEYNRYTWVTGREPLTYYDMNLSAQDHQTFFTCDSDHLRPADAIMQKAWRERNPQARISAAHEALEINECATAYILLAEEEATTIAEAEKLFKQALKAGDGCYRRSQQLQHHGSQYEAQHRRDTNVLVYIKRRLAMCARRLGRTREAVKMMRDLMKEFPLLSMFNIHENLLEALLELQAYADVQAVLAKYDDISLPKSATICYTAALLKARAVSDKFSPEAASRRGLSTAEMNAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLAHWKRVEGALNLLHCTWEGTFRMIPYPLEKGHLFYPYPICTETADRELLPSFHEVSVYPKKELPFFILFTAGLCSFTAMLALLTHQFPELMGVFAKAFLSTLFAPLNFVMEKVESILPSSLWHQLTRI>sp|Q9NRC1-3|ST7_HUMAN Isoform 3 of Suppressor of tumorigenicity 7protein OS=Homo sapiens OX=9606 GN=ST7MAEAATGFLEQLKSCIVWSWTYLWTVWFFIVLFLVYILRVPLKINDNLSTVSMFLNTLTPKFYVALTGTSSLISGLILIFEWWYFRKYGTSFIEQVSVSHLRPLLGGVDNNSSNNSDSNRQSVSECKVWRNPLNLFRGAEYNRYTWVTGREPLTYYDMNLSAQDHQTFFTCDSDHLRPADAIMQKAWRERNPQARISAAHEALEINECATAYILLAEEEATTIAEAEKLFKQALKAGDGCYRRSQQLQHHGSQYEAQHRRDTNVLVYIKRRLAMCARRLGRTREAVKMMRDLMKEFPLLSMFNIHENLLEALLELQAYADVQAVLAKYDDISLPKSATICYTAALLKARAVSDKFSPEAASRRGLSTAEMNAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLAHWKRVEGALNLLHCTWEGTFRMIPYPLEKGHLFYPYPICTETADRELLPSFHEVSVYPKKELPFFILFTAGLCSFTAMLALLTHQFPELMGVFAKAFLSTLFAPLNFVMEKVESILPSSLWHQLTRI>sp|Q9NRC1-4|ST7_HUMAN Isoform 4 of Suppressor of tumorigenicity 7protein OS=Homo sapiens OX=9606 GN=ST7MFGTESSVSMFLNTLTPKFYVALTGTSSLISGLILIFEWWYFRKYGTSFIEQVSVSHLRPLLGGVDNNSSNNSNSSNGDSDSNRQSVSECKVWRNPLNLFRGAEYNRYTWVTGREPLTYYDMNLSAQDHQTFFTCDSDHLRPADAIMQKAWRERNPQARISAAHEALEINEIRSRVEVPLIASSTIWEIKLLPKCATAYILLAEEEATTIAEAEKLFKQALKAGDGCYRRSQQLQHHGSQYEAQHRRDTNVLVYIKRRLAMCARRLGRTREAVKMMRDLMKEFPLLSMFNIHENLLEALLELQAYADVQAVLAKYDDISLPKSATICYTAALLKARAVSDKFSPEAASRRGLSTAEMNAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLAHWKRVEGALNLLHCTWEGTFRMIPYPLEKGHLFYPYPICTETADRELLPSFHEVSVYPKKELPFFILFTAGLCSFTAMLALLTHQFPELMGVFAKAFLSTLFAPLNFVMEKVESILPSSLWHQLTRI>sp|Q9NRC1-5|ST7_HUMAN Isoform 5 of Suppressor of tumorigenicity 7protein OS=Homo sapiens OX=9606 GN=ST7MFGTESSVSMFLNTLTPKFYVALTGTSSLISGLILIFEWWYFRKYGTSFIEQVSVSHLRPLLGGVDNNSSNNSNSSNGDSDSNRQSVSECKVWRNPLNLFRGAEYNRYTWVTGREPLTYYDMNLSAQDHQTFFTCDSDHLRPADAIMQKAWRERNPQARISAAHEALEINECATAYILLAEEEATTIAEAEKLFKQALKAGDGCYRRSQQLQHHGSQYEAQHRRDTNVLVYIKRRLAMCARRLGRTREAVKMMRDLMKEFPLLSMFNIHENLLEALLELQAYADVQAVLAKYDDISLPKSATICYTAALLKARAVSDKFSPEAASRRGLSTAEMNAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLAHWKRVEGALNLLHCTWEGTFRMIPYPLEKGHLFYPYPICTETADRELLPSFHEVSVYPKKELPFFILFTAGLCSFTAMLALLTHQFPELMGVFAKAFLSTLFAPLNFVMEKVESILPSSLWHQLTRI>sp|Q9NRC1-6|ST7_HUMAN Isoform 6 of Suppressor of tumorigenicity 7protein OS=Homo sapiens OX=9606 GN=ST7MSMFLNTLTPKFYVALTGTSSLISGLILIFEWWYFRKYGTSFIEQVSVSHLRPLLGGVDNNSSNNSNSSNGDSDSNRQSVSECKVWRNPLNLFRGAEYNRYTWVTGREPLTYYDMNLSAQDHQTFFTCDSDHLRPADAIMQKAWRERNPQARISAAHEALEINECATAYILLAEEEATTIAEAEKLFKQALKAGDGCYRRSQQLQHHGSQYEAQHRRDTNVLVYIKRRLAMCARRLGRTREAVKMMRDLMKEFPLLSMFNIHENLLEALLELQAYADVQAVLAKYDDISLPKSATICYTAALLKARAVSDKFSPEAASRRGLSTAEMNAVEAIHRAVEFNPHVPKYLLEMKSLILPPEHILKRGDSEAIAYAFFHLAHWKRVEGALNLLHSFRMIPYPLEKGHLFYPYPICTETADRELLPSFHEVSVYPKKELPFFILFTAGLCSFTAMLALLTHQFPELMGVFAKAFLSTLFAPLNFVMEKVESILPSSLWHQLTRI>sp|Q9NRC1-7|ST7_HUMAN Isoform 7 of Suppressor of tumorigenicity 7protein OS=Homo sapiens OX=9606 GN=ST7MAEAATGFLEQLKSCIVWSWTYLWTVWFFIVLFLVYILRVPLKINDNLSTVSMFLNTLTPKFYVALTGTSSLISGLILIFEWWYFRKYGTSFIEQVSVSHLRPLLGGVDNNSSNNSNSSNGDSDSNRQSVSECKVWRNPLNLFRGAEYNRYTWVTGREPLTYYDMNLSAQDHQTFFTCDSDHLRPADAIMQKAWRERNPQARISAAHEALEINECATAYILLAEEEATTIAEAEKLFKQALKAGDGCYRRSQQLQHHGSQYEAQHRRDTNVLVYIKRRLAMCARRLGRTREAVKMMRDLMKEFPLLSMFNIHENLLEALLELQAYADVQAVLAKYDDISLPKSATICYTAALLKARAVSDKFSPEAASRRGLSTAEMNAVEAIHRAVEFNPHVPKARWK>sp|P63165|SUMO1_HUMAN Small ubiquitin-related modifier 1 OS=Homo sapiensOX=9606 GN=SUMO1 PE=1 SV=1MSDQEAKPSTEDLGDKKEGEYIKLKVIGQDSSEIHFKVKMTTHLKKLKESYCQRQGVPMNSLRFLFEGQRIADNHTPKELGMEEEDVIEVYQEQTGGHSTV>sp|P63165-2|SUMO1_HUMAN Isoform 2 of Small ubiquitin-related modifier 1OS=Homo sapiens OX=9606 GN=SUMO1MSDQDSSEIHFKVKMTTHLKKLKESYCQRQGVPMNSLRFLFEGQRIADNHTPKELGMEEEDVIEVYQEQTGGHSTV>sp|Q9NY15|STAB1_HUMAN Stabilin-1 OS=Homo sapiens OX=9606 GN=STAB1 PE=1SV=3MAGPRGLLPLCLLAFCLAGFSFVRGQVLFKGCDVKTTFVTHVPCTSCAAIKKQTCPSGWLRELPDQITQDCRYEVQLGGSMVSMSGCRRKCRKQVVQKACCPGYWGSRCHECPGGAETPCNGHGTCLDGMDRNGTCVCQENFRGSACQECQDPNRFGPDCQSVCSCVHGVCNHGPRGDGSCLCFAGYTGPHCDQELPVCQELRCPQNTQCSAEAPSCRCLPGYTQQGSECRAPNPCWPSPCSLLAQCSVSPKGQAQCHCPENYHGDGMVCLPKDPCTDNLGGCPSNSTLCVYQKPGQAFCTCRPGLVSINSNASAGCFAFCSPFSCDRSATCQVTADGKTSCVCRESEVGDGRACYGHLLHEVQKATQTGRVFLQLRVAVAMMDQGCREILTTAGPFTVLVPSVSSFSSRTMNASLAQQLCRQHIIAGQHILEDTRTQQTRRWWTLAGQEITVTFNQFTKYSYKYKDQPQQTFNIYKANNIAANGVFHVVTGLRWQAPSGTPGDPKRTIGQILASTEAFSRFETILENCGLPSILDGPGPFTVFAPSNEAVDSLRDGRLIYLFTAGLSKLQELVRYHIYNHGQLTVEKLISKGRILTMANQVLAVNISEEGRILLGPEGVPLQRVDVMAANGVIHMLDGILLPPTILPILPKHCSEEQHKIVAGSCVDCQALNTSTCPPNSVKLDIFPKECVYIHDPTGLNVLKKGCASYCNQTIMEQGCCKGFFGPDCTQCPGGFSNPCYGKGNCSDGIQGNGACLCFPDYKGIACHICSNPNKHGEQCQEDCGCVHGLCDNRPGSGGVCQQGTCAPGFSGRFCNESMGDCGPTGLAQHCHLHARCVSQEGVARCRCLDGFEGDGFSCTPSNPCSHPDRGGCSENAECVPGSLGTHHCTCHKGWSGDGRVCVAIDECELDMRGGCHTDALCSYVGPGQSRCTCKLGFAGDGYQCSPIDPCRAGNGGCHGLATCRAVGGGQRVCTCPPGFGGDGFSCYGDIFRELEANAHFSIFYQWLKSAGITLPADRRVTALVPSEAAVRQLSPEDRAFWLQPRTLPNLVRAHFLQGALFEEELARLGGQEVATLNPTTRWEIRNISGRVWVQNASVDVADLLATNGVLHILSQVLLPPRGDVPGGQGLLQQLDLVPAFSLFRELLQHHGLVPQIEAATAYTIFVPTNRSLEAQGNSSHLDADTVRHHVVLGEALSMETLRKGGHRNSLLGPAHWIVFYNHSGQPEVNHVPLEGPMLEAPGRSLIGLSGVLTVGSSRCLHSHAEALREKCVNCTRRFRCTQGFQLQDTPRKSCVYRSGFSFSRGCSYTCAKKIQVPDCCPGFFGTLCEPCPGGLGGVCSGHGQCQDRFLGSGECHCHEGFHGTACEVCELGRYGPNCTGVCDCAHGLCQEGLQGDGSCVCNVGWQGLRCDQKITSPQCPRKCDPNANCVQDSAGASTCACAAGYSGNGIFCSEVDPCAHGHGGCSPHANCTKVAPGQRTCTCQDGYMGDGELCQEINSCLIHHGGCHIHAECIPTGPQQVSCSCREGYSGDGIRTCELLDPCSKNNGGCSPYATCKSTGDGQRTCTCDTAHTVGDGLTCRARVGLELLRDKHASFFSLRLLEYKELKGDGPFTIFVPHADLMSNLSQDELARIRAHRQLVFRYHVVGCRRLRSEDLLEQGYATALSGHPLRFSEREGSIYLNDFARVVSSDHEAVNGILHFIDRVLLPPEALHWEPDDAPIPRRNVTAAAQGFGYKIFSGLLKVAGLLPLLREASHRPFTMLWPTDAAFRALPPDRQAWLYHEDHRDKLAAILRGHMIRNVEALASDLPNLGPLRTMHGTPISFSCSRTRAGELMVGEDDARIVQRHLPFEGGLAYGIDQLLEPPGLGARCDHFETRPLRLNTCSICGLEPPCPEGSQEQGSPEACWRFYPKFWTSPPLHSLGLRSVWVHPSLWGRPQGLGRGCHRNCVTTTWKPSCCPGHYGSECQACPGGPSSPCSDRGVCMDGMSGSGQCLCRSGFAGTACELCAPGAFGPHCQACRCTVHGRCDEGLGGSGSCFCDEGWTGPRCEVQLELQPVCTPPCAPEAVCRAGNSCECSLGYEGDGRVCTVADLCQDGHGGCSEHANCSQVGTMVTCTCLPDYEGDGWSCRARNPCTDGHRGGCSEHANCLSTGLNTRRCECHAGYVGDGLQCLEESEPPVDRCLGQPPPCHSDAMCTDLHFQEKRAGVFHLQATSGPYGLNFSEAEAACEAQGAVLASFPQLSAAQQLGFHLCLMGWLANGSTAHPVVFPVADCGNGRVGIVSLGARKNLSERWDAYCFRVQDVACRCRNGFVGDGISTCNGKLLDVLAATANFSTFYGMLLGYANATQRGLDFLDFLDDELTYKTLFVPVNEGFVDNMTLSGPDLELHASNATLLSANASQGKLLPAHSGLSLIISDAGPDNSSWAPVAPGTVVVSRIIVWDIMAFNGIIHALASPLLAPPQPQAVLAPEAPPVAAGVGAVLAAGALLGLVAGALYLRARGKPMGFGFSAFQAEDDADDDFSPWQEGTNPTLVSVPNPVFGSDTFCEPFDDSLLEEDFPDTQRILTVK>sp|Q9NY15-2|STAB1_HUMAN Isoform 2 of Stabilin-1 OS=Homo sapiens OX=9606GN=STAB1MAGPRGLLPLCLLAFCLAGFSFVRGQVLFKGCDVKTTFVTHVPCTSCAAIKKQTCPSGWLRELPDQITQDCRYEVQLGGSMVSMSGCRRKCRKQVVQKACCPGYWGSRCHECPGGAETPCNGHGTCLDGMDRNGTCVCQENFRGSACQECQDPNRFGPDCQSVCSCVHGVCNHGPRGDGSCLCFAGYTGPHCDQELPVCQELRCPQNTQCSAEAPSCRCLPGYTQQGSECRAPNPCWPSPCSLLAQCSVSPKGQAQCHCPENYHGDGMVCLPKDPCTDNLGGCPSNSTLCVYQKPGQAFCTCRPGLVSINSNASAGCFAFCSPFSCDRSATCQVTADGKTSCVCRESEVGDGRACYGHLLHEVQKATQTGRVFLQLRVAVAMMDQGCREILTTAGPFTVLVPSVSSFSSRTMNASLAQQLCRQHIIAGQHILEDTRTQQTRRWWTLAGQEITVTFNQFTKYSYKYKDQPQQTFNIYKANNIAANGVFHVVTGLRWQAPSGTPGDPKRTIGQILASTEAFSRFETILENCGLPSILDGPGPFTVFAPSNEAVDSLRDGRLIYLFTAGLSKLQELVRYHIYNHGQLTVEKLISKGRILTMANQVLAVNISEEGRILLGPEGVPLQRVDVMAANGVIHMLDGILLPPTILPILPKHCSEEQHKIVAGSCVDCQALNTSTCPPNSVKLDIFPKECVYIHDPTGLNVLKKGCASYCNQTIMEQGCCKGFFGPDCTQCPGGFSNPCYGKGNVSPILSWGEVWGTQGLLHRLASDWLCVWAKPATLALGFSYLCSGKLDQIISHILIKNN>sp|Q9BXU1|STK31_HUMAN Serine/threonine-protein kinase 31 OS=Homo sapiensOX=9606 GN=STK31 PE=2 SV=2MWVQGHSSRASATESVSFSGIVQMDEDTHYDKVEDVVGSHIEDAVTFWAQSINRNKDIMKIGCSLSEVCPQASSVLGNLDPNKIYGGLFSEDQCWYRCKVLKIISVEKCLVRYIDYGNTEILNRSDIVEIPLELQFSSVAKKYKLWGLHIPSDQEVTQFDQGTTFLGSLIFEKEIKMRIKATSEDGTVIAQAEYGSVDIGEEVLKKGFAEKCRLASRTDICEEKKLDPGQLVLRNLKSPIPLWGHRSNQSTFSRPKGHLSEKMTLDLKDENDAGNLITFPKESLAVGDFNLGSNVSLEKIKQDQKLIEENEKLKTEKDALLESYKALELKVEQIAQELQQEKAAAVDLTNHLEYTLKTYIDTRMKNLAAKMEILKEMRHVDISVRFGKDLSDAIQVLDEGCFTTPASLNGLEIIWAEYSLAQENIKTCEYVSEGNILIAQRNEMQQKLYMSVEDFILEVDESSLNKRLKTLQDLSVSLEAVYGQAKEGANSDEILKKFYDWKCDKREEFTSVRSETDASLHRLVAWFQRTLKVFDLSVEGSLISEDAMDNIDEILEKTESSVCKELEIALVDQGDADKEIISNTYSQVLQKIHSEERLIATVQAKYKDSIEFKKQLIEYLNKSPSVDHLLSIKKTLKSLKALLRWKLVEKSNLEESDDPDGSQIEKIKEEITQLRNNVFQEIYHEREEYEMLTSLAQKWFPELPLLHPEIGLLKYMNSGGLLTMSLERDLLDAEPMKELSSKRPLVRSEVNGQIILLKGYSVDVDTEAKVIERAATYHRAWREAEGDSGLLPLIFLFLCKSDPMAYLMVPYYPRANLNAVQANMPLNSEETLKVMKGVAQGLHTLHKADIIHGSLHQNNVFALNREQGIVGDFDFTKSVSQRASVNMMVGDLSLMSPELKMGKPASPGSDLYAYGCLLLWLSVQNQEFEINKDGIPKVDQFHLDDKVKSLLCSLICYRSSMTAEQVLNAECFLMPKEQSVPNPEKDTEYTLYKKEEEIKTENLDKCMEKTRNGEANFDC>sp|Q9BXU1-2|STK31_HUMAN Isoform 2 of Serine/threonine-protein kinase 31OS=Homo sapiens OX=9606 GN=STK31MDEDTHYDKVEDVVGSHIEDAVTFWAQSINRNKDIMKIGCSLSEVCPQASSVLGNLDPNKIYGGLFSEDQCWYRCKVLKIISVEKCLVRYIDYGNTEILNRSDIVEIPLELQFSSVAKKYKLWGLHIPSDQEVTQFDQGTTFLGSLIFEKEIKMRIKATSEDGTVIAQAEYGSVDIGEEVLKKGFAEKCRLASRTDICEEKKLDPGQLVLRNLKSPIPLWGHRSNQSTFSRPKGHLSEKMTLDLKDENDAGNLITFPKESLAVGDFNLGSNVSLEKIKQDQKLIEENEKLKTEKDALLESYKALELKVEQIAQELQQEKAAAVDLTNHLEYTLKTYIDTRMKNLAAKMEILKEMRHVDISVRFGKDLSDAIQVLDEGCFTTPASLNGLEIIWAEYSLAQENIKTCEYVSEGNILIAQRNEMQQKLYMSVEDFILEVDESSLNKRLKTLQDLSVSLEAVYGQAKEGANSDEILKKFYDWKCDKREEFTSVRSETDASLHRLVAWFQRTLKVFDLSVEGSLISEDAMDNIDEILEKTESSVCKELEIALVDQGDADKEIISNTYSQVLQKIHSEERLIATVQAKYKDSIEFKKQLIEYLNKSPSVDHLLSIKKTLKSLKALLRWKLVEKSNLEESDDPDGSQIEKIKEEITQLRNNVFQEIYHEREEYEMLTSLAQKWFPELPLLHPEIGLLKYMNSGGLLTMSLERDLLDAEPMKELSSKRPLVRSEVNGQIILLKGYSVDVDTEAKVIERAATYHRAWREAEGDSGLLPLIFLFLCKSDPMAYLMVPYYPRANLNAVQANMPLNSEETLKVMKGVAQGLHTLHKADIIHGSLHQNNVFALNREQGIVGDFDFTKSVSQRASVNMMVGDLSLMSPELKMGKPASPGSDLYAYGCLLLWLSVQNQEFEINKDGIPKVDQFHLDDKVKSLLCSLICYRSSMTAEQVLNAECFLMPKEQSVPNPEKDTEYTLYKKEEEIKTENLDKCMEKTRNGEANFDC>sp|Q9BXU1-3|STK31_HUMAN Isoform 3 of Serine/threonine-protein kinase 31OS=Homo sapiens OX=9606 GN=STK31MWVQGHSSRASATESVSFSGIVQMDEDTHYDKVEDVVGSHIEDAVTFWAQSINRNKDIMKIGCSLSEVCPQASSVLGNLDPNKIYGGLFSEDQCWYRCKVLKIISVEKCLVRYIDYGNTEILNRSDIVEIPLELQFSSVAKKYKLWGLHIPSDQEVTQFDQGTTFLGSLIFEKEIKMRIKATSEDGTVIAQAEYGSVDIGEEVLKKGFAEKCRLASRTDICEEKKLDPGQLVLRNLKSPIPLWGHRSNQSTFSRPKGHLSEKMTLDLKDENDAGNLITFPKESLAVGDFNLGSNVSLEKIKQDQKLIEENEKLKTEKDALLESYKALELKVEQIAQELQQEKAAAVDLTNHLEYTLKTYIDTRMKNLAAKMEILKEMRHVDISVRFGKDLSDAIQVLDEGCFTTPASLNGLEIIWAEYSLAQENIKTCEYVSEGNILIAQRNEMQQKLYMSVEDFILEVDESSLNKRLKTLQDLSVSLEAVYGQAKEGANSDEILKKFYDWKCDKREEFTSVRSETDASLHRLVAWFQRTLKVFDLSVEGSLISEDAMDNIDEILEKTESSVCKELEIALVDQGDADKEIISNTYSQVLQKIHSEERLIATVQAKYKDSIEFKKQLIEYLNKSPSVDHLLSIKKTLKSLKALLRWKLVEKSNLEESDDPDGSQIEKIKEEITQLRNNVFQEIYHEREEYEMLTSLAQKWFPELPLLHPEIGLLKYMNSGGLLTMSLERDLLDAEPMKELSSKRPLVRSEVNGQIILLKGYSVDVDTEAKVIERAATYHRAWREAEGDSGLLPLIFLFLCKSDPMAYLMVPYYPRANLNAVQANMPLNSEETLKVMKGVAQGLHTLHKADIIHGSLHQNNVFALNREQGIVGDFDFTKSVSQRASVNMMVGDLSLMSPELKMGKPASPGSDLYAYGCLLLWDDKVKSLLCSLICYRSSMTAEQVLNAECFLMPKEQSVPNPEKDTEYTLYKKEEEIKTENLDKCMEKTRNGEANFDC>sp|O75486|SUPT3_HUMAN Transcription initiation protein SPT3 homologOS=Homo sapiens OX=9606 GN=SUPT3H PE=1 SV=3MNNTAASPMSTATSSSGRSTGKSISFATELQSMMYSLGDARRPLHETAVLVEDVVHTQLINLLQQAAEVSQLRGARVITPEDLLFLMRKDKKKLRRLLKYMFIRDYKSKIVKGIDEDDLLEDKLSGSNNANKRQKIAQDFLNSIDQTGELLAMFEDDEIDEVKQERMERAERQTRIMDSAQYAEFCESRQLSFSKKASKFRDWLDCSSMEIKPNVVAMEILAYLAYETVAQLVDLALLVRQDMVTKAGDPFSHAISATFIQYHNSAESTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTNAYRRNGMAFLAC>sp|O75486-4|SUPT3_HUMAN Isoform 2 of Transcription initiation proteinSPT3 homolog OS=Homo sapiens OX=9606 GN=SUPT3HMVVFGTTFFNFDSFIGKTDSIEIIGKSVFPYCYHNILPLLNDSGRYSLGDARRPLHETAVLVEDVVHTQLINLLQQAAEVSQLRGARVITPEDLLFLMRKDKKKLRRLLKYMFIRDYKSKIVKGIDEDDLLEDKLSGSNNANKRQKIAQDFLNSIDQTGELLAMFEDDEIDEVKQERMERAERQTRIMDSAQYAEFCESRQLSFSKKASKFRDWLDCSSMEIKPNVVAMEILAYLAYETVAQLVDLALLVRQDMVTKAGDPFSHAISATFIQYHNSAESTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTNAYRRNGMAFLAC>sp|Q9ULQ0|STRP2_HUMAN Striatin-interacting protein 2 OS=Homo sapiensOX=9606 GN=STRIP2 PE=1 SV=2MEDPAAPGTGGPPANGNGNGGGKGKQAAPKGREAFRSQRRESEGSVDCPTLEFEYGDADGHAAELSELYSYTENLEFTNNRRCFEEDFKTQVQGKEWLELEEDAQKAYIMGLLDRLEVVSRERRLKVARAVLYLAQGTFGECDSEVDVLHWSRYNCFLLYQMGTFSTFLELLHMEIDNSQACSSALRKPAVSIADSTELRVLLSVMYLMVENIRLERETDPCGWRTARETFRTELSFSMHNEEPFALLLFSMVTKFCSGLAPHFPIKKVLLLLWKVVMFTLGGFEHLQTLKVQKRAELGLPPLAEDSIQVVKSMRAASPPSYTLDLGESQLAPPPSKLRGRRGSRRQLLTKQDSLDIYNERDLFKTEEPATEEEEESAGDGERTLDGELDLLEQDPLVPPPPSQAPLSAERVAFPKGLPWAPKVRQKDIEHFLEMSRNKFIGFTLGQDTDTLVGLPRPIHESVKTLKQHKYISIADVQIKNEEELEKCPMSLGEEVVPETPCEILYQGMLYSLPQYMIALLKILLAAAPTSKAKTDSINILADVLPEEMPITVLQSMKLGIDVNRHKEIIVKSISTLLLLLLKHFKLNHIYQFEYVSQHLVFANCIPLILKFFNQNILSYITAKNSISVLDYPCCTIQDLPELTTESLEAGDNSQFCWRNLFSCINLLRLLNKLTKWKHSRTMMLVVFKSAPILKRALKVKQAMLQLYVLKLLKLQTKYLGRQWRKSNMKTMSAIYQKVRHRMNDDWAYGNDIDARPWDFQAEECTLRANIEAFNSRRYDRPQDSEFSPVDNCLQSVLGQRLDLPEDFHYSYELWLEREVFSQPICWEELLQNH>sp|Q9ULQ0-2|STRP2_HUMAN Isoform 2 of Striatin-interacting protein 2OS=Homo sapiens OX=9606 GN=STRIP2MEDPAAPGTGGPPANGNGNGGGKGKQAAPKGREAFRSQRRESEGSVDCPTLEFEYGDADGHAAELSELYSYTENLEFTNNRRCFEEDFKTQVQGKEWLELEEDAQKAYIMGLLDRLEVVSRERRLKVARAVLYLAQGTFGECDSEVDVLHWSRYNCFLLYQMGTFSTFLELLHMEIDNSQACSSALRKPAVSIADSTELRVLLSVMYLMVENIRLERETDPCGWRTARETFRTELSFSMHNEEPFALLLFSMVTKFCSGLAPHFPIKKVLLLLWKVVMFTLGGFEHLQTLKVQKRAELGLPPLAEDSIQVVKSMRAASPPSYTLDLGESQLAPPPSKLRGRRGSRRQLLTKQDSLDIYNERDLFKTEEPATEEEEESAGDGERTLDGELDLLEQDPLVPPPPSQAPLSAERVAFPKGLPWAPKVRQKDIEHFLEMSRNKFIGFTLGQDTDTLVGLPRPIHESVKTLKQHKYISIADVQIKNEEELEKCPMSLGEEVVPETPCEILYQGMLYSLPQYMIALLKILLAAAPTSKAKTDSINILADVLPEEMPITVLQSMKLGIDVNRHKEIIVKSISTLLLLLLKHFKLNHIYQFEYVSQHLVFANCIPLILKFFNQNILSYITAKNSISVLDYPCCTIQDLPELTTESLEAGDNSQFCWRNLFSCINLLRLLNKLTKWKHSRTMMLVVFKSAPILKRALKVKQAMLQLYVLKLLKLQTKYLGRQWRKSNMKTMSAIYQKVRHRMNDDWAYGNGESSQSS>sp|Q9NSY2|STAR5_HUMAN StAR-related lipid transfer protein 5 OS=Homosapiens OX=9606 GN=STARD5 PE=1 SV=2MDPALAAQMSEAVAEKMLQYRRDTAGWKICREGNGVSVSWRPSVEFPGNLYRGEGIVYGTLEEVWDCVKPAVGGLRVKWDENVTGFEIIQSITDTLCVSRTSTPSAAMKLISPRDFVDLVLVKRYEDGTISSNATHVEHPLCPPKPGFVRGFNHPCGCFCEPLPGEPTKTNLVTFFHTDLSGYLPQNVVDSFFPRSMTRFYANLQKAVKQFHE>sp|Q9NSY2-3|STAR5_HUMAN Isoform 2 of StAR-related lipid transfer protein5 OS=Homo sapiens OX=9606 GN=STARD5MDPALAAQMSEAVAEKMLQYRRDTAGWKICREGVPRRRHCIWDTRGGVGLCEASCWRPTSEVG>sp|Q8TB22|SPT20_HUMAN Spermatogenesis-associated protein 20 OS=Homosapiens OX=9606 GN=SPATA20 PE=2 SV=3MLGARAWLGRVLLLPRAGAGLAASRRGSSSRDKDRSATVSSSVPMPAGGKGSHPSSTPQRVPNRLIHEKSPYLLQHAYNPVDWYPWGQEAFDKARKENKPIFLSVGYSTCHWCHMMEEESFQNEEIGRLLSEDFVSVKVDREERPDVDKVYMTFVQATSSGGGWPMNVWLTPNLQPFVGGTYFPPEDGLTRVGFRTVLLRIREQWKQNKNTLLENSQRVTTALLARSEISVGDRQLPPSAATVNNRCFQQLDEGYDEEYGGFAEAPKFPTPVILSFLFSYWLSHRLTQDGSRAQQMALHTLKMMANGGIRDHVGQGFHRYSTDRQWHVPHFEKMLYDQAQLAVAYSQAFQLSGDEFYSDVAKGILQYVARSLSHRSGGFYSAEDADSPPERGQRPKEGAYYVWTVKEVQQLLPEPVLGATEPLTSGQLLMKHYGLTEAGNISPSQDPKGELQGQNVLTVRYSLELTAARFGLDVEAVRTLLNSGLEKLFQARKHRPKPHLDSKMLAAWNGLMVSGYAVTGAVLGQDRLINYATNGAKFLKRHMFDVASGRLMRTCYTGPGGTVEHSNPPCWGFLEDYAFVVRGLLDLYEASQESAWLEWALRLQDTQDKLFWDSQGGGYFCSEAELGAGLPLRLKDDQDGAEPSANSVSAHNLLRLHGFTGHKDWMDKCVCLLTAFSERMRRVPVALPEMVRALSAQQQTLKQIVICGDRQAKDTKALVQCVHSVYIPNKVLILADGDPSSFLSRQLPFLSTLRRLEDQATAYVCENQACSVPITDPCELRKLLHP>sp|Q8TB22-2|SPT20_HUMAN Isoform 2 of Spermatogenesis-associated protein20 OS=Homo sapiens OX=9606 GN=SPATA20MLGARAWLGRVLLLPRAGAGLAASRRCPGVWPRTWPHRSPSRGSSSRDKDRSATVSSSVPMPAGGKGSHPSSTPQRVPNRLIHEKSPYLLQHAYNPVDWYPWGQEAFDKARKENKPIFLSVGYSTCHWCHMMEEESFQNEEIGRLLSEDFVSVKVDREERPDVDKVYMTFVQATSSGGGWPMNVWLTPNLQPFVGGTYFPPEDGLTRVGFRTVLLRIREQWKQNKNTLLENSQRVTTALLARSEISVGDRQLPPSAATVNNRCFQQLDEGYDEEYGGFAEAPKFPTPVILSFLFSYWLSHRLTQDGSRAQQMALHTLKMMANGGIRDHVGQGFHRYSTDRQWHVPHFEKMLYDQAQLAVAYSQAFQLSGDEFYSDVAKGILQYVARSLSHRSGGFYSAEDADSPPERGQRPKEGAYYVWTVKEVQQLLPEPVLGATEPLTSGQLLMKHYGLTEAGNISPSQDPKGELQGQNVLTVRYSLELTAARFGLDVEAVRTLLNSGLEKLFQARKHRPKPHLDSKMLAAWNGLMVSGYAVTGAVLGQDRLINYATNGAKFLKRHMFDVASGRLMRTCYTGPGGTVEHSNPPCWGFLEDYAFVVRGLLDLYEASQESAWLEWALRLQDTQDKLFWDSQGGGYFCSEAELGAGLPLRLKDDQDGAEPSANSVSAHNLLRLHGFTGHKDWMDKCVCLLTAFSERMRRVPVALPEMVRALSAQQQTLKQIVICGDRQAKDTKALVQCVHSVYIPNKVLILADGDPSSFLSRQLPFLSTLRRLEDQATAYVCENQACSVPITDPCELRKLLHP>sp|Q8TB22-3|SPT20_HUMAN Isoform 3 of Spermatogenesis-associated protein20 OS=Homo sapiens OX=9606 GN=SPATA20MPAGGKGSHPSSTPQRVPNRLIHEKSPYLLQHAYNPVDWYPWGQEAFDKARKENKPIFLSVGYSTCHWCHMMEEESFQNEEIGRLLSEDFVSVKVDREERPDVDKVYMTFVQATSSGGGWPMNVWLTPNLQPFVGGTYFPPEDGLTRVGFRTVLLRIREQWKQNKNTLLENSQRVTTALLARSEISVGDRQLPPSAATVNNRCFQQLDEGYDEEYGGFAEAPKFPTPVILSFLFSYWLSHRLTQDGSRAQQMALHTLKMMANGGIRDHVGQGFHRYSTDRQWHVPHFEKMLYDQAQLAVAYSQAFQLSGDEFYSDVAKGILQYVARSLSHRSGGFYSAEDADSPPERGQRPKEGAYYVWTVKEVQQLLPEPVLGATEPLTSGQLLMKHYGLTEAGNISPSQDPKGELQGQNVLTVRYSLELTAARFGLDVEAVRTLLNSGLEKLFQARKHRPKPHLDSKMLAAWNGLMVSGYAVTGAVLGQDRLINYATNGAKFLKRHMFDVASGRLMRTCYTGPGGTVEHSNPPCWGFLEDYAFVVRGLLDLYEASQESAWLEWALRLQDTQDKLFWDSQGGGYFCSEAELGAGLPLRLKDDQDGAEPSANSVSAHNLLRLHGFTGHKDWMDKCVCLLTAFSERMRRVPVALPEMVRALSAQQQTLKQIVICGDRQAKDTKALVQCVHSVYIPNKVLILADGDPSSFLSRQLPFLSTLRRLEDQATAYVCENQACSVPITDPCELRKLLHP>sp|Q8TB22-4|SPT20_HUMAN Isoform 4 of Spermatogenesis-associated protein20 OS=Homo sapiens OX=9606 GN=SPATA20MSHLSSPPKKHKGEHKGHSLPHGSERGSSSRDKDRSATVSSSVPMPAGGKGSHPSSTPQRVPNRLIHEKSPYLLQHAYNPVDWYPWGQEAFDKARKENKPIFLSVGYSTCHWCHMMEEESFQNEEIGRLLSEDFVSVKVDREERPDVDKVYMTFVQATSSGGGWPMNVWLTPNLQPFVGGTYFPPEDGLTRVGFRTVLLRIREQWKQNKNTLLENSQRVTTALLARSEISVGDRQLPPSAATVNNRCFQQLDEGYDEEYGGFAEAPKFPTPVILSFLFSYWLSHRLTQDGSRAQQMALHTLKMMANGGIRDHVGQGFHRYSTDRQWHVPHFEKMLYDQAQLAVAYSQAFQLSGDEFYSDVAKGILQYVARSLSHRSGGFYSAEDADSPPERGQRPKEGAYYVWTVKEVQQLLPEPVLGATEPLTSGQLLMKHYGLTEAGNISPSQDPKGELQGQNVLTVRYSLELTAARFGLDVEAVRTLLNSGLEKLFQARKHRPKPHLDSKMLAAWNGGAAHLRPSLSA>sp|Q96A44|SPSB4_HUMAN SPRY domain-containing SOCS box protein 4 OS=Homosapiens OX=9606 GN=SPSB4 PE=1 SV=1MGQKLSGSLKSVEVREPALRPAKRELRGAEPGRPARLDQLLDMPAAGLAVQLRHAWNPEDRSLNVFVKDDDRLTFHRHPVAQSTDGIRGKVGHARGLHAWQINWPARQRGTHAVVGVATARAPLHSVGYTALVGSDAESWGWDLGRSRLYHDGKNQPGVAYPAFLGPDEAFALPDSLLVVLDMDEGTLSFIVDGQYLGVAFRGLKGKKLYPVVSAVWGHCEVTMRYINGLDPEPLPLMDLCRRSIRSALGRQRLQDISSLPLPQSLKNYLQYQ>sp|Q9NQ55|SSF1_HUMAN Suppressor of SWI4 1 homolog OS=Homo sapiensOX=9606 GN=PPAN PE=2 SV=1MGQSGRSRHQKRARAQAQLRNLEAYAANPHSFVFTRGCTGRNIRQLSLDVRRVMEPLTASRLQVRKKNSLKDCVAVAGPLGVTHFLILSKTETNVYFKLMRLPGGPTLTFQVKKYSLVRDVVSSLRRHRMHEQQFAHPPLLVLNSFGPHGMHVKLMATMFQNLFPSINVHKVNLNTIKRCLLIDYNPDSQELDFRHYSIKVVPVGASRGMKKLLQEKFPNMSRLQDISELLATGAGLSESEAEPDGDHNITELPQAVAGRGNMRAQQSAVRLTEIGPRMTLQLIKVQEGVGEGKVMFHSFVSKTEEELQAILEAKEKKLRLKAQRQAQQAQNVQRKQEQREAHRKKSLEGMKKARVGGSDEEASGIPSRTASLELGEDDDEQEDDDIEYFCQAVGEAPSEDLFPEAKQKRLAKSPGRKRKRWEMDRGRGRLCDQKFPKTKDKSQGAQARRGPRGASRDGGRGRGRGRPGKRVA>sp|Q9NQ55-2|SSF1_HUMAN Isoform 2 of Suppressor of SWI4 1 homolog OS=Homosapiens OX=9606 GN=PPANMGQSGRSRHQKRARAQAQLRNLEAYAANPHSFVFTRGCTGRNIRQLSLDVRRVMEPLTASRLQVRKKNSLKDCVAVAGPLGVTHFLILSKTETNVYFKLMRLPGGPTLTFQVKKYSLVRDVVSSLRRHRMHEQQFAHPPLLVLNSFGPHGMHVKLMATMFQNLFPSINVHKVNLNTIKRCLLIDYNPDSQELDFRHYSIKVVPVGASRGMKKLLQEKFPNMSRLQDISELLATGAGLSESEAEPDGDHNITELPQAVAGRGNMRAQQSAVRLTEIGPRMTLQLIKVQEGVGEGKVMFHSFVSKTEEELQAILEAKEKKLRLKAQRQAQQAQNVQRKQEQREAHRKKSLEGMKKARVGGSDEEASGIPSRTASLELGEDDDEQEDDDIEYFCQAVGEAPSEDLFPEAKQKRLAKSPGRKRKRWEMDRGRGRLCDQKFPKTKDKSRDGGRGRGRGRPGKRVA>sp|Q9NQ55-3|SSF1_HUMAN Isoform 3 of Suppressor of SWI4 1 homolog OS=Homosapiens OX=9606 GN=PPANMGQSGRSRHQKRARAQAQLRNLEAYAANPHSFVFTRGCTGRNIRQLSLDVRRVMEPLTASRLQVRKKNSLKDCVAVAGPLGVTHFLILSKTETNVYFKLMRLPGGPTLTFQVKKYSLVRDVVSSLRRHRMHEQQFAHPPLLVLNSFGPHGMHVKLMATMFQNLFPSINVHKVNLNTIKRCLLIDYNPDSQELDFRHYSIKVVPVGASRGMKKLLQEKFPNMSRLQDISELLATGAGLSESEAEPDGDHNITELPQAVAGRGNMRAQQSAVRLTEIGPRMTLQLIKVQEGVGEGKVMFHSFVSKTEEELQAILEAKEKKLRLKAQRQAQQAQNVQRKQEQREAHRKKSLEGMKKARVGGSDEEASGIPSRTASLELGEDDDEQEDDDIEYFCQAVGEAPSEDLFPEAKQKRLAKSPGRKRKRWEMDRGRGRLCDQKFPKTKDKSQGAQVPSPALPTSWQLPTTNSVGSRGTSCGPYWWLSSWWPWPAMAWPCTASASGSSAHGTPPWSSLSSWQSATCSAP>sp|P42224|STAT1_HUMAN Signal transducer and activator of transcription1-alpha/beta OS=Homo sapiens OX=9606 GN=STAT1 PE=1 SV=2MSQWYELQQLDSKFLEQVHQLYDDSFPMEIRQYLAQWLEKQDWEHAANDVSFATIRFHDLLSQLDDQYSRFSLENNFLLQHNIRKSKRNLQDNFQEDPIQMSMIIYSCLKEERKILENAQRFNQAQSGNIQSTVMLDKQKELDSKVRNVKDKVMCIEHEIKSLEDLQDEYDFKCKTLQNREHETNGVAKSDQKQEQLLLKKMYLMLDNKRKEVVHKIIELLNVTELTQNALINDELVEWKRRQQSACIGGPPNACLDQLQNWFTIVAESLQQVRQQLKKLEELEQKYTYEHDPITKNKQVLWDRTFSLFQQLIQSSFVVERQPCMPTHPQRPLVLKTGVQFTVKLRLLVKLQELNYNLKVKVLFDKDVNERNTVKGFRKFNILGTHTKVMNMEESTNGSLAAEFRHLQLKEQKNAGTRTNEGPLIVTEELHSLSFETQLCQPGLVIDLETTSLPVVVISNVSQLPSGWASILWYNMLVAEPRNLSFFLTPPCARWAQLSEVLSWQFSSVTKRGLNVDQLNMLGEKLLGPNASPDGLIPWTRFCKENINDKNFPFWLWIESILELIKKHLLPLWNDGCIMGFISKERERALLKDQQPGTFLLRFSESSREGAITFTWVERSQNGGEPDFHAVEPYTKKELSAVTFPDIIRNYKVMAAENIPENPLKYLYPNIDKDHAFGKYYSRPKEAPEPMELDGPKGTGYIKTELISVSEVHPSRLQTTDNLLPMSPEEFDEVSRIVGSVEFDSMMNTV>sp|P42224-2|STAT1_HUMAN Isoform Beta of Signal transducer and activatorof transcription 1-alpha/beta OS=Homo sapiens OX=9606 GN=STAT1MSQWYELQQLDSKFLEQVHQLYDDSFPMEIRQYLAQWLEKQDWEHAANDVSFATIRFHDLLSQLDDQYSRFSLENNFLLQHNIRKSKRNLQDNFQEDPIQMSMIIYSCLKEERKILENAQRFNQAQSGNIQSTVMLDKQKELDSKVRNVKDKVMCIEHEIKSLEDLQDEYDFKCKTLQNREHETNGVAKSDQKQEQLLLKKMYLMLDNKRKEVVHKIIELLNVTELTQNALINDELVEWKRRQQSACIGGPPNACLDQLQNWFTIVAESLQQVRQQLKKLEELEQKYTYEHDPITKNKQVLWDRTFSLFQQLIQSSFVVERQPCMPTHPQRPLVLKTGVQFTVKLRLLVKLQELNYNLKVKVLFDKDVNERNTVKGFRKFNILGTHTKVMNMEESTNGSLAAEFRHLQLKEQKNAGTRTNEGPLIVTEELHSLSFETQLCQPGLVIDLETTSLPVVVISNVSQLPSGWASILWYNMLVAEPRNLSFFLTPPCARWAQLSEVLSWQFSSVTKRGLNVDQLNMLGEKLLGPNASPDGLIPWTRFCKENINDKNFPFWLWIESILELIKKHLLPLWNDGCIMGFISKERERALLKDQQPGTFLLRFSESSREGAITFTWVERSQNGGEPDFHAVEPYTKKELSAVTFPDIIRNYKVMAAENIPENPLKYLYPNIDKDHAFGKYYSRPKEAPEPMELDGPKGTGYIKTELISVSEV>sp|Q9BR10|SPT25_HUMAN Spermatogenesis-associated protein 25 OS=Homosapiens OX=9606 GN=SPATA25 PE=1 SV=1MSYFRTPQTHPGPLPSGQGGAASPGLSLGLCSPVEPVVVASGGTGPLSQKAEQVAPAAQAWGPALAMPQARGCPGGTSWETLRKEYSRNCHKFPHVRQLESLGWDNGYSRSRAPDLGGPSRPRPLMLCGLSPRVLPVPSEAVGKEASSQPDICILTLAMMIAGIPTVPVPGVREEDLIWAAQAFMMAHPEPEGAVEGARWEQAHAHTASGKMPLVRSKRGQPPGSCL>sp|Q08117|TLE5_HUMAN TLE family member 5 OS=Homo sapiens OX=9606 GN=TLE5PE=1 SV=4MMFPQSRHSGSSHLPQQLKFTTSDSCDRIKDEFQLLQAQYHSLKLECDKLASEKSEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLNGICAQVLPYLSQEHQQQVLGAIERAKQVTAPELNSIIRQQLQAHQLSQLQALALPLTPLPVGLQPPSLPAVSAGTGLLSLSALGSQAHLSKEDKNGHDGDTHQEDDGEKSD>sp|Q08117-2|TLE5_HUMAN Isoform 2 of TLE family member 5 OS=Homo sapiensOX=9606 GN=TLE5MCHKNGFPQEGGITAAFLQKRKLRLSKNHRPARAKVTEHVRGTRPGRATAGPAASTRAAGSLFFDRWGNRGPAGCRGSSHLPQQLKFTTSDSCDRIKDEFQLLQAQYHSLKLECDKLASEKSEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLNGICAQVLPYLSQEHQQQVLGAIERAKQVTAPELNSIIRQQLQAHQLSQLQALALPLTPLPVGLQPPSLPAVSAGTGLLSLSALGSQAHLSKEDKNGHDGDTHQEDDGEKSD>sp|O76061|STC2_HUMAN Stanniocalcin-2 OS=Homo sapiens OX=9606 GN=STC2PE=1 SV=1MCAERLGQFMTLALVLATFDPARGTDATNPPEGPQDRSSQQKGRLSLQNTAEIQHCLVNAGDVGCGVFECFENNSCEIRGLHGICMTFLHNAGKFDAQGKSFIKDALKCKAHALRHRFGCISRKCPAIREMVSQLQRECYLKHDLCAAAQENTRVIVEMIHFKDLLLHEPYVDLVNLLLTCGEEVKEAITHSVQVQCEQNWGSLCSILSFCTSAIQKPPTAPPERQPQVDRTKLSRAHHGEAGHHLPEPSSRETGRGAKGERGSKSHPNAHARGRVGGLGAQGPSGSSEWEDEQSEYSDIRR>sp|Q9NZQ3|SPN90_HUMAN NCK-interacting protein with SH3 domain OS=Homosapiens OX=9606 GN=NCKIPSD PE=1 SV=1MYRALYAFRSAEPNALAFAAGETFLVLERSSAHWWLAARARSGETGYVPPAYLRRLQGLEQDVLQAIDRAIEAVHNTAMRDGGKYSLEQRGVLQKLIHHRKETLSRRGPSASSVAVMTSSTSDHHLDAAAARQPNGVCRAGFERQHSLPSSEHLGADGGLYQIPLPSSQIPPQPRRAAPTTPPPPVKRRDREALMASGSGGHNTMPSGGNSVSSGSSVSSTSLDTLYTSSSPSEPGSSCSPTPPPVPRRGTHTTVSQVQPPPSKASAPEPPAEEEVATGTTSASDDLEALGTLSLGTTEEKAAAEAAVPRTIGAELMELVRRNTGLSHELCRVAIGIIVGHIQASVPASSPVMEQVLLSLVEGKDLSMALPSGQVCHDQQRLEVIFADLARRKDDAQQRSWALYEDEGVIRCYLEELLHILTDADPEVCKKMCKRNEFESVLALVAYYQMEHRASLRLLLLKCFGAMCSLDAAIISTLVSSVLPVELARDMQTDTQDHQKLCYSALILAMVFSMGEAVPYAHYEHLGTPFAQFLLNIVEDGLPLDTTEQLPDLCVNLLLALNLHLPAADQNVIMAALSKHANVKIFSEKLLLLLNRGDDPVRIFKHEPQPPHSVLKFLQDVFGSPATAAIFYHTDMMALIDITVRHIADLSPGDKLRMEYLSLMHAIVRTTPYLQHRHRLPDLQAILRRILNEEETSPQCQMDRMIVREMCKEFLVLGEAPS>sp|Q9NZQ3-2|SPN90_HUMAN Isoform 2 of NCK-interacting protein with SH3domain OS=Homo sapiens OX=9606 GN=NCKIPSDMYRALYAFRSAEPNALAFAAGETFLVLERSSAHWWLAARARSGETGYVPPAYLRRLQGLEQDVLQAIDRAIEAVHNTAMRDGGKYSLEQRGVLQKLIHHRKETLSRRGPSASSVAVMTSSTSDHHLDAAAARQPNGVCRAGFERQHSLPSSEHLGADGGLYQIPLPSSQIPPQPRRAAPTTPPPPVKRRDREALMASGSGGHNTMPSGGNSVSSGSSVSSTSLDTLYTSSSPSEPGSSCSPTPPPVPRRGTHTTVSQVQPPPSKASAPEPPAEEEVATGTTSASDDLEALGTLSLGTTEEKAAAEAAVPRTIGAELMELVRRNTGLSHELCRVAIGIIVGHIQASVPASSPVMEQVLLSLVEGKDLSMALPSGQVCHDQQRLEVIFADLARRKDDAQQRSWALYEDEGVIRCYLEELLHILTDADPEVCKKMCKRNEFESVLALVAYYQMEHRASLRLLLLKCFGAMCSLDAAIISTLVSSVLPVELARDMQTDTQDHQKLCYSALILAMVFSMGEAVPYAHYEHLGTPFAQFLLNIVEDGLPLDTTEQLPDLCVNLLLALNLHLPAADQNVIMAALSKHANVKIFSEKLLLLLNRGDDPVRIFKHEPQPPHSVLKFLQDVFGSPATAAIFYHTDMMALIDITVRHIADLSPGDKGPFGAGQRPWPGVPRLLEPGSTPSREPHPVERSGVPALTSSWASGCPRPLHPALQLVIDSAFGGRSV>sp|Q9NZQ3-3|SPN90_HUMAN Isoform 3 of NCK-interacting protein with SH3domain OS=Homo sapiens OX=9606 GN=NCKIPSDMYRALYAFRSAEPNALAFAAGETFLVLERSSAHWWLAARARSGETGYVPPAYLRRLQGLEQDVLQAIDRAIEAVHNTAMRDGGKYSLEQRGVLQKLIHHRKETLSRRGPSASSVAVMTSSTSDHHLDAAAARQPNGVCRAGFERQHSLPSSEHLGADGGLYQIPPQPRRAAPTTPPPPVKRRDREALMASGSGGHNTMPSGGNSVSSGSSVSSTSLDTLYTSSSPSEPGSSCSPTPPPVPRRGTHTTVSQVQPPPSKASAPEPPAEEEVATGTTSASDDLEALGTLSLGTTEEKAAAEAAVPRTIGAELMELVRRNTGLSHELCRVAIGIIVGHIQASVPASSPVMEQVLLSLVEGKDLSMALPSGQVCHDQQRLEVIFADLARRKDDAQQRSWALYEDEGVIRCYLEELLHILTDADPEVCKKMCKRNEFESVLALVAYYQMEHRASLRLLLLKCFGAMCSLDAAIISTLVSSVLPVELARDMQTDTQDHQKLCYSALILAMVFSMGEAVPYAHYEHLGTPFAQFLLNIVEDGLPLDTTEQLPDLCVNLLLALNLHLPAADQNVIMAALSKHANVKIFSEKLLLLLNRGDDPVRIFKHEPQPPHSVLKFLQDVFGSPATAAIFYHTDMMALIDITVRHIADLSPGDKLRMEYLSLMHAIVRTTPYLQHRHRLPDLQAILRRILNEEETSPQCQMDRMIVREMCKEFLVLGEAPS>sp|Q9NZQ3-4|SPN90_HUMAN Isoform 4 of NCK-interacting protein with SH3domain OS=Homo sapiens OX=9606 GN=NCKIPSDMYRALYAFRSAEPNALAFAAGETFLVLERSSAHWWLAARARSGETGYVPPAYLRRLQGLEQDVLQAIDRAIEAVHNTAMRDGGKYSLEQRGVLQKLIHHRKETLSRRGPSASSVAVMTSSTSDHHLDAAAARQPNGVCRAGFERQHSLPSSEHLGADGGLYQIPPQPRRAAPTTPPPPVKRRDREALMASGSGGHNTMPSGGNSVSSGSSVSSTSLDTLYTSSSPSEPGSSCSPTPPPVPRRGTHTTVSQVQPPPSKASAPEPPAEEEVATGTTSASDDLEALGTLSLGTTEEKAAAEAAVPRTIGAELMELVRRNTGLSHELCRVAIGIIVGHIQASVPASSPVMEQVLLSLVEGKDLSMALPSGQVCHDQQRLEVIFADLARRKDDAQQRSWALYEDEGVIRCYLEELLHILTDADPEVCKKMCKRNEFESVLALVAYYQMEHRASLRLLLLKCFGAMCSLDAAIISTLVSSVLPVELARDMQTDTQDHQKLCYSALILAMVFSMGEAVPYAHYEHLGTPFAQFLLNIVEDGLPLDTTEQLPDLCVNLLLALNLHLPAADQNVIMAALSKHANVKIFSEKLLLLLNRGDDPVRIFKHEPQPPHSVLKFLQDVFGSPATAAIFYHTDMMALIDITVRHIADLSPGDKGVH>sp|Q9NZQ3-5|SPN90_HUMAN Isoform 5 of NCK-interacting protein with SH3domain OS=Homo sapiens OX=9606 GN=NCKIPSDMYRALYAFRSAEPNALAFAAGETFLVLERSSAHWWLAARARSGETGYVPPAYLRRLQGLEQDVLQAIDRAIEAVHNTAMRDGGKYSLEQRGVLQKLIHHRKETLSRRGPSASSVAVMTSSTSDHHLDAAAARQPNGVCRAGFERQHSLPSSEHLGADGGLYQIPLPSSQIPPQPRRAAPTTPPPPVKRRDREALMASGSGGHNTMPSGGNSVSSGSSVSSTSLDTLYTSSSPSEPGSSCSPTPPPVPRRGTHTTVSQVQPPPSKASAPEPPAEEEVATGTTSASDDLEALGTLSLGTTEEKAAAEAAVPRTIGAELMELVRRNTGLSHELCRVAIGIIVGHIQASVPASSPVMEQVLLSLVEGKDLSMALPSGQVCHDQQRLEVIFADLARRKDDAQQRSWALYEDEGVIRCYLEELLHILTDADPEVCKKMCKRNEFESVLALVAYYQMEHRASLRLLLLKCFGAMCSLDAAIISTLVSSVLPVELARDMQTDTQDHQKLCYSALILAMVFSMGEAVPYAHYEHLGTPFAQFLLNIVEDGLPLDTTEQLPDLCVNLLLALNLHLPGGVGPGWAVAEHMVALRLSTLSIPMSFLSC>sp|Q9NS25|SPNXB_HUMAN Sperm protein associated with the nucleus on the Xchromosome B1 OS=Homo sapiens OX=9606 GN=SPANXB1 PE=1 SV=2MGQQSSVRRLKRSVPCESNEANEANEANKTMPETPTGDSDPQPAPKKMKTSESSTILVVRYRRNVKRTSPEELLNDHARENRINPDQMEEEEFIEITTERPKK>sp|D6RBM5|U17LN_HUMAN Putative ubiquitin carboxyl-terminal hydrolase 17-like protein 23 OS=Homo sapiens OX=9606 GN=USP17L23 PE=5 SV=1MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMEKACLPGHKQV>sp|A0PK00|T120B_HUMAN Transmembrane protein 120B OS=Homo sapiens OX=9606GN=TMEM120B PE=1 SV=1MSGQLERCEREWHELEGEFQELQETHRIYKQKLEELAALQTLCSSSISKQKKHLKDLKLTLQRCKRHASREEAELVQQMAANIKERQDVFFDMEAYLPKKNGLYLNLVLGNVNVTLLSNQAKFAYKDEYEKFKLYLTIILLLGAVACRFVLHYRVTDEVFNFLLVWYYCTLTIRESILISNGSRIKGWWVSHHYVSTFLSGVMLTWPNGPIYQKFRNQFLAFSIFQSCVQFLQYYYQRGCLYRLRALGERNHLDLTVEGFQSWMWRGLTFLLPFLFCGHFWQLYNAVTLFELSSHEECREWQVFVLAFTFLILFLGNFLTTLKVVHAKLQKNRGKTKQP>sp|Q16563|SYPL1_HUMAN Synaptophysin-like protein 1 OS=Homo sapiensOX=9606 GN=SYPL1 PE=1 SV=1MAPNIYLVRQRISRLGQRMSGFQINLNPLKEPLGFIKVLEWIASIFAFATCGGFKGQTEIQVNCPPAVTENKTVTATFGYPFRLNEASFQPPPGVNICDVNWKDYVLIGDYSSSAQFYVTFAVFVFLYCIAALLLYVGYTSLYLDSRKLPMIDFVVTLVATFLWLVSTSAWAKALTDIKIATGHNIIDELPPCKKKAVLCYFGSVTSMGSLNVSVIFGFLNMILWGGNAWFVYKETSLHSPSNTSAPHSQGGIPPPTGI>sp|Q16563-2|SYPL1_HUMAN Isoform 2 of Synaptophysin-like protein 1OS=Homo sapiens OX=9606 GN=SYPL1MSGFQINLNPLKEPLGFIKVLEWIASIFAFATCGGFKGQTEIQVNCPPAVTENKTVTATFGYPFRLNEASFQPPPGVNICDVNWKDYVLIGDYSSSAQFYVTFAVFVFLYCIAALLLYVGYTSLYLDSRKLPMIDFVVTLVATFLWLVSTSAWAKALTDIKIATGHNIIDELPPCKKKAVLCYFGSVTSMGSLNVSVIFGFLNMILWGGNAWFVYKETSLHSPSNTSAPHSQGGIPPPTGI>sp|Q92750|TAF4B_HUMAN Transcription initiation factor TFIID subunit 4BOS=Homo sapiens OX=9606 GN=TAF4B PE=1 SV=2MPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSPVGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGTVLIKSNSGPLMLVSPQQTVTRAETTSNITSRPAVPANPQTVKICTVPNSSSQLIKKVAVTPVKKLAQIGTTVVTTVPKPSSVQSVAVPTSVVTVTPGKPLNTVTTLKPSSLGASSTPSNEPNLKAENSAAVQINLSPTMLENVKKCKNFLAMLIKLACSGSQSPEMGQNVKKLVEQLLDAKIEAEEFTRKLYVELKSSPQPHLVPFLKKSVVALRQLLPNSQSFIQQCVQQTSSDMVIATCTTTVTTSPVVTTTVSSSQSEKSIIVSGATAPRTVSVQTLNPLAGPVGAKAGVVTLHSVGPTAATGGTTAGTGLLQTSKPLVTSVANTVTTVSLQPEKPVVSGTAVTLSLPAVTFGETSGAAICLPSVKPVVSSAGTTSDKPVIGTPVQIKLAQPGPVLSQPAGIPQAVQVKQLVVQQPSGGNEKQVTTISHSSTLTIQKCGQKTMPVNTIIPTSQFPPASILKQITLPGNKILSLQASPTQKNRIKENVTSCFRDEDDINDVTSMAGVNLNEENACILATNSELVGTLIQSCKDEPFLFIGALQKRILDIGKKHDITELNSDAVNLISQATQERLRGLLEKLTAIAQHRMTTYKASENYILCSDTRSQLKFLEKLDQLEKQRKDLEEREMLLKAAKSRSNKEDPEQLRLKQKAKELQQLELAQIQHRDANLTALAAIGPRKKRPLESGIEGLKDNLLASGTSSLTATKQLHRPRITRICLRDLIFCMEQEREMKYSRALYLALLK>sp|Q92750-2|TAF4B_HUMAN Isoform 2 of Transcription initiation factorTFIID subunit 4B OS=Homo sapiens OX=9606 GN=TAF4BMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSPVGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGTVLIKSNSGPLMLVSPQQTVTRAETTSNITSRPAVPANPQTVKICTVPNSSSQLIKKVAVTPVKKLAQIGTTVVTTVPKPSSVQSVAVPTSVVTVTPGKPLNTVTTLKPSSLGASSTPSNEPNLKAENSAAVQINLSPTMLENVKKCKNFLAMLIKLACSGSQSPEMGQNVKKLVEQLLDAKIEAEEFTRKLYVELKSSPQPHLVPFLKKSVVALRQLLPNSQSFIQQCVQQTSSDMVIATCTTTVTTSPVVTTTVSSSQSEKSIIVSGATAPRTVSVQTLNPLAGPVGAKAGVVTLHSVGPTAATGGTTAGTGLLQTSKPLVTSVANTVTTVSLQPEKPVVSGTAVTLSLPAVTFGETSGAAICLPSVKPVVSSAGTTSDKPVIGTPVQIKLAQPGPVLSQPAGIPQAVQVKQLVVQQPSGGNEKQVTTISHSSTLTIQKCGQKTMPVNTIIPTSQFPPASILKQITLPGNKILSLQASPTQKNRIKENVTSCFRSTFICVY>sp|Q03518|TAP1_HUMAN Antigen peptide transporter 1 OS=Homo sapiensOX=9606 GN=TAP1 PE=1 SV=2MAELLASAGSACSWDFPRAPPSFPPPAASRGGLGGTRSFRPHRGAESPRPGRDRDGVRVPMASSRCPAPRGCRCLPGASLAWLGTVLLLLADWVLLRTALPRIFSLLVPTALPLLRVWAVGLSRWAVLWLGACGVLRATVGSKSENAGAQGWLAALKPLAAALGLALPGLALFRELISWGAPGSADSTRLLHWGSHPTAFVVSYAAALPAAALWHKLGSLWVPGGQGGSGNPVRRLLGCLGSETRRLSLFLVLVVLSSLGEMAIPFFTGRLTDWILQDGSADTFTRNLTLMSILTIASAVLEFVGDGIYNNTMGHVHSHLQGEVFGAVLRQETEFFQQNQTGNIMSRVTEDTSTLSDSLSENLSLFLWYLVRGLCLLGIMLWGSVSLTMVTLITLPLLFLLPKKVGKWYQLLEVQVRESLAKSSQVAIEALSAMPTVRSFANEEGEAQKFREKLQEIKTLNQKEAVAYAVNSWTTSISGMLLKVGILYIGGQLVTSGAVSSGNLVTFVLYQMQFTQAVEVLLSIYPRVQKAVGSSEKIFEYLDRTPRCPPSGLLTPLHLEGLVQFQDVSFAYPNRPDVLVLQGLTFTLRPGEVTALVGPNGSGKSTVAALLQNLYQPTGGQLLLDGKPLPQYEHRYLHRQVAAVGQEPQVFGRSLQENIAYGLTQKPTMEEITAAAVKSGAHSFISGLPQGYDTEVDEAGSQLSGGQRQAVALARALIRKPCVLILDDATSALDANSQLQVEQLLYESPERYSRSVLLITQHLSLVEQADHILFLEGGAIREGGTHQQLMEKKGCYWAMVQAPADAPE>sp|P59539|T2R45_HUMAN Taste receptor type 2 member 45 OS=Homo sapiensOX=9606 GN=TAS2R45 PE=2 SV=1MITFLPIIFSILVVVTFVIGNFANGFIALVNSTEWVKRQKISFADQIVTALAVSRVGLLWVLLLNWYSTVLNPAFCSVELRTTAYNIWAVTGHFSNWPATSLSIFYLLKIANFSNLIFLRLKRRVKSVILVVLLGPLLFLACHLFVVNMNQIVWTKEYEGNMTWKIKLRRAMYLSDTTVTMLANLVPFTVTLISFLLLVCSLCKHLKKMQLHGKGSQDPSTKVHIKVLQTVISFFLLRAIYFVSVIISVWSFKNLENKPVFMFCQAIGFSCSSAHPFILIWGNKKLKQTYLSVLWQMRY>sp|Q7RTR8|T2R42_HUMAN Taste receptor type 2 member 42 OS=Homo sapiensOX=9606 GN=TAS2R42 PE=2 SV=1MATELDKIFLILAIAEFIISMLGNVFIGLVNCSEGIKNQKVFSADFILTCLAISTIGQLLVILFDSFLVGLASHLYTTYRLGKTVIMLWHMTNHLTTWLATCLSIFYFFKIAHFPHSLFLWLRWRMNGMIVMLLILSLFLLIFDSLVLEIFIDISLNIIDKSNLTLYLDESKTLYDKLSILKTLLSLTSFIPFSLFLTSLLFLFLSLVRHTRNLKLSSLGSRDSSTEAHRRAMKMVMSFLFLFIVHFFSLQVANGIFFMLWNNKYIKFVMLALNAFPSCHSFILILGNSKLRQTAVRLLWHLRNYTKTPNALPL>sp|O00268|TAF4_HUMAN Transcription initiation factor TFIID subunit 4OS=Homo sapiens OX=9606 GN=TAF4 PE=1 SV=2MAAGSDLLDEVFFNSEVDEKVVSDLVGSLESQLAASAAHHHHLAPRTPEVRAAAAGALGNHVVSGSPAGAAGAGPAAPAEGAPGAAPEPPPAGRARPGGGGPQRPGPPSPRRPLVPAGPAPPAAKLRPPPEGSAGSCAPVPAAAAVAAGPEPAPAGPAKPAGPAALAARAGPGPGPGPGPGPGPGPGKPAGPGAAQTLNGSAALLNSHHAAAPAVSLVNNGPAALLPLPKPAAPGTVIQTPPFVGAAAPPAPAAPSPPAAPAPAAPAAAPPPPPPAPATLARPPGHPAGPPTAAPAVPPPAAAQNGGSAGAAPAPAPAAGGPAGVSGQPGPGAAAAAPAPGVKAESPKRVVQAAPPAAQTLAASGPASTAASMVIGPTMQGALPSPAAVPPPAPGTPTGLPKGAAGAVTQSLSRTPTATTSGIRATLTPTVLAPRLPQPPQNPTNIQNFQLPPGMVLVRSENGQLLMIPQQALAQMQAQAHAQPQTTMAPRPATPTSAPPVQISTVQAPGTPIIARQVTPTTIIKQVSQAQTTVQPSATLQRSPGVQPQLVLGGAAQTASLGTATAVQTGTPQRTVPGATTTSSAATETMENVKKCKNFLSTLIKLASSGKQSTETAANVKELVQNLLDGKIEAEDFTSRLYRELNSSPQPYLVPFLKRSLPALRQLTPDSAAFIQQSQQQPPPPTSQATTALTAVVLSSSVQRTAGKTAATVTSALQPPVLSLTQPTQVGVGKQGQPTPLVIQQPPKPGALIRPPQVTLTQTPMVALRQPHNRIMLTTPQQIQLNPLQPVPVVKPAVLPGTKALSAVSAQAAAAQKNKLKEPGGGSFRDDDDINDVASMAGVNLSEESARILATNSELVGTLTRSCKDETFLLQAPLQRRILEIGKKHGITELHPDVVSYVSHATQQRLQNLVEKISETAQQKNFSYKDDDRYEQASDVRAQLKFFEQLDQIEKQRKDEQEREILMRAAKSRSRQEDPEQLRLKQKAKEMQQQELAQMRQRDANLTALAAIGPRKKRKVDCPGPGSGAEGSGPGSVVPGSSGVGTPRQFTRQRITRVNLRDLIFCLENERETSHSLLLYKAFLK>sp|Q9HCH5|SYTL2_HUMAN Synaptotagmin-like protein 2 OS=Homo sapiensOX=9606 GN=SYTL2 PE=1 SV=3MIDLSFLTEEEQEAIMKVLQRDAALKRAEEERVRHLPEKIKDDQQLKNMSGQWFYEAKAKRHRDKIHGADIIRASMRKKRPQIAAEQSKDRENGAKESWVNNVNKDAFLPPELAGVVEEPEEDAAPASPSSSVVNPASSVIDMSQENTRKPNVSPEKRKNPFNSSKLPEGHSSQQTKNEQSKNGRTGLFQTSKEDELSESKEKSTVADTSIQKLEKSKQTLPGLSNGSQIKAPIPKARKMIYKSTDLNKDDNQSFPRQRTDSLKARGAPRGILKRNSSSSSTDSETLRYNHNFEPKSKIVSPGLTIHERISEKEHSLEDNSSPNSLEPLKHVRFSAVKDELPQSPGLIHGREVGEFSVLESDRLKNGMEDAGDTEEFQSDPKPSQYRKPSLFHQSTSSPYVSKSETHQPMTSGSFPINGLHSHSEVLTARPQSMENSPTINEPKDKSSELTRLESVLPRSPADELSHCVEPEPSQVPGGSSRDRQQGSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDVSTVPTQPDNPFSHPDKLKRMSKSVPAFLQDESDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-2|SYTL2_HUMAN Isoform 2 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MSKSVPAFLQDESDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-4|SYTL2_HUMAN Isoform 3 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MSKSVPAFLQDEVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-6|SYTL2_HUMAN Isoform 4 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MIDLSFLTEEEQEAIMKVLQRDAALKRAEEERVRHLPEKIKDDQQLKNMSGQWFYEAKAKRHRDKIHGADIIRASMRKKRPQIAAEQSKDRENGAKESWVNNVNKDAFLPPELAGVVEEPEEDAAPASPSSSVVNPASSVIDMSQENTRKPNVSPEKRKNPFNSSKLPEGHSSQQTKNEQSKNGRTGLFQTSKEDELSESKEKSTVADTSIQKLEKSKQTLPGLSNGSQIKAPIPKARKMIYKSTDLNKDDNQSFPRQRTDSLKARGAPRGILKRNSSSSSTDSETLRYNHNFEPKSKIVSPGLTIHERISEKEHSLEDNSSPNSLEPLKHVRFSAVKDELPQSPGLIHGREVGEFSVLESDRLKNGMEDAGDTEEFQSDPKPSQYRKPSLFHQSTSSPYVSKSETHQPMTSGSFPINGLHSHSEVLTARPQSMENSPTINEPKDKSSELTRLESVLPRSPADELSHCVEPEPSQVPGGSSRDRQQGSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDDEKPDQKPVTNECVPRISTVPTQPDNPFSHPDKLKRMSKSVPAFLQDEVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-7|SYTL2_HUMAN Isoform 5 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MDEPNAEQVYNPSQFENLRKFWDLEANSNSKDNDKNITTTSQKNSAPFNRQKHKEFSDIKLSGKNTHEAEVLLSPKKVMAREEMEKLNSKGILQVLPDEITFPLSPLRKYTYQLPGNESSKENVEKNTEGIVTPVFKEEKDYSEQEIQESIIKTNVLSKDCKDTFNDSLQKLLSETSTPAIQPSGGKVHGKQVLEPSVSENRTWPQKTDFADTEEEVKGPEKIINEHVDKTVVHPKVKRNSLTASLDKLLKEATGTSPSPLQAKLAPVITGTNSKLEEGRFFGKGIEQSHNTSADKREILAPFPVRDETFGNTALLKKAESGECQLSTQNLIQMAAEDSHPLDPTSQLSRKGSFGDVASPPQDMLFPQDAHLVPQARVHPSQTEISETVEKVILPPRPVLNDVSAALQKLCGEVWLSYPAGREVGPGEVNPEFPEAVQPVCSPLNPPGVISPWATMDTIVPDRKDFYSSNVVPDKTHEVGSYLAAQMSPSDQTLSSFASIVAQYGKGLPQEVEEIVRETIVQPKSEFLEFSAGLEKLLKEETETFPSKYESDTGNLSPSKLIGSTEEPRRATSECHPEELKETVEKAEAPLITESAFDAGFEKLLKEITEAPPYQPQVSVREETHEKESSQSEQTRFLGTVPHFYRAASQTSEMKDKSNGLESQVNQCDKMLGGDALVTDLLVDFCGSRSGVEIPRTPQLYVAHEIGTIKTVTPPEDRDSESGVAGGQGTLQEPGFGEASEAISVSRNRQPIPLLMNKENSTKTSKVELTLASPYMKQEKEEEKEGFSESDFSDGNTSSNAESWRNPSSSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDVSTVPTQPDNPFSHPDKLKRMSKSVPAFLQDESDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-8|SYTL2_HUMAN Isoform 6 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MDEPNAEQVYNPSQFENLRKFWDLEANSNSKDNDKNITTTSQKNSAPFNRQKHKEFSDIKLSGKNTHEAEVLLSPKKVMAREEMEKLNSKGILQVLPDEITFPLSPLRKYTYQLPGNESSKENVEKNTEGIVTPVFKEEKDYSEQEIQESIIKTNVLSKDCKDTFNDSLQKLLSETSTPAIQPSGGKVHGKQVLEPSVSENRTWPQKTDFADTEEEVKGPEKIINEHVDKTVVHPKVKRNSLTASLDKLLKEATGTSPSPLQAKLAPVITGTNSKLEEGRFFGKGIEQSHNTSADKREILAPFPVRDETFGNTALLKKAESGECQLSTQNLIQMAAEDSHPLDPTSQLSRKGSFGDVASPPQDMLFPQDAHLVPQARVHPSQTEISETVEKVILPPRPVLNDVSAALQKLCGEVWLSYPAGREVGPGEVNPEFPEAVQPVCSPLNPPGVISPWATMDTIVPDRKDFYSSNVVPDKTHEVGSYLAAQMSPSDQTLSSFASIVAQYGKGLPQEVEEIVRETIVQPKSEFLEFSAGLEKLLKEETETFPSKYESDTGNLSPSKLIGSTEEPRRATSECHPEELKETVEKAEAPLITESAFDAGFEKLLKEITEAPPYQPQVSVREETHEKESSQSEQTRFLGTVPHFYRAASQTSEMKDKSNGLESQVNQCDKMLGGDALVTDLLVDFCGSRSGVEIPRTPQLYVAHEIGTIKTVTPPEDRDSESGVAGGQGTLQEPGFGEASEAISVSRNRQPIPLLMNKENSTKTSKVELTLASPYMKQEKEEEKEGFSESDFSDGNTSSNAESWRNPSSSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDDEKPDQKPVTNECVPRISTVPTQPDNPFSHPDKLKRMSKSVPAFLQDESDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-9|SYTL2_HUMAN Isoform 7 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MSDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-11|SYTL2_HUMAN Isoform 8 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MDEPNAEQVYNPSQFENLRKFWDLEANSNSKDNDKNITTTSQKNSAPFNRQKHKEFSDIKLSGKNTHEAEVLLSPKKVMAREEMEKLNSKGILQVLPDEITFPLSPLRKYTYQLPGNESSKENVEKNTEGIVTPVFKEEKDYSEQEIQESIIKTNVLSKDCKDTFNDSLQKLLSETSTPAIQPSGGKVHGKQVLEPSVSENRTWPQKTDFADTEEEVKGPEKIINEHVDKTVVHPKVKRNSLTASLDKLLKEATGTSPSPLQAKLAPVITGTNSKLEEGRFFGKGIEQSHNTSADKREILAPFPVRDETFGNTALLKKAESGECQLSTQNLIQMAAEDSHPLDPTSQLSRKGSFGDVASPPQDMLFPQDAHLVPQARVHPSQTEISETVEKVILPPRPVLNDVSAALQKLCGEVWLSYPAGREVGPGEVNPEFPEAVQPVCSPLNPPGVISPWATMDTIVPDRKDFYSSNVVPDKTHEVGSYLAAQMSPSDQTLSSFASIVAQYGKGLPQEVEEIVRETIVQPKSEFLEFSAGLEKLLKEETETFPSKYESDTGNLSPSKLIGSTEEPRRATSECHPEELKETVEKAEAPLITESAFDAGFEKLLKEITEAPPYQPQVSVREETHEKESSQSEQTRFLGTVPHFYRAASQTSEMKDKSNGLESQVNQCDKMLGGDALVTDLLVDFCGSRSGVEIPRTPQLYVAHEIGTIKTVTPPEDRDSESGVAGGQGTLQEPGFGEASEAISVSRNRQPIPLLMNKENSTKTSKVELTLASPYMKQEKEEEKEGFSESDFSDGNTSSNAESWRNPSSSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDDEKPDQKPVTNECVPRISTVPTQPDNPFSHPDKLKRMSKSVPAFLQDEVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-12|SYTL2_HUMAN Isoform 9 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MLFPQDAHLVPQARVHPSQTEISETVEKVILPPRPVLNDVSAALQKLCGEVWLSYPAGREVGPGEVNPEFPEAVQPVCSPLNPPGVISPWATMDTIVPDRKDFYSSNVVPDKTHEVGSYLAAQMSPSDQTLSSFASIVAQYGKGLPQEVEEIVRETIVQPKSEFLEFSAGLEKLLKEETETFPSKYESDTGNLSPSKLIGSTEEPRRATSECHPEELKETVEKAEAPLITESAFDAGFEKLLKEITEAPPYQPQVSVREETHEKESSQSEQTRFLGTVPHFYRAASQTSEMKDKSNGLESQVNQCDKMLGGDALVTDLLVDFCGSRSGVEIPRTPQLYVAHEIGTIKTVTPPEDRDSESGVAGGQGTLQEPGFGEASEAISVSRNRQPIPLLMNKENSTKTSKVELTLASPYMKQEKEEEKEGFSESDFSDGNTSSNAESWRNPSSSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDVSTVPTQPDNPFSHPDKLKRMSKSVPAFLQDESDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-13|SYTL2_HUMAN Isoform 10 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MIDLSFLTEEEQEAIMKVLQRDAALKRAEEERVRHLPEKIKDDQQLKNMSGQWFYEAKAKRHRDKIHGADIIRASMRKKRPQIAAEQSKDRENGAKESWVNNVNKDAFLPPELAGVVEEPEEDAAPASPSSSVVNPASSVIDMSQENTRKPNVSPEKQRKNPFNSSKLPEGHSSQQTKNEQSKNGRTGLFQTSKEDELSESKEKSTVADTSIQKLEKSKQTLPGLSNGSQIKAPIPKARKMIYKSTDLNKDDNQSFPRQRTDSLKARGAPRGILKRNSSSSSTDSETLRYNHNFEPKSKIVSPGLTIHERISEKEHSLEDNSSPNSLEPLKHVRFSAVKDELPQSPGLIHGREVGEFSVLESDRLKNGMEDAGDTEEFQSDPKPSQYRKPSLFHQSTSSPYVSKSETHQPMTSGSFPINGLHSHSEVLTARPQSMENSPTINEPKDKSSELTRLESVLPRSPADELSHCVEPEPSQVPGGSSRDRQQGSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDVSTVPTQPDNPFSHPDKLKRMSKSVPAFLQDESDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-14|SYTL2_HUMAN Isoform 11 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MSGQWFYEAKAKRHRDKIHGADIIRASMRKKRPQIAAEQSKDRENGAKESWVNNVNKDAFLPPELAGVVEEPEEDAAPASPSSSVVNPASSVIDMSQENTRKPNVSPEKRKNPFNSSKLPEGHSSQQTKNEQSKNGRTGLFQTSKEDELSESKEKSTVADTSIQKLEKSKQTLPGLSNGSQIKAPIPKARKMIYKSTDLNKDDNQSFPRQRTDSLKARGAPRGILKRNSSSSSTDSETLRYNHNFEPKSKIVSPGLTIHERISEKEHSLEDNSSPNSLEPLKHVRFSAVKDELPQSPGLIHGREVGEFSVLESDRLKNGMEDAGDTEEFQSDPKPSQYRKPSLFHQSTSSPYVSKSETHQPMTSGSFPINGLHSHSEVLTARPQSMENSPTINEPKDKSSELTRLESVLPRSPADELSHCVEPEPSQVPGGSSRDRQQGSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDDEKPDQKPVTNECVPRISTVPTQPDNPFSHPDKLKRMSKSVPAFLQDESDDRETDTASESSYQLSRHKKSPSSLTNLSSSSGMTSLSSVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q9HCH5-15|SYTL2_HUMAN Isoform 12 of Synaptotagmin-like protein 2OS=Homo sapiens OX=9606 GN=SYTL2MSQENTRKPNVSPEKRKNPFNSSKLPEGHSSQQTKNEQSKNGRTGLFQTSKEDELSESKEKSTVADTSIQKLEKSKQTLPGLSNGSQIKAPIPKARKMIYKSTDLNKDDNQSFPRQRTDSLKARGAPRGILKRNSSSSSTDSETLRYNHNFEPKSKIVSPGLTIHERISEKEHSLEDNSSPNSLEPLKHVRFSAVKDELPQSPGLIHGREVGEFSVLESDRLKNGMEDAGDTEEFQSDPKPSQYRKPSLFHQSTSSPYVSKSETHQPMTSGSFPINGLHSHSEVLTARPQSMENSPTINEPKDKSSELTRLESVLPRSPADELSHCVEPEPSQVPGGSSRDRQQGSEEEPSPVLKTLERSAARKMPSKSLEDISSDSSNQAKVDNQPEELVRSAEDVSTVPTQPDNPFSHPDKLKRMSKSVPAFLQDEVSGSVMSVYSGDFGNLEVKGNIQFAIEYVESLKELHVFVAQCKDLAAADVKKQRSDPYVKAYLLPDKGKMGKKKTLVVKKTLNPVYNEILRYKIEKQILKTQKLNLSIWHRDTFKRNSFLGEVELDLETWDWDNKQNKQLRWYPLKRKTAPVALEAENRGEMKLALQYVPEPVPGKKLPTTGEVHIWVKECLDLPLLRGSHLNSFVKCTILPDTSRKSRQKTRAVGKTTNPIFNHTMVYDGFRPEDLMEACVELTVWDHYKLTNQFLGGLRIGFGTGKSYGTEVDWMDSTSEEVALWEKMVNSPNTWIEATLPLRMLLIAKISK>sp|Q4VX76|SYTL3_HUMAN Synaptotagmin-like protein 3 OS=Homo sapiensOX=9606 GN=SYTL3 PE=1 SV=3MAQEIDLSALKELEREAILQVLYRDQAVQNTEEERTRKLKTHLQHLRWKGAKNTDWEHKEKCCARCQQVLGFLLHRGAVCRGCSHRVCAQCRVFLRGTHAWKCTVCFEDRNVKIKTGEWFYEERAKKFPTGGKHETVGGQLLQSYQKLSKISVVPPTPPPVSESQCSRSPGRLQEFGQFRGFNKSVENLFLSLATHVKKLSKSQNDMTSEKHLLATGPRQCVGQTERRSQSDTAVNVTTRKVSAPDILKPLNQEDPKCSTNPILKQQNLPSSPAPSTIFSGGFRHGSLISIDSTCTEMGNFDNANVTGEIEFAIHYCFKTHSLEICIKACKNLAYGEEKKKKCNPYVKTYLLPDRSSQGKRKTGVQRNTVDPTFQETLKYQVAPAQLVTRQLQVSVWHLGTLARRVFLGEVIIPLATWDFEDSTTQSFRWHPLRAKAEKYEDSVPQSNGELTVRAKLVLPSRPRKLQEAQEGTDQPSLHGQLCLVVLGAKNLPVRPDGTLNSFVKGCLTLPDQQKLRLKSPVLRKQACPQWKHSFVFSGVTPAQLRQSSLELTVWDQALFGMNDRLLGGTRLGSKGDTAVGGDACSLSKLQWQKVLSSPNLWTDMTLVLH>sp|Q4VX76-2|SYTL3_HUMAN Isoform 2 of Synaptotagmin-like protein 3OS=Homo sapiens OX=9606 GN=SYTL3MAQEIDLSALKELEREAILQVLYRDQAVQNTEEERTRKLKTHLQHLRWKGAKNTDWEHKEKCCARCQQVLGFLLHRGAVCRGCSHRVCAQCRVFLRGTHAWKCTVCFEDRNVKIKTGEWFYEERAKKFPTGGKHETVGGQLLQSYQKLSKISVVPPTPPPVSESQCSRSPGRKVSAPDILKPLNQEDPKCSTNPILKQQNLPSSPAPSTIFSGGFRHGSLISIDSTCTEMGNFDNANVTGEIEFAIHYCFKTHSLEICIKACKNLAYGEEKKKKCNPYVKTYLLPDRSSQGKRKTGVQRNTVDPTFQETLKYQVAPAQLVTRQLQVSVWHLGTLARRVFLGEVIIPLATWDFEDSTTQSFRWHPLRAKAEKYEDSVPQSNGELTVRAKLVLPSRPRKLQEAQEGTDQPSLHGQLCLVVLGAKNLPVRPDGTLNSFVKGCLTLPDQQKLRLKSPVLRKQACPQWKHSFVFSGVTPAQLRQSSLELTVWDQALFGMNDRLLGGTRLGSKGDTAVGGDACSLSKLQWQKVLSSPNLWTDMTLVLH>sp|Q8IYJ3|SYTL1_HUMAN Synaptotagmin-like protein 1 OS=Homo sapiensOX=9606 GN=SYTL1 PE=1 SV=1MPQRGHPSQEGLWALPSLPMAHGPKPETEGLLDLSFLTEEEQEAIAGVLQRDARLRQLEEGRVSKLRASVADPGQLKILTGDWFQEARSQRHHNAHFGSDLVRASMRRKKSTRGDQAPGHDREAEAAVKEKEEGPEPRLTIDEAPQERLRETEGPDFPSPSVPLKASDPEEASQAQEDPGQGDQQVCAEEADPELEPASGGEQEPRPQQAQTKAASQILENGEEAPGPDPSLDRMLSSSSSVSSLNSSTLSGSQMSLSGDAEAVQVRGSVHFALHYEPGAAELRVHVIQCQGLAAARRRRSDPYVKSYLLPDKQSKRKTAVKKRNLNPVFNETLRYSVPQAELQGRVLSLSVWHRESLGRNIFLGEVEVPLDTWDWGSEPTWLPLQPRVPPSPDDLPSRGLLALSLKYVPAGSEGAGLPPSGELHFWVKEARDLLPLRAGSLDTYVQCFVLPDDSQASRQRTRVVRRSLSPVFNHTMVYDGFGPADLRQACAELSLWDHGALANRQLGGTRLSLGTGSSYGLQVPWMDSTPEEKQLWQALLEQPCEWVDGLLPLRTNLAPRT>sp|Q8IYJ3-2|SYTL1_HUMAN Isoform 2 of Synaptotagmin-like protein 1OS=Homo sapiens OX=9606 GN=SYTL1MPQRGHPSQEGLWALPSLPMAHGPKPETEGLLDLSFLTEEEQEAIAGVLQRDARLRQLEEGRVSKLRASVADPGQLKILTGDWFQEARSQRHHNAHFGSDLVRASMRRKKSTRGDQAPGHDREAEAAVKEKEEGPEPRLTIDEAPQERLRETEASDPEEASQAQEDPGQGDQQVCAEEADPELEPASGGEQEPRPQQAQTKAASQILENGEEAPGPDPSLDRMLSSSSSVSSLNSSTLSGSQMSLSGDAEAVQVRGSVHFALHYEPGAAELRVHVIQCQGLAAARRRRSDPYVKSYLLPDKQSKRKTAVKKRNLNPVFNETLRYSVPQAELQGRVLSLSVWHRESLGRNIFLGEVEVPLDTWDWGSEPTWLPLQPRVPPSPDDLPSRGLLALSLKYVPAGSEGAGLPPSGELHFWVKEARDLLPLRAGSLDTYVQCFVLPDDSQASRQRTRVVRRSLSPVFNHTMVYDGFGPADLRQACAELSLWDHGALANRQLGGTRLSLGTGSSYGLQVPWMDSTPEEKQLWQALLEQPCEWVDGLLPLRTNLAPRT>sp|P59535|T2R40_HUMAN Taste receptor type 2 member 40 OS=Homo sapiensOX=9606 GN=TAS2R40 PE=2 SV=1MATVNTDATDKDISKFKVTFTLVVSGIECITGILGSGFITAIYGAEWARGKTLPTGDRIMLMLSFSRLLLQIWMMLENIFSLLFRIVYNQNSVYILFKVITVFLNHSNLWFAAWLKVFYCLRIANFNHPLFFLMKRKIIVLMPWLLRLSVLVSLSFSFPLSRDVFNVYVNSSIPIPSSNSTEKKYFSETNMVNLVFFYNMGIFVPLIMFILAATLLILSLKRHTLHMGSNATGSRDPSMKAHIGAIKATSYFLILYIFNAIALFLSTSNIFDTYSSWNILCKIIMAAYPAGHSVQLILGNPGLRRAWKRFQHQVPLYLKGQTL>sp|P0DTE0|T2R36_HUMAN Putative taste receptor type 2 member 36 OS=Homosapiens OX=9606 GN=TAS2R36 PE=5 SV=1MICFLLIILSILVVFAFVLGNFSNGFIALVNVIDWVKRQKISSADQILTALVVSRVGLLWVILLHWYSNVLNSALYSSEVIIFISNAWAIINHFSIWLATSLSIFYLLKIVNFSRLIFHHLKRKAKSVVLVIVLGPLVFLVCHLVMKHTYINVWTKEYEGNVTWKIKLRNAIHLSNLTVSTLANLIPFTLTLISFLLLIYSLCKHLKKMQLHGKGSQDPSTKVHIKALQTVTSFLLLCAIYFLSMIISVCNFGRLEKQPVFMFCQAIIFSYPSTHPFILILGNKKLKQIFLSVFWQMRYWVKGEKPSSP>sp|P59541|T2R30_HUMAN Taste receptor type 2 member 30 OS=Homo sapiensOX=9606 GN=TAS2R30 PE=2 SV=3MITFLPIIFSILIVVIFVIGNFANGFIALVNSIEWVKRQKISFVDQILTALAVSRVGLLWVLLLHWYATQLNPAFYSVEVRITAYNVWAVTNHFSSWLATSLSMFYLLRIANFSNLIFLRIKRRVKSVVLVILLGPLLFLVCHLFVINMDETVWTKEYEGNVTWKIKLRSAMYHSNMTLTMLANFVPLTLTLISFLLLICSLCKHLKKMQLHGKGSQDPSTKVHIKALQTVTSFLLLCAIYFLSMIISVCNFGRLEKQPVFMFCQAIIFSYPSTHPFILILGNKKLKQIFLSVLRHVRYWVKDRSLRLHRFTRGALCVF>sp|Q16514|TAF12_HUMAN Transcription initiation factor TFIID subunit 12OS=Homo sapiens OX=9606 GN=TAF12 PE=1 SV=1MNQFGPSALINLSNFSSIKPEPASTPPQGSMANSTAVVKIPGTPGAGGRLSPENNQVLTKKKLQDLVREVDPNEQLDEDVEEMLLQIADDFIESVVTAACQLARHRKSSTLEVKDVQLHLERQWNMWIPGFGSEEIRPYKKACTTEAHKQRMALIRKTTKK>sp|Q16514-2|TAF12_HUMAN Isoform TAFII15 of Transcription initiationfactor TFIID subunit 12 OS=Homo sapiens OX=9606 GN=TAF12MANSTAVVKIPGTPGAGGRLSPENNQVLTKKKLQDLVREVDPNEQLDEDVEEMLLQIADDFIESVVTAACQLARHRKSSTLEVKDVQLHLERQWNMWIPGFGSEEIRPYKKACTTEAHKQRMALIRKTTKK>sp|P22735|TGM1_HUMAN Protein-glutamine gamma-glutamyltransferase KOS=Homo sapiens OX=9606 GN=TGM1 PE=1 SV=4MMDGPRSDVGRWGGNPLQPPTTPSPEPEPEPDGRSRRGGGRSFWARCCGCCSCRNAADDDWGPEPSDSRGRGSSSGTRRPGSRGSDSRRPVSRGSGVNAAGDGTIREGMLVVNGVDLLSSRSDQNRREHHTDEYEYDELIVRRGQPFHMLLLLSRTYESSDRITLELLIGNNPEVGKGTHVIIPVGKGGSGGWKAQVVKASGQNLNLRVHTSPNAIIGKFQFTVRTQSDAGEFQLPFDPRNEIYILFNPWCPEDIVYVDHEDWRQEYVLNESGRIYYGTEAQIGERTWNYGQFDHGVLDACLYILDRRGMPYGGRGDPVNVSRVISAMVNSLDDNGVLIGNWSGDYSRGTNPSAWVGSVEILLSYLRTGYSVPYGQCWVFAGVTTTVLRCLGLATRTVTNFNSAHDTDTSLTMDIYFDENMKPLEHLNHDSVWNFHVWNDCWMKRPDLPSGFDGWQVVDATPQETSSGIFCCGPCSVESIKNGLVYMKYDTPFIFAEVNSDKVYWQRQDDGSFKIVYVEEKAIGTLIVTKAISSNMREDITYLYKHPEGSDAERKAVETAAAHGSKPNVYANRGSAEDVAMQVEAQDAVMGQDLMVSVMLINHSSSRRTVKLHLYLSVTFYTGVSGTIFKETKKEVELAPGASDRVTMPVAYKEYRPHLVDQGAMLLNVSGHVKESGQVLAKQHTFRLRTPDLSLTLLGAAVVGQECEVQIVFKNPLPVTLTNVVFRLEGSGLQRPKILNVGDIGGNETVTLRQSFVPVRPGPRQLIASLDSPQLSQVHGVIQVDVAPAPGDGGFFSDAGGDSHLGETIPMASRGGA>sp|P22735-2|TGM1_HUMAN Isoform 2 of Protein-glutamine gamma-glutamyltransferase K OS=Homo sapiens OX=9606 GN=TGM1MKRPDLPSGFDGWQVVDATPQETSSGIFCCGPCSVESIKNGLVYMKYDTPFIFAEVNSDKVYWQRQDDGSFKIVYVEEKAIGTLIVTKAISSNMREDITYLYKHPEGSDAERKAVETAAAHGSKPNVYANRGSAEDVAMQVEAQDAVMGQDLMVSVMLINHSSSRRTVKLHLYLSVTFYTGVSGTIFKETKKEVELAPGASDRVTMPVAYKEYRPHLVDQGAMLLNVSGHVKESGQVLAKQHTFRLRTPDLSLTLLGAAVVGQECEVQIVFKNPLPVTLTNVVFRLEGSGLQRPKILNVGDIGGNETVTLRQSFVPVRPGPRQLIASLDSPQLSQVHGVIQVDVAPAPGDGGFFSDAGGDSHLGETIPMASRGGA>sp|Q13769|THOC5_HUMAN THO complex subunit 5 homolog OS=Homo sapiensOX=9606 GN=THOC5 PE=1 SV=2MSSESSKKRKPKVIRSDGAPAEGKRNRSDTEQEGKYYSEEAEVDLRDPGRDYELYKYTCQELQRLMAEIQDLKSRGGKDVAIEIEERRIQSCVHFMTLKKLNRLAHIRLKKGRDQTHEAKQKVDAYHLQLQNLLYEVMHLQKEITKCLEFKSKHEEIDLVSLEEFYKEAPPDISKAEVTMGDPHQQTLARLDWELEQRKRLAEKYRECLSNKEKILKEIEVKKEYLSSLQPRLNSIMQASLPVQEYLFMPFDQAHKQYETARHLPPPLYVLFVQATAYGQACDKTLSVAIEGSVDEAKALFKPPEDSQDDESDSDAEEEQTTKRRRPTLGVQLDDKRKEMLKRHPLSVMLDLKCKDDSVLHLTFYYLMNLNIMTVKAKVTTAMELITPISAGDLLSPDSVLSCLYPGDHGKKTPNPANQYQFDKVGILTLSDYVLELGHPYLWVQKLGGLHFPKEQPQQTVIADHSLSASHMETTMKLLKTRVQSRLALHKQFASLEHGIVPVTSDCQYLFPAKVVSRLVKWVTVAHEDYMELHFTKDIVDAGLAGDTNLYYMALIERGTAKLQAAVVLNPGYSSIPPVFQLCLNWKGEKTNSNDDNIRAMEGEVNVCYKELCGPWPSHQLLTNQLQRLCVLLDVYLETESHDDSVEGPKEFPQEKMCLRLFRGPSRMKPFKYNHPQGFFSHR>sp|Q9H1J7|WNT5B_HUMAN Protein Wnt-5b OS=Homo sapiens OX=9606 GN=WNT5BPE=2 SV=2MPSLLLLFTAALLSSWAQLLTDANSWWSLALNPVQRPEMFIIGAQPVCSQLPGLSPGQRKLCQLYQEHMAYIGEGAKTGIKECQHQFRQRRWNCSTADNASVFGRVMQIGSRETAFTHAVSAAGVVNAISRACREGELSTCGCSRTARPKDLPRDWLWGGCGDNVEYGYRFAKEFVDAREREKNFAKGSEEQGRVLMNLQNNEAGRRAVYKMADVACKCHGVSGSCSLKTCWLQLAEFRKVGDRLKEKYDSAAAMRVTRKGRLELVNSRFTQPTPEDLVYVDPSPDYCLRNESTGSLGTQGRLCNKTSEGMDGCELMCCGRGYNQFKSVQVERCHCKFHWCCFVRCKKCTEIVDQYICK>sp|Q9P202|WHRN_HUMAN Whirlin OS=Homo sapiens OX=9606 GN=WHRN PE=1 SV=4MNAPLDGLSVSSSSTGSLGSAAGAGGGGGAGLRLLSANVRQLHQALTALLSEAEREQFTHCLNAYHARRNVFDLVRTLRVLLDSPVKRRLLPMLRLVIPRSDQLLFDQYTAEGLYLPATTPYRQPAWGGPDSAGPGEVRLVSLRRAKAHEGLGFSIRGGSEHGVGIYVSLVEPGSLAEKEGLRVGDQILRVNDKSLARVTHAEAVKALKGSKKLVLSVYSAGRIPGGYVTNHIYTWVDPQGRSISPPSGLPQPHGGALRQQEGDRRSTLHLLQGGDEKKVNLVLGDGRSLGLTIRGGAEYGLGIYITGVDPGSEAEGSGLKVGDQILEVNGRSFLNILHDEAVRLLKSSRHLILTVKDVGRLPHARTTVDETKWIASSRIRETMANSAGFLGDLTTEGINKPGFYKGPAGSQVTLSSLGNQTRVLLEEQARHLLNEQEHATMAYYLDEYRGGSVSVEALVMALFKLLNTHAKFSLLSEVRGTISPQDLERFDHLVLRREIESMKARQPPGPGAGDTYSMVSYSDTGSSTGSHGTSTTVSSARNTLDLEETGEAVQGNINALPDVSVDDVRSTSQGLSSFKPLPRPPPLAQGNDLPLGQPRKLGREDLQPPSSMPSCSGTVFSAPQNRSPPAGTAPTPGTSSAQDLPSSPIYASVSPANPSSKRPLDAHLALVNQHPIGPFPRVQSPPHLKSPSAEATVAGGCLLPPSPSGHPDQTGTNQHFVMVEVHRPDSEPDVNEVRALPQTRTASTLSQLSDSGQTLSEDSGVDAGEAEASAPGRGRQSVSTKSRSSKELPRNERPTDGANKPPGLLEPTSTLVRVKKSAATLGIAIEGGANTRQPLPRIVTIQRGGSAHNCGQLKVGHVILEVNGLTLRGKEHREAARIIAEAFKTKDRDYIDFLVTEFNVML>sp|Q9P202-2|WHRN_HUMAN Isoform 2 of Whirlin OS=Homo sapiens OX=9606GN=WHRNMNAPLDGLSVSSSSTGSLGSAAGAGGGGGAGLRLLSANVRQLHQALTALLSEAEREQFTHCLNAYHARRNVFDLVRTLRVLLDSPVKRRLLPMLRLVIPRSDQLLFDQYTAEGLYLPATTPYRQPAWGGPDSAGPGEVRLVSLRRAKAHEGLGFSIRGGSEHGVGIYVSLVEPGSLAEKEGLRVGDQILRVNDKSLARVTHAEAVKALKGSKKLVLSVYSAGRIPGGYVTNHIYTWVDPQGRSISPPSGLPQPHGGALRQQEGDRRSTLHLLQGGDEKKVSGVGKGGQPLRHRILPPNPEQQSCLEAARRGWFCPGSVFPQVCTEGWCFFFAFLFDLCSVCYNTG>sp|Q9P202-3|WHRN_HUMAN Isoform 3 of Whirlin OS=Homo sapiens OX=9606GN=WHRNMANSAGFLGDLTTEGINKPGFYKGPAGSQVTLSSLGNQTRVLLEEQARHLLNEQEHATMAYYLDEYRGGSVSVEALVMALFKLLNTHAKFSLLSEVRGTISPQDLERFDHLVLRREIESMKARQPPGPGAGDTYSMVSYSDTGSSTGSHGTSTTVSSARNTLDLEETGEAVQGNINALPDVSVDDVRSTSQGLSSFKPLPRPPPLAQGNDLPLGQPRKLGREDLQPPSSMPSCSGTVFSAPQNRSPPAGTAPTPGTSSAQDLPSSPIYASVSPANPSSKRPLDAHLALVNQHPIGPFPRVQSPPHLKSPSAEATVAGGCLLPPSPSGHPDQTGTNQHFVMVEVHRPDSEPDVNEVRALPQTRTASTLSQLSDSGQTLSEDSGVDAGEAEASAPGRGRQSVSTKSRSSKELPRNERPTDGANKPPGLLEPTSTLVRVKKSAATLGIAIEGGANTRQPLPRIVTIQRGGSAHNCGQLKVGHVILEVNGLTLRGKEHREAARIIAEAFKTKDRDYIDFLVTEFNVML>sp|Q9P202-4|WHRN_HUMAN Isoform 4 of Whirlin OS=Homo sapiens OX=9606GN=WHRNMHGSLEALLFLPQVTLSLAHAHLICSNAQLEMCVFPHRFLGDLTTEGINKPGFYKGPAGSQVTLSSLGNQTRVLLEEQARHLLNEQEHATMAYYLDEYRGGSVSVEALVMALFKLLNTHAKFSLLSEVRGTISPQDLERFDHLVLRREIESMKARQPPGPGAGDTYSMVSYSDTGSSTGSHGTSTTVSSARNTLDLEETGEAVQGNINALPDVSVDDVRSTSQGLSSFKPLPRPPPLAQGNDLPLGQPRKLGREDLQPPSSMPSCSGTVFSAPQNRSPPAGTAPTPGTSSAQDLPSSPIYASVSPANPSSKRPLDAHLALVNQHPIGPFPRVQSPPHLKSPSAEATVAGGCLLPPSPSGHPDQTGTNQHFVMVEVHRPDSEPDVNEVRALPQTRTASTLSQLSDSGQTLSEDSGVDAGEAEASAPGRGRQSVSTKSRSSKELPRNERPTDGANKPPGLLEPTSTLVRVKKSAATLGIAIEGGANTRQPLPRIVTIQRGGSAHNCGQLKVGHVILEVNGLTLRGKEHREAARIIAEAFKTKDRDYIDFLVTEFNVML>sp|Q9Y5W5|WIF1_HUMAN Wnt inhibitory factor 1 OS=Homo sapiens OX=9606GN=WIF1 PE=1 SV=3MARRSAFPAAALWLWSILLCLLALRAEAGPPQEESLYLWIDAHQARVLIGFEEDILIVSEGKMAPFTHDFRKAQQRMPAIPVNIHSMNFTWQAAGQAEYFYEFLSLRSLDKGIMADPTVNVPLLGTVPHKASVVQVGFPCLGKQDGVAAFEVDVIVMNSEGNTILQTPQNAIFFKTCQQAECPGGCRNGGFCNERRICECPDGFHGPHCEKALCTPRCMNGGLCVTPGFCICPPGFYGVNCDKANCSTTCFNGGTCFYPGKCICPPGLEGEQCEISKCPQPCRNGGKCIGKSKCKCSKGYQGDLCSKPVCEPGCGAHGTCHEPNKCQCQEGWHGRHCNKRYEASLIHALRPAGAQLRQHTPSLKKAEERRDPPESNYIW>sp|O00755|WNT7A_HUMAN Protein Wnt-7a OS=Homo sapiens OX=9606 GN=WNT7APE=1 SV=2MNRKARRCLGHLFLSLGMVYLRIGGFSSVVALGASIICNKIPGLAPRQRAICQSRPDAIIVIGEGSQMGLDECQFQFRNGRWNCSALGERTVFGKELKVGSREAAFTYAIIAAGVAHAITAACTQGNLSDCGCDKEKQGQYHRDEGWKWGGCSADIRYGIGFAKVFVDAREIKQNARTLMNLHNNEAGRKILEENMKLECKCHGVSGSCTTKTCWTTLPQFRELGYVLKDKYNEAVHVEPVRASRNKRPTFLKIKKPLSYRKPMDTDLVYIEKSPNYCEEDPVTGSVGTQGRACNKTAPQASGCDLMCCGRGYNTHQYARVWQCNCKFHWCCYVKCNTCSERTEMYTCK>sp|P78423|X3CL1_HUMAN Fractalkine OS=Homo sapiens OX=9606 GN=CX3CL1 PE=1SV=1MAPISLSWLLRLATFCHLTVLLAGQHHGVTKCNITCSKMTSKIPVALLIHYQQNQASCGKRAIILETRQHRLFCADPKEQWVKDAMQHLDRQAAALTRNGGTFEKQIGEVKPRTTPAAGGMDESVVLEPEATGESSSLEPTPSSQEAQRALGTSPELPTGVTGSSGTRLPPTPKAQDGGPVGTELFRVPPVSTAATWQSSAPHQPGPSLWAEAKTSEAPSTQDPSTQASTASSPAPEENAPSEGQRVWGQGQSPRPENSLEREEMGPVPAHTDAFQDWGPGSMAHVSVVPVSSEGTPSREPVASGSWTPKAEEPIHATMDPQRLGVLITPVPDAQAATRRQAVGLLAFLGLLFCLGVAMFTYQSLQGCPRKMAGEMAEGLRYIPRSCGSNSYVLVPV>sp|P56706|WNT7B_HUMAN Protein Wnt-7b OS=Homo sapiens OX=9606 GN=WNT7BPE=1 SV=2MHRNFRKWIFYVFLCFGVLYVKLGALSSVVALGANIICNKIPGLAPRQRAICQSRPDAIIVIGEGAQMGINECQYQFRFGRWNCSALGEKTVFGQELRVGSREAAFTYAITAAGVAHAVTAACSQGNLSNCGCDREKQGYYNQAEGWKWGGCSADVRYGIDFSRRFVDAREIKKNARRLMNLHNNEAGRKVLEDRMQLECKCHGVSGSCTTKTCWTTLPKFREVGHLLKEKYNAAVQVEVVRASRLRQPTFLRIKQLRSYQKPMETDLVYIEKSPNYCEEDAATGSVGTQGRLCNRTSPGADGCDTMCCGRGYNTHQYTKVWQCNCKFHWCCFVKCNTCSERTEVFTCK>sp|O43516|WIPF1_HUMAN WAS/WASL-interacting protein family member 1OS=Homo sapiens OX=9606 GN=WIPF1 PE=1 SV=3MPVPPPPAPPPPPTFALANTEKPTLNKTEQAGRNALLSDISKGKKLKKTVTNDRSAPILDKPKGAGAGGGGGGFGGGGGFGGGGGGGGGGSFGGGGPPGLGGLFQAGMPKLRSTANRDNDSGGSRPPLLPPGGRSTSAKPFSPPSGPGRFPVPSPGHRSGPPEPQRNRMPPPRPDVGSKPDSIPPPVPSTPRPIQSSPHNRGSPPVPGGPRQPSPGPTPPPFPGNRGTALGGGSIRQSPLSSSSPFSNRPPLPPTPSRALDDKPPPPPPPVGNRPSIHREAVPPPPPQNNKPPVPSTPRPSASSQAPPPPPPPSRPGPPPLPPSSSGNDETPRLPQRNLSLSSSTPPLPSPGRSGPLPPPPSERPPPPVRDPPGRSGPLPPPPPVSRNGSTSRALPATPQLPSRSGVDSPRSGPRPPLPPDRPSAGAPPPPPPSTSIRNGFQDSPCEDEWESRFYFHPISDLPPPEPYVQTTKSYPSKLARNESRSGSNRRERGAPPLPPIPR>sp|O43516-2|WIPF1_HUMAN Isoform 2 of WAS/WASL-interacting protein familymember 1 OS=Homo sapiens OX=9606 GN=WIPF1MPVPPPPAPPPPPTFALANTEKPTLNKTEQAGRNALLSDISKGKKLKKTVTNDRSAPILDKPKGAGAGGGGGGFGGGGGFGGGGGGGGGGSFGGGGPPGLGGLFQAGMPKLRSTANRDNDSGGSRPPLLPPGGRSTSAKPFSPPSGPGRFPVPSPGHRSGPPEPQRNRMPPPRPDVGSKPDSIPPPVPSTPRPIQSSPHNRGSPPVPGGPRQPSPGPTPPPFPGNRGTALGGGSIRQSPLSSSSPFSNRPPLPPTPSRALDDKPPPPPPPVGNRPSIHREAVPPPPPQNNKPPVPSTPRPSASSQAPPPPPPPSRPGPPPLPPSSSGNDETPRLPQRNLSLSSSTPPLPSPGRSGPLPPPPSERPPPPVRDPPGRSGPLPPPPPVSRNGSTSRALPATPQLPSRSGVDSPRSGPRPPLPPDRPSAGAPPPPPPSTSIRNGFQDSPCEDEWESRFYFHPISDLPPPEPYVQTTKSYPSKLARNESRSEYFCQGF>sp|O43516-3|WIPF1_HUMAN Isoform 3 of WAS/WASL-interacting protein familymember 1 OS=Homo sapiens OX=9606 GN=WIPF1MPVPPPPAPPPPPTFALANTEKPTLNKTEQAGRNALLSDISKGKKLKKTVTNDRSAPILDKPKGAGAGGGGGGFGGGGGFGGGGGGGGGGSFGGGGPPGLGGLFQAGMPKLRSTANRDNDSGGSRPPLLPPGGRSTSAKPFSPPSGPGRFPVPSPGHRSGPPEPQRNRMPPPRPDVGSKPDSIPPPVPSTPRPIQSSPHNRGSPPVPGGPRQPSPGPTPPPFPGNRGTALGGGSIRQSPLSSSSPFSNRPPLPPTPSRALDDKPPPPPPPVGNRPSIHREAVPPPPPQNNKPPVPSTPRPSASSQAPPPPPPPSRPGPPPLPPSSSGNDETPRLPQRNLSLSSSTPPLPSPGRSGPLPPPPSERPPPPVRDPPGRSGPLPPPPPVSRNGSTSRALPATPQLPSRSGVDSPRSGPRPPLPPDRPSAGAPPPPPPSTSIRNGFQDSPCEDEWESRFYFHPISDLPPPEPYVQTTKSYPSKLARNESRSGSNRRERGAPPLPPIPRPPKQAAE>sp|O43516-4|WIPF1_HUMAN Isoform 4 of WAS/WASL-interacting protein familymember 1 OS=Homo sapiens OX=9606 GN=WIPF1MPVPPPPAPPPPPTFALANTEKPTLNKTEQAGRNALLSDISKGKKLKKTVTNDRSAPILDKPKGAGAGGGGGGFGGGGGFGGGGGGGGGGSFGGGGPPGLGGLFQAGMPKLRSTANRDNDSGGSRPPLLPPGGRSTSAKPFSPPSGPGRFPVPSPGHRSGPPEPQRNRMPPPRPDVGSKPDSIPPPVPSTPRPIQSSPHNRGSPPVPGGPRQPSPGPTPPPPPVRDPPGRSGPLPPPPPVSRNGSTSRALPATPQLPSRSGVDSPRSGPRPPLPPDRPSAGAPPPPPPSTSIRNGFQDSPCEDEWESRFYFHPISDLPPPEPYVQTTKSYPSKLARNESRSGSNRRERGAPPLPPIPR>sp|Q8TF74|WIPF2_HUMAN WAS/WASL-interacting protein family member 2OS=Homo sapiens OX=9606 GN=WIPF2 PE=1 SV=1MPIPPPPPPPPGPPPPPTFHQANTEQPKLSRDEQRGRGALLQDICKGTKLKKVTNINDRSAPILEKPKGSSGGYGSGGAALQPKGGLFQGGVLKLRPVGAKDGSENLAGKPALQIPSSRAAAPRPPVSAASGRPQDDTDSSRASLPELPRMQRPSLPDLSRPNTTSSTGMKHSSSAPPPPPPGRRANAPPTPLPMHSSKAPAYNREKPLPPTPGQRLHPGREGPPAPPPVKPPPSPVNIRTGPSGQSLAPPPPPYRQPPGVPNGPSSPTNESAPELPQRHNSLHRKTPGPVRGLAPPPPTSASPSLLSNRPPPPARDPPSRGAAPPPPPPVIRNGARDAPPPPPPYRMHGSEPPSRGKPPPPPSRTPAGPPPPPPPPLRNGHRDSITTVRSFLDDFESKYSFHPVEDFPAPEEYKHFQRIYPSKTNRAARGAPPLPPILR>sp|Q8TF74-2|WIPF2_HUMAN Isoform 2 of WAS/WASL-interacting protein familymember 2 OS=Homo sapiens OX=9606 GN=WIPF2MQRPSLPDLSRPNTTSSTGMKHSSSAPPPPPPGRRANAPPTPLPMHSSKAPAYNREKPLPPTPGQRLHPGREGPPAPPPVKPPPSPVNIRTGPSGQSLAPPPPPYRQPPGVPNGPSSPTNESAPELPQRHNSLHRKTPGPVRGLAPPPPTSASPSLLSNRPPPPARDPPSRGAAPPPPPPVIRNGARDAPPPPPPYRMHGSEPPSRGKPPPPPSRTPAGPPPPPPPPLRNGHRDSITTVRSFLDDFESKYSFHPVEDFPAPEEYKHFQRIYPSKTNRAARGAPPLPPILR>sp|Q9H1J5|WNT8A_HUMAN Protein Wnt-8a OS=Homo sapiens OX=9606 GN=WNT8APE=1 SV=2MGNLFMLWAALGICCAAFSASAWSVNNFLITGPKAYLTYTTSVALGAQSGIEECKFQFAWERWNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERISKLFVDSLEKGKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAEGHWVPAEAFLPSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTVKCDQCRHVVSKYYCARSPGSAQSLGKGSA>sp|Q9H1J5-2|WNT8A_HUMAN Isoform 2 of Protein Wnt-8a OS=Homo sapiensOX=9606 GN=WNT8AMGNLFMLWAALGICCAAFSASAWSVNNFLITGPKAYLTYTTSVALGAQSGIEECKFQFAWERWNCPENALQLSTHNRLRSATRETSFIHAISSAGVMYIITKNCSMGDFENCGCDGSNNGKTGGHGWIWGGCSDNVEFGERISKLFVDSLEKGKDARALMNLHNNRAGRLAVRATMKRTCKCHGISGSCSIQTCWLQLAEFREMGDYLKAKYDQALKIEMDKRQLRAGNSAEGHWVPAEAFLPSAEAELIFLEESPDYCTCNSSLGIYGTEGRECLQNSHNTSRWERRSCGRLCTECGLQVEERKTEVISSCNCKFQWCCTVKCDQCRHVVSKYYCARSPGSAQSLGRVWFGVYI>sp|A6NGB9|WIPF3_HUMAN WAS/WASL-interacting protein family member 3OS=Homo sapiens OX=9606 GN=WIPF3 PE=1 SV=4MPVPPPPPPPLPPPPPPLGAPPPPPPSAPPVSTDTSSLRRADPKGRSALLADIQQGTRLRKVTQINDRSAPQIESSKGTNKEGGGSANTRGASTPPTLGDLFAGGFPVLRPAGQRDVAGGKTGQGPGSRAPSPRLPNKTISGPLIPPASPRLGNTSEAHGAARTAPPRPNVPAPPPPTPPPPPPPLPPPLPSSSPIKTPLVSPPGPLTKGNLPVVAPPVPCAPPPPPPPPPPTPPPLPPASVLSDKAVKPQLAPLHLPPIPPPLPLLPPCGYPGLKAEPASPAQDAQEPPAPPPPLPPYASCSPRASLPAPPLPGVNSSSETPPPLPPKSPSFQAPPQKAGAQALPAPPAPPGSQPFLQKKRHGRPGAGGGKLNPPPAPPARSPTTELSSKSQQATAWTPTQQPGGQLRNGSLHIIDDFESKFTFHSVEDFPPPDEYKPCQKIYPSKIPRSRTPGPWLQAEAVGQSSDDIKGRNSQLSLKTLR>sp|Q9NZR4|VSX1_HUMAN Visual system homeobox 1 OS=Homo sapiens OX=9606GN=VSX1 PE=1 SV=2MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSDEDSQSEDRNDLKASPTLGKRKKRRHRTVFTAHQLEELEKAFSEAHYPDVYAREMLAVKTELPEDRIQVWFQNRRAKWRKREKRWGGSSVMAEYGLYGAMVRHCIPLPDSVLNSAEGGLLGSCAPWLLGMHKKSMGMIRKPGSEDKLAGLWGSDHFKEGSSQSESGSQRGSDKVSPENGLEDVAIDLSSSARQETKKVHPGAGAQGGSNSTALEGPQPGKVGAT>sp|Q9NZR4-2|VSX1_HUMAN Isoform 2 of Visual system homeobox 1 OS=Homosapiens OX=9606 GN=VSX1MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSDEDSQSEDRNDLKASPTLGKRKKRRHRTVFTAHQLEELEKAFSEAHYPDVYAREMLAVKTELPEDRIQVSGVPFLRSKDTTENVSFPHSVSQSAVPSL>sp|Q9NZR4-3|VSX1_HUMAN Isoform 3 of Visual system homeobox 1 OS=Homosapiens OX=9606 GN=VSX1MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSGNQARAFRSCPCPLGSEPRRGHRPSPHRTPGPSGPDLGGEPRARPRRGRGIRGAAPPAPCCILNPCLSSGVLFPQRCETATTWFRVEPFDETLGSSTTISRGPFFPPAPGASLRLWQLRGSGRPGPVVVTSSTEQDEDSQSEDRNDLKASPTLGKRKKRRHRTVFTAHQLEELEKAFSEAHYPDVYAREMLAVKTELPEDRIQVSGVPFLRSKDTTENVSFPHSVSQSAVPSL>sp|Q9NZR4-4|VSX1_HUMAN Isoform 4 of Visual system homeobox 1 OS=Homosapiens OX=9606 GN=VSX1MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSAM>sp|Q9NZR4-5|VSX1_HUMAN Isoform 5 of Visual system homeobox 1 OS=Homosapiens OX=9606 GN=VSX1MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSDEDSQSEDRNDLKASPTLGKRKKRRHRTVFTAHQLEELEKAFSEAHYPDVYAREMLAVKTELPEDRIQVWFQNRRAKWRKREKRWGGSSVMAEYGLYGAMVRHCIPLPDSVLNSAEGGLLGSCAPWLLEGETLGCREMK>sp|Q9NZR4-6|VSX1_HUMAN Isoform 6 of Visual system homeobox 1 OS=Homosapiens OX=9606 GN=VSX1MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSDEDSQSEDRNDLKASPTLGKRKKRRHRTVFTAHQLEELEKAFSEAHYPDVYAREMLAVKTELPEDRIQRVRHWAAEK>sp|Q9NZR4-7|VSX1_HUMAN Isoform 7 of Visual system homeobox 1 OS=Homosapiens OX=9606 GN=VSX1MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSDEDSQSEDRNDLKASPTLGKRKKRRHRTVFTAHQLEELEKAFSEAHYPDVYAREMLAVKTELPEDRIQCKLLLLEAPVHWTLQETHRLPRPRGGA>sp|Q9NZR4-8|VSX1_HUMAN Isoform 8 of Visual system homeobox 1 OS=Homosapiens OX=9606 GN=VSX1MTGRDSLSDGRTSSRALVPGGSPRGSRPRGFAITDLLGLEAELPAPAGPGQGSGCEGPAVAPCPGPGLDGSSLARGALPLGLGLLCGFGTQPPAAARAPCLLLADVPFLPPRGPEPAAPLAPSRPPPALGRQKRSDSVSTSDEDSQSEDRNDLKASPTLGKRKKRRHRTVFTAHQLEELEKAFSEAHYPDVYAREMLAVKTELPEDRIQVWFQNRRAKWRKREKRWGGSSVMAEYGLYGAMVRHCIPLPDSVLNSAEGGLLGSCAPWLLVQTSAPGGSRSLDFAGDTQAPQTPWWCLMTFS>sp|Q06250|WIT1_HUMAN Putative Wilms tumor upstream neighbor 1 geneprotein OS=Homo sapiens OX=9606 GN=WT1-AS PE=5 SV=2MQRRGQPLENHVALIHWQSAGIPASKVHNYCNMKKSRLGRSRAVRISQPLLSPRRCPLHLTERGAGLLQPQPQGPVRTPGPPSGSHPAAADN>sp|Q93098|WNT8B_HUMAN Protein Wnt-8b OS=Homo sapiens OX=9606 GN=WNT8BPE=2 SV=3MFLSKPSVYICLFTCVLQLSHSWSVNNFLMTGPKAYLIYSSSVAAGAQSGIEECKYQFAWDRWNCPERALQLSSHGGLRSANRETAFVHAISSAGVMYTLTRNCSLGDFDNCGCDDSRNGQLGGQGWLWGGCSDNVGFGEAISKQFVDALETGQDARAAMNLHNNEAGRKAVKGTMKRTCKCHGVSGSCTTQTCWLQLPEFREVGAHLKEKYHAALKVDLLQGAGNSAAGRGAIADTFRSISTRELVHLEDSPDYCLENKTLGLLGTEGRECLRRGRALGRWERRSCRRLCGDCGLAVEERRAETVSSCNCKFHWCCAVRCEQCRRRVTKYFCSRAERPRGGAAHKPGRKP>sp|Q5MNZ9|WIPI1_HUMAN WD repeat domain phosphoinositide-interactingprotein 1 OS=Homo sapiens OX=9606 GN=WIPI1 PE=1 SV=3MEAEAADAPPGGVESALSCFSFNQDCTSLATGTKAGYKLFSLSSVEQLDQVHGSNEIPDVYIVERLFSSSLVVVVSHTKPRQMNVYHFKKGTEICNYSYSSNILSIRLNRQRLLVCLEESIYIHNIKDMKLLKTLLDIPANPTGLCALSINHSNSYLAYPGSLTSGEIVLYDGNSLKTVCTIAAHEGTLAAITFNASGSKLASASEKGTVIRVFSVPDGQKLYEFRRGMKRYVTISSLVFSMDSQFLCASSNTETVHIFKLEQVTNSRPEEPSTWSGYMGKMFMAATNYLPTQVSDMMHQDRAFATARLNFSGQRNICTLSTIQKLPRLLVASSSGHLYMYNLDPQDGGECVLIKTHSLLGSGTTEENKENDLRPSLPQSYAATVARPSASSASTVPGYSEDGGALRGEVIPEHEFATGPVCLDDENEFPPIILCRGNQKGKTKQS>sp|Q5MNZ9-2|WIPI1_HUMAN Isoform 2 of WD repeat domain phosphoinositide-interacting protein 1 OS=Homo sapiens OX=9606 GN=WIPI1MDAPPGGVESALSCFSFNQDCTSLATGTKAGYKLFSLSSVEQLDQVHGSNEIPDVYIVERLFSSSLVVVVSHTKPRQMNVYHFKKGTEICNYSYSSNILSIRLNRQRLLVCLEESIYIHNIKDMKLLKTLLDIPANPTGLCALSINHSNSYLAYPGSLTSGEIVLYDGNSLKTVCTIAAHEGTLAAITFNASGSKLASASEKGTVIRVFSVPDGQKLYEFRRGMKRYVTISSLVFSMDSQFLCASSNTETVHIFKLEQVTNSRPEEPSTWSGYMGKMFMAATNYLPTQVSDMMHQDRAFATARLNFSGQRNICTLSTIQKLPRLLVASSSGHLYMYNLDPQDGGECVLIKTHSLLGSGTTEENKENDLRPSLPQSYAATVARPSASSASTVPGYSEDGGALRGEVIPEHEFATGPVCLDDENEFPPIILCRGNQKGKTKQS>sp|O14904|WNT9A_HUMAN Protein Wnt-9a OS=Homo sapiens OX=9606 GN=WNT9APE=1 SV=2MLDGSPLARWLAAAFGLTLLLAALRPSAAYFGLTGSEPLTILPLTLEPEAAAQAHYKACDRLKLERKQRRMCRRDPGVAETLVEAVSMSALECQFQFRFERWNCTLEGRYRASLLKRGFKETAFLYAISSAGLTHALAKACSAGRMERCTCDEAPDLENREAWQWGGCGDNLKYSSKFVKEFLGRRSSKDLRARVDFHNNLVGVKVIKAGVETTCKCHGVSGSCTVRTCWRQLAPFHEVGKHLKHKYETALKVGSTTNEAAGEAGAISPPRGRASGAGGSDPLPRTPELVHLDDSPSFCLAGRFSPGTAGRRCHREKNCESICCGRGHNTQSRVVTRPCQCQVRWCCYVECRQCTQREEVYTCKG>sp|Q92563|TICN2_HUMAN Testican-2 OS=Homo sapiens OX=9606 GN=SPOCK2 PE=1SV=1MRAPGCGRLVLPLLLLAAAALAEGDAKGLKEGETPGNFMEDEQWLSSISQYSGKIKHWNRFRDEVEDDYIKSWEDNQQGDEALDTTKDPCQKVKCSRHKVCIAQGYQRAMCISRKKLEHRIKQPTVKLHGNKDSICKPCHMAQLASVCGSDGHTYSSVCKLEQQACLSSKQLAVRCEGPCPCPTEQAATSTADGKPETCTGQDLADLGDRLRDWFQLLHENSKQNGSASSVAGPASGLDKSLGASCKDSIGWMFSKLDTSADLFLDQTELAAINLDKYEVCIRPFFNSCDTYKDGRVSTAEWCFCFWREKPPCLAELERIQIQEAAKKKPGIFIPSCDEDGYYRKMQCDQSSGDCWCVDQLGLELTGTRTHGSPDCDDIVGFSGDFGSGVGWEDEEEKETEEAGEEAEEEEGEAGEADDGGYIW>sp|Q92563-2|TICN2_HUMAN Isoform 2 of Testican-2 OS=Homo sapiens OX=9606GN=SPOCK2MRAPGCGRLVLPLLLLAAAALAEGDAKGLKEGETPGNFMEDEQWLSSISQYSGKIKHWNRFRDVPSSDPPSTTQATP>sp|Q08629|TICN1_HUMAN Testican-1 OS=Homo sapiens OX=9606 GN=SPOCK1 PE=1SV=1MPAIAVLAAAAAAWCFLQVESRHLDALAGGAGPNHGNFLDNDQWLSTVSQYDRDKYWNRFRDDDYFRNWNPNKPFDQALDPSKDPCLKVKCSPHKVCVTQDYQTALCVSRKHLLPRQKKGNVAQKHWVGPSNLVKCKPCPVAQSAMVCGSDGHSYTSKCKLEFHACSTGKSLATLCDGPCPCLPEPEPPKHKAERSACTDKELRNLASRLKDWFGALHEDANRVIKPTSSNTAQGRFDTSILPICKDSLGWMFNKLDMNYDLLLDPSEINAIYLDKYEPCIKPLFNSCDSFKDGKLSNNEWCYCFQKPGGLPCQNEMNRIQKLSKGKSLLGAFIPRCNEEGYYKATQCHGSTGQCWCVDKYGNELAGSRKQGAVSCEEEQETSGDFGSGGSVVLLDDLEYERELGPKDKEGKLRVHTRAVTEDDEDEDDDKEDEVGYIW>sp|O43435|TBX1_HUMAN T-box transcription factor TBX1 OS=Homo sapiensOX=9606 GN=TBX1 PE=1 SV=1MHFSTVTRDMEAFTASSLSSLGAAGGFPGAASPGADPYGPREPPPPPPRYDPCAAAAPGAPGPPPPPHAYPFAPAAGAATSAAAEPEGPGASCAAAAKAPVKKNAKVAGVSVQLEMKALWDEFNQLGTEMIVTKAGRRMFPTFQVKLFGMDPMADYMLLMDFVPVDDKRYRYAFHSSSWLVAGKADPATPGRVHYHPDSPAKGAQWMKQIVSFDKLKLTNNLLDDNGHIILNSMHRYQPRFHVVYVDPRKDSEKYAEENFKTFVFEETRFTAVTAYQNHRITQLKIASNPFAKGFRDCDPEDWPRNHRPGALPLMSAFARSRNPVASPTQPSGTEKGGHVLKDKEVKAETSRNTPEREVELLRDAGGCVNLGLPCPAECQPFNTQGLVAGRTAGDRLC>sp|O43435-2|TBX1_HUMAN Isoform B of T-box transcription factor TBX1OS=Homo sapiens OX=9606 GN=TBX1MHFSTVTRDMEAFTASSLSSLGAAGGFPGAASPGADPYGPREPPPPPPRYDPCAAAAPGAPGPPPPPHAYPFAPAAGAATSAAAEPEGPGASCAAAAKAPVKKNAKVAGVSVQLEMKALWDEFNQLGTEMIVTKAGRRMFPTFQVKLFGMDPMADYMLLMDFVPVDDKRYRYAFHSSSWLVAGKADPATPGRVHYHPDSPAKGAQWMKQIVSFDKLKLTNNLLDDNGHIILNSMHRYQPRFHVVYVDPRKDSEKYAEENFKTFVFEETRFTAVTAYQNHRITQLKIASNPFAKGFRDCDPEDWPRNHRPGALPLMSAFARSRNPVASPTQPSGTEKGLVTEGSGLQPGLLDVLLKPPSKKSESLRPPHCKDT>sp|O43435-3|TBX1_HUMAN Isoform C of T-box transcription factor TBX1OS=Homo sapiens OX=9606 GN=TBX1MHFSTVTRDMEAFTASSLSSLGAAGGFPGAASPGADPYGPREPPPPPPRYDPCAAAAPGAPGPPPPPHAYPFAPAAGAATSAAAEPEGPGASCAAAAKAPVKKNAKVAGVSVQLEMKALWDEFNQLGTEMIVTKAGRRMFPTFQVKLFGMDPMADYMLLMDFVPVDDKRYRYAFHSSSWLVAGKADPATPGRVHYHPDSPAKGAQWMKQIVSFDKLKLTNNLLDDNGHIILNSMHRYQPRFHVVYVDPRKDSEKYAEENFKTFVFEETRFTAVTAYQNHRITQLKIASNPFAKGFRDCDPEDWPRNHRPGALPLMSAFARSRNPVASPTQPSGTEKDAAEARREFQRDAGGPAVLGDPAHPPQLLARVLSPSLPGAGGAGGLVPLPGAPGGRPSPPNPELRLEAPGASEPLHHHPYKYPAAAYDHYLGAKSRPAPYPLPGLRGHGYHPHAHPHHHHHPVSPAAAAAAAAAAAAAAANMYSSAGAAPPGSYDYCPR>sp|Q6ZNK6|TIFAB_HUMAN TRAF-interacting protein with FHA domain-containing protein B OS=Homo sapiens OX=9606 GN=TIFAB PE=1 SV=2MEKPLTVLRVSLYHPTLGPSAFANVPPRLQHDTSPLLLGRGQDAHLQLQLPRLSRRHLSLEPYLEKGSALLAFCLKALSRKGCVWVNGLTLRYLEQVPLSTVNRVSFSGIQMLVRVEEGTSLEAFVCYFHVSPSPLIYRPEAEETDEWEGISQGQPPPGSG>sp|Q13263|TIF1B_HUMAN Transcription intermediary factor 1-beta OS=Homosapiens OX=9606 GN=TRIM28 PE=1 SV=5MAASAAAASAAAASAASGSPGPGEGSAGGEKRSTAPSAAASASASAAASSPAGGGAEALELLEHCGVCRERLRPEREPRLLPCLHSACSACLGPAAPAAANSSGDGGAAGDGTVVDCPVCKQQCFSKDIVENYFMRDSGSKAATDAQDANQCCTSCEDNAPATSYCVECSEPLCETCVEAHQRVKYTKDHTVRSTGPAKSRDGERTVYCNVHKHEPLVLFCESCDTLTCRDCQLNAHKDHQYQFLEDAVRNQRKLLASLVKRLGDKHATLQKSTKEVRSSIRQVSDVQKRVQVDVKMAILQIMKELNKRGRVLVNDAQKVTEGQQERLERQHWTMTKIQKHQEHILRFASWALESDNNTALLLSKKLIYFQLHRALKMIVDPVEPHGEMKFQWDLNAWTKSAEAFGKIVAERPGTNSTGPAPMAPPRAPGPLSKQGSGSSQPMEVQEGYGFGSGDDPYSSAEPHVSGVKRSRSGEGEVSGLMRKVPRVSLERLDLDLTADSQPPVFKVFPGSTTEDYNLIVIERGAAAAATGQPGTAPAGTPGAPPLAGMAIVKEEETEAAIGAPPTATEGPETKPVLMALAEGPGAEGPRLASPSGSTSSGLEVVAPEGTSAPGGGPGTLDDSATICRVCQKPGDLVMCNQCEFCFHLDCHLPALQDVPGEEWSCSLCHVLPDLKEEDGSLSLDGADSTGVVAKLSPANQRKCERVLLALFCHEPCRPLHQLATDSTFSLDQPGGTLDLTLIRARLQEKLSPPYSSPQEFAQDVGRMFKQFNKLTEDKADVQSIIGLQRFFETRMNEAFGDTKFSAVLVEPPPMSLPGAGLSSQELSGGPGDGP>sp|Q13263-2|TIF1B_HUMAN Isoform 2 of Transcription intermediary factor1-beta OS=Homo sapiens OX=9606 GN=TRIM28MAASAAAASAAAASAASGSPGPGEGSAGGEKRSTAPSAAASASASAAASSPAGGGAEALELLEHCGVCRERLRPEREPRLLPCLHSACSACLGPAAPAAANSSGDGGAAGDGTGPAKSRDGERTVYCNVHKHEPLVLFCESCDTLTCRDCQLNAHKDHQYQFLEDAVRNQRKLLASLVKRLGDKHATLQKSTKEVRSSIRQVSDVQKRVQVDVKMAILQIMKELNKRGRVLVNDAQKVTEGQQERLERQHWTMTKIQKHQEHILRFASWALESDNNTALLLSKKLIYFQLHRALKMIVDPVEPHGEMKFQWDLNAWTKSAEAFGKIVAERPGTNSTGPAPMAPPRAPGPLSKQGSGSSQPMEVQEGYGFGSGDDPYSSAEPHVSGVKRSRSGEGEVSGLMRKVPRVSLERLDLDLTADSQPPVFKVFPGSTTEDYNLIVIERGAAAAATGQPGTAPAGTPGAPPLAGMAIVKEEETEAAIGAPPTATEGPETKPVLMALAEGPGAEGPRLASPSGSTSSGLEVVAPEGTSAPGGGPGTLDDSATICRVCQKPGDLVMCNQCEFCFHLDCHLPALQDVPGEEWSCSLCHVLPDLKEEDGSLSLDGADSTGVVAKLSPANQRKCERVLLALFCHEPCRPLHQLATDSTFSLDQPGGTLDLTLIRARLQEKLSPPYSSPQEFAQDVGRMFKQFNKLTEDKADVQSIIGLQRFFETRMNEAFGDTKFSAVLVEPPPMSLPGAGLSSQELSGGPGDGP>sp|Q8N6K0|TEX29_HUMAN Testis-expressed protein 29 OS=Homo sapiensOX=9606 GN=TEX29 PE=1 SV=1MEYVLEVKNSPRHLLKQFTVCDVPLYDICDYNVSRDRCQELGCCFYEGVCYKKAVPIYIHVFSALIVIIAGAFVITIIYRVIQESRKEKAIPVDVALPQKSSEKAELASSSSKLGLKPASPGPPSAGPSMKSDEDKDDVTGTITEAEETED>sp|Q8N6V9|TEX9_HUMAN Testis-expressed protein 9 OS=Homo sapiens OX=9606GN=TEX9 PE=1 SV=1MAGRSLCLTRSSVPGTPFPPPVQQPSTPGPDLLALEEEYKRLNAELQAKTADVVQQAKEIIRDRQEVRSRPVSTQMKSCDDEDDYSLRGLLPSEGIVHLHSETKPKTKNIDPVNKVQNKLHSANKGRKTNSSVKLKYSDVQTADDVAIPEDFSDFSLAKTISKIEGQLEEEGLPEYIDDIFSGVSNDIGTEAQIRFLKAKLHVMQEELDNVVCECNKKEDEIQNLKSQVKNFEEDFMRQQRTINMQQSQVEKYKTLFEEANKKYDGLQQQLSSVERELENKRRLQKQAASSQSATEVRLNRALEEAEKYKLELSKLRQNNKDIANEEHKKIEVLKSENKKLEKQKGELMIGFKKQLKLIDVLKRQKMHIEAAKMLSFTEEEFMKALEWGNS>sp|Q8N6V9-2|TEX9_HUMAN Isoform 2 of Testis-expressed protein 9 OS=Homosapiens OX=9606 GN=TEX9MKSCDDEDDYSLRGLLPSEGIVHLHSETKPKTKNIDPVNKVQNKLHSANKGRKTNSSVKLKYSDVQTADDVAIPEDFSDFSLAKTISKIEGQLEEEGLPEYIDDIFSGVSNDIGTEAQIRFLKAKLHVMQEELDNVVCECNKKEDEIQNLKSQVKNFEEDFMRQQRTINMQQSQVEKYKTLFEEANKKYDGLQQQLSSVERELENKRRLQKQAASSQSATEVRLNRALEEAEKYKLELSKLRQNNKDIANEEHKKIEVLKSENKKLEKQKGELMIGFKKQLKLIDVLKRQKMHIEAAKMLSFTEEEFMKALEWGNS>sp|A0A1B0GTY4|TEX50_HUMAN Testis-expressed protein 50 OS=Homo sapiensOX=9606 GN=TEX50 PE=3 SV=1MSNQRLPLIFSLLFICFFGESFCICDGTVWTKVGWEILPEEVHYWKVKGSPSHCLPYLLDKLCCDFANMDIFQGCLYLIYNLLQAVFFVLFVLSVHYLWKKWKKHQKKLKKQASLEKPGNDLESPLINNIDQTLHRVATTASVIYKIWEHRSHHPSSKKIKHCKLKKKSKEEGARRY>sp|Q13888|TF2H2_HUMAN General transcription factor IIH subunit 2 OS=Homosapiens OX=9606 GN=GTF2H2 PE=1 SV=1MDEEPERTKRWEGGYERTWEILKEDESGSLKATIEDILFKAKRKRVFEHHGQVRLGMMRHLYVVVDGSRTMEDQDLKPNRLTCTLKLLEYFVEEYFDQNPISQIGIIVTKSKRAEKLTELSGNPRKHITSLKKAVDMTCHGEPSLYNSLSIAMQTLKHMPGHTSREVLIIFSSLTTCDPSNIYDLIKTLKAAKIRVSVIGLSAEVRVCTVLARETGGTYHVILDESHYKELLTHHVSPPPASSSSECSLIRMGFPQHTIASLSDQDAKPSFSMAHLDGNTEPGLTLGGYFCPQCRAKYCELPVECKICGLTLVSAPHLARSYHHLFPLDAFQEIPLEEYNGERFCYGCQGELKDQHVYVCAVCQNVFCVDCDVFVHDSLHCCPGCIHKIPAPSGV>sp|Q8IY51|TIGD4_HUMAN Tigger transposable element-derived protein 4OS=Homo sapiens OX=9606 GN=TIGD4 PE=1 SV=2MAEASVDASTLPVTVKKKKSLSIEEKIDIINAVESGKKKAEIAAEYGIKKNSLSSIMKNKDKVLEAFESLRFDPKRKRLRTAFYTDLEEALMRWYRIAQCLNVPVNGPMLRLKANDFAQKLGHNDFKCSNGWLDRFKSRYGLVFRAQPVEATGVPVDPSTVWYQNVLPYYLNDYHPKNVFNIKETGLLYRMLPTNTFAFKGETCSVGKLCKDRITLVVGTNMDGSEKLPLLVIGKKRTPHCFKGLKSLPVCYEANRMAWMTSDVFEQWMRKLDEEFQAQQRRVVIFVESFPAHPEVKNLKSIELAFFPSCLSSKCIAMKQGVIKSLKIKYRHCLIKKFLSSVEGSKEFTFSLLDAVDTLHLCWRAVTPETIVKSYEEAGFKSQKGESDITNAEKDTGLDLVADALGAGVEFPEGLSIEEYAALDDDLETCEAAPNGDSICTKESKSDETGFYTSDEEDDDGSPGTELPLPSKSEAITALDTLKKFLRSQDMNDGLQNSLADLENFINSLSPK>sp|O95947|TBX6_HUMAN T-box transcription factor TBX6 OS=Homo sapiensOX=9606 GN=TBX6 PE=1 SV=2MYHPRELYPSLGAGYRLGPAQPGADSSFPPALAEGYRYPELDTPKLDCFLSGMEAAPRTLAAHPPLPLLPPAMGTEPAPSAPEALHSLPGVSLSLENRELWKEFSSVGTEMIITKAGRRMFPACRVSVTGLDPEARYLFLLDVIPVDGARYRWQGRRWEPSGKAEPRLPDRVYIHPDSPATGAHWMRQPVSFHRVKLTNSTLDPHGHLILHSMHKYQPRIHLVRAAQLCSQHWGGMASFRFPETTFISVTAYQNPQITQLKIAANPFAKGFRENGRNCKRERDARVKRKLRGPEPAATEAYGSGDTPGGPCDSTLGGDIRESDPEQAPAPGEATAAPAPLCGGPSAEAYLLHPAAFHGAPSHLPTRSPSFPEAPDSGRSAPYSAAFLELPHGSGGSGYPAAPPAVPFAPHFLQGGPFPLPYTAPGGYLDVGSKPMY>sp|O95947-2|TBX6_HUMAN Isoform 2 of T-box transcription factor TBX6OS=Homo sapiens OX=9606 GN=TBX6MYHPRELYPSLGAGYRLGPAQPGADSSFPPALAEGYRYPELDTPKLDCFLSGMEAAPRTLAAHPPLPLLPPAMGTEPAPSAPEALHSLPGVSLSLENRELWKEFSSVGTEMIITKAGRRMFPACRVSVTGLDPEARYLFLLDVIPVDGARYRWQGRRWEPSGKAEPRLPDRVYIHPDSPATGAHWMRQPVSFHRVKLTNSTLDPHGHLILHSMHKYQPRIHLVRAAQLCSQHWGGMASFRFPETTFISVTAYQNPQITQLKIAANPFAKGFRENGRNCKRWELFIHLFMHSTNVY>sp|Q7L1V2|MON1B_HUMAN Vacuolar fusion protein MON1 homolog B OS=Homosapiens OX=9606 GN=MON1B PE=1 SV=1MEVGGDTAAPAPGGAEDLEDTQFPSEEAREGGGVHAVPPDPEDEGLEETGSKDKDQPPSPSPPPQSEALSSTSRLWSPAAPENSPTCSPESSSGGQGGDPSDEEWRSQRKHVFVLSEAGKPIYSRYGSVEALSATMGVMTALVSFVQSAGDAIRAIYAEDHKLVFLQQGPLLLVAMSRTSQSAAQLRGELLAVHAQIVSTLTRASVARIFAHKQNYDLRRLLAGSERTLDRLLDSMEQDPGALLLGAVRCVPLARPLRDALGALLRRCTAPGLALSVLAVGGRLITAAQERNVLAECRLDPADLQLLLDWVGAPAFAAGEAWAPVCLPRFNPDGFFYAYVARLDAMPVCLLLLGTQREAFHAMAACRRLVEDGMHALGAMRALGEAASFSNASSASAPAYSVQAVGAPGLRHFLYKPLDIPDHHRQLPQFTSPELEAPYSREEERQRLSDLYHRLHARLHSTSRPLRLIYHVAEKETLLAWVTSKFELYTCLSPLVTKAGAILVVTKLLRWVKKEEDRLFIRYPPKYSTPPATSTDQAAHNGLFTGL>sp|Q7L1V2-2|MON1B_HUMAN Isoform 2 of Vacuolar fusion protein MON1homolog B OS=Homo sapiens OX=9606 GN=MON1BMVSGQLRFGVKTEDHKLVFLQQGPLLLVAMSRTSQSAAQLRGELLAVHAQIVSTLTRASVARIFAHKQNYDLRRLLAGSERTLDRLLDSMEQDPGALLLGAVRCVPLARPLRDALGALLRRCTAPGLALSVLAVGGRLITAAQERNVLAECRLDPADLQLLLDWVGAPAFAAGEAWAPVCLPRFNPDGFFYAYVARLDAMPVCLLLLGTQREAFHAMAACRRLVEDGMHALGAMRALGEAASFSNASSASAPAYSVQAVGAPGLRHFLYKPLDIPDHHRQLPQFTSPELEAPYSREEERQRLSDLYHRLHARLHSTSRPLRLIYHVAEKETLLAWVTSKFELYTCLSPLVTKAGAILVVTKLLRWVKKEEDRLFIRYPPKYSTPPATSTDQAAHNGLFTGL>sp|P51512|MMP16_HUMAN Matrix metalloproteinase-16 OS=Homo sapiensOX=9606 GN=MMP16 PE=1 SV=2MILLTFSTGRRLDFVHHSGVFFLQTLLWILCATVCGTEQYFNVEVWLQKYGYLPPTDPRMSVLRSAETMQSALAAMQQFYGINMTGKVDRNTIDWMKKPRCGVPDQTRGSSKFHIRRKRYALTGQKWQHKHITYSIKNVTPKVGDPETRKAIRRAFDVWQNVTPLTFEEVPYSELENGKRDVDITIIFASGFHGDSSPFDGEGGFLAHAYFPGPGIGGDTHFDSDEPWTLGNPNHDGNDLFLVAVHELGHALGLEHSNDPTAIMAPFYQYMETDNFKLPNDDLQGIQKIYGPPDKIPPPTRPLPTVPPHRSIPPADPRKNDRPKPPRPPTGRPSYPGAKPNICDGNFNTLAILRREMFVFKDQWFWRVRNNRVMDGYPMQITYFWRGLPPSIDAVYENSDGNFVFFKGNKYWVFKDTTLQPGYPHDLITLGSGIPPHGIDSAIWWEDVGKTYFFKGDRYWRYSEEMKTMDPGYPKPITVWKGIPESPQGAFVHKENGFTYFYKGKEYWKFNNQILKVEPGYPRSILKDFMGCDGPTDRVKEGHSPPDDVDIVIKLDNTASTVKAIAIVIPCILALCLLVLVYTVFQFKRKGTPRHILYCKRSMQEWV>sp|P51512-2|MMP16_HUMAN Isoform Short of Matrix metalloproteinase-16OS=Homo sapiens OX=9606 GN=MMP16MILLTFSTGRRLDFVHHSGVFFLQTLLWILCATVCGTEQYFNVEVWLQKYGYLPPTDPRMSVLRSAETMQSALAAMQQFYGINMTGKVDRNTIDWMKKPRCGVPDQTRGSSKFHIRRKRYALTGQKWQHKHITYSIKNVTPKVGDPETRKAIRRAFDVWQNVTPLTFEEVPYSELENGKRDVDITIIFASGFHGDSSPFDGEGGFLAHAYFPGPGIGGDTHFDSDEPWTLGNPNHDGNDLFLVAVHELGHALGLEHSNDPTAIMAPFYQYMETDNFKLPNDDLQGIQKIYGPPDKIPPPTRPLPTVPPHRSIPPADPRKNDRPKPPRPPTGRPSYPGAKPNICDGNFNTLAILRREMFVFKDQWFWRVRNNRVMDGYPMQITYFWRGLPPSIDAVYENSDGNFVFFKVKGDTLSVIQDGWLYKYHWKWILEQRQSVPVLSRQTEKHKTYEELSSITY>sp|P39900|MMP12_HUMAN Macrophage metalloelastase OS=Homo sapiens OX=9606GN=MMP12 PE=1 SV=1MKFLLILLLQATASGALPLNSSTSLEKNNVLFGERYLEKFYGLEINKLPVTKMKYSGNLMKEKIQEMQHFLGLKVTGQLDTSTLEMMHAPRCGVPDVHHFREMPGGPVWRKHYITYRINNYTPDMNREDVDYAIRKAFQVWSNVTPLKFSKINTGMADILVVFARGAHGDFHAFDGKGGILAHAFGPGSGIGGDAHFDEDEFWTTHSGGTNLFLTAVHEIGHSLGLGHSSDPKAVMFPTYKYVDINTFRLSADDIRGIQSLYGDPKENQRLPNPDNSEPALCDPNLSFDAVTTVGNKIFFFKDRFFWLKVSERPKTSVNLISSLWPTLPSGIEAAYEIEARNQVFLFKDDKYWLISNLRPEPNYPKSIHSFGFPNFVKKIDAAVFNPRFYRTYFFVDNQYWRYDERRQMMDPGYPKLITKNFQGIGPKIDAVFYSKNKYYYFFQGSNQFEYDFLLQRITKTLKSNSWFGC>sp|Q6ZRQ5|MMS22_HUMAN Protein MMS22-like OS=Homo sapiens OX=9606GN=MMS22L PE=1 SV=3MENCSAASTFLTDSLELELGTEWCKPPYFSCAVDNRGGGKHFSGESYLCSGALKRLILNLDPLPTNFEEDTLEIFGIQWVTETALVNSSRELFHLFRQQLYNLETLLQSSCDFGKVSTLHCKADNIRQQCVLFLHYVKVFIFRYLKVQNAESHVPVHPYEALEAQLPSVLIDELHGLLLYIGHLSELPSVNIGAFVNQNQIKLFPPSWHLLHLHLDIHWLVLEILYMLGEKLKQVVYGHQFMNLASDNLTNISLFEEHCETLLCDLISLSLNRYDKVRSSESLMSDQCPCLCIKELWVLLIHLLDHRSKWFVSESFWNWLNKLLKTLLEKSSDRRRSSMPVIQSRDPLGFSWWIITHVASFYKFDRHGVPDEMRKVESNWNFVEELLKKSISVQGVILEEQLRMYLHCCLTLCDFWEPNIAIVTILWEYYSKNLNSSFSISWLPFKGLANTMKSPLSMLEMVKTCCCDKQDQELYKSSSSYTIFLCILAKVVKKAMKSNGPHPWKQVKGRIYSKFHQKRMEELTEVGLQNFFSLFLLLAAVAEVEDVASHVLDLLNFLKPAFVTSQRALIWKGHMAFLLMYAQKNLDIGVLAEKFSCAFREKAKEFLVSKNEEMVQRQTIWTLLSIYIDGVQEVFETSYCLYPSHEKLLNDGFSMLLRACRESELRTVLSFLQAVLARIRSMHQQLCQELQRDNVDLFVQSSLSAKERHLAAVASALWRHFFSFLKSQRMSQVVPFSQLADAAADFTLLAMDMPSTAPSDFQPQPVISIIQLFGWDDIICPQVVARYLSHVLQNSTLCEALSHSGYVSFQALTVRSWIRCVLQMYIKNLSGPDDLLIDKNLEEAVEKEYMKQLVKLTRLLFNLSEVKSIFSKAQVEYLSISEDPKKALVRFFEAVGVTYGNVQTLSDKSAMVTKSLEYLGEVLKYIKPYLGKKVFSAGLQLTYGMMGILVKSWAQIFATSKAQKLLFRIIDCLLLPHAVLQQEKELPAPMLSAIQKSLPLYLQGMCIVCCQSQNPNAYLNQLLGNVIEQYIGRFLPASPYVSDLGQHPVLLALRNTATIPPISSLKKCIVQVIRKSYLEYKGSSPPPRLASILAFILQLFKETNTDIYEVELLLPGILKCLVLVSEPQVKRLATENLQYMVKACQVGSEEEPSSQLTSVFRQFIQDYGMRYYYQVYSILETVATLDQQVVIHLISTLTQSLKDSEQKWGLGRNIAQREAYSKLLSHLGQMGQDEMQRLENDNT>sp|Q8WXI7|MUC16_HUMAN Mucin-16 OS=Homo sapiens OX=9606 GN=MUC16 PE=1SV=3MLKPSGLPGSSSPTRSLMTGSRSTKATPEMDSGLTGATLSPKTSTGAIVVTEHTLPFTSPDKTLASPTSSVVGRTTQSLGVMSSALPESTSRGMTHSEQRTSPSLSPQVNGTPSRNYPATSMVSGLSSPRTRTSSTEGNFTKEASTYTLTVETTSGPVTEKYTVPTETSTTEGDSTETPWDTRYIPVKITSPMKTFADSTASKENAPVSMTPAETTVTDSHTPGRTNPSFGTLYSSFLDLSPKGTPNSRGETSLELILSTTGYPFSSPEPGSAGHSRISTSAPLSSSASVLDNKISETSIFSGQSLTSPLSPGVPEARASTMPNSAIPFSMTLSNAETSAERVRSTISSLGTPSISTKQTAETILTFHAFAETMDIPSTHIAKTLASEWLGSPGTLGGTSTSALTTTSPSTTLVSEETNTHHSTSGKETEGTLNTSMTPLETSAPGEESEMTATLVPTLGFTTLDSKIRSPSQVSSSHPTRELRTTGSTSGRQSSSTAAHGSSDILRATTSSTSKASSWTSESTAQQFSEPQHTQWVETSPSMKTERPPASTSVAAPITTSVPSVVSGFTTLKTSSTKGIWLEETSADTLIGESTAGPTTHQFAVPTGISMTGGSSTRGSQGTTHLLTRATASSETSADLTLATNGVPVSVSPAVSKTAAGSSPPGGTKPSYTMVSSVIPETSSLQSSAFREGTSLGLTPLNTRHPFSSPEPDSAGHTKISTSIPLLSSASVLEDKVSATSTFSHHKATSSITTGTPEISTKTKPSSAVLSSMTLSNAATSPERVRNATSPLTHPSPSGEETAGSVLTLSTSAETTDSPNIHPTGTLTSESSESPSTLSLPSVSGVKTTFSSSTPSTHLFTSGEETEETSNPSVSQPETSVSRVRTTLASTSVPTPVFPTMDTWPTRSAQFSSSHLVSELRATSSTSVTNSTGSALPKISHLTGTATMSQTNRDTFNDSAAPQSTTWPETSPRFKTGLPSATTTVSTSATSLSATVMVSKFTSPATSSMEATSIREPSTTILTTETTNGPGSMAVASTNIPIGKGYITEGRLDTSHLPIGTTASSETSMDFTMAKESVSMSVSPSQSMDAAGSSTPGRTSQFVDTFSDDVYHLTSREITIPRDGTSSALTPQMTATHPPSPDPGSARSTWLGILSSSPSSPTPKVTMSSTFSTQRVTTSMIMDTVETSRWNMPNLPSTTSLTPSNIPTSGAIGKSTLVPLDTPSPATSLEASEGGLPTLSTYPESTNTPSIHLGAHASSESPSTIKLTMASVVKPGSYTPLTFPSIETHIHVSTARMAYSSGSSPEMTAPGETNTGSTWDPTTYITTTDPKDTSSAQVSTPHSVRTLRTTENHPKTESATPAAYSGSPKISSSPNLTSPATKAWTITDTTEHSTQLHYTKLAEKSSGFETQSAPGPVSVVIPTSPTIGSSTLELTSDVPGEPLVLAPSEQTTITLPMATWLSTSLTEEMASTDLDISSPSSPMSTFAIFPPMSTPSHELSKSEADTSAIRNTDSTTLDQHLGIRSLGRTGDLTTVPITPLTTTWTSVIEHSTQAQDTLSATMSPTHVTQSLKDQTSIPASASPSHLTEVYPELGTQGRSSSEATTFWKPSTDTLSREIETGPTNIQSTPPMDNTTTGSSSSGVTLGIAHLPIGTSSPAETSTNMALERRSSTATVSMAGTMGLLVTSAPGRSISQSLGRVSSVLSESTTEGVTDSSKGSSPRLNTQGNTALSSSLEPSYAEGSQMSTSIPLTSSPTTPDVEFIGGSTFWTKEVTTVMTSDISKSSARTESSSATLMSTALGSTENTGKEKLRTASMDLPSPTPSMEVTPWISLTLSNAPNTTDSLDLSHGVHTSSAGTLATDRSLNTGVTRASRLENGSDTSSKSLSMGNSTHTSMTYTEKSEVSSSIHPRPETSAPGAETTLTSTPGNRAISLTLPFSSIPVEEVISTGITSGPDINSAPMTHSPITPPTIVWTSTGTIEQSTQPLHAVSSEKVSVQTQSTPYVNSVAVSASPTHENSVSSGSSTSSPYSSASLESLDSTISRRNAITSWLWDLTTSLPTTTWPSTSLSEALSSGHSGVSNPSSTTTEFPLFSAASTSAAKQRNPETETHGPQNTAASTLNTDASSVTGLSETPVGASISSEVPLPMAITSRSDVSGLTSESTANPSLGTASSAGTKLTRTISLPTSESLVSFRMNKDPWTVSIPLGSHPTTNTETSIPVNSAGPPGLSTVASDVIDTPSDGAESIPTVSFSPSPDTEVTTISHFPEKTTHSFRTISSLTHELTSRVTPIPGDWMSSAMSTKPTGASPSITLGERRTITSAAPTTSPIVLTASFTETSTVSLDNETTVKTSDILDARKTNELPSDSSSSSDLINTSIASSTMDVTKTASISPTSISGMTASSSPSLFSSDRPQVPTSTTETNTATSPSVSSNTYSLDGGSNVGGTPSTLPPFTITHPVETSSALLAWSRPVRTFSTMVSTDTASGENPTSSNSVVTSVPAPGTWTSVGSTTDLPAMGFLKTSPAGEAHSLLASTIEPATAFTPHLSAAVVTGSSATSEASLLTTSESKAIHSSPQTPTTPTSGANWETSATPESLLVVTETSDTTLTSKILVTDTILFSTVSTPPSKFPSTGTLSGASFPTLLPDTPAIPLTATEPTSSLATSFDSTPLVTIASDSLGTVPETTLTMSETSNGDALVLKTVSNPDRSIPGITIQGVTESPLHPSSTSPSKIVAPRNTTYEGSITVALSTLPAGTTGSLVFSQSSENSETTALVDSSAGLERASVMPLTTGSQGMASSGGIRSGSTHSTGTKTFSSLPLTMNPGEVTAMSEITTNRLTATQSTAPKGIPVKPTSAESGLLTPVSASSSPSKAFASLTTAPPTWGIPQSTLTFEFSEVPSLDTKSASLPTPGQSLNTIPDSDASTASSSLSKSPEKNPRARMMTSTKAISASSFQSTGFTETPEGSASPSMAGHEPRVPTSGTGDPRYASESMSYPDPSKASSAMTSTSLASKLTTLFSTGQAARSGSSSSPISLSTEKETSFLSPTASTSRKTSLFLGPSMARQPNILVHLQTSALTLSPTSTLNMSQEEPPELTSSQTIAEEEGTTAETQTLTFTPSETPTSLLPVSSPTEPTARRKSSPETWASSISVPAKTSLVETTDGTLVTTIKMSSQAAQGNSTWPAPAEETGSSPAGTSPGSPEMSTTLKIMSSKEPSISPEIRSTVRNSPWKTPETTVPMETTVEPVTLQSTALGSGSTSISHLPTGTTSPTKSPTENMLATERVSLSPSPPEAWTNLYSGTPGGTRQSLATMSSVSLESPTARSITGTGQQSSPELVSKTTGMEFSMWHGSTGGTTGDTHVSLSTSSNILEDPVTSPNSVSSLTDKSKHKTETWVSTTAIPSTVLNNKIMAAEQQTSRSVDEAYSSTSSWSDQTSGSDITLGASPDVTNTLYITSTAQTTSLVSLPSGDQGITSLTNPSGGKTSSASSVTSPSIGLETLRANVSAVKSDIAPTAGHLSQTSSPAEVSILDVTTAPTPGISTTITTMGTNSISTTTPNPEVGMSTMDSTPATERRTTSTEHPSTWSSTAASDSWTVTDMTSNLKVARSPGTISTMHTTSFLASSTELDSMSTPHGRITVIGTSLVTPSSDASAVKTETSTSERTLSPSDTTASTPISTFSRVQRMSISVPDILSTSWTPSSTEAEDVPVSMVSTDHASTKTDPNTPLSTFLFDSLSTLDWDTGRSLSSATATTSAPQGATTPQELTLETMISPATSQLPFSIGHITSAVTPAAMARSSGVTFSRPDPTSKKAEQTSTQLPTTTSAHPGQVPRSAATTLDVIPHTAKTPDATFQRQGQTALTTEARATSDSWNEKEKSTPSAPWITEMMNSVSEDTIKEVTSSSSVLRTLNTLDINLESGTTSSPSWKSSPYERIAPSESTTDKEAIHPSTNTVETTGWVTSSEHASHSTIPAHSASSKLTSPVVTTSTREQAIVSMSTTTWPESTRARTEPNSFLTIELRDVSPYMDTSSTTQTSIISSPGSTAITKGPRTEITSSKRISSSFLAQSMRSSDSPSEAITRLSNFPAMTESGGMILAMQTSPPGATSLSAPTLDTSATASWTGTPLATTQRFTYSEKTTLFSKGPEDTSQPSPPSVEETSSSSSLVPIHATTSPSNILLTSQGHSPSSTPPVTSVFLSETSGLGKTTDMSRISLEPGTSLPPNLSSTAGEALSTYEASRDTKAIHHSADTAVTNMEATSSEYSPIPGHTKPSKATSPLVTSHIMGDITSSTSVFGSSETTEIETVSSVNQGLQERSTSQVASSATETSTVITHVSSGDATTHVTKTQATFSSGTSISSPHQFITSTNTFTDVSTNPSTSLIMTESSGVTITTQTGPTGAATQGPYLLDTSTMPYLTETPLAVTPDFMQSEKTTLISKGPKDVSWTSPPSVAETSYPSSLTPFLVTTIPPATSTLQGQHTSSPVSATSVLTSGLVKTTDMLNTSMEPVTNSPQNLNNPSNEILATLAATTDIETIHPSINKAVTNMGTASSAHVLHSTLPVSSEPSTATSPMVPASSMGDALASISIPGSETTDIEGEPTSSLTAGRKENSTLQEMNSTTESNIILSNVSVGAITEATKMEVPSFDATFIPTPAQSTKFPDIFSVASSRLSNSPPMTISTHMTTTQTGSSGATSKIPLALDTSTLETSAGTPSVVTEGFAHSKITTAMNNDVKDVSQTNPPFQDEASSPSSQAPVLVTTLPSSVAFTPQWHSTSSPVSMSSVLTSSLVKTAGKVDTSLETVTSSPQSMSNTLDDISVTSAATTDIETTHPSINTVVTNVGTTGSAFESHSTVSAYPEPSKVTSPNVTTSTMEDTTISRSIPKSSKTTRTETETTSSLTPKLRETSISQEITSSTETSTVPYKELTGATTEVSRTDVTSSSSTSFPGPDQSTVSLDISTETNTRLSTSPIMTESAEITITTQTGPHGATSQDTFTMDPSNTTPQAGIHSAMTHGFSQLDVTTLMSRIPQDVSWTSPPSVDKTSSPSSFLSSPAMTTPSLISSTLPEDKLSSPMTSLLTSGLVKITDILRTRLEPVTSSLPNFSSTSDKILATSKDSKDTKEIFPSINTEETNVKANNSGHESHSPALADSETPKATTQMVITTTVGDPAPSTSMPVHGSSETTNIKREPTYFLTPRLRETSTSQESSFPTDTSFLLSKVPTGTITEVSSTGVNSSSKISTPDHDKSTVPPDTFTGEIPRVFTSSIKTKSAEMTITTQASPPESASHSTLPLDTSTTLSQGGTHSTVTQGFPYSEVTTLMGMGPGNVSWMTTPPVEETSSVSSLMSSPAMTSPSPVSSTSPQSIPSSPLPVTALPTSVLVTTTDVLGTTSPESVTSSPPNLSSITHERPATYKDTAHTEAAMHHSTNTAVTNVGTSGSGHKSQSSVLADSETSKATPLMSTTSTLGDTSVSTSTPNISQTNQIQTEPTASLSPRLRESSTSEKTSSTTETNTAFSYVPTGAITQASRTEISSSRTSISDLDRPTIAPDISTGMITRLFTSPIMTKSAEMTVTTQTTTPGATSQGILPWDTSTTLFQGGTHSTVSQGFPHSEITTLRSRTPGDVSWMTTPPVEETSSGFSLMSPSMTSPSPVSSTSPESIPSSPLPVTALLTSVLVTTTNVLGTTSPEPVTSSPPNLSSPTQERLTTYKDTAHTEAMHASMHTNTAVANVGTSISGHESQSSVPADSHTSKATSPMGITFAMGDTSVSTSTPAFFETRIQTESTSSLIPGLRDTRTSEEINTVTETSTVLSEVPTTTTTEVSRTEVITSSRTTISGPDHSKMSPYISTETITRLSTFPFVTGSTEMAITNQTGPIGTISQATLTLDTSSTASWEGTHSPVTQRFPHSEETTTMSRSTKGVSWQSPPSVEETSSPSSPVPLPAITSHSSLYSAVSGSSPTSALPVTSLLTSGRRKTIDMLDTHSELVTSSLPSASSFSGEILTSEASTNTETIHFSENTAETNMGTTNSMHKLHSSVSIHSQPSGHTPPKVTGSMMEDAIVSTSTPGSPETKNVDRDSTSPLTPELKEDSTALVMNSTTESNTVFSSVSLDAATEVSRAEVTYYDPTFMPASAQSTKSPDISPEASSSHSNSPPLTISTHKTIATQTGPSGVTSLGQLTLDTSTIATSAGTPSARTQDFVDSETTSVMNNDLNDVLKTSPFSAEEANSLSSQAPLLVTTSPSPVTSTLQEHSTSSLVSVTSVPTPTLAKITDMDTNLEPVTRSPQNLRNTLATSEATTDTHTMHPSINTAVANVGTTSSPNEFYFTVSPDSDPYKATSAVVITSTSGDSIVSTSMPRSSAMKKIESETTFSLIFRLRETSTSQKIGSSSDTSTVFDKAFTAATTEVSRTELTSSSRTSIQGTEKPTMSPDTSTRSVTMLSTFAGLTKSEERTIATQTGPHRATSQGTLTWDTSITTSQAGTHSAMTHGFSQLDLSTLTSRVPEYISGTSPPSVEKTSSSSSLLSLPAITSPSPVPTTLPESRPSSPVHLTSLPTSGLVKTTDMLASVASLPPNLGSTSHKIPTTSEDIKDTEKMYPSTNIAVTNVGTTTSEKESYSSVPAYSEPPKVTSPMVTSFNIRDTIVSTSMPGSSEITRIEMESTFSLAHGLKGTSTSQDPIVSTEKSAVLHKLTTGATETSRTEVASSRRTSIPGPDHSTESPDISTEVIPSLPISLGITESSNMTIITRTGPPLGSTSQGTFTLDTPTTSSRAGTHSMATQEFPHSEMTTVMNKDPEILSWTIPPSIEKTSFSSSLMPSPAMTSPPVSSTLPKTIHTTPSPMTSLLTPSLVMTTDTLGTSPEPTTSSPPNLSSTSHEILTTDEDTTAIEAMHPSTSTAATNVETTSSGHGSQSSVLADSEKTKATAPMDTTSTMGHTTVSTSMSVSSETTKIKRESTYSLTPGLRETSISQNASFSTDTSIVLSEVPTGTTAEVSRTEVTSSGRTSIPGPSQSTVLPEISTRTMTRLFASPTMTESAEMTIPTQTGPSGSTSQDTLTLDTSTTKSQAKTHSTLTQRFPHSEMTTLMSRGPGDMSWQSSPSLENPSSLPSLLSLPATTSPPPISSTLPVTISSSPLPVTSLLTSSPVTTTDMLHTSPELVTSSPPKLSHTSDERLTTGKDTTNTEAVHPSTNTAASNVEIPSSGHESPSSALADSETSKATSPMFITSTQEDTTVAISTPHFLETSRIQKESISSLSPKLRETGSSVETSSAIETSAVLSEVSIGATTEISRTEVTSSSRTSISGSAESTMLPEISTTRKIIKFPTSPILAESSEMTIKTQTSPPGSTSESTFTLDTSTTPSLVITHSTMTQRLPHSEITTLVSRGAGDVPRPSSLPVEETSPPSSQLSLSAMISPSPVSSTLPASSHSSSASVTSLLTPGQVKTTEVLDASAEPETSSPPSLSSTSVEILATSEVTTDTEKIHPFSNTAVTKVGTSSSGHESPSSVLPDSETTKATSAMGTISIMGDTSVSTLTPALSNTRKIQSEPASSLTTRLRETSTSEETSLATEANTVLSKVSTGATTEVSRTEAISFSRTSMSGPEQSTMSQDISIGTIPRISASSVLTESAKMTITTQTGPSESTLESTLNLNTATTPSWVETHSIVIQGFPHPEMTTSMGRGPGGVSWPSPPFVKETSPPSSPLSLPAVTSPHPVSTTFLAHIPPSPLPVTSLLTSGPATTTDILGTSTEPGTSSSSSLSTTSHERLTTYKDTAHTEAVHPSTNTGGTNVATTSSGYKSQSSVLADSSPMCTTSTMGDTSVLTSTPAFLETRRIQTELASSLTPGLRESSGSEGTSSGTKMSTVLSKVPTGATTEISKEDVTSIPGPAQSTISPDISTRTVSWFSTSPVMTESAEITMNTHTSPLGATTQGTSTLDTSSTTSLTMTHSTISQGFSHSQMSTLMRRGPEDVSWMSPPLLEKTRPSFSLMSSPATTSPSPVSSTLPESISSSPLPVTSLLTSGLAKTTDMLHKSSEPVTNSPANLSSTSVEILATSEVTTDTEKTHPSSNRTVTDVGTSSSGHESTSFVLADSQTSKVTSPMVITSTMEDTSVSTSTPGFFETSRIQTEPTSSLTLGLRKTSSSEGTSLATEMSTVLSGVPTGATAEVSRTEVTSSSRTSISGFAQLTVSPETSTETITRLPTSSIMTESAEMMIKTQTDPPGSTPESTHTVDISTTPNWVETHSTVTQRFSHSEMTTLVSRSPGDMLWPSQSSVEETSSASSLLSLPATTSPSPVSSTLVEDFPSASLPVTSLLNPGLVITTDRMGISREPGTSSTSNLSSTSHERLTTLEDTVDTEDMQPSTHTAVTNVRTSISGHESQSSVLSDSETPKATSPMGTTYTMGETSVSISTSDFFETSRIQIEPTSSLTSGLRETSSSERISSATEGSTVLSEVPSGATTEVSRTEVISSRGTSMSGPDQFTISPDISTEAITRLSTSPIMTESAESAITIETGSPGATSEGTLTLDTSTTTFWSGTHSTASPGFSHSEMTTLMSRTPGDVPWPSLPSVEEASSVSSSLSSPAMTSTSFFSTLPESISSSPHPVTALLTLGPVKTTDMLRTSSEPETSSPPNLSSTSAEILATSEVTKDREKIHPSSNTPVVNVGTVIYKHLSPSSVLADLVTTKPTSPMATTSTLGNTSVSTSTPAFPETMMTQPTSSLTSGLREISTSQETSSATERSASLSGMPTGATTKVSRTEALSLGRTSTPGPAQSTISPEISTETITRISTPLTTTGSAEMTITPKTGHSGASSQGTFTLDTSSRASWPGTHSAATHRSPHSGMTTPMSRGPEDVSWPSRPSVEKTSPPSSLVSLSAVTSPSPLYSTPSESSHSSPLRVTSLFTPVMMKTTDMLDTSLEPVTTSPPSMNITSDESLATSKATMETEAIQLSENTAVTQMGTISARQEFYSSYPGLPEPSKVTSPVVTSSTIKDIVSTTIPASSEITRIEMESTSTLTPTPRETSTSQEIHSATKPSTVPYKALTSATIEDSMTQVMSSSRGPSPDQSTMSQDISTEVITRLSTSPIKTESTEMTITTQTGSPGATSRGTLTLDTSTTFMSGTHSTASQGFSHSQMTALMSRTPGDVPWLSHPSVEEASSASFSLSSPVMTSSSPVSSTLPDSIHSSSLPVTSLLTSGLVKTTELLGTSSEPETSSPPNLSSTSAEILAITEVTTDTEKLEMTNVVTSGYTHESPSSVLADSVTTKATSSMGITYPTGDTNVLTSTPAFSDTSRIQTKSKLSLTPGLMETSISEETSSATEKSTVLSSVPTGATTEVSRTEAISSSRTSIPGPAQSTMSSDTSMETITRISTPLTRKESTDMAITPKTGPSGATSQGTFTLDSSSTASWPGTHSATTQRFPQSVVTTPMSRGPEDVSWPSPLSVEKNSPPSSLVSSSSVTSPSPLYSTPSGSSHSSPVPVTSLFTSIMMKATDMLDASLEPETTSAPNMNITSDESLAASKATTETEAIHVFENTAASHVETTSATEELYSSSPGFSEPTKVISPVVTSSSIRDNMVSTTMPGSSGITRIEIESMSSLTPGLRETRTSQDITSSTETSTVLYKMPSGATPEVSRTEVMPSSRTSIPGPAQSTMSLDISDEVVTRLSTSPIMTESAEITITTQTGYSLATSQVTLPLGTSMTFLSGTHSTMSQGLSHSEMTNLMSRGPESLSWTSPRFVETTRSSSSLTSLPLTTSLSPVSSTLLDSSPSSPLPVTSLILPGLVKTTEVLDTSSEPKTSSSPNLSSTSVEIPATSEIMTDTEKIHPSSNTAVAKVRTSSSVHESHSSVLADSETTITIPSMGITSAVDDTTVFTSNPAFSETRRIPTEPTFSLTPGFRETSTSEETTSITETSAVLYGVPTSATTEVSMTEIMSSNRIHIPDSDQSTMSPDIITEVITRLSSSSMMSESTQMTITTQKSSPGATAQSTLTLATTTAPLARTHSTVPPRFLHSEMTTLMSRSPENPSWKSSLFVEKTSSSSSLLSLPVTTSPSVSSTLPQSIPSSSFSVTSLLTPGMVKTTDTSTEPGTSLSPNLSGTSVEILAASEVTTDTEKIHPSSSMAVTNVGTTSSGHELYSSVSIHSEPSKATYPVGTPSSMAETSISTSMPANFETTGFEAEPFSHLTSGFRKTNMSLDTSSVTPTNTPSSPGSTHLLQSSKTDFTSSAKTSSPDWPPASQYTEIPVDIITPFNASPSITESTGITSFPESRFTMSVTESTHHLSTDLLPSAETISTGTVMPSLSEAMTSFATTGVPRAISGSGSPFSRTESGPGDATLSTIAESLPSSTPVPFSSSTFTTTDSSTIPALHEITSSSATPYRVDTSLGTESSTTEGRLVMVSTLDTSSQPGRTSSSPILDTRMTESVELGTVTSAYQVPSLSTRLTRTDGIMEHITKIPNEAAHRGTIRPVKGPQTSTSPASPKGLHTGGTKRMETTTTALKTTTTALKTTSRATLTTSVYTPTLGTLTPLNASMQMASTIPTEMMITTPYVFPDVPETTSSLATSLGAETSTALPRTTPSVFNRESETTASLVSRSGAERSPVIQTLDVSSSEPDTTASWVIHPAETIPTVSKTTPNFFHSELDTVSSTATSHGADVSSAIPTNISPSELDALTPLVTISGTDTSTTFPTLTKSPHETETRTTWLTHPAETSSTIPRTIPNFSHHESDATPSIATSPGAETSSAIPIMTVSPGAEDLVTSQVTSSGTDRNMTIPTLTLSPGEPKTIASLVTHPEAQTSSAIPTSTISPAVSRLVTSMVTSLAAKTSTTNRALTNSPGEPATTVSLVTHPAQTSPTVPWTTSIFFHSKSDTTPSMTTSHGAESSSAVPTPTVSTEVPGVVTPLVTSSRAVISTTIPILTLSPGEPETTPSMATSHGEEASSAIPTPTVSPGVPGVVTSLVTSSRAVTSTTIPILTFSLGEPETTPSMATSHGTEAGSAVPTVLPEVPGMVTSLVASSRAVTSTTLPTLTLSPGEPETTPSMATSHGAEASSTVPTVSPEVPGVVTSLVTSSSGVNSTSIPTLILSPGELETTPSMATSHGAEASSAVPTPTVSPGVSGVVTPLVTSSRAVTSTTIPILTLSSSEPETTPSMATSHGVEASSAVLTVSPEVPGMVTSLVTSSRAVTSTTIPTLTISSDEPETTTSLVTHSEAKMISAIPTLAVSPTVQGLVTSLVTSSGSETSAFSNLTVASSQPETIDSWVAHPGTEASSVVPTLTVSTGEPFTNISLVTHPAESSSTLPRTTSRFSHSELDTMPSTVTSPEAESSSAISTTISPGIPGVLTSLVTSSGRDISATFPTVPESPHESEATASWVTHPAVTSTTVPRTTPNYSHSEPDTTPSIATSPGAEATSDFPTITVSPDVPDMVTSQVTSSGTDTSITIPTLTLSSGEPETTTSFITYSETHTSSAIPTLPVSPGASKMLTSLVISSGTDSTTTFPTLTETPYEPETTAIQLIHPAETNTMVPRTTPKFSHSKSDTTLPVAITSPGPEASSAVSTTTISPDMSDLVTSLVPSSGTDTSTTFPTLSETPYEPETTATWLTHPAETSTTVSGTIPNFSHRGSDTAPSMVTSPGVDTRSGVPTTTIPPSIPGVVTSQVTSSATDTSTAIPTLTPSPGEPETTASSATHPGTQTGFTVPIRTVPSSEPDTMASWVTHPPQTSTPVSRTTSSFSHSSPDATPVMATSPRTEASSAVLTTISPGAPEMVTSQITSSGAATSTTVPTLTHSPGMPETTALLSTHPRTETSKTFPASTVFPQVSETTASLTIRPGAETSTALPTQTTSSLFTLLVTGTSRVDLSPTASPGVSAKTAPLSTHPGTETSTMIPTSTLSLGLLETTGLLATSSSAETSTSTLTLTVSPAVSGLSSASITTDKPQTVTSWNTETSPSVTSVGPPEFSRTVTGTTMTLIPSEMPTPPKTSHGEGVSPTTILRTTMVEATNLATTGSSPTVAKTTTTFNTLAGSLFTPLTTPGMSTLASESVTSRTSYNHRSWISTTSSYNRRYWTPATSTPVTSTFSPGISTSSIPSSTAATVPFMVPFTLNFTITNLQYEEDMRHPGSRKFNATERELQGLLKPLFRNSSLEYLYSGCRLASLRPEKDSSATAVDAICTHRPDPEDLGLDRERLYWELSNLTNGIQELGPYTLDRNSLYVNGFTHRSSMPTTSTPGTSTVDVGTSGTPSSSPSPTTAGPLLMPFTLNFTITNLQYEEDMRRTGSRKFNTMESVLQGLLKPLFKNTSVGPLYSGCRLTLLRPEKDGAATGVDAICTHRLDPKSPGLNREQLYWELSKLTNDIEELGPYTLDRNSLYVNGFTHQSSVSTTSTPGTSTVDLRTSGTPSSLSSPTIMAAGPLLVPFTLNFTITNLQYGEDMGHPGSRKFNTTERVLQGLLGPIFKNTSVGPLYSGCRLTSLRSEKDGAATGVDAICIHHLDPKSPGLNRERLYWELSQLTNGIKELGPYTLDRNSLYVNGFTHRTSVPTSSTPGTSTVDLGTSGTPFSLPSPATAGPLLVLFTLNFTITNLKYEEDMHRPGSRKFNTTERVLQTLLGPMFKNTSVGLLYSGCRLTLLRSEKDGAATGVDAICTHRLDPKSPGVDREQLYWELSQLTNGIKELGPYTLDRNSLYVNGFTHWIPVPTSSTPGTSTVDLGSGTPSSLPSPTTAGPLLVPFTLNFTITNLKYEEDMHCPGSRKFNTTERVLQSLLGPMFKNTSVGPLYSGCRLTLLRSEKDGAATGVDAICTHRLDPKSPGVDREQLYWELSQLTNGIKELGPYTLDRNSLYVNGFTHQTSAPNTSTPGTSTVDLGTSGTPSSLPSPTSAGPLLVPFTLNFTITNLQYEEDMHHPGSRKFNTTERVLQGLLGPMFKNTSVGLLYSGCRLTLLRPEKNGAATGMDAICSHRLDPKSPGLNREQLYWELSQLTHGIKELGPYTLDRNSLYVNGFTHRSSVAPTSTPGTSTVDLGTSGTPSSLPSPTTAVPLLVPFTLNFTITNLQYGEDMRHPGSRKFNTTERVLQGLLGPLFKNSSVGPLYSGCRLISLRSEKDGAATGVDAICTHHLNPQSPGLDREQLYWQLSQMTNGIKELGPYTLDRNSLYVNGFTHRSSGLTTSTPWTSTVDLGTSGTPSPVPSPTTTGPLLVPFTLNFTITNLQYEENMGHPGSRKFNITESVLQGLLKPLFKSTSVGPLYSGCRLTLLRPEKDGVATRVDAICTHRPDPKIPGLDRQQLYWELSQLTHSITELGPYTLDRDSLYVNGFTQRSSVPTTSTPGTFTVQPETSETPSSLPGPTATGPVLLPFTLNFTITNLQYEEDMRRPGSRKFNTTERVLQGLLMPLFKNTSVSSLYSGCRLTLLRPEKDGAATRVDAVCTHRPDPKSPGLDRERLYWKLSQLTHGITELGPYTLDRHSLYVNGFTHQSSMTTTRTPDTSTMHLATSRTPASLSGPMTASPLLVLFTINFTITNLRYEENMHHPGSRKFNTTERVLQGLLRPVFKNTSVGPLYSGCRLTLLRPKKDGAATKVDAICTYRPDPKSPGLDREQLYWELSQLTHSITELGPYTLDRDSLYVNGFTQRSSVPTTSIPGTPTVDLGTSGTPVSKPGPSAASPLLVLFTLNFTITNLRYEENMQHPGSRKFNTTERVLQGLLRSLFKSTSVGPLYSGCRLTLLRPEKDGTATGVDAICTHHPDPKSPRLDREQLYWELSQLTHNITELGPYALDNDSLFVNGFTHRSSVSTTSTPGTPTVYLGASKTPASIFGPSAASHLLILFTLNFTITNLRYEENMWPGSRKFNTTERVLQGLLRPLFKNTSVGPLYSGCRLTLLRPEKDGEATGVDAICTHRPDPTGPGLDREQLYLELSQLTHSITELGPYTLDRDSLYVNGFTHRSSVPTTSTGVVSEEPFTLNFTINNLRYMADMGQPGSLKFNITDNVMQHLLSPLFQRSSLGARYTGCRVIALRSVKNGAETRVDLLCTYLQPLSGPGLPIKQVFHELSQQTHGITRLGPYSLDKDSLYLNGYNEPGPDEPPTTPKPATTFLPPLSEATTAMGYHLKTLTLNFTISNLQYSPDMGKGSATFNSTEGVLQHLLRPLFQKSSMGPFYLGCQLISLRPEKDGAATGVDTTCTYHPDPVGPGLDIQQLYWELSQLTHGVTQLGFYVLDRDSLFINGYAPQNLSIRGEYQINFHIVNWNLSNPDPTSSEYITLLRDIQDKVTTLYKGSQLHDTFRFCLVTNLTMDSVLVTVKALFSSNLDPSLVEQVFLDKTLNASFHWLGSTYQLVDIHVTEMESSVYQPTSSSSTQHFYLNFTITNLPYSQDKAQPGTTNYQRNKRNIEDALNQLFRNSSIKSYFSDCQVSTFRSVPNRHHTGVDSLCNFSPLARRVDRVAIYEEFLRMTRNGTQLQNFTLDRSSVLVDGYSPNRNEPLTGNSDLPFWAVILIGLAGLLGVITCLICGVLVTTRRRKKEGEYNVQQQCPGYYQSHLDLEDLQ>sp|Q6P582|MZT2A_HUMAN Mitotic-spindle organizing protein 2A OS=Homosapiens OX=9606 GN=MZT2A PE=1 SV=2MAAQGVGPGPGSAAPPGLEAARQKLALRRKKVLSTEEMELYELAQAAGGGIDPDVFKILVDLLKLNVAPLAVFQMLKSMCAGQRLASEPQDPAAVSLPTSSVPETRGRDKGSAALGGVLALAERSNHEGSSQRMPRQPSATRLPKGGGPGKSPTQGST>sp|P0CAP1|MYZAP_HUMAN Myocardial zonula adherens protein OS=Homo sapiensOX=9606 GN=MYZAP PE=1 SV=1MLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIESLKKKLQQKQLLILQLLEKISFLEGENNELQSRLDYLTETQAKTEVETREIGVGCDLLPSQTGRTREIVMPSRNYTPYTRVLELTMKKTLT>sp|P0CAP1-2|MYZAP_HUMAN Isoform 2 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIESLKKKLQQKQLLILQLLEKISFLEGENNELQSRLDYLTETQAKTEVETREIGVGCDLLPRRCKQSSQRKN>sp|P0CAP1-3|MYZAP_HUMAN Isoform 3 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIESLKKKLQQKQLLILQLLEKISFLEGENNELQSRLDYLTETQAKTEVETREIGVGCDLLPSQTGRTREIVMPSRNYTPYTRVLELTMKKTLT>sp|P0CAP1-4|MYZAP_HUMAN Isoform 4 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEENNELQSRLDYLTETQAKTEVETREIGVGCDLLPSQTGRTREIVMPSRNYTPYTRVLELTMKKTLT>sp|P0CAP1-5|MYZAP_HUMAN Isoform 5 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIMSHELFSRFSLRLFGR>sp|P0CAP1-6|MYZAP_HUMAN Isoform 6 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIESLKKKLQQKQLLILQLLEKISFLEGEGRKGLKGRLKMSC>sp|P0CAP1-7|MYZAP_HUMAN Isoform 7 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIESLKKKLQQKQLLILQLLEKISFLEGEVTFSTK>sp|P0CAP1-8|MYZAP_HUMAN Isoform 8 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEVTFSTK>sp|P0CAP1-9|MYZAP_HUMAN Isoform 9 of Myocardial zonula adherens proteinOS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEENNELQSRLDYLTETQAKTEVETREIGVGCDLLPRQSRKFEKVLNEFVQLLPLPHHLLWAFGNVCWRRHFGLLQ>sp|P0CAP1-10|MYZAP_HUMAN Isoform 10 of Myocardial zonula adherensprotein OS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIESLKKKLQQKQLLILQLLEKISFLEGENNELQSRLDYLTETQAKTEVETREIGVGCDLLPSQTGRTREIVMPSRNYTPYTRVLELTMKKTLT>sp|P0CAP1-11|MYZAP_HUMAN Isoform 11 of Myocardial zonula adherensprotein OS=Homo sapiens OX=9606 GN=MYZAPMLRSTSTVTLLSGGAARTPGAPSRRANVCRLRLTVPPESPVPEQCEKKIERKEQLLDLSNGEPTRKLPQGVVYGVVRRSDQNQQKEMVVYGWSTSQLKEEMNYIKDVRATLEKVRKRMYGDYDEMRQKIRQLTQELSVSHAQQEYLENHIQTQSSALDRFNAMNSALASDSIGLQKTLVDVTLENSNIKDQIRNLQQTYEASMDKLREKQRQLEVAQVENQLLKMKVESSQEANAEVMREMTKKLYSQYEEKLQEEQRKHSAEKEALLEETNSFLKAIEEANKKMQAAEISLEEKDQRIGELDRLIERMEKERHQLQLQLLEHETEMSGELTDSDKERYQQLEEASASLRERIRHLDDMVHCQQKKVKQMVEEIESLKKKLQQKQLLILQLLEKISFLEGENNELQSRLDYLTETQAKTEVETREIGVGCDLLPRLPFRQNDSSSHCQKSGSPISSEERRRRDKQHLDDITAARLLPLHHMPTQLLSIEESLALQKQQKQNYEEMQAKLAAQKLAERLNIKMRSYNPEGESSGRYREVRDEDDDWSSDEF>sp|Q32MK0|MYLK3_HUMAN Myosin light chain kinase 3 OS=Homo sapiensOX=9606 GN=MYLK3 PE=1 SV=3MSGTSKESLGHGGLPGLGKTCLTTMDTKLNMLNEKVDQLLHFQEDVTEKLQSMCRDMGHLERGLHRLEASRAPGPGGADGVPHIDTQAGWPEVLELVRAMQQDAAQHGARLEALFRMVAAVDRAIALVGATFQKSKVADFLMQGRVPWRRGSPGDSPEENKERVEEEGGKPKHVLSTSGVQSDAREPGEESQKADVLEGTAERLPPIRASGLGADPAQAVVSPGQGDGVPGPAQAFPGHLPLPTKVEAKAPETPSENLRTGLELAPAPGRVNVVSPSLEVAPGAGQGASSSRPDPEPLEEGTRLTPGPGPQCPGPPGLPAQARATHSGGETPPRISIHIQEMDTPGEMLMTGRGSLGPTLTTEAPAAAQPGKQGPPGTGRCLQAPGTEPGEQTPEGARELSPLQESSSPGGVKAEEEQRAGAEPGTRPSLARSDDNDHEVGALGLQQGKSPGAGNPEPEQDCAARAPVRAEAVRRMPPGAEAGSVVLDDSPAPPAPFEHRVVSVKETSISAGYEVCQHEVLGGGRFGQVHRCTEKSTGLPLAAKIIKVKSAKDREDVKNEINIMNQLSHVNLIQLYDAFESKHSCTLVMEYVDGGELFDRITDEKYHLTELDVVLFTRQICEGVHYLHQHYILHLDLKPENILCVNQTGHQIKIIDFGLARRYKPREKLKVNFGTPEFLAPEVVNYEFVSFPTDMWSVGVITYMLLSGLSPFLGETDAETMNFIVNCSWDFDADTFEGLSEEAKDFVSRLLVKEKSCRMSATQCLKHEWLNNLPAKASRSKTRLKSQLLLQKYIAQRKWKKHFYVVTAANRLRKFPTSP>sp|Q32MK0-4|MYLK3_HUMAN Isoform 2 of Myosin light chain kinase 3 OS=Homosapiens OX=9606 GN=MYLK3MDTPGEMLMTGRGSLGPTLTTEAPAAAQPGKQGPPGTGRCLQAPGTEPGEQTPEGARELSPLQESSSPGGVKAEEEQRAGAEPGTRPSLARSDDNDHEVGALGLQQGKSPGAGNPEPEQDCAARAPVRAEAVRRMPPGAEAGSVVLDDSPAPPAPFEHRVVSVKETSISAGYEVCQHEVLGGGRFGQVHRCTEKSTGLPLAAKIIKVKSAKDREDVKNEINIMNQLSHVNLIQLYDAFESKHSCTLVMEYVDGGELFDRITDEKYHLTELDVVLFTRQICEGVHYLHQHYILHLDLKPENILCVNQTGHQIKIIDFGLARRYKPREKLKVNFGTPEFLAPEVVNYEFVSFPTDMWSVGVITYMLLSGLSPFLGETDAETMNFIVNCSWDFDADTFEGLSEEAKDFVSRLLVKEKSCRMSATQCLKHEWLNNLPAKASRSKTRLKSQLLLQKYIAQRKWKKHFYVVTAANRLRKFPTSP>sp|Q68BL7|OLM2A_HUMAN Olfactomedin-like protein 2A OS=Homo sapiensOX=9606 GN=OLFML2A PE=2 SV=1MAAAALPPRPLLLLPLVLLLSGRPTRADSKVFGDLDQVRMTSEGSDCRCKCIMRPLSKDACSRVRSGRARVEDFYTVETVSSGTDCRCSCTAPPSSLNPCENEWKMEKLKKQAPELLKLQSMVDLLEGTLYSMDLMKVHAYVHKVASQMNTLEESIKANLSRENEVVKDSVRHLSEQLRHYENHSAIMLGIKKELSRLGLQLLQKDAAAAPATPATGTGSKAQDTARGKGKDISKYGSVQKSFADRGLPKPPKEKLLQVEKLRKESGKGSFLQPTAKPRALAQQQAVIRGFTYYKAGKQEVTEAVADNTLQGTSWLEQLPPKVEGRSNSAEPNSAEQDEAEPRSSERVDLASGTPTSIPATTTTATTTPTPTTSLLPTEPPSGPEVSSQGREASCEGTLRAVDPPVRHHSYGRHEGAWMKDPAARDDRIYVTNYYYGNSLVEFRNLENFKQGRWSNMYKLPYNWIGTGHVVYQGAFYYNRAFTKNIIKYDLRQRFVASWALLPDVVYEDTTPWKWRGHSDIDFAVDESGLWVIYPAVDDRDEAQPEVIVLSRLDPGDLSVHRETTWKTRLRRNSYGNCFLVCGILYAVDTYNQQEGQVAYAFDTHTGTDARPQLPFLNEHAYTTQIDYNPKERVLYAWDNGHQLTYTLHFVV>sp|Q68BL7-2|OLM2A_HUMAN Isoform 2 of Olfactomedin-like protein 2AOS=Homo sapiens OX=9606 GN=OLFML2AMTSEGSDCRCKCIMRPLSKDACSRVRSGRARVEDFYTVETVSSGTDCRCSCTAPPSSLNPCENEWKMEKLKKQAPELLKLQSMVDLLEGTLYSMDLMKVHAYVHKVASQMNTLEESIKANLSRENEVVKDSVRHLSEQLRHYENHSAIMLGIKKELSRLGLQLLQKDAAAAPATPATGTGSKAQDTARGKGKDISKYGSVQKSFADRGLPKPPKEKLLQVEKLRKESGKGSFLQPTAKPRALAQQQAVIRGFTYYKAGKQEVTEAVADNTLQGTSWLEQLPPKVEGRSNSAEPNSAEQDEAEPRSSERVDLASGTPTSIPATTTTATTTPTPTTSLLPTEPPSGPEVSSQGREASCEGTLRAVDPPVRHHSYGRHEGAWMKDPAARDDRIYVTNYYYGNSLVEFRNLENFKQGRWSNMYKLPYNWIGTGHVVYQGAFYYNRAFTKNIIKYDLRQRFVASWALLPDVVYEDTTPWKWRGHSDIDFAVDESGLWVIYPAVDDRDEAQPEVIVLSRLDPGDLSVHRETTWKTRLRRNSYGNCFLVCGILYAVDTYNQQEGQVAYAFDTHTGTDARPQLPFLNEHAYTTQIDYNPKERVLYAWDNGHQLTYTLHFVV>sp|Q68BL7-3|OLM2A_HUMAN Isoform 3 of Olfactomedin-like protein 2AOS=Homo sapiens OX=9606 GN=OLFML2AMSKRDKAGKDTARGKGKDISKYGSVQKSFADRGLPKPPKEKLLQVEKLRKESGKGSFLQPTAKPRALAQQQAVIRGFTYYKAGKQEVTEAVADNTLQGTSWLEQLPPKVEGRSNSAEPNSAEQDEAEPRSSERVDLASGTPTSIPATTTTATTTPTPTTSLLPTEPPSGPEVSSQGREASCEGTLRAVDPPVRHHSYGRHEGAWMKDPAARDDRIYVTNYYYGNSLVEFRNLENFKQGRWSNMYKLPYNWIGTGHVVYQGAFYYNRAFTKNIIKYDLRQRFVASWALLPDVVYEDTTPWKWRGHSDIDFAVDESGLWVIYPAVDDRDEAQPEVIVLSRLDPGDLSVHRETTWKTRLRRNSYGNCFLVCGILYAVDTYNQQEGQVAYAFDTHTGTDARPQLPFLNEHAYTTQIDYNPKERVLYAWDNGHQLTYTLHFVV>sp|Q8NGY5|OR6N1_HUMAN Olfactory receptor 6N1 OS=Homo sapiens OX=9606GN=OR6N1 PE=2 SV=1MDTGNWSQVAEFIILGFPHLQGVQIYLFLLLLLIYLMTVLGNLLIFLVVCLDSRLHTPMYHFVSILSFSELGYTAATIPKMLANLLSEKKTISFSGCLLQIYFFHSLGATECYLLTAMAYDRYLAICRPLHYPTLMTPTLCAEIAIGCWLGGLAGPVVEISLISRLPFCGPNRIQHVFCDFPPVLSLACTDTSINVLVDFVINSCKILATFLLILCSYVQIICTVLRIPSAAGKRKAISTCASHFTVVLIFYGSILSMYVQLKKSYSLDYDQALAVVYSVLTPFLNPFIYSLRNKEIKEAVRRQLKRIGILA>sp|Q96E52|OMA1_HUMAN Metalloendopeptidase OMA1, mitochondrial OS=Homosapiens OX=9606 GN=OMA1 PE=1 SV=1MSFICGLQSAARNHVFFRFNSLSNWRKCNTLASTSRGCHQVQVNHIVNKYQGLGVNQCDRWSFLPGNFHFYSTFNNKRTGGLSSTKSKEIWRITSKCTVWNDAFSRQLLIKEVTAVPSLSVLHPLSPASIRAIRNFHTSPRFQAAPVPLLLMILKPVQKLFAIIVGRGIRKWWQALPPNKKEVVKENIRKNKWKLFLGLSSFGLLFVVFYFTHLEVSPITGRSKLLLLGKEQFRLLSELEYEAWMEEFKNDMLTEKDARYLAVKEVLCHLIECNKDVPGISQINWVIHVVDSPIINAFVLPNGQMFVFTGFLNSVTDIHQLSFLLGHEIAHAVLGHAAEKAGMVHLLDFLGMIFLTMIWAICPRDSLALLCQWIQSKLQEYMFNRPYSRKLEAEADKIGLLLAAKACADIRASSVFWQQMEFVDSLHGQPKMPEWLSTHPSHGNRVEYLDRLIPQALKIREMCNCPPLSNPDPRLLFKLSTKHFLEESEKEDLNITKKQKMDTLPIQKQEQIPLTYIVEKRTGS>sp|Q96E52-2|OMA1_HUMAN Isoform 2 of Metalloendopeptidase OMA1,mitochondrial OS=Homo sapiens OX=9606 GN=OMA1MSFICGLQSAARNHVFFRFNSLSNWRKCNTLASTSRGCHQVQVNHIVNKYQGLGVNQCDRWSFLPGNFHFYSTFNNKRTGGLSSTKSKEIWRITSKCTVWNDAFSRQLLIKEVTAVPSLSVLHPLSPASIRAIRNFHTSPRFQAAPVPLLLMILKPVQKLFAIIVGRGIRKWWQALPPNKKEVVKENIRKNKWKLFLGLSSFGLLFVVFYFTHLEVSPITGRSKLLLLGKEQFRLLSELEYEAWMEEFKNDMLTEKDARYLAVKEVLCHLIECNKDVPGISQINWVIHVVDSPIINAFVLPNGQMFVFTGFLNSVTDIHQLSFLLGHEIAHAVLGHAAEKAGMVHLLDFLGMIFLTMIWAICPRDSLALLCQWIQSKLQEYMFNRPYSRKLEAEADKIGLLLAAKACADIRASSVFWQQMEFVDSLHGQPKMPEWLSTHPSHGNRVEYLDRLIPQLVREEKFIEQPEQIAELTLNSFIQNTEICRS>sp|Q16625|OCLN_HUMAN Occludin OS=Homo sapiens OX=9606 GN=OCLN PE=1 SV=1MSSRPLESPPPYRPDEFKPNHYAPSNDIYGGEMHVRPMLSQPAYSFYPEDEILHFYKWTSPPGVIRILSMLIIVMCIAIFACVASTLAWDRGYGTSLLGGSVGYPYGGSGFGSYGSGYGYGYGYGYGYGGYTDPRAAKGFMLAMAAFCFIAALVIFVTSVIRSEMSRTRRYYLSVIIVSAILGIMVFIATIVYIMGVNPTAQSSGSLYGSQIYALCNQFYTPAATGLYVDQYLYHYCVVDPQEAIAIVLGFMIIVAFALIIFFAVKTRRKMDRYDKSNILWDKEHIYDEQPPNVEEWVKNVSAGTQDVPSPPSDYVERVDSPMAYSSNGKVNDKRFYPESSYKSTPVPEVVQELPLTSPVDDFRQPRYSSGGNFETPSKRAPAKGRAGRSKRTEQDHYETDYTTGGESCDELEEDWIREYPPITSDQQRQLYKRNFDTGLQEYKSLQSELDEINKELSRLDKELDDYREESEEYMAAADEYNRLKQVKGSADYKSKKNHCKQLKSKLSHIKKMVGDYDRQKT>sp|Q16625-2|OCLN_HUMAN Isoform 2 of Occludin OS=Homo sapiens OX=9606GN=OCLNMSSRPLESPPPYRPDEFKPNHYAPSNDIYGGEMHVRPMLSQPAYSFYPEDEILHFYKWTSPPGVIRILSMLIIVMCIAIFACVASTLAWDRGYGTSLLGGSVGYPYGGSGFGSYGSGYGYGYGYGYGYGGYTDPRAAKGFMLAMAAFCFIAALVIFVTSVIRSEMSRTRRYYLSVIIVSAILGIMVFIATIVYIMGVNPTAQSSGSLYGSQIYALCNQFYTPAATGLYVDQYLYHYCVVDPQEVKNVSAGTQDVPSPPSDYVERVDSPMAYSSNGKVNDKRFYPESSYKSTPVPEVVQELPLTSPVDDFRQPRYSSGGNFETPSKRAPAKGRAGRSKRTEQDHYETDYTTGGESCDELEEDWIREYPPITSDQQRQLYKRNFDTGLQEYKSLQSELDEINKELSRLDKELDDYREESEEYMAAADEYNRLKQVKGSADYKSKKNHCKQLKSKLSHIKKMVGDYDRQKT>sp|Q16625-3|OCLN_HUMAN Isoform 3 of Occludin OS=Homo sapiens OX=9606GN=OCLNMSSRPLESPPPYRPDEFKPNHYAPSNDIYGGEMHVRPMLSQPAYSFYPEDEILHFYKWTSPPGVIRILSMLIIVMCIAIFACVASTLAWDRGYGTSLLGGSVGYPYGGSGFGSYGSGYGYGYGYGYGYGGYTDPRAAKGFMLAMAAFCFIAALVIFVTSVIRSEMSRTRRYYLSVIIVSAILGIMVFIATIVYIMGVNPTAQSSGSLYGSQIYALCNQFYTPAATGLYVDQYLYHYCVVDPQEAIAIVLGFMIIVAFALIIFFAVKTRRKMDRYDKSNILWDKEHIYDEQPPNVEEWVKNVSAGTQDVPSPPSDYVERVDSPMAYSSNGKVNDKRFYPESSYKSTPVPEVVQELPLTSPVDDFRQPRYSSGGNFETPSKRAPAKGRAGRSKRTEQDHYETDYTTGGESCDELEEDWIREYPPITSDQQRQLYKRNFDTGLQEYKSLQSELDEINKELSRLDKELDDYREESEEYMVNST>sp|Q16625-4|OCLN_HUMAN Isoform 4 of Occludin OS=Homo sapiens OX=9606GN=OCLNMIIVAFALIIFFAVKTRRKMDRYDKSNILWDKEHIYDEQPPNVEEWVKNVSAGTQDVPSPPSDYVERVDSPMAYSSNGKVNDKRFYPESSYKSTPVPEVVQELPLTSPVDDFRQPRYSSGGNFETPSKRAPAKGRAGRSKRTEQDHYETDYTTGGESCDELEEDWIREYPPITSDQQRQLYKRNFDTGLQEYKSLQSELDEINKELSRLDKELDDYREESEEYMAAADEYNRLKQVKGSADYKSKKNHCKQLKSKLSHIKKMVGDYDRQKT>sp|Q16625-5|OCLN_HUMAN Isoform 5 of Occludin OS=Homo sapiens OX=9606GN=OCLNMAYSSNGKVNDKRFYPESSYKSTPVPEVVQELPLTSPVDDFRQPRYSSGGNFETPSKRAPAKGRAGRSKRTEQDHYETDYTTGGESCDELEEDWIREYPPITSDQQRQLYKRNFDTGLQEYKSLQSELDEINKELSRLDKELDDYREESEEYMAAADEYNRLKQVKGSADYKSKKNHCKQLKSKLSHIKKMVGDYDRQKT>sp|Q16625-6|OCLN_HUMAN Isoform 6 of Occludin OS=Homo sapiens OX=9606GN=OCLNMSSRPLESPPPYRPDEFKPNHYAPSNDIYGGEMHVRPMLSQPAYSFYPEESLQAVKEQIVTHQEDGWRL>sp|Q16625-7|OCLN_HUMAN Isoform 7 of Occludin OS=Homo sapiens OX=9606GN=OCLNMSSRPLESPPPYRPDEFKPNHYAPSNDIYGGEMHVRPMLSQPAYSFYPEDEMTIEKKVKSTWLLLMNTID>sp|P54368|OAZ1_HUMAN Ornithine decarboxylase antizyme 1 OS=Homo sapiensOX=9606 GN=OAZ1 PE=1 SV=3MVKSSLQRILNSHCFAREKEGDKPSATIHASRTMPLLSLHSRGGSSSESSRVSLHCCSNPGPGPRWCSDAPHPPLKIPGGRGNSQRDHNLSANLFYSDDRLNVTEELTSNDKTRILNVQSRLTDAKRINWRTVLSGGSLYIEIPGGALPEGSKDSFAVLLEFAEEQLRADHVFICFHKNREDRAALLRTFSFLGFEIVRPGHPLVPKRPDACFMAYTFERESSGEEEE>sp|Q06495|NPT2A_HUMAN Sodium-dependent phosphate transport protein 2AOS=Homo sapiens OX=9606 GN=SLC34A1 PE=1 SV=1MLSYGERLGSPAVSPLPVRGGHVMRGTAFAYVPSPQVLHRIPGTSAYAFPSLGPVALAEHTCPCGEVLERHEPLPAKLALEEEQKPESRLVPKLRQAGAMLLKVPLMLTFLYLFVCSLDMLSSAFQLAGGKVAGDIFKDNAILSNPVAGLVVGILVTVLVQSSSTSTSIIVSMVSSGLLEVSSAIPIIMGSNIGTSVTNTIVALMQAGDRTDFRRAFAGATVHDCFNWLSVLVLLPLEAATGYLHHITRLVVASFNIHGGRDAPDLLKIITEPFTKLIIQLDESVITSIATGDESLRNHSLIQIWCHPDSLQAPTSMSRAEANSSQTLGNATMEKCNHIFVDTGLPDLAVGLILLAGSLVLLCTCLILLVKMLNSLLKGQVAKVIQKVINTDFPAPFTWVTGYFAMVVGASMTFVVQSSSVFTSAITPLIGLGVISIERAYPLTLGSNIGTTTTAILAALASPREKLSSAFQIALCHFFFNISGILLWYPVPCTRLPIRMAKALGKRTAKYRWFAVLYLLVCFLLLPSLVFGISMAGWQVMVGVGTPFGALLAFVVLINVLQSRSPGHLPKWLQTWDFLPRWMHSLKPLDHLITRATLCCARPEPRSPPLPPRVFLEELPPATPSPRLALPAHHNATRL>sp|Q06495-2|NPT2A_HUMAN Isoform 2 of Sodium-dependent phosphatetransport protein 2A OS=Homo sapiens OX=9606 GN=SLC34A1MLSYGERLGSPAVSPLPVRGGHVMRGTAFAYVPSPQVLHRIPGTSAYAFPSLGPVALAEHTCPCGEVLERHEPLPAKLALEEEQKPESRLVPKLRQAGAMLLKVPLMLTFLYLFVCSLDMLSSAFQLAGGKVAGDIFKDNAILSNPVAGLVVGILVTVLVQSSSTSTSIIVSMVSSGLLEVSSAIPIIMGSNIGTSVTNTIVALMQAGDRTDFRRAFAGATVHDCFNWLSVLVLLPLEAATGYLHHITRLVVASFNIHGGRDAPDLLKIITEPFTKLIIQLDESVITSIATGDESLRNHSLIQIWCHPDSLQQNLEGREITHFDLRKKQAMEDSSVPHCP>sp|A0A2R8YFL7|OSP4A_HUMAN Oocyte-secreted protein 4A OS=Homo sapiensOX=9606 GN=OOSP4A PE=3 SV=1MKISCVLGKLLMLFELIHGLQDLSITCSESWLQVKLRRTPLLNDLQPLQNELSLGIGCPVNMVEVDFFGFLYLLTFCGIRVSEHGVGILIESLIVYEPTNFDFNLHIPVSCYVQRRFPIILVMRGRENDSRRECRRSVGQHRSLSHELEDLEIRPRVSYVNSVPLLSYLIVSLPKCKNKAVHSG>sp|O76100|OR7AA_HUMAN Olfactory receptor 7A10 OS=Homo sapiens OX=9606GN=OR7A10 PE=3 SV=1MKSWNNTIILEFLLLGISEEPELQAFLFGLFLSMYLVTVLGNLLIILATISDSHLHTPMYFFLSNLSFVDICFVSTTVPKMLVNIQTHNKVITYAGCITQMCFFLLFVGLDNFLLTVMAYDRFVAICHPLHYMVIMNPQLCGLLVLASWIMSVLNSMLQSLMVLPLPFCTHMEIPHFFCEINQVVHLACSDTFLNDIVMYFAVALLGGGPLTGILYSYSKIVSSIRAISSAQGKYKAFSTCASHLSVVSLFYGTCLGVYLSSAATHNSHTGAAASVMYTVVTPMLNPFIYSLRNKHIKGAMKTFFRGKQ>sp|Q7Z3B4|NUP54_HUMAN Nucleoporin p54 OS=Homo sapiens OX=9606 GN=NUP54PE=1 SV=2MAFNFGAPSGTSGTAAATAAPAGGFGGFGTTSTTAGSAFSFSAPTNTGTTGLFGGTQNKGFGFGTGFGTTTGTSTGLGTGLGTGLGFGGFNTQQQQQTTLGGLFSQPTQAPTQSNQLINTASALSAPTLLGDERDAILAKWNQLQAFWGTGKGYFNNNIPPVEFTQENPFCRFKAVGYSCMPSNKDEDGLVVLVFNKKETEIRSQQQQLVESLHKVLGGNQTLTVNVEGTKTLPDDQTEVVIYVVERSPNGTSRRVPATTLYAHFEQANIKTQLQQLGVTLSMTRTELSPAQIKQLLQNPPAGVDPIIWEQAKVDNPDSEKLIPVPMVGFKELLRRLKVQDQMTKQHQTRLDIISEDISELQKNQTTSVAKIAQYKRKLMDLSHRTLQVLIKQEIQRKSGYAIQADEEQLRVQLDTIQGELNAPTQFKGRLNELMSQIRMQNHFGAVRSEERYYIDADLLREIKQHLKQQQEGLSHLISIIKDDLEDIKLVEHGLNETIHIRGGVFS>sp|Q7Z3B4-2|NUP54_HUMAN Isoform 2 of Nucleoporin p54 OS=Homo sapiensOX=9606 GN=NUP54MPSNKDEDGLVVLVFNKKETEIRSQQQQLVESLHKVLGGNQTLTVNVEGTKTLPDDQTEVVIYVVERSPNGTSRRVPATTLYAHFEQANIKTQLQQLGVTLSMTRTELSPAQIKQLLQNPPAGVDPIIWEQAKVDNPDSEKLIPVPMVGFKELLRRLKVQDQMTKQHQTRLDVLIKQEIQRKSGYAIQADEEQLRVQLDTIQGELNAPTQFKGRLNELMSQIRMQNHFGAVRSEERYYIDADLLREIKQHLKQQQEGLSHLISIIKDDLEDIKLVEHGLNETIHIRGGVFS>sp|Q7Z3B4-3|NUP54_HUMAN Isoform 3 of Nucleoporin p54 OS=Homo sapiensOX=9606 GN=NUP54MAFNFGAPSGTSGTAAATAAPAGGFGGFGTTSTTAGSAFSFSAPTNTGTTALGGLFSQPTQAPTQSNQLINTASALSAPTLLGDERDAILAKWNQLQAFWGTGKGYFNNNIPPVEFTQENPFCRFKAVGYSCMPSNKDEDGLVVLVFNKKETEIRSQQQQLVESLHKVLGGNQTLTVNVEGTKTLPDDQTEVVIYVVERSPNGTSRRVPATTLYAHFEQANIKTQLQQLGVTLSMTRTELSPAQIKQLLQNPPAGVDPIIWEQAKVDNPDSEKLIPVPMVGFKELLRRLKVQDQMTKQHQTRLDIISEDISELQKNQTTSVAKIAQYKRKLMDLSHRTLQVLIKQEIQRKSGYAIQADEEQLRVQLDTIQGELNAPTQFKGRLNELMSQIRMQNHFGAVRSEERYYIDADLLREIKQHLKQQQEGLSHLISIIKDDLEDIKLVEHGLNETIHIRGGVFS>sp|Q9H1Y3|OPN3_HUMAN Opsin-3 OS=Homo sapiens OX=9606 GN=OPN3 PE=1 SV=1MYSGNRSGGHGYWDGGGAAGAEGPAPAGTLSPAPLFSPGTYERLALLLGSIGLLGVGNNLLVLVLYYKFQRLRTPTHLLLVNISLSDLLVSLFGVTFTFVSCLRNGWVWDTVGCVWDGFSGSLFGIVSIATLTVLAYERYIRVVHARVINFSWAWRAITYIWLYSLAWAGAPLLGWNRYILDVHGLGCTVDWKSKDANDSSFVLFLFLGCLVVPLGVIAHCYGHILYSIRMLRCVEDLQTIQVIKILKYEKKLAKMCFLMIFTFLVCWMPYIVICFLVVNGHGHLVTPTISIVSYLFAKSNTVYNPVIYVFMIRKFRRSLLQLLCLRLLRCQRPAKDLPAAGSEMQIRPIVMSQKDGDRPKKKVTFNSSSIIFIITSDESLSVDDSDKTNGSKVDVIQVRPL>sp|Q9H1Y3-2|OPN3_HUMAN Isoform 2 of Opsin-3 OS=Homo sapiens OX=9606GN=OPN3MYSGNRSGGHGYWDGGGAAGAEGPAPAGTLSPAPLFSPGTYERLALLLGSIGLLGVGNNLLVLVLYYKFQRLRTPTHLLLVNISLSDLLVSLFGVTFTFVSCLRNGWVWDTVGCVWDGFSGSLFGWISQLQAATREARASMGPVQQGTICMQLRCVEDLQTIQVIKILKYEKKLAKMCFLMIFTFLVCWMPYIVICFLVVNGHGHLVTPTISIVSYLFAKSNTVYNPVIYVFMIRKFRRSLLQLLCLRLLRCQRPAKDLPAAGSEMQIRPIVMSQKDGDRPKKKVTFNSSSIIFIITSDESLSVDDSDKTNGSKVDVIQVRPL>sp|Q6ZVC0|NYAP1_HUMAN Neuronal tyrosine-phosphorylated phosphoinositide-3-kinase adapter 1 OS=Homo sapiens OX=9606 GN=NYAP1 PE=2 SV=1MNLLYRKTKLEWRQHKEEEAKRSSSKEVAPAGSAGPAAGQGPGVRVRDIASLRRSLRMGFMTMPASQEHTPHPCRSAMAPRSLSCHSVGSMDSVGGGPGGASGGLTEDSSTRRPPAKPRRHPSTKLSMVGPGSGAETPPSKKAGSQKPTPEGRESSRKVPPQKPRRSPNTQLSVSFDESCPPGPSPRGGNLPLQRLTRGSRVAGDPDVGAQEEPVYIEMVGDVFRGGGRSGGGLAGPPLGGGGPTPPAGADSDSEESEAIYEEMKYPLPEEAGEGRANGPPPLTATSPPQQPHALPPHAHRRPASALPSRRDGTPTKTTPCEIPPPFPNLLQHRPPLLAFPQAKSASRTPGDGVSRLPVLCHSKEPAGSTPAPQVPARERETPPPPPPPPAANLLLLGPSGRARSHSTPLPPQGSGQPRGERELPNSHSMICPKAAGAPAAPPAPAALLPGPPKDKAVSYTMVYSAVKVTTHSVLPAGPPLGAGEPKTEKEISVLHGMLCTSSRPPVPGKTSPHGGAMGAAAGVLHHRGCLASPHSLPDPTVGPLTPLWTYPATAAGLKRPPAYESLKAGGVLNKGCGVGAPSPMVKIQLQEQGTDGGAFASISCAHVIASAGTPEEEEEEVGAATFGAGWALQRKVLYGGRKAKELDKVEDGARAWNGSAEGPGKVEREDRGPGTSGIPVRSQGAEGLLARIHHGDRGGSRTALPIPCQTFPACHRNGDFTGGYRLGRSASTSGVRQVVLHTPRPCSQPRDALSQPHPALPLPLPLPPQPARERDGKLLEVIERKRCVCKEIKARHRPDRGLCKQESMPILPSWRRGPEPRKSGTPPCRRQHTVLWDTAI>sp|Q6ZVC0-2|NYAP1_HUMAN Isoform 2 of Neuronal tyrosine-phosphorylatedphosphoinositide-3-kinase adapter 1 OS=Homo sapiens OX=9606 GN=NYAP1MNLLYRKTKLEWRQHKEEEAKRSSSKEVAPAGSAGPAAGQGPGVRVRDIASLRRSLRMGFMTMPASQEHTPHPCRSAMAPRSLSCHSVGSMDSVGGGPGGASGGLTEDSSTRRPPAKPRRHPSTKLSMVGPGSGAETPPSKKAGSQKPTPEGRESSRKVPPQKPRRSPNTQLSVSFDESCPPGPSPRGGNLPLQRLTRGSRVAGDPDVGAQEEPVYIEMVGDVFRGGGRSGGGLAGPPLGGGGPTPPAGADSDSEESEAIYEEMKYPLPEEAGEGRANGPPPLTATSPPQQPHALPPHAHRRPASALPSRRDGTPTKTTPCEIPPPFPNLLQHRPPLLAFPQAKSASRTPGDGVSRLPVLCHSKEPAGSTPAPQVPARERETPPPPPPPPAANLLLLGPSGRARSHSTPLPPQGSGQPRGERELPNSHSMICPKAAGAPAAPPAPAALLPGPPKDKAVSYTMVYSAVKVTTHSVLPAGPPLGAGEPKTEKEISVLHGMLCTSSRPPVPGKTSPHGGAMGAAAGVLHHRGCLASPHSLPDPTVGPLTPLWTYPATAAGLKRPPAYESLKAGGVLNKGCGVGAPSPMVKIQLQEQGTDGGAFASISCAHVIASAGTPEEEEEEVGAATFGAGWALQRKVLYGGRKAKELDTEVEDGARAWNGSAEGPGKVEREDRGPGTSGIPVRSQGAEGLLARIHHGDRGGSRTALPIPCQTFPACHRNGDFTGGYRLGRSASTSGVRQVVLHTPRPCSQPRDALSQPHPALPLPLPLPPQPARERDGKLLEVIERKRCVCKEIKARHRPDRGLCKQESMPILPSWRRGPEPRKSGTPPCRRQHTVLWDTAI>sp|Q6IF42|OR2A2_HUMAN Olfactory receptor 2A2 OS=Homo sapiens OX=9606GN=OR2A2 PE=2 SV=2MEGNQTWITDITLLGFQVGPALAILLCGLFSVFYTLTLLGNGVIFGIICLDSKLHTPMYFFLSHLAIIDMSYASNNVPKMLANLMNQKRTISFVPCIMQTFLYLAFAVTECLILVVMSYDRYVAICHPFQYTVIMSWRVCTILVLTSWSCGFALSLVHEILLLRLPFCGPRDVNHLFCEILSVLKLACADTWVNQVVIFATCVFVLVGPLSLILVSYMHILGAILKIQTKEGRIKAFSTCSSHLCVVGLFFGIAMVVYMVPDSNQREEQEKMLSLFHSVFNPMLNPLIYSLRNAQLKGALHRALQRKRSMRTVYGLCL>sp|Q9H342|O51J1_HUMAN Olfactory receptor 51J1 OS=Homo sapiens OX=9606GN=OR51J1 PE=3 SV=2MKISNNSLGFLPTTFILVGIPGLESEHLWISVPFSLIYIIIFLGNGIILHVIRTDIALHQPMYLFLAMLALAEVRVSASTLPTVLGIFLFGNTEISLEACLFPDVLHPFFIHDGASCAAGHVFGPLYSHLQPTELHSYPDTAQGLWHRSYYRTEKHYAHGSVAHSLMASALLWPQCPLTFLLSAPQSYLSCGNISVNNIYGIFIVTSTFGLDSLLIVISYGLILHTVLGIATGEGRKKALNTCGSHVCAVLAYYVPMIGLSIVHRLGHRVSPLLQAMMANAYLFFPPVVNPIVYSIKTKEIHGAIVRMLLEKRRRV>sp|Q8NHA4|O2AE1_HUMAN Olfactory receptor 2AE1 OS=Homo sapiens OX=9606GN=OR2AE1 PE=2 SV=1MWQKNQTSLADFILEGLFDDSLTHLFLFSLTMVVFLIAVSGNTLTILLICIDPQLHTPMYFLLSQLSLMDLMHVSTIILKMATNYLSGKKSISFVGCATQHFLYLCLGGAECFLLAVMSYDRYVAICHPLRYAVLMNKKVGLMMAVMSWLGASVNSLIHMAILMHFPFCGPRKVYHFYCEFPAVVKLVCGDITVYETTVYISSILLLLPIFLISTSYVFILQSVIQMRSSGSKRNAFATCGSHLTVVSLWFGACIFSYMRPRSQCTLLQNKVGSVFYSIITPTLNSLIYTLRNKDVAKALRRVLRRDVITQCIQRLQLWLPRV>sp|P12004|PCNA_HUMAN Proliferating cell nuclear antigen OS=Homo sapiensOX=9606 GN=PCNA PE=1 SV=1MFEARLVQGSILKKVLEALKDLINEACWDISSSGVNLQSMDSSHVSLVQLTLRSEGFDTYRCDRNLAMGVNLTSMSKILKCAGNEDIITLRAEDNADTLALVFEAPNQEKVSDYEMKLMDLDVEQLGIPEQEYSCVVKMPSGEFARICRDLSHIGDAVVISCAKDGVKFSASGELGNGNIKLSQTSNVDKEEEAVTIEMNEPVQLTFALRYLNFFTKATPLSSTVTLSMSADVPLVVEYKIADMGHLKYYLAPKIEDEEGS>sp|P0C617|O5AL1_HUMAN Olfactory receptor 5AL1 OS=Homo sapiens OX=9606GN=OR5AL1 PE=3 SV=2MCALKGFLEENFYTYSVAKGNHSTVYEFILLGLTDNAELQVTLFGIFLVVYLASFMGNFGLIMLIQISPQLHTPMYFFLSHLAFVDFSFTSSVAPNTLVNFLCEVKSITFYACAIQVCCFITFVVCELYLLSIMAYDRYVAICNPLLYVILIPRKLCIKLIASTYVYGFTVGLVQTVATSYLSFCDSNVINHFYHDDVPLVALACSDTHVKELMLLIIAGFNTLCSLVIVLISYGFIFFAILRIHSAEGRQKAFSTSASHLTSITIFYGTIIFMYPQPKSSHSLNMDKVASVFNVVVIPTLNPLIYSLRNQEVKNALKRIIEKLCLAVK>sp|Q8NGK4|O52K1_HUMAN Olfactory receptor 52K1 OS=Homo sapiens OX=9606GN=OR52K1 PE=2 SV=2MLPSNITSTHPAVFLLVGIPGLEHLHAWISIPFCFAYTLALLGNCTLLFIIQADAALHEPMYLFLAMLATIDLVLSSTTLPKMLAIFWFRDQEINFFACLVQMFFLHSFSIMESAVLLAMAFDRYVAICKPLHYTTVLTGSLITKIGMAAVARAVTLMTPLPFLLRRFHYCRGPVIAHCYCEHMAVVRLACGDTSFNNIYGIAVAMFIVVLDLLFVILSYVFILQAVLQLASQEARYKAFGTCVSHIGAILSTYTPVVISSVMHRVARHAAPRVHILLAIFYLLFPPMVNPIIYGVKTKQIREYVLSLFQRKNM>sp|Q8NGF0|O52B6_HUMAN Olfactory receptor 52B6 OS=Homo sapiens OX=9606GN=OR52B6 PE=3 SV=3MAQVRALHKIMALFSANSIGAMNNSDTRIAGCFLTGIPGLEQLHIWLSIPFCIMYITALEGNGILICVILSQAILHEPMYIFLSMLASADVLLSTTTMPKALANLWLGYSLISFDGCLTQMFFIHFLFIHSAVLLAMAFDRYVAICSPLRYVTILTSKVIGKIVTAALSHSFIIMFPSIFLLEHLHYCQINIIAHTFCEHMGIAHLSCSDISINVWYGLAAALLSTGLDIMLITVSYIHILQAVFRLLSQDARSKALSTCGSHICVILLFYVPALFSVFAYRFGGRSVPCYVHILLASLYVVIPPMLNPVIYGVRTKPILEGAKQMFSNLAKGSK>sp|O00254|PAR3_HUMAN Proteinase-activated receptor 3 OS=Homo sapiensOX=9606 GN=F2RL2 PE=1 SV=1MKALIFAAAGLLLLLPTFCQSGMENDTNNLAKPTLPIKTFRGAPPNSFEEFPFSALEGWTGATITVKIKCPEESASHLHVKNATMGYLTSSLSTKLIPAIYLLVFVVGVPANAVTLWMLFFRTRSICTTVFYTNLAIADFLFCVTLPFKIAYHLNGNNWVFGEVLCRATTVIFYGNMYCSILLLACISINRYLAIVHPFTYRGLPKHTYALVTCGLVWATVFLYMLPFFILKQEYYLVQPDITTCHDVHNTCESSSPFQLYYFISLAFFGFLIPFVLIIYCYAAIIRTLNAYDHRWLWYVKASLLILVIFTICFAPSNIILIIHHANYYYNNTDGLYFIYLIALCLGSLNSCLDPFLYFLMSKTRNHSTAYLTK>sp|O00254-2|PAR3_HUMAN Isoform 2 of Proteinase-activated receptor 3OS=Homo sapiens OX=9606 GN=F2RL2MENDTNNLAKPTLPIKTFRGAPPNSFEEFPFSALEGWTGATITVKIKCPEESASHLHVKNATMGYLTSSLSTKLIPAIYLLVFVVGVPANAVTLWMLFFRTRSICTTVFYTNLAIADFLFCVTLPFKIAYHLNGNNWVFGEVLCRATTVIFYGNMYCSILLLACISINRYLAIVHPFTYRGLPKHTYALVTCGLVWATVFLYMLPFFILKQEYYLVQPDITTCHDVHNTCESSSPFQLYYFISLAFFGFLIPFVLIIYCYAAIIRTLNAYDHRWLWYVKASLLILVIFTICFAPSNIILIIHHANYYYNNTDGLYFIYLIALCLGSLNSCLDPFLYFLMSKTRNHSTAYLTK>sp|Q8NGJ9|O51T1_HUMAN Olfactory receptor 51T1 OS=Homo sapiens OX=9606GN=OR51T1 PE=3 SV=1MAIFNNTTSSSSNFLLTAFPGLECAHVWISIPVCCLYTIALLGNSMIFLVIITKRRLHKPMYYFLSMLAAVDLCLTITTLPTVLGVLWFHAREISFKACFIQMFFVHAFSLLESSVLVAMAFDRFVAICNPLNYATILTDRMVLVIGLVICIRPAVFLLPLLVAINTVSFHGGHELSHPFCYHPEVIKYTYSKPWISSFWGLFLQLYLNGTDVLFILFSYVLILRTVLGIVARKKQQKALSTCVCHICAVTIFYVPLISLSLAHRLFHSTPRVLCSTLANIYLLLPPVLNPIIYSLKTKTIRQAMFQLLQSKGSWGFNVRGLRGRWD>sp|P35372|OPRM_HUMAN Mu-type opioid receptor OS=Homo sapiens OX=9606GN=OPRM1 PE=1 SV=2MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQLENLEAETAPLP>sp|P35372-2|OPRM_HUMAN Isoform 2 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQVRSL>sp|P35372-3|OPRM_HUMAN Isoform 3 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQCLPIPSLSCWALEQGCLVVYPGPLQGPLVRYDLPAILHSSCLRGNTAPSPSGGAFLLS>sp|P35372-4|OPRM_HUMAN Isoform 4 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQGPPAKFVADQLAGSS>sp|P35372-5|OPRM_HUMAN Isoform 5 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQPPLAVSMAQIFTRYPPPTHREKTCNDYMKR>sp|P35372-6|OPRM_HUMAN Isoform 6 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQIRDPISNLPRVSVF>sp|P35372-7|OPRM_HUMAN Isoform 7 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQKIDLFQKSSLLNCEHTKG>sp|P35372-8|OPRM_HUMAN Isoform 8 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQRERRQKSDW>sp|P35372-9|OPRM_HUMAN Isoform 9 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQVELNLDCHCENAKPWPLSYNAGQSPFPFPGRV>sp|P35372-10|OPRM_HUMAN Isoform 10 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MCLHRRVPSEETYSLDRFAQNPPLFPPPSLPASESRMAHAPLLQRCGAARTGFCKKQQELWQRRKEAAEALGTRKVSVLLATSHSGARPAVSTMDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQLENLEAETAPLP>sp|P35372-11|OPRM_HUMAN Isoform 11 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQS>sp|P35372-12|OPRM_HUMAN Isoform 12 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQLENLEAETAPLP>sp|P35372-13|OPRM_HUMAN Isoform 13 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MMRAKSISTKAGKPSRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQLENLEAETAPLP>sp|P35372-14|OPRM_HUMAN Isoform 14 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQNYYIIHRCCCNTPLISQKPVLLWFCD>sp|P35372-15|OPRM_HUMAN Isoform 15 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGTILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIINVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALVTIPETTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCFREFCIPTSSNIEQQNSTRIRQNTRDHPSTANTVDRTNHQVRSL>sp|P35372-16|OPRM_HUMAN Isoform 16 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRYSWFVIGGPEGRRKQRRLGEDKRARGCGEKG>sp|P35372-17|OPRM_HUMAN Isoform 17 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVSSSWF>sp|P35372-18|OPRM_HUMAN Isoform 18 of Mu-type opioid receptor OS=Homosapiens OX=9606 GN=OPRM1MDSSAAPTNASNCTDALAYSSCSPAPSPGSWVNLSHLDGNLSDPCGPNRTDLGGRDSLCPPTGSPSMITAITIMALYSIVCVVGLFGNFLVMYVIVRFHRLYTNILSSNLVLGKPAEDLCFHLRLHYASAHHYRVLWTDDLAPQECPHALWLQRKGQESSKDHQDGAGGGGCVHRLLDSHSHLRHH>sp|Q13310|PABP4_HUMAN Polyadenylate-binding protein 4 OS=Homo sapiensOX=9606 GN=PABPC4 PE=1 SV=1MNAAASSYPMASLYVGDLHSDVTEAMLYEKFSPAGPVLSIRVCRDMITRRSLGYAYVNFQQPADAERALDTMNFDVIKGKPIRIMWSQRDPSLRKSGVGNVFIKNLDKSIDNKALYDTFSAFGNILSCKVVCDENGSKGYAFVHFETQEAADKAIEKMNGMLLNDRKVFVGRFKSRKEREAELGAKAKEFTNVYIKNFGEEVDDESLKELFSQFGKTLSVKVMRDPNGKSKGFGFVSYEKHEDANKAVEEMNGKEISGKIIFVGRAQKKVERQAELKRKFEQLKQERISRYQGVNLYIKNLDDTIDDEKLRKEFSPFGSITSAKVMLEDGRSKGFGFVCFSSPEEATKAVTEMNGRIVGSKPLYVALAQRKEERKAHLTNQYMQRVAGMRALPANAILNQFQPAAGGYFVPAVPQAQGRPPYYTPNQLAQMRPNPRWQQGGRPQGFQGMPSAIRQSGPRPTLRHLAPTGSECPDRLAMDFGGAGAAQQGLTDSCQSGGVPTAVQNLAPRAAVAAAAPRAVAPYKYASSVRSPHPAIQPLQAPQPAVHVQGQEPLTASMLAAAPPQEQKQMLGERLFPLIQTMHSNLAGKITGMLLEIDNSELLHMLESPESLRSKVDEAVAVLQAHHAKKEAAQKVGAVAAATS>sp|Q13310-2|PABP4_HUMAN Isoform 2 of Polyadenylate-binding protein 4OS=Homo sapiens OX=9606 GN=PABPC4MNAAASSYPMASLYVGDLHSDVTEAMLYEKFSPAGPVLSIRVCRDMITRRSLGYAYVNFQQPADAERALDTMNFDVIKGKPIRIMWSQRDPSLRKSGVGNVFIKNLDKSIDNKALYDTFSAFGNILSCKVVCDENGSKGYAFVHFETQEAADKAIEKMNGMLLNDRKVFVGRFKSRKEREAELGAKAKEFTNVYIKNFGEEVDDESLKELFSQFGKTLSVKVMRDPNGKSKGFGFVSYEKHEDANKAVEEMNGKEISGKIIFVGRAQKKVERQAELKRKFEQLKQERISRYQGVNLYIKNLDDTIDDEKLRKEFSPFGSITSAKVMLEDGRSKGFGFVCFSSPEEATKAVTEMNGRIVGSKPLYVALAQRKEERKAHLTNQYMQRVAGMRALPANAILNQFQPAAGGYFVPAVPQAQGRPPYYTPNQLAQMRPNPRWQQGGRPQGFQGMPSAIRQSGPRPTLRHLAPTGNAPASRGLPTTTQRVGVPTAVQNLAPRAAVAAAAPRAVAPYKYASSVRSPHPAIQPLQAPQPAVHVQGQEPLTASMLAAAPPQEQKQMLGERLFPLIQTMHSNLAGKITGMLLEIDNSELLHMLESPESLRSKVDEAVAVLQAHHAKKEAAQKVGAVAAATS>sp|Q13310-3|PABP4_HUMAN Isoform 3 of Polyadenylate-binding protein 4OS=Homo sapiens OX=9606 GN=PABPC4MNAAASSYPMASLYVGDLHSDVTEAMLYEKFSPAGPVLSIRVCRDMITRRSLGYAYVNFQQPADAERALDTMNFDVIKGKPIRIMWSQRDPSLRKSGVGNVFIKNLDKSIDNKALYDTFSAFGNILSCKVVCDENGSKGYAFVHFETQEAADKAIEKMNGMLLNDRKVFVGRFKSRKEREAELGAKAKEFTNVYIKNFGEEVDDESLKELFSQFGKTLSVKVMRDPNGKSKGFGFVSYEKHEDANKAVEEMNGKEISGKIIFVGRAQKKVERQAELKRKFEQLKQERISRYQGVNLYIKNLDDTIDDEKLRKEFSPFGSITSAKVMLEDGRSKGFGFVCFSSPEEATKAVTEMNGRIVGSKPLYVALAQRKEERKAHLTNQYMQRVAGMRALPANAILNQFQPAAGGYFVPAVPQAQGRPPYYTPNQLAQMRPNPRWQQGGRPQGFQGMPSAIRQSGPRPTLRHLAPTGNAPASRGLPTTTQRVGSECPDRLAMDFGGAGAAQQGLTDSCQSGGVPTAVQNLAPRAAVAAAAPRAVAPYKYASSVRSPHPAIQPLQAPQPAVHVQGQEPLTASMLAAAPPQEQKQMLGERLFPLIQTMHSNLAGKITGMLLEIDNSELLHMLESPESLRSKVDEAVAVLQAHHAKKEAAQKVGAVAAATS>sp|P32242|OTX1_HUMAN Homeobox protein OTX1 OS=Homo sapiens OX=9606GN=OTX1 PE=1 SV=1MMSYLKQPPYGMNGLGLAGPAMDLLHPSVGYPATPRKQRRERTTFTRSQLDVLEALFAKTRYPDIFMREEVALKINLPESRVQVWFKNRRAKCRQQQQSGSGTKSRPAKKKSSPVRESSGSESSGQFTPPAVSSSASSSSSASSSSANPAAAAAAGLGGNPVAAASSLSTPAASSIWSPASISPGSAPASVSVPEPLAAPSNTSCMQRSVAAGAATAAASYPMSYGQGGSYGQGYPTPSSSYFGGVDCSSYLAPMHSHHHPHQLSPMAPSSMAGHHHHHPHAHHPLSQSSGHHHHHHHHHHQGYGGSGLAFNSADCLDYKEPGAAAASSAWKLNFNSPDCLDYKDQASWRFQVL>sp|Q9H8K7|PAAT_HUMAN ATPase PAAT OS=Homo sapiens OX=9606 GN=PAAT PE=1SV=2METRTEDGGLTRRPTLASSWDVAGGALTHSLLLTRAGLGPGDFDWEELLAPPAPGQDLVILKRNHNNKDENPCFLYLRCGPDGGEEIASIGILSSARNMEVYLGEEYCGTSRGKNVCTVLDDSEHEKIILYKKNLKLESSTHACKIKLLSFGERQCVFISKVVVHMRSVFANSSTSSPALGSRIDLDKVQTIMESMGSKLSPGAQQLMDMVRCQQRNCIPIGEQLQSVLGNSGYKHMIGLQSSSTLGTLNKSSSTPFPFRTGLTSGNVTENLQTYIDKSTQLPGGENSTKLDECKVMPQNHSFLENDLKNAMASFLPKKVSDNSNIPNSELLPFLQNLCSQVNHLHVGNKTECQENITKHGERILGVGMEEQSICSYLEKILSKNMELMEKKLMDYIDQRIHELQEHIDDKIALLLDLLQNPNSPPTGIPLRHYDSGERLSNGER>sp|Q9BRP4|PAAF1_HUMAN Proteasomal ATPase-associated factor 1 OS=Homosapiens OX=9606 GN=PAAF1 PE=1 SV=2MAAPLRIQSDWAQALRKDEGEAWLSCHPPGKPSLYGSLTCQGIGLDGIPEVTASEGFTVNEINKKSIHISCPKENASSKFLAPYTTFSRIHTKSITCLDISSRGGLGVSSSTDGTMKIWQASNGELRRVLEGHVFDVNCCRFFPSGLVVLSGGMDAQLKIWSAEDASCVVTFKGHKGGILDTAIVDRGRNVVSASRDGTARLWDCGRSACLGVLADCGSSINGVAVGAADNSINLGSPEQMPSEREVGTEAKMLLLAREDKKLQCLGLQSRQLVFLFIGSDAFNCCTFLSGFLLLAGTQDGNIYQLDVRSPRAPVQVIHRSGAPVLSLLSVRDGFIASQGDGSCFIVQQDLDYVTELTGADCDPVYKVATWEKQIYTCCRDGLVRRYQLSDL>sp|Q9BRP4-2|PAAF1_HUMAN Isoform 2 of Proteasomal ATPase-associatedfactor 1 OS=Homo sapiens OX=9606 GN=PAAF1MLVPCFLYSLQNRKPSLYGSLTCQGIGLDGIPEVTASEGFTVNEINKKSIHISCPKENASSKFLAPYTTFSRIHTKSITCLDISSRGGLGVSSSTDGTMKIWQASNGELRRVLEGHVFDVNCCRFFPSGLVVLSGGMDAQLKIWSAEDASCVVTFKGHKGGILDTAIVDRGRNVVSASRDGTARLWDCGRSACLGVLADCGSSINGVAVGAADNSINLGSPEQMPSEREVGTEAKMLLLAREDKKLQCLGLQSRQLVFLFIGSDAFNCCTFLSGFLLLAGTQDGNIYQLDVRSPRAPVQVIHRSGAPVLSLLSVRDGFIASQGDGSCFIVQQDLDYVTELTGADCDPVYKVATWEKQIYTCCRDGLVRRYQLSDL>sp|Q9BRP4-3|PAAF1_HUMAN Isoform 3 of Proteasomal ATPase-associatedfactor 1 OS=Homo sapiens OX=9606 GN=PAAF1MKIWQASNGELRRVLEGHVFDVNCCRFFPSGLVVLSGGMDAQLKIWSAEDASCVVTFKGHKGGILDTAIVDRGRNVVSASRDGTARLWDCGRSACLGVLADCGSSINGVAVGAADNSINLGSPEQMPSEREVGTEAKMLLLAREDKKLQCLGLQSRQLVFLFIGSDAFNCCTFLSGFLLLAGTQDGNIYQLDVRSPRAPVQVIHRSGAPVLSLLSVRDGFIASQGDGSCFIVQQDLDYVTELTGADCDPVYKVATWEKQIYTCCRDGLVRRYQLSDL>sp|Q969Q6|P2R3C_HUMAN Serine/threonine-protein phosphatase 2A regulatorysubunit B'' subunit gamma OS=Homo sapiens OX=9606 GN=PPP2R3C PE=1 SV=1MDWKEVLRRRLATPNTCPNKKKSEQELKDEEMDLFTKYYSEWKGGRKNTNEFYKTIPRFYYRLPAEDEVLLQKLREESRAVFLQRKSRELLDNEELQNLWFLLDKHQTPPMIGEEAMINYENFLKVGEKAGAKCKQFFTAKVFAKLLHTDSYGRISIMQFFNYVMRKVWLHQTRIGLSLYDVAGQGYLRESDLENYILELIPTLPQLDGLEKSFYSFYVCTAVRKFFFFLDPLRTGKIKIQDILACSFLDDLLELRDEELSKESQETNWFSAPSALRVYGQYLNLDKDHNGMLSKEELSRYGTATMTNVFLDRVFQECLTYDGEMDYKTYLDFVLALENRKEPAALQYIFKLLDIENKGYLNVFSLNYFFRAIQELMKIHGQDPVSFQDVKDEIFDMVKPKDPLKISLQDLINSNQGDTVTTILIDLNGFWTYENREALVANDSENSADLDDT>sp|Q969Q6-2|P2R3C_HUMAN Isoform 2 of Serine/threonine-proteinphosphatase 2A regulatory subunit B'' subunit gamma OS=Homo sapiensOX=9606 GN=PPP2R3CMIGEEAMINYENFLKVGEKAGAKCKQFFTAKVFAKLLHTDSYGRISIMQFFNYVMRKVWLHQTRIGLSLYDVAGQGYLRESDLENYILELIPTLPQLDGLEKSFYSFYVCTAVRKFFFFLDPLRTGKIKIQDILACSFLDDLLELRDEELSKESQETNWFSAPSALRVYGQYLNLDKDHNGMLSKEELSRYGTATMTNVFLDRVFQECLTYDGEMDYKTYLDFVLALENRKEPAALQYIFKLLDIENKGYLNVFSLNYFFRAIQELMKIHGQDPVSFQDVKDEIFDMVKPKDPLKISLQDLINSNQGDTVTTILIDLNGFWTYENREALVANDSENSADLDDT>sp|Q9BYG4|PAR6G_HUMAN Partitioning defective 6 homolog gamma OS=Homosapiens OX=9606 GN=PARD6G PE=1 SV=1MNRSFHKSQTLRFYDCSAVEVKSKFGAEFRRFSLDRHKPGKFEDFYKLVVHTHHISNSDVTIGYADVHGDLLPINNDDNFCKAVSSANPLLRVFIQKREEAERGSLGAGSLCRRRRALGALRDEGPRRRAHLDIGLPRDFRPVSSIIDVDLVPETHRRVRLHRHGCEKPLGFYIRDGASVRVTPHGLEKVPGIFISRMVPGGLAESTGLLAVNDEVLEVNGIEVAGKTLDQVTDMMIANSHNLIVTVKPANQRNNVVRGGRALGSSGPPSDGTAGFVGPPAPRVLQNFHPDEAESDEDNDVVIEGTLEPARPPQTPGAPAGSLSRVNGAGLAQRLQRDLALDGGLQRLLSSLRADPRHSLALPPGGVEEHGPAVTL>sp|Q9BYG4-2|PAR6G_HUMAN Isoform 2 of Partitioning defective 6 homologgamma OS=Homo sapiens OX=9606 GN=PARD6GMNRSFHKSQTLRFYDCSAVEVKSKFGAEFRRFSLDRHKPGKFEDFYKLVVHTHHISNSDVTIGYADVHGDLLPINNDDNFCKAVSSANPLLRVFIQKRDDGALRPGT>sp|P55085|PAR2_HUMAN Proteinase-activated receptor 2 OS=Homo sapiensOX=9606 GN=F2RL1 PE=1 SV=1MRSPSAAWLLGAAILLAASLSCSGTIQGTNRSSKGRSLIGKVDGTSHVTGKGVTVETVFSVDEFSASVLTGKLTTVFLPIVYTIVFVVGLPSNGMALWVFLFRTKKKHPAVIYMANLALADLLSVIWFPLKIAYHIHGNNWIYGEALCNVLIGFFYGNMYCSILFMTCLSVQRYWVIVNPMGHSRKKANIAIGISLAIWLLILLVTIPLYVVKQTIFIPALNITTCHDVLPEQLLVGDMFNYFLSLAIGVFLFPAFLTASAYVLMIRMLRSSAMDENSEKKRKRAIKLIVTVLAMYLICFTPSNLLLVVHYFLIKSQGQSHVYALYIVALCLSTLNSCIDPFVYYFVSHDFRDHAKNALLCRSVRTVKQMQVSLTSKKHSRKSSSYSSSSTTVKTSY>sp|Q9NPG4|PCD12_HUMAN Protocadherin-12 OS=Homo sapiens OX=9606 GN=PCDH12PE=1 SV=1MMQLLQLLLGLLGPGGYLFLLGDCQEVTTLTVKYQVSEEVPSGTVIGKLSQELGREERRRQAGAAFQVLQLPQALPIQVDSEEGLLSTGRRLDREQLCRQWDPCLVSFDVLATGDLALIHVEIQVLDINDHQPRFPKGEQELEISESASLRTRIPLDRALDPDTGPNTLHTYTLSPSEHFALDVIVGPDETKHAELIVVKELDREIHSFFDLVLTAYDNGNPPKSGTSLVKVNVLDSNDNSPAFAESSLALEIQEDAAPGTLLIKLTATDPDQGPNGEVEFFLSKHMPPEVLDTFSIDAKTGQVILRRPLDYEKNPAYEVDVQARDLGPNPIPAHCKVLIKVLDVNDNIPSIHVTWASQPSLVSEALPKDSFIALVMADDLDSGHNGLVHCWLSQELGHFRLKRTNGNTYMLLTNATLDREQWPKYTLTLLAQDQGLQPLSAKKQLSIQISDINDNAPVFEKSRYEVSTRENNLPSLHLITIKAHDADLGINGKVSYRIQDSPVAHLVAIDSNTGEVTAQRSLNYEEMAGFEFQVIAEDSGQPMLASSVSVWVSLLDANDNAPEVVQPVLSDGKASLSVLVNASTGHLLVPIETPNGLGPAGTDTPPLATHSSRPFLLTTIVARDADSGANGEPLYSIRSGNEAHLFILNPHTGQLFVNVTNASSLIGSEWELEIVVEDQGSPPLQTRALLRVMFVTSVDHLRDSARKPGALSMSMLTVICLAVLLGIFGLILALFMSICRTEKKDNRAYNCREAESTYRQQPKRPQKHIQKADIHLVPVLRGQAGEPCEVGQSHKDVDKEAMMEAGWDPCLQAPFHLTPTLYRTLRNQGNQGAPAESREVLQDTVNLLFNHPRQRNASRENLNLPEPQPATGQPRSRPLKVAGSPTGRLAGDQGSEEAPQRPPASSATLRRQRHLNGKVSPEKESGPRQILRSLVRLSVAAFAERNPVEELTVDSPPVQQISQLLSLLHQGQFQPKPNHRGNKYLAKPGGSRSAIPDTDGPSARAGGQTDPEQEEGPLDPEEDLSVKQLLEEELSSLLDPSTGLALDRLSAPDPAWMARLSLPLTTNYRDNVISPDAAATEEPRTFQTFGKAEAPELSPTGTRLASTFVSEMSSLLEMLLEQRSSMPVEAASEALRRLSVCGRTLSLDLATSAASGMKVQGDPGGKTGTEGKSRGSSSSSRCL>sp|Q9H361|PABP3_HUMAN Polyadenylate-binding protein 3 OS=Homo sapiensOX=9606 GN=PABPC3 PE=1 SV=2MNPSTPSYPTASLYVGDLHPDVTEAMLYEKFSPAGPILSIRICRDLITSGSSNYAYVNFQHTKDAEHALDTMNFDVIKGKPVRIMWSQRDPSLRKSGVGNIFVKNLDKSINNKALYDTVSAFGNILSCNVVCDENGSKGYGFVHFETHEAAERAIKKMNGMLLNGRKVFVGQFKSRKEREAELGARAKEFPNVYIKNFGEDMDDERLKDLFGKFGPALSVKVMTDESGKSKGFGFVSFERHEDAQKAVDEMNGKELNGKQIYVGRAQKKVERQTELKRTFEQMKQDRITRYQVVNLYVKNLDDGIDDERLRKAFSPFGTITSAKVMMEGGRSKGFGFVCFSSPEEATKAVTEMNGRIVATKPLYVALAQRKEERQAYLTNEYMQRMASVRAVPNQRAPPSGYFMTAVPQTQNHAAYYPPSQIARLRPSPRWTAQGARPHPFQNKPSAIRPGAPRVPFSTMRPASSQVPRVMSTQRVANTSTQTVGPRPAAAAAAAATPAVRTVPRYKYAAGVRNPQQHRNAQPQVTMQQLAVHVQGQETLTASRLASAPPQKQKQMLGERLFPLIQAMHPTLAGKITGMLLEIDNSELLYMLESPESLRSKVDEAVAVLQAHQAKEATQKAVNSATGVPTV>sp|P41231|P2RY2_HUMAN P2Y purinoceptor 2 OS=Homo sapiens OX=9606GN=P2RY2 PE=1 SV=4MAADLGPWNDTINGTWDGDELGYRCRFNEDFKYVLLPVSYGVVCVPGLCLNAVALYIFLCRLKTWNASTTYMFHLAVSDALYAASLPLLVYYYARGDHWPFSTVLCKLVRFLFYTNLYCSILFLTCISVHRCLGVLRPLRSLRWGRARYARRVAGAVWVLVLACQAPVLYFVTTSARGGRVTCHDTSAPELFSRFVAYSSVMLGLLFAVPFAVILVCYVLMARRLLKPAYGTSGGLPRAKRKSVRTIAVVLAVFALCFLPFHVTRTLYYSFRSLDLSCHTLNAINMAYKVTRPLASANSCLDPVLYFLAGQRLVRFARDAKPPTGPSPATPARRRLGLRRSDRTDMQRIEDVLGSSEDSRRTESTPAGSENTKDIRL>sp|Q9Y5I2|PCDAA_HUMAN Protocadherin alpha-10 OS=Homo sapiens OX=9606GN=PCDHA10 PE=2 SV=1MVSRCSCLGVQCLLLSLLLLAAWEVGSGQLHYSVYEEARHGTFVGRIAQDLGLELAELVQRLFRVASKRHGDLLEVNLQNGILFVNSRIDREELCGRSVECSIHLEVIVDRPLQVFHVDVEVKDINDNPPRFSVTEQKLSIPESRLLDSRFPLEGASDADVGENALLTYKLSPNEYFVLDIINKKDKDKFPVLVLRKLLDREENPQLKLLLTATDGGKPEFTGSVSLLILVLDANDNAPIFDRPVYEVKMYENQVNQTLVIRLNASDSDEGINKEMMYSFSSLVPPTIRRKFWINERTGEIKVNDAIDFEDSNTYEIHVDVTDKGNPPMVGHCTVLVELLDENDNSPEVIVTSLSLPVKEDAQVGTVIALISVSDHDSGANGQVTCSLTPHVPFKLVSTYKNYYSLVLDSALDRERVSAYELVVTARDGGSPPLWATASVSVEVADVNDNAPAFAQSEYTVFVKENNPPGCHIFTVSAWDADAQENALVSYSLVERRLGERSLSSYVSVHAESGKVYALQPLDHEELELLQFQVSARDGGVPPLGSNLTLQVFVLDENDNAPALLASPAGSAGGAVSELVLRSVVAGHVVAKVRAVDADSGYNAWLSYELQSAAVGARIPFRVGLYTGEISTTRALDETDSPRQRLLVLVKDHGEPSLTATATVLVSLVEGSQAPKASSRASVGVAPEVALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSAAPTEGACGPVKPTLVCSSAVGSWSYSQQRRQRVCSGEGLPKADLMAFSPSLPPCPMVDVDGEDQSIGGDHSRKPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9Y5I2-2|PCDAA_HUMAN Isoform 2 of Protocadherin alpha-10 OS=Homosapiens OX=9606 GN=PCDHA10MVSRCSCLGVQCLLLSLLLLAAWEVGSGQLHYSVYEEARHGTFVGRIAQDLGLELAELVQRLFRVASKRHGDLLEVNLQNGILFVNSRIDREELCGRSVECSIHLEVIVDRPLQVFHVDVEVKDINDNPPRFSVTEQKLSIPESRLLDSRFPLEGASDADVGENALLTYKLSPNEYFVLDIINKKDKDKFPVLVLRKLLDREENPQLKLLLTATDGGKPEFTGSVSLLILVLDANDNAPIFDRPVYEVKMYENQVNQTLVIRLNASDSDEGINKEMMYSFSSLVPPTIRRKFWINERTGEIKVNDAIDFEDSNTYEIHVDVTDKGNPPMVGHCTVLVELLDENDNSPEVIVTSLSLPVKEDAQVGTVIALISVSDHDSGANGQVTCSLTPHVPFKLVSTYKNYYSLVLDSALDRERVSAYELVVTARDGGSPPLWATASVSVEVADVNDNAPAFAQSEYTVFVKENNPPGCHIFTVSAWDADAQENALVSYSLVERRLGERSLSSYVSVHAESGKVYALQPLDHEELELLQFQPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9Y5I2-3|PCDAA_HUMAN Isoform 3 of Protocadherin alpha-10 OS=Homosapiens OX=9606 GN=PCDHA10MVSRCSCLGVQCLLLSLLLLAAWEVGSGQLHYSVYEEARHGTFVGRIAQDLGLELAELVQRLFRVASKRHGDLLEVNLQNGILFVNSRIDREELCGRSVECSIHLEVIVDRPLQVFHVDVEVKDINDNPPRFSVTEQKLSIPESRLLDSRFPLEGASDADVGENALLTYKLSPNEYFVLDIINKKDKDKFPVLVLRKLLDREENPQLKLLLTATDGGKPEFTGSVSLLILVLDANDNAPIFDRPVYEVKMYENQVNQTLVIRLNASDSDEGINKEMMYSFSSLVPPTIRRKFWINERTGEIKVNDAIDFEDSNTYEIHVDVTDKGNPPMVGHCTVLVELLDENDNSPEVIVTSLSLPVKEDAQVGTVIALISVSDHDSGANGQVTCSLTPHVPFKLVSTYKNYYSLVLDSALDRERVSAYELVVTARDGGSPPLWATASVSVEVADVNDNAPAFAQSEYTVFVKENNPPGCHIFTVSAWDADAQENALVSYSLVERRLGERSLSSYVSVHAESGKVYALQPLDHEELELLQFQVSARDGGVPPLGSNLTLQVFVLDENDNAPALLASPAGSAGGAVSELVLRSVVAGHVVAKVRAVDADSGYNAWLSYELQSAAVGARIPFRVGLYTGEISTTRALDETDSPRQRLLVLVKDHGEPSLTATATVLVSLVEGSQAPKASSRASVGVAPEVALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSAAPTEGACGPVKPTLVCSSAVGSWSYSQQRRQRVCSGEGLPKADLMAFSPSLPPCPMVDVDGEDQSIGGDHSRKVGYYVFIFLLCFMNNIFSYRIFSNMYQNISFLSTFHLCLNISSDTFVI>sp|Q9Y5I3|PCDA1_HUMAN Protocadherin alpha-1 OS=Homo sapiens OX=9606GN=PCDHA1 PE=2 SV=1MVFSRRGGLGARDLLLWLLLLAAWEVGSGQLHYSIPEEAKHGTFVGRVAQDLGLELAELVPRLFRVASKTHRDLLEVNLQNGILFVNSRIDREELCQWSAECSIHLELIADRPLQVFHVEVKVKDINDNPPVFRGREQIIFIPESRLLNSRFPIEGAADADIGANALLTYTLSPSDYFSLDVEASDELSKSLWLELRKYLDREETPELHLLLTATDGGKPELQGTVELLITVLDVNDNAPLFDQAVYRVHLLETTANGTLVTTLNASDADEGVNGEVVFSFDSGISRDIQEKFKVDSSSGEIRLIDKLDYEETKSYEIQVKAVDKGSPPMSNHCKVLVKVLDVNDNAPELAVTSLYLPIREDAPLSTVIALITVSDRDSGANGQVTCSLMPHVPFKLVSTFKNYYSLVLDSALDRESLSVYELVVTARDGGSPSLWATARVSVEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERALSNYVSVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLAPRVGGTIGAVSELVPRLVGAGHVVAKVRAVDADSGYNAWLSYELQPAAGGARIPFRVGLYTGEISTTRVLDEADLSRYRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRASVGVAGPEAALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSVPPTEGAYVPGKPTLVCSSALGSWSNSQQRRQRVCSSEGPPKTDLMAFSPGLSPSLNTSERNEQPEANLDLSGNPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9Y5I3-2|PCDA1_HUMAN Isoform 2 of Protocadherin alpha-1 OS=Homosapiens OX=9606 GN=PCDHA1MVFSRRGGLGARDLLLWLLLLAAWEVGSGQLHYSIPEEAKHGTFVGRVAQDLGLELAELVPRLFRVASKTHRDLLEVNLQNGILFVNSRIDREELCQWSAECSIHLELIADRPLQVFHVEVKVKDINDNPPVFRGREQIIFIPESRLLNSRFPIEGAADADIGANALLTYTLSPSDYFSLDVEASDELSKSLWLELRKYLDREETPELHLLLTATDGGKPELQGTVELLITVLDVNDNAPLFDQAVYRVHLLETTANGTLVTTLNASDADEGVNGEVVFSFDSGISRDIQEKFKVDSSSGEIRLIDKLDYEETKSYEIQVKAVDKGSPPMSNHCKVLVKVLDVNDNAPELAVTSLYLPIREDAPLSTVIALITVSDRDSGANGQVTCSLMPHVPFKLVSTFKNYYSLVLDSALDRESLSVYELVVTARDGGSPSLWATARVSVEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERALSNYVSVHAESGKVYALQPLDHEELELLQFQPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9Y5I3-3|PCDA1_HUMAN Isoform 3 of Protocadherin alpha-1 OS=Homosapiens OX=9606 GN=PCDHA1MVFSRRGGLGARDLLLWLLLLAAWEVGSGQLHYSIPEEAKHGTFVGRVAQDLGLELAELVPRLFRVASKTHRDLLEVNLQNGILFVNSRIDREELCQWSAECSIHLELIADRPLQVFHVEVKVKDINDNPPVFRGREQIIFIPESRLLNSRFPIEGAADADIGANALLTYTLSPSDYFSLDVEASDELSKSLWLELRKYLDREETPELHLLLTATDGGKPELQGTVELLITVLDVNDNAPLFDQAVYRVHLLETTANGTLVTTLNASDADEGVNGEVVFSFDSGISRDIQEKFKVDSSSGEIRLIDKLDYEETKSYEIQVKAVDKGSPPMSNHCKVLVKVLDVNDNAPELAVTSLYLPIREDAPLSTVIALITVSDRDSGANGQVTCSLMPHVPFKLVSTFKNYYSLVLDSALDRESLSVYELVVTARDGGSPSLWATARVSVEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERALSNYVSVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLAPRVGGTIGAVSELVPRLVGAGHVVAKVRAVDADSGYNAWLSYELQPAAGGARIPFRVGLYTGEISTTRVLDEADLSRYRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRASVGVAGPEAALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSVPPTEGAYVPGKPTLVCSSALGSWSNSQQRRQRVCSSEGPPKTDLMAFSPGLSPSLNTSERNEQPEANLDLSGNVSPTFEFWL>sp|Q9Y5H9|PCDA2_HUMAN Protocadherin alpha-2 OS=Homo sapiens OX=9606GN=PCDHA2 PE=1 SV=1MASSIRRGRGAWTRLLSLLLLAAWEVGSGQLRYSVPEEAKHGTFVGRIAQDLGLELEELVPRLFRVASKRHGDLLEVNLQNGILFVNSRIDREELCGRSAECSIHVEVIVDRPLQVFHVEVEVKDINDNPPIFPMTVKTIRFPESRLLDSRFPLEGASDADIGVNALLSYKLSSSEFFFLDIQANDELSESLSLVLGKSLDREETAEVNLLLVATDGGKPELTGTVQILIKVLDVNDNEPTFAQSVYKVKLLENTANGTLVVKLNASDADEGPNSEIVYSLGSDVSSTIQTKFTIDPISGEIRTKGKLDYEEAKSYEIQVTATDKGTPSMSGHCKISLKLVDINDNTPEVSITSLSLPISENASLGTVIALITVSDRDSGTNGHVTCSLTPHVPFKLVSTFKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATTSVSIEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSAWDADAQENALVSYSLVERRVGERALSSYVSVHAESGKVYALQPLDHEEVELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLAPRAGTAAGAVSELVPWSVGAGHVVAKVRAVDADSGYNAWLSYELQLGTGSARIPFRVGLYTGEISTTRALDEADSPRHRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRAWVGAAGSEATLVDVNVYLIIAICAVSSLLVLTVLLYTALRCSVPPTEGARAPGKPTLVCSSAVGSWSYSQQRRQRVCSGEDPPKTDLMAFSPSLSQGPDSAEEKQLSESEYVGKPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9Y5H9-2|PCDA2_HUMAN Isoform 2 of Protocadherin alpha-2 OS=Homosapiens OX=9606 GN=PCDHA2MASSIRRGRGAWTRLLSLLLLAAWEVGSGQLRYSVPEEAKHGTFVGRIAQDLGLELEELVPRLFRVASKRHGDLLEVNLQNGILFVNSRIDREELCGRSAECSIHVEVIVDRPLQVFHVEVEVKDINDNPPIFPMTVKTIRFPESRLLDSRFPLEGASDADIGVNALLSYKLSSSEFFFLDIQANDELSESLSLVLGKSLDREETAEVNLLLVATDGGKPELTGTVQILIKVLDVNDNEPTFAQSVYKVKLLENTANGTLVVKLNASDADEGPNSEIVYSLGSDVSSTIQTKFTIDPISGEIRTKGKLDYEEAKSYEIQVTATDKGTPSMSGHCKISLKLVDINDNTPEVSITSLSLPISENASLGTVIALITVSDRDSGTNGHVTCSLTPHVPFKLVSTFKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATTSVSIEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSAWDADAQENALVSYSLVERRVGERALSSYVSVHAESGKVYALQPLDHEEVELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLAPRAGTAAGAVSELVPWSVGAGHVVAKVRAVDADSGYNAWLSYELQLGTGSARIPFRVGLYTGEISTTRALDEADSPRHRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRAWVGAAGSEATLVDVNVYLIIAICAVSSLLVLTVLLYTALRCSVPPTEGARAPGKPTLVCSSAVGSWSYSQQRRQRVCSGEDPPKTDLMAFSPSLSQGPDSAEEKQLSESEYVGKVSLLLFLANSKIVLFKKFYMISTSYLDS>sp|Q9Y5H9-3|PCDA2_HUMAN Isoform 3 of Protocadherin alpha-2 OS=Homosapiens OX=9606 GN=PCDHA2MASSIRRGRGAWTRLLSLLLLAAWEVGSGQLRYSVPEEAKHGTFVGRIAQDLGLELEELVPRLFRVASKRHGDLLEVNLQNGILFVNSRIDREELCGRSAECSIHVEVIVDRPLQVFHVEVEVKDINDNPPIFPMTVKTIRFPESRLLDSRFPLEGASDADIGVNALLSYKLSSSEFFFLDIQANDELSESLSLVLGKSLDREETAEVNLLLVATDGGKPELTGTVQILIKVLDVNDNEPTFAQSVYKVKLLENTANGTLVVKLNASDADEGPNSEIVYSLGSDVSSTIQTKFTIDPISGEIRTKGKLDYEEAKSYEIQVTATDKGTPSMSGHCKISLKLVDINDNTPEVSITSLSLPISENASLGTVIALITVSDRDSGTNGHVTCSLTPHVPFKLVSTFKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATTSVSIEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSAWDADAQENALVSYSLVERRVGERALSSYVSVHAESGKVYALQPLDHEEVELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLAPRAGTAAGAVSELVPWSVGAGHVVAKVRAVDADSGYNAWLSYELQLGTGSARIPFRVGLYTGEISTTRALDEADSPRHRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRAWVGAAGSEATLVDVNVYLIIAICAVSSLLVLTVLLYTALRCSVPPTEGARAPGKPTLVCSSAVGSWSYSQQRRQRVCSGEDPPKTDLMAFSPSLSQGPDSAEEKQLSESEYVGKIWNFNLQIQLAS>sp|O95453|PARN_HUMAN Poly(A)-specific ribonuclease PARN OS=Homo sapiensOX=9606 GN=PARN PE=1 SV=1MEIIRSNFKSNLHKVYQAIEEADFFAIDGEFSGISDGPSVSALTNGFDTPEERYQKLKKHSMDFLLFQFGLCTFKYDYTDSKYITKSFNFYVFPKPFNRSSPDVKFVCQSSSIDFLASQGFDFNKVFRNGIPYLNQEEERQLREQYDEKRSQANGAGALSYVSPNTSKCPVTIPEDQKKFIDQVVEKIEDLLQSEENKNLDLEPCTGFQRKLIYQTLSWKYPKGIHVETLETEKKERYIVISKVDEEERKRREQQKHAKEQEELNDAVGFSRVIHAIANSGKLVIGHNMLLDVMHTVHQFYCPLPADLSEFKEMTTCVFPRLLDTKLMASTQPFKDIINNTSLAELEKRLKETPFNPPKVESAEGFPSYDTASEQLHEAGYDAYITGLCFISMANYLGSFLSPPKIHVSARSKLIEPFFNKLFLMRVMDIPYLNLEGPDLQPKRDHVLHVTFPKEWKTSDLYQLFSAFGNIQISWIDDTSAFVSLSQPEQVKIAVNTSKYAESYRIQTYAEYMGRKQEEKQIKRKWTEDSWKEADSKRLNPQCIPYTLQNHYYRNNSFTAPSTVGKRNLSPSQEEAGLEDGVSGEISDTELEQTDSCAEPLSEGRKKAKKLKRMKKELSPAGSISKNSPATLFEVPDTW>sp|O95453-2|PARN_HUMAN Isoform 2 of Poly(A)-specific ribonuclease PARNOS=Homo sapiens OX=9606 GN=PARNMDFLLFQFGLCTFKYDYTDSKYITKSFNFYVFPKPFNRSSPDVKFVCQSSSIDFLASQGFDFNKVFRNGIPYLNQEEERQLREQYDEKRSQANGAGALSYVSPNTSKCPVTIPEDQKKFIDQVVEKIEDLLQSEENKNLDLEPCTGFQRKLIYQTLSWKYPKGIHVETLETEKKERYIVISKVDEEERKRREQQKHAKEQEELNDAVGFSRVIHAIANSGKLVIGHNMLLDVMHTVHQFYCPLPADLSEFKEMTTCVFPRLLDTKLMASTQPFKDIINNTSLAELEKRLKETPFNPPKVESAEGFPSYDTASEQLHEAGYDAYITGLCFISMANYLGSFLSPPKIHVSARSKLIEPFFNKLFLMRVMDIPYLNLEGPDLQPKRDHVLHVTFPKEWKTSDLYQLFSAFGNIQISWIDDTSAFVSLSQPEQVKIAVNTSKYAESYRIQTYAEYMGRKQEEKQIKRKWTEDSWKEADSKRLNPQCIPYTLQNHYYRNNSFTAPSTVGKRNLSPSQEEAGLEDGVSGEISDTELEQTDSCAEPLSEGRKKAKKLKRMKKELSPAGSISKNSPATLFEVPDTW>sp|O95453-3|PARN_HUMAN Isoform 3 of Poly(A)-specific ribonuclease PARNOS=Homo sapiens OX=9606 GN=PARNMEIIRSNFKSNLHKVYQAIEEADFFAIDGEFSGISDGPSVSALTNGFDTPEERSSPDVKFVCQSSSIDFLASQGFDFNKVFRNGIPYLNQEEERQLREQYDEKRSQANGAGALSYVSPNTSKCPVTIPEDQKKFIDQVVEKIEDLLQSEENKNLDLEPCTGFQRKLIYQTLSWKYPKGIHVETLETEKKERYIVISKVDEEERKRREQQKHAKEQEELNDAVGFSRVIHAIANSGKLVIGHNMLLDVMHTVHQFYCPLPADLSEFKEMTTCVFPRLLDTKLMASTQPFKDIINNTSLAELEKRLKETPFNPPKVESAEGFPSYDTASEQLHEAGYDAYITGLCFISMANYLGSFLSPPKIHVSARSKLIEPFFNKLFLMRVMDIPYLNLEGPDLQPKRDHVLHVTFPKEWKTSDLYQLFSAFGNIQISWIDDTSAFVSLSQPEQVKIAVNTSKYAESYRIQTYAEYMGRKQEEKQIKRKWTEDSWKEADSKRLNPQCIPYTLQNHYYRNNSFTAPSTVGKRNLSPSQEEAGLEDGVSGEISDTELEQTDSCAEPLSEGRKKAKKLKRMKKELSPAGSISKNSPATLFEVPDTW>sp|O95453-4|PARN_HUMAN Isoform 4 of Poly(A)-specific ribonuclease PARNOS=Homo sapiens OX=9606 GN=PARNMEIIRSNFKSNLHKVYQAIEEADFFAIDGEFSGISDGPSVSALTNGFDTPEERYQKLKKKERYIVISKVDEEERKRREQQKHAKEQEELNDAVGFSRVIHAIANSGKLVIGHNMLLDVMHTVHQFYCPLPADLSEFKEMTTCVFPRLLDTKLMASTQPFKDIINNTSLAELEKRLKETPFNPPKVESAEGFPSYDTASEQLHEAGYDAYITGLCFISMANYLGSFLSPPKIHVSARSKLIEPFFNKLFLMRVMDIPYLNLEGPDLQPKRDHVLHVTFPKEWKTSDLYQLFSAFGNIQISWIDDTSAFVSLSQPEQVKIAVNTSKYAESYRIQTYAEYMGRKQEEKQIKRKWTEDSWKEADSKRLNPQCIPYTLQNHYYRNNSFTAPSTVGKRNLSPSQEEAGLEDGVSGEISDTELEQTDSCAEPLSEGRKKAKKLKRMKKELSPAGSISKNSPATLFEVPDTW>sp|Q15070|OXA1L_HUMAN Mitochondrial inner membrane protein OXA1L OS=Homosapiens OX=9606 GN=OXA1L PE=1 SV=3MAMGLMCGRRELLRLLQSGRRVHSVAGPSQWLGKPLTTRLLFPVAPCCCRPHYLFLAASGPRSLSTSAISFAEVQVQAPPVVAATPSPTAVPEVASGETADVVQTAAEQSFAELGLGSYTPVGLIQNLLEFMHVDLGLPWWGAIAACTVFARCLIFPLIVTGQREAARIHNHLPEIQKFSSRIREAKLAGDHIEYYKASSEMALYQKKHGIKLYKPLILPVTQAPIFISFFIALREMANLPVPSLQTGGLWWFQDLTVSDPIYILPLAVTATMWAVLELGAETGVQSSDLQWMRNVIRMMPLITLPITMHFPTAVFMYWLSSNLFSLVQVSCLRIPAVRTVLKIPQRVVHDLDKLPPREGFLESFKKGWKNAEMTRQLREREQRMRNQLELAARGPLRQTFTHNPLLQPGKDNPPNIPSSSSKPKSKYPWHDTLG>sp|Q15070-2|OXA1L_HUMAN Isoform 2 of Mitochondrial inner membraneprotein OXA1L OS=Homo sapiens OX=9606 GN=OXA1LMRGTQVHSVAGPSQWLGKPLTTRLLFPVAPCCCRPHYLFLAASGPRSLSTSAISFAEVQVQAPPVVAATPSPTAVPEVASGETADVVQTAAEQSFAELGLGSYTPVGLIQNLLEFMHVDLGLPWWGAIAACTVFARCLIFPLIVTGQREAARIHNHLPEIQKFSSRIREAKLAGDHIEYYKASSEMALYQKKHGIKLYKPLILPVTQAPIFISFFIALREMANLPVPSLQTGGLWWFQDLTVSDPIYILPLAVTATMWAVLELGAETGVQSSDLQWMRNVIRMMPLITLPITMHFPTAVFMYWLSSNLFSLVQVSCLRIPAVRTVLKIPQRVVHDLDKLPPREGFLESFKKGWKNAEMTRQLREREQRMRNQLELAARGPLRQTFTHNPLLQPGKDNPPNIPSSSSKPKSKYPWHDTLG>sp|Q15070-3|OXA1L_HUMAN Isoform 3 of Mitochondrial inner membraneprotein OXA1L OS=Homo sapiens OX=9606 GN=OXA1LMAMGLMCGRRELLRLLQSGRRVHSVAGPSQWLGKPLTTRLLFPVAPCCCRPHYLFLAASGPRSLSTSAISFAEVQVQAPPVVAATPSPTAVPEVASGETADVVQTAAEQSFAELGLGSYTPVGLIQNLLEFMHVDLGLPWWGAIAAFFARCLIFPLIVTGQREAARIHNHLPEIQKFSSRIREAKLAGDHIEYYKASSEMALYQKKHGIKLYKPLILPVTQVSKNISFLISSSTHEISSLCFMCPRSPKKQVVVDYTWLSVVG>sp|Q9Y5H2|PCDGB_HUMAN Protocadherin gamma-A11 OS=Homo sapiens OX=9606GN=PCDHGA11 PE=2 SV=1MANRLQRGDRSRLLLLLCIFLGTLRGFRARQIRYSVPEETEKGSFVGNISKDLGLEPRELAKRGVRIVSRGKTQLFAVNPRSGSLITAGRIDREELCETVSSCFLNMELLVEDTLKIYGVEVEIIDINDNAPSFQEDEVEIKVSEHAIPGARFALPNARDPDVGVNSLQSYQLSPNNYFSLQLRGRTDGAKNPELVLEGSLDREKEAAHLLLLTALDGGDPIRKGAVPIRVVVLDVNDHIPMFTQSVYRVSVPENISSGTRVLMVNATDPDEGINGEVMYSFRNMESKASEIFQLDSQTGEVQVRGSLDFEKYRFYEMEIQGQDGGGLFTTTTMLITVVDVNDNAPEITITSSINSILENSPPGTVIALLNVQDQDSGENGQVSCFIPNHLPFKLEKTYGNYYKLITSRVLDRELVQSYNITLTATDQGSPPLSAETHVWLNVADDNDNPPVFPHSSYSAYIPENNPRGASIFSVTALDPDSKQNALVTYSLTDDTVQGVPLSSYVSINSNTGVLYALQSFDYEQFRDLELRVIARDSGDPPLSSNVSLSLFVLDQNDNAPEILYPALPTDGSTGVELAPRSAEPGYLVTKVVAVDKDSGQNAWLSYRLLKASEPGLFAVGEHTGEVRTARALLDRDALKQSLVVAVQDHGQPPLSATVTLTVAVADSIPEVLADLGSLESLANSETSDLSLYLVVAVAAVSCIFLVFVIVLLALRLWRWHKSRLLQASEGGLAGMPTSHFVGVDGVQAFLQTYSHEVSLIADSQKSHLIFPQPNYGDTLISQESCEKSEPLLIAEDSAIILGKCDPTSNQQAPPNTDWRFSQAQRPGTSGSQNGDDTGTWPNNQFDTEMLQAMILASASEAADGSSTLGGGAGTMGLSARYGPQFTLQHVPDYRQNVYIPGSNATLTNAAGKRDGKAPAGGNGNKKKSGKKEKK>sp|Q9Y5H2-2|PCDGB_HUMAN Isoform 2 of Protocadherin gamma-A11 OS=Homosapiens OX=9606 GN=PCDHGA11MANRLQRGDRSRLLLLLCIFLGTLRGFRARQIRYSVPEETEKGSFVGNISKDLGLEPRELAKRGVRIVSRGKTQLFAVNPRSGSLITAGRIDREELCETVSSCFLNMELLVEDTLKIYGVEVEIIDINDNAPSFQEDEVEIKVSEHAIPGARFALPNARDPDVGVNSLQSYQLSPNNYFSLQLRGRTDGAKNPELVLEGSLDREKEAAHLLLLTALDGGDPIRKGAVPIRVVVLDVNDHIPMFTQSVYRVSVPENISSGTRVLMVNATDPDEGINGEVMYSFRNMESKASEIFQLDSQTGEVQVRGSLDFEKYRFYEMEIQGQDGGGLFTTTTMLITVVDVNDNAPEITITSSINSILENSPPGTVIALLNVQDQDSGENGQVSCFIPNHLPFKLEKTYGNYYKLITSRVLDRELVQSYNITLTATDQGSPPLSAETHVWLNVADDNDNPPVFPHSSYSAYIPENNPRGASIFSVTALDPDSKQNALVTYSLTDDTVQGVPLSSYVSINSNTGVLYALQSFDYEQFRDLELRVIARDSGDPPLSSNVSLSLFVLDQNDNAPEILYPALPTDGSTGVELAPRSAEPGYLVTKVVAVDKDSGQNAWLSYRLLKASEPGLFAVGEHTGEVRTARALLDRDALKQSLVVAVQDHGQPPLSATVTLTVAVADSIPEVLADLGSLESLANSETSDLSLYLVVAVAAVSCIFLVFVIVLLALRLWRWHKSRLLQASEGGLAGMPTSHFVGVDGVQAFLQTYSHEVSLIADSQKSHLIFPQPNYGDTLISQESCEKSEPLLIAEDSAIILGKCDPTSNQVRFISLPPNCWCLGTSLLRRCFLSLL>sp|Q9Y5H2-3|PCDGB_HUMAN Isoform 3 of Protocadherin gamma-A11 OS=Homosapiens OX=9606 GN=PCDHGA11MANRLQRGDRSRLLLLLCIFLGTLRGFRARQIRYSVPEETEKGSFVGNISKDLGLEPRELAKRGVRIVSRGKTQLFAVNPRSGSLITAGRIDREELCETVSSCFLNMELLVEDTLKIYGVEVEIIDINDNAPSFQEDEVEIKVSEHAIPGARFALPNARDPDVGVNSLQSYQLSPNNYFSLQLRGRTDGAKNPELVLEGSLDREKEAAHLLLLTALDGGDPIRKGAVPIRVVVLDVNDHIPMFTQSVYRVSVPENISSGTRVLMVNATDPDEGINGEVMYSFRNMESKASEIFQLDSQTGEVQVRGSLDFEKYRFYEMEIQGQDGGGLFTTTTMLITVVDVNDNAPEITITSSINSILENSPPGTVIALLNVQDQDSGENGQVSCFIPNHLPFKLEKTYGNYYKLITSRVLDRELVQSYNITLTATDQGSPPLSAETHVWLNVADDNDNPPVFPHSSYSAYIPENNPRGASIFSVTALDPDSKQNALVTYSLTDDTVQGVPLSSYVSINSNTGVLYALQSFDYEQFRDLELRVIARDSGDPPLSSNVSLSLFVLDQNDNAPEILYPALPTDGSTGVELAPRSAEPGYLVTKVVAVDKDSGQNAWLSYRLLKASEPGLFAVGEHTGEQAPPNTDWRFSQAQRPGTSGSQNGDDTGTWPNNQFDTEMLQAMILASASEAADGSSTLGGGAGTMGLSARYGPQFTLQHVPDYRQNVYIPGSNATLTNAAGKRDGKAPAGGNGNKKKSGKKEKK>sp|Q9Y5F7|PCDGL_HUMAN Protocadherin gamma-C4 OS=Homo sapiens OX=9606GN=PCDHGC4 PE=2 SV=1MLRKVRSWTEIWRWATLLFLFYHLGYVCGQIRYPVPEESQEGTFVGNVAQDFLLDTDSLSARRLQVAGEVNQRHFRVDLDSGALLIKNPIDREALCGLSASCIVPLEFVTEGPLEMYRAEVEIVDVNDHAPRFPRQQLDLEIGEAAPPGQRFPLEKAQDADVGSNSISSYRLSSNEHFALDVKKRSDGSLVPELLLEKPLDREKQSDYRLVLTAVDGGNPPRSGTAELRVSVLDVNDNAPAFQQSSYRISVLESAPAGMVLIQLNASDPDLGPSGNVTFYFSGHTPDRVRNLFSLHPTTGKLTLLGPLDFESENYYEFDVRARDGGSPAMEQHCSLRVDLLDVNDNAPYITVTSELGTLPESAEPGTVVALISVQDPDSGSNGDVSLRIPDHLPFALKSAFRNQFSLVTAGPLDREAKSSYDIMVTASDAGNPPLSTHRTIFLNISDVNDNPPSFFQRSHEVFVPENNRPGDLLCSLAASDPDSGLNALISYSLLEPRNRDVSASSFISLNPQTGAVHATRSFDYEQTQTLQFEVQARDRGNPPLSSTVTVRLFVLDLNDNAPAVLRPRARPGSLCPQALPPSVGAGHLITKVTAVDLDSGYNAWVSYQLLEAPDPSLFAVSRYAGEVRTAVPIPADLPPQKLVIVVKDSGSPPLSTSVTLLVSLEEDTHPVVPDLRESSAPREGESRLTLYLAVSLVAICFVSFGSFVALLSKCLRGAACGVTCFPAGTCACLTRSRRREGLPPSNGILRIQLGSDDPIKFVDVGGHSHGCTPLASAPTRSDSFMMVKSPSAPMAGEPVRPSCPPSDLLYGLEQAPPNTDWRFSQAQRPGTSGSQNGDDTGTWPNNQFDTEMLQAMILASASEAADGSSTLGGGAGTMGLSARYGPQFTLQHVPDYRQNVYIPGSNATLTNAAGKRDGKAPAGGNGNKKKSGKKEKK>sp|Q9Y5F7-2|PCDGL_HUMAN Isoform 2 of Protocadherin gamma-C4 OS=Homosapiens OX=9606 GN=PCDHGC4MLRKVRSWTEIWRWATLLFLFYHLGYVCGQIRYPVPEESQEGTFVGNVAQDFLLDTDSLSARRLQVAGEVNQRHFRVDLDSGALLIKNPIDREALCGLSASCIVPLEFVTEGPLEMYRAEVEIVDVNDHAPRFPRQQLDLEIGEAAPPGQRFPLEKAQDADVGSNSISSYRLSSNEHFALDVKKRSDGSLVPELLLEKPLDREKQSDYRLVLTAVDGGNPPRSGTAELRVSVLDVNDNAPAFQQSSYRISVLESAPAGMVLIQLNASDPDLGPSGNVTFYFSGHTPDRVRNLFSLHPTTGKLTLLGPLDFESENYYEFDVRARDGGSPAMEQHCSLRVDLLDVNDNAPYITVTSELGTLPESAEPGTVVALISVQDPDSGSNGDVSLRIPDHLPFALKSAFRNQFSLVTAGPLDREAKSSYDIMVTASDAGNPPLSTHRTIFLNISDVNDNPPSFFQRSHEVFVPENNRPGDLLCSLAASDPDSGLNALISYSLLEPRNRDVSASSFISLNPQTGAVHATRSFDYEQTQTLQFEVQARDRGNPPLSSTVTVRLFVLDLNDNAPAVLRPRARPGSLCPQALPPSVGAGHLITKVTAVDLDSGYNAWVSYQLLEAPDPSLFAVSRYAGEVRTAVPIPADLPPQKLVIVVKDSGSPPLSTSVTLLVSLEEDTHPVVPDLRESSAPREGESRLTLYLAVSLVAICFVSFGSFVALLSKCLRGAACGVTCFPAGTCACLTRSRRREGLPPSNGILRIQLGSDDPIKFVDVGGHSHGCTPLASAPTRSDSFMMVKSPSAPMAGEPVRPSCPPSDLLYGLEVRPLQAQQMLEGYSDPGIWLGHVLESTGLSVSAHSDVTIFVRGNYVVDAVLCNCFVN>sp|Q8TE04|PANK1_HUMAN Pantothenate kinase 1 OS=Homo sapiens OX=9606GN=PANK1 PE=1 SV=2MLKLVGGGGGQDWACSVAGTSLGGEEAAFEVARPGDQGKAGGGSPGWGCAGIPDSAPGAGVLQAGAVGPARGGQGAEEVGESAGGGEERRVRHPQAPALRLLNRKPQGGSGEIKTPENDLQRGRLSRGPRTAPPAPGMGDRSGQQERSVPHSPGAPVGTSAAAVNGLLHNGFHPPPVQPPHVCSRGPVGGSDAAPQRLPLLPELQPQPLLPQHDSPAKKCRLRRRMDSGRKNRPPFPWFGMDIGGTLVKLVYFEPKDITAEEEQEEVENLKSIRKYLTSNTAYGKTGIRDVHLELKNLTMCGRKGNLHFIRFPSCAMHRFIQMGSEKNFSSLHTTLCATGGGAFKFEEDFRMIADLQLHKLDELDCLIQGLLYVDSVGFNGKPECYYFENPTNPELCQKKPYCLDNPYPMLLVNMGSGVSILAVYSKDNYKRVTGTSLGGGTFLGLCCLLTGCETFEEALEMAAKGDSTNVDKLVKDIYGGDYERFGLQGSAVASSFGNMMSKEKRDSISKEDLARATLVTITNNIGSIARMCALNENIDRVVFVGNFLRINMVSMKLLAYAMDFWSKGQLKALFLEHEGYFGAVGALLELFKMTDDK>sp|Q8TE04-2|PANK1_HUMAN Isoform 2 of Pantothenate kinase 1 OS=Homosapiens OX=9606 GN=PANK1MKLINGKKQTFPWFGMDIGGTLVKLVYFEPKDITAEEEQEEVENLKSIRKYLTSNTAYGKTGIRDVHLELKNLTMCGRKGNLHFIRFPSCAMHRFIQMGSEKNFSSLHTTLCATGGGAFKFEEDFRMIADLQLHKLDELDCLIQGLLYVDSVGFNGKPECYYFENPTNPELCQKKPYCLDNPYPMLLVNMGSGVSILAVYSKDNYKRVTGTSLGGGTFLGLCCLLTGCETFEEALEMAAKGDSTNVDKLVKDIYGGDYERFGLQGSAVASSFGNMMSKEKRDSISKEDLARATLVTITNNIGSIARMCALNENIDRVVFVGNFLRINMVSMKLLAYAMDFWSKGQLKALFLEHEGYFGAVGALLELFKMTDDK>sp|Q8TE04-3|PANK1_HUMAN Isoform 3 of Pantothenate kinase 1 OS=Homosapiens OX=9606 GN=PANK1MKLINGKKQTFPWFGMDIGGTLVKLVYFEPKDITAEEEQEEVENLKSIRKYLTSNTAYGKTGIRDVHLELKNLTMCGRKGNLHFIRFPSCAMHRFIQMGSEKNFSSLHTTLCATGGGAFKFEEDFRMIADLQLHKLDELDCLIQGLLYVDSVGFNGKPECYYFENPTNPELCQKKPYCLDNPYPMLLVNMGSGVSILAVYSKDNYKRVTGTSFGNMMSKEKRDSISKEDLARATLVTITNNIGSIARMCALNENIDRVVFVGNFLRINMVSMKLLAYAMDFWSKGQLKALFLEHEGYFGAVGALLELFKMTDDK>sp|Q8TE04-4|PANK1_HUMAN Isoform 4 of Pantothenate kinase 1 OS=Homosapiens OX=9606 GN=PANK1MAKSKHALLPFCHGMMQQEGLHQMQSLDLGLLSLQNSFPWFGMDIGGTLVKLVYFEPKDITAEEEQEEVENLKSIRKYLTSNTAYGKTGIRDVHLELKNLTMCGRKGNLHFIRFPSCAMHRFIQMGSEKNFSSLHTTLCATGGGAFKFEEDFRMIADLQLHKLDELDCLIQGLLYVDSVGFNGKPECYYFENPTNPELCQKKPYCLDNPYPMLLVNMGSGVSILAVYSKDNYKRVTGTSLGGGTFLGLCCLLTGCETFEEALEMAAKGDSTNVDKLVKDIYGGDYERFGLQGSAVASSFGNMMSKEKRDSISKEDLARATLVTITNNIGSIARMCALNENIDRVVFVGNFLRINMVSMKLLAYAMDFWSKGQLKALFLEHEGYFGAVGALLELFKMTDDK>sp|Q6GTS8|P20D1_HUMAN N-fatty-acyl-amino acid synthase/hydrolase PM20D1OS=Homo sapiens OX=9606 GN=PM20D1 PE=1 SV=3MAQRCVCVLALVAMLLLVFPTVSRSMGPRSGEHQRASRIPSQFSKEERVAMKEALKGAIQIPTVTFSSEKSNTTALAEFGKYIHKVFPTVVSTSFIQHEVVEEYSHLFTIQGSDPSLQPYLLMAHFDVVPAPEEGWEVPPFSGLERDGIIYGRGTLDDKNSVMALLQALELLLIRKYIPRRSFFISLGHDEESSGTGAQRISALLQSRGVQLAFIVDEGGFILDDFIPNFKKPIALIAVSEKGSMNLMLQVNMTSGHSSAPPKETSIGILAAAVSRLEQTPMPIIFGSGTVVTVLQQLANEFPFPVNIILSNPWLFEPLISRFMERNPLTNAIIRTTTALTIFKAGVKFNVIPPVAQATVNFRIHPGQTVQEVLELTKNIVADNRVQFHVLSAFDPLPVSPSDDKALGYQLLRQTVQSVFPEVNITAPVTSIGNTDSRFFTNLTTGIYRFYPIYIQPEDFKRIHGVNEKISVQAYETQVKFIFELIQNADTDQEPVSHLHKL>sp|Q6GTS8-2|P20D1_HUMAN Isoform 2 of N-fatty-acyl-amino acidsynthase/hydrolase PM20D1 OS=Homo sapiens OX=9606 GN=PM20D1MAQRCVCVLALVAMLLLVFPTVSRSMGPRSGEHQRASRIPSQFSKEERVAMKEALKGAIQIPTVTFSSEKSNTTALAEFGKYIHKVFPTVVSTSFIQHEVVEEYSHLFTIQGSDPSLQPYLLMAHFDVVPAPEEGWEVPPFSGLERDGIIYGRGTLDDKNSVMALLQALELLLIRKYIPRRSFFISLGHDEESSGTGAQRISALLQSRGVQLAFIVDEGGFILDDFIPNFKKPIALIAVSEKGSMNLMLQVNMTSGHSSAPPKETSIGILAAAVSRLEQTPMPIIFGSGTVVTVLQQLANEVYGEKSLNQCNNQDHHGTHHIQSRGQVQCHPPSGPGHSQLPDSPWTDSPRGPRTHEEHCG>sp|Q5VU65|P210L_HUMAN Nuclear pore membrane glycoprotein 210-likeOS=Homo sapiens OX=9606 GN=NUP210L PE=2 SV=1MTGCPASSRRRGFGLFFFLRLHRLLLLFLVLRGTLANKLNVPQVLLPFGREPGRVPFLLEAQRGCYTWHSTHHDAVTVEPLYENGTLCSQKAVLIAESTQPIRLSSIILAREIVTDHELRCDVKVDVINSIEIVSRARELYVDDSPLELMVRALDAEGNTFSSLAGMMFEWSIAQDNESAREELSSKIRILKYSEAEYAPPIYIAEMEKEEKQGDVILVSGIRTGAAVVKVRIHEPFYKKVAAALIRLLVLENIFLIPSHDIYLLVGTYIKYQVAKMVQGRVTEVKFPLEHYILELQDHRVALNGSHSEKVAILDDKTAMVTASQLGQTNLVFVHKNVHMRSVSGLPNCTIYVVEPGFLGFTVQPGNRWSLEVGQVYVITVDVFDKSSTKVYISDNLRITYDFPKEYFEEQLTTVNGSYHIVKALKDGVVVINASLTSIIYQNKDIQPIKFLIKHQQEVKIYFPIMLTPKFLAFPHHPMGMLYRYKVQVEGGSGNFTWTSSNETVVIVTTKGVVTAGQVRGNSTVLARDVQNPFRYGEIKIHVLKLNKMELLPFHADVEIGQIIEIPIAMYHINKETKEAMAFTDCSHLSLDLNMDKQGVFTLLKEGIQRPGPMHCSSTHIAAKSLGHTLVTVSVNECDKYLESSATFAAYEPLKALNPVEVALVTWQSVKEMVFEGGPRPWILEPSRFFLELNAEKTEKIGIAQVWLPSKRKQNQYIYRIQCLDLGEQVLTFRIGNHPGVLNPSPAVEVLQVRFICAHPASMSVTPVYKVPAGAQPCPLPQHNKWLIPVSRLRDTVLELAVFDQHRRKFDNFSSLMLEWKSSNETLAHFEDYKSVEMVAKDDGSGQTRLHGHQILKVHQIKGTVLIGVNFVGYSEKKSPKEISNLPRSVDVELLLVDDVTVVPENATIYNHPDVKETFSLVEGSGYFLVNSSEQGVVTITYMEAESSVELVPLHPGFFTLEVYDLCLAFLGPATAHLRVSDIQELELDLIDKVEIDKTVLVTVRVLGSSKRPFQNKYFRNMELKLQLASAIVTLTPMEQQDEYSENYILRATTIGQTTLVAIAKDKMGRKYTSTPRHIEVFPPFRLLPEKMTLIPMNMMQVMSEGGPQPQSIVHFSISNQTVAVVNRRGQVTGKIVGTAVVHGTIQTVNEDTGKVIVFSQDEVQIEVVQLRAVRILAAATRLITATKMPVYVMGVTSTQTPFSFSNANPGLTFHWSMSKRDVLDLVPRHSEVFLQLPVEHNFAMVVHTKAAGRTSIKVTVHCMNSSSGQFEGNLLELSDEVQILVFEKLQLFYPECQPEQILMPINSQLKLHTNREGAAFVSSRVLKCFPNSSVIEEDGEGLLKAGSIAGTAVLEVTSIEPFGVNQTTITGVQVAPVTYLRVSSQPKLYTAQGRTLSAFPLGMSLTFTVQFYNSIGEKFHTHNTQLYLALNRDDLLHIGPGNKNYTYMAQAVNRGLTLVGLWDRRHPGMADYIPVAVEHAIEPDTKLTFVGDIICFSTHLVSQHGEPGIWMISANNILQTDIVTGVGVARSPGTAMIFHDIPGVVKTYREVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQFSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQDIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNSTSSPPHFMSLQPPLAQSRLQHWLWSIRH>sp|Q5VU65-2|P210L_HUMAN Isoform 2 of Nuclear pore membrane glycoprotein210-like OS=Homo sapiens OX=9606 GN=NUP210LMTGCPASSRRRGFGLFFFLRLHRLLLLFLVLRGTLANKLNVPQVLLPFGREPGRVPFLLEAQRGCYTWHSTHHDAVTVEPLYENGTLCSQKAVLIAESTQPIRLSSIILAREIVTDHELRCDVKVDVINSIEIVSRARELYVDDSPLELMVRALDAEGNTFSSLAGMMFEWSIAQDNESAREELSSKIRILKYSEAEYAPPIYIAEMEKEEKQGDVILVSGIRTGAAVVKVRIHEPFYKKVAAALIRLLVLENIFLIPSHDIYLLVGTYIKYQVAKMVQGRVTEVKFPLEHYILELQDHRVALNGSHSEKVAILDDKTAMVTASQLGQTNLVFVHKNVHMRSVSGLPNCTIYVVEPGFLGFTVQPGNRWSLEVGQVYVITVDVFDKSSTKVYISDNLRITYDFPKEYFEEQLTTVNGSYHIVKALKDGVVVINASLTSIIYQNKDIQPIKFLIKHQQEVKIYFPIMLTPKFLAFPHHPMGMLYRYKVQVEGGSGNFTWTSSNETVVIVTTKGVVTAGQVRGNSTVLARDVQNPFRYGEIKIHVLKLNKMELLPFHADVEIGQIIEIPIAMYHINKETKEAMAFTDCSHLSLDLNMDKQGVFTLLKEGIQRPGPMHCSSTHIAAKSLGHTLVTVSVNECDKYLESSATFAAYEPLKALNPVEVALVTWQSVKEMVFEGGPRPWILEPSRFFLELNAEKTEKIGIAQVWLPSKRKQNQYIYRIQCLDLGEQVLTFRIGNHPGVLNPSPAVEVLQVRFICAHPASMSVTPVYKVPAGAQPCPLPQHNKWLIPVSRLRDTVLELAVFDQHRRKFDNFSSLMLEWKSSNETLAHFEDYKSVEMVAKDDGSGQTRLHGHQILKVHQIKGTVLIGVNFVGYSEKKSPKEISNLPRSVDVELLLVDDVTVVPENATIYNHPDVKETFSLVEGSGYFLVNSSEQGVVTITYMEAESSVELVPLHPGFFTLEVYDLCLAFLGPATAHLRVSDIQELELDLIDKVEIDKTVLVTVRVLGSSKRPFQNKYFRNMELKLQLASAIVTLTPMEQQDEYSENYILRATTIGQTTLVAIAKDKMGRKYTSTPRHIEVFPPFRLLPEKMTLIPMNMMQVMSEGGPQPQSIVHFSISNQTVAVVNRRGQVTGKIVGTAVVHGTIQTVNEDTGKVIVFSQDEVQIEVVQLRAVRILAAATRLITATKMPVYVMGVTSTQTPFSFSNANPGLTFHWSMSKRDVLDLVPRHSEVFLQLPVEHNFAMVVHTKAAGRTSIKVTVHCMNSSSGQFEGNLLELSDEVQILVFEKLQLFYPECQPEQILMPINSQLKLHTNREGAAFVSSRVLKCFPNSSVIEEDGEGLLKAGSIAGTAVLEVTSIEPFGVNQTTITGVQVAPVTYLRVSSQPKLYTAQGRTLSAFPLGMSLTFTVQFYNSIGEKFHTHNTQLYLALNRDDLLHIGPGNKNYTYMAQAVNRGLTLVGLWDRRHPGMADYIPVAVEHAIEPDTKLTFVGDIICFSTHLVSQHGEPGIWMISANNILQTDIVTGVGVARSPGTAMIFHDIPGVVKTYREVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQFSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNSTSSPPHFMSLQPPLAQSRLQHWLWSIRH>sp|P0C8F1|PATE4_HUMAN Prostate and testis expressed protein 4 OS=Homosapiens OX=9606 GN=PATE4 PE=2 SV=2MRKMNTLLLVSLSFLYLKEVMGLKCNTCIYTEGWKCMAGRGTCIAKENELCSTTAYFRGDKHMYSTHMCKYKCREEESSKRGLLRVTLCCDRNFCNVF>sp|Q9H2J4|PDCL3_HUMAN Phosducin-like protein 3 OS=Homo sapiens OX=9606GN=PDCL3 PE=1 SV=1MQDPNADTEWNDILRKKGILPPKESLKELEEEAEEEQRILQQSVVKTYEDMTLEELEDHEDEFNEEDERAIEMYRRRRLAEWKATKLKNKFGEVLEISGKDYVQEVTKAGEGLWVILHLYKQGIPLCALINQHLSGLARKFPDVKFIKAISTTCIPNYPDRNLPTIFVYLEGDIKAQFIGPLVFGGMNLTRDELEWKLSESGAIMTDLEENPKKPIEDVLLSSVRRSVLMKRDSDSEGD>sp|O15350|P73_HUMAN Tumor protein p73 OS=Homo sapiens OX=9606 GN=TP73PE=1 SV=1MAQSTATSPDGGTTFEHLWSSLEPDSTYFDLPQSSRGNNEVVGGTDSSMDVFHLEGMTTSVMAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPSHLQPPSYGPVLSPMNKVHGGMNKLPSVNQLVGQPPPHSSAATPNLGPVGPGMLNNHGHAVPANGEMSSSHSAQSMVSGSHCTPPPPYHADPSLVSFLTGLGCPNCIEYFTSQGLQSIYHLQNLTIEDLGALKIPEQYRMTIWRGLQDLKQGHDYSTAQQLLRSSNAATISIGGSGELQRQRVMEAVHFRVRHTITIPNRGGPGGGPDEWADFGFDLPDCKARKQPIKEEFTEAEIH>sp|O15350-2|P73_HUMAN Isoform Beta of Tumor protein p73 OS=Homo sapiensOX=9606 GN=TP73MAQSTATSPDGGTTFEHLWSSLEPDSTYFDLPQSSRGNNEVVGGTDSSMDVFHLEGMTTSVMAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPSHLQPPSYGPVLSPMNKVHGGMNKLPSVNQLVGQPPPHSSAATPNLGPVGPGMLNNHGHAVPANGEMSSSHSAQSMVSGSHCTPPPPYHADPSLVRTWGP>sp|O15350-3|P73_HUMAN Isoform Gamma of Tumor protein p73 OS=Homo sapiensOX=9606 GN=TP73MAQSTATSPDGGTTFEHLWSSLEPDSTYFDLPQSSRGNNEVVGGTDSSMDVFHLEGMTTSVMAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPPRDAQQPWPRSASQQRRDEQQPQRPVHGLGVPLHSATPLPRRPQPRQFFNRIGVSKLHRVFHLPRVTEHLPPAEPDH>sp|O15350-4|P73_HUMAN Isoform Delta of Tumor protein p73 OS=Homo sapiensOX=9606 GN=TP73MAQSTATSPDGGTTFEHLWSSLEPDSTYFDLPQSSRGNNEVVGGTDSSMDVFHLEGMTTSVMAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPTWGP>sp|O15350-5|P73_HUMAN Isoform Epsilon of Tumor protein p73 OS=Homosapiens OX=9606 GN=TP73MAQSTATSPDGGTTFEHLWSSLEPDSTYFDLPQSSRGNNEVVGGTDSSMDVFHLEGMTTSVMAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPPRDAQQPWPRSASQQRRDEQQPQRPVHGLGVPLHSATPLPRRPQPRDLGALKIPEQYRMTIWRGLQDLKQGHDYSTAQQLLRSSNAATISIGGSGELQRQRVMEAVHFRVRHTITIPNRGGPGGGPDEWADFGFDLPDCKARKQPIKEEFTEAEIH>sp|O15350-6|P73_HUMAN Isoform Zeta of Tumor protein p73 OS=Homo sapiensOX=9606 GN=TP73MAQSTATSPDGGTTFEHLWSSLEPDSTYFDLPQSSRGNNEVVGGTDSSMDVFHLEGMTTSVMAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPFLTGLGCPNCIEYFTSQGLQSIYHLQNLTIEDLGALKIPEQYRMTIWRGLQDLKQGHDYSTAQQLLRSSNAATISIGGSGELQRQRVMEAVHFRVRHTITIPNRGGPGGGPDEWADFGFDLPDCKARKQPIKEEFTEAEIH>sp|O15350-8|P73_HUMAN Isoform dN-Alpha of Tumor protein p73 OS=Homosapiens OX=9606 GN=TP73MLYVGDPARHLATAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPSHLQPPSYGPVLSPMNKVHGGMNKLPSVNQLVGQPPPHSSAATPNLGPVGPGMLNNHGHAVPANGEMSSSHSAQSMVSGSHCTPPPPYHADPSLVSFLTGLGCPNCIEYFTSQGLQSIYHLQNLTIEDLGALKIPEQYRMTIWRGLQDLKQGHDYSTAQQLLRSSNAATISIGGSGELQRQRVMEAVHFRVRHTITIPNRGGPGGGPDEWADFGFDLPDCKARKQPIKEEFTEAEIH>sp|O15350-9|P73_HUMAN Isoform dN-Beta of Tumor protein p73 OS=Homosapiens OX=9606 GN=TP73MLYVGDPARHLATAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPSHLQPPSYGPVLSPMNKVHGGMNKLPSVNQLVGQPPPHSSAATPNLGPVGPGMLNNHGHAVPANGEMSSSHSAQSMVSGSHCTPPPPYHADPSLVRTWGP>sp|O15350-10|P73_HUMAN Isoform dN-Gamma of Tumor protein p73 OS=Homosapiens OX=9606 GN=TP73MLYVGDPARHLATAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPPRDAQQPWPRSASQQRRDEQQPQRPVHGLGVPLHSATPLPRRPQPRQFFNRIGVSKLHRVFHLPRVTEHLPPAEPDH>sp|O15350-11|P73_HUMAN Isoform 10 of Tumor protein p73 OS=Homo sapiensOX=9606 GN=TP73MDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPSHLQPPSYGPVLSPMNKVHGGMNKLPSVNQLVGQPPPHSSAATPNLGPVGPGMLNNHGHAVPANGEMSSSHSAQSMVSGSHCTPPPPYHADPSLVSFLTGLGCPNCIEYFTSQGLQSIYHLQNLTIEDLGALKIPEQYRMTIWRGLQDLKQGHDYSTAQQLLRSSNAATISIGGSGELQRQRVMEAVHFRVRHTITIPNRGGPGGGPDEWADFGFDLPDCKARKQPIKEEFTEAEIH>sp|O15350-12|P73_HUMAN Isoform 11 of Tumor protein p73 OS=Homo sapiensOX=9606 GN=TP73MLYVGDPARHLATAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRP>sp|O15350-13|P73_HUMAN Isoform 12 of Tumor protein p73 OS=Homo sapiensOX=9606 GN=TP73MAQSTATSPDGGTTFEHLWSSLEPDSTYFDLPQSSRGNNEVVGGTDSSMDVFHLEGMTTSVMAQFNLLSSTMDQMSSRAASASPYTPEHAASVPTHSPYAQPSSTFDTMSPAPVIPSNTDYPGPHHFEVTFQQSSTAKSATWTYSPLLKKLYCQIAKTCPIQIKVSTPPPPGTAIRAMPVYKKAEHVTDVVKRCPNHELGRDFNEGQSAPASHLIRVEGNNLSQYVDDPVTGRQSVVVPYEPPQVGTEFTTILYNFMCNSSCVGGMNRRPILIIITLEMRDGQVLGRRSFEGRICACPGRDRKADEDHYREQQALNESSAKNGAASKRAFKQSPPAVPALGAGVKKRRHGDEDTYYLQVRGRENFEILMKLKESLELMELVPQPLVDSYRQQQQLLQRPPRDAQQPWPRSASQRRDEQQPQRPVHGLGVPLHSATPLPRRPQPRQDLGALKIPEQYRMTIWRGLQDLKQGHDYSTAQQLLRSSNAATISIGGSGELQRQRVMEAVHFRVRHTITIPNRGGPGGGPDEWADFGFDLPDCKARKQPIKEEFTEAEIH>sp|Q6P4D5|PBIR3_HUMAN PABIR family member 1 OS=Homo sapiens OX=9606GN=PABIR3 PE=1 SV=1MAQEKMKLGFKSLPSSTTADGNILRRVNSAPLINGLGFNSQVLQADMLRIRTNRTTFRNRRSLLLPPPPFHGSISRLHQIKQEEAMDLINRETMSEWKLQSEIQISHSWEEGLKLVKWHFNINQKRFSKAQPTCFLLILPNCQKIMCIYFQLLLMETTAMLDLLVIRQLKSALSQTLLCHLLILVLICSSRQTFN>sp|Q6P4D5-2|PBIR3_HUMAN Isoform 2 of PABIR family member 1 OS=Homosapiens OX=9606 GN=PABIR3MAQEKMKLGFKSLPSSTTADGNILRRVNSAPLINGLGFNSQVLQADMLRIRTNRTTFRNRRSLLLPPPPFHGSISRLHQIKQEEAMDLINRETMSEWKLQSEIQISHSWEEGLKLNDNGLQKSSSLKCIDLTPVSSMASSIKKTGKSTSSYF>sp|Q6P4D5-3|PBIR3_HUMAN Isoform 3 of PABIR family member 1 OS=Homosapiens OX=9606 GN=PABIR3MAYFPGTGRTDQETQLDLSLCGREPESLENLFLDPDMAQEKMKLGFKSLPSSTTADGNILRRVNSAPLINGLGFNSQVLQADMLRIRTNRTTFRNRRSLEITSPTSVEQKPKDLF>sp|P27986|P85A_HUMAN Phosphatidylinositol 3-kinase regulatory subunitalpha OS=Homo sapiens OX=9606 GN=PIK3R1 PE=1 SV=2MSAEGYQYRALYDYKKEREEDIDLHLGDILTVNKGSLVALGFSDGQEARPEEIGWLNGYNETTGERGDFPGTYVEYIGRKKISPPTPKPRPPRPLPVAPGSSKTEADVEQQALTLPDLAEQFAPPDIAPPLLIKLVEAIEKKGLECSTLYRTQSSSNLAELRQLLDCDTPSVDLEMIDVHVLADAFKRYLLDLPNPVIPAAVYSEMISLAPEVQSSEEYIQLLKKLIRSPSIPHQYWLTLQYLLKHFFKLSQTSSKNLLNARVLSEIFSPMLFRFSAASSDNTENLIKVIEILISTEWNERQPAPALPPKPPKPTTVANNGMNNNMSLQDAEWYWGDISREEVNEKLRDTADGTFLVRDASTKMHGDYTLTLRKGGNNKLIKIFHRDGKYGFSDPLTFSSVVELINHYRNESLAQYNPKLDVKLLYPVSKYQQDQVVKEDNIEAVGKKLHEYNTQFQEKSREYDRLYEEYTRTSQEIQMKRTAIEAFNETIKIFEEQCQTQERYSKEYIEKFKREGNEKEIQRIMHNYDKLKSRISEIIDSRRRLEEDLKKQAAEYREIDKRMNSIKPDLIQLRKTRDQYLMWLTQKGVRQKKLNEWLGNENTEDQYSLVEDDEDLPHHDEKTWNVGSSNRNKAENLLRGKRDGTFLVRESSKQGCYACSVVVDGEVKHCVINKTATGYGFAEPYNLYSSLKELVLHYQHTSLVQHNDSLNVTLAYPVYAQQRR>sp|P27986-2|P85A_HUMAN Isoform 2 of Phosphatidylinositol 3-kinaseregulatory subunit alpha OS=Homo sapiens OX=9606 GN=PIK3R1MYNTVWNMEDLDLEYAKTDINCGTDLMFYIEMDPPALPPKPPKPTTVANNGMNNNMSLQDAEWYWGDISREEVNEKLRDTADGTFLVRDASTKMHGDYTLTLRKGGNNKLIKIFHRDGKYGFSDPLTFSSVVELINHYRNESLAQYNPKLDVKLLYPVSKYQQDQVVKEDNIEAVGKKLHEYNTQFQEKSREYDRLYEEYTRTSQEIQMKRTAIEAFNETIKIFEEQCQTQERYSKEYIEKFKREGNEKEIQRIMHNYDKLKSRISEIIDSRRRLEEDLKKQAAEYREIDKRMNSIKPDLIQLRKTRDQYLMWLTQKGVRQKKLNEWLGNENTEDQYSLVEDDEDLPHHDEKTWNVGSSNRNKAENLLRGKRDGTFLVRESSKQGCYACSVVVDGEVKHCVINKTATGYGFAEPYNLYSSLKELVLHYQHTSLVQHNDSLNVTLAYPVYAQQRR>sp|P27986-3|P85A_HUMAN Isoform 3 of Phosphatidylinositol 3-kinaseregulatory subunit alpha OS=Homo sapiens OX=9606 GN=PIK3R1MHNLQTLPPKPPKPTTVANNGMNNNMSLQDAEWYWGDISREEVNEKLRDTADGTFLVRDASTKMHGDYTLTLRKGGNNKLIKIFHRDGKYGFSDPLTFSSVVELINHYRNESLAQYNPKLDVKLLYPVSKYQQDQVVKEDNIEAVGKKLHEYNTQFQEKSREYDRLYEEYTRTSQEIQMKRTAIEAFNETIKIFEEQCQTQERYSKEYIEKFKREGNEKEIQRIMHNYDKLKSRISEIIDSRRRLEEDLKKQAAEYREIDKRMNSIKPDLIQLRKTRDQYLMWLTQKGVRQKKLNEWLGNENTEDQYSLVEDDEDLPHHDEKTWNVGSSNRNKAENLLRGKRDGTFLVRESSKQGCYACSVVVDGEVKHCVINKTATGYGFAEPYNLYSSLKELVLHYQHTSLVQHNDSLNVTLAYPVYAQQRR>sp|P27986-4|P85A_HUMAN Isoform 4 of Phosphatidylinositol 3-kinaseregulatory subunit alpha OS=Homo sapiens OX=9606 GN=PIK3R1MSAEGYQYRALYDYKKEREEDIDLHLGDILTVNKGSLVALGFSDGQEARPEEIGWLNGYNETTGERGDFPGTYVEYIGRKKISPPTPKPRPPRPLPVAPGSSKTEADVEQQALTLPDLAEQFAPPDIAPPLLIKLVEAIEKKGLECSTLYRTQSSSNLAELRQLLDCDTPSVDLEMIDVHVLADAFKRYLLDLPNPVIPAAVYSEMISLAPEVQSSEEYIQLLKKLIRSPSIPHQYWLTLQYLLKHFFKLSQTSSKNLLNARVLSEIFSPMLFRFSAASSDNTENLIKVIEILISTEWNERQPAPALPPKPPKPTTVANNGMNNNMSLQDAEWYWGDISREEVNEKLRDTADGTFLVRDASTKMHGDYTLTLRKGGNNKLIKIFHRDGKYGFSDPLTFSSVVELINHYRNESLAQYNPKLDVKLLYPVSKYQQDQVVKEDNIEAVGKKLHEYNTQFQEKSREYDRLYEEYTRTSQEIQMKRTAIEAFNETIKIFEEQCQTQERYSKEYIEKFKREGNEKEIQRIMHNYDKLKSRISEIIDSRRRLEEDLKKQAAEYREIDKRMNSIKPDLIQLRKTRDQYLMWLTQKGVRQKKLNEWLGNENTEENFLSCLPSQYSLVEDDEDLPHHDEKTWNVGSSNRNKAENLLRGKRDGTFLVRESSKQGCYACSVVVDGEVKHCVINKTATGYGFAEPYNLYSSLKELVLHYQHTSLVQHNDSLNVTLAYPVYAQQRR>sp|P27986-5|P85A_HUMAN Isoform 5 of Phosphatidylinositol 3-kinaseregulatory subunit alpha OS=Homo sapiens OX=9606 GN=PIK3R1MHGDYTLTLRKGGNNKLIKIFHRDGKYGFSDPLTFSSVVELINHYRNESLAQYNPKLDVKLLYPVSKYQQDQVVKEDNIEAVGKKLHEYNTQFQEKSREYDRLYEEYTRTSQEIQMKRTAIEAFNETIKIFEEQCQTQERYSKEYIEKFKREGNEKEIQRIMHNYDKLKSRISEIIDSRRRLEEDLKKQAAEYREIDKRMNSIKPDLIQLRKTRDQYLMWLTQKGVRQKKLNEWLGNENTEDQYSLVEDDEDLPHHDEKTWNVGSSNRNKAENLLRGKRDGTFLVRESSKQGCYACSVVVDGEVKHCVINKTATGYGFAEPYNLYSSLKELVLHYQHTSLVQHNDSLNVTLAYPVYAQQRR>sp|P54750|PDE1A_HUMAN Calcium/calmodulin-dependent 3',5'-cyclicnucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1A PE=1SV=2MGSSATEIEELENTTFKYLTGEQTEKMWQRLKGILRCLVKQLERGDVNVVDLKKNIEYAASVLEAVYIDETRRLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQEARTSSQKCEFIHQ>sp|P54750-2|PDE1A_HUMAN Isoform 2 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMDDHVTIRKKHLQRPIFRLRCLVKQLERGDVNVVDLKKNIEYAASVLEAVYIDETRRLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQEARTSSQKCEFIHQ>sp|P54750-3|PDE1A_HUMAN Isoform 3 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMGKKINKLFCFNFLVQCFRGKSKPSKCQIRKKVKNHIERLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQEARTSSQKCEFIHQ>sp|P54750-4|PDE1A_HUMAN Isoform 4 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMGSSATEIEELENTTFKYLTGEQTEKMWQRLKGILRCLVKQLERGDVNVVDLKKNIEYAASVLEAVYIDETRRLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQGESDLHKNSEDLVNAEEKHDETHS>sp|P54750-5|PDE1A_HUMAN Isoform 5 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMGSSATEIEELENTTFKYLTGEQTEKMWQRLKGILRCLVKQLERGDVNVVDLKKNIEYAASVLEAVYIDETRRLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQGSVVYEALLPSLSVFTSPLRVWITSSRFLLL>sp|P54750-6|PDE1A_HUMAN Isoform 6 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMDDHVTIRKKHLQRPIFRLRCLVKQLERGDVNVVDLKKNIEYAASVLEAVYIDETRRLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQGESDLHKNSEDLVNAEEKHDETHS>sp|P54750-7|PDE1A_HUMAN Isoform 7 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMDDHVTIRKKHLQRPIFRLRCLVKQLERGDVNVVDLKKNIEYAASVLEAVYIDETRRLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQGSVVYEALLPSLSVFTSPLRVWITSSRFLLL>sp|P54750-8|PDE1A_HUMAN Isoform 8 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMGKKINKLFCFNFLVQCFRGKSKPSKCQIRKKVKNHIERLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQGESDLHKNSEDLVNAEEKHDETHS>sp|P54750-9|PDE1A_HUMAN Isoform 9 of Calcium/calmodulin-dependent 3',5'-cyclic nucleotide phosphodiesterase 1A OS=Homo sapiens OX=9606 GN=PDE1AMGKKINKLFCFNFLVQCFRGKSKPSKCQIRKKVKNHIERLLDTEDELSDIQTDSVPSEVRDWLASTFTRKMGMTKKKPEEKPKFRSIVHAVQAGIFVERMYRKTYHMVGLAYPAAVIVTLKDVDKWSFDVFALNEASGEHSLKFMIYELFTRYDLINRFKIPVSCLITFAEALEVGYSKYKNPYHNLIHAADVTQTVHYIMLHTGIMHWLTELEILAMVFAAAIHDYEHTGTTNNFHIQTRSDVAILYNDRSVLENHHVSAAYRLMQEEEMNILINLSKDDWRDLRNLVIEMVLSTDMSGHFQQIKNIRNSLQQPEGIDRAKTMSLILHAADISHPAKSWKLHYRWTMALMEEFFLQGDKEAELGLPFSPLCDRKSTMVAQSQIGFIDFIVEPTFSLLTDSTEKIVIPLIEEASKAETSSYVASSSTTIVGLHIADALRRSNTKGSMSDGSYSPDYSLAAVDLKSFKNNLVDIIQQNKERWKELAAQGSVVYEALLPSLSVFTSPLRVWITSSRFLLL>sp|P30039|PBLD_HUMAN Phenazine biosynthesis-like domain-containingprotein OS=Homo sapiens OX=9606 GN=PBLD PE=1 SV=2MKLPIFIADAFTARAFRGNPAAVCLLENELDEDMHQKIAREMNLSETAFIRKLHPTDNFAQSSCFGLRWFTPASEVPLCGHATLASAAVLFHKIKNMNSTLTFVTLSGELRARRAEDGIVLDLPLYPAHPQDFHEVEDLIKTAIGNTLVQDICYSPDTQKLLVRLSDVYNRSFLENLKVNTENLLQVENTGKVKGLILTLKGEPGGQTQAFDFYSRYFAPWVGVAEDPVTGSAHAVLSSYWSQHLGKKEMHAFQCSHRGGELGISLRPDGRVDIRGGAAVVLEGTLTA>sp|P30039-2|PBLD_HUMAN Isoform 2 of Phenazine biosynthesis-like domain-containing protein OS=Homo sapiens OX=9606 GN=PBLDMKLPIFIADAFTARAFRGNPAAVCLLENELDEDMHQKIAREMNLSETAFIRKLHPTDNFAQSSCFGLRWFTPASEVPLCGHATLASAAVLFHKIKNMNSTLTFVTLSGELRARRAEDGIVLDLPLYPAHPQDFHEVEDLIKTAIGNTLVQDICYSPDTQKLLVRLSDVYNRSFLENLKVNTENLLQVENTGKVKGLILTLKGEPGGQTQAFDFYSRYFAPWVGVAEDPVTGSAHAVLSSYWSQHLGKKEMHGRTALYQFLFYLPNSKLVFLLICTIPLKM>sp|Q9BRP8|PYM1_HUMAN Partner of Y14 and mago OS=Homo sapiens OX=9606GN=PYM1 PE=1 SV=1MEAAGSPAATETGKYIASTQRPDGTWRKQRRVKEGYVPQEEVPVYENKYVKFFKSKPELPPGLSPEATAPVTPSRPEGGEPGLSKTAKRNLKRKEKRRQQQEKGEAEALSRTLDKVSLEETAQLPSAPQGSRAAPTAASDQPDSAATTEKAKKIKNLKKKLRQVEELQQRIQAGEVSQPSKEQLEKLARRRALEEELEDLELGL>sp|Q9BRP8-2|PYM1_HUMAN Isoform 2 of Partner of Y14 and mago OS=Homosapiens OX=9606 GN=PYM1MATPYVTDETGGKYIASTQRPDGTWRKQRRVKEGYVPQEEVPVYENKYVKFFKSKPELPPGLSPEATAPVTPSRPEGGEPGLSKTAKRNLKRKEKRRQQQEKGEAEALSRTLDKVSLEETAQLPSAPQGSRAAPTAASDQPDSAATTEKAKKIKNLKKKLRQVEELQQRIQAGEVSQPSKEQLEKLARRRALEEELEDLELGL>sp|P68402|PA1B2_HUMAN Platelet-activating factor acetylhydrolase IBsubunit alpha2 OS=Homo sapiens OX=9606 GN=PAFAH1B2 PE=1 SV=1MSQGDSNPAAIPHAAEDIQGDDRWMSQHNRFVLDCKDKEPDVLFVGDSMVQLMQQYEIWRELFSPLHALNFGIGGDTTRHVLWRLKNGELENIKPKVIVVWVGTNNHENTAEEVAGGIEAIVQLINTRQPQAKIIVLGLLPRGEKPNPLRQKNAKVNQLLKVSLPKLANVQLLDTDGGFVHSDGAISCHDMFDFLHLTGGGYAKICKPLHELIMQLLEETPEEKQTTIA>sp|P68402-2|PA1B2_HUMAN Isoform 2 of Platelet-activating factoracetylhydrolase IB subunit alpha2 OS=Homo sapiens OX=9606 GN=PAFAH1B2MSQGDSNPAAIPHAAEDIQGDDRWMSQHNRFVLDCKDKEPDVLFVGDSMVQLMQQYEIWRELFSPLHALNFGIGGDTTRHVLWRLKNGELENIKPKVIVVWVGTNNHENTAEEVAGGIEAIVQLINTRQPQAKIIVLIIYWQDEQDYHERKVQMD>sp|P68402-3|PA1B2_HUMAN Isoform 3 of Platelet-activating factoracetylhydrolase IB subunit alpha2 OS=Homo sapiens OX=9606 GN=PAFAH1B2MSQGDSNPAAIPHAAEDIQGDDRWMSQHNRFVLDCKDKEPDVLFVGDSMVQLMQQYEIWRELFSPLHALNFGIGGDTTRHVLWRLKNGELENIKPKVIVVWVGTNNHENTAEEVAGGIEAIVQLINTRQPQA>sp|P68402-4|PA1B2_HUMAN Isoform 4 of Platelet-activating factoracetylhydrolase IB subunit alpha2 OS=Homo sapiens OX=9606 GN=PAFAH1B2MSQGDSNPAAIPHAAEDIQGDDRWMSQHNRFVLDCKDKEPDVLFVGDSMVQLMQQYEIWRELFSPLHALNFGIGGDTTRHVLWRLKNGELENIKPKVIVVWVGTNNHENTAEEVAGGIEAIVQLINTRQPQAKIIVLGKAAASKYSISEIVRLEQGSVNWSIGTYPDDTPATTRPAILQLFTGKMSRITMKEKSRWTEEILH>sp|A0A087WWA1|P3URF_HUMAN PIK3R3 upstream open reading frame proteinOS=Homo sapiens OX=9606 GN=P3R3URF PE=4 SV=1MGPSRLVRGPRPQGMRSPYRRPGMGWPRPRFPRMFKCSRRRYQQGLRGRTASSAAINPATRAMGINNTHTDTTIVWIFPPQVLRHLRQPGIFLIL>sp|O00408|PDE2A_HUMAN cGMP-dependent 3',5'-cyclic phosphodiesteraseOS=Homo sapiens OX=9606 GN=PDE2A PE=1 SV=1MGQACGHSILCRSQQYPAARPAEPRGQQVFLKPDEPPPPPQPCADSLQDALLSLGSVIDISGLQRAVKEALSAVLPRVETVYTYLLDGESQLVCEDPPHELPQEGKVREAIISQKRLGCNGLGFSDLPGKPLARLVAPLAPDTQVLVMPLADKEAGAVAAVILVHCGQLSDNEEWSLQAVEKHTLVALRRVQVLQQRGPREAPRAVQNPPEGTAEDQKGGAAYTDRDRKILQLCGELYDLDASSLQLKVLQYLQQETRASRCCLLLVSEDNLQLSCKVIGDKVLGEEVSFPLTGCLGQVVEDKKSIQLKDLTSEDVQQLQSMLGCELQAMLCVPVISRATDQVVALACAFNKLEGDLFTDEDEHVIQHCFHYTSTVLTSTLAFQKEQKLKCECQALLQVAKNLFTHLDDVSVLLQEIITEARNLSNAEICSVFLLDQNELVAKVFDGGVVDDESYEIRIPADQGIAGHVATTGQILNIPDAYAHPLFYRGVDDSTGFRTRNILCFPIKNENQEVIGVAELVNKINGPWFSKFDEDLATAFSIYCGISIAHSLLYKKVNEAQYRSHLANEMMMYHMKVSDDEYTKLLHDGIQPVAAIDSNFASFTYTPRSLPEDDTSMAILSMLQDMNFINNYKIDCPTLARFCLMVKKGYRDPPYHNWMHAFSVSHFCYLLYKNLELTNYLEDIEIFALFISCMCHDLDHRGTNNSFQVASKSVLAALYSSEGSVMERHHFAQAIAILNTHGCNIFDHFSRKDYQRMLDLMRDIILATDLAHHLRIFKDLQKMAEVGYDRNNKQHHRLLLCLLMTSCDLSDQTKGWKTTRKIAELIYKEFFSQGDLEKAMGNRPMEMMDREKAYIPELQISFMEHIAMPIYKLLQDLFPKAAELYERVASNREHWTKVSHKFTIRGLPSNNSLDFLDEEYEVPDLDGTRAPINGCCSLDAE>sp|O00408-2|PDE2A_HUMAN Isoform PDE2A1 of cGMP-dependent 3',5'-cyclicphosphodiesterase OS=Homo sapiens OX=9606 GN=PDE2AMRRQPAASLDPLAKEPGPPGSRDDRLEDALLSLGSVIDISGLQRAVKEALSAVLPRVETVYTYLLDGESQLVCEDPPHELPQEGKVREAIISQKRLGCNGLGFSDLPGKPLARLVAPLAPDTQVLVMPLADKEAGAVAAVILVHCGQLSDNEEWSLQAVEKHTLVALRRVQVLQQRGPREAPRAVQNPPEGTAEDQKGGAAYTDRDRKILQLCGELYDLDASSLQLKVLQYLQQETRASRCCLLLVSEDNLQLSCKVIGDKVLGEEVSFPLTGCLGQVVEDKKSIQLKDLTSEDVQQLQSMLGCELQAMLCVPVISRATDQVVALACAFNKLEGDLFTDEDEHVIQHCFHYTSTVLTSTLAFQKEQKLKCECQALLQVAKNLFTHLDDVSVLLQEIITEARNLSNAEICSVFLLDQNELVAKVFDGGVVDDESYEIRIPADQGIAGHVATTGQILNIPDAYAHPLFYRGVDDSTGFRTRNILCFPIKNENQEVIGVAELVNKINGPWFSKFDEDLATAFSIYCGISIAHSLLYKKVNEAQYRSHLANEMMMYHMKVSDDEYTKLLHDGIQPVAAIDSNFASFTYTPRSLPEDDTSMAILSMLQDMNFINNYKIDCPTLARFCLMVKKGYRDPPYHNWMHAFSVSHFCYLLYKNLELTNYLEDIEIFALFISCMCHDLDHRGTNNSFQVASKSVLAALYSSEGSVMERHHFAQAIAILNTHGCNIFDHFSRKDYQRMLDLMRDIILATDLAHHLRIFKDLQKMAEVGYDRNNKQHHRLLLCLLMTSCDLSDQTKGWKTTRKIAELIYKEFFSQGDLEKAMGNRPMEMMDREKAYIPELQISFMEHIAMPIYKLLQDLFPKAAELYERVASNREHWTKVSHKFTIRGLPSNNSLDFLDEEYEVPDLDGTRAPINGCCSLDAE>sp|O00408-3|PDE2A_HUMAN Isoform PDE2A2 of cGMP-dependent 3',5'-cyclicphosphodiesterase OS=Homo sapiens OX=9606 GN=PDE2AMVLVLHHILIAVVQFLRRGQQVFLKPDEPPPPPQPCADSLQDALLSLGSVIDISGLQRAVKEALSAVLPRVETVYTYLLDGESQLVCEDPPHELPQEGKVREAIISQKRLGCNGLGFSDLPGKPLARLVAPLAPDTQVLVMPLADKEAGAVAAVILVHCGQLSDNEEWSLQAVEKHTLVALRRVQVLQQRGPREAPRAVQNPPEGTAEDQKGGAAYTDRDRKILQLCGELYDLDASSLQLKVLQYLQQETRASRCCLLLVSEDNLQLSCKVIGDKVLGEEVSFPLTGCLGQVVEDKKSIQLKDLTSEDVQQLQSMLGCELQAMLCVPVISRATDQVVALACAFNKLEGDLFTDEDEHVIQHCFHYTSTVLTSTLAFQKEQKLKCECQALLQVAKNLFTHLDDVSVLLQEIITEARNLSNAEICSVFLLDQNELVAKVFDGGVVDDESYEIRIPADQGIAGHVATTGQILNIPDAYAHPLFYRGVDDSTGFRTRNILCFPIKNENQEVIGVAELVNKINGPWFSKFDEDLATAFSIYCGISIAHSLLYKKVNEAQYRSHLANEMMMYHMKVSDDEYTKLLHDGIQPVAAIDSNFASFTYTPRSLPEDDTSMAILSMLQDMNFINNYKIDCPTLARFCLMVKKGYRDPPYHNWMHAFSVSHFCYLLYKNLELTNYLEDIEIFALFISCMCHDLDHRGTNNSFQVASKSVLAALYSSEGSVMERHHFAQAIAILNTHGCNIFDHFSRKDYQRMLDLMRDIILATDLAHHLRIFKDLQKMAEVGYDRNNKQHHRLLLCLLMTSCDLSDQTKGWKTTRKIAELIYKEFFSQGDLEKAMGNRPMEMMDREKAYIPELQISFMEHIAMPIYKLLQDLFPKAAELYERVASNREHWTKVSHKFTIRGLPSNNSLDFLDEEYEVPDLDGTRAPINGCCSLDAE>sp|O00408-4|PDE2A_HUMAN Isoform PDE2A4 of cGMP-dependent 3',5'-cyclicphosphodiesterase OS=Homo sapiens OX=9606 GN=PDE2AMKKQRIQEGKSLAHRRGQQVFLKPDEPPPPPQPCADSLQDALLSLGSVIDISGLQRAVKEALSAVLPRVETVYTYLLDGESQLVCEDPPHELPQEGKVREAIISQKRLGCNGLGFSDLPGKPLARLVAPLAPDTQVLVMPLADKEAGAVAAVILVHCGQLSDNEEWSLQAVEKHTLVALRRVQVLQQRGPREAPRAVQNPPEGTAEDQKGGAAYTDRDRKILQLCGELYDLDASSLQLKVLQYLQQETRASRCCLLLVSEDNLQLSCKVIGDKVLGEEVSFPLTGCLGQVVEDKKSIQLKDLTSEDVQQLQSMLGCELQAMLCVPVISRATDQVVALACAFNKLEGDLFTDEDEHVIQHCFHYTSTVLTSTLAFQKEQKLKCECQALLQVAKNLFTHLDDVSVLLQEIITEARNLSNAEICSVFLLDQNELVAKVFDGGVVDDESYEIRIPADQGIAGHVATTGQILNIPDAYAHPLFYRGVDDSTGFRTRNILCFPIKNENQEVIGVAELVNKINGPWFSKFDEDLATAFSIYCGISIAHSLLYKKVNEAQYRSHLANEMMMYHMKVSDDEYTKLLHDGIQPVAAIDSNFASFTYTPRSLPEDDTSMAILSMLQDMNFINNYKIDCPTLARFCLMVKKGYRDPPYHNWMHAFSVSHFCYLLYKNLELTNYLEDIEIFALFISCMCHDLDHRGTNNSFQVASKSVLAALYSSEGSVMERHHFAQAIAILNTHGCNIFDHFSRKDYQRMLDLMRDIILATDLAHHLRIFKDLQKMAEVGYDRNNKQHHRLLLCLLMTSCDLSDQTKGWKTTRKIAELIYKEFFSQGDLEKAMGNRPMEMMDREKAYIPELQISFMEHIAMPIYKLLQDLFPKAAELYERVASNREHWTKVSHKFTIRGLPSNNSLDFLDEEYEVPDLDGTRAPINGCCSLDAE>sp|O00408-5|PDE2A_HUMAN Isoform 5 of cGMP-dependent 3',5'-cyclicphosphodiesterase OS=Homo sapiens OX=9606 GN=PDE2AMVLVLHHILIAVVQFLRRGQQVFLKPDEPPPPPQPCADSLQDALLSLGSVIDISGLQRAVKEALSAVLPRVETVYTYLLDGESQLVCEDPPHELPQEGKVRFTDEDEHVIQHCFHYTSTVLTSTLAFQKEQKLKCECQALLQVAKNLFTHLDDVSVLLQEIITEARNLSNAEICSVFLLDQNELVAKVFDGGVVDDESYEIRIPADQGIAGHVATTGQILNIPDAYAHPLFYRGVDDSTGFRTRNILCFPIKNENQEVIGVAELVNKINGPWFSKFDEDLATAFSIYCGISIAHSLLYKKVNEAQYRSHLANEMMMYHMKVSDDEYTKLLHDGIQPVAAIDSNFASFTYTPRSLPEDDTSMAILSMLQDMNFINNYKIDCPTLARFCLMVKKGYRDPPYHNWMHAFSVSHFCYLLYKNLELTNYLEDIEIFALFISCMCHDLDHRGTNNSFQVASKSVLAALYSSEGSVMERHHFAQAIAILNTHGCNIFDHFSRKDYQRMLDLMRDIILATDLAHHLRIFKDLQKMAEVGYDRNNKQHHRLLLCLLMTSCDLSDQTKGWKTTRKIAELIYKEFFSQGDLEKAMGNRPMEMMDREKAYIPELQISFMEHIAMPIYKLLQDLFPKAAELYERVASNREHWTKVSHKFTIRGLPSNNSLDFLDEEYEVPDLDGTRAPINGCCSLDAE>sp|O00408-6|PDE2A_HUMAN Isoform 6 of cGMP-dependent 3',5'-cyclicphosphodiesterase OS=Homo sapiens OX=9606 GN=PDE2AMRRQPAASLDPLAKEPGPPGSRDDRLEDALLSLGSVIDISGLQRAVKEALSAVLPRVETVYTYLLDGESQLVCEDPPHELPQEGKVREAIISQKRLGCNGLGFSDLPGKPLARLVAPLAPDTQVLVMPLADKEAGAVAAVILVHCGQLSDNEEWSLQAVEKHTLVALRRVQVLQQRGPREAPRAVQNPPEGTAEDQKGGAAYTDRDRKILQLCGELYDLDASSLQLKVLQYLQQETRASRCCLLLVSEDNLQLSCKVIGDKVLGEEVSFPLTGCLGQVVEDKKSIQLKDLTSEDVQQLQSMLGCELQAMLCVPVISRATDQVVALACAFNKLEGDLFTDEDEHVIQHCFHYTSTVLTSTLAFQKEQKLKCECQALLQVAKNLFTHLDDVSVLLQEIITEARNLSNAEICSVFLLDQNELVAKVFDGGVVDDESYEIRIPADQGIAGHVATTGQILNIPDAYAHPLFYRGVDDSTGFRTRNILCFPIKNENQEVIGVAELVNKINGPWFSKFDEDLATAFSIYCGISIAHSLLYKKVNEAQYRSHLANEMMMYHMKVSDDEYTKLLHDGIQPVAAIDSNFASFTYTPRSLPEDDTSMAILSMLQDMNFINNYKIDCPTLARFCLMVKKGYRDPPYHNWMHAFSVSHFCYLLYKNLELTNYLEDIEIFALFISCMCHDLDHRGTNNSFQVASKSVLAALYSSEGSVMERHHFAQAIAILNTHGCNIFDHFPLRTTTILMVGLGPGGYRGPRKKLPEGQLSALQRGALGRSRMGLMGRRDPRTGRQAQV>sp|Q6UXH9|PAMR1_HUMAN Inactive serine protease PAMR1 OS=Homo sapiensOX=9606 GN=PAMR1 PE=1 SV=1MELGCWTQLGLTFLQLLLISSLPREYTVINEACPGAEWNIMCRECCEYDQIECVCPGKREVVGYTIPCCRNEENECDSCLIHPGCTIFENCKSCRNGSWGGTLDDFYVKGFYCAECRAGWYGGDCMRCGQVLRAPKGQILLESYPLNAHCEWTIHAKPGFVIQLRFVMLSLEFDYMCQYDYVEVRDGDNRDGQIIKRVCGNERPAPIQSIGSSLHVLFHSDGSKNFDGFHAIYEEITACSSSPCFHDGTCVLDKAGSYKCACLAGYTGQRCENLLEERNCSDPGGPVNGYQKITGGPGLINGRHAKIGTVVSFFCNNSYVLSGNEKRTCQQNGEWSGKQPICIKACREPKISDLVRRRVLPMQVQSRETPLHQLYSAAFSKQKLQSAPTKKPALPFGDLPMGYQHLHTQLQYECISPFYRRLGSSRRTCLRTGKWSGRAPSCIPICGKIENITAPKTQGLRWPWQAAIYRRTSGVHDGSLHKGAWFLVCSGALVNERTVVVAAHCVTDLGKVTMIKTADLKVVLGKFYRDDDRDEKTIQSLQISAIILHPNYDPILLDADIAILKLLDKARISTRVQPICLAASRDLSTSFQESHITVAGWNVLADVRSPGFKNDTLRSGVVSVVDSLLCEEQHEDHGIPVSVTDNMFCASWEPTAPSDICTAETGGIAAVSFPGRASPEPRWHLMGLVSWSYDKTCSHRLSTAFTKVLPFKDWIERNMK>sp|Q6UXH9-2|PAMR1_HUMAN Isoform 2 of Inactive serine protease PAMR1OS=Homo sapiens OX=9606 GN=PAMR1MELGCWTQLGLTFLQLLLISSLPREYTVINEACPGAEWNIMCRECCEYDQIECVCPGKREVVGYTIPCCRNEENECDSCLIHPGCTIFENCKSCRNGSWGGTLDDFYVKGFYCAECRAGWYGGDCMRCGQVLRAPKGQILLESYPLNAHCEWTIHAKPGFVIQLRFVMLSLEFDYMCQYDYVEVRDGDNRDGQIIKRVCGNERPAPIQSIGSSLHVLFHSDGSKNFDGFHAIYEEITACSSSPCFHDGTCVLDKAGSYKCACLAGYTGQRCENLLEAGKSKIKASEDSLSVLEERNCSDPGGPVNGYQKITGGPGLINGRHAKIGTVVSFFCNNSYVLSGNEKRTCQQNGEWSGKQPICIKACREPKISDLVRRRVLPMQVQSRETPLHQLYSAAFSKQKLQSAPTKKPALPFGDLPMGYQHLHTQLQYECISPFYRRLGSSRRTCLRTGKWSGRAPSCIPICGKIENITAPKTQGLRWPWQAAIYRRTSGVHDGSLHKGAWFLVCSGALVNERTVVVAAHCVTDLGKVTMIKTADLKVVLGKFYRDDDRDEKTIQSLQISAIILHPNYDPILLDADIAILKLLDKARISTRVQPICLAASRDLSTSFQESHITVAGWNVLADVRSPGFKNDTLRSGVVSVVDSLLCEEQHEDHGIPVSVTDNMFCASWEPTAPSDICTAETGGIAAVSFPGRASPEPRWHLMGLVSWSYDKTCSHRLSTAFTKVLPFKDWIERNMK>sp|Q6UXH9-3|PAMR1_HUMAN Isoform 3 of Inactive serine protease PAMR1OS=Homo sapiens OX=9606 GN=PAMR1MELGCWTQLGLTFLQLLLISSLPREYTVINEACPGAEWNIMCRECCEYDQIECVCPGKREVVGYTIPCCRNEENECDSCLIHPGCTIFENCKSCRNGSWGGTLDDFYVKGFYCAECRAGWYGGDCMPCSSSPCFHDGTCVLDKAGSYKCACLAGYTGQRCENLLEERNCSDPGGPVNGYQKITGGPGLINGRHAKIGTVVSFFCNNSYVLSGNEKRTCQQNGEWSGKQPICIKACREPKISDLVRRRVLPMQVQSRETPLHQLYSAAFSKQKLQSAPTKKPALPFGDLPMGYQHLHTQLQYECISPFYRRLGSSRRTCLRTGKWSGRAPSCIPICGKIENITAPKTQGLRWPWQAAIYRRTSGVHDGSLHKGAWFLVCSGALVNERTVVVAAHCVTDLGKVTMIKTADLKVVLGKFYRDDDRDEKTIQSLQISAIILHPNYDPILLDADIAILKLLDKARISTRVQPICLAASRDLSTSFQESHITVAGWNVLADVRSPGFKNDTLRSGVVSVVDSLLCEEQHEDHGIPVSVTDNMFCASWEPTAPSDICTAETGGIAAVSFPGRASPEPRWHLMGLVSWSYDKTCSHRLSTAFTKVLPFKDWIERNMK>sp|Q9NXG6|P4HTM_HUMAN Transmembrane prolyl 4-hydroxylase OS=Homo sapiensOX=9606 GN=P4HTM PE=1 SV=2MAAAAVTGQRPETAAAEEASRPQWAPPDHCQAQAAAGLGDGEDAPVRPLCKPRGICSRAYFLVLMVFVHLYLGNVLALLLFVHYSNGDESSDPGPQHRAQGPGPEPTLGPLTRLEGIKVGHERKVQLVTDRDHFIRTLSLKPLLFEIPGFLTDEECRLIIHLAQMKGLQRSQILPTEEYEEAMSTMQVSQLDLFRLLDQNRDGHLQLREVLAQTRLGNGWWMTPESIQEMYAAIKADPDGDGVLSLQEFSNMDLRDFHKYMRSHKAESSELVRNSHHTWLYQGEGAHHIMRAIRQRVLRLTRLSPEIVELSEPLQVVRYGEGGHYHAHVDSGPVYPETICSHTKLVANESVPFETSCRYMTVLFYLNNVTGGGETVFPVADNRTYDEMSLIQDDVDLRDTRRHCDKGNLRVKPQQGTAVFWYNYLPDGQGWVGDVDDYSLHGGCLVTRGTKWIANNWINVDPSRARQALFQQEMARLAREGGTDSQPEWALDRAYRDARVEL>sp|Q9NXG6-2|P4HTM_HUMAN Isoform 2 of Transmembrane prolyl 4-hydroxylaseOS=Homo sapiens OX=9606 GN=P4HTMMAAAAVTGQRPETAAAEEASRPQWAPPDHCQAQAAAGLGDGEDAPVRPLCKPRGICSRAYFLVLMVFVHLYLGNVLALLLFVHYSNGDESSDPGPQHRAQGPGPEPTLGPLTRLEGIKVGHERKVQLVTDRDHFIRTLSLKPLLFEIPGFLTDEECRLIIHLAQMKGLQRSQILPTEEYEEAMSTMQVSQLDLFRLLDQNRDGHLQLREVLAQTRLGNGWWMTPESIQEMYAAIKADPDGDGVLSLQEFSNMDLRDFHKYMRSHKAESSELVRNSHHTWLYQGEGAHHIMRAIRQRVLRLTRLSPEIVELSEPLQVVRYGEGGHYHAHVDSGPVYPETICSHTKLVANESVPFETSCRQVSPNWGLPSILRPGTPMTQAQPCTVGVPLGMGPGDHWVIPVSDALTSPHKLFTQWLERGGYWSS>sp|Q9NXG6-3|P4HTM_HUMAN Isoform 3 of Transmembrane prolyl 4-hydroxylaseOS=Homo sapiens OX=9606 GN=P4HTMMAAAAVTGQRPETAAAEEASRPQWAPPDHCQAQAAAGLGDGEDAPVRPLCKPRGICSRAYFLVLMVFVHLYLGNVLALLLFVHYSNGDESSDPGPQHRAQGPGPEPTLGPLTRLEGIKVGHERKVQLVTDRDHFIRTLSLKPLLFEIPGFLTDEECRLIIHLAQMKGLQRSQILPTEEYEEAMSTMQVSQLDLFRLLDQNRDGHLQLREVLAQTRLGNGWWMTPESIQEMYAAIKADPDGDGVLSLQEFSNMDLRDFHKYMRSHKAESSELVRNSHHTWLYQGEGAHHIMRAIRQRVLRLTRLSPEIVELSEPLQVVRYGEGGHYHAHVDSGPVYPETICSHTKLVANESVPFETSCRQVSPNWGLPSILRPGTPMTQAQPCTVGVPLGMGPGDHWVIPVSPWEHPQLGTCSVPPLPYSYMTVLFYLNNVTGGGETVFPVADNRTYDEMSLIQDDVDLRDTRRHCDKGNLRVKPQQGTAVFWYNYLPDGQGWVGDVDDYSLHGGCLVTRGTKWIANNWINVDPSRARQALFQQEMARLAREGGTDSQPEWALDRAYRDARVEL>sp|Q5MIZ7|P4R3B_HUMAN Serine/threonine-protein phosphatase 4 regulatorysubunit 3B OS=Homo sapiens OX=9606 GN=PPP4R3B PE=1 SV=2MSDTRRRVKVYTLNEDRQWDDRGTGHVSSTYVEELKGMSLLVRAESDGSLLLESKINPNTAYQKQQDTLIVWSEAENYDLALSFQEKAGCDEIWEKICQVQGKDPSVEVTQDLIDESEEERFEEMPETSHLIDLPTCELNKLEEIADLVTSVLSSPIRREKLALALENEGYIKKLLQLFQACENLENTEGLHHLYEIIRGILFLNKATLFEVMFSDECIMDVVGCLEYDPALAQPKRHREFLTKTAKFKEVIPITDSELRQKIHQTYRVQYIQDIILPTPSVFEENFLSTLTSFIFFNKVEIVSMLQEDEKFLSEVFAQLTDEATDDDKRRELVNFFKEFCAFSQTLQPQNRDAFFKTLAKLGILPALEIVMGMDDLQVRSAATDIFSYLVEFSPSMVREFVMQEAQQSDDDILLINVVIEQMICDTDPELGGAVQLMGLLRTLIDPENMLATTNKTEKSEFLNFFYNHCMHVLTAPLLTNTSEDKCEKDFFLKHYRYSWSFICTPSHSHSHSTPSSSISQDNIVGSNKNNTICPDNYQTAQLLALILELLTFCVEHHTYHIKNYIMNKDLLRRVLVLMNSKHTFLALCALRFMRRIIGLKDEFYNRYITKGNLFEPVINALLDNGTRYNLLNSAVIELFEFIRVEDIKSLTAHIVENFYKALESIEYVQTFKGLKTKYEQEKDRQNQKLNSVPSILRSNRFRRDAKALEEDEEMWFNEDEEEEGKAVVAPVEKPKPEDDFPDNYEKFMETKKAKESEDKENLPKRTSPGGFKFTFSHSASAANGTNSKSVVAQIPPATSNGSSSKTTNLPTSVTATKGSLVGLVDYPDDEEEDEEEESSPRKRPRLGS>sp|Q5MIZ7-2|P4R3B_HUMAN Isoform 2 of Serine/threonine-proteinphosphatase 4 regulatory subunit 3B OS=Homo sapiens OX=9606 GN=PPP4R3BMSDTRRRVKVYTLNEDRQWDDRGTGHVSSTYVEELKGMSLLVRAESDGSLLLESKINPNTAYQKQQDTLIVWSEAENYDLALSFQEKAGCDEIWEKICQVQGKDPSVEVTQDLIDESEEERFEEMPETSHLIDLPTCELNKLEEIADLVTSVLSSPIRREKLALALENEGYIKKLLQLFQACENLENTEGLHHLYEIIRGILFLNKATLFEVMFSDECIMDVVGCLEYDPALAQPKRHREFLTKTAKFKEVIPITDSELRQKIHQTYRVQYIQDIILPTPSVFEENFLSTLTSFIFFNKVEIVSMLQEDEKFLSEVFAQLTDEATDDDKRRELVNFFKEFCAFSQTLQPQNRDAFFKTLAKLGILPALEIVMGMDDLQVRSAATDIFSYLVEFSPSMVREFVMQEAQQSDDDILLINVVIEQMICDTDPELGGAVQLMGLLRTLIDPENMLATTNKTEKSEFLNFFYNHCMHVLTAPLLTNTSEDKCEKDNIVGSNKNNTICPDNYQTAQLLALILELLTFCVEHHTYHIKNYIMNKDLLRRVLVLMNSKHTFLALCALRFMRRIIGLKDEFYNRYITKGNLFEPVINALLDNGTRYNLLNSAVIELFEFIRVEDIKSLTAHIVENFYKALESIEYVQTFKGLKTKYEQEKDRQNQKLNSVPSILRSNRFRRDAKALEEDEEMWFNEDEEEEGKAVVAPVEKPKPEDDFPDNYEKFMETKKAKESEDKENLPKRTSPGGFKFTFSHSASAANGTNSKSVVAQIPPATSNGSSSKTTNLPTSVTATKGSLVGLVDYPDDEEEDEEEESSPRKRPRLGS>sp|Q5MIZ7-3|P4R3B_HUMAN Isoform 3 of Serine/threonine-proteinphosphatase 4 regulatory subunit 3B OS=Homo sapiens OX=9606 GN=PPP4R3BMSDTRRRVKVYTLNEDRQWDDRGTGHVSSTYVEELKGMSLLVRAESDGSLLLESKINPNTAYQKQQDTLIVWSEAENYDLALSFQEKAGCDEIWEKICQVQGKDPSVEVTQDLIDESEEERFEEMPETSHLIDLPTCELNKLEEIADLVTSVLSSPIRREKLALALENEGYIKKLLQLFQACENLENTEGLHHLYEIIRGILFLNKATLFEVMFSDECIMDVVGCLEYDPALAQPKRHREFLTKTAKFKEVIPITDSELRQKIHQTYRVQYIQDIILPTPSVFEENFLSTLTSFIFFNKVEIVSMLQEDEKFLSEVFAQLTDEATDDDKRRELVNFFKEFCAFSQTLQPQNRDAFFKTLAKLGILPALEIVMGMDDLQVRSAATDIFSYLVEFSPSMVREFVMQEAQQSDDDILLINVVIEQMICDTDPELGGAVQLMGLLRTLIDPENMLATTNKTEKSEFLNFFYNHCMHVLTAPLLTNTSEDKCEKDNIVGSNKNNTICPGALRFMRRIIGLKDEFYNRYITKGNLFEPVINALLDNGTRYNLLNSAVIELFEFIRVEDIKSLTAHIVENFYKALESIEYVQTFKGLKTKYEQEKDRQNQKLNSVPSILRSNRFRRDAKALEEDEEMWFNEDEEEEGKAVVAPVEKPKPEDDFPDNYEKFMETKKAKESEDKENLPKRTSPGGFKFTFSHSASAANGTNSKSVVAQIPPATSNGSSSKTTNLPTSVTATKGSLVGLVDYPDDEEEDEEEESSPRKRPRLGS>sp|Q5MIZ7-4|P4R3B_HUMAN Isoform 4 of Serine/threonine-proteinphosphatase 4 regulatory subunit 3B OS=Homo sapiens OX=9606 GN=PPP4R3BMSDTRRRVKVYTLNEDRQWDDRGTGHVSSTYVEELKGMSLLVRAESDGKVIGTVE>sp|Q5MIZ7-5|P4R3B_HUMAN Isoform 5 of Serine/threonine-proteinphosphatase 4 regulatory subunit 3B OS=Homo sapiens OX=9606 GN=PPP4R3BMNKDLLRRVLVLMNSKHTFLALCALRFMRRIIGLKDEFYNRYITKGNLFEPVINALLDNGTRYNLLNSAVIELFEFIRVEDIKSLTAHIVENFYKALESIEYVQTFKGLKTKYEQEKDRQNQKLNSNRFRRDAKALEEDEEMWFNEDEEEEGKAVVAPVEKPKPEDDFPDNYEKFMETKKAKESEDKENLPKRTSPGGFKFTFSHSASAANGTNSKSVVAQIPPATSNGSSSKTTNLPTSVTATKGSLVGLVDYPDDEEEDEEEESSPRKRPRLGS>sp|Q13153|PAK1_HUMAN Serine/threonine-protein kinase PAK 1 OS=Homosapiens OX=9606 GN=PAK1 PE=1 SV=2MSNNGLDIQDKPPAPPMRNTSTMIGAGSKDAGTLNHGSKPLPPNPEEKKKKDRFYRSILPGDKTNKKKEKERPEISLPSDFEHTIHVGFDAVTGEFTGMPEQWARLLQTSNITKSEQKKNPQAVLDVLEFYNSKKTSNSQKYMSFTDKSAEDYNSSNALNVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVIEPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQHQFLKIAKPLSSLTPLIAAAKEATKNNH>sp|Q13153-2|PAK1_HUMAN Isoform 2 of Serine/threonine-protein kinase PAK1 OS=Homo sapiens OX=9606 GN=PAK1MSNNGLDIQDKPPAPPMRNTSTMIGAGSKDAGTLNHGSKPLPPNPEEKKKKDRFYRSILPGDKTNKKKEKERPEISLPSDFEHTIHVGFDAVTGEFTGMPEQWARLLQTSNITKSEQKKNPQAVLDVLEFYNSKKTSNSQKYMSFTDKSAEDYNSSNALNVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVIEPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEVAIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVIHRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLIATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQVRKLRFQVFSNFSMIAASIPEDCQAPLQPHSTDCCS>sp|Q8N6C7|PGSF1_HUMAN Putative uncharacterized protein encoded by MIR7-3HG OS=Homo sapiens OX=9606 GN=MIR7-3HG PE=5 SV=1MPGMRLVCRLAHGHFPRKGQRRRSLTVWKAETSRADCLGAPNIRTAPLGRSEKRTAICFSTGAQDSSQRAPFRLQNPGQLLQLGMHSLHLHPELPTTDPAFFCKLHFIKGNDPYCLTISHVKSVLTFS>sp|Q8N6C7-2|PGSF1_HUMAN Isoform 2 of Putative uncharacterized proteinencoded by MIR7-3HG OS=Homo sapiens OX=9606 GN=MIR7-3HGMPGMRLVCRLAHGHFPRKGQRRRSLTVWKAETSRADCLGAPNIRTAPLGRSEKRTAICFSTGAQDSSQRAPFRLQNPGQLLQPPKVLGLQA>sp|P61578|REC16_HUMAN Endogenous retrovirus group K member 16 Recprotein OS=Homo sapiens OX=9606 GN=ERVK-16 PE=1 SV=1MNPSEMQRKAPPRRRRHRNRAPSSHKMNKMMMSEEQMKLPSTNKAEPLTWAQLNKLTQLATKCLENTKMTQTPESMLLAALMIVSTVSAGVPNSSEETVTIENGP>sp|O94880|PHF14_HUMAN PHD finger protein 14 OS=Homo sapiens OX=9606GN=PHF14 PE=1 SV=2MDRSSKRRQVKPLAASLLEALDYDSSDDSDFKVGDASDSEGSGNGSEDASKDSGEGSCSDSEENILEEELNEDIKVKEEQLKNSAEEEVLSSEKQLIKMEKKEEEENGERPRKKKEKEKEKEKEKEKEKEREKEKEKATVSENVAASAAATTPATSPPAVNTSPSVPTTTTATEEQVSEPKKWNLRRNRPLLDFVSMEELNDMDDYDSEDDNDWRPTVVKRKGRSASQKEGSDGDNEDDEDEGSGSDEDENDEGNDEDHSSPASEGGCKKKKSKVLSRNSADDEELTNDSLTLSQSKSNEDSLILEKSQNWSSQKMDHILICCVCLGDNSEDADEIIQCDNCGITVHEGCYGVDGESDSIMSSASENSTEPWFCDACKCGVSPSCELCPNQDGIFKETDAGRWVHIVCALYVPGVAFGDIDKLRPVTLTEMNYSKYGAKECSFCEDPRFARTGVCISCDAGMCRAYFHVTCAQKEGLLSEAAAEEDIADPFFAYCKQHADRLDRKWKRKNYLALQSYCKMSLQEREKQLSPEAQARINARLQQYRAKAELARSTRPQAWVPREKLPRPLTSSASAIRKLMRKAELMGISTDIFPVDNSDTSSSVDGRRKHKQPALTADFVNYYFERNMRMIQIQENMAEQKNIKDKLENEQEKLHVEYNKLCESLEELQNLNGKLRSEGQGIWALLGRITGQKLNIPAILRAPKERKPSKKEGGTQKTSTLPAVLYSCGICKKNHDQHLLLLCDTCKLHYHLGCLDPPLTRMPRKTKNSYWQCSECDQAGSSDMEADMAMETLPDGTKRSRRQIKEPVKFVPQDVPPEPKKIPIRNTRTRGRKRSFVPEEEKHEERVPRERRQRQSVLQKKPKAEDLRTECATCKGTGDNENLVRYPS>sp|O94880-2|PHF14_HUMAN Isoform 2 of PHD finger protein 14 OS=Homosapiens OX=9606 GN=PHF14MIVQMTVILKLEMPQDSLILEKSQNWSSQKMDHILICCVCLGDNSEDADEIIQCDNCGITVHEGCYGVDGESDSIMSSASENSTEPWFCDACKCGVSPSCELCPNQDGIFKETDAGRWVHIVCALYVPGVAFGDIDKLRPVTLTEMNYSKYGAKECSFCEDPRFARTGVCISCDAGMCRAYFHVTCAQKEGLLSEAAAEEDIADPFFAYCKQHADRLDRKWKRKNYLALQSYCKMSLQEREKQLSPEAQARINARLQQYRAKAELARSTRPQAWVPREKLPRPLTSSASAIRKLMRKAELMGISTDIFPVDNSDTSSSVDGRRKHKQPALTADFVNYYFERNMRMIQIQENMAEQKNIKDKLENEQEKLHVEYNKLCESLEELQNLNGKLRSEGQGIWALLGRITGQKLNIPAILRAPKERKPSKKEGGTQKTSTLPAVLYSCGICKKNHDQHLLLLCDTCKLHYHLGCLDPPLTRMPRKTKNSYWQCSECDQAGSSDMEADMAMETLPDGTKRSRRQIKEPVKFVPQDVPPEPKKIPIRNTRTRGRKRSFVPEEEKHEERVPRERRQRQSVLQKKPKAEDLRTECATCKGTGDNENLVRCDECRLCYHFGCLDPPLKKSPKQTGYGWICQECDSSSSKEDENEAERKNISQELNMEQKNPKK>sp|Q9BVI0|PHF20_HUMAN PHD finger protein 20 OS=Homo sapiens OX=9606GN=PHF20 PE=1 SV=2MTKHPPNRRGISFEVGAQLEARDRLKNWYPAHIEDIDYEEGKVLIHFKRWNHRYDEWFCWDSPYLRPLEKIQLRKEGLHEEDGSSEFQINEQVLACWSDCRFYPAKVTAVNKDGTYTVKFYDGVVQTVKHIHVKAFSKDQNIVGNARPKETDHKSLSSSPDKREKFKEQRKATVNVKKDKEDKPLKTEKRPKQPDKEGKLICSEKGKVSEKSLPKNEKEDKENISENDREYSGDAQVDKKPENDIVKSPQENLREPKRKRGRPPSIAPTAVDSNSQTLQPITLELRRRKISKGCEVPLKRPRLDKNSSQEKSKNYSENTDKDLSRRRSSRLSTNGTHEILDPDLVVSDLVDTDPLQDTLSSTKESEEGQLKSALEAGQVSSALTCHSFGDGSGAAGLELNCPSMGENTMKTEPTSPLVELQEISTVEVTNTFKKTDDFGSSNAPAVDLDHKFRCKVVDCLKFFRKAKLLHYHMKYFHGMEKSLEPEESPGKRHVQTRGPSASDKPSQETLTRKRVSASSPTTKDKEKNKEKKFKEFVRVKPKKKKKKKKKTKPECPCSEEISDTSQEPSPPKAFAVTRCGSSHKPGVHMSPQLHGPESGHHKGKVKALEEDNLSESSSESFLWSDDEYGQDVDVTTNPDEELDGDDRYDFEVVRCICEVQEENDFMIQCEECQCWQHGVCMGLLEENVPEKYTCYVCQDPPGQRPGFKYWYDKEWLSRGHMHGLAFLEENYSHQNAKKIVATHQLLGDVQRVIEVLHGLQLKMSILQSREHPDLPLWCQPWKQHSGEGRSHFRNIPVTDTRSKEEAPSYRTLNGAVEKPRPLALPLPRSVEESYITSEHCYQKPRAYYPAVEQKLVVETRGSALDDAVNPLHENGDDSLSPRLGWPLDQDRSKGDSDPKPGSPKVKEYVSKKALPEEAPARKLLDRGGEGLLSSQHQWQFNLLTHVESLQDEVTHRMDSIEKELDVLESWLDYTGELEPPEPLARLPQLKHCIKQLLMDLGKVQQIALCCST>sp|Q9BVI0-2|PHF20_HUMAN Isoform 2 of PHD finger protein 20 OS=Homosapiens OX=9606 GN=PHF20MTKHPPNRRGISFEVGAQLEARDRLKNWYPAHIEDIDYEEGKVLIHFKRWNHRYDEWFCWDSPYLRPLEKIQLRKEGLHEEDGSSEFQINEQVLACWSDCRFYPAKVTAVNKDGTYTVKFYDGVVQTVKHIHVKAFSKDQNIVGNARPKETDHKSLSSSPDKREKFKEQRKATVNVKKDKEDKPLKTEKRPKQPDKEGKLICSEKGKVSEKSLPKNEKEDKENISENDREYSGDAQKTRQTPFHSSYCCGFKLSNFATNNIGTEKKENIKRM>sp|Q9H7Z7|PGES2_HUMAN Prostaglandin E synthase 2 OS=Homo sapiens OX=9606GN=PTGES2 PE=1 SV=1MDPAARVVRALWPGGCALAWRLGGRPQPLLPTQSRAGFAGAAGGPSPVAAARKGSPRLLGAAALALGGALGLYHTARWHLRAQDLHAERSAAQLSLSSRLQLTLYQYKTCPFCSKVRAFLDFHALPYQVVEVNPVRRAEIKFSSYRKVPILVAQEGESSQQLNDSSVIISALKTYLVSGQPLEEIITYYPAMKAVNEQGKEVTEFGNKYWLMLNEKEAQQVYGGKEARTEEMKWRQWADDWLVHLISPNVYRTPTEALASFDYIVREGKFGAVEGAVAKYMGAAAMYLISKRLKSRHRLQDNVREDLYEAADKWVAAVGKDRPFMGGQKPNLADLAVYGVLRVMEGLDAFDDLMQHTHIQPWYLRVERAITEASPAH>sp|O75167|PHAR2_HUMAN Phosphatase and actin regulator 2 OS=Homo sapiensOX=9606 GN=PHACTR2 PE=1 SV=2MDNAVDGLDKASIANSDGPTAGSQTPPFKRKGKLSTIGKIFKPWKWRKKKTSDKFRETSAVLERKISTRQSREELIRRGVLKELPDQDGDVTVNFENSNGHMIPIGEESTREENVVKSEEGNGSVSEKTPPLEEQAEDKKENTENHSETPAAPALPPSAPPKPRPKPKPKKSPVPPKGATAGASHKGDEVPPIKKNTKAPGKQAPVPPPKPASRNTTREAAGSSHSKKTTGSKASASPSTSSTSSRPKASKETVSSKAGTVGTTKGKRKTDKQPITSHLSSDTTTSGTSDLKGEPAETRVESFKLEQTVPGAEEQNTGKFKSMVPPPPVAPAPSPLAPPLPLEDQCITASDTPVVLVSVGADLPVSALDPSQLLWAEEPTNRTTLYSGTGLSVNRENAKCFTTKEELGKTVPQLLTPGLMGESSESFSASEDEGHREYQANDSDSDGPILYTDDEDEDEDEDGSGESALASKIRRRDTLAIKLGNRPSKKELEDKNILQRTSEEERQEIRQQIGTKLVRRLSQRPTTEELEQRNILKQKNEEEEQEAKMELKRRLSRKLSLRPTVAELQARRILRFNEYVEVTDSPDYDRRADKPWARLTPADKAAIRKELNEFKSTEMEVHEESRQFTRFHRP>sp|O75167-2|PHAR2_HUMAN Isoform 2 of Phosphatase and actin regulator 2OS=Homo sapiens OX=9606 GN=PHACTR2MGQTSVSTLSPQPGSVDGLDKASIANSDGPTAGSQTPPFKRKGKLSTIGKIFKPWKWRKKKTSDKFRETSAVLERKISTRQSREELIRRGVLKELPDQDGDVTVNFENSNGHMIPIGEESTREENVVKSEEGNGSVSEKTPPLEEQAEDKKAGSSHSKKTTGSKASASPSTSSTSSRPKASKETVSSKAGTVGTTKGKRKTDKQPITSHLSSDTTTSGTSDLKGEPAETRVESFKLEQTVPGAEEQNTGKFKSMVPPPPVAPAPSPLAPPLPLEDQCITASDTPVVLVSVGADLPVSALDPSQLLWAEEPTNRTTLYSGTGLSVNRENAKCFTTKEELGKTVPQLLTPGLMGESSESFSASEDEGHREYQANDSDSDGPILYTDDEDEDEDEDGSGESALASKIRRRDTLAIKLGNRPSKKELEDKNILQRTSEEERQEIRQQIGTKLVRRLSQRPTTEELEQRNILKQKNEEEEQEAKMELKRRLSRKLSLRPTVAELQARRILRFNEYVEVTDSPDYDRRADKPWARLTPADKAAIRKELNEFKSTEMEVHEESRQFTRFHRP>sp|O75167-4|PHAR2_HUMAN Isoform 4 of Phosphatase and actin regulator 2OS=Homo sapiens OX=9606 GN=PHACTR2MGQTSVSTLSPQPGSVDGLDKASIANSDGPTAGSQTPPFKRKGKLSTIGKIFKPWKWRKKKTSDKFRETSAVLERKISTRQSREELIRRGVLKELPDQDGDVTVNFENSNGHMIPIGEESTREENVVKSEEGNGSVSEKTPPLEEQAEDKKENTENHSETPAAPALPPSAPPKPRPKPKPKKSPVPPKGATAGASHKGDEVPPIKKNTKAPGKQAPVPPPKPASRNTTREAAGSSHSKKTTGSKASASPSTSSTSSRPKASKETVSSKAGTVGTTKGKRKTDKQPITSHLSSDTTTSGTSDLKGEPAETRVESFKLEQTVPGAEEQNTGKFKSMVPPPPVAPAPSPLAPPLPLEDQCITASDTPVVLVSVGADLPVSALDPSQLLWAEEPTNRTTLYSGTGLSVNRENAKCFTTKEELGKTVPQLLTPGLMGESSESFSASEDEGHREYQANDSDSDGPILYTDDEDEDEDEDGSGESALASKIRRRDTLAIKLGNRPSKKELEDKNILQRTSEEERQEIRQQIGTKLVRRLSQRPTTEELEQRNILKQKNEEEEQEAKMELKRRLSRKLSLRPTVAELQARRILRFNEYVEVTDSPDYDRRADKPWARLTPADKAAIRKELNEFKSTEMEVHEESRQFTRFHRP>sp|O75167-5|PHAR2_HUMAN Isoform 5 of Phosphatase and actin regulator 2OS=Homo sapiens OX=9606 GN=PHACTR2MDNAVDGLDKASIANSDGPTAGSQTPPFKRKGKLSTIGKIFKPWKWRKKKTSDKFRETSAVLERKISTRQSREELIRRGVLKELPDQDGDVTVNFENSNGHMIPIGEESTREENVVKSEEGNGSVSEKTPPLEEQAEDKKAGSSHSKKTTGSKASASPSTSSTSSRPKASKETVSSKAGTVGTTKGKRKTDKQPITSHLSSDTTTSGTSDLKGEPAETRVESFKLEQTVPGAEEQNTGKFKSMVPPPPVAPAPSPLAPPLPLEDQCITASDTPVVLVSVGADLPVSALDPSQLLWAEEPTNRTTLYSGTGLSVNRENAKCFTTKEELGKTVPQLLTPGLMGESSESFSASEDEGHREYQANDSDSDGPILYTDDEDEDEDEDGSGESALASKIRRRDTLAIKLGNRPSKKELEDKNILQRTSEEERQEIRQQIGTKLVRRLSQRPTTEELEQRNILKQKNEEEEQEAKMELKRRLSRKLSLRPTVAELQARRILRFNEYVEVTDSPDYDRRADKPWARLTPADKAAIRKELNEFKSTEMEVHEESRQFTRFHRP>sp|Q96FC7|PHIPL_HUMAN Phytanoyl-CoA hydroxylase-interacting protein-likeOS=Homo sapiens OX=9606 GN=PHYHIPL PE=1 SV=3MEVPRLDHALNSPTSPCEEVIKNLSLEAIQLCDRDGNKSQDSGIAEMEELPVPHNIKISNITCDSFKISWEMDSKSKDRITHYFIDLNKKENKNSNKFKHKDVPTKLVAKAVPLPMTVRGHWFLSPRTEYTVAVQTASKQVDGDYVVSEWSEIIEFCTADYSKVHLTQLLEKAEVIAGRMLKFSVFYRNQHKEYFDYVREHHGNAMQPSVKDNSGSHGSPISGKLEGIFFSCSTEFNTGKPPQDSPYGRYRFEIAAEKLFNPNTNLYFGDFYCMYTAYHYVILVIAPVGSPGDEFCKQRLPQLNSKDNKFLTCTEEDGVLVYHHAQDVILEVIYTDPVDLSVGTVAEITGHQLMSLSTANAKKDPSCKTCNISVGR>sp|Q96FC7-2|PHIPL_HUMAN Isoform 2 of Phytanoyl-CoA hydroxylase-interacting protein-like OS=Homo sapiens OX=9606 GN=PHYHIPLMCCDSDFVARNKSQDSGIAEMEELPVPHNIKISNITCDSFKISWEMDSKSKDRITHYFIDLNKKENKNSNKFKHKDVPTKLVAKAVPLPMTVRGHWFLSPRTEYTVAVQTASKQVDGDYVVSEWSEIIEFCTADYSKVHLTQLLEKAEVIAGRMLKFSVFYRNQHKEYFDYVREHHGNAMQPSVKDNSGSHGSPISGKLEGIFFSCSTEFNTGKPPQDSPYGRYRFEIAAEKLFNPNTNLYFGDFYCMYTAYHYVILVIAPVGSPGDEFCKQRLPQLNSKDNKFLTCTEEDGVLVYHHAQDVILEVIYTDPVDLSVGTVAEITGHQLMSLSTANAKKDPSCKTCNISVGR>sp|Q96FC7-3|PHIPL_HUMAN Isoform 3 of Phytanoyl-CoA hydroxylase-interacting protein-like OS=Homo sapiens OX=9606 GN=PHYHIPLMEVPRLDHALNSPTSPCEEVIKNLSLEAIQLCDRDVVFEELTSKQTRKG>sp|O15534|PER1_HUMAN Period circadian protein homolog 1 OS=Homo sapiensOX=9606 GN=PER1 PE=1 SV=2MSGPLEGADGGGDPRPGESFCPGGVPSPGPPQHRPCPGPSLADDTDANSNGSSGNESNGHESRGASQRSSHSSSSGNGKDSALLETTESSKSTNSQSPSPPSSSIAYSLLSASSEQDNPSTSGCSSEQSARARTQKELMTALRELKLRLPPERRGKGRSGTLATLQYALACVKQVQANQEYYQQWSLEEGEPCSMDMSTYTLEELEHITSEYTLQNQDTFSVAVSFLTGRIVYISEQAAVLLRCKRDVFRGTRFSELLAPQDVGVFYGSTAPSRLPTWGTGASAGSGLRDFTQEKSVFCRIRGGPDRDPGPRYQPFRLTPYVTKIRVSDGAPAQPCCLLIAERIHSGYEAPRIPPDKRIFTTRHTPSCLFQDVDERAAPLLGYLPQDLLGAPVLLFLHPEDRPLMLAIHKKILQLAGQPFDHSPIRFCARNGEYVTMDTSWAGFVHPWSRKVAFVLGRHKVRTAPLNEDVFTPPAPSPAPSLDTDIQELSEQIHRLLLQPVHSPSPTGLCGVGAVTSPGPLHSPGSSSDSNGGDAEGPGPPAPVTFQQICKDVHLVKHQGQQLFIESRARPQSRPRLPATGTFKAKALPCQSPDPELEAGSAPVQAPLALVPEEAERKEASSCSYQQINCLDSILRYLESCNLPSTTKRKCASSSSYTTSSASDDDRQRTGPVSVGTKKDPPSAALSGEGATPRKEPVVGGTLSPLALANKAESVVSVTSQCSFSSTIVHVGDKKPPESDIIMMEDLPGLAPGPAPSPAPSPTVAPDPAPDAYRPVGLTKAVLSLHTQKEEQAFLSRFRDLGRLRGLDSSSTAPSALGERGCHHGPAPPSRRHHCRSKAKRSRHHQNPRAEAPCYVSHPSPVPPSTPWPTPPATTPFPAVVQPYPLPVFSPRGGPQPLPPAPTSVPPAAFPAPLVTPMVALVLPNYLFPTPSSYPYGALQTPAEGPPTPASHSPSPSLPALAPSPPHRPDSPLFNSRCSSPLQLNLLQLEELPRAEGAAVAGGPGSSAGPPPPSAEAAEPEARLAEVTESSNQDALSGSSDLLELLLQEDSRSGTGSAASGSLGSGLGSGSGSGSHEGGSTSASITRSSQSSHTSKYFGSIDSSEAEAGAARGGAEPGDQVIKYVLQDPIWLLMANADQRVMMTYQVPSRDMTSVLKQDRERLRAMQKQQPRFSEDQRRELGAVHSWVRKGQLPRALDVMACVDCGSSTQDPGHPDDPLFSELDGLGLEPMEEGGGEQGSSGGGSGEGEGCEEAQGGAKASSSQDLAMEEEEEGRSSSSPALPTAGNCTS>sp|O15534-4|PER1_HUMAN Isoform 2 of Period circadian protein homolog 1OS=Homo sapiens OX=9606 GN=PER1MLEVLEEIWSVRARRAHRPCPGPSLADDTDANSNGSSGNESNGHESRGASQRSSHSSSSGNGKDSALLETTESSKSTNSQSPSPPSSSIAYSLLSASSEQDNPSTSGCSSEQSARARTQKELMTALRELKLRLPPERRGKGRSGTLATLQYALACVKQVQANQEYYQQWSLEEGEPCSMDMSTYTLEELEHITSEYTLQNQDTFSVAVSFLTGRIVYISEQAAVLLRCKRDVFRGTRFSELLAPQDVGVFYGSTAPSRLPTWGTGASAGSGLRDFTQEKSVFCRIRGGPDRDPGPRYQPFRLTPYVTKIRVSDGAPAQPCCLLIAERIHSGYEAPRIPPDKRIFTTRHTPSCLFQDVDERAAPLLGYLPQDLLGAPVLLFLHPEDRPLMLAIHKKILQLAGQPFDHSPIRFCARNGEYVTMDTSWAGFVHPWSRKVAFVLGRHKVRTAPLNEDVFTPPAPSPAPSLDTDIQELSEQIHRLLLQPVHSPSPTGLCGVGAVTSPGPLHSPGSSSDSNGGDAEGPGPPAPVTFQQICKDVHLVKHQGQQLFIESRARPQSRPRLPATGTFKAKALPCQSPDPELEAGSAPVQAPLALVPEEAERKEASSCSYQQINCLDSILRYLESCNLPSTTKRKCASSSSYTTSSASDDDRQRTGPVSVGTKKDPPSAALSGEGATPRKEPVVGGTLSPLALANKAESVVSVTSQCSFSSTIVHVGDKKPPESDIIMMEDLPGLAPGPAPSPAPSPTVAPDPAPDAYRPVGLTKAVLSLHTQKEEQAFLSRFRDLGRLRGLDSSSTAPSALGERGSHLGPPGACPLPSLGLDCWGVGLKGGVSAPGTQAGVASTTRPCLGTGPSLASPH>sp|P46060|RAGP1_HUMAN Ran GTPase-activating protein 1 OS=Homo sapiensOX=9606 GN=RANGAP1 PE=1 SV=1MASEDIAKLAETLAKTQVAGGQLSFKGKSLKLNTAEDAKDVIKEIEDFDSLEALRLEGNTVGVEAARVIAKALEKKSELKRCHWSDMFTGRLRTEIPPALISLGEGLITAGAQLVELDLSDNAFGPDGVQGFEALLKSSACFTLQELKLNNCGMGIGGGKILAAALTECHRKSSAQGKPLALKVFVAGRNRLENDGATALAEAFRVIGTLEEVHMPQNGINHPGITALAQAFAVNPLLRVINLNDNTFTEKGAVAMAETLKTLRQVEVINFGDCLVRSKGAVAIADAIRGGLPKLKELNLSFCEIKRDAALAVAEAMADKAELEKLDLNGNTLGEEGCEQLQEVLEGFNMAKVLASLSDDEDEEEEEEGEEEEEEAEEEEEEDEEEEEEEEEEEEEEPQQRGQGEKSATPSRKILDPNTGEPAPVLSSPPPADVSTFLAFPSPEKLLRLGPKSSVLIAQQTDTSDPEKVVSAFLKVSSVFKDEATVRMAVQDAVDALMQKAFNSSSFNSNTFLTRLLVHMGLLKSEDKVKAIANLYGPLMALNHMVQQDYFPKALAPLLLAFVTKPNSALESCSFARHSLLQTLYKV>sp|P23219|PGH1_HUMAN Prostaglandin G/H synthase 1 OS=Homo sapiensOX=9606 GN=PTGS1 PE=1 SV=2MSRSLLLWFLLFLLLLPPLPVLLADPGAPTPVNPCCYYPCQHQGICVRFGLDRYQCDCTRTGYSGPNCTIPGLWTWLRNSLRPSPSFTHFLLTHGRWFWEFVNATFIREMLMRLVLTVRSNLIPSPPTYNSAHDYISWESFSNVSYYTRILPSVPKDCPTPMGTKGKKQLPDAQLLARRFLLRRKFIPDPQGTNLMFAFFAQHFTHQFFKTSGKMGPGFTKALGHGVDLGHIYGDNLERQYQLRLFKDGKLKYQVLDGEMYPPSVEEAPVLMHYPRGIPPQSQMAVGQEVFGLLPGLMLYATLWLREHNRVCDLLKAEHPTWGDEQLFQTTRLILIGETIKIVIEEYVQQLSGYFLQLKFDPELLFGVQFQYRNRIAMEFNHLYHWHPLMPDSFKVGSQEYSYEQFLFNTSMLVDYGVEALVDAFSRQIAGRIGGGRNMDHHILHVAVDVIRESREMRLQPFNEYRKRFGMKPYTSFQELVGEKEMAAELEELYGDIDALEFYPGLLLEKCHPNSIFGESMIEIGAPFSLKGLLGNPICSPEYWKPSTFGGEVGFNIVKTATLKKLVCLNTKTCPYVSFRVPDASQDDGPAVERPSTEL>sp|P23219-2|PGH1_HUMAN Isoform 2 of Prostaglandin G/H synthase 1 OS=Homosapiens OX=9606 GN=PTGS1MSRSLLLWFLLFLLLLPPLPVLLADPGAPTPVNPCCYYPCQHQGICVRFGLDRYQCDCTRTGYSGPNCTIPGLWTWLRNSLRPSPSFTHFLLTHGRWFWEFVNATFIREMLMRLVLTVRSNLIPSPPTYNSAHDYISWESFSNVSYYTRILPSVPKDCPTPMGTKGKKQLPDAQLLARRFLLRRKFIPDPQGTNLMFAFFAQHFTHQFFKTSGKMGPGFTKALGHGVDLGHIYGDNLERQYQLRLFKDGKLKYQVLDGEMYPPSVEEAPVLMHYPRGIPPQSQMAVGQEVFGLLPGLMLYATLWLREHNRVCDLLKAEHPTWGDEQLFQTTRLILIGETIKIVIEEYVQQLSGYFLQLKFDPELLFGVQFQYRNRIAMEFNHLYHWHPLMPDSFKIGGGRNMDHHILHVAVDVIRESREMRLQPFNEYRKRFGMKPYTSFQELVGEKEMAAELEELYGDIDALEFYPGLLLEKCHPNSIFGESMIEIGAPFSLKGLLGNPICSPEYWKPSTFGGEVGFNIVKTATLKKLVCLNTKTCPYVSFRVPDASQDDGPAVERPSTEL>sp|P23219-3|PGH1_HUMAN Isoform 3 of Prostaglandin G/H synthase 1 OS=Homosapiens OX=9606 GN=PTGS1MRKPRLMNPCCYYPCQHQGICVRFGLDRYQCDCTRTGYSGPNCTIPGLWTWLRNSLRPSPSFTHFLLTHGRWFWEFVNATFIREMLMRLVLTVRSNLIPSPPTYNSAHDYISWESFSNVSYYTRILPSVPKDCPTPMGTKGKKQLPDAQLLARRFLLRRKFIPDPQGTNLMFAFFAQHFTHQFFKTSGKMGPGFTKALGHGVDLGHIYGDNLERQYQLRLFKDGKLKYQVLDGEMYPPSVEEAPVLMHYPRGIPPQSQMAVGQEVFGLLPGLMLYATLWLREHNRVCDLLKAEHPTWGDEQLFQTTRLILIGETIKIVIEEYVQQLSGYFLQLKFDPELLFGVQFQYRNRIAMEFNHLYHWHPLMPDSFKIGGGRNMDHHILHVAVDVIRESREMRLQPFNEYRKRFGMKPYTSFQELVGEKEMAAELEELYGDIDALEFYPGLLLEKCHPNSIFGESMIEIGAPFSLKGLLGNPICSPEYWKPSTFGGEVGFNIVKTATLKKLVCLNTKTCPYVSFRVPDASQDDGPAVERPSTEL>sp|P23219-4|PGH1_HUMAN Isoform 4 of Prostaglandin G/H synthase 1 OS=Homosapiens OX=9606 GN=PTGS1MLMRLVLTVRSNLIPSPPTYNSAHDYISWESFSNVSYYTRILPSVPKDCPTPMGTKGKKQLPDAQLLARRFLLRRKFIPDPQGTNLMFAFFAQHFTHQFFKTSGKMGPGFTKALGHGVDLGHIYGDNLERQYQLRLFKDGKLKYQVLDGEMYPPSVEEAPVLMHYPRGIPPQSQMAVGQEVFGLLPGLMLYATLWLREHNRVCDLLKAEHPTWGDEQLFQTTRLILIGETIKIVIEEYVQQLSGYFLQLKFDPELLFGVQFQYRNRIAMEFNHLYHWHPLMPDSFKVGSQEYSYEQFLFNTSMLVDYGVEALVDAFSRQIAGRIGGGRNMDHHILHVAVDVIRESREMRLQPFNEYRKRFGMKPYTSFQELVGEKEMAAELEELYGDIDALEFYPGLLLEKCHPNSIFGESMIEIGAPFSLKGLLGNPICSPEYWKPSTFGGEVGFNIVKTATLKKLVCLNTKTCPYVSFRVPDASQDDGPAVERPSTEL>sp|P23219-5|PGH1_HUMAN Isoform 5 of Prostaglandin G/H synthase 1 OS=Homosapiens OX=9606 GN=PTGS1MSRECDPGARWGIFLASGGALNARLSPSSLSSAGSLLLWFLLFLLLLPPLPVLLADPGAPTPVNPCCYYPCQHQGICVRFGLDRYQCDCTRTGYSGPNCTIPGLWTWLRNSLRPSPSFTHFLLTHGRWFWEFVNATFIREMLMRLVLTVRSNLIPSPPTYNSAHDYISWESFSNVSYYTRILPSVPKDCPTPMGTKGKKQLPDAQLLARRFLLRRKFIPDPQGTNLMFAFFAQHFTHQFFKTSGKMGPGFTKALGHGVDLGHIYGDNLERQYQLRLFKDGKLKYQVLDGEMYPPSVEEAPVLMHYPRGIPPQSQMAVGQEVFGLLPGLMLYATLWLREHNRVCDLLKAEHPTWGDEQLFQTTRLILIGETIKIVIEEYVQQLSGYFLQLKFDPELLFGVQFQYRNRIAMEFNHLYHWHPLMPDSFKVGSQEYSYEQFLFNTSMLVDYGVEALVDAFSRQIAGRIGGGRNMDHHILHVAVDVIRESREMRLQPFNEYRKRFGMKPYTSFQELVGEKEMAAELEELYGDIDALEFYPGLLLEKCHPNSIFGESMIEIGAPFSLKGLLGNPICSPEYWKPSTFGGEVGFNIVKTATLKKLVCLNTKTCPYVSFRVPDASQDDGPAVERPSTEL>sp|P23219-6|PGH1_HUMAN Isoform 6 of Prostaglandin G/H synthase 1 OS=Homosapiens OX=9606 GN=PTGS1MSRECDPGARWGIFLASWWSLECQLSPSSLSSAGSLLLWFLLFLLLLPPLPVLLADPGAPTPVNPCCYYPCQHQGICVRFGLDRYQCDCTRTGYSGPNCTIPGLWTWLRNSLRPSPSFTHFLLTHGRWFWEFVNATFIREMLMRLVLTVRSNLIPSPPTYNSAHDYISWESFSNVSYYTRILPSVPKDCPTPMGTKGKKQLPDAQLLARRFLLRRKFIPDPQGTNLMFAFFAQHFTHQFFKTSGKMGPGFTKALGHGVDLGHIYGDNLERQYQLRLFKDGKLKYQVLDGEMYPPSVEEAPVLMHYPRGIPPQSQMAVGQEVFGLLPGLMLYATLWLREHNRVCDLLKAEHPTWGDEQLFQTTRLILIGETIKIVIEEYVQQLSGYFLQLKFDPELLFGVQFQYRNRIAMEFNHLYHWHPLMPDSFKVGSQEYSYEQFLFNTSMLVDYGVEALVDAFSRQIAGRIGGGRNMDHHILHVAVDVIRESREMRLQPFNEYRKRFGMKPYTSFQELVGEKEMAAELEELYGDIDALEFYPGLLLEKCHPNSIFGESMIEIGAPFSLKGLLGNPICSPEYWKPSTFGGEVGFNIVKTATLKKLVCLNTKTCPYVSFRVPDASQDDGPAVERPSTEL>sp|P98175|RBM10_HUMAN RNA-binding protein 10 OS=Homo sapiens OX=9606GN=RBM10 PE=1 SV=3MEYERRGGRGDRTGRYGATDRSQDDGGENRSRDHDYRDMDYRSYPREYGSQEGKHDYDDSSEEQSAEDSYEASPGSETQRRRRRRHRHSPTGPPGFPRDGDYRDQDYRTEQGEEEEEEEDEEEEEKASNIVMLRMLPQAATEDDIRGQLQSHGVQAREVRLMRNKSSGQSRGFAFVEFSHLQDATRWMEANQHSLNILGQKVSMHYSDPKPKINEDWLCNKCGVQNFKRREKCFKCGVPKSEAEQKLPLGTRLDQQTLPLGGRELSQGLLPLPQPYQAQGVLASQALSQGSEPSSENANDTIILRNLNPHSTMDSILGALAPYAVLSSSNVRVIKDKQTQLNRGFAFIQLSTIVEAAQLLQILQALHPPLTIDGKTINVEFAKGSKRDMASNEGSRISAASVASTAIAAAQWAISQASQGGEGTWATSEEPPVDYSYYQQDEGYGNSQGTESSLYAHGYLKGTKGPGITGTKGDPTGAGPEASLEPGADSVSMQAFSRAQPGAAPGIYQQSAEASSSQGTAANSQSYTIMSPAVLKSELQSPTHPSSALPPATSPTAQESYSQYPVPDVSTYQYDETSGYYYDPQTGLYYDPNSQYYYNAQSQQYLYWDGERRTYVPALEQSADGHKETGAPSKEGKEKKEKHKTKTAQQIAKDMERWARSLNKQKENFKNSFQPISSLRDDERRESATADAGYAILEKKGALAERQHTSMDLPKLASDDRPSPPRGLVAAYSGESDSEEEQERGGPEREEKLTDWQKLACLLCRRQFPSKEALIRHQQLSGLHKQNLEIHRRAHLSENELEALEKNDMEQMKYRDRAAERREKYGIPEPPEPKRRKYGGISTASVDFEQPTRDGLGSDNIGSRMLQAMGWKEGSGLGRKKQGIVTPIEAQTRVRGSGLGARGSSYGVTSTESYKETLHKTMVTRFNEAQ>sp|P98175-2|RBM10_HUMAN Isoform 2 of RNA-binding protein 10 OS=Homosapiens OX=9606 GN=RBM10MEYERRGGRGDRTGRYGATDRSQDDGGENRSRDHDYRDMDYRSYPREYGSQEGKHDYDDSSEEQSAEDSYEASPGSETQRRRRRRHRHSPTGPPGFPRDGDYRDQDYRTEQGEEEEEEEDEEEEEKASNIVMLRMLPQAATEDDIRGQLQSHGVQAREVRLMRNKSSGQSRGFAFVEFSHLQDATRWMEANQHSLNILGQKVSMHYSDPKPKINEDWLCNKCGVQNFKRREKCFKCGVPKSEAEQKLPLGTRLDQQTLPLGGRELSQGLLPLPQPYQAQGVLASQALSQGSEPSSENANDTIILRNLNPHSTMDSILGALAPYAVLSSSNVRVIKDKQTQLNRGFAFIQLSTIEAAQLLQILQALHPPLTIDGKTINVEFAKGSKRDMASNEGSRISAASVASTAIAAAQWAISQASQGGEGTWATSEEPPVDYSYYQQDEGYGNSQGTESSLYAHGYLKGTKGPGITGTKGDPTGAGPEASLEPGADSVSMQAFSRAQPGAAPGIYQQSAEASSSQGTAANSQSYTIMSPAVLKSELQSPTHPSSALPPATSPTAQESYSQYPVPDVSTYQYDETSGYYYDPQTGLYYDPNSQYYYNAQSQQYLYWDGERRTYVPALEQSADGHKETGAPSKEGKEKKEKHKTKTAQQIAKDMERWARSLNKQKENFKNSFQPISSLRDDERRESATADAGYAILEKKGALAERQHTSMDLPKLASDDRPSPPRGLVAAYSGESDSEEEQERGGPEREEKLTDWQKLACLLCRRQFPSKEALIRHQQLSGLHKQNLEIHRRAHLSENELEALEKNDMEQMKYRDRAAERREKYGIPEPPEPKRRKYGGISTASVDFEQPTRDGLGSDNIGSRMLQAMGWKEGSGLGRKKQGIVTPIEAQTRVRGSGLGARGSSYGVTSTESYKETLHKTMVTRFNEAQ>sp|P98175-3|RBM10_HUMAN Isoform 3 of RNA-binding protein 10 OS=Homosapiens OX=9606 GN=RBM10MEYERRGGRGDRTGRYGATDRSQDDGGENRSRDHDYRDMDYRSYPREYGSQEGKHDYDDSSEEQSAEIRGQLQSHGVQAREVRLMRNKSSGQSRGFAFVEFSHLQDATRWMEANQHSLNILGQKVSMHYSDPKPKINEDWLCNKCGVQNFKRREKCFKCGVPKSEAEQKLPLGTRLDQQTLPLGGRELSQGLLPLPQPYQAQGVLASQALSQGSEPSSENANDTIILRNLNPHSTMDSILGALAPYAVLSSSNVRVIKDKQTQLNRGFAFIQLSTIVEAAQLLQILQALHPPLTIDGKTINVEFAKGSKRDMASNEGSRISAASVASTAIAAAQWAISQASQGGEGTWATSEEPPVDYSYYQQDEGYGNSQGTESSLYAHGYLKGTKGPGITGTKGDPTGAGPEASLEPGADSVSMQAFSRAQPGAAPGIYQQSAEASSSQGTAANSQSYTIMSPAVLKSELQSPTHPSSALPPATSPTAQESYSQYPVPDVSTYQYDETSGYYYDPQTGLYYDPNSQYYYNAQSQQYLYWDGERRTYVPALEQSADGHKETGAPSKEGKEKKEKHKTKTAQQIAKDMERWARSLNKQKENFKNSFQPISSLRDDERRESATADAGYAILEKKGALAERQHTSMDLPKLASDDRPSPPRGLVAAYSGESDSEEEQERGGPEREEKLTDWQKLACLLCRRQFPSKEALIRHQQLSGLHKQNLEIHRRAHLSENELEALEKNDMEQMKYRDRAAERREKYGIPEPPEPKRRKYGGISTASVDFEQPTRDGLGSDNIGSRMLQAMGWKEGSGLGRKKQGIVTPIEAQTRVRGSGLGARGSSYGVTSTESYKETLHKTMVTRFNEAQ>sp|P98175-4|RBM10_HUMAN Isoform 4 of RNA-binding protein 10 OS=Homosapiens OX=9606 GN=RBM10MEYERRGGRGDRTGRYGATDRSQDDGGENRSRDHDYRDMDYRSYPREYGSQEGKHDYDDSSEEQSAEIRGQLQSHGVQAREVRLMRNKSSGQSRGFAFVEFSHLQDATRWMEANQHSLNILGQKVSMHYSDPKPKINEDWLCNKCGVQNFKRREKCFKCGVPKSEAEQKLPLGTRLDQQTLPLGGRELSQGLLPLPQPYQAQGVLASQALSQGSEPSSENANDTIILRNLNPHSTMDSILGALAPYAVLSSSNVRVIKDKQTQLNRGFAFIQLSTIEAAQLLQILQALHPPLTIDGKTINVEFAKGSKRDMASNEGSRISAASVASTAIAAAQWAISQASQGGEGTWATSEEPPVDYSYYQQDEGYGNSQGTESSLYAHGYLKGTKGPGITGTKGDPTGAGPEASLEPGADSVSMQAFSRAQPGAAPGIYQQSAEASSSQGTAANSQSYTIMSPAVLKSELQSPTHPSSALPPATSPTAQESYSQYPVPDVSTYQYDETSGYYYDPQTGLYYDPNSQYYYNAQSQQYLYWDGERRTYVPALEQSADGHKETGAPSKEGKEKKEKHKTKTAQQIAKDMERWARSLNKQKENFKNSFQPISSLRDDERRESATADAGYAILEKKGALAERQHTSMDLPKLASDDRPSPPRGLVAAYSGESDSEEEQERGGPEREEKLTDWQKLACLLCRRQFPSKEALIRHQQLSGLHKQNLEIHRRAHLSENELEALEKNDMEQMKYRDRAAERREKYGIPEPPEPKRRKYGGISTASVDFEQPTRDGLGSDNIGSRMLQAMGWKEGSGLGRKKQGIVTPIEAQTRVRGSGLGARGSSYGVTSTESYKETLHKTMVTRFNEAQ>sp|P98175-5|RBM10_HUMAN Isoform 5 of RNA-binding protein 10 OS=Homosapiens OX=9606 GN=RBM10MSGSPSLTARAEKVSVDAGRGGGESLQEASPRLADHGSSSGGGWEVKRSQRLRRGPSSPRRPYQDMEYERRGGRGDRTGRYGATDRSQDDGGENRSRDHDYRDMDYRSYPREYGSQEGKHDYDDSSEEQSAEDSYEASPGSETQRRRRRRHRHSPTGPPGFPRDGDYRDQDYRTEQGEEEEEEEDEEEEEKASNIVMLRMLPQAATEDDIRGQLQSHGVQAREVRLMRNKSSGQSRGFAFVEFSHLQDATRWMEANQHSLNILGQKVSMHYSDPKPKINEDWLCNKCGVQNFKRREKCFKCGVPKSEAEQKLPLGTRLDQQTLPLGGRELSQGLLPLPQPYQAQGVLASQALSQGSEPSSENANDTIILRNLNPHSTMDSILGALAPYAVLSSSNVRVIKDKQTQLNRGFAFIQLSTIVEAAQLLQILQALHPPLTIDGKTINVEFAKGSKRDMASNEGSRISAASVASTAIAAAQWAISQASQGGEGTWATSEEPPVDYSYYQQDEGYGNSQGTESSLYAHGYLKGTKGPGITGTKGDPTGAGPEASLEPGADSVSMQAFSRAQPGAAPGIYQQSAEASSSQGTAANSQSYTIMSPAVLKSELQSPTHPSSALPPATSPTAQESYSQYPVPDVSTYQYDETSGYYYDPQTGLYYDPNSQYYYNAQSQQYLYWDGERRTYVPALEQSADGHKETGAPSKEGKEKKEKHKTKTAQQIAKDMERWARSLNKQKENFKNSFQPISSLRDDERRESATADAGYAILEKKGALAERQHTSMDLPKLASDDRPSPPRGLVAAYSGESDSEEEQERGGPEREEKLTDWQKLACLLCRRQFPSKEALIRHQQLSGLHKQNLEIHRRAHLSENELEALEKNDMEQMKYRDRAAERREKYGIPEPPEPKRRKYGGISTASVDFEQPTRDGLGSDNIGSRMLQAMGWKEGSGLGRKKQGIVTPIEAQTRVRGSGLGARGSSYGVTSTESYKETLHKTMVTRFNEAQ>sp|Q16816|PHKG1_HUMAN Phosphorylase b kinase gamma catalytic chain,skeletal muscle/heart isoform OS=Homo sapiens OX=9606 GN=PHKG1 PE=2 SV=3MTRDEALPDSHSAQDFYENYEPKEILGRGVSSVVRRCIHKPTSQEYAVKVIDVTGGGSFSPEEVRELREATLKEVDILRKVSGHPNIIQLKDTYETNTFFFLVFDLMKRGELFDYLTEKVTLSEKETRKIMRALLEVICTLHKLNIVHRDLKPENILLDDNMNIKLTDFGFSCQLEPGERLREVCGTPSYLAPEIIECSMNEDHPGYGKEVDMWSTGVIMYTLLAGSPPFWHRKQMLMLRMIMSGNYQFGSPEWDDYSDTVKDLVSRFLVVQPQNRYTAEEALAHPFFQQYLVEEVRHFSPRGKFKVIALTVLASVRIYYQYRRVKPVTREIVIRDPYALRPLRRLIDAYAFRIYGHWVKKGQQQNRAALFENTPKAVLLSLAEEDY>sp|Q16816-2|PHKG1_HUMAN Isoform 2 of Phosphorylase b kinase gammacatalytic chain, skeletal muscle/heart isoform OS=Homo sapiens OX=9606GN=PHKG1MTRDEALPDSHSAQDFYENYEPKEILGRGVSSVVRRCIHKPTSQEYAVKVIDVTGGGSFSPEEVRELREATLKEVDILRKVSGHPNIIQLKDTYETNTFFFLVFDLWEDTDTMEMEQKWCLGWDSPKSTNFRAQGRARMKRGELFDYLTEKVTLSEKETRKIMRALLEVICTLHKLNIVHRDLKPENILLDDNMNIKLTDFGFSCQLEPGERLREVCGTPSYLAPEIIECSMNEDHPGYGKEVDMWSTGVIMYTLLAGSPPFWHRKQMLMLRMIMSGNYQFGSPEWDDYSDTVKDLVSRFLVVQPQNRYTAEEALAHPFFQQYLVEEVRHFSPRGKFKVIALTVLASVRIYYQYRRVKPVTREIVIRDPYALRPLRRLIDAYAFRIYGHWVKKGQQQNRAALFENTPKAVLLSLAEEDY>sp|Q96S96|PEBP4_HUMAN Phosphatidylethanolamine-binding protein 4 OS=Homosapiens OX=9606 GN=PEBP4 PE=1 SV=3MGWTMRLVTAALLLGLMMVVTGDEDENSPCAHEALLDEDTLFCQGLEVFYPELGNIGCKVVPDCNNYRQKITSWMEPIVKFPGAVDGATYILVMVDPDAPSRAEPRQRFWRHWLVTDIKGADLKKGKIQGQELSAYQAPSPPAHSGFHRYQFFVYLQEGKVISLLPKENKTRGSWKMDRFLNRFHLGEPEASTQFMTQNYQDSPTLQAPRERASEPKHKNQAEIAAC>sp|O43374|RASL2_HUMAN Ras GTPase-activating protein 4 OS=Homo sapiensOX=9606 GN=RASA4 PE=2 SV=2MAKRSSLYIRIVEGKNLPAKDITGSSDPYCIVKVDNEPIIRTATVWKTLCPFWGEEYQVHLPPTFHAVAFYVMDEDALSRDDVIGKVCLTRDTIASHPKGFSGWAHLTEVDPDEEVQGEIHLRLEVWPGARACRLRCSVLEARDLAPKDRNGTSDPFVRVRYKGRTRETSIVKKSCYPRWNETFEFELQEGAMEALCVEAWDWDLVSRNDFLGKVVIDVQRLRVVQQEEGWFRLQPDQSKSRRHDEGNLGSLQLEVRLRDETVLPSSYYQPLVHLLCHEVKLGMQGPGQLIPLIEETTSTECRQDVATNLLKLFLGQGLAKDFLDLLFQLELSRTSETNTLFRSNSLASKSMESFLKVAGMQYLHGVLGPIINKVFEEKKYVELDPSKVEVKDVGCSGLHRPQTEAEVLEQSAQTLRAHLGALLSALSRSVRACPAVVRATFRQLFRRVRERFPGAQHENVPFIAVTSFLCLRFFSPAIMSPKLFHLRERHADARTSRTLLLLAKAVQNVGNMDTPASRAKEAWMEPLQPTVRQGVAQLKDFITKLVDIEEKDELDLQRTLSLQAPPVKEGPLFIHRTKGKGPLMSSSFKKLYFSLTTEALSFAKTPSSKKSALIKLANIRAAEKVEEKSFGGSHVMQVIYTDDAGRPQTAYLQCKCVNELNQWLSALRKVSINNTGLLGSYHPGVFRGDKWSCCHQKEKTGQGCDKTRSRVTLQEWNDPLDHDLEAQLIYRHLLGVEAMLWERHRELSGGAEAGTVPTSPGKVPEDSLARLLRVLQDLREAHSSSPAGSPPSEPNCLLELQT>sp|O43374-2|RASL2_HUMAN Isoform 2 of Ras GTPase-activating protein 4OS=Homo sapiens OX=9606 GN=RASA4MAKRSSLYIRIVEGKNLPAKDITGSSDPYCIVKVDNEPIIRTATVWKTLCPFWGEEYQVHLPPTFHAVAFYVMDEDALSRDDVIGKVCLTRDTIASHPKGFSGWAHLTEVDPDEEVQGEIHLRLEVWPGARACRLRCSVLEARDLAPKDRNGTSDPFVRVRYKGRTRETSIVKKSCYPRWNETFEFELQEGAMEALCVEAWDWDLVSRNDFLGKVVIDVQRLRVVQQEEGWFRLQPDQSKSRRHDEGNLGSLQLEVRLRDETVLPSSYYQPLVHLLCHEVKLGMQGPGQLIPLIEETTSTECRQDVATNLLKLFLGQGLAKDFLDLLFQLELSRTSETNTLFRSNSLASKSMESFLKVAGMQYLHGVLGPIINKVFEEKKYVELDPSKVEVKDVGCSGLHRPQTEAEVLEQSAQTLRAHLGALLSALSRSVRACPAVVRATFRQLFRRVRERFPGAQHENVPFIAVTSFLCLRFFSPAIMSPKLFHLRERHADARTSRTLLLLAKAVQNVGNMDTPASRAKEAWMEPLQPTVRQGVAQLKDFITKLVDIEEKDELDLQRTLSLQAPPVKEGPLFIHRTKGKGPLMSSSFKKLYFSLTTEALSFAKTPSSKCVNELNQWLSALRKVSINNTGLLGSYHPGVFRGDKWSCCHQKEKTGQGCDKTRSRVTLQEWNDPLDHDLEAQLIYRHLLGVEAMLWERHRELSGGAEAGTVPTSPGKVPEDSLARLLRVLQDLREAHSSSPAGSPPSEPNCLLELQT>sp|P54725|RD23A_HUMAN UV excision repair protein RAD23 homolog A OS=Homosapiens OX=9606 GN=RAD23A PE=1 SV=1MAVTITLKTLQQQTFKIRMEPDETVKVLKEKIEAEKGRDAFPVAGQKLIYAGKILSDDVPIRDYRIDEKNFVVVMVTKTKAGQGTSAPPEASPTAAPESSTSFPPAPTSGMSHPPPAAREDKSPSEESAPTTSPESVSGSVPSSGSSGREEDAASTLVTGSEYETMLTEIMSMGYERERVVAALRASYNNPHRAVEYLLTGIPGSPEPEHGSVQESQVSEQPATEAAGENPLEFLRDQPQFQNMRQVIQQNPALLPALLQQLGQENPQLLQQISRHQEQFIQMLNEPPGELADISDVEGEVGAIGEEAPQMNYIQVTPQEKEAIERLKALGFPESLVIQAYFACEKNENLAANFLLSQNFDDE>sp|P54725-2|RD23A_HUMAN Isoform 2 of UV excision repair protein RAD23homolog A OS=Homo sapiens OX=9606 GN=RAD23AMAVTITLKTLQQQTFKIRMEPDETVKVLKEKIEAEKGRDAFPVAGQKLIYAGKILSDDVPIRDYRIDEKNFVVVMVTKTKAGQGTSAPPEASPTAAPESSTSFPPAPTSGMSHPPPAAREDKSPSEESAPTTSPESVSGSVPSSGSSGREEDAASTLVTGSEYETMLTEIMSMGYERERVVAALRASYNNPHRAVEYLLTGIPGSPEPEHGSVQESQVSEQPATEAAGENPLEFLRDQPQFQNMRQVIQQNPALLPALLQQLGQENPQLLQLKALGFPESLVIQAYFACEKNENLAANFLLSQNFDDE>sp|P54725-3|RD23A_HUMAN Isoform 3 of UV excision repair protein RAD23homolog A OS=Homo sapiens OX=9606 GN=RAD23AMAVTITLKTLQQQTFKIRMEPDETVKVLKEKIEAEKGRDAFPVAGQKLIYAGKILSDDVPIRDYRIDEKNFVVVMVTKTKAGQGTSAPPEASPTAAPESSTSFPPAPTSGMSHPPPAAREDKSPSEESAPTTSPESVSGSVPSSGSSGREEDAASTLVTGSEYETMLTEIMSMGYERERVVAALRASYNNPHRAVEYLLTGIPGSPEPEHGSVQESQVSEQPATEAGENPLEFLRDQPQFQNMRQVIQQNPALLPALLQQLGQENPQLLQQISRHQEQFIQMLNEPPGELADISDVEGEVGAIGEEAPQMNYIQVTPQEKEAIERLKALGFPESLVIQAYFACEKNENLAANFLLSQNFDDE>sp|Q15907|RB11B_HUMAN Ras-related protein Rab-11B OS=Homo sapiensOX=9606 GN=RAB11B PE=1 SV=4MGTRDDEYDYLFKVVLIGDSGVGKSNLLSRFTRNEFNLESKSTIGVEFATRSIQVDGKTIKAQIWDTAGQERYRAITSAYYRGAVGALLVYDIAKHLTYENVERWLKELRDHADSNIVIMLVGNKSDLRHLRAVPTDEARAFAEKNNLSFIETSALDSTNVEEAFKNILTEIYRIVSQKQIADRAAHDESPGNNVVDISVPPTTDGQKPNKLQCCQNL>sp|Q15907-2|RB11B_HUMAN Isoform 2 of Ras-related protein Rab-11B OS=Homosapiens OX=9606 GN=RAB11BMGTRDDEYDYLFKVVLIGDSGVGKSNLLSRFTRNEFNLESKSTIGVEFATRSIQVDGKTIKAQIWDTAGQERYRAITSAYYRGAVGALLVYDIAKHLTYENVERWLKELRDHADSNIVIMLVGNKSDLRHLRAVPTDEARAFAEKNNLSFIETSALDSTNVEEAFKNILTGGRGPDGCG>sp|Q92698|RAD54_HUMAN DNA repair and recombination protein RAD54-likeOS=Homo sapiens OX=9606 GN=RAD54L PE=1 SV=2MRRSLAPSQLAKRKPEGRSCDDEDWQPGLVTPRKRKSSSETQIQECFLSPFRKPLSQLTNQPPCLDSSQHEAFIRSILSKPFKVPIPNYQGPLGSRALGLKRAGVRRALHDPLEKDALVLYEPPPLSAHDQLKLDKEKLPVHVVVDPILSKVLRPHQREGVKFLWECVTSRRIPGSHGCIMADEMGLGKTLQCITLMWTLLRQSPECKPEIDKAVVVSPSSLVKNWYNEVGKWLGGRIQPLAIDGGSKDEIDQKLEGFMNQRGARVSSPILIISYETFRLHVGVLQKGSVGLVICDEGHRLKNSENQTYQALDSLNTSRRVLISGTPIQNDLLEYFSLVHFVNSGILGTAHEFKKHFELPILKGRDAAASEADRQLGEERLRELTSIVNRCLIRRTSDILSKYLPVKIEQVVCCRLTPLQTELYKRFLRQAKPAEELLEGKMSVSSLSSITSLKKLCNHPALIYDKCVEEEDGFVGALDLFPPGYSSKALEPQLSGKMLVLDYILAVTRSRSSDKVVLVSNYTQTLDLFEKLCRARRYLYVRLDGTMSIKKRAKVVERFNSPSSPDFVFMLSSKAGGCGLNLIGANRLVMFDPDWNPANDEQAMARVWRDGQKKTCYIYRLLSAGTIEEKIFQRQSHKKALSSCVVDEEQDVERHFSLGELKELFILDEASLSDTHDRLHCRRCVNSRQIRPPPDGSDCTSDLAGWNHCTDKWGLRDEVLQAAWDAASTAITFVFHQRSHEEQRGLR>sp|Q86YV0|RASL3_HUMAN RAS protein activator like-3 OS=Homo sapiensOX=9606 GN=RASAL3 PE=1 SV=2MDPPSPSRTSQTQPTATSPLTSYRWHTGGGGEKAAGGFRWGRFAGWGRALSHQEPMVSTQPAPRSIFRRVLSAPPKESRTSRLRLSKALWGRHKNPPPEPDPEPEQEAPELEPEPELEPPTPQIPEAPTPNVPVWDIGGFTLLDGKLVLLGGEEEGPRRPRVGSASSEGSIHVAMGNFRDPDRMPGKTEPETAGPNQVHNVRGLLKRLKEKKKARLEPRDGPPSALGSRESLATLSELDLGAERDVRIWPLHPSLLGEPHCFQVTWTGGSRCFSCRSAAERDRWIEDLRRQFQPTQDNVEREETWLSVWVHEAKGLPRAAAGAPGVRAELWLDGALLARTAPRAGPGQLFWAERFHFEALPPARRLSLRLRGLGPGSAVLGRVALALEELDAPRAPAAGLERWFPLLGAPAGAALRARIRARRLRVLPSERYKELAEFLTFHYARLCGALEPALPAQAKEELAAAMVRVLRATGRAQALVTDLGTAELARCGGREALLFRENTLATKAIDEYMKLVAQDYLQETLGQVVRRLCASTEDCEVDPSKCPASELPEHQARLRNSCEEVFETIIHSYDWFPAELGIVFSSWREACKERGSEVLGPRLVCASLFLRLLCPAILAPSLFGLAPDHPAPGPARTLTLIAKVIQNLANRAPFGEKEAYMGFMNSFLEEHGPAMQCFLDQVAMVDVDAAPSGYQGSGDLALQLAVLHAQLCTIFAELDQTTRDTLEPLPTILRAIEEGQPVLVSVPMRLPLPPAQVHSSLSAGEKPGFLAPRDLPKHTPLISKSQSLRSVRRSESWARPRPDEERPLRRPRPVQRTQSVPVRRPARRRQSAGPWPRPKGSLSMGPAPRARPWTRDSASLPRKPSVPWQRQMDQPQDRNQALGTHRPVNKLAELQCEVAALREEQKVLSRLVESLSTQIRALTEQQEQLRGQLQDLDSRLRAGSSEFDSEHNLTSNEGHSLKNLEHRLNEMERTQAQLRDAVQSLQLSPRTRGSWSQPQPLKAPCLNGDTT>sp|Q86YV0-2|RASL3_HUMAN Isoform 2 of RAS protein activator like-3OS=Homo sapiens OX=9606 GN=RASAL3MDPPSPSRTSQTQPTATSPLTSYRWHTGGGGEKAAGGFRWGRFAGWGRALSHQEPMVSTQPAPRSIFRRVLSAPPKESRTSRLRLSKALWGRHKNPPPEPDPEPEQEAPELEPEPELEPPTPQIPEAPTPNVPVWDIGGFTLLDGKLVLLGGEEEGPRRPRVGSASSEGSIHVAMGNFRDPDRMPGKTEPETAGPNQVHNVRGLLKRLKEKKKARLEPRDGPPSALGSRESLATLSELDLGAERDVRIWPLHPSLLGEPHCFQVTWTGGSRCFSCRSAAERDRWIEDLRRQFQPTQDNVEREETWLSVWVHEAKGLPRAAAGAPGVRAELWLDGALLARTAPRAGPGQLFWAERFHFEALPPARRLSLRLRGLGPGSAVLGRVALALEELDAPRAPAAGLERWFPLLGAPAGAALRARIRARRLRVLPSERYKELAEFLTFHYARLCGALEPALPAQAKEELAAAMVRVLRATGRAQALVTDLGTAELARCGGREALLFRENTLATKAIDEYMKLVAQDYLQETLGQVVRRLCASTEDCEVDPSKCPASELPEHQARLRNSCEEVFETIIHSYDWFPAELGIVFSSWREACKERGSEVLGPRLVCASLFLRLLCPAILAPSLFGLAPDHPAPGPARTLTLIAKVIQNLANRAPFGEKEAYMGFMNSFLEEHGPAMQCFLDQVAMVDVDAAPSGYQGSGDLALQLAVLHAQLCTIFAELDQTTRDTLEPLPTILRAIEEGQPVLVSVPMRLPLPPAQVHSSLSAGEKPGFLAPRDLPKHTPLISKSQSLRSVRRSESWARPRPDEERPLRRPRPVQRTQSVPVRRPARRRQSAGPWPRPKGSLSMGPAPRARPWTRDSASLPRKPSVPWQRQMDQPQDRNQALGTHRPVNKLAELQCEVAALREEQKVLSRLVESLSTQIRALTEQQEQLRGQLQDLDSRLRAG>sp|P49792|RBP2_HUMAN E3 SUMO-protein ligase RanBP2 OS=Homo sapiensOX=9606 GN=RANBP2 PE=1 SV=2MRRSKADVERYIASVQGSTPSPRQKSMKGFYFAKLYYEAKEYDLAKKYICTYINVQERDPKAHRFLGLLYELEENTDKAVECYRRSVELNPTQKDLVLKIAELLCKNDVTDGRAKYWLERAAKLFPGSPAIYKLKEQLLDCEGEDGWNKLFDLIQSELYVRPDDVHVNIRLVEVYRSTKRLKDAVAHCHEAERNIALRSSLEWNSCVVQTLKEYLESLQCLESDKSDWRATNTDLLLAYANLMLLTLSTRDVQESRELLQSFDSALQSVKSLGGNDELSATFLEMKGHFYMHAGSLLLKMGQHSSNVQWRALSELAALCYLIAFQVPRPKIKLIKGEAGQNLLEMMACDRLSQSGHMLLNLSRGKQDFLKEIVETFANKSGQSALYDALFSSQSPKDTSFLGSDDIGNIDVREPELEDLTRYDVGAIRAHNGSLQHLTWLGLQWNSLPALPGIRKWLKQLFHHLPHETSRLETNAPESICILDLEVFLLGVVYTSHLQLKEKCNSHHSSYQPLCLPLPVCKQLCTERQKSWWDAVCTLIHRKAVPGNVAKLRLLVQHEINTLRAQEKHGLQPALLVHWAECLQKTGSGLNSFYDQREYIGRSVHYWKKVLPLLKIIKKKNSIPEPIDPLFKHFHSVDIQASEIVEYEEDAHITFAILDAVNGNIEDAVTAFESIKSVVSYWNLALIFHRKAEDIENDALSPEEQEECKNYLRKTRDYLIKIIDDSDSNLSVVKKLPVPLESVKEMLNSVMQELEDYSEGGPLYKNGSLRNADSEIKHSTPSPTRYSLSPSKSYKYSPKTPPRWAEDQNSLLKMICQQVEAIKKEMQELKLNSSNSASPHRWPTENYGPDSVPDGYQGSQTFHGAPLTVATTGPSVYYSQSPAYNSQYLLRPAANVTPTKGPVYGMNRLPPQQHIYAYPQQMHTPPVQSSSACMFSQEMYGPPALRFESPATGILSPRGDDYFNYNVQQTSTNPPLPEPGYFTKPPIAAHASRSAESKTIEFGKTNFVQPMPGEGLRPSLPTQAHTTQPTPFKFNSNFKSNDGDFTFSSPQVVTQPPPAAYSNSESLLGLLTSDKPLQGDGYSGAKPIPGGQTIGPRNTFNFGSKNVSGISFTENMGSSQQKNSGFRRSDDMFTFHGPGKSVFGTPTLETANKNHETDGGSAHGDDDDDGPHFEPVVPLPDKIEVKTGEEDEEEFFCNRAKLFRFDVESKEWKERGIGNVKILRHKTSGKIRLLMRREQVLKICANHYISPDMKLTPNAGSDRSFVWHALDYADELPKPEQLAIRFKTPEEAALFKCKFEEAQSILKAPGTNVAMASNQAVRIVKEPTSHDNKDICKSDAGNLNFEFQVAKKEGSWWHCNSCSLKNASTAKKCVSCQNLNPSNKELVGPPLAETVFTPKTSPENVQDRFALVTPKKEGHWDCSICLVRNEPTVSRCIACQNTKSANKSGSSFVHQASFKFGQGDLPKPINSDFRSVFSTKEGQWDCSACLVQNEGSSTKCAACQNPRKQSLPATSIPTPASFKFGTSETSKTLKSGFEDMFAKKEGQWDCSSCLVRNEANATRCVACQNPDKPSPSTSVPAPASFKFGTSETSKAPKSGFEGMFTKKEGQWDCSVCLVRNEASATKCIACQNPGKQNQTTSAVSTPASSETSKAPKSGFEGMFTKKEGQWDCSVCLVRNEASATKCIACQNPGKQNQTTSAVSTPASSETSKAPKSGFEGMFTKKEGQWDCSVCLVRNEASATKCIACQCPSKQNQTTAISTPASSEISKAPKSGFEGMFIRKGQWDCSVCCVQNESSSLKCVACDASKPTHKPIAEAPSAFTLGSEMKLHDSSGSQVGTGFKSNFSEKASKFGNTEQGFKFGHVDQENSPSFMFQGSSNTEFKSTKEGFSIPVSADGFKFGISEPGNQEKKSEKPLENGTGFQAQDISGQKNGRGVIFGQTSSTFTFADLAKSTSGEGFQFGKKDPNFKGFSGAGEKLFSSQYGKMANKANTSGDFEKDDDAYKTEDSDDIHFEPVVQMPEKVELVTGEEDEKVLYSQRVKLFRFDAEVSQWKERGLGNLKILKNEVNGKLRMLMRREQVLKVCANHWITTTMNLKPLSGSDRAWMWLASDFSDGDAKLEQLAAKFKTPELAEEFKQKFEECQRLLLDIPLQTPHKLVDTGRAAKLIQRAEEMKSGLKDFKTFLTNDQTKVTEEENKGSGTGAAGASDTTIKPNPENTGPTLEWDNYDLREDALDDSVSSSSVHASPLASSPVRKNLFRFGESTTGFNFSFKSALSPSKSPAKLNQSGTSVGTDEESDVTQEEERDGQYFEPVVPLPDLVEVSSGEENEQVVFSHRAKLYRYDKDVGQWKERGIGDIKILQNYDNKQVRIVMRRDQVLKLCANHRITPDMTLQNMKGTERVWLWTACDFADGERKVEHLAVRFKLQDVADSFKKIFDEAKTAQEKDSLITPHVSRSSTPRESPCGKIAVAVLEETTRERTDVIQGDDVADATSEVEVSSTSETTPKAVVSPPKFVFGSESVKSIFSSEKSKPFAFGNSSATGSLFGFSFNAPLKSNNSETSSVAQSGSESKVEPKKCELSKNSDIEQSSDSKVKNLFASFPTEESSINYTFKTPEKAKEKKKPEDSPSDDDVLIVYELTPTAEQKALATKLKLPPTFFCYKNRPDYVSEEEEDDEDFETAVKKLNGKLYLDGSEKCRPLEENTADNEKECIIVWEKKPTVEEKAKADTLKLPPTFFCGVCSDTDEDNGNGEDFQSELQKVQEAQKSQTEEITSTTDSVYTGGTEVMVPSFCKSEEPDSITKSISSPSVSSETMDKPVDLSTRKEIDTDSTSQGESKIVSFGFGSSTGLSFADLASSNSGDFAFGSKDKNFQWANTGAAVFGTQSVGTQSAGKVGEDEDGSDEEVVHNEDIHFEPIVSLPEVEVKSGEEDEEILFKERAKLYRWDRDVSQWKERGVGDIKILWHTMKNYYRILMRRDQVFKVCANHVITKTMELKPLNVSNNALVWTASDYADGEAKVEQLAVRFKTKEVADCFKKTFEECQQNLMKLQKGHVSLAAELSKETNPVVFFDVCADGEPLGRITMELFSNIVPRTAENFRALCTGEKGFGFKNSIFHRVIPDFVCQGGDITKHDGTGGQSIYGDKFEDENFDVKHTGPGLLSMANQGQNTNNSQFVITLKKAEHLDFKHVVFGFVKDGMDTVKKIESFGSPKGSVCRRITITECGQI>sp|Q9NYN1|RASLC_HUMAN Ras-like protein family member 12 OS=Homo sapiensOX=9606 GN=RASL12 PE=1 SV=1MSSVFGKPRAGSGPQSAPLEVNLAILGRRGAGKSALTVKFLTKRFISEYDPNLEDTYSSEETVDHQPVHLRVMDTADLDTPRNCERYLNWAHAFLVVYSVDSRQSFDSSSSYLELLALHAKETQRSIPALLLGNKLDMAQYRQVTKAEGVALAGRFGCLFFEVSACLDFEHVQHVFHEAVREARRELEKSPLTRPLFISEERALPHQAPLTARHGLASCTFNTLSTINLKEMPTVAQAKLVTVKSSRAQSKRKAPTLTLLKGFKIF>sp|Q9NYN1-2|RASLC_HUMAN Isoform 2 of Ras-like protein family member 12OS=Homo sapiens OX=9606 GN=RASL12MVIMGPELVGSWSDFKNEAADPRALTVKFLTKRFISEYDPNLEDTYSSEETVDHQPVHLRVMDTADLDTPRNCERYLNWAHAFLVVYSVDSRQSFDSSSSYLELLALHAKETQRSIPALLLGNKLDMAQYRQVTKAEGVALAGRFGCLFFEVSACLDFEHVQHVFHEAVREARRELEKSPLTRPLFISEERALPHQAPLTARHGLASCTFNTLSTINLKEMPTVAQAKLVTVKSSRAQSKRKAPTLTLLKGFKIF>sp|Q9NYN1-3|RASLC_HUMAN Isoform 3 of Ras-like protein family member 12OS=Homo sapiens OX=9606 GN=RASL12MSSVFGKPRAGSGPQSAPLEVNLAILGRRGAGKSEDTYSSEETVDHQPVHLRVMDTADLDTPRNCERYLNWAHAFLVVYSVDSRQSFDSSSSYLELLALHAKETQRSIPALLLGNKLDMAQYRQVTKAEGVALAGRFGCLFFEVSACLDFEHVQHVFHEAVREARRELEKSPLTRPLFISEERALPHQAPLTARHGLASCTFNTLSTINLKEMPTVAQAKLVTVKSSRAQSKRKAPTLTLLKGFKIF>sp|P54727|RD23B_HUMAN UV excision repair protein RAD23 homolog B OS=Homosapiens OX=9606 GN=RAD23B PE=1 SV=1MQVTLKTLQQQTFKIDIDPEETVKALKEKIESEKGKDAFPVAGQKLIYAGKILNDDTALKEYKIDEKNFVVVMVTKPKAVSTPAPATTQQSAPASTTAVTSSTTTTVAQAPTPVPALAPTSTPASITPASATASSEPAPASAAKQEKPAEKPAETPVATSPTATDSTSGDSSRSNLFEDATSALVTGQSYENMVTEIMSMGYEREQVIAALRASFNNPDRAVEYLLMGIPGDRESQAVVDPPQAASTGAPQSSAVAAAAATTTATTTTTSSGGHPLEFLRNQPQFQQMRQIIQQNPSLLPALLQQIGRENPQLLQQISQHQEHFIQMLNEPVQEAGGQGGGGGGGSGGIAEAGSGHMNYIQVTPQEKEAIERLKALGFPEGLVIQAYFACEKNENLAANFLLQQNFDED>sp|P54727-2|RD23B_HUMAN Isoform 2 of UV excision repair protein RAD23homolog B OS=Homo sapiens OX=9606 GN=RAD23BMVTKPKAVSTPAPATTQQSAPASTTAVTSSTTTTVAQAPTPVPALAPTSTPASITPASATASSEPAPASAAKQEKPAEKPAETPVATSPTATDSTSGDSSRSNLFEDATSALVTGQSYENMVTEIMSMGYEREQVIAALRASFNNPDRAVEYLLMGIPGDRESQAVVDPPQAASTGAPQSSAVAAAAATTTATTTTTSSGGHPLEFLRNQPQFQQMRQIIQQNPSLLPALLQQIGRENPQLLQQISQHQEHFIQMLNEPVQEAGGQGGGGGGGSGGIAEAGSGHMNYIQVTPQEKEAIERLKALGFPEGLVIQAYFACEKNENLAANFLLQQNFDED>sp|Q8IXT5|RB12B_HUMAN RNA-binding protein 12B OS=Homo sapiens OX=9606GN=RBM12B PE=1 SV=2MAVVIRLLGLPFIAGPVDIRHFFTGLTIPDGGVHIIGGEIGEAFIIFATDEDARRAISRSGGFIKDSSVELFLSSKAEMQKTIEMKRTDRVGRGRPGSGTSGVDSLSNFIESVKEEASNSGYGSSINQDAGFHTNGTGHGNLRPRKTRPLKAENPYLFLRGLPYLVNEDDVRVFFSGLCVDGVIFLKHHDGRNNGDAIVKFASCVDASGGLKCHRSFMGSRFIEVMQGSEQQWIEFGGNAVKEGDVLRRSEEHSPPRGINDRHFRKRSHSKSPRRTRSRSPLGFYVHLKNLSLSIDERDLRNFFRGTDLTDEQIRFLYKDENRTRYAFVMFKTLKDYNTALSLHKTVLQYRPVHIDPISRKQMLKFIARYEKKRSGSLERDRPGHVSQKYSQEGNSGQKLCIYIRNFPFDVTKVEVQKFFADFLLAEDDIYLLYDDKGVGLGEALVKFKSEEQAMKAERLNRRRFLGTEVLLRLISEAQIQEFGVNFSVMSSEKMQARSQSRERGDHSHLFDSKDPPIYSVGAFENFRHQLEDLRQLDNFKHPQRDFRQPDRHPPEDFRHSSEDFRFPPEDFRHSPEDFRRPREEDFRRPSEEDFRRPWEEDFRRPPEDDFRHPREEDWRRPLEEDWRRPLEEDFRRSPTEDFRQLPEEDFRQPPEEDLRWLPEEDFRRPPEEDWRRPPEEDFRRPLQGEWRRPPEDDFRRPPEEDFRHSPEEDFRQSPQEHFRRPPQEHFRRPPPEHFRRPPPEHFRRPPPEHFRRPPPEHFRRPPPEHFRRPPPEHFRRPPQEHFRRPPQEHFRRSREEDFRHPPDEDFRGPPDEDFRHPPDEDFRSPQEEDFRCPSDEDFRQLPEEDLREAPEEDPRLPDNFRPPGEDFRSPPDDFRSHRPFVNFGRPEGGKFDFGKHNMGSFPEGRFMPDPKINCGSGRVTPIKIMNLPFKANVNEILDFFHGYRIIPDSVSIQYNEQGLPTGEAIVAMINYNEAMAAIKDLNDRPVGPRKVKLTLL>sp|Q9UL26|RB22A_HUMAN Ras-related protein Rab-22A OS=Homo sapiensOX=9606 GN=RAB22A PE=1 SV=2MALRELKVCLLGDTGVGKSSIVWRFVEDSFDPNINPTIGASFMTKTVQYQNELHKFLIWDTAGQERFRALAPMYYRGSAAAIIVYDITKEETFSTLKNWVKELRQHGPPNIVVAIAGNKCDLIDVREVMERDAKDYADSIHAIFVETSAKNAININELFIEISRRIPSTDANLPSGGKGFKLRRQPSEPKRSCC>sp|Q99638|RAD9A_HUMAN Cell cycle checkpoint control protein RAD9AOS=Homo sapiens OX=9606 GN=RAD9A PE=1 SV=1MKCLVTGGNVKVLGKAVHSLSRIGDELYLEPLEDGLSLRTVNSSRSAYACFLFAPLFFQQYQAATPGQDLLRCKILMKSFLSVFRSLAMLEKTVEKCCISLNGRSSRLVVQLHCKFGVRKTHNLSFQDCESLQAVFDPASCPHMLRAPARVLGEAVLPFSPALAEVTLGIGRGRRVILRSYHEEEADSTAKAMVTEMCLGEEDFQQLQAQEGVAITFCLKEFRGLLSFAESANLNLSIHFDAPGRPAIFTIKDSLLDGHFVLATLSDTDSHSQDLGSPERHQPVPQLQAHSTPHPDDFANDDIDSYMIAMETTIGNEGSRVLPSISLSPGPQPPKSPGPHSEEEDEAEPSTVPGTPPPKKFRSLFFGSILAPVRSPQGPSPVLAEDSEGEG>sp|O00194|RB27B_HUMAN Ras-related protein Rab-27B OS=Homo sapiensOX=9606 GN=RAB27B PE=1 SV=4MTDGDYDYLIKLLALGDSGVGKTTFLYRYTDNKFNPKFITTVGIDFREKRVVYNAQGPNGSSGKAFKVHLQLWDTAGQERFRSLTTAFFRDAMGFLLMFDLTSQQSFLNVRNWMSQLQANAYCENPDIVLIGNKADLPDQREVNERQARELADKYGIPYFETSAATGQNVEKAVETLLDLIMKRMEQCVEKTQIPDTVNGGNSGNLDGEKPPEKKCIC>sp|Q6WBX8|RAD9B_HUMAN Cell cycle checkpoint control protein RAD9BOS=Homo sapiens OX=9606 GN=RAD9B PE=1 SV=2MLKCVMSGSQVKVFGKAVQALSRISDEFWLDPSKKGLALRCVNSSRSAYGCVLFSPVFFQHYQWSALVKMSENELDTTLHLKCKLGMKSILPIFRCLNSLERNIEKCRIFTRSDKCKVVIQFFYRHGIKRTHNICFQESQPLQVIFDKNVCTNTLMIQPRLLADAIVLFTSSQEEVTLAVTPLNFCLKSSNEESMDLSNAVHSEMFVGSDEFDFFQIGMDTEITFCFKELKGILTFSEATHAPISIYFDFPGKPLALSIDDMLVEANFILATLADEQSRASSPQSLCLSQKRKRSDLIEKKAGKNVTGQALECISKKAAPRRLYPKETLTNISALENCGSPAMKRVDGDVSEVSESSVSNTEEVPGSLCLRKFSCMFFGAVSSDQQEHFNHPFDSLARASDSEEDMNNVCCRKEFNGSDAKYFCII>sp|Q6WBX8-1|RAD9B_HUMAN Isoform 1 of Cell cycle checkpoint controlprotein RAD9B OS=Homo sapiens OX=9606 GN=RAD9BMLKCVMSGSQVKVFGKAVQALSRISDEFWLDPSKKGLALRCVNSSRSAYGCVLFSPVFFQHYQWSALVKMSENELDTTLHLKCKLGMKSILPIFRCLNSLERNIEKCRIFTRSDKCKVVIQFFYRHGIKRTHNICFQESQPLQVIFDKNVCTNTLMIQPRLLADAIVLFTSSQEEVTLAVTPLNFCLKSSNEESMDLSNAVHSEMFVGSDEFDFFQIGMDTEITFCFKELKGILTFSEATHAPISIYFDFPGKPLALSIDDMLVEANFILATLADEQSRASSPQSLCLSQKRKRSDLIEKKAGKNVTGQALECISKKAAPRRLYPKETLTNISALENCGSPAMKRVDGDVSEVSESSVSNTEEVPGSLCLRKFSCMFFGAVSSDQQEHFNHPFDSLARASDSEEDMNNGSFSIF>sp|Q6WBX8-2|RAD9B_HUMAN Isoform 2 of Cell cycle checkpoint controlprotein RAD9B OS=Homo sapiens OX=9606 GN=RAD9BMSENELDTTLHLKCKLGMKSILPIFRCLNSLERNIEKCRIFTRSDKCKVVIQFFYRHGIKRTHNICFQESQPLQVIFDKNVCTNTLMIQPRLLADAIVLFTSSQEEVTLAVTPLNFCLKSSNEESMDLSNAVHSEMFVGSDEFDFFQIGMDTEITFCFKELKGILTFSEATHAPISIYFDFPGKPLALSIDDMLVEANFILATLADEQSRASSPQSLCLSQKRKRSDLIEKKAGKNVTGQALECISKKAAPRRLYPKETLTNISALENCGSPAMKRVDGDVSEVSESSVSNTEEVPGSLCLRKFSCMFFGAVSSDQQEHFNHPFDSLARASDSEEDMNNGSFSIF>sp|Q6WBX8-3|RAD9B_HUMAN Isoform 3 of Cell cycle checkpoint controlprotein RAD9B OS=Homo sapiens OX=9606 GN=RAD9BMIQPRLLADAIVLFTSSQEEVTLAVTPLNFCLKSSNEESMDLSNAVHSEMFVGSDEFDFFQIGMDTEITFCFKELKGILTFSEATHAPISIYFDFPGKPLALSIDDMLVEANFILATLADEQSRASSPQSLCLSQKRKRSDLIEKKAGKNVTGQALECISKKAAPRRLYPKETLTNISALENCGSPAMKRVDGDVSEVSESSVSNTEEVPGSLCLRKFSCMFFGAVSSDQQEHFNHPFDSLARASDSEEDMNNGSFSIF>sp|Q6WBX8-4|RAD9B_HUMAN Isoform 4 of Cell cycle checkpoint controlprotein RAD9B OS=Homo sapiens OX=9606 GN=RAD9BMIQPRLLADAIVLFTSSQEEVTLAVTPLNFCLKSSNEESMDLSNAVHSEMFVGSDEFDFFQIGMDTEITFCFKELKGILTFSEATHAPISIYFDFPGKPLALSIDDMLVEANFILATLADEQSRASSPQSLCLSQKRKRSDLIEKKAGKNVTGQALECISKKAAPRRLYPKETLTNISALENCGSPAMKRVDGDVSEVSESSVSNTEEVPGSLCLRKFSCMFFGAVSSDQQEHFNHPFDSLARASDSEEDMNNVCCRKEFNGSDAKYFCII>sp|Q14964|RB39A_HUMAN Ras-related protein Rab-39A OS=Homo sapiensOX=9606 GN=RAB39A PE=1 SV=2METIWIYQFRLIVIGDSTVGKSCLLHRFTQGRFPGLRSPACDPTVGVDFFSRLLEIEPGKRIKLQLWDTAGQERFRSITRSYYRNSVGGFLVFDITNRRSFEHVKDWLEEAKMYVQPFRIVFLLVGHKCDLASQRQVTREEAEKLSADCGMKYIETSAKDATNVEESFTILTRDIYELIKKGEICIQDGWEGVKSGFVPNTVHSSEEAVKPRKECFC>sp|Q8NEN9|PDZD8_HUMAN PDZ domain-containing protein 8 OS=Homo sapiensOX=9606 GN=PDZD8 PE=1 SV=1MGLLLMILASAVLGSFLTLLAQFFLLYRRQPEPPADEAARAGEGFRYIKPVPGLLLREYLYGGGRDEEPSGAAPEGGATPTAAPETPAPPTRETCYFLNATILFLFRELRDTALTRRWVTKKIKVEFEELLQTKTAGRLLEGLSLRDVFLGETVPFIKTIRLVRPVVPSATGEPDGPEGEALPAACPEELAFEAEVEYNGGFHLAIDVDLVFGKSAYLFVKLSRVVGRLRLVFTRVPFTHWFFSFVEDPLIDFEVRSQFEGRPMPQLTSIIVNQLKKIIKRKHTLPNYKIRFKPFFPYQTLQGFEEDEEHIHIQQWALTEGRLKVTLLECSRLLIFGSYDREANVHCTLELSSSVWEEKQRSSIKTVELIKGNLQSVGLTLRLVQSTDGYAGHVIIETVAPNSPAAIADLQRGDRLIAIGGVKITSTLQVLKLIKQAGDRVLVYYERPVGQSNQGAVLQDNFGQLEENFLSSSCQSGYEEEAAGLTVDTESRELDSEFEDLASDVRAQNEFKDEAQSLSHSPKRVPTTLSIKPLGAISPVLNRKLAVGSHPLPPKIQSKDGNKPPPLKTSEITDPAQVSKPTQGSAFKPPVPPRPQAKVPLPSADAPNQAEPDVLVEKPEKVVPPPLVDKSAEKQAKNVDAIDDAAAPKQFLAKQEVAKDVTSETSCPTKDSSDDRQTWESSEILYRNKLGKWTRTRASCLFDIEACHRYLNIALWCRDPFKLGGLICLGHVSLKLEDVALGCLATSNTEYLSKLRLEAPSPKAIVTRTALRNLSMQKGFNDKFCYGDITIHFKYLKEGESDHHVVTNVEKEKEPHLVEEVSVLPKEEQFVGQMGLTENKHSFQDTQFQNPTWCDYCKKKVWTKAASQCMFCAYVCHKKCQEKCLAETSVCGATDRRIDRTLKNLRLEGQETLLGLPPRVDAEASKSVNKTTGLTRHIINTSSRLLNLRQVSKTRLSEPGTDLVEPSPKHTPNTSDNEGSDTEVCGPNSPSKRGNSTGIKLVRKEGGLDDSVFIAVKEIGRDLYRGLPTEERIQKLEFMLDKLQNEIDQELEHNNSLVREEKETTDTRKKSLLSAALAKSGERLQALTLLMIHYRAGIEDIETLESLSLDQHSKKISKYTDDTEEDLDNEISQLIDSQPFSSISDDLFGPSESV>sp|P34995|PE2R1_HUMAN Prostaglandin E2 receptor EP1 subtype OS=Homosapiens OX=9606 GN=PTGER1 PE=2 SV=3MSPCGPLNLSLAGEATTCAAPWVPNTSAVPPSGASPALPIFSMTLGAVSNLLALALLAQAAGRLRRRRSAATFLLFVASLLATDLAGHVIPGALVLRLYTAGRAPAGGACHFLGGCMVFFGLCPLLLGCGMAVERCVGVTRPLLHAARVSVARARLALAAVAAVALAVALLPLARVGRYELQYPGTWCFIGLGPPGGWRQALLAGLFASLGLVALLAALVCNTLSGLALLRARWRRRSRRPPPASGPDSRRRWGAHGPRSASASSASSIASASTFFGGSRSSGSARRARAHDVEMVGQLVGIMVVSCICWSPMLVLVALAVGGWSSTSLQRPLFLAVRLASWNQILDPWVYILLRQAVLRQLLRLLPPRAGAKGGPAGLGLTPSAWEASSLRSSRHSGLSHF>sp|Q8IXQ8|PDZD9_HUMAN PDZ domain-containing protein 9 OS=Homo sapiensOX=9606 GN=PDZD9 PE=2 SV=2MQKASHKNKKERGVSNKVKTSVHNLSKTQQTKLTVGSLGLGLIIIQHGPYLQITHLIRKGAAANDGKLQPGDVLISVGHANVLGYTLREFLQLLQHITIGTVLQIKVYRDFINIPEEWQEIYDLIPEAKFPVTSTPKKIELAKDESFTSSDDNENVDLDKRLQYYRYPWSTVHHPARRPISISRDWHGYKKKNHTISVGKDINCDVMIHRDDKKEVRAPSPYWIMVKQDNESSSSSTSSTSDAFWLEDCAQVEEGKAQLVSKVG>sp|Q8IXQ8-2|PDZD9_HUMAN Isoform 2 of PDZ domain-containing protein 9OS=Homo sapiens OX=9606 GN=PDZD9MAEGEEEGGDVLISVGHANVLGYTLREFLQLLQHITIGTVLQIKVYRDFINIPEEWQEIYDLIPEAKFPVTSTPKKIELAKDESFTSSDDNENVDLDKRLQYYRYPWSTVHHPARRPISISRDWHGYKKKNHTISVGKDINCDVMIHRDDKKEVRAPSPYWIMVKQDNESSSSSTSSTSDAFWLEDCAQVEEGKAQLVSKVG>sp|Q8IXQ8-3|PDZD9_HUMAN Isoform 3 of PDZ domain-containing protein 9OS=Homo sapiens OX=9606 GN=PDZD9MQKASHKNKKGDVLISVGHANVLGYTLREFLQLLQHITIGTVLQIKVYRDFINIPEEWQEIYDLIPEAKFPVTSTPKKIELAKDESFTSSDDNENVDLDKRLQYYRYPWSTVHHPARRPISISRDWHGYKKKNHTISVGKDINCDVMIHRDDKKEVRAPSPYWIMVKQDNESSSSSTSSTSDAFWLEDCAQVEEGKAQLVSKVG>sp|Q9HDD0|PLAT1_HUMAN Phospholipase A and acyltransferase 1 OS=Homosapiens OX=9606 GN=PLAAT1 PE=1 SV=1MAFNDCFSLNYPGNPCPGDLIEVFRPGYQHWALYLGDGYVINIAPVDGIPASFTSAKSVFSSKALVKMQLLKDVVGNDTYRINNKYDETYPPLPVEEIIKRSEFVIGQEVAYNLLVNNCEHFVTLLRYGEGVSEQANRAISTVEFVTAAVGVFSFLGLFPKGQRAKYY>sp|Q9HDD0-2|PLAT1_HUMAN Isoform 2 of Phospholipase A and acyltransferase1 OS=Homo sapiens OX=9606 GN=PLAAT1MVRASCRLGSARTPSPARRPPGVRASQSRGGAAGTVSAWRRWCWRWPWRTAPSDGWRLPPGCLPGTDGVVPRPPAARSAAARPRETPGHTQLPPGARRRPRLESEMAFNDCFSLNYPGNPCPGDLIEVFRPGYQHWALYLGDGYVINIAPVDGIPASFTSAKSVFSSKALVKMQLLKDVVGNDTYRINNKYDETYPPLPVEEIIKRSEFVIGQEVAYNLLVNNCEHFVTLLRYGEGVSEQANRAISTVEFVTAAVGVFSFLGLFPKGQRAKYY>sp|Q8TCS8|PNPT1_HUMAN Polyribonucleotide nucleotidyltransferase 1,mitochondrial OS=Homo sapiens OX=9606 GN=PNPT1 PE=1 SV=2MAACRYCCSCLRLRPLSDGPFLLPRRDRALTQLQVRALWSSAGSRAVAVDLGNRKLEISSGKLARFADGSAVVQSGDTAVMVTAVSKTKPSPSQFMPLVVDYRQKAAAAGRIPTNYLRREIGTSDKEILTSRIIDRSIRPLFPAGYFYDTQVLCNLLAVDGVNEPDVLAINGASVALSLSDIPWNGPVGAVRIGIIDGEYVVNPTRKEMSSSTLNLVVAGAPKSQIVMLEASAENILQQDFCHAIKVGVKYTQQIIQGIQQLVKETGVTKRTPQKLFTPSPEIVKYTHKLAMERLYAVFTDYEHDKVSRDEAVNKIRLDTEEQLKEKFPEADPYEIIESFNVVAKEVFRSIVLNEYKRCDGRDLTSLRNVSCEVDMFKTLHGSALFQRGQTQVLCTVTFDSLESGIKSDQVITAINGIKDKNFMLHYEFPPYATNEIGKVTGLNRRELGHGALAEKALYPVIPRDFPFTIRVTSEVLESNGSSSMASACGGSLALMDSGVPISSAVAGVAIGLVTKTDPEKGEIEDYRLLTDILGIEDYNGDMDFKIAGTNKGITALQADIKLPGIPIKIVMEAIQQASVAKKEILQIMNKTISKPRASRKENGPVVETVQVPLSKRAKFVGPGGYNLKKLQAETGVTISQVDEETFSVFAPTPSAMHEARDFITEICKDDQEQQLEFGAVYTATITEIRDTGVMVKLYPNMTAVLLHNTQLDQRKIKHPTALGLEVGQEIQVKYFGRDPADGRMRLSRKVLQSPATTVVRTLNDRSSIVMGEPISQSSSNSQ>sp|P53816|PLAT3_HUMAN Phospholipase A and acyltransferase 3 OS=Homosapiens OX=9606 GN=PLAAT3 PE=1 SV=2MRAPIPEPKPGDLIEIFRPFYRHWAIYVGDGYVVHLAPPSEVAGAGAASVMSALTDKAIVKKELLYDVAGSDKYQVNNKHDDKYSPLPCSKIIQRAEELVGQEVLYKLTSENCEHFVNELRYGVARSDQVRDVIIAASVAGMGLAAMSLIGVMFSRNKRQKQ>sp|Q9P212|PLCE1_HUMAN 1-phosphatidylinositol 4,5-bisphosphatephosphodiesterase epsilon-1 OS=Homo sapiens OX=9606 GN=PLCE1 PE=1 SV=3MTSEEMTASVLIPVTQRKVVSAQSAADESSEKVSDINISKAHTVRRSGETSHTISQLNKLKEEPSGSNLPKILSIAREKIVSDENSNEKCWEKIMPDSAKNLNINCNNILRNHQHGLPQRQFYEMYNSVAEEDLCLETGIPSPLERKVFPGIQLELDRPSMGISPLGNQSVIIETGRAHPDSRRAVFHFHYEVDRRMSDTFCTLSENLILDDCGNCVPLPGGEEKQKKNYVAYTCKLMELAKNCDNKNEQLQCDHCDTLNDKYFCFEGSCEKVDMVYSGDSFCRKDFTDSQAAKTFLSHFEDFPDNCDDVEEDAFKSKKERSTLLVRRFCKNDREVKKSVYTGTRAIVRTLPSGHIGLTAWSYIDQKRNGPLLPCGRVMEPPSTVEIRQDGSQRLSEAQWYPIYNAVRREETENTVGSLLHFLTKLPASETAHGRISVGPCLKQCVRDTVCEYRATLQRTSISQYITGSLLEATTSLGARSGLLSTFGGSTGRMMLKERQPGPSVANSNALPSSSAGISKELIDLQPLIQFPEEVASILMEQEQTIYRRVLPVDYLCFLTRDLGTPECQSSLPCLKASISASILTTQNGEHNALEDLVMRFNEVSSWVTWLILTAGSMEEKREVFSYLVHVAKCCWNMGNYNAVMEFLAGLRSRKVLKMWQFMDQSDIETMRSLKDAMAQHESSCEYRKVVTRALHIPGCKVVPFCGVFLKELCEVLDGASGLMKLCPRYNSQEETLEFVADYSGQDNFLQRVGQNGLKNSEKESTVNSIFQVIRSCNRSLETDEEDSPSEGNSSRKSSLKDKSRWQFIIGDLLDSDNDIFEQSKEYDSHGSEDSQKAFDHGTELIPWYVLSIQADVHQFLLQGATVIHYDQDTHLSARCFLQLQPDNSTLTWVKPTTASPASSKAKLGVLNNTAEPGKFPLLGNAGLSSLTEGVLDLFAVKAVYMGHPGIDIHTVCVQNKLGSMFLSETGVTLLYGLQTTDNRLLHFVAPKHTAKMLFSGLLELTRAVRKMRKFPDQRQQWLRKQYVSLYQEDGRYEGPTLAHAVELFGGRRWSARNPSPGTSAKNAEKPNMQRNNTLGISTTKKKKKILMRGESGEVTDDEMATRKAKMHKECRSRSGSDPQDINEQEESEVNAIANPPNPLPSRRAHSLTTAGSPNLAAGTSSPIRPVSSPVLSSSNKSPSSAWSSSSWHGRIKGGMKGFQSFMVSDSNMSFVEFVELFKSFSVRSRKDLKDLFDVYAVPCNRSGSESAPLYTNLTIDENTSDLQPDLDLLTRNVSDLGLFIKSKQQLSDNQRQISDAIAAASIVTNGTGIESTSLGIFGVGILQLNDFLVNCQGEHCTYDEILSIIQKFEPSISMCHQGLMSFEGFARFLMDKENFASKNDESQENIKELQLPLSYYYIESSHNTYLTGHQLKGESSVELYSQVLLQGCRSVELDCWDGDDGMPIIYHGHTLTTKIPFKEVVEAIDRSAFINSDLPIIISIENHCSLPQQRKMAEIFKTVFGEKLVTKFLFETDFSDDPMLPSPDQLRKKVLLKNKKLKAHQTPVDILKQKAHQLASMQVQAYNGGNANPRPANNEEEEDEEDEYDYDYESLSDDNILEDRPENKSCNDKLQFEYNEEIPKRIKKADNSACNKGKVYDMELGEEFYLDQNKKESRQIAPELSDLVIYCQAVKFPGLSTLNASGSSRGKERKSRKSIFGNNPGRMSPGETASFNKTSGKSSCEGIRQTWEESSSPLNPTTSLSAIIRTPKCYHISSLNENAAKRLCRRYSQKLTQHTACQLLRTYPAATRIDSSNPNPLMFWLHGIQLVALNYQTDDLPLHLNAAMFEANGGCGYVLKPPVLWDKNCPMYQKFSPLERDLDSMDPAVYSLTIVSGQNVCPSNSMGSPCIEVDVLGMPLDSCHFRTKPIHRNTLNPMWNEQFLFHVHFEDLVFLRFAVVENNSSAVTAQRIIPLKALKRGYRHLQLRNLHNEVLEISSLFINSRRMEENSSGNTMSASSMFNTEERKCLQTHRVTVHGVPGPEPFTVFTINGGTKAKQLLQQILTNEQDIKPVTTDYFLMEEKYFISKEKNECRKQPFQRAIGPEEEIMQILSSWFPEEGYMGRIVLKTQQENLEEKNIVQDDKEVILSSEEESFFVQVHDVSPEQPRTVIKAPRVSTAQDVIQQTLCKAKYSYSILSNPNPSDYVLLEEVVKDTTNKKTTTPKSSQRVLLDQECVFQAQSKWKGAGKFILKLKEQVQASREDKKKGISFASELKKLTKSTKQPRGLTSPSQLLTSESIQTKEEKPVGGLSSSDTMDYRQ>sp|Q9P212-2|PLCE1_HUMAN Isoform 2 of 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase epsilon-1 OS=Homo sapiens OX=9606 GN=PLCE1MVSEGSAAGRDFAGMEEVRQLHVRFCKGIKIWHQAWFLCSLLGREPQEREAGCQLWLCTLSAVLKVGWLFPLSEVPNFTLLKDGCGCWRLKEDQIYNAVRREETENTVGSLLHFLTKLPASETAHGRISVGPCLKQCVRDTVCEYRATLQRTSISQYITGSLLEATTSLGARSGLLSTFGGSTGRMMLKERQPGPSVANSNALPSSSAGISKELIDLQPLIQFPEEVASILMEQEQTIYRRVLPVDYLCFLTRDLGTPECQSSLPCLKASISASILTTQNGEHNALEDLVMRFNEVSSWVTWLILTAGSMEEKREVFSYLVHVAKCCWNMGNYNAVMEFLAGLRSRKVLKMWQFMDQSDIETMRSLKDAMAQHESSCEYRKVVTRALHIPGCKVVPFCGVFLKELCEVLDGASGLMKLCPRYNSQEETLEFVADYSGQDNFLQRVGQNGLKNSEKESTVNSIFQVIRSCNRSLETDEEDSPSEGNSSRKSSLKDKSRWQFIIGDLLDSDNDIFEQSKEYDSHGSEDSQKAFDHGTELIPWYVLSIQADVHQFLLQGATVIHYDQDTHLSARCFLQLQPDNSTLTWVKPTTASPASSKAKLGVLNNTAEPGKFPLLGNAGLSSLTEGVLDLFAVKAVYMGHPGIDIHTVCVQNKLGSMFLSETGVTLLYGLQTTDNRLLHFVAPKHTAKMLFSGLLELTRAVRKMRKFPDQRQQWLRKQYVSLYQEDGRYEGPTLAHAVELFGGRRWSARNPSPGTSAKNAEKPNMQRNNTLGISTTKKKKKILMRGESGEVTDDEMATRKAKMHKECRSRSGSDPQDINEQEESEVNAIANPPNPLPSRRAHSLTTAGSPNLAAGTSSPIRPVSSPVLSSSNKSPSSAWSSSSWHGRIKGGMKGFQSFMVSDSNMSFVEFVELFKSFSVRSRKDLKDLFDVYAVPCNRSGSESAPLYTNLTIDENTSDLQPDLDLLTRNVSDLGLFIKSKQQLSDNQRQISDAIAAASIVTNGTGIESTSLGIFGVGILQLNDFLVNCQGEHCTYDEILSIIQKFEPSISMCHQGLMSFEGFARFLMDKENFASKNDESQENIKELQLPLSYYYIESSHNTYLTGHQLKGESSVELYSQVLLQGCRSVELDCWDGDDGMPIIYHGHTLTTKIPFKEVVEAIDRSAFINSDLPIIISIENHCSLPQQRKMAEIFKTVFGEKLVTKFLFETDFSDDPMLPSPDQLRKKVLLKNKKLKAHQTPVDILKQKAHQLASMQVQAYNGGNANPRPANNEEEEDEEDEYDYDYESLSDDNILEDRPENKSCNDKLQFEYNEEIPKRIKKADNSACNKGKVYDMELGEEFYLDQNKKESRQIAPELSDLVIYCQAVKFPGLSTLNASGSSRGKERKSRKSIFGNNPGRMSPGETASFNKTSGKSSCEGIRQTWEESSSPLNPTTSLSAIIRTPKCYHISSLNENAAKRLCRRYSQKLTQHTACQLLRTYPAATRIDSSNPNPLMFWLHGIQLVALNYQTDDLPLHLNAAMFEANGGCGYVLKPPVLWDKNCPMYQKFSPLERDLDSMDPAVYSLTIVSGQNVCPSNSMGSPCIEVDVLGMPLDSCHFRTKPIHRNTLNPMWNEQFLFHVHFEDLVFLRFAVVENNSSAVTAQRIIPLKALKRGYRHLQLRNLHNEVLEISSLFINSRRMEENSSGNTMSASSMFNTEERKCLQTHRVTVHGVPGPEPFTVFTINGGTKAKQLLQQILTNEQDIKPVTTDYFLMEEKYFISKEKNECRKQPFQRAIGPEEEIMQILSSWFPEEGYMGRIVLKTQQENLEEKNIVQDDKEVILSSEEESFFVQVHDVSPEQPRTVIKAPRVSTAQDVIQQTLCKAKYSYSILSNPNPSDYVLLEEVVKDTTNKKTTTPKSSQRVLLDQECVFQAQSKWKGAGKFILKLKEQVQASREDKKKGISFASELKKLTKSTKQPRGLTSPSQLLTSESIQTKEEKPVGGLSSSDTMDYRQ>sp|Q96BK5|PINX1_HUMAN PIN2/TERF1-interacting telomerase inhibitor 1OS=Homo sapiens OX=9606 GN=PINX1 PE=1 SV=2MSMLAERRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQEQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGKDLSSRSKTDLDCIFGKRQSKKTPEGDASPSTPEENETTTTSAFTIQEYFAKRMAALKNKPQVPVPGSDISETQVERKRGKKRNKEATGKDVESYLQPKAKRHTEGKPERAEAQERVAKKKSAPAEEQLRGPCWDQSSKASAQDAGDHVQPPEGRDFTLKPKKRRGKKKLQKPVEIAEDATLEETLVKKKKKKDSK>sp|Q96BK5-2|PINX1_HUMAN Isoform 2 of PIN2/TERF1-interacting telomeraseinhibitor 1 OS=Homo sapiens OX=9606 GN=PINX1MSMLAERRRKQKWAVDPQNTAWSNDDSKFGQRMLEKMGWSKGKGLGAQEQGATDHIKVQVKNNHLGLGATINNEDNWIAHQDDFNQLLAELNTCHGQETTDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGRCQSLHSRGERNHDNQRLHHPGVLCQADGSTEEQAPGSSSRV>sp|Q9H875|PKRI1_HUMAN PRKR-interacting protein 1 OS=Homo sapiens OX=9606GN=PRKRIP1 PE=1 SV=1MASPAASSVRPPRPKKEPQTLVIPKNAAEEQKLKLERLMKNPDKAVPIPEKMSEWAPRPPPEFVRDVMGSSAGAGSGEFHVYRHLRRREYQRQDYMDAMAEKQKLDAEFQKRLEKNKIAAEEQTAKRRKKRQKLKEKKLLAKKMKLEQKKQEGPGQPKEQGSSSSAEASGTEEEEEVPSFTMGR>sp|Q9H875-2|PKRI1_HUMAN Isoform 2 of PRKR-interacting protein 1 OS=Homosapiens OX=9606 GN=PRKRIP1MKNPDKAVPIPEKMSEWAPRPPPEFVRDVMGSSAGAGSGEFHVYRHLRRREYQRQDYMDAMAEKQKLDAEFQKRLEKNKIAAEEQTAKRRKKRTRSAQGAGVQQLCGGIWNRGGGGSAQFHHGAMTMFATASAWNLARAVTRRERRLFGSFSPARTR>sp|P11086|PNMT_HUMAN Phenylethanolamine N-methyltransferase OS=Homosapiens OX=9606 GN=PNMT PE=1 SV=1MSGADRSPNAGAAPDSAPGQAAVASAYQRFEPRAYLRNNYAPPRGDLCNPNGVGPWKLRCLAQTFATGEVSGRTLIDIGSGPTVYQLLSACSHFEDITMTDFLEVNRQELGRWLQEEPGAFNWSMYSQHACLIEGKGECWQDKERQLRARVKRVLPIDVHQPQPLGAGSPAPLPADALVSAFCLEAVSPDLASFQRALDHITTLLRPGGHLLLIGALEESWYLAGEARLTVVPVSEEEVREALVRSGYKVRDLRTYIMPAHLQTGVDDVKGVFFAWAQKVGL>sp|Q02809|PLOD1_HUMAN Procollagen-lysine,2-oxoglutarate 5-dioxygenase 1OS=Homo sapiens OX=9606 GN=PLOD1 PE=1 SV=2MRPLLLLALLGWLLLAEAKGDAKPEDNLLVLTVATKETEGFRRFKRSAQFFNYKIQALGLGEDWNVEKGTSAGGGQKVRLLKKALEKHADKEDLVILFADSYDVLFASGPRELLKKFRQARSQVVFSAEELIYPDRRLETKYPVVSDGKRFLGSGGFIGYAPNLSKLVAEWEGQDSDSDQLFYTKIFLDPEKREQINITLDHRCRIFQNLDGALDEVVLKFEMGHVRARNLAYDTLPVLIHGNGPTKLQLNYLGNYIPRFWTFETGCTVCDEGLRSLKGIGDEALPTVLVGVFIEQPTPFVSLFFQRLLRLHYPQKHMRLFIHNHEQHHKAQVEEFLAQHGSEYQSVKLVGPEVRMANADARNMGADLCRQDRSCTYYFSVDADVALTEPNSLRLLIQQNKNVIAPLMTRHGRLWSNFWGALSADGYYARSEDYVDIVQGRRVGVWNVPYISNIYLIKGSALRGELQSSDLFHHSKLDPDMAFCANIRQQDVFMFLTNRHTLGHLLSLDSYRTTHLHNDLWEVFSNPEDWKEKYIHQNYTKALAGKLVETPCPDVYWFPIFTEVACDELVEEMEHFGQWSLGNNKDNRIQGGYENVPTIDIHMNQIGFEREWHKFLLEYIAPMTEKLYPGYYTRAQFDLAFVVRYKPDEQPSLMPHHDASTFTINIALNRVGVDYEGGGCRFLRYNCSIRAPRKGWTLMHPGRLTHYHEGLPTTRGTRYIAVSFVDP>sp|Q02809-2|PLOD1_HUMAN Isoform 2 of Procollagen-lysine,2-oxoglutarate5-dioxygenase 1 OS=Homo sapiens OX=9606 GN=PLOD1MRPLLLLALLGWLLLAEAKGDAKPEAPCCQEGLRAGGSGSLHLGRDFTVLAGARGSPSPSVSSIPRFWIPGSDNLLVLTVATKETEGFRRFKRSAQFFNYKIQALGLGEDWNVEKGTSAGGGQKVRLLKKALEKHADKEDLVILFADSYDVLFASGPRELLKKFRQARSQVVFSAEELIYPDRRLETKYPVVSDGKRFLGSGGFIGYAPNLSKLVAEWEGQDSDSDQLFYTKIFLDPEKREQINITLDHRCRIFQNLDGALDEVVLKFEMGHVRARNLAYDTLPVLIHGNGPTKLQLNYLGNYIPRFWTFETGCTVCDEGLRSLKGIGDEALPTVLVGVFIEQPTPFVSLFFQRLLRLHYPQKHMRLFIHNHEQHHKAQVEEFLAQHGSEYQSVKLVGPEVRMANADARNMGADLCRQDRSCTYYFSVDADVALTEPNSLRLLIQQNKNVIAPLMTRHGRLWSNFWGALSADGYYARSEDYVDIVQGRRVGVWNVPYISNIYLIKGSALRGELQSSDLFHHSKLDPDMAFCANIRQQDVFMFLTNRHTLGHLLSLDSYRTTHLHNDLWEVFSNPEDWKEKYIHQNYTKALAGKLVETPCPDVYWFPIFTEVACDELVEEMEHFGQWSLGNNKDNRIQGGYENVPTIDIHMNQIGFEREWHKFLLEYIAPMTEKLYPGYYTRAQFDLAFVVRYKPDEQPSLMPHHDASTFTINIALNRVGVDYEGGGCRFLRYNCSIRAPRKGWTLMHPGRLTHYHEGLPTTRGTRYIAVSFVDP>sp|Q9ULL4|PLXB3_HUMAN Plexin-B3 OS=Homo sapiens OX=9606 GN=PLXNB3 PE=1SV=2MCHAAQETPLLHHFMAPVMARWPPFGLCLLLLLLSPPPLPLTGAHRFSAPNTTLNHLALAPGRGTLYVGAVNRLFQLSPELQLEAVAVTGPVIDSPDCVPFRDPAECPQAQLTDNANQLLLVSSRAQELVACGQVRQGVCETRRLGDVAEVLYQAEDPGDGQFVAANTPGVATVGLVVPLPGRDLLLVARGLAGKLSAGVPPLAIRQLAGSQPFSSEGLGRLVVGDFSDYNNSYVGAFADARSAYFVFRRRGARAQAEYRSYVARVCLGDTNLYSYVEVPLACQGQGLIQAAFLAPGTLLGVFAAGPRGTQAALCAFPMVELGASMEQARRLCYTAGGRGPSGAEEATVEYGVTSRCVTLPLDSPESYPCGDEHTPSPIAGRQPLEVQPLLKLGQPVSAVAALQADGHMIAFLGDTQGQLYKVFLHGSQGQVYHSQQVGPPGSAISPDLLLDSSGSHLYVLTAHQVDRIPVAACPQFPDCASCLQAQDPLCGWCVLQGRCTRKGQCGRAGQLNQWLWSYEEDSHCLHIQSLLPGHHPRQEQGQVTLSVPRLPILDADEYFHCAFGDYDSLAHVEGPHVACVTPPQDQVPLNPPGTDHVTVPLALMFEDVTVAATNFSFYDCSAVQALEAAAPCRACVGSIWRCHWCPQSSHCVYGEHCPEGERTIYSAQEVDIQVRGPGACPQVEGLAGPHLVPVGWESHLALRVRNLQHFRGLPASFHCWLELPGELRGLPATLEETAGDSGLIHCQAHQFYPSMSQRELPVPIYVTQGEAQRLDNTHALYVILYDCAMGHPDCSHCQAANRSLGCLWCADGQPACRYGPLCPPGAVELLCPAPSIDAVEPLTGPPEGGLALTILGSNLGRAFADVQYAVSVASRPCNPEPSLYRTSARIVCVTSPAPNGTTGPVRVAIKSQPPGISSQHFTYQDPVLLSLSPRWGPQAGGTQLTIRGQHLQTGGNTSAFVGGQPCPILEPVCPEAIVCRTRPQAAPGEAAVLVVFGHAQRTLLASPFRYTANPQLVAAEPSASFRGGGRLIRVRGTGLDVVQRPLLSVWLEADAEVQASRAQPQDPQPRRSCGAPAADPQACIQLGGGLLQCSTVCSVNSSSLLLCRSPAVPDRAHPQRVFFTLDNVQVDFASASGGQGFLYQPNPRLAPLSREGPARPYRLKPGHVLDVEGEGLNLGISKEEVRVHIGRGECLVKTLTRTHLYCEPPAHAPQPANGSGLPQFVVQMGNVQLALGPVQYEAEPPLSAFPVEAQAGVGMGAAVLIAAVLLLTLMYRHKSKQALRDYQKVLVQLESLETGVGDQCRKEFTDLMTEMTDLSSDLEGSGIPFLDYRTYAERAFFPGHGGCPLQPKPEGPGEDGHCATVRQGLTQLSNLLNSKLFLLTLIHTLEEQPSFSQRDRCHVASLLSLALHGKLEYLTDIMRTLLGDLAAHYVHRNPKLMLRRTETMVEKLLTNWLSICLYAFLREVAGEPLYMLFRAIQYQVDKGPVDAVTGKAKRTLNDSRLLREDVEFQPLTLMVLVGPGAGGAAGSSEMQRVPARVLDTDTITQVKEKVLDQVYKGTPFSQRPSVHALDLEWRSGLAGHLTLSDEDLTSVTQNHWKRLNTLQHYKVPDGATVGLVPQLHRGSTISQSLAQRCPLGENIPTLEDGEEGGVCLWHLVKATEEPEGAKVRCSSLREREPARAKAIPEIYLTRLLSMKGTLQKFVDDTFQAILSVNRPIPIAVKYLFDLLDELAEKHGIEDPGTLHIWKTNSLLLRFWVNALKNPQLIFDVRVSDNVDAILAVIAQTFIDSCTTSEHKVGRDSPVNKLLYAREIPRYKQMVERYYADIRQSSPASYQEMNSALAELSGNYTSAPHCLEALQELYNHIHRYYDQIISALEEDPVGQKLQLACRLQQVAALVENKVTDL>sp|Q9ULL4-2|PLXB3_HUMAN Isoform 2 of Plexin-B3 OS=Homo sapiens OX=9606GN=PLXNB3MELTPASSLTCSLLSPRLPGSFPQLRRVPPCSRPWLPKAPVMARWPPFGLCLLLLLLSPPPLPLTGAHRFSAPNTTLNHLALAPGRGTLYVGAVNRLFQLSPELQLEAVAVTGPVIDSPDCVPFRDPAECPQAQLTDNANQLLLVSSRAQELVACGQVRQGVCETRRLGDVAEVLYQAEDPGDGQFVAANTPGVATVGLVVPLPGRDLLLVARGLAGKLSAGVPPLAIRQLAGSQPFSSEGLGRLVVGDFSDYNNSYVGAFADARSAYFVFRRRGARAQAEYRSYVARVCLGDTNLYSYVEVPLACQGQGLIQAAFLAPGTLLGVFAAGPRGTQAALCAFPMVELGASMEQARRLCYTAGGRGPSGAEEATVEYGVTSRCVTLPLDSPESYPCGDEHTPSPIAGRQPLEVQPLLKLGQPVSAVAALQADGHMIAFLGDTQGQLYKVFLHGSQGQVYHSQQVGPPGSAISPDLLLDSSGSHLYVLTAHQVDRIPVAACPQFPDCASCLQAQDPLCGWCVLQGRCTRKGQCGRAGQLNQWLWSYEEDSHCLHIQSLLPGHHPRQEQGQVTLSVPRLPILDADEYFHCAFGDYDSLAHVEGPHVACVTPPQDQVPLNPPGTDHVTVPLALMFEDVTVAATNFSFYDCSAVQALEAAAPCRACVGSIWRCHWCPQSSHCVYGEHCPEGERTIYSAQEVDIQVRGPGACPQVEGLAGPHLVPVGWESHLALRVRNLQHFRGLPASFHCWLELPGELRGLPATLEETAGDSGLIHCQAHQFYPSMSQRELPVPIYVTQGEAQRLDNTHALYVILYDCAMGHPDCSHCQAANRSLGCLWCADGQPACRYGPLCPPGAVELLCPAPSIDAVEPLTGPPEGGLALTILGSNLGRAFADVQYAVSVASRPCNPEPSLYRTSARIVCVTSPAPNGTTGPVRVAIKSQPPGISSQHFTYQDPVLLSLSPRWGPQAGGTQLTIRGQHLQTGGNTSAFVGGQPCPILEPVCPEAIVCRTRPQAAPGEAAVLVVFGHAQRTLLASPFRYTANPQLVAAEPSASFRGGGRLIRVRGTGLDVVQRPLLSVWLEADAEVQASRAQPQDPQPRRSCGAPAADPQACIQLGGGLLQCSTVCSVNSSSLLLCRSPAVPDRAHPQRVFFTLDNVQVDFASASGGQGFLYQPNPRLAPLSREGPARPYRLKPGHVLDVEGEGLNLGISKEEVRVHIGRGECLVKTLTRTHLYCEPPAHAPQPANGSGLPQFVVQMGNVQLALGPVQYEAEPPLSAFPVEAQAGVGMGAAVLIAAVLLLTLMYRHKSKQALRDYQKVLVQLESLETGVGDQCRKEFTDLMTEMTDLSSDLEGSGIPFLDYRTYAERAFFPGHGGCPLQPKPEGPGEDGHCATVRQGLTQLSNLLNSKLFLLTLIHTLEEQPSFSQRDRCHVASLLSLALHGKLEYLTDIMRTLLGDLAAHYVHRNPKLMLRRTETMVEKLLTNWLSICLYAFLREVAGEPLYMLFRAIQYQVDKGPVDAVTGKAKRTLNDSRLLREDVEFQPLTLMVLVGPGAGGAAGSSEMQRVPARVLDTDTITQVKEKVLDQVYKGTPFSQRPSVHALDLEWRSGLAGHLTLSDEDLTSVTQNHWKRLNTLQHYKVPDGATVGLVPQLHRGSTISQSLAQRCPLGENIPTLEDGEEGGVCLWHLVKATEEPEGAKVRCSSLREREPARAKAIPEIYLTRLLSMKGTLQKFVDDTFQAILSVNRPIPIAVKYLFDLLDELAEKHGIEDPGTLHIWKTNSLLLRFWVNALKNPQLIFDVRVSDNVDAILAVIAQTFIDSCTTSEHKVGRDSPVNKLLYAREIPRYKQMVERYYADIRQSSPASYQEMNSALAELSGNYTSAPHCLEALQELYNHIHRYYDQIISALEEDPVGQKLQLACRLQQVAALVENKVTDL>sp|O15031|PLXB2_HUMAN Plexin-B2 OS=Homo sapiens OX=9606 GN=PLXNB2 PE=1SV=3MALQLWALTLLGLLGAGASLRPRKLDFFRSEKELNHLAVDEASGVVYLGAVNALYQLDAKLQLEQQVATGPALDNKKCTPPIEASQCHEAEMTDNVNQLLLLDPPRKRLVECGSLFKGICALRALSNISLRLFYEDGSGEKSFVASNDEGVATVGLVSSTGPGGDRVLFVGKGNGPHDNGIIVSTRLLDRTDSREAFEAYTDHATYKAGYLSTNTQQFVAAFEDGPYVFFVFNQQDKHPARNRTLLARMCREDPNYYSYLEMDLQCRDPDIHAAAFGTCLAASVAAPGSGRVLYAVFSRDSRSSGGPGAGLCLFPLDKVHAKMEANRNACYTGTREARDIFYKPFHGDIQCGGHAPGSSKSFPCGSEHLPYPLGSRDGLRGTAVLQRGGLNLTAVTVAAENNHTVAFLGTSDGRILKVYLTPDGTSSEYDSILVEINKRVKRDLVLSGDLGSLYAMTQDKVFRLPVQECLSYPTCTQCRDSQDPYCGWCVVEGRCTRKAECPRAEEASHWLWSRSKSCVAVTSAQPQNMSRRAQGEVQLTVSPLPALSEEDELLCLFGESPPHPARVEGEAVICNSPSSIPVTPPGQDHVAVTIQLLLRRGNIFLTSYQYPFYDCRQAMSLEENLPCISCVSNRWTCQWDLRYHECREASPNPEDGIVRAHMEDSCPQFLGPSPLVIPMNHETDVNFQGKNLDTVKGSSLHVGSDLLKFMEPVTMQESGTFAFRTPKLSHDANETLPLHLYVKSYGKNIDSKLHVTLYNCSFGRSDCSLCRAANPDYRCAWCGGQSRCVYEALCNTTSECPPPVITRIQPETGPLGGGIRITILGSNLGVQAGDIQRISVAGRNCSFQPERYSVSTRIVCVIEAAETPFTGGVEVDVFGKLGRSPPNVQFTFQQPKPLSVEPQQGPQAGGTTLTIHGTHLDTGSQEDVRVTLNGVPCKVTKFGAQLQCVTGPQATRGQMLLEVSYGGSPVPNPGIFFTYRENPVLRAFEPLRSFASGGRSINVTGQGFSLIQRFAMVVIAEPLQSWQPPREAESLQPMTVVGTDYVFHNDTKVVFLSPAVPEEPEAYNLTVLIEMDGHRALLRTEAGAFEYVPDPTFENFTGGVKKQVNKLIHARGTNLNKAMTLQEAEAFVGAERCTMKTLTETDLYCEPPEVQPPPKRRQKRDTTHNLPEFIVKFGSREWVLGRVEYDTRVSDVPLSLILPLVIVPMVVVIAVSVYCYWRKSQQAEREYEKIKSQLEGLEESVRDRCKKEFTDLMIEMEDQTNDVHEAGIPVLDYKTYTDRVFFLPSKDGDKDVMITGKLDIPEPRRPVVEQALYQFSNLLNSKSFLINFIHTLENQREFSARAKVYFASLLTVALHGKLEYYTDIMHTLFLELLEQYVVAKNPKLMLRRSETVVERMLSNWMSICLYQYLKDSAGEPLYKLFKAIKHQVEKGPVDAVQKKAKYTLNDTGLLGDDVEYAPLTVSVIVQDEGVDAIPVKVLNCDTISQVKEKIIDQVYRGQPCSCWPRPDSVVLEWRPGSTAQILSDLDLTSQREGRWKRVNTLMHYNVRDGATLILSKVGVSQQPEDSQQDLPGERHALLEEENRVWHLVRPTDEVDEGKSKRGSVKEKERTKAITEIYLTRLLSVKGTLQQFVDNFFQSVLAPGHAVPPAVKYFFDFLDEQAEKHNIQDEDTIHIWKTNSLPLRFWVNILKNPHFIFDVHVHEVVDASLSVIAQTFMDACTRTEHKLSRDSPSNKLLYAKEISTYKKMVEDYYKGIRQMVQVSDQDMNTHLAEISRAHTDSLNTLVALHQLYQYTQKYYDEIINALEEDPAAQKMQLAFRLQQIAAALENKVTDL>sp|P51805|PLXA3_HUMAN Plexin-A3 OS=Homo sapiens OX=9606 GN=PLXNA3 PE=1SV=2MPSVCLLLLLFLAVGGALGNRPFRAFVVTDTTLTHLAVHRVTGEVFVGAVNRVFKLAPNLTELRAHVTGPVEDNARCYPPPSMRVCAHRLAPVDNINKLLLIDYAARRLVACGSIWQGICQFLRLDDLFKLGEPHHRKEHYLSGAQEPDSMAGVIVEQGQGPSKLFVGTAVDGKSEYFPTLSSRKLISDEDSADMFSLVYQDEFVSSQIKIPSDTLSLYPAFDIYYIYGFVSASFVYFLTLQLDTQQTLLDTAGEKFFTSKIVRMCAGDSEFYSYVEFPIGCSWRGVEYRLVQSAHLAKPGLLLAQALGVPADEDVLFTIFSQGQKNRASPPRQTILCLFTLSNINAHIRRRIQSCYRGEGTLALPWLLNKELPCINTPMQINGNFCGLVLNQPLGGLHVIEGLPLLADSTDGMASVAAYTYRQHSVVFIGTRSGSLKKVRVDGFQDAHLYETVPVVDGSPILRDLLFSPDHRHIYLLSEKQVSQLPVETCEQYQSCAACLGSGDPHCGWCVLRHRCCREGACLGASAPHGFAEELSKCVQVRVRPNNVSVTSPGVQLTVTLHNVPDLSAGVSCAFEAAAENEAVLLPSGELLCPSPSLQELRALTRGHGATRTVRLQLLSKETGVRFAGADFVFYNCSVLQSCMSCVGSPYPCHWCKYRHTCTSRPHECSFQEGRVHSPEGCPEILPSGDLLIPVGVMQPLTLRAKNLPQPQSGQKNYECVVRVQGRQQRVPAVRFNSSSVQCQNASYSYEGDEHGDTELDFSVVWDGDFPIDKPPSFRALLYKCWAQRPSCGLCLKADPRFNCGWCISEHRCQLRTHCPAPKTNWMHLSQKGTRCSHPRITQIHPLVGPKEGGTRVTIVGDNLGLLSREVGLRVAGVRCNSIPAEYISAERIVCEMEESLVPSPPPGPVELCVGDCSADFRTQSEQVYSFVTPTFDQVSPSRGPASGGTRLTISGSSLDAGSRVTVTVRDSECQFVRRDAKAIVCISPLSTLGPSQAPITLAIDRANISSPGLIYTYTQDPTVTRLEPTWSIINGSTAITVSGTHLLTVQEPRVRAKYRGIETTNTCQVINDTAMLCKAPGIFLGRPQPRAQGEHPDEFGFLLDHVQTARSLNRSSFTYYPDPSFEPLGPSGVLDVKPGSHVVLKGKNLIPAAAGSSRLNYTVLIGGQPCSLTVSDTQLLCDSPSQTGRQPVMVLVGGLEFWLGTLHISAERALTLPAMMGLAAGGGLLLLAITAVLVAYKRKTQDADRTLKRLQLQMDNLESRVALECKEAFAELQTDINELTNHMDEVQIPFLDYRTYAVRVLFPGIEAHPVLKELDTPPNVEKALRLFGQLLHSRAFVLTFIHTLEAQSSFSMRDRGTVASLTMVALQSRLDYATGLLKQLLADLIEKNLESKNHPKLLLRRTESVAEKMLTNWFTFLLHKFLKECAGEPLFLLYCAIKQQMEKGPIDAITGEARYSLSEDKLIRQQIDYKTLTLHCVCPENEGSAQVPVKVLNCDSITQAKDKLLDTVYKGIPYSQRPKAEDMDLEWRQGRMTRIILQDEDVTTKIECDWKRLNSLAHYQVTDGSLVALVPKQVSAYNMANSFTFTRSLSRYESLLRTASSPDSLRSRAPMITPDQETGTKLWHLVKNHDHADHREGDRGSKMVSEIYLTRLLATKGTLQKFVDDLFETVFSTAHRGSALPLAIKYMFDFLDEQADQRQISDPDVRHTWKSNCLPLRFWVNVIKNPQFVFDIHKNSITDACLSVVAQTFMDSCSTSEHRLGKDSPSNKLLYAKDIPNYKSWVERYYRDIAKMASISDQDMDAYLVEQSRLHASDFSVLSALNELYFYVTKYRQEILTALDRDASCRKHKLRQKLEQIISLVSSDS>sp|Q96AD5|PLPL2_HUMAN Patatin-like phospholipase domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=PNPLA2 PE=1 SV=1MFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVTGVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFIPVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLVLREMCKQGYRDGLRFLQRNGLLNRPNPLLALPPARPHGPEDKDQAVESAQAEDYSQLPGEDHILEHLPARLNEALLEACVEPTDLLTTLSNMLPVRLATAMMVPYTLPLESALSFTIRLLEWLPDVPEDIRWMKEQTGSICQYLVMRAKRKLGRHLPSRLPEQVELRRVQSLPSVPLSCAAYREALPGWMRNNLSLGDALAKWEECQRQLLLGLFCTNVAFPPEALRMRAPADPAPAPADPASPQHQLAGPAPLLSTPAPEARPVIGALGL>sp|Q96AD5-2|PLPL2_HUMAN Isoform 2 of Patatin-like phospholipase domain-containing protein 2 OS=Homo sapiens OX=9606 GN=PNPLA2MLPVRLATAMMVPYTLPLESALSFTIRLLEWLPDVPEDIRWMKEQTGSICQYLVMRAKRKLGRHLPSRLPEQVELRRVQSLPSVPLSCAAYREALPGWMRNNLSLGDALAKWEECQRQLLLGLFCTNVAFPPEALRMRAPADPAPAPADPASPQHQLAGPAPLLSTPAPEARPVIGALGL>sp|Q9NP80|PLPL8_HUMAN Calcium-independent phospholipase A2-gamma OS=Homosapiens OX=9606 GN=PNPLA8 PE=1 SV=1MSINLTVDIYIYLLSNARSVCGKQRSKQLYFLFSPKHYWRISHISLQRGFHTNIIRCKWTKSEAHSCSKHCYSPSNHGLHIGILKLSTSAPKGLTKVNICMSRIKSTLNSVSKAVFGNQNEMISRLAQFKPSSQILRKVSDSGWLKQKNIKQAIKSLKKYSDKSAEKSPFPEEKSHIIDKEEDIGKRSLFHYTSSITTKFGDSFYFLSNHINSYFKRKEKMSQQKENEHFRDKSELEDKKVEEGKLRSPDPGILAYKPGSESVHTVDKPTSPSAIPDVLQVSTKQSIANFLSRPTEGVQALVGGYIGGLVPKLKYDSKSQSEEQEEPAKTDQAVSKDRNAEEKKRLSLQREKIIARVSIDNRTRALVQALRRTTDPKLCITRVEELTFHLLEFPEGKGVAVKERIIPYLLRLRQIKDETLQAAVREILALIGYVDPVKGRGIRILSIDGGGTRGVVALQTLRKLVELTQKPVHQLFDYICGVSTGAILAFMLGLFHMPLDECEELYRKLGSDVFSQNVIVGTVKMSWSHAFYDSQTWENILKDRMGSALMIETARNPTCPKVAAVSTIVNRGITPKAFVFRNYGHFPGINSHYLGGCQYKMWQAIRASSAAPGYFAEYALGNDLHQDGGLLLNNPSALAMHECKCLWPDVPLECIVSLGTGRYESDVRNTVTYTSLKTKLSNVINSATDTEEVHIMLDGLLPPDTYFRFNPVMCENIPLDESRNEKLDQLQLEGLKYIERNEQKMKKVAKILSQEKTTLQKINDWIKLKTDMYEGLPFFSKL>sp|Q9NP80-2|PLPL8_HUMAN Isoform 2 of Calcium-independent phospholipaseA2-gamma OS=Homo sapiens OX=9606 GN=PNPLA8MSINLTVDIYIYLLSNARSVCGKQRSKQLYFLFSPKHYWRISHISLQRGFHTNIIRCKWTKSEAHSCSKHCYSPSNHGLHIGILKLSTSAPKGLTKVNICMSRIKSTLNSVSKAVFGNQNEMISRLAQFKPSSQILRKVSDSGWLKQKNIKQAIKSLKKYSDKSAEKSPFPEEKSHIIDKEEDIGKRSLFHYTSSITTKFGDSFYFLSNHINSYFKRKEKMSQQKENEHFRDKSELEDKKVEEGKLRSPDPGILAYKPGSESVHTVDKPTSPSAIPDVLQVSTKQSIANFLSRPTEGVQALVGGYIGGLVPKLKYDSKSQSEEQEEPAKTDQAVSKDRNAEEKKRLSLQREKIIARVSIDNRTRALVQALRRTTDPKLCITRVEELTFHLLEFPEGKGVAVKERIIPYLLRLRQIKDETLQAAVREILALIGYVDPVKGRGIRILSIDGGGTRGVVALQTLRKLVELTQKPVHQLFDYICGVSTGAILAFMLGLFHMPLDECEELYRKLGSDVFSQNVIVGTVKMSWSHAFYDSQTWENILKDRMGSALMIETARNPTCPKVAADGGLLLNNPSALAMHECKCLWPDVPLECIVSLGTGRYESDVRNTVTYTSLKTKLSNVINSATDTEEVHIMLDGLLPPDTYFRFNPVMCENIPLDESRNEKLDQLQLEGLKYIERNEQKMKKVAKILSQEKTTLQKINDWIKLKTDMYEGLPFFSKL>sp|Q9NP80-3|PLPL8_HUMAN Isoform 3 of Calcium-independent phospholipaseA2-gamma OS=Homo sapiens OX=9606 GN=PNPLA8MSRIKSTLNSVSKAVFGNQNEMISRLAQFKPSSQILRKVSDSGWLKQKNIKQAIKSLKKYSDKSAEKSPFPEEKSHIIDKEEDIGKRSLFHYTSSITTKFGDSFYFLSNHINSYFKRKEKMSQQKENEHFRDKSELEDKKVEEGKLRSPDPGILAYKPGSESVHTVDKPTSPSAIPDVLQVSTKQSIANFLSRPTEGVQALVGGYIGGLVPKLKYDSKSQSEEQEEPAKTDQAVSKDRNAEEKKRLSLQREKIIARVSIDNRTRALVQALRRTTDPKLCITRVEELTFHLLEFPEGKGVAVKERIIPYLLRLRQIKDETLQAAVREILALIGYVDPVKGRGIRILSIDGGGTRGVVALQTLRKLVELTQKPVHQLFDYICGVSTGAILAFMLGLFHMPLDECEELYRKLGSDVFSQNVIVGTVKMSWSHAFYDSQTWENILKDRMGSALMIETARNPTCPKVAAVSTIVNRGITPKAFVFRNYGHFPGINSHYLGGCQYKMWQAIRASSAAPGYFAEYALGNDLHQDGGLLLNNPSALAMHECKCLWPDVPLECIVSLGTGRYESDVRNTVTYTSLKTKLSNVINSATDTEEVHIMLDGLLPPDTYFRFNPVMCENIPLDESRNEKLDQLQLEGLKYIERNEQKMKKVAKILSQEKTTLQKINDWIKLKTDMYEGLPFFSKL>sp|Q9NST1|PLPL3_HUMAN 1-acylglycerol-3-phosphate O-acyltransferasePNPLA3 OS=Homo sapiens OX=9606 GN=PNPLA3 PE=1 SV=2MYDAERGWSLSFAGCGFLGFYHVGATRCLSEHAPHLLRDARMLFGASAGALHCVGVLSGIPLEQTLQVLSDLVRKARSRNIGIFHPSFNLSKFLRQGLCKCLPANVHQLISGKIGISLTRVSDGENVLVSDFRSKDEVVDALVCSCFIPFYSGLIPPSFRGVRYVDGGVSDNVPFIDAKTTITVSPFYGEYDICPKVKSTNFLHVDITKLSLRLCTGNLYLLSRAFVPPDLKVLGEICLRGYLDAFRFLEEKGICNRPQPGLKSSSEGMDPEVAMPSWANMSLDSSPESAALAVRLEGDELLDHLRLSILPWDESILDTLSPRLATALSEEMKDKGGYMSKICNLLPIRIMSYVMLPCTLPVESAIAIVQRLVTWLPDMPDDVLWLQWVTSQVFTRVLMCLLPASRSQMPVSSQQASPCTPEQDWPCWTPCSPKGCPAETKAEATPRSILRSSLNFFLGNKVPAGAEGLSTFPSFSLEKSL>sp|Q9NST1-2|PLPL3_HUMAN Isoform 2 of 1-acylglycerol-3-phosphate O-acyltransferase PNPLA3 OS=Homo sapiens OX=9606 GN=PNPLA3MYDAERGWSLSFAGCGFLGFYHVGATRCLSEHAPHLLRDARMLFGASAGALHCVGVLSEQTLQVLSDLVRKARSRNIGIFHPSFNLSKFLRQGLCKCLPANVHQLISGKIGISLTRVSDGENVLVSDFRSKDEVVDALVCSCFIPFYSGLIPPSFRGVRYVDGGVSDNVPFIDAKTTITVSPFYGEYDICPKVKSTNFLHVDITKLSLRLCTGNLYLLSRAFVPPDLKVLGEICLRGYLDAFRFLEEKGICNRPQPGLKSSSEGMDPEVAMPSWANMSLDSSPESAALAVRLEGDELLDHLRLSILPWDESILDTLSPRLATALSEEMKDKGGYMSKICNLLPIRIMSYVMLPCTLPVESAIAIVQRLVTWLPDMPDDVLWLQWVTSQVFTRVLMCLLPASRSQMPVSSQQASPCTPEQDWPCWTPCSPKGCPAETKAEATPRSILRSSLNFFLGNKVPAGAEGLSTFPSFSLEKSL>sp|Q53QZ3|RHG15_HUMAN Rho GTPase-activating protein 15 OS=Homo sapiensOX=9606 GN=ARHGAP15 PE=1 SV=2MQKSTNSDTSVETLNSTRQGTGAVQMRIKNANSHHDRLSQSKSMILTDVGKVTEPISRHRRNHSQHILKDVIPPLEQLMVEKEGYLQKAKIADGGKKLRKNWSTSWIVLSSRRIEFYKESKQQALSNMKTGHKPESVDLCGAHIEWAKEKSSRKNVFQITTVSGNEFLLQSDIDFIILDWFHAIKNAIDRLPKDSSCPSRNLELFKIQRSSSTELLSHYDSDIKEQKPEHRKSLMFRLHHSASDTSDKNRVKSRLKKFITRRPSLKTLQEKGLIKDQIFGSHLHKVCERENSTVPWFVKQCIEAVEKRGLDVDGIYRVSGNLATIQKLRFIVNQEEKLNLDDSQWEDIHVVTGALKMFFRELPEPLFPYSFFEQFVEAIKKQDNNTRIEAVKSLVQKLPPPNRDTMKVLFGHLTKIVAKASKNLMSTQSLGIVFGPTLLRAENETGNMAIHMVYQNQIAELMLSEYSKIFGSEED>sp|O43157|PLXB1_HUMAN Plexin-B1 OS=Homo sapiens OX=9606 GN=PLXNB1 PE=1SV=3MPALGPALLQALWAGWVLTLQPLPPTAFTPNGTYLQHLARDPTSGTLYLGATNFLFQLSPGLQLEATVSTGPVLDSRDCLPPVMPDECPQAQPTNNPNQLLLVSPGALVVCGSVHQGVCEQRRLGQLEQLLLRPERPGDTQYVAANDPAVSTVGLVAQGLAGEPLLFVGRGYTSRGVGGGIPPITTRALWPPDPQAAFSYEETAKLAVGRLSEYSHHFVSAFARGASAYFLFLRRDLQAQSRAFRAYVSRVCLRDQHYYSYVELPLACEGGRYGLIQAAAVATSREVAHGEVLFAAFSSAAPPTVGRPPSAAAGASGASALCAFPLDEVDRLANRTRDACYTREGRAEDGTEVAYIEYDVNSDCAQLPVDTLDAYPCGSDHTPSPMASRVPLEATPILEWPGIQLTAVAVTMEDGHTIAFLGDSQGQLHRVYLGPGSDGHPYSTQSIQQGSAVSRDLTFDGTFEHLYVMTQSTLLKVPVASCAQHLDCASCLAHRDPYCGWCVLLGRCSRRSECSRGQGPEQWLWSFQPELGCLQVAAMSPANISREETREVFLSVPDLPPLWPGESYSCHFGEHQSPALLTGSGVMCPSPDPSEAPVLPRGADYVSVSVELRFGAVVIAKTSLSFYDCVAVTELRPSAQCQACVSSRWGCNWCVWQHLCTHKASCDAGPMVASHQSPLVSPDPPARGGPSPSPPTAPKALATPAPDTLPVEPGAPSTATASDISPGASPSLLSPWGPWAGSGSISSPGSTGSPLHEEPSPPSPQNGPGTAVPAPTDFRPSATPEDLLASPLSPSEVAAVPPADPGPEALHPTVPLDLPPATVPATTFPGAMGSVKPALDWLTREGGELPEADEWTGGDAPAFSTSTLLSGDGDSAELEGPPAPLILPSSLDYQYDTPGLWELEEATLGASSCPCVESVQGSTLMPVHVEREIRLLGRNLHLFQDGPGDNECVMELEGLEVVVEARVECEPPPDTQCHVTCQQHQLSYEALQPELRVGLFLRRAGRLRVDSAEGLHVVLYDCSVGHGDCSRCQTAMPQYGCVWCEGERPRCVTREACGEAEAVATQCPAPLIHSVEPLTGPVDGGTRVTIRGSNLGQHVQDVLGMVTVAGVPCAVDAQEYEVSSSLVCITGASGEEVAGATAVEVPGRGRGVSEHDFAYQDPKVHSIFPARGPRAGGTRLTLNGSKLLTGRLEDIRVVVGDQPCHLLPEQQSEQLRCETSPRPTPATLPVAVWFGATERRLQRGQFKYTLDPNITSAGPTKSFLSGGREICVRGQNLDVVQTPRIRVTVVSRMLQPSQGLGRRRRVVPETACSLGPSCSSQQFEEPCHVNSSQLITCRTPALPGLPEDPWVRVEFILDNLVFDFATLNPTPFSYEADPTLQPLNPEDPTMPFRHKPGSVFSVEGENLDLAMSKEEVVAMIGDGPCVVKTLTRHHLYCEPPVEQPLPRHHALREAPDSLPEFTVQMGNLRFSLGHVQYDGESPGAFPVAAQVGLGVGTSLLALGVIIIVLMYRRKSKQALRDYKKVQIQLENLESSVRDRCKKEFTDLMTEMTDLTSDLLGSGIPFLDYKVYAERIFFPGHRESPLHRDLGVPESRRPTVEQGLGQLSNLLNSKLFLTKFIHTLESQRTFSARDRAYVASLLTVALHGKLEYFTDILRTLLSDLVAQYVAKNPKLMLRRTETVVEKLLTNWMSICLYTFVRDSVGEPLYMLFRGIKHQVDKGPVDSVTGKAKYTLNDNRLLREDVEYRPLTLNALLAVGPGAGEAQGVPVKVLDCDTISQAKEKMLDQLYKGVPLTQRPDPRTLDVEWRSGVAGHLILSDEDVTSEVQGLWRRLNTLQHYKVPDGATVALVPCLTKHVLRENQDYVPGERTPMLEDVDEGGIRPWHLVKPSDEPEPPRPRRGSLRGGERERAKAIPEIYLTRLLSMKGTLQKFVDDLFQVILSTSRPVPLAVKYFFDLLDEQAQQHGISDQDTIHIWKTNSLPLRFWINIIKNPQFVFDVQTSDNMDAVLLVIAQTFMDACTLADHKLGRDSPINKLLYARDIPRYKRMVERYYADIRQTVPASDQEMNSVLAELSWNYSGDLGARVALHELYKYINKYYDQIITALEEDGTAQKMQLGYRLQQIAAAVENKVTDL>sp|O43157-2|PLXB1_HUMAN Isoform 2 of Plexin-B1 OS=Homo sapiens OX=9606GN=PLXNB1MPALGPALLQALWAGWVLTLQPLPPTAFTPNGTYLQHLARDPTSGTLYLGATNFLFQLSPGLQLEATVSTGPVLDSRDCLPPVMPDECPQAQPTNNPNQLLLVSPGALVVCGSVHQGVCEQRRLGQLEQLLLRPERPGDTQYVAANDPAVSTVGLVAQGLAGEPLLFVGRGYTSRGVGGGIPPITTRALWPPDPQAAFSYEETAKLAVGRLSEYSHHFVSAFARGASAYFLFLRRDLQAQSRAFRAYVSRVCLRDQHYYSYVELPLACEGGRYGLIQAAAVATSREVAHGEVLFAAFSSAAPPTVGRPPSAAAGASGASALCAFPLDEVDRLANRTRDACYTREGRAEDGTEVAYIEYDVNSDCAQLPVDTLDAYPCGSDHTPSPMASRVPLEATPILEWPGIQLTAVAVTMEDGHTIAFLGDSQGQLHRVYLGPGSDGHPYSTQSIQQGSAVSRDLTFDGTFEHLYVMTQSTLLKVPVASCAQHLDCASCLAHRDPYCGWCVLLGRCSRRSECSRGQGPEQWLWSFQPELGCLQVAAMSPANISREETREVFLSVPDLPPLWPGESYSCHFGEHQSPALLTGSGVMCPSPDPSEAPVLPRGADYVSVSVELRFGAVVIAKTSLSFYDCVAVTELRPSAQCQACVSSRWGCNWCVWQHLCTHKASCDAGPMVASHQSPLVSPDPPARGDGDSAELEGPPAPLILPSSLDYQYDTPGLWELEEATLGASSCPCVESVQGSTLMPVHVEREIRLLGRNLHLFQDGPGDNECVMELEGLEVVVEARVECEPPPDTQCHVTCQQHQLSYEALQPELRVGLFLRRAGRLRVDSAEGLHVVLYDCSVGHGDCSRCQTAMPQYGCVWCEGERPRCVTREACGEAEAVATQCPAPLIHSVEPLTGPVDGGTRVTIRGSNLGQHVQDVLGMVTVAGVPCAVDAQEYEVSSSLVCITGASGEEVAGATAVEVPGRGRGVSEHDFAYQDPKVHSIFPARGPRAGGTRLTLNGSKLLTGRLEDIRVVVGDQPCHLLPEQQSEQLRCETSPRPTPATLPVAVWFGATERRLQRGQFKYTLDPNITSAGPTKSFLSGGREICVRGQNLDVVQTPRIRVTVVSRMLQPSQGLGRRRRVVPETACSLGPSCSSQQFEEPCHVNSSQLITCRTPALPGLPEDPWVRVEFILDNLVFDFATLNPTPFSYEADPTLQPLNPEDPTMPFRHKPGSVFSVEGENLDLAMSKEEVVAMIGDGPCVVKTLTRHHLYCEPPVEQPLPRHHALREAPDSLPEFTVQMGNLRFSLGHVQYDGESPGAFPVAAQVGLGVGTSLLALGVIIIVLMYRRKSKQALRDYKKVQIQLENLESSVRDRCKKEFTDLMTEMTDLTSDLLGSGIPFLDYKVYAERIFFPGHRESPLHRDLGVPESRRPTVEQGLGQLSNLLNSKLFLTKFIHTLESQRTFSARDRAYVASLLTVALHGKLEYFTDILRTLLSDLVAQYVAKNPKLMLRRTETVVEKLLTNWMSICLYTFVRDSVGEPLYMLFRGIKHQVDKGPVDSVTGKAKYTLNDNRLLREDVEYRPLTLNALLAVGPGAGEAQGVPVKVLDCDTISQAKEKMLDQLYKGVPLTQRPDPRTLDVEWRSGVAGHLILSDEDVTSEVQGLWRRLNTLQHYKVPDGATVALVPCLTKHVLRENQDYVPGERTPMLEDVDEGGIRPWHLVKPSDEPEPPRPRRGSLRGGERERAKAIPEIYLTRLLSMKGTLQKFVDDLFQVILSTSRPVPLAVKYFFDLLDEQAQQHGISDQDTIHIWKTNSLPLRFWINIIKNPQFVFDVQTSDNMDAVLLVIAQTFMDACTLADHKLGRDSPINKLLYARDIPRYKRMVERYYADIRQTVPASDQEMNSVLAELSWNYSGDLGARVALHELYKYINKYYDQIITALEEDGTAQKMQLGYRLQQIAAAVENKVTDL>sp|O43157-3|PLXB1_HUMAN Isoform 3 of Plexin-B1 OS=Homo sapiens OX=9606GN=PLXNB1MPALGPALLQALWAGWVLTLQPLPPTAFTPNGTYLQHLARDPTSGTLYLGATNFLFQLSPGLQLEATVSTGPVLDSRDCLPPVMPDECPQAQPTNNPNQLLLVSPGALVVCGSVHQGVCEQRRLGQLEQLLLRPERPGDTQYVAANDPAVSTVGLVAQGLAGEPLLFVGRGYTSRGVGGGIPPITTRALWPPDPQAAFSYEETAKLAVGRLSEYSHHFVSAFARGASAYFLFLRRDLQAQSRAFRAYVSRVCLRDQHYYSYVELPLACEGGRYGLIQAAAVATSREVAHGEVLFAAFSSAAPPTVGRPPSAAAGASGASALCAFPLDEVDRLANRTRDACYTREGRAEDGTEVAYIEYDVNSDCAQLPVDTLDAYPCGSDHTPSPMASRVPLEATPILEWPGIQLTAVAVTMEDGHTIAFLGDSQGQLHRVYLGPGSDGHPYSTQSIQQGSAVSRDLTFDGTFEHLYVMTQSTLLKVPVASCAQHLDCASCLAHRDPYCGWCVLLGRCSRRSECSRGQGPEQWLWSFQPELGCLQVAAMSPANISREETREVFLSVPDLPPLWPGESYSCHFGEHQSPALLTGSGVMCPSPDPSEAPVLPRGADYVSVSVELRFGAVVIAKTSLSFYDCVAVTELRPSAQCQACVSSRWGCNWCVWQHLCTHKASCDAGPMVASHQVMETQQSLRALPPPSSSRPASTTSMTPPGSGSWKRRPWGQAPAPVWRAFRAPR>sp|Q7Z6Z6|PLPL5_HUMAN Patatin-like phospholipase domain-containingprotein 5 OS=Homo sapiens OX=9606 GN=PNPLA5 PE=1 SV=1MGFLEEEGRWNLSFSGAGYLGAHHVGATECLRQRAPRLLQGARRIYGSSSGALNAVSIVCGKSVDFCCSHLLGMVGQLERLSLSILHPAYAPIEHVKQQLQDALPPDAHVLASQRLGISLTRWPDGRNFLVTDFATCDELIQALVCTLYFPFYCGLIPPEFRGERYIDGALSNNLPFADCPSTITVSPFHGTVDICPQSTSPNLHELNVFNFSFQISTENFFLGLICLIPPSLEVVADNCRQGYLDALRFLERRGLTKEPVLWTLVSKEPPAPADGNWDAGCDQRWKGGLSLNWKVPHVQVKDVPNFEQLSPELEAALKKACTRDPSRWARFWHSGPGQVLTYLLLPCTLPFEYIYFRSRRLVVWLPDVPADLWWMQGLLRNMALEVFSRTKAQLLGPISPPATRVLETSPLQPQIAPHREELGPTHQA>sp|Q7Z6Z6-2|PLPL5_HUMAN Isoform 2 of Patatin-like phospholipase domain-containing protein 5 OS=Homo sapiens OX=9606 GN=PNPLA5MGFLEEEGRWNLSFSGAGYLGAHHVGATECLRQRAPRLLQGARRIYGSSSGALNAVSIVCGKSVDCPSTITVSPFHGTVDICPQSTSPNLHELNVFNFSFQISTENFFLGLICLIPPSLEVVADNCRQGYLDALRFLERRGLTKEPVLWTLVSKEPPAPADGNWDAGCDQRWKGGLSLNWKVPHVQVKDVPNFEQLSPELEAALKKACTRDPSRWARFWHSGPGQVLTYLLLPCTLPFEYIYFRSRRLVVWLPDVPADLWWMQGLLRNMALEVFSRTKAQLLGPISPPATRVLETSPLQPQIAPHREELGPTHQA>sp|Q68EM7|RHG17_HUMAN Rho GTPase-activating protein 17 OS=Homo sapiensOX=9606 GN=ARHGAP17 PE=1 SV=1MKKQFNRMKQLANQTVGRAEKTEVLSEDLLQIERRLDTVRSICHHSHKRLVACFQGQHGTDAERRHKKLPLTALAQNMQEASTQLEDSLLGKMLETCGDAENQLALELSQHEVFVEKEIVDPLYGIAEVEIPNIQKQRKQLARLVLDWDSVRARWNQAHKSSGTNFQGLPSKIDTLKEEMDEAGNKVEQCKDQLAADMYNFMAKEGEYGKFFVTLLEAQADYHRKALAVLEKTLPEMRAHQDKWAEKPAFGTPLEEHLKRSGREIALPIEACVMLLLETGMKEEGLFRIGAGASKLKKLKAALDCSTSHLDEFYSDPHAVAGALKSYLRELPEPLMTFNLYEEWTQVASVQDQDKKLQDLWRTCQKLPPQNFVNFRYLIKFLAKLAQTSDVNKMTPSNIAIVLGPNLLWARNEGTLAEMAAATSVHVVAVIEPIIQHADWFFPEEVEFNVSEAFVPLTTPSSNHSFHTGNDSDSGTLERKRPASMAVMEGDLVKKESFGVKLMDFQAHRRGGTLNRKHISPAFQPPLPPTDGSTVVPAGPEPPPQSSRAESSSGGGTVPSSAGILEQGPSPGDGSPPKPKDPVSAAVPAPGRNNSQIASGQNQPQAAAGSHQLSMGQPHNAAGPSPHTLRRAVKKPAPAPPKPGNPPPGHPGGQSSSGTSQHPPSLSPKPPTRSPSPPTQHTGQPPGQPSAPSQLSAPRRYSSSLSPIQAPNHPPPQPPTQATPLMHTKPNSQGPPNPMALPSEHGLEQPSHTPPQTPTPPSTPPLGKQNPSLPAPQTLAGGNPETAQPHAGTLPRPRPVPKPRNRPSVPPPPQPPGVHSAGDSSLTNTAPTASKIVTDSNSRVSEPHRSIFPEMHSDSASKDVPGRILLDIDNDTESTAL>sp|Q68EM7-2|RHG17_HUMAN Isoform 2 of Rho GTPase-activating protein 17OS=Homo sapiens OX=9606 GN=ARHGAP17MKKQFNRMKQLANQTVGRAEKTEVLSEDLLQIERRLDTVRSICHHSHKRLVACFQGQHGTDAERRHKKLPLTALAQNMQEASTQLEDSLLGKMLETCGDAENQLALELSQHEVFVEKEIVDPLYGIAEVEIPNIQKQRKQLARLVLDWDSVRARWNQAHKSSGTNFQGLPSKIDTLKEEMDEAGNKVEQCKDQLAADMYNFMAKEGEYGKFFVTLLEAQADYHRKALAVLEKTLPEMRAHQDKWAEKPAFGTPLEEHLKRSGREIALPIEACVMLLLETGMKEEGLFRIGAGASKLKKLKAALDCSTSHLDEFYSDPHAVAGALKSYLRELPEPLMTFNLYEEWTQVASVQDQDKKLQDLWRTCQKLPPQNFVNFRYLIKFLAKLAQTSDVNKMTPSNIAIVLGPNLLWARNEGTLAEMAAATSVHVVAVIEPIIQHADWFFPEEVEFNVSEAFVPLTTPSSNHSFHTGNDSDSGTLERKRPASMAVMEGDLVKKESPPKPKDPVSAAVPAPGRNNSQIASGQNQPQAAAGSHQLSMGQPHNAAGPSPHTLRRAVKKPAPAPPKPGNPPPGHPGGQSSSGTSQHPPSLSPKPPTRSPSPPTQHTGQPPGQPSAPSQLSAPRRYSSSLSPIQAPNHPPPQPPTQATPLMHTKPNSQGPPNPMALPSEHGLEQPSHTPPQTPTPPSTPPLGKQNPSLPAPQTLAGGNPETAQPHAGTLPRPRPVPKPRNRPSVPPPPQPPGVHSAGDSSLTNTAPTASKIVTDSNSRVSEPHRSIFPEMHSDSASKDVPGRILLDIDNDTESTAL>sp|Q68EM7-3|RHG17_HUMAN Isoform 3 of Rho GTPase-activating protein 17OS=Homo sapiens OX=9606 GN=ARHGAP17MLLLETGMKEEGLFRIGAGASKLKKLKAALDCSTSHLDEFYSDPHAVAGALKSYLRELPEPLMTFNLYEEWTQVASVQDQDKKLQDLWRTCQKLPPQNFVNFRYLIKFLAKLAQTSDVNKMTPSNIAIVLGPNLLWARNEGTLAEMAAATSVHVVAVIEPIIQHADWFFPEEVEFNVSEAFVPLTTPSSNHSFHTGNDSDSGTLERKRPASMAVMEGDLVKKESFGVKLMDFQAHRRGGTLNRKHISPAFQPPLPPTDGSTVVPAGPEPPPQSSRAESSSGGGTVPSSAGILEQGPSPGDGSPPKPKDPVSAAVPAPGRNNSQIASGQNQPQAAAGSHQLSMGQPHNAAGPSPHTLRRAVKKPAPAPPKPGNPPPGHPGGQSSSGTSQHPPSLSPKPPTRSPSPPTQHTGQPPGQPSAPSQLSAPRRYSSSLSPIQAPNHPPPQPPTQATPLMHTKPNSQGPPNPMALPSEHGLEQPSHTPPQTPTPPSTPPLGKQNPSLPAPQTLAGGNPETAQPHAGTLPRPRPVPKPRNRPSVPPPPQPPGVHSAGDSSLTNTAPTASKIVTDSNSRVSEPHRSIFPEMHSDSASKDVPGRILLDIDNDTESTAL>sp|Q68EM7-4|RHG17_HUMAN Isoform 4 of Rho GTPase-activating protein 17OS=Homo sapiens OX=9606 GN=ARHGAP17MKKQFNRMKQLANQTVGRAEKTEVLSEDLLQIERRLDTVRSICHHSHKRLVACFQGQHGTDAERRHKKLPLTALAQNMQEASTQLEDSLLGKMLETCGDAENQLALELSQHEVFVEKEIVDPLYGIAEVEIPNIQKQRKQLARLVLDWDSVRARWNQAHKSSGTNFQGLPSKIDTLKEEMDEAGNKVEQCKDQLAADMYNFMAKEGEYGKFFVTISGRKNQPLGLP>sp|Q68EM7-5|RHG17_HUMAN Isoform 5 of Rho GTPase-activating protein 17OS=Homo sapiens OX=9606 GN=ARHGAP17MKKQFNRMKQLANQTVGRAEKTEVLSEDLLQIERRLDTVRSICHHSHKRLVACFQGQHGTDAERRHKKLPLTALAQNMQEASTQLEDSLLGKMLETCGDAENQLALELSQHEVFVEKEIVDPLYGIAEVEIPNIQKQRKQLARLVLDWDSVRARWNQAHKSSGTNFQGLPSKIDTLKEEMDEAGNKVEQCKDQLAADMYNFMAKEGEYGKFFVTLLEAQADYHRKALAVLEKTLPEMRAHQDKWAEKPAFGTPLEEHLKRSGREIALPIEACVMLLLETGMKEEGLFRIGAGASKLKKLKAALDCSTSHLDEFYSDPHAVAGALKSYLRELPEPLMTFNLYEEWTQVASVQDQDKKLQDLWRTCQKLPPQNFVNFRYLIKFLAKLAQTSDVNKMTPSNIAIVLGPNLLWARNEGTLAEMAAATSVHVVAVIEPIIQHADWFFPEEVEFNVSEAFVPLTTPSSNHSFHTGNDSDSGTLERKRPASMAVMEGDLVKKESFGVKLMDFQAHRRGGTLNRKHISPAFQPPLPPTDGSTVVPAGPEPPPQSSRAESSSGGGTVPSSAGILEQGPSPGDGSPPKPKDPVSAAVPAPGRNNSQIASGQNQPQAAAGSHQLSMGQPHNAAGPSPHTLRRAVKKPAPAPPKPGNPPPGHPGGQSSSGTSQHPPSLSPKPPTRSPSPPTQHTGQPPGQPSAPSQLSAPRRYSSSLSPIQAPNHPPPQPPTQATPLMHTKPNSQGPPNPMALPSEHGLEQPSHTPPQTPTPPSTPPLGKQNPSLPAPQTLAGGNPETAQPHAGTLPRPRPVPKPRNRPSVPPPPQPPGVHSAGDSSLTNTAPTASKIVTGFQNRIAASFLKCTQTQPAKTCLAASCWI>sp|Q68EM7-6|RHG17_HUMAN Isoform 6 of Rho GTPase-activating protein 17OS=Homo sapiens OX=9606 GN=ARHGAP17MKKQFNRMKQLANQTVGRAEKTEVLSEDLLQIERRLDTVRSICHHSHKRLVACFQGQHGTDAERRHKKLPLTALAQNMQEASTQLEDSLLGKMLETCGDAENQLALELSQHEVFVEKEIVDPLYGIAEVEIPNIQKQRKQLARLVLDWDSVRARWNQAHKSSGTNFQGLPSKIDTLKEEMDEAGNKVEQCKDQLAADMYNFMAKEGEYGKFFVTLLEAQADYHRKALAVLEKTLPEMRAHQDKWAEKPAFGTPLEEHLKRSGREIALPIEACVMLLLETGMKEEGLFRIGAGASKLKKLKAALDCSTSHLDEFYSDPHAVAGALKSYLRELPEPLMTFNLYEEWTQVASVQDQDKKLQDLWRTCQKLPPQNFVNFRYLIKFLAKLAQTSDVNKMTPSNIAIVLGPNLLWARNEGTLAEMAAATSVHVVAVIEPIIQHADWFFPEEVEFNVSEAFVPLTTPSSNHSFHTGNDSDSGTLERKRPASMAVMEGDLVKKESFGVKLMDFQAHRRGGTLNRKHISPAFQPPLPPTDGSTVVPAGPEPPPQSSRAESSSGGGTVPSSAGILEQGPSPGDGSPPKPKDPVSAAVPAPGRNNSQIASGQNQPQAAAGSHQLSMGQPHNAAGPSPHTLRRAVKKPAPAPPKPGNPPPGHPGGQSSSGTSQHPPSLSPKPPTRSPSPPTQHTGQPPGQPSAPSQLSAPRRYSSSLSPIQAPNHPPPQPPTQATPLMHTKPNSQGPPNPMALPSEHGLEQPSHTPPQTPTPPSTPPLGKQNPSLPAPQTLAGGNPETAQPHAGTLPRPRPVPKPRNRPSVPPPPQPPGVHSAGDSSLTNTAPTASKIVTDV>sp|Q68EM7-7|RHG17_HUMAN Isoform 7 of Rho GTPase-activating protein 17OS=Homo sapiens OX=9606 GN=ARHGAP17MCGFNTCGPMGFCLSSLLAWCVDCFFSLCSFGVKLMDFQAHRRGGTLNRKHISPAFQPPLPPTDGSTVVPAGPEPPPQSSRAESSSGGGTVPSSAGILEQGPSPGDGSPPKPKDPVSAAVPAPGRNNSQIASGQNQPQAAAGSHQLSMGQPHNAAGPSPHTLRRAVKKPAPAPPKPGNPPPGHPGGQSSSGTSQHPPSLSPKPPTRSPSPPTQHTGQPPGQPSAPSQLSAPRRYSSSLSPIQAPNHPPPQPPTQATPLMHTKPNSQGPPNPMALPSEHGLEQPSHTPPQTPTPPSTPPLGKQNPSLPAPQTLAGGNPETAQPHAGTLPRPRPVPKPRNRPSVPPPPQPPGVHSAGDSSLTNTAPTASKIVTDSNSRVSEPHRSIFPEMHSDSASKDVPGRILLDIDNDTESTAL>sp|Q9HBJ0|PLAC1_HUMAN Placenta-specific protein 1 OS=Homo sapiensOX=9606 GN=PLAC1 PE=2 SV=1MKVFKFIGLMILLTSAFSAGSGQSPMTVLCSIDWFMVTVHPFMLNNDVCVHFHELHLGLGCPPNHVQPHAYQFTYRVTECGIRAKAVSQDMVIYSTEIHYSSKGTPSKFVIPVSCAAPQKSPWLTKPCSMRVASKSRATAQKDEKCYEVFSLSQSSQRPNCDCPPCVFSEEEHTQVPCHQAGAQEAQPLQPSHFLDISEDWSLHTDDMIGSM>sp|Q9H4M7|PKHA4_HUMAN Pleckstrin homology domain-containing family Amember 4 OS=Homo sapiens OX=9606 GN=PLEKHA4 PE=1 SV=2MEGSRPRSSLSLASSASTISSLSSLSPKKPTRAVNKIHAFGKRGNALRRDPNLPVHIRGWLHKQDSSGLRLWKRRWFVLSGHCLFYYKDSREESVLGSVLLPSYNIRPDGPGAPRGRRFTFTAEHPGMRTYVLAADTLEDLRGWLRALGRASRAEGDDYGQPRSPARPQPGEGPGGPGGPPEVSRGEEGRISESPEVTRLSRGRGRPRLLTPSPTTDLHSGLQMRRARSPDLFTPLSRPPSPLSLPRPRSAPARRPPAPSGDTAPPARPHTPLSRIDVRPPLDWGPQRQTLSRPPTPRRGPPSEAGGGKPPRSPQHWSQEPRTQAHSGSPTYLQLPPRPPGTRASMVLLPGPPLESTFHQSLETDTLLTKLCGQDRLLRRLQEEIDQKQEEKEQLEAALELTRQQLGQATREAGAPGRAWGRQRLLQDRLVSVRATLCHLTQERERVWDTYSGLEQELGTLRETLEYLLHLGSPQDRVSAQQQLWMVEDTLAGLGGPQKPPPHTEPDSPSPVLQGEESSERESLPESLELSSPRSPETDWGRPPGGDKDLASPHLGLGSPRVSRASSPEGRHLPSPQLGTKAPVARPRMSAQEQLERMRRNQECGRPFPRPTSPRLLTLGRTLSPARRQPDVEQRPVVGHSGAQKWLRSSGSWSSPRNTTPYLPTSEGHRERVLSLSQALATEASQWHRMMTGGNLDSQGDPLPGVPLPPSDPTRQETPPPRSPPVANSGSTGFSRRGSGRGGGPTPWGPAWDAGIAPPVLPQDEGAWPLRVTLLQSSF>sp|Q9H4M7-2|PKHA4_HUMAN Isoform 2 of Pleckstrin homology domain-containing family A member 4 OS=Homo sapiens OX=9606 GN=PLEKHA4MEGSRPRSSLSLASSASTISSLSSLSPKKPTRAVNKIHAFGKRGNALRRDPNLPVHIRGWLHKQDSSGLRLWKRRWFVLSGHCLFYYKDSREESVLGSVLLPSYNIRPDGPGAPRGRRFTFTAEHPGMRTYVLAADTLEDLRGWLRALGRASRAEGDDYGQPRSPARPQPGEGPGGPGGPPEVSRGEEGRISESPEVTRLSRGRGRPRLLTPSPTTDLHSGLQMRRARSPDLFTPLSRPPSPLSLPRPRSAPARRPPAPSGDTAPPARPHTPLSRIDVRPPLDWGPQRQTLSRPPTPRRGPPSEAGGGKPPRSPQHWSQEPRTQPGPPLESTFHQSLETDTLLTKLCGQDRLLRRLQEEIDQKQEEKEQLEAALELTRQQLGQATREAGAPGRAWGRQRLLQDRLVSVRATLCHLTQERERVWDTYSGLEQELGTLRETLEYLLHLGSPQDRVSAQQQLWMVEDTLAGLGGPQKPPPHTEPDSPSPVLQGEESSERESLPESLELSSPRSPETDWGRPPGGDKDLASPHLGLGSPRVSRASSPEGRHLPSPQLGTKSKEHHPLLADFRRSPGAGSQPLPSPGY>sp|Q9UGC6|RGS17_HUMAN Regulator of G-protein signaling 17 OS=Homosapiens OX=9606 GN=RGS17 PE=1 SV=2MRKRQQSQNEGTPAVSQAPGNQRPNNTCCFCWCCCCSCSCLTVRNEERGENAGRPTHTTKMESIQVLEECQNPTAEEVLSWSQNFDKMMKAPAGRNLFREFLRTEYSEENLLFWLACEDLKKEQNKKVIEEKARMIYEDYISILSPKEVSLDSRVREVINRNLLDPNPHMYEDAQLQIYTLMHRDSFPRFLNSQIYKSFVESTAGSSSES>sp|Q9BXM0|PRAX_HUMAN Periaxin OS=Homo sapiens OX=9606 GN=PRX PE=1 SV=2MEARSRSAEELRRAELVEIIVETEAQTGVSGINVAGGGKEGIFVRELREDSPAARSLSLQEGDQLLSARVFFENFKYEDALRLLQCAEPYKVSFCLKRTVPTGDLALRPGTVSGYEIKGPRAKVAKLNIQSLSPVKKKKMVPGALGVPADLAPVDVEFSFPKFSRLRRGLKAEAVKGPVPAAPARRRLQLPRLRVREVAEEAQAARLAAAAPPPRKAKVEAEVAAGARFTAPQVELVGPRLPGAEVGVPQVSAPKAAPSAEAAGGFALHLPTLGLGAPAPPAVEAPAVGIQVPQVELPALPSLPTLPTLPCLETREGAVSVVVPTLDVAAPTVGVDLALPGAEVEARGEAPEVALKMPRLSFPRFGARAKEVAEAKVAKVSPEARVKGPRLRMPTFGLSLLEPRPAAPEVVESKLKLPTIKMPSLGIGVSGPEVKVPKGPEVKLPKAPEVKLPKVPEAALPEVRLPEVELPKVSEMKLPKVPEMAVPEVRLPEVELPKVSEMKLPKVPEMAVPEVRLPEVQLLKVSEMKLPKVPEMAVPEVRLPEVQLPKVSEMKLPEVSEVAVPEVRLPEVQLPKVPEMKVPEMKLPKVPEMKLPEMKLPEVQLPKVPEMAVPDVHLPEVQLPKVPEMKLPEMKLPEVKLPKVPEMAVPDVHLPEVQLPKVPEMKLPKMPEMAVPEVRLPEVQLPKVSEMKLPKVPEMAVPDVHLPEVQLPKVCEMKVPDMKLPEIKLPKVPEMAVPDVHLPEVQLPKVSEIRLPEMQVPKVPDVHLPKAPEVKLPRAPEVQLKATKAEQAEGMEFGFKMPKMTMPKLGRAESPSRGKPGEAGAEVSGKLVTLPCLQPEVDGEAHVGVPSLTLPSVELDLPGALGLQGQVPAAKMGKGERVEGPEVAAGVREVGFRVPSVEIVTPQLPAVEIEEGRLEMIETKVKPSSKFSLPKFGLSGPKVAKAEAEGAGRATKLKVSKFAISLPKARVGAEAEAKGAGEAGLLPALDLSIPQLSLDAHLPSGKVEVAGADLKFKGPRFALPKFGVRGRDTEAAELVPGVAELEGKGWGWDGRVKMPKLKMPSFGLARGKEAEVQGDRASPGEKAESTAVQLKIPEVELVTLGAQEEGRAEGAVAVSGMQLSGLKVSTAGQVVTEGHDAGLRMPPLGISLPQVELTGFGEAGTPGQQAQSTVPSAEGTAGYRVQVPQVTLSLPGAQVAGGELLVGEGVFKMPTVTVPQLELDVGLSREAQAGEAATGEGGLRLKLPTLGARARVGGEGAEEQPPGAERTFCLSLPDVELSPSGGNHAEYQVAEGEGEAGHKLKVRLPRFGLVRAKEGAEEGEKAKSPKLRLPRVGFSQSEMVTGEGSPSPEEEEEEEEEGSGEGASGRRGRVRVRLPRVGLAAPSKASRGQEGDAAPKSPVREKSPKFRFPRVSLSPKARSGSGDQEEGGLRVRLPSVGFSETGAPGPARMEGAQAAAV>sp|Q9BXM0-2|PRAX_HUMAN Isoform 2 of Periaxin OS=Homo sapiens OX=9606GN=PRXMEARSRSAEELRRAELVEIIVETEAQTGVSGINVAGGGKEGIFVRELREDSPAARSLSLQEGDQLLSARVFFENFKYEDALRLLQCAEPYKVSFCLKRTVPTGDLALRPGTVSGYEIKGPRAKVAKLVRVLSPAPALDCPSDPVSAP>sp|Q9BXM0-3|PRAX_HUMAN Isoform 3 of Periaxin OS=Homo sapiens OX=9606GN=PRXMVPGALGVPADLAPVDVEFSFPKFSRLRRGLKAEAVKGPVPAAPARRRLQLPRLRVREVAEEAQAARLAAAAPPPRKAKVEAEVAAGARFTAPQVELVGPRLPGAEVGVPQVSAPKAAPSAEAAGGFALHLPTLGLGAPAPPAVEAPAVGIQVPQVELPALPSLPTLPTLPCLETREGAVSVVVPTLDVAAPTVGVDLALPGAEVEARGEAPEVALKMPRLSFPRFGARAKEVAEAKVAKVSPEARVKGPRLRMPTFGLSLLEPRPAAPEVVESKLKLPTIKMPSLGIGVSGPEVKVPKGPEVKLPKAPEVKLPKVPEAALPEVRLPEVELPKVSEMKLPKVPEMAVPEVRLPEVELPKVSEMKLPKVPEMAVPEVRLPEVQLLKVSEMKLPKVPEMAVPEVRLPEVQLPKVSEMKLPEVSEVAVPEVRLPEVQLPKVPEMKVPEMKLPKVPEMKLPEMKLPEVQLPKVPEMAVPDVHLPEVQLPKVPEMKLPEMKLPEVKLPKVPEMAVPDVHLPEVQLPKVPEMKLPKMPEMAVPEVRLPEVQLPKVSEMKLPKVPEMAVPDVHLPEVQLPKVCEMKVPDMKLPEIKLPKVPEMAVPDVHLPEVQLPKVSEIRLPEMQVPKVPDVHLPKAPEVKLPRAPEVQLKATKAEQAEGMEFGFKMPKMTMPKLGRAESPSRGKPGEAGAEVSGKLVTLPCLQPEVDGEAHVGVPSLTLPSVELDLPGALGLQGQVPAAKMGKGERVEGPEVAAGVREVGFRVPSVEIVTPQLPAVEIEEGRLEMIETKVKPSSKFSLPKFGLSGPKVAKAEAEGAGRATKLKVSKFAISLPKARVGAEAEAKGAGEAGLLPALDLSIPQLSLDAHLPSGKVEVAGADLKFKGPRFALPKFGVRGRDTEAAELVPGVAELEGKGWGWDGRVKMPKLKMPSFGLARGKEAEVQGDRASPGEKAESTAVQLKIPEVELVTLGAQEEGRAEGAVAVSGMQLSGLKVSTAGQVVTEGHDAGLRMPPLGISLPQVELTGFGEAGTPGQQAQSTVPSAEGTAGYRVQVPQVTLSLPGAQVAGGELLVGEGVFKMPTVTVPQLELDVGLSREAQAGEAATGEGGLRLKLPTLGARARVGGEGAEEQPPGAERTFCLSLPDVELSPSGGNHAEYQVAEGEGEAGHKLKVRLPRFGLVRAKEGAEEGEKAKSPKLRLPRVGFSQSEMVTGEGSPSPEEEEEEEEEGSGEGASGRRGRVRVRLPRVGLAAPSKASRGQEGDAAPKSPVREKSPKFRFPRVSLSPKARSGSGDQEEGGLRVRLPSVGFSETGAPGPARMEGAQAAAV>sp|O60810|PRAM4_HUMAN PRAME family member 4 OS=Homo sapiens OX=9606GN=PRAMEF4 PE=2 SV=5MKMSIWTPPRLLELAGRSLLRDQALAMSTLEELPTELFPPLFMEAFSRRRCEALKLMVQSWPFRRLPLRPLIKMPCLEAFQAVLDGLDALLNLGVRPRRWKLQVLDLQDVCENFWMVWSEAMAHGCFLNAKRNKKPVEDCPRMKGRQPLTVFVELWLKNRTLDEYLTCLLLWVKQRKDLLHLCCKKLKILGMPFRNIRSILKMVNLDCIQEVEVNCKWVLPILTQFTPYLGHMRNLQKLILSHMDVSRYVSPEQKKEIVTQFTTQFLKLRCLQKLYMNSVSFLEGHLDQLLSCLKTSLKFLTITNCVLLESDLKHLSQCPSISQLKTLDLSGIRLTNYSLVPLQILLEKVAATLEYLDLDDCGIIDSQVNAILPALSRCFELNTFSFCGNPICMATLENLLSHTIILKNLCVELYPAPRESYGADGTLCWSRFAQIRAELMNRVRDLRHPKRILFCTDYCPDCGNRSFYDLEADQYCC>sp|Q96QH2|PRAM_HUMAN PML-RARA-regulated adapter molecule 1 OS=Homosapiens OX=9606 GN=PRAM1 PE=1 SV=3MAHHLPAAMESHQDFRSIKAKFQASQPEPSDLPKKPPKPEFGKLKKFSQPELSEHPKKAPLPEFGAVSLKPPPPEVTDLPKKPPPPEVTDLPKKPPPPEVTDLPKKPPPPEVTDLPKKPSKLELSDLSKKFPQLGATPFPRKPLQPEVGEAPLKASLPEPGAPARKPLQPDELSHPARPPSEPKSGAFPRKLWQPEAGEATPRSPQPELSTFPKKPAQPEFNVYPKKPPQPQVGGLPKKSVPQPEFSEAAQTPLWKPQSSEPKRDSSAFPKKASQPPLSDFPKKPPQPELGDLTRTSSEPEVSVLPKRPRPAEFKALSKKPPQPELGGLPRTSSEPEFNSLPRKLLQPERRGPPRKFSQPEPSAVLKRHPQPEFFGDLPRKPPLPSSASESSLPAAVAGFSSRHPLSPGFGAAGTPRWRSGGLVHSGGARPGLRPSHPPRRRPLPPASSLGHPPAKPPLPPGPVDMQSFRRPSAASIDLRRTRSAAGLHFQDRQPEDIPQVPDEIYELYDDVEPRDDSSPSPKGRDEAPSVQQAARRPPQDPALRKEKDPQPQQLPPMDPKLLKQLRKAEKAEREFRKKFKFEGEIVVHTKMMIDPNAKTRRGGGKHLGIRRGEILEVIEFTSNEEMLCRDPKGKYGYVPRTALLPLETEVYDDVDFCDPLENQPLPLGR>sp|Q5VXH4|PRAM6_HUMAN PRAME family member 6 OS=Homo sapiens OX=9606GN=PRAMEF6 PE=1 SV=1MSIRTPPRLLELAGRSLLRDQALAMSTLEELPTELFPPLFMEAFSRRRCEALKLMVQAWPFRRLPLRPLIKMPCLEAFQAVLDGLDALLTQGVHPRRWKLQVLDLQDVCENFWMVWSEAMARGCFLNAKRNKTPVQDCPRMRGQQPLTVFVELWLKNRTLDEYLTCLLLWVKQRKDLLHLCCKKLKILGMPFRNIRSILKMVNLDCIQEVEVNCKWVLPILTQFTPYLGHMRNLQKLVLSHMDVSRYVSPEQKKEIVTQFTTQFLKLCCLQKLSMNSVSFLEGHLDQLLSCLKTSLKVLTITNCVLLESDLKHLSQCPSISQLKTLDLSGIRLTNYSLVPLQILLEKVAATLEYLDLDDCGIIDSQVNAILPALSRCFELNTFSFCGNPISMATLENLLSHTIILKNLCVELYPAPRESYDADGTLCWSRFAQIRAELMKRVRDLRHPKRILFCTDCCPDCGNRSFYDLEADQCCC>sp|Q9NQW5|PRDM7_HUMAN Histone-lysine N-methyltransferase PRDM7 OS=Homosapiens OX=9606 GN=PRDM7 PE=1 SV=2MSPERSQEESPEGDTERTERKPMVKDAFKDISIYFTKEEWAEMGDWEKTRYRNVKMNYNALITVGLRATRPAFMCHRRQAIKLQVDDTEDSDEEWTPRQQVKPPWMAFRGEQSKHQKGMPKASFNNESSLRELSGTPNLLNTSDSEQAQKPVSPPGEASTSGQHSRLKLELRRKETEGKMYSLRERKGHAYKEISEPQDDDYLYCEMCQNFFIDSCAAHGPPTFVKDSAVDKGHPNRSALSLPPGLRIGPSGIPQAGLGVWNEASDLPLGLHFGPYEGRITEDEEAANSGYSWLITKGRNCYEYVDGKDKSSANWMRYVNCARDDEEQNLVAFQYHRQIFYRTCRVIRPGCELLVWSGDEYGQELGIRSSIEPAESLGQAVNCWSGMGMSMARNWASSGAASGRKSSWQGENQSQRSIHVPHAVWPFQVKNFSVNMWNAITPLRTSQDHLQENFSNQRIPAQGIRIRSGNILIHAAVMTKPKVKRSKKGPNS>sp|Q9NQW5-2|PRDM7_HUMAN Isoform 2 of Histone-lysine N-methyltransferasePRDM7 OS=Homo sapiens OX=9606 GN=PRDM7MCQNFFIDSCAAHGPPTFVKDSAVDKGHPNRSALSLPPGLRIGPSGIPQAGLGVWNEASDLPLGLHFGPYEGRITEDEEAANSGYSWLITKGRNCYEYVDGKDKSSANWMRTKARDPSMSLMLSGLFKSKISQSTCGTQSLLSELPRTICKKTSPTRESLPRGSESGAAIF>sp|Q9NQW5-1|PRDM7_HUMAN Isoform 3 of Histone-lysine N-methyltransferasePRDM7 OS=Homo sapiens OX=9606 GN=PRDM7MCQNFFIDSCAAHGPPTFVKDSAVDKGHPNRSALSLPPGLRIGPSGIPQAGLGVWNEASDLPLGLHFGPYEGRITEDEEAANSGYSWLITKGRNCYEYVDGKDKSSANWMRYVNCARDDEEQNLVAFQYHRQIFYRTCRVIRPGCELLVWSGDEYGQELGIKWGSKWKKELMAGREPKPEIHPCPSCCLAFSSQKFLSQHVERNHSSQNFPGPSARKLLQPENPCPGDQNQERQYSDPRCCNDKTKGQEIKERSKLLNKRTWQREISRAFSSPPKGQMGSSRVGERMMEEESRTGQKVNPGNTGKLFVGVGISRIAKVKYGECGQGFSDKSDVITHQRTHTGGKPYVCRECGEGFSRKSDLLSHQRTHTGEKPYVCRECERGFSRKSVLLIHQRTHRGEAPVCRKDE>sp|P30041|PRDX6_HUMAN Peroxiredoxin-6 OS=Homo sapiens OX=9606 GN=PRDX6PE=1 SV=3MPGGLLLGDVAPNFEANTTVGRIRFHDFLGDSWGILFSHPRDFTPVCTTELGRAAKLAPEFAKRNVKLIALSIDSVEDHLAWSKDINAYNCEEPTEKLPFPIIDDRNRELAILLGMLDPAEKDEKGMPVTARVVFVFGPDKKLKLSILYPATTGRNFDEILRVVISLQLTAEKRVATPVDWKDGDSVMVLPTIPEEEAKKLFPKGVFTKELPSGKKYLRYTPQP>sp|Q96S07|PRR25_HUMAN Proline-rich protein 25 OS=Homo sapiens OX=9606GN=PRR25 PE=4 SV=1MARTDQKPPCRGGCWGQPGHPNTGGAAAHPTYHPMGHRPRTCILLRGDQTTGGQAPSREISLGPWAAGTHFLAISTTPWGRKTPACISELPTSSGTAQPLANAVCEVQTVPGPGLRPQGTPAMRAPSHKGTPPTPNPWGPEQPQNRHKHPKKGVTGGPSPPPPAASRYGQTPGREPRVQAPGLGPCGRPASGRLLSLHLEKGDGKGTRQRIPLTDAAVGGDRTDIPSAIAAGPARTPDRHGLPIPGSTPTPMVGSGRLGAPVGRSGGGASARSSRPSCANVLLRADASLGTVLSVLWTGQLSRGWALLPPGDAGRHLETSVISAGVAAGIWLVEPGEAAQDPATRRTAPPRRTASPEPPAPGAPLPACPGRIPGAARFGPRSCPLGSPAVLAVTTGWSHRSV>sp|P04156|PRIO_HUMAN Major prion protein OS=Homo sapiens OX=9606 GN=PRNPPE=1 SV=1MANLGCWMLVLFVATWSDLGLCKKRPKPGGWNTGGSRYPGQGSPGGNRYPPQGGGGWGQPHGGGWGQPHGGGWGQPHGGGWGQPHGGGWGQGGGTHSQWNKPSKPKTNMKHMAGAAAAGAVVGGLGGYMLGSAMSRPIIHFGSDYEDRYYRENMHRYPNQVYYRPMDEYSNQNNFVHDCVNITIKQHTVTTTTKGENFTETDVKMMERVVEQMCITQYERESQAYYQRGSSMVLFSSPPVILLISFLIFLIVG>sp|Q5THK1|PR14L_HUMAN Protein PRR14L OS=Homo sapiens OX=9606 GN=PRR14LPE=1 SV=1MLSSGVETQPVPLDSSMSAVVQELYSELPVSVSRELHADPEPSVIPDVKPGASSSLLSQNRALPLELQRTHVESCCEETYETLDHGSEPGRCGLVDSTAGGSVASGILDRAKRSESMEPKVFRDPGGQAGIIREPSEGAKEDPHQHSTAAEEKTSPSQEDLLMQSSKELSHVDLPEDFLRSKEGNVQITAETLLKSAEVQGMKVNGTKTDNNEGHKNGNVSKDLSAGCGEFQEVDKIMTSDEVSETSTLVTPEPLTFVDPVLTEATPKEKECEELKSCPWLSLPGNSAISNVDNGKEELCKPNLVCEADDNHQQLHGHHNEQPSSTHDSPTATSPLKENSEVSCFTSDLSGPESRTISLENCGFEGGGLLKRSAEKTDSSYFYRGDDQGKNLASREENEERLLIPRSERGGPFLFNAREPEKEISGRCSGEKEPVVSPKENIHNNCIQDSLHTGNSSSLMPNSFTEATEVMLNKNDLKITVHVQGNLTNPEDHKETFTNMSHPGGHSEESSFSSLMQIEEAGQTTPVEPNILSKSFYTKDCNSLVSIQRNLEGNTQLNEASCNDFLFERKSIVSLMPEDQISPVSEVLKPKQGTALLLPSPEFDYRPESEKVIQTSHDDIPLLDEQSIACEMNELSCTNELVVNKVESECVLNQQVSLNSQEHANLPTDSLLHLNKEMPLATGRDAHQSHHPPLEGRADVIADIQTIPIQTKIKDISPPGNQTCGASSNCPTLNIKPVSLERKKEMADSGTKALHSRLRSNKREAAGFPQVVSVIECHSVQSQDISSCHRVRKNVSQENMCSASAAFKSSKISLQVDNSLITKYENAFQHRDHCCQGTGHSVEKSSCKVSYTSQERELDGKETNGSLPGDKIRNKMVAGLLNSGISNKTIHTSSSIKLSEEGLEGKEQDVSKETVFCKYNISDHAIQELNQTVNIPGPEKVLDQSPTVMFSSFKNVKSVETLDQKADEVLDCQSNQNRPDECKSEGQSAKEMLSSDQRETVTEPHGEVNHNQKDLLVSSGSNNSLPCGSPKKCNLKGAFVKMSGCDESTEGMVDIVYTDCSNKLAEGVLDVKASNLLDCGARQEKLAFQEDSRSTLSRRELDAAHTGTTGQDSDFPVTAASTVDFLKIKKSCEENVCRSLKDCEMEKCPDSCAHEMESVADHEPNKRILGRVNLSLNDSHYGQQDKGTSLRETQEMTEGSRLEPNSEFGKESTFGISSKESMSCHDESSVSLRSLKSIEIMPSQENSETNVNSEETDLKNLCKPKDGEMLCENVKDCTVLPEMKEIVSRDWSNSSDRDSVCTCVEKNACKACHPHENSSDRHLPLTVKTDIKVKGEETEEHQRGRLGYLTVGEQSEELVTRETGDGDPVSNISQTHFKCRGILNHAEKQQSPEVLDYMLQKEEKYIRQQKAHTISQQCISSSLLLDDAQNQNQPKADKDESTMINEITLAKLAKDSIVAQTQKLEDQKEERLHHPLRKDTESCTSPCLLGAPRKAQDPSSAGCDQIHGAFAKKGVLPLKKQPHRTCKKVSYQEQIIVGRKIGKIRSSAFLKSSSNPIPTKAHRLLSLCTLSAPTRLEPETAPTKSLVSHIPKQMSTPCHPLRSLNFRKTTKESALLNKLSILASKLAPAMKTQKLRYRRCSSELLPMAKSYKRLRYKRLLDGFSSSTEQLNPYLAASGWDKRPNSKPMALYSLESIKMTFIDLSNKMPSLLFGSEIFPVSFHVKSSSSDCTTESSRTFPEHCAPARLALGEALQCPSQPPKWTFSFFLSHGCPGMATFREDTGVHSQTHTQAPPQPPAPLQDYGGTAIVQTRADCSVLGLHTLLALCSPGCYRIWTKKRSFSSHMPTMQRLFMTQFTQGLKGLRSPASIADKVFCSLPYSVGRVLSIWSQHGPSVCSFEISSLHSPHCKRQPSLGTTSSHTMLPYVPLPGMEATYNTSGSQTRLEPPFPALVPKSCLVAESAVSKLLLSASEFQVRGLDELDGVKAACPCPQSSPPEQKEAEPEKRPKKVSQIRIRKTIPRPDPNLTPMGLPRPKRLKKKEFSLEEIYTNKNYKSPPANRCLETIFEEPKERNGTLISISQQKRKRVLEFQDFTVPRKRRARGKVKVAGSFTRAQKAAVQSRELDALLIQKLMELETFFAKEEEQEQSSGC>sp|Q5THK1-2|PR14L_HUMAN Isoform 2 of Protein PRR14L OS=Homo sapiensOX=9606 GN=PRR14LMLSSGVETQPVPLDSSMSAVVQELYSELPVSVSRELHADPEPSVIPDVKPGASSSLLSQNRALPLELQRTHVESCCEETYETLDHGSEPGRCGLVDSTAGGSVASGILDRAKRSESMEPKVFRDPGGQAGIIREPSEGAKEDPHQHSTAAEEKTSPSQEDLLMQSSKELSHVDLPEDFLRSKEGNVQITAETLLKSAEVQGMKVNGTKTDNNEGHKNGNVSKDLSAGCGEFQEVDKIMTSDEVSETSTLVTPEPLTFVDPVLTEATPKEKECEELKSCPWLSLPGNSAISNVDNGKEELCKPNLVCEADDNHQQLHGHHNEQPSSTHDSPTATSPLKENSEVSCFTSDLSGPESRTISLENCGFEGGGLLKRSAEKTDSSYFYRGDDQGKNLASREENEERLLIPRSERGGPFLFNAREPEKEISGRCSGEKEPVVSPKENIHNNCIQDSLHTGNSSSLMPNSFTEATEVMLNKNDLKITVHVQGNLTNPEDHKETFTNMSHPGGHSEESSFSSLMQIEEAGQTTPVEPNILSKSFYTKDCNSLVSIQRNLEGNTQLNEASCNDFLFERKSIVSLMPEDQISPVSEVLKPKQGTALLLPSPEFDYRPESEKVIQTSHDDIPLLDEQSIACEMNELSCTNELVVNKVESECVLNQQVSLNSQEHANLPTDSLLHLNKEMPLATGRDAHQSHHPPLEGRADVIADIQTIPIQTKIKDISPPGNQTCGASSNCPTLNIKPVSLERKKEMADSGTKALHSRLRSNKREAAGFPQVVSVIECHSVQSQDISSCHRVRKNVSQENMCSASAAFKSSKISLQVDNSLITKYENAFQHRDHCCQGTGHSVEKSSCKVSYTSQERELDGKETNGSLPGDKIRNKMVAGLLNSGISNKTIHTSSSIKLSEEGLEGKEQDVSKETVFCKYNISDHAIQELNQTVNIPGPEKVLDQSPTVMFSSFKNVKSVETLDQKADEVLDCQSNQNRPDECKSEGQSAKEMLSSDQRETVTEPHGEVNHNQKDLLVSSGSNNSLPCGSPKKCNLKGAFVKMSGCDESTEGMVDIVYTDCSNKLAEGVLDVKASNLLDCGARQEKLAFQEDSRSTLSRRELDAAHTGTTGQDSDFPVTAASTVDFLKIKKSCEENVCRSLKDCEMEKCPDSCAHEMESVADHEPNKRILGRVNLSLNDSHYGQQDKGTSLRETQEMTEGSRLEPNSEFGKESTFGISSKESMSCHDESSVSLRSLKSIEIMPSQENSETNVNSEETDLKNLCKPKDGEMLCENVKDCTVLPEMKEIVSRDWSNSSDRDSVCTCVEKNACKACHPHENSSDRHLPLTVKTDIKVKGEETEEHQRGRLGYLTVGEQSEELVTRETGDGDPVSNISQTHFKCRGILNHAEKQQSPEVLDYMLQKEEKYIRQQKAHTISQQCISSSLLLDDAQNQNQPKADKDESTMINEITLAKLAKDSIVAQTQKLEDQKEERLHHPLRKDTESCTSPCLLGAPRKAQDPSSAGCDQIHGAFAKKGVLPLKKQPHRTCKKVSYQEQIIVGRKIGKIRSSAFLKSSSNPIPTKAHRLLSLCTLSAPTRLEPETAPTKSLVSHIPKQMSTPCHPLRSLNFRKTTKESALLNKLSILASKLAPAMKTQKLRYRRCSSELLPMAKSYKRLRYKRLLDGFSSSTEQLNPYLAASGWDKRPNSKPMALYSLESIKMTFIDLSNKMPSLLFGSEIFPVSFHVKSSSSDCTTESSRTFPEHCAPARLALGEALQCPSQPPKWTFSFFLSHGCPGMATFREDTGVHSQTHTQAPPQPPAPLQDYGGTAIVQTRADCSVLGLHTLLALCSPGCYRIWTKKRSFSSHMPTMQRLFMTQFTQGLKGLRSPASIADKVFCSLPYSVGRVLSIWSQHGPSVCSFEISSLHSPHCKRQPSLGTTSSHTMLPYVPLPGMEATYNTSGSQTRLEPPFPALVPKSCLVAESAVSKLLLSASEFQVRGLDELDGVKAACPCPQSSPPEQKEVKEEGV>sp|Q5THK1-3|PR14L_HUMAN Isoform 3 of Protein PRR14L OS=Homo sapiensOX=9606 GN=PRR14LMLSSGVETQPVPLDSSMSAVVQELYSELPVSVSRELHADPEPSVIPDVKPGASSSLLSQNRALPLELQRTHVESCCEETYETLDHGSEPGRCGLVDSTAGGSVASGILDRAKRSESMEPKVFRDPGGQAGIIREPSEGAKEDPHQHSTAAEEKTSPSQEDLLMQSSKELSHVDLPEDFLRSKEGNVQITAETLLKSAEVQGMKVNGTKTDNNEGHKNGNVSKDLSAGCGEFQEVDKIMTSDEVSETSTLVTPEPLTFVDPVLTEATPKEKECEELKSCPWLSLPGNSAISNVDNGKEELCKPNLVCEADDNHQQLHGHHNEQPSSTHDSPTATSPLKENSEVSCFTSDLSGPESRTISLENCGFEGGGLLKRSAEKTDSSYFYRGDDQGKNLASREENEERLLIPRSERGGPFLFNAREPEKEISGRCSGEKEPVVSPKENIHNNCIQDSLHTGNSSSLMPNSFTEATEVMLNKNDLKITVHVQGNLTNPEDHKETFTNMSHPGGHSEESSFSSLMQIEEAGQTTPVEPNILSKSFYTKDCNSLVSIQRNLEGNTQLNEASCNDFLFERKSIVSLMPEDQISPVSEVLKPKQGTALLLPSPEFDYRPESEKVIQTSHDDIPLLDEQSIACEMNELSCTNELVVNKVESECVLNQQVSLNSQEHANLPTDSLLHLNKEMPLATGRDAHQSHHPPLEGRADVIADIQTIPIQTKIKDISPPGNQTCGASSNCPTLNIKPVSLERKKEMADSGTKALHSRLRSNKREAAGFPQVVSVIECHSVQSQDISSCHRVRKNVSQENMCSASAAFKSSKISLQVDNSLITKYENAFQHRDHCCQGTGHSVEKSSCKVSYTSQERELDGKETNGSLPGDKIRNKMVAGLLNSGISNKTIHTSSSIKLSEEGLEGKEQDVSKETVFCKYNISDHAIQELNQTVNIPGPEKVLDQSPTVMFSSFKNVKSVETLDQKADEVLDCQSNQNRPDECKSEGQSAKEMLSSDQRETVTEPHGEVNHNQKDLLVSSGSNNSLPCGSPKKCNLKGAFVKMSGCDESTEGMVDIVYTDCSNKLAEGVLDVKASNLLDCGARQEKLAFQEDSRSTLSRRELDAAHTGTTGQDSDFPVTAASTVDFLKIKKSCEENVCRSLKDCEMEKCPDSCAHEMESVADHEPNKRILGRVNLSLNDSHYGQQDKGTSLRETQEMTEGSRLEPNSEFGKESTFGISSKESMSCHDESSVSLRSPCLTT>sp|Q5THK1-4|PR14L_HUMAN Isoform 4 of Protein PRR14L OS=Homo sapiensOX=9606 GN=PRR14LMLSSGVETQPVPLDSSMSAVVQELYSELPVSVSRELHADPEPSVIPDVKPGASSSLLSQNRALPLELQRTHVESCCEETYETLDHGSEPGRCGLVDSTAGGSVASGILDRAKRSESMEPKVFRDPGGQAGIIREPSEGAKEDPHQHSTAAEEKTSPSQEDLLMQSSKELSHVDLPEDFLRSKEGNVQITAETLLKSAEVQGMKVNGTKTDNNEGHKNGNVSKDLSAGCGEFQEVDKIMTSDEVSETSTLVTPEPLTFVDPVLTEATPKEKECEELKSCPWLSLPGNSAISNVDNGKEELCKPNLVCEADDNHQQLHGHHNEQPSSTHDSPTATSPLKENSEVSCFTSDLSGPESRTISLENCGFEGGGLLKRSAEKTDSSYFYRGDDQGKNLASREENEERLLIPRSERGGPFLFNAREPEKEISGRCSGEKEPVVSPKENIHNNCIQDSLHTGNSSSLMPNSFTEATEVMLNKNDLKITVHVQGNLTNPEDHKETFTNMSHPGGHSEESSFSSLMQIEEAGQTTPVEPNILSKSFYTKDCNSLVSIQRNLEGNTQLNEASCNDFLFERKSIVSLMPEDQISPVSEVLKPKQGTALLLPSPEFDYRPESEKVIQTSHDDIPLLDEQSIACEMNELSCTNELVVNKVESECVLNQQVSLNSQEHANLPTDSLLHLNKEMPLATGRDAHQSHHPPLEGRADVIADIQTIPIQTKIKDISPPGNQTCGASSNCPTLNIKPVSLERKKEMADSGTKALHSRLRSNKREAAGFPQVVSVIECHSVQSQDISSCHRVRKNVSQENMCSASAAFKSSKISLQVDNSLITKYENAFQHRDHCCQGTGHSVEKSSCKVSYTSQERELDGKETNGSLPGDKIRNKMVAGLLNSGISNKTIHTSSSIKLSEEGLEGKEQDVSKETVFCKYNISDHAIQELNQTVNIPGPEKVLDQSPTVMFSSFKNVKSVETLDQKADEVLDCQSNQNRPDECKSEGQSAKEMLSSDQRETVTEPHGEVNHNQKDLLVSSGSNNSLPCGSPKKCNLKGAFVKMSGCDESTEGMVDIVYTDCSNKLAEGVLDVKASNLLDCGARQEKLAFQEDSRSTLSRRELDAAHTGTTGQDSDFPVTAASTVDFLKIKKSCEENVCRSLKDCEMEKCPDSCAHEMESVADHEPNKRILGRVNLSLNDSHYGQQDKGTSLRETQEMTEGSRLEPNSEFGKESTFGISSKESMSCHDESSVSLRSLKSIEIMPSQENSETNVNSEETDLKNLCKPKDGEMLCENVKDCTVLPEMKEIVSRDWSNSSDRDSVCTCVEKNACKACHPHENSSDRHLPLTVKTDIKVKGEETEEHQRGRLGYLTVGEQSEELVTRETGDGDPVSNISQTHFKCRGILNHAEKQQSPEVLDYMLQKEEKYIRQQKAHTISQQCISSSLLLDDAQNQNQPKADKDESTMINEITLAKLAKDSIVAQTQKLEDQKEERLHHPLRKDTESCTSPCLLGAPRKAQDPSSAGCDQIHGAFAKKGVLPLKKQPHRTCKKVSYQEQIIVGRKIGKIRSSAFLKSSSNPIPTKAHRLLSLCTLSAPTRLEPETAPTKSLVSHIPKQMSTPCHPLRSLNFRKTTKESALLNKLSILASKLAPAMKTQKLRYRRCSSELLPMAKSYKRLRYKRLLDGFSSSTEQLNPYLAASGWDKRPNSKPMALYSLESIKMTFIDLSNKMPSLLFGSEIFPVSFHVKSSSSDCTTESSRTFPEHCAPARLALGEALQCPSQPPKWTFSFFLSHGCPGMATFREDTGVHSQTHTQAPPQPPAPLQDYGGTAIVQTRADCSVLGLHTLLALCSPGCYRIWTKKRSFSSHMPTMQRLFMTQFTQGLKGLRSPASIADKVFCSLPYSVGRVLSIWSQHGPSVCSFEISSLHSPHCKRQPSLGTTSSHTMLPYVPLPGMEATYNTSGSQTRLEPPFPALVPKSCLVAESAVSKLLLSASEFQVRGLDELDGVKAACPCPQSSPPEQKEAEPEKRPKKVSQIRIRKTIPRPDPNLTPMGLPRPKRLKKKEFSLEEIYTNKNYKSPPANRDLDSSCPSTDSETGHFLVFGYAQRQAQPHPLLASRRLIGCSSPEGRGHPRSYPYWRRLLVLCWYLPGWRAGRVTWLRLATWAGRGDSSL>sp|Q96BP3|PPWD1_HUMAN Peptidylprolyl isomerase domain and WD repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=PPWD1 PE=1 SV=1MAAESGSDFQQRRRRRRDPEEPEKTELSERELAVAVAVSQENDEENEERWVGPLPVEATLAKKRKVLEFERVYLDNLPSASMYERSYMHRDVITHVVCTKTDFIITASHDGHVKFWKKIEEGIEFVKHFRSHLGVIESIAVSSEGALFCSVGDDKAMKVFDVVNFDMINMLKLGYFPGQCEWIYCPGDAISSVAASEKSTGKIFIYDGRGDNQPLHIFDKLHTSPLTQIRLNPVYKAVVSSDKSGMIEYWTGPPHEYKFPKNVNWEYKTDTDLYEFAKCKAYPTSVCFSPDGKKIATIGSDRKVRIFRFVTGKLMRVFDESLSMFTELQQMRQQLPDMEFGRRMAVERELEKVDAVRLINIVFDETGHFVLYGTMLGIKVINVETNRCVRILGKQENIRVMQLALFQGIAKKHRAATTIEMKASENPVLQNIQADPTIVCTSFKKNRFYMFTKREPEDTKSADSDRDVFNEKPSKEEVMAATQAEGPKRVSDSAIIHTSMGDIHTKLFPVECPKTVENFCVHSRNGYYNGHTFHRIIKGFMIQTGDPTGTGMGGESIWGGEFEDEFHSTLRHDRPYTLSMANAGSNTNGSQFFITVVPTPWLDNKHTVFGRVTKGMEVVQRISNVKVNPKTDKPYEDVSIINITVK>sp|Q96BP3-2|PPWD1_HUMAN Isoform 2 of Peptidylprolyl isomerase domain andWD repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=PPWD1MKVFDVVNFDMINMLKLGYFPGQCEWIYCPGDAISSVAASEKSTGKIFIYDGRGDNQPLHIFDKLHTSPLTQIRLNPVYKAVVSSDKSGMIEYWTGPPHEYKFPKNVNWEYKTDTDLYEFAKCKAYPTSVCFSPDGKKIATIGSDRKVRIFRFVTGKLMRVFDESLSMFTELQQMRQQLPDMEFGRRMAVERELEKVDAVRLINIVFDETGHFVLYGTMLGIKVINVETNRCVRILGKQENIRVMQLALFQGIAKKHRAATTIEMKASENPVLQNIQADPTIVCTSFKKNRFYMFTKREPEDTKSADSDRDVFNEKPSKEEVMAATQAEGPKRVSDSAIIHTSMGDIHTKLFPVECPKTVENFCVHSRNGYYNGHTFHRIIKGFMIQTGDPTGTGMGGESIWGGEFEDEFHSTLRHDRPYTLSMANAGSNTNGSQFFITVVPTPWLDNKHTVFGRVTKGMEVVQRISNVKVNPKTDKPYEDVSIINITVK>sp|Q8IYP2|PRS58_HUMAN Serine protease 58 OS=Homo sapiens OX=9606GN=PRSS58 PE=2 SV=1MKFILLWALLNLTVALAFNPDYTVSSTPPYLVYLKSDYLPCAGVLIHPLWVITAAHCNLPKLRVILGVTIPADSNEKHLQVIGYEKMIHHPHFSVTSIDHDIMLIKLKTEAELNDYVKLANLPYQTISENTMCSVSTWSYNVCDIYKEPDSLQTVNISVISKPQCRDAYKTYNITENMLCVGIVPGRRQPCKEVSAAPAICNGMLQGILSFADGCVLRADVGIYAKIFYYIPWIENVIQNN>sp|Q8NAV1|PR38A_HUMAN Pre-mRNA-splicing factor 38A OS=Homo sapiensOX=9606 GN=PRPF38A PE=1 SV=1MANRTVKDAHSIHGTNPQYLVEKIIRTRIYESKYWKEECFGLTAELVVDKAMELRFVGGVYGGNIKPTPFLCLTLKMLQIQPEKDIIVEFIKNEDFKYVRMLGALYMRLTGTAIDCYKYLEPLYNDYRKIKSQNRNGEFELMHVDEFIDELLHSERVCDIILPRLQKRYVLEEAEQLEPRVSALEEDMDDVESSEEEEEEDEKLERVPSPDHRRRSYRDLDKPRRSPTLRYRRSRSRSPRRRSRSPKRRSPSPRRERHRSKSPRRHRSRSRDRRHRSRSKSPGHHRSHRHRSHSKSPERSKKSHKKSRRGNE>sp|Q8NAV1-2|PR38A_HUMAN Isoform 2 of Pre-mRNA-splicing factor 38AOS=Homo sapiens OX=9606 GN=PRPF38AMDDVESSEEEEEEDEKLERVPSPDHRRRSYRDLDKPRRSPTLRYRRSRSRSPRRRSRSPKRRSPSPRRERHRSKSPRRHRSRSRDRRHRSRSKSPGHHRSHRHRSHSKSPERSKKSHKKSRRGNE>sp|P22234|PUR6_HUMAN Multifunctional protein ADE2 OS=Homo sapiensOX=9606 GN=PAICS PE=1 SV=3MATAEVLNIGKKLYEGKTKEVYELLDSPGKVLLQSKDQITAGNAARKNHLEGKAAISNKITSCIFQLLQEAGIKTAFTRKCGETAFIAPQCEMIPIEWVCRRIATGSFLKRNPGVKEGYKFYPPKVELFFKDDANNDPQWSEEQLIAAKFCFAGLLIGQTEVDIMSHATQAIFEILEKSWLPQNCTLVDMKIEFGVDVTTKEIVLADVIDNDSWRLWPSGDRSQQKDKQSYRDLKEVTPEGLQMVKKNFEWVAERVELLLKSESQCRVVVLMGSTSDLGHCEKIKKACGNFGIPCELRVTSAHKGPDETLRIKAEYEGDGIPTVFVAVAGRSNGLGPVMSGNTAYPVISCPPLTPDWGVQDVWSSLRLPSGLGCSTVLSPEGSAQFAAQIFGLSNHLVWSKLRASILNTWISLKQADKKIRECNL>sp|P22234-2|PUR6_HUMAN Isoform 2 of Multifunctional protein ADE2 OS=Homosapiens OX=9606 GN=PAICSMATAEVLNIGKKLYEGKTKEVYELLDSPGKVLLQSKDQITAGNAARKNHLEGKAAISNKITSCIFQLLQEAVTSYKSNRIKTAFTRKCGETAFIAPQCEMIPIEWVCRRIATGSFLKRNPGVKEGYKFYPPKVELFFKDDANNDPQWSEEQLIAAKFCFAGLLIGQTEVDIMSHATQAIFEILEKSWLPQNCTLVDMKIEFGVDVTTKEIVLADVIDNDSWRLWPSGDRSQQKDKQSYRDLKEVTPEGLQMVKKNFEWVAERVELLLKSESQCRVVVLMGSTSDLGHCEKIKKACGNFGIPCELRVTSAHKGPDETLRIKAEYEGDGIPTVFVAVAGRSNGLGPVMSGNTAYPVISCPPLTPDWGVQDVWSSLRLPSGLGCSTVLSPEGSAQFAAQIFGLSNHLVWSKLRASILNTWISLKQADKKIRECNL>sp|Q9UJV8|PURG_HUMAN Purine-rich element-binding protein gamma OS=Homosapiens OX=9606 GN=PURG PE=2 SV=1MERARRRGGGGGRGRGGKNVGGSGLSKSRLYPQAQHSHYPHYAASATPNQAGGAAEIQELASKRVDIQKKRFYLDVKQSSRGRFLKIAEVWIGRGRQDNIRKSKLTLSLSVAAELKDCLGDFIEHYAHLGLKGHRQEHGHSKEQGSRRRQKHSAPSPPVSVGSEEHPHSVLKTDYIERDNRKYYLDLKENQRGRFLRIRQTMMRGTGMIGYFGHSLGQEQTIVLPAQGMIEFRDALVQLIEDYGEGDIEERRGGDDDPLELPEGTSFRVDNKRFYFDVGSNKYGIFLKVSEVRPPYRNTITVPFKAWTRFGENFIKYEEEMRKICNSHKEKRMDGRKASGEEQECLD>sp|Q9UJV8-2|PURG_HUMAN Isoform 2 of Purine-rich element-binding proteingamma OS=Homo sapiens OX=9606 GN=PURGMERARRRGGGGGRGRGGKNVGGSGLSKSRLYPQAQHSHYPHYAASATPNQAGGAAEIQELASKRVDIQKKRFYLDVKQSSRGRFLKIAEVWIGRGRQDNIRKSKLTLSLSVAAELKDCLGDFIEHYAHLGLKGHRQEHGHSKEQGSRRRQKHSAPSPPVSVGSEEHPHSVLKTDYIERDNRKYYLDLKENQRGRFLRIRQTMMRGTGMIGYFGHSLGQEQTIVLPAQGMIEFRDALVQLIEDYGEGDIEERRGGDDDPLELPEGTSFRVDNKRFYFDVGSNKYGIFLKLTNYPKSRENINLFHCCQIKHKEQPHDTTKTVEE>sp|Q14997|PSME4_HUMAN Proteasome activator complex subunit 4 OS=Homosapiens OX=9606 GN=PSME4 PE=1 SV=2MEPAERAGVGEPPEPGGRPEPGPRGFVPQKEIVYNKLLPYAERLDAESDLQLAQIKCNLGRAVQLQELWPGGLFWTRKLSTYIRLYGRKFSKEDHVLFIKLLYELVSIPKLEISMMQGFARLLINLLKKKELLSRADLELPWRPLYDMVERILYSKTEHLGLNWFPNSVENILKTLVKSCRPYFPADATAEMLEEWRPLMCPFDVTMQKAITYFEIFLPTSLPPELHHKGFKLWFDELIGLWVSVQNLPQWEGQLVNLFARLATDNIGYIDWDPYVPKIFTRILRSLNLPVGSSQVLVPRFLTNAYDIGHAVIWITAMMGGPSKLVQKHLAGLFNSITSFYHPSNNGRWLNKLMKLLQRLPNSVVRRLHRERYKKPSWLTPVPDSHKLTDQDVTDFVQCIIQPVLLAMFSKTGSLEAAQALQNLALMRPELVIPPVLERTYPALETLTEPHQLTATLSCVIGVARSLVSGGRWFPEGPTHMLPLLMRALPGVDPNDFSKCMITFQFIATFSTLVPLVDCSSVLQERNDLTEVERELCSATAEFEDFVLQFMDRCFGLIESSTLEQTREETETEKMTHLESLVELGLSSTFSTILTQCSKEIFMVALQKVFNFSTSHIFETRVAGRMVADMCRAAVKCCPEESLKLFVPHCCSVITQLTMNDDVLNDEELDKELLWNLQLLSEITRVDGRKLLLYREQLVKILQRTLHLTCKQGYTLSCNLLHHLLRSTTLIYPTEYCSVPGGFDKPPSEYFPIKDWGKPGDLWNLGIQWHVPSSEEVSFAFYLLDSFLQPELVKLQHCGDGKLEMSRDDILQSLTIVHNCLIGSGNLLPPLKGEPVTNLVPSMVSLEETKLYTGLEYDLSRENHREVIATVIRKLLNHILDNSEDDTKSLFLIIKIIGDLLQFQGSHKHEFDSRWKSFNLVKKSMENRLHGKKQHIRALLIDRVMLQHELRTLTVEGCEYKKIHQDMIRDLLRLSTSSYSQVRNKAQQTFFAALGAYNFCCRDIIPLVLEFLRPDRQGVTQQQFKGALYCLLGNHSGVCLANLHDWDCIVQTWPAIVSSGLSQAMSLEKPSIVRLFDDLAEKIHRQYETIGLDFTIPKSCVEIAELLQQSKNPSINQILLSPEKIKEGIKRQQEKNADALRNYENLVDTLLDGVEQRNLPWKFEHIGIGLLSLLLRDDRVLPLRAIRFFVENLNHDAIVVRKMAISAVAGILKQLKRTHKKLTINPCEISGCPKPTQIIAGDRPDNHWLHYDSKTIPRTKKEWESSCFVEKTHWGYYTWPKNMVVYAGVEEQPKLGRSREDMTEAEQIIFDHFSDPKFVEQLITFLSLEDRKGKDKFNPRRFCLFKGIFRNFDDAFLPVLKPHLEHLVADSHESTQRCVAEIIAGLIRGSKHWTFEKVEKLWELLCPLLRTALSNITVETYNDWGACIATSCESRDPRKLHWLFELLLESPLSGEGGSFVDACRLYVLQGGLAQQEWRVPELLHRLLKYLEPKLTQVYKNVRERIGSVLTYIFMIDVSLPNTTPTISPHVPEFTARILEKLKPLMDVDEEIQNHVMEENGIGEEDERTQGIKLLKTILKWLMASAGRSFSTAVTEQLQLLPLFFKIAPVENDNSYDELKRDAKLCLSLMSQGLLYPHQVPLVLQVLKQTARSSSWHARYTVLTYLQTMVFYNLFIFLNNEDAVKDIRWLVISLLEDEQLEVREMAATTLSGLLQCNFLTMDSPMQIHFEQLCKTKLPKKRKRDPGSVGDTIPSAELVKRHAGVLGLGACVLSSPYDVPTWMPQLLMNLSAHLNDPQPIEMTVKKTLSNFRRTHHDNWQEHKQQFTDDQLLVLTDLLVSPCYYA>sp|Q14997-2|PSME4_HUMAN Isoform 2 of Proteasome activator complexsubunit 4 OS=Homo sapiens OX=9606 GN=PSME4MVADMCRAAVKCCPEESLKLFVPHCCSVITQLTMNDDVLNDEELDKELLWNLQLLSEITRVDGRKLLLYREQLVKILQRTLHLTCKQGYTLSCNLLHHLLRSTTLIYPTEYCSVPGGFDKPPSEYFPIKDWGKPGDLWNLGIQWHVPSSEEVSFAFYLLDSFLQPELVKLQHCGDGKLEMSRDDILQSLTIVHNCLIGSGNLLPPLKGEPVTNLVPSMVSLEETKLYTGLEYDLSRENHREVIATVIRKLLNHILDNSEDDTKSLFLIIKIIGDLLQFQGSHKHEFDSRWKSFNLVKKSMENRLHGKKQHIRALLIDRVMLQHELRTLTVEGCEYKKIHQDMIRDLLRLSTSSYSQVRNKAQQTFFAALGAYNFCCRDIIPLVLEFLRPDRQGVTQQQFKGALYCLLGNHSGVCLANLHDWDCIVQTWPAIVSSGLSQAMSLEKPSIVRLFDDLAEKIHRQYETIGLDFTIPKSCVEIAELLQQSKNPSINQILLSPEKIKEGIKRQQEKNADALRNYENLVDTLLDGVEQRNLPWKFEHIGIGLLSLLLRDDRVLPLRAIRFFVENLNHDAIVVRKMAISAVAGILKQLKRTHKKLTINPCEISGCPKPTQIIAGDRPDNHWLHYDSKTIPRTKKEWESSCFVEKTHWGYYTWPKNMVVYAGVEEQPKLGRSREDMTEAEQIIFDHFSDPKFVEQLITFLSLEDRKGKDKFNPRRFCLFKGIFRNFDDAFLPVLKPHLEHLVADSHESTQRCVAEIIAGLIRGSKHWTFEKVEKLWELLCPLLRTALSNITVETYNDWGACIATSCESRDPRKLHWLFELLLESPLSGEGGSFVDACRLYVLQGGLAQQEWRVPELLHRLLKYLEPKLTQVYKNVRERIGSVLTYIFMIDVSLPNTTPTISPHVPEFTARILEKLKPLMDVDEEIQNHVMEENGIGEEDERTQGIKLLKTILKWLMASAGRSFSTAVTEQLQLLPLFFKIAPVENDNSYDELKRDAKLCLSLMSQGLLYPHQVPLVLQVLKQTARSSSWHARYTVLTYLQTMVFYNLFIFLNNEDAVKDIRWLVISLLEDEQLEVREMAATTLSGLLQCNFLTMDSPMQIHFEQLCKTKLPKKRKRDPGSVGDTIPSAELVKRHAGVLGLGACVLSSPYDVPTWMPQLLMNLSAHLNDPQPIEMTVKKTLSNFRRTHHDNWQEHKQQFTDDQLLVLTDLLVSPCYYA>sp|Q14997-3|PSME4_HUMAN Isoform 3 of Proteasome activator complexsubunit 4 OS=Homo sapiens OX=9606 GN=PSME4MGENLAKKIMFFLLIIRKLLNHILDNSEDDTKSLFLIIKIIGDLLQFQGSHKHEFDSRWKSFNLVKKSMENRLHGKKQHIRALLIDRVMLQHELRTLTVEGCEYKKIHQDMIRDLLRLSTSSYSQVRNKAQQTFFAALGAYNFCCRDIIPLVLEFLRPDRQGVTQQQFKGALYCLLGNHSGVCLANLHDWDCIVQTWPAIVSSGLSQAMSLEKPSIVRLFDDLAEKIHRQYETIGLDFTIPKSCVEIAELLQQSKNPSINQILLSPEKIKEGIKRQQEKNADALRNYENLVDTLLDGVEQRNLPWKFEHIGIGLLSLLLRDDRVLPLRAIRFFVENLNHDAIVVRKMAISAVAGILKQLKRTHKKLTINPCEISGCPKPTQIIAGDRPDNHWLHYDSKTIPRTKKEWESSCFVEKTHWGYYTWPKNMVVYAGVEEQPKLGRSREDMTEAEQIIFDHFSDPKFVEQLITFLSLEDRKGKDKFNPRRFCLFKGIFRNFDDAFLPVLKPHLEHLVADSHESTQRCVAEIIAGLIRGSKHWTFEKVEKLWELLCPLLRTALSNITVETYNDWGACIATSCESRDPRKLHWLFELLLESPLSGEGGSFVDACRLYVLQGGLAQQEWRVPELLHRLLKYLEPKLTQVYKNVRERIGSVLTYIFMIDVSLPNTTPTISPHVPEFTARILEKLKPLMDVDEEIQNHVMEENGIGEEDERTQGIKLLKTILKWLMASAGRSFSTAVTEQLQLLPLFFKIAPVENDNSYDELKRDAKLCLSLMSQGLLYPHQVPLVLQVLKQTARSSSWHARYTVLTYLQTMVFYNLFIFLNNEDAVKDIRWLVISLLEDEQLEVREMAATTLSGLLQCNFLTMDSPMQIHFEQLCKTKLPKKRKRDPGSVGDTIPSAELVKRHAGVLGLGACVLSSPYDVPTWMPQLLMNLSAHLNDPQPIEMTVKKTLSNFRRTHHDNWQEHKQQFTDDQLLVLTDLLVSPCYYA>sp|Q14997-4|PSME4_HUMAN Isoform 4 of Proteasome activator complexsubunit 4 OS=Homo sapiens OX=9606 GN=PSME4MSQGLLYPHQVPLVLQVLKQTARSSSWHARYTVLTYLQTMVFYNLFIFLNNEDAVKDIRWLVISLLEDEQLEVREMAATTLSGLLQCNFLTMDSPMQIHFEQLCKTKLPKKRKRDPGSVGDTIPSAELVKRHAGVLGLGACVLSSPYDVPTWMPQLLMNLSAHLNDPQPIEMTVKKTLSNFRRTHHDNWQEHKQQFTDDQLLVLTDLLVSPCYYA>sp|A0A096LP55|QCR6L_HUMAN Cytochrome b-c1 complex subunit 6-like,mitochondrial OS=Homo sapiens OX=9606 GN=UQCRHL PE=3 SV=1MGLEDEQKMLTESGDPEEEEEEEEELVDPLTTVREQCEQLEKCVKARERLELYDEHVSSRSHTEEDCTEELFDFLHAKDHCVAHKLFNNLK>sp|Q56P42|PYDC2_HUMAN Pyrin domain-containing protein 2 OS=Homo sapiensOX=9606 GN=PYDC2 PE=1 SV=1MASSAELDFNLQALLEQLSQDELSKFKSLIRTISLGKELQTVPQTEVDKANGKQLVEIFTSHSCSYWAGMAAIQVFEKMNQTHLSGRADEHCVMPPP>sp|P06737|PYGL_HUMAN Glycogen phosphorylase, liver form OS=Homo sapiensOX=9606 GN=PYGL PE=1 SV=4MAKPLTDQEKRRQISIRGIVGVENVAELKKSFNRHLHFTLVKDRNVATTRDYYFALAHTVRDHLVGRWIRTQQHYYDKCPKRVYYLSLEFYMGRTLQNTMINLGLQNACDEAIYQLGLDIEELEEIEEDAGLGNGGLGRLAACFLDSMATLGLAAYGYGIRYEYGIFNQKIRDGWQVEEADDWLRYGNPWEKSRPEFMLPVHFYGKVEHTNTGTKWIDTQVVLALPYDTPVPGYMNNTVNTMRLWSARAPNDFNLRDFNVGDYIQAVLDRNLAENISRVLYPNDNFFEGKELRLKQEYFVVAATLQDIIRRFKASKFGSTRGAGTVFDAFPDQVAIQLNDTHPALAIPELMRIFVDIEKLPWSKAWELTQKTFAYTNHTVLPEALERWPVDLVEKLLPRHLEIIYEINQKHLDRIVALFPKDVDRLRRMSLIEEEGSKRINMAHLCIVGSHAVNGVAKIHSDIVKTKVFKDFSELEPDKFQNKTNGITPRRWLLLCNPGLAELIAEKIGEDYVKDLSQLTKLHSFLGDDVFLRELAKVKQENKLKFSQFLETEYKVKINPSSMFDVQVKRIHEYKRQLLNCLHVITMYNRIKKDPKKLFVPRTVIIGGKAAPGYHMAKMIIKLITSVADVVNNDPMVGSKLKVIFLENYRVSLAEKVIPATDLSEQISTAGTEASGTGNMKFMLNGALTIGTMDGANVEMAEEAGEENLFIFGMRIDDVAALDKKGYEAKEYYEALPELKLVIDQIDNGFFSPKQPDLFKDIINMLFYHDRFKVFADYEAYVKCQDKVSQLYMNPKAWNTMVLKNIAASGKFSSDRTIKEYAQNIWNVEPSDLKISLSNESNKVNGN>sp|P06737-2|PYGL_HUMAN Isoform 2 of Glycogen phosphorylase, liver formOS=Homo sapiens OX=9606 GN=PYGLMAKPLTDQEKRRQISIRGIVGVENVAELKKSFNRHLHFTLVKDRNVATTRDYYFALAHTVRDHLVGRWIRTQQHYYDKCPKLGLDIEELEEIEEDAGLGNGGLGRLAACFLDSMATLGLAAYGYGIRYEYGIFNQKIRDGWQVEEADDWLRYGNPWEKSRPEFMLPVHFYGKVEHTNTGTKWIDTQVVLALPYDTPVPGYMNNTVNTMRLWSARAPNDFNLRDFNVGDYIQAVLDRNLAENISRVLYPNDNFFEGKELRLKQEYFVVAATLQDIIRRFKASKFGSTRGAGTVFDAFPDQVAIQLNDTHPALAIPELMRIFVDIEKLPWSKAWELTQKTFAYTNHTVLPEALERWPVDLVEKLLPRHLEIIYEINQKHLDRIVALFPKDVDRLRRMSLIEEEGSKRINMAHLCIVGSHAVNGVAKIHSDIVKTKVFKDFSELEPDKFQNKTNGITPRRWLLLCNPGLAELIAEKIGEDYVKDLSQLTKLHSFLGDDVFLRELAKVKQENKLKFSQFLETEYKVKINPSSMFDVQVKRIHEYKRQLLNCLHVITMYNRIKKDPKKLFVPRTVIIGGKAAPGYHMAKMIIKLITSVADVVNNDPMVGSKLKVIFLENYRVSLAEKVIPATDLSEQISTAGTEASGTGNMKFMLNGALTIGTMDGANVEMAEEAGEENLFIFGMRIDDVAALDKKGYEAKEYYEALPELKLVIDQIDNGFFSPKQPDLFKDIINMLFYHDRFKVFADYEAYVKCQDKVSQLYMNPKAWNTMVLKNIAASGKFSSDRTIKEYAQNIWNVEPSDLKISLSNESNKVNGN>sp|W6CW81|PYDC5_HUMAN Pyrin domain-containing protein 5 OS=Homo sapiensOX=9606 GN=PYDC5 PE=1 SV=1MESKYKEILLLTSLDNITDEELDRFKCFLPDEFNIATGKLHTLNSTSSQLDLKRWHGVCSEEDRIFQKLNYMLVAKCLREEQETGICGSPSSARSVSQSRLGLSFHGISGNAC>sp|P11234|RALB_HUMAN Ras-related protein Ral-B OS=Homo sapiens OX=9606GN=RALB PE=1 SV=1MAANKSKGQSSLALHKVIMVGSGGVGKSALTLQFMYDEFVEDYEPTKADSYRKKVVLDGEEVQIDILDTAGQEDYAAIRDNYFRSGEGFLLVFSITEHESFTATAEFREQILRVKAEEDKIPLLVVGNKSDLEERRQVPVEEARSKAEEWGVQYVETSAKTRANVDKVFFDLMREIRTKKMSENKDKNGKKSSKNKKSFKERCCLL>sp|P11234-2|RALB_HUMAN Isoform 2 of Ras-related protein Ral-B OS=Homosapiens OX=9606 GN=RALBMKQRQSALQWVICVSQPQKTSEMAANKSKGQSSLALHKVIMVGSGGVGKSALTLQFMYDEFVEDYEPTKADSYRKKVVLDGEEVQIDILDTAGQEDYAAIRDNYFRSGEGFLLVFSITEHESFTATAEFREQILRVKAEEDKIPLLVVGNKSDLEERRQVPVEEARSKAEEWGVQYVETSAKTRANVDKVFFDLMREIRTKKMSENKDKNGKKSSKNKKSFKERCCLL>sp|P11234-3|RALB_HUMAN Isoform 3 of Ras-related protein Ral-B OS=Homosapiens OX=9606 GN=RALBMAANKSKGQSSLALHKVIMVGSGGVGKSALTLQFMNVSKSLAYDKKKYTANKKVEGILEFVEDYEPTKADSYRKKVVLDGEEVQIDILDTAGQEDYAAIRDNYFRSGEGFLLVFSITEHESFTATAEFREQILRVKAEEDKIPLLVVGNKSDLEERRQVPVEEARSKAEEWGVQYVETSAKTRANVDKVFFDLMREIRTKKMSENKDKNGKKSSKNKKSFKERCCLL>sp|O75901|RASF9_HUMAN Ras association domain-containing protein 9OS=Homo sapiens OX=9606 GN=RASSF9 PE=2 SV=2MAPFGRNLLKTRHKNRSPTKDMDSEEKEIVVWVCQEEKLVCGLTKRTTSADVIQALLEEHEATFGEKRFLLGKPSDYCIIEKWRGSERVLPPLTRILKLWKAWGDEQPNMQFVLVKADAFLPVPLWRTAEAKLVQNTEKLWELSPANYMKTLPPDKQKRIVRKTFRKLAKIKQDTVSHDRDNMETLVHLIISQDHTIHQQVKRMKELDLEIEKCEAKFHLDRVENDGENYVQDAYLMPSFSEVEQNLDLQYEENQTLEDLSESDGIEQLEERLKYYRILIDKLSAEIEKEVKSVCIDINEDAEGEAASELESSNLESVKCDLEKSMKAGLKIHSHLSGIQKEIKYSDSLLQMKAKEYELLAKEFNSLHISNKDGCQLKENRAKESEVPSSNGEIPPFTQRVFSNYTNDTDSDTGISSNHSQDSETTVGDVVLLST>sp|Q9H1K0|RBNS5_HUMAN Rabenosyn-5 OS=Homo sapiens OX=9606 GN=RBSN PE=1SV=2MASLDDPGEVREGFLCPLCLKDLQSFYQLHSHYEEEHSGEDRDVKGQIKSLVQKAKKAKDRLLKREGDDRAESGTQGYESFSYGGVDPYMWEPQELGAVRSHLSDFKKHRAARIDHYVVEVNKLIIRLEKLTAFDRTNTESAKIRAIEKSVVPWVNDQDVPFCPDCGNKFSIRNRRHHCRLCGSIMCKKCMELISLPLANKLTSASKESLSTHTSPSQSPNSVHGSRRGSISSMSSVSSVLDEKDDDRIRCCTHCKDTLLKREQQIDEKEHTPDIVKLYEKLRLCMEKVDQKAPEYIRMAASLNAGETTYSLEHASDLRVEVQKVYELIDALSKKILTLGLNQDPPPHPSNLRLQRMIRYSATLFVQEKLLGLMSLPTKEQFEELKKKRKEEMERKRAVERQAALESQRRLEERQSGLASRAANGEVASLRRGPAPLRKAEGWLPLSGGQGQSEDSDPLLQQIHNITSFIRQAKAAGRMDEVRTLQENLRQLQDEYDQQQTEKAIELSRRQAEEEDLQREQLQMLRERELEREREQFRVASLHTRTRSLDFREIGPFQLEPSREPRTHLAYALDLGSSPVPSSTAPKTPSLSSTQPTRVWSGPPAVGQERLPQSSMPQQHEGPSLNPFDEEDLSSPMEEATTGPPAAGVSLDPSARILKEYNPFEEEDEEEEAVAGNPFIQPDSPAPNPFSEEDEHPQQRLSSPLVPGNPFEEPTCINPFEMDSDSGPEAEEPIEEELLLQQIDNIKAYIFDAKQCGRLDEVEVLTENLRELKHTLAKQKGGTD>sp|Q9H1K0-2|RBNS5_HUMAN Isoform 2 of Rabenosyn-5 OS=Homo sapiens OX=9606GN=RBSNMASLDDPGEVREGFLCPLCLKDLQSFYQLHSHYEEEHSGEDRDVKGQIKSLVQKAKKAKDRLLKREGDDRAESGTQGYESFSYGGVDPYMWEPQELGAVRSHLSDFKKHRAARIDHYVVEVNKLIIRLEKLTAFDRTNTESAKIRAIEKSVVPWVNDQDVPFCPDCGNKFSIRNRRHHCRLCGSIMCKKCMELISLPLAKITTLHGES>sp|Q15283|RASA2_HUMAN Ras GTPase-activating protein 2 OS=Homo sapiensOX=9606 GN=RASA2 PE=1 SV=3MAAAAPAAAAASSEAPAASATAEPEAGDQDSREVRVLQSLRGKICEAKNLLPYLGPHKMRDCFCTINLDQEEVYRTQVVEKSLSPFFSEEFYFEIPRTFQYLSFYVYDKNVLQRDLRIGKVAIKKEDLCNHSGKETWFSLQPVDSNSEVQGKVHLELKLNELITENGTVCQQLVVHIKACHGLPLINGQSCDPYATVSLVGPSRNDQKKTKVKKKTSNPQFNEIFYFEVTRSSSYTRKSQFQVEEEDIEKLEIRIDLWNNGNLVQDVFLGEIKVPVNVLRTDSSHQAWYLLQPRDNGNKSSKTDDLGSLRLNICYTEDYVLPSEYYGPLKTLLLKSPDVQPISASAAYILSEICRDKNDAVLPLVRLLLHHDKLVPFATAVAELDLKDTQDANTIFRGNSLATRCLDEMMKIVGGHYLKVTLKPILDEICDSSKSCEIDPIKLKEGDNVENNKENLRYYVDKLFNTIVKSSMSCPTVMCDIFYSLRQMATQRFPNDPHVQYSAVSSFVFLRFFAVAVVSPHTFHLRPHHPDAQTIRTLTLISKTIQTLGSWGSLSKSKSSFKETFMCEFFKMFQEEGYIIAVKKFLDEISSTETKESSGTSEPVHLKEGEMYKRAQGRTRIGKKNFKKRWFCLTSRELTYHKQPGSKDAIYTIPVKNILAVEKLEESSFNKKNMFQVIHTEKPLYVQANNCVEANEWIDVLCRVSRCNQNRLSFYHPSVYLNGNWLCCQETGENTLGCKPCTAGVPADIQIDIDEDRETERIYSLFTLSLLKLQKMEEACGTIAVYQGPQKEPDDYSNFVIEDSVTTFKTIQQIKSIIEKLDEPHEKYRKKRSSSAKYGSKENPIVGKAS>sp|Q15283-2|RASA2_HUMAN Isoform 2 of Ras GTPase-activating protein 2OS=Homo sapiens OX=9606 GN=RASA2MAAAAPAAAAASSEAPAASATAEPEAGDQDSREVRVLQSLRGKICEAKNLLPYLGPHKMRDCFCTINLDQEEVYRTQVVEKSLSPFFSEEFYFEIPRTFQYLSFYVYDKNVLQRDLRIGKVAIKKEDLCNHSGKETWFSLQPVDSNSEVQGKVHLELKLNELITENGTVCQQLVVHIKACHGLPLINGQSCDPYATVSLVGPSRNDQKKTKVKKKTSNPQFNEIFYFEVTRSSSYTRKSQFQVEEEDIEKLEIRIDLWNNGNLVQDVFLGEIKVPVNVLRTDSSHQAWYLLQPRDNGNKSSKTDDLGSLRLNICYTEDYVLPSEYYGPLKTLLLKSPDVQPISASAAYILSEICRDKNDAVLPLVRLLLHHDKLVPFATAVAELDLKDTQDANTIFRGNSLATRCLDEMMKIVGGHYLKVTLKPILDEICDSSKSCEIDPIKLKEGDNVENNKENLRYYVDKLFNTIVKSSMSCPTVMCDIFYSLRQMATQRFPNDPHVQYSAVSSFVFLRFFAVAVVSPHTFHLRPHHPDAQTIRTLTLISKTIQTLGSWGSLSKSKSSFKETFMCEFFKMFQEEGYIIAVKKFLDEISSTETKESSGTSEPVHLKEGEMYKRAQGRTRIGKKNFKKRWFCLTSRELTYHKQPGKDAIYTIPVKNILAVEKLEESSFNKKNMFQVIHTEKPLYVQANNCVEANEWIDVLCRVSRCNQNRLSFYHPSVYLNGNWLCCQETGENTLGCKPCTAGVPADIQIDIDEDRETERIYSLFTLSLLKLQKMEEACGTIAVYQGPQKEPDDYSNFVIEDSVTTFKTIQQIKSIIEKLDEPHEKYRKKRSSSAKYGSKENPIVGKAS>sp|Q9NW13|RBM28_HUMAN RNA-binding protein 28 OS=Homo sapiens OX=9606GN=RBM28 PE=1 SV=3MAGLTLFVGRLPPSARSEQLEELFSQVGPVKQCFVVTEKGSKACRGFGYVTFSMLEDVQRALKEITTFEGCKINVTVAKKKLRNKTKEKGKNENSECPKKEPKAKKAKVADKKARLIIRNLSFKCSEDDLKTVFAQFGAVLEVNIPRKPDGKMRGFGFVQFKNLLEAGKALKGMNMKEIKGRTVAVDWAVAKDKYKDTQSVSAIGEEKSHESKHQESVKKKGREEEDMEEEENDDDDDDDDEEDGVFDDEDEEEENIESKVTKPVQIQKRAVKRPAPAKSSDHSEEDSDLEESDSIDDGEELAQSDTSTEEQEDKAVQVSNKKKRKLPSDVNEGKTVFIRNLSFDSEEEELGELLQQFGELKYVRIVLHPDTEHSKGCAFAQFMTQEAAQKCLLAASPENEAGGLKLDGRQLKVDLAVTRDEAAKLQTTKVKKPTGTRNLYLAREGLIRAGTKAAEGVSAADMAKRERFELLKHQKLKDQNIFVSRTRLCLHNLPKAVDDKQLRKLLLSATSGEKGVRIKECRVMRDLKGVHGNMKGQSLGYAFAEFQEHEHALKALRLINNNPEIFGPLKRPIVEFSLEDRRKLKMKELRIQRSLQKMRSKPATGEPQKGQPEPAKDQQQKAAQHHTEEQSKVPPEQKRKAGSTSWTGFQTKAEVEQVELPDGKKRRKVLALPSHRGPKIRLRDKGKVKPVHPKKPKPQINQWKQEKQQLSSEQVSRKKAKGNKTETRFNQLVEQYKQKLLGPSKGAPLAKRSKWFDS>sp|Q9NW13-2|RBM28_HUMAN Isoform 2 of RNA-binding protein 28 OS=Homosapiens OX=9606 GN=RBM28MAGLTLFVGRLPPSARSEQLEELFSQVGPVKQCFVVTEKGRTVAVDWAVAKDKYKDTQSVSAIGEEKSHESKHQESVKKKGREEEDMEEEENDDDDDDDDEEDGVFDDEDEEEENIESKVTKPVQIQKRAVKRPAPAKSSDHSEEDSDLEESDSIDDGEELAQSDTSTEEQEDKAVQVSNKKKRKLPSDVNEGKTVFIRNLSFDSEEEELGELLQQFGELKYVRIVLHPDTEHSKGCAFAQFMTQEAAQKCLLAASPENEAGGLKLDGRQLKVDLAVTRDEAAKLQTTKVKKPTGTRNLYLAREGLIRAGTKAAEGVSAADMAKRERFELLKHQKLKDQNIFVSRTRLCLHNLPKAVDDKQLRKLLLSATSGEKGVRIKECRVMRDLKGVHGNMKGQSLGYAFAEFQEHEHALKALRLINNNPEIFGPLKRPIVEFSLEDRRKLKMKELRIQRSLQKMRSKPATGEPQKGQPEPAKDQQQKAAQHHTEEQSKVPPEQKRKAGSTSWTGFQTKAEVEQVELPDGKKRRKVLALPSHRGPKIRLRDKGKVKPVHPKKPKPQINQWKQEKQQLSSEQVSRKKAKGNKTETRFNQLVEQYKQKLLGPSKGAPLAKRSKWFDS>sp|A6NK89|RASFA_HUMAN Ras association domain-containing protein 10OS=Homo sapiens OX=9606 GN=RASSF10 PE=1 SV=3MDPSEKKISVWICQEEKLVSGLSRRTTCSDVVRVLLEDGCRRRRRQRRSRRLGSAGDPHGPGELPEPPNEDDEDDDEALPQGMLCGPPQCYCIVEKWRGFERILPNKTRILRLWAAWGEEQENVRFVLVRSEASLPNAGPRSAEARVVLSRERPCPARGAPARPSLAMTQEKQRRVVRKAFRKLAKLNRRRQQQTPSSCSSTSSSTASSCSSSPRTHESASVERMETLVHLVLSQDHTIRQQVQRLHELDREIDHYEAKVHLDRMRRHGVNYVQDTYLVGAGIELDGSRPGEEPEEVAAEAEEAAAAPPLAGEAQAAALEELARRCDDLLRLQEQRVQQEELLERLSAEIQEELNQRWMRRRQEELAAREEPLEPDGGPDGELLLEQERVRTQLSTSLYIGLRLNTDLEAVKSDLDYSQQQWDSKKRELQGLLQTLHTLELTVAPDGAPGSGSPSREPGPQACADMWVDQARGLAKSGPGNDEDSDTGLSSMHSQDSDSLPMCESLV>sp|P0DJH9|RD3L_HUMAN Protein RD3-like OS=Homo sapiens OX=9606 GN=RD3LPE=4 SV=1MPLFGWMKWPKNDSYKPTHYPGSDIVTKTLLRELKWHLKERERLIQEIENEQKVKKTGVDYNWLRNYQNPHTTIPVTEQRQLEVLCSQVQPCQTGTILSRFREVLAENDVLPWEIVYIFKQVLKDFLSSSDRGSEQEDLEDSGSMDCSAPSVIQGDSSKRADKDEIPTISSYVDKNTKDRFPVFSHRIWNLPYYHPSS>sp|P62491|RB11A_HUMAN Ras-related protein Rab-11A OS=Homo sapiensOX=9606 GN=RAB11A PE=1 SV=3MGTRDDEYDYLFKVVLIGDSGVGKSNLLSRFTRNEFNLESKSTIGVEFATRSIQVDGKTIKAQIWDTAGQERYRAITSAYYRGAVGALLVYDIAKHLTYENVERWLKELRDHADSNIVIMLVGNKSDLRHLRAVPTDEARAFAEKNGLSFIETSALDSTNVEAAFQTILTEIYRIVSQKQMSDRRENDMSPSNNVVPIHVPPTTENKPKVQCCQNI>sp|P62491-2|RB11A_HUMAN Isoform 2 of Ras-related protein Rab-11A OS=Homosapiens OX=9606 GN=RAB11AMGTRDDEYDYLFKVVLIGDSGVGKSNLLSRFTRNEFNLESKSTIGVEFATRSIQVDGKTIKAQIWDTAGQERYRAITSAYYRGAVGALLVYDIAKHLTYENVERWLKELRDHADSNIVIMLVGNKSDLRHLRAVPTDEARAFAEKNEANVRQTRK>sp|Q7Z3Z2|RD3_HUMAN Protein RD3 OS=Homo sapiens OX=9606 GN=RD3 PE=1 SV=1MSLISWLRWNEAPSRLSTRSPAEMVLETLMMELTGQMREAERQQRERSNAVRKVCTGVDYSWLASTPRSTYDLSPIERLQLEDVCVKIHPSYCGPAILRFRQLLAEQEPEVQEVSQLFRSVLQEVLERMKQEEEAHKLTRQWSLRPRGSLATFKTRARISPFASDIRTISEDVERDTPPPLRSWSMPEFRAPKAD>sp|Q09028|RBBP4_HUMAN Histone-binding protein RBBP4 OS=Homo sapiensOX=9606 GN=RBBP4 PE=1 SV=3MADKEAAFDDAVEERVINEEYKIWKKNTPFLYDLVMTHALEWPSLTAQWLPDVTRPEGKDFSIHRLVLGTHTSDEQNHLVIASVQLPNDDAQFDASHYDSEKGEFGGFGSVSGKIEIEIKINHEGEVNRARYMPQNPCIIATKTPSSDVLVFDYTKHPSKPDPSGECNPDLRLRGHQKEGYGLSWNPNLSGHLLSASDDHTICLWDISAVPKEGKVVDAKTIFTGHTAVVEDVSWHLLHESLFGSVADDQKLMIWDTRSNNTSKPSHSVDAHTAEVNCLSFNPYSEFILATGSADKTVALWDLRNLKLKLHSFESHKDEIFQVQWSPHNETILASSGTDRRLNVWDLSKIGEEQSPEDAEDGPPELLFIHGGHTAKISDFSWNPNEPWVICSVSEDNIMQVWQMAENIYNDEDPEGSVDPEGQGS>sp|Q09028-2|RBBP4_HUMAN Isoform 2 of Histone-binding protein RBBP4OS=Homo sapiens OX=9606 GN=RBBP4MADKEAFDDAVEERVINEEYKIWKKNTPFLYDLVMTHALEWPSLTAQWLPDVTRPEGKDFSIHRLVLGTHTSDEQNHLVIASVQLPNDDAQFDASHYDSEKGEFGGFGSVSGKIEIEIKINHEGEVNRARYMPQNPCIIATKTPSSDVLVFDYTKHPSKPDPSGECNPDLRLRGHQKEGYGLSWNPNLSGHLLSASDDHTICLWDISAVPKEGKVVDAKTIFTGHTAVVEDVSWHLLHESLFGSVADDQKLMIWDTRSNNTSKPSHSVDAHTAEVNCLSFNPYSEFILATGSADKTVALWDLRNLKLKLHSFESHKDEIFQVQWSPHNETILASSGTDRRLNVWDLSKIGEEQSPEDAEDGPPELLFIHGGHTAKISDFSWNPNEPWVICSVSEDNIMQVWQMAENIYNDEDPEGSVDPEGQGS>sp|Q09028-3|RBBP4_HUMAN Isoform 3 of Histone-binding protein RBBP4OS=Homo sapiens OX=9606 GN=RBBP4MADKEAAFDDAVEERVINEEYKIWKKNTPFLYDLVMTHALEWPSLTAQWLPDVTRPEGKDFSIHRLVLGTHTSDEQNHLVIASVQLPNDDAQFDASHYDSEKGEFGGFGSVSGKIEIEIKINHEGEVNRARYMPQNPCIIATKTPSSDVLVFDYTKHPSKPDPSGECNPDLRLRGHQKEGYGLSWNPNLSGHLLSASDDHTICLWDISAVPKEGKVVDAKTIFTGHTAVVEDVSWHLLHESLFGSVADDQKLMIWDTRSNNTSKPSHSVDAHTAEVNCLSFNPYSEFILATGSADKTVALWDLRNLKLKLHSFESHKDEIFQVQWSPHNETILASSGTDRRLNVWDLSKIGEEQSPEDAEDGPPELLFIHGGHTAKISDFSWNPNEPWVICSVSEDNIMQVWQMELVLDH>sp|Q09028-4|RBBP4_HUMAN Isoform 4 of Histone-binding protein RBBP4OS=Homo sapiens OX=9606 GN=RBBP4MTHALEWPSLTAQWLPDVTRPEGKDFSIHRLVLGTHTSDEQNHLVIASVQLPNDDAQFDASHYDSEKGEFGGFGSVSGKIEIEIKINHEGEVNRARYMPQNPCIIATKTPSSDVLVFDYTKHPSKPDPSGECNPDLRLRGHQKEGYGLSWNPNLSGHLLSASDDHTICLWDISAVPKEGKVVDAKTIFTGHTAVVEDVSWHLLHESLFGSVADDQKLMIWDTRSNNTSKPSHSVDAHTAEVNCLSFNPYSEFILATGSADKTVALWDLRNLKLKLHSFESHKDEIFQVQWSPHNETILASSGTDRRLNVWDLSKIGEEQSPEDAEDGPPELLFIHGGHTAKISDFSWNPNEPWVICSVSEDNIMQVWQMAENIYNDEDPEGSVDPEGQGS>sp|Q3YEC7|RABL6_HUMAN Rab-like protein 6 OS=Homo sapiens OX=9606GN=RABL6 PE=1 SV=2MFSALKKLVGSDQAPGRDKNIPAGLQSMNQALQRRFAKGVQYNMKIVIRGDRNTGKTALWHRLQGRPFVEEYIPTQEIQVTSIHWSYKTTDDIVKVEVWDVVDKGKCKKRGDGLKMENDPQEAESEMALDAEFLDVYKNCNGVVMMFDITKQWTFNYILRELPKVPTHVPVCVLGNYRDMGEHRVILPDDVRDFIDNLDRPPGSSYFRYAESSMKNSFGLKYLHKFFNIPFLQLQRETLLRQLETNQLDMDATLEELSVQQETEDQNYGIFLEMMEARSRGHASPLAANGQSPSPGSQSPVVPAGAVSTGSSSPGTPQPAPQLPLNAAPPSSVPPVPPSEALPPPACPSAPAPRRSIISRLFGTSPATEAAPPPPEPVPAAEGPATVQSVEDFVPDDRLDRSFLEDTTPARDEKKVGAKAAQQDSDSDGEALGGNPMVAGFQDDVDLEDQPRGSPPLPAGPVPSQDITLSSEEEAEVAAPTKGPAPAPQQCSEPETKWSSIPASKPRRGTAPTRTAAPPWPGGVSVRTGPEKRSSTRPPAEMEPGKGEQASSSESDPEGPIAAQMLSFVMDDPDFESEGSDTQRRADDFPVRDDPSDVTDEDEGPAEPPPPPKLPLPAFRLKNDSDLFGLGLEEAGPKESSEEGKEGKTPSKEKKKKKKKGKEEEEKAAKKKSKHKKSKDKEEGKEERRRRQQRPPRSRERTAADELEAFLGGGAPGGRHPGGGDYEEL>sp|Q3YEC7-2|RABL6_HUMAN Isoform 2 of Rab-like protein 6 OS=Homo sapiensOX=9606 GN=RABL6MFSALKKLVGSDQAPGRDKNIPAGLQSMNQALQRRFAKGVQYNMKIVIRGDRNTGKTALWHRLQGRPFVEEYIPTQEIQVTSIHWSYKTTDDIVKVEVWDVVDKGKCKKRGDGLKMENDPQEAESEMALDAEFLDVYKNCNGVVMMFDITKQWTFNYILRELPKVPTHVPVCVLGNYRDMGEHRVILPDDVRDFIDNLDSRPPGSSYFRYAESSMKNSFGLKYLHKFFNIPFLQLQRETLLRQLETNQLDMDATLEELSVQQETEDQNYGIFLEMMEARSRGHASPLAANGQSPSPGSQSPVVPAGAVSTGSSSPGTPQPAPQLPLNAAPPSSVPPVPPSEALPPPACPSAPAPRRSIISRLFGTSPATEAAPPPPEPVPAAEGPATVQSVEDFVPDDRLDRSFLEDTTPARDEKKVGAKAAQQDSDSDGEALGGNPMVAGFQDDVDLEDQPRGSPPLPAGPVPSQDITLSSEEEAEVAAPTKGPAPAPQQCSEPETKWSSIPASKPRRGTAPTRTAAPPWPGGVSVRTGPEKRSSTRPPAEMEPGKGEQASSSESDPEGPIAAQMLSFVMDDPDFESEGSDTQRRADDFPVRDDPSDVTDEDEGPAEPPPPPKLPLPAFRLKNDSDLFGLGLEEAGPKESSEEGKEGKTPSKEKKKKKKKGKEEEEKAAKKKSKHKKSKDKEEGKEERRRRQQRPPRSRERTAADELEAFLGGGAPGGRHPGGGDYEEL>sp|Q3YEC7-3|RABL6_HUMAN Isoform 3 of Rab-like protein 6 OS=Homo sapiensOX=9606 GN=RABL6MFSALKKLVGSDQAPGRDKNIPAGLQSMNQALQRRFAKGVQYNMKIVIRGDRNTGKTALWHRLQGRPFVEEYIPTQEIQVTSIHWSYKTTDDIVKVEVWDVVDKGKCKKRGDGLKMENDPQEAESEMALDAEFLDVYKNCNGVVMMFDITKQWTFNYILRELPKVPTHVPVCVLGNYRDMGEHRVILPDDVRDFIDNLDRPPGSSYFRYAESSMKNSFGLKYLHKFFNIPFLQLQRETLLRQLETNQLDMDATLEELSVQQETEDQNYGIFLEMMEARSRGHASPLAANGQSPSPGSQSPVVPAGAVSTGSSSPGTPQPAPQLPLNAAPPSSVPPVPPSEALPPPACPSAPAPRRSIISRPPPWGWRLRGALGRRGQWPPWGGGRACHCLGRHLPLYHRLCRCPVAAVCASELEEAGHWWSPGWALQVLGLQAQCEPALQEGRGQLASARLGGHPGPLGAEPPVFLRDVTEAQEGPVRVCLQRLGRGRLAVGCALPRHLLALRAHLGPQHAYGSASGREP>sp|Q3YEC7-4|RABL6_HUMAN Isoform 4 of Rab-like protein 6 OS=Homo sapiensOX=9606 GN=RABL6MFSALKKLVGSDQAPGRDKNIPAGLQSMNQALQRRFAKGVQYNMKIVIRGDRNTGKTALWHRLQGRPFVEEYIPTQEIQVTSIHWSYKTTDDIVKVEVWDVVDKGKCKKRGDGLKMENDPQEAESEMALDAEFLDVYKNCNGVVMMFDITKQWTFNYILRELPKVPTHVPVCVLGNYRDMGEHRVILPDDVRDFIDNLDRPPGSSYFRYAESSMKNSFGLKYLHKFFNIPFLQLQVSTHHVGWSGCWSLTSFQVSPV>sp|Q3YEC7-5|RABL6_HUMAN Isoform 5 of Rab-like protein 6 OS=Homo sapiensOX=9606 GN=RABL6MFSALKKLVGSDQAPGRDKNIPAGLQSMNQALQRRFAKGVQYNMKIVIRGDRNTGKTALWHRLQGRPFVEEYIPTQEIQVTSIHWSYKTTDDIVKVEVWDVVDKGKCKKRGDGLKMENDPQEAESEMALDAEFLDVYKNCNGVVMMFDITKQWTFNYILRELPKVPTHVPVCVLGNYRDMGEHRVILPDDVRDFIDNLDSRPPGSSYFRYAESSMKNSFGLKYLHKFFNIPFLQLQVSTHHVGWSGCWSLTSFQVSPV>sp|Q3YEC7-6|RABL6_HUMAN Isoform 6 of Rab-like protein 6 OS=Homo sapiensOX=9606 GN=RABL6MFSALKKLVGSDQAPGRDKNIPAGLQSMNQALQRRFAKGVQYNMKIVIRGDRNTGKTALWHRLQGRPFVEEYIPTQEIQVTSIHWSYKTTDDIVKVEVWDVVDKGKCKKRGDGLKMENDPQEAESEMALDAEFLDVYKNCNGVVMMFDITKQWTFNYILRELPKVPTHVPVCVLGNYRDMGEHRVILPDDVRDFIDNLDRPPGSSYFRYAESSMKNSFGLKYLHKFFNIPFLQLQKDVRLAQERGCAVVLVSEEVRMPAGWDCCWGRLGWKEGGSQTCPVPALLGRPLLPAEPSPHHWVDYSLESSPLLSCSIP>sp|Q9HBD1|RC3H2_HUMAN Roquin-2 OS=Homo sapiens OX=9606 GN=RC3H2 PE=1SV=2MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLGENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANLWAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKVTKRDEDSSLMQLKEEFRSYEALRREHDAQIVHIAMEAGLRISPEQWSSLLYGDLAHKSHMQSIIDKLQSPESFAKSVQELTIVLQRTGDPANLNRLRPHLELLANIDPNPDAVSPTWEQLENAMVAVKTVVHGLVDFIQNYSRKGHETPQPQPNSKYKTSMCRDLRQQGGCPRGTNCTFAHSQEELEKYRLRNKKINATVRTFPLLNKVGVNNTVTTTAGNVISVIGSTETTGKIVPSTNGISNAENSVSQLISRSTDSTLRALETVKKVGKVGANGQNAAGPSADSVTENKIGSPPKTPVSNVAATSAGPSNVGTELNSVPQKSSPFLTRVPVYPPHSENIQYFQDPRTQIPFEVPQYPQTGYYPPPPTVPAGVAPCVPRFVRSNNVPESSLPPASMPYADHYSTFSPRDRMNSSPYQPPPPQPYGPVPPVPSGMYAPVYDSRRIWRPPMYQRDDIIRSNSLPPMDVMHSSVYQTSLRERYNSLDGYYSVACQPPSEPRTTVPLPREPCGHLKTSCEEQIRRKPDQWAQYHTQKAPLVSSTLPVATQSPTPPSPLFSVDFRADFSESVSGTKFEEDHLSHYSPWSCGTIGSCINAIDSEPKDVIANSNAVLMDLDSGDVKRRVHLFETQRRTKEEDPIIPFSDGPIISKWGAISRSSRTGYHTTDPVQATASQGSATKPISVSDYVPYVNAVDSRWSSYGNEATSSAHYVERDRFIVTDLSGHRKHSSTGDLLSLELQQAKSNSLLLQREANALAMQQKWNSLDEGRHLTLNLLSKEIELRNGELQSDYTEDATDTKPDRDIELELSALDTDEPDGQSEPIEEILDIQLGISSQNDQLLNGMAVENGHPVQQHQKEPPKQKKQSLGEDHVILEEQKTILPVTSCFSQPLPVSISNASCLPITTSVSAGNLILKTHVMSEDKNDFLKPVANGKMVNS>sp|Q9HBD1-2|RC3H2_HUMAN Isoform 2 of Roquin-2 OS=Homo sapiens OX=9606GN=RC3H2MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLGENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANLWAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKVTKRDEDSSLMQLKEEFRSYEALRREHDAQIVHIAMEAGLRISPEQWSSLLYGDLAHKSHMQSIIDKLQSPESFAKSVQELTIVLQRTGDPANLNRLRPHLELLANIDPNPDAVSPTWEQLENAMVAVKTVVHGLVDFIQNYSRKGHETPQPQPNSKYKTSMCRDLRQQGGCPRGTNCTFAHSQEELEKYRLRNKKINATEVLKQQGKLFQVQTEFQMQKTVFPS>sp|Q9HBD1-3|RC3H2_HUMAN Isoform 3 of Roquin-2 OS=Homo sapiens OX=9606GN=RC3H2MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLGENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANLWAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKVTKRDEDSSLMQLKEEFRSYEALRREHDAQIVHIAMEAGLRISPEQWSSLLYGDLAHKSHMQSIIDKLQSPESFAKSVQELTIVLQRTGDPANLNRLRPHLELLANIDPNPDAVSPTWEQLENAMVAVKTVVHGLVDFIQNYSRKGHETPQPQPNSKYKTSMCRDLRQQGGCPRGTNCTFAHSQEELEKCNPRGLYLHCCLLSSVASLGTVHNELYKQQHCDREKISVCAVKRAETCFSSQFFSPLEEPREED>sp|Q9HBD1-4|RC3H2_HUMAN Isoform 4 of Roquin-2 OS=Homo sapiens OX=9606GN=RC3H2MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLGENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANLWAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKVTKRDEDSSLMQLKEEFRSYEALRREHDAQIVHIAMEAGLRISPEQWSSLLYGDLAHKSHMQSIIDKLQSPESFAKSVQELTIVLQRTGDPANLNRLRPHLELLANIDPNPDAVSPTWEQLENAMVAVKTVVHGLVDFIQNYSRKGHETPQPQPNSKYKTSMCRDLRQQGGCPRGTNCTFAHSQEELEKYRLRNKKINATVRTFPLLNKVGVNNTVTTTAGNVISVIGSTETTGKIVPSTNGISNAENSVSQLISRSTDSTLRALETVKKVGKVGANGQNAAGPSADSVTENKIGSPPKTPVSNVAATSAGPSNVGTELNSVPQKSSPFLTRVPVYPPHSENIQYFQDPRTQIPFEVPQYPQTGYYPPPPTVPAGVAPCVPRFVRSNNVPESSLPPASMPYADHYSTFSPRDRMNSSPYQPPPPQPYGPVPPVPSGMYAPVYDSRRIWRPPMYQRDDIIRSNSLPPMDVMHSSVYQTSLRERYNSLDGYYSVACQPPSEPRTTVPLPREPCGHLKTSCEEQIRRKPDQWAQYHTQKAPLVSSTLPVATQSPTPPSPLFSVDFRADFSESVSGTKFEEDHLSHYSPWSCGTIGSCINAIDSEPKDVIANSNAVLMDLDSGDVKRRVHLFETQRRTKEEDPIIPFSDGPIISKWGAISRSSRTGYHTTDPVQATASQGSATKPISVSDYVPYVNAVDSRWSSYGNEATSSAHYVERDRFIVTDLSGHRKHSSTGDLLSLELQQAKSNSLLLQREANALAMQQKWNSLDEGRHLTLNLLSKEIELRNGEVKKLNLSASCLMYLFSAAASWLYHY>sp|Q9HBD1-5|RC3H2_HUMAN Isoform 5 of Roquin-2 OS=Homo sapiens OX=9606GN=RC3H2MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLGENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANLWAAVRARGCQFLGPGKIGYYLTFFISYWGLRMPISGAR>sp|Q9HBD1-6|RC3H2_HUMAN Isoform 6 of Roquin-2 OS=Homo sapiens OX=9606GN=RC3H2MQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKVTKRDEDSSLMQLKEEFRSYEALRREHDAQIVHIAMEAGLRISPEQWSSLLYGDLAHKSHMQSIIDKLQSPESFAKSVQELTIVLQRTGDPANLNRLRPHLELLANIDPNPDAVSPTWEQLENAMVAVKTVVHGLVDFIQNYSRKGHETPQPQPNSKYKTSMCRDLRQQGGCPRGTNCTFAHSQEELEKYRLRNKKINATVRTFPLLNKVGVNNTVTTTAGNVISVIGSTETTGKIVPSTNGISNAENSVSQLISRSTDSTLRALETVKKVGKVGANGQNAAGPSADSVTENKIGSPPKTPVSNVAATSAGPSNVGTELNSVPQKSSPFLTRVPVYPPHSENIQYFQDPRTQIPFEVPQYPQTGYYPPPPTVPAGVAPCVPRFVRSNNVPESSLPPASMPYADHYSTFSPRDRMNSSPYQPPPPQPYGPVPPVPSGMYAPVYDSRRIWRPPMYQRDDIIRSNSLPPMDVMHSSVYQTSLRERYNSLDGYYSVACQPPSEPRTTVPLPREPCGHLKTSCEEQIRRKPDQWAQYHTQKAPLVSSTLPVATQSPTPPSPLFSVDFRADFSESVSGTKFEEDHLSHYSPWSCGTIGSCINAIDSEPKDVIANSNAVLMDLDSGDVKRRVHLFETQRRTKEEDPIIPFSDGPIISKWGAISRSSRTGYHTTDPVQATASQGSATKPISVSDYVPYVNAVDSRWSSYGNEATSSAHYVERDRFIVTDLSGHRKHSSTGDLLSLELQQAKSNSLLLQREANALAMQQKWNSLDEGRHLTLNLLSKEIELRNGEVKKLNLSASCLMYLFSAAASWLYHY>sp|Q9H0U4|RAB1B_HUMAN Ras-related protein Rab-1B OS=Homo sapiens OX=9606GN=RAB1B PE=1 SV=1MNPEYDYLFKLLLIGDSGVGKSCLLLRFADDTYTESYISTIGVDFKIRTIELDGKTIKLQIWDTAGQERFRTITSSYYRGAHGIIVVYDVTDQESYANVKQWLQEIDRYASENVNKLLVGNKSDLTTKKVVDNTTAKEFADSLGIPFLETSAKNATNVEQAFMTMAAEIKKRMGPGAASGGERPNLKIDSTPVKPAGGGCC>sp|P61018|RAB4B_HUMAN Ras-related protein Rab-4B OS=Homo sapiens OX=9606GN=RAB4B PE=1 SV=1MAETYDFLFKFLVIGSAGTGKSCLLHQFIENKFKQDSNHTIGVEFGSRVVNVGGKTVKLQIWDTAGQERFRSVTRSYYRGAAGALLVYDITSRETYNSLAAWLTDARTLASPNIVVILCGNKKDLDPEREVTFLEASRFAQENELMFLETSALTGENVEEAFLKCARTILNKIDSGELDPERMGSGIQYGDASLRQLRQPRSAQAVAPQPCGC>sp|P61018-2|RAB4B_HUMAN Isoform 2 of Ras-related protein Rab-4B OS=Homosapiens OX=9606 GN=RAB4BMSVSLPLTVMVRERDWIGIHLFSLYLSLPVGIPDFGSIWSDFLFKFLVIGSAGTGKSCLLHQFIENKFKQDSNHTIGVEFGSRVVNVGGKTVKLQIWDTAGQERFRSVTRSYYRGAAGALLVYDITSRETYNSLAAWLTDARTLASPNIVVILCGNKKDLDPEREVTFLEASRFAQENELMFLETSALTGENVEEAFLKCARTILNKIDSGELDPERMGSGIQYGDASLRQLRQPRSAQAVAPQPCGC>sp|Q6NTF9|RHBD2_HUMAN Rhomboid domain-containing protein 2 OS=Homosapiens OX=9606 GN=RHBDD2 PE=1 SV=2MAASGPGCRSWCLCPEVPSATFFTALLSLLVSGPRLFLLQQPLAPSGLTLKSEALRNWQVYRLVTYIFVYENPISLLCGAIIIWRFAGNFERTVGTVRHCFFTVIFAIFSAIIFLSFEAVSSLSKLGEVEDARGFTPVAFAMLGVTTVRSRMRRALVFGMVVPSVLVPWLLLGASWLIPQTSFLSNVCGLSIGLAYGLTYCYSIDLSERVALKLDQTFPFSLMRRISVFKYVSGSSAERRAAQSRKLNPVPGSYPTQSCHPHLSPSHPVSQTQHASGQKLASWPSCTPGHMPTLPPYQPASGLCYVQNHFGPNPTSSSVYPASAGTSLGIQPPTPVNSPGTVYSGALGTPGAAGSKESSRVPMP>sp|Q6NTF9-2|RHBD2_HUMAN Isoform 2 of Rhomboid domain-containing protein2 OS=Homo sapiens OX=9606 GN=RHBDD2MGRGLWEAWPPAGSSAVAKGNCREEAEGAEDRQPASRRGAGTTAAMAASGPGCRSWCLCPEVPSATFFTALLSLLVSGPRLFLLQQPLAPSGLTLKSEALRNWQVYRLVTYIFVYENPISLLCGAIIIWRFAGNFERTVGTVRHCFFTVIFAIFSAIIFLSFEAVSSLSKLGEVEDARGFTPVAFAMLGVTTVRSRMRRALVFGMVVPSVLVPWLLLGASWLIPQTSFLSNVCGLSIGLAYGLTYCYSIDLSERVALKLDQTFPFSLMRRISVFKYVSGSSAERRAAQSRKLNPVPGSYPTQSCHPHLSPSHPVSQTQHASGQKLASWPSCTPGHMPTLPPYQPASGLCYVQNHFGPNPTSSSVYPASAGTSLGIQPPTPVNSPGTVYSGALGTPGAAGSKESSRVPMP>sp|Q6NTF9-3|RHBD2_HUMAN Isoform 3 of Rhomboid domain-containing protein2 OS=Homo sapiens OX=9606 GN=RHBDD2MLGVTTVRSRMRRALVFGMVVPSVLVPWLLLGASWLIPQTSFLSNVCGLSIGLAYGLTYCYSIDLSERVALKLDQTFPFSLMRRISVFKYVSGSSAERRAAQSRKLNPVPGSYPTQSCHPHLSPSHPVSQTQHASGQKLASWPSCTPGHMPTLPPYQPASGLCYVQNHFGPNPTSSSVYPASAGTSLGIQPPTPVNSPGTVYSGALGTPGAAGSKESSRVPMP>sp|Q8WXF3|REL3_HUMAN Relaxin-3 OS=Homo sapiens OX=9606 GN=RLN3 PE=1 SV=1MARYMLLLLLAVWVLTGELWPGAEARAAPYGVRLCGREFIRAVIFTCGGSRWRRSDILAHEAMGDTFPDADADEDSLAGELDEAMGSSEWLALTKSPQAFYRGRPSWQGTPGVLRGSRDVLAGLSSSCCKWGCSKSEISSLC>sp|P62745|RHOB_HUMAN Rho-related GTP-binding protein RhoB OS=Homosapiens OX=9606 GN=RHOB PE=1 SV=1MAAIRKKLVVVGDGACGKTCLLIVFSKDEFPEVYVPTVFENYVADIEVDGKQVELALWDTAGQEDYDRLRPLSYPDTDVILMCFSVDSPDSLENIPEKWVPEVKHFCPNVPIILVANKKDLRSDEHVRTELARMKQEPVRTDDGRAMAVRIQAYDYLECSAKTKEGVREVFETATRAALQKRYGSQNGCINCCKVL>sp|Q5UIP0|RIF1_HUMAN Telomere-associated protein RIF1 OS=Homo sapiensOX=9606 GN=RIF1 PE=1 SV=2MTARGQSPLAPLLETLEDPSASHGGQTDAYLTLTSRMTGEEGKEVITEIEKKLPRLYKVLKTHISSQNSELSSAALQALGFCLYNPKITSELSEANALELLSKLNDTIKNSDKNVRTRALWVISKQTFPSEVVGKMVSSIIDSLEILFNKGETHSAVVDFEALNVIVRLIEQAPIQMGEEAVRWAKLVIPLVVHSAQKVHLRGATALEMGMPLLLQKQQEIASITEQLMTTKLISELQKLFMSKNETYVLKLWPLFVKLLGRTLHRSGSFINSLLQLEELGFRSGAPMIKKIAFIAWKSLIDNFALNPDILCSAKRLKLLMQPLSSIHVRTETLALTKLEVWWYLLMRLGPHLPANFEQVCVPLIQSTISIDSNASPQGNSCHVATSPGLNPMTPVHKGASSPYGAPGTPRMNLSSNLGGMATIPSIQLLGLEMLLHFLLGPEALSFAKQNKLVLSLEPLEHPLISSPSFFSKHANTLITAVHDSFVAVGKDAPDVVVSAIWKELISLVKSVTESGNKKEKPGSEVLTLLLKSLESIVKSEVFPVSKTLVLMEITIKGLPQKVLGSPAYQVANMDILNGTPALFLIQLIFNNFLECGVSDERFFLSLESLVGCVLSGPTSPLAFSDSVLNVINQNAKQLENKEHLWKMWSVIVTPLTELINQTNEVNQGDALEHNFSAIYGALTLPVNHIFSEQRFPVATMKTLLRTWSELYRAFARCAALVATAEENLCCEELSSKIMSSLEDEGFSNLLFVDRIIYIITVMVDCIDFSPYNIKYQPKVKSPQRPSDWSKKKNEPLGKLTSLFKLIVKVIYSFHTLSFKEAHSDTLFTIGNSITGIISSVLGHISLPSMIRKIFATLTRPLALFYENSKLDEVPKVYSCLNNKLEKLLGEIIACLQFSYTGTYDSELLEQLSPLLCIIFLHKNKQIRKQSAQFWNATFAKVMMLVYPEELKPVLTQAKQKFLLLLPGLETVEMMEESSGPYSDGTENSQLNVKISGMERKSNGKRDSFLAQTKNKKENMKPAAKLKLESSSLKVKGEILLEEEKSTDFVFIPPEGKDAKERILTDHQKEVLKTKRCDIPAMYNNLDVSQDTLFTQYSQEEPMEIPTLTRKPKEDSKMMITEEQMDSDIVIPQDVTEDCGMAEHLEKSSLSNNECGSLDKTSPEMSNSNNDERKKALISSRKTSTECASSTENSFVVSSSSVSNTTVAGTPPYPTSRRQTFITLEKFDGSENRPFSPSPLNNISSTVTVKNNQETMIKTDFLPKAKQREGTFSKSDSEKIVNGTKRSSRRAGKAEQTGNKRSKPLMRSEPEKNTEESVEGIVVLENNPPGLLNQTECVSDNQVHLSESTMEHDNTKLKAATVENAVLLETNTVEEKNVEINLESKENTPPVVISADQMVNEDSQVQITPNQKTLRRSSRRRSEVVESTTESQDKENSHQKKERRKEEEKPLQKSPLHIKDDVLPKQKLIAEQTLQENLIEKGSNLHEKTLGETSANAETEQNKKKADPENIKSEGDGTQDIVDKSSEKLVRGRTRYQTRRASQGLLSSIENSESDSSEAKEEGSRKKRSGKWKNKSNESVDIQDQEEKVVKQECIKAENQSHDYKATSEEDVSIKSPICEKQDESNTVICQDSTVTSDLLQVPDDLPNVCEEKNETSKYAEYSFTSLPVPESNLRTRNAIKRLHKRDSFDNCSLGESSKIGISDISSLSEKTFQTLECQHKRSRRVRRSKGCDCCGEKSQPQEKSLIGLKNTENNDVEISETKKADVQAPVSPSETSQANPYSEGQFLDEHHSVNFHLGLKEDNDTINDSLIVSETKSKENTMQESLPSGIVNFREEICDMDSSEAMSLESQESPNENFKTVGPCLGDSKNVSQESLETKEEKPEETPKMELSLENVTVEGNACKVTESNLEKAKTMELNVGNEASFHGQERTKTGISEEAAIEENKRNDDSEADTAKLNAKEVATEEFNSDISLSDNTTPVKLNAQTEISEQTAAGELDGGNDVSDLHSSEETNTKMKNNEEMMIGEAMAETGHDGETENEGITTKTSKPDEAETNMLTAEMDNFVCDTVEMSTEEGIIDANKTETNTEYSKSEEKLDNNQMVMESDILQEDHHTSQKVEEPSQCLASGTAISELIIEDNNASPQKLRELDPSLVSANDSPSGMQTRCVWSPLASPSTSILKRGLKRSQEDEISSPVNKVRRVSFADPIYQAGLADDIDRRCSIVRSHSSNSSPIGKSVKTSPTTQSKHNTTSAKGFLSPGSRSPKFKSSKKCLISEMAKESIPCPTESVYPPLVNCVAPVDIILPQITSNMWARGLGQLIRAKNIKTIGDLSTLTASEIKTLPIRSPKVSNVKKALRIYHEQQVKTRGLEEIPVFDISEKTVNGIENKSLSPDEERLVSDIIDPVALEIPLSKNLLAQISALALQLDSEDLHNYSGSQLFEMHEKLSCMANSVIKNLQSRWRSPSHENSI>sp|Q5UIP0-2|RIF1_HUMAN Isoform 2 of Telomere-associated protein RIF1OS=Homo sapiens OX=9606 GN=RIF1MTARGQSPLAPLLETLEDPSASHGGQTDAYLTLTSRMTGEEGKEVITEIEKKLPRLYKVLKTHISSQNSELSSAALQALGFCLYNPKITSELSEANALELLSKLNDTIKNSDKNVRTRALWVISKQTFPSEVVGKMVSSIIDSLEILFNKGETHSAVVDFEALNVIVRLIEQAPIQMGEEAVRWAKLVIPLVVHSAQKVHLRGATALEMGMPLLLQKQQEIASITEQLMTTKLISELQKLFMSKNETYVLKLWPLFVKLLGRTLHRSGSFINSLLQLEELGFRSGAPMIKKIAFIAWKSLIDNFALNPDILCSAKRLKLLMQPLSSIHVRTETLALTKLEVWWYLLMRLGPHLPANFEQVCVPLIQSTISIDSNASPQGNSCHVATSPGLNPMTPVHKGASSPYGAPGTPRMNLSSNLGGMATIPSIQLLGLEMLLHFLLGPEALSFAKQNKLVLSLEPLEHPLISSPSFFSKHANTLITAVHDSFVAVGKDAPDVVVSAIWKELISLVKSVTESGNKKEKPGSEVLTLLLKSLESIVKSEVFPVSKTLVLMEITIKGLPQKVLGSPAYQVANMDILNGTPALFLIQLIFNNFLECGVSDERFFLSLESLVGCVLSGPTSPLAFSDSVLNVINQNAKQLENKEHLWKMWSVIVTPLTELINQTNEVNQGDALEHNFSAIYGALTLPVNHIFSEQRFPVATMKTLLRTWSELYRAFARCAALVATAEENLCCEELSSKIMSSLEDEGFSNLLFVDRIIYIITVMVDCIDFSPYNIKYQPKVKSPQRPSDWSKKKNEPLGKLTSLFKLIVKVIYSFHTLSFKEAHSDTLFTIGNSITGIISSVLGHISLPSMIRKIFATLTRPLALFYENSKLDEVPKVYSCLNNKLEKLLGEIIACLQFSYTGTYDSELLEQLSPLLCIIFLHKNKQIRKQSAQFWNATFAKVMMLVYPEELKPVLTQAKQKFLLLLPGLETVEMMEESSGPYSDGTENSQLNVKISGMERKSNGKRDSFLAQTKNKKENMKPAAKLKLESSSLKVKGEILLEEEKSTDFVFIPPEGKDAKERILTDHQKEVLKTKRCDIPAMYNNLDVSQDTLFTQYSQEEPMEIPTLTRKPKEDSKMMITEEQMDSDIVIPQDVTEDCGMAEHLEKSSLSNNECGSLDKTSPEMSNSNNDERKKALISSRKTSTECASSTENSFVVSSSSVSNTTVAGTPPYPTSRRQTFITLEKFDGSENRPFSPSPLNNISSTVTVKNNQETMIKTDFLPKAKQREGTFSKSDSEKIVNGTKRSSRRAGKAEQTGNKRSKPLMRSEPEKNTEESVEGIVVLENNPPGLLNQTECVSDNQVHLSESTMEHDNTKLKAATVENAVLLETNTVEEKNVEINLESKENTPPVVISADQMVNEDSQVQITPNQKTLRRSSRRRSEVVESTTESQDKENSHQKKERRKEEEKPLQKSPLHIKDDVLPKQKLIAEQTLQENLIEKGSNLHEKTLGETSANAETEQNKKKADPENIKSEGDGTQDIVDKSSEKLVRGRTRYQTRRASQGLLSSIENSESDSSEAKEEGSRKKRSGKWKNKSNESVDIQDQEEKVVKQECIKAENQSHDYKATSEEDVSIKSPICEKQDESNTVICQDSTVTSDLLQVPDDLPNVCEEKNETSKYAEYSFTSLPVPESNLRTRNAIKRLHKRDSFDNCSLGESSKIGISDISSLSEKTFQTLECQHKRSRRVRRSKGCDCCGEKSQPQEKSLIGLKNTENNDVEISETKKADVQAPVSPSETSQANPYSEGQFLDEHHSVNFHLGLKEDNDTINDSLIVSETKSKENTMQESLPSGIVNFREEICDMDSSEAMSLESQESPNENFKTVGPCLGDSKNVSQESLETKEEKPEETPKMELSLENVTVEGNACKVTESNLEKAKTMELNVGNEASFHGQERTKTGISEEAAIEENKRNDDSEADTAKLNAKEVATEEFNSDISLSDNTTPVKLNAQTEISEQTAAGELDGGNDVSDLHSSEETNTKMKNNEEMMIGEAMAETGHDGETENEGITTKTSKPDEAETNMLTAEMDNFVCDTVEMSTEEGIIDANKTETNTEYSKSEEKLDNNQMVMESDILQEDHHTSQKVEEPSQCLASGTAISELIIEDNNASPQKLRELDPSLVSANDSPSGMQTRCVWSPLASPSTSILKRGLKRSQEDEISSPVNKVRRVSFADPIYQAGLADDIDRRCSIVRSHSSNSSPIGKSVKTSPTTQSKISEMAKESIPCPTESVYPPLVNCVAPVDIILPQITSNMWARGLGQLIRAKNIKTIGDLSTLTASEIKTLPIRSPKVSNVKKALRIYHEQQVKTRGLEEIPVFDISEKTVNGIENKSLSPDEERLVSDIIDPVALEIPLSKNLLAQISALALQLDSEDLHNYSGSQLFEMHEKLSCMANSVIKNLQSRWRSPSHENSI>sp|Q9H628|RERGL_HUMAN Ras-related and estrogen-regulated growthinhibitor-like protein OS=Homo sapiens OX=9606 GN=RERGL PE=2 SV=1MSNFLHLKYNEKSVSVTKALTVRFLTKRFIGEYASNFESIYKKHLCLERKQLNLEIYDPCSQTQKAKFSLTSELHWADGFVIVYDISDRSSFAFAKALIYRIREPQTSHCKRAVESAVFLVGNKRDLCHVREVGWEEGQKLALENRCQFCELSAAEQSLEVEMMFIRIIKDILINFKLKEKRRPSGSKSMAKLINNVFGKRRKSV>sp|A7KAX9|RHG32_HUMAN Rho GTPase-activating protein 32 OS=Homo sapiensOX=9606 GN=ARHGAP32 PE=1 SV=1METESESSTLGDDSVFWLESEVIIQVTDCEEEEREEKFRKMKSSVHSEEDDFVPELHRNVHPRERPDWEETLSAMARGADVPEIPGDLTLKTCGSTASMKVKHVKKLPFTKGHFPKMAECAHFHYENVEFGSIQLSLSEEQNEVMKNGCESKELVYLVQIACQGKSWIVKRSYEDFRVLDKHLHLCIYDRRFSQLSELPRSDTLKDSPESVTQMLMAYLSRLSAIAGNKINCGPALTWMEIDNKGNHLLVHEESSINTPAVGAAHVIKRYTARAPDELTLEVGDIVSVIDMPPKVLSTWWRGKHGFQVGLFPGHCVELINQKVPQSVTNSVPKPVSKKHGKLITFLRTFMKSRPTKQKLKQRGILKERVFGCDLGEHLLNSGFEVPQVLQSCTAFIERYGIVDGIYRLSGVASNIQRLRHEFDSEHVPDLTKEPYVQDIHSVGSLCKLYFRELPNPLLTYQLYEKFSDAVSAATDEERLIKIHDVIQQLPPPHYRTLEFLMRHLSLLADYCSITNMHAKNLAIVWAPNLLRSKQIESACFSGTAAFMEVRIQSVVVEFILNHVDVLFSGRISMAMQEGAASLSRPKSLLVSSPSTKLLTLEEAQARTQAQVNSPIVTENKYIEVGEGPAALQGKFHTIIEFPLERKRPQNKMKKSPVGSWRSFFNLGKSSSVSKRKLQRNESEPSEMKAMALKGGRAEGTLRSAKSEESLTSLHAVDGDSKLFRPRRPRSSSDALSASFNGEMLGNRCNSYDNLPHDNESEEEGGLLHIPALMSPHSAEDVDLSPPDIGVASLDFDPMSFQCSPPKAESECLESGASFLDSPGYSKDKPSANKKDAETGSSQCQTPGSTASSEPVSPLQEKLSPFFTLDLSPTEDKSSKPSSFTEKVVYAFSPKIGRKLSKSPSMSISEPISVTLPPRVSEVIGTVSNTTAQNASSSTWDKCVEERDATNRSPTQIVKMKTNETVAQEAYESEVQPLDQVAAEEVELPGKEDQSVSSSQSKAVASGQTQTGAVTHDPPQDSVPVSSVSLIPPPPPPKNVARMLALALAESAQQASTQSLKRPGTSQAGYTNYGDIAVATTEDNLSSSYSAVALDKAYFQTDRPAEQFHLQNNAPGNCDHPLPETTATGDPTHSNTTESGEQHHQVDLTGNQPHQAYLSGDPEKARITSVPLDSEKSDDHVSFPEDQSGKNSMPTVSFLDQDQSPPRFYSGDQPPSYLGASVDKLHHPLEFADKSPTPPNLPSDKIYPPSGSPEENTSTATMTYMTTTPATAQMSTKEASWDVAEQPTTADFAAATLQRTHRTNRPLPPPPSQRSAEQPPVVGQVQAATNIGLNNSHKVQGVVPVPERPPEPRAMDDPASAFISDSGAAAAQCPMATAVQPGLPEKVRDGARVPLLHLRAESVPAHPCGFPAPLPPTRMMESKMIAAIHSSSADATSSSNYHSFVTASSTSVDDALPLPLPVPQPKHASQKTVYSSFARPDVTTEPFGPDNCLHFNMTPNCQYRPQSVPPHHNKLEQHQVYGARSEPPASMGLRYNTYVAPGRNASGHHSKPCSRVEYVSSLSSSVRNTCYPEDIPPYPTIRRVQSLHAPPSSMIRSVPISRTEVPPDDEPAYCPRPLYQYKPYQSSQARSDYHVTQLQPYFENGRVHYRYSPYSSSSSSYYSPDGALCDVDAYGTVQLRPLHRLPNRDFAFYNPRLQGKSLYSYAGLAPRPRANVTGYFSPNDHNVVSMPPAADVKHTYTSWDLEDMEKYRMQSIRRESRARQKVKGPVMSQYDNMTPAVQDDLGGIYVIHLRSKSDPGKTGLLSVAEGKESRHAAKAISPEGEDRFYRRHPEAEMDRAHHHGGHGSTQPEKPSLPQKQSSLRSRKLPDMGCSLPEHRAHQEASHRQFCESKNGPPYPQGAGQLDYGSKGIPDTSEPVSYHNSGVKYAASGQESLRLNHKEVRLSKEMERPWVRQPSAPEKHSRDCYKEEEHLTQSIVPPPKPERSHSLKLHHTQNVERDPSVLYQYQPHGKRQSSVTVVSQYDNLEDYHSLPQHQRGVFGGGGMGTYVPPGFPHPQSRTYATALGQGAFLPAELSLQHPETQIHAE>sp|A7KAX9-2|RHG32_HUMAN Isoform 2 of Rho GTPase-activating protein 32OS=Homo sapiens OX=9606 GN=ARHGAP32MKSRPTKQKLKQRGILKERVFGCDLGEHLLNSGFEVPQVLQSCTAFIERYGIVDGIYRLSGVASNIQRLRHEFDSEHVPDLTKEPYVQDIHSVGSLCKLYFRELPNPLLTYQLYEKFSDAVSAATDEERLIKIHDVIQQLPPPHYRTLEFLMRHLSLLADYCSITNMHAKNLAIVWAPNLLRSKQIESACFSGTAAFMEVRIQSVVVEFILNHVDVLFSGRISMAMQEGAASLSRPKSLLVSSPSTKLLTLEEAQARTQAQVNSPIVTENKYIEVGEGPAALQGKFHTIIEFPLERKRPQNKMKKSPVGSWRSFFNLGKSSSVSKRKLQRNESEPSEMKAMALKGGRAEGTLRSAKSEESLTSLHAVDGDSKLFRPRRPRSSSDALSASFNGEMLGNRCNSYDNLPHDNESEEEGGLLHIPALMSPHSAEDVDLSPPDIGVASLDFDPMSFQCSPPKAESECLESGASFLDSPGYSKDKPSANKKDAETGSSQCQTPGSTASSEPVSPLQEKLSPFFTLDLSPTEDKSSKPSSFTEKVVYAFSPKIGRKLSKSPSMSISEPISVTLPPRVSEVIGTVSNTTAQNASSSTWDKCVEERDATNRSPTQIVKMKTNETVAQEAYESEVQPLDQVAAEEVELPGKEDQSVSSSQSKAVASGQTQTGAVTHDPPQDSVPVSSVSLIPPPPPPKNVARMLALALAESAQQASTQSLKRPGTSQAGYTNYGDIAVATTEDNLSSSYSAVALDKAYFQTDRPAEQFHLQNNAPGNCDHPLPETTATGDPTHSNTTESGEQHHQVDLTGNQPHQAYLSGDPEKARITSVPLDSEKSDDHVSFPEDQSGKNSMPTVSFLDQDQSPPRFYSGDQPPSYLGASVDKLHHPLEFADKSPTPPNLPSDKIYPPSGSPEENTSTATMTYMTTTPATAQMSTKEASWDVAEQPTTADFAAATLQRTHRTNRPLPPPPSQRSAEQPPVVGQVQAATNIGLNNSHKVQGVVPVPERPPEPRAMDDPASAFISDSGAAAAQCPMATAVQPGLPEKVRDGARVPLLHLRAESVPAHPCGFPAPLPPTRMMESKMIAAIHSSSADATSSSNYHSFVTASSTSVDDALPLPLPVPQPKHASQKTVYSSFARPDVTTEPFGPDNCLHFNMTPNCQYRPQSVPPHHNKLEQHQVYGARSEPPASMGLRYNTYVAPGRNASGHHSKPCSRVEYVSSLSSSVRNTCYPEDIPPYPTIRRVQSLHAPPSSMIRSVPISRTEVPPDDEPAYCPRPLYQYKPYQSSQARSDYHVTQLQPYFENGRVHYRYSPYSSSSSSYYSPDGALCDVDAYGTVQLRPLHRLPNRDFAFYNPRLQGKSLYSYAGLAPRPRANVTGYFSPNDHNVVSMPPAADVKHTYTSWDLEDMEKYRMQSIRRESRARQKVKGPVMSQYDNMTPAVQDDLGGIYVIHLRSKSDPGKTGLLSVAEGKESRHAAKAISPEGEDRFYRRHPEAEMDRAHHHGGHGSTQPEKPSLPQKQSSLRSRKLPDMGCSLPEHRAHQEASHRQFCESKNGPPYPQGAGQLDYGSKGIPDTSEPVSYHNSGVKYAASGQESLRLNHKEVRLSKEMERPWVRQPSAPEKHSRDCYKEEEHLTQSIVPPPKPERSHSLKLHHTQNVERDPSVLYQYQPHGKRQSSVTVVSQYDNLEDYHSLPQHQRGVFGGGGMGTYVPPGFPHPQSRTYATALGQGAFLPAELSLQHPETQIHAE>sp|A7KAX9-3|RHG32_HUMAN Isoform 3 of Rho GTPase-activating protein 32OS=Homo sapiens OX=9606 GN=ARHGAP32MPPKVLSTWWRGKHGFQVGLFPGHCVELINQKVPQSVTNSVPKPVSKKHGKLITFLRTFMKSRPTKQKLKQRGILKERVFGCDLGEHLLNSGFEVPQVLQSCTAFIERYGIVDGIYRLSGVASNIQRLRHEFDSEHVPDLTKEPYVQDIHSVGSLCKLYFRELPNPLLTYQLYEKFSDAVSAATDEERLIKIHDVIQQLPPPHYRTLEFLMRHLSLLADYCSITNMHAKNLAIVWAPNLLRSKQIESACFSGTAAFMEVRIQSVVVEFILNHVDVLLPHFSARTELIVPFPLRLLRKQFTPPLLGPMSPLNPLVQITVCISI>sp|Q96B86|RGMA_HUMAN Repulsive guidance molecule A OS=Homo sapiensOX=9606 GN=RGMA PE=1 SV=3MQPPRERLVVTGRAGWMGMGRGAGRSALGFWPTLAFLLCSFPAATSPCKILKCNSEFWSATSGSHAPASDDTPEFCAALRSYALCTRRTARTCRGDLAYHSAVHGIEDLMSQHNCSKDGPTSQPRLRTLPPAGDSQERSDSPEICHYEKSFHKHSATPNYTHCGLFGDPHLRTFTDRFQTCKVQGAWPLIDNNYLNVQVTNTPVLPGSAATATSKLTIIFKNFQECVDQKVYQAEMDELPAAFVDGSKNGGDKHGANSLKITEKVSGQHVEIQAKYIGTTIVVRQVGRYLTFAVRMPEEVVNAVEDWDSQGLYLCLRGCPLNQQIDFQAFHTNAEGTGARRLAAASPAPTAPETFPYETAVAKCKEKLPVEDLYYQACVFDLLTTGDVNFTLAAYYALEDVKMLHSNKDKLHLYDRTRDLPGRAAAGLPLAPRPLLGALVPLLALLPVFC>sp|Q96B86-3|RGMA_HUMAN Isoform 2 of Repulsive guidance molecule AOS=Homo sapiens OX=9606 GN=RGMAMGMGRGAGRSALGFWPTLAFLLCSFPAATSPCKILKCNSEFWSATSGSHAPASDDTPEFCAALRSYALCTRRTARTCRGDLAYHSAVHGIEDLMSQHNCSKDGPTSQPRLRTLPPAGDSQERSDSPEICHYEKSFHKHSATPNYTHCGLFGDPHLRTFTDRFQTCKVQGAWPLIDNNYLNVQVTNTPVLPGSAATATSKLTIIFKNFQECVDQKVYQAEMDELPAAFVDGSKNGGDKHGANSLKITEKVSGQHVEIQAKYIGTTIVVRQVGRYLTFAVRMPEEVVNAVEDWDSQGLYLCLRGCPLNQQIDFQAFHTNAEGTGARRLAAASPAPTAPETFPYETAVAKCKEKLPVEDLYYQACVFDLLTTGDVNFTLAAYYALEDVKMLHSNKDKLHLYDRTRDLPGRAAAGLPLAPRPLLGALVPLLALLPVFC>sp|Q96B86-4|RGMA_HUMAN Isoform 3 of Repulsive guidance molecule AOS=Homo sapiens OX=9606 GN=RGMAMGGLGPRRAGTSRERLVVTGRAGWMGMGRGAGRSALGFWPTLAFLLCSFPAATSPCKILKCNSEFWSATSGSHAPASDDTPEFCAALRSYALCTRRTARTCRGDLAYHSAVHGIEDLMSQHNCSKDGPTSQPRLRTLPPAGDSQERSDSPEICHYEKSFHKHSATPNYTHCGLFGDPHLRTFTDRFQTCKVQGAWPLIDNNYLNVQVTNTPVLPGSAATATSKLTIIFKNFQECVDQKVYQAEMDELPAAFVDGSKNGGDKHGANSLKITEKVSGQHVEIQAKYIGTTIVVRQVGRYLTFAVRMPEEVVNAVEDWDSQGLYLCLRGCPLNQQIDFQAFHTNAEGTGARRLAAASPAPTAPETFPYETAVAKCKEKLPVEDLYYQACVFDLLTTGDVNFTLAAYYALEDVKMLHSNKDKLHLYDRTRDLPGRAAAGLPLAPRPLLGALVPLLALLPVFC>sp|Q7LG56|RIR2B_HUMAN Ribonucleoside-diphosphate reductase subunit M2 BOS=Homo sapiens OX=9606 GN=RRM2B PE=1 SV=1MGDPERPEAAGLDQDERSSSDTNESEIKSNEEPLLRKSSRRFVIFPIQYPDIWKMYKQAQASFWTAEEVDLSKDLPHWNKLKADEKYFISHILAFFAASDGIVNENLVERFSQEVQVPEARCFYGFQILIENVHSEMYSLLIDTYIRDPKKREFLFNAIETMPYVKKKADWALRWIADRKSTFGERVVAFAAVEGVFFSGSFAAIFWLKKRGLMPGLTFSNELISRDEGLHCDFACLMFQYLVNKPSEERVREIIVDAVKIEQEFLTEALPVGLIGMNCILMKQYIEFVADRLLVELGFSKVFQAENPFDFMENISLEGKTNFFEKRVSEYQRFAVMAETTDNVFTLDADF>sp|Q7LG56-2|RIR2B_HUMAN Isoform 2 of Ribonucleoside-diphosphatereductase subunit M2 B OS=Homo sapiens OX=9606 GN=RRM2BMGDPERPEAAGLDQDEVDLSKDLPHWNKLKADEKYFISHILAFFAASDGIVNENLVERFSQEVQVPEARCFYGFQILIENVHSEMYSLLIDTYIRDPKKREFLFNAIETMPYVKKKADWALRWIADRKSTFGERVVAFAAVEGVFFSGSFAAIFWLKKRGLMPGLTFSNELISRDEGLHCDFACLMFQYLVNKPSEERVREIIVDAVKIEQEFLTEALPVGLIGMNCILMKQYIEFVADRLLVELGFSKVFQAENPFDFMENISLEGKTNFFEKRVSEYQRFAVMAETTDNVFTLDADF>sp|Q7LG56-3|RIR2B_HUMAN Isoform 3 of Ribonucleoside-diphosphatereductase subunit M2 B OS=Homo sapiens OX=9606 GN=RRM2BMGDPERPEAAGLDQDEGLHCDFACLMFQYLVNKPSEERVREIIVDAVKIEQEFLTEALPVGLIGMNCILMKQYIEFVADRLLVELGFSKVFQAENPFDFMENISLEGKTNFFEKRVSEYQRFAVMAETTDNVFTLDADF>sp|Q7LG56-4|RIR2B_HUMAN Isoform 4 of Ribonucleoside-diphosphatereductase subunit M2 B OS=Homo sapiens OX=9606 GN=RRM2BMGDPERPEAAGLDQDEVFQAENPFDFMENISLEGKTNFFEKRVSEYQRFAVMAETTDNVFTLDADF>sp|Q7LG56-5|RIR2B_HUMAN Isoform 5 of Ribonucleoside-diphosphatereductase subunit M2 B OS=Homo sapiens OX=9606 GN=RRM2BMGDPERPEAAGLDQDERSSSDTNESEIKSNEEPLLRKSSRRSF>sp|Q7LG56-6|RIR2B_HUMAN Isoform 6 of Ribonucleoside-diphosphatereductase subunit M2 B OS=Homo sapiens OX=9606 GN=RRM2BMLLLRLPPHRSHASPLDCKLQDRCRKCYSPRSGQACPPALAAAWLRRCERRGGRPRGGRRKELTLGLRPARCSAPGPAKDDAWRPQAGRSSSDTNESEIKSNEEPLLRKSSRRFVIFPIQYPDIWKMYKQAQASFWTAEEVDLSKDLPHWNKLKADEKYFISHILAFFAASDGIVNENLVERFSQEVQVPEARCFYGFQILIENVHSEMYSLLIDTYIRDPKKREFLFNAIETMPYVKKKADWALRWIADRKSTFGERVVAFAAVEGVFFSGSFAAIFWLKKRGLMPGLTFSNELISRDEGLHCDFACLMFQYLVNKPSEERVREIIVDAVKIEQEFLTEALPVGLIGMNCILMKQYIEFVADRLLVELGFSKVFQAENPFDFMENISLEGKTNFFEKRVSEYQRFAVMAETTDNVFTLDADF>sp|P62424|RL7A_HUMAN 60S ribosomal protein L7a OS=Homo sapiens OX=9606GN=RPL7A PE=1 SV=2MPKGKKAKGKKVAPAPAVVKKQEAKKVVNPLFEKRPKNFGIGQDIQPKRDLTRFVKWPRYIRLQRQRAILYKRLKVPPAINQFTQALDRQTATQLLKLAHKYRPETKQEKKQRLLARAEKKAAGKGDVPTKRPPVLRAGVNTVTTLVENKKAQLVVIAHDVDPIELVVFLPALCRKMGVPYCIIKGKARLGRLVHRKTCTTVAFTQVNSEDKGALAKLVEAIRTNYNDRYDEIRRHWGGNVLGPKSVARIAKLEKAKAKELATKLG>sp|Q6UWP8|SBSN_HUMAN Suprabasin OS=Homo sapiens OX=9606 GN=SBSN PE=1SV=2MHLARLVGSCSLLLLLGALSGWAASDDPIEKVIEGINRGLSNAEREVGKALDGINSGITHAGREVEKVFNGLSNMGSHTGKELDKGVQGLNHGMDKVAHEINHGIGQAGKEAEKLGHGVNNAAGQVGKEADKLIHHGVHHGANQAGSEAGKFGQGVDNAAGQAGNEAGRFGQGVHHAAGQAGNEAGRFGQGVHHAAGQAGNEAGRFGQGAHHGLSEGWKETEKFGQGIHHAAGQVGKEAEKFGQGAHHAAGQAGNEAGRFGQGVHHGLSEGWKETEKFGQGVHHTAGQVGKEAEKFGQGAHHAAGQAGNEAGRFGQGAHHAAGQAGNEAGRFGQGVHHGLSEGWKETEKFGQGVHHAASQFGKETEKLGHGVHHGVNEAWKEAEKFGQGVHHAASQVGKEEDRVVQGLHHGVSQAGREAGQFGHDIHHTAGQAGKEGDIAVHGVQPGVHEAGKEAGQFGQGVHHTLEQAGKEADKAVQGFHTGVHQAGKEAEKLGQGVNHAADQAGKEVEKLGQGAHHAAGQAGKELQNAHNGVNQASKEANQLLNGNHQSGSSSHQGGATTTPLASGASVNTPFINLPALWRSVANIMP>sp|Q6UWP8-2|SBSN_HUMAN Isoform 2 of Suprabasin OS=Homo sapiens OX=9606GN=SBSNMHLARLVGSCSLLLLLGALSGWAASDDPIEKVIEGINRGLSNAEREVGKALDGINSGITHAGREVEKVFNGLSNMGSHTGKELDKGVQGLNHGMDKVAHEINHGIGQAGKEAEKLGHGVNNAAGQAGKEADKAVQGFHTGVHQAGKEAEKLGQGVNHAADQAGKEVEKLGQGAHHAAGQAGKELQNAHNGVNQASKEANQLLNGNHQSGSSSHQGGATTTPLASGASVNTPFINLPALWRSVANIMP>sp|Q8TEU7|RPGF6_HUMAN Rap guanine nucleotide exchange factor 6 OS=Homosapiens OX=9606 GN=RAPGEF6 PE=1 SV=2MNSPVDPGARQALRKKPPERTPEDLNTIYSYLHGMEILSNLREHQLRLMSARARYERYSGNQVLFCSETIARCWYILLSGSVLVKGSMVLPPCSFGKQFGGKRGCDCLVLEPSEMIVVENAKDNEDSILQREIPARQSRRRFRKINYKGERQTITDDVEVNSYLSLPADLTKMHLTENPHPQVTHVSSSQSGCSIASDSGSSSLSDIYQATESEVGDVDLTRLPEGPVDSEDDEEEDEEIDRTDPLQGRDLVRECLEKEPADKTDDDIEQLLEFMHQLPAFANMTMSVRRELCSVMIFEVVEQAGAIILEDGQELDSWYVILNGTVEISHPDGKVENLFMGNSFGITPTLDKQYMHGIVRTKVDDCQFVCIAQQDYWRILNHVEKNTHKVEEEGEIVMVHEHRELDRSGTRKGHIVIKATPERLIMHLIEEHSIVDPTYIEDFLLTYRTFLESPLDVGIKLLEWFKIDSLRDKVTRIVLLWVNNHFNDFEGDPAMTRFLEEFEKNLEDTKMNGHLRLLNIACAAKAKWRQVVLQKASRESPLQFSLNGGSEKGFGIFVEGVEPGSKAADSGLKRGDQIMEVNGQNFENITFMKAVEILRNNTHLALTVKTNIFVFKELLFRTEQEKSGVPHIPKIAEKKSNRHSIQHVPGDIEQTSQEKGSKKVKANTVSGGRNKIRKILDKTRFSILPPKLFSDGGLSQSQDDSIVGTRHCRHSLAIMPIPGTLSSSSPDLLQPTTSMLDFSNPSDIPDQVIRVFKVDQQSCYIIISKDTTAKEVVFHAVHEFGLTGASDTYSLCEVSVTPEGVIKQRRLPDQFSKLADRIQLNGRYYLKNNMETETLCSDEDAQELVKESQLSMLQLSTIEVATQLSMRDFDLFRNIEPTEYIDDLFKLNSKTGNTHLKRFEDIVNQETFWVASEILTEANQLKRMKIIKHFIKIALHCRECKNFNSMFAIISGLNLASVARLRGTWEKLPSKYEKHLQDLQDIFDPSRNMAKYRNILSSQSMQPPIIPLFPVVKKDMTFLHEGNDSKVDGLVNFEKLRMISKEIRQVVRMTSANMDPAMMFRQRSLSQGSTNSNMLDVQGGAHKKRARRSSLLNAKKLYEDAQMARKVKQYLSSLDVETDEEKFQMMSLQWEPAYGTLTKNLSEKRSAKSSEMSPVPMRSAGQTTKAHLHQPHRVSQVLQVPAVNLHPIRKKGQTKDPALNTSLPQKVLGTTEEISGKKHTEDTISVASSLHSSPPASPQGSPHKGYTLIPSAKSDNLSDSSHSEISSRSSIVSNCSVDSMSAALQDERCSSQALAVPESTGALEKTEHASGIGDHSQHGPGWTLLKPSLIKCLAVSSSVSNEEISQEHIIIEAADSGRGSWTSCSSSSHDNFQSLPNPKSWDFLNSYRHTHLDDPIAEVEPTDSEPYSCSKSCSRTCGQCKGSLERKSWTSSSSLSDTYEPNYGTVKQRVLESTPAESSEGLDPKDATDPVYKTVTSSTEKGLIVYCVTSPKKDDRYREPPPTPPGYLGISLADLKEGPHTHLKPPDYSVAVQRSKMMHNSLSRLPPASLSSNLVACVPSKIVTQPQRHNLQPFHPKLGDVTDADSEADENEQVSAV>sp|Q8TEU7-2|RPGF6_HUMAN Isoform 2 of Rap guanine nucleotide exchangefactor 6 OS=Homo sapiens OX=9606 GN=RAPGEF6MNSPVDPGARQALRKKPPERTPEDLNTIYSYLHGMEILSNLREHQLRLMSARARYERYSGNQVLFCSETIARCWYILLSGSVLVKGSMVLPPCSFGKQFGGKRGCDCLVLEPSEMIVVENAKDNEDSILQREIPARQSRRRFRKINYKGERQTITDDVEVNSYLSLPADLTKMHLTENPHPQVTHVSSSQSGCSIASDSGSSSLSDIYQATESEVGDVDLTRLPEGPVDSEDDEEEDEEIDRTDPLQGRDLVRECLEKEPADKTDDDIEQLLEFMHQLPAFANMTMSVRRELCSVMIFEVVEQAGAIILEDGQELDSWYVILNGTVEISHPDGKVENLFMGNSFGITPTLDKQYMHGIVRTKVDDCQFVCIAQQDYWRILNHVEKNTHKVEEEGEIVMVHEHRELDRSGTRKGHIVIKATPERLIMHLIEEHSIVDPTYIEDFLLTYRTFLESPLDVGIKLLEWFKIDSLRDKVTRIVLLWVNNHFNDFEGDPAMTRFLEEFEKNLEDTKMNGHLRLLNIACAAKAKWRQVVLQKASRESPLQFSLNGGSEKGFGIFVEGVEPGSKAADSGLKRGDQIMEVNGQNFENITFMKAVEILRNNTHLALTVKTNIFVFKELLFRTEQEKSGVPHIPKIAEKKSNRHSIQHVPGDIEQTSQEKGSKKVKANTVSGGRNKIRKILDKTRFSILPPKLFSDGGLSQSQDDSIVGTRHCRHSLAIMPIPGTLSSSSPDLLQPTTSMLDFSNPSDIPDQVIRVFKVDQQSCYIIISKDTTAKEVVFHAVHEFGLTGASDTYSLCEVSVTPEGVIKQRRLPDQFSKLADRIQLNGRYYLKNNMETETLCSDEDAQELVKESQLSMLQLSTIEVATQLSMRDFDLFRNIEPTEYIDDLFKLNSKTGNTHLKRFEDIVNQETFWVASEILTEANQLKRMKIIKHFIKIALHCRECKNFNSMFAIISGLNLASVARLRGTWEKLPSKYEKHLQDLQDIFDPSRNMAKYRNILSSQSMQPPIIPLFPVVKKDMTFLHEGNDSKVDGLVNFEKLRMISKEIRQVVRMTSANMDPAMMFRQRSLSQGSTNSNMLDVQGGAHKKRARRSSLLNAKKLYEDAQMARKVKQYLSSLDVETDEEKFQMMSLQWEPAYGTLTKNLSEKRSAKSSEMSPVPMRSAGQTTKAHLHQPHRVSQVLQVPAVNLHPIRKKGQTKDPALNTSLPQKVLGTTEEISGKKHTEDTISVASSLHSSPPASPQGSPHKVGSIISDHSSKISGQSCPGIGGAYLQKKILQITRSTAKRTDSTEKATEENRDRTSCENTTRKRMTSPFRRLRERMLSRERLVNSQKEDTDHNQATESCEKVKDVGSNIKDEKGSAIFNSNSQGNSNTLNCFYTRFKSKRRKTL>sp|Q8TEU7-3|RPGF6_HUMAN Isoform 3 of Rap guanine nucleotide exchangefactor 6 OS=Homo sapiens OX=9606 GN=RAPGEF6MNSPVDPGARQALRKKPPERTPEDLNTIYSYLHGMEILSNLREHQLRLMSARARYERYSGNQVLFCSETIARCWYILLSGSVLVKGSMVLPPCSFGKQFGGKRGCDCLVLEPSEMIVVENAKDNEDSILQREIPARQSRRRFRKINYKGERQTITDDVEVNSYLSLPADLTKMHLTENPHPQVTHVSSSQSGCSIASDSGSSSLSDIYQATESEVGDVDLTRLPEGPVDSEDDEEEDEEIDRTDPLQGRDLVRECLEKEPADKTDDDIEQLLEFMHQLPAFANMTMSVRRELCSVMIFEVVEQAGAIILEDGQELDSWYVILNGTVEISHPDGKVENLFMGNSFGITPTLDKQYMHGIVRTKVDDCQFVCIAQQDYWRILNHVEKNTHKVEEEGEIVMVHEHRELDRSGTRKGHIVIKATPERLIMHLIEEHSIVDPTYIEDFLLTYRTFLESPLDVGIKLLEWFKIDSLRDKVTRIVLLWVNNHFNDFEGDPAMTRFLEEFEKNLEDTKMNGHLRLLNIACAAKAKWRQVVLQKASRESPLQFSLNGGSEKGFGIFVEGVEPGSKAADSGLKRGDQIMEVNGQNFENITFMKAVEILRNNTHLALTVKTNIFVFKELLFRTEQEKSGVPHIPKIAEKKSNRHSIQHVPGDIEQTSQEKGSKKVKANTVSGGRNKIRKILDKTRFSILPPKLFSDGGLSQSQDDSIVGTRHCRHSLAIMPIPGTLSSSSPDLLQPTTSMLDFSNPSAVGFYYIPDQVIRVFKVDQQSCYIIISKDTTAKEVVFHAVHEFGLTGASDTYSLCEVSVTPEGVIKQRRLPDQFSKLADRIQLNGRYYLKNNMETETLCSDEDAQELVKESQLSMLQLSTIEVATQLSMRDFDLFRNIEPTEYIDDLFKLNSKTGNTHLKRFEDIVNQETFWVASEILTEANQLKRMKIIKHFIKIALHCRECKNFNSMFAIISGLNLASVARLRGTWEKLPSKYEKHLQDLQDIFDPSRNMAKYRNILSSQSMQPPIIPLFPVVKKDMTFLHEGNDSKVDGLVNFEKLRMISKEIRQVVRMTSANMDPAMMFRQRKKRWRSLGSLSQGSTNSNMLDVQGGAHKKRARRSSLLNAKKLYEDAQMARKVKQYLSSLDVETDEEKFQMMSLQWEPAYGTLTKNLSEKRSAKSSEMSPVPMRSAGQTTKAHLHQPHRVSQVLQVPAVNLHPIRKKGQTKDPALNTSLPQKVLGTTEEISGKKHTEDTISVASSLHSSPPASPQGSPHKGYTLIPSAKSDNLSDSSHSEISSRSSIVSNCSVDSMSAALQDERCSSQALAVPESTGALEKTEHASGIGDHSQHGPGWTLLKPSLIKCLAVSSSVSNEEISQEHIIIEAADSGRGSWTSCSSSSHDNFQSLPNPKSWDFLNSYRHTHLDDPIAEVEPTDSEPYSCSKSCSRTCGQCKGSLERKSWTSSSSLSDTYEPNYGTVKQRVLESTPAESSEGLDPKDATDPVYKTVTSSTEKGLIENEQVSAV>sp|Q8TEU7-4|RPGF6_HUMAN Isoform 4 of Rap guanine nucleotide exchangefactor 6 OS=Homo sapiens OX=9606 GN=RAPGEF6MNSPVDPGARQALRKKPPERTPEDLNTIYSYLHGMEILSNLREHQLRLMSARARYERYSGNQVLFCSETIARCWYILLSGSVLVKGSMVLPPCSFGKQFGGKRGCDCLVLEPSEMIVVENAKDNEDSILQREIPARQSRRRFRKINYKGERQTITDDVEVNSYLSLPADLTKMHLTENPHPQVTHVSSSQSGCSIASDSGSSSLSDIYQATESEVGDVDLTRLPEGPVDSEDDEEEDEEIDRTDPLQGRDLVRECLEKEPADKTDDDIEQLLEFMHQLPAFANMTMSVRRELCSVMIFEVVEQAGAIILEDGQELDSWYVILNGTVEISHPDGKVENLFMGNSFGITPTLDKQYMHGIVRTKVDDCQFVCIAQQDYWRILNHVEKNTHKVEEEGEIVMVHEHRELDRSGTRKGHIVIKATPERLIMHLIEEHSIVDPTYIEDFLLTYRTFLESPLDVGIKLLEWFKIDSLRDKVTRIVLLWVNNHFNDFEGDPAMTRFLEEFEKNLEDTKMNGHLRLLNIACAAKAKWRQVVLQKASRESPLQFSLNGGSEKGFGIFVEGVEPGSKAADSGLKRGDQIMEVNGQNFENITFMKAVEILRNNTHLALTVKTNIFVFKELLFRTEQEKSGVPHIPKIAEKKSNRHSIQHVPGDIEQTSQEKGSKKVKANTVSGGRNKIRKILDKTRFSILPPKLFSDGGLSQSQDDSIVGTRHCRHSLAIMPIPGTLSSSSPDLLQPTTSMLDFSNPSDIPDQVIRVFKVDQQSCYIIISKDTTAKEVVFHAVHEFGLTGASDTYSLCEVSVTPEGVIKQRRLPDQFSKLADRIQLNGRYYLKNNMETETLCSDEDAQELVKESQLSMLQLSTIEVATQLSMRDFDLFRNIEPTEYIDDLFKLNSKTGNTHLKRFEDIVNQETFWVASEILTEANQLKRMKIIKHFIKIALHCRECKNFNSMFAIISGLNLASVARLRGTWEKLPSKYEKHLQDLQDIFDPSRNMAKYRNILSSQSMQPPIIPLFPVVKKDMTFLHEGNDSKVDGLVNFEKLRMISKEIRQVVRMTSANMDPAMMFRQRKKRWRSLGSLSQGSTNSNMLDVQGGAHKKRARRSSLLNAKKLYEDAQMARKVKQYLSSLDVETDEEKFQMMSLQWEPAYGTLTKNLSEKRSAKSSEMSPVPMRSAGQTTKAHLHQPHRVSQVLQVPAVNLHPIRKKGQTKDPALNTSLPQKVLGTTEEISGKKHTEDTISVASSLHSSPPASPQGSPHKGYTLIPSAKSDNLSDSSHSEISSRSSIVSNCSVDSMSAALQDERCSSQALAVPESTGALEKTEHASGIGDHSQHGPGWTLLKPSLIKCLAVSSSVSNEEISQEHIIIEAADSGRGSWTSCSSSSHDNFQSLPNPKSWDFLNSYRHTHLDDPIAEVEPTDSEPYSCSKSCSRTCGQCKGSLERKSWTSSSSLSDTYEPNYGTVKQRVLESTPAESSEGLDPKDATDPVYKTVTSSTEKGLIVYCVTSPKKDDRYREPPPTPPGYLGISLADLKEGPHTHLKPPDYSVAVQRSKMMHNSLSRLPPASLSSNLVACVPSKIVTQPQRHNLQPFHPKLGDVTDADSEADENEQVSAV>sp|Q8TEU7-5|RPGF6_HUMAN Isoform 5 of Rap guanine nucleotide exchangefactor 6 OS=Homo sapiens OX=9606 GN=RAPGEF6MNSPVDPGARQALRKKPPERTPEDLNTIYSYLHGMEILSNLREHQLRLMSARARYERYSGNQVLFCSETIARCWYILLSGSVLVKGSMVLPPCSFGKQFGGKRGCDCLVLEPSEMIVVENAKDNEDSILQREIPARQSRRRFRKINYKGERQTITDDVEVNSYLSLPADLTKMHLTENPHPQVTHVSSSQSGCSIASDSGSSSLSDIYQATESEVGDVDLTRLPEGPVDSEDDEEEDEEIDRTDPLQGRDLVRECLEKEPADKTDDDIEQLLEFMHQLPAFANMTMSVRRELCSVMIFEVVEQAGAIILEDGQELDSWYVILNGTVEISHPDGKVENLFMGNSFGITPTLDKQYMHGIVRTKVDDCQFVCIAQQDYWRILNHVEKNTHKVEEEGEIVMVHEHRELDRSGTRKGHIVIKATPERLIMHLIEEHSIVDPTYIEDFLLTYRTFLESPLDVGIKLLEWFKIDSLRDKVTRIVLLWVNNHFNDFEGDPAMTRFLEEFEKNLEDTKMNGHLRLLNIACAAKAKWRQVVLQKASRESPLQFSLNGGSEKGFGIFVEGVEPGSKAADSGLKRGDQIMEVNGQNFENITFMKAVEILRNNTHLALTVKTNIFVFKELLFRTEQEKSGVPHIPKIAEKKSNRHSIQHVPGDIEQTSQEKGSKKVKANTVSGGRNKIRKILDKTRFSILPPKLFSDGGLSQSQDDSIVGTRHCRHSLAIMPIPGTLSSSSPDLLQPTTSMLDFSNPSDIPDQVIRVFKVDQQSCYIIISKDTTAKEVVFHAVHEFGLTGASDTYSLCEVSVTPEGVIKQRRLPDQFSKLADRIQLNGRYYLKNNMETETLCSDEDAQELVKESQLSMLQLSTIEVATQLSMRDFDLFRNIEPTEYIDDLFKLNSKTGNTHLKRFEDIVNQETFWVASEILTEANQLKRMKIIKHFIKIALHCRECKNFNSMFAIISGLNLASVARLRGTWEKLPSKYEKHLQDLQDIFDPSRNMAKYRNILSSQSMQPPIIPLFPVVKKDMTFLHEGNDSKVDGLVNFEKLRMISKEIRQVVRMTSANMDPAMMFRQRKKRWRSLGSLSQGSTNSNMLDVQGGAHKKRARRSSLLNAKKLYEDAQMARKVKQYLSSLDVETDEEKFQMMSLQWEPAYGTLTKNLSEKRSAKSSEMSPVPMRSAGQTTKAHLHQPHRVSQVLQVPAVNLHPIRKKGQTKDPALNTSLPQKVLGTTEEISGKKHTEDTISVASSLHSSPPASPQGSPHKGYTLIPSAKSDNLSDSSHSEISSRSSIVSNCSVDSMSAALQDERCSSQALAVPESTGALEKTEHASGIGDHSQHGPGWTLLKPSLIKCLAVSSSVSNEEISQEHIIIEAADSGRGSWTSCSSSSHDNFQSLPNPKSWDFLNSYRHTHLDDPIAEVEPTDSEPYSCSKSCSRTCGQCKGSLERKSWTSSSSLSDTYEPNYGTVKQRVLESTPAESSEGLDPKDATDPVYKTVTSSTEKGLIENEQVSAV>sp|Q8TEU7-6|RPGF6_HUMAN Isoform 6 of Rap guanine nucleotide exchangefactor 6 OS=Homo sapiens OX=9606 GN=RAPGEF6MNSPVDPGARQALRKKPPERTPEDLNTIYSYLHGMEILSNLREHQLRLMSARARYERYSGNQVLFCSETIARCWYILLSGSVLVKGSMVLPPCSFGKQFGGKRGCDCLVLEPSEMIVVENAKDNEDSILQREIPARQSRRRFRKINYKGERQTITDDVEVNSYLSLPADLTKMHLTENPHPQVTHVSSSQSGCSIASDSGSSSLSDIYQATESEVGDVDLTRLPEGPVDSEDDEEEDEEIDRTDPLQGRDLVRECLEKEPADKTDDDIEQLLEFMHQLPAFANMTMSVRRELCSVMIFEVVEQAGAIILEDGQELDSWYVILNGTVEISHPDGKVENLFMGNSFGITPTLDKQYMHGIVRTKVDDCQFVCIAQQDYWRILNHVEKNTHKVEEEGEIVMVHEHRELDRSGTRKGHIVIKATPERLIMHLIEEHSIVDPTYIEDFLLTYRTFLESPLDVGIKLLEWFKIDSLRDKVTRIVLLWVNNHFNDFEGDPAMTRFLEEFEKNLEDTKMNGHLRLLNIACAAKAKWRQVVLQKASRESPLQFSLNGGSEKGFGIFVEGVEPGSKAADSGLKRGDQIMEVNGQNFENITFMKAVEILRNNTHLALTVKTNIFVFKELLFRTEQEKSGVPHIPKIAEKKSNRHSIQHVPGDIEQTSQEKGSKKVKANTVSGGRNKIRKILDKTRFSILPPKLFSDGGLSQSQDDSIVGTRHCRHSLAIMPIPGTLSSSSPDLLQPTTSMLDFSNPSDIPDQVIRVFKVDQQSCYIIISKDTTAKEVVFHAVHEFGLTGASDTYSLCEVSVTPEGVIKQRRLPDQFSKLADRIQLNGR>sp|O75056|SDC3_HUMAN Syndecan-3 OS=Homo sapiens OX=9606 GN=SDC3 PE=1SV=2MKPGPPHRAGAAHGAGAGAGAAAGPGARGLLLPPLLLLLLAGRAAGAQRWRSENFERPVDLEGSGDDDSFPDDELDDLYSGSGSGYFEQESGIETAMRFSPDVALAVSTTPAVLPTTNIQPVGTPFEELPSERPTLEPATSPLVVTEVPEEPSQRATTVSTTMATTAATSTGDPTVATVPATVATATPSTPAAPPFTATTAVIRTTGVRRLLPLPLTTVATARATTPEAPSPPTTAAVLDTEAPTPRLVSTATSRPRALPRPATTQEPDIPERSTLPLGTTAPGPTEVAQTPTPETFLTTIRDEPEVPVSGGPSGDFELPEEETTQPDTANEVVAVGGAAAKASSPPGTLPKGARPGPGLLDNAIDSGSSAAQLPQKSILERKEVLVAVIVGGVVGALFAAFLVTLLIYRMKKKDEGSYTLEEPKQASVTYQKPDKQEEFYA>sp|Q05823|RN5A_HUMAN 2-5A-dependent ribonuclease OS=Homo sapiens OX=9606GN=RNASEL PE=1 SV=2MESRDHNNPQEGPTSSSGRRAAVEDNHLLIKAVQNEDVDLVQQLLEGGANVNFQEEEGGWTPLHNAVQMSREDIVELLLRHGADPVLRKKNGATPFILAAIAGSVKLLKLFLSKGADVNECDFYGFTAFMEAAVYGKVKALKFLYKRGANVNLRRKTKEDQERLRKGGATALMDAAEKGHVEVLKILLDEMGADVNACDNMGRNALIHALLSSDDSDVEAITHLLLDHGADVNVRGERGKTPLILAVEKKHLGLVQRLLEQEHIEINDTDSDGKTALLLAVELKLKKIAELLCKRGASTDCGDLVMTARRNYDHSLVKVLLSHGAKEDFHPPAEDWKPQSSHWGAALKDLHRIYRPMIGKLKFFIDEKYKIADTSEGGIYLGFYEKQEVAVKTFCEGSPRAQREVSCLQSSRENSHLVTFYGSESHRGHLFVCVTLCEQTLEACLDVHRGEDVENEEDEFARNVLSSIFKAVQELHLSCGYTHQDLQPQNILIDSKKAAHLADFDKSIKWAGDPQEVKRDLEDLGRLVLYVVKKGSISFEDLKAQSNEEVVQLSPDEETKDLIHRLFHPGEHVRDCLSDLLGHPFFWTWESRYRTLRNVGNESDIKTRKSESEILRLLQPGPSEHSKSFDKWTTKINECVMKKMNKFYEKRGNFYQNTVGDLLKFIRNLGEHIDEEKHKKMKLKIGDPSLYFQKTFPDLVIYVYTKLQNTEYRKHFPQTHSPNKPQCDGAGGASGLASPGC>sp|Q05823-2|RN5A_HUMAN Isoform 2 of 2-5A-dependent ribonuclease OS=Homosapiens OX=9606 GN=RNASELMESRDHNNPQEGPTSSSGRRAAVEDNHLLIKAVQNEDVDLVQQLLEGGANVNFQEEEGGWTPLHNAVQMSREDIVELLLRHGADPVLRKKNGATPFILAAIAGSVKLLKLFLSKGADVNECDFYGFTAFMEAAVYGKVKALKFLYKRGANVNLRRKTKEDQERLRKGGATALMDAAEKGHVEVLKILLDEMGADVNACDNMGRNALIHALLSSDDSDVEAITHLLLDHGADVNVRGERGKTPLILAVEKKHLGLVQRLLEQEHIEINDTDSDGKTALLLAVELKLKKIAELLCKRGASTDCGDLVMTARRNYDHSLVKVLLSHGAKEDFHPPAEDWKPQSSHWGAALKDLHRIYRPMIGKLKFFIDEKYKIADTSEGGIYLGFYEKQEVAVKTFCEGSPRAQREVSCLQSSRENSHLVTFYGSESHRGHLFVCVTLCEQTLEACLDVHRGEDVENEEDEFARNVLSSIFKAVQELHLSCGYTHQDLQPQNILIDSKKAAHLADFDKSIKWAGDPQEVKRDLEDLGRLVLYVVKKGSISFEDLKAQSNEEVVQLSPDEETKDLIHRLFHPGEHVRDCLSDLLGHPFFWTWESRYRTLRNVGNESDIKTRKSESEILRLLQPGPSEHSKSFDKWTTKMSKLRHRQIIFPTTQNQ>sp|Q5M7Z0|RNFT1_HUMAN E3 ubiquitin-protein ligase RNFT1 OS=Homo sapiensOX=9606 GN=RNFT1 PE=1 SV=2MPLFLLSLPTPPSASGHERRQRPEAKTSGSEKKYLRAMQANRSQLHSPPGTGSSEDASTPQCVHTRLTGEGSCPHSGDVHIQINSIPKECAENASSRNIRSGVHSCAHGCVHSRLRGHSHSEARLTDDTAAESGDHGSSSFSEFRYLFKWLQKSLPYILILSVKLVMQHITGISLGIGLLTTFMYANKSIVNQVFLRERSSKIQCAWLLVFLAGSSVLLYYTFHSQSLYYSLIFLNPTLDHLSFWEVFWIVGITDFILKFFFMGLKCLILLVPSFIMPFKSKGYWYMLLEELCQYYRTFVPIPVWFRYLISYGEFGNVTRWSLGILLALLYLILKLLEFFGHLRTFRQVLRIFFTQPSYGVAASKRQCSDVDDICSICQAEFQKPILLICQHIFCEECMTLWFNREKTCPLCRTVISDHINKWKDGATSSHLQIY>sp|Q5M7Z0-2|RNFT1_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNFT1OS=Homo sapiens OX=9606 GN=RNFT1MPLFLLSLPTPPSASGHERRQRPEAKTSGSEKKYLRAMQANRSQLHSPPGTGSSEDASTPQCVHTRLTGEGSCPHSGDVHIQINSIPKECAENASSRNIRSGVHSCAHGCVHSRLRGHSHSEARLTDDTAAESGDHGSSSFSEFRYLFKWLQKSLPYILILSVKLVMQHITGISLGIGLLTTFMYANKSIVNQVFLRVSITSN>sp|Q5M7Z0-3|RNFT1_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNFT1OS=Homo sapiens OX=9606 GN=RNFT1MPLFLLSLPTPPSASGHERRQRPEAKTSGSEKKYLRAMQANRSQLHSPPGTGSSEDASTPQCVHTRLTGEGSCPHSGDVHIQINSIPKECAENASSRNIRSGVHSCAHGCVHSRLRGHSHSEARLTDDTAAESGDHGSSSFSEFRYLFKWLQKSLPYILILSVKLVMQHITGISLGIGLLTTFMYANKSIVNQVFLRLNFFKSYFGPFELLGSILDCWNYRLHSEILFHGLKMPYFIGAFFHHAF>sp|Q9NYK5|RM39_HUMAN 39S ribosomal protein L39, mitochondrial OS=Homosapiens OX=9606 GN=MRPL39 PE=1 SV=3MEALAMGSRALRLWLVAPGGGIKWRFIATSSASQLSPTELTEMRNDLFNKEKARQLSLTPRTEKIEVKHVGKTDPGTVFVMNKNISTPYSCAMHLSEWYCRKSILALVDGQPWDMYKPLTKSCEIKFLTFKDCDPGEVNKAYWRSCAMMMGCVIERAFKDEYMVNLVRAPEVPVISGAFCYDVVLDSKLDEWMPTKENLRSFTKDAHALIYKDLPFETLEVEAKVALEIFQHSKYKVDFIEEKASQNPERIVKLHRIGDFIDVSEGPLIPRTSICFQYEVSAVHNLQPTQPSLIRRFQGVSLPVHLRAHFTIWDKLLERSRKMVTEDQSKATEECTST>sp|Q9NYK5-2|RM39_HUMAN Isoform 2 of 39S ribosomal protein L39,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL39MEALAMGSRALRLWLVAPGGGIKWRFIATSSASQLSPTELTEMRNDLFNKEKARQLSLTPRTEKIEVKHVGKTDPGTVFVMNKNISTPYSCAMHLSEWYCRKSILALVDGQPWDMYKPLTKSCEIKFLTFKDCDPGEVNKAYWRSCAMMMGCVIERAFKDEYMVNLVRAPEVPVISGAFCYDVVLDSKLDEWMPTKENLRSFTKDAHALIYKDLPFETLEVEAKVALEIFQHSKYKVDFIEEKASQNPERIVKLHRIGDFIDVSEGPLIPRTSICFQYEVSAVHNLQPTQPSLIRRFQGVSLPVHLRAHFTIWDKLLERSRKMTPFPILLLFTTQSFFTTSPESYLLHGTVSE>sp|Q9Y6G3|RM42_HUMAN 39S ribosomal protein L42, mitochondrial OS=Homosapiens OX=9606 GN=MRPL42 PE=1 SV=1MAVAAVKWVMSKRTILKHLFPVQNGALYCVCHKSTYSPLPDDYNCNVELALTSDGRTIVCYHPSVDIPYEHTKPIPRPDPVHNNEETHDQVLKTRLEEKVEHLEEGPMIEQLSKMFFTTKHRWYPHGRYHRCRKNLNPPKDR>sp|Q13405|RM49_HUMAN 39S ribosomal protein L49, mitochondrial OS=Homosapiens OX=9606 GN=MRPL49 PE=1 SV=1MAATMFRATLRGWRTGVQRGCGLRLLSQTQGPPDYPRFVESVDEYQFVERLLPATRIPDPPKHEHYPTPSGWQPPRDPPPNLPYFVRRSRMHNIPVYKDITHGNRQMTVIRKVEGDIWALQKDVEDFLSPLLGKTPVTQVNEVTGTLRIKGYFDQELKAWLLEKGF>sp|Q8WU17|RN139_HUMAN E3 ubiquitin-protein ligase RNF139 OS=Homo sapiensOX=9606 GN=RNF139 PE=1 SV=1MAAVGPPQQQVRMAHQQVWAALEVALRVPCLYIIDAIFNSYPDSSQSRFCIVLQIFLRLFGVFASSIVLILSQRSLFKFYTYSSAFLLAATSVLVNYYASLHIDFYGAYNTSAFGIELLPRKGPSLWMALIVLQLTFGIGYVTLLQIHSIYSQLIILDLLVPVIGLITELPLHIRETLLFTSSLILTLNTVFVLAVKLKWFYYSTRYVYLLVRHMYRIYGLQLLMEDTWKRIRFPDILRVFWLTRVTAQATVLMYILRMANETDSFFISWDDFWDLICNLIISGCDSTLTVLGMSAVISSVAHYLGLGILAFIGSTEEDDRRLGFVAPVLFFILALQTGLSGLRPEERLIRLSRNMCLLLTAVLHFIHGMTDPVLMSLSASHVSSFRRHFPVLFVSACLFILPVLLSYVLWHHYALNTWLFAVTAFCVELCLKVIVSLTVYTLFMIDGYYNVLWEKLDDYVYYVRSTGSIIEFIFGVVMFGNGAYTMMFESGSKIRAFMMCLHAYFNIYLQAKNGWKTFMNRRTAVKKINSLPEIKGSRLQEINDVCAICYHEFTTSARITPCNHYFHALCLRKWLYIQDTCPMCHQKVYIEDDIKDNSNVSNNNGFIPPNETPEEAVREAAAESDRELNEDDSTDCDDDVQRERNGVIQHTGAAAEEFNDDTD>sp|Q9Y508|RN114_HUMAN E3 ubiquitin-protein ligase RNF114 OS=Homo sapiensOX=9606 GN=RNF114 PE=1 SV=1MAAQQRDCGGAAQLAGPAAEADPLGRFTCPVCLEVYEKPVQVPCGHVFCSACLQECLKPKKPVCGVCRSALAPGVRAVELERQIESTETSCHGCRKNFFLSKIRSHVATCSKYQNYIMEGVKATIKDASLQPRNVPNRYTFPCPYCPEKNFDQEGLVEHCKLFHSTDTKSVVCPICASMPWGDPNYRSANFREHIQRRHRFSYDTFVDYDVDEEDMMNQVLQRSIIDQ>sp|Q9Y508-2|RN114_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF114OS=Homo sapiens OX=9606 GN=RNF114MAAQQRDCGGAAQLAGPAAEADPLGRFTCPVCLEVYEKPVQVPCGHVFCSACLQECLKPKKPVCGVCRSALAPGVRAVELERQIESTETSCHGCRKNFFLSKIRSHVATCSKYQNYIMEGVKATIKDASLQPRNVPNRYTFPCPYCPEKNFDQEGLVEHCKLFHSTDTKSVVSEQSPCLLSVSCYRASITY>sp|Q5XPI4|RN123_HUMAN E3 ubiquitin-protein ligase RNF123 OS=Homo sapiensOX=9606 GN=RNF123 PE=1 SV=1MASKGAGMSFSRKSYRLTSDAEKSRVTGIVQEKLLNDYLNRIFSSSEHAPPAATSRKPLNFQNLPEHLDQLLQVDNEEEESQGQVEGRLGPSTVVLDHTGGFEGLLLVDDDLLGVIGHSNFGTIRSTTCVYKGKWLYEVLISSQGLMQIGWCTISCRFNQEEGVGDTHNSYAYDGNRVRKWNVTTTNYGKAWAAGDIVSCLIDLDDGTLSFCLNGVSLGTAFENLSRGLGMAYFPAISLSFKESVAFNFGSRPLRYPVAGYRPLQDPPSADLVRAQRLLGCFRAVLSVELDPVEGRLLDKESSKWRLRGQPTVLLTLAHIFHHFAPLLRKVYLVEAVLMSFLLGIVEKGTPTQAQSVVHQVLDLLWLFMEDYEVQDCLKQLMMSLLRLYRFSPIVPDLGLQIHYLRLTIAILRHEKSRKFLLSNVLFDVLRSVVFFYIKSPLRVEEAGLQELIPTTWWPHCSSREGKESTEMKEETAEERLRRRAYERGCQRLRKRIEVVEELQVQILKLLLDNKDDNGGEASRYIFLTKFRKFLQENASGRGNMPMLCPPEYMVCFLHRLISALRYYWDEYKASNPHASFSEEAYIPPQVFYNGKVDYFDLQRLGGLLSHLRKTLKDDLASKANIVIDPLELQSTAMDDLDEDEEPAPAMAQRPMQALAVGGPLPLPRPGWLSSPTLGRANRFLSTAAVSLMTPRRPLSTSEKVKVRTLSVEQRTREDIEGSHWNEGLLLGRPPEEPEQPLTENSLLEVLDGAVMMYNLSVHQQLGKMVGVSDDVNEYAMALRDTEDKLRRCPKRRKDILAELTKSQKVFSEKLDHLSRRLAWVHATVYSQEKMLDIYWLLRVCLRTIEHGDRTGSLFAFMPEFYLSVAINSYSALKNYFGPVHSMEELPGYEETLTRLAAILAKHFADARIVGTDIRDSLMQALASYVCYPHSLRAVERIPEEQRIAMVRNLLAPYEQRPWAQTNWILVRLWRGCGFGYRYTRLPHLLKTKLEDANLPSLQKPCPSTLLQQHMADLLQQGPDVAPSFLNSVLNQLNWAFSEFIGMIQEIQQAAERLERNFVDSRQLKVCATCFDLSVSLLRVLEMTITLVPEIFLDWTRPTSEMLLRRLAQLLNQVLNRVTAERNLFDRVVTLRLPGLESVDHYPILVAVTGILVQLLVRGPASEREQATSVLLADPCFQLRSICYLLGQPEPPAPGTALPAPDRKRFSLQSYADYISADELAQVEQMLAHLTSASAQAAAASLPTSEEDLCPICYAHPISAVFQPCGHKSCKACINQHLMNNKDCFFCKTTIVSVEDWEKGANTSTTSSAA>sp|Q5XPI4-2|RN123_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF123OS=Homo sapiens OX=9606 GN=RNF123MASKGAGMSFSRKSYRLTSDAEKSRVTGIVQEKLLNDYLNRIFSSSEHAPPAATSRKPLNFQNLPEHLDQLLQVDNEEEESQGQVEGRLGPSTVVLDHTGGFEGLLLVDDDLLGVIGHSNFGTIRSTTCVYKGKWLYEVLISSQGLMQIGWCTISCRFNQEEGVGDTHNSYAYDGNRVRKWNVTTTNYGKAWAAGDIVSCLIDLDDGTLSFCLNGVSLGTAFENLSRGLGMAYFPAISLSFKESVAFNFGSRPLRYPVAGYRPLQDPPSADLVRAQRLLGCFRAVLSVELDPVEGRLLDKESSKWRLRGQPTVLLTLAHIFHHFAPLLRKVYLVEAVLMSFLLGIVEKGTPTQAQSVVHQVLDLLWLFMEDYEVQDCLKQLMMSLLRLYRFSPIVPDLGLQIHYLRLTIAILRHEKSRKFLLSNVLFDVLRSVVFFYIKSPLRVEEAGLQELIPTTWWPHCSSREGKESTEMKEETAEERLRRRAYERGCQRLRKRIEVVEELQVQILKLLLDNKDDNGGEASRYIFLTKFRKFLQENASGRGNMPMLCPPEYMVCFLHRLISALRYYWDEYKASNPHASFSEEAYIPPQVFYNGKVDYFDLQRLGGLLSHLRKTLKDDLASKANIVIDPLELQSTAMDDLDEDEEPAPAMAQRPMQALAVGGPLPLPRPGWLSSPTLGRANRFLSTAAVSLMTPRRPLSTSEKVKVRTLSVEQRTREDIEGSHWNEGLLLGRPPEEPEQPLTENSLLEVLDGAVMMYNLSVHQQLGKMVGVSDDVNEYAMALRDTEDKLRRCPKRRKDILAELTKSQKVFSEKLDHLSRRLAWVHATVYSQEKMLDIYWLLRVCLRTIEHGDRTGSLFAFMPEFYLSVAINSYSALKNYFGPVHSMEELPGYEETLTRLAAILAKHFADARIVGTDIRDSLMQALASYVCYPHSLRAVERIPEEQRIAMVRNLLAPYEQRPWAQTNWILVRLWRGCGFGYRYTRLPHLLKTKLEDANLPSLQKPCPSTLLQQHMADLLQQGPDVAPSFLNSVLNQLNWAFSEFIGMIQEIQQAAERLERNFVDSRQLKVCATCFDLSVSLLRVLEMTITLVPEIFLDWTRPTSEMLLRRLAQLLNQVLNRVTAERNLFDRVVTLRLPGLESVDHYPILVAVTGILVQLLVRGPASEREQATSVLLADPCFQLRSICYLLGQPEPPAPGTALPAPDRKRFSLQSYADYISADELAQVEQMLAHLTSASAQAAAASLPTSEEDLCPICYAHPISAVFQPCGHKSCKACINQHLMNNKDCFFCKTTTSNLLACLYPHWWEPSHGPNCA>sp|Q03395|ROM1_HUMAN Rod outer segment membrane protein 1 OS=Homosapiens OX=9606 GN=ROM1 PE=1 SV=2MAPVLPLVLPLQPRIRLAQGLWLLSWLLALAGGVILLCSGHLLVQLRHLGTFLAPSCQFPVLPQAALAAGAVALGTGLVGVGASRASLNAALYPPWRGVLGPLLVAGTAGGGGLLVVGLGLALALPGSLDEALEEGLVTALAHYKDTEVPGHCQAKRLVDELQLRYHCCGRHGYKDWFGVQWVSSRYLDPGDRDVADRIQSNVEGLYLTDGVPFSCCNPHSPRPCLQNRLSDSYAHPLFDPRQPNQNLWAQGCHEVLLEHLQDLAGTLGSMLAVTFLLQALVLLGLRYLQTALEGLGGVIDAGGETQGYLFPSGLKDMLKTAWLQGGVACRPAPEEAPPGEAPPKEDLSEA>sp|Q6ZMZ0|RN19B_HUMAN E3 ubiquitin-protein ligase RNF19B OS=Homo sapiensOX=9606 GN=RNF19B PE=1 SV=2MGSEKDSESPRSTSLHAAAPDPKCRSGGRRRRLTLHSVFSASARGRRARAKPQAEPPPPAAQPPPAPAPAAAQGPPPEALPAEPAAEAEAEAAAAAAEPGFDDEEAAEGGGPGAEEVECPLCLVRLPPERAPRLLSCPHRSCRDCLRHYLRLEISESRVPISCPECSERLNPHDIRLLLADPPLMHKYEEFMLRRYLASDPDCRWCPAPDCGYAVIAYGCASCPKLTCEREGCQTEFCYHCKQIWHPNQTCDMARQQRAQTLRVRTKHTSGLSYGQESGPADDIKPCPRCSAYIIKMNDGSCNHMTCAVCGCEFCWLCMKEISDLHYLSPSGCTFWGKKPWSRKKKILWQLGTLIGAPVGISLIAGIAIPAMVIGIPVYVGRKIHSRYEGRKTSKHKRNLAITGGVTLSVIASPVIAAVSVGIGVPIMLAYVYGVVPISLCRGGGCGVSTANGKGVKIEFDEDDGPITVADAWRALKNPSIGESSIEGLTSVLSTSGSPTDGLSVMQGPYSETASFAALSGGTLSGGILSSGKGKYSRLEVQADVQKEIFPKDTASLGAISDNASTRAMAGSIISSYNPQDRECNNMEIQVDIEAKPSHYQLVSGSSTEDSLHVHAQMAENEEEGSGGGGSEEDPPCRHQSCEQKDCLASKPWDISLAQPESIRSDLESSDAQSDDVPDITSDECGSPRSHTAACPSTPRAQGAPSPSAHMNLSALAEGQTVLKPEGGEARV>sp|Q6ZMZ0-2|RN19B_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF19BOS=Homo sapiens OX=9606 GN=RNF19BMGSEKDSESPRSTSLHAAAPDPKCRSGGRRRRLTLHSVFSASARGRRARAKPQAEPPPPAAQPPPAPAPAAAQGPPPEALPAEPAAEAEAEAAAAAAEPGFDDEEAAEGGGPGAEEVECPLCLVRLPPERAPRLLSCPHRSCRDCLRHYLRLEISESRVPISCPECSERLNPHDIRLLLADPPLMHKYEEFMLRRYLASDPDCRWCPAPDCGYAVIAYGCASCPKLTCEREGCQTEFCYHCKQIWHPNQTCDMARQQRAQTLRVRTKHTSGLSYGQESGPDDIKPCPRCSAYIIKMNDGSCNHMTCAVCGCEFCWLCMKEISDLHYLSPSGCTFWGKKPWSRKKKILWQLGTLIGAPVGISLIAGIAIPAMVIGIPVYVGRKIHSRYEGRKTSKHKRNLAITGGVTLSVIASPVIAAVSVGIGVPIMLAYVYGVVPISLCRGGGCGVSTANGKGVKIEFDEDDGPITVADAWRALKNPSIGESSIEGLTSVLSTSGSPTDGLSVMQGPYSETASFAALSGGTLSGGILSSGKGKYSRLEVQADVQKEIFPKDTASLGAISDNASTRAMAGSIISSYNPQDRFSMIHA>sp|Q6ZMZ0-3|RN19B_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNF19BOS=Homo sapiens OX=9606 GN=RNF19BMGSEKDSESPRSTSLHAAAPDPKCRSGGRRRRLLSCPHRSCRDCLRHYLRLEISESRVPISCPECSERLNPHDIRLLLADPPLMHKYEEFMLRRYLASDPDCRWCPAPDCGYAVIAYGCASCPKLTCEREGCQTEFCYHCKQIWHPNQTCDMARQQRAQTLRVRTKHTSGLSYGQESGPDDIKPCPRCSAYIIKMNDGSCNHMTCAVCGCEFCWLCMKEISDLHYLSPSGCTFWGKKPWSRKKKILWQLGTLIGAPVGISLIAGIAIPAMVIGIPVYVGRKIHSRYEGRKTSKHKRNLAITGGVTLSVIASPVIAAVSVGIGVPIMLAYVYGVVPISLCRGGGCGVSTANGKGVKIEFDEDDGPITVADAWRALKNPSIGESSIEGLTSVLSTSGSPTDGLSVMQGPYSETASFAALSGGTLSGGILSSGKGKYSRLEVQADVQKEIFPKDTASLGAISDNASTRAMAGSIISSYNPQDRFSMIHA>sp|Q6ZMZ0-4|RN19B_HUMAN Isoform 4 of E3 ubiquitin-protein ligase RNF19BOS=Homo sapiens OX=9606 GN=RNF19BMGSEKDSESPRSTSLHAAAPDPKCRSGGRRRRLTLHSVFSASARGRRARAKPQAEPPPPAAQPPPAPAPAAAQGPPPEALPAEPAAEAEAEAAAAAAEPGFDDEEAAEGGGPGAEEVECPLCLVRLPPERAPRLLSCPHRSCRDCLRHYLRLEISESRVPISCPECSERLNPHDIRLLLADPPLMHKYEEFMLRRYLASDPDCRWCPAPDCGYAVIAYGCASCPKLTCEREGCQTEFCYHCKQIWHPNQTCDMARQQRAQTLRVRTKHTSGLSYGQESGPDDIKPCPRCSAYIIKMNDGSCNHMTCAVCGCEFCWLCMKEISDLHYLSPSGCTFWGKKPWSRKKKILWQLGTLIGAPVGISLIAGIAIPAMVIGIPVYVGRKIHSRYEGRKTSKHKRNLAITGGVTLSVIASPVIAAVSVGIGVPIMLAYVYGVVPISLCRGGGCGVSTANGKGVKIEFDEDDGPITVADAWRALKNPSIGESSIEGLTSVLSTSGSPTDGLSVMQGPYSETASFAALSGGTLSGGILSSGKGKYSRLEVQADVQKEIFPKDTASLGAISDNASTRAMAGSIISSYNPQDRECNNMEIQVDIEAKPSHYQLVSGSSTEDSLHVHAQMAENEEEGSGGGGSEEDPPCRHQSCEQKDCLASKPWDISLAQPESIRSDLESSDAQSDDVPDITSDECGSPRSHTAACPSTPRAQGAPSPSAHMNLSALAEGQTVLKPEGGEARV>sp|Q495C1|RN212_HUMAN Probable E3 SUMO-protein ligase RNF212 OS=Homosapiens OX=9606 GN=RNF212 PE=2 SV=1MANWVFCNRCFQPPHRTSCFSLTNCGHVYCDACLGKGKKNECLICKAPCRTVLLSKHTDADIQAFFMSIDSLCKKYSRETSQILEFQEKHRKRLLAFYREKISRLEESLRKSVLQIEQLQSMRSSQQTAFSTIKSSVSTKPHGCLLPPHSSAPDRLESMEVDLSPSPIRKSEIAAGPARISMISPPQDGRMGPHLTASFCFIPWLTLSKPPVPGECVISRGSPCFCIDVCPHWLLLLAFSSGRHGELTNSKTLPIYAEVQRAVLFPFQQAEGTLDTFRTPAVSVVFPLCQFERKKSF>sp|Q495C1-2|RN212_HUMAN Isoform 2 of Probable E3 SUMO-protein ligaseRNF212 OS=Homo sapiens OX=9606 GN=RNF212MANWVFCNRCFQPPHRTSCFSLTNCGHVYCDACLGKGKKNECLICKAPCRTVLLSKHTDADIQAFFMSIDSLCKKYSRETSQILEFQEKHRKRLLAFYREKISRLEESLRKSVLQIEQLQSLR>sp|Q495C1-3|RN212_HUMAN Isoform 3 of Probable E3 SUMO-protein ligaseRNF212 OS=Homo sapiens OX=9606 GN=RNF212MANWVFCNRCFQPPHRTSCFSLTNCGHVYCDACLGKGKKNECLICKAPCRTVLLSKHTDADIQAFFMSIDSLCKKYSRETSQILEFQEKHRKRLLAFYREKISRLEESLRKSVLQIEQLQSMRSSQQTAFSTIKSSVSTKPHGCLLPPHSSAPDRLESMEVDLSPSPIRKSEIAAGPARISMISPPQDGRMG>sp|Q495C1-4|RN212_HUMAN Isoform 4 of Probable E3 SUMO-protein ligaseRNF212 OS=Homo sapiens OX=9606 GN=RNF212MANWVFCNRCFQPPHRTSCFSLTNCGHVYCDACLGKGKKNECLICKAPCRTVLLSKHTDADIQAFFMSIDSLCKKYSRETSQYLRLSRGCCRLKLCPATSSKEVPRGSTHGSQAAARDPQEHWVSTTRAPRPGCRRSQSQPEAQGNTIQDAPHPLTLLHPSRTLIHTKSPWGQKLLEFIKHVCYHRHQSHRPCAPGWFCQVLQRPGAVSGEKTQQTRPAPPATCLLCLSCLSGFRHGPWRWLAPAWAAQALPSDLVAPLFVSYTVEVSITNAGWSFPAAV>sp|Q495C1-5|RN212_HUMAN Isoform 5 of Probable E3 SUMO-protein ligaseRNF212 OS=Homo sapiens OX=9606 GN=RNF212MANWVFCNRCFQPPHRTSCFSLTNCGHVYCDACLGKGKKNECLICKAPCRTVLLSKHTDADIQAFFMSIDSLCKKYSRETSQILEFQEKHRKRLLAFYREKISRLEESLRKSVLQIEQLQSMRSSQQTAFSTIKSSVSTKPHGCLLPPHSSAPDRLESMEVDLSPSPIRKSEIAAGPARISMISPPQDGRMAPCARRVCHFQRFTMFLHRRLSSLAAPPSVQFWKARGTHQL>sp|Q495C1-6|RN212_HUMAN Isoform 6 of Probable E3 SUMO-protein ligaseRNF212 OS=Homo sapiens OX=9606 GN=RNF212MANWVFCNRCFQPPHRTSCFSLTNCGHVYCDACLGKGKKNECLICKAPCRTVLLSKHTDADIQAFFMSIDSLCKKYSRETSQYLRLSRGCCRLKLCPATSSKEVPRGSTHGSQAAARDPQEHWVSTTRAPRPGCRRSQSQPEAQGNTIQDAPHPLTLLHPSRTLIHTKSPWGQKLLEFIKHVCYHRHQSHRPCAPGWFCQVLQRPGAVSGEKTQQTRPAPPATCLLCLSCLSGFRHGPWRSQALPSDLVAPLFVSYTVEVSITNAGWSFPAAV>sp|Q8WZ75|ROBO4_HUMAN Roundabout homolog 4 OS=Homo sapiens OX=9606GN=ROBO4 PE=1 SV=1MGSGGDSLLGGRGSLPLLLLLIMGGMAQDSPPQILVHPQDQLFQGPGPARMSCQASGQPPPTIRWLLNGQPLSMVPPDPHHLLPDGTLLLLQPPARGHAHDGQALSTDLGVYTCEASNRLGTAVSRGARLSVAVLREDFQIQPRDMVAVVGEQFTLECGPPWGHPEPTVSWWKDGKPLALQPGRHTVSGGSLLMARAEKSDEGTYMCVATNSAGHRESRAARVSIQEPQDYTEPVELLAVRIQLENVTLLNPDPAEGPKPRPAVWLSWKVSGPAAPAQSYTALFRTQTAPGGQGAPWAEELLAGWQSAELGGLHWGQDYEFKVRPSSGRARGPDSNVLLLRLPEKVPSAPPQEVTLKPGNGTVFVSWVPPPAENHNGIIRGYQVWSLGNTSLPPANWTVVGEQTQLEIATHMPGSYCVQVAAVTGAGAGEPSRPVCLLLEQAMERATQEPSEHGPWTLEQLRATLKRPEVIATCGVALWLLLLGTAVCIHRRRRARVHLGPGLYRYTSEDAILKHRMDHSDSQWLADTWRSTSGSRDLSSSSSLSSRLGADARDPLDCRRSLLSWDSRSPGVPLLPDTSTFYGSLIAELPSSTPARPSPQVPAVRRLPPQLAQLSSPCSSSDSLCSRRGLSSPRLSLAPAEAWKAKKKQELQHANSSPLLRGSHSLELRACELGNRGSKNLSQSPGAVPQALVAWRALGPKLLSSSNELVTRHLPPAPLFPHETPPTQSQQTQPPVAPQAPSSILLPAAPIPILSPCSPPSPQASSLSGPSPASSRLSSSSLSSLGEDQDSVLTPEEVALCLELSEGEETPRNSVSPMPRAPSPPTTYGYISVPTASEFTDMGRTGGGVGPKGGVLLCPPRPCLTPTPSEGSLANGWGSASEDNAASARASLVSSSDGSFLADAHFARALAVAVDSFGFGLEPREADCVFIDASSPPSPRDEIFLTPNLSLPLWEWRPDWLEDMEVSHTQRLGRGMPPWPPDSQISSQRSQLHCRMPKAGASPVDYS>sp|Q8WZ75-2|ROBO4_HUMAN Isoform 2 of Roundabout homolog 4 OS=Homosapiens OX=9606 GN=ROBO4MGSGGDSLLGGRGSLPLLLLLIMGGMAQDSPPQILVHPQDQLFQGPGPARMSCQASGQPPPTIRWLLNGQPLSMVPPDPHHLLPDGTLLLLQPPARGHAHDGQALSTDLGVYTCEASNRLGTAVSRGARLSVAVLREDFQIQPRDMVAVVGEQFTLECGPPWGHPEPTVSWWKDGKPLALQPGRHTVSGGSLLMARAEKSDEGTYMCVATNSAGHRESRAARVSIQEPQDYTEPVELLAVRIQLENVTLLNPDPAEGPKPRPAVWLSWKVSGPAAPAQSYTALFRTQTAPGGQGAPWAEELLAGWQSAELGGLHWGQDYEFKVRPSSGRARGPDSNVLLLRLPEKVPSAPPQEVTLKPGNGTVFVSWVPPPAENHNGIIRGYQVWSLGNTSLPPANWTVVGEQTQLEIATHMPGSYCVQVAAVTGAGAGEPSRPVCLLLEQAMERATQEPSEHGPWTLEQLRATLKRPEVIATCGVALWLLLLGTAVCIHRRRRARVHLGPGLYRYTSEDAILKHRMDHSDSQWLADTWRSTSGSRDLSSSSSLSSRLGADARDPLDCRRSLLSWDSRSPGVPLLPDTSTFYGSLIAELPSSTPARPSPQVPAVRRLPPQLAQLSSPCSSSDSLCSRRGLSSPRLSLAPAEAWKAKKKQELQHANSSPLLRGSHSLELRACELGNRGSKNLSQSPGAVPQALVAWRALGPKLLSSSNELVTRHLPPAPLFPHETPPTQSQQTQPPVAPQAPSSILLPAAPIPILSPCSPPSPQASSLSGPSPASSRLSSSSLSSLGEDQDSVLTPEEVALCLELSEGEETPRNSVSPMPRAPSPPTTYGYISVPTASEFTDMGRTGGGVGPKGGVLLCPPRPCLTPTPSEGSLANGWGSASEDNAASARASLVSSSDGSFLADAHFARALAVAVDSFGFGLEPREADCVFIGM>sp|Q8WZ75-3|ROBO4_HUMAN Isoform 3 of Roundabout homolog 4 OS=Homosapiens OX=9606 GN=ROBO4MGSGGDSLLGGRGSLPLLLLLIMVLREDFQIQPRDMVAVVGEQFTLECGPPWGHPEPTVSWWKDGKPLALQPGRHTVSGGSLLMARAEKSDEGTYMCVATNSAGHRESRAARVSIQEPQDYTEPVELLAVRIQLENVTLLNPDPAEGPKPRPAVWLSWKVSGPAAPAQSYTALFRTQTAPGGQGAPWAEELLAGWQSAELGGLHWGQDYEFKVRPSSGRARGPDSNVLLLRLPEKVPSAPPQEVTLKPGNGTVFVSWVPPPAENHNGIIRGYQVWSLGNTSLPPANWTVVGEQTQLEIATHMPGSYCVQVAAVTGAGAGEPSRPVCLLLEQAMERATQEPSEHGPWTLEQLRATLKRPEVIATCGVALWLLLLGTAVCIHRRRRARVHLGPGLYRYTSEDAILKHRMDHSDSQWLADTWRSTSGSRDLSSSSSLSSRLGADARDPLDCRRSLLSWDSRSPGVPLLPDTSTFYGSLIAELPSSTPARPSPQVPAVRRLPPQLAQLSSPCSSSDSLCSRRGLSSPRLSLAPAEAWKAKKKQELQHANSSPLLRGSHSLELRACELGNRGSKNLSQSPGAVPQALVAWRALGPKLLSSSNELVTRHLPPAPLFPHETPPTQSQQTQPPVAPQAPSSILLPAAPIPILSPCSPPSPQASSLSGPSPASSRLSSSSLSSLGEDQDSVLTPEEVALCLELSEGEETPR>sp|Q8N4K4|RPRML_HUMAN Reprimo-like protein OS=Homo sapiens OX=9606GN=RPRML PE=2 SV=2MNATFLNHSGLEEVDGVGGGAGAALGNRTHGLGTWLGCCPGGAPLAASDGVPAGLAPDERSLWVSRVAQIAVLCVLSLTVVFGVFFLGCNLLIKSESMINFLVQERRPSKDVGAAILGLY>sp|P60880|SNP25_HUMAN Synaptosomal-associated protein 25 OS=Homo sapiensOX=9606 GN=SNAP25 PE=1 SV=1MAEDADMRNELEEMQRRADQLADESLESTRRMLQLVEESKDAGIRTLVMLDEQGEQLERIEEGMDQINKDMKEAEKNLTDLGKFCGLCVCPCNKLKSSDAYKKAWGNNQDGVVASQPARVVDEREQMAISGGFIRRVTNDARENEMDENLEQVSGIIGNLRHMALDMGNEIDTQNRQIDRIMEKADSNKTRIDEANQRATKMLGSG>sp|P60880-2|SNP25_HUMAN Isoform 2 of Synaptosomal-associated protein 25OS=Homo sapiens OX=9606 GN=SNAP25MAEDADMRNELEEMQRRADQLADESLESTRRMLQLVEESKDAGIRTLVMLDEQGEQLDRVEEGMNHINQDMKEAEKNLKDLGKCCGLFICPCNKLKSSDAYKKAWGNNQDGVVASQPARVVDEREQMAISGGFIRRVTNDARENEMDENLEQVSGIIGNLRHMALDMGNEIDTQNRQIDRIMEKADSNKTRIDEANQRATKMLGSG>sp|O00411|RPOM_HUMAN DNA-directed RNA polymerase, mitochondrial OS=Homosapiens OX=9606 GN=POLRMT PE=1 SV=2MSALCWGRGAAGLKRALRPCGRPGLPGKEGTAGGVCGPRRSSSASPQEQDQDRRKDWGHVELLEVLQARVRQLQAESVSEVVVNRVDVARLPECGSGDGSLQPPRKVQMGAKDATPVPCGRWAKILEKDKRTQQMRMQRLKAKLQMPFQSGEFKALTRRLQVEPRLLSKQMAGCLEDCTRQAPESPWEEQLARLLQEAPGKLSLDVEQAPSGQHSQAQLSGQQQRLLAFFKCCLLTDQLPLAHHLLVVHHGQRQKRKLLTLDMYNAVMLGWARQGAFKELVYVLFMVKDAGLTPDLLSYAAALQCMGRQDQDAGTIERCLEQMSQEGLKLQALFTAVLLSEEDRATVLKAVHKVKPTFSLPPQLPPPVNTSKLLRDVYAKDGRVSYPKLHLPLKTLQCLFEKQLHMELASRVCVVSVEKPTLPSKEVKHARKTLKTLRDQWEKALCRALRETKNRLEREVYEGRFSLYPFLCLLDEREVVRMLLQVLQALPAQGESFTTLARELSARTFSRHVVQRQRVSGQVQALQNHYRKYLCLLASDAEVPEPCLPRQYWEELGAPEALREQPWPLPVQMELGKLLAEMLVQATQMPCSLDKPHRSSRLVPVLYHVYSFRNVQQIGILKPHPAYVQLLEKAAEPTLTFEAVDVPMLCPPLPWTSPHSGAFLLSPTKLMRTVEGATQHQELLETCPPTALHGALDALTQLGNCAWRVNGRVLDLVLQLFQAKGCPQLGVPAPPSEAPQPPEAHLPHSAAPARKAELRRELAHCQKVAREMHSLRAEALYRLSLAQHLRDRVFWLPHNMDFRGRTYPCPPHFNHLGSDVARALLEFAQGRPLGPHGLDWLKIHLVNLTGLKKREPLRKRLAFAEEVMDDILDSADQPLTGRKWWMGAEEPWQTLACCMEVANAVRASDPAAYVSHLPVHQDGSCNGLQHYAALGRDSVGAASVNLEPSDVPQDVYSGVAAQVEVFRRQDAQRGMRVAQVLEGFITRKVVKQTVMTVVYGVTRYGGRLQIEKRLRELSDFPQEFVWEASHYLVRQVFKSLQEMFSGTRAIQHWLTESARLISHMGSVVEWVTPLGVPVIQPYRLDSKVKQIGGGIQSITYTHNGDISRKPNTRKQKNGFPPNFIHSLDSSHMMLTALHCYRKGLTFVSVHDCYWTHAADVSVMNQVCREQFVRLHSEPILQDLSRFLVKRFCSEPQKILEASQLKETLQAVPKPGAFDLEQVKRSTYFFS>sp|A6NHP3|SPE2B_HUMAN Speedy protein E2B OS=Homo sapiens OX=9606GN=SPDYE2B PE=3 SV=2MDRTETRFRKRGQITGKITTSRQPHPQNEQSPQRSTSGYPLQEVVDDEMLGPSAPGVDPSPPCRSLGWKRKREWSDESEEEPEKELAPEPEETWVVEMLCGLKMKLKQQRVSSILPEHHKDFNSQLAPGVDPSPPHRSFCWKRKMEWWDESEESLEEEPRKVLAPEPEEIWVAEMLCGLKMKLKRRRVSLVLPEHHEAFNRLLEDPVIKRFLAWDKDLRVSDKYLLAMVIAYFSRAGFPSWQYQRIHFFLALYLANDMEEDDEDSKQNIFHFLYRKNRSRIPLLRKPWFQLGHSMNPRARKNRSRIPLLRKRRFQLYRSTNPRARKNRSRIPLLRKRRFQLYRSMNSRARKNRSQIVLFQKRRFHFFCSMSCRAWVSPEELEEIQAYDPEHWVWARDRAHLS>sp|A6NHP3-2|SPE2B_HUMAN Isoform 2 of Speedy protein E2B OS=Homo sapiensOX=9606 GN=SPDYE2BMEWWDESEESLEEEPRKVLAPEPEEIWVAEMLCGLKMKLKRRRVSLVLPEHHEAFNRLLEDPVIKRFLAWDKDLRVSDKYLLAMVIAYFSRAGFPSWQYQRIHFFLALYLANDMEEDDEDSKQNIFHFLYRKNRSRIPLLRKPWFQLGHSMNPRARKNRSRIPLLRKRRFQLYRSTNPRARKNRSRIPLLRKRRFQLYRSMNSRARKNRSQIVLFQKRRFHFFCSMSCRAWVSPEELEEIQAYDPEHWVWARDRAHLS>sp|Q9NPB0|SMDC1_HUMAN SAYSvFN domain-containing protein 1 OS=Homosapiens OX=9606 GN=SAYSD1 PE=2 SV=1MEQRLAEFRAARKRAGLAAQPPAASQGAQTPGEKAEAAATLKAAPGWLKRFLVWKPRPASARAQPGLVQEAAQPQGSTSETPWNTAIPLPSCWDQSFLTNITFLKVLLWLVLLGLFVELEFGLAYFVLSLFYWMYVGTRGPEEKKEGEKSAYSVFNPGCEAIQGTLTAEQLERELQLRPLAGR>sp|Q9NPB0-2|SMDC1_HUMAN Isoform 2 of SAYSvFN domain-containing protein 1OS=Homo sapiens OX=9606 GN=SAYSD1MLEAAQPQGSTSETPWNTAIPLPSCWDQSFLTNITFLKVLLWLVLLGLFVELEFGLAYFVLSLFYWMYVGTRGPEEKKEGEKSAYSVFNPGCEAIQGTLTAEQLERELQLRPLAGR>sp|Q8N474|SFRP1_HUMAN Secreted frizzled-related protein 1 OS=Homosapiens OX=9606 GN=SFRP1 PE=1 SV=1MGIGRSEGGRRGAALGVLLALGAALLAVGSASEYDYVSFQSDIGPYQSGRFYTKPPQCVDIPADLRLCHNVGYKKMVLPNLLEHETMAEVKQQASSWVPLLNKNCHAGTQVFLCSLFAPVCLDRPIYPCRWLCEAVRDSCEPVMQFFGFYWPEMLKCDKFPEGDVCIAMTPPNATEASKPQGTTVCPPCDNELKSEAIIEHLCASEFALRMKIKEVKKENGDKKIVPKKKKPLKLGPIKKKDLKKLVLYLKNGADCPCHQLDNLSHHFLIMGRKVKSQYLLTAIHKWDKKNKEFKNFMKKMKNHECPTFQSVFK>sp|Q13485|SMAD4_HUMAN Mothers against decapentaplegic homolog 4 OS=Homosapiens OX=9606 GN=SMAD4 PE=1 SV=1MDNMSITNTPTSNDACLSIVHSLMCHRQGGESETFAKRAIESLVKKLKEKKDELDSLITAITTNGAHPSKCVTIQRTLDGRLQVAGRKGFPHVIYARLWRWPDLHKNELKHVKYCQYAFDLKCDSVCVNPYHYERVVSPGIDLSGLTLQSNAPSSMMVKDEYVHDFEGQPSLSTEGHSIQTIQHPPSNRASTETYSTPALLAPSESNATSTANFPNIPVASTSQPASILGGSHSEGLLQIASGPQPGQQQNGFTGQPATYHHNSTTTWTGSRTAPYTPNLPHHQNGHLQHHPPMPPHPGHYWPVHNELAFQPPISNHPAPEYWCSIAYFEMDVQVGETFKVPSSCPIVTVDGYVDPSGGDRFCLGQLSNVHRTEAIERARLHIGKGVQLECKGEGDVWVRCLSDHAVFVQSYYLDREAGRAPGDAVHKIYPSAYIKVFDLRQCHRQMQQQAATAQAAAAAQAAAVAGNIPGPGSVGGIAPAISLSAAAGIGVDDLRRLCILRMSFVKGWGPDYPRQSIKETPCWIEIHLHRALQLLDEVLHTMPIADPQPLD>sp|Q99523|SORT_HUMAN Sortilin OS=Homo sapiens OX=9606 GN=SORT1 PE=1 SV=3MERPWGAADGLSRWPHGLGLLLLLQLLPPSTLSQDRLDAPPPPAAPLPRWSGPIGVSWGLRAAAAGGAFPRGGRWRRSAPGEDEECGRVRDFVAKLANNTHQHVFDDLRGSVSLSWVGDSTGVILVLTTFHVPLVIMTFGQSKLYRSEDYGKNFKDITDLINNTFIRTEFGMAIGPENSGKVVLTAEVSGGSRGGRIFRSSDFAKNFVQTDLPFHPLTQMMYSPQNSDYLLALSTENGLWVSKNFGGKWEEIHKAVCLAKWGSDNTIFFTTYANGSCKADLGALELWRTSDLGKSFKTIGVKIYSFGLGGRFLFASVMADKDTTRRIHVSTDQGDTWSMAQLPSVGQEQFYSILAANDDMVFMHVDEPGDTGFGTIFTSDDRGIVYSKSLDRHLYTTTGGETDFTNVTSLRGVYITSVLSEDNSIQTMITFDQGGRWTHLRKPENSECDATAKNKNECSLHIHASYSISQKLNVPMAPLSEPNAVGIVIAHGSVGDAISVMVPDVYISDDGGYSWTKMLEGPHYYTILDSGGIIVAIEHSSRPINVIKFSTDEGQCWQTYTFTRDPIYFTGLASEPGARSMNISIWGFTESFLTSQWVSYTIDFKDILERNCEEKDYTIWLAHSTDPEDYEDGCILGYKEQFLRLRKSSVCQNGRDYVVTKQPSICLCSLEDFLCDFGYYRPENDSKCVEQPELKGHDLEFCLYGREEHLTTNGYRKIPGDKCQGGVNPVREVKDLKKKCTSNFLSPEKQNSKSNSVPIILAIVGLMLVTVVAGVLIVKKYVCGGRFLVHRYSVLQQHAEANGVDGVDALDTASHTNKSGYHDDSDEDLLE>sp|Q99523-2|SORT_HUMAN Isoform 2 of Sortilin OS=Homo sapiens OX=9606GN=SORT1MTFGQSKLYRSEDYGKNFKDITDLINNTFIRTEFGMAIGPENSGKVVLTAEVSGGSRGGRIFRSSDFAKNFVQTDLPFHPLTQMMYSPQNSDYLLALSTENGLWVSKNFGGKWEEIHKAVCLAKWGSDNTIFFTTYANGSCTDLGALELWRTSDLGKSFKTIGVKIYSFGLGGRFLFASVMADKDTTRRIHVSTDQGDTWSMAQLPSVGQEQFYSILAANDDMVFMHVDEPGDTGFGTIFTSDDRGIVYSKSLDRHLYTTTGGETDFTNVTSLRGVYITSVLSEDNSIQTMITFDQGGRWTHLRKPENSECDATAKNKNECSLHIHASYSISQKLNVPMAPLSEPNAVGIVIAHGSVGDAISVMVPDVYISDDGGYSWTKMLEGPHYYTILDSGGIIVAIEHSSRPINVIKFSTDEGQCWQTYTFTRDPIYFTGLASEPGARSMNISIWGFTESFLTSQWVSYTIDFKDILERNCEEKDYTIWLAHSTDPEDYEDGCILGYKEQFLRLRKSSVCQNGRDYVVTKQPSICLCSLEDFLCDFGYYRPENDSKCVEQPELKGHDLEFCLYGREEHLTTNGYRKIPGDKCQGGVNPVREVKDLKKKCTSNFLSPEKQNSKSNSVPIILAIVGLMLVTVVAGVLIVKKYVCGGRFLVHRYSVLQQHAEANGVDGVDALDTASHTNKSGYHDDSDEDLLE>sp|Q9BRV8|SIKE1_HUMAN Suppressor of IKBKE 1 OS=Homo sapiens OX=9606GN=SIKE1 PE=1 SV=1MSCTIEKILTDAKTLLERLREHDAAAESLVDQSAALHRRVAAMREAGTALPDQYQEDASDMKDMSKYKPHILLSQENTQIRDLQQENRELWISLEEHQDALELIMSKYRKQMLQLMVAKKAVDAEPVLKAHQSHSAEIESQIDRICEMGEVMRKAVQVDDDQFCKIQEKLAQLELENKELRELLSISSESLQARKENSMDTASQAIK>sp|Q9BRV8-2|SIKE1_HUMAN Isoform 2 of Suppressor of IKBKE 1 OS=Homosapiens OX=9606 GN=SIKE1MSCTIEKILTDAKTLLERLREHDAAAESLVDQSAALHRRVAAMREAGTALPDQVRQRYQEDASDMKDMSKYKPHILLSQENTQIRDLQQENRELWISLEEHQDALELIMSKYRKQMLQLMVAKKAVDAEPVLKAHQSHSAEIESQIDRICEMGEVMRKAVQVDDDQFCKIQEKLAQLELENKELRELLSISSESLQARKENSMDTASQAIK>sp|Q13239|SLAP1_HUMAN Src-like-adapter OS=Homo sapiens OX=9606 GN=SLAPE=1 SV=3MGNSMKSTPAPAERPLPNPEGLDSDFLAVLSDYPSPDISPPIFRRGEKLRVISDEGGWWKAISLSTGRESYIPGICVARVYHGWLFEGLGRDKAEELLQLPDTKVGSFMIRESETKKGFYSLSVRHRQVKHYRIFRLPNNWYYISPRLTFQCLEDLVNHYSEVADGLCCVLTTPCLTQSTAAPAVRASSSPVTLRQKTVDWRRVSRLQEDPEGTENPLGVDESLFSYGLRESIASYLSLTSEDNTSFDRKKKSISLMYGGSKRKSSFFSSPPYFED>sp|Q13239-2|SLAP1_HUMAN Isoform 2 of Src-like-adapter OS=Homo sapiensOX=9606 GN=SLAMIRESETKKGFYSLSVRHRQVKHYRIFRLPNNWYYISPRLTFQCLEDLVNHYSEVADGLCCVLTTPCLTQSTAAPAVRASSSPVTLRQKTVDWRRVSRLQEDPEGTENPLGVDESLFSYGLRESIASYLSLTSEDNTSFDRKKKSISLMYGGSKRKSSFFSSPPYFED>sp|Q13239-3|SLAP1_HUMAN Isoform 3 of Src-like-adapter OS=Homo sapiensOX=9606 GN=SLAMLHRLWASPAAPGKKKEMGNSMKSTPAPAERPLPNPEGLDSDFLAVLSDYPSPDISPPIFRRGEKLRVISDEGGWWKAISLSTGRESYIPGICVARVYHGWLFEGLGRDKAEELLQLPDTKVGSFMIRESETKKGFYSLSVRHRQVKHYRIFRLPNNWYYISPRLTFQCLEDLVNHYSEVADGLCCVLTTPCLTQSTAAPAVRASSSPVTLRQKTVDWRRVSRLQEDPEGTENPLGVDESLFSYGLRESIASYLSLTSEDNTSFDRKKKSISLMYGGSKRKSSFFSSPPYFED>sp|Q13239-4|SLAP1_HUMAN Isoform 4 of Src-like-adapter OS=Homo sapiensOX=9606 GN=SLAMLHRLWASPAAPGKKKEMGNSMKSTPAPAERPLPNPEGLDSDFLAVLSDYPSPDISPPIFRRGEKLRVISDEGGWWKAISLSTGRESYIPGICVARVYHGWLFEGLGRDKAEELLQLPDTKVGSFMIRESETKKEVADGLCCVLTTPCLTQSTAAPAVRASSSPVTLRQKTVDWRRVSRLQEDPEGTENPLGVDESLFSYGLRESIASYLSLTSEDNTSFDRKKKSISLMYGGSKRKSSFFSSPPYFED>sp|Q13239-5|SLAP1_HUMAN Isoform 5 of Src-like-adapter OS=Homo sapiensOX=9606 GN=SLAMLSKLGHSPLGGLRARLTFPVCLLYHRLWASPAAPGKKKEMGNSMKSTPAPAERPLPNPEGLDSDFLAVLSDYPSPDISPPIFRRGEKLRVISDEGGWWKAISLSTGRESYIPGICVARVYHGWLFEGLGRDKAEELLQLPDTKVGSFMIRESETKKGFYSLSVRHRQVKHYRIFRLPNNWYYISPRLTFQCLEDLVNHYSEVADGLCCVLTTPCLTQSTAAPAVRASSSPVTLRQKTVDWRRVSRLQEDPEGTENPLGVDESLFSYGLRESIASYLSLTSEDNTSFDRKKKSISLMYGGSKRKSSFFSSPPYFED>sp|Q6PI26|SHQ1_HUMAN Protein SHQ1 homolog OS=Homo sapiens OX=9606GN=SHQ1 PE=1 SV=2MLTPAFDLSQDPDFLTIAIRVPYARVSEFDVYFEGSDFKFYAKPYFLRLTLPGRIVENGSEQGSYDADKGIFTIRLPKETPGQHFEGLNMLTALLAPRKSRTAKPLVEEIGASEIPEEVVDDEEFDWEIEQTPCEEVSESALNPQCHYGFGNLRSGVLQRLQDELSDVIDIKDPDFTPAAERRQKRLAAELAKFDPDHYLADFFEDEAIEQILKYNPWWTDKYSKMMAFLEKSQEQENHATLVSFSEEEKYQLRKFVNKSYLLDKRACRQVCYSLIDILLAYCYETRVTEGEKNVESAWNIRKLSPTLCWFETWTNVHDIMVSFGRRVLCYPLYRHFKLVMKAYRDTIKILQLGKSAVLKCLLDIHKIFQENDPAYILNDLYISDYCVWIQKVKSKKLAALAEALKEVSLTKAQLGLELEELEAAALLVQEEETALKAAHSVSGQQTLCSSSEASDSEDSDSSVSSGNEDSGSDSEQDELKDSPSETVSSLQGPFLEESSAFLIVDGGVRRNTAIQESDASQGKPLASSWPLGVSGPLIEELGEQLKTTVQVSEPKGTTAVNRSNIQERDGCQTPNN>sp|Q6PI26-2|SHQ1_HUMAN Isoform 2 of Protein SHQ1 homolog OS=Homo sapiensOX=9606 GN=SHQ1MNKTWSLSLKNGDCSCGGPILTLPGRIVENGSEQGSYDADKGIFTIRLPKETPGQHFEGLNMLTALLAPRKSRTAKPLVEEIGASEIPEEVVDDEEFDWEIEQTPCEEVSESALNPQCHYGFGNLRSGVLQRLQDELSDVIDIKDPDFTPAAERRQKRLAAELAKFDPDHYLADFFEDEAIEQILKYNPWWTDKYSKMMAFLEKSQEQENHATLVSFSEEEKYQLRKFVNKSYLLDKRACRQVCYSLIDILLAYCYETRVTEGEKNVESAWNIRKLSPTLCWFETWTNVHDIMVSFGRRVLCYPLYRHFKLVMKAYRDTIKILQLGKSAVLKCLLDIHKIFQENDPAYILNDLYISDYCVWIQKVKSKKLAALAEALKEVSLTKAQLGLELEELEAAALLVQEEETALKAAHSVSGQQTLCSSSEASDSEDSDSSVSSGNEDSGSDSEQDELKDSPSETVSSLQGPFLEESSAFLIVDGGVRRNTAIQESDASQGKPLASSWPLGVSGPLIEELGEQLKTTVQVSEPKGTTAVNRSNIQERDGCQTPNN>sp|Q9NVD3|SETD4_HUMAN SET domain-containing protein 4 OS=Homo sapiensOX=9606 GN=SETD4 PE=1 SV=1MQKGKGRTSRIRRRKLCGSSESRGVNESHKSEFIELRKWLKARKFQDSNLAPACFPGTGRGLMSQTSLQEGQMIISLPESCLLTTDTVIRSYLGAYITKWKPPPSPLLALCTFLVSEKHAGHRSLWKPYLEILPKAYTCPVCLEPEVVNLLPKSLKAKAEEQRAHVQEFFASSRDFFSSLQPLFAEAVDSIFSYSALLWAWCTVNTRAVYLRPRQRECLSAEPDTCALAPYLDLLNHSPHVQVKAAFNEETHSYEIRTTSRWRKHEEVFICYGPHDNQRLFLEYGFVSVHNPHACVYVSREILVKYLPSTDKQMDKKISILKDHGYIENLTFGWDGPSWRLLTALKLLCLEAEKFTCWKKVLLGEVISDTNEKTSLDIAQKICYYFIEETNAVLQKVSHMKDEKEALINQLTLVESLWTEELKILRASAETLHSLQTAFT>sp|Q9NVD3-2|SETD4_HUMAN Isoform B of SET domain-containing protein 4OS=Homo sapiens OX=9606 GN=SETD4MQKGKGRTSRIRRRKLCGSSESRGVNESHKSEFIELRKWLKARKFQDSNLAPACFPGTGRGLMSQTSLQVEASSISSAGAVHLFSFRKACWAPISLEALPGDFTQGVYLPCLFGAGSGEPSSQIFKSKG>sp|Q9NVD3-3|SETD4_HUMAN Isoform 3 of SET domain-containing protein 4OS=Homo sapiens OX=9606 GN=SETD4MNESHKSEFIELRKWLKARKFQDSNLAPACFPGTGRGLMSQTSLQEGQMIISLPESCLLTTDTVIRSYLGAYITKWKPPPSPLLALCTFLVSEKHAGHRSLWKPYLEILPKAYTCPVCLEPEVVNLLPKSLKAKAEEQRAHVQEFFASSRDFFSSLQPLFAEAVDSIFSYSALLWAWCTVNTRAVYLRPRQRECLSAEPDTCALAPYLDLLNHSPHVQVKAAFNEETHSYEIRTTSRWRKHEEVFICYGPHDNQRLFLEYGFVSVHNPHACVYVSREILVKYLPSTDKQMDKKISILKDHGYIENLTFGWDGPSWRLLTALKLLCLEAEKFTCWKKVLLGEVISDTNEKTSLDIAQKICYYFIEETNAVLQKVSHMKDEKEALINQLTLVESLWTEELKILRASAETLHSLQTAFT>sp|Q9NVD3-4|SETD4_HUMAN Isoform 4 of SET domain-containing protein 4OS=Homo sapiens OX=9606 GN=SETD4MQKGKGRTSRIRRRKLCGSSESRGVNESHKSEFIELRKWLKARKFQDSNLAPACFPGTGRGLMSQTSLQEGQMIISLPESCLLTTDTVIRSYLGAYITKWKPPPSPLLALCTFLVSEKHAGHRSLWKPYLEILPKAYTCPVCLEPEVVNLLPKSLKAKAEEQRAHVQEFFASSRDFFSSLQPLFAEAVDSIFSYSALLWAWCTVNTRAVYLRPRQRECLSAEPDTCALAPYLDLLNHSPHVQVKAAFNEETHSYEIRTTSRWRKHEEVFICYGPHDNQRLFLEYGFVSVHNPHACVYVSRGWNQLCS>sp|Q9H6Q3|SLAP2_HUMAN Src-like-adapter 2 OS=Homo sapiens OX=9606 GN=SLA2PE=1 SV=3MGSLPSRRKSLPSPSLSSSVQGQGPVTMEAERSKATAVALGSFPAGGPAELSLRLGEPLTIVSEDGDWWTVLSEVSGREYNIPSVHVAKVSHGWLYEGLSREKAEELLLLPGNPGGAFLIRESQTRRGSYSLSVRLSRPASWDRIRHYRIHCLDNGWLYISPRLTFPSLQALVDHYSELADDICCLLKEPCVLQRAGPLPGKDIPLPVTVQRTPLNWKELDSSLLFSEAATGEESLLSEGLRESLSFYISLNDEAVSLDDA>sp|Q9H6Q3-2|SLAP2_HUMAN Isoform 2 of Src-like-adapter 2 OS=Homo sapiensOX=9606 GN=SLA2MGSLPSRRKSLPSPSLSSSVQGQGPVTMEAERSKATAVALGSFPAGGPAELSLRLGEPLTIVSEDGDWWTVLSEVSGREYNIPSVHVAKVSHGWLYEGLSREKAEELLLLPGNPGGAFLIRESQTRRGSYSLSVRLSRPASWDRIRHYRIHCLDNGWLYISPRLTFPSLQALVDHYSEGWPAPWQGYTPTCDCAEDTTQLERAGQLPPVF>sp|Q9H6Q3-3|SLAP2_HUMAN Isoform 3 of Src-like-adapter 2 OS=Homo sapiensOX=9606 GN=SLA2MEAERSKATAVALGSFPAGGPAELSLRLGEPLTIVSEDGDWWTVLSEVSGREYNIPSVHVAKVSHGWLYEGLSREKAEELLLLPGNPGGAFLIRESQTRRGSYSLSVRLSRPASWDRIRHYRIHCLDNGWLYISPRLTFPSLQALVDHYSELADDICCLLKEPCVLQRAGPLPGKDIPLPVTVQRTPLNWKELDSSLLFSEAATGEESLLSEGLRESLSFYISLNDEAVSLDDA>sp|Q9H6Q3-4|SLAP2_HUMAN Isoform 4 of Src-like-adapter 2 OS=Homo sapiensOX=9606 GN=SLA2MEAERSKATAVALGSFPAGGPAELSLRLGEPLTIVSEDGDWWTVLSEVSGREYNIPSVHVAKVSHGWLYEGLSREKAEELLLLPGNPGGAFLIRESQTRRGSYSLSVRLSRPASWDRIRHYRIHCLDNGWLYISPRLTFPSLQALVDHYSEGWPAPWQGYTPTCDCAEDTTQLERAGQLPPVF>sp|Q9C0A6|SETD5_HUMAN Histone-lysine N-methyltransferase SETD5 OS=Homosapiens OX=9606 GN=SETD5 PE=1 SV=2MSIAIPLGVTTSDTSYSDMAAGSDPESVEASPAVNEKSVYSTHNYGTTQRHGCRGLPYATIIPRSDLNGLPSPVEERCGDSPNSEGETVPTWCPCGLSQDGFLLNCDKCRGMSRGKVIRLHRRKQDNISGGDSSATESWDEELSPSTVLYTATQHTPTSITLTVRRTKPKKRKKSPEKGRAAPKTKKIKNSPSEAQNLDENTTEGWENRIRLWTDQYEEAFTNQYSADVQNALEQHLHSSKEFVGKPTILDTINKTELACNNTVIGSQMQLQLGRVTRVQKHRKILRAARDLALDTLIIEYRGKVMLRQQFEVNGHFFKKPYPFVLFYSKFNGVEMCVDARTFGNDARFIRRSCTPNAEVRHMIADGMIHLCIYAVSAITKDAEVTIAFDYEYSNCNYKVDCACHKGNRNCPIQKRNPNATELPLLPPPPSLPTIGAETRRRKARRKELEMEQQNEASEENNDQQSQEVPEKVTVSSDHEEVDNPEEKPEEEKEEVIDDQENLAHSRRTREDRKVEAIMHAFENLEKRKKRRDQPLEQSNSDVEITTTTSETPVGEETKTEAPESEVSNSVSNVTIPSTPQSVGVNTRRSSQAGDIAAEKLVPKPPPAKPSRPRPKSRISRYRTSSAQRLKRQKQANAQQAELSQAALEEGGSNSLVTPTEAGSLDSSGENRPLTGSDPTVVSITGSHVNRAASKYPKTKKYLVTEWLNDKAEKQECPVECPLRITTDPTVLATTLNMLPGLIHSPLICTTPKHYIRFGSPFIPERRRRPLLPDGTFSSCKKRWIKQALEEGMTQTSSVPQETRTQHLYQSNENSSSSSICKDNADLLSPLKKWKSRYLMEQNVTKLLRPLSPVTPPPPNSGSKSPQLATPGSSHPGEEECRNGYSLMFSPVTSLTTASRCNTPLQFELCHRKDLDLAKVGYLDSNTNSCADRPSLLNSGHSDLAPHPSLGPTSETGFPSRSGDGHQTLVRNSDQAFRTEFNLMYAYSPLNAMPRADGLYRGSPLVGDRKPLHLDGGYCSPAEGFSSRYEHGLMKDLSRGSLSPGGERACEGVPSAPQNPPQRKKVSLLEYRKRKQEAKENSAGGGGDSAQSKSKSAGAGQGSSNSVSDTGAHGVQGSSARTPSSPHKKFSPSHSSMSHLEAVSPSDSRGTSSSHCRPQENISSRWMVPTSVERLREGGSIPKVLRSSVRVAQKGEPSPTWESNITEKDSDPADGEGPETLSSALSKGATVYSPSRYSYQLLQCDSPRTESQSLLQQSSSPFRGHPTQSPGYSYRTTALRPGNPPSHGSSESSLSSTSYSSPAHPVSTDSLAPFTGTPGYFSSQPHSGNSTGSNLPRRSCPSSAASPTLQGPSDSPTSDSVSQSSTGTLSSTSFPQNSRSSLPSDLRTISLPSAGQSAVYQASRVSAVSNSQHYPHRGSGGVHQYRLQPLQGSGVKTQTGLS>sp|Q9C0A6-2|SETD5_HUMAN Isoform 2 of Histone-lysine N-methyltransferaseSETD5 OS=Homo sapiens OX=9606 GN=SETD5MSRGKVIRLHRRKQDNISGGDSSATESWDEELSPSTVLYTATQHTPTSITLTVRRTKPKKRKKSPEKGRAAPKTKKIKNSPSEAQNLDENTTEGWENRIRLWTDQYEEAFTNQYSADVQNALEQHLHSSKEFVGKPTILDTINKTELACNNTVIGSQMQLQLGRVTRVQKHRKILRAARDLALDTLIIEYRGKVMLRQQFEVNGHFFKKPYPFVLFYSKFNGVEMCVDARTFGNDARFIRRSCTPNAEVRHMIADGMIHLCIYAVSAITKDAEVTIAFDYEYSNCNYKVDCACHKGNRNCPIQKRNPNATELPLLPPPPSLPTIGAETRRRKARRKELEMEQQNEASEENNDQQSQEVPEKVTVSSDHEEVDNPEEKPEEEKEEVIDDQENLAHSRRTREDRKVEAIMHAFENLEKRKKRRDQPLEQSNSDVEITTTTSETPVGEETKTEAPESEVSNSVSNVTIPSTPQSVGVNTRRSSQAGDIAAEKLVPKPPPAKPSRPRPKSRISRYRTSSAQRLKRQKQANAQQAELSQAALEEGGSNSLVTPTEAGSLDSSGENRPLTGSDPTVVSITGSHVNRAASKYPKTKKYLVTEWLNDKAEKQECPVECPLRITTDPTVLATTLNMLPGLIHSPLICTTPKHYIRFGSPFIPERRRRPLLPDGTFSSCKKRWIKQALEEGMTQTSSVPQETRTQHLYQSNENSSSSSICKDNADLLSPLKKWKSRYLMEQNVTKLLRPLSPVTPPPPNSGSKSPQLATPGSSHPGEEECRNGYSLMFSPVTSLTTASRCNTPLQFELCHRKDLDLAKVGYLDSNTNSCADRPSLLNSGHSDLAPHPSLGPTSETGFPSRSGDGHQTLVRNSDQAFRTEFNLMYAYSPLNAMPRADGLYRGSPLVGDRKPLHLDGGYCSPAEGFSSRYEHGLMKDLSRGSLSPGGERACEGVPSAPQNPPQRKKVSLLEYRKRKQEAKENSAGGGGDSAQSKSKSAGAGQGSSNSVSDTGAHGVQGSSARTPSSPHKKFSPSHSSMSHLEAVSPSDSRGTSSSHCRPQENISSRWMVPTSVERLREGGSIPKVLRSSVRVAQKGEPSPTWESNITEKDSDPADGEGPETLSSALSKGATVYSPSRYSYQLLQCDSPRTESQSLLQQSSSPFRGHPTQSPGYSYRTTALRPGNPPSHGSSESSLSSTSYSSPAHPVSTDSLAPFTGTPGYFSSQPHSGNSTGSNLPRRSCPSSAASPTLQGPSDSPTSDSVSQSSTGTLSSTSFPQNSRSSLPSDLRTISLPSAGQSAVYQASRVSAVSNSQHYPHRGSGGVHQYRLQPLQGSGVKTQTGLS>sp|Q9C0A6-3|SETD5_HUMAN Isoform 3 of Histone-lysine N-methyltransferaseSETD5 OS=Homo sapiens OX=9606 GN=SETD5MSRGKVIRLHRRKQDNISGGDSSATESWDEELSPSTVLYTATQHTPTSITLTVRRTKPKKRKKSPEKGRAAPKTKKIKAFREGSRKSLRMKNSPSEAQNLDENTTEGWENRIRLWTDQYEEAFTNQYSADVQNALEQHLHSSKEFVGKPTILDTINKTELACNNTVIGSQMQLQLGRVTRVQKHRKILRAARDLALDTLIIEYRGKVMLRQQFEVNGHFFKKPYPFVLFYSKFNGVEMCVDARTFGNDARFIRRSCTPNAEVRHMIADGMIHLCIYAVSAITKDAEVTIAFDYEYSNCNYKVDCACHKGNRNCPIQKRNPNATELPLLPPPPSLPTIGAETRRRKARRKELEMEQQNEASEENNDQQSQEVPEKVTVSSDHEEVDNPEEKPEEEKEEVIDDQENLAHSRRTREDRKVEAIMHAFENLEKRKKRRDQPLEQSNSDVEITTTTSETPVGEETKTEAPESEVSNSVSNVTIPSTPQSVGVNTRRSSQAGDIAAEKLVPKPPPAKPSRPRPKSRISRYRTSSAQRLKRQKQANAQQAELSQAALEEGGSNSLVTPTEAGSLDSSGENRPLTGSDPTVVSITGSHVNRAASKYPKTKKYLVTEWLNDKAEKQECPVECPLRITTDPTVLATTLNMLPGLIHSPLICTTPKHYIRFGSPFIPERRRRPLLPDGTFSSCKKRWIKQALEEGMTQTSSVPQETRTQHLYQSNENSSSSSICKDNADLLSPLKKWKSRYLMEQNVTKLLRPLSPVTPPPPNSGSKSPQLATPGSSHPGEEECRNGYSLMFSPVTSLTTASRCNTPLQFELCHRKDLDLAKVGYLDSNTNSCADRPSLLNSGHSDLAPHPSLGPTSETGFPSRSGDGHQTLVRNSDQAFRTEFNLMYAYSPLNAMPRADGLYRGSPLVGDRKPLHLDGGYCSPAEGFSSRYEHGLMKDLSRGSLSPGGERACEGVPSAPQNPPQRKKVSLLEYRKRKQEAKENSAGGGGDSAQSKSKSAGAGQGSSNSVSDTGAHGVQGSSARTPSSPHKKFSPSHSSMSHLEAVSPSDSRGTSSSHCRPQENISSRWMVPTSVERLREGGSIPKVLRSSVRVAQKGEPSPTWESNITEKDSDPADGEGPETLSSALSKGATVYSPSRYSYQLLQCDSPRTESQSLLQQSSSPFRGHPTQSPGYSYRTTALRPGNPPSHGSSESSLSSTSYSSPAHPVSTDSLAPFTGTPGYFSSQPHSGNSTGSNLPRRSCPSSAASPTLQGPSDSPTSDSVSQSSTGTLSSTSFPQNSRSSLPSDLRTISLPSAGQSAVYQASRVSAVSNSQHYPHRGSGGVHQYRLQPLQGSGVKTQTGLS>sp|Q9H173|SIL1_HUMAN Nucleotide exchange factor SIL1 OS=Homo sapiensOX=9606 GN=SIL1 PE=1 SV=1MAPQSLPSSRMAPLGMLLGLLMAACFTFCLSHQNLKEFALTNPEKSSTKETERKETKAEEELDAEVLEVFHPTHEWQALQPGQAVPAGSHVRLNLQTGEREAKLQYEDKFRNNLKGKRLDINTNTYTSQDLKSALAKFKEGAEMESSKEDKARQAEVKRLFRPIEELKKDFDELNVVIETDMQIMVRLINKFNSSSSSLEEKIAALFDLEYYVHQMDNAQDLLSFGGLQVVINGLNSTEPLVKEYAAFVLGAAFSSNPKVQVEAIEGGALQKLLVILATEQPLTAKKKVLFALCSLLRHFPYAQRQFLKLGGLQVLRTLVQEKGTEVLAVRVVTLLYDLVTEKMFAEEEAELTQEMSPEKLQQYRQVHLLPGLWEQGWCEITAHLLALPEHDAREKVLQTLGVLLTTCRDRYRQDPQLGRTLASLQAEYQVLASLELQDGEDEGYFQELLGSVNSLLKELR>sp|P0DMW4|SIL2A_HUMAN Small integral membrane protein 10-like protein 2AOS=Homo sapiens OX=9606 GN=SMIM10L2A PE=4 SV=1MAASAALSAAAAAAALSGLAVRLSRSAAARGSYGAFCKGLTRTLLTFFDLAWRLRMNFPYFYIVASVMLNVRLQVRIE>sp|Q8NE22|SETD9_HUMAN SET domain-containing protein 9 OS=Homo sapiensOX=9606 GN=SETD9 PE=2 SV=2MPGRLLRGLWQRWRRYKYRFVPWIALNLSHNPRTLRYVPEESKDKVISDEDVLGTLLKVFQALFLNDFNKQSEILSMLPESVKSKYQDLLAVEHQGVKLLENRHQQQSTFKPEEILYKTLGFSVAQATSSLISAGKGVFVTKGLVPKGAVVSMYPGTVYQKYEPIFFQSIGNPFIFRCLDGVLIDGNDKGISKVVYRSCNGRDRLGPLKMSDSTWLTSEIHNPLAVGQYVNNCSNDRAANVCYQEFDVPAVFPIELKQYLPNIAYSYDKQSPLRCVVLVALRDINQGEELFSNYYTIVS>sp|Q8NE22-2|SETD9_HUMAN Isoform 2 of SET domain-containing protein 9OS=Homo sapiens OX=9606 GN=SETD9MPGRLLRGLWQRWRRYKYRFVPWIALNLSHNPRTLRYVPEESKDKVISDEDVLGTLLKVFQALFLNDFNKQSEILSMLPESVKSKYQDLLAVEHQGVKLLENRHQQQSTFKPEEILYKTLGFSVAQATSSLISAGKGVFVTKGLVPKGAVVSMYPGTVYQKYEPIFFQSIGNPFIFRCLDGVLIDGNDKGISKVVYRSCNGRDRLGPLKMSDSTWLTSEIHNPLAVGQYVNNCSNDRAANVCYQEFDVPAVFPIELKQYLPNIAYSYDKQR>sp|Q9H0F6|SHRPN_HUMAN Sharpin OS=Homo sapiens OX=9606 GN=SHARPIN PE=1SV=1MAPPAGGAAAAASDLGSAAVLLAVHAAVRPLGAGPDAEAQLRRLQLSADPERPGRFRLELLGAGPGAVNLEWPLESVSYTIRGPTQHELQPPPGGPGTLSLHFLNPQEAQRWAVLVRGATVEGQNGSKSNSPPALGPEACPVSLPSPPEASTLKGPPPEADLPRSPGNLTEREELAGSLARAIAGGDEKGAAQVAAVLAQHRVALSVQLQEACFPPGPIRLQVTLEDAASAASAASSAHVALQVHPHCTVAALQEQVFSELGFPPAVQRWVIGRCLCVPERSLASYGVRQDGDPAFLYLLSAPREAPATGPSPQHPQKMDGELGRLFPPSLGLPPGPQPAASSLPSPLQPSWSCPSCTFINAPDRPGCEMCSTQRPCTWDPLAAAST>sp|Q9H0F6-2|SHRPN_HUMAN Isoform 2 of Sharpin OS=Homo sapiens OX=9606GN=SHARPINMAPPAGGAAAAASDLGSAAVLLAVHAAVRPLGAGPDAEAQLRRLQLSADPERPGRFRLELLGAGPGAVNLEWPLESVSYTIRGPTQHELQPPPGGPGTLSLHFLNPQEAQRWAVLVRGATVEGQNGSKSNSPPALGPEACPVSLPSPPEASTLKGPPPEADLPRSPGNLTEREELAGSLARAIAGGDEKGAAQVAAVLAQHRVALSVQLQEACFPPGPIRLQVTLEDAASAASAASSAHVALQVHPHCTVAALQEQVFSELGFPPAVQRWVIGRCLCVPERSLASYGVRQDGDPAFLYLLSAPREAPAQLVLSFLHLHQCPRPPWL>sp|Q7Z3B0|SIM15_HUMAN Small integral membrane protein 15 OS=Homo sapiensOX=9606 GN=SMIM15 PE=3 SV=1MFDIKAWAEYVVEWAAKDPYGFLTTVILALTPLFLASAVLSWKLAKMIEAREKEQKKKQKRQENIAKAKRLKKD>sp|Q7Z333|SETX_HUMAN Probable helicase senataxin OS=Homo sapiens OX=9606GN=SETX PE=1 SV=4MSTCCWCTPGGASTIDFLKRYASNTPSGEFQTADEDLCYCLECVAEYHKARDELPFLHEVLWELETLRLINHFEKSMKAEIGDDDELYIVDNNGEMPLFDITGQDFENKLRVPLLEILKYPYLLLHERVNELCVEALCRMEQANCSFQVFDKHPGIYLFLVHPNEMVRRWAILTARNLGKVDRDDYYDLQEVLLCLFKVIELGLLESPDIYTSSVLEKGKLILLPSHMYDTTNYKSYWLGICMLLTILEEQAMDSLLLGSDKQNDFMQSILHTMEREADDDSVDPFWPALHCFMVILDRLGSKVWGQLMDPIVAFQTIINNASYNREIRHIRNSSVRTKLEPESYLDDMVTCSQIVYNYNPEKTKKDSGWRTAICPDYCPNMYEEMETLASVLQSDIGQDMRVHNSTFLWFIPFVQSLMDLKDLGVAYIAQVVNHLYSEVKEVLNQTDAVCDKVTEFFLLILVSVIELHRNKKCLHLLWVSSQQWVEAVVKCAKLPTTAFTRSSEKSSGNCSKGTAMISSLSLHSMPSNSVQLAYVQLIRSLLKEGYQLGQQSLCKRFWDKLNLFLRGNLSLGWQLTSQETHELQSCLKQIIRNIKFKAPPCNTFVDLTSACKISPASYNKEESEQMGKTSRKDMHCLEASSPTFSKEPMKVQDSVLIKADNTIEGDNNEQNYIKDVKLEDHLLAGSCLKQSSKNIFTERAEDQIKISTRKQKSVKEISSYTPKDCTSRNGPERGCDRGIIVSTRLLTDSSTDALEKVSTSNEDFSLKDDALAKTSKRKTKVQKDEICAKLSHVIKKQHRKSTLVDNTINLDENLTVSNIESFYSRKDTGVQKGDGFIHNLSLDPSGVLDDKNGEQKSQNNVLPKEKQLKNEELVIFSFHENNCKIQEFHVDGKELIPFTEMTNASEKKSSPFKDLMTVPESRDEEMSNSTSVIYSNLTREQAPDISPKSDTLTDSQIDRDLHKLSLLAQASVITFPSDSPQNSSQLQRKVKEDKRCFTANQNNVGDTSRGQVIIISDSDDDDDERILSLEKLTKQDKICLEREHPEQHVSTVNSKEEKNPVKEEKTETLFQFEESDSQCFEFESSSEVFSVWQDHPDDNNSVQDGEKKCLAPIANTTNGQGCTDYVSEVVKKGAEGIEEHTRPRSISVEEFCEIEVKKPKRKRSEKPMAEDPVRPSSSVRNEGQSDTNKRDLVGNDFKSIDRRTSTPNSRIQRATTVSQKKSSKLCTCTEPIRKVPVSKTPKKTHSDAKKGQNRSSNYLSCRTTPAIVPPKKFRQCPEPTSTAEKLGLKKGPRKAYELSQRSLDYVAQLRDHGKTVGVVDTRKKTKLISPQNLSVRNNKKLLTSQELQMQRQIRPKSQKNRRRLSDCESTDVKRAGSHTAQNSDIFVPESDRSDYNCTGGTEVLANSNRKQLIKCMPSEPETIKAKHGSPATDDACPLNQCDSVVLNGTVPTNEVIVSTSEDPLGGGDPTARHIEMAALKEGEPDSSSDAEEDNLFLTQNDPEDMDLCSQMENDNYKLIELIHGKDTVEVEEDSVSRPQLESLSGTKCKYKDCLETTKNQGEYCPKHSEVKAADEDVFRKPGLPPPASKPLRPTTKIFSSKSTSRIAGLSKSLETSSALSPSLKNKSKGIQSILKVPQPVPLIAQKPVGEMKNSCNVLHPQSPNNSNRQGCKVPFGESKYFPSSSPVNILLSSQSVSDTFVKEVLKWKYEMFLNFGQCGPPASLCQSISRPVPVRFHNYGDYFNVFFPLMVLNTFETVAQEWLNSPNRENFYQLQVRKFPADYIKYWEFAVYLEECELAKQLYPKENDLVFLAPERINEEKKDTERNDIQDLHEYHSGYVHKFRRTSVMRNGKTECYLSIQTQENFPANLNELVNCIVISSLVTTQRKLKAMSLLGSRNQLARAVLNPNPMDFCTKDLLTTTSERIIAYLRDFNEDQKKAIETAYAMVKHSPSVAKICLIHGPPGTGKSKTIVGLLYRLLTENQRKGHSDENSNAKIKQNRVLVCAPSNAAVDELMKKIILEFKEKCKDKKNPLGNCGDINLVRLGPEKSINSEVLKFSLDSQVNHRMKKELPSHVQAMHKRKEFLDYQLDELSRQRALCRGGREIQRQELDENISKVSKERQELASKIKEVQGRPQKTQSIIILESHIICCTLSTSGGLLLESAFRGQGGVPFSCVIVDEAGQSCEIETLTPLIHRCNKLILVGDPKQLPPTVISMKAQEYGYDQSMMARFCRLLEENVEHNMISRLPILQLTVQYRMHPDICLFPSNYVYNRNLKTNRQTEAIRCSSDWPFQPYLVFDVGDGSERRDNDSYINVQEIKLVMEIIKLIKDKRKDVSFRNIGIITHYKAQKTMIQKDLDKEFDRKGPAEVDTVDAFQGRQKDCVIVTCVRANSIQGSIGFLASLQRLNVTITRAKYSLFILGHLRTLMENQHWNQLIQDAQKRGAIIKTCDKNYRHDAVKILKLKPVLQRSLTHPPTIAPEGSRPQGGLPSSKLDSGFAKTSVAASLYHTPSDSKEITLTVTSKDPERPPVHDQLQDPRLLKRMGIEVKGGIFLWDPQPSSPQHPGATPPTGEPGFPVVHQDLSHIQQPAAVVAALSSHKPPVRGEPPAASPEASTCQSKCDDPEEELCHRREARAFSEGEQEKCGSETHHTRRNSRWDKRTLEQEDSSSKKRKLL>sp|Q7Z333-3|SETX_HUMAN Isoform 3 of Probable helicase senataxin OS=Homosapiens OX=9606 GN=SETXMSTCCWCTPGGASTIDFLKRYASNTPSGEFQTADEDLCYCLECVAEYHKARDELPFLHEVLWELETLRLINHFEKSMKAEIGDDDELYIVDNNGEMPLFDITGQDFENKLRVPLLEILKYPYLLLHERVNELCVEALCRMEQANCSFQVFDKHPGIYLFLVHPNEMVRRWAILTARNLGKVDRDDYYDLQEVLLCLFKVIELGLLESPDIYTSSVLEKGKLILLPSHMYDTTNYKSYWLGICMLLTILEEQAMDSLLLGSDKQNDFMQSILHTMEREADDDSVDPFWPALHCFMVILDRLGSKVWGQLMDPIVAFQTIINNASYNREIRHIRNSSVRTKLEPESYLDDMVTCSQIVYNYNPEKTKKDSGWRTAICPDYCPNMYEEMETLASVLQSDIGQDMRVHNSTFLWFIPFVQSLMDLKDLGVAYIAQVVNHLYSEVKEVLNQTDAVCDKVTEFFLLILVSVIELHRNKKCLHLLWVSSQQWVEAVVKCAKLPTTAFTRSSEKSSGNCSKGTAMISSLSLHSMPSNSVQLAYVQLIRSLLKEGYQLGQQSLCKRFWDKLNLFLRGNLSLGWQLTSQETHELQSCLKQIIRNIKFKAPPCNTFVDLTSACKISPASYNKEESEQMGKTSRKDMHCLEASSPTFSKEPMKVQDSVLIKADNTIEGDNNEQNYIKDVKLEDHLLAGSCLKQSSKNIFTERAEDQIKISTRKQKSVKEISSYTPKDCTSRNGPERGCDRGIIVSTRLLTDSSTDALEKVSTSNEDFSLKDDALAKTSKRKTKVQKDEICAKLSHVIKKQHRKSTLVDNTINLDENLTVSNIESFYSRKDTGVQKGDGFIHNLSLDPSGVLDDKNGEQKSQNNVLPKEKQLKNEELVIFSFHENNCKIQEFHVDGKELIPFTEMTNASEKKSSPFKDLMTVPESRDEEMSNSTSVIYSNLTREQAPDISPKSDTLTDSQIDRDLHKLSLLAQASVITFPSDSPQNSSQLQRKVKEDKRCFTANQNNVGDTSRGQVIIISDSDDDDDERILSLEKLTKQDKICLEREHPEQHVSTVNSKEEKNPVKEEKTETLFQFEESDSQCFEFESSSEVFSVWQDHPDDNNSVQDGEKKCLAPIANTTNGQGCTDYVSEVVKKGAEGIEEHTRPRSISVEEFCEIEVKKPKRKRSEKPMAEDPVRPSSSVRNEGQSDTNKRDLVGNDFKSIDRRTSTPNSRIQRATTVSQKKSSKLCTCTEPIRKVPVSKTPKKTHSDAKKGQNRSSNYLSCRTTPAIVPPKKFRQCPEPTSTAEKLGLKKGPRKAYELSQRSLDYVAQLRDHGKTVGVVDTRKKTKLISPQNLSVRNNKKLLTSQELQMQRQIRPKSQKNRRRLSDCESTDVKRAGSHTAQNSDIFVPESDRSDYNCTGGTEVLANSNRKQLIKCMPSEPETIKAKHGSPATDDACPLNQCDSVVLNGTVPTNEVIVSTSEDPLGGGDPTARHIEMAALKEGEPDSSSDAEEDNLFLTQNDPEDMDLCSQMENDNYKLIELIHGKDTVEVEEDSVSRPQLESLSGTKCKYKDCLETTKNQGEYCPKHSEVKAADEDVFRKPGLPPPASKPLRPTTKIFSSKSTSRIAGLSKSLETSSALSPSLKNKSKGIQSILKVPQPVPLIAQKPVGEMKNSCNVLHPQSPNNSNRQGCKVPFGESKYFPSSSPVNILLSSQSVSDTFVKEVLKWKYEMFLNFGQCGPPASLCQSISRPVPVRFHNYGDYFNVFFPLMVLNTFETVAQEWLNSPNRENFYQLQVRKFPADYIKYWEFAVYLEECELAKQLYPKENDLVFLAPERINEEKKDTERNDIQDLHEYHSGYVHKFRRTSVMRNGKTECYLSIQTQENFPANLNELVNCIVISSLVTTQRKLKAMSLLGSRNQLARAVLNPNPMDFCTKDLLTTTSERIIAYLRDFNEDQKKAIETAYAMVKHSPSVAKICLIHGPPGTGKSKTIVGLLYRLLTENQRKGHSDENSNAKIKQNRVLVCAPSNAAVDELMKKIILEFKEKCKDKKNPLGNCGDINLVRLGPEKSINSEVLKFSLDSQVNHRMKKELPSHVQAMHKRKEFLDYQLDELSRQRALCRGGREIQRQELDENISKVSKERQELASKIKEVQGRPQKTQSIIILESHIICCTLSTSGGLLLESAFRGQGGVPFSCVIVDEAGQSCEIETLTPLIHRCNKLILVGDPKQLPPTVISMKAQEYGYDQSMMARFCRLLEENVEHNMISRLPILQLTVQYRMHPDICLFPSNYVYNRNLKTNRQTEAIRCSSDWPFQPYLVFDVGDGSERRDNDSYINVQEIKLVMEIIKLIKDKRKDVSFRNIGIITHYKAQKTMIQKDLDKEFDRKGFLASLQRLNVTITRAKYSLFILGHLRTLMENQHWNQLIQDAQKRGAIIKTCDKNYRHDAVKILKLKPVLQRSLTHPPTIAPEGSRPQGGLPSSKLDSGFAKTSVAASLYHTPSDSKEITLTVTSKDPERPPVHDQLQDPRLLKRMGIEVKGGIFLWDPQPSSPQHPGATPPTGEPGFPVVHQDLSHIQQPAAVVAALSSHKPPVRGEPPAASPEASTCQSKCDDPEEELCHRREARAFSEGEQEKCGSETHHTRRNSRWDKRTLEQEDSSSKKRKLL>sp|Q7Z333-4|SETX_HUMAN Isoform 4 of Probable helicase senataxin OS=Homosapiens OX=9606 GN=SETXMSTCCWCTPGGASTIDFLKRYASNTPSGEFQTADEDLCYCLECVAEYHKARDELPFLHEVLWELETLRLINHFEKSMKAEIGDDDELYIVDNNGEMPLFDITGQDFENKLRVPLLEILKYPYLLLHERVNELCVEALCRMEQANCSFQVFDKHPGIYLFLVHPNEMVRRWAILTARNLGKVDRDDYYDLQEVLLCLFKVIELGLLESPDIYTSSVLEKGKLILLPSHMYDTTNYKSYWLGICMLLTILEEQAMDSLLLGSDKQNDFMQSILHTMEREADDDSVDPFWPALHCFMVILDRLGSKVWGQLMDPIVAFQTIINNASYNREIRHIRNSSVRTKLEPESYLDDMVTCSQIVYNYNPEKTKKDSGWRTAICPDYCPNMYEEMETLASVLQSDIGQDMRVHNSTFLWFIPFVQSLMDLKDLGVAYIAQVVNHLYSEVKEVLNQTDAVCDKVTEFFLLILVSVIELHRNKKCLHLLWVSSQQWVEAVVKCAKLPTTAFTRSSEKSSGNCSKGTAMISSLSLHSMPSNSVQLAYVQLIRSLLKEGYQLGQQSLCKRFWDKLNLFLRGNLSLGWQLTSQETHELQSCLKQIIRNIKFKAPPCNTFVDLTSACKISPASYNKEESEQMGKTSRKDMHCLEASSPTFSKEPMKVQDSVLIKADNTIEGDNNEQNYIKDVKLEDHLLAGSCLKQSSKNIFTERAEDQIKISTRKQKSVKEISSYTPKDCTSRNGPERGCDRGIIVSTRLLTDSSTDALEKVSTSNEDFSLKDDALAKTSKRKTKVQKDEICAKLSHVIKKQHRKSTLVDNTINLDENLTVSNIESFYSRKDTGVQKGDGFIHNLSLDPSGVLDDKNGEQKSQNNVLPKEKQLKNEELVIFSFHENNCKIQEFHVDGKELIPFTEMTNASEKKSSPFKDLMTVPESRDEEMSNSTSVIYSNLTREQAPDISPKSDTLTDSQIDRDLHKLSLLAQASVITFPSDSPQNSSQLQRKVKEDKRCFTANQNNVGDTSRGQVIIISDSDDDDDERILSLEKLTKQDKICLEREHPEQHVSTVNSKEEKNPVKEEKTETLFQFEESDSQCFEFESSSEVFSVWQDHPDDNNSVQDGEKKCLAPIANTTNGQGCTDYVSEVVKKGAEGIEEHTRPRSISVEEFCEIEVKKPKRKRSEKPMAEDPVRPSSSVRNEGQSDTNKRDLVGNDFKSIDRRTSTPNSRIQRATTVSQKKSSKLCTCTEPIRKVPVSKTPKKTHSDAKKGQNRSSNYLSCRTTPAIVPPKKFRQCPEPTSTAEKLGLKKGPRKAYELSQRSLDYVAQLRDHGKTVGVVDTRKKTKLISPQNLSVRNNKKLLTSQELQMQRQIRPKSQKNRRRLSDCESTDVKRAGSHTAQNSDIFVPESDRSDYNCTGGTEVLANSNRKQLIKCMPSEPETIKAKHGSPATDDACPLNQCDSVVLNGTVPTNEVIVSTSEDPLGGGDPTARHIEMAALKEGEPDSSSDAEEDNLFLTQNDPEDMDLCSQMENDNYKLIELIHGKDTVEVEEDSVSRPQLESLSGTKCKYKDCLETTKNQGEYCPKHSEVKAADEDVFRKPGLPPPASKPLRPTTKIFSSKSTSRIAGLSKSLETSSALSPSLKNKSKGIQSILKVPQPVPLIAQKPVGEMKNSCNVLHPQSPNNSNRQGCKVPFGESKYFPSSSPVNILLSSQSVSDTFVKEVLKWKYEMFLNFGQCGPPASLCQSISRPVPVRFHNYGDYFNVFFPLMVLNTFETVAQEWLNSPNRENFYQLQVRKFPADYIKYWEFAVYLEECELAKQLYPKENDLVFLAPERINEEKKDTERNDIQDLHEYHSGYVHKFRRTSVMRNGKTECYLSIQTQENFPANLNELVNCIVISSLVTTQRKLKAMSLLGSRNQLARAVLNPNPMDFCTKDLLTTTSERIIAYLRDFNEDQKKAIETAYAMVKHSPSVAKICLIHGPPGTGKSKTIVGLLYRLLTENQRKGHSDENSNAKIKQNRVLVCAPSNAAVDELMKKIILEFKEKCKDKKNPLGNCGDINLVRLGPEKSINSEVLKFSLDSQVNHRMKKELPSHVQAMHKRKEFLDYQLDELSRQRALCRGGREIQRQELDENISKVSKERQELASKIKEVQGRPQKTQSIIILESHIICCTLSTSGGLLLESAFRGQGGVPFSCVIVDEAGQSCEIETLTPLIHRCNKLILVGDPKQLPPTVISMKAQEYGYDQSMMARFCRLLEENVEHNMISRLPILQLTVQYRMHPDICLFPSNYVYNRNLKTNRQTEAIRCSSDWPFQPYLVFDVGDGSERRDNDSYINVQEIKLVMEIIKLIKDKRKDVSFRNIGIITHYKAQKTMIQKDLDKEFDRKGPAEVDTVDAFQGRQKDCVIVTCVRANSIQGSIGFLASLQRLNVTITRAKYSLFILGHLRTLMQLLPRSFCVHVNHSPFFSPEPKYLHWALKENQHWNQLIQDAQKRGAIIKTCDKNYRHDAVKILKLKPVLQRSLTHPPTIAPEGSRPQGGLPSSKLDSGFAKTSVAASLYHTPSDSKEITLTVTSKDPERPPVHDQLQDPRLLKRMGIEVKGGIFLWDPQPSSPQHPGATPPTGEPGFPVVHQDLSHIQQPAAVVAALSSHKPPVRGEPPAASPEASTCQSKCDDPEEELCHRREARAFSEGEQEKCGSETHHTRRNSRWDKRTLEQEDSSSKKRKLL>sp|A6NCI5|SIM16_HUMAN Putative transmembrane protein encoded byLINC00862 OS=Homo sapiens OX=9606 GN=LINC00862 PE=5 SV=1MVCYLYWETFPSISHLLKITLSARDCHVCGLNLFIFMDPVENQALHPVIMALILMPSLHCFGNILILLFLKSPAQLFCRMSVDLALLFPHK>sp|P0DL12|SIM17_HUMAN Small integral membrane protein 17 OS=Homo sapiensOX=9606 GN=SMIM17 PE=4 SV=1MQSLRPEQTRGLLEPERTKTLLPRESRAWEKPPHPACTKDWEAVEVGASSHDSDEKDLSSQETGLSQEWSSVEEDDESEGSQGFVEWSKAPQQTTIVLVVCVLFLFLVLTGMPMMFHI>sp|P0DKX4|SIM18_HUMAN Small integral membrane protein 18 OS=Homo sapiensOX=9606 GN=SMIM18 PE=4 SV=1MASSHWNETTTSVYQYLGFQVQKIYPFHDNWNTACFVILLLFIFTVVSLVVLAFLYEVLDCCCCVKNKTVKDLKSEPNPLRSMMDNIRKRETEVV>sp|Q14493|SLBP_HUMAN Histone RNA hairpin-binding protein OS=Homo sapiensOX=9606 GN=SLBP PE=1 SV=1MACRPRSPPRHQSRCDGDASPPSPARWSLGRKRRADGRRWRPEDAEEAEHRGAERRPESFTTPEGPKPRSRCSDWASAVEEDEMRTRVNKEMARYKRKLLINDFGRERKSSSGSSDSKESMSTVPADFETDESVLMRRQKQINYGKNTIAYDRYIKEVPRHLRQPGIHPKTPNKFKKYSRRSWDQQIKLWKVALHFWDPPAEEGCDLQEIHPVDLESAESSSEPQTSSQDDFDVYSGTPTKVRHMDSQVEDEFDLEACLTEPLRDFSAMS>sp|Q14493-2|SLBP_HUMAN Isoform 2 of Histone RNA hairpin-binding proteinOS=Homo sapiens OX=9606 GN=SLBPMACRPRSPPRHQSRCDGDASFTTPEGPKPRSRCSDWASAVEEDEMRTRVNKEMARYKRKLLINDFGRERKSSSGSSDSKESMSTVPADFETDESVLMRRQKQINYGKNTIAYDRYIKEVPRHLRQPGIHPKTPNKFKKYSRRSWDQQIKLWKVALHFWDPPAEEGCDLQEIHPVDLESAESSSEPQTSSQDDFDVYSGTPTKVRHMDSQVEDEFDLEACLTEPLRDFSAMS>sp|P04179|SODM_HUMAN Superoxide dismutase [Mn], mitochondrial OS=Homosapiens OX=9606 GN=SOD2 PE=1 SV=3MLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEKYQEALAKGDVTAQIALQPALKFNGGGHINHSIFWTNLSPNGGGEPKGELLEAIKRDFGSFDKFKEKLTAASVGVQGSGWGWLGFNKERGHLQIAACPNQDPLQGTTGLIPLLGIDVWEHAYYLQYKNVRPDYLKAIWNVINWENVTERYMACKK>sp|P04179-2|SODM_HUMAN Isoform 2 of Superoxide dismutase [Mn],mitochondrial OS=Homo sapiens OX=9606 GN=SOD2MLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEKYQEALAKGELLEAIKRDFGSFDKFKEKLTAASVGVQGSGWGWLGFNKERGHLQIAACPNQDPLQGTTGLIPLLGIDVWEHAYYLQYKNVRPDYLKAIWNVINWENVTERYMACKK>sp|P04179-3|SODM_HUMAN Isoform 3 of Superoxide dismutase [Mn],mitochondrial OS=Homo sapiens OX=9606 GN=SOD2MLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEKYQEALAKGDVTAQIALQPALKFNGGGHINHSIFWTNLSPNGGGEPKGLIPLLGIDVWEHAYYLQYKNVRPDYLKAIWNVINWENVTERYMACKK>sp|P04179-4|SODM_HUMAN Isoform 4 of Superoxide dismutase [Mn],mitochondrial OS=Homo sapiens OX=9606 GN=SOD2MQLHHSKHHAAYVNNLNVTEEKYQEALAKGDVTAQIALQPALKFNGGGHINHSIFWTNLSPNGGGEPKGELLEAIKRDFGSFDKFKEKLTAASVGVQGSGWGWLGFNKERGHLQIAACPNQDPLQGTTGLIPLLGIDVWEHAYYLQYKNVRPDYLKAIWNVINWENVTERYMACKK>sp|P81133|SIM1_HUMAN Single-minded homolog 1 OS=Homo sapiens OX=9606GN=SIM1 PE=1 SV=2MKEKSKNAARTRREKENSEFYELAKLLPLPSAITSQLDKASIIRLTTSYLKMRVVFPEGLGEAWGHSSRTSPLDNVGRELGSHLLQTLDGFIFVVAPDGKIMYISETASVHLGLSQVELTGNSIYEYIHPADHDEMTAVLTAHQPYHSHFVQEYEIERSFFLRMKCVLAKRNAGLTCGGYKVIHCSGYLKIRQYSLDMSPFDGCYQNVGLVAVGHSLPPSAVTEIKLHSNMFMFRASLDMKLIFLDSRVAELTGYEPQDLIEKTLYHHVHGCDTFHLRCAHHLLLVKGQVTTKYYRFLAKHGGWVWVQSYATIVHNSRSSRPHCIVSVNYVLTDTEYKGLQLSLDQISASKPAFSYTSSSTPTMTDNRKGAKSRLSSSKSKSRTSPYPQYSGFHTERSESDHDSQWGGSPLTDTASPQLLDPADRPGSQHDASCAYRQFSDRSSLCYGFALDHSRLVEERHFHTQACEGGRCEAGRYFLGTPQAGREPWWGSRAALPLTKASPESREAYENSMPHIASVHRIHGRGHWDEDSVVSSPDPGSASESGDRYRTEQYQSSPHEPSKIETLIRATQQMIKEEENRLQLRKAPSDQLASINGAGKKHSLCFANYQQPPPTGEVCHGSALANTSPCDHIQQREGKMLSPHENDYDNSPTALSRISSPNSDRISKSSLILAKDYLHSDISPHQTAGDHPTVSPNCFGSHRQYFDKHAYTLTGYALEHLYDSETIRNYSLGCNGSHFDVTSHLRMQPDPAQGHKGTSVIITNGS>sp|Q01105|SET_HUMAN Protein SET OS=Homo sapiens OX=9606 GN=SET PE=1 SV=3MAPKRQSPLPPQKKKPRPPPALGPEETSASAGLPKKGEKEQQEAIEHIDEVQNEIDRLNEQASEEILKVEQKYNKLRQPFFQKRSELIAKIPNFWVTTFVNHPQVSALLGEEDEEALHYLTRVEVTEFEDIKSGYRIDFYFDENPYFENKVLSKEFHLNESGDPSSKSTEIKWKSGKDLTKRSSQTQNKASRKRQHEEPESFFTWFTDHSDAGADELGEVIKDDIWPNPLQYYLVPDMDDEEGEGEEDDDDDEEEEGLEDIDEEGDEDEGEEDEDDDEGEEGEEDEGEDD>sp|Q01105-2|SET_HUMAN Isoform 2 of Protein SET OS=Homo sapiens OX=9606GN=SETMSAPAAKVSKKELNSNHDGADETSEKEQQEAIEHIDEVQNEIDRLNEQASEEILKVEQKYNKLRQPFFQKRSELIAKIPNFWVTTFVNHPQVSALLGEEDEEALHYLTRVEVTEFEDIKSGYRIDFYFDENPYFENKVLSKEFHLNESGDPSSKSTEIKWKSGKDLTKRSSQTQNKASRKRQHEEPESFFTWFTDHSDAGADELGEVIKDDIWPNPLQYYLVPDMDDEEGEGEEDDDDDEEEEGLEDIDEEGDEDEGEEDEDDDEGEEGEEDEGEDD>sp|Q01105-3|SET_HUMAN Isoform 3 of Protein SET OS=Homo sapiens OX=9606GN=SETMPRSHQPPPPPHEKEQQEAIEHIDEVQNEIDRLNEQASEEILKVEQKYNKLRQPFFQKRSELIAKIPNFWVTTFVNHPQVSALLGEEDEEALHYLTRVEVTEFEDIKSGYRIDFYFDENPYFENKVLSKEFHLNESGDPSSKSTEIKWKSGKDLTKRSSQTQNKASRKRQHEEPESFFTWFTDHSDAGADELGEVIKDDIWPNPLQYYLVPDMDDEEGEGEEDDDDDEEEEGLEDIDEEGDEDEGEEDEDDDEGEEGEEDEGEDD>sp|Q01105-4|SET_HUMAN Isoform 4 of Protein SET OS=Homo sapiens OX=9606GN=SETMGCRDLLPSLKPTLLEKEQQEAIEHIDEVQNEIDRLNEQASEEILKVEQKYNKLRQPFFQKRSELIAKIPNFWVTTFVNHPQVSALLGEEDEEALHYLTRVEVTEFEDIKSGYRIDFYFDENPYFENKVLSKEFHLNESGDPSSKSTEIKWKSGKDLTKRSSQTQNKASRKRQHEEPESFFTWFTDHSDAGADELGEVIKDDIWPNPLQYYLVPDMDDEEGEGEEDDDDDEEEEGLEDIDEEGDEDEGEEDEDDDEGEEGEEDEGEDD>sp|Q6UWI4|SHSA2_HUMAN Protein shisa-2 homolog OS=Homo sapiens OX=9606GN=SHISA2 PE=1 SV=1MWGARRSSVSSSWNAASLLQLLLAALLAAGARASGEYCHGWLDAQGVWRIGFQCPERFDGGDATICCGSCALRYCCSSAEARLDQGGCDNDRQQGAGEPGRADKDGPDGSAVPIYVPFLIVGSVFVAFIILGSLVAACCCRCLRPKQDPQQSRAPGGNRLMETIPMIPSASTSRGSSSRQSSTAASSSSSANSGARAPPTRSQTNCCLPEGTMNNVYVNMPTNFSVLNCQQATQIVPHQGQYLHPPYVGYTVQHDSVPMTAVPPFMDGLQPGYRQIQSPFPHTNSEQKMYPAVTV>sp|Q8N5G0|SIM20_HUMAN Small integral membrane protein 20 OS=Homo sapiensOX=9606 GN=SMIM20 PE=1 SV=3MSRNLRTALIFGGFISLIGAAFYPIYFRPLMRLEEYKKEQAINRAGIVQEDVQPPGLKVWSDPFGRK>sp|Q8N5G0-2|SIM20_HUMAN Isoform 2 of Small integral membrane protein 20OS=Homo sapiens OX=9606 GN=SMIM20MVKEVWRVLREEPGRRKESRQNRARGNRVQQNSSNLNPTPAPGPHSTESRGRRRAGSEAPPRPGSESLSTSSERGHGPAVGNLVSESAGRSAGQGSPGPDAMSRNLRTALIFGGFISLIGAAFYPIYFRPLMRLEEYKKEQAINRAGIVQEDVQPPGLKVWSDPFGRK>sp|A0PJX4|SHSA3_HUMAN Protein shisa-3 homolog OS=Homo sapiens OX=9606GN=SHISA3 PE=1 SV=1MRALLALCLLLGWLRWGPAGAQQSGEYCHGWVDVQGNYHEGFQCPEDFDTLDATICCGSCALRYCCAAADARLEQGGCTNDRRELEHPGITAQPVYVPFLIVGSIFIAFIILGSVVAIYCCTCLRPKEPSQQPIRFSLRSYQTETLPMILTSTSPRAPSRQSSTATSSSSTGGSIRRFSFARAEPGCLVPSPPPPYTTSHSIHLAQPSGFLVSPQYFAYPLQQEPPLPGKSCPDFSSS>sp|O95391|SLU7_HUMAN Pre-mRNA-splicing factor SLU7 OS=Homo sapiensOX=9606 GN=SLU7 PE=1 SV=2MSATVVDAVNAAPLSGSKEMSLEEPKKMTREDWRKKKELEEQRKLGNAPAEVDEEGKDINPHIPQYISSVPWYIDPSKRPTLKHQRPQPEKQKQFSSSGEWYKRGVKENSIITKYRKGACENCGAMTHKKKDCFERPRRVGAKFTGTNIAPDEHVQPQLMFDYDGKRDRWNGYNPEEHMKIVEEYAKVDLAKRTLKAQKLQEELASGKLVEQANSPKHQWGEEEPNSQMEKDHNSEDEDEDKYADDIDMPGQNFDSKRRITVRNLRIREDIAKYLRNLDPNSAYYDPKTRAMRENPYANAGKNPDEVSYAGDNFVRYTGDTISMAQTQLFAWEAYDKGSEVHLQADPTKLELLYKSFKVKKEDFKEQQKESILEKYGGQEHLDAPPAELLLAQTEDYVEYSRHGTVIKGQERAVACSKYEEDVKIHNHTHIWGSYWKEGRWGYKCCHSFFKYSYCTGEAGKEIVNSEECIINEITGEESVKKPQTLMELHQEKLKEEKKKKKKKKKKHRKSSSDSDDEEKKHEKLKKALNAEEARLLHVKETMQIDERKRPYNSMYETREPTEEEMEAYRMKRQRPDDPMASFLGQ>sp|K7EJ46|SIM22_HUMAN Small integral membrane protein 22 OS=Homo sapiensOX=9606 GN=SMIM22 PE=1 SV=2MAVSTEELEATVQEVLGRLKSHQFFQSTWDTVAFIVFLTFMGTVLLLLLLVVAHCCCCSSPGPRRESPRKERPKGVDNLALEP>sp|K7EJ46-2|SIM22_HUMAN Isoform 2 of Small integral membrane protein 22OS=Homo sapiens OX=9606 GN=SMIM22MAVSTEELEATVQEVLGRLKSHQFFQSTWDTVAFIVFLTFMGTVLLLLLLVVAHCCCCSSPGPRRESPRKVSPWKERPKGVDNLALEP>sp|Q96DD7|SHSA4_HUMAN Protein shisa-4 OS=Homo sapiens OX=9606 GN=SHISA4PE=1 SV=3MPPAGLRRAAPLTAIALLVLGAPLVLAGEDCLWYLDRNGSWHPGFNCEFFTFCCGTCYHRYCCRDLTLLITERQQKHCLAFSPKTIAGIASAVILFVAVVATTICCFLCSCCYLYRRRQQLQSPFEGQEIPMTGIPVQPVYPYPQDPKAGPAPPQPGFIYPPSGPAPQYPLYPAGPPVYNPAAPPPYMPPQPSYPGA>sp|Q9NXL6|SIDT1_HUMAN SID1 transmembrane family member 1 OS=Homo sapiensOX=9606 GN=SIDT1 PE=2 SV=2MRGCLRLALLCALPWLLLAASPGHPAKSPRQPPAPRRDPFDAARGADFDHVYSGVVNLSTENIYSFNYTSQPDQVTAVRVYVNSSSENLNYPVLVVVRQQKEVLSWQVPLLFQGLYQRSYNYQEVSRTLCPSEATNETGPLQQLIFVDVASMAPLGAQYKLLVTKLKHFQLRTNVAFHFTASPSQPQYFLYKFPKDVDSVIIKVVSEMAYPCSVVSVQNIMCPVYDLDHNVEFNGVYQSMTKKAAITLQKKDFPGEQFFVVFVIKPEDYACGGSFFIQEKENQTWNLQRKKNLEVTIVPSIKESVYVKSSLFSVFIFLSFYLGCLLVGFVHYLRFQRKSIDGSFGSNDGSGNMVASHPIAASTPEGSNYGTIDESSSSPGRQMSSSDGGPPGQSDTDSSVEESDFDTMPDIESDKNIIRTKMFLYLSDLSRKDRRIVSKKYKIYFWNIITIAVFYALPVIQLVITYQTVVNVTGNQDICYYNFLCAHPLGVLSAFNNILSNLGHVLLGFLFLLIVLRRDILHRRALEAKDIFAVEYGIPKHFGLFYAMGIALMMEGVLSACYHVCPNYSNFQFDTSFMYMIAGLCMLKLYQTRHPDINASAYSAYASFAVVIMVTVLGVVFGKNDVWFWVIFSAIHVLASLALSTQIYYMGRFKIDLGIFRRAAMVFYTDCIQQCSRPLYMDRMVLLVVGNLVNWSFALFGLIYRPRDFASYMLGIFICNLLLYLAFYIIMKLRSSEKVLPVPLFCIVATAVMWAAALYFFFQNLSSWEGTPAESREKNRECILLDFFDDHDIWHFLSATALFFSFLVLLTLDDDLDVVRRDQIPVF>sp|Q9NXL6-2|SIDT1_HUMAN Isoform 2 of SID1 transmembrane family member 1OS=Homo sapiens OX=9606 GN=SIDT1MRGCLRLALLCALPWLLLAASPGHPAKSPRQPPAPRRDPFDAARGADFDHVYSGVVNLSTENIYSFNYTSQPDQVTAVRVYVNSSSENLNYPVLVVVRQQKEVLSWQVPLLFQGLYQRSYNYQEVSRTLCPSEATNETGPLQQLIFVDVASMAPLGAQYKLLVTKLKHFQLRTNVAFHFTASPSQPQYFLYKFPKDVDSVIIKVVSEMAYPCSVVSVQNIMCPVYDLDHNVEFNGVYQSMTKKAAITLQKKDFPGEQFFVVFVIKPEDYACGGSFFIQEKENQTWNLQRKKNLEVTIVPSIKESVYVKSSLFSVFIFLSFYLGCLLVGFVHYLRFQRKSIDGSFGSNDGSGNMVASHPIAASTPEGSNYGTIDESSSSPGRQMSSSDGGPPGQSDTDSSVEESDFDTMPDIESDKNIIRTKMFLYLSDLSRKDRRIVSKKYKIYFWNIITIAVFYALPVIQLVITYQTVVNVTGNQDICYYNFLCAHPLGVLSAFNNILSNLGHVLLGFLFLLIVLRRDILHRRALEAKDIFAVEYGIPKHFGLFYAMGIALMMEGVLSACYHVCPNYSNFQFDTSFMYMIAGLCMLKLYQTRHPDINASAYSAYASFAVVIMVTVLGVVFGKNDVWFWVIFSAIHVLASLALSTQIYYMGRFKIDVSDTDLGIFRRAAMVFYTDCIQQCSRPLYMDRMVLLVVGNLVNWSFALFGLIYRPRDFASYMLGIFICNLLLYLAFYIIMKLRSSEKVLPVPLFCIVATAVMWAAALYFFFQNLSSWEGTPAESREKNRECILLDFFDDHDIWHFLSATALFFSFLVLLTLDDDLDVVRRDQIPVF>sp|A6NLE4|SIM23_HUMAN Small integral membrane protein 23 OS=Homo sapiensOX=9606 GN=SMIM23 PE=2 SV=3MATQQVDSRRQVAAEQVAAQLLERRRGSHCDDEKQTLLALLILVLYLSTEIWGSSWEVSERIRECNYYQNLAVPQGLEYQTNEPSEEPIKTIRNWLKEKLHVFSEKLEEEVQQLEQLAWDLELWLDALLGEPHQEEHCSTYKSHLWEWAWALGREHKGGEGLLEISLSGAEL>sp|O75264|SIM24_HUMAN Small integral membrane protein 24 OS=Homo sapiensOX=9606 GN=SMIM24 PE=2 SV=2METLGALLVLEFLLLSPVEAQQATEHRLKPWLVGLAAVVGFLFIVYLVLLANRLWCSKARAEDEEETTFRMESNLYQDQSEDKREKKEAKEKEEKRKKEKKTAKEGESNLGLDLEEKEPGDHERAKSTVM>sp|A0A096LP01|SIM26_HUMAN Small integral membrane protein 26 OS=Homosapiens OX=9606 GN=SMIM26 PE=3 SV=1MYRNEFTAWYRRMSVVYGIGTWSVLGSLLYYSRTMAKSSVDQKDGSASEVPSELSERPKGFYVETVVTYKEDFVPNTEKILNYWKSWTGGPGTEP>sp|Q8NBJ9|SIDT2_HUMAN SID1 transmembrane family member 2 OS=Homo sapiensOX=9606 GN=SIDT2 PE=1 SV=2MFALGLPFLVLLVASVESHLGVLGPKNVSQKDAEFERTYVDEVNSELVNIYTFNHTVTRNRTEGVRVSVNVLNKQKGAPLLFVVRQKEAVVSFQVPLILRGMFQRKYLYQKVERTLCQPPTKNESEIQFFYVDVSTLSPVNTTYQLRVSRMDDFVLRTGEQFSFNTTAAQPQYFKYEFPEGVDSVIVKVTSNKAFPCSVISIQDVLCPVYDLDNNVAFIGMYQTMTKKAAITVQRKDFPSNSFYVVVVVKTEDQACGGSLPFYPFAEDEPVDQGHRQKTLSVLVSQAVTSEAYVSGMLFCLGIFLSFYLLTVLLACWENWRQKKKTLLVAIDRACPESGHPRVLADSFPGSSPYEGYNYGSFENVSGSTDGLVDSAGTGDLSYGYQGRSFEPVGTRPRVDSMSSVEEDDYDTLTDIDSDKNVIRTKQYLYVADLARKDKRVLRKKYQIYFWNIATIAVFYALPVVQLVITYQTVVNVTGNQDICYYNFLCAHPLGNLSAFNNILSNLGYILLGLLFLLIILQREINHNRALLRNDLCALECGIPKHFGLFYAMGTALMMEGLLSACYHVCPNYTNFQFDTSFMYMIAGLCMLKLYQKRHPDINASAYSAYACLAIVIFFSVLGVVFGKGNTAFWIVFSIIHIIATLLLSTQLYYMGRWKLDSGIFRRILHVLYTDCIRQCSGPLYVDRMVLLVMGNVINWSLAAYGLIMRPNDFASYLLAIGICNLLLYFAFYIIMKLRSGERIKLIPLLCIVCTSVVWGFALFFFFQGLSTWQKTPAESREHNRDCILLDFFDDHDIWHFLSSIAMFGSFLVLLTLDDDLDTVQRDKIYVF>sp|Q8NBJ9-2|SIDT2_HUMAN Isoform 2 of SID1 transmembrane family member 2OS=Homo sapiens OX=9606 GN=SIDT2MFALGLPFLVLLVASVESHLGVLGPKNVSQKDAEFERTYVDEVNSELVNIYTFNHTVTRNRTEGVRVSVNVLNKQKGAPLLFVVRQKEAVVSFQVPLILRGMFQRKYLYQKVERTLCQPPTKNESEIQFFYVDVSTLSPVNTTYQLRVSRMDDFVLRTGEQFSFNTTAAQPQYFKYEFPEGVDSVIVKVTSNKAFPCSVISIQDVLCPVYDLDNNVAFIGMYQTMTKKAAITVQRKDFPSNSFYVVVVVKTEDQACGGSLPFYPFAEDEPVDQGHRQKTLSVLVSQAVTSEAYVSGMLFCLGIFLSFYLLTVLLACWENWRQKKKTLLVAIDRACPESGHPRVLADSFPGSSPYEGYNYGSFENVSGSTDGLVDSAGTGDLSYGYQGHDQFKRRLPSGQMRQLCIAMGRSFEPVGTRPRVDSMSSVEEDDYDTLTDIDSDKNVIRTKQYLYVADLARKDKRVLRKKYQIYFWNIATIAVFYALPVVQLVITYQTVVNVTGNQDICYYNFLCAHPLGNLSAFNNILSNLGYILLGLLFLLIILQREINHNRALLRNDLCALECGIPKHFGLFYAMGTALMMEGLLSACYHVCPNYTNFQFDTSFMYMIAGLCMLKLYQKRHPDINASAYSAYACLAIVIFFSVLGVVFGKGNTAFWIVFSIIHIIATLLLSTQLYYMGRWKLDSGIFRRILHVLYTDCIRQCSGPLYVDRMVLLVMGNVINWSLAAYGLIMRPNDFASYLLAIGICNLLLYFAFYIIMKLRSGERIKLIPLLCIVCTSVVWGFALFFFFQGLSTWQKTPAESREHNRDCILLDFFDDHDIWHFLSSIAMFGSFLVSGPPGAALRIT>sp|Q8N114|SHSA5_HUMAN Protein shisa-5 OS=Homo sapiens OX=9606 GN=SHISA5PE=1 SV=1MTAPVPAPRILLPLLLLLLLTPPPGARGEVCMASRGLSLFPESCPDFCCGTCDDQYCCSDVLKKFVWSEERCAVPEASVPASVEPVEQLGSALRFRPGYNDPMSGFGATLAVGLTIFVLSVVTIIICFTCSCCCLYKTCRRPRPVVTTTTSTTVVHAPYPQPPSVPPSYPGPSYQGYHTMPPQPGMPAAPYPMQYPPPYPAQPMGPPAYHETLAGGAAAPYPASQPPYNPAYMDAPKAAL>sp|Q8N114-2|SHSA5_HUMAN Isoform 2 of Protein shisa-5 OS=Homo sapiensOX=9606 GN=SHISA5MASRGLSLFPESCPDFCCGTCDDQYCCSDVLKKFVWSEERCAVPEASVPASVEPVEQLGSALRFRPGYNDPMSGFGATLAVGLTIFVLSVVTIIICFTCSCCCLYKTCRRPRPVVTTTTSTTVVHAPYPQPPSVPPSYPGPSYQGYHTMPPQPGMPAAPYPMQYPPPYPAQPMGPPAYHETLAGGAAAPYPASQPPYNPAYMDAPKAAL>sp|Q8N114-3|SHSA5_HUMAN Isoform 3 of Protein shisa-5 OS=Homo sapiensOX=9606 GN=SHISA5MGFGATLAVGLTIFVLSVVTIIICFTCSCCCLYKTCRRPRPVVTTTTSTTVVHAPYPQPPSVPPSYPGPSYQGYHTMPPQPGMPAAPYPMQYPPPYPAQPMGPPAYHETLAGGAAAPYPASQPPYNPAYMDAPKAAL>sp|Q8N114-4|SHSA5_HUMAN Isoform 4 of Protein shisa-5 OS=Homo sapiensOX=9606 GN=SHISA5MGFGATLAVGLTIFVLSVVTIIICFTCSCCCLYKTCRRPRPVVTTTTSTTVVHAPYPQPPSVPPSYPGPSYQGYHTMPPQPGMPAAPYPMQYPPPYPAQPMGPPAYHETLAGECPCQL>sp|Q8N114-5|SHSA5_HUMAN Isoform 5 of Protein shisa-5 OS=Homo sapiensOX=9606 GN=SHISA5MTAPVPAPRILLPLLLLLLLTPPPGARGEVCMASRGLSLFPESCPDFCCGTCDDQYCCSDVLKKFVWSEESVPASVEPVEQLGSALRFRPGYNDPMSGFGATLAVGLTIFVLSVVTIIICFTCSCCCLYKTCRRPRPVVTTTTSTTVVHAPYPQPPSVPPSYPGPSYQGYHTMPPQPGMPAAPYPMQYPPPYPAQPMGPPAYHETLAGGAAAPYPASQPPYNPAYMDAPKAAL>sp|A0A1B0GUW7|SIM27_HUMAN Small integral membrane protein 27 OS=Homosapiens OX=9606 GN=SMIM27 PE=3 SV=1MKPVSRRTLDWIYSVLLLAIVLISWGCIIYASMVSARRQLRKKYPDKIFGTNENL>sp|Q12872|SFSWA_HUMAN Splicing factor, suppressor of white-apricothomolog OS=Homo sapiens OX=9606 GN=SFSWAP PE=1 SV=3MYGASGGRAKPERKSGAKEEAGPGGAGGGGSRVELLVFGYACKLFRDDERALAQEQGQHLIPWMGDHKILIDRYDGRGHLHDLSEYDAEYSTWNRDYQLSEEEARIEALCDEERYLALHTDLLEEEARQEEEYKRLSEALAEDGSYNAVGFTYGSDYYDPSEPTEEEEPSKQREKNEAENLEENEEPFVAPLGLSVPSDVELPPTAKMHAIIERTASFVCRQGAQFEIMLKAKQARNSQFDFLRFDHYLNPYYKFIQKAMKEGRYTVLAENKSDEKKKSGVSSDNEDDDDEEDGNYLHPSLFASKKCNRLEELMKPLKVVDPDHPLAALVRKAQADSSTPTPHNADGAPVQPSQVEYTADSTVAAMYYSYYMLPDGTYCLAPPPPGIDVTTYYSTLPAGVTVSNSPGVTTTAPPPPGTTPLPPPTTAETSSGATSTTTTTSALAPVAAIIPPPPDVQPVIDKLAEYVARNGLKFETSVRAKNDQRFEFLQPWHQYNAYYEFKKQFFLQKEGGDSMQAVSAPEEAPTDSAPEKPSDAGEDGAPEDAAEVGARAGSGGKKEASSSKTVPDGKLVKASFAPISFAIKAKENDLLPLEKNRVKLDDDSDDDEESKEGQESSSSAANTNPAVAPPCVVVEEKKPQLTQEELEAKQAKQKLEDRLAAAAREKLAQASKESKEKQLQAERKRKAALFLQTLKNPLPEAEAGKIEESPFSVEESSTTPCPLLTGGRPLPTLEVKPPDRPSSKSKDPPREEEKEKKKKKHKKRSRTRSRSPKYHSSSKSRSRSHSKAKHSLPSAYRTVRRSRSRSRSPRRRAHSPERRREERSVPTAYRVSRSPGASRKRTRSRSPHEKKKKRRSRSRTKSKARSQSVSPSKQAAPRPAAPAAHSAHSASVSPVESRGSSQERSRGVSQEKEAQISSAIVSSVQSKITQDLMAKVRAMLAASKNLQTSAS>sp|Q12872-2|SFSWA_HUMAN Isoform 2 of Splicing factor, suppressor ofwhite-apricot homolog OS=Homo sapiens OX=9606 GN=SFSWAPMYGASGGRAKPERKSGAKEEAGPGGAGGGGSRVELLVFGYACKLFRDDERALAQEQGQHLIPWMGDHKILIDRYDGRGHLHDLSEYDAEYSTWNRDYQLSEEEARIEALCDEERYLALHTDLLEEEARQEEEYKRLSEALAEDGSYNAVGFTYGSDYYDPSEPTEEEEPSKQREKNEAENLEENEEPFVAPLGLSVPSDVELPPTAKMHAIIERTASFVCRQGAQFEIMLKAKQARNSQFDFLRFDHYLNPYYKFIQKAMKEGRYTVLAENKSDEKKKSGVSSDNEDDDDEEDGNYLHPSLFASKKCNRLEELMKPLKVVDPDHPLAALVRKAQADSSTPTPHNADGAPVQPSQVEYTADSTVAAMYYSYYMLPDGTYCLAPPPPGIDVTTYYSTLPAGVTVSNSPGVTTTAPPPPGTTPLPPPTTAETSSGATSTTTTTSALAPVAAIIPPPPDVQPVIDKLAEYVARNGLKFETSVRAKNDQRFEFLQPWHQYNAYYEFKKQFFLQKEGGDSMQAVSAPEEAPTDSAPEKPSDAGEDGAPEDAAEVGARAGSGGKKEASSSKTVPDGKLVKASFAPISFAIKAKENDLLPLEKNRVKLDDDSDDDEESKEGQESSSSAANTNPAVAPPCVVVEEKKPQLTQEELEAKQAKQKLEDRLAAAAREKLAQASKESKEKQLQAERKRKAALFLQTLKNPLPEAEAGKIEESPFSVEESSTTPCPLLTGGRPLPTLEVKPPDRPSSKSKDPPREEEKEKKKKKHKKRSRTRSRSPKYHSSSKSRSRSHSKAKHSLPSAYRTVRRSRVTASPGTLRAEPCQSSASVTAAAEPGSYQAASTTTRFDSASSFEGKPGKTSRSRSRSPRRRAHSPERRREERSVPTAYRVSRSPGASRKRTRSRSPHEKKKKRRSRSRTKSKARSQSVSPSKQAAPRPAAPAAHSAHSASVSPVESRGSSQERSRGVSQEKEAQISSAIVSSVQSKITQDLMAKVRAMLAASKNLQTSAS>sp|A0A1B0GU29|SIM28_HUMAN Small integral membrane protein 28 OS=Homosapiens OX=9606 GN=SMIM28 PE=3 SV=1MRGLLGSSWKKFGHAGRGTYEWLTSEPGLPLLETQLQGTQGVSSTQEDVEPFLCILLPATILLFLAFLLLFLYRRCKSPPPQGQVFSIDLPEHPPAGEVTDLLPGLAWSSEDFPYSPLPPEATLPSQCLPPSYEEATRNPPGEEAQGCSPSV>sp|Q86T20|SIM29_HUMAN Small integral membrane protein 29 OS=Homo sapiensOX=9606 GN=SMIM29 PE=2 SV=3MSNTTVPNAPQANSDSMVGYVLGPFFLITLVGVVVAVVMYVQKKKRVDRLRHHLLPMYSYDPAEELHEAEQELLSDMGDPKVVHGWQSGYQHKRMPLLDVKT>sp|Q86T20-2|SIM29_HUMAN Isoform 2 of Small integral membrane protein 29OS=Homo sapiens OX=9606 GN=SMIM29MSNTTVPNAPQANSDSMVMYVQKKKRVDRLRHHLLPMYSYDPAEELHEAEQELLSDMGDPKVVHGWQSGYQHKRMPLLDVKT>sp|Q07837|SLC31_HUMAN Neutral and basic amino acid transport proteinrBAT OS=Homo sapiens OX=9606 GN=SLC3A1 PE=1 SV=2MAEDKSKRDSIEMSMKGCQTNNGFVHNEDILEQTPDPGSSTDNLKHSTRGILGSQEPDFKGVQPYAGMPKEVLFQFSGQARYRIPREILFWLTVASVLVLIAATIAIIALSPKCLDWWQEGPMYQIYPRSFKDSNKDGNGDLKGIQDKLDYITALNIKTVWITSFYKSSLKDFRYGVEDFREVDPIFGTMEDFENLVAAIHDKGLKLIIDFIPNHTSDKHIWFQLSRTRTGKYTDYYIWHDCTHENGKTIPPNNWLSVYGNSSWHFDEVRNQCYFHQFMKEQPDLNFRNPDVQEEIKEILRFWLTKGVDGFSLDAVKFLLEAKHLRDEIQVNKTQIPDTVTQYSELYHDFTTTQVGMHDIVRSFRQTMDQYSTEPGRYRFMGTEAYAESIDRTVMYYGLPFIQEADFPFNNYLSMLDTVSGNSVYEVITSWMENMPEGKWPNWMIGGPDSSRLTSRLGNQYVNVMNMLLFTLPGTPITYYGEEIGMGNIVAANLNESYDINTLRSKSPMQWDNSSNAGFSEASNTWLPTNSDYHTVNVDVQKTQPRSALKLYQDLSLLHANELLLNRGWFCHLRNDSHYVVYTRELDGIDRIFIVVLNFGESTLLNLHNMISGLPAKMRIRLSTNSADKGSKVDTSGIFLDKGEGLIFEHNTKNLLHRQTAFRDRCFVSNRACYSSVLNILYTSC>sp|Q07837-2|SLC31_HUMAN Isoform B of Neutral and basic amino acidtransport protein rBAT OS=Homo sapiens OX=9606 GN=SLC3A1MKEQPDLNFRNPDVQEEIKEILRFWLTKGVDGFSLDAVKFLLEAKHLRDEIQVNKTQIPDTVTQYSELYHDFTTTQVGMHDIVRSFRQTMDQYSTEPGRYRFMGTEAYAESIDRTVMYYGLPFIQEADFPFNNYLSMLDTVSGNSVYEVITSWMENMPEGKWPNWMIGGPDSSRLTSRLGNQYVNVMNMLLFTLPGTPITYYGEEIGMGNIVAANLNESYDINTLRSKSPMQWDNSSNAGFSEASNTWLPTNSDYHTVNVDVQKTQPRSALKLYQDLSLLHANELLLNRGWFCHLRNDSHYVVYTRELDGIDRIFIVVLNFGESTLLNLHNMISGLPAKMRIRLSTNSADKGSKVDTSGIFLDKGEGLIFEHNTKNLLHRQTAFRDRCFVSNRACYSSVLNILYTSC>sp|Q07837-3|SLC31_HUMAN Isoform C of Neutral and basic amino acidtransport protein rBAT OS=Homo sapiens OX=9606 GN=SLC3A1MAEDKSKRDSIEMSMKGCQTNNGFVHNEDILEQTPDPGSSTDNLKHSTRGILGSQEPDFKGVQPYAGMPKEVLFQFSGQARYRIPREILFWLTVASVLVLIAATIAIIALSPKCLDWWQEGPMYQIYPRSFKDSNKDGNGDLKGIQDKLDYITALNIKTVWITSFYKSSLKDFRYGVEDFREVDPIFGTMEDFENLVAAIHDKGLKLIIDFIPNHTSDKHIWFQLSRTRTGKYTDYYIWHDCTHENGKTIPPNNWLSVYGNSSWHFDEVRNQCYFHQFMKEQPDLNFRNPDVQEEIKEILRFWLTKGVDGFSLDAVKFLLEAKHLRDEIQVNKTQIPDTVTQYSELYHDFTTTQVGMHDIVRSFRQTMDQYSTEPGRYRLTTAYALISSQA>sp|Q07837-4|SLC31_HUMAN Isoform D of Neutral and basic amino acidtransport protein rBAT OS=Homo sapiens OX=9606 GN=SLC3A1MTLNLVNSYRFMGTEAYAESIDRTVMYYGLPFIQEADFPFNNYLSMLDTVSGNSVYEVITSWMENMPEGKWPNWMIGGPDSSRLTSRLGNQYVNVMNMLLFTLPGTPITYYGEEIGMGNIVAANLNESYDINTLRSKSPMQWDNSSNAGFSEASNTWLPTNSDYHTVNVDVQKTQPRSALKLYQDLSLLHANELLLNRGWFCHLRNDSHYVVYTRELDGIDRIFIVVLNFGESTLLNLHNMISGLPAKMRIRLSTNSADKGSKVDTSGIFLDKGEGLIFEHNTKNLLHRQTAFRDRCFVSNRACYSSVLNILYTSC>sp|Q07837-5|SLC31_HUMAN Isoform E of Neutral and basic amino acidtransport protein rBAT OS=Homo sapiens OX=9606 GN=SLC3A1MAEDKSKRDSIEMSMKGCQTNNGFVHNEDILEQTPDPGSSTDNLKHSTRGILGSQEPDFKGVQPYAGMPKEVLFQFSGQARYRIPREILFWLTVASVLVLIAATIAIIALSPKCLDWWQEGPMYQIYPRSFKDSNKDGNGDLKGIQDKLDYITALNIKTVWITSFYKSSLKDFRYGVEDFREVDPIFGTMEDFENLVAAIHDKGLKLIIDFIPNHTSDKHIWFQLSRTRTGKYTDYYIWHDCTHENGKTIPPNNWLSVYGNSSWHFDEVRNQCYFHQFMKEQPDLNFRNPDVQEEIKEILRFWLTKGVDGFSLDAVKFLLEAKHLRDEIQVNKTQIPDTVTQYSELYHDFTTTQVGMHDIVRSFRQTMDQYSTEPGRYRFMGTEAYAESIDRTVMYYGLPFIQEADFPFNNYLSMLDTVSGNSVYEVITSWMENMPEGKWPNWMIGGPDSSRLTSRLGNQYVNVMNMLLFTLPGTPITYYGEEIGMGNIVAANLNESYDIVS>sp|Q07837-6|SLC31_HUMAN Isoform F of Neutral and basic amino acidtransport protein rBAT OS=Homo sapiens OX=9606 GN=SLC3A1MAEDKSKRDSIEMSMKGCQTNNGFVHNEDILEQTPDPGSSTDNLKHSTRGILGSQEPDFKGVQPYAGMPKEVLFQFSGQARYRIPREILFWLTVASVLVLIAATIAIIALSPKCLDWWQEGPMYQIYPRSFKDSNKDGNGDLKGIQDKLDYITALNIKTVWITSFYKSSLKDFRYGVEDFREVDPIFGTMEDFENLVAAIHDKGLKLIIDFIPNHTSDKHIWFQLSRTRTGKYTDYYIWHDCTHENGKTIPPNNWLSVYGNSSWHFDEVRNQCYFHQFMKEQPDLNFRNPDVQEEIKEILRFWLTKGVDGFSLDAVKFLLEAKHLRDEIQVNKTQIPDTVTQYSELYHDFTTTQVGMHDIVRSFRQTMDQYSTEPGRYRFMGTEAYAESIDRTVMYYGLPFIQEADFPFNNYLSMLDTVSGNSVYEVITSWMENMPEGKWPNWMIGGPDSSRLTSRLGNQYVNVMNMLLFTLPGTPITYYGEEIGMGNIVAANLNESYDINTLRSKSPMQWDNSSNAGFSEASNTWLPTNSDYHTVNVDVSISENFMLILETKKWVSTESTHSP>sp|Q07837-7|SLC31_HUMAN Isoform G of Neutral and basic amino acidtransport protein rBAT OS=Homo sapiens OX=9606 GN=SLC3A1MAEDKSKRDSIEMSMKGCQTNNGFVHNEDILEQTPDPGSSTDNLKHSTRGILGSQEPDFKGVQPYAGMPKEVLFQFSGQARYRIPREILFWLTVASVLVLIAATIAIIALSPKCLDWWQEGPMYQIYPRSFKDSNKDGNGDLKGIQDKLDYITALNIKTVWITSFYKSSLKDFRYGVEDFREVDPIFGTMEDFENLVAAIHDKGLKLIIDFIPNHTSDKHIWFQLSRTRTGKYTDYYIWHDCTHENGKTIPPNNWLSVYGNSSWHFDEVRNQCYFHQFMKEQPDLNFRNPDVQEEIKEILRFWLTKGVDGFSLDAVKFLLEAKHLRDEIQVNKTQIPDTVTQYSELYHDFTTTQVGMHDIVRSFRQTMDQYSTEPGRYRFMGTEAYAESIDRTVMYYGLPFIQEADFPFNNYLSMLDTVSGNSVYEVITSWMENMPEGKWPNWMIGGPDSSRLTSRLGNQYVNVMNMLLFTLPGTPITYYGEEIGMGNIVAANLNESYDINTLRSKSPMQWDNSSNAGFSEASNTWLPTNSDYHTVNVDVLLRHPCSSAVA>sp|Q6ZSJ9|SHSA6_HUMAN Protein shisa-6 OS=Homo sapiens OX=9606 GN=SHISA6PE=1 SV=2MALRRLLLLLLLSLESLDLLPSVHGARGRAANRTLSAGGAAVGGRRAGGALARGGRELNGTARAPGIPEAGSRRGQPAAAVAAAASAAVTYETCWGYYDVSGQYDKEFECNNSESGYLYCCGTCYYRFCCKKRHEKLDQRQCTNYQSPVWVQTPSTKVVSPGPENKYDPEKDKTNFTVYITCGVIAFVIVAGVFAKVSYDKAHRPPREMNIHRALADILRQQGPIPIAHCERETISAIDTSPKENTPVRSSSKNHYTPVRTAKQTPEKPRMNNILTSATEPYDLSFSRSFQNLAHLPPSYESAVKTNPSKYSSLKRLTDKEADEYYMRRRHLPDLAARGTLPLNVIQMSQQKPLPRERPRRPIRAMSQDRVLSPDRGLPDEFSMPYDRILSDEQLLSTERLHSQDPLLSPERTAFPEQSLSRAISHTDVFVSTPVLDRYRMSKMHSHPSASNNSYATLGQSQTAAKRHAFASRRHNTVEQLHYIPGHHTCYTASKTEVTV>sp|Q6ZSJ9-2|SHSA6_HUMAN Isoform 2 of Protein shisa-6 OS=Homo sapiensOX=9606 GN=SHISA6MALRRLLLLLLLSLESLDLLPSVHGARGRAANRTLSAGGAAVGGRRAGGALARGGRELNGTARAPGIPEAGSRRGQPAAAVAAAASAAVTYETCWGYYDVSGQYDKEFECNNSESGYLYCCGTCYYRFCCKKRHEKLDQRQCTNYQSPVWVQTPSTKVVSPGPENKYDPEKDKTNFTVYITCGVIAFVIVAGVFAKVSYDKAHRPPREMNIHRALADILRQQGPIPIAHCERETISAIDTSPKENTPVRSSSKNHYTPVRTAKQTPGHYGKDAYRSGGPDLHNFISSGFVTLGRGHTKEKPRMNNILTSATEPYDLSFSRSFQNLAHLPPSYESAVKTNPSKYSSLKRLTDKEADEYYMRRRHLPDLAARGTLPLNVIQMSQQKPLPRERPRRPIRAMSQDRVLSPDRGLPDEFSMPYDRILSDEQLLSTERLHSQDPLLSPERTAFPEQSLSRAISHTDVFVSTPVLDRYRMSKMHSHPSASNNSYATLGQSQTAAKRHAFASRRHNTVEQLHYIPGHHTCYTASKTEVTV>sp|Q6ZSJ9-3|SHSA6_HUMAN Isoform 3 of Protein shisa-6 OS=Homo sapiensOX=9606 GN=SHISA6MALRRLLLLLLLSLESLDLLPSVHGARGRAANRTLSAGGAAVGGRRAGGALARGGRELNGTARAPGIPEAGSRRGQPAAAVAAAASAAVTYETCWGYYDVSGQYDKEFECNNSESGYLYCCGTCYYRFCCKKRHEKLDQRQCTNYQSPVWVQTPSTKVVSPGPENKYDPEKDKTNFTVYITCGVIAFVIVAGVFAKVSYDKAHRPPREMNIHRALADILRQQGPIPIAHCERETISAIDTSPKENTPVRSSSKNHYTPVRTAKQTPGHYGKDAYRSGGPDLHNFISSGFVTLGRGHTKGDHQYNHPILSSVTQIPPHEKPRMNNILTSATEPYDLSFSRSFQNLAHLPPSYESAVKTNPSKYSSLKRLTDKEADEYYMRRRHLPDLAARGTLPLNVIQMSQQKPLPRERPRRPIRAMSQDRVLSPDRGLPDEFSMPYDRILSDEQLLSTERLHSQDPLLSPERTAFPEQSLSRAISHTDVFVSTPVLDRYRMSKMHSHPSASNNSYATLGQSQTAAKRHAFASRRHNTVEQLHYIPGHHTCYTASKTEVTV>sp|Q14190|SIM2_HUMAN Single-minded homolog 2 OS=Homo sapiens OX=9606GN=SIM2 PE=1 SV=2MKEKSKNAAKTRREKENGEFYELAKLLPLPSAITSQLDKASIIRLTTSYLKMRAVFPEGLGDAWGQPSRAGPLDGVAKELGSHLLQTLDGFVFVVASDGKIMYISETASVHLGLSQVELTGNSIYEYIHPSDHDEMTAVLTAHQPLHHHLLQEYEIERSFFLRMKCVLAKRNAGLTCSGYKVIHCSGYLKIRQYMLDMSLYDSCYQIVGLVAVGQSLPPSAITEIKLYSNMFMFRASLDLKLIFLDSRVTEVTGYEPQDLIEKTLYHHVHGCDVFHLRYAHHLLLVKGQVTTKYYRLLSKRGGWVWVQSYATVVHNSRSSRPHCIVSVNYVLTEIEYKELQLSLEQVSTAKSQDSWRTALSTSQETRKLVKPKNTKMKTKLRTNPYPPQQYSSFQMDKLECGQLGNWRASPPASAAAPPELQPHSESSDLLYTPSYSLPFSYHYGHFPLDSHVFSSKKPMLPAKFGQPQGSPCEVARFFLSTLPASGECQWHYANPLVPSSSSPAKNPPEPPANTARHSLVPSYEAPAAAVRRFGEDTAPPSFPSCGHYREEPALGPAKAARQAARDGARLALARAAPECCAPPTPEAPGAPAQLPFVLLNYHRVLARRGPLGGAAPAASGLACAPGGPEAATGALRLRHPSPAATSPPGAPLPHYLGASVIITNGR>sp|Q14190-2|SIM2_HUMAN Isoform SIM2S of Single-minded homolog 2 OS=Homosapiens OX=9606 GN=SIM2MKEKSKNAAKTRREKENGEFYELAKLLPLPSAITSQLDKASIIRLTTSYLKMRAVFPEGLGDAWGQPSRAGPLDGVAKELGSHLLQTLDGFVFVVASDGKIMYISETASVHLGLSQVELTGNSIYEYIHPSDHDEMTAVLTAHQPLHHHLLQEYEIERSFFLRMKCVLAKRNAGLTCSGYKVIHCSGYLKIRQYMLDMSLYDSCYQIVGLVAVGQSLPPSAITEIKLYSNMFMFRASLDLKLIFLDSRVTEVTGYEPQDLIEKTLYHHVHGCDVFHLRYAHHLLLVKGQVTTKYYRLLSKRGGWVWVQSYATVVHNSRSSRPHCIVSVNYVLTEIEYKELQLSLEQVSTAKSQDSWRTALSTSQETRKLVKPKNTKMKTKLRTNPYPPQQYSSFQMDKLECGQLGNWRASPPASAAAPPELQPHSESSDLLYTPSYSLPFSYHYGHFPLDSHVFSSKKPMLPAKFGQPQGSPCEVARFFLSTLPASGECQWHYANPLVPSSSSPAKNPPEPPANTARHSLVPSYEGGSGLLVGKVGGLRTAGSRSSHGGGWQMETEPSRFGQTCPLSASK>sp|Q8WV19|SFT2A_HUMAN Vesicle transport protein SFT2A OS=Homo sapiensOX=9606 GN=SFT2D1 PE=1 SV=1MEKLRRVLSGQDDEEQGLTAQVLDASSLSFNTRLKWFAICFVCGVFFSILGTGLLWLPGGIKLFAVFYTLGNLAALASTCFLMGPVKQLKKMFEATRLLATIVMLLCFIFTLCAALWWHKKGLAVLFCILQFLSMTWYSLSYIPYARDAVIKCCSSLLS>sp|A4D0T7|SIM30_HUMAN Small integral membrane protein 30 OS=Homo sapiensOX=9606 GN=SMIM30 PE=3 SV=2MTSVSTQLSLVLMSLLLVLPVVEAVEAGDAIALLLGVVLSITGICACLGVYARKRNGQM>sp|A6NL88|SHSA7_HUMAN Protein shisa-7 OS=Homo sapiens OX=9606 GN=SHISA7PE=2 SV=3MPALLLLVLLASSAGQARARPSNATSAEPAGPLPALLAHLRRLTGALTGGGGAASPGANGTRTGPAGGAGAAARAPPPAELCHGYYDVMGQYDATFNCSTGSYRFCCGTCHYRFCCEHRHMRLAQASCSNYDTPRWATTPPPLAGGAGGAGGAGGGPGPGQAGWLEGGRTGGAGGRGGEGPGGSTAYVVCGVISFALAVGVGAKVAFSKASRAPRAHRDINVPRALVDILRHQAGPGTRPDRARSSSLTPGIGGPDSMPPRTPKNLYNTVKTPNLDWRALPPPSPSLHYSTLSCSRSFHNLSHLPPSYEAAVKSELNRYSSLKRLAEKDLDEAYLKRRPLELPRGTLPLHALRRPGTGGGYRMEAWGGPEELGLAPAPNPRRVMSQEHLLGDGGRSRYEFTLPRARLVSQEHLLLSSPEALRQSREHLLSPPRSPALPPDPTARASLAASHSNLLLGPGGPPTPLRGLPPPSSLHAHHHHALHGSPQPAWMSDAGGGGGTLARRPPFQRQGTLEQLQFIPGHHLPQHLRTASKNEVTV>sp|A0A1B0GVY4|SIM31_HUMAN Small integral membrane protein 31 OS=Homosapiens OX=9606 GN=SMIM31 PE=3 SV=1MELPYTNLEMAFILLAFVIFSLFTLASIYTTPDDSNEEEEHEKKGREKKRKKSEKKKNCSEEEHRIEAVEL>sp|P55000|SLUR1_HUMAN Secreted Ly-6/uPAR-related protein 1 OS=Homosapiens OX=9606 GN=SLURP1 PE=1 SV=2MASRWAVQLLLVAAWSMGCGEALKCYTCKEPMTSASCRTITRCKPEDTACMTTLVTVEAEYPFNQSPVVTRSCSSSCVATDPDSIGAAHLIFCCFRDLCNSEL>sp|A0A1B0GUA5|SIM32_HUMAN Small integral membrane protein 32 OS=Homosapiens OX=9606 GN=SMIM32 PE=3 SV=1MYGDIFNATGGPEAAVGSALAPGATVKAEGALPLELATARGMRDGAATKPDLPTYLLLFFLLLLSVALVVLFIGCQLRHSAFAALPHDRSLRDARAPWKTRPV>sp|A0A1B0GW64|SIM33_HUMAN Small integral membrane protein 33 OS=Homosapiens OX=9606 GN=SMIM33 PE=3 SV=1MHQAGHYSWPSPAVNSSSEQEPQRQLPEVLSGTWEQPRVDGLPVVTVIVAVFVLLAVCIIVAVHFGPRLHQGHATLPTEPPTPKPDGGIYLIHWRVLGPQDSPEEAPPGPLVPGSCPAPDGPRPSIDEVTCL>sp|O95562|SFT2B_HUMAN Vesicle transport protein SFT2B OS=Homo sapiensOX=9606 GN=SFT2D2 PE=1 SV=1MDKLKKVLSGQDTEDRSGLSEVVEASSLSWSTRIKGFIACFAIGILCSLLGTVLLWVPRKGLHLFAVFYTFGNIASIGSTIFLMGPVKQLKRMFEPTRLIATIMVLLCFALTLCSAFWWHNKGLALIFCILQSLALTWYSLSFIPFARDAVKKCFAVCLA>sp|A0A1B0GVV1|SIM35_HUMAN Small integral membrane protein 35 OS=Homosapiens OX=9606 GN=SMIM35 PE=3 SV=1MTGEDSISTLGLILGVGLLLLLVSILGYSLAKWYQRGYCWEGPNFVFNLYQIRNLKDLEMGPPFTISGHISSTDGGYMKFSNGLV>sp|B8ZZ34|SHSA8_HUMAN Protein shisa-8 OS=Homo sapiens OX=9606 GN=SHISA8PE=3 SV=3MARAGARGLLGGRRPPGLRLALALRLALLLARPPSGRAGAPEAQGPAAPGTTAPEGGDRCRGYYDVMGQWDPPFNCSSGAYSFCCGTCGYRFCCHDGPRRLDQSRCSNYDTPAWVQTGRPPARARDTAAPRDPGRERSHTAVYAVCGVAALLVLAGIGARLGLERAHSPRARRTVTRALTELLKQPGPQEPLPPTLGPPLGGCVQVQMGDGLPRGSPHNSADKKRLNNAPRGSAAPGPPRGPRLQGGGSLTLQPDYAKYATFKAAALKAAEAAPRDFCQRFPALEPSPRQPPARAPRPSPDLPAPLDACPWAPPVYAPPAAPGPYAAWTSSRPARPAPLSHPTARAFQVPRRPGHAARRQFSVKMPETFNPQLPGLYGSAGRGSRYLRTNSKTEVTV>sp|B8ZZ34-3|SHSA8_HUMAN Isoform 1 of Protein shisa-8 OS=Homo sapiensOX=9606 GN=SHISA8MARAGARGLLGGRRPPGLRLALALRLALLLARPPSGRAGAPEAQGPAAPGTTAPEGGDRCRGYYDVMGQWDPPFNCSSGAYSFCCGTCGYRFCCHDGPRRLDQSRCSNYDTPAWVQTGRPPARARDTAAPRDPGRERSHTAVYAVCGVAALLVLAGIGARLGLERAHSPRARRTVTRALTELLKQPGPQEPLPPTLGPPLGGCVQVQMGDGLPRGSPHNSAGPRTPRLARASPPGEPFMRVAPPGLAAAAAARDSEPGPVPGAGGCGEDRLGSQPRPENGPPGSHRTASGRGLRRGDSEGGVNRGIGPSRVSLLAPDKKRLNNAPRGSAAPGPPRGPRLQGGGSLTLQPDYAKYATFKAAALKAAEAAPRDFCQRFPALEPSPRQPPARAPRPSPDLPAPLDACPWAPPVYAPPAAPGPYAAWTSSRPARPAPLSHPTARAFQVPRRPGHAARRQFSVKMPETFNPQLPGLYGSAGRGSRYLRTNSKTEVTV>sp|P0DP57|SLUR2_HUMAN Secreted Ly-6/uPAR domain-containing protein 2OS=Homo sapiens OX=9606 GN=SLURP2 PE=1 SV=1MQLGTGLLLAAVLSLQLAAAEAIWCHQCTGFGGCSHGSRCLRDSTHCVTTATRVLSNTEDLPLVTKMCHIGCPDIPSLGLGPYVSIACCQTSLCNHD>sp|A0A1B0GVT2|SIM36_HUMAN Small integral membrane protein 36 OS=Homosapiens OX=9606 GN=SMIM36 PE=3 SV=1MEFYLEIDPVTLNLIILVASYVILLLVFLISCVLYDCRGKDPSKEYAPEATLEAQPSIRLVVMHPSVAGPHWPKGPGLSLGDPAPLGKKSTMV>sp|Q587I9|SFT2C_HUMAN Vesicle transport protein SFT2C OS=Homo sapiensOX=9606 GN=SFT2D3 PE=2 SV=1MADLHRQLQEYLAQGKAGGPAAAEPLLAAEKAEEPGDRPAEEWLGRAGLRWTWARSPAESAAAGLTCLPSVTRGQRLAAGGGCLLLAALCFGLAALYAPVLLLRARKFALLWSLGSALALAGSALLRGGAACGRLLRCEEAPSRPALLYMAALGATLFAALGLRSTLLTVLGAGAQVAALLAALVGLLPWGGGTALRLALGRLGRGAGLAKVLPV>sp|A0A286YFK9|SIM38_HUMAN Small integral membrane protein 38 OS=Homosapiens OX=9606 GN=SMIM38 PE=3 SV=1MTSWPGGSFGPDPLLALLVVILLARLILWSCLGTYIDYRLAQRRPQKPKQD>sp|A0A1B0GW54|SIM39_HUMAN Small integral membrane protein 39 OS=Homosapiens OX=9606 GN=SMIM39 PE=3 SV=1MARAPQPRRGPAAPGNALRALLRCNLPPGAQRVVVSAVLALLVLINVVLIFLLAFR>sp|B4DS77|SHSA9_HUMAN Protein shisa-9 OS=Homo sapiens OX=9606 GN=SHISA9PE=2 SV=3MRRVLRLLLGCFLTELCARVCRAQERAGHGQLAQLGGVLLLAGGNRSGAASGEASEGAEASDAPPTRAPTPDFCRGYFDVMGQWDPPFNCSSGDFIFCCGTCGFRFCCTFKKRRLNQSTCTNYDTPLWLNTGKPPARKDDPLHDPTKDKTNLIVYIICGVVAVMVLVGIFTKLGLEKAHRPQREHMSRALADVMRPQGHCNTDHMERDLNIVVHVQHYENMDTRTPINNLHATQMNNAVPTSPLLQQMGHPHSYPNLGQISNPYEQQPPGKELNKYASLKAVGSSDGDWAVSTLKSPKADKVNDDFYTKRRHLAELAAKGNLPLHPVRVEDEPRAFSPEHGPAKQNGQKSRTNKMPPHPLAYTSTTNFKGWDPNEQSLRRQAYSNKGKLGTAETGSSDPLGTRPQHYPPPQPYFITNSKTEVTV>sp|B4DS77-2|SHSA9_HUMAN Isoform 2 of Protein shisa-9 OS=Homo sapiensOX=9606 GN=SHISA9MGQWDPPFNCSSGDFIFCCGTCGFRFCCTFKKRRLNQSTCTNYDTPLWLNTGKPPARKDDPLHDPTKDKTNLIVYIICGVVAVMVLVGIFTKLGLEKAHRPQREHMSRALADVMRPQGHCNTDHMERDLNIVVHVQHYENMDTRTPINNLHATQMNNAVPTSPLLQQMGHPHSYPNLGQISNPYEQQPPGKELNKYASLKAVGSSDGDWAVSTLKSPKADKVNDDFYTKRRHLAELAAKGNLPLHPVRVEDEPRAFSPEHGPAKQNGQKSRTNKMPPHPLAYTSTTNFKGWDPNEQSLRRQAYSNKGKLGTAETGSSDPLGTRPQHYPPPQPYFITNSKTEVTV>sp|B4DS77-3|SHSA9_HUMAN Isoform 3 of Protein shisa-9 OS=Homo sapiensOX=9606 GN=SHISA9MRRVLRLLLGCFLTELCARVCRAQERAGHGQLAQLGGVLLLAGGNRSGAASGEASEGAEASDAPPTRAPTPDFCRGYFDVMGQWDPPFNCSSGDFIFCCGTCGFRFCCTFKKRRLNQSTCTNYDTPLWLNTGKPPARKDDPLHDPTKDKTNLIVYIICGVVAVMVLVGIFTKLGLEKAHRPQREHMSRLYDNLLFMEAQISFQEDEPAPGEWSVGLQTWTV>sp|Q5STR5|SIM40_HUMAN Small integral membrane protein 40 OS=Homo sapiensOX=9606 GN=SMIM40 PE=1 SV=9MAEEGDVDEADVFLAFAQGPSPPRGPVRRALDKAFFIFLALFLTLLMLEAAYKLLWLLLWAKLGDWLLGTPQKEEELEL>sp|A0A2R8YCJ5|SIM41_HUMAN Small integral membrane protein 41 OS=Homosapiens OX=9606 GN=SMIM41 PE=3 SV=1MNGSQAGAAAQAAWLSSCCNQSASPPEPPEGPRAVQAVVLGVLSLLVLCGVLFLGGGLLLRAQGLTALLTREQRASREPEPGSASGEDGDDDS>sp|A0A5F9ZH02|SIM42_HUMAN Small integral membrane protein 42 OS=Homosapiens OX=9606 GN=SMIM42 PE=3 SV=1MSSPQLPAFLWDKGTLTTAISNPACLVNVLFFFTPLMTLVTLLILVWKVTKDKSNKNRETHPRKEATWLP>sp|Q4W5P6|SIM43_HUMAN Small integral membrane protein 43 OS=Homo sapiensOX=9606 GN=SMIM43 PE=3 SV=4MEWELNLLLYLALFFFLLFLLFLLLFVVIKQLKNSVANTAGALQPGRLSVHREPWGFSREQAV>sp|Q3SXP7|SHSL1_HUMAN Protein shisa-like-1 OS=Homo sapiens OX=9606GN=SHISAL1 PE=1 SV=2MTSCGQQSLNVLAVLFSLLFSAVLSAHFRVCEPYTDHKGRYHFGFHCPRLSDNKTFILCCHHNNTVFKYCCNETEFQAVMQANLTASSEGYMHNNYTALLGVWIYGFFVLMLLVLDLLYYSAMNYDICKVYLARWGIQGRWMKQDPRRWGNPARAPRPGQRAPQPQPPPGPLPQAPQAVHTLRGDAHSPPLMTFQSSSA>sp|Q8IWL2|SFTA1_HUMAN Pulmonary surfactant-associated protein A1 OS=Homosapiens OX=9606 GN=SFTPA1 PE=1 SV=2MWLCPLALNLILMAASGAVCEVKDVCVGSPGIPGTPGSHGLPGRDGRDGLKGDPGPPGPMGPPGEMPCPPGNDGLPGAPGIPGECGEKGEPGERGPPGLPAHLDEELQATLHDFRHQILQTRGALSLQGSIMTVGEKVFSSNGQSITFDAIQEACARAGGRIAVPRNPEENEAIASFVKKYNTYAYVGLTEGPSPGDFRYSDGTPVNYTNWYRGEPAGRGKEQCVEMYTDGQWNDRNCLYSRLTICEF>sp|Q8IWL2-2|SFTA1_HUMAN Isoform 2 of Pulmonary surfactant-associatedprotein A1 OS=Homo sapiens OX=9606 GN=SFTPA1MRPCQVPGAATGPRAMWLCPLALNLILMAASGAVCEVKDVCVGSPGIPGTPGSHGLPGRDGRDGLKGDPGPPGPMGPPGEMPCPPGNDGLPGAPGIPGECGEKGEPGERGPPGLPAHLDEELQATLHDFRHQILQTRGALSLQGSIMTVGEKVFSSNGQSITFDAIQEACARAGGRIAVPRNPEENEAIASFVKKYNTYAYVGLTEGPSPGDFRYSDGTPVNYTNWYRGEPAGRGKEQCVEMYTDGQWNDRNCLYSRLTICEF>sp|Q6UW10|SFTA2_HUMAN Surfactant-associated protein 2 OS=Homo sapiensOX=9606 GN=SFTA2 PE=1 SV=1MGSGLPLVLLLTLLGSSHGTGPGMTLQLKLKESFLTNSSYESSFLELLEKLCLLLHLPSGTSVTLHHARSQHHVVCNT>sp|Q8NDZ2|SIMC1_HUMAN SUMO-interacting motif-containing protein 1OS=Homo sapiens OX=9606 GN=SIMC1 PE=1 SV=3MAPASASGEDLRKLPTMAEVNGEQDFIDLTRETRPRTKDRSGLYVIDLTRAEGENRPIATLDLTLEPVTPSQKEPTSLQTCASLSGKAVMEGHVDRSSQPTARRIINSDPVDLDLVEENTFVGPPPATSISGGSVYPTEPNCSSATFTGNLSFLASLQLSSDVSSLSPTSNNSRSSSSSSNQKAPLPCPQQDVSRPPQALPCPLRPLPCPPRASPCPPRASSCPPRALSCPSQTMQCQLPALTHPPQEVPCPRQNIPGPPQDSLGLPQDVPGLPQSILHPQDVAYLQDMPRSPGDVPQSPSDVSPSPDAPQSPGGMPHLPGDVLHSPGDMPHSSGDVTHSPRDIPHLPGDRPDFTQNDVQNRDMPMDISALSSPSCSPSPQSETPLEKVPWLSVMETPARKEISLSEPAKPGSAHVQSRTPQGGLYNRPCLHRLKYFLRPPVHHLFFQTLIPDKDTRENKGQKLEPIPHRRLRMVTNTIEENFPLGTVQFLMDFVSPQHYPPREIVAHIIQKILLSGSETVDVLKEAYMLLMKIQQLHPANAKTVEWDWKLLTYVMEEEGQTLPGRVLFLRYVVQTLEDDFQQTLRRQRQHLQQSIANMVLSCDKQPHNVRDVIKWLVKAVTEDGLTQPPNGNQTSSGTGILKASSSHPSSQPNLTKNTNQLIVCQLQRMLSIAVEVDRTPTCSSNKIAEMMFGFVLDIPERSQREMFFTTMESHLLRCKVLEIIFLHSCETPTRLPLSLAQALYFLNNSTSLLKCQSDKSQWQTWDELVEHLQFLLSSYQHVLREHLRSSVIDRKDLIIKRIKPKPQQGDDITVVDVEKQIEAFRSRLIQMLGEPLVPQLQDKVHLLKLLLFYAADLNPDAEPFQKGWSGS>sp|Q8NDZ2-2|SIMC1_HUMAN Isoform 2 of SUMO-interacting motif-containingprotein 1 OS=Homo sapiens OX=9606 GN=SIMC1MEGHVDRSSQPTARRIINSDPVDLDLVEENTFVGPPPATSISGGSVYPTEPNCSSATFTGNLSFLASLQLSSDVSSLSPTSNNSRSSSSSSNQKAPLPCPQQDVSRPPQALPCPLRPLPCPPRASPCPPRASSCPPRALSCPSQTMQCQLPALTHPPQEVPCPRQNIPGPPQDSLGLPQDVPGLPQSILHPQDVAYLQDMPRSPGDVPQSPSDVSPSPDAPQSPGGMPHLPGDVLHSPGDMPHSSGDVTHSPRDIPHLPGDRPDFTQNDVQNRDMPMDISALSSPSCTPAWGTEQDSVSKKKKKKKRKEIPPNFLLFNLYRTRVKN>sp|Q8NDZ2-3|SIMC1_HUMAN Isoform 3 of SUMO-interacting motif-containingprotein 1 OS=Homo sapiens OX=9606 GN=SIMC1MEDFIVISDDSGSESSGGARPGRSRRPRRALSRTSGALPRRTVNKGQKLEPIPHRRLRMVTNTIEENFPLGTVQFLMDFVSPQHYPPREIVAHIIQKILLSGSETVDVLKEAYMLLMKIQQLHPANAKTVEWDWKLLTYVMEEEGQTLPGRVLFLRYVVQTLEDDFQQTLRRQRQHLQQSIANMVLSCDKQPHNVRDVIKWLVKAVTEDGLTQPPNGNQTSSGTGILKASSSHPSSQPNLTKNTNQLIVCQLQRMLSIAVEVDRTPTCSSNKIAEMMFGFVLDIPERSQREMFFTTMESHLLRCKVLEIIFLHSCETPTRLPLSLAQALYFLNNSTSLLKCQSDKSQWQTWDELVEHLQFLLSSYQHVLREHLRSSVIDRKDLIIKRIKPKPQQGDDITVVDVEKQIEAFRSRLIQMLGEPLVPQLQDKVHLLKLLLFYAADLNPDAEPFQKGWSGS>sp|Q8NDZ2-4|SIMC1_HUMAN Isoform 4 of SUMO-interacting motif-containingprotein 1 OS=Homo sapiens OX=9606 GN=SIMC1MPRSFEQVIILKKWFLKPYKGQTLPGRVLFLRYVVQTLEDDFQQTLRRQRQHLQQSIANMVLSCDKQPHNVRDVIKWLVKAVTEDGLTQPPNGNQTSSGTGILKASSSHPSSQPNLTKNTNQLIVCQLQRMLSIAVEVDRTPTCSSNKIAEMMFGFVLDIPERSQREMFFTTMESHLLRCKVLEIIFLHSCETPTRLPLSLAQALYFLNNSTSLLKCQSDKSQWQTWDELVEHLQFLLSSYQHVLREHLRSSVIDRKDLIIKRIKPKPQQGDDITVVDVEKQIEAFRSRLIQMLGEPLVPQLQDKVHLLKLLLFYAADLNPDAEPFQKGWSGS>sp|Q8NDZ2-5|SIMC1_HUMAN Isoform 5 of SUMO-interacting motif-containingprotein 1 OS=Homo sapiens OX=9606 GN=SIMC1MEDFIVISDDSGSESSGGARPGRSRRPRRALSRTSGALPRRTVDFIDLTRETRPRTKDRSGLYVIDLTRAEGENRPIATLDLTLEPVTPSQKEPTSLQTCASLSGKAVMEGHVDRSSQPTARRIINSDPVDLDLVEENTFVGPPPATSISGGSVYPTEPNCSSATFTGNLSFLASLQLSSDVSSLSPTSNNSRSSSSSSNQKAPLPCPQQDVSRPPQALPCPLRPLPCPPRASPCPPRASSCPPRALSCPSQTMQCQLPALTHPPQEVPCPRQNIPGPPQDSLGLPQDVPGLPQSILHPQDVAYLQDMPRSPGDVPQSPSDVSPSPDAPQSPGGMPHLPGDVLHSPGDMPHSSGDVTHSPRDIPHLPGDRPDFTQNDVQNRDMPMDISALSSPSCSPSPQSETPLEKVPWLSVMETPARKEISLSEPAKPGSAHVQSRTPQGGLYNRPCLHRLKYFLRPPVHHLFFQTLIPDKDTRENKGQKLEPIPHRRLRMVTNTIEENFPLGTVQFLMDFVSPQHYPPREIVAHIIQKILLSGSETVDVLKEAYMLLMKIQQLHPANAKTVEWDWKLLTYVMEEEGQTLPGRVLFLRYVVQTLEDDFQQTLRRQRQHLQQSIANMVLSCDKQPHNVRDVIKWLVKAVTEDGLTQPPNGNQTSSGTGILKASSSHPSSQPNLTKNTNQLIVCQLQRMLSIAVEVDRTPTCSSNKIAEMMFGFVLDIPERSQREMFFTTMESHLLRCKVLEIIFLHSCETPTRLPLSLAQALYFLNNSTSLLKCQSDKSQWQTWDELVEHLQFLLSSYQHVLREHLRSSVIDRKDLIIKRIKPKPQQGDDITVVDVEKQIEAFRSRLIQMLGEPLVPQLQDKVHLLKLLLFYAADLNPDAEPFQKGWSGS>sp|Q96LC7|SIG10_HUMAN Sialic acid-binding Ig-like lectin 10 OS=Homosapiens OX=9606 GN=SIGLEC10 PE=1 SV=3MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTALTQKPDVYIPETLEPGQPVTVICVFNWAFEECPPPSFSWTGAALSSQGTKPTTSHFSVLSFTPRPQDHNTDLTCHVDFSRKGVSAQRTVRLRVAYAPRDLVISISRDNTPALEPQPQGNVPYLEAQKGQFLRLLCAADSQPPATLSWVLQNRVLSSSHPWGPRPLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYSPKLLGPSCSWEAEGLHCSCSSQASPAPSLRWWLGEELLEGNSSQDSFEVTPSSAGPWANSSLSLHGGLSSGLRLRCEAWNVHGAQSGSILQLPDKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|Q96LC7-2|SIG10_HUMAN Isoform 2 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTALTQKPDVYIPETLEPGQPVTVICVFNWAFEECPPPSFSWTGAALSSQGTKPTTSHFSVLSFTPRPQDHNTDLTCHVDFSRKGVSAQRTVRLRVAYAPRDLVISISRDNTPALEPQPQGNVPYLEAQKGQFLRLLCAADSQPPATLSWVLQNRVLSSSHPWGPRPLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|Q96LC7-3|SIG10_HUMAN Isoform 3 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTVLSFTPRPQDHNTDLTCHVDFSRKGVSAQRTVRLRVAYAPRDLVISISRDNTPALEPQPQGNVPYLEAQKGQFLRLLCAADSQPPATLSWVLQNRVLSSSHPWGPRPLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYSPKLLGPSCSWEAEGLHCSCSSQASPAPSLRWWLGEELLEGNSSQDSFEVTPSSAGPWANSSLSLHGGLSSGLRLRCEAWNVHGAQSGSILQLPDKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|Q96LC7-4|SIG10_HUMAN Isoform 4 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSCHVDFSRKGVSAQRTVRLRVAYAPRDLVISISRDNTPALEPQPQGNVPYLEAQKGQFLRLLCAADSQPPATLSWVLQNRVLSSSHPWGPRPLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYSPKLLGPSCSWEAEGLHCSCSSQASPAPSLRWWLGEELLEGNSSQDSFEVTPSSAGPWANSSLSLHGGLSSGLRLRCEAWNVHGAQSGSILQLPDKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|Q96LC7-5|SIG10_HUMAN Isoform 5 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTGMRWGGNPCLSHWGGTLGTAYGLSREGSQGPLQHKNLPPRSLSQP>sp|Q96LC7-6|SIG10_HUMAN Isoform 6 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTVLSFTPRPQDHNTDLTCHVDFSRKGVSAQRTVRLRVAYAPRDLVISISRDNTPALEPQPQGNVPYLEAQKGQFLRLLCAADSQPPATLSWVLQNRVLSSSHPWGPRPLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|Q96LC7-7|SIG10_HUMAN Isoform 7 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTGTKPTTSHFSVLSFTPRPQDHNTDLTCHVDFSRKGVSAQRTVRLRVAYAPRDLVISISRDNTPALEPQPQGNVPYLEAQKGQFLRLLCAADSQPPATLSWVLQNRVLSSSHPWGPRPLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|Q96LC7-8|SIG10_HUMAN Isoform 8 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTVLSFTPRPQDHNTDLTCHVDFSRKGVSAQRTVRLRVAYAPRDLVISISRDNTPDPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|Q96LC7-9|SIG10_HUMAN Isoform 9 of Sialic acid-binding Ig-like lectin10 OS=Homo sapiens OX=9606 GN=SIGLEC10MLLPLLLSSLLGGSQAMDGRFWIRVQESVMVPEGLCISVPCSFSYPRQDWTGSTPAYGYWFKAVTETTKGAPVATNHQSREVEMSTRGRFQLTGDPAKGNCSLVIRDAQMQDESQYFFRVERGSYVRYNFMNDGFFLKVTALTQKTVRLRVAYAPRDLVISISRDNTPALEPQPQGNVPYLEAQKGQFLRLLCAADSQPPATLSWVLQNRVLSSSHPWGPRPLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLCLVCVTHSSPPARLSWTQRGQVLSPSQPSDPGVLELPRVQVEHEGEFTCHARHPLGSQHVSLSLSVHYKKGLISTAFSNGAFLGIGITALLFLCLALIIMKILPKRRTQTETPRPRFSRHSTILDYINVVPTAGPLAQKRNQKATPNSPRTPLPPGAPSPESKKNQKKQYQLPSFPEPKSSTQAPESQESQEELHYATLNFPGVRPRPEARMPKGTQADYAEVKFQ>sp|P0C7M3|SFTA3_HUMAN Surfactant-associated protein 3 OS=Homo sapiensOX=9606 GN=SFTA3 PE=1 SV=1MRAGFSDFQLIRDQVLFLQDQAQRLTEWLQLSGFENPVSESTTLCLREREKRIPTCVAVCVPSPGTVHTALLHPTTLSQSRSSSEAKMLIIHTA>sp|P0DMW3|SIML1_HUMAN Small integral membrane protein 10-like protein 1OS=Homo sapiens OX=9606 GN=SMIM10L1 PE=4 SV=2MAPAAAPSSLAVRASSPAATPTSYGVFCKGLSRTLLAFFELAWQLRMNFPYFYVAGSVILNIRLQVHI>sp|Q96RL6|SIG11_HUMAN Sialic acid-binding Ig-like lectin 11 OS=Homosapiens OX=9606 GN=SIGLEC11 PE=1 SV=2MVPGQAQPQSPEMLLLPLLLPVLGAGSLNKDPSYSLQVQRQVPVPEGLCVIVSCNLSYPRDGWDESTAAYGYWFKGRTSPKTGAPVATNNQSREVEMSTRDRFQLTGDPGKGSCSLVIRDAQREDEAWYFFRVERGSRVRHSFLSNAFFLKVTALTKKPDVYIPETLEPGQPVTVICVFNWAFKKCPAPSFSWTGAALSPRRTRPSTSHFSVLSFTPSPQDHDTDLTCHVDFSRKGVSAQRTVRLRVAYAPKDLIISISHDNTSALELQGNVIYLEVQKGQFLRLLCAADSQPPATLSWVLQDRVLSSSHPWGPRTLGLELRGVRAGDSGRYTCRAENRLGSQQQALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLRLVCVTHSSPPARLSWTRWGQTVGPSQPSDPGVLELPPIQMEHEGEFTCHAQHPLGSQHVSLSLSVHYPPQLLGPSCSWEAEGLHCSCSSQASPAPSLRWWLGEELLEGNSSQGSFEVTPSSAGPWANSSLSLHGGLSSGLRLRCKAWNVHGAQSGSVFQLLPGKLEHGGGLGLGAALGAGVAALLAFCSCLVVFRVKICRKEARKRAAAEQDVPSTLGPISQGHQHECSAGSSQDHPPPGAATYTPGKGEEQELHYASLSFQGLRLWEPADQEAPSTTEYSEIKIHTGQPLRGPGFGLQLEREMSGMVPK>sp|Q96RL6-2|SIG11_HUMAN Isoform 2 of Sialic acid-binding Ig-like lectin11 OS=Homo sapiens OX=9606 GN=SIGLEC11MVPGQAQPQSPEMLLLPLLLPVLGAGSLNKDPSYSLQVQRQVPVPEGLCVIVSCNLSYPRDGWDESTAAYGYWFKGRTSPKTGAPVATNNQSREVEMSTRDRFQLTGDPGKGSCSLVIRDAQREDEAWYFFRVERGSRVRHSFLSNAFFLKVTALTKKPDVYIPETLEPGQPVTVICVFNWAFKKCPAPSFSWTGAALSPRRTRPSTSHFSVLSFTPSPQDHDTDLTCHVDFSRKGVSAQRTVRLRVAYAPKDLIISISHDNTSALELQGNVIYLEVQKGQFLRLLCAADSQPPATLSWVLQDRVLSSSHPWGPRTLGLELRGVRAGDSGRYTCRAENRLGSQQQALDLSVQYPPENLRVMVSQANRTVLENLGNGTSLPVLEGQSLRLVCVTHSSPPARLSWTRWGQTVGPSQPSDPGVLELPPIQMEHEGEFTCHAQHPLGSQHVSLSLSVHWKLEHGGGLGLGAALGAGVAALLAFCSCLVVFRVKICRKEARKRAAAEQDVPSTLGPISQGHQHECSAGSSQDHPPPGAATYTPGKGEEQELHYASLSFQGLRLWEPADQEAPSTTEYSEIKIHTGQPLRGPGFGLQLEREMSGMVPK>sp|Q96PQ1|SIG12_HUMAN Sialic acid-binding Ig-like lectin 12 OS=Homosapiens OX=9606 GN=SIGLEC12 PE=1 SV=1MLLLLLLLPPLLCGRVGAKEQKDYLLTMQKSVTVQEGLCVSVLCSFSYPQNGWTASDPVHGYWFRAGDHVSRNIPVATNNPARAVQEETRDRFHLLGDPQNKDCTLSIRDTRESDAGTYVFCVERGNMKWNYKYDQLSVNVTASQDLLSRYRLEVPESVTVQEGLCVSVPCSVLYPHYNWTASSPVYGSWFKEGADIPWDIPVATNTPSGKVQEDTHGRFLLLGDPQTNNCSLSIRDARKGDSGKYYFQVERGSRKWNYIYDKLSVHVTALTHMPTFSIPGTLESGHPRNLTCSVPWACEQGTPPTITWMGASVSSLDPTITRSSMLSLIPQPQDHGTSLTCQVTLPGAGVTMTRAVRLNISYPPQNLTMTVFQGDGTASTTLRNGSALSVLEGQSLHLVCAVDSNPPARLSWTWGSLTLSPSQSSNLGVLELPRVHVKDEGEFTCRAQNPLGSQHISLSLSLQNEYTGKMRPISGVTLGAFGGAGATALVFLYFCIIFVVVRSCRKKSARPAVGVGDTGMEDANAVRGSASQGPLIESPADDSPPHHAPPALATPSPEEGEIQYASLSFHKARPQYPQEQEAIGYEYSEINIPK>sp|Q96PQ1-2|SIG12_HUMAN Isoform Short of Sialic acid-binding Ig-likelectin 12 OS=Homo sapiens OX=9606 GN=SIGLEC12MLLPLLWANEERDSGGWADPRFSTASQDLLSRYRLEVPESVTVQEGLCVSVPCSVLYPHYNWTASSPVYGSWFKEGADIPWDIPVATNTPSGKVQEDTHGRFLLLGDPQTNNCSLSIRDARKGDSGKYYFQVERGSRKWNYIYDKLSVHVTALTHMPTFSIPGTLESGHPRNLTCSVPWACEQGTPPTITWMGASVSSLDPTITRSSMLSLIPQPQDHGTSLTCQVTLPGAGVTMTRAVRLNISYPPQNLTMTVFQGDGTASTTLRNGSALSVLEGQSLHLVCAVDSNPPARLSWTWGSLTLSPSQSSNLGVLELPRVHVKDEGEFTCRAQNPLGSQHISLSLSLQNEYTGKMRPISGVTLGAFGGAGATALVFLYFCIIFVVVRSCRKKSARPAVGVGDTGMEDANAVRGSASQGPLIESPADDSPPHHAPPALATPSPEEGEIQYASLSFHKARPQYPQEQEAIGYEYSEINIPK>sp|Q08ET2|SIG14_HUMAN Sialic acid-binding Ig-like lectin 14 OS=Homosapiens OX=9606 GN=SIGLEC14 PE=1 SV=1MLPLLLLPLLWGGSLQEKPVYELQVQKSVTVQEGLCVLVPCSFSYPWRSWYSSPPLYVYWFRDGEIPYYAEVVATNNPDRRVKPETQGRFRLLGDVQKKNCSLSIGDARMEDTGSYFFRVERGRDVKYSYQQNKLNLEVTALIEKPDIHFLEPLESGRPTRLSCSLPGSCEAGPPLTFSWTGNALSPLDPETTRSSELTLTPRPEDHGTNLTCQVKRQGAQVTTERTVQLNVSYAPQNLAISIFFRNGTGTALRILSNGMSVPIQEGQSLFLACTVDSNPPASLSWFREGKALNPSQTSMSGTLELPNIGAREGGEFTCRVQHPLGSQHLSFILSVQRSSSSCICVTEKQQGSWPLVLTLIRGALMGAGFLLTYGLTWIYYTRCGGPQQSRAERPG>sp|Q6ZMC9|SIG15_HUMAN Sialic acid-binding Ig-like lectin 15 OS=Homosapiens OX=9606 GN=SIGLEC15 PE=1 SV=1MEKSIWLLACLAWVLPTGSFVRTKIDTTENLLNTEVHSSPAQRWSMQVPPEVSAEAGDAAVLPCTFTHPHRHYDGPLTAIWRAGEPYAGPQVFRCAAARGSELCQTALSLHGRFRLLGNPRRNDLSLRVERLALADDRRYFCRVEFAGDVHDRYESRHGVRLHVTAAPRIVNISVLPSPAHAFRALCTAEGEPPPALAWSGPALGNSLAAVRSPREGHGHLVTAELPALTHDGRYTCTAANSLGRSEASVYLFRFHGASGASTVALLLGALGFKALLLLGVLAARAARRRPEHLDTPDTPPRSQAQESNYENLSQMNPRSPPATMCSP>sp|Q6ZMC9-2|SIG15_HUMAN Isoform 2 of Sialic acid-binding Ig-like lectin15 OS=Homo sapiens OX=9606 GN=SIGLEC15MTATRAATASGSAPRIVNISVLPSPAHAFRALCTAEGEPPPALAWSGPALGNSLAAVRSPREGHGHLVTAELPALTHDGRYTCTAANSLGRSEASVYLFRFHGASGASTVALLLGALGFKALLLLGVLAARAARRRPEHLDTPDTPPRSQAQESNYENLSQMNPRSPPATMCSP>sp|A6NMB1|SIG16_HUMAN Sialic acid-binding Ig-like lectin 16 OS=Homosapiens OX=9606 GN=SIGLEC16 PE=2 SV=3MLLLPLLLPVLGAGSLNKDPSYSLQVQRQVPVPEGLCVIVSCNLSYPRDGWDESTAAYGYWFKGRTSPKTGAPVATNNQSREVAMSTRDRFQLTGDPGKGSCSLVIRDAQREDEAWYFFRVERGSRVRHSFLSNAFFLKVTALTQKPDVYIPETLEPGQPVTVICVFNWAFKKCPAPSFSWTGAALSPRRTRPSTSHFSVLSFTPSPQDHDTDLTCHVDFSRKGVSAQRTVRLRVASLELQGNVIYLEVQKGQFLRLLCAADSQPPATLSWVLQDRVLSSSHPWGPRTLGLELPGVKAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLRNGTSLRVLEGQSLRLVCVTHSSPPARLSWTWGEQTVGPSQPSDPGVLQLPRVQMEHEGEFTCHARHPLGSQRVSLSFSVHCKSGPMTGVVLVAVGEVAMKILLLCLCLILLRVRSCRRKAARAALGMEAADAVTD>sp|Q96ST3|SIN3A_HUMAN Paired amphipathic helix protein Sin3a OS=Homosapiens OX=9606 GN=SIN3A PE=1 SV=2MKRRLDDQESPVYAAQQRRIPGSTEAFPHQHRVLAPAPPVYEAVSETMQSATGIQYSVTPSYQVSAMPQSSGSHGPAIAAVHSSHHHPTAVQPHGGQVVQSHAHPAPPVAPVQGQQQFQRLKVEDALSYLDQVKLQFGSQPQVYNDFLDIMKEFKSQSIDTPGVISRVSQLFKGHPDLIMGFNTFLPPGYKIEVQTNDMVNVTTPGQVHQIPTHGIQPQPQPPPQHPSQPSAQSAPAPAQPAPQPPPAKVSKPSQLQAHTPASQQTPPLPPYASPRSPPVQPHTPVTISLGTAPSLQNNQPVEFNHAINYVNKIKNRFQGQPDIYKAFLEILHTYQKEQRNAKEAGGNYTPALTEQEVYAQVARLFKNQEDLLSEFGQFLPDANSSVLLSKTTAEKVDSVRNDHGGTVKKPQLNNKPQRPSQNGCQIRRHPTGTTPPVKKKPKLLNLKDSSMADASKHGGGTESLFFDKVRKALRSAEAYENFLRCLVIFNQEVISRAELVQLVSPFLGKFPELFNWFKNFLGYKESVHLETYPKERATEGIAMEIDYASCKRLGSSYRALPKSYQQPKCTGRTPLCKEVLNDTWVSFPSWSEDSTFVSSKKTQYEEHIYRCEDERFELDVVLETNLATIRVLEAIQKKLSRLSAEEQAKFRLDNTLGGTSEVIHRKALQRIYADKAADIIDGLRKNPSIAVPIVLKRLKMKEEEWREAQRGFNKVWREQNEKYYLKSLDHQGINFKQNDTKVLRSKSLLNEIESIYDERQEQATEENAGVPVGPHLSLAYEDKQILEDAAALIIHHVKRQTGIQKEDKYKIKQIMHHFIPDLLFAQRGDLSDVEEEEEEEMDVDEATGAVKKHNGVGGSPPKSKLLFSNTAAQKLRGMDEVYNLFYVNNNWYIFMRLHQILCLRLLRICSQAERQIEEENREREWEREVLGIKRDKSDSPAIQLRLKEPMDVDVEDYYPAFLDMVRSLLDGNIDSSQYEDSLREMFTIHAYIAFTMDKLIQSIVRQLQHIVSDEICVQVTDLYLAENNNGATGGQLNTQNSRSLLESTYQRKAEQLMSDENCFKLMFIQSQGQVQLTIELLDTEEENSDDPVEAERWSDYVERYMNSDTTSPELREHLAQKPVFLPRNLRRIRKCQRGREQQEKEGKEGNSKKTMENVDSLDKLECRFKLNSYKMVYVIKSEDYMYRRTALLRAHQSHERVSKRLHQRFQAWVDKWTKEHVPREMAAETSKWLMGEGLEGLVPCTTTCDTETLHFVSINKYRVKYGTVFKAP>sp|Q9H9B4|SFXN1_HUMAN Sideroflexin-1 OS=Homo sapiens OX=9606 GN=SFXN1PE=1 SV=4MSGELPPNINIKEPRWDQSTFIGRANHFFTVTDPRNILLTNEQLESARKIVHDYRQGIVPPGLTENELWRAKYIYDSAFHPDTGEKMILIGRMSAQVPMNMTITGCMMTFYRTTPAVLFWQWINQSFNAVVNYTNRSGDAPLTVNELGTAYVSATTGAVATALGLNALTKHVSPLIGRFVPFAAVAAANCINIPLMRQRELKVGIPVTDENGNRLGESANAAKQAITQVVVSRILMAAPGMAIPPFIMNTLEKKAFLKRFPWMSAPIQVGLVGFCLVFATPLCCALFPQKSSMSVTSLEAELQAKIQESHPELRRVYFNKGL>sp|Q9BWM7|SFXN3_HUMAN Sideroflexin-3 OS=Homo sapiens OX=9606 GN=SFXN3PE=1 SV=3MGELPLDINIQEPRWDQSTFLGRARHFFTVTDPRNLLLSGAQLEASRNIVQNYRAGVVTPGITEDQLWRAKYVYDSAFHPDTGEKVVLIGRMSAQVPMNMTITGCMLTFYRKTPTVVFWQWVNQSFNAIVNYSNRSGDTPITVRQLGTAYVSATTGAVATALGLKSLTKHLPPLVGRFVPFAAVAAANCINIPLMRQRELQVGIPVADEAGQRLGYSVTAAKQGIFQVVISRICMAIPAMAIPPLIMDTLEKKDFLKRRPWLGAPLQVGLVGFCLVFATPLCCALFPQKSSIHISNLEPELRAQIHEQNPSVEVVYYNKGL>sp|Q13309|SKP2_HUMAN S-phase kinase-associated protein 2 OS=Homo sapiensOX=9606 GN=SKP2 PE=1 SV=2MHRKHLQEIPDLSSNVATSFTWGWDSSKTSELLSGMGVSALEKEEPDSENIPQELLSNLGHPESPPRKRLKSKGSDKDFVIVRRPKLNRENFPGVSWDSLPDELLLGIFSCLCLPELLKVSGVCKRWYRLASDESLWQTLDLTGKNLHPDVTGRLLSQGVIAFRCPRSFMDQPLAEHFSPFRVQHMDLSNSVIEVSTLHGILSQCSKLQNLSLEGLRLSDPIVNTLAKNSNLVRLNLSGCSGFSEFALQTLLSSCSRLDELNLSWCFDFTEKHVQVAVAHVSETITQLNLSGYRKNLQKSDLSTLVRRCPNLVHLDLSDSVMLKNDCFQEFFQLNYLQHLSLSRCYDIIPETLLELGEIPTLKTLQVFGIVPDGTLQLLKEALPHLQINCSHFTTIARPTIGNKKNQEIWGIKCRLTLQKPSCL>sp|Q13309-2|SKP2_HUMAN Isoform 2 of S-phase kinase-associated protein 2OS=Homo sapiens OX=9606 GN=SKP2MHRKHLQEIPDLSSNVATSFTWGWDSSKTSELLSGMGVSALEKEEPDSENIPQELLSNLGHPESPPRKRLKSKGSDKDFVIVRRPKLNRENFPGVSWDSLPDELLLGIFSCLCLPELLKVSGVCKRWYRLASDESLWQTLDLTGKNLHPDVTGRLLSQGVIAFRCPRSFMDQPLAEHFSPFRVQHMDLSNSVIEVSTLHGILSQCSKLQNLSLEGLRLSDPIVNTLAKNSNLVRLNLSGCSGFSEFALQTLLSSCSRLDELNLSWCFDFTEKHVQVAVAHVSETITQLNLSGYRKNLQKSDLSTLVRRCPNLVHLDLSDSVMLKNDCFQEFFQLNYLQHLSLSRCYDIIPETLLLVTRAGVRIRLDSDIGCPQTYRTSKLKSSHKLFCQHVRVICIFVCDFYFYRLVLKQ>sp|Q13309-4|SKP2_HUMAN Isoform 3 of S-phase kinase-associated protein 2OS=Homo sapiens OX=9606 GN=SKP2MDQPLAEHFSTLAKNSNLVRLNLSGCSGFSEFALQTLLSSCSRLDELNLSWCFDFTEKHVQVAVAHVSETITQLNLSGYRKNLQKSDLSTLVRRCPNLVHLDLSDSVMLKNDCFQEFFQLNYLQHLSLSRCYDIIPETLLELGEIPTLKTLQVFGIVPDGTLQLLKEALPHLQINCSHFTTIARPTIGNKKNQEIWGIKCRLTLQKPSCL>sp|Q92185|SIA8A_HUMAN Alpha-N-acetylneuraminide alpha-2,8-sialyltransferase OS=Homo sapiens OX=9606 GN=ST8SIA1 PE=1 SV=1MSPCGRARRQTSRGAMAVLAWKFPRTRLPMGASALCVVVLCWLYIFPVYRLPNEKEIVQGVLQQGTAWRRNQTAARAFRKQMEDCCDPAHLFAMTKMNSPMGKSMWYDGEFLYSFTIDNSTYSLFPQATPFQLPLKKCAVVGNGGILKKSGCGRQIDEANFVMRCNLPPLSSEYTKDVGSKSQLVTANPSIIRQRFQNLLWSRKTFVDNMKIYNHSYIYMPAFSMKTGTEPSLRVYYTLSDVGANQTVLFANPNFLRSIGKFWKSRGIHAKRLSTGLFLVSAALGLCEEVAIYGFWPFSVNMHEQPISHHYYDNVLPFSGFHAMPEEFLQLWYLHKIGALRMQLDPCEDTSLQPTS>sp|Q92185-2|SIA8A_HUMAN Isoform 2 of Alpha-N-acetylneuraminide alpha-2,8-sialyltransferase OS=Homo sapiens OX=9606 GN=ST8SIA1MSPCGRARRQTSRGAMAVLAWKFPRTRLPMGASALCVVVLCWLYIFPVYRLPNEKEIVQGVLQQGTAWRRNQTAARAFRKQMEDCCDPAHLFAMTKMNSPMGKSMWYDGEFLYSFTIDNSTYSLFPQMQSPSFVK>sp|P01241|SOMA_HUMAN Somatotropin OS=Homo sapiens OX=9606 GN=GH1 PE=1SV=2MATGSRTSLLLAFGLLCLPWLQEGSAFPTIPLSRLFDNAMLRAHRLHQLAFDTYQEFEEAYIPKEQKYSFLQNPQTSLCFSESIPTPSNREETQQKSNLELLRISLLLIQSWLEPVQFLRSVFANSLVYGASDSNVYDLLKDLEEGIQTLMGRLEDGSPRTGQIFKQTYSKFDTNSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF>sp|P01241-2|SOMA_HUMAN Isoform 2 of Somatotropin OS=Homo sapiens OX=9606GN=GH1MATGSRTSLLLAFGLLCLPWLQEGSAFPTIPLSRLFDNAMLRAHRLHQLAFDTYQEFNPQTSLCFSESIPTPSNREETQQKSNLELLRISLLLIQSWLEPVQFLRSVFANSLVYGASDSNVYDLLKDLEEGIQTLMGRLEDGSPRTGQIFKQTYSKFDTNSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF>sp|P01241-3|SOMA_HUMAN Isoform 3 of Somatotropin OS=Homo sapiens OX=9606GN=GH1MATGSRTSLLLAFGLLCLPWLQEGSAFPTIPLSRLFDNAMLRAHRLHQLAFDTYQEFEEAYIPKEQKYSFLQNPQTSLCFSESIPTPSNREETQQKSNLELLRISLLLIQTLMGRLEDGSPRTGQIFKQTYSKFDTNSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF>sp|P01241-4|SOMA_HUMAN Isoform 4 of Somatotropin OS=Homo sapiens OX=9606GN=GH1MATGSRTSLLLAFGLLCLPWLQEGSAFPTIPLSRLFDNAMLRAHRLHQLAFDTYQEFEEAYIPKEQKYSFLQNPQTSLCFSESIPTPSNREETQQKSNLELLRISLLLIQSWLEPVQIFKQTYSKFDTNSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF>sp|P01241-5|SOMA_HUMAN Isoform 5 of Somatotropin OS=Homo sapiens OX=9606GN=GH1MATGSRTSLLLAFGLLCLPWLQEGSAFPTIPLSRLFDNAMLRAHRLHQLAFDTYQEFNLELLRISLLLIQSWLEPVQFLRSVFANSLVYGASDSNVYDLLKDLEEGIQTLMGRLEDGSPRTGQIFKQTYSKFDTNSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF>sp|Q9NUL5|SHFL_HUMAN Shiftless antiviral inhibitor of ribosomalframeshifting protein OS=Homo sapiens OX=9606 GN=SHFL PE=1 SV=2MSQEGVELEKSVRRLREKFHGKVSSKKAGALMRKFGSDHTGVGRSIVYGVKQKDGQELSNDLDAQDPPEDMKQDRDIQAVATSLLPLTEANLRMFQRAQDDLIPAVDRQFACSSCDHVWWRRVPQRKEVSRCRKCRKRYEPVPADKMWGLAEFHCPKCRHNFRGWAQMGSPSPCYGCGFPVYPTRILPPRWDRDPDRRSTHTHSCSAADCYNRREPHVPGTSCAHPKSRKQNHLPKVLHPSNPHISSGSTVATCLSQGGLLEDLDNLILEDLKEEEEEEEEVEDEEGGPRE>sp|Q9NUL5-2|SHFL_HUMAN Isoform 2 of Shiftless antiviral inhibitor ofribosomal frameshifting protein OS=Homo sapiens OX=9606 GN=SHFLMSQHQQACGICRQEDPPEDMKQDRDIQAVATSLLPLTEANLRMFQRAQDDLIPAVDRQFACSSCDHVWWRRVPQRKEVSRCRKCRKRYEPVPADKMWGLAEFHCPKCRHNFRGWAQMGSPSPCYGCGFPVYPTRILPPRWDRDPDRRSTHTHSCSAADCYNRREPHVPGTSCAHPKSRKQNHLPKVLHPSNPHISSGSTVATCLSQGGLLEDLDNLILEDLKEEEEEEEEVEDEEGGPRE>sp|Q9NUL5-3|SHFL_HUMAN Isoform 3 of Shiftless antiviral inhibitor ofribosomal frameshifting protein OS=Homo sapiens OX=9606 GN=SHFLMSQEGVELEKSVRRLREKFHGKVSSKKAGALMRKFGSDHTGVGRSIVYGVKQKDGQELSNDLDAQDPPEDMKQDRDIQAVATSLLPLTEANLRMFQRAQDDLIPAVDRQFACSSCDHVWWRRVPQRKEVSRCRKCRKRYEPVPADKMWGLAEFHCPKCRHNFR>sp|Q9NUL5-4|SHFL_HUMAN Isoform 4 of Shiftless antiviral inhibitor ofribosomal frameshifting protein OS=Homo sapiens OX=9606 GN=SHFLMSQEGVELEKSVRRLREKFHGKVSSKKAGALMRKFGSDHTGVGRSIVYGVKQKDGQELSNDLDAQDPPEDMKQDRDIQAVATSLLPLTEANLRMFQRAQDDLIPAVDRQFACSSCDHVWWRRVPQRKEVSRCRKCRKRYEPVPADKMWGLAEFHCPKCRHNFRTHTHSCSAADCYNRREPHVPGTSCAHPKSRKQNHLPKVLHPSNPHISSGSTVATCLSQGGLLEDLDNLILEDLKEEEEEEEEVEDEEGGPRE>sp|Q96PX8|SLIK1_HUMAN SLIT and NTRK-like protein 1 OS=Homo sapiensOX=9606 GN=SLITRK1 PE=1 SV=2MLLWILLLETSLCFAAGNVTGDVCKEKICSCNEIEGDLHVDCEKKGFTSLQRFTAPTSQFYHLFLHGNSLTRLFPNEFANFYNAVSLHMENNGLHEIVPGAFLGLQLVKRLHINNNKIKSFRKQTFLGLDDLEYLQADFNLLRDIDPGAFQDLNKLEVLILNDNLISTLPANVFQYVPITHLDLRGNRLKTLPYEEVLEQIPGIAEILLEDNPWDCTCDLLSLKEWLENIPKNALIGRVVCEAPTRLQGKDLNETTEQDLCPLKNRVDSSLPAPPAQEETFAPGPLPTPFKTNGQEDHATPGSAPNGGTKIPGNWQIKIRPTAAIATGSSRNKPLANSLPCPGGCSCDHIPGSGLKMNCNNRNVSSLADLKPKLSNVQELFLRDNKIHSIRKSHFVDYKNLILLDLGNNNIATVENNTFKNLLDLRWLYMDSNYLDTLSREKFAGLQNLEYLNVEYNAIQLILPGTFNAMPKLRILILNNNLLRSLPVDVFAGVSLSKLSLHNNYFMYLPVAGVLDQLTSIIQIDLHGNPWECSCTIVPFKQWAERLGSEVLMSDLKCETPVNFFRKDFMLLSNDEICPQLYARISPTLTSHSKNSTGLAETGTHSNSYLDTSRVSISVLVPGLLLVFVTSAFTVVGMLVFILRNRKRSKRRDANSSASEINSLQTVCDSSYWHNGPYNADGAHRVYDCGSHSLSD>sp|Q8NDV1|SIA7C_HUMAN Alpha-N-acetylgalactosaminide alpha-2,6-sialyltransferase 3 OS=Homo sapiens OX=9606 GN=ST6GALNAC3 PE=1 SV=1MACILKRKSVIAVSFIAAFLFLLVVRLVNEVNFPLLLNCFGQPGTKWIPFSYTYRRPLRTHYGYINVKTQEPLQLDCDLCAIVSNSGQMVGQKVGNEIDRSSCIWRMNNAPTKGYEEDVGRMTMIRVVSHTSVPLLLKNPDYFFKEANTTIYVIWGPFRNMRKDGNGIVYNMLKKTVGIYPNAQIYVTTEKRMSYCDGVFKKETGKDRVQSGSYLSTGWFTFLLAMDACYGIHVYGMINDTYCKTEGYRKVPYHYYEQGRDECDEYFLHEHAPYGGHRFITEKKVFAKWAKKHRIIFTHPNWTLS>sp|Q8NDV1-2|SIA7C_HUMAN Isoform 2 of Alpha-N-acetylgalactosaminidealpha-2,6-sialyltransferase 3 OS=Homo sapiens OX=9606 GN=ST6GALNAC3MACILKRKSVIAVSFIAAFLFLLVVRLVNEVNFPLLLNCFGQPGTKWIPFSYTYRRPLRTHYGYINVKTQEPLQLDCDLCAIVSNSGQMVGQKVGNEIDRSSCIWRMNNAPTKGYEEDVGRMTMIRVVSHTSVPLLLKNPDYFFKEANTTIYVIWGPFRNMRKDGNGIVYNMLKKTVGIYPNAQIYVTTEKRMSYCDGVFKKETGKDSTE>sp|Q7M4L6|SHF_HUMAN SH2 domain-containing adapter protein F OS=Homosapiens OX=9606 GN=SHF PE=1 SV=2MQQEGGPVRSAPCRTGTLEGSRQGSPGHRKRASPKGSLSSAQPHSWMLTPSPLNSHCAHREPISSSPQPVANGPKQKKKSNWRSTTRLRIIRLRDRLEPRPLAILEDYADPFDVQETGEGSAGASGAPEKVPENDGYMEPYEAQKMMAEIRGSKETATQPLPLYDTPYEPEEDGATAEGEGAPWPRESRLPEDDERPPEEYDQPWEWKKERISKAFAVDIKVIKDLPWPPPVGQLDSSPSLPDGDRDISGPASPLPEPSLEDSSAQFEGPEKSCLSPGREEKGRLPPRLSAGNPKSAKPLSMEPSSPLGEWTDPALPLENQVWYHGAISRTDAENLLRLCKEASYLVRNSETSKNDFSLSLKSSQGFMHMKLSRTKEHKYVLGQNSPPFSSVPEIVHHYASRKLPIKGAEHMSLLYPVAIRTL>sp|Q7M4L6-2|SHF_HUMAN Isoform 2 of SH2 domain-containing adapter proteinF OS=Homo sapiens OX=9606 GN=SHFMQQEGGPVRSAPCRTGTLEGSRQGSPGHRKRASPKGSLSSAQPHSWMLTPSPLNSHCAHREPISSSPQPVANGPKQKKKSNWRSTTRLRIIRLRDRLEPRPLAILEDYADPFDVQETGEGSAGASGAPEKVPENDGYMEPYEAQKMMAEIRGSKETATQPLPLYDTPYEPEEDGATAEGEGAPWPRESRLPEDDERPPEEYDQPWEWKKERISKAFAAQFEGPEKSCLSPGREEKGRLPPRLSAGNPKSAKPLSMEPSSPLGEWTDPALPLENQVWYHGAISRTDAENLLRLCKEASYLVRNSETSKNDFSLSLKSSQGFMHMKLSRTKEHKYVLGQNSPPFSSVPEIVHHYASRKLPIKGAEHMSLLYPVAIRTL>sp|Q9BWJ5|SF3B5_HUMAN Splicing factor 3B subunit 5 OS=Homo sapiensOX=9606 GN=SF3B5 PE=1 SV=1MTDRYTIHSQLEHLQSKYIGTGHADTTKWEWLVNQHRDSYCSYMGHFDLLNYFAIAENESKARVRFNLMEKMLQPCGPPADKPEEN>sp|Q9H156|SLIK2_HUMAN SLIT and NTRK-like protein 2 OS=Homo sapiensOX=9606 GN=SLITRK2 PE=1 SV=1MLSGVWFLSVLTVAGILQTESRKTAKDICKIRCLCEEKENVLNINCENKGFTTVSLLQPPQYRIYQLFLNGNLLTRLYPNEFVNYSNAVTLHLGNNGLQEIRTGAFSGLKTLKRLHLNNNKLEILREDTFLGLESLEYLQADYNYISAIEAGAFSKLNKLKVLILNDNLLLSLPSNVFRFVLLTHLDLRGNRLKVMPFAGVLEHIGGIMEIQLEENPWNCTCDLLPLKAWLDTITVFVGEIVCETPFRLHGKDVTQLTRQDLCPRKSASDSSQRGSHADTHVQRLSPTMNPALNPTRAPKASRPPKMRNRPTPRVTVSKDRQSFGPIMVYQTKSPVPLTCPSSCVCTSQSSDNGLNVNCQERKFTNISDLQPKPTSPKKLYLTGNYLQTVYKNDLLEYSSLDLLHLGNNRIAVIQEGAFTNLTSLRRLYLNGNYLEVLYPSMFDGLQSLQYLYLEYNVIKEIKPLTFDALINLQLLFLNNNLLRSLPDNIFGGTALTRLNLRNNHFSHLPVKGVLDQLPAFIQIDLQENPWDCTCDIMGLKDWTEHANSPVIINEVTCESPAKHAGEILKFLGREAICPDSPNLSDGTVLSMNHNTDTPRSLSVSPSSYPELHTEVPLSVLILGLLVVFILSVCFGAGLFVFVLKRRKGVPSVPRNTNNLDVSSFQLQYGSYNTETHDKTDGHVYNYIPPPVGQMCQNPIYMQKEGDPVAYYRNLQEFSYSNLEEKKEEPATPAYTISATELLEKQATPREPELLYQNIAERVKELPSAGLVHYNFCTLPKRQFAPSYESRRQNQDRINKTVLYGTPRKCFVGQSKPNHPLLQAKPQSEPDYLEVLEKQTAISQL>sp|Q9H156-2|SLIK2_HUMAN Isoform 2 of SLIT and NTRK-like protein 2OS=Homo sapiens OX=9606 GN=SLITRK2MLSGVWFLSVLTVAGILQTESRKTAKDICKIRCLCEEKENVLNINCENKGFTTVSLLQPPQYRIYQLFLNGNLLTRLYPNEFVNYSNAVTLHLGNNGLQEIRTGAFSGLKTLKRLHLNNNKLEILREDTFLGLESLEYLQADYNYISAIEAGAFSKLNKLKVLILNDNLLLSLPSNVFRFVLLTHLDLRGNRLKVMPFAGVLEHIGGIMEIQLEENPWNCTCDLLPLKAWLDTITVFVGEIVCETPFRLHGKDVTQLTRQDLCPRKSASDSSQRGSHADTHVQRLSPTMNPALNPTRAPKASRPPKMRNRPTPRVTVSKDRQSFGPIMVYQTKSPVPLTCPSSCVCTSQSSDNGLNVNCQERKFTNISDLQPKPTSPKKLYLTGNYLQTVYKNDLLEYSSLDLLHLGNNRIAVIQEGAFTNLTSLRRLYLNGNYLEVLYPSMFDGLQSLQYLYLEYNVIKEIKPLTFDALINLQLLFLNNNLLRSLPDNIFGGTALTRLNLRNNHFSHLPVKGVLDQLPAFIQIDLQENPWDCTCDIMGLKDWTEHANSPVIINEVTCESPAKHAGEILKFLGREAICPDSPNLSDGTVLSMNHNTDTPRSLSVSPSSYPELHTEVPLSVLILGLLVVFILSVCFGAGLFVFVLKRRKGVPSVPRNTNNLDVSSFQLQYGSYNTETHDKTDGHVYNYIPPPVGQMCQNPIYMQKEGDPVAYYRNLQEFKTSLENIWRPCLHKK>sp|Q9H4F1|SIA7D_HUMAN Alpha-N-acetyl-neuraminyl-2,3-beta-galactosyl-1,3-N-acetyl-galactosaminide alpha-2,6-sialyltransferase OS=Homo sapiensOX=9606 GN=ST6GALNAC4 PE=2 SV=2MKAPGRLVLIILCSVVFSAVYILLCCWAGLPLCLATCLDHHFPTGSRPTVPGPLHFSGYSSVPDGKPLVREPCRSCAVVSSSGQMLGSGLGAEIDSAECVFRMNQAPTVGFEADVGQRSTLRVVSHTSVPLLLRNYSHYFQKARDTLYMVWGQGRHMDRVLGGRTYRTLLQLTRMYPGLQVYTFTERMMAYCDQIFQDETGKNRRQSGSFLSTGWFTMILALELCEEIVVYGMVSDSYCREKSHPSVPYHYFEKGRLDECQMYLAHEQAPRSAHRFITEKAVFSRWAKKRPIVFAHPSWRTE>sp|O94933|SLIK3_HUMAN SLIT and NTRK-like protein 3 OS=Homo sapiensOX=9606 GN=SLITRK3 PE=1 SV=2MKPSIAEMLHRGRMLWIILLSTIALGWTTPIPLIEDSEEIDEPCFDPCYCEVKESLFHIHCDSKGFTNISQITEFWSRPFKLYLQRNSMRKLYTNSFLHLNNAVSINLGNNALQDIQTGAFNGLKILKRLYLHENKLDVFRNDTFLGLESLEYLQADYNVIKRIESGAFRNLSKLRVLILNDNLIPMLPTNLFKAVSLTHLDLRGNRLKVLFYRGMLDHIGRSLMELQLEENPWNCTCEIVQLKSWLERIPYTALVGDITCETPFHFHGKDLREIRKTELCPLLSDSEVEASLGIPHSSSSKENAWPTKPSSMLSSVHFTASSVEYKSSNKQPKPTKQPRTPRPPSTSQALYPGPNQPPIAPYQTRPPIPIICPTGCTCNLHINDLGLTVNCKERGFNNISELLPRPLNAKKLYLSSNLIQKIYRSDFWNFSSLDLLHLGNNRISYVQDGAFINLPNLKSLFLNGNDIEKLTPGMFRGLQSLHYLYFEFNVIREIQPAAFSLMPNLKLLFLNNNLLRTLPTDAFAGTSLARLNLRKNYFLYLPVAGVLEHLNAIVQIDLNENPWDCTCDLVPFKQWIETISSVSVVGDVLCRSPENLTHRDVRTIELEVLCPEMLHVAPAGESPAQPGDSHLIGAPTSASPYEFSPPGGPVPLSVLILSLLVLFFSAVFVAAGLFAYVLRRRRKKLPFRSKRQEGVDLTGIQMQCHRLFEDGGGGGGGSGGGGRPTLSSPEKAPPVGHVYEYIPHPVTQMCNNPIYKPREEEEVAVSSAQEAGSAERGGPGTQPPGMGEALLGSEQFAETPKENHSNYRTLLEKEKEWALAVSSSQLNTIVTVNHHHPHHPAVGGVSGVVGGTGGDLAGFRHHEKNGGVVLFPPGGGCGSGSMLLDRERPQPAPCTVGFVDCLYGTVPKLKELHVHPPGMQYPDLQQDARLKETLLFSAGKGFTDHQTQKSDYLELRAKLQTKPDYLEVLEKTTYRF>sp|Q9BVH7|SIA7E_HUMAN Alpha-N-acetylgalactosaminide alpha-2,6-sialyltransferase 5 OS=Homo sapiens OX=9606 GN=ST6GALNAC5 PE=1 SV=1MKTLMRHGLAVCLALTTMCTSLLLVYSSLGGQKERPPQQQQQQQQQQQQASATGSSQPAAESSTQQRPGVPAGPRPLDGYLGVADHKPLKMHCRDCALVTSSGHLLHSRQGSQIDQTECVIRMNDAPTRGYGRDVGNRTSLRVIAHSSIQRILRNRHDLLNVSQGTVFIFWGPSSYMRRDGKGQVYNNLHLLSQVLPRLKAFMITRHKMLQFDELFKQETGKDRKISNTWLSTGWFTMTIALELCDRINVYGMVPPDFCRDPNHPSVPYHYYEPFGPDECTMYLSHERGRKGSHHRFITEKRVFKNWARTFNIHFFQPDWKPESLAINHPENKPVF>sp|Q9Y3B4|SF3B6_HUMAN Splicing factor 3B subunit 6 OS=Homo sapiensOX=9606 GN=SF3B6 PE=1 SV=1MAMQAAKRANIRLPPEVNRILYIRNLPYKITAEEMYDIFGKYGPIRQIRVGNTPETRGTAYVVYEDIFDAKNACDHLSGFNVCNRYLVVLYYNANRAFQKMDTKKKEEQLKLLKEKYGINTDPPK>sp|Q8IW52|SLIK4_HUMAN SLIT and NTRK-like protein 4 OS=Homo sapiensOX=9606 GN=SLITRK4 PE=1 SV=1MFLWLFLILSALISSTNADSDISVEICNVCSCVSVENVLYVNCEKVSVYRPNQLKPPWSNFYHLNFQNNFLNILYPNTFLNFSHAVSLHLGNNKLQNIEGGAFLGLSALKQLHLNNNELKILRADTFLGIENLEYLQADYNLIKYIERGAFNKLHKLKVLILNDNLISFLPDNIFRFASLTHLDIRGNRIQKLPYIGVLEHIGRVVELQLEDNPWNCSCDLLPLKAWLENMPYNIYIGEAICETPSDLYGRLLKETNKQELCPMGTGSDFDVRILPPSQLENGYTTPNGHTTQTSLHRLVTKPPKTTNPSKISGIVAGKALSNRNLSQIVSYQTRVPPLTPCPAPCFCKTHPSDLGLSVNCQEKNIQSMSELIPKPLNAKKLHVNGNSIKDVDVSDFTDFEGLDLLHLGSNQITVIKGDVFHNLTNLRRLYLNGNQIERLYPEIFSGLHNLQYLYLEYNLIKEISAGTFDSMPNLQLLYLNNNLLKSLPVYIFSGAPLARLNLRNNKFMYLPVSGVLDQLQSLTQIDLEGNPWDCTCDLVALKLWVEKLSDGIVVKELKCETPVQFANIELKSLKNEILCPKLLNKPSAPFTSPAPAITFTTPLGPIRSPPGGPVPLSILILSILVVLILTVFVAFCLLVFVLRRNKKPTVKHEGLGNPDCGSMQLQLRKHDHKTNKKDGLSTEAFIPQTIEQMSKSHTCGLKESETGFMFSDPPGQKVVMRNVADKEKDLLHVDTRKRLSTIDELDELFPSRDSNVFIQNFLESKKEYNSIGVSGFEIRYPEKQPDKKSKKSLIGGNHSKIVVEQRKSEYFELKAKLQSSPDYLQVLEEQTALNKI>sp|Q969X2|SIA7F_HUMAN Alpha-N-acetylgalactosaminide alpha-2,6-sialyltransferase 6 OS=Homo sapiens OX=9606 GN=ST6GALNAC6 PE=1 SV=1MACSRPPSQCEPTSLPPGPPAGRRHLPLSRRRREMSSNKEQRSAVFVILFALITILILYSSNSANEVFHYGSLRGRSRRPVNLKKWSITDGYVPILGNKTLPSRCHQCVIVSSSSHLLGTKLGPEIERAECTIRMNDAPTTGYSADVGNKTTYRVVAHSSVFRVLRRPQEFVNRTPETVFIFWGPPSKMQKPQGSLVRVIQRAGLVFPNMEAYAVSPGRMRQFDDLFRGETGKDREKSHSWLSTGWFTMVIAVELCDHVHVYGMVPPNYCSQRPRLQRMPYHYYEPKGPDECVTYIQNEHSRKGNHHRFITEKRVFSSWAQLYGITFSHPSWT>sp|Q969X2-2|SIA7F_HUMAN Isoform 2 of Alpha-N-acetylgalactosaminidealpha-2,6-sialyltransferase 6 OS=Homo sapiens OX=9606 GN=ST6GALNAC6MSSNKEQRSAVFVILFALITILILYSSNSANEVFHYGSLRGRSRRPVNLKKWSITDGYVPILGNKTLPSRCHQCVIVSSSSHLLGTKLGPEIERAECTIRMNDAPTTGYSADVGNKTTYRVVAHSSVFRVLRRPQEFVNRTPETVFIFWGPPSKMQKPQGSLVRVIQRAGLVFPNMEAYAVSPGRMRQFDDLFRGETGKDREKSHSWLSTGWFTMVIAVELCDHVHVYGMVPPNYCSQRPRLQRMPYHYYEPKGPDECVTYIQNEHSRKGNHHRFITEKRVFSSWAQLYGITFSHPSWT>sp|Q969X2-3|SIA7F_HUMAN Isoform 3 of Alpha-N-acetylgalactosaminidealpha-2,6-sialyltransferase 6 OS=Homo sapiens OX=9606 GN=ST6GALNAC6MACSRPPSQCEPTSLPPGPPAGRRHLPLSRRRREMSSNKEQRSAVFVILFALITILILYSSNSANEVFHYGSLRGRSRRPVNLKKWSITDGYVPILGNKTLPSRCHQCVIVSSSSHLLGTKLGPEIERAECTIRMNDAPTTGYSADVGNKTTYRVVAHSSVFRVLRRPQEFVNRTPETVFIFWGPPSKMQKPQGSLVRVIQRAGLVFPNMEAYAVSPGRMRQFDDLFRGETGKDREKSHSWLSTGWFTMVIAVELCDHVHVYGMVPPNYCSGPASSACPTTTTSPRGRTNVSPTSRMSTVARATTTASSPRKGSSHRGPSCMASPSPTPPGPRPPSLWDLRRVRGEAASAQPLGQGPSSGQSRLAGVSPSQSGP>sp|Q92186|SIA8B_HUMAN Alpha-2,8-sialyltransferase 8B OS=Homo sapiensOX=9606 GN=ST8SIA2 PE=2 SV=1MQLQFRSWMLAALTLLVVFLIFADISEIEEEIGNSGGRGTIRSAVNSLHSKSNRAEVVINGSSSPAVVDRSNESIKHNIQPASSKWRHNQTLSLRIRKQILKFLDAEKDISVLKGTLKPGDIIHYIFDRDSTMNVSQNLYELLPRTSPLKNKHFGTCAIVGNSGVLLNSGCGQEIDAHSFVIRCNLAPVQEYARDVGLKTDLVTMNPSVIQRAFEDLVNATWREKLLQRLHSLNGSILWIPAFMARGGKERVEWVNELILKHHVNVRTAYPSLRLLHAVRGYWLTNKVHIKRPTTGLLMYTLATRFCKQIYLYGFWPFPLDQNQNPVKYHYYDSLKYGYTSQASPHTMPLEFKALKSLHEQGALKLTVGQCDGAT>sp|Q9BXP5|SRRT_HUMAN Serrate RNA effector molecule homolog OS=Homosapiens OX=9606 GN=SRRT PE=1 SV=1MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSDPYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFRRQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQEEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDDSFDEGSVSESESESESGQAEEEKEEAEEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASEPGTPPLPTSLPSQNPILKNITDYLIEEVSAEEEELLGSSGGAPPEEPPKEGNPAEINVERDEKLIKVLDKLLLYLRIVHSLDYYNTCEYPNEDEMPNRCGIIHVRGPMPPNRISHGEVLEWQKTFEEKLTPLLSVRESLSEEEAQKMGRKDPEQEVEKFVTSNTQELGKDKWLCPLSGKKFKGPEFVRKHIFNKHAEKIEEVKKEVAFFNNFLTDAKRPALPEIKPAQPPGPAQILPPGLTPGLPYPHQTPQGLMPYGQPRPPILGYGAGAVRPAVPTGGPPYPHAPYGAGRGNYDAFRGQGGYPGKPRNRMVRGDPRAIVEYRDLDAPDDVDFF>sp|Q9BXP5-2|SRRT_HUMAN Isoform 2 of Serrate RNA effector moleculehomolog OS=Homo sapiens OX=9606 GN=SRRTMGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSDPYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFRRQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQEEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDDSFDEGSVSESESESESGQAEEEKEEAEEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASEPGTPPLPTSLPSQNPILKNITDYLIEEVSAEEEELLGSSGGAPPEEPPKEGNPAEINVERDEKLIKVLDKLLLYLRIVHSLDYYNTCEYPNEDEMPNRCGIIHVRGPMPPNRISHGEVLEWQKTFEEKLTPLLSVRESLSEEEAQKMGRKDPEQEVEKFVTSNTQELGKDKWLCPLSGKKFKGPEFVRKHIFNKHAEKIEEVKKEVAFFNNFLTDAKRPALPEIKPAQPPGPAQSLTPGLPYPHQTPQGLMPYGQPRPPILGYGAGAVRPAVPTGGPPYPHAPYGAGRGNYDAFRGQGGYPGKPRNRMVRGDPRAIVEYRDLDAPDDVDFF>sp|Q9BXP5-3|SRRT_HUMAN Isoform 3 of Serrate RNA effector moleculehomolog OS=Homo sapiens OX=9606 GN=SRRTMGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSDPYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFRRQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQEEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDDSFDEGSVSESESESESGQAEEEKEEAEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASEPGTPPLPTSLPSQNPILKNITDYLIEEVSAEEEELLGSSGGAPPEEPPKEGNPAEINVERDEKLIKVLDKLLLYLRIVHSLDYYNTCEYPNEDEMPNRCGIIHVRGPMPPNRISHGEVLEWQKTFEEKLTPLLSVRESLSEEEAQKMGRKDPEQEVEKFVTSNTQELGKDKWLCPLSGKKFKGPEFVRKHIFNKHAEKIEEVKKEVAFFNNFLTDAKRPALPEIKPAQPPGPAQILPPGLTPGLPYPHQTPQGLMPYGQPRPPILGYGAGAVRPAVPTGGPPYPHAPYGAGRGNYDAFRGQGGYPGKPRNRMVRGDPRAIVEYRDLDAPDDVDFF>sp|Q9BXP5-4|SRRT_HUMAN Isoform 4 of Serrate RNA effector moleculehomolog OS=Homo sapiens OX=9606 GN=SRRTMGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSDPYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFRRQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQEEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDDSFDEGSVSESESESESGQAEEEKEEAEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASEPGTPPLPTSLPSQNPILKNITDYLIEEVSAEEEELLGSSGGAPPEEPPKEGNPAEINVERDEKLIKVLDKLLLYLRIVHSLDYYNTCEYPNEDEMPNRCGIIHVRGPMPPNRISHGEVLEWQKTFEEKLTPLLSVRESLSEEEAQKMGRKDPEQEVEKFVTSNTQELGKDKWLCPLSGKKFKGPEFVRKHIFNKHAEKIEEVKKEVAFFNNFLTDAKRPALPEIKPAQPPGPAQSLTPGLPYPHQTPQGLMPYGQPRPPILGYGAGAVRPAVPTGGPPYPHAPYGAGRGNYDAFRGQGGYPGKPRNRMVRGDPRAIVEYRDLDAPDDVDFF>sp|Q9BXP5-5|SRRT_HUMAN Isoform 5 of Serrate RNA effector moleculehomolog OS=Homo sapiens OX=9606 GN=SRRTMGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSDPYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFRRQQMQDFFLAHKDEEWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQEEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDDSFDEGSVSESESESESGQAEEEKEEAEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASEPGTPPLPTSLPSQNPILKNITDYLIEEVSAEEEELLGSSGGAPPEEPPKEGNPAEINVERDEKLIKVLDKLLLYLRIVHSLDYYNTCEYPNEDEMPNRCGIIHVRGPMPPNRISHGEVLEWQKTFEEKLTPLLSVRESLSEEEAQKMGRKDPEQEVEKFVTSNTQELGKDKWLCPLSGKKFKGPEFVRKHIFNKHAEKIEEVKKEVAFFNNFLTDAKRPALPEIKPAQPPGPAQILPPGLTPGLPYPHQTPQGLMPYGQPRPPILGYGAGAVRPAVPTGGPPYPHAPYGAGRGNYDAFRGQGGYPGKPRNRMVRGDPRAIVEYRDLDAPDDVDFF>sp|Q687X5|STEA4_HUMAN Metalloreductase STEAP4 OS=Homo sapiens OX=9606GN=STEAP4 PE=1 SV=1MEKTCIDALPLTMNSSEKQETVCIFGTGDFGRSLGLKMLQCGYSVVFGSRNPQKTTLLPSGAEVLSYSEAAKKSGIIIIAIHREHYDFLTELTEVLNGKILVDISNNLKINQYPESNAEYLAHLVPGAHVVKAFNTISAWALQSGALDASRQVFVCGNDSKAKQRVMDIVRNLGLTPMDQGSLMAAKEIEKYPLQLFPMWRFPFYLSAVLCVFLFFYCVIRDVIYPYVYEKKDNTFRMAISIPNRIFPITALTLLALVYLPGVIAAILQLYRGTKYRRFPDWLDHWMLCRKQLGLVALGFAFLHVLYTLVIPIRYYVRWRLGNLTVTQAILKKENPFSTSSAWLSDSYVALGILGFFLFVLLGITSLPSVSNAVNWREFRFVQSKLGYLTLILCTAHTLVYGGKRFLSPSNLRWYLPAAYVLGLIIPCTVLVIKFVLIMPCVDNTLTRIRQGWERNSKH>sp|Q687X5-2|STEA4_HUMAN Isoform 2 of Metalloreductase STEAP4 OS=Homosapiens OX=9606 GN=STEAP4MEKTCIDALPLTMNSSEKQETVCIFGTGDFGRSLGLKMLQCGYSVVFGSRNPQKTTLLPSGAEVLSYSEAAKKSGIIIIAIHREHYDFLTELTEVLNGKILVDISNNLKINQYPESNAEYLAHLVPGAHVVKAFNTISAWALQSGALDASRQAILKKENPFSTSSAWLSDSYVALGILGFFLFVLLGITSLPSVSNAVNWREFRFVQSKLGYLTLILCTAHTLVYGGKRFLSPSNLRWYLPAAYVLGLIIPCTVLVIKFVLIMPCVDNTLTRIRQGWERNSKH>sp|Q9NRA0|SPHK2_HUMAN Sphingosine kinase 2 OS=Homo sapiens OX=9606GN=SPHK2 PE=1 SV=2MNGHLEAEEQQDQRPDQELTGSWGHGPRSTLVRAKAMAPPPPPLAASTPLLHGEFGSYPARGPRFALTLTSQALHIQRLRPKPEARPRGGLVPLAEVSGCCTLRSRSPSDSAAYFCIYTYPRGRRGARRRATRTFRADGAATYEENRAEAQRWATALTCLLRGLPLPGDGEITPDLLPRPPRLLLLVNPFGGRGLAWQWCKNHVLPMISEAGLSFNLIQTERQNHARELVQGLSLSEWDGIVTVSGDGLLHEVLNGLLDRPDWEEAVKMPVGILPCGSGNALAGAVNQHGGFEPALGLDLLLNCSLLLCRGGGHPLDLLSVTLASGSRCFSFLSVAWGFVSDVDIQSERFRALGSARFTLGTVLGLATLHTYRGRLSYLPATVEPASPTPAHSLPRAKSELTLTPDPAPPMAHSPLHRSVSDLPLPLPQPALASPGSPEPLPILSLNGGGPELAGDWGGAGDAPLSPDPLLSSPPGSPKAALHSPVSEGAPVIPPSSGLPLPTPDARVGASTCGPPDHLLPPLGTPLPPDWVTLEGDFVLMLAISPSHLGADLVAAPHARFDDGLVHLCWVRSGISRAALLRLFLAMERGSHFSLGCPQLGYAAARAFRLEPLTPRGVLTVDGEQVEYGPLQAQMHPGIGTLLTGPPGCPGREP>sp|Q9NRA0-2|SPHK2_HUMAN Isoform 2 of Sphingosine kinase 2 OS=Homosapiens OX=9606 GN=SPHK2MAPPPPPLAASTPLLHGEFGSYPARGPRFALTLTSQALHIQRLRPKPEARPRGGLVPLAEVSGCCTLRSRSPSDSAAYFCIYTYPRGRRGARRRATRTFRADGAATYEENRAEAQRWATALTCLLRGLPLPGDGEITPDLLPRPPRLLLLVNPFGGRGLAWQWCKNHVLPMISEAGLSFNLIQTERQNHARELVQGLSLSEWDGIVTVSGDGLLHEVLNGLLDRPDWEEAVKMPVGILPCGSGNALAGAVNQHGGFEPALGLDLLLNCSLLLCRGGGHPLDLLSVTLASGSRCFSFLSVAWGFVSDVDIQSERFRALGSARFTLGTVLGLATLHTYRGRLSYLPATVEPASPTPAHSLPRAKSELTLTPDPAPPMAHSPLHRSVSDLPLPLPQPALASPGSPEPLPILSLNGGGPELAGDWGGAGDAPLSPDPLLSSPPGSPKAALHSPVSEGAPVIPPSSGLPLPTPDARVGASTCGPPDHLLPPLGTPLPPDWVTLEGDFVLMLAISPSHLGADLVAAPHARFDDGLVHLCWVRSGISRAALLRLFLAMERGSHFSLGCPQLGYAAARAFRLEPLTPRGVLTVDGEQVEYGPLQAQMHPGIGTLLTGPPGCPGREP>sp|Q9NRA0-3|SPHK2_HUMAN Isoform 3 of Sphingosine kinase 2 OS=Homosapiens OX=9606 GN=SPHK2MAPPPPPLAASTPLLHGEFGSYPARGPRFALTLTSQALHIQRLRPKPEARPRGGLVPLAEVSGCCTLRSRSPSDSAAYFCIYTYPRGRRGARRRATRTFRADGAATYEENRAEAQRWATALTCLLRGLPLPGDGEITPDLLPRPPRLLLLVNPFGGRGLAWQWCKNHVLPMISEAGLSFNLIQTERQNHARELVQGLSLSEWDGIVTVSGDGLLHEVLNGLLDRPDWEEAVKMPVGILPCGSGNALAGAVNQHGGPREDSDSSTSSSACPLWTTARSCPRAAASMPGSCPLLPQQLALGFSRFIQDRVNGGGGRIGSLTCRGHTQRTLPAPAREGGGSLFLKNINVFICKKKKKAHSLPRAKSELTLTPDPAPPMAHSPLHRSVSDLPLPLPQPALASPGSPEPLPILSLNGGGPELAGDWGGAGDAPLSPDPLLSSPPGSPKAALHSPVSEGAPVIPPSSGLPLPTPDARVGASTCGPPDHLLPPLGTPLPPDWVTLEGDFVLMLAISPSHLGADLVAAPHARFDDGLVHLCWVRSGISRAALLRLFLAMERGSHFSLGCPQLGYAAARAFRLEPLTPRGVLTVDGEQVEYGPLQAQMHPGIGTLLTGPPGCPGREP>sp|Q9NRA0-4|SPHK2_HUMAN Isoform 4 of Sphingosine kinase 2 OS=Homosapiens OX=9606 GN=SPHK2MNGHLEAEEQQDQALHIQRLRPKPEARPRGGLVPLAEVSGCCTLRSRSPSDSAAYFCIYTYPRGRRGARRRATRTFRADGAATYEENRAEAQRWATALTCLLRGLPLPGDGEITPDLLPRPPRLLLLVNPFGGRGLAWQWCKNHVLPMISEAGLSFNLIQTERQNHARELVQGLSLSEWDGIVTVSGDGLLHEVLNGLLDRPDWEEAVKMPVGILPCGSGNALAGAVNQHGGFEPALGLDLLLNCSLLLCRGGGHPLDLLSVTLASGSRCFSFLSVAWGFVSDVDIQSERFRALGSARFTLGTVLGLATLHTYRGRLSYLPATVEPASPTPAHSLPRAKSELTLTPDPAPPMAHSPLHRSVSDLPLPLPQPALASPGSPEPLPILSLNGGGPELAGDWGGAGDAPLSPDPLLSSPPGSPKAALHSPVSEGAPVIPPSSGLPLPTPDARVGASTCGPPDHLLPPLGTPLPPDWVTLEGDFVLMLAISPSHLGADLVAAPHARFDDGLVHLCWVRSGISRAALLRLFLAMERGSHFSLGCPQLGYAAARAFRLEPLTPRGVLTVDGEQVEYGPLQAQMHPGIGTLLTGPPGCPGREP>sp|Q9NRA0-5|SPHK2_HUMAN Isoform 5 of Sphingosine kinase 2 OS=Homosapiens OX=9606 GN=SPHK2MIGCLHARVSGPLWDAGLCPASSRSAHTCLSLSVSDAPVSPATAPHCLLLSTAPAPPCPCHGVLNSHPFSPPFPQRPDQELTGSWGHGPRSTLVRAKAMAPPPPPLAASTPLLHGEFGSYPARGPRFALTLTSQALHIQRLRPKPEARPRGGLVPLAEVSGCCTLRSRSPSDSAAYFCIYTYPRGRRGARRRATRTFRADGAATYEENRAEAQRWATALTCLLRGLPLPGDGEITPDLLPRPPRLLLLVNPFGGRGLAWQWCKNHVLPMISEAGLSFNLIQTERQNHARELVQGLSLSEWDGIVTVSGDGLLHEVLNGLLDRPDWEEAVKMPVGILPCGSGNALAGAVNQHGGFEPALGLDLLLNCSLLLCRGGGHPLDLLSVTLASGSRCFSFLSVAWGFVSDVDIQSERFRALGSARFTLGTVLGLATLHTYRGRLSYLPATVEPASPTPAHSLPRAKSELTLTPDPAPPMAHSPLHRSVSDLPLPLPQPALASPGSPEPLPILSLNGGGPELAGDWGGAGDAPLSPDPLLSSPPGSPKAALHSPVSEGAPVIPPSSGLPLPTPDARVGASTCGPPDHLLPPLGTPLPPDWVTLEGDFVLMLAISPSHLGADLVAAPHARFDDGLVHLCWVRSGISRAALLRLFLAMERGSHFSLGCPQLGYAAARAFRLEPLTPRGVLTVDGEQVEYGPLQAQMHPGIARGRTQTPALPAAPALYGRQPGAAHGLQPVCQGAALFFHNSWLWGSQDLFRIVLTEAVGG>sp|Q96GP6|SREC2_HUMAN Scavenger receptor class F member 2 OS=Homosapiens OX=9606 GN=SCARF2 PE=1 SV=5MEGAGPRGAGPARRRGAGGPPSPLLPSLLLLLLLWMLPDTVAPQELNPRGRNVCRAPGSQVPTCCAGWRQQGDECGIAVCEGNSTCSENEVCVRPGECRCRHGYFGANCDTKCPRQFWGPDCKELCSCHPHGQCEDVTGQCTCHARRWGARCEHACQCQHGTCHPRSGACRCEPGWWGAQCASACYCSATSRCDPQTGACLCHAGWWGRSCNNQCACNSSPCEQQSGRCQCRERTFGARCDRYCQCFRGRCHPVDGTCACEPGYRGKYCREPCPAGFYGLGCRRRCGQCKGQQPCTVAEGRCLTCEPGWNGTKCDQPCATGFYGEGCSHRCPPCRDGHACNHVTGKCTRCNAGWIGDRCETKCSNGTYGEDCAFVCADCGSGHCDFQSGRCLCSPGVHGPHCNVTCPPGLHGADCAQACSCHEDTCDPVTGACHLETNQRKGVMGAGALLVLLVCLLLSLLGCCCACRGKDPTRRPRPRRELSLGRKKAPHRLCGRFSRISMKLPRIPLRRQKLPKVVVAHHDLDNTLNCSFLEPPSGLEQPSPSWSSRASFSSFDTTDEGPVYCVPHEEAPAESRDPEVPTVPAEAPAPSPVPLTTPASAEEAIPLPASSDSERSASSVEGPGGALYARVARREARPARARGEIGGLSLSPSPERRKPPPPDPATKPKVSWIHGKHSAAAAGRAPSPPPPGSEAAPSPSKRKRTPSDKSAHTVEHGSPRTRDPTPRPPGLPEEATALAAPSPPRARARGRGPGLLEPTDAGGPPRSAPEAASMLAAELRGKTRSLGRAEVALGAQGPREKPAPPQKAKRSVPPASPARAPPATETPGPEKAATDLPAPETPRKKTPIQKPPRKKSREAAGELGRAGAPTL>sp|Q96GP6-2|SREC2_HUMAN Isoform 2 of Scavenger receptor class F member 2OS=Homo sapiens OX=9606 GN=SCARF2MEGAGPRGAGPARRRGAGGPPSPLLPSLLLLLLLWMLPDTVAPQELNPRGRNVCRAPGSQVPTCCAGWRQQGDECGIAVCEGNSTCSENEVCVRPGECRCRHGYFGANCDTKCPRQFWGPDCKELCSCHPHGQCEDVTGQCTCHARRWGARCEHACQCQHGTCHPRSGACRCEPGWWGAQCASACYCSATSRCDPQTGACLCHAGWWGRSCNNQCACNSSPCEQQSGRCQCRERTFGARCDRYCQCFRGRCHPVDGTCACEPGYRGKYCREPCPAGFYGLGCRRRCGQCKGQQPCTVAEGRCLTCEPGWNGTKCDQPCATGFYGEGCSHRCPPCRDGHACNHVTGKCTRCNAGWIGDRCETKCSNGTYGEDCAFVCADCGSGHCDFQSGRCLCSPGVHGPHCNVTCPPGLHGADCAQACSCHEDTCDPVTGACHLETNQRKGVMGAGALLVLLVCLLLSLLGCCCACRGKDPTRRELSLGRKKAPHRLCGRFSRISMKLPRIPLRRQKLPKVVVAHHDLDNTLNCSFLEPPSGLEQPSPSWSSRASFSSFDTTDEGPVYCVPHEEAPAESRDPEVPTVPAEAPAPSPVPLTTPASAEEAIPLPASSDSERSASSVEGPGGALYARVARREARPARARGEIGGLSLSPSPERRKPPPPDPATKPKVSWIHGKHSAAAAGRAPSPPPPGSEAAPSPSKRKRTPSDKSAHTVEHGSPRTRDPTPRPPGLPEEATALAAPSPPRARARGRGPGLLEPTDAGGPPRSAPEAASMLAAELRGKTRSLGRAEVALGAQGPREKPAPPQKAKRSVPPASPARAPPATETPGPEKAATDLPAPETPRKKTPIQKPPRKKSREAAGELGRAGAPTL>sp|P43307|SSRA_HUMAN Translocon-associated protein subunit alpha OS=Homosapiens OX=9606 GN=SSR1 PE=1 SV=3MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVEDKEEEDVSGEPEASPSADTTILFVKGEDFPANNIVKFLVGFTNKGTEDFIVESLDASFRYPQDYQFYIQNFTALPLNTVVPPQRQATFEYSFIPAEPMGGRPFGLVINLNYKDLNGNVFQDAVFNQTVTVIEREDGLDGETIFMYMFLAGLGLLVIVGLHQLLESRKRKRPIQKVEMGTSSQNDVDMSWIPQETLNQINKASPRRLPRKRAQKRSVGSDE>sp|P43307-2|SSRA_HUMAN Isoform 2 of Translocon-associated proteinsubunit alpha OS=Homo sapiens OX=9606 GN=SSR1MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVEDFPANNIVKFLVGFTNKGTEDFIVESLDASFRYPQDYQFYIQNFTALPLNTVVPPQRQATFEYSFIPAEPMGGRPFGLVINLNYKDLNGNVFQDAVFNQTVTVIEREDGLDGETIFMYMFLAGLGLLVIVGLHQLLESRKRKRPIQKVEMGTSSQNDVDMSWIPQETLNQINKASPRRLPRKRAQKRSVGSDE>sp|O43805|SSNA1_HUMAN Sjoegren syndrome nuclear autoantigen 1 OS=Homosapiens OX=9606 GN=SSNA1 PE=1 SV=2MTQQGAALQNYNNELVKCIEELCQKREELCRQIQEEEDEKQRLQNEVRQLTEKLARVNENLARKIASRNEFDRTIAETEAAYLKILESSQTLLSVLKREAGNLTKATAPDQKSSGGRDS>sp|Q9BRA2|TXD17_HUMAN Thioredoxin domain-containing protein 17 OS=Homosapiens OX=9606 GN=TXNDC17 PE=1 SV=1MARYEEVSVSGFEEFHRAVEQHNGKTIFAYFTGSKDAGGKSWCPDCVQAEPVVREGLKHISEGCVFIYCQVGEKPYWKDPNNDFRKNLKVTAVPTLLKYGTPQKLVESECLQANLVEMLFSED>sp|P22532|SPR2D_HUMAN Small proline-rich protein 2D OS=Homo sapiensOX=9606 GN=SPRR2D PE=2 SV=2MSYQQQQCKQPCQPPPVCPTPKCPEPCPPPKCPEPCPSPKCPQPCPPQQCQQKYPPVTPSPPCQPKCPPKSK>sp|Q9HCS7|SYF1_HUMAN Pre-mRNA-splicing factor SYF1 OS=Homo sapiensOX=9606 GN=XAB2 PE=1 SV=2MVVMARLSRPERPDLVFEEEDLPYEEEIMRNQFSVKCWLRYIEFKQGAPKPRLNQLYERALKLLPCSYKLWYRYLKARRAQVKHRCVTDPAYEDVNNCHERAFVFMHKMPRLWLDYCQFLMDQGRVTHTRRTFDRALRALPITQHSRIWPLYLRFLRSHPLPETAVRGYRRFLKLSPESAEEYIEYLKSSDRLDEAAQRLATVVNDERFVSKAGKSNYQLWHELCDLISQNPDKVQSLNVDAIIRGGLTRFTDQLGKLWCSLADYYIRSGHFEKARDVYEEAIRTVMTVRDFTQVFDSYAQFEESMIAAKMETASELGREEEDDVDLELRLARFEQLISRRPLLLNSVLLRQNPHHVHEWHKRVALHQGRPREIINTYTEAVQTVDPFKATGKPHTLWVAFAKFYEDNGQLDDARVILEKATKVNFKQVDDLASVWCQCGELELRHENYDEALRLLRKATALPARRAEYFDGSEPVQNRVYKSLKVWSMLADLEESLGTFQSTKAVYDRILDLRIATPQIVINYAMFLEEHKYFEESFKAYERGISLFKWPNVSDIWSTYLTKFIARYGGRKLERARDLFEQALDGCPPKYAKTLYLLYAQLEEEWGLARHAMAVYERATRAVEPAQQYDMFNIYIKRAAEIYGVTHTRGIYQKAIEVLSDEHAREMCLRFADMECKLGEIDRARAIYSFCSQICDPRTTGAFWQTWKDFEVRHGNEDTIKEMLRIRRSVQATYNTQVNFMASQMLKVSGSATGTVSDLAPGQSGMDDMKLLEQRAEQLAAEAERDQPLRAQSKILFVRSDASREELAELAQQVNPEEIQLGEDEDEDEMDLEPNEVRLEQQSVPAAVFGSLKED>sp|Q96RU2|UBP28_HUMAN Ubiquitin carboxyl-terminal hydrolase 28 OS=Homosapiens OX=9606 GN=USP28 PE=1 SV=1MTAELQQDDAAGAADGHGSSCQMLLNQLREITGIQDPSFLHEALKASNGDITQAVSLLTDERVKEPSQDTVATEPSEVEGSAANKEVLAKVIDLTHDNKDDLQAAIALSLLESPKIQADGRDLNRMHEATSAETKRSKRKRCEVWGENPNPNDWRRVDGWPVGLKNVGNTCWFSAVIQSLFQLPEFRRLVLSYSLPQNVLENCRSHTEKRNIMFMQELQYLFALMMGSNRKFVDPSAALDLLKGAFRSSEEQQQDVSEFTHKLLDWLEDAFQLAVNVNSPRNKSENPMVQLFYGTFLTEGVREGKPFCNNETFGQYPLQVNGYRNLDECLEGAMVEGDVELLPSDHSVKYGQERWFTKLPPVLTFELSRFEFNQSLGQPEKIHNKLEFPQIIYMDRYMYRSKELIRNKRECIRKLKEEIKILQQKLERYVKYGSGPARFPLPDMLKYVIEFASTKPASESCPPESDTHMTLPLSSVHCSVSDQTSKESTSTESSSQDVESTFSSPEDSLPKSKPLTSSRSSMEMPSQPAPRTVTDEEINFVKTCLQRWRSEIEQDIQDLKTCIASTTQTIEQMYCDPLLRQVPYRLHAVLVHEGQANAGHYWAYIYNQPRQSWLKYNDISVTESSWEEVERDSYGGLRNVSAYCLMYINDKLPYFNAEAAPTESDQMSEVEALSVELKHYIQEDNWRFEQEVEEWEEEQSCKIPQMESSTNSSSQDYSTSQEPSVASSHGVRCLSSEHAVIVKEQTAQAIANTARAYEKSGVEAALSEVMLSPAMQGVILAIAKARQTFDRDGSEAGLIKAFHEEYSRLYQLAKETPTSHSDPRLQHVLVYFFQNEAPKRVVERTLLEQFADKNLSYDERSISIMKVAQAKLKEIGPDDMNMEEYKKWHEDYSLFRKVSVYLLTGLELYQKGKYQEALSYLVYAYQSNAALLMKGPRRGVKESVIALYRRKCLLELNAKAASLFETNDDHSVTEGINVMNELIIPCIHLIINNDISKDDLDAIEVMRNHWCSYLGQDIAENLQLCLGEFLPRLLDPSAEIIVLKEPPTIRPNSPYDLCSRFAAVMESIQGVSTVTVK>sp|Q96RU2-2|UBP28_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 28 OS=Homo sapiens OX=9606 GN=USP28MTAELQQDDAAGAADGHGSSCQMLLNQLREITGIQDPSFLHEALKASNGDITQAVSLLTDERVKEPSQDTVATEPSEVEGSAANKEVLAKVIDLTHDNKDDLQAAIALSLLESPKIQADGRDLNRMHEATSAETKRSKRKRCEVWGENPNPNDWRRVDGWPVGLKNVGNTCWFSAVIQSLFQLPEFRRLVLSYSLPQNVLENCRSHTEKRNIMFMQELQYLFALMMGSNRKFVDPSAALDLLKGAFRSSEEQQQDVSEFTHKLLDWLEDAFQLAVNVNSPRNKSENPMVQLFYGTFLTEGVREGKPFCNNETFGQYPLQVNGYRNLDECLEGAMVEGDVELLPSDHSVKYGQERWFTKLPPVLTFELSRFEFNQSLGQPEKIHNKLEFPQIIYMDRYMYRSKELIRNKRECIRKLKEEIKILQQKLERYVKYGSGPARFPLPDMLKYVIEFASTKPASESCPPESDTHMTLPLSSVHCSVSDQTSKESTSTESSSQDVESTFSSPEDSLPKSKPLTSSRSSMEMPSQPAPRTVTDEEINFVKTCLQRWRSEIEQDIQDLKTCIASTTQTIEQMYCDPLLRQVPYRLHAVLVHEGQANAGHYWAYIYNQPRQSWLKYNDISVTESSWEEVERDSYGGLRNVSAYCLMYINDKLPYFNAEAAPTESDQMSEVEALSVELKHYIQEDNWRFEQEVEEWEEEQSCKIPQMESSTNSSSQDYSTSQEPSVASSHGVRCLSSEHAVIVKEQTAQAIANTARAYEKSGVEAALSEAFHEEYSRLYQLAKETPTSHSDPRLQHVLVYFFQNEAPKRVVERTLLEQFADKNLSYDERSISIMKVAQAKLKEIGPDDMNMEEYKKWHEDYSLFRKVSVYLLTGLELYQKGKYQEALSYLVYAYQSNAALLMKGPRRGVKESVIALYRRKCLLELNAKAASLFETNDDHSVTEGINVMNELIIPCIHLIINNDISKDDLDAIEVMRNHWCSYLGQDIAENLQLCLGEFLPRLLDPSAEIIVLKEPPTIRPNSPYDLCSRFAAVMESIQGVSTVTVK>sp|Q96RU2-3|UBP28_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 28 OS=Homo sapiens OX=9606 GN=USP28MTAELQQDDAAGAADGHGSSCQMLLNQLREITGIQDPSFLHEALKASNGDITQAVSLLTDERVKEPSQDTVATEPSEVEGSAANKEVLAKVIDLTHDNKDDLQAAIALSLLESPKIQADGRDLNRMHEATSAETKRSKRKRCEVWGENPNPNDWRRVDGWPVGLKNVGNTCWFSAVIQSLFQLPEFRRLVLSYSLPQNVLENCRSHTEKRNIMFMQELQYLFALMMGSNRKFVDPSAALDLLKGAFRSSEEQQQDVSEFTHKLLDWLEDAFQLAVNVNSPRNKSENPMVQLFYGTFLTEGVREGKPFCNNETFGQYPLQVNGYRNLDECLEGAMVEGDVELLPSDHSVKYGQERWFTKLPPVLTFELSRFEFNQSLGQPEKIHNKLEFPQIIYMDRYMYRSKELIRNKRECIRKLKEEIKILQQKLERYVKYGSGPARFPLPDMLKYVIEFASTKPASESCPPESDTHMTLPLSSVHCSVSDQTSKESTSTESSSQDVESTFSSPEDSLPKSKPLTSSRSSMEMPSQPAPRTVTDEEINFVKTCLQRWRSEIEQDIQDLKTCIASTTQTIEQMYCDPLLRQVE>sp|Q0WX57|U17LO_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 24 OS=Homo sapiens OX=9606 GN=USP17L24 PE=1 SV=2MEDDSLYLRGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQPNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSSTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|Q8IZU3|SYCP3_HUMAN Synaptonemal complex protein 3 OS=Homo sapiensOX=9606 GN=SYCP3 PE=1 SV=1MVSSGKKYSRKSGKPSVEDQFTRAYDFETEDKKDLSGSEEDVIEGKTAVIEKRRKKRSSAGVVEDMGGEVQNMLEGVGVDINKALLAKRKRLEMYTKASLKTSNQKIEHVWKTQQDQRQKLNQEYSQQFLTLFQQWDLDMQKAEEQEEKILNMFRQQQKILQQSRIVQSQRLKTIKQLYEQFIKSMEELEKNHDNLLTGAQNEFKKEMAMLQKKIMMETQQQEIASVRKSLQSMLF>sp|P19971|TYPH_HUMAN Thymidine phosphorylase OS=Homo sapiens OX=9606GN=TYMP PE=1 SV=2MAALMTPGTGAPPAPGDFSGEGSQGLPDPSPEPKQLPELIRMKRDGGRLSEADIRGFVAAVVNGSAQGAQIGAMLMAIRLRGMDLEETSVLTQALAQSGQQLEWPEAWRQQLVDKHSTGGVGDKVSLVLAPALAACGCKVPMISGRGLGHTGGTLDKLESIPGFNVIQSPEQMQVLLDQAGCCIVGQSEQLVPADGILYAARDVTATVDSLPLITASILSKKLVEGLSALVVDVKFGGAAVFPNQEQARELAKTLVGVGASLGLRVAAALTAMDKPLGRCVGHALEVEEALLCMDGAGPPDLRDLVTTLGGALLWLSGHAGTQAQGAARVAAALDDGSALGRFERMLAAQGVDPGLARALCSGSPAERRQLLPRAREQEELLAPADGTVELVRALPLALVLHELGAGRSRAGEPLRLGVGAELLVDVGQRLRRGTPWLRVHRDGPALSGPQSRALQEALVLSDRAPFAAPSPFAELVLPPQQ>sp|P19971-2|TYPH_HUMAN Isoform 2 of Thymidine phosphorylase OS=Homosapiens OX=9606 GN=TYMPMAALMTPGTGAPPAPGDFSGEGSQGLPDPSPEPKQLPELIRMKRDGGRLSEADIRGFVAAVVNGSAQGAQIGAMLMAIRLRGMDLEETSVLTQALAQSGQQLEWPEAWRQQLVDKHSTGGVGDKVSLVLAPALAACGCKVPMISGRGLGHTGGTLDKLESIPGFNVIQSPEQMQVLLDQAGCCIVGQSEQLVPADGILYAARDVTATVDSLPLITASILSKKLVEGLSALVVDVKFGGAAVFPNQEQARELAKTLVGVGASLGLRVAAALTAMDKPLGRCVGHALEVEEALLCMDGAGPPDLRDLVTTLGGALLWLSGHAGTQAQGAARVAAALDDGSALGRFERMLAAQGVDPGLARALCSGSPAERRQLLPRAREQEELLAPADAPLPAGTVELVRALPLALVLHELGAGRSRAGEPLRLGVGAELLVDVGQRLRRGTPWLRVHRDGPALSGPQSRALQEALVLSDRAPFAAPSPFAELVLPPQQ>sp|Q96LJ8|UBX10_HUMAN UBX domain-containing protein 10 OS=Homo sapiensOX=9606 GN=UBXN10 PE=1 SV=1MATEAPVNIAPPECSTVVSTAVDSLIWQPNSLNMHMIRPKSAKGRTRPSLQKSQGVEVCAHHIPSPPPAIPYELPSSQKPGACAPKSPNQGASDEIPELQQQVPTGASSSLNKYPVLPSINRKNLEEEAVETVAKKASSLQLSSIRALYQDETGTMKTSEEDSRARACAVERKFIVRTKKQGSSRAGNLEEPSDQEPRLLLAVRSPTGQRFVRHFRPTDDLQTIVAVAEQKNKTSYRHCSIETMEVPRRRFSDLTKSLQECRIPHKSVLGISLEDGEGWP>sp|H0YL09|U2Q2L_HUMAN Putative ubiquitin-conjugating enzyme E2Q2-likeprotein OS=Homo sapiens OX=9606 GN=UBE2Q2L PE=5 SV=1MGPAVLGQGQEGQPEARACSGLLQPPKRPIVFKEKLTMKTDSLMEEKLECSLWCCLSDPSIPGRCCVLERRIVPWMQQESYSSSSPIWSVDSDEPNLTSVLERLEDTKENSSVRKETKLFSLFLMNIIFRN>sp|Q14CS0|UBX2B_HUMAN UBX domain-containing protein 2B OS=Homo sapiensOX=9606 GN=UBXN2B PE=1 SV=1MAEGGGPEPGEQERRSSGPRPPSARDLQLALAELYEDEVKCKSSKSNRPKATVFKSPRTPPQRFYSSEHEYSGLNIVRPSTGKIVNELFKEAREHGAVPLNEATRASGDDKSKSFTGGGYRLGSSFCKRSEYIYGENQLQDVQILLKLWSNGFSLDDGELRPYNEPTNAQFLESVKRGEIPLELQRLVHGGQVNLDMEDHQDQEYIKPRLRFKAFSGEGQKLGSLTPEIVSTPSSPEEEDKSILNAVVLIDDSVPTTKIQIRLADGSRLIQRFNSTHRILDVRNFIVQSRPEFAALDFILVTSFPNKELTDESLTLLEADILNTVLLQQLK>sp|Q9Y5Z9|UBIA1_HUMAN UbiA prenyltransferase domain-containing protein 1OS=Homo sapiens OX=9606 GN=UBIAD1 PE=1 SV=1MAASQVLGEKINILSGETVKAGDRDPLGNDCPEQDRLPQRSWRQKCASYVLALRPWSFSASLTPVALGSALAYRSHGVLDPRLLVGCAVAVLAVHGAGNLVNTYYDFSKGIDHKKSDDRTLVDRILEPQDVVRFGVFLYTLGCVCAACLYYLSPLKLEHLALIYFGGLSGSFLYTGGIGFKYVALGDLIILITFGPLAVMFAYAIQVGSLAIFPLVYAIPLALSTEAILHSNNTRDMESDREAGIVTLAILIGPTFSYILYNTLLFLPYLVFSILATHCTISLALPLLTIPMAFSLERQFRSQAFNKLPQRTAKLNLLLGLFYVFGIILAPAGSLPKI>sp|Q9Y5Z9-2|UBIA1_HUMAN Isoform 2 of UbiA prenyltransferase domain-containing protein 1 OS=Homo sapiens OX=9606 GN=UBIAD1MAASQVLGEKINILSGETVKAGDRDPLGNDCPEQDRLPQRSWRQKCASYVLALRPWSFSASLTPVALGSALAYRSHGVLDPRLLVGCAVAVLAVHGAGNLVNTYYDFSKGIDHKKSDDRTLVDRILEPQDVVRFGVFLYTLGCVCAACLYYLSPLKLEHLALIYFGGLSGSFLYTGVLI>sp|Q9P2J2|TUTLA_HUMAN Protein turtle homolog A OS=Homo sapiens OX=9606GN=IGSF9 PE=1 SV=2MVWCLGLAVLSLVISQGADGRGKPEVVSVVGRAGESVVLGCDLLPPAGRPPLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVGRVRLQKGASLQIEGLRVEDQGWYECRVFFLDQHIPEDDFANGSWVHLTVNSPPQFQETPPAVLEVQELEPVTLRCVARGSPLPHVTWKLRGKDLGQGQGQVQVQNGTLRIRRVERGSSGVYTCQASSTEGSATHATQLLVLGPPVIVVPPKNSTVNASQDVSLACHAEAYPANLTYSWFQDNINVFHISRLQPRVRILVDGSLRLLATQPDDAGCYTCVPSNGLLHPPSASAYLTVLYPAQVTAMPPETPLPIGMPGVIRCPVRANPPLLFVSWTKDGKALQLDKFPGWSQGTEGSLIIALGNEDALGEYSCTPYNSLGTAGPSPVTRVLLKAPPAFIERPKEEYFQEVGRELLIPCSAQGDPPPVVSWTKVGRGLQGQAQVDSNSSLILRPLTKEAHGHWECSASNAVARVATSTNVYVLGTSPHVVTNVSVVALPKGANVSWEPGFDGGYLQRFSVWYTPLAKRPDRMHHDWVSLAVPVGAAHLLVPGLQPHTQYQFSVLAQNKLGSGPFSEIVLSAPEGLPTTPAAPGLPPTEIPPPLSPPRGLVAVRTPRGVLLHWDPPELVPKRLDGYVLEGRQGSQGWEVLDPAVAGTETELLVPGLIKDVLYEFRLVAFAGSFVSDPSNTANVSTSGLEVYPSRTQLPGLLPQPVLAGVVGGVCFLGVAVLVSILAGCLLNRRRAARRRRKRLRQDPPLIFSPTGKSAAPSALGSGSPDSVAKLKLQGSPVPSLRQSLLWGDPAGTPSPHPDPPSSRGPLPLEPICRGPDGRFVMGPTVAAPQERSGREQAEPRTPAQRLARSFDCSSSSPSGAPQPLCIEDISPVAPPPAAPPSPLPGPGPLLQYLSLPFFREMNVDGDWPPLEEPSPAAPPDYMDTRRCPTSSFLRSPETPPVSPRESLPGAVVGAGATAEPPYTALADWTLRERLLPGLLPAAPRGSLTSQSSGRGSASFLRPPSTAPSAGGSYLSPAPGDTSSWASGPERWPRREHVVTVSKRRNTSVDENYEWDSEFPGDMELLETLHLGLASSRLRPEAEPELGVKTPEEGCLLNTAHVTGPEARCAALREEFLAFRRRRDATRARLPAYRQPVPHPEQATLL>sp|Q9P2J2-2|TUTLA_HUMAN Isoform 2 of Protein turtle homolog A OS=Homosapiens OX=9606 GN=IGSF9MVWCLGLAVLSLVISQGADGRGKPEVVSVVGRAGESVVLGCDLLPPAGRPPLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVGRVRLQKGASLQIEGLRVEDQGWYECRVFFLDQHIPEDDFANGSWVHLTVNSPPQFQETPPAVLEVQELEPVTLRCVARGSPLPHVTWKLRGKDLGQGQGQVQVQNGTLRIRRVERGSSGVYTCQASSTEGSATHATQLLVLGPPVIVVPPKNSTVNASQDVSLACHAEAYPANLTYSWFQDNINVFHISRLQPRVRILVDGSLRLLATQPDDAGCYTCVPSNGLLHPPSASAYLTVLCMPGVIRCPVRANPPLLFVSWTKDGKALQLDKFPGWSQGTEGSLIIALGNEDALGEYSCTPYNSLGTAGPSPVTRVLLKAPPAFIERPKEEYFQEVGRELLIPCSAQGDPPPVVSWTKVGRGLQGQAQVDSNSSLILRPLTKEAHGHWECSASNAVARVATSTNVYVLGTSPHVVTNVSVVALPKGANVSWEPGFDGGYLQRFSVWYTPLAKRPDRMHHDWVSLAVPVGAAHLLVPGLQPHTQYQFSVLAQNKLGSGPFSEIVLSAPEGLPTTPAAPGLPPTEIPPPLSPPRGLVAVRTPRGVLLHWDPPELVPKRLDGYVLEGRQGSQGWEVLDPAVAGTETELLVPGLIKDVLYEFRLVAFAGSFVSDPSNTANVSTSGLEVYPSRTQLPGLLPQPVLAGVVGGVCFLGVAVLVSILAGCLLNRRRAARRRRKRLRQDPPLIFSPTGKSAAPSALGSGSPDSVAKLKLQGSPVPSLRQSLLWGDPAGTPSPHPDPPSSRGPLPLEPICRGPDGRFVMGPTVAAPQERSGREQAEPRTPAQRLARSFDCSSSSPSGAPQPLCIEDISPVAPPPAAPPSPLPGPGPLLQYLSLPFFREMNVDGDWPPLEEPSPAAPPDYMDTRRCPTSSFLRSPETPPVSPRESLPGAVVGAGATAEPPYTALADWTLRERLLPGLLPAAPRGSLTSQSSGRGSASFLRPPSTAPSAGGSYLSPAPGDTSSWASGPERWPRREHVVTVSKRRNTSVDENYEWDSEFPGDMELLETLHLGLASSRLRPEAEPELGVKTPEEGCLLNTAHVTGPEARCAALREEFLAFRRRRDATRARLPAYRQPVPHPEQATLL>sp|Q6NVH7|SWAP1_HUMAN ATPase SWSAP1 OS=Homo sapiens OX=9606 GN=SWSAP1PE=1 SV=1MPAAGPPLLLLGTPGSGKTALLFAAALEAAGEGQGPVLFLTRRPLQSMPRGTGTTLDPMRLQKIRFQYPPSTRELFRLLCSAHEAPGPAPSLLLLDGLEEYLAEDPEPQEAAYLIALLLDTAAHFSHRLGPGRDCGLMVALQTQEEAGSGDVLHLALLQRYFPAQCWLQPDAPGPGEHGLRACLEPGGLGPRTEWWVTFRSDGEMMIAPWPTQAGDPSSGKGSSSGGQP>sp|Q1ZZU3|SWI5_HUMAN DNA repair protein SWI5 homolog OS=Homo sapiensOX=9606 GN=SWI5 PE=1 SV=1MQRRGQRDLWRHNKSCARNRCPRPPRERGGAGFPWVRAQLSVRQFTLRVRVPGPVHLRGRSPTPALDPLAPLNPLIRGPRTPGLRRWIQSLALLLPNCSSSRIPTVPRPHSGLWVQSDFPLGFLSRTEPRLTRSCRGAFRSPRPLPKSGQADGTSEESLHLDIQKLKEKRDMLDKEISQFVSEGYSVDELEDHITQLHEYNDIKDVGQMLMGKLAVIRGVTTKELYPEFGLDMND>sp|Q17R31|TATD3_HUMAN Putative deoxyribonuclease TATDN3 OS=Homo sapiensOX=9606 GN=TATDN3 PE=1 SV=1MRAAGVGLVDCHCHLSAPDFDRDLDDVLEKAKKANVVALVAVAEHSGEFEKIMQLSERYNGFVLPCLGVHPVQGLPPEDQRSVTLKDLDVALPIIENYKDRLLAIGEVGLDFSPRFAGTGEQKEEQRQVLIRQIQLAKRLNLPVNVHSRSAGRPTINLLQEQGAEKVLLHAFDGRPSVAMEGVRAGYFFSIPPSIIRSGQKQKLVKQLPLTSICLETDSPALGPEKQVRNEPWNISISAEYIAQVKGISVEEVIEVTTQNALKLFPKLRHLLQK>sp|Q17R31-2|TATD3_HUMAN Isoform 2 of Putative deoxyribonuclease TATDN3OS=Homo sapiens OX=9606 GN=TATDN3MRAAGVGLVDCHCHLSAPDFDRDLDDVLEKAKKANVVALVAVAEHSGEFEKIMQLSERYNGFVLPCLGVHPVQGLPPEDQRSVTLKDLDVALPIIENYKDRLLAIGEVGLDFSPRFAGTGEQKEEQRQVLIRQIQLAKRLNLPVNVHSRSAGRPTINLLQEQGAEKVLLHAFDGRPSVAMEGVRAGYFFSIPPSIIRSGQQKLVKQLPLTSICLETDSPALGPEKQVRNEPWNISISAEYIAQVKGISVEEVIEVTTQNALKLFPKLRHLLQK>sp|Q17R31-3|TATD3_HUMAN Isoform 3 of Putative deoxyribonuclease TATDN3OS=Homo sapiens OX=9606 GN=TATDN3MRAAGVGLVDCHCHLSAPDFDRDLDDVLEKAKKANVVALVAVAEHSGEFEKIMQLSERYNGFVLPCLGVHPVQGLPPEDQRSVTLKDLDVALPIIENYKDRLLAIGEVGLDFSPRFAGTGEQKEEQRQVLIRQIQLAKRLNLPVNVHSRSAGRPTINLLQEQGAEKVLLHAFDGRPSVAMEGVRAGYFFSIPPSIIRSGQLLSLFSKKQKLVKQLPLTSICLETDSPALGPEKQVRNEPWNISISAEYIAQVKGISVEEVIEVTTQNALKLFPKLRHLLQK>sp|Q17R31-4|TATD3_HUMAN Isoform 4 of Putative deoxyribonuclease TATDN3OS=Homo sapiens OX=9606 GN=TATDN3MRAAGVGLVDCHCHLSAPDFDRDLDDVLEKAKKANVVALVAVAEHSGEFEKIMQLSERYNGFVLPCLGVHPVQGLPPEDQRSVTLKVGLDFSPRFAGTGEQKEEQRQVLIRQIQLAKRLNLPVNVHSRSAGRPTINLLQEQGAEKVLLHAFDGRPSVAMEGVRAGYFFSIPPSIIRSGQKQKLVKQLPLTSICLETDSPALGPEKQVRNEPWNISISAEYIAQVKGISVEEVIEVTTQNALKLFPKLRHLLQK>sp|Q17R31-5|TATD3_HUMAN Isoform 5 of Putative deoxyribonuclease TATDN3OS=Homo sapiens OX=9606 GN=TATDN3MRAAGVGLVDCHCHLSAPDFDRDLDDVLEKAKKANVVALVAVAEHSGEFEKIMQLSERYNGFVLPCLGVHPVQGLPPEDQRSVTLKDLDVALPIIENYKDRLLAIGEVGLDFSPRFAGTGEQKEEQRQVLIRQIQLAKRLNLPVNVHSRSAGRPTINLLQEQGAEKVLLHAFDGRPSVAMEGVRAGYFFSIPPSIIRSGQLLSLFSKKQKLVKQLPLTSICLETDSPALGPEKQQNILPR>sp|Q9H987|SYP2L_HUMAN Synaptopodin 2-like protein OS=Homo sapiensOX=9606 GN=SYNPO2L PE=1 SV=3MGAEEEVLVTLSGGAPWGFRLHGGAEQRKPLQVSKIRRRSQAGRAGLRERDQLLAINGVSCTNLSHASAMSLIDASGNQLVLTVQRLADEGPVQSPSPHELQVLSPLSPLSPEPPGAPVPQPLQPGSLRSPPDSEAYYGETDSDADGPATQEKPRRPRRRGPTRPTPPGAPPDEVYLSDSPAEPAPTIPGPPSQGDSRVSSPSWEDGAALQPPPAEALLLPHGPLRPGPHLIPMVGPVPHPVAEDLTTTYTQKAKQAKLQRAESLQEKSIKEAKTKCRTIASLLTAAPNPHSKGVLMFKKRRQRAKKYTLVSFGAAAGTGAEEEDGVPPTSESELDEEAFSDARSLTNQSDWDSPYLDMELARAGSRASEGQGSGLGGQLSEVSGRGVQLFEQQRQRADSSTQELARVEPAAMLNGEGLQSPPRAQSAPPEAAVLPPSPLPAPVASPRPFQPGGGAPTPAPSIFNRSARPFTPGLQGQRPTTTSVIFRPLAPKRANDSLGGLSPAPPPFLSSQGPTPLPSFTSGVPSHAPVSGSPSTPRSSGPVTATSSLYIPAPSRPVTPGGAPEPPAPPSAAAMTSTASIFLSAPLRPSARPEAPAPGPGAPEPPSAREQRISVPAARTGILQEARRRGTRKQMFRPGKEETKNSPNPELLSLVQNLDEKPRAGGAESGPEEDALSLGAEACNFMQPVGARSYKTLPHVTPKTPPPMAPKTPPPMTPKTPPPVAPKPPSRGLLDGLVNGAASSAGIPEPPRLQGRGGELFAKRQSRADRYVVEGTPGPGLGPRPRSPSPTPSLPPSWKYSPNIRAPPPIAYNPLLSPFFPQAARTLPKAQSQGPRATPKQGIKALDFMRHQPYQLKTAMFCFDEVPPTPGPIASGSPKTARVQEIRRFSTPAPQPTAEPLAPTVLAPRAATTLDEPIWRTELASAPVPSPAPPPEAPRGLGASPSSCGFQVARPRFSATRTGLQAHVWRPGAGHQ>sp|Q9H987-2|SYP2L_HUMAN Isoform 2 of Synaptopodin 2-like protein OS=Homosapiens OX=9606 GN=SYNPO2LMETFEPISQEPLSQASYDKAPDPVPELQDSFYAELQRAESLQEKSIKEAKTKCRTIASLLTAAPNPHSKGVLMFKKRRQRAKKYTLVSFGAAAGTGAEEEDGVPPTSESELDEEAFSDARSLTNQSDWDSPYLDMELARAGSRASEGQGSGLGGQLSEVSGRGVQLFEQQRQRADSSTQELARVEPAAMLNGEGLQSPPRAQSAPPEAAVLPPSPLPAPVASPRPFQPGGGAPTPAPSIFNRSARPFTPGLQGQRPTTTSVIFRPLAPKRANDSLGGLSPAPPPFLSSQGPTPLPSFTSGVPSHAPVSGSPSTPRSSGPVTATSSLYIPAPSRPVTPGGAPEPPAPPSAAAMTSTASIFLSAPLRPSARPEAPAPGPGAPEPPSAREQRISVPAARTGILQEARRRGTRKQMFRPGKEETKNSPNPELLSLVQNLDEKPRAGGAESGPEEDALSLGAEACNFMQPVGARSYKTLPHVTPKTPPPMAPKTPPPMTPKTPPPVAPKPPSRGLLDGLVNGAASSAGIPEPPRLQGRGGELFAKRQSRADRYVVEGTPGPGLGPRPRSPSPTPSLPPSWKYSPNIRAPPPIAYNPLLSPFFPQAARTLPKAQSQGPRATPKQGIKALDFMRHQPYQLKTAMFCFDEVPPTPGPIASGSPKTARVQEIRRFSTPAPQPTAEPLAPTVLAPRAATTLDEPIWRTELASAPVPSPAPPPEAPRGLGASPSSCGFQVARPRFSATRTGLQAHVWRPGAGHQ>sp|Q92844|TANK_HUMAN TRAF family member-associated NF-kappa-B activatorOS=Homo sapiens OX=9606 GN=TANK PE=1 SV=2MDKNIGEQLNKAYEAFRQACMDRDSAVKELQQKTENYEQRIREQQEQLSLQQTIIDKLKSQLLLVNSTQDNNYGCVPLLEDSETRKNNLTLDQPQDKVISGIAREKLPKVRRQEVSSPRKETSARSLGSPLLHERGNIEKTFWDLKEEFHKICMLAKAQKDHLSKLNIPDTATETQCSVPIQCTDKTDKQEALFKPQAKDDINRGAPSITSVTPRGLCRDEEDTSFESLSKFNVKFPPMDNDSTFLHSTPERPGILSPATSEAVCQEKFNMEFRDNPGNFVKTEETLFEIQGIDPIASAIQNLKTTDKTKPSNLVNTCIRTTLDRAACLPPGDHNALYVNSFPLLDPSDAPFPSLDSPGKAIRGPQQPIWKPFPNQDSDSVVLSGTDSELHIPRVCEFCQAVFPPSITSRGDFLRHLNSHFNGET>sp|Q92844-2|TANK_HUMAN Isoform Short of TRAF family member-associatedNF-kappa-B activator OS=Homo sapiens OX=9606 GN=TANKMDKNIGEQLNKAYEAFRQACMDRDSAVKELQQKTENYEQRIREQQEQLSLQQTIIDKLKSQLLLVNSTQDNNYGCVPLLEDSETRKNNLTLDQPQDKVISGIAREKLPKVDIASAES>sp|Q92844-3|TANK_HUMAN Isoform 3 of TRAF family member-associated NF-kappa-B activator OS=Homo sapiens OX=9606 GN=TANKMDKNIGEQLNKAYEAFRQACMDRDSAVKELQQKTENYEQRIREQQEQLSLQQTIIDKLKSQLLLVNSTQDNNYGCVPLLEDSETRKNNLTLDQPQDKVISGIAREKLPKVDIASAESSI>sp|P59537|T2R43_HUMAN Taste receptor type 2 member 43 OS=Homo sapiensOX=9606 GN=TAS2R43 PE=2 SV=2MITFLPIIFSSLVVVTFVIGNFANGFIALVNSIEWFKRQKISFADQILTALAVSRVGLLWVLLLNWYSTVLNPAFNSVEVRTTAYNIWAVINHFSNWLATTLSIFYLLKIANFSNFIFLHLKRRVKSVILVMLLGPLLFLACHLFVINMNEIVRTKEFEGNMTWKIKLKSAMYFSNMTVTMVANLVPFTLTLLSFMLLICSLCKHLKKMQLHGKGSQDPSTKVHIKALQTVISFLLLCAIYFLSIMISVWSFGSLENKPVFMFCKAIRFSYPSIHPFILIWGNKKLKQTFLSVFWQMRYWVKGEKTSSP>sp|P49788|TIG1_HUMAN Retinoic acid receptor responder protein 1 OS=Homosapiens OX=9606 GN=RARRES1 PE=1 SV=2MQPRRQRLPAPWSGPRGPRPTAPLLALLLLLAPVAAPAGSGDPDDPGQPQDAGVPRRLLQQAARAALHFFNFRSGSPSALRVLAEVQEGRAWINPKEGCKVHVVFSTERYNPESLLQEGEGRLGKCSARVFFKNQKPRPTINVTCTRLIEKKKRQQEDYLLYKQMKQLKNPLEIVSIPDNHGHIDPSLRLIWDLAFLGSSYVMWEMTTQVSHYYLAQLTSVRQWKTNDDTIDFDYTVLLHELSTQEIIPCRIHLVWYPGKPLKVKYHCQELQTPEEASGTEEGSAVVPTELSNF>sp|P49788-2|TIG1_HUMAN Isoform 1 of Retinoic acid receptor responderprotein 1 OS=Homo sapiens OX=9606 GN=RARRES1MQPRRQRLPAPWSGPRGPRPTAPLLALLLLLAPVAAPAGSGDPDDPGQPQDAGVPRRLLQQAARAALHFFNFRSGSPSALRVLAEVQEGRAWINPKEGCKVHVVFSTERYNPESLLQEGEGRLGKCSARVFFKNQKPRPTINVTCTRLIEKKKRQQEDYLLYKQMKQLKNPLEIVSIPDNHGHIDPSLRLIWDLAFLGSSYVMWEMTTQVSHYYLAQLTSVRQWVRKT>sp|Q9NXF1|TEX10_HUMAN Testis-expressed protein 10 OS=Homo sapiensOX=9606 GN=TEX10 PE=1 SV=2MTKKRKRQHDFQKVKLKVGKKKPKLQNATPTNFKTKTIHLPEQLKEDGTLPTNNRKLNIKDLLSQMHHYNAGVKQSALLGLKDLLSQYPFIIDAHLSNILSEVTAVFTDKDANVRLAAVQLLQFLAPKIRAEQISPFFPLVSAHLSSAMTHITEGIQEDSLKVLDILLEQYPALITGRSSILLKNFVELISHQQLSKGLINRDRSQSWILSVNPNRRLTSQQWRLKVLVRLSKFLQALADGSSRLRESEGLQEQKENPHATSNSIFINWKEHANDQQHIQVYENGGSQPNVSSQFRLRYLVGGLSGVDEGLSSTENLKGFIEIIIPLLIECWVEAVPPQLATPVGNGIEREPLQVMQQVLNIISLLWKLSKQQDETHKLESWLRKNYLIDFKHHFMSRFPYVLKEITKHKRKEPNKSIKHCTVLSNNIDHLLLNLTLSDIMVSLANASTLQKDCSWIEMIRKFVTETLEDGSRLNSKQLNRLLGVSWRLMQIQPNREDTETLIKAVYTLYQQRGLILPVRTLLLKFFSKIYQTEELRSCRFRYRSKVLSRWLAGLPLQLAHLGSRNPELSTQLIDIIHTAAARANKELLKSLQATALRIYDPQEGAVVVLPADSQQRLVQLVYFLPSLPADLLSRLSRCCIMGRLSSSLAAMLIGILHMRSSFSGWKYSAKDWLMSDVDYFSFLFSTLTGFSKEELTWLQSLRGVPHVIQTQLSPVLLYLTDLDQFLHHWDVTEAVFHSLLVIPARSQNFDILQSAISKHLVGLTVIPDSTAGCVFGVICKLLDHTCVVSETLLPFLASCCYSLLYFLLTIEKGEAEHLRKRDKLWGVCVSILALLPRVLRLMLQSLRVNRVGPEELPVVGQLLRLLLQHAPLRTHMLTNAILVQQIIKNITTLKSGSVQEQWLTDLHYCFNVYITGHPQGPSALATVY>sp|Q9NXF1-2|TEX10_HUMAN Isoform 2 of Testis-expressed protein 10 OS=Homosapiens OX=9606 GN=TEX10MSRMTKKRKRQHDFQKVKLKVGKKKPKLQNATPTNFKTKTIHLPEQLKEDGTLPTNNRKLNIKDLLSQMHHYNAGVKQSALLGLKDLLSQYPFIIDAHLSNILSEVTAVFTDKDANVRLAAVQLLQFLAPKIRAEQISPFFPLVSAHLSSAMTHITEGIQEDSLKVLDILLEQYPALITGRSSILLKNFVELISHQQLSKGLINRDRSQSWILSVNPNRRLTSQQWRLKVLVRLSKFLQALADGSSRLRESEGLQEQKENPHATSNSIFINWKEHANDQQHIQVYENGGSQPNVSSQFRLRYLVGGLSGVDEGLSSTENLKGFIEIIIPLLIECWVEAVPPQLATPVGNGIEREPLQVMQQVLNIISLLWKLSKQQDETHKLESWLRKNYLIDFKHHFMSRFPYVLKEITKHKRKEPNKSIKHCTVLSNNIDHLLLNLTLSDIMVSLANASTLQKDCSWIEMIRKFVTETLEDGSRLNSKQLNRLLGVSWRLMQIQPNREDTETLIKAVYTLYQQRGLILPVRTLLLKFFSKIYQTEELRSCRFRYRSKVLSRWLAGLPLQLAHLGSRNPELSTQLIDIIHTAAARANKELLKSLQATALRIYDPQEGAVVVLPADSQQRLVQLVYFLPSLPADLLSRLSRCCIMGRLSSSLAAMLIGILHMRSSFSGWKYSAKDWLMSDVDYFSFLFSTLTGFSKEELTWLQSLRGVPHVIQTQLSPVLLYLTDLDQFLHHWDVTEAVFHSLLVIPARSQNFDILQSAISKHLVGLTVIPDSTAGCVFGVICKLLDHTCVVSETLLPFLASCCYSLLYFLLTIEKGEAEHLRKRLMLQSLRVNRVGPEELPVVGQLLRLLLQHAPLRTHMLTNAILVQQIIKNITTLKSGSVQEQWLTDLHYCFNVYITGHPQGPSALATVY>sp|Q8IWB6|TEX14_HUMAN Inactive serine/threonine-protein kinase TEX14OS=Homo sapiens OX=9606 GN=TEX14 PE=1 SV=2MSRAVRLPVPCPVQLGTLRNDSLEAQLHEYVKQGNYVKVKKILKKGIYVDAVNSLGQTALFVAALLGLRKFVDVLVDYGSDPNHRCFDGSTPVHAAAFSGNQWILSKLLDAGGDLRLHDERGQNPKTWALTAGKERSTQIVEFMQRCASHMQAIIQGFSYDLLKKIDSPQRLVYSPSWCGGLVQGNPNGSPNRLLKAGVISAQNIYSFGFGKAMPWFQFYLTGATQMAYLGSLPVIGEKEVIQADDEPTFSFFSGPYMVMTNLVWNGSRVTVKELNLPTHPHCSRLRLADLLIAEQEHSSKLRHPYLLQLMAVCLSQDLEKTRLVYERITIGTLFSVLHERRSQFPVLHMEVIVHLLLQISDALRYLHFQGFIHRSLSSYAVHIISPGEARLTNLEYMLESEDRGVQRDLTRVPLPTQLYNWAAPEVILQKAATVKSDIYSFSMIMQEILTDDIPWKGLDGSVVKKAVVSGNYLEADVRLPKPYYDIVKSGIHVKQKDRTMNLQDIRYILKNDLKDFTGAQRTQPTESPRVQRYGLHPDVNVYLGLTSEHPRETPDMEIIELKEMGSQPHSPRVHSLFTEGTLDPQAPDPCLMARETQNQDAPCPAPFMAEEASSPSTGQPSLCSFEINEIYSGCLILEDDIEEPPGAASSLEADGPNQVDELKSMEEELDKMEREACCFGSEDESSSKAETEYSFDDWDWQNGSLSSLSLPESTREAKSNLNNMSTTEEYLISKCVLDLKIMQTIMHENDDRLRNIEQILDEVEMKQKEQEERMSLWATSREFTNAYKLPLAVGPPSLNYIPPVLQLSGGQKPDTSGNYPTLPRFPRMLPTLCDPGKQNTDEQFQCTQGAKDSLETSRIQNTSSQGRPRESTAQAKATQFNSALFTLSSHRQGPSASPSCHWDSTRMSVEPVSSEIYNAESRNKDDGKVHLKWKMEVKEMAKKAATGQLTVPPWHPQSSLTLESEAENEPDALLQPPIRSPENTDWQRVIEYHRENDEPRGNGKFDKTGNNDCDSDQHGRQPRLGSFTSIRHPSPRQKEQPEHSEAFQASSDTLVAVEKSYSHQSMQSTCSPESSEDITDEFLTPDGEYFYSSTAQENLALETSSPIEEDFEGIQGAFAQPQVSGEEKFQMRKILGKNAEILPRSQFQPVRSTEDEQEETSKESPKELKEKDISLTDIQDLSSISYEPDSSFKEASCKTPKINHAPTSVSTPLSPGSVSSAASQYKDCLESITFQVKTEFASCWNSQEFIQTLSDDFISVRERAKKLDSLLTSSETPPSRLTGLKRLSSFIGAGSPSLVKACDSSPPHATQRRSLPKVEAFSQHHIDELPPPSQELLDDIELLKQQQGSSTVLHENTASDGGGTANDQRHLEEQETDSKKEDSSMLLSKETEDLGEDTERAHSTLDEDLERWLQPPEESVELQDLPKGSERETNIKDQKVGEEKRKREDSITPERRKSEGVLGTSEEDELKSCFWKRLGWSESSRIIVLDQSDLSD>sp|Q8IWB6-2|TEX14_HUMAN Isoform 2 of Inactive serine/threonine-proteinkinase TEX14 OS=Homo sapiens OX=9606 GN=TEX14MSRAVRLPVPCPVQLGTLRNDSLEAQLHEYVKQGNYVKVKKILKKGIYVDAVNSLGQTALFVAALLGLRKFVDVLVDYGSDPNHRCFDGSTPVHAAAFSGNQWILSKLLDAGGDLRLHDERGQNPKTWALTAGKERSTQIVEFMQRCASHMQAIIQGFSYDLLKKIDSPQRLVYSPSWCGGLVQGNPNGSPNRLLKAGVISAQNIYSFGFGKFYLTGATQMAYLGSLPVIGEKEVIQADDEPTFSFFSGPYMVMTNLVWNGSRVTVKELNLPTHPHCSRLRLADLLIAEQEHSSKLRHPYLLQLMAVCLSQDLEKTRLVYERITIGTLFSVLHERRSQFPVLHMEVIVHLLLQISDALRYLHFQGFIHRSLSSYAVHIISPGEARLTNLEYMLESEDRGVQRDLTRVPLPTQLYNWAAPEVILQKAATVKSDIYSFSMIMQEILTDDIPWKGLDGSVVKKAVVSGNYLEADVRLPKPYYDIVKSGIHVKQKDRTMNLQDIRYILKNDLKDFTGAQRTQPTESPRVQRYGLHPDVNVYLGLTSEHPRETPDMEIIELKEMGSQPHSPRVHSLFTEGTLDPQAPDPCLMARETQNQDAPCPAPFMAEEASSPSTGQPSLCSFEINEIYSGCLILEDDIEEPPGAASSLEADGPNQVDELKSMEEELDKMEREACCFGSEDESSSKAETEYSFDDWDWQNGSLSSLSLPESTREAKSNLNNMSTTEEYLISKCVLDLKIMQTIMHENDDRLRNIEQILDEVEMKQKEQEERMSLWATSREFTNAYKLPLAVGPPSLNYIPPVLQLSGGQKPDTSGNYPTLPRFPRMLPTLCDPGKQNTDEQFQCTQGAKDSLETSRIQNTSSQGRPRESTAQAKATQFNSALFTLSSHRQGPSASPSCHWDSTRMSVEPVSSEIYNAESRNKDDGKVHLKWKMEVKEMAKKAATGQLTVPPWHPQSSLTLESEAENEPDALLQPPIRSPENTDWQRVIEYHRENDEPRGNGKFDKTGNNDCDSDQHGRQPRLGSFTSIRHPSPRQKEQPEHSEAFQASSDTLVAVEKSYSHQSMQSTCSPESSEDITDEFLTPDGEYFYSSTAQENLALETSSPIEEDFEGIQGAFAQPQVSGEEKFQMRKILGKNAEILPRSQFQPVRSTEDEQEETSKESPKELKEKDISLTDIQDLSSISYEPDSSFKEASCKTPKINHAPTSVSTPLSPGSVSSAASQYKDCLESITFQVKTEFASCWNSQEFIQTLSDDFISVRERAKKLDSLLTSSETPPSRLTGLKRLSSFIGAGSPSLVKACDSSPPHATQRRSLPKVEAFSQHHIDELPPPSQELLDDIELLKQQQGSSTVLHENTASDGGGTANDQRHLEEQETDSKKEDSSMLLSKETEDLGEDTERAHSTLDEDLERWLQPPEESVELQDLPKGSERETNIKDQKVGEEKRKREDSITPERRKSEGVLGTSEEDELKSCFWKRLGWSESSRIIVLDQSDLSD>sp|Q8IWB6-3|TEX14_HUMAN Isoform 3 of Inactive serine/threonine-proteinkinase TEX14 OS=Homo sapiens OX=9606 GN=TEX14MSRAVRLPVPCPVQLGTLRNDSLEAQLHEYVKQGNYVKVKKILKKGIYVDAVNSLGQTALFVAALLGLRKFVDVLVDYGSDPNHRCFDGSTPVHAAAFSGNQWILSKLLDAGGDLRLHDERGQNPKTWALTAGKERSTQIVEFMQRCASHMQAIIQGFSYDLLKKIDSPQRLVYSPSWCGGLVQGNPNGSPNRLLKAGVISAQNIYSFGFGKFYLTGATQMAYLGSLPVIGEKEVIQADDEPTFSFFSGPYMVMTNLVWNGSRVTVKELNLPTHPHCSRLRLADLLIAEQEHSSKLRHPYLLQLMAVCLSQDLEKTRLVYERITIGTLFSVLHERRSQFPVLHMEVIVHLLLQISDALRYLHFQGFIHRSLSSYAVHIISPGEARLTNLEYMLESEDRGVQRDLTRVPLPTQLYNWAAPEVILQKAATVKSDIYSFSMIMQEILTDDIPWKGLDGSVVKKAVVSGNYLEADVRLPKPYYDIVKSGIHVKQKDRTMNLQDIRYILKNDLKDFTGAQRTQPTESPRVQRYGLHPDVNVYLGLTSEHPRETPDMEIIELKEMGSQPHSPRVHSLFTEGTLDPQAPDPCLMARETQNQDAPCPAPFMAEEASSPSTGQPSLCSFEINEIYSGCLILEDDIEEPPGAASSLEADGPNQVDELKSMEEELDKMEREACCFGSEDESSSKAETEYSFDDWDWQNGSLSSLSLPESTREAKSNLNNMSTTEEYLISKCVLDLKIMQTIMHENDDRLRNIEQILDEVEMKQKEQEERMSLWATSREFTNAYKLPLAVGPPSLNYIPPVLQLSGGQKPDTSGNYPTLPRFPRMLPTLCDPGKQNTDEQFQCTQGAKDSLETSRIQNTSSQGRPRESTAQAKATQFNSALFTLSSHRQGPSASPSCHWDSTRMSVEPVSSEIYNAESRNKDDGKVHLKWKMEVKEMAKKAATGQLTVPPWHPQSSLTLESEAENEPDALLQPPIRSPENTDWQRVIEYHRENDEPRGNGKFDKTGNNDCDSDQHGRQPRLGSFTSIRHPSPRQKEQPEHSEAFQASSDTLVAVEKSYSTSSPIEEDFEGIQGAFAQPQVSGEEKFQMRKILGKNAEILPRSQFQPVRSTEDEQEETSKESPKELKEKDISLTDIQDLSSISYEPDSSFKEASCKTPKINHAPTSVSTPLSPGSVSSAASQYKDCLESITFQVKTEFASCWNSQEFIQTLSDDFISVRERAKKLDSLLTSSETPPSRLTGLKRLSSFIGAGSPSLVKACDSSPPHATQRRSLPKVEAFSQHHIDELPPPSQELLDDIELLKQQQGSSTVLHENTASDGGGTANDQRHLEEQETDSKKEDSSMLLSKETEDLGEDTERAHSTLDEDLERWLQPPEESVELQDLPKGSERETNIKDQKVGEEKRKREDSITPERRKSEGVLGTSEEDELKSCFWKRLGWSESSRIIVLDQSDLSD>sp|P04004|VTNC_HUMAN Vitronectin OS=Homo sapiens OX=9606 GN=VTN PE=1SV=1MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEECEGSSLSAVFEHFAMMQRDSWEDIFELLFWGRTSAGTRQPQFISRDWHGVPGQVDAAMAGRIYISGMAPRPSLAKKQRFRHRNRKGYRSQRGHSRGRNQNSRRPSRATWLSLFSSEESNLGANNYDDYRMDWLVPATCEPIQSVFFFSGDKYYRVNLRTRRVDTVDPPYPRSIAQYWLGCPAPGHL>sp|Q5T0J7|TEX35_HUMAN Testis-expressed protein 35 OS=Homo sapiensOX=9606 GN=TEX35 PE=1 SV=1MSAKRAELKKTHLSKNYKAVCLELKPEPTKTFDYKAVKQEGRFTKAGVTQDLKNELREVREELKEKMEEIKQIKDLMDKDFDKLHEFVEIMKEMQKDMDEKMDILINTQKNYKLPLRRAPKEQQELRLMGKTHREPQLRPKKMDGASGVNGAPCALHKKTMAPQKTKQGSLDPLHHCGTCCEKCLLCALKNNYNRGNIPSEASGLYKGGEEPVTTQPSVGHAVPAPKSQTEGR>sp|Q5T0J7-2|TEX35_HUMAN Isoform 2 of Testis-expressed protein 35 OS=Homosapiens OX=9606 GN=TEX35MSAKRAELKKTHLVKERHCWTSKNYKAVCLELKPEPTKTFDYKAVKQEGRFTKAGVTQDLKNELREVREELKEKMEEIKQIKDLMDKDFDKLHEFVEIMKEMQKDMDEKMDILINTQKNYKLPLRRAPKEQQELRLMGKTHREPQLRPKKMDGASGVNGAPCALHKKTMAPQKTKQGSLDPLHHCGTCCEKCLLCALKNNYNRGIYAAVGLLDLW>sp|Q5T0J7-3|TEX35_HUMAN Isoform 3 of Testis-expressed protein 35 OS=Homosapiens OX=9606 GN=TEX35MSAKRAELKKTHLSKNYKAVCLELKPEPTKTFDYKAVKQEGRFTKAGVTQDLKNELREVREELKEKMEEIKQIKDLMDKDFDKLHEFVEIMKEMQKDMDEKMDILINTQKNYKLPLRRAPKEQQELRLMGKTHREPQLRPKKMDGASGVNGAPCALHKKTMAPQKTKQGSLDPLHHCGTCCVSETLPEPSTGARPLAPAPW>sp|Q5T0J7-4|TEX35_HUMAN Isoform 4 of Testis-expressed protein 35 OS=Homosapiens OX=9606 GN=TEX35MDKDFDKLHEFVEIMKEMQKDMDEKMDILINTQKNYKLPLRRAPKEQQELRLMGKTHREPQLRPKKMDGASGVNGAPCALHKKTMAPQKTKQGSLDPLHHCGTCCEKCLLCALKNNYNRAAPLKEARHLLTANSIDPSAALVLLIEFLLLTLVTGAAAPGLDACGHQRNMRDEINSERR>sp|Q5T0J7-5|TEX35_HUMAN Isoform 5 of Testis-expressed protein 35 OS=Homosapiens OX=9606 GN=TEX35MSAKRAELKKTHLSKNYKAVCLELKPEPTKTFDYKAVKQEGRFTKAGVTQDLKNELREVREELKEKMEEIKQIKDLMDKDFDKLHEFVEIMKEMQKDMDEKMDILINTQKNYKLPLRRAPKEQQELRLMGKTHREPQLRPKKMDGASGVNGAPCALHKKTMAPQKTKQGSLDPLHHCGTCCEKCLLCALKNNYNRAQLQNLPAVPIHHLQAP>sp|P98155|VLDLR_HUMAN Very low-density lipoprotein receptor OS=Homosapiens OX=9606 GN=VLDLR PE=1 SV=1MGTSALWALWLLLALCWAPRESGATGTGRKAKCEPSQFQCTNGRCITLLWKCDGDEDCVDGSDEKNCVKKTCAESDFVCNNGQCVPSRWKCDGDPDCEDGSDESPEQCHMRTCRIHEISCGAHSTQCIPVSWRCDGENDCDSGEDEENCGNITCSPDEFTCSSGRCISRNFVCNGQDDCSDGSDELDCAPPTCGAHEFQCSTSSCIPISWVCDDDADCSDQSDESLEQCGRQPVIHTKCPASEIQCGSGECIHKKWRCDGDPDCKDGSDEVNCPSRTCRPDQFECEDGSCIHGSRQCNGIRDCVDGSDEVNCKNVNQCLGPGKFKCRSGECIDISKVCNQEQDCRDWSDEPLKECHINECLVNNGGCSHICKDLVIGYECDCAAGFELIDRKTCGDIDECQNPGICSQICINLKGGYKCECSRGYQMDLATGVCKAVGKEPSLIFTNRRDIRKIGLERKEYIQLVEQLRNTVALDADIAAQKLFWADLSQKAIFSASIDDKVGRHVKMIDNVYNPAAIAVDWVYKTIYWTDAASKTISVATLDGTKRKFLFNSDLREPASIAVDPLSGFVYWSDWGEPAKIEKAGMNGFDRRPLVTADIQWPNGITLDLIKSRLYWLDSKLHMLSSVDLNGQDRRIVLKSLEFLAHPLALTIFEDRVYWIDGENEAVYGANKFTGSELATLVNNLNDAQDIIVYHELVQPSGKNWCEEDMENGGCEYLCLPAPQINDHSPKYTCSCPSGYNVEENGRDCQSTATTVTYSETKDTNTTEISATSGLVPGGINVTTAVSEVSVPPKGTSAAWAILPLLLLVMAAVGGYLMWRNWQHKNMKSMNFDNPVYLKTTEEDLSIDIGRHSASVGHTYPAISVVSTDDDLA>sp|P98155-2|VLDLR_HUMAN Isoform Short of Very low-density lipoproteinreceptor OS=Homo sapiens OX=9606 GN=VLDLRMGTSALWALWLLLALCWAPRESGATGTGRKAKCEPSQFQCTNGRCITLLWKCDGDEDCVDGSDEKNCVKKTCAESDFVCNNGQCVPSRWKCDGDPDCEDGSDESPEQCHMRTCRIHEISCGAHSTQCIPVSWRCDGENDCDSGEDEENCGNITCSPDEFTCSSGRCISRNFVCNGQDDCSDGSDELDCAPPTCGAHEFQCSTSSCIPISWVCDDDADCSDQSDESLEQCGRQPVIHTKCPASEIQCGSGECIHKKWRCDGDPDCKDGSDEVNCPSRTCRPDQFECEDGSCIHGSRQCNGIRDCVDGSDEVNCKNVNQCLGPGKFKCRSGECIDISKVCNQEQDCRDWSDEPLKECHINECLVNNGGCSHICKDLVIGYECDCAAGFELIDRKTCGDIDECQNPGICSQICINLKGGYKCECSRGYQMDLATGVCKAVGKEPSLIFTNRRDIRKIGLERKEYIQLVEQLRNTVALDADIAAQKLFWADLSQKAIFSASIDDKVGRHVKMIDNVYNPAAIAVDWVYKTIYWTDAASKTISVATLDGTKRKFLFNSDLREPASIAVDPLSGFVYWSDWGEPAKIEKAGMNGFDRRPLVTADIQWPNGITLDLIKSRLYWLDSKLHMLSSVDLNGQDRRIVLKSLEFLAHPLALTIFEDRVYWIDGENEAVYGANKFTGSELATLVNNLNDAQDIIVYHELVQPSGKNWCEEDMENGGCEYLCLPAPQINDHSPKYTCSCPSGYNVEENGRDCQRINVTTAVSEVSVPPKGTSAAWAILPLLLLVMAAVGGYLMWRNWQHKNMKSMNFDNPVYLKTTEEDLSIDIGRHSASVGHTYPAISVVSTDDDLA>sp|Q96EI5|TCAL4_HUMAN Transcription elongation factor A protein-like 4OS=Homo sapiens OX=9606 GN=TCEAL4 PE=1 SV=2MEKLYSENEGMASNQGKMENEEQPQDERKPEVTCTLEDKKLENEGKTENKGKTGDEEMLKDKGKPESEGEAKEGKSEREGESEMEGGSEREGKPEIEGKPESEGEPGSETRAAGKRPAEDDVPRKAKRKTNKGLAHYLKEYKEAIHDMNFSNEDMIREFDNMAKVQDEKRKSKQKLGAFLWMQRNLQDPFYPRGPREFRGGCRAPRRDIEDIPYV>sp|Q96EI5-2|TCAL4_HUMAN Isoform 2 of Transcription elongation factor Aprotein-like 4 OS=Homo sapiens OX=9606 GN=TCEAL4MPAGGQAPQLTPVIPAFWEARGLPNSKGRDKVHICQCEEWKGHISYVERDITTSEIKSLPQVSVRAFHAASGTLEWRKGNGYGRGKGWGWGRVESREAGPSVDRDGGLRVCCSQRSAKPEKEEQPVQNPRRSVKDRKRRGNLDMEKLYSENEGMASNQGKMENEEQPQDERKPEVTCTLEDKKLENEGKTENKGKTGDEEMLKDKGKPESEGEAKEGKSEREGESEMEGGSEREGKPEIEGKPESEGEPGSETRAAGKRPAEDDVPRKAKRKTNKGLAHYLKEYKEAIHDMNFSNEDMIREFDNMAKVQDEKRKSKQKLGAFLWMQRNLQDPFYPRGPREFRGGCRAPRRDIEDIPYV>sp|Q8IUC6|TCAM1_HUMAN TIR domain-containing adapter molecule 1 OS=Homosapiens OX=9606 GN=TICAM1 PE=1 SV=1MACTGPSLPSAFDILGAAGQDKLLYLKHKLKTPRPGCQGQDLLHAMVLLKLGQETEARISLEALKADAVARLVARQWAGVDSTEDPEEPPDVSWAVARLYHLLAEEKLCPASLRDVAYQEAVRTLSSRDDHRLGELQDEARNRCGWDIAGDPGSIRTLQSNLGCLPPSSALPSGTRSLPRPIDGVSDWSQGCSLRSTGSPASLASNLEISQSPTMPFLSLHRSPHGPSKLCDDPQASLVPEPVPGGCQEPEEMSWPPSGEIASPPELPSSPPPGLPEVAPDATSTGLPDTPAAPETSTNYPVECTEGSAGPQSLPLPILEPVKNPCSVKDQTPLQLSVEDTTSPNTKPCPPTPTTPETSPPPPPPPPSSTPCSAHLTPSSLFPSSLESSSEQKFYNFVILHARADEHIALRVREKLEALGVPDGATFCEDFQVPGRGELSCLQDAIDHSAFIILLLTSNFDCRLSLHQVNQAMMSNLTRQGSPDCVIPFLPLESSPAQLSSDTASLLSGLVRLDEHSQIFARKVANTFKPHRLQARKAMWRKEQDTRALREQSQHLDGERMQAAALNAAYSAYLQSYLSYQAQMEQLQVAFGSHMSFGTGAPYGARMPFGGQVPLGAPPPFPTWPGCPQPPPLHAWQAGTPPPPSPQPAAFPQSLPFPQSPAFPTASPAPPQSPGLQPLIIHHAQMVQLGLNNHMWNQRGSQAPEDKTQEAE>sp|Q6YHU6|THADA_HUMAN Thyroid adenoma-associated protein OS=Homo sapiensOX=9606 GN=THADA PE=1 SV=1MGVKKKKEMQVAALTICHQDLETLKSFADVEGKNLASLLLHCVQLTDGVSQIHYIKQIVPLLEKADKNGMCDPTIQSCLDILAGIYLSLSLKNPLKKVLASSLNSLPDFFLPEAMHRFTSRLQEELNTTDLYSYRKVTDNISSCMENFNLGRASVNNLLKNVLHFLQKSLIEILEENRKCAGNHIIQTQLMNDLLVGIRVSMMLVQKVQDFQGNLWKTSDSPIWQNMCGLLSIFTKVLSDDDLLQTVQSTSGLAIILFIKTMFHPSEKIPHLISSVLLRSVDCTSVPEWFMSSCRSLCCGDISQSAVLFLCQGTLAMLDWQNGSMGRSGEALLLDTAHVLFTLSSQIKEPTLEMFLSRILASWTNSAIQVLESSSPSLTDSLNGNSSIVGRLLEYVYTHWEHPLDALRHQTKIMFKNLLQMHRLTVEGADFVPDPFFVELTESLLRLEWHIKGKYTCLGCLVECIGVEHILAIDKTIPSQILEVMGDQSLVPYASDLLETMFRNHKSHLKSQTAESSWIDQWHETWVSPLLFILCEGNLDQKSYVIDYYLPKLLSYSPESLQYMVKILQTSIDAKTGQEQSFPSLGSCNSRGALGALMACLRIARAHGHLQSATDTWENLVSDARIKQGLIHQHCQVRIDTLGLLCESNRSTEIVSMEEMQWIQFFITYNLNSQSPGVRQQICSLLKKLFCRIQESSQVLYKLEQSKSKREPENELTKQHPSVSLQQYKNFMSSICNSLFEALFPGSSYSTRFSALTILGSIAEVFHVPEGRIYTVYQLSHDIDVGRFQTLMECFTSTFEDVKILAFDLLMKLSKTAVHFQDSGKLQGLFQAALELSTSTKPYDCVTASYLLNFLIWQDALPSSLSAYLTQQVACDNGDRPAAVVERNTLMVIKCLMENLEEEVSQAENSLLQAAAAFPMYGRVHCITGALQKLSLNSLQLVSEWRPVVEKLLLMSYRLSTVVSPVIQSSSPEGLIPMDTDSESASRLQMILNEIQPRDTNDYFNQAKILKEHDSFDMKDLNASVVNIDTSTEIKGKEVKTCDVTAQMVLVCCWRSMKEVALLLGMLCQLLPMQPVPESSDGLLTVEQVKEIGDYFKQHLLQSRHRGAFELAYTGFVKLTEVLNRCPNVSLQKLPEQWLWSVLEEIKCSDPSSKLCATRRSAGIPFYIQALLASEPKKGRMDLLKITMKELISLAGPTDDIQSTVPQVHALNILRALFRDTRLGENIIPYVADGAKAAILGFTSPVWAVRNSSTLLFSALITRIFGVKRAKDEHSKTNRMTGREFFSRFPELYPFLLKQLETVANTVDSDMGEPNRHPSMFLLLLVLERLYASPMDGTSSALSMGPFVPFIMRCGHSPVYHSREMAARALVPFVMIDHIPNTIRTLLSTLPSCTDQCFRQNHIHGTLLQVFHLLQAYSDSKHGTNSDFQHELTDITVCTKAKLWLAKRQNPCLVTRAVYIDILFLLTCCLNRSAKDNQPVLESLGFWEEVRGIISGSELITGFPWAFKVPGLPQYLQSLTRLAIAAVWAAAAKSGERETNVPISFSQLLESAFPEVRSLTLEALLEKFLAAASGLGEKGVPPLLCNMGEKFLLLAMKENHPECFCKILKILHCMDPGEWLPQTEHCVHLTPKEFLIWTMDIASNERSEIQSVALRLASKVISHHMQTCVENRELIAAELKQWVQLVILSCEDHLPTESRLAVVEVLTSTTPLFLTNPHPILELQDTLALWKCVLTLLQSEEQAVRDAATETVTTAMSQENTCQSTEFAFCQVDASIALALALAVLCDLLQQWDQLAPGLPILLGWLLGESDDLVACVESMHQVEEDYLFEKAEVNFWAETLIFVKYLCKHLFCLLSKSGWRPPSPEMLCHLQRMVSEQCHLLSQFFRELPPAAEFVKTVEFTRLRIQEERTLACLRLLAFLEGKEGEDTLVLSVWDSYAESRQLTLPRTEAAC>sp|Q6YHU6-2|THADA_HUMAN Isoform 2 of Thyroid adenoma-associated proteinOS=Homo sapiens OX=9606 GN=THADAMSSCRSLCCGDISQSAVLFLCQGTLAMLDWQNGSMGRSGEALLLDTAHVLFTLSSQIKEPTLEMFLSRILASWTNSAIQVLESSSPSLTDSLNGNSSIVGRLLEYVYTHWEHPLDALRHQTKIMFKNLLQMHRLTVEGADFVPDPFFVELTESLLRLEWHIKGKYTCLGCLVECIGVEHILAIDKTIPSQILEVMGDQSLVPYASDLLETMFRNHKSHLKSQTAESSWIDQWHETWVSPLLFILCEGNLDQKSYVIDYYLPKLLSYSPESLQYMVKILQTSIDAKTGQEQSFPSLGSCNSRGALGALMACLRIARAHGHLQSATDTWENLVSDARIKQGLIHQHCQVRIDTLGLLCESNRSTEIVSMEEMQWIQFFITYNLNSQSPGVRQQICSLLKKLFCRIQESSQVLYKLEQSKSKREPENELTKQHPSVSLQQYKNFMSSICNSLFEALFPGSSYSTRFSALTILGSIAEVFHVPEGRIYTVYQLSHDIDVGRFQTLMECFTSTFEDVKILAFDLLMKLSKTAVHFQDSGKLQGLFQAALELSTSTKPYDCVTASYLLNFLIWQDALPSSLSAYLTQQVACDNGDRPAAVVERNTLMVIKCLMENLEEEVSQAENSLLQAAAAFPMYGRVHCITGALQKLSLNSLQLVSEWRPVVEKLLLMSYRLSTVVSPVIQSSSPEGLIPMDTDSESASRLQMILNEIQPRDTNDYFNQAKILKEHDSFDMKDLNASVVNIDTSTEIKGKEVKTCDVTAQMVLVCCWRSMKEVALLLGMLCQLLPMQPVPESSDGLLTVEQVKEIGDYFKQHLLQSRHRGAFELAYTGFVKLTEVLNRCPNVSLQKLPEQWLWSVLEEIKCSDPSSKLCATRRSAGIPFYIQALLASEPKKGRMDLLKITMKELISLAGPTDDIQSTVPQVHALNILRALFRDTRLGENIIPYVADGAKAAILGFTSPVWAMTGREFFSRFPELYPFLLKQLETVANTVDSDMGEPNRHPSMFLLLLVLERLYASPMDGTSSALSMGPFVPFIMRCGHSPVYHSREMAARALVPFVMIDHIPNTIRTLLSTLPSCTDQCFRQNHIHGTLLQVFHLLQAYSDSKHGTNSDFQHELTDITVCTKAKLWLAKRQNPCLVTRAVYIDILFLLTCCLNRSAKDNQPVLESLGFWEEVRGIISGSELITGFPWAFKVPGLPQYLQSLTRLAIAAVWAAAAKSGERETNVPISFSQLLESAFPEVRSLTLEALLEKFLAAASGLGEKGVPPLLCNMGEKFLLLAMKENHPECFCKILKILHCMDPGEWLPQTEHCVHLTPKEFLIWTMDIASNERSEIQSVALRLASKVISHHMQTCVENRELIAAELKQWVQLVILSCEDHLPTESRLAVVEVLTSTTPLFLTNPHPILELQDTLALWKCVLTLLQSEEQAVRDAATETVTTAMSQENTCQSTEFAFCQVDASIALALALAVLCDLLQQWDQLAPGLPILLGWLLGESDDLVACVESMHQVEEDYLFEKAEVNFWAETLIFVKYLCKHLFCLLSKSGWRPPSPEMLCHLQRMVSEQCHLLSQFFRELPPAAEFVKTVEFTRLRIQEERTLACLRLLAFLEGKEGEDTLVLSVWDSYAESRQLTLPRTEAAC>sp|Q6YHU6-3|THADA_HUMAN Isoform 3 of Thyroid adenoma-associated proteinOS=Homo sapiens OX=9606 GN=THADAMGVKKKKEMQVAALTICHQDLETLKSFADVEGKNLASLLLHCVQLTDGVSQIHYIKQIVPLLEKADKNGMCDPTIQSCLDILAGIYLSLSLKNPLKKVLASSLNSLPDFFLPEAMHRFTSRLQEELNTTDLYSYRKVTDNISSCMENFNLGRASVNNLLKNVLHFLQKSLIEILEENRKCAGNHIIQTQLMNDLLVGIRVSMMLVQKVQDFQGNLWKTSDSPIWQNMCGLLSIFTKVLSDDDLLQTVQSTSGLAIILFIKTMFHPSEKIPHLISSVLLRSVDCTSVPEWFMSSCRSLCCGDISQSAVLFLCQGTLAMLDWQNGSMGRSGEALLLDTAHVLFTLSSQIKEPTLEMFLSRILASWTNSAIQVLESSSPSLTDSLNGNSSIVGRLLEYVYTHWEHPLDALRHQTKIMFKNLLQMHRLTVEGADFVPDPFFVELTESLLRLEWHIKGKYTCLGCLVECIGVEHILAIDKTIPSQILEVMGDQSLVPYASDLLETMFRNHKSHLKSQTAESSWIDQWHETWVSPLLFILCEGNLDQKSYVIDYYLPKLLSYSPESLQYMVKILQTSIDAKTGQEQSFPSLGSCNSRGALGALMACLRIARAHGHLQSATDTWENLVSDARIKQGLIHQHCQVRIDTLGLLCESNRSTEIVSMEEMQWIQFFITYNLNSQSPGVRQQICSLLKKLFCRIQESSQVLYKLEQSKSKREPENELTKQHPSVSLQQYKNFMSSICNSLFEALFPGSSYSTRFSALTILGSIAEVFHVPEGRIYTVYQLSHDIDVGRFQTLMECFTSTFEDVKILAFDLLMKLSKTAVHFQDSGKLQGLFQAALELSTSTKPYDCVTASYLLNFLIWQDALPSSLSAYLTQQVACDNGDRPAAVVERNTLMVIKCLMENLEEEVSQAENSLLQAAAAFPMYGRVHCITGALQKLSLNSLQLVSEWRPVVEKLLLMSYRLSTVVSPVIQSSSPEGLIPMDTDSESASRLQMILNEIQPRDTNDYFNQAKILKEHDSFDMKDLNASVVNIDTSTEIKGKEVKTCDVTAQMVLVCCWRSMKEVALLLGMLCQLLPMQPVPESSDGLLTVEQVKEIGDYFKQHLLQSRHRGAFELAYTGFVKLTEVLNRCPNVSLQKLPEQWLWSVLEEIKCSDPSSKLCATRRSAGIPFYIQALLASEPKKGRMDLLKITMKELISLAGPTDDIQSTVPQVHALNILRALFRDTRLGENIIPYVADGAKAAILGFTSPVWAVRNSSTLLFSALITRIFGVKRAKDEHSKTNRCGHSPVYHSREMAARALVPFVMIDHIPNTIRTLLSTLPSCTDQCFRQNHIHGTLLQVFHLLQAYSDSKHGTNSDFQHELTDITVCTKAKLWLAKRQNPCLVTRAVYIDILFLLTCCLNRSAKDNQPVLESLGFWEEVRGIISGSELITGFPWAFKVPGLPQYLQSLTRLAIAAVWAAAAKSGERETNVPISFSQLLESAFPEVRSLTLEALLEKFLAAASGLGEKGVPPLLCNMGEKFLLLAMKENHPECFCKILKILHCMDPGEWLPQTEHCVHLTPKEFLIWTMDIASNERSEIQSVALRLASKVISHHMQTCVENRELIAAELKQWVQLVILSCEDHLPTESRLAVVEVLTSTTPLFLTNPHPILELQDTLALWKCVLTLLQSEEQAVRDAATETVTTAMSQENTCQSTEFAFCQVDASIALALALAVLCDLLQQWDQLAPGLPILLGWLLGESDDLVACVESMHQVEEDYLFEKAEVNFWAETLIFVKYLCKHLFCLLSKSGWRPPSPEMLCHLQRMVSEQCHLLSQFFRELPPAAEFVKTVEFTRLRIQEERTLACLRLLAFLEGKEGEDTLVLSVWDSYAESRQLTLPRTEAAC>sp|Q6YHU6-4|THADA_HUMAN Isoform 4 of Thyroid adenoma-associated proteinOS=Homo sapiens OX=9606 GN=THADAMTGREFFSRFPELYPFLLKQLETVANTVDSDMGEPNRHPSMFLLLLVLERLYASPMDGTSSALSMGPFVPFIMRCGHSPVYHSREMAARALVPFVMIDHIPNTIRTLLSTLPSCTDQCFRQNHIHGTLLQVFHLLQAYSDSKHGTNSDFQHELTDITVCTKAKLWLAKRQNPCLVTRAVYIDILFLLTCCLNRSAKDNQPVLESLGFWEEVRGIISGSELITGFPWAFKVPGLPQYLQSLTRLAIAAVWAAAAKSGERETNVPISFSQLLESAFPEVRSLTLEALLEKFLAAASGLGEKGVPPLLCNMGEKFLLLAMKENHPECFCKILKILHCMDPGEWLPQTEHCVHLTPKEFLIWTMDIASNERSEIQSVALRLASKVISHHMQTCVENRELIAAELKQWVQLVILSCEDHLPTESRLAVVEVLTSTTPLFLTNPHPILELQDTLALWKCVLTLLQSEEQAVRDAATETVTTAMSQENTCQSTEFAFCQVDASIALALALAVLCDLLQQWDQLAPGLPILLGWLLGESDDLVACVESMHQVEEDYLFEKAEVNFWAETLIFVKYLCKHLFCLLSKSGWRPPSPEMLCHLQRMVSEQCHLLSQFFRELPPAAEFVKTVEFTRLRIQEERTLACLRLLAFLEGKEGEDTLVLSVWDSYAESRQLTLPRTEAAC>sp|Q6YHU6-5|THADA_HUMAN Isoform 5 of Thyroid adenoma-associated proteinOS=Homo sapiens OX=9606 GN=THADAMGVKKKKEMQVAALTICHQDLETLKSFADVEGKNLASLLLHCVQLTDGVSQIHYIKQIVPLLEKADKNGMCDPTIQSCLDILAGIYLSLSLKNPLKKVLASSLNSLPDFFLPEAMHRFTSRLQEELNTTDLYSYRKVTDNISSCMENFNLGRASVNNLLKNVLHFLQKSLIEILEENRKCAGNHIIQTQLMNDLLVGIRVSMMLVQKVQDFQGNLWKTSDSPIWQNMCGLLSIFTKVLSDDDLLQTVQSTSGLAIILFIKTMFHPSEKIPHLISSVLLRSVDCTSVPEWFMSSCRSLCCGDISQSAVLFLCQGTLAMLDWQNGSMGRSGEALLLDTAHVLFTLSSQIKEPTLEMFLSRILASWTNSAIQVLESSSPSLTDSLNGNSSIVGRLLEYVYTHWEHPLDALRHQTKIMFKNLLQMHRLTVEGADFVPDPFFVELTESLLRLEWHIKGKYTCLGCLVECIGVEHILAIDKTIPSQILEVMGDQSLVPYASDLLETMFRNHKSHLKSQTAESSWIDQWHETWVSPLLFILCEGNLDQKSYVIDYYLPKLLSYSPESLQYMVKILQTSIDAKTGQEQSFPSLGSCNSRGALGALMACLRIARAHGHLQSATDTWENLVSDARIKQGLIHQHCQVRIDTLGLLCESNRSTEIVSMEEMQWIQFFITYNLNSQSPGVRQQICSLLKKLFCRIQESSQVLYKLEQSKSKREPENELTKQHPSVSLQQYKNFMSSICNSLFEALFPGSSYSTRFSALTILGSIAEVFHVPEGRIYTVYQLSHDIDVGRFQTLMECFTSTFEDVKILAFDLLMKLSKTAVHFQDSGKLQGLFQAALELSTSTKPYDCVTASYLLNFLIWQDALPSSLSAYLTQQVACDNGDRPAAVVERNTLMVIKCLMENLEEEVSQAENSLLQAAAAFPMYGRVHCITGALQKLSLK>sp|Q6YHU6-6|THADA_HUMAN Isoform 6 of Thyroid adenoma-associated proteinOS=Homo sapiens OX=9606 GN=THADAMGVKKKKEMQVAALTICHQDLETLKSFADVEGKNLASLLLHCVQLTDGVSQIHYIKQIVPLLEKADKNGMCDPTIQSCLDILAGIYLSLSLKNPLKKVLASSLNSLPDFFLPEAMHRFTSRLQEELNTTDLYSYRKVTDNISSCMENFNLGRASVNNLLKNVLHFLQKSLIEILEENRKCAGNHIIQTQLMNDLLVGIRVSMMLVQKVQDFQGNLWKTSDSPIWQNMCGLLSIFTKVLSDDDLLQTVQSTSGLAIILFIKTMFHPSEKIPHLISSVLLRSVDCTSVPEWFMSSCRSLCCGDISQSAVLFLCQGTLAMLDWQNGSMGRSGEALLLDTAHVLFTLSSQIKEPTLEMFLSRILASWTNSAIQVLESSSPSLTDSLNGNSSIVGRLLEYVYTHWEHPLDALRHQTKIMFKNLLQMHRLTVEGADFVPDPFFVELTESLLRLEWHIKGKYTCLGCLVECIGVEHILAIDKTIPSQILEVMGDQSLVPYASDLLETMFRNHKSHLKSQTAESSWIDQWHETWVSPLLFILCEGNLDQKSYVIDYYLPKLLSYSPESLQYMVKILQTSIDAKTGQEQSFPSLGSCNSRGALGALMACLRIARAHGHLQSATDTWENLVSDARIKQGLIHQHCQVRIDTLGLLCESNRSTEIVSMEEMQWIQFFITYNLNSQSPGVRQQICSLLKKLFCRIQESSQVLYKLEQSKSKREPENELTKQHPSVSLQQYKNFMSSICNSLFEALFPGSSYSTRFSALTILGSIAEVFHVPEGRIYTVYQLSHDIDVGRFQTLMECFTSTFEDVKILAFDLLMKLSKTAVHFQDSGKLQGLFQAALELSTSTKPYDCVTASYLLNFLIWQDALPSSLSAYLTQQVACDNGDRPAAVVERNTLMGLY>sp|Q8IYN2|TCAL8_HUMAN Transcription elongation factor A protein-like 8OS=Homo sapiens OX=9606 GN=TCEAL8 PE=1 SV=1MQKSCEENEGKPQNMPKAEEDRPLEDVPQEAEGNPQPSEEGVSQEAEGNPRGGPNQPGQGFKEDTPVRHLDPEEMIRGVDELERLREEIRRVRNKFVMMHWKQRHSRSRPYPVCFRP>sp|Q6IPX3|TCAL6_HUMAN Transcription elongation factor A protein-like 6OS=Homo sapiens OX=9606 GN=TCEAL6 PE=2 SV=1MEKPYNKNEGNLENEGKPEDEVEPDDEGKSDEEEKPDAEGKTECEGKRKAEGEPGDEGQLEDKGSQEKQGKSEGEGKPQGEGKPASQAKPEGQPRAAEKRPAGDYVPRKAKRKTDRGTDDSPKDSQEDLQERHLSSEEMMRECGDVSRAQEELRKKQKMGGFHWMQRDVQDPFAPRGQRGVRGVRGGGRGQRGLHDIPYL>sp|Q6IPX3-2|TCAL6_HUMAN Isoform 2 of Transcription elongation factor Aprotein-like 6 OS=Homo sapiens OX=9606 GN=TCEAL6MEKPYNKNEGNLENEGKPEDEVEPDDEGKSDEEEKPDAEGKTECEGKRKAEGEPGDEGQLEDKGSQEKQGKSEGEGKPQGEGKPASQAKPEGQPRAAEKRPAGDYVPRKAKRKTDRGTDDSPKDSQEDLQERHLSSEEMMRECGDVSRAQEELRKKQKMGGFHWMQRDVQDPFAQGDNGVSGE>sp|Q6NT04|TIGD7_HUMAN Tigger transposable element-derived protein 7OS=Homo sapiens OX=9606 GN=TIGD7 PE=1 SV=1MNKRGKYTTLNLEEKMKVLSRIEAGRSLKSVMDEFGISKSTFYDIKKNKKLILDFVLKQDMPLVGAEKRKRTTGAKYGDVDDAVYMWYQQKRSAGVPVRGVELQAAAERFARCFGRTDFKASTGWLFRFRNRHAIGNRKGCGEQVLSSVSENVEPFRQKLSMIIKEEKLCLAQLYSGDETDLFWKSMPENSQASRKDICLPGKKINKERLSAFLCANADGTHKLKSIIIGKSKLPKSVKEDTSTLPVIYKPSKDVWFTRELFSEWFFQNFVPEVRHFQLNVLRFHDEDVRALLLLDSCPAHPSSESLTSEDGRIKCMFFPHNTSTLIQPMNQGVILSCKRLYRWKQLEESLVIFEESDDEQEKGDKGVSKIKIYNIKSAIFNWAKSWEEVKQITIANAWENLLYKKEPEYDFQGLEHGDYREILEKCGELETKLDDDRVWLNGDEEKGCLLKTKGGITKEVVQKGGEAEKQTAEFKLSAVRESLDYLLDFVDATPEFQRFHFTLKEMQQEIVKKQFQSKIHSRIGSFLKPRPHNIKDSFSGPSTSGSNH>sp|Q6NT04-2|TIGD7_HUMAN Isoform 2 of Tigger transposable element-derivedprotein 7 OS=Homo sapiens OX=9606 GN=TIGD7MNKRGKYTTLNLEEKMKVLSRIEAGRSLKSVMDEFGISKSTFYDIKKNKKLILDFVLKQDMPLVGAEKRKRTTGAKYGDVDDAVYMWYQQKRSAGVPVRGVELQAAAERFARCFGRTDFKASTGWLFRFRNRHAIGNRKGCGEQVLSSVSENVEPFRQKLSMIIKEEKLCLAQLYSGDETDLFWKSMPENSQASRKDICLPGKKINKERLSAFLCANADGTHKLKSIIIGKSKLPKSVKEDTSTLPVIYKPSKDVWFTRELFSEWFFQNFVPEVRHFQLNVLRFHDEDVRALLLLDSCPAHPSSESLTSEDGRIKCMFFPHNTSTLIQPMNQGVILSCKRLYRWKQLEESLVIFEESDDEQEKGDKGVSKIKIYNIKSAIFNWAKSWEEVKQITIANAWENLLYKKEPEYDFQGLEHGDYREILEKCGELETKLDDDRVWLNGDEEKGCLLKTKGGITKEVVQKGGEAEKQTAEFKLSAVRESLDYLLDFVDATPEFQRFHFTLCEFSDDS>sp|B9A6J9|TBC3L_HUMAN TBC1 domain family member 3L OS=Homo sapiensOX=9606 GN=TBC1D3L PE=2 SV=1MDVVEVAGSWWAQEREDIIMKYEKGHRAGLPEDKGPKPFRSYNNNVDHLGIVHETELPPLTAREAKQIRREISRKSKWVDMLGDWEKYKSSRKLIDRAYKGMPMNIRGPMWSVLLNTEEMKLKNPGRYQIMKEKGKRSSEHIQRIDRDVSGTLRKHIFFRDRYGTKQRELLHILLAYEEYNPEVGYCRDLSHIAALFLLYLPEEDAFWALVQLLASERHSLQGFHSPNGGTVQGLQDQQEHVVATSQPKTMGHQDKKDLCGQCSPLGCLIRILIDGISLGLTLRLWDVYLVEGEQALMPITRIAFKVQQKRLTKTSRCGPWARFCNRFVDTWARDEDTVLKHLRASMKKLTRKQGDLQPPAKPEQGSSASRPVPASRGGKTLCKGDRQAPPGPPARFPRPIWSASPPRAPRSSTPCPGGAVREDTYPVGTQGVPSPALAQGGPQGSWRFLQWNSMPRLPTDLDVEGPWFRHYDFRQSCWVRAISQEDQLAPCWQAEHPAERVRSAFAAPSTDSDQGTPFRARDEQPCAPTSGPCLCGLHLESSQFPPGF>sp|Q71U36|TBA1A_HUMAN Tubulin alpha-1A chain OS=Homo sapiens OX=9606GN=TUBA1A PE=1 SV=1MRECISIHVGQAGVQIGNACWELYCLEHGIQPDGQMPSDKTIGGGDDSFNTFFSETGAGKHVPRAVFVDLEPTVIDEVRTGTYRQLFHPEQLITGKEDAANNYARGHYTIGKEIIDLVLDRIRKLADQCTGLQGFLVFHSFGGGTGSGFTSLLMERLSVDYGKKSKLEFSIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLIGQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLATYAPVISAEKAYHEQLSVAEITNACFEPANQMVKCDPRHGKYMACCLLYRGDVVPKDVNAAIATIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLDHKFDLMYAKRAFVHWYVGEGMEEGEFSEAREDMAALEKDYEEVGVDSVEGEGEEEGEEY>sp|Q71U36-2|TBA1A_HUMAN Isoform 2 of Tubulin alpha-1A chain OS=Homosapiens OX=9606 GN=TUBA1AMPSDKTIGGGDDSFNTFFSETGAGKHVPRAVFVDLEPTVIDEVRTGTYRQLFHPEQLITGKEDAANNYARGHYTIGKEIIDLVLDRIRKLADQCTGLQGFLVFHSFGGGTGSGFTSLLMERLSVDYGKKSKLEFSIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLIGQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLATYAPVISAEKAYHEQLSVAEITNACFEPANQMVKCDPRHGKYMACCLLYRGDVVPKDVNAAIATIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLDHKFDLMYAKRAFVHWYVGEGMEEGEFSEAREDMAALEKDYEEVGVDSVEGEGEEEGEEY>sp|Q9UPU7|TBD2B_HUMAN TBC1 domain family member 2B OS=Homo sapiensOX=9606 GN=TBC1D2B PE=1 SV=2MPGAGARAEEGGGGGEGAAQGAAAEPGAGPAREPARLCGYLQKLSGKGPLRGYRSRWFVFDARRCYLYYFKSPQDALPLGHLDIADACFSYQGPDEAAEPGTEPPAHFQVHSAGAVTVLKAPNRQLMTYWLQELQQKRWEYCNSLDMVKWDSRTSPTPGDFPKGLVARDNTDLIYPHPNASAEKARNVLAVETVPGELVGEQAANQPAPGHPNSINFYSLKQWGNELKNSMSSFRPGRGHNDSRRTVFYTNEEWELLDPTPKDLEESIVQEEKKKLTPEGNKGVTGSGFPFDFGRNPYKGKRPLKDIIGSYKNRHSSGDPSSEGTSGSGSVSIRKPASEMQLQVQSQQEELEQLKKDLSSQKELVRLLQQTVRSSQYDKYFTSSRLCEGVPKDTLELLHQKDDQILGLTSQLERFSLEKESLQQEVRTLKSKVGELNEQLGMLMETIQAKDEVIIKLSEGEGNGPPPTVAPSSPSVVPVARDQLELDRLKDNLQGYKTQNKFLNKEILELSALRRNAERRERDLMAKYSSLEAKLCQIESKYLILLQEMKTPVCSEDQGPTREVIAQLLEDALQVESQEQPEQAFVKPHLVSEYDIYGFRTVPEDDEEEKLVAKVRALDLKTLYLTENQEVSTGVKWENYFASTVNREMMCSPELKNLIRAGIPHEHRSKVWKWCVDRHTRKFKDNTEPGHFQTLLQKALEKQNPASKQIELDLLRTLPNNKHYSCPTSEGIQKLRNVLLAFSWRNPDIGYCQGLNRLVAVALLYLEQEDAFWCLVTIVEVFMPRDYYTKTLLGSQVDQRVFRDLMSEKLPRLHGHFEQYKVDYTLITFNWFLVVFVDSVVSDILFKIWDSFLYEGPKVIFRFALALFKYKEEEILKLQDSMSIFKYLRYFTRTILDARKLISISFGDLNPFPLRQIRNRRAYHLEKVRLELTELEAIREDFLRERDTSPDKGELVSDEEEDT>sp|Q9UPU7-2|TBD2B_HUMAN Isoform 2 of TBC1 domain family member 2BOS=Homo sapiens OX=9606 GN=TBC1D2BMPGAGARAEEGGGGGEGAAQGAAAEPGAGPAREPARLCGYLQKLSGKGPLRGYRSRWFVFDARRCYLYYFKSPQDALPLGHLDIADACFSYQGPDEAAEPGTEPPAHFQVHSAGAVTVLKAPNRQLMTYWLQELQQKRWEYCNSLDMVKWDSRTSPTPGDFPKGLVARDNTDLIYPHPNASAEKARNVLAVETVPGELVGEQAANQPAPGHPNSINFYSLKQWGNELKNSMSSFRPGRGHNDSRRTVFYTNEEWELLDPTPKDLEESIVQEEKKKLTPEGNKGVTGSGFPFDFGRNPYKGKRPLKDIIGSYKNRHSSGDPSSEGTSGSGSVSIRKPASEMQLQVQSQQEELEQLKKDLSSQKELVRLLQQTVRSSQYDKYFTSSRLCEGVPKDTLELLHQKDDQILGLTSQLERFSLEKESLQQEVRTLKSKVGELNEQLGMLMETIQAKDEVIIKLSEGEGNGPPPTVAPSSPSVVPVARDQLELDRLKDNLQGYKTQNKFLNKEILELSALRRNAERRERDLMAKYSSLEAKLCQIESKYLILLQEMKTPVCSEDQGPTREVIAQLLEDALQVESQEQPEQAFVKPHLVSEYDIYGFRTVPEDDEEEKLVAKVRALDLKTLYLTENQEVSTGVKWENYFASTVNREMMCSPELKNLIRAGIPHEHRSKVWKWCVDRHTRKFKDNTEPGHFQTLLQKALEKQNPASKQIELDLLRTLPNNKHYSCPTSEGIQKLRNVLLAFSWRNPDIGYCQGLNRLVAVALLYLEQEDAFWCLVTIVEVFMPRDYYTKTLLGSQVDQRVFRDLMSEKLPRLHGHFEQYKVDYTLITFNWFLVVFVDSVVSDILFKIWDSFLYEGPKVIFRFALALFKYKEEEILKLQDSMSIFKYLRYFTRTILDARSGTDAPTTWRKSGWS>sp|Q9UPU7-3|TBD2B_HUMAN Isoform 3 of TBC1 domain family member 2BOS=Homo sapiens OX=9606 GN=TBC1D2BMKTPVCSEDQGPTREVIAQLLEDALQVESQEQPEQAFVKPHLVSEYDIYGFRTVPEDDEEEKLVAKVRALDLKTLYLTENQEVSTGVKWENYFASTVNREMMCSPELKNLIRAGIPHEHRSKVWKWCVDRHTRKFKDNTEPGHFQTLLQKALEKQNPASKQIELDLLRTLPNNKHYSCPTSEGIQKLRNVLLAFSWRNPDIGYCQGLNRLVAVALLYLEQEDAFWCLVTIVEVFMPRDYYTKTLLGSQVDQRVFRDLMSEKLPRLHGHFEQYKVDYTLITFNWFLVVFVDSVVSDILFKIWDSFLYEGPKVS>sp|Q9P272|TRM9B_HUMAN Probable tRNA methyltransferase 9B OS=Homo sapiensOX=9606 GN=TRMT9B PE=2 SV=3MDHEAAQLEKQHVHNVYESTAPYFSDLQSKAWPRVRQFLQEQKPGSLIADIGCGTGKYLKVNSQVHTVGCDYCGPLVEIARNRGCEAMVCDNLNLPFRDEGFDAIISIGVIHHFSTKQRRIRAIKEMARVLVPGGQLMIYVWAMEQKNRHFEKQDVLVPWNRALCSQLFSESSQSGRKRQCGYPERGHPYHPPCSECSCSVCFKEQCGSKRSHSVGYEPAMARTCFANISKEGEEEYGFYSTLGKSFRSWFFSRSLDESTLRKQIERVRPLKNTEVWASSTVTVQPSRHSSLDFDHQEPFSTKGQSLDEEVFVESSSGKHLEWLRAPGTLKHLNGDHQGEMRRNGGGNFLDSTNTGVNCVDAGNIEDDNPSASKILRRISAVDSTDFNPDDTMSVEDPQTDVLDSTAFMRYYHVFREGELCSLLKENVSELRILSSGNDHGNWCIIAEKKRGCD>sp|Q9P272-3|TRM9B_HUMAN Isoform 2 of Probable tRNA methyltransferase 9BOS=Homo sapiens OX=9606 GN=TRMT9BMDHEAAQLEKQHVHNVYESTAPYFSDLQSKAWPRVRQFLQEQKPGSLIADIGNQAASSLT>sp|Q15629|TRAM1_HUMAN Translocating chain-associated membrane protein 1OS=Homo sapiens OX=9606 GN=TRAM1 PE=1 SV=3MAIRKKSTKSPPVLSHEFVLQNHADIVSCVAMVFLLGLMFEITAKASIIFVTLQYNVTLPATEEQATESVSLYYYGIKDLATVFFYMLVAIIIHAVIQEYMLDKINRRMHFSKTKHSKFNESGQLSAFYLFACVWGTFILISENYISDPTILWRAYPHNLMTFQMKFFYISQLAYWLHAFPELYFQKTKKEDIPRQLVYIGLYLFHIAGAYLLNLNHLGLVLLVLHYFVEFLFHISRLFYFSNEKYQKGFSLWAVLFVLGRLLTLILSVLTVGFGLARAENQKLDFSTGNFNVLAVRIAVLASICVTQAFMMWKFINFQLRRWREHSAFQAPAVKKKPTVTKGRSSKKGTENGVNGTLTSNVADSPRNKKEKSS>sp|Q15629-2|TRAM1_HUMAN Isoform 2 of Translocating chain-associatedmembrane protein 1 OS=Homo sapiens OX=9606 GN=TRAM1MVFLLGLMFEITAKASIIFVTLQYNVTLPATEEQATESVSLYYYGIKDLATVFFYMLVAIIIHAVIQEYMLDKINRRMHFSKTKHSKFNESGQLSAFYLFACVWGTFILISENYISDPTILWRAYPHNLMTFQMKFFYISQLAYWLHAFPELYFQKTKKEDIPRQLVYIGLYLFHIAGAYLLNLNHLGLVLLVLHYFVEFLFHISRLFYFSNEKYQKGFSLWAVLFVLGRLLTLILSVLTVGFGLARAENQKLDFSTGNFNVLAVRIAVLASICVTQAFMMWKFINFQLRRWREHSAFQAPAVKKKPTVTKGRSSKKGTENGVNGTLTSNVADSPRNKKEKSS>sp|Q9UI30|TR112_HUMAN Multifunctional methyltransferase subunit TRM112-like protein OS=Homo sapiens OX=9606 GN=TRMT112 PE=1 SV=1MKLLTHNLLSSHVRGVGSRGFPLRLQATEVRICPVEFNPNFVARMIPKVEWSAFLEAADNLRLIQVPKGPVEGYEENEEFLRTMHHLLLEVEVIEGTLQCPESGRMFPISRGIPNMLLSEEETES>sp|Q9UI30-2|TR112_HUMAN Isoform 2 of Multifunctional methyltransferasesubunit TRM112-like protein OS=Homo sapiens OX=9606 GN=TRMT112MKLLTHNLLSSHVRGVGSRGFPLRLQATEVRICPVEFNPNFVARMIPKVEWSAFLEAADNVPKGPVEGYEENEEFLRTMHHLLLEVEVIEGTLQCPESGRMFPISRGIPNMLLSEEETES>sp|Q4KMP7|TB10B_HUMAN TBC1 domain family member 10B OS=Homo sapiensOX=9606 GN=TBC1D10B PE=1 SV=3METGTAPLVAPPRRHGAPAAPSPPPRGSRAGPVVVVAPGPPVTTATSAPVTLVAPGEARPAWVPGSAETSAPAPAPAPAPAPAVTGSTVVVLTLEASPEAPKPQLPSGPESPEPAAVAGVETSRALAAGADSPKTEEARPSPAPGPGTPTGTPTRTPSRTAPGALTAKPPLAPKPGTTVASGVTARSASGQVTGGHGAAAATSASAGQAPEDPSGPGTGPSGTCEAPVAVVTVTPAPEPAENSQDLGSTSSLGPGISGPRGQAPDTLSYLDSVSLMSGTLESLADDVSSMGSDSEINGLALRKTDKYGFLGGSQYSGSLESSIPVDVARQRELKWLDMFSNWDKWLSRRFQKVKLRCRKGIPSSLRAKAWQYLSNSKELLEQNPGKFEELERAPGDPKWLDVIEKDLHRQFPFHEMFAARGGHGQQDLYRILKAYTIYRPDEGYCQAQAPVAAVLLMHMPAEQAFWCLVQICDKYLPGYYSAGLEAIQLDGEIFFALLRRASPLAHRHLRRQRIDPVLYMTEWFMCIFARTLPWASVLRVWDMFFCEGVKIIFRVALVLLRHTLGSVEKLRSCQGMYETMEQLRNLPQQCMQEDFLVHEVTNLPVTEALIERENAAQLKKWRETRGELQYRPSRRLHGSRAIHEERRRQQPPLGPSSSLLSLPGLKSRGSRAAGGAPSPPPPVRRASAGPAPGPVVTAEGLHPSLPSPTGNSTPLGSSKETRKQEKERQKQEKERQKQEKEREKERQKQEKEREKQEKEREKQEKERQKQEKKAQGRKLSLRRKADGPPGPHDGGDRPSAEARQDAYF>sp|Q4KMP7-2|TB10B_HUMAN Isoform 2 of TBC1 domain family member 10BOS=Homo sapiens OX=9606 GN=TBC1D10BMYETMEQLRNLPQQCMQEDFLVHEVTNLPVTEALIERENAAQLKKWRETRGELQYRPSRRLHGSRAIHEERRRQQPPLGPSSSLLSLPGLKSRGSRAAGGAPSPPPPVRRASAGPAPGPVVTAEGLHPSLPSPTGNSTPLGSSKETRKQEKERQKQEKERQKQEKEREKERQKQEKEREKQEKEREKQEKERQKQEKKAQGRKLSLRRKADGPPGPHDGGDRPSAEARQDAYF>sp|Q9ULW0|TPX2_HUMAN Targeting protein for Xklp2 OS=Homo sapiens OX=9606GN=TPX2 PE=1 SV=2MSQVKSSYSYDAPSDFINFSSLDDEGDTQNIDSWFEEKANLENKLLGKNGTGGLFQGKTPLRKANLQQAIVTPLKPVDNTYYKEAEKENLVEQSIPSNACSSLEVEAAISRKTPAQPQRRSLRLSAQKDLEQKEKHHVKMKAKRCATPVIIDEILPSKKMKVSNNKKKPEEEGSAHQDTAEKNASSPEKAKGRHTVPCMPPAKQKFLKSTEEQELEKSMKMQQEVVEMRKKNEEFKKLALAGIGQPVKKSVSQVTKSVDFHFRTDERIKQHPKNQEEYKEVNFTSELRKHPSSPARVTKGCTIVKPFNLSQGKKRTFDETVSTYVPLAQQVEDFHKRTPNRYHLRSKKDDINLLPSKSSVTKICRDPQTPVLQTKHRARAVTCKSTAELEAEELEKLQQYKFKARELDPRILEGGPILPKKPPVKPPTEPIGFDLEIEKRIQERESKKKTEDEHFEFHSRPCPTKILEDVVGVPEKKVLPITVPKSPAFALKNRIRMPTKEDEEEDEPVVIKAQPVPHYGVPFKPQIPEARTVEICPFSFDSRDKERQLQKEKKIKELQKGEVPKFKALPLPHFDTINLPEKKVKNVTQIEPFCLETDRRGALKAQTWKHQLEEELRQQKEAACFKARPNTVISQEPFVPKKEKKSVAEGLSGSLVQEPFQLATEKRAKERQELEKRMAEVEAQKAQQLEEARLQEEEQKKEELARLRRELVHKANPIRKYQGLEIKSSDQPLTVPVSPKFSTRFHC>sp|Q9ULW0-2|TPX2_HUMAN Isoform 2 of Targeting protein for Xklp2 OS=Homosapiens OX=9606 GN=TPX2MSQVKSSYSYDAPSDFINFSSLDDEGDTQNIDSWFEEKANLENKLLGKNGTGGLFQGKTPLRKANLQQAIVTPLKPVDNTYYKEAEKENLVEQSIPSNACSSLEVEAAISRKTPAQPQRRSLRLSAQKDLEQKEKHHVKMKAKRCATPVIIDEILPSKKMKVSNNKKKPEEEGSAHQDTAEKNASSPEKAKGRHTVPCMPPAKQKFLKSTEEQELEKSMKMQQEVVEMRKKNEEFKKLALAGIGQPVKKSVSQVTKSVDFHFRTDERIKQHPKNQEEYKEVNFTSELRKHPSSPARVTKGCTIVKPFNLSQGKKRTFDETVSTYVPLAQQVEDFHKRTPNRYHLRSKKDDIKTGSCSVTQAGVQWRDHGSLQCPTPGLKQSSCLSLPNLLPSKSSVTKICRDPQTPVLQTKHRARAVTCKSTAELEAEELEKLQQYKFKARELDPRILEGGPILPKKPPVKPPTEPIGFDLEIEKRIQERESKKKTEDEHFEFHSRPCPTKILEDVVGVPEKKVLPITVPKSPAFALKNRIRMPTKEDEEEDEPVVIKAQPVPHYGVPFKPQIPEARTVEICPFSFDSRDKERQLQKEKKIKELQKGEVPKFKALPLPHFDTINLPEKKVKNVTQIEPFCLETDRRGALKAQTWKHQLEEELRQQKEAACFKARPNTVISQEPFVPKKEKKSVAEGLSGSLVQEPFQLATEKRAKERQELEKRMAEVEAQKAQQLEEARLQEEEQKKEELARLRRELVHKANPIRKYQGLEIKSSDQPLTVPVSPKFSTRFHC>sp|Q9BTW9|TBCD_HUMAN Tubulin-specific chaperone D OS=Homo sapiensOX=9606 GN=TBCD PE=1 SV=2MALSDEPAAGGPEEEAEDETLAFGAALEAFGESAETRALLGRLREVHGGGAEREVALERFRVIMDKYQEQPHLLDPHLEWMMNLLLDIVQDQTSPASLVHLAFKFLYIITKVRGYKTFLRLFPHEVADVEPVLDLVTIQNPKDHEAWETRYMLLLWLSVTCLIPFDFSRLDGNLLTQPGQARMSIMDRILQIAESYLIVSDKARDAAAVLVSRFITRPDVKQSKMAEFLDWSLCNLARSSFQTMQGVITMDGTLQALAQIFKHGKREDCLPYAATVLRCLDGCRLPESNQTLLRKLGVKLVQRLGLTFLKPKVAAWRYQRGCRSLAANLQLLTQGQSEQKPLILTEDDDEDDDVPEGVERVIEQLLVGLKDKDTVVRWSAAKGIGRMAGRLPRALADDVVGSVLDCFSFQETDKAWHGGCLALAELGRRGLLLPSRLVDVVAVILKALTYDEKRGACSVGTNVRDAACYVCWAFARAYEPQELKPFVTAISSALVIAAVFDRDINCRRAASAAFQENVGRQGTFPHGIDILTTADYFAVGNRSNCFLVISVFIAGFPEYTQPMIDHLVTMKISHWDGVIRELAARALHNLAQQAPEFSATQVFPRLLSMTLSPDLHMRHGSILACAEVAYALYKLAAQENRPVTDHLDEQAVQGLKQIHQQLYDRQLYRGLGGQLMRQAVCVLIEKLSLSKMPFRGDTVIDGWQWLINDTLRHLHLISSHSRQQMKDAAVSALAALCSEYYMKEPGEADPAIQEELITQYLAELRNPEEMTRCGFSLALGALPGFLLKGRLQQVLTGLRAVTHTSPEDVSFAESRRDGLKAIARICQTVGVKAGAPDEAVCGENVSQIYCALLGCMDDYTTDSRGDVGTWVRKAAMTSLMDLTLLLARSQPELIEAHTCERIMCCVAQQASEKIDRFRAHAASVFLTLLHFDSPPIPHVPHRGELEKLFPRSDVASVNWSAPSQAFPRITQLLGLPTYRYHVLLGLVVSLGGLTESTIRHSTQSLFEYMKGIQSDPQALGSFSGTLLQIFEDNLLNERVSVPLLKTLDHVLTHGCFDIFTTEEDHPFAVKLLALCKKEIKNSKDIQKLLSGIAVFCEMVQFPGDVRRQALLQLCLLLCHRFPLIRKTTASQVYETLLTYSDVVGADVLDEVVTVLSDTAWDAELAVVREQRNRLCDLLGVPRPQLVPQPGAC>sp|Q9BTW9-2|TBCD_HUMAN Isoform 2 of Tubulin-specific chaperone D OS=Homosapiens OX=9606 GN=TBCDMKGIQSDPQALGSFSGTLLQIFEDNLLNERVSVPLLKTLDHVLTHGCFDIFTTEEDHPFAVKLLALCKKEIKNSKDIQKLLSGIAVFCEMVQFPGDVRRQALLQLCLLLCHRFPLIRKTTASQVYETLLTYSDVVGADVLDEVVTVLSDTAWDAELAVVREQRNRLCDLLGVPRPQLVPQPGAC>sp|Q9BTW9-3|TBCD_HUMAN Isoform 3 of Tubulin-specific chaperone D OS=Homosapiens OX=9606 GN=TBCDMFNSVFIAGFPEYTQPMIDHLVTMKISHWDGVIRELAARALHNLAQQAPEFSATQVFPRLLSMTLSPDLHMRHGSILACAEVAYALYKLAAQENRPVTDHLDEQAVQGLKQIHQQPCICSWGLMSPESKAEFCVCVCRISLGRQCVHLSGL>sp|Q9BTW9-4|TBCD_HUMAN Isoform 4 of Tubulin-specific chaperone D OS=Homosapiens OX=9606 GN=TBCDMALSDEPAAGGPEEEAEDETLAFGAALEAFGESAETRALLGRLREVHGGGAEREVALERFRVIMDKYQEQPHLLDPHLEWMMNLLLDIVQDQTSPASLVHLAFKFLYIITKVRGYKTFLRLFPHEVADVEPVLDLVTIQNPKDHEAWETRYMLLLWLSVTCLIPFDFSRLDGNLLTQPGQARMSIMDRILQIAESYLIVSDKARDAAAVLVSRFITRPDVKQSKMAEFLDWSLCNLARSSFQTMQGVITMDGTLQALAQIFKHGKREDCLPYAATVLRCLDGCRLPESNQTLLRKLGVKLVQRLGLTFLKPKVAAWRYQRGCRSLAANLQLLTQGQSEQKPLILTEDDDEDDDVPEGVERVIEQLLVGLKDKDTVVRWSAAKGIGRMAGRLPRALADDVVGSVLDCFSFQETDKAWHGGCLALAELGRRGLLLPSRLVDVVAVILKALTYDEKRGACSVGTNVRDAACYVCWAFARAYEPQELKPFVTAISSALVIAAVFDRDINCRRAASAAFQENVGRQGTFPHGIDILTTADYFAVGNRSNCFLVISVFIAGFPEYTQPMIDHLVTMKISHWDGVIRELAARALHNLAQQAPEFSATQVFPRLLSMTLSPDLHMRHGSILACAEVAYALYKLAAQENRPVTDHLDEQAVQGLKQIHQQLYDRQLYRGLGGQLMRQAVCVLIEKLSLSKMPFRGDTVIDGWQWLINDTLRHLHLISSHSRQQMKDAAVSALAALCSEYYMKEPGEADPAIQEELITQYLAELRNPEEMTRCGFSLALGALPGFLLKGRLQQVLTGLRAVTHTSPEDVSFAESRRDGLKAIARICQTVGVKAGAPDEAVCGENVSQIYCALLGCMDDYTTDSRGDVGTWVRKAAMTSLMDLTLLLARSQPELIEAHTCERIMCCVAQQASEKIDRFRAHAASVFLTLLHFDSPPIPHVPHRGELEKLFPRSDVASVNWSAPSQAFPRITQLLGLPTYRYHVLLGLVVSLGGLTESTIRHSTQSLFEYMKGIQSDPQALGSFSGTLLQIFEDNLLNERVSVPLLKTLDHVLTHGCFDIFTTEEDHPFAVKLLALCKKEIKNSKDIQKLLSGIAVDFPSATLVCVGTVQMYAHTHLRLGAPGPHCAHGSAMPRFCEMVQFPGDVRRQALLQLCLLLCHRFPLIRKTTASQVYETLLTYSDVVGADVLDEVVTVLSDTAWDAELAVVREQRNRLCDLLGVPSPTWCPAWCLLKPVLEPIPHPCLVRMSCS>sp|Q9BTW9-5|TBCD_HUMAN Isoform 5 of Tubulin-specific chaperone D OS=Homosapiens OX=9606 GN=TBCDMALSDEPAAGGPEEEAEDETLAFGAALEAFGESAETRALLGRLREVHGGGAEREVALERFREWMMNLLLDIVQDQTSPASLVHLAFKFLYIITKVRGYKTFLRLFPHEVADVEPVLDLVTIQNPKDHEAWETRYMLLLWLSVTCLIPFDFSRLDGNLLTQPGQARMSIMDRILQIAESYLIVSDKARDAAAVLVSRFITRPDVKQSKMAEFLDWSLCNLARSSFQTMQGVITMDGTLQALAQIFKHGKREDCLPYAATVLRCLDGCRLPESNQTLLRKLGVKLVQRLGLTFLKPKVAAWRYQRGCRSLAANLQLLTQGQSEQKPLILTEDDDEDDDVPEGVERVIEQLLVGLKDKDTVVRWSAAKGIGRMAGRLPRALADDVVGSVLDCFSFQETDKAWHGGCLALAELGRRGLLLPSRLVDVVAVILKALTYDEKRGACSVGTNVRDAACYVCWAFARAYEPQELKPFVTAISSALVIAAVFDRDINCRRAASAAFQENVGRQGTFPHGIDILTTADYFAVGNRSNCFLVISVFIAGFPEYTQPMIDHLVTMKISHWDGVIRELAARALHNLAQQAPEFSATQVFPRLLSMTLSPDLHMRHGSILACAEVAYALYKLAAQENRPVTDHLDEQAVQGLKQIHQQLYDRQLYRGLGGQLMRQAVCVLIEKLSLSKMPFRGDTVIDGWQWLINDTLRHLHLISSHSRQQMKDAAVSALAALCSDTAWDAELAVVREQRNRLCDLLGVPRPQLVPQPGAC>sp|Q15025|TNIP1_HUMAN TNFAIP3-interacting protein 1 OS=Homo sapiensOX=9606 GN=TNIP1 PE=1 SV=2MEGRGPYRIYDPGGSVPSGEASAAFERLVKENSRLKEKMQGIKMLGELLEESQMEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKASGERYHVEPHPEHLCGAYPYAYPPMPAMVPHHGFEDWSQIRYPPPPMAMEHPPPLPNSRLFHLPEYTWRLPCGGVRNPNQSSQVMDPPTARPTEPESPKNDREGPQ>sp|Q15025-2|TNIP1_HUMAN Isoform 2 of TNFAIP3-interacting protein 1OS=Homo sapiens OX=9606 GN=TNIP1MEGRGPYRIYDPGGSVPSGEASAAFERLVKENSRLKEKMQGIKMLGELLEESQMEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKASGERYHVEPHPEHLCGAYPYAYPPMPAMVPHHGFEDWSQIRYPPPPMAMEHPPPLPNSRLFHLPEYTWRLPCGGVRNPNQSSQVMDPPTARPTEPEPADLRLPRN>sp|Q15025-3|TNIP1_HUMAN Isoform 3 of TNFAIP3-interacting protein 1OS=Homo sapiens OX=9606 GN=TNIP1MEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKASGERYHVEPHPEHLCGAYPYAYPPMPAMVPHHGFEDWSQIRYPPPPMAMEHPPPLPNSRLFHLPEYTWRLPCGGVRNPNQSSQVMDPPTARPTEPESPKNDREGPQ>sp|Q15025-4|TNIP1_HUMAN Isoform 4 of TNFAIP3-interacting protein 1OS=Homo sapiens OX=9606 GN=TNIP1MEGRGPYRIYDPGGSVPSGEASAAFERLVKENSRLKEKMQGIKMLGELLEESQMEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKPEYTWRLPCGGVRNPNQSSQVMDPPTARPTEPESPKNDREGPQ>sp|Q15025-5|TNIP1_HUMAN Isoform 5 of TNFAIP3-interacting protein 1OS=Homo sapiens OX=9606 GN=TNIP1MEGRGPYRIYDPGGSVPSGEASAAFERLVKENSRLKEKMQGIKMLGELLEESQMEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKSLQKMTVRGLSETRLCHLAPPSSCRAS>sp|Q15025-6|TNIP1_HUMAN Isoform 6 of TNFAIP3-interacting protein 1OS=Homo sapiens OX=9606 GN=TNIP1MEGRGPYRIYDPGGSVPSGEASAAFERLVKENSRLKEKMQGIKMLGELLEESQMEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKPEYTWRLPCGGVRNPNQSSQVMDPPTARPTEPEPADLRLPRN>sp|Q15025-7|TNIP1_HUMAN Isoform 7 of TNFAIP3-interacting protein 1OS=Homo sapiens OX=9606 GN=TNIP1MEGRGPYRIYDPGGSVPSGEASAAFERLVKENSRLKEKMQGIKMLGELLEESQMEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKGTHRGCPRRLPERKVK>sp|Q15025-8|TNIP1_HUMAN Isoform 8 of TNFAIP3-interacting protein 1OS=Homo sapiens OX=9606 GN=TNIP1MEGRGPYRIYDPGGSVPSGEASAAFERLVKENSRLKEKMQGIKMLGELLEESQMEATRLRQKAEELVKDNELLPPPSPSLGSFDPLAELTGKDSNVTASPTAPACPSDKPAPVQKPPSSGTSSEFEVVTPEEQNSPESSSHANAMALGPLPREDGNLMLHLQRLETTLSVCAEEPDHGQLFTHLGRMALEFNRLASKVHKNEQRTSILQTLCEQLRKENEALKAKLDKGLEQRDQAAERLREENLELKKLLMSNGNKEGASGRPGSPKMEGTGKKAVAGQQQASVTAGKVPEVVALGAAEKKVKMLEQQRSELLEVNKQWDQHFRSMKQQYEQKITELRQKLADLQKQVTDLEAEREQKQRDFDRKLLLAKSKIEMEETDKEQLTAEAKELRQKVKYLQDQLSPLTRQREYQEKEIQRLNKALEEALSIQTPPSSPPTAFGSPEGAGALLRKQELVTQNELLKQQVKIFEEDFQRERSDRERMNEEKEELKKQVEKLQAQVTLSNAQLKAFKDEEKAREALRQQKRKAKSQLISDCQETRSHLHGVARASAG>sp|Q5BJH2|TM128_HUMAN Transmembrane protein 128 OS=Homo sapiens OX=9606GN=TMEM128 PE=1 SV=2MDSSRARQQLRRRFLLLPDAEAQLDREGDAGPETSTAVEKKEKPLPRLNIHSGFWILASIVVTYYVDFFKTLKENFHTSSWFLCGSALLLVSLSIAFYCIVYLEWYCGIGEYDVKYPALIPITTASFIAAGICFNIALWHVWSFFTPLLLFTQFMGVVMFITLLG>sp|Q5BJH2-2|TM128_HUMAN Isoform 2 of Transmembrane protein 128 OS=Homosapiens OX=9606 GN=TMEM128MPPFGYKTETSTAVEKKEKPLPRLNIHSGFWILASIVVTYYVDFFKTLKENFHTSSWFLCGSALLLVSLSIAFYCIVYLEWYCGIGEYDVKYPALIPITTASFIAAGICFNIALWHVWSFFTPLLLFTQFMGVVMFITLLG>sp|P43489|TNR4_HUMAN Tumor necrosis factor receptor superfamily member 4OS=Homo sapiens OX=9606 GN=TNFRSF4 PE=1 SV=1MCVGARRLGRGPCAALLLLGLGLSTVTGLHCVGDTYPSNDRCCHECRPGNGMVSRCSRSQNTVCRPCGPGFYNDVVSSKPCKPCTWCNLRSGSERKQLCTATQDTVCRCRAGTQPLDSYKPGVDCAPCPPGHFSPGDNQACKPWTNCTLAGKHTLQPASNSSDAICEDRDPPATQPQETQGPPARPITVQPTEAWPRTSQGPSTRPVEVPGGRAVAAILGLGLVLGLLGPLAILLALYLLRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKI>sp|P07204|TRBM_HUMAN Thrombomodulin OS=Homo sapiens OX=9606 GN=THBD PE=1SV=2MLGVLVLGALALAGLGFPAPAEPQPGGSQCVEHDCFALYPGPATFLNASQICDGLRGHLMTVRSSVAADVISLLLNGDGGVGRRRLWIGLQLPPGCGDPKRLGPLRGFQWVTGDNNTSYSRWARLDLNGAPLCGPLCVAVSAAEATVPSEPIWEEQQCEVKADGFLCEFHFPATCRPLAVEPGAAAAAVSITYGTPFAARGADFQALPVGSSAAVAPLGLQLMCTAPPGAVQGHWAREAPGAWDCSVENGGCEHACNAIPGAPRCQCPAGAALQADGRSCTASATQSCNDLCEHFCVPNPDQPGSYSCMCETGYRLAADQHRCEDVDDCILEPSPCPQRCVNTQGGFECHCYPNYDLVDGECVEPVDPCFRANCEYQCQPLNQTSYLCVCAEGFAPIPHEPHRCQMFCNQTACPADCDPNTQASCECPEGYILDDGFICTDIDECENGGFCSGVCHNLPGTFECICGPDSALARHIGTDCDSGKVDGGDSGSGEPPPSPTPGSTLTPPAVGLVHSGLLIGISIASLCLVVALLALLCHLRKKQGAARAKMEYKCAAPSKEVVLQHVRTERTPQRL>sp|Q6ICL3|TNG2_HUMAN Transport and Golgi organization protein 2 homologOS=Homo sapiens OX=9606 GN=TANGO2 PE=1 SV=1MCIIFFKFDPRPVSKNAYRLILAANRDEFYSRPSKLADFWGNNNEILSGLDMEEGKEGGTWLGISTRGKLAALTNYLQPQLDWQARGRGELVTHFLTTDVDSLSYLKKVSMEGHLYNGFNLIAADLSTAKGDVICYYGNRGEPDPIVLTPGTYGLSNALLETPWRKLCFGKQLFLEAVERSQALPKDVLIASLLDVLNNEEAQLPDPAIEDQGGEYVQPMLSKYAAVCVRCPGYGTRTNTIILVDADGHVTFTERSMMDKDLSHWETRTYEFTLQS>sp|Q6ICL3-2|TNG2_HUMAN Isoform 2 of Transport and Golgi organizationprotein 2 homolog OS=Homo sapiens OX=9606 GN=TANGO2MCIIFFKFDPRPVSKNAYRLILAANRDEFYSRPSKLADFWGNNNEILSGLDMEEGKEGGTWLGISTRGKLAALTNYLQPQLDWQARGRGTYGLSNALLETPWRKLCFGKQLFLEAVERSQALPKDVLIASLLDVLNNEEAQLPDPAIEDQGGEYVQPMLSKYAAVCVRCPGYGTRTNTIILVDADGHVTFTERSMMDKDLSHWETRTYEFTLQS>sp|Q6ICL3-3|TNG2_HUMAN Isoform 3 of Transport and Golgi organizationprotein 2 homolog OS=Homo sapiens OX=9606 GN=TANGO2MPLGAGTPVNVQRREDSATEGSHRLILAANRDEFYSRPSKLADFWGNNNEILSGLDMEEGKEGGTWLGISTRGKLAALTNYLQPQLDWQARGRGELVTHFLTTDVDSLSYLKKVSMEGHLYNGFNLIAADLSTAKGDVICYYGNRGEPDPIVLTPGTYGLSNALLETPWRKLCFGKQLFLEAVERSQALPKDVLNNEEAQLPDPAIEDQGGEYVQPMLSKYAAVCVRCPGYGTRTNTIILVDADGHVTFTERSMMDKDLSHWETRTYEFTLQS>sp|Q6ICL3-4|TNG2_HUMAN Isoform 4 of Transport and Golgi organizationprotein 2 homolog OS=Homo sapiens OX=9606 GN=TANGO2MPPKLLCAGRCVGQDGAAQAWHCPPGQGHSVWDAVRMPLGAGTPVNVQRREDSATEGSHRLILAANRDEFYSRPSKLADFWGNNNEILSGLDMEEGKEGGTWLGISTRGKLAALTNYLQPQLDWQARGRGELVTHFLTTDVDSLSYLKKVSMEGHLYNGFNLIAADLSTAKGDVICYYGNRGEPDPIVLTPGTYGLSNALLETPWRKLCFGKQLFLEAVERSQALPKDVLIASLLDVLNNEEAQLPDPAIEDQGGEYVQPMLSKYAAVCVRCPGYGTRTNTIILVDADGHVTFTERSMMDKDLSHWETRTYEFTLQS>sp|Q6ICL3-5|TNG2_HUMAN Isoform 5 of Transport and Golgi organizationprotein 2 homolog OS=Homo sapiens OX=9606 GN=TANGO2MAGHQHTWQAGSTHQLPAAAAGLAGPRASTAKGDVICYYGNRGEPDPIVLTPGTYGLSNALLETPWRKLCFGKQLFLEAVERSQALPKDVLIASLLDVLNNEEAQLPDPAIEDQGGEYVQPMLSKYAAVCVRCPGYGTRTNTIILVDADGHVTFTERSMMDKDLSHWETRTYEFTLQS>sp|Q6ICL3-6|TNG2_HUMAN Isoform 6 of Transport and Golgi organizationprotein 2 homolog OS=Homo sapiens OX=9606 GN=TANGO2MPPKLLCAGRCVGQDGAAQAWHCPPGQGHSVWDAVRMPLGAGTPVNVQRREDSATEGSHRLILAANRDEFYSRPSKLADFWGNNNEILSGLDMEEGKEGGTWLGISTRGKLAALTNYLQPQLDWQARGRGELVTHFLTTDVDSLSYLKKVSMEGHLYNGFNLIAADLSTAKGDVICYYGNRGEPDPIVLTPEPTLSSW>sp|I1YAP6|TRI77_HUMAN Tripartite motif-containing protein 77 OS=Homosapiens OX=9606 GN=TRIM77 PE=2 SV=2MASAITQCSTSELTCSICTDYLTDPVTICCGHRFCSPCLCLLWEDTLTPNCCPVCREISQQMYFKRIIFAEKQVIPTRESVPCQLSSSAMLICRRHQEIKNLICETDRSLLCFLCSQSPRHATHKHYMTREADEYYRKKLLIQMKSIWKKKQKNQRNLNRETNIIGTWEVFINLRSMMISAEYPKVCQYLREEEQKHVESLAREGRIIFQQLKRSQTRMAKMGILLREMYEKLKEMSCKADVNLPQDLGDVMKRNEFLRLAMPQPVNPQLSAWTITGVSERLNFFRVYITLDRKICSNHKLLFEDLRHLQCSLDDTDMSCNPTSTQYTSSWGAQILSSGKHYWEVDVKDSCNWVIGLCREAWTKRNDMRLDSEGIFLLLCLKVDDHFSLFSTSPLLPHYIPRPQGWLGVFLDYECGIVSFVNVAQSSLICSFLSRIFYFPLRPFICHGSK>sp|Q07011|TNR9_HUMAN Tumor necrosis factor receptor superfamily member 9OS=Homo sapiens OX=9606 GN=TNFRSF9 PE=1 SV=1MGNSCYNIVATLLLVLNFERTRSLQDPCSNCPAGTFCDNNRNQICSPCPPNSFSSAGGQRTCDICRQCKGVFRTRKECSSTSNAECDCTPGFHCLGAGCSMCEQDCKQGQELTKKGCKDCCFGTFNDQKRGICRPWTNCSLDGKSVLVNGTKERDVVCGPSPADLSPGASSVTPPAPAREPGHSPQIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL>sp|Q9NYK1|TLR7_HUMAN Toll-like receptor 7 OS=Homo sapiens OX=9606GN=TLR7 PE=1 SV=1MVFPMWTLKRQILILFNIILISKLLGARWFPKTLPCDVTLDVPKNHVIVDCTDKHLTEIPGGIPTNTTNLTLTINHIPDISPASFHRLDHLVEIDFRCNCVPIPLGSKNNMCIKRLQIKPRSFSGLTYLKSLYLDGNQLLEIPQGLPPSLQLLSLEANNIFSIRKENLTELANIEILYLGQNCYYRNPCYVSYSIEKDAFLNLTKLKVLSLKDNNVTAVPTVLPSTLTELYLYNNMIAKIQEDDFNNLNQLQILDLSGNCPRCYNAPFPCAPCKNNSPLQIPVNAFDALTELKVLRLHSNSLQHVPPRWFKNINKLQELDLSQNFLAKEIGDAKFLHFLPSLIQLDLSFNFELQVYRASMNLSQAFSSLKSLKILRIRGYVFKELKSFNLSPLHNLQNLEVLDLGTNFIKIANLSMFKQFKRLKVIDLSVNKISPSGDSSEVGFCSNARTSVESYEPQVLEQLHYFRYDKYARSCRFKNKEASFMSVNESCYKYGQTLDLSKNSIFFVKSSDFQHLSFLKCLNLSGNLISQTLNGSEFQPLAELRYLDFSNNRLDLLHSTAFEELHKLEVLDISSNSHYFQSEGITHMLNFTKNLKVLQKLMMNDNDISSSTSRTMESESLRTLEFRGNHLDVLWREGDNRYLQLFKNLLKLEELDISKNSLSFLPSGVFDGMPPNLKNLSLAKNGLKSFSWKKLQCLKNLETLDLSHNQLTTVPERLSNCSRSLKNLILKNNQIRSLTKYFLQDAFQLRYLDLSSNKIQMIQKTSFPENVLNNLKMLLLHHNRFLCTCDAVWFVWWVNHTEVTIPYLATDVTCVGPGAHKGQSVISLDLYTCELDLTNLILFSLSISVSLFLMVMMTASHLYFWDVWYIYHFCKAKIKGYQRLISPDCCYDAFIVYDTKDPAVTEWVLAELVAKLEDPREKHFNLCLEERDWLPGQPVLENLSQSIQLSKKTVFVMTDKYAKTENFKIAFYLSHQRLMDEKVDVIILIFLEKPFQKSKFLQLRKRLCGSSVLEWPTNPQAHPYFWQCLKNALATDNHVAYSQVFKETV>sp|Q9UBN6|TR10D_HUMAN Tumor necrosis factor receptor superfamily member10D OS=Homo sapiens OX=9606 GN=TNFRSF10D PE=1 SV=1MGLWGQSVPTASSARAGRYPGARTASGTRPWLLDPKILKFVVFIVAVLLPVRVDSATIPRQDEVPQQTVAPQQQRRSLKEEECPAGSHRSEYTGACNPCTEGVDYTIASNNLPSCLLCTVCKSGQTNKSSCTTTRDTVCQCEKGSFQDKNSPEMCRTCRTGCPRGMVKVSNCTPRSDIKCKNESAASSTGKTPAAEETVTTILGMLASPYHYLIIIVVLVIILAVVVVGFSCRKKFISYLKGICSGGGGGPERVHRVLFRRRSCPSRVPGAEDNARNETLSNRYLQPTQVSEQEIQGQELAELTGVTVESPEEPQRLLEQAEAEGCQRRRLLVPVNDADSADISTLLDASATLEEGHAKETIQDQLVGSEKLFYEEDEAGSATSCL>sp|P25445|TNR6_HUMAN Tumor necrosis factor receptor superfamily member 6OS=Homo sapiens OX=9606 GN=FAS PE=1 SV=1MLGIWTLLPLVLTSVARLSSKSVNAQVTDINSKGLELRKTVTTVETQNLEGLHHDGQFCHKPCPPGERKARDCTVNGDEPDCVPCQEGKEYTDKAHFSSKCRRCRLCDEGHGLEVEINCTRTQNTKCRCKPNFFCNSTVCEHCDPCTKCEHGIIKECTLTSNTKCKEEGSRSNLGWLCLLLLPIPLIVWVKRKEVQKTCRKHRKENQGSHESPTLNPETVAINLSDVDLSKYITTIAGVMTLSQVKGFVRKNGVNEAKIDEIKNDNVQDTAEQKVQLLRNWHQLHGKKEAYDTLIKDLKKANLCTLAEKIQTIILKDITSDSENSNFRNEIQSLV>sp|P25445-2|TNR6_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 6 OS=Homo sapiens OX=9606 GN=FASMLGIWTLLPLVLTSVARLSSKSVNAQVTDINSKGLELRKTVTTVETQNLEGLHHDGQFCHKPCPPDVNMESSRNAHSPATPSAKRKDPDLTWGGFVFFFCQFH>sp|P25445-3|TNR6_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 6 OS=Homo sapiens OX=9606 GN=FASMLGIWTLLPLVLTSVARLSSKSVNAQVTDINSKGLELRKTVTTVETQNLEGLHHDGQFCHKPCPPDVNMESSRNAHSPATPSAKRK>sp|P25445-4|TNR6_HUMAN Isoform 4 of Tumor necrosis factor receptorsuperfamily member 6 OS=Homo sapiens OX=9606 GN=FASMLGIWTLLPLVLTSVARLSSKSVNAQVTDINSKGLELRKTVTTVETQNLEGLHHDGQFCHKPCPPGERKARDCTVNGDEPDCVPCQEGKEYTDKAHFSSKCRRCRLCDEGHDVNMESSRNAHSPATPSAKRKDPDLTWGGFVFFFCQFH>sp|P25445-5|TNR6_HUMAN Isoform 5 of Tumor necrosis factor receptorsuperfamily member 6 OS=Homo sapiens OX=9606 GN=FASMLGIWTLLPLVLTSVARLSSKSVNAQVTDINSKGLELRKTVTTVETQNLEGLHHDGQFCHKPCPPGERKARDCTVNGDEPDCVPCQEGKEYTDKAHFSSKCRRCRLCDEGHDVNMESSRNAHSPATPSAKRK>sp|P25445-6|TNR6_HUMAN Isoform 6 of Tumor necrosis factor receptorsuperfamily member 6 OS=Homo sapiens OX=9606 GN=FASMLGIWTLLPLVLTSVARLSSKSVNAQVTDINSKGLELRKTVTTVETQNLEGLHHDGQFCHKPCPPGERKARDCTVNGDEPDCVPCQEGKEYTDKAHFSSKCRRCRLCDEGHGLEVEINCTRTQNTKCRCKPNFFCNSTVCEHCDPCTKCEHGIIKECTLTSNTKCKEEVKRKEVQKTCRKHRKENQGSHESPTLNPETVAINLSDVDLSKYITTIAGVMTLSQVKGFVRKNGVNEAKIDEIKNDNVQDTAEQKVQLLRNWHQLHGKKEAYDTLIKDLKKANLCTLAEKIQTIILKDITSDSENSNFRNEIQSLV>sp|P25445-7|TNR6_HUMAN Isoform 7 of Tumor necrosis factor receptorsuperfamily member 6 OS=Homo sapiens OX=9606 GN=FASMLGIWTLLPLVLTSVARLSSKSVNAQVTDINSKGLELRKTVTTVETQNLEGLHHDGQFCHKPCPPGERKARDCTVNGDEPDCVPCQEGKEYTDKAHFSSKCRRCRLCDEGHGLEVEINCTRTQNTKCRCKPNFFCNSTVCEHCDPCTKCEHGIIKECTLTSNTKCKEEGSRSNLGWLCLLLLPIPLIVWVKRKEVQKTCRKHRKENQGSHESPTLNPMLT>sp|Q96EY4|TMA16_HUMAN Translation machinery-associated protein 16OS=Homo sapiens OX=9606 GN=TMA16 PE=1 SV=2MPKAPKGKSAGREKKVIHPYSRKAAQITREAHKQEKKEKLKNEKALRLNLVGEKLQWFQNHLDPQKKRYSKKDACELIERYLNRFSSELEQIELHNSIRDRQGRRHCSRETVIKQTMERERQQFEGYGLEIPDILNASNLKTFREWDFDLKKLPNIKMRKICANDAIPKTCKRKTIITVDQDLGELELNDESSDSDEEMTAVA>sp|Q8WVP5|TP8L1_HUMAN Tumor necrosis factor alpha-induced protein 8-likeprotein 1 OS=Homo sapiens OX=9606 GN=TNFAIP8L1 PE=1 SV=2MDTFSTKSLALQAQKKLLSKMASKAVVAVLVDDTSSEVLDELYRATREFTRSRKEAQKMLKNLVKVALKLGLLLRGDQLGGEELALLRRFRHRARCLAMTAVSFHQVDFTFDRRVLAAGLLECRDLLHQAVGPHLTAKSHGRINHVFGHLADCDFLAALYGPAEPYRSHLRRICEGLGRMLDEGSL>sp|Q7Z404|TMC4_HUMAN Transmembrane channel-like protein 4 OS=Homosapiens OX=9606 GN=TMC4 PE=1 SV=3MEENPTLESEAWGSSRGWLAPREARGAPCSSPGPSLSSVLNELPSAATLRYRDPGVLPWGALEEEEEDGGRSRKAFTEVTQTELQDPHPSRELPWPMQARRAHRQRNASRDQVVYGSGTKTDRWARLLRRSKEKTKEGLRSLQPWAWTLKRIGGQFGAGTESYFSLLRFLLLLNVLASVLMACMTLLPTWLGGAPPGPPGPDISSPCGSYNPHSQGLVTFATQLFNLLSGEGYLEWSPLFYGFYPPRPRLAVTYLCWAFAVGLICLLLILHRSVSGLKQTLLAESEALTSYSHRVFSAWDFGLCGDVHVRLRQRIILYELKVELEETVVRRQAAVRTLGQQARVWLVRVLLNLLVVALLGAAFYGVYWATGCTVELQEMPLVQELPLLKLGVNYLPSIFIAGVNFVLPPVFKLIAPLEGYTRSRQIVFILLRTVFLRLASLVVLLFSLWNQITCGGDSEAEDCKTCGYNYKQLPCWETVLGQEMYKLLLFDLLTVLAVALLIQFPRKLLCGLCPGALGRLAGTQEFQVPDEVLGLIYAQTVVWVGSFFCPLLPLLNTVKFLLLFYLKKLTLFSTCSPAARTFRASAANFFFPLVLLLGLAISSVPLLYSIFLIPPSKLCGPFRGQSSIWAQIPESISSLPETTQNFLFFLGTQAFAVPLLLISSILMAYTVALANSYGRLISELKRQRQTEAQNKVFLARRAVALTSTKPAL>sp|Q7Z404-1|TMC4_HUMAN Isoform 2 of Transmembrane channel-like protein 4OS=Homo sapiens OX=9606 GN=TMC4MEENPTLESEAWGSSRGWLAPREARGGPSLSSVLNELPSAATLRYRDPGVLPWGALEEEEEDGGRSRKAFTEVTQTELQDPHPSRELPWPMQARRAHRQRNASRDQVVYGSGTKTDRWARLLRRSKEKTKEGLRSLQPWAWTLKRIGGQFGAGTESYFSLLRFLLLLNVLASVLMACMTLLPTWLGGAPPGPPGPDISSPCGSYNPHSQGLVTFATQLFNLLSGEGYLEWSPLFYGFYPPRPRLAVTYLCWAFAVGLICLLLILHRSVSGLKQTLLAESEALTSYSHRVFSAWDFGLCGDVHVRLRQRIILYELKVELEETVVRRQAAVRTLGQQARVWLVRVLLNLLVVALLGAAFYGVYWATGCTVELQEMPLVQELPLLKLGVNYLPSIFIAGVNFVLPPVFKLIAPLEGYTRSRQIVFILLRTVFLRLASLVVLLFSLWNQITCGGDSEAEDCKTCGYNYKQLPCWETVLGQEMYKLLLFDLLTVLAVALLIQFPRKLLCGLCPGALGRLAGTQEFQVPDEVLGLIYAQTVVWVGSFFCPLLPLLNTVKFLLLFYLKKLTLFSTCSPAARTFRASAANFFFPLVLLLGLAISSVPLLYSIFLIPPSKLCGPFRGQSSIWAQIPESISSLPETTQNFLFFLGTQAFAVPLLLISSILMAYTVALANSYGRLISELKRQRQTEAQNKVFLARRAVALTSTKPAL>sp|Q7Z404-3|TMC4_HUMAN Isoform 3 of Transmembrane channel-like protein 4OS=Homo sapiens OX=9606 GN=TMC4MKGGGGQRDVGADRTVFLRLASLVVLLFSLWNQITCGGDSEAEDCKTCGYNYKQLPCWETVLGQEMYKLLLFDLLTVLAVALLIQFPRKLLCGLCPGALGRLAGTQEFQVPDEVLGLIYAQTVVWVGSFFCPLLPLLNTVKFLLLFYLKKLTLFSTCSPAARTFRASAANFFFPLVLLLGLAISSVPLLYSIFLIPPSKLCGPFRGQSSIWAQIPESISSLPETTQNFLFFLGTQAFAVPLLLISSILMAYTVALANSYGRLISELKRQRQTEAQNKVFLARRAVALTSTKPAL>sp|Q7Z402|TMC7_HUMAN Transmembrane channel-like protein 7 OS=Homosapiens OX=9606 GN=TMC7 PE=1 SV=1MSESSGSALQPGRPSRQPAVHPENLSLDSSCFSSPPVNFLQELPSYRSIARRRTTVHSRDKQSGTLLKPTDSYSSQLEDRIAENLSSHSLRNYALNISEKRRLRDIQETQMKYLSEWDQWKRYSSKSWKRFLEKAREMTTHLELWREDIRSIEGKFGTGIQSYFSFLRFLVLLNLVIFLIIFMLVLLPVLLTKYKITNSSFVLIPFKDMDKQCTVYPVSSSGLIYFYSYIIDLLSGTGFLEETSLFYGHYTIDGVKFQNFTYDLPLAYLLSTIASLALSLLWIVKRSVEGFKINLIRSEEHFQSYCNKIFAGWDFCITNRSMADLKHSSLRYELRADLEEERMRQKIAERTSEETIRIYSLRLFLNCIVLAVLGACFYAIYVATVFSQEHMKKEIDKMVFGENLFILYLPSIVITLANFITPMIFAKIIRYEDYSPGFEIRLTILRCVFMRLATICVLVFTLGSKITSCDDDTCDLCGYNQKLYPCWETQVGQEMYKLMIFDFIIILAVTLFVDFPRKLLVTYCSSCKLIQCWGQQEFAIPDNVLGIVYGQTICWIGAFFSPLLPAIATLKFIIIFYVKEWSLLYTCRPSPRPFRASNSNFFFLLVLLIGLCLAIIPLTISISRIPSSKACGPFTNFNTTWEVIPKTVSTFPSSLQSFIHGVTSEAFAVPFFMIICLIMFYFIALAGAHKRVVIQLREQLSLESRDKCYLIQKLTEAQRDMRN>sp|Q7Z402-2|TMC7_HUMAN Isoform 2 of Transmembrane channel-like protein 7OS=Homo sapiens OX=9606 GN=TMC7MKYLSEWDQWKRYSSKSWKRFLEKAREMTTHLELWREDIRSIEGKFGTGIQSYFSFLRFLVLLNLVIFLIIFMLVLLPVLLTKYKITNSSFVLIPFKDMDKQCTVYPVSSSGLIYFYSYIIDLLSGTGFLEETSLFYGHYTIDGVKFQNFTYDLPLAYLLSTIASLALSLLWIVKRSVEGFKINLIRSEEHFQSYCNKIFAGWDFCITNRSMADLKHSSLRYELRADLEEERMRQKIAERTSEETIRIYSLRLFLNCIVLAVLGACFYAIYVATVFSQEHMKKEIDKMVFGENLFILYLPSIVITLANFITPMIFAKIIRYEDYSPGFEIRLTILRCVFMRLATICVLVFTLGSKITSCDDDTCDLCGYNQKLYPCWETQVGQEMYKLMIFDFIIILAVTLFVDFPRKLLVTYCSSCKLIQCWGQQEFAIPDNVLGIVYGQTICWIGAFFSPLLPAIATLKFIIIFYVKEWSLLYTCRPSPRPFRASNSNFFFLLVLLIGLCLAIIPLTISISRIPSSKACGPFTNFNTTWEVIPKTVSTFPSSLQSFIHGVTSEAFAVPFFMIICLIMFYFIALAGAHKRVVIQLREQLSLESRDKCYLIQKLTEAQRDMRN>sp|P19429|TNNI3_HUMAN Troponin I, cardiac muscle OS=Homo sapiens OX=9606GN=TNNI3 PE=1 SV=3MADGSSDAAREPRPAPAPIRRRSSNYRAYATEPHAKKKSKISASRKLQLKTLLLQIAKQELEREAEERRGEKGRALSTRCQPLELAGLGFAELQDLCRQLHARVDKVDEERYDIEAKVTKNITEIADLTQKIFDLRGKFKRPTLRRVRISADAMMQALLGARAKESLDLRAHLKQVKKEDTEKENREVGDWRKNIDALSGMEGRKKKFES>sp|P55327|TPD52_HUMAN Tumor protein D52 OS=Homo sapiens OX=9606 GN=TPD52PE=1 SV=2MDCREMDLYEDYQSPFDFDAGVNKSYLYLSPSGNSSPPGSPTLQKFGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSAYKKTSETLSQAGQKASAAFSSVGSVITKKLEDVKNSPTFKSFEEKVENLKSKVGGTKPAGGDFGEVLNSAANASATTTEPLPEKTQESL>sp|P55327-2|TPD52_HUMAN Isoform 2 of Tumor protein D52 OS=Homo sapiensOX=9606 GN=TPD52MDRGEQGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSAYKKTSETLSQAGQKASAAFSSVGSVITKKLEDVKNSPTFKSFEEKVENLKSKVGGTKPAGGDFGEVLNSAANASATTTEPLPEKTQESL>sp|P55327-3|TPD52_HUMAN Isoform 3 of Tumor protein D52 OS=Homo sapiensOX=9606 GN=TPD52MTPRESAPGRGRAAPPRPTPLGVGTSRESPAEARRSSARRGGRSEPGRAAGGGAAEDTRRRAGDMDRGEQGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSAYKKTSETLSQAGQKASAAFSSVGSVITKKLEDVKNSPTFKSFEEKVENLKSKVGGTKPAGGDFGEVLNSAANASATTTEPLPEKTQESL>sp|P55327-4|TPD52_HUMAN Isoform 4 of Tumor protein D52 OS=Homo sapiensOX=9606 GN=TPD52MDRGEQGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSAYKKTSETLSQAGQKASAAFSSVGSVITKKLEDVKLQAFSHSFSIRSIQHSISMPAMRNSPTFKSFEEKVENLKSKVGGTKPAGGDFGEVLNSAANASATTTEPLPEKTQESL>sp|P55327-5|TPD52_HUMAN Isoform 5 of Tumor protein D52 OS=Homo sapiensOX=9606 GN=TPD52MDCREMDLYEDYQSPFDFDAGVNKSYLYLSPSGNSSPPGSPTLQKFGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSAYKKTSETLSQAGQKASAAFSSVGSVITKKLEDVNIRSIQHSISMPAMRNSPTFKSFEEKVENLKSKVGGTKPAGGDFGEVLNSAANASATTTEPLPEKTQESL>sp|P55327-6|TPD52_HUMAN Isoform 6 of Tumor protein D52 OS=Homo sapiensOX=9606 GN=TPD52MDCREMDLYEDYQSPFDFDAGVNKSYLYLSPSGNSSPPGSPTLQKFGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSAYKKTSETLSQAGQKASAAFSSVGSVITKKLEDVKLQAFSHSFSIRSIQHSISMPAMRNSPTFKSFEEKVENLKSKVGGTKPAGGDFGEVLNSAANASATTTEPLPEKTQESL>sp|P55327-7|TPD52_HUMAN Isoform 7 of Tumor protein D52 OS=Homo sapiensOX=9606 GN=TPD52MDCREMDLYEDYQSPFDFDAGVNKSYLYLSPSGNSSPPGSPTLQKFGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSAYKKTSETLSQAGQKASAAFSSVGSVITKKLEDVKLQAFSHSFRNSPTFKSFEEKVENLKSKVGGTKPAGGDFGEVLNSAANASATTTEPLPEKTQESL>sp|P55327-8|TPD52_HUMAN Isoform 8 of Tumor protein D52 OS=Homo sapiensOX=9606 GN=TPD52MDCREMDLYEDYQSPFDFDAGVNKSYLYLSPSGNSSPPGSPTLQKFGLLRTDPVPEEGEDVAATISATETLSEEEQEELRRELAKVEEEIQTLSQVLAAKEKHLAEIKRKLGINSLQELKQNIAKGWQDVTATSARSKLLAAETELLCLLY>sp|Q6ZT21|TMPPE_HUMAN Transmembrane protein with metallophosphoesterasedomain OS=Homo sapiens OX=9606 GN=TMPPE PE=1 SV=2MAIFRQLSLGAKATLAAVTVFVSMIASRSYLAESLELRAWRWLLRLQLALFVNSLLLIGSLYIWRSTVSNLCHSPAAESTCFQLWKVVVLAFLALAHSSFFTMFFLVAEEPYLFSLAAYSCLGAYIIMLFFLFILSGMEQAYQLLAWRSGRVVGSLEKTRKLVLRPALAVGVTAVLSVAGILNAAQPPAVKTVEVPIHQLPASMNNLKIVLLSDIHLGPTVGRTKMEMFVRMVNVLEPDITVIVGDLSDSEASVLRTAVAPLGQLHSHLGAYFVTGNHEYYTSDVSNWFALLESLHVQPLHNENVKISATRAQRGGGGSGSGSEDEDWICLAGVDDIEADILHYSGHGMDLDKALEGCSPDHTIILLAHQPLAAKRALQARPDINLILSGHTHAGQIFPLNVAAYLLNPFFAGLYQVAQATFVYVSPGTAYYGIPMRLGSRAEITELILQRSP>sp|Q6ZT21-2|TMPPE_HUMAN Isoform 2 of Transmembrane protein withmetallophosphoesterase domain OS=Homo sapiens OX=9606 GN=TMPPEMEQAYQLLAWRSGRVVGSLEKTRKLVLRPALAVGVTAVLSVAGILNAAQPPAVKTVEVPIHQLPASMNNLKIVLLSDIHLGPTVGRTKMEMFVRMVNVLEPDITVIVGDLSDSEASVLRTAVAPLGQLHSHLGAYFVTGNHEYYTSDVSNWFALLESLHVQPLHNENVKISATRAQRGGGGSGSGSEDEDWICLAGVDDIEADILHYSGHGMDLDKALEGCSPDHTIILLAHQPLAAKRALQARPDINLILSGHTHAGQIFPLNVAAYLLNPFFAGLYQVAQATFVYVSPGTAYYGIPMRLGSRAEITELILQRSP>sp|Q5JTD0|TJAP1_HUMAN Tight junction-associated protein 1 OS=Homosapiens OX=9606 GN=TJAP1 PE=1 SV=1MTSAAPAKKPYRKAPPEHRELRLEIPGSRLEQEEPLTDAERMKLLQEENEELRRRLASATRRTEALERELEIGQDCLELELGQSREELDKFKDKFRRLQNSYTASQRTNQELEDKLHTLASLSHSWIFAIKKAEMDRKTLDWEIVELTNKLLDAKNTINKLEELNERYRLDCNLAVQLLKCNKSHFRNHKFADLPCELQDMVRKHLHSGQEAASPGPAPSLAPGAVVPTSVIARVLEKPESLLLNSAQSGSAGRPLAEDVFVHVDMSEGVPGDPASPPAPGSPTPQPNGECHSLGTARGSPEEELPLPAFEKLNPYPTPSPPHPLYPGRRVIEFSEDKVRIPRNSPLPNCTYATRQAISLSLVEEGSERARPSPVPSTPASAQASPHHQPSPAPLTLSAPASSASSEEDLLVSWQRAFVDRTPPPAAVAQRTAFGRDALPELQRHFAHSPADRDEVVQAPSARPEESELLLPTEPDSGFPREEEELNLPISPEEERQSLLPINRGTEEGPGTSHTEGRAWPLPSSSRPQRSPKRMGVHHLHRKDSLTQAQEQGNLLN>sp|Q5JTD0-2|TJAP1_HUMAN Isoform 2 of Tight junction-associated protein 1OS=Homo sapiens OX=9606 GN=TJAP1MTSAAPAKKPYRKAPPEHRELRLEIPGSRLEQEEPLTDAERMKLLQEENEELRRRLASATRRTEALERELEIGQDCLELELGQSREELDKFKDKFRRLQNSYTASQRTNQELEDKLHTLIKKAEMDRKTLDWEIVELTNKLLDAKNTINKLEELNERYRLDCNLAVQLLKCNKSHFRNHKFADLPCELQDMVRKHLHSGQEAASPGPAPSLAPGAVVPTSVIARVLEKPESLLLNSAQSGSAGRPLAEDVFVHVDMSEGVPGDPASPPAPGSPTPQPNGECHSLGTARGSPEEELPLPAFEKLNPYPTPSPPHPLYPGRRVIEFSEDKVRIPRNSPLPNCTYATRQAISLSLVEEGSERARPSPVPSTPASAQASPHHQPSPAPLTLSAPASSASSEEDLLVSWQRAFVDRTPPPAAVAQRTAFGRDALPELQRHFAHSPADRDEVVQAPSARPEESELLLPTEPDSGFPREEEELNLPISPEEERQSLLPINRGTEEGPGTSHTEGRAWPLPSSSRPQRSPKRMGVHHLHRKDSLTQAQEQGNLLN>sp|Q5JTD0-3|TJAP1_HUMAN Isoform 3 of Tight junction-associated protein 1OS=Homo sapiens OX=9606 GN=TJAP1MTSAAPAKKPYRKAPPEHRELRLEIPGSRLEQEEPLTDAERMK>sp|Q5JTD0-4|TJAP1_HUMAN Isoform 4 of Tight junction-associated protein 1OS=Homo sapiens OX=9606 GN=TJAP1MERELEIGQDCLELELGQSREELDKFKDKFRRLQNSYTASQRTNQELEDKLHTLIKKAEMDRKTLDWEIVELTNKLLDAKNTINKLEELNERYRLDCNLAVQLLKCNKSHFRNHKFADLPCELQDMVRKHLHSGQEAASPGPAPSLAPGAVVPTSVIARVLEKPESLLLNSAQSGSAGRPLAEDVFVHVDMSEGVPGDPASPPAPGSPTPQPNGECHSLGTARGSPEEELPLPAFEKLNPYPTPSPPHPLYPGRRVIEFSEDKVRIPRNSPLPNCTYATRQAISLSLVEEGSERARPSPVPSTPASAQASPHHQPSPAPLTLSAPASSASSEEDLLVSWQRAFVDRTPPPAAVAQRTAFGRDALPELQRHFAHSPADRDEVVQAPSARPEESELLLPTEPDSGFPREEEELNLPISPEEERQSLLPINRGTEEGPGTSHTEGRAWPLPSSSRPQRSPKRMGVHHLHRKDSLTQAQEQGNLLN>sp|B4DJY2|TM233_HUMAN Transmembrane protein 233 OS=Homo sapiens OX=9606GN=TMEM233 PE=3 SV=1MSQYAPSPDFKRALDSSPEANTEDDKTEEDVPMPKNYLWLTIVSCFCPAYPINIVALVFSIMSLNSYNDGDYEGARRLGRNAKWVAIASIIIGLLIIGISCAVHFTRNA>sp|P17752|TPH1_HUMAN Tryptophan 5-hydroxylase 1 OS=Homo sapiens OX=9606GN=TPH1 PE=1 SV=4MIEDNKENKDHSLERGRASLIFSLKNEVGGLIKALKIFQEKHVNLLHIESRKSKRRNSEFEIFVDCDINREQLNDIFHLLKSHTNVLSVNLPDNFTLKEDGMETVPWFPKKISDLDHCANRVLMYGSELDADHPGFKDNVYRKRRKYFADLAMNYKHGDPIPKVEFTEEEIKTWGTVFQELNKLYPTHACREYLKNLPLLSKYCGYREDNIPQLEDVSNFLKERTGFSIRPVAGYLSPRDFLSGLAFRVFHCTQYVRHSSDPFYTPEPDTCHELLGHVPLLAEPSFAQFSQEIGLASLGASEEAVQKLATCYFFTVEFGLCKQDGQLRVFGAGLLSSISELKHALSGHAKVKPFDPKITCKQECLITTFQDVYFVSESFEDAKEKMREFTKTIKRPFGVKYNPYTRSIQILKDTKSITSAMNELQHDLDVVSDALAKVSRKPSI>sp|P17752-2|TPH1_HUMAN Isoform 2 of Tryptophan 5-hydroxylase 1 OS=Homosapiens OX=9606 GN=TPH1MIEDNKENKDHSLERGRASLIFSLKNEVGGLIKALKIFQEKHVNLLHIESRKSKRRNSEFEIFVDCDINREQLNDIFHLLKSHTNVLSVNLPDNFTLKEDGMETVPWFPKKISDLDHCANRVLMYGSELDADHPGFKDNVYRKRRKYFADLAMNYKHGDPIPKVEFTEEEIKTWGTVFQELNKLYPTHACREYLKNLPLLSKYCGYREDNIPQLEDVSNFLKERTGFSIRPVAGYLSPRDFLSGLAFRVFHCTQYVRHSSDPFYTPEPDTCHELLGHVPLLAEPSFAQFSQEIGLASLGASEEAVQKLATCYFFTVEFGLCKQDGQLRVFGAGLLSSISELKHALSGHAKVKPFDPKITCKQECLITTFQDVYFVSESFEDAKEKMREFTKTIKRPFGVKYNPYTRSIQILKDTKSITSAMNELQHDLDVVSDALAKSLNEDVLQVSVFALLLFLPSLHGECHPDT>sp|Q9BVT8|TMUB1_HUMAN Transmembrane and ubiquitin-like domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=TMUB1 PE=1 SV=1MTLIEGVGDEVTVLFSVLACLLVLALAWVSTHTAEGGDPLPQPSGTPTPSQPSAAMAATDSMRGEAPGAETPSLRHRGQAAQPEPSTGFTATPPAPDSPQEPLVLRLKFLNDSEQVARAWPHDTIGSLKRTQFPGREQQVRLIYQGQLLGDDTQTLGSLHLPPNCVLHCHVSTRVGPPNPPCPPGSEPGPSGLEIGSLLLPLLLLLLLLLWYCQIQYRPFFPLTATLGLAGFTLLLSLLAFAMYRP>sp|Q6NT89|TRNP1_HUMAN TMF-regulated nuclear protein 1 OS=Homo sapiensOX=9606 GN=TRNP1 PE=2 SV=2MPGCRISACGPGAQEGTAEQRSPPPPWDPMPSSQPPPPTPTLTPTPTPGQSPPLPDAAGASAGAAEDQELQRWRQGASGIAGLAGPGGGSGAAAGAGGRALELAEARRRLLEVEGRRRLVSELESRVLQLHRVFLAAELRLAHRAESLSRLSGGVAQAELYLAAHGSRLKKGPRRGRRGRPPALLASALGLGGCVPWGAGRLRRGHGPEPDSPFRRSPPRGPASPQR>sp|Q2T9K0|TMM44_HUMAN Transmembrane protein 44 OS=Homo sapiens OX=9606GN=TMEM44 PE=1 SV=3MGEAPSPAPALWDWDYLDRCFARHRVCISFGLWICASSCWIAAHALLLYLRCAQKPRQDQSALCAACCLLTSLCDTVGALLARQLTIQVFTGAYLAAIDLVNFMFILFPVCGSKFKSNSDREARERKRRRQLRASVFALALPLSLGPCWALWVAVPKASATIRGPQRRLLASLLQENTEILGYLLGSVAAFGSWASRIPPLSRIAPPPTLGITTQHEIWRGQMSKPSQSPSRSPSGHWRAAAQRQVLGTEMCRGKTFPSIHLWTRLLSALAGLLYASAIVAHDQHPEYLLRATPWFLTSLGRAALDLAIIFLSCVMKSKMRQALGFAKEARESPDTQALLTCAEKEEENQENLDWVPLTTLSHCKSLRTMTAISRYMELTIEPVQQAGCSATRLPGDGQTSAGDASLQDPPSYPPVQVIRARVSSGSSSEVSSINSDLEWDPEDVNLEGSKENVELLGSQVHQDSVRTAHLSDDD>sp|Q2T9K0-2|TMM44_HUMAN Isoform 2 of Transmembrane protein 44 OS=Homosapiens OX=9606 GN=TMEM44MGEAPSPAPALWDWDYLDRCFARHRVCISFGLWICASSCWIAAHALLLYLRCAQKPRQDQSALCAACCLLTSLCDTVGALLARQLTIQVFTGAYLAAIDLVNFMFILFPVCGSKFKSNSDREARERKRRRQLRASVFALALPLSLGPCWALWVAVPKASATIRGPQRRLLASLLQENTEILGYLLGSVAAFGSWASRIPPLSRICRGKTFPSIHLWTRLLSALAGLLYASAIVAHDQHPEYLLRATPWFLTSLGRAALDLAIIFLSCVMKSKMRQALGFAKEARESPDTQALLTCAEKEEENQENLDWVPLTTLSHCKSLRTMTAISRYMELTIEPVQQAGCSATRLPGDGQTSAGDASLQDPPSYPPVQVIRARVSSGSSSEVSSINSDLEWDPEDVNLEGSKENVELLGSQVHQDSVRTAHLSDDD>sp|Q2T9K0-4|TMM44_HUMAN Isoform 3 of Transmembrane protein 44 OS=Homosapiens OX=9606 GN=TMEM44MGEAPSPAPALWDWDYLDRCFARHRVCISFGLWICASSCWIAAHALLLYLRCAQKPRQDQSALCAACCLLTSLCDTVGALLARQLTIQVFTGAYLAAIDLVNFMFILFPVCGSKFKSNSDREARERKRRRQLRASVFALALPLSLGPCWALWVAVPKASATIRGPQRRLLASLLQENTEILGYLLGSVAAFGSWASRIPPLSRICRGKTFPSIHLWTRLLSALAGLLYASAIVAHDQHPEYLLRATPWFLTSLGRAALDLAIIFLSCVMKSKMRQALGFAKEARESPDTQALLTCAEKEEENQENLDWVPLTTLSHCKSLRTMTAISRYMELTIEPVQQAAVPPGCQVTGRRAPEMRPCRTPRRTLPFRSSGPGCLPAAPLRSPPSTPTWSGTLKM>sp|Q2T9K0-6|TMM44_HUMAN Isoform 4 of Transmembrane protein 44 OS=Homosapiens OX=9606 GN=TMEM44MGEAPSPAPALWDWDYLDRCFARHRVCISFGLWICASSCWIAAHALLLYLRCAQKPRQDQSALCAACCLLTSLCDTVGALLARQLTIQVFTGAYLAAIDLVNFMFILFPVCGSKFKSNSDREARERKRRRQLRASVFALALPLSLGPCWALWVAVPKASATIRGPQRRLLASLLQENTEILGYLLGSVAAFGSWASRIPPLSRICRGKTFPSIHLWTRLLSALAGLLYASAIVAHDQHPEYLLRATPWFLTSLGRAALDLAIIFLSCVMKSKMRQALGFAKEARESPDTQALLTCAEKEEENQENLDWVPLTTLSHCKSLRTMTAISRYMELTIEPVQQAGCSATRLPGDGQTSAGDASLQDPPSYPPVQVIRARVSSGSSSEVSSINSDLEQKYWEALNSEQWDPEDVNLEGSKENVELLGSQVHQDSVRTAHLSDDD>sp|Q2T9K0-7|TMM44_HUMAN Isoform 5 of Transmembrane protein 44 OS=Homosapiens OX=9606 GN=TMEM44MGEAPSPAPALWDWDYLDRCFARHRVCISFGLWICASSCWIAAHALLLYLRCAQKPRQDQSALCAACCLLTSLCDTVGALLARQLTIQVFTGAYLAAIDLVNFMFILFPVCGSKFKSNSDREARERKRRRQLRASVFALALPLSLGPCWALWVAVPKASATIRGPQRRLLASLLQENTEILGYLLGSVAAFGSWASRIPPLSRICRGKTFPSIHLWTRLLSALAGLLYASAIVAHDQHPEYLLRATPWFLTSLGRAALDLAIIFLSCVMKSKMRQALGFAKEARESPDTQALLTCAEKEEENQENLDWVPLTTLSHCKSLRTMTAISRYMELTIEPVQQAGCSATRLPGDGQTSAGDASLQDPPSYPPVQVIRARVSSGSSSEVSSINSDLEKYWEALNSEQWDPEDVNLEGSKENVELLGSQVHQDSVRTAHLSDDD>sp|Q15361|TTF1_HUMAN Transcription termination factor 1 OS=Homo sapiensOX=9606 GN=TTF1 PE=1 SV=3MEGESSRFEIHTPVSDKKKKKCSIHKERPQKHSHEIFRDSSLVNEQSQITRRKKRKKDFQHLISSPLKKSRICDETANATSTLKKRKKRRYSALEVDEEAGVTVVLVDKENINNTPKHFRKDVDVVCVDMSIEQKLPRKPKTDKFQVLAKSHAHKSEALHSKVREKKNKKHQRKAASWESQRARDTLPQSESHQEESWLSVGPGGEITELPASAHKNKSKKKKKKSSNREYETLAMPEGSQAGREAGTDMQESQPTVGLDDETPQLLGPTHKKKSKKKKKKKSNHQEFEALAMPEGSQVGSEVGADMQESRPAVGLHGETAGIPAPAYKNKSKKKKKKSNHQEFEAVAMPESLESAYPEGSQVGSEVGTVEGSTALKGFKESNSTKKKSKKRKLTSVKRARVSGDDFSVPSKNSESTLFDSVEGDGAMMEEGVKSRPRQKKTQACLASKHVQEAPRLEPANEEHNVETAEDSEIRYLSADSGDADDSDADLGSAVKQLQEFIPNIKDRATSTIKRMYRDDLERFKEFKAQGVAIKFGKFSVKENKQLEKNVEDFLALTGIESADKLLYTDRYPEEKSVITNLKRRYSFRLHIGRNIARPWKLIYYRAKKMFDVNNYKGRYSEGDTEKLKMYHSLLGNDWKTIGEMVARSSLSVALKFSQISSQRNRGAWSKSETRKLIKAVEEVILKKMSPQELKEVDSKLQENPESCLSIVREKLYKGISWVEVEAKVQTRNWMQCKSKWTEILTKRMTNGRRIYYGMNALRAKVSLIERLYEINVEDTNEIDWEDLASAIGDVPPSYVQTKFSRLKAVYVPFWQKKTFPEIIDYLYETTLPLLKEKLEKMMEKKGTKIQTPAAPKQVFPFRDIFYYEDDSEGEDIEKESEGQAPCMAHACNSSTLGGQGRWII>sp|Q9BX84|TRPM6_HUMAN Transient receptor potential cation channelsubfamily M member 6 OS=Homo sapiens OX=9606 GN=TRPM6 PE=1 SV=2MKEQPVLERLQSQKSWIKGVFDKRECSTIIPSSKNPHRCTPVCQVCQNLIRCYCGRLIGDHAGIDYSWTISAAKGKESEQWSVEKHTTKSPTDTFGTINFQDGEHTHHAKYIRTSYDTKLDHLLHLMLKEWKMELPKLVISVHGGIQNFTMPSKFKEIFSQGLVKAAETTGAWIITEGINTGVSKHVGDALKSHSSHSLRKIWTVGIPPWGVIENQRDLIGKDVVCLYQTLDNPLSKLTTLNSMHSHFILSDDGTVGKYGNEMKLRRNLEKYLSLQKIHCRSRQGVPVVGLVVEGGPNVILSVWETVKDKDPVVVCEGTGRAADLLAFTHKHLADEGMLRPQVKEEIICMIQNTFNFSLKQSKHLFQILMECMVHRDCITIFDADSEEQQDLDLAILTALLKGTNLSASEQLNLAMAWDRVDIAKKHILIYEQHWKPDALEQAMSDALVMDRVDFVKLLIEYGVNLHRFLTIPRLEELYNTKQGPTNTLLHHLVQDVKQHTLLSGYRITLIDIGLVVEYLIGRAYRSNYTRKHFRALYNNLYRKYKHQRHSSGNRNESAESTLHSQFIRTAQPYKFKEKSIVLHKSRKKSKEQNVSDDPESTGFLYPYNDLLVWAVLMKRQKMAMFFWQHGEEATVKAVIACILYRAMAHEAKESHMVDDASEELKNYSKQFGQLALDLLEKAFKQNERMAMTLLTYELRNWSNSTCLKLAVSGGLRPFVSHTCTQMLLTDMWMGRLKMRKNSWLKIIISIILPPTILTLEFKSKAEMSHVPQSQDFQFMWYYSDQNASSSKESASVKEYDLERGHDEKLDENQHFGLESGHQHLPWTRKVYEFYSAPIVKFWFYTMAYLAFLMLFTYTVLVEMQPQPSVQEWLVSIYIFTNAIEVVREICISEPGKFTQKVKVWISEYWNLTETVAIGLFSAGFVLRWGDPPFHTAGRLIYCIDIIFWFSRLLDFFAVNQHAGPYVTMIAKMTANMFYIVIIMAIVLLSFGVARKAILSPKEPPSWSLARDIVFEPYWMIYGEVYAGEIDVCSSQPSCPPGSFLTPFLQAVYLFVQYIIMVNLLIAFFNNVYLDMESISNNLWKYNRYRYIMTYHEKPWLPPPLILLSHVGLLLRRLCCHRAPHDQEEGDVGLKLYLSKEDLKKLHDFEEQCVEKYFHEKMEDVNCSCEERIRVTSERVTEMYFQLKEMNEKVSFIKDSLLSLDSQVGHLQDLSALTVDTLKVLSAVDTLQEDEALLAKRKHSTCKKLPHSWSNVICAEVLGSMEIAGEKKYQYYSMPSSLLRSLAGGRHPPRVQRGALLEITNSKREATNVRNDQERQETQSSIVVSGVSPNRQAHSKYGQFLLVPSNLKRVPFSAETVLPLSRPSVPDVLATEQDIQTEVLVHLTGQTPVVSDWASVDEPKEKHEPIAHLLDGQDKAEQVLPTLSCTPEPMTMSSPLSQAKIMQTGGGYVNWAFSEGDETGVFSIKKKWQTCLPSTCDSDSSRSEQHQKQAQDSSLSDNSTRSAQSSECSEVGPWLQPNTSFWINPLRRYRPFARSHSFRFHKEEKLMKICKIKNLSGSSEIGQGAWVKAKMLTKDRRLSKKKKNTQGLQVPIITVNACSQSDQLNPEPGENSISEEEYSKNWFTVSKFSHTGVEPYIHQKMKTKEIGQCAIQISDYLKQSQEDLSKNSLWNSRSTNLNRNSLLKSSIGVDKISASLKSPQEPHHHYSAIERNNLMRLSQTIPFTPVQLFAGEEITVYRLEESSPLNLDKSMSSWSQRGRAAMIQVLSREEMDGGLRKAMRVVSTWSEDDILKPGQVFIVKSFLPEVVRTWHKIFQESTVLHLCLREIQQQRAAQKLIYTFNQVKPQTIPYTPRFLEVFLIYCHSANQWLTIEKYMTGEFRKYNNNNGDEITPTNTLEELMLAFSHWTYEYTRGELLVLDLQGVGENLTDPSVIKPEVKQSRGMVFGPANLGEDAIRNFIAKHHCNSCCRKLKLPDLKRNDYSPERINSTFGLEIKIESAEEPPARETGRNSPEDDMQL>sp|Q9BX84-2|TRPM6_HUMAN Isoform TRPM6b of Transient receptor potentialcation channel subfamily M member 6 OS=Homo sapiens OX=9606 GN=TRPM6MIILSKSQKSWIKGVFDKRECSTIIPSSKNPHRCTPVCQVCQNLIRCYCGRLIGDHAGIDYSWTISAAKGKESEQWSVEKHTTKSPTDTFGTINFQDGEHTHHAKYIRTSYDTKLDHLLHLMLKEWKMELPKLVISVHGGIQNFTMPSKFKEIFSQGLVKAAETTGAWIITEGINTGVSKHVGDALKSHSSHSLRKIWTVGIPPWGVIENQRDLIGKDVVCLYQTLDNPLSKLTTLNSMHSHFILSDDGTVGKYGNEMKLRRNLEKYLSLQKIHCRSRQGVPVVGLVVEGGPNVILSVWETVKDKDPVVVCEGTGRAADLLAFTHKHLADEGMLRPQVKEEIICMIQNTFNFSLKQSKHLFQILMECMVHRDCITIFDADSEEQQDLDLAILTALLKGTNLSASEQLNLAMAWDRVDIAKKHILIYEQHWKPDALEQAMSDALVMDRVDFVKLLIEYGVNLHRFLTIPRLEELYNTKQGPTNTLLHHLVQDVKQHTLLSGYRITLIDIGLVVEYLIGRAYRSNYTRKHFRALYNNLYRKYKHQRHSSGNRNESAESTLHSQFIRTAQPYKFKEKSIVLHKSRKKSKEQNVSDDPESTGFLYPYNDLLVWAVLMKRQKMAMFFWQHGEEATVKAVIACILYRAMAHEAKESHMVDDASEELKNYSKQFGQLALDLLEKAFKQNERMAMTLLTYELRNWSNSTCLKLAVSGGLRPFVSHTCTQMLLTDMWMGRLKMRKNSWLKIIISIILPPTILTLEFKSKAEMSHVPQSQDFQFMWYYSDQNASSSKESASVKEYDLERGHDEKLDENQHFGLESGHQHLPWTRKVYEFYSAPIVKFWFYTMAYLAFLMLFTYTVLVEMQPQPSVQEWLVSIYIFTNAIEVVREICISEPGKFTQKVKVWISEYWNLTETVAIGLFSAGFVLRWGDPPFHTAGRLIYCIDIIFWFSRLLDFFAVNQHAGPYVTMIAKMTANMFYIVIIMAIVLLSFGVARKAILSPKEPPSWSLARDIVFEPYWMIYGEVYAGEIDVCSSQPSCPPGSFLTPFLQAVYLFVQYIIMVNLLIAFFNNVYLDMESISNNLWKYNRYRYIMTYHEKPWLPPPLILLSHVGLLLRRLCCHRAPHDQEEGDVGLKLYLSKEDLKKLHDFEEQCVEKYFHEKMEDVNCSCEERIRVTSERVTEMYFQLKEMNEKVSFIKDSLLSLDSQVGHLQDLSALTVDTLKVLSAVDTLQEDEALLAKRKHSTCKKLPHSWSNVICAEVLGSMEIAGEKKYQYYSMPSSLLRSLAGGRHPPRVQRGALLEITNSKREATNVRNDQERQETQSSIVVSGVSPNRQAHSKYGQFLLVPSNLKRVPFSAETVLPLSRPSVPDVLATEQDIQTEVLVHLTGQTPVVSDWASVDEPKEKHEPIAHLLDGQDKAEQVLPTLSCTPEPMTMSSPLSQAKIMQTGGGYVNWAFSEGDETGVFSIKKKWQTCLPSTCDSDSSRSEQHQKQAQDSSLSDNSTRSAQSSECSEVGPWLQPNTSFWINPLRRYRPFARSHSFRFHKEEKLMKICKIKNLSGSSEIGQGAWVKAKMLTKDRRLSKKKKNTQGLQVPIITVNACSQSDQLNPEPGENSISEEEYSKNWFTVSKFSHTGVEPYIHQKMKTKEIGQCAIQISDYLKQSQEDLSKNSLWNSRSTNLNRNSLLKSSIGVDKISASLKSPQEPHHHYSAIERNNLMRLSQTIPFTPVQLFAGEEITVYRLEESSPLNLDKSMSSWSQRGRAAMIQVLSREEMDGGLRKAMRVVSTWSEDDILKPGQVFIVKSFLPEVVRTWHKIFQESTVLHLCLREIQQQRAAQKLIYTFNQVKPQTIPYTPRFLEVFLIYCHSANQWLTIEKYMTGEFRKYNNNNGDEITPTNTLEELMLAFSHWTYEYTRGELLVLDLQGVGENLTDPSVIKPEVKQSRGMVFGPANLGEDAIRNFIAKHHCNSCCRKLKLPDLKRNDYSPERINSTFGLEIKIESAEEPPARETGRNSPEDDMQL>sp|Q9BX84-3|TRPM6_HUMAN Isoform TRPM6c of Transient receptor potentialcation channel subfamily M member 6 OS=Homo sapiens OX=9606 GN=TRPM6MTAPVTSQKSWIKGVFDKRECSTIIPSSKNPHRCTPVCQVCQNLIRCYCGRLIGDHAGIDYSWTISAAKGKESEQWSVEKHTTKSPTDTFGTINFQDGEHTHHAKYIRTSYDTKLDHLLHLMLKEWKMELPKLVISVHGGIQNFTMPSKFKEIFSQGLVKAAETTGAWIITEGINTGVSKHVGDALKSHSSHSLRKIWTVGIPPWGVIENQRDLIGKDVVCLYQTLDNPLSKLTTLNSMHSHFILSDDGTVGKYGNEMKLRRNLEKYLSLQKIHCRSRQGVPVVGLVVEGGPNVILSVWETVKDKDPVVVCEGTGRAADLLAFTHKHLADEGMLRPQVKEEIICMIQNTFNFSLKQSKHLFQILMECMVHRDCITIFDADSEEQQDLDLAILTALLKGTNLSASEQLNLAMAWDRVDIAKKHILIYEQHWKPDALEQAMSDALVMDRVDFVKLLIEYGVNLHRFLTIPRLEELYNTKQGPTNTLLHHLVQDVKQHTLLSGYRITLIDIGLVVEYLIGRAYRSNYTRKHFRALYNNLYRKYKHQRHSSGNRNESAESTLHSQFIRTAQPYKFKEKSIVLHKSRKKSKEQNVSDDPESTGFLYPYNDLLVWAVLMKRQKMAMFFWQHGEEATVKAVIACILYRAMAHEAKESHMVDDASEELKNYSKQFGQLALDLLEKAFKQNERMAMTLLTYELRNWSNSTCLKLAVSGGLRPFVSHTCTQMLLTDMWMGRLKMRKNSWLKIIISIILPPTILTLEFKSKAEMSHVPQSQDFQFMWYYSDQNASSSKESASVKEYDLERGHDEKLDENQHFGLESGHQHLPWTRKVYEFYSAPIVKFWFYTMAYLAFLMLFTYTVLVEMQPQPSVQEWLVSIYIFTNAIEVVREICISEPGKFTQKVKVWISEYWNLTETVAIGLFSAGFVLRWGDPPFHTAGRLIYCIDIIFWFSRLLDFFAVNQHAGPYVTMIAKMTANMFYIVIIMAIVLLSFGVARKAILSPKEPPSWSLARDIVFEPYWMIYGEVYAGEIDVCSSQPSCPPGSFLTPFLQAVYLFVQYIIMVNLLIAFFNNVYLDMESISNNLWKYNRYRYIMTYHEKPWLPPPLILLSHVGLLLRRLCCHRAPHDQEEGDVGLKLYLSKEDLKKLHDFEEQCVEKYFHEKMEDVNCSCEERIRVTSERVTEMYFQLKEMNEKVSFIKDSLLSLDSQVGHLQDLSALTVDTLKVLSAVDTLQEDEALLAKRKHSTCKKLPHSWSNVICAEVLGSMEIAGEKKYQYYSMPSSLLRSLAGGRHPPRVQRGALLEITNSKREATNVRNDQERQETQSSIVVSGVSPNRQAHSKYGQFLLVPSNLKRVPFSAETVLPLSRPSVPDVLATEQDIQTEVLVHLTGQTPVVSDWASVDEPKEKHEPIAHLLDGQDKAEQVLPTLSCTPEPMTMSSPLSQAKIMQTGGGYVNWAFSEGDETGVFSIKKKWQTCLPSTCDSDSSRSEQHQKQAQDSSLSDNSTRSAQSSECSEVGPWLQPNTSFWINPLRRYRPFARSHSFRFHKEEKLMKICKIKNLSGSSEIGQGAWVKAKMLTKDRRLSKKKKNTQGLQVPIITVNACSQSDQLNPEPGENSISEEEYSKNWFTVSKFSHTGVEPYIHQKMKTKEIGQCAIQISDYLKQSQEDLSKNSLWNSRSTNLNRNSLLKSSIGVDKISASLKSPQEPHHHYSAIERNNLMRLSQTIPFTPVQLFAGEEITVYRLEESSPLNLDKSMSSWSQRGRAAMIQVLSREEMDGGLRKAMRVVSTWSEDDILKPGQVFIVKSFLPEVVRTWHKIFQESTVLHLCLREIQQQRAAQKLIYTFNQVKPQTIPYTPRFLEVFLIYCHSANQWLTIEKYMTGEFRKYNNNNGDEITPTNTLEELMLAFSHWTYEYTRGELLVLDLQGVGENLTDPSVIKPEVKQSRGMVFGPANLGEDAIRNFIAKHHCNSCCRKLKLPDLKRNDYSPERINSTFGLEIKIESAEEPPARETGRNSPEDDMQL>sp|Q9BX84-4|TRPM6_HUMAN Isoform TRPM6t of Transient receptor potentialcation channel subfamily M member 6 OS=Homo sapiens OX=9606 GN=TRPM6MKEQPVLERLQSQKSWIKGVFDKRECSTIIPSSKNPHRCTPVCQVCQNLIRCYCGRLIGDHAGIDYSWTISAAKGKESEQWSVEKHTTKSPTDTFGTINFQDGEHTHHAKYIRTSYDTKLDHLLHLMLKEWKMELPKLVISVHGGIQNFTMPSKFKEIFSQGLVKAAETTGAWIITEGINTGVSKHVGDALKSHSSHSLRKIWTVGIPPWGVIENQRDLIGKDVVCLYQTLDNPLSKLTTLNSMHSHFILSDDGTVGKYGNEMKLRRNLEKYLSLQKIHCRSRQGVPVVGLVVEGGPNVILSVWETVKDKDPVVVCEGTGRAADLLAFTHKHLADEGMLRPQVKEEIICMIQNTFNFSLKQSKHLFQILMECMVHRDCITIFDADSEEQQDLDLAILTALLKGTNLSASEQLNLAMAWDRVDIAKKHILIYEQHWKPDALEQAMSDALVMDRVDFVKLLIEYGVNLHRFLTIPRLEELYNTKQGPTNTLLHHLVQDVKQHTLLSGYRITLIDIGLVVEYLIGRAYRSNYTRKHFRALYNNLYRKYKHQRHSSGNRNESAESTLHSQFIRTAQPYKFKEKSIVLHKSRKKSKEQNVSDDPESTGFLYPYNDLLVWAVLMKRQKMAMFFWQHGEEATVKAVIACILYRAMAHEAKESHMVDDASEELKNYSKQFGQLALDLLEKAFKQNERMAMTLLTYELRNWSNSTCLKLAVSGGLRPFVSHTCTQMLLTDMWMGRLKMRKNSWLKIIISIILPPTILTLEFKSKAEMSHVPQSQDFQFMWYYSDQNASSSKESASVKEYDLERGHDEKLDENQHFGLESGHQHLPWTRKVYEFYSAPIVKFWFYTMAYLAFLMLFTYTVLVEMQPQPSVQEWLVSIYIFTNAIEVVREICISEPGKFTQKVKVWISEYWNLTETVAIGLFSAGFVLRWGDPPFHTAGRLIYCIDIIFWFSRLLDFFAVNQHAGPYVTMIAKMTANMFYIVIIMAIVLLSFGVARKAILSPKEPPSWSLARDIVFEPYWMIYGEVYAGEIDVCSSQPSCPPGSFLTPFLQAVYLFVQYIIMVNLLIAFFNNVYLDMESISNNLWKYNRYRYIMTYHEKPWLPPPLILLSHVGLLLRRLCCHRAPHDQEEGDVGLKLYLSKEDLKKLHDFEEQCVEKYFHEKMEDVNCSCEERIRVTSERVTEMYFQLKEMNEKVSFIKDSLLSLDSQVGHLQDLSALTVDTLKVLSAVDTLQEDEALLAKRKHSTCKKLPHSWSNVICAEVLGSMEIAGEKKYQYYSMPSSLLRSLAGGRHPPRVQRGALLEITNSKREATNVRNDQERQETQSSIVVSGVSPNRQAHSKYGQFLLVPSNLKRVPFSAETVLPLSRPSVPDVLATEQDIQTEVLVHLTGQTPVVSDWASVDEPKEKHEPIAHLLDGQDKAEQVLPTLSCTPEPMTMSSPLSQAKIMQTGGGYVNWAFSEGDETGVFSIKKKWQTCLPSTCDSDSSRSEQHQKQAQDSSLSDNSTRSAQSSECSEVGPWLQPNTSFWINPLRRYRPFARSHSFRFHKEEKLMKICKIKNLSGSSEIGQGAWVKAKMLTKDRRLSKKKKNTQGLQVPIITVNACSQSDQLNPEPGENSISEEEYSKNWFTVSKFSHTGVEPYIHQKMKTKEIGQCAIQISDYLKQSQEDLSKNSLWNSRSTNLNRNSLLKSSIGVDKISASLKSPQEPHHHYSAIERNNLMRLSQTIPFTPVQLFAGEEITVYRLEESSPLNLDKSMSSWSQRGRAAMIQVLSREEMDGGLRKAMRVVSTWSEDDILKPGQVFIVKSFLPEVVRTWHKIFQESTVLHLCLREIQQQRAAQKLIYTFNQVKPQTIPYTPRFLEVFLIYCHSANQWLTIEKYMTGEFRKYNNNNGDEITPTNTLEELMLAFSHWTYEYTRGELLVLDLQALWFWDSMLKARLGGWRM>sp|Q9BX84-5|TRPM6_HUMAN Isoform M6-kinase 1 of Transient receptorpotential cation channel subfamily M member 6 OS=Homo sapiens OX=9606GN=TRPM6MKEQPVLERLQSQKSWIKGVFDKRECSTIIPSSKNPHRCTPVCQVCQNLIRCYCGRLIGDHAGIDYSWTISAAKGKESEQWSVEKHTTKSPTDTFGTINFQDGEHTHHAKYIRTSYDTKLDHLLHLMLKEWKMELPKLVISVHGGIQNFTMPSKFKEIFSQGLVKAAETTGAWIITEGINTGVSKHVGDALKSHSSHSLRKIWTVGIPPWGVIENQRDLIGKDVVCLYQTLDNPLSKLTTLNSMHSHFILSDDGTVGKYGNEMKLRRNLEKYLSLQKIHCRSRQGVPVVGLVVEGGPNVILSVWETVKDKDPVVVCEGTGRAADLLAFTHKHLADEGMLRPQVKEEIICMIQNTFNFSLKQSKHLFQILMECMVHRDCITIFDADSEEQQDLDLAILTALLKGTNLSASEQLNLAMAWDRVDIAKKHILIYEQHWKPDALEQAMSDALVMDRVDFVKLLIEYGVNLHRFLTIPRLEELYNTKQGPTNTLLHHLVQDVKQHTLLSGYRITLIDIGLVVEYLIGRAYRSNYTRKHFRALYNNLYRKYKIITVNACSQSDQLNPEPGENSISEEEYSKNWFTVSKFSHTGVEPYIHQKMKTKEIGQCAIQISDYLKQSQEDLSKNSLWNSRSTNLNRNSLLKSSIGVDKISASLKSPQEPHHHYSAIERNNLMRLSQTIPFTPVQLFAGEEITVYRLEESSPLNLDKSMSSWSQRGRAAMIQVLSREEMDGGLRKAMRVVSTWSEDDILKPGQVFIVKSFLPEVVRTWHKIFQESTVLHLCLREIQQQRAAQKLIYTFNQVKPQTIPYTPRFLEVFLIYCHSANQWLTIEKYMTGEFRKYNNNNGDEITPTNTLEELMLAFSHWTYEYTRGELLVLDLQGVGENLTDPSVIKPEVKQSRGMVFGPANLGEDAIRNFIAKHHCNSCCRKLKLPDLKRNDYSPERINSTFGLEIKIESAEEPPARETGRNSPEDDMQL>sp|Q9BX84-6|TRPM6_HUMAN Isoform M6-kinase 2 of Transient receptorpotential cation channel subfamily M member 6 OS=Homo sapiens OX=9606GN=TRPM6MKEQPVLERLQSQKSWIKGVFDKRECSTIIPSSKNPHRCTPVCQVCQNLIRCYCGRLIGDHAGIDYSWTISAAKGKESEQWSVEKHTTKSPTDTFGTINFQDGEHTHHAKYIRTSYDTKLDHLLHLMLKEWKMELPKLVISVHGGIQNFTMPSKFKEIFSQGLVKAAETTGAWIITEGINTGVSKHVGDALKSHSSHSLRKIWTVGIPPWGVIENQRDLIGKDVVCLYQTLDNPLSKLTTLNSMHSHFILSDDGTVGKYGNEMKLRRNLEKYLSLQKIHCRSRQGVPVVGLVVEGGPNVILSVWETVKDKDPVVVCEGTGRAADLLAFTHKHLADEGMLRPQVKEEIICMIQNTFNFSLKQSKHLFQILMECMVHRDCITIFDADSEEQQDLDLAILTALLKGTNLSASEQLNLAMAWDRVDIAKKHILIYEQHWKPDALEQAMSDALVMDRVDFVKLLIEYGVNLHRFLTIPRLEELYNTKQGPTNTLLHHLVQDVKQDLSKNSLWNSRSTNLNRNSLLKSSIGVDKISASLKSPQEPHHHYSAIERNNLMRLSQTIPFTPVQLFAGEEITVYRLEESSPLNLDKSMSSWSQRGRAAMIQVLSREEMDGGLRKAMRVVSTWSEDDILKPGQVFIVKSFLPEVVRTWHKIFQESTVLHLCLREIQQQRAAQKLIYTFNQVKPQTIPYTPRFLEVFLIYCHSANQWLTIEKYMTGEFRKYNNNNGDEITPTNTLEELMLAFSHWTYEYTRGELLVLDLQGVGENLTDPSVIKPEVKQSRGMVFGPANLGEDAIRNFIAKHHCNSCCRKLKLPDLKRNDYSPERINSTFGLEIKIESAEEPPARETGRNSPEDDMQL>sp|Q9BX84-7|TRPM6_HUMAN Isoform M6-kinase 3 of Transient receptorpotential cation channel subfamily M member 6 OS=Homo sapiens OX=9606GN=TRPM6MKEQPVLERLQSQKSWIKGVFDKRECSTIIPSSKNPHRCTPVCQVCQNLIRCYCGRLIGDHAGIDYSWTISAAKGKESEQWSVEKHTTKSPTDTFGTINFQDGEHTHHAKYIRTSYDTKLDHLLHLMLKEWKMELPKLVISVHGGIQNFTMPSKFKEIFSQGLVKAAETTGAWIITEGINTGVSKHVGDALKSHSSHSLRKIWTVGIPPWGVIENQRDLIGKDVVCLYQTLDNPLSKLTTLNSMHSHFILSDDGTVGKYGNEMKLRRNLEKYLSLQKIHCPGEEITVYRLEESSPLNLDKSMSSWSQRGRAAMIQVLSREEMDGGLRKAMRVVSTWSEDDILKPGQVFIVKSFLPEVVRTWHKIFQESTVLHLCLREIQQQRAAQKLIYTFNQVKPQTIPYTPRFLEVFLIYCHSANQWLTIEKYMTGEFRKYNNNNGDEITPTNTLEELMLAFSHWTYEYTRGELLVLDLQGVGENLTDPSVIKPEVKQSRGMVFGPANLGEDAIRNFIAKHHCNSCCRKLKLPDLKRNDYSPERINSTFGLEIKIESAEEPPARETGRNSPEDDMQL>sp|Q5I0X7|TTC32_HUMAN Tetratricopeptide repeat protein 32 OS=Homosapiens OX=9606 GN=TTC32 PE=1 SV=1MEGQRQESHATLTLAQAHFNNGEYAEAEALYSAYIRRCACAASSDESPGSKCSPEDLATAYNNRGQIKYFRVDFYEAMDDYTSAIEVQPNFEVPYYNRGLILYRLGYFDDALEDFKKVLDLNPGFQDATLSLKQTILDKEEKQRRNVAKNY>sp|Q8IWX7|UN45B_HUMAN Protein unc-45 homolog B OS=Homo sapiens OX=9606GN=UNC45B PE=1 SV=1MAEVEAVQLKEEGNRHFQLQDYKAATNSYSQALKLTKDKALLATLYRNRAACGLKTESYVQAASDASRAIDINSSDIKALYRRCQALEHLGKLDQAFKDVQRCATLEPRNQNFQEMLRRLNTSIQEKLRVQFSTDSRVQKMFEILLDENSEADKREKAANNLIVLGREEAGAEKIFQNNGVALLLQLLDTKKPELVLAAVRTLSGMCSGHQARATVILHAVRIDRICSLMAVENEEMSLAVCNLLQAIIDSLSGEDKREHRGKEEALVLDTKKDLKQITSHLLDMLVSKKVSGQGRDQALNLLNKNVPRKDLAIHDNSRTIYVVDNGLRKILKVVGQVPDLPSCLPLTDNTRMLASILINKLYDDLRCDPERDHFRKICEEYITGKFDPQDMDKNLNAIQTVSGILQGPFDLGNQLLGLKGVMEMMVALCGSERETDQLVAVEALIHASTKLSRATFIITNGVSLLKQIYKTTKNEKIKIRTLVGLCKLGSAGGTDYGLRQFAEGSTEKLAKQCRKWLCNMSIDTRTRRWAVEGLAYLTLDADVKDDFVQDVPALQAMFELAKAGTSDKTILYSVATTLVNCTNSYDVKEVIPELVQLAKFSKQHVPEEHPKDKKDFIDMRVKRLLKAGVISALACMVKADSAILTDQTKELLARVFLALCDNPKDRGTIVAQGGGKALIPLALEGTDVGKVKAAHALAKIAAVSNPDIAFPGERVYEVVRPLVRLLDTQRDGLQNYEALLGLTNLSGRSDKLRQKIFKERALPDIENYMFENHDQLRQAATECMCNMVLHKEVQERFLADGNDRLKLVVLLCGEDDDKVQNAAAGALAMLTAAHKKLCLKMTQVTTQWLEILQRLCLHDQLSVQHRGLVIAYNLLAADAELAKKLVESELLEILTVVGKQEPDEKKAEVVQTARECLIKCMDYGFIKPVS>sp|Q8IWX7-2|UN45B_HUMAN Isoform 2 of Protein unc-45 homolog B OS=Homosapiens OX=9606 GN=UNC45BMAEVEAVQLKEEGNRHFQLQDYKAATNSYSQALKLTKDKALLATLYRNRAACGLKTESYVQAASDASRAIDINSSDIKALYRRCQALEHLGKLDQAFKDVQRCATLEPRNQNFQEMLRRLNTSIQEKLRVQFSTDSRVQKMFEILLDENSEADKREKAANNLIVLGREEAGAEKIFQNNGVALLLQLLDTKKPELVLAAVRTLSGMCSGHQARATVILHAVRIDRICSLMAVENEEMSLAVCNLLQAIIDSLSGEDKREHRGKEEALVLDTKKDLKQITSHLLDMLVSKKVSGQGRDQALNLLNKNVPRKDLAIHDNSRTIYVVDNGLRKILKVVGQVPDLPSCLPLTDNTRMLASILINKLYDDLRCDPERDHFRKICEEYITGKFDPQDMDKNLNAIQTVSGILQGPFDLGNQLLGLKGVMEMMVALCGSERETDQLVAVEALIHASTKLSRATFIITNGVSLLKQIYKTTKNEKIKIRTLVTSDKTILYSVATTLVNCTNSYDVKEVIPELVQLAKFSKQHVPEEHPKDKKDFIDMRVKRLLKAGVISALACMVKADSAILTDQTKELLARVFLALCDNPKDRGTIVAQGGGKALIPLALEGTDVGKVKAAHALAKIAAVSNPDIAFPGERVYEVVRPLVRLLDTQRDGLQNYEALLGLTNLSGRSDKLRQKIFKERALPDIENYMFENHDQLRQAATECMCNMVLHKEVQERFLADGNDRLKLVVLLCGEDDDKVQNAAAGALAMLTAAHKKLCLKMTQVTTQWLEILQRLCLHDQLSVQHRGLVIAYNLLAADAELAKKLVESELLEILTVVGKQEPDEKKAEVVQTARECLIKCMDYGFIKPVS>sp|Q8IWX7-3|UN45B_HUMAN Isoform 3 of Protein unc-45 homolog B OS=Homosapiens OX=9606 GN=UNC45BMAEVEAVQLKEEGNRHFQLQDYKAATNSYSQALKLTKDKALLATLYRNRAACGLKTESYVQAASDASRAIDINSSDIKALYRRCQALEHLGKLDQAFKDVQRCATLEPRNQNFQEMLRRLNTSIQEKLRVQFSTDSRVQKMFEILLDENSEADKREKAANNLIVLGREEAGAEKIFQNNGVALLLQLLDTKKPELVLAAVRTLSGMCSGHQARATVILHAVRIDRICSLMAVENEEMSLAVCNLLQAIIDSLSGEDKREHRGKEEALVLDTKKDLKQITSHLLDMLVSKKVSGQGRDQALNLLNKNVPRKDLAIHDNSRTIYVVDNGLRKILKVVGQVPDLPSCLPLTDNTRMLASILINKLYDDLRCDPERDHFRKICEEYITGKFDPQDMDKNLNAIQTVSGILQGPFDLGNQLLGLKGVMEMMVALCGSERETDQLVAVEALIHASTKLSRATFIITNGVSLLKQIYKTTKNEKIKIRTLVGLCKLGSAGGTDYGLRQFAEGSTEKLAKQCRKWLCNMSIDTRTRRWAVEGLAYLTLDADVKDDFVQDVPALQAMFELAKTSDKTILYSVATTLVNCTNSYDVKEVIPELVQLAKFSKQHVPEEHPKDKKDFIDMRVKRLLKAGVISALACMVKADSAILTDQTKELLARVFLALCDNPKDRGTIVAQGGGKALIPLALEGTDVGKVKAAHALAKIAAVSNPDIAFPGERVYEVVRPLVRLLDTQRDGLQNYEALLGLTNLSGRSDKLRQKIFKERALPDIENYMFENHDQLRQAATECMCNMVLHKEVQERFLADGNDRLKLVVLLCGEDDDKVQNAAAGALAMLTAAHKKLCLKMTQVTTQWLEILQRLCLHDQLSVQHRGLVIAYNLLAADAELAKKLVESELLEILTVVGKQEPDEKKAEVVQTARECLIKCMDYGFIKPVS>sp|P0C7P4|UCRIL_HUMAN Putative cytochrome b-c1 complex subunit Rieske-like protein 1 OS=Homo sapiens OX=9606 GN=UQCRFS1P1 PE=5 SV=1MQQIYTVKEIRSVAARSGPFAPVLSATSRGVAGALRPLVQATVPATPEQPVLDLKRPFLSRESLSGQAVRRPLVASVGLNVPASVCYSHTDIKVPDFSEYRRLEVLDSTKSSRESTEARKGFSYLVTGVTTVGVAYAAKNAVTQFVSSMSASADVLALAKIEIKLSDIPEGKNMAFKWRGKPLFVRHRTQKEIKQEAAVELSQLRDPQHDLDRVKKPEWVILIGVCTHLGCVPIANAGDFGGYYCPCHGSHYDASGRIRLGPATLNLEVPTYEFTSDDMVIVG>sp|P55916|UCP3_HUMAN Mitochondrial uncoupling protein 3 OS=Homo sapiensOX=9606 GN=UCP3 PE=1 SV=1MVGLKPSDVPPTMAVKFLGAGTAACFADLVTFPLDTAKVRLQIQGENQAVQTARLVQYRGVLGTILTMVRTEGPCSPYNGLVAGLQRQMSFASIRIGLYDSVKQVYTPKGADNSSLTTRILAGCTTGAMAVTCAQPTDVVKVRFQASIHLGPSRSDRKYSGTMDAYRTIAREEGVRGLWKGTLPNIMRNAIVNCAEVVTYDILKEKLLDYHLLTDNFPCHFVSAFGAGFCATVVASPVDVVKTRYMNSPPGQYFSPLDCMIKMVAQEGPTAFYKGFTPSFLRLGSWNVVMFVTYEQLKRALMKVQMLRESPF>sp|P55916-2|UCP3_HUMAN Isoform UCP3S of Mitochondrial uncoupling protein3 OS=Homo sapiens OX=9606 GN=UCP3MVGLKPSDVPPTMAVKFLGAGTAACFADLVTFPLDTAKVRLQIQGENQAVQTARLVQYRGVLGTILTMVRTEGPCSPYNGLVAGLQRQMSFASIRIGLYDSVKQVYTPKGADNSSLTTRILAGCTTGAMAVTCAQPTDVVKVRFQASIHLGPSRSDRKYSGTMDAYRTIAREEGVRGLWKGTLPNIMRNAIVNCAEVVTYDILKEKLLDYHLLTDNFPCHFVSAFGAGFCATVVASPVDVVKTRYMNSPPGQYFSPLDCMIKMVAQEGPTAFYKG>sp|P55916-3|UCP3_HUMAN Isoform 3 of Mitochondrial uncoupling protein 3OS=Homo sapiens OX=9606 GN=UCP3MVGLKPSDVPPTMAVKFLGAGTAACFADLVTFPLDTAKVRLQIQGENQAVQTARLVQYRGVLGTILTMVRTEGPCSPYNGLVAGLQRQMSFASIRIGLYDSVKQVYTPKGADNFPCHFVSAFGAGFCATVVASPVDVVKTRYMNSPPGQYFSPLDCMIKMVAQEGPTAFYKGFTPSFLRLGSWNVVMFVTYEQLKRALMKVQMLRESPF>sp|D6RBQ6|U17LH_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 17 OS=Homo sapiens OX=9606 GN=USP17L17 PE=3 SV=1MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTAASITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSSTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|Q9UHP3|UBP25_HUMAN Ubiquitin carboxyl-terminal hydrolase 25 OS=Homosapiens OX=9606 GN=USP25 PE=1 SV=4MTVEQNVLQQSAAQKHQQTFLNQLREITGINDTQILQQALKDSNGNLELAVAFLTAKNAKTPQQEETTYYQTALPGNDRYISVGSQADTNVIDLTGDDKDDLQRAIALSLAESNRAFRETGITDEEQAISRVLEASIAENKACLKRTPTEVWRDSRNPYDRKRQDKAPVGLKNVGNTCWFSAVIQSLFNLLEFRRLVLNYKPPSNAQDLPRNQKEHRNLPFMRELRYLFALLVGTKRKYVDPSRAVEILKDAFKSNDSQQQDVSEFTHKLLDWLEDAFQMKAEEETDEEKPKNPMVELFYGRFLAVGVLEGKKFENTEMFGQYPLQVNGFKDLHECLEAAMIEGEIESLHSENSGKSGQEHWFTELPPVLTFELSRFEFNQALGRPEKIHNKLEFPQVLYLDRYMHRNREITRIKREEIKRLKDYLTVLQQRLERYLSYGSGPKRFPLVDVLQYALEFASSKPVCTSPVDDIDASSPPSGSIPSQTLPSTTEQQGALSSELPSTSPSSVAAISSRSVIHKPFTQSRIPPDLPMHPAPRHITEEELSVLESCLHRWRTEIENDTRDLQESISRIHRTIELMYSDKSMIQVPYRLHAVLVHEGQANAGHYWAYIFDHRESRWMKYNDIAVTKSSWEELVRDSFGGYRNASAYCLMYINDKAQFLIQEEFNKETGQPLVGIETLPPDLRDFVEEDNQRFEKELEEWDAQLAQKALQEKLLASQKLRESETSVTTAQAAGDPEYLEQPSRSDFSKHLKEETIQIITKASHEHEDKSPETVLQSAIKLEYARLVKLAQEDTPPETDYRLHHVVVYFIQNQAPKKIIEKTLLEQFGDRNLSFDERCHNIMKVAQAKLEMIKPEEVNLEEYEEWHQDYRKFRETTMYLIIGLENFQRESYIDSLLFLICAYQNNKELLSKGLYRGHDEELISHYRRECLLKLNEQAAELFESGEDREVNNGLIIMNEFIVPFLPLLLVDEMEEKDILAVEDMRNRWCSYLGQEMEPHLQEKLTDFLPKLLDCSMEIKSFHEPPKLPSYSTHELCERFARIMLSLSRTPADGR>sp|Q9UHP3-1|UBP25_HUMAN Isoform USP25b of Ubiquitin carboxyl-terminalhydrolase 25 OS=Homo sapiens OX=9606 GN=USP25MTVEQNVLQQSAAQKHQQTFLNQLREITGINDTQILQQALKDSNGNLELAVAFLTAKNAKTPQQEETTYYQTALPGNDRYISVGSQADTNVIDLTGDDKDDLQRAIALSLAESNRAFRETGITDEEQAISRVLEASIAENKACLKRTPTEVWRDSRNPYDRKRQDKAPVGLKNVGNTCWFSAVIQSLFNLLEFRRLVLNYKPPSNAQDLPRNQKEHRNLPFMRELRYLFALLVGTKRKYVDPSRAVEILKDAFKSNDSQQQDVSEFTHKLLDWLEDAFQMKAEEETDEEKPKNPMVELFYGRFLAVGVLEGKKFENTEMFGQYPLQVNGFKDLHECLEAAMIEGEIESLHSENSGKSGQEHWFTELPPVLTFELSRFEFNQALGRPEKIHNKLEFPQVLYLDRYMHRNREITRIKREEIKRLKDYLTVLQQRLERYLSYGSGPKRFPLVDVLQYALEFASSKPVCTSPVDDIDASSPPSGSIPSQTLPSTTEQQGALSSELPSTSPSSVAAISSRSVIHKPFTQSRIPPDLPMHPAPRHITEEELSVLESCLHRWRTEIENDTRDLQESISRIHRTIELMYSDKSMIQVPYRLHAVLVHEGQANAGHYWAYIFDHRESRWMKYNDIAVTKSSWEELVRDSFGGYRNASAYCLMYINDKAQFLIQEEFNKETGQPLVGIETLPPDLRDFVEEDNQRFEKELEEWDAQLAQKALQEKLLASQKLRESETSVTTAQAAGDPEYLEQPSRSDFSKHLKEETIQIITKASHEHEDKSPETVLQSIMMTPNMQGIIMAIGKSRSVYDRCGPEAGFFKAIKLEYARLVKLAQEDTPPETDYRLHHVVVYFIQNQAPKKIIEKTLLEQFGDRNLSFDERCHNIMKVAQAKLEMIKPEEVNLEEYEEWHQDYRKFRETTMYLIIGLENFQRESYIDSLLFLICAYQNNKELLSKGLYRGHDEELISHYRRECLLKLNEQAAELFESGEDREVNNGLIIMNEFIVPFLPLLLVDEMEEKDILAVEDMRNRWCSYLGQEMEPHLQEKLTDFLPKLLDCSMEIKSFHEPPKLPSYSTHELCERFARIMLSLSRTPADGR>sp|Q9UHP3-3|UBP25_HUMAN Isoform USP25m of Ubiquitin carboxyl-terminalhydrolase 25 OS=Homo sapiens OX=9606 GN=USP25MTVEQNVLQQSAAQKHQQTFLNQLREITGINDTQILQQALKDSNGNLELAVAFLTAKNAKTPQQEETTYYQTALPGNDRYISVGSQADTNVIDLTGDDKDDLQRAIALSLAESNRAFRETGITDEEQAISRVLEASIAENKACLKRTPTEVWRDSRNPYDRKRQDKAPVGLKNVGNTCWFSAVIQSLFNLLEFRRLVLNYKPPSNAQDLPRNQKEHRNLPFMRELRYLFALLVGTKRKYVDPSRAVEILKDAFKSNDSQQQDVSEFTHKLLDWLEDAFQMKAEEETDEEKPKNPMVELFYGRFLAVGVLEGKKFENTEMFGQYPLQVNGFKDLHECLEAAMIEGEIESLHSENSGKSGQEHWFTELPPVLTFELSRFEFNQALGRPEKIHNKLEFPQVLYLDRYMHRNREITRIKREEIKRLKDYLTVLQQRLERYLSYGSGPKRFPLVDVLQYALEFASSKPVCTSPVDDIDASSPPSGSIPSQTLPSTTEQQGALSSELPSTSPSSVAAISSRSVIHKPFTQSRIPPDLPMHPAPRHITEEELSVLESCLHRWRTEIENDTRDLQESISRIHRTIELMYSDKSMIQVPYRLHAVLVHEGQANAGHYWAYIFDHRESRWMKYNDIAVTKSSWEELVRDSFGGYRNASAYCLMYINDKAQFLIQEEFNKETGQPLVGIETLPPDLRDFVEEDNQRFEKELEEWDAQLAQKALQEKLLASQKLRESETSVTTAQAAGDPEYLEQPSRSDFSKHLKEETIQIITKASHEHEDKSPETVLQSKPENTTSQPLSNQRVVEVAIPHVGKFMIESKEGGYDDEIMMTPNMQGIIMAIGKSRSVYDRCGPEAGFFKAIKLEYARLVKLAQEDTPPETDYRLHHVVVYFIQNQAPKKIIEKTLLEQFGDRNLSFDERCHNIMKVAQAKLEMIKPEEVNLEEYEEWHQDYRKFRETTMYLIIGLENFQRESYIDSLLFLICAYQNNKELLSKGLYRGHDEELISHYRRECLLKLNEQAAELFESGEDREVNNGLIIMNEFIVPFLPLLLVDEMEEKDILAVEDMRNRWCSYLGQEMEPHLQEKLTDFLPKLLDCSMEIKSFHEPPKLPSYSTHELCERFARIMLSLSRTPADGR>sp|Q9BZV1|UBXN6_HUMAN UBX domain-containing protein 6 OS=Homo sapiensOX=9606 GN=UBXN6 PE=1 SV=1MKKFFQEFKADIKFKSAGPGQKLKESVGEKAHKEKPNQPAPRPPRQGPTNEAQMAAAAALARLEQKQSRAWGPTSQDTIRNQVRKELQAEATVSGSPEAPGTNVVSEPREEGSAHLAVPGVYFTCPLTGATLRKDQRDACIKEAILLHFSTDPVAASIMKIYTFNKDQDRVKLGVDTIAKYLDNIHLHPEEEKYRKIKLQNKVFQERINCLEGTHEFFEAIGFQKVLLPAQDQEDPEEFYVLSETTLAQPQSLERHKEQLLAAEPVRAKLDRQRRVFQPSPLASQFELPGDFFNLTAEEIKREQRLRSEAVERLSVLRTKAMREKEEQRGLRKYNYTLLRVRLPDGCLLQGTFYARERLGAVYGFVREALQSDWLPFELLASGGQKLSEDENLALNECGLVPSALLTFSWDMAVLEDIKAAGAEPDSILKPELLSAIEKLL>sp|Q9BZV1-2|UBXN6_HUMAN Isoform 2 of UBX domain-containing protein 6OS=Homo sapiens OX=9606 GN=UBXN6MAAAAALARLEQKQSRAWGPTSQDTIRNQVRKELQAEATVSGSPEAPGTNVVSEPREEGSAHLAVPGVYFTCPLTGATLRKDQRDACIKEAILLHFSTDPVAASIMKIYTFNKDQDRVKLGVDTIAKYLDNIHLHPEEEKYRKIKLQNKVFQERINCLEGTHEFFEAIGFQKVLLPAQDQEDPEEFYVLSETTLAQPQSLERHKEQLLAAEPVRAKLDRQRRVFQPSPLASQFELPGDFFNLTAEEIKREQRLRSEAVERLSVLRTKAMREKEEQRGLRKYNYTLLRVRLPDGCLLQGTFYARERLGAVYGFVREALQSDWLPFELLASGGQKLSEDENLALNECGLVPSALLTFSWDMAVLEDIKAAGAEPDSILKPELLSAIEKLL>sp|Q8TAX9|GSDMB_HUMAN Gasdermin-B OS=Homo sapiens OX=9606 GN=GSDMB PE=1SV=2MFSVFEEITRIVVKEMDAGGDMIAVRSLVDADRFRCFHLVGEKRTFFGCRHYTTGLTLMDILDTDGDKWLDELDSGLQGQKAEFQILDNVDSTGELIVRLPKEITISGSFQGFHHQKIKISENRISQQYLATLENRKLKRELPFSFRSINTRENLYLVTETLETVKEETLKSDRQYKFWSQISQGHLSYKHKGQREVTIPPNRVLSYRVKQLVFPNKETMSAGLDIHFRGKTKSFPEGKSLGSEDSRNMKEKLEDMESVLKDLTEEKRKDVLNSLAKCLGKEDIRQDLEQRVSEVLISGELHMEDPDKPLLSSLFNAAGVLVEARAKAILDFLDALLELSEEQQFVAEALEKGTLPLLKDQVKSVMEQNWDELASSPPDMDYDPEARILCALYVVVSILLELAEGPTSVSS>sp|Q8TAX9-2|GSDMB_HUMAN Isoform 2 of Gasdermin-B OS=Homo sapiens OX=9606GN=GSDMBMFSVFEEITRIVVKEMDAGGDMIAVRSLVDADRFRCFHLVGEKRTFFGCRHYTTGLTLMDILDTDGDKWLDELDSGLQGQKAEFQILDNVDSTGELIVRLPKEITISGSFQGFHHQKIKISENRISQQYLATLENRKLKRELPFSFRSINTRENLYLVTETLETVKEETLKSDRQYKFWSQISQGHLSYKHKGQREVTIPPNRVLSYRVKQLVFPNKETMRKSLGSEDSRNMKEKLEDMESVLKDLTEEKRKDVLNSLAKCLGKEDIRQDLEQRVSEVLISGELHMEDPDKPLLSSLFNAAGVLVEARAKAILDFLDALLELSEEQQFVAEALEKGTLPLLKDQVKSVMEQNWDELASSPPDMDYDPEARILCALYVVVSILLELAEGPTSVSS>sp|Q8TAX9-3|GSDMB_HUMAN Isoform 3 of Gasdermin-B OS=Homo sapiens OX=9606GN=GSDMBMFSVFEEITRIVVKEMDAGGDMIAVRSLVDADRFRCFHLVGEKRTFFGCRHYTTGLTLMDILDTDGDKWLDELDSGLQGQKAEFQILDNVDSTGELIVRLPKEITISGSFQGFHHQKIKISENRISQQYLATLENRKLKRELPFSFRSINTRENLYLVTETLETVKEETLKSDRQYKFWSQISQGHLSYKHKGQREVTIPPNRVLSYRVKQLVFPNKETMKKDGASSCLGKSLGSEDSRNMKEKLEDMESVLKDLTEEKRKDVLNSLAKCLGKEDIRQDLEQRVSEVLISGELHMEDPDKPLLSSLFNAAGVLVEARAKAILDFLDALLELSEEQQFVAEALEKGTLPLLKDQVKSVMEQNWDELASSPPDMDYDPEARILCALYVVVSILLELAEGPTSVSS>sp|Q8TAX9-4|GSDMB_HUMAN Isoform 4 of Gasdermin-B OS=Homo sapiens OX=9606GN=GSDMBMFSVFEEITRIVVKEMDAGGDMIAVRSLVDADRFRCFHLVGEKRTFFGCRHYTTGLTLMDILDTDGDKWLDELDSGLQGQKAEFQILDNVDSTGELIVRLPKEITISGSFQGFHHQKIKISENRISQQYLATLENRKLKRELPFSFRSINTRENLYLVTETLETVKEETLKSDRQYKFWSQISQGHLSYKHKGQREVTIPPNRVLSYRVKQLVFPNKETMNIHFRGKTKSFPEEKDGASSCLGKSLGSEDSRNMKEKLEDMESVLKDLTEEKRKDVLNSLAKCLGKEDIRQDLEQRVSEVLISGELHMEDPDKPLLSSLFNAAGVLVEARAKAILDFLDALLELSEEQQFVAEALEKGTLPLLKDQVKSVMEQNWDELASSPPDMDYDPEARILCALYVVVSILLELAEGPTSVSS>sp|Q8TAX9-5|GSDMB_HUMAN Isoform 5 of Gasdermin-B OS=Homo sapiens OX=9606GN=GSDMBMKEKLEDMESVLKDLTEEKRKDVLNSLAKCLGKEDIRQDLEQRVSEVLISGELHMEDPDKPLLSSLFNAAGVLVEARAKAILDFLDALLELSEEQQFVAEALEKGTLPLLKDQVKSVMEQNWDELASSPPDMDYDPEARILCALYVVVSILLELAEGPTSVSS>sp|Q8TAX9-6|GSDMB_HUMAN Isoform 6 of Gasdermin-B OS=Homo sapiens OX=9606GN=GSDMBMFSVFEEITRIVVKEMDAGGDMIAVRSLVDADRFRCFHLVGEKRTFFGCRHYTTGLTLMDILDTDGDKWLDELDSGLQGQKAEFQILDNVDSTGELIVRLPKEITISGSFQGFHHQKIKISENRISQQYLATLENRKLKRELPFSFRSINTRENLYLVTETLETVKEETLKSDRQYKFWSQISQGHLSYKHKGQREVTIPPNRVLSYRVKQLVFPNKETMNIHFRGKTKSFPEGKSLGSEDSRNMKEKLEDMESVLKDLTEEKRKDVLNSLAKCLGKEDIRQDLEQRVSEVLISGELHMEDPDKPLLSSLFNAAGVLVEARAKAILDFLDALLELSEEQQFVAEALEKGTLPLLKDQVKSVMEQNWDELASSPPDMDYDPEARILCALYVVVSILLELAEGPTSVSS>sp|P57764|GSDMD_HUMAN Gasdermin-D OS=Homo sapiens OX=9606 GN=GSDMD PE=1SV=1MGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDILEPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGDNVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPATGHKRSTSEGAWPQLPSGLSMMRCLHNFLTDGVPAEGAFTEDFQGLRAEVETISKELELLDRELCQLLLEGLEGVLRDQLALRALEEALEQGQSLGPVEPLDGPAGAVLECLVLSSGMLVPELAIPVVYLLGALTMLSETQHKLLAEALESQTLLGPLELVGSLLEQSAPWQERSTMSLPPGLLGNSWGEGAPAWVLLDECGLELGEDTPHVCWEPQAQGRMCALYASLALLSGLSQEPH>sp|P0DMT0|MLN_HUMAN Myoregulin OS=Homo sapiens OX=9606 GN=MRLN PE=3 SV=1MTGKNWILISTTTPKSLEDEIVGRLLKILFVIFVDLISIIYVVITS>sp|Q495T6|MMEL1_HUMAN Membrane metallo-endopeptidase-like 1 OS=Homosapiens OX=9606 GN=MMEL1 PE=2 SV=2MGKSEGPVGMVESAGRAGQKRPGFLEGGLLLLLLLVTAALVALGVLYADRRGKQLPRLASRLCFLQEERTFVKRKPRGIPEAQEVSEVCTTPGCVIAAARILQNMDPTTEPCDDFYQFACGGWLRRHVIPETNSRYSIFDVLRDELEVILKAVLENSTAKDRPAVEKARTLYRSCMNQSVIEKRGSQPLLDILEVVGGWPVAMDRWNETVGLEWELERQLALMNSQFNRRVLIDLFIWNDDQNSSRHIIYIDQPTLGMPSREYYFNGGSNRKVREAYLQFMVSVATLLREDANLPRDSCLVQEDMVQVLELETQLAKATVPQEERHDVIALYHRMGLEELQSQFGLKGFNWTLFIQTVLSSVKIKLLPDEEVVVYGIPYLQNLENIIDTYSARTIQNYLVWRLVLDRIGSLSQRFKDTRVNYRKALFGTMVEEVRWRECVGYVNSNMENAVGSLYVREAFPGDSKSMVRELIDKVRTVFVETLDELGWMDEESKKKAQEKAMSIREQIGHPDYILEEMNRRLDEEYSNLNFSEDLYFENSLQNLKVGAQRSLRKLREKVDPNLWIIGAAVVNAFYSPNRNQIVFPAGILQPPFFSKEQPQALNFGGIGMVIGHEITHGFDDNGRNFDKNGNMMDWWSNFSTQHFREQSECMIYQYGNYSWDLADEQNVNGFNTLGENIADNGGVRQAYKAYLKWMAEGGKDQQLPGLDLTHEQLFFINYAQVWCGSYRPEFAIQSIKTDVHSPLKYRVLGSLQNLAAFADTFHCARGTPMHPKERCRVW>sp|Q495T6-2|MMEL1_HUMAN Isoform 2 of Membrane metallo-endopeptidase-like1 OS=Homo sapiens OX=9606 GN=MMEL1MGKSEGPVGMVESAGRAGQKRPGFLEGGLLLLLLLVTAALVALGVLYADRRGKQLPRLASRLCFLQEERTFVKRKPRGIPEAQEVSEVCTTPGCVIAAARILQNMDPTTEPCDDFYQFACGGWLRRHVIPETNSRYSIFDVLRDELEVILKAVLENSTAKDRPAVEKARTLYRSCMNQSVIEKRGSQPLLDILEVVGGWPVAMDRWNETVGLEWELERQLALMNSQFNRRVLIDLFIWNDDQNSSRHIIYIDQPTLGMPSREYYFNGGSNRKVREAYLQFMVSVATLLREDANLPRDSCLVQEDMVQVLELETQLAKATVPQEERHDVIALYHRMGLEELQSQFGLKGFNWTLFIQTVLSSVKIKLLPDEEVVVYGIPYLQNLENIIDTYSARTIQNYLVWRLVLDRIGSLSQRFKDTRVNYRKALFGTMVEEVRWRECVGYVNSNMENAVGSLYVREAFPGDSKSMVRELIDKVRTVFVETLDELGWMDEESKKKAQEKAMSIREQIGHPDYILEEMNRRLDEEYSNLNFSEDLYFENSLQNLKVGAQRSLRKLREKVDPNLWIIGAAVVNAFYSPNRNQIAYSLSRPWGQYSLPGSSSPPSSARSSHRP>sp|Q495T6-3|MMEL1_HUMAN Isoform 3 of Membrane metallo-endopeptidase-like1 OS=Homo sapiens OX=9606 GN=MMEL1MGKSEGPVGMVESAGRAGQKRPGFLEGGLLLLLLLVTAALVALGVLYADRRGKQLPRLASRLCFLQEERTFVKRKPRGIPEAQEVSEVCTTPGCVIAAARILQNMDPTTEPCDDFYQFACGGWLRRHVIPETNSRYSIFDVLRDELEVILKAVLENSTAKATVPQEERHDVIALYHRMGLEELQSQFGLKGFNWTLFIQTVLSSVKIKLLPDEEVVVYGIPYLQNLENIIDTYSARTIQNYLVWRLVLDRIGSLSQRFKDTRVNYRKALFGTMVEEVRWRECVGYVNSNMENAVGSLYVREAFPGDSKSMVRELIDKVRTVFVETLDELGWMDEESKKKAQEKAMSIREQIGHPDYILEEMNRRLDEEYSNLNFSEDLYFENSLQNLKVGAQRSLRKLREKVDPNLWIIGAAVVNAFYSPNRNQIVFPAGILQPPFFSKEQPQALNFGGIGMVIGHEITHGFDDNGRNFDKNGNMMDWWSNFSTQHFREQSECMIYQYGNYSWDLADEQNVNGFNTLGENIADNGGVRQAYKAYLKWMAEGGKDQQLPGLDLTHEQLFFINYAQVWCGSYRPEFAIQSIKTDVHSPLKYRVLGSLQNLAAFADTFHCARGTPMHPKERCRVW>sp|P13591|NCAM1_HUMAN Neural cell adhesion molecule 1 OS=Homo sapiensOX=9606 GN=NCAM1 PE=1 SV=3MLQTKDLIWTLFFLGTAVSLQVDIVPSQGEISVGESKFFLCQVAGDAKDKDISWFSPNGEKLTPNQQRISVVWNDDSSSTLTIYNANIDDAGIYKCVVTGEDGSESEATVNVKIFQKLMFKNAPTPQEFREGEDAVIVCDVVSSLPPTIIWKHKGRDVILKKDVRFIVLSNNYLQIRGIKKTDEGTYRCEGRILARGEINFKDIQVIVNVPPTIQARQNIVNATANLGQSVTLVCDAEGFPEPTMSWTKDGEQIEQEEDDEKYIFSDDSSQLTIKKVDKNDEAEYICIAENKAGEQDATIHLKVFAKPKITYVENQTAMELEEQVTLTCEASGDPIPSITWRTSTRNISSEEKASWTRPEKQETLDGHMVVRSHARVSSLTLKSIQYTDAGEYICTASNTIGQDSQSMYLEVQYAPKLQGPVAVYTWEGNQVNITCEVFAYPSATISWFRDGQLLPSSNYSNIKIYNTPSASYLEVTPDSENDFGNYNCTAVNRIGQESLEFILVQADTPSSPSIDQVEPYSSTAQVQFDEPEATGGVPILKYKAEWRAVGEEVWHSKWYDAKEASMEGIVTIVGLKPETTYAVRLAALNGKGLGEISAASEFKTQPVQGEPSAPKLEGQMGEDGNSIKVNLIKQDDGGSPIRHYLVRYRALSSEWKPEIRLPSGSDHVMLKSLDWNAEYEVYVVAENQQGKSKAAHFVFRTSAQPTAIPANGSPTSGLSTGAIVGILIVIFVLLLVVVDITCYFLNKCGLFMCIAVNLCGKAGPGAKGKDMEEGKAAFSKDESKEPIVEVRTEEERTPNHDGGKHTEPNETTPLTEPEKGPVEAKPECQETETKPAPAEVKTVPNDATQTKENESKA>sp|P13591-1|NCAM1_HUMAN Isoform 2 of Neural cell adhesion molecule 1OS=Homo sapiens OX=9606 GN=NCAM1MLQTKDLIWTLFFLGTAVSLQVDIVPSQGEISVGESKFFLCQVAGDAKDKDISWFSPNGEKLTPNQQRISVVWNDDSSSTLTIYNANIDDAGIYKCVVTGEDGSESEATVNVKIFQKLMFKNAPTPQEFREGEDAVIVCDVVSSLPPTIIWKHKGRDVILKKDVRFIVLSNNYLQIRGIKKTDEGTYRCEGRILARGEINFKDIQVIVNVPPTIQARQNIVNATANLGQSVTLVCDAEGFPEPTMSWTKDGEQIEQEEDDEKYIFSDDSSQLTIKKVDKNDEAEYICIAENKAGEQDATIHLKVFAKPKITYVENQTAMELEEQVTLTCEASGDPIPSITWRTSTRNISSEEKTLDGHMVVRSHARVSSLTLKSIQYTDAGEYICTASNTIGQDSQSMYLEVQYAPKLQGPVAVYTWEGNQVNITCEVFAYPSATISWFRDGQLLPSSNYSNIKIYNTPSASYLEVTPDSENDFGNYNCTAVNRIGQESLEFILVQADTPSSPSIDQVEPYSSTAQVQFDEPEATGGVPILKYKAEWRAVGEEVWHSKWYDAKEASMEGIVTIVGLKPETTYAVRLAALNGKGLGEISAASEFKTQPVQGEPSAPKLEGQMGEDGNSIKVNLIKQDDGGSPIRHYLVRYRALSSEWKPEIRLPSGSDHVMLKSLDWNAEYEVYVVAENQQGKSKAAHFVFRTSAQPTAIPANGSPTSGLSTGAIVGILIVIFVLLLVVVDITCYFLNKCGLFMCIAVNLCGKAGPGAKGKDMEEGKAAFSKDESKEPIVEVRTEEERTPNHDGGKHTEPNETTPLTEPEKGPVEAKPECQETETKPAPAEVKTVPNDATQTKENESKA>sp|P13591-3|NCAM1_HUMAN Isoform 3 of Neural cell adhesion molecule 1OS=Homo sapiens OX=9606 GN=NCAM1MLQTKDLIWTLFFLGTAVSLQVDIVPSQGEISVGESKFFLCQVAGDAKDKDISWFSPNGEKLTPNQQRISVVWNDDSSSTLTIYNANIDDAGIYKCVVTGEDGSESEATVNVKIFQKLMFKNAPTPQEFREGEDAVIVCDVVSSLPPTIIWKHKGRDVILKKDVRFIVLSNNYLQIRGIKKTDEGTYRCEGRILARGEINFKDIQVIVNVPPTIQARQNIVNATANLGQSVTLVCDAEGFPEPTMSWTKDGEQIEQEEDDEKYIFSDDSSQLTIKKVDKNDEAEYICIAENKAGEQDATIHLKVFAKPKITYVENQTAMELEEQVTLTCEASGDPIPSITWRTSTRNISSEEKTLDGHMVVRSHARVSSLTLKSIQYTDAGEYICTASNTIGQDSQSMYLEVQYAPKLQGPVAVYTWEGNQVNITCEVFAYPSATISWFRDGQLLPSSNYSNIKIYNTPSASYLEVTPDSENDFGNYNCTAVNRIGQESLEFILVQADTPSSPSIDQVEPYSSTAQVQFDEPEATGGVPILKYKAEWRAVGEEVWHSKWYDAKEASMEGIVTIVGLKPETTYAVRLAALNGKGLGEISAASEFKTQPVHSPPPPASASSSTPVPLSPPDTTWPLPALATTEPAKGEPSAPKLEGQMGEDGNSIKVNLIKQDDGGSPIRHYLVRYRALSSEWKPEIRLPSGSDHVMLKSLDWNAEYEVYVVAENQQGKSKAAHFVFRTSAQPTAIPATLGGNSASYTFVSLLFSAVTLLLLC>sp|P13591-4|NCAM1_HUMAN Isoform 4 of Neural cell adhesion molecule 1OS=Homo sapiens OX=9606 GN=NCAM1MLQTKDLIWTLFFLGTAVSLQVDIVPSQGEISVGESKFFLCQVAGDAKDKDISWFSPNGEKLTPNQQRISVVWNDDSSSTLTIYNANIDDAGIYKCVVTGEDGSESEATVNVKIFQKLMFKNAPTPQEFREGEDAVIVCDVVSSLPPTIIWKHKGRDVILKKDVRFIVLSNNYLQIRGIKKTDEGTYRCEGRILARGEINFKDIQVIVNVPPTIQARQNIVNATANLGQSVTLVCDAEGFPEPTMSWTKDGEQIEQEEDDEKYIFSDDSSQLTIKKVDKNDEAEYICIAENKAGEQDATIHLKVFAKPKITYVENQTAMELEEQVTLTCEASGDPIPSITWRTSTRNISSEEKTLDGHMVVRSHARVSSLTLKSIQYTDAGEYICTASNTIGQDSQSMYLEVQYAPKLQGPVAVYTWEGNQVNITCEVFAYPSATISWFRDGQLLPSSNYSNIKIYNTPSASYLEVTPDSENDFGNYNCTAVNRIGQESLEFILVQADTPSSPSIDQVEPYSSTAQVQFDEPEATGGVPILKYKAEWRAVGEEVWHSKWYDAKEASMEGIVTIVGLKPETTYAVRLAALNGKGLGEISAASEFKTQPVQGEPSAPKLEGQMGEDGNSIKVNLIKQDDGGSPIRHYLVRYRALSSEWKPEIRLPSGSDHVMLKSLDWNAEYEVYVVAENQQGKSKAAHFVFRTSAQPTAIPATLGGNSASYTFVSLLFSAVTLLLLC>sp|P13591-5|NCAM1_HUMAN Isoform 5 of Neural cell adhesion molecule 1OS=Homo sapiens OX=9606 GN=NCAM1MLQTKDLIWTLFFLGTAVSLQVDIVPSQGEISVGESKFFLCQVAGDAKDKDISWFSPNGEKLTPNQQRISVVWNDDSSSTLTIYNANIDDAGIYKCVVTGEDGSESEATVNVKIFQKLMFKNAPTPQEFREGEDAVIVCDVVSSLPPTIIWKHKGRDVILKKDVRFIVLSNNYLQIRGIKKTDEGTYRCEGRILARGEINFKDIQVIVNVPPTIQARQNIVNATANLGQSVTLVCDAEGFPEPTMSWTKDGEQIEQEEDDEKYIFSDDSSQLTIKKVDKNDEAEYICIAENKAGEQDATIHLKVFAKPKITYVENQTAMELEEQVTLTCEASGDPIPSITWRTSTRNISSEEKASWTRPEKQETLDGHMVVRSHARVSSLTLKSIQYTDAGEYICTASNTIGQDSQSMYLEVQYAPKLQGPVAVYTWEGNQVNITCEVFAYPSATISWFRDGQLLPSSNYSNIKIYNTPSASYLEVTPDSENDFGNYNCTAVNRIGQESLEFILVQADTPSSPSIDQVEPYSSTAQVQFDEPEATGGVPILKYKAEWRAVGEEVWHSKWYDAKEASMEGIVTIVGLKPETTYAVRLAALNGKGLGEISAASEFKTQPVHSPPPPASASSSTPVPLSPPDTTWPLPALATTEPAKNIAQNHCCNMFQAGLHNALMK>sp|P13591-6|NCAM1_HUMAN Isoform 6 of Neural cell adhesion molecule 1OS=Homo sapiens OX=9606 GN=NCAM1MLQTKDLIWTLFFLGTAVSLQVDIVPSQGEISVGESKFFLCQVAGDAKDKDISWFSPNGEKLTPNQQRISVVWNDDSSSTLTIYNANIDDAGIYKCVVTGEDGSESEATVNVKIFQKLMFKNAPTPQEFREGEDAVIVCDVVSSLPPTIIWKHKGRDVILKKDVRFIVLSNNYLQIRGIKKTDEGTYRCEGRILARGEINFKDIQVIVNVPPTIQARQNIVNATANLGQSVTLVCDAEGFPEPTMSWTKDGEQIEQEEDDEKYIFSDDSSQLTIKKVDKNDEAEYICIAENKAGEQDATIHLKVFAKPKITYVENQTAMELEEQVTLTCEASGDPIPSITWRTSTRNISSEEKASWTRPEKQEV>sp|Q15742|NAB2_HUMAN NGFI-A-binding protein 2 OS=Homo sapiens OX=9606GN=NAB2 PE=1 SV=1MHRAPSPTAEQPPGGGDSARRTLQPRLKPSARAMALPRTLGELQLYRVLQRANLLSYYETFIQQGGDDVQQLCEAGEEEFLEIMALVGMATKPLHVRRLQKALREWATNPGLFSQPVPAVPVSSIPLFKISETAGTRKGSMSNGHGSPGEKAGSARSFSPKSPLELGEKLSPLPGGPGAGDPRIWPGRSTPESDVGAGGEEEAGSPPFSPPAGGGVPEGTGAGGLAAGGTGGGPDRLEPEMVRMVVESVERIFRSFPRGDAGEVTSLLKLNKKLARSVGHIFEMDDNDSQKEEEIRKYSIIYGRFDSKRREGKQLSLHELTINEAAAQFCMRDNTLLLRRVELFSLSRQVARESTYLSSLKGSRLHPEELGGPPLKKLKQEVGEQSHPEIQQPPPGPESYVPPYRPSLEEDSASLSGESLDGHLQAVGSCPRLTPPPADLPLALPAHGLWSRHILQQTLMDEGLRLARLVSHDRVGRLSPCVPAKPPLAEFEEGLLDRCPAPGPHPALVEGRRSSVKVEAEASRQ>sp|Q15742-2|NAB2_HUMAN Isoform 2 of NGFI-A-binding protein 2 OS=Homosapiens OX=9606 GN=NAB2MHRAPSPTAEQPPGGGDSARRTLQPRLKPSARAMALPRTLGELQLYRVLQRANLLSYYETFIQQGGDDVQQLCEAGEEEFLEIMALVGMATKPLHVRRLQKALREWATNPGLFSQPVPAVPVSSIPLFKISETAGTRKGSMSNGHGSPGEKAGSARSFSPKSPLELGEKLSPLPGGPGAGDPRIWPGRSTPESDVGAGGEEEAGSPPFSPPAGGGVPEGTGAGGLAAGGTGGGPDRLEPEMVRMVVESVERIFRSFPRGDAGEVTSLLKLNKKLARSVGHIFEMDDNDSQKEEEIRKYSIIYGRFDSKRREGKQLSLHEASP>sp|Q15742-3|NAB2_HUMAN Isoform 3 of NGFI-A-binding protein 2 OS=Homosapiens OX=9606 GN=NAB2MHRAPSPTAEQPPGGGDSARRTLQPRLKPSARAMALPRTLGELQLYRVLQRANLLSYYETFIQQGGDDVQQLCEAGEEEFLEIMALVGMATKPLHVRRLQKALREWATNPGLFSQPVPAVPVSSIPLFKISETAGTRKGSMSNGHGSPGEKAGSARSFSPKSPLELGEKLSPLPGGPGAGDPRIWPGRSTPESDVGAGGEEEAGSPPFSPPAGGGVPEGTGAGGLAAGGTGGGPDRLEPEMVRMVVESVERIFRSFPRGDAGEVTSLLKLNKKLARSVGHIFEMDDNDSQKEEEIRKYSIIYGRFDSKRREGKQLSLHELTINEAAAQFCMRDNTLLLRRVELFSLSRQVARESTYLSSLKGSRLHPEELGGPPLKKLKQEVGEQSHPEIQQPPPGPESYVPPYRPSLEEDSASLSGESLDGHLQEFEEGLLDRCPAPGPHPALVEGRRSSVKVEAEASRQ>sp|P13349|MYF5_HUMAN Myogenic factor 5 OS=Homo sapiens OX=9606 GN=MYF5PE=1 SV=2MDVMDGCQFSPSEYFYDGSCIPSPEGEFGDEFVPRVAAFGAHKAELQGSDEDEHVRAPTGHHQAGHCLMWACKACKRKSTTMDRRKAATMRERRRLKKVNQAFETLKRCTTTNPNQRLPKVEILRNAIRYIESLQELLREQVENYYSLPGQSCSEPTSPTSNCSDGMPECNSPVWSRKSSTFDSIYCPDVSNVYATDKNSLSSLDCLSNIVDRITSSEQPGLPLQDLASLSPVASTDSQPATPGASSSRLIYHVL>sp|P12883|MYH7_HUMAN Myosin-7 OS=Homo sapiens OX=9606 GN=MYH7 PE=1 SV=5MGDSEMAVFGAAAPYLRKSEKERLEAQTRPFDLKKDVFVPDDKQEFVKAKIVSREGGKVTAETEYGKTVTVKEDQVMQQNPPKFDKIEDMAMLTFLHEPAVLYNLKDRYGSWMIYTYSGLFCVTVNPYKWLPVYTPEVVAAYRGKKRSEAPPHIFSISDNAYQYMLTDRENQSILITGESGAGKTVNTKRVIQYFAVIAAIGDRSKKDQSPGKGTLEDQIIQANPALEAFGNAKTVRNDNSSRFGKFIRIHFGATGKLASADIETYLLEKSRVIFQLKAERDYHIFYQILSNKKPELLDMLLITNNPYDYAFISQGETTVASIDDAEELMATDNAFDVLGFTSEEKNSMYKLTGAIMHFGNMKFKLKQREEQAEPDGTEEADKSAYLMGLNSADLLKGLCHPRVKVGNEYVTKGQNVQQVIYATGALAKAVYERMFNWMVTRINATLETKQPRQYFIGVLDIAGFEIFDFNSFEQLCINFTNEKLQQFFNHHMFVLEQEEYKKEGIEWTFIDFGMDLQACIDLIEKPMGIMSILEEECMFPKATDMTFKAKLFDNHLGKSANFQKPRNIKGKPEAHFSLIHYAGIVDYNIIGWLQKNKDPLNETVVGLYQKSSLKLLSTLFANYAGADAPIEKGKGKAKKGSSFQTVSALHRENLNKLMTNLRSTHPHFVRCIIPNETKSPGVMDNPLVMHQLRCNGVLEGIRICRKGFPNRILYGDFRQRYRILNPAAIPEGQFIDSRKGAEKLLSSLDIDHNQYKFGHTKVFFKAGLLGLLEEMRDERLSRIITRIQAQSRGVLARMEYKKLLERRDSLLVIQWNIRAFMGVKNWPWMKLYFKIKPLLKSAEREKEMASMKEEFTRLKEALEKSEARRKELEEKMVSLLQEKNDLQLQVQAEQDNLADAEERCDQLIKNKIQLEAKVKEMNERLEDEEEMNAELTAKKRKLEDECSELKRDIDDLELTLAKVEKEKHATENKVKNLTEEMAGLDEIIAKLTKEKKALQEAHQQALDDLQAEEDKVNTLTKAKVKLEQQVDDLEGSLEQEKKVRMDLERAKRKLEGDLKLTQESIMDLENDKQQLDERLKKKDFELNALNARIEDEQALGSQLQKKLKELQARIEELEEELEAERTARAKVEKLRSDLSRELEEISERLEEAGGATSVQIEMNKKREAEFQKMRRDLEEATLQHEATAAALRKKHADSVAELGEQIDNLQRVKQKLEKEKSEFKLELDDVTSNMEQIIKAKANLEKMCRTLEDQMNEHRSKAEETQRSVNDLTSQRAKLQTENGELSRQLDEKEALISQLTRGKLTYTQQLEDLKRQLEEEVKAKNALAHALQSARHDCDLLREQYEEETEAKAELQRVLSKANSEVAQWRTKYETDAIQRTEELEEAKKKLAQRLQEAEEAVEAVNAKCSSLEKTKHRLQNEIEDLMVDVERSNAAAAALDKKQRNFDKILAEWKQKYEESQSELESSQKEARSLSTELFKLKNAYEESLEHLETFKRENKNLQEEISDLTEQLGSSGKTIHELEKVRKQLEAEKMELQSALEEAEASLEHEEGKILRAQLEFNQIKAEIERKLAEKDEEMEQAKRNHLRVVDSLQTSLDAETRSRNEALRVKKKMEGDLNEMEIQLSHANRMAAEAQKQVKSLQSLLKDTQIQLDDAVRANDDLKENIAIVERRNNLLQAELEELRAVVEQTERSRKLAEQELIETSERVQLLHSQNTSLINQKKKMDADLSQLQTEVEEAVQECRNAEEKAKKAITDAAMMAEELKKEQDTSAHLERMKKNMEQTIKDLQHRLDEAEQIALKGGKKQLQKLEARVRELENELEAEQKRNAESVKGMRKSERRIKELTYQTEEDRKNLLRLQDLVDKLQLKVKAYKRQAEEAEEQANTNLSKFRKVQHELDEAEERADIAESQVNKLRAKSRDIGTKGLNEE>sp|P10244|MYBB_HUMAN Myb-related protein B OS=Homo sapiens OX=9606GN=MYBL2 PE=1 SV=1MSRRTRCEDLDELHYQDTDSDVPEQRDSKCKVKWTHEEDEQLRALVRQFGQQDWKFLASHFPNRTDQQCQYRWLRVLNPDLVKGPWTKEEDQKVIELVKKYGTKQWTLIAKHLKGRLGKQCRERWHNHLNPEVKKSCWTEEEDRIICEAHKVLGNRWAEIAKMLPGRTDNAVKNHWNSTIKRKVDTGGFLSESKDCKPPVYLLLELEDKDGLQSAQPTEGQGSLLTNWPSVPPTIKEEENSEEELAAATTSKEQEPIGTDLDAVRTPEPLEEFPKREDQEGSPPETSLPYKWVVEAANLLIPAVGSSLSEALDLIESDPDAWCDLSKFDLPEEPSAEDSINNSLVQLQASHQQQVLPPRQPSALVPSVTEYRLDGHTISDLSRSSRGELIPISPSTEVGGSGIGTPPSVLKRQRKRRVALSPVTENSTSLSFLDSCNSLTPKSTPVKTLPFSPSQFLNFWNKQDTLELESPSLTSTPVCSQKVVVTTPLHRDKTPLHQKHAAFVTPDQKYSMDNTPHTPTPFKNALEKYGPLKPLPQTPHLEEDLKEVLRSEAGIELIIEDDIRPEKQKRKPGLRRSPIKKVRKSLALDIVDEDVKLMMSTLPKSLSLPTTAPSNSSSLTLSGIKEDNSLLNQGFLQAKPEKAAVAQKPRSHFTTPAPMSSAWKTVACGGTRDQLFMQEKARQLLGRLKPSHTSRTLILS>sp|P10244-2|MYBB_HUMAN Isoform 2 of Myb-related protein B OS=Homosapiens OX=9606 GN=MYBL2MSRRTRCEDLDELHYQDTDSDVPEQRDSKCKVKWTHEENRTDQQCQYRWLRVLNPDLVKGPWTKEEDQKVIELVKKYGTKQWTLIAKHLKGRLGKQCRERWHNHLNPEVKKSCWTEEEDRIICEAHKVLGNRWAEIAKMLPGRTDNAVKNHWNSTIKRKVDTGGFLSESKDCKPPVYLLLELEDKDGLQSAQPTEGQGSLLTNWPSVPPTIKEEENSEEELAAATTSKEQEPIGTDLDAVRTPEPLEEFPKREDQEGSPPETSLPYKWVVEAANLLIPAVGSSLSEALDLIESDPDAWCDLSKFDLPEEPSAEDSINNSLVQLQASHQQQVLPPRQPSALVPSVTEYRLDGHTISDLSRSSRGELIPISPSTEVGGSGIGTPPSVLKRQRKRRVALSPVTENSTSLSFLDSCNSLTPKSTPVKTLPFSPSQFLNFWNKQDTLELESPSLTSTPVCSQKVVVTTPLHRDKTPLHQKHAAFVTPDQKYSMDNTPHTPTPFKNALEKYGPLKPLPQTPHLEEDLKEVLRSEAGIELIIEDDIRPEKQKRKPGLRRSPIKKVRKSLALDIVDEDVKLMMSTLPKSLSLPTTAPSNSSSLTLSGIKEDNSLLNQGFLQAKPEKAAVAQKPRSHFTTPAPMSSAWKTVACGGTRDQLFMQEKARQLLGRLKPSHTSRTLILS>sp|Q9UKX3|MYH13_HUMAN Myosin-13 OS=Homo sapiens OX=9606 GN=MYH13 PE=2SV=2MSSDAEMAIFGEAAPYLRKPEKERIEAQNRPFDSKKACFVADNKEMYVKGMIQTRENDKVIVKTLDDRMLTLNNDQVFPMNPPKFDKIEDMAMMTHLHEPAVLYNLKERYAAWMIYTYSGLFCVTVNPYKWLPVYKPEVVAAYRGKKRQEAPPHIFSISDNAYQFMLTDRDNQSILITGESGAGKTVNTKRVIQYFATIAVTGDKKKETQPGKMQGTLEDQIIQANPLLEAFGNAKTVRNDNSSRFGKFIRIHFGATGKLASADIETYLLEKSRVTFQLSSERSYHIFYQIMSNKKPELIDLLLISTNPFDFPFVSQGEVTVASIDDSEELLATDNAIDILGFSSEEKVGIYKLTGAVMHYGNMKFKQKQREEQAEPDGTEVADKAGYLMGLNSAEMLKGLCCPRVKVGNEYVTKGQNVQQVTNSVGALAKAVYEKMFLWMVTRINQQLDTKQPRQYFIGVLDIAGFEIFDFNSLEQLCINFTNEKLQQFFNHHMFVLEQEEYKKEGIEWEFIDFGMDLAACIELIEKPMGIFSILEEECMFPKATDTSFKNKLYDQHLGKSNNFQKPKPAKGKAEAHFSLVHYAGTVDYNIAGWLDKNKDPLNETVVGLYQKSSLKLLSFLFSNYAGAETGDSGGSKKGGKKKGSSFQTVSAVFRENLNKLMTNLRSTHPHFVRCLIPNETKTPGVMDHYLVMHQLRCNGVLEGIRICRKGFPSRILYADFKQRYRILNASAIPEGQFIDSKNASEKLLNSIDVDREQFRFGNTKVFFKAGLLGLLEEMRDEKLVTLMTSTQAVCRGYLMRVEFKKMMERRDSIFCIQYNIRSFMNVKHWPWMNLFFKIKPLLKSAEAEKEMATMKEDFERTKEELARSEARRKELEEKMVSLLQEKNDLQLQVQSETENLMDAEERCEGLIKSKILLEAKVKELTERLEEEEEMNSELVAKKRNLEDKCSSLKRDIDDLELTLTKVEKEKHATENKVKNLSEEMTALEENISKLTKEKKSLQEAHQQTLDDLQVEEDKVNGLIKINAKLEQQTDDLEGSLEQEKKLRADLERAKRKLEGDLKMSQESIMDLENDKQQIEEKLKKKEFELSQLQAKIDDEQVHSLQFQKKIKELQARIEELEEEIEAEHTLRAKIEKQRSDLARELEEISERLEEASGATSAQIEMNKKREAEFQKMRRDLEEATLQHEATAATLRKKQADSVAELGEQIDNLQRVKQKLEKEKSELKMEIDDMASNIEALSKSKSNIERTCRTVEDQFSEIKAKDEQQTQLIHDLNMQKARLQTQNGELSHRVEEKESLISQLTKSKQALTQQLEELKRQMEEETKAKNAMAHALQSSRHDCDLLREQYEEEQEAKAELQRALSKANSEVAQWRTKYETDAIQRTEELEEAKKKLAQRLQEAEENTETANSKCASLEKTKQRLQGEVEDLMRDLERSHTACATLDKKQRNFDKVLAEWKQKLDESQAELEAAQKESRSLSTELFKMRNAYEEVVDQLETLRRENKNLQEEISDLTEQIAETGKNLQEAEKTKKLVEQEKSDLQVALEEVEGSLEHEESKILRVQLELSQVKSELDRKVIEKDEEIEQLKRNSQRAAEALQSVLDAEIRSRNDALRLKKKMEGDLNEMEIQLGHSNRQMAETQKHLRTVQGQLKDSQLHLDDALRSNEDLKEQLAIVERRNGLLLEELEEMKVALEQTERTRRLSEQELLDASDRVQLLHSQNTSLINTKKKLEADIAQCQAEVENSIQESRNAEEKAKKAITDAAMMAEELKKEQDTSAHLERMKKNLEQTVKDLQHRLDEAEQLALKGGKKQIQKLENRVRELENELDVEQKRGAEALKGAHKYERKVKEMTYQAEEDHKNILRLQDLVDKLQAKVKSYKRQAEEAEEQANTQLSRCRRVQHELEEAAERADIAESQVNKLRAKSRDVGSQKMEE>sp|Q9H1R3|MYLK2_HUMAN Myosin light chain kinase 2, skeletal/cardiacmuscle OS=Homo sapiens OX=9606 GN=MYLK2 PE=1 SV=3MATENGAVELGIQNPSTDKAPKGPTGERPLAAGKDPGPPDPKKAPDPPTLKKDAKAPASEKGDGTLAQPSTSSQGPKGEGDRGGGPAEGSAGPPAALPQQTATPETSVKKPKAEQGASGSQDPGKPRVGKKAAEGQAAARRGSPAFLHSPSCPAIISSSEKLLAKKPPSEASELTFEGVPMTHSPTDPRPAKAEEGKNILAESQKEVGEKTPGQAGQAKMQGDTSRGIEFQAVPSEKSEVGQALCLTAREEDCFQILDDCPPPPAPFPHRMVELRTGNVSSEFSMNSKEALGGGKFGAVCTCMEKATGLKLAAKVIKKQTPKDKEMVLLEIEVMNQLNHRNLIQLYAAIETPHEIVLFMEYIEGGELFERIVDEDYHLTEVDTMVFVRQICDGILFMHKMRVLHLDLKPENILCVNTTGHLVKIIDFGLARRYNPNEKLKVNFGTPEFLSPEVVNYDQISDKTDMWSMGVITYMLLSGLSPFLGDDDTETLNNVLSGNWYFDEETFEAVSDEAKDFVSNLIVKDQRARMNAAQCLAHPWLNNLAEKAKRCNRRLKSQILLKKYLMKRRWKKNFIAVSAANRFKKISSSGALMALGV>sp|Q9NPH6|OBP2B_HUMAN Odorant-binding protein 2b OS=Homo sapiens OX=9606GN=OBP2B PE=2 SV=1MKTLFLGVTLGLAAALSFTLEEEDITGTWYVKAMVVDKDFPEDRRPRKVSPVKVTALGGGKLEATFTFMREDRCIQKKILMRKTEEPGKYSAYGGRKLMYLQELPRRDHYIFYCKDQHHGGLLHMGKLVGRNSDTNREALEEFKKLVQRKGLSEEDIFTPLQTGSCVPEH>sp|Q9NPH6-2|OBP2B_HUMAN Isoform Bb of Odorant-binding protein 2b OS=Homosapiens OX=9606 GN=OBP2BMKTLFLGVTLGLAAALSFTLEEEDITGTWYVKAMVVDKDFPEDRRPRKVSPVKVTALGGGKLEATFTFMREDRCIQKKILMRKTEEPGKYSACLSAVEMDQITPALWEALAIDTLRKLRIGTRRPRIRWGQEAHVPAGAAQEGPLHLLLQRPAPWGPAPHGKACG>sp|Q9NPH6-3|OBP2B_HUMAN Isoform Bg of Odorant-binding protein 2b OS=Homosapiens OX=9606 GN=OBP2BMKTLFLGVTLGLAAALSFTLEEEDEGGSVHPEENPDAEDGGAWQIQRLWGQEAHIPAGAAQEGPLHLLLQRPAPWGPAPHGKACG>sp|Q9GZM6|OR8D2_HUMAN Olfactory receptor 8D2 OS=Homo sapiens OX=9606GN=OR8D2 PE=2 SV=1MATSNHSSGAEFILAGLTQRPELQLPLFLLFLGIYVVTVVGNLGMIFLIALSSQLYPPVYYFLSHLSFIDLCYSSVITPKMLVNFVPEENIISFLECITQLYFFLIFVIAEGYLLTAMEYDRYVAICRPLLYNIVMSHRVCSIMMAVVYSLGFLWATVHTTRMSVLSFCRSHTVSHYFCDILPLLTLSCSSTHINEILLFIIGGVNTLATTLAVLISYAFIFSSILGIHSTEGQSKAFGTCSSHLLAVGIFFGSITFMYFKPPSSTTMEKEKVSSVFYITIIPMLNPLIYSLRNKDVKNALKKMTRGRQSS>sp|Q8NG95|OR7G3_HUMAN Olfactory receptor 7G3 OS=Homo sapiens OX=9606GN=OR7G3 PE=3 SV=1MKAGNFSDTPEFFLLGLSGDPELQPILFMLFLSMYLATMLGNLLIILAVNSDSHLHTPMYFLLSILSLVDICFTSTTMPKMLVNIQAQAQSINYTGCLTQICFVLVFVGLENGILVMMAYDRFVAICHPLRYNVIMNPKLCGLLLLLSFIVSVLDALLHTLMVLQLTFCIDLEIPHFFCELAHILKLACSDVLINNILVYLVTSLLGVVPLSGIIFSYTRIVSSVMKIPSAGGKYKAFSICGSHLIVVSLFYGTGFGVYLSSGATHSSRKGAIASVMYTVVTPMLNPLIYSLRNKDMLKALRKLISRIPSFH>sp|Q9BQT8|ODC_HUMAN Mitochondrial 2-oxodicarboxylate carrier OS=Homosapiens OX=9606 GN=SLC25A21 PE=1 SV=1MSAKPEVSLVREASRQIVAGGSAGLVEICLMHPLDVVKTRFQIQRCATDPNSYKSLVDSFRMIFQMEGLFGFYKGILPPILAETPKRAVKFFTFEQYKKLLGYVSLSPALTFAIAGLGSGLTEAIVVNPFEVVKVGLQANRNTFAEQPSTVGYARQIIKKEGWGLQGLNKGLTATLGRHGVFNMVYFGFYYNVKNMIPVNKDPILEFWRKFGIGLLSGTIASVINIPFDVAKSRIQGPQPVPGEIKYRTCFKTMATVYQEEGILALYKGLLPKIMRLGPGGAVMLLVYEYTYSWLQENW>sp|Q9BQT8-2|ODC_HUMAN Isoform 2 of Mitochondrial 2-oxodicarboxylatecarrier OS=Homo sapiens OX=9606 GN=SLC25A21MSAKPEVSLVREASRQIVAGGSAGLVEICLMHPLDVVKTRFQIQRCATDPNSYKSLVDSFRMIFQMEGLFGFYKGILPPILAETPKRAVKFFTFEQYKKLLGYVSLSPALTFAIAGLGSGLTEAIVVNPFEVVKVGLQANRNTFAEQPSTVGYARQIIKKEGWGLQGLNKGLTATLGRHGVFNMVYFGFYYNVKNMIPVNKDPILEFWRKFGIGLLSGTIASVINIPFDVAKSRIQGPQPVPGEIKYRTCFKTMATVYQEEGILALYKGLLPKIMRLGPGGAVMLLVYEYTYSWLQEN>sp|Q8NGF6|O10W1_HUMAN Olfactory receptor 10W1 OS=Homo sapiens OX=9606GN=OR10W1 PE=2 SV=1MEFVFLAYPSCPELHILSFLGVSLVYGLIITGNILIVVSIHTETCLCTSMYYFLGSLSGIEICYTAVVVPHILANTLQSEKTITLLGCATQMAFFIALGSADCFLLAAMAYDRYVAICHPLQYPLLMTLTLCVHLVVASVISGLFLSLQLVAFIFSLPFCQAQGIEHFFCDVPPVMHVVCAQSHIHEQSVLVAAILAIAVPFFLITTSYTFIVAALLKIHSAAGRHRAFSTCSSHLTVVLLQYGCCAFMYLCPSSSYNPKQDRFISLVYTLGTPLLNPLIYALRNSEMKGAVGRVLTRNCLSQNS>sp|Q8N4S7|PAQR4_HUMAN Progestin and adipoQ receptor family member 4OS=Homo sapiens OX=9606 GN=PAQR4 PE=2 SV=3MAFLAGPRLLDWASSPPHLQFNKFVLTGYRPASSGSGCLRSLFYLHNELGNIYTHGLALLGFLVLVPMTMPWGQLGKDGWLGGTHCVACLAPPAGSVLYHLFMCHQGGSAVYARLLALDMCGVCLVNTLGALPIIHCTLACRPWLRPAALVGYTVLSGVAGWRALTAPSTSARLRAFGWQAAARLLVFGARGVGLGSGAPGSLPCYLRMDALALLGGLVNVARLPERWGPGRFDYWGNSHQIMHLLSVGSILQLHAGVVPDLLWAAHHACPRD>sp|Q8N4S7-2|PAQR4_HUMAN Isoform 2 of Progestin and adipoQ receptorfamily member 4 OS=Homo sapiens OX=9606 GN=PAQR4MAFLAGPRLLDWASSPPHLQFNKFVLTGYRPASSGSGCLRSLFYLHNELGNIYTHGSVLYHLFMCHQGGSAVYARLLALDMCGVCLVNTLGALPIIHCTLACRPWLRPAALVGYTVLSGVAGWRALTAPSTSARLRAFGWQAAARLLVFGARGVGLGSGAPGSLPCYLRMDALALLGGLVNVARLPERWGPGRFDYWGNSHQIMHLLSVGSILQLHAGVVPDLLWAAHHACPRD>sp|Q8N4S7-3|PAQR4_HUMAN Isoform 3 of Progestin and adipoQ receptorfamily member 4 OS=Homo sapiens OX=9606 GN=PAQR4MAFLAGPRLLDWASSPPHLQFNKFVLTGYRPASSGSGCLRSLFYLHNELGNIYTHALPIIHCTLACRPWLRPAALVGYTVLSGVAGWRALTAPSTSARLRAFGWQAAARLLVFGARGVGLGSGAPGSLPCYLRMDALALLGGLVNVARLPERWGPGRFDYWGNSHQIMHLLSVGSILQLHAGVVPDLLWAAHHACPRD>sp|Q8NGM1|OR4CF_HUMAN Olfactory receptor 4C15 OS=Homo sapiens OX=9606GN=OR4C15 PE=3 SV=1MQNQSFVTEFVLLGLSQNPNVQEIVFVVFLFVYIATVGGNMLIVVTILSSPALLVSPMYFFLGFLSFLDACFSSVITPKMIVDSLYVTKTISFEGCMMQLFAEHFFAGVEVIVLTAMAYDRYVAICKPLHYSSIMNRRLCGILMGVAWTGGLLHSMIQILFTFQLPFCGPNVINHFMCDLYPLLELACTDTHIFGLMVVINSGFICIINFSLLLVSYAVILLSLRTHSSEGRWKALSTCGSHIAVVILFFVPCIFVYTRPPSAFSLDKMAAIFYIILNPLLNPLIYTFRNKEVKQAMRRIWNRLMVVSDEKENIKL>sp|Q99436|PSB7_HUMAN Proteasome subunit beta type-7 OS=Homo sapiensOX=9606 GN=PSMB7 PE=1 SV=1MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTIAGVVYKDGIVLGADTRATEGMVVADKNCSKIHFISPNIYCCGAGTAADTDMTTQLISSNLELHSLSTGRLPRVVTANRMLKQMLFRYQGYIGAALVLGGVDVTGPHLYSIYPHGSTDKLPYVTMGSGSLAAMAVFEDKFRPDMEEEEAKNLVSEAIAAGIFNDLGSGSNIDLCVISKNKLDFLRPYTVPNKKGTRLGRYRCEKGTTAVLTEKITPLEIEVLEETVQTMDTS>sp|Q99436-2|PSB7_HUMAN Isoform 2 of Proteasome subunit beta type-7OS=Homo sapiens OX=9606 GN=PSMB7MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTIAGVVYKDGIVLGADTRATEGMVVADKNCSKIHFISPNIYCCGAGTAADTDMTTQLISSNLELHSLSTGRLPRVVTANRMLKQMLFRFWLLGSNGCI>sp|Q9UQ72|PSG11_HUMAN Pregnancy-specific beta-1-glycoprotein 11 OS=Homosapiens OX=9606 GN=PSG11 PE=2 SV=3MGPLSAPPCTEHIKWKGLLLTALLLNFWNLPTTAQVMIEAQPPKVSEGKDVLLLVHNLPQNLTGYIWYKGQIRDLYHYITSYVVDGQIIIYGPAYSGRETVYSNASLLIQNVTREDAGSYTLHIIKRGDGTRGVTGYFTFTLYLETPKPSISSSNLNPREAMETVILTCNPETPDASYLWWMNGQSLPMTHRMQLSETNRTLFLFGVTKYTAGPYECEIWNSGSASRSDPVTLNLLHGPDLPRIFPSVTSYYSGENLDLSCFANSNPPAQYSWTINGKFQLSGQKLFIPQITPKHNGLYACSARNSATGEESSTSLTIRVIAPPGLGTFAFNNPT>sp|Q9UQ72-2|PSG11_HUMAN Isoform 2 of Pregnancy-specific beta-1-glycoprotein 11 OS=Homo sapiens OX=9606 GN=PSG11MGPLSAPPCTEHIKWKGLLLTVETPKPSISSSNLNPREAMETVILTCNPETPDASYLWWMNGQSLPMTHRMQLSETNRTLFLFGVTKYTAGPYECEIWNSGSASRSDPVTLNLLHGPDLPRIFPSVTSYYSGENLDLSCFANSNPPAQYSWTINGKFQLSGQKLFIPQITPKHNGLYACSARNSATGEESSTSLTIRVIAPPGLGTFAFNNPT>sp|P0DJ07|PT100_HUMAN Protein PET100 homolog, mitochondrial OS=Homosapiens OX=9606 GN=PET100 PE=1 SV=1MGVKLEIFRMIIYLTFPVAMFWVSNQAEWFEDDVIQRKRELWPPEKLQEIEEFKERLRKRREEKLLRDAQQNS>sp|Q8NHQ8|RASF8_HUMAN Ras association domain-containing protein 8OS=Homo sapiens OX=9606 GN=RASSF8 PE=1 SV=2MELKVWVDGVQRIVCGVTEVTTCQEVVIALAQAIGRTGRYTLIEKWRDTERHLAPHENPIISLNKWGQYASDVQLILRRTGPSLSERPTSDSVARIPERTLYRQSLPPLAKLRPQIDKSIKRREPKRKSLTFTGGAKGLMDIFGKGKETEFKQKVLNNCKTTADELKKLIRLQTEKLQSIEKQLESNEIEIRFWEQKYNSNLEEEIVRLEQKIKRNDVEIEEEEFWENELQIEQENEKQLKDQLQEIRQKITECENKLKDYLAQIRTMESGLEAEKLQREVQEAQVNEEEVKGKIGKVKGEIDIQGQQSLRLENGIKAVERSLGQATKRLQDKEQELEQLTKELRQVNLQQFIQQTGTKVTVLPAEPIEIEASHADIEREAPFQSGSLKRPGSSRQLPSNLRILQNPISSGFNPEGIYV>sp|Q8NHQ8-2|RASF8_HUMAN Isoform 2 of Ras association domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=RASSF8MELKVWVDGVQRIVCGVTEVTTCQEVVIALAQAIGRTGRYTLIEKWRDTERHLAPHENPIISLNKWGQYASDVQLILRRTGPSLSERPTSDSVARIPERTLYRQSLPPLAKLRPQIDKSIKRREPKRKSLTFTGGAKGLMDIFGKGKETEFKQKVLNNCKTTADELKKLIRLQTEKLQSIEKQLESNEIEIRFWEQKYNSNLEEEIVRLEQKIKRNDVEIEEEEFWENELQIEQENEKQLKDQLQEIRQKITECENKLKDYLAQIRTMESGLEAEKLQREVQEAQVNEEEVKGKIGKVKGEIDIQGQQSLRLENGIKAVERSLGQATKRLQDKEQELEQLTKELRQVNLQQFIQQTGTKVTVLPAEPIEIEASHADIERGIIILSDKQECKD>sp|Q99969|RARR2_HUMAN Retinoic acid receptor responder protein 2 OS=Homosapiens OX=9606 GN=RARRES2 PE=1 SV=1MRRLLIPLALWLGAVGVGVAELTEAQRRGLQVALEEFHKHPPVQWAFQETSVESAVDTPFPAGIFVRLEFKLQQTSCRKRDWKKPECKVRPNGRKRKCLACIKLGSEDKVLGRLVHCPIETQVLREAEEHQETQCLRVQRAGEDPHSFYFPGQFAFSKALPRS>sp|P01112|RASH_HUMAN GTPase HRas OS=Homo sapiens OX=9606 GN=HRAS PE=1SV=1MTEYKLVVVGAGGVGKSALTIQLIQNHFVDEYDPTIEDSYRKQVVIDGETCLLDILDTAGQEEYSAMRDQYMRTGEGFLCVFAINNTKSFEDIHQYREQIKRVKDSDDVPMVLVGNKCDLAARTVESRQAQDLARSYGIPYIETSAKTRQGVEDAFYTLVREIRQHKLRKLNPPDESGPGCMSCKCVLS>sp|P01112-2|RASH_HUMAN Isoform 2 of GTPase HRas OS=Homo sapiens OX=9606GN=HRASMTEYKLVVVGAGGVGKSALTIQLIQNHFVDEYDPTIEDSYRKQVVIDGETCLLDILDTAGQEEYSAMRDQYMRTGEGFLCVFAINNTKSFEDIHQYREQIKRVKDSDDVPMVLVGNKCDLAARTVESRQAQDLARSYGIPYIETSAKTRQGSRSGSSSSSGTLWDPPGPM>sp|Q9UKA8|RCAN3_HUMAN Calcipressin-3 OS=Homo sapiens OX=9606 GN=RCAN3PE=1 SV=1MLRDTMKSWNDSQSDLCSTDQEEEEEMIFGENEDDLDEMMDLSDLPTSLFACSVHEAVFEAREQKERFEALFTIYDDQVTFQLFKSFRRVRINFSKPEAAARARIELHETDFNGQKLKLYFAQVQMSGEVRDKSYLLPPQPVKQFLISPPASPPVGWKQSEDAMPVINYDLLCAVSKLGPGEKYELHAGTESTPSVVVHVCESETEEEEETKNPKQKIAQTRRPDPPTAALNEPQTFDCAL>sp|Q9UKA8-2|RCAN3_HUMAN Isoform 2 of Calcipressin-3 OS=Homo sapiensOX=9606 GN=RCAN3MLRDTMKSWNDSQSDLCSTDQEEEEEMIFGENEDDLDEMMDLSDLPTSLFACSVHEAVFEAREQKERFEALFTIYDDQVTFQLFKSFRRVRINFSKPEAAARARIELHETDFNGQKLKLYFAQSYLLPPQPVKQFLISPPASPPVGWKQSEDAMPVINYDLLCAVSKLGPGEKYELHAGTESTPSVVVHVCESETEEEEETKNPKQKIAQTRRPDPPTAALNEPQTFDCAL>sp|Q9UKA8-3|RCAN3_HUMAN Isoform 3 of Calcipressin-3 OS=Homo sapiensOX=9606 GN=RCAN3MLRDTMKSWNDSQSDLCSTDQEEEEEMIFGENEDDLDEMMDLSDLPTSLFACSVHEAVFEAREQKERFEALFTIYDDQVTFQLFKSFRRVRINFSKPEAAARARIELHETDFNGQKLKLYFAQERNMNFTREQSRHPAWWFMSVKVKLKRKKRQKTPNRKLPRRGAPTLRPQR>sp|Q9UKA8-4|RCAN3_HUMAN Isoform 4 of Calcipressin-3 OS=Homo sapiensOX=9606 GN=RCAN3MLRDTMKSWNDSQSDLCSTDQEEEEEMIFGENEDDLDEMMDLSDLPTSLFACSVHEAVFEAREQKERNMNFTREQSRHPAWWFMSVKVKLKRKKRQKTPNRKLPRRGAPTLRPQR>sp|Q9UKA8-5|RCAN3_HUMAN Isoform 5 of Calcipressin-3 OS=Homo sapiensOX=9606 GN=RCAN3MLRDTMKSWNDSQSDLCSTDQEEEEEMIFGENEDDLDEMMDLSDLPTSLFACSVHEAVFEAREQKVQMSGEVRDKSYLLPPQPVKQFLISPPASPPVGWKQSEDAMPVINYDLLCAVSKLGPGEKYELHAGTESTPSVVVHVCESETEEEEETKNPKQKIAQTRRPDPPTAALNEPQTFDCAL>sp|Q9UKA8-6|RCAN3_HUMAN Isoform 6 of Calcipressin-3 OS=Homo sapiensOX=9606 GN=RCAN3MSGEVRDKSYLLPPQPVKQFLISPPASPPVGWKQSEDAMPVINYDLLCAVSKLGPGEKYELHAGTESTPSVVVHVCESETEEEEETKNPKQKIAQTRRPDPPTAALNEPQTFDCAL>sp|P20339|RAB5A_HUMAN Ras-related protein Rab-5A OS=Homo sapiens OX=9606GN=RAB5A PE=1 SV=2MASRGATRPNGPNTGNKICQFKLVLLGESAVGKSSLVLRFVKGQFHEFQESTIGAAFLTQTVCLDDTTVKFEIWDTAGQERYHSLAPMYYRGAQAAIVVYDITNEESFARAKNWVKELQRQASPNIVIALSGNKADLANKRAVDFQEAQSYADDNSLLFMETSAKTSMNVNEIFMAIAKKLPKNEPQNPGANSARGRGVDLTEPTQPTRNQCCSN>sp|P20339-2|RAB5A_HUMAN Isoform 2 of Ras-related protein Rab-5A OS=Homosapiens OX=9606 GN=RAB5AMASRGATRPNGPNTGNKICQFKLVLLGESAVGKSSLVLRFVKGQFHEFQESTIGVKFEIWDTAGQERYHSLAPMYYRGAQAAIVVYDITNEESFARAKNWVKELQRQASPNIVIALSGNKADLANKRAVDFQEAQSYADDNSLLFMETSAKTSMNVNEIFMAIAKKLPKNEPQNPGANSARGRGVDLTEPTQPTRNQCCSN>sp|Q96I51|RCC1L_HUMAN RCC1-like G exchanging factor-like protein OS=Homosapiens OX=9606 GN=RCC1L PE=1 SV=2MALVALVAGARLGRRLSGPGLGRGHWTAARRSRSRREAAEAEAEVPVVQYVGERAARADRVFVWGFSFSGALGVPSFVVPSSGPGPRAGARPRRRIQPVPYRLELDQKISSAACGYGFTLLSSKTADVTKVWGMGLNKDSQLGFHRSRKDKTRGYEYVLEPSPVSLPLDRPQETRVLQVSCGRAHSLVLTDREGVFSMGNNSYGQCGRKVVENEIYSESHRVHRMQDFDGQVVQVACGQDHSLFLTDKGEVYSCGWGADGQTGLGHYNITSSPTKLGGDLAGVNVIQVATYGDCCLAVSADGGLFGWGNSEYLQLASVTDSTQVNVPRCLHFSGVGKVRQAACGGTGCAVLNGEGHVFVWGYGILGKGPNLVESAVPEMIPPTLFGLTEFNPEIQVSRIRCGLSHFAALTNKGELFVWGKNIRGCLGIGRLEDQYFPWRVTMPGEPVDVACGVDHMVTLAKSFI>sp|Q96I51-2|RCC1L_HUMAN Isoform 2 of RCC1-like G exchanging factor-likeprotein OS=Homo sapiens OX=9606 GN=RCC1LMALVALVAGARLGRRLSGPGLGRGHWTAARRSRSRREAAEAEAEVPVVQYVGERAARADRVFVWGFSFSGALGVPSFVVPSSGPGPRAGARPRRRIQPVPYRLELDQKISSAACGYGFTLLSSKTADVTKVWGMGLNKDSQLGFHRSRKDKTRGYEYVLEPSPVSLPLDRPQETRVLQVSCGRAHSLVLTDREGVFSMGNNSYGQCGRKVVENEIYSESHRVHRMQDFDGQVVQVACGQDHSLFLTDKGEVYSCGWGADGQTGLGHYNITSSPTKLGGDLAGVNVIQVATYGDCCLAVSADGGLFGWGNSEYLQLASVTDSTQVNVPRCLHFSGVGKVRQAACGGTGCAVLNDTWPQS>sp|Q96I51-3|RCC1L_HUMAN Isoform 3 of RCC1-like G exchanging factor-likeprotein OS=Homo sapiens OX=9606 GN=RCC1LMALVALVAGARLGRRLSGPGLGRGHWTAARRSRSRREAAEAEAEVPVVQYVGERAARADRVFVWGFSFSGALGVPSFVVPSSGPGPRAGARPRRRIQPVPYRLELDQKISSAACGYGFTLLSSKTADVTKVWGMGLNKDSQLGFHRSRKDKTRGYEYVLEPSPVSLPLDRPQETRVLQVSCGRAHSLVLTDREGVFSMGNNSYGQCGRKVVENEIYSESHRVHRMQDFDGQVVQVACGQDHSLFLTDKGEVYSCGWGADGQTGLGHYNITSSPTKLGGDLAGVNVIQVATYGDCCLAVSADGGLFGWGNSEYLQLASVTDSTQVNVPRCLHFSGVGKVRQAACGGTGCAVLNGEGHVFVWGYGILGKGPNLVESAVPEMIPPTLFGLTEFNPEIQVSRIRCGLSHFAALTNKGELFVWGKNIRGCLGIGRLEDQYFPWRAPAPSASAKTTGPLL>sp|Q12829|RB40B_HUMAN Ras-related protein Rab-40B OS=Homo sapiensOX=9606 GN=RAB40B PE=1 SV=1MSALGSPVRAYDFLLKFLLVGDSDVGKGEILASLQDGAAESPYGHPAGIDYKTTTILLDGRRVKLQLWDTSGQGRFCTIFRSYSRGAQGVILVYDIANRWSFDGIDRWIKEIDEHAPGVPKILVGNRLHLAFKRQVPTEQAQAYAERLGVTFFEVSPLCNFNITESFTELARIVLLRHGMDRLWRPSKVLSLQDLCCRAVVSCTPVHLVDKLPLPIALRSHLKSFSMANGLNARMMHGGSYSLTTSSTHKRSSLRKVKLVRPPQSPPKNCTRNSCKIS>sp|P06400|RB_HUMAN Retinoblastoma-associated protein OS=Homo sapiensOX=9606 GN=RB1 PE=1 SV=2MPPKTPRKTAATAAAAAAEPPAPPPPPPPEEDPEQDSGPEDLPLVRLEFEETEEPDFTALCQKLKIPDHVRERAWLTWEKVSSVDGVLGGYIQKKKELWGICIFIAAVDLDEMSFTFTELQKNIEISVHKFFNLLKEIDTSTKVDNAMSRLLKKYDVLFALFSKLERTCELIYLTQPSSSISTEINSALVLKVSWITFLLAKGEVLQMEDDLVISFQLMLCVLDYFIKLSPPMLLKEPYKTAVIPINGSPRTPRRGQNRSARIAKQLENDTRIIEVLCKEHECNIDEVKNVYFKNFIPFMNSLGLVTSNGLPEVENLSKRYEEIYLKNKDLDARLFLDHDKTLQTDSIDSFETQRTPRKSNLDEEVNVIPPHTPVRTVMNTIQQLMMILNSASDQPSENLISYFNNCTVNPKESILKRVKDIGYIFKEKFAKAVGQGCVEIGSQRYKLGVRLYYRVMESMLKSEEERLSIQNFSKLLNDNIFHMSLLACALEVVMATYSRSTSQNLDSGTDLSFPWILNVLNLKAFDFYKVIESFIKAEGNLTREMIKHLERCEHRIMESLAWLSDSPLFDLIKQSKDREGPTDHLESACPLNLPLQNNHTAADMYLSPVRSPKKKGSTTRVNSTANAETQATSAFQTQKPLKSTSLSLFYKKVYRLAYLRLNTLCERLLSEHPELEHIIWTLFQHTLQNEYELMRDRHLDQIMMCSMYGICKVKNIDLKFKIIVTAYKDLPHAVQETFKRVLIKEEEYDSIIVFYNSVFMQRLKTNILQYASTRPPTLSPIPHIPRSPYKFPSSPLRIPGGNIYISPLKSPYKISEGLPTPTKMTPRSRILVSIGESFGTSEKFQKINQMVCNSDRVLKRSAEGSNPPKPLKKLRFDIEGSDEADGSKHLPGESKFQQKLAEMTSTRTRMQKQKMNDSMDTSNKEEK>sp|P0C0E4|RB40L_HUMAN Ras-related protein Rab-40A-like OS=Homo sapiensOX=9606 GN=RAB40AL PE=1 SV=1MSAPGSPDQAYDFLLKFLLVGDRDVGKSEILESLQDGTAESPYSHLGGIDYKTTTILLDGQRVKLKLWDTSGQGRFCTIFRSYSRGAQGVILVYDIANRWSFEGMDRWIKKIEEHAPGVPKILVGNRLHLAFKRQVPREQAQAYAERLGVTFFEVSPLCNFNIIESFTELARIVLLRHRLNWLGRPSKVLSLQDLCCRTIVSCTPVHLVDKLPLPIALRSHLKSFSMAKGLNARMMRGLSYSLTTSSTHKRSSLCKVKIVCPPQSPPKNCTRNSCKIS>sp|Q9H0T7|RAB17_HUMAN Ras-related protein Rab-17 OS=Homo sapiens OX=9606GN=RAB17 PE=1 SV=2MAQAHRTPQPRAAPSQPRVFKLVLLGSGSVGKSSLALRYVKNDFKSILPTVGCAFFTKVVDVGATSLKLEIWDTAGQEKYHSVCHLYFRGANAALLVYDITRKDSFLKAQQWLKDLEEELHPGEVLVMLVGNKTDLSQEREVTFQEGKEFADSQKLLFMETSAKLNHQVSEVFNTVAQELLQRSDEEGQALRGDAAVALNKGPARQAKCCAH>sp|Q9H0T7-2|RAB17_HUMAN Isoform 2 of Ras-related protein Rab-17 OS=Homosapiens OX=9606 GN=RAB17MLVGNKTDLSQEREVTFQEGKEFADSQKLLFMETSAKLNHQVSEVFNTVAQELLQRSDEEGQALRGDAAVALNKGPARQAKCCAH>sp|Q5HYI8|RABL3_HUMAN Rab-like protein 3 OS=Homo sapiens OX=9606GN=RABL3 PE=1 SV=1MASLDRVKVLVLGDSGVGKSSLVHLLCQNQVLGNPSWTVGCSVDVRVHDYKEGTPEEKTYYIELWDVGGSVGSASSVKSTRAVFYNSVNGIIFVHDLTNKKSSQNLRRWSLEALNRDLVPTGVLVTNGDYDQEQFADNQIPLLVIGTKLDQIHETKRHEVLTRTAFLAEDFNPEEINLDCTNPRYLAAGSSNAVKLSRFFDKVIEKRYFLREGNQIPGFPDRKRFGAGTLKSLHYD>sp|P61254|RL26_HUMAN 60S ribosomal protein L26 OS=Homo sapiens OX=9606GN=RPL26 PE=1 SV=1MKFNPFVTSDRSKNRKRHFNAPSHIRRKIMSSPLSKELRQKYNVRSMPIRKDDEVQVVRGHYKGQQIGKVVQVYRKKYVIYIERVQREKANGTTVHVGIHPSKVVITRLKLDKDRKKILERKAKSRQVGKEKGKYKEETIEKMQE>sp|Q9NSD7|RL3R1_HUMAN Relaxin-3 receptor 1 OS=Homo sapiens OX=9606GN=RXFP3 PE=1 SV=1MQMADAATIATMNKAAGGDKLAELFSLVPDLLEAANTSGNASLQLPDLWWELGLELPDGAPPGHPPGSGGAESADTEARVRILISVVYWVVCALGLAGNLLVLYLMKSMQGWRKSSINLFVTNLALTDFQFVLTLPFWAVENALDFKWPFGKAMCKIVSMVTSMNMYASVFFLTAMSVTRYHSVASALKSHRTRGHGRGDCCGRSLGDSCCFSAKALCVWIWALAALASLPSAIFSTTVKVMGEELCLVRFPDKLLGRDRQFWLGLYHSQKVLLGFVLPLGIIILCYLLLVRFIADRRAAGTKGGAAVAGGRPTGASARRLSKVTKSVTIVVLSFFLCWLPNQALTTWSILIKFNAVPFSQEYFLCQVYAFPVSVCLAHSNSCLNPVLYCLVRREFRKALKSLLWRIASPSITSMRPFTATTKPEHEDQGLQAPAPPHAAAEPDLLYYPPGVVVYSGGRYDLLPSSSAY>sp|P22090|RS4Y1_HUMAN 40S ribosomal protein S4, Y isoform 1 OS=Homosapiens OX=9606 GN=RPS4Y1 PE=1 SV=2MARGPKKHLKRVAAPKHWMLDKLTGVFAPRPSTGPHKLRECLPLIVFLRNRLKYALTGDEVKKICMQRFIKIDGKVRVDVTYPAGFMDVISIEKTGEHFRLVYDTKGRFAVHRITVEEAKYKLCKVRKITVGVKGIPHLVTHDARTIRYPDPVIKVNDTVQIDLGTGKIINFIKFDTGNLCMVIGGANLGRVGVITNRERHPGSFDVVHVKDANGNSFATRLSNIFVIGNGNKPWISLPRGKGIRLTVAEERDKRLATKQSSG>sp|P36578|RL4_HUMAN 60S ribosomal protein L4 OS=Homo sapiens OX=9606GN=RPL4 PE=1 SV=5MACARPLISVYSEKGESSGKNVTLPAVFKAPIRPDIVNFVHTNLRKNNRQPYAVSELAGHQTSAESWGTGRAVARIPRVRGGGTHRSGQGAFGNMCRGGRMFAPTKTWRRWHRRVNTTQKRYAICSALAASALPALVMSKGHRIEEVPELPLVVEDKVEGYKKTKEAVLLLKKLKAWNDIKKVYASQRMRAGKGKMRNRRRIQRRGPCIIYNEDNGIIKAFRNIPGITLLNVSKLNILKLAPGGHVGRFCIWTESAFRKLDELYGTWRKAASLKSNYNLPMHKMINTDLSRILKSPEIQRALRAPRKKIHRRVLKKNPLKNLRIMLKLNPYAKTMRRNTILRQARNHKLRVDKAAAAAAALQAKSDEKAAVAGKKPVVGKKGKKAAVGVKKQKKPLVGKKAAATKKPAPEKKPAEKKPTTEEKKPAA>sp|O75526|RMXL2_HUMAN RNA-binding motif protein, X-linked-like-2 OS=Homosapiens OX=9606 GN=RBMXL2 PE=1 SV=3MVEADRPGKLFIGGLNLETDEKALEAEFGKYGRIVEVLLMKDRETNKSRGFAFVTFESPADAKAAARDMNGKSLDGKAIKVAQATKPAFESSRRGPPPPRSRGRPRFLRGTRGGGGGPRRSPSRGGPDDDGGYTADFDLRPSRAPMPMKRGPPPRRVGPPPKRAAPSGPARSSGGGMRGRALAVRGRDGYSGPPRREPLPPRRDPYLGPRDEGYSSRDGYSSRDYREPRGFAPSPGEYTHRDYGHSSVRDDCPLRGYSDRDGYGGRDRDYGDHLSRGSHREPFESYGELRGAAPGRGTPPSYGGGGRYEEYRGYSPDAYSGGRDSYSSSYGRSDRYSRGRHRVGRPDRGLSLSMERGCPPQRDSYSRSGCRVPRGGGRLGGRLERGGGRSRY>sp|Q8N983|RM43_HUMAN 39S ribosomal protein L43, mitochondrial OS=Homosapiens OX=9606 GN=MRPL43 PE=1 SV=1MTARGTPSRFLASVLHNGLGRYVQQLQRLSFSVSRDGASSRGAREFVEREVIDFARRNPGVVIYVNSRPCCVPRVVAEYLNGAVREESIHCKSVEEISTLVQKLADQSGLDVIRIRKPFHTDNPSIQGQWHPFTNKPTTFRGLRPREVQDPAPAQDTGLRLSAVAPQILLPGWPDPPDLPTVDPISSSLTSAPAPMLSAVSCLPIVPALTTVCSA>sp|Q8N983-2|RM43_HUMAN Isoform 2 of 39S ribosomal protein L43,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL43MTARGTPSRFLASVLHNGLGRYVQQLQRLSFSVSRDGASSRGAREFVEREVIDFARRNPGVVIYVNSRPCCVPRVVAEYLNGAVREESIHCKSVEEISTLVQKLADQSGLDVIRIRKPFHTDNPSIQGQWHPFTNKPTTFRGLRPREVQDPAPAQDTGLRLSAVAPQILLPGWPDPISVQSSDLPWGNTHYRPEPLSSTTWL>sp|Q8N983-3|RM43_HUMAN Isoform 3 of 39S ribosomal protein L43,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL43MTARGTPSRFLASVLHNGLGRYVQQLQRLSFSVSRDGASSRGAREFVEREVIDFARRNPGVVIYVNSRPCCVPRVVAEYLNGAVREESIHCKSVEEISTLVQKLADQSGLDVIRIRKPFHTDNPSIQGQWHPFTNKPTTFRGLRPREVQDPAPAQCLLLGAVTL>sp|Q8N983-4|RM43_HUMAN Isoform 4 of 39S ribosomal protein L43,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL43MTARGTPSRFLASVLHNGLGRYVQQLQRLSFSVSRDGASSRGAREFVEREVIDFARRNPGVVIYVNSRPCCVPRVVAEYLNGAVREESIHCKSVEEISTLVQKLADQSGLDVIRIRKPFHTDNPSIQGQWHPFTNKPTTFRGLRPREVQDPAPAQVQAQ>sp|Q8N983-6|RM43_HUMAN Isoform 5 of 39S ribosomal protein L43,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL43MTARGTPSRFLASVLHNGLGRYVQQLQRLSFSVSRDGASSRGAREFVEREVIDFARRNPGVVIYVNSRPCCVPRVVAEYLNGAVREESIHCKSVEEISTLVQKLADQSGLDVIRIRKPFHTDNPSIQGQWHPFTNKPTTFRGLRPREVQDPAPAQDAAEFLGEGAGPCWYSIVALPQKHIAIAIHPPQPAGQCHQAIGHWPETVCSCTADPPARLARPNISSVIRSSLGKYPLPS>sp|Q8N983-7|RM43_HUMAN Isoform 6 of 39S ribosomal protein L43,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL43MTARGTPSRFLASVLHNGLGRYVQQLQRLSFSVSRDGASSRGAREFVEREVIDFARRNPGVVIYVNSRPCCVPRVVAEYLNGAVREESIHCKSVEEISTLVQKLADQSGLDVIRIRKPFHTDNPSIQGQWHPFTNKPTTFRGLRPREVQDPAPAQDAAEFLGEGAGPCWYSIVALPQKHIAIAIHPPQPAGQCHQAIGHWPETVCSCTADPPARLARPTRPPHSGSYLILIDLCSSPYAVRSFLPPDCPCTDHCVLSVKAA>sp|O75116|ROCK2_HUMAN Rho-associated protein kinase 2 OS=Homo sapiensOX=9606 GN=ROCK2 PE=1 SV=4MSRPPPTGKMPGAPETAPGDGAGASRQRKLEALIRDPRSPINVESLLDGLNSLVLDLDFPALRKNKNIDNFLNRYEKIVKKIRGLQMKAEDYDVVKVIGRGAFGEVQLVRHKASQKVYAMKLLSKFEMIKRSDSAFFWEERDIMAFANSPWVVQLFYAFQDDRYLYMVMEYMPGGDLVNLMSNYDVPEKWAKFYTAEVVLALDAIHSMGLIHRDVKPDNMLLDKHGHLKLADFGTCMKMDETGMVHCDTAVGTPDYISPEVLKSQGGDGFYGRECDWWSVGVFLYEMLVGDTPFYADSLVGTYSKIMDHKNSLCFPEDAEISKHAKNLICAFLTDREVRLGRNGVEEIRQHPFFKNDQWHWDNIRETAAPVVPELSSDIDSSNFDDIEDDKGDVETFPIPKAFVGNQLPFIGFTYYRENLLLSDSPSCRETDSIQSRKNEESQEIQKKLYTLEEHLSNEMQAKEELEQKCKSVNTRLEKTAKELEEEITLRKSVESALRQLEREKALLQHKNAEYQRKADHEADKKRNLENDVNSLKDQLEDLKKRNQNSQISTEKVNQLQRQLDETNALLRTESDTAARLRKTQAESSKQIQQLESNNRDLQDKNCLLETAKLKLEKEFINLQSALESERRDRTHGSEIINDLQGRICGLEEDLKNGKILLAKVELEKRQLQERFTDLEKEKSNMEIDMTYQLKVIQQSLEQEEAEHKATKARLADKNKIYESIEEAKSEAMKEMEKKLLEERTLKQKVENLLLEAEKRCSLLDCDLKQSQQKINELLKQKDVLNEDVRNLTLKIEQETQKRCLTQNDLKMQTQQVNTLKMSEKQLKQENNHLMEMKMNLEKQNAELRKERQDADGQMKELQDQLEAEQYFSTLYKTQVRELKEECEEKTKLGKELQQKKQELQDERDSLAAQLEITLTKADSEQLARSIAEEQYSDLEKEKIMKELEIKEMMARHKQELTEKDATIASLEETNRTLTSDVANLANEKEELNNKLKDVQEQLSRLKDEEISAAAIKAQFEKQLLTERTLKTQAVNKLAEIMNRKEPVKRGNDTDVRRKEKENRKLHMELKSEREKLTQQMIKYQKELNEMQAQIAEESQIRIELQMTLDSKDSDIEQLRSQLQALHIGLDSSSIGSGPGDAEADDGFPESRLEGWLSLPVRNNTKKFGWVKKYVIVSSKKILFYDSEQDKEQSNPYMVLDIDKLFHVRPVTQTDVYRADAKEIPRIFQILYANEGESKKEQEFPVEPVGEKSNYICHKGHEFIPTLYHFPTNCEACMKPLWHMFKPPPALECRRCHIKCHKDHMDKKEEIIAPCKVYYDISTAKNLLLLANSTEEQQKWVSRLVKKIPKKPPAPDPFARSSPRTSMKIQQNQSIRRPSRQLAPNKPS>sp|Q8N6D2|RN182_HUMAN E3 ubiquitin-protein ligase RNF182 OS=Homo sapiensOX=9606 GN=RNF182 PE=1 SV=1MASQPPEDTAESQASDELECKICYNRYNLKQRKPKVLECCHRVCAKCLYKIIDFGDSPQGVIVCPFCRFETCLPDDEVSSLPDDNNILVNLTCGGKGKKCLPENPTELLLTPKRLASLVSPSHTSSNCLVITIMEVQRESSPSLSSTPVVEFYRPASFDSVTTVSHNWTVWNCTSLLFQTSIRVLVWLLGLLYFSSLPLGIYLLVSKKVTLGVVFVSLVPSSLVILMVYGFCQCVCHEFLDCMAPPS>sp|Q96D59|RN183_HUMAN E3 ubiquitin-protein ligase RNF183 OS=Homo sapiensOX=9606 GN=RNF183 PE=1 SV=2MAEQQGRELEAECPVCWNPFNNTFHTPKMLDCCHSFCVECLAHLSLVTPARRRLLCPLCRQPTVLASGQPVTDLPTDTAMLALLRLEPHHVILEGHQLCLKDQPKSRYFLRQPQVYTLDLGPQPGGQTGPPPDTASATVSTPILIPSHHSLRECFRNPQFRIFAYLMAVILSVTLLLIFSIFWTKQFLWGVG>sp|P10155|RO60_HUMAN 60 kDa SS-A/Ro ribonucleoprotein OS=Homo sapiensOX=9606 GN=RO60 PE=1 SV=2MEESVNQMQPLNEKQIANSQDGYVWQVTDMNRLHRFLCFGSEGGTYYIKEQKLGLENAEALIRLIEDGRGCEVIQEIKSFSQEGRTTKQEPMLFALAICSQCSDISTKQAAFKAVSEVCRIPTHLFTFIQFKKDLKESMKCGMWGRALRKAIADWYNEKGGMALALAVTKYKQRNGWSHKDLLRLSHLKPSSEGLAIVTKYITKGWKEVHELYKEKALSVETEKLLKYLEAVEKVKRTRDELEVIHLIEEHRLVREHLLTNHLKSKEVWKALLQEMPLTALLRNLGKMTANSVLEPGNSEVSLVCEKLCNEKLLKKARIHPFHILIALETYKTGHGLRGKLKWRPDEEILKALDAAFYKTFKTVEPTGKRFLLAVDVSASMNQRVLGSILNASTVAAAMCMVVTRTEKDSYVVAFSDEMVPCPVTTDMTLQQVLMAMSQIPAGGTDCSLPMIWAQKTNTPADVFIVFTDNETFAGGVHPAIALREYRKKMDIPAKLIVCGMTSNGFTIADPDDRGMLDMCGFDTGALDVIRNFTLDMI>sp|P10155-2|RO60_HUMAN Isoform Short of 60 kDa SS-A/Ro ribonucleoproteinOS=Homo sapiens OX=9606 GN=RO60MEESVNQMQPLNEKQIANSQDGYVWQVTDMNRLHRFLCFGSEGGTYYIKEQKLGLENAEALIRLIEDGRGCEVIQEIKSFSQEGRTTKQEPMLFALAICSQCSDISTKQAAFKAVSEVCRIPTHLFTFIQFKKDLKESMKCGMWGRALRKAIADWYNEKGGMALALAVTKYKQRNGWSHKDLLRLSHLKPSSEGKHKIFIGKKGG>sp|P10155-3|RO60_HUMAN Isoform 3 of 60 kDa SS-A/Ro ribonucleoproteinOS=Homo sapiens OX=9606 GN=RO60MEESVNQMQPLNEKQIANSQDGYVWQVTDMNRLHRFLCFGSEGGTYYIKEQKLGLENAEALIRLIEDGRGCEVIQEIKSFSQEGRTTKQEPMLFALAICSQCSDISTKQAAFKAVSEVCRIPTHLFTFIQFKKDLKESMKCGMWGRALRKAIADWYNEKGGMALALAVTKYKQRNGWSHKDLLRLSHLKPSSEGLAIVTKYITKGWKEVHELYKEKALSVETEKLLKYLEAVEKVKRTRDELEVIHLIEEHRLVREHLLTNHLKSKEVWKALLQEMPLTALLRNLGKMTANSVLEPGNSEVSLVCEKLCNEKLLKKARIHPFHILIALETYKTGHGLRGKLKWRPDEEILKALDAAFYKTFKTVEPTGKRFLLAVDVSASMNQRVLGSILNASTVAAAMCMVVTRTEKDSYVVAFSDEMVPCPVTTDMTLQQVLMAMSQIPAGGTDCSLPMIWAQKTNTPADVFIVFTDNETFAGGVHPAIALREYRKKMDIPAKLIVCGMTSNGFTIADPDDRDTVK>sp|P10155-4|RO60_HUMAN Isoform 4 of 60 kDa SS-A/Ro ribonucleoproteinOS=Homo sapiens OX=9606 GN=RO60MEESVNQMQPLNEKQIANSQDGYVWQVTDMNRLHRFLCFGSEGGTYYIKEQKLGLENAEALIRLIEDGRGCEVIQEIKSFSQEGRTTKQEPMLFALAICSQCSDISTKQAAFKAVSEVCRIPTHLFTFIQFKKDLKESMKCGMWGRALRKAIADWYNEKGGMALALAVTKYKQRNGWSHKDLLRLSHLKPSSEGLAIVTKYITKGWKEVHELYKEKALSVETEKLLKYLEAVEKVKRTRDELEVIHLIEEHRLVREHLLTNHLKSKEVWKALLQEMPLTALLRNLGKMTANSVLEPGNSEVSLVCEKLCNEKLLKKARIHPFHILIALETYKTGHGLRGKLKWRPDEEILKALDAAFYKTFKTVEPTGKRFLLAVDVSASMNQRVLGSILNASTVAAAMCMVVTRTEKDSYVVAFSDEMVPCPVTTDMTLQQVLMAMSQIPAGGTDCSLPMIWAQKTNTPADVFIVFTDNETFAGGVHPAIALREYRKKMDIPAKLIVCGMTSNGFTIADPDDRGMLDMCGFDTGALDPCKIPY>sp|P10155-5|RO60_HUMAN Isoform 5 of 60 kDa SS-A/Ro ribonucleoproteinOS=Homo sapiens OX=9606 GN=RO60MEESVNQMQPLNEKQIANSQDGYVWQVTDMNRLHRFLCFGSEGGTYYIKEQKLGLENAEALIRLIEDGRGCEVIQEIKSFSQEGRTTKQEPMLFALAICSQCSDISTKQAAFKAVSEVCRIPTHLFTFIQFKKDLKESMKCGMWGRALRKAIADWYNEKGGMALALAVTKYKQRNGWSHKDLLRLSHLKPSSEGLAIVTKYITKGWKEVHELYKEKALSVETEKLLKYLEAVEKVKRTRDELEVIHLIEEHRLVREHLLTNHLKSKEVWKALLQEMPLTALLRNLGKMTANSVLEPGNSEVSLVCEKLCNEKLLKKARIHPFHILIALETYKTGHGLRGKLKWRPDEEILKALDAAFYKTFKTVEPTGKRFLLAVDVSASMNQRVLGSILNASTVAAAMCMVVTRTEKDSYVVAFSDEMVPCPVTTDMTLQQVLMAMSQIPAGGTDCSLPMIWAQKTNTPADVFIVFTDNETFAGGVHPAIALREYRKKMDIPAKLIVCGMTSNGFTIADPDDRALQNTLLNKSF>sp|Q92753|RORB_HUMAN Nuclear receptor ROR-beta OS=Homo sapiens OX=9606GN=RORB PE=1 SV=3MCENQLKTKADATAQIEVIPCKICGDKSSGIHYGVITCEGCKGFFRRSQQNNASYSCPRQRNCLIDRTNRNRCQHCRLQKCLALGMSRDAVKFGRMSKKQRDSLYAEVQKHQQRLQEQRQQQSGEAEALARVYSSSISNGLSNLNNETSGTYANGHVIDLPKSEGYYNVDSGQPSPDQSGLDMTGIKQIKQEPIYDLTSVPNLFTYSSFNNGQLAPGITMTEIDRIAQNIIKSHLETCQYTMEELHQLAWQTHTYEEIKAYQSKSREALWQQCAIQITHAIQYVVEFAKRITGFMELCQNDQILLLKSGCLEVVLVRMCRAFNPLNNTVLFEGKYGGMQMFKALGSDDLVNEAFDFAKNLCSLQLTEEEIALFSSAVLISPDRAWLIEPRKVQKLQEKIYFALQHVIQKNHLDDETLAKLIAKIPTITAVCNLHGEKLQVFKQSHPEIVNTLFPPLYKELFNPDCATGCK>sp|Q92753-1|RORB_HUMAN Isoform 1 of Nuclear receptor ROR-beta OS=Homosapiens OX=9606 GN=RORBMRAQIEVIPCKICGDKSSGIHYGVITCEGCKGFFRRSQQNNASYSCPRQRNCLIDRTNRNRCQHCRLQKCLALGMSRDAVKFGRMSKKQRDSLYAEVQKHQQRLQEQRQQQSGEAEALARVYSSSISNGLSNLNNETSGTYANGHVIDLPKSEGYYNVDSGQPSPDQSGLDMTGIKQIKQEPIYDLTSVPNLFTYSSFNNGQLAPGITMTEIDRIAQNIIKSHLETCQYTMEELHQLAWQTHTYEEIKAYQSKSREALWQQCAIQITHAIQYVVEFAKRITGFMELCQNDQILLLKSGCLEVVLVRMCRAFNPLNNTVLFEGKYGGMQMFKALGSDDLVNEAFDFAKNLCSLQLTEEEIALFSSAVLISPDRAWLIEPRKVQKLQEKIYFALQHVIQKNHLDDETLAKLIAKIPTITAVCNLHGEKLQVFKQSHPEIVNTLFPPLYKELFNPDCATGCK>sp|Q8N7C7|RN148_HUMAN RING finger protein 148 OS=Homo sapiens OX=9606GN=RNF148 PE=2 SV=2MSFLRITPSTHSSVSSGLLRLSIFLLLSFPDSNGKAIWTAHLNITFQVGNEITSELGESGVFGNHSPLERVSGVVALPEGWNQNACHPLTNFSRPKQADSWLALIERGGCTFTHKINVAAEKGANGVIIYNYQGTGSKVFPMSHQGTENIVAVMISNLKGMEILHSIQKGVYVTVIIEVGRMHMQWVSHYIMYLFTFLAATIAYFYLDCVWRLTPRVPNSFTRRRSQIKTDVKKAIDQLQLRVLKEGDEELDLNEDNCVVCFDTYKPQDVVRILTCKHFFHKACIDPWLLAHRTCPMCKCDILKT>sp|Q96MS0|ROBO3_HUMAN Roundabout homolog 3 OS=Homo sapiens OX=9606GN=ROBO3 PE=1 SV=2MLRYLLKTLLQMNLFADSLAGDISNSSELLLGFNSSLAALNHTLLPPGDPSLNGSRVGPEDAMPRIVEQPPDLLVSRGEPATLPCRAEGRPRPNIEWYKNGARVATVREDPRAHRLLLPSGALFFPRIVHGRRARPDEGVYTCVARNYLGAAASRNASLEVAVLRDDFRQSPGNVVVAVGEPAVLECVPPRGHPEPSVSWRKDGARLKEEEGRITIRGGKLMMSHTLKSDAGMYVCVASNMAGERESAAAEVMVLERPSFLRRPVNQVVLADAPVTFLCEVKGDPPPRLRWRKEDGELPTGRYEIRSDHSLWIGHVSAEDEGTYTCVAENSVGRAEASGSLSVHVPPQLVTQPQDQMAAPGESVAFQCETKGNPPPAIFWQKEGSQVLLFPSQSLQPTGRFSVSPRGQLNITAVQRGDAGYYVCQAVSVAGSILAKALLEIKGASLDGLPPVILQGPANQTLVLGSSVWLPCRVTGNPQPSVRWKKDGQWLQGDDLQFKTMANGTLYIANVQEMDMGFYSCVAKSSTGEATWSGWLKMREDWGVSPDPPTEPSSPPGAPSQPVVTEITKNSITLTWKPNPQTGAAVTSYVIEAFSPAAGNTWRTVADGVQLETHTVSGLQPNTIYLFLVRAVGAWGLSEPSPVSEPVRTQDSSPSRPVEDPWRGQQGLAEVAVRLQEPIVLGPRTLQVSWTVDGPVQLVQGFRVSWRVAGPEGGSWTMLDLQSPSQQSTVLRGLPPGTQIQIKVQAQGQEGLGAESLSVTRSIPEEAPSGPPQGVAVALGGDGNSSITVSWEPPLPSQQNGVITEYQIWCLGNESRFHLNRSAAGWARSAMLRGLVPGLLYRTLVAAATSAGVGVPSAPVLVQLPSPPDLEPGLEVGAGLAVRLARVLREPAFLAGSGAACGALLLGLCAALYWRRKQRKELSHYTASFAYTPAVSFPHSEGLSGASSRPPMGLGPAPYSWLADSWPHPSRSPSAQEPRGSCCPSNPDPDDRYYNEAGISLYLAQTARGTAAPGEGPVYSTIDPAGEELQTFHGGFPQHPSGDLGPWSQYAPPEWSQGDSGAKGGKVKLLGKPVQMPSLNWPEALPPPPPSCELSCLEGPEEELEGSSEPEEWCPPMPERSHLTEPSSSGGCLVTPSRRETPSPTPSYGQQSTATLTPSPPDPPQPPTDMPHLHQMPRRVPLGPSSPLSVSQPMLGIREARPAGLGAGPAASPHLSPSPAPSTASSAPGRTWQGNGEMTPPLQGPRARFRKKPKALPYRRENSPGDLPPPPLPPPEEEASWALELRAAGSMSSLERERSGERKAVQAVPLAAQRVLHPDEEAWLPYSRPSFLSRGQGTSTCSTAGSNSSRGSSSSRGSRGPGRSRSRSQSRSQSQRPGQKRREEPR>sp|Q96MS0-2|ROBO3_HUMAN Isoform 2 of Roundabout homolog 3 OS=Homosapiens OX=9606 GN=ROBO3MLRYLLKTLLQMNLFADSLAGDISNSSELLLGFNSSLAALNHTLLPPGDPSLNGSRVGPEDAMPRIVEQPPDLLVSRGEPATLPCRAEGRPRPNIEWYKNGARVATVREDPRAHRLLLPSGALFFPRIVHGRRARPDEGVYTCVARNYLGAAASRNASLEVAVLRDDFRQSPGNVVVAVGEPAVLECVPPRGHPEPSVSWRKDGARLKEEEGRITIRGGKLMMSHTLKSDAGMYVCVASNMAGERESAAAEVMVLERPSFLRRPVNQVVLADAPVTFLCEVKGDPPPRLRWRKEDGELPTGRYEIRSDHSLWIGHVSAEDEGTYTCVAENSVGRAEASGSLSVHVPPQLVTQPQDQMAAPGESVAFQCETKGNPPPAIFWQKEGSQVLLFPSQSLQPTGRFSVSPRGQLNITAVQRGDAGYYVCQAVSVAGSILAKALLEIKGASLDGLPPVILQGPANQTLVLGSSVWLPCRVTGNPQPSVRWKKDGQWLQGDDLQFKTMANGTLYIANVQEMDMGFYSCVAKSSTGEATWSGWLKMREDWGVSPDPPTEPSSPPGAPSQPVVTEITKNSITLTWKPNPQTGAAVTSYVIEAFSPAAGNTWRTVADGVQLETHTVSGLQPNTIYLFLVRAVGAWGLSEPSPVSEPVRTQDSSPSRPVEDPWRGQQGLAEVAVRLQEPIVLGPRTLQVSWTVDGPVQLVQGFRVSWRVAGPEGGSWTMLDLQSPSQQSTVLRGLPPGTQIQIKVQAQGQEGLGAESLSVTRSIPEEAPSGPPQGVAVALGGDGNSSITVSWEPPLPSQQNGVITEYQIWCLGNESRFHLNRSAAGWARSAMLRGLVPGLLYRTLVAAATSAGVGVPSAPVLVQLPSPPDLEPGLEVGAGLAVRLARVLREPAFLAGSGAACGALLLGLCAALYWRRKQRKELSHYTASFAYTPAVSFPHSEGLSGASSRPPMGLGPAPYSWLADSWPHPSRSPSAQEPRGSCCPSNPDPDDRYYNEAGISLYLAQTARGTAAPGEGPVYSTIDPLTTPLLILTT>sp|Q01973|ROR1_HUMAN Inactive tyrosine-protein kinase transmembranereceptor ROR1 OS=Homo sapiens OX=9606 GN=ROR1 PE=1 SV=2MHRPRRRGTRPPLLALLAALLLAARGAAAQETELSVSAELVPTSSWNISSELNKDSYLTLDEPMNNITTSLGQTAELHCKVSGNPPPTIRWFKNDAPVVQEPRRLSFRSTIYGSRLRIRNLDTTDTGYFQCVATNGKEVVSSTGVLFVKFGPPPTASPGYSDEYEEDGFCQPYRGIACARFIGNRTVYMESLHMQGEIENQITAAFTMIGTSSHLSDKCSQFAIPSLCHYAFPYCDETSSVPKPRDLCRDECEILENVLCQTEYIFARSNPMILMRLKLPNCEDLPQPESPEAANCIRIGIPMADPINKNHKCYNSTGVDYRGTVSVTKSGRQCQPWNSQYPHTHTFTALRFPELNGGHSYCRNPGNQKEAPWCFTLDENFKSDLCDIPACDSKDSKEKNKMEILYILVPSVAIPLAIALLFFFICVCRNNQKSSSAPVQRQPKHVRGQNVEMSMLNAYKPKSKAKELPLSAVRFMEELGECAFGKIYKGHLYLPGMDHAQLVAIKTLKDYNNPQQWTEFQQEASLMAELHHPNIVCLLGAVTQEQPVCMLFEYINQGDLHEFLIMRSPHSDVGCSSDEDGTVKSSLDHGDFLHIAIQIAAGMEYLSSHFFVHKDLAARNILIGEQLHVKISDLGLSREIYSADYYRVQSKSLLPIRWMPPEAIMYGKFSSDSDIWSFGVVLWEIFSFGLQPYYGFSNQEVIEMVRKRQLLPCSEDCPPRMYSLMTECWNEIPSRRPRFKDIHVRLRSWEGLSSHTSSTTPSGGNATTQTTSLSASPVSNLSNPRYPNYMFPSQGITPQGQIAGFIGPPIPQNQRFIPINGYPIPPGYAAFPAAHYQPTGPPRVIQHCPPPKSRSPSSASGSTSTGHVTSLPSSGSNQEANIPLLPHMSIPNHPGGMGITVFGNKSQKPYKIDSKQASLLGDANIHGHTESMISAEL>sp|Q01973-2|ROR1_HUMAN Isoform Short of Inactive tyrosine-protein kinasetransmembrane receptor ROR1 OS=Homo sapiens OX=9606 GN=ROR1MLFEYINQGDLHEFLIMRSPHSDVGCSSDEDGTVKSSLDHGDFLHIAIQIAAGMEYLSSHFFVHKDLAARNILIGEQLHVKISDLGLSREIYSADYYRVQSKSLLPIRWMPPEAIMYGKFSSDSDIWSFGVVLWEIFSFGLQPYYGFSNQEVIEMVRKRQLLPCSEDCPPRMYSLMTECWNEIPSRRPRFKDIHVRLRSWEGLSSHTSSTTPSGGNATTQTTSLSASPVSNLSNPRYPNYMFPSQGITPQGQIAGFIGPPIPQNQRFIPINGYPIPPGYAAFPAAHYQPTGPPRVIQHCPPPKSRSPSSASGSTSTGHVTSLPSSGSNQEANIPLLPHMSIPNHPGGMGITVFGNKSQKPYKIDSKQASLLGDANIHGHTESMISAEL>sp|Q01973-3|ROR1_HUMAN Isoform 3 of Inactive tyrosine-protein kinasetransmembrane receptor ROR1 OS=Homo sapiens OX=9606 GN=ROR1MHRPRRRGTRPPLLALLAALLLAARGAAAQETELSVSAELVPTSSWNISSELNKDSYLTLDEPMNNITTSLGQTAELHCKVSGNPPPTIRWFKNDAPVVQEPRRLSFRSTIYGSRLRIRNLDTTDTGYFQCVATNGKEVVSSTGVLFVKFGPPPTASPGYSDEYEEDGFCQPYRGIACARFIGNRTVYMESLHMQGEIENQITAAFTMIGTSSHLSDKCSQFAIPSLCHYAFPYCDETSSVPKPRDLCRDECEILENVLCQTEYIFARSNPMILMRLKLPNCEDLPQPESPEAANCIRIGIPMADPINKNHKCYNSTGVDYRGTVSVTKSGRQCQPWNSQYPHTHTFTALRFPELNGGHSYCRNPGNQKEAPWCFTLDENFKSDLCDIPACGK>sp|Q96HU1|SGSM3_HUMAN Small G protein signaling modulator 3 OS=Homosapiens OX=9606 GN=SGSM3 PE=1 SV=1MSGSHTPACGPFSALTPSIWPQEILAKYTQKEESAEQPEFYYDEFGFRVYKEEGDEPGSSLLANSPLMEDAPQRLRWQAHLEFTHNHDVGDLTWDKIAVSLPRSEKLRSLVLAGIPHGMRPQLWMRLSGALQKKRNSELSYREIVKNSSNDETIAAKQIEKDLLRTMPSNACFASMGSIGVPRLRRVLRALAWLYPEIGYCQGTGMVAACLLLFLEEEDAFWMMSAIIEDLLPASYFSTTLLGVQTDQRVLRHLIVQYLPRLDKLLQEHDIELSLITLHWFLTAFASVVDIKLLLRIWDLFFYEGSRVLFQLTLGMLHLKEEELIQSENSASIFNTLSDIPSQMEDAELLLGVAMRLAGSLTDVAVETQRRKHLAYLIADQGQLLGAGTLTNLSQVVRRRTQRRKSTITALLFGEDDLEALKAKNIKQTELVADLREAILRVARHFQCTDPKNCSVELTPDYSMESHQRDHENYVACSRSHRRRAKALLDFERHDDDELGFRKNDIITIVSQKDEHCWVGELNGLRGWFPAKFVEVLDERSKEYSIAGDDSVTEGVTDLVRGTLCPALKALFEHGLKKPSLLGGACHPWLFIEEAAGREVERDFASVYSRLVLCKTFRLDEDGKVLTPEELLYRAVQSVNVTHDAVHAQMDVKLRSLICVGLNEQVLHLWLEVLCSSLPTVEKWYQPWSFLRSPGWVQIKCELRVLCCFAFSLSQDWELPAKREAQQPLKEGVRDMLVKHHLFSWDVDG>sp|Q96HU1-2|SGSM3_HUMAN Isoform 2 of Small G protein signaling modulator3 OS=Homo sapiens OX=9606 GN=SGSM3MSGSHTPACGPFSALTPSIWPQEILAKYTQKEESAEQPEFYYDEFGFRVYKEEGDEPGSSLLANSPLMEDAPQRLRWQAHLEFTHNHDVGDLTWDKIAVSLPRSEKLRSLVLAGIPHGMRPQLWMRLSGALQKKRNSELSYREIVKNSSNDETIAAKQIEKDLLRTMPSNACFASMGSIGVPRLRRVLRALAWLYPEIGYCQGTGMVAACLLLFLEEEDAFWMMSAIIEDLLPASYFSTTLLGVQTDQRVLRHLIVQYLPRLDKLLQEHDIELSLITLHWFLTAFASVVDIKLLLRIWDLFFYEGSRVLFQLTLGMLHLKEEELIQSENSASIFNTLSDIPSQMEDAELLLGVAMRLAGSLTDVAVETQRRKHLAYLIADQGQLLGAGTLTNLSQVVRRRTQRRKSTITALLFGEDDLEALKAKNIKQTELVADLREAILRVARHFQCTDPKNCSVVSRQLPGLLPNTALTPPTPLVGLCSLWQELTPDYSMESHQRDHENYVACSRSHRRRAKALLDFERHDDDELGFRKNDIITIVSQKDEHCWVGELNGLRGWFPAKFVEVLDERSKEYSIAGDDSVTEGVTDLVRGTLCPALKALFEHGLKKPSLLGGACHPWLFIEEAAGREVERDFASVYSRLVLCKTFRLDEDGKVLTPEELLYRAVQSVNVTHDAVHAQMDVKLRSLICVGLNEQVLHLWLEVLCSSLPTVEKWYQPWSFLRSPGWVQIKCELRVLCCFAFSLSQDWELPAKREAQQPLKEGVRDMLVKHHLFSWDVDG>sp|P12757|SKIL_HUMAN Ski-like protein OS=Homo sapiens OX=9606 GN=SKILPE=1 SV=2MENLQTNFSLVQGSTKKLNGMGDDGSPPAKKMITDIHANGKTINKVPTVKKEHLDDYGEAPVETDGEHVKRTCTSVPETLHLNPSLKHTLAQFHLSSQSSLGGPAAFSARHSQESMSPTVFLPLPSPQVLPGPLLIPSDSSTELTQTVLEGESISCFQVGGEKRLCLPQVLNSVLREFTLQQINTVCDELYIYCSRCTSDQLHILKVLGILPFNAPSCGLITLTDAQRLCNALLRPRTFPQNGSVLPAKSSLAQLKETGSAFEVEHECLGKCQGLFAPQFYVQPDAPCIQCLECCGMFAPQTFVMHSHRSPDKRTCHWGFESAKWHCYLHVNQKYLGTPEEKKLKIILEEMKEKFSMRSGKRNQSKTDAPSGMELQSWYPVIKQEGDHVSQTHSFLHPSYYLYMCDKVVAPNVSLTSAVSQSKELTKTEASKSISRQSEKAHSSGKLQKTVSYPDVSLEEQEKMDLKTSRELCSRLDASISNNSTSKRKSESATCNLVRDINKVGIGLVAAASSPLLVKDVICEDDKGKIMEEVMRTYLKQQEKLNLILQKKQQLQMEVKMLSSSKSMKELTEEQQNLQKELESLQNEHAQRMEEFYVEQKDLEKKLEQIMKQKCTCDSNLEKDKEAEYAGQLAELRQRLDHAEADRQELQDELRQEREARQKLEMMIKELKLQILKSSKTAKE>sp|P12757-2|SKIL_HUMAN Isoform SNOA of Ski-like protein OS=Homo sapiensOX=9606 GN=SKILMENLQTNFSLVQGSTKKLNGMGDDGSPPAKKMITDIHANGKTINKVPTVKKEHLDDYGEAPVETDGEHVKRTCTSVPETLHLNPSLKHTLAQFHLSSQSSLGGPAAFSARHSQESMSPTVFLPLPSPQVLPGPLLIPSDSSTELTQTVLEGESISCFQVGGEKRLCLPQVLNSVLREFTLQQINTVCDELYIYCSRCTSDQLHILKVLGILPFNAPSCGLITLTDAQRLCNALLRPRTFPQNGSVLPAKSSLAQLKETGSAFEVEHECLGKCQGLFAPQFYVQPDAPCIQCLECCGMFAPQTFVMHSHRSPDKRTCHWGFESAKWHCYLHVNQKYLGTPEEKKLKIILEEMKEKFSMRSGKRNQSKASFLYQFLIMVMVYFEMKILCLVCNLTCMLNIAHATTTKYRLIYLYCSF>sp|P12757-3|SKIL_HUMAN Isoform SNON2 of Ski-like protein OS=Homo sapiensOX=9606 GN=SKILMENLQTNFSLVQGSTKKLNGMGDDGSPPAKKMITDIHANGKTINKVPTVKKEHLDDYGEAPVETDGEHVKRTCTSVPETLHLNPSLKHTLAQFHLSSQSSLGGPAAFSARHSQESMSPTVFLPLPSPQVLPGPLLIPSDSSTELTQTVLEGESISCFQVGGEKRLCLPQVLNSVLREFTLQQINTVCDELYIYCSRCTSDQLHILKVLGILPFNAPSCGLITLTDAQRLCNALLRPRTFPQNGSVLPAKSSLAQLKETGSAFEVEHECLGKCQGLFAPQFYVQPDAPCIQCLECCGMFAPQTFVMHSHRSPDKRTCHWGFESAKWHCYLHVNQKYLGTPEEKKLKIILEEMKEKFSMRSGKRNQSKTDAPSGMELQSWYPVIKQEGDHVSQTHSFLHPSYYLYMCDKVVAPNVSLTSAVSQSKELTKTEANASISNNSTSKRKSESATCNLVRDINKVGIGLVAAASSPLLVKDVICEDDKGKIMEEVMRTYLKQQEKLNLILQKKQQLQMEVKMLSSSKSMKELTEEQQNLQKELESLQNEHAQRMEEFYVEQKDLEKKLEQIMKQKCTCDSNLEKDKEAEYAGQLAELRQRLDHAEADRQELQDELRQEREARQKLEMMIKELKLQILKSSKTAKE>sp|P12757-4|SKIL_HUMAN Isoform SNOI of Ski-like protein OS=Homo sapiensOX=9606 GN=SKILMENLQTNFSLVQGSTKKLNGMGDDGSPPAKKMITDIHANGKTINKVPTVKKEHLDDYGEAPVETDGEHVKRTCTSVPETLHLNPSLKHTLAQFHLSSQSSLGGPAAFSARHSQESMSPTVFLPLPSPQVLPGPLLIPSDSSTELTQTVLEGESISCFQVGGEKRLCLPQVLNSVLREFTLQQINTVCDELYIYCSRCTSDQLHILKVLGILPFNAPSCGLITLTDAQRLCNALLRPRTFPQNGSVLPAKSSLAQLKETGSAFEVEHECLGKCQGLFAPQFYVQPDAPCIQCLECCGMFAPQTFVMHSHRSPDKRTCHWGFESAKWHCYLHVNQKYLGTPEEKKLKIILEEMKEKFSMRSGKRNQSKTDAPSGMELQSWYPVIKQEGDHVSQTHSFLHPS>sp|P12757-5|SKIL_HUMAN Isoform 5 of Ski-like protein OS=Homo sapiensOX=9606 GN=SKILMGDDGSPPAKKMITDIHANGKTINKVPTVKKEHLDDYGEAPVETDGEHVKRTCTSVPETLHLNPSLKHTLAQFHLSSQSSLGGPAAFSARHSQESMSPTVFLPLPSPQVLPGPLLIPSDSSTELTQTVLEGESISCFQVGGEKRLCLPQVLNSVLREFTLQQINTVCDELYIYCSRCTSDQLHILKVLGILPFNAPSCGLITLTDAQRLCNALLRPRTFPQNGSVLPAKSSLAQLKETGSAFEVEHECLGKCQGLFAPQFYVQPDAPCIQCLECCGMFAPQTFVMHSHRSPDKRTCHWGFESAKWHCYLHVNQKYLGTPEEKKLKIILEEMKEKFSMRSGKRNQSKTDAPSGMELQSWYPVIKQEGDHVSQTHSFLHPSYYLYMCDKVVAPNVSLTSAVSQSKELTKTEASKSISRQSEKAHSSGKLQKTVSYPDVSLEEQEKMDLKTSRELCSRLDASISNNSTSKRKSESATCNLVRDINKVGIGLVAAASSPLLVKDVICEDDKGKIMEEVMRTYLKQQEKLNLILQKKQQLQMEVKMLSSSKSMKELTEEQQNLQKELESLQNEHAQRMEEFYVEQKDLEKKLEQIMKQKCTCDSNLEKDKEAEYAGQLAELRQRLDHAEADRQELQDELRQEREARQKLEMMIKELKLQILKSSKTAKE>sp|Q9NQ39|RS10L_HUMAN Putative 40S ribosomal protein S10-like OS=Homosapiens OX=9606 GN=RPS10P5 PE=5 SV=1MLMPKKNRIAIHELLFKEGVMVAKKDVHMPKHPELADKNVPNLHVMKAMQSLKSRGCVKEQFAWRHFYWYLTNEGSQYLRDYLHLPPEIVPATLHLPPEIVPATLHRSRPETGRPRPKGLEGKRPARLTRREADRDTYRRCSVPPGADKKAEAGAGSATEFQFRGRCGRGRGQPPQ>sp|Q15573|TAF1A_HUMAN TATA box-binding protein-associated factor RNApolymerase I subunit A OS=Homo sapiens OX=9606 GN=TAF1A PE=1 SV=1MSDFSEELKGPVTDDEEVETSVLSGAGMHFPWLQTYVETVAIGGKRRKDFAQTTSACLSFIQEALLKHQWQQAAEYMYSYFQTLEDSDSYKRQAAPEIIWKLGSEILFYHPKSNMESFNTFANRMKNIGVMNYLKISLQHALYLLHHGMLKDAKRNLSEAETWRHGENTSSREILINLIQAYKGLLQYYTWSEKKMELSKLDKDDYAYNAVAQDVFNHSWKTSANISALIKIPGVWDPFVKSYVEMLEFYGDRDGAQEVLTNYAYDEKFPSNPNAHIYLYNFLKRQKAPRSKLISVLKILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEKAFVAGLLLGKGCRYFRYILKQDHQILGKKIKRMKRSVKKYSIVNPRL>sp|Q15573-2|TAF1A_HUMAN Isoform 2 of TATA box-binding protein-associatedfactor RNA polymerase I subunit A OS=Homo sapiens OX=9606 GN=TAF1AMESFNTFANRMKNIGVMNYLKISLQHALYLLHHGMLKDAKRNLSEAETWRHGENTSSREILINLIQAYKGLLQYYTWSEKKMELSKLDKDDYAYNAVAQDVFNHSWKTSANISALIKIPGVWDPFVKSYVEMLEFYGDRDGAQEVLTNYAYDEKFPSNPNAHIYLYNFLKRQKAPRSKLISVLKILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEKAFVAGLLLGKGCRYFRYILKQDHQILGKKIKRMKRSVKKYSIVNPRL>sp|Q8N4U5|T11L2_HUMAN T-complex protein 11-like protein 2 OS=Homosapiens OX=9606 GN=TCP11L2 PE=1 SV=1MPFNGEKQCVGEDQPSDSDSSRFSESMASLSDYECSRQSFASDSSSKSSSPASTSPPRVVTFDEVMATARNLSNLTLAHEIAVNENFQLKQEALPEKSLAGRVKHIVHQAFWDVLDSELNADPPEFEHAIKLFEEIREILLSFLTPGGNRLRNQICEVLDTDLIRQQAEHSAVDIQGLANYVISTMGKLCAPVRDNDIRELKATGNIVEVLRQIFHVLDLMQMDMANFTIMSLRPHLQRQLVEYERTKFQEILEETPSALDQTTEWIKESVNEELFSLSESALTPGAENTSKPSLSPTLVLNNSYLKLLQWDYQKKELPETLMTDGARLQELTEKLNQLKIIACLSLITNNMVGAITGGLPELASRLTRISAVLLEGMNKETFNLKEVLNSIGIQTCVEVNKTLMERGLPTLNAEIQANLIGQFSSIEEEDNPIWSLIDKRIKLYMRRLLCLPSPQKCMPPMPGGLAVIQQELEALGSQYANIVNLNKQVYGPFYANILRKLLFNEEAMGKVDASPPTN>sp|Q8N4U5-2|T11L2_HUMAN Isoform 2 of T-complex protein 11-like protein 2OS=Homo sapiens OX=9606 GN=TCP11L2MPFNGEKQCVGEDQPSDSDSSRFSESMASLSDYECSRQSFASDSSSKSSSPASTSPPRVVTFDEVMATARNLSNLTLAHEIAVNENFQLKQEALPEKSLAGRVKHIVHQAFWDVLDSELNADPPEFEHAIKLFEEIREILLSFLTPGGNRLRNQICEVLDTDLIRQQAEHSAVDIQGLANYVISTMGKLCAPVRDNDIRELKATGNIVEVLRQIFHVLDLMQMDMANFTIMSLRPHLQRQLVEYERTKFQEILEETPRKAEVAGAS>sp|P08247|SYPH_HUMAN Synaptophysin OS=Homo sapiens OX=9606 GN=SYP PE=1SV=3MLLLADMDVVNQLVAGGQFRVVKEPLGFVKVLQWVFAIFAFATCGSYSGELQLSVDCANKTESDLSIEVEFEYPFRLHQVYFDAPTCRGGTTKVFLVGDYSSSAEFFVTVAVFAFLYSMGALATYIFLQNKYRENNKGPMLDFLATAVFAFMWLVSSSAWAKGLSDVKMATDPENIIKEMPVCRQTGNTCKELRDPVTSGLNTSVVFGFLNLVLWVGNLWFVFKETGWAAPFLRAPPGAPEKQPAPGDAYGDAGYGQGPGGYGPQDSYGPQGGYQPDYGQPAGSGGSGYGPQGDYGQQGYGPQGAPTSFSNQM>sp|P08247-2|SYPH_HUMAN Isoform 2 of Synaptophysin OS=Homo sapiensOX=9606 GN=SYPMGALATYIFLQNKYRENNKGPMLDFLATAVFAFMWLVSSSAWAKGLSDVKMATDPENIIKEMPVCRQTGNTCKELRDPVTSGLNTSVVFGFLNLVLWVGNLWFVFKETGWAAPFLRAPPGAPEKQPAPGDAYGDAGYGQGPGGYGPQDSYGPQGGYQPDYGQPAGSGGSGYGPQGDYGQQGYGPQGAPTSFSNQM>sp|Q24JP5|T132A_HUMAN Transmembrane protein 132A OS=Homo sapiens OX=9606GN=TMEM132A PE=1 SV=1MCARMAGRTTAAPRGPYGPWLCLLVALALDVVRVDCGQAPLDPVYLPAALELLDAPEHFRVQQVGHYPPANSSLSSRSETFLLLQPWPRAQPLLRASYPPFATQQVVPPRVTEPHQRPVPWDVRAVSVEAAVTPAEPYARVLFHLKGQDWPPGSGSLPCARLHATHPAGTAHQACRFQPSLGACVVELELPSHWFSQASTTRAELAYTLEPAAEGPGGCGSGEENDPGEQALPVGGVELRPADPPQYQEVPLDEAVTLRVPDMPVRPGQLFSATLLLRHNFTASLLTLRIKVKKGLHVTAARPAQPTLWTAKLDRFKGSRHHTTLITCHRAGLTEPDSSPLELSEFLWVDFVVENSTGGGVAVTRPVTWQLEYPGQAPEAEKDKMVWEILVSERDIRALIPLAKAEELVNTAPLTGVPQHVPVRLVTVDGGGALVEVTEHVGCESANTQVLQVSEACDAVFVAGKESRGARGVRVDFWWRRLRASLRLTVWAPLLPLRIELTDTTLEQVRGWRVPGPAEGPAEPAAEASDEAERRARGCHLQYQRAGVRFLAPFAAHPLDGGRRLTHLLGPDWLLDVSHLVAPHARVLDSRVASLEGGRVVVGREPGVTSIEVRSPLSDSILGEQALAVTDDKVSVLELRVQPVMGISLTLSRGTAHPGEVTATCWAQSALPAPKQEVALSLWLSFSDHTVAPAELYDRRDLGLSVSAEEPGAILPAEEQGAQLGVVVSGAGAEGLPLHVALHPPEPCRRGRHRVPLASGTAWLGLPPASTPAPALPSSPAWSPPATEATMGGKRQVAGSVGGNTGVRGKFERAEEEARKEETEAREEEEEEEEEMVPAPQHVTELELGMYALLGVFCVAIFIFLVNGVVFVLRYQRKEPPDSATDPTSPQPHNWVWLGTDQEELSRQLDRQSPGPPKGEGSCPCESGGGGEAPTLAPGPPGGTTSSSSTLARKEAGGRRKRVEFVTFAPAPPAQSPEEPVGAPAVQSILVAGEEDIRWVCEDMGLKDPEELRNYMERIRGSS>sp|Q24JP5-2|T132A_HUMAN Isoform 2 of Transmembrane protein 132A OS=Homosapiens OX=9606 GN=TMEM132AMCARMAGRTTAAPRGPYGPWLCLLVALALDVVRVDCGQAPLDPVYLPAALELLDAPEHFRVQQVGHYPPANSSLSSRSETFLLLQPWPRAQPLLRASYPPFATQQVVPPRVTEPHQRPVPWDVRAVSVEAAVTPAEPYARVLFHLKGQDWPPGSGSLPCARLHATHPAGTAHQACRFQPSLGACVVELELPSHWFSQASTTRAELAYTLEPAAEGPGGCGSGEENDPGEQALPVGGVELRPADPPQYQEVPLDEAVTLRVPDMPVRPGQLFSATLLLRHNFTASLLTLRIKVKKGLHVTAARPAQPTLWTAKLDRFKGSRHHTTLITCHRAGLTEPDSSSPLELSEFLWVDFVVENSTGGGVAVTRPVTWQLEYPGQAPEAEKDKMVWEILVSERDIRALIPLAKAEELVNTAPLTGVPQHVPVRLVTVDGGGALVEVTEHVGCESANTQVLQVSEACDAVFVAGKESRGARGVRVDFWWRRLRASLRLTVWAPLLPLRIELTDTTLEQVRGWRVPGPAEGPAEPAAEASDEAERRARGCHLQYQRAGVRFLAPFAAHPLDGGRRLTHLLGPDWLLDVSHLVAPHARVLDSRVASLEGGRVVVGREPGVTSIEVRSPLSDSILGEQALAVTDDKVSVLELRVQPVMGISLTLSRGTAHPGEVTATCWAQSALPAPKQEVALSLWLSFSDHTVAPAELYDRRDLGLSVSAEEPGAILPAEEQGAQLGVVVSGAGAEGLPLHVALHPPEPCRRGRHRVPLASGTAWLGLPPASTPAPALPSSPAWSPPATEATMGGKRQVAGSVGGNTGVRGKFERAEEEARKEETEAREEEEEEEEEMVPAPQHVTELELGMYALLGVFCVAIFIFLVNGVVFVLRYQRKEPPDSATDPTSPQPHNWVWLGTDQEELSRQLDRQSPGPPKGEGSCPCESGGGGEAPTLAPGPPGGTTSSSSTLARKEAGGRRKRVEFVTFAPAPPAQSPEEPVGAPAVQSILVAGEEDIRWVCEDMGLKDPEELRNYMERIRGSS>sp|Q24JP5-3|T132A_HUMAN Isoform 3 of Transmembrane protein 132A OS=Homosapiens OX=9606 GN=TMEM132AMAPGSAPASSGAVIISPSYASSVDCGQAPLDPVYLPAALELLDAPEHFRVQQVGHYPPANSSLSSRSETFLLLQPWPRAQPLLRASYPPFATQQVVPPRVTEPHQRPVPWDVRAVSVEAAVTPAEPYARVLFHLKGQDWPPGSGSLPCARLHATHPAGTAHQACRFQPSLGACVVELELPSHWFSQASTTRAELAYTLEPAAEGPGGCGSGEENDPGEQALPVGGVELRPADPPQYQEVPLDEAVTLRVPDMPVRPGQLFSATLLLRHNFTASLLTLRIKVKKGLHVTAARPAQPTLWTAKLDRFKGSRHHTTLITCHRAGLTEPDSSPLELSEFLWVDFVVENSTGGGVAVTRPVTWQLEYPGQAPEAEKDKMVWEILVSERDIRALIPLAKVRRPPSLPGKAGGQVPGAP>sp|Q24JP5-4|T132A_HUMAN Isoform 4 of Transmembrane protein 132A OS=Homosapiens OX=9606 GN=TMEM132AMCARMAGRTTAAPRGPYGPWLCLLVALALDVVRVDCGQAPLDPVYLHVTAARPAQPTLWTAKLDRFKGSRHHTTLITCHRAGLTEPDSSSPLELSEFLWVDFVVENSTGGGVAVTRPVTWQLEYPGQAPEAEKDKMVWEILVSERDIRALIPLAKAEELVNTAPLTGVPQHVPVRLVTVDGGGALVEVTEHVGCESANTQVLQVSEACDAVFVAGKESRGARGVRVDFWWRRLRASLRLTVWAPLLPLRIELTDTTLEQVRGWRVPGPAEGPAEPAAEASDEAERRARGCHLQYQRAGVRFLAPFAAHPLDGGRRLTHLLGPDWLLDVSHLVAPHARVLDSRVASLEGGRVVVGREPGVTSIEVRSPLSDSILGEQALAVTDDKVSVLELRVQPVMGISLTLSRGTAHPGEVTATCWAQSALPAPKQEVALSLWLSFSDHTVAPAELYDRRDLGLSVSAEEPGAILPAEEQGAQLGVVVSGAGAEGLPLHVALHPPEPCRRGRHRVPLASGTAWLGLPPASTPAPALPSSPAWSPPATEATMGGKRQVAGSVGGNTGVRGKFERAEEEARKEETEAREEEEEEEEEMVPAPQHVTELELGMYALLGVFCVAIFIFLVNGVVFVLRYQRKEPPDSATDPTSPQPHNWVWLGTDQEELSRQLDRQSPGPPKGEGSCPCESGGGGEAPTLAPGPPGGTTSSSSTLARKEAGGRRKRVEFVTFAPAPPAQSPEEPVGAPAVQSILVAGEEDIRWVCEDMGLKDPEELRNYMERIRGSS>sp|Q9C0D5|TANC1_HUMAN Protein TANC1 OS=Homo sapiens OX=9606 GN=TANC1PE=1 SV=3MLKAVLKKSREGGKGGKKEAGSDFGPETSPVLHLDHSADSPVSSLPTAEDTYRVSLAKGVSMSLPSSPLLPRQSHLVQSRVNKKSPGPVRKPKYVESPRVPGDAVIMPFREVAKPTEPDEHEAKADNEPSCSPAAQELLTRLGFLLGEGIPSATHITIEDKNETMCTALSQGISPCSTLTSSTASPSTDSPCSTLNSCVSKTAANKSPCETISSPSSTLESKDSGIIATITSSSENDDRSGSSLEWNKDGNLRLGVQKGVLHDRRADNCSPVAEEETTGSAESTLPKAESSAGDGPVPYSQGSSSLIMPRPNSVAATSSTKLEDLSYLDGQRNAPLRTSIRLPWHNTAGGRAQEVKARFAPYKPQDILLKPLLFEVPSITTDSVFVGRDWLFHQIEENLRNTELAENRGAVVVGNVGFGKTAIISKLVALSCHGSRMRQIASNSPGSSPKTSDPTQDLHFTPLLSPSSSTSASSTAKTPLGSISAENQRPREDAVKYLASKVVAYHYCQADNTYTCLVPEFVHSIAALLCRSHQLAAYRDLLIKEPQLQSMLSLRSCVQDPVAAFKRGVLEPLTNLRNEQKIPEEEYIILIDGLNEAEFHKPDYGDTLSSFITKIISKFPAWLKLIVTVRANFQEIISALPFVKLSLDDFPDNKDIHSDLHAYVQHRVHSSQDILSNISLNGKADATLIGKVSSHLVLRSLGSYLYLKLTLDLFQRGHLVIKSASYKVVPVSLSELYLLQCNMKFMTQSAFERALPILNVALASLHPMTDEQIFQAINAGHIQGEQGWEDFQQRMDALSCFLIKRRDKTRMFCHPSFREWLVWRADGENTAFLCEPRNGHALLAFMFSRQEGKLNRQQTMELGHHILKAHIFKGLSKKTGISSSHLQALWIGYSTEGLSAALASLRNLYTPNVKVSRLLILGGANVNYRTEVLNNAPILCVQSHLGHEEVVTLLLEFGACLDGTSENGMTALCYAAAAGHMKLVCLLTKKGVRVDHLDKKGQCALVHSALRGHGDILQYLLTCEWSPGPPQPGTLRKSHALQQALTAAASMGHSSVVQCLLGMEKEHEVEVNGTDTLWGETALTAAAGRGKLEVCELLLGHGAAVSRTNRRGVPPLFCAARQGHWQIVRLLLERGCDVNLSDKQGRTPLMVAACEGHLSTVEFLLSKGAALSSLDKEGLSALSWACLKGHRAVVQYLVEEGAAIDQTDKNGRTPLDLAAFYGDAETVLYLVEKGAVIEHVDHSGMRPLDRAIGCRNTSVVVALLRKGAKLGNAAWAMATSKPDILIILLQKLMEEGNVMYKKGKMKEAAQRYQYALRKFPREGFGEDMRPFNELRVSLYLNLSRCRRKTNDFGMAEEFASKALELKPKSYEAFYARARAKRNSRQFVAALADLQEAVKLCPTNQEVKRLLARVEEECKQLQRSQQQKQQGPLPAPLNDSENEEDTPTPGLSDHFHSEETEEEETSPQEESVSPTPRSQPSSSVPSSYIRNLQEGLQSKGRPVSPQSRAGIGKSLREPVAQPGLLLQPSKQAQIVKTSQHLGSGQSAVRNGSMKVQISSQNPPPSPMPGRIAATPAGSRTQHLEGTGTFTTRAGCGHFGDRLGPSQNVRLQCGENGPAHPLPSKTKTTERLLSHSSVAVDAAPPNQGGLATCSDVRHPASLTSSGSSGSPSSSIKMSSSTSSLTSSSSFSDGFKVQGPDTRIKDKVVTHVQSGTAEHRPRNTPFMGIMDKTARFQQQSNPPSRSWHCPAPEGLLTNTSSAAGLQSANTEKPSLMQVGGYNNQAKTCSVSTLSASVHNGAQVKELEESKCQIPVHSQENRITKTVSHLYQESISKQQPHISNEAHRSHLTAAKPKRSFIESNV>sp|Q9C0D5-2|TANC1_HUMAN Isoform 2 of Protein TANC1 OS=Homo sapiensOX=9606 GN=TANC1MLKAVLKKSREGGKGGKKEAGSDFGPETSPVLHLDHSADSPVSSLPTAEDTYRVSLAKGVSMSLPSSPLLPRQSHLVQSRVNKKSPGPVRKPKYVESPRVPGDAVIMPFREVAKPTEPDEHATITSSSENDDRSGSSLEWNKDGNLRLGVQKGVLHDRRADNCSPVAEEETTGSAESTLPKAESSAGDGPVPYSQGSSSLIMPRPNSVAATSSTKLEDLSYLDGQRNAPLRTSIRLPWHNTAGGRAQEVKARFAPYKPQDILLKPLLFEVPSITTDSVFVGRDWLFHQIEENLRNTELAENRGAVVVGNVGFGKTAIISKLVALSCHGSRMRQIASNSPGSSPKTSDPTQDLHFTPLLSPSSSTSASSTAKTPLGSISAENQRPREDAVKYLASKVVAYHYCQADNTYTCLVPEFVHSIAALLCRSHQLAAYRDLLIKEPQLQSMLSLRSCVQDPVAAFKRGVLEPLTNLRNEQKIPEEEYIILIDGLNEAEFHKPDYGDTLSSFITKIISKFPAWLKLIVTVRANFQEIISALPFVKLSLDDFPDNKDIHSDLHAYVQHRVHSSQDILSNISLNGKADATLIGKVSSHLVLRSLGSYLYLKLTLDLFQRGHLVIKSASYKVVPVSLSELYLLQCNMKFMTQSAFERALPILNVALASLHPMTDEQIFQAINAGHIQGEQGWEDFQQRMDALSCFLIKRRDKTRMFCHPSFREWLVWRADGENTAFLCEPRNGHALLAFMFSRQEGKLNRQQTMELGHHILKAHIFKGLSKKTGISSSHLQALWIGYSTEGLSAALASLRNLYTPNVKVSRLLILGGANVNYRTEVLNNAPILCVQSHLGHEEVVTLLLEFGACLDGTSENGMTALCYAAAAGHMKLVCLLTKKGVRVDHLDKKGQCALVHSALRGHGDILQYLLTCEWSPGPPQPGTLRKSHALQQALTAAASMGHSSVVQCLLGMEKEHEVEVNGTDTLWGETALTAAAGRGKLEVCELLLGHGAAVSRTNRRGVPPLFCAARQGHWQIVRLLLERGCDVNLSDKQGRTPLMVAACEGHLSTVEFLLSKGAALSSLDKEGLSALSWACLKGHRAVVQYLVEEGAAIDQTDKNGRTPLDLAAFYGDAETVLYLVEKGAVIEHVDHSGMRPLDRAIGCRNTSVVVALLRKGAKLGNAAWAMATSKPDILIILLQKLMEEGNVMYKKGKMKEAAQRYQYALRKFPREGFGEDMRPFNELRVSLYLNLSRCRRKTNDFGMAEEFASKALELKPKSYEAFYARARAKRNSRQFVAALADLQEAVKLCPTNQEVKRLLARVEEECKQLQRSQQQKQQGPLPAPLNDSENEEDTPTPGLSDHFHSEETEEEETSPQEESVSPTPRSQPSSSVPSSYIRNLQEGLQSKGRPVSPQSRAGIGKSLREPVAQPGLLLQPSKQAQIVKTSQHLGSGQSAVRNGSMKVQISSQNPPPSPMPGRIAATPAGSRTQHLEGTGTFTTRAGCGHFGDRLGPSQNVRLQCGENGPAHPLPSKTKTTERLLSHSSVAVDAAPPNQGGLATCSDVRHPASLTSSGSSGSPSSSIKMSSSTSSLTSSSSFSDGFKVQGPDTRIKDKVVTHVQSGTAEHRPRNTPFMGIMDKTARFQQQSNPPSRSWHCPAPEGLLTNTSSAAGLQSANTEKPSLMQVGGYNNQAKTCSVSTLSASVHNGAQVKELEESKCQIPVHSQENRITKTVSHLYQESISKQQPHISNEAHRSHLTAAKPKRSFIESNV>sp|P17600|SYN1_HUMAN Synapsin-1 OS=Homo sapiens OX=9606 GN=SYN1 PE=1SV=3MNYLRRRLSDSNFMANLPNGYMTDLQRPQPPPPPPGAHSPGATPGPGTATAERSSGVAPAASPAAPSPGSSGGGGFFSSLSNAVKQTTAAAAATFSEQVGGGSGGAGRGGAASRVLLVIDEPHTDWAKYFKGKKIHGEIDIKVEQAEFSDLNLVAHANGGFSVDMEVLRNGVKVVRSLKPDFVLIRQHAFSMARNGDYRSLVIGLQYAGIPSVNSLHSVYNFCDKPWVFAQMVRLHKKLGTEEFPLIDQTFYPNHKEMLSSTTYPVVVKMGHAHSGMGKVKVDNQHDFQDIASVVALTKTYATAEPFIDAKYDVRVQKIGQNYKAYMRTSVSGNWKTNTGSAMLEQIAMSDRYKLWVDTCSEIFGGLDICAVEALHGKDGRDHIIEVVGSSMPLIGDHQDEDKQLIVELVVNKMAQALPRQRQRDASPGRGSHGQTPSPGALPLGRQTSQQPAGPPAQQRPPPQGGPPQPGPGPQRQGPPLQQRPPPQGQQHLSGLGPPAGSPLPQRLPSPTSAPQQPASQAAPPTQGQGRQSRPVAGGPGAPPAARPPASPSPQRQAGPPQATRQTSVSGPAPPKASGAPPGGQQRQGPPQKPPGPAGPTRQASQAGPVPRTGPPTTQQPRPSGPGPAGRPKPQLAQKPSQDVPPPATAAAGGPPHPQLNKSQSLTNAFNLPEPAPPRPSLSQDEVKAETIRSLRKSFASLFSD>sp|P17600-2|SYN1_HUMAN Isoform IB of Synapsin-1 OS=Homo sapiens OX=9606GN=SYN1MNYLRRRLSDSNFMANLPNGYMTDLQRPQPPPPPPGAHSPGATPGPGTATAERSSGVAPAASPAAPSPGSSGGGGFFSSLSNAVKQTTAAAAATFSEQVGGGSGGAGRGGAASRVLLVIDEPHTDWAKYFKGKKIHGEIDIKVEQAEFSDLNLVAHANGGFSVDMEVLRNGVKVVRSLKPDFVLIRQHAFSMARNGDYRSLVIGLQYAGIPSVNSLHSVYNFCDKPWVFAQMVRLHKKLGTEEFPLIDQTFYPNHKEMLSSTTYPVVVKMGHAHSGMGKVKVDNQHDFQDIASVVALTKTYATAEPFIDAKYDVRVQKIGQNYKAYMRTSVSGNWKTNTGSAMLEQIAMSDRYKLWVDTCSEIFGGLDICAVEALHGKDGRDHIIEVVGSSMPLIGDHQDEDKQLIVELVVNKMAQALPRQRQRDASPGRGSHGQTPSPGALPLGRQTSQQPAGPPAQQRPPPQGGPPQPGPGPQRQGPPLQQRPPPQGQQHLSGLGPPAGSPLPQRLPSPTSAPQQPASQAAPPTQGQGRQSRPVAGGPGAPPAARPPASPSPQRQAGPPQATRQTSVSGPAPPKASGAPPGGQQRQGPPQKPPGPAGPTRQASQAGPVPRTGPPTTQQPRPSGPGPAGRPKPQLAQKPSQDVPPPATAAAGGPPHPQLKASPAQAQP>sp|Q01995|TAGL_HUMAN Transgelin OS=Homo sapiens OX=9606 GN=TAGLN PE=1SV=4MANKGPSYGMSREVQSKIEKKYDEELEERLVEWIIVQCGPDVGRPDRGRLGFQVWLKNGVILSKLVNSLYPDGSKPVKVPENPPSMVFKQMEQVAQFLKAAEDYGVIKTDMFQTVDLFEGKDMAAVQRTLMALGSLAVTKNDGHYRGDPNWFMKKAQEHKREFTESQLQEGKHVIGLQMGSNRGASQAGMTGYGRPRQIIS>sp|P59538|T2R31_HUMAN Taste receptor type 2 member 31 OS=Homo sapiensOX=9606 GN=TAS2R31 PE=2 SV=2MTTFIPIIFSSVVVVLFVIGNFANGFIALVNSIERVKRQKISFADQILTALAVSRVGLLWVLLLNWYSTVFNPAFYSVEVRTTAYNVWAVTGHFSNWLATSLSIFYLLKIANFSNLIFLHLKRRVKSVILVMLLGPLLFLACQLFVINMKEIVRTKEYEGNLTWKIKLRSAVYLSDATVTTLGNLVPFTLTLLCFLLLICSLCKHLKKMQLHGKGSQDPSTKVHIKALQTVIFFLLLCAVYFLSIMISVWSFGSLENKPVFMFCKAIRFSYPSIHPFILIWGNKKLKQTFLSVLRQVRYWVKGEKPSSP>sp|Q86TJ2|TAD2B_HUMAN Transcriptional adapter 2-beta OS=Homo sapiensOX=9606 GN=TADA2B PE=1 SV=2MAELGKKYCVYCLAEVSPLRFRCTECQDIELCPECFSAGAEIGHHRRYHGYQLVDGGRFTLWGPEAEGGWTSREEQLLLDAIEQFGFGNWEDMAAHVGASRTPQEVMEHYVSMYIHGNLGKACIPDTIPNRVTDHTCPSGGPLSPSLTTPLPPLDISVAEQQQLGYMPLRDDYEIEYDQDAETLISGLSVNYDDDDVEIELKRAHVDMYVRKLKERQRRKNIARDYNLVPAFLGKDKKEKEKALKRKITKEEKELRLKLRPLYQFMSCKEFDDLFENMHKEKMLRAKIRELQRYRRNGITKMEESAEYEAARHKREKRKENKNLAGSKRGKEDGKDSEFAAIENLPGFELLSDREKVLCSSLNLSPARYVTVKTIIIKDHLQKRQGIPSKSRLPSYLDKVLKKRILNFLTESGWISRDAS>sp|Q86TJ2-2|TAD2B_HUMAN Isoform 2 of Transcriptional adapter 2-betaOS=Homo sapiens OX=9606 GN=TADA2BMAELGKKYCVYCLAEEDMAAHVGASRTPQEVMEHYVSMYIHGNLGKACIPDTIPNRVTDHTCPSGGPLSPSLTTPLPPLDISVAEQQQLGYMPLRDDYEIEYDQDAETLISGLSVNYDDDDVEIELKRAHVDMYVRKLKERQRRKNIARDYNLVPAFLGKDKKEKEKALKRKITKEEKELRLKLRPLYQFMSCKEFDDLFENMHKEKMLRAKIRELQRYRRNGITKMEESAEYEAARHKREKRKENKNLAGSKRGKEDGKDSEFAAIENLPGFELLSDREKVLCSSLNLSPARYVTVKTIIIKDHLQKRQGIPSKSRLPSYLDKVLKKRILNFLTESGWISRDAS>sp|Q86TJ2-3|TAD2B_HUMAN Isoform 3 of Transcriptional adapter 2-betaOS=Homo sapiens OX=9606 GN=TADA2BMAAHVGASRTPQEVMEHYVSMYIHGNLGKACIPDTIPNRVTDHTCPSGGPLSPSLTTPLPPLDISVAEQQQLGYMPLRDDYEIEYDQDAETLISGLSVNYDDDDVEIELKRAHVDMYVRKLKERQRRKNIARDYNLVPAFLGKDKKEKEKALKRKITKEEKELRLKLRPLYQFMSCKEFDDLFENMHKEKMLRAKIRELQRYRRNGITKMEESAEYEAARHKREKRKENKNLAGSKRGKEDGKDSEFAAIENLPGFELLSDREKVLCSSLNLSPARYVTVKTIIIKDHLQKRQGIPSKSRLPSYLDKVLKKRILNFLTESGWISRDAS>sp|P59534|T2R39_HUMAN Taste receptor type 2 member 39 OS=Homo sapiensOX=9606 GN=TAS2R39 PE=2 SV=3MLGRCFPPDTKEKQQLRMTKLCDPAESELSPFLITLILAVLLAEYLIGIIANGFIMAIHAAEWVQNKAVSTSGRILVFLSVSRIALQSLMMLEITISSTSLSFYSEDAVYYAFKISFIFLNFCSLWFAAWLSFFYFVKIANFSYPLFLKLRWRITGLIPWLLWLSVFISFSHSMFCINICTVYCNNSFPIHSSNSTKKTYLSEINVVGLAFFFNLGIVTPLIMFILTATLLILSLKRHTLHMGSNATGSNDPSMEAHMGAIKAISYFLILYIFNAVALFIYLSNMFDINSLWNNLCQIIMAAYPASHSILLIQDNPGLRRAWKRLQLRLHLYPKEWTL>sp|O75478|TAD2A_HUMAN Transcriptional adapter 2-alpha OS=Homo sapiensOX=9606 GN=TADA2A PE=1 SV=3MDRLGPFSNDPSDKPPCRGCSSYLMEPYIKCAECGPPPFFLCLQCFTRGFEYKKHQSDHTYEIMTSDFPVLDPSWTAQEEMALLEAVMDCGFGNWQDVANQMCTKTKEECEKHYMKHFINNPLFASTLLNLKQAEEAKTADTAIPFHSTDDPPRPTFDSLLSRDMAGYMPARADFIEEFDNYAEWDLRDIDFVEDDSDILHALKMAVVDIYHSRLKERQRRKKIIRDHGLINLRKFQLMERRYPKEVQDLYETMRRFARIVGPVEHDKFIESHALEFELRREIKRLQEYRTAGITNFCSARTYDHLKKTREEERLKRTMLSEVLQYIQDSSACQQWLRRQADIDSGLSPSIPMASNSGRRSAPPLNLTGLPGTEKLNEKEKELCQMVRLVPGAYLEYKSALLNECNKQGGLRLAQARALIKIDVNKTRKIYDFLIREGYITKG>sp|O75478-2|TAD2A_HUMAN Isoform 2 of Transcriptional adapter 2-alphaOS=Homo sapiens OX=9606 GN=TADA2AMDRLGPFSNDPSDKPPCRGCSSYLMEPYIKCAECGPPPFFLCLQCFTRGFEYKKHQSDHTYEIMTSDFPVLDPSWTAQEEMALLEAVMDCGFGNWQDVANQMCTKTKEECEKHYMKHFINNPLFASTLLNLKQAEEAKTADTAIPFHSTDDPPRPTFDSLLSRDMAGYMPARADFIEEFDNYAEWDLRDIDFVEDDSDILHALKMAVVDIYHSRLKERQRRKKIIRDHGLINLRKFQLMERRYPKEVQDLYETMRRFARIVGPVEHDKFIESHACRWFLSLEQYLCVYIYINRRDNGVFYVKFYK>sp|O75528|TADA3_HUMAN Transcriptional adapter 3 OS=Homo sapiens OX=9606GN=TADA3 PE=1 SV=1MSELKDCPLQFHDFKSVDHLKVCPRYTAVLARSEDDGIGIEELDTLQLELETLLSSASRRLRVLEAETQILTDWQDKKGDRRFLKLGRDHELGAPPKHGKPKKQKLEGKAGHGPGPGPGRPKSKNLQPKIQEYEFTDDPIDVPRIPKNDAPNRFWASVEPYCADITSEEVRTLEELLKPPEDEAEHYKIPPLGKHYSQRWAQEDLLEEQKDGARAAAVADKKKGLMGPLTELDTKDVDALLKKSEAQHEQPEDGCPFGALTQRLLQALVEENIISPMEDSPIPDMSGKESGADGASTSPRNQNKPFSVPHTKSLESRIKEELIAQGLLESEDRPAEDSEDEVLAELRKRQAELKALSAHNRTKKHDLLRLAKEEVSRQELRQRVRMADNEVMDAFRKIMAARQKKRTPTKKEKDQAWKTLKERESILKLLDG>sp|O75528-2|TADA3_HUMAN Isoform 2 of Transcriptional adapter 3 OS=Homosapiens OX=9606 GN=TADA3MSELKDCPLQFHDFKSVDHLKVCPRYTAVLARSEDDGIGIEELDTLQLELETLLSSASRRLRVLEAETQILTDWQDKKGDRRFLKLGRDHELGAPPKHGKPKKQKLEGKAGHGPGPGPGRPKSKNLQPKIQEYEFTDDPIDVPRIPKNDAPNRFWASVEPYCADITSEEVRTLEELLKPPEDEAEHYKIPPLGKHYSQRWAQEDLLEEQKDGARAAAVADKKKGLMGPLTELDTKDVDALLKKSEAQHEQPEDGCPFGALTQRLLQALVEENIISPMEDSPIPDMSGKESGADGASTSPRNQNKPFSVPHTKSLESRIKEELIAQGLLESEDRPAEDSEDEVLAELRKRQAELKALSAHNRTKKHDLLR>sp|Q68CQ4|UTP25_HUMAN U3 small nucleolar RNA-associated protein 25homolog OS=Homo sapiens OX=9606 GN=UTP25 PE=1 SV=2MGKRGSRSQSQLLNTLTKKQKKHLRDFGEEHPFYDRVSRKEAKPQICQLSESSDSSDSESDSESEPQQVSGYHRLLATLKNVSEEEEEDEEEEEEEDSIVDDAEMNDEDGGSDVSVEEEMAAESTESPENVALSADPEGKEDGEEPPGTSQTSPEEFTDAKHESLFSLETNFLEEESGDNSSLKASQDPFLQHVNKELKEKAIQAVATNPKTTHELKWPILGQLFFSSKFQKLETFKPPKDIDLKSLHLQKPLESTWTKTNSQFLSGPQKSSSPFTPLQKELFLIMNSYRDLFYPERTALKNGEEIRHVYCLHVINHILKANAQVLGNNSRRRSQKFGVGDDDDFRDQGLTRPKVLIVVPFREAALRVVQLFISLLEGDSKKKIIVSNKKRFQGEYGSDPEERPPNLKRPEDYEAVFVGNIDDHFRIGVAILQRSIRLYAPFYSSDILIASPLGLRTIIGGEGEKKRDFDFLSSIELLIIDQADIYLMQNWEHVLHLMNHMNLLPLDSHGVDFSRVRMWSLNNWSKYYRQTLLFGALQDAQINSVFNKYCVNMQGQVAVRNVPMTGSISHVLVQLPHVFQRMEAENLASVIDARFNFFVNKILPQYRDAVMSHTLIYIPSYFDFVRLRNYFKKEELNFTHICEYTQKSGVSRARHFFLQGEKQFLLFTERFHFYKRYTIKGIRNLIFYELPTYPHFYSEICNMLRATNRGEEATWTCTVLYSKYDAQRLAAVVGVERAAQMLQSNKNVHLFITGEK>sp|Q8TAG6|VEXIN_HUMAN Vexin OS=Homo sapiens OX=9606 GN=VXN PE=1 SV=2MMHQIYSCSDENIEVFTTVIPSKVSSPARRRAKSSQHLLTKNVVIESDLYTHQPLELLPHRGDRRDPGDRRRFGRLQTARPPTAHPAKASARPVGISEPKTSNLCGNRAYGKSLIPPVPRISVKTSASASLEATAMGTEKGAVLMRGSRHLKKMTEEYPALPQGAEASLPLTGSASCGVPGILRKMWTRHKKKSEYVGATNSAFEAD>sp|Q8TAG6-2|VEXIN_HUMAN Isoform 2 of Vexin OS=Homo sapiens OX=9606GN=VXNMMHQIYSCSDENIEVFTTVIPSKVSSPARRRAKSSQHLLTKNVVIESDLYTHQPLELLPHRGDRRDPGDRRRFGRLQTARPPTAHPAKASARPDTASAPDLSENFSLCLIGGDSHGHREGSCSDERIQTSQEDD>sp|P52735|VAV2_HUMAN Guanine nucleotide exchange factor VAV2 OS=Homosapiens OX=9606 GN=VAV2 PE=1 SV=2MEQWRQCGRWLIDCKVLPPNHRVVWPSAVVFDLAQALRDGVLLCQLLHNLSPGSIDLKDINFRPQMSQFLCLKNIRTFLKVCHDKFGLRNSELFDPFDLFDVRDFGKVISAVSRLSLHSIAQNKGIRPFPSEETTENDDDVYRSLEELADEHDLGEDIYDCVPCEDGGDDIYEDIIKVEVQQPMIRYMQKMGMTEDDKRNCCLLEIQETEAKYYRTLEDIEKNYMSPLRLVLSPADMAAVFINLEDLIKVHHSFLRAIDVSVMVGGSTLAKVFLDFKERLLIYGEYCSHMEHAQNTLNQLLASREDFRQKVEECTLKVQDGKFKLQDLLVVPMQRVLKYHLLLKELLSHSAERPERQQLKEALEAMQDLAMYINEVKRDKETLRKISEFQSSIENLQVKLEEFGRPKIDGELKVRSIVNHTKQDRYLFLFDKVVIVCKRKGYSYELKEIIELLFHKMTDDPMNNKDVKKSHGKMWSYGFYLIHLQGKQGFQFFCKTEDMKRKWMEQFEMAMSNIKPDKANANHHSFQMYTFDKTTNCKACKMFLRGTFYQGYMCTKCGVGAHKECLEVIPPCKFTSPADLDASGAGPGPKMVAMQNYHGNPAPPGKPVLTFQTGDVLELLRGDPESPWWEGRLVQTRKSGYFPSSSVKPCPVDGRPPISRPPSREIDYTAYPWFAGNMERQQTDNLLKSHASGTYLIRERPAEAERFAISIKFNDEVKHIKVVEKDNWIHITEAKKFDSLLELVEYYQCHSLKESFKQLDTTLKYPYKSRERSASRASSRSPASCASYNFSFLSPQGLSFASQGPSAPFWSVFTPRVIGTAVARYNFAARDMRELSLREGDVVRIYSRIGGDQGWWKGETNGRIGWFPSTYVEEEGIQ>sp|P52735-2|VAV2_HUMAN Isoform 2 of Guanine nucleotide exchange factorVAV2 OS=Homo sapiens OX=9606 GN=VAV2MEQWRQCGRWLIDCKVLPPNHRVVWPSAVVFDLAQALRDGVLLCQLLHNLSPGSIDLKDINFRPQMSQFLCLKNIRTFLKVCHDKFGLRNSELFDPFDLFDVRDFGKVISAVSRLSLHSIAQNKGIRPFPSEETTENDDDVYRSLEELADEHDLGEDIYDCVPCEDGGDDIYEDIIKVEVQQPMKMGMTEDDKRNCCLLEIQETEAKYYRTLEDIEKNYMSPLRLVLSPADMAAVFINLEDLIKVHHSFLRAIDVSVMVGGSTLAKVFLDFKERLLIYGEYCSHMEHAQNTLNQLLASREDFRQKVEECTLKVQDGKFKLQDLLVVPMQRVLKYHLLLKELLSHSAERPERQQLKEALEAMQDLAMYINEVKRDKETLRKISEFQSSIENLQVKLEEFGRPKIDGELKVRSIVNHTKQDRYLFLFDKVVIVCKRKGYSYELKEIIELLFHKMTDDPMNNKDVKKWSYGFYLIHLQGKQGFQFFCKTEDMKRKWMEQFEMAMSNIKPDKANANHHSFQMYTFDKTTNCKACKMFLRGTFYQGYMCTKCGVGAHKECLEVIPPCKFTSPADLDASGAGPGPKMVAMQNYHGNPAPPGKPVLTFQTGDVLELLRGDPESPWWEGRLVQTRKSGYFPSSSVKPCPVDGRPPISRPPSREIDYTAYPWFAGNMERQQTDNLLKSHASGTYLIRERPAEAERFAISIKFNDEVKHIKVVEKDNWIHITEAKKFDSLLELVEYYQCHSLKESFKQLDTTLKYPYKSRERSASRASSRSPASCASYNFSFLSPQGLSFASQGPSAPFWSVFTPRVIGTAVARYNFAARDMRELSLREGDVVRIYSRIGGDQGWWKGETNGRIGWFPSTYVEEEGIQ>sp|P52735-3|VAV2_HUMAN Isoform 3 of Guanine nucleotide exchange factorVAV2 OS=Homo sapiens OX=9606 GN=VAV2MEQWRQCGRWLIDCKVLPPNHRVVWPSAVVFDLAQALRDGVLLCQLLHNLSPGSIDLKDINFRPQMSQFLCLKNIRTFLKVCHDKFGLRNSELFDPFDLFDVRDFGKVISAVSRLSLHSIAQNKGIRPFPSEETTENDDDVYRSLEELADEHDLGEDIYDCVPCEDGGDDIYEDIIKVEVQQPMKMGMTEDDKRNCCLLEIQETEAKYYRTLEDIEKNYMSPLRLVLSPADMAAVFINLEDLIKVHHSFLRAIDVSVMVGGSTLAKVFLDFKERLLIYGEYCSHMEHAQNTLNQLLASREDFRQKVEECTLKVQDGKFKLQDLLVVPMQRVLKYHLLLKELLSHSAERPERQQLKEALEAMQDLAMYINEVKRDKETLRKISEFQSSIENLQVKLEEFGRPKIDGELKVRSIVNHTKQDRYLFLFDKVVIVCKRKGYSYELKEIIELLFHKMTDDPMNNKDVKKWSYGFYLIHLQGKQGFQFFCKTEDMKRKWMEQFEMAMSNIKPDKANANHHSFQMYTFDKTTNCKACKMFLRGTFYQGYMCTKCGVGAHKECLEVIPPCKFTSPADLDASGAGPGPKMVAMQNYHGNPAPPGKPVLTFQTGDVLELLRGDPESPWWEGRLVQTRKSGYFPSSSVKPCPVDGRPPISRPPSREIDYTAYPWFAGNMERQQTDNLLKSHASGTYLIRERPAEAERFAISIKFNDEVKHIKVVEKDNWIHITEAKKFDSLLELVEYYQCHSLKESFKQLDTTLKYPYKSRERSASRASSRSPVFTPRVIGTAVARYNFAARDMRELSLREGDVVRIYSRIGGDQGWWKGETNGRIGWFPSTYVEEEGIQ>sp|Q9UKW4|VAV3_HUMAN Guanine nucleotide exchange factor VAV3 OS=Homosapiens OX=9606 GN=VAV3 PE=1 SV=1MEPWKQCAQWLIHCKVLPTNHRVTWDSAQVFDLAQTLRDGVLLCQLLNNLRAHSINLKEINLRPQMSQFLCLKNIRTFLTACCETFGMRKSELFEAFDLFDVRDFGKVIETLSRLSRTPIALATGIRPFPTEESINDEDIYKGLPDLIDETLVEDEEDLYDCVYGEDEGGEVYEDLMKAEEAHQPKCPENDIRSCCLAEIKQTEEKYTETLESIEKYFMAPLKRFLTAAEFDSVFINIPELVKLHRNLMQEIHDSIVNKNDQNLYQVFINYKERLVIYGQYCSGVESAISSLDYISKTKEDVKLKLEECSKRANNGKFTLRDLLVVPMQRVLKYHLLLQELVKHTTDPTEKANLKLALDAMKDLAQYVNEVKRDNETLREIKQFQLSIENLNQPVLLFGRPQGDGEIRITTLDKHTKQERHIFLFDLAVIVCKRKGDNYEMKEIIDLQQYKIANNPTTDKENKKWSYGFYLIHTQGQNGLEFYCKTKDLKKKWLEQFEMALSNIRPDYADSNFHDFKMHTFTRVTSCKVCQMLLRGTFYQGYLCFKCGARAHKECLGRVDNCGRVNSGEQGTLKLPEKRTNGLRRTPKQVDPGLPKMQVIRNYSGTPPPALHEGPPLQLQAGDTVELLKGDAHSLFWQGRNLASGEVGFFPSDAVKPCPCVPKPVDYSCQPWYAGAMERLQAETELINRVNSTYLVRHRTKESGEYAISIKYNNEAKHIKILTRDGFFHIAENRKFKSLMELVEYYKHHSLKEGFRTLDTTLQFPYKEPEHSAGQRGNRAGNSLLSPKVLGIAIARYDFCARDMRELSLLKGDVVKIYTKMSANGWWRGEVNGRVGWFPSTYVEEDE>sp|Q9UKW4-2|VAV3_HUMAN Isoform 2 of Guanine nucleotide exchange factorVAV3 OS=Homo sapiens OX=9606 GN=VAV3MQLPDCPCRAHLPVIETLSRLSRTPIALATGIRPFPTEESINDEDIYKGLPDLIDETLVEDEEDLYDCVYGEDEGGEVYEDLMKAEEAHQPKCPENDIRSCCLAEIKQTEEKYTETLESIEKYFMAPLKRFLTAAEFDSVFINIPELVKLHRNLMQEIHDSIVNKNDQNLYQVFINYKERLVIYGQYCSGVESAISSLDYISKTKEDVKLKLEECSKRANNGKFTLRDLLVVPMQRVLKYHLLLQELVKHTTDPTEKANLKLALDAMKDLAQYVNEVKRDNETLREIKQFQLSIENLNQPVLLFGRPQGDGEIRITTLDKHTKQERHIFLFDLAVIVCKRKGDNYEMKEIIDLQQYKIANNPTTDKENKKWSYGFYLIHTQGQNGLEFYCKTKDLKKKWLEQFEMALSNIRPDYADSNFHDFKMHTFTRVTSCKVCQMLLRGTFYQGYLCFKCGARAHKECLGRVDNCGRVNSGEQGTLKLPEKRTNGLRRTPKQVDPGLPKMQVIRNYSGTPPPALHEGPPLQLQAGDTVELLKGDAHSLFWQGRNLASGEVGFFPSDAVKPCPCVPKPVDYSCQPWYAGAMERLQAETELINRVNSTYLVRHRTKESGEYAISIKYNNEAKHIKILTRDGFFHIAENRKFKSLMELVEYYKHHSLKEGFRTLDTTLQFPYKEPEHSAGQRGNRAGNSLLSPKVLGIAIARYDFCARDMRELSLLKGDVVKIYTKMSANGWWRGEVNGRVGWFPSTYVEEDE>sp|Q9UKW4-3|VAV3_HUMAN Isoform 3 of Guanine nucleotide exchange factorVAV3 OS=Homo sapiens OX=9606 GN=VAV3MPIFTFLSEQGTLKLPEKRTNGLRRTPKQVDPGLPKMQVIRNYSGTPPPALHEGPPLQLQAGDTVELLKGDAHSLFWQGRNLASGEVGFFPSDAVKPCPCVPKPVDYSCQPWYAGAMERLQAETELINRVNSTYLVRHRTKESGEYAISIKYNNEAKHIKILTRDGFFHIAENRKFKSLMELVEYYKHHSLKEGFRTLDTTLQFPYKEPEHSAGQRGNRAGNSLLSPKVLGIAIARYDFCARDMRELSLLKGDVVKIYTKMSANGWWRGEVNGRVGWFPSTYVEEDE>sp|Q9UKW4-4|VAV3_HUMAN Isoform 4 of Guanine nucleotide exchange factorVAV3 OS=Homo sapiens OX=9606 GN=VAV3MEPWKQCAQWLIHCKVLPTNHRVTWDSAQVFDLAQTLRDGVLLCQLLNNLRAHSINLKEINLRPQMSQFLCLKNIRTFLTACCETFGMRKSELFEAFDLFDVRDFGKVIETLSRLSRTPIALATGIRPFPTEESINDEDIYKGLPDLIDETLVEDEEDLYDCVYGEDEGGEVYEDLMKAEEAHQPKCPENDIRSCCLAEIKQTEEKYTETLESIEKYFMAPLKRFLTAAEFDSVFINIPELVKLHRNLMQEIHDSIVNKNDQNLYQVFINYKERLVIYGQYCSGVESAISSLDYISKTKEDVKLKLEECSKRANNGKFTLRDLLVVPMQRVLKYHLLLQELVKHTTDPTEKANLKLALDAMKDLAQYVNEVKRDNETLREIKQFQLSIENLNQPVLLFGRPQGDGEIRITTLDKHTKQERHIFLFDLAVIVCKRKGDNYEMKEIIDLQQYKIANNPTTDKENKKWSYGFYLIHTQGQNGLEFYCKTKDLKKKWLEQFEMALSNIRPDYADSNFHDFKMHTFTRVTSCKVCQMLLRGTFYQGYLCFKCGARAHKECLGRVDNCGRVNSGEQGTLKLPEKRTNGLRRTPKQVDPGLPKMQVIRNYSGTPPPALHEGPPLQLQAGDTVELLKGDAHSLFWQGRNLASGEVGFFPSDAVKPCPCVPKPVDYSCQPWYAGAMERLQAETELINRVNSTYLVRHRTKESGEYAISIKYNNEAKHIKILTRDGFFHIAENRKFKSLMELVEYYKHHSLKEGFRTLDTTLQFPYKEPEHSAGQRGNRAGNSSPSLFCGFSFVTPPDYSFVPPSSTPFWSVLSPKVLGIAIARYDFCARDMRELSLLKGDVVKIYTKMSANGWWRGEVNGRVGWFPSTYVEEDE>sp|Q969X6|UTP4_HUMAN U3 small nucleolar RNA-associated protein 4 homologOS=Homo sapiens OX=9606 GN=UTP4 PE=1 SV=1MGEFKVHRVRFFNYVPSGIRCVAYNNQSNRLAVSRTDGTVEIYNLSANYFQEKFFPGHESRATEALCWAEGQRLFSAGLNGEIMEYDLQALNIKYAMDAFGGPIWSMAASPSGSQLLVGCEDGSVKLFQITPDKIQFERNFDRQKSRILSLSWHPSGTHIAAGSIDYISVFDVKSGSAVHKMIVDRQYMGVSKRKCIVWGVAFLSDGTIISVDSAGKVQFWDSATGTLVKSHLIANADVQSIAVADQEDSFVVGTAEGTVFHFQLVPVTSNSSEKQWVRTKPFQHHTHDVRTVAHSPTALISGGTDTHLVFRPLMEKVEVKNYDAALRKITFPHRCLISCSKKRQLLLFQFAHHLELWRLGSTVATGKNGDTLPLSKNADHLLHLKTKGPENIICSCISPCGSWIAYSTVSRFFLYRLNYEHDNISLKRVSKMPAFLRSALQILFSEDSTKLFVASNQGALHIVQLSGGSFKHLHAFQPQSGTVEAMCLLAVSPDGNWLAASGTSAGVHVYNVKQLKLHCTVPAYNFPVTAMAIAPNTNNLVIAHSDQQVFEYSIPDKQYTDWSRTVQKQGFHHLWLQRDTPITHISFHPKRPMHILLHDAYMFCIIDKSLPLPNDKTLLYNPFPPTNESDVIRRRTAHAFKISKIYKPLLFMDLLDERTLVAVERPLDDIIAQLPPPIKKKKFGT>sp|Q969X6-2|UTP4_HUMAN Isoform 2 of U3 small nucleolar RNA-associatedprotein 4 homolog OS=Homo sapiens OX=9606 GN=UTP4MGEFKVHRVRFFNYVPSGIRCVAYNNQSNRLAVSRTDGTVEIYNLSANYFQEKFFPGHESRATEALCWAEGQRLFSAGLNGEIMEYDLQALNIKYAMDAFGGPIWSMAASPSGSQLLVGCEDGSVKLFQITPDKIQFERNFDRQKSRILSLSWHPSGTHIAAGSIDYISVFDVKSGSAVHKMIVDRQYMGVSKRKCIVWGVAFLSDGTIISVDSAGKVQFWDSATGTLVKSHLIANADVQSIAVADQEDSFVVGTAEGTVFHFQLVPVTSNSSEKQWVRTKPFQHHTHDVRTVAHSPTALISGGTDTHLVFRPLMEKVEVKNYDAALRKITFPHRCLISCSKKRQLLLFQFAHHLELWRLGSTVATGTVEAMCLLAVSPDGNWLAASGTSAGVHVYNVKQLKLHCTVPAYNFPVTAMAIAPNTNNLVIAHSDQQVFEYSIPDKQYTDWSRTVQKQGFHHLWLQRDTPITHISFHPKRPMHILLHDAYMFCIIDKSLPLPNDKTLLYNPFPPTNESDVIRRRTAHAFKISKIYKPLLFMDLLDERTLVAVERPLDDIIAQLPPPIKKKKFGT>sp|Q969X6-3|UTP4_HUMAN Isoform 3 of U3 small nucleolar RNA-associatedprotein 4 homolog OS=Homo sapiens OX=9606 GN=UTP4MGEFKVHRVRFFNYVPSGIRCVAYNNQSNRLAVSRTDGTVEIYNLSANYFQEKFFPGHESRATEALCWAEGQRLFSAGLNGEIMEYDLQALNIKYAMDAFGGPIWSMAASPSGSQLLVGCEDGSVKLFQITPDKIQFERNFDRQKSRILSLSWHPSGTHIAAGSIDYISVFDVKSGSAVHKMIVDRQYMGVSKRKCIVWGVAFLSDGTIISVDSAGKVQFWDSATGTLVKSHLIANADVQSIAVADQEDSFVVGTAEGTVFHFQLVPVTSNSSEKQWVRTKPFQHHTHDVRTVAHSPTALISGGTDTHLVFRPLMEKVEVKNYDAALRKITFPHRCLISCSKKRQLLLFQFAHHLELWRLGSTVATGKNGDTLPLSKNADHLLHLKTKGPENIICSCISPCGSWIAYSTVSRFFLYRLNYEHDNISLKRVSKMPAFLRSALQILFSEDSTKLFVASNQGALHIVQLSGGSFKHLHAFQPQSGTVEAMCLLAVSPDGNWLAASGTSAGVHVYNVKQLKLHCTVPAYNFPVTAMAIAPNTNNLVIAHSDQQVFEYSIPDKQYTDWSRTVQKQGFHHLWLQRDTPITHISFHPKRPMHILLHDAYMFCIIDKSLVSSSLLPPKSSSES>sp|Q9UKP6|UR2R_HUMAN Urotensin-2 receptor OS=Homo sapiens OX=9606GN=UTS2R PE=1 SV=1MALTPESPSSFPGLAATGSSVPEPPGGPNATLNSSWASPTEPSSLEDLVATGTIGTLLSAMGVVGVVGNAYTLVVTCRSLRAVASMYVYVVNLALADLLYLLSIPFIVATYVTKEWHFGDVGCRVLFGLDFLTMHASIFTLTVMSSERYAAVLRPLDTVQRPKGYRKLLALGTWLLALLLTLPVMLAMRLVRRGPKSLCLPAWGPRAHRAYLTLLFATSIAGPGLLIGLLYARLARAYRRSQRASFKRARRPGARALRLVLGIVLLFWACFLPFWLWQLLAQYHQAPLAPRTARIVNYLTTCLTYGNSCANPFLYTLLTRNYRDHLRGRVRGPGSGGGRGPVPSLQPRARFQRCSGRSLSSCSPQPTDSLVLAPAAPARPAPEGPRAPA>sp|Q5SQQ9|VAX1_HUMAN Ventral anterior homeobox 1 OS=Homo sapiens OX=9606GN=VAX1 PE=1 SV=1MFGKPDKMDVRCHSDAEAARVSKNAHKESRESKGAEGNLPAAFLKEPQGAFSASGAAEDCNKSKSNSAADPDYCRRILVRDAKGSIREIILPKGLDLDRPKRTRTSFTAEQLYRLEMEFQRCQYVVGRERTELARQLNLSETQVKVWFQNRRTKQKKDQGKDSELRSVVSETAATCSVLRLLEQGRLLSPPGLPALLPPCATGALGSALRGPSLPALGAGAAAGSAAAAAAAAPGPAGAASPHPPAVGGAPGPGPAGPGGLHAGAPAAGHSLFSLPVPSLLGSVASRLSSAPLTMAGSLAGNLQELSARYLSSSAFEPYSRTNNKEGAEKKALD>sp|Q5SQQ9-2|VAX1_HUMAN Isoform 2 of Ventral anterior homeobox 1 OS=Homosapiens OX=9606 GN=VAX1MFGKPDKMDVRCHSDAEAARVSKNAHKESRESKGAEGNLPAAFLKEPQGAFSASGAAEDCNKSKSNSAADPDYCRRILVRDAKGSIREIILPKGLDLDRPKRTRTSFTAEQLYRLEMEFQRCQYVVGRERTELARQLNLSETQANSEENNERFKRGIKKQKKKRKKEPANDESRRGDSGGRGWQPL>sp|Q9UIW0|VAX2_HUMAN Ventral anterior homeobox 2 OS=Homo sapiens OX=9606GN=VAX2 PE=1 SV=1MGDGGAERDRGPARRAESGGGGGRCGDRSGAGDLRADGGGHSPTEVAGTSASSPAGSRESGADSDGQPGPGEADHCRRILVRDAKGTIREIVLPKGLDLDRPKRTRTSFTAEQLYRLEMEFQRCQYVVGRERTELARQLNLSETQVKVWFQNRRTKQKKDQSRDLEKRASSSASEAFATSNILRLLEQGRLLSVPRAPSLLALTPSLPGLPASHRGTSLGDPRNSSPRLNPLSSASASPPLPPPLPAVCFSSAPLLDLPAGYELGSSAFEPYSWLERKVGSASSCKKANT>sp|A6NGE7|URAD_HUMAN Putative 2-oxo-4-hydroxy-4-carboxy-5-ureidoimidazoline decarboxylase OS=Homo sapiens OX=9606 GN=URAD PE=5 SV=2MDIEKVNSMDLGEFVDVFGNATERCPLIAAAVWSQRPFSDLEDLEKHFFAFIDALAQSGQEGILRCHPDLAGSELQRGTLTAESQREQSGAGLRSLGADERLRLAELNAQYRARFGFPFVLAARFSDRTAVPRELARRLLCPSAQELRTALGEVKKIGSLRLADLLRADPAKL>sp|Q96HZ7|URAS1_HUMAN Putative uncharacterized protein URB1-AS1 OS=Homosapiens OX=9606 GN=URB1-AS1 PE=5 SV=1MGRADTPRHPPPPAAGFGVHRGAFLIPVALRVLLAGRTPRPFTPGLADPRRLGPRRVQAAQ>sp|Q6Q795|VBPC1_HUMAN Putative viral protein-binding protein C1 OS=Homosapiens OX=9606 PE=5 SV=1MEEVIQAGLAQWSRQKGLALPWDRTRGHPDVPWRNLTSSPTRPLAQPAGSCMPAEPSPAAHYHQLHVHLQLLPSDLSERPGLRLAPLALVEVGMTLPVPQTPLPHVTQQQKLAPGRQLCPW>sp|P46939|UTRN_HUMAN Utrophin OS=Homo sapiens OX=9606 GN=UTRN PE=1 SV=2MAKYGEHEASPDNGQNEFSDIIKSRSDEHNDVQKKTFTKWINARFSKSGKPPINDMFTDLKDGRKLLDLLEGLTGTSLPKERGSTRVHALNNVNRVLQVLHQNNVELVNIGGTDIVDGNHKLTLGLLWSIILHWQVKDVMKDVMSDLQQTNSEKILLSWVRQTTRPYSQVNVLNFTTSWTDGLAFNAVLHRHKPDLFSWDKVVKMSPIERLEHAFSKAQTYLGIEKLLDPEDVAVQLPDKKSIIMYLTSLFEVLPQQVTIDAIREVETLPRKYKKECEEEAINIQSTAPEEEHESPRAETPSTVTEVDMDLDSYQIALEEVLTWLLSAEDTFQEQDDISDDVEEVKDQFATHEAFMMELTAHQSSVGSVLQAGNQLITQGTLSDEEEFEIQEQMTLLNARWEALRVESMDRQSRLHDVLMELQKKQLQQLSAWLTLTEERIQKMETCPLDDDVKSLQKLLEEHKSLQSDLEAEQVKVNSLTHMVVIVDENSGESATAILEDQLQKLGERWTAVCRWTEERWNRLQEINILWQELLEEQCLLKAWLTEKEEALNKVQTSNFKDQKELSVSVRRLAILKEDMEMKRQTLDQLSEIGQDVGQLLDNSKASKKINSDSEELTQRWDSLVQRLEDSSNQVTQAVAKLGMSQIPQKDLLETVRVREQAITKKSKQELPPPPPPKKRQIHVDIEAKKKFDAISAELLNWILKWKTAIQTTEIKEYMKMQDTSEMKKKLKALEKEQRERIPRADELNQTGQILVEQMGKEGLPTEEIKNVLEKVSSEWKNVSQHLEDLERKIQLQEDINAYFKQLDELEKVIKTKEEWVKHTSISESSRQSLPSLKDSCQRELTNLLGLHPKIEMARASCSALMSQPSAPDFVQRGFDSFLGRYQAVQEAVEDRQQHLENELKGQPGHAYLETLKTLKDVLNDSENKAQVSLNVLNDLAKVEKALQEKKTLDEILENQKPALHKLAEETKALEKNVHPDVEKLYKQEFDDVQGKWNKLKVLVSKDLHLLEEIALTLRAFEADSTVIEKWMDGVKDFLMKQQAAQGDDAGLQRQLDQCSAFVNEIETIESSLKNMKEIETNLRSGPVAGIKTWVQTRLGDYQTQLEKLSKEIATQKSRLSESQEKAANLKKDLAEMQEWMTQAEEEYLERDFEYKSPEELESAVEEMKRAKEDVLQKEVRVKILKDNIKLLAAKVPSGGQELTSELNVVLENYQLLCNRIRGKCHTLEEVWSCWIELLHYLDLETTWLNTLEERMKSTEVLPEKTDAVNEALESLESVLRHPADNRTQIRELGQTLIDGGILDDIISEKLEAFNSRYEDLSHLAESKQISLEKQLQVLRETDQMLQVLQESLGELDKQLTTYLTDRIDAFQVPQEAQKIQAEISAHELTLEELRRNMRSQPLTSPESRTARGGSQMDVLQRKLREVSTKFQLFQKPANFEQRMLDCKRVLDGVKAELHVLDVKDVDPDVIQTHLDKCMKLYKTLSEVKLEVETVIKTGRHIVQKQQTDNPKGMDEQLTSLKVLYNDLGAQVTEGKQDLERASQLARKMKKEAASLSEWLSATETELVQKSTSEGLLGDLDTEISWAKNVLKDLEKRKADLNTITESSAALQNLIEGSEPILEERLCVLNAGWSRVRTWTEDWCNTLMNHQNQLEIFDGNVAHISTWLYQAEALLDEIEKKPTSKQEEIVKRLVSELDDANLQVENVRDQALILMNARGSSSRELVEPKLAELNRNFEKVSQHIKSAKLLIAQEPLYQCLVTTETFETGVPFSDLEKLENDIENMLKFVEKHLESSDEDEKMDEESAQIEEVLQRGEEMLHQPMEDNKKEKIRLQLLLLHTRYNKIKAIPIQQRKMGQLASGIRSSLLPTDYLVEINKILLCMDDVELSLNVPELNTAIYEDFSFQEDSLKNIKDQLDKLGEQIAVIHEKQPDVILEASGPEAIQIRDTLTQLNAKWDRINRMYSDRKGCFDRAMEEWRQFHCDLNDLTQWITEAEELLVDTCAPGGSLDLEKARIHQQELEVGISSHQPSFAALNRTGDGIVQKLSQADGSFLKEKLAGLNQRWDAIVAEVKDRQPRLKGESKQVMKYRHQLDEIICWLTKAEHAMQKRSTTELGENLQELRDLTQEMEVHAEKLKWLNRTELEMLSDKSLSLPERDKISESLRTVNMTWNKICREVPTTLKECIQEPSSVSQTRIAAHPNVQKVVLVSSASDIPVQSHRTSEISIPADLDKTITELADWLVLIDQMLKSNIVTVGDVEEINKTVSRMKITKADLEQRHPQLDYVFTLAQNLKNKASSSDMRTAITEKLERVKNQWDGTQHGVELRQQQLEDMIIDSLQWDDHREETEELMRKYEARLYILQQARRDPLTKQISDNQILLQELGPGDGIVMAFDNVLQKLLEEYGSDDTRNVKETTEYLKTSWINLKQSIADRQNALEAEWRTVQASRRDLENFLKWIQEAETTVNVLVDASHRENALQDSILARELKQQMQDIQAEIDAHNDIFKSIDGNRQKMVKALGNSEEATMLQHRLDDMNQRWNDLKAKSASIRAHLEASAEKWNRLLMSLEELIKWLNMKDEELKKQMPIGGDVPALQLQYDHCKALRRELKEKEYSVLNAVDQARVFLADQPIEAPEEPRRNLQSKTELTPEERAQKIAKAMRKQSSEVKEKWESLNAVTSNWQKQVDKALEKLRDLQGAMDDLDADMKEAESVRNGWKPVGDLLIDSLQDHIEKIMAFREEIAPINFKVKTVNDLSSQLSPLDLHPSLKMSRQLDDLNMRWKLLQVSVDDRLKQLQEAHRDFGPSSQHFLSTSVQLPWQRSISHNKVPYYINHQTQTTCWDHPKMTELFQSLADLNNVRFSAYRTAIKIRRLQKALCLDLLELSTTNEIFKQHKLNQNDQLLSVPDVINCLTTTYDGLEQMHKDLVNVPLCVDMCLNWLLNVYDTGRTGKIRVQSLKIGLMSLSKGLLEEKYRYLFKEVAGPTEMCDQRQLGLLLHDAIQIPRQLGEVAAFGGSNIEPSVRSCFQQNNNKPEISVKEFIDWMHLEPQSMVWLPVLHRVAAAETAKHQAKCNICKECPIVGFRYRSLKHFNYDVCQSCFFSGRTAKGHKLHYPMVEYCIPTTSGEDVRDFTKVLKNKFRSKKYFAKHPRLGYLPVQTVLEGDNLETPITLISMWPEHYDPSQSPQLFHDDTHSRIEQYATRLAQMERTNGSFLTDSSSTTGSVEDEHALIQQYCQTLGGESPVSQPQSPAQILKSVEREERGELERIIADLEEEQRNLQVEYEQLKDQHLRRGLPVGSPPESIISPHHTSEDSELIAEAKLLRQHKGRLEARMQILEDHNKQLESQLHRLRQLLEQPESDSRINGVSPWASPQHSALSYSLDPDASGPQFHQAAGEDLLAPPHDTSTDLTEVMEQIHSTFPSCCPNVPSRPQAM>sp|P46939-2|UTRN_HUMAN Isoform 2 of Utrophin OS=Homo sapiens OX=9606GN=UTRNMSGLAATTFHWKKCRLDLPGHVALQACKSRSDEHNDVQKKTFTKWINARFSKSGKPPINDMFTDLKDGRKLLDLLEGLTGTSLPKERGSTRVHALNNVNRVLQVLHQNNVELVNIGGTDIVDGNHKLTLGLLWSIILHWQVKDVMKDVMSDLQQTNSEKILLSWVRQTTRPYSQVNVLNFTTSWTDGLAFNAVLHRHKPDLFSWDKVVKMSPIERLEHAFSKAQTYLGIEKLLDPEDVAVQLPDKKSIIMYLTSLFEVLPQQVTIDAIREVETLPRKYKKECEEEAINIQSTAPEEEHESPRAETPSTVTEVDMDLDSYQIALEEVLTWLLSAEDTFQEQDDISDDVEEVKDQFATHEAFMMELTAHQSSVGSVLQAGNQLITQGTLSDEEEFEIQEQMTLLNARWEALRVESMDRQSRLHDVLMELQKKQLQQLSAWLTLTEERIQKMETCPLDDDVKSLQKLLEEHKSLQSDLEAEQVKVNSLTHMVVIVDENSGESATAILEDQLQKLGERWTAVCRWTEERWNRLQEINILWQELLEEQCLLKAWLTEKEEALNKVQTSNFKDQKELSVSVRRLAILKEDMEMKRQTLDQLSEIGQDVGQLLDNSKASKKINSDSEELTQRWDSLVQRLEDSSNQVTQAVAKLGMSQIPQKDLLETVRVREQAITKKSKQELPPPPPPKKRQIHVDIEAKKKFDAISAELLNWILKWKTAIQTTEIKEYMKMQDTSEMKKKLKALEKEQRERIPRADELNQTGQILVEQMGKEGLPTEEIKNVLEKVSSEWKNVSQHLEDLERKIQLQEDINAYFKQLDELEKVIKTKEEWVKHTSISESSRQSLPSLKDSCQRELTNLLGLHPKIEMARASCSALMSQPSAPDFVQRGFDSFLGRYQAVQEAVEDRQQHLENELKGQPGHAYLETLKTLKDVLNDSENKAQVSLNVLNDLAKVEKALQEKKTLDEILENQKPALHKLAEETKALEKNVHPDVEKLYKQEFDDVQGKWNKLKVLVSKDLHLLEEIALTLRAFEADSTVIEKWMDGVKDFLMKQQAAQGDDAGLQRQLDQCSAFVNEIETIESSLKNMKEIETNLRSGPVAGIKTWVQTRLGDYQTQLEKLSKEIATQKSRLSESQEKAANLKKDLAEMQEWMTQAEEEYLERDFEYKSPEELESAVEEMKRAKEDVLQKEVRVKILKDNIKLLAAKVPSGGQELTSELNVVLENYQLLCNRIRGKCHTLEEVWSCWIELLHYLDLETTWLNTLEERMKSTEVLPEKTDAVNEALESLESVLRHPADNRTQIRELGQTLIDGGILDDIISEKLEAFNSRYEDLSHLAESKQISLEKQLQVLRETDQMLQVLQESLGELDKQLTTYLTDRIDAFQVPQEAQKIQAEISAHELTLEELRRNMRSQPLTSPESRTARGGSQMDVLQRKLREVSTKFQLFQKPANFEQRMLDCKRVLDGVKAELHVLDVKDVDPDVIQTHLDKCMKLYKTLSEVKLEVETVIKTGRHIVQKQQTDNPKGMDEQLTSLKVLYNDLGAQVTEGKQDLERASQLARKMKKEAASLSEWLSATETELVQKSTSEGLLGDLDTEISWAKNVLKDLEKRKADLNTITESSAALQNLIEGSEPILEERLCVLNAGWSRVRTWTEDWCNTLMNHQNQLEIFDGNVAHISTWLYQAEALLDEIEKKPTSKQEEIVKRLVSELDDANLQVENVRDQALILMNARGSSSRELVEPKLAELNRNFEKVSQHIKSAKLLIAQEPLYQCLVTTETFETGVPFSDLEKLENDIENMLKFVEKHLESSDEDEKMDEESAQIEEVLQRGEEMLHQPMEDNKKEKIRLQLLLLHTRYNKIKAIPIQQRKMGQLASGIRSSLLPTDYLVEINKILLCMDDVELSLNVPELNTAIYEDFSFQEDSLKNIKDQLDKLGEQIAVIHEKQPDVILEASGPEAIQIRDTLTQLNAKWDRINRMYSDRKGCFDRAMEEWRQFHCDLNDLTQWITEAEELLVDTCAPGGSLDLEKARIHQQELEVGISSHQPSFAALNRTGDGIVQKLSQADGSFLKEKLAGLNQRWDAIVAEVKDRQPRLKGESKQVMKYRHQLDEIICWLTKAEHAMQKRSTTELGENLQELRDLTQEMEVHAEKLKWLNRTELEMLSDKSLSLPERDKISESLRTVNMTWNKICREVPTTLKECIQEPSSVSQTRIAAHPNVQKVVLVSSASDIPVQSHRTSEISIPADLDKTITELADWLVLIDQMLKSNIVTVGDVEEINKTVSRMKITKADLEQRHPQLDYVFTLAQNLKNKASSSDMRTAITEKLERVKNQWDGTQHGVELRQQQLEDMIIDSLQWDDHREETEELMRKYEARLYILQQARRDPLTKQISDNQILLQELGPGDGIVMAFDNVLQKLLEEYGSDDTRNVKETTEYLKTSWINLKQSIADRQNALEAEWRTVQASRRDLENFLKWIQEAETTVNVLVDASHRENALQDSILARELKQQMQDIQAEIDAHNDIFKSIDGNRQKMVKALGNSEEATMLQHRLDDMNQRWNDLKAKSASIRAHLEASAEKWNRLLMSLEELIKWLNMKDEELKKQMPIGGDVPALQLQYDHCKALRRELKEKEYSVLNAVDQARVFLADQPIEAPEEPRRNLQSKTELTPEERAQKIAKAMRKQSSEVKEKWESLNAVTSNWQKQVDKALEKLRDLQGAMDDLDADMKEAESVRNGWKPVGDLLIDSLQDHIEKIMAFREEIAPINFKVKTVNDLSSQLSPLDLHPSLKMSRQLDDLNMRWKLLQVSVDDRLKQLQEAHRDFGPSSQHFLSTSVQLPWQRSISHNKVPYYINHQTQTTCWDHPKMTELFQSLADLNNVRFSAYRTAIKIRRLQKALCLDLLELSTTNEIFKQHKLNQNDQLLSVPDVINCLTTTYDGLEQMHKDLVNVPLCVDMCLNWLLNVYDTGRTGKIRVQSLKIGLMSLSKGLLEEKYRYLFKEVAGPTEMCDQRQLGLLLHDAIQIPRQLGEVAAFGGSNIEPSVRSCFQQNNNKPEISVKEFIDWMHLEPQSMVWLPVLHRVAAAETAKHQAKCNICKECPIVGFRYRSLKHFNYDVCQSCFFSGRTAKGHKLHYPMVEYCIPTTSGEDVRDFTKVLKNKFRSKKYFAKHPRLGYLPVQTVLEGDNLETPITLISMWPEHYDPSQSPQLFHDDTHSRIEQYATRLAQMERTNGSFLTDSSSTTGSVEDEHALIQQYCQTLGGESPVSQPQSPAQILKSVEREERGELERIIADLEEEQRNLQVEYEQLKDQHLRRGLPVGSPPESIISPHHTSEDSELIAEAKLLRQHKGRLEARMQILEDHNKQLESQLHRLRQLLEQPESDSRINGVSPWASPQHSALSYSLDPDASGPQFHQAAGEDLLAPPHDTSTDLTEVMEQIHSTFPSCCPNVPSRPQAM>sp|P46939-3|UTRN_HUMAN Isoform Up71 of Utrophin OS=Homo sapiens OX=9606GN=UTRNMKFFDFLFIFKILPPYYINFFSSHQTQTTCWDHPKMTELFQSLADLNNVRFSAYRTAIKIRRLQKALCLDLLELSTTNEIFKQHKLNQNDQLLSVPDVINCLTTTYDGLEQMHKDLVNVPLCVDMCLNWLLNVYDTGRTGKIRVQSLKIGLMSLSKGLLEEKYRYLFKEVAGPTEMCDQRQLGLLLHDAIQIPRQLGEVAAFGGSNIEPSVRSCFQQNNNKPEISVKEFIDWMHLEPQSMVWLPVLHRVAAAETAKHQAKCNICKECPIVGFRYRSLKHFNYDVCQSCFFSGRTAKGHKLHYPMVEYCIPTTSGEDVRDFTKVLKNKFRSKKYFAKHPRLGYLPVQTVLEGDNLETPITLISMWPEHYDPSQSPQLFHDDTHSRIEQYATRLAQMERTNGSFLTDSSSTTGSVEDEHALIQQYCQTLGGESPVSQPQSPAQILKSVEREERGELERIIADLEEEQRNLQVEYEQLKDQHLRRGLPVGSPPESIISPHHTSEDSELIAEAKLLRQHKGRLEARMQILEDHNKQLESQLHRLRQLLEQPESDSRINGVSPWASPQHSALSYSLDPDASGPQFHQAAGEDLLAPPHDTSTDLTEVMEQIHSTFPSCCPNVPSRPQAM>sp|P46939-4|UTRN_HUMAN Isoform Up140 of Utrophin OS=Homo sapiens OX=9606GN=UTRNMKYRHQLDEIICWLTKAEHAMQKRSTTELGENLQELRDLTQEMEVHAEKLKWLNRTELEMLSDKSLSLPERDKISESLRTVNMTWNKICREVPTTLKECIQEPSSVSQTRIAAHPNVQKVVLVSSASDIPVQSHRTSEISIPADLDKTITELADWLVLIDQMLKSNIVTVGDVEEINKTVSRMKITKADLEQRHPQLDYVFTLAQNLKNKASSSDMRTAITEKLERVKNQWDGTQHGVELRQQQLEDMIIDSLQWDDHREETEELMRKYEARLYILQQARRDPLTKQISDNQILLQELGPGDGIVMAFDNVLQKLLEEYGSDDTRNVKETTEYLKTSWINLKQSIADRQNALEAEWRTVQASRRDLENFLKWIQEAETTVNVLVDASHRENALQDSILARELKQQMQDIQAEIDAHNDIFKSIDGNRQKMVKALGNSEEATMLQHRLDDMNQRWNDLKAKSASIRAHLEASAEKWNRLLMSLEELIKWLNMKDEELKKQMPIGGDVPALQLQYDHCKALRRELKEKEYSVLNAVDQARVFLADQPIEAPEEPRRNLQSKTELTPEERAQKIAKAMRKQSSEVKEKWESLNAVTSNWQKQVDKALEKLRDLQGAMDDLDADMKEAESVRNGWKPVGDLLIDSLQDHIEKIMAFREEIAPINFKVKTVNDLSSQLSPLDLHPSLKMSRQLDDLNMRWKLLQVSVDDRLKQLQEAHRDFGPSSQHFLSTSVQLPWQRSISHNKVPYYINHQTQTTCWDHPKMTELFQSLADLNNVRFSAYRTAIKIRRLQKALCLDLLELSTTNEIFKQHKLNQNDQLLSVPDVINCLTTTYDGLEQMHKDLVNVPLCVDMCLNWLLNVYDTGRTGKIRVQSLKIGLMSLSKGLLEEKYRYLFKEVAGPTEMCDQRQLGLLLHDAIQIPRQLGEVAAFGGSNIEPSVRSCFQQNNNKPEISVKEFIDWMHLEPQSMVWLPVLHRVAAAETAKHQAKCNICKECPIVGFRYRSLKHFNYDVCQSCFFSGRTAKGHKLHYPMVEYCIPTTSGEDVRDFTKVLKNKFRSKKYFAKHPRLGYLPVQTVLEGDNLETPITLISMWPEHYDPSQSPQLFHDDTHSRIEQYATRLAQMERTNGSFLTDSSSTTGSVEDEHALIQQYCQTLGGESPVSQPQSPAQILKSVEREERGELERIIADLEEEQRNLQVEYEQLKDQHLRRGLPVGSPPESIISPHHTSEDSELIAEAKLLRQHKGRLEARMQILEDHNKQLESQLHRLRQLLEQPESDSRINGVSPWASPQHSALSYSLDPDASGPQFHQAAGEDLLAPPHDTSTDLTEVMEQIHSTFPSCCPNVPSRPQAM>sp|Q96BW1|UPP_HUMAN Uracil phosphoribosyltransferase homolog OS=Homosapiens OX=9606 GN=UPRT PE=1 SV=1MATELQCPDSMPCHNQQVNSASTPSPEQLRPGDLILDHAGGNRASRAKVILLTGYAHSSLPAELDSGACGGSSLNSEGNSGSGDSSSYDAPAGNSFLEDCELSRQIGAQLKLLPMNDQIRELQTIIRDKTASRGDFMFSADRLIRLVVEEGLNQLPYKECMVTTPTGYKYEGVKFEKGNCGVSIMRSGEAMEQGLRDCCRSIRIGKILIQSDEETQRAKVYYAKFPPDIYRRKVLLMYPILSTGNTVIEAVKVLIEHGVQPSVIILLSLFSTPHGAKSIIQEFPEITILTTEVHPVAPTHFGQKYFGTD>sp|Q96BW1-2|UPP_HUMAN Isoform 2 of Uracil phosphoribosyltransferasehomolog OS=Homo sapiens OX=9606 GN=UPRTMATELQCPDSMPCHNQQVNSASTPSPEQLRPGDLILDHAGGNRASRAKVILLTGYAHSSLPAELDSGACGGSSLNSEGNSGSGDSSSYDAPAGNSFLEDCELSRQIGAQLKLLPMNDQIRELQTIIRDKTASRGDFMFSADRLVLPEDLFQKSIDNSCSAFHHQTCCGRGIESAAI>sp|Q96BW1-3|UPP_HUMAN Isoform 3 of Uracil phosphoribosyltransferasehomolog OS=Homo sapiens OX=9606 GN=UPRTMNDQIRELQTIIRDKTASRGDFMFSADRLIRLVVEEGLNQLPYKECMVTTPTGYKYEGVKFEKGNCGVSIMRSGEAMEQGLRDCCRSIRIGKILIQSDEETQRAKVYYAKFPPDIYRRKVLLMYPILSTGNTVIEAVKVLIEHGVQPSVIILLSLFSTPHGEFSMRQ>sp|Q765I0|UTS2B_HUMAN Urotensin-2B OS=Homo sapiens OX=9606 GN=UTS2B PE=3SV=2MNKILSSTVCFGLLTLLSVLSFLQSVHGRPYLTQGNEIFPDKKYTNREELLLALLNKNFDFQRPFNTDLALPNKLEELNQLEKLKEQLVEEKDSETSYAVDGLFSSHPSKRACFWKYCV>sp|P19320|VCAM1_HUMAN Vascular cell adhesion protein 1 OS=Homo sapiensOX=9606 GN=VCAM1 PE=1 SV=1MPGKMVVILGASNILWIMFAASQAFKIETTPESRYLAQIGDSVSLTCSTTGCESPFFSWRTQIDSPLNGKVTNEGTTSTLTMNPVSFGNEHSYLCTATCESRKLEKGIQVEIYSFPKDPEIHLSGPLEAGKPITVKCSVADVYPFDRLEIDLLKGDHLMKSQEFLEDADRKSLETKSLEVTFTPVIEDIGKVLVCRAKLHIDEMDSVPTVRQAVKELQVYISPKNTVISVNPSTKLQEGGSVTMTCSSEGLPAPEIFWSKKLDNGNLQHLSGNATLTLIAMRMEDSGIYVCEGVNLIGKNRKEVELIVQEKPFTVEISPGPRIAAQIGDSVMLTCSVMGCESPSFSWRTQIDSPLSGKVRSEGTNSTLTLSPVSFENEHSYLCTVTCGHKKLEKGIQVELYSFPRDPEIEMSGGLVNGSSVTVSCKVPSVYPLDRLEIELLKGETILENIEFLEDTDMKSLENKSLEMTFIPTIEDTGKALVCQAKLHIDDMEFEPKQRQSTQTLYVNVAPRDTTVLVSPSSILEEGSSVNMTCLSQGFPAPKILWSRQLPNGELQPLSENATLTLISTKMEDSGVYLCEGINQAGRSRKEVELIIQVTPKDIKLTAFPSESVKEGDTVIISCTCGNVPETWIILKKKAETGDTVLKSIDGAYTIRKAQLKDAGVYECESKNKVGSQLRSLTLDVQGRENNKDYFSPELLVLYFASSLIIPAIGMIIYFARKANMKGSYSLVEAQKSKV>sp|P19320-2|VCAM1_HUMAN Isoform 2 of Vascular cell adhesion protein 1OS=Homo sapiens OX=9606 GN=VCAM1MPGKMVVILGASNILWIMFAASQAFKIETTPESRYLAQIGDSVSLTCSTTGCESPFFSWRTQIDSPLNGKVTNEGTTSTLTMNPVSFGNEHSYLCTATCESRKLEKGIQVEIYSFPKDPEIHLSGPLEAGKPITVKCSVADVYPFDRLEIDLLKGDHLMKSQEFLEDADRKSLETKSLEVTFTPVIEDIGKVLVCRAKLHIDEMDSVPTVRQAVKELQVYISPKNTVISVNPSTKLQEGGSVTMTCSSEGLPAPEIFWSKKLDNGNLQHLSGNATLTLIAMRMEDSGIYVCEGVNLIGKNRKEVELIVQAFPRDPEIEMSGGLVNGSSVTVSCKVPSVYPLDRLEIELLKGETILENIEFLEDTDMKSLENKSLEMTFIPTIEDTGKALVCQAKLHIDDMEFEPKQRQSTQTLYVNVAPRDTTVLVSPSSILEEGSSVNMTCLSQGFPAPKILWSRQLPNGELQPLSENATLTLISTKMEDSGVYLCEGINQAGRSRKEVELIIQVTPKDIKLTAFPSESVKEGDTVIISCTCGNVPETWIILKKKAETGDTVLKSIDGAYTIRKAQLKDAGVYECESKNKVGSQLRSLTLDVQGRENNKDYFSPELLVLYFASSLIIPAIGMIIYFARKANMKGSYSLVEAQKSKV>sp|P19320-3|VCAM1_HUMAN Isoform 3 of Vascular cell adhesion protein 1OS=Homo sapiens OX=9606 GN=VCAM1MPGKMVVILGASNILWIMFAASQAFKIETTPESRYLAQIGDSVSLTCSTTGSFPKDPEIHLSGPLEAGKPITVKCSVADVYPFDRLEIDLLKGDHLMKSQEFLEDADRKSLETKSLEVTFTPVIEDIGKVLVCRAKLHIDEMDSVPTVRQAVKELQVYISPKNTVISVNPSTKLQEGGSVTMTCSSEGLPAPEIFWSKKLDNGNLQHLSGNATLTLIAMRMEDSGIYVCEGVNLIGKNRKEVELIVQEKPFTVEISPGPRIAAQIGDSVMLTCSVMGCESPSFSWRTQIDSPLSGKVRSEGTNSTLTLSPVSFENEHSYLCTVTCGHKKLEKGIQVELYSFPRDPEIEMSGGLVNGSSVTVSCKVPSVYPLDRLEIELLKGETILENIEFLEDTDMKSLENKSLEMTFIPTIEDTGKALVCQAKLHIDDMEFEPKQRQSTQTLYVNVAPRDTTVLVSPSSILEEGSSVNMTCLSQGFPAPKILWSRQLPNGELQPLSENATLTLISTKMEDSGVYLCEGINQAGRSRKEVELIIQVTPKDIKLTAFPSESVKEGDTVIISCTCGNVPETWIILKKKAETGDTVLKSIDGAYTIRKAQLKDAGVYECESKNKVGSQLRSLTLDVQGRENNKDYFSPELLVLYFASSLIIPAIGMIIYFARKANMKGSYSLVEAQKSKV>sp|O95399|UTS2_HUMAN Urotensin-2 OS=Homo sapiens OX=9606 GN=UTS2 PE=1SV=1MYKLASCCLLFIGFLNPLLSLPLLDSREISFQLSAPHEDARLTPEELERASLLQILPEMLGAERGDILRKADSSTNIFNPRGNLRKFQDFSGQDPNILLSHLLARIWKPYKKRETPDCFWKYCV>sp|O95399-2|UTS2_HUMAN Isoform 2 of Urotensin-2 OS=Homo sapiens OX=9606GN=UTS2METNVFHLMLCVTSARTHKSTSLCFGHFNSYPSLPLIHDLLLEISFQLSAPHEDARLTPEELERASLLQILPEMLGAERGDILRKADSSTNIFNPRGNLRKFQDFSGQDPNILLSHLLARIWKPYKKRETPDCFWKYCV>sp|Q8WWU5|TCP11_HUMAN T-complex protein 11 homolog OS=Homo sapiensOX=9606 GN=TCP11 PE=1 SV=1MPDVKESVPPKYPGDSEGRSCKPETSGPPQEDKSGSEDPPPFLSVTGLTETVNEVSKLSNKIGMNCDYYMEEKVLPPSSLEGKVKETVHNAFWDHLKEQLSATPPDFSCALELLKEIKEILLSLLLPRQNRLRIEIEEALDMDLLKQEAEHGALKVLYLSKYVLNMMALLCAPVRDEAVQKLENITDPVWLLRGIFQVLGRMKMDMVNYTIQSLQPHLQEHSIQYERAKFQELLNKQPSLLNHTTKWLTQAAGDLTMSPPTCPDTSDSSSVAGPSPNEAANNPEPLSPTMVLCQGFLNLLLWDLENEEFPETLLMDRTRLQELKSQLHQLTVMASVLLVASSFSGSVLFGSPQFVDKLKRITKSLLEDFHSRPEEAILTVSEQVSQEIHQSLKNMGLVALSSDNTASLMGQLQNIAKKENCVCSVIDQRIHLFLKCCLVLGVQRSLLDLPGGLTLIEAELAELGQKFVNLTHHNQQVFGPYYTEILKTLISPAQALETKVESV>sp|Q8WWU5-2|TCP11_HUMAN Isoform 2 of T-complex protein 11 homologOS=Homo sapiens OX=9606 GN=TCP11MAPKGILGSFPTAMNLSLEGKVKETVHNAFWDHLKEQLSATPPDFSCALELLKEIKEILLSLLLPRQNRLRIEIEEALDMDLLKQEAEHGALKVLYLSKYVLNMMALLCAPVRDEAVQKLENITDPVWLLRGIFQVLGRMKMDMVNYTIQSLQPHLQEHSIQYERAKFQELLNKQPSLLNHTTKWLTQAAGDLTMSPPTCPDTSDSSSVAGPSPNEAANNPEPLSPTMVLCQGFLNLLLWDLENEEFPETLLMDRTRLQELKSQLHQLTVMASVLLVASSFSGSVLFGSPQFVDKLKRITKSLLEDFHSRPEEAILTVSEQVSQEIHQSLKNMGLVALSSDNTASLMGQLQNIAKKENCVCSVIDQRIHLFLKCCLVLGVQRSLLDLPGGLTLIEAELAELGQKFVNLTHHNQQVFGPYYTEILKTLISPAQALETKVESV>sp|Q8WWU5-3|TCP11_HUMAN Isoform 3 of T-complex protein 11 homologOS=Homo sapiens OX=9606 GN=TCP11MNCDYYMEEKVLPPSSLEGKVKETVHNAFWDHLKEQLSATPPDFSCALELLKEIKEILLSLLLPRQNRLRIEIEEALDMDLLKQEAEHGALKVLYLSKYVLNMMALLCAPVRDEAVQKLENITDPVWLLRGIFQVLGRMKMDMVNYTIQSLQPHLQEHSIQYERAKFQELLNKQPSLLNHTTKWLTQAAGDLTMSPPTCPDTSDSSSVAGPSPNEAANNPEPLSPTMVLCQGFLNLLLWDLENEEFPETLLMDRTRLQELKSQLHQLTVMASVLLVASSFSGSVLFGSPQFVDKLKRITKSLLEDFHSRPEEAILTVSEQVSQEIHQSLKNMGLVALSSDNTASLMGQLQNIAKKENCVCSVIDQRIHLFLKCCLVLGVQRSLLDLPGGLTLIEAELAELGQKFVNLTHHNQQVFGPYYTEILKTLISPAQALETKVESV>sp|Q8WWU5-4|TCP11_HUMAN Isoform 4 of T-complex protein 11 homologOS=Homo sapiens OX=9606 GN=TCP11MTRGGGGGVLSVTGLTETVNEVSKLSNKIGMNCDYYMEEKVLPPSSLEGKVKETVHNAFWDHLKEQLSATPPDFSCALELLKEIKEILLSLLLPRQNRLRIEIEEALDMDLLKQEAEHGALKVLYLSKYVLNMMALLCAPVRDEAVQKLENITDPVWLLRGIFQVLGRMKMDMVNYTIQSLQPHLQEHSIQYERAKFQELLNKQPSLLNHTTKWLTQAAGDLTMSPPTCPDTSDSSSVAGPSPNEAANNPEPLSPTMVLCQGFLNLLLWDLENEEFPETLLMDRTRLQELKSQLHQLTVMASVLLVASSFSGSVLFGSPQFVDKLKRITKSLLEDFHSRPEEAILTVSEQVSQEIHQSLKNMGLVALSSDNTASLMGQLQNIAKKENCVCSVIDQRIHLFLKCCLVLGVQRSLLDLPGGLTLIEAELAELGQKFVNLTHHNQQVFGPYYTEILKTLISPAQALETKVESV>sp|Q8WWU5-5|TCP11_HUMAN Isoform 5 of T-complex protein 11 homologOS=Homo sapiens OX=9606 GN=TCP11MTRGGGGGDTISKMPDVKESVPPKYPGDSEGRSCKPETSGPPQEDKSGSEDPPPCLTETVNEVSKLSNKIGMNCDYYMEEKVLPPSSLEGKVKETVHNAFWDHLKEQLSATPPDFSCALELLKEIKEILLSLLLPRQNRLRIEIEEALDMDLLKQEAEHGALKVLYLSKYVLNMMALLCAPVRDEAVQKLENITDPVWLLRGIFQVLGRMKMDMVNYTIQSLQPHLQEHSIQYERAKFQELLNKQPSLLNHTTKWLTQAAGDLTMSPPTCPDTSDSSSVAGPSPNEAANNPEPLSPTMVLCQGFLNLLLWDLENEEFPETLLMDRTRLQELKSQLHQLTVMASVLLVASSFSGSVLFGSPQFVDKLKRITKSLLEDFHSRPEEAILTVSEQVSQEIHQSLKNMGLVALSSDNTASLMGQLQNIAKKENCVCSVIDQRIHLFLKCCLVLGVQRSLLDLPGGLTLIEAELAELGQKFVNLTHHNQQVFGPYYTEILKTLISPAQALETKVESV>sp|Q8WWU5-6|TCP11_HUMAN Isoform 6 of T-complex protein 11 homologOS=Homo sapiens OX=9606 GN=TCP11MTRGGGGGGLTETVNEVSKLSNKIGMNCDYYMEEKVLPPSSLEGKVKETVHNAFWDHLKEQLSATPPDFSCALELLKEIKEILLSLLLPRQNRLRIEIEEALDMDLLKQEAEHGALKVLYLSKYVLNMMALLCAPVRDEAVQKLENITDPVWLLRGIFQVLGRMKMDMVNYTIQSLQPHLQEHSIQYERAKFQELLNKQPSLLNHTTKWLTQAAGDLTMSPPTCPDTSDSSSVAGPSPNEAANNPEPLSPTMVLCQGFLNLLLWDLENEEFPETLLMDRTRLQELKSQLHQLTVMASVLLVASSFSGSVLFGSPQFVDKLKRITKSLLEDFHSRPEEAILTVSEQVSQEIHQSLKNMGLVALSSDNTASLMGQLQNIAKKENCVCSVIDQRIHLFLKCCLVLGVQRSLLDLPGGLTLIEAELAELGQKFVNLTHHNQQVFGPYYTEILKTLISPAQALETKVESV>sp|Q8WWU5-7|TCP11_HUMAN Isoform 7 of T-complex protein 11 homologOS=Homo sapiens OX=9606 GN=TCP11MTRGGGGGDTISKMPDVKESVPPKYPGDSEGRSCKPETSGPPQEDKSGSEDPPPFLSVTGLTETVNEVSKLSNKIGMNCDYYMEEKVLPPSSLEGKVKETVHNAFWDHLKEQLSATPPDFSCALELLKEIKEILLSLLLPRQNRLRIEIEEALDMDLLKQEAEHGALKVLYLSKYVLNMMALLCAPVRDEAVQKLENITDPVWLLRGIFQVLGRMKMDMVNYTIQSLQPHLQEHSIQYERAKFQELLNKQPSLLNHTTKWLTQAAGDLTMSPPTCPDTSDSSSVAGPSPNEAANNPEPLSPTMVLCQGFLNLLLWDLENEEFPETLLMDRTRLQELKSQLHQLTVMASVLLVASSFSGSVLFGSPQFVDKLKRITKSLLEDFHSRPEEAILTVSEQVSQEIHQSLKNMGLVALSSDNTASLMGQLQNIAKKENCVCSVIDQRIHLFLKCCLVLGVQRSLLDLPGGLTLIEAELAELGQKFVNLTHHNQQVFGPYYTEILKTLISPAQALETKVESV>sp|Q9BWD1|THIC_HUMAN Acetyl-CoA acetyltransferase, cytosolic OS=Homosapiens OX=9606 GN=ACAT2 PE=1 SV=2MNAGSDPVVIVSAARTIIGSFNGALAAVPVQDLGSTVIKEVLKRATVAPEDVSEVIFGHVLAAGCGQNPVRQASVGAGIPYSVPAWSCQMICGSGLKAVCLAVQSIGIGDSSIVVAGGMENMSKAPHLAYLRTGVKIGEMPLTDSILCDGLTDAFHNCHMGITAENVAKKWQVSREDQDKVAVLSQNRTENAQKAGHFDKEIVPVLVSTRKGLIEVKTDEFPRHGSNIEAMSKLKPYFLTDGTGTVTPANASGINDGAAAVVLMKKSEADKRGLTPLARIVSWSQVGVEPSIMGIGPIPAIKQAVTKAGWSLEDVDIFEINEAFAAVSAAIVKELGLNPEKVNIEGGAIALGHPLGASGCRILVTLLHTLERMGRSRGVAALCIGGGMGIAMCVQRE>sp|Q9BWD1-2|THIC_HUMAN Isoform 2 of Acetyl-CoA acetyltransferase,cytosolic OS=Homo sapiens OX=9606 GN=ACAT2MGSHPVLRIWGNRRATAASLGRSGGRLSSPRLLRVVAPTLTFAQTSRCSFNGALAAVPVQDLGSTVIKEVLKRATVAPEDVSEVIFGHVLAAGCGQNPVRQASVGAGIPYSVPAWSCQMICGSGLKAVCLAVQSIGIGDSSIVVAGGMENMSKAPHLAYLRTGVKIGEMPLTDSILCDGLTDAFHNCHMGITAENVAKKWQVSREDQDKVAVLSQNRTENAQKAGHFDKEIVPVLVSTRKGLIEVKTDEFPRHGSNIEAMSKLKPYFLTDGTGTVTPANASGINDGAAAVVLMKKSEADKRGLTPLARIVSWSQVGVEPSIMGIGPIPAIKQAVTKAGWSLEDVDIFEINEAFAAVSAAIVKELGLNPEKVNIEGGAIALGHPLGASGCRILVTLLHTLERMGRSRGVAALCIGGGMGIAMCVQRE>sp|P21980|TGM2_HUMAN Protein-glutamine gamma-glutamyltransferase 2OS=Homo sapiens OX=9606 GN=TGM2 PE=1 SV=2MAEELVLERCDLELETNGRDHHTADLCREKLVVRRGQPFWLTLHFEGRNYEASVDSLTFSVVTGPAPSQEAGTKARFPLRDAVEEGDWTATVVDQQDCTLSLQLTTPANAPIGLYRLSLEASTGYQGSSFVLGHFILLFNAWCPADAVYLDSEEERQEYVLTQQGFIYQGSAKFIKNIPWNFGQFEDGILDICLILLDVNPKFLKNAGRDCSRRSSPVYVGRVVSGMVNCNDDQGVLLGRWDNNYGDGVSPMSWIGSVDILRRWKNHGCQRVKYGQCWVFAAVACTVLRCLGIPTRVVTNYNSAHDQNSNLLIEYFRNEFGEIQGDKSEMIWNFHCWVESWMTRPDLQPGYEGWQALDPTPQEKSEGTYCCGPVPVRAIKEGDLSTKYDAPFVFAEVNADVVDWIQQDDGSVHKSINRSLIVGLKISTKSVGRDEREDITHTYKYPEGSSEEREAFTRANHLNKLAEKEETGMAMRIRVGQSMNMGSDFDVFAHITNNTAEEYVCRLLLCARTVSYNGILGPECGTKYLLNLNLEPFSEKSVPLCILYEKYRDCLTESNLIKVRALLVEPVINSYLLAERDLYLENPEIKIRILGEPKQKRKLVAEVSLQNPLPVALEGCTFTVEGAGLTEEQKTVEIPDPVEAGEEVKVRMDLLPLHMGLHKLVVNFESDKLKAVKGFRNVIIGPA>sp|P21980-2|TGM2_HUMAN Isoform 2 of Protein-glutamine gamma-glutamyltransferase 2 OS=Homo sapiens OX=9606 GN=TGM2MAEELVLERCDLELETNGRDHHTADLCREKLVVRRGQPFWLTLHFEGRNYEASVDSLTFSVVTGPAPSQEAGTKARFPLRDAVEEGDWTATVVDQQDCTLSLQLTTPANAPIGLYRLSLEASTGYQGSSFVLGHFILLFNAWCPADAVYLDSEEERQEYVLTQQGFIYQGSAKFIKNIPWNFGQFEDGILDICLILLDVNPKFLKNAGRDCSRRSSPVYVGRVVSGMVNCNDDQGVLLGRWDNNYGDGVSPMSWIGSVDILRRWKNHGCQRVKYGQCWVFAAVACTVLRCLGIPTRVVTNYNSAHDQNSNLLIEYFRNEFGEIQGDKSEMIWNFHCWVESWMTRPDLQPGYEGWQALDPTPQEKSEGTYCCGPVPVRAIKEGDLSTKYDAPFVFAEVNADVVDWIQQDDGSVHKSINRSLIVGLKISTKSVGRDEREDITHTYKYPEGSSEEREAFTRANHLNKLAEKEETGMAMRIRVGQSMNMGSDFDVFAHITNNTAEEYVCRLLLCARTVSYNGILGPECGTKYLLNLNLEPFSGKALCSWSIC>sp|P21980-3|TGM2_HUMAN Isoform 3 of Protein-glutamine gamma-glutamyltransferase 2 OS=Homo sapiens OX=9606 GN=TGM2MAEELVLERCDLELETNGRDHHTADLCREKLVVRRGQPFWLTLHFEGRNYEASVDSLTFSVVTGPAPSQEAGTKARFPLRDAVEEGDWTATVVDQQDCTLSLQLTTPANAPIGLYRLSLEASTGYQGSSFVLGHFILLFNAWCPADAVYLDSEEERQEYVLTQQGFIYQGSAKFIKNIPWNFGQFEDGILDICLILLDVNPKFLKNAGRDCSRRSSPVYVGRVVSGMVNCNDDQGVLLGRWDNNYGDGVSPMSWIGSVDILRRWKNHGCQRVKYGQCWVFAAVACTGELHAGMWVMSPGRGHEEHWSRNQDIPALVLPPATNTLNALCGLEPVTTLSGPLSNSHPSSGC>sp|Q6GPH4|XAF1_HUMAN XIAP-associated factor 1 OS=Homo sapiens OX=9606GN=XAF1 PE=1 SV=1MEGDFSVCRNCKRHVVSANFTLHEAYCLRFLVLCPECEEPVPKETMEEHCKLEHQQVGCTMCQQSMQKSSLEFHKANECQERPVECKFCKLDMQLSKLELHESYCGSRTELCQGCGQFIMHRMLAQHRDVCRSEQAQLGKGERISAPEREIYCHYCNQMIPENKYFHHMGKCCPDSEFKKHFPVGNPEILPSSLPSQAAENQTSTMEKDVRPKTRSINRFPLHSESSSKKAPRSKNKTLDPLLMSEPKPRTSSPRGDKAAYDILRRCSQCGILLPLPILNQHQEKCRWLASSKGKQVRNFS>sp|Q6GPH4-2|XAF1_HUMAN Isoform 2 of XIAP-associated factor 1 OS=Homosapiens OX=9606 GN=XAF1MEGDFSVCRNCKRHVVSANFTLHEAYCLRFLVLCPECEEPVPKETMEEHCKLEHQQANECQERPVECKFCKLDMQLSKLELHESYCGSRTELCQGCGQFIMHRMLAQHRDVCRSEQAQLGKGERISAPEREIYCHYCNQMIPENKYFHHMGKCCPDSEFKKHFPVGNPEILPSSLPSQAAENQTSTMEKDVRPKTRSINRFPLHSESSSKKAPRSKNKTLDPLLMSEPKPRTSSPRGDKAAYDILRRCSQCGILLPLPILNQHQEKCRWLASSKGKQVRNFS>sp|Q6GPH4-3|XAF1_HUMAN Isoform 3 of XIAP-associated factor 1 OS=Homosapiens OX=9606 GN=XAF1MEGDFSVCRNCKRHVVSANFTLHEAYCLRFLVLCPECEEPVPKETMEEHCKLEHQQVGCTMCQQSMQKSSLEFHKANECQERPVECKFCKLDMQLSKLELHESYCGSRTELCQGCGQFIMHRMLAQHRDVCRSEQAQLGKG>sp|Q6GPH4-4|XAF1_HUMAN Isoform 4 of XIAP-associated factor 1 OS=Homosapiens OX=9606 GN=XAF1MEGDFSVCRNCKRHVVSANFTLHEAYCLRFLVLCPECEEPVPKETMEEHCKLEHQQANECQERPVECKFCKLDMQLSKLELHESYCGSRTELCQGCGQFIMHRMLAQHRDVCRSEQAQLGKG>sp|Q6GPH4-5|XAF1_HUMAN Isoform 5 of XIAP-associated factor 1 OS=Homosapiens OX=9606 GN=XAF1MEGDFSVCRNCKRHVVSANFTLHEAYCLRFLVLCPECEEPVPKETMEEHCKLEHQQVGCTMCQQSMQKSSLEFHKANECQERPVECKFCKLDMQLSKLELHESYCGSRTELCQGCGQFIMHRMLAQHRDVCRSEQAQLGKETSPDPGKCLSITVAAALSAHLWPFT>sp|Q6GPH4-6|XAF1_HUMAN Isoform 6 of XIAP-associated factor 1 OS=Homosapiens OX=9606 GN=XAF1MSLHYGCCCPECTSVAIKEMMWVIRPRVACVVKDAGSAGERISAPEREIYCHYCNQMIPENKYFHHMGKCCPDSEFKKHFPVGNPEILPSSLPSQAAENQTSTMEKDVRPKTRSINRFPLHSESSSKKAPRSKNKTLDPLLMSEPKPRTSSPRGDKAAYDILRRCSQCGILLPLPILNQHQEKCRWLASSKGKQVRNFS>sp|Q6GPH4-7|XAF1_HUMAN Isoform 7 of XIAP-associated factor 1 OS=Homosapiens OX=9606 GN=XAF1MEGDFSVCRNCKRHVVSANFTLHEAYCLRFLVLCPECEEPVPKETMEEHCKLEHQQGKEFQLLKGKSTVIIATKKANECQERPVECKFCKLDMQLSKLELHESYCGSRTELCQGCGQFIMHRMLAQHRDVCRSEQAQLGKGERISAPEREIYCHYCNQMIPENKYFHHMGKCCPDSEFKKHFPVGNPEILPSSLPSQAAENQTSTMEKDVRPKTRSINRFPLHSESSSKKAPRSKNKTLDPLLMSEPKPRTSSPRGDKAAYDILRRCSQCGILLPLPILNQHQEKCRWLASSKGKQVRNFS>sp|P50991|TCPD_HUMAN T-complex protein 1 subunit delta OS=Homo sapiensOX=9606 GN=CCT4 PE=1 SV=4MPENVAPRSGATAGAAGGRGKGAYQDRDKPAQIRFSNISAAKAVADAIRTSLGPKGMDKMIQDGKGDVTITNDGATILKQMQVLHPAARMLVELSKAQDIEAGDGTTSVVIIAGSLLDSCTKLLQKGIHPTIISESFQKALEKGIEILTDMSRPVELSDRETLLNSATTSLNSKVVSQYSSLLSPMSVNAVMKVIDPATATSVDLRDIKIVKKLGGTIDDCELVEGLVLTQKVSNSGITRVEKAKIGLIQFCLSAPKTDMDNQIVVSDYAQMDRVLREERAYILNLVKQIKKTGCNVLLIQKSILRDALSDLALHFLNKMKIMVIKDIEREDIEFICKTIGTKPVAHIDQFTADMLGSAELAEEVNLNGSGKLLKITGCASPGKTVTIVVRGSNKLVIEEAERSIHDALCVIRCLVKKRALIAGGGAPEIELALRLTEYSRTLSGMESYCVRAFADAMEVIPSTLAENAGLNPISTVTELRNRHAQGEKTAGINVRKGGISNILEELVVQPLLVSVSALTLATETVRSILKIDDVVNTR>sp|P50991-2|TCPD_HUMAN Isoform 2 of T-complex protein 1 subunit deltaOS=Homo sapiens OX=9606 GN=CCT4MPENVAPRSGATAGAAGGRGKGAYQDRDKPAQIRFSNISAAKAVADAIRTSLGPKGMDKMLVELSKAQDIEAGDGTTSVVIIAGSLLDSCTKLLQKGIHPTIISESFQKALEKGIEILTDMSRPVELSDRETLLNSATTSLNSKVVSQYSSLLSPMSVNAVMKVIDPATATSVDLRDIKIVKKLGGTIDDCELVEGLVLTQKVSNSGITRVEKAKIGLIQFCLSAPKTDMDNQIVVSDYAQMDRVLREERAYILNLVKQIKKTGCNVLLIQKSILRDALSDLALHFLNKMKIMVIKDIEREDIEFICKTIGTKPVAHIDQFTADMLGSAELAEEVNLNGSGKLLKITGCASPGKTVTIVVRGSNKLVIEEAERSIHDALCVIRCLVKKRALIAGGGAPEIELALRLTEYSRTLSGMESYCVRAFADAMEVIPSTLAENAGLNPISTVTELRNRHAQGEKTAGINVRKGGISNILEELVVQPLLVSVSALTLATETVRSILKIDDVVNTR>sp|Q6UX27|VSTM1_HUMAN V-set and transmembrane domain-containing protein1 OS=Homo sapiens OX=9606 GN=VSTM1 PE=1 SV=2MTAEFLSLLCLGLCLGYEDEKKNEKPPKPSLHAWPSSVVEAESNVTLKCQAHSQNVTFVLRKVNDSGYKQEQSSAENEAEFPFTDLKPKDAGRYFCAYKTTASHEWSESSEHLQLVVTDKHDELEAPSMKTDTRTIFVAIFSCISILLLFLSVFIIYRCSQHSSSSEESTKRTSHSKLPEQEAAEADLSNMERVSLSTADPQGVTYAELSTSALSEAASDTTQEPPGSHEYAALKV>sp|Q6UX27-2|VSTM1_HUMAN Isoform 2 of V-set and transmembrane domain-containing protein 1 OS=Homo sapiens OX=9606 GN=VSTM1MTAEFLSLLCLGLCLGYEDEKKNEKPPKPSLHAWPSSVVEAESNVTLKCQAHSQNVTFVLRKVNDSGYKQEQSSAENEAEFPFTDLKPKDAGRYFCAYKTTASHEWSESSEHLQLVVTDKHDELEAPSMKTGSSSEESTKRTSHSKLPEQEAAEADLSNMERVSLSTADPQGVTYAELSTSALSEAASDTTQEPPGSHEYAALKV>sp|Q6UX27-3|VSTM1_HUMAN Isoform 3 of V-set and transmembrane domain-containing protein 1 OS=Homo sapiens OX=9606 GN=VSTM1MTAEFLSLLCLGLCLGYEDEKKNEKPPKPSLHAWPSSVVEAESNVTLKCQAHSQNVTFVLRKVNDSGYKQEQSSAENEAEFPFTDLKPKDAGRYFCAYKTTASHEWSESSEHLQLVVTDKHDELEAPSMKTDTRTIFVAIFSCISILLLFLSVFIIYRCSQHSELRERKGREGE>sp|Q8IW00|VSTM4_HUMAN V-set and transmembrane domain-containing protein4 OS=Homo sapiens OX=9606 GN=VSTM4 PE=1 SV=3MRLLALAAAALLARAPAPEVCAALNVTVSPGPVVDYLEGENATLLCHVSQKRRKDSLLAVRWFFAHSFDSQEALMVKMTKLRVVQYYGNFSRSAKRRRLRLLEEQRGALYRLSVLTLQPSDQGHYVCRVQEISRHRNKWTAWSNGSSATEMRVISLKASEESSFEKTKETWAFFEDLYVYAVLVCCVGILSILLFMLVIVWQSVFNKRKSRVRHYLVKCPQNSSGETVTSVTSLAPLQPKKGKRQKEKPDIPPAVPAKAPIAPTFHKPKLLKPQRKVTLPKIAEENLTYAELELIKPHRAAKGAPTSTVYAQILFEENKL>sp|Q8IW00-2|VSTM4_HUMAN Isoform 2 of V-set and transmembrane domain-containing protein 4 OS=Homo sapiens OX=9606 GN=VSTM4MRLLALAAAALLARAPAPEVCAALNVTVSPGPVVDYLEGENATLLCHVSQKRRKDSLLAVRWFFAHSFDSQEALMVKMTKLRVVQYYGNFSRSAKRRRLRLLEEQRGALYRLSVLTLQPSDQGHYVCRVQEISRHRNKWTAWSNGSSATEMRGVSSHPVERGAFLGISLVILPHSLPFTADLTMASFLQSS>sp|Q6N021|TET2_HUMAN Methylcytosine dioxygenase TET2 OS=Homo sapiensOX=9606 GN=TET2 PE=1 SV=3MEQDRTNHVEGNRLSPFLIPSPPICQTEPLATKLQNGSPLPERAHPEVNGDTKWHSFKSYYGIPCMKGSQNSRVSPDFTQESRGYSKCLQNGGIKRTVSEPSLSGLLQIKKLKQDQKANGERRNFGVSQERNPGESSQPNVSDLSDKKESVSSVAQENAVKDFTSFSTHNCSGPENPELQILNEQEGKSANYHDKNIVLLKNKAVLMPNGATVSASSVEHTHGELLEKTLSQYYPDCVSIAVQKTTSHINAINSQATNELSCEITHPSHTSGQINSAQTSNSELPPKPAAVVSEACDADDADNASKLAAMLNTCSFQKPEQLQQQKSVFEICPSPAENNIQGTTKLASGEEFCSGSSSNLQAPGGSSERYLKQNEMNGAYFKQSSVFTKDSFSATTTPPPPSQLLLSPPPPLPQVPQLPSEGKSTLNGGVLEEHHHYPNQSNTTLLREVKIEGKPEAPPSQSPNPSTHVCSPSPMLSERPQNNCVNRNDIQTAGTMTVPLCSEKTRPMSEHLKHNPPIFGSSGELQDNCQQLMRNKEQEILKGRDKEQTRDLVPPTQHYLKPGWIELKAPRFHQAESHLKRNEASLPSILQYQPNLSNQMTSKQYTGNSNMPGGLPRQAYTQKTTQLEHKSQMYQVEMNQGQSQGTVDQHLQFQKPSHQVHFSKTDHLPKAHVQSLCGTRFHFQQRADSQTEKLMSPVLKQHLNQQASETEPFSNSHLLQHKPHKQAAQTQPSQSSHLPQNQQQQQKLQIKNKEEILQTFPHPQSNNDQQREGSFFGQTKVEECFHGENQYSKSSEFETHNVQMGLEEVQNINRRNSPYSQTMKSSACKIQVSCSNNTHLVSENKEQTTHPELFAGNKTQNLHHMQYFPNNVIPKQDLLHRCFQEQEQKSQQASVLQGYKNRNQDMSGQQAAQLAQQRYLIHNHANVFPVPDQGGSHTQTPPQKDTQKHAALRWHLLQKQEQQQTQQPQTESCHSQMHRPIKVEPGCKPHACMHTAPPENKTWKKVTKQENPPASCDNVQQKSIIETMEQHLKQFHAKSLFDHKALTLKSQKQVKVEMSGPVTVLTRQTTAAELDSHTPALEQQTTSSEKTPTKRTAASVLNNFIESPSKLLDTPIKNLLDTPVKTQYDFPSCRCVEQIIEKDEGPFYTHLGAGPNVAAIREIMEERFGQKGKAIRIERVIYTGKEGKSSQGCPIAKWVVRRSSSEEKLLCLVRERAGHTCEAAVIVILILVWEGIPLSLADKLYSELTETLRKYGTLTNRRCALNEERTCACQGLDPETCGASFSFGCSWSMYYNGCKFARSKIPRKFKLLGDDPKEEEKLESHLQNLSTLMAPTYKKLAPDAYNNQIEYEHRAPECRLGLKEGRPFSGVTACLDFCAHAHRDLHNMQNGSTLVCTLTREDNREFGGKPEDEQLHVLPLYKVSDVDEFGSVEAQEEKKRSGAIQVLSSFRRKVRMLAEPVKTCRQRKLEAKKAAAEKLSSLENSSNKNEKEKSAPSRTKQTENASQAKQLAELLRLSGPVMQQSQQPQPLQKQPPQPQQQQRPQQQQPHHPQTESVNSYSASGSTNPYMRRPNPVSPYPNSSHTSDIYGSTSPMNFYSTSSQAAGSYLNSSNPMNPYPGLLNQNTQYPSYQCNGNLSVDNCSPYLGSYSPQSQPMDLYRYPSQDPLSKLSLPPIHTLYQPRFGNSQSFTSKYLGYGNQNMQGDGFSSCTIRPNVHHVGKLPPYPTHEMDGHFMGATSRLPPNLSNPNMDYKNGEHHSPSHIIHNYSAAPGMFNSSLHALHLQNKENDMLSHTANGLSKMLPALNHDRTACVQGGLHKLSDANGQEKQPLALVQGVASGAEDNDEVWSDSEQSFLDPDIGGVAVAPTHGSILIECAKRELHATTPLKNPNRNHPTRISLVFYQHKSMNEPKHGLALWEAKMAEKAREKEEECEKYGPDYVPQKSHGKKVKREPAEPHETSEPTYLRFIKSLAERTMSVTTDSTVTTSPYAFTRVTGPYNRYI>sp|Q6N021-2|TET2_HUMAN Isoform 2 of Methylcytosine dioxygenase TET2OS=Homo sapiens OX=9606 GN=TET2MEQDRTNHVEGNRLSPFLIPSPPICQTEPLATKLQNGSPLPERAHPEVNGDTKWHSFKSYYGIPCMKGSQNSRVSPDFTQESRGYSKCLQNGGIKRTVSEPSLSGLLQIKKLKQDQKANGERRNFGVSQERNPGESSQPNVSDLSDKKESVSSVAQENAVKDFTSFSTHNCSGPENPELQILNEQEGKSANYHDKNIVLLKNKAVLMPNGATVSASSVEHTHGELLEKTLSQYYPDCVSIAVQKTTSHINAINSQATNELSCEITHPSHTSGQINSAQTSNSELPPKPAAVVSEACDADDADNASKLAAMLNTCSFQKPEQLQQQKSVFEICPSPAENNIQGTTKLASGEEFCSGSSSNLQAPGGSSERYLKQNEMNGAYFKQSSVFTKDSFSATTTPPPPSQLLLSPPPPLPQVPQLPSEGKSTLNGGVLEEHHHYPNQSNTTLLREVKIEGKPEAPPSQSPNPSTHVCSPSPMLSERPQNNCVNRNDIQTAGTMTVPLCSEKTRPMSEHLKHNPPIFGSSGELQDNCQQLMRNKEQEILKGRDKEQTRDLVPPTQHYLKPGWIELKAPRFHQAESHLKRNEASLPSILQYQPNLSNQMTSKQYTGNSNMPGGLPRQAYTQKTTQLEHKSQMYQVEMNQGQSQGTVDQHLQFQKPSHQVHFSKTDHLPKAHVQSLCGTRFHFQQRADSQTEKLMSPVLKQHLNQQASETEPFSNSHLLQHKPHKQAAQTQPSQSSHLPQNQQQQQKLQIKNKEEILQTFPHPQSNNDQQREGSFFGQTKVEECFHGENQYSKSSEFETHNVQMGLEEVQNINRRNSPYSQTMKSSACKIQVSCSNNTHLVSENKEQTTHPELFAGNKTQNLHHMQYFPNNVIPKQDLLHRCFQEQEQKSQQASVLQGYKNRNQDMSGQQAAQLAQQRYLIHNHANVFPVPDQGGSHTQTPPQKDTQKHAALRWHLLQKQEQQQTQQPQTESCHSQMHRPIKVEPGCKPHACMHTAPPENKTWKKVTKQENPPASCDNVQQKSIIETMEQHLKQFHAKSLFDHKALTLKSQKQVKVEMSGPVTVLTRQTTAAELDSHTPALEQQTTSSEKTPTKRTAASVLNNFIESPSKLLDTPIKNLLDTPVKTQYDFPSCRCVGKCQKCTETHGVYPELANLSSDMGFSFFF>sp|Q6N021-3|TET2_HUMAN Isoform 3 of Methylcytosine dioxygenase TET2OS=Homo sapiens OX=9606 GN=TET2MEQDRTNHVEGNRLSPFLIPSPPICQTEPLATKLQNGSPLPERAHPEVNGDTKWHSFKSYYGIPCMKGSQNSRVSPDFTQESRGYSKCLQNGGIKRTVSEPSLSGLLQIKKLKQDQKANGERRNFGVSQERNPGESSQPNVSDLSDKKESVSSVAQENAVKDFTSFSTHNCSGPENPELQILNEQEGKSANYHDKNIVLLKNKAVLMPNGATVSASSVEHTHGELLEKTLSQYYPDCVSIAVQKTTSHINAINSQATNELSCEITHPSHTSGQINSAQTSNSELPPKPAAVVSEACDADDADNASKLAAMLNTCSFQKPEQLQQQKSVFEICPSPAENNIQGTTKLASGEEFCSGSSSNLQAPGGSSERYLKQNEMNGAYFKQSSVFTKDSFSATTTPPPPSQLLLSPPPPLPQVPQLPSEGKSTLNGGVLEEHHHYPNQSNTTLLREVKIEGKPEAPPSQSPNPSTHVCSPSPMLSERPQNNCVNRNDIQTAGTMTVPLCSEKTRPMSEHLKHNPPIFGSSGELQDNCQQLMRNKEQEILKGRDKEQTRDLVPPTQHYLKPGWIELKAPRFHQAESHLKRNEASLPSILQYQPNLSNQMTSKQYTGNSNMPGGLPRQAYTQKTTQLEHKSQMYQVEMNQGQSQGTVDQHLQFQKPSHQVHFSKTDHLPKAHVQSLCGTRFHFQQRADSQTEKLMSPVLKQHLNQQASETEPFSNSHLLQHKPHKQAAQTQPSQSSHLPQNQQQQQKLQIKNKEEILQTFPHPQSNNDQQREGSFFGQTKVEECFHGENQYSKSSEFETHNVQMGLEEVQNINRRNSPYSQTMKSSACKIQVSCSNNTHLVSENKEQTTHPELFAGNKTQNLHHMQYFPNNVIPKQDLLHRCFQEQEQKSQQASVLQGYKNRNQDMSGQQAAQLAQQRYLIHNHANVFPVPDQGGSHTQTPPQKDTQKHAALRWHLLQKQEQQQTQQPQTESCHSQMHRPIKVEPGCKPHACMHTAPPENKTWKKVTKQENPPASCDNVQQKSIIETMEQHLKQFHAKSLFDHKALTLKSQKQVKVEMSGPVTVLTRQTTAAELDSHTPALEQQTTSSEKTPTKRTAASVLNNFIESPSKLLDTPIKNLLDTPVKTQYDFPSCRCVGLDRRVKLLGLKESSILVKKAKVLRDVLLLSGWFAEAAVKRSYCVWCGSELATPVRLQ>sp|Q99832|TCPH_HUMAN T-complex protein 1 subunit eta OS=Homo sapiensOX=9606 GN=CCT7 PE=1 SV=2MMPTPVILLKEGTDSSQGIPQLVSNISACQVIAEAVRTTLGPRGMDKLIVDGRGKATISNDGATILKLLDVVHPAAKTLVDIAKSQDAEVGDGTTSVTLLAAEFLKQVKPYVEEGLHPQIIIRAFRTATQLAVNKIKEIAVTVKKADKVEQRKLLEKCAMTALSSKLISQQKAFFAKMVVDAVMMLDDLLQLKMIGIKKVQGGALEDSQLVAGVAFKKTFSYAGFEMQPKKYHNPKIALLNVELELKAEKDNAEIRVHTVEDYQAIVDAEWNILYDKLEKIHHSGAKVVLSKLPIGDVATQYFADRDMFCAGRVPEEDLKRTMMACGGSIQTSVNALSADVLGRCQVFEETQIGGERYNFFTGCPKAKTCTFILRGGAEQFMEETERSLHDAIMIVRRAIKNDSVVAGGGAIEMELSKYLRDYSRTIPGKQQLLIGAYAKALEIIPRQLCDNAGFDATNILNKLRARHAQGGTWYGVDINNEDIADNFEAFVWEPAMVRINALTAASEAACLIVSVDETIKNPRSTVDAPTAAGRGRGRGRPH>sp|Q99832-2|TCPH_HUMAN Isoform 2 of T-complex protein 1 subunit etaOS=Homo sapiens OX=9606 GN=CCT7MMDSQLVAGVAFKKTFSYAGFEMQPKKYHNPKIALLNVELELKAEKDNAEIRVHTVEDYQAIVDAEWNILYDKLEKIHHSGAKVVLSKLPIGDVATQYFADRDMFCAGRVPEEDLKRTMMACGGSIQTSVNALSADVLGRCQVFEETQIGGERYNFFTGCPKAKTCTFILRGGAEQFMEETERSLHDAIMIVRRAIKNDSVVAGGGAIEMELSKYLRDYSRTIPGKQQLLIGAYAKALEIIPRQLCDNAGFDATNILNKLRARHAQGGTWYGVDINNEDIADNFEAFVWEPAMVRINALTAASEAACLIVSVDETIKNPRSTVDAPTAAGRGRGRGRPH>sp|Q99832-3|TCPH_HUMAN Isoform 3 of T-complex protein 1 subunit etaOS=Homo sapiens OX=9606 GN=CCT7MDKLIVDGRGKATISNDGATILKLLDVVHPAAKTLVDIAKSQDAEVGDGTTSVTLLAAEFLKQVKPYVEEGLHPQIIIRAFRTATQLAVNKIKEIAVTVKKADKVEQRKLLEKCAMTALSSKLISQQKAFFAKMVVDAVMMLDDLLQLKMIGIKKVQGGALEDSQLVAGVAFKKTFSYAGFEMQPKKYHNPKIALLNVELELKAEKDNAEIRVHTVEDYQAIVDAEWNILYDKLEKIHHSGAKVVLSKLPIGDVATQYFADRDMFCAGRVPEEDLKRTMMACGGSIQTSVNALSADVLGRCQVFEETQIGGERYNFFTGCPKAKTCTFILRGGAEQFMEETERSLHDAIMIVRRAIKNDSVVAGGGAIEMELSKYLRDYSRTIPGKQQLLIGAYAKALEIIPRQLCDNAGFDATNILNKLRARHAQGGTWYGVDINNEDIADNFEAFVWEPAMVRINALTAASEAACLIVSVDETIKNPRSTVDAPTAAGRGRGRGRPH>sp|Q99832-4|TCPH_HUMAN Isoform 4 of T-complex protein 1 subunit etaOS=Homo sapiens OX=9606 GN=CCT7MMVGDGTTSVTLLAAEFLKQVKPYVEEGLHPQIIIRAFRTATQLAVNKIKEIAVTVKKADKVEQRKLLEKCAMTALSSKLISQQKAFFAKMVVDAVMMLDDLLQLKMIGIKKVQGGALEDSQLVAGVAFKKTFSYAGFEMQPKKYHNPKIALLNVELELKAEKDNAEIRVHTVEDYQAIVDAEWNILYDKLEKIHHSGAKVVLSKLPIGDVATQYFADRDMFCAGRVPEEDLKRTMMACGGSIQTSVNALSADVLGRCQVFEETQIGGERYNFFTGCPKAKTCTFILRGGAEQFMEETERSLHDAIMIVRRAIKNDSVVAGGGAIEMELSKYLRDYSRTIPGKQQLLIGAYAKALEIIPRQLCDNAGFDATNILNKLRARHAQGGTWYGVDINNEDIADNFEAFVWEPAMVRINALTAASEAACLIVSVDETIKNPRSTVDAPTAAGRGRGRGRPH>sp|A6NM43|TCPQL_HUMAN Putative T-complex protein 1 subunit theta-like 1OS=Homo sapiens OX=9606 GN=CCT8L1P PE=5 SV=1MDSTVPSALELPQRLALNPRESPRSPEEEEPHLLSSLAAVQTLANVIRPCYGPHGRQKFLVTMKGETVCTGCATAILRALELEHPAAWLLREAAQTQAENSGDGTAFVVLLTEALLEQAEQLLKFGLPRPQLREAYATATAEVLATLPSLAIQSLGPLEDPSWALHSVMNTHTLPPMNHLTKLVAHACWAIKELDGSFKPERVGVCTLHGGTLEDSCLLQGLAISGKLCGQMAAVLSGARVALFACPFGPAHPNAPATACLSSPADLAQFSKGSDQLLEKQVGQLAAAGINVAVVLGEVDEETLTLADKYGIVVIQARSRMEIIYLSEVLDTPLLPRLLPPQRPGKCQRVYRQELGDGLAVVFEWECTGTPALTVVLRGATTQGLRSAEQAVYHSIDAYFQPCQDPRLIPGAGATEMALAKMLSDKGSRLEGPNGPAFLAFARALKYLPKTLAENAGLAVSDVVAEMSGVHQGGNLLMGVGAEGIINVAQEGVWDTLIVKAQGFRAVAEVVLQLVTVDEIVVAKKSPTHQQIWNPDSKKTKKRPPPVEKKKILGMNN>sp|A6NFQ2|TCAF2_HUMAN TRPM8 channel-associated factor 2 OS=Homo sapiensOX=9606 GN=TCAF2 PE=1 SV=2MATIAAAAFEALMDGVTCWDVPRGPIPSELLLIGEAAFPVMVNDKGQVLIAASSYGRGRLVVVSHEGYLSHTGLAPFLLNAVSWLCPCPGAPVGVHPSLAPLVNILQDAGLEAQVKPEPGEPLGVYCINAYNDTLTATLIQFVKHGGGLLIGGQAWYWASQHGPDKVLSRFPGNKVTSVAGVYFTDTYGDRDRFKVSKKVPKIPLHVRYGEDVRQDQQQLLEGISELDIRTGGVPSQLLVHGALAFPLGLDASLNCFLAAAHYGRGRVVLAAHECLLCAPKMGPFLLNAVRWLARGQTGKVGVNTNLKDLCPLLSEHGLQCSLEPHLNSDLCVYCCKAYSDKEAKQLQEFVAEGGGLLIGGQAWWWASQNPGHCPLAGFPGNIILNCFGLSILPQTLKAGCFPVPTPEMRSYHFRKALSQFQAILNHENGNLEKSCLAKLRVDGAAFLQIPAEGVPAYISLHRLLRKMLRGSGLPAVSRENPVASDSYEAAVLSLATGLAHSGTDCSQLAQGLGTWTCSSSLYPSKHPITVEINGINPGNNDCWVSTGLYLLEGQNAEVSLSEAAASAGLRVQIGCHTDDLTKARKLSRAPVVTHQCWMDRTERSVSCLWGGLLYVIVPKGSQLGPVPVTIRGAVPAPYYKLGKTSLEEWKRQMQENLAPWGELATDNIILTVPTTNLQALKDPEPVLRLWDEMMQAVARLAAEPFPFRRPERIVADVQISAGWMHSGYPIMCHLESVKEIINEMDMRSRGVWGPIHELGHNQQRHGWEFPPHTTEATCNLWSVYVHETVLGIPRAQAHEALSPPERERRIKAHLGKGAPLCDWNVWTALETYLQLQEAFGWEPFTQLFAEYQTLSHLPKDNTGRMNLWVKKFSEKVKKNLVPFFEAWGWPIQKEVADSLASLPEWQENPMQVYLRARK>sp|A6NFQ2-2|TCAF2_HUMAN Isoform 2 of TRPM8 channel-associated factor 2OS=Homo sapiens OX=9606 GN=TCAF2MATIAAAAFEALMDGVTCWDVPRGPIPSELLLIGEAAFPVMVNDKGQVLIAASSYGRGRLVVVSHEGYLSHTGLAPFLLNAVSWLCPCPGAPVGVHPSLAPLVNILQDAGLEAQVKPEPGEPLGVYCINAYNDTLTATLIQFVKHGGGLLIGGQAWYWASQHGPDKVLSRFPGNKVTSVAGVYFTDTYGDRDRFKVSKKVPKIPLHVRYGEDVRQDQQQLLEGISELDIRTGGVPSQLLVHGALAFPLGLDASLNCFLAAAHYGRGRVVLAAHECLLCAPKMGPFLLNAVRWLARGQTGKVGVNTNLKDLCPLLSEHGLQCSLEPHLNSDLCVYCCKAYSDKEAKQLQEFVAEGGGLLIGGQAWWWASQNPGHCPLAGFPGNIILNCFGLSILPQTLKAGCFPVPTPEMRSYHFRKALSQFQAILNHENGNLEKSCLAKLRVDGAAFLQIPAEGVPAYISLHRLLRKMLRGSGLPAVSRENPVASDSYEAAVLSLATGLAHSGTDCSQLAQGLGTWTCSSSLYPSKHPITVEINGINPGNNDCWVSTGLYLLEGQNAEVSLSEAAASAGLRVQIGCHTDDLTKARKLSRAPVVTHQCWMDRTERSVSCLWGGLLYVIVPKGSQLGPVPVTIRGAVPAPYYKLGKTSLEEWKRQMQENLAPWGELATDNIILTVPTTNLQALKDPEPVLRLWDEMMQAVARLAAEPFPFRRPERIVADVQISAGWMHSGYPIMCHLESVKEIINEMDMRSRGVWGPIHELGHNQQRHGWEFPPHTTEATCNLWSVYVHETVLGIPRAQAHEALSPPERERRIKAHLGKGAPLCDWNVWTALETYLQVLSRNSGRRG>sp|A6NFQ2-3|TCAF2_HUMAN Isoform 3 of TRPM8 channel-associated factor 2OS=Homo sapiens OX=9606 GN=TCAF2MKIFQKEFKFILKKCTPIQKYREENGNSSSSPHHQLQSHASGPRYGEDVRQDQQQLLEGISELDIRTGGVPSQLLVHGALAFPLGLDASLNCFLAAAHYGRGRVVLAAHECLLCAPKMGPFLLNAVRWLARGQTGKVGVNTNLKDLCPLLSEHGLQCSLEPHLNSDLCVYCCKAYSDKEAKQLQEFVAEGGGLLIGGQAWWWASQNPGHCPLAGFPGNIILNCFGLSILPQTLKAGCFPVPTPEMRSYHFRKALSQFQAILNHENGNLEKSCLAKLRVDGAAFLQIPAEGVPAYISLHRLLRKMLRGSGLPAVSRENPVASDSYEAAVLSLATGLAHSGTDCSQLAQGLGTWTCSSSLYPSKHPITVEINGINPESHSVIQVGMQWRDLSSCNLHLLGLSNSSLSASCVAGTTGTRHHAWLIFVFLVEREFHRKGNNDCWVSTGLYLLEGQNAEVSLSEAAASAGLRVQIGCHTDDLTKARKLSRAPVVTHQCWMDRTERSVSCLWGGLLYVIVPKGSQLGPVPVTIRGAVPAPYYKLGKTSLEEWKRQMQENLAPWGELATDNIILTVPTTNLQALKDPEPVLRLWDEMMQAVARLAAEPFPFRRPERIVADVQISAGWMHSGYPIMCHLESVKEIINEMDMRSRGVWGPIHELGHNQQRHGWEFPPHTTEATCNLWSVYVHETVLGIPRAQAHEALSPPERERRIKAHLGKGAPLCDWNVWTALETYLQLQEAFGWEPFTQLFAEYQTLSHLPKDNTGRMNLWVKKFSEKVKKNLVPFFEAWGWPIQKEVADSLASLPEWQENPMQVYLRARK>sp|Q8N7U7|TPRX1_HUMAN Tetra-peptide repeat homeobox protein 1 OS=Homosapiens OX=9606 GN=TPRX1 PE=1 SV=3MLSLREQQLQVWFKNRRAKLARERRLQQQPQRVPGQRGRGARAAPLVPAASASAPQRGPSGILPAAEPTICSLHQAWGGPGCRAQKGIPAALSPGPGPIPAPIPGPAQIPGPLPGSIPGPIPGPAQIPSPIPAPIPGPISGPVQIPGPFRGPIPGPISGPAPIPGPISGPFSGPNPGPIPGPNPGPIPGPISGPIPGPISVPIPGPIPGPISGPISGPNPGPIPGPIPGPISGPNPGPIPGPISGPNPGLIPGPIPGPISGPGPIIGPIPSPAQIPGPGRLQGPGPILSPGRMRSPGSLPGLAPILGPGSGPGSGSVPAPIPGPGSLPAPAPLWPQSPDASDFLPDTQLFPHFTELLLPLDPLEGSSVSTMTSQYQEGDDSMGKKHSGSQPQEEGGSVNENHSGPRLLLDL>sp|Q8N7U7-2|TPRX1_HUMAN Isoform 2 of Tetra-peptide repeat homeoboxprotein 1 OS=Homo sapiens OX=9606 GN=TPRX1MLSLREQQLQVWFKNRRAKLARERRLQQQPQRVPGQRGRGARAAPLVPAASASAPQRGPSGILPAAEPTICSLHQAWGGPGCRAQKGIPAALSPGPGPIPAPIPGPAQIPGPLPGSIPGPIPGPAQIPSPIPAPIPGPISGPVQIPGPFRGPIPGPISGPAPIPGPISGPFSGPNPGPIPGPNPGPIPGPISGPIPGPISVPIPGPISGPISGPNPGPIPGPIPGPISGPNPGPIPGPISGPNPGLIPGPIPGPISGPGPIIGPIPSPAQIPGPGRLQGPGPILSPGRMRSPGSLPGLAPILGPGSGPGSGSVPAPIPGPGSLPAPAPLWPQSPDASDFLPDTQLFPHFTELLLPLDPLEGSSVSTMTSQYQEGDDSMGKKHSGSQPQEEGGSVNENHSGPRLLLDL>sp|Q15814|TBCC_HUMAN Tubulin-specific chaperone C OS=Homo sapiensOX=9606 GN=TBCC PE=1 SV=2MESVSCSAAAVRTGDMESQRDLSLVPERLQRREQERQLEVERRKQKRQNQEVEKENSHFFVATFVRERAAVEELLERAESVERLEEAASRLQGLQKLINDSVFFLAAYDLRQGQEALARLQAALAERRRGLQPKKRFAFKTRGKDAASSTKVDAAPGIPPAVESIQDSPLPKKAEGDLGPSWVCGFSNLESQVLEKRASELHQRDVLLTELSNCTVRLYGNPNTLRLTKAHSCKLLCGPVSTSVFLEDCSDCVLAVACQQLRIHSTKDTRIFLQVTSRAIVEDCSGIQFAPYTWSYPEIDKDFESSGLDRSKNNWNDVDDFNWLARDMASPNWSILPEEERNIQWD>sp|Q9P0S9|TM14C_HUMAN Transmembrane protein 14C OS=Homo sapiens OX=9606GN=TMEM14C PE=1 SV=1MQDTGSVVPLHWFGFGYAALVASGGIIGYVKAGSVPSLAAGLLFGSLAGLGAYQLSQDPRNVWVFLATSGTLAGIMGMRFYHSGKFMPAGLIAGASLLMVAKVGVSMFNRPH>sp|Q9NZ01|TECR_HUMAN Very-long-chain enoyl-CoA reductase OS=Homo sapiensOX=9606 GN=TECR PE=1 SV=1MKHYEVEILDAKTREKLCFLDKVEPHATIAEIKNLFTKTHPQWYPARQSLRLDPKGKSLKDEDVLQKLPVGTTATLYFRDLGAQISWVTVFLTEYAGPLFIYLLFYFRVPFIYGHKYDFTSSRHTVVHLACICHSFHYIKRLLETLFVHRFSHGTMPLRNIFKNCTYYWGFAAWMAYYINHPLYTPPTYGAQQVKLALAIFVICQLGNFSIHMALRDLRPAGSKTRKIPYPTKNPFTWLFLLVSCPNYTYEVGSWIGFAIMTQCLPVALFSLVGFTQMTIWAKGKHRSYLKEFRDYPPLRMPIIPFLL>sp|Q9NZ01-2|TECR_HUMAN Isoform 2 of Very-long-chain enoyl-CoA reductaseOS=Homo sapiens OX=9606 GN=TECRMKHYEVEILDAKTREKLCFFAAWMAYYINHPLYTPPTYGAQQVKLALAIFVICQLGNFSIHMALRDLRPAGSKTRKIPYPTKNPFTWLFLLVSCPNYTYEVGSWIGFAIMTQCLPVALFSLVGFTQMTIWAKGKHRSYLKEFRDYPPLRMPIIPFLL>sp|Q9C0C2|TB182_HUMAN 182 kDa tankyrase-1-binding protein OS=Homosapiens OX=9606 GN=TNKS1BP1 PE=1 SV=4MKVSTLRESSAMASPLPREMEEELVPTGSEPGDTRAKPPVKPKPRALPAKPALPAKPSLLVPVGPRPPRGPLAELPSARKMNMLAGPQPYGGSKRPLPFAPRPAVEASTGGEATQETGKEEAGKEEPPPLTPPARCAAPGGVRKAPAPFRPASERFAATTVEEILAKMEQPRKEVLASPDRLWGSRLTFNHDGSSRYGPRTYGTTTAPRDEDGSTLFRGWSQEGPVKSPAECREEHSKTPEERSLPSDLAFNGDLAKAASSELPADISKPWIPSSPAPSSENGGPASPGLPAEASGSGPGSPHLHPPDKSSPCHSQLLEAQTPEASQASPCPAVTPSAPSAALPDEGSRHTPSPGLPAEGAPEAPRPSSPPPEVLEPHSLDQPPATSPRPLIEVGELLDLTRTFPSGGEEEAKGDAHLRPTSLVQRRFSEGVLQSPSQDQEKLGGSLAALPQGQGSQLALDRPFGAESNWSLSQSFEWTFPTRPSGLGVWRLDSPPPSPITEASEAAEAAEAGNLAVSSREEGVSQQGQGAGSAPSGSGSSWVQGDDPSMSLTQKGDGESQPQFPAVPLEPLPTTEGTPGLPLQQAEERYESQEPLAGQESPLPLATREAALPILEPVLGQEQPAAPDQPCVLFADAPEPGQALPVEEEAVTLARAETTQARTEAQDLCRASPEPPGPESSSRWLDDLLASPPPSGGGARRGAGAELKDTQSPSTCSEGLLGWSQKDLQSEFGITGDPQPSSFSPSSWCQGASQDYGLGGASPRGDPGLGERDWTSKYGQGAGEGSTREWASRCGIGQEEMEASSSQDQSKVSAPGVLTAQDRVVGKPAQLGTQRSQEADVQDWEFRKRDSQGTYSSRDAELQDQEFGKRDSLGTYSSRDVSLGDWEFGKRDSLGAYASQDANEQGQDLGKRDHHGRYSSQDADEQDWEFQKRDVSLGTYGSRAAEPQEQEFGKSAWIRDYSSGGSSRTLDAQDRSFGTRPLSSGFSPEEAQQQDEEFEKKIPSVEDSLGEGSRDAGRPGERGSGGLFSPSTAHVPDGALGQRDQSSWQNSDASQEVGGHQERQQAGAQGPGSADLEDGEMGKRGWVGEFSLSVGPQREAAFSPGQQDWSRDFCIEASERSYQFGIIGNDRVSGAGFSPSSKMEGGHFVPPGKTTAGSVDWTDQLGLRNLEVSSCVGSGGSSEARESAVGQMGWSGGLSLRDMNLTGCLESGGSEEPGGIGVGEKDWTSDVNVKSKDLAEVGEGGGHSQARESGVGQTDWSGVEAGEFLKSRERGVGQADWTPDLGLRNMAPGAVCSPGESKELGVGQMDWGNNLGLRDLEVTCDPDSGGSQGLRGCGVGQMDWTQDLAPQNVELFGAPSEAREHGVGGVSQCPEPGLRHNGSLSPGLEARDPLEARELGVGETSGPETQGEDYSSSSLEPHPADPGMETGEALSFGASPGRCPARPPPSGSQGLLEEMLAASSSKAVARRESAASGLGGLLEEEGAGAGAAQEEVLEPGRDSPPSWRPQPDGEASQTEDVDGTWGSSAARWSDQGPAQTSRRPSQGPPARSPSQDFSFIEDTEILDSAMYRSRANLGRKRGHRAPVIRPGGTLGLSEAADSDAHLFQDSTEPRASRVPSSDEEVVEEPQSRRTRMSLGTKGLKVNLFPGLSPSALKAKLRPRNRSAEEGELAESKSSQKESAVQRSKSCKVPGLGKPLTLPPKPEKSSGSEGSSPNWLQALKLKKKKV>sp|Q9C0C2-2|TB182_HUMAN Isoform 2 of 182 kDa tankyrase-1-binding proteinOS=Homo sapiens OX=9606 GN=TNKS1BP1MSLTQKGDGESQPQFPAVPLEPLPTTEGTPGLPLQQAEERYESQEPLAGQESPLPLATREAALPILEPVLGQEQPAAPDQPCVLFADAPEPGQALPVEEEAVTLARAETTQARTEAQDLCRASPEPPGPESSSRWLDDLLASPPPSGGGARRGAGAELKDTQSPSTCSEGLLGWSQKDLQSEFGITGDPQPSSFSPSSWCQGASQDYGLGGASPRGDPGLGERDWTSKYGQGAGEGSTREWASRCGIGQEEMEASSSQDQSKVSAPGVLTAQDRVVGKPAQLGTQRSQEADVQDWEFRKRDSQGTYSSRDAELQDQEFGKRDSLGTYSSRDVSLGDWEFGKRDSLGAYASQDANEQGQDLGKRDHHGRYSSQDADEQDWEFQKRDVSLGTYGSRAAEPQEQEFGKSAWIRDYSSGGSSRTLDAQDRSFGTRPLSSGFSPEEAQQQDEEFEKKIPSVEDSLGEGSRDAGRPGERGSGGLFSPSTAHVPDGALGQRDQSSWQNSDASQEVGGHQERQQAGAQGPGSADLEDGEMGKRGWVGEFSLSVGPQREAAFSPGQQDWSRDFCIEASERSYQFGIIGNDRVSGAGFSPSSKMEGGHFVPPGKTTAGSVDWTDQLGLRNLEVSSCVGSGGSSEARESAVGQMGWSGGLSLRDMNLTGCLESGGSEEPGGIGVGEKDWTSDVNVKSKDLAEVGEGGGHSQARESGVGQTDWSGVEAGEFLKSRERLGRHIYALCITLRTPPTPSLPWISSLVVEGFVPSSPPSLSLSASSSSLPWVFF>sp|O60504|VINEX_HUMAN Vinexin OS=Homo sapiens OX=9606 GN=SORBS3 PE=1SV=2MQGPPRSLRAGLSLDDFIPGHLQSHIGSSSRGTRVPVIRNGGSNTLNFQFHDPAPRTVCNGGYTPRRDASQHPDPAWYQTWPGPGSKPSASTKIPASQHTQNWSATWTKDSKRRDKRWVKYEGIGPVDESGMPIAPRSSVDRPRDWYRRMFQQIHRKMPDLQLDWTFEEPPRDPRHLGAQQRPAHRPGPATSSSGRSWDHSEELPRSTFNYRPGAFSTVLQPSNQVLRRREKVDNVWTEESWNQFLQELETGQRPKKPLVDDPGEKPSQPIEVLLERELAELSAELDKDLRAIETRLPSPKSSPAPRRAPEQRPPAGPASAWSSSYPHAPYLGSARSLSPHKMADGGSPFLGRRDFVYPSSTRDPSASNGGGSPARREEKKRKAARLKFDFQAQSPKELTLQKGDIVYIHKEVDKNWLEGEHHGRLGIFPANYVEVLPADEIPKPIKPPTYQVLEYGEAVAQYTFKGDLEVELSFRKGEHICLIRKVNENWYEGRITGTGRQGIFPASYVQVSREPRLRLCDDGPQLPTSPRLTAAARSARHPSSPSALRSPADPIDLGGQTSPRRTGFSFPTQEPRPQTQNLGTPGPALSHSRGPSHPLDLGTSSPNTSQIHWTPYRAMYQYRPQNEDELELREGDRVDVMQQCDDGWFVGVSRRTQKFGTFPGNYVAPV>sp|O60504-2|VINEX_HUMAN Isoform Beta of Vinexin OS=Homo sapiens OX=9606GN=SORBS3MADGGSPFLGRRDFVYPSSTRDPSASNGGGSPARREEKKRKAARLKFDFQAQSPKELTLQKGDIVYIHKEVDKNWLEGEHHGRLGIFPANYVEVLPADEIPKPIKPPTYQVLEYGEAVAQYTFKGDLEVELSFRKGEHICLIRKVNENWYEGRITGTGRQGIFPASYVQVSREPRLRLCDDGPQLPTSPRLTAAARSARHPSSPSALRSPADPIDLGGQTSPRRTGFSFPTQEPRPQTQNLGTPGPALSHSRGPSHPLDLGTSSPNTSQIHWTPYRAMYQYRPQNEDELELREGDRVDVMQQCDDGWFVGVSRRTQKFGTFPGNYVAPV>sp|Q16635|TAZ_HUMAN Tafazzin OS=Homo sapiens OX=9606 GN=TAFAZZIN PE=1SV=1MPLHVKWPFPAVPPLTWTLASSVVMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGAEFFQAENEGKGVLDTGRHMPGAGKRREKGDGVYQKGMDFILEKLNHGDWVHIFPEGKVNMSSEFLRFKWGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-2|TAZ_HUMAN Isoform 2 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGAEFFQAENEGKGVLDTGRHMPGAGKRREKGDGVYQKGMDFILEKLNHGDWVHIFPEGKVNMSSEFLRFKWGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-3|TAZ_HUMAN Isoform 3 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMPLHVKWPFPAVPPLTWTLASSVVMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGDGVYQKGMDFILEKLNHGDWVHIFPEGKVNMSSEFLRFKWGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-4|TAZ_HUMAN Isoform 4 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMPLHVKWPFPAVPPLTWTLASSVVMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGAEFFQAENEGKGVLDTGRHMPGAGKRREKGKVNMSSEFLRFKWGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-5|TAZ_HUMAN Isoform 5 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMPLHVKWPFPAVPPLTWTLASSVVMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGAEFFQAENEGKGVLDTGRHMPGAGKRREKGDGVYQKGMDFILEKLNHGDWVHIFPEGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-6|TAZ_HUMAN Isoform 6 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGAEFFQAENEGKGVLDTGRHMPGAGKRREKGDGVYQKGMDFILEKLNHGDWVHIFPEGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-7|TAZ_HUMAN Isoform 7 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMPLHVKWPFPAVPPLTWTLASSVVMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGDGVYQKGMDFILEKLNHGDWVHIFPEGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-8|TAZ_HUMAN Isoform 8 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGDGVYQKGMDFILEKLNHGDWVHIFPEGKVNMSSEFLRFKWGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|Q16635-9|TAZ_HUMAN Isoform 9 of Tafazzin OS=Homo sapiens OX=9606GN=TAFAZZINMGLVGTYSCFWTKYMNHLTVHNREVLYELIEKRGPATPLITVSNHQSCMDDPHLWGILKLRHIWNLKLMRWTPAAADICFTKELHSHFFSLGKCVPVCRGDGVYQKGMDFILEKLNHGDWVHIFPEGIGRLIAECHLNPIILPLWHVGMNDVLPNSPPYFPRFGQKITVLIGKPFSALPVLERLRAENKSAVEMRKALTDFIQEEFQHLKTQAEQLHNHLQPGR>sp|P28908|TNR8_HUMAN Tumor necrosis factor receptor superfamily member 8OS=Homo sapiens OX=9606 GN=TNFRSF8 PE=1 SV=1MRVLLAALGLLFLGALRAFPQDRPFEDTCHGNPSHYYDKAVRRCCYRCPMGLFPTQQCPQRPTDCRKQCEPDYYLDEADRCTACVTCSRDDLVEKTPCAWNSSRVCECRPGMFCSTSAVNSCARCFFHSVCPAGMIVKFPGTAQKNTVCEPASPGVSPACASPENCKEPSSGTIPQAKPTPVSPATSSASTMPVRGGTRLAQEAASKLTRAPDSPSSVGRPSSDPGLSPTQPCPEGSGDCRKQCEPDYYLDEAGRCTACVSCSRDDLVEKTPCAWNSSRTCECRPGMICATSATNSCARCVPYPICAAETVTKPQDMAEKDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHRRACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTQLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRDLPEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLPTAASGK>sp|P28908-2|TNR8_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 8 OS=Homo sapiens OX=9606 GN=TNFRSF8MSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRDLPEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLPTAASGK>sp|P28908-3|TNR8_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 8 OS=Homo sapiens OX=9606 GN=TNFRSF8MFCSTSAVNSCARCFFHSVCPAGMIVKFPGTAQKNTVCEPASPGVSPACASPENCKEPSSGTIPQAKPTPVSPATSSASTMPVRGGTRLAQEAASKLTRAPDSPSSVGRPSSDPGLSPTQPCPEGSGDCRKQCEPDYYLDEAGRCTACVSCSRDDLVEKTPCAWNSSRTCECRPGMICATSATNSCARCVPYPICAAETVTKPQDMAEKDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHRRACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRDLPEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLPTAASGK>sp|P59282|TPPP2_HUMAN Tubulin polymerization-promoting protein familymember 2 OS=Homo sapiens OX=9606 GN=TPPP2 PE=1 SV=2MASEAEKTFHRFAAFGESSSSGTEMNNKNFSKLCKDCGIMDGKTVTSTDVDIVFSKVKAKNARTITFQQFKEAVKELGQKRFKGKSPDEVLENIYGLMEGKDPATTGATKATTVGAVDRLTDTSKYTGTHKERFDESGKGKGIAGREEMTDNTGYVSGYKGSGTYDKKTK>sp|O14798|TR10C_HUMAN Tumor necrosis factor receptor superfamily member10C OS=Homo sapiens OX=9606 GN=TNFRSF10C PE=1 SV=3MARIPKTLKFVVVIVAVLLPVLAYSATTARQEEVPQQTVAPQQQRHSFKGEECPAGSHRSEHTGACNPCTEGVDYTNASNNEPSCFPCTVCKSDQKHKSSCTMTRDTVCQCKEGTFRNENSPEMCRKCSRCPSGEVQVSNCTSWDDIQCVEEFGANATVETPAAEETMNTSPGTPAPAAEETMNTSPGTPAPAAEETMTTSPGTPAPAAEETMTTSPGTPAPAAEETMITSPGTPASSHYLSCTIVGIIVLIVLLIVFV>sp|O75962|TRIO_HUMAN Triple functional domain protein OS=Homo sapiensOX=9606 GN=TRIO PE=1 SV=2MSGSSGGAAAPAASSGPAAAASAAGSGCGGGAGEGAEEAAKDLADIAAFFRSGFRKNDEMKAMDVLPILKEKVAYLSGGRDKRGGPILTFPARSNHDRIRQEDLRRLISYLACIPSEEVCKRGFTVIVDMRGSKWDSIKPLLKILQESFPCCIHVALIIKPDNFWQKQRTNFGSSKFEFETNMVSLEGLTKVVDPSQLTPEFDGCLEYNHEEWIEIRVAFEDYISNATHMLSRLEELQDILAKKELPQDLEGARNMIEEHSQLKKKVIKAPIEDLDLEGQKLLQRIQSSESFPKKNSGSGNADLQNLLPKVSTMLDRLHSTRQHLHQMWHVRKLKLDQCFQLRLFEQDAEKMFDWITHNKGLFLNSYTEIGTSHPHAMELQTQHNHFAMNCMNVYVNINRIMSVANRLVESGHYASQQIRQIASQLEQEWKAFAAALDERSTLLDMSSIFHQKAEKYMSNVDSWCKACGEVDLPSELQDLEDAIHHHQGIYEHITLAYSEVSQDGKSLLDKLQRPLTPGSSDSLTASANYSKAVHHVLDVIHEVLHHQRQLENIWQHRKVRLHQRLQLCVFQQDVQQVLDWIENHGEAFLSKHTGVGKSLHRARALQKRHEDFEEVAQNTYTNADKLLEAAEQLAQTGECDPEEIYQAAHQLEDRIQDFVRRVEQRKILLDMSVSFHTHVKELWTWLEELQKELLDDVYAESVEAVQDLIKRFGQQQQTTLQVTVNVIKEGEDLIQQLRDSAISSNKTPHNSSINHIETVLQQLDEAQSQMEELFQERKIKLELFLQLRIFERDAIDIISDLESWNDELSQQMNDFDTEDLTIAEQRLQHHADKALTMNNLTFDVIHQGQDLLQYVNEVQASGVELLCDRDVDMATRVQDLLEFLHEKQQELDLAAEQHRKHLEQCVQLRHLQAEVKQVLGWIRNGESMLNAGLITASSLQEAEQLQREHEQFQHAIEKTHQSALQVQQKAEAMLQANHYDMDMIRDCAEKVASHWQQLMLKMEDRLKLVNASVAFYKTSEQVCSVLESLEQEYKREEDWCGGADKLGPNSETDHVTPMISKHLEQKEAFLKACTLARRNADVFLKYLHRNSVNMPGMVTHIKAPEQQVKNILNELFQRENRVLHYWTMRKRRLDQCQQYVVFERSAKQALEWIHDNGEFYLSTHTSTGSSIQHTQELLKEHEEFQITAKQTKERVKLLIQLADGFCEKGHAHAAEIKKCVTAVDKRYRDFSLRMEKYRTSLEKALGISSDSNKSSKSLQLDIIPASIPGSEVKLRDAAHELNEEKRKSARRKEFIMAELIQTEKAYVRDLRECMDTYLWEMTSGVEEIPPGIVNKELIIFGNMQEIYEFHNNIFLKELEKYEQLPEDVGHCFVTWADKFQMYVTYCKNKPDSTQLILEHAGSYFDEIQQRHGLANSISSYLIKPVQRITKYQLLLKELLTCCEEGKGEIKDGLEVMLSVPKRANDAMHLSMLEGFDENIESQGELILQESFQVWDPKTLIRKGRERHLFLFEMSLVFSKEVKDSSGRSKYLYKSKLFTSELGVTEHVEGDPCKFALWVGRTPTSDNKIVLKASSIENKQDWIKHIREVIQERTIHLKGALKEPIHIPKTAPATRQKGRRDGEDLDSQGDGSSQPDTISIASRTSQNTLDSDKLSGGCELTVVIHDFTACNSNELTIRRGQTVEVLERPHDKPDWCLVRTTDRSPAAEGLVPCGSLCIAHSRSSMEMEGIFNHKDSLSVSSNDASPPASVASLQPHMIGAQSSPGPKRPGNTLRKWLTSPVRRLSSGKADGHVKKLAHKHKKSREVRKSADAGSQKDSDDSAATPQDETVEERGRNEGLSSGTLSKSSSSGMQSCGEEEGEEGADAVPLPPPMAIQQHSLLQPDSQDDKASSRLLVRPTSSETPSAAELVSAIEELVKSKMALEDRPSSLLVDQGDSSSPSFNPSDNSLLSSSSPIDEMEERKSSSLKRRHYVLQELVETERDYVRDLGYVVEGYMALMKEDGVPDDMKGKDKIVFGNIHQIYDWHRDFFLGELEKCLEDPEKLGSLFVKHERRLHMYIAYCQNKPKSEHIVSEYIDTFFEDLKQRLGHRLQLTDLLIKPVQRIMKYQLLLKDFLKYSKKASLDTSELERAVEVMCIVPRRCNDMMNVGRLQGFDGKIVAQGKLLLQDTFLVTDQDAGLLPRCRERRIFLFEQIVIFSEPLDKKKGFSMPGFLFKNSIKVSCLCLEENVENDPCKFALTSRTGDVVETFILHSSSPSVRQTWIHEINQILENQRNFLNALTSPIEYQRNHSGGGGGGGSGGSGGGGGSGGGGAPSGGSGHSGGPSSCGGAPSTSRSRPSRIPQPVRHHPPVLVSSAASSQAEADKMSGTSTPGPSLPPPGAAPEAGPSAPSRRPPGADAEGSEREAEPIPKMKVLESPRKGAANASGSSPDAPAKDARASLGTLPLGKPRAGAASPLNSPLSSAVPSLGKEPFPPSSPLQKGGSFWSSIPASPASRPGSFTFPGDSDSLQRQTPRHAAPGKDTDRMSTCSSASEQSVQSTQSNGSESSSSSNISTMLVTHDYTAVKEDEINVYQGEVVQILASNQQNMFLVFRAATDQCPAAEGWIPGFVLGHTSAVIVENPDGTLKKSTSWHTALRLRKKSEKKDKDGKREGKLENGYRKSREGLSNKVSVKLLNPNYIYDVPPEFVIPLSEVTCETGETVVLRCRVCGRPKASITWKGPEHNTLNNDGHYSISYSDLGEATLKIVGVTTEDDGIYTCIAVNDMGSASSSASLRVLGPGMDGIMVTWKDNFDSFYSEVAELGRGRFSVVKKCDQKGTKRAVATKFVNKKLMKRDQVTHELGILQSLQHPLLVGLLDTFETPTSYILVLEMADQGRLLDCVVRWGSLTEGKIRAHLGEVLEAVRYLHNCRIAHLDLKPENILVDESLAKPTIKLADFGDAVQLNTTYYIHQLLGNPEFAAPEIILGNPVSLTSDTWSVGVLTYVLLSGVSPFLDDSVEETCLNICRLDFSFPDDYFKGVSQKAKEFVCFLLQEDPAKRPSAALALQEQWLQAGNGRSTGVLDTSRLTSFIERRKHQNDVRPIRSIKNFLQSRLLPRV>sp|O75962-2|TRIO_HUMAN Isoform 2 of Triple functional domain proteinOS=Homo sapiens OX=9606 GN=TRIOMSGSSGGAAAPAASSGPAAAASAAGSGCGGGAGEGAEEAAKDLADIAAFFRSGFRKNDEMKAMDVLPILKEKVAYLSGGRDKRGGPILTFPARSNHDRIRQEDLRRLISYLACIPSEEVCKRGFTVIVDMRGSKWDSIKPLLKILQESFPCCIHVALIIKPDNFWQKQRTNFGSSKFEFETNMVSLEGLTKVVDPSQLTPEFDGCLEYNHEEWIEIRVAFEDYISNATHMLSRLEELQDILAKKELPQDLEGARNMIEEHSQLKKKVIKAPIEDLDLEGQKLLQRIQSSESFPKKNSGSGNADLQNLLPKVSTMLDRLHSTRQHLHQMWHVRKLKLDQCFQLRLFEQDAEKMFDWITHNKGLFLNSYTEIGTSHPHAMELQTQHNHFAMNCMNVYVNINRIMSVANRLVESGHYASQQIRQIASQLEQEWKAFAAALDERSTLLDMSSIFHQKAEKYMSNVDSWCKACGEVDLPSELQDLEDAIHHHQGIYEHITLAYSEVSQDGKSLLDKLQRPLTPGSSDSLTASANYSKAVHHVLDVIHEVLHHQRQLENIWQHRKVRLHQRLQLCVFQQDVQQVLDWIENHGEAFLSKHTGVGKSLHRARALQKRHEDFEEVAQNTYTNADKLLEAAEQLAQTGECDPEEIYQAAHQLEDRIQDFVRRVEQRKILLDMSVSFHTHVKELWTWLEELQKELLDDVYAESVEAVQDLIKRFGQQQQTTLQVTVNVIKEGEDLIQQLRDSAISSNKTPHNSSINHIETVLQQLDEAQSQMEELFQERKIKLELFLQLRIFERDAIDIISDLESWNDELSQQMNDFDTEDLTIAEQRLQHHADKALTMNNLTFDVIHQGQDLLQYVNEVQASGVELLCDRDVDMATRVQDLLEFLHEKQQELDLAAEQHRKHLEQCVQLRHLQAEVKQVLGWIRNGESMLNAGLITASSLQEAEQLQREHEQFQHAIEKTHQSALQVQQKAEAMLQANHYDMDMIRDCAEKVASHWQQLMLKMEDRLKLVNASVAFYKTSEQVCSVLESLEQEYKREEDWCGGADKLGPNSETDHVTPMISKHLEQKEAFLKACTLARRNADVFLKYLHRNSVNMPGMVTHIKAPEQQVKNILNELFQRENRVLHYWTMRKRRLDQCQQYVVFERSAKQALEWIHDNGEFYLSTHTSTGSSIQHTQELLKEHEEFQITAKQTKERVKLLIQLADGFCEKGHAHAAEIKKCVTAVDKRYRDFSLRMEKYRTSLEKALGISSDSNKSSKSLQLDIIPASIPGSEVKLRDAAHELNEEKRKSARRKEFIMAELIQTEKAYVRDLRECMDTYLWEMTSGVEEIPPGIVNKELIIFGNMQEIYEFHNNIFLKELEKYEQLPEDVGHCFVTWADKFQMYVTYCKNKPDSTQLILEHAGSYFDEIQQRHGLANSISSYLIKPVQRITKYQLLLKELLTCCEEGKGEIKDGLEVMLSVPKRANDAMHLSMLEGFDENIESQGELILQESFQVWDPKTLIRKGRERHLFLFEMSLVFSKEVKDSSGRSKYLYKSKLFTSELGVTEHVEGDPCKFALWVGRTPTSDNKIVLKASSIENKQDWIKHIREVIQERTIHLKGALKEPIHIPKTAPATRQKGRRDGEDLDSQGDGSSQPDTISIASRTSQNTLDSDKLSGGCELTVVIHDFTACNSNELTIRRGQTVEVLERPHDKPDWCLVRTTDRSPAAEGLVPCGSLCIAHSRSSMEMEGIFNHKDSLSVSSNDASPPASVASLQPHMIGAQSSPGPKRPGNTLRKWLTSPVRRLSSGKADGHVKKLAHKHKKSREVRKSADAGSQKDSDDSAATPQDETVEERGRNEGLSSGTLSKSSSSGMQSCGEEEGEEGADAVPLPPPMAIQQHSLLQPDSQDDKASSRLLVRPTSSETPSAAELVSAIEELVKSKMALEDRPSSLLVDQGDSSSPSFNPSDNSLLSSSSPIDEMEERKSSSLKRRHYVLQELVETERDYVRDLGYVVEGYMALMKEDGVPDDMKGKDKIVFGNIHQIYDWHRDFFLGELEKCLEDPEKLGSLFVKHERRLHMYIAYCQNKPKSEHIVSEYIDTFFEDLKQRLGHRLQLTDLLIKPVQRIMKYQLLLKDFLKYSKKASLDTSELERAVEVMCIVPRRCNDMMNVGRLQGFDGKIVAQGKLLLQDTFLVTDQDAGLLPRCRERRIFLFEQIVIFSEPLDKKKGFSMPGFLFKNSIKVSCLCLEENVENDPCKFALTSRTGDVVETFILHSSSPSVRQTWIHEINQILENQRNFLNALTSPIEYQRNHSGGGGGGGSGGSGGGGGSGGGGAPSGGSGHSGGPSSCGGAPSTSRSRPSRIPQPVRHHPPVLVSSAASSQAEADKMSESESSSSSNISTMLVTHDYTAVKEDEINVYQGEVVQILASNQQNMFLVFRAATDQCPAAEGWIPGFVLGHTSAVIVENPDGTLKKSTSWHTALRLRKKSEKKDKDGKREGKLENGYRKSREGLSNKVSVKLLNPNYIYDVPPEFVIPLSEVTCETGETVVLRCRVCGRPKASITWKGPEHNTLNNDGHYSISYSDLGEATLKIVGVTTEDDGIYTCIAVNDMGSASSSASLRVLGPGMDGIMVTWKDNFDSFYSEVAELGRGRFSVVKKCDQKGTKRAVATKFVNKKLMKRDQVTHELGILQSLQHPLLVGLLDTFETPTSYILVLEMADQGRLLDCVVRWGSLTEGKIRAHLGEVLEAVRYLHNCRIAHLDLKPENILVDESLAKPTIKLADFGDAVQLNTTYYIHQLLGNPEFAAPEIILGNPVSLTSDTWSVGVLTYVLLSGVSPFLDDSVEETCLNICRLDFSFPDDYFKGVSQKAKEFVCFLLQEDPAKRPSAALALQEQWLQAGNGRSTGVLDTSRLTSFIERRKHQNDVRPIRSIKNFLQSRLLPRV>sp|O75962-3|TRIO_HUMAN Isoform 3 of Triple functional domain proteinOS=Homo sapiens OX=9606 GN=TRIOMLPSQAQGLLWWVFPLFPASSLSYPPVSYRADGLARNTFLKACSESSSSSNISTMLVTHDYTAVKEDEINVYQGEVVQILASNQQNMFLVFRAATDQCPAAEGWIPGFVLGHTSAVIVENPDGTLKKSTSWHTALRLRKKSEKKDKDGKREGKLENGYRKSREGLSNKVSVKLLNPNYIYDVPPEFVIPLSEVTCETGETVVLRCRVCGRPKASITWKGPEHNTLNNDGHYSISYSDLGEATLKIVGVTTEDDGIYTCIAVNDMGSASSSASLRVLGPGMDGIMVTWKDNFDSFYSEVAELGRGRFSVVKKCDQKGTKRAVATKFVNKKLMKRDQVTHELGILQSLQHPLLVGLLDTFETPTSYILVLEMADQGRLLDCVVRWGSLTEGKIRAHLGEVLEAVRYLHNCRIAHLDLKPENILVDESLAKPTIKLADFGDAVQLNTTYYIHQLLGNPEFAAPEIILGNPVSLTSDTWSVGVLTYVLLSGVSPFLDDSVEETCLNICRLDFSFPDDYFKGVSQKAKEFVCFLLQEDPAKRPSAALALQEQWLQAGNGRSTGVLDTSRLTSFIERRKHQNDVRPIRSIKNFLQSRLLPRV>sp|O75962-4|TRIO_HUMAN Isoform 4 of Triple functional domain proteinOS=Homo sapiens OX=9606 GN=TRIOMKAMDVLPILKEKVAYLSGGRDKRGGPILTFPARSNHDRIRQEDLRRLISYLACIPSEEVCKRGFTVIVDMRGSKWDSIKPLLKILQESFPCCIHVALIIKPDNFWQKQRTNFGSSKFEFETNMVSLEGLTKVVDPSQLTPEFDGCLEYNHEEWIEIRVAFEDYISNATHMLSRLEELQDILAKKELPQDLEGARNMIEEHSQLKKKVIKAPIEDLDLEGQKLLQRIQSSESFPKKNSGSGNADLQNLLPKVSTMLDRLHSTRQHLHQMWHVRKLKLDQCFQLRLFEQDAEKMFDWITHNKGLFLNSYTEIGTSHPHAMELQTQHNHFAMNCMNVYVNINRIMSVANRLVESGHYASQQIRQIASQLEQEWKAFAAALDERSTLLDMSSIFHQKAEKYMSNVDSWCKACGEVDLPSELQDLEDAIHHHQGIYEHITLAYSEVSQDGKSLLDKLQRPLTPGSSDSLTASANYSKAVHHVLDVIHEVLHHQRQLENIWQHRKVRLHQRLQLCVFQQDVQQVLDWIENHGEAFLSKHTGVGKSLHRARALQKRHEDFEEVAQNTYTNADKLLEAAEQLAQTGECDPEEIYQAAHQLEDRIQDFVRRVEQRKILLDMSVSFHTHVKELWTWLEELQKELLDDVYAESVEAVQDLIKRFGQQQQTTLQVTVNVIKEGEDLIQQLRDSAISSNKTPHNSSINHIETVLQQLDEAQSQMEELFQERKIKLELFLQLRIFERDAIDIISDLESWNDELSQQMNDFDTEDLTIAEQRLQHHADKALTMNNLTFDVIHQGQDLLQYVNEVQASGVELLCDRDVDMATRVQDLLEFLHEKQQELDLAAEQHRKHLEQCVQLRHLQAEVKQVLGWIRNGESMLNAGLITASSLQEAEQLQREHEQFQHAIEKTHQSALQVQQKAEAMLQANHYDMDMIRDCAEKVASHWQQLMLKMEDRLKLVNASVAFYKTSEQVCSVLESLEQEYKREEDWCGGADKLGPNSETDHVTPMISKHLEQKEAFLKACTLARRNADVFLKYLHRNSVNMPGMVTHIKAPEQQVKNILNELFQRENRVLHYWTMRKRRLDQCQQYVVFERSAKQALEWIHDNGEFYLSTHTSTGSSIQHTQELLKEHEEFQITAKQTKERVKLLIQLADGFCEKGHAHAAEIKKCVTAVDKRYRDFSLRMEKYRTSLEKALGISSDSNKSSKSLQLDIIPASIPGSEVKLRDAAHELNEEKRKSARRKEFIMAELIQTEKAYVRDLRECMDTYLWEMTSGVEEIPPGIVNKELIIFGNMQEIYEFHNNIFLKELEKYEQLPEDVGHCFVTWADKFQMYVTYCKNKPDSTQLILEHAGSYFDEIQQRHGLANSISSYLIKPVQRITKYQLLLKELLTCCEEGKGEIKDGLEVMLSVPKRANDAMHLSMLEGFDENIESQGELILQESFQVWDPKTLIRKGRERHLFLFEMSLVFSKEVKDSSGRSKYLYKSKLFTSELGVTEHVEGDPCKFALWVGRTPTSDNKIVLKASSIENKQDWIKHIREVIQERTIHLKGALKEPIHIPKTAPATRQKGRRDGEDLDSQGDGSSQPDTISIASRTSQNTLDSDKLSGGCELTVVIHDFTACNSNELTIRRGQTVEVLERPHDKPDWCLVRTTDRSPAAEGLVPCGSLCIAHSRSSMEMEGIFNHKDSLSVSSNDASPPASVASLQPHMIGAQSSPGPKRPGNTLRKWLTSPVRRLSSGKADGHVKKLAHKHKKSREVRKSADAGSQKDSDDSAATPQDETVEERGRNEGLSSGTLSKSSSSGMQSCGEEEGEEGADAVPLPPPMAIQQHSLLQPDSQDDKASSRLLVRPTSSETPSAAELVSAIEELVKSKMALEDRPSSLLVDQGDSSSPSFNPSDNSLLSSSSPIDEMEERKSSSLKRRHYVLQELVETERDYVRDLGYVVEGYMALMKEDGVPDDMKGKDKIVFGNIHQIYDWHRDFFLGELEKCLEDPEKLGSLFVKHERRLHMYIAYCQNKPKSEHIVSEYIDTFFEDLKQRLGHRLQLTDLLIKPVQRIMKYQLLLKDFLKYSKKASLDTSELERAVEVMCIVPRRCNDMMNVGRLQGFDGKIVAQGKLLLQDTFLVTDQDAGLLPRCRERRIFLFEQIVIFSEPLDKKKGFSMPGFLFKNSIKVSCLCLEENVENDPCKFALTSRTGDVVETFILHSSSPSVRQTWIHEINQILENQRNFLNALTSPIEYQRNHSGGGGGGGSGGSGGGGGSGGGGAPSGGSGHSGGPSSCGGAPSTSRSRPSRIPQPVRHHPPVLVSSAASSQAEADKMSGTSTPGPSLPPPGAAPEAGPSAPSRRPPGADAEGSEREAEPIPKMKVLESPRKGAANASGSSPDAPAKDARASLGTLPLGKPRAGAASPLNSPLSSAVPSLGKEPFPPSSPLQKGGSFWSSIPASPASRPGSFTFPGDSDSLQRQTPRHAAPGKDTDRMSTCSSASEQSVQSTQSNGSESSSSSNISTMLVTHDYTAVKEDEINVYQGEVVQILASNQQNMFLVFRAATDQCPAAEGWIPGFVLGHTSAVIVENPDGTLKKSTSWHTALRLRKKSEKKDKDGKREGKLENGYRKSREGLSNKVSVKLLNPNYIYDVPPEFVIPLSEVTCETGETVVLRCRVCGRPKASITWKGPEHNTLNNDGHYSISYSDLGEATLKIVGVTTEDDGIYTCIAVNDMGSASSSASLRVLGPGMDGIMVTWKDNFDSFYSEVAELGRGRFSVVKKCDQKGTKRAVATKFVNKKLMKRDQVTHELGILQSLQHPLLVGLLDTFETPTSYILVLEMADQGRLLDCVVRWGSLTEGKIRAHLGEVLEAVRYLHNCRIAHLDLKPENILVDESLAKPTIKLADFGDAVQLNTTYYIHQLLGNPEFAAPEIILGNPVSLTSDTWSVGVLTYVLLSGVSPFLDDSVEETCLNICRLDFSFPDDYFKGVSQKAKEFVCFLLQEDPAKRPSAALALQEQWLQAGNGRSTGVLDTSRLTSFIERRKHQNDVRPIRSIKNFLQSRLLPRV>sp|O75962-5|TRIO_HUMAN Isoform 5 of Triple functional domain proteinOS=Homo sapiens OX=9606 GN=TRIOMSGSSGGAAAPAASSGPAAAASAAGSGCGGGAGEGAEEAAKDLADIAAFFRSGFRKNDEMKAMDVLPILKEKVAYLSGGRDKRGGPILTFPARSNHDRIRQEDLRRLISYLACIPSEEVCKRGFTVIVDMRGSKWDSIKPLLKILQESFPCCIHVALIIKPDNFWQKQRTNFGSSKFEFETNMVSLEGLTKVVDPSQLTPEFDGCLEYNHEEWIEIRVAFEDYISNATHMLSRLEELQDILAKKELPQDLEGARNMIEEHSQLKKKVIKAPIEDLDLEGQKLLQRIQSSESFPKKNSGSGNADLQNLLPKVSTMLDRLHSTRQHLHQMWHVRKLKLDQCFQLRLFEQDAEKMFDWITHNKGLFLNSYTEIGTSHPHAMELQTQHNHFAMNCMNVYVNINRIMSVANRLVESGHYASQQIRQIASQLEQEWKAFAAALDERSTLLDMSSIFHQKAEKYMSNVDSWCKACGEVDLPSELQDLEDAIHHHQGIYEHITLAYSEVSQDGKSLLDKLQRPLTPGSSDSLTASANYSKAVHHVLDVIHEVLHHQRQLENIWQHRKVRLHQRLQLCVFQQDVQQVLDWIENHGEAFLSKHTGVGKSLHRARALQKRHEDFEEVAQNTYTNADKLLEAAEQLAQTGECDPEEIYQAAHQLEDRIQDFVRRVEQRKILLDMSVSFHTHVKELWTWLEELQKELLDDVYAESVEAVQDLIKRFGQQQQTTLQVTVNVIKEGEDLIQQLRDSAISSNKTPHNSSINHIETVLQQLDEAQSQMEELFQERKIKLELFLQLRIFERDAIDIISDLESWNDELSQQMNDFDTEDLTIAEQRLQHHADKALTMNNLTFDVIHQGQDLLQYVNEVQASGVELLCDRDVDMATRVQDLLEFLHEKQQELDLAAEQHRKHLEQCVQLRHLQAEVKQVLGWIRNGESMLNAGLITASSLQEAEQLQREHEQFQHAIEKTHQSALQVQQKAEAMLQANHYDMDMIRDCAEKVASHWQQLMLKMEDRLKLVNASVAFYKTSEQVCSVLESLEQEYKREEDWCGGADKLGPNSETDHVTPMISKHLEQKEAFLKACTLARRNADVFLKYLHRNSVNMPGMVTHIKAPEQQVKNILNELFQRENRVLHYWTMRKRRLDQCQQYVVFERSAKQALEWIHDNGEFYLSTHTSTGSSIQHTQELLKEHEEFQITAKQTKERVKLLIQLADGFCEKGHAHAAEIKKCVTAVDKRYRDFSLRMEKYRTSLEKALGISSDSNKSSKSLQLDIIPASIPGSEVKLRDAAHELNEEKRKSARRKEFIMAELIQTEKAYVRDLRECMDTYLWEMTSGVEEIPPGIVNKELIIFGNMQEIYEFHNNIFLKELEKYEQLPEDVGHCFVTWADKFQMYVTYCKNKPDSTQLILEHAGSYFDEIQQRHGLANSISSYLIKPVQRITKYQLLLKELLTCCEEGKGEIKDGLEVMLSVPKRANDAMHLSMLEGFDENIESQGELILQESFQVWDPKTLIRKGRERHLFLFEMSLVFSKEVKDSSGRSKYLYKSKLFTSELGVTEHVEGDPCKFALWVGRTPTSDNKIVLKASSIENKQDWIKHIREVIQERTIHLKGALKEPIHIPKTAPATRQKGRRDGEDLDSQGDGSSQPDTISIASRTSQNTLDSDKLSGGCELTVVIHDFTACNSNELTIRRGQTVEVLERPHDKPDWCLVRTTDRSPAAEGLVPCGSLCIAHSRSSMEMEGIFNHKDSLSVSSNDASPPASVASLQPHMIGAQSSPGPKRPGNTLRKWLTSPVRRLSSGKADGHVKKLAHKHKKSREVRKSADAGSQKDSDDSAATPQDETVEERGRNEGLSSGTLSKSSSSGMQSCGEEEGEEGADAVPLPPPMAIQQHSLLQPDSQDDKASSRLLVRPTSSETPSAAELVSAIEELVKSKMALEDRPSSLLVDQGDSSSPSFNPSDNSLLSSSSPIDEMEERKSSSLKRRHYVLQELVETERDYVRDLGYVVEGYMALMKEDGVPDDMKGKDKIVFGNIHQIYDWHRDFFLGELEKCLEDPEKLGSLFVKHERRLHMYIAYCQNKPKSEHIVSEYIDTFFEDLKQRLGHRLQLTDLLIKPVQRIMKYQLLLKDFLKYSKKASLDTSELERAVEVMCIVPRRCNDMMNVGRLQGFDGKIVAQGKLLLQDTFLVTDQDAGLLPRCRERRIFLFEQIVIFSEPLDKKKGFSMPGFLFKNSIKVSCLCLEENVENDPCKFALTSRTGDVVETFILHSSSPSVRQTWIHEINQILENQRNFLNALTSPIEYQRNHSGGGGGGGSGGSGGGGGSGGGGAPSGGSGHSGGPSSCGGAPSTSRSRPSRIPQPVRHHPPVLVSSAASSQAEADKMSGTSTPGPSLPPPGAAPEAGPSAPSRRPPGADAEGSEREAEPIPKMKVLESPRKGAANASGSSPDAPAKDARASLGTLPLGKPRAGAASPLNSPLSSAVPSLGKEPFPPSSPLQKGGSFWSSIPASPASRPGSFTFPGDSDSLQRQTPRHAAPGKDTDRMSTCSSASEQSVQSTQSNGVSASGGPRPPAPLPLSRQL>sp|Q5T9Z0|TEDM1_HUMAN Transmembrane epididymal protein 1 OS=Homo sapiensOX=9606 GN=TEDDM1 PE=2 SV=1MILKGCLLYPLCSPRNKQRCARLWKIAYGGLLKIVTGSLLTFYVVLCLDGGMVLMRKQVPSRFMYPKEWQHLTMFILLTLNGCVDFMSKNVLPQRCVGLEKGTLVLIIYELLLLMVSHVKDSEGVELHVYSLLILVVFLLLLVLTAELWAPNMCHLQLMETFLILMMGSWLMQAGFILYRPVSGYPWQDDDISDIMFVTTFFCWHVMINASFLLGIYGFSSFWYHCFRPSLKLTGPKEAPYYASTPGPLYKLLQEVEQSEKEDQALLLPKSSP>sp|Q12888|TP53B_HUMAN TP53-binding protein 1 OS=Homo sapiens OX=9606GN=TP53BP1 PE=1 SV=2MDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLKENKVADPVDSSNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDTSGNTTHSLGAEDTASSQLGFGVLELSQSQDVEENTVPYEVDKEQLQSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVKEQNPPPARSEDMPFSPKASVAAMEAKEQLSAQELMESGLQIQKSPEPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSLVQDSLSTNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPPGSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHRIDEDGENTQIEDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISILATGCKGREETVAEDVCIDLTCDSGSQAVPSPATRSEALSSVLDQEEAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQGLCLQKEMPKKECSEAMEVETSVISIDSPQKLAILDQELEHKEQEAWEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAENRLDTKEEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSFCESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKLCLRMKLVSPETEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARSEDPPTTPIRGNLLHFPSSQGEEEKEKLEGDHTIRQSQQPMKPISPVKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQNNIGIQTMECSLRVPETVSAATQTIKNVCEQGTSTVDQNFGKQDATVQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLVTRVITDVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTEPADFALPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTPRGRGRRGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKSFSRVVPRVPDSTRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKWSSNGYFYSGKITRDVGAGKYKLLFDDGYECDVLGKDILLCDPIPLDTEVTALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNRLREQYGLGPYEAVTPLTKAADISLDNLVEGKRKRRSNVSSPATPTASSSSSTTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPGAVGAGEFVSPCESGDNTGEPSALEEQRGPLPLNKTLFLGYAFLLTMATTSDKLASRSKLPDGPTGSSEEEEEFLEIPPFNKQYTESQLRAGAGYILEDFNEAQCNTAYQCLLIADQHCRTRKYFLCLASGIPCVSHVWVHDSCHANQLQNYRNYLLPAGYSLEEQRILDWQPRENPFQNLKVLLVSDQQQNFLELWSEILMTGGAASVKQHHSSAHNKDIALGVFDVVVTDPSCPASVLKCAEALQLPVVSQEWVIQCLIVGERIGFKQHPKYKHDYVSH>sp|Q12888-2|TP53B_HUMAN Isoform 2 of TP53-binding protein 1 OS=Homosapiens OX=9606 GN=TP53BP1MPGEQMDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLKENKVADPVDSSNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDTSGNTTHSLGAEDTASSQLGFGVLELSQSQDVEENTVPYEVDKEQLQSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVKEQNPPPARSEDMPFSPKASVAAMEAKEQLSAQELMESGLQIQKSPEPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSLVQDSLSTNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPPGSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHRIDEDGENTQIEDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISILATGCKGREETVAEDVCIDLTCDSGSQAVPSPATRSEALSSVLDQEEAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQGLCLQKEMPKKECSEAMEVETSVISIDSPQKLAILDQELEHKEQEAWEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAENRLDTKEEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSFCESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKLCLRMKLVSPETEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARSEDPPTTPIRGNLLHFPSSQGEEEKEKLEGDHTIRQSQQPMKPISPVKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQNNIGIQTMECSLRVPETVSAATQTIKNVCEQGTSTVDQNFGKQDATVQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLVTRVITDVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTEPADFALPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTPRGRGRRGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKSFSRVVPRVPDSTRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKWSSNGYFYSGKITRDVGAGKYKLLFDDGYECDVLGKDILLCDPIPLDTEVTALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNRLREQYGLGPYEAVTPLTKAADISLDNLVEGKRKRRSNVSSPATPTASSSSSTTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPGAVGAGEFVSPCESGDNTGEPSALEEQRGPLPLNKTLFLGYAFLLTMATTSDKLASRSKLPDGPTGSSEEEEEFLEIPPFNKQYTESQLRAGAGYILEDFNEAQCNTAYQCLLIADQHCRTRKYFLCLASGIPCVSHVWVHDSCHANQLQNYRNYLLPAGYSLEEQRILDWQPRENPFQNLKVLLVSDQQQNFLELWSEILMTGGAASVKQHHSSAHNKDIALGVFDVVVTDPSCPASVLKCAEALQLPVVSQEWVIQCLIVGERIGFKQHPKYKHDYVSH>sp|Q12888-3|TP53B_HUMAN Isoform 3 of TP53-binding protein 1 OS=Homosapiens OX=9606 GN=TP53BP1MPGEQMDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLKENKVADPVDSSNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDTSGNTTHSLGAEDTASSQLGFGVLELSQSQDVEENTVPYEVDKEQLQSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVKEQNPPPARSEDMPFSPKASVAAMEAKEQLSAQELMESGLQIQKSPEPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSLVQDSLSTNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPPGSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHRIDEDGENTQIEDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISILATGCKGREETVAEDVCIDLTCDSGSQAVPSPATRSEALSSVLDQEEAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQGLCLQKEMPKKECSEAMEVETSVISIDSPQKLAILDQELEHKEQEAWEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAENRLDTKEEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSFCESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKLCLRMKLVSPETEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARSEDPPTTPIRGNLLHFPSSQGEEEKEKLEGDHTIRQSQQPMKPISPVKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQNNIGIQTMECSLRVPETVSAATQTIKNVCEQGTSTVDQNFGKQDATVQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLVTRVITDVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTEPADFALPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTPRGRGRRGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKSFSRVVPRVPDSTRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKWSSNGYFYSGKITRDVGAGKYKLLFDDGYECDVLGKDILLCDPIPLDTEVTALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNRLREQYGLGPYEAVTPLTKAADISLDNLVEGKRKRRSNVSSPATPTASSSSSTTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPVGAGEFVSPCESGDNTGEPSALEEQRGPLPLNKTLFLGYAFLLTMATTSDKLASRSKLPDGPTGSSEEEEEFLEIPPFNKQYTESQLRAGAGYILEDFNEAQCNTAYQCLLIADQHCRTRKYFLCLASGIPCVSHVWVHDSCHANQLQNYRNYLLPAGYSLEEQRILDWQPRENPFQNLKVLLVSDQQQNFLELWSEILMTGGAASVKQHHSSAHNKDIALGVFDVVVTDPSCPASVLKCAEALQLPVVSQEWVIQCLIVGERIGFKQHPKYKHDYVSH>sp|Q5GJ75|TP8L3_HUMAN Tumor necrosis factor alpha-induced protein 8-likeprotein 3 OS=Homo sapiens OX=9606 GN=TNFAIP8L3 PE=1 SV=1MGKPRQNPSTLVSTLCEAEPKGKLWVNGYAGTQGTRDATLQTRLIPLSFHLQRGKGLAAPLSALSAPRLPERPADGRVAVDAQPAARSMDSDSGEQSEGEPVTAAGPDVFSSKSLALQAQKKILSKIASKTVANMLIDDTSSEIFDELYKVTKEHTHNKKEAHKIMKDLIKVAIKIGILYRNNQFSQEELVIVEKFRKKLNQTAMTIVSFYEVEYTFDRNVLSNLLHECKDLVHELVQRHLTPRTHGRINHVFNHFADVEFLSTLYSLDGDCRPNLKRICEGINKLLDEKVL>sp|A6NKF7|TM88B_HUMAN Transmembrane protein 88B OS=Homo sapiens OX=9606GN=TMEM88B PE=3 SV=1MSEQGRETEEEEGGGGASDTAPMLPRGPPDHQASALTCPGWSGPPLLPGRLLAGLLLHLLLPAAAFLLVLLPAAAVVYLGFLCHSRVHPAPGPRCRALFSDRGSAALIVFGLLSLPPLLVLASAVRARLARRLRPLLPPPAGTPGPRRPPGRPDEDEQLCAWV>sp|Q7Z5M5|TMC3_HUMAN Transmembrane channel-like protein 3 OS=Homosapiens OX=9606 GN=TMC3 PE=2 SV=3MKTSKASQRYRGIRRNASQCYLYQESLLLSNLDDSFSADETGDSNDPEQIFQNIQFQKDLMANIRCRPWTMGQKLRALRQAKNIVLKFEGRLTRTRGYQAAGAELWRKFARLACNFVVIFIPWEMRIKKIESHFGSGVASYFIFLRWLFGINIVLTIMTGAFIVIPELIAGQPFGSTARKTIPKEQVSSAQDLDTVWSLGGYLQYSVLFYGYYGRERKIGRAGYRLPLAYFLVGMAVFAYSFIILLKKMAKNSRTSLASASNENYTFCWRVFCAWDYLIGNPEAAESKTAAIVNSIREAILEEQEKKKSKNLAVTICLRIIANILVLLSLAGSIYLIYFVVDRSQKLEQSKKELTLWEKNEVSVVVSLVTMIAPSAFDLIAALEMYHPRTTLRFQLARVLVLYLGNLYSLIIALLDKVNSMSIEEMATKNNTSHWIDSTTFFATRTAPEEEKWSTSRPGMGLRRNNTWALEETSISAYTMPLIKANKTSLHTQSPQDQCWETYVGQEMLKLSIIDMLFTVASILLIDFFRGLFVRYLSDYWCWDLESKFPEYGEFKIAENVLHLVYNQGMIWMGAFFSPCLPAFNVLKLIGLMYLRSWAVLTCNVPHQQVFRASRSNNFYLAMLLFMLFLCMLPTIFAIVRYKPSLNCGPFSGQEKIYDIVSETIEKDFPVWFGSVVGHISSPVVILPAVLLLFMLIYYLQSIARSLKLSNHQLKMQIQNARSEDKKKVAQMVEARIQTQEESTKKLPNDSDLTSQLSSAHSGTPQNNGNVAHFDSGSSKSGRIETVAQSMPQSPRPGDRAPSSPLPGVPKSRLEHETNRYLHGLCASTSDLHRNRSRTPMTFTTHIEDVHSEPLFRKDFQQINPPHRGPQASTLLAQGPRPHAPRYYVINECDSYKKKHLNVWPERHFKIDASGDIVELYPRNVRQYASRVPRQPPSPQLSEEEEETPSRDWIKRSLPPRSLIDLRRAPHFYIGERSESQTRDPEHQGRVHYKSWNEDFEGHLERPAYVPRKPRSRNFQYPQPPLKPRGKPRFEPSLTESDSVSAASSSDQQNSSADQYLQVTHSQGRFPRSVGQPSRRKAKSGQELTVDLDDLICSDV>sp|Q7Z5M5-2|TMC3_HUMAN Isoform 2 of Transmembrane channel-like protein 3OS=Homo sapiens OX=9606 GN=TMC3MKTSKASQRYRGIRRNASQCYLYQESLLLSNLDDSFSADETGDSNDPEQIFQNIQFQKDLMANIRCRPWTMGQKLRALRQAKNIVLKFEGRLTRTRGYQAAGAELWRKFARLACNFVVIFIPWEMRIKKIESHFGSGVASYFIFLRWLFGINIVLTIMTGAFIVIPELIAGQPFGSTARKTIPKEQVSSAQDLDTVWSLGGYLQYSVLFYGYYGRERKIGRAGYRLPLAYFLVGMAVFAYSFIILLKKMAKNSRTSLASASNENYTFCWRVFCAWDYLIGNPEAAESKTAAIVNSIREAILEEQEKKKSKNLAVTICLRIIANILVLLSLAGSIYLIYFVVDRSQKLEQSKKELTLWEKNEVSVVVSLVTMIAPSAFDLIAALEMYHPRTTLRFQLARVLVLYLGNLYSLIIALLDKVNSMSIEEMATKNNTSHWIDSTTFFATRTAPEEEKWSTSRPGMGLRRNNTWALEETSISAYTMPLIKANKTSLHTQSPQDQCWETYVGQEMLKLSIIDMLFTVASILLIDFFRGLFVRYLSDYWCWDLESKFPEYGEFKIAENVLHLVYNQGMIWMGAFFSPCLPAFNVLKLIGLMYLRSWAVLTCNVPHQQVFRASRSNNFYLAMLLFMLFLCMLPTIFAIVRYKPSLNCGPFSGQEKIYDIVSETIEKDFPVWFGSVVGHISSPVVILPAVLLLFMLIYYLQSIARSLKLSNHQLKMQIQNASIS>sp|Q969Z4|TR19L_HUMAN Tumor necrosis factor receptor superfamily member19L OS=Homo sapiens OX=9606 GN=RELT PE=1 SV=1MKPSLLCRPLSCFLMLLPWPLATLTSTTLWQCPPGEEPDLDPGQGTLCRPCPPGTFSAAWGSSPCQPHARCSLWRRLEAQVGMATRDTLCGDCWPGWFGPWGVPRVPCQPCSWAPLGTHGCDEWGRRARRGVEVAAGASSGGETRQPGNGTRAGGPEETAAQYAVIAIVPVFCLMGLLGILVCNLLKRKGYHCTAHKEVGPGPGGGGSGINPAYRTEDANEDTIGVLVRLITEKKENAAALEELLKEYHSKQLVQTSHRPVSKLPPAPPNVPHICPHRHHLHTVQGLASLSGPCCSRCSQKKWPEVLLSPEAVAATTPVPSLLPNPTRVPKAGAKAGRQGEITILSVGRFRVARIPEQRTSSMVSEVKTITEAGPSWGDLPDSPQPGLPPEQQALLGSGGSRTKWLKPPAENKAEENRYVVRLSESNLVI>sp|P0DKB5|TPBGL_HUMAN Trophoblast glycoprotein-like OS=Homo sapiensOX=9606 GN=TPBGL PE=3 SV=1MAPRAGQPGLQGLLLVAAALSQPAAPCPFQCYCFGGPKLLLRCASGAELRQPPRDVPPDARNLTIVGANLTVLRAAAFAGGDGDGDQAAGVRLPLLSALRLTHNHIEVVEDGAFDGLPSLAALDLSHNPLRALGGGAFRGLPALRSLQLNHALVRGGPALLAALDAALAPLAELRLLGLAGNALSRLPPAALRLARLEQLDVRLNALAGLDPDELRALERDGGLPGPRLLLADNPLRCGCAARPLLAWLRNATERVPDSRRLRCAAPRALLDRPLLDLDGARLRCADSGADARGEEAEAAGPELEASYVFFGLVLALIGLIFLMVLYLNRRGIQRWMRNLREACRDQMEGYHYRYEQDADPRRAPAPAAPAGSRATSPGSGL>sp|Q9NP99|TREM1_HUMAN Triggering receptor expressed on myeloid cells 1OS=Homo sapiens OX=9606 GN=TREM1 PE=1 SV=1MRKTRLWGLLWMLFVSELRAATKLTEEKYELKEGQTLDVKCDYTLEKFASSQKAWQIIRDGEMPKTLACTERPSKNSHPVQVGRIILEDYHDHGLLRVRMVNLQVEDSGLYQCVIYQPPKEPHMLFDRIRLVVTKGFSGTPGSNENSTQNVYKIPPTTTKALCPLYTSPRTVTQAPPKSTADVSTPDSEINLTNVTDIIRVPVFNIVILLAGGFLSKSLVFSVLFAVTLRSFVP>sp|Q9NP99-2|TREM1_HUMAN Isoform 2 of Triggering receptor expressed onmyeloid cells 1 OS=Homo sapiens OX=9606 GN=TREM1MRKTRLWGLLWMLFVSELRAATKLTEEKYELKEGQTLDVKCDYTLEKFASSQKAWQIIRDGEMPKTLACTERPSKNSHPVQVGRIILEDYHDHGLLRVRMVNLQVEDSGLYQCVIYQPPKEPHMLFDRIRLVVTKGFRCSTLSFSWLVDS>sp|Q9NP99-3|TREM1_HUMAN Isoform 3 of Triggering receptor expressed onmyeloid cells 1 OS=Homo sapiens OX=9606 GN=TREM1MRKTRLWGLLWMLFVSELRAATKLTEEKYELKEGQTLDVKCDYTLEKFASSQKAWQIIRDGEMPKTLACTERPSKNSHPVQVGRIILEDYHDHGLLRVRMVNLQVEDSGLYQCVIYQPPKEPHMLFDRIRLVVTKGFSGTPGSNENSTQNVYKIPPTTTKALCPLYTSPRTVTQAPPKSTADVSTPDSEINLTNVTDIIRYSFQVPGPLVWTLSPLFPSLCAERM>sp|P61165|TM258_HUMAN Transmembrane protein 258 OS=Homo sapiens OX=9606GN=TMEM258 PE=1 SV=1MELEAMSRYTSPVNPAVFPHLTVVLLAIGMFFTAWFFVYEVTSTKYTRDIYKELLISLVASLFMGFGVLFLLLWVGIYV>sp|Q969K7|TMM54_HUMAN Transmembrane protein 54 OS=Homo sapiens OX=9606GN=TMEM54 PE=1 SV=1MCLRLGGLSVGDFRKVLMKTGLVLVVLGHVSFITAALFHGTVLRYVGTPQDAVALQYCVVNILSVTSAIVVITSGIAAIVLSRYLPSTPLRWTVFSSSVACALLSLTCALGLLASIAMTFATQGKALLAACTFGSSELLALAPDCPFDPTRIYSSSLCLWGIALVLCVAENVFAVRCAQLTHQLLELRPWWGKSSHHMMRENPELVEGRDLLSCTSSEPLTL>sp|Q969K7-2|TMM54_HUMAN Isoform 2 of Transmembrane protein 54 OS=Homosapiens OX=9606 GN=TMEM54MCLRLGGLSVGDFRKVLMKTGLVLVVLGHVSFITAALFHGTVLRYVGTPQDAVALQYCVVNILSVTSAIVRWTVFSSSVACALLSLTCALGLLASIAMTFATQGKALLAACTFGSSELLALAPDCPFDPTRIYSSSLCLWGIALVLCVAENVFAVRCAQLTHQLLELRPWWGKSSHHMMRENPELVEGRDLLSCTSSEPLTL>sp|Q969K7-3|TMM54_HUMAN Isoform 3 of Transmembrane protein 54 OS=Homosapiens OX=9606 GN=TMEM54MCLRLGGLSVGDFRKVLMKTGLVLVVLGHVSFITAALFHGTVLRYVGTPQDAVALQYCVVNILSVTSAIVGKALLAACTFGSSELLALAPDCPFDPTRIYSSSLCLWGIALVLCVAENVFAVRCAQLTHQLLELRPWWGKSSHHMMRENPELVEGRDLLSCTSSEPLTL>sp|Q9HBA0|TRPV4_HUMAN Transient receptor potential cation channelsubfamily V member 4 OS=Homo sapiens OX=9606 GN=TRPV4 PE=1 SV=2MADSSEGPRAGPGEVAELPGDESGTPGGEAFPLSSLANLFEGEDGSLSPSPADASRPAGPGDGRPNLRMKFQGAFRKGVPNPIDLLESTLYESSVVPGPKKAPMDSLFDYGTYRHHSSDNKRWRKKIIEKQPQSPKAPAPQPPPILKVFNRPILFDIVSRGSTADLDGLLPFLLTHKKRLTDEEFREPSTGKTCLPKALLNLSNGRNDTIPVLLDIAERTGNMREFINSPFRDIYYRGQTALHIAIERRCKHYVELLVAQGADVHAQARGRFFQPKDEGGYFYFGELPLSLAACTNQPHIVNYLTENPHKKADMRRQDSRGNTVLHALVAIADNTRENTKFVTKMYDLLLLKCARLFPDSNLEAVLNNDGLSPLMMAAKTGKIGIFQHIIRREVTDEDTRHLSRKFKDWAYGPVYSSLYDLSSLDTCGEEASVLEILVYNSKIENRHEMLAVEPINELLRDKWRKFGAVSFYINVVSYLCAMVIFTLTAYYQPLEGTPPYPYRTTVDYLRLAGEVITLFTGVLFFFTNIKDLFMKKCPGVNSLFIDGSFQLLYFIYSVLVIVSAALYLAGIEAYLAVMVFALVLGWMNALYFTRGLKLTGTYSIMIQKILFKDLFRFLLVYLLFMIGYASALVSLLNPCANMKVCNEDQTNCTVPTYPSCRDSETFSTFLLDLFKLTIGMGDLEMLSSTKYPVVFIILLVTYIILTFVLLLNMLIALMGETVGQVSKESKHIWKLQWATTILDIERSFPVFLRKAFRSGEMVTVGKSSDGTPDRRWCFRVDEVNWSHWNQNLGIINEDPGKNETYQYYGFSHTVGRLRRDRWSSVVPRVVELNKNSNPDEVVVPLDSMGNPRCDGHQQGYPRKWRTDDAPL>sp|Q9HBA0-2|TRPV4_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily V member 4 OS=Homo sapiens OX=9606 GN=TRPV4MADSSEGPRAGPGEVAELPGDESGTPGGEAFPLSSLANLFEGEDGSLSPSPADASRPAGPGDGRPNLRMKFQGAFRKGVPNPIDLLESTLYESSVVPGPKKAPMDSLFDYGTYRHHSSDNKRWRKKIIEKQPQSPKAPAPQPPPILKVFNRPILFDIVSRGSTADLDGLLPFLLTHKKRLTDEEFREPSTGKTCLPKALLNLSNGRNDTIPVLLDIAERTGNMREFINSPFRDIYYRGQTALHIAIERRCKHYVELLVAQGADVHAQARGRFFQPKDEGGYFYFGELPLSLAACTNQPHIVNYLTENPHKKADMRRQDSRGNTVLHALVAIADNTRENTKFVTKMYDLLLLKCARLFPDSNLEAVLNNDGLSPLMMAAKTGKIGNRHEMLAVEPINELLRDKWRKFGAVSFYINVVSYLCAMVIFTLTAYYQPLEGTPPYPYRTTVDYLRLAGEVITLFTGVLFFFTNIKDLFMKKCPGVNSLFIDGSFQLLYFIYSVLVIVSAALYLAGIEAYLAVMVFALVLGWMNALYFTRGLKLTGTYSIMIQKILFKDLFRFLLVYLLFMIGYASALVSLLNPCANMKVCNEDQTNCTVPTYPSCRDSETFSTFLLDLFKLTIGMGDLEMLSSTKYPVVFIILLVTYIILTFVLLLNMLIALMGETVGQVSKESKHIWKLQWATTILDIERSFPVFLRKAFRSGEMVTVGKSSDGTPDRRWCFRVDEVNWSHWNQNLGIINEDPGKNETYQYYGFSHTVGRLRRDRWSSVVPRVVELNKNSNPDEVVVPLDSMGNPRCDGHQQGYPRKWRTDDAPL>sp|Q9HBA0-3|TRPV4_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily V member 4 OS=Homo sapiens OX=9606 GN=TRPV4MADSSEGPRAGPGEVAELPGDESGTPGGEAFPLSSLANLFEGEDGSLSPSPADASRPAGPGDGRPNLRMKFQGAFRKGVPNPIDLLESTLYESSVVPGPKKAPMDSLFDYGTYRHHSSDNKRWRKKIIEKQPQSPKAPAPQPPPILKVFNRPILFDIVSRGSTADLDGLLPFLLTHKKRLTDEEFREPSTGKTCLPKALLNLSNGRNDTIPVLLDIAERTGNMREFINSPFRDIYYRGQTALHIAIERRCKHYVELLVAQGADVHAQARGRFFQPKDEGGYFYFGELPLSLAACTNQPHIVNYLTENPHKKADMRRQDSRGNTVLHALVAIADNTRENTKFVTKMYDLLLLKCARLFPDSNLEAVLNNDGLSPLMMAAKTGKIGIFQHIIRREVTDEDTRHLSRKFKDWAYGPVYSSLYDLSSLDTCGEEASVLEILVYNSKIENRHEMLAVEPINELLRDKWRKFGAVSFYINVVSYLCAMVIFTLTAYYQPLEGTPPYPYRTTVDYLRLAGEVITLFTGVLFFFTNIKDLFMKKCPGVNSLFIDGSFQLLYFIYSVLVIVSAALYLAGIEAYLAVMVFALVLGWMNALYFTRGLKLTGTYSIMIQKILFKDLFRFLLVYLLFMIGYASALVSLLNPCANMKVCNEDQTNCTVPTYPSCRDSETFSTFLLDLFKLTIGMGDLEMLSSTKYPVVFIILLVTYIILTFVLLLNMLIALMGETVGQVSKESKHIWKLQWATTILDIERSFPVFLRKAFRSGEMVTVGKSSDGTPDRRWCFRVDEVNWSHWNQNLGIINEDPGKNETYQYYGFSHTVGRLRRDRWSSVVPRVVELNKNSNPDEVVVRHLCRVRRKR>sp|Q9HBA0-4|TRPV4_HUMAN Isoform 4 of Transient receptor potential cationchannel subfamily V member 4 OS=Homo sapiens OX=9606 GN=TRPV4MADSSEGPRAGPGEVAELPGDESGTPGGEAFPLSSLANLFEGEDGSLSPSPADASRPAGPGDGRPNLRMKFQGAFRKGVPNPIDLLESTLYESSVVPGPKKAPMDSLFDYGTYRHHSSDNKRWRKKIIEKQPQSPKAPAPQPPPILKVFNRPILFDIVSRGSTADLDGLLPFLLTHKKRLTDEEFREPSTGKTCLPKALLNLSNGRNDTIPVLLDIAERTGNMREFINSPFRDIYYRGELPLSLAACTNQPHIVNYLTENPHKKADMRRQDSRGNTVLHALVAIADNTRENTKFVTKMYDLLLLKCARLFPDSNLEAVLNNDGLSPLMMAAKTGKIGIFQHIIRREVTDEDTRHLSRKFKDWAYGPVYSSLYDLSSLDTCGEEASVLEILVYNSKIENRHEMLAVEPINELLRDKWRKFGAVSFYINVVSYLCAMVIFTLTAYYQPLEGTPPYPYRTTVDYLRLAGEVITLFTGVLFFFTNIKDLFMKKCPGVNSLFIDGSFQLLYFIYSVLVIVSAALYLAGIEAYLAVMVFALVLGWMNALYFTRGLKLTGTYSIMIQKILFKDLFRFLLVYLLFMIGYASALVSLLNPCANMKVCNEDQTNCTVPTYPSCRDSETFSTFLLDLFKLTIGMGDLEMLSSTKYPVVFIILLVTYIILTFVLLLNMLIALMGETVGQVSKESKHIWKLQWATTILDIERSFPVFLRKAFRSGEMVTVGKSSDGTPDRRWCFRVDEVNWSHWNQNLGIINEDPGKNETYQYYGFSHTVGRLRRDRWSSVVPRVVELNKNSNPDEVVVPLDSMGNPRCDGHQQGYPRKWRTDDAPL>sp|Q9HBA0-5|TRPV4_HUMAN Isoform 5 of Transient receptor potential cationchannel subfamily V member 4 OS=Homo sapiens OX=9606 GN=TRPV4MADSSEGPRAGPGEVAELPGDESGTPGDGRPNLRMKFQGAFRKGVPNPIDLLESTLYESSVVPGPKKAPMDSLFDYGTYRHHSSDNKRWRKKIIEKQPQSPKAPAPQPPPILKVFNRPILFDIVSRGSTADLDGLLPFLLTHKKRLTDEEFREPSTGKTCLPKALLNLSNGRNDTIPVLLDIAERTGNMREFINSPFRDIYYRGQTALHIAIERRCKHYVELLVAQGADVHAQARGRFFQPKDEGGYFYFGELPLSLAACTNQPHIVNYLTENPHKKADMRRQDSRGNTVLHALVAIADNTRENTKFVTKMYDLLLLKCARLFPDSNLEAVLNNDGLSPLMMAAKTGKIGIFQHIIRREVTDEDTRHLSRKFKDWAYGPVYSSLYDLSSLDTCGEEASVLEILVYNSKIENRHEMLAVEPINELLRDKWRKFGAVSFYINVVSYLCAMVIFTLTAYYQPLEGTPPYPYRTTVDYLRLAGEVITLFTGVLFFFTNIKDLFMKKCPGVNSLFIDGSFQLLYFIYSVLVIVSAALYLAGIEAYLAVMVFALVLGWMNALYFTRGLKLTGTYSIMIQKILFKDLFRFLLVYLLFMIGYASALVSLLNPCANMKVCNEDQTNCTVPTYPSCRDSETFSTFLLDLFKLTIGMGDLEMLSSTKYPVVFIILLVTYIILTFVLLLNMLIALMGETVGQVSKESKHIWKLQWATTILDIERSFPVFLRKAFRSGEMVTVGKSSDGTPDRRWCFRVDEVNWSHWNQNLGIINEDPGKNETYQYYGFSHTVGRLRRDRWSSVVPRVVELNKNSNPDEVVVPLDSMGNPRCDGHQQGYPRKWRTDDAPL>sp|Q9HBA0-6|TRPV4_HUMAN Isoform 6 of Transient receptor potential cationchannel subfamily V member 4 OS=Homo sapiens OX=9606 GN=TRPV4MADSSEGPRAGPGEVAELPGDESGTPGGEAFPLSSLANLFEGEDGSLSPSPADASRPAGPGDGRPNLRMKFQGAFRKGVPNPIDLLESTLYESSVVPGPKKAPMDSLFDYGTYRHHSSDNKRWRKKIIEKQPQSPKAPAPQPPPILKVFNRPILFDIVSRGSTADLDGLLPFLLTHKKRLTDEEFREPSTGKTCLPKALLNLSNGRNDTIPVLLDIAERTGNMREFINSPFRDIYYRGELPLSLAACTNQPHIVNYLTENPHKKADMRRQDSRGNTVLHALVAIADNTRENTKFVTKMYDLLLLKCARLFPDSNLEAVLNNDGLSPLMMAAKTGKIGNRHEMLAVEPINELLRDKWRKFGAVSFYINVVSYLCAMVIFTLTAYYQPLEGTPPYPYRTTVDYLRLAGEVITLFTGVLFFFTNIKDLFMKKCPGVNSLFIDGSFQLLYFIYSVLVIVSAALYLAGIEAYLAVMVFALVLGWMNALYFTRGLKLTGTYSIMIQKILFKDLFRFLLVYLLFMIGYASALVSLLNPCANMKVCNEDQTNCTVPTYPSCRDSETFSTFLLDLFKLTIGMGDLEMLSSTKYPVVFIILLVTYIILTFVLLLNMLIALMGETVGQVSKESKHIWKLQWATTILDIERSFPVFLRKAFRSGEMVTVGKSSDGTPDRRWCFRVDEVNWSHWNQNLGIINEDPGKNETYQYYGFSHTVGRLRRDRWSSVVPRVVELNKNSNPDEVVVPLDSMGNPRCDGHQQGYPRKWRTDDAPL>sp|Q9Y5J7|TIM9_HUMAN Mitochondrial import inner membrane translocasesubunit Tim9 OS=Homo sapiens OX=9606 GN=TIMM9 PE=1 SV=1MAAQIPESDQIKQFKEFLGTYNKLTETCFLDCVKDFTTREVKPEETTCSEHCLQKYLKMTQRISMRFQEYHIQQNEALAAKAGLLGQPR>sp|A6PVC2|TTLL8_HUMAN Protein monoglycylase TTLL8 OS=Homo sapiensOX=9606 GN=TTLL8 PE=2 SV=4MEPERKGLSLASSSDGDGREENKLKQGISQDLASSSRLDRYKIARQLTEKAIKEKKIFSIYGHYPVVRAALRRKGWVEKKFHFLPKVIPDVEDEGARVNDDTCAKVKENQEMALEKTDNIHDVMSRLVKNEMPYLLWTIKRDIIDYHSLTYDQMLNHYAKTASFTTKIGLCVNMRSLPWYVPANPDSFFPRCYSLCTESEQQEFLEDFRRTMASSILKWVVSHQSCSRSSRSKPRDQREEAGSSDLSSRQDAENAEAKLRGLPGQLVDIACKVCQAYLGQLEHEDIDTSADAVEDLTEAEWEDLTQQYYSLVHGDAFISNSRNYFSQCQALLNRITSVNPQTDIDGLRNIWIIKPAAKSRGRDIVCMDRVEEILELAAADHPLSRDNKWVVQKYIETPLLICDTKFDIRQWFLVTDWNPLTIWFYKESYLRFSTQRFSLDKLDSAIHLCNNAVQKYLKNDVGRSPLLPAHNMWTSTRFQEYLQRQGRGAVWGSVIYPSMKKAIAHAMKVAQDHVEPRKNSFELYGADFVLGRDFRPWLIEINSSPTMHPSTPVTAQLCAQVQEDTIKVAVDRSCDIGNFELLWRQPVVEPPPFSGSDLCVAGVSVRRARRQVLPVCNLKASASLLDAQPLKARGPSAMPDPAQGPPSPALQRDLGLKEEKGLPLALLAPLRGAAESGGAAQPTRTKAAGKVELPACPCRHVDSQAPNTGVPVAQPAKSWDPNQLNAHPLEPVLRGLKTAEGALRPPPGGKGEGTVCSRLPHHGHHVAACQTTGTTWDGGPGVCFLRQLLASELPMGPGLPRDPRAPPCLVCRGLLPPAGPCKRCRSFCAAVLQGASFVRLGGRSCSPRTP>sp|A6PVC2-2|TTLL8_HUMAN Isoform 2 of Protein monoglycylase TTLL8 OS=Homosapiens OX=9606 GN=TTLL8MRLLDGKQTSRYSENACEKKIFSIYGHYPVVRAALRRKGWVEKKFHFLPKVIPDVEDEGARVNDDTCAKVKENQEMALEKTDNIHDVMSRLVKNEMPYLLWTIKRDIIDYHSLTYDQMLNHYAKTASFTTKIGLCVNMRSLPWYVPANPDSFFPRCYSLCTESEQQEFLEDFRRTMASSILKWVVSHQSCSRSSRSKPRDQREEAGSSDLSSRQDAENAEAKLRGLPGQLVDIACKVCQAYLGQLEHEDIDTSADAVEDLTEAEWEDLTQQYYSLVQVPLGSSIVLCIFKIQKVMMSFEPPTARDRQCQALLNRITSVNPQTDIDGLRNIWIIKPAAKSRGRGESPDIVCMDRVEEILELAAADHPLSRDNKWVVQKYIETPLLICDTKFDIRQWFLVTDWNPLTIWFYKESYLRFSTQRFSLDKLDSAIHLCNNAVQKYLKNDVGRSPLLPAHNMWTSTRFQEYLQRQGRGAVWGSVIYPSMKKAIAHAMKVAQDHVEPRKNSFELYGADFVLGRDFRPWLIEINSSPTMHPSTPVTAQLCAQVQEDTIKVAVDRSCDIGNFELLWRQPVVEPPPFSGSDLCVAGVSVRRARRQVLPVCNLKASASLLDAQPLKARGPSAMPDPAQGPPSPALQRDLGLKEEKGLPLALLAPLRGAAESGGAAQPTRTKAAGKVELPACPCRHVDSQAPNTGVPVAQPAKSWDPNQLNAHPLEPVLRGLKTAEGALRPPPGGKGEGTVCSRLPHHGHHVAACQTTGTTWDGGPGVCFLRQLLASELPMGPGLPRDPRAPPCLVCRGLLPPAGPCKRCRSFCAAVLQGASFVRLGGRSCSPRTP>sp|Q9Y4A5|TRRAP_HUMAN Transformation/transcription domain-associatedprotein OS=Homo sapiens OX=9606 GN=TRRAP PE=1 SV=3MAFVATQGATVVDQTTLMKKYLQFVAALTDVNTPDETKLKMMQEVSENFENVTSSPQYSTFLEHIIPRFLTFLQDGEVQFLQEKPAQQLRKLVLEIIHRIPTNEHLRPHTKNVLSVMFRFLETENEENVLICLRIIIELHKQFRPPITQEIHHFLDFVKQIYKELPKVVNRYFENPQVIPENTVPPPEMVGMITTIAVKVNPEREDSETRTHSIIPRGSLSLKVLAELPIIVVLMYQLYKLNIHNVVAEFVPLIMNTIAIQVSAQARQHKLYNKELYADFIAAQIKTLSFLAYIIRIYQELVTKYSQQMVKGMLQLLSNCPAETAHLRKELLIAAKHILTTELRNQFIPCMDKLFDESILIGSGYTARETLRPLAYSTLADLVHHVRQHLPLSDLSLAVQLFAKNIDDESLPSSIQTMSCKLLLNLVDCIRSKSEQESGNGRDVLMRMLEVFVLKFHTIARYQLSAIFKKCKPQSELGAVEAALPGVPTAPAAPGPAPSPAPVPAPPPPPPPPPPATPVTPAPVPPFEKQGEKDKEDKQTFQVTDCRSLVKTLVCGVKTITWGITSCKAPGEAQFIPNKQLQPKETQIYIKLVKYAMQALDIYQVQIAGNGQTYIRVANCQTVRMKEEKEVLEHFAGVFTMMNPLTFKEIFQTTVPYMVERISKNYALQIVANSFLANPTTSALFATILVEYLLDRLPEMGSNVELSNLYLKLFKLVFGSVSLFAAENEQMLKPHLHKIVNSSMELAQTAKEPYNYFLLLRALFRSIGGGSHDLLYQEFLPLLPNLLQGLNMLQSGLHKQHMKDLFVELCLTVPVRLSSLLPYLPMLMDPLVSALNGSQTLVSQGLRTLELCVDNLQPDFLYDHIQPVRAELMQALWRTLRNPADSISHVAYRVLGKFGGSNRKMLKESQKLHYVVTEVQGPSITVEFSDCKASLQLPMEKAIETALDCLKSANTEPYYRRQAWEVIKCFLVAMMSLEDNKHALYQLLAHPNFTEKTIPNVIISHRYKAQDTPARKTFEQALTGAFMSAVIKDLRPSALPFVASLIRHYTMVAVAQQCGPFLLPCYQVGSQPSTAMFHSEENGSKGMDPLVLIDAIAICMAYEEKELCKIGEVALAVIFDVASIILGSKERACQLPLFSYIVERLCACCYEQAWYAKLGGVVSIKFLMERLPLTWVLQNQQTFLKALLFVMMDLTGEVSNGAVAMAKTTLEQLLMRCATPLKDEERAEEIVAAQEKSFHHVTHDLVREVTSPNSTVRKQAMHSLQVLAQVTGKSVTVIMEPHKEVLQDMVPPKKHLLRHQPANAQIGLMEGNTFCTTLQPRLFTMDLNVVEHKVFYTELLNLCEAEDSALTKLPCYKSLPSLVPLRIAALNALAACNYLPQSREKIIAALFKALNSTNSELQEAGEACMRKFLEGATIEVDQIHTHMRPLLMMLGDYRSLTLNVVNRLTSVTRLFPNSFNDKFCDQMMQHLRKWMEVVVITHKGGQRSDGNESISECGRCPLSPFCQFEEMKICSAIINLFHLIPAAPQTLVKPLLEVVMKTERAMLIEAGSPFREPLIKFLTRHPSQTVELFMMEATLNDPQWSRMFMSFLKHKDARPLRDVLAANPNRFITLLLPGGAQTAVRPGSPSTSTMRLDLQFQAIKIISIIVKNDDSWLASQHSLVSQLRRVWVSENFQERHRKENMAATNWKEPKLLAYCLLNYCKRNYGDIELLFQLLRAFTGRFLCNMTFLKEYMEEEIPKNYSIAQKRALFFRFVDFNDPNFGDELKAKVLQHILNPAFLYSFEKGEGEQLLGPPNPEGDNPESITSVFITKVLDPEKQADMLDSLRIYLLQYATLLVEHAPHHIHDNNKNRNSKLRRLMTFAWPCLLSKACVDPACKYSGHLLLAHIIAKFAIHKKIVLQVFHSLLKAHAMEARAIVRQAMAILTPAVPARMEDGHQMLTHWTRKIIVEEGHTVPQLVHILHLIVQHFKVYYPVRHHLVQHMVSAMQRLGFTPSVTIEQRRLAVDLSEVVIKWELQRIKDQQPDSDMDPNSSGEGVNSVSSSIKRGLSVDSAQEVKRFRTATGAISAVFGRSQSLPGADSLLAKPIDKQHTDTVVNFLIRVACQVNDNTNTAGSPGEVLSRRCVNLLKTALRPDMWPKSELKLQWFDKLLMTVEQPNQVNYGNICTGLEVLSFLLTVLQSPAILSSFKPLQRGIAACMTCGNTKVLRAVHSLLSRLMSIFPTEPSTSSVASKYEELECLYAAVGKVIYEGLTNYEKATNANPSQLFGTLMILKSACSNNPSYIDRLISVFMRSLQKMVREHLNPQAASGSTEATSGTSELVMLSLELVKTRLAVMSMEMRKNFIQAILTSLIEKSPDAKILRAVVKIVEEWVKNNSPMAANQTPTLREKSILLVKMMTYIEKRFPEDLELNAQFLDLVNYVYRDETLSGSELTAKLEPAFLSGLRCAQPLIRAKFFEVFDNSMKRRVYERLLYVTCSQNWEAMGNHFWIKQCIELLLAVCEKSTPIGTSCQGAMLPSITNVINLADSHDRAAFAMVTHVKQEPRERENSESKEEDVEIDIELAPGDQTSTPKTKELSEKDIGNQLHMLTNRHDKFLDTLREVKTGALLSAFVQLCHISTTLAEKTWVQLFPRLWKILSDRQQHALAGEISPFLCSGSHQVQRDCQPSALNCFVEAMSQCVPPIPIRPCVLKYLGKTHNLWFRSTLMLEHQAFEKGLSLQIKPKQTTEFYEQESITPPQQEILDSLAELYSLLQEEDMWAGLWQKRCKYSETATAIAYEQHGFFEQAQESYEKAMDKAKKEHERSNASPAIFPEYQLWEDHWIRCSKELNQWEALTEYGQSKGHINPYLVLECAWRVSNWTAMKEALVQVEVSCPKEMAWKVNMYRGYLAICHPEEQQLSFIERLVEMASSLAIREWRRLPHVVSHVHTPLLQAAQQIIELQEAAQINAGLQPTNLGRNNSLHDMKTVVKTWRNRLPIVSDDLSHWSSIFMWRQHHYQGKPTWSGMHSSSIVTAYENSSQHDPSSNNAMLGVHASASAIIQYGKIARKQGLVNVALDILSRIHTIPTVPIVDCFQKIRQQVKCYLQLAGVMGKNECMQGLEVIESTNLKYFTKEMTAEFYALKGMFLAQINKSEEANKAFSAAVQMHDVLVKAWAMWGDYLENIFVKERQLHLGVSAITCYLHACRHQNESKSRKYLAKVLWLLSFDDDKNTLADAVDKYCIGVPPIQWLAWIPQLLTCLVGSEGKLLLNLISQVGRVYPQAVYFPIRTLYLTLKIEQRERYKSDPGPIRATAPMWRCSRIMHMQRELHPTLLSSLEGIVDQMVWFRENWHEEVLRQLQQGLAKCYSVAFEKSGAVSDAKITPHTLNFVKKLVSTFGVGLENVSNVSTMFSSAASESLARRAQATAQDPVFQKLKGQFTTDFDFSVPGSMKLHNLISKLKKWIKILEAKTKQLPKFFLIEEKCRFLSNFSAQTAEVEIPGEFLMPKPTHYYIKIARFMPRVEIVQKHNTAARRLYIRGHNGKIYPYLVMNDACLTESRREERVLQLLRLLNPCLEKRKETTKRHLFFTVPRVVAVSPQMRLVEDNPSSLSLVEIYKQRCAKKGIEHDNPISRYYDRLATVQARGTQASHQVLRDILKEVQSNMVPRSMLKEWALHTFPNATDYWTFRKMFTIQLALIGFAEFVLHLNRLNPEMLQIAQDTGKLNVAYFRFDINDATGDLDANRPVPFRLTPNISEFLTTIGVSGPLTASMIAVARCFAQPNFKVDGILKTVLRDEIIAWHKKTQEDTSSPLSAAGQPENMDSQQLVSLVQKAVTAIMTRLHNLAQFEGGESKVNTLVAAANSLDNLCRMDPAWHPWL>sp|Q9Y4A5-2|TRRAP_HUMAN Isoform 2 of Transformation/transcriptiondomain-associated protein OS=Homo sapiens OX=9606 GN=TRRAPMAFVATQGATVVDQTTLMKKYLQFVAALTDVNTPDETKLKMMQEVSENFENVTSSPQYSTFLEHIIPRFLTFLQDGEVQFLQEKPAQQLRKLVLEIIHRIPTNEHLRPHTKNVLSVMFRFLETENEENVLICLRIIIELHKQFRPPITQEIHHFLDFVKQIYKELPKVVNRYFENPQVIPENTVPPPEMVGMITTIAVKVNPEREDSETRTHSIIPRGSLSLKVLAELPIIVVLMYQLYKLNIHNVVAEFVPLIMNTIAIQVSAQARQHKLYNKELYADFIAAQIKTLSFLAYIIRIYQELVTKYSQQMVKGMLQLLSNCPAETAHLRKELLIAAKHILTTELRNQFIPCMDKLFDESILIGSGYTARETLRPLAYSTLADLVHHVRQHLPLSDLSLAVQLFAKNIDDESLPSSIQTMSCKLLLNLVDCIRSKSEQESGNGRDVLMRMLEVFVLKFHTIARYQLSAIFKKCKPQSELGAVEAALPGVPTAPAAPGPAPSPAPVPAPPPPPPPPPPATPVTPAPVPPFEKQGEKDKEDKQTFQVTDCRSLVKTLVCGVKTITWGITSCKAPGEAQFIPNKQLQPKETQIYIKLVKYAMQALDIYQVQIAGNGQTYIRVANCQTVRMKEEKEVLEHFAGVFTMMNPLTFKEIFQTTVPYMVERISKNYALQIVANSFLANPTTSALFATILVEYLLDRLPEMGSNVELSNLYLKLFKLVFGSVSLFAAENEQMLKPHLHKIVNSSMELAQTAKEPYNYFLLLRALFRSIGGGSHDLLYQEFLPLLPNLLQGLNMLQSGLHKQHMKDLFVELCLTVPVRLSSLLPYLPMLMDPLVSALNGSQTLVSQGLRTLELCVDNLQPDFLYDHIQPVRAELMQALWRTLRNPADSISHVAYRVLGKFGGSNRKMLKESQKLHYVVTEVQGPSITVEFSDCKASLQLPMEKAIETALDCLKSANTEPYYRRQAWEVIKCFLVAMMSLEDNKHALYQLLAHPNFTEKTIPNVIISHRYKAQDTPARKTFEQALTGAFMSAVIKDLRPSALPFVASLIRHYTMVAVAQQCGPFLLPCYQVGSQPSTAMFHSEENGSKGMDPLVLIDAIAICMAYEEKELCKIGEVALAVIFDVASIILGSKERACQLPLFSYIVERLCACCYEQAWYAKLGGVVSIKFLMERLPLTWVLQNQQTFLKALLFVMMDLTGEVSNGAVAMAKTTLEQLLMRCATPLKDEERAEEIVAAQEKSFHHVTHDLVREVTSPNSTVRKQAMHSLQVLAQVTGKSVTVIMEPHKEVLQDMVPPKKHLLRHQPANAQIGLMEGNTFCTTLQPRLFTMDLNVVEHKVFYTELLNLCEAEDSALTKLPCYKSLPSLVPLRIAALNALAACNYLPQSREKIIAALFKALNSTNSELQEAGEACMRKFLEGATIEVDQIHTHMRPLLMMLGDYRSLTLNVVNRLTSVTRLFPNSFNDKFCDQMMQHLRKWMEVVVITHKGGQRSDGNEMKICSAIINLFHLIPAAPQTLVKPLLEVVMKTERAMLIEAGSPFREPLIKFLTRHPSQTVELFMMEATLNDPQWSRMFMSFLKHKDARPLRDVLAANPNRFITLLLPGGAQTAVRPGSPSTSTMRLDLQFQAIKIISIIVKNDDSWLASQHSLVSQLRRVWVSENFQERHRKENMAATNWKEPKLLAYCLLNYCKRNYGDIELLFQLLRAFTGRFLCNMTFLKEYMEEEIPKNYSIAQKRALFFRFVDFNDPNFGDELKAKVLQHILNPAFLYSFEKGEGEQLLGPPNPEGDNPESITSVFITKVLDPEKQADMLDSLRIYLLQYATLLVEHAPHHIHDNNKNRNSKLRRLMTFAWPCLLSKACVDPACKYSGHLLLAHIIAKFAIHKKIVLQVFHSLLKAHAMEARAIVRQAMAILTPAVPARMEDGHQMLTHWTRKIIVEEGHTVPQLVHILHLIVQHFKVYYPVRHHLVQHMVSAMQRLGFTPSVTIEQRRLAVDLSEVVIKWELQRIKDQQPDSDMDPNSSGEGVNSVSSSIKRGLSVDSAQEVKRFRTATGAISAVFGRSQSLPGADSLLAKPIDKQHTDTVVNFLIRVACQVNDNTNTAGSPGEVLSRRCVNLLKTALRPDMWPKSELKLQWFDKLLMTVEQPNQVNYGNICTGLEVLSFLLTVLQSPAILSSFKPLQRGIAACMTCGNTKVLRAVHSLLSRLMSIFPTEPSTSSVASKYEELECLYAAVGKVIYEGLTNYEKATNANPSQLFGTLMILKSACSNNPSYIDRLISVFMRSLQKMVREHLNPQAASGSTEATSGTSELVMLSLELVKTRLAVMSMEMRKNFIQAILTSLIEKSPDAKILRAVVKIVEEWVKNNSPMAANQTPTLREKSILLVKMMTYIEKRFPEDLELNAQFLDLVNYVYRDETLSGSELTAKLEPAFLSGLRCAQPLIRAKFFEVFDNSMKRRVYERLLYVTCSQNWEAMGNHFWIKQCIELLLAVCEKSTPIGTSCQGAMLPSITNVINLADSHDRAAFAMVTHVKQEPRERENSESKEEDVEIDIELAPGDQTSTPKTKELSEKDIGNQLHMLTNRHDKFLDTLREVKTGALLSAFVQLCHISTTLAEKTWVQLFPRLWKILSDRQQHALAGEISPFLCSGSHQVQRDCQPSALNCFVEAMSQCVPPIPIRPCVLKYLGKTHNLWFRSTLMLEHQAFEKGLSLQIKPKQTTEFYEQESITPPQQEILDSLAELYSLLQEEDMWAGLWQKRCKYSETATAIAYEQHGFFEQAQESYEKAMDKAKKEHERSNASPAIFPEYQLWEDHWIRCSKELNQWEALTEYGQSKGHINPYLVLECAWRVSNWTAMKEALVQVEVSCPKEMAWKVNMYRGYLAICHPEEQQLSFIERLVEMASSLAIREWRRLPHVVSHVHTPLLQAAQQIIELQEAAQINAGLQPTNLGRNNSLHDMKTVVKTWRNRLPIVSDDLSHWSSIFMWRQHHYQAIVTAYENSSQHDPSSNNAMLGVHASASAIIQYGKIARKQGLVNVALDILSRIHTIPTVPIVDCFQKIRQQVKCYLQLAGVMGKNECMQGLEVIESTNLKYFTKEMTAEFYALKGMFLAQINKSEEANKAFSAAVQMHDVLVKAWAMWGDYLENIFVKERQLHLGVSAITCYLHACRHQNESKSRKYLAKVLWLLSFDDDKNTLADAVDKYCIGVPPIQWLAWIPQLLTCLVGSEGKLLLNLISQVGRVYPQAVYFPIRTLYLTLKIEQRERYKSDPGPIRATAPMWRCSRIMHMQRELHPTLLSSLEGIVDQMVWFRENWHEEVLRQLQQGLAKCYSVAFEKSGAVSDAKITPHTLNFVKKLVSTFGVGLENVSNVSTMFSSAASESLARRAQATAQDPVFQKLKGQFTTDFDFSVPGSMKLHNLISKLKKWIKILEAKTKQLPKFFLIEEKCRFLSNFSAQTAEVEIPGEFLMPKPTHYYIKIARFMPRVEIVQKHNTAARRLYIRGHNGKIYPYLVMNDACLTESRREERVLQLLRLLNPCLEKRKETTKRHLFFTVPRVVAVSPQMRLVEDNPSSLSLVEIYKQRCAKKGIEHDNPISRYYDRLATVQARGTQASHQVLRDILKEVQSNMVPRSMLKEWALHTFPNATDYWTFRKMFTIQLALIGFAEFVLHLNRLNPEMLQIAQDTGKLNVAYFRFDINDATGDLDANRPVPFRLTPNISEFLTTIGVSGPLTASMIAVARCFAQPNFKVDGILKTVLRDEIIAWHKKTQEDTSSPLSAAGQPENMDSQQLVSLVQKAVTAIMTRLHNLAQFEGGESKVNTLVAAANSLDNLCRMDPAWHPWL>sp|A8MYJ7|TTC34_HUMAN Tetratricopeptide repeat protein 34 OS=Homosapiens OX=9606 GN=TTC34 PE=2 SV=2MLQRSPRAGPSRAQGRREAAETGGPTTQEGVACGVHQLATLLMELDSEDEASRLLAADALYRLGRLEETHKALLVALSRRPQAAPVLARLALLQLRRGFFYDANQLVKKLVQSGDTACLQPTLDVFCHEDRQLLQGHCHARALAILRARPGGADGRVHTKEAIAYLSLAIFAAGSQASESLLARARCYGFLGQKKTAMFDFNTVLRAEPGNVQALCGRALVHLALDQLQEAVDDIVSALKLGPGTVVPELRSLKPEAQALITQGLYSHCRALLSQLPDTGAPLEDKDTQGLLAVGEALIKIDSGQPHWHLLLADILMAQGSYEEAGTHLEKALHRAPTSEAARARLGLLQLKKGDVPGAARDLQSLAEVDAPDLSCLLHLLEASERQSLAQAAAQEAGTLLDAGQPRQALGYCSLSVLASGSSACHLRLRATCLAELQEFGRALRDLDHVLQEALGDGDLPRRAEDFCRQGRLLLSLGDEAAAAGAFAQALKLAPSLAQNSLCRQPGRAPTARMFLLRGQCCLEEQRHAEAWTAVESGLLVDPDHRGLKRLKARIRREASSGCWLQ>sp|Q8N584|TT39C_HUMAN Tetratricopeptide repeat protein 39C OS=Homosapiens OX=9606 GN=TTC39C PE=2 SV=2MAGSEQQRPRRRDDGDSDAAAAAAAPLQDAELALAGINMLLNNGFRESDQLFKQYRNHSPLMSFGASFVSFLNAMMTFEEEKMQLACDDLKTTEKLCESEEAGVIETIKNKIKKNVDVRKSAPSMVDRLQRQIIIADCQVYLAVLSFVKQELSAYIKGGWILRKAWKIYNKCYLDINALQELYQKKLTEESLTSDAANDNHIVAEGVSEESLNRLKGAVSFGYGLFHLCISMVPPNLLKIINLLGFPGDRLQGLSSLMYASESKDMKAPLATLALLWYHTVVRPFFALDGSDNKAGLDEAKEILLKKEAAYPNSSLFMFFKGRIQRLECQINSALTSFHTALELAVDQREIQHVCLYEIGWCSMIELNFKDAFDSFERLKNESRWSQCYYAYLTAVCQGATGDVDGAQIVFKEVQKLFKRKNNQIEQFSVKKAERFRKQTPTKALCVLASIEVLYLWKALPNCSFPNLQRMSQACHEVDDSSVVGLKYLLLGAIHKCLGNSEDAVQYFQRAVKDELCRQNNLYVQPYACYELGCLLLDKPETVGRGRALLLQAKEDFSGYDFENRLHVRIHAALASLRELVPQ>sp|Q8N584-2|TT39C_HUMAN Isoform 2 of Tetratricopeptide repeat protein39C OS=Homo sapiens OX=9606 GN=TTC39CMSFGASFVSFLNAMMTFEEEKMQLACDDLKTTEKLCESEEAGVIETIKNKIKKNVDVRKSAPSMVDRLQRQIIIADCQVYLAVLSFVKQELSAYIKGGWILRKAWKIYNKCYLDINALQELYQKKLTEESLTSDAANDNHIVAEGVSEESLNRLKGAVSFGYGLFHLCISMVPPNLLKIINLLGFPGDRLQGLSSLMYASESKDMKAPLATLALLWYHTVVRPFFALDGSDNKAGLDEAKEILLKKEAAYPNSSLFMFFKGRIQRLECQINSALTSFHTALELAVDQREIQHVCLYEIGWCSMIELNFKDAFDSFERLKNESRWSQCYYAYLTAVCQGATGDVDGAQIVFKEVQKLFKRKNNQIEQFSVKKAERFRKQTPTKALCVLASIEVLYLWKALPNCSFPNLQRMSQACHEVDDSSVVGLKYLLLGAIHKCLGNSEDAVQYFQRAVKDELCRQNNLYVQPYACYELGCLLLDKPETVGRGRALLLQAKEDFSGYDFENRLHVRIHAALASLRELVPQ>sp|Q8N584-3|TT39C_HUMAN Isoform 3 of Tetratricopeptide repeat protein39C OS=Homo sapiens OX=9606 GN=TTC39CMAGSEQQRPRRRDDGDSDAAAAAAAPLQDAELALAGINMLLNNGFRESDQLFKQYRKSFLTSEKTSALPGETQRRL>sp|Q14694|UBP10_HUMAN Ubiquitin carboxyl-terminal hydrolase 10 OS=Homosapiens OX=9606 GN=USP10 PE=1 SV=2MALHSPQYIFGDFSPDEFNQFFVTPRSSVELPPYSGTVLCGTQAVDKLPDGQEYQRIEFGVDEVIEPSDTLPRTPSYSISSTLNPQAPEFILGCTASKITPDGITKEASYGSIDCQYPGSALALDGSSNVEAEVLENDGVSGGLGQRERKKKKKRPPGYYSYLKDGGDDSISTEALVNGHANSAVPNSVSAEDAEFMGDMPPSVTPRTCNSPQNSTDSVSDIVPDSPFPGALGSDTRTAGQPEGGPGADFGQSCFPAEAGRDTLSRTAGAQPCVGTDTTENLGVANGQILESSGEGTATNGVELHTTESIDLDPTKPESASPPADGTGSASGTLPVSQPKSWASLFHDSKPSSSSPVAYVETKYSPPAISPLVSEKQVEVKEGLVPVSEDPVAIKIAELLENVTLIHKPVSLQPRGLINKGNWCYINATLQALVACPPMYHLMKFIPLYSKVQRPCTSTPMIDSFVRLMNEFTNMPVPPKPRQALGDKIVRDIRPGAAFEPTYIYRLLTVNKSSLSEKGRQEDAEEYLGFILNGLHEEMLNLKKLLSPSNEKLTISNGPKNHSVNEEEQEEQGEGSEDEWEQVGPRNKTSVTRQADFVQTPITGIFGGHIRSVVYQQSSKESATLQPFFTLQLDIQSDKIRTVQDALESLVARESVQGYTTKTKQEVEISRRVTLEKLPPVLVLHLKRFVYEKTGGCQKLIKNIEYPVDLEISKELLSPGVKNKNFKCHRTYRLFAVVYHHGNSATGGHYTTDVFQIGLNGWLRIDDQTVKVINQYQVVKPTAERTAYLLYYRRVDLL>sp|Q14694-2|UBP10_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 10 OS=Homo sapiens OX=9606 GN=USP10MCSKDTVLSVCALYWRKGIQSHTPLIGAWRRGKQREQPEDRGVPMKRAAALHSPQYIFGDFSPDEFNQFFVTPRSSVELPPYSGTVLCGTQAVDKLPDGQEYQRIEFGVDEVIEPSDTLPRTPSYSISSTLNPQAPEFILGCTASKITPDGITKEASYGSIDCQYPGSALALDGSSNVEAEVLENDGVSGGLGQRERKKKKKRPPGYYSYLKDGGDDSISTEALVNGHANSAVPNSVSAEDAEFMGDMPPSVTPRTCNSPQNSTDSVSDIVPDSPFPGALGSDTRTAGQPEGGPGADFGQSCFPAEAGRDTLSRTAGAQPCVGTDTTENLGVANGQILESSGEGTATNGVELHTTESIDLDPTKPESASPPADGTGSASGTLPVSQPKSWASLFHDSKPSSSSPVAYVETKYSPPAISPLVSEKQVEVKEGLVPVSEDPVAIKIAELLENVTLIHKPVSLQPRGLINKGNWCYINATLQALVACPPMYHLMKFIPLYSKVQRPCTSTPMIDSFVRLMNEFTNMPVPPKPRQALGDKIVRDIRPGAAFEPTYIYRLLTVNKSSLSEKGRQEDAEEYLGFILNGLHEEMLNLKKLLSPSNEKLTISNGPKNHSVNEEEQEEQGEGSEDEWEQVGPRNKTSVTRQADFVQTPITGIFGGHIRSVVYQQSSKESATLQPFFTLQLDIQSDKIRTVQDALESLVARESVQGYTTKTKQEVEISRRVTLEKLPPVLVLHLKRFVYEKTGGCQKLIKNIEYPVDLEISKELLSPGVKNKNFKCHRTYRLFAVVYHHGNSATGGHYTTDVFQIGLNGWLRIDDQTVKVINQYQVVKPTAERTAYLLYYRRVDLL>sp|Q14694-3|UBP10_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 10 OS=Homo sapiens OX=9606 GN=USP10MPWLPSPGIGQYIFGDFSPDEFNQFFVTPRSSVELPPYSGTVLCGTQAVDKLPDGQEYQRIEFGVDEVIEPSDTLPRTPSYSISSTLNPQAPEFILGCTASKITPDGITKEASYGSIDCQYPGSALALDGSSNVEAEVLENDGVSGGLGQRERKKKKKRPPGYYSYLKDGGDDSISTEALVNGHANSAVPNSVSAEDAEFMGDMPPSVTPRTCNSPQNSTDSVSDIVPDSPFPGALGSDTRTAGQPEGGPGADFGQSCFPAEAGRDTLSRTAGAQPCVGTDTTENLGVANGQILESSGEGTATNGVELHTTESIDLDPTKPESASPPADGTGSASGTLPVSQPKSWASLFHDSKPSSSSPVAYVETKYSPPAISPLVSEKQVEVKEGLVPVSEDPVAIKIAELLENVTLIHKPVSLQPRGLINKGNWCYINATLQALVACPPMYHLMKFIPLYSKVQRPCTSTPMIDSFVRLMNEFTNMPVPPKPRQALGDKIVRDIRPGAAFEPTYIYRLLTVNKSSLSEKGRQEDAEEYLGFILNGLHEEMLNLKKLLSPSNEKLTISNGPKNHSVNEEEQEEQGEGSEDEWEQVGPRNKTSVTRQADFVQTPITGIFGGHIRSVVYQQSSKESATLQPFFTLQLDIQSDKIRTVQDALESLVARESVQGYTTKTKQEVEISRRVTLEKLPPVLVLHLKRFVYEKTGGCQKLIKNIEYPVDLEISKELLSPGVKNKNFKCHRTYRLFAVVYHHGNSATGGHYTTDVFQIGLNGWLRIDDQTVKVINQYQVVKPTAERTAYLLYYRRVDLL>sp|Q8WVN8|UB2Q2_HUMAN Ubiquitin-conjugating enzyme E2 Q2 OS=Homo sapiensOX=9606 GN=UBE2Q2 PE=1 SV=1MSVSGLKAELKFLASIFDKNHERFRIVSWKLDELHCQFLVPQQGSPHSLPPPLTLHCNITESYPSSSPIWFVDSEDPNLTSVLERLEDTKNNNLLRQQLKWLICELCSLYNLPKHLDVEMLDQPLPTGQNGTTEEVTSEEEEEEEEMAEDIEDLDHYEMKEEEPISGKKSEDEGIEKENLAILEKIRKTQRQDHLNGAVSGSVQASDRLMKELRDIYRSQSYKTGIYSVELINDSLYDWHVKLQKVDPDSPLHSDLQILKEKEGIEYILLNFSFKDNFPFDPPFVRVVLPVLSGGYVLGGGALCMELLTKQGWSSAYSIESVIMQINATLVKGKARVQFGANKNQYNLARAQQSYNSIVQIHEKNGWYTPPKEDG>sp|Q8WVN8-2|UB2Q2_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 Q2OS=Homo sapiens OX=9606 GN=UBE2Q2MSVSGLKAELKFLASIFDKNHERFRIVSWKLDELHCQFLVPQQGSPHSLPPPLTLHCNITESYPSSSPIWFVDSEDPNLTSVLERLEDTKNNNLLRQQLKWLICELCSLYNLPKHLDVEMLDQPLPTGQNGTTEEVTSEEEEEEEEMAEDIEDLDHYEMKEEEPISGKKSEDEGIEKENLAILEKIRKTQRQDHLNGAVSGSVQASDRLMKELRDIYRSQSYKTGIYSVELINDSLYDWHVKLQKVDPDSPLHSDLQILKEKEGIEYILLNFSFKDNFPFDPPFVRVVLPVLSGGLVHPSKGRWLNMLTVVCLD>sp|Q8WVN8-3|UB2Q2_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 Q2OS=Homo sapiens OX=9606 GN=UBE2Q2MRMDSLTEEKLECRLWCCLSDPSPPGLAARCCVLERSIVPSLRQESYPSSSPIWFVDSEDPNLTSVLERLEDTKNNNLLRQQLKWLICELCSLYNLPKHLDVEMLDQPLPTGQNGTTEEVTSEEEEEEEEMAEDIEDLDHYEMKEEEPISGKKSEDEGIEKENLAILEKIRKTQRQDHLNGAVSGSVQASDRLMKELRDIYRSQSYKTGIYSVELINDSLYDWHVKLQKVDPDSPLHSDLQILKEKEGIEYILLNFSFKDNFPFDPPFVRVVLPVLSGGYVLGGGALCMELLTKQGWSSAYSIESVIMQINATLVKGKARVQFGANKNQYNLARAQQSYNSIVQIHEKNGWYTPPKEDG>sp|Q8WVN8-4|UB2Q2_HUMAN Isoform 4 of Ubiquitin-conjugating enzyme E2 Q2OS=Homo sapiens OX=9606 GN=UBE2Q2MSVSGLKAELKFLASIFDKNHERFRIVSWKLDELHCQFLVPQQGSPHSLPPPLTLHCNITESYPSSSPIWFVDSEDPNLTSVLERLEDTKNNNLNGTTEEVTSEEEEEEEEMAEDIEDLDHYEMKEEEPISGKKSEDEGIEKENLAILEKIRKTQRQDHLNGAVSGSVQASDRLMKELRDIYRSQSYKTGIYSVELINDSLYDWHVKLQKVDPDSPLHSDLQILKEKEGIEYILLNFSFKDNFPFDPPFVRVVLPVLSGGYVLGGGALCMELLTKQGWSSAYSIESVIMQINATLVKGKARVQFGANKNQYNLARAQQSYNSIVQIHEKNGWYTPPKEDG>sp|P49427|UB2R1_HUMAN Ubiquitin-conjugating enzyme E2 R1 OS=Homo sapiensOX=9606 GN=CDC34 PE=1 SV=2MARPLVPSSQKALLLELKGLQEEPVEGFRVTLVDEGDLYNWEVAIFGPPNTYYEGGYFKARLKFPIDYPYSPPAFRFLTKMWHPNIYETGDVCISILHPPVDDPQSGELPSERWNPTQNVRTILLSVISLLNEPNTFSPANVDASVMYRKWKESKGKDREYTDIIRKQVLGTKVDAERDGVKVPTTLAEYCVKTKAPAPDEGSDLFYDDYYEDGEVEEEADSCFGDDEDDSGTEES>sp|Q99990|VGLL1_HUMAN Transcription cofactor vestigial-like protein 1OS=Homo sapiens OX=9606 GN=VGLL1 PE=1 SV=1MEEMKKTAIRLPKGKQKPIKTEWNSRCVLFTYFQGDISSVVDEHFSRALSNIKSPQELTPSSQSEGVMLKNDDSMSPNQWRYSSPWTKPQPEVPVTNRAANCNLHVPGPMAVNQFSPSLARRASVRPGELWHFSSLAGTSSLEPGYSHPFPARHLVPEPQPDGKREPLLSLLQQDRCLARPQESAARENGNPGQIAGSTGLLFNLPPGSVHYKKLYVSRGSASTSLPNETLSELETPGKYSLTPPNHWGHPHRYLQHL>sp|A8MV65|VGLL3_HUMAN Transcription cofactor vestigial-like protein 3OS=Homo sapiens OX=9606 GN=VGLL3 PE=1 SV=1MSCAEVMYHPQPYGASQYLPNPMAATTCPTAYYQPAPQPGQQKKLAVFSKMQDSLEVTLPSKQEEEDEEEEEEEKDQPAEMEYLNSRCVLFTYFQGDIGSVVDEHFSRALGQAITLHPESAISKSKMGLTPLWRDSSALSSQRNSFPTSFWTSSYQPPPAPCLGGVHPDFQVTGPPGTFSAADPSPWPGHNLHQTGPAPPPAVSESWPYPLTSQVSPSYSHMHDVYMRHHHPHAHMHHRHRHHHHHHHPPAGSALDPSYGPLLMPSVHAARIPAPQCDITKTEPTTVTSATSAWAGAFHGTVDIVPSVGFDTGLQHQDKSKESPWY>sp|A8MV65-2|VGLL3_HUMAN Isoform 2 of Transcription cofactor vestigial-like protein 3 OS=Homo sapiens OX=9606 GN=VGLL3MSCAEVMYHPQPYGASQYLPNPMAATTCPTAYYQPAPQPGQQKKLAVFSKMQDSLEVTLPSKQEEEDEEEEEEEKDQPAEMEYLNSRCVLFTYFQGDIGSVVDEHFSRALGQAITLHPESAISKSKMGLTPLWRDSSALSSQRNSFPTSFWTSSYQPPPAPCLGGVHPDFQVTGPPGTFSAADPSPWPGHNLHQTGPAPPPAVSESWPYPLTSQVSPSYSHMHDVYMRHHHPHAHMHHRHRHHHHHHHPPAGSALDPSYGPLLMPSVHAARIPAPQCDITKTEPTTVTSATSAWAGAFHGTVDIVPSVGFDTGWSAMARS>sp|Q15849|UT2_HUMAN Urea transporter 2 OS=Homo sapiens OX=9606GN=SLC14A2 PE=1 SV=3MSDPHSSPLLPEPLSSRYKLYEAEFTSPSWPSTSPDTHPALPLLEMPEEKDLRSSNEDSHIVKIEKLNERSKRKDDGVAHRDSAGQRCICLSKAVGYLTGDMKEYRIWLKDKHLALQFIDWVLRGTAQVMFINNPLSGLIIFIGLLIQNPWWTITGGLGTVVSTLTALALGQDRSAIASGLHGYNGMLVGLLMAVFSEKLDYYWWLLFPVTFTAMSCPVLSSALNSIFSKWDLPVFTLPFNIAVTLYLAATGHYNLFFPTTLVEPVSSVPNITWTEMEMPLLLQAIPVGVGQVYGCDNPWTGGVFLVALFISSPLICLHAAIGSIVGLLAALSVATPFETIYTGLWSYNCVLSCIAIGGMFYALTWQTHLLALICALFCAYMEAAISNIMSVVGVPPGTWAFCLATIIFLLLTTNNPAIFRLPLSKVTYPEANRIYYLTVKSGEEEKAPSGGGGEHPPTAGPKVEEGSEAVLSKHRSVFHIEWSSIRRRSKVFGKGEHQERQNKDPFPYRYRKPTVELLDLDTMEESSEIKVETNISKTSWIRSSMAASGKRVSKALSYITGEMKECGEGLKDKSPVFQFFDWVLRGTSQVMFVNNPLSGILIILGLFIQNPWWAISGCLGTIMSTLTALILSQDKSAIAAGFHGYNGVLVGLLMAVFSDKGDYYWWLLLPVIIMSMSCPILSSALGTIFSKWDLPVFTLPFNITVTLYLAATGHYNLFFPTTLLQPASAMPNITWSEVQVPLLLRAIPVGIGQVYGCDNPWTGGIFLIALFISSPLICLHAAIGSTMGMLAALTIATPFDSIYFGLCGFNSTLACIAIGGMFYVITWQTHLLAIACALFAAYLGAALANMLSVFGLPPCTWPFCLSALTFLLLTTNNPAIYKLPLSKVTYPEANRIYYLSQERNRRASIITKYQAYDVS>sp|Q15849-2|UT2_HUMAN Isoform 2 of Urea transporter 2 OS=Homo sapiensOX=9606 GN=SLC14A2MEESSEIKVETNISKTSWIRSSMAASGKRVSKALSYITGEMKECGEGLKDKSPVFQFFDWVLRGTSQVMFVNNPLSGILIILGLFIQNPWWAISGCLGTIMSTLTALILSQDKSAIAAGFHGYNGVLVGLLMAVFSDKGDYYWWLLLPVIIMSMSCPILSSALGTIFSKWDLPVFTLPFNITVTLYLAATGHYNLFFPTTLLQPASAMPNITWSEVQVPLLLRAIPVGIGQVYGCDNPWTGGIFLIALFISSPLICLHAAIGSTMGMLAALTIATPFDSIYFGLCGFNSTLACIAIGGMFYVITWQTHLLAIACALFAAYLGAALANMLSVFGLPPCTWPFCLSALTFLLLTTNNPAIYKLPLSKVTYPEANRIYYLSQERNRRASIITKYQAYDVS>sp|Q5TAP6|UT14C_HUMAN U3 small nucleolar RNA-associated protein 14homolog C OS=Homo sapiens OX=9606 GN=UTP14C PE=1 SV=1MNVNQVAENLALSHQEELVDLPKNYPLSENEDEGDSDGERKHQKLLEAIISLDGKNRRKLAERSEASLKVSEFSVSSEGSGEKLGLADLLEPVKTSSSLATVKKQLNRVKSKKVVELPLNKEKIEQIHREVAFSKTSQVLSKWDPIILKNQQAEQLVFPLGKEQPAIAPIEHALSGWKARTPLEQEIFNLLHKNKQPVTDPLLTPMEKASLQAMSLEEAKMHRAELQRARALQSYYEAKARKEKKIKSKKYHKVVKKGKAKKALKEFEQLQKVNPTVALEEMEKIENARMMERMSLKHQNSGKWAKSKAIMAKYDLEARQAMQEQLAKNKELTQKLQVASESEEEEGGTEVEELLVPHVANEVQMNVDGPNPWMFRSCTSDTKEAATQEDPEQVPELAAHEVSASEAEERPVAEEEILLREFEERQSLRKRSELNQDAEPASSQETKDSSSQEVLSELRALSQKLKEKHQSRKQKASSEGTVPQVQREEPAPEEAEPLLLQRSERVQTLEELEELGKEDCFQNKELPRPVLEGQQSERTPNNRPDAPKEKKEKEQLINLQNFLTTQSPSVRSLAVPTIIEELEDEEERDQRQMIKEAFAGDDVIRDFLKEKREAVEASKPKDVDLTLPGWGEWGGVGLKPSAKKRRQFLIKAPEGPPRKDKNLPNVIISEKRNIHAAAHQVQVLPYPFTHHRQFERTIQTPIGSTWNTQRAFQKLTTPKVVTKPGHIIKPIKAEDVGYQSSSRSDLPVIQRNPKRITTRHNKEEKL>sp|P04628|WNT1_HUMAN Proto-oncogene Wnt-1 OS=Homo sapiens OX=9606GN=WNT1 PE=1 SV=1MGLWALLPGWVSATLLLALAALPAALAANSSGRWWGIVNVASSTNLLTDSKSLQLVLEPSLQLLSRKQRRLIRQNPGILHSVSGGLQSAVRECKWQFRNRRWNCPTAPGPHLFGKIVNRGCRETAFIFAITSAGVTHSVARSCSEGSIESCTCDYRRRGPGGPDWHWGGCSDNIDFGRLFGREFVDSGEKGRDLRFLMNLHNNEAGRTTVFSEMRQECKCHGMSGSCTVRTCWMRLPTLRAVGDVLRDRFDGASRVLYGNRGSNRASRAELLRLEPEDPAHKPPSPHDLVYFEKSPNFCTYSGRLGTAGTAGRACNSSSPALDGCELLCCGRGHRTRTQRVTERCNCTFHWCCHVSCRNCTHTRVLHECL>sp|P04275|VWF_HUMAN von Willebrand factor OS=Homo sapiens OX=9606 GN=VWFPE=1 SV=4MIPARFAGVLLALALILPGTLCAEGTRGRSSTARCSLFGSDFVNTFDGSMYSFAGYCSYLLAGGCQKRSFSIIGDFQNGKRVSLSVYLGEFFDIHLFVNGTVTQGDQRVSMPYASKGLYLETEAGYYKLSGEAYGFVARIDGSGNFQVLLSDRYFNKTCGLCGNFNIFAEDDFMTQEGTLTSDPYDFANSWALSSGEQWCERASPPSSSCNISSGEMQKGLWEQCQLLKSTSVFARCHPLVDPEPFVALCEKTLCECAGGLECACPALLEYARTCAQEGMVLYGWTDHSACSPVCPAGMEYRQCVSPCARTCQSLHINEMCQERCVDGCSCPEGQLLDEGLCVESTECPCVHSGKRYPPGTSLSRDCNTCICRNSQWICSNEECPGECLVTGQSHFKSFDNRYFTFSGICQYLLARDCQDHSFSIVIETVQCADDRDAVCTRSVTVRLPGLHNSLVKLKHGAGVAMDGQDVQLPLLKGDLRIQHTVTASVRLSYGEDLQMDWDGRGRLLVKLSPVYAGKTCGLCGNYNGNQGDDFLTPSGLAEPRVEDFGNAWKLHGDCQDLQKQHSDPCALNPRMTRFSEEACAVLTSPTFEACHRAVSPLPYLRNCRYDVCSCSDGRECLCGALASYAAACAGRGVRVAWREPGRCELNCPKGQVYLQCGTPCNLTCRSLSYPDEECNEACLEGCFCPPGLYMDERGDCVPKAQCPCYYDGEIFQPEDIFSDHHTMCYCEDGFMHCTMSGVPGSLLPDAVLSSPLSHRSKRSLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHDFYCSRLLDLVFLLDGSSRLSEAEFEVLKAFVVDMMERLRISQKWVRVAVVEYHDGSHAYIGLKDRKRPSELRRIASQVKYAGSQVASTSEVLKYTLFQIFSKIDRPEASRITLLLMASQEPQRMSRNFVRYVQGLKKKKVIVIPVGIGPHANLKQIRLIEKQAPENKAFVLSSVDELEQQRDEIVSYLCDLAPEAPPPTLPPDMAQVTVGPGLLGVSTLGPKRNSMVLDVAFVLEGSDKIGEADFNRSKEFMEEVIQRMDVGQDSIHVTVLQYSYMVTVEYPFSEAQSKGDILQRVREIRYQGGNRTNTGLALRYLSDHSFLVSQGDREQAPNLVYMVTGNPASDEIKRLPGDIQVVPIGVGPNANVQELERIGWPNAPILIQDFETLPREAPDLVLQRCCSGEGLQIPTLSPAPDCSQPLDVILLLDGSSSFPASYFDEMKSFAKAFISKANIGPRLTQVSVLQYGSITTIDVPWNVVPEKAHLLSLVDVMQREGGPSQIGDALGFAVRYLTSEMHGARPGASKAVVILVTDVSVDSVDAAADAARSNRVTVFPIGIGDRYDAAQLRILAGPAGDSNVVKLQRIEDLPTMVTLGNSFLHKLCSGFVRICMDEDGNEKRPGDVWTLPDQCHTVTCQPDGQTLLKSHRVNCDRGLRPSCPNSQSPVKVEETCGCRWTCPCVCTGSSTRHIVTFDGQNFKLTGSCSYVLFQNKEQDLEVILHNGACSPGARQGCMKSIEVKHSALSVELHSDMEVTVNGRLVSVPYVGGNMEVNVYGAIMHEVRFNHLGHIFTFTPQNNEFQLQLSPKTFASKTYGLCGICDENGANDFMLRDGTVTTDWKTLVQEWTVQRPGQTCQPILEEQCLVPDSSHCQVLLLPLFAECHKVLAPATFYAICQQDSCHQEQVCEVIASYAHLCRTNGVCVDWRTPDFCAMSCPPSLVYNHCEHGCPRHCDGNVSSCGDHPSEGCFCPPDKVMLEGSCVPEEACTQCIGEDGVQHQFLEAWVPDHQPCQICTCLSGRKVNCTTQPCPTAKAPTCGLCEVARLRQNADQCCPEYECVCDPVSCDLPPVPHCERGLQPTLTNPGECRPNFTCACRKEECKRVSPPSCPPHRLPTLRKTQCCDEYECACNCVNSTVSCPLGYLASTATNDCGCTTTTCLPDKVCVHRSTIYPVGQFWEEGCDVCTCTDMEDAVMGLRVAQCSQKPCEDSCRSGFTYVLHEGECCGRCLPSACEVVTGSPRGDSQSSWKSVGSQWASPENPCLINECVRVKEEVFIQQRNVSCPQLEVPVCPSGFQLSCKTSACCPSCRCERMEACMLNGTVIGPGKTVMIDVCTTCRCMVQVGVISGFKLECRKTTCNPCPLGYKEENNTGECCGRCLPTACTIQLRGGQIMTLKRDETLQDGCDTHFCKVNERGEYFWEKRVTGCPPFDEHKCLAEGGKIMKIPGTCCDTCEEPECNDITARLQYVKVGSCKSEVEVDIHYCQGKCASKAMYSIDINDVQDQCSCCSPTRTEPMQVALHCTNGSVVYHEVLNAMECKCSPRKCSK>sp|P04275-2|VWF_HUMAN Isoform 2 of von Willebrand factor OS=Homo sapiensOX=9606 GN=VWFMGAQDEEEGIQDLDGLLVFDKIVEVTLLNLPWYNEETEGQRGEMTAPKSPRAKIRGTLCAEGTRGRSSTARCSLFGSDFVNTFDGSMYSFAGYCSYLLAGGCQKRSFSIIGDFQNGKRVSLSVYLGEFFDIHLFVNGTVTQGDQRVSMPYASKGLYLETEAGYYKLSGEAYGFVARIDGSGNFQVLLSDRYFNKTCGLCGNFNIFAEDDFMTQEGTLTSDPYDFANSWALSSGEQWCERASPPSSSCNISSGEMQKEEPECNDITARLQYVKVGSCKSEVEVDIHYCQGKCASKAMYSIDINDVQDQCSCCSPTRTEPMQVALHCTNGSVVYHEVLNAMECKCSPRKCSKI>sp|Q9C0J8|WDR33_HUMAN pre-mRNA 3' end processing protein WDR33 OS=Homosapiens OX=9606 GN=WDR33 PE=1 SV=2MATEIGSPPRFFHMPRFQHQAPRQLFYKRPDFAQQQAMQQLTFDGKRMRKAVNRKTIDYNPSVIKYLENRIWQRDQRDMRAIQPDAGYYNDLVPPIGMLNNPMNAVTTKFVRTSTNKVKCPVFVVRWTPEGRRLVTGASSGEFTLWNGLTFNFETILQAHDSPVRAMTWSHNDMWMLTADHGGYVKYWQSNMNNVKMFQAHKEAIREASFSPTDNKFATCSDDGTVRIWDFLRCHEERILRGHGADVKCVDWHPTKGLVVSGSKDSQQPIKFWDPKTGQSLATLHAHKNTVMEVKLNLNGNWLLTASRDHLCKLFDIRNLKEELQVFRGHKKEATAVAWHPVHEGLFASGGSDGSLLFWHVGVEKEVGGMEMAHEGMIWSLAWHPLGHILCSGSNDHTSKFWTRNRPGDKMRDRYNLNLLPGMSEDGVEYDDLEPNSLAVIPGMGIPEQLKLAMEQEQMGKDESNEIEMTIPGLDWGMEEVMQKDQKKVPQKKVPYAKPIPAQFQQAWMQNKVPIPAPNEVLNDRKEDIKLEEKKKTQAEIEQEMATLQYTNPQLLEQLKIERLAQKQVEQIQPPPSSGTPLLGPQPFPGQGPMSQIPQGFQQPHPSQQMPMNMAQMGPPGPQGQFRPPGPQGQMGPQGPPLHQGGGGPQGFMGPQGPQGPPQGLPRPQDMHGPQGMQRHPGPHGPLGPQGPPGPQGSSGPQGHMGPQGPPGPQGHIGPQGPPGPQGHLGPQGPPGTQGMQGPPGPRGMQGPPHPHGIQGGPGSQGIQGPVSQGPLMGLNPRGMQGPPGPRENQGPAPQGMIMGHPPQEMRGPHPPGGLLGHGPQEMRGPQEIRGMQGPPPQGSMLGPPQELRGPPGSQSQQGPPQGSLGPPPQGGMQGPPGPQGQQNPARGPHPSQGPIPFQQQKTPLLGDGPRAPFNQEGQSTGPPPLIPGLGQQGAQGRIPPLNPGQGPGPNKGDSRGPPNHHMGPMSERRHEQSGGPEHGPERGPFRGGQDCRGPPDRRGPHPDFPDDFSRPDDFHPDKRFGHRLREFEGRGGPLPQEEKWRRGGPGPPFPPDHREFSEGDGRGAARGPPGAWEGRRPGDERFPRDPEDPRFRGRREESFRRGAPPRHEGRAPPRGRDGFPGPEDFGPEENFDASEEAARGRDLRGRGRGTPRGGRKGLLPTPDEFPRFEGGRKPDSWDGNREPGPGHEHFRDTPRPDHPPHDGHSPASRERSSSLQGMDMASLPPRKRPWHDGPGTSEHREMEAPGGPSEDRGGKGRGGPGPAQRVPKSGRSSSLDGEHHDGYHRDEPFGGPPGSGTPSRGGRSGSNWGRGSNMNSGPPRRGASRGGGRGR>sp|Q9C0J8-2|WDR33_HUMAN Isoform 2 of pre-mRNA 3' end processing proteinWDR33 OS=Homo sapiens OX=9606 GN=WDR33MATEIGSPPRFFHMPRFQHQAPRQLFYKRPDFAQQQAMQQLTFDGKRMRKAVNRKTIDYNPSVIKYLENRIWQRDQRDMRAIQPDAGYYNDLVPPIGMLNNPMNAVTTKFVRTSTNKVKCPVFVVRWTPEGRRLVTGASSGEFTLWNGLTFNFETILQAHDSPVRAMTWSHNDMWMLTADHGGYVKYWQSNMNNVKMFQAHKEAIREARFIHNIPFSVVPIVMVKLFSKCILGAEMHGLCQFLGNFLHPINTIFFFVFTHSPFCWHLSEVVLSRYQPLQYVRDVLSAAFCTGFLFSFMINNVYTLFLFIIYCVRQEYFIPNKEFSL>sp|Q9C0J8-3|WDR33_HUMAN Isoform 3 of pre-mRNA 3' end processing proteinWDR33 OS=Homo sapiens OX=9606 GN=WDR33MATEIGSPPRFFHMPRFQHQAPRQLFYKRPDFAQQQAMQQLTFDGKRMRKAVNRKTIDYNPSVIKYLENRIWQRDQRDMRAIQPDAGYYNDLVPPIGMLNNPMNAVTTKFVRTSTNKVKCPVFVVRWTPEGRRLVTGASSGEFTLWNGLTFNFETILQAHDSPVRAMTWSHNDMWMLTADHGGYVKYWQSNMNNVKMFQAHKEAIREASFSPTDNKFATCSDDGTVRIWDFLRCHEERILRDTCFHHCRCYFLSVKR>sp|P17017|ZNF14_HUMAN Zinc finger protein 14 OS=Homo sapiens OX=9606GN=ZNF14 PE=2 SV=3MDSVSFEDVAVNFTLEEWALLDSSQKKLYEDVMQETFKNLVCLGKKWEDQDIEDDHRNQGKNRRCHMVERLCESRRGSKCGETTSQMPNVNINKETFTGAKPHECSFCGRDFIHHSSLNRHMRSHTGQKPNEYQEYEKQPCKCKAVGKTFSYHHCFRKHERTHTGVKPYECKQCGKAFIYYQPFQRHERTHAGQKPYECKQCGKTFIYYQSFQKHAHTGKKPYECKQCGKAFICYQSFQRHKRTHTGEKPYECKQCGKAFSCPTYFRTHERTHTGEKPYKCKECGKAFSFLSSFRRHKRTHSGEKPYECKECGKAFFYSASFRAHVIIHTGARPYKCKECGKAFNSSNSCRVHERTHIGEKPYECKRCGKSFSWSISLRLHERTHTGEKPYECKQCHKTFSFSSSLREHETTHTGEKPYECKQCGKTFSFSSSLQRHERTHNAEKPYECKQCGKAFRCSSYFRIHERSHTGEKPYECKQCGKVFIRSSSFRLHERTHTGEKPYECKLCGKTFSFSSSLREHEKIHTGNKPFECKQCGKAFLRSSQIRLHERTHTGEKPYQCKQCGKAFISSSKFRMHERTHTGEKPYRCKQCGKAFRFSSSVRIHERSHTGEKPYECKQCGKAFISSSHFRLHERTHMGEKV>sp|P0CG24|ZN883_HUMAN Zinc finger protein 883 OS=Homo sapiens OX=9606GN=ZNF883 PE=1 SV=1MESEKIYMTANPYLCTECGKGYTCLASLTQHQKTHIGEKPYECKICGKSFTRNSNLVQHQRIHTGEKPYECNECGKAFSQSTNLIQHQRVHTGEKPYECNECEKTFSHRSSLRNHERIHTGEKPYPCNECGKAFSHISALTQHHRIHTGKKPYECTECGKTFSRSTHLIEHQGIHSEEKSYQCKQCRKVFCHSTSLIRHQRTHTGEKPYECNECGKAFSHTPAFIQHQRIHTGEKPYECNACGKAFNRSAHLTEHQRTHTGEKPYVCKECGKTFSRSTHLTEHLKIHSCVKPYQCNECQKLFCYRTSLIRHQRTHTGEKPYQCNECGKSFSLSSALTKHKRIHTRERPYQCTKCGDVFCHSTSLIRHQKTHFRKETLAE>sp|Q9H6B1|Z385D_HUMAN Zinc finger protein 385D OS=Homo sapiens OX=9606GN=ZNF385D PE=2 SV=1MRNIMYFGGTCQSPALPALVRPPAPPLQPSLDIKPFLPFPLDTAAAVNLFPNFNAMDPIQKAVINHTFGVPLPHRRKQIISCNICQLRFNSDSQAAAHYKGTKHAKKLKALEAMKNKQKSVTAKDSAKTTFTSITTNTINTSSDKTDGTAGTPAISTTTTVEIRKSSVMTTEITSKVEKSPTTATGNSSCPSTETEEEKAKRLLYCSLCKVAVNSASQLEAHNSGTKHKTMLEARNGSGTIKAFPRAGVKGKGPVNKGNTGLQNKTFHCEICDVHVNSETQLKQHISSRRHKDRAAGKPPKPKYSPYNKLQKTAHPLGVKLVFSKEPSKPLAPRILPNPLAAAAAAAAVAVSSPFSLRTAPAATLFQTSALPPALLRPAPGPIRTAHTPVLFAPY>sp|Q9Y2H8|ZN510_HUMAN Zinc finger protein 510 OS=Homo sapiens OX=9606GN=ZNF510 PE=2 SV=1MSPHPEAITDCVTLNTVGQLAEGGYPLRFSTLFQEQQKMNISQASVSFKDVTIEFTQEEWQQMAPVQKNLYRDVMLENYSNLVSVGYCCFKPEVIFKLEQGEEPWFSEEEFSNQSHPKDYRGDDLIKQNKKIKDKHLEQAICINNKTLTTEEEKVLGKPFTLHVAAVASTKMSCKCNSWEVNLQSISEFIINNRNYSTKKIGCGNVCENSPFKINFEKTQTGEKFYEHNKNMKALNYNENLPKHPKFQTLEQAFECNKIGKAFNDKANCVKHNSSHTGETSSKDDEFRKNCDKKTLFDHRRTGTGKKHLHLNQCGKSFEKSTVEEYNKLNMGIKHYELNPSGNNFNRKAHLTDPQTAVIEENPLVSNDRTQTWVKSSEYHENKKSYQTSVHRVRRRSHSMMKPYKCNECGKSFCQKGHLIQHQRTHTGEKPFECSECGKTFSQKSHLSTHQRIHTAEKPYKCNECGKTFVQKSTLRGHQRIHTGEKPYECSECGKTFVQKSTLRDHHRIHTGEKSFQCNQCGKTFGQKSNLRIHQRTHTGEKTYQCNECEKSFWRKDHLIQHQKTHTGEKPFKCNECGKTFARTSTLRVHQRIHTGEKPFKCNECGKKFVRKAILSDHQRIHTGEKPFQCNKCGKTFGQKSNLRIHQRTHSGEKSYECNEYGKLCKKSTLSLYQKIQGEGNPY>sp|Q969W8|ZN566_HUMAN Zinc finger protein 566 OS=Homo sapiens OX=9606GN=ZNF566 PE=1 SV=1MAQESVMFSDVSVDFSQEEWECLNDDQRDLYRDVMLENYSNLVSMGHSISKPNVISYLEQGKEPWLADRELTRGQWPVLESRCETKKLFLKKEIYEIESTQWEIMEKLTRRDFQCSSFRDDWECNRQFKKELGSQGGHFNQLVFTHEDLPTLSHHPSFTLQQIINSKKKFCASKEYRKTFRHGSQFATHEIIHTIEKPYECKECGKSFRHPSRLTHHQKIHTGKKPFECKECGKTFICGSDLTRHHRIHTGEKPYECKECGKAFSSGSNFTRHQRIHTGEKPYECKECGKAFSSGSNFTQHQRIHTGEKPYECKECGNAFSQSSQLIKHQRIHTGEKPYECKECEKAFRSGSDLTRHQRIHTGEKPYECKICGKAYSQSSQLISHHRIHTSEKPYEYRECGKNFNYDPQLIQHQNLYW>sp|Q969W8-2|ZN566_HUMAN Isoform 2 of Zinc finger protein 566 OS=Homosapiens OX=9606 GN=ZNF566MAQESVMFSDVSVDFSQEEWECLNDDQRDLYRDVMLENYSNLVSMAGHSISKPNVISYLEQGKEPWLADRELTRGQWPVLESRCETKKLFLKKEIYEIESTQWEIMEKLTRRDFQCSSFRDDWECNRQFKKELGSQGGHFNQLVFTHEDLPTLSHHPSFTLQQIINSKKKFCASKEYRKTFRHGSQFATHEIIHTIEKPYECKECGKSFRHPSRLTHHQKIHTGKKPFECKECGKTFICGSDLTRHHRIHTGEKPYECKECGKAFSSGSNFTRHQRIHTGEKPYECKECGKAFSSGSNFTQHQRIHTGEKPYECKECGNAFSQSSQLIKHQRIHTGEKPYECKECEKAFRSGSDLTRHQRIHTGEKPYECKICGKAYSQSSQLISHHRIHTSEKPYEYRECGKNFNYDPQLIQHQNLYW>sp|O15342|VA0E1_HUMAN V-type proton ATPase subunit e 1 OS=Homo sapiensOX=9606 GN=ATP6V0E1 PE=1 SV=2MAYHGLTVPLIVMSVFWGFVGFLVPWFIPKGPNRGVIITMLVTCSVCCYLFWLIAILAQLNPLFGPQLKNETIWYLKYHWP>sp|Q9H322|VCX2_HUMAN Variable charge X-linked protein 2 OS=Homo sapiensOX=9606 GN=VCX2 PE=2 SV=3MSPKPRASGPPAKATEAGKRKSSSQPSPSDPKKKTTKVAKKGKAVRRGRRGKKGAATKMAAVTAPEAESAPAAPGPSDQPSQELPQHELPPEEPVSEGTQHDPLSQESEVEEPLSQESEVEEPLTVWMASFSPVSESTD>sp|P49765|VEGFB_HUMAN Vascular endothelial growth factor B OS=Homosapiens OX=9606 GN=VEGFB PE=1 SV=2MSPLLRRLLLAALLQLAPAQAPVSQPDAPGHQRKVVSWIDVYTRATCQPREVVVPLTVELMGTVAKQLVPSCVTVQRCGGCCPDDGLECVPTGQHQVRMQILMIRYPSSQLGEMSLEEHSQCECRPKKKDSAVKPDRAATPHHRPQPRSVPGWDSAPGAPSPADITHPTPAPGPSAHAAPSTTSALTPGPAAAAADAAASSVAKGGA>sp|P49765-2|VEGFB_HUMAN Isoform VEGF-B167 of Vascular endothelial growthfactor B OS=Homo sapiens OX=9606 GN=VEGFBMSPLLRRLLLAALLQLAPAQAPVSQPDAPGHQRKVVSWIDVYTRATCQPREVVVPLTVELMGTVAKQLVPSCVTVQRCGGCCPDDGLECVPTGQHQVRMQILMIRYPSSQLGEMSLEEHSQCECRPKKKDSAVKPDSPRPLCPRCTQHHQRPDPRTCRCRCRRRSFLRCQGRGLELNPDTCRCRKLRR>sp|Q9Y2P7|ZN256_HUMAN Zinc finger protein 256 OS=Homo sapiens OX=9606GN=ZNF256 PE=1 SV=2MAAAELTAPAQGIVTFEDVAVYFSWKEWGLLDEAQKCLYHDVMLENLTLTTSLGGSGAGDEEAPYQQSTSPQRVSQVRIPKALPSPQKTNPCEICGPVLRQILHLVEHQGTHHGQKLYTDGACRKQLQFTAYLHQHQKQHVGQKHFRSNGGRDMFLSSCTFEVSGKPFTCKEVGKDFLVRSRFLQQQAAHTRKKSNRTKSAVAFHSVKNHYNWGECVKAFSYKHVRVQHQGDLIRERSYMCSECGKSFSTSCSLSDHLRVHTSEKPYTCGECGKSYRQSSSLITHRRIHTGVRPHQCDECGKLFNRKYDLLIHQRVHTGERPYKCSECGKSFSHSSSLITHQRIHTGMRPYECSECGKSFIHSSSLITHQRVHTGTRPYMCSECGKSFSQSCHLIKHRRLHIGEGPYECSECGKLFTYRSRFFQHQRVHTGVRSHECHECGKLFSRKFDLIVHERVHTGERPYECSECGKSFTCKSYLISHWKVHTGARPYECGECGKSFTHSSTLLQHQRVHTGERPYECNECGKFFSQSSSLIRHRRSHTGERPYECSECWKSFSNHSSLVKHRRVHTGERPYECSECGKSFSQSSNLTNHQRIHSGERPYECSDCGKFFTFNSNLLKHQNVHKG>sp|Q9Y2P7-2|ZN256_HUMAN Isoform 2 of Zinc finger protein 256 OS=Homosapiens OX=9606 GN=ZNF256MFLSSCTFEVSGKPFTCKEVGKDFLVRSRFLQQQAAHTRKKSNRTKSAVAFHSVKNHYNWGECVKAFSYKHVRVQHQGDLIRERSYMCSECGKSFSTSCSLSDHLRVHTSEKPYTCGECGKSYRQSSSLITHRRIHTGVRPHQCDECGKLFNRKYDLLIHQRVHTGERPYKCSECGKSFSHSSSLITHQRIHTGMRPYECSECGKSFIHSSSLITHQRVHTGTRPYMCSECGKSFSQSCHLIKHRRLHIGEGPYECSECGKLFTYRSRFFQHQRVHTGVRSHECHECGKLFSRKFDLIVHERVHTGERPYECSECGKSFTCKSYLISHWKVHTGARPYECGECGKSFTHSSTLLQHQRVHTGERPYECNECGKFFSQSSSLIRHRRSHTGERPYECSECWKSFSNHSSLVKHRRVHTGERPYECSECGKSFSQSSNLTNHQRIHSGERPYECSDCGKFFTFNSNLLKHQNVHKG>sp|Q86YA3|ZGRF1_HUMAN Protein ZGRF1 OS=Homo sapiens OX=9606 GN=ZGRF1PE=1 SV=3MESQEFIVLYTHQKMKKSKVWQDGILKITHLGNKAILYDDKGACLESLFLKCLEVKPGDDLESDRYLITVEEVKVAGAIGIVKQNVNKEAPELNSRTFISSGRSLGCQPSGLKRKFTGFQGPRQVPKKMVIMESGESAASHEAKKTGPTIFSPFCSMPPLFPTVGKKDVNNILADPENIVTYKNRERNAMDFSSVFSPSFQINPEVLCEENYFCSPVNSGNKLSDSLLTNEPVKRDSLASHYSGVSQNIRSKAQILALLKSESSSSCEELNSEMTEHFPQKQPQGSLKIATKPKYLIQQEECAEMKSTENLYYQHQSENTMRNKSRWAMYLSSQSSPIHSSTVDGNDTERKPKAQEDDVNSNLKDLSLQKIIQFVETYAEERKKYNVDQSVGNNDPSWNQEVKLEIPSFNESSSLQVTCSSAENDGILSESDIQEDNKIPFNQNDKGCIKGSVLIKENAQEVNTCGTLEKEYEQSESSLPELKHLQIESSNNSRISDDITDMISESKMDNESLNSIHESLSNVTQPFLEVTFNLNNFETSDTEEESQESNKISQDSESWVKDILVNDGNSCFQKRSENTNCEEIEGEHLPFLTSVSDKPTVTFPVKETLPSQFCDKTYVGFDMGICKTENTGKEIEEYSDTLSNFESFKWTDAVYGDNKEDANKPIQEVRINYDFALPPNKSKGINMNLHIPHIQNQIAENSNLFSEDAQPQPFILGSDLDKNDEHVLPSTSSSDNSVQLLNTNQNHYECIALDKSNTHISNSLFYPLGKKHLISKDTEAHISEPEDLGKIRSPPPDHVEVETAREGKQYWNPRNSSELSGLVNTISILKSLCEHSTALDSLEILKKKNTVFQQGTQQTYEPDSPPEVRKPFITVVSPKSPHLHKDSQQILKEDEVELSEPLQSVQFSSSGSKEETAFQAVIPKQIERKTCDPKPVEFQGHQVKGSATSGVMVRGHSSQLGCSQFPDSTEYENFMTETPELPSTCMQIDFLQVTSPEENISTLSPVSTFSLNSRDEDFMVEFSETSLKARTLPDDLHFLNLEGMKKSRSLENENLQRLSLLSRTQVPLITLPRTDGPPDLDSHSYMINSNTYESSGSPMLNLCEKSAVLSFSIEPEDQNETFFSEESREVNPGDVSLNNISTQSKWLKYQNTSQCNVATPNRVDKRITDGFFAEAVSGMHFRDTSERQSDAVNESSLDSVHLQMIKGMLYQQRQDFSSQDSVSRKKVLSLNLKQTSKTEEIKNVLGGSTCYNYSVKDLQEISGSELCFPSGQKIKSAYLPQRQIHIPAVFQSPAHYKQTFTSCLIEHLNILLFGLAQNLQKALSKVDISFYTSLKGEKLKNAENNVPSCHHSQPAKLVMVKKEGPNKGRLFYTCDGPKADRCKFFKWLEDVTPGYSTQEGARPGMVLSDIKSIGLYLRSQKIPLYEECQLLVRKGFDFQRKQYGKLKKFTTVNPEFYNEPKTKLYLKLSRKERSSAYSKNDLWVVSKTLDFELDTFIACSAFFGPSSINEIEILPLKGYFPSNWPTNMVVHALLVCNASTELTTLKNIQDYFNPATLPLTQYLLTTSSPTIVSNKRVSKRKFIPPAFTNVSTKFELLSLGATLKLASELIQVHKLNKDQATALIQIAQMMASHESIEEVKELQTHTFPITIIHGVFGAGKSYLLAVVILFFVQLFEKSEAPTIGNARPWKLLISSSTNVAVDRVLLGLLSLGFENFIRVGSVRKIAKPILPYSLHAGSENESEQLKELHALMKEDLTPTERVYVRKSIEQHKLGTNRTLLKQVRVVGVTCAACPFPCMNDLKFPVVVLDECSQITEPASLLPIARFECEKLILVGDPKQLPPTIQGSDAAHENGLEQTLFDRLCLMGHKPILLRTQYRCHPAISAIANDLFYKGALMNGVTEIERSPLLEWLPTLCFYNVKGLEQIERDNSFHNVAEATFTLKLIQSLIASGIAGSMIGVITLYKSQMYKLCHLLSAVDFHHPDIKTVQVSTVDAFQGAEKEIIILSCVRTRQVGFIDSEKRMNVALTRGKRHLLIVGNLACLRKNQLWGRVIQHCEGREDGLQHANQYEPQLNHLLKDYFEKQVEEKQKKKSEKEKSKDKSHS>sp|Q86YA3-2|ZGRF1_HUMAN Isoform 2 of Protein ZGRF1 OS=Homo sapiensOX=9606 GN=ZGRF1MGHKPILLRTQYRCHPAISAIANDLFYKGALMNGVTEIERSPLLEWLPTLCFYNVKGLEQIERDNSFHNVAEATFTLKLIQSLIASGIAGSMIGVITLYKSQMYKLCHLLSAVDFHHPDIKTVQVSTVDAFQGAEKEIIILSCVRTRQVGFIDSEKRMNVALTRGKRHLLIVGNLACLRKNQLWGRVIQHCEGREDGLQHANQYEPQLNHLLKDYFEKQVEEKQKKKSEKEKSKDKSHS>sp|Q86YA3-3|ZGRF1_HUMAN Isoform 3 of Protein ZGRF1 OS=Homo sapiensOX=9606 GN=ZGRF1MESQEFIVLYTHQKMKKSKVWQDGILKITHLGNKAILYDDKGACLESLFLKCLEVKPGDDLESDRYLITVEEVKVAGAIGIVKQNVNKEAPELNSRTFISSGRSLGCQPSGLKRKFTGFQGPRQVPKKMVIMESGESAASHEAKKTGPTIFSPFCSMPPLFPTVGKKDVNNILADPENIVTYKNRERNAMDFSSVFSPSFQINPEVLCEENYFCSPVNSGNKLSDSLLTNEPVKRDSLASHYSGVSQNIRSKAQILALLKSESSSSCEELNSEMTEHFPQKQPQGSLKIATKPKYLIQQEECAEMKSTENLYYQHQSENTMRNKSRWAMYLSSQSSPIHSSTVDGNDTERKPKAQEDDVNSNLKDLSLQKIIQFVETYAEERKKYNVDQSVGNNDPSWNQEVKLEIPSFNESSSLQVTCSSAENDGILSESDIQEDNKIPFNQNDKGCIKGSVLIKENAQEVNTCGTLEKEYEQSESSLPELKHLQIESSNNSRISDDITDMISESKMDNESLNSIHESLSNVTQPFLEVTFNLNNFETSDTEEESQESNKISQDSESWVKDILVNDGNSCFQKRSENTNCEEIEGEHLPFLTSVSDLDKNDEHVLPSTSSSDNSVQLLNTNQNHYECIALDKSNTHISNSLFYPLGKKHLISKDTEAHISEPEDLGKIRSPPPDHVEVETAREGKQYWNPRNSSELSGLVNTISILKSLCEHSTALDSLEILKKKNTVFQQGTQQTYEPDSPPEVRKPFITVVSPKSPHLHKDSQQILKEDEVELSEPLQSVQFSSSGSKEETAFQAVIPKQIERKTCDPKVKFVKNIDLFNQLHFLFCLK>sp|Q86YA3-4|ZGRF1_HUMAN Isoform 4 of Protein ZGRF1 OS=Homo sapiensOX=9606 GN=ZGRF1MESQEFIVLYTHQKMKKSKVWQDGILKITHLGNKAILYDDKGACLESLFLKCLEVKPGDDLESDRYLITVEEVKVAGAIGIVKQNVNKEAPELNSRTFISSGRSLGCQPSGLKRKFTGFQGPRQVPKKMVIMESGESAASHEAKKTGPTIFSPFCSMPPLFPTVGKKDVNNILADPENIVTYKNRERNAMDFSSVFSPSFQINPEVLCEENYFCSPVNSGNKLSDSLLTNEPVKRDSLASHYSGVSQNIRSKAQILALLKSESSSSCEELNSEMTEHFPQKQPQGSLKIATKPKYLIQQEECAEMKSTENLYYQHQSENTMRNKSRWAMYLSSQSSPIHSSTVDGNDTERKPKAQEDDVNSNLKDLSLQKIIQFVETYAEERKKYNVDQSVGNNDPSWNQEVKLEIPSFNESSSLQVTCSSAENDGILSESDIQEDNKIPFNQNDKGCIKGSVLIKENAQEVNTCGTLEKEYEQSESSLPELKHLQIESSNNSRISDDITDMISESKMDNESLNSIHESLSNVTQPFLEVTFNLNNFETSDTEEESQESNKISQDSESWVKDILVNDGNSCFQKRSENTNCEEIEGEHLPFLTSVSDKPTVTFPVKETLPSQFCDKTYVGFDMGICKTENTGKEIEEYSDTLSNFESFKWTDAVYGDNKEDANKPIQEVRINYDFALPPNKSKGINMNLHIPHIQNQIAENSNLFSEDAQPQPFILGSDLDKNDEHVLPSTSSSDNSVQLLNTNQNHYECIALDKSNTHISNSLFYPLGKKHLISKDTEAHISEPEDLGKIRSPPPDHVEVETAREGKQYWNPRNSSELSGLVNTISILKSLCEHSTALDSLEILKKKNTVFQQGTQQTYEPDSPPEVRKPFITVVSPKSPHLHKDSQQILKEDEVELSEPLQSVQFSSSGSKEETAFQAVIPKQIERKTCDPKPVEFQGHQVKGSATSGVMVRGHSSQLGCSQFPDSTEYENFMTETPELPSTCMQIDFLQVTSPEENISTLSPVSTFSLNSRDEDFMVEFSETSLKARTLPDDLHFLNLEGSRYHIALISVYSFKMKFFI>sp|Q86YA3-5|ZGRF1_HUMAN Isoform 5 of Protein ZGRF1 OS=Homo sapiensOX=9606 GN=ZGRF1MESQEFIVLYTHQKMKKSKVWQDGILKITHLGNKAILYDDKGACLESLFLKCLEVKPGDDLESDRYLITVEEVKVAGAIGIVKQNVNKEAPELNSRTFISSGRSLGCQPSGLKRKFTGFQGPRQVPKKMVIMESGESAASHEAKKTGPTIFSPFCSMPPLFPTVGKKDVNNILADPENIVTYKNRERNAMDFSSVFSPSFQINPEVLCEENYFCSPVNSGNKLSDSLLTNEPVKRDSLASHYSGVSQNIRSKAQILALLKSESSSSCEELNSEMTEHFPQKQPQGSLKIATKPKYLIQQEECAEMKSTENLYYQHQSENTMRNKSRWAMYLSSQSSPIHSSTVDGNDTERKPKAQEDDVNSNLKDLSLQKIIQFVETYAEERKKYNVDQSVGNNDPSWNQEVKLEIPSFNESSSLQVTCSSAENDGILSESDIQEDNKIPFNQNDKGCIKGSVLIKENAQEVNTCGTLEKEYEQSESSLPELKHLQIESSNNSRISDDITDMISESKMDNESLNSIHESLSNVTQPFLEVTFNLNNFETSDTEEESQESNKISQDSESWVKDILVNDGNSCFQKRSENTNCEEIEGEHLPFLTSVSDKPTVTFPVKETLPSQFCDKTYVGFDMGICKTENTGKEIEEYSDTLSNFESFKWTDAVYGDNKEDANKPIQEVRINYDFALPPNKSKGINMNLHIPHIQNQIAENSNLFSEDAQPQPFILGSDLDKNDEHVLPSTSSSDNSVQLLNTNQNHYECIALDKSNTHISNSLFYPLGKKHLISKDTEAHISEPEDLGKIRSPPPDHVEVETAREGKQYWNPRNSSELSGLVNTISILKSLCEHSTALDSLEILKKKNTVFQQGTQQTYEPDSPPEVRKPFITVVSPKSPHLHKDSQQILKEDEVELSEPLQSVQTGSYSVTQTRVQWHSHSSLQP>sp|Q86YA3-6|ZGRF1_HUMAN Isoform 6 of Protein ZGRF1 OS=Homo sapiensOX=9606 GN=ZGRF1MFQAILYDDKGACLESLFLKCLEVKPGDDLESDRYLITVEEVKVAGAIGIVKQNVNKEAPELNSRTFISSGRSLGCQPSGLKRKFTGFQGPRQVPKKMVIMESGESAASHEAKKTGPTIFSPFCSMPPLFPTVGKKDVNNILADPENIVTYKNRERNAMDFSSVFSPSFQINPEVLCEENYFCSPVNSGNKLSDSLLTNEPVKRDSLASHYSGVSQNIRSKAQILALLKSESSSSCEELNSEMTEHFPQKQPQGSLKIATKPKYLIQQEECAEMKSTENLYYQHQSENTMRNKSRWAMYLSSQSSPIHSSTVDGNDTERKPKAQEDDVNSNLKDLSLQKIIQFVETYAEERKKYNVDQSVGNNDPSWNQEVKLEIPSFNESSSLQVTCSSAENDGILSESDIQEDNKIPFNQNDKGCIKGSVLIKENAQEVNTCGTLEKEYEQSESSLPELKHLQIESSNNSRISDDITDMISESKMDNESLNSIHESLSNVTQPFLEVTFNLNNFETSDTEEESQESNKISQDSESWVKDILVNDGNSCFQKRSENTNCEEIEGEHLPFLTSVSDKPTVTFPVKETLPSQFCDKTYVGFDMGICKTENTGKEIEEYSDTLSNFESFKWTDAVYGDNKEDANKPIQEVRINYDFALPPNKSKGINMNLHIPHIQNQIAENSNLFSEDAQPQPFILGSDLDKNDEHVLPSTSSSDNSVQLLNTNQNHYECIALDKSNTHISNSLFYPLGKKHLISKDTEAHISEPEDLGKIRSPPPDHVEVETAREGKQYWNPRNSSELSGLVNTISILKSLCEHSTALDSLEILKKKNTVFQQGTQQTYEPDSPPEVRKPFITVVSPKSPHLHKDSQQKTVKKKIKPTLPLRIFINVSRFFCVQLKKMVRLMYINSFISFPLNIVVLSYIINNSS>sp|Q86YA3-7|ZGRF1_HUMAN Isoform 7 of Protein ZGRF1 OS=Homo sapiensOX=9606 GN=ZGRF1MNYSTHLFQMPLFLKLFICFIFIRSSPTIVSNKRVSKRKFIPPAFTNVSTKFELLSLGATLKLASELIQVHKLNKDQATALIQIAQMMASHESIEEVKELQTHTFPITIIHGVFGAGKSYLLAVVILFFVQLFEKSEAPTIGNARPWKLLISSSTNVAVDRVLLGLLSLGFENFIRVGSVRKIAKPILPYSLHAGSENESEQLKELHALMKEDLTPTERVYVRKSIEQHKLGTNRTLLKQVRVVGVTCAACPFPCMNDLKFPVVVLDECSQITEPASLLPIARFECEKLILVGDPKQLPPTIQGSDAAHENGLEQTLFDRLCLMGHKPILLRTQYRCHPAISAIANDLFYKGALMNGVTEIERSPLLEWLPTLCFYNVKGLEQIERDNSFHNVAEATFTLKLIQSLIASGIAGSMIGVITLYKSQMYKLCHLLSAVDFHHPDIKTVQVSTVDAFQGAEKEIIILSCVRTRQVGFIDSEKRMNVALTRGKRHLLIVGNLACLRKNQLWGRVIQHCEGREDGLQHANQYEPQLNHLLKDYFEKQVEEKQKKKSEKEKSKDKSHS>sp|Q96GY0|ZC21A_HUMAN Zinc finger C2HC domain-containing protein 1AOS=Homo sapiens OX=9606 GN=ZC2HC1A PE=1 SV=2MEGLEENGGVVQVGELLPCKICGRTFFPVALKKHGPICQKTATKKRKTFDSSRQRAEGTDIPTVKPLKPRPEPPKKPSNWRRKHEEFIATIRAAKGLDQALKEGGKLPPPPPPSYDPDYIQCPYCQRRFNENAADRHINFCKEQAARISNKGKFSTDTKGKPTSRTQVYKPPALKKSNSPGTASSGSSRLPQPSGAGKTVVGVPSGKVSSSSSSLGNKLQTLSPSHKGIAAPHAGANVKPRNSTPPSLARNPAPGVLTNKRKTYTESYIARPDGDCASSLNGGNIKGIEGHSPGNLPKFCHECGTKYPVEWAKFCCECGIRRMIL>sp|Q96GC6|ZN274_HUMAN Neurotrophin receptor-interacting factor homologOS=Homo sapiens OX=9606 GN=ZNF274 PE=1 SV=2MASRLPTAWSCEPVTFEDVTLGFTPEEWGLLDLKQKSLYREVMLENYRNLVSVEHQLSKPDVVSQLEEAEDFWPVERGIPQDTIPEYPELQLDPKLDPLPAESPLMNIEVVEVLTLNQEVAGPRNAQIQALYAEDGSLSADAPSEQVQQQGKHPGDPEAARQRFRQFRYKDMTGPREALDQLRELCHQWLQPKARSKEQILELLVLEQFLGALPVKLRTWVESQHPENCQEVVALVEGVTWMSEEEVLPAGQPAEGTTCCLEVTAQQEEKQEDAAICPVTVLPEEPVTFQDVAVDFSREEWGLLGPTQRTEYRDVMLETFGHLVSVGWETTLENKELAPNSDIPEEEPAPSLKVQESSRDCALSSTLEDTLQGGVQEVQDTVLKQMESAQEKDLPQKKHFDNRESQANSGALDTNQVSLQKIDNPESQANSGALDTNQVLLHKIPPRKRLRKRDSQVKSMKHNSRVKIHQKSCERQKAKEGNGCRKTFSRSTKQITFIRIHKGSQVCRCSECGKIFRNPRYFSVHKKIHTGERPYVCQDCGKGFVQSSSLTQHQRVHSGERPFECQECGRTFNDRSAISQHLRTHTGAKPYKCQDCGKAFRQSSHLIRHQRTHTGERPYACNKCGKAFTQSSHLIGHQRTHNRTKRKKKQPTS>sp|Q96GC6-2|ZN274_HUMAN Isoform 2 of Neurotrophin receptor-interactingfactor homolog OS=Homo sapiens OX=9606 GN=ZNF274MASRLPTAWSCEPVTFEDVTLGFTPEEWGLLDLKQKSLYREVMLENYRNLVSVEYPELQLDPKLDPLPAESPLMNIEVVEVLTLNQEVAGPRNAQIQALYAEDGSLSADAPSEQVQQQGKHPGDPEAARQRFRQFRYKDMTGPREALDQLRELCHQWLQPKARSKEQILELLVLEQFLGALPVKLRTWVESQHPENCQEVVALVEGVTWMSEEEVLPAGQPAEGTTCCLEVTAQQEEKQEDAAICPVTVLPEEPVTFQDVAVDFSREEWGLLGPTQRTEYRDVMLETFGHLVSVGWETTLENKELAPNSDIPEEEPAPSLKVQESSRDCALSSTLEDTLQGGVQEVQDTVLKQMESAQEKDLPQKKHFDNRESQANSGALDTNQVSLQKIDNPESQANSGALDTNQVLLHKIPPRKRLRKRDSQVKSMKHNSRVKIHQKSCERQKAKEGNGCRKTFSRSTKQITFIRIHKGSQVCRCSECGKIFRNPRYFSVHKKIHTGERPYVCQDCGKGFVQSSSLTQHQRVHSGERPFECQECGRTFNDRSAISQHLRTHTGAKPYKCQDCGKAFRQSSHLIRHQRTHTGERPYACNKCGKAFTQSSHLIGHQRTHNRTKRKKKQPTS>sp|Q96GC6-3|ZN274_HUMAN Isoform 3 of Neurotrophin receptor-interactingfactor homolog OS=Homo sapiens OX=9606 GN=ZNF274MNIEVVEVLTLNQEVAGPRNAQIQALYAEDGSLSADAPSEQVQQQGKHPGDPEAARQRFRQFRYKDMTGPREALDQLRELCHQWLQPKARSKEQILELLVLEQFLGALPVKLRTWVESQHPENCQEVVALVEGVTWMSEEEVLPAGQPAEGTTCCLEVTAQQEEKQEDAAICPVTVLPEEPVTFQDVAVDFSREEWGLLGPTQRTEYRDVMLETFGHLVSVGWETTLENKELAPNSDIPEEEPAPSLKVQESSRDCALSSTLEDTLQGGVQEVQDTVLKQMESAQEKDLPQKKHFDNRESQANSGALDTNQVSLQKIDNPESQANSGALDTNQVLLHKIPPRKRLRKRDSQVKSMKHNSRVKIHQKSCERQKAKEGNGCRKTFSRSTKQITFIRIHKGSQVCRCSECGKIFRNPRYFSVHKKIHTGERPYVCQDCGKGFVQSSSLTQHQRVHSGERPFECQECGRTFNDRSAISQHLRTHTGAKPYKCQDCGKAFRQSSHLIRHQRTHTGERPYACNKCGKAFTQSSHLIGHQRTHNRTKRKKKQPTS>sp|Q96GC6-4|ZN274_HUMAN Isoform 4 of Neurotrophin receptor-interactingfactor homolog OS=Homo sapiens OX=9606 GN=ZNF274MLQEPVTFQDVAVDFSREEWGLLGPTQRTEYRDVMLETFGHLVSVGWETTLENKELAPNSDIPEEEPAPSLKVQESSRDCALSSTLEDTLQGGVQEVQDTVLKQMESAQEKDLPQKKHFDNRESQANSGALDTNQVSLQKIDNPESQANSGALDTNQVLLHKIPPRKRLRKRDSQVKSMKHNSRVKIHQKSCERQKAKEGNGCRKTFSRSTKQITFIRIHKGSQVCRCSECGKIFRNPRYFSVHKKIHTGERPYVCQDCGKGFVQSSSLTQHQRVHSGERPFECQECGRTFNDRSAISQHLRTHTGAKPYKCQDCGKAFRQSSHLIRHQRTHTGERPYACNKCGKAFTQSSHLIGHQRTHNRTKRKKKQPTS>sp|P0C7U3|ZH11B_HUMAN Probable palmitoyltransferase ZDHHC11B OS=Homosapiens OX=9606 GN=ZDHHC11B PE=3 SV=1MDTRSGSQCSVTPEAIRNNEELVLPPRISRVNGWSLPLHYFRVVTWAVFVGLSLATFRIFIPLLPHSWKYIAYVVTGGIFSFHLVVHLIASCIDPADSNVRLMKNYSQPMPLFDRSKHAHVIQNQFCHLCKVTVNKKTKHCISCNKCVSGFDHHCKWINNCVGSRNYWFFFSTVASATAGMLCLIAILLYVLVQYLVNPRVLRTDPRYEDVKNMNTWLLFLPLFPVQVQTLIVVIIRMLVLLLDLLGLVQLGQLLIFHIYLKAKKMTTFEYLINTRKEESSKHQAVRKDPYVQMDKGFLQQGAGALGSSAQGVKAKSSLLIYKCPCHFCTSVNQDGDSKAQEADDAPSTSTLGLQQETTEPMKTDSAESED>sp|Q5TFG8|ZC21B_HUMAN Zinc finger C2HC domain-containing protein 1BOS=Homo sapiens OX=9606 GN=ZC2HC1B PE=1 SV=2MAGAEPFLADGNQELFPCEVCGRRFAADVLERHGPICKKLFNRKRKPFSSLKQRLQGTDIPTVKKTPQSKSPPVRKSNWRQQHEDFINAIRSAKQCMLAIKEGRPLPPPPPPSLNPDYIQRPYCMRRFNESAAERHTNFCKDQSSRRVFNPAQTAAKLASRAQGRAQMGPKKEPTVTSAVGALLQNRVLVATNEVPTKSGLAMDPASGAKLRQGFSKSSKKD>sp|Q93097|WNT2B_HUMAN Protein Wnt-2b OS=Homo sapiens OX=9606 GN=WNT2BPE=1 SV=2MLRPGGAEEAAQLPLRRASAPVPVPSPAAPDGSRASARLGLACLLLLLLLTLPARVDTSWWYIGALGARVICDNIPGLVSRQRQLCQRYPDIMRSVGEGAREWIRECQHQFRHHRWNCTTLDRDHTVFGRVMLRSSREAAFVYAISSAGVVHAITRACSQGELSVCSCDPYTRGRHHDQRGDFDWGGCSDNIHYGVRFAKAFVDAKEKRLKDARALMNLHNNRCGRTAVRRFLKLECKCHGVSGSCTLRTCWRALSDFRRTGDYLRRRYDGAVQVMATQDGANFTAARQGYRRATRTDLVYFDNSPDYCVLDKAAGSLGTAGRVCSKTSKGTDGCEIMCCGRGYDTTRVTRVTQCECKFHWCCAVRCKECRNTVDVHTCKAPKKAEWLDQT>sp|Q93097-2|WNT2B_HUMAN Isoform 1 of Protein Wnt-2b OS=Homo sapiensOX=9606 GN=WNT2BMLDGLGVVAISIFGIQLKTEGSLRTAVPGIPTQSAFNKCLQRYIGALGARVICDNIPGLVSRQRQLCQRYPDIMRSVGEGAREWIRECQHQFRHHRWNCTTLDRDHTVFGRVMLRSSREAAFVYAISSAGVVHAITRACSQGELSVCSCDPYTRGRHHDQRGDFDWGGCSDNIHYGVRFAKAFVDAKEKRLKDARALMNLHNNRCGRTAVRRFLKLECKCHGVSGSCTLRTCWRALSDFRRTGDYLRRRYDGAVQVMATQDGANFTAARQGYRRATRTDLVYFDNSPDYCVLDKAAGSLGTAGRVCSKTSKGTDGCEIMCCGRGYDTTRVTRVTQCECKFHWCCAVRCKECRNTVDVHTCKAPKKAEWLDQT>sp|Q8IUA0|WFDC8_HUMAN WAP four-disulfide core domain protein 8 OS=Homosapiens OX=9606 GN=WFDC8 PE=2 SV=2MWTVRTEGGHFPLHSPTFSWRNVAFLLLLSLALEWTSAMLTKKIKHKPGLCPKERLTCTTELPDSCNTDFDCKEYQKCCFFACQKKCMDPFQEPCMLPVRHGNCNHEAQRWHFDFKNYRCTPFKYRGCEGNANNFLNEDACRTACMLIVKDGQCPLFPFTERKECPPSCHSDIDCPQTDKCCESRCGFVCARAWTVKKGFCPRKPLLCTKIDKPKCLQDEECPLVEKCCSHCGLKCMDPRR>sp|P46094|XCR1_HUMAN Chemokine XC receptor 1 OS=Homo sapiens OX=9606GN=XCR1 PE=1 SV=1MESSGNPESTTFFYYDLQSQPCENQAWVFATLATTVLYCLVFLLSLVGNSLVLWVLVKYESLESLTNIFILNLCLSDLVFACLLPVWISPYHWGWVLGDFLCKLLNMIFSISLYSSIFFLTIMTIHRYLSVVSPLSTLRVPTLRCRVLVTMAVWVASILSSILDTIFHKVLSSGCDYSELTWYLTSVYQHNLFFLLSLGIILFCYVEILRTLFRSRSKRRHRTVKLIFAIVVAYFLSWGPYNFTLFLQTLFRTQIIRSCEAKQQLEYALLICRNLAFSHCCFNPVLYVFVGVKFRTHLKHVLRQFWFCRLQAPSPASIPHSPGAFAYEGASFY>sp|O14905|WNT9B_HUMAN Protein Wnt-9b OS=Homo sapiens OX=9606 GN=WNT9BPE=1 SV=3MRPPPALALAGLCLLALPAAAASYFGLTGREVLTPFPGLGTAAAPAQGGAHLKQCDLLKLSRRQKQLCRREPGLAETLRDAAHLGLLECQFQFRHERWNCSLEGRMGLLKRGFKETAFLYAVSSAALTHTLARACSAGRMERCTCDDSPGLESRQAWQWGVCGDNLKYSTKFLSNFLGSKRGNKDLRARADAHNTHVGIKAVKSGLRTTCKCHGVSGSCAVRTCWKQLSPFRETGQVLKLRYDSAVKVSSATNEALGRLELWAPARQGSLTKGLAPRSGDLVYMEDSPSFCRPSKYSPGTAGRVCSREASCSSLCCGRGYDTQSRLVAFSCHCQVQWCCYVECQQCVQEELVYTCKH>sp|P12956|XRCC6_HUMAN X-ray repair cross-complementing protein 6 OS=Homosapiens OX=9606 GN=XRCC6 PE=1 SV=2MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQCIQSVYISKIISSDRDLLAVVFYGTEKDKNSVNFKNIYVLQELDNPGAKRILELDQFKGQQGQKRFQDMMGHGSDYSLSEVLWVCANLFSDVQFKMSHKRIMLFTNEDNPHGNDSAKASRARTKAGDLRDTGIFLDLMHLKKPGGFDISLFYRDIISIAEDEDLRVHFEESSKLEDLLRKVRAKETRKRALSRLKLKLNKDIVISVGIYNLVQKALKPPPIKLYRETNEPVKTKTRTFNTSTGGLLLPSDTKRSQIYGSRQIILEKEETEELKRFDDPGLMLMGFKPLVLLKKHHYLRPSLFVYPEESLVIGSSTLFSALLIKCLEKEVAALCRYTPRRNIPPYFVALVPQEEELDDQKIQVTPPGFQLVFLPFADDKRKMPFTEKIMATPEQVGKMKAIVEKLRFTYRSDSFENPVLQQHFRNLEALALDLMEPEQAVDLTLPKVEAMNKRLGSLVDEFKELVYPPDYNPEGKVTKRKHDNEGSGSKRPKVEYSEEELKTHISKGTLGKFTVPMLKEACRAYGLKSGLKKQELLEALTKHFQD>sp|P12956-2|XRCC6_HUMAN Isoform 2 of X-ray repair cross-complementingprotein 6 OS=Homo sapiens OX=9606 GN=XRCC6MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQELDNPGAKRILELDQFKGQQGQKRFQDMMGHGSDYSLSEVLWVCANLFSDVQFKMSHKRIMLFTNEDNPHGNDSAKASRARTKAGDLRDTGIFLDLMHLKKPGGFDISLFYRDIISIAEDEDLRVHFEESSKLEDLLRKVRAKETRKRALSRLKLKLNKDIVISVGIYNLVQKALKPPPIKLYRETNEPVKTKTRTFNTSTGGLLLPSDTKRSQIYGSRQIILEKEETEELKRFDDPGLMLMGFKPLVLLKKHHYLRPSLFVYPEESLVIGSSTLFSALLIKCLEKEVAALCRYTPRRNIPPYFVALVPQEEELDDQKIQVTPPGFQLVFLPFADDKRKMPFTEKIMATPEQVGKMKAIVEKLRFTYRSDSFENPVLQQHFRNLEALALDLMEPEQAVDLTLPKVEAMNKRLGSLVDEFKELVYPPDYNPEGKVTKRKHDNEGSGSKRPKVEYSEEELKTHISKGTLGKFTVPMLKEACRAYGLKSGLKKQELLEALTKHFQD>sp|P41221|WNT5A_HUMAN Protein Wnt-5a OS=Homo sapiens OX=9606 GN=WNT5APE=1 SV=2MKKSIGILSPGVALGMAGSAMSSKFFLVALAIFFSFAQVVIEANSWWSLGMNNPVQMSEVYIIGAQPLCSQLAGLSQGQKKLCHLYQDHMQYIGEGAKTGIKECQYQFRHRRWNCSTVDNTSVFGRVMQIGSRETAFTYAVSAAGVVNAMSRACREGELSTCGCSRAARPKDLPRDWLWGGCGDNIDYGYRFAKEFVDARERERIHAKGSYESARILMNLHNNEAGRRTVYNLADVACKCHGVSGSCSLKTCWLQLADFRKVGDALKEKYDSAAAMRLNSRGKLVQVNSRFNSPTTQDLVYIDPSPDYCVRNESTGSLGTQGRLCNKTSEGMDGCELMCCGRGYDQFKTVQTERCHCKFHWCCYVKCKKCTEIVDQFVCK>sp|P41221-2|WNT5A_HUMAN Isoform 2 of Protein Wnt-5a OS=Homo sapiensOX=9606 GN=WNT5AMAGSAMSSKFFLVALAIFFSFAQVVIEANSWWSLGMNNPVQMSEVYIIGAQPLCSQLAGLSQGQKKLCHLYQDHMQYIGEGAKTGIKECQYQFRHRRWNCSTVDNTSVFGRVMQIGSRETAFTYAVSAAGVVNAMSRACREGELSTCGCSRAARPKDLPRDWLWGGCGDNIDYGYRFAKEFVDARERERIHAKGSYESARILMNLHNNEAGRRTVYNLADVACKCHGVSGSCSLKTCWLQLADFRKVGDALKEKYDSAAAMRLNSRGKLVQVNSRFNSPTTQDLVYIDPSPDYCVRNESTGSLGTQGRLCNKTSEGMDGCELMCCGRGYDQFKTVQTERCHCKFHWCCYVKCKKCTEIVDQFVCK>sp|Q9Y6I7|WSB1_HUMAN WD repeat and SOCS box-containing protein 1 OS=Homosapiens OX=9606 GN=WSB1 PE=1 SV=1MASFPPRVNEKEIVRLRTIGELLAPAAPFDKKCGRENWTVAFAPDGSYFAWSQGHRTVKLVPWSQCLQNFLLHGTKNVTNSSSLRLPRQNSDGGQKNKPREHIIDCGDIVWSLAFGSSVPEKQSRCVNIEWHRFRFGQDQLLLATGLNNGRIKIWDVYTGKLLLNLVDHTEVVRDLTFAPDGSLILVSASRDKTLRVWDLKDDGNMMKVLRGHQNWVYSCAFSPDSSMLCSVGASKAVFLWNMDKYTMIRKLEGHHHDVVACDFSPDGALLATASYDTRVYIWDPHNGDILMEFGHLFPPPTPIFAGGANDRWVRSVSFSHDGLHVASLADDKMVRFWRIDEDYPVQVAPLSNGLCCAFSTDGSVLAAGTHDGSVYFWATPRQVPSLQHLCRMSIRRVMPTQEVQELPIPSKLLEFLSYRI>sp|Q9Y6I7-2|WSB1_HUMAN Isoform 2 of WD repeat and SOCS box-containingprotein 1 OS=Homo sapiens OX=9606 GN=WSB1MASFPPRVNEKEIGKLLLNLVDHTEVVRDLTFAPDGSLILVSASRDKTLRVWDLKDDGNMMKVLRGHQNWVYSCAFSPDSSMLCSVGASKAVFLWNMDKYTMIRKLEGHHHDVVACDFSPDGALLATASYDTRVYIWDPHNGDILMEFGHLFPPPTPIFAGGANDRWVRSVSFSHDGLHVASLADDKMVRFWRIDEDYPVQVAPLSNGLCCAFSTDGSVLAAGTHDGSVYFWATPRQVPSLQHLCRMSIRRVMPTQEVQELPIPSKLLEFLSYRI>sp|Q9Y6I7-3|WSB1_HUMAN Isoform 3 of WD repeat and SOCS box-containingprotein 1 OS=Homo sapiens OX=9606 GN=WSB1MASFPPRVNEKEIVRLRTIGELLAPAAPFDKKCGRENWTVAFAPDGSYFAWSQGHRTVKLVPWSQCLQNFLLHGTKNVTNSSSLRLPRQNSDGGQKNKPREHIIDCGDIVWSLAFGSSVPEKQSRCVNIEWHRFRFGQDQLLLATGLNNGRIKIWDVYTGKLLLNLVDHTEVVRDLTFAPDGSLILVSASRDKTLRVWDLKDDGNMMKVLRGHQNWVYSCAFSPDSSMLCSVGASKAVVAAILV>sp|Q9Y6I7-4|WSB1_HUMAN Isoform 4 of WD repeat and SOCS box-containingprotein 1 OS=Homo sapiens OX=9606 GN=WSB1MLNIILIKFSSFSIRCAILSSVCLNEAITFAFLLQVFLWNMDKYTMIRKLEGHHHDVVACDFSPDGALLATASYDTRVYIWDPHNGDILMEFGHLFPPPTPIFAGGANDRWVRSVSFSHDGLHVASLADDKMVRFWRIDEDYPVQVAPLSNGLCCAFSTDGSVLAAGTHDGSVYFWATPRQVPSLQHLCRMSIRRVMPTQEVQELPIPSKLLEFLSYRI>sp|Q6PP77|XKR2_HUMAN XK-related protein 2 OS=Homo sapiens OX=9606GN=XKRX PE=2 SV=2MDRVYEIPEEPNVDPVSSLEEDVIRGANPRFTFPFSILFSTFLYCGEAASALYMVRIYRKNSETYWMTYTFSFFMFSSIMVQLTLIFVHRDLAKDKPLSLFMHLILLGPVIRCLEAMIKYLTLWKKEEQEEPYVSLTRKKMLIDGEEVLIEWEVGHSIRTLAMHRNAYKRMSQIQAFLGSVPQLTYQLYVSLISAEVPLGRVVLMVFSLVSVTYGATLCNMLAIQIKYDDYKIRLGPLEVLCITIWRTLEITSRLLILVLFSATLKLKAVPFLVLNFLIILFEPWIKFWRSGAQMPNNIEKNFSRVGTLVVLISVTILYAGINFSCWSALQLRLADRDLVDKGQNWGHMGLHYSVRLVENVIMVLVFKFFGVKVLLNYCHSLIALQLIIAYLISIGFMLLFFQYLHPLRSLFTHNVVDYLHCVCCHQHPRTRVENSEPPFETEARQSVV>sp|Q6PP77-2|XKR2_HUMAN Isoform 2 of XK-related protein 2 OS=Homo sapiensOX=9606 GN=XKRXMVFSLVSVTYGATLCNMLAIQIKYDDYKIRLGPLEVLCITIWRTLEITSRLLILVLFSATLKLKAVPFLVLNFLIILFEPWIKFWRSGAQMPNNIEKNFSRVGTLVVLISVTILYAGINFSCWSALQLRLADRDLVDKGQNWGHMGLHYSVRLVENVIMVLVFKFFGVKVLLNYCHSLIALQLIIAYLISIGFMLLFFQYLHPLRSLFTHNVVDYLHCVCCHQHPRTRVENSEPPFETEARQSVV>sp|Q15061|WDR43_HUMAN WD repeat-containing protein 43 OS=Homo sapiensOX=9606 GN=WDR43 PE=1 SV=3MAAGGGGSCDPLAPAGVPCAFSPHSQAYFALASTDGHLRVWETANNRLHQEYVPSAHLSGTCTCLAWAPARLQAKESPQRKKRKSEAVGMSNQTDLLALGTAVGSILLYSTVKGELHSKLISGGHDNRVNCIQWHQDSGCLYSCSDDKHIVEWNVQTCKVKCKWKGDNSSVSSLCISPDGKMLLSAGRTIKLWVLETKEVYRHFTGHATPVSSLMFTTIRPPNESQPFDGITGLYFLSGAVHDRLLNVWQVRSENKEKSAVMSFTVTDEPVYIDLTLSENKEEPVKLAVVCRDGQVHLFEHILNGYCKKPLTSNCTIQIATPGKGKKSTPKPIPILAAGFCSDKMSLLLVYGSWFQPTIERVALNSREPHMCLVRDISNCWAPKVETAITKVRTPVMNSEAKVLVPGIPGHHAAIKPAPPQTEQVESKRKSGGNEVSIEERLGAMDIDTHKKGKEDLQTNSFPVLLTQGLESNDFEMLNKVLQTRNVNLIKKTVLRMPLHTIIPLLQELTKRLQGHPNSAVLMVQWLKCVLTVHASYLSTLPDLVPQLGTLYQLMESRVKTFQKLSHLHGKLILLITQVTASEKTKGATSPGQKAKLVYEEESSEEESDDEIADKDSEDNWDEDEEESESEKDEDVEEEDEDAEGKDEENGEDRDTASEKELNGDSDLDPENESEEE>sp|Q2TB10|ZN800_HUMAN Zinc finger protein 800 OS=Homo sapiens OX=9606GN=ZNF800 PE=1 SV=1MPLRDKYCQTDHHHHGCCEPVYILEPGDPPLLQQPLQTSKSGIQQIIECFRSGTKQLKHILLKDVDTIFECKLCRSLFRGLPNLITHKKFYCPPSLQMDDNLPDVNDKQSQAINDLLEAIYPSVDKREYIIKLEPIETNQNAVFQYISRTDNPIEVTESSSTPEQTEVQIQETSTEQSKTVPVTDTEVETVEPPPVEIVTDEVAPTSDEQPQESQADLETSDNSDFGHQLICCLCRKEFNSRRGVRRHIRKVHKKKMEELKKYIETRKNPNQSSKGRSKNVLVPLSRSCPVCCKSFATKANVRRHFDEVHRGLRRDSITPDIATKPGQPLFLDSISPKKSFKTRKQKSSSKAEYNLTACKCLLCKRKYSSQIMLKRHMQIVHKITLSGTNSKREKGPNNTANSSEIKVKVEPADSVESSPPSITHSPQNELKGTNHSNEKKNTPAAQKNKVKQDSESPKSTSPSAAGGQQKTRKPKLSAGFDFKQLYCKLCKRQFTSKQNLTKHIELHTDGNNIYVKFYKCPLCTYETRRKRDVIRHITVVHKKSSRYLGKITASLEIRAIKKPIDFVLNKVAKRGPSRDEAKHSDSKHDGTSNSPSKKYEVADVGIEVKVTKNFSLHRCNKCGKAFAKKTYLEHHKKTHKANASNSPEGNKTKGRSTRSKALV>sp|Q8TF68|ZN384_HUMAN Zinc finger protein 384 OS=Homo sapiens OX=9606GN=ZNF384 PE=1 SV=2MEESHFNSNPYFWPSIPTVSGQIENTMFINKMKDQLLPEKGCGLAPPHYPTLLTVPASVSLPSGISMDTESKSDQLTPHSQASVTQNITVVPVPSTGLMTAGVSCSQRWRREGSQSRGPGLVITSPSGSLVTTASSAQTFPISAPMIVSALPPGSQALQVVPDLSKKVASTLTEEGGGGGGGGGSVAPKPPRGRKKKRMLESGLPEMNDPYVLSPEDDDDHQKDGKTYRCRMCSLTFYSKSEMQIHSKSHTETKPHKCPHCSKTFANSSYLAQHIRIHSGAKPYSCNFCEKSFRQLSHLQQHTRIHSKMHTETIKPHKCPHCSKTFANTSYLAQHLRIHSGAKPYNCSYCQKAFRQLSHLQQHTRIHTGDRPYKCAHPGCEKAFTQLSNLQSHRRQHNKDKPFKCHNCHRAYTDAASLEVHLSTHTVKHAKVYTCTICSRAYTSETYLMKHMRKHNPPDLQQQVQAAAAAAAVAQAQAQAQAQAQAQAQAQAQAQASQASQQQQQQQQQQQQQQQQPPPHFQSPGAAPQGGGGGDSNPNPPPQCSFDLTPYKTAEHHKDICLTVTTSTIQVEHLASS>sp|Q8TF68-2|ZN384_HUMAN Isoform 2 of Zinc finger protein 384 OS=Homosapiens OX=9606 GN=ZNF384MEESHFNSNPYFWPSIPTVSGQIENTMFINKMKDQLLPEKGCGLAPPHYPTLLTVPASVSLPSGISMDTESKSDQLTPHSQASVTQNITVVPVPSTGLMTAGVSCSQRWRREGSQSRGPGLVITSPSGSLVTTASSAQTFPISAPMIVSALPPGSQALQVVPDLSKKVASTLTEEGGGGGGGGGSVAPKPPRGRKKKRMLESGLPEMNDPYVLSPEDDDDHQKDGKTYRCRMCSLTFYSKSEMQIHSKSHTETKPHKCPHCSKTFANSSYLAQHIRIHSGAKPYSCNFCEKSFRQLSHLQQHTRIHTGDRPYKCAHPGCEKAFTQLSNLQSHRRQHNKDKPFKCHNCHRAYTDAASLEVHLSTHTVKHAKVYTCTICSRAYTSETYLMKHMRKHNPPDLQQQVQAAAAAAAVAQAQAQAQAQAQAQAQAQAQAQASQASQQQQQQQQQQQQQQQQPPPHFQSPGAAPQGGGGGDSNPNPPPQCSFDLTPYKTAEHHKDICLTVTTSTIQVEHLASS>sp|Q8TF68-3|ZN384_HUMAN Isoform 3 of Zinc finger protein 384 OS=Homosapiens OX=9606 GN=ZNF384MEESHFNSNPYFWPSIPTVSGQIENTMFINKMKDQLLPEKGCGLAPPHYPTLLTVPASVSLPSGISMDTESKSDQLTPHSQASVTQNITVVPVPSTGLMTAALQVVPDLSKKVASTLTEEGGGGGGGGGSVAPKPPRGRKKKRMLESGLPEMNDPYVLSPEDDDDHQKDGKTYRCRMCSLTFYSKSEMQIHSKSHTETKPHKCPHCSKTFANSSYLAQHIRIHSGAKPYSCNFCEKSFRQLSHLQQHTRIHTGDRPYKCAHPGCEKAFTQLSNLQSHRRQHNKDKPFKCHNCHRAYTDAASLEVHLSTHTVKHAKVYTCTICSRAYTSETYLMKHMRKHNPPDLQQQVQAAAAAAAVAQAQAQAQAQAQAQAQAQAQAQASQASQQQQQQQQQQQQQQQQPPPHFQSPGAAPQGGGGGDSNPNPPPQCSFDLTPYKTAEHHKDICLTVTTSTIQVEHLASS>sp|Q8N6M9|ZFN2A_HUMAN AN1-type zinc finger protein 2A OS=Homo sapiensOX=9606 GN=ZFAND2A PE=1 SV=2MEFPDLGKHCSEKTCKQLDFLPVKCDACKQDFCKDHFPYAAHKCPFAFQKDVHVPVCPLCNTPIPVKKGQIPDVVVGDHIDRDCDSHPGKKKEKIFTYRCSKEGCKKKEMLQMVCAQCHGNFCIQHRHPLDHSCRHGSRPTIKAG>sp|Q6ZR52|ZN493_HUMAN Zinc finger protein 493 OS=Homo sapiens OX=9606GN=ZNF493 PE=1 SV=3MNECNVHKEGYNELNQYLTTTQSKIFQCDKYVKVFHKLLNSNRHNTKHTGKKPFKCKKCGKSFCMLLHLCQHKRIHIRENSYRCEECGKAFIWFSTLTRHRRVHTGEKSYKYECGKSFNQDSNLTTHKRIHTGQKPYKCEECGTSFYQFSYLTRHKLIHTREKPYKCEQYGKTFNQSSTLTGHKIIHNGEKPYKCEECGKAFSIFSTPTKHKIIHTEEKSHRCEEYCKAYKESSHLTTHKRIHTGEKPYKCEECGKAFSIFSTLTKHKIIHTEEKSHRCEECGKAYKESSHLTTHKRIHTGEKPYKCEECGKTFSVFSILTKHKIIHTEEKPYKCEECGKAFKRSSTLTKHRIIHTEEKPYKCEECGKAFNQSSTLSIHKIIHTGEKPYKCEECGKAFKRSSTLTIHKMIHTGEKPYKCEECGKAFNRSSHLTTHKRIHTGHKPYKCKECGKSFSVFSTLTKHKIIHTDKKPYKCEECGKAFNRSSILSIHKKIHTGEKPYKCEECGKAFKRSSHLAGHKQIHSVQKPYKCEECGKAFSIFSTLTKHKIIHTEEKPYKCEKCGKTFYRFSNLNTHKIIHTGEKPCKCEECGKAFNHSSNLIKHKLIHTGDKPYKCEACGKAFRRSSHLSRHKIIHIGIHTEETVQK>sp|Q6ZR52-2|ZN493_HUMAN Isoform 2 of Zinc finger protein 493 OS=Homosapiens OX=9606 GN=ZNF493MPGPPESLDMGPLTFRDVAIEFSLEEWQCLDTAQQDLYRKVMLENYRNLVFLGIAVSKPDLVTCLEQGKDPWNMKGHSTVVKPPVICSHFAEDFCPGPGIKDSFQKVILREYVKCGHKDLQLRKGCKSMNECNVHKEGYNELNQYLTTTQSKIFQCDKYVKVFHKLLNSNRHNTKHTGKKPFKCKKCGKSFCMLLHLCQHKRIHIRENSYRCEECGKAFIWFSTLTRHRRVHTGEKSYKYECGKSFNQDSNLTTHKRIHTGQKPYKCEECGTSFYQFSYLTRHKLIHTREKPYKCEQYGKTFNQSSTLTGHKIIHNGEKPYKCEECGKAFSIFSTPTKHKIIHTEEKSHRCEEYCKAYKESSHLTTHKRIHTGEKPYKCEECGKAFSIFSTLTKHKIIHTEEKSHRCEECGKAYKESSHLTTHKRIHTGEKPYKCEECGKTFSVFSILTKHKIIHTEEKPYKCEECGKAFKRSSTLTKHRIIHTEEKPYKCEECGKAFNQSSTLSIHKIIHTGEKPYKCEECGKAFKRSSTLTIHKMIHTGEKPYKCEECGKAFNRSSHLTTHKRIHTGHKPYKCKECGKSFSVFSTLTKHKIIHTDKKPYKCEECGKAFNRSSILSIHKKIHTGEKPYKCEECGKAFKRSSHLAGHKQIHSVQKPYKCEECGKAFSIFSTLTKHKIIHTEEKPYKCEKCGKTFYRFSNLNTHKIIHTGEKPCKCEECGKAFNHSSNLIKHKLIHTGDKPYKCEACGKAFRRSSHLSRHKIIHIGIHTEETVQK>sp|Q6ZR52-3|ZN493_HUMAN Isoform 3 of Zinc finger protein 493 OS=Homosapiens OX=9606 GN=ZNF493MPGPPESLDMGPLTFRDVAIEFSLEEWQCLDTAQQDLYRKVMLENYRNLVFLAGIAVSKPDLVTCLEQGKDPWNMKGHSTVVKPPVETGFHRFSQDGLYLLTS>sp|P25942|TNR5_HUMAN Tumor necrosis factor receptor superfamily member 5OS=Homo sapiens OX=9606 GN=CD40 PE=1 SV=1MVRLPLQCVLWGCLLTAVHPEPPTACREKQYLINSQCCSLCQPGQKLVSDCTEFTETECLPCGESEFLDTWNRETHCHQHKYCDPNLGLRVQQKGTSETDTICTCEEGWHCTSEACESCVLHRSCSPGFGVKQIATGVSDTICEPCPVGFFSNVSSAFEKCHPWTSCETKDLVVQQAGTNKTDVVCGPQDRLRALVVIPIIFGILFAILLVLVFIKKVAKKPTNKAPHPKQEPQEINFPDDLPGSNTAAPVQETLHGCQPVTQEDGKESRISVQERQ>sp|P25942-2|TNR5_HUMAN Isoform II of Tumor necrosis factor receptorsuperfamily member 5 OS=Homo sapiens OX=9606 GN=CD40MVRLPLQCVLWGCLLTAVHPEPPTACREKQYLINSQCCSLCQPGQKLVSDCTEFTETECLPCGESEFLDTWNRETHCHQHKYCDPNLGLRVQQKGTSETDTICTCEEGWHCTSEACESCVLHRSCSPGFGVKQIATGVSDTICEPCPVGFFSNVSSAFEKCHPWTRSPGSAESPGGDPHHLRDPVCHPLGAGLYQKGGQEANQ>sp|O43617|TPPC3_HUMAN Trafficking protein particle complex subunit 3OS=Homo sapiens OX=9606 GN=TRAPPC3 PE=1 SV=1MSRQANRGTESKKMSSELFTLTYGALVTQLCKDYENDEDVNKQLDKMGFNIGVRLIEDFLARSNVGRCHDFRETADVIAKVAFKMYLGITPSITNWSPAGDEFSLILENNPLVDFVELPDNHSSLIYSNLLCGVLRGALEMVQMAVEAKFVQDTLKGDGVTEIRMRFIRRIEDNLPAGEE>sp|O43617-2|TPPC3_HUMAN Isoform 2 of Trafficking protein particlecomplex subunit 3 OS=Homo sapiens OX=9606 GN=TRAPPC3MGFNIGVRLIEDFLARSNVGRCHDFRETADVIAKVAFKMYLGITPSITNWSPAGDEFSLILENNPLVDFVELPDNHSSLIYSNLLCGVLRGALEMVQMAVEAKFVQDTLKGDGVTEIRMRFIRRIEDNLPAGEE>sp|Q12999|TSN31_HUMAN Tetraspanin-31 OS=Homo sapiens OX=9606 GN=TSPAN31PE=1 SV=1MVCGGFACSKNALCALNVVYMLVSLLLIGVAAWGKGLGLVSSIHIIGGVIAVGVFLLLIAVAGLVGAVNHHQVLLFFYMIILGLVFIFQFVISCSCLAINRSKQTDVINASWWVMSNKTRDELERSFDCCGLFNLTTLYQQDYDFCTAICKSQSPTCQMCGEKFLKHSDEALKILGGVGLFFSFTEILGVWLAMRFRNQKDPRANPSAFL>sp|Q9Y5U2|TSSC4_HUMAN Protein TSSC4 OS=Homo sapiens OX=9606 GN=TSSC4PE=1 SV=3MAEAGTGEPSPSVEGEHGTEYDTLPSDTVSLSDSDSDLSLPGGAEVEALSPMGLPGEEDSGPDEPPSPPSGLLPATVQPFHLRGMSSTFSQRSRDIFDCLEGAARRAPSSVAHTSMSDNGGFKRPLAPSGRSPVEGLGRAHRSPASPRVPPVPDYVAHPERWTKYSLEDVTEVSEQSNQATALAFLGSQSLAAPTDCVSSFNQDPSSCGEGRVIFTKPVRGVEARHERKRVLGKVGEPGRGGLGNPATDRGEGPVELAHLAGPGSPEAEEWGSHHGGLQEVEALSGSVHSGSVPGLPPVETVGFHGSRKRSRDHFRNKSSSPEDPGAEV>sp|Q9Y5U2-2|TSSC4_HUMAN Isoform 2 of Protein TSSC4 OS=Homo sapiensOX=9606 GN=TSSC4MAEAGTGLLPATVQPFHLRGMSSTFSQRSRDIFDCLEGAARRAPSSVAHTSMSDNGGFKRPLAPSGRSPVEGLGRAHRSPASPRVPPVPDYVAHPERWTKYSLEDVTEVSEQSNQATALAFLGSQSLAAPTDCVSSFNQDPSSCGEGRVIFTKPVRGVEARHERKRVLGKVGEPGRGGLGNPATDRGEGPVELAHLAGPGSPEAEEWGSHHGGLQEVEALSGSVHSGSVPGLPPVETVGFHGSRKRSRDHFRNKSSSPEDPGAEV>sp|Q86TS7|U730_HUMAN Putative UPF0730 protein encoded by LINC00643OS=Homo sapiens OX=9606 GN=LINC00643 PE=5 SV=1MVQECCSQSLYYEELHSYHIVPYASENAIYEMGYTSSHLEQNSQLLIYKMN>sp|P50607|TUB_HUMAN Tubby protein homolog OS=Homo sapiens OX=9606 GN=TUBPE=1 SV=1MTSKPHSDWIPYSVLDDEGRNLRQQKLDRQRALLEQKQKKKRQEPLMVQANADGRPRSRRARQSEEQAPLVESYLSSSGSTSYQVQEADSLASVQLGATRPTAPASAKRTKAAATAGGQGGAARKEKKGKHKGTSGPAALAEDKSEAQGPVQILTVGQSDHAQDAGETAAGGGERPSGQDLRATMQRKGISSSMSFDEDEEDEEENSSSSSQLNSNTRPSSATSRKSVREAASAPSPTAPEQPVDVEVQDLEEFALRPAPQGITIKCRITRDKKGMDRGMYPTYFLHLDREDGKKVFLLAGRKRKKSKTSNYLISVDPTDLSRGGDSYIGKLRSNLMGTKFTVYDNGVNPQKASSSTLESGTLRQELAAVCYETNVLGFKGPRKMSVIVPGMNMVHERVSIRPRNEHETLLARWQNKNTESIIELQNKTPVWNDDTQSYVLNFHGRVTQASVKNFQIIHGNDPDYIVMQFGRVAEDVFTMDYNYPLCALQAFAIALSSFDSKLACE>sp|P50607-2|TUB_HUMAN Isoform 2 of Tubby protein homolog OS=Homo sapiensOX=9606 GN=TUBMGARTPLPSFWVSFFAETGILFPGGTPWPMGSQHSKQHRKPGPLKRGHRRDRRTTRRKYWKEGREIARVLDDEGRNLRQQKLDRQRALLEQKQKKKRQEPLMVQANADGRPRSRRARQSEEQAPLVESYLSSSGSTSYQVQEADSLASVQLGATRPTAPASAKRTKAAATAGGQGGAARKEKKGKHKGTSGPAALAEDKSEAQGPVQILTVGQSDHAQDAGETAAGGGERPSGQDLRATMQRKGISSSMSFDEDEEDEEENSSSSSQLNSNTRPSSATSRKSVREAASAPSPTAPEQPVDVEVQDLEEFALRPAPQGITIKCRITRDKKGMDRGMYPTYFLHLDREDGKKVFLLAGRKRKKSKTSNYLISVDPTDLSRGGDSYIGKLRSNLMGTKFTVYDNGVNPQKASSSTLESGTLRQELAAVCYETNVLGFKGPRKMSVIVPGMNMVHERVSIRPRNEHETLLARWQNKNTESIIELQNKTPVWNDDTQSYVLNFHGRVTQASVKNFQIIHGNDPDYIVMQFGRVAEDVFTMDYNYPLCALQAFAIALSSFDSKLACE>sp|P62837|UB2D2_HUMAN Ubiquitin-conjugating enzyme E2 D2 OS=Homo sapiensOX=9606 GN=UBE2D2 PE=1 SV=1MALKRIHKELNDLARDPPAQCSAGPVGDDMFHWQATIMGPNDSPYQGGVFFLTIHFPTDYPFKPPKVAFTTRIYHPNINSNGSICLDILRSQWSPALTISKVLLSICSLLCDPNPDDPLVPEIARIYKTDREKYNRIAREWTQKYAM>sp|P62837-2|UB2D2_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 D2OS=Homo sapiens OX=9606 GN=UBE2D2MFHWQATIMGPNDSPYQGGVFFLTIHFPTDYPFKPPKVAFTTRIYHPNINSNGSICLDILRSQWSPALTISKVLLSICSLLCDPNPDDPLVPEIARIYKTDREKYNRIAREWTQKYAM>sp|P60604|UB2G2_HUMAN Ubiquitin-conjugating enzyme E2 G2 OS=Homo sapiensOX=9606 GN=UBE2G2 PE=1 SV=1MAGTALKRLMAEYKQLTLNPPEGIVAGPMNEENFFEWEALIMGPEDTCFEFGVFPAILSFPLDYPLSPPKMRFTCEMFHPNIYPDGRVCISILHAPGDDPMGYESSAERWSPVQSVEKILLSVVSMLAEPNDESGANVDASKMWRDDREQFYKIAKQIVQKSLGL>sp|P60604-2|UB2G2_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 G2OS=Homo sapiens OX=9606 GN=UBE2G2MNEENFFEWEALIMGPEDTCFEFGVFPAILSFPLDYPLSPPKMRFTCEMFHPNIYPDGRVCISILHAPGDDPMGYESSAERWSPVQSVEKILLSVVSMLAEPNDESGANVDASKMWRDDREQFYKIAKQIVQKSLGL>sp|C9JJH3|U17LA_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 10 OS=Homo sapiens OX=9606 GN=USP17L10 PE=3 SV=1MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKPPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYKPPLANYMLFREHSQTCHRHKGCMLCTMQAHITRALHIPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMRKACLPGHKQVDRHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHNSAKVLILVLKRFPDVTGNKIAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHNGHYSSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGVEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRRVEGTVPPDVLVIHQSKYKCRMKNHHPEQQSSLLNLSSTTPTDQESMNTGTLASLRGRTRRSKGKNKHSKRALLVCQ>sp|D6R9N7|U17LI_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 18 OS=Homo sapiens OX=9606 GN=USP17L18 PE=3 SV=1MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQTNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRAKQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSTTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|Q3LFD5|UBP41_HUMAN Putative ubiquitin carboxyl-terminal hydrolase 41OS=Homo sapiens OX=9606 GN=USP41 PE=1 SV=2MDGVLFRAHQCQYVHPCVHVYVTVGLMDPLCERKEKASKQERENPLAHLAAWGLVGLHNIGQTCCLNSLIQVFVMNVDFARILKRITVPRGADEQRRSVPFQMLLLLEKMQDSRQKAVWPLELAYCLQKYNVPLFVQHDAAQLYLKLWNLIKDQIADVHLVERLQALYMIRMKDSLICLDCAMESSRNSSMLTLRLSFFDVDSKPLKTLEDALHCFFQPRELSSKSKCFCENCGKKTRGKQVLKLTHLPQTLTIHLMRFSIRNSQTRKICHSLYFPQSLDFSQILPMKRESCDAEEQSGGQYELFAVIAHVGMADSGHYCVYIRNAVDGKWFCFNDSNICLVSWEDIQCTYGNPNYHW>sp|Q9BZA5|TXNG2_HUMAN Putative gamma-taxilin 2 OS=Homo sapiens OX=9606GN=TXLNGY PE=5 SV=3MEEAGLCGLREKADMLCNSESHDILQHQDSNCSATSNKHLLEDEEGRDFITKNRSWVSPVHCTQESRRELPEQEVAPPSGQQALQCNRNKEKVLGKEVLLLMQALNTLSTPEEKLAALCKKYADLGNSPLL>sp|Q70EL1|UBP54_HUMAN Inactive ubiquitin carboxyl-terminal hydrolase 54OS=Homo sapiens OX=9606 GN=USP54 PE=1 SV=4MSWKRNYFSGGRGSVQGMFAPRSSTSIAPSKGLSNEPGQNSCFLNSALQVLWHLDIFRRSFRQLTTHKCMGDSCIFCALKGIFNQFQCSSEKVLPSDTLRSALAKTFQDEQRFQLGIMDDAAECFENLLMRIHFHIADETKEDICTAQHCISHQKFAMTLFEQCVCTSCGATSDPLPFIQMVHYISTTSLCNQAICMLERREKPSPSMFGELLQNASTMGDLRNCPSNCGERIRIRRVLMNAPQIITIGLVWDSDHSDLAEDVIHSLGTCLKLGDLFFRVTDDRAKQSELYLVGMICYYGKHYSTFFFQTKIRKWMYFDDAHVKEIGPKWKDVVTKCIKGHYQPLLLLYADPQGTPVSTQDLPPQAEFQSYSRTCYDSEDSGREPSISSDTRTDSSTESYPYKHSHHESVVSHFSSDSQGTVIYNVENDSMSQSSRDTGHLTDSECNQKHTSKKGSLIERKRSSGRVRRKGDEPQASGYHSEGETLKEKQAPRNASKPSSSTNRLRDFKETVSNMIHNRPSLASQTNVGSHCRGRGGDQPDKKPPRTLPLHSRDWEIESTSSESKSSSSSKYRPTWRPKRESLNIDSIFSKDKRKHCGYTQLSPFSEDSAKEFIPDEPSKPPSYDIKFGGPSPQYKRWGPARPGSHLLEQHPRLIQRMESGYESSERNSSSPVSLDAALPESSNVYRDPSAKRSAGLVPSWRHIPKSHSSSILEVDSTASMGGWTKSQPFSGEEISSKSELDELQEEVARRAQEQELRRKREKELEAAKGFNPHPSRFMDLDELQNQGRSDGFERSLQEAESVFEESLHLEQKGDCAAALALCNEAISKLRLALHGASCSTHSRALVDKKLQISIRKARSLQDRMQQQQSPQQPSQPSACLPTQAGTLSQPTSEQPIPLQVLLSQEAQLESGMDTEFGASSFFHSPASCHESHSSLSPESSAPQHSSPSRSALKLLTSVEVDNIEPSAFHRQGLPKAPGWTEKNSHHSWEPLDAPEGKLQGSRCDNSSCSKLPPQEGRGIAQEQLFQEKKDPANPSPVMPGIATSERGDEHSLGCSPSNSSAQPSLPLYRTCHPIMPVASSFVLHCPDPVQKTNQCLQGQSLKTSLTLKVDRGSEETYRPEFPSTKGLVRSLAEQFQRMQGVSMRDSTGFKDRSLSGSLRKNSSPSDSKPPFSQGQEKGHWPWAKQQSSLEGGDRPLSWEESTEHSSLALNSGLPNGETSSGGQPRLAEPDIYQEKLSQVRDVRSKDLGSSTDLGTSLPLDSWVNITRFCDSQLKHGAPRPGMKSSPHDSHTCVTYPERNHILLHPHWNQDTEQETSELESLYQASLQASQAGCSGWGQQDTAWHPLSQTGSADGMGRRLHSAHDPGLSKTSTAEMEHGLHEARTVRTSQATPCRGLSRECGEDEQYSAENLRRISRSLSGTVVSEREEAPVSSHSFDSSNVRKPLETGHRCSSSSSLPVIHDPSVFLLGPQLYLPQPQFLSPDVLMPTMAGEPNRLPGTSRSVQQFLAMCDRGETSQGAKYTGRTLNYQSLPHRSRTDNSWAPWSETNQHIGTRFLTTPGCNPQLTYTATLPERSKGLQVPHTQSWSDLFHSPSHPPIVHPVYPPSSSLHVPLRSAWNSDPVPGSRTPGPRRVDMPPDDDWRQSSYASHSGHRRTVGEGFLFVLSDAPRREQIRARVLQHSQW>sp|Q70EL1-4|UBP54_HUMAN Isoform 2 of Inactive ubiquitin carboxyl-terminal hydrolase 54 OS=Homo sapiens OX=9606 GN=USP54MSWKRNYFSGGRGSVQGMFAPRSSTSIAPSKGLSNEPGQNSCFLNSALQVLWHLDIFRRSFRQLTTHKCMGDSCIFCALKGIFNQFQCSSEKVLPSDTLRSALAKTFQDEQRFQLGIMDDAAECFENLLMRIHFHIADETKEDICTAQHCISHQKFAMTLFEQCVCTSCGATSDPLPFIQMVHYISTTSLCNQAICMLERREKPSPSMFGELLQNASTMGDLRNCPSNCGERIRIRRVLMNAPQIITIGLVWDSDHSDLAEDVIHSLGTCLKLGDLFFRVTDDRAKQSELYLVGMICYYGKHYSTFFFQTKIRKWMYFDDAHVKEIGPKWKDVVTKCIKGHYQPLLLLYADPQGTPVSTQDLPPQAEFQSYSRTCYDSEDSGEQPGSLPLLSPHPMRSNSWDS>sp|Q70EL1-6|UBP54_HUMAN Isoform 3 of Inactive ubiquitin carboxyl-terminal hydrolase 54 OS=Homo sapiens OX=9606 GN=USP54MSWKRNYFSGGRGSVQGMFAPRSSTSIAPSKGLSNEPGQNSCFLNSALQVLWHLDIFRRSFRQLTTHKCMGDSCIFCALKGIFNQFQCSSEKVLPSDTLRSALAKTFQDEQRFQLGIMDDAAECFENLLMRIHFHIADETKEDICTAQHCISHQKFAMTLFEQCVCTSCGATSDPLPFIQMVHYISTTSLCNQAICMLERREKPSPSMFGELLQNASTMGDLRNCPSNCGERIRIRRVLMNAPQIITIGLVWDSDHSDLAEDVIHSLGTCLKLGDLFFRVTDDRAKQSELYLVGMICYYGKHYSTFFFQTKIRKWMYFDDAHVKEIGPKWKDVVTKCIKGHYQPLLLLYADPQGTPVSTQDLPPQAEFQSYSRTCYDSEDSGREPSISSDTRTDSSTESYPYKHSHHESVVSHFSSDSQGTVIYNVENDSMSQSSRDTGHLTDSECNQKHTSKKGSLIERKRSSGRVRRKGDEPQASGYHSEGETLKEKQAPRNASKPSSSTNRLRDFKETVSNMIHNRPSLASQTNVGSHCRGRGGDQPDKKPPRTLPLHSRDWEIESTSSESKSSSSSKYRPTWRPKRESLNIDSIFSKDKRKHCGYTQLSPFSEDSAKEFIPDEPSKPPSYDIKFGGPSPQYKRWGPARPGSHLLEQHPRLIQRMESGYESSERNSSSPVSLDAALPESSNVYRDPSAKRSAGLVPSWRHIPKSHSSSILEVDSTASMGGWTKSQPFSGEEISSKSELDELQEEVARRAQEQELRRKREKELEAAKGFNPHPSRFMDLDELQNQGRSDGFERSLQEAESVFEESLHLEQKGDCAAALALCNEAISKLRLALHGASCSTHSRALVDKKLQISIRKARSLQDRMQQQQSPQQPSQPSACLPTQAGTLSQPTR>sp|Q70EL1-7|UBP54_HUMAN Isoform 4 of Inactive ubiquitin carboxyl-terminal hydrolase 54 OS=Homo sapiens OX=9606 GN=USP54MSWKRNYFSGGRGSVQGMFAPRSSTSIAPSKGLSNEPGQNSCFLNSALQVLWHLDIFRRSFRQLTTHKCMGDSCIFCALKGIFNQFQCSSEKVLPSDTLRSALAKTFQDEQRFQLGIMDDAAECFLFFRVTDDRAKQSELYLVGMICYYGKHYSTFFFQTKIRKWMYFDDAHVKEIGPKWKDVVTKCIKGHYQPLLLLYADPQGTPVSTQDLPPQAEFQSYSRTCYDSEDSGREPSISSDTRTDSSTESYPYKHSHHESVVSHFSSDSQGTVIYNVENDSMSQSSRDTGHLTDSECNQKHTSKKGSLIERKRSSGRVRRKGDEPQASGYHSEGETLKEKQAPRNASKPSSSTNRLRDFKETVSNMIHNRPSLASQTNVGSHCRGRGGDQPDKKPPRTLPLHSRDWEIESTSSESKSSSSSKYRPTWRPKRESLNIDSIFSKDKRKHCGYTQLSPFSEDSAKEFIPDEPSKPPSYDIKFGGPSPQYKRWGPARPGSHLLEQHPRLIQRMESGYESSERNSSSPVSLDAALPESSNVYRDPSAKRSAGLVPSWRHIPKSHSSSILEVDSTASMGGWTKSQPFSGEEISSKSELDELQEEVARRAQEQELRRKREKELEAAKGFNPHPSRFMDLDELQNQGRSDGFERSLQEAESVFEESLHLEQKGDCAAALALCNEAISKLRLALHGASCSTHSRALVDKKLQISIRKARSLQDRMQQQQSPQQPSQPSACLPTQAGTLSQPTSEQPIPLQVLLSQEAQLESGMDTEFGASSFFHSPASCHESHSSLSPESSAPQHSSPSRSALKLLTSVEVDNIEPSAFHRQGLPKAPGWTEKNSHHSWEPLDAPEGKLQGSRCDNSSCSKLPPQEGRGIAQEQLFQEKKDPANPSPVMPGIATSERGDEHSLGCSPSNSSAQPSLPLYRTCHPIMPVASSFVLHCPDPVQKTNQCLQGQSLKTSLTLKVDRGSEETYRPEFPSTKGLVRSLAEQFQRMQGVSMRDSTGFKDRSLSGSLRKNSSPSDSKPPFSQGQEKGHWPWAKQQSSLEGGDRPLSWEESTEHSSLALNSGLPNGETSSGGQPRLAEPDIYQEKLSQVRDVRSKDLGSSTDLGTSLPLDSWVNITRFCDSQLKHGAPRPGMKSSPHDSHTCVTYPERNHILLHPHWNQDTEQETSELESLYQASLQASQAGCSGWGQQDTAWHPLSQTGSADGMGRRLHSAHDPGLSKTSTAEMEHGLHEARTVRTSQATPCRGLSRECGEDEQYSAENLRRISRSLSGTVVSEREEAPVSSHSFDSSNVRKPLETGHRCSSSSSLPVIHDPSVFLLGPQLYLPQPQFLSPDVLMPTMAGEPNRLPGTSRSVQQFLAMCDRGETSQGAKYTGRTLNYQSLPHRSRTDNSWAPWSETNQHIGTRFLTTPGCNPQLTYTATLPERSKGLQVPHTQSWSDLFHSPSHPPIVHPVYPPSSSLHVPLRSAWNSDPVPGSRTPGPRRVDMPPDDDWRQSSYASHSGHRRTVGEGFLFVLSDAPRREQIRARVLQHSQW>sp|Q70EL1-8|UBP54_HUMAN Isoform 5 of Inactive ubiquitin carboxyl-terminal hydrolase 54 OS=Homo sapiens OX=9606 GN=USP54MDTEFGASSFFHSPASCHESHSSLSPESSAPQHSSPSRSALKLLTSVEVDNIEPSAFHRQGLPKAPGWTEKNSHHSWEPLDAPEGKLQGSRCDNSSCSKLPPQEGRGIAQEQLFQEKKDPANPSPVMPGIATSERGDEHSLGCSPSNSSAQPSLPLYRTCHPIMPVASSFVLHCPDPVQKTNQCLQGQSLKTSLTLKVDRGSEETYRPEFPSTKGLVRSLAEQFQRMQGVSMRDSTGFKDRSLSGSLRKNSSPSDSKPPFSQGQEKGHWPWAKQQSSLEGGDRPLSWEESTEHSSLALNSGLPNGETSSGGQPRLAEPDIYQEKLSQVRDVRSKDLGSSTDLGTSLPLDSWVNITRFCDSQLKHGAPRPGMKSSPHDSHTCVTYPERNHILLHPHWNQDTEQETSELESLYQASLQASQAGCSGWGQQDTAWHPLSQTGSADGMGRRLHSAHDPGLSKTSTAEMEHGLHEARTVRTSQATPCRGLSRECGEDEQYSAENLRRISRSLSGTVVSEREEAPVSSHSFDSSNVRKPLETGHRCSSSSSLPVIHDPSVFLLGPQLYLPQPQFLSPDVLMPTMAGEPNRLPGTSRSVQQFLAMCDRGETSQGAKYTGRTLNYQSLPHRSRTDNSWAPWSETNQHIGTRFLTTPGCNPQLTYTATLPERSKGLQVPHTQSWSDLFHSPSHPPIVHPVYPPSSSLHVPLRSAWNSDPVPGSRTPGPRRVDMPPDDDWRQSSYASHSGHRRTVGEGFLFVLSDAPRREQIRARVLQHSQW>sp|Q70EL1-9|UBP54_HUMAN Isoform 6 of Inactive ubiquitin carboxyl-terminal hydrolase 54 OS=Homo sapiens OX=9606 GN=USP54MDTEFGASSFFHSPASCHESHSSLSPESSAPQHSSPSRSALKLLTSVEVDNIEPSAFHRQGLPKAPGWTEKNSHHSWEPLDAPEGKLQGSRCDNSSCSKLPPQEGRGIAQEQLFQEKKDPANPSPVMPGIATSERGDEHSLGCSPSNSSAQPSLPLYRTCHPIMPVASSFVLHCPDPVQKTNQCLQGQSLKTSLTLKVDRGSEETYRPEFPSTKGLVRSLAEQFQRMQGVSMRDSTGFKDRSLSGSLRKNSSPSDSKPPFSQGQEKGHWPWAKQQSSLEGGDRPLSWEESTEHSSLALNSGLPNGETSSGGQPRLAEPDIYQEKLSQVRDVRSKDLGSSTDLGTSLPLDSWVNITRFCDSQLKHGAPRPGMKSSPHDSHTCVTYPERNHILLHPHWNQDTEQETSELESLYQASLQASQAGCSGWGQQDTAWHPLSQTGSADGMGRRLHSAHDPGLSKTSTAEMEHGLHEARTVRTSQDSSNVRKPLETGHRCSSSSSLPVIHDPSVFLLGPQLYLPQPQFLSPDVLMPTMAGEPNRLPGTSRSVQQFLAMCDRGETSQGAKYTGRTLNYQSLPHRSRTDNSWAPWSETNQHIGTRFLTTPGCNPQLTYTATLPERSKGLQVPHTQSWSDLFHSPSHPPIVHPVYPPSSSLHVPLRSAWNSDPVPGSRTPGPRRVDMPPDDDWRQSSYASHSGHRRTVGEGFLFVLSDAPRREQIRARVLQHSQW>sp|Q70EL1-10|UBP54_HUMAN Isoform 7 of Inactive ubiquitin carboxyl-terminal hydrolase 54 OS=Homo sapiens OX=9606 GN=USP54MDTEFGASSFFHSPASCHESHSSLSPESSAPQHSSPSRSALKLLTSVEVDNIEPSAFHRQGLPKAPGWTEKNSHHSWEPLDAPEGKLQGSRCDNSSCSKLPPQEGRGIAQEQLFQEKKDPANPSPVMPGIATSERGDEHSLGCSPSNSSAQPSLPLYRTCHPIMPVASSFVLHCPDPVQKTNQCLQGQSLKTSLTLKVDRGSEETYRPEFPSTKGLVRSLAEQFQRMQGVSMRDSTGFKDRSLSGSLRKNSSPSDSKPPFSQGQEKGHWPWAKQQSSLEGGDRPLSWEESTEHSSLALNSGLPNGETSSGGQPRLAEPDIYQEKLSQVRDVRSKDLGSSTDLGTSLPLDSWVNITRFCDSQLKHGAPRPGMKSSPHDSHTCVTYPERNHILLHPHWNQDTEQETSELESLYQASLQASQAGCSGWGQQDTAWHPLSQTGSADGMGRRLHSAHDPGLSKTSTAEMEHGLHEARTATPCRGLSRECGEDEQYSAENLRRISRSLSGTVVSEREEAPVSSHSFDSSNVRKPLETGHRCSSSSSLPVIHDPSVFLLGPQLYLPQPQFLSPDVLMPTMAGEPNRLPGTSRSVQQFLAMCDRGETSQGAKYTGRTLNYQSLPHRSRTDNSWAPWSETNQHIGTRFLTTPGCNPQLTYTATLPERSKGLQVPHTQSWSDLFHSPSHPPIVHPVYPPSSSLHVPLRSAWNSDPVPGSRTPGPRRVDMPPDDDWRQSSYASHSGHRRTVGEGFLFVLSDAPRREQIRARVLQHSQW>sp|Q9NQW7|XPP1_HUMAN Xaa-Pro aminopeptidase 1 OS=Homo sapiens OX=9606GN=XPNPEP1 PE=1 SV=3MPPKVTSELLRQLRQAMRNSEYVTEPIQAYIIPSGDAHQSEYIAPCDCRRAFVSGFDGSAGTAIITEEHAAMWTDGRYFLQAAKQMDSNWTLMKMGLKDTPTQEDWLVSVLPEGSRVGVDPLIIPTDYWKKMAKVLRSAGHHLIPVKENLVDKIWTDRPERPCKPLLTLGLDYTGISWKDKVADLRLKMAERNVMWFVVTALDEIAWLFNLRGSDVEHNPVFFSYAIIGLETIMLFIDGDRIDAPSVKEHLLLDLGLEAEYRIQVHPYKSILSELKALCADLSPREKVWVSDKASYAVSETIPKDHRCCMPYTPICIAKAVKNSAESEGMRRAHIKDAVALCELFNWLEKEVPKGGVTEISAADKAEEFRRQQADFVDLSFPTISSTGPNGAIIHYAPVPETNRTLSLDEVYLIDSGAQYKDGTTDVTRTMHFGTPTAYEKECFTYVLKGHIAVSAAVFPTGTKGHLLDSFARSALWDSGLDYLHGTGHGVGSFLNVHEGPCGISYKTFSDEPLEAGMIVTDEPGYYEDGAFGIRIENVVLVVPVKTKYNFNNRGSLTFEPLTLVPIQTKMIDVDSLTDKECDWLNNYHLTCRDVIGKELQKQGRQEALEWLIRETQPISKQH>sp|Q9NQW7-2|XPP1_HUMAN Isoform 2 of Xaa-Pro aminopeptidase 1 OS=Homosapiens OX=9606 GN=XPNPEP1MPPKVTSELLRQLRQAMRNSEYVTEPIQAYIIPSGDAHQSEYIAPCDCRRAFVSGFDGSAGTAIITEEHAAMWTDGRYFLQAAKQMDSNWTLMKMGLKDTPTQEDWLVSVLPEGSRVGVDPLIIPTDYWKKMAKVLRSAGHHLIPVKENLVDKIWTDRPERPCKPLLTLGLDYTGISWKDKVADLRLKMAERNVMWFVVTALDEIAWLFNLRGSDVEHNPVFFSYAIIGLETIMLFIDGDRIDAPSVKEHLLLDLGLEAEYRIQVHPYKSILSELKALCADLSPREKVWVSDKASYAVSETIPKDHRCCMPYTPICIAKAVKNSAESEGMRRAHIKDAVALCELFNWLEKEVPKGGVTEISAADKAEEFRRQQADFVDLSFPTISSTGPNGAIIHYADGTTDVTRTMHFGTPTAYEKECFTYVLKGHIAVSAAVFPTGTKGHLLDSFARSALWDSGLDYLHGTGHGVGSFLNVHEGPCGISYKTFSDEPLEAGMIVTDEPGYYEDGAFGIRIENVVLVVPVKTKYNFNNRGSLTFEPLTLVPIQTKMIDVDSLTDKECDWLNNYHLTCRDVIGKELQKQGRQEALEWLIRETQPISKQH>sp|Q9NQW7-3|XPP1_HUMAN Isoform 3 of Xaa-Pro aminopeptidase 1 OS=Homosapiens OX=9606 GN=XPNPEP1MAASRKPPRVRVNHQDFQLRNLRIIEPNEVTHSGDTGVETDGRMPPKVTSELLRQLRQAMRNSEYVTEPIQAYIIPSGDAHQSEYIAPCDCRRAFVSGFDGSAGTAIITEEHAAMWTDGRYFLQAAKQMDSNWTLMKMGLKDTPTQEDWLVSVLPEGSRVGVDPLIIPTDYWKKMAKVLRSAGHHLIPVKENLVDKIWTDRPERPCKPLLTLGLDYTGISWKDKVADLRLKMAERNVMWFVVTALDEIAWLFNLRGSDVEHNPVFFSYAIIGLETIMLFIDGDRIDAPSVKEHLLLDLGLEAEYRIQVHPYKSILSELKALCADLSPREKVWVSDKASYAVSETIPKDHRCCMPYTPICIAKAVKNSAESEGMRRAHIKDAVALCELFNWLEKEVPKGGVTEISAADKAEEFRRQQADFVDLSFPTISSTGPNGAIIHYAPVPETNRTLSLDEVYLIDSGAQYKDGTTDVTRTMHFGTPTAYEKECFTYVLKGHIAVSAAVFPTGTKGHLLDSFARSALWDSGLDYLHGTGHGVGSFLNVHEGPCGISYKTFSDEPLEAGMIVTDEPGYYEDGAFGIRIENVVLVVPVKTKYNFNNRGSLTFEPLTLVPIQTKMIDVDSLTDKECDWLNNYHLTCRDVIGKELQKQGRQEALEWLIRETQPISKQH>sp|Q9NQW7-4|XPP1_HUMAN Isoform 4 of Xaa-Pro aminopeptidase 1 OS=Homosapiens OX=9606 GN=XPNPEP1MAASRKPPRVRVNHQDFQLRNLRIIEPNEVTHSGDTGVETDGRMPPKVTSELLRQLRQAMRNSEYVTEPIQAYIIPSGDAHQSEYIAPCDCRRAFVSGFDGSAGTAIITEEHAAMWTDGRYFLQAAKQMDSNWTLMKMGLKDTPTQEDWLVSVLPEGSRVGVDPLIIPTDYWKKMAKVLRSAGHHLIPVKENLVDKIWTDRPERPCKPLLTLGLDYTGISWKDKVADLRLKMAERNVMWFVVTALDEIAWLFNLRGSDVEHNPVFFSYAIIGLETIMLFIDGDRIDAPSVKEHLLLDLGLEAEYRIQVHPYKSILSELKALCADLSPREKVWVSDKASYAVSETIPKDHRCCMPYTPICIAKAVKNSAESEGMRRAHIKDAVALCELFNWLEKEVPKGGVTEISAADKAEEFRRQQADFVDLSFPTISSTGPNGAIIHYADGTTDVTRTMHFGTPTAYEKECFTYVLKGHIAVSAAVFPTGTKGHLLDSFARSALWDSGLDYLHGTGHGVGSFLNVHEGPCGISYKTFSDEPLEAGMIVTDEPGYYEDGAFGIRIENVVLVVPVKTKYNFNNRGSLTFEPLTLVPIQTKMIDVDSLTDKECDWLNNYHLTCRDVIGKELQKQGRQEALEWLIRETQPISKQH>sp|Q6ZMY6|WDR88_HUMAN WD repeat-containing protein 88 OS=Homo sapiensOX=9606 GN=WDR88 PE=1 SV=2MASPPRCSPTAHDRECKLPPPSAPASEYCPGKLSWGTMARALGRFKLSIPHTHLLATLDPLALDREPPPHLLPEKHQVPEKLIWGDQDPLSKIPFKILSGHEHAVSTCHFCVDDTKLLSGSYDCTVKLWDPVDGSVVRDFEHRPKAPVVECSITGDSSRVIAASYDKTVRAWDLETGKLLWKVRYDTFIVSCKFSPDGKYVVSGFDVDHGICIMDAENITTVSVIKDHHTRSITSCCFDPDSQRVASVSLDRCIKIWDVTSQATLLTITKAHSNAISNCCFTFSGHFLCTSSWDKNLKIWNVHTGEFRNCGACVTLMQGHEGSVSSCHFARDSSFLISGGFDRTVAIWDVAEGYRKLSLKGHNDWVMDVAISNNKKWILSASKDRTMRLWNIEEIDEIPLVIKYKKAVGLKLKQCERCDRPFSIFKSDTSSEMFTQCVFCRIDTRGLPADTSSSSSSSERENSPPPRGSKDD>sp|Q6ZMY6-2|WDR88_HUMAN Isoform 2 of WD repeat-containing protein 88OS=Homo sapiens OX=9606 GN=WDR88MASPPRCSPTAHDRECKLPPPSAPASEYCPGKLSWGTMARALGRFKLSIPHTHLLATLDPLALDREPPPHLLPEKHQVPEKLIWGDQDPLSKIPFKILSGHEHAVSTCHFCVDDTKLLSGSYDCTVKLWDPVDGSVVRDFEHRPKAPVVECSITGDSSRVIAASYDKTVRAWDLETGKLLWKVRYDTFIVSCKFSPDGKYVVSGFDVDHGICIMDAENITTVSVIKDHHTRSITSCCFDPDSQRVASVSLDRCIKIWDVTSQATLLTITKAHSNAISNCCFTFSGHFLCTSSWDKNLKIWNVHTGEFRNCGACVTLMQGHEGSVSSCHFARDSSFLISGGFDRTVAIWDVAEGYRKLSLKGHNDWVMDVAISNNKKWILSASKDRTMRLWNIEEIDEIPLVIKYKKAVGLKLKQEKKEAYLKLKQG>sp|Q8N895|ZN366_HUMAN Zinc finger protein 366 OS=Homo sapiens OX=9606GN=ZNF366 PE=1 SV=1MQKEMKMIKDEDVHFDLAVKKTPSFPHCLQPVASRGKAPQRHPFPEALRGPFSQFRYEPPPGDLDGFPGVFEGAGSRKRKSMPTKMPYNHPAEEVTLALHSEENKNHGLPNLPLLFPQPPRPKYDSQMIDLCNVGFQFYRSLEHFGGKPVKQEPIKPSAVWPQPTPTPFLPTPYPYYPKVHPGLMFPFFVPSSSPFPFSRHTFLPKQPPEPLLPRKAEPQESEETKQKVERVDVNVQIDDSYYVDVGGSQKRWQCPTCEKSYTSKYNLVTHILGHSGIKPHACTHCGKLFKQLSHLHTHMLTHQGTRPHKCQVCHKAFTQTSHLKRHMMQHSEVKPHNCRVCGRGFAYPSELKAHEAKHASGRENICVECGLDFPTLAQLKRHLTTHRGPIQYNCSECDKTFQYPSQLQNHMMKHKDIRPYICSECGMEFVQPHHLKQHSLTHKGVKEHKCGICGREFTLLANMKRHVLIHTNIRAYQCHLCYKSFVQKQTLKAHMIVHSDVKPFKCKLCGKEFNRMHNLMGHMHLHSDSKPFKCLYCPSKFTLKGNLTRHMKVKHGVMERGLHSQGLGRGRIALAQTAGVLRSLEQEEPFDLSQKRRAKVPVFQSDGESAQGSHCHEEEEEDNCYEVEPYSPGLAPQSQQLCTPEDLSTKSEHAPEVLEEACKEEKEDASKGEWEKRSKGDLGAEGGQERDCAGRDECLSLRAFQSTRRGPSFSDYLYFKHRDESLKELLERKMEKQAVLLGI>sp|P62699|YPEL5_HUMAN Protein yippee-like 5 OS=Homo sapiens OX=9606GN=YPEL5 PE=1 SV=1MGRIFLDHIGGTRLFSCANCDTILTNRSELISTRFTGATGRAFLFNKVVNLQYSEVQDRVMLTGRHMVRDVSCKNCNSKLGWIYEFATEDSQRYKEGRVILERALVRESEGFEEHVPSDNS>sp|Q96JC4|ZN479_HUMAN Zinc finger protein 479 OS=Homo sapiens OX=9606GN=ZNF479 PE=1 SV=1MAKRPGPPGSREMGLLTFRDIAIEFSLEEWQCLDCAQRNLYRDVMLENYRNLVSLGIAVSKPDLITCLEQNKESQNIKRNEMVAKHPVTRSHFTQDLQPEQGIKDSLQKVIPRTYGKCGHEKLQFKKCCKSVGEYEVHKGGYSEVNQCLSTTQNKIFQTHKYVKVFGKFSNSNRDKTRYTGNKHFKCNKYGKSFCMLSHLNQHQVIHTREKSYKCKECGKSFNCSSNHTTHKIIHTGEKPYRCEECGKAFSWSANLTRHKRTHTGEKPYTCEECGQAFRRSSALTNHKRIHTGERPYKCEECGKAFSVSSTLTDHKRIHTGEKPCRCEECGKAFSWSSNLTRHKRIHTREKPYACEECGQAFSLSSNLMRHRRIHTGEKPYTCEECGQDFRRSSALTIHKRIHTGERPYKCEECGKVFSLSSTLTDHKRIHTGERPYKCEECGKAFSLSSTLTDHKRIHTGERPYTCEECGKAFNCSSTLMQHKRIHTGEKPYKCEECEQAFKWHSSLAKHKIIHTGEKPYKCE>sp|Q6ZNA1|ZN836_HUMAN Zinc finger protein 836 OS=Homo sapiens OX=9606GN=ZNF836 PE=2 SV=2MALTQGPLTFRDVAIEFSQEEWKSLDPVQKALYWDVMLENYRNLVFLGILPKCMTKELPPIGNSNTGEKCQTVTLERHECYDVENFYLREIQKNLQDLEFQWKDGEINYKEVPMTYKNNLNGKRGQHSQEDVENKCIENQLTLSFQSRLTELQKFQTEGKIYECNQSEKTVNNSSLVSPLQRILPSVQTNISKKYENEFLQLSLPTQLEKTHIREKPYMCKGCGKAFRVSSSLINHQMVHTTEKPYKCNECGKAFHRGSLLTIHQIVHTRGKPYQCGVCGKIFRQNSDLVNHRRSHTGEKPYKCNECGKSFSQSYNLAIHQRIHTGEKPYKCNECGKTFKQGSCLTTHQIIHTGEKPYQCDICGKVFRQNSNLVNHQRIHTGEKPYKCNICGKSFSQSSNLATHQTVHSGNKPYKCDECGKTFKRSSSLTTHQIIHTGEKPYTCDVCDKVFSQRSQLARHQRSHTGEKPYKCNECGKVFSQTSHLVGHRRIHTGEKPYKCDKCGKAFKQGSLLTRHKIIHTREKRYQCGECGKVFSENSCLVRHLRIHTGEQPYKCNVCGKVFNYSGNLSIHKRIHTGEKPFQCNECGTVFRNYSCLARHLRIHTGQKPYKCNVCGKVFNDSGNLSNHKRIHTGEKPFQCNECGKVFSYYSCLARHRKIHTGEKPYKCNDCGKAYTQRSSLTKHLIIHTGEKPYNCNEFGGAFIQSSKLARYHRNPTGEKPHKCSHCGRTFSHITGLTYHQRRHTGEMPYKCIECGQVFNSTSNLARHRRIHTGEKPYKCNECGKVFRHQSTLARHRSIHTGEKPYVCNECGKAFRVRSILVNHQKMHTGDKPYKCNECGKAFIERSKLVYHQRNHTGEKPYKCIECGKAFGRFSCLNKHQMIHSGEKPYKCNECGKSFISRSGLTKHQTKHTAESLKTKFNVEKPLDVLLTSGFK>sp|E7ETH6|Z587B_HUMAN Zinc finger protein 587B OS=Homo sapiens OX=9606GN=ZNF587B PE=1 SV=1MAVVATLRLSAQGTVTFEDVAVKFTQEEWNLLSEAQRCLYRDVTLENLALMSSLGCWCGVEDEAAPSKQSIYIQRETQVRTPVTGVSPKKAHPCEMCGPILGDILHVADHQGTHHKQKLHRCEAWGNKLYDSGNFHQHQNEHIGEKPYRGSVEEALFVKRCKLHVSGESSVFSESGKDFLPRSGLLQQEASHTGEKSNSKTECVSPFQCGGAHYSHGDSMKHFSTKHILSQHQRLLPREECYVCCECGKSFSKYVSFSNHQRVHSGKRPYECGECEKSFSQKSSLIQHQQFHTGGKPYGCEECGKYFSLEGYLRRHQKVHAGKGPYECGECGKSFSSNVNLKSHQRIHTGERPYKCGECEKSFSRKPSLSYHQRFGRPRWVDHKDRKEFKTSLGNIVKSCLF>sp|Q9NZV7|ZIM2_HUMAN Zinc finger imprinted 2 OS=Homo sapiens OX=9606GN=ZIM2 PE=1 SV=1MYQPEDDNNSDVTSDDDMTRNRRESSPPHSVHSFSGDRDWDRRGRSRDMEPRDRWSHTRNPRSRMPPRDLSLPVVAKTSFEMDREDDRDSRAYESRSQDAESYQNVVDLAEDRKPHNTIQDNMENYRKLLSLGFLAQDSVPAEKRNTEMLDNLPSAGSQFPDFKHLGTFLVFEELVTFEDVLVDFSPEELSSLSAAQRNLYREVMLENYRNLVSLGHQFSKPDIISRLEEEESYAMETDSRHTVICQGESHDDPLEPHQGNQEKLLTPITMNDPKTLTPERSYGSDEFERSSNLSKQSKDPLGKDPQEGTAPGICTSPQSASQENKHNRCEFCKRTFSTQVALRRHERIHTGKKPYECKQCAEAFYLMPHLNRHQKTHSGRKTSGCNEGRKPSVQCANLCERVRIHSQEDYFECFQCGKAFLQNVHLLQHLKAHEAARVLPPGLSHSKTYLIRYQRKHDYVGERACQCCDCGRVFSRNSYLIQHYRTHTQERPYQCQLCGKCFGRPSYLTQHYQLHSQEKTVECDHC>sp|Q8N9K5|ZN565_HUMAN Zinc finger protein 565 OS=Homo sapiens OX=9606GN=ZNF565 PE=2 SV=2MRRGPWERWSLASHRLDAGLCTCPREESREIRAGQIVLKAMAQGLVTFRDVAIEFSLEEWKCLEPAQRDLYREVTLENFGHLASLGLSISKPDVVSLLEQGKEPWMIANDVTGPWCPDLESRCEKFLQKDIFEIGAFNWEIMESLKCSDLEGSDFRADWECEGQFERQVNEECYFKQVNVTYGHMPVFQHHTSHTVRQSRETGEKLMECHECGKAFSRGSHLIQHQKIHTGEKPFGCKECGKAFSRASHLVQHQRIHTGEKPYDCKDCGKAFGRTSELILHQRLHTGVKPYECKECGKTFRQHSQLILHQRTHTGEKPYVCKDCGKAFIRGSQLTVHRRIHTGARPYECKECGKAFRQHSQLTVHQRIHTGEKPYECKECGKGFIHSSEVTRHQRIHSGEKPYECKECGKAFRQHAQLTRHQRVHTGDRPYECKDCGKAFSRSSYLIQHQRIHTGDKPYECKECGKAFIRVSQLTHHQRIHTCEKPYECRECGMAFIRSSQLTEHQRIHPGIKPYECRECGQAFILGSQLIEHYRIHTG>sp|Q8N9K5-2|ZN565_HUMAN Isoform 2 of Zinc finger protein 565 OS=Homosapiens OX=9606 GN=ZNF565MAQGLVTFRDVAIEFSLEEWKCLEPAQRDLYREVTLENFGHLASLGLSISKPDVVSLLEQGKEPWMIANDVTGPWCPDLESRCEKFLQKDIFEIGAFNWEIMESLKCSDLEGSDFRADWECEGQFERQVNEECYFKQVNVTYGHMPVFQHHTSHTVRQSRETGEKLMECHECGKAFSRGSHLIQHQKIHTGEKPFGCKECGKAFSRASHLVQHQRIHTGEKPYDCKDCGKAFGRTSELILHQRLHTGVKPYECKECGKTFRQHSQLILHQRTHTGEKPYVCKDCGKAFIRGSQLTVHRRIHTGARPYECKECGKAFRQHSQLTVHQRIHTGEKPYECKECGKGFIHSSEVTRHQRIHSGEKPYECKECGKAFRQHAQLTRHQRVHTGDRPYECKDCGKAFSRSSYLIQHQRIHTGDKPYECKECGKAFIRVSQLTHHQRIHTCEKPYECRECGMAFIRSSQLTEHQRIHPGIKPYECRECGQAFILGSQLIEHYRIHTG>sp|Q92536|YLAT2_HUMAN Y+L amino acid transporter 2 OS=Homo sapiensOX=9606 GN=SLC7A6 PE=1 SV=3MEAREPGRPTPTYHLVPNTSQSQVEEDVSSPPQRSSETMQLKKEISLLNGVSLVVGNMIGSGIFVSPKGVLVHTASYGMSLIVWAIGGLFSVVGALCYAELGTTITKSGASYAYILEAFGGFIAFIRLWVSLLVVEPTGQAIIAITFANYIIQPSFPSCDPPYLACRLLAAACICLLTFVNCAYVKWGTRVQDTFTYAKVVALIAIIVMGLVKLCQGHSEHFQDAFEGSSWDMGNLSLALYSALFSYSGWDTLNFVTEEIKNPERNLPLAIGISMPIVTLIYILTNVAYYTVLNISDVLSSDAVAVTFADQTFGMFSWTIPIAVALSCFGGLNASIFASSRLFFVGSREGHLPDLLSMIHIERFTPIPALLFNCTMALIYLIVEDVFQLINYFSFSYWFFVGLSVVGQLYLRWKEPKRPRPLKLSVFFPIVFCICSVFLVIVPLFTDTINSLIGIGIALSGVPFYFMGVYLPESRRPLFIRNVLAAITRGTQQLCFCVLTELDVAEEKKDERKTD>sp|Q6IV72|ZN425_HUMAN Zinc finger protein 425 OS=Homo sapiens OX=9606GN=ZNF425 PE=1 SV=1MAEPASVTVTFDDVALYFSEQEWEILEKWQKQMYKQEMKTNYETLDSLGYAFSKPDLITWMEQGRMLLISEQGCLDKTRRTTSPPTDEQLNMKNTGKLLCFDDEGTPRTKEEDCRLNGPQKQDLCAALRGKERKILLAQTATFQSPSLRETEILNKKVSITAYDPDKKDLRHKPRETPGRLEIPTGPRCYSCYVCRKVFQVRRDLLKHKRSHSKSQLCRYPKYKNSSRGKSELRRTQRLLCQKKRFQCSECEKSYFLKGSLVTHQVVHTGQRPYPCPECDKTFRYRANLKKHLCLHRGERPFCCGECGRAFVQQCELTEHLRLHSGEKPFQCPQCDRCFRLKRGMKVHLTQHSGKRPFHCPECGRSFSRKAALKTHQRTHSEEKPFSCGECGRKFIYKIKLDEHIRVHTGEKPFSCPECNKSFRLKRSLKAHGLQHIGKRPFQCPECSRGFFWRNAMRAHQRLHSEQKPFPCAECGKRFTRPSKLACHTRVHDRQKEFPCGECKKTFSQQSRLTQHLKVHTTEKPFSCAECGRSFRRRAHLTEHTRLHSGEEPFQCPECDKSFSWKASMKFHQRMHRDEKPFACGECDKTYTHQSQLTEHLRLHSGEKPYQCPECEKTFRLKGNLKSHLLQHSGQKPFSCVMCGKSFTQQYRLTEHIRVHSGEKPFQCPECDKSYCIRGSLKVHLYKHSGERPFQCPECGKGFLQKRSLKAHLCLHSGERPFSCDECGRSFTYVGALKTHIAVHAKEKPSSL>sp|O95049|ZO3_HUMAN Tight junction protein ZO-3 OS=Homo sapiens OX=9606GN=TJP3 PE=1 SV=3MEELTIWEQHTATLSKDPRRGFGIAISGGRDRPGGSMVVSDVVPGGPAEGRLQTGDHIVMVNGVSMENATSAFAIQILKTCTKMANITVKRPRRIHLPATKASPSSPGRQDSDEDDGPQRVEEVDQGRGYDGDSSSGSGRSWDERSRRPRPGRRGRAGSHGRRSPGGGSEANGLALVSGFKRLPRQDVQMKPVKSVLVKRRDSEEFGVKLGSQIFIKHITDSGLAARHRGLQEGDLILQINGVSSQNLSLNDTRRLIEKSEGKLSLLVLRDRGQFLVNIPPAVSDSDSSPLEDISDLASELSQAPPSHIPPPPRHAQRSPEASQTDSPVESPRLRRESSVDSRTISEPDEQRSELPRESSYDIYRVPSSQSMEDRGYSPDTRVVRFLKGKSIGLRLAGGNDVGIFVSGVQAGSPADGQGIQEGDQILQVNDVPFQNLTREEAVQFLLGLPPGEEMELVTQRKQDIFWKMVQSRVGDSFYIRTHFELEPSPPSGLGFTRGDVFHVLDTLHPGPGQSHARGGHWLAVRMGRDLREQERGIIPNQSRAEQLASLEAAQRAVGVGPGSSAGSNARAEFWRLRGLRRGAKKTTQRSREDLSALTRQGRYPPYERVVLREASFKRPVVILGPVADIAMQKLTAEMPDQFEIAETVSRTDSPSKIIKLDTVRVIAEKDKHALLDVTPSAIERLNYVQYYPIVVFFIPESRPALKALRQWLAPASRRSTRRLYAQAQKLRKHSSHLFTATIPLNGTSDTWYQELKAIIREQQTRPIWTAEDQLDGSLEDNLDLPHHGLADSSADLSCDSRVNSDYETDGEGGAYTDGEGYTDGEGGPYTDVDDEPPAPALARSSEPVQADESQSPRDRGRISAHQGAQVDSRHPQGQWRQDSMRTYEREALKKKFMRVHDAESSDEDGYDWGPATDL>sp|O95049-3|ZO3_HUMAN Isoform 3 of Tight junction protein ZO-3 OS=Homosapiens OX=9606 GN=TJP3MNLCGLMPIFPAPLDQVADMEELTIWEQHTATLSKDPRRGFGIAISGGRDRPGGSMVVSDVVPGGPAEGRLQTGDHIVMVNGVSMENATSAFAIQILKTCTKMANITVKRPRRIHLPATKASPSSPGRQDSDEDDGPQRVEEVDQGRGYDGDSSSGSGRSWDERSRRPRPGRRGRAGSHGRRSPGGGSEANGLALVSGFKRLPRQDVQMKPVKSVLVKRRDSEEFGVKLGSQIFIKHITDSGLAARHRGLQEGDLILQINGVSSQNLSLNDTRRLIEKSEGKLSLLVLRDRGQFLVNIPPAVSDSDSSPLEDISDLASELSQAPPSHIPPPPRHAQRSPEASQTDSPVESPRLRRESSVDSRTISEPDEQRSELPRESSYDIYRVPSSQSMEDRGYSPDTRVVRFLKGKSIGLRLAGGNDVGIFVSGVQAGSPADGQGIQEGDQILQVNDVPFQNLTREEAVQFLLGLPPGEEMELVTQRKQDIFWKMVQSRVGDSFYIRTHFELEPSPPSGLGFTRGDVFHVLDTLHPGPGQSHARGGHWLAVRMGRDLREQERGIIPNQSRAEQLASLEAAQRAVGVGPGSSAGSNARAEFWRLRGLRRGAKKTTQRSREDLSALTRQGRYPPYERVVLREASFKRPVVILGPVADIAMQKLTAEMPDQFEIAETVSRTDSPSKIIKLDTVRVIAEKDKHALLDVTPSAIERLNYVQYYPIVVFFIPESRPALKALRQWLAPASRRSTRRLYAQAQKLRKHSSHLFTATIPLNGTSDTWYQELKAIIREQQTRPIWTAEDQLDGSLEDNLDLPHHGLADSSADLSCDSRVNSDYETDGEGGAYTDGEGYTDGEGGPYTDVDDEPPAPALARSSEPVQADESQSPRDRGRISAHQGAQVDSRHPQGQWRQDSMRTYEREALKKKFMRVHDAESSDEDGYDWGPATDL>sp|O95049-4|ZO3_HUMAN Isoform 4 of Tight junction protein ZO-3 OS=Homosapiens OX=9606 GN=TJP3MAVRFQVADMEELTIWEQHTATLSKDPRRGFGIAISGGRDRPGGSMVVSDVVPGGPAEGRLQTGDHIVMVNGVSMENATSAFAIQILKTCTKMANITVKRPRRIHLPATKASPSSPGRQDSDEDDGPQRVEEVDQGRGYDGDSSSGSGRSWDERSRRPRPGRRGRAGSHGRRSPGGGSEANGLALVSGFKRLPRQDVQMKPVKSVLVKRRDSEEFGVKLGSQIFIKHITDSGLAARHRGLQEGDLILQINGVSSQNLSLNDTRRLIEKSEGKLSLLVLRDRGQFLVNIPPAVSDSDSSPLEDISDLASELSQAPPSHIPPPPRHAQRSPEASQTDSPVESPRLRRESSVDSRTISEPDEQRSELPRESSYDIYRVPSSQSMEDRGYSPDTRVVRFLKGKSIGLRLAGGNDVGIFVSGVQAGSPADGQGIQEGDQILQVNDVPFQNLTREEAVQFLLGLPPGEEMELVTQRKQDIFWKMVQSRVGDSFYIRTHFELEPSPPSGLGFTRGDVFHVLDTLHPGPGQSHARGGHWLAVRMGRDLREQERGIIPNQSRAEQLASLEAAQRAVGVGPGSSAGSNARAEFWRLRGLRRGAKKTTQRSREDLSALTRQGRYPPYERVVLREASFKRPVVILGPVADIAMQKLTAEMPDQFEIAETVSRTDSPSKIIKLDTVRVIAEKDKHALLDVTPSAIERLNYVQYYPIVVFFIPESRPALKALRQWLAPASRRSTRRLYAQAQKLRKHSSHLFTATIPLNGTSDTWYQELKAIIREQQTRPIWTAEDQLDGSLEDNLDLPHHGLADSSADLSCDSRVNSDYETDGEGGAYTDGEGYTDGEGGPYTDVDDEPPAPALARSSEPVQADESQSPRDRGRISAHQGAQVDSRHPQGQWRQDSMRTYEREALKKKFMRVHDAESSDEDGYDWGPATDL>sp|O95049-5|ZO3_HUMAN Isoform 6 of Tight junction protein ZO-3 OS=Homosapiens OX=9606 GN=TJP3MVVSDVVPGGPAEGRLQTGDHIVMVNGVSMENATSAFAIQILKTCTKMANITVKRPRRIHLPATKASPSSPGRQDSDEDDGPQRVEEVDQGRGYDGDSSSGSGRSWDERSRRPRPGRRGRAGSHGRRSPGGGSEANGLALVSGFKRLPRQDVQMKPVKSVLVKRRDSEEFGVKLGSQIFIKHITDSGLAARHRGLQEGDLILQINGVSSQNLSLNDTRRLIEKSEGKLSLLVLRDRGQFLVNIPPAVSDSDSSPLEDISDLASELSQAPPSHIPPPPRHAQRSPEASQTDSPVESPRLRRESSVDSRTISEPDEQRSELPRESSYDIYRVPSSQSMEDRGYSPDTRVVRFLKGKSIGLRLAGGNDVGIFVSGVQAGSPADGQGIQEGDQILQVNDVPFQNLTREEAVQFLLGLPPGEEMELVTQRKQDIFWKMVQSRVGDSFYIRTHFELEPSPPSGLGFTRGDVFHVLDTLHPGPGQSHARGGHWLAVRMGRDLREQERGIIPNQSRAEQLASLEAAQRAVGVGPGSSAGSNARAEFWRLRGLRRGAKKTTQRSREDLSALTRQGRYPPYERVVLREASFKRPVVILGPVADIAMQKLTAEMPDQFEIAETVSRTDSPSKIIKLDTVRVIAEKDKHALLDVTPSAIERLNYVQYYPIVVFFIPESRPALKALRQWLAPASRRSTRRLYAQAQKLRKHSSHLFTATIPLNGTSDTWYQELKAIIREQQTRPIWTAEDQLDGSLEDNLDLPHHGLADSSADLSCDSRVNSDYETDGEGGAYTDGEGYTDGEGGPYTDVDDEPPAPALARSSEPVQADESQSPRDRGRISAHQGAQVDSRHPQGQWRQDSMRTYEREALKKKFMRVHDAESSDEDGYDWGPATDL>sp|Q969R2|OSBP2_HUMAN Oxysterol-binding protein 2 OS=Homo sapiensOX=9606 GN=OSBP2 PE=1 SV=2MGKAAAPSRGGGCGGRSRGLSSLFTVVPCLSCHTAAPGMSASTSGSGPEPKPQPQPVPEPERGPLSEQVSEAVSEAVPRSEPVSETTSEPEPGAGQPSELLQGSRPGSESSSGVGAGPFTKAASEPLSRAVGSATFLRPESGSLPALKPLPLLRPGQAKTPLGVPMSGTGTTSSAPLALLPLDSFEGWLLKWTNYLKGYQRRWFVLGNGLLSYYRNQGEMAHTCRGTINLSTAHIDTEDSCGILLTSGARSYHLKASSEVDRQQWITALELAKAKAVRVMNTHSDDSGDDDEATTPADKSELHHTLKNLSLKLDDLSTCNDLIAKHGAALQRSLTELDGLKIPSESGEKLKVVNERATLFRITSNAMINACRDFLELAEIHSRKWQRALQYEQEQRVHLEETIEQLAKQHNSLERAFHSAPGRPANPSKSFIEGSLLTPKGEDSEEDEDTEYFDAMEDSTSFITVITEAKEDSRKAEGSTGTSSVDWSSADNVLDGASLVPKGSSKVKRRVRIPNKPNYSLNLWSIMKNCIGRELSRIPMPVNFNEPLSMLQRLTEDLEYHHLLDKAVHCTSSVEQMCLVAAFSVSSYSTTVHRIAKPFNPMLGETFELDRLDDMGLRSLCEQVSHHPPSAAHYVFSKHGWSLWQEITISSKFRGKYISIMPLGAIHLEFQASGNHYVWRKSTSTVHNIIVGKLWIDQSGDIEIVNHKTNDRCQLKFLPYSYFSKEAARKVTGVVSDSQGKAHYVLSGSWDEQMECSKVMHSSPSSPSSDGKQKTVYQTLSAKLLWKKYPLPENAENMYYFSELALTLNEHEEGVAPTDSRLRPDQRLMEKGRWDEANTEKQRLEEKQRLSRRRRLEACGPGSSCSSEEEKEADAYTPLWFEKRLDPLTGEMACVYKGGYWEAKEKQDWHMCPNIF>sp|Q969R2-2|OSBP2_HUMAN Isoform 2 of Oxysterol-binding protein 2 OS=Homosapiens OX=9606 GN=OSBP2MGKAAAPSRGGGCGGRSRGLSSLFTVVPCLSCHTAAPGMSASTSGSGPEPKPQPQPVPEPERGPLSEQVSEAVSEAVPRSEPVSETTSEPEPGAGQPSELLQGSRPGSESSSGVGAGPFTKAASEPLSRAVGSATFLRPESGSLPALKPLPLLRPGQAKTPLGVPMSGTGTTSSAPLALLPLDSFEGWLLKWTNYLKGYQRRWFVLGNGLLSYYRNQGEMAHTCRGTINLSTAHIDTEDSCGILLTSGARSYHLKASSEVDRQQWITALELAKAKAVRVMNTHSDDSGDDDEATTPADKSELHHTLKNLSLKLDDLSTCNDLIAKHGAALQRSLTELDGLKIPSESGEKLKVVNERATLFRITSNAMINACRDFLELAEIHSRKWQRALQYEQEQRVHLEETIEQLAKQHNSLERAFHSAPGRPANPSKSFIEGSLLTPKGEDSEEDEDTEYFDAMEDSTSFITVITEAKEDRKAEGSTGTSSVDWSSADNVLDGASLVPKGSSKVKRRVRIPNKPNYSLNLWSIMKNCIGRELSRIPMPVNFNEPLSMLQRLTEDLEYHHLLDKAVHCTSSVEQMCLVAAFSVSSYSTTVHRIAKPFNPMLGETFELDRLDDMGLRSLCEQVSHHPPSAAHYVFSKHGWSLWQEITISSKFRGKYISIMPLGAIHLEFQASGNHYVWRKSTSTVHNIIVGKLWIDQSGDIEIVNHKTNDRCQLKFLPYSYFSKEAARKVTGVVSDSQGKAHYVLSGSWDEQMECSKVMHSSPSSPSSDGKQKTVYQTLSAKLLWKKYPLPENAENMYYFSELALTLNEHEEGVAPTDSRLRPDQRLMEKGRWDEANTEKQRLEEKQRLSRRRRLEACGPGSSCSSEEEKEADAYTPLWFEKRLDPLTGEMACVYKGGYWEAKEKQDWHMCPNIF>sp|Q969R2-3|OSBP2_HUMAN Isoform 3 of Oxysterol-binding protein 2 OS=Homosapiens OX=9606 GN=OSBP2MHRQRTRTMSSLAAKRLGMNRRPAGSGGGGGEAATWGHRFWRPQERPTDRNQGEMAHTCRGTINLSTAHIDTEDSCGILLTSGARSYHLKASSEVDRQQWITALELAKAKAVRVMNTHSDDSGDDDEATTPADKSELHHTLKNLSLKLDDLSTCNDLIAKHGAALQRSLTELDGLKIPSESGEKLKVVNERATLFRITSNAMINACRDFLELAEIHSRKWQRALQYEQEQRVHLEETIEQLAKQHNSLERAFHSAPGRPANPSKSFIEGSLLTPKGEDSEEDEDTEYFDAMEDSTSFITVITEAKEDRKAEGSTGTSSVDWSSADNVLDGASLVPKGSSKVKRRVRIPNKPNYSLNLWSIMKNCIGRELSRIPMPVNFNEPLSMLQRLTEDLEYHHLLDKAVHCTSSVEQMCLVAAFSVSSYSTTVHRIAKPFNPMLGETFELDRLDDMGLRSLCEQVSHHPPSAAHYVFSKHGWSLWQEITISSKFRGKYISIMPLGAIHLEFQASGNHYVWRKSTSTVHNIIVGKLWIDQSGDIEIVNHKTNDRCQLKFLPYSYFSKEAARKVTGVVSDSQGKAHYVLSGSWDEQMECSKVMHSSPSSPSSDGKQKTVYQTLSAKLLWKKYPLPENAENMYYFSELALTLNEHEEGVAPTDSRLRPDQRLMEKGRWDEANTEKQRLEEKQRLSRRRRLEACGPGSSCSSEEEKEADAYTPLWFEKRLDPLTGEMACVYKGGYWEAKEKQDWHMCPNIF>sp|Q969R2-4|OSBP2_HUMAN Isoform 4 of Oxysterol-binding protein 2 OS=Homosapiens OX=9606 GN=OSBP2MINACRDFLELAEIHSRKWQRALQYEQEQRVHLEETIEQLAKQHNSLERAFHSAPGRPANPSKSFIEGSLLTPKGEDSEEDEDTEYFDAMEDSTSFITVITEAKEDRKAEGSTGTSSVDWSSADNVLDGASLVPKGSSKVKRRVRIPNKPNYSLNLWSIMKNCIGRELSRIPMPVNFNEPLSMLQRLTEDLEYHHLLDKAVHCTSSVEQMCLVAAFSVSSYSTTVHRIAKPFNPMLGETFELDRLDDMGLRSLCEQVSHHPPSAAHYVFSKHGWSLWQEITISSKFRGKYISIMPLGAIHLEFQASGNHYVWRKSTSTVHNIIVGKLWIDQSGDIEIVNHKTNDRCQLKFLPYSYFSKEAARKVTGVVSDSQGKAHYVLSGSWDEQMECSKVMHSSPSSPSSDGKQKTVYQTLSAKLLWKKYPLPENAENMYYFSELALTLNEHEEGVAPTDSRLRPDQRLMEKGRWDEANTEKQRLEEKQRLSRRRRLEACGPGSSCSSEEEKEADAYTPLWFEKRLDPLTGEMACVYKGGYWEAKEKQDWHMCPNIF>sp|Q969R2-5|OSBP2_HUMAN Isoform 5 of Oxysterol-binding protein 2 OS=Homosapiens OX=9606 GN=OSBP2MEDSTSFITVITEAKEDRKAEGSTGTSSVDWSSADNVLDGASLVPKGSSKVKRRVRIPNKPNYSLNLWSIMKNCIGRELSRIPMPVNFNEPLSMLQRLTEDLEYHHLLDKAVHCTSSVEQMCLVAAFSVSSYSTTVHRIAKPFNPMLGETFELDRLDDMGLRSLCEQVSHHPPSAAHYVFSKHGWSLWQEITISSKFRGKYISIMPLGAIHLEFQASGNHYVWRKSTSTVHNIIVGKLWIDQSGDIEIVNHKTNDRCQLKFLPYSYFSKEAARKVTGVVSDSQGKAHYVLSGSWDEQMECSKVMHSSPSSPSSDGKQKTVYQTLSAKLLWKKYPLPENAENMYYFSELALTLNEHEEGVAPTDSRLRPDQRLMEKGRWDEANTEKQRLEEKQRLSRRRRLEACGPGSSCSSEEEKEADAYTPLWFEKRLDPLTGEMACVYKGGYWEAKEKQDWHMCPNIF>sp|Q969R2-6|OSBP2_HUMAN Isoform 6 of Oxysterol-binding protein 2 OS=Homosapiens OX=9606 GN=OSBP2MKGRGCWDTASVRSFCSSGCLNKFKKDDSGDDDEATTPADKSELHHTLKNLSLKLDDLSTCNDLIAKHGAALQRSLTELDGLKIPSESGEKLKVVNERATLFRITSNAMINACRDFLELAEIHSRKWQRALQYEQEQRVHLEETIEQLAKQHNSLERAFHSAPGRPANPSKSFIEGSLLTPKGEDSEEDEDTEYFDAMEDSTSFITVITEAKEDSRKAEGSTGTSSVDWSSADNVLDGASLVPKGSSKVKRRVRIPNKPNYSLNLWSIMKNCIGRELSRIPMPVNFNEPLSMLQRLTEDLEYHHLLDKAVHCTSSVEQMCLVAAFSVSSYSTTVHRIAKPFNPMLGETFELDRLDDMGLRSLCEQVSHHPPSAAHYVFSKHGWSLWQEITISSKFRGKYISIMPLGAIHLEFQASGNHYVWRKSTSTVHNIIVGKLWIDQSGDIEIVNHKTNDRCQLKFLPYSYFSKEAARKVTGVVSDSQGKAHYVLSGSWDEQMECSKVMHSSPSSPSSDGKQKTVYQTLSAKLLWKKYPLPENAENMYYFSELALTLNEHEEGVAPTDSRLRPDQRLMEKGRWDEANTEKQRLEEKQRLSRRRRLEACGPGSSCSSEEAEKEADAYTPLWFEKRLDPLTGEMACVYKGGYWEAKEKQDWHMCPNIF>sp|Q8NGR6|OR1B1_HUMAN Olfactory receptor 1B1 OS=Homo sapiens OX=9606GN=OR1B1 PE=3 SV=2MMSFAPNASHSPVFLLLGFSRANISYTLLFFLFLAIYLTTILGNVTLVLLISWDSRLHSPMYYLLRGLSVIDMGLSTVTLPQLLAHLVSHYPTIPAARCLAQFFFFYAFGVTDTLVIAVMALDRYVAICDPLHYALVMNHQRCACLLALSWVVSILHTMLRVGLVLPLCWTGDAGGNVNLPHFFCDHRPLLRASCSDIHSNELAIFFEGGFLMLGPCALIVLSYVRIGAAILRLPSAAGRRRAVSTCGSHLTMVGFLYGTIICVYFQPPFQNSQYQDMVASVMYTAITPLANPFVYSLHNKDVKGALCRLLEWVKVDP>sp|O43749|OR1F1_HUMAN Olfactory receptor 1F1 OS=Homo sapiens OX=9606GN=OR1F1 PE=2 SV=1MSGTNQSSVSEFLLLGLSRQPQQQHLLFVFFLSMYLATVLGNLLIILSVSIDSCLHTPMYFFLSNLSFVDICFSFTTVPKMLANHILETQTISFCGCLTQMYFVFMFVDMDNFLLAVMAYDHFVAVCHPLHYTAKMTHQLCALLVAGLWVVANLNVLLHTLLMAPLSFCADNAITHFFCDVTPLLKLSCSDTHLNEVIILSEGALVMITPFLCILASYMHITCTVLKVPSTKGRWKAFSTCGSHLAVVLLFYSTIIAVYFNPLSSHSAEKDTMATVLYTVVTPMLNPFIYSLRNRYLKGALKKVVGRVVFSV>sp|Q8NGR9|OR1N2_HUMAN Olfactory receptor 1N2 OS=Homo sapiens OX=9606GN=OR1N2 PE=2 SV=2MEGFYLRRSHELQGMGKPGRVNQTTVSDFLLLGLSEWPEEQPLLFGIFLGMYLVTMVGNLLIILAISSDPHLHTPMYFFLANLSLTDACFTSASIPKMLANIHTQSQIISYSGCLAQLYFLLMFGGLDNCLLAVMAYDRYVAICQPLHYSTSMSPQLCALMLGVCWVLTNCPALMHTLLLTRVAFCAQKAIPHFYCDPSALLKLACSDTHVNELMIITMGLLFLTVPLLLIVFSYVRIFWAVFVISSPGGRWKAFSTCGSHLTVVLLFYGSLMGVYLLPPSTYSTERESRAAVLYMVIIPTLNPFIYSLRNRDMKEALGKLFVSGKTFFL>sp|Q9UBM4|OPT_HUMAN Opticin OS=Homo sapiens OX=9606 GN=OPTC PE=1 SV=1MRLLAFLSLLALVLQETGTASLPRKERKRREEQMPREGDSFEVLPLRNDVLNPDNYGEVIDLSNYEELTDYGDQLPEVKVTSLAPATSISPAKSTTAPGTPSSNPTMTRPTTAGLLLSSQPNHGLPTCLVCVCLGSSVYCDDIDLEDIPPLPRRTAYLYARFNRISRIRAEDFKGLTKLKRIDLSNNLISSIDNDAFRLLHALQDLILPENQLEALPVLPSGIEFLDVRLNRLQSSGIQPAAFRAMEKLQFLYLSDNLLDSIPGPLPLSLRSVHLQNNLIETMQRDVFCDPEEHKHTRRQLEDIRLDGNPINLSLFPSAYFCLPRLPIGRFT>sp|Q9UBD5|ORC3_HUMAN Origin recognition complex subunit 3 OS=Homosapiens OX=9606 GN=ORC3 PE=1 SV=1MATSSMSKGCFVFKPNSKKRKISLPIEDYFNKGKNEPEDSKLRFETYQLIWQQMKSENERLQEELNKNLFDNLIEFLQKSHSGFQKNSRDLGGQIKLREIPTAALVLGVNVTDHDLTFGSLTEALQNNVTPYVVSLQAKDCPDMKHFLQKLISQLMDCCVDIKSKEEESVHVTQRKTHYSMDSLSSWYMTVTQKTDPKMLSKKRTTSSQWQSPPVVVILKDMESFATKVLQDFIIISSQHLHEFPLILIFGIATSPIIIHRLLPHAVSSLLCIELFQSLSCKEHLTTVLDKLLLTTQFPFKINEKVLQVLTNIFLYHDFSVQNFIKGLQLSLLEHFYSQPLSVLCCNLPEAKRRINFLSNNQCENIRRLPSFRRYVEKQASEKQVALLTNERYLKEETQLLLENLHVYHMNYFLVLRCLHKFTSSLPKYPLGRQIRELYCTCLEKNIWDSEEYASVLQLLRMLAKDELMTILEKCFKVFKSYCENHLGSTAKRIEEFLAQFQSLDETKEEEDASGSQPKGLQKTDLYHLQKSLLEMKELRRSKKQTKFEVLRENVVNFIDCLVREYLLPPETQPLHEVVYFSAAHALREHLNAAPRIALHTALNNPYYYLKNEALKSEEGCIPNIAPDICIAYKLHLECSRLINLVDWSEAFATVVTAAEKMDANSATSEEMNEIIHARFIRAVSELELLGFIKPTKQKTDHVARLTWGGC>sp|Q9UBD5-2|ORC3_HUMAN Isoform 2 of Origin recognition complex subunit 3OS=Homo sapiens OX=9606 GN=ORC3MATSSMSKGCFVFKPNSKKRKISLPIEDYFNKGKNEPEDSKLRFETYQLIWQQMKSENERLQEELNKNLFDNLIEFLQKSHSGFQKNSRDLGGQIKLREIPTAALVLGVNVTDHDLTFGSLTEALQNNVTPYVVSLQAKDCPDMKHFLQKLISQLMDCCVDIKSKEEESVHVTQRKTHYSMDSLSSWYMTVTQKTDPKMLSKKRTTSSQWQSPPVVVILKDMESFATKVLQDFIIISSQHLHEFPLILIFGIATSPIIIHRLLPHAVSSLLCIELFQSLSCKEHLTTVLDKLLLTTQFPFKINEKVLQVLTNIFLYHDFSVQNFIKGLQLSLLEHFYSQPLSVLCCNLPEAKRRINFLSNNQCENIRRLPSFRRYVEKQASEKQVALLTNERYLKEETQLLLENLHVYHMNYFLVLRCLHKFTSSLPKYPLGRQIRELYCTCLEKNIWDSEEYASVLQLLRMLAKDELMTILEKCFKVFKSYCENHLGSTAKRIEEFLAQFQSLDAETKEEEDASGSQPKGLQKTDLYHLQKSLLEMKELRRSKKQTKFEVLRENVVNFIDCLVREYLLPPETQPLHEVVYFSAAHALREHLNAAPRIALHTALNNPYYYLKNEALKSEEGCIPNIAPDICIAYKLHLECSRLINLVDWSEAFATVVTAAEKMDANSATSEEMNEIIHARFIRAVSELELLGFIKPTKQKTDHVARLTWGGC>sp|Q9UBD5-3|ORC3_HUMAN Isoform 3 of Origin recognition complex subunit 3OS=Homo sapiens OX=9606 GN=ORC3MKHFLQKLISQLMDCCVDIKSKEEESVHVTQRKTHYSMDSLSSWYMTVTQKTDPKMLSKKRTTSSQWQSPPVVVILKDMESFATKVLQDFIIISSQHLHEFPLILIFGIATSPIIIHRLLPHAVSSLLCIELFQSLSCKEHLTTVLDKLLLTTQFPFKINEKVLQVLTNIFLYHDFSVQNFIKGLQLSLLEHFYSQPLSVLCCNLPEAKRRINFLSNNQCENIRRLPSFRRYVEKQASEKQVALLTNERYLKEETQLLLENLHVYHMNYFLVLRCLHKFTSSLPKYPLGRQIRELYCTCLEKNIWDSEEYASVLQLLRMLAKDELMTILEKCFKVFKSYCENHLGSTAKRIEEFLAQFQSLDETKEEEDASGSQPKGLQKTDLYHLQKSLLEMKELRRSKKQTKFEVLRENVVNFIDCLVREYLLPPETQPLHEVVYFSAAHALREHLNAAPRIALHTALNNPYYYLKNEALKSEEGCIPNIAPDICIAYKLHLECSRLINLVDWSEAFATVVTAAEKMDANSATSEEMNEIIHARFIRAVSELELLGFIKPTKQKTDHVARLTWGGC>sp|O15504|NUP42_HUMAN Nucleoporin NUP42 OS=Homo sapiens OX=9606 GN=NUP42PE=1 SV=1MAICQFFLQGRCRFGDRCWNEHPGARGAGGGRQQPQQQPSGNNRRGWNTTSQRYSNVIQPSSFSKSTPWGGSRDQEKPYFSSFDSGASTNRKEGFGLSENPFASLSPDEQKDEKKLLEGIVKDMEVWESSGQWMFSVYSPVKKKPNISGFTDISPEELRLEYHNFLTSNNLQSYLNSVQRLINQWRNRVNELKSLNISTKVALLSDVKDGVNQAAPAFGFGSSQAATFMSPGFPVNNSSSDNAQNFSFKTNSGFAAASSGSPAGFGSSPAFGAAASTSSGISTSAPAFGFGKPEVTSAASFSFKSPAASSFGSPGFSGLPASLATGPVRAPVAPAFGGGSSVAGFGSPGSHSHTAFSKPSSDTFGNSSISTSLSASSSIIATDNVLFTPRDKLTVEELEQFQSKKFTLGKIPLKPPPLELLNV>sp|O15504-2|NUP42_HUMAN Isoform 2 of Nucleoporin NUP42 OS=Homo sapiensOX=9606 GN=NUP42MAICQFFLQGRCRFGDRCWNEHPGARGAGGGRQQPQQQPSGNNRRGWNTTSQRYSNVIQPSSFSKSTPWGGSRDQEKPYFSSFDSGASTNRKEGFGLSENPFASLSPDEQKDEKKLLEGIVKDMEVWESSGQWMFSVYSPVKKKPNISGFTDISPEELRLEYHNFLTSNNLQSYLNSVQRLINQWRNRVNELKSLNISTKVALKCLWKIYTHLSPKIYGPDCAL>sp|O15504-3|NUP42_HUMAN Isoform 3 of Nucleoporin NUP42 OS=Homo sapiensOX=9606 GN=NUP42MSPGFPVNNSSSDNAQNFSFKTNSGFAAASSGSPAGFGSSPAFGAAASTSSGISTSAPAFGFGKPEVTSAASFSFKSPAASSFGSPGFSGLPASLATGPVRAPVAPAFGGGSSVAGFGSPGSHSHTAFSKPSSDTFGNSSISTSLSASSSIIATDNVLFTPRDKLTVEELEQFQSKKFTLGKIPLKPPPLELLNV>sp|Q14990|ODFP1_HUMAN Outer dense fiber protein 1 OS=Homo sapiensOX=9606 GN=ODF1 PE=1 SV=2MAALSCLLDSVRRDIKKVDRELRQLRCIDEFSTRCLCDLYMHPYCCCDLHPYPYCLCYSKRSRSCGLCDLYPCCLCDYKLYCLRPSLRSLERKAIRAIEDEKRELAKLRRTTNRILASSCCSSNILGSVNVCGFEPDQVKVRVKDGKVCVSAERENRYDCLGSKKYSYMNICKEFSLPPCVDEKDVTYSYGLGSCVKIESPCYPCTSPCSPCSPCSPCNPCSPCNPCSPYDPCNPCYPCGSRFSCRKMIL>sp|Q8N323|NXPE1_HUMAN NXPE family member 1 OS=Homo sapiens OX=9606GN=NXPE1 PE=1 SV=2MSSNTMLQKTLLILISFSVVTWMIFIISQNFTKLWSALNLSISVHYWNNSAKSLFPKTSLIPLKPLTETELRIKEIIEKLDQQIPPRPFTHVNTTTSATHSTATILNPRDTYCRGDQLDILLEVRDHLGQRKQYGGDFLRARMSSPALTAGASGKVMDFNNGTYLVSFTLFWEGQVSLSLLLIHPSEGASALWRARNQGYDKIIFKGKFVNGTSHVFTECGLTLNSNAELCEYLDDRDQEAFYCMKPQHMPCEALTYMTTRNREVSYLTDKENSLFHRSKVGVEMMKDRKHIDVTNCNKREKIEETCQVGMKPPVPGGYTLQGKWITTFCNQVQLDTIKINGCLKGKLIYLLGDSTLRQWIYYFPKVVKTLKFFDLHETGIFKKHLLLDAERHTQIQWKKHSYPFVTFQLYSLIDHDYIPREIDRLSGDKNTAIVITFGQHFRPFPIDIFIRRAIGVQKAIERLFLRSPATKVIIKTENIREMHIETERFGDFHGYIHYLIMKDIFKDLNVGIIDAWDMTIAYGTDTIHPPDHVIGNQINMFLNYIC>sp|Q8N323-2|NXPE1_HUMAN Isoform 2 of NXPE family member 1 OS=Homosapiens OX=9606 GN=NXPE1MSSPALTAGASGKVMDFNNGTYLVSFTLFWEGQVSLSLLLIHPSEGASALWRARNQGYDKIIFKGKFVNGTSHVFTECGLTLNSNAELCEYLDDRDQEAFYCMKPQHMPCEALTYMTTRNREVSYLTDKENSLFHRSKVGVEMMKDRKHIDVTNCNKREKIEETCQVGMKPPVPGGYTLQGKWITTFCNQVQLDTIKINGCLKGKLIYLLGDSTLRQWIYYFPKVVKTLKFFDLHETGIFKKHLLLDAERHTQIQWKKHSYPFVTFQLYSLIDHDYIPREIDRLSGDKNTAIVITFGQHFRPFPIDIFIRRAIGVQKAIERLFLRSPATKVIIKTENIREMHIETERFGDFHGYIHYLIMKDIFKDLNVGIIDAWDMTIAYGTDTIHPPDHVIGNQINMFLNYIC>sp|Q8NGK9|OR5DG_HUMAN Olfactory receptor 5D16 OS=Homo sapiens OX=9606GN=OR5D16 PE=3 SV=1MFLTERNTTSEATFTLLGFSDYLELQIPLFFVFLAVYGFSVVGNLGMIVIIKINPKLHTPMYFFLNHLSFVDFCYSSIIAPMMLVNLVVEDRTISFSGCLVQFFFFCTFVVTELILFAVMAYDHFVAICNPLLYTVAISQKLCAMLVVVLYAWGVACSLTLACSALKLSFHGFNTINHFFCELSSLISLSYPDSYLSQLLLFTVATFNEISTLLIILTSYAFIIVTTLKMPSASGHRKVFSTCASHLTAITIFHGTILFLYCVPNSKNSRHTVKVASVFYTVVIPLLNPLIYSLRNKDVKDAIRKIINTKYFHIKHRHWYPFNFVIEQ>sp|Q8NHB7|OR5K1_HUMAN Olfactory receptor 5K1 OS=Homo sapiens OX=9606GN=OR5K1 PE=2 SV=2MAEENHTMKNEFILTGFTDHPELKTLLFVVFFAIYLITVVGNISLVALIFTHRRLHTPMYIFLGNLALVDSCCACAITPKMLENFFSENKRISLYECAVQFYFLCTVETADCFLLAAMAYDRYVAICNPLQYHIMMSKKLCIQMTTGAFIAGNLHSMIHVGLVFRLVFCGSNHINHFYCDILPLYRLSCVDPYINELVLFIFSGSVQVFTIGSVLISYLYILLTIFKMKSKEGRAKAFSTCASHFLSVSLFYGSLFFMYVRPNLLEEGDKDIPAAILFTIVVPLLNPFIYSLRNREVISVLRKILMKK>sp|Q8NH07|O11H2_HUMAN Olfactory receptor 11H2 OS=Homo sapiens OX=9606GN=OR11H2 PE=3 SV=1MCPLTLHVTGLMNVSEPNSSFAFVNEFILQGFSCEWTIQIFLFSLFTTIYALTITGNGAIAFVLWCDRRLHTPMYMFLGNFSFLEIWYVSSTVPKMLVNFLSEKKNISFAGCFLQFYFFFSLGTSECLLLTVMAFDQYLAICRPLLYPNIMTGHLYAKLVILCWVCGFLWFLIPIVLISQKPFCGPNIIDHVVCDPGPLFALDCVSAPRIQLFCYTLSSLVIFGNFLFIIGSYTLVLKAVLGMPSSTGRHKAFSTCGSHLAVVSLCYSPLMVMYVSPGLGHSTGMQKIETLFYAMVTPLFNPLIYSLQNKEIKAALRKVLGSSNII>sp|P0C628|O5AC1_HUMAN Olfactory receptor 5AC1 OS=Homo sapiens OX=9606GN=OR5AC1 PE=3 SV=1MAEENKILVTHFVLTGLTDHPGLQAPLFLVFLVIYLITLVGNLGLMALIWKDPHLHTPIYLFLGSLAFADACTSSSVTSKMLINFLSKNHMLSMAKCATQFYFFGSNATTECFLLVVMAYDRYVAICNPLLYPVVMSNSLCTQFIGISYFIGFLHSAIHVGLLFRLTFCRSNIIHYFYCEILQLFKISCTNPTVNILLIFIFSAFIQVFTFMTLIVSYSYILSAILKKKSEKGRSKAFSTCSAHLLSVSLFYGTLFFMYVSSRSGSAADQAKMYSLFYTIIIPLLNPFIYSLRNKEVIDALRRIMKK>sp|Q8NGZ9|O2T10_HUMAN Olfactory receptor 2T10 OS=Homo sapiens OX=9606GN=OR2T10 PE=2 SV=1MRLANQTLGGDFFLLGIFSQISHPGRLCLLIFSIFLMAVSWNITLILLIHIDSSLHTPMYFFINQLSLIDLTYISVTVPKMLVNQLAKDKTISVLGCGTQMYFYLQLGGAECCLLAAMAYDRYVAICHPLRYSVLMSHRVCLLLASGCWFVGSVDGFMLTPIAMSFPFCRSHEIQHFFCEVPAVLKLSCSDTSLYKIFMYLCCVIMLLIPVTVISVSYYYIILTIHKMNSVEGRKKAFTTCSSHITVVSLFYGAAIYNYMLPSSYQTPEKDMMSSFFYTILTPVLNPIIYSFRNKDVTRALKKMLSVQKPPY>sp|Q8NGC7|O11H6_HUMAN Olfactory receptor 11H6 OS=Homo sapiens OX=9606GN=OR11H6 PE=3 SV=1MFFIIHSLVTSVFLTALGPQNRTMHFVTEFVLLGFHGQREMQSCFFSFILVLYLLTLLGNGAIVCAVKLDRRLHTPMYILLGNFAFLEIWYISSTVPNMLVNILSEIKTISFSGCFLQFYFFFSLGTTECFFLSVMAYDRYLAICRPLHYPSIMTGKFCIILVCVCWVGGFLCYPVPIVLISQLPFCGPNIIDHLVCDPGPLFALACISAPSTELICYTFNSMIIFGPFLSILGSYTLVIRAVLCIPSGAGRTKAFSTCGSHLMVVSLFYGTLMVMYVSPTSGNPAGMQKIITLVYTAMTPFLNPLIYSLRNKDMKDALKRVLGLTVSQN>sp|O95006|OR2F2_HUMAN Olfactory receptor 2F2 OS=Homo sapiens OX=9606GN=OR2F2 PE=2 SV=1MEIDNQTWVREFILLGLSSDWCTQISLFSLFLVTYLMTVLGNCLIVLLIRLDSRLHTPMYFFLTNLSLVDVSYATSVVPQLLAHFLAEHKAIPFQSCAAQLFFSLALGGIEFVLLAVMAYDRHVAVSDRLRYSAIMHGGLCARLAITSWVSGSINSLVQTAITFQLPMCTNKFIDHISCELLAVVRLACVDTSSNEAAIMVSSIVLLMTPFCLVLLSYIRIISTILKIQSREGRKKAFHTCASHLTVVALCYGTTIFTYIQPHSGPSVLQEKLISVFYAIVMPLLNPVIYSLRNKEVKGAWHKLLEKFSGLTSKLGT>sp|Q13332|PTPRS_HUMAN Receptor-type tyrosine-protein phosphatase SOS=Homo sapiens OX=9606 GN=PTPRS PE=1 SV=3MAPTWGPGMVSVVGPMGLLVVLLVGGCAAEEPPRFIKEPKDQIGVSGGVASFVCQATGDPKPRVTWNKKGKKVNSQRFETIEFDESAGAVLRIQPLRTPRDENVYECVAQNSVGEITVHAKLTVLREDQLPSGFPNIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDPSASNGRIKQLRSETFESTPIRGALQIESSEETDQGKYECVATNSAGVRYSSPANLYVRELREVRRVAPRFSILPMSHEIMPGGNVNITCVAVGSPMPYVKWMQGAEDLTPEDDMPVGRNVLELTDVKDSANYTCVAMSSLGVIEAVAQITVKSLPKAPGTPMVTENTATSITITWDSGNPDPVSYYVIEYKSKSQDGPYQIKEDITTTRYSIGGLSPNSEYEIWVSAVNSIGQGPPSESVVTRTGEQAPASAPRNVQARMLSATTMIVQWEEPVEPNGLIRGYRVYYTMEPEHPVGNWQKHNVDDSLLTTVGSLLEDETYTVRVLAFTSVGDGPLSDPIQVKTQQGVPGQPMNLRAEARSETSITLSWSPPRQESIIKYELLFREGDHGREVGRTFDPTTSYVVEDLKPNTEYAFRLAARSPQGLGAFTPVVRQRTLQSKPSAPPQDVKCVSVRSTAILVSWRPPPPETHNGALVGYSVRYRPLGSEDPEPKEVNGIPPTTTQILLEALEKWTQYRITTVAHTEVGPGPESSPVVVRTDEDVPSAPPRKVEAEALNATAIRVLWRSPAPGRQHGQIRGYQVHYVRMEGAEARGPPRIKDVMLADAQWETDDTAEYEMVITNLQPETAYSITVAAYTMKGDGARSKPKVVVTKGAVLGRPTLSVQQTPEGSLLARWEPPAGTAEDQVLGYRLQFGREDSTPLATLEFPPSEDRYTASGVHKGATYVFRLAARSRGGLGEEAAEVLSIPEDTPRGHPQILEAAGNASAGTVLLRWLPPVPAERNGAIVKYTVAVREAGALGPARETELPAAAEPGAENALTLQGLKPDTAYDLQVRAHTRRGPGPFSPPVRYRTFLRDQVSPKNFKVKMIMKTSVLLSWEFPDNYNSPTPYKIQYNGLTLDVDGRTTKKLITHLKPHTFYNFVLTNRGSSLGGLQQTVTAWTAFNLLNGKPSVAPKPDADGFIMVYLPDGQSPVPVQSYFIVMVPLRKSRGGQFLTPLGSPEDMDLEELIQDISRLQRRSLRHSRQLEVPRPYIAARFSVLPPTFHPGDQKQYGGFDNRGLEPGHRYVLFVLAVLQKSEPTFAASPFSDPFQLDNPDPQPIVDGEEGLIWVIGPVLAVVFIICIVIAILLYKNKPDSKRKDSEPRTKCLLNNADLAPHHPKDPVEMRRINFQTPDSGLRSPLREPGFHFESMLSHPPIPIADMAEHTERLKANDSLKLSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVILQPIEGIMGSDYINANYVDGYRCQNAYIATQGPLPETFGDFWRMVWEQRSATIVMMTRLEEKSRIKCDQYWPNRGTETYGFIQVTLLDTIELATFCVRTFSLHKNGSSEKREVRQFQFTAWPDHGVPEYPTPFLAFLRRVKTCNPPDAGPIVVHCSAGVGRTGCFIVIDAMLERIKPEKTVDVYGHVTLMRSQRNYMVQTEDQYSFIHEALLEAVGCGNTEVPARSLYAYIQKLAQVEPGEHVTGMELEFKRLANSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWENNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDEYQFCYQAALEYLGSFDHYAT>sp|Q13332-2|PTPRS_HUMAN Isoform PTPS-MEA of Receptor-type tyrosine-protein phosphatase S OS=Homo sapiens OX=9606 GN=PTPRSMAPTWGPGMVSVVGPMGLLVVLLVGGCAAEEPPRFIKEPKDQIGVSGGVASFVCQATGDPKPRVTWNKKGKKVNSQRFETIEFDESAGAVLRIQPLRTPRDENVYECVAQNSVGEITVHAKLTVLREDQLPSGFPNIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDPSASNGRIKQLRSGALQIESSEETDQGKYECVATNSAGVRYSSPANLYVRELREVRRVAPRFSILPMSHEIMPGGNVNITCVAVGSPMPYVKWMQGAEDLTPEDDMPVGRNVLELTDVKDSANYTCVAMSSLGVIEAVAQITVKSLPKAPGTPMVTENTATSITITWDSGNPDPVSYYVIEYKSKSQDGPYQIKEDITTTRYSIGGLSPNSEYEIWVSAVNSIGQGPPSESVVTRTGEQAPASAPRNVQARMLSATTMIVQWEEPVEPNGLIRGYRVYYTMEPEHPVGNWQKHNVDDSLLTTVGSLLEDETYTVRVLAFTSVGDGPLSDPIQVKTQQGVPGQPMNLRAEARSETSITLSWSPPRQESIIKYELLFREGDHGREVGRTFDPTTSYVVEDLKPNTEYAFRLAARSPQGLGAFTPVVRQRTLQSKPSAPPQDVKCVSVRSTAILVSWRPPPPETHNGALVGYSVRYRPLGSEDPEPKEVNGIPPTTTQILLEALEKWTQYRITTVAHTEVGPGPESSPVVVRTDEDVPSAPPRKVEAEALNATAIRVLWRSPAPGRQHGQIRGYQVHYVRMEGAEARGPPRIKDVMLADAQWETDDTAEYEMVITNLQPETAYSITVAAYTMKGDGARSKPKVVVTKGAVLGRPTLSVQQTPEGSLLARWEPPAGTAEDQVLGYRLQFGREDSTPLATLEFPPSEDRYTASGVHKGATYVFRLAARSRGGLGEEAAEVLSIPEDTPRGHPQILEAAGNASAGTVLLRWLPPVPAERNGAIVKYTVAVREAGALGPARETELPAAAEPGAENALTLQGLKPDTAYDLQVRAHTRRGPGPFSPPVRYRTFLRDQVSPKNFKVKMIMKTSVLLSWEFPDNYNSPTPYKIQYNGLTLDVDGRTTKKLITHLKPHTFYNFVLTNRGSSLGGLQQTVTAWTAFNLLNGKPSVAPKPDADGFIMVYLPDGQSPVPVQSYFIVMVPLRKSRGGQFLTPLGSPEDMDLEELIQDISRLQRRSLRHSRQLEVPRPYIAARFSVLPPTFHPGDQKQYGGFDNRGLEPGHRYVLFVLAVLQKSEPTFAASPFSDPFQLDNPDPQPIVDGEEGLIWVIGPVLAVVFIICIVIAILLYKNKPDSKRKDSEPRTKCLLNNADLAPHHPKDPVEMRRINFQTPDSGLRSPLREPGFHFESMLSHPPIPIADMAEHTERLKANDSLKLSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVILQPIEGIMGSDYINANYVDGYRCQNAYIATQGPLPETFGDFWRMVWEQRSATIVMMTRLEEKSRIKCDQYWPNRGTETYGFIQVTLLDTIELATFCVRTFSLHKNGSSEKREVRQFQFTAWPDHGVPEYPTPFLAFLRRVKTCNPPDAGPIVVHCSAGVGRTGCFIVIDAMLERIKPEKTVDVYGHVTLMRSQRNYMVQTEDQYSFIHEALLEAVGCGNTEVPARSLYAYIQKLAQVEPGEHVTGMELEFKRLANSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWENNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDEYQFCYQAALEYLGSFDHYAT>sp|Q13332-3|PTPRS_HUMAN Isoform PTPS-MEB of Receptor-type tyrosine-protein phosphatase S OS=Homo sapiens OX=9606 GN=PTPRSMAPTWGPGMVSVVGPMGLLVVLLVGGCAAEEPPRFIKEPKDQIGVSGGVASFVCQATGDPKPRVTWNKKGKKVNSQRFETIEFDESAGAVLRIQPLRTPRDENVYECVAQNSVGEITVHAKLTVLREDQLPSGFPNIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDPSASNGRIKQLRSETFESTPIRGALQIESSEETDQGKYECVATNSAGVRYSSPANLYVRVRRVAPRFSILPMSHEIMPGGNVNITCVAVGSPMPYVKWMQGAEDLTPEDDMPVGRNVLELTDVKDSANYTCVAMSSLGVIEAVAQITVKSLPKAPGTPMVTENTATSITITWDSGNPDPVSYYVIEYKSKSQDGPYQIKEDITTTRYSIGGLSPNSEYEIWVSAVNSIGQGPPSESVVTRTGEQAPASAPRNVQARMLSATTMIVQWEEPVEPNGLIRGYRVYYTMEPEHPVGNWQKHNVDDSLLTTVGSLLEDETYTVRVLAFTSVGDGPLSDPIQVKTQQGVPGQPMNLRAEARSETSITLSWSPPRQESIIKYELLFREGDHGREVGRTFDPTTSYVVEDLKPNTEYAFRLAARSPQGLGAFTPVVRQRTLQSKPSAPPQDVKCVSVRSTAILVSWRPPPPETHNGALVGYSVRYRPLGSEDPEPKEVNGIPPTTTQILLEALEKWTQYRITTVAHTEVGPGPESSPVVVRTDEDVPSAPPRKVEAEALNATAIRVLWRSPAPGRQHGQIRGYQVHYVRMEGAEARGPPRIKDVMLADAQWETDDTAEYEMVITNLQPETAYSITVAAYTMKGDGARSKPKVVVTKGAVLGRPTLSVQQTPEGSLLARWEPPAGTAEDQVLGYRLQFGREDSTPLATLEFPPSEDRYTASGVHKGATYVFRLAARSRGGLGEEAAEVLSIPEDTPRGHPQILEAAGNASAGTVLLRWLPPVPAERNGAIVKYTVAVREAGALGPARETELPAAAEPGAENALTLQGLKPDTAYDLQVRAHTRRGPGPFSPPVRYRTFLRDQVSPKNFKVKMIMKTSVLLSWEFPDNYNSPTPYKIQYNGLTLDVDGRTTKKLITHLKPHTFYNFVLTNRGSSLGGLQQTVTAWTAFNLLNGKPSVAPKPDADGFIMVYLPDGQSPVPVQSYFIVMVPLRKSRGGQFLTPLGSPEDMDLEELIQDISRLQRRSLRHSRQLEVPRPYIAARFSVLPPTFHPGDQKQYGGFDNRGLEPGHRYVLFVLAVLQKSEPTFAASPFSDPFQLDNPDPQPIVDGEEGLIWVIGPVLAVVFIICIVIAILLYKNKPDSKRKDSEPRTKCLLNNADLAPHHPKDPVEMRRINFQTPGMLSHPPIPIADMAEHTERLKANDSLKLSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVILQPIEGIMGSDYINANYVDGYRCQNAYIATQGPLPETFGDFWRMVWEQRSATIVMMTRLEEKSRIKCDQYWPNRGTETYGFIQVTLLDTIELATFCVRTFSLHKNGSSEKREVRQFQFTAWPDHGVPEYPTPFLAFLRRVKTCNPPDAGPIVVHCSAGVGRTGCFIVIDAMLERIKPEKTVDVYGHVTLMRSQRNYMVQTEDQYSFIHEALLEAVGCGNTEVPARSLYAYIQKLAQVEPGEHVTGMELEFKRLANSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWENNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDEYQFCYQAALEYLGSFDHYAT>sp|Q13332-4|PTPRS_HUMAN Isoform PTPS-MEC of Receptor-type tyrosine-protein phosphatase S OS=Homo sapiens OX=9606 GN=PTPRSMAPTWGPGMVSVVGPMGLLVVLLVGGCAAEEPPRFIKEPKDQIGVSGGVASFVCQATGDPKPRVTWNKKGKKVNSQRFETIEFDESAGAVLRIQPLRTPRDENVYECVAQNSVGEITVHAKLTVLREDQLPSGFPNIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDPSASNGRIKQLRSETFESTPIRGALQIESSEETDQGKYECVATNSAGVRYSSPANLYVRELREVRRVAPRFSILPMSHEIMPGGNVNITCVAVGSPMPYVKWMQGAEDLTPEDDMPVGRNVLELTDVKDSANYTCVAMSSLGVIEAVAQITVKSLPKAPGTPMVTENTATSITITWDSGNPDPVSYYVIEYKSKSQDGPYQIKEDITTTRYSIGGLSPNSEYEIWVSAVNSIGQGPPSESVVTRTGEQAPASAPRNVQARMLSATTMIVQWEEPVEPNGLIRGYRVYYTMEPEHPVGNWQKHNVDDSLLTTVGSLLEDETYTVRVLAFTSVGDGPLSDPIQVKTQQGVPGQPMNLRAEARSETSITLSWSPPRQESIIKYELLFREGDHGREVGRTFDPTTSYVVEDLKPNTEYAFRLAARSPQGLGAFTPVVRQRTLQSKPSAPPQDVKCVSVRSTAILVSWRPPPPETHNGALVGYSVRYRPLGSEDPEPKEVNGIPPTTTQILLEALEKWTQYRITTVAHTEVGPGPESSPVVVRTDEDVPSAPPRKVEAEALNATAIRVLWRSPAPGRQHGQIRGYQVHYVRMEGAEARGPPRIKDVMLADAQEMVITNLQPETAYSITVAAYTMKGDGARSKPKVVVTKGAVLGRPTLSVQQTPEGSLLARWEPPAGTAEDQVLGYRLQFGREDSTPLATLEFPPSEDRYTASGVHKGATYVFRLAARSRGGLGEEAAEVLSIPEDTPRGHPQILEAAGNASAGTVLLRWLPPVPAERNGAIVKYTVAVREAGALGPARETELPAAAEPGAENALTLQGLKPDTAYDLQVRAHTRRGPGPFSPPVRYRTFLRDQVSPKNFKVKMIMKTSVLLSWEFPDNYNSPTPYKIQYNGLTLDVDGRTTKKLITHLKPHTFYNFVLTNRGSSLGGLQQTVTAWTAFNLLNGKPSVAPKPDADGFIMVYLPDGQSPVPVQSYFIVMVPLRKSRGGQFLTPLGSPEDMDLEELIQDISRLQRRSLRHSRQLEVPRPYIAARFSVLPPTFHPGDQKQYGGFDNRGLEPGHRYVLFVLAVLQKSEPTFAASPFSDPFQLDNPDPQPIVDGEEGLIWVIGPVLAVVFIICIVIAILLYKNKPDSKRKDSEPRTKCLLNNADLAPHHPKDPVEMRRINFQTPDSGLRSPLREPGFHFESMLSHPPIPIADMAEHTERLKANDSLKLSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVILQPIEGIMGSDYINANYVDGYRCQNAYIATQGPLPETFGDFWRMVWEQRSATIVMMTRLEEKSRIKCDQYWPNRGTETYGFIQVTLLDTIELATFCVRTFSLHKNGSSEKREVRQFQFTAWPDHGVPEYPTPFLAFLRRVKTCNPPDAGPIVVHCSAGVGRTGCFIVIDAMLERIKPEKTVDVYGHVTLMRSQRNYMVQTEDQYSFIHEALLEAVGCGNTEVPARSLYAYIQKLAQVEPGEHVTGMELEFKRLANSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWENNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDEYQFCYQAALEYLGSFDHYAT>sp|Q13332-5|PTPRS_HUMAN Isoform PTPS-F4-7 of Receptor-type tyrosine-protein phosphatase S OS=Homo sapiens OX=9606 GN=PTPRSMAPTWGPGMVSVVGPMGLLVVLLVGGCAAEEPPRFIKEPKDQIGVSGGVASFVCQATGDPKPRVTWNKKGKKVNSQRFETIEFDESAGAVLRIQPLRTPRDENVYECVAQNSVGEITVHAKLTVLREDQLPSGFPNIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDPSASNGRIKQLRSETFESTPIRGALQIESSEETDQGKYECVATNSAGVRYSSPANLYVRELREVRRVAPRFSILPMSHEIMPGGNVNITCVAVGSPMPYVKWMQGAEDLTPEDDMPVGRNVLELTDVKDSANYTCVAMSSLGVIEAVAQITVKSLPKAPGTPMVTENTATSITITWDSGNPDPVSYYVIEYKSKSQDGPYQIKEDITTTRYSIGGLSPNSEYEIWVSAVNSIGQGPPSESVVTRTGEQAPASAPRNVQARMLSATTMIVQWEEPVEPNGLIRGYRVYYTMEPEHPVGNWQKHNVDDSLLTTVGSLLEDETYTVRVLAFTSVGDGPLSDPIQVKTQQGVPGQPMNLRAEARSETSITLSWSPPRQESIIKYELLFREGDHGREVGRTFDPTTSYVVEDLKPNTEYAFRLAARSPQGLGAFTPVVRQRTLQSISPKNFKVKMIMKTSVLLSWEFPDNYNSPTPYKIQYNGLTLDVDGRTTKKLITHLKPHTFYNFVLTNRGSSLGGLQQTVTAWTAFNLLNGKPSVAPKPDADGFIMVYLPDGQSPVPVQSYFIVMVPLRKSRGGQFLTPLGSPEDMDLEELIQDISRLQRRSLRHSRQLEVPRPYIAARFSVLPPTFHPGDQKQYGGFDNRGLEPGHRYVLFVLAVLQKSEPTFAASPFSDPFQLDNPDPQPIVDGEEGLIWVIGPVLAVVFIICIVIAILLYKNKPDSKRKDSEPRTKCLLNNADLAPHHPKDPVEMRRINFQTPDSGLRSPLREPGFHFESMLSHPPIPIADMAEHTERLKANDSLKLSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVILQPIEGIMGSDYINANYVDGYRCQNAYIATQGPLPETFGDFWRMVWEQRSATIVMMTRLEEKSRIKCDQYWPNRGTETYGFIQVTLLDTIELATFCVRTFSLHKNGSSEKREVRQFQFTAWPDHGVPEYPTPFLAFLRRVKTCNPPDAGPIVVHCSAGVGRTGCFIVIDAMLERIKPEKTVDVYGHVTLMRSQRNYMVQTEDQYSFIHEALLEAVGCGNTEVPARSLYAYIQKLAQVEPGEHVTGMELEFKRLANSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWENNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDEYQFCYQAALEYLGSFDHYAT>sp|Q13332-6|PTPRS_HUMAN Isoform 2 of Receptor-type tyrosine-proteinphosphatase S OS=Homo sapiens OX=9606 GN=PTPRSMAPTWGPGMVSVVGPMGLLVVLLVGGCAAEEPPRFIKEPKDQIGVSGGVASFVCQATGDPKPRVTWNKKGKKVNSQRFETIEFDESAGAVLRIQPLRTPRDENVYECVAQNSVGEITVHAKLTVLREDQLPSGFPNIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDPSASNGRIKQLRSGALQIESSEETDQGKYECVATNSAGVRYSSPANLYVRVRRVAPRFSILPMSHEIMPGGNVNITCVAVGSPMPYVKWMQGAEDLTPEDDMPVGRNVLELTDVKDSANYTCVAMSSLGVIEAVAQITVKSLPKAPGTPMVTENTATSITITWDSGNPDPVSYYVIEYKSKSQDGPYQIKEDITTTRYSIGGLSPNSEYEIWVSAVNSIGQGPPSESVVTRTGEQAPASAPRNVQARMLSATTMIVQWEEPVEPNGLIRGYRVYYTMEPEHPVGNWQKHNVDDSLLTTVGSLLEDETYTVRVLAFTSVGDGPLSDPIQVKTQQGVPGQPMNLRAEARSETSITLSWSPPRQESIIKYELLFREGDHGREVGRTFDPTTSYVVEDLKPNTEYAFRLAARSPQGLGAFTPVVRQRTLQSKPSAPPQDVKCVSVRSTAILVSWRPPPPETHNGALVGYSVRYRPLGSEDPEPKEVNGIPPTTTQILLEALEKWTQYRITTVAHTEVGPGPESSPVVVRTDEDVPSAPPRKVEAEALNATAIRVLWRSPAPGRQHGQIRGYQVHYVRMEGAEARGPPRIKDVMLADAQEMVITNLQPETAYSITVAAYTMKGDGARSKPKVVVTKGAVLGRPTLSVQQTPEGSLLARWEPPAGTAEDQVLGYRLQFGREDSTPLATLEFPPSEDRYTASGVHKGATYVFRLAARSRGGLGEEAAEVLSIPEDTPRGHPQILEAAGNASAGTVLLRWLPPVPAERNGAIVKYTVAVREAGALGPARETELPAAAEPGAENALTLQGLKPDTAYDLQVRAHTRRGPGPFSPPVRYRTFLRDQVSPKNFKVKMIMKTSVLLSWEFPDNYNSPTPYKIQYNGLTLDVDGRTTKKLITHLKPHTFYNFVLTNRGSSLGGLQQTVTAWTAFNLLNGKPSVAPKPDADGFIMVYLPDGQSPVPVQSYFIVMVPLRKSRGGQFLTPLGSPEDMDLEELIQDISRLQRRSLRHSRQLEVPRPYIAARFSVLPPTFHPGDQKQYGGFDNRGLEPGHRYVLFVLAVLQKSEPTFAASPFSDPFQLDNPDPQPIVDGEEGLIWVIGPVLAVVFIICIVIAILLYKNKPDSKRKDSEPRTKCLLNNADLAPHHPKDPVEMRRINFQTPGMLSHPPIPIADMAEHTERLKANDSLKLSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVILQPIEGIMGSDYINANYVDGYRCQNAYIATQGPLPETFGDFWRMVWEQRSATIVMMTRLEEKSRIKCDQYWPNRGTETYGFIQVTLLDTIELATFCVRTFSLHKNGSSEKREVRQFQFTAWPDHGVPEYPTPFLAFLRRVKTCNPPDAGPIVVHCSAGVGRTGCFIVIDAMLERIKPEKTVDVYGHVTLMRSQRNYMVQTEDQYSFIHEALLEAVGCGNTEVPARSLYAYIQKLAQVEPGEHVTGMELEFKRLANSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWENNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDEYQFCYQAALEYLGSFDHYAT>sp|Q13332-7|PTPRS_HUMAN Isoform 3 of Receptor-type tyrosine-proteinphosphatase S OS=Homo sapiens OX=9606 GN=PTPRSMAPTWGPGMVSVVGPMGLLVVLLVGGCAAEEPPRFIKEPKDQIGVSGGVASFVCQATGDPKPRVTWNKKGKKVNSQRFETIEFDESAGAVLRIQPLRTPRDENVYECVAQNSVGEITVHAKLTVLREDQLPSGFPNIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDPSASNGRIKQLRSGALQIESSEETDQGKYECVATNSAGVRYSSPANLYVRVRRVAPRFSILPMSHEIMPGGNVNITCVAVGSPMPYVKWMQGAEDLTPEDDMPVGRNVLELTDVKDSANYTCVAMSSLGVIEAVAQITVKSLPKAPGTPMVTENTATSITITWDSGNPDPVSYYVIEYKSKSQDGPYQIKEDITTTRYSIGGLSPNSEYEIWVSAVNSIGQGPPSESVVTRTGEQAPASAPRNVQARMLSATTMIVQWEEPVEPNGLIRGYRVYYTMEPEHPVGNWQKHNVDDSLLTTVGSLLEDETYTVRVLAFTSVGDGPLSDPIQVKTQQGVPGQPMNLRAEARSETSITLSWSPPRQESIIKYELLFREGDHGREVGRTFDPTTSYVVEDLKPNTEYAFRLAARSPQGLGAFTPVVRQRTLQSISPKNFKVKMIMKTSVLLSWEFPDNYNSPTPYKIQYNGLTLDVDGRTTKKLITHLKPHTFYNFVLTNRGSSLGGLQQTVTAWTAFNLLNGKPSVAPKPDADGFIMVYLPDGQSPVPVQSYFIVMVPLRKSRGGQFLTPLGSPEDMDLEELIQDISRLQRRSLRHSRQLEVPRPYIAARFSVLPPTFHPGDQKQYGGFDNRGLEPGHRYVLFVLAVLQKSEPTFAASPFSDPFQLDNPDPQPIVDGEEGLIWVIGPVLAVVFIICIVIAILLYKNKPDSKRKDSEPRTKCLLNNADLAPHHPKDPVEMRRINFQTPGMLSHPPIPIADMAEHTERLKANDSLKLSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVILQPIEGIMGSDYINANYVDGYRCQNAYIATQGPLPETFGDFWRMVWEQRSATIVMMTRLEEKSRIKCDQYWPNRGTETYGFIQVTLLDTIELATFCVRTFSLHKNGSSEKREVRQFQFTAWPDHGVPEYPTPFLAFLRRVKTCNPPDAGPIVVHCSAGVGRTGCFIVIDAMLERIKPEKTVDVYGHVTLMRSQRNYMVQTEDQYSFIHEALLEAVGCGNTEVPARSLYAYIQKLAQVEPGEHVTGMELEFKRLANSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWENNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDEYQFCYQAALEYLGSFDHYAT>sp|Q9BT73|PSMG3_HUMAN Proteasome assembly chaperone 3 OS=Homo sapiensOX=9606 GN=PSMG3 PE=1 SV=1MEDTPLVISKQKTEVVCGVPTQVVCTAFSSHILVVVTQFGKMGTLVSLEPSSVASDVSKPVLTTKVLLGQDEPLIHVFAKNLVAFVSQEAGNRAVLLAVAVKDKSMEGLKALREVIRVCQVW>sp|Q9UNM6|PSD13_HUMAN 26S proteasome non-ATPase regulatory subunit 13OS=Homo sapiens OX=9606 GN=PSMD13 PE=1 SV=2MKDVPGFLQQSQNSGPGQPAVWHRLEELYTKKLWHQLTLQVLDFVQDPCFAQGDGLIKLYENFISEFEHRVNPLSLVEIILHVVRQMTDPNVALTFLEKTREKVKSSDEAVILCKTAIGALKLNIGDLQVTKETIEDVEEMLNNLPGVTSVHSRFYDLSSKYYQTIGNHASYYKDALRFLGCVDIKDLPVSEQQERAFTLGLAGLLGEGVFNFGELLMHPVLESLRNTDRQWLIDTLYAFNSGNVERFQTLKTAWGQQPDLAANEAQLLRKIQLLCLMEMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDILT>sp|Q9UNM6-2|PSD13_HUMAN Isoform 2 of 26S proteasome non-ATPaseregulatory subunit 13 OS=Homo sapiens OX=9606 GN=PSMD13MKDVPGFLQQSQNSGPGQPAVWHRLEELYTKNFMKTLSVNLNTGKSLSSVFHFENECIDARRCSKAGGFYFRVNPLSLVEIILHVVRQMTDPNVALTFLEKTREKVKSSDEAVILCKTAIGALKLNIGDLQVTKETIEDVEEMLNNLPGVTSVHSRFYDLSSKYYQTIGNHASYYKDALRFLGCVDIKDLPVSEQQERAFTLGLAGLLGEGVFNFGELLMHPVLESLRNTDRQWLIDTLYAFNSGNVERFQTLKTAWGQQPDLAANEAQLLRKIQLLCLMEMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDILT>sp|O43653|PSCA_HUMAN Prostate stem cell antigen OS=Homo sapiens OX=9606GN=PSCA PE=1 SV=2MAGLALQPGTALLCYSCKAQVSNEDCLQVENCTQLGEQCWTARIRAVGLLTVISKGCSLNCVDDSQDYYVGKKNITCCDTDLCNASGAHALQPAAAILALLPALGLLLWGPGQL>sp|A6NKH3|RL37L_HUMAN Putative 60S ribosomal protein L37a-like proteinOS=Homo sapiens OX=9606 GN=RPL37AP8 PE=5 SV=2MAKCTKKVGGIVSKYRTHHGASLWKMVKEIEISQHTKYTCSFCGKTKMKRRAVKIRHCNSCMKTVAGSAWTYNTTSAVMVKSAIRRLKELKDQ>sp|Q02878|RL6_HUMAN 60S ribosomal protein L6 OS=Homo sapiens OX=9606GN=RPL6 PE=1 SV=3MAGEKVEKPDTKEKKPEAKKVDAGGKVKKGNLKAKKPKKGKPHCSRNPVLVRGIGRYSRSAMYSRKAMYKRKYSAAKSKVEKKKKEKVLATVTKPVGGDKNGGTRVVKLRKMPRYYPTEDVPRKLLSHGKKPFSQHVRKLRASITPGTILIILTGRHRGKRVVFLKQLASGLLLVTGPLVLNRVPLRRTHQKFVIATSTKIDISNVKIPKHLTDAYFKKKKLRKPRHQEGEIFDTEKEKYEITEQRKIDQKAVDSQILPKIKAIPQLQGYLRSVFALTNGIYPHKLVF>sp|O00337|S28A1_HUMAN Sodium/nucleoside cotransporter 1 OS=Homo sapiensOX=9606 GN=SLC28A1 PE=1 SV=2MENDPSRRRESISLTPVAKGLENMGADFLESLEEGQLPRSDLSPAEIRSSWSEAAPKPFSRWRNLQPALRARSFCREHMQLFRWIGTGLLCTGLSAFLLVACLLDFQRALALFVLTCVVLTFLGHRLLKRLLGPKLRRFLKPQGHPRLLLWFKRGLALAAFLGLVLWLSLDTSQRPEQLVSFAGICVFVALLFACSKHHCAVSWRAVSWGLGLQFVLGLLVIRTEPGFIAFEWLGEQIRIFLSYTKAGSSFVFGEALVKDVFAFQVLPIIVFFSCVISVLYHVGLMQWVILKIAWLMQVTMGTTATETLSVAGNIFVSQTEAPLLIRPYLADMTLSEVHVVMTGGYATIAGSLLGAYISFGIDATSLIAASVMAAPCALALSKLVYPEVEESKFRREEGVKLTYGDAQNLIEAASTGAAISVKVVANIAANLIAFLAVLDFINAALSWLGDMVDIQGLSFQLICSYILRPVAFLMGVAWEDCPVVAELLGIKLFLNEFVAYQDLSKYKQRRLAGAEEWVGDRKQWISVRAEVLTTFALCGFANFSSIGIMLGGLTSMVPQRKSDFSQIVLRALFTGACVSLVNACMAGILYMPRGAEVDCMSLLNTTLSSSSFEIYQCCREAFQSVNPEFSPEALDNCCRFYNHTICAQ>sp|O00337-2|S28A1_HUMAN Isoform 2 of Sodium/nucleoside cotransporter 1OS=Homo sapiens OX=9606 GN=SLC28A1MENDPSRRRESISLTPVAKGLENMGADFLESLEEGQLPRSDLSPAEIRSSWSEAAPKPFSRWRNLQPALRARSFCREHMQLFRWIGTGLLCTGLSAFLLVACLLDFQRALALFVLTCVVLTFLGHRLLKRLLGPKLRRFLKPQGHPRLLLWFKRDPRPWSKEGPNQYLPQITWTV>sp|P51991|ROA3_HUMAN Heterogeneous nuclear ribonucleoprotein A3 OS=Homosapiens OX=9606 GN=HNRNPA3 PE=1 SV=2MEVKPPPGRPQPDSGRRRRRRGEEGHDPKEPEQLRKLFIGGLSFETTDDSLREHFEKWGTLTDCVVMRDPQTKRSRGFGFVTYSCVEEVDAAMCARPHKVDGRVVEPKRAVSREDSVKPGAHLTVKKIFVGGIKEDTEEYNLRDYFEKYGKIETIEVMEDRQSGKKRGFAFVTFDDHDTVDKIVVQKYHTINGHNCEVKKALSKQEMQSAGSQRGRGGGSGNFMGRGGNFGGGGGNFGRGGNFGGRGGYGGGGGGSRGSYGGGDGGYNGFGGDGGNYGGGPGYSSRGGYGGGGPGYGNQGGGYGGGGGYDGYNEGGNFGGGNYGGGGNYNDFGNYSGQQQSNYGPMKGGSFGGRSSGSPYGGGYGSGGGSGGYGSRRF>sp|P51991-2|ROA3_HUMAN Isoform 2 of Heterogeneous nuclearribonucleoprotein A3 OS=Homo sapiens OX=9606 GN=HNRNPA3MEGHDPKEPEQLRKLFIGGLSFETTDDSLREHFEKWGTLTDCVVMRDPQTKRSRGFGFVTYSCVEEVDAAMCARPHKVDGRVVEPKRAVSREDSVKPGAHLTVKKIFVGGIKEDTEEYNLRDYFEKYGKIETIEVMEDRQSGKKRGFAFVTFDDHDTVDKIVVQKYHTINGHNCEVKKALSKQEMQSAGSQRGRGGGSGNFMGRGGNFGGGGGNFGRGGNFGGRGGYGGGGGGSRGSYGGGDGGYNGFGGDGGNYGGGPGYSSRGGYGGGGPGYGNQGGGYGGGGGYDGYNEGGNFGGGNYGGGGNYNDFGNYSGQQQSNYGPMKGGSFGGRSSGSPYGGGYGSGGGSGGYGSRRF>sp|Q13151|ROA0_HUMAN Heterogeneous nuclear ribonucleoprotein A0 OS=Homosapiens OX=9606 GN=HNRNPA0 PE=1 SV=1MENSQLCKLFIGGLNVQTSESGLRGHFEAFGTLTDCVVVVNPQTKRSRCFGFVTYSNVEEADAAMAASPHAVDGNTVELKRAVSREDSARPGAHAKVKKLFVGGLKGDVAEGDLIEHFSQFGTVEKAEIIADKQSGKKRGFGFVYFQNHDAADKAAVVKFHPIQGHRVEVKKAVPKEDIYSGGGGGGSRSSRGGRGGRGRGGGRDQNGLSKGGGGGYNSYGGYGGGGGGGYNAYGGGGGGSSYGGSDYGNGFGGFGSYSQHQSSYGPMKSGGGGGGGGSSWGGRSNSGPYRGGYGGGGGYGGSSF>sp|O94813|SLIT2_HUMAN Slit homolog 2 protein OS=Homo sapiens OX=9606GN=SLIT2 PE=1 SV=1MRGVGWQMLSLSLGLVLAILNKVAPQACPAQCSCSGSTVDCHGLALRSVPRNIPRNTERLDLNGNNITRITKTDFAGLRHLRVLQLMENKISTIERGAFQDLKELERLRLNRNHLQLFPELLFLGTAKLYRLDLSENQIQAIPRKAFRGAVDIKNLQLDYNQISCIEDGAFRALRDLEVLTLNNNNITRLSVASFNHMPKLRTFRLHSNNLYCDCHLAWLSDWLRQRPRVGLYTQCMGPSHLRGHNVAEVQKREFVCSGHQSFMAPSCSVLHCPAACTCSNNIVDCRGKGLTEIPTNLPETITEIRLEQNTIKVIPPGAFSPYKKLRRIDLSNNQISELAPDAFQGLRSLNSLVLYGNKITELPKSLFEGLFSLQLLLLNANKINCLRVDAFQDLHNLNLLSLYDNKLQTIAKGTFSPLRAIQTMHLAQNPFICDCHLKWLADYLHTNPIETSGARCTSPRRLANKRIGQIKSKKFRCSAKEQYFIPGTEDYRSKLSGDCFADLACPEKCRCEGTTVDCSNQKLNKIPEHIPQYTAELRLNNNEFTVLEATGIFKKLPQLRKINFSNNKITDIEEGAFEGASGVNEILLTSNRLENVQHKMFKGLESLKTLMLRSNRITCVGNDSFIGLSSVRLLSLYDNQITTVAPGAFDTLHSLSTLNLLANPFNCNCYLAWLGEWLRKKRIVTGNPRCQKPYFLKEIPIQDVAIQDFTCDDGNDDNSCSPLSRCPTECTCLDTVVRCSNKGLKVLPKGIPRDVTELYLDGNQFTLVPKELSNYKHLTLIDLSNNRISTLSNQSFSNMTQLLTLILSYNRLRCIPPRTFDGLKSLRLLSLHGNDISVVPEGAFNDLSALSHLAIGANPLYCDCNMQWLSDWVKSEYKEPGIARCAGPGEMADKLLLTTPSKKFTCQGPVDVNILAKCNPCLSNPCKNDGTCNSDPVDFYRCTCPYGFKGQDCDVPIHACISNPCKHGGTCHLKEGEEDGFWCICADGFEGENCEVNVDDCEDNDCENNSTCVDGINNYTCLCPPEYTGELCEEKLDFCAQDLNPCQHDSKCILTPKGFKCDCTPGYVGEHCDIDFDDCQDNKCKNGAHCTDAVNGYTCICPEGYSGLFCEFSPPMVLPRTSPCDNFDCQNGAQCIVRINEPICQCLPGYQGEKCEKLVSVNFINKESYLQIPSAKVRPQTNITLQIATDEDSGILLYKGDKDHIAVELYRGRVRASYDTGSHPASAIYSVETINDGNFHIVELLALDQSLSLSVDGGNPKIITNLSKQSTLNFDSPLYVGGMPGKSNVASLRQAPGQNGTSFHGCIRNLYINSELQDFQKVPMQTGILPGCEPCHKKVCAHGTCQPSSQAGFTCECQEGWMGPLCDQRTNDPCLGNKCVHGTCLPINAFSYSCKCLEGHGGVLCDEEEDLFNPCQAIKCKHGKCRLSGLGQPYCECSSGYTGDSCDREISCRGERIRDYYQKQQGYAACQTTKKVSRLECRGGCAGGQCCGPLRSKRRKYSFECTDGSSFVDEVEKVVKCGCTRCVS>sp|O94813-2|SLIT2_HUMAN Isoform 2 of Slit homolog 2 protein OS=Homosapiens OX=9606 GN=SLIT2MRGVGWQMLSLSLGLVLAILNKVAPQACPAQCSCSGSTVDCHGLALRSVPRNIPRNTERLDLNGNNITRITKTDFAGLRHLRVLQLMENKISTIERGAFQDLKELERLRLNRNHLQLFPELLFLGTAKLYRLDLSENQIQAIPRKAFRGAVDIKNLQLDYNQISCIEDGAFRALRDLEVLTLNNNNITRLSVASFNHMPKLRTFRLHSNNLYCDCHLAWLSDWLRQRPRVGLYTQCMGPSHLRGHNVAEVQKREFVCSDEEEGHQSFMAPSCSVLHCPAACTCSNNIVDCRGKGLTEIPTNLPETITEIRLEQNTIKVIPPGAFSPYKKLRRIDLSNNQISELAPDAFQGLRSLNSLVLYGNKITELPKSLFEGLFSLQLLLLNANKINCLRVDAFQDLHNLNLLSLYDNKLQTIAKGTFSPLRAIQTMHLAQNPFICDCHLKWLADYLHTNPIETSGARCTSPRRLANKRIGQIKSKKFRCSGTEDYRSKLSGDCFADLACPEKCRCEGTTVDCSNQKLNKIPEHIPQYTAELRLNNNEFTVLEATGIFKKLPQLRKINFSNNKITDIEEGAFEGASGVNEILLTSNRLENVQHKMFKGLESLKTLMLRSNRITCVGNDSFIGLSSVRLLSLYDNQITTVAPGAFDTLHSLSTLNLLANPFNCNCYLAWLGEWLRKKRIVTGNPRCQKPYFLKEIPIQDVAIQDFTCDDGNDDNSCSPLSRCPTECTCLDTVVRCSNKGLKVLPKGIPRDVTELYLDGNQFTLVPKELSNYKHLTLIDLSNNRISTLSNQSFSNMTQLLTLILSYNRLRCIPPRTFDGLKSLRLLSLHGNDISVVPEGAFNDLSALSHLAIGANPLYCDCNMQWLSDWVKSEYKEPGIARCAGPGEMADKLLLTTPSKKFTCQGPVDVNILAKCNPCLSNPCKNDGTCNSDPVDFYRCTCPYGFKGQDCDVPIHACISNPCKHGGTCHLKEGEEDGFWCICADGFEGENCEVNVDDCEDNDCENNSTCVDGINNYTCLCPPEYTGELCEEKLDFCAQDLNPCQHDSKCILTPKGFKCDCTPGYVGEHCDIDFDDCQDNKCKNGAHCTDAVNGYTCICPEGYSGLFCEFSPPMVLPRTSPCDNFDCQNGAQCIVRINEPICQCLPGYQGEKCEKLVSVNFINKESYLQIPSAKVRPQTNITLQIATDEDSGILLYKGDKDHIAVELYRGRVRASYDTGSHPASAIYSVETINDGNFHIVELLALDQSLSLSVDGGNPKIITNLSKQSTLNFDSPLYVGGMPGKSNVASLRQAPGQNGTSFHGCIRNLYINSELQDFQKVPMQTGILPGCEPCHKKVCAHGTCQPSSQAGFTCECQEGWMGPLCDQRTNDPCLGNKCVHGTCLPINAFSYSCKCLEGHGGVLCDEEEDLFNPCQAIKCKHGKCRLSGLGQPYCECSSGYTGDSCDREISCRGERIRDYYQKQQGYAACQTTKKVSRLECRGGCAGGQCCGPLRSKRRKYSFECTDGSSFVDEVEKVVKCGCTRCVS>sp|O94813-3|SLIT2_HUMAN Isoform 3 of Slit homolog 2 protein OS=Homosapiens OX=9606 GN=SLIT2MRGVGWQMLSLSLGLVLAILNKVAPQACPAQCSCSGSTVDCHGLALRSVPRNIPRNTERLDLNGNNITRITKTDFAGLRHLRVLQLMENKISTIERGAFQDLKELERLRLNRNHLQLFPELLFLGTAKLYRLDLSENQIQAIPRKAFRGAVDIKNLQLDYNQISCIEDGAFRALRDLEVLTLNNNNITRLSVASFNHMPKLRTFRLHSNNLYCDCHLAWLSDWLRQRPRVGLYTQCMGPSHLRGHNVAEVQKREFVCSGHQSFMAPSCSVLHCPAACTCSNNIVDCRGKGLTEIPTNLPETITEIRLEQNTIKVIPPGAFSPYKKLRRIDLSNNQISELAPDAFQGLRSLNSLVLYGNKITELPKSLFEGLFSLQLLLLNANKINCLRVDAFQDLHNLNLLSLYDNKLQTIAKGTFSPLRAIQTMHLAQNPFICDCHLKWLADYLHTNPIETSGARCTSPRRLANKRIGQIKSKKFRCSGTEDYRSKLSGDCFADLACPEKCRCEGTTVDCSNQKLNKIPEHIPQYTAELRLNNNEFTVLEATGIFKKLPQLRKINFSNNKITDIEEGAFEGASGVNEILLTSNRLENVQHKMFKGLESLKTLMLRSNRITCVGNDSFIGLSSVRLLSLYDNQITTVAPGAFDTLHSLSTLNLLANPFNCNCYLAWLGEWLRKKRIVTGNPRCQKPYFLKEIPIQDVAIQDFTCDDGNDDNSCSPLSRCPTECTCLDTVVRCSNKGLKVLPKGIPRDVTELYLDGNQFTLVPKELSNYKHLTLIDLSNNRISTLSNQSFSNMTQLLTLILSYNRLRCIPPRTFDGLKSLRLLSLHGNDISVVPEGAFNDLSALSHLAIGANPLYCDCNMQWLSDWVKSEYKEPGIARCAGPGEMADKLLLTTPSKKFTCQGPVDVNILAKCNPCLSNPCKNDGTCNSDPVDFYRCTCPYGFKGQDCDVPIHACISNPCKHGGTCHLKEGEEDGFWCICADGFEGENCEVNVDDCEDNDCENNSTCVDGINNYTCLCPPEYTGELCEEKLDFCAQDLNPCQHDSKCILTPKGFKCDCTPGYVGEHCDIDFDDCQDNKCKNGAHCTDAVNGYTCICPEGYSGLFCEFSPPMVLPRTSPCDNFDCQNGAQCIVRINEPICQCLPGYQGEKCEKLVSVNFINKESYLQIPSAKVRPQTNITLQIATDEDSGILLYKGDKDHIAVELYRGRVRASYDTGSHPASAIYSVETINDGNFHIVELLALDQSLSLSVDGGNPKIITNLSKQSTLNFDSPLYVGGMPGKSNVASLRQAPGQNGTSFHGCIRNLYINSELQDFQKVPMQTGILPGCEPCHKKVCAHGTCQPSSQAGFTCECQEGWMGPLCDQRTNDPCLGNKCVHGTCLPINAFSYSCKCLEGHGGVLCDEEEDLFNPCQAIKCKHGKCRLSGLGQPYCECSSGYTGDSCDREISCRGERIRDYYQKQQGYAACQTTKKVSRLECRGGCAGGQCCGPLRSKRRKYSFECTDGSSFVDEVEKVVKCGCTRCVS>sp|Q96M53|TBATA_HUMAN Protein TBATA OS=Homo sapiens OX=9606 GN=TBATAPE=1 SV=3MATDVQLADYPLMSPKAELKLEKKSGRKPRSPRDSGPQKELVIPGIVDFERIRRALRTPKPQTPGTYCFGRLSHHSFFSRHHPHPQHVTHIQDLTGKPVCVVRDFPAPLPESTVFSGCQMGIPTISVPIGDPQSNRNPQLSSEAWKKELKELASRVAFLTKEDELKKKEKEQKEEPLREQGAKYSAETGRLIPASTRAVGRRRSHQGQQSQSSSRHEGVQAFLLQDQELLVLELLCRILETDLLSAIQFWLLYAPPKEKDLALGLLQTAVAQLLPQPLVSIPTEKLLSQLPEVHEPPQEKQEPPCSQSPKKTKISPFTKSEKPEYIGEAQVLQMHSSQNTEKKTSKPRAES>sp|Q96M53-2|TBATA_HUMAN Isoform 2 of Protein TBATA OS=Homo sapiensOX=9606 GN=TBATAMATDVQLADYPLMSPKAELKLEKKSGRKPRSPRDSGPQKELVIPGIVDFERIRRALRTPKPQTPGTYCFGRLSHHSFFSRHHPHPQHVTHIQDLTGKPVCVVRDFPAPLPESTVFSGCQMGIPTISVPIGDPQSNRNPQLSSEAWKKELKELASRVAFLTKEDELKKKEKEQKEEPLREQGAKYSAETGRLIPASTRAVGRRRSHQGQQSQSSSRHEGVQAFLLQDQELLKKTSLWDSCRQQWLSSFPSP>sp|Q9NX00|TM160_HUMAN Transmembrane protein 160 OS=Homo sapiens OX=9606GN=TMEM160 PE=1 SV=1MGGGWWWARAARLARLRFRRSLLPPQRPRSGGARGSFAPGHGPRAGASPPPVSELDRADAWLLRKAHETAFLSWFRNGLLASGIGVISFMQSDMGREAAYGFFLLGGLCVVWGSASYAVGLAALRGPMQLTLGGAAVGAGAVLAASLLWACAVGLYMGQLELDVELVPEDDGTASAEGPDEAGRPPPE>sp|P06753|TPM3_HUMAN Tropomyosin alpha-3 chain OS=Homo sapiens OX=9606GN=TPM3 PE=1 SV=2MMEAIKKKMQMLKLDKENALDRAEQAEAEQKQAEERSKQLEDELAAMQKKLKGTEDELDKYSEALKDAQEKLELAEKKAADAEAEVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRALKDEEKMELQEIQLKEAKHIAEEADRKYEEVARKLVIIEGDLERTEERAELAESKCSELEEELKNVTNNLKSLEAQAEKYSQKEDKYEEEIKILTDKLKEAETRAEFAERSVAKLEKTIDDLEDELYAQKLKYKAISEELDHALNDMTSI>sp|P06753-2|TPM3_HUMAN Isoform 2 of Tropomyosin alpha-3 chain OS=Homosapiens OX=9606 GN=TPM3MAGITTIEAVKRKIQVLQQQADDAEERAERLQREVEGERRAREQAEAEVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRALKDEEKMELQEIQLKEAKHIAEEADRKYEEVARKLVIIEGDLERTEERAELAESRCREMDEQIRLMDQNLKCLSAAEEKYSQKEDKYEEEIKILTDKLKEAETRAEFAERSVAKLEKTIDDLEDKLKCTKEEHLCTQRMLDQTLLDLNEM>sp|P06753-3|TPM3_HUMAN Isoform 3 of Tropomyosin alpha-3 chain OS=Homosapiens OX=9606 GN=TPM3MAGITTIEAVKRKIQVLQQQADDAEERAERLQREVEGERRAREQAEAEVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRALKDEEKMELQEIQLKEAKHIAEEADRKYEEVARKLVIIEGDLERTEERAELAESRCREMDEQIRLMDQNLKCLSAAEEKYSQKEDKYEEEIKILTDKLKEAETRAEFAERSVAKLEKTIDDLEERLYSQLERNRLLSNELKLTLHDLCD>sp|P06753-4|TPM3_HUMAN Isoform 4 of Tropomyosin alpha-3 chain OS=Homosapiens OX=9606 GN=TPM3MAGITTIEAVKRKIQVLQQQADDAEERAERLQREVEGERRAREQAEAEVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRALKDEEKMELQEIQLKEAKHIAEEADRKYEEVARKLVIIEGDLERTEERAELAESKCSELEEELKNVTNNLKSLEAQAEKYSQKEDKYEEEIKILTDKLKEAETRAEFAERSVAKLEKTIDDLEERLYSQLERNRLLSNELKLTLHDLCD>sp|P06753-5|TPM3_HUMAN Isoform 5 of Tropomyosin alpha-3 chain OS=Homosapiens OX=9606 GN=TPM3MAGITTIEAVKRKIQVLQQQADDAEERAERLQREVEGERRAREQAEAEVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRALKDEEKMELQEIQLKEAKHIAEEADRKYEEVARKLVIIEGDLERTEERAELAESKCSELEEELKNVTNNLKSLEAQAEKYSQKEDKYEEEIKILTDKLKEAETRAEFAERSVAKLEKTIDDLEDKLKCTKEEHLCTQRMLDQTLLDLNEM>sp|P06753-6|TPM3_HUMAN Isoform 6 of Tropomyosin alpha-3 chain OS=Homosapiens OX=9606 GN=TPM3MAGITTIEAVKRKIQVLQQQADDAEERAERLQREVEGERRAREQAEAEVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRALKDEEKMELQEIQLKEAKHIAEEADRKYEEVARKLVIIEGDLERTEERAELAESRCREMDEQIRLMDQNLKCLSAAEEKYSQKEDKYEEEIKILTDKLKEAETRAEFAERSVAKLEKTIDDLEDELYAQKLKYKAISEELDHALNDMTSI>sp|P06753-7|TPM3_HUMAN Isoform 7 of Tropomyosin alpha-3 chain OS=Homosapiens OX=9606 GN=TPM3MKVIENRALKDEEKMELQEIQLKEAKHIAEEADRKYEEVARKLVIIEGDLERTEERAELAESKCSELEEELKNVTNNLKSLEAQAEKYSQKEDKYEEEIKILTDKLKEAETRAEFAERSVAKLEKTIDDLEDKLKCTKEEHLCTQRMLDQTLLDLNEM>sp|Q6UXN7|TO20L_HUMAN TOMM20-like protein 1 OS=Homo sapiens OX=9606GN=TOMM20L PE=1 SV=1MPSVRSLLRLLAAAAACGAFAFLGYCIYLNRKRRGDPAFKRRLRDKRRAEPQKAEEQGTQLWDPTKNKKLQELFLQEVRMGELWLSRGEHRMGIQHLGNALLVCEQPRELLKVFKHTLPPKVFEMLLHKIPLICQQFEADMNEQDCLEDDPD>sp|O14717|TRDMT_HUMAN tRNA (cytosine(38)-C(5))-methyltransferase OS=Homosapiens OX=9606 GN=TRDMT1 PE=1 SV=1MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRIGRQGDMTDSRTNSFLHILDILPRLQKLPKYILLENVKGFEVSSTRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFGFPEKITVKQRYRLLGNSLNVHVVAKLIKILYE>sp|O14717-2|TRDMT_HUMAN Isoform B of tRNA (cytosine(38)-C(5))-methyltransferase OS=Homo sapiens OX=9606 GN=TRDMT1MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRLQKLPKYILLENVKGFEVSSTRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFGFPEKITVKQRYRLLGNSLNVHVVAKLIKILYE>sp|O14717-3|TRDMT_HUMAN Isoform C of tRNA (cytosine(38)-C(5))-methyltransferase OS=Homo sapiens OX=9606 GN=TRDMT1MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFGFPEKITVKQRYRLLGNSLNVHVVAKLIKILYE>sp|O14717-4|TRDMT_HUMAN Isoform D of tRNA (cytosine(38)-C(5))-methyltransferase OS=Homo sapiens OX=9606 GN=TRDMT1MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEDWPAG>sp|O14717-5|TRDMT_HUMAN Isoform E of tRNA (cytosine(38)-C(5))-methyltransferase OS=Homo sapiens OX=9606 GN=TRDMT1MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEITKITKVYSFGKC>sp|O14717-6|TRDMT_HUMAN Isoform F of tRNA (cytosine(38)-C(5))-methyltransferase OS=Homo sapiens OX=9606 GN=TRDMT1MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIERPLDTNNRKLWLSVPRVYIISNLSWHSKFKATIFSYCKASVRAITLSSP>sp|O75204|TM127_HUMAN Transmembrane protein 127 OS=Homo sapiens OX=9606GN=TMEM127 PE=1 SV=1MYAPGGAGLPGGRRRRSPGGSALPKQPERSLASALPGALSITALCTALAEPAWLHIHGGTCSRQELGVSDVLGYVHPDLLKDFCMNPQTVLLLRVIAAFCFLGILCSLSAFLLDVFGPKHPALKITRRYAFAHILTVLQCATVIGFSYWASELILAQQQQHKKYHGSQVYVTFAVSFYLVAGAGGASILATAANLLRHYPTEEEEQALELLSEMEENEPYPAEYEVINQFQPPPAYTP>sp|Q8IY95|TM192_HUMAN Transmembrane protein 192 OS=Homo sapiens OX=9606GN=TMEM192 PE=1 SV=1MAAGGRMEDGSLDITQSIEDDPLLDAQLLPHHSLQAHFRPRFHPLPTVIIVNLLWFIHLVFVVLAFLTGVLCSYPNPNEDKCPGNYTNPLKVQTVIILGKVILWILHLLLECYIQYHHSKIRNRGYNLIYRSTRHLKRLALMIQSSGNTVLLLILCMQHSFPEPGRLYLDLILAILALELICSLICLLIYTVKIRRFNKAKPEPDILEEEKIYAYPSNITSETGFRTISSLEEIVEKQGDTIEYLKRHNALLSKRLLALTSSDLGCQPSRT>sp|Q8IY95-2|TM192_HUMAN Isoform 2 of Transmembrane protein 192 OS=Homosapiens OX=9606 GN=TMEM192MNKATGSLDITQSIEDDPLLDAQLLPHHSLQAHFRPRFHPLPTVIIVNLLWFIHLVFVVLAFLTGVLCSYPNPNEDKCPGNYTNPLKVQTVIILGKVILWILHLLLECYIQYHHSKIRNRGYNLIYRSTRHLKRLALMIQSSGNTVLLLILCMQHSFPEPGRLYLDLILAILALELICSLICLLIYTVKIRRFNKAKPEPDILEEEKIYAYPSNITSETGFRTISSLEEIVEKQGDTIEYLKRHNALLSKRLLALTSSDLGCQPSRT>sp|P58753|TIRAP_HUMAN Toll/interleukin-1 receptor domain-containingadapter protein OS=Homo sapiens OX=9606 GN=TIRAP PE=1 SV=2MASSTSLPAPGSRPKKPLGKMADWFRQTLLKKPKKRPNSPESTSSDASQPTSQDSPLPPSLSSVTSPSLPPTHASDSGSSRWSKDYDVCVCHSEEDLVAAQDLVSYLEGSTASLRCFLQLRDATPGGAIVSELCQALSSSHCRVLLITPGFLQDPWCKYQMLQALTEAPGAEGCTIPLLSGLSRAAYPPELRFMYYVDGRGPDGGFRQVKEAVMRYLQTLS>sp|P58753-2|TIRAP_HUMAN Isoform 2 of Toll/interleukin-1 receptor domain-containing adapter protein OS=Homo sapiens OX=9606 GN=TIRAPMASSTSLPAPGSRPKKPLGKMADWFRQTLLKKPKKRPNSPESTSSDASQPTSQDSPLPPSLSSVTSPSLPPTHASDSGSSRWSKDYDVCVCHSEEDLVAAQDLVSYLEGSTASLRCFLQLRDATPGGAIVSELCQALSSSHCRVLLITPGFLQDPWCKYQMLQALTEAPGAEGCTIPLLSGLSRAAYPPELRFMYYVDGRGPDGGFRQVKEAVMRCKLLQEGEGERDSATVSDLL>sp|P58753-3|TIRAP_HUMAN Isoform 3 of Toll/interleukin-1 receptor domain-containing adapter protein OS=Homo sapiens OX=9606 GN=TIRAPMASSTSLPAPGSRPKKPLGKMADWFRQTLLKKPKKRPNSPESTSSDASQPTSQDSPLPPSLSSVTSPSLPPTHASDSGSSRWSKDYDVCVCHSEEDLVAAQDLVSYLEGSTASLRCFLQLRDATPGGAIVSELCQALSSSHCRVLLITPGFLQDPWCKYQMLQALTEAPGAEGCTIPLLSGLSRAAYPPELRFMYYVDGRGPDGGFRQVKEAVMRYLQTLWHLLYHGTPEIGVKLETENPCRASDSHKCDKRYRE>sp|Q7Z4K8|TRI46_HUMAN Tripartite motif-containing protein 46 OS=Homosapiens OX=9606 GN=TRIM46 PE=2 SV=2MAEGEDMQTFTSIMDALVRISTSMKNMEKELLCPVCQEMYKQPLVLPCTHNVCQACAREVLGQQGYIGHGGDPSSEPTSPASTPSTRSPRLSRRTLPKPDRLDRLLKSGFGTYPGRKRGALHPQVIMFPCPACQGDVELGERGLAGLFRNLTLERVVERYRQSVSVGGAILCQLCKPPPLEATKGCTECRATFCNECFKLFHPWGTQKAQHEPTLPTLSFRPKGLMCPDHKEEVTHYCKTCQRLVCQLCRVRRTHSGHKITPVLSAYQALKDKLTKSLTYILGNQDTVQTQICELEEAVRHTEVSGQQAKEEVSQLVRGLGAVLEEKRASLLQAIEECQQERLARLSAQIQEHRSLLDGSGLVGYAQEVLKETDQPCFVQAAKQLHNRIARATEALQTFRPAASSSFRHCQLDVGREMKLLTELNFLRVPEAPVIDTQRTFAYDQIFLCWRLPPHSPPAWHYTVEFRRTDVPAQPGPTRWQRREEVRGTSALLENPDTGSVYVLRVRGCNKAGYGEYSEDVHLHTPPAPVLHFFLDSRWGASRERLAISKDQRAVRSVPGLPLLLAADRLLTGCHLSVDVVLGDVAVTQGRSYWACAVDPASYLVKVGVGLESKLQESFQGAPDVISPRYDPDSGHDSGAEDATVEASPPFAFLTIGMGKILLGSGASSNAGLTGRDGPTAGCTVPLPPRLGICLDYERGRVSFLDAVSFRGLLECPLDCSGPVCPAFCFIGGGAVQLQEPVGTKPERKVTIGGFAKLD>sp|Q7Z4K8-2|TRI46_HUMAN Isoform 2 of Tripartite motif-containing protein46 OS=Homo sapiens OX=9606 GN=TRIM46MAEGEDMQTFTSIMDALVRISTSMKNMEKELLCPVCQEMYKQPLVLPCTHNVCQACAREVLGQQGYIGHGGDPSSEPTSPASTPSTRSPRLSRRTLPKPDRLDRLLKSGFGTYPGRKRGALHPQVIMFPCPACQGDVELGERGLAGLFRNLTLERVVERYRQSVSVGGAILCQLCKPPPLEATKGCTECRATFCNECFKLFHPWGTQKAQHEPTLPTLSFRPKGLMCPDHKEEVTHYCKTCQRLVCQLCRVRRTHSGHKITPVLSAYQALKDKLTKSLTYILGNQDTVQTQICELEEAVRHTEVSGQQAKEEVSQLVRGLGAVLEEKRASLLQAIEECQQERLARLSAQIQEHRSLLDGSGLVGYAQEVLKETDQPCFVQAAKQLHNRIARATEALQTFRPAASSSFRHCQLDVGREMKLLTELNFLRVPEAPVIDTQRTFAYDQIFLCWRLPPHSPPAWHYTVEFRRTDVPAQPGPTRWQRREEVRGTSALLENPDTGSVYVLRVRGCNKAGYGEYSEDVHLHTPPAPGIQNLARRGGACLQFQLLGRLR>sp|Q7Z4K8-3|TRI46_HUMAN Isoform 3 of Tripartite motif-containing protein46 OS=Homo sapiens OX=9606 GN=TRIM46MERAGWSANLAWLSGGITLCSGEREARDRGLGRSVNQPKAGALEKLQTSMKNMEKELLCPVCQEMYKQPLVLPCTHNVCQACAREVLGQQGYIGHGGDPSSEPTSPASTPSTRSPRLSRRTLPKPDRLDRLLKSGFGTYPGRKRGALHPQVIMFPCPACQGDVELGERGLAGLFRNLTLERVVERYRQSVSVGGAILCQLCKPPPLEATKGCTECRATFCNECFKLFHPWGTQKAQHEPTLPTLSFRPKGLMCPDHKEEVTHYCKTCQRLVCQLCRVRRTHSGHKITPVLSAYQALKDKLTKSLTYILGNQDTVQTQICELEEAVRHTEVSGQQAKEEVSQLVRGLGAVLEEKRASLLQAIEECQQERLARLSAQIQEHRSLLDGSGLVGYAQEVLKETDQPCFVQAAKQLHNRIARATEALQTFRPAASSSFRHCQLDVGREMKLLTELNFLRGCGHRGLCSGAPQCLRPPSLTPSAPLPMIRSSCAGGCPPIHHLPGTIPLSSGARMCLLSQAPPAGSGGRR>sp|Q7Z4K8-4|TRI46_HUMAN Isoform 4 of Tripartite motif-containing protein46 OS=Homo sapiens OX=9606 GN=TRIM46MAEGEDMQTFTSIMDALVRISTSMKNMEKELLCPVCQEMYKQPLVLPCTHNVCQACAREVLGQQGYIGHGGDPSSEPTSPASTPSTRSPRLSRRTLPKPDRLDRLLKSGFGTYPGRKRGALHPQVIMFPCPACQGDVELGERGLAGLFRNLTLERVVERYRQSVSVGGAILCQLCKPPPLEATKGCTECRATFCNECFKLFHPWGTQKAQHEPTLPTLSFRPKGLMCPDHKEEVTHYCKTCQRLVCQLCRVRRTHSGHKITPVLSAYQALKDKLTKSLTYILGNQDTVQTQICELEEAVRHTEVSGQQAKEEVSQLVRGLGAVLEEKRASLLQAIEECQQERLARLSAQIQEHRSLLDGSGLVGYAQEVLKETDQPCFVQAAKQLHNRIARATEALQTFRPAASSSFRHCQLDVGREMKLLTELNFLRGCGHRGLCSGAPQCLRPPSLTPSAPLPMIRSSCAGGCPPIHHLPGTIPLSSGARMCLLSQAPPAGSGGRR>sp|Q7Z4K8-5|TRI46_HUMAN Isoform 5 of Tripartite motif-containing protein46 OS=Homo sapiens OX=9606 GN=TRIM46MKNMEKELLCPVCQEMYKQPLVLPCTHNVCQACAREVLGQQGYIGHGGDPSSEPTSPASTPSTRSPRLSRRTLPKPDRLDRLLKSGFGTYPGRKRGALHPQVIMFPCPACQGDVELGERGLAGLFRNLTLERVVERYRQSVSVGGAILCQLCKPPPLEATKGCTECRATFCNECFKLFHPWGTQKAQHEPTLPTLSFRPKGLMCPDHKEEVTHYCKTCQRLVCQLCRVRRTHSGHKITPVLSAYQALKDKLTKSLTYILGNQDTVQTQICELEEAVRHTEVSGQQAKEEVSQLVRGLGAVLEEKRASLLQAIEECQQERLARLSAQIQEHRSLLDGSGLVGYAQEVLKETDQPCFVQAAKQLHNRIARATEALQTFRPAASSSFRHCQLDVGREMKLLTELNFLRVPEAPVIDTQRTFAYDQIFLCWRLPPHSPPAWHYTVEFRRTDVPAQPGPTRWQRREEVRGTSALLENPDTGSVYVLRVRGCNKAGYGEYSEDVHLHTPPAPVLHFFLDSRWGASRERLAISKDQRAVRSVPGLPLLLAADRLLTGCHLSVDVVLGDVAVTQGRSYWACAVDPASYLVKVGVGLESKLQESFQGAPDVISPRYDPDSGHDSGAEDATVEASPPFAFLTIGMGKILLGSGASSNAGLTGRDGPTAGCTVPLPPRLGICLDYERGRVSFLDAVSFRGLLECPLDCSGPVCPAFCFIGGGAVQLQEPVGTKPERKVTIGGFAKLD>sp|Q9BZR9|TRIM8_HUMAN E3 ubiquitin-protein ligase TRIM8 OS=Homo sapiensOX=9606 GN=TRIM8 PE=1 SV=2MAENWKNCFEEELICPICLHVFVEPVQLPCKHNFCRGCIGEAWAKDSGLVRCPECNQAYNQKPGLEKNLKLTNIVEKFNALHVEKPPAALHCVFCRRGPPLPAQKVCLRCEAPCCQSHVQTHLQQPSTARGHLLVEADDVRAWSCPQHNAYRLYHCEAEQVAVCQYCCYYSGAHQGHSVCDVEIRRNEIRKMLMKQQDRLEEREQDIEDQLYKLESDKRLVEEKVNQLKEEVRLQYEKLHQLLDEDLRQTVEVLDKAQAKFCSENAAQALHLGERMQEAKKLLGSLQLLFDKTEDVSFMKNTKSVKILMDRTQTCTSSSLSPTKIGHLNSKLFLNEVAKKEKQLRKMLEGPFSTPVPFLQSVPLYPCGVSSSGAEKRKHSTAFPEASFLETSSGPVGGQYGAAGTASGEGQSGQPLGPCSSTQHLVALPGGAQPVHSSPVFPPSQYPNGSAAQQPMLPQYGGRKILVCSVDNCYCSSVANHGGHQPYPRSGHFPWTVPSQEYSHPLPPTPSVPQSLPSLAVRDWLDASQQPGHQDFYRVYGQPSTKHYVTS>sp|Q86WT6|TRI69_HUMAN E3 ubiquitin-protein ligase TRIM69 OS=Homo sapiensOX=9606 GN=TRIM69 PE=1 SV=2MEVSTNPSSNIDPGDYVEMNDSITHLPSKVVIQDITMELHCPLCNDWFRDPLMLSCGHNFCEACIQDFWRLQAKETFCPECKMLCQYNNCTFNPVLDKLVEKIKKLPLLKGHPQCPEHGENLKLFSKPDGKLICFQCKDARLSVGQSKEFLQISDAVHFFTEELAIQQGQLETTLKELQTLRNMQKEAIAAHKENKLHLQQHVSMEFLKLHQFLHSKEKDILTELREEGKALNEEMELNLSQLQEQCLLAKDMLVSIQAKTEQQNSFDFLKDITTLLHSLEQGMKVLATRELISRKLNLGQYKGPIQYMVWREMQDTLCPGLSPLTLDPKTAHPNLVLSKSQTSVWHGDIKKIMPDDPERFDSSVAVLGSRGFTSGKWYWEVEVAKKTKWTVGVVRESIIRKGSCPLTPEQGFWLLRLRNQTDLKALDLPSFSLTLTNNLDKVGIYLDYEGGQLSFYNAKTMTHIYTFSNTFMEKLYPYFCPCLNDGGENKEPLHILHPQ>sp|Q86WT6-2|TRI69_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM69OS=Homo sapiens OX=9606 GN=TRIM69MEEELAIQQGQLETTLKELQTLRNMQKEAIAAHKENKLHLQQHVSMEFLKLHQFLHSKEKDILTELREEGKALNEEMELNLSQLQEQCLLAKDMLVSIQAKTEQQNSFDFLKDITTLLHSLEQGMKVLATRELISRKLNLGQYKGPIQYMVWREMQDTLCPGLSPLTLDPKTAHPNLVLSKSQTSVWHGDIKKIMPDDPERFDSSVAVLGSRGFTSGKWYWEVEVAKKTKWTVGVVRESIIRKGSCPLTPEQGFWLLRLRNQTDLKALDLPSFSLTLTNNLDKVGIYLDYEGGQLSFYNAKTMTHIYTFSNTFMEKLYPYFCPCLNDGGENKEPLHILHPQ>sp|Q86WT6-3|TRI69_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM69OS=Homo sapiens OX=9606 GN=TRIM69MEFLKLHQFLHSKEKDILTELREEGKALNEEMELNLSQLQEQCLLAKDMLVSIQAKTEQQNSFDFLKDITTLLHSLEQGMKVLATRELISRKLNLGQYKGPIQYMVWREMQDTLCPGLSPLTLDPKTAHPNLVLSKSQTSVWHGDIKKIMPDDPERFDSSVAVLGSRGFTSGKWYWEVEVAKKTKWTVGVVRESIIRKGSCPLTPEQGFWLLRLRNQTDLKALDLPSFSLTLTNNLDKVGIYLDYEGGQLSFYNAKTMTHIYTFSNTFMEKLYPYFCPCLNDGGENKEPLHILHPQ>sp|Q86WT6-4|TRI69_HUMAN Isoform 4 of E3 ubiquitin-protein ligase TRIM69OS=Homo sapiens OX=9606 GN=TRIM69MEFLKLHQFLHSKEKDILTELREEGKALNEEMELNLSQLQEQCLLAKDMLDITTLLHSLEQGMKVLATRELISRKLNLGQYKGPIQYMVWREMQDTLCPGLSPLTLDPKTAHPNLVLSKSQTSVWHGDIKKIMPDDPERFDSSVAVLGSRGFTSGKWYWEVEVAKKTKWTVGVVRESIIRKGSCPLTPEQGFWLLRLRNQTDLKALDLPSFSLTLTNNLDKVGIYLDYEGGQLSFYNAKTMTHIYTFSNTFMEKLYPYFCPCLNDGGENKEPLHILHPQ>sp|A0A075B6R0|TRGV2_HUMAN T cell receptor gamma variable 2 OS=Homosapiens OX=9606 GN=TRGV2 PE=1 SV=1MQWALAVLLAFLSPASQKSSNLEGRTKSVIRQTGSSAEITCDLAEGSNGYIHWYLHQEGKAPQRLQYYDSYNSKVVLESGVSPGKYYTYASTRNNLRLILRNLIENDFGVYYCATWDG>sp|Q86TN4|TRPT1_HUMAN tRNA 2'-phosphotransferase 1 OS=Homo sapiensOX=9606 GN=TRPT1 PE=1 SV=2MNFSGGGRQEAAGSRGRRAPRPREQDRDVQLSKALSYALRHGALKLGLPMGADGFVPLGTLLQLPQFRGFSAEDVQRVVDTNRKQRFALQLGDPSTGLLIRANQGHSLQVPKLELMPLETPQALPPMLVHGTFWKHWPSILLKGLSCQGRTHIHLAPGLPGDPGIISGMRSHCEIAVFIDGPLALADGIPFFRSANGVILTPGNTDGFLLPKYFKEALQLRPTRKPLSLAGDEETECQSSPKHSSRERRRIQQ>sp|Q86TN4-2|TRPT1_HUMAN Isoform 2 of tRNA 2'-phosphotransferase 1OS=Homo sapiens OX=9606 GN=TRPT1MGADGFVPLGTLLQLPQFRGFSAEDVQRVVDTNRKQRFALQLGDPSTGLLIRANQGHSLQVPKLELMPLETPQALPPMLVHGTFWKHWPSILLKGLSCQGRTHIHLAPGLPGDPGIISGMRSHCEIAVFIDGPLALADGIPFFRSANGVILTPGNTDGFLLPKYFKEALQLRPTRKPLSLAGDEETECQSSPKHSSRERRRIQQ>sp|Q86TN4-3|TRPT1_HUMAN Isoform 3 of tRNA 2'-phosphotransferase 1OS=Homo sapiens OX=9606 GN=TRPT1MNFSGGGRQEAAGSRGRRAPRPREQDRDVQLSKALSYALRHGALKLGLPMGADGFVPLGTLLQLPQFRGFSAEDVQRVVDTNRKQRFALQLGDPSTGLLIRANQGHSLQVPKLELMPLETPQALPPMLVHGTFWKHWPSILLKGLSCQGRTHIHLAPGLPGDPGIISGMRSHCEIAVFIDGPLALAGKPLSLAGDEETECQSSPKHSSRERRRIQQ>sp|Q86TN4-4|TRPT1_HUMAN Isoform 4 of tRNA 2'-phosphotransferase 1OS=Homo sapiens OX=9606 GN=TRPT1MNFSGGGRQEAAGSRGRRAPRPREQDRDVQLSKALSYALRHGALKLGLPMGADGFVPLGTLLQLPQFRGFSAEDVQRVVDTNRKQRFALQLGDPSTGLLIRANQGHSLQVGVPKLELMPLETPQALPPMLVHGTFWKHWPSILLKGLSCQGRTHIHLAPGLPGDPGIISGMRSHCEIAVFIDGPLALADGIPFFRSANGVILTPGNTDGFLLPKYFKEALQLRPTRKPLSLAGDEETECQSSPKHSSRERRRIQQ>sp|Q99816|TS101_HUMAN Tumor susceptibility gene 101 protein OS=Homosapiens OX=9606 GN=TSG101 PE=1 SV=2MAVSESQLKKMVSKYKYRDLTVRETVNVITLYKDLKPVLDSYVFNDGSSRELMNLTGTIPVPYRGNTYNIPICLWLLDTYPYNPPICFVKPTSSMTIKTGKHVDANGKIYLPYLHEWKHPQSDLLGLIQVMIVVFGDEPPVFSRPISASYPPYQATGPPNTSYMPGMPGGISPYPSGYPPNPSGYPGCPYPPGGPYPATTSSQYPSQPPVTTVGPSRDGTISEDTIRASLISAVSDKLRWRMKEEMDRAQAELNALKRTEEDLKKGHQKLEEMVTRLDQEVAEVDKNIELLKKKDEELSSALEKMENQSENNDIDEVIIPTAPLYKQILNLYAEENAIEDTIFYLGEALRRGVIDLDVFLKHVRLLSRKQFQLRALMQKARKTAGLSDLY>sp|Q99816-2|TS101_HUMAN Isoform 2 of Tumor susceptibility gene 101protein OS=Homo sapiens OX=9606 GN=TSG101MAVSESQLKKMVSKPQSDLLGLIQVMIVVFGDEPPVFSRPISASYPPYQATGPPNTSYMPGMPGGISPYPSGYPPNPSGYPGCPYPPGGPYPATTSSQYPSQPPVTTVGPSRDGTISEDTIRASLISAVSDKLRWRMKEEMDRAQAELNALKRTEEDLKKGHQKLEEMVTRLDQEVAEVDKNIELLKKKDEELSSALEKMENQSENNDIDEVIIPTAPLYKQILNLYAEENAIEDTIFYLGEALRRGVIDLDVFLKHVRLLSRKQFQLRALMQKARKTAGLSDLY>sp|O15050|TRNK1_HUMAN TPR and ankyrin repeat-containing protein 1OS=Homo sapiens OX=9606 GN=TRANK1 PE=2 SV=4MWDPRAARVPPRDLAVLLCNKSNAFFSLGKWNEAFVAAKECLQWDPTYVKGYYRAGYSLLRLHQPYEAARMFFEGLRLVQRSQDQAPVADFLVGVFTTMSSDSIVLQSFLPCFDHIFTTGFPTEVWQSVIEKLAKKGLWHSFLLLSAKKDRLPRNIHVPELSLKSLFEKYVFIGLYEKMEQVPKLVQWLISIGASVETIGPYPLHALMRLCIQARENHLFRWLMDHKPEWKGRINQKDGDGCTVLHVVAAHSPGYLVKRQTEDVQMLLRFGADPTLLDRQSRSVVDVLKRNKNFKAIEKINSHLEKLATCSKDLSGFSNGDGPTSENDIFRKVLEQLVKYMNSGNRLLHKNFLKQEVVQRFLRLLSTLQEIPPDLVCDINQDCATTVFKFLLEKQRWPEVLLLLTRKVSGEPPLGDCLIKDCNFSDLDICTIIPHLSTWDQRKKQLLGCLIDSGALPDGLQESQERPVVTCLKHEDFELAFLLLTKGADPRAISLTEGDTPLHAALHIFLEIKADIGFSFLSHLLDLFWSNPTEFDYLNPNVQDSNGNTLMHILFQKGMLKRVKKLLDLLVKFDINFNLKNKEGKDARHRIKKNDSLLLAWNKALMENRRRSRQDSAAHLGKLSKSTAPGHTSQLKSQGSFKSVPCGATARTLPEGSAVPDSWETLPGTQVTRKEPGALRPCSLRDCLMQDITVLIQQVEVDPSFPEDCLQSSEPLEAGAGKEGKKDDKPTLGAGAPDCSEVGEGHAQVGLGALQLVPDDNRGKEGNDDQDDWSTQEIEACLQDFDNMTWEIECTSEMLKKLSSKVMTKVIKKKIILAIQQLGNGEWTQGLQKRLKHLKGSIQLFEAKLDKGARMLWELAIDFSPRCSENPEKIIATEQNTCAMEKSGRIYTEIIRIWDIVLDHCKLADSIKAICNAYNRGLSCVLRKKLKGINKGQVSANMKIQKRIPRCYVEDTEAEKGREHVNPEYFPPASAVETEYNIMKFHSFSTNMAFNILNDTTATVEYPFRVGELEYAVIDLNPRPLEPIILIGRSGTGKTTCCLYRLWKKFHVYWEKAEQAGSPLLAKQVWLKRRLEVEPGKESPGGEEEEEEEDEEEEDSIEVETVESIDEQEYEACAGGAGVEPAGDGQAAEVCAPEHPHQLEHLHQIFVTKNHVLCQEVQRNFIELSKSTKATSHYKPLDPNIHKLQDLRDENFPLFVTSKQLLLLLDASLPKPFFLRNEDGSLKRTIIGWSAQEESTIPSWQEDEEEAEVDGDYSEEDKAVEMRTGDSDPRVYVTFEVFKNEIWPKMTKGRTAYNPALIWKEIKSFLKGSFEALSCPHGRLTEEVYKKLGRKRCPNFKEDRSEIYSLFSLYQQIRSQKGYFDEEDVLYNISRRLSKLRVLPWSIHELYGDEIQDFTQAELALLMKCINDPNSMFLTGDTAQSIMKGVAFRFSDLRSLFHYASRNTIDKQCAVRKPKKIHQLYQNYRSHSGILNLASGVVDLLQFYFPESFDRLPRDSGLFDGPKPTVLESCSVSDLAILLRGNKRKTQPIEFGAHQVILVANETAKEKIPEELGLALVLTIYEAKGLEFDDVLLYNFFTDSEAYKEWKIISSFTPTSTDSREENRPLVEVPLDKPGSSQGRSLMVNPEMYKLLNGELKQLYTAITRARVNLWIFDENREKRAPAFKYFIRRDFVQVVKTDENKDFDDSMFVKTSTPAEWIAQGDYYAKHQCWKVAAKCYQKGGAFEKEKLALAHDTALSMKSKKVSPKEKQLEYLELAKTYLECKEPTLSLKCLSYAKEFQLSAQLCERLGKIRDAAYFYKRSQCYKDAFRCFEQIQEFDLALKMYCQEELFEEAAIAVEKYEEMLKTKTLPISKLSYSASQFYLEAAAKYLSANKMKEMMAVLSKLDIEDQLVFLKSRKRLAEAADLLNREGRREEAALLMKQHGCLLEAARLTADKDFQASCLLGAARLNVARDSDIEHTKDILREALDICYQTGQLSGIAEAHFLQGVILRDFQKLRDAFFKFDTLNHSAGVVEALYEAASQCEAEPEKILGLAPGGLEILLSLVRALKRVTNNAEKEMVKSCFEFFGISQVDAKYCQIAQNDPGPILRIIFDLDLNLREKKTKDHFLIMTDQVKLALNKHLLGRLCQITRSLLGKTYRGVCMRFIVGLKCEDENCEHFHRPLRRCEAKCLVQSKMNLVAINGLLLEAKKVFPKILAEELKEIDYILSTDMYGLCKSILDVLFPKHFHQRVLSENPMACKEILKPNYKSFRFYRFALKEYIHFLFENESARNRRESTDLWLSAMQAFLLSSNYPEEFEKLLHQEEDNYNRELKALESEKDERGRGRGSRIKGIEGKFGMLAPNRDDENMDKTHLCFIRLLENCIDQFYVYRNPEDYKRLFFRFMNVLIKRCKEPLIPSIGNTVALLEFQFIHCGVVLARLWKNVILCLPKSYIALLHYWEFLFSKKDKELGDVFSIIQEYKPKDVTRAIQDFRFHLSYLAKVLCGYENVNFNVLLDAFSEIDYVVSGEAERTLVLCLVMLVNAEEILQPYCKPLLYRHFREIESRLQLMSMDCPGQVPERLLKVVKRVLVAVNVKSVAEALQDLLFERDEEYLMDCDWRWDPVHTKGSIVRGLYYEEVRLNRLLCLDPVDYFAEPECEFGQDEMDELALEDRDHVLATILSQKQRKASIQRKLRRACLVVSLCISWRRRVGTQMERVREEAREPRAGNFKKADVDRTQCDLCGVKFTRGPENYFSPSKAFEGAASEVAVLSRAELEREECQERNSESYEQHIHLEHHQRQQVAYQKYSEFFHEKVDPAIDEGKLVVQDIEQSVWIHSHVGSKEHSHMLQKVQEHIKRVSDMVEDLYRRKAWAGAEEAMTRLVNILILSVRDARDWLMKTETRLKKEGIVQEDDYENEVEDFGELRPRRRSRKCGKQRKY>sp|A0JNW5|UH1BL_HUMAN UHRF1-binding protein 1-like OS=Homo sapiensOX=9606 GN=UHRF1BP1L PE=1 SV=2MAGIIKKQILKHLSRFTKNLSPDKINLSTLKGEGELKNLELDEEVLQNMLDLPTWLAINKVFCNKASIRIPWTKLKTHPICLSLDKVIMEMSTCEEPRSPNGPSPIATASGQSEYGFAEKVVEGISVSVNSIVIRIGAKAFNASFELSQLRIYSVNAHWEHGDLRFTRIQDPQRGEVLTFKEINWQMIRIEADATQSSHLEIMCAPVRLITNQSKIRVTLKRRLKDCNVIATKLVLILDDLLWVLTDSQLKAMVQYAKSLSEAIEKSTEQRKSMAPEPTQSSTVVASAQQVKTTQTSNAPDVNDAIVKLFNDFDVKETSHHLVISHLDLHICDDIHAKEKESNRRITGGAMQLSFTQLTIDYYPYHKAGDSCNHWMYFSDATKTKNGWANELLHEFECNVEMLKQAVKDHNVGSPPKSPTHASPQHTQTEKDYPLKGTCRTPSVLSQQSKAKLMSSSVVVRLADFNIYQVSTAEQCRSSPKSMICCNKKSLYLPQEMSAVYIEFTEYYYPDGKDFPIPSPNLYSQLNALQFTVDERSILWLNQFLLDLKQSLNQFMAVYKLNDNSKSDEHVDVRVDGLMLKFVIPSEVKSECHQDQPRAISIQSSEMIATNTRHCPNCRHSDLEALFQDFKDCDFFSKTYTSFPKSCDNFNLLHPIFQRHAHEQDTKMHEIYKGNITPQLNKNTLKTSAATDVWAVYFSQFWIDYEGMKSGKGRPISFVDSFPLSIWICQPTRYAESQKEPQTCNQVSLNTSQSESSDLAGRLKRKKLLKEYYSTESEPLTNGGQKPSSSDTFFRFSPSSSEADIHLLVHVHKHVSMQINHYQYLLLLFLHESLILLSENLRKDVEAVTGSPASQTSICIGILLRSAELALLLHPVDQANTLKSPVSESVSPVVPDYLPTENGDFLSSKRKQISRDINRIRSVTVNHMSDNRSMSVDLSHIPLKDPLLFKSASDTNLQKGISFMDYLSDKHLGKISEDESSGLVYKSGSGEIGSETSDKKDSFYTDSSSILNYREDSNILSFDSDGNQNILSSTLTSKGNETIESIFKAEDLLPEAASLSENLDISKEETPPVRTLKSQSSLSGKPKERCPPNLAPLCVSYKNMKRSSSQMSLDTISLDSMILEEQLLESDGSDSHMFLEKGNKKNSTTNYRGTAESVNAGANLQNYGETSPDAISTNSEGAQENHDDLMSVVVFKITGVNGEIDIRGEDTEICLQVNQVTPDQLGNISLRHYLCNRPVGSDQKAVIHSKSSPEISLRFESGPGAVIHSLLAEKNGFLQCHIENFSTEFLTSSLMNIQHFLEDETVATVMPMKIQVSNTKINLKDDSPRSSTVSLEPAPVTVHIDHLVVERSDDGSFHIRDSHMLNTGNDLKENVKSDSVLLTSGKYDLKKQRSVTQATQTSPGVPWPSQSANFPEFSFDFTREQLMEENESLKQELAKAKMALAEAHLEKDALLHHIKKMTVE>sp|A0JNW5-2|UH1BL_HUMAN Isoform 2 of UHRF1-binding protein 1-likeOS=Homo sapiens OX=9606 GN=UHRF1BP1LMAGIIKKQILKHLSRFTKNLSPDKINLSTLKGEGELKNLELDEEVLQNMLDLPTWLAINKVFCNKASIRIPWTKLKTHPICLSLDKVIMEMSTCEEPRSPNGPSPIATASGQSEYGFAEKVVEGISVSVNSIVIRIGAKAFNASFELSQLRIYSVNAHWEHGDLRFTRIQDPQRGEVLTFKEINWQMIRIEADATQSSHLEIMCAPVRLITNQSKIRVTLKRRLKDCNVIATKLVLILDDLLWVLTDSQLKAMVQYAKSLSEAIEKSTEQRKSMAPEPTQSSTVVASAQQVKTTQTSNAPDVNDAIVKLFNDFDVKETSHHLVISHLDLHICDDIHAKEKESNRRITGGAMQLSFTQLTIDYYPYHKAGDSCNHWMYFSDATKTKNGWANELLHEFECNVEMLKQAVKDHNVGSPPKSPTHASPQHTQTEKDYPLKGTCRTPSVLSQQSKAKLMSSSVVVRLADFNIYQVSTAEQCRSSPKSMICCNKKSLYLPQEMSAVYIEFTEYYYPDGKDFPTAFLSR>sp|O43396|TXNL1_HUMAN Thioredoxin-like protein 1 OS=Homo sapiens OX=9606GN=TXNL1 PE=1 SV=3MVGVKPVGSDPDFQPELSGAGSRLAVVKFTMRGCGPCLRIAPAFSSMSNKYPQAVFLEVDVHQCQGTAATNNISATPTFLFFRNKVRIDQYQGADAVGLEEKIKQHLENDPGSNEDTDIPKGYMDLMPFINKAGCECLNESDEHGFDNCLRKDTTFLESDCDEQLLITVAFNQPVKLYSMKFQGPDNGQGPKYVKIFINLPRSMDFEEAERSEPTQALELTEDDIKEDGIVPLRYVKFQNVNSVTIFVQSNQGEEETTRISYFTFIGTPVQATNMNDFKRVVGKKGESH>sp|Q5T4D3|TMTC4_HUMAN Protein O-mannosyl-transferase TMTC4 OS=Homosapiens OX=9606 GN=TMTC4 PE=1 SV=2MAVLDTDLDHILPSSVLPPFWAKLVVGSVAIVCFARSYDGDFVFDDSEAIVNNKDLQAETPLGDLWHHDFWGSRLSSNTSHKSYRPLTVLTFRINYYLSGGFHPVGFHVVNILLHSGISVLMVDVFSVLFGGLQYTSKGRRLHLAPRASLLAALLFAVHPVHTECVAGVVGRADLLCALFFLLSFLGYCKAFRESNKEGAHSSTFWVLLSIFLGAVAMLCKEQGITVLGLNAVFDILVIGKFNVLEIVQKVLHKDKSLENLGMLRNGGLLFRMTLLTSGGAGMLYVRWRIMGTGPPAFTEVDNPASFADSMLVRAVNYNYYYSLNAWLLLCPWWLCFDWSMGCIPLIKSISDWRVIALAALWFCLIGLICQALCSEDGHKRRILTLGLGFLVIPFLPASNLFFRVGFVVAERVLYLPSVGYCVLLTFGFGALSKHTKKKKLIAAVVLGILFINTLRCVLRSGEWRSEEQLFRSALSVCPLNAKVHYNIGKNLADKGNQTAAIRYYREAVRLNPKYVHAMNNLGNILKERNELQEAEELLSLAVQIQPDFAAAWMNLGIVQNSLKRFEAAEQSYRTAIKHRRKYPDCYYNLGRLYADLNRHVDALNAWRNATVLKPEHSLAWNNMIILLDNTGNLAQAEAVGREALELIPNDHSLMFSLANVLGKSQKYKESEALFLKAIKANPNAASYHGNLAVLYHRWGHLDLAKKHYEISLQLDPTASGTKENYGLLRRKLELMQKKAV>sp|Q5T4D3-2|TMTC4_HUMAN Isoform 2 of Protein O-mannosyl-transferaseTMTC4 OS=Homo sapiens OX=9606 GN=TMTC4MAVLDTDLDHILPSSVLPPFWAKLVVGSVAIVCFARSYDGDFVFDDSEAIVNNKDLQAETPLGDLWHHDFWGSRLSSNTSHKSYRPLTVLTFRINYYLSGGFHPVGFHVVNILLHSGISVLMVDVFSVLFGGLQYTSKGRRLHLAPRASLLAALLFAVHPVHTECVAGVVGRADLLCALFFLLSFLGYCKAFRESNKEGAHSSTFWVLLSIFLGAVAMLCKEQGITVLGLNAVFDILVIGKFNVLEIVQKVLHKDKSLENLGMLRNGGLLFRMTLLTSGGAGMLYVRWRIMGTGPPAFTEVDNPASFADSMLVRAVNYNYYYSLNAWLLLCPWWLCFDWSMGCIPLIKSISDWRVIALAALWFCLIGLICQALCSEDGHKRRILTLGLGFLVIPFLPASNLFFRVGFVVAERVLYLPSVGYCVLLTFGFGALSKHTKKKKLIAAVVLGILFINTLRCVLRSGEWRSEEQLFRSALSVCPLNAKVHYNIGKNLADKGNQTAAIRYYREAVRLNPKYVHAMNNLGNILKERNELQEAEELLSLAVQIQPDFAAAWMNLGIVQNSLKRFEAAEQSYRTAIKHRRKYPDCYYNLGRLVSAGCPVPVEGKMGYFSYL>sp|Q5T4D3-3|TMTC4_HUMAN Isoform 3 of Protein O-mannosyl-transferaseTMTC4 OS=Homo sapiens OX=9606 GN=TMTC4MIPNQHNAGAGSHQPAVFRMAVLDTDLDHILPSSVLPPFWAKLVVGSVAIVCFARSYDGDFVFDDSEAIVNNKDLQAETPLGDLWHHDFWGSRLSSNTSHKSYRPLTVLTFRINYYLSGGFHPVGFHVVNILLHSGISVLMVDVFSVLFGGLQYTSKGRRLHLAPRASLLAALLFAVHPVHTECVAGVVGRADLLCALFFLLSFLGYCKAFRESNKEGAHSSTFWVLLSIFLGAVAMLCKEQGITVLGLNAVFDILVIGKFNVLEIVQKVLHKDKSLENLGMLRNGGLLFRMTLLTSGGAGMLYVRWRIMGTGPPAFTEVDNPASFADSMLVRAVNYNYYYSLNAWLLLCPWWLCFDWSMGCIPLIKSISDWRVIALAALWFCLIGLICQALCSEDGHKRRILTLGLGFLVIPFLPASNLFFRVGFVVAERVLYLPSVGYCVLLTFGFGALSKHTKKKKLIAAVVLGILFINTLRCVLRSGEWRSEEQLFRSALSVCPLNAKVHYNIGKNLADKGNQTAAIRYYREAVRLNPKYVHAMNNLGNILKERNELQEAEELLSLAVQIQPDFAAAWMNLGIVQNSLKRFEAAEQSYRTAIKHRRKYPDCYYNLGRLYADLNRHVDALNAWRNATVLKPEHSLAWNNMIILLDNTGNLAQAEAVGREALELIPNDHSLMFSLANVLGKSQKYKESEALFLKAIKANPNAASYHGNLAVLYHRWGHLDLAKKHYEISLQLDPTASGTKENYGLLRRKLELMQKKAV>sp|Q5T4D3-4|TMTC4_HUMAN Isoform 4 of Protein O-mannosyl-transferaseTMTC4 OS=Homo sapiens OX=9606 GN=TMTC4MAVLDTDLDHILPSSVLPPFWAKLVVGSVAIVCFARSYDGDFVFDDSEAIVNNKVAGVVGRADLLCALFFLLSFLGYCKAFRESNKEGAHSSTFWVLLSIFLGAVAMLCKEQGITVLGLNAVFDILVIGKFNVLEIVQKVLHKDKSLENLGMLRNGGLLFRMTLLTSGGAGMLYVRWRIMGTGPPAFTEVDNPASFADSMLVRAVNYNYYYSLNAWLLLCPWWLCFDWSMGCIPLIKSISDWRVIALAALWFCLIGLICQALCSEDGHKRRILTLGLGFLVIPFLPASNLFFRVGFVVAERVLYLPSVGYCVLLTFGFGALSKHTKKKKLIAAVVLGILFINTLRCVLRSGEWRSEEQLFRSALSVCPLNAKVHYNIGKNLADKGNQTAAIRYYREAVRLNPKYVHAMNNLGNILKERNELQEAEELLSLAVQIQPDFAAAWMNLGIVQNSLKRFEAAEQSYRTAIKHRRKYPDCYYNLGRLYADLNRHVDALNAWRNATVLKPEHSLAWNNMIILLDNTGNLAQAEAVGREALELIPNDHSLMFSLANVLGKSQKYKESEALFLKAIKANPNAASYHGNLAVLYHRWGHLDLAKKHYEISLQLDPTASGTKENYGLLRRKLELMQKKAV>sp|Q96AY4|TTC28_HUMAN Tetratricopeptide repeat protein 28 OS=Homosapiens OX=9606 GN=TTC28 PE=1 SV=4MEQSPPPAPEPTQGPTPARSRRRREPESPPASAPIPLFGADTIGQRSPDGPVLSKAEFVEKVRQSNQACHDGDFHTAIVLYNEALAVDPQNCILYSNRSAAYMKIQQYDKALDDAIKARLLNPKWPKAYFRQGVALQYLGRHADALAAFASGLAQDPKSLQLLVGMVEAAMKSPMRDSLEPTYQQLQKMKLDKSPFVVVSVVGQELLTAGHHGASVVVLEAALKIGTCSLKLRGSVFSALSSAYWSLGNTEKSTGYMQQDLDVAKTLGDQTGECRAHGNLGSAFFSKGNYREALTNHRHQLVLAMKLKDREAASSALSSLGHVYTAIGDYPNALASHKQCVLLAKQSKDELSEARELGNMGAVYIAMGDFENAVQCHEQHLKIAKDLGNKREEARAYSNLGSAYHYRRNFDKAMSYHNYVLELAQELMEKAIEMRAYAGLGHAARCMQDLERAKQYHEQQLGIAEDLKDRAAEGRASSNLGIIHQMKGDYDTALKLHKTHLCIAQELSDYAAQGRAYGNMGNAYNALGMYDQAVKYHRQELQISMEVNDRASQASTHGNLAVAYQALGAHDRALQHYQNHLNIARELRDIQSEARALSNLGNFHCSRGEYVQAAPYYEQYLRLAPDLQDMEGEGKVCHNLGYAHYCLGNYQEAVKYYEQDLALAKDLHDKLSQAKAYCNLGLAFKALLNFSKAEECQKYLLSLAQSLNNSQAKFRALGNLGDIFICKKDINGAIKFYEQQLGLAHQVKDRRLEASAYAALGTAYRMIQKYDKALGYHTQELEVYQELSDLPGECRAHGHLAAVYMALGKYTMAFKCYEEQLDLGQKLKDPSLEAQVYGNMGITKMNMNVMEEAIGYFEQQLAMLQQLSGNESVLDRGRAYGNLGDCYEALGDYEEAIKYYEQYLSVAQSLNRMQDQAKAYRGLGNGHRAMGSLQQALVCFEKRLVVAHELGEAFNKAQAYGELGSLHSQLGNYEQAISCLERQLNIARDMKDRALESDAACGLGGVYQQMGEYDTALQYHQLDLQIAEETNNPTCQGRAYGNLGLTYESLGTFERAVVYQEQHLSIAAQMNDLAAKTVSYSSLGRTHHALQNYSQAVMYLQEGLRLAEQLGRREDEAKIRHGLGLSLWASGNLEEAQHQLYRASALFETIRHEAQLSTDYKLSLFDLQTSSYQALQRVLVSLGHHDEALAVAERGRTRAFADLLVERQTGQQDSDPYSPVTIDQILEMVNGQRGLVLYYSLAAGYLYSWLLAPGAGIVKFHEHYLGENTVENSSDFQASSSVTLPTATGSALEQHIASVREALGVESHYSRACASSETESEAGDIMDQQFEEMNNKLNSVTDPTGFLRMVRRNNLFNRSCQSMTSLFSNTVSPTQDGTSSLPRRQSSFAKPPLRALYDLLIAPMEGGLMHSSGPVGRHRQLILVLEGELYLIPFALLKGSSSNEYLYERFGLLAVPSIRSLSVQSKSHLRKNPPTYSSSTSMAAVIGNPKLPSAVMDRWLWGPMPSAEEEAYMVSELLGCQPLVGSVATKERVMSALTQAECVHFATHISWKLSALVLTPSMDGNPASSKSSFGHPYTIPESLRVQDDASDGESISDCPPLQELLLTAADVLDLQLPVKLVVLGSSQESNSKVTADGVIALTRAFLAAGAQCVLVSLWPVPVAASKMFIHAFYSSLLNGLKASAALGEAMKVVQSSKAFSHPSNWAGFMLIGSDVKLNSPSSLIGQALTEILQHPERARDALRVLLHLVEKSLQRIQNGQRNAMYTSQQSVENKVGGIPGWQALLTAVGFRLDPPTSGLPAAVFFPTSDPGDRLQQCSSTLQSLLGLPNPALQALCKLITASETGEQLISRAVKNMVGMLHQVLVQLQAGEKEQDLASAPIQVSISVQLWRLPGCHEFLAALGFDLCEVGQEEVILKTGKQANRRTVHFALQSLLSLFDSTELPKRLSLDSSSSLESLASAQSVSNALPLGYQQPPFSPTGADSIASDAISVYSLSSIASSMSFVSKPEGGSEGGGPGGRQDHDRSKNAYLQRSTLPRSQLPPQTRPAGNKDEEEYEGFSIISNEPLATYQENRNTCFSPDHKQPQPGTAGGMRVSVSSKGSISTPNSPVKMTLIPSPNSPFQKVGKLASSDTGESDQSSTETDSTVKSQEESNPKLDPQELAQKILEETQSHLIAVERLQRSGGQVSKSNNPEDGVQAPSSTAVFRASETSAFSRPVLSHQKSQPSPVTVKPKPPARSSSLPKVSSGYSSPTTSEMSIKDSPSQHSGRPSPGCDSQTSQLDQPLFKLKYPSSPYSAHISKSPRNMSPSSGHQSPAGSAPSPALSYSSAGSARSSPADAPDIDKLKMAAIDEKVQAVHNLKMFWQSTPQHSTGPMKIFRGAPGTMTSKRDVLSLLNLSPRHNKKEEGVDKLELKELSLQQHDGAPPKAPPNGHWRTETTSLGSLPLPAGPPATAPARPLRLPSGNGYKFLSPGRFFPSSKC>sp|Q8NA56|TTC29_HUMAN Tetratricopeptide repeat protein 29 OS=Homosapiens OX=9606 GN=TTC29 PE=1 SV=2MTTLPPLPMTRPKLTALARQKLPCSSRKIPRSQLIKEKDDIDHYLEVNFKGLSKEEVAAYRNSYKKNICVDMLRDGYHKSFTELFALMERWDALREAARVRSLFWLQKPLEEQPDKLDYLYHYLTRAEDAERKESFEDVHNNLYALACYFNNSEDKWVRNHFYERCFKIAQLIKIDCGKKEAEAHMHMGLLYEEDGQLLEAAEHYEAFHQLTQGRIWKDETGRSLNLLACESLLRTYRLLSDKMLENKEYKQAIKILIKASEIAKEGSDKKMEAEASYYLGLAHLAAEEYETALTVLDTYCKISTDLDDDLSLGRGYEAIAKVLQSQGEMTEAIKYLKKFVKIARNNFQSLDLVRASTMLGDIYNEKGYYNKASECFQQAFDTTVELMSMPLMDETKVHYGIAKAHQMMLTVNNYIESADLTSLNYLLSWKESRGNIEPDPVTEEFRGSTVEAVSQNSERLEELSRFPGDQKNET>sp|Q8NA56-2|TTC29_HUMAN Isoform 2 of Tetratricopeptide repeat protein 29OS=Homo sapiens OX=9606 GN=TTC29MIPMFTVTLEDSGTLWKSLHSSSESETTLPPLPMTRPKLTALARQKLPCSSRKIPRSQLIKEKDDIDHYLEVNFKGLSKEEVAAYRNSYKKNICVDMLRDGYHKSFTELFALMERWDALREAARVRSLFWLQKPLEEQPDKLDYLYHYLTRAEDAERKESFEDVHNNLYALACYFNNSEDKWVRNHFYERCFKIAQLIKIDCGKKEAEAHMHMGLLYEEDGQLLEAAEHYEAFHQLTQGRIWKDETGRSLNLLACESLLRTYRLLSDKMLENKEYKQAIKILIKASEIAKEGSDKKMEAEASYYLGLAHLAAEEYETALTVLDTYCKISTDLDDDLSLGRGYEAIAKVLQSQGEMTEAIKYLKKFVKIARNNFQSLDLVRASTMLGDIYNEKGYYNKASECFQQAFDTTVELMSMPLMDETKVHYGIAKAHQMMLTVNNYIESADLTSLNYLLSWKESRGNIEPDPVTEEFRGSTVEAVSQNSERLEELSRFPGDQKNET>sp|Q70EL3|UBP50_HUMAN Inactive ubiquitin carboxyl-terminal hydrolase 50OS=Homo sapiens OX=9606 GN=USP50 PE=2 SV=1MTSQPSLPADDFDIYHVLAECTDYYDTLPVKEADGNQPHFQGVTGLWNLGNTCCVNAISQCLCSILPLVEYFLTGKYITALQKFLLPSDCSEVATAFAYLMTDMWLGDSDCVSPEIFWSALGNLYPAFTKKMQQDAQEFLICVLNELHEALKKYHYSRRRSYEKGSTQRCCRKWITTETSIITQLFEEQLNYSIVCLKCEKCTYKNEVFTVFSLPIPSKYECSLRDCLQCFFQQDALTWNNEIHCSFCETKQETAVRASISKAPKIIIFHLKRFDIQGTTKRKLRTDIHYPLTNLDLTPYICSIFRKYPKYNLCAVVNHFGDLDGGHYTAFCKNSVTQA>sp|Q70EL3-2|UBP50_HUMAN Isoform 2 of Inactive ubiquitin carboxyl-terminal hydrolase 50 OS=Homo sapiens OX=9606 GN=USP50MTSQPSLPADDFDIYHVLAECTDYYDTLPVKEADGNQPHFQGVTGLWNLGNTCCVNAISQCLCSILPLVEYFLTGKYITALQNDCSEVATAFAYLMTDMWLGDSDCVSPEIFWSALGNLYPAFTKKMQQDAQEFLICVLNELHEALKKYHYSRRRSYEKGSTQRCCRKWITTETSIITQLFEEQLNYSIVCLKCEKCTYKNEVFTVFSLPIPSKYECSLRDCLQCFFQQDALTWNNEIHCSFCETKQETAVRASISKAPKIIIFHLKRFDIQGTTKRKLRTDIHYPLTNLDLTPYICSIFRKYPKYNLCAVVNHFGDLDGGHYTAFCKNSVTQA>sp|Q16864|VATF_HUMAN V-type proton ATPase subunit F OS=Homo sapiensOX=9606 GN=ATP6V1F PE=1 SV=2MAGRGKLIAVIGDEDTVTGFLLGGIGELNKNRHPNFLVVEKDTTINEIEDTFRQFLNRDDIGIILINQYIAEMVRHALDAHQQSIPAVLEIPSKEHPYDAAKDSILRRARGMFTAEDLR>sp|Q16864-2|VATF_HUMAN Isoform 2 of V-type proton ATPase subunit FOS=Homo sapiens OX=9606 GN=ATP6V1FMAGRGKLIAVIGDEDTVTGFLLGGIGELNKNRHPNFLVVEKDTTINEIEDTFRSLGSLPGSVVEANPNQRDPPLWDEIDSRQFLNRDDIGIILINQYIAEMVRHALDAHQQSIPAVLEIPSKEHPYDAAKDSILRRARGMFTAEDLR>sp|Q15836|VAMP3_HUMAN Vesicle-associated membrane protein 3 OS=Homosapiens OX=9606 GN=VAMP3 PE=1 SV=3MSTGPTAATGSNRRLQQTQNQVDEVVDIMRVNVDKVLERDQKLSELDDRADALQAGASQFETSAAKLKRKYWWKNCKMWAIGITVLVIFIIIIIVWVVSS>sp|Q9HCJ6|VAT1L_HUMAN Synaptic vesicle membrane protein VAT-1 homolog-like OS=Homo sapiens OX=9606 GN=VAT1L PE=1 SV=2MAKEGVEKAEETEQMIEKEAGKEPAEGGGGDGSHRLGDAQEMRAVVLAGFGGLNKLRLFRKAMPEPQDGELKIRVKACGLNFIDLMVRQGNIDNPPKTPLVPGFECSGIVEALGDSVKGYEIGDRVMAFVNYNAWAEVVCTPVEFVYKIPDDMSFSEAAAFPMNFVTAYVMLFEVANLREGMSVLVHSAGGGVGQAVAQLCSTVPNVTVFGTASTFKHEAIKDSVTHLFDRNADYVQEVKRISAEGVDIVLDCLCGDNTGKGLSLLKPLGTYILYGSSNMVTGETKSFFSFAKSWWQVEKVNPIKLYEENKVIAGFSLLNLLFKQGRAGLIRGVVEKLIGLYNQKKIKPVVDSLWALEEVKEAMQRIHDRGNIGKLILDVEKTPTPLMANDSTETSEAGEEEEDHEGDSENKERMPFIQ>sp|Q14135|VGLL4_HUMAN Transcription cofactor vestigial-like protein 4OS=Homo sapiens OX=9606 GN=VGLL4 PE=1 SV=4METPLDVLSRAASLVHADDEKREAALRGEPRMQTLPVASALSSHRTGPPPISPSKRKFSMEPGDEDLDCDNDHVSKMSRIFNPHLNKTANGDCRRDPRERSRSPIERAVAPTMSLHGSHLYTSLPSLGLEQPLALTKNSLDASRPAGLSPTLTPGERQQNRPSVITCASAGARNCNLSHCPIAHSGCAAPGPASYRRPPSAATTCDPVVEEHFRRSLGKNYKEPEPAPNSVSITGSVDDHFAKALGDTWLQIKAAKDGASSSPESASRRGQPASPSAHMVSHSHSPSVVS>sp|Q14135-2|VGLL4_HUMAN Isoform 2 of Transcription cofactor vestigial-like protein 4 OS=Homo sapiens OX=9606 GN=VGLL4MQTLPVASALSSHRTGPPPISPSKRKFSMEPGDEDLDCDNDHVSKMSRIFNPHLNKTANGDCRRDPRERSRSPIERAVAPTMSLHGSHLYTSLPSLGLEQPLALTKNSLDASRPAGLSPTLTPGERQQNRPSVITCASAGARNCNLSHCPIAHSGCAAPGPASYRRPPSAATTCDPVVEEHFRRSLGKNYKEPEPAPNSVSITGSVDDHFAKALGDTWLQIKAAKDGASSSPESASRRGQPASPSAHMVSHSHSPSVVS>sp|Q14135-3|VGLL4_HUMAN Isoform 3 of Transcription cofactor vestigial-like protein 4 OS=Homo sapiens OX=9606 GN=VGLL4METPLDVLSRAASLVHADDEKPSPGNLLEMQNRSPRCGTDD>sp|Q14135-4|VGLL4_HUMAN Isoform 4 of Transcription cofactor vestigial-like protein 4 OS=Homo sapiens OX=9606 GN=VGLL4MLFMKMDLLNYQYLDKMNNNIGILCYEGEAALRGEPRMQTLPVASALSSHRTGPPPISPSKRKFSMEPGDEDLDCDNDHVSKMSRIFNPHLNKTANGDCRRDPRERSRSPIERAVAPTMSLHGSHLYTSLPSLGLEQPLALTKNSLDASRPAGLSPTLTPGERQQNRPSVITCASAGARNCNLSHCPIAHSGCAAPGPASYRRPPSAATTCDPVVEEHFRRSLGKNYKEPEPAPNSVSITGSVDDHFAKALGDTWLQIKAAKDGASSSPESASRRGQPASPSAHMVSHSHSPSVVS>sp|Q14135-5|VGLL4_HUMAN Isoform 5 of Transcription cofactor vestigial-like protein 4 OS=Homo sapiens OX=9606 GN=VGLL4MNKTANGDCRRDPRERSRSPIERAVAPTMSLHGSHLYTSLPSLGLEQPLALTKNSLDASRPAGLSPTLTPGERQQNRPSVITCASAGARNCNLSHCPIAHSGCAAPGPASYRRPPSAATTCDPVVEEHFRRSLGKNYKEPEPAPNSVSITGSVDDHFAKALGDTWLQIKAAKDGASSSPESASRRGQPASPSAHMVSHSHSPSVVS>sp|Q14135-6|VGLL4_HUMAN Isoform 6 of Transcription cofactor vestigial-like protein 4 OS=Homo sapiens OX=9606 GN=VGLL4MIKVRNKTANGDCRRDPRERSRSPIERAVAPTMSLHGSHLYTSLPSLGLEQPLALTKNSLDASRPAGLSPTLTPGERQQNRPSVITCASAGARNCNLSHCPIAHSGCAAPGPASYRRPPSAATTCDPVVEEHFRRSLGKNYKEPEPAPNSVSITGSVDDHFAKALGDTWLQIKAAKDGASSSPESASRRGQPASPSAHMVSHSHSPSVVS>sp|Q9Y6N9|USH1C_HUMAN Harmonin OS=Homo sapiens OX=9606 GN=USH1C PE=1SV=3MDRKVAREFRHKVDFLIENDAEKDYLYDVLRMYHQTMDVAVLVGDLKLVINEPSRLPLFDAIRPLIPLKHQVEYDQLTPRRSRKLKEVRLDRLHPEGLGLSVRGGLEFGCGLFISHLIKGGQADSVGLQVGDEIVRINGYSISSCTHEEVINLIRTKKTVSIKVRHIGLIPVKSSPDEPLTWQYVDQFVSESGGVRGSLGSPGNRENKEKKVFISLVGSRGLGCSISSGPIQKPGIFISHVKPGSLSAEVGLEIGDQIVEVNGVDFSNLDHKEAVNVLKSSRSLTISIVAAAGRELFMTDRERLAEARQRELQRQELLMQKRLAMESNKILQEQQEMERQRRKEIAQKAAEENERYRKEMEQIVEEEEKFKKQWEEDWGSKEQLLLPKTITAEVHPVPLRKPKYDQGVEPELEPADDLDGGTEEQGEQDFRKYEEGFDPYSMFTPEQIMGKDVRLLRIKKEGSLDLALEGGVDSPIGKVVVSAVYERGAAERHGGIVKGDEIMAINGKIVTDYTLAEAEAALQKAWNQGGDWIDLVVAVCPPKEYDDELTFF>sp|Q9Y6N9-2|USH1C_HUMAN Isoform 2 of Harmonin OS=Homo sapiens OX=9606GN=USH1CMYHQTMDVAVLVGDLKLVINEPSRLPLFDAIRPLIPLKHQVEYDQLTPRRSRKLKEVRLDRLHPEGLGLSVRGGLEFGCGLFISHLIKGGQADSVGLQVGDEIVRINGYSISSCTHEEVINLIRTKKTVSIKVRHIGLIPVKSSPDEPLTWQYVDQFVSESGGVRGSLGSPGNRENKEKKVFISLVGSRGLGCSISSGPIQKPGIFISHVKPGSLSAEVGLEIGDQIVEVNGVDFSNLDHKEAVNVLKSSRSLTISIVAAAGRELFMTDRERLAEARQRELQRQELLMQKRLAMESNKILQEQQEMERQRRKEIAQKAAEENERYRKEMEQIVEEEEKFKKQWEEDWGSKEQLLLPKTITAEVHPVPLRKPKYDQGVEPELEPADDLDGGTEEQGEQDFRKYEEGFDPYSMFTPEQIMGKDVRLLRIKKEGSLDLALEGGVDSPIGKVVVSAVYERGAAERHGGIVKGDEIMAINGKIVTDYTLAEAEAALQKAWNQGGDWIDLVVAVCPPKEYDDELTFF>sp|Q9Y6N9-3|USH1C_HUMAN Isoform 3 of Harmonin OS=Homo sapiens OX=9606GN=USH1CMDRKVAREFRHKVDFLIENDAEKDYLYDVLRMYHQTMDVAVLVGDLKLVINEPSRLPLFDAIRPLIPLKHQVEYDQLTPRRSRKLKEVRLDRLHPEGLGLSVRGGLEFGCGLFISHLIKGGQADSVGLQVGDEIVRINGYSISSCTHEEVINLIRTKKTVSIKVRHIGLIPVKSSPDEPLTWQYVDQFVSESGGVRGSLGSPGNRENKEKKVFISLVGSRGLGCSISSGPIQKPGIFISHVKPGSLSAEVGLEIGDQIVEVNGVDFSNLDHKEAVNVLKSSRSLTISIVAAAGRELFMTDRERLAEARQRELQRQELLMQKRLAMESNKILQEQQEMERQRRKEIAQKAAEENERYRKEMEQIVEEEEKFKKQWEEDWGSKEQLLLPKTITAEVHPVPLRKPK>sp|Q9Y6N9-4|USH1C_HUMAN Isoform 4 of Harmonin OS=Homo sapiens OX=9606GN=USH1CMDRKVAREFRHKVDFLIENDAEKDYLYDVLRMYHQTMDVAVLVGDLKLVINEPSRLPLFDAIRPLIPLKHQVEYDQLTPRRSRKLKEVRLDRLHPEGLGLSVRGGLEFGCGLFISHLIKGGQADSVGLQVGDEIVRINGYSISSCTHEEVINLIRTKKTVSIKVRHIGLIPVKSSPDEPLTWQYVDQFVSESGGVRGSLGSPGNRENKEKKVFISLVGSRGLGCSISSGPIQKPGIFISHVKPGSLSAEVGLEIGDQIVEVNGVDFSNLDHKEGRELFMTDRERLAEARQRELQRQELLMQKRLAMESNKILQEQQEMERQRRKEIAQKAAEENERYRKEMEQIVEEEEKFKKQWEEDWGSKEQLLLPKTITAEVHPVPLRKPKYDQGVEPELEPADDLDGGTEEQGEQDFRKYEEGFDPYSMFTPEQIMGKDVRLLRIKKEGSLDLALEGGVDSPIGKVVVSAVYERGAAERHGGIVKGDEIMAINGKIVTDYTLAEAEAALQKAWNQGGDWIDLVVAVCPPKEYDDELTFF>sp|Q9Y6N9-5|USH1C_HUMAN Isoform 5 of Harmonin OS=Homo sapiens OX=9606GN=USH1CMDRKVAREFRHKVDFLIENDAEKDYLYDVLRMYHQTMDVAVLVGDLKLVINEPSRLPLFDAIRPLIPLKHQVEYDQLTPRRSRKLKEVRLDRLHPEGLGLSVRGGLEFGCGLFISHLIKGGQADSVGLQVGDEIVRINGYSISSCTHEEVINLIRTKKTVSIKVRHIGLIPVKSSPDEPLTWQYVDQFVSESGGVRGSLGSPGNRENKEKKVFISLVGSRGLGCSISSGPIQKPGIFISHVKPGSLSAEVGLEIGDQIVEVNGVDFSNLDHKEAVNVLKSSRSLTISIVAAAGRELFMTDRERLAEARQRELQRQELLMQKRLAMESNKILQEQQEMERQRRKEIAQKAAEENERYRKEMEQIVEEEEKFKKQWEEDWGSKEQLLLPKTITAEVHPVPLRKPKSFGWFYRYDGKFPTIRKKGKDKKKAKYGSLQDLRKNKKELEFEQKLYKEKEEMLEKEKQLKINRLAQEVSETEREDLEESEKIQYWVERLCQTRLEQISSADNEISEMTTGPPPPPPSVSPLAPPLRRFAGGLHLHTTDLDDIPLDMFYYPPKTPSALPVMPHPPPSNPPHKVPAPPVLPLSGHVSASSSPWVQRTPPPIPIPPPPSVPTQDLTPTRPLPSALEEALSNHPFRTGDTGNPVEDWEAKNHSGKPTNSPVPEQSFPPTPKTFCPSPQPPRGPGVSTISKPVMVHQEPNFIYRPAVKSEVLPQEMLKRMVVYQTAFRQDFRKYEEGFDPYSMFTPEQIMGKDVRLLRIKKEGSLDLALEGGVDSPIGKVVVSAVYERGAAERHGGIVKGDEIMAINGKIVTDYTLAEAEAALQKAWNQGGDWIDLVVAVCPPKEYDDELASLPSSVAESPQPVRKLLEDRAAVHRHGFLLQLEPTDLLLKSKRGNQIHR>sp|Q14119|VEZF1_HUMAN Vascular endothelial zinc finger 1 OS=Homo sapiensOX=9606 GN=VEZF1 PE=1 SV=2MEANWTAFLFQAHEASHHQQQAAQNSLLPLLSSAVEPPDQKPLLPIPITQKPQGAPETLKDAIGIKKEKPKTSFVCTYCSKAFRDSYHLRRHESCHTGIKLVSRPKKTPTTVVPLISTIAGDSSRTSLVSTIAGILSTVTTSSSGTNPSSSASTTAMPVTQSVKKPSKPVKKNHACEMCGKAFRDVYHLNRHKLSHSDEKPFECPICNQRFKRKDRMTYHVRSHEGGITKPYTCSVCGKGFSRPDHLSCHVKHVHSTERPFKCQTCTAAFATKDRLRTHMVRHEGKVSCNICGKLLSAAYITSHLKTHGQSQSINCNTCKQGISKTCMSEETSNQKQQQQQQQQQQQQQQQQQQHVTSWPGKQVETLRLWEEAVKARKKEAANLCQTSTAATTPVTLTTPFSITSSVSSGTMSNPVTVAAAMSMRSPVNVSSAVNITSPMNIGHPVTITSPLSMTSPLTLTTPVNLPTPVTAPVNIAHPVTITSPMNLPTPMTLAAPLNIAMRPVESMPFLPQALPTSPPW>sp|Q14146|URB2_HUMAN Unhealthy ribosome biogenesis protein 2 homologOS=Homo sapiens OX=9606 GN=URB2 PE=1 SV=2MAAVYSGISLKLKSKTTSWEDKLKLAHFAWISHQCFLPNKEQVLLDWARQSLVAFYKKKLELKEDIVERLWIYIDNILHSRKLQNLLKNGKTINLQISLVKIINERVAEFSLSGSQRNICAVLRCCQGILSTPALAVIYTAKQELMVALLSQLCWSACRQPEGAVVAQLFEVIHLALGHYLLILQQQVNPRRAFGDVTAHLLQPCLVLRHLLSGGTWTQAGQGQLRQVLSRDIRSQIEAMFRGGIFQPELLSSYKEGLLDQQQGDVKTGAMKNLLAPMDTVLNRLVDAGYCAASLHTSVVANSVALLYKLFLDSYFKEGNQLLCFQVLPRLFGCLKISHLQEEQSKALSTSDWTTELLVVEQLLNSVANNNIYNIAADRIRHEEAQFRFYRHVAELLINHAQAPIPAWFRCLKTLISLNHLILEPDLDDLLASAWIDAEVTEFRTKKAQEALIRTVFQTYAKLRQVPRLFEEVLGVICRPAAEALRQPVLASGPSTVLSACLLELPPSQILDTWSLVLEKFQSLVLPYLQSDADMALKSLSLSLLLHCIMFNMRSLDSSTPLPIVRRTQCMMERMMRELVQPLLALLPDTPGPEPELWLQKVSDSVLLLSYTWAQVDAMFSLNCSQYHSMSGPLIGVALEISNLPSLLPGVKTQHWKKIEKFTAQFSSLGTYCLEQLYLQKMKRTLMQTSFRSEGAIQSLRCDAAFIIGSGRKSLNQRTTASWDGQVGMVSGLTYPVAHWHLIVSNLTILISYLCPDDVGYLASVLLRTLPMGKAQEVSIDEEAYITLEKISKAFLHSPLFPEMQSLHSAFLTCVTTSCSSILCSGAQRDSGLVSQQLPWLFEKDHMVVGHWENRFAKAGPEGIEPRGEIAQNLLSLVKSDFPIQLEGEQLESILGLLEVISALQLDSLLPPYHVHYFLVLLSMAVTKLGCSCSSSLALKFLTTCYQLLGYLQKGKSARSVFKIMYGSDIFEVVLTSLFRASSRFLIEMDDPAWLEFLQVIGTFLEELMQMLIQMKLSLVLNFRKITAFLSSSKPYTEAASSKQLENQNPQGRQLLLVSLTRLCHVLGPFLKEQKLGQEAPAALSELLQQVVLQTGAVLQLCSVPGARGWRLPSVLISSVSTLLEADLGQHCRDGGADISQGSDRTLLSHVALYQGVYSQILLELPALAGHDQSFQAALQFLTLFFLAPELHPKKDSVFTSMFHSVRRVLADPEIPVQVTQDIEPHLGALFTQMLEVGTTEDLRLVMQCILQGLDVSNMWKADVQAVVSAVTLLRLLLNCPLSGEKASLLWRACPQIVTALTLLNREASQEQPVSLTVVGPVLDVLAALLRQGEEAIGNPHHVSLAFSILLTVPLDHLKPLEYGSVFPRLHNVLFSILQCHPKVMLKAIPSFLNSFNRLVFSVMREGRQKDKGSIDDLPTVLKCARLVERMYSHIAARAEEFAVFSPFMVAQYVLEVQKVTLYPAVKSLLQEGIYLILDLCIEPDVQFLRASLQPGMRDIFKELYNDYLKYHKAKHEGEKRYTA>sp|O75348|VATG1_HUMAN V-type proton ATPase subunit G 1 OS=Homo sapiensOX=9606 GN=ATP6V1G1 PE=1 SV=3MASQSQGIQQLLQAEKRAAEKVSEARKRKNRRLKQAKEEAQAEIEQYRLQREKEFKAKEAAALGSRGSCSTEVEKETQEKMTILQTYFRQNRDEVLDNLLAFVCDIRPEIHENYRING>sp|Q9NS37|ZHANG_HUMAN CREB/ATF bZIP transcription factor OS=Homo sapiensOX=9606 GN=CREBZF PE=1 SV=2MRHSLTKLLAASGSNSPTRSESPEPAATCSLPSDLTRAAAGEEETAAAGSPGRKQQFGDEGELEAGRGSRGGVAVRAPSPEEMEEEAIASLPGEETEDMDFLSGLELADLLDPRQPDWHLDPGLSSPGPLSSSGGGSDSGGLWRGDDDDEAAAAEMQRFSDLLQRLLNGIGGCSSSSDSGSAEKRRRKSPGGGGGGGSGNDNNQAATKSPRKAAAAAARLNRLKKKEYVMGLESRVRGLAAENQELRAENRELGKRVQALQEESRYLRAVLANETGLARLLSRLSGVGLRLTTSLFRDSPAGDHDYALPVGKQKQDLLEEDDSAGGVCLHVDKDKVSVEFCSACARKASSSLKM>sp|Q9Y2X9|ZN281_HUMAN Zinc finger protein 281 OS=Homo sapiens OX=9606GN=ZNF281 PE=1 SV=1MKIGSGFLSGGGGTGSSGGSGSGGGGSGGGGGGGSSGRRAEMEPTFPQGMVMFNHRLPPVTSFTRPAGSAAPPPQCVLSSSTSAAPAAEPPPPPAPDMTFKKEPAASAAAFPSQRTSWGFLQSLVSIKQEKPADPEEQQSHHHHHHHHYGGLFAGAEERSPGLGGGEGGSHGVIQDLSILHQHVQQQPAQHHRDVLLSSSSRTDDHHGTEEPKQDTNVKKAKRPKPESQGIKAKRKPSASSKPSLVGDGEGAILSPSQKPHICDHCSAAFRSSYHLRRHVLIHTGERPFQCSQCSMGFIQKYLLQRHEKIHSREKPFGCDQCSMKFIQKYHMERHKRTHSGEKPYKCDTCQQYFSRTDRLLKHRRTCGEVIVKGATSAEPGSSNHTNMGNLAVLSQGNTSSSRRKTKSKSIAIENKEQKTGKTNESQISNNINMQSYSVEMPTVSSSGGIIGTGIDELQKRVPKLIFKKGSRKNTDKNYLNFVSPLPDIVGQKSLSGKPSGSLGIVSNNSVETIGLLQSTSGKQGQISSNYDDAMQFSKKRRYLPTASSNSAFSINVGHMVSQQSVIQSAGVSVLDNEAPLSLIDSSALNAEIKSCHDKSGIPDEVLQSILDQYSNKSESQKEDPFNIAEPRVDLHTSGEHSELVQEENLSPGTQTPSNDKASMLQEYSKYLQQAFEKSTNASFTLGHGFQFVSLSSPLHNHTLFPEKQIYTTSPLECGFGQSVTSVLPSSLPKPPFGMLFGSQPGLYLSALDATHQQLTPSQELDDLIDSQKNLETSSAFQSSSQKLTSQKEQKNLESSTGFQIPSQELASQIDPQKDIEPRTTYQIENFAQAFGSQFKSGSRVPMTFITNSNGEVDHRVRTSVSDFSGYTNMMSDVSEPCSTRVKTPTSQSYR>sp|Q9Y2X9-2|ZN281_HUMAN Isoform 2 of Zinc finger protein 281 OS=Homosapiens OX=9606 GN=ZNF281MKIGSGFLSGGGGTGSSGGSGSGGGGSGGGGGGGSSGRRAEMEPTFPQAPAAEPPPPPAPDMTFKKEPAASAAAFPSQRTSWGFLQSLVSIKQEKPADPEEQQSHHHHHHHHYGGLFAGAEERSPGLGGGEGGSHGVIQDLSILHQHVQQQPAQHHRDVLLSSSSRTDDHHGTEEPKQDTNVKKAKRPKPESQGIKAKRKPSASSKPSLVGDGEGAILSPSQKPHICDHCSAAFRSSYHLRRHVLIHTGERPFQCSQCSMGFIQKYLLQRHEKIHSREKPFGCDQCSMKFIQKYHMERHKRTHSGEKPYKCDTCQQYFSRTDRLLKHRRTCGEVIVKGATSAEPGSSNHTNMGNLAVLSQGNTSSSRRKTKSKSIAIENKEQKTGKTNESQISNNINMQSYSVEMPTVSSSGGIIGTGIDELQKRVPKLIFKKGSRKNTDKNYLNFVSPLPDIVGQKSLSGKPSGSLGIVSNNSVETIGLLQSTSGKQGQISSNYDDAMQFSKKRRYLPTASSNSAFSINVGHMVSQQSVIQSAGVSVLDNEAPLSLIDSSALNAEIKSCHDKSGIPDEVLQSILDQYSNKSESQKEDPFNIAEPRVDLHTSGEHSELVQEENLSPGTQTPSNDKASMLQEYSKYLQQAFEKSTNASFTLGHGFQFVSLSSPLHNHTLFPEKQIYTTSPLECGFGQSVTSVLPSSLPKPPFGMLFGSQPGLYLSALDATHQQLTPSQELDDLIDSQKNLETSSAFQSSSQKLTSQKEQKNLESSTGFQIPSQELASQIDPQKDIEPRTTYQIENFAQAFGSQFKSGSRVPMTFITNSNGEVDHRVRTSVSDFSGYTNMMSDVSEPCSTRVKTPTSQSYR>sp|Q9H9H4|VP37B_HUMAN Vacuolar protein sorting-associated protein 37BOS=Homo sapiens OX=9606 GN=VPS37B PE=1 SV=1MAGAGSEARFAGLSLVQLNELLEDEGQLTEMVQKMEETQNVQLNKEMTLASNRSLAEGNLLYQPQLDTLKARLTQKYQELQVLFEAYQIKKTKLDRQSSSASLETLLALLQAEGAKIEEDTENMAEKFLDGELPLDSFIDVYQSKRKLAHMRRVKIEKLQEMVLKGQRLPQALAPLPPRLPELAPTAPLPYPAPEASGPPAVAPRRIPPPPPPVPAGRLATPFTAAMSSGQAVPYPGLQCPPLPPRVGLPTQQGFSSQFVSPYPPPLPQRPPPRLPPHQPGFILQ>sp|Q9P2L0|WDR35_HUMAN WD repeat-containing protein 35 OS=Homo sapiensOX=9606 GN=WDR35 PE=1 SV=3MFFYLSKKISIPNNVKLQCVSWNKEQGFIACGGEDGLLKVLKLETQTDDAKLRGLAAPSNLSMNQTLEGHSGSVQVVTWNEQYQKLTTSDENGLIIVWMLYKGSWIEEMINNRNKSVVRSMSWNADGQKICIVYEDGAVIVGSVDGNRIWGKDLKGIQLSHVTWSADSKVLLFGMANGEIHIYDNQGNFMIKMKLSCLVNVTGAISIAGIHWYHGTEGYVEPDCPCLAVCFDNGRCQIMRHENDQNPVLIDTGMYVVGIQWNHMGSVLAVAGFQKAAMQDKDVNIVQFYTPFGEHLGTLKVPGKEISALSWEGGGLKIALAVDSFIYFANIRPNYKWGYCSNTVVYAYTRPDRPEYCVVFWDTKNNEKYVKYVKGLISITTCGDFCILATKADENHPQEENEMETFGATFVLVLCNSIGTPLDPKYIDIVPLFVAMTKTHVIAASKEAFYTWQYRVAKKLTALEINQITRSRKEGRERIYHVDDTPSGSMDGVLDYSKTIQGTRDPICAITASDKILIVGRESGTIQRYSLPNVGLIQKYSLNCRAYQLSLNCNSSRLAIIDISGVLTFFDLDARVTDSTGQQVVGELLKLERRDVWDMKWAKDNPDLFAMMEKTRMYVFRNLDPEEPIQTSGYICNFEDLEIKSVLLDEILKDPEHPNKDYLINFEIRSLRDSRALIEKVGIKDASQFIEDNPHPRLWRLLAEAALQKLDLYTAEQAFVRCKDYQGIKFVKRLGKLLSESMKQAEVVGYFGRFEEAERTYLEMDRRDLAIGLRLKLGDWFRVLQLLKTGSGDADDSLLEQANNAIGDYFADRQKWLNAVQYYVQGRNQERLAECYYMLEDYEGLENLAISLPENHKLLPEIAQMFVRVGMCEQAVTAFLKCSQPKAAVDTCVHLNQWNKAVELAKNHSMKEIGSLLARYASHLLEKNKTLDAIELYRKANYFFDAAKLMFKIADEEAKKGSKPLRVKKLYVLSALLIEQYHEQMKNAQRGKVKGKSSEATSALAGLLEEEVLSTTDRFTDNAWRGAEAYHFFILAQRQLYEGCVDTALKTALHLKDYEDIIPPVEIYSLLALCACASRAFGTCSKAFIKLKSLETLSSEQKQQYEDLALEIFTKHTSKDNRKPELDSLMEGGEGKLPTCVATGSPITEYQFWMCSVCKHGVLAQEISHYSFCPLCHSPVG>sp|Q9P2L0-2|WDR35_HUMAN Isoform 2 of WD repeat-containing protein 35OS=Homo sapiens OX=9606 GN=WDR35MFFYLSKKISIPNNVKLQCVSWNKEQGFIACGGEDGLLKVLKLETQTDDAKLRGLAAPSNLSMNQTLEGHSGSVQVVTWNEQYQKLTTSDENGLIIVWMLYKGSWIEEMINNRNKSVVRSMSWNADGQKICIVYEDGAVIVGSVDGNRIWGKDLKGIQLSHVTWSADSKVLLFGMANGEIHIYDNQGNFMIKMKLSCLVNVTGAISIAGIHWYHGTEGYVEPDCPCLAVCFDNGRCQIMRHENDQNPVLIDTGMYVVGIQWNHMGSVLAVAGFQKAAMQDKDVNIVQFYTPFGEHLGTLKVPGKEISALSWEGGGLKIALAVDSFIYFANIRPNYKWGYCSNTVVYAYTRPDRPEYCVVFWDTKNNEKYVKYVKGLISITTCGDFCILATKADENHPQFVLVLCNSIGTPLDPKYIDIVPLFVAMTKTHVIAASKEAFYTWQYRVAKKLTALEINQITRSRKEGRERIYHVDDTPSGSMDGVLDYSKTIQGTRDPICAITASDKILIVGRESGTIQRYSLPNVGLIQKYSLNCRAYQLSLNCNSSRLAIIDISGVLTFFDLDARVTDSTGQQVVGELLKLERRDVWDMKWAKDNPDLFAMMEKTRMYVFRNLDPEEPIQTSGYICNFEDLEIKSVLLDEILKDPEHPNKDYLINFEIRSLRDSRALIEKVGIKDASQFIEDNPHPRLWRLLAEAALQKLDLYTAEQAFVRCKDYQGIKFVKRLGKLLSESMKQAEVVGYFGRFEEAERTYLEMDRRDLAIGLRLKLGDWFRVLQLLKTGSGDADDSLLEQANNAIGDYFADRQKWLNAVQYYVQGRNQERLAECYYMLEDYEGLENLAISLPENHKLLPEIAQMFVRVGMCEQAVTAFLKCSQPKAAVDTCVHLNQWNKAVELAKNHSMKEIGSLLARYASHLLEKNKTLDAIELYRKANYFFDAAKLMFKIADEEAKKGSKPLRVKKLYVLSALLIEQYHEQMKNAQRGKVKGKSSEATSALAGLLEEEVLSTTDRFTDNAWRGAEAYHFFILAQRQLYEGCVDTALKTALHLKDYEDIIPPVEIYSLLALCACASRAFGTCSKAFIKLKSLETLSSEQKQQYEDLALEIFTKHTSKDNRKPELDSLMEGGEGKLPTCVATGSPITEYQFWMCSVCKHGVLAQEISHYSFCPLCHSPVG>sp|O00308|WWP2_HUMAN NEDD4-like E3 ubiquitin-protein ligase WWP2 OS=Homosapiens OX=9606 GN=WWP2 PE=1 SV=2MASASSSRAGVALPFEKSQLTLKVVSAKPKVHNRQPRINSYVEVAVDGLPSETKKTGKRIGSSELLWNEIIILNVTAQSHLDLKVWSCHTLRNELLGTASVNLSNVLKNNGGKMENMQLTLNLQTENKGSVVSGGELTIFLDGPTVDLGNVPNGSALTDGSQLPSRDSSGTAVAPENRHQPPSTNCFGGRSRTHRHSGASARTTPATGEQSPGARSRHRQPVKNSGHSGLANGTVNDEPTTATDPEEPSVVGVTSPPAAPLSVTPNPNTTSLPAPATPAEGEEPSTSGTQQLPAAAQAPDALPAGWEQRELPNGRVYYVDHNTKTTTWERPLPPGWEKRTDPRGRFYYVDHNTRTTTWQRPTAEYVRNYEQWQSQRNQLQGAMQHFSQRFLYQSSSASTDHDPLGPLPPGWEKRQDNGRVYYVNHNTRTTQWEDPRTQGMIQEPALPPGWEMKYTSEGVRYFVDHNTRTTTFKDPRPGFESGTKQGSPGAYDRSFRWKYHQFRFLCHSNALPSHVKISVSRQTLFEDSFQQIMNMKPYDLRRRLYIIMRGEEGLDYGGIAREWFFLLSHEVLNPMYCLFEYAGKNNYCLQINPASSINPDHLTYFRFIGRFIAMALYHGKFIDTGFTLPFYKRMLNKRPTLKDLESIDPEFYNSIVWIKENNLEECGLELYFIQDMEILGKVTTHELKEGGESIRVTEENKEEYIMLLTDWRFTRGVEEQTKAFLDGFNEVAPLEWLRYFDEKELELMLCGMQEIDMSDWQKSTIYRHYTKNSKQIQWFWQVVKEMDNEKRIRLLQFVTGTCRLPVGGFAELIGSNGPQKFCIDKVGKETWLPRSHTCFNRLDLPPYKSYEQLREKLLYAIEETEGFGQE>sp|O00308-2|WWP2_HUMAN Isoform 2 of NEDD4-like E3 ubiquitin-proteinligase WWP2 OS=Homo sapiens OX=9606 GN=WWP2MQLTLNLQTENKGSVVSGGELTIFLDGPTVDLGNVPNGSALTDGSQLPSRDSSGTAVAPENRHQPPSTNCFGGRSRTHRHSGASARTTPATGEQSPGARSRHRQPVKNSGHSGLANGTVNDEPTTATDPEEPSVVGVTSPPAAPLSVTPNPNTTSLPAPATPAEGEEPSTSGTQQLPAAAQAPDALPAGWEQRELPNGRVYYVDHNTKTTTWERPLPPGWEKRTDPRGRFYYVDHNTRTTTWQRPTAEYVRNYEQWQSQRNQLQGAMQHFSQRFLYQSSSASTDHDPLGPLPPGWEKRQDNGRVYYVNHNTRTTQWEDPRTQGMIQEPALPPGWEMKYTSEGVRYFVDHNTRTTTFKDPRPGFESGTKQGSPGAYDRSFRWKYHQFRFLCHSNALPSHVKISVSRQTLFEDSFQQIMNMKPYDLRRRLYIIMRGEEGLDYGGIAREWFFLLSHEVLNPMYCLFEYAGKNNYCLQINPASSINPDHLTYFRFIGRFIAMALYHGKFIDTGFTLPFYKRMLNKRPTLKDLESIDPEFYNSIVWIKENNLEECGLELYFIQDMEILGKVTTHELKEGGESIRVTEENKEEYIMLLTDWRFTRGVEEQTKAFLDGFNEVAPLEWLRYFDEKELELMLCGMQEIDMSDWQKSTIYRHYTKNSKQIQWFWQVVKEMDNEKRIRLLQFVTGTCRLPVGGFAELIGSNGPQKFCIDKVGKETWLPRSHTCFNRLDLPPYKSYEQLREKLLYAIEETEGFGQE>sp|O00308-3|WWP2_HUMAN Isoform 3 of NEDD4-like E3 ubiquitin-proteinligase WWP2 OS=Homo sapiens OX=9606 GN=WWP2MIQEPALPPGWEMKYTSEGVRYFVDHNTRTTTFKDPRPGFESGTKQGSPGAYDRSFRWKYHQFRFLCHSNALPSHVKISVSRQTLFEDSFQQIMNMKPYDLRRRLYIIMRGEEGLDYGGIAREWFFLLSHEVLNPMYCLFEYAGKNNYCLQINPASSINPDHLTYFRFIGRFIAMALYHGKFIDTGFTLPFYKRMLNKRPTLKDLESIDPEFYNSIVWIKENNLEECGLELYFIQDMEILGKVTTHELKEGGESIRVTEENKEEYIMLLTDWRFTRGVEEQTKAFLDGFNEVAPLEWLRYFDEKELELMLCGMQEIDMSDWQKSTIYRHYTKNSKQIQWFWQVVKEMDNEKRIRLLQFVTGTCRLPVGGFAELIGSNGPQKFCIDKVGKETWLPRSHTCFNRLDLPPYKSYEQLREKLLYAIEETEGFGQE>sp|O00308-4|WWP2_HUMAN Isoform 4 of NEDD4-like E3 ubiquitin-proteinligase WWP2 OS=Homo sapiens OX=9606 GN=WWP2MASASSSRAGVALPFEKSQLTLKVVSAKPKVHNRQPRINSYVEVAVDGLPSETKKTGKRIGSSELLWNEIIILNVTAQSHLDLKVWSCHTLRNELLGTASVNLSNVLKNNGGKMENMQLTLNLQTENKGSVVSGGELTIFLDGPTVDLGNVPNGSALTDGSQLPSRDSSGTAVAPENRHQPPSTNCFGGRSRTHRHSGASARTTPATGEQSPGARSRHRQPVKNSGHSGLANGTVNDEPTTATDPEEPSVVGVTSPPAAPLSVTPNPNTTSLPAPATPAEGEEPSTSGTQQLPAAAQAPDALPAGWEQRELPNGRVYYVDHNTKTTTWERPLPPG>sp|Q5JSH3|WDR44_HUMAN WD repeat-containing protein 44 OS=Homo sapiensOX=9606 GN=WDR44 PE=1 SV=1MASESDTEEFYDAPEDVHLGGGYPVGSPGKVGLSTFKETENTAYKVGNESPVQELKQDVSKKIIESIIEESQKVLQLEDDSLDSKGKELSDQATASPIVARTDLSNIPGLLAIDQVLPEESQKAESQNTFEETELELKKCFPSDETCEKPVDETTKLTQTSSTEQLNVLETETEVLNKEAVEVKGGGDVLEPVSSDSLSTKDFAAVEEVAPAKPPRHLTPEPDIVASTKKPVPARPPPPTNFPPPRPPPPSRPAPPPRKRKSELEFETLKTPDIDVPKENITSDSLLTASMASESTVKDSQPSLDLASATSGDKIVTAQENGKAPDGQTVAGEVMGPQRPRSNSGRELTDEEILASVMIKNLDTGEEIPLSLAEEKLPTGINPLTLHIMRRTKEYVSNDAAQSDDEEKLQSQPTDTDGGRLKQKTTQLKKFLGKSVKRAKHLAEEYGERAINKVKSVRDEVFHTDQDDPSSSDDEGMPYTRPVKFKAAHGFKGPYDFDQIKVVQDLSGEHMGAVWTMKFSHCGRLLASAGQDNVVRIWALKNAFDYFNNMRMKYNTEGRVSPSPSQESLSSSKSDTDTGVCSGTDEDPDDKNAPFRQRPFCKYKGHTADLLDLSWSKNYFLLSSSMDKTVRLWHISRRECLCCFQHIDFVTAIAFHPRDDRYFLSGSLDGKLRLWNIPDKKVALWNEVDGQTKLITAANFCQNGKYAVIGTYDGRCIFYDTEHLKYHTQIHVRSTRGRNKVGRKITGIEPLPGENKILVTSNDSRIRLYDLRDLSLSMKYKGYVNSSSQIKASFSHDFTYLVSGSEDKYVYIWSTYHDLSKFTSVRRDRNDFWEGIKAHNAVVTSAIFAPNPSLMLSLDVQSEKSEGNEKSEDAEVLDATPSGIMKTDNTEVLLSADFTGAIKVFVNKRKNVS>sp|Q5JSH3-2|WDR44_HUMAN Isoform 2 of WD repeat-containing protein 44OS=Homo sapiens OX=9606 GN=WDR44MASESDTEEFYDAPEDVHLGGGYPVGSPGKVGLSTFKETENTAYKVGNESPVQELKQDVSKKIIESIIEESQKVLQLEDDSLDSKGKELSDQATASPIVARTDLSNIPGLLAIDQVLPEESQKAESQNTFEETELELKKCFPSDETCEKPVDETTKLTQTSSTEQLNVLETETEVLNKEAVEVKGGGDVLEPVSSDSLSTKDFAAVEEVAPAKPPRHLTPEPDIVASTKKPVPARPPPPTNFPPPRPPPPSRPAPPPRKRKSELEFETLKTPDIDVPKENITSDSLLTASMASESTVKDSQPSLDLASATSGDKIVTAQENGKAPDGQTVAGEVMGPQRPRSNSGRELTDEEILASVMIKNLDTGEEIPLSLAEEKLPTGINPLTLHIMRRTKEYVSNDAAQSDDEEKLQSQPTDTDGGRLKQKTTQLKKFLGKSVKRAKHLAEEYGERAINKVKSVRDEVFHTDQDDPSSSDDEGMPYTRPVKFKAAHGFKGPYDFDQIKVVQDLSGEHMGAVWTMKFSHCGRLLASAGQDNVVRIWALKNAFDYFNNMRMKYNTEGRVSPSPSQESLSSSKSDTDTGVCSGTDEDPDDKNAPFRQRPFCKYKGHTADLLDLSWSKNYFLLSSSMDKTVRLWHISRRECLCCFQHIDFVTAIAFHPRDDRYFLSGSLDGKLRLWNIPDKKVALWNEVDGQTKLITAANFCQNGKYAVIGTYDGRCIFYDTEHLKYHTQIHVRSTRGRNKVGRKITGIEPLPGENKILVTSNDSRIRLYDLRDLSLSMKYKGYVNSSSQIKASFSGSEDKYVYIWSTYHDLSKFTSVRRDRNDFWEGIKAHNAVVTSAIFAPNPSLMLSLDVQSEKSEGNEKSEDAEVLDATPSGIMKTDNTEVLLSADFTGAIKVFVNKRKNVS>sp|Q5JSH3-3|WDR44_HUMAN Isoform 3 of WD repeat-containing protein 44OS=Homo sapiens OX=9606 GN=WDR44MVNVPYTRPVKFKAAHGFKGPYDFDQIKVVQDLSGEHMGAVWTMKFSHCGRLLASAGQDNVVRIWALKNAFDYFNNMRMKYNTEGRVSPSPSQESLSSSKSDTDTGVCSGTDEDPDDKNAPFRQRPFCKYKGHTADLLDLSWSKNYFLLSSSMDKTVRLWHISRRECLCCFQHIDFVTAIAFHPRDDRYFLSGSLDGKLRLWNIPDKKVALWNEVDGQTKLITAANFCQNGKYAVIGTYDGRCIFYDTEHLKYHTQIHVRSTRGRNKVGRKITGIEPLPGENKILVTSNDSRIRLYDLRDLSLSMKYKGYVNSSSQIKASFSHDFTYLVSGSEDKYVYIWSTYHDLSKFTSVRRDRNDFWEGIKAHNAVVTSAIFAPNPSLMLSLDVQSEKSEGNEKSEDAEVLDATPSGAVAHACNPSTLGGRGRRIT>sp|Q5JSH3-4|WDR44_HUMAN Isoform 4 of WD repeat-containing protein 44OS=Homo sapiens OX=9606 GN=WDR44MASESDTEEFYDAPEDVHLGGGYPVGSPGKVGLSTFKIIESIIEESQKVLQLEDDSLDSKGKELSDQATASPIVARTDLSNIPGLLAIDQVLPEESQKAESQNTFEETELELKKCFPSDETCEKPVDETTKLTQTSSTEQLNVLETETEVLNKEAVEVKGGGDVLEPVSSDSLSTKDFAAVEEVAPAKPPRHLTPEPDIVASTKKPVPARPPPPTNFPPPRPPPPSRPAPPPRKRKSELEFETLKTPDIDVPKENITSDSLLTASMASESTVKDSQPSLDLASATSGDKIVTAQENGKAPDGQTVAGEVMGPQRPRSNSGRELTDEEILASVMIKNLDTGEEIPLSLAEEKLPTGINPLTLHIMRRTKEYVSNDAAQSDDEEKLQSQPTDTDGGRLKQKTTQLKKFLGKSVKRAKHLAEEYGERAINKVKSVRDEVFHTDQDDPSSSDDEGMPYTRPVKFKAAHGFKGPYDFDQIKVVQDLSGEHMGAVWTMKFSHCGRLLASAGQDNVVRIWALKNAFDYFNNMRMKYNTEGRVSPSPSQESLSSSKSDTDTGVCSGTDEDPDDKNAPFRQRPFCKYKGHTADLLDLSWSKNYFLLSSSMDKTVRLWHISRRECLCCFQHIDFVTAIAFHPRHLKYHTQIHVRSTRGRNKVGRKITGIEPLPGENKILVTSNDSRIRLYDLRDLSLSMKYKGYVNSSSQIKASFSHDFTYLVSGSEDKYVYIWSTYHDLSKFTSVRRDRNDFWEGIKAHNAVVTSAIFAPNPSLMLSLDVQSEKSEGNEKSEDAEVLDATPSGIMKTDNTEVLLSADFTGAIKVFVNKRKNVS>sp|P52741|ZN134_HUMAN Zinc finger protein 134 OS=Homo sapiens OX=9606GN=ZNF134 PE=1 SV=2MTLVTAGGAWTGPGCWHEVKDEESSSEQSISIAVSHVNTSKAGLPAQTALPCDICGPILKDILHLDEHQGTHHGLKLHTCGACGRQFWFSANLHQYQKCYSIEQPLRRDKSEASIVKNCTVSKEPHPSEKPFTCKEEQKNFQATLGGCQQKAIHSKRKTHRSTESGDAFHGEQMHYKCSECGKAFSRKDTLVQHQRIHSGEKPYECSECGKAFSRKATLVQHQRIHTGERPYECSECGKTFSRKDNLTQHKRIHTGEMPYKCNECGKYFSHHSNLIVHQRVHNGARPYKCSDCGKVFRHKSTLVQHESIHTGENPYDCSDCGKSFGHKYTLIKHQRIHTESKPFECIECGKFFSRSSDYIAHQRVHTGERPFVCSKCGKDFIRTSHLVRHQRVHTGERPYECSECGKAYSLSSHLNRHQKVHTAGRL>sp|P52741-2|ZN134_HUMAN Isoform 2 of Zinc finger protein 134 OS=Homosapiens OX=9606 GN=ZNF134MWGMWETILVQCNLHQYQKCYSIEQPLRRDKSEASIVKNCTVSKEPHPSEKPFTCKEEQKNFQATLGGCQQKAIHSKRKTHRSTESGDAFHGEQMHYKCSECGKAFSRKDTLVQHQRIHSGEKPYECSECGKAFSRKATLVQHQRIHTGERPYECSECGKTFSRKDNLTQHKRIHTGEMPYKCNECGKYFSHHSNLIVHQRVHNGARPYKCSDCGKVFRHKSTLVQHESIHTGENPYDCSDCGKSFGHKYTLIKHQRIHTESKPFECIECGKFFSRSSDYIAHQRVHTGERPFVCSKCGKDFIRTSHLVRHQRVHTGERPYECSECGKAYSLSSHLNRHQKVHTAGRL>sp|Q8NF99|ZN397_HUMAN Zinc finger protein 397 OS=Homo sapiens OX=9606GN=ZNF397 PE=1 SV=2MAVESGVISTLIPQDPPEQELILVKVEDNFSWDEKFKQNGSTQSCQELFRQQFRKFCYQETPGPREALSRLQELCYQWLMPELHTKEQILELLVLEQFLSILPEELQIWVQQHNPESGEEAVTLLEDLEREFDDPGQQVPASPQGPAVPWKDLTCLRASQESTDIHLQPLKTQLKSWKPCLSPKSDCENSETATKEGISEEKSQGLPQEPSFRGISEHESNLVWKQGSATGEKLRSPSQGGSFSQVIFTNKSLGKRDLYDEAERCLILTTDSIMCQKVPPEERPYRCDVCGHSFKQHSSLTQHQRIHTGEKPYKCNQCGKAFSLRSYLIIHQRIHSGEKAYECSECGKAFNQSSALIRHRKIHTGEKACKCNECGKAFSQSSYLIIHQRIHTGEKPYECNECGKTFSQSSKLIRHQRIHTGERPYECNECGKAFRQSSELITHQRIHSGEKPYECSECGKAFSLSSNLIRHQRIHSGEEPYQCNECGKTFKRSSALVQHQRIHSGDEAYICNECGKAFRHRSVLMRHQRVHTIK>sp|Q8NF99-2|ZN397_HUMAN Isoform 2 of Zinc finger protein 397 OS=Homosapiens OX=9606 GN=ZNF397MAVESGVISTLIPQDPPEQELILVKVEDNFSWDEKFKQNGSTQSCQELFRQQFRKFCYQETPGPREALSRLQELCYQWLMPELHTKEQILELLVLEQFLSILPEELQIWVQQHNPESGEEAVTLLEDLEREFDDPGQQVPASPQGPAVPWKDLTCLRASQESTDIHLQPLKTQLKSWKPCLSPKSDCENSETATKEGISEEKSQGLPQEPSFRGIKLSRPPKASSAIRWECVSPGSFPGDIIAAEATHSTISCFAINTLPATILPSKNVNRKYFS>sp|Q8NF99-3|ZN397_HUMAN Isoform 3 of Zinc finger protein 397 OS=Homosapiens OX=9606 GN=ZNF397MAVESGVISTLIPQDPPEQELILVKVEDNFSWDEKFKQNGSTQSCQELFRQQFRKFCYQETPGPREALSRLQELCYQWLMPELHTKEQILELLVLEQFLSILPEELQIWVQQHNPESGEEAVTLLEDLEREFDDPGQQVPASPQGPAVPWKDLTCLRASQESTDIHLQPLKTQLKSWKPCLSPKSGEEWEIIWKLLTLRPLFLRMQN>sp|Q7Z4V0|ZN438_HUMAN Zinc finger protein 438 OS=Homo sapiens OX=9606GN=ZNF438 PE=1 SV=1MQNSVSVPPKDEGESNIPSGTIQSRKGLQNKSQFRTIAPKIVPKVLTSRMLPCHSPSRSDQVNLGPSINSKLLGMSTQNYALMQVAGQEGTFSLVALPHVASAQPIQKPRMSLPENLKLPIPRYQPPRNSKASRKKPILIFPKSGCSKAPAQTQMCPQMSPSPPHHPELLYKPSPFEEVPSLEQAPASISTAALTNGSDHGDLRPPVTNTHGSLNPPATPASSTPEEPAKQDLTALSGKAHFVSKITSSKPSAVASEKFKEQVDLAKTMTNLSPTILGNAVQLISSVPKGKLPIPPYSRMKTMEVYKIKSDANIAGFSLPGPKADCDKIPSTTEGFNAATKVASRLPVPQVSQQSACESAFCPPTKLDLNHKTKLNSGAAKRKGRKRKVPDEILAFQGKRRKYIINKCRDGKERVKNDPQEFRDQKLGTLKKYRSIMPKPIMVIPTLASLASPTTLQSQMLGGLGQDVLLNNSLTPKYLGCKQDNSSSPKPSSVFRNGFSGIKKPWHRCHVCNHHFQFKQHLRDHMNTHTNRRPYSCRICRKSYVRPGSLSTHMKLHHGENRLKKLMCCEFCAKVFGHIRVYFGHLKEVHRVVISTEPAPSELQPGDIPKNRDMSVRGMEGSLERENKSNLEEDFLLNQADEVKLQIKCGRCQITAQSFAEIKFHLLDVHGEEIEGRLQEGTFPGSKGTQEELVQHASPDWKRHPERGKPEKVHSSSEESHACPRLKRQLHLHQNGVEMLMENEGPQSGTNKPRETCQGPECPGLHTFLLWSHSGFNCLLCAEMLGRKEDLLHHWKHQHNCEDPSKLWAILNTVSNQGVIELSSEAEK>sp|Q7Z4V0-2|ZN438_HUMAN Isoform 2 of Zinc finger protein 438 OS=Homosapiens OX=9606 GN=ZNF438MDSESNIPSGTIQSRKGLQNKSQFRTIAPKIVPKVLTSRMLPCHSPSRSDQVNLGPSINSKLLGMSTQNYALMQVAGQEGTFSLVALPHVASAQPIQKPRMSLPENLKLPIPRYQPPRNSKASRKKPILIFPKSGCSKAPAQTQMCPQMSPSPPHHPELLYKPSPFEEVPSLEQAPASISTAALTNGSDHGDLRPPVTNTHGSLNPPATPASSTPEEPAKQDLTALSGKAHFVSKITSSKPSAVASEKFKEQVDLAKTMTNLSPTILGNAVQLISSVPKGKLPIPPYSRMKTMEVYKIKSDANIAGFSLPGPKADCDKIPSTTEGFNAATKVASRLPVPQVSQQSACESAFCPPTKLDLNHKTKLNSGAAKRKGRKRKVPDEILAFQGKRRKYIINKCRDGKERVKNDPQEFRDQKLGTLKKYRSIMPKPIMVIPTLASLASPTTLQSQMLGGLGQDVLLNNSLTPKYLGCKQDNSSSPKPSSVFRNGFSGIKKPWHRCHVCNHHFQFKQHLRDHMNTHTNRRPYSCRICRKSYVRPGSLSTHMKLHHGENRLKKLMCCEFCAKVFGHIRVYFGHLKEVHRVVISTEPAPSELQPGDIPKNRDMSVRGMEGSLERENKSNLEEDFLLNQADEVKLQIKCGRCQITAQSFAEIKFHLLDVHGEEIEGRLQEGTFPGSKGTQEELVQHASPDWKRHPERGKPEKVHSSSEESHACPRLKRQLHLHQNGVEMLMENEGPQSGTNKPRETCQGPECPGLHTFLLWSHSGFNCLLCAEMLGRKEDLLHHWKHQHNCEDPSKLWAILNTVSNQGVIELSSEAEK>sp|Q7Z4V0-3|ZN438_HUMAN Isoform 3 of Zinc finger protein 438 OS=Homosapiens OX=9606 GN=ZNF438MLPCHSPSRSDQVNLGPSINSKLLGMSTQNYALMQVAGQEGTFSLVALPHVASAQPIQKPRMSLPENLKLPIPRYQPPRNSKASRKKPILIFPKSGCSKAPAQTQMCPQMSPSPPHHPELLYKPSPFEEVPSLEQAPASISTAALTNGSDHGDLRPPVTNTHGSLNPPATPASSTPEEPAKQDLTALSGKAHFVSKITSSKPSAVASEKFKEQVDLAKTMTNLSPTILGNAVQLISSVPKGKLPIPPYSRMKTMEVYKIKSDANIAGFSLPGPKADCDKIPSTTEGFNAATKVASRLPVPQVSQQSACESAFCPPTKLDLNHKTKLNSGAAKRKGRKRKVPDEILAFQGKRRKYIINKCRDGKERVKNDPQEFRDQKLGTLKKYRSIMPKPIMVIPTLASLASPTTLQSQMLGGLGQDVLLNNSLTPKYLGCKQDNSSSPKPSSVFRNGFSGIKKPWHRCHVCNHHFQFKQHLRDHMNTHTNRRPYSCRICRKSYVRPGSLSTHMKLHHGENRLKKLMCCEFCAKVFGHIRVYFGHLKEVHRVVISTEPAPSELQPGDIPKNRDMSVRGMEGSLERENKSNLEEDFLLNQADEVKLQIKCGRCQITAQSFAEIKFHLLDVHGEEIEGRLQEGTFPGSKGTQEELVQHASPDWKRHPERGKPEKVHSSSEESHACPRLKRQLHLHQNGVEMLMENEGPQSGTNKPRETCQGPECPGLHTFLLWSHSGFNCLLCAEMLGRKEDLLHHWKHQHNCEDPSKLWAILNTVSNQGVIELSSEAEK>sp|Q9UK33|ZN580_HUMAN Zinc finger protein 580 OS=Homo sapiens OX=9606GN=ZNF580 PE=1 SV=1MLLLPPRPPHPRSSSPEAMDPPPPKAPPFPKAEGPSSTPSSAAGPRPPRLGRHLLIDANGVPYTYTVQLEEEPRGPPQREAPPGEPGPRKGYSCPECARVFASPLRLQSHRVSHSDLKPFTCGACGKAFKRSSHLSRHRATHRARAGPPHTCPLCPRRFQDAAELAQHVRLH>sp|Q8NGT9|OR2A1_HUMAN Olfactory receptor 2A1/2A42 OS=Homo sapiensOX=9606 GN=OR2A1 PE=3 SV=2MGENQTMVTEFLLLGFLLGPRIQMLLFGLFSLFYIFTLLGNGAILGLISLDSRLHTPMYFFLSHLAVVDIAYTRNTVPQMLANLLHPAKPISFAGCMTQTFLCLSFGHSECLLLVLMSYDRYVAICHPLRYSVIMTWRVCITLAVTSWTCGSLLALAHVVLILRLPFSGPHEINHFFCEILSVLRLACADTWLNQVVIFAACVFFLVGPPSLVLVSYSHILAAILRIQSGEGRRKAFSTCSSHLCVVGLFFGSAIIMYMAPKSRHPEEQQKVFFLFYSFFNPTLNPLIYSLRNGEVKGALRRALGKESHS>sp|O60422|ONEC3_HUMAN One cut domain family member 3 OS=Homo sapiensOX=9606 GN=ONECUT3 PE=1 SV=2MELSLESLGGLHSVAHAQAGELLSPGHARSAAAQHRGLVAPGRPGLVAGMASLLDGGGGGGGGGAGGAGGAGSAGGGADFRGELAGPLHPAMGMACEAPGLGGTYTTLTPLQHLPPLAAVADKFHQHAAAAAVAGAHGGHPHAHPHPAAAPPPPPPPQRLAASVSGSFTLMRDERAALASVGHLYGPYGKELPAMGSPLSPLPNALPPALHGAPQPPPPPPPPPLAAYGPPGHLAGDKLLPPAAFEPHAALLGRAEDALARGLPGGGGGTGSGGAGSGSAAGLLAPLGGLAAAGAHGPHGGGGGPGGSGGGPSAGAAAEEINTKEVAQRITAELKRYSIPQAIFAQRILCRSQGTLSDLLRNPKPWSKLKSGRETFRRMWKWLQEPEFQRMSALRLAACKRKEQEQQKERALQPKKQRLVFTDLQRRTLIAIFKENKRPSKEMQVTISQQLGLELNTVSNFFMNARRRCMNRWAEEPSTAPGGPAGATATFSKA>sp|Q13438|OS9_HUMAN Protein OS-9 OS=Homo sapiens OX=9606 GN=OS9 PE=1SV=1MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQSQSSDVVIVSSKYKQRYECRLPAGAIHFQREREEETPAYQGPGIPELLSPMRDAPCLLKTKDWWTYEFCYGRHIQQYHMEDSEIKGEVLYLGYYQSAFDWDDETAKASKQHRLKRYHSQTYGNGSKCDLNGRPREAEVRFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQADSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSEVKAGMERELENIIQETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTEEDPEHRVRVRVTKLRLGGPNQDLTVLEMKRENPQLKQIEGLVKELLEREGLTAAGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|Q13438-2|OS9_HUMAN Isoform 2 of Protein OS-9 OS=Homo sapiens OX=9606GN=OS9MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQSQSSDVVIVSSKYKQRYECRLPAGAIHFQREREEETPAYQGPGIPELLSPMRDAPCLLKTKDWWTYEFCYGRHIQQYHMEDSEIKGEVLYLGYYQSAFDWDDETAKASKQHRLKRYHSQTYGNGSKCDLNGRPREAEVRFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQADSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSEVKAGMERELENIIQETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|Q13438-3|OS9_HUMAN Isoform 3 of Protein OS-9 OS=Homo sapiens OX=9606GN=OS9MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQSQSSDVVIVSSKYKQRYECRLPAGAIHFQREREEETPAYQGPGIPELLSPMRDAPCLLKTKDWWTYEFCYGRHIQQYHMEDSEIKGEVLYLGYYQSAFDWDDETAKASKQHRLKRYHSQTYGNGSKCDLNGRPREAEVRFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQADSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|Q13438-4|OS9_HUMAN Isoform 4 of Protein OS-9 OS=Homo sapiens OX=9606GN=OS9MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQSQSSDVVIVSSKYKQRYECRLPAGAIHFQREREEETPAYQGPGIPELLSPMRDAPCLLKTKDWWTYEFCYGRHIQQYHMEDSEIKGEVLYLGYYQSAFDWDDETAKASKQHRLKRYHSQTYGNGSKCDLNGRPREAEVRFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQADSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTEEDPEHRVRVRVTKLRLGGPNQDLTVLEMKRENPQLKQIEGLVKELLEREGLTAAGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|Q13438-5|OS9_HUMAN Isoform 5 of Protein OS-9 OS=Homo sapiens OX=9606GN=OS9MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQSQSSDVVIVSSKYKQRYECRLPAGAIHFQREREEETPAYQGPGIPELLSPMRDAPCLLKTKDWWTYEFCYGRHIQQYHMEDSEIKGEVLYLGYYQSAFDWDDETAKFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQAVDSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSEVKAGMERELENIIQETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|Q13438-6|OS9_HUMAN Isoform 6 of Protein OS-9 OS=Homo sapiens OX=9606GN=OS9MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQSQSSDVVIVSSKYKQRYECRLPAGAIHFQREREEETPAYQGPGIPELLSPMRDAPCLLKTKDWWTYEFCYGRHIQQYHMEDSEIKGEFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQADSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSEVKAGMERELENIIQETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|Q13438-7|OS9_HUMAN Isoform 7 of Protein OS-9 OS=Homo sapiens OX=9606GN=OS9MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQSQSSDVVIVSSKYKQRYECRLPAGAIHFQREREEETPAYQGPGIPELLSPMRDAPCLLKTKDWWTYEFCYGRHIQQYHMEDSEIKGEVLYLGYYQSAFDWDDETAKASKQHRLKRYHSQTYGNGSKCDLNGRPREAEVRFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQAVDSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSEVKAGMERELENIIQETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|Q13438-8|OS9_HUMAN Isoform 8 of Protein OS-9 OS=Homo sapiens OX=9606GN=OS9MAAETLLSSLLGLLLLGLLLPASLTGGVGSLNLEELSEMRYGIEILPLPVMGGQTKDWWTYEFCYGRHIQQYHMEDSEIKGEVLYLGYYQSAFDWDDETAKASKQHRLKRYHSQTYGNGSKCDLNGRPREAEVRFLCDEGAGISGDYIDRVDEPLSCSYVLTIRTPRLCPHPLLRPPPSAAPQAILCHPSLQPEEYMAYVQRQADSKQYGDKIIEELQDLGPQVWSETKSGVAPQKMAGASPTKDDSKDSDFWKMLNEPEDQAPGGEEVPAEEQDPSPEAADSASGAPNDFQNNVQVKVIRSPADLIRFIEELKGGTKKGKPNIGQEQPVDDAAEVPQREPEKERGDPERQREMEEEEDEDEDEDEDEDERQLLGEFEKELEGILLPSDRDRLRSETEKELDPDGLKKESERDRAMLALTSTLNKLIKRLEEKQSPELVKKHKKKRVVPKKPPPSPQPTGKIEIKIVRPWAEGTEEGARWLTDEDTRNLKEIFFNILVPGAEEAQKERQRQKELESNYRRVWGSPGGEGTGDLDEFDF>sp|O60356|NUPR1_HUMAN Nuclear protein 1 OS=Homo sapiens OX=9606 GN=NUPR1PE=1 SV=1MATFPPATSAPQQPPGPEDEDSSLDESDLYSLAHSYLGGGGRKGRTKREAAANTNRPSPGGHERKLVTKLQNSERKKRGARR>sp|O60356-2|NUPR1_HUMAN Isoform 2 of Nuclear protein 1 OS=Homo sapiensOX=9606 GN=NUPR1MATFPPATSAPQQPPGPEDEDSSLDESDLYSLAHSYLGPLIMPMPTSPLTPALVTGGGGRKGRTKREAAANTNRPSPGGHERKLVTKLQNSERKKRGARR>sp|A6NMU1|O52A4_HUMAN Olfactory receptor 52A4 OS=Homo sapiens OX=9606GN=OR52A4P PE=2 SV=1MALPITNGTLFMPFVLTFIGIPGFESVQCWIGIPFCATYVIALIGNSLLLIIIKSEPSLHEPMYIFLATLGATDISLSTSIVPKMLDIFWFHLPEIYFDACLFQMWLIHTFQGIESGVLLAMALDRCVAICYPLRRAIVFTRQLVTYIVVGVTLRPAILVIPCLLLIKCHLKLYRTKLIYHTYCERVALVKLATEDVYINKVYGILGAFIVGGLDFIFITLSYIQIFITVFHLPLKEARLKVFNTCIPHIYVFFQFYLLAFFFIFYSQIWILYPIICTYHLVQSLPTGPTIPQPLYLWVKDQTH>sp|Q9H343|O51I1_HUMAN Olfactory receptor 51I1 OS=Homo sapiens OX=9606GN=OR51I1 PE=2 SV=1MLGLNGTPFQPATLQLTGIPGIQTGLTWVALIFCILYMISIVGNLSILTLVFWEPALHQPMYYFLSMLALNDLGVSFSTLPTVISTFCFNYNHVAFNACLVQMFFIHTFSFMESGILLAMSLDRFVAICYPLRYVTVLTHNRILAMGLGILTKSFTTLFPFPFVVKRLPFCKGNVLHHSYCLHPDLMKVACGDIHVNNIYGLLVIIFTYGMDSTFILLSYALILRAMLVIISQEQRLKALNTCMSHICAVLAFYVPIIAVSMIHRFWKSAPPVVHVMMSNVYLFVPPMLNPIIYSVKTKEIRKGILKFFHKSQA>sp|P41145|OPRK_HUMAN Kappa-type opioid receptor OS=Homo sapiens OX=9606GN=OPRK1 PE=1 SV=2MDSPIQIFRGEPGPTCAPSACLPPNSSAWFPGWAEPDSNGSAGSEDAQLEPAHISPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVISIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPDDDYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSGSREKDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSTSHSTAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFPLKMRMERQSTSRVRNTVQDPAYLRDIDGMNKPV>sp|P41145-2|OPRK_HUMAN Isoform 2 of Kappa-type opioid receptor OS=Homosapiens OX=9606 GN=OPRK1MKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVISIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPDDDYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSGSREKDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSTSHSTAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFPLKMRMERQSTSRVRNTVQDPAYLRDIDGMNKPV>sp|Q8NH60|O52J3_HUMAN Olfactory receptor 52J3 OS=Homo sapiens OX=9606GN=OR52J3 PE=3 SV=2MFYHNKSIFHPVTFFLIGIPGLEDFHMWISGPFCSVYLVALLGNATILLVIKVEQTLREPMFYFLAILSTIDLALSTTSVPRMLGIFWFDAHEINYGACVAQMFLIHAFTGMEAEVLLAMAFDRYVAVCAPLHYATILTSQVLVGISMCIVIRPVLLTLPMVYLIYRLPFCQAHIIAHSYCEHMGIAKLSCGNIRINGIYGLFVVSFFVLNLVLIGISYVYILRAVFRLPSHDAQLKALSTCGAHVGVICVFYIPSVFSFLTHRFGHQIPGYIHILVANLYLIIPPSLNPIIYGVRTKQIRERVLYVFTKK>sp|A3KFT3|OR2M5_HUMAN Olfactory receptor 2M5 OS=Homo sapiens OX=9606GN=OR2M5 PE=3 SV=1MAWENQTFNSDFILLGIFNHSPTHTFLFFLVLAIFSVAFMGNSVMVLLIYLDTQLHTPMYFLLSQLFLMDLMLICSTVPKMAFNYLSGSKSISMAGCATQIFFYVSLLGSECFLLAVMSYDRYIAICHPLRYTNLMRPKICGLMTAFSWILGSMDAIIDAVATFSFSYCGSREIAHFFCDFPSLLILSCNDTSIFEKVLFICCIVMIVFPVAIIIASYARVILAVIHMGSGEGRRKAFTTCSSHLMVVGMYYGAGLFMYIRPTSDRSPMQDKLVSVFYTILTPMLNPLIYSLRNKEVTRALRKVLGKGKCGE>sp|A6NIJ9|O6C70_HUMAN Olfactory receptor 6C70 OS=Homo sapiens OX=9606GN=OR6C70 PE=3 SV=1MKNHTRQIEFILLGLTDNSQLQIVIFLFLLLNCVLSMIGNFTIIALILLDSQLKTPMYFFLRNFSFLEISFTTACIPRFLITIVTREKTISCNGCISQLFFYIFLGVTEFFLLAALSYDRYVAICKPLRYMSIMSNKVCYQLVFSSWVTGFLIIFTPLILGLNLDFCASNIIDHFICDISLILQLSCSDTHLLELIAFLLAVMTLIVTLFLVILSYSYIIKTILKFPSAQQKKKAFSTCSSHMIVVSITYGSCMFIYIKPSANERVALSKGVTVLNTSVAPLLNPFIYTLRNQQVKQAFKAVFRKIFSASDK>sp|Q8NG80|OR2L5_HUMAN Olfactory receptor 2L5 OS=Homo sapiens OX=9606GN=OR2L5 PE=3 SV=1MENYNQTSTDFILLGLFPPSKIGLFLFILFVLIFLMALIGNLSMILLIFLDTHLHTPMYFLLSQLSLIDLNYISTIVPKMASDFLYGNKSISFIGCGIQSFFFMTFAGAEALLLTSMAYDRYVAICFPLHYPIRMSKRMYVLMITGSWMIGSINSCAHTVYAFRIPYCKSRAINHFFCDVPAMLTLACTDTWVYEYTVFLSSTIFLVFPFTGIACSYGWVLLAVYRMHSAEGRKKAYSTCSTHLTVVTFYYAPFAYTYLCPRSLRSLTEDKVLAVFYTILTPMLNPIIYSLRNKEVMGALTRVIQNIFSVKM>sp|P39656|OST48_HUMAN Dolichyl-diphosphooligosaccharide--proteinglycosyltransferase 48 kDa subunit OS=Homo sapiens OX=9606 GN=DDOST PE=1SV=4MGYFRCARAGSFGRRRKMEPSTAARAWALFWLLLPLLGAVCASGPRTLVLLDNLNVRETHSLFFRSLKDRGFELTFKTADDPSLSLIKYGEFLYDNLIIFSPSVEDFGGNINVETISAFIDGGGSVLVAASSDIGDPLRELGSECGIEFDEEKTAVIDHHNYDISDLGQHTLIVADTENLLKAPTIVGKSSLNPILFRGVGMVADPDNPLVLDILTGSSTSYSFFPDKPITQYPHAVGKNTLLIAGLQARNNARVIFSGSLDFFSDSFFNSAVQKAAPGSQRYSQTGNYELAVALSRWVFKEEGVLRVGPVSHHRVGETAPPNAYTVTDLVEYSIVIQQLSNGKWVPFDGDDIQLEFVRIDPFVRTFLKKKGGKYSVQFKLPDVYGVFQFKVDYNRLGYTHLYSSTQVSVRPLQHTQYERFIPSAYPYYASAFSMMLGLFIFSIVFLHMKEKEKSD>sp|P39656-2|OST48_HUMAN Isoform 2 of Dolichyl-diphosphooligosaccharide--protein glycosyltransferase 48 kDa subunit OS=Homo sapiens OX=9606GN=DDOSTMGYFRCARAGSFGRRRKMEPSTAARAWALFWLLLPLLGAVCASGPRTLVLLDNLNVRETHSLFFRSLKDFGGNINVETISAFIDGGGSVLVAASSDIGDPLRELGSECGIEFDEEKTAVIDHHNYDISDLGQHTLIVADTENLLKAPTIVGKSSLNPILFRGVGMVADPDNPLVLDILTGSSTSYSFFPDKPITQYPHAVGKNTLLIAGLQARNNARVIFSGSLDFFSDSFFNSAVQKAAPGSQRYSQTGNYELAVALSRWVFKEEGVLRVGPVSHHRVGETAPPNAYTVTDLVEYSIVIQQLSNGKWVPFDGDDIQLEFVRIDPFVRTFLKKKGGKYSVQFKLPDVYGVFQFKVDYNRLGYTHLYSSTQVSVRPLQHTQYERFIPSAYPYYASAFSMMLGLFIFSIVFLHMKEKEKSD>sp|P39656-3|OST48_HUMAN Isoform 3 of Dolichyl-diphosphooligosaccharide--protein glycosyltransferase 48 kDa subunit OS=Homo sapiens OX=9606GN=DDOSTMGYFRCARAGSFGRRRKMEPSTAARAWALFWLLLPLLGAVCASGPRTLVLLDNLNVRETHSLFFRSLKDRGFELTFKTADDPSLSLIKYGEFLYDNLIIFSPSVEDFGGNINVETISAFIDGGGSECGIEFDEEKTAVIDHHNYDISDLGQHTLIVADTENLLKAPTIVGKSSLNPILFRGVGMVADPDNPLVLDILTGSSTSYSFFPDKPITQYPHAVGKNTLLIAGLQARNNARVIFSGSLDFFSDSFFNSAVQKAAPGSQRYSQTGNYELAVALSRWVFKEEGVLRVGPVSHHRVGETAPPNAYTVTDLVEYSIVIQQLSNGKWVPFDGDDIQLEFVRIDPFVRTFLKKKGGKYSVQFKLPDVYGVFQFKVDYNRLGYTHLYSSTQVSVRPLQHTQYERFIPSAYPYYASAFSMMLGLFIFSIVFLHMKEKEKSD>sp|O43316|PAX4_HUMAN Paired box protein Pax-4 OS=Homo sapiens OX=9606GN=PAX4 PE=1 SV=1MHQDGISSMNQLGGLFVNGRPLPLDTRQQIVRLAVSGMRPCDISRILKVSNGCVSKILGRYYRTGVLEPKGIGGSKPRLATPPVVARIAQLKGECPALFAWEIQRQLCAEGLCTQDKTPSVSSINRVLRALQEDQGLPCTRLRSPAVLAPAVLTPHSGSETPRGTHPGTGHRNRTIFSPSQAEALEKEFQRGQYPDSVARGKLATATSLPEDTVRVWFSNRRAKWRRQEKLKWEMQLPGASQGLTVPRVAPGIISAQQSPGSVPTAALPALEPLGPSCYQLCWATAPERCLSDTPPKACLKPCWDCGSFLLPVIAPSCVDVAWPCLDASLAHHLIGGAGKATPTHFSHWP>sp|O43316-2|PAX4_HUMAN Isoform 2 of Paired box protein Pax-4 OS=Homosapiens OX=9606 GN=PAX4MHQDGISSMNQLGGLFVNGRPLPLDTRQQIVRLAVSGMRPCDISRILKVSNGCVSKILGRYYRTGVLEPKGIGGSKPRLATPPVVARIAQLKGECPALFAWEIQRQLCAEGLCTQDKTPSVSSINRVLRALQEDQGLPCTRLRSPAVLAPAVLTPHSGSETPRGTHPGTGHRNRTIFSPSQAEALEKEFQRGQYPDSVARGKLATATSLPEDTVRVWFSNRRAKWRRQEKLKWEMQLPAVPWQCAHSSPACPGTTGSLLLSAVLGNSTRKVSE>sp|O43316-4|PAX4_HUMAN Isoform 3 of Paired box protein Pax-4 OS=Homosapiens OX=9606 GN=PAX4MNQLGGLFVNGRPLPLDTRQQIVRLAVSGMRPCDISRILKVSNGCVSKILGRYYRTGVLEPKGIGGSKPRLATPPVVARIAQLKGECPALFAWEIQRQLCAEGLCTQDKTPSVSSINRVLRALQEDQGLPCTRLRSPAVLAPAVLTPHSGSETPRGTHPGTGHRNRTIFSPSQAEALEKEFQRGQYPDSVARGKLATATSLPEDTVRVWFSNRRAKWRRQEKLKWEMQLPGASQGLTVPRVAPGIISAQQSPGSVPTAALPALEPLGPSCYQLCWATAPERCLSDTPPKACLKPCWGHLPPQPNSLDSGLLCLPCPSSHCHLASLSGSQALLWPGCPLLYGLE>sp|Q9UBL9|P2RX2_HUMAN P2X purinoceptor 2 OS=Homo sapiens OX=9606GN=P2RX2 PE=1 SV=1MAAAQPKYPAGATARRLARGCWSALWDYETPKVIVVRNRRLGVLYRAVQLLILLYFVWYVFIVQKSYQESETGPESSIITKVKGITTSEHKVWDVEEYVKPPEGGSVFSIITRVEATHSQTQGTCPESIRVHNATCLSDADCVAGELDMLGNGLRTGRCVPYYQGPSKTCEVFGWCPVEDGASVSQFLGTMAPNFTILIKNSIHYPKFHFSKGNIADRTDGYLKRCTFHEASDLYCPIFKLGFIVEKAGESFTELAHKGGVIGVIINWDCDLDLPASECNPKYSFRRLDPKHVPASSGYNFRFAKYYKINGTTTRTLIKAYGIRIDVIVHGQAGKFSLIPTIINLATALTSVGVGSFLCDWILLTFMNKNKVYSHKKFDKVCTPSHPSGSWPVTLARVLGQAPPEPGHRSEDQHPSPPSGQEGQQGAECGPAFPPLRPCPISAPSEQMVDTPASEPAQASTPTDPKGLAQL>sp|Q9UBL9-2|P2RX2_HUMAN Isoform B of P2X purinoceptor 2 OS=Homo sapiensOX=9606 GN=P2RX2MAAAQPKYPAGATARRLARGCWSALWDYETPKVIVVRNRRLGVLYRAVQLLILLYFVWYVFIVQKSYQESETGPESSIITKVKGITTSEHKVWDVEEYVKPPEGGSVFSIITRVEATHSQTQGTCPESIRVHNATCLSDADCVAGELDMLGNGLRTGRCVPYYQGPSKTCEVFGWCPVEDGASVSQFLGTMAPNFTILIKNSIHYPKFHFSKGNIADRTDGYLKRCTFHEASDLYCPIFKLGFIVEKAGESFTELAHKGGVIGVIINWDCDLDLPASECNPKYSFRRLDPKHVPASSGYNFRFAKYYKINGTTTRTLIKAYGIRIDVIVHGQAGKFSLIPTIINLATALTSVGVGSFLCDWILLTFMNKNKVYSHKKFDKMVDTPASEPAQASTPTDPKGLAQL>sp|Q9UBL9-3|P2RX2_HUMAN Isoform C of P2X purinoceptor 2 OS=Homo sapiensOX=9606 GN=P2RX2MAAAQPKYPAGATARRLARGCWSALWDYETPKVIVVRNRRLGVLYRAVQLLILLYFVWYVFIVQKSYQESETGPESSIITKVKGITTSEHKVWDVEEYVKPPESIRVHNATCLSDADCVAGELDMLGNGLRTGRCVPYYQGPSKTCEVFGWCPVEDGASVSQFLGTMAPNFTILIKNSIHYPKFHFSKGNIADRTDGYLKRCTFHEASDLYCPIFKLGFIVEKAGESFTELAHKGGVIGVIINWDCDLDLPASECNPKYSFRRLDPKHVPASSGYNFRFAKYYKINGTTTRTLIKAYGIRIDVIVHGQAGKFSLIPTIINLATALTSVGVGSFLCDWILLTFMNKNKVYSHKKFDKVCTPSHPSGSWPVTLARVLGQAPPEPGHRSEDQHPSPPSGQEGQQGAECGPAFPPLRPCPISAPSEQMVDTPASEPAQASTPTDPKGLAQL>sp|Q9UBL9-4|P2RX2_HUMAN Isoform D of P2X purinoceptor 2 OS=Homo sapiensOX=9606 GN=P2RX2MAAAQPKYPAGATARRLARGCWSALWDYETPKVIVVRNRRLGVLYRAVQLLILLYFVWYVFIVQKSYQESETGPESSIITKVKGITTSEHKVWDVEEYVKPPEGGSVFSIITRVEATHSQTQGTCPESIRVHNATCLSDADCVAGELDMLGNGLRTGRCVPYYQGPSKTCEVFGWCPVEDGASVSQFLGTMAPNFTILIKNSIHYPKFHFSKGNIADRTDGYLKRCTFHEASDLYCPIFKLGFIVEKAGESFTELAHKGGVIGVIINWDCDLDLPASECNPKYSFRRLDPKHVPASSGYNFRFAKYYKINGTTTRTLIKAYGIRIDVIVHGQAGKFSLIPTIINLATALTSVGVVRNPLWGPSGCGGSTRPLHTGLCWPQGSFLCDWILLTFMNKNKVYSHKKFDKVCTPSHPSGSWPVTLARVLGQAPPEPGHRSEDQHPSPPSGQEGQQGAECGPAFPPLRPCPISAPSEQMVDTPASEPAQASTPTDPKGLAQL>sp|Q9UBL9-5|P2RX2_HUMAN Isoform H of P2X purinoceptor 2 OS=Homo sapiensOX=9606 GN=P2RX2MAAAQPKYPAGATARRLARGCWSALWDYETPKVIVSIRVHNATCLSDADCVAGELDMLGNGLRTGRCVPYYQGPSKTCEVFGWCPVEDGASVSQFLGTMAPNFTILIKNSIHYPKFHFSKGNIADRTDGYLKRCTFHEASDLYCPIFKLGFIVEKAGESFTELAHKGGVIGVIINWDCDLDLPASECNPKYSFRRLDPKHVPASSGYNFRFAKYYKINGTTTRTLIKAYGIRIDVIVHGQAGKFSLIPTIINLATALTSVGVGSFLCDWILLTFMNKNKVYSHKKFDKVCTPSHPSGSWPVTLARVLGQAPPEPGHRSEDQHPSPPSGQEGQQGAECGPAFPPLRPCPISAPSEQMVDTPASEPAQASTPTDPKGLAQL>sp|Q9UBL9-6|P2RX2_HUMAN Isoform I of P2X purinoceptor 2 OS=Homo sapiensOX=9606 GN=P2RX2MAAAQPKYPAGATARRLARGCWSALWDYETPKVIVVRIHRAEKLPGERDGPRELHHHQGQGDHHVRAQSVGRGGVREAPRGLRTGRCVPYYQGPSKTCEVFGWCPVEDGASVSQFLGTMAPNFTILIKNSIHYPKFHFSKGNIADRTDGYLKRCTFHEASDLYCPIFKLGFIVEKAGESFTELAHKGGVIGVIINWDCDLDLPASECNPKYSFRRLDPKHVPASSGYNFRFAKYYKINGTTTRTLIKAYGIRIDVIVHGQAGKFSLIPTIINLATALTSVGVGSFLCDWILLTFMNKNKVYSHKKFDKVCTPSHPSGSWPVTLARVLGQAPPEPGHRSEDQHPSPPSGQEGQQGAECGPAFPPLRPCPISAPSEQMVDTPASEPAQASTPTDPKGLAQL>sp|Q9UBL9-7|P2RX2_HUMAN Isoform K of P2X purinoceptor 2 OS=Homo sapiensOX=9606 GN=P2RX2MAAAQPKYPAGATARRLARGCWSALWDYETPKVIVVRNRRLGVLYRAVQLLILLYFVWYVFIVQKSYQESETGPESSIITKVKGITTSEHKVWDVEEYVKPPESIRVHNATCLSDADCVAGELDMLGNGALQDLRGVRLVPGGRWGLCQPISGYDGPKFHHPHQEQHPLPQIPLLQGQHRRPHRRVPEALHVPRGLRPLLPHLQAGLYRGEGWGELHRARTQGRGGVIGVIINWDCDLDLPASECNPKYSFRRLDPKHVPASSGYNFRFAKYYKINGTTTRTLIKAYGIRIDVIVHGQAGKFSLIPTIINLATALTSVGVGSFLCDWILLTFMNKNKVYSHKKFDKMVDTPASEPAQASTPTDPKGLAQL>sp|Q9H340|O51B6_HUMAN Olfactory receptor 51B6 OS=Homo sapiens OX=9606GN=OR51B6 PE=3 SV=2MGLNKSASTFQLTGFPGMEKAHHWIFIPLLAAYISILLGNGTLLFLIRNDHNLHEPMYYFLAMLAATDLGVTLTTMPTVLGVLWLDHREIGHGACFSQAYFIHTLSVMESGVLLAMAYDCFITIRSPLRYTSILTNTQVMKIGVRVLTRAGLSIMPIVVRLHWFPYCRSHVLSHAFCLHQDVIKLACADITFNRLYPVVVLFAMVLLDFLIIFFSYILILKTVMGIGSGGERAKALNTCVSHICCILVFYVTVVCLTFIHRFGKHVPHVVHITMSYIHFLFPPFMNPFIYSIKTKQIQSGILRLFSLPHSRA>sp|Q8N5Y8|PAR16_HUMAN Protein mono-ADP-ribosyltransferase PARP16 OS=Homosapiens OX=9606 GN=PARP16 PE=1 SV=2MQPSGWAAAREAAGRDMLAADLRCSLFASALQSYKRDSVLRPFPASYARGDCKDFEALLADASKLPNLKELLQSSGDNHKRAWDLVSWILSSKVLTIHSAGKAEFEKIQKLTGAPHTPVPAPDFLFEIEYFDPANAKFYETKGERDLIYAFHGSRLENFHSIIHNGLHCHLNKTSLFGEGTYLTSDLSLALIYSPHGHGWQHSLLGPILSCVAVCEVIDHPDVKCQTKKKDSKEIDRRRARIKHSEGGDIPPKYFVVTNNQLLRVKYLLVYSQKPPKRASSQLSWFSSHWFTVMISLYLLLLLIVSVINSSAFQHFWNRAKR>sp|Q8N5Y8-2|PAR16_HUMAN Isoform 2 of Protein mono-ADP-ribosyltransferasePARP16 OS=Homo sapiens OX=9606 GN=PARP16MQPSGWAAAREAAGRDMLAADLRCSLFASALQSYKRDSVLRPFPASYARGDCKDFEALTSLFGEGTYLTSDLSLALIYSPHGHGWQHSLLGPILSCVAVCEVIDHPDVKCQTKKKDSKEIDRRRARIKHSEGGDIPPKYFVVTNNQLLRVKYLLVYSQKPPKRASSQLSWFSSHWFTVMISLYLLLLLIVSVINSSAFQHFWNRAKR>sp|Q8N5Y8-3|PAR16_HUMAN Isoform 3 of Protein mono-ADP-ribosyltransferasePARP16 OS=Homo sapiens OX=9606 GN=PARP16MQPSGWAAAREAAGRDMLAADLRCSLFASALQSYKRDSVLRPFPASYARGDCKDFEALLADASKLPNLKELLQSSGDNHKRAWDLVSWILSSKVLTIHSAGKAEFEKIQKLTGAPHTPVPAPDFLFEIEYFDPANAKFYETKGERDLIYAFHGSRLENFHSIIHNGLHCHLNKTSLFGEGTYLTSDLSLALIYSPHGHGWQHSLLGPILSCVAVCEVIDHPDVKCQTKKKDSKEIDRRRARIKHSEGGDIPPKYFVVTNNQLLRVKYLLVYSQKPPKSRASSQLSWFSSHWFTVMISLYLLLLLIVSVINSSAFQHFWNRAKR>sp|Q8NEB9|PK3C3_HUMAN Phosphatidylinositol 3-kinase catalytic subunittype 3 OS=Homo sapiens OX=9606 GN=PIK3C3 PE=1 SV=1MGEAEKFHYIYSCDLDINVQLKIGSLEGKREQKSYKAVLEDPMLKFSGLYQETCSDLYVTCQVFAEGKPLALPVRTSYKAFSTRWNWNEWLKLPVKYPDLPRNAQVALTIWDVYGPGKAVPVGGTTVSLFGKYGMFRQGMHDLKVWPNVEADGSEPTKTPGRTSSTLSEDQMSRLAKLTKAHRQGHMVKVDWLDRLTFREIEMINESEKRSSNFMYLMVEFRCVKCDDKEYGIVYYEKDGDESSPILTSFELVKVPDPQMSMENLVESKHHKLARSLRSGPSDHDLKPNAATRDQLNIIVSYPPTKQLTYEEQDLVWKFRYYLTNQEKALTKFLKCVNWDLPQEAKQALELLGKWKPMDVEDSLELLSSHYTNPTVRRYAVARLRQADDEDLLMYLLQLVQALKYENFDDIKNGLEPTKKDSQSSVSENVSNSGINSAEIDSSQIITSPLPSVSSPPPASKTKEVPDGENLEQDLCTFLISRACKNSTLANYLYWYVIVECEDQDTQQRDPKTHEMYLNVMRRFSQALLKGDKSVRVMRSLLAAQQTFVDRLVHLMKAVQRESGNRKKKNERLQALLGDNEKMNLSDVELIPLPLEPQVKIRGIIPETATLFKSALMPAQLFFKTEDGGKYPVIFKHGDDLRQDQLILQIISLMDKLLRKENLDLKLTPYKVLATSTKHGFMQFIQSVPVAEVLDTEGSIQNFFRKYAPSENGPNGISAEVMDTYVKSCAGYCVITYILGVGDRHLDNLLLTKTGKLFHIDFGYILGRDPKPLPPPMKLNKEMVEGMGGTQSEQYQEFRKQCYTAFLHLRRYSNLILNLFSLMVDANIPDIALEPDKTVKKVQDKFRLDLSDEEAVHYMQSLIDESVHALFAAVVEQIHKFAQYWRK>sp|Q496M5|PLK5_HUMAN Inactive serine/threonine-protein kinase PLK5OS=Homo sapiens OX=9606 GN=PLK5 PE=1 SV=4MYTVLTGTPPFMASPLSEMYQNIREGHYPEPAHLSANARRLIVHLLAPNPAERPSLDHLLQDDFFTQGFTPDRLPAHSCHSPPIFAIPPPLGRIFRKVGQRLLTQCRPPCPFTPKEASGPGEGGPDPDSMEWDGESSLSAKEVPCLEGPIHLVAQGTLQSDLAGPEGSRRPEVEAALRHLQLCLDVGPPATQDPLGEQQPILWAPKWVDYSSKYGFGYQLLDGGRTGRHPHGPATPRREGTLPTPVPPAGPGLCLLRFLASEHALLLLFSNGMVQVSFSGVPAQLVLSGEGEGLQLTLWEQGSPGTSYSLDVPRSHGCAPTTGQHLHHALRMLQSI>sp|Q496M5-2|PLK5_HUMAN Isoform 2 of Inactive serine/threonine-proteinkinase PLK5 OS=Homo sapiens OX=9606 GN=PLK5MYTVLTGTPPFMASPLSEMYQNIREGHYPEPAHLSANARRLIVHLLAPNPAERPSLDHLLQDDFFTQGFTPDRLPAHSCHSPPIFAIPPPLGRIFRKVGQRLLTQCRPPCPFTPKEASGPGEGGPDPDSMEWDGESSLSAKEVPCLEGPIHLVAQGTLQSDLAGPEGSRRPEVEAALRHLQLCLDVGPPATQDPLGEQQPILWAPKWVDYSSKYGFGYQLLDGGRTGRHPHGPATPRRVSFSGVPAQLVLSGEGEGLQLTLWEQGSPGTSYSLDVPRSHGCAPTTGQHLHHALRMLQSI>sp|Q9BRC7|PLCD4_HUMAN 1-phosphatidylinositol 4,5-bisphosphatephosphodiesterase delta-4 OS=Homo sapiens OX=9606 GN=PLCD4 PE=1 SV=1MASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSELLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLMNVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSDSGKLRHVLSMDGFLSYLCSKDGDIFNPACLPIYQDMTQPLNHYFICSSHNTYLVGDQLCGQSSVEGYIRALKRGCRCVEVDVWDGPSGEPVVYHGHTLTSRILFKDVVATVAQYAFQTSDYPVILSLETHCSWEQQQTMARHLTEILGEQLLSTTLDGVLPTQLPSPEELRRKILVKGKKLTLEEDLEYEEEEAEPELEESELALESQFETEPEPQEQNLQNKDKKKKSKPILCPALSSLVIYLKSVSFRSFTHSKEHYHFYEISSFSETKAKRLIKEAGNEFVQHNTWQLSRVYPSGLRTDSSNYNPQELWNAGCQMVAMNMQTAGLEMDICDGHFRQNGGCGYVLKPDFLRDIQSSFHPEKPISPFKAQTLLIQVISGQQLPKVDKTKEGSIVDPLVKVQIFGVRLDTARQETNYVENNGFNPYWGQTLCFRVLVPELAMLRFVVMDYDWKSRNDFIGQYTLPWTCMQQGYRHIHLLSKDGISLRPASIFVYICIQEGLEGDES>sp|Q9BRC7-2|PLCD4_HUMAN Isoform 2 of 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase delta-4 OS=Homo sapiens OX=9606 GN=PLCD4MASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSELLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLMNVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSDSGASEEDPGEGEEVNT>sp|A0A1B0GUJ8|PNM8C_HUMAN Paraneoplastic antigen-like protein 8C OS=Homosapiens OX=9606 GN=PNMA8C PE=3 SV=1MLFGVKDIALLEHGCKALEVDSYKSLMILGIPEDCNHEEFEEIIRLPLKPLGKFEVAGKAYLEEDKSKAAIIQLTEDINYAVVPREIKGKGGVWRVVYMPRKQDIEFLTKLNLFLQSEGRTVEDMARVLRQELCPPATGPRELPARKCSVPGLGEKPEAGATVQMDVVPPLDSSEKESKAGVGKRGKRKNKKNRRRHHASDKKL>sp|O00444|PLK4_HUMAN Serine/threonine-protein kinase PLK4 OS=Homosapiens OX=9606 GN=PLK4 PE=1 SV=3MATCIGEKIEDFKVGNLLGKGSFAGVYRAESIHTGLEVAIKMIDKKAMYKAGMVQRVQNEVKIHCQLKHPSILELYNYFEDSNYVYLVLEMCHNGEMNRYLKNRVKPFSENEARHFMHQIITGMLYLHSHGILHRDLTLSNLLLTRNMNIKIADFGLATQLKMPHEKHYTLCGTPNYISPEIATRSAHGLESDVWSLGCMFYTLLIGRPPFDTDTVKNTLNKVVLADYEMPSFLSIEAKDLIHQLLRRNPADRLSLSSVLDHPFMSRNSSTKSKDLGTVEDSIDSGHATISTAITASSSTSISGSLFDKRRLLIGQPLPNKMTVFPKNKSSTDFSSSGDGNSFYTQWGNQETSNSGRGRVIQDAEERPHSRYLRRAYSSDRSGTSNSQSQAKTYTMERCHSAEMLSVSKRSGGGENEERYSPTDNNANIFNFFKEKTSSSSGSFERPDNNQALSNHLCPGKTPFPFADPTPQTETVQQWFGNLQINAHLRKTTEYDSISPNRDFQGHPDLQKDTSKNAWTDTKVKKNSDASDNAHSVKQQNTMKYMTALHSKPEIIQQECVFGSDPLSEQSKTRGMEPPWGYQNRTLRSITSPLVAHRLKPIRQKTKKAVVSILDSEEVCVELVKEYASQEYVKEVLQISSDGNTITIYYPNGGRGFPLADRPPSPTDNISRYSFDNLPEKYWRKYQYASRFVQLVRSKSPKITYFTRYAKCILMENSPGADFEVWFYDGVKIHKTEDFIQVIEKTGKSYTLKSESEVNSLKEEIKMYMDHANEGHRICLALESIISEEERKTRSAPFFPIIIGRKPGSTSSPKALSPPPSVDSNYPTRERASFNRMVMHSAASPTQAPILNPSMVTNEGLGLTTTASGTDISSNSLKDCLPKSAQLLKSVFVKNVGWATQLTSGAVWVQFNDGSQLVVQAGVSSISYTSPNGQTTRYGENEKLPDYIKQKLQCLSSILLMFSNPTPNFH>sp|O00444-2|PLK4_HUMAN Isoform 2 of Serine/threonine-protein kinase PLK4OS=Homo sapiens OX=9606 GN=PLK4MATCIGEKIEDFKVGNLLGKGSFAGVYRAESIHTGLEVAIKMLYNYFEDSNYVYLVLEMCHNGEMNRYLKNRVKPFSENEARHFMHQIITGMLYLHSHGILHRDLTLSNLLLTRNMNIKIADFGLATQLKMPHEKHYTLCGTPNYISPEIATRSAHGLESDVWSLGCMFYTLLIGRPPFDTDTVKNTLNKVVLADYEMPSFLSIEAKDLIHQLLRRNPADRLSLSSVLDHPFMSRNSSTKSKDLGTVEDSIDSGHATISTAITASSSTSISGSLFDKRRLLIGQPLPNKMTVFPKNKSSTDFSSSGDGNSFYTQWGNQETSNSGRGRVIQDAEERPHSRYLRRAYSSDRSGTSNSQSQAKTYTMERCHSAEMLSVSKRSGGGENEERYSPTDNNANIFNFFKEKTSSSSGSFERPDNNQALSNHLCPGKTPFPFADPTPQTETVQQWFGNLQINAHLRKTTEYDSISPNRDFQGHPDLQKDTSKNAWTDTKVKKNSDASDNAHSVKQQNTMKYMTALHSKPEIIQQECVFGSDPLSEQSKTRGMEPPWGYQNRTLRSITSPLVAHRLKPIRQKTKKAVVSILDSEEVCVELVKEYASQEYVKEVLQISSDGNTITIYYPNGGRGFPLADRPPSPTDNISRYSFDNLPEKYWRKYQYASRFVQLVRSKSPKITYFTRYAKCILMENSPGADFEVWFYDGVKIHKTEDFIQVIEKTGKSYTLKSESEVNSLKEEIKMYMDHANEGHRICLALESIISEEERKTRSAPFFPIIIGRKPGSTSSPKALSPPPSVDSNYPTRERASFNRMVMHSAASPTQAPILNPSMVTNEGLGLTTTASGTDISSNSLKDCLPKSAQLLKSVFVKNVGWATQLTSGAVWVQFNDGSQLVVQAGVSSISYTSPNGQTTRYGENEKLPDYIKQKLQCLSSILLMFSNPTPNFH>sp|O00444-3|PLK4_HUMAN Isoform 3 of Serine/threonine-protein kinase PLK4OS=Homo sapiens OX=9606 GN=PLK4MIDKKAMYKAGMVQRVQNEVKIHCQLKHPSILELYNYFEDSNYVYLVLEMCHNGEMNRYLKNRVKPFSENEARHFMHQIITGMLYLHSHGILHRDLTLSNLLLTRNMNIKIADFGLATQLKMPHEKHYTLCGTPNYISPEIATRSAHGLESDVWSLGCMFYTLLIGRPPFDTDTVKNTLNKVVLADYEMPSFLSIEAKDLIHQLLRRNPADRLSLSSVLDHPFMSRNSSTKSKDLGTVEDSIDSGHATISTAITASSSTSISGSLFDKRRLLIGQPLPNKMTVFPKNKSSTDFSSSGDGNSFYTQWGNQETSNSGRGRVIQDAEERPHSRYLRRAYSSDRSGTSNSQSQAKTYTMERCHSAEMLSVSKRSGGGENEERYSPTDNNANIFNFFKEKTSSSSGSFERPDNNQALSNHLCPGKTPFPFADPTPQTETVQQWFGNLQINAHLRKTTEYDSISPNRDFQGHPDLQKDTSKNAWTDTKVKKNSDASDNAHSVKQQNTMKYMTALHSKPEIIQQECVFGSDPLSEQSKTRGMEPPWGYQNRTLRSITSPLVAHRLKPIRQKTKKAVVSILDSEEVCVELVKEYASQEYVKEVLQISSDGNTITIYYPNGGRGFPLADRPPSPTDNISRYSFDNLPEKYWRKYQYASRFVQLVRSKSPKITYFTRYAKCILMENSPGADFEVWFYDGVKIHKTEDFIQVIEKTGKSYTLKSESEVNSLKEEIKMYMDHANEGHRICLALESIISEEERKTRSAPFFPIIIGRKPGSTSSPKALSPPPSVDSNYPTRERASFNRMVMHSAASPTQAPILNPSMVTNEGLGLTTTASGTDISSNSLKDCLPKSAQLLKSVFVKNVGWATQLTSGAVWVQFNDGSQLVVQAGVSSISYTSPNGQTTRYGENEKLPDYIKQKLQCLSSILLMFSNPTPNFH>sp|Q8TCW9|PKR1_HUMAN Prokineticin receptor 1 OS=Homo sapiens OX=9606GN=PROKR1 PE=1 SV=1METTMGFMDDNATNTSTSFLSVLNPHGAHATSFPFNFSYSDYDMPLDEDEDVTNSRTFFAAKIVIGMALVGIMLVCGIGNFIFIAALVRYKKLRNLTNLLIANLAISDFLVAIVCCPFEMDYYVVRQLSWEHGHVLCTSVNYLRTVSLYVSTNALLAIAIDRYLAIVHPLRPRMKCQTATGLIALVWTVSILIAIPSAYFTTETVLVIVKSQEKIFCGQIWPVDQQLYYKSYFLFIFGIEFVGPVVTMTLCYARISRELWFKAVPGFQTEQIRKRLRCRRKTVLVLMCILTAYVLCWAPFYGFTIVRDFFPTVFVKEKHYLTAFYIVECIAMSNSMINTLCFVTVKNDTVKYFKKIMLLHWKASYNGGKSSADLDLKTIGMPATEEVDCIRLK>sp|O43660|PLRG1_HUMAN Pleiotropic regulator 1 OS=Homo sapiens OX=9606GN=PLRG1 PE=1 SV=1MVEEVQKHSVHTLVFRSLKRTHDMFVADNGKPVPLDEESHKRKMAIKLRNEYGPVLHMPTSKENLKEKGPQNATDSYVHKQYPANQGQEVEYFVAGTHPYPPGPGVALTADTKIQRMPSESAAQSLAVALPLQTKADANRTAPSGSEYRHPGASDRPQPTAMNSIVMETGNTKNSALMAKKAPTMPKPQWHPPWKLYRVISGHLGWVRCIAVEPGNQWFVTGSADRTIKIWDLASGKLKLSLTGHISTVRGVIVSTRSPYLFSCGEDKQVKCWDLEYNKVIRHYHGHLSAVYGLDLHPTIDVLVTCSRDSTARIWDVRTKASVHTLSGHTNAVATVRCQAAEPQIITGSHDTTIRLWDLVAGKTRVTLTNHKKSVRAVVLHPRHYTFASGSPDNIKQWKFPDGSFIQNLSGHNAIINTLTVNSDGVLVSGADNGTMHLWDWRTGYNFQRVHAAVQPGSLDSESGIFACAFDQSESRLLTAEADKTIKVYREDDTATEETHPVSWKPEIIKRKRF>sp|O43660-2|PLRG1_HUMAN Isoform 2 of Pleiotropic regulator 1 OS=Homosapiens OX=9606 GN=PLRG1MVEEVQKHSVHTLVFRSLKRTHDMFVADNGKPVPLDEESHKRKMAIKLRNEYGPVLHMPTSKENLKEKGPQNATDSYVHKQYPANQGQEVEYFVAGVALTADTKIQRMPSESAAQSLAVALPLQTKADANRTAPSGSEYRHPGASDRPQPTAMNSIVMETGNTKNSALMAKKAPTMPKPQWHPPWKLYRVISGHLGWVRCIAVEPGNQWFVTGSADRTIKIWDLASGKLKLSLTGHISTVRGVIVSTRSPYLFSCGEDKQVKCWDLEYNKVIRHYHGHLSAVYGLDLHPTIDVLVTCSRDSTARIWDVRTKASVHTLSGHTNAVATVRCQAAEPQIITGSHDTTIRLWDLVAGKTRVTLTNHKKSVRAVVLHPRHYTFASGSPDNIKQWKFPDGSFIQNLSGHNAIINTLTVNSDGVLVSGADNGTMHLWDWRTGYNFQRVHAAVQPGSLDSESGIFACAFDQSESRLLTAEADKTIKVYREDDTATEETHPVSWKPEIIKRKRF>sp|Q0VAA5|PLCX2_HUMAN PI-PLC X domain-containing protein 2 OS=Homosapiens OX=9606 GN=PLCXD2 PE=2 SV=1MLAVRKARRKLRMGTICSPNPSGTKTSSEVCNADWMASLPPHLHNLPLSNLAIPGSHDSFSYWVDEKSPVGPDQTQAIKRLARISLVKKLMKKWSVTQNLTFREQLEAGIRYFDLRVSSKPGDADQEIYFIHGLFGIKVWDGLMEIDSFLTQHPQEIIFLDFNHFYAMDETHHKCLVLRIQEAFGNKLCPACSVESLTLRTLWEKNCQVLIFYHCPFYKQYPFLWPGKKIPAPWANTTSVRKLILFLETTLSERASRGSFHVSQAILTPRVKTIARGLVGGLKNTLVHSNRWNSHGPSLLSQERS>sp|Q0VAA5-2|PLCX2_HUMAN Isoform 2 of PI-PLC X domain-containing protein2 OS=Homo sapiens OX=9606 GN=PLCXD2MLAVRKARRKLRMGTICSPNPSGTKTSSEVCNADWMASLPPHLHNLPLSNLAIPGSHDSFSYWVDEKSPVGPDQTQAIKRLARISLVKKLMKKWSVTQNLTFREQLEAGIRYFDLRVSSKPGDADQEIYFIHGLFGIKVWDGLMEIDSFLTQHPQEIIFLDFNHFYAMDETHHKCLVLRIQEAFGNKLCPACSVESLTLRTLWEKNCQVLIFYHCPFYKQYPFLWPGKKIPAPWANTTSVRKLILFLETTLSERASRGSFHVSQAILTPRVKTIARGLVGGLKNTLVHRLALIPVYPLRFSRRS>sp|Q6T4P5|PLPR3_HUMAN Phospholipid phosphatase-related protein type 3OS=Homo sapiens OX=9606 GN=PLPPR3 PE=2 SV=1MISTKEKNKIPKDSMTLLPCFYFVELPIVASSIVSLYFLELTDLFKPAKVGFQCYDRTLSMPYVETNEELIPLLMLLSLAFAAPAASIMVAEGMLYCLQSRLWGRAGGPAGAEGSINAGGCNFNSFLRRTVRFVGVHVFGLCATALVTDVIQLATGYHTPFFLTVCKPNYTLLGTSCEVNPYITQDICSGHDIHAILSARKTFPSQHATLSAFAAVYVSMYFNSVISDTTKLLKPILVFAFAIAAGVCGLTQITQYRSHPVDVYAGFLIGAGIAAYLACHAVGNFQAPPAEKPAAPAPAKDALRALTQRGHDSVYQQNKSVSTDELGPPGRLEGAPRPVAREKTSLGSLKRASVDVDLLAPRSPMAKENMVTFSHTLPRASAPSLDDPARRHMTIHVPLDASRSKQLISEWKQKSLEGRGLGLPDDASPGHLRAPAEPMAEEEEEEEDEEEEEEEEEEEDEGPAPPSLYPTVQARPGLGPRVILPPRAGPPPLVHIPEEGAQTGAGLSPKSGAGVRAKWLMMAEKSGAAVANPPRLLQVIAMSKAPGAPGPKAAETASSSSASSDSSQYRSPSDRDSASIVTIDAHAPHHPVVHLSAGGAPWEWKAAGGGAKAEADGGYELGDLARGFRGGAKPPGVSPGSSVSDVDQEEPRFGAVATVNLATGEGLPPLGAADGALGPGSRESTLRRHAGGLGLAEREAEAEAEGYFRKMQARRFPD>sp|Q6T4P5-2|PLPR3_HUMAN Isoform 2 of Phospholipid phosphatase-relatedprotein type 3 OS=Homo sapiens OX=9606 GN=PLPPR3MISTKEKNKIPKDSMTLLPCFYFVELPIVASSIVSLYFLELTDLFKPAKVGFQCYDRTLSMPYVETNEELIPLLMLLSLAFAAPAASIMVAEGMLYCLQSRLWGRAGGPAGAEGSINAGGCNFNSFLRRTVRFVGGVHVFGLCATALVTDVIQLATGYHTPFFLTVCKPNYTLLGTSCEVNPYITQDICSGHDIHAILSARKTFPSQHATLSAFAAVYVSMYFNSVISDTTKLLKPILVFAFAIAAGVCGLTQITQYRSHPVDVYAGFLIGAGIAAYLACHAVGNFQAPPAEKPAAPAPAKDALRALTQRGHDSVYQQNKSVSTDELGPPGRLEGAPRPVAREKTSLGSLKRASVDVDLLAPRSPMAKENMVTFSHTLPRASAPSLDDPARRHMTIHVPLDASRSKQLISEWKQKSLEGRGLGLPDDASPGHLRAPAEPMAEEEEEEEDEEEEEEEEEEEDEGPAPPSLYPTVQARPGLGPRVILPPRAGPPPLVHIPEEGAQTGAGLSPKSGAGVRAKWLMMAEKSGAAVANPPRLLQVIAMSKAPGAPGPKAAETASSSSASSDSSQYRSPSDRDSASIVTIDAHAPHHPVVHLSAGGAPWEWKAAGGGAKAEADGGYELGDLARGFRGGAKPPGVSPGSSVSDVDQEEPRFGAVATVNLATGEGLPPLGAADGALGPGSRESTLRRHAGGLGLAEREAEAEAEGYFRKMQARRFPD>sp|Q6T4P5-3|PLPR3_HUMAN Isoform 3 of Phospholipid phosphatase-relatedprotein type 3 OS=Homo sapiens OX=9606 GN=PLPPR3MISTKEKNKIPKDSMTLLPCFYFVELPIVASSIVSLYFLELTDLFKPAKVGFQCYDRTLSMPYVETNEELIPLLMLLSLAFAAPAASIMVAEGMLYCLQSRLWGRAGGPAGAEGSINAGGCNFNSFLRRTVRFVGVHVFGLCATALVTDVIQLATGYHTPFFLTVCKPNYTLLGTSCEVNPYITQDICSGHDIHAILSARKTFPSQHATLSAFAAVYVSVSPAPHCPSQALLLTRGEPSLTPTPMPQMYFNSVISDTTKLLKPILVFAFAIAAGVCGLTQITQYRSHPVDVYAGFLIGAGIAAYLACHAVGNFQAPPAEKPAAPAPAKDALRALTQRGHDSVYQQNKSVSTDELGPPGRLEGAPRPVAREKTSLGSLKRASVDVDLLAPRSPMAKENMVTFSHTLPRASAPSLDDPARRHMTIHVPLDASRSKQLISEWKQKSLEGRGLGLPDDASPGHLRAPAEPMAEEEEEEEDEEEEEEEEEEEDEGPAPPSLYPTVQARPGLGPRVILPPRAGPPPLVHIPEEGAQTGAGLSPKSGAGVRAKWLMMAEKSGAAVANPPRLLQVIAMSKAPGAPGPKAAETASSSSASSDSSQYRSPSDRDSASIVTIDAHAPHHPVVHLSAGGAPWEWKAAGGGAKAEADGGYELGDLARGFRGGAKPPGVSPGSSVSDVDQEEPRFGAVATVNLATGEGLPPLGAADGALGPGSRESTLRRHAGGLGLAEREAEAEAEGYFRKMQARRFPD>sp|Q6T4P5-4|PLPR3_HUMAN Isoform 4 of Phospholipid phosphatase-relatedprotein type 3 OS=Homo sapiens OX=9606 GN=PLPPR3MTIHVPLDASRSKQLISEWKQKSLEGRGLGLPDDASPGHLRAPAEPMAEEEEEEEDEEEEEEEEEEEDEGPAPPSLYPTVQARPGLGPRVILPPRAGPPPLVHIPEEGAQTGAGLSPKSGAGVRAKWLMMAEKSGAAVANPPRLLQVIAMSKAPGAPGPKAAETASSSSASSDSSQYRSPSDRDSASIVTIDAHAPHHPVVHLSAGGAPWEWKAAGGGAKAEADGGYELGDLARGFRGGAKPPGVSPGSSVSDVDQEEPRFGAVATVNLATGEGLPPLGAADGALGPGSRESTLRRHAGGLGLAEREAEAEAEGYFRKMQARRFPD>sp|Q96LQ0|PPR36_HUMAN Protein phosphatase 1 regulatory subunit 36OS=Homo sapiens OX=9606 GN=PPP1R36 PE=1 SV=1MYRVPEFYARRKRLGGQTPYLMDQLGLRLGMWYWKDETRTLEFRRFAAEDSVQWLLKHHPHFTPAAEVKEKGKKGKAVHFAETDGPASDRLTDKRLAAKDDKSAKAVEKRGQQGTITLDDVKFVTLLLLQDTEMQRICSFTTFMRNKNLDNFLMALLYYLSHYLEKNSLEKKPKSYMVGLVEKKEMELVLSELEAAQRYLAQKYCILVLGLAVPDKHHMCCGKEKISDTQKDWKFFESFYTFCTYVAWIVFRRQHLTEIEEEVGRLFRTNMFNIPRRRREDEESGGEKKRMTFVQFRRMMAKRPAIKKAINMRSPVMSTLLPSLREKAQNVFEKKYHQVDVRFPAEMQKHVGTLDSVPMPVVGILGEPRCLFNPHTLHPLDPEENTKSFGRYPSLMENNNMRIQDTLDLVMKTLSSHTSCPK>sp|Q99496|RING2_HUMAN E3 ubiquitin-protein ligase RING2 OS=Homo sapiensOX=9606 GN=RNF2 PE=1 SV=1MSQAVQTNGTQPLSKTWELSLYELQRTPQEAITDGLEIVVSPRSLHSELMCPICLDMLKNTMTTKECLHRFCADCIITALRSGNKECPTCRKKLVSKRSLRPDPNFDALISKIYPSRDEYEAHQERVLARINKHNNQQALSHSIEEGLKIQAMNRLQRGKKQQIENGSGAEDNGDSSHCSNASTHSNQEAGPSNKRTKTSDDSGLELDNNNAAMAIDPVMDGASEIELVFRPHPTLMEKDDSAQTRYIKTSGNATVDHLSKYLAVRLALEELRSKGESNQMNLDTASEKQYTIYIATASGQFTVLNGSFSLELVSEKYWKVNKPMELYYAPTKEHK>sp|Q99496-2|RING2_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RING2OS=Homo sapiens OX=9606 GN=RNF2MSQAVQTNGTQPLSKTWELSLYELQRTPQEAITDGLEIVVSPRSLHSELMCPICLDMLKNTMTTKECLHRFCADCIITALRSGLQRGKKQQIENGSGAEDNGDSSHCSNASTHSNQEAGPSNKRTKTSDDSGLELDNNNAAMAIDPVMDGASEIELVFRPHPTLMEKDDSAQTRYIKTSGNATVDHLSKYLAVRLALEELRSKGESNQMNLDTASEKQYTIYIATASGQFTVLNGSFSLELVSEKYWKVNKPMELYYAPTKEHK>sp|P60900|PSA6_HUMAN Proteasome subunit alpha type-6 OS=Homo sapiensOX=9606 GN=PSMA6 PE=1 SV=1MSRGSSAGFDRHITIFSPEGRLYQVEYAFKAINQGGLTSVAVRGKDCAVIVTQKKVPDKLLDSSTVTHLFKITENIGCVMTGMTADSRSQVQRARYEAANWKYKYGYEIPVDMLCKRIADISQVYTQNAEMRPLGCCMILIGIDEEQGPQVYKCDPAGYYCGFKATAAGVKQTESTSFLEKKVKKKFDWTFEQTVETAITCLSTVLSIDFKPSEIEVGVVTVENPKFRILTEAEIDAHLVALAERD>sp|P60900-2|PSA6_HUMAN Isoform 2 of Proteasome subunit alpha type-6OS=Homo sapiens OX=9606 GN=PSMA6MAGLRREYAFKAINQGGLTSVAVRGKDCAVIVTQKKVPDKLLDSSTVTHLFKITENIGCVMTGMTADSRSQVQRARYEAANWKYKYGYEIPVDMLCKRIADISQVYTQNAEMRPLGCCMILIGIDEEQGPQVYKCDPAGYYCGFKATAAGVKQTESTSFLEKKVKKKFDWTFEQTVETAITCLSTVLSIDFKPSEIEVGVVTVENPKFRILTEAEIDAHLVALAERD>sp|P60900-3|PSA6_HUMAN Isoform 3 of Proteasome subunit alpha type-6OS=Homo sapiens OX=9606 GN=PSMA6MTGMTADSRSQVQRARYEAANWKYKYGYEIPVDMLCKRIADISQVYTQNAEMRPLGCCMILIGIDEEQGPQVYKCDPAGYYCGFKATAAGVKQTESTSFLEKKVKKKFDWTFEQTVETAITCLSTVLSIDFKPSEIEVGVVTVENPKFRILTEAEIDAHLVALAERD>sp|Q8TF05|PP4R1_HUMAN Serine/threonine-protein phosphatase 4 regulatorysubunit 1 OS=Homo sapiens OX=9606 GN=PPP4R1 PE=1 SV=1MADLSLLQEDLQEDADGFGVDDYSSESDVIIIPSALDFVSQDEMLTPLGRLDKYAASENIFNRQMVARSLLDTLREVCDDERDCIAVLERISRLADDSEPTVRAELMEQVPHIALFCQENRPSIPYAFSKFLLPIVVRYLADQNNQVRKTSQAALLALLEQELIERFDVETKVCPVLIELTAPDSNDDVKTEAVAIMCKMAPMVGKDITERLILPRFCEMCCDCRMFHVRKVCAANFGDICSVVGQQATEEMLLPRFFQLCSDNVWGVRKACAECFMAVSCATCQEIRRTKLSALFINLISDPSRWVRQAAFQSLGPFISTFANPSSSGQYFKEESKSSEEMSVENKNRTRDQEAPEDVQVRPEDTPSDLSVSNSSVILENTMEDHAAEASGKPLGEISVPLDSSLLCTLSSESHQEAASNENDKKPGNYKSMLRPEVGTTSQDSALLDQELYNSFHFWRTPLPEIDLDIELEQNSGGKPSPEGPEEESEGPVPSSPNITMATRKELEEMIENLEPHIDDPDVKAQVEVLSAALRASSLDAHEETISIEKRSDLQDELDINELPNCKINQEDSVPLISDAVENMDSTLHYIHSDSDLSNNSSFSPDEERRTKVQDVVPQALLDQYLSMTDPSRAQTVDTEIAKHCAYSLPGVALTLGRQNWHCLRETYETLASDMQWKVRRTLAFSIHELAVILGDQLTAADLVPIFNGFLKDLDEVRIGVLKHLHDFLKLLHIDKRREYLYQLQEFLVTDNSRNWRFRAELAEQLILLLELYSPRDVYDYLRPIALNLCADKVSSVRWISYKLVSEMVKKLHAATPPTFGVDLINELVENFGRCPKWSGRQAFVFVCQTVIEDDCLPMDQFAVHLMPHLLTLANDRVPNVRVLLAKTLRQTLLEKDYFLASASCHQEAVEQTIMALQMDRDSDVKYFASIHPASTKISEDAMSTASSTY>sp|Q8TF05-2|PP4R1_HUMAN Isoform 2 of Serine/threonine-proteinphosphatase 4 regulatory subunit 1 OS=Homo sapiens OX=9606 GN=PPP4R1MADLSLLQEDLQEDADGSLDFVSQDEMLTPLGRLDKYAASENIFNRQMVARSLLDTLREVCDDERDCIAVLERISRLADDSEPTVRAELMEQVPHIALFCQENRPSIPYAFSKFLLPIVVRYLADQNNQVRKTSQAALLALLEQELIERFDVETKVCPVLIELTAPDSNDDVKTEAVAIMCKMAPMVGKDITERLILPRFCEMCCDCRMFHVRKVCAANFGDICSVVGQQATEEMLLPRFFQLCSDNVWGVRKACAECFMAVSCATCQEIRRTKLSALFINLISDPSRWVRQAAFQSLGPFISTFANPSSSGQYFKEESKSSEEMSVENKNRTRDQEAPEDVQVRPEDTPSDLSVSNSSVILENTMEDHAAEASGKPLGEISVPLDSSLLCTLSSESHQEAASNENDKKPGNYKSMLRPEVGTTSQDSALLDQELYNSFHFWRTPLPEIDLDIELEQNSGGKPSPEGPEEESEGPVPSSPNITMATRKELEEMIENLEPHIDDPDVKAQVEVLSAALRASSLDAHEETISIEKRSDLQDELDINELPNCKINQEDSVPLISDAVENMDSTLHYIHSDSDLSNNSSFSPDEERRTKVQDVVPQALLDQYLSMTDPSRAQTVDTEIAKHCAYSLPGVALTLGRQNWHCLRETYETLASDMQWKVRRTLAFSIHELAVILGDQLTAADLVPIFNGFLKDLDEVRIGVLKHLHDFLKLLHIDKRREYLYQLQEFLVTDNSRNWRFRAELAEQLILLLELYSPRDVYDYLRPIALNLCADKVSSVRWISYKLVSEMVKKLHAATPPTFGVDLINELVENFGRCPKWSGRQAFVFVCQTVIEDDCLPMDQFAVHLMPHLLTLANDRVPNVRVLLAKTLRQTLLEKDYFLASASCHQEAVEQTIMALQMDRDSDVKYFASIHPASTKISEDAMSTASSTY>sp|Q13046|PSG7_HUMAN Putative pregnancy-specific beta-1-glycoprotein 7OS=Homo sapiens OX=9606 GN=PSG7 PE=5 SV=3MGPLSAPPCTQHITWKGLLLTASLLNFWNPPTTAQVTIEAQPPKVSEGKDVLLLVHNLPQNLTGYIWYKGQIRDLYHYVTSYIVDGQIIKYGPAYSGRETVYSNASLLIQNVTQEDTGSYTLHIIKRGDGTGGVTGRFTFTLYLETPKPSISSSNFNPREATEAVILTCDPETPDASYLWWMNGQSLPMTHSLQLSETNRTLYLFGVTNYTAGPYECEIRNPVSASRSDPVTLNLLPKLPKPYITINNLNPRENKDVSTFTCEPKSENYTYIWWLNGQSLPVSPRVKRRIENRILILPSVTRNETGPYQCEIRDRYGGIRSDPVTLNVLYGPDLPRIYPSFTYYHSGQNLYLSCFADSNPPAQYSWTINGKFQLSGQKLSIPQITTKHSGLYACSVRNSATGKESSKSVTVRVSDWTLP>sp|P62888|RL30_HUMAN 60S ribosomal protein L30 OS=Homo sapiens OX=9606GN=RPL30 PE=1 SV=2MVAAKKTKKSLESINSRLQLVMKSGKYVLGYKQTLKMIRQGKAKLVILANNCPALRKSEIEYYAMLAKTGVHHYSGNNIELGTACGKYYRVCTLAIIDPGDSDIIRSMPEQTGEK>sp|P05387|RLA2_HUMAN 60S acidic ribosomal protein P2 OS=Homo sapiensOX=9606 GN=RPLP2 PE=1 SV=1MRYVASYLLAALGGNSSPSAKDIKKILDSVGIEADDDRLNKVISELNGKNIEDVIAQGIGKLASVPAGGAVAVSAAPGSAAPAAGSAPAAAEEKKDEKKEESEESDDDMGFGLFD>sp|Q92622|RUBIC_HUMAN Run domain Beclin-1-interacting and cysteine-richdomain-containing protein OS=Homo sapiens OX=9606 GN=RUBCN PE=1 SV=4MRPEGAGMELGGGEERLPEESRREHWQLLGNLKTTVEGLVSTNSPNVWSKYGGLERLCRDMQSILYHGLIRDQACRRQTDYWQFVKDIRWLSPHSALHVEKFISVHENDQSSADGASERAVAELWLQHSLQYHCLSAQLRPLLGDRQYIRKFYTDAAFLLSDAHVTAMLQCLEAVEQNNPRLLAQIDASMFARKHESPLLVTKSQSLTALPSSTYTPPNSYAQHSYFGSFSSLHQSVPNNGSERRSTSFPLSGPPRKPQESRGHVSPAEDQTIQAPPVSVSALARDSPLTPNEMSSSTLTSPIEASWVSSQNDSPGDASEGPEYLAIGNLDPRGRTASCQSHSSNAESSSSNLFSSSSSQKPDSAASSLGDQEGGGESQLSSVLRRSSFSEGQTLTVTSGAKKSHIRSHSDTSIASRGAPESCNDKAKLRGPLPYSGQSSEVSTPSSLYMEYEGGRYLCSGEGMFRRPSEGQSLISYLSEQDFGSCADLEKENAHFSISESLIAAIELMKCNMMSQCLEEEEVEEEDSDREIQELKQKIRLRRQQIRTKNLLPMYQEAEHGSFRVTSSSSQFSSRDSAQLSDSGSADEVDEFEIQDADIRRNTASSSKSFVSSQSFSHCFLHSTSAEAVAMGLLKQFEGMQLPAASELEWLVPEHDAPQKLLPIPDSLPISPDDGQHADIYKLRIRVRGNLEWAPPRPQIIFNVHPAPTRKIAVAKQNYRCAGCGIRTDPDYIKRLRYCEYLGKYFCQCCHENAQMAIPSRVLRKWDFSKYYVSNFSKDLLIKIWNDPLFNVQDINSALYRKVKLLNQVRLLRVQLCHMKNMFKTCRLAKELLDSFDTVPGHLTEDLHLYSLNDLTATRKGELGPRLAELTRAGATHVERCMLCQAKGFICEFCQNEDDIIFPFELHKCRTCEECKACYHKACFKSGSCPRCERLQARREALARQSLESYLSDYEEEPAEALALEAAVLEAT>sp|Q92622-2|RUBIC_HUMAN Isoform 2 of Run domain Beclin-1-interacting andcysteine-rich domain-containing protein OS=Homo sapiens OX=9606 GN=RUBCNMQSILYHGLIRDQACRRQTDYWQFVKDIRWLSPHSALHVEKFISVHENDQSSADGASERAVAELWLQHSLQYHCLSAQLRPLLGDRQYIRKFYTDAAFLLSDAHVTAMLQCLEAVEQNNPRLLAQIDASMFARKHESPLLVTKSQSLTALPSSTYTPPNSYAQHSYFGSFSSLHQSVPNNGSERRSTSFPLSGPPRKPQESRGHVSPAEDQTIQAPPVSVSALARDSPLTPNEMSSSTLTSPIEASWVSSQNDSPGDASEGPEYLAIGNLDPRGRTASCQSHSSNAESSSSNLFSSSSSQKPDSAASSLGDQEGGGESQLSSVLRRSSFSEGQTLTVTSGAKKSHIRSHSDTSIASRGAPGGPRNITIIVEDPIAESCNDKAKLRGPLPYSGQSSEVSTPSSLYMEYEGGRYLCSGEGMFRRPSEGQSLISYLSEQDFGSCADLEKENAHFSISESLIAAIELMKCNMMSQCLEEEEVEEEDSDREIQELKQKIRLRRQQIRTKNLLPMYQEAEHGSFRVTSSSSQFSSRDSAQLSDSGSADEVDEFEIQDADIRRNTASSSKSFVSSQSFSHCFLHSTSAEAVAMGLLKQFEGMQLPAASELEWLVPEHDAPQKLLPIPDSLPISPDDGQHADIYKLRIRVRGNLEWAPPRPQIIFNVHPAPTRKIAVAKQNYRCAGCGIRTDPDYIKRLRYCEYLGKYFCQCCHENAQMAIPSRVLRKWDFSKYYVSNFSKDLLIKIWNDPLFNVQDINSALYRKVKLLNQVRLLRVQLCHMKNMFKTCRLAKELLDSFDTVPGHLTEDLHLYSLNDLTATRKGELGPRLAELTRAGATHVERCMLCQAKGFICEFCQNEDDIIFPFELHKCRTCEECKACYHKACFKSGSCPRCERLQARREALARQSLESYLSDYEEEPAEALALEAAVLEAT>sp|Q92622-3|RUBIC_HUMAN Isoform 3 of Run domain Beclin-1-interacting andcysteine-rich domain-containing protein OS=Homo sapiens OX=9606 GN=RUBCNMRPEGAGMELGGGEERLPEESRREHWQLLGNLKTTVEGLVSTNSPNVWSKYGGLERLCRDMQSILYHGLIRDQACRRQTDYWQFVKDIRWLSPHSALHVEKFISVHENDQSSADGASERAVAELWLQHSLQYHCLSAQLRPLLGDRQYIRKFYTDAAFLLSDAHVTAMLQCLEAVEQNNPRLLAQIDASMFARKHESPLLVTKSQSLTALPSSTYTPPNSYAQHSYFGSFSSLHQSVPNNGSERRSTSFPLSGPPRKPQESRGHVSPAEDQTIQAPPVSVSALARDSPLTPNEMSSSTLTSPIEASWVSSQNDSPGDASEGPEYLAIGNLDPRGRTASCQSHSSNAESSSSNLFSSSSSQKPDSAASSLGDQEGGGESQLSSVLRRSSFSEGQTLTVTSGAKKSHIRSHSDTSIASRGAPESCNDKAKLRGPLPYSGQSSEVSTPSSLYMEYEGGRYLCSGEGMFRRPSEGQSLISYLSEQDFGSCADLEKENAHFSISESLIAAIELMKCNMMSQCLEEEEVEEEDSDREIQELKQKIRLRRQQIRTKNLLPMYQEAEHGSFRVTSSSSQFSSRDSAQLSDSGSADEVDEFEIQDGSEGSNLTHISKNGLSVSLASMFSDADIRRNTASSSKSFVSSQSFSHCFLHSTSAEAVAMGLLKQFEGMQLPAASELEWLVPEHDAPQKLLPIPDSLPISPDDGQHADIYKLRIRVRGNLEWAPPRPQIIFNVHPAPTRKIAVAKQNYRCAGCGIRTDPDYIKRLRYCEYLGKYFCQCCHENAQMAIPSRVLRKWDFSKYYVSNFSKDLLIKIWNDPLFNVQDINSALYRKVKLLNQVRLLRVQLCHMKNMFKTCRLAKELLDSFDTVPGHLTEDLHLYSLNDLTATRKGELGPRLAELTRAGATHVERCMVRKSHCSMQLSPCF>sp|Q8N4L4|SPEM1_HUMAN Spermatid maturation protein 1 OS=Homo sapiensOX=9606 GN=SPEM1 PE=2 SV=1MAMVERPRPEWASYHNCNSNSCQDLGNSVLLLLGLIICINISINIVTLLWSRFRGVLYQVFHDTICEKEAPKSSLLRKQTQPPKKQSSPAVHLRCTMDPVMMTVSPPPAHRHRRRGSPTRCAHCPVAWAPDTDDEKPHQYPAICSYHWDVPEDWEGFQHTQGTWVPWSQDAPESPPQTIRFQPTVEERPLKTGIWSELGLRAYVYPVNPPPPSPEAPSHKNGGEGAVPEAEAAQYQPVPAPTLGPAVIPEFSRHRSSGRIVYDARDMRRRLRELTREVEALSGCYPLASGSSTAEETSKNWVYRSLTGR>sp|Q9HA77|SYCM_HUMAN Probable cysteine--tRNA ligase, mitochondrialOS=Homo sapiens OX=9606 GN=CARS2 PE=1 SV=1MLRTTRGPGLGPPLLQAALGLGRAGWHWPAGRAASGGRGRAWLQPTGRETGVQVYNSLTGRKEPLIVAHAEAASWYSCGPTVYDHAHLGHACSYVRFDIIRRILTKVFGCSIVMVMGITDVDDKIIKRANEMNISPASLASLYEEDFKQDMAALKVLPPTVYLRVTENIPQIISFIEGIIARGNAYSTAKGNVYFDLKSRGDKYGKLVGVVPGPVGEPADSDKRHASDFALWKAAKPQEVFWASPWGPGRPGWHIECSAIASMVFGSQLDIHSGGIDLAFPHHENEIAQCEVFHQCEQWGNYFLHSGHLHAKGKEEKMSKSLKNYITIKDFLKTFSPDVFRFFCLRSSYRSAIDYSDSAMLQAQQLLLGLGSFLEDARAYMKGQLACGSVREAMLWERLSSTKRAVKAALADDFDTPRVVDAILGLAHHGNGQLRASLKEPEGPRSPAVFGAIISYFEQFFETVGISLANQQYVSGDGSEATLHGVVDELVRFRQKVRQFALAMPEATGDARRQQLLERQPLLEACDTLRRGLTAHGINIKDRSSTTSTWELLDQRTKDQKSAG>sp|Q8N8V8|TM105_HUMAN Transmembrane protein 105 OS=Homo sapiens OX=9606GN=TMEM105 PE=2 SV=1MLLKVRRASLKPPATPHQGAFRAGNVIGQLIYLLTWSLFTAWLRPPTLLQGPRTSPQGSPPRSPWGDCAEPSCLCEMKIRRRRHEGPAWGQSGFLAGGLHLVPSSLSLAACGVVRMKGLWGRGAGIRGR>sp|Q07352|TISB_HUMAN mRNA decay activator protein ZFP36L1 OS=Homosapiens OX=9606 GN=ZFP36L1 PE=1 SV=1MTTTLVSATIFDLSEVLCKGNKMLNYSAPSAGGCLLDRKAVGTPAGGGFPRRHSVTLPSSKFHQNQLLSSLKGEPAPALSSRDSRFRDRSFSEGGERLLPTQKQPGGGQVNSSRYKTELCRPFEENGACKYGDKCQFAHGIHELRSLTRHPKYKTELCRTFHTIGFCPYGPRCHFIHNAEERRALAGARDLSADRPRLQHSFSFAGFPSAAATAAATGLLDSPTSITPPPILSADDLLGSPTLPDGTNNPFAFSSQELASLFAPSMGLPGGGSPTTFLFRPMSESPHMFDSPPSPQDSLSDQEGYLSSSSSSHSGSDSPTLDNSRRLPIFSRLSISDD>sp|Q9H2G4|TSYL2_HUMAN Testis-specific Y-encoded-like protein 2 OS=Homosapiens OX=9606 GN=TSPYL2 PE=1 SV=1MDRPDEGPPAKTRRLSSSESPQRDPPPPPPPPPLLRLPLPPPQQRPRLQEETEAAQVLADMRGVGLGPALPPPPPYVILEEGGIRAYFTLGAECPGWDSTIESGYGEAPPPTESLEALPTPEASGGSLEIDFQVVQSSSFGGEGALETCSAVGWAPQRLVDPKSKEEAIIIVEDEDEDERESMRSSRRRRRRRRRKQRKVKRESRERNAERMESILQALEDIQLDLEAVNIKAGKAFLRLKRKFIQMRRPFLERRDLIIQHIPGFWVKAFLNHPRISILINRRDEDIFRYLTNLQVQDLRHISMGYKMKLYFQTNPYFTNMVIVKEFQRNRSGRLVSHSTPIRWHRGQEPQARRHGNQDASHSFFSWFSNHSLPEADRIAEIIKNDLWVNPLRYYLRERGSRIKRKKQEMKKRKTRGRCEVVIMEDAPDYYAVEDIFSEISDIDETIHDIKISDFMETTDYFETTDNEITDINENICDSENPDHNEVPNNETTDNNESADDHETTDNNESADDNNENPEDNNKNTDDNEENPNNNENTYGNNFFKGGFWGSHGNNQDSSDSDNEADEASDDEDNDGNEGDNEGSDDDGNEGDNEGSDDDDRDIEYYEKVIEDFDKDQADYEDVIEIISDESVEEEGIEEGIQQDEDIYEEGNYEEEGSEDVWEEGEDSDDSDLEDVLQVPNGWANPGKRGKTG>sp|Q8NDW8|TT21A_HUMAN Tetratricopeptide repeat protein 21A OS=Homosapiens OX=9606 GN=TTC21A PE=1 SV=3MSSNDSSLMAGIIYYSQEKYFHHVQQAAAVGLEKFSNDPVLKFFKAYGVLKEEHIQDAISDLESIRHHPDVSLCSTMALIYAHKRCEIIDREAIQELEYSLKEIRKTVSGTALYYAGLFLWLIGRHDKAKEYIDRMLKISRGFREAYVLRGWVDLTSDKPHTAKKAIEYLEQGIQDTKDVLGLMGKAMYFMMQQNYSEALEVVNQITVTSGSFLPALVLKMQLFLARQDWEQTVEMGHRILEKDESNIDACQILTVHELAREGNMTTVSSLKTQKATNHVRNLIKALETREPENPSLHLKKIIVVSRLCGSHQVILGLVCSFIERTFMATPSYVHVATELGYLFILKNQVKEALLWYSEAMKLDKDGMAGLTGIILCHILEGHLEEAEYRLEFLKEVQKSLGKSEVLIFLQALLMSRKHKGEEETTALLKEAVELHFSSMQGIPLGSEYFEKLDPYFLVCIAKEYLLFCPKQPRLPGQIVSPLLKQVAVILNPVVKAAPALIDPLYLMAQVRYYSELENAQSILQRCLELDPASVDAHLLMCQIYLAQGNFGMCFHCLELGVSHNFQVRDHPLYHLIKARALNKAGDYPEAIKTLKMVIKLPALKKEEGRKFLRPSVQPSQRASILLELVEALRLNGELHEATKVMQDTINEFGGTPEENRITIANVDLVLSKGNVDVALNMLRNILPKQSCYMEAREKMANIYLQTLRDRRLYIRCYRELCEHLPGPHTSLLLGDALMSILEPEKALEVYDEAYRQNPHDASLASRIGHAYVKAHQYTEAIEYYEAAQKINGQDFLCCDLGKLLLKLKKVNKAEKVLKQALEHDIVQDIPSMMNDVKCLLLLAKVYKSHKKEAVIETLNKALDLQSRILKRVPLEQPEMIPSQKQLAASICIQFAEHYLAEKEYDKAVQSYKDVFSYLPTDNKVMLELAQLYLLQGHLDLCEQHCAILLQTEQNHETASVLMADLMFRKQKHEAAINLYHQVLEKAPDNFLVLHKLIDLLRRSGKLEDIPAFFELAKKVSSRVPLEPGFNYCRGIYCWHIGQPNEALKFLNKARKDSTWGQSAIYHMVQICLNPDNEVVGGEAFENQGAESNYMEKKELEQQGVSTAEKLLREFYPHSDSSQTQLRLLQGLCRLATREKANMEAALGSFIQIAQAEKDSVPALLALAQAYVFLKQIPKARMQLKRLAKTPWVLSEAEDLEKSWLLLADIYCQGSKFDLALELLRRCVQYNKSCYKAYEYMGFIMEKEQSYKDAVTNYKLAWKYSHHANPAIGFKLAFNYLKDKKFVEAIEICNDVLREHPDYPKIREEILEKARRSLRP>sp|Q8NDW8-3|TT21A_HUMAN Isoform 3 of Tetratricopeptide repeat protein21A OS=Homo sapiens OX=9606 GN=TTC21AMIPSQKQLAASICIQFAEHYLAEKEYDKAVQSYKDVFSYLPTDNKVMLELAQLYLLQGHLDLCEQHCAILLQTEQNHETASVLMADLMFRKQKHEAAINLYHQVLEKAPDNFLVLHKLIDLLRRSGKLEDIPAFFELAKKVSSRVPLEPGFNYCRGIYCWHIGQPNEALKFLNKARKDSTWGQSAIYHMVQICLNPDNEVVGGEAFENQGAESNYMEKKELEQQGVSTAEKLLREFYPHSDSSQTQLRLLQGLCRLATREKANMEAALGSFIQIAQAEKDSVPALLALAQAYVFLKQIPKARMQLKRLAKTPWVLSEAEDLEKSWLLLADIYCQGSKFDLALELLRRCVQYNKSCYKAYEYMGFIMEKEQSYKDAVTNYKLAWKYSHHANPAIGFKLAFNYLKDKKFVEAIEICNDVLREHPDYPKIREEILEKARRSLRP>sp|Q8NDW8-5|TT21A_HUMAN Isoform 5 of Tetratricopeptide repeat protein21A OS=Homo sapiens OX=9606 GN=TTC21AMSSNDSSLMAGIIYYSQEKYFHHVQQAAAVGLEKFSNDPVLKFFKAYGVLKEEHIQDAISDLESIRHHPDVSLCSTMALIYAHKRCEIIDREAIQELEYSLKEIRKTVSGTALYYAGLFLWLIGRHDKAKEYIDRMLKISRGFREAYVLRGWVDLTSDKPHTAKKAIEYLEQGIQDTKDVLGLMGKAMYFMMQQNYSEALEVVNQITVTSGSFLPALVLKMQLFLARQDWEQTVEMGHRILEKDESNIDACQILTVHELAREGNMTTATNHVRNLIKALETREPENPSLHLKKIIVVSRLCGSHQVILGLVCSFIERTFMATPSYVHVATELGYLFILKNQVKEALLWYSEAMKLDKDGMAGLTGIILCHILEGHLEVQKSLGKSEVLIFLQALLMSRKHKGEEETTALLKEAVELHFSSMQGIPLGSEYFEKLDPYFLVCIAKEYLLFCPKQPRLPGQIVSPLLKQVAVILNPVVKAAPALIDPLYLMAQVRYYSGELENAQSILQRCLELDPASVDAHLLMCQIYLAQGNFGMCFHCLELGVSHNFQVRDHPLYHLIKARALNKAGDYPEAIKTLKMVIKLPALKKEEGRKFLRPSVQPSQRASILLELVEALRLNGELHEATKVMQDTINEFGGTPEENRITIANVDLVLSKGNVDVALNMLRNILPKQSCYMEAREKMANIYLQTLRDRRLYIRCYRELCEHLPGPHTSLLLGDALMSILEPEKALEVYDEAYRQNPHDASLASRIGHAYVKAHQYTEAIEYYEAAQKINGQDFLCCDLGKLLLKLKKVNKAEKVLKQALEHDIVQDIPSMMNDVKCLLLLAKVYKSHKKEAVIETLNKALDLQSRILKRVPLEQPEMIPSQKQLAASICIQFAEHYLAEKEYDKAVQSYKDVFSYLPTDNKVMLELAQLYLLQGHLDLCEQHCAILLQTEQNHETASVLMADLMFRKQKHEAAINLYHQVLEKAPDNFLVLHKLIDLLRRSGKLEDIPAFFELAKKVSSRVPLEPGFNYCRGIYCWHIGQPNEALKFLNKARKDSTWGQSAIYHMVQICLNPDNEVVGGEAFENQGAESNYMEKKELEQQGVSTAEKLLREFYPHSDSSQTQLRLLQGLCRLATREKANMEAALGSFIQIAQAEKDSVPALLALAQAYVFLKQIPKARMQLKRLAKTPWVLSEAEDLEKSWLLLADIYCQGSKFDLALELLRRCVQYNKSCYKAYEYMGFIMEKEQSYKDAVTNYKLAWKYSHHANPAIGFKLAFNYLKDKKFVEAIEICNDVLREHPDYPKIREEILEKARRSLRP>sp|Q8NDW8-6|TT21A_HUMAN Isoform 6 of Tetratricopeptide repeat protein21A OS=Homo sapiens OX=9606 GN=TTC21AMSSNDSSLMAGIIYYSQEKYFHHVQQAAAVGLEKFSNDPVLKFFKAYGVLKEEHIQDAISDLESIRHHPDVSLCSTMALIYAHKRCEIIDREAIQELEYSLKEIRKTVSGTALYYAGLFLWLIGRHDKAKEYIDRMLKISRGFREAMYFMMQQNYSEALEVVNQITVTSGSFLPALVLKMQLFLARQDWEQTVEMGHRILEKDESNIDACQILTVHELAREGNMTTATNHVRNLIKALETREPENPSLHLKKIIVVSRLCGSHQVILGLVCSFIERTFMATPSYVHVATELGYLFILKNQVKEALLWYSEAMKLDKDGMAGLTGIILCHILEGHLEEAEYRLEFLKEVQKSLGKSEVLIFLQALLMSRKHKGEEETTALLKEAVELHFSSMQGIPLGSEYFEKLDPYFLVCIAKEYLLFCPKQPRLPGQIVSPLLKQVAVILNPVVKAAPALIDPLYLMAQVRYYSGELENAQSILQRCLELDPASVDAHLLMCQIYLAQGNFGMCFHCLELGVSHNFQVRDHPLYHLIKARALNKAGDYPEAIKTLKMVIKLPALKKEEGRKFLRPSVQPSQRASILLELVEALRLNGELHEATKVMQDTINEFGGTPEENRITIANVDLVLSKGNVDVALNMLRNILPKQSCYMEAREKMANIYLQTLRDRRLYIRCYRELCEHLPGPHTSLLLGDALMSILEPEKALEVYDEAYRQNPHDASLASRIGHAYVKAHQYTEAIEYYEAAQKINGQDFLCCDLGKLLLKLKKVNKAEKVLKQALEHDIVQDIPSMMNDVKCLLLLAKVYKSHKKEAVIETLNKALDLQSRILKRVPLEQPEMIPSQKQLAASICIQFAEHYLAEKEYDKAVQSYKDVFSYLPTDNKVMLELAQLYLLQGHLDLCEQHCAILLQTEQNHETASVLMADLMFRKQKHEAAINLYHQVLEKAPDNFLVLHKLIDLLRRSGKLEDIPAFFELAKKVSSRVPLEPGFNYCRGIYCWHIGQPNEALKFLNKARKDSTWGQSAIYHMVQICLNPDNEVVGGEAFENQGAESNYMEKKELEQQGVSTAEKLLREFYPHSDSSQTQLRLLQGLCRLATREKANMEAALGSFIQIAQAEKDSVPALLALAQAYVFLKQIPKARMQLKRLAKTPWVLSEAEDLEKSWLLLADIYCQGSKFDLALELLRRCVQYNKSCYKAYEYMGFIMEKEQSYKDAVTNYKLAWKYSHHANPAIGFKLAFNYLKDKKFVEAIEICNDVLREHPDYPKIREEILEKARRSLRP>sp|Q8NDW8-7|TT21A_HUMAN Isoform 7 of Tetratricopeptide repeat protein21A OS=Homo sapiens OX=9606 GN=TTC21AMSSNDSSLMAGIIYYSQEKYFHHVQQAAAVGLEKFSNDPVLKFFKAYGVLKEEHIQDAISDLESIRHHPDVSLCSTMALIYAHKRCEIIDREAIQELEYSLKEIRKTVSGTALYYAGLFLWLIGRHDKAKEYIDRMLKISRGFREAYVLRGWVDLTSDKPHTAKKAIEYLEQGIQDTKDVLGLMGKAMYFMMQQNYSEALEVVNQITVTSGSFLPALVLKMQLFLARQDWEQTVEMGHRILEKDESNIDACQILTVHELAREGNMTTVSSLKTQKATNHVRNLIKALETREPENPSLHLKKIIVVSRLCGSHQVILGLVCSFIERTFMATPSYVHVATELGYLFILKNQVKEALLWYSEAMKLDKDGMAGLTGIILCHILEGHLEEAEYRLEFLKEVQKSLGKSEVLIFLQALLMSRKHKGEEETTALLKEAVELHFSSMQGIPLGSEYFEKLDPYFLVCIAKEYLLFCPKQPRLPGQIVSPLLKQVAVILNPVVKAAPALIDPLYLMAQVRYYSGELENAQSILQRCLELDPASVDAHLLMCQIYLAQGNFGMCFHCLELGVSHNFQVRDHPLYHLIKARALNKAGDYPEAIKTLKMVIKLPALKKEEGRKFLRPSVQPSQRASILLELVEALRLNGELHEATKVMQDTINEFGGTPEENRITIANVDLVLSKGNVDVALNMLRNILPKQSCYMEAREKMANIYLQTLRDRRLYIRCYRELCEHLPGPHTSLLLGDALMSILEPEKALEVYDEAYRQNPHDASLASRIGHAYVKAHQYTEAIEYYEAAQKINGQDFLCCDLGKLLLKLKKVNKAEKVLKQALEHDIVQDIPSMMNDVKCLLLLAKVYKSHKKEAVIETLNKALDLQSRILKRVPLEQPEMIPSQKQLAASICIQFAEHYLAEKEYDKAVQSYKDVFSYLPTDNKVMLELAQLYLLQGHLDLCEQHCAILLQTEQNHETASVLMADLMFRKQKHEAAINLYHQVLEKAPDNFLVLHKLIDLLRRSGKLEDIPAFFELAKKVSSRVPLEPGFNYCRGIYCWHIGQPNEALKFLNKARKDSTWGQSAIYHMVQICLNPDNEVVGGEAFENQGAESNYMEKKELEQQGVSTAEKLLREFYPHSDSSQTQLRLLQGLCRLATREKANMEAALGSFIQIAQAEKDSVPALLALAQAYVFLKQIPKARMQLKRLAKTPWVLSEAEDLEKSWLLLADIYCQGSKFDLALELLRRCVQYNKSCYKAYEYMGFIMEKEQSYKDAVTNYKLAWKYSHHANPAIGFKLAFNYLKDKKFVEAIEICNDVLREHPDYPKIREEILEKARRSLRP>sp|Q8N4P2|TT30B_HUMAN Tetratricopeptide repeat protein 30B OS=Homosapiens OX=9606 GN=TTC30B PE=1 SV=2MAGLSGAQIPDGEFTAVVYRLIRNARYAEAVQLLGGELQRSPRSRAGLSLLGYCYYRLQEFALAAECYEQLGQLHPELEQYRLYQAQALYKACLYAEATRVAFLLLDNPAYHSRVLRLQAAIKYSEGDLPGSRSLVEQLPSREGGEESGGENETDGQINLGCLLYKEGQYEAACSKFFAALQASGYQPDLSYNLALAYYSSRQYASALKHIAEIIERGIRQHPELGVGMTTEGIDVRSVGNTLVLHQTALVEAFNLKAAIEYQLRNYEAAQEALTDMPPRAEEELDPVTLHNQALMNMDARPTEGFEKLQFLLQQNPFPPETFGNLLLLYCKYEYFDLAADVLAENAHLIYKFLTPYLYDFLDAVITCQTAPEEAFIKLDGLAGMLTEVLRKLTIQVQEARHNRDDEAIKKAVNEYDETMEKYIPVLMAQAKIYWNLENYPMVEKIFRKSVEFCNDHDVWKLNVAHVLFMQENKYKEAIGFYEPIVKKHYDNILNVSAIVLANLCVSYIMTSQNEEAEELMRKIEKEEEQLSYDDPDKKMYHLCIVNLVIGTLYCAKGNYDFGISRVIKSLEPYNKKLGTDTWYYAKRCFLSLLENMSKHTIMLRDSVIQECVQFLEHCELHGRNIPAVIEQPLEEERMHVGKNTVTYESRQLKALIYEIIGWNI>sp|Q9UPW8|UN13A_HUMAN Protein unc-13 homolog A OS=Homo sapiens OX=9606GN=UNC13A PE=2 SV=4MSLLCVGVKKAKFDGAQEKFNTYVTLKVQNVKSTTIAVRGSQPSWEQDFMFEINRLDLGLTVEVWNKGLIWDTMVGTVWIPLRTIRQSNEEGPGEWLTLDSQVIMADSEICGTKDPTFHRILLDTRFELPLDIPEEEARYWAKKLEQLNAMRDQDEYSFQDEQDKPLPVPSNQCCNWNYFGWGEQHNDDPDSAVDDRDSDYRSETSNSIPPPYYTTSQPNASVHQYSVRPPPLGSRESYSDSMHSYEEFSEPQALSPTGSSRYASSGELSQGSSQLSEDFDPDEHSLQGSDMEDERDRDSYHSCHSSVSYHKDSPRWDQDEEELEEDLEDFLEEEELPEDEEELEEEEEEVPDDLGSYAQREDVAVAEPKDFKRISLPPAAPGKEDKAPVAPTEAPDMAKVAPKPATPDKVPAAEQIPEAEPPKDEESFRPREDEEGQEGQDSMSRAKANWLRAFNKVRMQLQEARGEGEMSKSLWFKGGPGGGLIIIDSMPDIRKRKPIPLVSDLAMSLVQSRKAGITSALASSTLNNEELKNHVYKKTLQALIYPISCTTPHNFEVWTATTPTYCYECEGLLWGIARQGMRCTECGVKCHEKCQDLLNADCLQRAAEKSSKHGAEDRTQNIIMVLKDRMKIRERNKPEIFELIQEIFAVTKTAHTQQMKAVKQSVLDGTSKWSAKISITVVCAQGLQAKDKTGSSDPYVTVQVGKTKKRTKTIYGNLNPVWEENFHFECHNSSDRIKVRVWDEDDDIKSRVKQRFKRESDDFLGQTIIEVRTLSGEMDVWYNLDKRTDKSAVSGAIRLHISVEIKGEEKVAPYHVQYTCLHENLFHFVTDVQNNGVVKIPDAKGDDAWKVYYDETAQEIVDEFAMRYGVESIYQAMTHFACLSSKYMCPGVPAVMSTLLANINAYYAHTTASTNVSASDRFAASNFGKERFVKLLDQLHNSLRIDLSMYRNNFPASSPERLQDLKSTVDLLTSITFFRMKVQELQSPPRASQVVKDCVKACLNSTYEYIFNNCHELYSREYQTDPAKKGEVLPEEQGPSIKNLDFWSKLITLIVSIIEEDKNSYTPCLNQFPQELNVGKISAEVMWNLFAQDMKYAMEEHDKHRLCKSADYMNLHFKVKWLYNEYVTELPAFKDRVPEYPAWFEPFVIQWLDENEEVSRDFLHGALERDKKDGFQQTSEHALFSCSVVDVFSQLNQSFEIIKKLECPDPQIVGHYMRRFAKTISNVLLQYADIISKDFASYCSKEKEKVPCILMNNTQQLRVQLEKMFEAMGGKELDAEASDILKELQVKLNNVLDELSRVFATSFQPHIEECVKQMGDILSQVKGTGNVPASACSSVAQDADNVLQPIMDLLDSNLTLFAKICEKTVLKRVLKELWKLVMNTMEKTIVLPPLTDQTMIGNLLRKHGKGLEKGRVKLPSHSDGTQMIFNAAKELGQLSKLKDHMVREEAKSLTPKQCAVVELALDTIKQYFHAGGVGLKKTFLEKSPDLQSLRYALSLYTQATDLLIKTFVQTQSAQGLGVEDPVGEVSVHVELFTHPGTGEHKVTVKVVAANDLKWQTSGIFRPFIEVNIIGPQLSDKKRKFATKSKNNSWAPKYNESFQFTLSADAGPECYELQVCVKDYCFAREDRTVGLAVLQLRELAQRGSAACWLPLGRRIHMDDTGLTVLRILSQRSNDEVAKEFVKLKSDTRSAEEGGAAPAP>sp|P30536|TSPO_HUMAN Translocator protein OS=Homo sapiens OX=9606GN=TSPO PE=1 SV=3MAPPWVPAMGFTLAPSLGCFVGSRFVHGEGLRWYAGLQKPSWHPPHWVLGPVWGTLYSAMGYGSYLVWKELGGFTEKAVVPLGLYTGQLALNWAWPPIFFGARQMGWALVDLLLVSGAAAATTVAWYQVSPLAARLLYPYLAWLAFTTTLNYCVWRDNHGWRGGRRLPE>sp|Q5XG85|U633C_HUMAN Putative UPF0633 protein LOC554249 OS=Homo sapiensOX=9606 PE=5 SV=1MRKLRLRASNPGPSGAPGTRRHFSTSRGGHHCARRWLRRVRRSRSQTPSCQNLDPNPPIARFLLPLERISEVPRRACLHGRDASSVWPPPERSD>sp|Q9H1C4|UN93B_HUMAN Protein unc-93 homolog B1 OS=Homo sapiens OX=9606GN=UNC93B1 PE=1 SV=2MEAEPPLYPMAGAAGPQGDEDLLGVPDGPEAPLDELVGAYPNYNEEEEERRYYRRKRLGVLKNVLAASAGGMLTYGVYLGLLQMQLILHYDETYREVKYGNMGLPDIDSKMLMGINVTPIAALLYTPVLIRFFGTKWMMFLAVGIYALFVSTNYWERYYTLVPSAVALGMAIVPLWASMGNYITRMAQKYHEYSHYKEQDGQGMKQRPPRGSHAPYLLVFQAIFYSFFHLSFACAQLPMIYFLNHYLYDLNHTLYNVQSCGTNSHGILSGFNKTVLRTLPRSGNLIVVESVLMAVAFLAMLLVLGLCGAAYRPTEEIDLRSVGWGNIFQLPFKHVRDYRLRHLVPFFIYSGFEVLFACTGIALGYGVCSVGLERLAYLLVAYSLGASAASLLGLLGLWLPRPVPLVAGAGVHLLLTFILFFWAPVPRVLQHSWILYVAAALWGVGSALNKTGLSTLLGILYEDKERQDFIFTIYHWWQAVAIFTVYLGSSLHMKAKLAVLLVTLVAAAVSYLRMEQKLRRGVAPRQPRIPRPQHKVRGYRYLEEDNSDESDAEGEHGDGAEEEAPPAGPRPGPEPAGLGRRPCPYEQAQGGDGPEEQ>sp|Q9Y2X8|UB2D4_HUMAN Ubiquitin-conjugating enzyme E2 D4 OS=Homo sapiensOX=9606 GN=UBE2D4 PE=1 SV=1MALKRIQKELTDLQRDPPAQCSAGPVGDDLFHWQATIMGPNDSPYQGGVFFLTIHFPTDYPFKPPKVAFTTKIYHPNINSNGSICLDILRSQWSPALTVSKVLLSICSLLCDPNPDDPLVPEIAHTYKADREKYNRLAREWTQKYAM>sp|Q16851|UGPA_HUMAN UTP--glucose-1-phosphate uridylyltransferaseOS=Homo sapiens OX=9606 GN=UGP2 PE=1 SV=5MSRFVQDLSKAMSQDGASQFQEVIRQELELSVKKELEKILTTASSHEFEHTKKDLDGFRKLFHRFLQEKGPSVDWGKIQRPPEDSIQPYEKIKARGLPDNISSVLNKLVVVKLNGGLGTSMGCKGPKSLIGVRNENTFLDLTVQQIEHLNKTYNTDVPLVLMNSFNTDEDTKKILQKYNHCRVKIYTFNQSRYPRINKESLLPVAKDVSYSGENTEAWYPPGHGDIYASFYNSGLLDTFIGEGKEYIFVSNIDNLGATVDLYILNHLMNPPNGKRCEFVMEVTNKTRADVKGGTLTQYEGKLRLVEIAQVPKAHVDEFKSVSKFKIFNTNNLWISLAAVKRLQEQNAIDMEIIVNAKTLDGGLNVIQLETAVGAAIKSFENSLGINVPRSRFLPVKTTSDLLLVMSNLYSLNAGSLTMSEKREFPTVPLVKLGSSFTKVQDYLRRFESIPDMLELDHLTVSGDVTFGKNVSLKGTVIIIANHGDRIDIPPGAVLENKIVSGNLRILDH>sp|Q16851-2|UGPA_HUMAN Isoform 2 of UTP--glucose-1-phosphateuridylyltransferase OS=Homo sapiens OX=9606 GN=UGP2MSQDGASQFQEVIRQELELSVKKELEKILTTASSHEFEHTKKDLDGFRKLFHRFLQEKGPSVDWGKIQRPPEDSIQPYEKIKARGLPDNISSVLNKLVVVKLNGGLGTSMGCKGPKSLIGVRNENTFLDLTVQQIEHLNKTYNTDVPLVLMNSFNTDEDTKKILQKYNHCRVKIYTFNQSRYPRINKESLLPVAKDVSYSGENTEAWYPPGHGDIYASFYNSGLLDTFIGEGKEYIFVSNIDNLGATVDLYILNHLMNPPNGKRCEFVMEVTNKTRADVKGGTLTQYEGKLRLVEIAQVPKAHVDEFKSVSKFKIFNTNNLWISLAAVKRLQEQNAIDMEIIVNAKTLDGGLNVIQLETAVGAAIKSFENSLGINVPRSRFLPVKTTSDLLLVMSNLYSLNAGSLTMSEKREFPTVPLVKLGSSFTKVQDYLRRFESIPDMLELDHLTVSGDVTFGKNVSLKGTVIIIANHGDRIDIPPGAVLENKIVSGNLRILDH>sp|O95258|UCP5_HUMAN Brain mitochondrial carrier protein 1 OS=Homosapiens OX=9606 GN=SLC25A14 PE=2 SV=1MGIFPGIILIFLRVKFATAAVIVSGHQKSTTVSHEMSGLNWKPFVYGGLASIVAEFGTFPVDLTKTRLQVQGQSIDARFKEIKYRGMFHALFRICKEEGVLALYSGIAPALLRQASYGTIKIGIYQSLKRLFVERLEDETLLINMICGVVSGVISSTIANPTDVLKIRMQAQGSLFQGSMIGSFIDIYQQEGTRGLWRGVVPTAQRAAIVVGVELPVYDITKKHLILSGMMGDTILTHFVSSFTCGLAGALASNPVDVVRTRMMNQRAIVGHVDLYKGTVDGILKMWKHEGFFALYKGFWPNWLRLGPWNIIFFITYEQLKRLQI>sp|O95258-2|UCP5_HUMAN Isoform 2 of Brain mitochondrial carrier protein1 OS=Homo sapiens OX=9606 GN=SLC25A14MGIFPGIILIFLRVKFATAAVIHQKSTTVSHEMSGLNWKPFVYGGLASIVAEFGTFPVDLTKTRLQVQGQSIDARFKEIKYRGMFHALFRICKEEGVLALYSGIAPALLRQASYGTIKIGIYQSLKRLFVERLEDETLLINMICGVVSGVISSTIANPTDVLKIRMQAQGSLFQGSMIGSFIDIYQQEGTRGLWRGVVPTAQRAAIVVGVELPVYDITKKHLILSGMMGDTILTHFVSSFTCGLAGALASNPVDVVRTRMMNQRAIVGHVDLYKGTVDGILKMWKHEGFFALYKGFWPNWLRLGPWNIIFFITYEQLKRLQI>sp|O95258-3|UCP5_HUMAN Isoform 3 of Brain mitochondrial carrier protein1 OS=Homo sapiens OX=9606 GN=SLC25A14MGIFPGIILIFLRVKFATAAVIHQKSTTVSHEMSGLNWKPFVYGGLASIVAEFGTFPVDLTKTRLQVQGQSIDARFKEIKYRGMFHALFRICKEEGVLALYSGIAPALLRQASYGTIKIGIYQSLKRLFVERLEDETLLINMICGVVSGVISSTIANPTDVLKIRMQAQGSLFQGSMIGSFIDIYQQEGTRGLWRCLCSKAVTGCVLWLMPVIPALWEANAGGSLEGVVPTAQRAAIVVGVELPVYDITKKHLILSGMMGDTILTHFVSSFTCGLAGALASNPVDVVRTRMMNQRAIVGHVDLYKGTVDGILKMWKHEGFFALYKGFWPNWLRLGPWNIIFFITYEQLKRLQI>sp|Q8NBM4|UBAC2_HUMAN Ubiquitin-associated domain-containing protein 2OS=Homo sapiens OX=9606 GN=UBAC2 PE=1 SV=1MFTSTGSSGLYKAPLSKSLLLVPSALSLLLALLLPHCQKLFVYDLHAVKNDFQIWRLICGRIICLDLKDTFCSSLLIYNFRIFERRYGSRKFASFLLGSWVLSALFDFLLIEAMQYFFGITAASNLPSGFLAPVFALFVPFYCSIPRVQVAQILGPLSITNKTLIYILGLQLFTSGSYIWIVAISGLMSGLCYDSKMFQVHQVLCIPSWMAKFFSWTLEPIFSSSEPTSEARIGMGATLDIQRQQRMELLDRQLMFSQFAQGRRQRQQQGGMINWNRLFPPLRQRQNVNYQGGRQSEPAAPPLEVSEEQVARLMEMGFSRGDALEALRASNNDLNVATNFLLQH>sp|Q8NBM4-2|UBAC2_HUMAN Isoform 2 of Ubiquitin-associated domain-containing protein 2 OS=Homo sapiens OX=9606 GN=UBAC2MCFFFSLQEEFLDKHTLMRVLSSGGKLGSRGEGAQLCCWMLLFSWRVSGGQQTRRLCRRAFCWSPVPSPSCSPSSCLTARSSLCMTFTQSRTTSSLAPVFALFVPFYCSIPRVQVAQILGPLSITNKTLIYILGLQLFTSGSYIWIVAISGLMSGLCYDSKMFQVHQVLCIPSWMAKFFSWTLEPIFSSSEPTSEARIGMGATLDIQRQQRMELLDRQLMFSQFAQGRRQRQQQGGMINWNRLFPPLRQRQNVNYQGGRQSEPAAPPLEVSEEQVARLMEMGFSRGDALEALRASNNDLNVATNFLLQH>sp|Q8NBM4-3|UBAC2_HUMAN Isoform 3 of Ubiquitin-associated domain-containing protein 2 OS=Homo sapiens OX=9606 GN=UBAC2MQYFFGITAASNLPSGFLAPVFALFVPFYCSIPRVQVAQILGPLSITNKTLIYILGLQLFTSGSYIWIVAISGLMSGLCYDSKMFQVHQVLCIPSWMAKFFSWTLEPIFSSSEPTSEARIGMGATLDIQRQQRMELLDRQLMFSQFAQGRRQRQQQGGMINWNRLFPPLRQRQNVNYQGGRQSEPAAPPLEVSEEQVARLMEMGFSRGDALEALRASNNDLNVATNFLLQH>sp|Q8NBM4-4|UBAC2_HUMAN Isoform 4 of Ubiquitin-associated domain-containing protein 2 OS=Homo sapiens OX=9606 GN=UBAC2MSGLCYDSKMFQVHQVLCIPSWMAKFFSWTLEPIFSSSEPTSEARIGMGATLDIQRQQRMELLDRQLMFSQFAQGRRQRQQQGGMINWNRLFPPLRQRQNVNYQGGRQSEPAAPPLEVSEEQVARLMEMGFSRGDALEALRASNNDLNVATNFLLQH>sp|Q8NBM4-5|UBAC2_HUMAN Isoform 5 of Ubiquitin-associated domain-containing protein 2 OS=Homo sapiens OX=9606 GN=UBAC2MFTSTGSSGLYKAPLSKSLLLVPSALSLLLALLLPHCQKLFVYDLHAVKNDFQPGTCVCSVCTILLLHTKSPSGTNSGSVVHHKQDIDLYIGTAAFHLWFLHLDCSHKWTYVRSVLRQQNVPGASGALHPQLDGKILFLDT>sp|Q9HAW7|UD17_HUMAN UDP-glucuronosyltransferase 1A7 OS=Homo sapiensOX=9606 GN=UGT1A7 PE=1 SV=2MARAGWTGLLPLYVCLLLTCGFAKAGKLLVVPMDGSHWFTMQSVVEKLILRGHEVVVVMPEVSWQLGRSLNCTVKTYSTSYTLEDQDREFMVFADARWTAPLRSAFSLLTSSSNGIFDLFFSNCRSLFNDRKLVEYLKESCFDAVFLDPFDACGLIVAKYFSLPSVVFARGIFCHYLEEGAQCPAPLSYVPRLLLGFSDAMTFKERVWNHIMHLEEHLFCPYFFKNVLEIASEILQTPVTAYDLYSHTSIWLLRTDFVLEYPKPVMPNMIFIGGINCHQGKPVPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|Q9HAW7-2|UD17_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A7OS=Homo sapiens OX=9606 GN=UGT1A7MARAGWTGLLPLYVCLLLTCGFAKAGKLLVVPMDGSHWFTMQSVVEKLILRGHEVVVVMPEVSWQLGRSLNCTVKTYSTSYTLEDQDREFMVFADARWTAPLRSAFSLLTSSSNGIFDLFFSNCRSLFNDRKLVEYLKESCFDAVFLDPFDACGLIVAKYFSLPSVVFARGIFCHYLEEGAQCPAPLSYVPRLLLGFSDAMTFKERVWNHIMHLEEHLFCPYFFKNVLEIASEILQTPVTAYDLYSHTSIWLLRTDFVLEYPKPVMPNMIFIGGINCHQGKPVPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|Q5T6F2|UBAP2_HUMAN Ubiquitin-associated protein 2 OS=Homo sapiensOX=9606 GN=UBAP2 PE=1 SV=1MMTSVSSDHCRGAREKPQISAAQSTQPQKQVVQATAEQMRLAQVIFDKNDSDFEAKVKQLMEVTGKNQDECIVALHDCNGDVNKAINILLEGNSDTTSWETVGCKKKNFAKENSENKENREKKSEKESSRGRGNNNRKGRGGNRGREFRGEENGIDCNQVDKPSDRGKRARGRGFGRGRGRGAGRFSTQGMGTFNPADYSDSTSTDVCGTKLVVWEAAQNGADEGTELASNTHNIAQDLSNKSSYGLKGAWKNSVEEWTTEDWTEDLSETKVFTASSAPAENHILPGQSIDLVALLQKPVPHSQASEANSFETSQQQGFGQALVFTNSQHNNQMAPGTGSSTAVNSCSPQSLSSVLGSGFGELAPPKMANITSSQILDQLKAPSLGQFTTTPSTQQNSTSHPTTTTSWDLKPPTSQSSVLSHLDFKSQPEPSPVLSQLSQRQQHQSQAVTVPPPGLESFPSQAKLRESTPGDSPSTVNKLLQLPSTTIENISVSVHQPQPKHIKLAKRRIPPASKIPASAVEMPGSADVTGLNVQFGALEFGSEPSLSEFGSAPSSENSNQIPISLYSKSLSEPLNTSLSMTSAVQNSTYTTSVITSCSLTSSSLNSASPVAMSSSYDQSSVHNRIPYQSPVSSSESAPGTIMNGHGGGRSQQTLDTPKTTGPPSALPSVSSLPSTTSCTALLPSTSQHTGDLTSSPLSQLSSSLSSHQSSLSAHAALSSSTSHTHASVESASSHQSSATFSTAATSVSSSASSGASLSSSMNTANSLCLGGTPASASSSSSRAAPLVTSGKAPPNLPQGVPPLLHNQYLVGPGGLLPAYPIYGYDELQMLQSRLPVDYYGIPFAAPTALASRDGSLANNPYPGDVTKFGRGDSASPAPATTPAQPQQSQSQTHHTAQQPFVNPALPPGYSYTGLPYYTGMPSAFQYGPTMFVPPASAKQHGVNLSTPTPPFQQASGYGQHGYSTGYDDLTQGTAAGDYSKGGYAGSSQAPNKSAGSGPGKGVSVSSSTTGLPDMTGSVYNKTQTFDKQGFHAGTPPPFSLPSVLGSTGPLASGAAPGYAPPPFLHILPAHQQPHSQLLHHHLPQDAQSGSGQRSQPSSLQPKSQASKPAYGNSPYWTN>sp|Q5T6F2-2|UBAP2_HUMAN Isoform 2 of Ubiquitin-associated protein 2OS=Homo sapiens OX=9606 GN=UBAP2MNTANSLCLGGTPASASSSSSRAAPLVTSGKAPPNLPQGVPPLLHNQYLVGPGGLLPAYPIYGYDELQMLQSRLPVDYYGIPFAAPTALASRDGSLANNPYPGDVTKFGRGDSASPAPATTPAQPQQSQSQTHHTAQQPFVNPALPPGYSYTGLPYYTGMPSAFQYGPTMFVPPASAKQHGVNLSTPTPPFQQASGYGQHGYSTGYDDLTQGTAAGDYSKGGYAGSSQAPNKSAGSGPGKGVSVSSSTTGLPDMTGSVYNKTQTFDKQGFHAGTPPPFSLPSVLGSTGPLASGAAPGYAPPPFLHILPAHQQPHSQLLHHHLPQDAQSGSGQRSQPSSLQPKSQASKPAYGNSPYWTN>sp|P19224|UD16_HUMAN UDP-glucuronosyltransferase 1-6 OS=Homo sapiensOX=9606 GN=UGT1A6 PE=1 SV=2MACLLRSFQRISAGVFFLALWGMVVGDKLLVVPQDGSHWLSMKDIVEVLSDRGHEIVVVVPEVNLLLKESKYYTRKIYPVPYDQEELKNRYQSFGNNHFAERSFLTAPQTEYRNNMIVIGLYFINCQSLLQDRDTLNFFKESKFDALFTDPALPCGVILAEYLGLPSVYLFRGFPCSLEHTFSRSPDPVSYIPRCYTKFSDHMTFSQRVANFLVNLLEPYLFYCLFSKYEELASAVLKRDVDIITLYQKVSVWLLRYDFVLEYPRPVMPNMVFIGGINCKKRKDLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|P19224-2|UD16_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1-6OS=Homo sapiens OX=9606 GN=UGT1A6MPNMVFIGGINCKKRKDLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|P19224-3|UD16_HUMAN Isoform 3 of UDP-glucuronosyltransferase 1-6OS=Homo sapiens OX=9606 GN=UGT1A6MACLLRSFQRISAGVFFLALWGMVVGDKLLVVPQDGSHWLSMKDIVEVLSDRGHEIVVVVPEVNLLLKESKYYTRKIYPVPYDQEELKNRYQSFGNNHFAERSFLTAPQTEYRNNMIVIGLYFINCQSLLQDRDTLNFFKESKFDALFTDPALPCGVILAEYLGLPSVYLFRGFPCSLEHTFSRSPDPVSYIPRCYTKFSDHMTFSQRVANFLVNLLEPYLFYCLFSKYEELASAVLKRDVDIITLYQKVSVWLLRYDFVLEYPRPVMPNMVFIGGINCKKRKDLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|P14679|TYRO_HUMAN Tyrosinase OS=Homo sapiens OX=9606 GN=TYR PE=1 SV=3MLLAVLYCLLWSFQTSAGHFPRACVSSKNLMEKECCPPWSGDRSPCGQLSGRGSCQNILLSNAPLGPQFPFTGVDDRESWPSVFYNRTCQCSGNFMGFNCGNCKFGFWGPNCTERRLLVRRNIFDLSAPEKDKFFAYLTLAKHTISSDYVIPIGTYGQMKNGSTPMFNDINIYDLFVWMHYYVSMDALLGGSEIWRDIDFAHEAPAFLPWHRLFLLRWEQEIQKLTGDENFTIPYWDWRDAEKCDICTDEYMGGQHPTNPNLLSPASFFSSWQIVCSRLEEYNSHQSLCNGTPEGPLRRNPGNHDKSRTPRLPSSADVEFCLSLTQYESGSMDKAANFSFRNTLEGFASPLTGIADASQSSMHNALHIYMNGTMSQVQGSANDPIFLLHHAFVDSIFEQWLRRHRPLQEVYPEANAPIGHNRESYMVPFIPLYRNGDFFISSKDLGYDYSYLQDSDPDSFQDYIKSYLEQASRIWSWLLGAAMVGAVLTALLAGLVSLLCRHKRKQLPEEKQPLLMEKEDYHSLYQSHL>sp|P14679-2|TYRO_HUMAN Isoform 2 of Tyrosinase OS=Homo sapiens OX=9606GN=TYRMLLAVLYCLLWSFQTSAGHFPRACVSSKNLMEKECCPPWSGDRSPCGQLSGRGSCQNILLSNAPLGPQFPFTGVDDRESWPSVFYNRTCQCSGNFMGFNCGNCKFGFWGPNCTERRLLVRRNIFDLSAPEKDKFFAYLTLAKHTISSDYVIPIGTYGQMKNGSTPMFNDINIYDLFVWMHYYVSMDALLGGSEIWRDIDFAHEAPAFLPWHRLFLLRWEQEIQKLTGDENFTIPYWDWRDAEKCDICTDEYMGGQHPTNPNLLSPASFFSSWQIVCSRLEEYNSHQSLCNGTPEGPLRRNPGNHDKSRTPRLPSSADVEFCLSLTQYESGSMDKAANFSFRNTLEEMGFLHVGWAGLKLLTSRDPPPWPPKMLGLQA>sp|A0A0B4J277|TVA22_HUMAN T cell receptor alpha variable 22 OS=Homosapiens OX=9606 GN=TRAV22 PE=1 SV=1MKRILGALLGLLSAQVCCVRGIQVEQSPPDLILQEGANSTLRCNFSDSVNNLQWFHQNPWGQLINLFYIPSGTKQNGRLSATTVATERYSLLYISSSQTTDSGVYFCAVE>sp|Q06418|TYRO3_HUMAN Tyrosine-protein kinase receptor TYRO3 OS=Homosapiens OX=9606 GN=TYRO3 PE=1 SV=1MALRRSMGRPGLPPLPLPPPPRLGLLLAALASLLLPESAAAGLKLMGAPVKLTVSQGQPVKLNCSVEGMEEPDIQWVKDGAVVQNLDQLYIPVSEQHWIGFLSLKSVERSDAGRYWCQVEDGGETEISQPVWLTVEGVPFFTVEPKDLAVPPNAPFQLSCEAVGPPEPVTIVWWRGTTKIGGPAPSPSVLNVTGVTQSTMFSCEAHNLKGLASSRTATVHLQALPAAPFNITVTKLSSSNASVAWMPGADGRALLQSCTVQVTQAPGGWEVLAVVVPVPPFTCLLRDLVPATNYSLRVRCANALGPSPYADWVPFQTKGLAPASAPQNLHAIRTDSGLILEWEEVIPEAPLEGPLGPYKLSWVQDNGTQDELTVEGTRANLTGWDPQKDLIVRVCVSNAVGCGPWSQPLVVSSHDRAGQQGPPHSRTSWVPVVLGVLTALVTAAALALILLRKRRKETRFGQAFDSVMARGEPAVHFRAARSFNRERPERIEATLDSLGISDELKEKLEDVLIPEQQFTLGRMLGKGEFGSVREAQLKQEDGSFVKVAVKMLKADIIASSDIEEFLREAACMKEFDHPHVAKLVGVSLRSRAKGRLPIPMVILPFMKHGDLHAFLLASRIGENPFNLPLQTLIRFMVDIACGMEYLSSRNFIHRDLAARNCMLAEDMTVCVADFGLSRKIYSGDYYRQGCASKLPVKWLALESLADNLYTVQSDVWAFGVTMWEIMTRGQTPYAGIENAEIYNYLIGGNRLKQPPECMEDVYDLMYQCWSADPKQRPSFTCLRMELENILGQLSVLSASQDPLYINIERAEEPTAGGSLELPGRDQPYSGAGDGSGMGAVGGTPSDCRYILTPGGLAEQPGQAEHQPESPLNETQRLLLLQQGLLPHSSC>sp|P61421|VA0D1_HUMAN V-type proton ATPase subunit d 1 OS=Homo sapiensOX=9606 GN=ATP6V0D1 PE=1 SV=1MSFFPELYFNVDNGYLEGLVRGLKAGVLSQADYLNLVQCETLEDLKLHLQSTDYGNFLANEASPLTVSVIDDRLKEKMVVEFRHMRNHAYEPLASFLDFITYSYMIDNVILLITGTLHQRSIAELVPKCHPLGSFEQMEAVNIAQTPAELYNAILVDTPLAAFFQDCISEQDLDEMNIEIIRNTLYKAYLESFYKFCTLLGGTTADAMCPILEFEADRRAFIITINSFGTELSKEDRAKLFPHCGRLYPEGLAQLARADDYEQVKNVADYYPEYKLLFEGAGSNPGDKTLEDRFFEHEVKLNKLAFLNQFHFGVFYAFVKLKEQECRNIVWIAECIAQRHRAKIDNYIPIF>sp|Q9HBM0|VEZA_HUMAN Vezatin OS=Homo sapiens OX=9606 GN=VEZT PE=1 SV=3MTPEFDEEVVFENSPLYQYLQDLGHTDFEICSSLSPKTEKCTTEGQQKPPTRVLPKQGILLKVAETIKSWIFFSQCNKKDDLLHKLDIGFRLDSLHTILQQEVLLQEDVELIELLDPSILSAGQSQQQENGHLPTLCSLATPNIWDLSMLFAFISLLVMLPTWWIVSSWLVWGVILFVYLVIRALRLWRTAKLQVTLKKYSVHLEDMATNSRAFTNLVRKALRLIQETEVISRGFTLVSAACPFNKAGQHPSQHLIGLRKAVYRTLRANFQAARLATLYMLKNYPLNSESDNVTNYICVVPFKELGLGLSEEQISEEEAHNFTDGFSLPALKVLFQLWVAQSSEFFRRLALLLSTANSPPGPLLTPALLPHRILSDVTQGLPHAHSACLEELKRSYEFYRYFETQHQSVPQCLSKTQQKSRELNNVHTAVRSLQLHLKALLNEVIILEDELEKLVCTKETQELVSEAYPILEQKLKLIQPHVQASNNCWEEAISQVDKLLRRNTDKKGKPEIACENPHCTVVPLKQPTLHIADKDPIPEEQELEAYVDDIDIDSDFRKDDFYYLSQEDKERQKREHEESKRVLQELKSVLGFKASEAERQKWKQLLFSDHAVLKSLSPVDPVEPISNSEPSMNSDMGKVSKNDTEEESNKSATTDNEISRTEYLCENSLEGKNKDNSSNEVFPQGAEERMCYQCESEDEPQADGSGLTTAPPTPRDSLQPSIKQRLARLQLSPDFTFTAGLAAEVAARSLSFTTMQEQTFGGEEEEQIIEENKNEIEEK>sp|Q9HBM0-2|VEZA_HUMAN Isoform 2 of Vezatin OS=Homo sapiens OX=9606GN=VEZTMLKEWAIKQGILLKVAETIKSWIFFSQCNKKDDLLHKLDIGFRLDSLHTILQQEVLLQEDVELIELLDPSILSAGQSQQQENGHLPTLCSLATPNIWDLSMLFAFISLLVMLPTWWIVSSWLVWGVILFVYLVIRALRLWRTAKLQVTLKKYSVHLEDMATNSRAFTNLVRKALRLIQETEVISRGFTLVSAACPFNKAGQHPSQHLIGLRKAVYRTLRANFQAARLATLYMLKNYPLNSESDNVTNYICVVPFKELGLGLSEEQISEEEAHNFTDGFSLPALKVLFQLWVAQSSEFFRRLALLLSTANSPPGPLLTPALLPHRILSDVTQGLPHAHSACLEELKRSYEFYRYFETQHQSVPQCLSKTQQKSRELNNVHTAVRSLQLHLKALLNEVIILEDELEKLVCTKETQELVSEAYPILEQKLKLIQPHVQASNNCWEEAISQVDKLLRRNTDKKGKPEIACENPHCTVVPLKQPTLHIADKDPIPEEQELEAYVDDIDIDSDFRKDDFYYLSQEDKERQKREHEESKRVLQELKSVLGFKASEAERQKWKQLLFSDHGVKSAWN>sp|Q9HBM0-5|VEZA_HUMAN Isoform 5 of Vezatin OS=Homo sapiens OX=9606GN=VEZTMTPEFDEEVVFENSPLYQYLQDLGHTDFEICSSLSPKTEKCTTEGQQKPPTRVLPKGSLSAICLH>sp|Q9HBM0-6|VEZA_HUMAN Isoform 6 of Vezatin OS=Homo sapiens OX=9606GN=VEZTMTPEFDEEVVFENSPLYQYLQDLGHTDFEICSSLSPKTEKCTTEGQQKPPTRVLPKYLGYSNHSMNINCTYWHAQGMGY>sp|Q8N8G2|VGLL2_HUMAN Transcription cofactor vestigial-like protein 2OS=Homo sapiens OX=9606 GN=VGLL2 PE=1 SV=1MSCLDVMYQVYGPPQPYFAAAYTPYHQKLAYYSKMQEAQECNASPSSSGSGSSSFSSQTPASIKEEEGSPEKERPPEAEYINSRCVLFTYFQGDISSVVDEHFSRALSQPSSYSPSCTSSKAPRSSGPWRDCSFPMSQRSFPASFWNSAYQAPVPPPLGSPLATAHSELPFAAADPYSPAALHGHLHQGATEPWHHAHPHHAHPHHPYALGGALGAQAAPYPRPAAVHEVYAPHFDPRYGPLLMPAASGRPARLATAPAPAPGSPPCELSGKGEPAGAAWAGPGGPFASPSGDVAQGLGLSVDSARRYSLCGASLLS>sp|Q8N8G2-2|VGLL2_HUMAN Isoform 2 of Transcription cofactor vestigial-like protein 2 OS=Homo sapiens OX=9606 GN=VGLL2MSCLDVMYQVYGPPQPYFAAAYTPYHQKLAYYSKMQEAQECNASPSSSGSGSSSFSSQTPASIKEEEGSPEKERPPEAEYINSRCVLFTYFQGDISSVVDEHFSRALSQPSSYSPSCTSSKAPRSSGPWRARRYSLCGASLLS>sp|Q6ZRF7|ZN818_HUMAN Putative zinc finger protein 818 OS=Homo sapiensOX=9606 GN=ZNF818P PE=5 SV=1MLERNLTSMMSVEEPLPRPLTSLYIRLSILERNHMNMTYMAKSSVKIHISKVIIGFVLKRSLTNVCGKVLSQNSHLVNHQRIHTGEKSYRCHECGKAFTQGSRFINHQIVHTGENFPNVLNVARLLRMALNSGLTK>sp|Q8N8N7|PTGR2_HUMAN Prostaglandin reductase 2 OS=Homo sapiens OX=9606GN=PTGR2 PE=1 SV=1MIVQRVVLNSRPGKNGNPVAENFRMEEVYLPDNINEGQVQVRTLYLSVDPYMRCRMNEDTGTDYITPWQLSQVVDGGGIGIIEESKHTNLTKGDFVTSFYWPWQTKVILDGNSLEKVDPQLVDGHLSYFLGAIGMPGLTSLIGIQEKGHITAGSNKTMVVSGAAGACGSVAGQIGHFLGCSRVVGICGTHEKCILLTSELGFDAAINYKKDNVAEQLRESCPAGVDVYFDNVGGNISDTVISQMNENSHIILCGQISQYNKDVPYPPPLSPAIEAIQKERNITRERFLVLNYKDKFEPGILQLSQWFKEGKLKIKETVINGLENMGAAFQSMMTGGNIGKQIVCISEEISL>sp|Q8N8N7-2|PTGR2_HUMAN Isoform 2 of Prostaglandin reductase 2 OS=Homosapiens OX=9606 GN=PTGR2MIVQRVVLNSRPGKNGNPVAENFRMEEVYLPDNINEGQVQVRTLYLSVDPYMRCRMNEDTGTDYITPWQLSQVVDGGGIGIIEESKHTNLTKGDFVTSFYWPWQTKVILDGNSLEKVDPQLVDGHLSYFLGAIGMPGLTSLIGIQEKGHITAGSNKTMVVSGAAGACGSVAGQVNFLRII>sp|P41222|PTGDS_HUMAN Prostaglandin-H2 D-isomerase OS=Homo sapiensOX=9606 GN=PTGDS PE=1 SV=1MATHHTLWMGLALLGVLGDLQAAPEAQVSVQPNFQQDKFLGRWFSAGLASNSSWLREKKAALSMCKSVVAPATDGGLNLTSTFLRKNQCETRTMLLQPAGSLGSYSYRSPHWGSTYSVSVVETDYDQYALLYSQGSKGPGEDFRMATLYSRTQTPRAELKEKFTAFCKAQGFTEDTIVFLPQTDKCMTEQ>sp|Q9UQ74|PSG8_HUMAN Pregnancy-specific beta-1-glycoprotein 8 OS=Homosapiens OX=9606 GN=PSG8 PE=2 SV=2MGLLSAPPCTQRITWKGLLLTASLLNFWNPPTTAQVTIEAQPTKVSEGKDVLLLVHNLPQNLTGYIWYKGQIRDLYHYITSYVVDGQIIIYGPAYSGRETIYSNASLLIQNVTQEDAGSYTLHIIMGGDENRGVTGHFTFTLYLETPKPSISSSKLNPREAMEAVSLTCDPETPDASYLWWMNGQSLPMSHRLQLSETNRTLFLLGVTKYTAGPYECEIRNPVSASRSDPFTLNLLPKLPKPYITINNLKPRENKDVLNFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIRDQYGGIRSYPVTLNVLYGPDLPRIYPSFTYYRSGEVLYLSCSADSNPPAQYSWTINGKFQLSGQKLFIPQITTKHSGLYACSVRNSATGKESSKSMTVKVSGKRIPVSLAIGI>sp|Q9UQ74-2|PSG8_HUMAN Isoform 2 of Pregnancy-specific beta-1-glycoprotein 8 OS=Homo sapiens OX=9606 GN=PSG8MGLLSAPPCTQRITWKGLLLTVETPKPSISSSKLNPREAMEAVSLTCDPETPDASYLWWMNGQSLPMSHRLQLSETNRTLFLLGVTKYTAGPYECEIRNPVSASRSDPFTLNLLPKLPKPYITINNLKPRENKDVLNFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIRDQYGGIRSYPVTLNVLYGPDLPRIYPSFTYYRSGEVLYLSCSADSNPPAQYSWTINGKFQLSGQKLFIPQITTKHSGLYACSVRNSATGKESSKSMTVKVSDWTLP>sp|Q9UQ74-3|PSG8_HUMAN Isoform 3 of Pregnancy-specific beta-1-glycoprotein 8 OS=Homo sapiens OX=9606 GN=PSG8MGLLSAPPCTQRITWKGLLLTASLLNFWNPPTTAQVTIEAQPTKVSEGKDVLLLVHNLPQNLTGYIWYKGQIRDLYHYITSYVVDGQIIIYGPAYSGRETIYSNASLLIQNVTQEDAGSYTLHIIMGGDENRGVTGHFTFTLYLETPKPSISSSKLNPREAMEAVSLTCDPETPDASYLWWMNGQSLPMSHRLQLSETNRTLFLLGVTKYTAGPYECEIRNPVSASRSDPFTLNLLPKLPKPYITINNLKPRENKDVLNFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIRDQYGGIRSYPVTLNVLYGPDLPRIYPSFTYYRSGEVLYLSCSADSNPPAQYSWTINGKFQLSGQKLFIPQITTKHSGLYACSVRNSATGKESSKSMTVKVSDWTLP>sp|Q15238|PSG5_HUMAN Pregnancy-specific beta-1-glycoprotein 5 OS=Homosapiens OX=9606 GN=PSG5 PE=1 SV=3MGPLSAPPCTQHITWKGLLLTASLLNFWNLPITAQVTIEALPPKVSEGKDVLLLVHNLPQNLAGYIWYKGQLMDLYHYITSYVVDGQINIYGPAYTGRETVYSNASLLIQNVTREDAGSYTLHIIKRGDRTRGVTGYFTFNLYLKLPKPYITINNSKPRENKDVLAFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYECEIRDRDGGMRSDPVTLNVLYGPDLPSIYPSFTYYRSGENLYLSCFAESNPPAEYFWTINGKFQQSGQKLSIPQITTKHRGLYTCSVRNSATGKESSKSMTVEVSAPSGIGRLPLLNPI>sp|Q3KNS1|PTHD3_HUMAN Patched domain-containing protein 3 OS=Homosapiens OX=9606 GN=PTCHD3 PE=1 SV=3MPWVEPKPRPGPEQKPKLTKPDSATGPQWYQESQESESEGKQPPPGPLAPPKSPEPSGPLASEQDAPLPEGDDAPPRPSMLDDAPRLPLELDDAPLPEEETPEPTAICRHRHRCHTDCLEGLLSRTFQWLGWQVGAHPWIFLLAPLMLTAALGTGFLYLPKDEEEDLEEHYTPVGSPAKAERRFVQGHFTTNDSYRFSASRRSTEANFVSLLVVSYSDSLLDPATFAEVSKLDGAVQDLRVAREKGSQIQYQQVCARYRALCVPPNPILYAWQVNKTLNLSSISFPAYNHGRHPLYLTGFFGGYILGGSLGMGQLLLRAKAMRLLYYLKTEDPEYDVQSKQWLTHLLDQFTNIKNILALKKIEVVHFTSLSRQLEFEATSVTVIPVFHLAYILIILFAVTSCFRFDCIRNKMCVAAFGVISAFLAVVSGFGLLLHIGVPFVIIVANSPFLILGVGVDDMFIMISAWHKTNLADDIRERMSNVYSKAAVSITITTITNILALYTGIMSSFRSVQCFCIYTGMTLLFCYFYNITCFGAFMALDGKREVVCLCWLKKADPKWPSFKKFCCFPFGSVPDEHGTDIHPISLFFRDYFGPFLTRSESKYFVVFIYVLYIISSIYGCFHVQEGLDLRNLASDDSYITPYFNVEENYFSDYGPRVMVIVTKKVDYWDKDVRQKLENCTKIFEKNVYVDKNLTEFWLDAYVQYLKGNSQDPNEKNTFMNNIPDFLSNFPNFQHDINISSSNEIISSRGFIQTTDVSSSAKKKILLF>sp|Q15008|PSMD6_HUMAN 26S proteasome non-ATPase regulatory subunit 6OS=Homo sapiens OX=9606 GN=PSMD6 PE=1 SV=1MPLENLEEEGLPKNPDLRIAQLRFLLSLPEHRGDAAVRDELMAAVRDNNMAPYYEALCKSLDWQIDVDLLNKMKKANEDELKRLDEELEDAEKNLGESEIRDAMMAKAEYLCRIGDKEGALTAFRKTYDKTVALGHRLDIVFYLLRIGLFYMDNDLITRNTEKAKSLIEEGGDWDRRNRLKVYQGLYCVAIRDFKQAAELFLDTVSTFTSYELMDYKTFVTYTVYVSMIALERPDLREKVIKGAEILEVLHSLPAVRQYLFSLYECRYSVFFQSLAVVEQEMKKDWLFAPHYRYYVREMRIHAYSQLLESYRSLTLGYMAEAFGVGVEFIDQELSRFIAAGRLHCKIDKVNEIVETNRPDSKNWQYQETIKKGDLLLNRVQKLSRVINM>sp|Q15008-2|PSMD6_HUMAN Isoform 2 of 26S proteasome non-ATPaseregulatory subunit 6 OS=Homo sapiens OX=9606 GN=PSMD6MNESNDSTNYDMAPYYEALCKSLDWQIDVDLLNKMKKANEDELKRLDEELEDAEKNLGESEIRDAMMAKAEYLCRIGDKEGALTAFRKTYDKTVALGHRLDIVFYLLRIGLFYMDNDLITRNTEKAKSLIEEGGDWDRRNRLKVYQGLYCVAIRDFKQAAELFLDTVSTFTSYELMDYKTFVTYTVYVSMIALERPDLREKVIKGAEILEVLHSLPAVRQYLFSLYECRYSVFFQSLAVVEQEMKKDWLFAPHYRYYVREMRIHAYSQLLESYRSLTLGYMAEAFGVGVEFIDQELSRFIAAGRLHCKIDKVNEIVETNRPDSKNWQYQETIKKGDLLLNRVQKLSRVINM>sp|Q15008-3|PSMD6_HUMAN Isoform 3 of 26S proteasome non-ATPaseregulatory subunit 6 OS=Homo sapiens OX=9606 GN=PSMD6MPLENLEEEDMAPYYEALCKSLDWQIDVDLLNKMKKANEDELKRLDEELEDAEKNLGESEIRDAMMAKAEYLCRIGDKEGALTAFRKTYDKTVALGHRLDIVFYLLRIGLFYMDNDLITRNTEKAKSLIEEGGDWDRRNRLKVYQGLYCVAIRDFKQAAELFLDTVSTFTSYELMDYKTFVTYTVYVSMIALERPDLREKVIKGAEILEVLHSLPAVRQYLFSLYECRYSVFFQSLAVVEQEMKKDWLFAPHYRYYVREMRIHAYSQLLESYRSLTLGYMAEAFGVGVEFIDQELSRFIAAGRLHCKIDKVNEIVETNRPDSKNWQYQETIKKGDLLLNRVQKLSRVINM>sp|Q15008-4|PSMD6_HUMAN Isoform 4 of 26S proteasome non-ATPaseregulatory subunit 6 OS=Homo sapiens OX=9606 GN=PSMD6MPLENLEEEGLPKNPDLRIAQLRFLLSLPEHRGDAAVRDELMAAVRDNNFWNRIRQEQTEDCPPSSPSRGWHCQDWPSRKPPTSIRLCFAKPIIKRHRMPSYMAPYYEALCKSLDWQIDVDLLNKMKKANEDELKRLDEELEDAEKNLGESEIRDAMMAKAEYLCRIGDKEGALTAFRKTYDKTVALGHRLDIVFYLLRIGLFYMDNDLITRNTEKAKSLIEEGGDWDRRNRLKVYQGLYCVAIRDFKQAAELFLDTVSTFTSYELMDYKTFVTYTVYVSMIALERPDLREKVIKGAEILEVLHSLPAVRQYLFSLYECRYSVFFQSLAVVEQEMKKDWLFAPHYRYYVREMRIHAYSQLLESYRSLTLGYMAEAFGVGVEFIDQELSRFIAAGRLHCKIDKVNEIVETNRPDSKNWQYQETIKKGDLLLNRVQKLSRVINM>sp|Q9UL46|PSME2_HUMAN Proteasome activator complex subunit 2 OS=Homosapiens OX=9606 GN=PSME2 PE=1 SV=4MAKPCGVRLSGEARKQVEVFRQNLFQEAEEFLYRFLPQKIIYLNQLLQEDSLNVADLTSLRAPLDIPIPDPPPKDDEMETDKQEKKEVHKCGFLPGNEKVLSLLALVKPEVWTLKEKCILVITWIQHLIPKIEDGNDFGVAIQEKVLERVNAVKTKVEAFQTTISKYFSERGDAVAKASKETHVMDYRALVHERDEAAYGELRAMVLDLRAFYAELYHIISSNLEKIVNPKGEEKPSMY>sp|Q5JQD4|PYY3_HUMAN Putative peptide YY-3 OS=Homo sapiens OX=9606GN=PYY3 PE=5 SV=1MVSVCRPWPAVAIALLALLVCLGALVDTCPIKPEAPGEDESLEELSHYYASLCHYLNVVTRQWWEGADMW>sp|Q9UDW1|QCR9_HUMAN Cytochrome b-c1 complex subunit 9 OS=Homo sapiensOX=9606 GN=UQCR10 PE=1 SV=3MAAATLTSKLYSLLFRRTSTFALTIIVGVMFFERAFDQGADAIYDHINEGKLWKHIKHKYENK>sp|Q9UDW1-2|QCR9_HUMAN Isoform 2 of Cytochrome b-c1 complex subunit 9OS=Homo sapiens OX=9606 GN=UQCR10MAAATLTSKLYSLLFRRTSTFALTIIVGVMFFERAFDQGADAIYDHINEGVRACAIPDLGPA>sp|O60894|RAMP1_HUMAN Receptor activity-modifying protein 1 OS=Homosapiens OX=9606 GN=RAMP1 PE=1 SV=1MARALCRLPRRGLWLLLAHHLFMTTACQEANYGALLRELCLTQFQVDMEAVGETLWCDWGRTIRSYRELADCTWHMAEKLGCFWPNAEVDRFFLAVHGRYFRSCPISGRAVRDPPGSILYPFIVVPITVTLLVTALVVWQSKRTEGIV>sp|Q5TGL8|PXDC1_HUMAN PX domain-containing protein 1 OS=Homo sapiensOX=9606 GN=PXDC1 PE=2 SV=3MASAVFEGTSLVNMFVRGCWVNGIRRLIVSRRGDEEEFFEIRTEWSDRSVLYLHRSLADLGRLWQRLRDAFPEDRSELAQGPLRQGLVAIKEAHDIETRLNEVEKLLKTIISMPCKYSRSEVVLTFFERSPLDQVLKNDNVHKIQPSFQSPVKISEIMRSNGFCLANTETIVIDHSIPNGRDQQLGVDPTEHLFENGSEFPSELEDGDDPAAYVTNLSYYHLVPFETDIWD>sp|Q93062|RBPMS_HUMAN RNA-binding protein with multiple splicing OS=Homosapiens OX=9606 GN=RBPMS PE=1 SV=1MNNGGKAEKENTPSEANLQEEEVRTLFVSGLPLDIKPRELYLLFRPFKGYEGSLIKLTSKQPVGFVSFDSRSEAEAAKNALNGIRFDPEIPQTLRLEFAKANTKMAKNKLVGTPNPSTPLPNTVPQFIAREPYELTVPALYPSSPEVWAPYPLYPAELAPALPPPAFTYPASLHAQMRWLPPSEATSQGWKSRQFC>sp|Q93062-2|RBPMS_HUMAN Isoform B of RNA-binding protein with multiplesplicing OS=Homo sapiens OX=9606 GN=RBPMSMNNGGKAEKENTPSEANLQEEEVRTLFVSGLPLDIKPRELYLLFRPFKGYEGSLIKLTSKQPVGFVSFDSRSEAEAAKNALNGIRFDPEIPQTLRLEFAKANTKMAKNKLVGTPNPSTPLPNTVPQFIAREPYELTVPALYPSSPEVWAPYPLYPAELAPALPPPAFTYPASLHAQLCEGQTVRRSHPLSAPSPDSASLAWFPV>sp|Q93062-3|RBPMS_HUMAN Isoform C of RNA-binding protein with multiplesplicing OS=Homo sapiens OX=9606 GN=RBPMSMNNGGKAEKENTPSEANLQEEEVRTLFVSGLPLDIKPRELYLLFRPFKGYEGSLIKLTSKQPVGFVSFDSRSEAEAAKNALNGIRFDPEIPQTLRLEFAKANTKMAKNKLVGTPNPSTPLPNTVPQFIAREPYELTVPALYPSSPEVWAPYPLYPAELAPALPPPAFTYPASLHAQCFSPEAKPNTPVFCPLLQQIRFVSGNVFVTYQPTADQQRELPC>sp|Q93062-4|RBPMS_HUMAN Isoform D of RNA-binding protein with multiplesplicing OS=Homo sapiens OX=9606 GN=RBPMSMNNGGKAEKENTPSEANLQEEEVRTLFVSGLPLDIKPRELYLLFRPFKGYEGSLIKLTSKQPVGFVSFDSRSEAEAAKNALNGIRFDPEIPQTLRLEFAKANTKMAKNKLVGTPNPSTPLPNTVPQFIAREPLGGANEHGERQ>sp|Q93062-5|RBPMS_HUMAN Isoform E of RNA-binding protein with multiplesplicing OS=Homo sapiens OX=9606 GN=RBPMSMNNGGKAEKENTPSEANLQEEEVRTLFVSGLPLDIKPRELYLLFRPFKGYEGSLIKLTSKQPVGFVSFDSRSEAEAAKNALNGIRFDPEIPQTLRLEFAKANTKMAKNKLVGTPNPSTPLPNTVPQFIAREPMRWLPPSEATSQGWKSRQFC>sp|P15918|RAG1_HUMAN V(D)J recombination-activating protein 1 OS=Homosapiens OX=9606 GN=RAG1 PE=1 SV=2MAASFPPTLGLSSAPDEIQHPHIKFSEWKFKLFRVRSFEKTPEEAQKEKKDSFEGKPSLEQSPAVLDKADGQKPVPTQPLLKAHPKFSKKFHDNEKARGKAIHQANLRHLCRICGNSFRADEHNRRYPVHGPVDGKTLGLLRKKEKRATSWPDLIAKVFRIDVKADVDSIHPTEFCHNCWSIMHRKFSSAPCEVYFPRNVTMEWHPHTPSCDICNTARRGLKRKSLQPNLQLSKKLKTVLDQARQARQHKRRAQARISSKDVMKKIANCSKIHLSTKLLAVDFPEHFVKSISCQICEHILADPVETNCKHVFCRVCILRCLKVMGSYCPSCRYPCFPTDLESPVKSFLSVLNSLMVKCPAKECNEEVSLEKYNHHISSHKESKEIFVHINKGGRPRQHLLSLTRRAQKHRLRELKLQVKAFADKEEGGDVKSVCMTLFLLALRARNEHRQADELEAIMQGKGSGLQPAVCLAIRVNTFLSCSQYHKMYRTVKAITGRQIFQPLHALRNAEKVLLPGYHHFEWQPPLKNVSSSTDVGIIDGLSGLSSSVDDYPVDTIAKRFRYDSALVSALMDMEEDILEGMRSQDLDDYLNGPFTVVVKESCDGMGDVSEKHGSGPVVPEKAVRFSFTIMKITIAHSSQNVKVFEEAKPNSELCCKPLCLMLADESDHETLTAILSPLIAEREAMKSSELMLELGGILRTFKFIFRGTGYDEKLVREVEGLEASGSVYICTLCDATRLEASQNLVFHSITRSHAENLERYEVWRSNPYHESVEELRDRVKGVSAKPFIETVPSIDALHCDIGNAAEFYKIFQLEIGEVYKNPNASKEERKRWQATLDKHLRKKMNLKPIMRMNGNFARKLMTKETVDAVCELIPSEERHEALRELMDLYLKMKPVWRSSCPAKECPESLCQYSFNSQRFAELLSTKFKYRYEGKITNYFHKTLAHVPEIIERDGSIGAWASEGNESGNKLFRRFRKMNARQSKCYEMEDVLKHHWLYTSKYLQKFMNAHNALKTSGFTMNPQASLGDPLGIEDSLESQDSMEF>sp|P15918-2|RAG1_HUMAN Isoform 2 of V(D)J recombination-activatingprotein 1 OS=Homo sapiens OX=9606 GN=RAG1MAASFPPTLGLSSAPDEIQHPHIKFSEWKFKLFRVRSFEKTPEEAQKEKKDSFEGKPSLEQSPAVLDKADGQKPVPTQPLLKAHPKFSKKFHDNEKARGKAIHQANLRHLCRICGNSFRADEHNRRYPVHGPVDGKTLGLLRKKEKRATSWPDLIAKVFRIDVKADVDSIHPTEFCHNCWSIMHRKFSSAPCEVYFPRNVTMEWHPHTPSCDICNTARRGLKRKSLQPNLQLSKKLKTVLDQARQARQHKRRAQARISSKDVMKKIANCSKIHLSTKLLAVDFPEHFVKSISCQICEHILADPVETNCKHVFCRVCILRCLKVMGSYCPSCRYPCFPTDLESPVKSFLSVLNSLMVKCPAKECNEEVSLEKYNHHISSHKESKEIFVHINKGGRPRQHLLSLTRRAQKHRLRELKLQVKAFADKEEGGDVKSVCMTLFLLALRARNEHRQADELEAIMQGKGSGLQPAVCLAIRVNTFLSCSQYHKMYRTVKAITGRQIFQPLHALRNAEKVLLPGYHHFEWQPPLKNVSSSTDVGIIDGLSGLSSSVDDYPVDTIAKRFRYDSALVSALMDMEEDILEGMRSQDLDDYLNGPFTVVVKESCDGMGDVSEKHGSGPVVPEKAVRFSFTIMKITIAHSSQNVKVFEEAKPNSELCCKPLCLMLADESDHETLTAILSPLIAEREAMKSSELMLELGGILRTFKFIFRGTGYDEKLVREVEGLEASGSVYICTLCDATRLEASQNLVFHSITRSHAENLERYEVWRSNPYHESVEELRDRVKGVSAKPFIETVPSIDALHCDIGNAAEFYKIFQLEIGEVYKNPNASKEERKRWQATLDKHLRKKMNLKPIMRMNGNFARKLMTKETVDAVCELIPSEERHEALRELMDLYLKMKPVWRSSCPAKECPESLCQYSFNSQRFAELLSTKFKYRN>sp|Q06609|RAD51_HUMAN DNA repair protein RAD51 homolog 1 OS=Homo sapiensOX=9606 GN=RAD51 PE=1 SV=1MAMQMQLEANADTSVEEESFGPQPISRLEQCGINANDVKKLEEAGFHTVEAVAYAPKKELINIKGISEAKADKILAEAAKLVPMGFTTATEFHQRRSEIIQITTGSKELDKLLQGGIETGSITEMFGEFRTGKTQICHTLAVTCQLPIDRGGGEGKAMYIDTEGTFRPERLLAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALLIVDSATALYRTDYSGRGELSARQMHLARFLRMLLRLADEFGVAVVITNQVVAQVDGAAMFAADPKKPIGGNIIAHASTTRLYLRKGRGETRICKIYDSPCLPEAEAMFAINADGVGDAKD>sp|Q06609-2|RAD51_HUMAN Isoform 2 of DNA repair protein RAD51 homolog 1OS=Homo sapiens OX=9606 GN=RAD51MAMQMQLEANADTSVEEESFGPQPISRLEQCGINANDVKKLEEAGFHTVEAVAYAPKKELINIKGISEAKADKILAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALLIVDSATALYRTDYSGRGELSARQMHLARFLRMLLRLADEFGVAVVITNQVVAQVDGAAMFAADPKKPIGGNIIAHASTTRLYLRKGRGETRICKIYDSPCLPEAEAMFAINADGVGDAKD>sp|Q06609-3|RAD51_HUMAN Isoform 3 of DNA repair protein RAD51 homolog 1OS=Homo sapiens OX=9606 GN=RAD51MAMQMQLEANADTSVEEESFGPQPISRLEQCGINANDVKKLEEAGFHTVEAVAYAPKKELINIKGISEAKADKILAEAAKLVPMGFTTATEFHQRRSEIIQITTGSKELDKLLQGGIETGSITEMFGEFRTGKTQICHTLAVTCQLPIDRGGGEGKAMYIDTEGTFRPERLLAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALLIVDSATALYRTDYSGRGELSARQMHLARFLRMLLRLADEIVSEERKRGNQNLQNLRLSLSS>sp|Q06609-4|RAD51_HUMAN Isoform 4 of DNA repair protein RAD51 homolog 1OS=Homo sapiens OX=9606 GN=RAD51MAMQMQLEANADTSVEEESFGPQPISRLEQCGINANDVKKLEEAGFHTVEAVAYAPKKELINIKGISEAKADKILTESRSVARLECNSVILVYCTLRLSGSSDSPASASRVVGTTGGIETGSITEMFGEFRTGKTQICHTLAVTCQLPIDRGGGEGKAMYIDTEGTFRPERLLAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALLIVDSATALYRTDYSGRGELSARQMHLARFLRMLLRLADEFGVAVVITNQVVAQVDGAAMFAADPKKPIGGNIIAHASTTRLYLRKGRGETRICKIYDSPCLPEAEAMFAINADGVGDAKD>sp|Q6VN20|RBP10_HUMAN Ran-binding protein 10 OS=Homo sapiens OX=9606GN=RANBP10 PE=1 SV=1MAAATADPGAGNPQPGDSSGGGAGGGLPSPGEQELSRRLQRLYPAVNQQETPLPRSWSPKDKYNYIGLSQGNLRVHYKGHGKNHKDAASVRATHPIPAACGIYYFEVKIVSKGRDGYMGIGLSAQGVNMNRLPGWDKHSYGYHGDDGHSFCSSGTGQPYGPTFTTGDVIGCCVNLINGTCFYTKNGHSLGIAFTDLPANLYPTVGLQTPGEIVDANFGQQPFLFDIEDYMREWRAKVQGTVHCFPISARLGEWQAVLQNMVSSYLVHHGYCATATAFARMTETPIQEEQASIKNRQKIQKLVLEGRVGEAIETTQRFYPGLLEHNPNLLFMLKCRQFVEMVNGTDSEVRSLSSRSPKSQDSYPGSPSLSPRHGPSSSHMHNTGADSPSCSNGVASTKSKQNHSKYPAPSSSSSSSSSSSSSSPSSVNYSESNSTDSTKSQHHSSTSNQETSDSEMEMEAEHYPNGVLGSMSTRIVNGAYKHEDLQTDESSMDDRHPRRQLCGGNQAATERIILFGRELQALSEQLGREYGKNLAHTEMLQDAFSLLAYSDPWSCPVGQQLDPIQREPVCAALNSAILESQNLPKQPPLMLALGQASECLRLMARAGLGSCSFARVDDYLH>sp|Q6VN20-2|RBP10_HUMAN Isoform 2 of Ran-binding protein 10 OS=Homosapiens OX=9606 GN=RANBP10MGIGLSAQGVNMNRLPGWDKHSYGYHGDDGHSFCSSGTGQPYGPTFTTGDVIGCCVNLINGTCFYTKNGHSLGIAFTDLPANLYPTVGLQTPGEIVDANFGQQPFLFDIEDYMREWRAKVQGTVHCFPISARLGEWQAVLQNMVSSYLVHHGYCATATAFARMTETPIQEEQASIKNRQKIQKLVLEGRVGEAIETTQRFYPGLLEHNPNLLFMLKCRQFVEMVNGTDSEVRSLSSRSPKSQDSYPGSPSLSPRHGPSSSHMHNTGADSPSCSNGVASTKSKQNHSKYPAPSSSSSSSSSSSSSSPSSVNYSESNSTDSTKSQHHSSTSNQETSNPWLQLERRPNQAAPTTPPGPTPTSTPPHSDSEMEMEAEHYPNGVLGSMSTRIVNGAYKHEDLQTDESSMDDRHPRRQLCGGNQAATERIILFGRELQALSEQLGREYGKNLAHTEMLQDAFSLLAYSDPWSCPVGQQLDPIQREPVCAALNSAILESQNLPKQPPLMLALGQASECLRLMARAGLGSCSFARVDDYLH>sp|Q6VN20-3|RBP10_HUMAN Isoform 3 of Ran-binding protein 10 OS=Homosapiens OX=9606 GN=RANBP10MAAATADPGAGNPQPGDSSGGGAGGGLPSPGEQELSRRLQRLYPAVNQQETPLPRSWSPKDKYNYIGLSQGNLRVHYKGHGKNHKDAASVRATHPIPAACGIYYFEVKIVSKGRDGYMGIGLSAQGVNMNRLPGIAFTDLPANLYPTVGLQTPGEIVDANFGQQPFLFDIEDYMREWRAKVQGTVHCFPISARLGEWQAVLQNMVSSYLVHHGYCATATAFARMTETPIQEEQASIKNRQKIQKLVLEGRVGEAIETTQRFYPGLLEHNPNLLFMLKCRQFVEMVNGTDSEVRSLSSRSPKSQDSYPGSPSLSPRHGPSSSHMHNTGADSPSCSNGVASTKSKQNHSKYPAPSSSSSSSSSSSSSSPSSVNYSESNSTDSTKSQHHSSTSNQETSNPWLQLERRPNQAAPTTPPGPTPTSTPPHSDSEMEMEAEHYPNGVLGSMSTRIVNGAYKHEDLQTDESSMDDRHPRRQLCGGNQAATERIILFGRELQALSEQLGREYGKNLAHTEMLQDAFSLLAYSDPWSCPVGQQLDPIQREPVCAALNSAILESQNLPKQPPLMLALGQASECLRLMARAGLGSCSFARVDDYLH>sp|O95199|RCBT2_HUMAN RCC1 and BTB domain-containing protein 2 OS=Homosapiens OX=9606 GN=RCBTB2 PE=1 SV=1MEEELPLFSGDSGKPVQATLSSLKMLDVGKWPIFSLCSEEELQLIRQACVFGSAGNEVLYTTVNDEIFVLGTNCCGCLGLGDVQSTIEPRRLDSLNGKKIACLSYGSGPHIVLATTEGEVFTWGHNAYSQLGNGTTNHGLVPCHISTNLSNKQVIEVACGSYHSLVLTSDGEVFAWGYNNSGQVGSGSTVNQPIPRRVTGCLQNKVVVTIACGQMCCMAVVDTGEVYVWGYNGNGQLGLGNSGNQPTPCRVAALQGIRVQRVACGYAHTLVLTDEGQVYAWGANSYGQLGTGNKSNQSYPTPVTVEKDRIIEIAACHSTHTSAAKTQGGHVYMWGQCRGQSVILPHLTHFSCTDDVFACFATPAVTWRLLSVEPDDHLTVAESLKREFDNPDTADLKFLVDGKYIYAHKVLLKIRCEHFRSSLEDNEDDIVEMSEFSYPVYRAFLEYLYTDSISLSPEEAVGLLDLATFYRENRLKKLCQQTIKQGICEENAIALLSAAVKYDAQDLEEFCFRFCINHLTVVTQTSGFAEMDHDLLKNFISKASRVGAFKN>sp|O95199-2|RCBT2_HUMAN Isoform 2 of RCC1 and BTB domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RCBTB2MLDVGKWPIFSLCSEEELQLIRQACVFGSAGNEVLYTTVNDEIFVLGTNCCGCLGLGDVQSTIEPRRLDSLNGKKIACLSYGSGPHIVLATTEGEVFTWGHNAYSQLGNGTTNHGLVPCHISTNLSNKQVIEVACGSYHSLVLTSDGEVFAWGYNNSGQVGSGSTVNQPIPRRVTGCLQNKVVVTIACGQMCCMAVVDTGEVYVWGYNGNGQLGLGNSGNQPTPCRVAALQGIRVQRVACGYAHTLVLTDEGQVYAWGANSYGQLGTGNKSNQSYPTPVTVEKDRIIEIAACHSTHTSAAKTQGGHVYMWGQCRGQSVILPHLTHFSCTDDVFACFATPAVTWRLLSVEPDDHLTVAESLKREFDNPDTADLKFLVDGKYIYAHKVLLKIRCEHFRSSLEDNEDDIVEMSEFSYPVYRAFLEYLYTDSISLSPEEAVGLLDLATFYRENRLKKLCQQTIKQGICEENAIALLSAAVKYDAQDLEEFCFRFCINHLTVVTQTSGFAEMDHDLLKNFISKASRVGAFKN>sp|P59190|RAB15_HUMAN Ras-related protein Rab-15 OS=Homo sapiens OX=9606GN=RAB15 PE=1 SV=1MAKQYDVLFRLLLIGDSGVGKTCLLCRFTDNEFHSSHISTIGVDFKMKTIEVDGIKVRIQIWDTAGQERYQTITKQYYRRAQGIFLVYDISSERSYQHIMKWVSDVDEYAPEGVQKILIGNKADEEQKRQVGREQGQQLAKEYGMDFYETSACTNLNIKESFTRLTELVLQAHRKELEGLRMRASNELALAELEEEEGKPEGPANSSKTCWC>sp|P59190-2|RAB15_HUMAN Isoform 2 of Ras-related protein Rab-15 OS=Homosapiens OX=9606 GN=RAB15MAKQYDVLFRLLLIGDSGVGKTCLLCRFTDNEFHSSHISTIGVDFKMKTIEVDGIKVRIQIWDTAGQERYQTITKQYYRRAQGIFLVYDISSERSYQHIMKWVSDVDEVGDATSLPGCGEGASPGKARRGPDGKANASRKLCLPQPWMKTSGTHQKASRRSLLGIRLMRSRNGRWEESKGSSWRRSMAWTSMKQVPAPTSTLKSHSRV>sp|Q9BSD3|RHNO1_HUMAN RAD9, HUS1, RAD1-interacting nuclear orphanprotein 1 OS=Homo sapiens OX=9606 GN=RHNO1 PE=1 SV=1MPPRKKRRQPSQKAPLLFHQQPLEGPKHSCASTQLPITHTRQVPSKPIDHSTITSWVSPDFDTAAGSLFPAYQKHQNRARHSSRKPTTSKFPHLTFESPQSSSSETLGIPLIRECPSESEKDVSRRPLVPVLSPQSCGNMSVQALQSLPYVFIPPDIQTPESSSVKEELIPQDQKENSLLSCTLHTGTPNSPEPGPVLVKDTPEDKYGIKVTWRRRQHLLAYLRERGKLSRSQFLVKS>sp|Q9BSD3-2|RHNO1_HUMAN Isoform 2 of RAD9, HUS1, RAD1-interactingnuclear orphan protein 1 OS=Homo sapiens OX=9606 GN=RHNO1MPPRKKRRQPSQKAPLLFHQQPLEGPKHSCASTQLPITHTRQVSPDFDTAAGSLFPAYQKHQNRARHSSRKPTTSKFPHLTFESPQSSSSETLGIPLIRECPSESEKDVSRRPLVPVLSPQSCGNMSVQALQSLPYVFIPPDIQTPESSSVKEELIPQDQKENSLLSCTLHTGTPNSPEPGPVLVKDTPEDKYGIKVTWRRRQHLLAYLRERGKLSRSQFLVKS>sp|Q14699|RFTN1_HUMAN Raftlin OS=Homo sapiens OX=9606 GN=RFTN1 PE=1 SV=4MGCGLNKLEKRDEKRPGNIYSTLKRPQVETKIDVSYEYRFLEFTTLSAAELPGSSAVRLASLRDLPAQLLELYQQGFSLAALHPFVQPTHEREKTPLEHIFRAILIKKTDRSQKTDLHNEGYILELDCCSSLDHPTDQKLIPEFIKKIQEAASQGLKFVGVIPQYHSSVNSAGSSAPVSTANSTEDARDAKNARGDHASLENEKPGTGDVCSAPAGRNQSPEPSSGPRGEVPLAKQPSSPSGEGDGGELSPQGVSKTLDGPESNPLEVHEEPLSGKMEIFTLFNKPKSHQKCRQYYPVTIPLHVSKNGQTVSGLDANWLEHMSDHFRKGGMLVNAVFYLGIVNDSLHGLTDGVFIFEAVSTEDSKTIQGYDAIVVEQWTVLEGVEVQTDYVPLLNSLAAYGWQLTCVLPTPVVKTTSEGSVSTKQIVFLQRPCLPQKIKKKESKFQWRFSREEMHNRQMRKSKGKLSARDKQQAEENEKNLEDQSSKAGDMGNCVSGQQQEGGVSEEMKGPVQEDKGEQLSPGGLLCGVGVEGEAVQNGPASHSRALVGICTGHSNPGEDARDGDAEEVRELGTVEEN>sp|O75678|RFPL2_HUMAN Ret finger protein-like 2 OS=Homo sapiens OX=9606GN=RFPL2 PE=2 SV=3MEVAELGFPETAVSQSRICLCAVLCGHWDFADMMVIRSLSLIRLEGVEGRDPVGGGNLTNKRPSCAPSPQDLSAQWKQLEDRGASSRRVDMAALFQEASSCPVCSDYLEKPMSLECGCAVCLKCINSLQKEPHGEDLLCCCSSMVSRKNKIRRNRQLERLASHIKELEPKLKKILQMNPRMRKFQVDMTLDANTANNFLLISDDLRSVRSGRIRQNRQDLAERFDVSVCILGSPRFTCGRHCWEVDVGTSTEWDLGVCRESVHRKGRIQLTTELGFWTVSLRDGGRLSATTVPLTFLFVDRKLQRVGIFLDMGMQNVSFFDAESGSHVYTFRSVSAEEPLRPFLAPSVPPNGDQGVLSICPLMNSGTTDAPVRPGEAK>sp|O75678-2|RFPL2_HUMAN Isoform 2 of Ret finger protein-like 2 OS=Homosapiens OX=9606 GN=RFPL2MEVAELGFPETAVSQSRICLCAVLCGHWDFADMMVIRSLSGHGCTLPRSKQLSRLLRLSGKTNVPGVWMRRLPQVH>sp|O75678-3|RFPL2_HUMAN Isoform 3 of Ret finger protein-like 2 OS=Homosapiens OX=9606 GN=RFPL2MKRLSLVTTNRLSPHGNFFTLCTFPLAVDMAALFQEASSCPVCSDYLEKPMSLECGCAVCLKCINSLQKEPHGEDLLCCCSSMVSRKNKIRRNRQLERLASHIKELEPKLKKILQMNPRMRKFQVDMTLDANTANNFLLISDDLRSVRSGRIRQNRQDLAERFDVSVCILGSPRFTCGRHCWEVDVGTSTEWDLGVCRESVHRKGRIQLTTELGFWTVSLRDGGRLSATTVPLTFLFVDRKLQRVGIFLDMGMQNVSFFDAESGSHVYTFRSVSAEEPLRPFLAPSVPPNGDQGVLSICPLMNSGTTDAPVRPGEAK>sp|Q9Y572|RIPK3_HUMAN Receptor-interacting serine/threonine-proteinkinase 3 OS=Homo sapiens OX=9606 GN=RIPK3 PE=1 SV=2MSCVKLWPSGAPAPLVSIEELENQELVGKGGFGTVFRAQHRKWGYDVAVKIVNSKAISREVKAMASLDNEFVLRLEGVIEKVNWDQDPKPALVTKFMENGSLSGLLQSQCPRPWPLLCRLLKEVVLGMFYLHDQNPVLLHRDLKPSNVLLDPELHVKLADFGLSTFQGGSQSGTGSGEPGGTLGYLAPELFVNVNRKASTASDVYSFGILMWAVLAGREVELPTEPSLVYEAVCNRQNRPSLAELPQAGPETPGLEGLKELMQLCWSSEPKDRPSFQECLPKTDEVFQMVENNMNAAVSTVKDFLSQLRSSNRRFSIPESGQGGTEMDGFRRTIENQHSRNDVMVSEWLNKLNLEEPPSSVPKKCPSLTKRSRAQEEQVPQAWTAGTSSDSMAQPPQTPETSTFRNQMPSPTSTGTPSPGPRGNQGAERQGMNWSCRTPEPNPVTGRPLVNIYNCSGVQVGDNNYLTMQQTTALPTWGLAPSGKGRGLQHPPPVGSQEGPKDPEAWSRPQGWYNHSGK>sp|Q9Y572-2|RIPK3_HUMAN Isoform 2 of Receptor-interactingserine/threonine-protein kinase 3 OS=Homo sapiens OX=9606 GN=RIPK3MSCVKLWPSGAPAPLVSIEELENQELVGKGGFGTVFRAQHRKWGYDVAVKIVNSKAISREVKAMASLDNEFVLRLEGVIEKVNWDQDPKPALVTKFMENGSLSGLLQSQCPRPWPLLCRLLKEVVLGMFYLHDQNPVLLHRDLKPSNVLLDPELHVKLADFGLSTFQGGSQSGTGSGEPGGTLGYLAPELFVNVNRKASTASDVYSFGILMWAVLAGRECQPNHHSCTKQCATGRTGLHWLSCPKPGLRLPA>sp|Q9Y572-3|RIPK3_HUMAN Isoform 3 of Receptor-interactingserine/threonine-protein kinase 3 OS=Homo sapiens OX=9606 GN=RIPK3MSCVKLWPSGAPAPLVSIEELENQELVGKGGFGTVFRAQHRKWGYDVAVKIVNSKAISREVKAMASLDNEFVLRLEGVIEKVNWDQDPKPALVTKFMENGSLSGLLQSQCPRPWPLLCRLLKEVVLGMFYLHDQNPVLLHRDLKPSNVLLDPELHVKLADFGLSTFQGGSQSGTGSGEPGGTLGYLAPELFVNVNRKASTASDVYSFGILMWAVLAGREVECKTLGGFWDP>sp|Q6ZS17|RIPR1_HUMAN Rho family-interacting cell polarization regulator1 OS=Homo sapiens OX=9606 GN=RIPOR1 PE=1 SV=1MMSLSVRPQRRLLSARVNRSQSFAGVLGSHERGPSLSFRSFPVFSPPGPPRKPPALSRVSRMFSVAHPAAKVPQPERLDLVYTALKRGLTAYLEVHQQEQEKLQGQIRESKRNSRLGFLYDLDKQVKSIERFLRRLEFHASKIDELYEAYCVQRRLRDGAYNMVRAYTTGSPGSREARDSLAEATRGHREYTESMCLLESELEAQLGEFHLRMKGLAGFARLCVGDQYEICMKYGRQRWKLRGRIEGSGKQVWDSEETIFLPLLTEFLSIKVTELKGLANHVVVGSVSCETKDLFAALPQVVAVDINDLGTIKLSLEVTWSPFDKDDQPSAASSVNKASTVTKRFSTYSQSPPDTPSLREQAFYNMLRRQEELENGTAWSLSSESSDDSSSPQLSGTARHSPAPRPLVQQPEPLPIQVAFRRPETPSSGPLDEEGAVAPVLANGHAPYSRTLSHISEASVDAALAEASVEAVGPESLAWGPSPPTHPAPTHGEHPSPVPPALDPGHSATSSTLGTTGSVPTSTDPAPSAHLDSVHKSTDSGPSELPGPTHTTTGSTYSAITTTHSAPSPLTHTTTGSTHKPIISTLTTTGPTLNIIGPVQTTTSPTHTMPSPTHTTASPTHTSTSPTHTPTSPTHKTSMSPPTTTSPTPSGMGLVQTATSPTHPTTSPTHPTTSPILINVSPSTSLELATLSSPSKHSDPTLPGTDSLPCSPPVSNSYTQADPMAPRTPHPSPAHSSRKPLTSPAPDPSESTVQSLSPTPSPPTPAPQHSDLCLAMAVQTPVPTAAGGSGDRSLEEALGALMAALDDYRGQFPELQGLEQEVTRLESLLMQRQGLTRSRASSLSITVEHALESFSFLNEDEDEDNDVPGDRPPSSPEAGAEDSIDSPSARPLSTGCPALDAALVRHLYHCSRLLLKLGTFGPLRCQEAWALERLLREARVLEAVCEFSRRWEIPASSAQEVVQFSASRPGFLTFWDQCTERLSCFLCPVERVLLTFCNQYGARLSLRQPGLAEAVCVKFLEDALGQKLPRRPQPGPGEQLTVFQFWSFVETLDSPTMEAYVTETAEEVLLVRNLNSDDQAVVLKALRLAPEGRLRRDGLRALSSLLVHGNNKVMAAVSTQLRSLSLGPTFRERALLCFLDQLEDEDVQTRVAGCLALGCIKAPEGIEPLVYLCQTDTEAVREAARQSLQQCGEEGQSAHRRLEESLDALPRIFGPGSMASTAF>sp|Q6ZS17-2|RIPR1_HUMAN Isoform 2 of Rho family-interacting cellpolarization regulator 1 OS=Homo sapiens OX=9606 GN=RIPOR1MMSLSVRPQRRLLSARVNRSQSFAGVLGSHERGPRSFPVFSPPGPPRKPPALSRVSRMFSVAHPAAKVPQPERLDLVYTALKRGLTAYLEVHQQEQEKLQGQIRESKRNSRLGFLYDLDKQVKSIERFLRRLEFHASKIDELYEAYCVQRRLRDGAYNMVRAYTTGSPGSREARDSLAEATRGHREYTESMCLLESELEAQLGEFHLRMKGLAGFARLCVGDQYEICMKYGRQRWKLRGRIEGSGKQVWDSEETIFLPLLTEFLSIKVTELKGLANHVVVGSVSCETKDLFAALPQVVAVDINDLGTIKLSLEVTWSPFDKDDQPSAASSVNKASTVTKRFSTYSQSPPDTPSLREQAFYNMLRRQEELENGTAWSLSSESSDDSSSPQLSGTARHSPAPRPLVQQPEPLPIQVAFRRPETPSSGPLDEEGAVAPVLANGHAPYSRTLSHISEASVDAALAEASVEAVGPESLAWGPSPPTHPAPTHGEHPSPVPPALDPGHSATSSTLGTTGSVPTSTDPAPSAHLDSVHKSTDSGPSELPGPTHTTTGSTYSAITTTHSAPSPLTHTTTGSTHKPIISTLTTTGPTLNIIGPVQTTTSPTHTMPSPTHTTASPTHTSTSPTHTPTSPTHKTSMSPPTTTSPTPSGMGLVQTATSPTHPTTSPTHPTTSPILINVSPSTSLELATLSSPSKHSDPTLPGTDSLPCSPPVSNSYTQADPMAPRTPHPSPAHSSRKPLTSPAPDPSESTVQSLSPTPSPPTPAPQHSDLCLAMAVQTPVPTAAGGSGDRSLEEALGALMAALDDYRGQFPELQGLEQEVTRLESLLMQRQGLTRSRASSLSITVEHALESFSFLNEDEDEDNDVPGDRPPSSPEAGAEDSIDSPSARPLSTGCPALDAALVRHLYHCSRLLLKLGTFGPLRCQEAWALERLLREARVLEAVCEFSRRWEIPASSAQEVVQFSASRPGFLTFWDQCTERLSCFLCPVERVLLTFCNQYGARLSLRQPGLAEAVCVKFLEDALGQKLPRRPQPGPGEQLTVFQFWSFVETLDSPTMEAYVTETAEEVLLVRNLNSDDQAVVLKALRLAPEGRLRRDGLRALSSLLVHGNNKVMAAVSTQLRSLSLGPTFRERALLCFLDQLEDEDVQTRVAGCLALGCIKAPEGIEPLVYLCQTDTEAVREAARQSLQQCGEEGQSAHRRLEESLDALPRIFGPGSMASTAF>sp|Q6ZS17-3|RIPR1_HUMAN Isoform 3 of Rho family-interacting cellpolarization regulator 1 OS=Homo sapiens OX=9606 GN=RIPOR1MNTKKRGSPARTHSMMSLSVRPQRRLLSARVNRSQSFAGVLGSHERGPRSFPVFSPPGPPRKPPALSRVSRMFSVAHPAAKVPQPERLDLVYTALKRGLTAYLEVHQQEQEKLQGQIRESKRNSRLGFLYDLDKQVKSIERFLRRLEFHASKIDELYEAYCVQRRLRDGAYNMVRAYTTGSPGSREARDSLAEATRGHREYTESMCLLESELEAQLGEFHLRMKGLAGFARLCVGDQYEICMKYGRQRWKLRGRIEGSGKQVWDSEETIFLPLLTEFLSIKVTELKGLANHVVVGSVSCETKDLFAALPQVVAVDINDLGTIKLSLEVTWSPFDKDDQPSAASSVNKASTVTKRFSTYSQSPPDTPSLREQAFYNMLRRQEELENGTAWSLSSESSDDSSSPQLSGTARHSPAPRPLVQQPEPLPIQVAFRRPETPSSGPLDEEGAVAPVLANGHAPYSRTLSHISEASVDAALAEASVEAVGPESLAWGPSPPTHPAPTHGEHPSPVPPALDPGHSATSSTLGTTGSVPTSTDPAPSAHLDSVHKSTDSGPSELPGPTHTTTGSTYSAITTTHSAPSPLTHTTTGSTHKPIISTLTTTGPTLNIIGPVQTTTSPTHTMPSPTHTTASPTHTSTSPTHTPTSPTHKTSMSPPTTTSPTPSGMGLVQTATSPTHPTTSPTHPTTSPILINVSPSTSLELATLSSPSKHSDPTLPGTDSLPCSPPVSNSYTQADPMAPRTPHPSPAHSSRKPLTSPAPDPSESTVQSLSPTPSPPTPAPQHSDLCLAMAVQTPVPTAAGGSGDRSLEEALGALMAALDDYRGQFPELQGLEQEVTRLESLLMQRQGLTRSRASSLSITVEHALESFSFLNEDEDEDNDVPGDRPPSSPEAGAEDSIDSPSARPLSTGCPALDAALVRHLYHCSRLLLKLGTFGPLRCQEAWALERLLREARVLEAVCEFSRRWEIPASSAQEVVQFSASRPGFLTFWDQCTERLSCFLCPVERVLLTFCNQYGARLSLRQPGLAEAVCVKFLEDALGQKLPRRPQPGPGEQLTVFQFWSFVETLDSPTMEAYVTETAEEVLLVRNLNSDDQAVVLKALRLAPEGRLRRDGLRALSSLLVHGNNKVMAAVSTQLRSLSLGPTFRERALLCFLDQLEDEDVQTRVAGCLALGCIKAPEGIEPLVYLCQTDTEAVREAARQSLQQCGEEGQSAHRRLEESLDALPRIFGPGSMASTAF>sp|Q6ZS17-4|RIPR1_HUMAN Isoform 4 of Rho family-interacting cellpolarization regulator 1 OS=Homo sapiens OX=9606 GN=RIPOR1MTIWQMQKQAQRGSPARTHSMMSLSVRPQRRLLSARVNRSQSFAGVLGSHERGPRSFPVFSPPGPPRKPPALSRVSRMFSVAHPAAKVPQPERLDLVYTALKRGLTAYLEVHQQEQEKLQGQIRESKRNSRLGFLYDLDKQVKSIERFLRRLEFHASKIDELYEAYCVQRRLRDGAYNMVRAYTTGSPGSREARDSLAEATRGHREYTESMCLLESELEAQLGEFHLRMKGLAGFARLCVGDQYEICMKYGRQRWKLRGRIEGSGKQVWDSEETIFLPLLTEFLSIKVTELKGLANHVVVGSVSCETKDLFAALPQVVAVDINDLGTIKLSLEVTWSPFDKDDQPSAASSVNKASTVTKRFSTYSQSPPDTPSLREQAFYNMLRRQEELENGTAWSLSSESSDDSSSPQLSGTARHSPAPRPLVQQPEPLPIQVAFRRPETPSSGPLDEEGAVAPVLANGHAPYSRTLSHISEASVDAALAEASVEAVGPESLAWGPSPPTHPAPTHGEHPSPVPPALDPGHSATSSTLGTTGSVPTSTDPAPSAHLDSVHKSTDSGPSELPGPTHTTTGSTYSAITTTHSAPSPLTHTTTGSTHKPIISTLTTTGPTLNIIGPVQTTTSPTHTMPSPTHTTASPTHTSTSPTHTPTSPTHKTSMSPPTTTSPTPSGMGLVQTATSPTHPTTSPTHPTTSPILINVSPSTSLELATLSSPSKHSDPTLPGTDSLPCSPPVSNSYTQADPMAPRTPHPSPAHSSRKPLTSPAPDPSESTVQSLSPTPSPPTPAPQHSDLCLAMAVQTPVPTAAGGSGDRSLEEALGALMAALDDYRGQFPELQGLEQEVTRLESLLMQRQGLTRSRASSLSITVEHALESFSFLNEDEDEDNDVPGDRPPSSPEAGAEDSIDSPSARPLSTGCPALDAALVRHLYHCSRLLLKLGTFGPLRCQEAWALERLLREARVLEAVCEFSRRWEIPASSAQEVVQFSASRPGFLTFWDQCTERLSCFLCPVERVLLTFCNQYGARLSLRQPGLAEAVCVKFLEDALGQKLPRRPQPGPGEQLTVFQFWSFVETLDSPTMEAYVTETAEEVLLVRNLNSDDQAVVLKALRLAPEGRLRRDGLRALSSLLVHGNNKVMAAVSTQLRSLSLGPTFRERALLCFLDQLEDEDVQTRVAGCLALGCIKAPEGIEPLVYLCQTDTEAVREAARQSLQQCGEEGQSAHRRLEESLDALPRIFGPGSMASTAF>sp|Q5JTH9|RRP12_HUMAN RRP12-like protein OS=Homo sapiens OX=9606GN=RRP12 PE=1 SV=2MGRSGKLPSGVSAKLKRWKKGHSSDSNPAICRHRQAARSRFFSRPSGRSDLTVDAVKLHNELQSGSLRLGKSEAPETPMEEEAELVLTEKSSGTFLSGLSDCTNVTFSKVQRFWESNSAAHKEICAVLAAVTEVIRSQGGKETETEYFAALMTTMEAVESPESLAAVAYLLNLVLKRVPSPVLIKKFSDTSKAFMDIMSAQASSGSTSVLRWVLSCLATLLRKQDLEAWGYPVTLQVYHGLLSFTVHPKPKIRKAAQHGVCSVLKGSEFMFEKAPAHHPAAISTAKFCIQEIEKSGGSKEATTTLHMLTLLKDLLPCFPEGLVKSCSETLLRVMTLSHVLVTACAMQAFHSLFHARPGLSTLSAELNAQIITALYDYVPSENDLQPLLAWLKVMEKAHINLVRLQWDLGLGHLPRFFGTAVTCLLSPHSQVLTAATQSLKEILKECVAPHMADIGSVTSSASGPAQSVAKMFRAVEEGLTYKFHAAWSSVLQLLCVFFEACGRQAHPVMRKCLQSLCDLRLSPHFPHTAALDQAVGAAVTSMGPEVVLQAVPLEIDGSEETLDFPRSWLLPVIRDHVQETRLGFFTTYFLPLANTLKSKAMDLAQAGSTVESKIYDTLQWQMWTLLPGFCTRPTDVAISFKGLARTLGMAISERPDLRVTVCQALRTLITKGCQAEADRAEVSRFAKNFLPILFNLYGQPVAAGDTPAPRRAVLETIRTYLTITDTQLVNSLLEKASEKVLDPASSDFTRLSVLDLVVALAPCADEAAISKLYSTIRPYLESKAHGVQKKAYRVLEEVCASPQGPGALFVQSHLEDLKKTLLDSLRSTSSPAKRPRLKCLLHIVRKLSAEHKEFITALIPEVILCTKEVSVGARKNAFALLVEMGHAFLRFGSNQEEALQCYLVLIYPGLVGAVTMVSCSILALTHLLFEFKGLMGTSTVEQLLENVCLLLASRTRDVVKSALGFIKVAVTVMDVAHLAKHVQLVMEAIGKLSDDMRRHFRMKLRNLFTKFIRKFGFELVKRLLPEEYHRVLVNIRKAEARAKRHRALSQAAVEEEEEEEEEEEPAQGKGDSIEEILADSEDEEDNEEEERSRGKEQRKLARQRSRAWLKEGGGDEPLNFLDPKVAQRVLATQPGPGRGRKKDHGFKVSADGRLIIREEADGNKMEEEEGAKGEDEEMADPMEDVIIRNKKHQKLKHQKEAEEEELEIPPQYQAGGSGIHRPVAKKAMPGAEYKAKKAKGDVKKKGRPDPYAYIPLNRSKLNRRKKMKLQGQFKGLVKAARRGSQVGHKNRRKDRRP>sp|Q5JTH9-2|RRP12_HUMAN Isoform 2 of RRP12-like protein OS=Homo sapiensOX=9606 GN=RRP12MGRSGKLPSGVSAKLKRWKKGHSSDSNPAICRHRQAARSRFFSRPSGRSDLTVDAVKLHNELQSGSLRLGKSEAPETPMEEEAELVLTEKSSGTFLSGLSDCTNVTFSKVQRFWESNSAAHKEICAVLAAVTEVIRSQGGKETETEYFAALIRKAAQHGVCSVLKGSEFMFEKAPAHHPAAISTAKFCIQEIEKSGGSKEATTTLHMLTLLKDLLPCFPEGLVKSCSETLLRVMTLSHVLVTACAMQAFHSLFHARPGLSTLSAELNAQIITALYDYVPSENDLQPLLAWLKVMEKAHINLVRLQWDLGLGHLPRFFGTAVTCLLSPHSQVLTAATQSLKEILKECVAPHMADIGSVTSSASGPAQSVAKMFRAVEEGLTYKFHAAWSSVLQLLCVFFEACGRQAHPVMRKCLQSLCDLRLSPHFPHTAALDQAVGAAVTSMGPEVVLQAVPLEIDGSEETLDFPRSWLLPVIRDHVQETRLGFFTTYFLPLANTLKSKAMDLAQAGSTVESKIYDTLQWQMWTLLPGFCTRPTDVAISFKGLARTLGMAISERPDLRVTVCQALRTLITKGCQAEADRAEVSRFAKNFLPILFNLYGQPVAAGDTPAPRRAVLETIRTYLTITDTQLVNSLLEKASEKVLDPASSDFTRLSVLDLVVALAPCADEAAISKLYSTIRPYLESKAHGVQKKAYRVLEEVCASPQGPGALFVQSHLEDLKKTLLDSLRSTSSPAKRPRLKCLLHIVRKLSAEHKEFITALIPEVILCTKEVSVGARKNAFALLVEMGHAFLRFGSNQEEALQCYLVLIYPGLVGAVTMVSCSILALTHLLFEFKGLMGTSTVEQLLENVCLLLASRTRDVVKSALGFIKVAVTVMDVAHLAKHVQLVMEAIGKLSDDMRRHFRMKLRNLFTKFIRKFGFELVKRLLPEEYHRVLVNIRKAEARAKRHRALSQAAVEEEEEEEEEEEPAQGKGDSIEEILADSEDEEDNEEEERSRGKEQRKLARQRSRAWLKEGGGDEPLNFLDPKVAQRVLATQPGPGRGRKKDHGFKVSADGRLIIREEADGNKMEEEEGAKGEDEEMADPMEDVIIRNKKHQKLKHQKEAEEEELEIPPQYQAGGSGIHRPVAKKAMPGAEYKAKKAKGDVKKKGRPDPYAYIPLNRSKLNRRKKMKLQGQFKGLVKAARRGSQVGHKNRRKDRRP>sp|Q5JTH9-3|RRP12_HUMAN Isoform 3 of RRP12-like protein OS=Homo sapiensOX=9606 GN=RRP12MGRSGKLPSGVSAKLKRWKKGHSSDSNPAICRHRQAARSRFFSRPSGRSDLTVDAVKLHNELQSGSLRLGKSEAPETPMEEEAELVLTEKSSGTFLSGLSDCTNVTFSKVQRFWESNSAAHKEICAVLAAVTEVIRSQGGKETETEYFAALVLSCLATLLRKQDLEAWGYPVTLQVYHGLLSFTVHPKPKIRKAAQHGVCSVLKGSEFMFEKAPAHHPAAISTAKFCIQEIEKSGGSKEATTTLHMLTLLKDLLPCFPEGLVKSCSETLLRVMTLSHVLVTACAMQAFHSLFHARPGLSTLSAELNAQIITALYDYVPSENDLQPLLAWLKVMEKAHINLVRLQWDLGLGHLPRFFGTAVTCLLSPHSQVLTAATQSLKEILKECVAPHMADIGSVTSSASGPAQSVAKMFRAVEEGLTYKFHAAWSSVLQLLCVFFEACGRQAHPVMRKCLQSLCDLRLSPHFPHTAALDQAVGAAVTSMGPEVVLQAVPLEIDGSEETLDFPRSWLLPVIRDHVQETRLGFFTTYFLPLANTLKSKAMDLAQAGSTVESKIYDTLQWQMWTLLPGFCTRPTDVAISFKGLARTLGMAISERPDLRVTVCQALRTLITKGCQAEADRAEVSRFAKNFLPILFNLYGQPVAAGDTPAPRRAVLETIRTYLTITDTQLVNSLLEKASEKVLDPASSDFTRLSVLDLVVALAPCADEAAISKLYSTIRPYLESKAHGVQKKAYRVLEEVCASPQGPGALFVQSHLEDLKKTLLDSLRSTSSPAKRPRLKCLLHIVRKLSAEHKEFITALIPEVILCTKEVSVGARKNAFALLVEMGHAFLRFGSNQEEALQCYLVLIYPGLVGAVTMVSCSILALTHLLFEFKGLMGTSTVEQLLENVCLLLASRTRDVVKSALGFIKVAVTVMDVAHLAKHVQLVMEAIGKLSDDMRRHFRMKLRNLFTKFIRKFGFELVKRLLPEEYHRVLVNIRKAEARAKRHRALSQAAVEEEEEEEEEEEPAQGKGDSIEEILADSEDEEDNEEEERSRGKEQRKLARQRSRAWLKEGGGDEPLNFLDPKVAQRVLATQPGPGRGRKKDHGFKVSADGRLIIREEADGNKMEEEEGAKGEDEEMADPMEDVIIRNKKHQKLKHQKEAEEEELEIPPQYQAGGSGIHRPVAKKAMPGAEYKAKKAKGDVKKKGRPDPYAYIPLNRSKLNRRKKMKLQGQFKGLVKAARRGSQVGHKNRRKDRRP>sp|P18583|SON_HUMAN Protein SON OS=Homo sapiens OX=9606 GN=SON PE=1 SV=4MATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEPVDISTAMSERALAQKRLSENAFDLEAMSMLNRAQERIDAWAQLNSIPGQFTGSTGVQVLTQEQLANTGAQAWIKKDQFLRAAPVTGGMGAVLMRKMGWREGEGLGKNKEGNKEPILVDFKTDRKGLVAVGERAQKRSGNFSAAMKDLSGKHPVSALMEICNKRRWQPPEFLLVHDSGPDHRKHFLFRVLRNGALTRPNCMFFLNRY>sp|P18583-2|SON_HUMAN Isoform A of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTQRSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEPVDISTAMSERALAQKRLSENAFDLEAMSMLNRAQERIDAWAQLNSIPGQFTGSTGVQVLTQEQLANTGAQAWIKKDQFLRAAPVTGGMGAVLMRKMGWREGEGLGKNKEGNKEPILVDFKTDRKGLVAVGERAQKRSGNFSAAMKDLSGKHPVSALMEICNKRRWQPPEFLLVHDSGPDHRKHFLFRVLINGSAYQPSFASPNKKHAKATAATVVLQAMGLVPKDLMANATCFRSASRR>sp|P18583-3|SON_HUMAN Isoform B of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEGRVKRQGRVRRQMKQPAASHLTVTRCNSLCGTKPQSEKHRIAENSVITSLPNIGPSLHLWEGSPRYNYLASRFASRLYSSRFWW>sp|P18583-4|SON_HUMAN Isoform C of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEPVDISTAMSERALAQKRLSENAFDLEAMSMLNRAQERIDAWAQLNSIPGQFTGSTGVQVLTQEQLANTGAQAWIKKGQILVAVFLPRSVPAVLFTTLLLPRPRISS>sp|P18583-5|SON_HUMAN Isoform D of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEPVDISTAMSERALAQKRLSENAFDLEAMSMLNRAQERIDAWAQLNSIPGQFTGSTGVQVLTQEQLANTGAQAWIKKDQFLRAAPVTGGMGAVLMRKMGWREGEGLGKNKEGNKEPILVDFKTDRKGLVAVGERAQKRSGNFSAAMKDLSGKHPVSALMEICNKRRWQPPEFLLVHDSGPDHRKHFLFRVLINGSAYQPSFASPNKKHAKATAATVVLQAMGLVPKDLMANATCFRSASRR>sp|P18583-6|SON_HUMAN Isoform E of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEF>sp|P18583-7|SON_HUMAN Isoform G of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEPVDISTAMSERALAQKRLSENAFDLEAMSMLNRAQERIDAWAQLNSIPGQFTGSTGVQVLTQEQLANTGAQAWIKKDQFLRAAPVTGGMGAVLMRKMGWREGEGLGKNKEGNKEPILVDFKTDRKGLVAVGERAQKRSGNFSAAMKDLSGKHPVSALMEICNKRRWQPPEFLLVHDSGPDHRKHFLFRVLRNGALTRPNCMFFLNRY>sp|P18583-8|SON_HUMAN Isoform H of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTNVPPNCMFFLNRY>sp|P18583-9|SON_HUMAN Isoform I of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEPVDISTAMSERALAQKRLSENAFDLEAMSMLNRAQERIDAWAQLNSIPGQFTGSTGVQVLTQEQLANTGAQAWIKKDQFLRAAPVTGGMGAVLMRKMGWREGEGLGKNKEGNKEPILVDFKTDRKGLVAVGERAQKRSGNFSAAMKDLSGKHPVSALMEICNKRRWQPPEFLLVHDSGPDHRKHFLFRVLRNGALTRPNCMFFLNRY>sp|P18583-10|SON_HUMAN Isoform J of Protein SON OS=Homo sapiens OX=9606GN=SONMATNIEQIFRSFVVSKFREIQQELSSGRNEGQLNGETNTPIEGNQAGDAAASARSLPNEEIVQKIEEVLSGVLDTELRYKPDLKEGSRKSRCVSVQTDPTDEIPTKKSKKHKKHKNKKKKKKKEKEKKYKRQPEESESKTKSHDDGNIDLESDSFLKFDSEPSAVALELPTRAFGPSETNESPAVVLEPPVVSMEVSEPHILETLKPATKTAELSVVSTSVISEQSEQSVAVMPEPSMTKILDSFAAAPVPTTTLVLKSSEPVVTMSVEYQMKSVLKSVESTSPEPSKIMLVEPPVAKVLEPSETLVVSSETPTEVYPEPSTSTTMDFPESSAIEALRLPEQPVDVPSEIADSSMTRPQELPELPKTTALELQESSVASAMELPGPPATSMPELQGPPVTPVLELPGPSATPVPELPGPLSTPVPELPGPPATAVPELPGPSVTPVPQLSQELPGLPAPSMGLEPPQEVPEPPVMAQELPGLPLVTAAVELPEQPAVTVAMELTEQPVTTTELEQPVGMTTVEHPGHPEVTTATGLLGQPEATMVLELPGQPVATTALELPGQPSVTGVPELPGLPSATRALELSGQPVATGALELPGPLMAAGALEFSGQSGAAGALELLGQPLATGVLELPGQPGAPELPGQPVATVALEISVQSVVTTSELSTMTVSQSLEVPSTTALESYNTVAQELPTTLVGETSVTVGVDPLMAPESHILASNTMETHILASNTMDSQMLASNTMDSQMLASNTMDSQMLASSTMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSSMDSQMLATSTMDSQMLATSTMDSQMLATSSMDSQMLASGTMDSQMLASGTMDAQMLASGTMDAQMLASSTQDSAMLGSKSPDPYRLAQDPYRLAQDPYRLGHDPYRLGHDAYRLGQDPYRLGHDPYRLTPDPYRMSPRPYRIAPRSYRIAPRPYRLAPRPLMLASRRSMMMSYAAERSMMSSYERSMMSYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMAERSMMSAYERSMMSAYERSMMSPMADRSMMSMGADRSMMSSYSAADRSMMSSYSAADRSMMSSYTADRSMMSMAADSYTDSYTDTYTEAYMVPPLPPEEPPTMPPLPPEEPPMTPPLPPEEPPEGPALPTEQSALTAENTWPTEVPSSPSEESVSQPEPPVSQSEISEPSAVPTDYSVSASDPSVLVSEAAVTVPEPPPEPESSITLTPVESAVVAEEHEVVPERPVTCMVSETPAMSAEPTVLASEPPVMSETAETFDSMRASGHVASEVSTSLLVPAVTTPVLAESILEPPAMAAPESSAMAVLESSAVTVLESSTVTVLESSTVTVLEPSVVTVPEPPVVAEPDYVTIPVPVVSALEPSVPVLEPAVSVLQPSMIVSEPSVSVQESTVTVSEPAVTVSEQTQVIPTEVAIESTPMILESSIMSSHVMKGINLSSGDQNLAPEIGMQEIALHSGEEPHAEEHLKGDFYESEHGINIDLNINNHLIAKEMEHNTVCAAGTSPVGEIGEEKILPTSETKQRTVLDTYPGVSEADAGETLSSTGPFALEPDATGTSKGIEFTTASTLSLVNKYDVDLSLTTQDTEHDMVISTSPSGGSEADIEGPLPAKDIHLDLPSNNNLVSKDTEEPLPVKESDQTLAALLSPKESSGGEKEVPPPPKETLPDSGFSANIEDINEADLVRPLLPKDMERLTSLRAGIEGPLLASDVGRDRSAASPVVSSMPERASESSSEEKDDYEIFVKVKDTHEKSKKNKNRDKGEKEKKRDSSLRSRSKRSKSSEHKSRKRTSESRSRARKRSSKSKSHRSQTRSRSRSRRRRRSSRSRSKSRGRRSVSKEKRKRSPKHRSKSRERKRKRSSSRDNRKTVRARSRTPSRRSRSHTPSRRRRSRSVGRRRSFSISPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRSRTPSRRRRSRSVVRRRSFSISPVRLRRSRTPLRRRFSRSPIRRKRSRSSERGRSPKRLTDLDKAQLLEIAKANAAAMCAKAGVPLPPNLKPAPPPTIEEKVAKKSGGATIEELTEKCKQIAQSKEDDDVIVNKPHVSDEEEEEPPFYHHPFKLSEPKPIFFNLNIAAAKPTPPKSQVTLTKEFPVSSGSQHRKKEADSVYGEWVPVEKNGEENKDDDNVFSSNLPSEPVDISTAMSERALAQKRLSENAFDLEAMSMLNRAQERVCSSFLKKIIIYHQPTHTNVPVLMSK>sp|P46783|RS10_HUMAN 40S ribosomal protein S10 OS=Homo sapiens OX=9606GN=RPS10 PE=1 SV=1MLMPKKNRIAIYELLFKEGVMVAKKDVHMPKHPELADKNVPNLHVMKAMQSLKSRGYVKEQFAWRHFYWYLTNEGIQYLRDYLHLPPEIVPATLRRSRPETGRPRPKGLEGERPARLTRGEADRDTYRRSAVPPGADKKAEAGAGSATEFQFRGGFGRGRGQPPQ>sp|Q9BUL9|RPP25_HUMAN Ribonuclease P protein subunit p25 OS=Homo sapiensOX=9606 GN=RPP25 PE=1 SV=1MENFRKVRSEEAPAGCGAEGGGPGSGPFADLAPGAVHMRVKEGSKIRNLMAFATASMAQPATRAIVFSGCGRATTKTVTCAEILKRRLAGLHQVTRLRYRSVREVWQSLPPGPTQGQTPGEPAASLSVLKNVPGLAILLSKDALDPRQPGYQPPNPHPGPSSPPAAPASKRSLGEPAAGEGSAKRSQPEPGVADEDQTA>sp|P78345|RPP38_HUMAN Ribonuclease P protein subunit p38 OS=Homo sapiensOX=9606 GN=RPP38 PE=1 SV=2MAAAPQAPGRGSLRKTRPLVVKTSLNNPYIIRWSALESEDMHFILQTLEDRLKAIGLQKIEDKKKKNKTPFLKKESREKCSIAVDISENLKEKKTDAKQQVSGWTPAHVRKQLAIGVNEVTRALERRELLLVLVCKSVKPAMITSHLIQLSLSRSVPACQVPRLSERIAPVIGLKCVLALAFKKNTTDFVDEVRAIIPRVPSLSVPWLQDRIEDSGENLETEPLESQDRELLDTSFEDLSKPKRKLADGRQASVTLQPLKIKKLIPNPNKIRKPPKSKKATPK>sp|Q15532|SSXT_HUMAN Protein SSXT OS=Homo sapiens OX=9606 GN=SS18 PE=1SV=3MSVAFAAPRQRGKGEITPAAIQKMLDDNNHLIQCIMDSQNKGKTSECSQYQQMLHTNLVYLATIADSNQNMQSLLPAPPTQNMPMGPGGMNQSGPPPPPRSHNMPSDGMVGGGPPAPHMQNQMNGQMPGPNHMPMQGPGPNQLNMTNSSMNMPSSSHGSMGGYNHSVPSSQSMPVQNQMTMSQGQPMGNYGPRPNMSMQPNQGPMMHQQPPSQQYNMPQGGGQHYQGQQPPMGMMGQVNQGNHMMGQRQIPPYRPPQQGPPQQYSGQEDYYGDQYSHGGQGPPEGMNQQYYPDGHNDYGYQQPSYPEQGYDRPYEDSSQHYYEGGNSQYGQQQDAYQGPPPQQGYPPQQQQYPGQQGYPGQQQGYGPSQGGPGPQYPNYPQGQGQQYGGYRPTQPGPPQPPQQRPYGYDQGQYGNYQQ>sp|Q15532-2|SSXT_HUMAN Isoform 2 of Protein SSXT OS=Homo sapiens OX=9606GN=SS18MSVAFAAPRQRGKGEITPAAIQKMLDDNNHLIQCIMDSQNKGKTSECSQYQQMLHTNLVYLATIADSNQNMQSLLPAPPTQNMPMGPGGMNQSGPPPPPRSHNMPSDGMVGGGPPAPHMQNQMNGQMPGPNHMPMQGPGPNQLNMTNSSMNMPSSSHGSMGGYNHSVPSSQSMPVQNQMTMSQGQPMGNYGPRPNMSMQPNQGPMMHQQPPSQQYNMPQGGGQHYQGQQPPMGMMGQVNQGNHMMGQRQIPPYRPPQQGPPQQYSGQEDYYGDQYSHGGQGPPEGMNQQYYPDGNSQYGQQQDAYQGPPPQQGYPPQQQQYPGQQGYPGQQQGYGPSQGGPGPQYPNYPQGQGQQYGGYRPTQPGPPQPPQQRPYGYDQGQYGNYQQ>sp|D6RJB6|U17LK_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 20 OS=Homo sapiens OX=9606 GN=USP17L20 PE=3 SV=1MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQPNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSTTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|Q9Y4P3|TBL2_HUMAN Transducin beta-like protein 2 OS=Homo sapiensOX=9606 GN=TBL2 PE=1 SV=1MELSQMSELMGLSVLLGLLALMATAAVARGWLRAGEERSGRPACQKANGFPPDKSSGSKKQKQYQRIRKEKPQQHNFTHRLLAAALKSHSGNISCMDFSSNGKYLATCADDRTIRIWSTKDFLQREHRSMRANVELDHATLVRFSPDCRAFIVWLANGDTLRVFKMTKREDGGYTFTATPEDFPKKHKAPVIDIGIANTGKFIMTASSDTTVLIWSLKGQVLSTINTNQMNNTHAAVSPCGRFVASCGFTPDVKVWEVCFGKKGEFQEVVRAFELKGHSAAVHSFAFSNDSRRMASVSKDGTWKLWDTDVEYKKKQDPYLLKTGRFEEAAGAAPCRLALSPNAQVLALASGSSIHLYNTRRGEKEECFERVHGECIANLSFDITGRFLASCGDRAVRLFHNTPGHRAMVEEMQGHLKRASNESTRQRLQQQLTQAQETLKSLGALKK>sp|Q3MII6|TBC25_HUMAN TBC1 domain family member 25 OS=Homo sapiensOX=9606 GN=TBC1D25 PE=1 SV=2MATASGASDLSGSGAPPPGVGAQAAAAAEEEEREVVRVRVKKCESFLPPEFRSFAVDPQITSLDVLQHILIRAFDLSGKKNFGISYLGRDRLGQEVYLSLLSDWDLSTAFATASKPYLQLRVDIRPSEDSPLLEDWDIISPKDVIGSDVLLAEKRSSLTTAALPFTQSILTQVGRTLSKVQQVLSWSYGEDVKPFKPPLSDAEFHTYLNHEGQLSRPEELRLRIYHGGVEPSLRKVVWRYLLNVYPDGLTGRERMDYMKRKSREYEQLKSEWAQRANPEDLEFIRSTVLKDVLRTDRAHPYYAGPEDGPHLRALHDLLTTYAVTHPQVSYCQGMSDLASPILAVMDHEGHAFVCFCGIMKRLAANFHPDGRAMATKFAHLKLLLRHADPDFYQYLQEAGADDLFFCYRWLLLELKREFAFDDALRMLEVTWSSLPPDPPEHEVELVGPPSQVADAGFGGHRGWPVRQRHMLRPAGGGGSTFEDAVDHLATASQGPGGGGRLLRQASLDGLQQLRDNMGSRRDPLVQLPHPAALISSKSLSEPLLNSPDPLLSSFSHPDSPSSSSPPSTQEASPTGDMAVGSPLMQEVGSPKDPGKSLPPVPPMGLPPPQEFGRGNPFMLFLCLAILLEHRDHIMRNGLDYNELAMHFDRLVRKHHLGRVLRRARALFADYLQSEVWDSEEGAEATAAS>sp|Q3MII6-2|TBC25_HUMAN Isoform 2 of TBC1 domain family member 25OS=Homo sapiens OX=9606 GN=TBC1D25MATASGASDLSGSGAPPPGVGAQAAAAAEEEEREVVRVRVKKCESFLPPEFRSFAVDPQITSLDVLQHILIRAFDLSGPIARRLGHNQPQRCHWLRRVAG>sp|O95935|TBX18_HUMAN T-box transcription factor TBX18 OS=Homo sapiensOX=9606 GN=TBX18 PE=1 SV=3MAEKRRGSPCSMLSLKAHAFSVEALIGAEKQQQLQKKRRKLGAEEAAGAVDDGGCSRGGGAGEKGSSEGDEGAALPPPAGATSGPARSGADLERGAAGGCEDGFQQGASPLASPGGSPKGSPARSLARPGTPLPSPQAPRVDLQGAELWKRFHEIGTEMIITKAGRRMFPAMRVKISGLDPHQQYYIAMDIVPVDNKRYRYVYHSSKWMVAGNADSPVPPRVYIHPDSPASGETWMRQVISFDKLKLTNNELDDQGHIILHSMHKYQPRVHVIRKDCGDDLSPIKPVPSGEGVKAFSFPETVFTTVTAYQNQQITRLKIDRNPFAKGFRDSGRNRMGLEALVESYAFWRPSLRTLTFEDIPGIPKQGNASSSTLLQGTGNGVPATHPHLLSGSSCSSPAFHLGPNTSQLCSLAPADYSACARSGLTLNRYSTSLAETYNRLTNQAGETFAPPRTPSYVGVSSSTSVNMSMGGTDGDTFSCPQTSLSMQISGMSPQLQYIMPSPSSNAFATNQTHQGSYNTFRLHSPCALYGYNFSTSPKLAASPEKIVSSQGSFLGSSPSGTMTDRQMLPPVEGVHLLSSGGQQSFFDSRTLGSLTLSSSQVSAHMV>sp|P23258|TBG1_HUMAN Tubulin gamma-1 chain OS=Homo sapiens OX=9606GN=TUBG1 PE=1 SV=2MPREIITLQLGQCGNQIGFEFWKQLCAEHGISPEGIVEEFATEGTDRKDVFFYQADDEHYIPRAVLLDLEPRVIHSILNSPYAKLYNPENIYLSEHGGGAGNNWASGFSQGEKIHEDIFDIIDREADGSDSLEGFVLCHSIAGGTGSGLGSYLLERLNDRYPKKLVQTYSVFPNQDEMSDVVVQPYNSLLTLKRLTQNADCVVVLDNTALNRIATDRLHIQNPSFSQINQLVSTIMSASTTTLRYPGYMNNDLIGLIASLIPTPRLHFLMTGYTPLTTDQSVASVRKTTVLDVMRRLLQPKNVMVSTGRDRQTNHCYIAILNIIQGEVDPTQVHKSLQRIRERKLANFIPWGPASIQVALSRKSPYLPSAHRVSGLMMANHTSISSLFERTCRQYDKLRKREAFLEQFRKEDMFKDNFDEMDTSREIVQQLIDEYHAATRPDYISWGTQEQ>sp|P31314|TLX1_HUMAN T-cell leukemia homeobox protein 1 OS=Homo sapiensOX=9606 GN=TLX1 PE=1 SV=1MEHLGPHHLHPGHAEPISFGIDQILNSPDQGGCMGPASRLQDGEYGLGCLVGGAYTYGGGGSAAATGAGGAGAYGTGGPGGPGGPAGGGGACSMGPLTGSYNVNMALAGGPGPGGGGGSSGGAGALSAAGVIRVPAHRPLAGAVAHPQPLATGLPTVPSVPAMPGVNNLTGLTFPWMESNRRYTKDRFTGHPYQNRTPPKKKKPRTSFTRLQICELEKRFHRQKYLASAERAALAKALKMTDAQVKTWFQNRRTKWRRQTAEEREAERQQANRILLQLQQEAFQKSLAQPLPADPLCVHNSSLFALQNLQPWSDDSTKITSVTSVASACE>sp|P31314-2|TLX1_HUMAN Isoform 2 of T-cell leukemia homeobox protein 1OS=Homo sapiens OX=9606 GN=TLX1MEHLGPHHLHPGHAEPISFGIDQILNSPDQGGCMGPASRLQDGEYGLGCLVGGAYTYGGGGSAAATGAGGAGAYGTGGPGGPGGPAGGGGACSMGPLTGSYNVNMALAGGPGPGGGGGSSGGAGALSAAGVIRVPAHRPLAGAVAHPQPLATGLPTVPSVPAMPGVNNLTGLTFPWMESNRRYTKDRFTGHPYQNRTPPKKKKPRTSFTRLQICELEKRFHRQKYLASAERAALAKALKMTDAQVKTWFQNRRTKWR>sp|Q6ZVM7|TM1L2_HUMAN TOM1-like protein 2 OS=Homo sapiens OX=9606GN=TOM1L2 PE=1 SV=1MEFLLGNPFSTPVGQCLEKATDGSLQSEDWTLNMEICDIINETEEGPKDAIRALKKRLNGNRNYREVMLALTVLETCVKNCGHRFHILVANRDFIDSVLVKIISPKNNPPTIVQDKVLALIQAWADAFRSSPDLTGVVHIYEELKRKGVEFPMADLDALSPIHTPQRSVPEVDPAATMPRSQSQQRTSAGSYSSPPPAPYSAPQAPALSVTGPITANSEQIARLRSELDVVRGNTKVMSEMLTEMVPGQEDSSDLELLQELNRTCRAMQQRIVELISRVSNEEVTEELLHVNDDLNNVFLRYERFERYRSGRSVQNASNGVLNEVTEDNLIDLGPGSPAVVSPMVGNTAPPSSLSSQLAGLDLGTESVSGTLSSLQQCNPRDGFDMFAQTRGNSLAEQRKTVTYEDPQAVGGLASALDNRKQSSEGIPVAQPSVMDDIEVWLRTDLKGDDLEEGVTSEEFDKFLEERAKAAEMVPDLPSPPMEAPAPASNPSGRKKPERSEDALFAL>sp|Q6ZVM7-2|TM1L2_HUMAN Isoform 2 of TOM1-like protein 2 OS=Homo sapiensOX=9606 GN=TOM1L2MEFLLGNPFSTPVGQCLEKATDGSLQSEDWTLNMEICDIINETEEGPKDAIRALKKRLNGNRNYREVMLALTAWADAFRSSPDLTGVVHIYEELKRKGVEFPMADLDALSPIHTPQRSVPEVDPAATMPRSQSQQRTSAGSYSSPPPAPYSAPQAPALSVTGPITANSEQIARLRSELDVVRGNTKVMSEMLTEMVPGQEDSSDLELLQELNRTCRAMQQRIVELISRVSNEEVTEELLHVNDDLNNVFLRYERFERYRSGRSVQNASNGVLNEVTEDNLIDLGPGSPAVVSPMVGNTAPPSSLSSQLAGLDLGTESVSGTLSSLQQCNPRDGFDMFAQTRGNSLAEQRKTVTYEDPQAVGGLASALDNRKQSSEGIPVAQPSVMDDIEVWLRTDLKGDDLEEGVTSEEFDKFLEERAKAAEMVPDLPSPPMEAPAPASNPSGRKKPERSEDALFAL>sp|Q6ZVM7-3|TM1L2_HUMAN Isoform 3 of TOM1-like protein 2 OS=Homo sapiensOX=9606 GN=TOM1L2MEFLLGNPFSTPVGQCLEKATDGSLQSEDWTLNMEICDIINETEEGPKDAIRALKKRLNGNRNYREVMLALTVLETCVKNCGHRFHILVANRDFIDSVLVKIISPKNNPPTIVQDKVLALIQSVPEVDPAATMPRSQSQQRTSAGSYSSPPPAPYSAPQAPALSVTGPITANSEQIARLRSELDVVRGNTKVMSEMLTEMVPGQEDSSDLELLQELNRTCRAMQQRIVELISRVSNEEVTEELLHVNDDLNNVFLRYERFERYRSGRSVQNASNGVLNEVTEDNLIDLGPGSPAVVSPMVGNTAPPSSLSSQLAGLDLGTESVSGTLSSLQQCNPRDGFDMFAQTRGNSLAEQRKTVTYEDPQAVGGLASALDNRKQSSEGIPVAQPSVMDDIEVWLRTDLKGDDLEEGVTSEEFDKFLEERAKAAEMVPDLPSPPMEAPAPASNPSGRKKPERSEDALFAL>sp|Q6ZVM7-4|TM1L2_HUMAN Isoform 4 of TOM1-like protein 2 OS=Homo sapiensOX=9606 GN=TOM1L2MQQRIVELISRVSNEEVTEELLHVNDDLNNVFLRYERFERYRSGRSVQNASNGVLNEVTEDNLIDLGPGSPAVVSPMVGNTAPPSSLSSQLAGLDLGTESVSGTLSSLQQCNPRDGFDMFAQTRGNSLAEQRKTVTYEDPQAVGGLASALDNRKQSSEGIPVAQPSVMDDIEVWLRTDLKGDDLEEGVTSEEFDKFLEERAKAAEMVPDLPSPPMEAPAPASNPSGRKKPERSEDALFAL>sp|Q6ZVM7-5|TM1L2_HUMAN Isoform 5 of TOM1-like protein 2 OS=Homo sapiensOX=9606 GN=TOM1L2MEFLLGNPFSTPVGQCLEKATDGSLQSEDWTLNMEICDIINETEEGPKDAIRALKKRLNGNRNYREVMLALTVLETCVKNCGHRFHILVANRDFIDSVLVKIISPKNNPPTIVQDKVLALIQAWADAFRSSPDLTGVVHIYEELKRKGVEFPMADLDALSPIHTPQRIARLRSELDVVRGNTKVMSEMLTEMVPGQEDSSDLELLQELNRTCRAMQQRIVELISRVSNEEVTEELLHVNDDLNNVFLRYERFERYRSGRSVQNASNGVLNEVTEDNLIDLGPGSPAVVSPMVGNTAPPSSLSSQLAGLDLGTESVSGTLSSLQQCNPRDGFDMFAQTRGNSLAEQRKTVTYEDPQAVGGLASALDNRKQSSEGTFLSSAQKRGRGGESDLEPIDSWLITQGMIPVAQPSVMDDIEVWLRTDLKGDDLEEGVTSEEFDKFLEERAKAAEMVPDLPSPPMEAPAPASNPSGRKKPERSEDALFAL>sp|Q9BSA9|TM175_HUMAN Endosomal/lysosomal potassium channel TMEM175OS=Homo sapiens OX=9606 GN=TMEM175 PE=1 SV=1MSQPRTPEQALDTPGDCPPGRRDEDAGEGIQCSQRMLSFSDALLSIIATVMILPVTHTEISPEQQFDRSVQRLLATRIAVYLMTFLIVTVAWAAHTRLFQVVGKTDDTLALLNLACMMTITFLPYTFSLMVTFPDVPLGIFLFCVCVIAIGVVQALIVGYAFHFPHLLSPQIQRSAHRALYRRHVLGIVLQGPALCFAAAIFSLFFVPLSYLLMVTVILLPYVSKVTGWCRDRLLGHREPSAHPVEVFSFDLHEPLSKERVEAFSDGVYAIVATLLILDICEDNVPDPKDVKERFSGSLVAALSATGPRFLAYFGSFATVGLLWFAHHSLFLHVRKATRAMGLLNTLSLAFVGGLPLAYQQTSAFARQPRDELERVRVSCTIIFLASIFQLAMWTTALLHQAETLQPSVWFGGREHVLMFAKLALYPCASLLAFASTCLLSRFSVGIFHLMQIAVPCAFLLLRLLVGLALATLRVLRGLARPEHPPPAPTGQDDPQSQLLPAPC>sp|Q9BSA9-2|TM175_HUMAN Isoform 2 of Endosomal/lysosomal potassiumchannel TMEM175 OS=Homo sapiens OX=9606 GN=TMEM175MMTITFLPYTFSLMVTFPDVPLGIFLFCVCVIAIGVVQALIVGYAFHFPHLLSPQIQRSAHRALYRRHVLGIVLQGPALCFAAAIFSLFFVPLSYLLMVTVILLPYVSKVTGWCRDRLLGHREPSAHPVEVFSFDLHEPLSKERVEAFSDGVYAIVATLLILDICEDNVPDPKDVKERFSGSLVAALSATGPRFLAYFGSFATVGLLWFAHHSLFLHVRKATRAMGLLNTLSLAFVGGLPLAYQQTSAFARQPRDELERVRVSCTIIFLASIFQLAMWTTALLHQAETLQPSVWFGGREHVLMFAKLALYPCASLLAFASTCLLSRFSVGIFHLMQIAVPCAFLLLRLLVGLALATLRVLRGLARPEHPPPAPTGQDDPQSQLLPAPC>sp|Q86W33|TPRA1_HUMAN Transmembrane protein adipocyte-associated 1OS=Homo sapiens OX=9606 GN=TPRA1 PE=1 SV=1MDTLEEVTWANGSTALPPPLAPNISVPHRCLLLLYEDIGTSRVRYWDLLLLIPNVLFLIFLLWKLPSARAKIRITSSPIFITFYILVFVVALVGIARAVVSMTVSTSNAATVADKILWEITRFFLLAIELSVIILGLAFGHLESKSSIKRVLAITTVLSLAYSVTQGTLEILYPDAHLSAEDFNIYGHGGRQFWLVSSCFFFLVYSLVVILPKTPLKERISLPSRRSFYVYAGILALLNLLQGLGSVLLCFDIIEGLCCVDATTFLYFSFFAPLIYVAFLRGFFGSEPKILFSYKCQVDETEEPDVHLPQPYAVARREGLEAAGAAGASAASYSSTQFDSAGGVAYLDDIASMPCHTGSINSTDSERWKAINA>sp|Q86W33-2|TPRA1_HUMAN Isoform 2 of Transmembrane protein adipocyte-associated 1 OS=Homo sapiens OX=9606 GN=TPRA1MDTLEEVTWANGSTALPPPLAPNISVPHRCLLLLYEDIGTSRVRYWDLLLLIPNVLFLIFLLWKLPSARAKIRITSSPIFITFYILVFVVALVGIARAVVSMTVSTSNAATVADKILWEITRFFLLAIELSVIILGLAFGHLESKSSIKRVLAITTVLSLAYSVTQGTLEILYPDAHLSAEDFNIYGHGGRQFWLVSSCFFFLLGGASTCMRASWHCSTYCRGWGVCCCASTSSRGSAV>sp|Q86W33-3|TPRA1_HUMAN Isoform 3 of Transmembrane protein adipocyte-associated 1 OS=Homo sapiens OX=9606 GN=TPRA1MDTLEEVTWANGSTALPPPLAPNISVPHRCLLLLYEDIGTSRVRYWDLLLLIPNVLFLIFLLWKLPSARAKIRITSSPIFITFYILVFVVALVGIARAVVSMTVSTSNAATVADKILWEITRFFLLAIELSVIILGLAFGHLESKSSIKRVLAITTVLSLAYSVTQGTLEILYPDAHLSAEDFNIYGHGGRQFWLVSSCFFFLLCRCHNLPVLQLLRSAHLRGFPPGLLRLGAQDPLLLQMPSGRDRGARCTPTPALRCGPAGGPGGCRGCWGLSCQLLEHAVRLCRRGGLPG>sp|Q12899|TRI26_HUMAN Tripartite motif-containing protein 26 OS=Homosapiens OX=9606 GN=TRIM26 PE=1 SV=1MATSAPLRSLEEEVTCSICLDYLRDPVTIDCGHVFCRSCTTDVRPISGSRPVCPLCKKPFKKENIRPVWQLASLVENIERLKVDKGRQPGEVTREQQDAKLCERHREKLHYYCEDDGKLLCVMCRESREHRPHTAVLMEKAAQPHREKILNHLSTLRRDRDKIQGFQAKGEADILAALKKLQDQRQYIVAEFEQGHQFLREREEHLLEQLAKLEQELTEGREKFKSRGVGELARLALVISELEGKAQQPAAELMQDTRDFLNRYPRKKFWVGKPIARVVKKKTGEFSDKLLSLQRGLREFQGKLLRDLEYKTVSVTLDPQSASGYLQLSEDWKCVTYTSLYKSAYLHPQQFDCEPGVLGSKGFTWGKVYWEVEVEREGWSEDEEEGDEEEEGEEEEEEEEAGYGDGYDDWETDEDEESLGDEEEEEEEEEEEVLESCMVGVARDSVKRKGDLSLRPEDGVWALRLSSSGIWANTSPEAELFPALRPRRVGIALDYEGGTVTFTNAESQELIYTFTATFTRRLVPFLWLKWPGTRLLLRP>sp|Q96IK0|TM101_HUMAN Transmembrane protein 101 OS=Homo sapiens OX=9606GN=TMEM101 PE=1 SV=1MASKIGSRRWMLQLIMQLGSVLLTRCPFWGCFSQLMLYAERAEARRKPDIPVPYLYFDMGAAVLCASFMSFGVKRRWFALGAALQLAISTYAAYIGGYVHYGDWLKVRMYSRTVAIIGGFLVLASGAGELYRRKPRSRSLQSTGQVFLGIYLICVAYSLQHSKEDRLAYLNHLPGGELMIQLFFVLYGILALAFLSGYYVTLAAQILAVLLPPVMLLIDGNVAYWHNTRRVEFWNQMKLLGESVGIFGTAVILATDG>sp|Q63HR2|TNS2_HUMAN Tensin-2 OS=Homo sapiens OX=9606 GN=TNS2 PE=1 SV=2MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRVCKVATHRKCEAKVTSACQALPPVELRRNTAPVRRIEHLGSTKSLNHSKQRSTLPRSFSLDPLMERRWDLDLTYVTERILAAAFPARPDEQRHRGHLRELAHVLQSKHRDKYLLFNLSEKRHDLTRLNPKVQDFGWPELHAPPLDKLCSICKAMETWLSADPQHVVVLYCKGNKGKLGVIVSAYMHYSKISAGADQALATLTMRKFCEDKVATELQPSQRRYISYFSGLLSGSIRMNSSPLFLHYVLIPMLPAFEPGTGFQPFLKIYQSMQLVYTSGVYHIAGPGPQQLCISLEPALLLKGDVMVTCYHKGGRGTDRTLVFRVQFHTCTIHGPQLTFPKDQLDEAWTDERFPFQASVEFVFSSSPEKIKGSTPRNDPSVSVDYNTTEPAVRWDSYENFNQHHEDSVDGSLTHTRGPLDGSPYAQVQRPPRQTPPAPSPEPPPPPMLSVSSDSGHSSTLTTEPAAESPGRPPPTAAERQELDRLLGGCGVASGGRGAGRETAILDDEEQPTVGGGPHLGVYPGHRPGLSRHCSCRQGYREPCGVPNGGYYRPEGTLERRRLAYGGYEGSPQGYAEASMEKRRLCRSLSEGLYPYPPEMGKPATGDFGYRAPGYREVVILEDPGLPALYPCPACEEKLALPTAALYGLRLEREAGEGWASEAGKPLLHPVRPGHPLPLLLPACGHHHAPMPDYSCLKPPKAGEEGHEGCSYTMCPEGRYGHPGYPALVTYSYGGAVPSYCPAYGRVPHSCGSPGEGRGYPSPGAHSPRAGSISPGSPPYPQSRKLSYEIPTEEGGDRYPLPGHLASAGPLASAESLEPVSWREGPSGHSTLPRSPRDAPCSASSELSGPSTPLHTSSPVQGKESTRRQDTRSPTSAPTQRLSPGEALPPVSQAGTGKAPELPSGSGPEPLAPSPVSPTFPPSSPSDWPQERSPGGHSDGASPRSPVPTTLPGLRHAPWQGPRGPPDSPDGSPLTPVPSQMPWLVASPEPPQSSPTPAFPLAASYDTNGLSQPPLPEKRHLPGPGQQPGPWGPEQASSPARGISHHVTFAPLLSDNVPQTPEPPTQESQSNVKFVQDTSKFWYKPHLSRDQAIALLKDKDPGAFLIRDSHSFQGAYGLALKVATPPPSAQPWKGDPVEQLVRHFLIETGPKGVKIKGCPSEPYFGSLSALVSQHSISPISLPCCLRIPSKDPLEETPEAPVPTNMSTAADLLRQGAACSVLYLTSVETESLTGPQAVARASSAALSCSPRPTPAVVHFKVSAQGITLTDNQRKLFFRRHYPVNSITFSSTDPQDRRWTNPDGTTSKIFGFVAKKPGSPWENVCHLFAELDPDQPAGAIVTFITKVLLGQRK>sp|Q63HR2-2|TNS2_HUMAN Isoform 2 of Tensin-2 OS=Homo sapiens OX=9606GN=TNS2MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRVCKVATHRKCEAKVTSACQALPPVELRRNTAPVRRIEHLGSTKSLNHSKQRSTLPRSFSLDPLMERRWDLDLTYVTERILAAAFPARPDEQRHRGHLRELAHVLQSKHRDKYLLFNLSEKRHDLTRLNPKVQDFGWPELHAPPLDKLCSICKAMETWLSADPQHVVVLYCKGNKGKLGVIVSAYMHYSKISAGADQALATLTMRKFCEDKVATELQPSQRRYISYFSGLLSGSIRMNSSPLFLHYVLIPMLPAFEPGTGFQPFLKIYQSMQLVYTSGVYHIAGPGPQQLCISLEPALLLKGDVMVTCYHKGGRGTDRTLVFRVQFHTCTIHGPQLTFPKDQLDEAWTDERFPFQASVEFVFSSSPEKIKGSTPRNDPSVSVDYNTTEPAVRWDSYENFNQHHEDSVDGSLTHTRGPLDGSPYAQVQRPPRQTPPAPSPEPPPPPMLSVSSDSGHSSTLTTEPAAESPGRPPPTAAERQELDRLLGGCGVASGGRGAGRETAILDDEEQPTVGGGPHLGVYPGHRPGLSRHCSCRQGYREPCGVPNGGYYRPEGTLERRRLAYGGYEGSPQGYAEASMEKRRLCRSLSEGLYPYPPEMGKPATGDFGYRAPGYREVVILEDPGLPALYPCPACEEKLALPTAALYGLRLEREAGEGWASEAGKPLLHPVRPGHPLPLLLPACGHHHAPMPDYSCLKPPKAGEEGHEGCSYTMCPEESLEPVSWREGPSGHSTLPRSPRDAPCSASSELSGPSTPLHTSSPVQGKESTRRQDTRSPTSAPTQRLSPGEALPPVSQAGTGKAPELPSGSGPEPLAPSPVSPTFPPSSPSDWPQERSPGGHSDGASPRSPVPTTLPGLRHAPWQGPRGPPDSPDGSPLTPVPSQMPWLVASPEPPQSSPTPAFPLAASYDTNGLSQPPLPEKRHLPGPGQQPGPWGPEQASSPARGISHHVTFAPLLSDNVPQTPEPPTQESQSNVKFVQDTSKFWYKPHLSRDQAIALLKDKDPGAFLIRDSHSFQGAYGLALKVATPPPSAQPWKGDPVEQLVRHFLIETGPKGVKIKGCPSEPYFGSLSALVSQHSISPISLPCCLRIPSKDPLEETPEAPVPTNMSTAADLLRQGAACSVLYLTSVETESLTGPQAVARASSAALSCSPRPTPAVVHFKVSAQGITLTDNQRKLFFRRHYPVNSITFSSTDPQDRRWTNPDGTTSKIFGFVAKKPGSPWENVCHLFAELDPDQPAGAIVTFITKVLLGQRK>sp|Q63HR2-4|TNS2_HUMAN Isoform 4 of Tensin-2 OS=Homo sapiens OX=9606GN=TNS2MDGGGVCVGRGDLLSSPQALGQLLRKESRPRRAMKPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRVCKVATHRKCEAKVTSACQALPPVELRRNTAPVRRIEHLGSTKSLNHSKQRSTLPRSFSLDPLMERRWDLDLTYVTERILAAAFPARPDEQRHRGHLRELAHVLQSKHRDKYLLFNLSEKRHDLTRLNPKVQDFGWPELHAPPLDKLCSICKAMETWLSADPQHVVVLYCKGNKGKLGVIVSAYMHYSKISAGADQALATLTMRKFCEDKVATELQPSQRRYISYFSGLLSGSIRMNSSPLFLHYVLIPMLPAFEPGTGFQPFLKIYQSMQLVYTSGVYHIAGPGPQQLCISLEPALLLKGDVMVTCYHKGGRGTDRTLVFRVQFHTCTIHGPQLTFPKDQLDEAWTDERFPFQASVEFVFSSSPEKIKGSTPRNDPSVSVDYNTTEPAVRWDSYENFNQHHEDSVDGSLTHTRGPLDGSPYAQVQRPPRQTPPAPSPEPPPPPMLSVSSDSGHSSTLTTEPAAESPGRPPPTAAERQELDRLLGGCGVASGGRGAGRETAILDDEEQPTVGGGPHLGVYPGHRPGLSRHCSCRQGYREPCGVPNGGYYRPEGTLERRRLAYGGYEGSPQGYAEASMEKRRLCRSLSEGLYPYPPEMGKPATGDFGYRAPGYREVVILEDPGLPALYPCPACEEKLALPTAALYGLRLEREAGEGWASEAGKPLLHPVRPGHPLPLLLPACGHHHAPMPDYSCLKPPKAGEEGHEGCSYTMCPEGRYGHPGYPALVTYSYGGAVPSYCPAYGRVPHSCGSPGEGRGYPSPGAHSPRAGSISPGSPPYPQSRKLSYEIPTEEGGDRYPLPGHLASAGPLASAESLEPVSWREGPSGHSTLPRSPRDAPCSASSELSGPSTPLHTSSPVQGKESTRRQDTRSPTSAPTQRLSPGEALPPVSQAGTGKAPELPSGSGPEPLAPSPVSPTFPPSSPSDWPQERSPGGHSDGASPRSPVPTTLPGLRHAPWQGPRGPPDSPDGSPLTPVPSQMPWLVASPEPPQSSPTPAFPLAASYDTNGLSQPPLPEKRHLPGPGQQPGPWGPEQASSPARGISHHVTFAPLLSDNVPQTPEPPTQESQSNVKFVQDTSKFWYKPHLSRDQAIALLKDKDPGAFLIRDSHSFQGAYGLALKVATPPPSAQPWKGDPVEQLVRHFLIETGPKGVKIKGCPSEPYFGSLSALVSQHSISPISLPCCLRIPSKDPLEETPEAPVPTNMSTAADLLRQGAACSVLYLTSVETESLTGPQAVARASSAALSCSPRPTPAVVHFKVSAQGITLTDNQRKLFFRRHYPVNSITFSSTDPQDRRWTNPDGTTSKIFGFVAKKPGSPWENVCHLFAELDPDQPAGAIVTFITKVLLGQRK>sp|Q63HR2-5|TNS2_HUMAN Isoform 5 of Tensin-2 OS=Homo sapiens OX=9606GN=TNS2MERRWDLDLTYVTERILAAAFPARPDEQRHRGHLRELAHVLQSKHRDKYLLFNLSEKRHDLTRLNPKVQDFGWPELHAPPLDKLCSICKAMETWLSADPQHVVVLYCKGNKGKLGVIVSAYMHYSKISAGADQALATLTMRKFCEDKVATELQPSQRRYISYFSGLLSGSIRMNSSPLFLHYVLIPMLPAFEPGTGFQPFLKIYQSMQLVYTSGVYHIAGPGPQQLCISLEPALLLKGDVMVTCYHKGGRGTDRTLVFRVQFHTCTIHGPQLTFPKDQLDEAWTDERFPFQASVEFVFSSSPEKIKGSTPRNDPSVSVDYNTTEPAVRWDSYENFNQHHEDSVDGSLTHTRGPLDGSPYAQVQRPPRQTPPAPSPEPPPPPMLSVSSDSGHSSTLTTEPAAESPGRPPPTAAERQELDRLLGGCGVASGGRGAGRETAILDDEEQPTVGGGPHLGVYPGHRPGLSRHCSCRQGYREPCGVPNGGYYRPEGTLERRRLAYGGYEGSPQGYAEASMEKRRLCRSLSEGLYPYPPEMGKPATGDFGYRAPGYREVVILEDPGLPALYPCPACEEKLALPTAALYGLRLEREAGEGWASEAGKPLLHPVRPGHPLPLLLPACGHHHAPMPDYSCLKPPKAGEEGHEGCSYTMCPEGRYGHPGYPALVTYSYGGAVPSYCPAYGRVPHSCGSPGEGRGYPSPGAHSPRAGSISPGSPPYPQSRKLSYEIPTEEGGDRYPLPGHLASAGPLASAESLEPVSWREGPSGHSTLPRSPRDAPCSASSELSGPSTPLHTSSPVQGKESTRRQDTRSPTSAPTQRLSPGEALPPVSQAGTGKAPELPSGSGPEPLAPSPVSPTFPPSSPSDWPQERSPGGHSDGASPRSPVPTTLPGLRHAPWQGPRGPPDSPDGSPLTPVPSQMPWLVASPEPPQSSPTPAFPLAASYDTNGLSQPPLPEKRHLPGPGQQPGPWGPEQASSPARGISHHVTFAPLLSDNVPQTPEPPTQESQSNVKFVQDTSKFWYKPHLSRDQAIALLKDKDPGAFLIRDSHSFQGAYGLALKVATPPPSAQPWKGDPVEQLVRHFLIETGPKGVKIKGCPSEPYFGSLSALVSQHSISPISLPCCLRIPSKDPLEETPEAPVPTNMSTAADLLRQGAACSVLYLTSVETESLTGPQAVARASSAALSCSPRPTPAVVHFKVSAQGITLTDNQRKLFFRRHYPVNSITFSSTDPQDRRWTNPDGTTSKIFGFVAKKPGSPWENVCHLFAELDPDQPAGAIVTFITKVLLGQRK>sp|Q63HR2-6|TNS2_HUMAN Isoform 6 of Tensin-2 OS=Homo sapiens OX=9606GN=TNS2MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRVCKVATHRKCEAKVTSACQALPPVELRRNTAPVRRIEHLGSTKSLNHSKQRSTLPRSFSLDPLMERRWDLDLTYVTERILAAAFPARPDEQRHRGHLRELAHVLQSKHRDKYLLFNLSEKRHDLTRLNPKVQDFGWPELHAPPLDKLCSICKAMETWLSADPQHVVVLYCKGNKGKLGVIVSAYMHYSKISAGADQALATLTMRKFCEDKVATELQPSQRRYISYFSGLLSGSIRMNSSPLFLHYVLIPMLPAFEPGTGFQPFLKIYQSMQLVYTSGVYHIAGPGPQQLCISLEPALLLKGDVMVTCYHKGGRGTDRTLVFRVQFHTCTIHGPQLTFPKDQLDEAWTDERFPFQASVEFVFSSSPEKIKGSTPRNDPSVSVDYNTTEPAVRWDSYENFNQHHEDSVDGSLTHTRGPLDGSPYAQVQRPPRQTPPAPSPEPPPPPMLSVSSDSGHSSTLTTEPAAESPGRPPPTAAERQELDRLLGGCGVASGGRGAGRETAILDDEEQPTVGGGPHLGVYPGHRPGLSRHCSCRQGYREPCGVPNGGYYRPEGTLERRRLAYGGYEGSPQGYAEASMEKRRLCRSLSEGLYPYPPEMGKPATGDFGYRAPGYREVVILEDPGLPALYPCPACEEKLALPTAALYGLRLEREAGEGWASEAGKPLLHPVRPGHPLPLLLPACGHHHAPMPDYSCLKPPKAGEEGHEGCSYTMCPEGRYGHPGYPALVTYSYGGAVPSYCPAYGRVPHSCGSPGEGRGYPSPGAHSPRAGSISPGSPPYPQSRKLSYEIPTEEGGDRYPLPGHLASAGPLASAESLEPVSWREGPSGHSTLPRSPRDAPCSASSELSGPSTPLHTSSPVQGKESTRRQDTRSPTSAPTQRLSPGEALPPVSQAGTGKAPELPSGSGPEPLAPSPVSPTFPPSSPSDWPQERSPGGHSDGASPRSPVPTTLPGLRHAPWQGPRGPPDSPDGSPLTPVPSQMPWLVASPEPPQSSPTPAFPLAASYDTNGLSQPPLPEKRHLPGPGQQPGPWGPEQASSPARGISHHVTFAPLLSDNVPQTPEPPTQESQSNVKFVQDTSKFWYKPHLSRDQAIALLKDKDPGAFLIRDSHSFQGAYGLALKVATPPPSAQPWKGDPVEQLVRHFLIETGPKGVKIKGCPSEPYFGSLSALVSQHSISPISLPCCLRIPSKDPLEETPEAPVPTNMSTAADLLRQACSVLYLTSVETESLTGPQAVARASSAALSCSPRPTPAVVHFKVSAQGITLTDNQRKLFFRRHYPVNSITFSSTDPQDRRWTNPDGTTSKIFGFVAKKPGSPWENVCHLFAELDPDQPAGAIVTFITKVLLGQRK>sp|Q9GZM7|TINAL_HUMAN Tubulointerstitial nephritis antigen-like OS=Homosapiens OX=9606 GN=TINAGL1 PE=1 SV=1MWRCPLGLLLLLPLAGHLALGAQQGRGRRELAPGLHLRGIRDAGGRYCQEQDLCCRGRADDCALPYLGAICYCDLFCNRTVSDCCPDFWDFCLGVPPPFPPIQGCMHGGRIYPVLGTYWDNCNRCTCQENRQWQCDQEPCLVDPDMIKAINQGNYGWQAGNHSAFWGMTLDEGIRYRLGTIRPSSSVMNMHEIYTVLNPGEVLPTAFEASEKWPNLIHEPLDQGNCAGSWAFSTAAVASDRVSIHSLGHMTPVLSPQNLLSCDTHQQQGCRGGRLDGAWWFLRRRGVVSDHCYPFSGRERDEAGPAPPCMMHSRAMGRGKRQATAHCPNSYVNNNDIYQVTPVYRLGSNDKEIMKELMENGPVQALMEVHEDFFLYKGGIYSHTPVSLGRPERYRRHGTHSVKITGWGEETLPDGRTLKYWTAANSWGPAWGERGHFRIVRGVNECDIESFVLGVWGRVGMEDMGHH>sp|Q9GZM7-2|TINAL_HUMAN Isoform 2 of Tubulointerstitial nephritisantigen-like OS=Homo sapiens OX=9606 GN=TINAGL1MVLGSSTQVKIGGSWNPAAAGGLKIKLQKALDLVALQCQWAPEGQARAEQEADRATFILQTVLNPGEVLPTAFEASEKWPNLIHEPLDQGNCAGSWAFSTAAVASDRVSIHSLGHMTPVLSPQNLLSCDTHQQQGCRGGRLDGAWWFLRRRGYAATGDVGREEGKELRGHGLGHDALSLSAFAPSCCLCRVVSDHCYPFSGRERDEAGPAPPCMMHSRAMGRGKRQATAHCPNSYVNNNDIYQVTPVYRLGSNDKEIMKELMENGPVQGKPPYPAPWFQKLVPA>sp|Q9GZM7-3|TINAL_HUMAN Isoform 3 of Tubulointerstitial nephritisantigen-like OS=Homo sapiens OX=9606 GN=TINAGL1MWRCPLGLLLLLPLAGHLALGAQQGRGRRELAPGLHLRGIRDAGGRYCQEQDLCCRGRADDCALPYLGAICYCDLFCNRTVSDCCPDFWDFCLGVPPPFPPIQGCMHGGRIYPVLGTYWDNCNRCWQAGNHSAFWGMTLDEGIRYRLGTIRPSSSVMNMHEIYTVLNPGEVLPTAFEASEKWPNLIHEPLDQGNCAGSWAFSTAAVASDRVSIHSLGHMTPVLSPQNLLSCDTHQQQGCRGGRLDGAWWFLRRRGVVSDHCYPFSGRERDEAGPAPPCMMHSRAMGRGKRQATAHCPNSYVNNNDIYQVTPVYRLGSNDKEIMKELMENGPVQALMEVHEDFFLYKGGIYSHTPVSLGRPERYRRHGTHSVKITGWGEETLPDGRTLKYWTAANSWGPAWGERGHFRIVRGVNECDIESFVLGVWGRVGMEDMGHH>sp|O14668|TMG1_HUMAN Transmembrane gamma-carboxyglutamic acid protein 1OS=Homo sapiens OX=9606 GN=PRRG1 PE=1 SV=1MGRVFLTGEKANSILKRYPRANGFFEEIRQGNIERECKEEFCTFEEAREAFENNEKTKEFWSTYTKAQQGESNRGSDWFQFYLTFPLIFGLFIILLVIFLIWRCFLRNKTRRQTVTEGHIPFPQHLNIITPPPPPDEVFDSSGLSPGFLGYVVGRSDSVSTRLSNCDPPPTYEEATGQVNLQRSETEPHLDPPPEYEDIVNSNSASAIPMVPVVTTIK>sp|O14668-2|TMG1_HUMAN Isoform 2 of Transmembrane gamma-carboxyglutamicacid protein 1 OS=Homo sapiens OX=9606 GN=PRRG1MGRVFLTGEKANSILKRYPRANGFFEEIRQGNIERECKEEFCTFEEAREAFENNEKTGLVLLPRLECSCEHGSLQPQLPVPK>sp|Q8N841|TTLL6_HUMAN Tubulin polyglutamylase TTLL6 OS=Homo sapiensOX=9606 GN=TTLL6 PE=1 SV=2MPQCPTLESQEGENSEEKGDSSKEDPKETVALAFVRENPGAQNGLQNAQQQGKKKRKKKRLVINLSSCRYESVRRAAQQYGFREGGEDDDWTLYWTDYSVSLERVMEMKSYQKINHFPGMSEICRKDLLARNMSRMLKMFPKDFRFFPRTWCLPADWGDLQTYSRSRKNKTYICKPDSGCQGKGIFITRTVKEIKPGEDMICQLYISKPFIIDGFKFDLRIYVLVTSCDPLRIFVYNEGLARFATTSYSRPCTDNLDDICMHLTNYSINKHSSNFSRDAHSGSKRKLSTFSAYLEDHSYNVEQIWRDIEDVIIKTLISAHPIIRHNYHTCFPNHTLNSACFEILGFDILLDHKLKPWLLEVNHSPSFSTDSRLDKEVKDGLLYDTLVLINLESCDKKKVLEEERQRGQFLQQCCSREMRIEEAKGFRAVQLKKTETYEKENCGGFRLIYPSLNSEKYEKFFQDNNSLFQNTVASRAREEYARQLIQELRLKREKKPFQMKKKVEMQGESAGEQVRKKGMRGWQQKQQQKDKAATQASKQYIQPLTLVSYTPDLLLSVRGERKNETDSSLNQEAPTEEASSVFPKLTSAKPFSSLPDLRNINLSSSKLEPSKPNFSIKEAKSASAVNVFTGTVHLTSVETTPESTTQLSISPKSPPTLAVTASSEYSGPETDRVVSFKCKKQQTPPHLTQKKMLKSFLPTKSKSFWESPNTNWTLLKSDMNKPHLISELLTKLQLSGKLSFFPAHYNPKLGMNNLSQNPSLPGECHSRSDSSGEKRQLDVSSLLLQSPQSYNVTLRDLLVIATPAQLDPRPCRSHASAMRDPCMQDQEAYSHCLISGQKGCERS>sp|Q8N841-2|TTLL6_HUMAN Isoform 2 of Tubulin polyglutamylase TTLL6OS=Homo sapiens OX=9606 GN=TTLL6MEGCLGVAELRKLSTFSAYLEDHSYNVEQIWRDIEDVIIKTLISAHPIIRHNYHTCFPNHTLNSACFEILGFDILLDHKLKPWLLEVNHSPSFSTDSRLDKEVKDGLLYDTLVLINLESCDKKKVLEEERQRGQFLQQCCSREMRIEEAKGFRAVQLKKTETYEKENCGGFRLIYPSLNSEKYEKFFQDNNSLFQNTVASRAREEYARQLIQELRLKREKKPFQMKKKVEMQGESAGEQVRKKGMRGWQQKQQQKDKAATQASKQYIQPLTLVSYTPDLLLSVRGERKNETDSSLNQEAPTEEASSVFPKLTSAKPFSSLPDLRNINLSSSKLEPSKPNFSIKEAKSASAVNVFTGTVHLTSVETTPESTTQLSISPKSPPTLAVTASSEYSGPETDRVVSFKCKKQQTPPHLTQKKMLKSFLPTKSKSFWESPNTNWTLLKSDMNKPHLISELLTKLQLSGKLSFFPAHYNPKLGMNNLSQNPSLPGECHSRSDSSGEKRQLDVSSLLLQSPQSYNVTLRDLLVIATPAQLDPRPCRSHASAMRDPCMQDQEAYSHCLISGQKGCERS>sp|Q86VQ6|TRXR3_HUMAN Thioredoxin reductase 3 OS=Homo sapiens OX=9606GN=TXNRD3 PE=1 SV=4MERSPPQSPGPGKAGDAPNRRSGHVRGARVLSPPGRRARLSSPGPSRSSEAREELRRHLVGLIERSRVVIFSKSYCPHSTRVKELFSSLGVECNVLELDQVDDGARVQEVLSEITNQKTVPNIFVNKVHVGGCDQTFQAYQSGLLQKLLQEDLAYDYDLIIIGGGSGGLSCAKEAAILGKKVMVLDFVVPSPQGTSWGLGGTCVNVGCIPKKLMHQAALLGQALCDSRKFGWEYNQQVRHNWETMTKAIQNHISSLNWGYRLSLREKAVAYVNSYGEFVEHHKIKATNKKGQETYYTAAQFVIATGERPRYLGIQGDKEYCITSDDLFSLPYCPGKTLVVGASYVALECAGFLAGFGLDVTVMVRSILLRGFDQEMAEKVGSYMEQHGVKFLRKFIPVMVQQLEKGSPGKLKVLAKSTEGTETIEGVYNTVLLAIGRDSCTRKIGLEKIGVKINEKSGKIPVNDVEQTNVPYVYAVGDILEDKPELTPVAIQSGKLLAQRLFGASLEKCDYINVPTTVFTPLEYGCCGLSEEKAIEVYKKENLEIYHTLFWPLEWTVAGRENNTCYAKIICNKFDHDRVIGFHILGPNAGEVTQGFAAAMKCGLTKQLLDDTIGIHPTCGEVFTTLEITKSSGLDITQKGCUG>sp|O43156|TTI1_HUMAN TELO2-interacting protein 1 homolog OS=Homo sapiensOX=9606 GN=TTI1 PE=1 SV=3MAVFDTPEEAFGVLRPVCVQLTKTQTVENVEHLQTRLQAVSDSALQELQQYILFPLRFTLKTPGPKRERLIQSVVECLTFVLSSTCVKEQELLQELFSELSACLYSPSSQKPAAVSEELKLAVIQGLSTLMHSAYGDIILTFYEPSILPRLGFAVSLLLGLAEQEKSKQIKIAALKCLQVLLLQCDCQDHPRSLDELEQKQLGDLFASFLPGISTALTRLITGDFKQGHSIVVSSLKIFYKTVSFIMADEQLKRISKVQAKPAVEHRVAELMVYREADWVKKTGDKLTILIKKIIECVSVHPHWKVRLELVELVEDLLLKCSQSLVECAGPLLKALVGLVNDESPEIQAQCNKVLRHFADQKVVVGNKALADILSESLHSLATSLPRLMNSQDDQGKFSTLSLLLGYLKLLGPKINFVLNSVAHLQRLSKALIQVLELDVADIKIVEERRWNSDDLNASPKTSATQPWNRIQRRYFRFFTDERIFMLLRQVCQLLGYYGNLYLLVDHFMELYHQSVVYRKQAAMILNELVTGAAGLEVEDLHEKHIKTNPEELREIVTSILEEYTSQENWYLVTCLETEEMGEELMMEHPGLQAITSGEHTCQVTSFLAFSKPSPTICSMNSNIWQICIQLEGIGQFAYALGKDFCLLLMSALYPVLEKAGDQTLLISQVATSTMMDVCRACGYDSLQHLINQNSDYLVNGISLNLRHLALHPHTPKVLEVMLRNSDANLLPLVADVVQDVLATLDQFYDKRAASFVSVLHALMAALAQWFPDTGNLGHLQEQSLGEEGSHLNQRPAALEKSTTTAEDIEQFLLNYLKEKDVADGNVSDFDNEEEEQSVPPKVDENDTRPDVEPPLPLQIQIAMDVMERCIHLLSDKNLQIRLKVLDVLDLCVVVLQSHKNQLLPLAHQAWPSLVHRLTRDAPLAVLRAFKVLRTLGSKCGDFLRSRFCKDVLPKLAGSLVTQAPISARAGPVYSHTLAFKLQLAVLQGLGPLCERLDLGEGDLNKVADACLIYLSVKQPVKLQEAARSVFLHLMKVDPDSTWFLLNELYCPVQFTPPHPSLHPVQLHGASGQQNPYTTNVLQLLKELQ>sp|P20231|TRYB2_HUMAN Tryptase beta-2 OS=Homo sapiens OX=9606 GN=TPSB2PE=1 SV=2MLNLLLLALPVLASRAYAAPAPGQALQRVGIVGGQEAPRSKWPWQVSLRVHGPYWMHFCGGSLIHPQWVLTAAHCVGPDVKDLAALRVQLREQHLYYQDQLLPVSRIIVHPQFYTAQIGADIALLELEEPVNVSSHVHTVTLPPASETFPPGMPCWVTGWGDVDNDERLPPPFPLKQVKVPIMENHICDAKYHLGAYTGDDVRIVRDDMLCAGNTRRDSCQGDSGGPLVCKVNGTWLQAGVVSWGEGCAQPNRPGIYTRVTYYLDWIHHYVPKKP>sp|Q8WUA8|TSK_HUMAN Tsukushi OS=Homo sapiens OX=9606 GN=TSKU PE=1 SV=3MPWPLLLLLAVSGAQTTRPCFPGCQCEVETFGLFDSFSLTRVDCSGLGPHIMPVPIPLDTAHLDLSSNRLEMVNESVLAGPGYTTLAGLDLSHNLLTSISPTAFSRLRYLESLDLSHNGLTALPAESFTSSPLSDVNLSHNQLREVSVSAFTTHSQGRALHVDLSHNLIHRLVPHPTRAGLPAPTIQSLNLAWNRLHAVPNLRDLPLRYLSLDGNPLAVIGPGAFAGLGGLTHLSLASLQRLPELAPSGFRELPGLQVLDLSGNPKLNWAGAEVFSGLSSLQELDLSGTNLVPLPEALLLHLPALQSVSVGQDVRCRRLVREGTYPRRPGSSPKVALHCVDTRDSAARGPTIL>sp|Q6IQ55|TTBK2_HUMAN Tau-tubulin kinase 2 OS=Homo sapiens OX=9606GN=TTBK2 PE=1 SV=2MSGGGEQLDILSVGILVKERWKVLRKIGGGGFGEIYDALDMLTRENVALKVESAQQPKQVLKMEVAVLKKLQGKDHVCRFIGCGRNDRFNYVVMQLQGRNLADLRRSQSRGTFTISTTLRLGRQILESIESIHSVGFLHRDIKPSNFAMGRFPSTCRKCYMLDFGLARQFTNSCGDVRPPRAVAGFRGTVRYASINAHRNREMGRHDDLWSLFYMLVEFVVGQLPWRKIKDKEQVGSIKERYDHRLMLKHLPPEFSIFLDHISSLDYFTKPDYQLLTSVFDNSIKTFGVIESDPFDWEKTGNDGSLTTTTTSTTPQLHTRLTPAAIGIANATPIPGDLLRENTDEVFPDEQLSDGENGIPVGVSPDKLPGSLGHPRPQEKDVWEEMDANKNKIKLGICKAATEEENSHGQANGLLNAPSLGSPIRVRSEITQPDRDIPLVRKLRSIHSFELEKRLTLEPKPDTDKFLETCLEKMQKDTSAGKESILPALLHKPCVPAVSRTDHIWHYDEEYLPDASKPASANTPEQADGGGSNGFIAVNLSSCKQEIDSKEWVIVDKEQDLQDFRTNEAVGHKTTGSPSDEEPEVLQVLEASPQDEKLQLGPWAENDHLKKETSGVVLALSAEGPPTAASEQYTDRLELQPGAASQFIAATPTSLMEAQAEGPLTAITIPRPSVASTQSTSGSFHCGQQPEKKDLQPMEPTVELYSPRENFSGLVVTEGEPPSGGSRTDLGLQIDHIGHDMLPNIRESNKSQDLGPKELPDHNRLVVREFENLPGETEEKSILLESDNEDEKLSRGQHCIEISSLPGDLVIVEKDHSATTEPLDVTKTQTFSVVPNQDKNNEIMKLLTVGTSEISSRDIDPHVEGQIGQVAEMQKNKISKDDDIMSEDLPGHQGDLSTFLHQEGKREKITPRNGELFHCVSENEHGAPTRKDMVRSSFVTRHSRIPVLAQEIDSTLESSSPVSAKEKLLQKKAYQPDLVKLLVEKRQFKSFLGDLSSASDKLLEEKLATVPAPFCEEEVLTPFSRLTVDSHLSRSAEDSFLSPIISQSRKSKIPRPVSWVNTDQVNSSTSSQFFPRPPPGKPPTRPGVEARLRRYKVLGSSNSDSDLFSRLAQILQNGSQKPRSTTQCKSPGSPHNPKTPPKSPVVPRRSPSASPRSSSLPRTSSSSPSRAGRPHHDQRSSSPHLGRSKSPPSHSGSSSSRRSCQQEHCKPSKNGLKGSGSLHHHSASTKTPQGKSKPASKLSR>sp|Q6IQ55-2|TTBK2_HUMAN Isoform 2 of Tau-tubulin kinase 2 OS=Homosapiens OX=9606 GN=TTBK2MESGKDHVCRFIGCGRNDRFNYVVMQLQGRNLADLRRSQSRGTFTISTTLRLGRQILESIESIHSVGFLHRDIKPSNFAMGRFPSTCRKCYMLDFGLARQFTNSCGDVRPPRAVAGFRGTVRYASINAHRNREMGRHDDLWSLFYMLVEFVVGQLPWRKIKDKEQVGSIKERYDHRLMLKHLPPEFSIFLDHISSLDYFTKPDYQLLTSVFDNSIKTFGVIESDPFDWEKTGNDGSLTTTTTSTTPQLHTRLTPAAIGIANATPIPGDLLRENTDEVFPDEQLSDGENGIPVGVSPDKLPGSLGHPRPQEKDVWEEMDANKNKIKLGICKAATEEENSHGQANGLLNAPSLGSPIRVRSEITQPDRDIPLVRKLRSIHSFELEKRLTLEPKPDTDKFLETCLEKMQKDTSAGKESILPALLHKPCVPAVSRTDHIWHYDEEYLPDASKPASANTPEQADGGGSNGFIAVNLSSCKQEIDSKEWVIVDKEQDLQDFRTNEAVGHKTTGSPSDEEPEVLQVLEASPQDEKLQLGPWAENDHLKKETSGVVLALSAEGPPTAASEQYTDRLELQPGAASQFIAATPTSLMEAQAEGPLTAITIPRPSVASTQSTSGSFHCGQQPEKKDLQPMEPTVELYSPRENFSGLVVTEGEPPSGGSRTDLGLQIDHIGHDMLPNIRESNKSQDLGPKELPDHNRLVVREFENLPGETEEKSILLESDNEDEKLSRGQHCIEISSLPGDLVIVEKDHSATTEPLDVTKTQTFSVVPNQDKNNEIMKLLTVGTSEISSRDIDPHVEGQIGQVAEMQKNKISKDDDIMSEDLPGHQGDLSTFLHQEGKREKITPRNGELFHCVSENEHGAPTRKDMVRSSFVTRHSRIPVLAQEIDSTLESSSPVSAKEKLLQKKAYQPDLVKLLVEKRQFKSFLGDLSSASDKLLEEKLATVPAPFCEEEVLTPFSRLTVDSHLSRSAEDSFLSPIISQSRKSKIPRPVSWVNTDQVNSSTSSQFFPRPPPGKPPTRPGVEARLRRYKVLGSSNSDSDLFSRLAQILQNGSQKPRSTTQCKSPGSPHNPKTPPKSPVVPRRSPSASPRSSSLPRTSSSSPSRAGRPHHDQRSSSPHLGRSKSPPSHSGSSSSRRSCQQEHCKPSKNGLKGSGSLHHHSASTKTPPREE>sp|Q6IQ55-3|TTBK2_HUMAN Isoform 3 of Tau-tubulin kinase 2 OS=Homosapiens OX=9606 GN=TTBK2MSGGGEQLDILSVGILVKERWKVLRKIGGGGFGEIYDALDMLTRENVALKVESAQQPKQVLKMEVAVLKKLQGKDHVCRFIGCGRNDRFNYVVMQLQGRNLADLRRSQSRGTFTISTTLRLGRQILESIESIHSVGFLHRDIKPSNFAMGRFPSTCRKCYMLDFGLARQFTNSCGDVRPPRAVAGFRGTVRYASINAHRNREMGRHDDLWSLFYMLVEFVVGQLPWRKIKDKEQVGSIKERYDHRLMLKHLPPEFSIFLDHISSLDYFTKPDYQLLTSVFDNSIKTFGVIESDPFDWEKTGNDGSLTTTTTSTTPQLHTRLTPAAIGIANATPIPGDLLRENTDEVFPDEQLSDGENGIPVGVSPDKLPGSLGHPRPQEKDVWEEMDANKNKIKLGICKAATEEENSHGQANGLLNAPSLGSPIRVRSEITQPDRDIPLVRKLRSIHSFELEKRLTLEPKPDTDKFLETWYKIVYFSF>sp|P07996|TSP1_HUMAN Thrombospondin-1 OS=Homo sapiens OX=9606 GN=THBS1PE=1 SV=2MGLAWGLGVLFLMHVCGTNRIPESGGDNSVFDIFELTGAARKGSGRRLVKGPDPSSPAFRIEDANLIPPVPDDKFQDLVDAVRAEKGFLLLASLRQMKKTRGTLLALERKDHSGQVFSVVSNGKAGTLDLSLTVQGKQHVVSVEEALLATGQWKSITLFVQEDRAQLYIDCEKMENAELDVPIQSVFTRDLASIARLRIAKGGVNDNFQGVLQNVRFVFGTTPEDILRNKGCSSSTSVLLTLDNNVVNGSSPAIRTNYIGHKTKDLQAICGISCDELSSMVLELRGLRTIVTTLQDSIRKVTEENKELANELRRPPLCYHNGVQYRNNEEWTVDSCTECHCQNSVTICKKVSCPIMPCSNATVPDGECCPRCWPSDSADDGWSPWSEWTSCSTSCGNGIQQRGRSCDSLNNRCEGSSVQTRTCHIQECDKRFKQDGGWSHWSPWSSCSVTCGDGVITRIRLCNSPSPQMNGKPCEGEARETKACKKDACPINGGWGPWSPWDICSVTCGGGVQKRSRLCNNPTPQFGGKDCVGDVTENQICNKQDCPIDGCLSNPCFAGVKCTSYPDGSWKCGACPPGYSGNGIQCTDVDECKEVPDACFNHNGEHRCENTDPGYNCLPCPPRFTGSQPFGQGVEHATANKQVCKPRNPCTDGTHDCNKNAKCNYLGHYSDPMYRCECKPGYAGNGIICGEDTDLDGWPNENLVCVANATYHCKKDNCPNLPNSGQEDYDKDGIGDACDDDDDNDKIPDDRDNCPFHYNPAQYDYDRDDVGDRCDNCPYNHNPDQADTDNNGEGDACAADIDGDGILNERDNCQYVYNVDQRDTDMDGVGDQCDNCPLEHNPDQLDSDSDRIGDTCDNNQDIDEDGHQNNLDNCPYVPNANQADHDKDGKGDACDHDDDNDGIPDDKDNCRLVPNPDQKDSDGDGRGDACKDDFDHDSVPDIDDICPENVDISETDFRRFQMIPLDPKGTSQNDPNWVVRHQGKELVQTVNCDPGLAVGYDEFNAVDFSGTFFINTERDDDYAGFVFGYQSSSRFYVVMWKQVTQSYWDTNPTRAQGYSGLSVKVVNSTTGPGEHLRNALWHTGNTPGQVRTLWHDPRHIGWKDFTAYRWRLSHRPKTGFIRVVMYEGKKIMADSGPIYDKTYAGGRLGLFVFSQEMVFFSDLKYECRDP>sp|P07996-2|TSP1_HUMAN Isoform 2 of Thrombospondin-1 OS=Homo sapiensOX=9606 GN=THBS1MGLAWGLGVLFLMHVCGTLLALERKDHSGQVFSVVSNGKAGTLDLSLTVQGKQHVVSVEEALLATGQWKSITLFVQEDRAQLYIDCEKMENAELDVPIQSVFTRDLASIARLRIAKGGVNDNFQGVLQNVRFVFGTTPEDILRNKGCSSSTSVLLTLDNNVVNGSSPAIRTNYIGHKTKDLQAICGISCDELSSMVLELRGLRTIVTTLQDSIRKVTEENKELANELRRPPLCYHNGVQYRNNEEWTVDSCTECHCQNSVTICKKVSCPIMPCSNATVPDGECCPRCWPSDSADDGWSPWSEWTSCSTSCGNGIQQRGRSCDSLNNRCEGSSVQTRTCHIQECDKRFKQDGGWSHWSPWSSCSVTCGDGVITRIRLCNSPSPQMNGKPCEGEARETKACKKDACPINGGWGPWSPWDICSVTCGGGVQKRSRLCNNPTPQFGGKDCVGDVTENQICNKQDCPIDGCLSNPCFAGVKCTSYPDGSWKCGACPPGYSGNGIQCTDVDECKEVPDACFNHNGEHRCENTDPGYNCLPCPPRFTGSQPFGQGVEHATANKQVCKPRNPCTDGTHDCNKNAKCNYLGHYSDPMYRCECKPGYAGNGIICGEDTDLDGWPNENLVCVANATYHCKKDNCPNLPNSGQEDYDKDGIGDACDDDDDNDKIPDDRDNCPFHYNPAQYDYDRDDVGDRCDNCPYNHNPDQADTDNNGEGDACAADIDGDGILNERDNCQYVYNVDQRDTDMDGVGDQCDNCPLEHNPDQLDSDSDRIGDTCDNNQDIDEDGHQNNLDNCPYVPNANQADHDKDGKGDACDHDDDNDGIPDDKDNCRLVPNPDQKDSDGDGRGDACKDDFDHDSVPDIDDICPENVDISETDFRRFQMIPLDPKGTSQNDPNWVVRHQGKELVQTVNCDPGLAVGYDEFNAVDFSGTFFINTERDDDYAGFVFGYQSSSRFYVVMWKQVTQSYWDTNPTRAQGYSGLSVKVVNSTTGPGEHLRNALWHTGNTPGQVRTLWHDPRHIGWKDFTAYRWRLSHRPKTGFIRVVMYEGKKIMADSGPIYDKTYAGGRLGLFVFSQEMVFFSDLKYECRDP>sp|Q96S82|UBL7_HUMAN Ubiquitin-like protein 7 OS=Homo sapiens OX=9606GN=UBL7 PE=1 SV=2MSLSDWHLAVKLADQPLTPKSILRLPETELGEYSLGGYSISFLKQLIAGKLQESVPDPELIDLIYCGRKLKDDQTLDFYGIQPGSTVHVLRKSWPEPDQKPEPVDKVAAMREFRVLHTALHSSSSYREAVFKMLSNKESLDQIIVATPGLSSDPIALGVLQDKDLFSVFADPNMLDTLVPAHPALVNAIVLVLHSVAGSAPMPGTDSSSRSMPSSSYRDMPGGFLFEGLSDDEDDFHPNTRSTPSSSTPSSRPASLGYSGAAGPRPITQSELATALALASTPESSSHTPTPGTQGHSSGTSPMSSGVQSGTPITNDLFSQALQHALQASGQPSLQSQWQPQLQQLRDMGIQDDELSLRALQATGGDIQAALELIFAGGAP>sp|Q15631|TSN_HUMAN Translin OS=Homo sapiens OX=9606 GN=TSN PE=1 SV=1MSVSEIFVELQGFLAAEQDIREEIRKVVQSLEQTAREILTLLQGVHQGAGFQDIPKRCLKAREHFGTVKTHLTSLKTKFPAEQYYRFHEHWRFVLQRLVFLAAFVVYLETETLVTREAVTEILGIEPDREKGFHLDVEDYLSGVLILASELSRLSVNSVTAGDYSRPLHISTFINELDSGFRLLNLKNDSLRKRYDGLKYDVKKVEEVVYDLSIRGFNKETAAACVEK>sp|Q15631-2|TSN_HUMAN Isoform 2 of Translin OS=Homo sapiens OX=9606GN=TSNMSVSEIFVELQGFLAAEQDIREEIRKVVQSLEQTAREILTLLQGVHQGAGFQDIPKRCLKAREHFGTVKTHLTSLKTKFPAEQYYRFHEHWRFVLQRLVFLAAFVVYLETETLVTREAVTEILGIEAVCQQRDCWRLLPTPPHLHLHQ>sp|P0DTE5|UD2A2_HUMAN UDP-glucuronosyltransferase 2A2 OS=Homo sapiensOX=9606 GN=UGT2A2 PE=1 SV=1MVSIRDFTMPKKFVQMLVFNLTLTEVVLSGNVLIWPTDGSHWLNIKIILEELIQRNHNVTVLASSATLFINSNPDSPVNFEVIPVSYKKSNIDSLIEHMIMLWIDHRPTPLTIWAFYKELGKLLDTFFQINIQLCDGVLKNPKLMARLQKGGFDVLVADPVTICGDLVALKLGIPFMYTLRFSPASTVERHCGKIPAPVSYVPAALSELTDQMTFGERIKNTISYSLQDYIFQSYWGEWNSYYSKILGRPTTLCETMGKAEIWLIRTYWDFEFPRPYLPNFEFVGGLHCKPAKPLPKEMEEFIQSSGKNGVVVFSLGSMVKNLTEEKANLIASALAQIPQKVLWRYKGKKPATLGNNTQLFDWIPQNDLLGHPKTKAFITHGGTNGIYEAIYHGVPMVGVPMFADQPDNIAHMKAKGAAVEVNLNTMTSVDLLSALRTVINEPSYKENAMRLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVIGFLLVCVTTAIFLVIQCCLFSCQKFGKIGKKKKRE>sp|P0DTE5-2|UD2A2_HUMAN Isoform 2 of UDP-glucuronosyltransferase 2A2OS=Homo sapiens OX=9606 GN=UGT2A2MVSIRDFTMPKKFVQMLVFNLTLTEVVLSGNVLIWPTDGSHWLNIKIILEELIQRNHNVTVLASSATLFINSNPDSPVNFEVIPVSYKKSNIDSLIEHMIMLWIDHRPTPLTIWAFYKELGKLLDTFFQINIQLCDGVLKNPKLMARLQKGGFDVLVADPVTICGDLVALKLGIPFMYTLRFSPASTVERHCGKIPAPVSYVPAALSELTDQMTFGERIKNTISYSLQDYIFQSYWGEWNSYYSKILGRPTTLCETMGKAEIWLIRTYWDFEFPRPYLPNFEFVGGLHCKPAKPLPKVLWRYKGKKPATLGNNTQLFDWIPQNDLLGHPKTKAFITHGGTNGIYEAIYHGVPMVGVPMFADQPDNIAHMKAKGAAVEVNLNTMTSVDLLSALRTVINEPSYKENAMRLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVIGFLLVCVTTAIFLVIQCCLFSCQKFGKIGKKKKRE>sp|A0A0B4J272|TVA24_HUMAN T cell receptor alpha variable 24 OS=Homosapiens OX=9606 GN=TRAV24 PE=1 SV=1MEKNPLAAPLLILWFHLDCVSSILNVEQSPQSLHVQEGDSTNFTCSFPSSNFYALHWYRWETAKSPEALFVMTLNGDEKKKGRISATLNTKEGYSYLYIKGSQPEDSATYLCAF>sp|Q6EMK4|VASN_HUMAN Vasorin OS=Homo sapiens OX=9606 GN=VASN PE=1 SV=1MCSRVPLLLPLLLLLALGPGVQGCPSGCQCSQPQTVFCTARQGTTVPRDVPPDTVGLYVFENGITMLDAGSFAGLPGLQLLDLSQNQIASLPSGVFQPLANLSNLDLTANRLHEITNETFRGLRRLERLYLGKNRIRHIQPGAFDTLDRLLELKLQDNELRALPPLRLPRLLLLDLSHNSLLALEPGILDTANVEALRLAGLGLQQLDEGLFSRLRNLHDLDVSDNQLERVPPVIRGLRGLTRLRLAGNTRIAQLRPEDLAGLAALQELDVSNLSLQALPGDLSGLFPRLRLLAAARNPFNCVCPLSWFGPWVRESHVTLASPEETRCHFPPKNAGRLLLELDYADFGCPATTTTATVPTTRPVVREPTALSSSLAPTWLSPTEPATEAPSPPSTAPPTVGPVPQPQDCPPSTCLNGGTCHLGTRHHLACLCPEGFTGLYCESQMGQGTRPSPTPVTPRPPRSLTLGIEPVSPTSLRVGLQRYLQGSSVQLRSLRLTYRNLSGPDKRLVTLRLPASLAEYTVTQLRPNATYSVCVMPLGPGRVPEGEEACGEAHTPPAVHSNHAPVTQAREGNLPLLIAPALAAVLLAALAAVGAAYCVRRGRAMAAAAQDKGQVGPGAGPLELEGVKVPLEPGPKATEGGGEALPSGSECEVPLMGFPGPGLQSPLHAKPYI>sp|Q2YD98|UVSSA_HUMAN UV-stimulated scaffold protein A OS=Homo sapiensOX=9606 GN=UVSSA PE=1 SV=2MDQKLSKLVEELTTSGEPRLNPEKMKELKKICKSSEEQLSRAYRLLIAQLTQEHAEIRLSAFQIVEELFVRSHQFRMLVVSNFQEFLELTLGTDPAQPLPPPREAAQRLRQATTRAVEGWNEKFGEAYKKLALGYHFLRHNKKVDFQDTNARSLAERKREEEKQKHLDKIYQERASQAEREMQEMSGEIESCLTEVESCFRLLVPFDFDPNPETESLGMASGMSDALRSSCAGQVGPCRSGTPDPRDGEQPCCSRDLPASAGHPRAGGGAQPSQTATGDPSDEDEDSDLEEFVRSHGLGSHKYTLDVELCSEGLKVQENEDNLALIHAARDTLKLIRNKFLPAVCSWIQRFTRVGTHGGCLKRAIDLKAELELVLRKYKELDIEPEGGERRRTEALGDAEEDEDDEDFVEVPEKEGYEPHIPDHLRPEYGLEAAPEKDTVVRCLRTRTRMDEEVSDPTSAAAQLRQLRDHLPPPSSASPSRALPEPQEAQKLAAERARAPVVPYGVDLHYWGQELPTAGKIVKSDSQHRFWKPSEVEEEVVNADISEMLRSRHITFAGKFEPVQHWCRAPRPDGRLCERQDRLKCPFHGKIVPRDDEGRPLDPEDRAREQRRQLQKQERPEWQDPELMRDVEAATGQDLGSSRYSGKGRGKKRRYPSLTNLKAQADTARARIGRKVFAKAAVRRVVAAMNRMDQKKHEKFSNQFNYALN>sp|Q2YD98-2|UVSSA_HUMAN Isoform 2 of UV-stimulated scaffold protein AOS=Homo sapiens OX=9606 GN=UVSSAMDEEVSDPTSAAAQLRQLRDHLPPPSSASPSRALPEPQEAQKLAAERARAPVVPYGVDLHYWGQELPTAGKIVKSDSQHRFWKPSEVEEEVVNADISEMLRSRHITFAGKFEPVQHWCRAPRPDGRLCERQDRLKCPFHGKIVPRDDEGRPLDPEDRAREQRRQLQKQERPEWQDPELMRDVEAATGQDLGSSRYSGKGRGKKRRYPSLTNLKAQADTARARIGRKVFAKAAVRRVVAAMNRMDQKKHEKFSNQFNYALN>sp|P32241|VIPR1_HUMAN Vasoactive intestinal polypeptide receptor 1OS=Homo sapiens OX=9606 GN=VIPR1 PE=1 SV=1MRPPSPLPARWLCVLAGALAWALGPAGGQAARLQEECDYVQMIEVQHKQCLEEAQLENETIGCSKMWDNLTCWPATPRGQVVVLACPLIFKLFSSIQGRNVSRSCTDEGWTHLEPGPYPIACGLDDKAASLDEQQTMFYGSVKTGYTIGYGLSLATLLVATAILSLFRKLHCTRNYIHMHLFISFILRAAAVFIKDLALFDSGESDQCSEGSVGCKAAMVFFQYCVMANFFWLLVEGLYLYTLLAVSFFSERKYFWGYILIGWGVPSTFTMVWTIARIHFEDYGCWDTINSSLWWIIKGPILTSILVNFILFICIIRILLQKLRPPDIRKSDSSPYSRLARSTLLLIPLFGVHYIMFAFFPDNFKPEVKMVFELVVGSFQGFVVAILYCFLNGEVQAELRRKWRRWHLQGVLGWNPKYRHPSGGSNGATCSTQVSMLTRVSPGARRSSSFQAEVSLV>sp|P32241-2|VIPR1_HUMAN Isoform Long of Vasoactive intestinalpolypeptide receptor 1 OS=Homo sapiens OX=9606 GN=VIPR1MPPPPLLSLRRLGGGWSAVTRLVVAAAGARSRGGRGGSRGAGGGGRGGVARRRRLELRAARSLLGSSLQEECDYVQMIEVQHKQCLEEAQLENETIGCSKMWDNLTCWPATPRGQVVVLACPLIFKLFSSIQGRNVSRSCTDEGWTHLEPGPYPIACGLDDKAASLDEQQTMFYGSVKTGYTIGYGLSLATLLVATAILSLFRKLHCTRNYIHMHLFISFILRAAAVFIKDLALFDSGESDQCSEGSVGCKAAMVFFQYCVMANFFWLLVEGLYLYTLLAVSFFSERKYFWGYILIGWGVPSTFTMVWTIARIHFEDYGCWDTINSSLWWIIKGPILTSILVNFILFICIIRILLQKLRPPDIRKSDSSPYSRLARSTLLLIPLFGVHYIMFAFFPDNFKPEVKMVFELVVGSFQGFVVAILYCFLNGEVQAELRRKWRRWHLQGVLGWNPKYRHPSGGSNGATCSTQVSMLTRVSPGARRSSSFQAEVSLV>sp|P32241-3|VIPR1_HUMAN Isoform 3 of Vasoactive intestinal polypeptidereceptor 1 OS=Homo sapiens OX=9606 GN=VIPR1MTRQRVWMRWAVRQPWSFSNIVSWLTSSGCWWRASTCTPCLPSPSSLSGSTSGGVPSTFTMVWTIARIHFEDYGCWDTINSSLWWIIKGPILTSILVNFILFICIIRILLQKLRPPDIRKSDSSPYSRLARSTLLLIPLFGVHYIMFAFFPDNFKPEVKMVFELVVGSFQGFVVAILYCFLNGEVQAELRRKWRRWHLQGVLGWNPKYRHPSGGSNGATCSTQVSMLTRVSPGARRSSSFQAEVSLV>sp|P32241-4|VIPR1_HUMAN Isoform 4 of Vasoactive intestinal polypeptidereceptor 1 OS=Homo sapiens OX=9606 GN=VIPR1MRAGRRPRLGPWAGGCSKMWDNLTCWPATPRGQVVVLACPLIFKLFSSIQGRNVSRSCTDEGWTHLEPGPYPIACGLDDKAASLDEQTMFYGSVKTGYTIGYGLSLATLLVATAILSLFRKLHCTRNYIHMHLFISFILRAAAVFIKDLALFDSGESDQCSEGSVGCKAAMVFFQYCVMANFFWLLVEGLYLYTLLAVSFFSERKYFWGYILIGWGVPSTFTMVWTIARIHFEDYGCWDTINSSLWWIIKGPILTSILVNFILFICIIRILLQKLRPPDIRKSDSSPYSRLARSTLLLIPLFGVHYIMFAFFPDNFKPEVKMVFELVVGSFQGFVVAILYCFLNGEVQAELRRKWRRWHLQGVLGWNPKYRHPSGGSNGATCSTQVSMLTRVSPGARRSSSFQAEVSLV>sp|P32241-5|VIPR1_HUMAN Isoform 5 of Vasoactive intestinal polypeptidereceptor 1 OS=Homo sapiens OX=9606 GN=VIPR1MIEVQHKQCLEEAQLENETIGCSKMWDNLTCWPATPRGQVVVLACPLIFKLFSSIQGRNVSRSCTDEGWTHLEPGPYPIACGLDDKAASLDEQQTMFYGSVKTGYTIGYGLSLATLLVATAILSLFRKLHCTRNYIHMHLFISFILRAAAVFIKDLALFDSGESDQCSEGSVGCKAAMVFFQYCVMANFFWLLVEGLYLYTLLAVSFFSERKYFWGYILIGWGVPSTFTMVWTIARIHFEDYGCWDTINSSLWWIIKGPILTSILVNFILFICIIRILLQKLRPPDIRKSDSSPYSRLARSTLLLIPLFGVHYIMFAFFPDNFKPEVKMVFELVVGSFQGFVVAILYCFLNGEVQAELRRKWRRWHLQGVLGWNPKYRHPSGGSNGATCSTQVSMLTRVSPGARRSSSFQAEVSLV>sp|Q86WZ6|ZN227_HUMAN Zinc finger protein 227 OS=Homo sapiens OX=9606GN=ZNF227 PE=1 SV=1MPSQNYDLPQKKQEKMTKFQEAVTFKDVAVVFSREELRLLDLTQRKLYRDVMVENFKNLVAVGHLPFQPDMVSQLEAEEKLWMMETETQRSSKHQNKMETLQKFALKYLSNQELSCWQIWKQVASELTRCLQGKSSQLLQGDSIQVSENENNIMNPKGDSSIYIENQEFPFWRTQHSCGNTYLSESQIQSRGKQIDVKNNLQIHEDFMKKSPFHEHIKTDTEPKPCKGNEYGKIISDGSNQKLPLGEKPHPCGECGRGFSYSPRLPLHPNVHTGEKCFSQSSHLRTHQRIHPGEKLNRCHESGDCFNKSSFHSYQSNHTGEKSYRCDSCGKGFSSSTGLIIHYRTHTGEKPYKCEECGKCFSQSSNFQCHQRVHTEEKPYKCEECGKGFGWSVNLRVHQRVHRGEKPYKCEECGKGFTQAAHFHIHQRVHTGEKPYKCDVCGKGFSHNSPLICHRRVHTGEKPYKCEACGKGFTRNTDLHIHFRVHTGEKPYKCKECGKGFSQASNLQVHQNVHTGEKRFKCETCGKGFSQSSKLQTHQRVHTGEKPYRCDVCGKDFSYSSNLKLHQVIHTGEKPYKCEECGKGFSWRSNLHAHQRVHSGEKPYKCEQCDKSFSQAIDFRVHQRVHTGEKPYKCGVCGKGFSQSSGLQSHQRVHTGEKPYKCDVCGKGFRYSSQFIYHQRGHTGEKPYKCEECGKGFGRSLNLRHHQRVHTGEKPHICEECGKAFSLPSNLRVHLGVHTREKLFKCEECGKGFSQSARLEAHQRVHTGEKPYKCDICDKDFRHRSRLTYHQKVHTGKKL>sp|Q86WZ6-2|ZN227_HUMAN Isoform 2 of Zinc finger protein 227 OS=Homosapiens OX=9606 GN=ZNF227MVENFKNLVAVGHLPFQPDMVSQLEAEEKLWMMETETQRSSKHQNKMETLQKFALKYLSNQELSCWQIWKQVASELTRCLQGKSSQLLQGDSIQVSENENNIMNPKGDSSIYIENQEFPFWRTQHSCGNTYLSESQIQSRGKQIDVKNNLQIHEDFMKKSPFHEHIKTDTEPKPCKGNEYGKIISDGSNQKLPLGEKPHPCGECGRGFSYSPRLPLHPNVHTGEKCFSQSSHLRTHQRIHPGEKLNRCHESGDCFNKSSFHSYQSNHTGEKSYRCDSCGKGFSSSTGLIIHYRTHTGEKPYKCEECGKCFSQSSNFQCHQRVHTEEKPYKCEECGKGFGWSVNLRVHQRVHRGEKPYKCEECGKGFTQAAHFHIHQRVHTGEKPYKCDVCGKGFSHNSPLICHRRVHTGEKPYKCEACGKGFTRNTDLHIHFRVHTGEKPYKCKECGKGFSQASNLQVHQNVHTGEKRFKCETCGKGFSQSSKLQTHQRVHTGEKPYRCDVCGKDFSYSSNLKLHQVIHTGEKPYKCEECGKGFSWRSNLHAHQRVHSGEKPYKCEQCDKSFSQAIDFRVHQRVHTGEKPYKCGVCGKGFSQSSGLQSHQRVHTGEKPYKCDVCGKGFRYSSQFIYHQRGHTGEKPYKCEECGKGFGRSLNLRHHQRVHTGEKPHICEECGKAFSLPSNLRVHLGVHTREKLFKCEECGKGFSQSARLEAHQRVHTGEKPYKCDICDKDFRHRSRLTYHQKVHTGKKL>sp|C9JLR9|ZFTA_HUMAN Zinc finger translocation-associated proteinOS=Homo sapiens OX=9606 GN=ZFTA PE=1 SV=1MEPGGDHRSRSSGGRGGPGPAVASARGRRLPPAGSSGSAEPEEDEGGQDLQLEGGALGSWGSAPLPSSRARGPASSGRKYSDHCEARASRPGKSRIPGRDHRRYYHDHWRLEYLMDFNPARHGMVCMVCGSSLATLKLSTIKRHIRQKHPYSLHWSPREKEVISNSWDAHLGLGACGEAEGLGVQGAEEEEEEEEEEEEEGAGVPACPPKGPGKAPAGGGCRRQRRGGPVAPRARRLRLSASRRAGGSRGLGARRLERRLKESLQNWFRAECLMDYDPRGNRLVCMACGRALPSLHLDDIRAHVLEVHPGSLGLSGPQRSALLQAWGGQPEALSELTQSPPGDDLAPQDLTGKSRDSASAAGAPSSQDLSPPDVKEEAGWVPERPGPAEEEEELEEGEGERAGVPGRSPRGRAHRRHPQERWRLEYLMELDGGRRGLVCGVCGGALASLKMSTIERHIRRRHPGSTRLGGPVQALIAREWSEKAAHLLALGPPRPESPQGPIPPGTAAASDEGGGDEEEEPEEEEEEWGDVPLSPGAPLERPAEEEEDEEDGQEPGGLALPPPPPPPPPPPPRSREQRRNYQPRWRGEYLMDYDGSRRGLVCMVCGGALATLKVSTIKRHILQVHPFSMDFTPEERQTILEAYEEAALRCYGHEGFGPPAPAPRDGGADLKSGAVCRA>sp|Q6ZMS7|ZN783_HUMAN Protein ZNF783 OS=Homo sapiens OX=9606 GN=ZNF783PE=1 SV=1MAEAAPARDPETDKHTEDQSPSTPLPQPAAEKNSYLYSTEITLWTVVAAIQALEKKVDSCLTRLLTLEGRTGTAEKKLADCEKTAVEFGNQLEGKWAVLGTLLQEYGLLQRRLENVENLLRNRNFWILRLPPGSKGEAPKVPVTFDDVAVYFSELEWGKLEDWQKELYKHVMRGNYETLVSLDYAISKPDILTRIERGEEPCLDRWGQEKGNEVEVGRPRMMGTGLPPYPEHLTSPLSPAQEELKEGQAPKQQQDSEARVAPAGPEAGLALRTDLQGEAQI>sp|Q6ZMS7-2|ZN783_HUMAN Isoform 2 of Protein ZNF783 OS=Homo sapiensOX=9606 GN=ZNF783MAEAAPARDPETDKHTEDQSPSTPLPQPAAEKNSYLYSTEITLWTVVAAIQALEKKVDSCLTRLLTLEGRTGTAEKKLADCEKTAVEFGNQLEGKWAVLGTLLQEYGLLQRRLENVENLLRNRNFWILRLPPGSKGEAPKVPVTFDDVAVYFSELEWGKLEDWQKELYKHVMRGNYETLVSLDYAISKPDILTRIERGEEPCLDRWGQEKGNEVEVGRPRMMGTGLPPYPEHLTSPLSPAQEELKEGQAPKQQQDSEARVAPAGPEAGGGVAIKTEAQSEDEMTPERLFLGVSRGQTECRIPRGPRNRPGGPSRHQAQGMPRVRAGEPRPPGASGETPRVLSRRRQRAFPCPDCGQSFRLKINLTIHQRTHVEEGRQEAPGRSPTSCGDSQAMLEPGEVVVPGPVIRWLPEEPEGRRSVAGGRALVGRRPAASKMYHCSECLRFFQQRKSLLLHQRLHTGNGQGWPACPYCGKAFRRPSDLFRHQRIHTGERPYQCPQCGRTFNRNHHLAVHMQTHARGQVGPHFPAAPARHGSLPLPWPSRKEEG>sp|P17024|ZNF20_HUMAN Zinc finger protein 20 OS=Homo sapiens OX=9606GN=ZNF20 PE=1 SV=2MMFQDSVAFEDVAVSFTQEEWALLDPSQKNLYRDVMQETFKNLTSVGKTWKVQNIEDEYKNPRRNLSLMREKLCESKESHHCGESFNQIADDMLNRKTLPGITPCESSVCGEVGTGHSSLNTHIRADTGHKSSEYQEYGENPYRNKECKKAFSYLDSFQSHDKACTKEKPYDGKECTETFISHSCIQRHRVMHSGDGPYKCKFCGKAFYFLNLCLIHERIHTGVKPYKCKQCGKAFTRSTTLPVHERTHTGVNADECKECGNAFSFPSEIRRHKRSHTGEKPYECKQCGKVFISFSSIQYHKMTHTGEKPYECKQCGKAFRCGSHLQKHGRTHTGEKPYECRQCGKAFRCTSDLQRHEKTHTEDKPYGCKQCGKGFRCASQLQIHERTHSGEKPHECKECGKVFKYFSSLRIHERTHTGEKPHECKQCGKAFRYFSSLHIHERTHTGDKPYECKVCGKAFTCSSSIRYHERTHTGEKPYECKHCGKAFISNYIRYHERTHTGEKPYQCKQCGKAFIRASSCREHERTHTINR>sp|Q49A33|Z876P_HUMAN Putative zinc finger protein 876 OS=Homo sapiensOX=9606 GN=ZNF876P PE=5 SV=3MHTGEKPYTCEECVKLLTNPQALLYTGAFILNKNFTNVKNAAKPLLNPHPLINKRIHTGEKPYTCEECGKAFYRSSHLTEHKNIHTGEKSYKCEECGNAFYRSSHLTKHKRIHSGQKPYKCEECGKAFRQSSALNEHKKIHTAEKPYKCKECGKAFRWSRSLNEHTNIHIGEKPYTCEECGKDFTWSSTLTVHQRIQTGEKHS>sp|Q8N3Z6|ZCHC7_HUMAN Zinc finger CCHC domain-containing protein 7OS=Homo sapiens OX=9606 GN=ZCCHC7 PE=1 SV=2MMFGGYETIEAYEDDLYRDESSSELSVDSEVEFQLYSQIHYAQDLDDVIREEEHEEKNSGNSESSSSKPNQKKLIVLSDSEVIQLSDGSEVITLSDEDSIYRCKGKNVRVQAQENAHGLSSSLQSNELVDKKCKSDIEKPKSEERSGVIREVMIIEVSSSEEEESTISEGDNVESWMLLGCEVDDKDDDILLNLVGCENSVTEGEDGINWSISDKDIEAQIANNRTPGRWTQRYYSANKNIICRNCDKRGHLSKNCPLPRKVRRCFLCSRRGHLLYSCPAPLCEYCPVPKMLDHSCLFRHSWDKQCDRCHMLGHYTDACTEIWRQYHLTTKPGPPKKPKTPSRPSALAYCYHCAQKGHYGHECPEREVYDPSPVSPFICYYDDKYEIQEREKRLKQKIKVLKKNGVIPEPSKLPYIKAANENPHHDIRKGRASWKSNRWPQENKETQKEMKNKNRNWEKHRKADRHREVDEDFPRGPKTYSSPGSFKTQKPSKPFHRSSHYHTSREDKSPKEGKRGKQKKKERCWEDDDNDNLFLIKQRKKKS>sp|Q8N3Z6-2|ZCHC7_HUMAN Isoform 2 of Zinc finger CCHC domain-containingprotein 7 OS=Homo sapiens OX=9606 GN=ZCCHC7MMFGGYETIEAYEDDLYRDESSSELSVDSEVEFQLYSQIHYAQDLDDVIREEEHEEKNSGNSESSSSKPNQKKLIVLSDSEVIQLSDGSEVITLSDEDSIYRCKGKNVRVQAQENAHGLSSSLQSNELVDKKCKSDIEKPKSEERSGVIREVMIIEVSSSEEEESTISEGDNVESWMLLGCEVDDKDDDILLNLVGCENSVTEGQE>sp|Q6P9A3|ZN549_HUMAN Zinc finger protein 549 OS=Homo sapiens OX=9606GN=ZNF549 PE=1 SV=2MAEAALVITPQIPMVTEEFVKPSQGHVTFEDIAVYFSQEEWGLLDEAQRCLYHDVMLENFSLMASVGCLHGIEAEEAPSEQTLSAQGVSQARTPKLGPSIPNAHSCEMCILVMKDILYLSEHQGTLPWQKPYTSVASGKWFSFGSNLQQHQNQDSGEKHIRKEESSALLLNSCKIPLSDNLFPCKDVEKDFPTILGLLQHQTTHSRQEYAHRSRETFQQRRYKCEQVFNEKVHVTEHQRVHTGEKAYKRREYGKSLNSKYLFVEHQRTHNAEKPYVCNICGKSFLHKQTLVGHQQRIHTRERSYVCIECGKSLSSKYSLVEHQRTHNGEKPYVCNVCGKSFRHKQTFVGHQQRIHTGERPYVCMECGKSFIHSYDRIRHQRVHTGEGAYQCSECGKSFIYKQSLLDHHRIHTGERPYECKECGKAFIHKKRLLEHQRIHTGEKPYVCIICGKSFIRSSDYMRHQRIHTGERAYECSDCGKAFISKQTLLKHHKIHTRERPYECSECGKGFYLEVKLLQHQRIHTREQLCECNECGKVFSHQKRLLEHQKVHTGEKPCECSECGKCFRHRTSLIQHQKVHSGERPYNCTACEKAFIYKNKLVEHQRIHTGEKPYECGKCGKAFNKRYSLVRHQKVHITEEP>sp|Q6P9A3-2|ZN549_HUMAN Isoform 2 of Zinc finger protein 549 OS=Homosapiens OX=9606 GN=ZNF549MAEAALVITPQGHVTFEDIAVYFSQEEWGLLDEAQRCLYHDVMLENFSLMASVGCLHGIEAEEAPSEQTLSAQGVSQARTPKLGPSIPNAHSCEMCILVMKDILYLSEHQGTLPWQKPYTSVASGKWFSFGSNLQQHQNQDSGEKHIRKEESSALLLNSCKIPLSDNLFPCKDVEKDFPTILGLLQHQTTHSRQEYAHRSRETFQQRRYKCEQVFNEKVHVTEHQRVHTGEKAYKRREYGKSLNSKYLFVEHQRTHNAEKPYVCNICGKSFLHKQTLVGHQQRIHTRERSYVCIECGKSLSSKYSLVEHQRTHNGEKPYVCNVCGKSFRHKQTFVGHQQRIHTGERPYVCMECGKSFIHSYDRIRHQRVHTGEGAYQCSECGKSFIYKQSLLDHHRIHTGERPYECKECGKAFIHKKRLLEHQRIHTGEKPYVCIICGKSFIRSSDYMRHQRIHTGERAYECSDCGKAFISKQTLLKHHKIHTRERPYECSECGKGFYLEVKLLQHQRIHTREQLCECNECGKVFSHQKRLLEHQKVHTGEKPCECSECGKCFRHRTSLIQHQKVHSGERPYNCTACEKAFIYKNKLVEHQRIHTGEKPYECGKCGKAFNKRYSLVRHQKVHITEEP>sp|Q7RTV3|ZN367_HUMAN Zinc finger protein 367 OS=Homo sapiens OX=9606GN=ZNF367 PE=1 SV=1MIRGFEAPMAENPPPPPPPVIFCHDSPKRVLVSVIRTTPIKPTCGGGGEPEPPPPLIPTSPGFSDFMVYPWRWGENAHNVTLSPGAAGAAASAALPAAAAAEHSGLRGRGAPPPAASASAAASGGEDEEEASSPDSGHLKDGIRRGRPRADTVRDLINEGEHSSSRIRCNICNRVFPREKSLQAHKRTHTGERPYLCDYPDCGKAFVQSGQLKTHQRLHTGEKPFVCSENGCLSRFTHANRHCPKHPYARLKREEPTDTLSKHQAADNKAAAEWLARYWEMREQRTPTLKGKLVQKADQEQQDPLEYLQSDEEDDEKRGAQRRLQEQRERLHGALALIELANLTGAPLRQ>sp|Q7RTV3-2|ZN367_HUMAN Isoform 2 of Zinc finger protein 367 OS=Homosapiens OX=9606 GN=ZNF367MIRGFEAPMAENPPPPPPPVIFCHDSPKRVLVSVIRTTPIKPTCGGGGEPEPPPPLIPTSPGFSDFMVYPWRWGENAHNVTLSPGAAGAAASAALPAAAAAEHSGLRGRGAPPPAASASAAASGGEDEEEASSPDSGHLKDGIRRGRPRADTVRDLINEGEHSSSRIRCNICNRVFPREKSLQAHKRTHTGERPYLCDYPDCGKAFVQSGQLKTHQRLHTGEKPFVCSENGCLSRFTHANRHCPKHPYARLKREEPTDTLSKHQAADNKAAAEWLARSGMLPLVHREDAQRGLGLCQGPGHASHFK>sp|Q96IQ9|ZN414_HUMAN Zinc finger protein 414 OS=Homo sapiens OX=9606GN=ZNF414 PE=1 SV=2MEEKPSGPIPDMLATAEPSSSETDKEVLSPAVPAAAPSSSMSEEPGPEQAATPPVWERGGAGGMQQGSSPAPDSCQPGPGPSPGLTSIVSGTSEDLRPPRRRPPPGKQIPCSSPGCCLSFPSVRDLAQHLRTHCPPTQSLEGKLFRCSALSCTETFPSMQELVAHSKLHYKPNRYFKCENCLLRFRTHRSLFKHLHVCAEHAQSPAPPPPPALDREPPAPERPPEVDPASAPGLPFPLLEPFTTPAPAPTGPFLPYLNPAPFGLSPPRLRPFLAAAPGPPASSAAVWKKSQGAGSSPRRPQGGSDAPSGACR>sp|Q96IQ9-2|ZN414_HUMAN Isoform 2 of Zinc finger protein 414 OS=Homosapiens OX=9606 GN=ZNF414MEEKPSGPIPDMLATAEPSSSETDKEVLSPAVPAAAPSSSMSEEPGPEQAATPPVWERGGAGGMQQGSSPAPDSCQPGPGPSPGLTSIVSGTSEDLRPPRRRPPPGKQIPCSSPGCCLSFPSVRDLAQHLRTHCPPTQSLEGKLFRCSALSCTETFPSMQELVAHSKLHYKPNRYFKCENCLLRFRTHRSLFKHLHVCAEHAQSPAPPPPPALDREPPAPERPPEVDPASAPGLPFPLLEPFTTPAPAPTGPFLPYLNPAPFGLSPPRLRPFLAAAPGPPASSAAVWKKSQGAGSSPRRPQGGSDAPSGHAAPSRIVWEHTRGRYSCMQCAFSTASRPAMTLHLEDHRPGAPAAPAAGPPRPDAPADPAPLAPKVSPLLSEGELPVFSQL>sp|Q8NE65|ZN738_HUMAN Protein ZNF738 OS=Homo sapiens OX=9606 GN=ZNF738PE=2 SV=1MDDLRYGVYPVKGASGYPGAERNLLEYSYFEKGPLTFRDVVIEFSQEEWQCLDTAQQDLYRKVMLENFRNLVFLGIDVSKPDLITCLEQGKDPWNMKRHSMVATPPESGVLKFPTIIILLSRCFFQSVNICFIYLEP>sp|P17021|ZNF17_HUMAN Zinc finger protein 17 OS=Homo sapiens OX=9606GN=ZNF17 PE=1 SV=3MNLTEDYMVFEDVAIHFSQEEWGILNDVQRHLHSDVMLENFALLSSVGCWHGAKDEEAPSKQCVSVGVSQVTTLKPALSTQKAQPCETCSSLLKDILHLAEHDGTHPKRTAKLYLHQKEHLREKLTRSDEGRPSFVNDSVHLAKRNLTCMQGGKDFTGDSDLQQQALHSGWKPHRDTHGVEAFQSGQNNYSCTQCGKDFCHQHTLFEHQKIHTEERPYECSECGKLFRYNSDLIKHQRNHTGERPYKCSECGKAFSLKYNVVQHQKIHTGERPYECSECGKAFLRKSHLLQHQRIHTRPRPYVCSECGKAFLTQAHLVGHQKIHTGERPYGCNECGKYFMYSSALIRHQKVHTGERPFYCCECGKFFMDSCTLIIHQRVHTGEKPYECNECGKFFRYRSTLIRHQKVHTGEKPYECSECGKFFMDTSTLIIHQRVHTGEKPYECNKCGKFFRYCFTLNRHQRVHSGERPYECSECGKFFVDSCTLKSHQRVHTGERPFECSICGKSFRCRSTLDTHQRIHTGERPYECSECGKFFRHNSNHIRHRRNHFGERSFECTECGRVFSQNSHLIRHQKVHTRERTYKCSKCGKFFMDSSTLISHERVHTGEKPYECSECGKVFRYNSSLIKHRRIHTGERPYQCSECGRVFNQNSHLIQHQKVHTR>sp|P17021-2|ZNF17_HUMAN Isoform 2 of Zinc finger protein 17 OS=Homosapiens OX=9606 GN=ZNF17MLMDAGQDYMVFEDVAIHFSQEEWGILNDVQRHLHSDVMLENFALLSSVGCWHGAKDEEAPSKQCVSVGVSQVTTLKPALSTQKAQPCETCSSLLKDILHLAEHDGTHPKRTAKLYLHQKEHLREKLTRSDEGRPSFVNDSVHLAKRNLTCMQGGKDFTGDSDLQQQALHSGWKPHRDTHGVEAFQSGQNNYSCTQCGKDFCHQHTLFEHQKIHTEERPYECSECGKLFRYNSDLIKHQRNHTGERPYKCSECGKAFSLKYNVVQHQKIHTGERPYECSECGKAFLRKSHLLQHQRIHTRPRPYVCSECGKAFLTQAHLVGHQKIHTGERPYGCNECGKYFMYSSALIRHQKVHTGERPFYCCECGKFFMDSCTLIIHQRVHTGEKPYECNECGKFFRYRSTLIRHQKVHTGEKPYECSECGKFFMDTSTLIIHQRVHTGEKPYECNKCGKFFRYCFTLNRHQRVHSGERPYECSECGKFFVDSCTLKSHQRVHTGERPFECSICGKSFRCRSTLDTHQRIHTGERPYECSECGKFFRHNSNHIRHRRNHFGERSFECTECGRVFSQNSHLIRHQKVHTRERTYKCSKCGKFFMDSSTLISHERVHTGEKPYECSECGKVFRYNSSLIKHRRIHTGERPYQCSECGRVFNQNSHLIQHQKVHTR>sp|P17021-3|ZNF17_HUMAN Isoform 3 of Zinc finger protein 17 OS=Homosapiens OX=9606 GN=ZNF17MGLPLPSKVIMHFMSISVLGCWHGAKDEEAPSKQCVSVGVSQVTTLKPALSTQKAQPCETCSSLLKDILHLAEHDGTHPKRTAKLYLHQKEHLREKLTRSDEGRPSFVNDSVHLAKRNLTCMQGGKDFTGDSDLQQQALHSGWKPHRDTHGVEAFQSGQNNYSCTQCGKDFCHQHTLFEHQKIHTEERPYECSECGKLFRYNSDLIKHQRNHTGERPYKCSECGKAFSLKYNVVQHQKIHTGERPYECSECGKAFLRKSHLLQHQRIHTRPRPYVCSECGKAFLTQAHLVGHQKIHTGERPYGCNECGKYFMYSSALIRHQKVHTGERPFYCCECGKFFMDSCTLIIHQRVHTGEKPYECNECGKFFRYRSTLIRHQKVHTGEKPYECSECGKFFMDTSTLIIHQRVHTGEKPYECNKCGKFFRYCFTLNRHQRVHSGERPYECSECGKFFVDSCTLKSHQRVHTGERPFECSICGKSFRCRSTLDTHQRIHTGERPYECSECGKFFRHNSNHIRHRRNHFGERSFECTECGRVFSQNSHLIRHQKVHTRERTYKCSKCGKFFMDSSTLISHERVHTGEKPYECSECGKVFRYNSSLIKHRRIHTGERPYQCSECGRVFNQNSHLIQHQKVHTR>sp|P52737|ZN136_HUMAN Zinc finger protein 136 OS=Homo sapiens OX=9606GN=ZNF136 PE=1 SV=1MDSVAFEDVDVNFTQEEWALLDPSQKNLYRDVMWETMRNLASIGKKWKDQNIKDHYKHRGRNLRSHMLERLYQTKDGSQRGGIFSQFANQNLSKKIPGVKLCESIVYGEVSMGQSSLNRHIKDHSGHEPKEYQEYGEKPDTRNQCWKPFSSHHSFRTHEIIHTGEKLYDCKECGKTFFSLKRIRRHIITHSGYTPYKCKVCGKAFDYPSRFRTHERSHTGEKPYECQECGKAFTCITSVRRHMIKHTGDGPYKCKVCGKPFHSLSSFQVHERIHTGEKPFKCKQCGKAFSCSPTLRIHERTHTGEKPYECKQCGKAFSYLPSLRLHERIHTGEKPFVCKQCGKAFRSASTFQIHERTHTGEKPYECKECGEAFSCIPSMRRHMIKHTGEGPYKCKVCGKPFHSLSPFRIHERTHTGEKPYVCKHCGKAFVSSTSIRIHERTHTGEKPYECKQCGKAFSYLNSFRTHEMIHTGEKPFECKRCGKAFRSSSSFRLHERTHTGQKPYHCKECGKAYSCRASFQRHMLTHAEDGPPYKCMWESL>sp|Q96SK3|ZN607_HUMAN Zinc finger protein 607 OS=Homo sapiens OX=9606GN=ZNF607 PE=1 SV=3MSYGSITFGDVAIDFSHQEWEYLSLVQKTLYQEVMMENYDNLVSLAGHSVSKPDLITLLEQGKEPWMIVREETRGECTDLDSRCEIISDGKMQLYRKHSCVTLHQRIHNGQKPYECKQCQKSFSHLTELMVHQTIHTSEEPDQCEKFRKAFSHLTDLRKHQKINAREKPYECEECGKVFSYPANLAQHGKVHVEKPYECKECGEAFRTSRQLTVHHRFHYGEKPYECKECGKAFSVYGRLSRHQSIHTGEKPFECNKCGKSFRLKAGLKVHQSIHTGEKPHECKECGKAFRQFSHLVGHKRIHTGEKPYECKECGKGFTCRYQLTMHQRIYSGEKHYECKENGEAFSSGHQLTAPHTFESVEKPYKCEECGKAFSVHGRLTRHQGIHSGKKPYECNKCGKSFRLNSSLKIHQNIHTGEKPYKCKECGKAFSQRAHLAHHNRIHTGYKPFECKECGKSFRCASYLVIHERIHTGEKPYVCQECGKGFSYSHKLTIHRRVHTGEKPYECKECGKAFSVSGQLTQHLSIHSGKKPFECNKCGKSFRFISVLKAHQNIHSAEKPYECKECGKAFRHATSLIYHDRTHAGEKSYECKECGETFSHASHLIIHERIHTSDKPYECKRCGKAFHCASYLVRHESVHADGNPYMCEECGKAFNSSHELSIHHRVHTGEKPFKCNKCRRSFRLRSILEVHQRIHI>sp|Q96SK3-2|ZN607_HUMAN Isoform 2 of Zinc finger protein 607 OS=Homosapiens OX=9606 GN=ZNF607MHQRIYSGEKHYECKENGEAFSSGHQLTAPHTFESVEKPYKCEECGKAFSVHGRLTRHQGIHSGKKPYECNKCGKSFRLNSSLKIHQNIHTGEKPYKCKECGKAFSQRAHLAHHNRIHTGYKPFECKECGKSFRCASYLVIHERIHTGEKPYVCQECGKGFSYSHKLTIHRRVHTGEKPYECKECGKAFSVSGQLTQHLSIHSGKKPFECNKCGKSFRFISVLKAHQNIHSAEKPYECKECGKAFRHATSLIYHDRTHAGEKSYECKECGETFSHASHLIIHERIHTSDKPYECKRCGKAFHCASYLVRHESVHADGNPYMCEECGKAFNSSHELSIHHRVHTGEKPFKCNKCRRSFRLRSILEVHQRIHI>sp|Q96SK3-3|ZN607_HUMAN Isoform 3 of Zinc finger protein 607 OS=Homosapiens OX=9606 GN=ZNF607MSYGSITFGDVAIDFSHQEWEYLSLVQKTLYQEVMMENYDNLVSLGHSVSKPDLITLLEQGKEPWMIVREETRGECTDLDSRCEIISDGKMQLYRKHSCVTLHQRIHNGQKPYECKQCQKSFSHLTELMVHQTIHTSEEPDQCEKFRKAFSHLTDLRKHQKINAREKPYECEECGKVFSYPANLAQHGKVHVEKPYECKECGEAFRTSRQLTVHHRFHYGEKPYECKECGKAFSVYGRLSRHQSIHTGEKPFECNKCGKSFRLKAGLKVHQSIHTGEKPHECKECGKAFRQFSHLVGHKRIHTGEKPYECKECGKGFTCRYQLTMHQRIYSGEKHYECKENGEAFSSGHQLTAPHTFESVEKPYKCEECGKAFSVHGRLTRHQGIHSGKKPYECNKCGKSFRLNSSLKIHQNIHTGEKPYKCKECGKAFSQRAHLAHHNRIHTGYKPFECKECGKSFRCASYLVIHERIHTGEKPYVCQECGKGFSYSHKLTIHRRVHTGEKPYECKECGKAFSVSGQLTQHLSIHSGKKPFECNKCGKSFRFISVLKAHQNIHSAEKPYECKECGKAFRHATSLIYHDRTHAGEKSYECKECGETFSHASHLIIHERIHTSDKPYECKRCGKAFHCASYLVRHESVHADGNPYMCEECGKAFNSSHELSIHHRVHTGEKPFKCNKCRRSFRLRSILEVHQRIHI>sp|Q8IZM8|ZN654_HUMAN Zinc finger protein 654 OS=Homo sapiens OX=9606GN=ZNF654 PE=2 SV=4MAEEESDQEAERLGEELVAIVESPLGPVGLRAAGDGRGGAGSGNCGGGVGISSRDYCRRFCQVVEDYAGRWQVPLPQLQVLQTALCCFTTASASFPDECEHVQYVLSSLAVSFFELLLFFGRDEFYEEPLKDILGSFQECQNHLRRYGNVNLELVTRIIRDGGPWEDPVLQAVLKAQPASQEIVNKYLSSENPLFFELRARYLIACERIPEAMALIKSCINHPEISKDLYFHQALFTCLFMSPVEDQLFREHLLKTDCKSGIDIICNAEKEGKTMLALQLCESFLIPQLQNGDMYCIWELIFIWSKLQLKSNPSKQVFVDQCYQLLRTATNVRVIFPFMKIIKDEVEEEGLQICVEICGCALQLDLHDDPKTKCLIYKTIAHFLPNDLEILRICALSIFFLERSLEAYRTVEELYKRPDEEYNEGTSSVQNRVRFELLPILKKGLFFDPEFWNFVMIKKNCVALLSDKSAVRFLNESTLENNAGNLKRTEEQQGLDEGFDSLTDQSTGETDPDDVSGVQPKGHINTKKNLTALSTSKVDHNVPRHRCMLCNKEFLGGHIVRHAQAHQKKGSFACVICGRKFRNRGLMQKHLKNHVKKIQRQQIAAAQQDDQEVTALEEINCSSSSISFENGNSDSKDLEVETLTASSEGNKEVIPEHVAEFIEIPISVPEDVIENVIENGSPNNSLNNVFKPLTECGDDYEEEEDEEGDYEEDDYDLNQETSVIHKINGTVCHPKDIYATDQEGNFKCPALGCVRIFKRIGFLNKHAMTVHPTDLNVRQTVMKWSKGKCKFCQRQFEDSQHFIDHLNRHSYPNVYFCLHFNCNESFKLPFQLAQHTKSHRIFQAQCSFPECHELFEDLPLLYEHEAQHYLSKTPESSAQPSETILWDVQTDSNPNQEKDSSSNEKQTISLPVSTSKSRKESTEPKTCIESMEKKTDSLVQNGNERSDDTVSNISLIDQKMPDIEPNSENNCSSSDIVNGHSEIEQTPLVSSDPALKIDTNRIRTENGSILPSVVPQEHNTLPVSQAPSKPNLTSEHTSYGLILTKPYVRPLPPSYLDERYLSMPKRRKFLTDRVDACSDQDNVYKKSVKRLRCGKCLTTYCNAEALEAHLAQKKCQTLFGFDSDDESA>sp|Q9HD43|PTPRH_HUMAN Receptor-type tyrosine-protein phosphatase HOS=Homo sapiens OX=9606 GN=PTPRH PE=1 SV=4MAGAGGGLGVWGNLVLLGLCSWTGARAPAPNPGRNLTVETQTTSSISLSWEVPDGLDSQNSNYWVQCTGDGGTTETRNTTATNVTVDGLGPGSLYTCSVWVEKDGVNSSVGTVTTATAPNPVRNLRVEAQTNSSIALTWEVPDGPDPQNSTYGVEYTGDGGRAGTRSTAHTNITVDGLEPGCLYAFSMWVGKNGINSSRETRNATTAHNPVRNLRVEAQTTSSISLSWEVPDGTDPQNSTYCVQCTGDGGRTETRNTTDTRVTVDGLGPGSLYTCSVWVEKDGVNSSVEIVTSATAPNPVRNLTVEAQTNSSIALTWEVPDGPDPQNSTYGVEYTGDGGRAGTRSTAHTNITVDRLEPGCLYVFSVWVGKNGINSSRETRNATTAPNPVRNLHMETQTNSSIALCWEVPDGPYPQDYTYWVEYTGDGGGTETRNTTNTSVTAERLEPGTLYTFSVWAEKNGARGSRQNVSISTVPNAVTSLSKQDWTNSTIALRWTAPQGPGQSSYSYWVSWVREGMTDPRTQSTSGTDITLKELEAGSLYHLTVWAERNEVRGYNSTLTAATAPNEVTDLQNETQTKNSVMLWWKAPGDPHSQLYVYWVQWASKGHPRRGQDPQANWVNQTSRTNETWYKVEALEPGTLYNFTVWAERNDVASSTQSLCASTYPDTVTITSCVSTSAGYGVNLIWSCPQGGYEAFELEVGGQRGSQDRSSCGEAVSVLGLGPARSYPATITTIWDGMKVVSHSVVCHTESAGVIAGAFVGILLFLILVGLLIFFLKRRNKKKQQKPELRDLVFSSPGDIPAEDFADHVRKNERDSNCGFADEYQQLSLVGHSQSQMVASASENNAKNRYRNVLPYDWSRVPLKPIHEEPGSDYINASFMPGLWSPQEFIATQGPLPQTVGDFWRLVWEQQSHTLVMLTNCMEAGRVKCEHYWPLDSQPCTHGHLRVTLVGEEVMENWTVRELLLLQVEEQKTLSVRQFHYQAWPDHGVPSSPDTLLAFWRMLRQWLDQTMEGGPPIVHCSAGVGRTGTLIALDVLLRQLQSEGLLGPFSFVRKMRESRPLMVQTEAQYVFLHQCILRFLQQSAQAPAEKEVPYEDVENLIYENVAAIQAHKLEV>sp|Q9HD43-2|PTPRH_HUMAN Isoform 2 of Receptor-type tyrosine-proteinphosphatase H OS=Homo sapiens OX=9606 GN=PTPRHMAGAGGGLGVWGNLVLLGLCSWTGARAPAPNPGRNLTVETQTTSSISLSWEVPDGLDSQNSNYWVQCTGDGGTTETRNTTATNVTVDGLGPGSLYTCSVWVEKDGVNSSVEIVTSATAPNPVRNLTVEAQTNSSIALTWEVPDGPDPQNSTYGVEYTGDGGRAGTRSTAHTNITVDRLEPGCLYVFSVWVGKNGINSSRETRNATTAPNPVRNLHMETQTNSSIALCWEVPDGPYPQDYTYWVEYTGDGGGTETRNTTNTSVTAERLEPGTLYTFSVWAEKNGARGSRQNVSISTVPNAVTSLSKQDWTNSTIALRWTAPQGPGQSSYSYWVSWVREGMTDPRTQSTSGTDITLKELEAGSLYHLTVWAERNEVRGYNSTLTAATAPNEVTDLQNETQTKNSVMLWWKAPGDPHSQLYVYWVQWASKGHPRRGQDPQANWVNQTSRTNETWYKVEALEPGTLYNFTVWAERNDVASSTQSLCASTYPDTVTITSCVSTSAGYGVNLIWSCPQGGYEAFELEVGGQRGSQDRSSCGEAVSVLGLGPARSYPATITTIWDGMKVVSHSVVCHTESAGVIAGAFVGILLFLILVGLLIFFLKRRNKKKQQKPELRDLVFSSPGDIPAEDFADHVRKNERDSNCGFADEYQQLSLVGHSQSQMVASASENNAKNRYRNVLPYDWSRVPLKPIHEEPGSDYINASFMPGLWSPQEFIATQGPLPQTVGDFWRLVWEQQSHTLVMLTNCMEAGRVKCEHYWPLDSQPCTHGHLRVTLVGEEVMENWTVRELLLLQVEEQKTLSVRQFHYQAWPDHGVPSSPDTLLAFWRMLRQWLDQTMEGGPPIVHCSAGVGRTGTLIALDVLLRQLQSEGLLGPFSFVRKMRESRPLMVQTEAQYVFLHQCILRFLQQSAQAPAEKEVPYEDVENLIYENVAAIQAHKLEV>sp|Q9HD43-3|PTPRH_HUMAN Isoform 3 of Receptor-type tyrosine-proteinphosphatase H OS=Homo sapiens OX=9606 GN=PTPRHMAGAGGGLGVWGNLVLLGLCSWTGARAPAPNPGRNLTVETQTTSSISLSWEVPDGLDSQNSNYWVQCTGDGGTTETRNTTATNVTVDGLGPGSLYTCSVWVEKDGVNSSVGTVTTATAPNPVRNLTVEAQTNSSIALTWEVPDGPDPQNSTYGVEYTGDGGRAGTRSTAHTNITVDRLEPGCLYVFSVWVGKNGINSSRETRNATTAPNPVRNLHMETQTNSSIALCWEVPDGPYPQDYTYWVEYTGDGGGTETRNTTNTSVTAERLEPGTLYTFSVWAEKNGARGSRQNVSISTVPNAVTSLSKQDWTNSTIALRWTAPQGPGQSSYSYWVSWVREGMTDPRTQSTSGTDITLKELEAGSLYHLTVWAERNEVRGYNSTLTAATAPNEVTDLQNETQTKNSVMLWWKAPGDPHSQLYVYWVQWASKGHPRRGQDPQANWVNQTSRTNETWYKVEALEPGTLYNFTVWAERNDVASSTQSLCASTYPDTVTITSCVSTSAGYGVNLIWSCPQGGYEAFELEVGGQRGSQDRSSCGEAVSVLGLGPARSYPATITTIWDGMKVVSHSVVCHTESAGVIAGAFVGILLFLILVGLLIFFLKRRNKKKQQKPELRDLVFSSPGDIPAEDFADHVRKNERDSNCGFADEYQQLSLVGHSQSQMVASASENNAKNRYRNVLPYDWSRVPLKPIHEEPGSDYINASFMPGLWSPQEFIATQGPLPQTVGDFWRLVWEQQSHTLVMLTNCMEAGRVKCEHYWPLDSQPCTHGHLRVTLVGEEVMENWTVRELLLLQVEEQKTLSVRQFHYQAWPDHGVPSSPDTLLAFWRMLRQWLDQTMEGGPPIVHCSAGVGRTGTLIALDVLLRQLQSEGLLGPFSFVRKMRESRPLMVQTEAQYVFLHQCILRFLQQSAQAPAEKEVPYEDVENLIYENVAAIQAHKLEV>sp|P11217|PYGM_HUMAN Glycogen phosphorylase, muscle form OS=Homo sapiensOX=9606 GN=PYGM PE=1 SV=6MSRPLSDQEKRKQISVRGLAGVENVTELKKNFNRHLHFTLVKDRNVATPRDYYFALAHTVRDHLVGRWIRTQQHYYEKDPKRIYYLSLEFYMGRTLQNTMVNLALENACDEATYQLGLDMEELEEIEEDAGLGNGGLGRLAACFLDSMATLGLAAYGYGIRYEFGIFNQKISGGWQMEEADDWLRYGNPWEKARPEFTLPVHFYGHVEHTSQGAKWVDTQVVLAMPYDTPVPGYRNNVVNTMRLWSAKAPNDFNLKDFNVGGYIQAVLDRNLAENISRVLYPNDNFFEGKELRLKQEYFVVAATLQDIIRRFKSSKFGCRDPVRTNFDAFPDKVAIQLNDTHPSLAIPELMRILVDLERMDWDKAWDVTVRTCAYTNHTVLPEALERWPVHLLETLLPRHLQIIYEINQRFLNRVAAAFPGDVDRLRRMSLVEEGAVKRINMAHLCIAGSHAVNGVARIHSEILKKTIFKDFYELEPHKFQNKTNGITPRRWLVLCNPGLAEVIAERIGEDFISDLDQLRKLLSFVDDEAFIRDVAKVKQENKLKFAAYLEREYKVHINPNSLFDIQVKRIHEYKRQLLNCLHVITLYNRIKREPNKFFVPRTVMIGGKAAPGYHMAKMIIRLVTAIGDVVNHDPAVGDRLRVIFLENYRVSLAEKVIPAADLSEQISTAGTEASGTGNMKFMLNGALTIGTMDGANVEMAEEAGEENFFIFGMRVEDVDKLDQRGYNAQEYYDRIPELRQVIEQLSSGFFSPKQPDLFKDIVNMLMHHDRFKVFADYEDYIKCQEKVSALYKNPREWTRMVIRNIATSGKFSSDRTIAQYAREIWGVEPSRQRLPAPDEAI>sp|P11217-2|PYGM_HUMAN Isoform 2 of Glycogen phosphorylase, muscle formOS=Homo sapiens OX=9606 GN=PYGMMSRPLSDQEKRKQISVRGLAGVENVTELKKNFNRHLHFTLVKDRNVATPRDYYFALAHTVRDHLVGRWIRTQQHYYEKDPKKISGGWQMEEADDWLRYGNPWEKARPEFTLPVHFYGHVEHTSQGAKWVDTQVVLAMPYDTPVPGYRNNVVNTMRLWSAKAPNDFNLKDFNVGGYIQAVLDRNLAENISRVLYPNDNFFEGKELRLKQEYFVVAATLQDIIRRFKSSKFGCRDPVRTNFDAFPDKVAIQLNDTHPSLAIPELMRILVDLERMDWDKAWDVTVRTCAYTNHTVLPEALERWPVHLLETLLPRHLQIIYEINQRFLNRVAAAFPGDVDRLRRMSLVEEGAVKRINMAHLCIAGSHAVNGVARIHSEILKKTIFKDFYELEPHKFQNKTNGITPRRWLVLCNPGLAEVIAERIGEDFISDLDQLRKLLSFVDDEAFIRDVAKVKQENKLKFAAYLEREYKVHINPNSLFDIQVKRIHEYKRQLLNCLHVITLYNRIKREPNKFFVPRTVMIGGKAAPGYHMAKMIIRLVTAIGDVVNHDPAVGDRLRVIFLENYRVSLAEKVIPAADLSEQISTAGTEASGTGNMKFMLNGALTIGTMDGANVEMAEEAGEENFFIFGMRVEDVDKLDQRGYNAQEYYDRIPELRQVIEQLSSGFFSPKQPDLFKDIVNMLMHHDRFKVFADYEDYIKCQEKVSALYKNPREWTRMVIRNIATSGKFSSDRTIAQYAREIWGVEPSRQRLPAPDEAI>sp|Q96HA9|PX11C_HUMAN Peroxisomal membrane protein 11C OS=Homo sapiensOX=9606 GN=PEX11G PE=1 SV=1MASLSGLASALESYRGRDRLIRVLGYCCQLVGGVLVEQCPARSEVGTRLLVVSTQLSHCRTILRLFDDLAMFVYTKQYGLGAQEEDAFVRCVSVLGNLADQLYYPCEHVAWAADARVLHVDSSRWWTLSTTLWALSLLLGVARSLWMLLKLRQRLRSPTAPFTSPLPRGKRRAMEAQMQSEALSLLSNLADLANAVHWLPRGVLWAGRFPPWLVGLMGTISSILSMYQAARAGGQAEATTP>sp|Q96HA9-2|PX11C_HUMAN Isoform 2 of Peroxisomal membrane protein 11COS=Homo sapiens OX=9606 GN=PEX11GMFVYTKQYGLGAQEEDAFVRCVSVLGNLADQLYYPCEHVAWAADARVLHVDSSRWWTLSTTLWALSLLLGVARSLWMLLKLRQRLRSPTAPFTSPLPRGKRRAMEAQMQSEALSLLSNLADLANAVHWLPRGVLWAGRFPPWLVGLMGTISSILSMYQAARAGGQAEATTP>sp|Q9H974|QTRT2_HUMAN Queuine tRNA-ribosyltransferase accessory subunit2 OS=Homo sapiens OX=9606 GN=QTRT2 PE=1 SV=1MKLSLTKVVNGCRLGKIKNLGKTGDHTMDIPGCLLYTKTGSAPHLTHHTLHNIHGVPAMAQLTLSSLAEHHEVLTEYKEGVGKFIGMPESLLYCSLHDPVSPCPAGYVTNKSVSVWSVAGRVEMTVSKFMAIQKALQPDWFQCLSDGEVSCKEATSIKRVRKSVDRSLLFLDNCLRLQEESEVLQKSVIIGVIEGGDVMEERLRSARETAKRPVGGFLLDGFQGNPTTLEARLRLLSSVTAELPEDKPRLISGVSRPDEVLECIERGVDLFESFFPYQVTERGCALTFSFDYQPNPEETLLQQNGTQEEIKCMDQIKKIETTGCNQEITSFEINLKEKKYQEDFNPLVRGCSCYCCKNHTRAYIHHLLVTNELLAGVLLMMHNFEHYFGFFHYIREALKSDKLAQLKELIHRQAS>sp|Q9H974-2|QTRT2_HUMAN Isoform 2 of Queuine tRNA-ribosyltransferaseaccessory subunit 2 OS=Homo sapiens OX=9606 GN=QTRT2MTVSKFMAIQKALQPDWFQCLSDGEVSCKEATSIKRVRKSVDRSLLFLDNCLRLQEESEVLQKSVIIGVIEGGDVMEERLRSARETAKRPVGGFLLDGFQGNPTTLEARLRLLSSVTAELPEDKPRLISGVSRPDEVLECIERGVDLFESFFPYQVTERGCALTFSFDYQPNPEETLLQQNGTQEEIKCMDQIKKIETTGCNQEITSFEINLKEKKYQEDFNPLVRGCSCYCCKNHTRAYIHHLLVTNELLAGVLLMMHNFEHYFGFFHYIREALKSDKLAQLKELIHRQAS>sp|Q9H974-3|QTRT2_HUMAN Isoform 3 of Queuine tRNA-ribosyltransferaseaccessory subunit 2 OS=Homo sapiens OX=9606 GN=QTRT2MVCWQSVSVWSVAGRVEMTVSKFMAIQKALQPDWFQCLSDGEVSCKEATSIKRVRKSVDRSLLFLDNCLRLQEESEVLQKSVIIGVIEGGDVMEERLRSARETAKRPVGGFLLDGFQGNPTTLEARLRLLSSVTAELPEDKPRLISGVSRPDEVLECIERGVDLFESFFPYQVTERGCALTFSFDYQPNPEETLLQQNGTQEEIKCMDQIKKIETTGCNQEITSFEINLKEKKYQEDFNPLVRGCSCYCCKNHTRAYIHHLLVTNELLAGVLLMMHNFEHYFGFFHYIREALKSDKLAQLKELIHRQAS>sp|Q9H974-4|QTRT2_HUMAN Isoform 4 of Queuine tRNA-ribosyltransferaseaccessory subunit 2 OS=Homo sapiens OX=9606 GN=QTRT2MVCWQDLEESLRMKLSLTKVVNGCRLGKIKNLGKTGDHTMDIPGCLLYTKTGSAPHLTHHTLHNIHGVPAMAQLTLSSLAEHHEVLTEYKEGVGKFIGMPESLLYCSLHDPVSPCPAGYVTNKSVSVWSVAGRVEMTVSKFMAIQKALQPDWFQCLSDGEVSCKEATSIKRVRKSVDRSLLFLDNCLRLQEESEVLQKSVIIGVIEGGDVMEERLRSARETAKRPVGGFLLDGFQGNPTTLEARLRLLSSVTAELPEDKPRLISGVSRPDEVLECIERGVDLFESFFPYQVTERGCALTFSFDYQPNPEETLLQQNGTQEEIKCMDQIKKIETTGCNQEITSFEINLKEKKYQEDFNPLVRGCSCYCCKNHTRAYIHHLLVTNELLAGVLLMMHNFEHYFGFFHYIREALKSDKLAQLKELIHRQAS>sp|P42696|RBM34_HUMAN RNA-binding protein 34 OS=Homo sapiens OX=9606GN=RBM34 PE=1 SV=2MALEGMSKRKRKRSVQEGENPDDGVRGSPPEDYRLGQVASSLFRGEHHSRGGTGRLASLFSSLEPQIQPVYVPVPKQTIKKTKRNEEEESTSQIERPLSQEPAKKVKAKKKHTNAEKKLADRESALASADLEEEIHQKQGQKRKNSQPGVKVADRKILDDTEDTVVSQRKKIQINQEEERLKNERTVFVGNLPVTCNKKKLKSFFKEYGQIESVRFRSLIPAEGTLSKKLAAIKRKIHPDQKNINAYVVFKEESAATQALKRNGAQIADGFRIRVDLASETSSRDKRSVFVGNLPYKVEESAIEKHFLDCGSIMAVRIVRDKMTGIGKGFGYVLFENTDSVHLALKLNNSELMGRKLRVMRSVNKEKFKQQNSNPRLKNVSKPKQGLNFTSKTAEGHPKSLFIGEKAVLLKTKKKGQKKSGRPKKQRKQK>sp|P42696-2|RBM34_HUMAN Isoform 2 of RNA-binding protein 34 OS=Homosapiens OX=9606 GN=RBM34MALEGMSKRKRKRSVQEGENPDDGVRGSPPEDYRLGQVASSLFRGEHHSRGGTGRLASLFSSLEPQIQPVYVPVPKQTIKKTKRNEEEESTSQIERPLSQEPAKKVKAKKKHTNAEKKLADRESALASADLEEEIHQKQGQKRKNSQPGVKVADRKILDDTEDTVVSQRKKIQINQEEERLKNERTVFVGNLPVTCNKKKLKSFFKEYGQIESVRFRSLVCFIPP>sp|Q9ULC3|RAB23_HUMAN Ras-related protein Rab-23 OS=Homo sapiens OX=9606GN=RAB23 PE=1 SV=1MLEEDMEVAIKMVVVGNGAVGKSSMIQRYCKGIFTKDYKKTIGVDFLERQIQVNDEDVRLMLWDTAGQEEFDAITKAYYRGAQACVLVFSTTDRESFEAVSSWREKVVAEVGDIPTVLVQNKIDLLDDSCIKNEEAEALAKRLKLRFYRTSVKEDLNVNEVFKYLAEKYLQKLKQQIAEDPELTHSSSNKIGVFNTSGGSHSGQNSGTLNGGDVINLRPNKQRTKKNRNPFSSCSIP>sp|Q9BZG1|RAB34_HUMAN Ras-related protein Rab-34 OS=Homo sapiens OX=9606GN=RAB34 PE=1 SV=1MNILAPVRRDRVLAELPQCLRKEAALHGHKDFHPRVTCACQEHRTGTVGFKISKVIVVGDLSVGKTCLINRFCKDTFDKNYKATIGVDFEMERFEVLGIPFSLQLWDTAGQERFKCIASTYYRGAQAIIIVFNLNDVASLEHTKQWLADALKENDPSSVLLFLVGSKKDLSTPAQYALMEKDALQVAQEMKAEYWAVSSLTGENVREFFFRVAALTFEANVLAELEKSGARRIGDVVRINSDDSNLYLTASKKKPTCCP>sp|Q9BZG1-2|RAB34_HUMAN Isoform 2 of Ras-related protein Rab-34 OS=Homosapiens OX=9606 GN=RAB34MNILAPVRRDRVLAELPQCLRKEAALHGHKDFHPRVTCACQEHRTGTVGFKISKVIVVGDLSVGKTCLINRFCKDTFDKNYKATIGVDFEMERFEVLGIPFSLQLWDTAGQERFKCIASTYYRGAQAIIIVFNLNDVASLEHTKQWLADALKENDPSSVLLFLTPAQYALMEKDALQVAQEMKAEYWAVSSLTGENVREFFFRVAALTFEANVLAELEKSGARRIGDVVRINSDDSNLYLTASKKKPTCCP>sp|Q9BZG1-4|RAB34_HUMAN Isoform 4 of Ras-related protein Rab-34 OS=Homosapiens OX=9606 GN=RAB34MNILAPVRRDRVLAELPQCLRKEAALHGHKDFHPRVTCACQEHRTGTVGFCKDTFDKNYKATIGVDFEMERFEVLGIPFSLQLWDTAGQERFKCIASTYYRGAQAIIIVFNLNDVASLEHTKQWLADALKENDPSSVLLFLVGSKKDLSTPAQYALMEKDALQVAQEMKAEYWAVSSLTGENVREFFFRVAALTFEANVLAELEKSGARRIGDVVRINSDDSNLYLTASKKKPTCCP>sp|Q9NP90|RAB9B_HUMAN Ras-related protein Rab-9B OS=Homo sapiens OX=9606GN=RAB9B PE=1 SV=1MSGKSLLLKVILLGDGGVGKSSLMNRYVTNKFDSQAFHTIGVEFLNRDLEVDGRFVTLQIWDTAGQERFKSLRTPFYRGADCCLLTFSVDDRQSFENLGNWQKEFIYYADVKDPEHFPFVVLGNKVDKEDRQVTTEEAQTWCMENGDYPYLETSAKDDTNVTVAFEEAVRQVLAVEEQLEHCMLGHTIDLNSGSKAGSSCC>sp|Q00765|REEP5_HUMAN Receptor expression-enhancing protein 5 OS=Homosapiens OX=9606 GN=REEP5 PE=1 SV=3MSAAMRERFDRFLHEKNCMTDLLAKLEAKTGVNRSFIALGVIGLVALYLVFGYGASLLCNLIGFGYPAYISIKAIESPNKEDDTQWLTYWVVYGVFSIAEFFSDIFLSWFPFYYMLKCGFLLWCMAPSPSNGAELLYKRIIRPFFLKHESQMDSVVKDLKDKAKETADAITKEAKKATVNLLGEEKKST>sp|Q00765-2|REEP5_HUMAN Isoform 2 of Receptor expression-enhancingprotein 5 OS=Homo sapiens OX=9606 GN=REEP5MSAAMRERFDRFLHEKNCMTDLLAKLEAKTGVNRSFIALGVIGLVALYLVFGYGASLLCNLIGFGYPAYISIKAIESPNKEDDTQWLTYWVVYGVFSIAEFFSDIFLSWFPFYYMLKVWSGLGFLLPRCLL>sp|Q9NS39|RED2_HUMAN Double-stranded RNA-specific editase B2 OS=Homosapiens OX=9606 GN=ADARB2 PE=1 SV=1MASVLGSGRGSGGLSSQLKCKSKRRRRRRSKRKDKVSILSTFLAPFKHLSPGITNTEDDDTLSTSSAEVKENRNVGNLAARPPPSGDRARGGAPGAKRKRPLEEGNGGHLCKLQLVWKKLSWSVAPKNALVQLHELRPGLQYRTVSQTGPVHAPVFAVAVEVNGLTFEGTGPTKKKAKMRAAELALRSFVQFPNACQAHLAMGGGPGPGTDFTSDQADFPDTLFQEFEPPAPRPGLAGGRPGDAALLSAAYGRRRLLCRALDLVGPTPATPAAPGERNPVVLLNRLRAGLRYVCLAEPAERRARSFVMAVSVDGRTFEGSGRSKKLARGQAAQAALQELFDIQMPGHAPGRARRTPMPQEFADSISQLVTQKFREVTTDLTPMHARHKALAGIVMTKGLDARQAQVVALSSGTKCISGEHLSDQGLVVNDCHAEVVARRAFLHFLYTQLELHLSKRREDSERSIFVRLKEGGYRLRENILFHLYVSTSPCGDARLHSPYEITTDLHSSKHLVRKFRGHLRTKIESGEGTVPVRGPSAVQTWDGVLLGEQLITMSCTDKIARWNVLGLQGALLSHFVEPVYLQSIVVGSLHHTGHLARVMSHRMEGVGQLPASYRHNRPLLSGVSDAEARQPGKSPPFSMNWVVGSADLEIINATTGRRSCGGPSRLCKHVLSARWARLYGRLSTRTPSPGDTPSMYCEAKLGAHTYQSVKQQLFKAFQKAGLGTWVRKPPEQQQFLLTL>sp|Q9NS39-2|RED2_HUMAN Isoform 2 of Double-stranded RNA-specific editaseB2 OS=Homo sapiens OX=9606 GN=ADARB2MGLWSPVPGNSVPRAPVMAGLGLGHSQGAPQGPHDGKTDRSSGPGRRRTERTRLPGLLGGAPLTAGSPHRWNVLGLQGALLSHFVEPVYLQSIVVGSLHHTGHLARVMSHRMEGVGQLPASYRHNRPLLSGVSDAEARQPGKSPPFSMNWVVGSADLEIINATTGRRSCGGPSRLCKHVLSARWARLYGRLSTRTPSPGDTPSMYCEAKLGAHTYQSVKQQLFKAFQKAGLGTWVRKPPEQQQFLLTL>sp|O75783|RHBL1_HUMAN Rhomboid-related protein 1 OS=Homo sapiens OX=9606GN=RHBDL1 PE=1 SV=1MGRVEDGGTTEELEDWDPGTSALPAPGIKQGPREQTGTGPLSQKCWEPEPDAPSQPGPALWSRGRARTQALAGGSSLQQLDPENTGFIGADTFTGLVHSHELPLDPAKLDMLVALAQSNEQGQVCYQELVDLISSKRSSSFKRAIANGQRALPRDGPLDEPGLGVYKRFVRYVAYEILPCEVDRRWYFYRHRSCPPPVFMASVTLAQIIVFLCYGARLNKWVLQTYHPEYMKSPLVYHPGHRARAWRFLTYMFMHVGLEQLGFNALLQLMIGVPLEMVHGLLRISLLYLAGVLAGSLTVSITDMRAPVVGGSGGVYALCSAHLANVVMNWAGMRCPYKLLRMVLALVCMSSEVGRAVWLRFSPPLPASGPQPSFMAHLAGAVVGVSMGLTILRSYEERLRDQCGWWVVLLAYGTFLLFAVFWNVFAYDLLGAHIPPPP>sp|O75783-2|RHBL1_HUMAN Isoform 2 of Rhomboid-related protein 1 OS=Homosapiens OX=9606 GN=RHBDL1MDRSSLLQLIQEQQLDPENTGFIGADTFTGLVHSHELPLDPAKLDMLVALAQSNEQGQVCYQELVDLISSKRSSSFKRAIANGQRALPRDGPLDEPGLGVYKRFVRYVAYEILPCEVDRRWYFYRHRSCPPPVFMASVTLAQIIVFLCYGARLNKWVLQTYHPEYMKSPLVYHPGHRARAWRFLTYMFMHVGLEQLGFNALLQLMIGVPLEMVHGLLRISLLYLAGVLAGSLTVSITDMRAPVVGGSGGVYALCSAHLANVVMNWAGMRCPYKLLRMVLALVCMSSEVGRAVWLRFSPPLPASGPQPSFMAHLAGAVVGVSMGLTILRSYEERLRDQCGWWVVLLAYGTFLLFAVFWNVFAYDLLGAHIPPPP>sp|Q8TEB9|RHBL4_HUMAN Rhomboid-related protein 4 OS=Homo sapiens OX=9606GN=RHBDD1 PE=1 SV=1MQRRSRGINTGLILLLSQIFHVGINNIPPVTLATLALNIWFFLNPQKPLYSSCLSVEKCYQQKDWQRLLLSPLHHADDWHLYFNMASMLWKGINLERRLGSRWFAYVITAFSVLTGVVYLLLQFAVAEFMDEPDFKRSCAVGFSGVLFALKVLNNHYCPGGFVNILGFPVPNRFACWVELVAIHLFSPGTSFAGHLAGILVGLMYTQGPLKKIMEACAGGFSSSVGYPGRQYYFNSSGSSGYQDYYPHGRPDHYEEAPRNYDTYTAGLSEEEQLERALQASLWDRGNTRNSPPPYGFHLSPEEMRRQRLHRFDSQ>sp|Q8TEB9-2|RHBL4_HUMAN Isoform 2 of Rhomboid-related protein 4 OS=Homosapiens OX=9606 GN=RHBDD1MPVFLFKPKGGFSSSVGYPGRQYYFNSSGSSGYQDYYPHGRPDHYEEAPRNYDTYTAGLSEEEQLERALQASLWDRGNTRNSPPPYGFHLSPEEMRRQRLHRFDSQ>sp|Q8N5L8|RP25L_HUMAN Ribonuclease P protein subunit p25-like proteinOS=Homo sapiens OX=9606 GN=RPP25L PE=1 SV=1MEHYRKAGSVELPAPSPMPQLPPDTLEMRVRDGSKIRNLLGLALGRLEGGSARHVVFSGSGRAAGKAVSCAEIVKRRVPGLHQLTKLRFLQTEDSWVPASPDTGLDPLTVRRHVPAVWVLLSRDPLDPNECGYQPPGAPPGLGSMPSSSCGPRSRRRARDTRS>sp|Q9BYZ6|RHBT2_HUMAN Rho-related BTB domain-containing protein 2OS=Homo sapiens OX=9606 GN=RHOBTB2 PE=1 SV=2MDSDMDYERPNVETIKCVVVGDNAVGKTRLICARACNATLTQYQLLATHVPTVWAIDQYRVCQEVLERSRDVVDDVSVSLRLWDTFGDHHKDRRFAYGRSDVVVLCFSIANPNSLHHVKTMWYPEIKHFCPRAPVILVGCQLDLRYADLEAVNRARRPLARPIKPNEILPPEKGREVAKELGIPYYETSVVAQFGIKDVFDNAIRAALISRRHLQFWKSHLRNVQRPLLQAPFLPPKPPPPIIVVPDPPSSSEECPAHLLEDPLCADVILVLQERVRIFAHKIYLSTSSSKFYDLFLMDLSEGELGGPSEPGGTHPEDHQGHSDQHHHHHHHHHGRDFLLRAASFDVCESVDEAGGSGPAGLRASTSDGILRGNGTGYLPGRGRVLSSWSRAFVSIQEEMAEDPLTYKSRLMVVVKMDSSIQPGPFRAVLKYLYTGELDENERDLMHIAHIAELLEVFDLRMMVANILNNEAFMNQEITKAFHVRRTNRVKECLAKGTFSDVTFILDDGTISAHKPLLISSCDWMAAMFGGPFVESSTREVVFPYTSKSCMRAVLEYLYTGMFTSSPDLDDMKLIILANRLCLPHLVALTEQYTVTGLMEATQMMVDIDGDVLVFLELAQFHCAYQLADWCLHHICTNYNNVCRKFPRDMKAMSPENQEYFEKHRWPPVWYLKEEDHYQRARKEREKEDYLHLKRQPKRRWLFWNSPSSPSSSAASSSSPSSSSAVV>sp|Q9BYZ6-2|RHBT2_HUMAN Isoform 2 of Rho-related BTB domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RHOBTB2MQAWRKGPDGPQKTSSDSMSRLMDSDMDYERPNVETIKCVVVGDNAVGKTRLICARACNATLTQYQLLATHVPTVWAIDQYRVCQEVLERSRDVVDDVSVSLRLWDTFGDHHKDRRFAYGRSDVVVLCFSIANPNSLHHVKTMWYPEIKHFCPRAPVILVGCQLDLRYADLEAVNRARRPLARPIKPNEILPPEKGREVAKELGIPYYETSVVAQFGIKDVFDNAIRAALISRRHLQFWKSHLRNVQRPLLQAPFLPPKPPPPIIVVPDPPSSSEECPAHLLEDPLCADVILVLQERVRIFAHKIYLSTSSSKFYDLFLMDLSEGELGGPSEPGGTHPEDHQGHSDQHHHHHHHHHGRDFLLRAASFDVCESVDEAGGSGPAGLRASTSDGILRGNGTGYLPGRGRVLSSWSRAFVSIQEEMAEDPLTYKSRLMVVVKMDSSIQPGPFRAVLKYLYTGELDENERDLMHIAHIAELLEVFDLRMMVANILNNEAFMNQEITKAFHVRRTNRVKECLAKGTFSDVTFILDDGTISAHKPLLISSCDWMAAMFGGPFVESSTREVVFPYTSKSCMRAVLEYLYTGMFTSSPDLDDMKLIILANRLCLPHLVALTEQYTVTGLMEATQMMVDIDGDVLVFLELAQFHCAYQLADWCLHHICTNYNNVCRKFPRDMKAMSPENQEYFEKHRWPPVWYLKEEDHYQRARKEREKEDYLHLKRQPKRRWLFWNSPSSPSSSAASSSSPSSSSAVV>sp|Q9BYZ6-3|RHBT2_HUMAN Isoform 3 of Rho-related BTB domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RHOBTB2MKARSRLMDSDMDYERPNVETIKCVVVGDNAVGKTRLICARACNATLTQYQLLATHVPTVWAIDQYRVCQEVLERSRDVVDDVSVSLRLWDTFGDHHKDRRFAYGRSDVVVLCFSIANPNSLHHVKTMWYPEIKHFCPRAPVILVGCQLDLRYADLEAVNRARRPLARPIKPNEILPPEKGREVAKELGIPYYETSVVAQFGIKDVFDNAIRAALISRRHLQFWKSHLRNVQRPLLQAPFLPPKPPPPIIVVPDPPSSSEECPAHLLEDPLCADVILVLQERVRIFAHKIYLSTSSSKFYDLFLMDLSEGELGGPSEPGGTHPEDHQGHSDQHHHHHHHHHGRDFLLRAASFDVCESVDEAGGSGPAGLRASTSDGILRGNGTGYLPGRGRVLSSWSRAFVSIQEEMAEDPLTYKSRLMVVVKMDSSIQPGPFRAVLKYLYTGELDENERDLMHIAHIAELLEVFDLRMMVANILNNEAFMNQEITKAFHVRRTNRVKECLAKGTFSDVTFILDDGTISAHKPLLISSCDWMAAMFGGPFVESSTREVVFPYTSKSCMRAVLEYLYTGMFTSSPDLDDMKLIILANRLCLPHLVALTEQYTVTGLMEATQMMVDIDGDVLVFLELAQFHCAYQLADWCLHHICTNYNNVCRKFPRDMKAMSPENQEYFEKHRWPPVWYLKEEDHYQRARKEREKEDYLHLKRQPKRRWLFWNSPSSPSSSAASSSSPSSSSAVV>sp|O94955|RHBT3_HUMAN Rho-related BTB domain-containing protein 3OS=Homo sapiens OX=9606 GN=RHOBTB3 PE=1 SV=2MSIHIVALGNEGDTFHQDNRPSGLIRTYLGRSPLVSGDESSLLLNAASTVARPVFTEYQASAFGNVKLVVHDCPVWDIFDSDWYTSRNLIGGADIIVIKYNVNDKFSFHEVKDNYIPVIKRALNSVPVIIAAVGTRQNEELPCTCPLCTSDRGSCVSTTEGIQLAKELGATYLELHSLDDFYIGKYFGGVLEYFMIQALNQKTSEKMKKRKMSNSFHGIRPPQLEQPEKMPVLKAEASHYNSDLNNLLFCCQCVDVVFYNPNLKKVVEAHKIVLCAVSHVFMLLFNVKSPTDIQDSSIIRTTQDLFAINRDTAFPGASHESSGNPPLRVIVKDALFCSCLSDILRFIYSGAFQWEELEEDIRKKLKDSGDVSNVIEKVKCILKTPGKINCLRNCKTYQARKPLWFYNTSLKFFLNKPMLADVVFEIQGTTVPAHRAILVARCEVMAAMFNGNYMEAKSVLIPVYGVSKETFLSFLEYLYTDSCCPAGIFQAMCLLICAEMYQVSRLQHICELFIITQLQSMPSRELASMNLDIVDLLKKAKFHHSDCLSTWLLHFIATNYLIFSQKPEFQDLSVEERSFVEKHRWPSNMYLKQLAEYRKYIHSRKCRCLVM>sp|Q9UBD6|RHCG_HUMAN Ammonium transporter Rh type C OS=Homo sapiensOX=9606 GN=RHCG PE=1 SV=1MAWNTNLRWRLPLTCLLLQVIMVILFGVFVRYDFEADAHWWSERTHKNLSDMENEFYYRYPSFQDVHVMVFVGFGFLMTFLQRYGFSAVGFNFLLAAFGIQWALLMQGWFHFLQDRYIVVGVENLINADFCVASVCVAFGAVLGKVSPIQLLIMTFFQVTLFAVNEFILLNLLKVKDAGGSMTIHTFGAYFGLTVTRILYRRNLEQSKERQNSVYQSDLFAMIGTLFLWMYWPSFNSAISYHGDSQHRAAINTYCSLAACVLTSVAISSALHKKGKLDMVHIQNATLAGGVAVGTAAEMMLMPYGALIIGFVCGIISTLGFVYLTPFLESRLHIQDTCGINNLHGIPGIIGGIVGAVTAASASLEVYGKEGLVHSFDFQGFNGDWTARTQGKFQIYGLLVTLAMALMGGIIVGLILRLPFWGQPSDENCFEDAVYWEMPEGNSTVYIPEDPTFKPSGPSVPSVPMVSPLPMASSVPLVP>sp|P61586|RHOA_HUMAN Transforming protein RhoA OS=Homo sapiens OX=9606GN=RHOA PE=1 SV=1MAAIRKKLVIVGDGACGKTCLLIVFSKDQFPEVYVPTVFENYVADIEVDGKQVELALWDTAGQEDYDRLRPLSYPDTDVILMCFSIDSPDSLENIPEKWTPEVKHFCPNVPIILVGNKKDLRNDEHTRRELAKMKQEPVKPEEGRDMANRIGAFGYMECSAKTKDGVREVFEMATRAALQARRGKKKSGCLVL>sp|Q9UBS8|RNF14_HUMAN E3 ubiquitin-protein ligase RNF14 OS=Homo sapiensOX=9606 GN=RNF14 PE=1 SV=1MSSEDREAQEDELLALASIYDGDEFRKAESVQGGETRIYLDLPQNFKIFVSGNSNECLQNSGFEYTICFLPPLVLNFELPPDYPSSSPPSFTLSGKWLSPTQLSALCKHLDNLWEEHRGSVVLFAWMQFLKEETLAYLNIVSPFELKIGSQKKVQRRTAQASPNTELDFGGAAGSDVDQEEIVDERAVQDVESLSNLIQEILDFDQAQQIKCFNSKLFLCSICFCEKLGSECMYFLECRHVYCKACLKDYFEIQIRDGQVQCLNCPEPKCPSVATPGQVKELVEAELFARYDRLLLQSSLDLMADVVYCPRPCCQLPVMQEPGCTMGICSSCNFAFCTLCRLTYHGVSPCKVTAEKLMDLRNEYLQADEANKRLLDQRYGKRVIQKALEEMESKEWLEKNSKSCPCCGTPIEKLDGCNKMTCTGCMQYFCWICMGSLSRANPYKHFNDPGSPCFNRLFYAVDVDDDIWEDEVED>sp|Q9UBS8-2|RNF14_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF14OS=Homo sapiens OX=9606 GN=RNF14MQFLKEETLAYLNIVSPFELKIGSQKKVQRRTAQASPNTELDFGGAAGSDVDQEEIVDERAVQDVESLSNLIQEILDFDQAQQIKCFNSKLFLCSICFCEKLGSECMYFLECRHVYCKACLKDYFEIQIRDGQVQCLNCPEPKCPSVATPGQVKELVEAELFARYDRLLLQSSLDLMADVVYCPRPCCQLPVMQEPGCTMGICSSCNFAFCTLCRLTYHGVSPCKVTAEKLMDLRNEYLQADEANKRLLDQRYGKRVIQKALEEMESKEWLEKNSKSCPCCGTPIEKLDGCNKMTCTGCMQYFCWICMGSLSRANPYKHFNDPGSPCFNRLFYAVDVDDDIWEDEVED>sp|O00212|RHOD_HUMAN Rho-related GTP-binding protein RhoD OS=Homosapiens OX=9606 GN=RHOD PE=1 SV=2MTAAQAAGEEAPPGVRSVKVVLVGDGGCGKTSLLMVFADGAFPESYTPTVFERYMVNLQVKGKPVHLHIWDTAGQDDYDRLRPLFYPDASVLLLCFDVTSPNSFDNIFNRWYPEVNHFCKKVPIIVVGCKTDLCKDKSLVNKLRRNGLEPVTYHRGQEMARSVGAVAYLECSARLHDNVHAVFQEAAEVALSSRGRNFWRRITQGFCVVT>sp|P08134|RHOC_HUMAN Rho-related GTP-binding protein RhoC OS=Homosapiens OX=9606 GN=RHOC PE=1 SV=1MAAIRKKLVIVGDGACGKTCLLIVFSKDQFPEVYVPTVFENYIADIEVDGKQVELALWDTAGQEDYDRLRPLSYPDTDVILMCFSIDSPDSLENIPEKWTPEVKHFCPNVPIILVGNKKDLRQDEHTRRELAKMKQEPVRSEEGRDMANRISAFGYLECSAKTKEGVREVFEMATRAGLQVRKNKRRRGCPIL>sp|P52758|RIDA_HUMAN 2-iminobutanoate/2-iminopropanoate deaminaseOS=Homo sapiens OX=9606 GN=RIDA PE=1 SV=1MSSLIRRVISTAKAPGAIGPYSQAVLVDRTIYISGQIGMDPSSGQLVSGGVAEEAKQALKNMGEILKAAGCDFTNVVKTTVLLADINDFNTVNEIYKQYFKSNFPARAAYQVAALPKGSRIEIEAVAIQGPLTTASL>sp|Q02161|RHD_HUMAN Blood group Rh(D) polypeptide OS=Homo sapiensOX=9606 GN=RHD PE=1 SV=3MSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAAIGLGFLTSSFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPSGKVVITLFSIRLATMSALSVLISVDAVLGKVNLAQLVVMVLVEVTALGNLRMVISNIFNTDYHMNMMHIYVFAAYFGLSVAWCLPKPLPEGTEDKDQTATIPSLSAMLGALFLWMFWPSFNSALLRSPIERKNAVFNTYYAVAVSVVTAISGSSLAHPQGKISKTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISVGGAKYLPGCCNRVLGIPHSSIMGYNFSLLGLLGEIIYIVLLVLDTVGAGNGMIGFQVLLSIGELSLAIVIALMSGLLTGLLLNLKIWKAPHEAKYFDDQVFWKFPHLAVGF>sp|Q02161-2|RHD_HUMAN Isoform 2 of Blood group Rh(D) polypeptide OS=Homosapiens OX=9606 GN=RHDMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAAIGLGFLTSSFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPSGKVVITLFSIRLATMSALSVLISVDAVLGKVNLAQLVVMVLVEVTALGNLRMVISNIFNTDYHMNMMHIYVFAAYFGLSVAWCLPKPLPEGTEDKDQTATIPSLSAMLGALFLWMFWPSFNSALLRSPIERKNAVFNTYYAVAVSVVTAISGSSLAHPQGKISKTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISVGGAKYLPFPHLAVGF>sp|Q02161-3|RHD_HUMAN Isoform 3 of Blood group Rh(D) polypeptide OS=Homosapiens OX=9606 GN=RHDMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAAIGLGFLTSSFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPSGKVVITLFSIRLATMSALSVLISVDAVLGKVNLAQLVVMVLVEVTALGNLRMVISNIFNTDYHMNMMHIYVFAAYFGLSVAWCLPKPLPEGTEDKDQTATIPSLSAMLGALFLWMFWPSFNSALLRSPIERKNAVFNTYYAVAVSVVTAISGSSLAHPQGKISKTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISVGGAKYLPGCS>sp|Q02161-4|RHD_HUMAN Isoform 4 of Blood group Rh(D) polypeptide OS=Homosapiens OX=9606 GN=RHDMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAAIGLGFLTSSFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPSGKVVITLFSIRLATMSALSVLISVDAVLGKVNLAQLVVMVLVEVTALGNLRMVISNIFNTDYHMNMMHIYVFAAYFGLSVAWCLPKPLPEGTEDKDQTATIPSLSAMLGALFLWMFWPSFNSALLRSPIERKNAVFNTYYAVAVSVVTAISGSSLAHPQGKISKTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISVGGAKYLPGCCNRVLGIPHSSIMGYNFSLLGLLGEIIYIVLLVLDTVGAGNGMSLGWNLAVKMAEAGDEELMRLDVSQRNHGGAAVPTGSWMPSTETTIAPNYRDHISVVSSFGCWILSKSIQEKQGLFKNKTTSSHCCLHLYVRNAHDSKVSNVRAGTGVRENGVESFLCHSLRRISPFIMHCRIQQ>sp|Q02161-5|RHD_HUMAN Isoform 5 of Blood group Rh(D) polypeptide OS=Homosapiens OX=9606 GN=RHDMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAAIGLGFLTSSFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPSGKVVITLFSIRLATMSALSVLISVDAVLGKVNLAQLVVMVLVEVTALGNLRMVISNIFNTDYHMNMMHIYVFAAYFGLSVAWCLPKPLPEGTEDKDQTATIPSLSAMLGALFLWMFWPSFNSALLRSPIERKNAVFNTYYAVAVSVVTAISGSSLAHPQGKISKTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISVGGAKYLPGCCNRVLGIPHSSIMGYNFSLLGLLGEIIYIVLLVLDTVGAGNGIFLIWLLDFKQKHPRKTRPVQKQDNFLSLLPAFVREKRS>sp|Q02161-6|RHD_HUMAN Isoform 6 of Blood group Rh(D) polypeptide OS=Homosapiens OX=9606 GN=RHDMSSKYPRSVRRCLPLWALTLEAALILLFYFFTHYDASLEDQKGLVASYQVGQDLTVMAAIGLGFLTSSFRRHSWSSVAFNLFMLALGVQWAILLDGFLSQFPSGKVVITLFSIRLATMSALSVLISVDAVLGKVNLAQLVVMVLVEVTALGNLRMVISNIFNTDYHMNMMHIYVFAAYFGLSVAWCLPKPLPEGTEDKDQTATIPSLSAMLGALFLWMFWPSFNSALLRSPIERKNAVFNTYYAVAVSVVTAISGSSLAHPQGKISKTYVHSAVLAGGVAVGTSCHLIPSPWLAMVLGLVAGLISVGGAKYLPDWLPGPPQHWGTQLGHRDSSHVWSPDSFLIWLLDFKQKHPRKTRPVQKQDNFLSLLPAFVREKRS>sp|Q9BXT8|RNF17_HUMAN RING finger protein 17 OS=Homo sapiens OX=9606GN=RNF17 PE=1 SV=3MAAEASKTGPSRSSYQRMGRKSQPWGAAEIQCTRCGRRVSRSSGHHCELQCGHAFCELCLLMTEECTTIICPDCEVATAVNTRQRYYPMAGYIKEDSIMEKLQPKTIKNCSQDFKKTADQLTTGLERSASTDKTLLNSSAVMLDTNTAEEIDEALNTAHHSFEQLSIAGKALEHMQKQTIEERERVIEVVEKQFDQLLAFFDSRKKNLCEEFARTTDDYLSNLIKAKSYIEEKKNNLNAAMNIARALQLSPSLRTYCDLNQIIRTLQLTSDSELAQVSSPQLRNPPRLSVNCSEIICMFNNMGKIEFRDSTKCYPQENEIRQNVQKKYNNKKELSCYDTYPPLEKKKVDMSVLTSEAPPPPLQPETNDVHLEAKNFQPQKDVATASPKTIAVLPQMGSSPDVIIEEIIEDNVESSAELVFVSHVIDPCHFYIRKYSQIKDAKVLEKKVNEFCNRSSHLDPSDILELGARIFVSSIKNGMWCRGTITELIPIEGRNTRKPCSPTRLFVHEVALIQIFMVDFGNSEVLIVTGVVDTHVRPEHSAKQHIALNDLCLVLRKSEPYTEGLLKDIQPLAQPCSLKDIVPQNSNEGWEEEAKVEFLKMVNNKAVSMKVFREEDGVLIVDLQKPPPNKISSDMPVSLRDALVFMELAKFKSQSLRSHFEKNTTLHYHPPILPKEMTDVSVTVCHINSPGDFYLQLIEGLDILFLLKTIEEFYKSEDGENLEILCPVQDQACVAKFEDGIWYRAKVIGLPGHQEVEVKYVDFGNTAKITIKDVRKIKDEFLNAPEKAIKCKLAYIEPYKRTMQWSKEAKEKFEEKAQDKFMTCSVIKILEDNVLLVELFDSLGAPEMTTTSINDQLVKEGLASYEIGYILKDNSQKHIEVWDPSPEEIISNEVHNLNPVSAKSLPNENFQSLYNKELPVHICNVISPEKIYVQWLLTENLLNSLEEKMIAAYENSKWEPVKWENDMHCAVKIQDKNQWRRGQIIRMVTDTLVEVLLYDVGVELVVNVDCLRKLEENLKTMGRLSLECSLVDIRPAGGSDKWTATACDCLSLYLTGAVATIILQVDSEENNTTWPLPVKIFCRDEKGERVDVSKYLIKKGLALRERRINNLDNSHSLSEKSLEVPLEQEDSVVTNCIKTNFDPDKKTADIISEQKVSEFQEKILEPRTTRGYKPPAIPNMNVFEATVSCVGDDGTIFVVPKLSEFELIKMTNEIQSNLKCLGLLEPYFWKKGEACAVRGSDTLWYRGKVMEVVGGAVRVQYLDHGFTEKIPQCHLYPILLYPDIPQFCIPCQLHNTTPVGNVWQPDAIEVLQQLLSKRQVDIHIMELPKNPWEKLSIHLYFDGMSLSYFMAYYKYCTSEHTEEMLKEKPRSDHDKKYEEEQWEIRFEELLSAETDTPLLPPYLSSSLPSPGELYAVQVKHVVSPNEVYICLDSIETSNQSNQHSDTDDSGVSGESESESLDEALQRVNKKVEALPPLTDFRTEMPCLAEYDDGLWYRAKIVAIKEFNPLSILVQFVDYGSTAKLTLNRLCQIPSHLMRYPARAIKVLLAGFKPPLRDLGETRIPYCPKWSMEALWAMIDCLQGKQLYAVSMAPAPEQIVTLYDDEQHPVHMPLVEMGLADKDE>sp|Q9BXT8-1|RNF17_HUMAN Isoform 2 of RING finger protein 17 OS=Homosapiens OX=9606 GN=RNF17MAAEASKTGPSRSSYQRMGRKSQPWGAAEIQCTRCGRRVSRSSGHHCELQCGHAFCELCLLMTEECTTIICPDCEVATAVNTRQRYYPMAGYIKEDSIMEKLQPKTIKNCSQDFKKTADQLTTGLERSASTDKTLLNSSAVMLDTNTAEEIDEALNTAHHSFEQLSIAGKALEHMQKQTIEERERVIEVVEKQFDQLLAFFDSRKKNLCEEFARTTDDYLSNLIKAKSYIEEKKNNLNAAMNIARALQLSPSLRTYCDLNQIIRTLQLTSDSELAQVSSPQLRNPPRLSVNCSEIICMFNNMGKIEFRDSTKCYPQENEIRQNVQKKYNNKKELSCYDTYPPLEKKKVDMSVLTSEAPPPPLQPETNDVHLEAKNFQPQKDVATASPKTIAVLPQMGSSPDVIIEEIIEDNVESSAELVFVSHVIDPCHFYIRKYSQIKDAKVLEKKVNEFCNRSSHLDPSDILELGARIFVSSIKNGMWCRGTITELIPIEGRNTRKPCSPTRLFVHEVALIQIFMVDFGNSEVLIVTGVVDTHVRPEHSAKQHIALNDLCLVLRKSEPYTEGLLKDIQPLAQPCSLKDIVPQNSNEGWEEEAKVEFLKMVNNKAVSMKVFREEDGVLIVDLQKPPPNKISSDMPVSLRDALVFMELAKDLI>sp|Q9BXT8-2|RNF17_HUMAN Isoform 3 of RING finger protein 17 OS=Homosapiens OX=9606 GN=RNF17MAAEASKTGPSRSSYQRMGRKSQPWGAAEIQCTRCGRRVSRSSGHHCELQCGHAFCELCLLMTEECTTIICPDCEVATAVNTRQRYYPMAGYIKEDSIMEKLQPKTIKNCSQDFKKTADQLTTGLERSASTDKTLLNSSAVMLDTNTAEEIDEALNTAHHSFEQLSIAGKALEHMQKQTIEERERVIEVVEKQFDQLLAFFDSRKKNLCEEFARTTDDYLSNLIKAKSYIEEKKNNLNAAMNIARALQLSPSLRTYCDLNQIIRTLQLTSDSELAQVSSPQLRNPPRLSVNCSEIICMFNNMGKIEFRDSTKCYPQENEIRQNVQKKYNNKKELSCYDTYPPLEKKKVDMSVLTSEAPPPPLQPETNDVHLEAKNFQPQKDVATASPKTIAVLPQMGSSPDVIIEEIIEDNVETCGTDDLGETPRYPKKPLQKNSSVPFGSKADTVTTV>sp|Q9BXT8-4|RNF17_HUMAN Isoform 4 of RING finger protein 17 OS=Homosapiens OX=9606 GN=RNF17MAAEASKTGPSRSSYQRMGRKSQPWGAAEIQCTRCGRRVSRSSGHHCELQCGHAFCELCLLMTEECTTIICPDCEVATAVNTRQRYYPMAGYIKEDSIMEKLQPKTIKNCSQDFKKTADQLTTGLERSASTDKTLLNSSAVMLDTNTAEEIDEALNTAHHSFEQLSIAGKALEHMQKQTIEERERVIEVVEKQFDQLLAFFDSRKKNLCEEFARTTDDYLSNLIKAKSYIEEKKNNLNAAMNIARALQLSPSLRTYCDLNQIIRTLQLTSDSELAQVSSPQLRNPPRLSVNCSEIICMFNNMGKIEFRDSTKCYPQENEIRQNVQKKYNNKKELSCYDTYPPLEKKKVDMSVLTSEAPPPPLQPETNDVHLEAKNFQPQKDVATASPKTIAVLPQMGSSPDVIIEEIIEDNVESSAELVFVSHVIDPCHFYIRKYSQIKDAKVLEKKVNEFCNRSSHLDPSDILELGARIFVSSIKNGMWCRGTITELIPIEGRNTRKPCSPTRLFVHEVALIQIFMVDFGNSEVLIVTGVVDTHVRPEHSAKQHIALNDLCLVLRKSEPYTEGLLKDIQPLAQPCSLKDIVPQNSNEGWEEEAKVEFLKMVNNKAVSMKVFREEDGVLIVDLQKPPPNKISSDMPVSLRDALVFMELAKFKSQSLRSHFEKNTTLHYHPPILPKEMTDVSVTVCHINSPGDFYLQLIEGLDILFLLKTIEEFYKSEDGENLEILCPVQDQACVAKFEDGIWYRAKVIGLPGHQEVEVKYVDFGNTAKITIKDVRKIKDEFLNAPEKAIKCKLAYIEPYKRTMQWSKEAKEKFEEKAQDKFMTCSVIKILEDNVLLVELFDSLGAPEMTTTSINDQLVKEGLASYEIGYILKDNSQKHIEVWDPSPEEIISNEVHNLNPVSAKSLPNENFQSLYNKELPVHICNVISPEKIYVQWLLTENLLNSLEEKMIAAYENSKWEPVKWENDMHCAVKIQDKNQWRRGQIIRMVTDTLVEVLLYDVGVELVVNVDCLRKLEENLKTMGRLSLECSLVDIRPAGGSDKWTATACDCLSLYLTGAVATIILQVDSEENNTTWPLPVKIFCRDEKGERVDVSKYLIKKGLALRERRINNLDNSHSLSEKSLEVPLEQEDSVVTNCIKTNFDPDKKTADIISEQKVSEFQEKILEPRTTRGYKPPAIPNMNVFEATVSCVGDDGTIFVVPKLSEFELIKMTNEIQSNLKCLGLLEPYFWKKGEACAVRGSDTLWYRGKVMEVVGGAVRVQYLDHGFTEKIPQCHLYPILLYPDIPQFCIPCQLHNTTPVGNVWQPDAIEVLQQLLSKRQVDIHIMKPRSDHDKKYEEEQWEIRFEELLSAETDTPLLPPYLSSSLPSPGELYAVQVKHVVSPNEVYICLDSIETSNQSNQHSDTDDSGVSGESESESLDEALQRVNKKVEALPPLTDFRTEMPCLAEYDDGLWYRAKIVAIKEFNPLSILVQFVDYGSTAKLTLNRLCQIPSHLMRYPARAIKVLLAGFKPPLRDLGETRIPYCPKWSMEALWAMIDCLQGKQLYAVSMAPAPEQIVTLYDDEQHPVHMPLVEMGLADKDE>sp|Q9BXT8-5|RNF17_HUMAN Isoform 5 of RING finger protein 17 OS=Homosapiens OX=9606 GN=RNF17MAAEASKTGPSRSSYQRMGRKSQPWGAAEIQCTRCGRRVSRSSGHHCELQCGHAFCELCLLMTEECTTIICPDCEVATAVNTRQRYYPMAGYIKEDSIMEKLQPKTIKNCSQDFKKTADQLTTGLERSASTDKTLLNSSAVMLDTNTAEEIDEALNTAHHSFEQLSIAGKALEHMQKQTIEERERVIEVVEKQFDQLLAFFDSRKKNLCEEFARTTDDYLSNLIKAKSYIEEKKNNLNAAMNIARALQLSPSLRTYCDLNQIIRTLQLTSDSELAQVSSPQLRNPPRLSVNCSEIICMFNNMGKIEFRDSTKCYPQENEIRQNVQKKYNNKKELSCYDTYPPLEKKKVDMSVLTSEAPPPPLQPETNDVHLEAKNFQPQKDVATASPKTIAVLPQMGSSPDVIIEEIIEDNVESSAELVFVSHVIDPCHFYIRKYSQIKDAKVLEKKVNEFCNRSSHLDPSDILELGARIFVSSIKNGMWCRGTITELIPIEGRNTRKPCSPTRLFVHEVALIQIFMVDFGNSEVLIVTGVVDTHVRPEHSAKQHIALNDLCLVLRKSEPYTEGLLKDIQPLAQPCSLKDIVPQNSNEGWEEEAKVEFLKMVNNKAVSMKVFREEDGVLIVDLQKPPPNKISSDMPVSLRDALVFMELAKFKSQSLRSHFEKNTTLHYHPPILPKEMTDVSVTVCHINSPGDFYLQLIEGLDILFLLKTIEEFYKSEDGENLEILCPVQDQACVAKFEDGIWYRAKVIGLPGHQEVEVKYVDFGNTAKITIKDVRKIKDEFLNAPEKAIKCKLAYIEPYKRTMQWSKEAKEKFEEKAQDKFMTCSVIKILEDNVLLVELFDSLGAPEMTTTSINDQLVKEGLASYEIGYILKDNSQKHIEVWDPSPEEIISNEVHNLNPVSAKSLPNENFQSLYNKELPVHICNVISPEKIYVQWLLTENLLNSLEEKMIAAYENSKWEPVKWENDMHCAVKIQDKNQWRRGQIIRMVTDTLVEVLLYDVGVELVVNVDCLRKLEENLKTMGRLSLECSLVDIRPAGGSDKWTATACDCLSLYLTGAVATIILQVDSEENNTTWPLPVKIFCRDEKGERVDVSKYLIKKGLALRERRINNLDNSHSLSEKSLEVPLEQEDSVVTNCIKTNFDPDKKTADIISEQKVSEFQEKILEPRTTRGYKPPAIPNMNVFEATVSCVGDDGTIFVVPKLSEFELIKMTNEIQSNLKCLGLLEPYFWKKGEACAVRGSDTLWYRGKVMEVVGGAVRVQYLDHGFTEKIPQCHLYPILLYPDIPQFCIPCQLHNTTPVGNVWQPDAIEVLQQLLSKRQELPKNPWEKLSIHLYFDGMSLSYFMAYYKYCTSEHTEEMLKEKPRSDHDKKYEEEQWEIRFEELLSAETDTPLLPPYLSSSLPSPGELYAVQVKHVVSPNEVYICLDSIETSNQSNQHSDTDDSGVSGESESESLDEALQRVNKKVEALPPLTDFRTEMPCLAEYDDGLWYRAKIVAIKEFNPLSILVQFVDYGSTAKLTLNRLCQIPSHLMRYPARAIKVLLAGFKPPLRDLGETRIPYCPKWSMEALWAMIDCLQGKQLYAVSMAPAPEQIVTLYDDEQHPVHMPLVEMGLADKDE>sp|Q9Y2J0|RP3A_HUMAN Rabphilin-3A OS=Homo sapiens OX=9606 GN=RPH3A PE=1SV=1MTDTVFSNSSNRWMYPSDRPLQSNDKEQLQAGWSVHPGGQPDRQRKQEELTDEEKEIINRVIARAEKMEEMEQERIGRLVDRLENMRKNVAGDGVNRCILCGEQLGMLGSACVVCEDCKKNVCTKCGVETNNRLHSVWLCKICIEQREVWKRSGAWFFKGFPKQVLPQPMPIKKTKPQQPVSEPAAPEQPAPEPKHPARAPARGDSEDRRGPGQKTGPDPASAPGRGNYGPPVRRASEARMSSSSRDSESWDHSGGAGDSSRSPAGLRRANSVQASRPAPGSVQSPAPPQPGQPGTPGGSRPGPGPAGRFPDQKPEVAPSDPGTTAPPREERTGGVGGYPAVGAREDRMSHPSGPYSQASAAAPQPAAARQPPPPEEEEEEANSYDSDEATTLGALEFSLLYDQDNSSLQCTIIKAKGLKPMDSNGLADPYVKLHLLPGASKSNKLRTKTLRNTRNPIWNETLVYHGITDEDMQRKTLRISVCDEDKFGHNEFIGETRFSLKKLKPNQRKNFNICLERVIPMKRAGTTGSARGMALYEEEQVERVGDIEERGKILVSLMYSTQQGGLIVGIIRCVHLAAMDANGYSDPFVKLWLKPDMGKKAKHKTQIKKKTLNPEFNEEFFYDIKHSDLAKKSLDISVWDYDIGKSNDYIGGCQLGISAKGERLKHWYECLKNKDKKIERWHQLQNENHVSSD>sp|Q9Y2J0-2|RP3A_HUMAN Isoform 2 of Rabphilin-3A OS=Homo sapiens OX=9606GN=RPH3AMTDTVFSNSSNRWMYPSDRPLQSKLQAGWSVHPGGQPDRQRKQEELTDEEKEIINRVIARAEKMEEMEQERIGRLVDRLENMRKNVAGDGVNRCILCGEQLGMLGSACVVCEDCKKNVCTKCGVETNNRLHSVWLCKICIEQREVWKRSGAWFFKGFPKQVLPQPMPIKKTKPQQPVSEPAAPEQPAPEPKHPARAPARGDSEDRRGPGQKTGPDPASAPGRGNYGPPVRRASEARMSSSSRDSESWDHSGGAGDSSRSPAGLRRANSVQASRPAPGSVQSPAPPQPGQPGTPGGSRPGPGPAGRFPDQKPEVAPSDPGTTAPPREERTGGVGGYPAVGAREDRMSHPSGPYSQASAAAPQPAAARQPPPPEEEEEEANSYDSDEATTLGALEFSLLYDQDNSSLQCTIIKAKGLKPMDSNGLADPYVKLHLLPGASKSNKLRTKTLRNTRNPIWNETLVYHGITDEDMQRKTLRISVCDEDKFGHNEFIGETRFSLKKLKPNQRKNFNICLERVIPMKRAGTTGSARGMALYEEEQVERVGDIEERGKILVSLMYSTQQGGLIVGIIRCVHLAAMDANGYSDPFVKLWLKPDMGKKAKHKTQIKKKTLNPEFNEEFFYDIKHSDLAKKSLDISVWDYDIGKSNDYIGGCQLGISAKGERLKHWYECLKNKDKKIERWHQLQNENHVSSD>sp|Q15287|RNPS1_HUMAN RNA-binding protein with serine-rich domain 1OS=Homo sapiens OX=9606 GN=RNPS1 PE=1 SV=1MDLSGVKKKSLLGVKENNKKSSTRAPSPTKRKDRSDEKSKDRSKDKGATKESSEKDRGRDKTRKRRSASSGSSSTRSRSSSTSSSGSSTSTGSSSGSSSSSASSRSGSSSTSRSSSSSSSSGSPSPSRRRHDNRRRSRSKSKPPKRDEKERKRRSPSPKPTKVHIGRLTRNVTKDHIMEIFSTYGKIKMIDMPVERMHPHLSKGYAYVEFENPDEAEKALKHMDGGQIDGQEITATAVLAPWPRPPPRRFSPPRRMLPPPPMWRRSPPRMRRRSRSPRRRSPVRRRSRSPGRRRHRSRSSSNSSR>sp|Q15287-2|RNPS1_HUMAN Isoform 2 of RNA-binding protein with serine-rich domain 1 OS=Homo sapiens OX=9606 GN=RNPS1MAPSPTKRKDRSDEKSKDRSKDKGATKESSEKDRGRDKTRKRRSASSGSSSTRSRSSSTSSSGSSTSTGSSSGSSSSSASSRSGSSSTSRSSSSSSSSGSPSPSRRRHDNRRRSRSKSKPPKRDEKERKRRSPSPKPTKVHIGRLTRNVTKDHIMEIFSTYGKIKMIDMPVERMHPHLSKGYAYVEFENPDEAEKALKHMDGGQIDGQEITATAVLAPWPRPPPRRFSPPRRMLPPPPMWRRSPPRMRRRSRSPRRRSPVRRRSRSPGRRRHRSRSSSNSSR>sp|Q15287-3|RNPS1_HUMAN Isoform 3 of RNA-binding protein with serine-rich domain 1 OS=Homo sapiens OX=9606 GN=RNPS1MAPSPTKRKDRSDEKSKDRSKDKGATKESSEKDRGRDKTRKRRSASSSGSSTSTGSSSGSSSSSASSRSGSSSTSRSSSSSSSSGSPSPSRRRHDNRRRSRSKSKPPKRDEKERKRRSPSPKPTKVHIGRLTRNVTKDHIMEIFSTYGKIKMIDMPVERMHPHLSKGYAYVEFENPDEAEKALKHMDGGQIDGQEITATAVLAPWPRPPPRRFSPPRRMLPPPPMWRRSPPRMRRRSRSPRRRSPVRRRSRSPGRRRHRSRSSSNSSR>sp|Q2PPJ7|RGPA2_HUMAN Ral GTPase-activating protein subunit alpha-2OS=Homo sapiens OX=9606 GN=RALGAPA2 PE=1 SV=2MFSRRSHGDVKKSTQKVLDPKKDVLTRLKHLRALLDNVDANDLKQFFETNYSQIYFIFYENFIALENSLKLKGNNKSQREELDSILFLFEKILQFLPERIFFRWHYQSIGSTLKKLLHTGNSIKIRCEGIRLFLLWLQALQTNCAEEQVLIFACLVPGFPAVMSSRGPCTLETLINPSPSVADVKIYPEEITPLLPAISGEKIAEDQTCFFLQILLKYMVIQAASLEWKNKENQDTGFKFLFTLFRKYYLPHLFPSFTKLTNIYKPVLDIPHLRPKPVYITTTRDNENIYSTKIPYMAARVVFIKWIVTFFLEKKYLTATQNTKNGVDVLPKIIQTVGGGAVQERAPELDGGGPTEQDKSHSNSSTLSDRRLSNSSLCSIEEEHRMVYEMVQRILLSTRGYVNFVNEVFHQAFLLPSCEIAVTRKVVQVYRKWILQDKPVFMEEPDRKDVAQEDAEKLGFSETDSKEASSESSGHKRSSSWGRTYSFTSAMSRGCVTEEENTNVKAGVQALLQVFLTNSANIFLLEPCAEVPVLLKEQVDACKAVLIIFRRMIMELTMNKKTWEQMLQILLRITEAVMQKPKDKQIKDLFAQSLAGLLFRTLMVAWIRANLCVYISRELWDDFLGVLSSLTEWEELINEWANIMDSLTAVLARTVYGVEMTNLPLDKLSEQKEKKQRGKGCVLDPQKGTTVGRSFSLSWRSHPDVTEPMRFRSATTSGAPGVEKARNIVRQKATEVEECQQSENAPAAGSGHLTVGQQQQVLRSSSTSDIPEPLCSDSSQGQKAENTQNSSSSEPQPIQENKGHVKREHEGITILVRRSSSPAELDLKDDLQQTQGKCRERQKSESTNSDTTLGCTNEAELSMGPWQTCEEDPELNTPTDVVADADARHWLQLSPTDASNLTDSSECLTDDCSIIAGGSLTGWHPDSAAVLWRRVLGILGDVNNIQSPKIHARVFCYLYELWYKLAKIRDNLAISLDNQSSPSPPVLIPPLRMFASWLFKAATLPNEYKEGKLQAYRLICAMMTRRQDVLPNSDFLVHFYLVMHLGLTSEDQDILNTIIRHCPPRFFSLGFPGFSMLVGDFITAAARVLSTDILTAPRSEAVTVLGSLVCFPNTYQEIPLLQSVPEVNEAITGTEDVKHYLINILLKNATEEPNEYARCIAVCSLGVWICEELAQCTSHPQVKEAINVIGVTLKFPNKIVAQVACDVLQLLVSYWEKLQMFETSLPRKMAEILVATVAFLLPSAEYSSVETDKKFIVSLLLCLLDWCMALPVSVLLHPVSTAVLEEQHSARAPLLDYIYRVLHCCVCGSSTYTQQSHYILTLADLSSTDYDPFLPLANVKSSEPVQYHSSAELGNLLTVEEEKKRRSLELIPLTARMVMAHLVNHLGHYPLSGGPAILHSLVSENHDNAHVEGSELSFEVFRSPNLQLFVFNDSTLISYLQTPTEGPVGGSPVGSLSDVRVIVRDISGKYSWDGKVLYGPLEGCLAPNGRNPSFLISSWHRDTFGPQKDSSQVEEGDDVLDKLLENIGHTSPECLLPSQLNLNEPSLTPCGMNYDQEKEIIEVILRQNAQEDEYIQSHNFDSAMKVTSQGQPSPVEPRGPFYFCRLLLDDLGMNSWDRRKNFHLLKKNSKLLRELKNLDSRQCRETHKIAVFYIAEGQEDKCSILSNERGSQAYEDFVAGLGWEVDLSTHCGFMGGLQRNGSTGQTAPYYATSTVEVIFHVSTRMPSDSDDSLTKKLRHLGNDEVHIVWSEHSRDYRRGIIPTAFGDVSIIIYPMKNHMFFIAITKKPEVPFFGPLFDGAIVSGKLLPSLVCATCINASRAVKCLIPLYQSFYEERALYLEAIIQNHREVMTFEDFAAQVFSPSPSYSLSGTD>sp|Q2PPJ7-2|RGPA2_HUMAN Isoform 2 of Ral GTPase-activating proteinsubunit alpha-2 OS=Homo sapiens OX=9606 GN=RALGAPA2MFSRRSHGDVKKSTQKVLDPKKDVLTRLKHLRALLDNVDANDLKQFFETNYSQIYFIFYENFIALENSLKLKGNNKSQREELDSILFLFEKILQFLPERIFFRWHYQSIGSTLKKLLHTGNSIKIRCEGIRLFLLWLQALQTNCAEEQVLIFACLVPGFPAVMSSRGPCTLETLINPSPSVADVKIYPEEITPLLPAISGEKIAEDQTCFFLQILLKYMVIQAASLEWKNKENQDTGFKFLFTLFRKYYLPHLFPSFTKLTNIYKPVLDIPHLRPKPVYITTTRDNENIYSTKIPYMAARVVFIKWIVTFFLEKKYLTATQNTKNGVDVLPKIIQTVGGGAVQERAPELDGGGPTEQDKSHSNSSTLSDRRLSNSSLCSIEEEHRMVYEMVQRILLSTRGYVNFVNEVFHQAFLLPSCEIAVTRKVVQVYRKWILQDKPVFMEEPDRKDVAQEDAEKLGFSETDSKEASSESSGHKRSSSWGRTYSFTSAMSRGCVTEEENTNVKAGVQALLQVFLTNSANIFLLEPCAEVPVLLKEQVDACKAVLIIFRRMIMELTMNKKTWEQMLQILLRITEAVMQKPKDKQIKDLFAQSLAGLLFRTLMVAWIRANLCVYISRELWDDFLGVLSSLTEWEELINEWANIMDSLTAVLARTVYGVEMTNLPLDKLSEQKEKKQRGKGCVLDPQKGTTVGRSFSLSWRSHPDVTEPMRFRSATTSGAPGVEKARNIVRQKATEVEECQQSENAPAAGSGHLTVGQQQQVLRSSSTSDIPEPLCSDSSQGQKAENTQNSSSSEPQPIQENKGHVKREHEGITILVRRSSSPAELDLKDDLQQTQGKCRERQKSESTNSDTTLGCTNEAELSMGPWQTCEEDPELNTPTDVVADADARHWLQLSPTDASNLTDSSECLTDDCSIIAGGSLTGWHPDSAAVLWRRVLGILGDVNNIQSPKIHARVFCYLYELWYKLAKIRDNLAISLDNQSSPSPPVLIPPLRMFASWLFKAATLPNEYKEGKLQAYRLICAMMTRRQDVLPNSDFLVHFYLVMHLGLTSEDQDILNTIIRHCPPRFFSLGFPGFSMLVGDFITAAARVLSTDILTAPRSEAVTVLGSLVCFPNTYQEIPLLQSVPEVNEAITGTEDVKHYLINILLKNATEEPNEYARCIAVCSLGVWICEELAQCTSHPQVKEAINVIGVTLKFPNKIVAQVACDVLQLLVSYWEKLQMFETSLPRKMAEILVATVAFLLPSAEYSSVETDKKFIVSLLLCLLDWCMALPVSVLLHPVSTAVLEEQHSARAPLLDYIYRVLHCCVCGSSTYTQQSHYILTLADLSSTDYDPFLPLANVKSSEPVQYHSSAELGNLLTVEEEKKRRSLELIPLTARMVMAHLVNHLGHYPLSGGPAILHSLVSENHDNAHVEGSELSFEVFRSPNLQLFVFNDSTLISYLQTPTEGPVGGSPVGSLSDVRVIVRDISGKYSWDGKVLYGPLEGCLAPNGRNPSFLISSWHRDTFGPQKDSSQVEEGDDVLDKLLENIGHTSPECLLPSQLNLNEPSLTPCGMNYDQEKEIIEVILRQNAQEDEYIQSHNFDSAMKVTSQGQPSPVEPRGPFYFCRLLLDDLGMNSWDRRKNFHLLKKNSKLLRELKNLDSRQCRETHKIAVFYIAEGQEDKCSILSNERGSQAYEDFVAGLGWEVDLSTHCGFMGGLQRNGSTGQTAPYYATSTVEVIFHVSTRMPSDSDDSLTKKLRHLGNDEVHIVWSEHSRDYRRGIIPTAFGDVSIIIYPMKNHMFFIAITKKPEVPFFGPLFDGAIVSGKLLPSLVCATCINASRAVKCLIPLYQSLYLFALNV>sp|Q2PPJ7-3|RGPA2_HUMAN Isoform 3 of Ral GTPase-activating proteinsubunit alpha-2 OS=Homo sapiens OX=9606 GN=RALGAPA2MFSRRSHGDVKKSTQKVLDPKKDVLTRLKHLRALLDNVDANDLKQFFETNYSQIYFIFYENFIALENSLKLKGNNKSQREELDSILFLFEKILQFLPERIFFRWHYQSIGSTLKKLLHTGNSIKIRCEGIRLFLLWLQALQTNCAEEQVLIFACLVPGFPAVMSSRGPCTLETLINPSPSVADVKIYPEEITPLLPAISGEKIAEDQTCFFLQILLKYMVIQAASLEWKNKENQDTGFKFLFTLFRKYYLPHLFPSFTKLTNIYKPVLDIPHLRPKPVYITTTRDNENIYSTKIPYMAARVVFIKWIVTFFLEKKYLTATQNTKNGVDVLPKIIQTVGGGAVQERAPELDGGGPTEQDKSHSNSSTLSDRRLSNSSLCSIEEEHRMVYEMVQRILLSTRGYVNFVNEVFHQAFLLPSCEIAVTRKVVQVYRKWILQDKPVFMEEPDRKDVAQEDAEKLGFSETDSKEASSESSGHKRSSSWGRTYSFTSAMSRGCVTEEENTNVKAGVQALLQVFLTNSANIFLLEPCAEVPVLLKEQVDACKAVLIIFRRMIMELTMNKKTWEQMLQILLRITEAVMQKPKDKQIKDLFAQSLAGLLFRTLMVAWIRANLCVYISRELWDDFLGVLSSLTEWEELINEWANIMDSLTAVLARTVYGVEMTNLPLDKLSEQKEKKQRGKGCVLDPQKGTTVGRSFSLSWRSHPDVTEPMRFRSATTSGAPGVEKARNIVRQKATEVEECQQSENAPAAGSGHLTVGQQQQVLRSSSTSDIPEPLCSDSSQGQKAENTQNSSSSEPQPIQENKGHVKREHEGITILVRRSSSPAELDLKDDLQQTQGKCRERQKSESTNSDTTLGCTNEAELSMGPWQTCEEDPELNTPTDVVADADARHWLQLSPTDASNLTDSSECLTDDCSIIAGGSLTGWHPDSAAVLWRRVLGILGDVNNIQSPKIHARVFCYLYELWYKLAKIRDNLAISLDNQSSPSPPVLIPPLRMFASWLFKAATLPNEYKEGKLQAYRLICAMMTRRQDVLPNSDFLVHFYLVMHLGLTSEDQDILNTIIRHCPPRFFSLGFPGFSMLVGDFITAAARVLSTDILTAPRSEAVTVLGSLVCFPNTYQEIPLLQSVPEVNEAITGTEDVKHYLINILLKNATEEPNEYARCIAVCSLGVWICEELAQCTSHPQVKEAINVIGVTLKFPNKIVAQVACDVLQLLVSYWEKLQMFETSLPRKMAEILVATVAFLLPSAEYSSVETDKKFIVSLLLCLLDWCMALPVSVLLHPVSTAVLEEQHSARAPLLDYIYRVLHCCVCGSSTYTQQSHYILTLADLSSTDYDPFLPLANVKSSEPVQYHSSAELGNLLTVEEEKKRRSLELIPLTARMVMAHLVNHLGHYPLSGGPAILHSLVSENHDNAHVEGSELSFEVFRSPNLQLFVFNDSTLISYLQTPTEGPVGGSPVGSLSDVRVIVRDISGKYSWDGKVLYGPLEGCLAPNGRNPSFLISSWHRDTFGPQKDSSQVEEGDDVLDKLLENIGHTSPECLLPSQLNLNEPSLTPCGMNYDQEKEIIEVILRQNAQEDEYIQSHNFDSAMKVTSQGQPSPVEPRGPFYFCRLLLDDLGMNSWDRRKNFHLLKKNSKLLRELKNLDSRQCRETHKIAVFYIAEGQEDKCSILSNERGSQAYEDFVAGLGWEVDLSTHCGFMGGLQRNGSTGQTAPYYATSTVEVIFHVSTRMPSDSDDSLTKKLRHLGNDEVHIVWSEHSRDYRRGIIPTAFGDVSIIIYPMKNHMFFIAITKKPEVPFFGPLFDGAIVSGKLLPSLVCATCINASRAVKCLIPLYQSPRVR>sp|P0C7M4|RHF2B_HUMAN Rhox homeobox family member 2B OS=Homo sapiensOX=9606 GN=RHOXF2B PE=1 SV=1MEPPDQCSQYMTSLLSPAVDDEKELQDMNAMVLSLTEEVKEEEEDAQPEPEQGTAAGEKLKSAGAQGGEEKDGGGEEKDGGGAGVPGHLWEGNLEGTSGSDGNVEDSDQSEKEPGQQYSRPQGAVGGLEPGNAQQPNVHAFTPLQLQELECIFQREQFPSEFLRRRLARSMNVTELAVQIWFENRRAKWRRHQRALMARNMLPFMAVGQPVMVTAAEAITAPLFISGMRDDYFWDHSHSSSLCFPMPPFPPPSLPLPLMLLPPMPPAGQAEFGPFPFVIVPSFTFPNV>sp|Q969G6|RIFK_HUMAN Riboflavin kinase OS=Homo sapiens OX=9606 GN=RFKPE=1 SV=2MRHLPYFCRGQVVRGFGRGSKQLGIPTANFPEQVVDNLPADISTGIYYGWASVGSGDVHKMVVSIGWNPYYKNTKKSMETHIMHTFKEDFYGEILNVAIVGYLRPEKNFDSLESLISAIQGDIEEAKKRLELPEHLKIKEDNFFQVSKSKIMNGH>sp|P0DJD1|RGPD2_HUMAN RANBP2-like and GRIP domain-containing protein 2OS=Homo sapiens OX=9606 GN=RGPD2 PE=2 SV=1MRRSKAYGERYLASVQGSAPSPGKKLRGFYFAKLYYEAKEYDLAKKYVCTYLSVQERDPRAHRFLGLLYELEENTEKAVECYRRSLELNPPQKDLVLKIAELLCKNDVTDGRAKYWVERAAKLFPGSPAIYKLKEHLLDCEGEDGWNKLFDWIQSELYVRPDDVHMNIRLVELYRSNKRLKDAVARCHEAERNIALRSSLEWNSCVVQTLKEYLESLQCLESDKSDWRATNTDLLLAYANLMLLTLSTRDVQESRELLESFDSALQSAKSSLGGNDELSATFLEMKGHFYMHAGSLLLKMGQHGNNVQWQALSELAALCYVIAFQVPRPKIKLIKGEAGQNLLEMMACDRLSQSGHMLLNLSRGKQDFLKEVVETFANKSGQSVLYNALFSSQSSKDTSFLGSDDIGNIDVQEPELEDLARYDVGAIQAHNGSLQHLTWLGLQWNSLPALPGIRKWLKQLFHHLPQETSRLETNAPESICILDLEVFLLGVVYTSHLQLKEKCNSHHSSYQPLCLPLPVCKRLCTERQKSWWDAVCTLIHRKAVPGNSAELRLVVQHEINTLRAQEKHGLQPALLVHWAKCLQKMGRGLNSSYDQQEYIGRSVHYWKKVLPLLKIIKKNSIPEPIDPLFKHFHSVDIQASEIVEYEEDAHITFAILDAVHGNIEDAVTAFESIKSVVSYWNLALIFHRKAEDIENDAVFPEEQEECKNYLRKTRDYLIKIIDDSDSNLSVVKKLPVPLESVKEMLKSVMQELEDYSEGGPLYKNGSLRNADSEIKHSTPSPTKYSLSPSKSYKYSPKTPPRWAEDQNSLRKMICQEVKAITKLNSSKSASRHRWPTENYGPDSVPDGYQGSQTFHGAPLTVATTGPSVYYSQSPAYNSQYLLRPAANVTPTKGSSNTEFKSTKEGFSIAVSADGFKFGISEPGNQEKKSEKPLENDTGFQAQDISGQKNGRGVIFGQTSSTFTFADVAKSTSGEGFQFGKKDPNFKGFSGAGEKLFSSQCGKMANKANTSGDFEKDDDACKTEDSDDIHFEPVVQMPEKVELVTGEEGEKVLYSQGVKLFRFDAEISQWKERGLGNLKILKNEVNGKPRMLMRRDQVLKVCANHWITTTMNLKPLSGSDRAWMWLASDFSDGDAKLERLAAQFKTPELAEEFKQKFEECQRLLLDIPLQTPHKLVDTGRAAKLIQRAEEMKSGLKDFKTFLTNDQTKVTEEENKGSGTGAAGASDTTIKPNPENTGPTLEWDNYDLREDALDDNVSSSSVHDSPLASSPVRKNIFRFDESTTGFNFSFKSALSLSKSPAKLNQSGTSVGTDEESDVTQEEERDGQYFEPVVPLPDLVEVSSGEENEQVVFSHMAELYRYDKDVGQWKERGIGDIKILQNYDNKQVRIVMRRDQVLKLCANHRITPDMSLQNMKGTERVWVWTACDFADGERKVEHLAVRFKLQDVADSFKKIFDEAKTAQEKDSLITPHVSRSSTPRESPCGKIAVAVLEETTRERTDVIQGDDVADAASEVEVSSTSETTTKAVVSPPKFVFGSESVKRIFSSEKSNPFAFGNSSATGSLFGFSFNAPLKSNDSETSSVAQSGSESKVEPKKCELSKNSDIEQSSDSKVKNLSASFPMEESSINYTFKTPEKEPPLWHAEFTKEELVQKLSSTTKSADQLNGLLRETEATSAVLMEQIKLLKSEIRRLERNQEESAANVEHLKNVLLQFIFLKPGSERESLLPVINTMLQLSPEEKGKLAAVAQGLQETSIPKKK>sp|A6NKT7|RGPD3_HUMAN RanBP2-like and GRIP domain-containing protein 3OS=Homo sapiens OX=9606 GN=RGPD3 PE=3 SV=2MSCSKAYGERYVASVQGSAPSPRKKSTRGFYFAKLYYEAKEYDLAKKYICTYINVREMDPRAHRFLGLLYELEENTEKAVECYRRSVELNPTQKDLVLKIAELLCKNDVTDGRAEYWVERAAKLFPGSPAIYKLKEQLLDCEGEDGWNKLFDLIQSELYVRPDDVHVNIRLVELYRSTKRLKDAVARCHEAERNIALRSSLEWNSCVVQTLKEYLESLQCLESDKSDWRATNTDLLLAYANLMLLTLSTRDVQESRELLESFDSALQSAKSSLGGNDELSATFLEMKGHFYMHAGSLLLKMGQHGNNVQWRALSELAALCYLIAFQVPRPKIKLIKGEAGQNLLEMMACDRLSQSGHMLLNLSRGKQDFLKVVVETFANKSGQSALYDALFSSQSPKDTSFLGSDDIGNIDVQEPELEDLARYDVGAIRAHNGSLQHLTWLGLQWNSLPALPGIRKWLKQLFHHLPQETSRLETNAPESICILDLEVFLLGVVYTSHLQLKEKCNSHHSSYQPLCLPLPVCKQLCTERQKSWWDAVCTLIHRKAVPGNSAKLRLLVQHEINTLRAQEKHGLQPALLVHWAKCLQKMGSGLNSFYDQREYIGRSVHYWKKVLPLLKIIKKKNSIPEPIDPLFKHFHSVDIQASEIVEYEEDAHVTFAILDAVNGNIEDAMTAFESIKSVVSYWNLALIFHRKAEDIANDALSPEEQEECKNYLRKTRGYLIKILDDSDSNLSVVKKLPVPLESVKEMLKSVMQELENYSEGGPLYKNGSLRNADSEIKHSTPSPTKYSLSPSKSYKYSPKTPPRWAEDQNSLLKMIRQEVKAIKEEMQELKLNSSKSASHHRWPTENYGPDSVPDGYQGSQTFHGAPLTVATTGPSVYYSQSPAYNSQYLLRPAANVTPTKGSSNTEFKSTKEGFSIPVSADGFKFGISEPGNQEKKSEKPLENDTGLQAQDISGRKKGRGVIFGQTSSTFTFADVAKSTSGEGFQFGKKDLNFKGFSGAGEKLFSSQYGKMANKANTSGDFEKDDDAYKTEDSDDIHFEPVVQMPEKVELVTGEEGEKVLYSQGVKLFRFDAEVSQWKERGLGNLKILKNEVNGKVRMLMQREQVLKVCANHWITTTMNLKPLSGSDRAWMWSASDFSDGDAKLERLAAKFKTPELAEEFKQKFEECQRLLLDIPLQTPHKLVDTGRAAKLIQRAEEMKSGLKDFKTFLTNDQTKVAEEENKGSGTGAAGASDTTIKPNAENTGPTLEWDNYDLREDALDDSVSSSSVHASPLASSPVRKNLFHFDESTTGSNFSFKSALSLSKSPAKLNQSGTSVGTDEESDVTQEEERDGQYFEPVVPLPDLVEVSSGEENEQVVFSHRAEFYRYDKDVGQWKERGIGDIKILQNYDNKHVRILMRRDQVLKLCANHRITPDMSLQNMKGTERVWVWTACDFADGERKVEHLAVRFKLQDVADSFKKIFDEAKTAQEKDSLITPHVSRSSTPRESPCGKIAVAVLEETTRERTDVIQGDDVADAASEVEVSSTSETTTKAVVSPPKFVFGSESVKRIFSSEKSKPFAFGNSSATGSLFGFSFNAPLKSNNSETSSVAQSGSESKVEPKKCELSKNSDIEQSSDSKVKNLSASFPTEESSINYTFKTPEKEPPLWYAEFTKEELVQKLSSTTKSADHLNGLLREIEATNAVLMEQIKLLKSEIRRLERNQEQEVSAANVEHLKNVLLQFIFLKPGSERERLLPVINTMLQLSLEEKGKLAAVAQGEE>sp|Q68DV7|RNF43_HUMAN E3 ubiquitin-protein ligase RNF43 OS=Homo sapiensOX=9606 GN=RNF43 PE=1 SV=1MSGGHQLQLAALWPWLLMATLQAGFGRTGLVLAAAVESERSAEQKAIIRVIPLKMDPTGKLNLTLEGVFAGVAEITPAEGKLMQSHPLYLCNASDDDNLEPGFISIVKLESPRRAPRPCLSLASKARMAGERGASAVLFDITEDRAAAEQLQQPLGLTWPVVLIWGNDAEKLMEFVYKNQKAHVRIELKEPPAWPDYDVWILMTVVGTIFVIILASVLRIRCRPRHSRPDPLQQRTAWAISQLATRRYQASCRQARGEWPDSGSSCSSAPVCAICLEEFSEGQELRVISCLHEFHRNCVDPWLHQHRTCPLCMFNITEGDSFSQSLGPSRSYQEPGRRLHLIRQHPGHAHYHLPAAYLLGPSRSAVARPPRPGPFLPSQEPGMGPRHHRFPRAAHPRAPGEQQRLAGAQHPYAQGWGLSHLQSTSQHPAACPVPLRRARPPDSSGSGESYCTERSGYLADGPASDSSSGPCHGSSSDSVVNCTDISLQGVHGSSSTFCSSLSSDFDPLVYCSPKGDPQRVDMQPSVTSRPRSLDSVVPTGETQVSSHVHYHRHRHHHYKKRFQWHGRKPGPETGVPQSRPPIPRTQPQPEPPSPDQQVTRSNSAAPSGRLSNPQCPRALPEPAPGPVDASSICPSTSSLFNLQKSSLSARHPQRKRRGGPSEPTPGSRPQDATVHPACQIFPHYTPSVAYPWSPEAHPLICGPPGLDKRLLPETPGPCYSNSQPVWLCLTPRQPLEPHPPGEGPSEWSSDTAEGRPCPYPHCQVLSAQPGSEEELEELCEQAV>sp|Q68DV7-2|RNF43_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF43OS=Homo sapiens OX=9606 GN=RNF43MSGGHQLQLAALWPWLLMATLQAGFGRTGLVLAAAVESERSAEQKAIIRVIPLKMDPTGKLNLTLEGVFAGVAEITPAEGKLMQARMAGERGASAVLFDITEDRAAAEQLQQPLGLTWPVVLIWGNDAEKLMEFVYKNQKAHVRIELKEPPAWPDYDVWILMTVVGTIFVIILASVLRIRCRPRHSRPDPLQQRTAWAISQLATRRYQASCRQARGEWPDSGSSCSSAPVCAICLEEFSEGQELRVISCLHEFHRNCVDPWLHQHRTCPLCMFNITEGDSFSQSLGPSRSYQEPGRRLHLIRQHPGHAHYHLPAAYLLGPSRSAVARPPRPGPFLPSQEPGMGPRHHRFPRAAHPRAPGEQQRLAGAQHPYAQGWGLSHLQSTSQHPAACPVPLRRARPPDSSGSGESYCTERSGYLADGPASDSSSGPCHGSSSDSVVNCTDISLQGVHGSSSTFCSSLSSDFDPLVYCSPKGDPQRVDMQPSVTSRPRSLDSVVPTGETQVSSHVHYHRHRHHHYKKRFQWHGRKPGPETGVPQSRPPIPRTQPQPEPPSPDQQVTRSNSAAPSGRLSNPQCPRALPEPAPGPVDASSICPSTSSLFNLQKSSLSARHPQRKRRGGPSEPTPGSRPQDATVHPACQIFPHYTPSVAYPWSPEAHPLICGPPGLDKRLLPETPGPCYSNSQPVWLCLTPRQPLEPHPPGEGPSEWSSDTAEGRPCPYPHCQVLSAQPGSEEELEELCEQAV>sp|Q68DV7-3|RNF43_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNF43OS=Homo sapiens OX=9606 GN=RNF43MAGERGASAVLFDITEDRAAAEQLQQPLGLTWPVVLIWGNDAEKLMEFVYKNQKAHVRIELKEPPAWPDYDVWILMTVVGTIFVIILASVLRIRCRPRHSRPDPLQQRTAWAISQLATRRYQASCRQARGEWPDSGSSCSSAPVCAICLEEFSEGQELRVISCLHEFHRNCVDPWLHQHRTCPLCMFNITEGDSFSQSLGPSRSYQEPGRRLHLIRQHPGHAHYHLPAAYLLGPSRSAVARPPRPGPFLPSQEPGMGPRHHRFPRAAHPRAPGEQQRLAGAQHPYAQGWGLSHLQSTSQHPAACPVPLRRARPPDSSGSGESYCTERSGYLADGPASDSSSGPCHGSSSDSVVNCTDISLQGVHGSSSTFCSSLSSDFDPLVYCSPKGDPQRVDMQPSVTSRPRSLDSVVPTGETQVSSHVHYHRHRHHHYKKRFQWHGRKPGPETGVPQSRPPIPRTQPQPEPPSPDQQVTRSNSAAPSGRLSNPQCPRALPEPAPGPVDASSICPSTSSLFNLQKSSLSARHPQRKRRGGPSEPTPGSRPQDATVHPACQIFPHYTPSVAYPWSPEAHPLICGPPGLDKRLLPETPGPCYSNSQPVWLCLTPRQPLEPHPPGEGPSEWSSDTAEGRPCPYPHCQVLSAQPGSEEELEELCEQAV>sp|Q68DV7-4|RNF43_HUMAN Isoform 4 of E3 ubiquitin-protein ligase RNF43OS=Homo sapiens OX=9606 GN=RNF43MSGGHQLQLAALWPWLLMATLQAGFGRTGLVLAAAVESERSAEQKAIIRVIPLKMDPTGKLNLTLEGVFAGVAEITPAEGKLMQSHPLYLCNASDDDNLEPGFISIVKLESPRRAPRPCLSLASKARMAGERGASAVLFDITEDRAAAEQLQQPLGLTWPVVLIWGNDAEKLMEFVYKNQKAHVRIELKEPPAWPDYDVWILMTVVGTIFVIILASVLRIRCRPRHSRPDPLQQRTAWAISQLATRRYQASCRQARGEWPDSGSSCSSAPVCAICLEEFSEGQELRVISCLHEFHRNCVDPWLHQHRTCPLCMFNITEGDSFSQSLGPSRSYQEPGRRLHLIRQHPGHAHYHLPAAYLLGPSRSAVARPPRPGPFLPSQEPGMGPRHHRFPRAAHPRAPGEQQRLAGAQHPYAQGWGLSHLQSTSQHPAACPVPLRRARPPDSSGSGESYCTERSGYLADGPASDSSSGPCHGSSSDSVVNCTDISLQGVHGSSSTFCSSLSSDFDPLVYCSPKGDPQRVDMQPSVTSRPRSLDSVVPTGETQVSSHVHYHRHRHHHYKKRFQWHGRKPGPETGVPQSRPPIPRTQPQPEPPSPDQQVTRSNSAAPSGRLSNPQCPRALPEPAPGPVDASSICPSTSSLFNLQKSSLSARHPQRKRRGGPSEPTPGSRPQDATVHPACQIFPHYTPSVAYPWSPEAHPLICGPPGLDKRLLPETPGPCYSNSQPVWLCLTPRQPLEPHPPGEGPSEWSSDTAEGRPCPYPHCQVLSAQPGEFSEGSGCGRERRLQLNISGQVKSANKGLMEAEKDTAEMTTKILNHRDSVSCWLECRNTPPLPGATPLVGRSQGGPREVLVWLRHQKGTWKAGCDGSCL>sp|O14827|RGRF2_HUMAN Ras-specific guanine nucleotide-releasing factor 2OS=Homo sapiens OX=9606 GN=RASGRF2 PE=1 SV=2MQKSVRYNEGHALYLAFLARKEGTKRGFLSKKTAEASRWHEKWFALYQNVLFYFEGEQSCRPAGMYLLEGCSCERTPAPPRAGAGQGGVRDALDKQYYFTVLFGHEGQKPLELRCEEEQDGKEWMEAIHQASYADILIEREVLMQKYIHLVQIVETEKIAANQLRHQLEDQDTEIERLKSEIIALNKTKERMRPYQSNQEDEDPDIKKIKKVQSFMRGWLCRRKWKTIVQDYICSPHAESMRKRNQIVFTMVEAESEYVHQLYILVNGFLRPLRMAASSKKPPISHDDVSSIFLNSETIMFLHEIFHQGLKARIANWPTLILADLFDILLPMLNIYQEFVRNHQYSLQVLANCKQNRDFDKLLKQYEANPACEGRMLETFLTYPMFQIPRYIITLHELLAHTPHEHVERKSLEFAKSKLEELSRVMHDEVSDTENIRKNLAIERMIVEGCDILLDTSQTFIRQGSLIQVPSVERGKLSKVRLGSLSLKKEGERQCFLFTKHFLICTRSSGGKLHLLKTGGVLSLIDCTLIEEPDASDDDSKGSGQVFGHLDFKIVVEPPDAAAFTVVLLAPSRQEKAAWMSDISQCVDNIRCNGLMTIVFEENSKVTVPHMIKSDARLHKDDTDICFSKTLNSCKVPQIRYASVERLLERLTDLRFLSIDFLNTFLHTYRIFTTAAVVLGKLSDIYKRPFTSIPVRSLELFFATSQNNRGEHLVDGKSPRLCRKFSSPPPLAVSRTSSPVRARKLSLTSPLNSKIGALDLTTSSSPTTTTQSPAASPPPHTGQIPLDLSRGLSSPEQSPGTVEENVDNPRVDLCNKLKRSIQKAVLESAPADRAGVESSPAADTTELSPCRSPSTPRHLRYRQPGGQTADNAHCSVSPASAFAIATAAAGHGSPPGFNNTERTCDKEFIIRRTATNRVLNVLRHWVSKHAQDFELNNELKMNVLNLLEEVLRDPDLLPQERKAAANILRALSQDDQDDIHLKLEDIIQMTDCMKAECFESLSAMELAEQITLLDHVIFRSIPYEEFLGQGWMKLDKNERTPYIMKTSQHFNDMSNLVASQIMNYADVSSRANAIEKWVAVADICRCLHNYNGVLEITSALNRSAIYRLKKTWAKVSKQTKALMDKLQKTVSSEGRFKNLRETLKNCNPPAVPYLGMYLTDLAFIEEGTPNFTEEGLVNFSKMRMISHIIREIRQFQQTSYRIDHQPKVAQYLLDKDLIIDEDTLYELSLKIEPRLPA>sp|P85298|RHG08_HUMAN Rho GTPase-activating protein 8 OS=Homo sapiensOX=9606 GN=ARHGAP8 PE=1 SV=1MAGQDPALSTSHPFYDVARHGILQVAGDDRFGRRVVTFSCCRMPPSHELDHQRLLEYLKYTLDQYVENDYTIVYFHYGLNSRNKPSLGWLQSAYKEFDRKDGDLTMWPRLVSNSKLKRSSHLSLPKYWDYRYKKNLKALYVVHPTSFIKVLWNILKPLISHKFGKKVIYFNYLSELHEHLKYDQLVIPPEVLRYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEAVPRTQATGLTKPTLPPSPLMAARRRL>sp|P85298-2|RHG08_HUMAN Isoform 2 of Rho GTPase-activating protein 8OS=Homo sapiens OX=9606 GN=ARHGAP8MAGQDPALSTSHPFYDVARHGILQVAGDDRFGRRVVTFSCCRMPPSHELDHQRLLEYLKYTLDQYVENDYTIVYFHYGLNSRNKPSLGWLQSAYKEFDRKYKKNLKALYVVHPTSFIKVLWNILKPLISHKFGKKVIYFNYLSELHEHLKYDQLVIPPEVLRYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCA>sp|P85298-3|RHG08_HUMAN Isoform 3 of Rho GTPase-activating protein 8OS=Homo sapiens OX=9606 GN=ARHGAP8MAGQDPALSTSHPFYDVARHGILQVAGDDRFGRRVVTFSCCRMPPSHELDHQRLLEYLKYTLDQYVENDYTIVYFHYGLNSRNKPSLGWLQSAYKEFDRKDGDLTMWPRLVSNSKLKRSSHLSLPKYKKNLKALYVVHPTSFIKVLWNILKPLISHKFGKKVIYFNYLSELHEHLKYDQLVIPPEVLRYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEAVPRTQATGLTKPTLPPSPLMAARRRL>sp|P85298-4|RHG08_HUMAN Isoform 4 of Rho GTPase-activating protein 8OS=Homo sapiens OX=9606 GN=ARHGAP8MAGQDPALSTSHPFYDVARHGILQVAGDDRFGRRVVTFSCCRMPPSHELDHQRLLEYLKYTLDQYVENDYTIVYFHYGLNSRNKPSLGWLQSAYKEFDRKYKKNLKALYVVHPTSFIKVLWNILKPLISHKFGKKVIYFNYLSELHEHLKYDQLVIPPEVLRYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEAVPRTQATGLTKPTLPPSPLMAARRRL>sp|P85298-5|RHG08_HUMAN Isoform 5 of Rho GTPase-activating protein 8OS=Homo sapiens OX=9606 GN=ARHGAP8MAGQDPALSTSHPFYDVARHGILQVAGDDRFGRRVVTFSCCRMPPSHELDHQRLLEYLKYTLDQYVENDYTIVYFHYGLNSRNKPSLGWLQSAYKEFDRKYKKNLKALYVVHPTSFIKVLWNILKPLISHKFGKKVIYFNYLSELHEHLKYDQLVIPPEVLRYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVPGEHLQQNEQL>sp|A1A4S6|RHG10_HUMAN Rho GTPase-activating protein 10 OS=Homo sapiensOX=9606 GN=ARHGAP10 PE=1 SV=1MGLQPLEFSDCYLDSPWFRERIRAHEAELERTNKFIKELIKDGKNLIAATKSLSVAQRKFAHSLRDFKFEFIGDAVTDDERCIDASLREFSNFLKNLEEQREIMALSVTETLIKPLEKFRKEQLGAVKEEKKKFDKETEKNYSLIDKHLNLSAKKKDSHLQEADIQVEQNRQHFYELSLEYVCKLQEIQERKKFEFVEPMLSFFQGMFTFYHQGHELAKDFNHYKMELQINIQNTRNRFEGTRSEVEELMNKIRQNPKDHKRASQFTAEGYLYVQEKRPAPFGSSWVKHYCMYRKAAKKFNMIPFEHRSGGKLGDGEVFFLKECTKRHTDSIDRRFCFDIEAADRPGVSLTMQAFSEEERKQWLEALGGKEALSHSFNTAIIPRPEGNAQLDKMGFTIIRKCISAVETRGINDQGLYRVVGVSSKVQRLLSMLMDVKTCNEVDLENSADWEVKTITSALKQYLRSLPEPLMTYELHGDFIVPAKSGSPESRVNAIHFLVHKLPEKNKEMLDILVKHLTNVSNHSKQNLMTVANLGVVFGPTLMRPQEETVAALMDLKFQNIVVEILIENHEKIFRTPPDTTFPEPTCLSASPPNAPPRQSKRQGQRTKRPVAVYNLCLELEDGDNPYPSKEDTPTSSLDSLSSPSPVTTAVPGPPGPDKNHLLADGGSFGDWASTIPGQTRSSMVQWLNPQSPTTTSSNSAVTPLSPGSSPFPFSPPATVADKPPESIRSRKARAVYPCEAEHSSELSFEIGAIFEDVQTSREPGWLEGTLNGKRGLIPQNYVKLL>sp|P78317|RNF4_HUMAN E3 ubiquitin-protein ligase RNF4 OS=Homo sapiensOX=9606 GN=RNF4 PE=1 SV=1MSTRKRRGGAINSRQAQKRTREATSTPEISLEAEPIELVETAGDEIVDLTCESLEPVVVDLTHNDSVVIVDERRRPRRNARRLPQDHADSCVVSSDDEELSRDRDVYVTTHTPRNARDEGATGLRPSGTVSCPICMDGYSEIVQNGRLIVSTECGHVFCSQCLRDSLKNANTCPTCRKKINHKRYHPIYI>sp|P78317-2|RNF4_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF4OS=Homo sapiens OX=9606 GN=RNF4MSTRKRRGGAINSRQAQKRTREATSTPEISLEAEPIELVETAGDEIVDLTCESLEPVVVDLTHNDSVVIVDGPQVLSVVPSAWTDTQRSCRMDVSSFPQNAAMSSVASASVIP>sp|Q9NVU0|RPC5_HUMAN DNA-directed RNA polymerase III subunit RPC5OS=Homo sapiens OX=9606 GN=POLR3E PE=1 SV=1MANEEDDPVVQEIDVYLAKSLAEKLYLFQYPVRPASMTYDDIPHLSAKIKPKQQKVELEMAIDTLNPNYCRSKGEQIALNVDGACADETSTYSSKLMDKQTFCSSQTTSNTSRYAAALYRQGELHLTPLHGILQLRPSFSYLDKADAKHREREAANEAGDSSQDEAEDDVKQITVRFSRPESEQARQRRVQSYEFLQKKHAEEPWVHLHYYGLRDSRSEHERQYLLCPGSSGVENTELVKSPSEYLMMLMPPSQEEEKDKPVAPSNVLSMAQLRTLPLADQIKILMKNVKVMPFANLMSLLGPSIDSVAVLRGIQKVAMLVQGNWVVKSDILYPKDSSSPHSGVPAEVLCRGRDFVMWKFTQSRWVVRKEVATVTKLCAEDVKDFLEHMAVVRINKGWEFILPYDGEFIKKHPDVVQRQHMLWTGIQAKLEKVYNLVKETMPKKPDAQSGPAGLVCGDQRIQVAKTKAQQNHALLERELQRRKEQLRVPAVPPGVRIKEEPVSEEGEEDEEQEAEEEPMDTSPSGLHSKLANGLPLGRAAGTDSFNGHPPQGCASTPVARELKAFVEATFQRQFVLTLSELKRLFNLHLASLPPGHTLFSGISDRMLQDTVLAAGCKQILVPFPPQTAASPDEQKVFALWESGDMSDQHRQVLLEIFSKNYRVRRNMIQSRLTQECGEDLSKQEVDKVLKDCCVSYGGMWYLKGTVQS>sp|Q9NVU0-2|RPC5_HUMAN Isoform 2 of DNA-directed RNA polymerase IIIsubunit RPC5 OS=Homo sapiens OX=9606 GN=POLR3EMANEEDDPVVQEIDVYLAKSLAEKLYLFQYPVRPASMTYDDIPHLSAKIKPKQQKVELEMAIDTLNPNYCRSKGEQIALNVDGACADETSTYSSKLMDKQTFCSSQTTSNTSRYAAALYRQGELHLTPLHGILQLRPSFSYLDKADAKHREREAANEAGDSSQDEAEDDVKQITVRFSRPESEQARQRRVQSYEFLQKKHAEEPWVHLHYYGLRDSRSEHERQYLLCPGSSGVENTELVKSPSEYLMMLMPPSQEEEKDKPVAPSNVLSMAQLRTLPLADQIKILMKNVKVMPFANLMSLLGPSIDSVAVLRGIQKVAMLVQGNWVVKSDILYPKDSSSPHSGVPAEVLCRGRDFVMWKFTQSRWVVRKEVATVTKLCAEDVKDFLEHMAVVRINKGWEFILPYDGEFIKKHPDVVQRQHMLWTGIQAKLEKVYNLVKETMPKKPDAQSGPAGLVCGDQRIQVAKTKAQQNHALLERELQRRKEQLRVPAVPPGVRIKEEPVSEEGEEDEEQEAEEEPMDTSPSGLHSKLANGLPLGRAAGTDSFNGHPPQGCASTPVARELKAFVEATFQRQFVLTLSELKRLFNLHLASLPPGHTLFSGISDRMLQDTVLAAGCKQILVPFPPQTAASPDEQKVFALWESGDMSDQDCCVSYGGMWYLKGTVQS>sp|Q9NVU0-3|RPC5_HUMAN Isoform 3 of DNA-directed RNA polymerase IIIsubunit RPC5 OS=Homo sapiens OX=9606 GN=POLR3EMANEEDDPVVQEIDVYLAKSLAEKLYLFQYPVRPASMTYDDIPHLSAKIKPKQQKVELEMAIDTLNPNYCRSKGEQIALNVDGACADETSTYSSKLMDKQTFCSSQTTSNTSRYAAALYRQGELHLTPLHGILQLRPSFSYLDKADAKHREREAANEAGDSSQDEAEDDVKQITVRFSRPESEQARQRRVQSYEFLQKKHAEEPWVHLHYYGLRDSRSEHERQYLLCPGSSGVENTELVKSPSEYLMMLMPPSQEEEKDKPVAPSNVLSMAQLRTLPLADQIKILMKNVKVMPFANLMSLLGPSIDSVAVLRGIQKVAMLVQGNWVVKSDILYPKDSSSPHSGVPAEVLCRGRDFVMWKFTQSRWVVRKEVATVTKLCAEDVKDFLEHMAVVRINKGWEFILPYDGEFIKKHPDVVQRQHMLWTGIQAKLEKVYNLVKETMPKKPDAQSGPAGLVCGDQRIQVAKTKAQQNHALLERELQRRKEQLRVPAVPPGVRIKEEPVSEEGEEDEEQEAEEEPMDTSPSGLHSKLANGLPLGRAAGTDSFNGHPPQGCASTPVARELKAFVEATFQRQFVLTLSELKRLFNLHLASLPPGHTLFSGISDRMLQDTVLAAGCKQILVPVSRALPARGMGGGGWGEPAVGRPRGDTGGHAW>sp|Q9NVU0-4|RPC5_HUMAN Isoform 4 of DNA-directed RNA polymerase IIIsubunit RPC5 OS=Homo sapiens OX=9606 GN=POLR3EMANEEDDPVVQEIDVYLAKSLAEKLYLFQYPVRPASMTYDDIPHLSAKIKPKQQKVELEMAIDTLNPNYCRSKGEQIALNVDGACADETSTYSSKLMDKQTFCSSQTTSNTSRYAAALYRQGELHLTPLHGILQLRPSFSYLDKADAKHREREAANEAGDSSQDEAEDDVKQITVRFSRPESEQARQRRVQSYEFLQKKHAEEPWVHLHYYGLRDSRSEHERQYLLCPGSSGVENTELVKSPSEYLMMLMPPSQEEEKDKPVAPSNVLSMAQLRTLPLADQIKILMKNVKVMPFANLMSLLGPSIDSVAVLRGIQKVAMLVQGNWVVKSDILYPKDSSSPHSGVPAEVLCRGRDFVMWKFTQSRWVVRKEVATVTKLCAEDVKDFLEHMAVVRINKGWEFILPYDGEFIKKHPDVVQRQHMLWTGIQAKLEKVYNLVKETMPKKPDAQSGPAGLVCGDQRIQVAKTKAQQNHALLERELQRRKEQLRVPAVPPGVRIKEEPVSEEGEEDEEQEAEEEPMDTSPSGLHSKLANGLPLGRAAGTDSFNGHPPQGCASTPVARELKAFVEATFQRQFVLTLSELKRLFNLHLASLPPGHTLFSGISDRMLQDTVLAAGCKQILVPFPPQTAASPDEQKVFALWESGDMSDQSRLTQECGEDLSKQEVDKVLKDCCVSYGGMWYLKGTVQS>sp|Q9NVU0-5|RPC5_HUMAN Isoform 5 of DNA-directed RNA polymerase IIIsubunit RPC5 OS=Homo sapiens OX=9606 GN=POLR3EMANEEDDPVVQEIKPKQQKVELEMAIDTLNPNYCRSKGEQIALNVDGACADETSTYSSKLMDKQTFCSSQTTSNTSRYAAALYRQGELHLTPLHGILQLRPSFSYLDKADAKHREREAANEAGDSSQDEAEDDVKQITVRFSRPESEQARQRRVQSYEFLQKKHAEEPWVHLHYYGLRDSRSEHERQYLLCPGSSGVENTELVKSPSEYLMMLMPPSQEEEKDKPVAPSNVLSMAQLRTLPLADQIKILMKNVKVMPFANLMSLLGPSIDSVAVLRGIQKVAMLVQGNWVVKSDILYPKDSSSPHSGVPAEVLCRGRDFVMWKFTQSRWVVRKEVATVTKLCAEDVKDFLEHMAVVRINKGWEFILPYDGEFIKKHPDVVQRQHMLWTGIQAKLEKVYNLVKETMPKKPDAQSGPAGLVCGDQRIQVAKTKAQQNHALLERELQRRKEQLRVPAVPPGVRIKEEPVSEEGEEDEEQEAEEEPMDTSPSGLHSKLANGLPLGRAAGTDSFNGHPPQGCASTPVARELKAFVEATFQRQFVLTLSELKRLFNLHLASLPPGHTLFSGISDRMLQDTVLAAGCKQILVPFPPQTAASPDEQKVFALWESGDMSDQHRQVLLEIFSKNYRVRRNMIQSRLTQECGEDLSKQEVDKVLKDCCVSYGGMWYLKGTVQS>sp|Q99942|RNF5_HUMAN E3 ubiquitin-protein ligase RNF5 OS=Homo sapiensOX=9606 GN=RNF5 PE=1 SV=1MAAAEEEDGGPEGPNRERGGAGATFECNICLETAREAVVSVCGHLYCWPCLHQWLETRPERQECPVCKAGISREKVVPLYGRGSQKPQDPRLKTPPRPQGQRPAPESRGGFQPFGDTGGFHFSFGVGAFPFGFFTTVFNAHEPFRRGTGVDLGQGHPASSWQDSLFLFLAIFFFFWLLSI>sp|O95602|RPA1_HUMAN DNA-directed RNA polymerase I subunit RPA1 OS=Homosapiens OX=9606 GN=POLR1A PE=1 SV=2MLISKNMPWRRLQGISFGMYSAEELKKLSVKSITNPRYLDSLGNPSANGLYDLALGPADSKEVCSTCVQDFSNCSGHLGHIELPLTVYNPLLFDKLYLLLRGSCLNCHMLTCPRAVIHLLLCQLRVLEVGALQAVYELERILNRFLEENPDPSASEIREELEQYTTEIVQNNLLGSQGAHVKNVCESKSKLIALFWKAHMNAKRCPHCKTGRSVVRKEHNSKLTITFPAMVHRTAGQKDSEPLGIEEAQIGKRGYLTPTSAREHLSALWKNEGFFLNYLFSGMDDDGMESRFNPSVFFLDFLVVPPSRYRPVSRLGDQMFTNGQTVNLQAVMKDVVLIRKLLALMAQEQKLPEEVATPTTDEEKDSLIAIDRSFLSTLPGQSLIDKLYNIWIRLQSHVNIVFDSEMDKLMMDKYPGIRQILEKKEGLFRKHMMGKRVDYAARSVICPDMYINTNEIGIPMVFATKLTYPQPVTPWNVQELRQAVINGPNVHPGASMVINEDGSRTALSAVDMTQREAVAKQLLTPATGAPKPQGTKIVCRHVKNGDILLLNRQPTLHRPSIQAHRARILPEEKVLRLHYANCKAYNADFDGDEMNAHFPQSELGRAEAYVLACTDQQYLVPKDGQPLAGLIQDHMVSGASMTTRGCFFTREHYMELVYRGLTDKVGRVKLLSPSILKPFPLWTGKQVVSTLLINIIPEDHIPLNLSGKAKITGKAWVKETPRSVPGFNPDSMCESQVIIREGELLCGVLDKAHYGSSAYGLVHCCYEIYGGETSGKVLTCLARLFTAYLQLYRGFTLGVEDILVKPKADVKRQRIIEESTHCGPQAVRAALNLPEAASYDEVRGKWQDAHLGKDQRDFNMIDLKFKEEVNHYSNEINKACMPFGLHRQFPENSLQMMVQSGAKGSTVNTMQISCLLGQIELEGRRPPLMASGKSLPCFEPYEFTPRAGGFVTGRFLTGIKPPEFFFHCMAGREGLVDTAVKTSRSGYLQRCIIKHLEGLVVQYDLTVRDSDGSVVQFLYGEDGLDIPKTQFLQPKQFPFLASNYEVIMKSQHLHEVLSRADPKKALHHFRAIKKWQSKHPNTLLRRGAFLSYSQKIQEAVKALKLESENRNGRSPGTQEMLRMWYELDEESRRKYQKKAAACPDPSLSVWRPDIYFASVSETFETKVDDYSQEWAAQTEKSYEKSELSLDRLRTLLQLKWQRSLCEPGEAVGLLAAQSIGEPSTQMTLNTFHFAGRGEMNVTLGIPRLREILMVASANIKTPMMSVPVLNTKKALKRVKSLKKQLTRVCLGEVLQKIDVQESFCMEEKQNKFQVYQLRFQFLPHAYYQQEKCLRPEDILRFMETRFFKLLMESIKKKNNKASAFRNVNTRRATQRDLDNAGELGRSRGEQEGDEEEEGHIVDAEAEEGDADASDAKRKEKQEEEVDYESEEEEEREGEENDDEDMQEERNPHREGARKTQEQDEEVGLGTEEDPSLPALLTQPRKPTHSQEPQGPEAMERRVQAVREIHPFIDDYQYDTEESLWCQVTVKLPLMKINFDMSSLVVSLAHGAVIYATKGITRCLLNETTNNKNEKELVLNTEGINLPELFKYAEVLDLRRLYSNDIHAIANTYGIEAALRVIEKEIKDVFAVYGIAVDPRHLSLVADYMCFEGVYKPLNRFGIRSNSSPLQQMTFETSFQFLKQATMLGSHDELRSPSACLVVGKVVRGGTGLFELKQPLR>sp|Q9Y252|RNF6_HUMAN E3 ubiquitin-protein ligase RNF6 OS=Homo sapiensOX=9606 GN=RNF6 PE=1 SV=1MNQSRSRSDGGSEETLPQDHNHHENERRWQQERLHREEAYYQFINELNDEDYRLMRDHNLLGTPGEITSEELQQRLDGVKEQLASQPDLRDGTNYRDSEVPRESSHEDSLLEWLNTFRRTGNATRSGQNGNQTWRAVSRTNPNNGEFRFSLEIHVNHENRGFEIHGEDYTDIPLSDSNRDHTANRQQRSTSPVARRTRSQTSVNFNGSSSNIPRTRLASRGQNPAEGSFSTLGRLRNGIGGAAGIPRANASRTNFSSHTNQSGGSELRQREGQRFGAAHVWENGARSNVTVRNTNQRLEPIRLRSTSNSRSRSPIQRQSGTVYHNSQRESRPVQQTTRRSVRRRGRTRVFLEQDRERERRGTAYTPFSNSRLVSRITVEEGEESSRSSTAVRRHPTITLDLQVRRIRPGENRDRDSIANRTRSRVGLAENTVTIESNSGGFRRTISRLERSGIRTYVSTITVPLRRISENELVEPSSVALRSILRQIMTGFGELSSLMEADSESELQRNGQHLPDMHSELSNLGTDNNRSQHREGSSQDRQAQGDSTEMHGENETTQPHTRNSDSRGGRQLRNPNNLVETGTLPILRLAHFFLLNESDDDDRIRGLTKEQIDNLSTRHYEHNSIDSELGKICSVCISDYVTGNKLRQLPCMHEFHIHCIDRWLSENCTCPICRQPVLGSNIANNG>sp|Q9Y252-2|RNF6_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF6OS=Homo sapiens OX=9606 GN=RNF6MQLEVDKMGTKLGELLVSRITVEEGEESSRSSTAVRRHPTITLDLQVRRIRPGENRDRDSIANRTRSRVGLAENTVTIESNSGGFRRTISRLERSGIRTYVSTITVPLRRISENELVEPSSVALRSILRQIMTGFGELSSLMEADSESELQRNGQHLPDMHSELSNLGTDNNRSQHREGSSQDRQAQGDSTEMHGENETTQPHTRNSDSRGGRQLRNPNNLVETGTLPILRLAHFFLLNESDDDDRIRGLTKEQIDNLSTRHYEHNSIDSELGKICSVCISDYVTGNKLRQLPCMHEFHIHCIDRWLSENCTCPICRQPVLGSNIANNG>sp|Q9Y252-3|RNF6_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNF6OS=Homo sapiens OX=9606 GN=RNF6MNQSRSRSDGGSEETLPQDHNHHENERRWQQERLHREEAYYQFINELNDEDYRLMRDHNLLGTPGEITSEELQQRLDGVKEQLASQPDLRDGTNYRDSEVPRESSHEDSLLEWLNTFRRTGNATRSGQNGNQTWRAALPDTS>sp|Q8N5N7|RM50_HUMAN 39S ribosomal protein L50, mitochondrial OS=Homosapiens OX=9606 GN=MRPL50 PE=1 SV=2MAARSVSGITRRVFMWTVSGTPCREFWSRFRKEKEPVVVETVEEKKEPILVCPPLRSRAYTPPEDLQSRLESYVKEVFGSSLPSNWQDISLEDSRLKFNLLAHLADDLGHVVPNSRLHQMCRVRDVLDFYNVPIQDRSKFDELSASNLPPNLKITWSY>sp|Q8N5N7-2|RM50_HUMAN Isoform 2 of 39S ribosomal protein L50,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL50MAARSVSGITRRVFMWTVSGTPCREFWSRFRKEKEPVVVETVEEKKEPILVCPPLRSRAYTPPEDLQSRLESYVKEVFGSSLPSNWQDISLEDSRLKFNLLAHLADDLGHVVPNSRLHQMCRGYSFEEGKIQLGI>sp|Q9H1D9|RPC6_HUMAN DNA-directed RNA polymerase III subunit RPC6OS=Homo sapiens OX=9606 GN=POLR3F PE=1 SV=1MAEVKVKVQPPDADPVEIENRIIELCHQFPHGITDQVIQNEMPHIEAQQRAVAINRLLSMGQLDLLRSNTGLLYRIKDSQNAGKMKGSDNQEKLVYQIIEDAGNKGIWSRDIRYKSNLPLTEINKILKNLESKKLIKAVKSVAASKKKVYMLYNLQPDRSVTGGAWYSDQDFESEFVEVLNQQCFKFLQSKAETARESKQNPMIQRNSSFASSHEVWKYICELGISKVELSMEDIETILNTLIYDGKVEMTIIAAKEGTVGSVDGHMKLYRAVNPIIPPTGLVRAPCGLCPVFDDCHEGGEISPSNCIYMTEWLEF>sp|Q9BT43|RPC7L_HUMAN DNA-directed RNA polymerase III subunit RPC7-likeOS=Homo sapiens OX=9606 GN=POLR3GL PE=1 SV=1MASRGGGRGRGRGQLTFNVEAVGIGKGDALPPPTLQPSPLFPPLEFRPVPLPSGEEGEYVLALKQELRGAMRQLPYFIRPAVPKRDVERYSDKYQMSGPIDNAIDWNPDWRRLPRELKIRVRKLQKERITILLPKRPPKTTEDKEETIQKLETLEKKEEEVTSEEDEEKEEEEEKEEEEEEEYDEEEHEEETDYIMSYFDNGEDFGGDSDDNMDEAIY>sp|Q4U2R6|RM51_HUMAN 39S ribosomal protein L51, mitochondrial OS=Homosapiens OX=9606 GN=MRPL51 PE=1 SV=1MAGNLLSGAGRRLWDWVPLACRSFSLGVPRLIGIRLTLPPPKVVDRWNEKRAMFGVYDNIGILGNFEKHPKELIRGPIWLRGWKGNELQRCIRKRKMVGSRMFADDLHNLNKRIRYLYKHFNRHGKFR>sp|O76064|RNF8_HUMAN E3 ubiquitin-protein ligase RNF8 OS=Homo sapiensOX=9606 GN=RNF8 PE=1 SV=1MGEPGFFVTGDRAGGRSWCLRRVGMSAGWLLLEDGCEVTVGRGFGVTYQLVSKICPLMISRNHCVLKQNPEGQWTIMDNKSLNGVWLNRARLEPLRVYSIHQGDYIQLGVPLENKENAEYEYEVTEEDWETIYPCLSPKNDQMIEKNKELRTKRKFSLDELAGPGAEGPSNLKSKINKVSCESGQPVKSQGKGEVASTPSDNLDPKLTALEPSKTTGAPIYPGFPKVTEVHHEQKASNSSASQRSLQMFKVTMSRILRLKIQMQEKHEAVMNVKKQTQKGNSKKVVQMEQELQDLQSQLCAEQAQQQARVEQLEKTFQEEEQHLQGLEIAQGEKDLKQQLAQALQEHWALMEELNRSKKDFEAIIQAKNKELEQTKEEKEKMQAQKEEVLSHMNDVLENELQCIICSEYFIEAVTLNCAHSFCSYCINEWMKRKIECPICRKDIKSKTYSLVLDNCINKMVNNLSSEVKERRIVLIRERKAKRLF>sp|O76064-2|RNF8_HUMAN Isoform 2 of E3 ubiquitin-protein ligase RNF8OS=Homo sapiens OX=9606 GN=RNF8MGEPGFFVTGDRAGGRSWCLRRVGMSAGWLLLEDGCEVTVGRGFGVTYQLVSKICPLMISRNHCVLKQNPEGQWTIMDNKSFPSEKAEDFTAAGERFL>sp|O76064-3|RNF8_HUMAN Isoform 3 of E3 ubiquitin-protein ligase RNF8OS=Homo sapiens OX=9606 GN=RNF8MGEPGFFVTGDRAGGRSWCLRRVGMSAGWLLLEDGCEVTVGRGFGVTYQLVSKICPLMISRNHCVLKQNPEGQWTIMDNKSLNGVWLNRARLEPLRVYSIHQGDYIQLGVPLENKENAEYEYEVTEEDWETIYPCLSPKNDQMIEKNKELRTKRKFSLDELAGPGAEGPSNLKSKINKVSCESGQPVKSQGKGEVASTPSDNLDPKLTALEPSKTTGAPIYPGFPKVTEVHHEQKASNSSASQRSLQMFKVTMSRILRLKIQMQEKHEAVMNVKKQTQKGNSKKVVQMEQELQDLQSQLCAEQAQQQARVEQLEKTFQEEEQHLQGLEIAQGEKDLKQQLAQALQEHWALMEELNRSKKDFEAIIQAKNKELEQTKEEKEKMQAQKEEVLSHMNDVLENELQCIICSEYFIEQRDCSEDRALRAFERLPGSASLRWSGGFSLAVTPLL>sp|O15318|RPC7_HUMAN DNA-directed RNA polymerase III subunit RPC7OS=Homo sapiens OX=9606 GN=POLR3G PE=1 SV=2MAGNKGRGRAAYTFNIEAVGFSKGEKLPDVVLKPPPLFPDTDYKPVPLKTGEGEEYMLALKQELRETMKRMPYFIETPEERQDIERYSKRYMKVYKEEWIPDWRRLPREMMPRNKCKKAGPKPKKAKDAGKGTPLTNTEDVLKKMEELEKRGDGEKSDEENEEKEGSKEKSKEGDDDDDDDAAEQEEYDEEEQEEENDYINSYFEDGDDFGADSDDNMDEATY>sp|Q9H9Y6|RPA2_HUMAN DNA-directed RNA polymerase I subunit RPA2 OS=Homosapiens OX=9606 GN=POLR1B PE=1 SV=2MDPGSRWRNLPSGPSLKHLTDPSYGIPREQQKAALQELTRAHVESFNYAVHEGLGLAVQAIPPFEFAFKDERISFTILDAVISPPTVPKGTICKEANVYPAECRGRRSTYRGKLTADINWAVNGISKGIIKQFLGYVPIMVKSKLCNLRNLPPQALIEHHEEAEEMGGYFIINGIEKVIRMLIMPRRNFPIAMIRPKWKTRGPGYTQYGVSMHCVREEHSAVNMNLHYLENGTVMLNFIYRKELFFLPLGFALKALVSFSDYQIFQELIKGKEDDSFLRNSVSQMLRIVMEEGCSTQKQVLNYLGECFRVKLNVPDWYPNEQAAEFLFNQCICIHLKSNTEKFYMLCLMTRKLFALAKGECMEDNPDSLVNQEVLTPGQLFLMFLKEKLEGWLVSIKIAFDKKAQKTSVSMNTDNLMRIFTMGIDLTKPFEYLFATGNLRSKTGLGLLQDSGLCVVADKLNFIRYLSHFRCVHRGADFAKMRTTTVRRLLPESWGFLCPVHTPDGEPCGLMNHLTAVCEVVTQFVYTASIPALLCNLGVTPIDGAPHRSYSECYPVLLDGVMVGWVDKDLAPGIADSLRHFKVLREKRIPPWMEVVLIPMTGKPSLYPGLFLFTTPCRLVRPVQNLALGKEELIGTMEQIFMNVAIFEDEVFAGVTTHQELFPHSLLSVIANFIPFSDHNQSPRNMYQCQMGKQTMGFPLLTYQDRSDNKLYRLQTPQSPLVRPSMYDYYDMDNYPIGTNAIVAVISYTGYDMEDAMIVNKASWERGFAHGSVYKSEFIDLSEKIKQGDSSLVFGIKPGDPRVLQKLDDDGLPFIGAKLQYGDPYYSYLNLNTGESFVMYYKSKENCVVDNIKVCSNDTGSGKFKCVCITMRVPRNPTIGDKFASRHGQKGILSRLWPAEDMPFTESGMVPDILFNPHGFPSRMTIGMLIESMAGKSAALHGLCHDATPFIFSEENSALEYFGEMLKAAGYNFYGTERLYSGISGLELEADIFIGVVYYQRLRHMVSDKFQVRTTGARDRVTNQPIGGRNVQGGIRFGEMERDALLAHGTSFLLHDRLFNCSDRSVAHVCVKCGSLLSPLLEKPPPSWSAMRNRKYNCTLCSRSDTIDTVSVPYVFRYFVAELAAMNIKVKLDVV>sp|Q9H9Y6-2|RPA2_HUMAN Isoform 2 of DNA-directed RNA polymerase Isubunit RPA2 OS=Homo sapiens OX=9606 GN=POLR1BMDPGSRWRNLPSGPSLKHLTDPSYGIPREQQKAALQELTRAHVESFNYAVHEGLGLAVQADINWAVNGISKGIIKQFLGYVPIMVKSKLCNLRNLPPQALIEHHEEAEEMGGYFIINGIEKVIRMLIMPRRNFPIAMIRPKWKTRGPGYTQYGVSMHCVREEHSAVNMNLHYLENGTVMLNFIYRKELFFLPLGFALKALVSFSDYQIFQELIKGKEDDSFLRNSVSQMLRIVMEEGCSTQKQVLNYLGECFRVKLNVPDWYPNEQAAEFLFNQCICIHLKSNTEKFYMLCLMTRKLFALAKGECMEDNPDSLVNQEVLTPGQLFLMFLKEKLEGWLVSIKIAFDKKAQKTSVSMNTDNLMRIFTMGIDLTKPFEYLFATGNLRSKTGLGLLQDSGLCVVADKLNFIRYLSHFRCVHRGADFAKMRTTTVRRLLPESWGFLCPVHTPDGEPCGLMNHLTAVCEVVTQFVYTASIPALLCNLGVTPIDGAPHRSYSECYPVLLDGVMVGWVDKDLAPGIADSLRHFKVLREKRIPPWMEVVLIPMTGKPSLYPGLFLFTTPCRLVRPVQNLALGKEELIGTMEQIFMNVAIFEDEVFAGVTTHQELFPHSLLSVIANFIPFSDHNQSPRNMYQCQMGKQTMGFPLLTYQDRSDNKLYRLQTPQSPLVRPSMYDYYDMDNYPIGTNAIVAVISYTGYDMEDAMIVNKASWERGFAHGSVYKSEFIDLSEKIKQGDSSLVFGIKPGDPRVLQKLDDDGLPFIGAKLQYGDPYYSYLNLNTGESFVMYYKSKENCVVDNIKVCSNDTGSGKFKCVCITMRVPRNPTIGDKFASRHGQKGILSRLWPAEDMPFTESGMVPDILFNPHGFPSRMTIGMLIESMAGKSAALHGLCHDATPFIFSEENSALEYFGEMLKAAGYNFYGTERLYSGISGLELEADIFIGVVYYQRLRHMVSDKFQVRTTGARDRVTNQPIGGRNVQGGIRFGEMERDALLAHGTSFLLHDRLFNCSDRSVAHVCVKCGSLLSPLLEKPPPSWSAMRNRKYNCTLCSRSDTIDTVSVPYVFRYFVAELAAMNIKVKLDVV>sp|Q9H9Y6-3|RPA2_HUMAN Isoform 3 of DNA-directed RNA polymerase Isubunit RPA2 OS=Homo sapiens OX=9606 GN=POLR1BMRAKEAAETGLRPLLPACTERLASGVYRETGVRCAGGHMDPGSRWRNLPSGPSLKHLTDPSYGIPREQQKAALQELTRAHVESFNYAVHEGLGLAVQAIPPFEFAFKDERISFTILDAVISPPTVPKGTICKEANVYPAECRGRRSTYRGKLTADINWAVNGISKGIIKQFLGYVPIMVKSKLCNLRNLPPQALIEHHEEAEEMGGYFIINGIEKVIRMLIMPRRNFPIAMIRPKWKTRGPGYTQYGVSMHCVREEHSAVNMNLHYLENGTVMLNFIYRKELFFLPLGFALKALVSFSDYQIFQELIKGKEDDSFLRNSVSQMLRIVMEEGCSTQKQVLNYLGECFRVKLNVPDWYPNEQAAEFLFNQCICIHLKSNTEKFYMLCLMTRKLFALAKGECMEDNPDSLVNQEVLTPGQLFLMFLKEKLEGWLVSIKIAFDKKAQKTSVSMNTDNLMRIFTMGIDLTKPFEYLFATGNLRSKTGLGLLQDSGLCVVADKLNFIRYLSHFRCVHRGADFAKMRTTTVRRLLPESWGFLCPVHTPDGEPCGLMNHLTAVCEVVTQFVYTASIPALLCNLGVTPIDGAPHRSYSECYPVLLDGVMVGWVDKDLAPGIADSLRHFKVLREKRIPPWMEVVLIPMTGKPSLYPGLFLFTTPCRLVRPVQNLALGKEELIGTMEQIFMNVAIFEDEVFAGVTTHQELFPHSLLSVIANFIPFSDHNQSPRNMYQCQMGKQTMGFPLLTYQDRSDNKLYRLQTPQSPLVRPSMYDYYDMDNYPIGTNAIVAVISYTGYDMEDAMIVNKASWERGFAHGSVYKSEFIDLSEKIKQGDSSLVFGIKPGDPRVLQKLDDDGLPFIGAKLQYGDPYYSYLNLNTGESFVMYYKSKENCVVDNIKVCSNDTGSGKFKCVCITMRVPRNPTIGDKFASRHGQKGILSRLWPAEDMPFTESGMVPDILFNPHGFPSRMTIGMLIESMAGKSAALHGLCHDATPFIFSEENSALEYFGEMLKAAGYNFYGTERLYSGISGLELEADIFIGVVYYQRLRHMVSDKFQVRTTGARDRVTNQPIGGRNVQGGIRFGEMERDALLAHGTSFLLHDRLFNCSDRSVAHVCVKCGSLLSPLLEKPPPSWSAMRNRKYNCTLCSRSDTIDTVSVPYVFRYFVAELAAMNIKVKLDVV>sp|Q9H9Y6-4|RPA2_HUMAN Isoform 4 of DNA-directed RNA polymerase Isubunit RPA2 OS=Homo sapiens OX=9606 GN=POLR1BMHCVREEHSAVNMNLHYLENGTVMLNFIYRKELFFLPLGFALKALVSFSDYQIFQELIKGKEDDSFLRNSVSQMLRIVMEEGCSTQKQVLNYLGECFRVKLNVPDWYPNEQAAEFLFNQCICIHLKSNTEKFYMLCLMTRKLFALAKGECMEDNPDSLVNQEVLTPGQLFLMFLKEKLEGWLVSIKIAFDKKAQKTSVSMNTDNLMRIFTMGIDLTKPFEYLFATGNLRSKTGLGLLQDSGLCVVADKLNFIRYLSHFRCVHRGADFAKMRTTTVRRLLPESWGFLCPVHTPDGEPCGLMNHLTAVCEVVTQFVYTASIPALLCNLGVTPIDGAPHRSYSECYPVLLDGVMVGWVDKDLAPGIADSLRHFKVLREKRIPPWMEVVLIPMTGKPSLYPGLFLFTTPCRLVRPVQNLALGKEELIGTMEQIFMNVAIFEDEVFAGVTTHQELFPHSLLSVIANFIPFSDHNQSPRNMYQCQMGKQTMGFPLLTYQDRSDNKLYRLQTPQSPLVRPSMYDYYDMDNYPIGTNAIVAVISYTGYDMEDAMIVNKASWERGFAHGSVYKSEFIDLSEKIKQGDSSLVFGIKPGDPRVLQKLDDDGLPFIGAKLQYGDPYYSYLNLNTGESFVMYYKSKENCVVDNIKVCSNDTGSGKFKCVCITMRVPRNPTIGDKFASRHGQKGILSRLWPAEDMPFTESGMVPDILFNPHGFPSRMTIGMLIESMAGKSAALHGLCHDATPFIFSEENSALEYFGEMLKAAGYNFYGTERLYSGISGLELEADIFIGVVYYQRLRHMVSDKFQVRTTGARDRVTNQPIGGRNVQGGIRFGEMERDALLAHGTSFLLHDRLFNCSDRSVAHVCVKCGSLLSPLLEKPPPSWSAMRNRKYNCTLCSRSDTIDTVSVPYVFRYFVAELAAMNIKVKLDVV>sp|Q9H9Y6-5|RPA2_HUMAN Isoform 5 of DNA-directed RNA polymerase Isubunit RPA2 OS=Homo sapiens OX=9606 GN=POLR1BMDPGSRWRNLPSGPSLKHLTDPSYGIPREQQKAALQELTRAHVESFNYAVHEGLGLAVQAIPPFEFAFKDERISFTILDAVISPPTVPKGTICKEANVYPAECRGRRSTYRGKLTADINWAVNGISKGIIKQFLGYVPIMVKSKLCNLRNLPPQALIEHHEEAEEMGGYFIINGIEKVIRMLIMPRRNFPIAMIRPKWKTRGPGYTQYGVSMHCVREEHSAVNMNLHYLENGTVMLNFIYRKELFFLPLGFALKALVSFSDYQIFQELIKGKEDDSFLRNSVSQMLRIVMEEGCSTQKQVLNYLGECFRVKLNVPDWYPNEQAAEFLFNQCICIHLKSNTEKFYMLCLMTRKLFALAKGECMEDNPDSLVNQEVLTPGQLFLMFLKGSLPLMELPTDHTVLREKRIPPWMEVVLIPMTGKPSLYPGLFLFTTPCRLVRPVQNLALGKEELIGTMEQIFMNVAIFEDEVFAGVTTHQELFPHSLLSVIANFIPFSDHNQSPRNMYQCQMGKQTMGFPLLTYQDRSDNKLYRLQTPQSPLVRPSMYDYYDMDNYPIGTNAIVAVISYTGYDMEDAMIVNKASWERGFAHGSVYKSEFIDLSEKIKQGDSSLVFGIKPGDPRVLQKLDDDGLPFIGAKLQYGDPYYSYLNLNTGESFVMYYKSKENCVVDNIKVCSNDTGSGKFKCVCITMRVPRNPTIGDKFASRHGQKGILSRLWPAEDMPFTESGMVPDILFNPHGFPSRMTIGMLIESMAGKSAALHGLCHDATPFIFSEENSALEYFGEMLKAAGYNFYGTERLYSGISGLELEADIFIGVVYYQRLRHMVSDKFQVRTTGARDRVTNQPIGGRNVQGGIRFGEMERDALLAHGTSFLLHDRLFNCSDRSVAHVCVKCGSLLSPLLEKPPPSWSAMRNRKYNCTLCSRSDTIDTVSVPYVFRYFVAELAAMNIKVKLDVV>sp|Q86TS9|RM52_HUMAN 39S ribosomal protein L52, mitochondrial OS=Homosapiens OX=9606 GN=MRPL52 PE=1 SV=2MAALGTVLFTGVRRLHCSVAAWAGGQWRLQQGLAANPSGYGPLTELPDWSYADGRPAPPMKGQLRRKAERETFARRVVLLSQEMDAGLQAWQLRQQKLQEEQRKQENALKPKGASLKSPLPSQ>sp|Q86TS9-2|RM52_HUMAN Isoform 2 of 39S ribosomal protein L52,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL52MKGQLRRKAERETFARRVVLLSQEMDAGLQAWQLRQQKLQEEQRKQENALKPKGASLKSPLPSQ>sp|Q86TS9-3|RM52_HUMAN Isoform 3 of 39S ribosomal protein L52,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL52MAALGTVLFSVRRLHCSVAAWAGGQWRLQQGLAANPSGYGPLTELPDWSYADGRPAPPMKGQLRRKAERETFARRVVLLSQEMDAGLQAWQLRQQKLQEEQRKQENALKPKGASLKSPLPSQ>sp|Q86TS9-4|RM52_HUMAN Isoform 4 of 39S ribosomal protein L52,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL52MAALGTVLFTGVRRLHCSVAAWAGGQWRLQQGLAANPSGYGPLTELPDWSYAETSCTAVTGNGRWITSMAAQAAEVAGRTKEAGKCS>sp|Q9Y535|RPC8_HUMAN DNA-directed RNA polymerase III subunit RPC8OS=Homo sapiens OX=9606 GN=POLR3H PE=1 SV=1MFVLVEMVDTVRIPPWQFERKLNDSIAEELNKKLANKVVYNVGLCICLFDITKLEDAYVFPGDGASHTKVHFRCVVFHPFLDEILIGKIKGCSPEGVHVSLGFFDDILIPPESLQQPAKFDEAEQVWVWEYETEEGAHDLYMDTGEEIRFRVVDESFVDTSPTGPSSADATTSSEELPKKEAPYTLVGSISEPGLGLLSWWTSN>sp|Q9Y535-2|RPC8_HUMAN Isoform 2 of DNA-directed RNA polymerase IIIsubunit RPC8 OS=Homo sapiens OX=9606 GN=POLR3HMFVLVEMVDTVRIPPWQFERKLNDSIAEELNKKLANKVVYNVGLCICLFDITKLEDAYVFPGDGASHTKVSLGFFDDILIPPESLQQPAKFDEAEQVWVWEYETEEGAHDLYMDTGEEIRFRVVDESFVDTSPTGPSSADATTSSEELPKKEAPYTLVGSISEPGLGLLSWWTSN>sp|Q96EL3|RM53_HUMAN 39S ribosomal protein L53, mitochondrial OS=Homosapiens OX=9606 GN=MRPL53 PE=1 SV=1MAAALARLGLRPVKQVRVQFCPFEKNVESTRTFLQTVSSEKVRSTNLNCSVIADVRHDGSEPCVDVLFGDGHRLIMRGAHLTALEMLTAFASHIRARDAAGSGDKPGADTGR>sp|Q6P161|RM54_HUMAN 39S ribosomal protein L54, mitochondrial OS=Homosapiens OX=9606 GN=MRPL54 PE=1 SV=1MATKRLFGATRTWAGWGAWELLNPATSGRLLARDYAKKPVMKGAKSGKGAVTSEALKDPDVCTDPVQLTTYAMGVNIYKEGQDVPLKPDAEYPEWLFEMNLGPPKTLEELDPESREYWRRLRKQNIWRHNRLSKNKRL>sp|O15446|RPA34_HUMAN DNA-directed RNA polymerase I subunit RPA34OS=Homo sapiens OX=9606 GN=POLR1G PE=1 SV=1MEEPQAGDAARFSCPPNFTAKPPASESPRFSLEALTGPDTELWLIQAPADFAPECFNGRHVPLSGSQIVKGKLAGKRHRYRVLSSCPQAGEATLLAPSTEAGGGLTCASAPQGTLRILEGPQQSLSGSPLQPIPASPPPQIPPGLRPRFCAFGGNPPVTGPRSALAPNLLTSGKKKKEMQVTEAPVTQEAVNGHGALEVDMALGSPEMDVRKKKKKKNQQLKEPEAAGPVGTEPTVETLEPLGVLFPSTTKKRKKPKGKETFEPEDKTVKQEQINTEPLEDTVLSPTKKRKRQKGTEGMEPEEGVTVESQPQVKVEPLEEAIPLPPTKKRKKEKGQMAMMEPGTEAMEPVEPEMKPLESPGGTMAPQQPEGAKPQAQAALAAPKKKTKKEKQQDATVEPETEVVGPELPDDLEPQAAPTSTKKKKKKKERGHTVTEPIQPLEPELPGEGQPEARATPGSTKKRKKQSQESRMPETVPQEEMPGPPLNSESGEEAPTGRDKKRKQQQQQPV>sp|O15446-2|RPA34_HUMAN Isoform 2 of DNA-directed RNA polymerase Isubunit RPA34 OS=Homo sapiens OX=9606 GN=POLR1GMEEPQAGGEDAARFSCPPNFTAKPPASESPRFSLEALTGPDTELWLIQAPADFAPECFNGRHVPLSGSQIVKGKLAGKRHRYRVLSSCPQAGEATLLAPSTEAGGGLTCASAPQGTLRILEGPQQSLSGSPLQPIPASPPPQIPPGLRPRFCAFGGNPPVTGPRSALAPNLLTSGKKKKEMQVTEAPVTQEAVNGHGALEVDMALGSPEMDVRKKKKKKNQQLKEPEAAGPVGTEPTVETLEPLGVLFPSTTKKRKKPKGKETFEPEDKTVKQEQINTEPLEDTVLSPTKKRKRQKGTEGMEPEEGVTVESQPQVKVEPLEEAIPLPPTKKRKKEKGQMAMMEPGTEAMEPVEPEMKPLESPGGTMAPQQPEGAKPQAQAALAAPKKKTKKEKQQDATVEPETEVVGPELPDDLEPQAAPTSTKKKKKKKERGHTVTEPIQPLEPELPGEGQPEARATPGSTKKRKKQSQESRMPETVPQEEMPGPPLNSESGEEAPTGRDKKRKQQQQQPV>sp|Q7Z7F7|RM55_HUMAN 39S ribosomal protein L55, mitochondrial OS=Homosapiens OX=9606 GN=MRPL55 PE=1 SV=1MAAVGSLLGRLRQSTVKATGPALRRLHTSSWRADSSRASLTRVHRQAYARLYPVLLVKQDGSTIHIRYREPRRMLAMPIDLDTLSPEERRARLRKREAQLQSRKEYEQELSDDLHVERYRQFWTRTKK>sp|Q7Z7F7-2|RM55_HUMAN Isoform 2 of 39S ribosomal protein L55,mitochondrial OS=Homo sapiens OX=9606 GN=MRPL55MAAVGSLLGLAASSWLGGQNASDHSLWLLRKPRGSSCPGTGHQLCRLRQSTVKATGPALRRLHTSSWRADSSRASLTRVHRQAYARLYPVLLVKQDGSTIHIRYREPRRMLAMPIDLDTLSPEERRARLRKREAQLQSRKEYEQELSDDLHVERYRQFWTRTKK>sp|Q8NE09|RGS22_HUMAN Regulator of G-protein signaling 22 OS=Homosapiens OX=9606 GN=RGS22 PE=1 SV=3MPEKRLTAEPPTITEEEFEDSLATDDFLVDYFNEFLSLPTFSEAIRFNADYGVFEVANDAPQFLEKQLKKILQNQQPRNPIYDVVRKGKNEVKPVQMNAPDEDETINVNYNIMCLSREEGIKWIKKERLPAFLESDCYFEYRLAKLVSQVRWSKSGMNFTVGSNFSPWIVKKPPSLPPPATEEDNLVIMKKFYVSLGEASYTQTKDWFALAKQSQQTVSTFSLPCCVPYNKLKSPAISSVSENFIFDDGVHPRTKKDPSKTNKLISEFEEEEGEEEEVSVSLQDTPSQALLRVYLEKKQDVDESLTMHFSTCEEFLSSYIYFILRGAIQQIVGKPVGETPDYINFNNITKVSFDDCFESIHGKNFLSELVQTTKERSEEIEQTSLSSKNESAGPESRADWCISHRTYDIGNRKEFERFKKFIKGTLGERYWWLWMDIERLKVLKDPGRHQRHLEKMKKCYLVSNGDYYLSAEILSKFKLLDGSQWNEEHLRNIQSEVLKPLLLYWAPRFCVTHSASTKYASAELKFWHLRQAKPRKDIDPFPQMATLLPLRPKSCIPQIPEIQKEEFSLSQPPKSPNKSPEVKTATQKPWKRELLYPGSSKDDVIEKGSKYMSESSKVIHLTSFTDISECLKPQLDRRYAYTEEPRVKTVSDVGALGGSDMENLLQSLYVENRAGFFFTKFCEHSGNKLWKNSVYFWFDLQAYHQLFYQETLQPFKVCKQAQYLFATYVAPSATLDIGLQQEKKKEIYMKIQPPFEDLFDTAEEYILLLLLEPWTKMVKSDQIAYKKVELVEETRQLDSTYFRKLQALHKETFSKKAEDTTCEIGTGILSLSNVSKRTEYWDNVPAEYKHFKFSDLLNNKLEFEHFRQFLETHSSSMDLMCWTDIEQFRRITYRDRNQRKAKSIYIKNKYLNKKYFFGPNSPASLYQQNQVMHLSGGWGKILHEQLDAPVLVEIQKHVQNRLENVWLPLFLASEQFAARQKIKVQMKDIAEELLLQKAEKKIGVWKPVESKWISSSCKIIAFRKALLNPVTSRQFQRFVALKGDLLENGLLFWQEVQKYKDLCHSHCDESVIQKKITTIINCFINSSIPPALQIDIPVEQAQKIIEHRKELGPYVFREAQMTIFGVLFKFWPQFCEFRKNLTDENIMSVLERRQEYNKQKKKLAVLEDEKSGKDGIKQYANTSVPAIKTALLSDSFLGLQPYGRQPTWCYSKYIEALEQERILLKIQEELEKKLFAGLQPLTNFKASSSTMSLKKNMSAHSSQK>sp|Q8NE09-2|RGS22_HUMAN Isoform 2 of Regulator of G-protein signaling 22OS=Homo sapiens OX=9606 GN=RGS22MPEKRLTAEPPTITEEEFEDSLATDDFLVDYFNEFLSLPTFSEAIRFNADYGVFEVANDAPQFLEKQLKKILQNQQPRNPIYDVVRKGKNEVKPVQMNAPDEDETINVNYNIMCLSREEGIKWIKKERLPAFLESDCYFEYRLAKLVSQVRWSKSGMNFTVGSNFSPWIVKKPPSLPPPATEEDNLVIMKKFYVSLGEASYTQTKDWFALAKQSQQTVSTFSLPCCVPYNKLKSPAISSVSENFIFDDGVHPRTKKDPSKTNKLISEFEEEEGEEEEVSVSLQDTPSQALLRVYLEKKQDVDESLTMHFSTCEEFLSSYIYFILRGAIQQIVGKPVGETPDYINFNNITKVSFDDCFESIHGKNFLSELVQTTKERSEEIEQTSLSSKNESAGPESRADWCISHRTYDIGNRKEFERFKKFIKGTLGERYWWLWMDIERLKVLKDPGRHQRHLEKMKKCYLVSNGDYYLSAEILSKFKLLDGSQWNEEHLRNIQSEVLKPLLLY>sp|Q8NE09-3|RGS22_HUMAN Isoform 3 of Regulator of G-protein signaling 22OS=Homo sapiens OX=9606 GN=RGS22MPEKRLTAEPPTITEEEFEDSLATDDFLVDYFNEFLSLPTFSEAIRFNADYGVFEVANDAPQFLEKQLKKILQNQQPRNPIYDVVRKGKNEVKPVQMNAPDEDETINVNYNIMCLSREEGIKWIKKERLPAFLESDCYFEYRLAKLVSQVRWSKSGMNFTVGSNFSPWIVKKPPSLPPPATEEDNLASYTQTKDWFALAKQSQQTVSTFSLPCCVPYNKLKSPAISSVSENFIFDDGVHPRTKKDPSKTNKLISEFEEEEGEEEEVSVSLQDTPSQALLRVYLEKKQDVDESLTMHFSTCEEFLSSYIYFILRGAIQQIVGKPVGETPDYINFNNITKVSFDDCFESIHGKNFLSELVQTTKERSEEIEQTSLSSKNESAGPESRADWCISHRTYDIGNRKEFERFKKFIKGTLGERYWWLWMDIERLKVLKDPGRHQRHLEKMKKCYLVSNGDYYLSAEILSKFKLLDGSQWNEEHLRNIQSEVLKPLLLYWAPRFCVTHSASTKYASAELKFWHLRQAKPRKDIDPFPQMATLLPLRPKSCIPQIPEIQKEEFSLSQPPKSPNKSPEVKTATQKPWKRELLYPGSSKDDVIEKGSKYMSESSKVIHLTSFTDISECLKPQLDRRYAYTEEPRVKTVSDVGALGGSDMENLLQSLYVENRAGFFFTKFCEHSGNKLWKNSVYFWFDLQAYHQLFYQETLQPFKVCKQAQYLFATYVAPSATLDIGLQQEKKKEIYMKIQPPFEDLFDTAEEYILLLLLEPWTKMVKSDQIAYKKVELVEETRQLDSTYFRKLQALHKETFSKKAEDTTCEIGTGILSLSNVSKRTEYWDNVPAEYKHFKFSDLLNNKLEFEHFRQFLETHSSSMDLMCWTDIEQFRRITYRDRNQRKAKSIYIKNKYLNKKYFFGPNSPASLYQQNQVMHLSGGWGKILHEQLDAPVLVEIQKHVQNRLENVWLPLFLASEQFAARQKIKVQMKDIAEELLLQKAEKKIGVWKPVESKWISSSCKIIAFRKALLNPVTSRQFQRFVALKGDLLENGLLFWQEVQKYKDLCHSHCDESVIQKKITTIINCFINSSIPPALQIDIPVEQAQKIIEHRKELGPYVFREAQMTIFGVLFKFWPQFCEFRKNLTDENIMSVLERRQEYNKQKKKLAVLEDEKSGKDGIKQYANTSVPAIKTALLSDSFLGLQPYGRQPTWCYSKYIEALEQERILLKIQEELEKKLFAGLQPLTNFKASSSTMSLKKNMSAHSSQK>sp|Q9P2N2|RHG28_HUMAN Rho GTPase-activating protein 28 OS=Homo sapiensOX=9606 GN=ARHGAP28 PE=1 SV=3MEVEDSGGVVLTAYHSYARAQPPNAESRCAPRAAASHPLSRKSIPRCRRINRMLSNESLHPPAFSRSNSEASVDSASMEDFWREIESIKDSSMGGQEEPPPAEVTPVDEGELEAEWLQDVGLSTLISGDEEEDGKALLSTLTRTQAAAVQKRYHTYTQTMRKKDKQSIRDVRDIFGVSESPPRDTCGNHTNQLDGTKEERELPRVIKTSGSMPDDASLNSTTLSDASQDKEGSFAVPRSDSVAILETIPVLPVHSNGSPEPGQPVQNAISDDDFLEKNIPPEAEELSFEVSYSEMVTEALKRNKLKKSEIKKEDYVLTKFNVQKTRFGLTEAGDLSAEDMKKIRHLSLIELTAFFDAFGIQLKRNKTEKVKGRDNGIFGVPLTVLLDGDRKKDPGVKVPLVLQKFFEKVEESGLESEGIFRLSGCTAKVKQYREELDAKFNADKFKWDKMCHREAAVMLKAFFRELPTSLFPVEYIPAFISLMERGPHVKVQFQALHLMVMALPDANRDAAQALMTFFNKVIANESKNRMSLWNISTVMAPNLFFSRSKHSDYEELLLANTAAHIIRLMLKYQKILWKVPSFLITQVRRMNEATMLLKKQLPSVRKLLRRKTLERETASPKTSKVLQKSPSARRMSDVPEGVIRVHAPLLSKVSMAIQLNNQTKAKDILAKFQYENSHGSSECIKIQNQRLYEIGGNIGEHCLDPDAYILDVYRINPQAEWVIKPQQSS>sp|Q9P2N2-2|RHG28_HUMAN Isoform 2 of Rho GTPase-activating protein 28OS=Homo sapiens OX=9606 GN=ARHGAP28MLSNESLHPPAFSRSNSEASVDSASMEDFWREIESIKDSSMGGQEEPPPAEVTPVDEGELEAEWLQDVGLSTLISGDEEEDGKALLSTLTRTQAAAVQKRYHTYTQTMRKKDKQSIRDVRDIFGVSESPPRDTCGNHTNQLDGTKEERELPRVIKTSGSMPDDASLNSTTLSDASQDKEGSFAVPRSDSVAILETIPVLPVHSNGSPEPGQPVQNAISDDDFLEKNIPPEAEELSFEVSYSEMVTEALKRNKLKKSEIKKEDYVLTKFNVQKTRFGLTEAGDLSAEDMKKIRHLSLIELTAFFDAFGIQLKRNKTEKVKGRDNGIFGVPLTVLLDGDRKKDPGVKVPLVLQKFFEKVEESGLESEGIFRLSGCTAKVKQYREELDAKFNADKFKWDKMCHREAAVMLKAFFRELPTSLFPVEYIPAFISLMERGPHVKVQFQALHLMVMALPDANRDAAQALMTFFNKVIANESKNRMSLWNISTVMAPNLFFSRSKHSDYEELLLANTAAHIIRLMLKYQKILWKVPSFLITQVRRMNEATMLLKKQLPSVRKLLRRKTLERETASPKTSKVLQKSPSARRMSDVPEGVIRVHAPLLSKVSMAIQLNNQTKAKDILAKFQYENRILHWQRAALSFLNGKWVKKEREESTETNRSPKHVFLFTIGLDIST>sp|Q9P2N2-3|RHG28_HUMAN Isoform 3 of Rho GTPase-activating protein 28OS=Homo sapiens OX=9606 GN=ARHGAP28MNELPRDTCGNHTNQLDGTKEERELPRVIKTSGSMPDDASLNSTTLSDASQDKEGSFAVPRSDSVAILETIPVLPVHSNGSPEPGQPVQNAISDDDFLEKNIPPEAEELSFEVSYSEMVTEALKRNKLKKSEIKKEDYVLTKFNVQKTRFGLTEAGDLSAEDMKKIRHLSLIELTAFFDAFGIQLKRNKTEKVKGRDNGIFGVPLTVLLDGDRKKDPGVKVPLVLQKFFEKVEESGLESEGIFRLSGCTAKVKQYREELDAKFNADKFKWDKMCHREAAVMLKAFFRELPTSLFPVEYIPAFISLMERGPHVKVQFQALHLMVMALPDANRDAAQALMTFFNKVIANESKNRMSLWNISTVMAPNLFFSRSKHSDYEELLLANTAAHIIRLMLKYQKILWKVPSFLITQVRRMNEATMLLKKQLPSVRKLLRRKTLERETASPKTSKVLQKSPSARRMSDVPEGVIRVHAPLLSKVSMAIQLNNQTKAKDILAKFQYENRILHWQRAALSFLNGKWVKKEREESTETNRSPKHVFLFTIGLDIST>sp|Q9P2N2-5|RHG28_HUMAN Isoform 5 of Rho GTPase-activating protein 28OS=Homo sapiens OX=9606 GN=ARHGAP28MRKKDKQSIRDVRDIFGVSESPPRDTCGNHTNQLDGTKEERELPRVIKTSGSMPDDASLNSTTLSDASQDKEGSFAVPRSDSVAILETIPVLPVHSNGSPEPGQPVQNAISDDDFLEKNIPPEAEELSFEVSYSEMVTEALKRNKLKKSEIKKEDYVLTKFNVQKTRFGLTEAGDLSAEDMKKIRHLSLIELTAFFDAFGIQLKRNKTEKVKGRDNGIFGVPLTVLLDGDRKKDPGVKVPLVLQKFFEKVEESGLESEGIFRLSGCTAKVKQYREELDAKFNADKFKWDKMCHREAAVMLKAFFRELPTSLFPVEYIPAFISLMERGPHVKVQFQALHLMVMALPDANRDAAQALMTFFNKVIANESKNRMSLWNISTVMAPNLFFSRSKHSDYEELLLANTAAHIIRLMLKYQKILWKVPSFLITQVRRMNEATMLLKKQLPSVRKLLRRKTLERETASPKTSKVLQKSPSARRMSDVPEGVIRVHAPLLSKVSMAIQLNNQTKAKDILAKFQYENSHGSSECIKIQNQRLYEIGGNIGEHCLDPDAYILDVYRINPQAEWVIKPQQSS>sp|O15539|RGS5_HUMAN Regulator of G-protein signaling 5 OS=Homo sapiensOX=9606 GN=RGS5 PE=1 SV=1MCKGLAALPHSCLERAKEIKIKLGILLQKPDSVGDLVIPYNEKPEKPAKTQKTSLDEALQWRDSLDKLLQNNYGLASFKSFLKSEFSEENLEFWIACEDYKKIKSPAKMAEKAKQIYEEFIQTEAPKEVNIDHFTKDITMKNLVEPSLSSFDMAQKRIHALMEKDSLPRFVRSEFYQELIK>sp|O15539-2|RGS5_HUMAN Isoform 2 of Regulator of G-protein signaling 5OS=Homo sapiens OX=9606 GN=RGS5MAEKAKQIYEEFIQTEAPKEVNIDHFTKDITMKNLVEPSLSSFDMAQKRIHALMEKDSLPRFVRSEFYQELIK>sp|O15539-3|RGS5_HUMAN Isoform 3 of Regulator of G-protein signaling 5OS=Homo sapiens OX=9606 GN=RGS5MCKGLAALPHSCLERAKEIKIKLGILLQKPDSVGDLVIPYNEKPEKPAKTQKTSLDEALQWRDSLDKLLQNNYGLASFKSFLKSEFSEENLEFWIACEDYKKIKSPAKMAEKAKQIYEEFIQTEAPKEVGLWVNIDHFTKDITMKNLVEPSLSSFDMAQKRIHALMEKDSLPRFVRSEFYQELIK>sp|Q5T5U3|RHG21_HUMAN Rho GTPase-activating protein 21 OS=Homo sapiensOX=9606 GN=ARHGAP21 PE=1 SV=2MMATRRTGLSEGDGDKLKACEVSKNKDGKEQSETVSLSEDETFSWPGPKTVTLKRTSQGFGFTLRHFIVYPPESAIQFSYKDEENGNRGGKQRNRLEPMDTIFVKQVKEGGPAFEAGLCTGDRIIKVNGESVIGKTYSQVIALIQNSDTTLELSVMPKDEDILQVLQFTKDVTALAYSQDAYLKGNEAYSGNARNIPEPPPICYPWLPSAPSAMAQPVEISPPDSSLSKQQTSTPVLTQPGRAYRMEIQVPPSPTDVAKSNTAVCVCNESVRTVIVPSEKVVDLLSNRNNHTGPSHRTEEVRYGVSEQTSLKTVSRTTSPPLSIPTTHLIHQPAGSRSLEPSGILLKSGNYSGHSDGISSSRSQAVEAPSVSVNHYSPNSHQHIDWKNYKTYKEYIDNRRLHIGCRTIQERLDSLRAASQSTTDYNQVVPNRTTLQGRRRSTSHDRVPQSVQIRQRSVSQERLEDSVLMKYCPRSASQGALTSPSVSFSNHRTRSWDYIEGQDETLENVNSGTPIPDSNGEKKQTYKWSGFTEQDDRRGICERPRQQEIHKSFRGSNFTVAPSVVNSDNRRMSGRGVGSVSQFKKIPPDLKTLQSNRNFQTTCGMSLPRGISQDRSPLVKVRSNSLKAPSTHVTKPSFSQKSFVSIKDQRPVNHLHQNSLLNQQTWVRTDSAPDQQVETGKSPSLSGASAKPAPQSSENAGTSDLELPVSQRNQDLSLQEAETEQSDTLDNKEAVILREKPPSGRQTPQPLRHQSYILAVNDQETGSDTTCWLPNDARREVHIKRMEERKASSTSPPGDSLASIPFIDEPTSPSIDHDIAHIPASAVISASTSQVPSIATVPPCLTTSAPLIRRQLSHDHESVGPPSLDAQPNSKTERSKSYDEGLDDYREDAKLSFKHVSSLKGIKIADSQKSSEDSGSRKDSSSEVFSDAAKEGWLHFRPLVTDKGKRVGGSIRPWKQMYVVLRGHSLYLYKDKREQTTPSEEEQPISVNACLIDISYSETKRKNVFRLTTSDCECLFQAEDRDDMLAWIKTIQESSNLNEEDTGVTNRDLISRRIKEYNNLMSKAEQLPKTPRQSLSIRQTLLGAKSEPKTQSPHSPKEESERKLLSKDDTSPPKDKGTWRKGIPSIMRKTFEKKPTATGTFGVRLDDCPPAHTNRYIPLIVDICCKLVEERGLEYTGIYRVPGNNAAISSMQEELNKGMADIDIQDDKWRDLNVISSLLKSFFRKLPEPLFTNDKYADFIEANRKEDPLDRLKTLKRLIHDLPEHHYETLKFLSAHLKTVAENSEKNKMEPRNLAIVFGPTLVRTSEDNMTHMVTHMPDQYKIVETLIQHHDWFFTEEGAEEPLTTVQEESTVDSQPVPNIDHLLTNIGRTGVSPGDVSDSATSDSTKSKGSWGSGKDQYSRELLVSSIFAAASRKRKKPKEKAQPSSSEDELDNVFFKKENVEQCHNDTKEESKKESETLGRKQKIIIAKENSTRKDPSTTKDEKISLGKESTPSEEPSPPHNSKHNKSPTLSCRFAILKESPRSLLAQKSSHLEETGSDSGTLLSTSSQASLARFSMKKSTSPETKHSEFLANVSTITSDYSTTSSATYLTSLDSSRLSPEVQSVAESKGDEADDERSELISEGRPVETDSESEFPVFPTALTSERLFRGKLQEVTKSSRRNSEGSELSCTEGSLTSSLDSRRQLFSSHKLIECDTLSRKKSARFKSDSGSLGDAKNEKEAPSLTKVFDVMKKGKSTGSLLTPTRGESEKQEPTWKTKIADRLKLRPRAPADDMFGVGNHKVNAETAKRKSIRRRHTLGGHRDATEISVLNFWKVHEQSGERESELSAVNRLKPKCSAQDLSISDWLARERLRTSTSDLSRGEIGDPQTENPSTREIATTDTPLSLHCNTGSSSSTLASTNRPLLSIPPQSPDQINGESFQNVSKNASSAANAQPHKLSETPGSKAEFHPCL>sp|Q5T5U3-3|RHG21_HUMAN Isoform 3 of Rho GTPase-activating protein 21OS=Homo sapiens OX=9606 GN=ARHGAP21MMATRRTGLSEGDGDKLKACEVSKNKDGKEQSETVSLSEDETFSWPGPKTVTLKRTSQGFGFTLRHFIVYPPESAIQFSYKDEENGNRGGKQRNRLEPMDTIFVKQVKEGGPAFEAGLCTGDRIIKVNGESVIGKTYSQVIALIQNSDTTLELSVMPKDEDILQVAYSQDAYLKGNEAYSGNARNIPEPPPICYPWLPSAPSAMAQPVEISPPDSSLSKQQTSTPVLTQPGRAYRMEIQVPPSPTDVAKSNTAVCVCNESVRTVIVPSEKVVDLLSNRNNHTGPSHRTEEVRYGVSEQTSLKTVSRTTSPPLSIPTTHLIHQPAGSRSLEPSGILLKSGNYSGHSDGISSSRSQAVEAPSVSVNHYSPNSHQHIDWKNYKTYKEYIDNRRLHIGCRTIQERLDSLRAASQSTTDYNQVVPNRTTLQGRRRSTSHDRVPQSVQIRQRSVSQERLEDSVLMKYCPRSASQGALTSPSVSFSNHRTRSWDYIEGQDETLENVNSGTPIPDSNGEKKQTYKWSGFTEQDDRRGICERPRQQEIHKSFRGSNFTVAPSVVNSDNRRMSGRGVGSVSQFKKIPPDLKTLQSNRNFQTTCGMSLPRGISQDRSPLVKVRSNSLKAPSTHVTKPSFSQKSFVSIKDQRPVNHLHQNSLLNQQTWVRTDSAPDQQVETGKSPSLSGASAKPAPQSSENAGTSDLELPVSQRNQDLSLQEAETEQSDTLDNKEAVILREKPPSGRQTPQPLRHQSYILAVNDQETGSDTTCWLPNDARREVHIKRMEERKASSTSPPGDSLASIPFIDEPTSPSIDHDIAHIPASAVISASTSQVPSIATVPPCLTTSAPLIRRQLSHDHESVGPPSLDAQPNSKTERSKSYDEGLDDYREDAKLSFKHVSSLKGIKIADSQKSSEDSGSRKDSSSEVFSDAAKEGWLHFRPLVTDKGKRVGGSIRPWKQMYVVLRGHSLYLYKDKREQTTPSEEEQPISVNACLIDISYSETKRKNVFRLTTSDCECLFQAEDRDDMLAWIKTIQESSNLNEEDTGVTNRDLISRRIKEYNNLMSKAEQLPKTPRQSLSIRQTLLGAKSEPKTQSPHSPKEESERKLLSKDDTSPPKDKGTWRKGIPSIMRKTFEKKPTATGTFGVRLDDCPPAHTNRVGDTSPPDFLKSLIQF>sp|O15034|RIMB2_HUMAN RIMS-binding protein 2 OS=Homo sapiens OX=9606GN=RIMBP2 PE=1 SV=3MREAAERRQQLQLEHDQALAVLSAKQQEIDLLQKSKVRELEEKCRTQSEQFNLLSRDLEKFRQHAGKIDLLGGSAVAPLDISTAPSKPFPQFMNGLATSLGKGQESAIGGSSAIGEYIRPLPQPGDRPEPLSAKPTFLSRSGSARCRSESDMENERNSNTSKQRYSGKVHLCVARYSYNPFDGPNENPEAELPLTAGKYLYVYGDMDEDGFYEGELLDGQRGLVPSNFVDFVQDNESRLASTLGNEQDQNFINHSGIGLEGEHILDLHSPTHIDAGITDNSAGTLDVNIDDIGEDIVPYPRKITLIKQLAKSVIVGWEPPAVPPGWGTVSSYNVLVDKETRMNLTLGSRTKALIEKLNMAACTYRISVQCVTSRGSSDELQCTLLVGKDVVVAPSHLRVDNITQISAQLSWLPTNSNYSHVIFLNEEEFDIVKAARYKYQFFNLRPNMAYKVKVLAKPHQMPWQLPLEQREKKEAFVEFSTLPAGPPAPPQDVTVQAGVTPATIRVSWRPPVLTPTGLSNGANVTGYGVYAKGQRVAEVIFPTADSTAVELVRLRSLEAKGVTVRTLSAQGESVDSAVAAVPPELLVPPTPHPRPAPQSKPLASSGVPETKDEHLGPHARMDEAWEQSRAPGPVHGHMLEPPVGPGRRSPSPSRILPQPQGTPVSTTVAKAMAREAAQRVAESSRLEKRSVFLERSSAGQYAASDEEDAYDSPDFKRRGASVDDFLKGSELGKQPHCCHGDEYHTESSRGSDLSDIMEEDEEELYSEMQLEDGGRRRPSGTSHNALKILGNPASAGRVDHMGRRFPRGSAGPQRSRPVTVPSIDDYGRDRLSPDFYEESETDPGAEELPARIFVALFDYDPLTMSPNPDAAEEELPFKEGQIIKVYGDKDADGFYRGETCARLGLIPCNMVSEIQADDEEMMDQLLRQGFLPLNTPVEKIERSRRSGRRHSVSTRRMVALYDYDPRESSPNVDVEAELTFCTGDIITVFGEIDEDGFYYGELNGQKGLVPSNFLEEVPDDVEVYLSDAPSHYSQDTPMRSKAKRKKSVHFTP>sp|O15034-2|RIMB2_HUMAN Isoform 2 of RIMS-binding protein 2 OS=Homosapiens OX=9606 GN=RIMBP2MNGLATSLGKGQESAIGGSSAIGEYIRPLPQPGDRPEPLSAKPTFLSRSGSARCRSESDMENERNSNTSKQRYSGKVHLCVARYSYNPFDGPNENPEAELPLTAGKYLYVYGDMDEDGFYEGELLDGQRGLVPSNFVDFVQDNESRLASTLGNEQDQNFINHSGIGLEGEHILDLHSPTHIDAGITDNSAGTLDVNIDDIGEDIVPYPRKITLIKQLAKSVIVGWEPPAVPPGWGTVSSYNVLVDKETRMNLTLGSRTKALIEKLNMAACTYRISVQCVTSRGSSDELQCTLLVGKDVVVAPSHLRVDNITQISAQLSWLPTNSNYSHVIFLNEEEFDIVKAARYKYQFFNLRPNMAYKVKVLAKPHQMPWQLPLEQREKKEAFVEFSTLPAGPPAPPQDVTVQAGVTPATIRVSWRPPVLTPTGLSNGANVTGYGVYAKGQRVAEVIFPTADSTAVELVRLRSLEAKGVTVRTLSAQGESVDSAVAAVPPELLVPPTPHPRPAPQSKPLASSGVPETKDEHLGPHARMDEAWEQSRAPGPVHGHMLEPPVGPGRRSPSPSRILPQPQGTPVSTTVAKAMAREAAQRVAESSRLEKRSVFLERSSAGQYAASDEEDAYDSPDFKRRGASVDDFLKGSELGKQMVS>sp|O15034-3|RIMB2_HUMAN Isoform 3 of RIMS-binding protein 2 OS=Homosapiens OX=9606 GN=RIMBP2MSPNPDAAEEELPFKEGQIIKVYGDKDADGFYRGETCARLGLIPCNMVSEIQADDEEMMDQLLRQGFLPLNTPVEKIERSRRSGRRHSVSTRRMVALYDYDPRESSPNVDVEAELTFCTGDIITVFGEIDEDGFYYGELNGQKGLVPSNFLEEVPDDVEVYLSDAPSHYSQDTPMRSKAKRVSKPI>sp|Q9H4K1|RIBC2_HUMAN RIB43A-like with coiled-coils protein 2 OS=Homosapiens OX=9606 GN=RIBC2 PE=1 SV=2MGSQTMAVALPRDLRQDANLAKRRHAELCRQKRVFNARNRIIGGDTEAWDVQVHDQKIKEATEKARHETFAAEMRQNDKIMCILENRKKRDRKNLCRAINDFQQSFQKPETRREFDLSDPLALKKDLPARQSDNDVRNTISGMQKFMGEDLNFHERKKFQEEQNREWSLQQQREWKNARAEQKCAEALYTETRLQFDETAKHLQKLESTTRKAVCASVKDFNKSQAIESVERKKQEKKQEQEDNLAEITNLLRGDLLSENPQQAASSFGPHRVVPDRWKGMTQEQLEQIRLVQKQQIQEKLRLQEEKRQRDLDWDRRRIQGARATLLFERQQWRRQRDLRRALDSSNLSLAKEQHLQKKYMNEVYTNQPTGDYFTQFNTGSR>sp|Q3KRB8|RHGBB_HUMAN Inactive Rho GTPase-activating protein 11B OS=Homosapiens OX=9606 GN=ARHGAP11B PE=1 SV=1MWDQRLVKLALLQHLRAFYGIKVKGVRGQCDRRRHETAATEIGGKIFGVPFNALPHSAVPEYGHIPSFLVDACTSLEEHIHTEGLFRKSGSVIRLKALKNKVDHGEGCLSSAPPCDIAGLLKQFFRELPEPILPADLHEALLKAQQLGTEEKNKAILLLSCLLADHTVHVLRYFFNFLRNVSLRSSENKMDSSNLAVIFAPNLLQTSEGHEKMSSNAEKKGVYQTLSWKRYQPCWVLMVSVLLHHWKALKKVNMKLLVNIREREDNV>sp|P02753|RET4_HUMAN Retinol-binding protein 4 OS=Homo sapiens OX=9606GN=RBP4 PE=1 SV=3MKWVWALLLLAALGSGRAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEGLFLQDNIVAEFSVDETGQMSATAKGRVRLLNNWDVCADMVGTFTDTEDPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAVQYSCRLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQEELCLARQYRLIVHNGYCDGRSERNLL>sp|Q8HWS3|RFX6_HUMAN DNA-binding protein RFX6 OS=Homo sapiens OX=9606GN=RFX6 PE=1 SV=2MAKVPELEDTFLQAQPAPQLSPGIQEDCCVQLLGKGLLVYPEETVYLAAEGQPGGEQGGGEKGEDPELPGAVKSEMHLNNGNFSSEEEDADNHDSKTKAADQYLSQKKTITQIVKDKKKQTQLTLQWLEENYIVCEGVCLPRCILYAHYLDFCRKEKLEPACAATFGKTIRQKFPLLTTRRLGTRGHSKYHYYGIGIKESSAYYHSVYSGKGLTRFSGSKLKNEGGFTRKYSLSSKTGTLLPEFPSAQHLVYQGCISKDKVDTLIMMYKTHCQCILDNAINGNFEEIQHFLLHFWQGMPDHLLPLLENPVIIDIFCVCDSILYKVLTDVLIPATMQEMPESLLADIRNFAKNWEQWVVSSLENLPEALTDKKIPIVRRFVSSLKRQTSFLHLAQIARPALFDQHVVNSMVSDIERVDLNSIGSQALLTISGSTDTESGIYTEHDSITVFQELKDLLKKNATVEAFIEWLDTVVEQRVIKTSKQNGRSLKKRAQDFLLKWSFFGARVMHNLTLNNASSFGSFHLIRMLLDEYILLAMETQFNNDKEQELQNLLDKYMKNSDASKAAFTASPSSCFLANRNKGSMVSSDAVKNESHVETTYLPLPSSQPGGLGPALHQFPAGNTDNMPLTGQMELSQIAGHLMTPPISPAMASRGSVINQGPMAGRPPSVGPVLSAPSHCSTYPEPIYPTLPQANHDFYSTSSNYQTVFRAQPHSTSGLYPHHTEHGRCMAWTEQQLSRDFFSGSCAGSPYNSRPPSSYGPSLQAQDSHNMQFLNTGSFNFLSNTGAASCQGATLPPNSPNGYYGSNINYPESHRLGSMVNQHVSVISSIRSLPPYSDIHDPLNILDDSGRKQTSSFYTDTSSPVACRTPVLASSLQTPIPSSSSQCMYGTSNQYPAQETLDSHGTSSREMVSSLPPINTVFMGTAAGGT>sp|Q6ZV50|RFX8_HUMAN DNA-binding protein RFX8 OS=Homo sapiens OX=9606GN=RFX8 PE=2 SV=2MAEGVPASPSSGEGSRGPHSGVIQWLVDNFCICEECSVPRCLMYEIYVETCGQNTENQVNPATFGKLVRLVFPDLGTRRLGTRGSARYHYDGICIKKSSFFYAQYCYLIGEKRYHSGDAIAFEKSTNYNSIIQQEATCEDHSPMKTDPVGSPLSEFRRCPFLEQEQAKKYSCNMMAFLADEYCNYCRDILRNVEDLLTSFWKSLQQDTVMLMSLPDVCQLFKCYDVQLYKGIEDVLLHDFLEDVSIQYLKSVQLFSKKFKLWLLNALEGVPALLQISKLKEVTLFVKRLRRKTYLSNMAKTMRMVLKSKRRVSVLKSDLQAIINQGTLATSKKALASDRSGADELENNPEMKCLRNLISLLGTSTDLRVFLSCLSSHLQAFVFQTSRSKEEFTKLAASFQLRWNLLLTAVSKAMTLCHRDSFGSWHLFHLLLLEYMIHILQSCLEEEEEEEDMGTVKEMLPDDPTLGQPDQALFHSLNSSLSQACASPSMEPLGVMPTHMGQGRYPVGVSNMVLRILGFLVDTAMGNKLIQVLLEDETTESAVKLSLPMGQEALITLKDGQQFVIQISDVPQSSEDIYFRENNANV>sp|Q6ZV50-2|RFX8_HUMAN Isoform 2 of DNA-binding protein RFX8 OS=Homosapiens OX=9606 GN=RFX8MYEIYVETCGQNTENQVNPATFGKMAFLADEYCNYCRDILRNVRN>sp|Q6ZV50-3|RFX8_HUMAN Isoform 3 of DNA-binding protein RFX8 OS=Homosapiens OX=9606 GN=RFX8MYEIYVETCGQNTENQVNPATFGKCEDHSPMKTDPVGSPLSEFRRCPFLEQEQAKKYSCNMMAFLADEYCNYCRDILRNVEDLLTSFWKSLQQDTVMLMSLPDVCQLFKCYDVQLYKGIEDVLLHDFLEDVSIQYLKSVQLFSKKFKLWLLNALEGVPALLQISKLKEVTLFVKRLRRKTYLSNMAKTMRMVLKSKRRVSVLKSDLQAIINQGTLATSKKALASDRSGADELENNPEMKCLRNLISLLGTSTDLRVFLSCLSSHLQAFVFQTSRSKEEFTKLAASFQLRWNLLLTAVSKAMTLCHRDSFGSWHLFHLLLLEYMIHILQSCLEEEEEEEDMGTVKEMLPDDPTLGQPDQALFHSLNSSLSQACASPSMEPLGVMPTHMGQGRYPVGVSNMVLRILGFLVDTAMGNKLIQVLLEDETTESAVKLSLPMGQEALITLKDGQQFVIQISDVPQSSEDIYFRENNANV>sp|P60153|RNAS9_HUMAN Inactive ribonuclease-like protein 9 OS=Homosapiens OX=9606 GN=RNASE9 PE=1 SV=1MMRTLITTHPLPLLLLPQQLLQLVQFQEVDTDFDFPEEDKKEEFEECLEKFFSTGPARPPTKEKVKRRVLIEPGMPLNHIEYCNHEIMGKNVYYKHRWVAEHYFLLMQYDELQKICYNRFVPCKNGIRKCNRSKGLVEGVYCNLTEAFEIPACKYESLYRKGYVLITCSWQNEMQKRIPHTINDLVEPPEHRSFLSEDGVFVISP>sp|P60153-2|RNAS9_HUMAN Isoform 2 of Inactive ribonuclease-like protein9 OS=Homo sapiens OX=9606 GN=RNASE9MSAGKMMRTLITTHPLPLLLLPQQLLQLVQFQEVDTDFDFPEEDKKEEFEECLEKFFSTGPARPPTKEKVKRRVLIEPGMPLNHIEYCNHEIMGKNVYYKHRWVAEHYFLLMQYDELQKICYNRFVPCKNGIRKCNRSKGLVEGVYCNLTEAFEIPACKYESLYRKGYVLITCSWQNEMQKRIPHTINDLVEPPEHRSFLSEDGVFVISP>sp|P50914|RL14_HUMAN 60S ribosomal protein L14 OS=Homo sapiens OX=9606GN=RPL14 PE=1 SV=4MVFRRFVEVGRVAYVSFGPHAGKLVAIVDVIDQNRALVDGPCTQVRRQAMPFKCMQLTDFILKFPHSAHQKYVRQAWQKADINTKWAATRWAKKIEARERKAKMTDFDRFKVMKAKKMRNRIIKNEVKKLQKAALLKASPKKAPGTKGTAAAAAAAAAAKVPAKKITAASKKAPAQKVPAQKATGQKAAPAPKAQKGQKAPAQKAPAPKASGKKA>sp|Q6ZWI9|RFPLB_HUMAN Ret finger protein-like 4B OS=Homo sapiens OX=9606GN=RFPL4B PE=2 SV=2MAKRLQAELSCPVCLDFFSCSISLSCTHVFCFDCIQRYILENHDFRAMCPLCRDVVKVPALEEWQVSVLTLMTKQHNSRLEQSLHVREELRHFREDVTLDAATASSLLVFSNDLRSAQCKKIHHDLTKDPRLACVLGTPCFSSGQHYWEVEVGEVKSWSLGVCKEPADRKSNDLFPEHGFWISMKAGAIHANTHLERIPASPRLRRVGIFLDADLEEIQFFDVDNNVLIYTHDGFFSLELLCPFFCLELLGEGESGNVLTICP>sp|P40429|RL13A_HUMAN 60S ribosomal protein L13a OS=Homo sapiens OX=9606GN=RPL13A PE=1 SV=2MAEVQVLVLDGRGHLLGRLAAIVAKQVLLGRKVVVVRCEGINISGNFYRNKLKYLAFLRKRMNTNPSRGPYHFRAPSRIFWRTVRGMLPHKTKRGQAALDRLKVFDGIPPPYDKKKRMVVPAALKVVRLKPTRKFAYLGRLAHEVGWKYQAVTATLEEKRKEKAKIHYRKKKQLMRLRKQAEKNVEKKIDKYTEVLKTHGLLV>sp|Q8IUX1|T126B_HUMAN Complex I assembly factor TMEM126B, mitochondrialOS=Homo sapiens OX=9606 GN=TMEM126B PE=1 SV=2MVVFGYEAGTKPRDSGVVPVGTEEAPKVFKMAASMHGQPSPSLEDAKLRRPMVIEIIEKNFDYLRKEMTQNIYQMATFGTTAGFSGIFSNFLFRRCFKVKHDALKTYASLATLPFLSTVVTDKLFVIDALYSDNISKENCVFRSSLIGIVCGVFYPSSLAFTKNGRLATKYHTVPLPPKGRVLIHWMTLCQTQMKLMAIPLVFQIMFGILNGLYHYAVFEETLEKTIHEE>sp|Q8IUX1-2|T126B_HUMAN Isoform 2 of Complex I assembly factor TMEM126B,mitochondrial OS=Homo sapiens OX=9606 GN=TMEM126BMWIQVWMTVGTEEAPKVFKMAASMHGQPSPSLEDAKLRRPMVIEIIEKNFDYLRKEMTQNIYQMATFGTTAGFSGIFSNFLFRRCFKVKHDALKTYASLATLPFLSTVVTDKLFVIDALYSDNISKENCVFRSSLIGIVCGVFYPSSLAFTKNGRLATKYHTVPLPPKGRVLIHWMTLCQTQMKLMAIPLVFQIMFGILNGLYHYAVFEETLEKTIHEE>sp|Q8IUX1-3|T126B_HUMAN Isoform 3 of Complex I assembly factor TMEM126B,mitochondrial OS=Homo sapiens OX=9606 GN=TMEM126BMAASMHGQPSPSLEDAKLRRPMVIEIIEKNFDYLRKEMTQNIYQMATFGTTAGFSGIFSNFLFRRCFKVKHDALKTYASLATLPFLSTVVTDKLFVIDALYSGEFKFTNV>sp|Q8IUX1-4|T126B_HUMAN Isoform 4 of Complex I assembly factor TMEM126B,mitochondrial OS=Homo sapiens OX=9606 GN=TMEM126BMVVFGYEAGTKPRDSGVVPVGTEEAPKVFKMAASMHGQPSPSLEDAKLRRPMVIEIIEKNFDYLRKEMTQNIYQMATFGTTAGFSGIFSNFLFRRCFKVKHDALKTYASLATLPFLSTVVTDKLFVIDALYSDNISKENCVFRSSLIGIVCGVFYPSSLAFTKNGRLATK>sp|Q8IUX1-5|T126B_HUMAN Isoform 5 of Complex I assembly factor TMEM126B,mitochondrial OS=Homo sapiens OX=9606 GN=TMEM126BMAASMHGQPSPSLEDAKLRRPMVIEIIEKNFDYLRKEMTQNIYQMATFGTTAGFSGIFSNFLFRRCFKVKHDALKTYASLATLPFLSTVVTDKLFVIDALYSDNISKENCVFRSSLIGIVCGVFYPSSLAFTKNGRLATKYHTVPLPPKGRVLIHWMTLCQTQMKLMAIPLVFQIMFGILNGLYHYAVFEETLEKTIHEE>sp|Q13077|TRAF1_HUMAN TNF receptor-associated factor 1 OS=Homo sapiensOX=9606 GN=TRAF1 PE=1 SV=1MASSSGSSPRPAPDENEFPFGCPPTVCQDPKEPRALCCAGCLSENPRNGEDQICPKCRGEDLQSISPGSRLRTQEKAHPEVAEAGIGCPFAGVGCSFKGSPQSVQEHEVTSQTSHLNLLLGFMKQWKARLGCGLESGPMALEQNLSDLQLQAAVEVAGDLEVDCYRAPCSESQEELALQHFMKEKLLAELEGKLRVFENIVAVLNKEVEASHLALATSIHQSQLDRERILSLEQRVVELQQTLAQKDQALGKLEQSLRLMEEASFDGTFLWKITNVTRRCHESACGRTVSLFSPAFYTAKYGYKLCLRLYLNGDGTGKRTHLSLFIVIMRGEYDALLPWPFRNKVTFMLLDQNNREHAIDAFRPDLSSASFQRPQSETNVASGCPLFFPLSKLQSPKHAYVKDDTMFLKCIVETST>sp|Q13077-2|TRAF1_HUMAN Isoform 2 of TNF receptor-associated factor 1OS=Homo sapiens OX=9606 GN=TRAF1MKQWKARLGCGLESGPMALEQNLSDLQLQAAVEVAGDLEVDCYRAPCSESQEELALQHFMKEKLLAELEGKLRVFENIVAVLNKEVEASHLALATSIHQSQLDRERILSLEQRVVELQQTLAQKDQALGKLEQSLRLMEEASFDGTFLWKITNVTRRCHESACGRTVSLFSPAFYTAKYGYKLCLRLYLNGDGTGKRTHLSLFIVIMRGEYDALLPWPFRNKVTFMLLDQNNREHAIDAFRPDLSSASFQRPQSETNVASGCPLFFPLSKLQSPKHAYVKDDTMFLKCIVETST>sp|A7MCY6|TBKB1_HUMAN TANK-binding kinase 1-binding protein 1 OS=Homosapiens OX=9606 GN=TBKBP1 PE=1 SV=1MESMFEDDISILTQEALGPSEVWLDSPGDPSLGGDMCSASHFALITAYGDIKERLGGLERENATLRRRLKVYEIKYPLISDFGEEHGFSLYEIKDGSLLEVEKVSLQQRLNQFQHELQKNKEQEEQLGEMIQAYEKLCVEKSDLETELREMRALVETHLRQICGLEQQLRQQQGLQDAAFSNLSPPPAPAPPCTDLDLHYLALRGGSGLSHAGWPGSTPSVSDLERRRLEEALEAAQGEARGAQLREEQLQAECERLQGELKQLQETRAQDLASNQSERDMAWVKRVGDDQVNLALAYTELTEELGRLRELSSLQGRILRTLLQEQARSGGQRHSPLSQRHSPAPQCPSPSPPARAAPPCPPCQSPVPQRRSPVPPCPSPQQRRSPASPSCPSPVPQRRSPVPPSCQSPSPQRRSPVPPSCPAPQPRPPPPPPPGERTLAERAYAKPPSHHVKAGFQGRRSYSELAEGAAYAGASPPWLQAEAATLPKPRAYGSELYGPGRPLSPRRAFEGIRLRFEKQPSEEDEWAVPTSPPSPEVGTIRCASFCAGFPIPESPAATAYAHAEHAQSWPSINLLMETVGSDIRSCPLCQLGFPVGYPDDALIKHIDSHLENSKI>sp|A7MCY6-2|TBKB1_HUMAN Isoform 2 of TANK-binding kinase 1-bindingprotein 1 OS=Homo sapiens OX=9606 GN=TBKBP1MESMFEDDISILTQEALGPSEVWLDSPGDPSLGGDMCSASHFALITAYGDIKERLGGLERENATLRRRLKVYEIKYPLISDFGEEHGFSLYEIKDGSLLEVEKVSLQQRLNQFQHELQKNKEQEEQLGEMIQAYEKLCVEKSDLETELREMRALVETHLRQICGLEQQLRQQQGLQDAAFSNLSPRRARAVLAVHQLADGDGGLRHPQLPPLPAGFPCRVPG>sp|Q9Y4K3|TRAF6_HUMAN TNF receptor-associated factor 6 OS=Homo sapiensOX=9606 GN=TRAF6 PE=1 SV=1MSLLNCENSCGSSQSESDCCVAMASSCSAVTKDDSVGGTASTGNLSSSFMEEIQGYDVEFDPPLESKYECPICLMALREAVQTPCGHRFCKACIIKSIRDAGHKCPVDNEILLENQLFPDNFAKREILSLMVKCPNEGCLHKMELRHLEDHQAHCEFALMDCPQCQRPFQKFHINIHILKDCPRRQVSCDNCAASMAFEDKEIHDQNCPLANVICEYCNTILIREQMPNHYDLDCPTAPIPCTFSTFGCHEKMQRNHLARHLQENTQSHMRMLAQAVHSLSVIPDSGYISEVRNFQETIHQLEGRLVRQDHQIRELTAKMETQSMYVSELKRTIRTLEDKVAEIEAQQCNGIYIWKIGNFGMHLKCQEEEKPVVIHSPGFYTGKPGYKLCMRLHLQLPTAQRCANYISLFVHTMQGEYDSHLPWPFQGTIRLTILDQSEAPVRQNHEEIMDAKPELLAFQRPTIPRNPKGFGYVTFMHLEALRQRTFIKDDTLLVRCEVSTRFDMGSLRREGFQPRSTDAGV>sp|O60296|TRAK2_HUMAN Trafficking kinesin-binding protein 2 OS=Homosapiens OX=9606 GN=TRAK2 PE=1 SV=2MSQSQNAIFTSPTGEENLMNSNHRDSESITDVCSNEDLPEVELVSLLEEQLPQYRLKVDTLFLYENQDWTQSPHQRQHASDALSPVLAEETFRYMILGTDRVEQMTKTYNDIDMVTHLLAERDRDLELAARIGQALLKRNHVLSEQNESLEEQLGQAFDQVNQLQHELCKKDELLRIVSIASEESETDSSCSTPLRFNESFSLSQGLLQLEMLQEKLKELEEENMALRSKACHIKTETVTYEEKEQQLVSDCVKELRETNAQMSRMTEELSGKSDELIRYQEELSSLLSQIVDLQHKLKEHVIEKEELKLHLQASKDAQRQLTMELHELQDRNMECLGMLHESQEEIKELRSRSGPTAHLYFSQSYGAFTGESLAAEIEGTMRKKLSLDEESSLFKQKAQQKRVFDTVRIANDTRGRSISFPALLPIPGSNRSSVIMTAKPFESGLQQTEDKSLLNQGSSSEEVAGSSQKMGQPGPSGDSDLATALHRLSLRRQNYLSEKQFFAEEWQRKIQVLADQKEGVSGCVTPTESLASLCTTQSEITDLSSASCLRGFMPEKLQIVKPLEGSQTLYHWQQLAQPNLGTILDPRPGVITKGFTQLPGDAIYHISDLEEDEEEGITFQVQQPLEVEEKLSTSKPVTGIFLPPITSAGGPVTVATANPGKCLSCTNSTFTFTTCRILHPSDITQVTPSSGFPSLSCGSSGSSSSNTAVNSPALSYRLSIGESITNRRDSTTTFSSTMSLAKLLQERGISAKVYHSPISENPLQPLPKSLAIPSTPPNSPSHSPCPSPLPFEPRVHLSENFLASRPAETFLQEMYGLRPSRNPPDVGQLKMNLVDRLKRLGIARVVKNPGAQENGRCQEAEIGPQKPDSAVYLNSGSSLLGGLRRNQSLPVIMGSFAAPVCTSSPKMGVLKED>sp|O60296-2|TRAK2_HUMAN Isoform 2 of Trafficking kinesin-binding protein2 OS=Homo sapiens OX=9606 GN=TRAK2MSQSQNAIFTSPTGEENLMNSNHRDSESITDVCSNEDLPEVELVSLLEEQLPQYRLKVDTLFLYENQDWTQSPHQRQHASDALSPVLAEETFRYMILGTDRVEQMTKTYNDIDMVTHLLAERDRDLELAARIGQALLKRNHVLSEQNESLEEQLGQAFDQVNQLQHELCKKDELLRIVSIASEESETDSSCSTPLRFNESFSLSQGLLQLEMLQEKLKELEEENMALRSKACHIKTETVTYEEKEQQLVSDCVKELRETNAQMSRMTEELSGKSDELIRYQEELSSLLSQIVDLQHKLKEVGLFIHSTDIC>sp|P50591|TNF10_HUMAN Tumor necrosis factor ligand superfamily member 10OS=Homo sapiens OX=9606 GN=TNFSF10 PE=1 SV=1MAMMEVQGGPSLGQTCVLIVIFTVLLQSLCVAVTYVYFTNELKQMQDKYSKSGIACFLKEDDSYWDPNDEESMNSPCWQVKWQLRQLVRKMILRTSEETISTVQEKQQNISPLVRERGPQRVAAHITGTRGRSNTLSSPNSKNEKALGRKINSWESSRSGHSFLSNLHLRNGELVIHEKGFYYIYSQTYFRFQEEIKENTKNDKQMVQYIYKYTSYPDPILLMKSARNSCWSKDAEYGLYSIYQGGIFELKENDRIFVSVTNEHLIDMDHEASFFGAFLVG>sp|P50591-2|TNF10_HUMAN Isoform 2 of Tumor necrosis factor ligandsuperfamily member 10 OS=Homo sapiens OX=9606 GN=TNFSF10MAMMEVQGGPSLGQTCVLIVIFTVLLQSLCVAVTYVYFTNELKQMQDKYSKSGIACFLKEDDSYWDPNDEESMNSPCWQVKWQLRQLVRKTPRMKRLWAAK>sp|Q9Y577|TRI17_HUMAN E3 ubiquitin-protein ligase TRIM17 OS=Homo sapiensOX=9606 GN=TRIM17 PE=1 SV=1MEAVELARKLQEEATCSICLDYFTDPVMTTCGHNFCRACIQLSWEKARGKKGRRKRKGSFPCPECREMSPQRNLLPNRLLTKVAEMAQQHPGLQKQDLCQEHHEPLKLFCQKDQSPICVVCRESREHRLHRVLPAEEAVQGYKLKLEEDMEYLREQITRTGNLQAREEQSLAEWQGKVKERRERIVLEFEKMNLYLVEEEQRLLQALETEEEETASRLRESVACLDRQGHSLELLLLQLEERSTQGPLQMLQDMKEPLSRKNNVSVQCPEVAPPTRPRTVCRVPGQIEVLRGFLEDVVPDATSAYPYLLLYESRQRRYLGSSPEGSGFCSKDRFVAYPCAVGQTAFSSGRHYWEVGMNITGDALWALGVCRDNVSRKDRVPKCPENGFWVVQLSKGTKYLSTFSALTPVMLMEPPSHMGIFLDFEAGEVSFYSVSDGSHLHTYSQATFPGPLQPFFCLGAPKSGQMVISTVTMWVKG>sp|Q9Y577-2|TRI17_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM17OS=Homo sapiens OX=9606 GN=TRIM17MEAVELARKLQEEATCSICLDYFTDPVMTTCGHNFCRACIQLSWEKARGKKGRRKRKGSFPCPECREMSPQRNLLPNRLLTKVAEMAQQHPGLQKQDLCQEHHEPLKLFCQKDQSPICVVCRESREHRLHRVLPAEEAVQGYKLKLEEDMEYLREQITRTGNLQAREEQSLAEWQGKVKERRERIVLEFEKMNLYLVEEEQRLLQALETEEEETASRLRESVACLDRQGHSLELLLLQLEERSTQGPLQMLQDMKEPLSRKNNVSVQCPEVAPPTRPRTVCRVPGQIEVLRGFLGKWAPRARTSDPGSLGDAPLYPLASEATNGGGSTSALPGDGHWLFTVPS>sp|P47974|TISD_HUMAN mRNA decay activator protein ZFP36L2 OS=Homosapiens OX=9606 GN=ZFP36L2 PE=1 SV=3MSTTLLSAFYDVDFLCKTEKSLANLNLNNMLDKKAVGTPVAAAPSSGFAPGFLRRHSASNLHALAHPAPSPGSCSPKFPGAANGSSCGSAAAGGPTSYGTLKEPSGGGGTALLNKENKFRDRSFSENGDRSQHLLHLQQQQKGGGGSQINSTRYKTELCRPFEESGTCKYGEKCQFAHGFHELRSLTRHPKYKTELCRTFHTIGFCPYGPRCHFIHNADERRPAPSGGASGDLRAFGTRDALHLGFPREPRPKLHHSLSFSGFPSGHHQPPGGLESPLLLDSPTSRTPPPPSCSSASSCSSSASSCSSASAASTPSGAPTCCASAAAAAAAALLYGTGGAEDLLAPGAPCAACSSASCANNAFAFGPELSSLITPLAIQTHNFAAVAAAAYYRSQQQQQQQGLAPPAQPPAPPSATLPAGAAAPPSPPFSFQLPRRLSDSPVFDAPPSPPDSLSDRDSYLSGSLSSGSLSGSESPSLDPGRRLPIFSRLSISDD>sp|O95361|TRI16_HUMAN Tripartite motif-containing protein 16 OS=Homosapiens OX=9606 GN=TRIM16 PE=1 SV=3MAELDLMAPGPLPRATAQPPAPLSPDSGSPSPDSGSASPVEEEDVGSSEKLGRETEEQDSDSAEQGDPAGEGKEVLCDFCLDDTRRVKAVKSCLTCMVNYCEEHLQPHQVNIKLQSHLLTEPVKDHNWRYCPAHHSPLSAFCCPDQQCICQDCCQEHSGHTIVSLDAARRDKEAELQCTQLDLERKLKLNENAISRLQANQKSVLVSVSEVKAVAEMQFGELLAAVRKAQANVMLFLEEKEQAALSQANGIKAHLEYRSAEMEKSKQELERMAAISNTVQFLEEYCKFKNTEDITFPSVYVGLKDKLSGIRKVITESTVHLIQLLENYKKKLQEFSKEEEYDIRTQVSAVVQRKYWTSKPEPSTREQFLQYAYDITFDPDTAHKYLRLQEENRKVTNTTPWEHPYPDLPSRFLHWRQVLSQQSLYLHRYYFEVEIFGAGTYVGLTCKGIDRKGEERNSCISGNNFSWSLQWNGKEFTAWYSDMETPLKAGPFRRLGVYIDFPGGILSFYGVEYDTMTLVHKFACKFSEPVYAAFWLSKKENAIRIVDLGEEPEKPAPSLVGTAP>sp|O95361-2|TRI16_HUMAN Isoform 2 of Tripartite motif-containing protein16 OS=Homo sapiens OX=9606 GN=TRIM16MQFGELLAAVRKAQANVMLFLEEKEQAALSQANGIKAHLEYRSAEMEKSKQELERMAAISNTVQFLEEYCKFKNTEDITFPSVYVGLKDKLSGIRKVITESTVHLIQLLENYKKKLQEFSKEEEYDIRTQVSAVVQRKYWTSKPEPSTREQFLQYAYDITFDPDTAHKYLRLQEENRKVTNTTPWEHPYPDLPSRFLHWRQVLSQQSLYLHRYYFEVEIFGAGTYVGLTCKGIDRKGEERNSCISGNNFSWSLQWNGKEFTAWYSDMETPLKAGPFRRLGVYIDFPGGILSFYGVEYDTMTLVHKFACKFSEPVYAAFWLSKKENAIRIVDLGEEPEKPAPSLVGTAP>sp|Q86UV7|TRI73_HUMAN Tripartite motif-containing protein 73 OS=Homosapiens OX=9606 GN=TRIM73 PE=2 SV=1MAWQVSLLELEDRLQCPICLEVFKESLMLQCGHSYCKGCLVSLSYHLDTKVRCPMCWQVVDGSSSLPNVSLAWVIEALRLPGDPEPKVCVHHRNPLSLFCEKDQELICGLCGLLGSHQHHPVTPVSTVCSRMKEELAALFSELKQEQKKVDELIAKLVKNRTRIVNESDVFSWVIRREFQELRHPVDEEKARCLEGIGGHTRGLVASLDMQLEQAQGTRERLAQAECVLEQFGNEDHHEFIWKFHSMASR>sp|P01375|TNFA_HUMAN Tumor necrosis factor OS=Homo sapiens OX=9606GN=TNF PE=1 SV=1MSTESMIRDVELAEEALPKKTGGPQGSRRCLFLSLFSFLIVAGATTLFCLLHFGVIGPQREEFPRDLSLISPLAQAVRSSSRTPSDKPVAHVVANPQAEGQLQWLNRRANALLANGVELRDNQLVVPSEGLYLIYSQVLFKGQGCPSTHVLLTHTISRIAVSYQTKVNLLSAIKSPCQRETPEGAEAKPWYEPIYLGGVFQLEKGDRLSAEINRPDYLDFAESGQVYFGIIAL>sp|Q8NER1|TRPV1_HUMAN Transient receptor potential cation channelsubfamily V member 1 OS=Homo sapiens OX=9606 GN=TRPV1 PE=1 SV=2MKKWSSTDLGAAADPLQKDTCPDPLDGDPNSRPPPAKPQLSTAKSRTRLFGKGDSEEAFPVDCPHEEGELDSCPTITVSPVITIQRPGDGPTGARLLSQDSVAASTEKTLRLYDRRSIFEAVAQNNCQDLESLLLFLQKSKKHLTDNEFKDPETGKTCLLKAMLNLHDGQNTTIPLLLEIARQTDSLKELVNASYTDSYYKGQTALHIAIERRNMALVTLLVENGADVQAAAHGDFFKKTKGRPGFYFGELPLSLAACTNQLGIVKFLLQNSWQTADISARDSVGNTVLHALVEVADNTADNTKFVTSMYNEILMLGAKLHPTLKLEELTNKKGMTPLALAAGTGKIGVLAYILQREIQEPECRHLSRKFTEWAYGPVHSSLYDLSCIDTCEKNSVLEVIAYSSSETPNRHDMLLVEPLNRLLQDKWDRFVKRIFYFNFLVYCLYMIIFTMAAYYRPVDGLPPFKMEKTGDYFRVTGEILSVLGGVYFFFRGIQYFLQRRPSMKTLFVDSYSEMLFFLQSLFMLATVVLYFSHLKEYVASMVFSLALGWTNMLYYTRGFQQMGIYAVMIEKMILRDLCRFMFVYIVFLFGFSTAVVTLIEDGKNDSLPSESTSHRWRGPACRPPDSSYNSLYSTCLELFKFTIGMGDLEFTENYDFKAVFIILLLAYVILTYILLLNMLIALMGETVNKIAQESKNIWKLQRAITILDTEKSFLKCMRKAFRSGKLLQVGYTPDGKDDYRWCFRVDEVNWTTWNTNVGIINEDPGNCEGVKRTLSFSLRSSRVSGRHWKNFALVPLLREASARDRQSAQPEEVYLRQFSGSLKPEDAEVFKSPAASGEK>sp|Q8NER1-3|TRPV1_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily V member 1 OS=Homo sapiens OX=9606 GN=TRPV1METLTPGHLQPSPSSPRPRAAPGSLGRVTRRRLSRWIALTRKVSWTPARPSQSALLSPSRGQETAPPVPGCCPRTLSPPAPRRPSGSMIAGVSLKPLLRITARIWRACCSSCRRARSTSQTTSSKVAPALGSGRAPALACPDPPLCLSDPETGKTCLLKAMLNLHDGQNTTIPLLLEIARQTDSLKELVNASYTDSYYKGQTALHIAIERRNMALVTLLVENGADVQAAAHGDFFKKTKGRPGFYFGELPLSLAACTNQLGIVKFLLQNSWQTADISARDSVGNTVLHALVEVADNTADNTKFVTSMYNEILMLGAKLHPTLKLEELTNKKGMTPLALAAGTGKIGVLAYILQREIQEPECRHLSRKFTEWAYGPVHSSLYDLSCIDTCEKNSVLEVIAYSSSETPNRHDMLLVEPLNRLLQDKWDRFVKRIFYFNFLVYCLYMIIFTMAAYYRPVDGLPPFKMEKTGDYFRVTGEILSVLGGVYFFFRGIQYFLQRRPSMKTLFVDSYSEMLFFLQSLFMLATVVLYFSHLKEYVASMVFSLALGWTNMLYYTRGFQQMGIYAVMIEKMILRDLCRFMFVYIVFLFGFSTAVVTLIEDGKNDSLPSESTSHRWRGPACRPPDSSYNSLYSTCLELFKFTIGMGDLEFTENYDFKAVFIILLLAYVILTYILLLNMLIALMGETVNKIAQESKNIWKLQRAITILDTEKSFLKCMRKAFRSGKLLQVGYTPDGKDDYRWCFRVDEVNWTTWNTNVGIINEDPGNCEGVKRTLSFSLRSSRVSGRHWKNFALVPLLREASARDRQSAQPEEVYLRQFSGSLKPEDAEVFKSPAASGEK>sp|Q5TAA0|TTC22_HUMAN Tetratricopeptide repeat protein 22 OS=Homosapiens OX=9606 GN=TTC22 PE=2 SV=1MAELEAVADDLDALIDDLDYLPGHFHLEMQLNFEPRSPAPQRARDLKLQREGLRQELQLAAAPQRPAVRHLLGAFAFYLEELDEARECFLEVAHEHPGNLNAWANLAHVYGRLGQEEEEEACAARLADLMGLAEEPEAAGDPQLRAARCLAEQGYAHGFDVGCASPEERARGLAAGIALYDKALGYGQQIPMEEKRGWYFTMATLYIRLDGIFLELGSEEQKRLPAFNRTLALLRQVLKSEDPRHRALAWCYLGMLLERKDTFSTTPMGVHDCGYSGTDPLDCFGKAIEIAKNQPPILNRLAKIFYFLGKQDMAIGTCNMALDVLRDPELNWQAYCTRAKIHIRAYLHDLKRAKMGLGGMPDRNHLACAKADLEEVVRVCPGFKAYLDIGQVYYYMGVDAVQELLAVDEAALNQALVFLAKAGESELGATLPELQLLRGKCLRIKGEDANAAACFKRAVELDDAGSSHTDGFGCLLEALLAQWSQAQLSDGELGREVDAWLRRAQDKYPAARLRQELQRVWRGHTDEVLGLARALVAQGRPALVRLLFETMEREGEGASAPRDRRAVSF>sp|Q5TAA0-2|TTC22_HUMAN Isoform 2 of Tetratricopeptide repeat protein 22OS=Homo sapiens OX=9606 GN=TTC22MAELEAVADDLDALIDDLDYLPGHFHLEMQLNFEPRSPAPQRARDLKLQREGLRQELQLAAAPQRPAVRHLLGAFAFYLEELDEARECFLEVAHEHPGNLNAWANLAHVYGRLGQEEEEEACAARLADLMGLAEEPEAAGDPQLRAARCLAEQGYAHGFDVGCASPEERARGLAAGIALYDKALGYGQQIPMEEKRGWYFTMATLYIRLDGIFLELGSEEQKRLPAFNRTLALLRQVLKSEDPRHRALAWCYLGMLLERKDTFSTTPMGVHDCGYSGTDPLDCFGKAIEIAKNQPPILNRLAKIFYFLGKQDMAIGTCNMALDVLRDPELNWQAYCTRAKRRGLTMLPRLVSNSWAQAVLPPRPPKVLEFQV>sp|Q9NNX1|TUFT1_HUMAN Tuftelin OS=Homo sapiens OX=9606 GN=TUFT1 PE=1SV=1MNGTRNWCTLVDVHPEDQAAGSVDILRLTLQGELTGDELEHIAQKAGRKTYAMVSSHSAGHSLASELVESHDGHEEIIKVYLKGRSGDKMIHEKNINQLKSEVQYIQEARNCLQKLREDISSKLDRNLGDSLHRQEIQVVLEKPNGFSQSPTALYSSPPEVDTCINEDVESLRKTVQDLLAKLQEAKRQHQSDCVAFEVTLSRYQREAEQSNVALQREEDRVEQKEAEVGELQRRLLGMETEHQALLAKVREGEVALEELRSNNADCQAEREKAATLEKEVAGLREKIHHLDDMLKSQQRKVRQMIEQLQNSKAVIQSKDATIQELKEKIAYLEAENLEMHDRMEHLIEKQISHGNFSTQARAKTENPGSIRISKPPSPKPMPVIRVVET>sp|Q9NNX1-2|TUFT1_HUMAN Isoform 2 of Tuftelin OS=Homo sapiens OX=9606GN=TUFT1MNGTRNWCTLVDVHPEDQAAAGRKTYAMVSSHSAGHSLASELVESHDGHEEIIKVYLKGRSGDKMIHEKNINQLKSEVQYIQEARNCLQKLREDISSKLDRNLGDSLHRQEIQVVLEKPNGFSQSPTALYSSPPEVDTCINEDVESLRKTVQDLLAKLQEAKRQHQSDCVAFEVTLSRYQREAEQSNVALQREEDRVEQKEAEVGELQRRLLGMETEHQALLAKVREGEVALEELRSNNADCQAEREKAATLEKEVAGLREKIHHLDDMLKSQQRKVRQMIEQLQNSKAVIQSKDATIQELKEKIAYLEAENLEMHDRMEHLIEKQISHGNFSTQARAKTENPGSIRISKPPSPKPMPVIRVVET>sp|Q9NNX1-3|TUFT1_HUMAN Isoform 3 of Tuftelin OS=Homo sapiens OX=9606GN=TUFT1MNGTRNWCTLVDVHPEDQAAVYLKGRSGDKMIHEKNINQLKSEVQYIQEARNCLQKLREDISSKLDRNLGDSLHRQEIQVVLEKPNGFSQSPTALYSSPPEVDTCINEDVESLRKTVQDLLAKLQEAKRQHQSDCVAFEVTLSRYQREAEQSNVALQREEDRVEQKEAEVGELQRRLLGMETEHQALLAKVREGEVALEELRSNNADCQAEREKAATLEKEVAGLREKIHHLDDMLKSQQRKVRQMIEQLQNSKAVIQSKDATIQELKEKIAYLEAENLEMHDRMEHLIEKQISHGNFSTQARAKTENPGSIRISKPPSPKPMPVIRVVET>sp|O95857|TSN13_HUMAN Tetraspanin-13 OS=Homo sapiens OX=9606 GN=TSPAN13PE=2 SV=1MVCGGFACSKNCLCALNLLYTLVSLLLIGIAAWGIGFGLISSLRVVGVVIAVGIFLFLIALVGLIGAVKHHQVLLFFYMIILLLVFIVQFSVSCACLALNQEQQGQLLEVGWNNTASARNDIQRNLNCCGFRSVNPNDTCLASCVKSDHSCSPCAPIIGEYAGEVLRFVGGIGLFFSFTEILGVWLTYRYRNQKDPRANPSAFL>sp|Q9UPT9|UBP22_HUMAN Ubiquitin carboxyl-terminal hydrolase 22 OS=Homosapiens OX=9606 GN=USP22 PE=1 SV=2MVSRPEPEGEAMDAELAVAPPGCSHLGSFKVDNWKQNLRAIYQCFVWSGTAEARKRKAKSCICHVCGVHLNRLHSCLYCVFFGCFTKKHIHEHAKAKRHNLAIDLMYGGIYCFLCQDYIYDKDMEIIAKEEQRKAWKMQGVGEKFSTWEPTKRELELLKHNPKRRKITSNCTIGLRGLINLGNTCFMNCIVQALTHTPLLRDFFLSDRHRCEMQSPSSCLVCEMSSLFQEFYSGHRSPHIPYKLLHLVWTHARHLAGYEQQDAHEFLIAALDVLHRHCKGDDNGKKANNPNHCNCIIDQIFTGGLQSDVTCQVCHGVSTTIDPFWDISLDLPGSSTPFWPLSPGSEGNVVNGESHVSGTTTLTDCLRRFTRPEHLGSSAKIKCSGCHSYQESTKQLTMKKLPIVACFHLKRFEHSAKLRRKITTYVSFPLELDMTPFMASSKESRMNGQYQQPTDSLNNDNKYSLFAVVNHQGTLESGHYTSFIRQHKDQWFKCDDAIITKASIKDVLDSEGYLLFYHKQFLEYE>sp|Q9UPT9-2|UBP22_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 22 OS=Homo sapiens OX=9606 GN=USP22MAPGWPSLSAGSRQEAPQLAAGGSAYQAVGRQFQPRATALQGPSQAKSCICHVCGVHLNRLHSCLYCVFFGCFTKKHIHEHAKAKRHNLAIDLMYGGIYCFLCQDYIYDKDMEIIAKEEQRKAWKMQGVGEKFSTWEPTKRELELLKHNPKRRKITSNCTIGLRGLINLGNTCFMNCIVQALTHTPLLRDFFLSDRHRCEMQSPSSCLVCEMSSLFQEFYSGHRSPHIPYKLLHLVWTHARHLAGYEQQDAHEFLIAALDVLHRHCKGDDNGKKANNPNHCNCIIDQIFTGGLQSDVTCQVCHGVSTTIDPFWDISLDLPGSSTPFWPLSPGSEGNVVNGESHVSGTTTLTDCLRRFTRPEHLGSSAKIKCSGCHSYQESTKQLTMKKLPIVACFHLKRFEHSAKLRRKITTYVSFPLELDMTPFMASSKESRMNGQYQQPTDSLNNDNKYSLFAVVNHQGTLESGHYTSFIRQHKDQWFKCDDAIITKASIKDVLDSEGYLLFYHKQFLEYE>sp|O95045|UPP2_HUMAN Uridine phosphorylase 2 OS=Homo sapiens OX=9606GN=UPP2 PE=1 SV=1MASVIPASNRSMRSDRNTYVGKRFVHVKNPYLDLMDEDILYHLDLGTKTHNLPAMFGDVKFVCVGGSPNRMKAFALFMHKELGFEEAEEDIKDICAGTDRYCMYKTGPVLAISHGMGIPSISIMLHELIKLLHHARCCDVTIIRIGTSGGIGIAPGTVVITDIAVDSFFKPRFEQVILDNIVTRSTELDKELSEELFNCSKEIPNFPTLVGHTMCTYDFYEGQGRLDGALCSFSREKKLDYLKRAFKAGVRNIEMESTVFAAMCGLCGLKAAVVCVTLLDRLDCDQINLPHDVLVEYQQRPQLLISNFIRRRLGLCD>sp|O95045-2|UPP2_HUMAN Isoform 2 of Uridine phosphorylase 2 OS=Homosapiens OX=9606 GN=UPP2MLAPGCELDPDQEVVRTRPEDVPASPSTSTMIVSVLRPPSHASCTACGTVTFHIVERMASVIPASNRSMRSDRNTYVGKRFVHVKNPYLDLMDEDILYHLDLGTKTHNLPAMFGDVKFVCVGGSPNRMKAFALFMHKELGFEEAEEDIKDICAGTDRYCMYKTGPVLAISHGMGIPSISIMLHELIKLLHHARCCDVTIIRIGTSGGIGIAPGTVVITDIAVDSFFKPRFEQVILDNIVTRSTELDKELSEELFNCSKEIPNFPTLVGHTMCTYDFYEGQGRLDGALCSFSREKKLDYLKRAFKAGVRNIEMESTVFAAMCGLCGLKAAVVCVTLLDRLDCDQINLPHDVLVEYQQRPQLLISNFIRRRLGLCD>sp|Q8N2C9|UMAS1_HUMAN Uncharacterized protein UMODL1-AS1 OS=Homo sapiensOX=9606 GN=UMODL1-AS1 PE=2 SV=3MAWGLPCHQNTAGANPHLFLGCYSTSSLQGLEYGGQRGDAHGKPGVLHGELEPHDHTSRLERHDLHSQLPTSVQVRHHWWEGALDLAKKRQQQTSINVFTTIKQGSRCDRWMVLGAISLLYNQEEAPDDRPLRARREVRSQHLSWAFPGTAGPGLVCAGDSQ>sp|Q8IZJ1|UNC5B_HUMAN Netrin receptor UNC5B OS=Homo sapiens OX=9606GN=UNC5B PE=1 SV=2MGARSGARGALLLALLLCWDPRLSQAGTDSGSEVLPDSFPSAPAEPLPYFLQEPQDAYIVKNKPVELRCRAFPATQIYFKCNGEWVSQNDHVTQEGLDEATGLRVREVQIEVSRQQVEELFGLEDYWCQCVAWSSAGTTKSRRAYVRIAYLRKNFDQEPLGKEVPLDHEVLLQCRPPEGVPVAEVEWLKNEDVIDPTQDTNFLLTIDHNLIIRQARLSDTANYTCVAKNIVAKRRSTTATVIVYVNGGWSSWAEWSPCSNRCGRGWQKRTRTCTNPAPLNGGAFCEGQAFQKTACTTICPVDGAWTEWSKWSACSTECAHWRSRECMAPPPQNGGRDCSGTLLDSKNCTDGLCMQNKKTLSDPNSHLLEASGDAALYAGLVVAIFVVVAILMAVGVVVYRRNCRDFDTDITDSSAALTGGFHPVNFKTARPSNPQLLHPSVPPDLTASAGIYRGPVYALQDSTDKIPMTNSPLLDPLPSLKVKVYSSSTTGSGPGLADGADLLGVLPPGTYPSDFARDTHFLHLRSASLGSQQLLGLPRDPGSSVSGTFGCLGGRLSIPGTGVSLLVPNGAIPQGKFYEMYLLINKAESTLPLSEGTQTVLSPSVTCGPTGLLLCRPVILTMPHCAEVSARDWIFQLKTQAHQGHWEEVVTLDEETLNTPCYCQLEPRACHILLDQLGTYVFTGESYSRSAVKRLQLAVFAPALCTSLEYSLRVYCLEDTPVALKEVLELERTLGGYLVEEPKPLMFKDSYHNLRLSLHDLPHAHWRSKLLAKYQEIPFYHIWSGSQKALHCTFTLERHSLASTELTCKICVRQVEGEGQIFQLHTTLAETPAGSLDTLCSAPGSTVTTQLGPYAFKIPLSIRQKICNSLDAPNSRGNDWRMLAQKLSMDRYLNYFATKASPTGVILDLWEALQQDDGDLNSLASALEEMGKSEMLVAVATDGDC>sp|Q8IZJ1-2|UNC5B_HUMAN Isoform 2 of Netrin receptor UNC5B OS=Homosapiens OX=9606 GN=UNC5BMGARSGARGALLLALLLCWDPRLSQAGTDSGSEVLPDSFPSAPAEPLPYFLQEPQDAYIVKNKPVELRCRAFPATQIYFKCNGEWVSQNDHVTQEGLDEATGLRVREVQIEVSRQQVEELFGLEDYWCQCVAWSSAGTTKSRRAYVRIAYLRKNFDQEPLGKEVPLDHEVLLQCRPPEGVPVAEVEWLKNEDVIDPTQDTNFLLTIDHNLIIRQARLSDTANYTCVAKNIVAKRRSTTATVIVYVNGGWSSWAEWSPCSNRCGRGWQKRTRTCTNPAPLNGGAFCEGQAFQKTACTTICPVDGAWTEWSKWSACSTECAHWRSRECMAPPPQNGGRDCSGTLLDSKNCTDGLCMQMLEASGDAALYAGLVVAIFVVVAILMAVGVVVYRRNCRDFDTDITDSSAALTGGFHPVNFKTARPSNPQLLHPSVPPDLTASAGIYRGPVYALQDSTDKIPMTNSPLLDPLPSLKVKVYSSSTTGSGPGLADGADLLGVLPPGTYPSDFARDTHFLHLRSASLGSQQLLGLPRDPGSSVSGTFGCLGGRLSIPGTGVSLLVPNGAIPQGKFYEMYLLINKAESTLPLSEGTQTVLSPSVTCGPTGLLLCRPVILTMPHCAEVSARDWIFQLKTQAHQGHWEEVVTLDEETLNTPCYCQLEPRACHILLDQLGTYVFTGESYSRSAVKRLQLAVFAPALCTSLEYSLRVYCLEDTPVALKEVLELERTLGGYLVEEPKPLMFKDSYHNLRLSLHDLPHAHWRSKLLAKYQEIPFYHIWSGSQKALHCTFTLERHSLASTELTCKICVRQVEGEGQIFQLHTTLAETPAGSLDTLCSAPGSTVTTQLGPYAFKIPLSIRQKICNSLDAPNSRGNDWRMLAQKLSMDRYLNYFATKASPTGVILDLWEALQQDDGDLNSLASALEEMGKSEMLVAVATDGDC>sp|Q6PHR2|ULK3_HUMAN Serine/threonine-protein kinase ULK3 OS=Homosapiens OX=9606 GN=ULK3 PE=1 SV=2MAGPGWGPPRLDGFILTERLGSGTYATVYKAYAKKDTREVVAIKCVAKKSLNKASVENLLTEIEILKGIRHPHIVQLKDFQWDSDNIYLIMEFCAGGDLSRFIHTRRILPEKVARVFMQQLASALQFLHERNISHLDLKPQNILLSSLEKPHLKLADFGFAQHMSPWDEKHVLRGSPLYMAPEMVCQRQYDARVDLWSMGVILYEALFGQPPFASRSFSELEEKIRSNRVIELPLRPLLSRDCRDLLQRLLERDPSRRISFQDFFAHPWVDLEHMPSGESLGRATALVVQAVKKDQEGDSAAALSLYCKALDFFVPALHYEVDAQRKEAIKAKVGQYVSRAEELKAIVSSSNQALLRQGTSARDLLREMARDKPRLLAALEVASAAMAKEEAAGGEQDALDLYQHSLGELLLLLAAEPPGRRRELLHTEVQNLMARAEYLKEQVKMRESRWEADTLDKEGLSESVRSSCTLQ>sp|Q6PHR2-2|ULK3_HUMAN Isoform 2 of Serine/threonine-protein kinase ULK3OS=Homo sapiens OX=9606 GN=ULK3MAGPGWGPPRLDGFILTERLGSGTYATVYKAYAKKDTREVVAIKCVAKKSLNKASVENLLTEIEILKGIRHPHIVQLKDFQWDSDNIYLIMEFCAGGDLSRFIHTRRILPEKVARVFMQQLASALQFLHERNISHLDLKPQNILLSSLEKPHLKLADFGFAQHMSPWDEKHVLRGSPLYMAPEMVCQRQYDARVDLWSMGVILYGETSFPCFSP>sp|Q6PHR2-3|ULK3_HUMAN Isoform 3 of Serine/threonine-protein kinase ULK3OS=Homo sapiens OX=9606 GN=ULK3MAGPGWGPPRLDGFILTERLGSGTYATVYKAYAKKDTREVVAIKCVAKKSLNKASVENLLTEIEILKGIRHPHIVQLKDFQWDSDNIYLIMEFCAGGDLSRFIHTRRILPEKVARVFMQQLASALQFLHERNISHLDLKPQNILLSSLEKPHLKLADFGFAQHMSPWDEKHVLRGSPLYMAPEMVCQRQYDARVDLWSMGVILYEALFGQPPFASRSFSELEEKIRSNRVIELPLRPLLSRDCRDLLQRLLERDPSRRISFQDFFAHPWVDLEHMPSGESLGRATALVVQAVKKDQEGDSAAALSLYCKALDFFVPALHYEVDAQRKEAIKAKVGQYVSRAEELKAIVSSSNQALLRQGTSARDLLREMARDKPRLLAALEVASAAMAKEEAAGGEQDALDLYQHSLGELLLLLAAEPPGRRRELLHTEVQNLMARAEYLKEQMRESRWEADTLDKEGLSESVRSSCTLQ>sp|Q6PHR2-4|ULK3_HUMAN Isoform 4 of Serine/threonine-protein kinase ULK3OS=Homo sapiens OX=9606 GN=ULK3MQRNGSASRGLEKTRLRLCREARIPESAFLTGLTRESWEARCWCAKDTREVVAIKCVAKKSLNKASVENLLTEIEILKGIRHPHIVQLKDFQWDSDNIYLIMEFCAGGDLSRFIHTRRILPEKVARVFMQQLASALQFLHERNISHLDLKPQNILLSSLEKPHLKLADFGFAQHMSPWDEKHVLRGSPLYMAPEMVCQRQYDARVDLWSMGVILYEALFGQPPFASRSFSELEEKIRSNRVIELPLRPLLSRDCRDLLQRLLERDPSRRISFQDFFAHPWVDLEHMPSGESLGRATALVVQAVKKDQEGDSAAALSLYCKALDFFVPALHYEVDAQRKEAIKAKVGQYVSRAEELKAIVSSSNQALLRQGTSARDLLREMARDKPRLLAALEVASAAMAKEEAAGGEQDALDLYQHSLGELLLLLAAEPPGRRRELLHTEVQNLMARAEYLKEQVKMRESRWEADTLDKEGLSESVRSSCTLQ>sp|Q9NVE5|UBP40_HUMAN Ubiquitin carboxyl-terminal hydrolase 40 OS=Homosapiens OX=9606 GN=USP40 PE=1 SV=3MFGDLFEEEYSTVSNNQYGKGKKLKTKALEPPAPREFTNLSGIRNQGGTCYLNSLLQTLHFTPEFREALFSLGPEELGLFEDKDKPDAKVRIIPLQLQRLFAQLLLLDQEAASTADLTDSFGWTSNEEMRQHDVQELNRILFSALETSLVGTSGHDLIYRLYHGTIVNQIVCKECKNVSERQEDFLDLTVAVKNVSGLEDALWNMYVEEEVFDCDNLYHCGTCDRLVKAAKSAKLRKLPPFLTVSLLRFNFDFVKCERYKETSCYTFPLRINLKPFCEQSELDDLEYIYDLFSVIIHKGGCYGGHYHVYIKDVDHLGNWQFQEEKSKPDVNLKDLQSEEEIDHPLMILKAILLEENNLIPVDQLGQKLLKKIGISWNKKYRKQHGPLRKFLQLHSQIFLLSSDESTVRLLKNSSLQAESDFQRNDQQIFKMLPPESPGLNNSISCPHWFDINDSKVQPIREKDIEQQFQGKESAYMLFYRKSQLQRPPEARANPRYGVPCHLLNEMDAANIELQTKRAECDSANNTFELHLHLGPQYHFFNGALHPVVSQTESVWDLTFDKRKTLGDLRQSIFQLLEFWEGDMVLSVAKLVPAGLHIYQSLGGDELTLCETEIADGEDIFVWNGVEVGGVHIQTGIDCEPLLLNVLHLDTSSDGEKCCQVIESPHVFPANAEVGTVLTALAIPAGVIFINSAGCPGGEGWTAIPKEDMRKTFREQGLRNGSSILIQDSHDDNSLLTKEEKWVTSMNEIDWLHVKNLCQLESEEKQVKISATVNTMVFDIRIKAIKELKLMKELADNSCLRPIDRNGKLLCPVPDSYTLKEAELKMGSSLGLCLGKAPSSSQLFLFFAMGSDVQPGTEMEIVVEETISVRDCLKLMLKKSGLQGDAWHLRKMDWCYEAGEPLCEEDATLKELLICSGDTLLLIEGQLPPLGFLKVPIWWYQLQGPSGHWESHQDQTNCTSSWGRVWRATSSQGASGNEPAQVSLLYLGDIEISEDATLAELKSQAMTLPPFLEFGVPSPAHLRAWTVERKRPGRLLRTDRQPLREYKLGRRIEICLEPLQKGENLGPQDVLLRTQVRIPGERTYAPALDLVWNAAQGGTAGSLRQRVADFYRLPVEKIEIAKYFPEKFEWLPISSWNQQITKRKKKKKQDYLQGAPYYLKDGDTIGVKNLLIDDDDDFSTIRDDTGKEKQKQRALGRRKSQEALHEQSSYILSSAETPARPRAPETSLSIHVGSFR>sp|Q9NVE5-2|UBP40_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 40 OS=Homo sapiens OX=9606 GN=USP40MGSSLGLCLGKAPSSSQLFLFFAMGSDVQPGTEMEIVVEETISVRDCLKLMLKKSGLQGDAWHLRKMDWCYEAGEPLCEEDATLKELLICSGDTLLLIEGQLPPLGFLKVPIWWYQLQGPSGHWESHQDQTNCTSSWGRVWRATSSQGENRMGFQQPVHHKEK>sp|Q9NVE5-3|UBP40_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 40 OS=Homo sapiens OX=9606 GN=USP40MSLFLRVVFSFTMFGDLFEEEYSTVSNNQYGKGKKLKTKALEPPAPREFTNLSGIRNQGGTCYLNSLLQTLHFTPEFREALFSLGPEELGLFEDKDKPDAKVRIIPLQLQRLFAQLLLLDQEAASTADLTDSFGWTSNEEMRQHDVQELNRILFSALETSLVGTSGHDLIYRLYHGTIVNQIVCKECKNVSERQEDFLDLTVAVKNVSGLEDALWNMYVEEEVFDCDNLYHCGTCDRLVKAAKSAKLRKLPPFLTVSLLRFNFDFVKCERYKETSCYTFPLRINLKPFCEQSELDDLEYIYDLFSVIIHKGGCYGGHYHVYIKDVDHLGNWQFQEEKSKPDVNLKDLQSEEEIDHPLMILKAILLEENNLIPVDQLGQKLLKKIGISWNKKYRKQHGPLRKFLQLHSQIFLLSSDESTVRLLKNSSLQAESDFQRNDQQIFKMLPPESPGLNNSISCPHWFDINDSKVQPIREKDIEQQFQGKESAYMLFYRKSQLQRPPEARANPRYGVPCHLLNEMDAANIELQTKRAECDSANNTFELHLHLGPQYHFFNGALHPVVSQTESVWDLTFDKRKTLGDLRQSIFQLLEFWEGDMVLSVAKLVPAGLHIYQSLGGDELTLCETEIADGEDIFVWNGVEVGGVHIQTGIDCEPLLLNVLHLDTSSDGEKCCQVIESPHVFPANAEVGTVLTALAIPAGVIFINSAGCPGGEGWTAIPKEDMRKTFREQGLRNGSSILIQDSHDDNSLLTKEEKWVTSMNEIDWLHVKNLCQLESEEKQVKISATVNTMVFDIRIKAIKELKLMKELADNSCLRPIDRNGKLLCPVPDSYTLKEAELKMGSSLGLCLGKAPSSSQLFLFFAMGSDVQPGTEMEIVVEETISVRDCLKLMLKKSGLQGDAWHLRKMDWCYEAGEPLCEEDATLKELLICSGDTLLLIEGQLPPLGFLKVPIWWYQLQGPSGHWESHQDQTNCTSSWGRVWRATSSQGASGNEPAQVSLLYLGDIEISEDATLAELKSQAMTLPPFLEFGVPSPAHLRAWTVERKRPGRLLRTDRQPLREYKLGRRIEICLEPLQKGENLGPQDVLLRTQVRIPGERTYAPALDLVWNAAQGGTAGSLRQRVADFYRLPVEKIEIAKYFPEKFEWLPISSWNQQITKRKKKKKQDYLQGAPYYLKDGDTIGVKNLLIDDDDDFSTIRDDTGKEKQKQRALGRRKSQEALHEQSSYILSSAETPARPRAPETSLSIHVGSFR>sp|P55089|UCN1_HUMAN Urocortin OS=Homo sapiens OX=9606 GN=UCN PE=1 SV=1MRQAGRAALLAALLLLVQLCPGSSQRSPEAAGVQDPSLRWSPGARNQGGGARALLLLLAERFPRRAGPGRLGLGTAGERPRRDNPSLSIDLTFHLLRTLLELARTQSQRERAEQNRIIFDSVGK>sp|Q9NRR5|UBQL4_HUMAN Ubiquilin-4 OS=Homo sapiens OX=9606 GN=UBQLN4 PE=1SV=2MAEPSGAETRPPIRVTVKTPKDKEEIVICDRASVKEFKEEISRRFKAQQDQLVLIFAGKILKDGDTLNQHGIKDGLTVHLVIKTPQKAQDPAAATASSPSTPDPASAPSTTPASPATPAQPSTSGSASSDAGSGSRRSSGGGPSPGAGEGSPSATASILSGFGGILGLGSLGLGSANFMELQQQMQRQLMSNPEMLSQIMENPLVQDMMSNPDLMRHMIMANPQMQQLMERNPEISHMLNNPELMRQTMELARNPAMMQEMMRNQDRALSNLESIPGGYNALRRMYTDIQEPMFSAAREQFGNNPFSSLAGNSDSSSSQPLRTENREPLPNPWSPSPPTSQAPGSGGEGTGGSGTSQVHPTVSNPFGINAASLGSGMFNSPEMQALLQQISENPQLMQNVISAPYMRSMMQTLAQNPDFAAQMMVNVPLFAGNPQLQEQLRLQLPVFLQQMQNPESLSILTNPRAMQALLQIQQGLQTLQTEAPGLVPSLGSFGISRTPAPSAGSNAGSTPEAPTSSPATPATSSPTGASSAQQQLMQQMIQLLAGSGNSQVQTPEVRFQQQLEQLNSMGFINREANLQALIATGGDINAAIERLLGSQLS>sp|Q9NRR5-2|UBQL4_HUMAN Isoform 2 of Ubiquilin-4 OS=Homo sapiens OX=9606GN=UBQLN4MAEPSGAETRPPIRVTVKTPKDKEEIVICDRASVKEFKEEISRRFKAQQDQLVLIFAGKILKDGDTLNQHGIKDGLTVHLVIKTPQKAQDPAPPAAPSLPAADAEPRVTLHPYQSPSHAGIAADPAGTTDLADRGPWAGTQPWLLWDIPDPSTLSRQQRRVYARGPHFLTSHASHIFSNRGFQRPAATHAADDPAFGWKWKLTGADARSEISAAAGAAQLHGLHQS>sp|Q9UHF7|TRPS1_HUMAN Zinc finger transcription factor Trps1 OS=Homosapiens OX=9606 GN=TRPS1 PE=1 SV=2MVRKKNPPLRNVASEGEGQILEPIGTESKVSGKNKEFSADQMSENTDQSDAAELNHKEEHSLHVQDPSSSSKKDLKSAVLSEKAGFNYESPSKGGNFPSFPHDEVTDRNMLAFSSPAAGGVCEPLKSPQRAEADDPQDMACTPSGDSLETKEDQKMSPKATEETGQAQSGQANCQGLSPVSVASKNPQVPSDGGVRLNKSKTDLLVNDNPDPAPLSPELQDFKCNICGYGYYGNDPTDLIKHFRKYHLGLHNRTRQDAELDSKILALHNMVQFSHSKDFQKVNRSVFSGVLQDINSSRPVLLNGTYDVQVTSGGTFIGIGRKTPDCQGNTKYFRCKFCNFTYMGNSSTELEQHFLQTHPNKIKASLPSSEVAKPSEKNSNKSIPALQSSDSGDLGKWQDKITVKAGDDTPVGYSVPIKPLDSSRQNGTEATSYYWCKFCSFSCESSSSLKLLEHYGKQHGAVQSGGLNPELNDKLSRGSVINQNDLAKSSEGETMTKTDKSSSGAKKKDFSSKGAEDNMVTSYNCQFCDFRYSKSHGPDVIVVGPLLRHYQQLHNIHKCTIKHCPFCPRGLCSPEKHLGEITYPFACRKSNCSHCALLLLHLSPGAAGSSRVKHQCHQCSFTTPDVDVLLFHYESVHESQASDVKQEANHLQGSDGQQSVKESKEHSCTKCDFITQVEEEISRHYRRAHSCYKCRQCSFTAADTQSLLEHFNTVHCQEQDITTANGEEDGHAISTIKEEPKIDFRVYNLLTPDSKMGEPVSESVVKREKLEEKDGLKEKVWTESSSDDLRNVTWRGADILRGSPSYTQASLGLLTPVSGTQEQTKTLRDSPNVEAAHLARPIYGLAVETKGFLQGAPAGGEKSGALPQQYPASGENKSKDESQSLLRRRRGSGVFCANCLTTKTSLWRKNANGGYVCNACGLYQKLHSTPRPLNIIKQNNGEQIIRRRTRKRLNPEALQAEQLNKQQRGSNEEQVNGSPLERRSEDHLTESHQREIPLPSLSKYEAQGSLTKSHSAQQPVLVSQTLDIHKRMQPLHIQIKSPQESTGDPGNSSSVSEGKGSSERGSPIEKYMRPAKHPNYSPPGSPIEKYQYPLFGLPFVHNDFQSEADWLRFWSKYKLSVPGNPHYLSHVPGLPNPCQNYVPYPTFNLPPHFSAVGSDNDIPLDLAIKHSRPGPTANGASKEKTKAPPNVKNEGPLNVVKTEKVDRSTQDELSTKCVHCGIVFLDEVMYALHMSCHGDSGPFQCSICQHLCTDKYDFTTHIQRGLHRNNAQVEKNGKPKE>sp|Q9UHF7-2|TRPS1_HUMAN Isoform 2 of Zinc finger transcription factorTrps1 OS=Homo sapiens OX=9606 GN=TRPS1MPYEVNAGYDFTNMVRKKNPPLRNVASEGEGQILEPIGTESKVSGKNKEFSADQMSENTDQSDAAELNHKEEHSLHVQDPSSSSKKDLKSAVLSEKAGFNYESPSKGGNFPSFPHDEVTDRNMLAFSSPAAGGVCEPLKSPQRAEADDPQDMACTPSGDSLETKEDQKMSPKATEETGQAQSGQANCQGLSPVSVASKNPQVPSDGGVRLNKSKTDLLVNDNPDPAPLSPELQDFKCNICGYGYYGNDPTDLIKHFRKYHLGLHNRTRQDAELDSKILALHNMVQFSHSKDFQKVNRSVFSGVLQDINSSRPVLLNGTYDVQVTSGGTFIGIGRKTPDCQGNTKYFRCKFCNFTYMGNSSTELEQHFLQTHPNKIKASLPSSEVAKPSEKNSNKSIPALQSSDSGDLGKWQDKITVKAGDDTPVGYSVPIKPLDSSRQNGTEATSYYWCKFCSFSCESSSSLKLLEHYGKQHGAVQSGGLNPELNDKLSRGSVINQNDLAKSSEGETMTKTDKSSSGAKKKDFSSKGAEDNMVTSYNCQFCDFRYSKSHGPDVIVVGPLLRHYQQLHNIHKCTIKHCPFCPRGLCSPEKHLGEITYPFACRKSNCSHCALLLLHLSPGAAGSSRVKHQCHQCSFTTPDVDVLLFHYESVHESQASDVKQEANHLQGSDGQQSVKESKEHSCTKCDFITQVEEEISRHYRRAHSCYKCRQCSFTAADTQSLLEHFNTVHCQEQDITTANGEEDGHAISTIKEEPKIDFRVYNLLTPDSKMGEPVSESVVKREKLEEKDGLKEKVWTESSSDDLRNVTWRGADILRGSPSYTQASLGLLTPVSGTQEQTKTLRDSPNVEAAHLARPIYGLAVETKGFLQGAPAGGEKSGALPQQYPASGENKSKDESQSLLRRRRGSGVFCANCLTTKTSLWRKNANGGYVCNACGLYQKLHSTPRPLNIIKQNNGEQIIRRRTRKRLNPEALQAEQLNKQQRGSNEEQVNGSPLERRSEDHLTESHQREIPLPSLSKYEAQGSLTKSHSAQQPVLVSQTLDIHKRMQPLHIQIKSPQESTGDPGNSSSVSEGKGSSERGSPIEKYMRPAKHPNYSPPGSPIEKYQYPLFGLPFVHNDFQSEADWLRFWSKYKLSVPGNPHYLSHVPGLPNPCQNYVPYPTFNLPPHFSAVGSDNDIPLDLAIKHSRPGPTANGASKEKTKAPPNVKNEGPLNVVKTEKVDRSTQDELSTKCVHCGIVFLDEVMYALHMSCHGDSGPFQCSICQHLCTDKYDFTTHIQRGLHRNNAQVEKNGKPKE>sp|Q9UHF7-3|TRPS1_HUMAN Isoform 3 of Zinc finger transcription factorTrps1 OS=Homo sapiens OX=9606 GN=TRPS1MQSNMVRKKNPPLRNVASEGEGQILEPIGTESKVSGKNKEFSADQMSENTDQSDAAELNHKEEHSLHVQDPSSSSKKDLKSAVLSEKAGFNYESPSKGGNFPSFPHDEVTDRNMLAFSSPAAGGVCEPLKSPQRAEADDPQDMACTPSGDSLETKEDQKMSPKATEETGQAQSGQANCQGLSPVSVASKNPQVPSDGGVRLNKSKTDLLVNDNPDPAPLSPELQDFKCNICGYGYYGNDPTDLIKHFRKYHLGLHNRTRQDAELDSKILALHNMVQFSHSKDFQKVNRSVFSGVLQDINSSRPVLLNGTYDVQVTSGGTFIGIGRKTPDCQGNTKYFRCKFCNFTYMGNSSTELEQHFLQTHPNKIKASLPSSEVAKPSEKNSNKSIPALQSSDSGDLGKWQDKITVKAGDDTPVGYSVPIKPLDSSRQNGTEATSYYWCKFCSFSCESSSSLKLLEHYGKQHGAVQSGGLNPELNDKLSRGSVINQNDLAKSSEGETMTKTDKSSSGAKKKDFSSKGAEDNMVTSYNCQFCDFRYSKSHGPDVIVVGPLLRHYQQLHNIHKCTIKHCPFCPRGLCSPEKHLGEITYPFACRKSNCSHCALLLLHLSPGAAGSSRVKHQCHQCSFTTPDVDVLLFHYESVHESQASDVKQEANHLQGSDGQQSVKESKEHSCTKCDFITQVEEEISRHYRRAHSCYKCRQCSFTAADTQSLLEHFNTVHCQEQDITTANGEEDGHAISTIKEEPKIDFRVYNLLTPDSKMGEPVSESVVKREKLEEKDGLKEKVWTESSSDDLRNVTWRGADILRGSPSYTQASLGLLTPVSGTQEQTKTLRDSPNVEAAHLARPIYGLAVETKGFLQGAPAGGEKSGALPQQYPASGENKSKDESQSLLRRRRGSGVFCANCLTTKTSLWRKNANGGYVCNACGLYQKLHSTPRPLNIIKQNNGEQIIRRRTRKRLNPEALQAEQLNKQQRGSNEEQVNGSPLERRSEDHLTESHQREIPLPSLSKYEAQGSLTKSHSAQQPVLVSQTLDIHKRMQPLHIQIKSPQESTGDPGNSSSVSEGKGSSERGSPIEKYMRPAKHPNYSPPGSPIEKYQYPLFGLPFVHNDFQSEADWLRFWSKYKLSVPGNPHYLSHVPGLPNPCQNYVPYPTFNLPPHFSAVGSDNDIPLDLAIKHSRPGPTANGASKEKTKAPPNVKNEGPLNVVKTEKVDRSTQDELSTKCVHCGIVFLDEVMYALHMSCHGDSGPFQCSICQHLCTDKYDFTTHIQRGLHRNNAQVEKNGKPKE>sp|Q5TAX3|TUT4_HUMAN Terminal uridylyltransferase 4 OS=Homo sapiensOX=9606 GN=TUT4 PE=1 SV=3MEESKTLKSENHEPKKNVICEESKAVQVIGNQTLKARNDKSVKEIENSSPNRNSSKKNKQNDICIEKTEVKSCKVNAANLPGPKDLGLVLRDQSHCKAKKFPNSPVKAEKATISQAKSEKATSLQAKAEKSPKSPNSVKAEKASSYQMKSEKVPSSPAEAEKGPSLLLKDMRQKTELQQIGKKIPSSFTSVDKVNIEAVGGEKCALQNSPRSQKQQTCTDNTGDSDDSASGIEDVSDDLSKMKNDESNKENSSEMDYLENATVIDESALTPEQRLGLKQAEERLERDHIFRLEKRSPEYTNCRYLCKLCLIHIENIQGAHKHIKEKRHKKNILEKQEESELRSLPPPSPAHLAALSVAVIELAKEHGITDDDLRVRQEIVEEMSKVITTFLPECSLRLYGSSLTRFALKSSDVNIDIKFPPKMNHPDLLIKVLGILKKNVLYVDVESDFHAKVPVVVCRDRKSGLLCRVSAGNDMACLTTDLLTALGKIEPVFIPLVLAFRYWAKLCYIDSQTDGGIPSYCFALMVMFFLQQRKPPLLPCLLGSWIEGFDPKRMDDFQLKGIVEEKFVKWECNSSSATEKNSIAEENKAKADQPKDDTKKTETDNQSNAMKEKHGKSPLALETPNRVSLGQLWLELLKFYTLDFALEEYVICVRIQDILTRENKNWPKRRIAIEDPFSVKRNVARSLNSQLVYEYVVERFRAAYRYFACPQTKGGNKSTVDFKKREKGKISNKKPVKSNNMATNGCILLGETTEKINAEREQPVQCDEMDCTSQRCIIDNNNLLVNELDFADHGQDSSSLSTSKSSEIEPKLDKKQDDLAPSETCLKKELSQCNCIDLSKSPDPDKSTGTDCRSNLETESSHQSVCTDTSATSCNCKATEDASDLNDDDNLPTQELYYVFDKFILTSGKPPTIVCSICKKDGHSKNDCPEDFRKIDLKPLPPMTNRFREILDLVCKRCFDELSPPCSEQHNREQILIGLEKFIQKEYDEKARLCLFGSSKNGFGFRDSDLDICMTLEGHENAEKLNCKEIIENLAKILKRHPGLRNILPITTAKVPIVKFEHRRSGLEGDISLYNTLAQHNTRMLATYAAIDPRVQYLGYTMKVFAKRCDIGDASRGSLSSYAYILMVLYFLQQRKPPVIPVLQEIFDGKQIPQRMVDGWNAFFFDKTEELKKRLPSLGKNTESLGELWLGLLRFYTEEFDFKEYVISIRQKKLLTTFEKQWTSKCIAIEDPFDLNHNLGAGVSRKMTNFIMKAFINGRKLFGTPFYPLIGREAEYFFDSRVLTDGELAPNDRCCRVCGKIGHYMKDCPKRKSLLFRLKKKDSEEEKEGNEEEKDSRDVLDPRDLHDTRDFRDPRDLRCFICGDAGHVRRECPEVKLARQRNSSVAAAQLVRNLVNAQQVAGSAQQQGDQSIRTRQSSECSESPSYSPQPQPFPQNSSQSAAITQPSSQPGSQPKLGPPQQGAQPPHQVQMPLYNFPQSPPAQYSPMHNMGLLPMHPLQIPAPSWPIHGPVIHSAPGSAPSNIGLNDPSIIFAQPAARPVAIPNTSHDGHWPRTVAPNSLVNSGAVGNSEPGFRGLTPPIPWEHAPRPHFPLVPASWPYGLHQNFMHQGNARFQPNKPFYTQDRCATRRCRERCPHPPRGNVSE>sp|Q5TAX3-2|TUT4_HUMAN Isoform 2 of Terminal uridylyltransferase 4OS=Homo sapiens OX=9606 GN=TUT4MEESKTLKSENHEPKKNVICEESKAVQVIGNQTLKARNDKSVKEIENSSPNRNSSKKNKQNDICIEKTEVKSCKVNAANLPGPKDLGLVLRDQSHCKAKKFPNSPVKAEKATISQAKSEKATSLQAKAEKSPKSPNSVKAEKASSYQMKSEKVPSSPAEAEKGPSLLLKDMRQKTELQQIGKKIPSSFTSVDKVNIEAVGGEKCALQNSPRSQKQQTCTDNTGDSDDSASGIEDVSDDLSKMKNDESNKENSSEMDYLENATVIDESALTPEQRLGLKQAEERLERDHIFRLEKRSPEYTNCRYLCKLCLIHIENIQGAHKHIKEKRHKKNILEKQEESELRSLPPPSPAHLAALSVAVIELAKEHGITDDDLRVRQEIVEEMSKVITTFLPECSLRLYGSSLTRFALKSSDVNIDIKFPPKMNHPDLLIKVLGILKKNVLYVDVESDFHAKVPVVVCRDRKSGLLCRVSAGNDMACLTTDLLTALGKIEPVFIPLVLAFRYWAKLCYIDSQTDGGIPSYCFALMVMFFLQQRKPPLLPCLLGSWIEGFDPKRMDDFQLKGIVEEKFVKWECNSSSATEKNSIAEENKAKADQPKDDTKKTETDNQSNAMKEKHGKSPLALETPNRVSLGQLWLELLKFYTLDFALEEYVICVRIQDILTRENKNWPKRRIAIEDPFSVKRNVALQPGRQEWKLCLKKKKKNSVKYTFIYEIQVSLFVI>sp|Q99437|VATO_HUMAN V-type proton ATPase 21 kDa proteolipid subunitOS=Homo sapiens OX=9606 GN=ATP6V0B PE=1 SV=1MTGLALLYSGVFVAFWACALAVGVCYTIFDLGFRFDVAWFLTETSPFMWSNLGIGLAISLSVVGAAWGIYITGSSIIGGGVKAPRIKTKNLVSIIFCEAVAIYGIIMAIVISNMAEPFSATDPKAIGHRNYHAGYSMFGAGLTVGLSNLFCGVCVGIVGSGAALADAQNPSLFVKILIVEIFGSAIGLFGVIVAILQTSRVKMGD>sp|Q99437-2|VATO_HUMAN Isoform 2 of V-type proton ATPase 21 kDaproteolipid subunit OS=Homo sapiens OX=9606 GN=ATP6V0BMWSNLGIGLAISLSVVGAAWGIYITGSSIIGGGVKAPRIKTKNLVSIIFCEAVAIYGIIMAIVISNMAEPFSATDPKAIGHRNYHAGYSMFGAGLTVGLSNLFCGVCVGIVGSGAALADAQNPSLFVKILIVEIFGSAIGLFGVIVAILQTSRVKMGD>sp|Q9NRM2|ZN277_HUMAN Zinc finger protein 277 OS=Homo sapiens OX=9606GN=ZNF277 PE=1 SV=2MAASKTQGAVARMQEDRDGSCSTVGGVGYGDSKDCILEPLSLPESPGGTTTLEGSPSVPCIFCEEHFPVAEQDKLLKHMIIEHKIVIADVKLVADFQRYILYWRKRFTEQPITDFCSVIRINSTAPFEEQENYFLLCDVLPEDRILREELQKQRLREILEQQQQERNDTNFHGVCMFCNEEFLGNRSVILNHMAREHAFNIGLPDNIVNCNEFLCTLQKKLDNLQCLYCEKTFRDKNTLKDHMRKKQHRKINPKNREYDRFYVINYLELGKSWEEVQLEDDRELLDHQEDDWSDWEEHPASAVCLFCEKQAETIEKLYVHMEDAHEFDLLKIKSELGLNFYQQVKLVNFIRRQVHQCRCYGCHVKFKSKADLRTHMEETKHTSLLPDRKTWDQLEYYFPTYENDTLLCTLSDSESDLTAQEQNENVPIISEDTSKLYALKQSSILNQLLL>sp|Q15906|VPS72_HUMAN Vacuolar protein sorting-associated protein 72homolog OS=Homo sapiens OX=9606 GN=VPS72 PE=1 SV=1MSLAGGRAPRKTAGNRLSGLLEAEEEDEFYQTTYGGFTEESGDDEYQGDQSDTEDEVDSDFDIDEGDEPSSDGEAEEPRRKRRVVTKAYKEPLKSLRPRKVNTPAGSSQKAREEKALLPLELQDDGSDSRKSMRQSTAEHTRQTFLRVQERQGQSRRRKGPHCERPLTQEELLREAKITEELNLRSLETYERLEADKKKQVHKKRKCPGPIITYHSVTVPLVGEPGPKEENVDIEGLDPAPSVSALTPHAGTGPVNPPARCSRTFITFSDDATFEEWFPQGRPPKVPVREVCPVTHRPALYRDPVTDIPYATARAFKIIREAYKKYITAHGLPPTASALGPGPPPPEPLPGSGPRALRQKIVIK>sp|Q15906-2|VPS72_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 72 homolog OS=Homo sapiens OX=9606 GN=VPS72MSLAGGRAPRKTAGNRLSGLLEAEEEDEFYQTTYGGFTEESGDDEYQGDQSDTEDEVDSDFDIDEGDEPSSDGEAEEPRRKRRVVTKAYKEPLKSLRPRKVNTPAGSSQKAREEKALLPLELQDDGSDSRKSMRQSTAEHTRQTFLRVQERQGQSRRRKGPHCERPLTQEELLREAKITEELNLRSLETYERLEADKKKQVHKKRKCPGPIITYHSVTVPLVGEPGPKEENVDIEGSLCFSLSFVLRLDPAPSVSALTPHAGTGPVNPPARCSRTFITFSDDATFEEWFPQGRPPKVPVREVCPVTHRPALYRDPVTDIPYATARAFKIIREAYKKYITAHGLPPTASALGPGPPPPEPLPGSGPRALRQKIVIK>sp|Q8TDU5|VNRL4_HUMAN Putative vomeronasal receptor-like protein 4OS=Homo sapiens OX=9606 GN=VN1R17P PE=5 SV=1MEMTKLFSYIVIKNVYYPQVSFGISANTFLLLFHIFTFAYTHRLKPIDMTISHLPLIHILLLFTQAILVSSDLFESWNIQNNDLKCKIITFLNRVMRGVSICTTCLLSVLQAITISPSTSFLEKFKHISANHTLGFILFSWVLNMFITNNLLLFIVPTPNRIGASLLFVTEHCYVLPMSYTHRSLFFILMVLRDVIFIGLMVLSSGYG>sp|Q7L0L9|YA043_HUMAN Transmembrane protein LOC653160 OS=Homo sapiensOX=9606 PE=2 SV=2MKGLRVAKAFQPSQGCSRQALGHLSGRGPSPRSEMNSSVGDLGVGGCSLWDDPARFIVVPAAYALALGLGLPANVAALAMFIRSGGRLGQALLLYLFNLALVDEFFTLTLQLWLTYYLGLARRPPATRPGPPTTCPPMRRWSSPRSSACAAAASYAVPGPGRLPAWPGAYGAPRALPAPSPGWRAWPLPAWSTAGQARGWPPPRWPSRPPSCWCSRPT>sp|O14709|ZN197_HUMAN Zinc finger protein 197 OS=Homo sapiens OX=9606GN=ZNF197 PE=2 SV=1MTRENVAHNALRQEGLVKGKDDTWKWGTSFQGSSSSVWETSHLHFRQLRYHETSGPQEALSRLRELCRRWLRPEARTKAQILELLVLEQFLSILPGEIRTWVQLHHPGSGEEAVALVEELQKDLDGPAIQVPVLVKDQDTLQKVVSAPGTTLPPVLPGSHIAAEICPHPPTDLVAFNLQDPQHDSPAPEASALSQEENPRNQLMALMLLTAQPQELVMFEEVSVCFTSEEWACLGPIQRALYWDVMLENYGNVTSLEWETMTENEEVTSKPSSSQRADSHKGTSKRLQGSVPQVLDFEEECEWQVLASQWGNETDERADTVKKVSLCERDKKKRTPPEKQGQKWKELGDSLTFGSAISESLIGTEGKKFYKCDMCCKHFNKISHLINHRRIHTGEKPHKCKECGKGFIQRSSLLMHLRNHSGEKPYKCNECGKAFSQSAYLLNHQRIHTGEKPYKCKECGKGFYRHSGLIIHLRRHSGERPYKCNECGKVFSQNAYLIDHQRLHKGEEPYKCNKCQKAFILKKSLILHQRIHSGEKPYKCDECGKTFAQTTYLIDHQRLHSAENPYKCKECGKVFIRSKSLLLHQRVHTEKKTFGCKKCGKIFSSKSNFIDHKRMHSREKPYKCTECGKAFTQSAYLFDHQRLHNGEKPYECNECGKVFILKKSLILHQRFHTGENLYECKDCGKVFGSNRNLIDHERLHNGEKPYECRECGKTFIMSKSFMVHQKLHTQEKAYKCEDCGKAFSYNSSLLVHRRIHTGEKPFECSECGRAFSSNRNLIEHKRIHSGEKPYECDECGKCFILKKSLIGHQRIHTREKSYKCNDCGKVFSYRSNLIAHQRIHTGEKPYACSECGKGFTYNRNLIEHQRIHSGEKTYECHVCRKVLTSSRNLMVHQRIHTGEKPYKCNECGKDFSQNKNLVVHQRMHTGEKPYECDKCRKSFTSKRNLVGHQRIHTGEKPYGCNDCSKVFRQRKNLTVHQKIHTDEKPCECDVSEKEFSQTSNLHLQQKIHTIEEFSWLQNTNESKIEIQKI>sp|O14709-2|ZN197_HUMAN Isoform 2 of Zinc finger protein 197 OS=Homosapiens OX=9606 GN=ZNF197MTRENVAHNALRQEGLVKGKDDTWKWGTSFQGSSSSVWETSHLHFRQLRYHETSGPQEALSRLRELCRRWLRPEARTKAQILELLVLEQFLSILPGEIRTWVQLHHPGSGEEAVALVEELQKDLDGPAIQVPVLVKDQDTLQKVVSAPGTTLPPVLPGSHIAAEICPHPPTDLVAFNLQDPQHDSPAPEASALSQEENPRNQLMALMLLTAQPQELVMFEEVSVCFTSEEWACLGPIQRALYWDVMLENYGNVTSLGYRKYRRQRNK>sp|Q68DI1|ZN776_HUMAN Zinc finger protein 776 OS=Homo sapiens OX=9606GN=ZNF776 PE=1 SV=2MAAAALRPPAQGTVTFEDVAVNFSQEEWSLLSEAQRCLYHDVMLENLTLISSLGCWYGAKDETPSKQTLSIQQESPLRTHWTGVCTKKVHLWGMCGPLLGDILHQGTQHNQKLNGFGAYEKKLDDDANHHQDQKQHIGEKSYRSNAKGTSFVKNCKFHMSHEPFIFHEVGKDFLSSLRLLQQEDIHTSGKSNFETKHGIPLQGGKTHYICGESTIPFSNKHSLVLHQRLLPREGPYVCSDSGKFTSKSNSFNNHQGVRTGKRPYQCGQCDESFWYKAHLTEHQRVHTGERPYECGECDKSFSHKHSLVDHQRVHTGERPYECDECGKSFSHKRSLVHHQRVHTGERPYQCGECGKSFNHKCNLIQHQRVHTGERPFECTACGKLFRSNSHLKEHQRVHTGERPYECKECRKSFRYKSHLTEHQRVHTGERPYECRECGKCFHQKGSLIQHQQIHSGERPHECGECGKCFHQKGSLIRHQQIHSGERPHECGECGKCFRQKGNLIKHQRVHTGERHHEC>sp|O75437|ZN254_HUMAN Zinc finger protein 254 OS=Homo sapiens OX=9606GN=ZNF254 PE=2 SV=3MPGPPRSLEMGLLTFRDVAIEFSLEEWQHLDIAQQNLYRNVMLENYRNLAFLGIAVSKPDLITCLEQGKEPWNMKRHEMVDEPPGMCPHFAQDLWPEQGMEDSFQKAILRRYGKYGHENLQLRKGCKSVDEYKVNKEGYNGLNQCFTTAQSKVFQCDKYLKVFYKFLNSNRPKIRHTEKKSFKCKKRVKLFCMLSHKTQHKSIYHREKSYKCKECGKTFNWSSTLTNHRKIYTEEKPYKCEEYNKSPKQLSTLTTHEIIHAGEKLYKCEECGEAFNRSSNLTTHKIIHTGEKPYKCEECGKAFIWSSTLTEHKKIHTRKKPYKCEECGKAFIWSSTLTRHKRMHTGEKPYKCEECGKAFSQSSTLTTHKIIHTGEKRYKCLECGKAFKQLSTLTTHKIIHVGEKLYKCEECGKGFNRSSNLTTHKIIHTGEKPYKCEECGKAFIWSSTLTKHKRIHTREKPYKCEECGKAFIWSSTLTRHKRMHTGEKPYKCEECGKSFSQSSTLTTHKIIHTGEKPYKCEECGKAFNWSSTLTKHKIIHTEEKPYKCEKCGKAFKQSSILTNHKRIHTGEKPYKCEECGKSFNRSSTFTKHKVIHTGVKPYKCEECGKAFFWSSTLTKHKRIHTGEQPYKWEKFGKAFNRSSHLTTDKITHWREILQV>sp|O75437-2|ZN254_HUMAN Isoform 2 of Zinc finger protein 254 OS=Homosapiens OX=9606 GN=ZNF254MPGPPRSLEMGLLTFRDVAIEFSLEEWQHLDIAQQNLYRNVMLENYRNLAFLGIAVSKPDLITCLEQGKEPWNMKRHEMVDEPPGMCPHFAQDLWPEQGMEDSFQKAILRRYGKYGHENLQLRKGCKSVDEYKVNKEGYNGLNQCFTTAQSKVFQCDKYLKVFYKFLNSNRPKIRHTEKKSFKCKKRVKLFCMLSHKTQHKSIYHREKSYKCKECGKTFNWSSTLTNHRKIYTEEKPYKCEEYNKSPKQLSTLTTHEIIHAGEKLYKCEECGEAFNRSSTFTKHKVIHTGVKPYKCEECGKAFFWSSTLTKHKRIHTGEQPYKWEKFGKAFNRSSHLTTDKITHWREILQV>sp|Q5SVQ8|ZBT41_HUMAN Zinc finger and BTB domain-containing protein 41OS=Homo sapiens OX=9606 GN=ZBTB41 PE=1 SV=1MKKRRKVTSNLEKIHLGYHKDSSEGNVAVECDQVTYTHSAGRPTPEALHCYQELPPSPDQRKLLSSLQYNKNLLKYLNDDRQKQPSFCDLLIIVEGKEFSAHKVVVAVGSSYFHACLSKNPSTDVVTLDHVTHSVFQHLLEFLYTSEFFVYKYEIPLVLEAAKFLDIIDAVKLLNNENVAPFHSELTEKSSPEETLNELTGRLSNNHQCKFCSRHFCYKKSLENHLAKTHRSLLLGKKHGLKMLERSFSARRSKRNRKCPVKFDDTSDDEQESGDGSDNLNQENFDKEKSDRNDSEDPGSEYNAEEDELEEEMSDEYSDIEEQSEKDHNDAEEEPEAGDSVGNVHEGLTPVVIQNSNKKILQCPKCDKTFDRIGKYESHTRVHTGEKPFECDICHQRYSTKSNLTVHRKKHSNETEFHKKEHKCPYCNKLHASKKTLAKHVKRFHPENAQEFISIKKTKSESWKCDICKKSFTRRPHLEEHMILHSQDKPFKCTYCEEHFKSRFARLKHQEKFHLGPFPCDICGRQFNDTGNLKRHIECTHGGKRKWTCFICGKSVRERTTLKEHLRIHSGEKPHLCSICGQSFRHGSSYRLHLRVHHDDKRYECDECGKTFIRHDHLTKHKKIHSGEKAHQCEECGKCFGRRDHLTVHYKSVHLGEKVWQKYKATFHQCDVCKKIFKGKSSLEMHFRTHSGEKPYKCQICNQSFRIKKTLTKHLVIHSDARPFNCQHCNATFKRKDKLKYHIDHVHEIKSPDDPLSTSEEKLVSLPVEYSSDDKIFQTETKQYMDQPKVYQSEAKTMLQNVSAEVCVPVTLVPVQMPDTPSDLVRHTTTLPPSSHEILSPQPQSTDYPRAADLAFLEKYTLTPQPANIVHPVRPEQMLDPREQSYLGTLLGLDSTTGVQNISTNEHHS>sp|Q5SVQ8-2|ZBT41_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 41 OS=Homo sapiens OX=9606 GN=ZBTB41MKKRRKVTSNLEKIHLGYHKDSSEGNVAVECDQVTYTHSAGRPTPEALHCYQELPPSPDQRKLLSSLQYNKNLLKYLNDDRQKQPSFCDLLIIVEGKEFSAHKVVVAVGSSYFHACLSKNPSTDVVTLDHVTHSVFQHLLEFLYTSEFFVYKYEIPLVLEAAKFLDIIDAVKLLNNENVAPFHSELTEKSSPEETLNELTGRLSNNHQCKFCSRHFCYKKSLENHLAKTHRSLLLGKKHGLKMLERSFSARRSKRNRKCPVKFDDTSDDEQESGDGSDNLNQENFDKEKSDRNDSEDPGSEYNAEEDELEEEMSDEYSDIEEQSEKDHNDAEEEPEAGDSVGNVHEGLTPVVIQNSNKKILQCPKCDKTFDRIGKYESHTRVHTGEKPFECDICHQRYSTKSNLTVHRKKHSNETEFHKKEHKCPYCNKLHASKKTLAKHVKRFHPENAQEFISIKKTKSESWKCDICKKSFTRRPHLEEHMILHSQDKPFKCTYCEEHFKSRFARLKHQEKFHLGPFPCDICGRQFNDTGNLKRHIECTHGGKRKWTCFICGKSVRERTTLKEHLRIHSGEKPHLCSICGQSFRHGSSYRLHLRVHHDDKRYECDECGKTFIRHDHLTKHKKIHSD>sp|Q8IVQ6|ZDH21_HUMAN Palmitoyltransferase ZDHHC21 OS=Homo sapiensOX=9606 GN=ZDHHC21 PE=1 SV=1MGLRIHFVVDPHGWCCMGLIVFVWLYNIVLIPKIVLFPHYEEGHIPGILIIIFYGISIFCLVALVRASITDPGRLPENPKIPHGEREFWELCNKCNLMRPKRSHHCSRCGHCVRRMDHHCPWINNCVGEDNHWLFLQLCFYTELLTCYALMFSFCHYYYFLPLKKRNLDLFVFRHELAIMRLAAFMGITMLVGITGLFYTQLIGIITDTTSIEKMSNCCEDISRPRKPWQQTFSEVFGTRWKILWFIPFRQRQPLRVPYHFANHV>sp|Q13106|ZN154_HUMAN Zinc finger protein 154 OS=Homo sapiens OX=9606GN=ZNF154 PE=2 SV=3MAAATLRTPTQGTVTFEDVAVHFSWEEWGLLDEAQRCLYRDVMLENLALLTSLDVHHQKQHLGEKHFRSNVGRALFVKTCTFHVSGEPSTCREVGKDFLAKLGFLHQQAAHTGEQSNSKSDGGAISHRGKTHYNCGEHTKAFSGKHTLVQQQRTLTTERCYICSECGKSFSKSYSLNDHWRLHTGEKPYECRECGKSFRQSSSLIQHRRVHTAVRPHECDECGKLFSNKSNLIKHRRVHTGERPYECSECGKSFSQRSALLQHRGVHTGERPYECSECGKFFTYHSSLIKHQKVHSGSRPYECSECGKSFSQNSSLIEHHRVHTGERPYKCSECGKSFSQRSALLQHRGVHTGERPYECSECGKFFPYSSSLRKHQRVHTGSRPYECSECGKSFTQNSGLIKHRRVHTGEKPYECTECGKSFSHNSSLIKHQRIHSR>sp|Q6ZTK2|YP015_HUMAN Putative uncharacterized protein LOC400499 OS=Homosapiens OX=9606 PE=2 SV=1MGWSDLQPAMGGEAERFQAQLEVKLVTGGSPVVFTGNLTRQVGSKLAFSASLSHLLSDQANVTALLERKEENGRRVAALGAELFVPGLVGLRALGLLQQQGQLWTNSLRIQYSLLGQAKQAAHECSTSQKLRADSGSDGAYRLELRHELHCTQILAFSHKVQLWHEEDSGHLHSQLEVSYGKQWDKNSNKRHLRVSQTFKNDSGPALSNHFMEFVLQVPERQVDCRVQLYHLSLRLPYVESSSHLKVQYNGRPLFVAGGQWKDTSRATLWKWEGVLNLDSPWLMVSAAHRLYWPHRAVFQAVLELTLGKAWTLKDLVVSVGCRSQGPNREGKIQVYTAATTYLRVSTVTVLAQSLFHSWSELESAWNTAVQGEIHAENSRDRKILNCWLKGPQQELNLTAAYRHLEWPRKTQVSLTAVWIGAQGQPRGLQLEGELEELRQDRTLYRKRGALLLRHPLHLPIPQSLLLQETFTADRRHQRYSLETRVVLNGREETLQTMVLGCQAGHPYVCAGLMHPYDGKVIPRNTEGCLVTWNQHTSLALLSGLESGVQ>sp|Q6PDB4|ZN880_HUMAN Zinc finger protein 880 OS=Homo sapiens OX=9606GN=ZNF880 PE=2 SV=2MLRRGHLAFRDVAIEFPQEEWKCLDPAQRTLYREVMVENYRNLVFLGICLPDLSVISMLEQRRDPRNLQSEVKIANNPGGRECIKGVNAESSSKLGSNAGNKSLKNQLGLTFQLHLSELQLFQAERNISGCKHVEKPINNSLVSPLQKIYSSVKSHILNKYRNDFDDSPFLPQEQKAQIREKPCECNEHGKAFRVSSRLANNQVIHTADNPYKCNECDKVFSNSSNLVQHQRIHTGEKPYKCHECGKLFNRISLLARHQRIHTGEKPYKCHECGKVFTQNSHLANHHRIHTGEKPYKCNECGKVFNRNAHLARHQKIHSGEKPYKCKECGKAFSGGSGLTAHLVIHTGEKLYKCNKCGKVFNRNAHLTRHQRIHTGEKPYECKECGKVFRHKFCLTNHHRMHTGEQPYKCNECGKAFRDCSGLTAHLLIHTGEKPYKCKECAKVFRHRLSLSNHQRFHTGEKPYRCDECGKDFTRNSNLANHHRIHTGEKPYKCSECHKVFSHNSHLARHRQIHTGEKSYKCNECGKVFSHKLYLKKHERIHTGEKPYRCHECGKDFTRNSNLANHHRIHTGEKPYR>sp|Q6PDB4-2|ZN880_HUMAN Isoform 2 of Zinc finger protein 880 OS=Homosapiens OX=9606 GN=ZNF880MLRRGHLAFRDVAIEFPQEEWKCLDPAQRTLYREVMVENYRNLVFLGICLPDLSVISMLEQRRDPRNLQSEVKIANNPGSCSVTQAVVEWQSSVAIVA>sp|B4DX44|ZN736_HUMAN Zinc finger protein 736 OS=Homo sapiens OX=9606GN=ZNF736 PE=2 SV=2MGVLTFRDVAVEFSPEEWECLDSAQQRLYRDVMLENYGNLVSLGLAIFKPDLMTCLEQRKEPWKVKRQEAVAKHPAGSFHFTAEILPDHDIKDSFQKVILRKYGSCDLNNLHLKKDYQSVGNCKGQKSSYNGLHQCLSATHSKTCQCNKCGRGFQLCSIFTEHKDIFSREKCHKCEECGKDCRLFSDFTRHKKIHTVERCYKCEECGKAFKKFSNLTEHKRVHTGEKPYKCEGCGKTFTCSSTLVKHKRNHTGDRPYKCEECGKAFKCFSDLTNHKRIHTGEKPYKCEECNKAYRWFSDLAKHKIIHTGDKPYTCNECGKAFKWFSALSKHKRIHTGEKPYICEECGKAFTRSSTLFNHKRIHMEERPYKCEECSKTFKCFSDLTNHKRIHTGEKPYKCEECGKASSWFSHLIRHKRIHTREKLHKC>sp|O95625|ZBT11_HUMAN Zinc finger and BTB domain-containing protein 11OS=Homo sapiens OX=9606 GN=ZBTB11 PE=1 SV=2MSSEESYRAILRYLTNEREPYAPGTEGNVKRKIRKAAACYVVRGGTLYYQRRQRHRKTFAELEVVLQPERRRDLIEAAHLGPGGTHHTRHQTWHYLSKTYWWRGILKQVKDYIKQCSKCQEKLDRSRPISDVSEMLEELGLDLESGEESNESEDDLSNFTSSPTTASKPAKKKPVSKHELVFVDTKGVVKRSSPKHCQAVLKQLNEQRLSNQFCDVTLLIEGEEYKAHKSVLSANSEYFRDLFIEKGAVSSHEAVVDLSGFCKASFLPLLEFAYTSVLSFDFCSMADVAILARHLFMSEVLEICESVHKLMEEKQLTVYKKGEVQTVASTQDLRVQNGGTAPPVASSEGTTTSLPTELGDCEIVLLVNGELPEAEQNGEVGRQPEPQVSSEAESALSSVGCIADSHPEMESVDLITKNNQTELETSNNRENNTVSNIHPKLSKENVISSSPEDSGMGNDISAEDICAEDIPKHRQKVDQPLKDQENLVASTAKTDFGPDDDTYRSRLRQRSVNEGAYIRLHKGMEKKLQKRKAVPKSAVQQVAQKLVQRGKKMKQPKRDAKENTEEASHKCGECGMVFQRRYALIMHKLKHERARDYKCPLCKKQFQYSASLRAHLIRHTRKDAPSSSSSNSTSNEASGTSSEKGRTKREFICSICGRTLPKLYSLRIHMLKHTGVKPHACQVCGKTFIYKHGLKLHQSLHQSQKQFQCELCVKSFVTKRSLQEHMSIHTGESKYLCSVCGKSFHRGSGLSKHFKKHQPKPEVRGYHCTQCEKSFFEARDLRQHMNKHLGVKPFQCQFCDKCYSWKKDWYSHVKSHSVTEPYRCNICGKEFYEKALFRRHVKKATHGKKGRAKQNLERVCEKCGRKFTQLREYRRHMNNHEGVKPFECLTCGVAWADARSLKRHVRTHTGERPYVCPVCSEAYIDARTLRKHMTKFHRDYVPCKIMLEKDTLQFHNQGTQVAHAVSILTAGMQEQESSGPQELETVVVTGETMEALEAVAATEEYPSVSTLSDQSIMQVVNYVLAQQQGQKLSEVAEAIQTVKVEVAHISGGE>sp|Q6ZMV8|ZN730_HUMAN Putative zinc finger protein 730 OS=Homo sapiensOX=9606 GN=ZNF730 PE=2 SV=1MGALTFRDVAIEFSLEEWQCLDTEQQNLYRNVMLDNYRNLVFLGIAVSKPDLITCLEQEKEPWNLKTHDMVAKPPVICSHIAQDLWPEQGIKDYFQEVILRQYKKCRHENLLLRKGCKNVDEFKMHKKGYNRHNQCLTTSHSKIFQCDKYVKVFHKFSNSNRHKIRHTSKKPFKCKECGKLFCILSHLAQHKKIHTGEKSYKCEEYGKAFNESSNCTTHKRITEKKPYKCKECGKAFNWFSHFTTHKRIHTGEKPYQCEKCGKFFNQSTNLTTHKRIHTGEKPYKCEECGKAFNQSSNLTEHKKIHTKEQPYKCEKCGKAFKWSSTLTKHKRIHNGEKPYKCEECGKAFNRSSTLNRHKITHTGGKPYKYKECGKAFNQSSTLTIHKIIHTVEKFYKCEECGKAFSRISHLTTHKRIHTGEKPYKCEECGRAFNQSSTLTTHKRIHTGEKPYECEECGKAFNRSSTLTTHKIIHSGEKIYKCKECGKAFRRFSHLTRHKTIHT>sp|Q96IU2|ZBED3_HUMAN Zinc finger BED domain-containing protein 3OS=Homo sapiens OX=9606 GN=ZBED3 PE=1 SV=1MRSGEPACTMDQARGLDDAAARGGQCPGLGPAPTPTPPGRLGAPYSEAWGYFHLAPGRPGHPSGHWATCRLCGEQVGRGPGFHAGTSALWRHLRSAHRRELESSGAGSSPPAAPCPPPPGPAAAPEGDWARLLEQMGALAVRGSRRERELERRELAVEQGERALERRRRALQEEERAAAQARRELQAEREALQARLRDVSRREGALGWAPAAPPPLKDDPEGDRDGCVITKVLL>sp|Q96LX8|ZN597_HUMAN Zinc finger protein 597 OS=Homo sapiens OX=9606GN=ZNF597 PE=1 SV=1MASMPPTPEAQGPILFEDLAVYFSQEECVTLHPAQRSLSKDGTKESLEDAALMGEEGKPEINQQLSLESMELDELALEKYPIAAPLVPYPEKSSEDGVGNPEAKILSGTPTYKRRVISLLVTIENHTPLVELSEYLGTNTLSEILDSPWEGAKNVYKCPECDQNFSDHSYLVLHQKIHSGEKKHKCGDCGKIFNHRANLRTHRRIHTGEKPYKCAKCSASFRQHSHLSRHMNSHVKEKPYTCSICGRGFMWLPGLAQHQKSHSAENTYESTNCDKHFNEKPNLALPEETFVSGPQYQHTKCMKSFRQSLYPALSEKSHDEDSERCSDDGDNFFSFSKFKPLQCPDCDMTFPCFSELISHQNIHTEERPHKCKTCEESFALDSELACHQKSHMLAEPFKCTVCGKTFKSNLHLITHKRTHIKNTT>sp|P62891|RL39_HUMAN 60S ribosomal protein L39 OS=Homo sapiens OX=9606GN=RPL39 PE=1 SV=2MSSHKTFRIKRFLAKKQKQNRPIPQWIRMKTGNKIRYNSKRRHWRRTKLGL>sp|Q13129|RLF_HUMAN Zinc finger protein Rlf OS=Homo sapiens OX=9606GN=RLF PE=1 SV=2MADGKGDAAAVAGAGAEAPAVAGAGDGVETESMVRGHRPVSPAPGASGLRPCLWQLETELREQEVSEVSSLNYCRSFCQTLLQYASNKNASEHIVYLLEVYRLAIQSFASARPYLTTECEDVLLVLGRLVLSCFELLLSVSESELPCEVWLPFLQSLQESHDALLEFGNNNLQILVHVTKEGVWKNPVLLKILSQQPVETEEVNKLIAQEGPSFLQMRIKHLLKSNCIPQATALSKLCAESKEISNVSSFQQAYITCLCSMLPNEDAIKEIAKVDCKEVLDIICNLESEGQDNTAFVLCTTYLTQQLQTASVYCSWELTLFWSKLQRRIDPSLDTFLERCRQFGVIAKTQQHLFCLIRVIQTEAQDAGLGVSILLCVRALQLRSSEDEEMKASVCKTIACLLPEDLEVRRACQLTEFLIEPSLDGFNMLEELYLQPDQKFDEENAPVPNSLRCELLLALKAHWPFDPEFWDWKTLKRHCHQLLGQEASDSDDDLSGYEMSINDTDVLESFLSDYDEGKEDKQYRRRDLTDQHKEKRDKKPIGSSERYQRWLQYKFFCLLCKRECIEARILHHSKMHMEDGIYTCPVCIKKFKRKEMFVPHVMEHVKMPPSRRDRSKKKLLLKGSQKGICPKSPSAIPEQNHSLNDQAKGESHEYVTFSKLEDCHLQDRDLYPCPGTDCSRVFKQFKYLSVHLKAEHQNNDENAKHYLDMKNRREKCTYCRRHFMSAFHLREHEQVHCGPQPYMCVSIDCYARFGSVNELLNHKQKHDDLRYKCELNGCNIVFSDLGQLYHHEAQHFRDASYTCNFLGCKKFYYSKIEYQNHLSMHNVENSNGDIKKSVKLEESATGEKQDCINQPHLLNQTDKSHLPEDLFCAESANSQIDTETAENLKENSDSNSSDQLSHSSSASMNEELIDTLDHSETMQDVLLSNEKVFGPSSLKEKCSSMAVCFDGTKFTCGFDGCGSTYKNARGMQKHLRKVHPYHFKPKKIKTKDLFPSLGNEHNQTTEKLDAEPKPCSDTNSDSPDEGLDHNIHIKCKREHQGYSSESSICASKRPCTEDTMLELLLRLKHLSLKNSITHGSFSGSLQGYPSSGAKSLQSVSSISDLNFQNQDENMPSQYLAQLAAKPFFCELQGCKYEFVTREALLMHYLKKHNYSKEKVLQLTMFQHRYSPFQCHICQRSFTRKTHLRIHYKNKHQIGSDRATHKLLDNEKCDHEGPCSVDRLKGDCSAELGGDPSSNSEKPHCHPKKDECSSETDLESSCEETESKTSDISSPIGSHREEQEGREGRGSRRTVAKGNLCYILNKYHKPFHCIHKTCNSSFTNLKGLIRHYRTVHQYNKEQLCLEKDKARTKRELVKCKKIFACKYKECNKRFLCSKALAKHCSDSHNLDHIEEPKVLSEAGSAARFSCNQPQCPAVFYTFNKLKHHLMEQHNIEGEIHSDYEIHCDLNGCGQIFTHRSNYSQHVYYRHKDYYDDLFRSQKVANERLLRSEKVCQTADTQGHEHQTTRRSFNAKSKKCGLIKEKKAPISFKTRAEALHMCVEHSEHTQYPCMVQGCLSVVKLESSIVRHYKRTHQMSSAYLEQQMENLVVCVKYGTKIKEEPPSEADPCIKKEENRSCESERTEHSHSPGDSSAPIQNTDCCHSSERDGGQKGCIESSSVFDADTLLYRGTLKCNHSSKTTSLEQCNIVQPPPPCKIENSIPNPNGTESGTYFTSFQLPLPRIKESETRQHSSGQENTVKNPTHVPKENFRKHSQPRSFDLKTYKPMGFESSFLKFIQESEEKEDDFDDWEPSEHLTLSNSSQSSNDLTGNVVANNMVNDSEPEVDIPHSSSDSTIHENLTAIPPLIVAETTTVPSLENLRVVLDKALTDCGELALKQLHYLRPVVVLERSKFSTPILDLFPTKKTDELCVGSS>sp|Q6DKI1|RL7L_HUMAN 60S ribosomal protein L7-like 1 OS=Homo sapiensOX=9606 GN=RPL7L1 PE=1 SV=2MISSCTTRKMAEQEQRKIPLVPENLLKKRKAYQALKATQAKQALLAKKEQKKGKGLRFKRLESFLHDSWRQKRDKVRLRRLEVKPHALELPDKHSLAFVVRIERIDGVSLLVQRTIARLRLKKIFSGVFVKVTPQNLKMLRIVEPYVTWGFPNLKSVRELILKRGQAKVKNKTIPLTDNTVIEEHLGKFGVICLEDLIHEIAFPGKHFQEISWFLCPFHLSVARHATKNRVGFLKEMGTPGYRGERINQLIRQLN>sp|Q6DKI1-2|RL7L_HUMAN Isoform 2 of 60S ribosomal protein L7-like 1OS=Homo sapiens OX=9606 GN=RPL7L1MISSCTTRKMAEQEQRKIPLVPENLLKKRKAYQALKATQAKQALLAKKEQKKGKGLRFKRLESFLHDSWRQKRDKVRLRRLEVKPHALELPDKHSLAFVVRIERIDGVSLLVQRTIARLRLKKIFSGVFVKVTPQNLKMLRIVEPYVTWGEVWRHLLGRPHS>sp|P62875|RPAB5_HUMAN DNA-directed RNA polymerases I, II, and IIIsubunit RPABC5 OS=Homo sapiens OX=9606 GN=POLR2L PE=1 SV=1MIIPVRCFTCGKIVGNKWEAYLGLLQAEYTEGDALDALGLKRYCCRRMLLAHVDLIEKLLNYAPLEK>sp|Q9H9Y2|RPF1_HUMAN Ribosome production factor 1 OS=Homo sapiensOX=9606 GN=RPF1 PE=1 SV=2MAKAGDKSSSSGKKSLKRKAAAEELQEAAGAGDGATENGVQPPKAAAFPPGFSISEIKNKQRRHLMFTRWKQQQRKEKLAAKKKLKKEREALGDKAPPKPVPKTIDNQRVYDETTVDPNDEEVAYDEATDEFASYFNKQTSPKILITTSDRPHGRTVRLCEQLSTVIPNSHVYYRRGLALKKIIPQCIARDFTDLIVINEDRKTPNGLILSHLPNGPTAHFKMSSVRLRKEIKRRGKDPTEHIPEIILNNFTTRLGHSIGRMFASLFPHNPQFIGRQVATFHNQRDYIFFRFHRYIFRSEKKVGIQELGPRFTLKLRSLQKGTFDSKYGEYEWVHKPREMDTSRRKFHL>sp|O15160|RPAC1_HUMAN DNA-directed RNA polymerases I and III subunitRPAC1 OS=Homo sapiens OX=9606 GN=POLR1C PE=1 SV=1MAASQAVEEMRSRVVLGEFGVRNVHTTDFPGNYSGYDDAWDQDRFEKNFRVDVVHMDENSLEFDMVGIDAAIANAFRRILLAEVPTMAVEKVLVYNNTSIVQDEILAHRLGLIPIHADPRLFEYRNQGDEEGTEIDTLQFRLQVRCTRNPHAAKDSSDPNELYVNHKVYTRHMTWIPLGNQADLFPEGTIRPVHDDILIAQLRPGQEIDLLMHCVKGIGKDHAKFSPVATASYRLLPDITLLEPVEGEAAEELSRCFSPGVIEVQEVQGKKVARVANPRLDTFSREIFRNEKLKKVVRLARVRDHYIFSVESTGVLPPDVLVSEAIKVLMGKCRRFLDELDAVQMD>sp|O15160-2|RPAC1_HUMAN Isoform 2 of DNA-directed RNA polymerases I andIII subunit RPAC1 OS=Homo sapiens OX=9606 GN=POLR1CMAASQAVEEMRSRVVLGEFGVRNVHTTDFPGNYSGYDDAWDQDRFEKNFRVDVVHMDENSLEFDMVGIDAAIANAFRRILLAEVPTMAVEKVLVYNNTSIVQDEILAHRLGLIPIHADPRLFEYRNQGDEEGTEIDTLQFRLQVRCTRNPHAAKDSSDPNELYVNHKVYTRHMTWIPLGNQADLFPEGTIRPVHDDILIAQLRPGQEIDLLMHCVKGIGKDHAKFSPVATASYRLLPDITLLEPVEGEAAEELSRCFSPGVIEVQEVQGKKVARVANPRLDTFSREIFRNEKLKKVVRLARVRDHYICKKDLLAAVAHTCNPSTLGGQGEWITGSRERDHPG>sp|O94763|RMP_HUMAN Unconventional prefoldin RPB5 interactor 1 OS=Homosapiens OX=9606 GN=URI1 PE=1 SV=3MEAPTVETPPDPSPPSAPAPALVPLRAPDVARLREEQEKVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKLVHTNEVTVLLGDNWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKAKHRIAHKPHSKPKTSDIFEADIANDVKSKDLLADKELWARLEELERQEELLGELDSKPDTVIANGEDTTSSEEEKEDRNTNVNAMHQVTDSHTPCHKDVASSEPFSGQVNSQLNCSVNGSSSYHSDDDDDDDDDDDDDNIDDDDGDNDHEALGVGDNSIPTIYFSHTVEPKRVRINTGKNTTLKFSEKKEEAKRKRKNSTGSGHSAQELPTIRTPADIYRAFVDVVNGEYVPRKSILKSRSRENSVCSDTSESSAAEFDDRRGVLRSISCEEATCSDTSESILEEEPQENQKKLLPLSVTPEAFSGTVIEKEFVSPSLTPPPAIAHPALPTIPERKEVLLEASEETGKRVSKFKAARLQQKD>sp|O94763-2|RMP_HUMAN Isoform 2 of Unconventional prefoldin RPB5interactor 1 OS=Homo sapiens OX=9606 GN=URI1MVPFGPFAFMPGKLVHTNEVTVLLGDNWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKAKHRIAHKPHSKPKTSDIFEADIANDVKSKDLLADKELWARLEELERQEELLGELDSKPDTVIANGEDTTSSEEEKEDRNTNVNAMHQVTDSHTPCHKDVASSEPFSGQVNSQLNCSVNGSSSYHSDDDDDDDDDDDDDNIDDDDGDNDHEALGVGDNSIPTIYFSHTVEPKRVRINTGKNTTLKFSEKKEEAKRKRKNSTGSGHSAQELPTIRTPADIYRAFVDVVNGEYVPRKSILKSRSRENSVCSDTSESSAAEFDDRRGVLRSISCEEATCSDTSESILEEEPQENQKKLLPLSVTPEAFSGTVIEKEFVSPSLTPPPAIAHPALPTIPERKEVLLEASEETGKRVSKFKAARLQQKD>sp|O94763-3|RMP_HUMAN Isoform 3 of Unconventional prefoldin RPB5interactor 1 OS=Homo sapiens OX=9606 GN=URI1MRLGNVDFTLGSNVPCVYLVFSVNRKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKLVHTNEVTVLLGDNWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKAKHRIAHKPHSKPKTSDIFEADIANDVKSKDLLADKELWARLEELERQEELLGELDSKPDTVIANGEDTTSSEEEKEDRNTNVNAMHQVTDSHTPCHKDVASSEPFSGQVNSQLNCSVNGSSSYHSDDDDDDDDDDDDDNIDDDDGDNDHEALGVGDNSIPTIYFSHTVEPKRVRINTGKNTTLKFSEKKEEAKRKRKNSTGSGHSAQELPTIRTPADIYRAFVDVVNGEYVPRKSILKSRSRENSVCSDTSESSAAEFDDRRGVLRSISCEEATCSDTSESILEEEPQENQKKLLPLSVTPEAFSGTVIEKEFVSPSLTPPPAIAHPALPTIPERKEVLLEASEETGKRVSKFKAARLQQKD>sp|O94763-4|RMP_HUMAN Isoform 4 of Unconventional prefoldin RPB5interactor 1 OS=Homo sapiens OX=9606 GN=URI1MTTWSSLQGSHVSKRALAYALVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKLVHTNEVTVLLGDNWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKAKHRIAHKPHSKPKTSDIFEADIANDVKSKDLLADKELWARLEELERQEELLGELDSKPDTVIANGEDTTSSEEEKEDRNTNVNAMHQVTDSHTPCHKDVASSEPFSGQVNSQLNCSVNGSSSYHSDDDDDDDDDDDDDNIDDDDGDNDHEALGVGDNSIPTIYFSHTVEPKRVRINTGKNTTLKFSEKKEEAKRKRKNSTGSGHSAQELPTIRTPADIYRAFVDVVNGEYVPRKSILKSRSRENSVCSDTSESSAAEFDDRRGVLRSISCEEATCSDTSESILEEEPQENQKKLLPLSVTPEVLRLVGYSRNLAPLNVIL>sp|P0DPB6|RPAC2_HUMAN DNA-directed RNA polymerases I and III subunitRPAC2 OS=Homo sapiens OX=9606 GN=POLR1D PE=1 SV=1MEEDQELERKISGLKTSMAEGERKTALEMVQAAGTDRHCVTFVLHEEDHTLGNSLRYMIMKNPEVEFCGYTTTHPSESKINLRIQTRGTLPAVEPFQRGLNELMNVCQHVLDKFEASIKDYKDQKASRNESTF>sp|P52435|RPB11_HUMAN DNA-directed RNA polymerase II subunit RPB11-aOS=Homo sapiens OX=9606 GN=POLR2J PE=1 SV=1MNAPPAFESFLLFEGEKKITINKDTKVPNACLFTINKEDHTLGNIIKSQLLKDPQVLFAGYKVPHPLEHKIIIRVQTTPDYSPQEAFTNAITDLISELSLLEERFRVAIKDKQEGIE>sp|P52815|RM12_HUMAN 39S ribosomal protein L12, mitochondrial OS=Homosapiens OX=9606 GN=MRPL12 PE=1 SV=2MLPAAARPLWGPCLGLRAAAFRLARRQVPCVCAVRHMRSSGHQRCEALAGAPLDNAPKEYPPKIQQLVQDIASLTLLEISDLNELLKKTLKIQDVGLVPMGGVMSGAVPAAAAQEAVEEDIPIAKERTHFTVRLTEAKPVDKVKLIKEIKNYIQGINLVQAKKLVESLPQEIKANVAKAEAEKIKAALEAVGGTVVLE>sp|Q9P015|RM15_HUMAN 39S ribosomal protein L15, mitochondrial OS=Homosapiens OX=9606 GN=MRPL15 PE=1 SV=1MAGPLQGGGARALDLLRGLPRVSLANLKPNPGSKKPERRPRGRRRGRKCGRGHKGERQRGTRPRLGFEGGQTPFYIRIPKYGFNEGHSFRRQYKPLSLNRLQYLIDLGRVDPSQPIDLTQLVNGRGVTIQPLKRDYGVQLVEEGADTFTAKVNIEVQLASELAIAAIEKNGGVVTTAFYDPRSLDIVCKPVPFFLRGQPIPKRMLPPEELVPYYTDAKNRGYLADPAKFPEARLELARKYGYILPDITKDELFKMLCTRKDPRQIFFGLAPGWVVNMADKKILKPTDENLLKYYTS>sp|Q9NX20|RM16_HUMAN 39S ribosomal protein L16, mitochondrial OS=Homosapiens OX=9606 GN=MRPL16 PE=1 SV=1MWRLLARASAPLLRVPLSDSWALLPASAGVKTLLPVPSFEDVSIPEKPKLRFIERAPLVPKVRREPKNLSDIRGPSTEATEFTEGNFAILALGGGYLHWGHFEMMRLTINRSMDPKNMFAIWRVPAPFKPITRKSVGHRMGGGKGAIDHYVTPVKAGRLVVEMGGRCEFEEVQGFLDQVAHKLPFAAKAVSRGTLEKMRKDQEERERNNQNPWTFERIATANMLGIRKVLSPYDLTHKGKYWGKFYMPKRV>sp|Q5TEA6|SE1L2_HUMAN Protein sel-1 homolog 2 OS=Homo sapiens OX=9606GN=SEL1L2 PE=2 SV=2MKPLSLLIEILIILGVTIKTIKAEEHNKRQKERNVTTQVSVNEIKQYLSHILEQRTSSNVINKRENLLEKKKNQRKIRIKGIQNKDILKRNKNHLQKQAEKNFTDEGDQLFKMGIKVLQQSKSQKQKEEAYLLFAKAADMGNLKAMEKMADALLFGNFGVQNITAAIQLYESLAKEGSCKAQNALGFLSSYGIGMEYDQAKALIYYTFGSAGGNMMSQMILGYRYLSGINVLQNCEVALSYYKKVADYIADTFEKSEGVPVEKVRLTERPENLSSNSEILDWDIYQYYKFLAERGDVQIQVSLGQLHLIGRKGLDQDYYKALHYFLKAAKAGSANAMAFIGKMYLEGNAAVPQNNATAFKYFSMAASKGNAIGLHGLGLLYFHGKGVPLNYAEALKYFQKAAEKGWPDAQFQLGFMYYSGSGIWKDYKLAFKYFYLASQSGQPLAIYYLAKMYATGTGVVRSCRTAVELYKGVCELGHWAEKFLTAYFAYKDGDIDSSLVQYALLAEMGYEVAQSNSAFILESKKANILEKEKMYPMALLLWNRAAIQGNAFARVKIGDYHYYGYGTKKDYQTAATHYSIAANKYHNAQAMFNLAYMYEHGLGITKDIHLARRLYDMAAQTSPDAHIPVLFAVMKLETTHLLRDILFFNFTTRWNWLKLDNTIGPHWDLFVIGLIVPGLILLLRNHHG>sp|Q5TEA6-2|SE1L2_HUMAN Isoform 2 of Protein sel-1 homolog 2 OS=Homosapiens OX=9606 GN=SEL1L2MKPLSLLIEILIILGVTIKTIKAEEHNKRQKERNVTTQVSVNEIKQYLSHILEQRTSSNVINKRENLLEKKKNQRKIRIKGIQNKDILKRNKNHLQKQAEKNFTDEGDQLFKMGIKVLQQSKSQKQKEEAYLLFAKAADMGNLKAMEKMADALLFGNFGVQNITAAIQLYESLAKEGSCKAQNALGFLSSYGIGMEYDQAKALIYYTFGSAGGNMMSQMILGYRYLSGINVLQNCEVALSYYKKVADYIADTFEKSEGVPVEKVRLTERPENLSSNSEILDWDIYQYYKFLAERGDVQIQVSLGQLHLIGRKGLDQDYYKALHYFLKAAKAGSANAMAFIGKMYLEGNAAVPQNNATAFKYFSMAASKGNAIGLHGLGLLYFHGKGVPLNYAEALKYFQKAAEKGWPDAQFQLGFMYYSGSGIWKDYKLAFKYFYLASQSGQPLAIYYLAKMYATGTGVVRSCRTAVEKRLTFLKKRRCIQWRFSYGIELPFKDIHLARRLYDMAAQTSPDAHIPVLFAVMKLETTHLLRDILFFNFTTRWNWLKLDNTIGPHWDLFVIGLIVPGLILLLRNHHG>sp|P51571|SSRD_HUMAN Translocon-associated protein subunit delta OS=Homosapiens OX=9606 GN=SSR4 PE=1 SV=1MAAMASLGALALLLLSSLSRCSAEACLEPQITPSYYTTSDAVISTETVFIVEISLTCKNRVQNMALYADVGGKQFPVTRGQDVGRYQVSWSLDHKSAHAGTYEVRFFDEESYSLLRKAQRNNEDISIIPPLFTVSVDHRGTWNGPWVSTEVLAAAIGLVIYYLAFSAKSHIQA>sp|Q7Z6B7|SRGP1_HUMAN SLIT-ROBO Rho GTPase-activating protein 1 OS=Homosapiens OX=9606 GN=SRGAP1 PE=1 SV=1MSTPSRFKKDKEIIAEYESQVKEIRAQLVEQQKCLEQQTEMRVQLLQDLQDFFRKKAEIETEYSRNLEKLAERFMAKTRSTKDHQQYKKDQNLLSPVNCWYLLLNQVRRESKDHATLSDIYLNNVIMRFMQISEDSTRMFKKSKEIAFQLHEDLMKVLNELYTVMKTYHMYHAESISAESKLKEAEKQEEKQIGRSGDPVFHIRLEERHQRRSSVKKIEKMKEKRQAKYSENKLKSIKARNEYLLTLEATNASVFKYYIHDLSDLIDCCDLGYHASLNRALRTYLSAEYNLETSRHEGLDIIENAVDNLEPRSDKQRFMEMYPAAFCPPMKFEFQSHMGDEVCQVSAQQPVQAELMLRYQQLQSRLATLKIENEEVKKTTEATLQTIQDMVTIEDYDVSECFQHSRSTESVKSTVSETYLSKPSIAKRRANQQETEQFYFMKLREYLEGSNLITKLQAKHDLLQRTLGEGHRAEYMTTRPPNVPPKPQKHRKSRPRSQYNTKLFNGDLETFVKDSGQVIPLIVESCIRFINLYGLQHQGIFRVSGSQVEVNDIKNSFERGENPLADDQSNHDINSVAGVLKLYFRGLENPLFPKERFNDLISCIRIDNLYERALHIRKLLLTLPRSVLIVMRYLFAFLNHLSQYSDENMMDPYNLAICFGPTLMPVPEIQDQVSCQAHVNEIIKTIIIHHETIFPDAKELDGPVYEKCMAGDDYCDSPYSEHGTLEEVDQDAGTEPHTSEDECEPIEAIAKFDYVGRSARELSFKKGASLLLYHRASEDWWEGRHNGIDGLVPHQYIVVQDMDDTFSDTLSQKADSEASSGPVTEDKSSSKDMNSPTDRHPDGYLARQRKRGEPPPPVRRPGRTSDGHCPLHPPHALSNSSVDLGSPSLASHPRGLLQNRGLNNDSPERRRRPGHGSLTNISRHDSLKKIDSPPIRRSTSSGQYTGFNDHKPLDPETIAQDIEETMNTALNELRELERQSTAKHAPDVVLDTLEQVKNSPTPATSTESLSPLHNVALRSSEPQIRRSTSSSSDTMSTFKPMVAPRMGVQLKPPALRPKPAVLPKTNPTIGPAPPPQGPTDKSCTM>sp|Q7Z6B7-2|SRGP1_HUMAN Isoform 2 of SLIT-ROBO Rho GTPase-activatingprotein 1 OS=Homo sapiens OX=9606 GN=SRGAP1MSTPSRFKKDKEIIAEYESQVKEIRAQLVEQQKCLEQQTEMRVQLLQDLQDFFRKKAEIETEYSRNLEKLAERFMAKTRSTKDHQQYKKDQNLLSPVNCWYLLLNQVRRESKDHATLSDIYLNNVIMRFMQISEDSTRMFKKSKEIAFQLHEDLMKVLNELYTVMKTYHMYHAESISAESKLKEAEKQEEKQIGRSGDPVFHIRLEERHQRRSSVKKIEKMKEKRQAKYSENKLKSIKARNEYLLTLEATNASVFKYYIHDLSDLIDCCDLGYHASLNRALRTYLSAEYNLETSRHEGLDIIENAVDNLEPRSDKQRFMEMYPAAFCPPMKFEFQSHMGDEVCQVSAQQPVQAELMLRYQQLQSRLATLKIENEEVKKTTEATLQTIQDMVTIEDYDVSECFQHSRSTESVKSTVSETYLSKPSIAKRRANQQETEQFYFMKLREYLEGSNLITKLQAKHDLLQRTLGEGHRAEYMTTSRGRRNSHTRHQDSGQVIPLIVESCIRFINLYGLQHQGIFRVSGSQVEVNDIKNSFERGENPLADDQSNHDINSVAGVLKLYFRGLENPLFPKERFNDLISCIRIDNLYERALHIRKLLLTLPRSVLIVMRYLFAFLNHLSQYSDENMMDPYNLAICFGPTLMPVPEIQDQVSCQAHVNEIIKTIIIHHETIFPDAKELDGPVYEKCMAGDDYCDSPYSEHGTLEEVDQDAGTEPHTSEDECEPIEAIAKFDYVGRSARELSFKKGASLLLYHRASEDWWEGRHNGIDGLVPHQYIVVQDMDDTFSDTLSQKADSEASSGPVTEDKSSSKDMNSPTDRHPDGYLARQRKRGEPPPPVRRPGRTSDGHCPLHPPHALSNSSVDLGSPSLASHPRGLLQNRGLNNDSPERRRRPGHGSLTNISRHDSLKKIDSPPIRRSTSSGQYTGFNDHKPLDPETIAQDIEETMNTALNELRELERQSTAKHAPDVVLDTLEQVKNSPTPATSTESLSPLHNVALRSSEPQIRRSTSSSSDTMSTFKPMVAPRMGVQLKPPALRPKPAVLPKTNPTIGPAPPPQGPTDKSCTM>sp|D6R901|U17LL_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 21 OS=Homo sapiens OX=9606 GN=USP17L21 PE=3 SV=1MEEDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSNRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKMLTLLTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQPNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSSTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|D6RA61|U17LM_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 22 OS=Homo sapiens OX=9606 GN=USP17L22 PE=3 SV=1MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLKLSSTTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|Q9GZX9|TWSG1_HUMAN Twisted gastrulation protein homolog 1 OS=Homosapiens OX=9606 GN=TWSG1 PE=1 SV=1MKLHYVAVLTLAILMFLTWLPESLSCNKALCASDVSKCLIQELCQCRPGEGNCSCCKECMLCLGALWDECCDCVGMCNPRNYSDTPPTSKSTVEELHEPIPSLFRALTEGDTQLNWNIVSFPVAEELSHHENLVSFLETVNQPHHQNVSVPSNNVHAPYSSDKEHMCTVVYFDDCMSIHQCKISCESMGASKYRWFHNACCECIGPECIDYGSKTVKCMNCMF>sp|Q9GZX9-2|TWSG1_HUMAN Isoform 2 of Twisted gastrulation proteinhomolog 1 OS=Homo sapiens OX=9606 GN=TWSG1MKLHYVAVLTLAILMFLTWLPESLSCNKALCASDVSKCLIQELCQCRPGEGNCSCCKECMLCLGALWDECCDCVD>sp|Q6NXT6|TAPT1_HUMAN Transmembrane anterior posterior transformationprotein 1 homolog OS=Homo sapiens OX=9606 GN=TAPT1 PE=1 SV=1MAGVGDAAAPGEGGGGGVDGPQRDGRGEAEQPGGSGGQGPPPAPQLTETLGFYESDRRRERRRGRTELSLLRFLSAELTRGYFLEHNEAKYTERRERVYTCLRIPRELEKLMVFGIFLCLDAFLYVFTLLPLRVFLALFRLLTLPCYGLRDRRLLQPAQVCDILKGVILVICYFMMHYVDYSMMYHLIRGQSVIKLYIIYNMLEVADRLFSSFGQDILDALYWTATEPKERKRAHIGVIPHFFMAVLYVFLHAILIMVQATTLNVAFNSHNKSLLTIMMSNNFVEIKGSVFKKFEKNNLFQMSNSDIKERFTNYVLLLIVCLRNMEQFSWNPDHLWVLFPDVCMVIASEIAVDIVKHAFITKFNDITADVYSEYRASLAFDLVSSRQKNAYTDYSDSVARRMGFIPLPLAVLLIRVVTSSIKVQGILSYACVILFYFGLISLKVLNSIVLLGKSCQYVKEAKMEEKLSNPPATCTPGKPSSKSQNKCKPSQGLSTEENLSASITKQPIHQKENIIPLLVTSNSDQFLTTPDGDEKDITQDNSELKHRSSKKDLLEIDRFTICGNRID>sp|Q6NXT6-2|TAPT1_HUMAN Isoform 2 of Transmembrane anterior posteriortransformation protein 1 homolog OS=Homo sapiens OX=9606 GN=TAPT1MAGVGDAAAPGEGGGGGVDGPQRDGRGEAEQPGGSGGQGPPPAPQLTETLGFYESDRRRERRRGRTELSLLRFLSAELTRGYFLEHNEAKYTERRERVYTCLRIPRELEKLMVFGIFLCLDAFLYVFTLLPLRVFLALFRLLTLPCYGLRDRRLLQPAQVCDILKGVILVICYFMMHYVDYSMMYHLIRGQSVIKLYIIYNMLEVADRLFSSFGQDILDALYWTATEPKERKRAHIGVIPHFFMAVLYVFLHAILIMVQATTLNVAFNSHNKSLLTIMMSNNFVEIKGSVFKKFEKNNLFQMSNSDIKERFTNYVLLLIVCLRNMEQFSWNPDHLWVLFPDVCMVIASEIAVDIVKHAFITKFNDITADVYSEYRASLAFDLVSSRQKNAYTDYSDSVARRMGFIPLPLAVLLIRVVTSSIKVQGILSYACVILFYFGLISLKVLNSIVLLGKSCQYVKEAKMEEKLSNPPATCTPGKPSSKSQNKCKPSQGLSTEENLSASITKQPIHQKENIIPLLVTSNSDQFLTTPDGDEKDITQDNSELKHRSSKSVLLCQSGLPEC>sp|Q5H9J9|T11X2_HUMAN T-complex protein 11 X-linked protein 2 OS=Homosapiens OX=9606 GN=TCP11X2 PE=3 SV=1MYNAFWNHLKEQLLSTPPDFTCALELLKDVKENRLRNEIEEALDTDLLKQEAEHGALDVPHLSNYILNLMALLCAPVRDEAIQKLETIRDPVQLLRGILRVLGLMKMDMVNYTIQSFRPYLQEHSIQYEQAKFQELLDKQPSLLDYTTKWLTKAATDITTLCPSSPDSPSSSCSMACSLPSGAGNNSEPPSPTMVLYQGYLNLLLWDLENVEFPETLLMDRIRLQELAFQLHQLTVLASVLLVARSFSGEVLFRSPEFVDRLKCTTKALTEEFISRPEETMLSVSEQVSQEVHQGLKDMGLTTLSSENTASLLGQLQNITKKENCIRSIVDQWIRFFLKCCLLHGMQESLLHFPGGLILIEKELAELGWKFLNLMHHNQQVFGPYYAEILKHIIHPAQAQETDVEPN>sp|Q9NUM4|T106B_HUMAN Transmembrane protein 106B OS=Homo sapiens OX=9606GN=TMEM106B PE=1 SV=2MGKSLSHLPLHSSKEDAYDGVTSENMRNGLVNSEVHNEDGRNGDVSQFPYVEFTGRDSVTCPTCQGTGRIPRGQENQLVALIPYSDQRLRPRRTKLYVMASVFVCLLLSGLAVFFLFPRSIDVKYIGVKSAYVSYDVQKRTIYLNITNTLNITNNNYYSVEVENITAQVQFSKTVIGKARLNNITIIGPLDMKQIDYTVPTVIAEEMSYMYDFCTLISIKVHNIVLMMQVTVTTTYFGHSEQISQERYQYVDCGRNTTYQLGQSEYLNVLQPQQ>sp|Q15542|TAF5_HUMAN Transcription initiation factor TFIID subunit 5OS=Homo sapiens OX=9606 GN=TAF5 PE=1 SV=3MAALAEEQTEVAVKLEPEGPPTLLPPQAGDGAGEGSGGTTNNGPNGGGGNVAASSSTGGDGGTPKPTVAVSAAAPAGAAPVPAAAPDAGAPHDRQTLLAVLQFLRQSKLREAEEALRREAGLLEEAVAGSGAPGEVDSAGAEVTSALLSRVTASAPGPAAPDPPGTGASGATVVSGSASGPAAPGKVGSVAVEDQPDVSAVLSAYNQQGDPTMYEEYYSGLKHFIECSLDCHRAELSQLFYPLFVHMYLELVYNQHENEAKSFFEKFHGDQECYYQDDLRVLSSLTKKEHMKGNETMLDFRTSKFVLRISRDSYQLLKRHLQEKQNNQIWNIVQEHLYIDIFDGMPRSKQQIDAMVGSLAGEAKREANKSKVFFGLLKEPEIEVPLDDEDEEGENEEGKPKKKKPKKDSIGSKSKKQDPNAPPQNRIPLPELKDSDKLDKIMNMKETTKRVRLGPDCLPSICFYTFLNAYQGLTAVDVTDDSSLIAGGFADSTVRVWSVTPKKLRSVKQASDLSLIDKESDDVLERIMDEKTASELKILYGHSGPVYGASFSPDRNYLLSSSEDGTVRLWSLQTFTCLVGYKGHNYPVWDTQFSPYGYYFVSGGHDRVARLWATDHYQPLRIFAGHLADVNCTRFHPNSNYVATGSADRTVRLWDVLNGNCVRIFTGHKGPIHSLTFSPNGRFLATGATDGRVLLWDIGHGLMVGELKGHTDTVCSLRFSRDGEILASGSMDNTVRLWDAIKAFEDLETDDFTTATGHINLPENSQELLLGTYMTKSTPVVHLHFTRRNLVLAAGAYSPQ>sp|Q15542-2|TAF5_HUMAN Isoform Short of Transcription initiation factorTFIID subunit 5 OS=Homo sapiens OX=9606 GN=TAF5MAALAEEQTEVAVKLEPEGPPTLLPPQAGDGAGEGSGGTTNNGPNGGGGNVAASSSTGGDGGTPKPTVAVSAAAPAGAAPVPAAAPDAGAPHDRQTLLAVLQFLRQSKLREAEEALRREAGLLEEAVAGSGAPGEVDSAGAEVTSALLSRVTASAPGPAAPDPPGTGASGATVVSGSASGPAAPGKVGSVAVEDQPDVSAVLSAYNQQGDPTMYEEYYSGLKHFIECSLDCHRAELSQLFYPLFVHMYLELVYNQHENEAKSFFEKFHGDQECYYQDDLRVLSSLTKKEHMKGNETMLDFRTSKFVLRISRDSYQLLKRHLQEKQNNQIWNIVQEHLYIDIFDGMPRSKQQIDAMVGSLAGEAKREANKSKVFFGLLKEPEIEVPLDDEDEEGENEEGKPKKKKPKKDSIGSKSKKQDPNAPPQNRIPLPELKDSDKLDKIMNMKETTKRVRLGPDCLPSICFYTFLNAYQGLTAVDVTDDSSLIAGGFADSTVRVWSVTPKKLRSVKQASDLSLIDKESDDVLERIMDEKTASELKILYGHSGPVYGASFSPDRLWATDHYQPLRIFAGHLADVNCTRFHPNSNYVATGSADRTVRLWDVLNGNCVRIFTGHKGPIHSLTFSPNGRFLATGATDGRVLLWDIGHGLMVGELKGHTDTVCSLRFSRDGEILASGSMDNTVRLWDAIKAFEDLETDDFTTATGHINLPENSQELLLGTYMTKSTPVVHLHFTRRNLVLAAGAYSPQ>sp|P59540|T2R46_HUMAN Taste receptor type 2 member 46 OS=Homo sapiensOX=9606 GN=TAS2R46 PE=2 SV=2MITFLPIIFSILIVVTFVIGNFANGFIALVNSIEWFKRQKISFADQILTALAVSRVGLLWVLVLNWYATELNPAFNSIEVRITAYNVWAVINHFSNWLATSLSIFYLLKIANFSNLIFLHLKRRVKSVVLVILLGPLLFLVCHLFVINMNQIIWTKEYEGNMTWKIKLRSAMYLSNTTVTILANLVPFTLTLISFLLLICSLCKHLKKMQLHGKGSQDPSMKVHIKALQTVTSFLLLCAIYFLSIIMSVWSFESLENKPVFMFCEAIAFSYPSTHPFILIWGNKKLKQTFLSVLWHVRYWVKGEKPSSS>sp|A6NC51|T150B_HUMAN Modulator of macroautophagy TMEM150B OS=Homosapiens OX=9606 GN=TMEM150B PE=2 SV=1MWGYLSLMPVFLAVWAISGVWIVFAIAVTNRTVDLSKGFPYISICGSFPPQSCIFSQVLNMGAALAAWICIVRYHQLRDWGVRRWPNQLILWTGLLCALGTSVVGNFQEKNQRPTHLAGAFLAFILGNVYFWLQLLLWRLKRLPQPGAAWIGPLRLGLCSVCTILIVAMIVLHACSLRSVSAACEWVVAMLLFALFGLLAVDFSALESCTLCVQPWPSLSPPPASPISLPVQL>sp|P21731|TA2R_HUMAN Thromboxane A2 receptor OS=Homo sapiens OX=9606GN=TBXA2R PE=1 SV=3MWPNGSSLGPCFRPTNITLEERRLIASPWFAASFCVVGLASNLLALSVLAGARQGGSHTRSSFLTFLCGLVLTDFLGLLVTGTIVVSQHAALFEWHAVDPGCRLCRFMGVVMIFFGLSPLLLGAAMASERYLGITRPFSRPAVASQRRAWATVGLVWAAALALGLLPLLGVGRYTVQYPGSWCFLTLGAESGDVAFGLLFSMLGGLSVGLSFLLNTVSVATLCHVYHGQEAAQQRPRDSEVEMMAQLLGIMVVASVCWLPLLVFIAQTVLRNPPAMSPAGQLSRTTEKELLIYLRVATWNQILDPWVYILFRRAVLRRLQPRLSTRPRSLSLQPQLTQRSGLQ>sp|P21731-2|TA2R_HUMAN Isoform 2 of Thromboxane A2 receptor OS=Homosapiens OX=9606 GN=TBXA2RMWPNGSSLGPCFRPTNITLEERRLIASPWFAASFCVVGLASNLLALSVLAGARQGGSHTRSSFLTFLCGLVLTDFLGLLVTGTIVVSQHAALFEWHAVDPGCRLCRFMGVVMIFFGLSPLLLGAAMASERYLGITRPFSRPAVASQRRAWATVGLVWAAALALGLLPLLGVGRYTVQYPGSWCFLTLGAESGDVAFGLLFSMLGGLSVGLSFLLNTVSVATLCHVYHGQEAAQQRPRDSEVEMMAQLLGIMVVASVCWLPLLVFIAQTVLRNPPAMSPAGQLSRTTEKELLIYLRVATWNQILDPWVYILFRRAVLRRLQPRLSTRPRRSLTLWPSLEYSGTISAHCNLRLPGSSDSRASASRAAGITGVSHCARPCMLFDPEFDLLAGVQLLPFEPPTGKALSRKD>sp|Q9NYW0|T2R10_HUMAN Taste receptor type 2 member 10 OS=Homo sapiensOX=9606 GN=TAS2R10 PE=1 SV=3MLRVVEGIFIFVVVSESVFGVLGNGFIGLVNCIDCAKNKLSTIGFILTGLAISRIFLIWIIITDGFIQIFSPNIYASGNLIEYISYFWVIGNQSSMWFATSLSIFYFLKIANFSNYIFLWLKSRTNMVLPFMIVFLLISSLLNFAYIAKILNDYKTKNDTVWDLNMYKSEYFIKQILLNLGVIFFFTLSLITCIFLIISLWRHNRQMQSNVTGLRDSNTEAHVKAMKVLISFIILFILYFIGMAIEISCFTVRENKLLLMFGMTTTAIYPWGHSFILILGNSKLKQASLRVLQQLKCCEKRKNLRVT>sp|Q9NYV8|T2R14_HUMAN Taste receptor type 2 member 14 OS=Homo sapiensOX=9606 GN=TAS2R14 PE=1 SV=1MGGVIKSIFTFVLIVEFIIGNLGNSFIALVNCIDWVKGRKISSVDRILTALAISRISLVWLIFGSWCVSVFFPALFATEKMFRMLTNIWTVINHFSVWLATGLGTFYFLKIANFSNSIFLYLKWRVKKVVLVLLLVTSVFLFLNIALINIHINASINGYRRNKTCSSDSSNFTRFSSLIVLTSTVFIFIPFTLSLAMFLLLIFSMWKHRKKMQHTVKISGDASTKAHRGVKSVITFFLLYAIFSLSFFISVWTSERLEENLIILSQVMGMAYPSCHSCVLILGNKKLRQASLSVLLWLRYMFKDGEPSGHKEFRESS>sp|P27449|VATL_HUMAN V-type proton ATPase 16 kDa proteolipid subunitOS=Homo sapiens OX=9606 GN=ATP6V0C PE=1 SV=1MSESKSGPEYASFFAVMGASAAMVFSALGAAYGTAKSGTGIAAMSVMRPEQIMKSIIPVVMAGIIAIYGLVVAVLIANSLNDDISLYKSFLQLGAGLSVGLSGLAAGFAIGIVGDAGVRGTAQQPRLFVGMILILIFAEVLGLYGLIVALILSTK>sp|P59543|T2R20_HUMAN Taste receptor type 2 member 20 OS=Homo sapiensOX=9606 GN=TAS2R20 PE=2 SV=2MMSFLHIVFSILVVVAFILGNFANGFIALINFIAWVKRQKISSADQIIAALAVSRVGLLWVILLHWYSTVLNPTSSNLKVIIFISNAWAVTNHFSIWLATSLSIFYLLKIVNFSRLIFHHLKRKAKSVVLVIVLGSLFFLVCHLVMKHTYINVWTEECEGNVTWKIKLRNAMHLSNLTVAMLANLIPFTLTLISFLLLIYSLCKHLKKMQLHGKGSQDPSTKIHIKALQTVTSFLILLAIYFLCLIISFWNFKMRPKEIVLMLCQAFGIIYPSFHSFILIWGNKTLKQTFLSVLWQVTCWAKGQNQSTP>sp|P50990|TCPQ_HUMAN T-complex protein 1 subunit theta OS=Homo sapiensOX=9606 GN=CCT8 PE=1 SV=4MALHVPKAPGFAQMLKEGAKHFSGLEEAVYRNIQACKELAQTTRTAYGPNGMNKMVINHLEKLFVTNDAATILRELEVQHPAAKMIVMASHMQEQEVGDGTNFVLVFAGALLELAEELLRIGLSVSEVIEGYEIACRKAHEILPNLVCCSAKNLRDIDEVSSLLRTSIMSKQYGNEVFLAKLIAQACVSIFPDSGHFNVDNIRVCKILGSGISSSSVLHGMVFKKETEGDVTSVKDAKIAVYSCPFDGMITETKGTVLIKTAEELMNFSKGEENLMDAQVKAIADTGANVVVTGGKVADMALHYANKYNIMLVRLNSKWDLRRLCKTVGATALPRLTPPVLEEMGHCDSVYLSEVGDTQVVVFKHEKEDGAISTIVLRGSTDNLMDDIERAVDDGVNTFKVLTRDKRLVPGGGATEIELAKQITSYGETCPGLEQYAIKKFAEAFEAIPRALAENSGVKANEVISKLYAVHQEGNKNVGLDIEAEVPAVKDMLEAGILDTYLGKYWAIKLATNAAVTVLRVDQIIMAKPAGGPKPPSGKKDWDDDQND>sp|P50990-2|TCPQ_HUMAN Isoform 2 of T-complex protein 1 subunit thetaOS=Homo sapiens OX=9606 GN=CCT8MHFSGLEEAVYRNIQACKELAQTTRTAYGPNGMNKMVINHLEKLFVTNDAATILRELEVQHPAAKMIVMASHMQEQEVGDGTNFVLVFAGALLELAEELLRIGLSVSEVIEGYEIACRKAHEILPNLVCCSAKNLRDIDEVSSLLRTSIMSKQYGNEVFLAKLIAQACVSIFPDSGHFNVDNIRVCKILGSGISSSSVLHGMVFKKETEGDVTSVKDAKIAVYSCPFDGMITETKGTVLIKTAEELMNFSKGEENLMDAQVKAIADTGANVVVTGGKVADMALHYANKYNIMLVRLNSKWDLRRLCKTVGATALPRLTPPVLEEMGHCDSVYLSEVGDTQVVVFKHEKEDGAISTIVLRGSTDNLMDDIERAVDDGVNTFKVLTRDKRLVPGGGATEIELAKQITSYGETCPGLEQYAIKKFAEAFEAIPRALAENSGVKANEVISKLYAVHQEGNKNVGLDIEAEVPAVKDMLEAGILDTYLGKYWAIKLATNAAVTVLRVDQIIMAKPAGGPKPPSGKKDWDDDQND>sp|P50990-3|TCPQ_HUMAN Isoform 3 of T-complex protein 1 subunit thetaOS=Homo sapiens OX=9606 GN=CCT8MDQMVQHPAAKMIVMASHMQEQEVGDGTNFVLVFAGALLELAEELLRIGLSVSEVIEGYEIACRKAHEILPNLVCCSAKNLRDIDEVSSLLRTSIMSKQYGNEVFLAKLIAQACVSIFPDSGHFNVDNIRVCKILGSGISSSSVLHGMVFKKETEGDVTSVKDAKIAVYSCPFDGMITETKGTVLIKTAEELMNFSKGEENLMDAQVKAIADTGANVVVTGGKVADMALHYANKYNIMLVRLNSKWDLRRLCKTVGATALPRLTPPVLEEMGHCDSVYLSEVGDTQVVVFKHEKEDGAISTIVLRGSTDNLMDDIERAVDDGVNTFKVLTRDKRLVPGGGATEIELAKQITSYGETCPGLEQYAIKKFAEAFEAIPRALAENSGVKANEVISKLYAVHQEGNKNVGLDIEAEVPAVKDMLEAGILDTYLGKYWAIKLATNAAVTVLRVDQIIMAKPAGGPKPPSGKKDWDDDQND>sp|Q9NXG2|THUM1_HUMAN THUMP domain-containing protein 1 OS=Homo sapiensOX=9606 GN=THUMPD1 PE=1 SV=2MAAPAQQTTQPGGGKRKGKAQYVLAKRARRCDAGGPRQLEPGLQGILITCNMNERKCVEEAYSLLNEYGDDMYGPEKFTDKDQQPSGSEGEDDDAEAALKKEVGDIKASTEMRLRRFQSVESGANNVVFIRTLGIEPEKLVHHILQDMYKTKKKKTRVILRMLPISGTCKAFLEDMKKYAETFLEPWFKAPNKGTFQIVYKSRNNSHVNREEVIRELAGIVCTLNSENKVDLTNPQYTVVVEIIKAVCCLSVVKDYMLFRKYNLQEVVKSPKDPSQLNSKQGNGKEAKLESADKSDQNNTAEGKNNQQVPENTEELGQTKPTSNPQVVNEGGAKPELASQATEGSKSNENDFS>sp|Q8NEK8|TET5D_HUMAN Terminal nucleotidyltransferase 5D OS=Homo sapiensOX=9606 GN=TENT5D PE=1 SV=1MSEIRFTNLTWDQVITLDQVLDEVIPIHGKGNFPTMEVKPKDIIHVVKDQLIGQGIIVKDARLNGSVASYILASHNGISYKDLDVIFGVELPGNEEFQVVKDAVLDCLLDFLPKDVKKEKLSPDIMKDAYVQKLVKVCNGHDCWSLISLSNNTGKNLELKFVSSLRRQFEFSVDSFQIVLDPMLDFYSDKNAKLTKESYPVVVAESMYGDFQEAMTHLQHKLICTRKPEEIRGGGLLKYCSLLVHGFKPACMSEIKNLERYMCSRFFIDFPHIEEQQKKIESYLHNHFIGEGMTKYDYLMTLHGVVNESTVCLMSYERRQILHLITMMALKVLGELNILPNTQKVTCFYQPAPYFAAEARYPIYVIPEPPPVSFQPYHPLHFRGSNGMS>sp|Q9NVV9|THAP1_HUMAN THAP domain-containing protein 1 OS=Homo sapiensOX=9606 GN=THAP1 PE=1 SV=1MVQSCSAYGCKNRYDKDKPVSFHKFPLTRPSLCKEWEAAVRRKNFKPTKYSSICSEHFTPDCFKRECNNKLLKENAVPTIFLCTEPHDKKEDLLEPQEQLPPPPLPPPVSQVDAAIGLLMPPLQTPVNLSVFCDHNYTVEDTMHQRKRIHQLEQQVEKLRKKLKTAQQRCRRQERQLEKLKEVVHFQKEKDDVSERGYVILPNDYFEIVEVPA>sp|Q9NVV9-2|THAP1_HUMAN Isoform 2 of THAP domain-containing protein 1OS=Homo sapiens OX=9606 GN=THAP1MVQSCSAYGCKNRYDKDKPVSFHKKKIFWSHRNSFPHLLYRLLFPRLMLLLDY>sp|O95759|TBCD8_HUMAN TBC1 domain family member 8 OS=Homo sapiensOX=9606 GN=TBC1D8 PE=1 SV=3MWLKPEEVLLKNALKLWVTQKSSCYFILQRRRGHGEGGGRLTGRLVGALDAVLDSNARVAPFRILLQVPGSQVYSPIACGATLEEINQHWDWLEQNLLHTLSVFDNKDDIASFVKGKVKALIAEETSSRLAEQEEEPEKFREALVKFEARFNFPEAEKLVTYYSCCCWKGRVPRQGWLYLSINHLCFYSFFLGKELKLVVPWVDIQKLERTSNVFLTDTIRITTQNKERDFSMFLNLDEVFKVMEQLADVTLRRLLDNEVFDLDPDLQEPSQITKRDLEARAQNEFFRAFFRLPRKEKLHAVVDCSLWTPFSRCHTTGRMFASDSYICFASREDGCCKIILPLREVVSIEKMEDTSLLPHPIIVSIRSKVAFQFIELRDRDSLVEALLARLKQVHANHPVHYDTSADDDMASLVFHSTSMCSDHRFGDLEMMSSQNSEESEKEKSPLMHPDALVTAFQQSGSQSPDSRMSREQIKISLWNDHFVEYGRTVCMFRTEKIRKLVAMGIPESLRGRLWLLFSDAVTDLASHPGYYGNLVEESLGKCCLVTEEIERDLHRSLPEHPAFQNETGIAALRRVLTAYAHRNPKIGYCQSMNILTSVLLLYTKEEEAFWLLVAVCERMLPDYFNHRVIGAQVDQSVFEELIKGHLPELAEHMNDLSALASVSLSWFLTLFLSIMPLESAVNVVDCFFYDGIKAIFQLGLAVLEANAEDLCSSKDDGQALMILSRFLDHIKNEDSPGPPVGSHHAFFSDDQEPYPVTDISDLIRDSYEKFGDQSVEQIEHLRYKHRIRVLQGHEDTTKQNVLRVVIPEVSILPEDLEELYDLFKREHMMSCYWEQPRPMASRHDPSRPYAEQYRIDARQFAHLFQLVSPWTCGAHTEILAERTFRLLDDNMDQLIEFKAFVSCLDIMYNGEMNEKIKLLYRLHIPPALTENDRDSQSPLRNPLLSTSRPLVFGKPNGDAVDYQKQLKQMIKDLAKEKDKTEKELPKMSQREFIQFCKTLYSMFHEDPEENDLYQAIATVTTLLLQIGEVGQRGSSSGSCSQECGEELRASAPSPEDSVFADTGKTPQDSQAFPEAAERDWTVSLEHILASLLTEQSLVNFFEKPLDMKSKLENAKINQYNLKTFEMSHQSQSELKLSNL>sp|O95759-2|TBCD8_HUMAN Isoform 2 of TBC1 domain family member 8 OS=Homosapiens OX=9606 GN=TBC1D8MEQLADVTLRRLLDNEVFDLDPDLQEPSQITKRDLEARAQNEFFRAFFRLPRKEKLHAVVDCSLWTPFSRCHTTGRMFASDSYICFASREDGCCKIILPLREVVSIEKMEDTSLLPHPIIVSIRSKVAFQFIELRDRDSLVEALLARLKQVHANHPVHYDTSADDDMASLVFHSTSMCSDHRFGDLEMMSSQNSEESEKEKSPLMHPDALVTAFQQSGSQSPDSRMSREQIKISLWNDHFVEYGRTVCMFRTEKIRKLVAMGIPESLRGRLWLLFSDAVTDLASHPGYYGNLVEESLGKCCLVTEEIERDLHRSLPEHPAFQNETGIAALRRVLTAYAHRNPKIGYCQSMNILTSVLLLYTKEEEAFWLLVAVCERMLPDYFNHRVIGAQVDQSVFEELIKGHLPELAEHMNDLSALASVSLSWFLTLFLSIMPLESAVNVVDCFFYDGIKAIFQLGLAVLEANAEDLCSSKDDGQALMILSRFLDHIKNEDSPGPPVGSHHAFFSDDQEPYPVTDISDLIRDSYEKFGDQSVEQIEHLRYKHRIRVLQGHEDTTKQNVLRVVIPEVSILPEDLEELYDLFKREHMMSCYWEQPRPMASRHDPSRPYAEQYRIDARQFAHLFQLVSPWTCGAHTEILAERTFRLLDDNMDQLIEFKAFVSCLDIMYNGEMNEKIKLLYRLHIPPALTENDRDSQSPLRNPLLSTSRPLVFGKPNGDAVDYQKQLKQMIKDLAKEKDKTEKELPKMSQREFIQFCKTLYSMFHEDPEENDLYQAIATVTTLLLQIGEVGQRGSSSGSCSQECGEELRASAPSPEDSVFADTGKTPQDSQAFPEAAERDWTVSLEHILASLLTEQSLVNFFEKPLDMKSKLENAKINQYNLKTFEMSHQSQSELKLSNL>sp|Q5HYJ1|TECRL_HUMAN Trans-2,3-enoyl-CoA reductase-like OS=Homo sapiensOX=9606 GN=TECRL PE=1 SV=1MFKRHKSLASERKRALLSQRATRFILKDDMRNFHFLSKLVLSAGPLRPTPAVKHSKTTHFEIEIFDAQTRKQICILDKVTQSSTIHDVKQKFHKACPKWYPSRVGLQLECGGPFLKDYITIQSIAASSIVTLYATDLGQQVSWTTVFLAEYTGPLLIYLLFYLRIPCIYDGKESARRLRHPVVHLACFCHCIHYIRYLLETLFVHKVSAGHTPLKNLIMSCAFYWGFTSWIAYYINHPLYTPPSFGNRQITVSAINFLICEAGNHFINVMLSHPNHTGNNACFPSPNYNPFTWMFFLVSCPNYTYEIGSWISFTVMTQTLPVGIFTLLMSIQMSLWAQKKHKIYLRKFNSYIHRKSAMIPFIL>sp|Q9HC07|TM165_HUMAN Transmembrane protein 165 OS=Homo sapiens OX=9606GN=TMEM165 PE=1 SV=1MAAAAPGNGRASAPRLLLLFLVPLLWAPAAVRAGPDEDLSHRNKEPPAPAQQLQPQPVAVQGPEPARVEKIFTPAAPVHTNKEDPATQTNLGFIHAFVAAISVIIVSELGDKTFFIAAIMAMRYNRLTVLAGAMLALGLMTCLSVLFGYATTVIPRVYTYYVSTVLFAIFGIRMLREGLKMSPDEGQEELEEVQAELKKKDEEFQRTKLLNGPGDVETGTSITVPQKKWLHFISPIFVQALTLTFLAEWGDRSQLTTIVLAAREDPYGVAVGGTVGHCLCTGLAVIGGRMIAQKISVRTVTIIGGIVFLAFAFSALFISPDSGF>sp|Q9HC07-2|TM165_HUMAN Isoform 2 of Transmembrane protein 165 OS=Homosapiens OX=9606 GN=TMEM165MEIPMQKIFTPAAPVHTNKEDPATQTNLGFIHAFVAAISVIIVSELGDKTFFIAAIMAMRYNRLTVLAGAMLALGLMTCLSVLFGYATTVIPRVYTYYVSTVLFAIFGIRMLREGLKMSPDEGQEELEEVQAELKKKDEEFQRTKLLNGPGDVETGTSITVPQKKWLHFISPIFVQALTLTFLAEWGDRSQLTTIVLAAREDPYGVAVGGTVGHCLCTGLAVIGGRMIAQKISVRTVTIIGGIVFLAFAFSALFISPDSGF>sp|Q9Y296|TPPC4_HUMAN Trafficking protein particle complex subunit 4OS=Homo sapiens OX=9606 GN=TRAPPC4 PE=1 SV=1MAIFSVYVVNKAGGLIYQLDSYAPRAEAEKTFSYPLDLLLKLHDERVLVAFGQRDGIRVGHAVLAINGMDVNGRYTADGKEVLEYLGNPANYPVSIRFGRPRLTSNEKLMLASMFHSLFAIGSQLSPEQGSSGIEMLETDTFKLHCYQTLTGIKFVVLADPRQAGIDSLLRKIYEIYSDFALKNPFYSLEMPIRCELFDQNLKLALEVAEKAGTFGPGS>sp|Q9Y296-2|TPPC4_HUMAN Isoform 2 of Trafficking protein particlecomplex subunit 4 OS=Homo sapiens OX=9606 GN=TRAPPC4MAIFSVYVVNKAGGLIYQLDSYAPRAEAEKTFSYPLDLLLKLHDERVLVAFGQRDGIRVGHAVLAINGMDVNGRYTADGKEMLETDTFKLHCYQTLTGIKFVVLADPRQAGIDSLLRKIYEIYSDFALKNPFYSLEMPIRCELFDQNLKLALEVAEKAGTFGPGS>sp|Q15813|TBCE_HUMAN Tubulin-specific chaperone E OS=Homo sapiensOX=9606 GN=TBCE PE=1 SV=1MSDTLTADVIGRRVEVNGEHATVRFAGVVPPVAGPWLGVEWDNPERGKHDGSHEGTVYFKCRHPTGGSFIRPNKVNFGTDFLTAIKNRYVLEDGPEEDRKEQIVTIGNKPVETIGFDSIMKQQSQLSKLQEVSLRNCAVSCAGEKGGVAEACPNIRKVDLSKNLLSSWDEVIHIADQLRHLEVLNVSENKLKFPSGSVLTGTLSVLKVLVLNQTGITWAEVLRCVAGCPGLEELYLESNNIFISERPTDVLQTVKLLDLSSNQLIDENQLYLIAHLPRLEQLILSDTGISSLHFPDAGIGCKTSMFPSLKYLVVNDNQISQWSFFNELEKLPSLRALSCLRNPLTKEDKEAETARLLIIASIGQLKTLNKCEILPEERRRAELDYRKAFGNEWKQAGGHKDPEKNRLSEEFLTAHPRYQFLCLKYGAPEDWELKTQQPLMLKNQLLTLKIKYPHQLDQKVLEKQLPGSMTIQKVKGLLSRLLKVPVSDLLLSYESPKKPGREIELENDLKSLQFYSVENGDCLLVRW>sp|Q15813-2|TBCE_HUMAN Isoform 2 of Tubulin-specific chaperone E OS=Homosapiens OX=9606 GN=TBCEMSDTLTADVIGRRVEVNGEHATVRFAGVVPPVAGPWLGVEWDNPERGKHDGSHEGTVYFKCRHPTGGSFIRPNKVNFGTDFLTAIKNRYVLEDGPEEDRKEQIVTIGNKPVETIGFDSIMKQQSQLSKLQEVSLRNCAVSCAGEKGGVAEACPNIRKVDLSKNLLSSWDEVIHIADQLRHLEVLNVSENKLKFPSGSVLTGTLSVLKVLVLNQTGITWAEAHAQCGGSRHGLDMQKDASKFVDLCVLQKCSTSNCIISAKDHTSMRMNVAKVLRCVAGCPGLEELYLESNNIFISERPTDVLQTVKLLDLSSNQLIDENQLYLIAHLPRLEQLILSDTGISSLHFPDAGIGCKTSMFPSLKYLVVNDNQISQWSFFNELEKLPSLRALSCLRNPLTKEDKEAETARLLIIASIGQLKTLNKCEILPEERRRAELDYRKAFGNEWKQAGGHKDPEKNRLSEEFLTAHPRYQFLCLKYGAPEDWELKTQQPLMLKNQLLTLKIKYPHQLDQKVLEKQLPGSMTIQKVKGLLSRLLKVPVSDLLLSYESPKKPGREIELENDLKSLQFYSVENGDCLLVRW>sp|B7Z8K6|TRDC_HUMAN T cell receptor delta constant OS=Homo sapiensOX=9606 GN=TRDC PE=1 SV=2SQPHTKPSVFVMKNGTNVACLVKEFYPKDIRINLVSSKKITEFDPAIVISPSGKYNAVKLGKYEDSNSVTCSVQHDNKTVHSTDFEVKTDSTDHVKPKETENTKQPSKSCHKPKAIVHTEKVNMMSLTVLGLRMLFAKTVAVNFLLTAKLFFL>sp|P0CAT3|TLXNB_HUMAN Putative TLX1 neighbor protein OS=Homo sapiensOX=9606 GN=TLX1NB PE=5 SV=1MAPLQLLHPWGRRGAWASQHSLLSQEAMGPGEGAEPTPWGYLRAEHWGASPSGAPTLPFAPDECSLTPGSPPHPLNKQKHHPPHPSQTQKDLVPRSPQLEKSRIRLRRTLRNLGGGRGQRGQ>sp|Q68D42|TM215_HUMAN Transmembrane protein 215 OS=Homo sapiens OX=9606GN=TMEM215 PE=2 SV=1MRPDDINPRTGLVVALVSVFLVFGFMFTVSGMKGETLGNIPLLAIGPAICLPGIAAIALARKTEGCTKWPENELLWVRKLPCFRKPKDKEVVELLRTPSDLESGKGSSDELAKKAGLRGKPPPQSQGEVSVASSINSPTPTEEGECQSLVQNGHQEETSRYLDGYCPSGSSLTYSALDVKCSARDRSECPEPEDSIFFVPQDSIIVCSYKQNSPYDRYCCYINQIQGRWDHETIV>sp|Q6ZMU5|TRI72_HUMAN Tripartite motif-containing protein 72 OS=Homosapiens OX=9606 GN=TRIM72 PE=1 SV=2MSAAPGLLHQELSCPLCLQLFDAPVTAECGHSFCRACLGRVAGEPAADGTVLCPCCQAPTRPQALSTNLQLARLVEGLAQVPQGHCEEHLDPLSIYCEQDRALVCGVCASLGSHRGHRLLPAAEAHARLKTQLPQQKLQLQEACMRKEKSVAVLEHQLVEVEETVRQFRGAVGEQLGKMRVFLAALEGSLDREAERVRGEAGVALRRELGSLNSYLEQLRQMEKVLEEVADKPQTEFLMKYCLVTSRLQKILAESPPPARLDIQLPIISDDFKFQVWRKMFRALMPALEELTFDPSSAHPSLVVSSSGRRVECSEQKAPPAGEDPRQFDKAVAVVAHQQLSEGEHYWEVDVGDKPRWALGVIAAEAPRRGRLHAVPSQGLWLLGLREGKILEAHVEAKEPRALRSPERRPTRIGLYLSFGDGVLSFYDASDADALVPLFAFHERLPRPVYPFFDVCWHDKGKNAQPLLLVGPEGAEA>sp|Q6ZMU5-2|TRI72_HUMAN Isoform 2 of Tripartite motif-containing protein72 OS=Homo sapiens OX=9606 GN=TRIM72MSAAPGLLHQELSCPLCLQLFDAPVTAECGHSFCRACLGRVAGEPAADGTVLCPCCQAPTRPQALSTNLQLARLVEGLAQVPQGHCEEHLDPLSIYCEQDRALVCGVCASLGSHRGHRLLPAAEAHARLKTQLPQQKLQLQEACMRKEKSVAVLEHQLVEVEETVRQFRGAVGEQLGKMRVFLAALEGSLDREAERVRGEAGVALRRELGSLNSYLEQLRQMEKVLEEVADKPQTEFLMKYCLVTSRLQKILAESPPPARLDIQLPIIS>sp|Q9C029|TRIM7_HUMAN E3 ubiquitin-protein ligase TRIM7 OS=Homo sapiensOX=9606 GN=TRIM7 PE=1 SV=2MAAVGPRTGPGTGAEALALAAELQGEATCSICLELFREPVSVECGHSFCRACIGRCWERPGAGSVGAATRAPPFPLPCPQCREPARPSQLRPNRQLAAVATLLRRFSLPAAAPGEHGSQAAAARAAAARCGQHGEPFKLYCQDDGRAICVVCDRAREHREHAVLPLDEAVQEAKELLESRLRVLKKELEDCEVFRSTEKKESKELLKQMAAEQEKVGAEFQALRAFLVEQEGRLLGRLEELSREVAQKQNENLAQLGVEITQLSKLSSQIQETAQKPDLDFLQEFKSTLSRCSNVPGPKPTTVSSEMKNKVWNVSLKTFVLKGMLKKFKEDLRGELEKEEKVELTLDPDTANPRLILSLDLKGVRLGERAQDLPNHPCRFDTNTRVLASCGFSSGRHHWEVEVGSKDGWAFGVARESVRRKGLTPFTPEEGVWALQLNGGQYWAVTSPERSPLSCGHLSRVRVALDLEVGAVSFYAVEDMRHLYTFRVNFQERVFPLFSVCSTGTYLRIWP>sp|Q9C029-3|TRIM7_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM7OS=Homo sapiens OX=9606 GN=TRIM7MAAEQEKVGAEFQALRAFLVEQEGRLLGRLEELSREVAQKQNENLAQLGVEITQLSKLSSQIQETAQKPDLDFLQEFKSTLSRCSNVPGPKPTTVSSEMKNKVWNVSLKTFVLKGMLKKFKEDLRGELEKEEKVELTLDPDTANPRLILSLDLKGVRLGERAQDLPNHPCRFDTNTRVLASCGFSSGRHHWEVEVGSKDGWAFGVARESVRRKGLTPFTPEEGVWALQLNGGQYWAVTSPERSPLSCGHLSRVRVALDLEVGAVSFYAVEDMRHLYTFRVNFQERVFPLFSVCSTGTYLRIWP>sp|Q9C029-4|TRIM7_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM7OS=Homo sapiens OX=9606 GN=TRIM7MTQATGQMLCLHVQVPLQLLLLGQKQMAAEQEKVGAEFQALRAFLVEQEGRLLGRLEELSREVAQKQNENLAQLGVEITQLSKLSSQIQETAQKPDLDFLQEFKSTLSRCSNVPGPKPTTVSSEMKNKVWNVSLKTFVLKGMLKKFKEDLRGELEKEEKVELTLDPDTANPRLILSLDLKGVRLGERAQDLPNHPCRFDTNTRVLASCGFSSGRHHWEVEVGSKDGWAFGVARESVRRKGLTPFTPEEGVWALQLNGGQYWAVTSPERSPLSCGHLSRVRVALDLEVGAVSFYAVEDMRHLYTFRVNFQERVFPLFSVCSTGTYLRIWP>sp|Q9C029-1|TRIM7_HUMAN Isoform 4 of E3 ubiquitin-protein ligase TRIM7OS=Homo sapiens OX=9606 GN=TRIM7MAAVGPRTGPGTGAEALALAAELQGEATCSICLELFREPVSVECGHSFCRACIGRCWERPGAGSVGAATRAPPFPLPCPQCREPARPSQLRPNRQLAAVATLLRRFSLPAAAPGEHGSQAAAARAAAARCGQHGEPFKLYCQDDGRAICVVCDRAREHREHAVLPLDEAVQEAKELLESRLRVLKKELEDCEVFRSTEKKESKELLVSQAPAGPPWDITEA>sp|Q495X7|TRI60_HUMAN Tripartite motif-containing protein 60 OS=Homosapiens OX=9606 GN=TRIM60 PE=1 SV=2MEFVTALVNLQEESSCPICLEYLKDPVTINCGHNFCRSCLSVSWKDLDDTFPCPVCRFCFPYKSFRRNPQLRNLTEIAKQLQIRRSKRKRQKENAMCEKHNQFLTLFCVKDLEILCTQCSFSTKHQKHYICPIKKAASYHREILEGSLEPLRNNIERVEKVIILQGSKSVELKKKVEYKREEINSEFEQIRLFLQNEQEMILRQIQDEEMNILAKLNENLVELSDYVSTLKHLLREVEGKSVQSNLELLTQAKSMHHKYQNLKCPELFSFRLTKYGFSLPPQYSGLDRIIKPFQVDVILDLNTAHPQLLVSEDRKAVRYERKKRNICYDPRRFYVCPAVLGSQRFSSGRHYWEVEVGNKPKWILGVCQDCLLRNWQDQPSVLGGFWAIGRYMKSGYVASGPKTTQLLPVVKPSKIGIFLDYELGDLSFYNMNDRSILYTFNDCFTEAVWPYFYTGTDSEPLKICSVSDSER>sp|Q63HK5|TSH3_HUMAN Teashirt homolog 3 OS=Homo sapiens OX=9606 GN=TSHZ3PE=1 SV=2MPRRKQQAPRRAAAYVSEELKAAALVDEGLDPEEHTADGEPSAKYMCPEKELARACPSYQNSPAAEFSCHEMDSESHISETSDRMADFESGSIKNEEETKEVTVPLEDTTVSDSLEQMKAVYNNFLSNSYWSNLNLNLHQPSSEKNNGSSSSSSSSSSSCGSGSFDWHQSAMAKTLQQVSQSRMLPEPSLFSTVQLYRQSSKLYGSIFTGASKFRCKDCSAAYDTLVELTVHMNETGHYRDDNHETDNNNPKRWSKPRKRSLLEMEGKEDAQKVLKCMYCGHSFESLQDLSVHMIKTKHYQKVPLKEPVTPVAAKIIPATRKKASLELELPSSPDSTGGTPKATISDTNDALQKNSNPYITPNNRYGHQNGASYAWHFEARKSQILKCMECGSSHDTLQELTAHMMVTGHFIKVTNSAMKKGKPIVETPVTPTITTLLDEKVQSVPLAATTFTSPSNTPASISPKLNVEVKKEVDKEKAVTDEKPKQKDKPGEEEEKCDISSKYHYLTENDLEESPKGGLDILKSLENTVTSAINKAQNGTPSWGGYPSIHAAYQLPNMMKLSLGSSGKSTPLKPMFGNSEIVSPTKNQTLVSPPSSQTSPMPKTNFHAMEELVKKVTEKVAKVEEKMKEPDGKLSPPKRATPSPCSSEVGEPIKMEASSDGGFRSQENSPSPPRDGCKDGSPLAEPVENGKELVKPLASSLSGSTAIITDHPPEQPFVNPLSALQSVMNIHLGKAAKPSLPALDPMSMLFKMSNSLAEKAAVATPPPLQSKKADHLDRYFYHVNNDQPIDLTKGKSDKGCSLGSVLLSPTSTAPATSSSTVTTAKTSAVVSFMSNSPLRENALSDISDMLKNLTESHTSKSSTPSSISEKSDIDGATLEEAEESTPAQKRKGRQSNWNPQHLLILQAQFAASLRQTSEGKYIMSDLSPQERMHISRFTGLSMTTISHWLANVKYQLRRTGGTKFLKNLDTGHPVFFCNDCASQIRTPSTYISHLESHLGFRLRDLSKLSTEQINSQIAQTKSPSEKMVTSSPEEDLGTSYQCKLCNRTFASKHAVKLHLSKTHGKSPEDHLLYVSELEKQ>sp|O75954|TSN9_HUMAN Tetraspanin-9 OS=Homo sapiens OX=9606 GN=TSPAN9PE=1 SV=1MARGCLCCLKYMMFLFNLIFWLCGCGLLGVGIWLSVSQGNFATFSPSFPSLSAANLVIAIGTIVMVTGFLGCLGAIKENKCLLLSFFIVLLVILLAELILLILFFVYMDKVNENAKKDLKEGLLLYHTENNVGLKNAWNIIQAEMRCCGVTDYTDWYPVLGENTVPDRCCMENSQGCGRNATTPLWRTGCYEKVKMWFDDNKHVLGTVGMCILIMQILGMAFSMTLFQHIHRTGKKYDA>sp|P16473|TSHR_HUMAN Thyrotropin receptor OS=Homo sapiens OX=9606GN=TSHR PE=1 SV=2MRPADLLQLVLLLDLPRDLGGMGCSSPPCECHQEEDFRVTCKDIQRIPSLPPSTQTLKLIETHLRTIPSHAFSNLPNISRIYVSIDVTLQQLESHSFYNLSKVTHIEIRNTRNLTYIDPDALKELPLLKFLGIFNTGLKMFPDLTKVYSTDIFFILEITDNPYMTSIPVNAFQGLCNETLTLKLYNNGFTSVQGYAFNGTKLDAVYLNKNKYLTVIDKDAFGGVYSGPSLLDVSQTSVTALPSKGLEHLKELIARNTWTLKKLPLSLSFLHLTRADLSYPSHCCAFKNQKKIRGILESLMCNESSMQSLRQRKSVNALNSPLHQEYEENLGDSIVGYKEKSKFQDTHNNAHYYVFFEEQEDEIIGFGQELKNPQEETLQAFDSHYDYTICGDSEDMVCTPKSDEFNPCEDIMGYKFLRIVVWFVSLLALLGNVFVLLILLTSHYKLNVPRFLMCNLAFADFCMGMYLLLIASVDLYTHSEYYNHAIDWQTGPGCNTAGFFTVFASELSVYTLTVITLERWYAITFAMRLDRKIRLRHACAIMVGGWVCCFLLALLPLVGISSYAKVSICLPMDTETPLALAYIVFVLTLNIVAFVIVCCCYVKIYITVRNPQYNPGDKDTKIAKRMAVLIFTDFICMAPISFYALSAILNKPLITVSNSKILLVLFYPLNSCANPFLYAIFTKAFQRDVFILLSKFGICKRQAQAYRGQRVPPKNSTDIQVQKVTHDMRQGLHNMEDVYELIENSHLTPKKQGQISEEYMQTVL>sp|P16473-2|TSHR_HUMAN Isoform Short of Thyrotropin receptor OS=Homosapiens OX=9606 GN=TSHRMRPADLLQLVLLLDLPRDLGGMGCSSPPCECHQEEDFRVTCKDIQRIPSLPPSTQTLKLIETHLRTIPSHAFSNLPNISRIYVSIDVTLQQLESHSFYNLSKVTHIEIRNTRNLTYIDPDALKELPLLKFLGIFNTGLKMFPDLTKVYSTDIFFILEITDNPYMTSIPVNAFQGLCNETLTLKLYNNGFTSVQGYAFNGTKLDAVYLNKNKYLTVIDKDAFGGVYSGPSLLLPLGRKSLSFETQKAPRSSMPS>sp|P16473-3|TSHR_HUMAN Isoform 3 of Thyrotropin receptor OS=Homo sapiensOX=9606 GN=TSHRMRPADLLQLVLLLDLPRDLGGMGCSSPPCECHQEEDFRVTCKDIQRIPSLPPSTQTLKLIETHLRTIPSHAFSNLPNISRIYVSIDVTLQQLESHSFYNLSKVTHIEIRNTRNLTYIDPDALKELPLLKFLGIFNTGLKMFPDLTKVYSTDIFFILEITDNPYMTSIPVNAFQGLCNETLTLKLYNNGFTSVQGYAFNGTKLDAVYLNKNKYLTVIDKDAFGGVYSGPSLLVENVAVSGKGFCKSLFSWLYRLPLGRKSLSFETQKAPRSSMPS>sp|Q9H3U1|UN45A_HUMAN Protein unc-45 homolog A OS=Homo sapiens OX=9606GN=UNC45A PE=1 SV=1MTVSGPGTPEPRPATPGASSVEQLRKEGNELFKCGDYGGALAAYTQALGLDATPQDQAVLHRNRAACHLKLEDYDKAETEASKAIEKDGGDVKALYRRSQALEKLGRLDQAVLDLQRCVSLEPKNKVFQEALRNIGGQIQEKVRYMSSTDAKVEQMFQILLDPEEKGTEKKQKASQNLVVLAREDAGAEKIFRSNGVQLLQRLLDMGETDLMLAALRTLVGICSEHQSRTVATLSILGTRRVVSILGVESQAVSLAACHLLQVMFDALKEGVKKGFRGKEGAIIVDPARELKVLISNLLDLLTEVGVSGQGRDNALTLLIKAVPRKSLKDPNNSLTLWVIDQGLKKILEVGGSLQDPPGELAVTANSRMSASILLSKLFDDLKCDAERENFHRLCENYIKSWFEGQGLAGKLRAIQTVSCLLQGPCDAGNRALELSGVMESVIALCASEQEEEQLVAVEALIHAAGKAKRASFITANGVSLLKDLYKCSEKDSIRIRALVGLCKLGSAGGTDFSMKQFAEGSTLKLAKQCRKWLCNDQIDAGTRRWAVEGLAYLTFDADVKEEFVEDAAALKALFQLSRLEERSVLFAVASALVNCTNSYDYEEPDPKMVELAKYAKQHVPEQHPKDKPSFVRARVKKLLAAGVVSAMVCMVKTESPVLTSSCRELLSRVFLALVEEVEDRGTVVAQGGGRALIPLALEGTDVGQTKAAQALAKLTITSNPEMTFPGERIYEVVRPLVSLLHLNCSGLQNFEALMALTNLAGISERLRQKILKEKAVPMIEGYMFEEHEMIRRAATECMCNLAMSKEVQDLFEAQGNDRLKLLVLYSGEDDELLQRAAAGGLAMLTSMRPTLCSRIPQVTTHWLEILQALLLSSNQELQHRGAVVVLNMVEASREIASTLMESEMMEILSVLAKGDHSPVTRAAAACLDKAVEYGLIQPNQDGE>sp|Q9H3U1-2|UN45A_HUMAN Isoform 2 of Protein unc-45 homolog A OS=Homosapiens OX=9606 GN=UNC45AMTASSVEQLRKEGNELFKCGDYGGALAAYTQALGLDATPQDQAVLHRNRAACHLKLEDYDKAETEASKAIEKDGGDVKALYRRSQALEKLGRLDQAVLDLQRCVSLEPKNKVFQEALRNIGGQIQEKVRYMSSTDAKVEQMFQILLDPEEKGTEKKQKASQNLVVLAREDAGAEKIFRSNGVQLLQRLLDMGETDLMLAALRTLVGICSEHQSRTVATLSILGTRRVVSILGVESQAVSLAACHLLQVMFDALKEGVKKGFRGKEGAIIVDPARELKVLISNLLDLLTEVGVSGQGRDNALTLLIKAVPRKSLKDPNNSLTLWVIDQGLKKILEVGGSLQDPPGELAVTANSRMSASILLSKLFDDLKCDAERENFHRLCENYIKSWFEGQGLAGKLRAIQTVSCLLQGPCDAGNRALELSGVMESVIALCASEQEEEQLVAVEALIHAAGKAKRASFITANGVSLLKDLYKCSEKDSIRIRALVGLCKLGSAGGTDFSMKQFAEGSTLKLAKQCRKWLCNDQIDAGTRRWAVEGLAYLTFDADVKEEFVEDAAALKALFQLSRLEERSVLFAVASALVNCTNSYDYEEPDPKMVELAKYAKQHVPEQHPKDKPSFVRARVKKLLAAGVVSAMVCMVKTESPVLTSSCRELLSRVFLALVEEVEDRGTVVAQGGGRALIPLALEGTDVGQTKAAQALAKLTITSNPEMTFPGERIYEVVRPLVSLLHLNCSGLQNFEALMALTNLAGISERLRQKILKEKAVPMIEGYMFEEHEMIRRAATECMCNLAMSKEVQDLFEAQGNDRLKLLVLYSGEDDELLQRAAAGGLAMLTSMRPTLCSRIPQVTTHWLEILQALLLSSNQELQHRGAVVVLNMVEASREIASTLMESEMMEILSVLAKGDHSPVTRAAAACLDKAVEYGLIQPNQDGE>sp|Q9H3U1-3|UN45A_HUMAN Isoform 3 of Protein unc-45 homolog A OS=Homosapiens OX=9606 GN=UNC45AMTFPGERIYEVVRPLVSLLHLNCSGLQNFEALMALTNLAGISERLRQKILKEKAVPMIEGYMFEEHEMIRRAATECMCNLAMSKEVQDLFEAQGNDRLKLLVLYSGEDDELLQRAAAGGLAMLTSMRPTLCSRIPQVTTHWLEILQALLLSSNQELQHRGAVVVLNMVEASREIASTLMESEMMEILSVLAKGDHSPVTRAAAACLDKAVEYGLIQPNQDGE>sp|Q9BZ97|TTY13_HUMAN Putative transcript Y 13 protein OS=Homo sapiensOX=9606 GN=TTTY13 PE=5 SV=1MKTQDDGVLPPYDVNQLLGWDLNLSLFLGLCLMLLLAGSCLPSPGITGLSHGSNREDR>sp|Q96FV3|TSN17_HUMAN Tetraspanin-17 OS=Homo sapiens OX=9606 GN=TSPAN17PE=2 SV=2MPGKHQHFQEPEVGCCGKYFLFGFNIVFWVLGALFLAIGLWAWGEKGVLSNISALTDLGGLDPVWLFVVVGGVMSVLGFAGCIGALRENTFLLKFFSVFLGLIFFLELATGILAFVFKDWIRDQLNLFINNNVKAYRDDIDLQNLIDFAQEYWSCCGARGPNDWNLNIYFNCTDLNPSRERCGVPFSCCVRDPAEDVLNTQCGYDVRLKLELEQQGFIHTKGCVGQFEKWLQDNLIVVAGVFMGIALLQIFGICLAQNLVSDIKAVKANW>sp|Q96FV3-3|TSN17_HUMAN Isoform 2 of Tetraspanin-17 OS=Homo sapiensOX=9606 GN=TSPAN17MPGKHQHFQEPEVGCCGKYFLFGFNIVFWVLGALFLAIGLWAWGEKGVLSNISALTDLGGLDPVWLFVVVGGVMSVLGFAGCIGALRENTFLLKFFSVFLGLIFFLELATGILAFVFKDWIRDQLNLFINNNVKAYRDDIDLQNLIDFAQEYWSCCGARGPNDWNLNIYFNCTDLNPSRERCGVPFSCCVRDPAEDVLNTQCGYDVRLKLELEQQGFIHTKGCVGQFEKWLQDNLIVVAGVFMGIALLQIFGICLAQNLEQME>sp|Q96FV3-2|TSN17_HUMAN Isoform 3 of Tetraspanin-17 OS=Homo sapiensOX=9606 GN=TSPAN17MPGKHQHFQEPEVGCCGKYFLFGFNIVFWFSVFLGLIFFLELATGILAFVFKDWIRDQLNLFINNNVKAYRDDIDLQNLIDFAQEYEDVLNTQCGYDVRLKLELEQQGFIHTKGCVGQFEKWLQDNLIVVAGVFMGIALLQVPLWPHVPLPLPGPPSLSPHLSSVLQIFGICLAQNLVSDIKAVKANW>sp|Q96FV3-4|TSN17_HUMAN Isoform 4 of Tetraspanin-17 OS=Homo sapiensOX=9606 GN=TSPAN17MPGKHQHFQEPEVGCCGKYFLFGFNIVFWVLGALFLAIGLWAWGEKGVLSNISALTDLGGLDPVWLFVVVGGVMSVLGFAGCIGALRENTFLLKFFSVFLGLIFFLELATGILAFVFKDWIRDQLNLFINNNVKAYRDDIDLQNLIDFAQEYWSCCGARGPNDWNLNIYFNCTDLNPSRERCGVPFSCCVRDPAEDVLNTQCGYDVRLKLELEQQGFIHTKGCVGQFEKWLQDNLIVVAGVFMGIALLQIFGICLAQNLVSDIKAVKANWSKWNDDFENHWLTPTISEVLSTAGPQQNSLTGAPGPAPPSRHVFFGLGGLYPEPTFKNW>sp|P0CW01|TSPYA_HUMAN Testis-specific Y-encoded protein 10 OS=Homosapiens OX=9606 GN=TSPY10 PE=1 SV=2MRPEGSLTYRVPERLRQGFCGVGRAAQALVCASAKEGTAFRMEAVQEGAAGVESEQAALGEEAVLLLDDIMAEVEVVAEEEGLVERREEAQRAQQAVPGPGPMTPESALEELLAVQVELEPVNAQARKAFSRQREKMERRRKPHLDRRGAVIQSVPGFWANVIANHPQMSALITDEDEDMLSYMVSLEVEEEKHPVHLCKIMLFFRSNPYFQNKVITKEYLVNITEYRASHSTPIEWYPDYEVEAYRRRHHNSSLNFFNWFSDHNFAGSNKIAEILCKDLWRNPLQYYKRMKPPEEGTETSGDSQLLS>sp|Q9BZM4|ULBP3_HUMAN UL16-binding protein 3 OS=Homo sapiens OX=9606GN=ULBP3 PE=1 SV=1MAAAASPAILPRLAILPYLLFDWSGTGRADAHSLWYNFTIIHLPRHGQQWCEVQSQVDQKNFLSYDCGSDKVLSMGHLEEQLYATDAWGKQLEMLREVGQRLRLELADTELEDFTPSGPLTLQVRMSCECEADGYIRGSWQFSFDGRKFLLFDSNNRKWTVVHAGARRMKEKWEKDSGLTTFFKMVSMRDCKSWLRDFLMHRKKRLEPTAPPTMAPGLAQPKAIATTLSPWSFLIILCFILPGI>sp|P30530|UFO_HUMAN Tyrosine-protein kinase receptor UFO OS=Homo sapiensOX=9606 GN=AXL PE=1 SV=4MAWRCPRMGRVPLAWCLALCGWACMAPRGTQAEESPFVGNPGNITGARGLTGTLRCQLQVQGEPPEVHWLRDGQILELADSTQTQVPLGEDEQDDWIVVSQLRITSLQLSDTGQYQCLVFLGHQTFVSQPGYVGLEGLPYFLEEPEDRTVAANTPFNLSCQAQGPPEPVDLLWLQDAVPLATAPGHGPQRSLHVPGLNKTSSFSCEAHNAKGVTTSRTATITVLPQQPRNLHLVSRQPTELEVAWTPGLSGIYPLTHCTLQAVLSDDGMGIQAGEPDPPEEPLTSQASVPPHQLRLGSLHPHTPYHIRVACTSSQGPSSWTHWLPVETPEGVPLGPPENISATRNGSQAFVHWQEPRAPLQGTLLGYRLAYQGQDTPEVLMDIGLRQEVTLELQGDGSVSNLTVCVAAYTAAGDGPWSLPVPLEAWRPGQAQPVHQLVKEPSTPAFSWPWWYVLLGAVVAAACVLILALFLVHRRKKETRYGEVFEPTVERGELVVRYRVRKSYSRRTTEATLNSLGISEELKEKLRDVMVDRHKVALGKTLGEGEFGAVMEGQLNQDDSILKVAVKTMKIAICTRSELEDFLSEAVCMKEFDHPNVMRLIGVCFQGSERESFPAPVVILPFMKHGDLHSFLLYSRLGDQPVYLPTQMLVKFMADIASGMEYLSTKRFIHRDLAARNCMLNENMSVCVADFGLSKKIYNGDYYRQGRIAKMPVKWIAIESLADRVYTSKSDVWSFGVTMWEIATRGQTPYPGVENSEIYDYLRQGNRLKQPADCLDGLYALMSRCWELNPQDRPSFTELREDLENTLKALPPAQEPDEILYVNMDEGGGYPEPPGAAGGADPPTQPDPKDSCSCLTAAEVHPAGRYVLCPSTTPSPAQPADRGSPAAPGQEDGA>sp|P30530-2|UFO_HUMAN Isoform Short of Tyrosine-protein kinase receptorUFO OS=Homo sapiens OX=9606 GN=AXLMAWRCPRMGRVPLAWCLALCGWACMAPRGTQAEESPFVGNPGNITGARGLTGTLRCQLQVQGEPPEVHWLRDGQILELADSTQTQVPLGEDEQDDWIVVSQLRITSLQLSDTGQYQCLVFLGHQTFVSQPGYVGLEGLPYFLEEPEDRTVAANTPFNLSCQAQGPPEPVDLLWLQDAVPLATAPGHGPQRSLHVPGLNKTSSFSCEAHNAKGVTTSRTATITVLPQQPRNLHLVSRQPTELEVAWTPGLSGIYPLTHCTLQAVLSDDGMGIQAGEPDPPEEPLTSQASVPPHQLRLGSLHPHTPYHIRVACTSSQGPSSWTHWLPVETPEGVPLGPPENISATRNGSQAFVHWQEPRAPLQGTLLGYRLAYQGQDTPEVLMDIGLRQEVTLELQGDGSVSNLTVCVAAYTAAGDGPWSLPVPLEAWRPVKEPSTPAFSWPWWYVLLGAVVAAACVLILALFLVHRRKKETRYGEVFEPTVERGELVVRYRVRKSYSRRTTEATLNSLGISEELKEKLRDVMVDRHKVALGKTLGEGEFGAVMEGQLNQDDSILKVAVKTMKIAICTRSELEDFLSEAVCMKEFDHPNVMRLIGVCFQGSERESFPAPVVILPFMKHGDLHSFLLYSRLGDQPVYLPTQMLVKFMADIASGMEYLSTKRFIHRDLAARNCMLNENMSVCVADFGLSKKIYNGDYYRQGRIAKMPVKWIAIESLADRVYTSKSDVWSFGVTMWEIATRGQTPYPGVENSEIYDYLRQGNRLKQPADCLDGLYALMSRCWELNPQDRPSFTELREDLENTLKALPPAQEPDEILYVNMDEGGGYPEPPGAAGGADPPTQPDPKDSCSCLTAAEVHPAGRYVLCPSTTPSPAQPADRGSPAAPGQEDGA>sp|E5RIL1|UPKL2_HUMAN Uroplakin-3b-like protein 2 OS=Homo sapiensOX=9606 GN=UPK3BL2 PE=3 SV=2MDNSWRLGPAIGLSAGQSQLLVSLLLLLTRVQPGTDVAAPEHISYVPQLSNDTLAGRLTLSTFTLEQPLGQFSSHNISDLDTIWLVVALSNATQSFTAPRTNQDIPAPANFSQRGYYLTLRANRVLYQTRGQLHVLRVGNDTHCQPTKIGCNHPLPGPGPYRVKFLVMNDEGPVAETKWSSDTRLQQAQALRAVPGPQSPGTVVIIAILSILLAVLLTVLLAVLIYTCFNSCRSTSLSGPEEAGSVRRYTTHLAFSTPAEGAS>sp|Q14157|UBP2L_HUMAN Ubiquitin-associated protein 2-like OS=Homosapiens OX=9606 GN=UBAP2L PE=1 SV=2MMTSVGTNRARGNWEQPQNQNQTQHKQRPQATAEQIRLAQMISDHNDADFEEKVKQLIDITGKNQDECVIALHDCNGDVNRAINVLLEGNPDTHSWEMVGKKKGVSGQKDGGQTESNEEGKENRDRDRDYSRRRGGPPRRGRGASRGREFRGQENGLDGTKSGGPSGRGTERGRRGRGRGRGGSGRRGGRFSAQGMGTFNPADYAEPANTDDNYGNSSGNTWNNTGHFEPDDGTSAWRTATEEWGTEDWNEDLSETKIFTASNVSSVPLPAENVTITAGQRIDLAVLLGKTPSTMENDSSNLDPSQAPSLAQPLVFSNSKQTAISQPASGNTFSHHSMVSMLGKGFGDVGEAKGGSTTGSQFLEQFKTAQALAQLAAQHSQSGSTTTSSWDMGSTTQSPSLVQYDLKNPSDSAVHSPFTKRQAFTPSSTMMEVFLQEKSPAVATSTAAPPPPSSPLPSKSTSAPQMSPGSSDNQSSSPQPAQQKLKQQKKKASLTSKIPALAVEMPGSADISGLNLQFGALQFGSEPVLSDYESTPTTSASSSQAPSSLYTSTASESSSTISSNQSQESGYQSGPIQSTTYTSQNNAQGPLYEQRSTQTRRYPSSISSSPQKDLTQAKNGFSSVQATQLQTTQSVEGATGSAVKSDSPSTSSIPPLNETVSAASLLTTTNQHSSSLGGLSHSEEIPNTTTTQHSSTLSTQQNTLSSSTSSGRTSTSTLLHTSVESEANLHSSSSTFSTTSSTVSAPPPVVSVSSSLNSGSSLGLSLGSNSTVTASTRSSVATTSGKAPPNLPPGVPPLLPNPYIMAPGLLHAYPPQVYGYDDLQMLQTRFPLDYYSIPFPTPTTPLTGRDGSLASNPYSGDLTKFGRGDASSPAPATTLAQPQQNQTQTHHTTQQTFLNPALPPGYSYTSLPYYTGVPGLPSTFQYGPAVFPVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPDISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQTGSGQRSQTSSIPQKPQTNKSAYNSYSWGAN>sp|Q14157-1|UBP2L_HUMAN Isoform 2 of Ubiquitin-associated protein 2-likeOS=Homo sapiens OX=9606 GN=UBAP2LMMTSVGTNRARGNWEQPQNQNQTQHKQRPQATAEQIRLAQMISDHNDADFEEKVKQLIDITGKNQDECVIALHDCNGDVNRAINVLLEGNPDTHSWEMVGKKKGVSGQKDGGQTESNEEGKENRDRDRDYSRRRGGPPRRGRGASRGREFRGQENGLDGTKSGGPSGRGTERGRRGRGRGRGGSGRRGGRFSAQGMGTFNPADYAEPANTDDNYGNSSGNTWNNTGHFEPDDGTSAWRTATEEWGTEDWNEDLSETKIFTASNVSSVPLPAENVTITAGQRIDLAVLLGKTPSTMENDSSNLDPSQAPSLAQPLVFSNSKQTAISQPASGNTFSHHSMVSMLGKGFGDVGEAKGGSTTGSQFLEQFKTAQALAQLAAQHSQSGSTTTSSWDMGSTTQSPSLVQYDLKNPSDSAVHSPFTKRQAFTPSSTMMEVFLQEKSPAVATSTAAPPPPSSPLPSKSTSAPQMSPGSSDNQSSSPQPAQQKLKQQKKKASLTSKIPALAVEMPGSADISGLNLQFGALQFGSEPVLSDYESTPTTSASSSQAPSSLYTSTASESSSTISSNQSQESGYQSGPIQSTTYTSQNNAQGPLYEQRSTQTRRYPSSISSSPQKDLTQAKNGFSSVQATQLQTTQSVEGATGSAVKSDSPSTSSIPPLNETVSAASLLTTTNQHSSSLGGLSHSEEIPNTTTTQHSSTLSTQQNTLSSSTSSGRTSTSTLLHTSVESEANLHSSSSTFSTTSSTVSAPPPVVSVSSSLNSGSSLGLSLGSNSTVTASTRSSVATTSGKAPPNLPPGVPPLLPNPYIMAPGLLHAYPPQVYGYDDLQMLQTRFPLDYYSIPFPTPTTPLTGRDGSLASNPYSGDLTKFGRGDASSPAPATTLAQPQQNQTQTHHTTQQTFLNPALPPGYSYTSLPYYTGVPGLPSTFQYGPAVFPVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGRKYPPPYKHFWTAES>sp|Q14157-3|UBP2L_HUMAN Isoform 3 of Ubiquitin-associated protein 2-likeOS=Homo sapiens OX=9606 GN=UBAP2LMMTSVGTNRARGNWEQPQNQNQTQHKQRPQATAEQIRLAQMISDHNDADFEEKVKQLIDITGKNQDECVIALHDCNGDVNRAINVLLEGNPDTHSWEMVGKKKGVSGQKDGGQTESNEEGKENRDRDRDYSRRRGGPPRRGRGASRGREFRGQENGLDGTKSGGPSGRGTERGRRGRGRGRGGSGRRGGRFSAQGMGTFNPADYAEPANTDDNYGNSSGNTWNNTGHFEPDDGTSAWRTATEEWGTEDWNEDLSETKIFTASNVSSVPLPAENVTITAGQRIDLAVLLGKTPSTMENDSSNLDPSQAPSLAQPLVFSNSKQTAISQPASGNTFSHHSMVSMLGKGFGDVGEAKGGSTTGSQFLEQFKTAQALAQLAAQHSQSGSTTTSSWDMGSTTQSPSLVQYDLKNPSDSAVHSPFTKRQAFTPSSTMMEVFLQEKSPAVATSTAAPPPPSSPLPSKSTSAPQMSPGSSDNQSSSPQPAQQKLKQQKKKASLTSKIPALAVEMPGSADISGLNLQFGALQFGSEPVLSDYESTPTTSASSSQAPSSLYTSTASESSSTISSNQSQESGYQSGPIQSTTYTSQNNAQGPLYEQRSTQTRRYPSSISSSPQKDLTQAKNGFSSVQATQLQTTQSVEGATGSAVKSDSPSTSSIPPLNETVSAASLLTTTNQHSSSLGGLSHSEEIPNTTTTQHSSTLSTQQNTLSSSTSSGRTSTSTLLHTSVESEANLHSSSSTFSTTSSTVSAPPPVVSVSSSLNSGSSLGLSLGSNSTVTASTRSSVATTSGKAPPNLPPGVPPLLPNPYIMAPGLLHAYPPQVYGYDDLQMLQTRFPLDYYSIPFPTPTTPLTGRDGSLASNPYSGDLTKFGRGDASSPAPATTLAQPQQNQTQTHHTTQQTFLNPALPPGYSYTSLPYYTGVPGLPSTFQYGPAVFPVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPDISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQDILNFVDDQLGE>sp|Q14157-4|UBP2L_HUMAN Isoform 4 of Ubiquitin-associated protein 2-likeOS=Homo sapiens OX=9606 GN=UBAP2LMMTSVGTNRARGNWEQPQNQNQTQHKQRPQATAEQIRLAQMISDHNDADFEEKVKQLIDITGKNQDECVIALHDCNGDVNRAINVLLEGNPDTHSWEMVGKKKGVSGQKDGGQTESNEEGKENRDRDRDYSRRRGGPPRRGRVRGQENGLDGTKSGGPSGRGTERGRRGRGRGRGGSGRRGGRFSAQGMGTFNPADYAEPANTDDNYGNSSGNTWNNTGHFEPDDGTSAWRTATEEWGTEDWNEDLSETKIFTASNVSSVPLPAENVTITAGQRIDLAVLLGKTPSTMENDSSNLDPSQAPSLAQPLVFSNSKQTAISQPASGNTFSHHSMVSMLGKGFGDVGEAKGGSTTGSQFLEQFKTAQALAQLAAQHSQSGSTTTSSWDMGSTTQSPSLVQYDLKNPSDSAVHSPFTKRQAFTPSSTMMEVFLQEKSPAVATSTAAPPPPSSPLPSKSTSAPQMSPGSSDNQSSSPQPAQQKLKQQKKKASLTSKIPALAVEMPGSADISGLNLQFGALQFGSEPVLSDYESTPTTSASSSQAPSSLYTSTASESSSTISSNQSQESGYQSGPIQSTTYTSQNNAQGPLYEQRSTQTRRYPSSISSSPQKDLTQAKNGFSSVQATQLQTTQSVEGATGSAVKSDSPSTSSIPPLNETVSAASLLTTTNQHSSSLGGLSHSEEIPNTTTTQHSSTLSTQQNTLSSSTSSGRTSTSTLLHTSVESEANLHSSSSTFSTTSSTVSAPPPVVSVSSSLNSGSSLGLSLGSNSTVTASTRSSVATTSGKAPPNLPPGVPPLLPNPYIMAPGLLHAYPPQVYGYDDLQMLQTRFPLDYYSIPFPTPTTPLTGRDGSLASNPYSGDLTKFGRGDASSPAPATTLAQPQQNQTQTHHTTQQTFLNPALPPGYSYTSLPYYTGVPGLPSTFQYGPAVFPVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGRKYPPPYKHFWTAES>sp|Q14157-5|UBP2L_HUMAN Isoform 5 of Ubiquitin-associated protein 2-likeOS=Homo sapiens OX=9606 GN=UBAP2LMMTSVGTNRARGNWEQPQNQNQTQHKQRPQATAEQIRLAQMISDHNDADFEEKVKQLIDITGKNQDECVIALHDCNGDVNRAINVLLEGNPDTHSWEMVGKKKGVSGQKDGGQTESNEEGKENRDRDRDYSRRRGGPPRRGRGASRGREFRGQENGLDGTKSGGPSGRGTERGRRGRGRGRGGSGRRGGRFSAQGMGTFNPADYAEPANTDDNYGNSSGNTWNNTGHFEPDDGTSAWRTATEEWGTEDWNEDLSETKIFTASNVSSVPLPAENVTITAGQRIDLAVLLGKTPSTMENDSSNLDPSQAPSLAQPLVFSNSKQTAISQPASGNTFSHHSMVSMLGKGFGDVGEAKGGSTTGSQFLEQFKTAQALAQLAAQHSQSGSTTTSSWDMGSTTQSPSLVQYDLKNPSDSAVHSPFTKRQAFTPSSTMMEVFLQEKSPAVATSTAAPPPPSSPLPSKSTSAPQMSPGSSDNQSSSPQPAQQKLKQQKKKASLTSKIPALAVEMPGSADISGLNLQFGALQFGSEPVLSDYESTPTTSASSSQAPSSLYTSTASESSSTISSNQSQESGYQSGPIQSTTYTSQNNAQGPLYEQRSTQTRRYPSSISSSPQKDLTQAKNGFSSVQATQLQTTQSVEGATGSAVKSDSPSTSSIPPLNETVSAASLLTTTNQHSSSLGGLSHSEEIPNTTTTQHSSTLSTQQNTLSSSTSSGRTSTSTLLHTSVESEANLHSSSSTFSTTSSTVSAPPPVVSVSSSLNSGSSLGLSLGSNSTVTASTRSSVATTSGKAPPNLPPGVPPLLPNPYIMAPGLLHAYPPQVYGYDDLQMLQTRFPLDYYSIPFPTPTTPLTGRDGSLASNPYSGDLTKFGRGDASSPAPATTLAQPQQNQTQTHHTTQQTFLNPALPPGYSYTSLPYYTGVPGLPSTFQYGPAVFPVAPTSSKQHGVNVSVNASATPFQQPSGYGSHGYNTGVSVTSSNTGVPDISGSVYSKTQQSFEKQGFHSGTPAASFNLPSALGSGGPINPATAAAYPPAPFMHILTPHQQPHSQILHHHLQQDGQLPYLQMILCCQRQQEEQTGSGQRSQTSSIPQKPQTNKSAYNSYSWGAN>sp|O95881|TXD12_HUMAN Thioredoxin domain-containing protein 12 OS=Homosapiens OX=9606 GN=TXNDC12 PE=1 SV=1METRPRLGATCLLGFSFLLLVISSDGHNGLGKGFGDHIHWRTLEDGKKEAAASGLPLMVIIHKSWCGACKALKPKFAESTEISELSHNFVMVNLEDEEEPKDEDFSPDGGYIPRILFLDPSGKVHPEIINENGNPSYKYFYVSAEQVVQGMKEAQERLTGDAFRKKHLEDEL>sp|O75631|UPK3A_HUMAN Uroplakin-3a OS=Homo sapiens OX=9606 GN=UPK3A PE=1SV=3MPPLWALLALGCLRFGSAVNLQPQLASVTFATNNPTLTTVALEKPLCMFDSKEALTGTHEVYLYVLVDSAISRNASVQDSTNTPLGSTFLQTEGGRTGPYKAVAFDLIPCSDLPSLDAIGDVSKASQILNAYLVRVGANGTCLWDPNFQGLCNAPLSAATEYRFKYVLVNMSTGLVEDQTLWSDPIRTNQLTPYSTIDTWPGRRSGGMIVITSILGSLPFFLLVGFAGAIALSLVDMGSSDGETTHDSQITQEAVPKSLGASESSYTSVNRGPPLDRAEVYSSKLQD>sp|O75631-2|UPK3A_HUMAN Isoform 2 of Uroplakin-3a OS=Homo sapiensOX=9606 GN=UPK3AMPPLWALLALGCLRFGSAVNLQPQLASVTFATNNPTLTTVALEKPLCMFDSKEALTGTHEVYLYVLVDSVTPYSTIDTWPGRRSGGMIVITSILGSLPFFLLVGFAGAIALSLVDMGSSDGETTHDSQITQEAVPKSLGASESSYTSVNRGPPLDRAEVYSSKLQD>sp|Q9NUQ3|TXLNG_HUMAN Gamma-taxilin OS=Homo sapiens OX=9606 GN=TXLNGPE=1 SV=2MATRVEEAARGRGGGAEEATEAGRGGRRRSPRQKFEIGTMEEAGICGLGVKADMLCNSQSNDILQHQGSNCGGTSNKHSLEEDEGSDFITENRNLVSPAYCTQESREEIPGGEARTDPPDGQQDSECNRNKEKTLGKEVLLLMQALNTLSTPEEKLAALCKKYADLLEESRSVQKQMKILQKKQAQIVKEKVHLQSEHSKAILARSKLESLCRELQRHNKTLKEENMQQAREEEERRKEATAHFQITLNEIQAQLEQHDIHNAKLRQENIELGEKLKKLIEQYALREEHIDKVFKHKELQQQLVDAKLQQTTQLIKEADEKHQREREFLLKEATESRHKYEQMKQQEVQLKQQLSLYMDKFEEFQTTMAKSNELFTTFRQEMEKMTKKIKKLEKETIIWRTKWENNNKALLQMAEEKTVRDKEYKALQIKLERLEKLCRALQTERNELNEKVEVLKEQVSIKAAIKAANRDLATPVMQPCTALDSHKELNTSSKRALGAHLEAEPKSQRSAVQKPPSTGSAPAIESVD>sp|Q9NUQ3-2|TXLNG_HUMAN Isoform 2 of Gamma-taxilin OS=Homo sapiensOX=9606 GN=TXLNGMATRVEEAARGRGGGAEEATEAGRGGRRRSPRQKLEESRSVQKQMKILQKKQAQIVKEKVHLQSEHSKAILARSKLESLCRELQRHNKTLKEENMQQAREEEERRKEATAHFQITLNEIQAQLEQHDIHNAKLRQENIELGEKLKKLIEQYALREEHIDKVFKHKELQQQLVDAKLQQTTQLIKEADEKHQREREFLLKEATESRHKYEQMKQQEVQLKQQLSLYMDKFEEFQTTMAKSNELFTTFRQEMEKMTKKIKKLEKETIIWRTKWENNNKALLQMAEEKTVRDKEYKALQIKLERLEKLCRALQTERNELNEKVEVLKEQVSIKAAIKAANRDLATPVMQPCTALDSHKELNTSSKRALGAHLEAEPKSQRSAVQKPPSTGSAPAIESVD>sp|P35125|UBP6_HUMAN Ubiquitin carboxyl-terminal hydrolase 6 OS=Homosapiens OX=9606 GN=USP6 PE=1 SV=2MDMVENADSLQAQERKDILMKYDKGHRAGLPEDKGPEPVGINSSIDRFGILHETELPPVTAREAKKIRREMTRTSKWMEMLGEWETYKHSSKLIDRVYKGIPMNIRGPVWSVLLNIQEIKLKNPGRYQIMKERGKRSSEHIHHIDLDVRTTLRNHVFFRDRYGAKQRELFYILLAYSEYNPEVGYCRDLSHITALFLLYLPEEDAFWALVQLLASERHSLPGFHSPNGGTVQGLQDQQEHVVPKSQPKTMWHQDKEGLCGQCASLGCLLRNLIDGISLGLTLRLWDVYLVEGEQVLMPITSIALKVQQKRLMKTSRCGLWARLRNQFFDTWAMNDDTVLKHLRASTKKLTRKQGDLPPPAKREQGSLAPRPVPASRGGKTLCKGYRQAPPGPPAQFQRPICSASPPWASRFSTPCPGGAVREDTYPVGTQGVPSLALAQGGPQGSWRFLEWKSMPRLPTDLDIGGPWFPHYDFEWSCWVRAISQEDQLATCWQAEHCGEVHNKDMSWPEEMSFTANSSKIDRQKVPTEKGATGLSNLGNTCFMNSSIQCVSNTQPLTQYFISGRHLYELNRTNPIGMKGHMAKCYGDLVQELWSGTQKSVAPLKLRRTIAKYAPKFDGFQQQDSQELLAFLLDGLHEDLNRVHEKPYVELKDSDGRPDWEVAAEAWDNHLRRNRSIIVDLFHGQLRSQVKCKTCGHISVRFDPFNFLSLPLPMDSYMDLEITVIKLDGTTPVRYGLRLNMDEKYTGLKKQLRDLCGLNSEQILLAEVHDSNIKNFPQDNQKVQLSVSGFLCAFEIPVPSSPISASSPTQIDFSSSPSTNGMFTLTTNGDLPKPIFIPNGMPNTVVPCGTEKNFTNGMVNGHMPSLPDSPFTGYIIAVHRKMMRTELYFLSPQENRPSLFGMPLIVPCTVHTRKKDLYDAVWIQVSWLARPLPPQEASIHAQDRDNCMGYQYPFTLRVVQKDGNSCAWCPQYRFCRGCKIDCGEDRAFIGNAYIAVDWHPTALHLRYQTSQERVVDKHESVEQSRRAQAEPINLDSCLRAFTSEEELGESEMYYCSKCKTHCLATKKLDLWRLPPFLIIHLKRFQFVNDQWIKSQKIVRFLRESFDPSAFLVPRDPALCQHKPLTPQGDELSKPRILAREVKKVDAQSSAGKEDMLLSKSPSSLSANISSSPKGSPSSSRKSGTSCPSSKNSSPNSSPRTLGRSKGRLRLPQIGSKNKPSSSKKNLDASKENGAGQICELADALSRGHMRGGSQPELVTPQDHEVALANGFLYEHEACGNGCGDGYSNGQLGNHSEEDSTDDQREDTHIKPIYNLYAISCHSGILSGGHYITYAKNPNCKWYCYNDSSCEELHPDEIDTDSAYILFYEQQGIDYAQFLPKIDGKKMADTSSTDEDSESDYEKYSMLQ>sp|P35125-2|UBP6_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 6 OS=Homo sapiens OX=9606 GN=USP6MPQRLPHARQHTPLPLGSADYRRVVSVRPQGPHRDPKDSRDAAKREQGSLAPRPVPASRGGKTLCKGYRQAPPGPPAQFQRPICSASPPWASRFSTPCPGGAVREDTYPVGTQGVPSLALAQGGPQGSWRFLEWKSMPRLPTDLDIGGPWFPHYDFEWSCWVRAISQEDQLATCWQAEHCGEVHNKDMSWPEEMSFTANSSKIDRQKVPTEKGATGLSNLGNTCFMNSSIQCVSNTQPLTQYFISGRHLYELNRTNPIGMKGHMAKCYGDLVQELWSGTQKSVAPLKLRRTIAKYAPKFDGFQQQDSQELLAFLLDGLHEDLNRVHEKPYVELKDSDGRPDWEVAAEAWDNHLRRNRSIIVDLFHGQLRSQVKCKTCGHISVRFDPFNFLSLPLPMDSYMDLEITVIKLDGTTPVRYGLRLNMDEKYTGLKKQLRDLCGLNSEQILLAEVHDSNIKNFPQDNQKVQLSVSGFLCAFEIPVPSSPISASSPTQIDFSSSPSTNGMFTLTTNGDLPKPIFIPNGMPNTVVPCGTEKNFTNGMVNGHMPSLPDSPFTGYIIAVHRKMMRTELYFLSPQENRPSLFGMPLIVPCTVHTRKKDLYDAVWIQVSWLARPLPPQEASIHAQDRDNCMGYQYPFTLRVVQKDGNSCAWCPQYRFCRGCKIDCGEDRAFIGNAYIAVDWHPTALHLRYQTSQERVVDKHESVEQSRRAQAEPINLDSCLRAFTSEEELGESEMYYCSKCKTHCLATKKLDLWRLPPFLIIHLKRFQFVNDQWIKSQKIVRFLRESFDPSAFLVPRDPALCQHKPLTPQGDELSKPRILAREVKKVDAQSSAGKEDMLLSKSPSSLSANISSSPKGSPSSSRKSGTSCPSSKNSSPNSSPRTLGRSKGRLRLPQIGSKNKPSSSKKNLDASKENGAGQICELADALSRGHMRGGSQPELVTPQDHEVALANGFLYEHEACGNGCGDGYSNGQLGNHSEEDSTDDQREDTHIKPIYNLYAISCHSGILSGGHYITYAKNPNCKWYCYNDSSCEELHPDEIDTDSAYILFYEQQGIDYAQFLPKIDGKKMADTSSTDEDSESDYEKYSMLQ>sp|P35125-3|UBP6_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 6 OS=Homo sapiens OX=9606 GN=USP6MDMVENADSLQAQERKDILMKYDKGHRAGLPEDKGPEPVGINSSIDRFGILHETELPPVTAREAKKIRREMTRTSKWMEMLGEWETYKHSSKLIDRVYKGIPMNIRGPVWSVLLNIQEIKLKNPGRYQIMKERGKRSSEHIHHIDLDVRTTLRNHVFFRDRYGAKQRELFYILLAYSEYNPEVGYCRDLSHITALFLLYLPEEDAFWALVQLLASERHSLPGFHSPNGGTVQGLQDQQEHVVPKSQPKTMWHQDKEGLCGQCASLGCLLRNLIDGISLGLTLRLWDVYLVEGEQVLMPITSIALKVQQKRLMKTSRCGLWARLRNQFFDTWAMNDDTVLKHLRASTKKLTRKQGDLPPPAKREQGSLAPRPVPASRGGKTLCKGYRQAPPGPPAQFQRPICSASPPWASRFSTPCPGGAVREDTYPVGTQGVPSLALAQGGPQGSWRFLEWKSMPRLPTDLDIGGPWFPHYDFEWSCWVRAISQEDQLATCWQAEHCGEVHNKDMSWPEEMSFTANSSKIDRQKVPTEKGATGLSNLGNTCFMNSSIQCVSNTQPLTQYFISGRHLYELNRTNPIGMKGHMAKCYGDLVQELWSGTQKSVAPLKLRRTIAKYAPKFDGFQQQDSQELLAFLLDGLHEDLNRVHEKPYVELKDSDGRPDWEVAAEAWDNHLRRNRSIIVDLFHGQLRSQVKCKTCGHISVRFDPFNFLSLPLPMDSYMDLEITVIKLDGTTPVRYGLRLNMDEKYTGLKKQLRDLCGLNSEQILLAEVHDSNIKISPLHHLQMECSP>sp|Q9NZ09|UBAP1_HUMAN Ubiquitin-associated protein 1 OS=Homo sapiensOX=9606 GN=UBAP1 PE=1 SV=1MASKKLGADFHGTFSYLDDVPFKTGDKFKTPAKVGLPIGFSLPDCLQVVREVQYDFSLEKKTIEWAEEIKKIEEAEREAECKIAEAEAKVNSKSGPEGDSKMSFSKTHSTATMPPPINPILASLQHNSILTPTRVSSSATKQKVLSPPHIKADFNLADFECEEDPFDNLELKTIDEKEELRNILVGTTGPIMAQLLDNNLPRGGSGSVLQDEEVLASLERATLDFKPLHKPNGFITLPQLGNCEKMSLSSKVSLPPIPAVSNIKSLSFPKLDSDDSNQKTAKLASTFHSTSCLRNGTFQNSLKPSTQSSASELNGHHTLGLSALNLDSGTEMPALTSSQMPSLSVLSVCTEESSPPNTGPTVTPPNFSVSQVPNMPSCPQAYSELQMLSPSERQCVETVVNMGYSYECVLRAMKKKGENIEQILDYLFAHGQLCEKGFDPLLVEEALEMHQCSEEKMMEFLQLMSKFKEMGFELKDIKEVLLLHNNDQDNALEDLMARAGAS>sp|Q9NZ09-2|UBAP1_HUMAN Isoform 2 of Ubiquitin-associated protein 1OS=Homo sapiens OX=9606 GN=UBAP1MASKKLGADFHGTFSYLDDVPFKTGDKFKTPAKVGLPIGFSLPDCLQVVREVQYDFSLEKKTIEWAEEIKKIEEAEREAECKIAEAEAKVNSKSGPEGDSKMSFSKTHSTATMPPPINPILASLQHNSILTPTRVSSSATKQKVLSPPHIKADFNLADFECEEDPFDNLELKTIDEKEELRNILVGTTGPIMAQLLDNNLPRGGSGSVLQDEEVLASLERATLDFKPLHKPNGFITLPQLGNCEKMSLSSKVSLPPIPAVSNIKSLSFPKLDSDDSNQKTAKLASTFHSTSCLRNGTFQNSLKPSTQSSASELNGHHTLGLSALNLDSGTEMPALTSSQMPSLSVLSVCTEESSPPNTGPTILDYLFAHGQLCEKGFDPLLVEEALEMHQCSEEKMMEFLQLMSKFKEMGFELKDIKEVLLLHNNDQDNALEDLMARAGAS>sp|Q9NZ09-3|UBAP1_HUMAN Isoform 3 of Ubiquitin-associated protein 1OS=Homo sapiens OX=9606 GN=UBAP1MSGAVRGRRREVGLQHGGCGTGGGYGDGLARSGQSWRWWRSLSLGAVGSSAGTEPGRPAGASTFRLLRRRQQRHSGSKWLLRSWVQIFMYDFSLEKKTIEWAEEIKKIEEAEREAECKIAEAEAKVNSKSGPEGDSKMSFSKTHSTATMPPPINPILASLQHNSILTPTRVSSSATKQKVLSPPHIKADFNLADFECEEDPFDNLELKTIDEKEELRNILVGTTGPIMAQLLDNNLPRGGSGSVLQDEEVLASLERATLDFKPLHKPNGFITLPQLGNCEKMSLSSKVSLPPIPAVSNIKSLSFPKLDSDDSNQKTAKLASTFHSTSCLRNGTFQNSLKPSTQSSASELNGHHTLGLSALNLDSGTEMPALTSSQMPSLSVLSVCTEESSPPNTGPTVTPPNFSVSQVPNMPSCPQAYSELQMLSPSERQCVETVVNMGYSYECVLRAMKKKGENIEQILDYLFAHGQLCEKGFDPLLVEEALEMHQCSEEKMMEFLQLMSKFKEMGFELKDIKEVLLLHNNDQDNALEDLMARAGAS>sp|Q9NZ09-4|UBAP1_HUMAN Isoform 4 of Ubiquitin-associated protein 1OS=Homo sapiens OX=9606 GN=UBAP1MSGAVRGRRREVGLQHGGCGTGGGYGDGLARSGQSWRWWRSLSLGAVGSSAGTEPGRPAGASTFRLLRRRQQRHSGTFSYLDDVPFKTGDKFKTPAKVGLPIGFSLPDCLQVVREVQYDFSLEKKTIEWAEEIKKIEEAEREAECKIAEAEAKVNSKSGPEGDSKMSFSKTHSTATMPPPINPILASLQHNSILTPTRVSSSATKQKVLSPPHIKADFNLADFECEEDPFDNLELKTIDEKEELRNILVGTTGPIMAQLLDNNLPRGGSGSVLQDEEVLASLERATLDFKPLHKPNGFITLPQLGNCEKMSLSSKVSLPPIPAVSNIKSLSFPKLDSDDSNQKTAKLASTFHSTSCLRNGTFQNSLKPSTQSSASELNGHHTLGLSALNLDSGTEMPALTSSQMPSLSVLSVCTEESSPPNTGPTVTPPNFSVSQVPNMPSCPQAYSELQMLSPSERQCVETVVNMGYSYECVLRAMKKKGENIEQILDYLFAHGQLCEKGFDPLLVEEALEMHQCSEEKMMEFLQLMSKFKEMGFELKDIKEVLLLHNNDQDNALEDLMARAGAS>sp|A0A075B6W5|TVA23_HUMAN T cell receptor alpha variable 23/deltavariable 6 OS=Homo sapiens OX=9606 GN=TRAV23DV6 PE=3 SV=1MDKILGASFLVLWLQLCWVSGQQKEKSDQQQVKQSPQSLIVQKGGISIINCAYENTAFDYFPWYQQFPGKGPALLIAIRPDVSEKKEGRFTISFNKSAKQFSSHIMDSQPGDSATYFCAAS>sp|Q9P2Y5|UVRAG_HUMAN UV radiation resistance-associated gene proteinOS=Homo sapiens OX=9606 GN=UVRAG PE=1 SV=1MSASASVGGPVPQPPPGPAAALPPGSAARALHVELPSQQRRLRHLRNIAARNIVNRNGHQLLDTYFTLHLCSTEKIYKEFYRSEVIKNSLNPTWRSLDFGIMPDRLDTSVSCFVVKIWGGKENIYQLLIEWKVCLDGLKYLGQQIHARNQNEIIFGLNDGYYGAPFEHKGYSNAQKTILLQVDQNCVRNSYDVFSLLRLHRAQCAIKQTQVTVQKIGKEIEEKLRLTSTSNELKKKSECLQLKILVLQNELERQKKALGREVALLHKQQIALQDKGSAFSAEHLKLQLQKESLNELRKECTAKRELFLKTNAQLTIRCRQLLSELSYIYPIDLNEHKDYFVCGVKLPNSEDFQAKDDGSIAVALGYTAHLVSMISFFLQVPLRYPIIHKGSRSTIKDNINDKLTEKEREFPLYPKGGEKLQFDYGVYLLNKNIAQLRYQHGLGTPDLRQTLPNLKNFMEHGLMVRCDRHHTSSAIPVPKRQSSIFGGADVGFSGGIPSPDKGHRKRASSENERLQYKTPPPSYNSALAQPVTTVPSMGETERKITSLSSSLDTSLDFSKENKKKGEDLVGSLNGGHANVHPSQEQGEALSGHRATVNGTLLPSEQAGSASVQLPGEFHPVSEAELCCTVEQAEEIIGLEATGFASGDQLEAFNCIPVDSAVAVECDEQVLGEFEEFSRRIYALNENVSSFRRPRRSSDK>sp|Q9P2Y5-2|UVRAG_HUMAN Isoform 2 of UV radiation resistance-associatedgene protein OS=Homo sapiens OX=9606 GN=UVRAGMISFFLQVPLRYPIIHKGSRSTIKDNINDKLTEKEREFPLYPKGGEKLQFDYGVYLLNKNIAQLRYQHGLGTPDLRQTLPNLKNFMEHGLMVRCDRHHTSSAIPVPKRQSSIFGGADVGFSGGIPSPDKGHRKRASSENERLQYKTPPPSYNSALAQPVTTVPSMGETERKITSLSSSLDTSLDFSKENKKKGEDLVGSLNGGHANVHPSQEQGEALSGHRATVNGTLLPSEQAGSASVQLPGEFHPVSEAELCCTVEQAEEIIGLEATGFASGDQLEAFNCIPVDSAVAVECDEQVLGEFEEFSRRIYALNENVSSFRRPRRSSDK>sp|Q9NSD4|ZN275_HUMAN Zinc finger protein 275 OS=Homo sapiens OX=9606GN=ZNF275 PE=1 SV=2MMSHPCVSLLGVPVLNPALVPHLAQGQVLLVSDPSPNTDPAKYSESTSATRHQMKGEDAQPQEMASTSFPRASGPSPEFRQHGDSDGKRGSPQNLPIEHHFACKECGDTFRLKVLLVQHQRVHSEEKGWECGDCGKVFRGVAEFNEHRKSHVAAEPQPGPSRALENAAEKREQMEREAKPFECEECGKRFKKNAGLSQHLRVHSREKPFDCEECGRSFKVNTHLFRHQKLHTSEKPFACKACSRDFLDRQELLKHQRMHTGHLPFDCDDCGKSFRGVNGLAEHQRIHSGAKPYGCPHCGKLFRRSSELTKHRRIHTGEKPYACGQCGKAFRQSSSLLEHARIHSGERPYACGECGKAFRGPSDLIKHRRIHSGLKPYECDKCGKAFRRSSGLSRHRRIHSGARRCECSQCGRVFKRRSALQKHQPTHHE>sp|Q9NSD4-2|ZN275_HUMAN Isoform 2 of Zinc finger protein 275 OS=Homosapiens OX=9606 GN=ZNF275MKGEDAQPQEMASTSFPRASGPSPEFRQHGDSDGKRGSPQNLPIEHHFACKECGDTFRLKVLLVQHQRVHSEEKGWECGDCGKVFRGVAEFNEHRKSHVAAEPQPGPSRALENAAEKREQMEREAKPFECEECGKRFKKNAGLSQHLRVHSREKPFDCEECGRSFKVNTHLFRHQKLHTSEKPFACKACSRDFLDRQELLKHQRMHTGHLPFDCDDCGKSFRGVNGLAEHQRIHSGAKPYGCPHCGKLFRRSSELTKHRRIHTGEKPYACGQCGKAFRQSSSLLEHARIHSGERPYACGECGKAFRGPSDLIKHRRIHSGLKPYECDKCGKAFRRSSGLSRHRRIHSGARRCECSQCGRVFKRRSALQKHQPTHHE>sp|O43543|XRCC2_HUMAN DNA repair protein XRCC2 OS=Homo sapiens OX=9606GN=XRCC2 PE=1 SV=1MCSAFHRAESGTELLARLEGRSSLKEIEPNLFADEDSPVHGDILEFHGPEGTGKTEMLYHLTARCILPKSEGGLEVEVLFIDTDYHFDMLRLVTILEHRLSQSSEEIIKYCLGRFFLVYCSSSTHLLLTLYSLESMFCSHPSLCLLILDSLSAFYWIDRVNGGESVNLQESTLRKCSQCLEKLVNDYRLVLFATTQTIMQKASSSSEEPSHASRRLCDVDIDYRPYLCKAWQQLVKHRMFFSKQDDSQSSNQFSLVSRCLKSNSLKKHFFIIGESGVEFC>sp|P13010|XRCC5_HUMAN X-ray repair cross-complementing protein 5 OS=Homosapiens OX=9606 GN=XRCC5 PE=1 SV=3MVRSGNKAAVVLCMDVGFTMSNSIPGIESPFEQAKKVITMFVQRQVFAENKDEIALVLFGTDGTDNPLSGGDQYQNITVHRHLMLPDFDLLEDIESKIQPGSQQADFLDALIVSMDVIQHETIGKKFEKRHIEIFTDLSSRFSKSQLDIIIHSLKKCDISLQFFLPFSLGKEDGSGDRGDGPFRLGGHGPSFPLKGITEQQKEGLEIVKMVMISLEGEDGLDEIYSFSESLRKLCVFKKIERHSIHWPCRLTIGSNLSIRIAAYKSILQERVKKTWTVVDAKTLKKEDIQKETVYCLNDDDETEVLKEDIIQGFRYGSDIVPFSKVDEEQMKYKSEGKCFSVLGFCKSSQVQRRFFMGNQVLKVFAARDDEAAAVALSSLIHALDDLDMVAIVRYAYDKRANPQVGVAFPHIKHNYECLVYVQLPFMEDLRQYMFSSLKNSKKYAPTEAQLNAVDALIDSMSLAKKDEKTDTLEDLFPTTKIPNPRFQRLFQCLLHRALHPREPLPPIQQHIWNMLNPPAEVTTKSQIPLSKIKTLFPLIEAKKKDQVTAQEIFQDNHEDGPTAKKLKTEQGGAHFSVSSLAEGSVTSVGSVNPAENFRVLVKQKKASFEEASNQLINHIEQFLDTNETPYFMKSIDCIRAFREEAIKFSEEQRFNNFLKALQEKVEIKQLNHFWEIVVQDGITLITKEEASGSSVTAEEAKKFLAPKDKPSGDTAAVFEEGGDVDDLLDMI>sp|P37275|ZEB1_HUMAN Zinc finger E-box-binding homeobox 1 OS=Homosapiens OX=9606 GN=ZEB1 PE=1 SV=2MADGPRCKRRKQANPRRNNVTNYNTVVETNSDSDDEDKLHIVEEESVTDAADCEGVPEDDLPTDQTVLPGRSSEREGNAKNCWEDDRKEGQEILGPEAQADEAGCTVKDDECESDAENEQNHDPNVEEFLQQQDTAVIFPEAPEEDQRQGTPEASGHDENGTPDAFSQLLTCPYCDRGYKRFTSLKEHIKYRHEKNEDNFSCSLCSYTFAYRTQLERHMTSHKSGRDQRHVTQSGCNRKFKCTECGKAFKYKHHLKEHLRIHSGEKPYECPNCKKRFSHSGSYSSHISSKKCISLIPVNGRPRTGLKTSQCSSPSLSASPGSPTRPQIRQKIENKPLQEQLSVNQIKTEPVDYEFKPIVVASGINCSTPLQNGVFTGGGPLQATSSPQGMVQAVVLPTVGLVSPISINLSDIQNVLKVAVDGNVIRQVLENNQANLASKEQETINASPIQQGGHSVISAISLPLVDQDGTTKIIINYSLEQPSQLQVVPQNLKKENPVATNSCKSEKLPEDLTVKSEKDKSFEGGVNDSTCLLCDDCPGDINALPELKHYDLKQPTQPPPLPAAEAEKPESSVSSATGDGNLSPSQPPLKNLLSLLKAYYALNAQPSAEELSKIADSVNLPLDVVKKWFEKMQAGQISVQSSEPSSPEPGKVNIPAKNNDQPQSANANEPQDSTVNLQSPLKMTNSPVLPVGSTTNGSRSSTPSPSPLNLSSSRNTQGYLYTAEGAQEEPQVEPLDLSLPKQQGELLERSTITSVYQNSVYSVQEEPLNLSCAKKEPQKDSCVTDSEPVVNVIPPSANPINIAIPTVTAQLPTIVAIADQNSVPCLRALAANKQTILIPQVAYTYSTTVSPAVQEPPLKVIQPNGNQDERQDTSSEGVSNVEDQNDSDSTPPKKKMRKTENGMYACDLCDKIFQKSSSLLRHKYEHTGKRPHECGICKKAFKHKHHLIEHMRLHSGEKPYQCDKCGKRFSHSGSYSQHMNHRYSYCKREAEERDSTEQEEAGPEILSNEHVGARASPSQGDSDERESLTREEDEDSEKEEEEEDKEMEELQEEKECEKPQGDEEEEEEEEEVEEEEVEEAENEGEEAKTEGLMKDDRAESQASSLGQKVGESSEQVSEEKTNEA>sp|P37275-2|ZEB1_HUMAN Isoform 2 of Zinc finger E-box-binding homeobox 1OS=Homo sapiens OX=9606 GN=ZEB1MADGPRCKRRKQANPRRNNVTNYNTVVETNSDSDDEDKLHIVEEESVTDAADCEGVPEDDLPTDQTVLPGRSSEREGNAKNCWEDDTGKEGQEILGPEAQADEAGCTVKDDECESDAENEQNHDPNVEEFLQQQDTAVIFPEAPEEDQRQGTPEASGHDENGTPDAFSQLLTCPYCDRGYKRFTSLKEHIKYRHEKNEDNFSCSLCSYTFAYRTQLERHMTSHKSGRDQRHVTQSGCNRKFKCTECGKAFKYKHHLKEHLRIHSGEKPYECPNCKKRFSHSGSYSSHISSKKCISLIPVNGRPRTGLKTSQCSSPSLSASPGSPTRPQIRQKIENKPLQEQLSVNQIKTEPVDYEFKPIVVASGINCSTPLQNGVFTGGGPLQATSSPQGMVQAVVLPTVGLVSPISINLSDIQNVLKVAVDGNVIRQVLENNQANLASKEQETINASPIQQGGHSVISAISLPLVDQDGTTKIIINYSLEQPSQLQVVPQNLKKENPVATNSCKSEKLPEDLTVKSEKDKSFEGGVNDSTCLLCDDCPGDINALPELKHYDLKQPTQPPPLPAAEAEKPESSVSSATGDGNLSPSQPPLKNLLSLLKAYYALNAQPSAEELSKIADSVNLPLDVVKKWFEKMQAGQISVQSSEPSSPEPGKVNIPAKNNDQPQSANANEPQDSTVNLQSPLKMTNSPVLPVGSTTNGSRSSTPSPSPLNLSSSRNTQGYLYTAEGAQEEPQVEPLDLSLPKQQGELLERSTITSVYQNSVYSVQEEPLNLSCAKKEPQKDSCVTDSEPVVNVIPPSANPINIAIPTVTAQLPTIVAIADQNSVPCLRALAANKQTILIPQVAYTYSTTVSPAVQEPPLKVIQPNGNQDERQDTSSEGVSNVEDQNDSDSTPPKKKMRKTENGMYACDLCDKIFQKSSSLLRHKYEHTGKRPHECGICKKAFKHKHHLIEHMRLHSGEKPYQCDKCGKRFSHSGSYSQHMNHRYSYCKREAEERDSTEQEEAGPEILSNEHVGARASPSQGDSDERESLTREEDEDSEKEEEEEDKEMEELQEEKECEKPQGDEEEEEEEEEVEEEEVEEAENEGEEAKTEGLMKDDRAESQASSLGQKVGESSEQVSEEKTNEA>sp|P37275-3|ZEB1_HUMAN Isoform 3 of Zinc finger E-box-binding homeobox 1OS=Homo sapiens OX=9606 GN=ZEB1MADGPRCKRRKQANPRRNNGKEGQEILGPEAQADEAGCTVKDDECESDAENEQNHDPNVEEFLQQQDTAVIFPEAPEEDQRQGTPEASGHDENGTPDAFSQLLTCPYCDRGYKRFTSLKEHIKYRHEKNEDNFSCSLCSYTFAYRTQLERHMTSHKSGRDQRHVTQSGCNRKFKCTECGKAFKYKHHLKEHLRIHSGEKPYECPNCKKRFSHSGSYSSHISSKKCISLIPVNGRPRTGLKTSQCSSPSLSASPGSPTRPQIRQKIENKPLQEQLSVNQIKTEPVDYEFKPIVVASGINCSTPLQNGVFTGGGPLQATSSPQGMVQAVVLPTVGLVSPISINLSDIQNVLKVAVDGNVIRQVLENNQANLASKEQETINASPIQQGGHSVISAISLPLVDQDGTTKIIINYSLEQPSQLQVVPQNLKKENPVATNSCKSEKLPEDLTVKSEKDKSFEGGVNDSTCLLCDDCPGDINALPELKHYDLKQPTQPPPLPAAEAEKPESSVSSATGDGNLSPSQPPLKNLLSLLKAYYALNAQPSAEELSKIADSVNLPLDVVKKWFEKMQAGQISVQSSEPSSPEPGKVNIPAKNNDQPQSANANEPQDSTVNLQSPLKMTNSPVLPVGSTTNGSRSSTPSPSPLNLSSSRNTQGYLYTAEGAQEEPQVEPLDLSLPKQQGELLERSTITSVYQNSVYSVQEEPLNLSCAKKEPQKDSCVTDSEPVVNVIPPSANPINIAIPTVTAQLPTIVAIADQNSVPCLRALAANKQTILIPQVAYTYSTTVSPAVQEPPLKVIQPNGNQDERQDTSSEGVSNVEDQNDSDSTPPKKKMRKTENGMYACDLCDKIFQKSSSLLRHKYEHTGKRPHECGICKKAFKHKHHLIEHMRLHSGEKPYQCDKCGKRFSHSGSYSQHMNHRYSYCKREAEERDSTEQEEAGPEILSNEHVGARASPSQGDSDERESLTREEDEDSEKEEEEEDKEMEELQEEKECEKPQGDEEEEEEEEEVEEEEVEEAENEGEEAKTEGLMKDDRAESQASSLGQKVGESSEQVSEEKTNEA>sp|P37275-4|ZEB1_HUMAN Isoform 4 of Zinc finger E-box-binding homeobox 1OS=Homo sapiens OX=9606 GN=ZEB1MADGPRCKRRKQANPRRNNVTNYNTVVETNSDSDDEDKLHIVEEESVTDAADCEGVPEDDLPTDQTVLPGRSSEREGNAKNCWEDDIKDDECESDAENEQNHDPNVEEFLQQQDTAVIFPEAPEEDQRQGTPEASGHDENGTPDAFSQLLTCPYCDRGYKRFTSLKEHIKYRHEKNEDNFSCSLCSYTFAYRTQLERHMTSHKSGRDQRHVTQSGCNRKFKCTECGKAFKYKHHLKEHLRIHSGEKPYECPNCKKRFSHSGSYSSHISSKKCISLIPVNGRPRTGLKTSQCSSPSLSASPGSPTRPQIRQKIENKPLQEQLSVNQIKTEPVDYEFKPIVVASGINCSTPLQNGVFTGGGPLQATSSPQGMVQAVVLPTVGLVSPISINLSDIQNVLKVAVDGNVIRQVLENNQANLASKEQETINASPIQQGGHSVISAISLPLVDQDGTTKIIINYSLEQPSQLQVVPQNLKKENPVATNSCKSEKLPEDLTVKSEKDKSFEGGVNDSTCLLCDDCPGDINALPELKHYDLKQPTQPPPLPAAEAEKPESSVSSATGDGNLSPSQPPLKNLLSLLKAYYALNAQPSAEELSKIADSVNLPLDVVKKWFEKMQAGQISVQSSEPSSPEPGKVNIPAKNNDQPQSANANEPQDSTVNLQSPLKMTNSPVLPVGSTTNGSRSSTPSPSPLNLSSSRNTQGYLYTAEGAQEEPQVEPLDLSLPKQQGELLERSTITSVYQNSVYSVQEEPLNLSCAKKEPQKDSCVTDSEPVVNVIPPSANPINIAIPTVTAQLPTIVAIADQNSVPCLRALAANKQTILIPQVAYTYSTTVSPAVQEPPLKVIQPNGNQDERQDTSSEGVSNVEDQNDSDSTPPKKKMRKTENGMYACDLCDKIFQKSSSLLRHKYEHTGKRPHECGICKKAFKHKHHLIEHMRLHSGEKPYQCDKCGKRFSHSGSYSQHMNHRYSYCKREAEERDSTEQEEAGPEILSNEHVGARASPSQGDSDERESLTREEDEDSEKEEEEEDKEMEELQEEKECEKPQGDEEEEEEEEEVEEEEVEEAENEGEEAKTEGLMKDDRAESQASSLGQKVGESSEQVSEEKTNEA>sp|P37275-5|ZEB1_HUMAN Isoform 5 of Zinc finger E-box-binding homeobox 1OS=Homo sapiens OX=9606 GN=ZEB1MKVTNYNTVVETNSDSDDEDKLHIVEEESVTDAADCEGVPEDDLPTDQTVLPGRSSEREGNAKNCWEDDTGKEGQEILGPEAQADEAGCTVKDDECESDAENEQNHDPNVEEFLQQQDTAVIFPEAPEEDQRQGTPEASGHDENGTPDAFSQLLTCPYCDRGYKRFTSLKEHIKYRHEKNEDNFSCSLCSYTFAYRTQLERHMTSHKSGRDQRHVTQSGCNRKFKCTECGKAFKYKHHLKEHLRIHSGEKPYECPNCKKRFSHSGSYSSHISSKKCISLIPVNGRPRTGLKTSQCSSPSLSASPGSPTRPQIRQKIENKPLQEQLSVNQIKTEPVDYEFKPIVVASGINCSTPLQNGVFTGGGPLQATSSPQGMVQAVVLPTVGLVSPISINLSDIQNVLKVAVDGNVIRQVLENNQANLASKEQETINASPIQQGGHSVISAISLPLVDQDGTTKIIINYSLEQPSQLQVVPQNLKKENPVATNSCKSEKLPEDLTVKSEKDKSFEGGVNDSTCLLCDDCPGDINALPELKHYDLKQPTQPPPLPAAEAEKPESSVSSATGDGNLSPSQPPLKNLLSLLKAYYALNAQPSAEELSKIADSVNLPLDVVKKWFEKMQAGQISVQSSEPSSPEPGKVNIPAKNNDQPQSANANEPQDSTVNLQSPLKMTNSPVLPVGSTTNGSRSSTPSPSPLNLSSSRNTQGYLYTAEGAQEEPQVEPLDLSLPKQQGELLERSTITSVYQNSVYSVQEEPLNLSCAKKEPQKDSCVTDSEPVVNVIPPSANPINIAIPTVTAQLPTIVAIADQNSVPCLRALAANKQTILIPQVAYTYSTTVSPAVQEPPLKVIQPNGNQDERQDTSSEGVSNVEDQNDSDSTPPKKKMRKTENGMYACDLCDKIFQKSSSLLRHKYEHTGKRPHECGICKKAFKHKHHLIEHMRLHSGEKPYQCDKCGKRFSHSGSYSQHMNHRYSYCKREAEERDSTEQEEAGPEILSNEHVGARASPSQGDSDERESLTREEDEDSEKEEEEEDKEMEELQEEKECEKPQGDEEEEEEEEEVEEEEVEEAENEGEEAKTEGLMKDDRAESQASSLGQKVGESSEQVSEEKTNEA>sp|A2RRH5|WDR27_HUMAN WD repeat-containing protein 27 OS=Homo sapiensOX=9606 GN=WDR27 PE=1 SV=3MENPQDIFSSNGGCLSDIVIEKYLVESKESVSHVQLACSMQDCAFPLDGTELCIWNTKDPSHQLLILRGHHQPITAMAFGNKVNPLLICSASLDYVIMWNLDECREKVLQGLVPRGTVMGSLLGKVLCLQLSLDDHVVAVCAGNKIFMLDIETQAVRAELQGHLGPVTAVEFCPWRAGTLISASEDRGFKVWDHCTGSLIYSSSVLSAYPLLSLFIDAESRQLVTGCADGQLWIFSLMDGHHYRRVARVDLRKKTETFSTRRVKSGLCSQPEESQLPSTSALGKGEQVEVTFPVLRLAPCDLSLIPNSACGCLSSENTRCVWIGSSVGLFVFNLANLEVEAALYYKDFQSLSILLAGSCALRNRTADQKVLCLLASLFGGKIAVLEINPAALVRAQQCPSMGQSLSVPASSCVLPTSPLYLGIAKEKSTKAASEQRRAARNVMKDQRLVFHSKVRSSGYASAPHVTMFSPKTNIKSEGKGSSRSRSSCAREAYPVECAVPTKPGPQVAAAPTCTRVCCIQYSGDGQWLACGLANHLLLVFDASLTGTPAVFSGHDGAVNAVCWSQDRRWLLSAARDGTLRMWSARGAELALLLGKDMFSKPIQSAQFYYIDAFILLSSGPEFQLLRYHIDTCKDEIKRYKQKSKSKLICRLSTTGAVDMTSLSAVNDFYSHIVLAAGRNRTVEVFDLNAGCSAAVIAEAHSRPVHQICQNKGSSFTTQQPQAYNLFLTTAIGDGMRLWDLRTLRCERHFEGHPTRGYPCGIAFSPCGRFAACGAEDRHAYVYEMGSSTFSHRLAGHTDTVTGVAFNPSAPQLATATLDGKLQLFLAE>sp|A2RRH5-2|WDR27_HUMAN Isoform 2 of WD repeat-containing protein 27OS=Homo sapiens OX=9606 GN=WDR27MENPQDIFSSNGGCLSDIVIEKYLVESKESVSHVQLACSMQDCAFPLDGTELCIWNTKDPSHQLLILRGHHQPITAMAFGNKVNPLLICSASLDYVIMWNLDECREKVLQAYPLLSLFIDAESRQLVTGCADGQLWIFSLMDGHHYRRVARVDLRKKTETFSTRRVKSGLCSQPEESQLPSTSALGKGEQVEVTFPVLRLAPCDLSLIPNSACGCLSSENTRCVWIGSSVGLFVFNLANLEVEAALYYKDFQSLSILLAGSCALRNRTADQKVLCLLASLFGGKIAVLEINPAALVRAQQCPSMGQSLSVPASSCVLPTSPLYLGIAKEKSTKAASEQRRAARNVMKDQRLVFHSKVRSSGYASAPHVTMFSPKTNIKSEGKGSSRSRSSCAREAYPVECAVPTKPGPQVAAAPTCTRVCCIQYSGDGQWLACGLANHLLLVFDASLTGTPAVFSGHDGAVNAVCWSQDRRWLLSAARDGTLRMWSARGAELALLLGKDMFSKPIQSAQFYYIDAFILLSSGPEFQLLRYHIDTCKDEIKRYKQKSKSKLICRLSTTGAVDMTSLSAVNDFYSHIVLAAGRNRTVEVFDLNAGCSAAVIAEAHSRPVHQICQNKGSSFTTQQPQAYNLFLTTAIGDGMRLWDLRTLRCERHFEGHPTRGYPCGIAFSPCGRFAACGAEDRHAYVYEMGSSTFSHRLAGHTDTVTGVAFNPSAPQLATATLDGKLQLFLAE>sp|A2RRH5-3|WDR27_HUMAN Isoform 3 of WD repeat-containing protein 27OS=Homo sapiens OX=9606 GN=WDR27MENPQDIFSSNGGCLSDIVIEKYLVESKESVSHVQLACSMQDCAFPLDGTELCIWNTKDPSHQLLILRGHHQPITAMAFGNKVNPLLICSASLDYVIMWNLDECREKVLQGK>sp|A2RRH5-4|WDR27_HUMAN Isoform 4 of WD repeat-containing protein 27OS=Homo sapiens OX=9606 GN=WDR27MENPQDIFSSNGGCLSDIVIEKYLVESKESVSHVQLACSMQDCAFPLDGTELCIWNTKDPSHQLLILRGHHQPITAMAFGNKVNPLLICSASLDYVIMWNLDECREKVLQGLVPRGTVMGSLLGKVLCLQLSLDDHVVAVCAGNKIFMLDIEQRFSVTYIERPDVNNRHKVPPPTFLHTFSQTQAVRAELQGHLGPVTAVEFCPWRAGTLISASEDRGFKVWDHCTGSLIYSSSVLSAYPLLSLFIDAESRQLVTGCADGQLWIFSLMDGHHYRRVARVDLRKKTETFSTRRVKSGLCSQPEESQLPSTSALGKGEQVEVTFPVLRLAPCDLSLIPNSACGCLSSENTRCVWIGSSVGLFVFNLANLEVEAALYYKDFQSLSILLAGSCALRNRTADQKVLCLLASLFGGKIAVLEINPAALVRAQQCPSMGQSLSVPASSCVLPTSPLYLGIAKEKSTKAASEQRRAARNVMKDQRLVFHSKVRSSGYASAPHVTMFSPKTNIKSEGKGSSRSRSSCAREAYPVECAVPTKPGPQVAAAPTCTRVCCIQYSGDGQWLACGLANHLLLVFDASLTGTPAVFSGHDGAVNAVCWSQDRRWLLSAARDGTLRMWSARGAELALLLGKDMFSKPIQSAQFYYIDAFILLSSGPEFQLLRYHIDTCKDEIKRYKQKSKSKLICRLSTTGAVDMTSLSAVNDFYSHIVLAAGRNRTVEVFDLNAGCSAAVIAEAHSRPVHQICQNKGSSFTTQQPQAYNLFLTTAIGDGMRLWDLRTLRCERHFEGHPTRGYPCGIAFSPCGRFAACGAEDRHAYVYEMGSSTFSHRLAGHTDTVTGVAFNPSAPQMESRSVAHAGVQWHDLGSLQPPPSRFKQFFCLSLPSSWDYSLPQLPWMVNSSSF>sp|Q8N2E2|VWDE_HUMAN von Willebrand factor D and EGF domain-containingprotein OS=Homo sapiens OX=9606 GN=VWDE PE=2 SV=4MPGGACVLVIALMFLAWGEAQECSPGGHQFLRSPYRSVRFDSWHLQQSAVQDLICDHSLSPGWYRFLILDRPAEMPTKCVEMNHCGTQAPIWLSLRDSETLPSPGEIKQLTACATWQFLFSTTKDCCLFQIPVSVRNCGNFSVYLLQPTQGCMGYCAEAISDARLHPCGSDETETGGDCVRQLAASLPPPPAGRPEVLVELIESRLFCRCSFDVPATKNSVGFHIAWSRLSSQEVKEELTQETTVQAFSLLELDGINLRLGDRIFCSASVFFLENPHVQSVAIESQEFFAGFKLQPELSTISEDGKEYYLRIESTVPIICSEFSELDQECKISLKLKTIGQGREHLGLNLALSSCHVDLLQTSSCANGTCSHTFVYYTAVTDFSRDGDRVSNIVVQPIVNEDFLWNNYIPDSIQIKVKDVPTAYCYTFTDPHIITFDGRVYDNFKTGTFVLYKSMSRDFEVHVRQWDCRSLHYPVSCNCGFVAQEGGDIVTFDMCNGQLRESQPYLFIKSQDVTRNIKISESYLGRKVTIWFSSGAFIRADLGEWGMSLTIRAPSVDYRNTLGLCGTFDENPENDFHDKNGMQIDQNFNNYVAFINEWRILPGKSMSDTLPVSMTSPGKPSYCSCSLDTAAYPSSEDLDSVSRSEIALGCKDLNHVSLSSLIPELDVTSEYINSDTLVREINKHTSPEEYNLNLFLQEKKHINLTKLGLNVQKHPGNEKEDSLQYLANKKYTQGRGSHSQEMRYNRQNRWKRQNFHEFPPLFAFPSLSQTDLEELTYFFPEDHAEDVQQEFFPSWPTPSGLTEYSTLTLCQETLANSSIGRLCLAFLGKRLDSVIEMCVKDVLLKDDLSWAEAGVALLENECEKRIVEEGKYNTEEYGTSIEDILSVLKCPNLCSGNGQCMEWGCACSPSFSSYDCSDSYDKAPEITELGNAGFCDVQKYNCMMVRVFGKGFKELPSIKCEVTKLQYNSSEWMPGEPIYTQTVFHNSRAVDCQLPTDVQQFDTMDLVGGKPTGKWQLKVSNDGYKFSNPKITVIYDGACQVCGLYKNDSCTIKENVCIIDGLCYVEGDKNPTSPCLICRPKISRFTWSFLENNQPPVIQALQDKLQTFYGENFEYQFVAFDPEGSDIHFTLDSGPEGASVSSAGLFMWKTDLLTTQQITVRLNDDCDAETRVTIEVTVKSCDCLNGGSCVSDRNFSPGSGVYLCVCLPGFHGSLCEVDISGCQSNPCGLGSYISGFHSYSCDCPPELKVETQFVNQFTTQTVVLTRSDKSVNKEEDDKNAQGRKRHVKPTSGNAFTICKYPCGKSRECVAPNICKCKPGYIGSNCQTALCDPDCKNHGKCIKPNICQCLPGHGGATCDEEHCNPPCQHGGTCLAGNLCTCPYGFVGPRCETMVCNRHCENGGQCLTPDICQCKPGWYGPTCSTALCDPVCLNGGSCNKPNTCLCPNGFFGEHCQNAFCHPPCKNGGHCMRNNVCVCREGYTGRRFQKSICDPTCMNGGKCVGPSTCSCPSGWSGKRCNTPICLQKCKNGGECIAPSICHCPSSWEGVRCQIPICNPKCLYGGRCIFPNVCSCRTEYSGVKCEKKIQIRRH>sp|Q8N2E2-3|VWDE_HUMAN Isoform 2 of von Willebrand factor D and EGFdomain-containing protein OS=Homo sapiens OX=9606 GN=VWDEMSLTIRAPSVDYRNTLGLCGTFDENPENDFHDKNGMQIDQNFNNYVAFINEWRILPGKSMSDTLPVSMTSPGKPSYCSCSLDTAAYPSSEDLDSVSRSEIALGCKDLNHVSLSSLIPELDVTSEYINSDTLVREINKHTSPEEYNLNLFLQEKKHINLTKLGLNVQKHPGNEKEDSLQYLANKKYTQGRGSHSQEMRYNRQNRWKRQNFHEFPPLFAFPSLSQTDLEELTYFFPEDHAEDVQQEFFPSWPTPSGLTEYSTLTLCQETLANSSIGRLCLAFLGKRLDSVIEMCVKDVLLKDDLSWAEAGVALLENECEKRIVEEGKYNTEEYGTSIEDILSVLKCPNLCSGNGQCMEWGCACSPSFSSYDCSDSYDKAPEITELGNAGFCDVQKYNCMMVRVFGKGFKELPSIKCEVTKLQYNSSEWMPGEPIYTQTVFHNSRAVDCQLPTDVQQFDTMDLVGGKPTGKWQLKVSNDGYKFSNPKITVIYDGACQVCGLYKNDSCTIKENVCIIDGLCYVEGDKNPTSPCLICRPKISRFTWSFLENNQPPVIQALQDKLQTFYGENFEYQFVAFDPEGSDIHFTLDSGPEGASVSSAGLFMWKTDLLTTQQITVRLNDDCDAETRVTIEVTVKSCDCLNGGSCVSDRNFSPGSGVYLCVCLPGFHGSLCEVDISGCQSNPCGLGSYISGFHSYSCDCPPELKVETQFVNQFTTQTVVLTRSDKSVNKEEDDKNAQGRKRHVKPTSGNAFTICKYPCGKSRECVAPNICKCKPGYIGSNCQTALCDPDCKNHGKCIKPNICQCLPGHGGATCDEEHCNPPCQHGGTCLAGNLCTCPYGFVGPRCETMVCNRHCENGGQCLTPDICQCKPGWYGPTCSTALCDPVCLNGGSCNKPNTCLCPNGFFGEHCQNAFCHPPCKNGGHCMRNNVCVCREGYTGRRFQKSICDPTCMNGGKCVGPSTCSCPSGWSGKRCNTPICLQKCKNGGECIAPSICHCPSSWEGVRCQIPICNPKCLYGGRCIFPNVCSCRTEYSGVKCEKKIQIRRH>sp|Q9NP79|VTA1_HUMAN Vacuolar protein sorting-associated protein VTA1homolog OS=Homo sapiens OX=9606 GN=VTA1 PE=1 SV=1MAALAPLPPLPAQFKSIQHHLRTAQEHDKRDPVVAYYCRLYAMQTGMKIDSKTPECRKFLSKLMDQLEALKKQLGDNEAITQEIVGCAHLENYALKMFLYADNEDRAGRFHKNMIKSFYTASLLIDVITVFGELTDENVKHRKYARWKATYIHNCLKNGETPQAGPVGIEEDNDIEENEDAGAASLPTQPTQPSSSSTYDPSNMPSGNYTGIQIPPGAHAPANTPAEVPHSTGVASNTIQPTPQTIPAIDPALFNTISQGDVRLTPEDFARAQKYCKYAGSALQYEDVSTAVQNLQKALKLLTTGRE>sp|Q9NP79-2|VTA1_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein VTA1 homolog OS=Homo sapiens OX=9606 GN=VTA1MTSETLWWLITLKKQLGDNEAITQEIVGCAHLENYALKMFLYADNEDRAGRFHKNMIKSFYTASLLIDVITVFGELTDENVKHRKYARWKATYIHNCLKNGETPQAGPVGIEEDNDIEENEDAGAASLPTQPTQPSSSSTYDPSNMPSGNYTGIQIPPGAHAPANTPAEVPHSTGDVRLTPEDFARAQKYCKYAGSALQYEDVSTAVQNLQKALKLLTTGRE>sp|O43895|XPP2_HUMAN Xaa-Pro aminopeptidase 2 OS=Homo sapiens OX=9606GN=XPNPEP2 PE=1 SV=3MARAHWGCCPWLVLLCACAWGHTKPVDLGGQDVRNCSTNPPYLPVTVVNTTMSLTALRQQMQTQNLSAYIIPGTDAHMNEYIGQHDERRAWITGFTGSAGTAVVTMKKAAVWTDSRYWTQAERQMDCNWELHKEVGTTPIVTWLLTEIPAGGRVGFDPFLLSIDTWESYDLALQGSNRQLVSITTNLVDLVWGSERPPVPNQPIYALQEAFTGSTWQEKVSGVRSQMQKHQKVPTAVLLSALEETAWLFNLRASDIPYNPFFYSYTLLTDSSIRLFANKSRFSSETLSYLNSSCTGPMCVQIEDYSQVRDSIQAYSLGDVRIWIGTSYTMYGIYEMIPKEKLVTDTYSPVMMTKAVKNSKEQALLKASHVRDAVAVIRYLVWLEKNVPKGTVDEFSGAEIVDKFRGEEQFSSGPSFETISASGLNAALAHYSPTKELNRKLSSDEMYLLDSGGQYWDGTTDITRTVHWGTPSAFQKEAYTRVLIGNIDLSRLIFPAATSGRMVEAFARRALWDAGLNYGHGTGHGIGNFLCVHEWPVGFQSNNIAMAKGMFTSIEPGYYKDGEFGIRLEDVALVVEAKTKYPGSYLTFEVVSFVPYDRNLIDVSLLSPEHLQYLNRYYQTIREKVGPELQRRQLLEEFEWLQQHTEPLAARAPDTASWASVLVVSTLAILGWSV>sp|A4UGR9|XIRP2_HUMAN Xin actin-binding repeat-containing protein 2OS=Homo sapiens OX=9606 GN=XIRP2 PE=1 SV=2MSPESGHSRIFEATAGPNKPESGFAEDSAARGEGVSDLHEVVSLKERMARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKTESEYEETFKPSSVVSTSSTSCVSTSQRKETSTTRYSDHSVTSSTLAQINATSSGMTEEFPPPPPDVLQTSVDVTAFSQSPELPSPPRRLPVPKDVYSKQRNLYELNRLYKHIHPELRKNLEKDYISEVSEIVSSQMNSGSSVSADVQQARYVFENTNDSSQKDLNSEREYLEWDEILKGEVQSIRWIFENQPLDSINNGSPDEGDISRGIADQEIIAGGDVKYTTWMFETQPIDTLGAYSSDTVENAEKIPELARGDVCTARWMFETRPLDSMNKMHQSQEESAVTISKDITGGDVKTVRYMFETQHLDQLGQLHSVDEVHLLQLRSELKEIKGNVKRSIKCFETQPLYVIRDGSGQMLEIKTVHREDVEKGDVRTARWMFETQPLDTINKDITEIKVVRGISMEENVKGGVSKAKWLFETQPLEKIKESEEVIIEKEKIIGTDVSRKCWMFETQPLDILKEVPDADSLQREEIIGGDVQTTKHLFETLPIEALKDSPDIGKLQKITASEEEKGDVRHQKWIFETQPLEDIRKDKKEYTRTVKLEEVDRGDVKNYTHIFESNNLIKFDASHKIEVEGVTRGAVELNKSLFETTPLYAIQDPLGKYHQVKTVQQEEIVRGDVRSCRWLFETRPIDQFDESIHKFQIIRGISAQEIQTGNVKSAKWLFETQPLDSIKYFSDVEETESKTEQTRDIVKGDVKTCKWLFETQPMESLYEKVSLMTSSEEIHKGDVKTCTWLFETQPLDTIKDDSETAVKLQTVKQEEIQGGDVRTACFLFETENLDSIQGEEVKEIKPVEMDIQAGDVSSMRYKFENQSLDSISSSSEEVLKKIKTLKTEDIQKGNVLNCRWLFENQPIDKIKESQEGDECVKTVTDIQGGDVRKGCFIFETFSLDEIKEESDYISTKKTITEEVIQGDVKSYRMLFETQPLYAIQDREGSYHEVTTVKKEEVIHGDVRGTRWLFETKPLDSINKSETVYVIKSVTQEDIQKGDVSSVRYRFETQPLDQISEESHNIMPSIDHIQGGNVKTSRQFFESENFDKNNYIRTVSVNEIQKGNVKTSTWLFETHTMDELRGEGLEYENIKTVTQEDVQKGDVKQAVWLFENRTFDSIMEAHKGITKMTKEEIPPSDVKTTTWLFETTPLHEFNETRVEKIEIIGKSIKETLEDLYSQKVIQAPGIIIEADEIGDVRMAKYKLMNQASPEIQKEEIIRADLRNIMVNLLSKRDCTEREILISEEEKGNVNLTKTQLLNRSTEFHAEKEEIVKGDVQQAIKNLFSEERSVKKGILIQEDEKGDINMTIYCLLHENDGDTIEREEVIGGDVKRTIHNLLSSTSNNKISERAKIDASERGNVQFFTTCIEAGALDYLKQLHTESNETLTAKKQEGEKEIIGGDVEGTKLLLKKRQSLVERTVSETDIIPGDVHNTVKVFMTEPQSTFGKIPKEEIIKGDLTSTLNSLSQAVNQKTVTKTEEIIKGNMLATLKSLKESSHRWKESKQPDAIPGDIEKAIECLEKATNTKTEILKKELLKDDLETSLRSLKEAQRSFKEVHKEGVIKKDAKAVMAGSSGEQKTDIHQVAVQRNKNSLLQPKPGPFEPAAKWQGGADTLSQTMGKSCHGNLVEERTEVNLPKAPKGTVKIVIDREQNNDALEKSLRRLSNSHHKSNVLESGDKTGVWTDTTGEQHLRDEYMSRQLTSTVSVKNNLTTKESDRAVRELKKDDVFNSIQSAGKTVGKQQTYELRNDHQKMEGFHIKSPKKTKNIKILTDTQSSKPSPTQHPVSMPVGGTYDLSGDFQKQTLLKQETKYSNKDIKKKNINLQPMWQLLPVEQDTSNVTEMKVSEKSHNTFKATNKKRETDVHLKSQDFLMKTNTSTGLKMAMERSLNPINFNPENNVKESECPLPPPSPPPPPPSNASSEIEFPLPPPPPLMMFPEKNGFLPSLSTEKIKAEFESFPGLPLPPPPVDEKSERESSSMFLPPPPPPTPSQKPAHLLSSSAPEKHSGDFMQQYSQKEASNSQNSQAKIITGKTGVLPPPTLPKPKLPKHIKDNKNDFSPKVELATSLSDMECKITTSKDQKKVMVMTSSEHTETKQNVISKSLDERKQLSIDSANCLSHTVPGTSAPRKKQIAPLIKSHSFPESSGQQNPKPYMRKFKTPLMIAEEKYRQQKEEIEKQKQESSYYNIVKTQSQNQHITEVEKEMPLQKTNEEVSLSGIDSECTVVQPSPGSQSNARILGVCSDNQLSTTSPETVAAKRLHHVLAASEDKDKMKKEVLQSSRDIMQSKSACEIKQSHQECSTQQTQQKKYLEQLHLPQSKPISPNFKVKTIKLPTLDHTLNETDHSYESHKQQSEIDVQTFTKKQYLKTKKTEASTECSHKQSLAERHYQLPKKEKRVTVQLPTESIQKNQEDKLKMVPRKQREFSGSDRGKLPGSEEKNQGPSMIGRKEERLITERKHEHLKNKSAPKVVKQKVIDAHLDSQTQNFQQTQIQTAESKAEHKKLPQPYNSLQEEKCLEVKGIQEKQVFSNTKDSKQEITQNKSFFSSVKESQRDDGKGALNIVEFLRKREELQQILSRVKQFEAEPNKSGLKTFQTLLNTIPGWLISEDKREYAVHIAMENNLEKVKEEITHIKTQAEDMLVSYENIIQTAMMSSKTGKPGNKPTSLDETSSKVSNVHVSNNKNSEQKENKIAKEKTVQHQVAAHHEATVRSHVKTHQEIKLDDSNIPPPSLKTRPPSPTFITIESTARRTENPTKNELSQSPKKDSYVEPPPRRPMSQKSEIHRANTSPSPPRSRSEQLVRLKDTTAKLSKGAIPCPAATPVPIVEKRSEIIMSPATLRRQIKIETRGRDSPPTITIPVNINHAASGSFRESVDAQEEIRKVEKRATYVHKDGLNSTDHMVPDTESYDAVEIIRKVAVPPRLSEHTQRYEAANRTVQMAENFVNDPENEINRWFREFEHGPVSEAKSNRRVYAKGETNHNIQQESRTFCKEEFGLTSLGNTSFTDFSCKHPRELREKIPVKQPRICSETRSLSEHFSGMDAFESQIVESKMKTSSSHSSEAGKSGCDFKHAPPTYEDVIAGHILDISDSPKEVRKNFQKTWQESGRVFKGLGYATADASATEMRTTFQEESAFISEAAAPRQGNMYTLSKDSLSNGVPSGRQAEFS>sp|A4UGR9-2|XIRP2_HUMAN Isoform 2 of Xin actin-binding repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=XIRP2MARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKTESEYEETFKPSSVVSTSSTSCVSTSQRKETSTTRYSDHSVTSSTLAQINATSSGMTEEFPPPPPDVLQTSVDVTAFSQSPELPSPPRRLPVPKDVYSKQRNLYELNRLYKHIHPELRKNLEKDYISEVSEIVSSQMNSGSSVSADVQQARYVFENTNDSSQKDLNSEREYLEWDEILKGEVQSIRWIFENQPLDSINNGSPDEGDISRGIADQEIIAGGDVKYTTWMFETQPIDTLGAYSSDTVENAEKIPELARGDVCTARWMFETRPLDSMNKMHQSQEESAVTISKDITGGDVKTVRYMFETQHLDQLGQLHSVDEVHLLQLRSELKEIKGNVKRSIKCFETQPLYVIRDGSGQMLEIKTVHREDVEKGDVRTARWMFETQPLDTINKDITEIKVVRGISMEENVKGGVSKAKWLFETQPLEKIKESEEVIIEKEKIIGTDVSRKCWMFETQPLDILKEVPDADSLQREEIIGGDVQTTKHLFETLPIEALKDSPDIGKLQKITASEEEKGDVRHQKWIFETQPLEDIRKDKKEYTRTVKLEEVDRGDVKNYTHIFESNNLIKFDASHKIEVEGVTRGAVELNKSLFETTPLYAIQDPLGKYHQVKTVQQEEIVRGDVRSCRWLFETRPIDQFDESIHKFQIIRGISAQEIQTGNVKSAKWLFETQPLDSIKYFSDVEETESKTEQTRDIVKGDVKTCKWLFETQPMESLYEKVSLMTSSEEIHKGDVKTCTWLFETQPLDTIKDDSETAVKLQTVKQEEIQGGDVRTACFLFETENLDSIQGEEVKEIKPVEMDIQAGDVSSMRYKFENQSLDSISSSSEEVLKKIKTLKTEDIQKGNVLNCRWLFENQPIDKIKESQEGDECVKTVTDIQGGDVRKGCFIFETFSLDEIKEESDYISTKKTITEEVIQGDVKSYRMLFETQPLYAIQDREGSYHEVTTVKKEEVIHGDVRGTRWLFETKPLDSINKSETVYVIKSVTQEDIQKGDVSSVRYRFETQPLDQISEESHNIMPSIDHIQGGNVKTSRQFFESENFDKNNYIRTVSVNEIQKGNVKTSTWLFETHTMDELRGEGLEYENIKTVTQEDVQKGDVKQAVWLFENRTFDSIMEAHKGITKMTKEEIPPSDVKTTTWLFETTPLHEFNETRVEKIEIIGKSIKETLEDLYSQKVIQAPGIIIEADEIGDVRMAKYKLMNQASPEIQKEEIIRADLRNIMVNLLSKRDCTEREILISEEEKGNVNLTKTQLLNRSTEFHAEKEEIVKGDVQQAIKNLFSEERSVKKGILIQEDEKGDINMTIYCLLHENDGDTIEREEVIGGDVKRTIHNLLSSTSNNKISERAKIDASERGNVQFFTTCIEAGALDYLKQLHTESNETLTAKKQEGEKEIIGGDVEGTKLLLKKRQSLVERTVSETDIIPGDVHNTVKVFMTEPQSTFGKIPKEEIIKGDLTSTLNSLSQAVNQKTVTKTEEIIKGNMLATLKSLKESSHRWKESKQPDAIPGDIEKAIECLEKATNTKTEILKKELLKDDLETSLRSLKEAQRSFKEVHKEGVIKKDAKAVMAGSSGEQKTDIHQVAVQRNKNSLLQPKPGPFEPAAKWQGGADTLSQTMGKSCHGNLVEERTEVNLPKAPKGTVKIVIDREQNNDALEKSLRRLSNSHHKSNVLESGDKTGVWTDTTGEQHLRDEYMSRQLTSTVSVKNNLTTKESDRAVRELKKDDVFNSIQSAGKTVGKQQTYELRNDHQKMEGFHIKSPKKTKNIKILTDTQSSKPSPTQHPVSMPVGGTYDLSGDFQKQTLLKQETKYSNKDIKKKNINLQPMWQLLPVEQDTSNVTEMKVSEKSHNTFKATNKKRETDVHLKSQDFLMKTNTSTGLKMAMERSLNPINFNPENNVKESECPLPPPSPPPPPPSNASSEIEFPLPPPPPLMMFPEKNGFLPSLSTEKIKAEFESFPGLPLPPPPVDEKSERESSSMFLPPPPPPTPSQKPAHLLSSSAPEKHSGDFMQQYSQKEASNSQNSQAKIITGKTGVLPPPTLPKPKLPKHIKDNKNDFSPKVELATSLSDMECKITTSKDQKKVMVMTSSEHTETKQNVISKSLDERKQLSIDSANCLSHTVPGTSAPRKKQIAPLIKSHSFPESSGQQNPKPYMRKFKTPLMIAEEKYRQQKEEIEKQKQESSYYNIVKTQSQNQHITEVEKEMPLQKTNEEVSLSGIDSECTVVQPSPGSQSNARILGVCSDNQLSTTSPETVAAKRLHHVLAASEDKDKMKKEVLQSSRDIMQSKSACEIKQSHQECSTQQTQQKKYLEQLHLPQSKPISPNFKVKTIKLPTLDHTLNETDHSYESHKQQSEIDVQTFTKKQYLKTKKTEASTECSHKQSLAERHYQLPKKEKRVTVQLPTESIQKNQEDKLKMVPRKQREFSGSDRGKLPGSEEKNQGPSMIGRKEERLITERKHEHLKNKSAPKVVKQKVIDAHLDSQTQNFQQTQIQTAESKAEHKKLPQPYNSLQEEKCLEVKGIQEKQVFSNTKDSKQEITQNKSFFSSVKESQRDDGKGALNIVEFLRKREELQQILSRVKQFEAEPNKSGLKTFQTLLNTIPGWLISEDKREYAVHIAMENNLEKVKEEITHIKTQAEDMLVSYENIIQTAMMSSKTGKPGNKPTSLDETSSKVSNVHVSNNKNSEQKENKIAKEKTVQHQVAAHHEATVRSHVKTHQEIKLDDSNIPPPSLKTRPPSPTFITIESTARRTENPTKNELSQSPKKDSYVEPPPRRPMSQKSEIHRANTSPSPPRSRSEQLVRLKDTTAKLSKGAIPCPAATPVPIVEKRSEIIMSPATLRRQIKIETRGRDSPPTITIPVNINHAASGSFRESVDAQEEIRKVEKRATYVHKDGLNSTDHMVPDTESYDAVEIIRKVAVPPRLSEHTQRYEAANRTVQMAENFVNDPENEINRWFREFEHGPVSEAKSNRRVYAKGETNHNIQQESRTFCKEEFGLTSLGNTSFTDFSCKHPRELREKIPVKQPRICSETRSLSEHFSGMDAFESQIVESKMKTSSSHSSEAGKSGCDFKHAPPTYEDVIAGHILDISDSPKEVRKNFQKTWQESGRVFKGLGYATADASATEMRTTFQEESAFISEAAAPRQGNMYTLSKDSLSNGVPSGRQAEFS>sp|A4UGR9-3|XIRP2_HUMAN Isoform 3 of Xin actin-binding repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=XIRP2MSPESGHSRIFEATAGPNKPESGFAEDSAARGEGVSDLHEVVSLKERMARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKTESEYEETFKPSSVVSTSSTSCVSTSQRKETSTTRYSDHSVTSSTLAQINATSSGMTEEFPPPPPDVLQTSVDVTAFSQSPELPSPPRRLPVPKDVYSKQRNLYELNRLYKHIHPELRKNLEKDYISEVSEIVSSQMNSGSSVSADVQQARYVFENTNDSSQKDLNSEREYLEWDEILKGEVQSIRWIFENQPLDSINNGSPDEGDISRGIADQEIIAGGDVKYTTWMFETQPIDTLGAYSSDTVENAEKIPELARGDVCTARWMFETRPLDSMNKMHQSQEESAVTISKDITGGDVKTVRYMFETQHLDQLGQLHSVDEVHLLQLRSELKEIKGNVKRSIKCFETQPLYVIRDGSGQMLEIKTVHREDVEKGDVRTARWMFETQPLDTINKDITEIKVVRGISMEENVKGGVSKAKWLFETQPLEKIKESEEVIIEKEKIIGTDVSRKCWMFETQPLDILKEVPDADSLQREEIIGGDVQTTKHLFETLPIEALKDSPDIGKLQKITASEEEKGDVRHQKWIFETQPLEDIRKDKKEYTRTVKLEEVDRGDVKNYTHIFESNNLIKFDASHKIEVEGVTRGAVELNKSLFETTPLYAIQDPLGKYHQVKTVQQEEIVRGDVRSCRWLFETRPIDQFDESIHKFQIIRGISAQEIQTGNVKSAKWLFETQPLDSIKYFSDVEETESKTEQTRDIVKGDVKTCKWLFETQPMESLYEKVSLMTSSEEIHKGDVKTCTWLFETQPLDTIKDDSETAVKLQTVKQEEIQGGDVRTACFLFETENLDSIQGEEVKEIKPVEMDIQAGDVSSMRYKFENQSLDSISSSSEEVLKKIKTLKTEDIQKGNVLNCRWLFENQPIDKIKESQEGDECVKTVTDIQGGDVRKGCFIFETFSLDEIKEESDYISTKKTITEEVIQGDVKSYRMLFETQPLYAIQDREGSYHEVTTVKKEEVIHGDVRGTRWLFETKPLDSINKSETVYVIKSVTQEDIQKGDVSSVRYRFETQPLDQISEESHNIMPSIDHIQGGNVKTSRQFFESENFDKNNYIRTVSVNEIQKGNVKTSTWLFETHTMDELRGEGLEYENIKTVTQEDVQKGDVKQAVWLFENRTFDSIMEAHKGITKMTKEEIPPSDVKTTTWLFETTPLHEFNETRVEKIEIIGKSIKETLEDLYSQKVIQAPGIIIEADEIGDVRMAKYKLMNQASPEIQKEEIIRADLRNIMVNLLSKRDCTEREILISEEEKGNVNLTKTQLLNRSTEFHAEKEEIVKGDVQQAIKNLFSEERSVKKGILIQEDEKGDINMTIYCLLHENDGDTIEREEVIGGDVKRTIHNLLSSTSNNKISERAKIDASERGNVQFFTTCIEAGALDYLKQLHTESNETLTAKKQEGEKEIIGGDVEGTKLLLKKRQSLVERTVSETDIIPGDVHNTVKVFMTEPQSTFGKIPKEEIIKGDLTSTLNSLSQAVNQKTVTKTEEIIKGNMLATLKSLKESSHRWKESKQPDAIPGDIEKAIECLEKATNTKTEILKKELLKDDLETSLRSLKEAQRSFKEVHKEGVIKKDAKAVMAGSSGEQKTDIHQVAVQRNKNSLLQPKPGPFEPAAKWQGGADTLSQTMGKSCHGNLVEERTEVNLPKAPKGTVKIVIDREQNNDALEKSLRRLSNSHHKSNVLESGDKTGVWTDTTGEQHLRDEYMSRQLTSTVSVKNNLTTKESDRAVRELKKDDVFNSIQSAGKTVGKQQTYELRNDHQKMEGFHIKSPKKTKNIKILTDTQSSKPSPTQHPVSMPVGGTYDLSGDFQKQTLLKQETKYSNKDIKKKNINLQPMWQLLPVEQDTSNVTEMKVSEKSHNTFKATNKKRETDVHLKSQDFLMKTNTSTGLKMAMERSLNPINFNPENNVKESECPLPPPSPPPPPPSNASSEIEFPLPPPPPLMMFPEKNGFLPSLSTEKIKAEFESFPGLPLPPPPVDEKSERESSSMFLPPPPPPTPSQKPAHLLSSSAPEKHSGDFMQQYSQKEASNSQNSQAKIITGKTGVLPPPTLPKPKLPKHIKDNKNDFSPKVELATSLSDMECKITTSKDQKKVMVMTSSEHTETKQNVISKSLDERKQLSIDSANCLSHTVPGTSAPRKKQIAPLIKSHSFPESSGQQNPKPYMRKFKTPLMIAEEKYRQQKEEIEKQKQESSYYNIVKTQSQNQHITEVEKEMPLQKTNEEVSLSGIDSECTVVQPSPGSQSNARILGVCSDNQLSTTSPETVAAKRLHHVLAASEDKDKMKKEVLQSSRDIMQSKSACEIKQSHQECSTQQTQQKKYLEQLHLPQSKPISPNFKVKTIKLPTLDHTLNETDHSYESHKQQSEIDVQTFTKKQYLKTKKTEASTECSHKQSLAERHYQLPKKEKRVTVQLPTESIQKNQEDKLKMVPRKQREFSGSDRGKLPGSEEKNQGPSMIGRKEERLITERKHEHLKNKSAPKVVKQKVIDAHLDSQTQNFQQTQIQTAESKAEHKKLPQPYNSLQEEKCLEVKGIQEKQVFSNTKDSKQEITQNKSFFSSVKESQRDDGKGALNIVEFLRKREELQQILSRVKQFEAEPNKSGLKTFQTLLNTIPGWLISEDKREYAVHIAMENNLEKVKEEITHIKTQAEDMLVSYENIIQTAMMSSKTGKPGNKPTSLDETSSKVSNVHVSNNKNSEQKENKIAKEKTVQHQVAAHHEATVRSHVKTHQEIKLDDSNIPPPSLKTRPPSPTFITIESTARRTENPTKNELSQSPKKDSYVEPPPRRPMSQKSEIHRANTSPSPPRSRSEQLVRLKDTTAKLSKGAIPCPAATPVPIVEKRSEIIMSPATLRRQIKIETRGRDSPPTITIPVNINHAASGSFRESVDAQEEIRKVEKRATYVHKDGLNSTDHMVPDTESYDAVEIIRKVAVPPRLSEHTQRYEAANRTVQMAENFVNDPENEINRWFREFEHGPVSEAKSNRRVYAKGETNHNIQQESRTFCKEEFGLTSLGNTSFTDFSCKHPRELREKIPVKQPRICSETRSLSEHFSGMDAFESQIVESKMKTSSSHSSEAGKSGCDFKHAPPTYEDVIAGHILDISDSPKEVRKNFQKTWQESGRVFKGLGYATADASATEMRTTFQEESAFISGK>sp|A4UGR9-4|XIRP2_HUMAN Isoform 4 of Xin actin-binding repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=XIRP2MFPMQKGSLNLLRQKWESCDYQRSECHPRDSHCTIFQPQESKLLAPEGEVVSAPQSLDPTSLPYSTGEEMWSSKPEEKDSVDKSNNTREYGRPEVLKEDSLSSRRRIERFSIALDELRSVFEAPKSGNKPAEYGGKEVEIERSLCSPAFKSHPGSQLEDSVKDSDKKGKETSFDKMSPESGHSRIFEATAGPNKPESGFAEDSAARGEGVSDLHEVVSLKERMARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKKLLLQDKEICILCQKTVYPMECLVADKQNFHKSCFRCHHCNSKLSLGNYASLHGQIYCKPHFKQLFKSKGNYDEGFGHKQHKDRWNCKNQSRSVDFIPNEEPNMCKNIAENTLVPGDRNEHLDAGNSEGQRNDLRKLGERGKLKVIWPPSKEIPKKTLPFEEELKMSKPKWPPEMTTLLSPEFKSESLLEDVRTPENKGQRQDHFPFLQPYLQSTHVCQKEDVIGIKEMKMPEGRKDEKKEGRKNVQDRPSEAEDTKSNRKSAMDLNDNNNVIVQSAEKEKNEKTNQTNGAEVLQVTNTDDEMMPENHKENLNKNNNNNYVAVSYLNNCRQKTSILEFLDLLPLSSEANDTANEYEIEKLENTSRISELLGIFESEKTYSRNVLAMALKKQTDRAAAGSPVQPAPKPSLSRGLMVKGGSSIISPDTNLLNIKGSHSKSKNLHFFFSNTVKITAFSKKNENIFNCDLIDSVDQIKNMPCLDLREFGKDVKPWHVETTEAARNNENTGFDALSHECTAKPLFPRVEVQSEQLTVEEQIKRNRCYSDTE>sp|A4UGR9-5|XIRP2_HUMAN Isoform 5 of Xin actin-binding repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=XIRP2MSPESGHSRIFEATAGPNKPESGFAEDSAARGEGVSDLHEVVSLKERMARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKKLLLQDKEICILCQKTVYPMECLVADKQNFHKSCFRCHHCNSKLSLGNYASLHGQIYCKPHFKQLFKSKGNYDEGFGHKQHKDRWNCKNQSRSVDFIPNEEPNMCKNIAENTLVPGDRNEHLDAGNSEGQRNDLRKLGERGKLKVIWPPSKEIPKKTLPFEEELKMSKPKWPPEMTTLLSPEFKSESLLEDVRTPENKGQRQDHFPFLQPYLQSTHVCQKEDVIGIKEMKMPEGRKDEKKEGRKNVQDRPSEAEDTKSNRKSAMDLNDNNNVIVQSAEKEKNEKTNQTNGAEVLQVTNTDDEMMPENHKENLNKNNNNNYVAVSYLNNCRQKTSILEFLDLLPLSSEANDTANEYEIEKLENTSRISELLGIFESEKTYSRNVLAMALKKQTDRAAAGSPVQPAPKPSLSRGLMVKGGSSIISPDTNLLNIKGSHSKSKNLHFFFSNTVKITAFSKKNENIFNCDLIDSVDQIKNMPCLDLREFGKDVKPWHVETTEAARNNENTGFDALSHECTAKPLFPRVEVQSEQLTVEEQIKRNRCYSDTE>sp|A4UGR9-6|XIRP2_HUMAN Isoform 6 of Xin actin-binding repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=XIRP2MFPMQKGSLNLLRQKWESCDYQRSECHPRDSHCTIFQPQESKLLAPEGEVVSAPQSLDPTSLPYSTGEEMWSSKPEEKDSVDKSNNTREYGRPEVLKEDSLSSRRRIERFSIALDELRSVFEAPKSGNKPAEYGGKEVEIERSLCSPAFKSHPGSQLEDSVKDSDKKGKETSFDKMSPESGHSRIFEAVFSTDQAQILRLHLHPKLTKTPKNSLKSSTYISTAGPNKPESGFAEDSAARGEGVSDLHEVVSLKERMARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKKLLLQDKEICILCQKTVYPMECLVADKQNFHKSCFRCHHCNSKLSLGNYASLHGQIYCKPHFKQLFKSKGNYDEGFGHKQHKDRWNCKNQSRSVDFIPNEEPNMCKNIAENTLVPGDRNEHLDAGNSEGQRNDLRKLGERGKLKVIWPPSKEIPKKTLPFEEELKMSKPKWPPEMTTLLSPEFKSESLLEDVRTPENKGQRQDHFPFLQPYLQSTHVCQKEDVIGIKEMKMPEGRKDEKKEGRKNVQDRPSEAEDTKSNRKSAMDLNDNNNVIVQSAEKEKNEKTNQTNGAEVLQVTNTDDEMMPENHKENLNKNNNNNYVAVSYLNNCRQKTSILEFLDLLPLSSEANDTANEYEIEKLENTSRISELLGIFESEKTYSRNVLAMALKKQTDRAAAGSPVQPAPKPSLSRGLMVKGGSSIISPDTNLLNIKGSHSKSKNLHFFFSNTVKITAFSKKNENIFNCDLIDSVDQIKNMPCLDLREFGKDVKPWHVETTEAARNNENTGFDALSHECTAKPLFPRVEVQSEQLTVEEQIKRNRCYSDTE>sp|A4UGR9-7|XIRP2_HUMAN Isoform 7 of Xin actin-binding repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=XIRP2MARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKKLLLQDKEICILCQKTVYPMECLVADKQNFHKSCFRCHHCNSKLSLGNYASLHGQIYCKPHFKQLFKSKGNYDEGFGHKQHKDRWNCKNQSRSVDFIPNEEPNMCKNIAENTLVPGDRNEHLDAGNSEGQRNDLRKLGERGKLKVIWPPSKEIPKKTLPFEEELKMSKPKWPPEMTTLLSPEFKSESLLEDVRTPENKGQRQDHFPFLQPYLQSTHVCQKEDVIGIKEMKMPEGRKDEKKEGRKNVQDRPSEAEDTKSNRKSAMDLNDNNNVIVQSAEKEKNEKTNQTNGAEVLQVTNTDDEMMPENHKENLNKNNNNNYVAVSYLNNCRQKTSILEFLDLLPLSSEANDTANEYEIEKLENTSRISELLGIFESEKTYSRNVLAMALKKQTDRAAAGSPVQPAPKPSLSRGLMVKGGSSIISPDTNLLNIKGSHSKSKNLHFFFSNTVKITAFSKKNENIFNCDLIDSVDQIKNMPCLDLREFGKDVKPWHVETTEAARNNENTGFDALSHECTAKPLFPRVEVQSEQLTVEEQIKRNRCYSDTE>sp|A4UGR9-8|XIRP2_HUMAN Isoform 8 of Xin actin-binding repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=XIRP2MFPMQKGSLNLLRQKWESCDYQRSECHPRDSHCTIFQPQESKLLAPEGEVVSAPQSLDPTSLPYSTGEEMWSSKPEEKDSVDKSNNTREYGRPEVLKEDSLSSRRRIERFSIALDELRSVFEAPKSGNKPAEYGGKEVEIERSLCSPAFKSHPGSQLEDSVKDSDKKGKETSFDKMSPESGHSRIFEATAGPNKPESGFAEDSAARGEGVSDLHEVVSLKERMARYQAAVSRGDCRSFSANMMEESEMCAVPGGLAKVKKQFEDEITSSRNTFAQYQYQHQNRSEQEAIHSSQVGTSRSSQEMARNEQEGSKVQKIDVHGTEMVSHLEKHTEEVNQASQFHQYVQETVIDTPEDEEIPKVSTKLLKEQFEKSAQEKILYSDKEMTTPAKQIKTESEYEETFKPSSVVSTSSTSCVSTSQRKETSTTRYSDHSVTSSTLAQINATSSGMTEEFPPPPPDVLQTSVDVTAFSQSPELPSPPRRLPVPKDVYSKQRNLYELNRLYKHIHPELRKNLEKDYISEVSEIVSSQMNSGSSVSADVQQARYVFENTNDSSQKDLNSEREYLEWDEILKGEVQSIRWIFENQPLDSINNGSPDEGDISRGIADQEIIAGGDVKYTTWMFETQPIDTLGAYSSDTVENAEKIPELARGDVCTARWMFETRPLDSMNKMHQSQEESAVTISKDITGGDVKTVRYMFETQHLDQLGQLHSVDEVHLLQLRSELKEIKGNVKRSIKCFETQPLYVIRDGSGQMLEIKTVHREDVEKGDVRTARWMFETQPLDTINKDITEIKVVRGISMEENVKGGVSKAKWLFETQPLEKIKESEEVIIEKEKIIGTDVSRKCWMFETQPLDILKEVPDADSLQREEIIGGDVQTTKHLFETLPIEALKDSPDIGKLQKITASEEEKGDVRHQKWIFETQPLEDIRKDKKEYTRTVKLEEVDRGDVKNYTHIFESNNLIKFDASHKIEVEGVTRGAVELNKSLFETTPLYAIQDPLGKYHQVKTVQQEEIVRGDVRSCRWLFETRPIDQFDESIHKFQIIRGISAQEIQTGNVKSAKWLFETQPLDSIKYFSDVEETESKTEQTRDIVKGDVKTCKWLFETQPMESLYEKVSLMTSSEEIHKGDVKTCTWLFETQPLDTIKDDSETAVKLQTVKQEEIQGGDVRTACFLFETENLDSIQGEEVKEIKPVEMDIQAGDVSSMRYKFENQSLDSISSSSEEVLKKIKTLKTEDIQKGNVLNCRWLFENQPIDKIKESQEGDECVKTVTDIQGGDVRKGCFIFETFSLDEIKEESDYISTKKTITEEVIQGDVKSYRMLFETQPLYAIQDREGSYHEVTTVKKEEVIHGDVRGTRWLFETKPLDSINKSETVYVIKSVTQEDIQKGDVSSVRYRFETQPLDQISEESHNIMPSIDHIQGGNVKTSRQFFESENFDKNNYIRTVSVNEIQKGNVKTSTWLFETHTMDELRGEGLEYENIKTVTQEDVQKGDVKQAVWLFENRTFDSIMEAHKGITKMTKEEIPPSDVKTTTWLFETTPLHEFNETRVEKIEIIGKSIKETLEDLYSQKVIQAPGIIIEADEIGDVRMAKYKLMNQASPEIQKEEIIRADLRNIMVNLLSKRDCTEREILISEEEKGNVNLTKTQLLNRSTEFHAEKEEIVKGDVQQAIKNLFSEERSVKKGILIQEDEKGDINMTIYCLLHENDGDTIEREEVIGGDVKRTIHNLLSSTSNNKISERAKIDASERGNVQFFTTCIEAGALDYLKQLHTESNETLTAKKQEGEKEIIGGDVEGTKLLLKKRQSLVERTVSETDIIPGDVHNTVKVFMTEPQSTFGKIPKEEIIKGDLTSTLNSLSQAVNQKTVTKTEEIIKGNMLATLKSLKESSHRWKESKQPDAIPGDIEKAIECLEKATNTKTEILKKELLKDDLETSLRSLKEAQRSFKEVHKEGVIKKDAKAVMAGSSGEQKTDIHQVAVQRNKNSLLQPKPGPFEPAAKWQGGADTLSQTMGKSCHGNLVEERTEVNLPKAPKGTVKIVIDREQNNDALEKSLRRLSNSHHKSNVLESGDKTGVWTDTTGEQHLRDEYMSRQLTSTVSVKNNLTTKESDRAVRELKKDDVFNSIQSAGKTVGKQQTYELRNDHQKMEGFHIKSPKKTKNIKILTDTQSSKPSPTQHPVSMPVGGTYDLSGDFQKQTLLKQETKYSNKDIKKKNINLQPMWQLLPVEQDTSNVTEMKVSEKSHNTFKATNKKRETDVHLKSQDFLMKTNTSTGLKMAMERSLNPINFNPENNVKESECPLPPPSPPPPPPSNASSEIEFPLPPPPPLMMFPEKNGFLPSLSTEKIKAEFESFPGLPLPPPPVDEKSERESSSMFLPPPPPPTPSQKPAHLLSSSAPEKHSGDFMQQYSQKEASNSQNSQAKIITGKTGVLPPPTLPKPKLPKHIKDNKNDFSPKVELATSLSDMECKITTSKDQKKVMVMTSSEHTETKQNVISKSLDERKQLSIDSANCLSHTVPGTSAPRKKQIAPLIKSHSFPESSGQQNPKPYMRKFKTPLMIAEEKYRQQKEEIEKQKQESSYYNIVKTQSQNQHITEVEKEMPLQKTNEEVSLSGIDSECTVVQPSPGSQSNARILGVCSDNQLSTTSPETVAAKRLHHVLAASEDKDKMKKEVLQSSRDIMQSKSACEIKQSHQECSTQQTQQKKYLEQLHLPQSKPISPNFKVKTIKLPTLDHTLNETDHSYESHKQQSEIDVQTFTKKQYLKTKKTEASTECSHKQSLAERHYQLPKKEKRVTVQLPTESIQKNQEDKLKMVPRKQREFSGSDRGKLPGSEEKNQGPSMIGRKEERLITERKHEHLKNKSAPKVVKQKVIDAHLDSQTQNFQQTQIQTAESKAEHKKLPQPYNSLQEEKCLEVKGIQEKQVFSNTKDSKQEITQNKSFFSSVKESQRDDGKGALNIVEFLRKREELQQILSRVKQFEAEPNKSGLKTFQTLLNTIPGWLISEDKREYAVHIAMENNLEKVKEEITHIKTQAEDMLVSYENIIQTAMMSSKTGKPGNKPTSLDETSSKVSNVHVSNNKNSEQKENKIAKEKTVQHQVAAHHEATVRSHVKTHQEIKLDDSNIPPPSLKTRPPSPTFITIESTARRTENPTKNELSQSPKKDSYVEPPPRRPMSQKSEIHRANTSPSPPRSRSEQLVRLKDTTAKLSKGAIPCPAATPVPIVEKRSEIIMSPATLRRQIKIETRGRDSPPTITIPVNINHAASGSFRESVDAQEEIRKVEKRATYVHKDGLNSTDHMVPDTESYDAVEIIRKVAVPPRLSEHTQRYEAANRTVQMAENFVNDPENEINRWFREFEHGPVSEAKSNRRVYAKGETNHNIQQESRTFCKEEFGLTSLGNTSFTDFSCKHPRELREKIPVKQPRICSETRSLSEHFSGMDAFESQIVESKMKTSSSHSSEAGKSGCDFKHAPPTYEDVIAGHILDISDSPKEVRKNFQKTWQESGRVFKGLGYATADASATEMRTTFQEESAFISEAAAPRQGNMYTLSKDSLSNGVPSGRQAEFS>sp|Q86TI4|WDR86_HUMAN WD repeat-containing protein 86 OS=Homo sapiensOX=9606 GN=WDR86 PE=2 SV=3MGGGGSALRVCADHRGGINWLSLSPDGQRLLTGSEDGTARLWSTADGQCCALLQGHESYVTFCQLEDEAAFTCSADCTIRRWDVLTGQCLQVYRGHTSIVNRILVANNQLFSSSYDRTARVWSVDKGQMSREFRGHRNCVLTLAYSAPWDLPSTPCAEEAAAGGLLVTGSTDGTAKVWQVASGCCHQTLRGHTGAVLCLVLDTPGHTAFTGSTDATIRAWDILSGEQLRVFREHRGSVICLELVNRLVYSGSADRTVKCWLADTGECVRTFTAHRRNVSALKYHAGTLFTGSGDACARAFDAQSGELRRVFRGHTFIINCIQVHGQVLYTASHDGALRLWDVRGLRGAPRPPPPMRSLSRLFSNKVGCAAAPLQPA>sp|Q86TI4-1|WDR86_HUMAN Isoform 1 of WD repeat-containing protein 86OS=Homo sapiens OX=9606 GN=WDR86MGGGGSALRVCADHRGGINWLSLSPDGQRLLTGSEDGTARLWSTADGQCCALLQGRPSHSLPDLFAAAHRPQTADPSSCARRPLSRSPAPAHPGTLAEERLSGPSIWLLSARQGRVPCGLFVANCALLLAFPVDDSHSNNRRLLRASGAEKCAVVTLCYPTYRRGNRLGGHESYVTFCQLEDEAAFTCSADCTIRRWDVLTGQCLQVYRGHTSIVNRILVANNQLFSSSYDRTARVWSVDKGQMSREFRGHRNCVLTLAYSAPWDLPSTPCAEEAAAGGLLVTGSTDGTAKVWQVASGCCHQTLRGHTGAVLCLVLDTPGHTAFTGSTDATIRAWDILSGEQLRVFREHRGSVICLELVNRLVYSGSADRTVKCWLADTGECVRTFTAHRRNVSALKYHAGTLFTGSGDACARAFDAQSGELRRVFRGHTFIINCIQVHGQVLYTASHDGALRLWDVRGLRGAPRPPPPMRSLSRLFSNKVGCAAAPLQPA>sp|Q86TI4-2|WDR86_HUMAN Isoform 2 of WD repeat-containing protein 86OS=Homo sapiens OX=9606 GN=WDR86MSREFRGHRNCVLTLAYSAPWDLPSTPCAEEAAAGGLLVTGSTDGTAKVWQVASGCCHQTLRGHTGAVLCLVLDTPGHTAFTGSTDATIRAWDILSGEQLRVFREHRGSVICLECSRAAGTLAPGPSTRSLESCGGCSGATHSSSTASRCTARCSTPPRTTAPCASGTCAGSEVPRGPLRPCAASRGSSATRWAAPPRPCSRPDPAGPLQTPAQTPSGSQSAPPCYPRWWRPMAGEGRGARKPGREESPSQASGFSLVARRRWERECSPWGPPPFPF>sp|Q86TI4-4|WDR86_HUMAN Isoform 4 of WD repeat-containing protein 86OS=Homo sapiens OX=9606 GN=WDR86MGGGGSALRVCADHRGGINWLSLSPDGQRLLTGSEDGTARLWSTADGQCCALLQGHESYVTFCQLEDEAAFTCSADCTIRRWDVLTGQCLQVYRGHTSIVNRILVANNQLFSSSYDRTARVWSVDKGQMSREFRGHRNCVLTLAYSAPWDLPSTPCAEEAAAGGLLVTGSTDGTAKVWQVASGCCHQTLRGHTGAVLCLVLDTPGHTAFTGSTDATIRAWDILSGEQLRVFREHRGSVICLERERSGGLQSCPSCRPSLLLLAAGEPTRVLWQRGQDRQVLAGRHRGVCAHVHGPQTQRERPQVPRGHLVHGQRGRLRPGLRRAVWRAAEGVPGPHIHHQLHPGARPGALHRLARRRPAPLGRARAPRCPAAPSAHAQPLAALQQQGGLRRRAPAAGLIPRGPCRRQPRHPAAPRAPRPATRGGGARWPARGEERGSPGGRRARRRRLVFLWWPGGAGSGSARPGDRPLFPFRVAPVLPPHP>sp|Q6ZUG5|YC006_HUMAN Uncharacterized protein FLJ43738 OS=Homo sapiensOX=9606 PE=2 SV=1MPVYCKYQFHKTPVHKTKGEPHGTHVYFQDINVIFLGALHPSDLREYLEGPPMVVEVHDRDRKSEECSQKPVLFGEDPLDSYLNFQALISPRETENNPFESQNKMWYPYGIAQVSFADLLLGHKYLNLAVPIHSCEVQPTHCGQDSRRRKVVGLGVPRDGHQHGPMPRGNYLEADSQLKLRVDIAVPLRAGARAADPDLGGSQFGRIIFVFDFKKVSLLHSLLQDITMINAKALGLDSYPVRTLQQILSAFKVRVRVQEQQHLDVLTGFHLLDGKTHLFILEGLADQGLRQLWENHQSWIPRSEHRKYKVLYNSQLLFRSRLYGDLEAILYHVHLFQPTELLLQQAVFFLRDTERRRVFQALARIHDICYNSTTLWDVTVRDLLPSSAMIKDLSQEFGMPLSQEELTDEKLFALPPQPAPNLEDYHSRNSTLTLEIHAHQEPRKRFTYSQDYLSAMVEPLDLKEEEKKAQKKSRQAWLTARGFQVTGLQSDTESSFQDLKLPPIKELNEEWKENSLFANVLEPVLDRDRWSWDRHHVDFDLYKKPPPFLELLPSPAPKPVTVRKKKGNSPIS>sp|Q6AWC8|YK026_HUMAN Putative uncharacterized protein LOC100129027OS=Homo sapiens OX=9606 PE=5 SV=1MYWQNWTHNGRLWGAGVHLYLSRKQCALKNTSLSKFQTSHICKGSALQPQQASPGASSFLTCPELGVMYLKLVLGQMVQAVRRDSGLQPFGSLFLLITQKRAVLTPFLTKTWHSLRALVYRVWSLEESRYLQREKGLVDSFGVLWEE>sp|Q9BRP9|YK016_HUMAN Putative uncharacterized protein MGC13053 OS=Homosapiens OX=9606 PE=5 SV=2MQPSWTPAPVQRTACNITAWGGEFGKEGEGRCEQVALSSGPPEGALHASREGPQPPGAENLRPSTGETFVQSGRWDGGWRGAMKGRRHRQASTPPTRPESIFVPTAQDGAQMVCKAHTRTTQYTEQDSVVTARGLLDAKRVGVAGGS>sp|A1L4Q6|YK033_HUMAN Putative uncharacterized protein FLJ41423 OS=Homosapiens OX=9606 PE=5 SV=1MAALSSRCPRSAAGPAYLQEAARSAHWASPPLVPLRTFQSSLFSSGSFHSREEEEEGVSLLRTALVGQGPVPLFLGSLFCAGCRQGPSVWSCGEPVPRRIWVTASVTPSPRQALHPCSDSLDILKALHLLPAAFSPFIWVQVFAEPSNKESRGENDGGEERESANIY>sp|Q8N377|YJ004_HUMAN Putative uncharacterized protein LOC387726 OS=Homosapiens OX=9606 PE=5 SV=2MDFRQISPTTCTTPASSSSAAPPTPASSSSAAPPTPASSSSAAPPTPANCSTAAPPTPANCSTAAPPTPASSGSAAPPTPAPDHWWMEAPHHWLPGLLARCGSRQLPSSVGLACFGTAAVPRKPVNWACQGSHGELEASQVGSGKAGPCTPHPSLLGF>sp|Q6UXV3|YV010_HUMAN Uncharacterized protein UNQ6126/PRO20091 OS=Homosapiens OX=9606 GN=UNQ6126/PRO20091 PE=2 SV=1MLPEQGPQPSTMPLWCLLAACTSLPRQAATMLEEAASPNEAVHASTSGSGALTDQTFTDLSAAEASSEEVPDFMEVPHSVHHKINCFFYLEKQLCQLPSPLCLSSLLTLKLKTTVPAPGRWWSFQPHKAFPLLVGTPGSWQSTIDPAWAAPSQPSPG>sp|O95789|ZMYM6_HUMAN Zinc finger MYM-type protein 6 OS=Homo sapiensOX=9606 GN=ZMYM6 PE=1 SV=2MKEPLDGECGKAVVPQQELLDKIKEEPDNAQEYGCVQQPKTQESKLKIGGVSSVNERPIAQQLNPGFQLSFASSGPSVLLPSVPAVAIKVFCSGCKKMLYKGQTAYHKTGSTQLFCSTRCITRHSSPACLPPPPKKTCTNCSKDILNPKDVITTRFENSYPSKDFCSQSCLSSYELKKKPVVTIYTKSISTKCSMCQKNADTRFEVKYQNVVHGLCSDACFSKFHSTNNLTMNCCENCGSYCYSSSGPCQSQKVFSSTSVTAYKQNSAQIPPYALGKSLRPSAEMIETTNDSGKTELFCSINCLSAYRVKTVTSSGVQVSCHSCKTSAIPQYHLAMSNGTIYSFCSSSCVVAFQNVFSKPKGTNSSAVPLSQGQVVVSPPSSRSAVSIGGGNTSAVSPSSIRGSAAASLQPLAEQSQQVALTHTVVKLKCQHCNHLFATKPELLFYKGKMFLFCGKNCSDEYKKKNKVVAMCDYCKLQKIIKETVRFSGVDKPFCSEVCKFLSARDFGERWGNYCKMCSYCSQTSPNLVENRLEGKLEEFCCEDCMSKFTVLFYQMAKCDGCKRQGKLSESIKWRGNIKHFCNLFCVLEFCHQQIMNDCLPQNKVNISKAKTAVTELPSARTDTTPVITSVMSLAKIPATLSTGNTNSVLKGAVTKEAAKIIQDESTQEDAMKFPSSQSSQPSRLLKNKGISCKPVTQTKATSCKPHTQHKECQTDLPMPNEKNDAELDSPPSKKKRLGFFQTYDTEYLKVGFIICPGSKESSPRPQCVICGEILSSENMKPANLSHHLKTKHSELENKPVDFFEQKSLEMECQNSSLKKCLLVEKSLVKASYLIAFQTAASKKPFSIAEELIKPYLVEMCSEVLGSSAGDKMKTIPLSNVTIQHRIDELSADIEDQLIQKVRESKWFALQIDESSEISNITLLLCYIRFIDYDCRDVKEELLFCIEMPTQITGFEIFELINKYIDSKSLNWKHCVGLCTDGAASMTGRYSGLKAKIQEVAMNTAAFTHCFIHRERLVAEKLSPCLHKILLQSAQILSFIKSNALNSRMLTILCEEMGSEHVSLPLHAEVRWISRGRMLKRLFELRHEIEIFLSQKHSDLAKYFHDEEWVGKLAYLSDIFSLINELNLSLQGTLTTFFNLCNKIDVFKRKLKMWLKRTQENDYDMFPSFSEFSNSSGLNMTDITRIIFEHLEGLSQVFSDCFPPEQDLRSGNLWIIHPFMNHQNNNLTDFEEEKLTELSSDLGLQALFKSVSVTQFWINAKTSYPELHERAMKFLLPFSTVYLCDAAFSALTESKQKNLLGSGPALRLAVTSLIPRIEKLVKEKE>sp|O95789-2|ZMYM6_HUMAN Isoform 2 of Zinc finger MYM-type protein 6OS=Homo sapiens OX=9606 GN=ZMYM6MKEPLDGECGKAVVPQQELLDKIKEEPDNAQEYGCVQQPKTQESKLKIGGVSSVNERPIAQQLNPGFQLSFASSGPSVLLPSVPAVAIKVFCSGCKKMLYKGQTAYHKTGSTQLFCSTRCITRHSSPACLPPPPKKTCTNCSKYKILNIPFYFTFF>sp|O95789-1|ZMYM6_HUMAN Isoform 1 of Zinc finger MYM-type protein 6OS=Homo sapiens OX=9606 GN=ZMYM6MKEPLDGECGKAVVPQQELLDKIKEEPDNAQEYGCVQQPKTQESKLKIGGVSSVNERPIAQQLNPGFQLSFASSGPSVLLPSVPAVAIKVFCSGCKKMLYKGQTAYHKTGSTQLFCSTRCITRHSSPACLPPPPKKTCTNCSKDILNPKDVITTRFENSYPSKDFCSQSCLSSYELKKKPVVTIYTKSISTKCSMCQKNADTRFEVKYQNVVHGLCSDACFSKFHSTNNLTMNCCENCGSYCYSSSGPCQSQKVFSSTSVTAYKQNSAQIPPYALGKSLRPSAEMIETTNDSGKTELFCSINCLSAYRVKTVTSSGVQVSCHSCKTSAIPQYHLAMSNGTIYSFCSSSCVVAFQNVFSKPKGTNSSAVPLSQGQVVVSPPSSRSAVSIGGGNTSAVSPSSIRGSAAASLQPLAEQSQQVALTHTVVKLKCQHCNHLFATKPELLFYKGKMFLFCGKNCSDEYKKKNKVVAMCDYCKLQKIIKETVRFSGVDKPFCSEVCKFLSARDFGERWGNYCKMCSYCSQTSPNLVENRLEGKLEEFCCEDCMSKFTVLFYQMAKCDGCKRQGKLSESIKWRGNIKHFCNLFCVLEFCHQQIMNDCLPQNKVNISKAKTAVTELPSARTDTTPVITSVMSLAKIPATLSTGNTNSVLKGAVTKEAAKIIQDESTQEDAMKFPSSQSSQPSRLLKNKGISCKPVTQTKATSCKPHTQHKECQTECPVRAVC>sp|O95789-4|ZMYM6_HUMAN Isoform 4 of Zinc finger MYM-type protein 6OS=Homo sapiens OX=9606 GN=ZMYM6MKEPLDGECGKAVVPQQELLDKIKEEPDNAQEYGCVQQPKTQESKLKIGGVSSVNERPIAQQLNPGFQLSFASSGPSVLLPSVPAVAIKVFCSGCKKMLYKGQTAYHKTGSTQLFCSTRCITRHSSPACLPPPPKKTCTNCSKYKILNIPFYFTFFLVCILFSSNILLIL>sp|O95789-5|ZMYM6_HUMAN Isoform 5 of Zinc finger MYM-type protein 6OS=Homo sapiens OX=9606 GN=ZMYM6MNFKYVGRYIKNIAYLFLKITVIQIFHSDLPMPNEKNDAELDSPPSKKKRLGFFQTYDTEYLKVGFIICPGSKESSPRPQCVICGEILSSENMKPANLSHHLKTKHSELENKPVDFFEQKSLEMECQNSSLKKCLLVEKSLVKASYLIAFQTAASKKPFSIAEELIKPYLVEMCSEVLGSSAGDKMKTIPLSNVTIQHRIDELSADIEDQLIQKVRESKWFALQIDESSEISNITLLLCYIRFIDYDCRDVKEELLFCIEMPTQITGFEIFELINKYIDSKSLNWKHCVGLCTDGAASMTGRYSGLKAKIQEVAMNTAAFTHCFIHRERLVAEKLSPCLHKILLQSAQILSFIKSNALNSRMLTILCEEMGSEHVSLPLHAEVRWISRGRMLKRLFELRHEIEIFLSQKHSDLAKYFHDEEWVGKLAYLSDIFSLINELNLSLQGTLTTFFNLCNKIDVFKRKLKMWLKRTQENDYDMFPSFSEFSNSSGLNMTDITRIIFEHLEGLSQVFSDCFPPEQDLRSGNLWIIHPFMNHQNNNLTDFEEEKLTELSSDLGLQALFKSVSVTQFWINAKTSYPELHERAMKFLLPFSTVYLCDAAFSALTESKQKNLLGSGPALRLAVTSLIPRIEKLVKEKE>sp|Q147U1|ZN846_HUMAN Zinc finger protein 846 OS=Homo sapiens OX=9606GN=ZNF846 PE=1 SV=2MDSSQHLVTFEDVAVDFTQEEWTLLDQAQRDLYRDVMLENYKNLIILAGSELFKRSLMSGLEQMEELRTGVTGVLQELDLQLKTKGSPLLQDISAERSPNGVQLERSNTAEKLYDSNHSGKVFNEHPFLMTHMITHIGEKTSEDNQSGKALRKNFPHSFYKKSHAEGKMPKCVKHEKAFNQFPNLTRQNKTHTQEKLCECKDCWRTFLNQSSLKLHIRSHNGDKHYVCKECGKAFSNSSHLIGHGRIHSGEKPYVCKECGKAFTQSTGLKLHIRTHSGEKPYKCKECGKAFTHSSYLTDHTRIHSGKKPYVCMECGKAFTRSTGLILHMRIHTGEKPYECKECGKAFIHSSYLTKHVRIHSGEKLYLCKACGKAFTRSSGLVLHMRTHTGEKPYECKECGKAFNNSSMLSQHVRIHTGEKPYECKECGKAFTQSSGLSTHLRTHTGEKACECKECGKAFARSTNLNMHMRTHTGEKPYACKECGKAFRYSTYLNVHTRTHTGAKPYECKKCGKNFTQSSALAKHLRTKACEKT>sp|Q147U1-3|ZN846_HUMAN Isoform 2 of Zinc finger protein 846 OS=Homosapiens OX=9606 GN=ZNF846MTHMITHIGEKTSEDNQSGKALRKNFPHSFYKKSHAEGKMPKCVKHEKAFNQFPNLTRQNKTHTQEKLCECKDCWRTFLNQSSLKLHIRSHNGDKHYVCKECGKAFSNSSHLIGHGRIHSGEKPYVCKECGKAFTQSTGLKLHIRTHSGEKPYKCKECGKAFTHSSYLTDHTRIHSGKKPYVCMECGKAFTRSTGLILHMRIHTGEKPYE>sp|Q9HA38|ZMAT3_HUMAN Zinc finger matrin-type protein 3 OS=Homo sapiensOX=9606 GN=ZMAT3 PE=1 SV=1MILLQHAVLPPPKQPSPSPPMSVATRSTGTLQLPPQKPFGQEASLPLAGEEELSKGGEQDCALEELCKPLYCKLCNVTLNSAQQAQAHYQGKNHGKKLRNYYAANSCPPPARMSNVVEPAATPVVPVPPQMGSFKPGGRVILATENDYCKLCDASFSSPAVAQAHYQGKNHAKRLRLAEAQSNSFSESSELGQRRARKEGNEFKMMPNRRNMYTVQNNSAGPYFNPRSRQRIPRDLAMCVTPSGQFYCSMCNVGAGEEMEFRQHLESKQHKSKVSEQRYRNEMENLGYV>sp|Q9HA38-2|ZMAT3_HUMAN Isoform 2 of Zinc finger matrin-type protein 3OS=Homo sapiens OX=9606 GN=ZMAT3MILLQHAVLPPPKQPSPSPPMSVATRSTGTLQLPPQKPFGQEASLPLAGEEELSKGGEQDCALEELCKPLYCKLCNVTLNSAQQAQAHYQGKNHGKKLRNYYAANSCPPPARMSNVVEPAATPVVPVPPQMGSFKPGGRVILATENDYCKLCDASFSSPAVAQAHYQGKNHAKRLRLAEAQSNSFSESSELGQRRARKEGNEFKMMPNRRNMYTVQNNSGPYFNPRSRQRIPRDLAMCVTPSGQFYCSMCNVGAGEEMEFRQHLESKQHKSKVSEQRYRNEMENLGYV>sp|Q8N7K0|ZN433_HUMAN Zinc finger protein 433 OS=Homo sapiens OX=9606GN=ZNF433 PE=1 SV=1MMFQDSVAFEDVAVTFTQEEWALLDPSQKNLCRDVMQETFRNLASIGKKWKPQNIYVEYENLRRNLRIVGERLFESKEGHQHGEILTQVPDDMLKKTTTGVKSCESSVYGEVGSAHSSLNRHIRDDTGHKAYEYQEYGQKPYKCKYCKKPFNCLSSVQTHERAHSGRKLYVCEECGKTFISHSNLQRHRIMHRGDGPYKCKFCGKALMFLSLYLIHKRTHTGEKPYQCKQCGKAFSHSSSLRIHERTHTGEKPYKCNECGKAFHSSTCLHAHKRTHTGEKPYECKQCGKAFSSSHSFQIHERTHTGEKPYECKECGKAFKCPSSVRRHERTHSRKKPYECKHCGKVLSYLTSFQNHLGMHTGEISHKCKICGKAFYSPSSLQTHEKTHTGEKPYKCNQCGKAFNSSSSFRYHERTHTGEKPYECKQCGKAFRSASLLQTHGRTHTGEKPYACKECGKPFSNFSFFQIHERMHREEKPYECKGYGKTFSLPSLFHRHERTHTGGKTYECKQCGRSFNCSSSFRYHGRTHTGEKPYECKQCGKAFRSASQLQIHGRTHTGEKPYECKQCGKAFGSASHLQMHGRTHTGEKPYECKQCGKSFGCASRLQMHGRTHTGEKPYKCKQCGKAFGCPSNLRRHGRTHTGEKPYKCNQCGKVFRCSSQLQVHGRAHCIDTP>sp|Q8N7K0-2|ZN433_HUMAN Isoform 2 of Zinc finger protein 433 OS=Homosapiens OX=9606 GN=ZNF433MQETFRNLASIGKKWKPQNIYVEYENLRRNLRIVGERLFESKEGHQHGEILTQVPDDMLKKTTTGVKSCESSVYGEVGSAHSSLNRHIRDDTGHKAYEYQEYGQKPYKCKYCKKPFNCLSSVQTHERAHSGRKLYVCEECGKTFISHSNLQRHRIMHRGDGPYKCKFCGKALMFLSLYLIHKRTHTGEKPYQCKQCGKAFSHSSSLRIHERTHTGEKPYKCNECGKAFHSSTCLHAHKRTHTGEKPYECKQCGKAFSSSHSFQIHERTHTGEKPYECKECGKAFKCPSSVRRHERTHSRKKPYECKHCGKVLSYLTSFQNHLGMHTGEISHKCKICGKAFYSPSSLQTHEKTHTGEKPYKCNQCGKAFNSSSSFRYHERTHTGEKPYECKQCGKAFRSASLLQTHGRTHTGEKPYACKECGKPFSNFSFFQIHERMHREEKPYECKGYGKTFSLPSLFHRHERTHTGGKTYECKQCGRSFNCSSSFRYHGRTHTGEKPYECKQCGKAFRSASQLQIHGRTHTGEKPYECKQCGKAFGSASHLQMHGRTHTGEKPYECKQCGKSFGCASRLQMHGRTHTGEKPYKCKQCGKAFGCPSNLRRHGRTHTGEKPYKCNQCGKVFRCSSQLQVHGRAHCIDTP>sp|P59923|ZN445_HUMAN Zinc finger protein 445 OS=Homo sapiens OX=9606GN=ZNF445 PE=1 SV=1MPPGRWHAAYPAQAQSSRERGRLQTVKKEEEDESYTPVQAARPQTLNRPGQELFRQLFRQLRYHESSGPLETLSRLRELCRWWLRPDVLSKAQILELLVLEQFLSILPGELRVWVQLHNPESGEEAVALLEELQRDLDGTSWRDPGPAQSPDVHWMGTGALRSAQIWSLASPLRSSSALGDHLEPPYEIEARDFLAGQSDTPAAQMPALFPREGCPGDQVTPTRSLTAQLQETMTFKDVEVTFSQDEWGWLDSAQRNLYRDVMLENYRNMASLVGPFTKPALISWLEAREPWGLNMQAAQPKGNPVAAPTGDDLQSKTNKFILNQEPLEEAETLAVSSGCPATSVSEGIGLRESFQQKSRQKDQCENPIQVRVKKEETNFSHRTGKDSEVSGSNSLDLKHVTYLRVSGRKESLKHGCGKHFRMSSHHYDYKKYGKGLRHMIGGFSLHQRIHSGLKGNKKDVCGKDFSLSSHHQRGQSLHTVGVSFKCSDCGRTFSHSSHLAYHQRLHTQEKAFKCRVCGKAFRWSSNCARHEKIHTGVKPYKCDLCEKAFRRLSAYRLHRETHAKKKFLELNQYRAALTYSSGFDHHLGDQSGEKLFDCSQCRKSFHCKSYVLEHQRIHTQEKPYKCTKCRKTFRWRSNFTRHMRLHEEEKFYKQDECREGFRQSPDCSQPQGAPAVEKTFLCQQCGKTFTRKKTLVDHQRIHTGEKPYQCSDCGKDFAYRSAFIVHKKKHAMKRKPEGGPSFSQDTVFQVPQSSHSKEEPYKCSQCGKAFRNHSFLLIHQRVHTGEKPYKCRECGKAFRWSSNLYRHQRIHSLQKQYDCHESEKTPNVEPKILTGEKRFWCQECGKTFTRKRTLLDHKGIHSGEKRYKCNLCGKSYDRNYRLVNHQRIHSTERPFKCQWCGKEFIGRHTLSSHQRKHTRAAQAERSPPARSSSQDTKLRLQKLKPSEEMPLEDCKEACSQSSRLTGLQDISIGKKCHKCSICGKTFNKSSQLISHKRFHTRERPFKCSKCGKTFRWSSNLARHMKNHIRD>sp|Q9UHA3|RLP24_HUMAN Probable ribosome biogenesis protein RLP24 OS=Homosapiens OX=9606 GN=RSL24D1 PE=1 SV=1MRIEKCYFCSGPIYPGHGMMFVRNDCKVFRFCKSKCHKNFKKKRNPRKVRWTKAFRKAAGKELTVDNSFEFEKRRNEPIKYQRELWNKTIDAMKRVEEIKQKRQAKFIMNRLKKNKELQKVQDIKEVKQNIHLIRAPLAGKGKQLEEKMVQQLQEDVDMEDAP>sp|Q8IXW5|RPAP2_HUMAN Putative RNA polymerase II subunit B1 CTDphosphatase RPAP2 OS=Homo sapiens OX=9606 GN=RPAP2 PE=1 SV=1MADFAGPSSAGRKAGAPRCSRKAAGTKQTSTLKQEDASKRKAELEAAVRKKIEFERKALHIVEQLLEENITEEFLMECGRFITPAHYSDVVDERSIVKLCGYPLCQKKLGIVPKQKYKISTKTNKVYDITERKSFCSNFCYQASKFFEAQIPKTPVWVREEERHPDFQLLKEEQSGHSGEEVQLCSKAIKTSDIDNPSHFEKQYESSSSSTHSDSSSDNEQDFVSSILPGNRPNSTNIRPQLHQKSIMKKKAGHKANSKHKDKEQTVVDVTEQLGDCKLDSQEKDATCELPLQKVNTQSSSNSTLPERLKASENSESEYSRSEITLVGISKKSAEHFKRKFAKSNQVSRSVSSSVQVCPEVGKRNLLKVLKETLIEWKTEETLRFLYGQNYASVCLKPEASLVKEELDEDDIISDPDSHFPAWRESQNSLDESLPFRGSGTAIKPLPSYENLKKETEKLNLRIREFYRGRYVLGEETTKSQDSEEHDSTFPLIDSSSQNQIRKRIVLEKLSKVLPGLLVPLQITLGDIYTQLKNLVRTFRLTNRNIIHKPAEWTLIAMVLLSLLTPILGIQKHSQEGMVFTRFLDTLLEELHLKNEDLESLTIIFRTSCLPE>sp|Q8IXW5-2|RPAP2_HUMAN Isoform 2 of Putative RNA polymerase II subunitB1 CTD phosphatase RPAP2 OS=Homo sapiens OX=9606 GN=RPAP2MADFAGPSSAGRKAGAPRCSRKAAGTKQTSTLKQEDASKRKAELEAAVRKKIEFERKALHIVEQLLEENITEEFLMECGRFITPAHYSDVVDERSIVKLCGYPLCQKKLGIVPKQKYKISTKTNKVYDITERKSFCSNFCYQASKFFEAQIPKTPVWVREEERHPDFQLLKEEQSGHSGEEVQLCSKAIKTSDIDNPSHFEKQYESSSSSTHSDSSSDNEQDFVSSILPGNRPNSTNIRPQLHQKSIMKKKAGHKANSKHKDKEQTVVDVTEQLGDCKLDSQEKDATCELPLQKVNTQSSSNSTLPERLKASENSESEYSRSEITLVGISKKSAEHFKRKFAKSNQVSRSVSSSVQVCPEVGKRNLLKVLKETLIEWKTEETLRFLYGQNYASVCLKPEASLVKEELDEDDIISDPDSHFPAWRESQNSLDESLPFRGSGTAIKPLPSYENLKKETEKLNLRIREFYRGRYVLGEETTKSQDSEEHDSTFPLIDSSSQNQIRKRIVLEKLSKVLPGLLVPLQITLGDIYTQLKNLVRTFRLTNRNIIHKPAEWTLIAMVLLSFLLNVKTRIKTFMMIYFHLMNS>sp|Q92565|RPGF5_HUMAN Rap guanine nucleotide exchange factor 5 OS=Homosapiens OX=9606 GN=RAPGEF5 PE=1 SV=1MGSSRLRVFDPHLERKDSAAALSDRELPLPTFDVPYFKYIDEEDEDDEWSSRSQSSTEDDSVDSLLSDRYVVVSGTPEKILEHLLNDLHLEEVQDKETETLLDDFLLTYTVFMTTDDLCQALLRHYSAKKYQGKEENSDVPRRKRKVLHLVSQWIALYKDWLPEDEHSKMFLKTIYRNVLDDVYEYPILEKELKEFQKILGMHRRHTVDEYSPQKKNKALFHQFSLKENWLQHRGTVTETEEIFCHVYITEHSYVSVKAKVSSIAQEILKVVAEKIQYAEEDLALVAITFSGEKHELQPNDLVISKSLEASGRIYVYRKDLADTLNPFAENEESQQRSMRILGMNTWDLALELMNFDWSLFNSIHEQELIYFTFSRQGSGEHTANLSLLLQRCNEVQLWVATEILLCSQLGKRVQLVKKFIKIAAHCKAQRNLNSFFAIVMGLNTASVSRLSQTWEKIPGKFKKLFSELESLTDPSLNHKAYRDAFKKMKPPKIPFMPLLLKDVTFIHEGNKTFLDNLVNFEKLHMIADTVRTLRHCRTNQFGDLSPKEHQELKSYVNHLYVIDSQQALFELSHRIEPRV>sp|Q92565-2|RPGF5_HUMAN Isoform 2 of Rap guanine nucleotide exchangefactor 5 OS=Homo sapiens OX=9606 GN=RAPGEF5MGSSRLRVFDPHLERKDSAAALSDRELPLPTFDVPYFKYIDEEDEDDEWSSRSQSSTEDDSVDSLLSDRYVVVSGTPEKILEHLLNDLHLEEVQDKETETLLDDFLLTYTVFMTTDDLCQALLRHYSAKKYQGKEENSDVPRRKRKVLHLVSQWIALYKDWLPEDEHSKMFLKTIYRNVLDDVYEYPILEKELKEFQKILGMHRRHTVDEYSPQKKNKALFHQFSLKENWLQHRGTVTETEEIFCHVYITEHSYVSVKAKVSSIAQEILLCSQLGKRVQLVKKFIKIAAHCKAQRNLNSFFAIVMGLNTASVSRLSQTWEKIPGKFKKLFSELESLTDPSLNHKAYRDAFKKMKPPKIPFMPLLLKDVTFIHEGNKTFLDNLVNFEKLHMIADTVRTLRHCRTNQFGDLSPKEHQELKSYVNHLYVIDSQQALFELSHRIEPRV>sp|Q8IVN8|SBSPO_HUMAN Somatomedin-B and thrombospondin type-1 domain-containing protein OS=Homo sapiens OX=9606 GN=SBSPON PE=1 SV=2MRTLWMALCALSRLWPGAQAGCAEAGRCCPGRDPACFARGWRLDRVYGTCFCDQACRFTGDCCFDYDRACPARPCFVGEWSPWSGCADQCKPTTRVRRRSVQQEPQNGGAPCPPLEERAGCLEYSTPQGQDCGHTYVPAFITTSAFNKERTRQATSPHWSTHTEDAGYCMEFKTESLTPHCALENWPLTRWMQYLREGYTVCVDCQPPAMNSVSLRCSGDGLDSDGNQTLHWQAIGNPRCQGTWKKVRRVDQCSCPAVHSFIFI>sp|Q9Y6S9|RPKL1_HUMAN Ribosomal protein S6 kinase-like 1 OS=Homo sapiensOX=9606 GN=RPS6KL1 PE=2 SV=1MSLVACECLPSPGLEPEPCSRARSQAHVYLEQIRNRVALGVPDMTKRDYLVDAATQIRLALERDVSEDYEAAFNHYQNGVDVLLRGIHVDPNKERREAVKLKITKYLRRAEEIFNCHLQRPLSSGASPSAGFSSLRLRPIRTLSSAVEQLRGCRVVGVIEKVQLVQDPATGGTFVVKSLPRCHMVSRERLTIIPHGVPYMTKLLRYFVSEDSIFLHLEHVQGGTLWSHLLSQAHSRHSGLSSGSTQERMKAQLNPHLNLLTPARLPSGHAPGQDRIALEPPRTSPNLLLAGEAPSTRPQREAEGEPTARTSTSGSSDLPKAPGGHLHLQARRAGQNSDAGPPRGLTWVPEGAGPVLGGCGRGMDQSCLSADGAGRGCGRATWSVREEQVKQWAAEMLVALEALHEQGVLCRDLHPGNLLLDQAGHIRLTYFGQWSEVEPQCCGEAVDNLYSAPEVGGISELTEACDWWSFGSLLYELLTGMALSQSHPSGIQAHTQLQLPEWLSRPAASLLTELLQFEPTRRLGMGEGGVSKLKSHPFFSTIQWSKLVG>sp|Q9Y6S9-2|RPKL1_HUMAN Isoform 2 of Ribosomal protein S6 kinase-like 1OS=Homo sapiens OX=9606 GN=RPS6KL1MSLVACECLPSPGLEPEPCSRARSQAHVYLEQIRNRVALGVPDMTKRDYLVDAATQIRLALERDVSEDYEAAFNHYQNGVDVLLRGIHVDPNKERREAVKLKITKYLRRAEEIFNCHLQRPLSSGASPSAVQLVQDPATGGTFVVKSLPRCHMVSRERLTIIPHGVPYMTKLLRYFVSEDSIFLHLEHVQGGTLWSHLLSQAHSRHSGLSSGSTQERMKAQLNPHLNLLTPARLPSGHAPGQDRIALEPPRTSPNLLLAGEAPSTRPQREAEGEPTARTSTSGSSDLPKAPGGHLHLQARRAGQNSDAGPPRGLTWVPEGAGPVLGGCGRGMDQSCLSADGAGRGCGRATWSVREEQVKQWAAEMLVALEALHEQGVLCRDLHPGNLLLDQAGHIRLTYFGQWSEVEPQCCGEAVDNLYSAPEVGGISELTEACDWWSFGSLLYELLTGMALSQSHPSGIQAHTQLQLPEWLSRPAASLLTELLQFEPTRRLGMGEGGVSKLKSHPFFSTIQWSKLVGTSLETHLRTLIHWLSGPKPDCPG>sp|Q9Y6S9-4|RPKL1_HUMAN Isoform 4 of Ribosomal protein S6 kinase-like 1OS=Homo sapiens OX=9606 GN=RPS6KL1MSLVACECLPSPGLEPEPCSRARSQAHVYLEQIRNRVALGVPDMTKRDYLVDAATQIRLALERDVSEDYEAAFNHYQNGVDVLLRGIHVDPNKERREAVKLKITKYLRRAEEIFNCHLQRPLSSGASPSAGFSSLRLRPIRTLSSAVEQLRGCRVVGVIEKVQLVQDPATGGTFVVKSLPRCHMVSRERLTIIPHGVPYMTKLLRYFVSEDSIFLHLEHVQGEQAWGPLSAPQAFGVCRQPLKCGALAGRGGSRL>sp|P07998|RNAS1_HUMAN Ribonuclease pancreatic OS=Homo sapiens OX=9606GN=RNASE1 PE=1 SV=4MALEKSLVRLLLLVLILLVLGWVQPSLGKESRAKKFQRQHMDSDSSPSSSSTYCNQMMRRRNMTQGRCKPVNTFVHEPLVDVQNVCFQEKVTCKNGQGNCYKSNSSMHITDCRLTNGSRYPNCAYRTSPKERHIIVACEGSPYVPVHFDASVEDST>sp|P20132|SDHL_HUMAN L-serine dehydratase/L-threonine deaminase OS=Homosapiens OX=9606 GN=SDS PE=1 SV=2MMSGEPLHVKTPIRDSMALSKMAGTSVYLKMDSAQPSGSFKIRGIGHFCKRWAKQGCAHFVCSSAGNAGMAAAYAARQLGVPATIVVPSTTPALTIERLKNEGATVKVVGELLDEAFELAKALAKNNPGWVYIPPFDDPLIWEGHASIVKELKETLWEKPGAIALSVGGGGLLCGVVQGLQEVGWGDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAKALGVKTVGAQALKLFQEHPIFSEVISDQEAVAAIEKFVDDEKILVEPACGAALAAVYSHVIQKLQLEGNLRTPLPSLVVIVCGGSNISLAQLRALKEQLGMTNRLPK>sp|Q2KHN1|RN151_HUMAN RING finger protein 151 OS=Homo sapiens OX=9606GN=RNF151 PE=1 SV=1MGGGYDLNLFASPPDSNFVCSVCHGVLKRPARLPCSHIFCKKCILRWLARQKTCPCCRKEVKRKKVVHMNKLRKTIGRLEVKCKNADAGCIVTCPLAHRKGHQDSCPFELTACPNEGCTSQVPRGTLAEHRQHCQQGSQQRCPLGCGATLDPAERARHNCYRELHNAWSVRQERRRPLLLSLLRRVRWLDQATSVVRRELAELSNFLEEDTALLEGAPQEEAEAAPEGNVGAEVVGEPRANIPCK>sp|Q96C74|ROP1L_HUMAN Ropporin-1-like protein OS=Homo sapiens OX=9606GN=ROPN1L PE=1 SV=2MPLPDTMFCAQQIHIPPELPDILKQFTKAAIRTQPADVLRWSAGYFSALSRGDPLPVKDRMEMPTATQKTDTGLTQGLLKVLHKQCHHKRYVELTDLEQKWKNLCLPKEKFKALLQLDPCENKIKWINFLALGCSMLGGSLNTALKHLCEILTDDPEGGPARIPFKTFSYVYRYLARLDSDVSPLETESYLASLKENIDARKNGMIGLSDFFFPKRKLLESIENSEDVGH>sp|Q01974|ROR2_HUMAN Tyrosine-protein kinase transmembrane receptor ROR2OS=Homo sapiens OX=9606 GN=ROR2 PE=1 SV=2MARGSALPRRPLLCIPAVWAAAALLLSVSRTSGEVEVLDPNDPLGPLDGQDGPIPTLKGYFLNFLEPVNNITIVQGQTAILHCKVAGNPPPNVRWLKNDAPVVQEPRRIIIRKTEYGSRLRIQDLDTTDTGYYQCVATNGMKTITATGVLFVRLGPTHSPNHNFQDDYHEDGFCQPYRGIACARFIGNRTIYVDSLQMQGEIENRITAAFTMIGTSTHLSDQCSQFAIPSFCHFVFPLCDARSRTPKPRELCRDECEVLESDLCRQEYTIARSNPLILMRLQLPKCEALPMPESPDAANCMRIGIPAERLGRYHQCYNGSGMDYRGTASTTKSGHQCQPWALQHPHSHHLSSTDFPELGGGHAYCRNPGGQMEGPWCFTQNKNVRMELCDVPSCSPRDSSKMGILYILVPSIAIPLVIACLFFLVCMCRNKQKASASTPQRRQLMASPSQDMEMPLINQHKQAKLKEISLSAVRFMEELGEDRFGKVYKGHLFGPAPGEQTQAVAIKTLKDKAEGPLREEFRHEAMLRARLQHPNVVCLLGVVTKDQPLSMIFSYCSHGDLHEFLVMRSPHSDVGSTDDDRTVKSALEPPDFVHLVAQIAAGMEYLSSHHVVHKDLATRNVLVYDKLNVKISDLGLFREVYAADYYKLLGNSLLPIRWMAPEAIMYGKFSIDSDIWSYGVVLWEVFSYGLQPYCGYSNQDVVEMIRNRQVLPCPDDCPAWVYALMIECWNEFPSRRPRFKDIHSRLRAWGNLSNYNSSAQTSGASNTTQTSSLSTSPVSNVSNARYVGPKQKAPPFPQPQFIPMKGQIRPMVPPPQLYVPVNGYQPVPAYGAYLPNFYPVQIPMQMAPQQVPPQMVPKPSSHHSGSGSTSTGYVTTAPSNTSMADRAALLSEGADDTQNAPEDGAQSTVQEAEEEEEGSVPETELLGDCDTLQVDEAQVQLEA>sp|E7ERA6|RN223_HUMAN RING finger protein 223 OS=Homo sapiens OX=9606GN=RNF223 PE=2 SV=1MSSGQQVWHTAVPPPRRSSSIASMPRSPSSAGSPRSPGTPGSERVASPLECSICFSGYDNIFKTPKELSCTHVFCLECLARLAAAQPVGRPGGEAVPCPFCRQPTAVPPAGAPALCTSRQLQARMPAHLRREEPVWLEGTKLCCQPLPTTPGREPGFVCVDVGLSKPAEPPAPARDPAPRRGRLARCWARCRDWRRMALVSALLLMLFCVALWPVQCALKTGNLRCLPLPPRPPATSTAASPLGPLTDN>sp|Q9P2E9|RRBP1_HUMAN Ribosome-binding protein 1 OS=Homo sapiens OX=9606GN=RRBP1 PE=1 SV=5MDIYDTQTLGVVVFGGFMVVSAIGIFLVSTFSMKETSYEEALANQRKEMAKTHHQKVEKKKKEKTVEKKGKTKKKEEKPNGKIPDHDPAPNVTVLLREPVRAPAVAVAPTPVQPPIIVAPVATVPAMPQEKLASSPKDKKKKEKKVAKVEPAVSSVVNSIQVLTSKAAILETAPKEVPMVVVPPVGAKGNTPATGTTQGKKAEGTQNQSKKAEGAPNQGRKAEGTPNQGKKTEGTPNQGKKAEGTPNQGKKAEGTPNQGKKAEGAQNQGKKVDTTPNQGKKVEGAPTQGRKAEGAQNQAKKVEGAQNQGKKAEGAQNQGKKGEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKVEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGKKVEGAQNQGKKAEGAQNQGKKAEGAQNQGKKAEGAQNQGQKGEGAQNQGKKTEGAQGKKAERSPNQGKKGEGAPIQGKKADSVANQGTKVEGITNQGKKAEGSPSEGKKAEGSPNQGKKADAAANQGKKTESASVQGRNTDVAQSPEAPKQEAPAKKKSGSKKKGEPGPPDADGPLYLPYKTLVSTVGSMVFNEGEAQRLIEILSEKAGIIQDTWHKATQKGDPVAILKRQLEEKEKLLATEQEDAAVAKSKLRELNKEMAAEKAKAAAGEAKVKKQLVAREQEITAVQARMQASYREHVKEVQQLQGKIRTLQEQLENGPNTQLARLQQENSILRDALNQATSQVESKQNAELAKLRQELSKVSKELVEKSEAVRQDEQQRKALEAKAAAFEKQVLQLQASHRESEEALQKRLDEVSRELCHTQSSHASLRADAEKAQEQQQQMAELHSKLQSSEAEVRSKCEELSGLHGQLQEARAENSQLTERIRSIEALLEAGQARDAQDVQASQAEADQQQTRLKELESQVSGLEKEAIELREAVEQQKVKNNDLREKNWKAMEALATAEQACKEKLLSLTQAKEESEKQLCLIEAQTMEALLALLPELSVLAQQNYTEWLQDLKEKGPTLLKHPPAPAEPSSDLASKLREAEETQSTLQAECDQYRSILAETEGMLRDLQKSVEEEEQVWRAKVGAAEEELQKSRVTVKHLEEIVEKLKGELESSDQVREHTSHLEAELEKHMAAASAECQNYAKEVAGLRQLLLESQSQLDAAKSEAQKQSDELALVRQQLSEMKSHVEDGDIAGAPASSPEAPPAEQDPVQLKTQLEWTEAILEDEQTQRQKLTAEFEEAQTSACRLQEELEKLRTAGPLESSETEEASQLKERLEKEKKLTSDLGRAATRLQELLKTTQEQLAREKDTVKKLQEQLEKAEDGSSSKEGTSV>sp|Q9P2E9-3|RRBP1_HUMAN Isoform 2 of Ribosome-binding protein 1 OS=Homosapiens OX=9606 GN=RRBP1MDIYDTQTLGVVVFGGFMVVSAIGIFLVSTFSMKETSYEEALANQRKEMAKTHHQKVEKKKKEKTVEKKGKTKKKEEKPNGKIPDHDPAPNVTVLLREPVRAPAVAVAPTPVQPPIIVAPVATVPAMPQEKLASSPKDKKKKEKKVAKVEPAVSSVVNSIQVLTSKAAILETAPKEGRNTDVAQSPEAPKQEAPAKKKSGSKKKGPPDADGPLYLPYKTLVSTVGSMVFNEGEAQRLIEILSEKAGIIQDTWHKATQKGDPVAILKRQLEEKEKLLATEQEDAAVAKSKLRELNKEMAAEKAKAAAGEAKVKKQLVAREQEITAVQARMQASYREHVKEVQQLQGKIRTLQEQLENGPNTQLARLQQENSILRDALNQATSQVESKQNAELAKLRQELSKVSKELVEKSEAVRQDEQQRKALEAKAAAFEKQVLQLQASHRESEEALQKRLDEVSRELCHTQSSHASLRADAEKAQEQQQQMAELHSKLQSSEAEVRSKCEELSGLHGQLQEARAENSQLTERIRSIEALLEAGQARDAQDVQASQAEADQQQTRLKELESQVSGLEKEAIELREAVEQQKVKNNDLREKNWKAMEALATAEQACKEKLLSLTQAKEESEKQLCLIEAQTMEALLALLPELSVLAQQNYTEWLQDLKEKGPTLLKHPPAPAEPSSDLASKLREAEETQSTLQAECDQYRSILAETEGMLRDLQKSVEEEEQVWRAKVGAAEEELQKSRVTVKHLEEIVEKLKGELESSDQVREHTSHLEAELEKHMAAASAECQNYAKEVAGLRQLLLESQSQLDAAKSEAQKQSDELALVRQQLSEMKSHVEDGDIAGAPASSPEAPPAEQDPVQLKTQLEWTEAILEDEQTQRQKLTAEFEEAQTSACRLQEELEKLRTAGPLESSETEEASQLKERLEKEKKLTSDLGRAATRLQELLKTTQEQLAREKDTVKKLQEQLEKAEDGSSSKEGTSV>sp|P39019|RS19_HUMAN 40S ribosomal protein S19 OS=Homo sapiens OX=9606GN=RPS19 PE=1 SV=2MPGVTVKDVNQQEFVRALAAFLKKSGKLKVPEWVDTVKLAKHKELAPYDENWFYTRAASTARHLYLRGGAGVGSMTKIYGGRQRNGVMPSHFSRGSKSVARRVLQALEGLKMVEKDQDGGRKLTPQGQRDLDRIAGQVAAANKKH>sp|P62249|RS16_HUMAN 40S ribosomal protein S16 OS=Homo sapiens OX=9606GN=RPS16 PE=1 SV=2MPSKGPLQSVQVFGRKKTATAVAHCKRGNGLIKVNGRPLEMIEPRTLQYKLLEPVLLLGKERFAGVDIRVRVKGGGHVAQIYAIRQSISKALVAYYQKYVDEASKKEIKDILIQYDRTLLVADPRRCESKKFGGPGARARYQKSYR>sp|P62857|RS28_HUMAN 40S ribosomal protein S28 OS=Homo sapiens OX=9606GN=RPS28 PE=1 SV=1MDTSRVQPIKLARVTKVLGRTGSQGQCTQVRVEFMDDTSRSIIRNVKGPVREGDVLTLLESEREARRLR>sp|P48436|SOX9_HUMAN Transcription factor SOX-9 OS=Homo sapiens OX=9606GN=SOX9 PE=1 SV=1MNLLDPFMKMTDEQEKGLSGAPSPTMSEDSAGSPCPSGSGSDTENTRPQENTFPKGEPDLKKESEEDKFPVCIREAVSQVLKGYDWTLVPMPVRVNGSSKNKPHVKRPMNAFMVWAQAARRKLADQYPHLHNAELSKTLGKLWRLLNESEKRPFVEEAERLRVQHKKDHPDYKYQPRRRKSVKNGQAEAEEATEQTHISPNAIFKALQADSPHSSSGMSEVHSPGEHSGQSQGPPTPPTTPKTDVQPGKADLKREGRPLPEGGRQPPIDFRDVDIGELSSDVISNIETFDVNEFDQYLPPNGHPGVPATHGQVTYTGSYGISSTAATPASAGHVWMSKQQAPPPPPQQPPQAPPAPQAPPQPQAAPPQQPAAPPQQPQAHTLTTLSSEPGQSQRTHIKTEQLSPSHYSEQQQHSPQQIAYSPFNLPHYSPSYPPITRSQYDYTDHQNSSSYYSHAAGQGTGLYSTFTYMNPAQRPMYTPIADTSGVPSIPQTHSPQHWEQPVYTQLTRP>sp|Q9UPX8|SHAN2_HUMAN SH3 and multiple ankyrin repeat domains protein 2OS=Homo sapiens OX=9606 GN=SHANK2 PE=1 SV=3MKSLLNAFTKKEVPFREAPAYSNRRRRPPNTLAAPRVLLRSNSDNNLNASAPDWAVCSTATSHRSLSPQLLQQMPSKPEGAAKTIGSYVPGPRSRSPSLNRLGGAGEDGKRPQPLWHVGSPFALGANKDSLSAFEYPGPKRKLYSAVPGRLFVAVKPYQPQVDGEIPLHRGDRVKVLSIGEGGFWEGSARGHIGWFPAECVEEVQCKPRDSQAETRADRSKKLFRHYTVGSYDSFDTSSDCIIEEKTVVLQKKDNEGFGFVLRGAKADTPIEEFTPTPAFPALQYLESVDEGGVAWQAGLRTGDFLIEVNNENVVKVGHRQVVNMIRQGGNHLVLKVVTVTRNLDPDDTARKKAPPPPKRAPTTALTLRSKSMTSELEELVDKASVRKKKDKPEEIVPASKPSRAAENMAVEPRVATIKQRPSSRCFPAGSDMNSVYERQGIAVMTPTVPGSPKAPFLGIPRGTMRRQKSIDSRIFLSGITEEERQFLAPPMLKFTRSLSMPDTSEDIPPPPQSVPPSPPPPSPTTYNCPKSPTPRVYGTIKPAFNQNSAAKVSPATRSDTVATMMREKGMYFRRELDRYSLDSEDLYSRNAGPQANFRNKRGQMPENPYSEVGKIASKAVYVPAKPARRKGMLVKQSNVEDSPEKTCSIPIPTIIVKEPSTSSSGKSSQGSSMEIDPQAPEPPSQLRPDESLTVSSPFAAAIAGAVRDREKRLEARRNSPAFLSTDLGDEDVGLGPPAPRTRPSMFPEEGDFADEDSAEQLSSPMPSATPREPENHFVGGAEASAPGEAGRPLNSTSKAQGPESSPAVPSASSGTAGPGNYVHPLTGRLLDPSSPLALALSARDRAMKESQQGPKGEAPKADLNKPLYIDTKMRPSLDAGFPTVTRQNTRGPLRRQETENKYETDLGRDRKGDDKKNMLIDIMDTSQQKSAGLLMVHTVDATKLDNALQEEDEKAEVEMKPDSSPSEVPEGVSETEGALQISAAPEPTTVPGRTIVAVGSMEEAVILPFRIPPPPLASVDLDEDFIFTEPLPPPLEFANSFDIPDDRAASVPALSDLVKQKKSDTPQSPSLNSSQPTNSADSKKPASLSNCLPASFLPPPESFDAVADSGIEEVDSRSSSDHHLETTSTISTVSSISTLSSEGGENVDTCTVYADGQAFMVDKPPVPPKPKMKPIIHKSNALYQDALVEEDVDSFVIPPPAPPPPPGSAQPGMAKVLQPRTSKLWGDVTEIKSPILSGPKANVISELNSILQQMNREKLAKPGEGLDSPMGAKSASLAPRSPEIMSTISGTRSTTVTFTVRPGTSQPITLQSRPPDYESRTSGTRRAPSPVVSPTEMNKETLPAPLSAATASPSPALSDVFSLPSQPPSGDLFGLNPAGRSRSPSPSILQQPISNKPFTTKPVHLWTKPDVADWLESLNLGEHKEAFMDNEIDGSHLPNLQKEDLIDLGVTRVGHRMNIERALKQLLDR>sp|Q9UPX8-2|SHAN2_HUMAN Isoform 2 of SH3 and multiple ankyrin repeatdomains protein 2 OS=Homo sapiens OX=9606 GN=SHANK2MMMNVPGGGAAAVMMTGYNNGRCPRNSLYSDCIIEEKTVVLQKKDNEGFGFVLRGAKADTPIEEFTPTPAFPALQYLESVDEGGVAWQAGLRTGDFLIEVNNENVVKVGHRQVVNMIRQGGNHLVLKVVTVTRNLDPDDTARKKAPPPPKRAPTTALTLRSKSMTSELEELVDKASVRKKKDKPEEIVPASKPSRAAENMAVEPRVATIKQRPSSRCFPAGSDMNSVYERQGIAVMTPTVPGSPKAPFLGIPRGTMRRQKSIGKKCGTPPQKLPLGFQTQP>sp|Q9UPX8-3|SHAN2_HUMAN Isoform 3 of SH3 and multiple ankyrin repeatdomains protein 2 OS=Homo sapiens OX=9606 GN=SHANK2MPRSPTSSEDEMAQSFSDYSVGSESDSSKEETIYDTIRATAEKPGGARTEESQGNTLVIRVVIHDLQQTKCIRFNPDATVWVAKQRILCTLTQSLKDVLNYGLFQPASNGRDGKFLDEERLLREYPQPVGEGVPSLEFRYKKRVYKQASLDEKQLAKLHTKTNLKKCMDHIQHRLVEKITKMLDRGLDPNFHDPETGETPLTLAAQLDDSVEVIKALKNGGAHLDFRAKDGMTALHKAARARNQVALKTLLELGASPDYKDSYGLTPLYHTAIVGGDPYCCELLLHEHATVCCKDENGWHEIHQACRYGHVQHLEHLLFYGADMSAQNASGNTALHICALYNQDSCARVLLFRGGNKELKNYNSQTPFQVAIIAGNFELAEYIKNHKETDIVPFREAPAYSNRRRRPPNTLAAPRVLLRSNSDNNLNASAPDWAVCSTATSHRSLSPQLLQQMPSKPEGAAKTIGSYVPGPRSRSPSLNRLGGAGEDGKRPQPLWHVGSPFALGANKDSLSAFEYPGPKRKLYSAVPGRLFVAVKPYQPQVDGEIPLHRGDRVKVLSIGEGGFWEGSARGHIGWFPAECVEEVQCKPRDSQAETRADRSKKLFRHYTVGSYDSFDTSSDCIIEEKTVVLQKKDNEGFGFVLRGAKADTPIEEFTPTPAFPALQYLESVDEGGVAWQAGLRTGDFLIEVNNENVVKVGHRQVVNMIRQGGNHLVLKVVTVTRNLDPDDTARKKAPPPPKRAPTTALTLRSKSMTSELEELVDKASVRKKKDKPEEIVPASKPSRAAENMAVEPRVATIKQRPSSRCFPAGSDMNSVYERQGIAVMTPTVPGSPKAPFLGIPRGTMRRQKSIDSRIFLSGITEEERQFLAPPMLKFTRSLSMPDTSEDIPPPPQSVPPSPPPPSPTTYNCPKSPTPRVYGTIKPAFNQNSAAKVSPATRSDTVATMMREKGMYFRRELDRYSLDSEDLYSRNAGPQANFRNKRGQMPENPYSEVGKIASKAVYVPAKPARRKGMLVKQSNVEDSPEKTCSIPIPTIIVKEPSTSSSGKSSQGSSMEIDPQAPEPPSQLRPDESLTVSSPFAAAIAGAVRDREKRLEARRNSPAFLSTDLGDEDVGLGPPAPRTRPSMFPEEGDFADEDSAEQLSSPMPSATPREPENHFVGGAEASAPGEAGRPLNSTSKAQGPESSPAVPSASSGTAGPGNYVHPLTGRLLDPSSPLALALSARDRAMKESQQGPKGEAPKADLNKPLYIDTKMRPSLDAGFPTVTRQNTRGPLRRQETENKYETDLGRDRKGDDKKNMLIDIMDTSQQKSAGLLMVHTVDATKLDNALQEEDEKAEVEMKPDSSPSEVPEGVSETEGALQISAAPEPTTVPGRTIVAVGSMEEAVILPFRIPPPPLASVDLDEDFIFTEPLPPPLEFANSFDIPDDRAASVPALSDLVKQKKSDTPQSPSLNSSQPTNSADSKKPASLSNCLPASFLPPPESFDAVADSGIEEVDSRSSSDHHLETTSTISTVSSISTLSSEGGENVDTCTVYADGQAFMVDKPPVPPKPKMKPIIHKSNALYQDALVEEDVDSFVIPPPAPPPPPGSAQPGMAKVLQPRTSKLWGDVTEIKSPILSGPKANVISELNSILQQMNREKLAKPGEGLDSPMGAKSASLAPRSPEIMSTISGTRSTTVTFTVRPGTSQPITLQSRPPDYESRTSGTRRAPSPVVSPTEMNKETLPAPLSAATASPSPALSDVFSLPSQPPSGDLFGLNPAGRSRSPSPSILQQPISNKPFTTKPVHLWTKPDVADWLESLNLGEHKEAFMDNEIDGSHLPNLQKEDLIDLGVTRVGHRMNIERALKQLLDR>sp|Q9UPX8-4|SHAN2_HUMAN Isoform 4 of SH3 and multiple ankyrin repeatdomains protein 2 OS=Homo sapiens OX=9606 GN=SHANK2MMMNVPGGGAAAVMMTGYNNGRCPRNSLYSDCIIEEKTVVLQKKDNEGFGFVLRGAKADTPIEEFTPTPAFPALQYLESVDEGGVAWQAGLRTGDFLIEVNNENVVKVGHRQVVNMIRQGGNHLVLKVVTVTRNLDPDDTARKKAPPPPKRAPTTALTLRSKSMTSELEELVDKDKPEEIVPASKPSRAAENMAVEPRVATIKQRPSSRCFPAGSDMNSVYERQGIAVMTPTVPGSPKAPFLGIPRGTMRRQKSIDSRIFLSGITEEERQFLAPPMLKFTRSLSMPDTSEDIPPPPQSVPPSPPPPSPTTYNCPKSPTPRVYGTIKPAFNQNSAAKVSPATRSDTVATMMREKGMYFRRELDRYSLDSEDLYSRNAGPQANFRNKRGQMPENPYSEVGKIASKAVYVPAKPARRKGMLVKQSNVEDSPEKTCSIPIPTIIVKEPSTSSSGKSSQGSSMEIDPQAPEPPSQLRPDESLTVSSPFAAAIAGAVRDREKRLEARRNSPAFLSTDLGDEDVGLGPPAPRTRPSMFPEEGDFADEDSAEQLSSPMPSATPREPENHFVGGAEASAPGEAGRPLNSTSKAQGPESSPAVPSASSGTAGPGNYVHPLTGRLLDPSSPLALALSARDRAMKESQQGPKGEAPKADLNKPLYIDTKMRPSLDAGFPTVTRQNTRGPLRRQETENKYETDLGRDRKGDDKKNMLIDIMDTSQQKSAGLLMVHTVDATKLDNALQEEDEKAEVEMKPDSSPSEVPEGVSETEGALQISAAPEPTTVPGRTIVAVGSMEEAVILPFRIPPPPLASVDLDEDFIFTEPLPPPLEFANSFDIPDDRAASVPALSDLVKQKKSDTPQSPSLNSSQPTNSADSKKPASLSNCLPASFLPPPESFDAVADSGIEEVDSRSSSDHHLETTSTISTVSSISTLSSEGGENVDTCTVYADGQAFMVDKPPVPPKPKMKPIIHKSNALYQDALVEEDVDSFVIPPPAPPPPPGSAQPGMAKVLQPRTSKLWGDVTEIKSPILSGPKANVISELNSILQQMNREKLAKPGEGLDSPMGAKSASLAPRSPEIMSTISGTRSTTVTFTVRPGTSQPITLQSRPPDYESRTSGTRRAPSPVVSPTEMNKETLPAPLSAATASPSPALSDVFSLPSQPPSGDLFGLNPAGRSRSPSPSILQQPISNKPFTTKPVHLWTKPDVADWLESLNLGEHKEAFMDNEIDGSHLPNLQKEDLIDLGVTRVGHRMNIERALKQLLDR>sp|Q92925|SMRD2_HUMAN SWI/SNF-related matrix-associated actin-dependentregulator of chromatin subfamily D member 2 OS=Homo sapiens OX=9606GN=SMARCD2 PE=1 SV=3MSGRGAGGFPLPPLSPGGGAVAAALGAPPPPAGPGMLPGPALRGPGPAGGVGGPGAAAFRPMGPAGPAAQYQRPGMSPGNRMPMAGLQVGPPAGSPFGAAAPLRPGMPPTMMDPFRKRLLVPQAQPPMPAQRRGLKRRKMADKVLPQRIRELVPESQAYMDLLAFERKLDQTIARKRMEIQEAIKKPLTQKRKLRIYISNTFSPSKAEGDSAGTAGTPGGTPAGDKVASWELRVEGKLLDDPSKQKRKFSSFFKSLVIELDKELYGPDNHLVEWHRMPTTQETDGFQVKRPGDLNVKCTLLLMLDHQPPQYKLDPRLARLLGVHTQTRAAIMQALWLYIKHNQLQDGHEREYINCNRYFRQIFSCGRLRFSEIPMKLAGLLQHPDPIVINHVISVDPNDQKKTACYDIDVEVDDPLKAQMSNFLASTTNQQEIASLDVKIHETIESINQLKTQRDFMLSFSTDPQDFIQEWLRSQRRDLKIITDVIGNPEEERRAAFYHQPWAQEAVGRHIFAKVQQRRQELEQVLGIRLT>sp|Q92925-2|SMRD2_HUMAN Isoform 2 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily D member 2 OS=Homosapiens OX=9606 GN=SMARCD2MSGRGAGGFPLPPLSPGGGAVAAALGAPPPPAGPGMLPGPALRGPGPAQYQRPGMSPGNRMPMARLAGGTPCWLPIWCSSSASTWHPTHHDGSIPKTPACAPAQPPMPAQRRGLKRRKMADKVLPQRIRELVPESQAYMDLLAFERKLDQTIARKRMEIQEAIKKPLTQKRKLRIYISNTFSPSKAEGDSAGTAGTPGGTPAGDKVASWELRVEGKLLDDPSKQKRKFSSFFKSLVIELDKELYGPDNHLVEWHRMPTTQETDGFQVKRPGDLNVKCTLLLMLDHQPPQYKLDPRLARLLGVHTQTRAAIMQALWLYIKHNQLQDGHEREYINCNRYFRQIFSCGRLRFSEIPMKLAGLLQHPDPIVINHVISVDPNDQKKTACYDIDVEVDDPLKAQMSNFLASTTNQQEIASLDVKIHETIESINQLKTQRDFMLSFSTDPQDFIQEWLRSQRRDLKIITDVIGNPEEERRAAFYHQPWAQEAVGRHIFAKVQQRRQELEQVLGIRLT>sp|Q92925-3|SMRD2_HUMAN Isoform 3 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily D member 2 OS=Homosapiens OX=9606 GN=SMARCD2MGRRVGVEVTPRWAPQKCQGARPQRPGMSPGNRMPMAGLQVGPPAGSPFGAAAPLRPGMPPTMMDPFRKRLLVPQAQPPMPAQRRGLKRRKMADKVLPQRIRELVPESQAYMDLLAFERKLDQTIARKRMEIQEAIKKPLTQKRKLRIYISNTFSPSKAEGDSAGTAGTPGGTPAGDKVASWELRVEGKLLDDPSKQKRKFSSFFKSLVIELDKELYGPDNHLVEWHRMPTTQETDGFQVKRPGDLNVKCTLLLMLDHQPPQYKLDPRLARLLGVHTQTRAAIMQALWLYIKHNQLQDGHEREYINCNRYFRQIFSCGRLRFSEIPMKLAGLLQHPDPIVINHVISVDPNDQKKTACYDIDVEVDDPLKAQMSNFLASTTNQQEIASLDVKIHETIESINQLKTQRDFMLSFSTDPQDFIQEWLRSQRRDLKIITDVIGNPEEERRAAFYHQPWAQEAVGRHIFAKVQQRRQELEQVLGIRLT>sp|P08047|SP1_HUMAN Transcription factor Sp1 OS=Homo sapiens OX=9606GN=SP1 PE=1 SV=3MSDQDHSMDEMTAVVKIEKGVGGNNGGNGNGGGAFSQARSSSTGSSSSTGGGGQESQPSPLALLAATCSRIESPNENSNNSQGPSQSGGTGELDLTATQLSQGANGWQIISSSSGATPTSKEQSGSSTNGSNGSESSKNRTVSGGQYVVAAAPNLQNQQVLTGLPGVMPNIQYQVIPQFQTVDGQQLQFAATGAQVQQDGSGQIQIIPGANQQIITNRGSGGNIIAAMPNLLQQAVPLQGLANNVLSGQTQYVTNVPVALNGNITLLPVNSVSAATLTPSSQAVTISSSGSQESGSQPVTSGTTISSASLVSSQASSSSFFTNANSYSTTTTTSNMGIMNFTTSGSSGTNSQGQTPQRVSGLQGSDALNIQQNQTSGGSLQAGQQKEGEQNQQTQQQQILIQPQLVQGGQALQALQAAPLSGQTFTTQAISQETLQNLQLQAVPNSGPIIIRTPTVGPNGQVSWQTLQLQNLQVQNPQAQTITLAPMQGVSLGQTSSSNTTLTPIASAASIPAGTVTVNAAQLSSMPGLQTINLSALGTSGIQVHPIQGLPLAIANAPGDHGAQLGLHGAGGDGIHDDTAGGEEGENSPDAQPQAGRRTRREACTCPYCKDSEGRGSGDPGKKKQHICHIQGCGKVYGKTSHLRAHLRWHTGERPFMCTWSYCGKRFTRSDELQRHKRTHTGEKKFACPECPKRFMRSDHLSKHIKTHQNKKGGPGVALSVGTLPLDSGAGSEGSGTATPSALITTNMVAMEAICPEGIARLANSGINVMQVADLQSINISGNGF>sp|P08047-2|SP1_HUMAN Isoform 2 of Transcription factor Sp1 OS=Homosapiens OX=9606 GN=SP1MDEMTAVVKIEKGVGGNNGGNGNGGGAFSQARSSSTGSSSSTGGGGQESQPSPLALLAATCSRIESPNENSNNSQGPSQSGGTGELDLTATQLSQGANGWQIISSSSGATPTSKEQSGSSTNGSNGSESSKNRTVSGGQYVVAAAPNLQNQQVLTGLPGVMPNIQYQVIPQFQTVDGQQLQFAATGAQVQQDGSGQIQIIPGANQQIITNRGSGGNIIAAMPNLLQQAVPLQGLANNVLSGQTQYVTNVPVALNGNITLLPVNSVSAATLTPSSQAVTISSSGSQESGSQPVTSGTTISSASLVSSQASSSSFFTNANSYSTTTTTSNMGIMNFTTSGSSGTNSQGQTPQRVSGLQGSDALNIQQNQTSGGSLQAGQQKEGEQNQQTQQQQILIQPQLVQGGQALQALQAAPLSGQTFTTQAISQETLQNLQLQAVPNSGPIIIRTPTVGPNGQVSWQTLQLQNLQVQNPQAQTITLAPMQGVSLGQTSSSNTTLTPIASAASIPAGTVTVNAAQLSSMPGLQTINLSALGTSGIQVHPIQGLPLAIANAPGDHGAQLGLHGAGGDGIHDDTAGGEEGENSPDAQPQAGRRTRREACTCPYCKDSEGRGSGDPGKKKQHICHIQGCGKVYGKTSHLRAHLRWHTGERPFMCTWSYCGKRFTRSDELQRHKRTHTGEKKFACPECPKRFMRSDHLSKHIKTHQNKKGGPGVALSVGTLPLDSGAGSEGSGTATPSALITTNMVAMEAICPEGIARLANSGINVMQVADLQSINISGNGF>sp|P08047-3|SP1_HUMAN Isoform 3 of Transcription factor Sp1 OS=Homosapiens OX=9606 GN=SP1MSDQDHSMDEMTAVVKIEKGVGGNNGGNGNGGGAFSQARSSSTGSSSSTGGGGQGANGWQIISSSSGATPTSKEQSGSSTNGSNGSESSKNRTVSGGQYVVAAAPNLQNQQVLTGLPGVMPNIQYQVIPQFQTVDGQQLQFAATGAQVQQDGSGQIQIIPGANQQIITNRGSGGNIIAAMPNLLQQAVPLQGLANNVLSGQTQYVTNVPVALNGNITLLPVNSVSAATLTPSSQAVTISSSGSQESGSQPVTSGTTISSASLVSSQASSSSFFTNANSYSTTTTTSNMGIMNFTTSGSSGTNSQGQTPQRVSGLQGSDALNIQQNQTSGGSLQAGQQKEGEQNQQTQQQQILIQPQLVQGGQALQALQAAPLSGQTFTTQAISQETLQNLQLQAVPNSGPIIIRTPTVGPNGQVSWQTLQLQNLQVQNPQAQTITLAPMQGVSLGQTSSSNTTLTPIASAASIPAGTVTVNAAQLSSMPGLQTINLSALGTSGIQVHPIQGLPLAIANAPGDHGAQLGLHGAGGDGIHDDTAGGEEGENSPDAQPQAGRRTRREACTCPYCKDSEGRGSGDPGKKKQHICHIQGCGKVYGKTSHLRAHLRWHTGERPFMCTWSYCGKRFTRSDELQRHKRTHTGEKKFACPECPKRFMRSDHLSKHIKTHQNKKGGPGVALSVGTLPLDSGAGSEGSGTATPSALITTNMVAMEAICPEGIARLANSGINVMQVADLQSINISGNGF>sp|P98077|SHC2_HUMAN SHC-transforming protein 2 OS=Homo sapiens OX=9606GN=SHC2 PE=1 SV=4MTQGPGGRAPPAPPAPPEPEAPTTFCALLPRMPQWKFAAPGGFLGRGPAAARAAGASGGADPQPEPAGPGGVPALAAAVLGACEPRCAAPCPLPALSRCRGAGSRGSRGGRGAAGSGDAAAAAEWIRKGSFIHKPAHGWLHPDARVLGPGVSYVVRYMGCIEVLRSMRSLDFNTRTQVTREAINRLHEAVPGVRGSWKKKAPNKALASVLGKSNLRFAGMSISIHISTDGLSLSVPATRQVIANHHMPSISFASGGDTDMTDYVAYVAKDPINQRACHILECCEGLAQSIISTVGQAFELRFKQYLHSPPKVALPPERLAGPEESAWGDEEDSLEHNYYNSIPGKEPPLGGLVDSRLALTQPCALTALDQGPSPSLRDACSLPWDVGSTGTAPPGDGYVQADARGPPDHEEHLYVNTQGLDAPEPEDSPKKDLFDMRPFEDALKLHECSVAAGVTAAPLPLEDQWPSPPTRRAPVAPTEEQLRQEPWYHGRMSRRAAERMLRADGDFLVRDSVTNPGQYVLTGMHAGQPKHLLLVDPEGVVRTKDVLFESISHLIDHHLQNGQPIVAAESELHLRGVVSREP>sp|Q9H3E2|SNX25_HUMAN Sorting nexin-25 OS=Homo sapiens OX=9606 GN=SNX25PE=1 SV=2MDKALKEVFDYSYRDYILSWYGNLSRDEGQLYHLLLEDFWEIARQLHHRLSHVDVVKVVCNDVVRTLLTHFCDLKAANARHEEQPRPFVLHACLRNSDDEVRFLQTCSRVLVFCLLPSKDVQSLSLRIMLAEILTTKVLKPVVELLSNPDYINQMLLAQLAYREQMNEHHKRAYTYAPSYEDFIKLINSNSDVEFLKQLRYQIVVEIIQATTISSFPQLKRHKGKETAAMKADLLRARNMKRYINQLTVAKKQCEKRIRILGGPAYDQQEDGALDEGEGPQSQKILQFEDILANTFYREHFGMYMERMDKRALISFWESVEHLKNANKNEIPQLVGEIYQNFFVESKEISVEKSLYKEIQQCLVGNKGIEVFYKIQEDVYETLKDRYYPSFIVSDLYEKLLIKEEEKHASQMISNKDEMGPRDEAGEEAVDDGTNQINEQASFAVNKLRELNEKLEYKRQALNSIQNAPKPDKKIVSKLKDEIILIEKERTDLQLHMARTDWWCENLGMWKASITSGEVTEENGEQLPCYFVMVSLQEVGGVETKNWTVPRRLSEFQNLHRKLSECVPSLKKVQLPSLSKLPFKSIDQKFMEKSKNQLNKFLQNLLSDERLCQSEALYAFLSPSPDYLKVIDVQGKKNSFSLSSFLERLPRDFFSHQEEETEEDSDLSDYGDDVDGRKDALAEPCFMLIGEIFELRGMFKWVRRTLIALVQVTFGRTINKQIRDTVSWIFSEQMLVYYINIFRDAFWPNGKLAPPTTIRSKEQSQETKQRAQQKLLENIPDMLQSLVGQQNARHGIIKIFNALQETRANKHLLYALMELLLIELCPELRVHLDQLKAGQV>sp|Q9H3E2-2|SNX25_HUMAN Isoform 2 of Sorting nexin-25 OS=Homo sapiensOX=9606 GN=SNX25MKADLLRARNMKRYINQLTVAKKQCEKRIRILGGPAYDQQEDGALDEGEGPQSQKILQFEDILANTFYREHFGMYMERMDKRALISFWESVEHLKNANKNEIPQLVGEIYQNFFVESKEISVEKSLYKEIQQCLVGNKGIEVFYKIQEDVYETLKDRYYPSFIVSDLYEKLLIKEEEKHASQMISNKDEMGPRDEAGEEAVDDGTNQINEQASFAVNKLRELNEKLEYKRQALNSIQNAPKPDKKIVSKLKDEIILIEKERTDLQLHMARTDWWCENLGMWKASITSGEVTEENGEQLPCYFVMVSLQEVGGVETKNWTVPRRLSEFQNLHRKLSECVPSLKKVQLPSLSKLPFKSIDQKFMEKSKNQLNKFLQEETEEDSDLSDYGDDVDGRKDALAEPCFMLIGEIFELRGMFKWVRRTLIALVQVTFGRTINKQIRDTVSWIFSEQMLVYYINIFRDAFWPNGKLAPPTTIRSKEQSQETKQRAQQKLLENIPDMLQSLVGQQNARHGIIKIFNALQETRANKHLLYALMELLLIELCPELRVHLDQLKAGQV>sp|Q14683|SMC1A_HUMAN Structural maintenance of chromosomes protein 1AOS=Homo sapiens OX=9606 GN=SMC1A PE=1 SV=2MGFLKLIEIENFKSYKGRQIIGPFQRFTAIIGPNGSGKSNLMDAISFVLGEKTSNLRVKTLRDLIHGAPVGKPAANRAFVSMVYSEEGAEDRTFARVIVGGSSEYKINNKVVQLHEYSEELEKLGILIKARNFLVFQGAVESIAMKNPKERTALFEEISRSGELAQEYDKRKKEMVKAEEDTQFNYHRKKNIAAERKEAKQEKEEADRYQRLKDEVVRAQVQLQLFKLYHNEVEIEKLNKELASKNKEIEKDKKRMDKVEDELKEKKKELGKMMREQQQIEKEIKEKDSELNQKRPQYIKAKENTSHKIKKLEAAKKSLQNAQKHYKKRKGDMDELEKEMLSVEKARQEFEERMEEESQSQGRDLTLEENQVKKYHRLKEEASKRAATLAQELEKFNRDQKADQDRLDLEERKKVETEAKIKQKLREIEENQKRIEKLEEYITTSKQSLEEQKKLEGELTEEVEMAKRRIDEINKELNQVMEQLGDARIDRQESSRQQRKAEIMESIKRLYPGSVYGRLIDLCQPTQKKYQIAVTKVLGKNMDAIIVDSEKTGRDCIQYIKEQRGEPETFLPLDYLEVKPTDEKLRELKGAKLVIDVIRYEPPHIKKALQYACGNALVCDNVEDARRIAFGGHQRHKTVALDGTLFQKSGVISGGASDLKAKARRWDEKAVDKLKEKKERLTEELKEQMKAKRKEAELRQVQSQAHGLQMRLKYSQSDLEQTKTRHLALNLQEKSKLESELANFGPRINDIKRIIQSREREMKDLKEKMNQVEDEVFEEFCREIGVRNIREFEEEKVKRQNEIAKKRLEFENQKTRLGIQLDFEKNQLKEDQDKVHMWEQTVKKDENEIEKLKKEEQRHMKIIDETMAQLQDLKNQHLAKKSEVNDKNHEMEEIRKKLGGANKEMTHLQKEVTAIETKLEQKRSDRHNLLQACKMQDIKLPLSKGTMDDISQEEGSSQGEDSVSGSQRISSIYAREALIEIDYGDLCEDLKDAQAEEEIKQEMNTLQQKLNEQQSVLQRIAAPNMKAMEKLESVRDKFQETSDEFEAARKRAKKAKQAFEQIKKERFDRFNACFESVATNIDEIYKALSRNSSAQAFLGPENPEEPYLDGINYNCVAPGKRFRPMDNLSGGEKTVAALALLFAIHSYKPAPFFVLDEIDAALDNTNIGKVANYIKEQSTCNFQAIVISLKEEFYTKAESLIGVYPEQGDCVISKVLTFDLTKYPDANPNPNEQ>sp|O76094|SRP72_HUMAN Signal recognition particle subunit SRP72 OS=Homosapiens OX=9606 GN=SRP72 PE=1 SV=3MASGGSGGVSVPALWSEVNRYGQNGDFTRALKTVNKILQINKDDVTALHCKVVCLIQNGSFKEALNVINTHTKVLANNSLSFEKAYCEYRLNRIENALKTIESANQQTDKLKELYGQVLYRLERYDECLAVYRDLVRNSQDDYDEERKTNLSAVVAAQSNWEKVVPENLGLQEGTHELCYNTACALIGQGQLNQAMKILQKAEDLCRRSLSEDTDGTEEDPQAELAIIHGQMAYILQLQGRTEEALQLYNQIIKLKPTDVGLLAVIANNIITINKDQNVFDSKKKVKLTNAEGVEFKLSKKQLQAIEFNKALLAMYTNQAEQCRKISASLQSQSPEHLLPVLIQAAQLCREKQHTKAIELLQEFSDQHPENAAEIKLTMAQLKISQGNISKACLILRSIEELKHKPGMVSALVTMYSHEEDIDSAIEVFTQAIQWYQNHQPKSPAHLSLIREAANFKLKYGRKKEAISDLQQLWKQNPKDIHTLAQLISAYSLVDPEKAKALSKHLPSSDSMSLKVDVEALENSAGATYIRKKGGKVTGDSQPKEQGQGDLKKKKKKKKGKLPKNYDPKVTPDPERWLPMRERSYYRGRKKGKKKDQIGKGTQGATAGASSELDASKTVSSPPTSPRPGSAATVSASTSNIIPPRHQKPAGAPATKKKQQQKKKKGGKGGW>sp|O76094-2|SRP72_HUMAN Isoform 2 of Signal recognition particle subunitSRP72 OS=Homo sapiens OX=9606 GN=SRP72MASGGSGGVSVPALWSEVNRYGQNGDFTRALKTVNKILQINKDDVTALHCKVVCLIQNGSFKEALNVINTHTKVLANNSLSFEKAYCEYRLNRIENALKTIESANQQTDKLKELYGQVLYRLERYDECLAVYRDLVRNSQDDYDEERKTNLSAVVAAQSNWEKVVPENLGLQEGTHELCYNTACALIGQGQLNQAMKILQKAEDLCRRSLSEDTDQNVFDSKKKVKLTNAEGVEFKLSKKQLQAIEFNKALLAMYTNQAEQCRKISASLQSQSPEHLLPVLIQAAQLCREKQHTKAIELLQEFSDQHPENAAEIKLTMAQLKISQGNISKACLILRSIEELKHKPGMVSALVTMYSHEEDIDSAIEVFTQAIQWYQNHQPKSPAHLSLIREAANFKLKYGRKKEAISDLQQLWKQNPKDIHTLAQLISAYSLVDPEKAKALSKHLPSSDSMSLKVDVEALENSAGATYIRKKGGKVTGDSQPKEQGQGDLKKKKKKKKGKLPKNYDPKVTPDPERWLPMRERSYYRGRKKGKKKDQIGKGTQGATAGASSELDASKTVSSPPTSPRPGSAATVSASTSNIIPPRHQKPAGAPATKKKQQQKKKKGGKGGW>sp|Q8NCJ5|SPRY3_HUMAN SPRY domain-containing protein 3 OS=Homo sapiensOX=9606 GN=SPRYD3 PE=1 SV=2MRRTRRPRFVLMNKMDDLNLHYRFLNWRRRIREIREVRAFRYQERFKHILVDGDTLSYHGNSGEVGCYVASRPLTKDSNYFEVSIVDSGVRGTIAVGLVPQYYSLDHQPGWLPDSVAYHADDGKLYNGRAKGRQFGSKCNSGDRIGCGIEPVSFDVQTAQIFFTKNGKRVGSTIMPMSPDGLFPAVGMHSLGEEVRLHLNAELGREDDSVMMVDSYEDEWGRLHDVRVCGTLLEYLGKGKSIVDVGLAQARHPLSTRSHYFEVEIVDPGEKCYIALGLARKDYPKNRHPGWSRGSVAYHADDGKIFHGSGVGDPFGPRCYKGDIMGCGIMFPRDYILDSEGDSDDSCDTVILSPTARAVRNVRNVMYLHQEGEEEEEEEEEEEDGEEIEPEHEGRKVVVFFTRNGKIIGKKDAVVPSGGFFPTIGMLSCGEKVKVDLHPLSG>sp|Q8WW59|SPRY4_HUMAN SPRY domain-containing protein 4 OS=Homo sapiensOX=9606 GN=SPRYD4 PE=1 SV=2MALLFARSLRLCRWGAKRLGVASTEAQRGVSFKLEEKTAHSSLALFRDDMGVKYGLVGLEPTKVALNVERFREWAVVLADTAVTSGRHYWEVTVKRSQQFRIGVADVDMSRDSCIGVDDRSWVFTYAQRKWYTMLANEKAPVEGIGQPEKVGLLLEYEAQKLSLVDVSQVSVVHTLQTDFRGPVVPAFALWDGELLTHSGLEVPEGL>sp|P35321|SPR1A_HUMAN Cornifin-A OS=Homo sapiens OX=9606 GN=SPRR1A PE=1SV=2MNSQQQKQPCTPPPQPQQQQVKQPCQPPPQEPCIPKTKEPCHPKVPEPCHPKVPEPCQPKVPEPCQPKVPEPCPSTVTPAPAQQKTKQK>sp|O43597|SPY2_HUMAN Protein sprouty homolog 2 OS=Homo sapiens OX=9606GN=SPRY2 PE=1 SV=1MEARAQSGNGSQPLLQTPRDGGRQRGEPDPRDALTQQVHVLSLDQIRAIRNTNEYTEGPTVVPRPGLKPAPRPSTQHKHERLHGLPEHRQPPRLQHSQVHSSARAPLSRSISTVSSGSRSSTRTSTSSSSSEQRLLGSSFSSGPVADGIIRVQPKSELKPGELKPLSKEDLGLHAYRCEDCGKCKCKECTYPRPLPSDWICDKQCLCSAQNVIDYGTCVCCVKGLFYHCSNDDEDNCADNPCSCSQSHCCTRWSAMGVMSLFLPCLWCYLPAKGCLKLCQGCYDRVNRPGCRCKNSNTVCCKVPTVPPRNFEKPT>sp|Q6ZRS2|SRCAP_HUMAN Helicase SRCAP OS=Homo sapiens OX=9606 GN=SRCAPPE=1 SV=3MQSSPSPAHPQLPVLQTQMVSDGMTGSNPVSPASSSSPASSGAGGISPQHIAQDSSLDGPPGPPDGATVPLEGFSLSQAADLANKGPKWEKSHAEIAEQAKHEAEIETRIAELRKEGFWSLKRLPKVPEPPRPKGHWDYLCEEMQWLSADFAQERRWKRGVARKVVRMVIRHHEEQRQKEERARREEQAKLRRIASTMAKDVRQFWSNVEKVVQFKQQSRLEEKRKKALDLHLDFIVGQTEKYSDLLSQSLNQPLTSSKAGSSPCLGSSSAASSPPPPASRLDDEDGDFQPQEDEEEDDEETIEVEEQQEGNDAEAQRREIELLRREGELPLEELLRSLPPQLLEGPSSPSQTPSSHDSDTRDGPEEGAEEEPPQVLEIKPPPSAVTQRNKQPWHPDEDDEEFTANEEEAEDEEDTIAAEEQLEGEVDHAMELSELAREGELSMEELLQQYAGAYAPGSGSSEDEDEDEVDANSSDCEPEGPVEAEEPPQEDSSSQSDSVEDRSEDEEDEHSEEEETSGSSASEESESEESEDAQSQSQADEEEEDDDFGVEYLLARDEEQSEADAGSGPPTPGPTTLGPKKEITDIAAAAESLQPKGYTLATTQVKTPIPLLLRGQLREYQHIGLDWLVTMYEKKLNGILADEMGLGKTIQTISLLAHLACEKGNWGPHLIIVPTSVMLNWEMELKRWCPSFKILTYYGAQKERKLKRQGWTKPNAFHVCITSYKLVLQDHQAFRRKNWRYLILDEAQNIKNFKSQRWQSLLNFNSQRRLLLTGTPLQNSLMELWSLMHFLMPHVFQSHREFKEWFSNPLTGMIEGSQEYNEGLVKRLHKVLRPFLLRRVKVDVEKQMPKKYEHVIRCRLSKRQRCLYDDFMAQTTTKETLATGHFMSVINILMQLRKVCNHPNLFDPRPVTSPFITPGICFSTASLVLRATDVHPLQRIDMGRFDLIGLEGRVSRYEADTFLPRHRLSRRVLLEVATAPDPPPRPKPVKMKVNRMLQPVPKQEGRTVVVVNNPRAPLGPVPVRPPPGPELSAQPTPGPVPQVLPASLMVSASPAGPPLIPASRPPGPVLLPPLQPNSGSLPQVLPSPLGVLSGTSRPPTPTLSLKPTPPAPVRLSPAPPPGSSSLLKPLTVPPGYTFPPAAATTTSTTTATATTTAVPAPTPAPQRLILSPDMQARLPSGEVVSIGQLASLAQRPVANAGGSKPLTFQIQGNKLTLTGAQVRQLAVGQPRPLQRNVVHLVSAGGQHHLISQPAHVALIQAVAPTPGPTPVSVLPSSTPSTTPAPTGLSLPLAANQVPPTMVNNTGVVKIVVRQAPRDGLTPVPPLAPAPRPPSSGLPAVLNPRPTLTPGRLPTPTLGTARAPMPTPTLVRPLLKLVHSPSPEVSASAPGAAPLTISSPLHVPSSLPGPASSPMPIPNSSPLASPVSSTVSVPLSSSLPISVPTTLPAPASAPLTIPISAPLTVSASGPALLTSVTPPLAPVVPAAPGPPSLAPSGASPSASALTLGLATAPSLSSSQTPGHPLLLAPTSSHVPGLNSTVAPACSPVLVPASALASPFPSAPNPAPAQASLLAPASSASQALATPLAPMAAPQTAILAPSPAPPLAPLPVLAPSPGAAPVLASSQTPVPVMAPSSTPGTSLASASPVPAPTPVLAPSSTQTMLPAPVPSPLPSPASTQTLALAPALAPTLGGSSPSQTLSLGTGNPQGPFPTQTLSLTPASSLVPTPAQTLSLAPGPPLGPTQTLSLAPAPPLAPASPVGPAPAHTLTLAPASSSASLLAPASVQTLTLSPAPVPTLGPAAAQTLALAPASTQSPASQASSLVVSASGAAPLPVTMVSRLPVSKDEPDTLTLRSGPPSPPSTATSFGGPRPRRQPPPPPRSPFYLDSLEEKRKRQRSERLERIFQLSEAHGALAPVYGTEVLDFCTLPQPVASPIGPRSPGPSHPTFWTYTEAAHRAVLFPQQRLDQLSEIIERFIFVMPPVEAPPPSLHACHPPPWLAPRQAAFQEQLASELWPRARPLHRIVCNMRTQFPDLRLIQYDCGKLQTLAVLLRQLKAEGHRVLIFTQMTRMLDVLEQFLTYHGHLYLRLDGSTRVEQRQALMERFNADKRIFCFILSTRSGGVGVNLTGADTVVFYDSDWNPTMDAQAQDRCHRIGQTRDVHIYRLISERTVEENILKKANQKRMLGDMAIEGGNFTTAYFKQQTIRELFDMPLEEPSSSSVPSAPEEEEETVASKQTHILEQALCRAEDEEDIRAATQAKAEQVAELAEFNENDGFPAGEGEEAGRPGAEDEEMSRAEQEIAALVEQLTPIERYAMKFLEASLEEVSREELKQAEEQVEAARKDLDQAKEEVFRLPQEEEEGPGAGDESSCGTGGGTHRRSKKAKAPERPGTRVSERLRGARAETQGANHTPVISAHQTRSTTTPPRCSPARERVPRPAPRPRPTPASAPAAIPALVPVPVSAPVPISAPNPITILPVHILPSPPPPSQIPPCSSPACTPPPACTPPPAHTPPPAQTCLVTPSSPLLLGPPSVPISASVTNLPLGLRPEAELCAQALASPESLELASVASSETSSLSLVPPKDLLPVAVEILPVSEKNLSLTPSAPSLTLEAGSIPNGQEQEAPDSAEGTTLTVLPEGEELPLCVSESNGLELPPSAASDEPLQEPLEADRTSEELTEAKTPTSSPEKPQELVTAEVAAPSTSSSATSSPEGPSPARPPRRRTSADVEIRGQGTGRPGQPPGPKVLRKLPGRLVTVVEEKELVRRRRQQRGAASTLVPGVSETSASPGSPSVRSMSGPESSPPIGGPCEAAPSSSLPTPPQQPFIARRHIELGVTGGGSPENGDGALLAITPPAVKRRRGRPPKKNRSPADAGRGVDEAPSSTLKGKTNGADPVPGPETLIVADPVLEPQLIPGPQPLGPQPVHRPNPLLSPVEKRRRGRPPKARDLPIPGTISSAGDGNSESRTQPPPHPSPLTPLPPLLVCPTATVANTVTTVTISTSPPKRKRGRPPKNPPSPRPSQLPVLDRDSTSVLESCGLGRRRQPQGQGESEGSSSDEDGSRPLTRLARLRLEAEGMRGRKSGGSMVVAVIQDDLDLADSGPGGLELTPPVVSLTPKLRSTRLRPGSLVPPLETEKLPRKRAGAPVGGSPGLAKRGRLQPPSPLGPEGSVEESEAEASGEEEEGDGTPRRRPGPRRLVGTTNQGDQRILRSSAPPSLAGPAVSHRGRKAKT>sp|Q6ZRS2-2|SRCAP_HUMAN Isoform 2 of Helicase SRCAP OS=Homo sapiensOX=9606 GN=SRCAPMQSSPSPAHPQLPVLQTQMVSDGMTGSNPVSPASSSSPASSGAGGISPQHIAQDSSLDGPPGPPDGATVPLEGFSLSQAADLANKGPKWEKSHAEIAEQAKHEAEIETRIAELRKEGFWSLKRLPKVPEPPRPKGHWDYLCEEMQWLSADFAQERRWKRGVARKVVRMVIRHHEEQRQKEERARREEQAKLRRIASTMAKDVRQFWSNVEKVVQFKQQSRLEEKRKKALDLHLDFIVGQTEKYSDLLSQSLNQPLTSSKAGSSPCLGSSSAASSPPPPASRLDDEDGDFQPQEDEEEDDEETIEVEEQQEGNDAEAQRREIELLRREGELPLEELLRSLPPQLLEGPSSPSQTPSSHDSDTRDGPEEGAEEEPPQVLEIKPPPSAVTQRNKQPWHPDEDDEEFTANEEEAEDEEDTIAAEEQLEGEVDHAMELSELAREGELSMEELLQQYAGAYAPGSGSSEDEDEDEVDANSSDCEPEGPVEAEEPPQEDSSSQSDSVEDRSEDEEDEHSEEEETSGSSASEESESEESEDAQSQSQADEEEEDDDFGVEYLLARDEEQSEADAGSGPPTPGPTTLGPKKEITDIAAAAESLQPKGYTLATTQVKTPIPLLLRGQLREYQHIGLDWLVTMYEKKLNGILADEMGLGKTIQTISLLAHLACEKGNWGPHLIIVPTSVMLNWEMELKRWCPSFKILTYYGAQKERKLKRQGWTKPNAFHVCITSYKLVLQDHQAFRRKNWRYLILDEAQNIKNFKSQRWQSLLNFNSQRRLLLTGTPLQNSLMELWSLMHFLMPHVFQSHREFKEWFSNPLTGMIEGSQEYNEGLVKRLHKVLRPFLLRRVKVDVEKQMPKKYEHVIRCRLSKRQRCLYDDFMAQTTTKETLATGHFMSVINILMQLRKVCNHPNLFDPRPVTSPFITPGICFSTASLVLRATDVHPLQRIDMGRFDLIGLEGRVSRYEADTFLPRHRLSRRVLLEVATAPDPPPRPKPVKMKVNRMLQPVPKQEGRTVVVVNNPRAPLGPVPVRPPPGPELSAQPTPGPVPQVLPASLMVSASPAGPPLIPASRPPGPVLLPPLQPNSGSLPQVLPSPLGVLSGTSRPPTPTLSLKPTPPAPVRLSPAPPPGSSSLLKPLTVPPGYTFPPAAATTTSTTTATATTTAVPAPTPAPQRLILSPDMQARLPSGEVVSIGQLASLAQRPVANAGGSKPLTFQIQGNKLTLTGAQVRQLAVGQPRPLQMPPTMVNNTGVVKIVVRQAPRDGLTPVPPLAPAPRPPSSGLPAVLNPRPTLTPGRLPTPTLGTARAPMPTPTLVRPLLKLVHSPSPEVSASAPGAAPLTISSPLHVPSSLPGPASSPMPIPNSSPLASPVSSTVSVPLSSSLPISVPTTLPAPASAPLTIPISAPLTVSASGPALLTSVTPPLAPVVPAAPGPPSLAPSGASPSASALTLGLATAPSLSSSQTPGHPLLLAPTSSHVPGLNSTVAPACSPVLVPASALASPFPSAPNPAPAQASLLAPASSASQALATPLAPMAAPQTAILAPSPAPPLAPLPVLAPSPGAAPVLASSQTPVPVMAPSSTPGTSLASASPVPAPTPVLAPSSTQTMLPAPVPSPLPSPASTQTLALAPALAPTLGGSSPSQTLSLGTGNPQGPFPTQTLSLTPASSLVPTPAQTLSLAPGPPLGPTQTLSLAPAPPLAPASPVGPAPAHTLTLAPASSSASLLAPASVQTLTLSPAPVPTLGPAAAQTLALAPASTQSPASQASSLVVSASGAAPLPVTMVSRLPVSKDEPDTLTLRSGPPSPPSTATSFGGPRPRRQPPPPPRSPFYLDSLEEKRKRQRSERLERIFQLSEAHGALAPVYGTEVLDFCTLPQPVASPIGPRSPGPSHPTFWTYTEAAHRAVLFPQQRLDQLSEIIERFIFVMPPVEAPPPSLHACHPPPWLAPRQAAFQEQLASELWPRARPLHRIVCNMRTQFPDLRLIQYDCGKLQTLAVLLRQLKAEGHRVLIFTQMTRMLDVLEQFLTYHGHLYLRLDGSTRVEQRQALMERFNADKRIFCFILSTRSGGVGVNLTGADTVVFYDSDWNPTMDAQAQDRCHRIGQTRDVHIYRLISERTVEENILKKANQKRMLGDMAIEGGNFTTAYFKQQTIRELFDMPLEEPSSSSVPSAPEEEEETVASKQTHILEQALCRAEDEEDIRAATQAKAEQVAELAEFNENDGFPAGEGEEAGRPGAEDEEMSRAEQEIAALVEQLTPIERYAMKFLEASLEEVSREELKQAEEQVEAARKDLDQAKEEVFRLPQEEEEGPGAGDESSCGTGGGTHRRSKKAKAPERPGTRVSERLRGARAETQGANHTPVISAHQTRSTTTPPRCSPARERVPRPAPRPRPTPASAPAAIPALVPVPVSAPVPISAPNPITILPVHILPSPPPPSQIPPCSSPACTPPPACTPPPAHTPPPAQTCLVTPSSPLLLGPPSVPISASVTNLPLGLRPEAELCAQALASPESLELASVASSETSSLSLVPPKDLLPVAVEILPVSEKNLSLTPSAPSLTLEAGSIPNGQEQEAPDSAEGTTLTVLPEGEELPLCVSESNGLELPPSAASDEPLQEPLEADRTSEELTEAKTPTSSPEKPQELVTAEVAAPSTSSSATSSPEGPSPARPPRRRTSADVEIRGQGTGRPGQPPGPKVLRKLPGRLVTVVEEKELVRRRRQQRGAASTLVPGVSETSASPGSPSVRSMSGPESSPPIGGPCEAAPSSSLPTPPQQPFIARRHIELGVTGGGSPENGDGALLAITPPAVKRRRGRPPKKNRSPADAGRGVDEAPSSTLKGKTNGADPVPGPETLIVADPVLEPQLIPGPQPLGPQPVHRPNPLLSPVEKRRRGRPPKARDLPIPGTISSAGDGNSESRTQPPPHPSPLTPLPPLLVCPTATVANTVTTVTISTSPPKRKRGRPPKNPPSPRPSQLPVLDRDSTSVLESCGLGRRRQPQGQGESEGSSSDEDGSRPLTRLARLRLEAEGMRGRKSGGSMVVAVIQDDLDLADSGPGGLELTPPVVSLTPKLRSTRLRPGSLVPPLETEKLPRKRAGAPVGGSPGLAKRGRLQPPSPLGPEGSVEESEAEASGEEEEGDGTPRRRPGPRRLVGTTNQGDQRILRSSAPPSLAGPAVSHRGRKAKT>sp|Q6ZRS2-3|SRCAP_HUMAN Isoform 3 of Helicase SRCAP OS=Homo sapiensOX=9606 GN=SRCAPMQSSPSPAHPQLPVLQTQMVSDGMTGSNPVSPASSSSPASSGAGGISPQHIAQDSSLDGPPGPPDGATVPLEGFSLSQAADLANKGPKWEKSHAEIAEQAKHEAEIETRIAELRKEGFWSLKRLPKVPEPPRPKGHWDYLCEEMQWLSADFAQERRWKRGVARKVVRMVIRHHEEQRQKEERARREEQAKLRRIASTMAKDVRQFWSNVEKVVQFKQQSRLEEKRKKALDLHLDFIVGQTEKYSDLLSQSLNQPLTSSKAGSSPCLGSSSAASSPPPPASRLDDEDGDFQPQEDEEEDDEETIEVEEQQEGNDAEAQRREIELLRREGELPLEELLRSLPPQLLEGPSSPSQTPSSHDSDTRDGPEEGAEEEPPQVLEIKPPPSAVTQRNKQPWHPDEDDEEFTANEEEAEDEEDTIAAEEQLEGEVDHAMELSELAREGELSMEELLQQYAGAYAPGSGSSEDEDEDEVDANSSDCEPEGPVEAEEPPQEDSSSQSDSVEDRSEDEEDEHSEEEETSGSSASEESESEESEDAQSQSQADEEEEDDDFGVEYLLARDEEQSEADAGSGPPTPGPTTLGPKKEITDIAAAAESLQPKGYTLATTQVKTPIPLLLRGQLREYQHIGLDWLVTMYEKKLNGILADEMGLGKTIQTISLLAHLACEKGNWGPHLIIVPTSVMLNWEMELKRWCPSFKILTYYGAQKERKLKRQGWTKPNAFHVCITSYKLVLQDHQAFRRKNWRYLILDEAQNIKNFKSQRWQSLLNFNSQRRLLLTGTPLQNSLMELWSLMHFLMPHVFQSHREFKEWFSNPLTGMIEGSQEYNEGLVKRLHKVLRPFLLRRVKVDVEKQMPKKYEHVIRCRLSKRQRCLYDDFMAQTTTKETLATGHFMSVINILMQLRKVCNHPNLFDPRPVTSPFITPGICFSTASLVLRATDVHPLQRIDMGRFDLIGLEGRVSRYEADTFLPRHRLSRRVLLEVATAPDPPPRPKPVKMKVNRMLQPVPKQEGRTVVVVNNPRAPLGPVPVRPPPGPELSAQPTPGPVPQVLPASLMVSASPAGPPLIPASRPPGPVLLPPLQPNSGSLPQAGEVVSIGQLASLAQRPVANAGGSKPLTFQIQGNKLTLTGAQVRQLAVGQPRPLQMPPTMVNNTGVVKIVVRQAPRDGLTPVPPLAPAPRPPSSGLPAVLNPRPTLTPGRLPTPTLGTARAPMPTPTLVRPLLKLVHSPSPEVSASAPGAAPLTISSPLHVPSSLPGPASSPMPIPNSSPLASPVSSTVSVPLSSSLPISVPTTLPAPASAPLTIPISAPLTVSASGPALLTSVTPPLAPVVPAAPGPPSLAPSGASPSASALTLGLATAPSLSSSQTPGHPLLLAPTSSHVPGLNSTVAPACSPVLVPASALASPFPSAPNPAPAQASLLAPASSASQALATPLAPMAAPQTAILAPSPAPPLAPLPVLAPSPGAAPVLASSQTPVPVMAPSSTPGTSLASASPVPAPTPVLAPSSTQTMLPAPVPSPLPSPASTQTLALAPALAPTLGGSSPSQTLSLGTGNPQGPFPTQTLSLTPASSLVPTPAQTLSLAPGPPLGPTQTLSLAPAPPLAPASPVGPAPAHTLTLAPASSSASLLAPASVQTLTLSPAPVPTLGPAAAQTLALAPASTQSPASQASSLVVSASGAAPLPVTMVSRLPVSKDEPDTLTLRSGPPSPPSTATSFGGPRPRRQPPPPPRSPFYLDSLEEKRKRQRSERLERIFQLSEAHGALAPVYGTEVLDFCTLPQPVASPIGPRSPGPSHPTFWTYTEAAHRAVLFPQQRLDQLSEIIERFIFVMPPVEAPPPSLHACHPPPWLAPRQAAFQEQLASELWPRARPLHRIVCNMRTQFPDLRLIQYDCGKLQTLAVLLRQLKAEGHRVLIFTQMTRMLDVLEQFLTYHGHLYLRLDGSTRVEQRQALMERFNADKRIFCFILSTRSGGVGVNLTGADTVVFYDSDWNPTMDAQAQDRCHRIGQTRDVHIYRLISERTVEENILKKANQKRMLGDMAIEGGNFTTAYFKQQTIRELFDMPLEEPSSSSVPSAPEEEEETVASKQTHILEQALCRAEDEEDIRAATQAKAEQVAELAEFNENDGFPAGEGEEAGRPGAEDEEMSRAEQEIAALVEQLTPIERYAMKFLEASLEEVSREELKQAEEQVEAARKDLDQAKEEVFRLPQEEEEGPGAGDESSCGTGGGTHRRSKKAKAPERPGTRVSERLRGARAETQGANHTPVISAHQTRSTTTPPRCSPARERVPRPAPRPRPTPASAPAAIPALVPVPVSAPVPISAPNPITILPVHILPSPPPPSQIPPCSSPACTPPPACTPPPAHTPPPAQTCLVTPSSPLLLGPPSVPISASVTNLPLGLRPEAELCAQALASPESLELASVASSETSSLSLVPPKDLLPVAVEILPVSEKNLSLTPSAPSLTLEAGSIPNGQEQEAPDSAEGTTLTVLPEGEELPLCVSESNGLELPPSAASDEPLQEPLEADRTSEELTEAKTPTSSPEKPQELVTAEVAAPSTSSSATSSPEGPSPARPPRRRTSADVEIRGQGTGRPGQPPGPKVLRKLPGRLVTVVEEKELVRRRRQQRGAASTLVPGVSETSASPGSPSVRSMSGPESSPPIGGPCEAAPSSSLPTPPQQPFIARRHIELGVTGGGSPENGDGALLAITPPAVKRRRGRPPKKNRSPADAGRGVDEAPSSTLKGKTNGADPVPGPETLIVADPVLEPQLIPGPQPLGPQPVHRPNPLLSPVEKRRRGRPPKARDLPIPGTISSAGDGNSESRTQPPPHPSPLTPLPPLLVCPTATVANTVTTVTISTSPPKRKRGRPPKNPPSPRPSQLPVLDRDSTSVLESCGLGRRRQPQGQGESEGSSSDEDGSRPLTRLARLRLEAEGMRGRKSGGSMVVAVIQDDLDLADSGPGGLELTPPVVSLTPKLRSTRLRPGSLVPPLETEKLPRKRAGAPVGGSPGLAKRGRLQPPSPLGPEGSVEESEAEASGEEEEGDGTPRRRPGPRRLVGTTNQGDQRILRSSAPPSLAGPAVSHRGRKAKT>sp|Q8NFT2|STEA2_HUMAN Metalloreductase STEAP2 OS=Homo sapiens OX=9606GN=STEAP2 PE=1 SV=3MESISMMGSPKSLSETFLPNGINGIKDARKVTVGVIGSGDFAKSLTIRLIRCGYHVVIGSRNPKFASEFFPHVVDVTHHEDALTKTNIIFVAIHREHYTSLWDLRHLLVGKILIDVSNNMRINQYPESNAEYLASLFPDSLIVKGFNVVSAWALQLGPKDASRQVYICSNNIQARQQVIELARQLNFIPIDLGSLSSAREIENLPLRLFTLWRGPVVVAISLATFFFLYSFVRDVIHPYARNQQSDFYKIPIEIVNKTLPIVAITLLSLVYLAGLLAAAYQLYYGTKYRRFPPWLETWLQCRKQLGLLSFFFAMVHVAYSLCLPMRRSERYLFLNMAYQQVHANIENSWNEEEVWRIEMYISFGIMSLGLLSLLAVTSIPSVSNALNWREFSFIQSTLGYVALLISTFHVLIYGWKRAFEEEYYRFYTPPNFVLALVLPSIVILGKIILFLPCISRKLKRIKKGWEKSQFLEEGMGGTIPHVSPERVTVM>sp|Q8NFT2-2|STEA2_HUMAN Isoform 2 of Metalloreductase STEAP2 OS=Homosapiens OX=9606 GN=STEAP2MESISMMGSPKSLSETFLPNGINGIKDARKVTVGVIGSGDFAKSLTIRLIRCGYHVVIGSRNPKFASEFFPHVVDVTHHEDALTKTNIIFVAIHREHYTSLWDLRHLLVGKILIDVSNNMRINQYPESNAEYLASLFPDSLIVKGFNVVSAWALQLGPKDASRQVYICSNNIQARQQVIELARQLNFIPIDLGSLSSAREIENLPLRLFTLWRGPVVVAISLATFFFLYSFVRDVIHPYARNQQSDFYKIPIEIVNKTLPIVAITLLSLVYLAGLLAAAYQLYYGTKYRRFPPWLETWLQCRKQLGLLSFFFAMVHVAYSLCLPMRRSERYLFLNMAYQQVHANIENSWNEEEVWRIEMYISFGIMSLGLLSLLAVTSIPSVSNALNWREFSFIQSTLGYVALLISTFHVLIYGWKRAFEEEYYRFYTPPNFVLALVLPSIVILDLLQLCRYPD>sp|Q8NFT2-3|STEA2_HUMAN Isoform 3 of Metalloreductase STEAP2 OS=Homosapiens OX=9606 GN=STEAP2MESISMMGSPKSLSETFLPNGINGIKDARKVTVGVIGSGDFAKSLTIRLIRCGYHVVIGSRNPKFASEFFPHVVDVTHHEDALTKTNIIFVAIHREHYTSLWDLRHLLVGKILIDVSNNMRINQYPESNAEYLASLFPDSLIVKGFNVVSAWALQLGPKDASRQVYICSNNIQARQQVIELARQLNFIPIDLGSLSSAREIENLPLRLFTLWRGPVVVAISLATFFFLYSFVRDVIHPYARNQQSDFYKIPIEIVNKTLPIVAITLLSLVYLAGLLAAAYQLYYGTKYRRFPPWLETWLQCRKQLGLLSFFFAMVHVAYSLCLPMRRSERYLFLNMAYQQVHANIENSWNEEEVWRIEMYISFGIMSLGLLSLLAVTSIPSVSNALNWREFSFIQIFCSFADTQTELELEFVFLLTLLL>sp|Q7Z698|SPRE2_HUMAN Sprouty-related, EVH1 domain-containing protein 2OS=Homo sapiens OX=9606 GN=SPRED2 PE=1 SV=2MTEETHPDDDSYIVRVKAVVMTRDDSSGGWFPQEGGGISRVGVCKVMHPEGNGRSGFLIHGERQKDKLVVLECYVRKDLVYTKANPTFHHWKVDNRKFGLTFQSPADARAFDRGVRKAIEDLIEGSTTSSSTIHNEAELGDDDVFTTATDSSSNSSQKREQPTRTISSPTSCEHRRIYTLGHLHDSYPTDHYHLDQPMPRPYRQVSFPDDDEEIVRINPREKIWMTGYEDYRHAPVRGKYPDPSEDADSSYVRFAKGEVPKHDYNYPYVDSSDFGLGEDPKGRGGSVIKTQPSRGKSRRRKEDGERSRCVYCRDMFNHEENRRGHCQDAPDSVRTCIRRVSCMWCADSMLYHCMSDPEGDYTDPCSCDTSDEKFCLRWMALIALSFLAPCMCCYLPLRACYHCGVMCRCCGGKHKAAA>sp|Q7Z698-2|SPRE2_HUMAN Isoform 2 of Sprouty-related, EVH1 domain-containing protein 2 OS=Homo sapiens OX=9606 GN=SPRED2MASPGSDSYIVRVKAVVMTRDDSSGGWFPQEGGGISRVGVCKVMHPEGNGRSGFLIHGERQKDKLVVLECYVRKDLVYTKANPTFHHWKVDNRKFGLTFQSPADARAFDRGVRKAIEDLIEGSTTSSSTIHNEAELGDDDVFTTATDSSSNSSQKREQPTRTISSPTSCEHRRIYTLGHLHDSYPTDHYHLDQPMPRPYRQVSFPDDDEEIVRINPREKIWMTGYEDYRHAPVRGKYPDPSEDADSSYVRFAKGEVPKHDYNYPYVDSSDFGLGEDPKGRGGSVIKTQPSRGKSRRRKEDGERSRCVYCRDMFNHEENRRGHCQDAPDSVRTCIRRVSCMWCADSMLYHCMSDPEGDYTDPCSCDTSDEKFCLRWMALIALSFLAPCMCCYLPLRACYHCGVMCRCCGGKHKAAA>sp|Q86TD4|SRCA_HUMAN Sarcalumenin OS=Homo sapiens OX=9606 GN=SRL PE=1SV=3MRALVLLGCLLASLLFSGQAEETEDANEEAPLRDRSHIEKTLMLNEDKPSDDYSAVLQRLRKIYHSSIKPLEQSYKYNELRQHEITDGEITSKPMVLFLGPWSVGKSTMINYLLGLENTRYQLYTGAEPTTSEFTVLMHGPKLKTIEGIVMAADSARSFSPLEKFGQNFLEKLIGIEVPHKLLERVTFVDTPGIIENRKQQERGYPFNDVCQWFIDRADLIFVVFDPTKLDVGLELEMLFRQLKGRESQIRIILNKADNLATQMLMRVYGALFWSLAPLINVTEPPRVYVSSFWPQEYKPDTHQELFLQEEISLLEDLNQVIENRLENKIAFIRQHAIRVRIHALLVDRYLQTYKDKMTFFSDGELVFKDIVEDPDKFYIFKTILAKTNVSKFDLPNREAYKDFFGINPISSFKLLSQQCSYMGGCFLEKIERAITQELPGLLGSLGLGKNPGALNCDKTGCSETPKNRYRKH>sp|Q86TD4-1|SRCA_HUMAN Isoform 2 of Sarcalumenin OS=Homo sapiens OX=9606GN=SRLMRALVLLGCLLASLLFSGQAELQVSASGGTEDVGNLLENHFSAGDASLEEKERALYADTAPQDKKLLLHYPDGREAESPKKTPASAASAGPDPEASLSNASATESPPPGERDDRDAAGPGEEKNGPPVASALPPGGAKGPVEEEWPEPSSGEGQGEEETGFGLPTEGTASGEAGGQAGGHELPEEVQEVQGDSLVQGAVAGTAEPKAEGASPHSEGDGVGPLNAEAEGSPGPGEEPAVPEGAPDVAAVGGESEPDIDTQASEGTEDQGEPGPAAEASAEPGGAQSVKAGDTEESQAPEMTEEDADEASSEEESGDGSGSEEEGGVPSEEESEEDSGDGASSEEAEGASEEATEPQEAGEPQEAREPQEGGDLQEAEESQEGGDPQEAEEPQEGGAPQEGGEPQEGGDPQEAREPQEAREPQEGAELPEATGTTSHRDRGAQPGPEELNTESMGSETLDMKAEEPEEGHQGRESPIIVAQEETEDANEEAPLRDRSHIEKTLMLNEDKPSDDYSAVLQRLRKIYHSSIKPLEQSYKYNELRQHEITDGEITSKPMVLFLGPWSVGKSTMINYLLGLENTRYQLYTGAEPTTSEFTVLMHGPKLKTIEGIVMAADSARSFSPLEKFGQNFLEKLIGIEVPHKLLERVTFVDTPGIIENRKQQERGYPFNDVCQWFIDRADLIFVVFDPTKLDVGLELEMLFRQLKGRESQIRIILNKADNLATQMLMRVYGALFWSLAPLINVTEPPRVYVSSFWPQEYKPDTHQELFLQEEISLLEDLNQVIENRLENKIAFIRQHAIRVRIHALLVDRYLQTYKDKMTFFSDGELVFKDIVEDPDKFYIFKTILAKTNVSKFDLPNREAYKDFFGINPISSFKLLSQQCSYMGGCFLEKIERAITQELPGLLGSLGLGKNPGALNCDKTGCSETPKNRYRKH>sp|Q86TD4-3|SRCA_HUMAN Isoform 3 of Sarcalumenin OS=Homo sapiens OX=9606GN=SRLMLNEDKPSDDYSAVLQRLRKIYHSSIKPLEQSYKYNELRQHEITDGEITSKPMVLFLGPWSVGKSTMINYLLGLENTRYQLYTGAEPTTSEFTVLMHGPKLKTIEGIVMAADSARSFSPLEKFGQNFLEKLIGIEVPHKLLERVTFVDTPGIIENRKQQERGYPFNDVCQWFIDRADLIFVVFDPTKLDVGLELEMLFRQLKGRESQIRIILNKADNLATQMLMRVYGALFWSLAPLINVTEPPRVYVSSFWPQEYKPDTHQELFLQEEISLLEDLNQVIENRLENKIAFIRQHAIRVRIHALLVDRYLQTYKDKMTFFSDGELVFKDIVEDPDKFYIFKTILAKTNVSKFDLPNREAYKDFFGINPISSFKLLSQQCSYMGGCFLEKIERAITQELPGLLGSLGLGKNPGALNCDKTGCSETPKNRYRKH>sp|P37108|SRP14_HUMAN Signal recognition particle 14 kDa protein OS=Homosapiens OX=9606 GN=SRP14 PE=1 SV=2MVLLESEQFLTELTRLFQKCRTSGSVYITLKKYDGRTKPIPKKGTVEGFEPADNKCLLRATDGKKKISTVVSSKEVNKFQMAYSNLLRANMDGLKKRDKKNKTKKTKAAAAAAAAAPAAAATAPTTAATTAATAAQ>sp|Q15772|SPEG_HUMAN Striated muscle preferentially expressed proteinkinase OS=Homo sapiens OX=9606 GN=SPEG PE=1 SV=4MQKARGTRGEDAGTRAPPSPGVPPKRAKVGAGGGAPVAVAGAPVFLRPLKNAAVCAGSDVRLRVVVSGTPQPSLRWFRDGQLLPAPAPEPSCLWLRRCGAQDAGVYSCMAQNERGRASCEAVLTVLEVGDSETAEDDISDVQGTQRLELRDDGAFSTPTGGSDTLVGTSLDTPPTSVTGTSEEQVSWWGSGQTVLEQEAGSGGGTRRLPGSPRQAQATGAGPRHLGVEPLVRASRANLVGASWGSEDSLSVASDLYGSAFSLYRGRALSIHVSVPQSGLRREEPDLQPQLASEAPRRPAQPPPSKSALLPPPSPRVGKRSPPGPPAQPAATPTSPHRRTQEPVLPEDTTTEEKRGKKSKSSGPSLAGTAESRPQTPLSEASGRLSALGRSPRLVRAGSRILDKLQFFEERRRSLERSDSPPAPLRPWVPLRKARSLEQPKSERGAPWGTPGASQEELRAPGSVAERRRLFQQKAASLDERTRQRSPASDLELRFAQELGRIRRSTSREELVRSHESLRATLQRAPSPREPGEPPLFSRPSTPKTSRAVSPAAAQPPSPSSAEKPGDEPGRPRSRGPAGRTEPGEGPQQEVRRRDQFPLTRSRAIQECRSPVPPPAADPPEARTKAPPGRKREPPAQAVRFLPWATPGLEGAAVPQTLEKNRAGPEAEKRLRRGPEEDGPWGPWDRRGARSQGKGRRARPTSPELESSDDSYVSAGEEPLEAPVFEIPLQNVVVAPGADVLLKCIITANPPPQVSWHKDGSALRSEGRLLLRAEGERHTLLLREARAADAGSYMATATNELGQATCAASLTVRPGGSTSPFSSPITSDEEYLSPPEEFPEPGETWPRTPTMKPSPSQNRRSSDTGSKAPPTFKVSLMDQSVREGQDVIMSIRVQGEPKPVVSWLRNRQPVRPDQRRFAEEAEGGLCRLRILAAERGDAGFYTCKAVNEYGARQCEARLEVRAHPESRSLAVLAPLQDVDVGAGEMALFECLVAGPTDVEVDWLCRGRLLQPALLKCKMHFDGRKCKLLLTSVHEDDSGVYTCKLSTAKDELTCSARLTVRPSLAPLFTRLLEDVEVLEGRAARFDCKISGTPPPVVTWTHFGCPMEESENLRLRQDGGLHSLHIAHVGSEDEGLYAVSAVNTHGQAHCSAQLYVEEPRTAASGPSSKLEKMPSIPEEPEQGELERLSIPDFLRPLQDLEVGLAKEAMLECQVTGLPYPTISWFHNGHRIQSSDDRRMTQYRDVHRLVFPAVGPQHAGVYKSVIANKLGKAACYAHLYVTDVVPGPPDGAPQVVAVTGRMVTLTWNPPRSLDMAIDPDSLTYTVQHQVLGSDQWTALVTGLREPGWAATGLRKGVQHIFRVLSTTVKSSSKPSPPSEPVQLLEHGPTLEEAPAMLDKPDIVYVVEGQPASVTVTFNHVEAQVVWRSCRGALLEARAGVYELSQPDDDQYCLRICRVSRRDMGALTCTARNRHGTQTCSVTLELAEAPRFESIMEDVEVGAGETARFAVVVEGKPLPDIMWYKDEVLLTESSHVSFVYEENECSLVVLSTGAQDGGVYTCTAQNLAGEVSCKAELAVHSAQTAMEVEGVGEDEDHRGRRLSDFYDIHQEIGRGAFSYLRRIVERSSGLEFAAKFIPSQAKPKASARREARLLARLQHDCVLYFHEAFERRRGLVIVTELCTEELLERIARKPTVCESEIRAYMRQVLEGIHYLHQSHVLHLDVKPENLLVWDGAAGEQQVRICDFGNAQELTPGEPQYCQYGTPEFVAPEIVNQSPVSGVTDIWPVGVVAFLCLTGISPFVGENDRTTLMNIRNYNVAFEETTFLSLSREARGFLIKVLVQDRLRPTAEETLEHPWFKTQAKGAEVSTDHLKLFLSRRRWQRSQISYKCHLVLRPIPELLRAPPERVWVTMPRRPPPSGGLSSSSDSEEEELEELPSVPRPLQPEFSGSRVSLTDIPTEDEALGTPETGAATPMDWQEQGRAPSQDQEAPSPEALPSPGQEPAAGASPRRGELRRGSSAESALPRAGPRELGRGLHKAASVELPQRRSPSPGATRLARGGLGEGEYAQRLQALRQRLLRGGPEDGKVSGLRGPLLESLGGRARDPRMARAASSEAAPHHQPPLENRGLQKSSSFSQGEAEPRGRHRRAGAPLEIPVARLGARRLQESPSLSALSEAQPSSPARPSAPKPSTPKSAEPSATTPSDAPQPPAPQPAQDKAPEPRPEPVRASKPAPPPQALQTLALPLTPYAQIIQSLQLSGHAQGPSQGPAAPPSEPKPHAAVFARVASPPPGAPEKRVPSAGGPPVLAEKARVPTVPPRPGSSLSSSIENLESEAVFEAKFKRSRESPLSLGLRLLSRSRSEERGPFRGAEEEDGIYRPSPAGTPLELVRRPERSRSVQDLRAVGEPGLVRRLSLSLSQRLRRTPPAQRHPAWEARGGDGESSEGGSSARGSPVLAMRRRLSFTLERLSSRLQRSGSSEDSGGASGRSTPLFGRLRRATSEGESLRRLGLPHNQLAAQAGATTPSAESLGSEASATSGSSAPGESRSRLRWGFSRPRKDKGLSPPNLSASVQEELGHQYVRSESDFPPVFHIKLKDQVLLEGEAATLLCLPAACPAPHISWMKDKKSLRSEPSVIIVSCKDGRQLLSIPRAGKRHAGLYECSATNVLGSITSSCTVAVARVPGKLAPPEVPQTYQDTALVLWKPGDSRAPCTYTLERRVDGESVWHPVSSGIPDCYYNVTHLPVGVTVRFRVACANRAGQGPFSNSSEKVFVRGTQDSSAVPSAAHQEAPVTSRPARARPPDSPTSLAPPLAPAAPTPPSVTVSPSSPPTPPSQALSSLKAVGPPPQTPPRRHRGLQAARPAEPTLPSTHVTPSEPKPFVLDTGTPIPASTPQGVKPVSSSTPVYVVTSFVSAPPAPEPPAPEPPPEPTKVTVQSLSPAKEVVSSPGSSPRSSPRPEGTTLRQGPPQKPYTFLEEKARGRFGVVRACRENATGRTFVAKIVPYAAEGKRRVLQEYEVLRTLHHERIMSLHEAYITPRYLVLIAESCGNRELLCGLSDRFRYSEDDVATYMVQLLQGLDYLHGHHVLHLDIKPDNLLLAPDNALKIVDFGSAQPYNPQALRPLGHRTGTLEFMAPEMVKGEPIGSATDIWGAGVLTYIMLSGRSPFYEPDPQETEARIVGGRFDAFQLYPNTSQSATLFLRKVLSVHPWSRPSLQDCLAHPWLQDAYLMKLRRQTLTFTTNRLKEFLGEQRRRRAEAATRHKVLLRSYPGGP>sp|Q15772-3|SPEG_HUMAN Isoform 2 of Striated muscle preferentiallyexpressed protein kinase OS=Homo sapiens OX=9606 GN=SPEGMATATNELGQATCAASLTVRPGGSTSPFSSPITSDEEYLSPPEEFPEPGETWPRTPTMKPSPSQNRRSSDTGSKAPPTFKVSLMDQSVREGQDVIMSIRVQGEPKPVVSWLRNRQPVRPDQRRFAEEAEGGLCRLRILAAERGDAGFYTCKAVNEYGARQCEARLEVRGE>sp|Q15772-4|SPEG_HUMAN Isoform 3 of Striated muscle preferentiallyexpressed protein kinase OS=Homo sapiens OX=9606 GN=SPEGMKPSPSQNRRSSDTGSKAPPTFKVSLMDQSVREGQDVIMSIRVQGEPKPVVSWLRNRQPVRPDQRRFAEEAEGGLCRLRILAAERGDAGFYTCKAVNEYGARQCEARLEVRGE>sp|Q15772-1|SPEG_HUMAN Isoform 1 of Striated muscle preferentiallyexpressed protein kinase OS=Homo sapiens OX=9606 GN=SPEGMQKARGTRGEDAGTRAPPSPGVPPKRAKVGAGGGAPVAVAGAPVFLRPLKNAAVCAGSDVRLRVVVSGTPQPSLRWFRDGQLLPAPAPEPSCLWLRRCGAQDAGVYSCMAQNERGRASCEAVLTVLEVGDSETAEDDISDVQGTQRLELRDDGAFSTPTGGSDTLVGTSLDTPPTSVTGTSEEQVSWWGSGQTVLEQEAGSGGGTRRLPGSPRQAQATGAGPRHLGVEPLVRASRANLVGASWGSEDSLSVASDLYGSAFSLYRGRALSIHVSVPQSGLRREEPDLQPQLASEAPRRPAQPPPSKSALLPPPSPRVGKRSPPGPPAQPAATPTSPHRRTQEPVLPEDTTTEEKRGKKSKSSGPSLAGTAESRPQTPLSEASGRLSALGRSPRLVRAGSRILDKLQFFEERRRSLERSDSPPAPLRPWVPLRKARSLEQPKSERGAPWGTPGASQEELRAPGSVAERRRLFQQKAASLDERTRQRSPASDLELRFAQELGRIRRSTSREELVRSHESLRATLQRAPSPREPGEPPLFSRPSTPKTSRAVSPAAAQPPSPSSAEKPGDEPGRPRSRGPAGRTEPGEGPQQEVRRRDQFPLTRSRAIQECRSPVPPPAADPPEARTKAPPGRKREPPAQAVRFLPWATPGLEGAAVPQTLEKNRAGPEAEKRLRRGPEEDGPWGPWDRRGARSQGKGRRARPTSPELESSDDSYVSAGEEPLEAPVFEIPLQNVVVAPGADVLLKCIITANPPPQVSWHKDGSALRSEGRLLLRAEGERHTLLLREARAADAGSYMATATNELGQATCAASLTVRPGGSTSPFSSPITSDEEYLSPPEEFPEPGETWPRTPTMKPSPSQNRRSSDTGSKAPPTFKVSLMDQSVREGQDVIMSIRVQGEPKPVVSWLRNRQPVRPDQRRFAEEAEGGLCRLRILAAERGDAGFYTCKAVNEYGARQCEARLEVRAHPESRSLAVLAPLQDVDVGAGEMALFECLVAGPTDVEVDWLCRGRLLQPALLKCKMHFDGRKCKLLLTSVHEDDSGVYTCKLSTAKDELTCSARLTVRPSLAPLFTRLLEDVEVLEGRAARFDCKISGTPPPVVTWTHFGCPMEESENLRLRQDGGLHSLHIAHVGSEDEGLYAVSAVNTHGQAHCSAQLYVEEPRTAASGPSSKLEKMPSIPEEPEQGELERLSIPDFLRPLQDLEVGLAKEAMLECQVTGLPYPTISWFHNGHRIQSSDDRRMTQYRDVHRLVFPAVGPQHAGVYKSVIANKLGKAACYAHLYVTDVVPGPPDGAPQVVAVTGRMVTLTWNPPRSLDMAIDPDSLTYTVQHQVLGSDQWTALVTGLREPGWAATGLRKGVQHIFRVLSTTVKSSSKPSPPSEPVQLLEHGPTLEEAPAMLDKPDIVYVVEGQPASVTVTFNHVEAQVVWRSCRGALLEARAGVYELSQPDDDQYCLRICRVSRRDMGALTCTARNRHGTQTCSVTLELAEAPRFESIMEDVEVGAGETARFAVVVEGKPLPDIMWYKDEVLLTESSHVSFVYEENECSLVVLSTGAQDGGVYTCTAQNLAGEVSCKAELAVHSAQTAMEVEGVGEDEDHRGRRLSDFYDIHQEIGRGAFSYLRRIVERSSGLEFAAKFIPSQAKPKASARREARLLARLQHDCVLYFHEAFERRRGLVIVTELCTEELLERIARKPTVCESEIRAYMRQVLEGIHYLHQSHVLHLDVKPENLLVWDGAAGEQQVRICDFGNAQELTPGEPQYCQYGTPEFVAPEIVNQSPVSGVTDIWPVGVVAFLCLTGISPFVGENDRTTLMNIRNYNVAFEETTFLSLSREARGFLIKVLVQDRLRPTAEETLEHPWFKTQAKGAEVSTDHLKLFLSRRRWQRSQISYKCHLVLRPIPELLRAPPERVWVTMPRRPPPSGGLSSSSDSEEEELEELPSVPRPLQPEFSGSRVSLTDIPTEDEALGTPETGAATPMDWQEQGRAPSQDQEAPSPEALPSPGQEPAAGASPRRGELRRGSSAESALPRAGPRELGRGLHKAASVELPQRRSPSPGATRLARGGLGEGEYAQRLQALRQRLLRGGPEDGKVSGLRGPLLESLGGRARDPRMARAASSEAAPHHQPPLENRGLQKSSSFSQGEAEPRGRHRRAGAPLEIPVARLGARRLQESPSLSALSEAQPSSPARPSAPKPSTPKSAEPSATTPSDAPQPPAPQPAQDKAPEPRPEPVRASKPAPPPQALQTLALPLTPYAQIIQSLQLSGHAQGPSQGPAAPPSEPKPHAAVFARVASPPPGAPEKRVPSAGGPPVLAEKARVPTVPPRPGSSLSSSIENLESEAVFEAKFKRSRESPLSLGLRLLSRSRSEERGPFRGAEEEDGIYRPSPAGTPLELVRRPERSRSVQDLRAVGEPGLVRRLSLSLSQRLRRTPPAQRHPAWEARGGDGESSEGGSSARGSPVLAMRRRLSFTLERLSSRLQRSGSSEDSGGASGRSTPLFGRLRRATSEGESLRRLGLPHNQLAAQAGATTPSAESLGSEASATSGSSAPGESRSRLRWGFSRPRKDKGLSPPNLSASVQEELGHQYVRSESDFPPVFHIKLKDQVLLEGEAATLLCLPAACPAPHISWMKDKKSLRSEPSVIIVSCKDGRQLLSIPRAGKRHAGLYECSATNVLGSITSSCTVAVARVPGKLAPPEVPQTYQDTALVLWKPGDSRAPCTYTLERRVDGESVWHPVSSGIPDCYYNVTHLPVGVTVRFRVACANRAGQGPFSNSSEKVFVRGTQDSSAVPSAAHQEAPVTSRPARARPPDSPTSLAPPLAPAAPTPPSVTVSPSSPPTPPSQALSSLKAVGPPPQTPPRRHRGLQAARPAEPTLPSTHVTPSEPKPFVLDTGTPIPASTPQGVKPVSSSTPVYVVTSFVSAPPAPEPPAPEPPPEPTKVTVQSLSPAKEVVSSPGSSPRSSPRPEGTTLRQGPPQKPYTFLEEKARGRFGVVRACRENATGRTFVAKIVPYAAEGKRRVLQEYEVLRTLHHERIMSLHEAYITPRYLVLIAESCGNRELLCGLSDRFRYSEDDVATYMVQLLQGLDYLHGHHVLHLDIKPDNLLLAPDNALKIVDFGSAQPYNPQALRPLGHRTGTLEFMAPEMVKGEPIGSATDIWGAGVLTYIMLSGRSPFYEPDPQETEARIVGGRFDAFQLYPNTSQSATLFLRKVLSVHPWSRPSSCLSVCHKEIKMASS>sp|Q9UMS6|SYNP2_HUMAN Synaptopodin-2 OS=Homo sapiens OX=9606 GN=SYNPO2PE=1 SV=2MGTGDFICISMTGGAPWGFRLQGGKEQKQPLQVAKIRNQSKASGSGLCEGDEVVSINGNPCADLTYPEVIKLMESITDSLQMLIKRPSSGISEALISENENKNLEHLTHGGYVESTTLQIRPATKTQCTEFFLAPVKTEVPLAENQRSGPDCAGSLKEETGPSYQRAPQMPDSQRGRVAEELILREKVEAVQPGPVVELQLSLSQERHKGASGPLVALPGAEKSKSPDPDPNLSHDRIVHINSIPTNEKADPFLRSSKIIQISSGRELRVIQESEAGDAGLPRVEVILDCSDRQKTEGCRLQAGKECVDSPVEGGQSEAPPSLVSFAVSSEGTEQGEDPRSEKDHSRPHKHRARHARLRRSESLSEKQVKEAKSKCKSIALLLTDAPNPNSKGVLMFKKRRRRARKYTLVSYGTGELEREADEEEEGDKEDTCEVAFLGASESEVDEELLSDVDDNTQVVNFDWDSGLVDIEKKLNRGDKMEMLPDTTGKGALMFAKRRERMDQITAQKEEDKVGGTPSREQDAAQTDGLRTTTSYQRKEEESVRTQSSVSKSYIEVSHGLGHVPQQNGFSGTSETANIQRMVPMNRTAKPFPGSVNQPATPFSPTRNMTSPIADFPAPPPYSAVTPPPDAFSRGVSSPIAGPAQPPPWPQPAPWSQPAFYDSSERIASRDERISVPAKRTGILQEAKRRSTTKPMFTFKEPKVSPNPELLSLLQNSEGKRGTGAGGDSGPEEDYLSLGAEACNFMQSSSAKQKTPPPVAPKPAVKSSSSQPVTPVSPVWSPGVAPTQPPAFPTSNPSKGTVVSSIKIAQPSYPPARPASTLNVAGPFKGPQAAVASQNYTPKPTVSTPTVNAVQPGAVGPSNELPGMSGRGAQLFAKRQSRMEKYVVDSDTVQAHAARAQSPTPSLPASWKYSSNVRAPPPVAYNPIHSPSYPLAALKSQPSAAQPSKMGKKKGKKPLNALDVMKHQPYQLNASLFTFQPPDAKDGLPQKSSVKVNSALAMKQALPPRPVNAASPTNVQASSVYSVPAYTSPPSFFAEASSPVSASPVPVGIPTSPKQESASSSYFVAPRPKFSAKKSGVTIQVWKPSVVEE>sp|Q9UMS6-2|SYNP2_HUMAN Isoform 2 of Synaptopodin-2 OS=Homo sapiensOX=9606 GN=SYNPO2MGTGDFICISMTGGAPWGFRLQGGKEQKQPLQVAKIRNQSKASGSGLCEGDEVVSINGNPCADLTYPEVIKLMESITDSLQMLIKRPSSGISEALISENENKNLEHLTHGGYVESTTLQIRPATKTQCTEFFLAPVKTEVPLAENQRSGPDCAGSLKEETGPSYQRAPQMPDSQRGRVAEELILREKVEAVQPGPVVELQLSLSQERHKGASGPLVALPGAEKSKSPDPDPNLSHDRIVHINSIPTNEKADPFLRSSKIIQISSGRELRVIQESEAGDAGLPRVEVILDCSDRQKTEGCRLQAGKECVDSPVEGGQSEAPPSLVSFAVSSEGTEQGEDPRSEKDHSRPHKHRARHARLRRSESLSEKQVKEAKSKCKSIALLLTDAPNPNSKGVLMFKKRRRRARKYTLVSYGTGELEREADEEEEGDKEDTCEVAFLGASESEVDEELLSDVDDNTQVVNFDWDSGLVDIEKKLNRGDKMEMLPDTTGKGALMFAKRRERMDQITAQKEEDKVGGTPSREQDAAQTDGLRTTTSYQRKEEESVRTQSSVSKSYIEVSHGLGHVPQQNGFSGTSETANIQRMVPMNRTAKPFPGSVNQPATPFSPTRNMTSPIADFPAPPPYSAVTPPPDAFSRGVSSPIAGPAQPPPWPQPAPWSQPAFYDSSERIASRDERISVPAKRTGILQEAKRRSTTKPMFTFKEPKVSPNPELLSLLQNSEGKRGTGAGGDSGPEEDYLSLGAEACNFMQSSSAKQKTPPPVAPKPAVKSSSSQPVTPVSPVWSPGVAPTQPPAFPTSNPSKGTVVSSIKIAQPSYPPARPASTLNVAGPFKGPQAAVASQNYTPKPTVSTPTVNAVQPGAVGPSNELPGMSGRGAQLFAKRQSRMEKYVVDSDTVQAHAARAQSPTPSLPASWKYSSNVRAPPPVAYNPIHSPSYPLAALKSQPSAAQPSKMGKKKGKKPLNALDVMKHQPYQLNASLFTFQPPDAKDGLPQKSSVKVNSALAMKQALPPRPVNAASPTNVQASSVYSVPAYTSPPSFFAEASSPVSASPVPVGIPTSPKQESASSSYFVAPRPKFSAKKSGVTIQESGRSLSLPGRSVPPPISTSPWVYQPTYSYSSKPTDGLEKANKRPTPWEAAAKSPLGLVDDAFQPRNIQESIVANVVSAARRKVLPGPPEDWNERLSYIPQTQKAYMGSCGRQEYNVTANNNMSTTSQYGSQLPYAYYRQASRNDSAIMSMETRSDYCLPVADYNYNPHPRGWRRQT>sp|Q9UMS6-3|SYNP2_HUMAN Isoform 3 of Synaptopodin-2 OS=Homo sapiensOX=9606 GN=SYNPO2MGTGDFICISMTGGAPWGFRLQGGKEQKQPLQVAKIRNQSKASGSGLCEGDEVVSINGNPCADLTYPEVIKLMESITDSLQMLIKRPSSGISEALISENENKNLEHLTHGGYVESTTLQIRPATKTQCTEFFLAPVKTEVPLAENQRSGPDCAGSLKEETGPSYQRAPQMPDSQRGRVAEELILREKVEAVQPGPVVELQLSLSQERHKGASGPLVALPGAEKSKSPDPDPNLSHDRIVHINSIPTNEKADPFLRSSKIIQISSGRELRVIQESEAGDAGLPRVEVILDCSDRQKTEGCRLQAGKECVDSPVEGGQSEAPPSLVSFAVSSEGTEQGEDPRSEKDHSRPHKHRARHARLRRSESLSEKQVKEAKSKCKSIALLLTDAPNPNSKGVLMFKKRRRRARKYTLVSYGTGELEREADEEEEGDKEDTCEVAFLGASESEVDEELLSDVDDNTQVVNFDWDSGLVDIEKKLNRGDKMEMLPDTTGKGALMFAKRRERMDQITAQKEEDKVGGTPSREQDAAQTDGLRTTTSYQRKEEESVRTQSSVSKSYIEVSHGLGHVPQQNGFSGTSETANIQRMVPMNRTAKPFPGSVNQPATPFSPTRNMTSPIADFPAPPPYSAVTPPPDAFSRGVSSPIAGPAQPPPWPQPAPWSQPAFYDSSERIASRDERISVPAKRTGILQEAKRRSTTKPMFTFKEPKVSPNPELLSLLQNSEGKRGTGAGGDSGPEEDYLSLGAEACNFMQSSSAKQKTPPPVAPKPAVKSSSSQPVTPVSPVWSPGVAPTQPPAFPTSNPSKGTVVSSIKIAQPSYPPARPASTLNVAGPFKGPQAAVASQNYTPKPTVSTPTVNAVQPGAVGPSNELPGMSGRGAQLFAKRQSRMEKYVVDSDTVQAHAARAQSPTPSLPASWKYSSNVRAPPPVAYNPIHSPSYPLAALKSQPSAAQPSKMGKKKGKKPLNALDVMKHQPYQLNASLFTFQPPDAKDGLPQKSSVKVNSALAMKQALPPRPVNAASPTNVQASSVYSVPAYTSPPSFFAEASSPVSASPVPVGIPTSPKQESASSSYFVAPRPKFSAKKSGVTIQVKCKSGIHSQDIIRTYFPAYLSSST>sp|Q9UMS6-4|SYNP2_HUMAN Isoform 4 of Synaptopodin-2 OS=Homo sapiensOX=9606 GN=SYNPO2MVTQIRNQSKASGSGLCEGDEVVSINGNPCADLTYPEVIKLMESITDSLQMLIKRPSSGISEALISENENKNLEHLTHGGYVESTTLQIRPATKTQCTEFFLAPVKTEVPLAENQRSGPDCAGSLKEETGPSYQRAPQMPDSQRGRVAEELILREKVEAVQPGPVVELQLSLSQERHKGASGPLVALPGAEKSKSPDPDPNLSHDRIVHINSIPTNEKADPFLRSSKIIQISSGRELRVIQESEAGDAGLPRVEVILDCSDRQKTEGCRLQAGKECVDSPVEGGQSEAPPSLVSFAVSSEGTEQGEDPRSEKDHSRPHKHRARHARLRRSESLSEKQVKEAKSKCKSIALLLTDAPNPNSKGVLMFKKRRRRARKYTLVSYGTGELEREADEEEEGDKEDTCEVAFLGASESEVDEELLSDVDDNTQVVNFDWDSGLVDIEKKLNRGDKMEMLPDTTGKGALMFAKRRERMDQITAQKEEDKVGGTPSREQDAAQTDGLRTTTSYQRKEEESVRTQSSVSKSYIEVSHGLGHVPQQNGFSGTSETANIQRMVPMNRTAKPFPGSVNQPATPFSPTRNMTSPIADFPAPPPYSAVTPPPDAFSRGVSSPIAGPAQPPPWPQPAPWSQPAFYDSSERIASRDERISVPAKRTGILQEAKRRSTTKPMFTFKEPKVSPNPELLSLLQNSEGKRGTGAGGDSGPEEDYLSLGAEACNFMQSSSAKQKTPPPVAPKPAVKSSSSQPVTPVSPVWSPGVAPTQPPAFPTSNPSKGTVVSSIKIAQPSYPPARPASTLNVAGPFKGPQAAVASQNYTPKPTVSTPTVNAVQPGAVGPSNELPGMSGRGAQLFAKRQSRMEKYVVDSDTVQAHAARAQSPTPSLPASWKYSSNVRAPPPVAYNPIHSPSYPLAALKSQPSAAQPSKMGKKKGKKPLNALDVMKHQPYQLNASLFTFQPPDAKDGLPQKSSVKVNSALAMKQALPPRPVNAASPTNVQASSVYSVPAYTSPPSFFAEASSPVSASPVPVGIPTSPKQESASSSYFVAPRPKFSAKKSGVTIQESGRSLSLPGRSVPPPISTSPWVYQPTYSYSSKPTDGLEKANKRPTPWEAAAKSPLGLVDDAFQPRNIQESIVANVVSAARRKVLPGPPEDWNERLSYIPQTQKAYMGSCGRQEYNVTANNNMSTTSQYGSQLPYAYYRQASRNDSAIMSMETRSDYCLPVADYNYNPHPRGWRRQT>sp|Q9UMS6-5|SYNP2_HUMAN Isoform 5 of Synaptopodin-2 OS=Homo sapiensOX=9606 GN=SYNPO2MFKKRRRRARKYTLVSYGTGELEREADEEEEGDKEDTCEVAFLGASESEVDEELLSDVDDNTQVVNFDWDSGLVDIEKKLNRGDKMEMLPDTTGKGALMFAKRRERMDQITAQKEEDKVGGTPSREQDAAQTDGLRTTTSYQRKEEESVRTQSSVSKSYIEVSHGLGHVPQQNGFSGTSETANIQRMVPMNRTAKPFPGSVNQPATPFSPTRNMTSPIADFPAPPPYSAVTPPPDAFSRGVSSPIAGPAQPPPWPQPAPWSQPAFYDSSERIASRDERISVPAKRTGILQEAKRRSTTKPMFTFKEPKVSPNPELLSLLQNSEGKRGTGAGGDSGPEEDYLSLGAEACNFMQSSSAKQKTPPPVAPKPAVKSSSSQPVTPVSPVWSPGVAPTQPPAFPTSNPSKGTVVSSIKIAQPSYPPARPASTLNVAGPFKGPQAAVASQNYTPKPTVSTPTVNAVQPGAVGPSNELPGMSGRGAQLFAKRQSRMEKYVVDSDTVQAHAARAQSPTPSLPASWKYSSNVRAPPPVAYNPIHSPSYPLAALKSQPSAAQPSKMGKKKGKKPLNALDVMKHQPYQLNASLFTFQPPDAKDGLPQKSSVKVNSALAMKQALPPRPVNAASPTNVQASSVYSVPAYTSPPSFFAEASSPVSASPVPVGIPTSPKQESASSSYFVAPRPKFSAKKSGVTIQVWKPSVVEE>sp|Q15543|TAF13_HUMAN Transcription initiation factor TFIID subunit 13OS=Homo sapiens OX=9606 GN=TAF13 PE=1 SV=1MADEEEDPTFEEENEEIGGGAEGGQGKRKRLFSKELRCMMYGFGDDQNPYTESVDILEDLVIEFITEMTHKAMSIGRQGRVQVEDIVFLIRKDPRKFARVKDLLTMNEELKRARKAFDEANYGS>sp|Q9Y5J6|T10B_HUMAN Mitochondrial import inner membrane translocasesubunit Tim10 B OS=Homo sapiens OX=9606 GN=TIMM10B PE=1 SV=1MERQQQQQQQLRNLRDFLLVYNRMTELCFQRCVPSLHHRALDAEEEACLHSCAGKLIHSNHRLMAAYVQLMPALVQRRIADYEAASAVPGVAAEQPGVSPSGS>sp|Q9NS62|THSD1_HUMAN Thrombospondin type-1 domain-containing protein 1OS=Homo sapiens OX=9606 GN=THSD1 PE=1 SV=1MKPMLKDFSNLLLVVLCDYVLGEAEYLLLREPGHVALSNDTVYVDFQYFDGANGTLRNVSVLLLEANTNQTVTTKYLLTNQSQGTLKFECFYFKEAGDYWFTMTPEATDNSTPFPWWEKSAFLKVEWPVFHVDLNRSAKAAEGTFQVGLFTSQPLCPFPVDKPNIVVDVIFTNSLPEARRNSRQPLEIRTSKRTELAQGQWVEFGCAPLGPEAYVTVVLKLLGRDSVITSTGPIDLAQKFGYKLVMVPELTCESGVEVTVLPPPCTFVQGVVTVFKEAPRYPGKRTIHLAENSLPLGERRTIFNCTLFDMGKNKYCFDFGISSRSHFSAKEECMLIQRNTETWGLWQPWSQCSATCGDGVRERRRVCLTSFPSSPVCPGMSLEASLCSLEECAAFQPSSPSPLQPQGPVKSNNIVTVTGISLCLFIIIATVLITLWRRFGRPAKCSTPARHNSIHSPSFRKNSDEENICELSEQRGSFSDGGDGPTGSPGDTGIPLTYRRSGPVPPEDDASGSESFQSNAQKIIPPLFSYRLAQQQLKEMKKKGLTETTKVYHVSQSPLTDTAIDAAPSAPLDLESPEEAAANKFRIKSPFPEQPAVSAGERPPSRLDLNVTQASCAISPSQTLIRKSQARHVGSRGGPSERSHARNAHFRRTASFHEARQARPFRERSMSTLTPRQAPAYSSRTRTCEQAEDRFRPQSRGAHLFPEKLEHFQEASGTRGPLNPLPKSYTLGQPLRKPDLGDHQAGLVAGIERTEPHRARRGPSPSHKSVSRKQSSPISPKDNYQRVSSLSPSQCRKDKCQSFPTHPEFAFYDNTSFGLTEAEQRMLDLPGYFGSNEEDETTSTLSVEKLVI>sp|Q9NS62-2|THSD1_HUMAN Isoform 2 of Thrombospondin type-1 domain-containing protein 1 OS=Homo sapiens OX=9606 GN=THSD1MKPMLKDFSNLLLVVLCDYVLGEAEYLLLREPGHVALSNDTVYVDFQYFDGANGTLRNVSVLLLEANTNQTVTTKYLLTNQSQGTLKFECFYFKEAGDYWFTMTPEATDNSTPFPWWEKSAFLKVEWPVFHVDLNRSAKAAEGTFQVGLFTSQPLCPFPVDKPNIVVDVIFTNSLPEARRNSRQPLEIRTSKRTELAQGQWVEFGCAPLGPEAYVTVVLKLLGRDSVITSTGPIDLAQKFGYKLVMVPELTCESGVEVTVLPPPCTFVQGVVTVFKEAPRYPGKRTIHLAENSLPLGERRTIFNCTLFDMGKNKYCFDFGISSRSHFSAKEECMLIQRNTAFQPSSPSPLQPQGPVKSNNIVTVTGISLCLFIIIATVLITLWRRFGRPAKCSTPARHNSIHSPSFRKNSDEENICELSEQRGSFSDGGDGPTGSPGDTGIPLTYRRSGPVPPEDDASGSESFQSNAQKIIPPLFSYRLAQQQLKEMKKKGLTETTKVYHVSQSPLTDTAIDAAPSAPLDLESPEEAAANKFRIKSPFPEQPAVSAGERPPSRLDLNVTQASCAISPSQTLIRKSQARHVGSRGGPSERSHARNAHFRRTASFHEARQARPFRERSMSTLTPRQAPAYSSRTRTCEQAEDRFRPQSRGAHLFPEKLEHFQEASGTRGPLNPLPKSYTLGQPLRKPDLGDHQAGLVAGIERTEPHRARRGPSPSHKSVSRKQSSPISPKDNYQRVSSLSPSQCRKDKCQSFPTHPEFAFYDNTSFGLTEAEQRMLDLPGYFGSNEEDETTSTLSVEKLVI>sp|Q9NS62-3|THSD1_HUMAN Isoform 3 of Thrombospondin type-1 domain-containing protein 1 OS=Homo sapiens OX=9606 GN=THSD1MKPMLKDFSNLLLVVLCDYVLGEAEYLLLREPGHVALSNDTVYVDFQYFDGANGTLRNVSVLLLEANTNQTVTTKYLLTNQSQGTLKFECFYFKEAGDYWFTMTPEATDNSTPFPWWEKSAFLKVEWPVFHVDLNRSAKAAEGTFQVGLFTSQPLCPFPVDKPNIVVDVIFTNSLPEARRNSRQPLEIRTSKRTELAQGQWVEFGCAPLGPEAYVTVVLKLLGRDSVITSTGPIDLAQKFGYKLVMVPELTCESGVEVTVLPPPCTFVQGVVTVFKEAPRYPGKRTIHLAENSLPLGERRTIFNCTLFDMGKNKYCFDFGISSRSHFSAKEECMLIQRNTETWGLWQPWSQCSATCGDGVRERRRVCLTSFPSSPVCPGMSLEASLCSLEECAGGFSLCCPGWSAVARSWLTTSSASRVHAILLPQPPE>sp|O60806|TBX19_HUMAN T-box transcription factor TBX19 OS=Homo sapiensOX=9606 GN=TBX19 PE=1 SV=3MAMSELGTRKPSDGTVSHLLNVVESELQAGREKGDPTEKQLQIILEDAPLWQRFKEVTNEMIVTKNGRRMFPVLKISVTGLDPNAMYSLLLDFVPTDSHRWKYVNGEWVPAGKPEVSSHSCVYIHPDSPNFGAHWMKAPISFSKVKLTNKLNGGGQIMLNSLHKYEPQVHIVRVGSAHRMVTNCSFPETQFIAVTAYQNEEITALKIKYNPFAKAFLDAKERNHLRDVPEAISESQHVTYSHLGGWIFSNPDGVCTAGNSNYQYAAPLPLPAPHTHHGCEHYSGLRGHRQAPYPSAYMHRNHSPSVNLIESSSNNLQVFSGPDSWTSLSSTPHASILSVPHTNGPINPGPSPYPCLWTISNGAGGPSGPGPEVHASTPGAFLLGNPAVTSPPSVLSTQAPTSAGVEVLGEPSLTSIAVSTWTAVASHPFAGWGGPGAGGHHSPSSLDG>sp|Q9UL17|TBX21_HUMAN T-box transcription factor TBX21 OS=Homo sapiensOX=9606 GN=TBX21 PE=1 SV=1MGIVEPGCGDMLTGTEPMPGSDEGRAPGADPQHRYFYPEPGAQDADERRGGGSLGSPYPGGALVPAPPSRFLGAYAYPPRPQAAGFPGAGESFPPPADAEGYQPGEGYAAPDPRAGLYPGPREDYALPAGLEVSGKLRVALNNHLLWSKFNQHQTEMIITKQGRRMFPFLSFTVAGLEPTSHYRMFVDVVLVDQHHWRYQSGKWVQCGKAEGSMPGNRLYVHPDSPNTGAHWMRQEVSFGKLKLTNNKGASNNVTQMIVLQSLHKYQPRLHIVEVNDGEPEAACNASNTHIFTFQETQFIAVTAYQNAEITQLKIDNNPFAKGFRENFESMYTSVDTSIPSPPGPNCQFLGGDHYSPLLPNQYPVPSRFYPDLPGQAKDVVPQAYWLGAPRDHSYEAEFRAVSMKPAFLPSAPGPTMSYYRGQEVLAPGAGWPVAPQYPPKMGPASWFRPMRTLPMEPGPGGSEGRGPEDQGPPLVWTEIAPIRPESSDSGLGEGDSKRRRVSPYPSSGDSSSPAGAPSPFDKEAEGQFYNYFPN>sp|A0A1B0GUV7|TEX48_HUMAN Testis-expressed protein 48 OS=Homo sapiensOX=9606 GN=TEX48 PE=1 SV=1MAAHQNLILKIFCLCCRDCQEPYAINDSKVPSQTQEHKPSTQNLLLQKDELDRQNPKRINAVSHLPSRTPLIQTKKSTSSSSSEFEDLNAYASQRNFYKRNLNRYCQEHWPFQPCLTGRP>sp|Q9BRU2|TCAL7_HUMAN Transcription elongation factor A protein-like 7OS=Homo sapiens OX=9606 GN=TCEAL7 PE=2 SV=2MQKPCKENEGKPKCSVPKREEKRPYGEFERQQTEGNFRQRLLQSLEEFKEDIDYRHFKDEEMTREGDEMERCLEEIRGLRKKFRALHSNHRHSRDRPYPI>sp|Q8N3R3|TCAIM_HUMAN T-cell activation inhibitor, mitochondrial OS=Homosapiens OX=9606 GN=TCAIM PE=2 SV=2MFCHLRPMRRLCLEKIFPHWFPFSRALSGAEAVNALRPFYFAVHPDFFGQHPVEREINENSLKRLSVYLENLQKPGFKSLKPTQLTFYVRETDQSSSDGQEPFSTSGFRAVKFTLHTRDLLSTVLYILNSCSLSVEHIQSLNTNMHTQPLKEAKRMPDRPIKWDKSYYSFTGFKDPDEDLEQVSRVETTLTSWLDNNGKSAVKKLKNSLPLRKELDRLKDELSHQLQLSDIRWQRSWGIAHRCSQLHSLSRLAQQNLETLKKAKGCTIIFTDRSGMSAVGHVMLGTMDVHHHWTKLFERLPSYFDLQRRLMILEDQISYLLGGIQVVYIEELQPVLTLEEYYSLLDVFYNRLLKSRILFHPRSLRGLQMILNSDRYAPSLHELGHFNIPTLCDPANLQWFILTKAQQARENMKRKEELKVIENELIQASTKKFSLEKLYKEPSISSIQMVDCCKRLLEQSLPYLHGMHLCISHFYSVMQDGDLCIPWNWKNGEAIK>sp|Q8N3R3-2|TCAIM_HUMAN Isoform 2 of T-cell activation inhibitor,mitochondrial OS=Homo sapiens OX=9606 GN=TCAIMMFCHLRPMRRLCLEKIFPHWFPFSRALSGAEAVNALRPFYFAVHPDFFGQHPVEREINENSLKRLSVYLENLQKPGFKSLKPTQLTFYVRETDQSSSDGQEPFSTSVYLLNISKA>sp|Q8N3R3-3|TCAIM_HUMAN Isoform 3 of T-cell activation inhibitor,mitochondrial OS=Homo sapiens OX=9606 GN=TCAIMMFCHLRPMRRLCLEKIFPHWFPFSRALSGAEAVNALRPFYFAVHPDFFGQHPVERDDTWKSFQCPSDFSL>sp|Q8N3R3-4|TCAIM_HUMAN Isoform 4 of T-cell activation inhibitor,mitochondrial OS=Homo sapiens OX=9606 GN=TCAIMMHTQPLKEAKRMPDRPIKWDKSYYSFTGFKDPDEDLEQVSRVETTLTSWLDNNGKSAVKKLKNSLPLRKELDRLKDELSHQLQLSDIRWQRSWGIAHRCSQLHSLSRLAQQNLETLKKAKGCTIIFTDRSGMSAVGHVMLGTMDVHHHWTKLFERLPSYFDLQRRLMILEDQISYLLGGIQVVYIEELQPVLTLEEYYSLLDVFYNRLLKSRILFHPRSLRGLQMILNSDRYAPSLHELGHFNIPTLCDPANLQWFILTKAQQARENMKRKEELKVIENELIQASTKKFSLEKLYKEPSISSIQMVDCCKRLLEQSLPYLHGMHLCISHFYSVMQDGDLCIPWNWKNGEAIK>sp|Q6ZNM6|TEX43_HUMAN Testis-expressed protein 43 OS=Homo sapiensOX=9606 GN=TEX43 PE=1 SV=1MASGKDTCPTLPKLTNNCSDESLYKSANKYEEIHLPRFSLKQGMIPRRYVMPWKENMIFRNVNLKQAEVCGIHTGPLEDSLFLNHSERLCHGEDRKVVFQKGPPEIKIADMPLHSPLSRYQSTVISHGFRRRLV>sp|Q9Y334|VWA7_HUMAN von Willebrand factor A domain-containing protein 7OS=Homo sapiens OX=9606 GN=VWA7 PE=2 SV=4MLPTEVPQSHPGPSALLLLQLLLPPTSAFFPNIWSLLAAPGSITHQDLTEEAALNVTLQLFLEQPPPGRPPLRLEDFLGRTLLADDLFAAYFGPGSSRRFRAALGEVSRANAAQDFLPTSRNDPDLHFDAERLGQGRARLVGALRETVVAARALDHTLARQRLGAALHALQDFYSHSNWVELGEQQPHPHLLWPRQELQNLAQVADPTCSDCEELSCPRNWLGFTLLTSGYFGTHPPKPPGKCSHGGHFDRSSSQPPRGGINKDSTSPGFSPHHMLHLQAAKLALLASIQAFSLLRSRLGDRDFSRLLDITPASSLSFVLDTTGSMGEEINAAKIQARHLVEQRRGSPMEPVHYVLVPFHDPGFGPVFTTSDPDSFWQQLNEIHALGGGDEPEMCLSALQLALLHTPPLSDIFVFTDASPKDAFLTNQVESLTQERRCRVTFLVTEDTSRVQGRARREILSPLRFEPYKAVALASGGEVIFTKDQHIRDVAAIVGESMAALVTLPLDPPVVVPGQPLVFSVDGLLQKITVRIHGDISSFWIKNPAGVSQGQEEGGGPLGHTRRFGQFWMVTMDDPPQTGTWEIQVTAEDTPGVRVQAQTSLDFLFHFGIPMEDGPHPGLYPLTQPVAGLQTQLLVEVTGLGSRANPGDPQPHFSHVILRGVPEGAELGQVPLEPVGPPERGLLAASLSPTLLSTPRPFSLELIGQDAAGRRLHRAAPQPSTVVPVLLELSGPSGFLAPGSKVPLSLRIASFSGPQDLDLRTFVNPSFSLTSNLSRAHLELNESAWGRLWLEVPDSAAPDSVVMVTVTAGGREANPVPPTHAFLRLLVSAPAPQDRHTTPTGSSDPILTTATPAFSPFTLVTQGRAGAGLAAGSPWWGTVGGVLLLLGLASW>sp|Q9Y334-2|VWA7_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 7 OS=Homo sapiens OX=9606 GN=VWA7MLPTEVPQSHPGPSALLLLQLLLPPTSAFFPNIWSLLAAPGSITHQDLTEEAALNVTLQLFLEQPPPGRPPLRLEDFLGRTLLADDLFAAYFGPGSSRRFRAALGEVSRANAAQDFLPTSRNDPDLHFDAERLGQGRARLVGALRETVVAARALDHTLARQRLGAALHALQDFYSHSNWVELGEQQPHPHLLWPRQELQNLAQVADPTCSDCEELSCPRNWLGFTLLTSGYFGTHPPKPPGKCSHGGHFDRSSSQPPRGGINKDSTSPGFSPHHMLHLQAAKLALLASIQAFSLLRSRLGDRDFSRLLDITPASSLSFVLDTTGSMGEEINAAKIQARHLVEQRRGSPMEPVHYVLVPFHDPGFGPVFTTSDPDSFWQQLNEIHALGGGDEPEMCLSALQLALLHTPPLSDIFVFTDASPKDAFLTNQVESLTQERRCRVTFLVTEDTSRVQGRARREILSPLRFEPYKAVALASGGEVIFTKDQHIRDVAAIVGESMAALVTLPLDPPVVVPGQPLVFSVDGLLQKITVRIHGDISSFWIKNPAGVSQGQEEGGGPLGHTRRFGQFWMVTMDDPPQTGTWEIQVTAEDTPGVRVQAQTSLDFLFHFGIPMEDGPHPGLYPLTQPVAGLQTQLLVEVTGLGSRANPGDPQPHFSHVILRGVPEGAELGQVPLEPVGPPERGLLAASLSPTLLSTPRPFSLELIGQDAAGRRLHRAAPQPSTVVPVLLELSGPSGFLAPGSKVPLSLRIASFSGPQDLDLRTFVNPSFSLTSNLSRAHLELNESAWGRLWLEVPDSAAPDSVVMVTVTAGGREANPVPPTHAFLRLLVSAPAPQVRNHYFPSQGPAHHPYRLI>sp|P10600|TGFB3_HUMAN Transforming growth factor beta-3 proproteinOS=Homo sapiens OX=9606 GN=TGFB3 PE=1 SV=1MKMHLQRALVVLALLNFATVSLSLSTCTTLDFGHIKKKRVEAIRGQILSKLRLTSPPEPTVMTHVPYQVLALYNSTRELLEEMHGEREEGCTQENTESEYYAKEIHKFDMIQGLAEHNELAVCPKGITSKVFRFNVSSVEKNRTNLFRAEFRVLRVPNPSSKRNEQRIELFQILRPDEHIAKQRYIGGKNLPTRGTAEWLSFDVTDTVREWLLRRESNLGLEISIHCPCHTFQPNGDILENIHEVMEIKFKGVDNEDDHGRGDLGRLKKQKDHHNPHLILMMIPPHRLDNPGQGGQRKKRALDTNYCFRNLEENCCVRPLYIDFRQDLGWKWVHEPKGYYANFCSGPCPYLRSADTTHSTVLGLYNTLNPEASASPCCVPQDLEPLTILYYVGRTPKVEQLSNMVVKSCKCS>sp|P10600-2|TGFB3_HUMAN Isoform 2 of Transforming growth factor beta-3proprotein OS=Homo sapiens OX=9606 GN=TGFB3MKMHLQRALVVLALLNFATVSLSLSTCTTLDFGHIKKKRVEAIRGQILSKLRLTSPPEPTVMTHVPYQVLALYNSTRELLEEMHGEREEGCTQENTESEYYAKEIHKFDMIQGLAEHNELAVCPKGITSKVFRFNVSSVEKNRTNLFRAEFRVLRVPNPSSKRNEQRIELFQILRPDEHIAKQRYIGGKNLPTRGTAEWLSFDVTDTVREWLLRRESNLGLEISIHCPCHTFQPNGDILENIHEVMEIKFKGVDNEDDHGRGDLGRLKKQKDHHNPHLILMMIPPHRLDNPGQGGQRKKRALDTNYCFR>sp|Q9NYB0|TE2IP_HUMAN Telomeric repeat-binding factor 2-interactingprotein 1 OS=Homo sapiens OX=9606 GN=TERF2IP PE=1 SV=1MAEAMDLGKDPNGPTHSSTLFVRDDGSSMSFYVRPSPAKRRLSTLILHGGGTVCRVQEPGAVLLAQPGEALAEASGDFISTQYILDCVERNERLELEAYRLGPASAADTGSEAKPGALAEGAAEPEPQRHAGRIAFTDADDVAILTYVKENARSPSSVTGNALWKAMEKSSLTQHSWQSLKDRYLKHLRGQEHKYLLGDAPVSPSSQKLKRKAEEDPEAADSGEPQNKRTPDLPEEEYVKEEIQENEEAVKKMLVEATREFEEVVVDESPPDFEIHITMCDDDPPTPEEDSETQPDEEEEEEEEKVSQPEVGAAIKIIRQLMEKFNLDLSTVTQAFLKNSGELEATSAFLASGQRADGYPIWSRQDDIDLQKDDEDTREALVKKFGAQNVARRIEFRKK>sp|P0DPH8|TBA3D_HUMAN Tubulin alpha-3D chain OS=Homo sapiens OX=9606GN=TUBA3D PE=1 SV=1MRECISIHVGQAGVQIGNACWELYCLEHGIQPDGQMPSDKTIGGGDDSFNTFFSETGAGKHVPRAVFVDLEPTVVDEVRTGTYRQLFHPEQLITGKEDAANNYARGHYTIGKEIVDLVLDRIRKLADLCTGLQGFLIFHSFGGGTGSGFASLLMERLSVDYGKKSKLEFAIYPAPQVSTAVVEPYNSILTTHTTLEHSDCAFMVDNEAIYDICRRNLDIERPTYTNLNRLIGQIVSSITASLRFDGALNVDLTEFQTNLVPYPRIHFPLATYAPVISAEKAYHEQLSVAEITNACFEPANQMVKCDPRHGKYMACCMLYRGDVVPKDVNAAIATIKTKRTIQFVDWCPTGFKVGINYQPPTVVPGGDLAKVQRAVCMLSNTTAIAEAWARLDHKFDLMYAKRAFVHWYVGEGMEEGEFSEAREDLAALEKDYEEVGVDSVEAEAEEGEEY>sp|Q9UHD2|TBK1_HUMAN Serine/threonine-protein kinase TBK1 OS=Homosapiens OX=9606 GN=TBK1 PE=1 SV=1MQSTSNHLWLLSDILGQGATANVFRGRHKKTGDLFAIKVFNNISFLRPVDVQMREFEVLKKLNHKNIVKLFAIEEETTTRHKVLIMEFCPCGSLYTVLEEPSNAYGLPESEFLIVLRDVVGGMNHLRENGIVHRDIKPGNIMRVIGEDGQSVYKLTDFGAARELEDDEQFVSLYGTEEYLHPDMYERAVLRKDHQKKYGATVDLWSIGVTFYHAATGSLPFRPFEGPRRNKEVMYKIITGKPSGAISGVQKAENGPIDWSGDMPVSCSLSRGLQVLLTPVLANILEADQEKCWGFDQFFAETSDILHRMVIHVFSLQQMTAHKIYIHSYNTATIFHELVYKQTKIISSNQELIYEGRRLVLEPGRLAQHFPKTTEENPIFVVSREPLNTIGLIYEKISLPKVHPRYDLDGDASMAKAITGVVCYACRIASTLLLYQELMRKGIRWLIELIKDDYNETVHKKTEVVITLDFCIRNIEKTVKVYEKLMKINLEAAELGEISDIHTKLLRLSSSQGTIETSLQDIDSRLSPGGSLADAWAHQEGTHPKDRNVEKLQVLLNCMTEIYYQFKKDKAERRLAYNEEQIHKFDKQKLYYHATKAMTHFTDECVKKYEAFLNKSEEWIRKMLHLRKQLLSLTNQCFDIEEEVSKYQEYTNELQETLPQKMFTASSGIKHTMTPIYPSSNTLVEMTLGMKKLKEEMEGVVKELAENNHILERFGSLTMDGGLRNVDCL>sp|Q86VP1|TAXB1_HUMAN Tax1-binding protein 1 OS=Homo sapiens OX=9606GN=TAX1BP1 PE=1 SV=2MTSFQEVPLQTSNFAHVIFQNVAKSYLPNAHLECHYTLTPYIHPHPKDWVGIFKVGWSTARDYYTFLWSPMPEHYVEGSTVNCVLAFQGYYLPNDDGEFYQFCYVTHKGEIRGASTPFQFRASSPVEELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPATSASTVDVKPSPSAAEADFDIVTKGQVCEMTKEIADKTEKYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLENPAERKMEGQNSQSPQCFKTCSEQNGYVLTLSNAQPVLQYGNPYASQETRDGADGAFYPDEIQRPPVRVPSWGLEDNVVCSQPARNFSRPDGLEDSEDSKEDENVPTAPDPPSQHLRGHGTGFCFDSSFDVHKKCPLCELMFPPNYDQSKFEEHVESHWKVCPMCSEQFPPDYDQQVFERHVQTHFDQNVLNFD>sp|Q86VP1-2|TAXB1_HUMAN Isoform 2 of Tax1-binding protein 1 OS=Homosapiens OX=9606 GN=TAX1BP1MTSFQEVPLQTSNFAHVIFQNVAKSYLPNAHLECHYTLTPYIHPHPKDWVGIFKVGWSTARDYYTFLWSPMPEHYVEGSTVNCVLAFQGYYLPNDDGEFYQFCYVTHKGEIRGASTPFQFRASSPVEELLTMEDEGNSDMLVVTTKAGLLELKIEKTMKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPATSASTVDVKPSPSAAEADFDIVTKGQVCEMTKEIADKTEKYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLENPAERKMEDGADGAFYPDEIQRPPVRVPSWGLEDNVVCSQPARNFSRPDGLEDSEDSKEDENVPTAPDPPSQHLRGHGTGFCFDSSFDVHKKCPLCELMFPPNYDQSKFEEHVESHWKVCPMCSEQFPPDYDQQVFERHVQTHFDQNVLNFD>sp|Q86VP1-3|TAXB1_HUMAN Isoform 3 of Tax1-binding protein 1 OS=Homosapiens OX=9606 GN=TAX1BP1MERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPATSASTVDVKPSPSAAEADFDIVTKGQVCEMTKEIADKTEKYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLENPAERKMEDGADGAFYPDEIQRPPVRVPSWGLEDNVVCSQPARNFSRPDGLEDSEDSKEDENVPTAPDPPSQHLRGHGTGFCFDSSFDVHKKCPLCELMFPPNYDQSKFEEHVESHWKVCPMCSEQFPPDYDQQVFERHVQTHFDQNVLNFD>sp|Q86VP1-4|TAXB1_HUMAN Isoform 4 of Tax1-binding protein 1 OS=Homosapiens OX=9606 GN=TAX1BP1MKEKEELLKLIAVLEKETAQLREQVGRMERELNHEKERCDQLQAEQKGLTEVTQSLKMENEEFKKRFSDATSKAHQLEEDIVSVTHKAIEKETELDSLKDKLKKAQHEREQLECQLKTEKDEKELYKVHLKNTEIENTKLMSEVQTLKNLDGNKESVITHFKEEIGRLQLCLAEKENLQRTFLLTTSSKEDTCFLKEQLRKAEEQVQATRQEVVFLAKELSDAVNVRDRTMADLHTARLENEKVKKQLADAVAELKLNAMKKDQDKTDTLEHELRREVEDLKLRLQMAADHYKEKFKECQRLQKQINKLSDQSANNNNVFTKKTGNQQKVNDASVNTDPATSASTVDVKPSPSAAEADFDIVTKGQVCEMTKEIADKTEKYNKCKQLLQDEKAKCNKYADELAKMELKWKEQVKIAENVKLELAEVQDNYKELKRSLENPAERKMEDGADGAFYPDEIQRPPVRVPSWGLEDNVVCSQPARNFSRPDGLEDSEDSKEDENVPTAPDPPSQHLRGHGTGFCFDSSFDVHKKCPLCELMFPPNYDQSKFEEHVESHWKVCPMCSEQFPPDYDQQVFERHVQTHFDQNVLNFD>sp|Q8TEA7|TBCK_HUMAN TBC domain-containing protein kinase-like proteinOS=Homo sapiens OX=9606 GN=TBCK PE=1 SV=4MFPLKDAEMGAFTFFASALPHDVCGSNGLPLTPNSIKILGRFQILKTITHPRLCQYVDISRGKHERLVVVAEHCERSLEDLLRERKPVSCSTVLCIAFEVLQGLQYMNKHGIVHRALSPHNILLDRKGHIKLAKFGLYHMTAHGDDVDFPIGYPSYLAPEVIAQGIFKTTDHMPSKKPLPSGPKSDVWSLGIILFELCVGRKLFQSLDISERLKFLLTLDCVDDTLIVLAEEHGCLDIIKELPETVIDLLNKCLTFHPSKRPTPDQLMKDKVFSEVSPLYTPFTKPASLFSSSLRCADLTLPEDISQLCKDINNDYLAERSIEEVYYLWCLAGGDLEKELVNKEIIRSKPPICTLPNFLFEDGESFGQGRDRSSLLDDTTVTLSLCQLRNRLKDVGGEAFYPLLEDDQSNLPHSNSNNELSAAATLPLIIREKDTEYQLNRIILFDRLLKAYPYKKNQIWKEARVDIPPLMRGLTWAALLGVEGAIHAKYDAIDKDTPIPTDRQIEVDIPRCHQYDELLSSPEGHAKFRRVLKAWVVSHPDLVYWQGLDSLCAPFLYLNFNNEALAYACMSAFIPKYLYNFFLKDNSHVIQEYLTVFSQMIAFHDPELSNHLNEIGFIPDLYAIPWFLTMFTHVFPLHKIFHLWDTLLLGNSSFPFCIGVAILQQLRDRLLANGFNECILLFSDLPEIDIERCVRESINLFCWTPKSATYRQHAQPPKPSSDSSGGRSSAPYFSAECPDPPKTDLSRESIPLNDLKSEVSPRISAEDLIDLCELTVTGHFKTPSKKTKSSKPKLLVVDIRNSEDFIRGHISGSINIPFSAAFTAEGELTQGPYTAMLQNFKGKVIVIVGHVAKHTAEFAAHLVKMKYPRICILDGGINKIKPTGLLTIPSPQI>sp|Q8TEA7-2|TBCK_HUMAN Isoform 2 of TBC domain-containing proteinkinase-like protein OS=Homo sapiens OX=9606 GN=TBCKMFPLKDAEMGAFTFFASALPHDVCGSNGLPLTPNSIKILGRFQILKTITHPRLCQYVDISRGKHERLVVVAEHCERSLEDLLRERKPVSCSTVLCIAFEVLQGLQYMNKHGIVHRALSPHNILLDRKGHIKLAKFGLYHMTAHGDDVDFPIGYPSYLAPEGRKLFQSLDISERLKFLLTLDCVDDTLIVLAEEHGCLDIIKELPETVIDLLNKCLTFHPSKRPTPDQLMKDKVFSEVSPLYTPFTKPASLFSSSLRCADLTLPEDISQLCKDINNDYLAERSIEEVYYLWCLAGGDLEKELVNKEIIRSKPPICTLPNFLFEDGESFGQGRDRSSLLDDTTVTLSLCQLRNRLKDVGGEAFYPLLEDDQSNLPHSNSNNELSAAATLPLIIREKDTEYQLNRIILFDRLLKAYPYKKNQIWKEARVDIPPLMRGLTWAALLGVEGAIHAKYDAIDKDTPIPTDRQIEVDIPRCHQYDELLSSPEGHAKFRRVLKAWVVSHPDLVYWQGLDSLCAPFLYLNFNNEALAYACMSAFIPKYLYNFFLKDNSHVIQEYLTVFSQMIAFHDPELSNHLNEIGFIPDLYAIPWFLTMFTHVFPLHKIFHLWDTLLLGNSSFPFCIGVAILQQLRDRLLANGFNECILLFSDLPEIDIERCVRESINLFCWTPKSATYRQHAQPPKPSSDSSGGRSSAPYFSAECPDPPKTDLSRESIPLNDLKSEVSPRISAEDLIDLCELTVTGHFKTPSKKTKSSKPKLLVVDIRNSEDFIRGHISGSINIPFSAAFTAEGELTQGPYTAMLQNFKGKVIVIVGHVAKHTAEFAAHLVKMKYPRICILDGGINKIKPTGLLTIPSPQI>sp|Q8TEA7-3|TBCK_HUMAN Isoform 3 of TBC domain-containing proteinkinase-like protein OS=Homo sapiens OX=9606 GN=TBCKMFPLKDAEMGAFTFFASALPHDVCGSNGLPLTPNSIKILGRFQILKTITHPRLCQYVDISRGKHERLVVVAEHCERSLEDLLRERKPVRYPSYLAPEVIAQGIFKTTDHMPSKKPLPSGPKSDVWSLGIILFELCVGRKLFQSLDISERLKFLLTLDCVDDTLIVLAEEHGCLDIIKELPETVIDLLNKCLTFHPSKRPTPDQLMKDKVFSEVSPLYTPFTKPASLFSSSLRCADLTLPEDISQLCKDINNDYLAERSIEEVYYLWCLAGGDLEKELVNKEIIRSKPPICTLPNFLFEDGESFGQGRDRSSLLDDTTVTLSLCQLRNRLKDVGGEAFYPLLEDDQSNLPHSNSNNELSAAATLPLIIREKDTEYQLNRIILFDRLLKAYPYKKNQIWKEARVDIPPLMRGLTWAALLGVEGAIHAKYDAIDKDTPIPTDRQIEVDIPRCHQYDELLSSPEGHAKFRRVLKAWVVSHPDLVYWQGLDSLCAPFLYLNFNNEALAYACMSAFIPKYLYNFFLKDNSHVIQEYLTVFSQMIAFHDPELSNHLNEIGFIPDLYAIPWFLTMFTHVFPLHKIFHLWDTLLLGNSSFPFCIGVAILQQLRDRLLANGFNECILLFSDLPEIDIERCVRESINLFCWTPKSATYRQHAQPPKPSSDSSGGRSSAPYFSAECPDPPKTDLSRESIPLNDLKSEVSPRISAEDLIDLCELTVTGHFKTPSKKTKSSKPKLLVVDIRNSEDFIRGHISGSINIPFSAAFTAEGELTQGPYTAMLQNFKGKVIVIVGHVAKHTAEFAAHLVKMKYPRICILDGGINKIKPTGLLTIPSPQI>sp|Q8TC07|TBC15_HUMAN TBC1 domain family member 15 OS=Homo sapiensOX=9606 GN=TBC1D15 PE=1 SV=2MAAAGVVSGKIIYEQEGVYIHSSCGKTNDQDGLISGILRVLEKDAEVIVDWRPLDDALDSSSILYARKDSSSVVEWTQAPKERGHRGSEHLNSYEAEWDMVNTVSFKRKPHTNGDAPSHRNGKSKWSFLFSLTDLKSIKQNKEGMGWSYLVFCLKDDVVLPALHFHQGDSKLLIESLEKYVVLCESPQDKRTLLVNCQNKSLSQSFENLLDEPAYGLIQAGLLDRRKLLWAIHHWKKIKKDPYTATMIGFSKVTNYIFDSLRGSDPSTHQRPPSEMADFLSDAIPGLKINQQEEPGFEVITRIDLGERPVVQRREPVSLEEWTKNIDSEGRILNVDNMKQMIFRGGLSHALRKQAWKFLLGYFPWDSTKEERTQLQKQKTDEYFRMKLQWKSISQEQEKRNSRLRDYRSLIEKDVNRTDRTNKFYEGQDNPGLILLHDILMTYCMYDFDLGYVQGMSDLLSPLLYVMENEVDAFWCFASYMDQMHQNFEEQMQGMKTQLIQLSTLLRLLDSGFCSYLESQDSGYLYFCFRWLLIRFKREFSFLDILRLWEVMWTELPCTNFHLLLCCAILESEKQQIMEKHYGFNEILKHINELSMKIDVEDILCKAEAISLQMVKCKELPQAVCEILGLQGSEVTTPDSDVGEDENVVMTPCPTSAFQSNALPTLSASGARNDSPTQIPVSSDVCRLTPA>sp|Q8TC07-2|TBC15_HUMAN Isoform 2 of TBC1 domain family member 15OS=Homo sapiens OX=9606 GN=TBC1D15MAAAGVVSGKIIYEQEGVYIHSSCGKTNDQDGLISGILRVLEKDAEVIVDWRPLDDALDSSSILYARKDSSSVVEWTQAPKERGHRGSEHLNSYEAEWDMVNTVSFKRKPHTNGDAPSHRNGKSKWSFLFSLTDLKSIKQNKEGMGWSYLVFCLKDDVVLPALHFHQGDSKLLIESLEKYVVLCESPQDKRTLLVNCQNKSLSQSFENLLDEPAYGLIQKIKKDPYTATMIGFSKVTNYIFDSLRGSDPSTHQRPPSEMADFLSDAIPGLKINQQEEPGFEVITRIDLGERPVVQRREPVSLEEWTKNIDSEGRILNVDNMKQMIFRGGLSHALRKQAWKFLLGYFPWDSTKEERTQLQKQKTDEYFRMKLQWKSISQEQEKRNSRLRDYRSLIEKDVNRTDRTNKFYEGQDNPGLILLHDILMTYCMYDFDLGYVQGMSDLLSPLLYVMENEVDAFWCFASYMDQMHQNFEEQMQGMKTQLIQLSTLLRLLDSGFCSYLESQDSGYLYFCFRWLLIRFKREFSFLDILRLWEVMWTELPCTNFHLLLCCAILESEKQQIMEKHYGFNEILKHINELSMKIDVEDILCKAEAISLQMVKCKELPQAVCEILGLQGSEVTTPDSDVGEDENVVMTPCPTSAFQSNALPTLSASGARNDSPTQIPVSSDVCRLTPA>sp|Q8TC07-3|TBC15_HUMAN Isoform 3 of TBC1 domain family member 15OS=Homo sapiens OX=9606 GN=TBC1D15MCPGLYPYSSLLEYGRSMIIYEQEGVYIHSSCGKTNDQDGLISGILRVLEKDAEVIVDWRPLDDALDSSSILYARKDSSSVVEWTQAPKERGHRGSEHLNSYEAEWDMVNTVSFKRKPHTNGDAPSHRNGKSKWSFLFSLTDLKSIKQNKEGMGWSYLVFCLKDDVVLPALHFHQGDSKLLIESLEKYVVLCESPQDKRTLLVNCQNKSLSQSFENLLDEPAYGLIQKIKKDPYTATMIGFSKVTNYIFDSLRGSDPSTHQRPPSEMADFLSDAIPGLKINQQEEPGFEVITRIDLGERPVVQRREPVSLEEWTKNIDSEGRILNVDNMKQMIFRGGLSHALRKQAWKFLLGYFPWDSTKEERTQLQKQKTDEYFRMKLQWKSISQEQEKRNSRLRDYRSLIEKDVNRTDRTNKFYEGQDNPGLILLHDILMTYCMYDFDLGYVQGMSDLLSPLLYVMENEVDAFWCFASYMDQMHQNFEEQMQGMKTQLIQLSTLLRLLDSGFCSYLESQDSGYLYFCFRWLLIRFKREFSFLDILRLWEVMWTELPCTNFHLLLCCAILESEKQQIMEKHYGFNEILKHINELSMKIDVEDILCKAEAISLQMVKCKELPQAVCEILGLQGSEVTTPDSDVGEDENVVMTPCPTSAFQSNALPTLSASGARNDSPTQIPVSSDVCRLTPA>sp|O14776|TCRG1_HUMAN Transcription elongation regulator 1 OS=Homosapiens OX=9606 GN=TCERG1 PE=1 SV=2MAERGGDGGESERFNPGELRMAQQQALRFRGPAPPPNAVMRGPPPLMRPPPPFGMMRGPPPPPRPPFGRPPFDPNMPPMPPPGGIPPPMGPPHLQRPPFMPPPMSSMPPPPGMMFPPGMPPVTAPGTPALPPTEEIWVENKTPDGKVYYYNARTRESAWTKPDGVKVIQQSELTPMLAAQAQVQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQVQAQVQAQVQAQAVGASTPTTSSPAPAVSTSTSSSTPSSTTSTTTTATSVAQTVSTPTTQDQTPSSAVSVATPTVSVSTPAPTATPVQTVPQPHPQTLPPAVPHSVPQPTTAIPAFPPVMVPPFRVPLPGMPIPLPGVAMMQIVSCPYVKTVATTKTGVLPGMAPPIVPMIHPQVAIAASPATLAGATAVSEWTEYKTADGKTYYYNNRTLESTWEKPQELKEKEKLEEKIKEPIKEPSEEPLPMETEEEDPKEEPIKEIKEEPKEEEMTEEEKAAQKAKPVATAPIPGTPWCVVWTGDERVFFYNPTTRLSMWDRPDDLIGRADVDKIIQEPPHKKGMEELKKLRHPTPTMLSIQKWQFSMSAIKEEQELMEEINEDEPVKAKKRKRDDNKDIDSEKEAAMEAEIKAARERAIVPLEARMKQFKDMLLERGVSAFSTWEKELHKIVFDPRYLLLNPKERKQVFDQYVKTRAEEERREKKNKIMQAKEDFKKMMEEAKFNPRATFSEFAAKHAKDSRFKAIEKMKDREALFNEFVAAARKKEKEDSKTRGEKIKSDFFELLSNHHLDSQSRWSKVKDKVESDPRYKAVDSSSMREDLFKQYIEKIAKNLDSEKEKELERQARIEASLREREREVQKARSEQTKEIDREREQHKREEAIQNFKALLSDMVRSSDVSWSDTRRTLRKDHRWESGSLLEREEKEKLFNEHIEALTKKKREHFRQLLDETSAITLTSTWKEVKKIIKEDPRCIKFSSSDRKKQREFEEYIRDKYITAKADFRTLLKETKFITYRSKKLIQESDQHLKDVEKILQNDKRYLVLDCVPEERRKLIVAYVDDLDRRGPPPPPTASEPTRRSTK>sp|O14776-2|TCRG1_HUMAN Isoform 2 of Transcription elongation regulator1 OS=Homo sapiens OX=9606 GN=TCERG1MAERGGDGGESERFNPGELRMAQQQALRFRGPAPPPNAVMRGPPPLMRPPPPFGMMRGPPPPPRPPFGRPPFDPNMPPMPPPGGIPPPMGPPHLQRPPFMPPPMSSMPPPPGMMFPPGMPPVTAPGTPALPPTEEIWVENKTPDGKVYYYNARTRESAWTKPDGVKVIQQSELTPMLAAQAQVQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQAQVQAQVQAQVQAQAVGASTPTTSSPAPAVSTSTSSSTPSSTTSTTTTATSVAQTVSTPTTQDQTPSSAVSVATPTVSVSTPAPTATPVQTVPQPHPQTLPPAVPHSVPQPTTAIPAFPPVMVPPFRVPLPGMPIPLPGVLPGMAPPIVPMIHPQVAIAASPATLAGATAVSEWTEYKTADGKTYYYNNRTLESTWEKPQELKEKEKLEEKIKEPIKEPSEEPLPMETEEEDPKEEPIKEIKEEPKEEEMTEEEKAAQKAKPVATAPIPGTPWCVVWTGDERVFFYNPTTRLSMWDRPDDLIGRADVDKIIQEPPHKKGMEELKKLRHPTPTMLSIQKWQFSMSAIKEEQELMEEINEDEPVKAKKRKRDDNKDIDSEKEAAMEAEIKAARERAIVPLEARMKQFKDMLLERGVSAFSTWEKELHKIVFDPRYLLLNPKERKQVFDQYVKTRAEEERREKKNKIMQAKEDFKKMMEEAKFNPRATFSEFAAKHAKDSRFKAIEKMKDREALFNEFVAAARKKEKEDSKTRGEKIKSDFFELLSNHHLDSQSRWSKVKDKVESDPRYKAVDSSSMREDLFKQYIEKIAKNLDSEKEKELERQARIEASLREREREVQKARSEQTKEIDREREQHKREEAIQNFKALLSDMVRSSDVSWSDTRRTLRKDHRWESGSLLEREEKEKLFNEHIEALTKKKREHFRQLLDETSAITLTSTWKEVKKIIKEDPRCIKFSSSDRKKQREFEEYIRDKYITAKADFRTLLKETKFITYRSKKLIQESDQHLKDVEKILQNDKRYLVLDCVPEERRKLIVAYVDDLDRRGPPPPPTASEPTRRSTK>sp|P20226|TBP_HUMAN TATA-box-binding protein OS=Homo sapiens OX=9606GN=TBP PE=1 SV=2MDQNNSLPPYAQGLASPQGAMTPGIPIFSPMMPYGTGLTPQPIQNTNSLSILEEQQRQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQAVAAAAVQQSTSQQATQGTSGQAPQLFHSQTLTTAPLPGTTPLYPSPMTPMTPITPATPASESSGIVPQLQNIVSTVNLGCKLDLKTIALRARNAEYNPKRFAAVIMRIREPRTTALIFSSGKMVCTGAKSEEQSRLAARKYARVVQKLGFPAKFLDFKIQNMVGSCDVKFPIRLEGLVLTHQQFSSYEPELFPGLIYRMIKPRIVLLIFVSGKVVLTGAKVRAEIYEAFENIYPILKGFRKTT>sp|P20226-2|TBP_HUMAN Isoform 2 of TATA-box-binding protein OS=Homosapiens OX=9606 GN=TBPMTPGIPIFSPMMPYGTGLTPQPIQNTNSLSILEEQQRQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQAVAAAAVQQSTSQQATQGTSGQAPQLFHSQTLTTAPLPGTTPLYPSPMTPMTPITPATPASESSGIVPQLQNIVSTVNLGCKLDLKTIALRARNAEYNPKRFAAVIMRIREPRTTALIFSSGKMVCTGAKSEEQSRLAARKYARVVQKLGFPAKFLDFKIQNMVGSCDVKFPIRLEGLVLTHQQFSSYEPELFPGLIYRMIKPRIVLLIFVSGKVVLTGAKVRAEIYEAFENIYPILKGFRKTT>sp|P40238|TPOR_HUMAN Thrombopoietin receptor OS=Homo sapiens OX=9606GN=MPL PE=1 SV=1MPSWALFMVTSCLLLAPQNLAQVSSQDVSLLASDSEPLKCFSRTFEDLTCFWDEEEAAPSGTYQLLYAYPREKPRACPLSSQSMPHFGTRYVCQFPDQEEVRLFFPLHLWVKNVFLNQTRTQRVLFVDSVGLPAPPSIIKAMGGSQPGELQISWEEPAPEISDFLRYELRYGPRDPKNSTGPTVIQLIATETCCPALQRPHSASALDQSPCAQPTMPWQDGPKQTSPSREASALTAEGGSCLISGLQPGNSYWLQLRSEPDGISLGGSWGSWSLPVTVDLPGDAVALGLQCFTLDLKNVTCQWQQQDHASSQGFFYHSRARCCPRDRYPIWENCEEEEKTNPGLQTPQFSRCHFKSRNDSIIHILVEVTTAPGTVHSYLGSPFWIHQAVRLPTPNLHWREISSGHLELEWQHPSSWAAQETCYQLRYTGEGHQDWKVLEPPLGARGGTLELRPRSRYRLQLRARLNGPTYQGPWSSWSDPTRVETATETAWISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAALSPPKATVSDTCEEVEPSLLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLPLSYWQQP>sp|P40238-2|TPOR_HUMAN Isoform 2 of Thrombopoietin receptor OS=Homosapiens OX=9606 GN=MPLMPSWALFMVTSCLLLAPQNLAQVSSQDVSLLASDSEPLKCFSRTFEDLTCFWDEEEAAPSGTYQLLYAYPREKPRACPLSSQSMPHFGTRYVCQFPDQEEVRLFFPLHLWVKNVFLNQTRTQRVLFVDSVGLPAPPSIIKAMGGSQPGELQISWEEPAPEISDFLRYELRYGPRDPKNSTGPTVIQLIATETCCPALQRPHSASALDQSPCAQPTMPWQDGPKQTSPSREASALTAEGGSCLISGLQPGNSYWLQLRSEPDGISLGGSWGSWSLPVTVDLPGDAVALGLQCFTLDLKNVTCQWQQQDHASSQGFFYHSRARCCPRDRYPIWENCEEEEKTNPGLQTPQFSRCHFKSRNDSIIHILVEVTTAPGTVHSYLGSPFWIHQAVRLPTPNLHWREISSGHLELEWQHPSSWAAQETCYQLRYTGEGHQDWKVLEPPLGARGGTLELRPRSRYRLQLRARLNGPTYQGPWSSWSDPTRVETATETAWISLVTALHLVLGLSAVLGLLLLRWQFPAHYRYRPRQAGDWRWTRWSRTCKQAFLVRSVTPDLRPPPVRTYGFALPARHLWDSPRLLTL>sp|O94972|TRI37_HUMAN E3 ubiquitin-protein ligase TRIM37 OS=Homo sapiensOX=9606 GN=TRIM37 PE=1 SV=2MDEQSVESIAEVFRCFICMEKLRDARLCPHCSKLCCFSCIRRWLTEQRAQCPHCRAPLQLRELVNCRWAEEVTQQLDTLQLCSLTKHEENEKDKCENHHEKLSVFCWTCKKCICHQCALWGGMHGGHTFKPLAEIYEQHVTKVNEEVAKLRRRLMELISLVQEVERNVEAVRNAKDERVREIRNAVEMMIARLDTQLKNKLITLMGQKTSLTQETELLESLLQEVEHQLRSCSKSELISKSSEILMMFQQVHRKPMASFVTTPVPPDFTSELVPSYDSATFVLENFSTLRQRADPVYSPPLQVSGLCWRLKVYPDGNGVVRGYYLSVFLELSAGLPETSKYEYRVEMVHQSCNDPTKNIIREFASDFEVGECWGYNRFFRLDLLANEGYLNPQNDTVILRFQVRSPTFFQKSRDQHWYITQLEAAQTSYIQQINNLKERLTIELSRTQKSRDLSPPDNHLSPQNDDALETRAKKSACSDMLLEGGPTTASVREAKEDEEDEEKIQNEDYHHELSDGDLDLDLVYEDEVNQLDGSSSSASSTATSNTEENDIDEETMSGENDVEYNNMELEEGELMEDAAAAGPAGSSHGYVGSSSRISRRTHLCSAATSSLLDIDPLILIHLLDLKDRSSIENLWGLQPRPPASLLQPTASYSRKDKDQRKQQAMWRVPSDLKMLKRLKTQMAEVRCMKTDVKNTLSEIKSSSAASGDMQTSLFSADQAALAACGTENSGRLQDLGMELLAKSSVANCYIRNSTNKKSNSPKPARSSVAGSLSLRRAVDPGENSRSKGDCQTLSEGSPGSSQSGSRHSSPRALIHGSIGDILPKTEDRQCKALDSDAVVVAVFSGLPAVEKRRKMVTLGANAKGGHLEGLQMTDLENNSETGELQPVLPEGASAAPEEGMSSDSDIECDTENEEQEEHTSVGGFHDSFMVMTQPPDEDTHSSFPDGEQIGPEDLSFNTDENSGR>sp|O94972-2|TRI37_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM37OS=Homo sapiens OX=9606 GN=TRIM37MHGGHTFKPLAEIYEQHVTKVNEEVAKLRRRLMELISLVQEVERNVEAVRNAKDERVREIRNAVEMMIARLDTQLKNKLITLMGQKTSLTQETELLESLLQEVEHQLRSCSKSELISKSSEILMMFQQVHRKPMASFVTTPVPPDFTSELVPSYDSATFVLENFSTLRQRADPVYSPPLQVSGLCWRLKVYPDGNGVVRGYYLSVFLELSAGLPETSKYEYRVEMVHQSCNDPTKNIIREFASDFEVGECWGYNRFFRLDLLANEGYLNPQNDTVILRFQVRSPTFFQKSRDQHWYITQLEAAQTSYIQQINNLKERLTIELSRTQKSRDLSPPDNHLSPQNDDALETRAKKSACSDMLLEGGPTTASVREAKEDEEDEEKIQNEDYHHELSDGDLDLDLVYEDEVNQLDGSSSSASSTATSNTEENDIDEETMSGENDVEYNNMELEEGELMEDAAAAGPAGSSHGYVGSSSRISRRTHLCSAATSSLLDIDPLILIHLLDLKDRSSIENLWGLQPRPPASLLQPTASYSRKDKDQRKQQAMWRVPSDLKMLKRLKTQMAEVRCMKTDVKNTLSEIKSSSAASGDMQTSLFSADQAALAACGTENSGRLQDLGMELLAKSSVANCYIRNSTNKKSNSPKPARSSVAGSLSLRRAVDPGENSRSKGDCQTLSEGSPGSSQSGSRHSSPRALIHGSIGDILPKTEDRQCKALDSDAVVVAVFSGLPAVEKRRKMVTLGANAKGGHLEGLQMTDLENNSETGELQPVLPEGASAAPEEDTHSSFPDGEQIGPEDLSFNTDENSGR>sp|O94972-3|TRI37_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM37OS=Homo sapiens OX=9606 GN=TRIM37MDEQSVERWLTEQRAQCPHCRAPLQLRELVNCRWAEEVTQQLDTLQLCSLTKHEENEKDKCENHHEKLSVFCWTCKKCICHQCALWGGMHGGHTFKPLAEIYEQHVTKVNEEVAKLRRRLMELISLVQEVERNVEAVRNAKDERVREIRNAVEMMIARLDTQLKNKLITLMGQKTSLTQETELLESLLQEVEHQLRSCSKSELISKSSEILMMFQQVHRKPMASFVTTPVPPDFTSELVPSYDSATFVLENFSTLRQRADPVYSPPLQVSGLCWRLKVYPDGNGVVRGYYLSVFLELSAGLPETSKYEYRVEMVHQSCNDPTKNIIREFASDFEVGECWGYNRFFRLDLLANEGYLNPQNDTVILRFQVRSPTFFQKSRDQHWYITQLEAAQTSYIQQINNLKERLTIELSRTQKSRDLSPPDNHLSPQNDDALETRAKKSACSDMLLEGGPTTASVREAKEDEEDEEKIQNEDYHHELSDGDLDLDLVYEDEVNQLDGSSSSASSTATSNTEENDIDEETMSGENDVEYNNMELEEGELMEDAAAAGPAGSSHGYVGSSSRISRRTHLCSAATSSLLDIDPLILIHLLDLKDRSSIENLWGLQPRPPASLLQPTASYSRKDKDQRKQQAMWRVPSDLKMLKRLKTQMAEVRCMKTDVKNTLSEIKSSSAASGDMQTSLFSADQAALAACGTENSGRLQDLGMELLAKSSVANCYIRNSTNKKSNSPKPARSSVAGSLSLRRAVDPGENSRSKGDCQTLSEGSPGSSQSGSRHSSPRALIHGSIGDILPKTEDRQCKALDSDAVVVAVFSGLPAVEKRRKMVTLGANAKGGHLEGLQMTDLENNSETGELQPVLPEGASAAPEEGMSSDSDIECDTENEEQEEHTSVGGFHDSFMVMTQPPDEDTHSSFPDGEQIGPEDLSFNTDENSGR>sp|Q9C040|TRIM2_HUMAN Tripartite motif-containing protein 2 OS=Homosapiens OX=9606 GN=TRIM2 PE=1 SV=1MASEGTNIPSPVVRQIDKQFLICSICLERYKNPKVLPCLHTFCERCLQNYIPAHSLTLSCPVCRQTSILPEKGVAALQNNFFITNLMDVLQRTPGSNAEESSILETVTAVAAGKPLSCPNHDGNVMEFYCQSCETAMCRECTEGEHAEHPTVPLKDVVEQHKASLQVQLDAVNKRLPEIDSALQFISEIIHQLTNQKASIVDDIHSTFDELQKTLNVRKSVLLMELEVNYGLKHKVLQSQLDTLLQGQESIKSCSNFTAQALNHGTETEVLLVKKQMSEKLNELADQDFPLHPRENDQLDFIVETEGLKKSIHNLGTILTTNAVASETVATGEGLRQTIIGQPMSVTITTKDKDGELCKTGNAYLTAELSTPDGSVADGEILDNKNGTYEFLYTVQKEGDFTLSLRLYDQHIRGSPFKLKVIRSADVSPTTEGVKRRVKSPGSGHVKQKAVKRPASMYSTGKRKENPIEDDLIFRVGTKGRNKGEFTNLQGVAASTNGKILIADSNNQCVQIFSNDGQFKSRFGIRGRSPGQLQRPTGVAVHPSGDIIIADYDNKWVSIFSSDGKFKTKIGSGKLMGPKGVSVDRNGHIIVVDNKACCVFIFQPNGKIVTRFGSRGNGDRQFAGPHFAAVNSNNEIIITDFHNHSVKVFNQEGEFMLKFGSNGEGNGQFNAPTGVAVDSNGNIIVADWGNSRIQVFDGSGSFLSYINTSADPLYGPQGLALTSDGHVVVADSGNHCFKVYRYLQ>sp|Q9C040-2|TRIM2_HUMAN Isoform 2 of Tripartite motif-containing protein2 OS=Homo sapiens OX=9606 GN=TRIM2MHRSGRYGTQQQRAGSKTAGPPCQWSRMASEGTNIPSPVVRQIDKQFLICSICLERYKNPKVLPCLHTFCERCLQNYIPAHSLTLSCPVCRQTSILPEKGVAALQNNFFITNLMDVLQRTPGSNAEESSILETVTAVAAGKPLSCPNHDGNVMEFYCQSCETAMCRECTEGEHAEHPTVPLKDVVEQHKASLQVQLDAVNKRLPEIDSALQFISEIIHQLTNQKASIVDDIHSTFDELQKTLNVRKSVLLMELEVNYGLKHKVLQSQLDTLLQGQESIKSCSNFTAQALNHGTETEVLLVKKQMSEKLNELADQDFPLHPRENDQLDFIVETEGLKKSIHNLGTILTTNAVASETVATGEGLRQTIIGQPMSVTITTKDKDGELCKTGNAYLTAELSTPDGSVADGEILDNKNGTYEFLYTVQKEGDFTLSLRLYDQHIRGSPFKLKVIRSADVSPTTEGVKRRVKSPGSGHVKQKAVKRPASMYSTGKRKENPIEDDLIFRVGTKGRNKGEFTNLQGVAASTNGKILIADSNNQCVQIFSNDGQFKSRFGIRGRSPGQLQRPTGVAVHPSGDIIIADYDNKWVSIFSSDGKFKTKIGSGKLMGPKGVSVDRNGHIIVVDNKACCVFIFQPNGKIVTRFGSRGNGDRQFAGPHFAAVNSNNEIIITDFHNHSVKVFNQEGEFMLKFGSNGEGNGQFNAPTGVAVDSNGNIIVADWGNSRIQVFDGSGSFLSYINTSADPLYGPQGLALTSDGHVVVADSGNHCFKVYRYLQ>sp|Q12893|TM115_HUMAN Transmembrane protein 115 OS=Homo sapiens OX=9606GN=TMEM115 PE=1 SV=1MQRALPGARQHLGAILASASVVVKALCAAVLFLYLLSFAVDTGCLAVTPGYLFPPNFWIWTLATHGLMEQHVWDVAISLTTVVVAGRLLEPLWGALELLIFFSVVNVSVGLLGAFAYLLTYMASFNLVYLFTVRIHGALGFLGGVLVALKQTMGDCVVLRVPQVRVSVMPMLLLALLLLLRLATLLQSPALASYGFGLLSSWVYLRFYQRHSRGRGDMADHFAFATFFPEILQPVVGLLANLVHSLLVKVKICQKTVKRYDVGAPSSITISLPGTDPQDAERRRQLALKALNERLKRVEDQSIWPSMDDDEEESGAKVDSPLPSDKAPTPPGKGAAPESSLITFEAAPPTL>sp|P29144|TPP2_HUMAN Tripeptidyl-peptidase 2 OS=Homo sapiens OX=9606GN=TPP2 PE=1 SV=4MATAATEEPFPFHGLLPKKETGAASFLCRYPEYDGRGVLIAVLDTGVDPGAPGMQVTTDGKPKIVDIIDTTGSGDVNTATEVEPKDGEIVGLSGRVLKIPASWTNPSGKYHIGIKNGYDFYPKALKERIQKERKEKIWDPVHRVALAEACRKQEEFDVANNGSSQANKLIKEELQSQVELLNSFEKKYSDPGPVYDCLVWHDGEVWRACIDSNEDGDLSKSTVLRNYKEAQEYGSFGTAEMLNYSVNIYDDGNLLSIVTSGGAHGTHVASIAAGHFPEEPERNGVAPGAQILSIKIGDTRLSTMETGTGLIRAMIEVINHKCDLVNYSYGEATHWPNSGRICEVINEAVWKHNIIYVSSAGNNGPCLSTVGCPGGTTSSVIGVGAYVSPDMMVAEYSLREKLPANQYTWSSRGPSADGALGVSISAPGGAIASVPNWTLRGTQLMNGTSMSSPNACGGIALILSGLKANNIDYTVHSVRRALENTAVKADNIEVFAQGHGIIQVDKAYDYLVQNTSFANKLGFTVTVGNNRGIYLRDPVQVAAPSDHGVGIEPVFPENTENSEKISLQLHLALTSNSSWVQCPSHLELMNQCRHINIRVDPRGLREGLHYTEVCGYDIASPNAGPLFRVPITAVIAAKVNESSHYDLAFTDVHFKPGQIRRHFIEVPEGATWAEVTVCSCSSEVSAKFVLHAVQLVKQRAYRSHEFYKFCSLPEKGTLTEAFPVLGGKAIEFCIARWWASLSDVNIDYTISFHGIVCTAPQLNIHASEGINRFDVQSSLKYEDLAPCITLKNWVQTLRPVSAKTKPLGSRDVLPNNRQLYEMVLTYNFHQPKSGEVTPSCPLLCELLYESEFDSQLWIIFDQNKRQMGSGDAYPHQYSLKLEKGDYTIRLQIRHEQISDLERLKDLPFIVSHRLSNTLSLDIHENHSFALLGKKKSSNLTLPPKYNQPFFVTSLPDDKIPKGAGPGCYLAGSLTLSKTELGKKADVIPVHYYLIPPPTKTKNGSKDKEKDSEKEKDLKEEFTEALRDLKIQWMTKLDSSDIYNELKETYPNYLPLYVARLHQLDAEKERMKRLNEIVDAANAVISHIDQTALAVYIAMKTDPRPDAATIKNDMDKQKSTLVDALCRKGCALADHLLHTQAQDGAISTDAEGKEEEGESPLDSLAETFWETTKWTDLFDNKVLTFAYKHALVNKMYGRGLKFATKLVEEKPTKENWKNCIQLMKLLGWTHCASFTENWLPIMYPPDYCVF>sp|Q9H3S4|TPK1_HUMAN Thiamin pyrophosphokinase 1 OS=Homo sapiens OX=9606GN=TPK1 PE=1 SV=1MEHAFTPLEPLLSTGNLKYCLVILNQPLDNYFRHLWNKALLRACADGGANRLYDITEGERESFLPEFINGDFDSIRPEVREYYATKGCELISTPDQDHTDFTKCLKMLQKKIEEKDLKVDVIVTLGGLAGRFDQIMASVNTLFQATHITPFPIIIIQEESLIYLLQPGKHRLHVDTGMEGDWCGLIPVGQPCMQVTTTGLKWNLTNDVLAFGTLVSTSNTYDGSGVVTVETDHPLLWTMAIKS>sp|Q9H3S4-2|TPK1_HUMAN Isoform 2 of Thiamin pyrophosphokinase 1 OS=Homosapiens OX=9606 GN=TPK1MVDVIVTLGGLAGRFDQIMASVNTLFQATHITPFPIIIIQEESLIYLLQPGKHRLHVDTGMEGDWCGLIPVGQPCMQVTTTGLKWNLRTCDYTRTTWIAKDNPVPRLIRLIRLNHICKVPLAIK>sp|Q93096|TP4A1_HUMAN Protein tyrosine phosphatase type IVA 1 OS=Homosapiens OX=9606 GN=PTP4A1 PE=1 SV=2MARMNRPAPVEVTYKNMRFLITHNPTNATLNKFIEELKKYGVTTIVRVCEATYDTTLVEKEGIHVLDWPFDDGAPPSNQIVDDWLSLVKIKFREEPGCCIAVHCVAGLGRAPVLVALALIEGGMKYEDAVQFIRQKRRGAFNSKQLLYLEKYRPKMRLRFKDSNGHRNNCCIQ>sp|Q9UJW2|TINAG_HUMAN Tubulointerstitial nephritis antigen OS=Homosapiens OX=9606 GN=TINAG PE=2 SV=3MWTGYKILIFSYLTTEIWMEKQYLSQREVDLEAYFTRNHTVLQGTRFKRAIFQGQYCRNFGCCEDRDDGCVTEFYAANALCYCDKFCDRENSDCCPDYKSFCREEKEWPPHTQPWYPEGCFKDGQHYEEGSVIKENCNSCTCSGQQWKCSQHVCLVRSELIEQVNKGDYGWTAQNYSQFWGMTLEDGFKFRLGTLPPSPMLLSMNEMTASLPATTDLPEFFVASYKWPGWTHGPLDQKNCAASWAFSTASVAADRIAIQSKGRYTANLSPQNLISCCAKNRHGCNSGSIDRAWWYLRKRGLVSHACYPLFKDQNATNNGCAMASRSDGRGKRHATKPCPNNVEKSNRIYQCSPPYRVSSNETEIMKEIMQNGPVQAIMQVREDFFHYKTGIYRHVTSTNKESEKYRKLQTHAVKLTGWGTLRGAQGQKEKFWIAANSWGKSWGENGYFRILRGVNESDIEKLIIAAWGQLTSSDEP>sp|Q9UJW2-2|TINAG_HUMAN Isoform 2 of Tubulointerstitial nephritisantigen OS=Homo sapiens OX=9606 GN=TINAGMWTGYKILIFSYLTTEIWMEKQYLSQREVDLEAYFTRNHTVLQGTRFKRAIFQGQYCRNFGCCEDRDDGCVTEFYAANALCYCDKFCDRENSDCCPDYKSFCREEKEWPPHTQPWYPEGWTAQNYSQFWGMTLEDGFKFRLGTLPPSPMLLSMNEMTLVSHACYPLFKDQNATNNGCAMASRSDGRGKRHATKPCPNNVEKSNRIYQCSPPYRVSSNETEIMKEIMQNGPVQAIMQVREDFFHYKTGIYRHVTSTNKESEKYRKLQTHAVKLTGWGTLRGAQGQKEKFWIAANSWGKSWGENGYFRILRGVNESDIEKLIIAAWGQLTSSDEP>sp|Q9UL62|TRPC5_HUMAN Short transient receptor potential channel 5OS=Homo sapiens OX=9606 GN=TRPC5 PE=1 SV=1MAQLYYKKVNYSPYRDRIPLQIVRAETELSAEEKAFLNAVEKGDYATVKQALQEAEIYYNVNINCMDPLGRSALLIAIENENLEIMELLLNHSVYVGDALLYAIRKEVVGAVELLLSYRRPSGEKQVPTLMMDTQFSEFTPDITPIMLAAHTNNYEIIKLLVQKRVTIPRPHQIRCNCVECVSSSEVDSLRHSRSRLNIYKALASPSLIALSSEDPILTAFRLGWELKELSKVENEFKAEYEELSQQCKLFAKDLLDQARSSRELEIILNHRDDHSEELDPQKYHDLAKLKVAIKYHQKEFVAQPNCQQLLATLWYDGFPGWRRKHWVVKLLTCMTIGFLFPMLSIAYLISPRSNLGLFIKKPFIKFICHTASYLTFLFMLLLASQHIVRTDLHVQGPPPTVVEWMILPWVLGFIWGEIKEMWDGGFTEYIHDWWNLMDFAMNSLYLATISLKIVAYVKYNGSRPREEWEMWHPTLIAEALFAISNILSSLRLISLFTANSHLGPLQISLGRMLLDILKFLFIYCLVLLAFANGLNQLYFYYETRAIDEPNNCKGIRCEKQNNAFSTLFETLQSLFWSVFGLLNLYVTNVKARHEFTEFVGATMFGTYNVISLVVLLNMLIAMMNNSYQLIADHADIEWKFARTKLWMSYFDEGGTLPPPFNIIPSPKSFLYLGNWFNNTFCPKRDPDGRRRRRNLRSFTERNADSLIQNQHYQEVIRNLVKRYVAAMIRNSKTHEGLTEENFKELKQDISSFRYEVLDLLGNRKHPRSFSTSSTELSQRDDNNDGSGGARAKSKSVSFNLGCKKKTCHGPPLIRTMPRSSGAQGKSKAESSSKRSFMGPSLKKLGLLFSKFNGHMSEPSSEPMYTISDGIVQQHCMWQDIRYSQMEKGKAEACSQSEINLSEVELGEVQGAAQSSECPLACSSSLHCASSICSSNSKLLDSSEDVFETWGEACDLLMHKWGDGQEEQVTTRL>sp|Q7RTX1|TS1R1_HUMAN Taste receptor type 1 member 1 OS=Homo sapiensOX=9606 GN=TAS1R1 PE=2 SV=1MLLCTARLVGLQLLISCCWAFACHSTESSPDFTLPGDYLLAGLFPLHSGCLQVRHRPEVTLCDRSCSFNEHGYHLFQAMRLGVEEINNSTALLPNITLGYQLYDVCSDSANVYATLRVLSLPGQHHIELQGDLLHYSPTVLAVIGPDSTNRAATTAALLSPFLVPMISYAASSETLSVKRQYPSFLRTIPNDKYQVETMVLLLQKFGWTWISLVGSSDDYGQLGVQALENQATGQGICIAFKDIMPFSAQVGDERMQCLMRHLAQAGATVVVVFSSRQLARVFFESVVLTNLTGKVWVASEAWALSRHITGVPGIQRIGMVLGVAIQKRAVPGLKAFEEAYARADKKAPRPCHKGSWCSSNQLCRECQAFMAHTMPKLKAFSMSSAYNAYRAVYAVAHGLHQLLGCASGACSRGRVYPWQLLEQIHKVHFLLHKDTVAFNDNRDPLSSYNIIAWDWNGPKWTFTVLGSSTWSPVQLNINETKIQWHGKDNQVPKSVCSSDCLEGHQRVVTGFHHCCFECVPCGAGTFLNKSDLYRCQPCGKEEWAPEGSQTCFPRTVVFLALREHTSWVLLAANTLLLLLLLGTAGLFAWHLDTPVVRSAGGRLCFLMLGSLAAGSGSLYGFFGEPTRPACLLRQALFALGFTIFLSCLTVRSFQLIIIFKFSTKVPTFYHAWVQNHGAGLFVMISSAAQLLICLTWLVVWTPLPAREYQRFPHLVMLECTETNSLGFILAFLYNGLLSISAFACSYLGKDLPENYNEAKCVTFSLLFNFVSWIAFFTTASVYDGKYLPAANMMAGLSSLSSGFGGYFLPKCYVILCRPDLNSTEHFQASIQDYTRRCGST>sp|Q7RTX1-2|TS1R1_HUMAN Isoform 2 of Taste receptor type 1 member 1OS=Homo sapiens OX=9606 GN=TAS1R1MLLCTARLVGLQLLISCCWAFACHSTESSPDFTLPGDYLLAGLFPLHSGCLQVRHRPEVTLCDRSCSFNEHGYHLFQAMRLGVEEINNSTALLPNITLGYQLYDVCSDSANVYATLRVLSLPGQHHIELQGDLLHYSPTVLAVIGPDSTNRAATTAALLSPFLVPMLLEQIHKVHFLLHKDTVAFNDNRDPLSSYNIIAWDWNGPKWTFTVLGSSTWSPVQLNINETKIQWHGKDNQVPKSVCSSDCLEGHQRVVTGFHHCCFECVPCGAGTFLNKSDLYRCQPCGKEEWAPEGSQTCFPRTVVFLALREHTSWVLLAANTLLLLLLLGTAGLFAWHLDTPVVRSAGGRLCFLMLGSLAAGSGSLYGFFGEPTRPACLLRQALFALGFTIFLSCLTVRSFQLIIIFKFSTKVPTFYHAWVQNHGAGLFVMISSAAQLLICLTWLVVWTPLPAREYQRFPHLVMLECTETNSLGFILAFLYNGLLSISAFACSYLGKDLPENYNEAKCVTFSLLFNFVSWIAFFTTASVYDGKYLPAANMMAGLSSLSSGFGGYFLPKCYVILCRPDLNSTEHFQASIQDYTRRCGST>sp|Q7RTX1-3|TS1R1_HUMAN Isoform 3 of Taste receptor type 1 member 1OS=Homo sapiens OX=9606 GN=TAS1R1MLLCTARLVGLQLLISCCWAFACHSTESSPDFTLPGDYLLAGLFPLHSGCLQVRHRPEVTLCDRSCSFNEHGYHLFQAMRLGVEEINNSTALLPNITLGYQLYDVCSDSANVYATLRVLSLPGQHHIELQGDLLHYSPTVLAVIGPDSTNRAATTAALLSPFLVPMLSYAASSETLSVKRQYPSFLRTIPNDKYQVETMVLLLQKFGWTWISLVGSSDDYGQLGVQALENQATGQGICIAFKDIMPFSAQVGDERMQCLMRHLAQAGATVVVVFSSRQLARVFFESVVLTNLTGKVWVASEAWALSRHITGVPGIQRIGMVLGVAIQKRAVPGLKAFEEAYARADKKAPRPCHKGSWCSSNQLCRECQAFMAHTMPKLKAFSMSSAYNAYRAVYAVAHGLHQLLGCASGACSRGRVYPWQTSTDASLVGKKSGHLREARPASRALWCFWLCVSTPLGCCWQLTRCCCCCCLGLLACLPGT>sp|Q7RTX1-4|TS1R1_HUMAN Isoform 4 of Taste receptor type 1 member 1OS=Homo sapiens OX=9606 GN=TAS1R1MLLCTARLVGLQLLISCCWAFACHSTESSPDFTLPGDYLLAGLFPLHSGCLQVRHRPEVTLCDRSCSFNEHGYHLFQAMRLGVEEINNSTALLPNITLGYQLYDVCSDSANVYATLRVLSLPGQHHIELQGDLLHYSPTVLAVIGPDSTNRAATTAALLSPFLVPMLLEQIHKVHFLLHKDTVAFNDNRDPLSSYNIIAWDWNGPKWTFTVLGSSTWSPVQLNINETKIQWHGKDNQVPKSVCSSDCLEGHQRVVTGFHHCCFECVPCGAGTFLNKSATWVRTCQRTTTRTNVSPSACSSTSCPGSPSSPRPASTTAXTC>sp|Q3SXZ7|TTLL9_HUMAN Probable tubulin polyglutamylase TTLL9 OS=Homosapiens OX=9606 GN=TTLL9 PE=2 SV=3MVPSREALLGPGTTAIRCPKKLQNQNYKGHGLSKGKEREQRASIRFKTTLMNTLMDVLRHRPGWVEVKDEGEWDFYWCDVSWLRENFDHTYMDEHVRISHFRNHYELTRKNYMVKNLKRFRKQLEREAGKLEAAKCDFFPKTFEMPCEYHLFVEEFRKNPGITWIMKPVARSQGKGIFLFRRLKDIVDWRKDTRSSDDQKDDIPVENYVAQRYIENPYLIGGRKFDLRVYVLVMSVFAECLLWSGHRRQDVHLTNVAVQKTSPDYHPKKGCKWTLQRFRQYLASKHGPEAVETLFRDIDNIFVKSLQSVQKVIISDKHCFELYGYDILIDQDLKPWLLEVNASPSLTASSQEDYELKTCLLEDTLHVVDMEARLTGREKRVGGFDLMWNDGPVSREEGAPDLSGMGNFVTNTHLGCVNDRKKQLRQLFCSLQVQKKASS>sp|Q3SXZ7-2|TTLL9_HUMAN Isoform 2 of Probable tubulin polyglutamylaseTTLL9 OS=Homo sapiens OX=9606 GN=TTLL9MNTLMDVLRHRPGWVEVKDEGEWDFYWCDVSWLRENFDHTYMDEHVRISHFRNHYELTRKNYMVKNLKRFRKQLEREAGKLEAAKCDFFPKTFEMPCEYHLFVEEFRKNPGITWIMKPVARSQGKGIFLFRRLKDIVDWRKDTRSSDDQKDDIPVENYVAQRYIENPYLIGGRKFDLRVYVLVMSYIPLRAWLYRDGFARFSNTRFTLNSIDDQYVHLTNVAVQKTSPDYHPKKGCKWTLQRFRQYLASKHGPEAVETLFRDIDNIFVKSLQSVQKVIISDKHCFELYGYDILIDQDLKPWLLEVNASPSLTASSQEDYELKTCLLEDTLHVVDMEARSLRADSPCW>sp|Q3SXZ7-3|TTLL9_HUMAN Isoform 3 of Probable tubulin polyglutamylaseTTLL9 OS=Homo sapiens OX=9606 GN=TTLL9MNTLMDVLRHRPGWVEVKDEGEWDFYWCDVSWLRENFDHTYMDEHVRISHFRNHYELTRKNYMVKNLKRFRKQLEREAGKLEAAKCDFFPKTFEMPCEYHLFVEEFRKNPGITWIMKPDTRSSDDQKDDIPVENYVAQRYIENPYLIGGRKFDLRVYVLVMSYIPLRAWLYRDGFARFSNTRFTLNSIDDQYVHLTNVAVQKTSPDYHPKKVAPGGQCVPITDSQQPGRL>sp|Q96QS1|TSN32_HUMAN Tetraspanin-32 OS=Homo sapiens OX=9606 GN=TSPAN32PE=2 SV=1MGPWSRVRVAKCQMLVTCFFILLLGLSVATMVTLTYFGAHFAVIRRASLEKNPYQAVHQWAFSAGLSLVGLLTLGAVLSAAATVREAQGLMAGGFLCFSLAFCAQVQVVFWRLHSPTQVEDAMLDTYDLVYEQAMKGTSHVRRQELAAIQDVFLCCGKKSPFSRLGSTEADLCQGEEAAREDCLQGIRSFLRTHQQVASSLTSIGLALTVSALLFSSFLWFAIRCGCSLDRKGKYTLTPRACGRQPQEPSLLRCSQGGPTHCLHSEAVAIGPRGCSGSLRWLQESDAAPLPLSCHLAAHRALQGRSRGGLSGCPERGLSD>sp|Q96QS1-2|TSN32_HUMAN Isoform 2 of Tetraspanin-32 OS=Homo sapiensOX=9606 GN=TSPAN32MVTLTYFGAHFAVIRRASLEKNPYQAVHQWAFSAGLSLVGLLTLGAVLSAAATVREAQGLMAGGFLCFSLAFCAQVQVVFWRLHSPTQVEDAMLDTYDLVYEQAMKGTSHVRRQELAAIQDVFLCCGKKSPFSRLGSTEADLCQGEEAAREDCLQGIRSFLRTHQQVASSLTSIGLALTVSALLFSSFLWFAIRCGCSLDRKGKYTLTPRACGRQPQEPSLLRCSQGGPTHCLHSEAVAIGPRGCSGSLRWLQESDAAPLPLSCHLAAHRALQGRSRGGLSGCPERGLSD>sp|Q96QS1-3|TSN32_HUMAN Isoform 3 of Tetraspanin-32 OS=Homo sapiensOX=9606 GN=TSPAN32MGPWSRVRVAKCQMLVTCFFILLLGLSVATMVTLTYFGAHFAVIRRASLEKNPYQAVHQWAFSAGLSLVGLLTLGAVLSAAATVREAQGLMAGGFLCFSLAFCAQVQVVFWRLHSPTQVEDAMLDTYDLVYEQAMKGTSHVRRQELAAIQDVFLCCGKKSPFSRLGSTEADLCQGEEAAREDCLQGIRSFLRTHQQVASSLTSIGLALTVSALLFSSFLWFAIRCGCSLDRKGKYTLTPRSPGQKSRWAQWVP>sp|Q96QS1-4|TSN32_HUMAN Isoform 4 of Tetraspanin-32 OS=Homo sapiensOX=9606 GN=TSPAN32MVTLTYFGAHFAVIRRASLEKNPYQAVHQWAFSAGLSLVGLLTLGAVLSAAATVREAQGLMAGGFLCFSLAFCAQVQVVFWRLHSPTQVEDAMLDTYDLVYEQAMKVSVLWEEVSFQPSGEHRG>sp|Q96QS1-5|TSN32_HUMAN Isoform 5 of Tetraspanin-32 OS=Homo sapiensOX=9606 GN=TSPAN32MGPWSRVRVAKCQMLVTCFFILLLGLSVATMVTLTYFGAHFAVIRRASLEKNPYQAVHQWAFSAGLSLVGLLTLGAVLSAAATVREAQGLMAGGFLCFSLAFCAQVQVVFWRLHSPTQVEDAMLDTYDLVYEQAMKGTSHVRRQELAAIQDVFLCCGKKSPFSRLGSTEADLCQGEEAAREDCLQGIRSFLRTHQQVASSLTSIGLALTLGPQGQIHPDPTSMWPPAPGAQPLEMLPGWTHTLSPLRSSCYWSKRMLG>sp|Q9BSA4|TTYH2_HUMAN Protein tweety homolog 2 OS=Homo sapiens OX=9606GN=TTYH2 PE=1 SV=3MQAARVDYIAPWWVVWLHSVPHVGLRLQPVNSTFSPGDESYQESLLFLGLVAAVCLGLNLIFLVAYLVCACHCRRDDAVQTKQHHSCCITWTAVVAGLICCAAVGVGFYGNSETNDGAYQLMYSLDDANHTFSGIDALVSGTTQKMKVDLEQHLARLSEIFAARGDYLQTLKFIQQMAGSVVVQLSGLPVWREVTMELTKLSDQTGYVEYYRWLSYLLLFILDLVICLIACLGLAKRSKCLLASMLCCGALSLLLSWASLAADGSAAVATSDFCVAPDTFILNVTEGQISTEVTRYYLYCSQSGSSPFQQTLTTFQRALTTMQIQVAGLLQFAVPLFSTAEEDLLAIQLLLNSSESSLHQLTAMVDCRGLHKDYLDALAGICYDGLQGLLYLGLFSFLAALAFSTMICAGPRAWKHFTTRNRDYDDIDDDDPFNPQAWRMAAHSPPRGQLHSFCSYSSGLGSQTSLQPPAQTISNAPVSEYMNQAMLFGRNPRYENVPLIGRASPPPTYSPSMRATYLSVADEHLRHYGNQFPA>sp|Q9BSA4-2|TTYH2_HUMAN Isoform 2 of Protein tweety homolog 2 OS=Homosapiens OX=9606 GN=TTYH2MQIQVAGLLQFAVPLFSTAEEDLLAIQLLLNSSESSLHQLTAMVDCRGLHKDYLDALAGICYDGLQGLLYLGLFSFLAALAFSTMICAGPRAWKHFTTRNRDYDDIDDDDPFNPQAWRMAAHSPPRGQLHSFCSYSSGLGSQTSLQPPAQTISNAPVSEYMNQAMLFGRNPRYENVPLIGRASPPPTYSPSMRATYLSVADEHLRHYGNQFPA>sp|P0CW00|TSPY8_HUMAN Testis-specific Y-encoded protein 8 OS=Homosapiens OX=9606 GN=TSPY8 PE=3 SV=2MRPEGSLTYWVPERLRQGFCGVGRAAQALVCASAKEGTAFRMEAVQEGAAGVESEQAALGEEAVLLLDDIMAEVEVVAEEEGLVERREEAQRAQQAVPGPGPMTPESALEELLAVQVELEPVNAQARKAFSRQREKMERRRKPHLDRRGAVIQSVPGFWANVIANHPQMSALITDEDEDMLSYMVSLEVEEEKHPVHLCKIMLFFRSNPYFQNKVITKEYLVNITEYRASHSTPIEWYLDYEVEAYRRRHHNSSLNFFNWFSDHNFAGSNKIAEILCKDLWRNPLQYYKRMKPPEEGTETSGDSQLLS>sp|Q9H489|TSY26_HUMAN Putative testis-specific Y-encoded-like protein 3OS=Homo sapiens OX=9606 GN=TSPY26P PE=5 SV=1MADKRAGTPEAAARPPPGLAREGDARTVPAARAREAGGRGSLHPAAGPGTAFPSPGRGEAASTATTPSLENGRVRDEAPETCGAEGLGTRAGASEKAEDANKEEGAIFKKEPAEEVEKQQEGEEKQEVAAEAQEGPRLLNLGALIVDPLEAIQWEAEAVSAQADRAYLPLERRFGRMHRLYLARRSFIIQNIPGFWVTAFLNHPQLSAMISPRDEDMLCYLMNLEVRELRHSRTGCKFKFRFWSNPYFQNKVIVKEYECRASGRVVSIATRIRWHWGQEPPALVHRNRDTVRSFFSWFSQHSLPEADRVAQIIKDDLWPNPLQYYLLGDRPCRARGGLARWPTETPSRPYGFQSG>sp|Q96PF2|TSSK2_HUMAN Testis-specific serine/threonine-protein kinase 2OS=Homo sapiens OX=9606 GN=TSSK2 PE=1 SV=2MDDATVLRKKGYIVGINLGKGSYAKVKSAYSERLKFNVAVKIIDRKKTPTDFVERFLPREMDILATVNHGSIIKTYEIFETSDGRIYIIMELGVQGDLLEFIKCQGALHEDVARKMFRQLSSAVKYCHDLDIVHRDLKCENLLLDKDFNIKLSDFGFSKRCLRDSNGRIILSKTFCGSAAYAAPEVLQSIPYQPKVYDIWSLGVILYIMVCGSMPYDDSDIRKMLRIQKEHRVDFPRSKNLTCECKDLIYRMLQPDVSQRLHIDEILSHSWLQPPKPKATSSASFKREGEGKYRAECKLDTKTGLRPDHRPDHKLGAKTQHRLLVVPENENRMEDRLAETSRAKDHHISGAEVGKAST>sp|O75795|UDB17_HUMAN UDP-glucuronosyltransferase 2B17 OS=Homo sapiensOX=9606 GN=UGT2B17 PE=1 SV=1MSLKWMSVFLLMQLSCYFSSGSCGKVLVWPTEYSHWINMKTILEELVQRGHEVIVLTSSASILVNASKSSAIKLEVYPTSLTKNDLEDFFMKMFDRWTYSISKNTFWSYFSQLQELCWEYSDYNIKLCEDAVLNKKLMRKLQESKFDVLLADAVNPCGELLAELLNIPFLYSLRFSVGYTVEKNGGGFLFPPSYVPVVMSELSDQMIFMERIKNMIYMLYFDFWFQAYDLKKWDQFYSEVLGRPTTLFETMGKAEMWLIRTYWDFEFPRPFLPNVDFVGGLHCKPAKPLPKEMEEFVQSSGENGIVVFSLGSMISNMSEESANMIASALAQIPQKVLWRFDGKKPNTLGSNTRLYKWLPQNDLLGHPKTKAFITHGGTNGIYEAIYHGIPMVGIPLFADQHDNIAHMKAKGAALSVDIRTMSSRDLLNALKSVINDPIYKENIMKLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHNLTWIQYHSLDVIAFLLACVATMIFMITKCCLFCFRKLAKTGKKKKRD>sp|Q96RL1|UIMC1_HUMAN BRCA1-A complex subunit RAP80 OS=Homo sapiensOX=9606 GN=UIMC1 PE=1 SV=2MPRRKKKVKEVSESRNLEKKDVETTSSVSVKRKRRLEDAFIVISDSDGEEPKEENGLQKTKTKQSNRAKCLAKRKIAQMTEEEQFALALKMSEQEAREVNSQEEEEEELLRKAIAESLNSCRPSDASATRSRPLATGPSSQSHQEKTTDSGLTEGIWQLVPPSLFKGSHISQGNEAEEREEPWDHTEKTEEEPVSGSSGSWDQSSQPVFENVNVKSFDRCTGHSAEHTQCGKPQESTGRGSAFLKAVQGSGDTSRHCLPTLADAKGLQDTGGTVNYFWGIPFCPDGVDPNQYTKVILCQLEVYQKSLKMAQRQLLNKKGFGEPVLPRPPSLIQNECGQGEQASEKNECISEDMGDEDKEERQESRASDWHSKTKDFQESSIKSLKEKLLLEEEPTTSHGQSSQGIVEETSEEGNSVPASQSVAALTSKRSLVLMPESSAEEITVCPETQLSSSETFDLEREVSPGSRDILDGVRIIMADKEVGNKEDAEKEVAISTFSSSNQVSCPLCDQCFPPTKIERHAMYCNGLMEEDTVLTRRQKEAKTKSDSGTAAQTSLDIDKNEKCYLCKSLVPFREYQCHVDSCLQLAKADQGDGPEGSGRACSTVEGKWQQRLKNPKEKGHSEGRLLSFLEQSEHKTSDADIKSSETGAFRVPSPGMEEAGCSREMQSSFTRRDLNESPVKSFVSISEATDCLVDFKKQVTVQPGSRTRTKAGRGRRRKF>sp|Q96RL1-2|UIMC1_HUMAN Isoform 2 of BRCA1-A complex subunit RAP80OS=Homo sapiens OX=9606 GN=UIMC1MPRRKKKVKEVSESRNLEKKDVETTSSVSVKRKRRLEDAFIVISDSDGEEPKEENGLQKTKTKQSNRAKCLAKRKIAQMTEEEQFALALKMSEQEAREVNSQEEEEEELLRKAIAESLNSCRPSDASATRSRPLATGPSSQSHQEKTTDSGLTEGIWQLVPPSLFKGSHISQGNEAEEREEPWDHTEKTEEEPVSGSSGSWDQSSQPVFENVNVKSFDRCTGHSAEHTQCGKPQSSQGIVEETSEEGNSVPASQSVAALTSKRSLVLMPESSAEEITVCPETQLSSSETFDLEREVSPGSRDILDGVRIIMADKEVGNKEDAEKEVAISTFSSSNQVSCPLCDQCFPPTKIERHAMYCNGLMEEDTVLTRRQKEAKTKSDSGTAAQTSLDIDKNEKCYLCKSLVPFREYQCHVDSCLQLAKADQGDGPEGSGRACSTVEGKWQQRLKNPKEKGHSEGRLLSFLEQSEHKTSDADIKSSETGAFRVPSPGMEEAGCSREMQSSFTRRDLNESPVKSFVSISEATDCLVDFKKQVTVQPGSRTRTKAGRGRRRKF>sp|Q96RL1-3|UIMC1_HUMAN Isoform 3 of BRCA1-A complex subunit RAP80OS=Homo sapiens OX=9606 GN=UIMC1MTEEEQFALALKMSEQEAREVNSQEEEEEELLRKAIAESLNSCRPSDASATRSRPLATGPSSQSHQEKTTDSGLTEGIWQLVPPSLFKGSHISQGNEAEEREEPWDHTEKTEEEPVSGSSGSWDQSSQPVFENVNVKSFDRCTGHSAEHTQCGKPQESTGRGSAFLKAVQGSGDTSRHCLPTLADAKGLQDTGGTVNYFWGIPFCPDGVDPNQYTKVILCQLEVYQKSLKMAQRQLLNKKGFGEPVLPRPPSLIQNECGQGEQASEKNECISEDMGDEDKEERQESRASDWHSKTKDFQESSIKSLKEKLLLEEEPTTSHGQSSQGIVEETSEEGNSVPASQSVAALTSKRSLVLMPESSAEEITVCPETQLSSSETFDLEREVSPGSRDILDGVRIIMADKEVGNKEDAEKEVAISTFSSSNQVSCPLCDQCFPPTKIERHAMYCNGLMEEDTVLTRRQKEAKTKSDSGTAAQTSLDIDKNEKCYLCKSLVPFREYQCHVDSCLQLAKADQGDGPEGSGRACSTVEGKWQQRLKNPKEKGHSEGRLLSFLEQSEHKTSDADIKSSETGAFRVPSPGMEEAGCSREMQSSFTRRDLNESPVKSFVSISEATDCLVDFKKQVTVQPGSRTRTKAGRGRRRKF>sp|Q96RL1-4|UIMC1_HUMAN Isoform 4 of BRCA1-A complex subunit RAP80OS=Homo sapiens OX=9606 GN=UIMC1MLPLPDLDLWPLDRLPSPIKRKPQTLGSLKSSQGIVEETSEEGNSVPASQSVAALTSKRSLVLMPESSAEEITVCPETQLSSSETFDLEREVSPGSRDILDGVRIIMADKEVGNKEDAEKEVAISTFSSSNQVSCPLCDQCFPPTKIERHAMYCNGLMEEDTVLTRRQKEAKTKSDSGTAAQTSLDIDKNEKCYLCKSLVPFREYQCHVDSCLQLAKADQGDGPEGSGRACSTVEGKWQQRLKNPKEKGHSEGRLLSFLEQSEHKTSDADIKSSETGAFRVPSPGMEEAGCSREMQSSFTRRDLNESPVKSFVSISEATDCLVDFKKQVTVQPGSRTRTKAGRGRRRKF>sp|Q96RL1-5|UIMC1_HUMAN Isoform 5 of BRCA1-A complex subunit RAP80OS=Homo sapiens OX=9606 GN=UIMC1MPRRKKKVKEVSESRNLEKKDVETTSSVSVKRKRRLEDAFIVISDSDGEEPKEENGLQKTKTKQSNRAKCLAKRKIAQMTEEEQFALALKMSEQEAREVNSQEEEEEELLRKAIAESLNVNMPCCKSLWRLISYIFDFCGVVVALGTSCSHL>sp|Q9HA47|UCK1_HUMAN Uridine-cytidine kinase 1 OS=Homo sapiens OX=9606GN=UCK1 PE=1 SV=1MASAGGEDCESPAPEADRPHQRPFLIGVSGGTASGKSTVCEKIMELLGQNEVEQRQRKVVILSQDRFYKVLTAEQKAKALKGQYNFDHPDAFDNDLMHRTLKNIVEGKTVEVPTYDFVTHSRLPETTVVYPADVVLFEGILVFYSQEIRDMFHLRLFVDTDSDVRLSRRVLRDVRRGRDLEQILTQYTTFVKPAFEEFCLPTKKYADVIIPRGVDNMVAINLIVQHIQDILNGDICKWHRGGSNGRSYKRTFSEPGDHPGMLTSGKRSHLESSSRPH>sp|Q9HA47-2|UCK1_HUMAN Isoform 2 of Uridine-cytidine kinase 1 OS=Homosapiens OX=9606 GN=UCK1MASAGGEDCESPAPEADRPHQRPFLIGVSGGTASGKSTVCEKIMELLGQNEVEQRQRKVVILSQDRFYKVLTAEQKAKALKGQYNFDHPDAFDNDLMHRTLKNIVEGKTVEVPTYDFVTHSRLPETTVVYPADVVLFEGILVFYSQEIRDMFHLRLFVDTDSDVRLSRRDKEVCRCDHPARSGQYGCHQPDRAAHPGHSEW>sp|Q9HA47-3|UCK1_HUMAN Isoform 3 of Uridine-cytidine kinase 1 OS=Homosapiens OX=9606 GN=UCK1MASAGGEDCESPAPEADRPHQRPFLIGSTVCEKIMELLGQNEVEQRQRKVVILSQDRFYKVLTAEQKAKALKGQYNFDHPDAFDNDLMHRTLKNIVEGKTVEVPTYDFVTHSRLPETTVVYPADVVLFEGILVFYSQEIRDMFHLRLFVDTDSDVRLSRRVLRDVRRGRDLEQILTQYTTFVKPAFEEFCLPTKKYADVIIPRGVDNMVAINLIVQHIQDILNGDICKWHRGGSNGRSYKRTFSEPGDHPGMLTSGKRSHLESSSRPH>sp|Q9HA47-4|UCK1_HUMAN Isoform 4 of Uridine-cytidine kinase 1 OS=Homosapiens OX=9606 GN=UCK1MASAGGEDCESPAPEADRPHQRPFLIGDERFQAGIPLLCLQSTVCEKIMELLGQNEVEQRQRKVVILSQDRFYKVLTAEQKAKALKGQYNFDHPDAFDNDLMHRTLKNIVEGKTVEVPTYDFVTHSRLPETTVVYPADVVLFEGILVFYSQEIRDMFHLRLFVDTDSDVRLSRRVLRDVRRGRDLEQILTQYTTFVKPAFEEFCLPTKKYADVIIPRGVDNMVAINLIVQHIQDILNGDICKWHRGGSNGRSYKRTFSEPGDHPGMLTSGKRSHLESSSRPH>sp|Q6UWH6|TX261_HUMAN Protein TEX261 OS=Homo sapiens OX=9606 GN=TEX261PE=2 SV=1MWFMYLLSWLSLFIQVAFITLAVAAGLYYLAELIEEYTVATSRIIKYMIWFSTAVLIGLYVFERFPTSMIGVGLFTNLVYFGLLQTFPFIMLTSPNFILSCGLVVVNHYLAFQFFAEEYYPFSEVLAYFTFCLWIIPFAFFVSLSAGENVLPSTMQPGDDVVSNYFTKGKRGKRLGILVVFSFIKEAILPSRQKIY>sp|Q9Y3A2|UTP11_HUMAN Probable U3 small nucleolar RNA-associated protein11 OS=Homo sapiens OX=9606 GN=UTP11 PE=1 SV=2MAAAFRKAAKSRQREHRERSQPGFRKHLGLLEKKKDYKLRADDYRKKQEYLKALRKKALEKNPDEFYYKMTRVKLQDGVHIIKETKEEVTPEQLKLMRTQDVKYIEMKRVAEAKKIERLKSELHLLDFQGKQQNKHVFFFDTKKEVEQFDVATHLQTAPELVDRVFNRPRIETLQKEKVKGVTNQTGLKRIAKERQKQYNCLTQRIEREKKLFVIAQKIQTRKDLMDKTQKVKVKKETVNSPAIYKFQSRRKR>sp|Q9Y3A2-2|UTP11_HUMAN Isoform 2 of Probable U3 small nucleolar RNA-associated protein 11 OS=Homo sapiens OX=9606 GN=UTP11MAAAFRKAAKSRQREHRERSQPGFRKHLGLLEKKKDYKLRADDYRKKQEYLKALRKKALEKNPDEFYYKMTRVKLQDGVHIIKETKEEVTPEQLKLMRTQDVKYIEMKRVAEAKKIERLKSELHLLDFQGKQQNKHVFFFDTKKEANS>sp|P11473|VDR_HUMAN Vitamin D3 receptor OS=Homo sapiens OX=9606 GN=VDRPE=1 SV=1MEAMAASTSLPDPGDFDRNVPRICGVCGDRATGFHFNAMTCEGCKGFFRRSMKRKALFTCPFNGDCRITKDNRRHCQACRLKRCVDIGMMKEFILTDEEVQRKREMILKRKEEEALKDSLRPKLSEEQQRIIAILLDAHHKTYDPTYSDFCQFRPPVRVNDGGGSHPSRPNSRHTPSFSGDSSSSCSDHCITSSDMMDSSSFSNLDLSEEDSDDPSVTLELSQLSMLPHLADLVSYSIQKVIGFAKMIPGFRDLTSEDQIVLLKSSAIEVIMLRSNESFTMDDMSWTCGNQDYKYRVSDVTKAGHSLELIEPLIKFQVGLKKLNLHEEEHVLLMAICIVSPDRPGVQDAALIEAIQDRLSNTLQTYIRCRHPPPGSHLLYAKMIQKLADLRSLNEEHSKQYRCLSFQPECSMKLTPLVLEVFGNEIS>sp|P11473-2|VDR_HUMAN Isoform 2 of Vitamin D3 receptor OS=Homo sapiensOX=9606 GN=VDRMEWRNKKRSDWLSMVLRTAGVEEAFGSEVSVRPHRRAPLGSTYLPPAPSGMEAMAASTSLPDPGDFDRNVPRICGVCGDRATGFHFNAMTCEGCKGFFRRSMKRKALFTCPFNGDCRITKDNRRHCQACRLKRCVDIGMMKEFILTDEEVQRKREMILKRKEEEALKDSLRPKLSEEQQRIIAILLDAHHKTYDPTYSDFCQFRPPVRVNDGGGSHPSRPNSRHTPSFSGDSSSSCSDHCITSSDMMDSSSFSNLDLSEEDSDDPSVTLELSQLSMLPHLADLVSYSIQKVIGFAKMIPGFRDLTSEDQIVLLKSSAIEVIMLRSNESFTMDDMSWTCGNQDYKYRVSDVTKAGHSLELIEPLIKFQVGLKKLNLHEEEHVLLMAICIVSPDRPGVQDAALIEAIQDRLSNTLQTYIRCRHPPPGSHLLYAKMIQKLADLRSLNEEHSKQYRCLSFQPECSMKLTPLVLEVFGNEIS>sp|P63120|VPK19_HUMAN Endogenous retrovirus group K member 19 Proprotein OS=Homo sapiens OX=9606 GN=ERVK-19 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPLYSPTSQKIMTKMGYILGKGLGKNEDGIKIPVEAKINQKREGIGYPF>sp|Q5GFL6|VWA2_HUMAN von Willebrand factor A domain-containing protein 2OS=Homo sapiens OX=9606 GN=VWA2 PE=1 SV=1MPPFLLLEAVCVFLFSRVPPSLPLQEVHVSKETIGKISAASKMMWCSAAVDIMFLLDGSNSVGKGSFERSKHFAITVCDGLDISPERVRVGAFQFSSTPHLEFPLDSFSTQQEVKARIKRMVFKGGRTETELALKYLLHRGLPGGRNASVPQILIIVTDGKSQGDVALPSKQLKERGVTVFAVGVRFPRWEELHALASEPRGQHVLLAEQVEDATNGLFSTLSSSAICSSATPDCRVEAHPCEHRTLEMVREFAGNAPCWRGSRRTLAVLAAHCPFYSWKRVFLTHPATCYRTTCPGPCDSQPCQNGGTCVPEGLDGYQCLCPLAFGGEANCALKLSLECRVDLLFLLDSSAGTTLDGFLRAKVFVKRFVRAVLSEDSRARVGVATYSRELLVAVPVGEYQDVPDLVWSLDGIPFRGGPTLTGSALRQAAERGFGSATRTGQDRPRRVVVLLTESHSEDEVAGPARHARARELLLLGVGSEAVRAELEEITGSPKHVMVYSDPQDLFNQIPELQGKLCSRQRPGCRTQALDLVFMLDTSASVGPENFAQMQSFVRSCALQFEVNPDVTQVGLVVYGSQVQTAFGLDTKPTRAAMLRAISQAPYLGGVGSAGTALLHIYDKVMTVQRGARPGVPKAVVVLTGGRGAEDAAVPAQKLRNNGISVLVVGVGPVLSEGLRRLAGPRDSLIHVAAYADLRYHQDVLIEWLCGEAKQPVNLCKPSPCMNEGSCVLQNGSYRCKCRDGWEGPHCENRFLRRP>sp|Q5GFL6-2|VWA2_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 2 OS=Homo sapiens OX=9606 GN=VWA2MPPFLLLEAVCVFLFSRVPPSLPLQEVHVSKETIGKISAASKMMWCSAAVDIMFLLDGSNSVGKGSFERSKHFAITVCDGLDISPERVRVGAFQFSSTPHLEFPLDSFSTQQEVKARIKRMVFKGGRTETELALKYLLHRGLPGGRNASVPQILIIVTDGKSQGDVALPSKQLKERGVTVFAVGVRFPRWEELHALASEPRGQHVLLAEQVEDATNGLFSTLSSSAICSSATPDCRVEAHPCEHRTLEMVREFAGNAPCWRGSRRTLAVLAAHCPFYSWKRVFLTHPATCYRTTCPGPCDSQPCQNGGTCVPEGLDGYQCLCPLAFGGEANCALKLSLECRVDLLFLLDSSAGTTLDGFLRAKVFVKRFVRAVLSEDSRARVGVATYSRELLVAVPVGEYQDVPDLVWSLDGIPFRGGPTLTGSALRQAAERGFGSATRTGQDRPRRVVVLLTESHSEDEVAGPARHARARELLLLGVGSEAVRAELEEITGSPKHVMVYSDPQDLFNQIPELQGKLCSRQRPGCRTQALDLVFMLDTSASVGPENFAQMQSFVRSCALQFEVNPDVTQVGLVVYGSQVQTAFGLDTKPTRAAMLRAISQAPYLGGVGSAGTALLHIYDKVMTVQRGARPGVPKAVVVLTGGRGAEDAAVPAQKLRNNGISVLVVGVGPVLSEGLRRLAGPRDSLIHVAAYADLRYHQDVLIEWLCGGEWGNPHPQGCPHGRPSA>sp|Q5GFL6-3|VWA2_HUMAN Isoform 3 of von Willebrand factor A domain-containing protein 2 OS=Homo sapiens OX=9606 GN=VWA2MEAHVFQKDWTATSASARWPLEGRLTVVALKLSLECRVDLLFLLDSSAGTTLDGFLRAKVFVKRFVRAVLSEDSRARVGVATYSRELLVAVPVGEYQDVPDLVWSLDGIPFRGGPTLTGSALRQAAERGFGSATRTGQDRPRRVVVLLTESHSEDEVAGPARHARARELLLLGVGSEAVRAELEEITGSPKHVMVYSDPQDLFNQIPELQGKLCSRQRPGCRTQALDLVFMLDTSASVGPENFAQMQSFVRSCALQFEVNPDVTQVGLVVYGSQVQTAFGLDTKPTRAAMLRAISQAPYLGGVGSAGTALLHIYDKVMTVQRGARPGVPKAVVVLTGGRGAEDAAVPAQKLRNNGISVLVVGVGPVLSEGLRRLAGPRDSLIHVAAYADLRYHQDVLIEWLCGGEWGNPHPQGCPHGRPSA>sp|Q8NEX6|WFD11_HUMAN Protein WFDC11 OS=Homo sapiens OX=9606 GN=WFDC11PE=3 SV=1MVSLMKLWIPMLMTFFCTVLLSVLGEMRKKRYDRKELLLEECWGKPNVKECTNKCSKAFRCKDKNYTCCWTYCGNICWINVETSGDY>sp|Q9H0D6|XRN2_HUMAN 5'-3' exoribonuclease 2 OS=Homo sapiens OX=9606GN=XRN2 PE=1 SV=1MGVPAFFRWLSRKYPSIIVNCVEEKPKECNGVKIPVDASKPNPNDVEFDNLYLDMNGIIHPCTHPEDKPAPKNEDEMMVAIFEYIDRLFSIVRPRRLLYMAIDGVAPRAKMNQQRSRRFRASKEGMEAAVEKQRVREEILAKGGFLPPEEIKERFDSNCITPGTEFMDNLAKCLRYYIADRLNNDPGWKNLTVILSDASAPGEGEHKIMDYIRRQRAQPNHDPNTHHCLCGADADLIMLGLATHEPNFTIIREEFKPNKPKPCGLCNQFGHEVKDCEGLPREKKGKHDELADSLPCAEGEFIFLRLNVLREYLERELTMASLPFTFDVERSIDDWVFMCFFVGNDFLPHLPSLEIRENAIDRLVNIYKNVVHKTGGYLTESGYVNLQRVQMIMLAVGEVEDSIFKKRKDDEDSFRRRQKEKRKRMKRDQPAFTPSGILTPHALGSRNSPGSQVASNPRQAAYEMRMQNNSSPSISPNTSFTSDGSPSPLGGIKRKAEDSDSEPEPEDNVRLWEAGWKQRYYKNKFDVDAADEKFRRKVVQSYVEGLCWVLRYYYQGCASWKWYYPFHYAPFASDFEGIADMPSDFEKGTKPFKPLEQLMGVFPAASGNFLPPSWRKLMSDPDSSIIDFYPEDFAIDLNGKKYAWQGVALLPFVDERRLRAALEEVYPDLTPEETRRNSLGGDVLFVGKHHPLHDFILELYQTGSTEPVEVPPELCHGIQGKFSLDEEAILPDQIVCSPVPMLRDLTQNTVVSINFKDPQFAEDYIFKAVMLPGARKPAAVLKPSDWEKSSNGRQWKPQLGFNRDRRPVHLDQAAFRTLGHVMPRGSGTGIYSNAAPPPVTYQGNLYRPLLRGQAQIPKLMSNMRPQDSWRGPPPLFQQQRFDRGVGAEPLLPWNRMLQTQNAAFQPNQYQMLAGPGGYPPRRDDRGGRQGYPREGRKYPLPPPSGRYNWN>sp|Q9H0D6-2|XRN2_HUMAN Isoform 2 of 5'-3' exoribonuclease 2 OS=Homosapiens OX=9606 GN=XRN2MMVAIFEYIDRLFSIVRPRRLLYMAIDGVAPRAKMNQQRSRRFRASKEGMEAAVEKQRVREEILAKGGFLPPEEIKERFDSNCITPGTEFMDNLAKCLRYYIADRLNNDPGWKNLTVILSDASAPGEGEHKIMDYIRRQRAQPNHDPNTHHCLCGADADLIMLGLATHEPNFTIIREEFKPNKPKPCGLCNQFGHEVKDCEGLPREKKGKHDELADSLPCAEGEFIFLRLNVLREYLERELTMASLPFTFDVERSIDDWVFMCFFVGNDFLPHLPSLEIRENAIDRLVNIYKNVVHKTGGYLTESGYVNLQRVQMIMLAVGEVEDSIFKKRKDDEDSFRRRQKEKRKRMKRDQPAFTPSGILTPHALGSRNSPGSQVASNPRQAAYEMRMQNNSSPSISPNTSFTSDGSPSPLGGIKRKAEDSDSEPEPEDNVRLWEAGWKQRYYKNKFDVDAADEKFRRKVVQSYVEGLCWVLRYYYQGCASWKWYYPFHYAPFASDFEGIADMPSDFEKGTKPFKPLEQLMGVFPAASGNFLPPSWRKLMSDPDSSIIDFYPEDFAIDLNGKKYAWQGVALLPFVDERRLRAALEEVYPDLTPEETRRNSLGGDVLFVGKHHPLHDFILELYQTGSTEPVEVPPELCHGIQGKFSLDEEAILPDQIVCSPVPMLRDLTQNTVVSINFKDPQFAEDYIFKAVMLPGARKPAAVLKPSDWEKSSNGRQWKPQLGFNRDRRPVHLDQAAFRTLGHVMPRGSGTGIYSNAAPPPVTYQGNLYRPLLRGQAQIPKLMSNMRPQDSWRGPPPLFQQQRFDRGVGAEPLLPWNRMLQTQNAAFQPNQYQMLAGPGGYPPRRDDRGGRQGYPREGRKYPLPPPSGRYNWN>sp|Q8NA23|WDR31_HUMAN WD repeat-containing protein 31 OS=Homo sapiensOX=9606 GN=WDR31 PE=1 SV=1MLLLRCQLKQAPPQKVSFRFCVVMGKQQSKLKHSTYKYGRPDEIIEERIQTKAFQEYSPAHMDTVSVVAALNSDLCVSGGKDKTVVAYNWKTGNVVKRFKGHEHEITKVACIPKSSQFFSASRDRMVMMWDLHGSSQPRQQLCGHAMVVTGLAVSPDSSQLCTGSRDNTLLLWDVVTGQSVERASVSRNVVTHLCWVPREPYILQTSEDKTLRLWDSRGLQVAHMFPAKQHIQTYCEVSVDGHKCISCSNGFGGEGCEATLWDLRQTRNRICEYKGHFQTVASCVFLPRALALMPLIATSSHDCKVKIWNQDTGACLFTLSLDGSGPLTSLAVGDAISLLCASFNRGIHLLRMDHSQGLELQEVAAF>sp|Q8NA23-2|WDR31_HUMAN Isoform 2 of WD repeat-containing protein 31OS=Homo sapiens OX=9606 GN=WDR31MLLLRCQLKQAPPQKVSFRFCVVMGKQQSKLKHSTYKYGPDEIIEERIQTKAFQEYSPAHMDTVSVVAALNSDLCVSGGKDKTVVAYNWKTGNVVKRFKGHEHEITKVACIPKSSQFFSASRDRMVMMWDLHGSSQPRQQLCGHAMVVTGLAVSPDSSQLCTGSRDNTLLLWDVVTGQSVERASVSRNVVTHLCWVPREPYILQTSEDKTLRLWDSRGLQVAHMFPAKQHIQTYCEVSVDGHKCISCSNGFGGEGCEATLWDLRQTRNRICEYKGHFQTVASCVFLPRALALMPLIATSSHDCKVKIWNQDTGACLFTLSLDGSGPLTSLAVGDAISLLCASFNRGIHLLRMDHSQGLELQEVAAF>sp|O15213|WDR46_HUMAN WD repeat-containing protein 46 OS=Homo sapiensOX=9606 GN=WDR46 PE=1 SV=3METAPKPGKDVPPKKDKLQTKRKKPRRYWEEETVPTTAGASPGPPRNKKNRELRPQRPKNAYILKKSRISKKPQVPKKPREWKNPESQRGLSGTQDPFPGPAPVPVEVVQKFCRIDKSRKLPHSKAKTRSRLEVAEAEEEETSIKAARSELLLAEEPGFLEGEDGEDTAKICQADIVEAVDIASAAKHFDLNLRQFGPYRLNYSRTGRHLAFGGRRGHVAALDWVTKKLMCEINVMEAVRDIRFLHSEALLAVAQNRWLHIYDNQGIELHCIRRCDRVTRLEFLPFHFLLATASETGFLTYLDVSVGKIVAALNARAGRLDVMSQNPYNAVIHLGHSNGTVSLWSPAMKEPLAKILCHRGGVRAVAVDSTGTYMATSGLDHQLKIFDLRGTYQPLSTRTLPHGAGHLAFSQRGLLVAGMGDVVNIWAGQGKASPPSLEQPYLTHRLSGPVHGLQFCPFEDVLGVGHTGGITSMLVPGAGEPNFDGLESNPYRSRKQRQEWEVKALLEKVPAELICLDPRALAEVDVISLEQGKKEQIERLGYDPQAKAPFQPKPKQKGRSSTASLVKRKRKVMDEEHRDKVRQSLQQQHHKEAKAKPTGARPSALDRFVR>sp|Q8TBZ3|WDR20_HUMAN WD repeat-containing protein 20 OS=Homo sapiensOX=9606 GN=WDR20 PE=1 SV=2MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKAADLSKPIDKRIYKGTQPTCHDFNHLTATAESVSLLVGFSAGQVQLIDPIKKETSKLFNEERLIDKSRVTCVKWVPGSESLFLVAHSSGNMYLYNVEHTCGTTAPHYQLLKQGESFAVHTCKSKSTRNPLLKWTVGEGALNEFAFSPDGKFLACVSQDGFLRVFNFDSVELHGTMKSYFGGLLCVCWSPDGKYIVTGGEDDLVTVWSFVDCRVIARGHGHKSWVSVVAFDPYTTSVEEGDPMEFSGSDEDFQDLLHFGRDRANSTQSRLSKRNSTDSRPVSVTYRFGSVGQDTQLCLWDLTEDILFPHQPLSRARTHTNVMNATSPPAGSNGNSVTTPGNSVPPPLPRSNSLPHSAVSNAGSKSSVMDGAIASGVSKFATLSLHDRKERHHEKDHKRNHSMGHISSKSSDKLNLVTKTKTDPAKTLGTPLCPRMEDVPLLEPLICKKIAHERLTVLIFLEDCIVTACQEGFICTWGRPGKVVSFNP>sp|Q8TBZ3-2|WDR20_HUMAN Isoform 2 of WD repeat-containing protein 20OS=Homo sapiens OX=9606 GN=WDR20MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKAADLSKPIDKRIYKGTQPTCHDFNHLTATAESVSLLVGFSAGQVQLIDPIKKETSKLFNEERLIDKSRVTCVKWVPGSESLFLVAHSSGNMYLYNVEHTCGTTAPHYQLLKQGESFAVHTCKSKSTRNPLLKWTVGEGALNEFAFSPDGKFLACVSQDGFLRVFNFDSVELHGTMKSYFGGLLCVCWSPDGKYIVTGGEDDLVTVWSFVDCRVIARGHGHKSWVSVVAFDPYTTSVEEGDPMEFSGSDEDFQDLLHFGRDRANSTQSRLSKRNSTDSRPVSVTYRFGSVGQDTQLCLWDLTEDILFPHQPLSRARTHTNVMNATSPPAGSNGNSVTTPGNSVPPPLPRSNSLPHSAVSNAGSKSSVMDGAIASGVSKFATLSLHDRKERHHEKDHKRNHSMGHISSKSSDKLNLVTKTKTDPAKTLGTPLCPRMEDVPLLEPLICKKIAHERLTVLIFLEDCIVTACQEGFICTWGRPGKVGSLSSPSQASSPGGTVV>sp|Q8TBZ3-3|WDR20_HUMAN Isoform 3 of WD repeat-containing protein 20OS=Homo sapiens OX=9606 GN=WDR20MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKAADLSKPIDKRIYKGTQPTCHDFNHLTATAESVSLLVGFSAGQVQLIDPIKKETSKLFNEENSCQHLWKVDWNEERQNEGSKTSEEALVTVQPAEHFCRQEDRMQGVLQDQN>sp|Q8TBZ3-4|WDR20_HUMAN Isoform 4 of WD repeat-containing protein 20OS=Homo sapiens OX=9606 GN=WDR20MNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKRLIDKSRVTCVKWVPGSESLFLVAHSSGNMYLYNVEHTCGTTAPHYQLLKQGESFAVHTCKSKSTRNPLLKWTVGEGALNEFAFSPDGKFLACVSQDGFLRVFNFDSVELHGTMKSYFGGLLCVCWSPDGKYIVTGGEDDLVTVWSFVDCRVIARGHGHKSWVSVVAFDPYTTSVEEGDPMEFSGSDEDFQDLLHFGRDRANSTQSRLSKRNSTDSRPVSVTYRFGSVGQDTQLCLWDLTEDILFPHQPLSRARTHTNVMNATSPPAGSNGNSVTTPGNSVPPPLPRSNSLPHSAVSNAGSKSSVMDGAIASGVSKFATLSLHDRKERHHEKDHKRNHSMGHISSKSSDKLNLVTKTKTDPAKTLGTPLCPRMEDVPLLEPLICKKIAHERLTVLIFLEDCIVTACQEGFICTWGRPGKVVSFNP>sp|Q8TBZ3-5|WDR20_HUMAN Isoform 5 of WD repeat-containing protein 20OS=Homo sapiens OX=9606 GN=WDR20MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKRLIDKSRVTCVKWVPGSESLFLVAHSSGNMYLYNVEHTCGTTAPHYQLLKQGESFAVHTCKSKSTRNPLLKWTVGEGALNEFAFSPDGKFLACVSQDGFLRVFNFDSVELHGTMKSYFGGLLCVCWSPDGKYIVTGGEDDLVTVWSFVDCRVIARGHGHKSWVSVVAFDPYTTSVEEGDPMEFSGSDEDFQDLLHFGRDRANSTQSRLSKRNSTDSRPVSVTYRFGSVGQDTQLCLWDLTEDILFPHQPLSRARTHTNVMNATSPPAGSNGNSVTTPGNSVPPPLPRSNSLPHSAVSNAGSKSSVMDGAIASGVSKFATLSLHDRKERHHEKDHKRNHSMGHISSKSSDKLNLVTKTKTDPAKTLGTPLCPRMEDVPLLEPLICKKIAHERLTVLIFLEDCIVTACQEGFICTWGRPGKVVSFNP>sp|Q8TBZ3-6|WDR20_HUMAN Isoform 6 of WD repeat-containing protein 20OS=Homo sapiens OX=9606 GN=WDR20MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKRLIDKSRVTCVKWVPGSESLFLVAHSSGNMYLYNVEHTCGTTAPHYQLLKQGESFAVHTCKSKSTRNPLLKWTVGEGALNEFAFSPDGKFLACVSQDGFLRVFNFDSVELHGTMKSYFGGLLCVCWSPDGKYIVTGGEDDLVTVWSFVDCRVIARGHGHKSWVSVVAFDPYTTSVEEGDPMEFSGSDEDFQDLLHFGRDRANSTQSRLSKRNSTDSRPVSVTYRFGSVGQDTQLCLWDLTEDILFPHQPLSRARTHTNVMNATSPPAGSNGNSVTTPGNSVPPPLPRSNSLPHSAVSNAGSKSSVMDGAIASGVSKFATLSLHDRKERHHEKDHKRNHSMGHISSKSSDKLNLVTKTKTDPAKTLGTPLCPRMEDVPLLEPLICKKIAHERLTVLIFLEDCIVTACQEGFICTWGRPGKVGSLSSPSQASSPGGTVV>sp|Q8TBZ3-7|WDR20_HUMAN Isoform 7 of WD repeat-containing protein 20OS=Homo sapiens OX=9606 GN=WDR20MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKAADLSKPIDKRIYKGTQPTCHDFNHLTATAESVSLLVGFSAGQVQLIDPIKKETSKLFNEENSCQHLWKVDWNEERQNEGSKTSEEALVTVQRLIDKSRVTCVKWVPGSESLFLVAHSSGNMYLYNVEHTCGTTAPHYQLLKQGESFAVHTCKSKSTRNPLLKWTVGEGALNEFAFSPDGKFLACVSQDGFLRVFNFDSVELHGTMKSYFGGLLCVCWSPDGKYIVTGGEDDLVTVWSFVDCRVIARGHGHKSWVSVVAFDPYTTSVEEGDPMEFSGSDEDFQDLLHFGRDRANSTQSRLSKRNSTDSRPVSVTYRFGSVGQDTQLCLWDLTEDILFPHQPLSRARTHTNVMNATSPPAGSNGNSVTTPGNSVPPPLPRSNSLPHSAVSNAGSKSSVMDGAIASGVSKFATLSLHDRKERHHEKDHKRNHSMGHISSKSSDKLNLVTKTKTDPAKTLGTPLCPRMEDVPLLEPLICKKIAHERLTVLIFLEDCIVTACQEGFICTWGRPGKVVSFNP>sp|Q8TBZ3-8|WDR20_HUMAN Isoform 8 of WD repeat-containing protein 20OS=Homo sapiens OX=9606 GN=WDR20MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGDRLCFNVGRELYFYIYKGVRKTIP>sp|Q9ULE0|WWC3_HUMAN Protein WWC3 OS=Homo sapiens OX=9606 GN=WWC3 PE=1SV=3MDHINKLTQIEDPREQWRREQERMLKEYLIVAQEALNAKKEIYQIKQQRFELAQEEYQQLHKMCEDDSRSYASSFSGYSTNTKYDPHQIKAEIASRRDRLSRLKRELTQMKQELQYKEKGVETLQEIDRKMSSTHTSYKLDEAQAIMSELRTIKKAICTGEKERRDLMHSLAKLTDSFKNSCSVTDSLVDFPHHVGVPGDAGVPQQFCDAGSQTDIIGEFVFDDKTRLVDRVRLNWQYEEARKRVANIQQQLARLDNESWPSTAEADRDRLQLIKEKEALLQELQLIIAQRRSAGDVARLEEERERLEEELRRARATSAQGATERILLQEKRNCLLMQLEEATRLTSYLQSQLKSLCASTLTVSSGSSRGSLASSRGSLASSRGSLSSVSFTDIYGLPQYEKPDAEGSQLLRFDLIPFDSLGRDAPFSEPPGPSGFHKQRRSLDTPQSLASLSSRSSLSSLSPPSSPLDTPFLPASRDSPLAQLADSCEGPGLGALDRLRAHASAMGDEDLPGMAALQPHGVPGDGEGPHERGPPPASAPVGGTVTLREDSAKRLERRARRISACLSDYSLASDSGVFEPLTKRNEDAEEPAYGDTASNGDPQIHVGLLRDSGSECLLVHVLQLKNPAGLAVKEDCKVHIRVYLPPLDSGTPNTYCSKALEFQVPLVFNEVFRIPVHSSALTLKSLQLYVCSVTPQLQEELLGIAQINLADYDSLSEMQLRWHSVQVFTSSEPSRTREAGCAGESSARDPAHTISISGKTDAVTVLLARTTAQLQAVERELAEERAKLEYTEEEVLEMERKEEQAEAISERSWQADSVDSGCSNCTQTSPPYPEPCCMGIDSILGHPFAAQAGPYSPEKFQPSPLKVDKETNTEDLFLEEAASLVKERPSRRARGSPFVRSGTIVRSQTFSPGARSQYVCRLYRSDSDSSTLPRKSPFVRNTLERRTLRYKQSCRSSLAELMARTSLDLELDLQASRTRQRQLNEELCALRELRQRLEDAQLRGQTDLPPWVLRDERLRGLLREAERQTRQTKLDYRHEQAAEKMLKKASKEIYQLRGQSHKEPIQVQTFREKIAFFTRPRINIPPLPADDV>sp|Q9ULE0-2|WWC3_HUMAN Isoform 2 of Protein WWC3 OS=Homo sapiens OX=9606GN=WWC3MDHINKLTQIEDPREQWRREQERMLKEYLIVAQEALNAKKEIYQIKQQRFELAQEEYQQLHKMCEDDSRSYASSFSGYSTNTKYDPHQIKAEIASRRDRLSRLKRELTQMKQELQYKEKGVETLQEIDRKMSSTHTSYKLDEAQAIMSELRTIKKAICTGEKERRDLMHSLAKLTDSFKNSCSVTDSLVDFPHHVGVPGDAGVPQQFCDAGSQTDIIGEFVFDDKTRLVDRVRLNWQYEEARKRVANIQQQLARLDNESWPSTAEADRDRLQLIKEKEALLQELQLIIAQRRSAGDVARLEEERERLEEELRRARATSAQGATERILLQEKRNCLLMQLEEATRLTSYLQSQLKSLCASTLTVSSGSSRGSLASSRGSLASSRGSLSSVSFTDIYGLPQYEKPDAEGSQLLRFDLIPFDSLGRDAPFSEPPGPSGFHKQRRSLDTPQSLASLSSRSSLSSLSPPSSPLDTPFLPASRDSPLAQLADSCEGPGLGALDRLRAHASAMGDEDLPGMAALQPHGVPGDGEGPHERGPPPASAPVGGSKCSLSDSSRRQCQEVGEEGTPHLRMSVGLFASQRQWGV>sp|Q9H977|WDR54_HUMAN WD repeat-containing protein 54 OS=Homo sapiensOX=9606 GN=WDR54 PE=1 SV=1MFRWERSIPLRGSAAALCNNLSVLQLPARNLTYFGVVHGPSAQLLSAAPEGVPLAQRQLHAKEGAGVSPPLITQVHWCVLPFRVLLVLTSHRGIQMYESNGYTMVYWHALDSGDASPVQAVFARGIAASGHFICVGTWSGRVLVFDIPAKGPNIVLSEELAGHQMPITDIATEPAQGQDCVADMVTADDSGLLCVWRSGPEFTLLTRIPGFGVPCPSVQLWQGIIAAGYGNGQVHLYEATTGNLHVQINAHARAICALDLASEVGKLLSAGEDTFVHIWKLSRNPESGYIEVEHCHGECVADTQLCGARFCDSSGNSFAVTGYDLAEIRRFSSV>sp|Q9H977-3|WDR54_HUMAN Isoform 3 of WD repeat-containing protein 54OS=Homo sapiens OX=9606 GN=WDR54MVAADLEGPYEPGVRRADLGLQVHWCVLPFRVLLVLTSHRGIQMYESNGYTMVYWHALDSGDASPVQAVFARGIAASGHFICVGTWSGRVLVFDIPAKGPNIVLSEELAGHQMPITDIATEPAQGQDCVADMVTADDSGLLCVWRSGPEFTLLTRIPGFGVPCPSVQLWQGIIAAGYGNGQVHLYEATTGNLHVQINAHARAICALDLASEVGKLLSAGEDTFVHIWKLSRNPESGYIEATPLL>sp|Q9H977-4|WDR54_HUMAN Isoform 2 of WD repeat-containing protein 54OS=Homo sapiens OX=9606 GN=WDR54MVAADLEGPYEPGVRMFRWERSIPLRGSAAALCNNLSVLQLPARNLTYFGVVHGPSAQLLSAAPEGVPLAQRQLHAKEGAGVSPPLITQVHWCVLPFRVLLVLTSHRGIQMYESNGYTMVYWHALDSGDASPVQAVFARGIAASGHFICVGTWSGRVLVFDIPAKGPNIVLSEELAGHQMPITDIATEPAQGQDCVADMVTADDSGLLCVWRSGPEFTLLTRIPGFGVPCPSVQLWQGIIAAGYGNGQVHLYEATTGNLHVQINAHARAICALDLASEVGKLLSAGEDTFVHIWKLSRNPESGYIEVEHCHGECVADTQLCGARFCDSSGNSFAVTGYDLAEIRRFSSV>sp|Q9C0E2|XPO4_HUMAN Exportin-4 OS=Homo sapiens OX=9606 GN=XPO4 PE=1SV=2MMAAALGPPEVIAQLENAAKVLMAPPSMVNNEQRQHAEHIFLSFRKSKSPFAVCKHILETSKVDYVLFQAATAIMEAVVREWILLEKGSIESLRTFLLTYVLQRPNLQKYVREQILLAVAVIVKRGSLDKSIDCKSIFHEVSQLISSGNPTVQTLACSILTALLSEFSSSSKTSNIGLSMEFHGNCKRVFQEEDLRQIFMLTVEVLQEFSRRENLNAQMSSVFQRYLALANQVLSWNFLPPNLGRHYIAMFESSQNVLLKPTESWRETLLDSRVMELFFTVHRKIREDSDMAQDSLQCLAQLASLHGPIFPDEGSQVDYLAHFIEGLLNTINGIEIEDSEAVGISSIISNLITVFPRNVLTAIPSELFSSFVNCLTHLTCSFGRSAALEEVLDKDDMVYMEAYDKLLESWLTLVQDDKHFHKGFFTQHAVQVFNSYIQCHLAAPDGTRNLTANGVASREEEEISELQEDDRDQFSDQLASVGMLGRIAAEHCIPLLTSLLEERVTRLHGQLQRHQQQLLASPGSSTVDNKMLDDLYEDIHWLILVTGYLLADDTQGETPLIPPEIMEYSIKHSSEVDINTTLQILGSPGEKASSIPGYNRTDSVIRLLSAILRVSEVESRAIRADLTHLLSPQMGKDIVWFLKRWAKTYLLVDEKLYDQISLPFSTAFGADTEGSQWIIGYLLQKVISNLSVWSSEQDLANDTVQLLVTLVERRERANLVIQCENWWNLAKQFASRSPPLNFLSSPVQRTLMKALVLGGFAHMDTETKQQYWTEVLQPLQQRFLRVINQENFQQMCQQEEVKQEITATLEALCGIAEATQIDNVAILFNFLMDFLTNCIGLMEVYKNTPETVNLIIEVFVEVAHKQICYLGESKAMNLYEACLTLLQVYSKNNLGRQRIDVTAEEEQYQDLLLIMELLTNLLSKEFIDFSDTDEVFRGHEPGQAANRSVSAADVVLYGVNLILPLMSQDLLKFPTLCNQYYKLITFICEIFPEKIPQLPEDLFKSLMYSLELGMTSMSSEVCQLCLEALTPLAEQCAKAQETDSPLFLATRHFLKLVFDMLVLQKHNTEMTTAAGEAFYTLVCLHQAEYSELVETLLSSQQDPVIYQRLADAFNKLTASSTPPTLDRKQKMAFLKSLEEFMANVGGLLCVK>sp|Q9P2F9|ZN319_HUMAN Zinc finger protein 319 OS=Homo sapiens OX=9606GN=ZNF319 PE=1 SV=2MSESWQQPPQTQPQQPQPPQPQHHAEPPPALAEHTLPPGTAENPLGCAVYGILLQPDPGLQPPQHAPLQAAGEPGPKCGVCGHDLAHLSSPHEHQCLAGHDRSFQCTQCLKIFHQATDLLEHQCVQAEQKPFVCGVCKMGFSLLTSLAQHHSSHSGLVKCSICEKTYKPAEAAEPATTAAPSLPAAPAPSTVTPAEQADKPYSCPICQKPFKHLSELSRHERIHTGEKPYKCTLCDKSFSQSSHLVHHKRTHSSERPYKCAVCEKTFKHRSHLVRHMYAHSGEHHLFRCNVCELHFKESSELLQHPCTPSGERPFRCGECQKAFKRPSDLRQHERTHSAERPFKCDLCPMGFKQQYALMRHRRTHKTEEPFKCGLCEKGFGQPSHLLYHQHVHTLETLFKCPVCQKGFDQSAELLRHKCLPGAAERPFKCPVCNKAYKRASALQKHQLAHCAAAEKPLRCTLCERRFFSSSEFVQHRCDPAREKPLKCPDCEKRFKYASDLQRHRRVHTGEKPYKCPNCDKAFKQREHLNKHQGVHAREQQFKCVWCGERFLDVALLQEHSAQHSAAAAAAEGAYQVAACLP>sp|Q96IQ7|VSIG2_HUMAN V-set and immunoglobulin domain-containing protein2 OS=Homo sapiens OX=9606 GN=VSIG2 PE=1 SV=1MAELPGPFLCGALLGFLCLSGLAVEVKVPTEPLSTPLGKTAELTCTYSTSVGDSFALEWSFVQPGKPISESHPILYFTNGHLYPTGSKSKRVSLLQNPPTVGVATLKLTDVHPSDTGTYLCQVNNPPDFYTNGLGLINLTVLVPPSNPLCSQSGQTSVGGSTALRCSSSEGAPKPVYNWVRLGTFPTPSPGSMVQDEVSGQLILTNLSLTSSGTYRCVATNQMGSASCELTLSVTEPSQGRVAGALIGVLLGVLLLSVAAFCLVRFQKERGKKPKETYGGSDLREDAIAPGISEHTCMRADSSKGFLERPSSASTVTTTKSKLPMVV>sp|Q96IQ7-2|VSIG2_HUMAN Isoform 2 of V-set and immunoglobulin domain-containing protein 2 OS=Homo sapiens OX=9606 GN=VSIG2MAELPGPFLCGALLGFLCLSGLAVEVKVPTEPLSTPLGKTAELTCTYSTSVGDSFALEWSFVQPGKPISESHPILYFTNGHLYPTGSKSKRVSLLQNPPTVGVATLKLTDVHPSDTGTYLCQVNNPPDFYTNGLGLINLTVLVPPSNPLCSQSGQTSVGGSTALRCSSSEGAPKPVYNWVRLGTFPTPSPGSMVQDEVSGQLILTNLSLTSSGTYRCVATNQMGSASCELTLSVTEPSQGRVAGALIGVLLGVLLLSVAAFCLVRFQKERGKKPKETYGGSDLR>sp|Q8TAU3|ZN417_HUMAN Zinc finger protein 417 OS=Homo sapiens OX=9606GN=ZNF417 PE=1 SV=2MAAAAPRRPTQQGTVTFEDVAVNFSQEEWCLLSEAQRCLYRDVMLENLALISSLGCWCGSKDEEAPCKQRISVQRESQSRTPRAGVSPKKAHPCEMCGLILEDVFHFADHQETHHKQKLNRSGACGKNLDDTAYLHQHQKQHIGEKFYRKSVREASFVKKRKLRVSQEPFVFREFGKDVLPSSGLCQEAAAVEKTDSETMHGPPFQEGKTNYSCGKRTKAFSTKHSVIPHQKLFTRDGCYVCSDCGKSFSRYVSFSNHQRDHTAKGPYDCGECGKSYSRKSSLIQHQRVHTGKTAYPCEECGKSFSQKGSLISHQRVHTGERPYECREYGKSFGQKGNLIQHQQGHTGERAYHCGECGKSFRQKFCFINHQRVHTGERPYKCGECGKSFGQKGNLVQHQRGHTGERPYECKECGKSFRYRSHLTEHQRLHTGERPYNCRECGKLFNRKYHLLVHERVHTGERPYACEVCGKLFGNKNCVTIHQRIHTGERPYECNECGKSFLSSSALHVHKRVHSGQKPYKCSECGKSFAECSSLIKHRRIHTGERPYECTKCGKTFQRSSTLLHHQSSHRRKAL>sp|Q8TAU3-2|ZN417_HUMAN Isoform 2 of Zinc finger protein 417 OS=Homosapiens OX=9606 GN=ZNF417MHGPPFQEGKTNYSCGKRTKAFSTKHSVIPHQKLFTRDGCYVCSDCGKSFSRYVSFSNHQRDHTAKGPYDCGECGKSYSRKSSLIQHQRVHTGKTAYPCEECGKSFSQKGSLISHQRVHTGERPYECREYGKSFGQKGNLIQHQQGHTGERAYHCGECGKSFRQKFCFINHQRVHTGERPYKCGECGKSFGQKGNLVQHQRGHTGERPYECKECGKSFRYRSHLTEHQRLHTGERPYNCRECGKLFNRKYHLLVHERVHTGERPYACEVCGKLFGNKNCVTIHQRIHTGERPYECNECGKSFLSSSALHVHKRVHSGQKPYKCSECGKSFAECSSLIKHRRIHTGERPYECTKCGKTFQRSSTLLHHQSSHRRKAL>sp|Q96N22|ZN681_HUMAN Zinc finger protein 681 OS=Homo sapiens OX=9606GN=ZNF681 PE=2 SV=2MEPLKFRDVAIEFSLEEWQCLDTIQQNLYRNVMLENYRNLVFLGIVVSKPDLITCLEQEKEPWTRKRHRMVAEPPVICSHFAQDFSPEQNIKDSFQKVTPRRYGKCEHENLQLSKSVDECKVQKGGYNGLNQCLPTTQSKIFQCDKYMKIFHKFSNLNGHKVRHTRKKPFKYKEFGKSFCIFSNLTQHKIICTRVNFYKCEDCGKAFNGSSIFTKHKRIHIGEKSYICEECGKACNQFTNLTTHKIIYTRDKLYKREECSKAFNLSSHITTHTIIHTGENPYKREECDKAFNQSLTLTTHKIIHTREKLNEYKECGKAFNQSSHLTRHKIIHTGEKPYKCEECGKAFNQSSHLTRHKIIHTGEKPYRCEECGKAFRQSSHLTTHKIIHTGEKPYKCEECGKAFNKSSHLTRHKSIHTGEKPYQCEKCGKASNQSSNLTEHKNIHTEEKPYKCEECGKAFNQFSNLTTHKRIHTGEKPYKCEECGKAFNQSSILTTHKRIHTGEKSYKCEECGKAFYRSSKLTEHKKIHTGEKPYTCEECGKAFNHSSHLATHKVIHTGEKPYQCEECGKAFNQSSHLTRHKRIHTGEKPYQCEKCGKAFNQSSNLTGHKKIHTGEKLYKPKRCNSDFENTSKFSKHKRNYAGEKS>sp|Q96N22-2|ZN681_HUMAN Isoform 2 of Zinc finger protein 681 OS=Homosapiens OX=9606 GN=ZNF681MVAEPPVICSHFAQDFSPEQNIKDSFQKVTPRRYGKCEHENLQLSKSVDECKVQKGGYNGLNQCLPTTQSKIFQCDKYMKIFHKFSNLNGHKVRHTRKKPFKYKEFGKSFCIFSNLTQHKIICTRVNFYKCEDCGKAFNGSSIFTKHKRIHIGEKSYICEECGKACNQFTNLTTHKIIYTRDKLYKREECSKAFNLSSHITTHTIIHTGENPYKREECDKAFNQSLTLTTHKIIHTREKLNEYKECGKAFNQSSHLTRHKIIHTGEKPYKCEECGKAFNQSSHLTRHKIIHTGEKPYRCEECGKAFRQSSHLTTHKIIHTGEKPYKCEECGKAFNKSSHLTRHKSIHTGEKPYQCEKCGKASNQSSNLTEHKNIHTEEKPYKCEECGKAFNQFSNLTTHKRIHTGEKPYKCEECGKAFNQSSILTTHKRIHTGEKSYKCEECGKAFYRSSKLTEHKKIHTGEKPYTCEECGKAFNHSSHLATHKVIHTGEKPYQCEECGKAFNQSSHLTRHKRIHTGEKPYQCEKCGKAFNQSSNLTGHKKIHTGEKLYKPKRCNSDFENTSKFSKHKRNYAGEKS>sp|A8MT66|YU005_HUMAN Putative uncharacterized protein ENSP00000383407OS=Homo sapiens OX=9606 PE=5 SV=1MNLFCISLEGSMDSLYEPIPEQQANQENMSSRTDSPIPPFGESEQTPNNLFVGVSNLENAKPKKRKLFRRFMSENKIFEGKTVNDKIWQEHSKHKNDSHIRRPCQLKDLNENDFLSNNIHTYQGKTLQGTSYQVTSECWSPFHYQRHVETTVDELVRHFFPDVTI>sp|O75554|WBP4_HUMAN WW domain-binding protein 4 OS=Homo sapiens OX=9606GN=WBP4 PE=1 SV=1MADYWKSQPKKFCDYCKCWIADNRPSVEFHERGKNHKENVAKRISEIKQKSLDKAKEEEKASKEFAAMEAAALKAYQEDLKRLGLESEILEPSITPVTSTIPPTSTSNQQKEKKEKKKRKKDPSKGRWVEGITSEGYHYYYDLISGASQWEKPEGFQGDLKKTAVKTVWVEGLSEDGFTYYYNTETGESRWEKPDDFIPHTSDLPSSKVNENSLGTLDESKSSDSHSDSDGEQEAEEGGVSTETEKPKIKFKEKNKNSDGGSDPETQKEKSIQKQNSLGSNEEKSKTLKKSNPYGEWQEIKQEVESHEEVDLELPSTENEYVSTSEADGGGEPKVVFKEKTVTSLGVMADGVAPVFKKRRTENGKSRNLRQRGDDQ>sp|O75554-2|WBP4_HUMAN Isoform 2 of WW domain-binding protein 4 OS=Homosapiens OX=9606 GN=WBP4MADYWKSQPKKFCDYCKCWIADNRPIKQKSLDKAKEEEKASKEFAAMEAAALKAYQEDLKRLGLESEILEPSITPVTSTIPPTSTSNQQKEKKEKKKRKKDPSKGRWVEGITSEGYHYYYDLISGASQWEKPEGFQGDLKKTAVKTVWVEGLSEDGFTYYYNTETGESRWEKPDDFIPHTSDLPSSKVNENSLGTLDESKSSDSHSDSDGEQEAEEGGVSTETEKPKIKFKEKNKNSDGGSDPETQKEKSIQKQNSLGSNEEKSKTLKKSNPYGEWQEIKQEVESHEEVDLELPSTENEYVSTSEADGGGEPKVVFKEKTVTSLGVMADGVAPVFKKRRTENGKSRNLRQRGDDQ>sp|Q8NFZ6|VN1R2_HUMAN Vomeronasal type-1 receptor 2 OS=Homo sapiensOX=9606 GN=VN1R2 PE=2 SV=2MTHTLYPTPFALYPINISAAWHLGPLPVSCFVSNKYQCSLAFGATTGLRVLVVVVPQTQLSFLSSLCLVSLFLHSLVSAHGEKPTKPVGLDPTLFQVVVGILGNFSLLYYYMFLYFRGYKPRSTDLILRHLTVADSLVILSKRIPETMATFGLKHFDNYFGCKFLLYAHRVGRGVSIGSTCLLSVFQVITINPRNSRWAEMKVKAPTYIGLSNILCWAFHMLVNAIFPIYTTGKWSNNNITKKGDLGYCSAPLSDEVTKSVYAALTSFHDVLCLGLMLWASSSIVLVLYRHKQQVQHICRNNLYPNSSPGNRAIQSILALVSTFALCYALSFITYVYLALFDNSSWWLVNTAALIIACFPTISPFVLMCRDPSRSRLCSICCRRNRRFFHDFRKM>sp|Q6PFW1|VIP1_HUMAN Inositol hexakisphosphate and diphosphoinositol-pentakisphosphate kinase 1 OS=Homo sapiens OX=9606 GN=PPIP5K1 PE=1 SV=1MWSLTASEGESTTAHFFLGAGDEGLGTRGIGMRPEESDSELLEDEEDEVPPEPQIIVGICAMTKKSKSKPMTQILERLCRFDYLTVVILGEDVILNEPVENWPSCHCLISFHSKGFPLDKAVAYSKLRNPFLINDLAMQYYIQDRREVYRILQEEGIDLPRYAVLNRDPARPEECNLIEGEDQVEVNGAVFPKPFVEKPVSAEDHNVYIYYPSSAGGGSQRLFRKIGSRSSVYSPESSVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEIRYPVMLTAMEKLVARKVCVAFKQTVCGFDLLRANGHSFVCDVNGFSFVKNSMKYYDDCAKILGNTIMRELAPQFQIPWSIPTEAEDIPIVPTTSGTMMELRCVIAIIRHGDRTPKQKMKMEVKHPRFFALFEKHGGYKTGKLKLKRPEQLQEVLDITRLLLAELEKEPGGEIEEKTGKLEQLKSVLEMYGHFSGINRKVQLTYYPHGVKASNEGQDPQRETLAPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTFRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDGDSLSSCQHRVKARLHHILQQDAPFGPEDYDQLAPTRSTSLLNSMTIIQNPVKVCDQVFALIENLTHQIRERMQDPRSVDLQLYHSETLELMLQRWSKLERDFRQKSGRYDISKIPDIYDCVKYDVQHNGSLGLQGTAELLRLSKALADVVIPQEYGISREEKLEIAVGFCLPLLRKILLDLQRTHEDESVNKLHPLCYLRYSRGVLSPGRHVRTRLYFTSESHVHSLLSVFRYGGLLDETQDAQWQRALDYLSAISELNYMTQIVIMLYEDNTQDPLSEERFHVELHFSPGVKGVEEEGSAPAGCGFRPASSENEEMKTNQGSMENLCPGKASDEPDRALQTSPQPPEGPGLPRRSPLIRNRKAGSMEVLSETSSSRPGGYRLFSSSRPPTEMKQSGLGSQCTGLFSTTVLGGSSSAPNLQDYARSHGKKLPPASLKHRDELLFVPAVKRFSVSFAKHPTNGFEGCSMVPTIYPLETLHNALSLRQVSEFLSRVCQRHTDAQAQASAALFDSMHSSQASDNPFSPPRTLHSPPLQLQQRSEKPPWYSSGPSSTVSSAGPSSPTTVDGNSQFGFSDQPSLNSHVAEEHQGLGLLQETPGSGAQELSIEGEQELFEPNQSPQVPPMETSQPYEEVSQPCQEVPDISQPCQDISEALSQPCQKVPDISQQCQENHDNGNHTCQEVPHISQPCQKSSQLCQKVSEEVCQLCLENSEEVSQPCQGVSVEVGKLVHKFHVGVGSLVQETLVEVGSPAEEIPEEVIQPYQEFSVEVGRLAQETSAINLLSQGIPEIDKPSQEFPEEIDLQAQEVPEEIN>sp|Q6PFW1-2|VIP1_HUMAN Isoform 2 of Inositol hexakisphosphate anddiphosphoinositol-pentakisphosphate kinase 1 OS=Homo sapiens OX=9606GN=PPIP5K1MWSLTASEGESTTAHFFLGAGDEGLGTRGIGMRPEESDSELLEDEEDEVPPEPQIIVGICAMTKKSKSKPMTQILERLCRFDYLTVVILGEDVILNEPVENWPSCHCLISFHSKGFPLDKAVAYSKLRNPFLINDLAMQYYIQDRREVYRILQEEGIDLPRYAVLNRDPARPEECNLIEGEDQVEVNGAVFPKPFVEKPVSAEDHNVYIYYPSSAGGGSQRLFRKIGSRSSVYSPESSVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEIRYPVMLTAMEKLVARKVCVAFKQTVCGFDLLRANGHSFVCDVNGFSFVKNSMKYYDDCAKILGNTIMRELAPQFQIPWSIPTEAEDIPIVPTTSGTMMELRCVIAIIRHGDRTPKQKMKMEVKHPRFFALFEKHGGYKTGKLKLKRPEQLQEVLDITRLLLAELEKEPGGEIEEKTGKLEQLKSVLEMYGHFSGINRKVQLTYYPHGVKASNEGQDPQRETLAPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTFRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDGDSLSSCQHRVKARLHHILQQDAPFGPEDYDQLAPTRSTSLLNSMTIIQNPVKVCDQVFALIENLTHQIRERMQDPRSVDLQLYHSETLELMLQRWSKLERDFRQKSGRYDISKIPDIYDCVKYDVQHNGSLGLQGTAELLRLSKALADVVIPQEYGISREEKLEIAVGFCLPLLRKILLDLQRTHEDESVNKLHPLYSRGVLSPGRHVRTRLYFTSESHVHSLLSVFRYGGLLDETQDAQWQRALDYLSAISELNYMTQIVIMLYEDNTQDPLSEERFHVELHFSPGVKGVEEEGSAPAGCGFRPASSENEEMKTNQGSMENLCPGKASDEPDRALQTSPQPPEGPGLPRRSPLIRNRKAGSMEVLSETSSSRPGGYRLFSSSRPPTEMKQSGLGSQCTGLFSTTVLGGSSSAPNLQDYARSHGKKLPPASLKHRDELLFVPAVKRFSVSFAKHPTNGGFEGCSMVPTIYPLETLHNALSLRQVSEFLSRVCQRHTDAQAQASAALFDSMHSSQASDNPFSPPRTLHSPPLQLQQRSEKPPWYSSGPSSTVSSAGPSSPTTVDGNSQFGFSDQPSLNSHVAEEHQGLGLLQETPGSGAQELSIEGEQELFEPNQSPQVPPMETSQPYEEVSQPCQEVPDISQPCQDISEALSQPCQKVPDISQQCQENHDNGNHTCQEVPHISQPCQKSSQLCQKVSEEVCQLCLENSEEVSQPCQGVSVEVGKLVHKFHVGVGSLVQETLVEVGSPAEEIPEEVIQPYQEFSVEVGRLAQETSAINLLSQGIPEIDKPSQEFPEEIDLQAQEVPEEIN>sp|Q6PFW1-3|VIP1_HUMAN Isoform 3 of Inositol hexakisphosphate anddiphosphoinositol-pentakisphosphate kinase 1 OS=Homo sapiens OX=9606GN=PPIP5K1MWSLTASEGESTTAHFFLGAGDEGLGTRGIGMRPEESDSELLEDEEDEVPPEPQIIVGICAMTKKSKSKPMTQILERLCRFDYLTVVILGEDVILNEPVENWPSCHCLISFHSKGFPLDKAVAYSKLRNPFLINDLAMQYYIQDRREVYRILQEEGIDLPRYAVLNRDPARPEECNLIEGEDQVEVNGAVFPKPFVEKPVSAEDHNVYIYYPSSAGGGSQRLFRKIGSRSSVYSPESSVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEIRYPVMLTAMEKLVARKVCVAFKQTVCGFDLLRANGHSFVCDVNGFSFVKNSMKYYDDCAKILGNTIMRELAPQFQIPWSIPTEAEDIPIVPTTSGTMMELRCVIAIIRHGDRTPKQKMKMEVKHPRFFALFEKHGGYKTGKLKLKRPEQLQEVLDITRLLLAELEKEPGGEIEEKTGKLEQLKSVLEMYGHFSGINRKVQLTYYPHGVKASNEGQDPQRETLAPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTFRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDGDSLSSCQHRVKARLHHILQQDAPFGPEDYDQLAPTRSTSLLNSMTIIQNPVKVCDQVFALIENLTHQIRERMQDPRSVDLQLYHSETLELMLQRWSKLERDFRQKSGRYDISKIPDIYDCVKYDVQHNGSLGLQGTAELLRLSKALADVVIPQEYGISREEKLEIAVGFCLPLLRKILLDLQRTHEDESVNKLHPLYSRGVLSPGRHVRTRLYFTSESHVHSLLSVFRYGGLLDETQDAQWQRALDYLSAISELNYMTQIVIMLYEDNTQDPLSEERFHVELHFSPGVKGVEEEGSAPAGCGFRPASSENEEMKTNQGSMENLCPGKASDEPDRALQTSPQPPEGPGLPRRSPLIRNRKAGSMEVLSETSSSRPGGYRLFSSSRPPTEMKQSGLGSQCTGLFSTTVLGGSSSAPNLQDYARSHGKKLPPASLKHRDGFEGCSMVPTIYPLETLHNALSLRQVSEFLSRVCQRHTDAQAQASAALFDSMHSSQASDNPFSPPRTLHSPPLQLQQRSEKPPWYSSGPSSTVSSAGPSSPTTVDGNSQFGFSDQPSLNSHVAEEHQGLGLLQETPGSGAQELSIEGEQELFEPNQSPQVPPMETSQPYEEVSQPCQEVPDISQPCQDISEALSQPCQKVPDISQQCQENHDNGNHTCQEVPHISQPCQKSSQLCQKVSEEVCQLCLENSEEVSQPCQGVSVEVGKLVHKFHVGVGSLVQETLVEVGSPAEEIPEEVIQPYQEFSVEVGRLAQETSAINLLSQGIPEIDKPSQEFPEEIDLQAQEVPEEIN>sp|Q6PFW1-4|VIP1_HUMAN Isoform 4 of Inositol hexakisphosphate anddiphosphoinositol-pentakisphosphate kinase 1 OS=Homo sapiens OX=9606GN=PPIP5K1MWSLTASEGESTTAHFFLGAGDEGLGTRGIGMRPEESDSELLEDEEDEVPPEPQIIVGICAMTKKSKSKPMTQILERLCRFDYLTVVILGEDVILNEPVENWPSCHCLISFHSKGFPLDKAVAYSKLRNPFLINDLAMQYYIQDRREVYRILQEEGIDLPRYAVLNRDPARPEECNLIEGEDQVEVNGAVFPKPFVEKPVSAEDHNVYIYYPSSAGGGSQRLFRKIGSRSSVYSPESSVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEIRYPVMLTAMEKLVARKVCVAFKQTVCGFDLLRANGHSFVCDVNGFSFVKNSMKYYDDCAKILGNTIMRELAPQFQIPWSIPTEAEDIPIVPTTSGTMMELRCVIAIIRHGDRTPKQKMKMEVKHPRFFALFEKHGGYKTGKLKLKRPEQLQEVLDITRLLLAELEKEPGGEIEEKTGKLEQLKSVLEMYGHFSGINRKVQLTYYPHGVKASNEGQDPQRETLAPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTFRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDGDSLSSCQHRVKARLHHILQQDAPFGPEDYDQAPTRSTSLLNSMTIIQNPVKVCDQVFALIENLTHQIRERMQDPRSVDLQLYHSETLELMLQRWSKLERDFRQKSGRYDISKIPDIYDCVKYDVQHNGSLGLQGTAELLRLSKALADVVIPQEYGISREEKLEIAVGFCLPLLRKILLDLQRTHEDESVNKLHPLYSRGVLSPGRHVRTRLYFTSESHVHSLLSVFRYGGLLDETQDAQWQRALDYLSAISELNYMTQIVIMLYEDNTQDPLSEERFHVELHFSPGVKGVEEEGSAPAGCGFRPASSENEEMKTNQGSMENLCPGKASDEPDRALQTSPQPPEGPGLPRRSPLIRNRKAGSMEVLSETSSSRPGGYRLFSSSRPPTEMKQSGLGSQCTGLFSTTVLGGSSSAPNLQDYARSHGKKLPPASLKHRDGFEGCSMVPTIYPLETLHNALSLRQVSEFLSRVCQRHTDAQAQASAALFDSMHSSQASDNPFSPPRTLHSPPLQLQQRSEKPPWYSSGPSSTVSSAGPSSPTTVDGNSQFGFSDQPSLNSHVAEEHQGLGLLQETPGSGAQELSIEGEQELFEPNQSPQVPPMETSQPYEEVSQPCQEVPDISQPCQDISEALSQPCQKVPDISQQCQENHDNGNHTCQEVPHISQPCQKSSQLCQKVSEEVCQLCLENSEEVSQPCQGVSVEVGKLVHKFHVGVGSLVQETLVEVGSPAEEIPEEVIQPYQEFSVEVGRLAQETSAINLLSQGIPEIDKPSQEFPEEIDLQAQEVPEEIN>sp|Q6PFW1-5|VIP1_HUMAN Isoform 5 of Inositol hexakisphosphate anddiphosphoinositol-pentakisphosphate kinase 1 OS=Homo sapiens OX=9606GN=PPIP5K1MWSLTASEGESTTAHFFLGAGDEGLGTRGIGMRPEESDSELLEDEEDEVPPEPQIIVGICAMTKKSKSKPMTQILERLCRFDYLTVVILGEDVILNEPVENWPSCHCLISFHSKGFPLDKAVAYSKLRNPFLINDLAMQYYIQDRREVYRILQEEGIDLPRYAVLNRDPARPEECNLIEGEDQVEVNGAVFPKPFVEKPVSAEDHNVYIYYPSSAGGGSQRLFRKIGSRSSVYSPESSVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEIRYPVMLTAMEKLVARKVCVAFKQTVCGFDLLRANGHSFVCDVNGFSFVKNSMKYYDDCAKILGNTIMRELAPQFQIPWSIPTEAEDIPIVPTTSGTMMELRCVIAIIRHGDRTPKQKMKMEVKHPRFFALFEKHGGYKTGKLKLKRPEQLQEVLDITRLLLAELEKEPGGEIEEKTGKLEQLKSVLEMYGHFSGINRKVQLTYYPHGVKASNEGQDPQRETLAPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTFRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDGDSLSSCQHRVKARLHHILQQDAPFGPEDYDQLAPTRSTSLLNSMTIIQNPVKVCDQVFALIENLTHQIRERMQDPRSVDLQLYHSETLELMLQRWSKLERDFRQKSGRYDISKIPDIYDCVKYDVQHNGSLGLQGTAELLRLSKALADVVIPQEYGISREEKLEIAVGFCLPLLRKILLDLQRTHEDEYSRGVLSPGRHVRTRLYFTSESHVHSLLSVFRYGGLLDETQDADRALQTSPQPPEGPGLPRRSPLIRNRKAGSMEVLSETSSSRPGGYRLFSSSRPPTEMKQSGLGSQCTGLFSTTVLGGSSSAPNLQDYARSHGKKLPPASLKHRDELLFVPAVKRFSVSFAKHPTNGFEGCSMVPTIYPLETLHNALSLRQVPPMETSQPYEEVSQPCQEVPDISQPCQDISEALSQPCQKVPDISQQCQENHDNGNHTCQEVPHISQPCQKSSQLCQKVSEEVCQLCLENSEEVSQPCQGVSVEVGKLVHKFHVGVGSLVQETLVEVGSPAEEIPEEVIQPYQEFSVEVGRLAQETSAINLLSQGIPEIDKPSQEFPEEIDLQAQEVPEEIN>sp|Q6PFW1-6|VIP1_HUMAN Isoform 6 of Inositol hexakisphosphate anddiphosphoinositol-pentakisphosphate kinase 1 OS=Homo sapiens OX=9606GN=PPIP5K1MWSLTASEGESTTAHFFLGAGDEGLGTRGIGMRPEESDSELLEDEEDEVPPEPQIIVGICAMTKKSKSKPMTQILERLCRFDYLTVVILGEDVILNEPVENWPSCHCLISFHSKGFPLDKAVAYSKLRNPFLINDLAMQYYIQDRREVYRILQEEGIDLPRYAVLNRDPARPEECNLIEGEDQVEVNGAVFPKPFVEKPVSAEDHNVYIYYPSSAGGGSQRLFRKIGSRSSVYSPESSVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEIRYPVMLTAMEKLVARKVCVAFKQTVCGFDLLRANGHSFVCDVNGFSFVKNSMKYYDDCAKILGNTIMRELAPQFQIPWSIPTEAEDIPIVPTTSGTMMELRCVIAIIRHGDRTPKQKMKMEVKHPRFFALFEKHGGYKTGKLKLKRPEQLQEVLDITRLLLAELEKEPGGEIEEKTGKLEQLKSVLEMYGHFSGINRKVQLTYYPHGVKASNEGQDPQRETLAPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTFRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDGDSLSSCQHRVKARLHHILQQDAPFGPEDYDQLAPTRSTSLLNSMTIIQNPVKVCDQVFALIENLTHQIRERMQDPRSVDLQLYHSETLELMLQRWSKLERDFRQKSGRYDISKIPDIYDCVKYDVQHNGSLGLQGTAELLRLSKALADVVIPQEYGISREEKLEIAVGFCLPLLRKILLDLQRTHEDESVNKLHPL>sp|Q6PFW1-7|VIP1_HUMAN Isoform 7 of Inositol hexakisphosphate anddiphosphoinositol-pentakisphosphate kinase 1 OS=Homo sapiens OX=9606GN=PPIP5K1MWSLTASEGESTTAHFFLGAGDEGLGTRGIGMRPEESDSELLEDEEDEVPPEPQIIVGICAMTKKSKSKPMTQILERLCRFDYLTVVILGEDVILNEPVENWPSCHCLISFHSKGFPLDKAVAYSKLRNPFLINDLAMQYYIQDRREVYRILQEEGIDLPRYAVLNRDPARPEECNLIEGEDQVEVNGAVFPKPFVEKPVSAEDHNVYIYYPSSAGGGSQRLFRKIGSRSSVYSPESSVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEIRYPVMLTAMEKLVARKVCVAFKQTVCGFDLLRANGHSFVCDVNGFSFVKNSMKYYDDCAKILGNTIMRELAPQFQIPWSIPTEAEDIPIVPTTSGTMMELRCVIAIIRHGDRTPKQKMKMEVKHPRFFALFEKHGGYKTGKLKLKRPEQLQEVLDITRLLLAELEKEPGGEIEEKTGKLEQLKSVLEMYGHFSGINRKVQLTYYPHGVKASNEGQDPQRETLAPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTFRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDGDSLSSCQHRVKARLHHILQQDAPFGPEDYDQLAPTRSTSLLNSMTIIQNPVKVCDQVFALIENLTHQIRERMQDPRSVDLQLYHSETLELMLQRWSKLERDFRQKSGRYDISKIPDIYDCVKYDVQHNGSLGLQGTAELLRLSKALADVVIPQEYGISREEKLEIAVGFCLPLLRKILLDLQRTHEDESVNKLHPLYSRGVLSPGRHVRTRLYFTSESHVHSLLSVFRYGGLLDETQDAQWQRALDYLSAISELNYMTQIVIMLYEDNTQDPLSEERFHVELHFSPGVKGVEEEGSAPAGCGFRPASSENEEMKTNQGSMENLCPGKASDEPDRALQTSPQPPEGPGLPRRSPLIRNRKAGSMEVLSETSSSRPGGYRLFSSSRPPTEMKQSGLGFEGCSMVPTIYPLETLHNALSLRQVSEFLSRVCQRHTDAQAQASAALFDSMHSSQASDNPFSPPRTLHSPPLQLQQRSEKPPWLETRFCHVGQAGLELLTSSDLPASASQSAGITGVSHRTQPDSSGPSSTVSSAGPSSPTTVDGNSQFGFSDQPSLNSHVAEEHQGLGLLQETPGSGAQELSIEGEQELFEPNQSPQVPPMETSQPYEEVSQPCQEVPDISQPCQDISEALSQPCQKVPDISQQCQENHDNGNHTCQEVPHISQPCQKSSQLCQKVSEEVCQLCLENSEEVSQPCQGVSVEVGKLVHKFHVGVGSLVQETLVEVGSPAEEIPEEVIQPYQEFSVEVGRLAQETSAINLLSQGIPEIDKPSQEFPEEIDLQAQEVPEEIN>sp|Q709C8|VP13C_HUMAN Vacuolar protein sorting-associated protein 13COS=Homo sapiens OX=9606 GN=VPS13C PE=1 SV=1MVLESVVADLLNRFLGDYVENLNKSQLKLGIWGGNVALDNLQIKENALSELDVPFKVKAGQIDKLTLKIPWKNLYGEAVVATLEGLYLLVVPGASIKYDAVKEEKSLQDVKQKELSRIEEALQKAAEKGTHSGEFIYGLENFVYKDIKPGRKRKKHKKHFKKPFKGLDRSKDKPKEAKKDTFVEKLATQVIKNVQVKITDIHIKYEDDVTDPKRPLSFGVTLGELSLLTANEHWTPCILNEADKIIYKLIRLDSLSAYWNVNCSMSYQRSREQILDQLKNEILTSGNIPPNYQYIFQPISASAKLYMNPYAESELKTPKLDCNIEIQNIAIELTKPQYLSMIDLLESVDYMVRNAPYRKYKPYLPLHTNGRRWWKYAIDSVLEVHIRRYTQMWSWSNIKKHRQLLKSYKIAYKNKLTQSKVSEEIQKEIQDLEKTLDVFNIILARQQAQVEVIRSGQKLRKKSADTGEKRGGWFSGLWGKKESKKKDEESLIPETIDDLMTPEEKDKLFTAIGYSESTHNLTLPKQYVAHIMTLKLVSTSVTIRENKNIPEILKIQIIGLGTQVSQRPGAQALKVEAKLEHWYITGLRQQDIVPSLVASIGDTTSSLLKIKFETNPEDSPADQTLIVQSQPVEVIYDAKTVNAVVEFFQSNKGLDLEQITSATLMKLEEIKERTATGLTHIIETRKVLDLRINLKPSYLVVPQTGFHHEKSDLLILDFGTFQLNSKDQGLQKTTNSSLEEIMDKAYDKFDVEIKNVQLLFARAEETWKKCRFQHPSTMHILQPMDIHVELAKAMVEKDIRMARFKVSGGLPLMHVRISDQKMKDVLYLMNSIPLPQKSSAQSPERQVSSIPIISGGTKGLLGTSLLLDTVESESDDEYFDAEDGEPQTCKSMKGSELKKAAEVPNEELINLLLKFEIKEVILEFTKQQKEEDTILVFNVTQLGTEATMRTFDLTVVSYLKKISLDYHEIEGSKRKPLHLISSSDKPGLDLLKVEYIKADKNGPSFQTAFGKTEQTVKVAFSSLNLLLQTQALVASINYLTTIIPSDDQSISVAKEVQISTEKQQKNSTLPKAIVSSRDSDIIDFRLFAKLNAFCVIVCNEKNNIAEIKIQGLDSSLSLQSRKQSLFARLENIIVTDVDPKTVHKKAVSIMGNEVFRFNLDLYPDATEGDLYTDMSKVDGVLSLNVGCIQIVYLHKFLMSLLNFLNNFQTAKESLSAATAQAAERAATSVKDLAQRSFRVSINIDLKAPVIVIPQSSISTNAVVVDLGLIRVHNQFSLVSDEDYLNPPVIDRMDVQLTKLTLYRTVIQPGIYHPDIQLLHPINLEFLVNRNLAASWYHKVPVVEIKGHLDSMNVSLNQEDLNLLFRILTENLCEGTEDLDKVKPRVQETGEIKEPLEISISQDVHDSKNTLTTGVEEIRSVDIINMLLNFEIKEVVVTLMKKSEKKGRPLHELNVLQLGMEAKVKTYDMTAKAYLKKISMQCFDFTDSKGEPLHIINSSNVTDEPLLKMLLTKADSDGPEFKTIHDSTKQRLKVSFASLDLVLHLEALLSFMDFLSSAAPFSEPSSSEKESELKPLVGESRSIAVKAVSSNISQKDVFDLKITAELNAFNVFVCDQKCNIADIKIHGMDASISVKPKQTDVFARLKDIIVMNVDLQSIHKKAVSILGDEVFRFQLTLYPDATEGEAYADMSKVDGKLSFKVGCIQIVYVHKFFMSLLNFLNNFQTAKEALSTATVQAAERAASSMKDLAQKSFRLLMDINLKAPVIIIPQSSVSPNAVIADLGLIRVENKFSLVPMEHYSLPPVIDKMNIELTQLKLSRTILQASLPQNDIEILKPVNMLLSIQRNLAAAWYVQIPGMEIKGKLKPMQVALSEDDLTVLMKILLENLGEASSQPSPTQSVQETVRVRKVDVSSVPDHLKEQEDWTDSKLSMNQIVSLQFDFHFESLSIILYNNDINQESGVAFHNDSFQLGELRLHLMASSGKMFKDGSMNVSVKLKTCTLDDLREGIERATSRMIDRKNDQDNNSSMIDISYKQDKNGSQIDAVLDKLYVCASVEFLMTVADFFIKAVPQSPENVAKETQILPRQTATGKVKIEKDDSVRPNMTLKAMITDPEVVFVASLTKADAPALTASFQCNLSLSTSKLEQMMEASVRDLKVLACPFLREKRGKNITTVLQPCSLFMEKCTWASGKQNINIMVKEFIIKISPIILNTVLTIMAALSPKTKEDGSKDTSKEMENLWGIKSINDYNTWFLGVDTATEITESFKGIEHSLIEENCGVVVESIQVTLECGLGHRTVPLLLAESKFSGNIKNWTSLMAAVADVTLQVHYYNEIHAVWEPLIERVEGKRQWNLRLDVKKNPVQDKSLLPGDDFIPEPQMAIHISSGNTMNITISKSCLNVFNNLAKGFSEGTASTFDYSLKDRAPFTVKNAVGVPIKVKPNCNLRVMGFPEKSDIFDVDAGQNLELEYASMVPSSQGNLSILSRQESSFFTLTIVPHGYTEVANIPVARPGRRLYNVRNPNASHSDSVLVQIDATEGNKVITLRSPLQIKNHFSIAFIIYKFVKNVKLLERIGIARPEEEFHVPLDSYRCQLFIQPAGILEHQYKESTTYISWKEELHRSREVRCMLQCPSVEVSFLPLIVNTVALPDELSYICTHGEDWDVAYIIHLYPSLTLRNLLPYSLRYLLEGTAETHELAEGSTADVLHSRISGEIMELVLVKYQGKNWNGHFRIRDTLPEFFPVCFSSDSTEVTTVDLSVHVRRIGSRMVLSVFSPYWLINKTTRVLQYRSEDIHVKHPADFRDIILFSFKKKNIFTKNKVQLKISTSAWSSSFSLDTVGSYGCVKCPANNMEYLVGVSIKMSSFNLSRIVTLTPFCTIANKSSLELEVGEIASDGSMPTNKWNYIASSECLPFWPESLSGKLCVRVVGCEGSSKPFFYNRQDNGTLLSLEDLNGGILVDVNTAEHSTVITFSDYHEGSAPALIMNHTPWDILTYKQSGSPEEMVLLPRQARLFAWADPTGTRKLTWTYAANVGEHDLLKDGCGQFPYDANIQIHWVSFLDGRQRVLLFTDDVALVSKALQAEEMEQADYEITLSLHSLGLSLVNNESKQEVSYIGITSSGVVWEVKPKQKWKPFSQKQIILLEQSYQKHQISRDHGWIKLDNNFEVNFDKDPMEMRLPIRSPIKRDFLSGIQIEFKQSSHQRSLRARLYWLQVDNQLPGAMFPVVFHPVAPPKSIALDSEPKPFIDVSVITRFNEYSKVLQFKYFMVLIQEMALKIDQGFLGAIIALFTPTTDPEAERRRTKLIQQDIDALNAELMETSMTDMSILSFFEHFHISPVKLHLSLSLGSGGEESDKEKQEMFAVHSVNLLLKSIGATLTDVDDLIFKLAYYEIRYQFYKRDQLIWSVVRHYSEQFLKQMYVLVLGLDVLGNPFGLIRGLSEGVEALFYEPFQGAVQGPEEFAEGLVIGVRSLFGHTVGGAAGVVSRITGSVGKGLAAITMDKEYQQKRREELSRQPRDFGDSLARGGKGFLRGVVGGVTGIITKPVEGAKKEGAAGFFKGIGKGLVGAVARPTGGIVDMASSTFQGIQRAAESTEEVSSLRPPRLIHEDGIIRPYDRQESEGSDLLENHIKKLEGETYRYHCAIPGSKKTILMVTNRRVLCIKEVEILGLMCVDWQCPFEDFVFPPSVSENVLKISVKEQGLFHKKDSANQGCVRKVYLKDTATAERACNAIEDAQSTRQQQKLMKQSSVRLLRPQLPS>sp|Q709C8-2|VP13C_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 13C OS=Homo sapiens OX=9606 GN=VPS13CMVLESVVADLLNRFLGDYVENLNKSQLKLGIWGGNVALDNLQIKENALSELDVPFKVKAGQIDKLTLKIPWKNLYGEAVVATLEGLYLLVVPGASIKYDAVKEEKSLQDVKQKELSRIEEALQKAAEKGTHSGEFIYGLENFVYKDIKPGRKRKKHKKHFKKPFKGLDRSKDKPKEAKKDTFVEKLATQVIKNVQVKITDIHIKYEDDVTDPKRPLSFGVTLGELSLLTANEHWTPCILNEADKIIYKLIRLDSLSAYWNVNCSMSYQRSREQILDQLKNEILTSGNIPPNYQYIFQPISASAKLYMNPYAESELKTPKLDCNIEIQNIAIELTKPQYLSMIDLLESVDYMVRNAPYRKYKPYLPLHTNGRRWWKYAIDSVLEVHIRRYTQMWSWSNIKKHRQLLKSYKIAYKNKLTQSKVSEEIQKEIQDLEKTLDVFNIILARQQAQVEVIRSGQKLRKKSADTGEKRGGWFSGLWGKKESKKKDEESLIPETIDDLMTPEEKDKLFTAIGYSESTHNLTLPKQYVAHIMTLKLVSTSVTIRENKNIPEILKIQIIGLGTQVSQRPGAQALKVEAKLEHWYITGLRQQDIVPSLVASIGDTTSSLLKIKFETNPEDSPADQTLIVQSQPVEVIYDAKTVNAVVEFFQSNKGLDLEQITSATLMKLEEIKERTATGLTHIIETRKVLDLRINLKPSYLVVPQTGFHHEKSDLLILDFGTFQLNSKDQGLQKTTNSSLEEIMDKAYDKFDVEIKNVQLLFARAEETWKKCRFQHPSTMHILQPMDIHVELAKAMVEKDIRMARFKVSGGLPLMHVRISDQKMKDVLYLMNSIPLPQKSSAQSPERQVSSIPIISGGTKGLLGTSLLLDTVESESDDEYFDAEDGEPQTCKSMKGSELKKAAEVPNEELINLLLKFEIKEVILEFTKQQKEEDTILVFNVTQLGTEATMRTFDLTVVSYLKKISLDYHEIEGSKRKPLHLISSSDKPGLDLLKVEYIKADKNGPSFQTAFGKTEQTVKVAFSSLNLLLQTQALVASINYLTTIIPSDDQSISVAKEVQISTEKQQKNSTLPKAIVSSRDSDIIDFRLFAKLNAFCVIVCNEKNNIAEIKIQGLDSSLSLQSRKQSLFARLENIIVTDVDPKTVHKKAVSIMGNEVFRFNLDLYPDATEGDLYTDMSKVDGVLSLNVGCIQIVYLHKFLMSLLNFLNNFQTAKESLSAATAQAAERAATSVKDLAQRSFRVSINIDLKAPVIVIPQSSISTNAVVVDLGLIRVHNQFSLVSDEDYLNPPVIDRMDVQLTKLTLYRTVIQPGIYHPDIQLLHPINLEFLVNRNLAASWYHKVPVVEIKGHLDSMNVSLNQEDLNLLFRILTENLCEGTEDLDKVKPRVQETGEIKEPLEISISQDVHDSKNTLTTGVEEIRSVDIINMLLNFEIKEVVVTLMKKSEKKGRPLHELNVLQLGMEAKVKTYDMTAKAYLKKISMQCFDFTDSKGEPLHIINSSNVTDEPLLKMLLTKADSDGPEFKTIHDSTKQRLKVSFASLDLVLHLEALLSFMDFLSSAAPFSEPSSSEKESELKPLVGESRSIAVKAVSSNISQKDVFDLKITAELNAFNVFVCDQKCNIADIKIHGMDASISVKPKQTDVFARLKDIIVMNVDLQSIHKKAVSILGDEVFRFQLTLYPDATEGEAYADMSKVDGKLSFKVGCIQIVYVHKFFMSLLNFLNNFQTAKEALSTATVQAAERAASSMKDLAQKSFRLLMDINLKAPVIIIPQSSVSPNAVIADLGLIRVENKFSLVPMEHYSLPPVIDKMNIELTQLKLSRTILQASLPQNDIEILKPVNMLLSIQRNLAAAWYVQIPGMEIKGKLKPMQVALSEDDLTVLMKILLENLGEASSQPSPTQSVQETVRVRKVDVSSVPDHLKEQEDWTDSKLSMNQIVSLQFDFHFESLSIILYNNDINQESGVAFHNDSFQLGELRLHLMASSGKMFKDGSMNVSVKLKTCTLDDLREGIERATSRMIDRKNDQDNNSSMIDISYKQDKNGSQIDAVLDKLYVCASVEFLMTVADFFIKAVPQSPENVAKETQILPRQTATGKVKIEKDDSVRPNMTLKAMITDPEVVFVASLTKADAPALTASFQCNLSLSTSKLEQMMEASVRDLKVLACPFLREKRGKNITTVLQPCSLFMEKCTWASGKQNINIMVKEFIIKISPIILNTVLTIMAALSPKTKEDGSKDTSKEMENLWGIKSINDYNTWFLGVDTATEITESFKGIEHSLIEENCGVVVESIQVTLECGLGHRTVPLLLAESKFSGNIKNWTSLMAAVADVTLQVHYYNEIHAVWEPLIERVEGKRQWNLRLDVKKNPVQDKSLLPGDDFIPEPQMAIHISSGNTMNITISKSCLNVFNNLAKGFSEGTASTFDYSLKDRAPFTVKNAVGVPIKVKPNCNLRVMGFPEKSDIFDVDAGQNLELEYASMVPSSQGNLSILSRQESSFFTLTIVPHGYTEVANIPVARPGRRLYNVRNPNASHSDSVLVQIDATEGNKVITLRSPLQIKNHFSIAFIIYKFVKNVKLLERIGIARPEEEFHVPLDSYRCQLFIQPAGILEHQYKESTTYISWKEELHRSREVRCMLQCPSVEVSFLPLIVNTVALPDELSYICTHGEDWDVAYIIHLYPSLTLRNLLPYSLRYLLEGTAETHELAEGSTADVLHSRISGEIMELVLVKYQGKNWNGHFRIRDTLPEFFPVCFSSDSTEVTTVDLSVHVRRIGSRMVLSVFSPYWLINKTTRVLQYRSEDIHVKHPADFRDIILFSFKKKNIFTKNKVQLKISTSAWSSSFSLDTVGSYGCVKCPANNMEYLVGVSIKMSSFNLSRIVTLTPFCTIANKSSLELEVGEIASDGSMPTNKWNYIASSECLPFWPESLSGKLCVRVVGCEGSSKPFFYNRQDNGTLLSLEDLNGGILVDVNTAEHSTVITFSDYHEGSAPALIMNHTPWDILTYKQSGSPEEMVLLPRQARLFAWADPTGTRKLTWTYAANVGEHDLLKDGCGQFPYDANIQIHWVSFLDGRQRVLLFTDDVALVSKALQAEEMEQADYEITLSLHSLGLSLVNNESKQEVSYIGITSSGVVWEVKPKQKWKPFSQKQIILLEQSYQKHQISRDHGWIKLDNNFEVNFDKDPMEMRLPIRSPIKRDFLSGIQIEFKQSSHQRSLRARLYWLQVDNQLPGAMFPVVFHPVAPPKSIALDSEPKPFIDVSVITRFNEYSKVLQFKYFMVLIQEMALKIDQGFLGAIIALFTPTTDPEAERRRTKLIQQDIDALNAELMETSMTDMSILSFFEHFHISPVKLHLSLSLGSGGEESDKEKQEMFAVHSVNLLLKSIGATLTDVDDLIFKLAYYEIRYQFYKRDQLIWSVVRHYSEQFLKQMYVLVLGLDVLGNPFGLIRGLSEGVEALFYEPFQGAVQGPEEFAEGLVIGVRSLFGHTVGGAAGVVSRITGSVGKGLAAITMDKEYQQKRREELSRQPRDFGDSLARGGKGFLRGVVGGVTGIITKPVEGAKKEGAAGFFKGIGKGLVGAVARPTGGIVDMASSTFQGIQRAAESTEEVSSLRPPRLIHEDGIIRPYDRQESEGSDLLEQELEIQE>sp|Q709C8-3|VP13C_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 13C OS=Homo sapiens OX=9606 GN=VPS13CMVLESVVADLLNRFLGDYVENLNKSQLKLGIWGGNVALDNLQIKENALSELDVPFKVKAGQIDKLTLKIPWKNLYGEAVVATLEGLYLLVVPGASIKYDAVKEEKSLQDVKQKELSRIEEALQKAAEKDKPKEAKKDTFVEKLATQVIKNVQVKITDIHIKYEDDVTDPKRPLSFGVTLGELSLLTANEHWTPCILNEADKIIYKLIRLDSLSAYWNVNCSMSYQRSREQILDQLKNEILTSGNIPPNYQYIFQPISASAKLYMNPYAESELKTPKLDCNIEIQNIAIELTKPQYLSMIDLLESVDYMVRNAPYRKYKPYLPLHTNGRRWWKYAIDSVLEVHIRRYTQMWSWSNIKKHRQLLKSYKIAYKNKLTQSKVSEEIQKEIQDLEKTLDVFNIILARQQAQVEVIRSGQKLRKKSADTGEKRGGWFSGLWGKKESKKKDEESLIPETIDDLMTPEEKDKLFTAIGYSESTHNLTLPKQYVAHIMTLKLVSTSVTIRENKNIPEILKIQIIGLGTQVSQRPGAQALKVEAKLEHWYITGLRQQDIVPSLVASIGDTTSSLLKIKFETNPEDSPADQTLIVQSQPVEVIYDAKTVNAVVEFFQSNKGLDLEQITSATLMKLEEIKERTATGLTHIIETRKVLDLRINLKPSYLVVPQTGFHHEKSDLLILDFGTFQLNSKDQGLQKTTNSSLEEIMDKAYDKFDVEIKNVQLLFARAEETWKKCRFQHPSTMHILQPMDIHVELAKAMVEKDIRMARFKVSGGLPLMHVRISDQKMKDVLYLMNSIPLPQKSSAQSPERQVSSIPIISGGTKGLLGTSLLLDTVESESDDEYFDAEDGEPQTCKSMKGSELKKAAEVPNEELINLLLKFEIKEVILEFTKQQKEEDTILVFNVTQLGTEATMRTFDLTVVSYLKKISLDYHEIEGSKRKPLHLISSSDKPGLDLLKVEYIKADKNGPSFQTAFGKTEQTVKVAFSSLNLLLQTQALVASINYLTTIIPSDDQSISVAKEVQISTEKQQKNSTLPKAIVSSRDSDIIDFRLFAKLNAFCVIVCNEKNNIAEIKIQGLDSSLSLQSRKQSLFARLENIIVTDVDPKTVHKKAVSIMGNEVFRFNLDLYPDATEGDLYTDMSKVDGVLSLNVGCIQIVYLHKFLMSLLNFLNNFQTAKESLSAATAQAAERAATSVKDLAQRSFRVSINIDLKAPVIVIPQSSISTNAVVVDLGLIRVHNQFSLVSDEDYLNPPVIDRMDVQLTKLTLYRTVIQPGIYHPDIQLLHPINLEFLVNRNLAASWYHKVPVVEIKGHLDSMNVSLNQEDLNLLFRILTENLCEGTEDLDKVKPRVQETGEIKEPLEISISQDVHDSKNTLTTGVEEIRSVDIINMLLNFEIKEVVVTLMKKSEKKGRPLHELNVLQLGMEAKVKTYDMTAKAYLKKISMQCFDFTDSKGEPLHIINSSNVTDEPLLKMLLTKADSDGPEFKTIHDSTKQRLKVSFASLDLVLHLEALLSFMDFLSSAAPFSEPSSSEKESELKPLVGESRSIAVKAVSSNISQKDVFDLKITAELNAFNVFVCDQKCNIADIKIHGMDASISVKPKQTDVFARLKDIIVMNVDLQSIHKKAVSILGDEVFRFQLTLYPDATEGEAYADMSKVDGKLSFKVGCIQIVYVHKFFMSLLNFLNNFQTAKEALSTATVQAAERAASSMKDLAQKSFRLLMDINLKAPVIIIPQSSVSPNAVIADLGLIRVENKFSLVPMEHYSLPPVIDKMNIELTQLKLSRTILQASLPQNDIEILKPVNMLLSIQRNLAAAWYVQIPGMEIKGKLKPMQVALSEDDLTVLMKILLENLGEASSQPSPTQSVQETVRVRKVDVSSVPDHLKEQEDWTDSKLSMNQIVSLQFDFHFESLSIILYNNDINQESGVAFHNDSFQLGELRLHLMASSGKMFKDGSMNVSVKLKTCTLDDLREGIERATSRMIDRKNDQDNNSSMIDISYKQDKNGSQIDAVLDKLYVCASVEFLMTVADFFIKAVPQSPENVAKETQILPRQTATGKVKIEKDDSVRPNMTLKAMITDPEVVFVASLTKADAPALTASFQCNLSLSTSKLEQMMEASVRDLKVLACPFLREKRGKNITTVLQPCSLFMEKCTWASGKQNINIMVKEFIIKISPIILNTVLTIMAALSPKTKEDGSKDTSKEMENLWGIKSINDYNTWFLGVDTATEITESFKGIEHSLIEENCGVVVESIQVTLECGLGHRTVPLLLAESKFSGNIKNWTSLMAAVADVTLQVHYYNEIHAVWEPLIERVEGKRQWNLRLDVKKNPVQDKSLLPGDDFIPEPQMAIHISSGNTMNITISKSCLNVFNNLAKGFSEGTASTFDYSLKDRAPFTVKNAVGVPIKVKPNCNLRVMGFPEKSDIFDVDAGQNLELEYASMVPSSQGNLSILSRQESSFFTLTIVPHGYTEVANIPVARPGRRLYNVRNPNASHSDSVLVQIDATEGNKVITLRSPLQIKNHFSIAFIIYKFVKNVKLLERIGIARPEEEFHVPLDSYRCQLFIQPAGILEHQYKESTTYISWKEELHRSREVRCMLQCPSVEVSFLPLIVNTVALPDELSYICTHGEDWDVAYIIHLYPSLTLRNLLPYSLRYLLEGTAETHELAEGSTADVLHSRISGEIMELVLVKYQGKNWNGHFRIRDTLPEFFPVCFSSDSTEVTTVDLSVHVRRIGSRMVLSVFSPYWLINKTTRVLQYRSEDIHVKHPADFRDIILFSFKKKNIFTKNKVQLKISTSAWSSSFSLDTVGSYGCVKCPANNMEYLVGVSIKMSSFNLSRIVTLTPFCTIANKSSLELEVGEIASDGSMPTNKWNYIASSECLPFWPESLSGKLCVRVVGCEGSSKPFFYNRQDNGTLLSLEDLNGGILVDVNTAEHSTVITFSDYHEGSAPALIMNHTPWDILTYKQSGSPEEMVLLPRQARLFAWADPTGTRKLTWTYAANVGEHDLLKDGCGQFPYDANIQIHWVSFLDGRQRVLLFTDDVALVSKALQAEEMEQADYEITLSLHSLGLSLVNNESKQEVSYIGITSSGVVWEVKPKQKWKPFSQKQIILLEQSYQKHQISRDHGWIKLDNNFEVNFDKDPMEMRLPIRSPIKRDFLSGIQIEFKQSSHQRSLRARLYWLQVDNQLPGAMFPVVFHPVAPPKSIALDSEPKPFIDVSVITRFNEYSKVLQFKYFMVLIQEMALKIDQGFLGAIIALFTPTTDPEAERRRTKLIQQDIDALNAELMETSMTDMSILSFFEHFHISPVKLHLSLSLGSGGEESDKEKQEMFAVHSVNLLLKSIGATLTDVDDLIFKLAYYEIRYQFYKRDQLIWSVVRHYSEQFLKQMYVLVLGLDVLGNPFGLIRGLSEGVEALFYEPFQGAVQGPEEFAEGLVIGVRSLFGHTVGGAAGVVSRITGSVGKGLAAITMDKEYQQKRREELSRQPRDFGDSLARGGKGFLRGVVGGVTGIITKPVEGAKKEGAAGFFKGIGKGLVGAVARPTGGIVDMASSTFQGIQRAAESTEEVSSLRPPRLIHEDGIIRPYDRQESEGSDLLENHIKKLEGETYRYHCAIPGSKKTILMVTNRRVLCIKEVEILGLMCVDWQCPFEDFVFPPSVSENVLKISVKEQGLFHKKDSANQGCVRKVYLKDTATAERACNAIEDAQSTRQQQKLMKQSSVRLLRPQLPS>sp|Q709C8-4|VP13C_HUMAN Isoform 4 of Vacuolar protein sorting-associatedprotein 13C OS=Homo sapiens OX=9606 GN=VPS13CMVLESVVADLLNRFLGDYVENLNKSQLKLGIWGGNVALDNLQIKENALSELDVPFKVKAGQIDKLTLKIPWKNLYGEAVVATLEGLYLLVVPGASIKYDAVKEEKSLQDVKQKELSRIEEALQKAAEKDKPKEAKKDTFVEKLATQVIKNVQVKITDIHIKYEDDVTDPKRPLSFGVTLGELSLLTANEHWTPCILNEADKIIYKLIRLDSLSAYWNVNCSMSYQRSREQILDQLKNEILTSGNIPPNYQYIFQPISASAKLYMNPYAESELKTPKLDCNIEIQNIAIELTKPQYLSMIDLLESVDYMVRNAPYRKYKPYLPLHTNGRRWWKYAIDSVLEVHIRRYTQMWSWSNIKKHRQLLKSYKIAYKNKLTQSKVSEEIQKEIQDLEKTLDVFNIILARQQAQVEVIRSGQKLRKKSADTGEKRGGWFSGLWGKKESKKKDEESLIPETIDDLMTPEEKDKLFTAIGYSESTHNLTLPKQYVAHIMTLKLVSTSVTIRENKNIPEILKIQIIGLGTQVSQRPGAQALKVEAKLEHWYITGLRQQDIVPSLVASIGDTTSSLLKIKFETNPEDSPADQTLIVQSQPVEVIYDAKTVNAVVEFFQSNKGLDLEQITSATLMKLEEIKERTATGLTHIIETRKVLDLRINLKPSYLVVPQTGFHHEKSDLLILDFGTFQLNSKDQGLQKTTNSSLEEIMDKAYDKFDVEIKNVQLLFARAEETWKKCRFQHPSTMHILQPMDIHVELAKAMVEKDIRMARFKVSGGLPLMHVRISDQKMKDVLYLMNSIPLPQKSSAQSPERQVSSIPIISGGTKGLLGTSLLLDTVESESDDEYFDAEDGEPQTCKSMKGSELKKAAEVPNEELINLLLKFEIKEVILEFTKQQKEEDTILVFNVTQLGTEATMRTFDLTVVSYLKKISLDYHEIEGSKRKPLHLISSSDKPGLDLLKVEYIKADKNGPSFQTAFGKTEQTVKVAFSSLNLLLQTQALVASINYLTTIIPSDDQSISVAKEVQISTEKQQKNSTLPKAIVSSRDSDIIDFRLFAKLNAFCVIVCNEKNNIAEIKIQGLDSSLSLQSRKQSLFARLENIIVTDVDPKTVHKKAVSIMGNEVFRFNLDLYPDATEGDLYTDMSKVDGVLSLNVGCIQIVYLHKFLMSLLNFLNNFQTAKESLSAATAQAAERAATSVKDLAQRSFRVSINIDLKAPVIVIPQSSISTNAVVVDLGLIRVHNQFSLVSDEDYLNPPVIDRMDVQLTKLTLYRTVIQPGIYHPDIQLLHPINLEFLVNRNLAASWYHKVPVVEIKGHLDSMNVSLNQEDLNLLFRILTENLCEGTEDLDKVKPRVQETGEIKEPLEISISQDVHDSKNTLTTGVEEIRSVDIINMLLNFEIKEVVVTLMKKSEKKGRPLHELNVLQLGMEAKVKTYDMTAKAYLKKISMQCFDFTDSKGEPLHIINSSNVTDEPLLKMLLTKADSDGPEFKTIHDSTKQRLKVSFASLDLVLHLEALLSFMDFLSSAAPFSEPSSSEKESELKPLVGESRSIAVKAVSSNISQKDVFDLKITAELNAFNVFVCDQKCNIADIKIHGMDASISVKPKQTDVFARLKDIIVMNVDLQSIHKKAVSILGDEVFRFQLTLYPDATEGEAYADMSKVDGKLSFKVGCIQIVYVHKFFMSLLNFLNNFQTAKEALSTATVQAAERAASSMKDLAQKSFRLLMDINLKAPVIIIPQSSVSPNAVIADLGLIRVENKFSLVPMEHYSLPPVIDKMNIELTQLKLSRTILQASLPQNDIEILKPVNMLLSIQRNLAAAWYVQIPGMEIKGKLKPMQVALSEDDLTVLMKILLENLGEASSQPSPTQSVQETVRVRKVDVSSVPDHLKEQEDWTDSKLSMNQIVSLQFDFHFESLSIILYNNDINQESGVAFHNDSFQLGELRLHLMASSGKMFKDGSMNVSVKLKTCTLDDLREGIERATSRMIDRKNDQDNNSSMIDISYKQDKNGSQIDAVLDKLYVCASVEFLMTVADFFIKAVPQSPENVAKETQILPRQTATGKVKIEKDDSVRPNMTLKAMITDPEVVFVASLTKADAPALTASFQCNLSLSTSKLEQMMEASVRDLKVLACPFLREKRGKNITTVLQPCSLFMEKCTWASGKQNINIMVKEFIIKISPIILNTVLTIMAALSPKTKEDGSKDTSKEMENLWGIKSINDYNTWFLGVDTATEITESFKGIEHSLIEENCGVVVESIQVTLECGLGHRTVPLLLAESKFSGNIKNWTSLMAAVADVTLQVHYYNEIHAVWEPLIERVEGKRQWNLRLDVKKNPVQDKSLLPGDDFIPEPQMAIHISSGNTMNITISKSCLNVFNNLAKGFSEGTASTFDYSLKDRAPFTVKNAVGVPIKVKPNCNLRVMGFPEKSDIFDVDAGQNLELEYASMVPSSQGNLSILSRQESSFFTLTIVPHGYTEVANIPVARPGRRLYNVRNPNASHSDSVLVQIDATEGNKVITLRSPLQIKNHFSIAFIIYKFVKNVKLLERIGIARPEEEFHVPLDSYRCQLFIQPAGILEHQYKESTTYISWKEELHRSREVRCMLQCPSVEVSFLPLIVNTVALPDELSYICTHGEDWDVAYIIHLYPSLTLRNLLPYSLRYLLEGTAETHELAEGSTADVLHSRISGEIMELVLVKYQGKNWNGHFRIRDTLPEFFPVCFSSDSTEVTTVDLSVHVRRIGSRMVLSVFSPYWLINKTTRVLQYRSEDIHVKHPADFRDIILFSFKKKNIFTKNKVQLKISTSAWSSSFSLDTVGSYGCVKCPANNMEYLVGVSIKMSSFNLSRIVTLTPFCTIANKSSLELEVGEIASDGSMPTNKWNYIASSECLPFWPESLSGKLCVRVVGCEGSSKPFFYNRQDNGTLLSLEDLNGGILVDVNTAEHSTVITFSDYHEGSAPALIMNHTPWDILTYKQSGSPEEMVLLPRQARLFAWADPTGTRKLTWTYAANVGEHDLLKDGCGQFPYDANIQIHWVSFLDGRQRVLLFTDDVALVSKALQAEEMEQADYEITLSLHSLGLSLVNNESKQEVSYIGITSSGVVWEVKPKQKWKPFSQKQIILLEQSYQKHQISRDHGWIKLDNNFEVNFDKDPMEMRLPIRSPIKRDFLSGIQIEFKQSSHQRSLRARLYWLQVDNQLPGAMFPVVFHPVAPPKSIALDSEPKPFIDVSVITRFNEYSKVLQFKYFMVLIQEMALKIDQGFLGAIIALFTPTTDPEAERRRTKLIQQDIDALNAELMETSMTDMSILSFFEHFHISPVKLHLSLSLGSGGEESDKEKQEMFAVHSVNLLLKSIGATLTDVDDLIFKLAYYEIRYQFYKRDQLIWSVVRHYSEQFLKQMYVLVLGLDVLGNPFGLIRGLSEGVEALFYEPFQGAVQGPEEFAEGLVIGVRSLFGHTVGGAAGVVSRITGSVGKGLAAITMDKEYQQKRREELSRQPRDFGDSLARGGKGFLRGVVGGVTGIITKPVEGAKKEGAAGFFKGIGKGLVGAVARPTGGIVDMASSTFQGIQRAAESTEEVSSLRPPRLIHEDGIIRPYDRQESEGSDLLEQELEIQE>sp|Q6ZRP5|YD019_HUMAN Putative uncharacterized protein FLJ46204 OS=Homosapiens OX=9606 PE=5 SV=2MRIFRGCTQPSTLGQGVHSPLMKAQFITHHSRKQVKPGEGWGRSSFTRACRDHTTILSGNRSFSAVAATPAKHKHMHTRTHTHMHTHTGMHTLTGTHVHTPHTQMHTRILTLSHMHTHAHTHAHTHGHTHTRAHSTHAHTHAHSHYHTRTLTLTHSHAHSCTLTSTITHMHTHTHMHTHTSTLTRTLTLTHTHMHTFLSLVSHLAGYISCQFIFSSENPRLCH>sp|Q9NZL3|ZN224_HUMAN Zinc finger protein 224 OS=Homo sapiens OX=9606GN=ZNF224 PE=1 SV=3MTTFKEAMTFKDVAVVFTEEELGLLDLAQRKLYRDVMLENFRNLLSVGHQAFHRDTFHFLREEKIWMMKTAIQREGNSGDKIQTEMETVSEAGTHQEWSFQQIWEKIASDLTRSQDLMINSSQFSKEGDFPCQTEAGLSVIHTRQKSSQGNGYKPSFSDVSHFDFHQQLHSGEKSHTCDECGKNFCYISALRIHQRVHMGEKCYKCDVCGKEFSQSSHLQTHQRVHTGEKPFKCVECGKGFSRRSALNVHHKLHTGEKPYNCEECGKAFIHDSQLQEHQRIHTGEKPFKCDICGKSFCGRSRLNRHSMVHTAEKPFRCDTCDKSFRQRSALNSHRMIHTGEKPYKCEECGKGFICRRDLYTHHMVHTGEKPYNCKECGKSFRWASCLLKHQRVHSGEKPFKCEECGKGFYTNSQCYSHQRSHSGEKPYKCVECGKGYKRRLDLDFHQRVHTGEKLYNCKECGKSFSRAPCLLKHERLHSGEKPFQCEECGKRFTQNSHLHSHQRVHTGEKPYKCEKCGKGYNSKFNLDMHQKVHTGERPYNCKECGKSFGWASCLLKHQRLHSGEKPFKCEECGKRFTQNSQLHSHQRVHTGEKPYKCDECGKGFSWSSTRLTHQRRHSRETPLKCEQHGKNIVQNSFSKVQEKVHSVEKPYKCEDCGKGYNRRLNLDMHQRVHMGEKTWKCRECDMCFSQASSLRLHQNVHVGEKP>sp|Q9BQ24|ZFY21_HUMAN Zinc finger FYVE domain-containing protein 21OS=Homo sapiens OX=9606 GN=ZFYVE21 PE=1 SV=1MSSEVSARRDAKKLVRSPSGLRMVPEHRAFGSPFGLEEPQWVPDKECRRCMQCDAKFDFLTRKHHCRRCGKCFCDRCCSQKVPLRRMCFVDPVRQCAECALVSLKEAEFYDKQLKVLLSGATFLVTFGNSEKPETMTCRLSNNQRYLFLDGDSHYEIEIVHISTVQILTEGFPPGGGNARATGMFLQYTVPGTEGVTQLKLTVVEDVTVGRRQAVAWLVAMHKAAKLLYESRDQ>sp|Q9BQ24-2|ZFY21_HUMAN Isoform 2 of Zinc finger FYVE domain-containingprotein 21 OS=Homo sapiens OX=9606 GN=ZFYVE21MSSEVSARRDAKKLVRSPSGLRMVPEHRAFGSPFGLEEPQWVPDKECRRCMQCDAKFDFLTRKHHCRRCGKCFCDRCCSQKVPLRRMCFVDPVRQCAECALVSLKEAEFYDKQLKVLLSGATFLVTFGNSEKPETMTCRLSNNQRYLFLDGDSHYEIEIVHISTVQILTEGFPPGEKDIHAYTSLRGSQPASEGGNARATGMFLQYTVPGTEGVTQLKLTVVEDVTVGRRQAVAWLVAMHKAAKLLYESRDQ>sp|Q6ZS92|YD022_HUMAN Putative uncharacterized protein FLJ45721 OS=Homosapiens OX=9606 PE=5 SV=2MCMNTSIHAHTYARTHTHSVFMSSNVTVFQWMRLMRASSRSFTQAIPAGQLLQTACSHLFTTQNTCQNALGNNTRLQHTEKVRLSIGLADFGLPGIARNTFVVPDSISRYCREGSVIGKCCPSRKSALLNKQGSLKKFKITRGETQPGVTISVLELAEIDQRF>sp|Q8N141|ZFP82_HUMAN Zinc finger protein 82 homolog OS=Homo sapiensOX=9606 GN=ZFP82 PE=1 SV=1MALRSVMFSDVSIDFSPEEWEYLDLEQKDLYRDVMLENYSNLVSLGCFISKPDVISSLEQGKEPWKVVRKGRRQYPDLETKYETKKLSLENDIYEINLSQWKIMERIENHGLKGLILKNDWESTGKIEGQERPQEGYFSSVKMPSEKVSSYQKRTSVTPHQRLHFVDKPYECKECGKAFRVRQQLTFHHRIHTGEKPYECKECGMAFRQTAHLTRHQRLHSGEKLYECKECGEAFICGADLRVHQKMHIGEKPYECKECGKAFRVRGQLTLHQRIHTGEKPYVCKECGKAFRQYAHLTRHQKLNSADRLYECKECGKAFLCGSGLRVHHKLHTGEKPYECKECGKAFRVRQQLTLHQRIHTGEKPYECKECGKTFSRGYHLILHHRIHTGEKPYECKECWKAFSRYSQLISHQSIHIGVKPYDCKECGKAFRLLSQLTQHQSIHIGEKPYKCKECGKAFRLRQKLTLHQSIHTGEKPFECKECRKAFRLNSSLIQHLRIHSGEKPYECKECKKAFRQHSHLTHHLKIHNVKI>sp|Q9HBF4|ZFYV1_HUMAN Zinc finger FYVE domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZFYVE1 PE=1 SV=1MSAQTSPAEKGLNPGLMCQESYACSGTDEAIFECDECCSLQCLRCEEELHRQERLRNHERIRLKPGHVPYCDLCKGLSGHLPGVRQRAIVRCQTCKINLCLECQKRTHSGGNKRRHPVTVYNVSNLQESLEAEEMDEETKRKKMTEKVVSFLLVDENEEIQVTNEEDFIRKLDCKPDQHLKVVSIFGNTGDGKSHTLNHTFFYGREVFKTSPTQESCTVGVWAAYDPVHKVAVIDTEGLLGATVNLSQRTRLLLKVLAISDLVIYRTHADRLHNDLFKFLGDASEAYLKHFTKELKATTARCGLDVPLSTLGPAVIIFHETVHTQLLGSDHPSEVPEKLIQDRFRKLGRFPEAFSSIHYKGTRTYNPPTDFSGLRRALEQLLENNTTRSPRHPGVIFKALKALSDRFSGEIPDDQMAHSSFFPDEYFTCSSLCLSCGVGCKKSMNHGKEGVPHEAKSRCRYSHQYDNRVYTCKACYERGEEVSVVPKTSASTDSPWMGLAKYAWSGYVIECPNCGVVYRSRQYWFGNQDPVDTVVRTEIVHVWPGTDGFLKDNNNAAQRLLDGMNFMAQSVSELSLGPTKAVTSWLTDQIAPAYWRPNSQILSCNKCATSFKDNDTKHHCRACGEGFCDSCSSKTRPVPERGWGPAPVRVCDNCYEARNVQLAVTEAQVDDEGGTLIARKVGEAVQNTLGAVVTAIDIPLGLVKDAARPAYWVPDHEILHCHNCRKEFSIKLSKHHCRACGQGFCDECSHDRRAVPSRGWDHPVRVCFNCNKKPGDL>sp|Q9HBF4-2|ZFYV1_HUMAN Isoform 2 of Zinc finger FYVE domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=ZFYVE1MAHSSFFPDEYFTCSSLCLSCGVGCKKSMNHGKEGVPHEAKSRCRYSHQYDNRVYTCKACYERGEEVSVVPKTSASTDSPWMGLAKYAWSGYVIECPNCGVVYRSRQYWFGNQDPVDTVVRTEIVHVWPGTDGFLKDNNNAAQRLLDGMNFMAQSVSELSLGPTKAVTSWLTDQIAPAYWRPNSQILSCNKCATSFKDNDTKHHCRACGEGFCDSCSSKTRPVPERGWGPAPVRVCDNCYEARNVQLAVTEAQVDDEGGTLIARKVGEAVQNTLGAVVTAIDIPLGLVKDAARPAYWVPDHEILHCHNCRKEFSIKLSKHHCRACGQGFCDECSHDRRAVPSRGWDHPVRVCFNCNKKPGDL>sp|Q9HBF4-3|ZFYV1_HUMAN Isoform 3 of Zinc finger FYVE domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=ZFYVE1MSAQTSPAEKGLNPGLMCQESYACSGTDEAIFECDECCSLQCLRCEEELHRQERLRNHERIRLKPGHVPYCDLCKGLSGHLPGVRQRAIVRCQTCKINLCLECQKRTHSGGNKRRHPVTVYNVSNLQESLEAEEMDEETKRKKMTEKVVSFLLVDENEEIQVTNEEDFIRKLDCKPDQHLKVVSIFGNTGDGKSHTLNHTFFYGREVFKTSPTQESCTVGVWAAYDPVHKVAVIDTEGLLGATVNLSQRTRLLLKVLAISDLVIYRTHADRLHNDLFKFLGDASEAYLKHFTKELKATTARCGLDVPLSTLGPAVIIFHETVHTQLLGSDHPSEVPEKLIQDRFRKLGRFPEAFSSIHYKGTRTYNPPTDFSGLRRALEQLLENNTTRSPRHPGVIFKALKALSDRFSGEIPDDQMAHSSFFPDEYFTCSSLCLSCGVGCKKSMNHGKEGVPHEAKSRCRYSHQYDNRVYTCKACYERGEEVSVVPKTSASTDSPWMGLAKYAWSGRQYWFGNQDPVDTVVRTEIVHVWPGTDGFLKDNNNAAQRLLDGMNFMAQSVSELSLGPTKAVTSWLTDQIAPAYWRPNSQILSCNKCATSFKDNDTKHHCRACGEGFCDSCSSKTRPVPERGWGPAPVRVCDNCYEARNVQLAVTEAQVDDEGGTLIARKVGEAVQNTLGAVVTAIDIPLGLVKDAARPAYWVPDHEILHCHNCRKEFSIKLSKHHCRACGQGFCDECSHDRRAVPSRGWDHPVRVCFNCNKKPGDL>sp|Q14584|ZN266_HUMAN Zinc finger protein 266 OS=Homo sapiens OX=9606GN=ZNF266 PE=1 SV=2MLENYKNLATVGYQLFKPSLISWLEQEESRTVQRGDFQASEWKVQLKTKELALQQDVLGEPTSSGIQMIGSHNGGEVSDVKQCGDVSSEHSCLKTHVRTQNSENTFECYLYGVDFLTLHKKTSTGEQRSVFSQCGKAFSLNPDVVCQRTCTGEKAFDCSDSGKSFINHSHLQGHLRTHNGESLHEWKECGRGFIHSTDLAVRIQTHRSEKPYKCKECGKGFRYSAYLNIHMGTHTGDNPYECKECGKAFTRSCQLTQHRKTHTGEKPYKCKDCGRAFTVSSCLSQHMKIHVGEKPYECKECGIAFTRSSQLTEHLKTHTAKDPFECKICGKSFRNSSCLSDHFRIHTGIKPYKCKDCGKAFTQNSDLTKHARTHSGERPYECKECGKAFARSSRLSEHTRTHTGEKPFECVKCGKAFAISSNLSGHLRIHTGEKPFECLECGKAFTHSSSLNNHMRTHSAKKPFTCMECGKAFKFPTCVNLHMRIHTGEKPYKCKQCGKSFSYSNSFQLHERTHTGEKPYECKECGKAFSSSSSFRNHERRHADERLSA>sp|Q9UIJ5|ZDHC2_HUMAN Palmitoyltransferase ZDHHC2 OS=Homo sapiensOX=9606 GN=ZDHHC2 PE=1 SV=1MAPSGPGSSARRRCRRVLYWIPVVFITLLLGWSYYAYAIQLCIVSMENTGEQVVCLMAYHLLFAMFVWSYWKTIFTLPMNPSKEFHLSYAEKDLLEREPRGEAHQEVLRRAAKDLPIYTRTMSGAIRYCDRCQLIKPDRCHHCSVCDKCILKMDHHCPWVNNCVGFSNYKFFLLFLAYSLLYCLFIAATDLQYFIKFWTNGLPDTQAKFHIMFLFFAAAMFSVSLSSLFGYHCWLVSKNKSTLEAFRSPVFRHGTDKNGFSLGFSKNMRQVFGDEKKYWLLPIFSSLGDGCSFPTCLVNQDPEQASTPAGLNSTAKNLENHQFPAKPLRESQSHLLTDSQSWTESSINPGKCKAGMSNPALTMENET>sp|A8MZ25|YQ037_HUMAN Putative uncharacterized protein FLJ38767 OS=Homosapiens OX=9606 PE=5 SV=1MGQKKTMGTERSRGGKRGPQPGAERPEEPGATFSKKPPEGARAPRCLSRPTAPKSGACLARRRPPGSPCSIRDAPFHTGDDRFLARENFPNVLQPLPRMFAVQQAADFESQCPRRWDSRKRPSEGLPSAGWGRWRGRPIHLGLWVSGSVRRKVSGSHVSRSLHL>sp|Q12901|ZN155_HUMAN Zinc finger protein 155 OS=Homo sapiens OX=9606GN=ZNF155 PE=1 SV=4MTTFKEAVTFKDVAVVFTEEELGLLDPAQRKLYRDVMLENFRNLLSVGHQPFHQDTCHFLREEKFWMMGTATQREGNSGGKIQTELESVPEAGAHEEWSCQQIWEQIAKDLTRSQDSIINNSQFFENGDVPSQVEAGLPTIHTGQKPSQGGKCKQSISDVPIFDLPQQLYSEEKSYTCDECGKSICYISALHVHQRVHVGEKLFMCDVCGKEFSQSSHLQTHQRVHTGEKPFKCEQCGKGFSRRSALNVHRKLHTGEKPYICEACGKAFIHDSQLKEHKRIHTGEKPFKCDICGKTFYFRSRLKSHSMVHTGEKPFRCDTCDKSFHQRSALNRHCMVHTGEKPYRCEQCGKGFIGRLDFYKHQVVHTGEKPYNCKECGKSFRWSSCLLNHQRVHSGEKSFKCEECGKGFYTNSQLSSHQRSHSGEKPYKCEECGKGYVTKFNLDLHQRVHTGERPYNCKECGKNFSRASSILNHKRLHCQKKPFKCEDCGKRLVHRTYRKDQPRDYSGENPSKCEDCGRRYKRRLNLDILLSLFLNDT>sp|Q12901-2|ZN155_HUMAN Isoform 2 of Zinc finger protein 155 OS=Homosapiens OX=9606 GN=ZNF155MIKRSKVLVFCSKIMEEAVTFKDVAVVFTEEELGLLDPAQRKLYRDVMLENFRNLLSVGHQPFHQDTCHFLREEKFWMMGTATQREGNSGGKIQTELESVPEAGAHEEWSCQQIWEQIAKDLTRSQDSIINNSQFFENGDVPSQVEAGLPTIHTGQKPSQGGKCKQSISDVPIFDLPQQLYSEEKSYTCDECGKSICYISALHVHQRVHVGEKLFMCDVCGKEFSQSSHLQTHQRVHTGEKPFKCEQCGKGFSRRSALNVHRKLHTGEKPYICEACGKAFIHDSQLKEHKRIHTGEKPFKCDICGKTFYFRSRLKSHSMVHTGEKPFRCDTCDKSFHQRSALNRHCMVHTGEKPYRCEQCGKGFIGRLDFYKHQVVHTGEKPYNCKECGKSFRWSSCLLNHQRVHSGEKSFKCEECGKGFYTNSQLSSHQRSHSGEKPYKCEECGKGYVTKFNLDLHQRVHTGERPYNCKECGKNFSRASSILNHKRLHCQKKPFKCEDCGKRLVHRTYRKDQPRDYSGENPSKCEDCGRRYKRRLNLDILLSLFLNDT>sp|Q8N7M2|ZN283_HUMAN Zinc finger protein 283 OS=Homo sapiens OX=9606GN=ZNF283 PE=1 SV=4MESRSVAQAGVQWCDLGSLQAPPPGFTLFSCLSLLSSWDYSSGFSGFCASPIEESHGALISSCNSRTMTDGLVTFRDVAIDFSQEEWECLDPAQRDLYVDVMLENYSNLVSLDLESKTYETKKIFSENDIFEINFSQWEMKDKSKTLGLEASIFRNNWKCKSIFEGLKGHQEGYFSQMIISYEKIPSYRKSKSLTPHQRIHNTEKSYVCKECGKACSHGSKLVQHERTHTAEKHFECKECGKNYLSAYQLNVHQRFHTGEKPYECKECGKTFSWGSSLVKHERIHTGEKPYECKECGKAFSRGYHLTQHQKIHTGVKSYKCKECGKAFFWGSSLAKHEIIHTGEKPYKCKECGKAFSRGYQLTQHQKIHTGKKPYECKICGKAFCWGYQLTRHQIFHTGEKPYECKECGKAFNCGSSLIQHERIHTGEKPYECKECGKAFSRGYHLSQHQKIHTGEKPFECKECGKAFSWGSSLVKHERVHTGEKSHECKECGKTFCSGYQLTRHQVFHTGEKPYECKECGKAFNCGSSLVQHERIHTGEKPYECKECGKAFSRGYHLTQHQKIHTGEKPFKCKECGKAFSWGSSLVKHERVHTNEKSYECKDCGKAFGSGYQLSVHQRFHTGEKLYQRKEFGKTFTCGSKLVHERTHSNDKPYKYNECGEAFLWTTYSNEKIDTDETL>sp|Q9HCX3|ZN304_HUMAN Zinc finger protein 304 OS=Homo sapiens OX=9606GN=ZNF304 PE=1 SV=2MAAAVLMDRVQSCVTFEDVFVYFSREEWELLEEAQRFLYRDVMLENFALVATLGFWCEAEHEAPSEQSVSVEGVSQVRTAESGLFQKAHPCEMCDPLLKDILHLAEHQGSHLTQKLCTRGLCRRRFSFSANFYQHQKQHNGENCFRGDDGGASFVKSCTVHMLGRSFTCREEGMDLPDSSGLFQHQTTYNRVSPCRRTECMESFPHSSSLRQHQGDYDGQMLFSCGDEGKAFLDTFTLLDSQMTHAEVRPFRCLPCGNVFKEKSALINHRKIHSGEISHVCKECGKAFIHLHHLKMHQKFHTGKRHYTCSECGKAFSRKDTLVQHQRVHTGERSYDCSECGKAYSRSSHLVQHQRIHTGERPYKCNKCGKAFSRKDTLVQHQRFHTGERPYECSECGKFFSQSSHLIEHWRIHTGARPYECIECGKFFSHNSSLIKHRRVHTGARSYVCSKCGKAFGCKDTLVQHQIIHTGARPYECSECGKAFSRKDTLVQHQKIHTGERPYECGECGKFFSHSSNLIVHQRIHTGAKPYECNECGKCFSHNSSLILHQRVHTGARPYVCSECGKAYISSSHLVQHKKVHTGARPYECSECGKFFSRNSGLILHQRVHTGEKPYVCSECGKAYSRSSHLVRHQKAHTGERAHECNSFGGPLAASLKLV>sp|Q86UD4|ZN329_HUMAN Zinc finger protein 329 OS=Homo sapiens OX=9606GN=ZNF329 PE=1 SV=2MRLKMTTRNFPEREVPCDVEVERFTREVPCLSSLGDGWDCENQEGHLRQSALTLEKPGTQEAICEYPGFGEHLIASSDLPPSQRVLATNGFHAPDSNVSGLDCDPALPSYPKSYADKRTGDSDACGKGFNHSMEVIHGRNPVREKPYKYPESVKSFNHFTSLGHQKIMKRGKKSYEGKNFENIFTLSSSLNENQRNLPGEKQYRCTECGKCFKRNSSLVLHHRTHTGEKPYTCNECGKSFSKNYNLIVHQRIHTGEKPYECSKCGKAFSDGSALTQHQRIHTGEKPYECLECGKTFNRNSSLILHQRTHTGEKPYRCNECGKPFTDISHLTVHLRIHTGEKPYECSKCGKAFRDGSYLTQHERTHTGEKPFECAECGKSFNRNSHLIVHQKIHSGEKPYECKECGKTFIESAYLIRHQRIHTGEKPYGCNQCQKLFRNIAGLIRHQRTHTGEKPYECNQCGKAFRDSSCLTKHQRIHTKETPYQCPECGKSFKQNSHLAVHQRLHSREGPSRCPQCGKMFQKSSSLVRHQRAHLGEQPMET>sp|O76080|ZFAN5_HUMAN AN1-type zinc finger protein 5 OS=Homo sapiensOX=9606 GN=ZFAND5 PE=1 SV=1MAQETNQTPGPMLCSTGCGFYGNPRTNGMCSVCYKEHLQRQQNSGRMSPMGTASGSNSPTSDSASVQRADTSLNNCEGAAGSTSEKSRNVPVAALPVTQQMTEMSISREDKITTPKTEVSEPVVTQPSPSVSQPSTSQSEEKAPELPKPKKNRCFMCRKKVGLTGFDCRCGNLFCGLHRYSDKHNCPYDYKAEAAAKIRKENPVVVAEKIQRI>sp|Q8NHY6|ZFP28_HUMAN Zinc finger protein 28 homolog OS=Homo sapiensOX=9606 GN=ZFP28 PE=1 SV=1MRGAASASVREPTPLPGRGAPRTKPRAGRGPTVGTPATLALPARGRPRSRNGLASKGQRGAAPTGPGHRALPSRDTALPQERNKKLEAVGTGIEPKAMSQGLVTFGDVAVDFSQEEWEWLNPIQRNLYRKVMLENYRNLASLGLCVSKPDVISSLEQGKEPWTVKRKMTRAWCPDLKAVWKIKELPLKKDFCEGKLSQAVITERLTSYNLEYSLLGEHWDYDALFETQPGLVTIKNLAVDFRQQLHPAQKNFCKNGIWENNSDLGSAGHCVAKPDLVSLLEQEKEPWMVKRELTGSLFSGQRSVHETQELFPKQDSYAEGVTDRTSNTKLDCSSFRENWDSDYVFGRKLAVGQETQFRQEPITHNKTLSKERERTYNKSGRWFYLDDSEEKVHNRDSIKNFQKSSVVIKQTGIYAGKKLFKCNECKKTFTQSSSLTVHQRIHTGEKPYKCNECGKAFSDGSSFARHQRCHTGKKPYECIECGKAFIQNTSLIRHWRYYHTGEKPFDCIDCGKAFSDHIGLNQHRRIHTGEKPYKCDVCHKSFRYGSSLTVHQRIHTGEKPYECDVCRKAFSHHASLTQHQRVHSGEKPFKCKECGKAFRQNIHLASHLRIHTGEKPFECAECGKSFSISSQLATHQRIHTGEKPYECKVCSKAFTQKAHLAQHQKTHTGEKPYECKECGKAFSQTTHLIQHQRVHTGEKPYKCMECGKAFGDNSSCTQHQRLHTGQRPYECIECGKAFKTKSSLICHRRSHTGEKPYECSVCGKAFSHRQSLSVHQRIHSGKKPYECKECRKTFIQIGHLNQHKRVHTGERSYNYKKSRKVFRQTAHLAHHQRIHTGESSTCPSLPSTSNPVDLFPKFLWNPSSLPSP>sp|Q8NHY6-2|ZFP28_HUMAN Isoform 2 of Zinc finger protein 28 homologOS=Homo sapiens OX=9606 GN=ZFP28MRGAASASVREPTPLPGRGAPRTKPRAGRGPTVGTPATLALPARGRPRSRNGLASKGQRGAAPTGPGHRALPSRDTALPQERNKKLEAVGTGIEPKAMSQGLVTFGDVAVDFSQEEWEWLNPIQRNLYRKVMLENYRNLASLGLCVSKPDVISSLEQGKEPWTVKRKMTRAWCPDLKAVWKIKELPLKKDFCEGKLSQAVITERLTSYNLEYSLLGEHWDYDALFETQPGLVTIKNLAVDFRQQLHPAQKNFCKNGIWENNSDLGSAGHCVAKPDLVSLLEQEKEPWMVKRELTGSLFSGECRRAWCGKSTARESGAFTKKAASSLIYSRKLYPGSLGLERKLNSGSSK>sp|Q8TF39|ZN483_HUMAN Zinc finger protein 483 OS=Homo sapiens OX=9606GN=ZNF483 PE=1 SV=3MQAVVPLNKMTAISPEPQTLASTEQNEVPRVVTSGEQEAILRGNAADAESFRQRFRWFCYSEVAGPRKALSQLWELCNQWLRPDIHTKEQILELLVFEQFLTILPGEIRIWVKSQHPESSEEVVTLIEDLTQMLEEKDPVSQDSTVSQEENSKEDKMVTVCPNTESCESITLKDVAVNFSRGEWKKLEPFQKELYKEVLLENLRNLEFLDFPVSKLELISQLKWVELPWLLEEVSKSSRLDESALDKIIERCLRDDDHGLMEESQQYCGSSEEDHGNQGNSKGRVAQNKTLGSGSRGKKFDPDKSPFGHNFKETSDLIKHLRVYLRKKSRRYNESKKPFSFHSDLVLNRKEKTAGEKSRKSNDGGKVLSHSSALTEHQKRQKIHLGDRSQKCSKCGIIFIRRSTLSRRKTPMCEKCRKDSCQEAALNKDEGNESGEKTHKCSKCGKAFGYSASLTKHRRIHTGEKPYMCNECGKAFSDSSSLTPHHRTHSGEKPFKCDDCGKGFTLSAHLIKHQRIHTGEKPYKCKDCGRPFSDSSSLIQHQRIHTGEKPYTCSNCGKSFSHSSSLSKHQRIHTGEKPYKCGECGKAFRQNSCLTRHQRIHTGEKPYLCNDCGMTFSHFTSVIYHQRLHSGEKPYKCNQCEKAFPTHSLLSRHQRIHTGVKPYKCKECGKSFSQSSSLNEHHRIHTGEKPYECNYCGATFSRSSILVEHLKIHTGRREYECNECEKTFKSNSGLIRHRGFHSAE>sp|Q8TF39-2|ZN483_HUMAN Isoform 2 of Zinc finger protein 483 OS=Homosapiens OX=9606 GN=ZNF483MQAVVPLNKMTAISPEPQTLASTEQNEVPRVVTSGEQEAILRGNAADAESFRQRFRWFCYSEVAGPRKALSQLWELCNQWLRPDIHTKEQILELLVFEQFLTILPGEIRIWVKSQHPESSEEVVTLIEDLTQMLEEKDPVSQDSTVSQEENSKEDKMVTVCPNTESCESITLKDVAVNFSRGEWKKLEPFQKELYKEVLLENLRNLEFLDFPVSKLELISQLKWVELPWLLEEVSKSSRLDIHGAVKKMQMFSEAE>sp|Q9UFV3|YO007_HUMAN Putative uncharacterized protein DKFZp434L187OS=Homo sapiens OX=9606 PE=5 SV=2MAETYRRSRQHEQLPGQRHMDLLTGYSKLIQSRLKLLLHLGSQPPVGKTFFFSCWCHPLFHGSKTTPNVWYKFSETALSILNSCQASQLGVRKMPGDMSSSPRVREFSALVAIKEKIHILPTNAKVGSKFGS>sp|Q9BUY5|ZN426_HUMAN Zinc finger protein 426 OS=Homo sapiens OX=9606GN=ZNF426 PE=1 SV=1MAAADLSHGHYLSGDPVCLHEEKTPAGRIVADCLTDCYQDSVTFDDVAVDFTQEEWTLLDSTQRSLYSDVMLENYKNLATVGGQIIKPSLISWLEQEESRTVQGGVLQGWEMRLETQWSILQQDFLRGQTSIGIQLEGKHNGRELCDCEQCGEVFSEHSCLKTHVRTQSTGNTHDCNQYGKDFLTLCEKTSTGEKLSEFNQSEKIFSLTPNIVYQRTSTQEKSFECSHCGKSFINESYLQAHMRTHNGEKLYEWRNYGPGFIDSTSLSVLIETLNAKKPYKCKECGKGYRYPAYLSIHMRTHTGEKPYECKECGKAFNYSNSFQIHGRTHTGEKPYVCKECGKAFTQYSGLSMHVRSHSGDKPYECKECGKSFLTSSRLIQHIRTHTGEKPFVCVECGKAFAVSSNLSGHLRTHTEEKACECKICGKVFGYPSCLNNHMRTHSAQKPYTCKECGKAFNYSTHLKIHMRIHTGEKPYECKQCGKAFSHSSSFQIHERTHTGEKPYECKECGKAFTCSSSFRIHEKTHTEEKPYKCQQCGKAYSHPRSLRRHEQIH>sp|A8K8V0|ZN785_HUMAN Zinc finger protein 785 OS=Homo sapiens OX=9606GN=ZNF785 PE=1 SV=1MGPPLAPRPAHVPGEAGPRRTRESRPGAVSFADVAVYFSPEEWECLRPAQRALYRDVMRETFGHLGALGFSVPKPAFISWVEGEVEAWSPEAQDPDGESSAAFSRGQGQEAGSRDGNEEKERLKKCPKQKEVAHEVAVKEWWPSVACPEFCNPRQSPMNPWLKDTLTRRLPHSCPDCGRNFSYPSLLASHQRVHSGERPFSCGQCQARFSQRRYLLQHQFIHTGEKPYPCPDCGRRFRQRGSLAIHRRAHTGEKPYACSDCKSRFTYPYLLAIHQRKHTGEKPYSCPDCSLRFAYTSLLAIHRRIHTGEKPYPCPDCGRRFTYSSLLLSHRRIHSDSRPFPCVECGKGFKRKTALEAHRWIHRSCSERRAWQQAVVGRSEPIPVLGGKDPPVHFRHFPDIFQECG>sp|A8K8V0-2|ZN785_HUMAN Isoform 2 of Zinc finger protein 785 OS=Homosapiens OX=9606 GN=ZNF785MGPPLAPRPAHVPGEAGPRRTRESRPGAVSFADVAVYFSPEEWECLRPAQRALYRDVMRETFGHLGALGFSVPKPAFISWVEGEVEAWSPEAQDPDGSRDGNEEKERLKKCPKQKEVAHEVAVKEWWPSVACPEFCNPRQSPMNPWLKDTLTRRLPHSCPDCGRNFSYPSLLASHQRVHSGERPFSCGQCQARFSQRRYLLQHQFIHTGEKPYPCPDCGRRFRQRGSLAIHRRAHTGEKPYACSDCKSRFTYPYLLAIHQRKHTGEKPYSCPDCSLRFAYTSLLAIHRRIHTGEKPYPCPDCGRRFTYSSLLLSHRRIHSDSRPFPCVECGKGFKRKTALEAHRWIHRSCSERRAWQQAVVGRSEPIPVLGGKDPPVHFRHFPDIFQECG>sp|A8MUU9|YV023_HUMAN Putative uncharacterized protein ENSP00000383309OS=Homo sapiens OX=9606 PE=5 SV=3MPPTASLTRSPPTASQTRTLPRASRTRTPPRASLTRSPPTASLRRTPSRASRTRTPPRASLKRTPSRASLTRTLSRASLTRLKSRASHTRTPSRASLTRTPPTASRTRSLPRASRTRTPPRTSQRRMPPRTSQTRTPPRASLRRTPSRASRTRTPPRASLRRTPSRASLTRTPSRASLTRLKSRASHTRTPSRASLTRTPPTASLTRASRTRTPPRTSQTRTPPRASLRRTPSRASLTRTPSRASLTRTPSRASLTRLKSRASHTRTPSRASLTRTPPTASLTRTPPTASLTRTPPRASLTRSPPRASLTRTPPTASLTRSPPTASLTRTPPRASLTRSPPRASLTRTPSTASLTRTPSRASLTRSKSRASHTRTPSRASLTRTPPRASLTRTPPRASLTRSPPTASLTRMPPTASLTRSPPRASLTRTPPRASLTRSPSTASLTRTPPGTWLRRTPPRTSLTRTPPTASLTRTPYTASLTRTPYTASLMRMPYMTSLMTPYKAR>sp|Q15935|ZNF77_HUMAN Zinc finger protein 77 OS=Homo sapiens OX=9606GN=ZNF77 PE=1 SV=2MDCVIFEEVAVNFTPEEWALLDHAQRSLYRDVMLETCRNLASLDCYIYVRTSGSSSQRDVFGNGISNDEEIVKFTGSDSWSIFGENWRFDNTGDQHQIPQRHLRSQLGRLCESNEGHQCGETLSQTANLLVHKSYPTEAKPSECTKCGKAFENRQRSHTGQRPCKECGQACSCLSCQSPPMKTQTVEKPCNCQDSRTASVTYVKSLSSKKSYECQKCGKAFICPSSFRGHVNSHHGQKTHACKVCGKTFMYYSYLTRHVRTHTGEKPYECKECGKAFSCPSYFREHVRTHTGEKPYECKHCGKSFSCYSSFRDHVRTHTGEKPCQCKHCGKAFTCYSSLREHGRTHSGEKPYECKECGKAFRYPSSLRAHMRMHTGEKPYVCKQCGKAFGCPTYFRRHVKTHSGVKPYQCKECGKAYSFSSSLRIHVRTHTGEKPFECKHCGKAFSCHSSLREHVRTHSGEKPYECNQCGKAFSHAQYFQKHVRSHSGVKPYECTECGKAYSCSSSLRVHVRTHTGERPYECKQCGKTFRYLASLQAHVRTHAGA>sp|P0CH99|Z705D_HUMAN Zinc finger protein 705D OS=Homo sapiens OX=9606GN=ZNF705D PE=1 SV=1MHSLEKVTFEDVAIDFTQEEWDMMDTSKRKLYRDVMLENISHLVSLGYQISKSYIILQLEQGKELWREGRVFLQDQNPDRESALKKKHMISMHPIIRKDASTSMTMENSLILEDPFEYNDSGEDCTHSSTITQCLLTHSGKKPCVSKQCGKSLRNLLSPKPRKQIHTKGKSYQCNLCEKAYTNCFYLRRHKMTHTGERPYACHLCGKAFTQCSHLRRHEKTHTGERPYKCHQCGKAFIQSFNLRRHERTHLGQKCYECDKSGKAFSQSSGFRGNKIIHIGEKPHACLLCGKAFSLSSDLR>sp|Q6ZN08|ZNF66_HUMAN Putative zinc finger protein 66 OS=Homo sapiensOX=9606 GN=ZNF66 PE=5 SV=3MGPLQFRDVAIEFSLEEWHCLDMAQRNLYRDVMLENYRNLVFLGIVVSKPDLITHLEQGKKPSTMQRHEMVANPSVLCSHFNQDLWPEQSIKDSFQKLILRRHKKCGHDNLQLKKGCESVDKCKVHKRGYNGLNQCLTTTQSKMFQCDKHGKVFHQFSNTNRHKIRHTGKNPCKFTECGKAFNRSSTFTTHKKIHTGEKPYKCIECGKAFNRSSHLTTHKIIHTGEKRYKCEDCGKAFNRSSNLTTHKKIHTGEKPYKCEECGKAFKRSSILTTHKRIHTGEKPYKCEECGKVFKYLSSLSTHKIIHTGEKPYKCEECGKAFNWSSHLTTHKRIHTGEKPYKCEECGKGFKYSSTLTKHKIIHTGEKPYKCEECGEAFKYSCSLTAHKIIHTGKKPYKCEECGKVFKHSSPLSKHKRIHTGEKPYKCEECGKAFSRSSILTTHKIIHTGEKPYECEDCGKAFNRSSNLTKHKKIHTGEKPYKCEECGKAFKCSSILTTHKRIHTADKPYKCEECGKDFKYSSTLTRHKKIHTGGKPHKCNKCGKAFISSSNLSRHEIIHMGGNPYKCENVAKP>sp|Q9BYJ9|YTHD1_HUMAN YTH domain-containing family protein 1 OS=Homosapiens OX=9606 GN=YTHDF1 PE=1 SV=1MSATSVDTQRTKGQDNKVQNGSLHQKDTVHDNDFEPYLTGQSNQSNSYPSMSDPYLSSYYPPSIGFPYSLNEAPWSTAGDPPIPYLTTYGQLSNGDHHFMHDAVFGQPGGLGNNIYQHRFNFFPENPAFSAWGTSGSQGQQTQSSAYGSSYTYPPSSLGGTVVDGQPGFHSDTLSKAPGMNSLEQGMVGLKIGDVSSSAVKTVGSVVSSVALTGVLSGNGGTNVNMPVSKPTSWAAIASKPAKPQPKMKTKSGPVMGGGLPPPPIKHNMDIGTWDNKGPVPKAPVPQQAPSPQAAPQPQQVAQPLPAQPPALAQPQYQSPQQPPQTRWVAPRNRNAAFGQSGGAGSDSNSPGNVQPNSAPSVESHPVLEKLKAAHSYNPKEFEWNLKSGRVFIIKSYSEDDIHRSIKYSIWCSTEHGNKRLDSAFRCMSSKGPVYLLFSVNGSGHFCGVAEMKSPVDYGTSAGVWSQDKWKGKFDVQWIFVKDVPNNQLRHIRLENNDNKPVTNSRDTQEVPLEKAKQVLKIISSYKHTTSIFDDFAHYEKRQEEEEVVRKERQSRNKQ>sp|Q9BYJ9-2|YTHD1_HUMAN Isoform 2 of YTH domain-containing familyprotein 1 OS=Homo sapiens OX=9606 GN=YTHDF1MLFLGSLGAWGTTSISTGSIFSLKTLRSQHGGQVGLKVSRPRAPRMGAATPTPRAPWVARWLMGSQAFTATPSARPPPPIKHNMDIGTWDNKGPVPKAPVPQQAPSPQAAPQPQQVAQPLPAQPPALAQPQYQSPQQPPQTRWVAPRNRNAAFGQSGGAGSDSNSPGNVQPNSAPSVESHPVLEKLKAAHSYNPKEF>sp|Q9HCE3|ZN532_HUMAN Zinc finger protein 532 OS=Homo sapiens OX=9606GN=ZNF532 PE=1 SV=2MTMGDMKTPDFDDLLAAFDIPDMVDPKAAIESGHDDHESHMKQNAHGEDDSHAPSSSDVGVSVIVKNVRNIDSSEGGEKDGHNPTGNGLHNGFLTASSLDSYSKDGAKSLKGDVPASEVTLKDSTFSQFSPISSAEEFDDDEKIEVDDPPDKEDMRSSFRSNVLTGSAPQQDYDKLKALGGENSSKTGLSTSGNVEKNKAVKRETEASSINLSVYEPFKVRKAEDKLKESSDKVLENRVLDGKLSSEKNDTSLPSVAPSKTKSSSKLSSCIAAIAALSAKKAASDSCKEPVANSRESSPLPKEVNDSPRAADKSPESQNLIDGTKKPSLKQPDSPRSISSENSSKGSPSSPAGSTPAIPKVRIKTIKTSSGEIKRTVTRVLPEVDLDSGKKPSEQTASVMASVTSLLSSPASAAVLSSPPRAPLQSAVVTNAVSPAELTPKQVTIKPVATAFLPVSAVKTAGSQVINLKLANNTTVKATVISAASVQSASSAIIKAANAIQQQTVVVPASSLANAKLVPKTVHLANLNLLPQGAQATSELRQVLTKPQQQIKQAIINAAASQPPKKVSRVQVVSSLQSSVVEAFNKVLSSVNPVPVYIPNLSPPANAGITLPTRGYKCLECGDSFALEKSLTQHYDRRSVRIEVTCNHCTKNLVFYNKCSLLSHARGHKEKGVVMQCSHLILKPVPADQMIVSPSSNTSTSTSTLQSPVGAGTHTVTKIQSGITGTVISAPSSTPITPAMPLDEDPSKLCRHSLKCLECNEVFQDETSLATHFQQAADTSGQKTCTICQMLLPNQCSYASHQRIHQHKSPYTCPECGAICRSVHFQTHVTKNCLHYTRRVGFRCVHCNVVYSDVAALKSHIQGSHCEVFYKCPICPMAFKSAPSTHSHAYTQHPGIKIGEPKIIYKCSMCDTVFTLQTLLYRHFDQHIENQKVSVFKCPDCSLLYAQKQLMMDHIKSMHGTLKSIEGPPNLGINLPLSIKPATQNSANQNKEDTKSMNGKEKLEKKSPSPVKKSMETKKVASPGWTCWECDCLFMQRDVYISHVRKEHGKQMKKHPCRQCDKSFSSSHSLCRHNRIKHKGIRKVYACSHCPDSRRTFTKRLMLEKHVQLMHGIKDPDLKEMTDATNEEETEIKEDTKVPSPKRKLEEPVLEFRPPRGAITQPLKKLKINVFKVHKCAVCGFTTENLLQFHEHIPQHKSDGSSYQCRECGLCYTSHVSLSRHLFIVHKLKEPQPVSKQNGAGEDNQQENKPSHEDESPDGAVSDRKCKVCAKTFETEAALNTHMRTHGMAFIKSKRMSSAEK>sp|Q9H4I2|ZHX3_HUMAN Zinc fingers and homeoboxes protein 3 OS=Homosapiens OX=9606 GN=ZHX3 PE=1 SV=3MASKRKSTTPCMIPVKTVVLQDASMEAQPAETLPEGPQQDLPPEASAASSEAAQNPSSTDGSTLANGHRSTLDGYLYSCKYCDFRSHDMTQFVGHMNSEHTDFNKDPTFVCSGCSFLAKTPEGLSLHNATCHSGEASFVWNVAKPDNHVVVEQSIPESTSTPDLAGEPSAEGADGQAEIIITKTPIMKIMKGKAEAKKIHTLKENVPSQPVGEALPKLSTGEMEVREGDHSFINGAVPVSQASASSAKNPHAANGPLIGTVPVLPAGIAQFLSLQQQPPVHAQHHVHQPLPTAKALPKVMIPLSSIPTYNAAMDSNSFLKNSFHKFPYPTKAELCYLTVVTKYPEEQLKIWFTAQRLKQGISWSPEEIEDARKKMFNTVIQSVPQPTITVLNTPLVASAGNVQHLIQAALPGHVVGQPEGTGGGLLVTQPLMANGLQATSSPLPLTVTSVPKQPGVAPINTVCSNTTSAVKVVNAAQSLLTACPSITSQAFLDASIYKNKKSHEQLSALKGSFCRNQFPGQSEVEHLTKVTGLSTREVRKWFSDRRYHCRNLKGSRAMIPGDHSSIIIDSVPEVSFSPSSKVPEVTCIPTTATLATHPSAKRQSWHQTPDFTPTKYKERAPEQLRALESSFAQNPLPLDEELDRLRSETKMTRREIDSWFSERRKKVNAEETKKAEENASQEEEEAAEDEGGEEDLASELRVSGENGSLEMPSSHILAERKVSPIKINLKNLRVTEANGRNEIPGLGACDPEDDESNKLAEQLPGKVSCKKTAQQRHLLRQLFVQTQWPSNQDYDSIMAQTGLPRPEVVRWFGDSRYALKNGQLKWYEDYKRGNFPPGLLVIAPGNRELLQDYYMTHKMLYEEDLQNLCDKTQMSSQQVKQWFAEKMGEETRAVADTGSEDQGPGTGELTAVHKGMGDTYSEVSENSESWEPRVPEASSEPFDTSSPQAGRQLETD>sp|Q9H4I2-2|ZHX3_HUMAN Isoform 2 of Zinc fingers and homeoboxes protein3 OS=Homo sapiens OX=9606 GN=ZHX3MASKRKSTTPCMIPVKTVVLQDASMEAQPAETLPEGPQQDLPPEASAASSEAAQNPSSTDGSTLANGHRSTLDGYLYSCKYCDFRSHDMTQFVGHMNSEHTDFNKDPTFVCSGCSFLAKTPEGLSLHNATCHSGEASFVWNVAKPDNHVVVEQSIPESTSTPDLAGEPSAEGADGQAEIIITKTPIMKIMKGKAEAKKIHTLKENVPSQPVGEALPKLSTGEMEVREGDHSFINGAVPVSQASASSAKNPHAANGPLIGTVPVLPAGIAQFLSLQQQPPVHAQHHVHQPLPTAKALPKVMIPLSSIPTYNAAMDSNSFLKNSFHKFPYPTKAELCYLTVVTKYPEEQLKIWFTAQRLKQGISWSPEEIEDARKKMFNTVIQSVPQPTITVLNTPLVASAGNVQHLIQAALPGHVVGQPEGTGGGLLVTQPLMANGLQATSSPLPLTVTSVPKQPGVAPINTVCSNTTSAVKVVNAAQSLLTACPSITSQAFLDASIYKNKKSHEQLSALKGSFCRNQFPGQSEVEHLTKVTGLSTREVRKWFSDRRYHCRNLKGSRAMIPGDHSSIIIDSVPEVSFSPSSKVPEVTCIPTTATLATHPSAKRQSWHQTPDFTPTKYKERAPEQLRALESSFAQNPLPLDEELDRLRSETKMTRREIDSWFSERRKKVNAEETKKAEENASQEEEEAAEDEGGEEDLASELRVSGENGSLEMPSSHILAERKVSPIKINLKNLRVTEANGRNEIPGLGACDPEDDESNKLAEQLPGKVSCKKTAQQRHLLRQLFVQTQWPSNQDYDSIMAQTGLPRPEVVRWFGDSRYALKNGQLKWYEDYKRGNFPPGLLVIAPGNRELLQDYYMTHKMLYEEDLQNLCDKTQMSSQQKQTEFDLINVKDWPVWETACHVEEPNPTLCCHMPFPCPAAGHLGELPESSQTAQSLPLPSACPPPSKQQARWGSHQFFLPQCRTFPLPSNG>sp|Q86VX9|MON1A_HUMAN Vacuolar fusion protein MON1 homolog A OS=Homosapiens OX=9606 GN=MON1A PE=1 SV=3MHPGGGPSRAERLELGLGRERPAKAIFLHRRPGEGGGRERCLRCGHVCVRRGPGPREAVPSGRPRPDTLTPPWVRQRAVTGTFCASWTPLRNRRAQRMATDMQRKRSSECLDGTLTPSDGQSMERAESPTPGMAQGMEPGAGQEGAMFVHARSYEDLTESEDGAASGDSHKEGTRGPPPLPTDMRQISQDFSELSTQLTGVARDLQEEMLPGSSEDWLEPPGAVGRPATEPPREGTTEGDEEDATEAWRLHQKHVFVLSEAGKPVYSRYGSEEALSSTMGVMVALVSFLEADKNAIRSIHADGYKVVFVRRSPLVLVAVARTRQSAQELAQELLYIYYQILSLLTGAQLSHIFQQKQNYDLRRLLSGSERITDNLLQLMARDPSFLMGAARCLPLAAAVRDTVSASLQQARARSLVFSILLARNQLVALVRRKDQFLHPIDLHLLFNLISSSSSFREGEAWTPVCLPKFNAAGFFHAHISYLEPDTDLCLLLVSTDREDFFAVSDCRRRFQERLRKRGAHLALREALRTPYYSVAQVGIPDLRHFLYKSKSSGLFTSPEIEAPYTSEEEQERLLGLYQYLHSRAHNASRPLKTIYYTGPNENLLAWVTGAFELYMCYSPLGTKASAVSAIHKLMRWIRKEEDRLFILTPLTY>sp|Q86VX9-2|MON1A_HUMAN Isoform 2 of Vacuolar fusion protein MON1homolog A OS=Homo sapiens OX=9606 GN=MON1AMATDMQRKRSSECLDGTLTPSDGQSMERAESPTPGMAQGMEPDGYKVVFVRRSPLVLVAVARTRQSAQELAQELLYIYYQILSLLTGAQLSHIFQQKQNYDLRRLLSGSERITDNLLQLMARDPSFLMGAARCLPLAAAVRDTVSASLQQARARSLVFSILLARNQLVALVRRKDQFLHPIDLHLLFNLISSSSSFREGEAWTPVCLPKFNAAGFFHAHISYLEPDTDLCLLLVSTDREDFFAVSDCRRRFQERLRKRGAHLALREALRTPYYSVAQVGIPDLRHFLYKSKSSGLFTSPEIEAPYTSEEEQERLLGLYQYLHSRAHNASRPLKTIYYTGPNENLLAWVTGAFELYMCYSPLGTKASAVSAIHKLMRWIRKEEDRLFILTPLTY>sp|Q86VX9-3|MON1A_HUMAN Isoform 3 of Vacuolar fusion protein MON1homolog A OS=Homo sapiens OX=9606 GN=MON1AMATDMQRKRSSECLDGTLTPSDGQSMERAESPTPGMAQGMEPDGYKVVFVRRSPLVLVAVARTRQSAQELAQELLYIYYQILSLLTGAQLSHIFQQKQNYDLRRLLSGSERITDNLLQLMARDPSFLMGAARCLPLAAAVRDTVSASLQQARARSLVFSILLARNQLVALVRRKDQFLHPIDLHLLFNLISSSSSFREGEAWTPVCLPKFNAAGFFHAHISYLEPDTDLCLLLVSTDREDFFAVSDCRRRFQERLRKRGAHLALREALRTPYYSVAQVGIPDLRHFLYKSKSSGLFTR>sp|Q86VX9-4|MON1A_HUMAN Isoform 4 of Vacuolar fusion protein MON1homolog A OS=Homo sapiens OX=9606 GN=MON1AMHPGGGPSRAERLELGLGRERPAKAIFLHRRPGEGGGRERCLRCGHVCVRRGPGPREAVPSGRPRPDTLTPPWVRQRAVTGTFCASWTPLRNRRAQRMATDMQRKRSSECLDGTLTPSDGQSMERAESPTPGMAQGMEPDGYKVVFVRRSPLVLVAVARTRQSAQELAQELLYIYYQILSLLTGAQLSHIFQQKQNYDLRRLLSGSERITDNLLQLMARDPSFLMGAARCLPLAAAVRDTVSASLQQARARSLVFSILLARNQLVALVRRKDQFLHPIDLHLLFNLISSSSSFREGEAWTPVCLPKFNAAGFFHAHISYLEPDTDLCLLLVSTDREDFFAVSDCRRRFQERLRKRGAHLALREALRTPYYSVAQVGIPDLRHFLYKSKSSGLFTSPEIEAPYTSEEEQERLLGLYQYLHSRAHNASRPLKTIYYTGPNENLLAWVTGAFELYMCYSPLGTKASAVSAIHKLMRWIRKEEDRLFILTPLTY>sp|Q86VX9-5|MON1A_HUMAN Isoform 5 of Vacuolar fusion protein MON1homolog A OS=Homo sapiens OX=9606 GN=MON1AMATDMQRKRSSECLDGTLTPSDGQSMERAESPTPGMAQGMEPGAGQEGAMFVHARSYEDLTESEDGAASGDSHKEGTRGPPPLPTDMRQISQDFSELSTQLTGVARDLQEEMLPGSSEDWLEPPGAVGRPATEPPREGTTEGDEEDATEAWRLHQKHVFVLSEAGKPVYSRYGSEEALSSTMGVMVALVSFLEADKNAIRSIHADGYKVVFVRRSPLVLVAVARTRQSAQELAQELLYIYYQILSLLTGAQLSHIFQQKQNYDLRRLLSGSERITDNLLQLMARDPSFLMGAARCLPLAAAVRDTVSASLQQARARSLVFSILLARNQLVALVRRKDQFLHPIDLHLLFNLISSSSSFREGEAWTPVCLPKFNAAGFFHAHISYLEPDTDLCLLLVSTDREDFFAVSDCRRRFQERLRKRGAHLALREALRTPYYSVAQVGIPDLRHFLYKSKSSGLFTSPEIEAPYTSEEEQERLLGLYQYLHSRAHNASRPLKTIYYTGPNENLLAWVTGAFELYMCYSPLGTKASAVSAIHKLMRWIRKEEDRLFILTPLTY>sp|P24347|MMP11_HUMAN Stromelysin-3 OS=Homo sapiens OX=9606 GN=MMP11PE=1 SV=3MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDAHHLHAERRGPQPWHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYWHGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDAQGHIWFFQGAQYWVYDGEKPVLGPAPLTELGLVRFPVHAALVWGPEKNKIYFFRGRDYWRFHPSTRRVDSPVPRRATDWRGVPSEIDAAFQDADGYAYFLRGRLYWKFDPVKVKALEGFPRLVGPDFFGCAEPANTFL>sp|Q9UBU8|MO4L1_HUMAN Mortality factor 4-like protein 1 OS=Homo sapiensOX=9606 GN=MORF4L1 PE=1 SV=2MAPKQDPKPKFQEGERVLCFHGPLLYEAKCVKVAIKDKQVKYFIHYSGWNKKSAVRPRRSEKSLKTHEDIVALFPVPEGAPSVHHPLLTSSWDEWVPESRVLKYVDTNLQKQRELQKANQEQYAEGKMRGAAPGKKTSGLQQKNVEVKTKKNKQKTPGNGDGGSTSETPQPPRKKRARVDPTVENEETFMNRVEVKVKIPEELKPWLVDDWDLITRQKQLFYLPAKKNVDSILEDYANYKKSRGNTDNKEYAVNEVVAGIKEYFNVMLGTQLLYKFERPQYAEILADHPDAPMSQVYGAPHLLRLFVRIGAMLAYTPLDEKSLALLLNYLHDFLKYLAKNSATLFSASDYEVAPPEYHRKAV>sp|Q9UBU8-2|MO4L1_HUMAN Isoform 2 of Mortality factor 4-like protein 1OS=Homo sapiens OX=9606 GN=MORF4L1MAPKQDPKPKFQEGERVLCFHGPLLYEAKCVKVAIKDKQVKYFIHYSGWNKNWDEWVPESRVLKYVDTNLQKQRELQKANQEQYAEGKMRGAAPGKKTSGLQQKNVEVKTKKNKQKTPGNGDGGSTSETPQPPRKKRARVDPTVENEETFMNRVEVKVKIPEELKPWLVDDWDLITRQKQLFYLPAKKNVDSILEDYANYKKSRGNTDNKEYAVNEVVAGIKEYFNVMLGTQLLYKFERPQYAEILADHPDAPMSQVYGAPHLLRLFVRIGAMLAYTPLDEKSLALLLNYLHDFLKYLAKNSATLFSASDYEVAPPEYHRKAV>sp|Q9UBU8-3|MO4L1_HUMAN Isoform 3 of Mortality factor 4-like protein 1OS=Homo sapiens OX=9606 GN=MORF4L1MRGAAPGKKTSGLQQKNVEVKTKKNKQKTPGNGDGGSTSETPQPPRKKRARVDPTVENEETFMNRVEVKVKIPEELKPWLVDDWDLITRQKQLFYLPAKKNVDSILEDYANYKKSRGNTDNKEYAVNEVVAGIKEYFNVMLGTQLLYKFERPQYAEILADHPDAPMSQVYGAPHLLRLFVRIGAMLAYTPLDEKSLALLLNYLHDFLKYLAKNSATLFSASDYEVAPPEYHRKAV>sp|Q9BU76|MMTA2_HUMAN Multiple myeloma tumor-associated protein 2OS=Homo sapiens OX=9606 GN=MMTAG2 PE=1 SV=1MFGSSRGGVRGGQDQFNWEDVKTDKQRENYLGNSLMAPVGRWQKGRDLTWYAKGRAPCAGPSREEELAAVREAEREALLAALGYKNVKKQPTGLSKEDFAEVCKREGGDPEEKGVDRLLGLGSASGSVGRVAMSREDKEAAKLGLSVFTHHRVESGGPGTSAASARRKPRAEDQTESSCESHRKSKKEKKKKKKRKHKKEKKKKDKEHRRPAEATSSPTSPERPRHHHHDSDSNSPCCKRRKRGHSGDRRSPSRRWHDRGSEA>sp|Q9BU76-2|MMTA2_HUMAN Isoform 2 of Multiple myeloma tumor-associatedprotein 2 OS=Homo sapiens OX=9606 GN=MMTAG2MFGSSRGGVRGGQDQFNWEDVKTDKQRENYLGNSLMAPVGRWQKGRDLTWYAKGRAPCAGPSREEELAAVREAEREALLAALGYKNVKKQPTGLSKEDFAEVCKREGGDPEEKGVDRLLGLGSARCGRVSRGGQHWARLLG>sp|Q9BU76-3|MMTA2_HUMAN Isoform 3 of Multiple myeloma tumor-associatedprotein 2 OS=Homo sapiens OX=9606 GN=MMTAG2MFGSSRGGVRGGQDQFNWEDVKTDKQRENYLGNSLMAPVGRWQKGRDLTWYAKGRAPCAGPSREEELAAVREAEREALLAALGYKNVKKQPTGLSKEDFAEVCKREGGDPEEKGVDRLLGLGSASGSVGRVAMSREDKEAAKLGLSVFTVIPRPA>sp|Q9BU76-4|MMTA2_HUMAN Isoform 4 of Multiple myeloma tumor-associatedprotein 2 OS=Homo sapiens OX=9606 GN=MMTAG2MFGSSRGGVRGGQDQFNWEDVKTDKQRENYLGNSLMAPVGRWQKGRDLTWYAKGRAPCAGPSREEELAAVREAEREALLAALGYKNVKKQPTGLSKEDFAEVCKREGGDPEEKGVDRLLGLGSASGSVGRVAMSREDKEAAKLGLSVFTHHRVESGGPGTSAASARRKPRAEDQTESRGVSRVTLEERS>sp|Q6ZUA9|MROH5_HUMAN Maestro heat-like repeat family member 5 OS=Homosapiens OX=9606 GN=MROH5 PE=2 SV=2MDRQCSERPYSCTPTGRVSSAVSQNSRISPPVSTSMKDSSCMKVHQDSARRDRWSHPTTILLHKSQSSQATLMLQEHRMFMGEAYSAATGFKMLQDMNSADPFHLKYIIKKIKNMAHGSPKLVMETIHDYFIDNPEISSRHKFRLFQTLEMVIGASDVLEETWEKTFTRLALENMTKATELEDIYQDAASNMLVAICRHSWRVVAQHLETELLTGVFPHRSLLYVMGVLSSSEELFSQEDKACWEEQLIQMAIKSVPFLSTDVWSKELLWTLTTPSWTQQEQSPEKAFLFTYYGLILQAEKNGATVRRHLQALLETSHQWPKQREGMALTLGLAATRHLDDVWAVLDQFGRSRPIRWSLPSSSPKNSEDLRWKWASSTILLAYGQVAAKARAHILPWVDNIVSRMVFYFHYSSWDETLKQSFLTATLMLMGAVSRSEGAHSYEFFQTSELLQCLMVLMEKEPQDTLCTRSRQQAMHIASSLCKLRPPIDLERKSQLLSTCFRSVFALPLLDALEKHTCLFLEPPNIQLWPVARERAGWTHQGWGPRAVLHCSEHLQSLYSRTMEALDFMLQSLIMQNPTADELHFLLSHLYIWLASEKAHERQRAVHSCMILLKFLNHNGYLDPKEDFKRIGQLVGILGMLCQDPDRATQRCSLEGASHLYQLLMCHKTGEALQAESQAPKELSQAHSDGAPLWNSRDQKATPLGPQEMAKNHIFQLCSFQVIKDIMQQLTLAELSDLIWTAIDGLGSTSPFRVQAASEMLLTAVQEHGAKLEIVSSMAQAIRLRLCSVHIPQAKEKTLHAITLLARSHTCELVATFLNISIPLDSHTFQLWRALGAGQPTSHLVLTTLLACLQERPLPTGASDSSPCPKEKTYLRLLAAMNMLHELQFAREFKQAVQEGYPKLFLALLTQMHYVLELNLPSEPQPKQQAQEAAVPSPQSCSTSLEALKSLLSTTGHWHDFAHLELQGSWELFTTIHTYPKGVGLLARAMVQNHCRQIPAVLRQLLPSLQSPQERERKVAILILTKFLYSPVLLEVLPKQAALTVLAQGLHDPSPEVRVLSLQGLSNILFHPDKGSLLQGQLRPLLDGFFQSSDQVIVCIMGTVSDTLHRLGAQGTGSQSLGVAISTRSFFNDERDGIRAAAMALFGDLVAAMADRELSGLRTQVHQSMVPLLLHLKDQCPAVATQAKFTFYRCAVLLRWRLLHTLFCTLAWERGLSARHFLWTCLMTRSQEEFSIHLSQALSYLHSHSCHIKTWVTLFIGHTICYHPQAVFQMLNAVDTNLLFRTFEHLRSDPEPSIREFATSQLSFLQKVSARPKQ>sp|Q9UNF0|PACN2_HUMAN Protein kinase C and casein kinase substrate inneurons protein 2 OS=Homo sapiens OX=9606 GN=PACSIN2 PE=1 SV=2MSVTYDDSVGVEVSSDSFWEVGNYKRTVKRIDDGHRLCSDLMNCLHERARIEKAYAQQLTEWARRWRQLVEKGPQYGTVEKAWMAFMSEAERVSELHLEVKASLMNDDFEKIKNWQKEAFHKQMMGGFKETKEAEDGFRKAQKPWAKKLKEVEAAKKAHHAACKEEKLAISREANSKADPSLNPEQLKKLQDKIEKCKQDVLKTKEKYEKSLKELDQGTPQYMENMEQVFEQCQQFEEKRLRFFREVLLEVQKHLDLSNVAGYKAIYHDLEQSIRAADAVEDLRWFRANHGPGMAMNWPQFEEWSADLNRTLSRREKKKATDGVTLTGINQTGDQSLPSKPSSTLNVPSNPAQSAQSQSSYNPFEDEDDTGSTVSEKDDTKAKNVSSYEKTQSYPTDWSDDESNNPFSSTDANGDSNPFDDDATSGTEVRVRALYDYEGQEHDELSFKAGDELTKMEDEDEQGWCKGRLDNGQVGLYPANYVEAIQ>sp|Q9UNF0-2|PACN2_HUMAN Isoform 2 of Protein kinase C and casein kinasesubstrate in neurons protein 2 OS=Homo sapiens OX=9606 GN=PACSIN2MSVTYDDSVGVEVSSDSFWEVGNYKRTVKRIDDGHRLCSDLMNCLHERARIEKAYAQQLTEWARRWRQLVEKGPQYGTVEKAWMAFMSEAERVSELHLEVKASLMNDDFEKIKNWQKEAFHKQMMGGFKETKEAEDGFRKAQKPWAKKLKEVEAAKKAHHAACKEEKLAISREANSKADPSLNPEQLKKLQDKIEKCKQDVLKTKEKYEKSLKELDQGTPQYMENMEQVFEQCQQFEEKRLRFFREVLLEVQKHLDLSNVAGYKAIYHDLEQSIRAADAVEDLRWFRANHGPGMAMNWPQFEEWSADLNRTLSRREKKKATDGVTLTGINQTGDQSLPSKPSSVSSYEKTQSYPTDWSDDESNNPFSSTDANGDSNPFDDDATSGTEVRVRALYDYEGQEHDELSFKAGDELTKMEDEDEQGWCKGRLDNGQVGLYPANYVEAIQ>sp|P15941|MUC1_HUMAN Mucin-1 OS=Homo sapiens OX=9606 GN=MUC1 PE=1 SV=3MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAVSMTSSVLSSHSPGSGSSTTQGQDVTLAPATEPASGSAATWGQDVTSVPVTRPALGSTTPPAHDVTSAPDNKPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDNRPALGSTAPPVHNVTSASGSASGSASTLVHNGTSARATTTPASKSTPFSIPSHHSDTPTTLASHSTKTDASSTHHSSVPPLTSSNHSTSPQLSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-2|MUC1_HUMAN Isoform 2 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTATTAPKPATVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAVSMTSSVLSSHSPGSGSSTTQGQDVTLAPATEPASGSAATWGQDVTSVPVTRPALGSTTPPAHDVTSAPDNKPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDNRPALGSTAPPVHNVTSASGSASGSASTLVHNGTSARATTTPASKSTPFSIPSHHSDTPTTLASHSTKTDASSTHHSSVPPLTSSNHSTSPQLSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-3|MUC1_HUMAN Isoform 3 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTGSGHASSTPGGEKETSATQRSSVPSSTEKNAVSMTSSVLSSHSPGSGSSTTQGQDVTLAPATEPASGSAATWGQDVTSVPVTRPALGSTTPPAHDVTSAPDNKPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDNRPALGSTAPPVHNVTSASGSASGSASTLVHNGTSARATTTPASKSTPFSIPSHHSDTPTTLASHSTKTDASSTHHSSVPPLTSSNHSTSPQLSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-4|MUC1_HUMAN Isoform 4 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTGGEKETSATQRSSVPSSTEKNAVSMTSSVLSSHSPGSGSSTTQGQDVTLAPATEPASGSAATWGQDVTSVPVTRPALGSTTPPAHDVTSAPDNKPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDNRPALGSTAPPVHNVTSASGSASGSASTLVHNGTSARATTTPASKSTPFSIPSHHSDTPTTLASHSTKTDASSTHHSSVPPLTSSNHSTSPQLSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-5|MUC1_HUMAN Isoform 5 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAVSMTSSVLSSHSPGSGSSTTQGQDVTLAPATEPASGSAATWGQDVTSVPVTRPALGSTTPPAHDVTSAPDNKPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDNRPALGSTAPPVHNVTSASGSASGSASTLVHNGTSARATTTPASKSTPFSIPSHHSDTPTTLASHSTKTDASSTHHSSVPPLTSSNHSTSPQLSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMVSIGLSFPMLP>sp|P15941-6|MUC1_HUMAN Isoform 6 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAIPAPTTTKSCRETFLKWPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-7|MUC1_HUMAN Isoform Y of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-8|MUC1_HUMAN Isoform 8 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNALSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-9|MUC1_HUMAN Isoform 9 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNALSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-10|MUC1_HUMAN Isoform F of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAIPAPTTTKSCRETFLKCFCRFINKGVFWASPILSSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-11|MUC1_HUMAN Isoform Y-LSP of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTATTAPKPATVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-12|MUC1_HUMAN Isoform S2 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTATTAPKPATVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAFNSSLEDPSTDYYQELQRDISEMAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-13|MUC1_HUMAN Isoform M6 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNALSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSGCLSVPPKELRAAGHLSSPGYLPSYERVPHLPHPWALCAP>sp|P15941-14|MUC1_HUMAN Isoform ZD of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAIPAPTTTKSCRETFLKCFCRFINKGVFWASPILSSGQDLWWYN>sp|P15941-15|MUC1_HUMAN Isoform T10 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTATTAPKPATVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-16|MUC1_HUMAN Isoform E2 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTATTAPKPATVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNASGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAATSANL>sp|P15941-17|MUC1_HUMAN Isoform J13 of Mucin-1 OS=Homo sapiens OX=9606GN=MUC1MTPGTQSPFFLLLLLTVLTATTAPKPATVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKRQNGWSTMPRGALPEESQG>sp|Q02817|MUC2_HUMAN Mucin-2 OS=Homo sapiens OX=9606 GN=MUC2 PE=1 SV=2MGLPLARLAAVCLALSLAGGSELQTEGRTRYHGRNVCSTWGNFHYKTFDGDVFRFPGLCDYNFASDCRGSYKEFAVHLKRGPGQAEAPAGVESILLTIKDDTIYLTRHLAVLNGAVVSTPHYSPGLLIEKSDAYTKVYSRAGLTLMWNREDALMLELDTKFRNHTCGLCGDYNGLQSYSEFLSDGVLFSPLEFGNMQKINQPDVVCEDPEEEVAPASCSEHRAECERLLTAEAFADCQDLVPLEPYLRACQQDRCRCPGGDTCVCSTVAEFSRQCSHAGGRPGNWRTATLCPKTCPGNLVYLESGSPCMDTCSHLEVSSLCEEHRMDGCFCPEGTVYDDIGDSGCVPVSQCHCRLHGHLYTPGQEITNDCEQCVCNAGRWVCKDLPCPGTCALEGGSHITTFDGKTYTFHGDCYYVLAKGDHNDSYALLGELAPCGSTDKQTCLKTVVLLADKKKNAVVFKSDGSVLLNQLQVNLPHVTASFSVFRPSSYHIMVSMAIGVRLQVQLAPVMQLFVTLDQASQGQVQGLCGNFNGLEGDDFKTASGLVEATGAGFANTWKAQSTCHDKLDWLDDPCSLNIESANYAEHWCSLLKKTETPFGRCHSAVDPAEYYKRCKYDTCNCQNNEDCLCAALSSYARACTAKGVMLWGWREHVCNKDVGSCPNSQVFLYNLTTCQQTCRSLSEADSHCLEGFAPVDGCGCPDHTFLDEKGRCVPLAKCSCYHRGLYLEAGDVVVRQEERCVCRDGRLHCRQIRLIGQSCTAPKIHMDCSNLTALATSKPRALSCQTLAAGYYHTECVSGCVCPDGLMDDGRGGCVVEKECPCVHNNDLYSSGAKIKVDCNTCTCKRGRWVCTQAVCHGTCSIYGSGHYITFDGKYYDFDGHCSYVAVQDYCGQNSSLGSFSIITENVPCGTTGVTCSKAIKIFMGRTELKLEDKHRVVIQRDEGHHVAYTTREVGQYLVVESSTGIIVIWDKRTTVFIKLAPSYKGTVCGLCGNFDHRSNNDFTTRDHMVVSSELDFGNSWKEAPTCPDVSTNPEPCSLNPHRRSWAEKQCSILKSSVFSICHSKVDPKPFYEACVHDSCSCDTGGDCECFCSAVASYAQECTKEGACVFWRTPDLCPIFCDYYNPPHECEWHYEPCGNRSFETCRTINGIHSNISVSYLEGCYPRCPKDRPIYEEDLKKCVTADKCGCYVEDTHYPPGASVPTEETCKSCVCTNSSQVVCRPEEGKILNQTQDGAFCYWEICGPNGTVEKHFNICSITTRPSTLTTFTTITLPTTPTSFTTTTTTTTPTSSTVLSTTPKLCCLWSDWINEDHPSSGSDDGDREPFDGVCGAPEDIECRSVKDPHLSLEQHGQKVQCDVSVGFICKNEDQFGNGPFGLCYDYKIRVNCCWPMDKCITTPSPPTTTPSPPPTTTTTLPPTTTPSPPTTTTTTPPPTTTPSPPITTTTTPLPTTTPSPPISTTTTPPPTTTPSPPTTTPSPPTTTPSPPTTTTTTPPPTTTPSPPMTTPITPPASTTTLPPTTTPSPPTTTTTTPPPTTTPSPPTTTPITPPTSTTTLPPTTTPSPPPTTTTTPPPTTTPSPPTTTTPSPPTITTTTPPPTTTPSPPTTTTTTPPPTTTPSPPTTTPITPPTSTTTLPPTTTPSPPPTTTTTPPPTTTPSPPTTTTPSPPITTTTTPPPTTTPSSPITTTPSPPTTTMTTPSPTTTPSSPITTTTTPSSTTTPSPPPTTMTTPSPTTTPSPPTTTMTTLPPTTTSSPLTTTPLPPSITPPTFSPFSTTTPTTPCVPLCNWTGWLDSGKPNFHKPGGDTELIGDVCGPGWAANISCRATMYPDVPIGQLGQTVVCDVSVGLICKNEDQKPGGVIPMAFCLNYEINVQCCECVTQPTTMTTTTTENPTPPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTPTTTPITTTTTVTPTPTPTGTQTGPPTHTSTAPIAELTTSNPPPESSTPQTSRSTSSPLTESTTLLSTLPPAIEMTSTAPPSTPTAPTTTSGGHTLSPPPSTTTSPPGTPTRGTTTGSSSAPTPSTVQTTTTSAWTPTPTPLSTPSIIRTTGLRPYPSSVLICCVLNDTYYAPGEEVYNGTYGDTCYFVNCSLSCTLEFYNWSCPSTPSPTPTPSKSTPTPSKPSSTPSKPTPGTKPPECPDFDPPRQENETWWLCDCFMATCKYNNTVEIVKVECEPPPMPTCSNGLQPVRVEDPDGCCWHWECDCYCTGWGDPHYVTFDGLYYSYQGNCTYVLVEEISPSVDNFGVYIDNYHCDPNDKVSCPRTLIVRHETQEVLIKTVHMMPMQVQVQVNRQAVALPYKKYGLEVYQSGINYVVDIPELGVLVSYNGLSFSVRLPYHRFGNNTKGQCGTCTNTTSDDCILPSGEIVSNCEAAADQWLVNDPSKPHCPHSSSTTKRPAVTVPGGGKTTPHKDCTPSPLCQLIKDSLFAQCHALVPPQHYYDACVFDSCFMPGSSLECASLQAYAALCAQQNICLDWRNHTHGACLVECPSHREYQACGPAEEPTCKSSSSQQNNTVLVEGCFCPEGTMNYAPGFDVCVKTCGCVGPDNVPREFGEHFEFDCKNCVCLEGGSGIICQPKRCSQKPVTHCVEDGTYLATEVNPADTCCNITVCKCNTSLCKEKPSVCPLGFEVKSKMVPGRCCPFYWCESKGVCVHGNAEYQPGSPVYSSKCQDCVCTDKVDNNTLLNVIACTHVPCNTSCSPGFELMEAPGECCKKCEQTHCIIKRPDNQHVILKPGDFKSDPKNNCTFFSCVKIHNQLISSVSNITCPNFDASICIPGSITFMPNGCCKTCTPRNETRVPCSTVPVTTEVSYAGCTKTVLMNHCSGSCGTFVMYSAKAQALDHSCSCCKEEKTSQREVVLSCPNGGSLTHTYTHIESCQCQDTVCGLPTGTSRRARRSPRHLGSG>sp|Q9BSU3|NAA11_HUMAN N-alpha-acetyltransferase 11 OS=Homo sapiensOX=9606 GN=NAA11 PE=1 SV=3MNIRNAQPDDLMNMQHCNLLCLPENYQMKYYLYHGLSWPQLSYIAEDEDGKIVGYVLAKMEEEPDDVPHGHITSLAVKRSHRRLGLAQKLMDQASRAMIENFNAKYVSLHVRKSNRPALHLYSNTLNFQISEVEPKYYADGEDAYAMKRDLSQMADELRRQMDLKKGGYVVLGSRENQETQGSTLSDSEEACQQKNPATEESGSDSKEPKESVESTNVQDSSESSDSTS>sp|Q9BV20|MTNA_HUMAN Methylthioribose-1-phosphate isomerase OS=Homosapiens OX=9606 GN=MRI1 PE=1 SV=1MTLEAIRYSRGSLQILDQLLLPKQSRYEAVGSVHQAWEAIRAMKVRGAPAIALVGCLSLAVELQAGAGGPGLAALVAFVRDKLSFLVTARPTAVNMARAARDLADVAAREAEREGATEEAVRERVICCTEDMLEKDLRDNRSIGDLGARHLLERVAPSGGKVTVLTHCNTGALATAGYGTALGVIRSLHSLGRLEHAFCTETRPYNQGARLTAFELVYEQIPATLITDSMVAAAMAHRGVSAVVVGADRVVANGDTANKVGTYQLAIVAKHHGIPFYVAAPSSSCDLRLETGKEIIIEERPGQELTDVNGVRIAAPGIGVWNPAFDVTPHDLITGGIITELGVFAPEELRTALTTTISSRDGTLDGPQM>sp|Q9BV20-2|MTNA_HUMAN Isoform 2 of Methylthioribose-1-phosphateisomerase OS=Homo sapiens OX=9606 GN=MRI1MTLEAIRYSRGSLQILDQLLLPKQSRYEAVGSVHQAWEAIRAMKVRGAPAIALVGCLSLAVELQAGAGGPGLAALVAFVRDKLSFLVTARPTAVNMARAARDLADVAAREAEREGATEEAVRERRETELCEHWEEHTRQRELPLRGPLGGTVLETRPYNQGARLTAFELVYEQIPATLITDSMVAAAMAHRGVSAVVVGADRVVANGDTANKVGTYQLAIVAKHHGIPFYVAAPSSSCDLRLETGKEIIIEERPGQELTDVNGVRIAAPGIGVWNPAFDVTPHDLITGGIITELGVFAPEELRTALTTTISSRDGTLDGPQM>sp|O15394|NCAM2_HUMAN Neural cell adhesion molecule 2 OS=Homo sapiensOX=9606 GN=NCAM2 PE=1 SV=2MSLLLSFYLLGLLVSSGQALLQVTISLSKVELSVGESKFFTCTAIGEPESIDWYNPQGEKIISTQRVVVQKEGVRSRLTIYNANIEDAGIYRCQATDAKGQTQEATVVLEIYQKLTFREVVSPQEFKQGEDAEVVCRVSSSPAPAVSWLYHNEEVTTISDNRFAMLANNNLQILNINKSDEGIYRCEGRVEARGEIDFRDIIVIVNVPPAISMPQKSFNATAERGEEMTFSCRASGSPEPAISWFRNGKLIEENEKYILKGSNTELTVRNIINSDGGPYVCRATNKAGEDEKQAFLQVFVQPHIIQLKNETTYENGQVTLVCDAEGEPIPEITWKRAVDGFTFTEGDKSLDGRIEVKGQHGSSSLHIKDVKLSDSGRYDCEAASRIGGHQKSMYLDIEYAPKFISNQTIYYSWEGNPINISCDVKSNPPASIHWRRDKLVLPAKNTTNLKTYSTGRKMILEIAPTSDNDFGRYNCTATNHIGTRFQEYILALADVPSSPYGVKIIELSQTTAKVSFNKPDSHGGVPIHHYQVDVKEVASEIWKIVRSHGVQTMVVLNNLEPNTTYEIRVAAVNGKGQGDYSKIEIFQTLPVREPSPPSIHGQPSSGKSFKLSITKQDDGGAPILEYIVKYRSKDKEDQWLEKKVQGNKDHIILEHLQWTMGYEVQITAANRLGYSEPTVYEFSMPPKPNIIKDTLFNGLGLGAVIGLGVAALLLILVVTDVSCFFIRQCGLLMCITRRMCGKKSGSSGKSKELEEGKAAYLKDGSKEPIVEMRTEDERVTNHEDGSPVNEPNETTPLTEPEKLPLKEEDGKEALNPETIEIKVSNDIIQSKEDDSKA>sp|O15394-2|NCAM2_HUMAN Isoform 2 of Neural cell adhesion molecule 2OS=Homo sapiens OX=9606 GN=NCAM2MVRSDSGGQVYLDYHNRQGLFVDWKYNEALYLEEGQPETYYRTALLQVTISLSKVELSVGESKFFTCTAIGEPESIDWYNPQGEKIISTQRVVVQKEGVRSRLTIYNANIEDAGIYRCQATDAKGQTQEATVVLEIYQKLTFREVVSPQEFKQGEDAEVVCRVSSSPAPAVSWLYHNEEVTTISDNRFAMLANNNLQILNINKSDEGIYRCEGRVEARGEIDFRDIIVIVNVPPAISMPQKSFNATAERGEEMTFSCRASGSPEPAISWFRNGKLIEENEKYILKGSNTELTVRNIINSDGGPYVCRATNKAGEDEKQAFLQVFVQPHIIQLKNETTYENGQVTLVCDAEGEPIPEITWKRAVDGFTFTEGDKSLDGRIEVKGQHGSSSLHIKDVKLSDSGRYDCEAASRIGGHQKSMYLDIES>sp|Q14CX7|NAA25_HUMAN N-alpha-acetyltransferase 25, NatB auxiliarysubunit OS=Homo sapiens OX=9606 GN=NAA25 PE=1 SV=1MATRGHVQDPNDRRLRPIYDYLDNGNNKMAIQQADKLLKKHKDLHCAKVLKAIGLQRTGKQEEAFTLAQEVAALEPTDDNSLQALTILYREMHRPELVTKLYEAAVKKVPNSEEYHSHLFMAYARVGEYKKMQQAGMALYKIVPKNPYYFWSVMSLIMQSISAQDENLSKTMFLPLAERMVEKMVKEDKIEAEAEVELYYMILERLGKYQEALDVIRGKLGEKLTSEIQSRENKCMAMYKKLSRWPECNALSRRLLLKNSDDWQFYLTYFDSVFRLIEEAWSPPAEGEHSLEGEVHYSAEKAVKFIEDRITEESKSSRHLRGPHLAKLELIRRLRSQGCNDEYKLGDPEELMFQYFKKFGDKPCCFTDLKVFVDLLPATQCTKFINQLLGVVPLSTPTEDKLALPADIRALQQHLCVVQLTRLLGLYHTMDKNQKLSVVRELMLRYQHGLEFGKTCLKTELQFSDYYCLLAVHALIDVWRETGDETTVWQALTLLEEGLTHSPSNAQFKLLLVRIYCMLGAFEPVVDLYSSLDAKHIQHDTIGYLLTRYAESLGQYAAASQSCNFALRFFHSNQKDTSEYIIQAYKYGAFEKIPEFIAFRNRLNNSLHFAQVRTERMLLDLLLEANISTSLAESIKSMNLRPEEDDIPWEDLRDNRDLNVFFSWDPKDRDVSEEHKKLSLEEETLWLRIRSLTLRLISGLPSLNHPVEPKNSEKTAENGVSSRIDILRLLLQQLEATLETGKRFIEKDIQYPFLGPVPTRMGGFFNSGCSQCQISSFYLVNDIYELDTSGLEDTMEIQERIENSFKSLLDQLKDVFSKCKGDLLEVKDGNLKTHPTLLENLVFFVETISVILWVSSYCESVLRPYKLNLQKKKKKKKETSIIMPPVFTSFQDYVTGLQTLISNVVDHIKGLETHLIALKLEELILEDTSLSPEERKFSKTVQGKVQSSYLHSLLEMGELLKKRLETTKKLKI>sp|Q14CX7-2|NAA25_HUMAN Isoform 2 of N-alpha-acetyltransferase 25, NatBauxiliary subunit OS=Homo sapiens OX=9606 GN=NAA25MATRGHVQDPNDRRLRPIYDYLDNGNNKMAIQQADKLLKKHKDLHCAKVLKAIGLQRTGKQEEAFTLAQEVAALEPTDDNSLQALTILYREMHRPELVTKLYEAAVKKVPNSEEYHSHLFMAYARVGEYKKMQQAGMALYKIVPKNPYYFWSVMSLIMQSISAQDENLSKTMFLPLAERMVEKMVKEDKIEAEAEVELYYMILERLGKYQEALDVIRGKLGEKLTSEIQSRENKCMAMYKKLSRWPECNALSRRLLLKNSDDWQFYLTYFDSVFRLIEEAWSPPAEGEHSLEGEVHYSAEKAVKFIEDRITEESKSSRHLRGPHLAKLELIRRLRSQGCNDEYKLGDPEELMFQYFKKFGDKPCCFTDLKVFVDLLPATQCTKFINQLLGVVPLSTPTEDKLALPADIRALQQHLCVVQLTRLLGLYHTMDKNQKLSVVRELMLRYQHGLEFGKTCLKTELQFSDYYCLLAVHALIDVWRETGDETTVWQALTLLEEGLTHSPSNAQFKLLLVRIYCMLGAFEPVVDLYSSLDAKHIQHDTIGYLLTRYAESLGQYAAASQSCNFALRFFHSNQKDTSEYIIQAYKYGAFEKIPEFIAFRNRLNNSLHFAQVRTERMLLDLLLEANISTSLAESIKSMNLRPEEDDIPWEDLRDNRDLNVFFSWDPKDRDVSEEHKKLSLEEETLWLRIRSLTLRLISGLPSLNHPVEPKNSEKTAENGVSSRIDILRLLLQQLEATLETGKRFIEKDIQYPFLGPVPTRMGGFFNSGCSQCQISSFYLVNDIYELDTSGLEDTMEIQERIENSFKSLLDQLKDVFSKCKGDLLEVKDGNLKTHPTLLENLVFFVEVSFCSLPKRHCCS>sp|Q08AG7|MZT1_HUMAN Mitotic-spindle organizing protein 1 OS=Homosapiens OX=9606 GN=MZT1 PE=1 SV=2MASSSGAGAAAAAAAANLNAVRETMDVLLEISRILNTGLDMETLSICVRLCEQGINPEALSSVIKELRKATEALKAAENMTS>sp|P12882|MYH1_HUMAN Myosin-1 OS=Homo sapiens OX=9606 GN=MYH1 PE=1 SV=3MSSDSEMAIFGEAAPFLRKSERERIEAQNKPFDAKTSVFVVDPKESFVKATVQSREGGKVTAKTEAGATVTVKDDQVFPMNPPKYDKIEDMAMMTHLHEPAVLYNLKERYAAWMIYTYSGLFCVTVNPYKWLPVYNAEVVTAYRGKKRQEAPPHIFSISDNAYQFMLTDRENQSILITGESGAGKTVNTKRVIQYFATIAVTGEKKKEEVTSGKMQGTLEDQIISANPLLEAFGNAKTVRNDNSSRFGKFIRIHFGTTGKLASADIETYLLEKSRVTFQLKAERSYHIFYQIMSNKKPDLIEMLLITTNPYDYAFVSQGEITVPSIDDQEELMATDSAIEILGFTSDERVSIYKLTGAVMHYGNMKFKQKQREEQAEPDGTEVADKAAYLQNLNSADLLKALCYPRVKVGNEYVTKGQTVQQVYNAVGALAKAVYDKMFLWMVTRINQQLDTKQPRQYFIGVLDIAGFEIFDFNSLEQLCINFTNEKLQQFFNHHMFVLEQEEYKKEGIEWTFIDFGMDLAACIELIEKPMGIFSILEEECMFPKATDTSFKNKLYEQHLGKSNNFQKPKPAKGKPEAHFSLIHYAGTVDYNIAGWLDKNKDPLNETVVGLYQKSAMKTLALLFVGATGAEAEAGGGKKGGKKKGSSFQTVSALFRENLNKLMTNLRSTHPHFVRCIIPNETKTPGAMEHELVLHQLRCNGVLEGIRICRKGFPSRILYADFKQRYKVLNASAIPEGQFIDSKKASEKLLGSIDIDHTQYKFGHTKVFFKAGLLGLLEEMRDEKLAQLITRTQAMCRGFLARVEYQKMVERRESIFCIQYNVRAFMNVKHWPWMKLYFKIKPLLKSAETEKEMANMKEEFEKTKEELAKTEAKRKELEEKMVTLMQEKNDLQLQVQAEADSLADAEERCDQLIKTKIQLEAKIKEVTERAEDEEEINAELTAKKRKLEDECSELKKDIDDLELTLAKVEKEKHATENKVKNLTEEMAGLDETIAKLTKEKKALQEAHQQTLDDLQAEEDKVNTLTKAKIKLEQQVDDLEGSLEQEKKIRMDLERAKRKLEGDLKLAQESTMDIENDKQQLDEKLKKKEFEMSGLQSKIEDEQALGMQLQKKIKELQARIEELEEEIEAERASRAKAEKQRSDLSRELEEISERLEEAGGATSAQIEMNKKREAEFQKMRRDLEEATLQHEATAATLRKKHADSVAELGEQIDNLQRVKQKLEKEKSEMKMEIDDLASNMETVSKAKGNLEKMCRALEDQLSEIKTKEEEQQRLINDLTAQRARLQTESGEYSRQLDEKDTLVSQLSRGKQAFTQQIEELKRQLEEEIKAKSALAHALQSSRHDCDLLREQYEEEQEAKAELQRAMSKANSEVAQWRTKYETDAIQRTEELEEAKKKLAQRLQDAEEHVEAVNAKCASLEKTKQRLQNEVEDLMIDVERTNAACAALDKKQRNFDKILAEWKQKCEETHAELEASQKESRSLSTELFKIKNAYEESLDQLETLKRENKNLQQEISDLTEQIAEGGKRIHELEKIKKQVEQEKSELQAALEEAEASLEHEEGKILRIQLELNQVKSEVDRKIAEKDEEIDQMKRNHIRIVESMQSTLDAEIRSRNDAIRLKKKMEGDLNEMEIQLNHANRMAAEALRNYRNTQAILKDTQLHLDDALRSQEDLKEQLAMVERRANLLQAEIEELRATLEQTERSRKIAEQELLDASERVQLLHTQNTSLINTKKKLETDISQIQGEMEDIIQEARNAEEKAKKAITDAAMMAEELKKEQDTSAHLERMKKNLEQTVKDLQHRLDEAEQLALKGGKKQIQKLEARVRELEGEVESEQKRNVEAVKGLRKHERKVKELTYQTEEDRKNILRLQDLVDKLQAKVKSYKRQAEEAEEQSNVNLSKFRRIQHELEEAEERADIAESQVNKLRVKSREVHTKIISEE>sp|Q8N9F0|NAT8L_HUMAN N-acetylaspartate synthetase OS=Homo sapiensOX=9606 GN=NAT8L PE=1 SV=3MHCGPPDMVCETKIVAAEDHEALPGAKKDALLAAAGAMWPPLPAAPGPAAAPPAPPPAPVAQPHGGAGGAGPPGGRGVCIREFRAAEQEAARRIFYDGIMERIPNTAFRGLRQHPRAQLLYALLAALCFAVSRSLLLTCLVPAALLGLRYYYSRKVIRAYLECALHTDMADIEQYYMKPPGSCFWVAVLDGNVVGIVAARAHEEDNTVELLRMSVDSRFRGKGIAKALGRKVLEFAVVHNYSAVVLGTTAVKVAAHKLYESLGFRHMGASDHYVLPGMTLSLAERLFFQVRYHRYRLQLREE>sp|O43908|NKG2F_HUMAN NKG2-F type II integral membrane protein OS=Homosapiens OX=9606 GN=KLRC4 PE=2 SV=2MNKQRGTYSEVSLAQDPKRQQRKLKGNKISISGTKQEIFQVELNLQNASSDHQGNDKTYHCKGLLPPPEKLTAEVLGIICIVLMATVLKTIVLIPCIGVLEQNNFSLNRRMQKARHCGHCPEEWITYSNSCYYIGKERRTWEERVCWPVLRRTLICFL>sp|Q9H792|PEAK1_HUMAN Inactive tyrosine-protein kinase PEAK1 OS=Homosapiens OX=9606 GN=PEAK1 PE=1 SV=4MSACNTFTEHVWKPGECKNCFKPKSLHQLPPDPEKAPITHGNVKTNANHSNNHRIRNTGNFRPPVAKKPTIAVKPTMIVADGQSICGELSIQEHCENKPVIIGWNRNRAALSQKPLNNNNEDDEGISHVPKPYGNNDSAKKMSDNNNGLTEVLKEIAGLDTAPQIRGNETNSRETFLGRINDCYKRSLERKLPPSCMIGGIKETQGKHVILSGSTEVISNEGGRFCYPEFSSGEESEEDVLFSNMEEEHESWDESDEELLAMEIRMRGQPRFANFRANTLSPVRFFVDKKWNTIPLRNKSLQRICAVDYDDSYDEILNGYEENSVVSYGQGSIQSMVSSDSTSPDSSLTEESRSETASSLSQKICNGGLSPGNPGDSKDMKEIEPNYESPSSNNQDKDSSQASKSSIKVPETHKAVLALRLEEKDGKIAVQTEKEESKASTDVAGQAVTINLVPTEEQAKPYRVVNLEQPLCKPYTVVDVSAAMASEHLEGPVNSPKTKSSSSTPNSPVTSSSLTPGQISAHFQKSSAIRYQEVWTSSTSPRQKIPKVELITSGTGPNVPPRKNCHKSAPTSPTATNISSKTIPVKSPNLSEIKFNSYNNAGMPPFPIIIHDEPTYARSSKNAIKVPIVINPNAYDNLAIYKSFLGTSGELSVKEKTTSVISHTYEEIETESKVPDNTTSKTTDCLQTKGFSNSTEHKRGSVAQKVQEFNNCLNRGQSSPQRSYSSSHSSPAKIQRATQEPVAKIEGTQESQMVGSSSTREKASTVLSQIVASIQPPQSPPETPQSGPKACSVEELYAIPPDADVAKSTPKSTPVRPKSLFTSQPSGEAEAPQTTDSPTTKVQKDPSIKPVTPSPSKLVTSPQSEPPAPFPPPRSTSSPYHAGNLLQRHFTNWTKPTSPTRSTEAESVLHSEGSRRAADAKPKRWISFKSFFRRRKTDEEDDKEKEREKGKLVGLDGTVIHMLPPPPVQRHHWFTEAKGESSEKPAIVFMYRCDPAQGQLSVDQSKARTDQAAVMEKGRAENALLQDSEKKRSHSSPSQIPKKILSHMTHEVTEDFSPRDPRTVVGKQDGRGCTSVTTALSLPELEREDGKEDISDPMDPNPCSATYSNLGQSRAAMIPPKQPRQPKGAVDDAIAFGGKTDQEAPNASQPTPPPLPKKMIIRANTEPISKDLQKSMESSLCVMANPTYDIDPNWDASSAGSSISYELKGLDIESYDSLERPLRKERPVPSAANSISSLTTLSIKDRFSNSMESLSSRRGPSCRQGRGIQKPQRQALYRGLENREEVVGKIRSLHTDALKKLAVKCEDLFMAGQKDQLRFGVDSWSDFRLTSDKPCCEAGDAVYYTASYAKDPLNNYAVKICKSKAKESQQYYHSLAVRQSLAVHFNIQQDCGHFLAEVPNRLLPWEDPDDPEKDEDDMEETEEDAKGETDGKNPKPCSEAASSQKENQGVMSKKQRSHVVVITREVPCLTVADFVRDSLAQHGKSPDLYERQVCLLLLQLCSGLEHLKPYHVTHCDLRLENLLLVHYQPGGTAQGFGPAEPSPTSSYPTRLIVSNFSQAKQKSHLVDPEILRDQSRLAPEIITATQYKKCDEFQTGILIYEMLHLPNPFDENPELKEREYTRADLPRIPFRSPYSRGLQQLASCLLNPNPSERILISDAKGILQCLLWGPREDLFQTFTACPSLVQRNTLLQNWLDIKRTLLMIKFAEKSLDREGGISLEDWLCAQYLAFATTDSLSCIVKILQHR>sp|Q8N987|NECA1_HUMAN N-terminal EF-hand calcium-binding protein 1OS=Homo sapiens OX=9606 GN=NECAB1 PE=1 SV=1MEDSQETSPSSNNSSEELSSALHLSKGMSIFLDILRRADKNDDGKLSFEEFKAYFADGVLSGEELHELFHTIDTHNTNNLDTEELCEYFSQHLGEYENVLAALEDLNLSILKAMGKTKKDYQEASNLEQFVTRFLLKETLNQLQSLQNSLECAMETTEEQTRQERQGPAKPEVLSIQWPGKRSSRRVQRHNSFSPNSPQFNVSGPGLLEEDNQWMTQINRLQKLIDRLEKKDLKLEPPEEEIIEGNTKSHIMLVQRQMSVIEEDLEEFQLALKHYVESASSQSGCLRISIQKLSNESRYMIYEFWENSSVWNSHLQTNYSKTFQRSNVDFLETPELTSTMLVPASWWILNN>sp|Q8N987-2|NECA1_HUMAN Isoform 2 of N-terminal EF-hand calcium-bindingprotein 1 OS=Homo sapiens OX=9606 GN=NECAB1MLVQRQMSVIEEDLEEFQLALKHYVESASSQSGCLRISIQKLSNESRYMIYEFWENSSVWNSHLQTNYSKTFQRSNVDFLETPELTSTMLVPASWWILNN>sp|O43920|NDUS5_HUMAN NADH dehydrogenase [ubiquinone] iron-sulfurprotein 5 OS=Homo sapiens OX=9606 GN=NDUFS5 PE=1 SV=3MPFLDIQKRFGLNIDRWLTIQSGEQPYKMAGRCHAFEKEWIECAHGIGYTRAEKECKIEYDDFVECLLRQKTMRRAGTIRKQRDKLIKEGKYTPPPHHIGKGEPRP>sp|Q5SYE7|NHSL1_HUMAN NHS-like protein 1 OS=Homo sapiens OX=9606GN=NHSL1 PE=1 SV=2MKKEGSSGSFRLQPNTGSLSRAVSWINFSSLSRQTKRLFRSDGELSVCGQQVEVDDENWIYRAQPRKAVSNLDEESRWTVHYTAPWHQQENVFLPTTRPPCVEDLHRQAKLNLKSVLRECDKLRHDGYRSSQYYSQGPTFAANASPFCDDYQDEDEETDQKCSLSSSEEERFISIRRPKTPASSDFSDLNTQTNWTKSLPLPTPEEKMRQQAQTVQADVVPINITASGTGQDDADGHSVYTPDHYSTLGRFNSCRSAGQRSETRDSSCQTEDVKVVPPSMRRIRAQKGQGIAAQMGHFSGSSGNMSVLSDSAGIVFPSRLDSDAGFHSLPRSGARANIQSLEPRLGALGPAGDMNGTFLYQRGHPQADENLGHLGGASGTGTLLRPKSQELRHFESENIMSPACVVSPHATYSTSIIPNATLSSSSEVIAIPTAQSAGQRESKSSGSSHARIKSRDHLISRHAVKGDPQSPGRHWNEGHATILSQDLDPHSPGEPALLSLCDSAVPLNAPANRENGSQAMPYNCRNNLAFPAHPQDVDGKSESSYSGGGGHSSSEPWEYKSSGNGRASPLKPHLATPGYSTPTSNMSSCSLDQTSNKEDAGSLYSEDHDGYCASVHTDSGHGSGNLCNSSDGFGNPRHSVINVFVGRAQKNQGDRSNYQDKSLSRNISLKKAKKPPLPPSRTDSLRRIPKKSSQCNGQVLNESLIATLQHSLQLSLPGKSGSSPSQSPCSDLEEPWLPRSRSQSTVSAGSSMTSATTPNVYSLCGATPSQSDTSSVKSEYTDPWGYYIDYTGMQEDPGNPAGGCSTSSGVPTGNGPVRHVQEGSRATMPQVPGGSVKPKIMSPEKSHRVISPSSGYSSQSNTPTALTPVPVFLKSVSPANGKGKPKPKVPERKSSLISSVSISSSSTSLSSSTSTEGSGTMKKLDPAVGSPPAPPPPPVPSPPFPCPADRSPFLPPPPPVTDCSQGSPLPHSPVFPPPPPEALIPFCSPPDWCLSPPRPALSPILPDSPVSLPLPPPLLPSSEPPPAPPLDPKFMKDTRPPFTNSGQPESSRGSLRPPSTKEETSRPPMPLITTEALQMVQLRPVRKNSGAEAAQLSERTAQEQRTPVAPQYHLKPSAFLKSRNSTNEMESESQPASVTSSLPTPAKSSSQGDHGSAAERGGPVSRSPGAPSAGEAEARPSPSTTPLPDSSPSRKPPPISKKPKLFLVVPPPQKDFAVEPAENVSEALRAVPSPTTGEEGSVHSREAKESSAAQAGSHATHPGTSVLEGGAAGSMSPSRVEANVPMVQPDVSPAPKQEEPAENSADTGGDGESCLSQQDGAAGVPETNAAGSSSEACDFLKEDGNDEVMTPSRPRTTEDLFAAIHRSKRKVLGRRDSDDDHSRNHSPSPPVTPTGAAPSLASPKQVGSIQRSIRKSSTSSDNFKALLLKKGSRSDTSARMSAAEMLKNTDPRFQRSRSEPSPDAPESPSSCSPSKNRRAQEEWAKNEGLMPRSLSFSGPRYGRSRTPPSAASSRYSMRNRIQSSPMTVISEGEGEAVEPVDSIARGALGAAEGCSLDGLAREEMDEGGLLCGEGPAASLQPQAPGPVDGTASAEGREPSPQCGGSLSEES>sp|Q5SYE7-2|NHSL1_HUMAN Isoform 2 of NHS-like protein 1 OS=Homo sapiensOX=9606 GN=NHSL1MVVFINAKIKSLIKLFKKKTVSNLDEESRWTVHYTAPWHQQENVFLPTTRPPCVEDLHRQAKLNLKSVLRECDKLRHDGYRSSQYYSQGPTFAANASPFCDDYQDEDEETDQKCSLSSSEEERFISIRRPKTPASSDFSDLNTQTNWTKSLPLPTPEEKMRQQAQTVQADVVPINITGENFDRQASLRRSLIYTDTLVRRPKKVKRRKTITGVPDNIQKELASGTGQDDADGHSVYTPDHYSTLGRFNSCRSAGQRSETRDSSCQTEDVKVVPPSMRRIRAQKGQGIAAQMGHFSGSSGNMSVLSDSAGIVFPSRLDSDAGFHSLPRSGARANIQSLEPRLGALGPAGDMNGTFLYQRGHPQADENLGHLGGASGTGTLLRPKSQELRHFESENIMSPACVVSPHATYSTSIIPNATLSSSSEVIAIPTAQSAGQRESKSSGSSHARIKSRDHLISRHAVKGDPQSPGRHWNEGHATILSQDLDPHSPGEPALLSLCDSAVPLNAPANRENGSQAMPYNCRNNLAFPAHPQDVDGKSESSYSGGGGHSSSEPWEYKSSGNGRASPLKPHLATPGYSTPTSNMSSCSLDQTSNKEDAGSLYSEDHDGYCASVHTDSGHGSGNLCNSSDGFGNPRHSVINVFVGRAQKNQGDRSNYQDKSLSRNISLKKAKKPPLPPSRTDSLRRIPKKSSQCNGQVLNESLIATLQHSLQLSLPGKSGSSPSQSPCSDLEEPWLPRSRSQSTVSAGSSMTSATTPNVYSLCGATPSQSDTSSVKSEYTDPWGYYIDYTGMQEDPGNPAGGCSTSSGVPTGNGPVRHVQEGSRATMPQVPGGSVKPKIMSPEKSHRVISPSSGYSSQSNTPTALTPVPVFLKSVSPANGKGKPKPKVPERKSSLISSVSISSSSTSLSSSTSTEGSGTMKKLDPAVGSPPAPPPPPVPSPPFPCPADRSPFLPPPPPVTDCSQGSPLPHSPVFPPPPPEALIPFCSPPDWCLSPPRPALSPILPDSPVSLPLPPPLLPSSEPPPAPPLDPKFMKDTRPPFTNSGQPESSRGSLRPPSTKEETSRPPMPLITTEALQMVQLRPVRKNSGAEAAQLSERTAQEQRTPVAPQYHLKPSAFLKSRNSTNEMESESQPASVTSSLPTPAKSSSQGDHGSAAERGGPVSRSPGAPSAGEAEARPSPSTTPLPDSSPSRKPPPISKKPKLFLVVPPPQKDFAVEPAENVSEALRAVPSPTTGEEGSVHSREAKESSAAQAGSHATHPGTSVLEGGAAGSMSPSRVEANVPMVQPDVSPAPKQEEPAENSADTGGDGESCLSQQDGAAGVPETNAAGSSSEACDFLKEDGNDEVMTPSRPRTTEDLFAAIHRSKRKVLGRRDSDDDHSRNHSPSPPVTPTGAAPSLASPKQVGSIQRSIRKSSTSSDNFKALLLKKGSRSDTSARMSAAEMLKNTDPRFQRSRSEPSPDAPESPSSCSPSKNRRAQEEWAKNEGLMPRSLSFSGPRYGRSRTPPSAASSRYSMRNRIQSSPMTVISEGEGEAVEPVDSIARGALGAAEGCSLDGLAREEMDEGGLLCGEGPAASLQPQAPGPVDGTASAEGREPSPQCGGSLSEES>sp|Q5T2W1|NHRF3_HUMAN Na(+)/H(+) exchange regulatory cofactor NHE-RF3OS=Homo sapiens OX=9606 GN=PDZK1 PE=1 SV=2MTSTFNPRECKLSKQEGQNYGFFLRIEKDTEGHLVRVVEKCSPAEKAGLQDGDRVLRINGVFVDKEEHMQVVDLVRKSGNSVTLLVLDGDSYEKAVKTRVDLKELGQSQKEQGLSDNILSPVMNGGVQTWTQPRLCYLVKEGGSYGFSLKTVQGKKGVYMTDITPQGVAMRAGVLADDHLIEVNGENVEDASHEEVVEKVKKSGSRVMFLLVDKETDKRHVEQKIQFKRETASLKLLPHQPRIVEMKKGSNGYGFYLRAGSEQKGQIIKDIDSGSPAEEAGLKNNDLVVAVNGESVETLDHDSVVEMIRKGGDQTSLLVVDKETDNMYRLAHFSPFLYYQSQELPNGSVKEAPAPTPTSLEVSSPPDTTEEVDHKPKLCRLAKGENGYGFHLNAIRGLPGSFIKEVQKGGPADLAGLEDEDVIIEVNGVNVLDEPYEKVVDRIQSSGKNVTLLVCGKKAYDYFQAKKIPIVSSLADPLDTPPDSKEGIVVESNHDSHMAKERAHSTASHSSSNSEDTEM>sp|Q5T2W1-2|NHRF3_HUMAN Isoform 2 of Na(+)/H(+) exchange regulatorycofactor NHE-RF3 OS=Homo sapiens OX=9606 GN=PDZK1MTSTFNPRECKLSKQEGQNYGFFLRIEKDTEGHLVRVVEKCSPAEKAGLQDGDRVLRINGVFVDKEEHMQVVDLVRKSGNSVTLLVLDGDSYEKAVKTRVDLKELGQSQKEQGLSDNILSPVMNGGVQTWTQPRLCYLVKEGGSYGFSLKTVQGQIIKDIDSGSPAEEAGLKNNDLVVAVNGESVETLDHDSVVEMIRKGGDQTSLLVVDKETDNMYRLAHFSPFLYYQSQELPNGSVKEAPAPTPTSLEVSSPPDTTEEVDHKPKLCRLAKGENGYGFHLNAIRGLPGSFIKEVQKGGPADLAGLEDEDVIIEVNGVNVLDEPYEKVVDRIQSSGKNVTLLVCGKKAYDYFQAKKIPIVSSLADPLDTPPDSKEGIVVESNHDSHMAKERAHSTASHSSSNSEDTEM>sp|P55058|PLTP_HUMAN Phospholipid transfer protein OS=Homo sapiensOX=9606 GN=PLTP PE=1 SV=1MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLDMLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASVTIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHSALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEVVTNHAGFLTIGADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV>sp|P55058-2|PLTP_HUMAN Isoform 2 of Phospholipid transfer proteinOS=Homo sapiens OX=9606 GN=PLTPMALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFLKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLDMLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASVTIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHSALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEVVTNHAGFLTIGADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV>sp|P55058-3|PLTP_HUMAN Isoform 3 of Phospholipid transfer proteinOS=Homo sapiens OX=9606 GN=PLTPMALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGHFYYNISEKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLDMLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASVTIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHSALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEVVTNHAGFLTIGADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV>sp|P55058-4|PLTP_HUMAN Isoform 4 of Phospholipid transfer proteinOS=Homo sapiens OX=9606 GN=PLTPMLQITNASLGLRFRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLDMLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASVTIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHSALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEVVTNHAGFLTIGADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV>sp|Q13232|NDK3_HUMAN Nucleoside diphosphate kinase 3 OS=Homo sapiensOX=9606 GN=NME3 PE=1 SV=2MICLVLTIFANLFPAACTGAHERTFLAVKPDGVQRRLVGEIVRRFERKGFKLVALKLVQASEELLREHYAELRERPFYGRLVKYMASGPVVAMVWQGLDVVRTSRALIGATNPADAPPGTIRGDFCIEVGKNLIHGSDSVESARREIALWFRADELLCWEDSAGHWLYE>sp|Q8TB73|NDNF_HUMAN Protein NDNF OS=Homo sapiens OX=9606 GN=NDNF PE=1SV=2MVLLHWCLLWLLFPLSSRTQKLPTRDEELFQMQIRDKAFFHDSSVIPDGAEISSYLFRDTPKRYFFVVEEDNTPLSVTVTPCDAPLEWKLSLQELPEDRSGEGSGDLEPLEQQKQQIINEEGTELFSYKGNDVEYFISSSSPSGLYQLDLLSTEKDTHFKVYATTTPESDQPYPELPYDPRVDVTSLGRTTVTLAWKPSPTASLLKQPIQYCVVINKEHNFKSLCAVEAKLSADDAFMMAPKPGLDFSPFDFAHFGFPSDNSGKERSFQAKPSPKLGRHVYSRPKVDIQKICIGNKNIFTVSDLKPDTQYYFDVFVVNINSNMSTAYVGTFARTKEEAKQKTVELKDGKITDVFVKRKGAKFLRFAPVSSHQKVTFFIHSCLDAVQIQVRRDGKLLLSQNVEGIQQFQLRGKPKAKYLVRLKGNKKGASMLKILATTRPTKQSFPSLPEDTRIKAFDKLRTCSSATVAWLGTQERNKFCIYKKEVDDNYNEDQKKREQNQCLGPDIRKKSEKVLCKYFHSQNLQKAVTTETIKGLQPGKSYLLDVYVIGHGGHSVKYQSKVVKTRKFC>sp|Q9H649|NSUN3_HUMAN tRNA (cytosine(34)-C(5))-methyltransferase,mitochondrial OS=Homo sapiens OX=9606 GN=NSUN3 PE=1 SV=1MLTQLKAKSEGKLAKQICKVVLDHFEKQYSKELGDAWNTVREILTSPSCWQYAVLLNRFNYPFELEKDLHLKGYHTLSQGSLPNYPKSVKCYLSRTPGRIPSERHQIGNLKKYYLLNAASLLPVLALELRDGEKVLDLCAAPGGKSIALLQCACPGYLHCNEYDSLRLRWLRQTLESFIPQPLINVIKVSELDGRKMGDAQPEMFDKVLVDAPCSNDRSWLFSSDSQKASCRISQRRNLPLLQIELLRSAIKALRPGGILVYSTCTLSKAENQDVISEILNSHGNIMPMDIKGIARTCSHDFTFAPTGQECGLLVIPDKGKAWGPMYVAKLKKSWSTGKW>sp|Q99748|NRTN_HUMAN Neurturin OS=Homo sapiens OX=9606 GN=NRTN PE=1 SV=1MQRWKAAALASVLCSSVLSIWMCREGLLLSHRLGPALVPLHRLPRTLDARIARLAQYRALLQGAPDAMELRELTPWAGRPPGPRRRAGPRRRRARARLGARPCGLRELEVRVSELGLGYASDETVLFRYCAGACEAAARVYDLGLRRLRQRRRLRRERVRAQPCCRPTAYEDEVSFLDAHSRYHTVHELSARECACV>sp|Q9NPB1|NT5M_HUMAN 5'(3')-deoxyribonucleotidase, mitochondrial OS=Homosapiens OX=9606 GN=NT5M PE=1 SV=1MIRLGGWCARRLCSAAVPAGRRGAAGGLGLAGGRALRVLVDMDGVLADFEGGFLRKFRARFPDQPFIALEDRRGFWVSEQYGRLRPGLSEKAISIWESKNFFFELEPLPGAVEAVKEMASLQNTDVFICTSPIKMFKYCPYEKYAWVEKYFGPDFLEQIVLTRDKTVVSADLLIDDRPDITGAEPTPSWEHVLFTACHNQHLQLQPPRRRLHSWADDWKAILDSKRPC>sp|Q99946|PRRT1_HUMAN Proline-rich transmembrane protein 1 OS=Homosapiens OX=9606 GN=PRRT1 PE=1 SV=2MSSEKSGLPDSVPHTSPPPYNAPQPPAEPPAPPPQAAPSSHHHHHHHYHQSGTATLPRLGAGGLASSAATAQRGPSSSATLPRPPHHAPPGPAAGAPPPGCATLPRMPPDPYLQETRFEGPLPPPPPAAAAPPPPAPAQTAQAPGFVVPTHAGTVGTLPLGGYVAPGYPLQLQPCTAYVPVYPVGTPYAGGTPGGTGVTSTLPPPPQGPGLALLEPRRPPHDYMPIAVLTTICCFWPTGIIAIFKAVQVRTALARGDMVSAEIASREARNFSFISLAVGIAAMVLCTILTVVIIIAAQHHENYWDP>sp|Q99946-2|PRRT1_HUMAN Isoform 2 of Proline-rich transmembrane protein1 OS=Homo sapiens OX=9606 GN=PRRT1MPGTQTPAPAEDPHSGCRDPVPARPQACHPKSQETRFEGPLPPPPPAAAAPPPPAPAQTAQAPGFVVPTHAGTVGTLPLGGYVAPGYPLQLQPCTAYVPVYPVGTPYAGGTPGGTGVTSTLPPPPQGPGLALLEPRRPPHDYMPIAVLTTICCFWPTGIIAIFKAVQVRTALARGDMVSAEIASREARNFSFISLAVGIAAMVLCTILTVVIIIAAQHHENYWDP>sp|Q8N3Z0|PRS35_HUMAN Inactive serine protease 35 OS=Homo sapiensOX=9606 GN=PRSS35 PE=1 SV=2MENMLLWLIFFTPGWTLIDGSEMEWDFMWHLRKVPRIVSERTFHLTSPAFEADAKMMVNTVCGIECQKELPTPSLSELEDYLSYETVFENGTRTLTRVKVQDLVLEPTQNITTKGVSVRRKRQVYGTDSRFSILDKRFLTNFPFSTAVKLSTGCSGILISPQHVLTAAHCVHDGKDYVKGSKKLRVGLLKMRNKSGGKKRRGSKRSRREASGGDQREGTREHLRERAKGGRRRKKSGRGQRIAEGRPSFQWTRVKNTHIPKGWARGGMGDATLDYDYALLELKRAHKKKYMELGISPTIKKMPGGMIHFSGFDNDRADQLVYRFCSVSDESNDLLYQYCDAESGSTGSGVYLRLKDPDKKNWKRKIIAVYSGHQWVDVHGVQKDYNVAVRITPLKYAQICLWIHGNDANCAYG>sp|O43930|PRKY_HUMAN Putative serine/threonine-protein kinase PRKYOS=Homo sapiens OX=9606 GN=PRKY PE=5 SV=1MEAPGPAQAAAAESNSREVTEDAADWAPALCPSPEARSPEAPAYRLQDCDALVTMGTGTFGRVHLVKEKTAKHFFALKVMSIPDVIRRKQEQHVHNEKSVLKEVSHPFLIRLFWTWHEERFLYMLMEYVPGGELFSYLRNRGHFSSTTGLFYSAEIICAIEYLHSKEIVYRDLKPENILLDRDGHIKLTDFGFAKKLVDRTWTLCGTPEYLAPEVIQSKGHGRAVDWWALGILIFEMLSGFPPFFDDNPFGIYQKILAGKLYFPRHLDFHVKTGRMM>sp|Q12980|NPRL3_HUMAN GATOR complex protein NPRL3 OS=Homo sapiensOX=9606 GN=NPRL3 PE=1 SV=1MRDNTSPISVILVSSGSRGNKLLFRYPFQRSQEHPASQTSKPRSRYAASNTGDHADEQDGDSRFSDVILATILATKSEMCGQKFELKIDNVRFVGHPTLLQHALGQISKTDPSPKREAPTMILFNVVFALRANADPSVINCLHNLSRRIATVLQHEERRCQYLTREAKLILALQDEVSAMADGNEGPQSPFHHILPKCKLARDLKEAYDSLCTSGVVRLHINSWLEVSFCLPHKIHYAASSLIPPEAIERSLKAIRPYHALLLLSDEKSLLGELPIDCSPALVRVIKTTSAVKNLQQLAQDADLALLQVFQLAAHLVYWGKAIIIYPLCENNVYMLSPNASVCLYSPLAEQFSHQFPSHDLPSVLAKFSLPVSLSEFRNPLAPAVQETQLIQMVVWMLQRRLLIQLHTYVCLMASPSEEEPRPREDDVPFTARVGGRSLSTPNALSFGSPTSSDDMTLTSPSMDNSSAELLPSGDSPLNQRMTENLLASLSEHERAAILSVPAAQNPEDLRMFARLLHYFRGRHHLEEIMYNENTRRSQLLMLFDKFRSVLVVTTHEDPVIAVFQALLP>sp|E9PQR5|NPIB8_HUMAN Nuclear pore complex-interacting protein familymember B8 OS=Homo sapiens OX=9606 GN=NPIPB8 PE=3 SV=1MVKLSIVLTPQFLSHDQGQLTKELQQHVKSVTCPCEYLRKVINSLAVYRHRETDFGVGVRDHPGQHGKTPSPQKLDNLIIIIIGFLRCYTFNILFCTSCLCVSFLKTIFWSRNGHDGSMDVQQRAWRSNRSRQKGLRSICMHTKKRVSSFRGNKIGLKDVITLRRHVETKVRAKIRKRKVTTKINRHDKINGKRKTARKQKMFQRAQELRRRAEDYHKCKIPPSARKPLCNWVRMAAAEHRHSSGLPYWLYLTAETLKNRMGRQPPPPTQQHSITDNSLSLKTPPECLLTPLPPSVDDNIKECPLAPLPPSPLPPSVDDNLKECLFVPLPPSPLPPSVDDNLKECLFVPLPPSPLPPSVDDNLKTPPLATQEAEVEKPPKPKRWRVDEVEQSPKPKRQREAEAQQLPKPKRRRLSKLRTRHCTQAWAIRINP>sp|Q8NGZ6|OR6F1_HUMAN Olfactory receptor 6F1 OS=Homo sapiens OX=9606GN=OR6F1 PE=2 SV=1MDTGNKTLPQDFLLLGFPGSQTLQLSLFMLFLVMYILTVSGNVAILMLVSTSHQLHTPMYFFLSNLSFLEIWYTTAAVPKALAILLGRSQTISFTSCLLQMYFVFSLGCTEYFLLAAMAYDRCLAICYPLHYGAIMSSLLSAQLALGSWVCGFVAIAVPTALISGLSFCGPRAINHFFCDIAPWIALACTNTQAVELVAFVIAVVVILSSCLITFVSYVYIISTILRIPSASGRSKAFSTCSSHLTVVLIWYGSTVFLHVRTSIKDALDLIKAVHVLNTVVTPVLNPFIYTLRNKEVRETLLKKWKGK>sp|Q9GZU5|NYX_HUMAN Nyctalopin OS=Homo sapiens OX=9606 GN=NYX PE=1 SV=1MKGRGMLVLLLHAVVLGLPSAWAVGACARACPAACACSTVERGCSVRCDRAGLLRVPAELPCEAVSIDLDRNGLRFLGERAFGTLPSLRRLSLRHNNLSFITPGAFKGLPRLAELRLAHNGDLRYLHARTFAALSRLRRLDLAACRLFSVPERLLAELPALRELAAFDNLFRRVPGALRGLANLTHAHLERGRIEAVASSSLQGLRRLRSLSLQANRVRAVHAGAFGDCGVLEHLLLNDNLLAELPADAFRGLRRLRTLNLGGNALDRVARAWFADLAELELLYLDRNSIAFVEEGAFQNLSGLLALHLNGNRLTVLAWVAFQPGFFLGRLFLFRNPWCCDCRLEWLRDWMEGSGRVTDVPCASPGSVAGLDLSQVTFGRSSDGLCVDPEELNLTTSSPGPSPEPAATTVSRFSSLLSKLLAPRVPVEEAANTTGGLANASLSDSLSSRGVGGAGRQPWFLLASCLLPSVAQHVVFGLQMD>sp|Q96PU9|ODF3A_HUMAN Outer dense fiber protein 3 OS=Homo sapiensOX=9606 GN=ODF3 PE=1 SV=1MTEEVWMGTWRPHRPRGPIMALYSSPGPKYLIPPTTGFMKHTPTKLRAPAYSFRGAPMLLAENCSPGPRYNVNPKILRTGKDLGPAYSILGRYQTKTMLTPGPGDYFPEKSTKYVFDSAPSHSISARTKAFRVDSTPGPAAYMLPMVMGPNTVGKASQPSFSIKGRSKLGGFSDDLHKTPGPAAYRQTDVRVTKFKAPQYTMAARVEPPGDKTLKPGPGAHSPEKVTLTKPCAPVVTFGIKHSDYMTPLLVDVE>sp|Q96PU9-2|ODF3A_HUMAN Isoform 2 of Outer dense fiber protein 3 OS=Homosapiens OX=9606 GN=ODF3MTEEVWMGTWRPHRPRGPIMALYSSPGPKYLIPPTTGFMKHTPTKLRAPAYSFRGAPMLLAENCSPGPRYNVNPKILRTGKDLGPAYSILGRYQTKTMLTPGPALKSAFPSWTPRDPTWSPPVLEPRGPTPRMLGSPP>sp|Q96PU9-3|ODF3A_HUMAN Isoform 3 of Outer dense fiber protein 3 OS=Homosapiens OX=9606 GN=ODF3MTEEVWMGTWRPHRPRGPIMALYSSPGPKYLIPPTTGFMKHTPTKLRAPAYSFRGAPMLLAENCSPGPRYNVNPKILRTGKDLGPAYSILGRYQTKTMLTPGPGDYFPEKSTKYVFDSAPSHSISARTKAFRVDSTPGPAAYMLPMVMGPNTVGKASQPSFSIKGRSKLGGFSDDLHKVTLTKPCAPVVTFGIKHSDYMTPLLVDVE>sp|E9PIF3|NPIA2_HUMAN Nuclear pore complex-interacting protein familymember A2 OS=Homo sapiens OX=9606 GN=NPIPA2 PE=3 SV=1MVKLSIVLTPRFLSHDQGQLTKELQQHVKSVTCPCEYLRKVINTLADHRHRGTDFGGSPWLLIITVFLRSYKFAISLCTSYLCVSFLKTIFPSQNGHDGSTDVQQRARRSNRRRQEGIKIVLEDIFTLWRQVETKVRAKICKMKVTTKVNRHDKINGKRKTAKEHLRKLSMKEREHGEKERQVSEAEENGKLDMKEIHTYMEMFQRAQALRRRAEDYYRCKITPSARKPLCNRVRMAAAEHRHSSGLPYWPYLTAETLKNRMGHQPPPPTQQHSIIDNSLSLKTPPECLLTPLPPSALPSADDNLKTPAECLLYPLPPSADDNLKTPPECLLTPLPPSAPPSADDNLKTPPKCVCSLPFHPQRMIISRN>sp|P36957|ODO2_HUMAN Dihydrolipoyllysine-residue succinyltransferasecomponent of 2-oxoglutarate dehydrogenase complex, mitochondrial OS=Homosapiens OX=9606 GN=DLST PE=1 SV=4MLSRSRCVSRAFSRSLSAFQKGNCPLGRRSLPGVSLCQGPGYPNSRKVVINNSVFSVRFFRTTAVCKDDLVTVKTPAFAESVTEGDVRWEKAVGDTVAEDEVVCEIETDKTSVQVPSPANGVIEALLVPDGGKVEGGTPLFTLRKTGAAPAKAKPAEAPAAAAPKAEPTAAAVPPPAAPIPTQMPPVPSPSQPPSGKPVSAVKPTVAPPLAEPGAGKGLRSEHREKMNRMRQRIAQRLKEAQNTCAMLTTFNEIDMSNIQEMRARHKEAFLKKHNLKLGFMSAFVKASAFALQEQPVVNAVIDDTTKEVVYRDYIDISVAVATPRGLVVPVIRNVEAMNFADIERTITELGEKARKNELAIEDMDGGTFTISNGGVFGSLFGTPIINPPQSAILGMHGIFDRPVAIGGKVEVRPMMYVALTYDHRLIDGREAVTFLRKIKAAVEDPRVLLLDL>sp|P36957-2|ODO2_HUMAN Isoform 2 of Dihydrolipoyllysine-residuesuccinyltransferase component of 2-oxoglutarate dehydrogenase complex,mitochondrial OS=Homo sapiens OX=9606 GN=DLSTMTWLQSKPQRLQNLSQREMSGGRKTSVQVPSPANGVIEALLVPDGGKVEGGTPLFTLRKTGAAPAKAKPAEAPAAAAPKAEPTAAAVPPPAAPIPTQMPPVPSPSQPPSGKPVSAVKPTVAPPLAEPGAGKGLRSEHREKMNRMRQRIAQRLKEAQNTCAMLTTFNEIDMSNIQEMRARHKEAFLKKHNLKLGFMSAFVKASAFALQEQPVVNAVIDDTTKEVVYRDYIDISVAVATPRGLVVPVIRNVEAMNFADIERTITELGEKARKNELAIEDMDGGTFTISNGGVFGSLFGTPIINPPQSAILGMHGIFDRPVAIGGKVEVRPMMYVALTYDHRLIDGREAVTFLRKIKAAVEDPRVLLLDL>sp|P29728|OAS2_HUMAN 2'-5'-oligoadenylate synthase 2 OS=Homo sapiensOX=9606 GN=OAS2 PE=1 SV=3MGNGESQLSSVPAQKLGWFIQEYLKPYEECQTLIDEMVNTICDVLQEPEQFPLVQGVAIGGSYGRKTVLRGNSDGTLVLFFSDLKQFQDQKRSQRDILDKTGDKLKFCLFTKWLKNNFEIQKSLDGFTIQVFTKNQRISFEVLAAFNALSLNDNPSPWIYRELKRSLDKTNASPGEFAVCFTELQQKFFDNRPGKLKDLILLIKHWHQQCQKKIKDLPSLSPYALELLTVYAWEQGCRKDNFDIAEGVRTVLELIKCQEKLCIYWMVNYNFEDETIRNILLHQLQSARPVILDPVDPTNNVSGDKICWQWLKKEAQTWLTSPNLDNELPAPSWNVLPAPLFTTPGHLLDKFIKEFLQPNKCFLEQIDSAVNIIRTFLKENCFRQSTAKIQIVRGGSTAKGTALKTGSDADLVVFHNSLKSYTSQKNERHKIVKEIHEQLKAFWREKEEELEVSFEPPKWKAPRVLSFSLKSKVLNESVSFDVLPAFNALGQLSSGSTPSPEVYAGLIDLYKSSDLPGGEFSTCFTVLQRNFIRSRPTKLKDLIRLVKHWYKECERKLKPKGSLPPKYALELLTIYAWEQGSGVPDFDTAEGFRTVLELVTQYQQLCIFWKVNYNFEDETVRKFLLSQLQKTRPVILDPAEPTGDVGGGDRWCWHLLAKEAKEWLSSPCFKDGTGNPIPPWKVPTMQTPGSCGARIHPIVNEMFSSRSHRILNNNSKRNF>sp|P29728-2|OAS2_HUMAN Isoform p69 of 2'-5'-oligoadenylate synthase 2OS=Homo sapiens OX=9606 GN=OAS2MGNGESQLSSVPAQKLGWFIQEYLKPYEECQTLIDEMVNTICDVLQEPEQFPLVQGVAIGGSYGRKTVLRGNSDGTLVLFFSDLKQFQDQKRSQRDILDKTGDKLKFCLFTKWLKNNFEIQKSLDGFTIQVFTKNQRISFEVLAAFNALSLNDNPSPWIYRELKRSLDKTNASPGEFAVCFTELQQKFFDNRPGKLKDLILLIKHWHQQCQKKIKDLPSLSPYALELLTVYAWEQGCRKDNFDIAEGVRTVLELIKCQEKLCIYWMVNYNFEDETIRNILLHQLQSARPVILDPVDPTNNVSGDKICWQWLKKEAQTWLTSPNLDNELPAPSWNVLPAPLFTTPGHLLDKFIKEFLQPNKCFLEQIDSAVNIIRTFLKENCFRQSTAKIQIVRGGSTAKGTALKTGSDADLVVFHNSLKSYTSQKNERHKIVKEIHEQLKAFWREKEEELEVSFEPPKWKAPRVLSFSLKSKVLNESVSFDVLPAFNALGQLSSGSTPSPEVYAGLIDLYKSSDLPGGEFSTCFTVLQRNFIRSRPTKLKDLIRLVKHWYKECERKLKPKGSLPPKYALELLTIYAWEQGSGVPDFDTAEGFRTVLELVTQYQQLCIFWKVNYNFEDETVRKFLLSQLQKTRPVILDPAEPTGDVGGGDRWCWHLLAKEAKEWLSSPCFKDGTGNPIPPWKVPVKVI>sp|P29728-3|OAS2_HUMAN Isoform 3 of 2'-5'-oligoadenylate synthase 2OS=Homo sapiens OX=9606 GN=OAS2MGNGESQLSSVPAQKLGWFIQEYLKPYEECQTLIDEMVNTICDVLQEPEQFPLVQGVAIGGSYGRKTVLRGNSDGTLVLFFSDLKQFQDQKRSQRDILDKTGDKLKFCLFTKWLKNNFEIQKSLDGFTIQVFTKNQRISFEVLAAFNALSKHCWVSGEKSQRSGCQTALCNL>sp|Q8NGE3|O10P1_HUMAN Olfactory receptor 10P1 OS=Homo sapiens OX=9606GN=OR10P1 PE=2 SV=1MAGENHTTLPEFLLLGFSDLKALQGPLFWVVLLVYLVTLLGNSLIILLTQVSPALHSPMYFFLRQLSVVELFYTTDIVPRTLANLGSPHPQAISFQGCAAQMYVFIVLGISECCLLTAMAYDRYVAICQPLRYSTLLSPRACMAMVGTSWLTGIITATTHASLIFSLPFRSHPIIPHFLCDILPVLRLASAGKHRSEISVMTATIVFIMIPFSLIVTSYIRILGAILAMASTQSRRKVFSTCSSHLLVVSLFFGTASITYIRPQAGSSVTTDRVLSLFYTVITPMLNPIIYTLRNKDVRRALRHLVKRQRPSP>sp|P08559|ODPA_HUMAN Pyruvate dehydrogenase E1 component subunit alpha,somatic form, mitochondrial OS=Homo sapiens OX=9606 GN=PDHA1 PE=1 SV=3MRKMLAAVSRVLSGASQKPASRVLVASRNFANDATFEIKKCDLHRLEEGPPVTTVLTREDGLKYYRMMQTVRRMELKADQLYKQKIIRGFCHLCDGQEACCVGLEAGINPTDHLITAYRAHGFTFTRGLSVREILAELTGRKGGCAKGKGGSMHMYAKNFYGGNGIVGAQVPLGAGIALACKYNGKDEVCLTLYGDGAANQGQIFEAYNMAALWKLPCIFICENNRYGMGTSVERAAASTDYYKRGDFIPGLRVDGMDILCVREATRFAAAYCRSGKGPILMELQTYRYHGHSMSDPGVSYRTREEIQEVRSKSDPIMLLKDRMVNSNLASVEELKEIDVEVRKEIEDAAQFATADPEPPLEELGYHIYSSDPPFEVRGANQWIKFKSVS>sp|P08559-2|ODPA_HUMAN Isoform 2 of Pyruvate dehydrogenase E1 componentsubunit alpha, somatic form, mitochondrial OS=Homo sapiens OX=9606GN=PDHA1MRKMLAAVSRVLSGASQKPASRVLVASRNFANDATFEIKKCDLHRLEEGPPVTTVLTREDGLKYYRMMQTVRRMELKADQLYKQKIIRGFCHLCDGQFLLPLTQEACCVGLEAGINPTDHLITAYRAHGFTFTRGLSVREILAELTGRKGGCAKGKGGSMHMYAKNFYGGNGIVGAQVPLGAGIALACKYNGKDEVCLTLYGDGAANQGQIFEAYNMAALWKLPCIFICENNRYGMGTSVERAAASTDYYKRGDFIPGLRVDGMDILCVREATRFAAAYCRSGKGPILMELQTYRYHGHSMSDPGVSYRTREEIQEVRSKSDPIMLLKDRMVNSNLASVEELKEIDVEVRKEIEDAAQFATADPEPPLEELGYHIYSSDPPFEVRGANQWIKFKSVS>sp|P08559-3|ODPA_HUMAN Isoform 3 of Pyruvate dehydrogenase E1 componentsubunit alpha, somatic form, mitochondrial OS=Homo sapiens OX=9606GN=PDHA1MRKMLAAVSRVLSGASQKPASRVLVASRNFANDATFEIKKCDLHRLEEGPPVTTVLTREDGLKYYRMMQTVRRMELKADQLYKQKIIRGFCHLCDGQEACCVGLEAGINPTDHLITAYRAHGFTFTRGLSVREILAELTGRKGGCAKGKGGSMHMYAKNFYGGNGIVGAQGQIFEAYNMAALWKLPCIFICENNRYGMGTSVERAAASTDYYKRGDFIPGLRVDGMDILCVREATRFAAAYCRSGKGPILMELQTYRYHGHSMSDPGVSYRTREEIQEVRSKSDPIMLLKDRMVNSNLASVEELKEIDVEVRKEIEDAAQFATADPEPPLEELGYHIYSSDPPFEVRGANQWIKFKSVS>sp|P08559-4|ODPA_HUMAN Isoform 4 of Pyruvate dehydrogenase E1 componentsubunit alpha, somatic form, mitochondrial OS=Homo sapiens OX=9606GN=PDHA1MRKMLAAVSRVLSGASQKPRHGLATLPSLVSISRLKQSSHLGLPKCWDYSHSLKTRQASRVLVASRNFANDATFEIKKCDLHRLEEGPPVTTVLTREDGLKYYRMMQTVRRMELKADQLYKQKIIRGFCHLCDGQEACCVGLEAGINPTDHLITAYRAHGFTFTRGLSVREILAELTGRKGGCAKGKGGSMHMYAKNFYGGNGIVGAQVPLGAGIALACKYNGKDEVCLTLYGDGAANQGQIFEAYNMAALWKLPCIFICENNRYGMGTSVERAAASTDYYKRGDFIPGLRVDGMDILCVREATRFAAAYCRSGKGPILMELQTYRYHGHSMSDPGVSYRTREEIQEVRSKSDPIMLLKDRMVNSNLASVEELKEIDVEVRKEIEDAAQFATADPEPPLEELGYHIYSSDPPFEVRGANQWIKFKSVS>sp|Q02218|ODO1_HUMAN 2-oxoglutarate dehydrogenase, mitochondrial OS=Homosapiens OX=9606 GN=OGDH PE=1 SV=3MFHLRTCAAKLRPLTASQTVKTFSQNRPAAARTFQQIRCYSAPVAAEPFLSGTSSNYVEEMYCAWLENPKSVHKSWDIFFRNTNAGAPPGTAYQSPLPLSRGSLAAVAHAQSLVEAQPNVDKLVEDHLAVQSLIRAYQIRGHHVAQLDPLGILDADLDSSVPADIISSTDKLGFYGLDESDLDKVFHLPTTTFIGGQESALPLREIIRRLEMAYCQHIGVEFMFINDLEQCQWIRQKFETPGIMQFTNEEKRTLLARLVRSTRFEEFLQRKWSSEKRFGLEGCEVLIPALKTIIDKSSENGVDYVIMGMPHRGRLNVLANVIRKELEQIFCQFDSKLEAADEGSGDVKYHLGMYHRRINRVTDRNITLSLVANPSHLEAADPVVMGKTKAEQFYCGDTEGKKVMSILLHGDAAFAGQGIVYETFHLSDLPSYTTHGTVHVVVNNQIGFTTDPRMARSSPYPTDVARVVNAPIFHVNSDDPEAVMYVCKVAAEWRSTFHKDVVVDLVCYRRNGHNEMDEPMFTQPLMYKQIRKQKPVLQKYAELLVSQGVVNQPEYEEEISKYDKICEEAFARSKDEKILHIKHWLDSPWPGFFTLDGQPRSMSCPSTGLTEDILTHIGNVASSVPVENFTIHGGLSRILKTRGEMVKNRTVDWALAEYMAFGSLLKEGIHIRLSGQDVERGTFSHRHHVLHDQNVDKRTCIPMNHLWPNQAPYTVCNSSLSEYGVLGFELGFAMASPNALVLWEAQFGDFHNTAQCIIDQFICPGQAKWVRQNGIVLLLPHGMEGMGPEHSSARPERFLQMCNDDPDVLPDLKEANFDINQLYDCNWVVVNCSTPGNFFHVLRRQILLPFRKPLIIFTPKSLLRHPEARSSFDEMLPGTHFQRVIPEDGPAAQNPENVKRLLFCTGKVYYDLTRERKARDMVGQVAITRIEQLSPFPFDLLLKEVQKYPNAELAWCQEEHKNQGYYDYVKPRLRTTISRAKPVWYAGRDPAAAPATGNKKTHLTELQRLLDTAFDLDVFKNFS>sp|Q02218-2|ODO1_HUMAN Isoform 2 of 2-oxoglutarate dehydrogenase,mitochondrial OS=Homo sapiens OX=9606 GN=OGDHMFHLRTCAAKLRPLTASQTVKTFSQNRPAAARTFQQIRCYSAPVAAEPFLSGTSSNYVEEMYCAWLENPKSVHKSWDIFFRNTNAGAPPGTAYQSPLPLSRGSLAAVAHAQSLVEAQPNVDKLVEDHLAVQSLIRAYQVRGHHIAKLDPLGISCVNFDDAPVTVSSNVGFYGLDESDLDKVFHLPTTTFIGGQESALPLREIIRRLEMAYCQHIGVEFMFINDLEQCQWIRQKFETPGIMQFTNEEKRTLLARLVRSTRFEEFLQRKWSSEKRFGLEGCEVLIPALKTIIDKSSENGVDYVIMGMPHRGRLNVLANVIRKELEQIFCQFDSKLEAADEGSGDVKYHLGMYHRRINRVTDRNITLSLVANPSHLEAADPVVMGKTKAEQFYCGDTEGKKVMSILLHGDAAFAGQGIVYETFHLSDLPSYTTHGTVHVVVNNQIGFTTDPRMARSSPYPTDVARVVNAPIFHVNSDDPEAVMYVCKVAAEWRSTFHKDVVVDLVCYRRNGHNEMDEPMFTQPLMYKQIRKQKPVLQKYAELLVSQGVVNQPEYEEEISKYDKICEEAFARSKDEKILHIKHWLDSPWPGFFTLDGQPRSMSCPSTGLTEDILTHIGNVASSVPVENFTIHGGLSRILKTRGEMVKNRTVDWALAEYMAFGSLLKEGIHIRLSGQDVERGTFSHRHHVLHDQNVDKRTCIPMNHLWPNQAPYTVCNSSLSEYGVLGFELGFAMASPNALVLWEAQFGDFHNTAQCIIDQFICPGQAKWVRQNGIVLLLPHGMEGMGPEHSSARPERFLQMCNDDPDVLPDLKEANFDINQLYDCNWVVVNCSTPGNFFHVLRRQILLPFRKPLIIFTPKSLLRHPEARSSFDEMLPGTHFQRVIPEDGPAAQNPENVKRLLFCTGKVYYDLTRERKARDMVGQVAITRIEQLSPFPFDLLLKEVQKYPNAELAWCQEEHKNQGYYDYVKPRLRTTISRAKPVWYAGRDPAAAPATGNKKTHLTELQRLLDTAFDLDVFKNFS>sp|Q02218-3|ODO1_HUMAN Isoform 3 of 2-oxoglutarate dehydrogenase,mitochondrial OS=Homo sapiens OX=9606 GN=OGDHMFHLRTCAAKLRPLTASQTVKTFSQNRPAAARTFQQIRCYSAPVAAEPFLSGTSSNYVEEMYCAWLENPKSVHKSWDIFFRNTNAGAPPGTAYQSPLPLSRGSLAAVAHAQSLVEAQPNVDKLVEDHLAVQSLIRAYQIRGHHVAQLDPLGILDADLDSSVPADIISSTDKLGFYGLDESDLDKVFHLPTTTFIGGQESALPLREIIRRLEMAYCQHIGVEFMFINDLEQCQWIRQKFETPGIMQFTNEEKRTLLARLVRSTRFEEFLQRKWSSEKRFGLEGCEVLIPALKTIIDKSSENGVDYVIMGMPHRGRLNVLANVIRKELEQIFCQFDSKLEAADEGSGDVKYHLGMYHRRINRVTDRNITLSLVANPSHLEAADPVVMGKTKAEQFYCGDTEGKKVRPRERRARQIVKAPCSSMEFRSPT>sp|Q9UKG9|OCTC_HUMAN Peroxisomal carnitine O-octanoyltransferase OS=Homosapiens OX=9606 GN=CROT PE=1 SV=2MENQLAKSTEERTFQYQDSLPSLPVPSLEESLKKYLESVKPFANQEEYKKTEEIVQKFQSGIGEKLHQKLLERAKGKRNWLEEWWLNVAYLDVRIPSQLNVNFAGPAAHFEHYWPPKEGTQLERGSITLWHNLNYWQLLRKEKVPVHKVGNTPLDMNQFRMLFSTCKVPGITRDSIMNYFRTESEGRSPNHIVVLCRGRAFVFDVIHEGCLVTPPELLRQLTYIHKKCHSEPDGPGIAALTSEERTRWAKAREYLIGLDPENLALLEKIQSSLLVYSMEDSSPHVTPEDYSEIIAAILIGDPTVRWGDKSYNLISFSNGVFGCNCDHAPFDAMIMVNISYYVDEKIFQNEGRWKGSEKVRDIPLPEELIFIVDEKVLNDINQAKAQYLREASDLQIAAYAFTSFGKKLTKNKMLHPDTFIQLALQLAYYRLHGHPGCCYETAMTRHFYHGRTETMRSCTVEAVRWCQSMQDPSVNLRERQQKMLQAFAKHNKMMKDCSAGKGFDRHLLGLLLIAKEEGLPVPELFTDPLFSKSGGGGNFVLSTSLVGYLRVQGVVVPMVHNGYGFFYHIRDDRFVVACSAWKSCPETDAEKLVQLTFCAFHDMIQLMNSTHL>sp|Q9UKG9-2|OCTC_HUMAN Isoform 2 of Peroxisomal carnitine O-octanoyltransferase OS=Homo sapiens OX=9606 GN=CROTMENQLAKSTEERTFQYQDSLPSLPVPSLEESLKKYLESVKPFANQEEYKKTEEIVQKFQSGIGEKLHQKLLERAKGKRNWVFVVIIE>sp|Q9UKG9-3|OCTC_HUMAN Isoform 3 of Peroxisomal carnitine O-octanoyltransferase OS=Homo sapiens OX=9606 GN=CROTMENQLAKSTEERTFQYQDSLPSLPVPSLEESLKKYLESVTRTCYQIRGLDPDAKRGFLDLTREGIQVKPFANQEEYKKTEEIVQKFQSGIGEKLHQKLLERAKGKRNWLEEWWLNVAYLDVRIPSQLNVNFAGPAAHFEHYWPPKEGTQLERGSITLWHNLNYWQLLRKEKVPVHKVGNTPLDMNQFRMLFSTCKVPGITRDSIMNYFRTESEGRSPNHIVVLCRGRAFVFDVIHEGCLVTPPELLRQLTYIHKKCHSEPDGPGIAALTSEERTRWAKAREYLIGLDPENLALLEKIQSSLLVYSMEDSSPHVTPEDYSEIIAAILIGDPTVRWGDKSYNLISFSNGVFGCNCDHAPFDAMIMVNISYYVDEKIFQNEGRWKGSEKVRDIPLPEELIFIVDEKVLNDINQAKAQYLREASDLQIAAYAFTSFGKKLTKNKMLHPDTFIQLALQLAYYRLHGHPGCCYETAMTRHFYHGRTETMRSCTVEAVRWCQSMQDPSVNLRERQQKMLQAFAKHNKMMKDCSAGKGFDRHLLGLLLIAKEEGLPVPELFTDPLFSKSGGGGNFVLSTSLVGYLRVQGVVVPMVHNGYGFFYHIRDDRFVVACSAWKSCPETDAEKLVQLTFCAFHDMIQLMNSTHL>sp|Q9Y236|OSGI2_HUMAN Oxidative stress-induced growth inhibitor 2OS=Homo sapiens OX=9606 GN=OSGIN2 PE=2 SV=1MPLVEETSLLEDSSVTFPVVIIGNGPSGICLSYMLSGYRPYLSSEAIHPNTILNSKLEEARHLSIVDQDLEYLSEGLEGRSSNPVAVLFDTLLHPDADFGYDYPSVLHWKLEQHHYIPHVVLGKGPPGGAWHNMEGSMLTISFGSWMELPGLKFKDWVSSKRRSLKGDRVMPEEIARYYKHYVKVMGLQKNFRENTYITSVSRLYRDQDDDDIQDRDISTKHLQIEKSNFIKRNWEIRGYQRIADGSHVPFCLFAENVALATGTLDSPAHLEIEGEDFPFVFHSMPEFGAAINKGKLRGKVDPVLIVGSGLTAADAVLCAYNSNIPVIHVFRRRVTDPSLIFKQLPKKLYPEYHKVYHMMCTQSYSVDSNLLSDYTSFPEHRVLSFKSDMKCVLQSVSGLKKIFKLSAAVVLIGSHPNLSFLKDQGCYLGHKSSQPITCKGNPVEIDTYTYECIKEANLFALGPLVGDNFVRFLKGGALGVTRCLATRQKKKHLFVERGGGDGIA>sp|Q9Y236-2|OSGI2_HUMAN Isoform 2 of Oxidative stress-induced growthinhibitor 2 OS=Homo sapiens OX=9606 GN=OSGIN2MPVWCCRCSLAGHFRNYSDTETEGEIFNSLVQYFGDNLGRKVKAMPLVEETSLLEDSSVTFPVVIIGNGPSGICLSYMLSGYRPYLSSEAIHPNTILNSKLEEARHLSIVDQDLEYLSEGLEGRSSNPVAVLFDTLLHPDADFGYDYPSVLHWKLEQHHYIPHVVLGKGPPGGAWHNMEGSMLTISFGSWMELPGLKFKDWVSSKRRSLKGDRVMPEEIARYYKHYVKVMGLQKNFRENTYITSVSRLYRDQDDDDIQDRDISTKHLQIEKSNFIKRNWEIRGYQRIADGSHVPFCLFAENVALATGTLDSPAHLEIEGEDFPFVFHSMPEFGAAINKGKLRGKVDPVLIVGSGLTAADAVLCAYNSNIPVIHVFRRRVTDPSLIFKQLPKKLYPEYHKVYHMMCTQSYSVDSNLLSDYTSFPEHRVLSFKSDMKCVLQSVSGLKKIFKLSAAVVLIGSHPNLSFLKDQGCYLGHKSSQPITCKGNPVEIDTYTYECIKEANLFALGPLVGDNFVRFLKGGALGVTRCLATRQKKKHLFVERGGGDGIA>sp|Q6DKJ4|NXN_HUMAN Nucleoredoxin OS=Homo sapiens OX=9606 GN=NXN PE=1SV=2MSGFLEELLGEKLVTGGGEEVDVHSLGARGISLLGLYFGCSLSAPCAQLSASLAAFYGRLRGDAAAGPGPGAGAGAAAEPEPRRRLEIVFVSSDQDQRQWQDFVRDMPWLALPYKEKHRKLKLWNKYRISNIPSLIFLDATTGKVVCRNGLLVIRDDPEGLEFPWGPKPFREVIAGPLLRNNGQSLESSSLEGSHVGVYFSAHWCPPCRSLTRVLVESYRKIKEAGQNFEIIFVSADRSEESFKQYFSEMPWLAVPYTDEARRSRLNRLYGIQGIPTLIMLDPQGEVITRQGRVEVLNDEDCREFPWHPKPVLELSDSNAAQLNEGPCLVLFVDSEDDGESEAAKQLIQPIAEKIIAKYKAKEEEAPLLFFVAGEDDMTDSLRDYTNLPEAAPLLTILDMSARAKYVMDVEEITPAIVEAFVNDFLAEKLKPEPI>sp|Q6DKJ4-2|NXN_HUMAN Isoform 2 of Nucleoredoxin OS=Homo sapiens OX=9606GN=NXNMQELRNSLKLWNKYRISNIPSLIFLDATTGKVVCRNGLLVIRDDPEGLEFPWGPKPFREVIAGPLLRNNGQSLESSSLEGSHVGVYFSAHWCPPCRSLTRVLVESYRKIKEAGQNFEIIFVSADRSEESFKQYFSEMPWLAVPYTDEARRSRLNRLYGIQGRRSRPRLRVAPGNLLT>sp|Q6DKJ4-3|NXN_HUMAN Isoform 3 of Nucleoredoxin OS=Homo sapiens OX=9606GN=NXNMADVSLHRNPATLKLWNKYRISNIPSLIFLDATTGKVVCRNGLLVIRDDPEGLEFPWGPKPFREVIAGPLLRNNGQSLESSSLEGSHVGVYFSAHWCPPCRSLTRVLVESYRKIKEAGQNFEIIFVSADRSEESFKQYFSEMPWLAVPYTDEARRSRLNRLYGIQGIPTLIMLDPQGEVITRQGRVEVLNDEDCREFPWHPKPVLELSDSNAAQLNEGPCLVLFVDSEDDGESEAAKQLIQPIAEKIIAKYKAKEEEAPLLFFVAGEDDMTDSLRDYTNLPEAAPLLTILDMSARAKYVMDVEEITPAIVEAFVNDFLAEKLKPEPI>sp|Q8NGS2|OR1J2_HUMAN Olfactory receptor 1J2 OS=Homo sapiens OX=9606GN=OR1J2 PE=2 SV=1MSPENQSSVSEFLLLGLPIRPEQQAVFFTLFLGMYLTTVLGNLLIMLLIQLDSHLHTPMYFFLSHLALTDISFSSVTVPKMLMDMRTKYKSILYEECISQMYFFIFFTDLDSFLITSMAYDRYVAICHPLHYTVIMREELCVFLVAVSWILSCASSLSHTLLLTRLSFCAANTIPHVFCDLAALLKLSCSDIFLNELVMFTVGVVVITLPFMCILVSYGYIGATILRVPSTKGIHKALSTCGSHLSVVSLYYGSIFGQYLFPTVSSSIDKDVIVALMYTVVTPMLNPFIYSLRNRDMKEALGKLFSRATFFSW>sp|Q8IYS5|OSCAR_HUMAN Osteoclast-associated immunoglobulin-like receptorOS=Homo sapiens OX=9606 GN=OSCAR PE=1 SV=3MALVLILQLLTLWPLCHTDITPSVPPASYHPKPWLGAQPATVVTPGVNVTLRCRAPQPAWRFGLFKPGEIAPLLFRDVSSELAEFFLEEVTPAQGGIYRCCYRRPDWGPGVWSQPSDVLELLVTEELPRPSLVALPGPVVGPGANVSLRCAGRLRNMSFVLYREGVAAPLQYRHSAQPWADFTLLGARAPGTYSCYYHTPSAPYVLSQRSEVLVISWEGEGPEARPASSAPGMQAPGPPPSDPGAQAPSLSSFRPRGLVLQPLLPQTQDSWDPAPPPSDPGV>sp|Q8IYS5-2|OSCAR_HUMAN Isoform 2 of Osteoclast-associatedimmunoglobulin-like receptor OS=Homo sapiens OX=9606 GN=OSCARMALVLILQLLTLWPLCHTDITPSVPPASYHPKPWLGAQPATVVTPGVNVTLRCRAPQPAWRFGLFKPGEIAPLLFRDVSSELAEFFLEEVTPAQGGIYRCCYRRPDWGPGVWSQPSDVLELLVTEELPRPSLVALPGPVVGPGANVSLRCAGRLRNMSFVLYREGVAAPLQYRHSAQPWADFTLLGARAPGTYSCYYHTPSAPYVLSQRSEVLVISWEDSGSSDYTRGNLVRLGLAGLVLISLGALVTFDWRSQNRAPAGIRP>sp|Q8IYS5-3|OSCAR_HUMAN Isoform 3 of Osteoclast-associatedimmunoglobulin-like receptor OS=Homo sapiens OX=9606 GN=OSCARMALVLILQLLTLWPLCHTDITPSVAIIVPPASYHPKPWLGAQPATVVTPGVNVTLRCRAPQPAWRFGLFKPGEIAPLLFRDVSSELAEFFLEEVTPAQGGIYRCCYRRPDWGPGVWSQPSDVLELLVTEELPRPSLVALPGPVVGPGANVSLRCAGRLRNMSFVLYREGVAAPLQYRHSAQPWADFTLLGARAPGTYSCYYHTPSAPYVLSQRSEVLVISWEDSGSSDYTRGNLVRLGLAGLVLISLGALVTFDWRSQNRAPAGIRP>sp|Q8IYS5-4|OSCAR_HUMAN Isoform 4 of Osteoclast-associatedimmunoglobulin-like receptor OS=Homo sapiens OX=9606 GN=OSCARMALVLILQLLTLFPPASYHPKPWLGAQPATVVTPGVNVTLRCRAPQPAWRFGLFKPGEIAPLLFRDVSSELAEFFLEEVTPAQGGIYRCCYRRPDWGPGVWSQPSDVLELLVTEELPRPSLVALPGPVVGPGANVSLRCAGRLRNMSFVLYREGVAAPLQYRHSAQPWADFTLLGARAPGTYSCYYHTPSAPYVLSQRSEVLVISWEGEGPEARPASSAPGMQAPGPPPSDPGAQAPSLSSFRPRGLVLQPLLPQTQDSWDPAPPPSDPGV>sp|Q8IYS5-5|OSCAR_HUMAN Isoform 5 of Osteoclast-associatedimmunoglobulin-like receptor OS=Homo sapiens OX=9606 GN=OSCARMALVLILQLLTLWPLCHTDITPSVPPASYHPKPWLGAQPATVVTPGVNVTLRCRAPQPAWRFGLFKPGEIAPLLFRDVSSELAEFFLEEVTPAQGGIYRCCYRRPDWGPGVWSQPSDVLELLVTEELPLPGPVVGPGANVSLRCAGRLRNMSFVLYREGVAAPLQYRHSAQPWADFTLLGARAPGTYSCYYHTPSAPYVLSQRSEVLVISWEGEGPEARPASSAPGMQAPGPPPSDPGAQAPSLSSFRPRGLVLQPLLPQTQDSWDPAPPPSDPGV>sp|Q8IYS5-7|OSCAR_HUMAN Isoform 7 of Osteoclast-associatedimmunoglobulin-like receptor OS=Homo sapiens OX=9606 GN=OSCARMALVLILQLLTLWPLCHTDITPSVAIIVPPASYHPKPWLGAQPATVVTPGVNVTLRCRAPQPAWRFGLFKPGEIAPLLFRDVSSELAEFFLEEVTPAQGGIYRCCYRRPDWGPGVWSQPSDVLELLVTEELPRPSLVALPGPVVGPGANVSLRCAGRLRNMSFVLYREGVAAPLQYRHSAQPWADFTLLGARAPGTYSCYYHTPSAPYVLSQRSEVLVISWEGEGPEARPASSAPGMQAPGPPPSDPGAQAPSLSSFRPRGLVLQPLLPQTQDSWDPAPPPSDPGV>sp|Q8IYS5-6|OSCAR_HUMAN Isoform 6 of Osteoclast-associatedimmunoglobulin-like receptor OS=Homo sapiens OX=9606 GN=OSCARMALVLILQLLTLFPPASYHPKPWLGAQPATVVTPGVNVTLRCRAPQPAWRFGLFKPGEIAPLLFRDVSSELAEFFLEEVTPAQGGIYRCCYRRPDWGPGVWSQPSDVLELLVTEELPRPSLVALPGPVVGPGANVSLRCAGRLRNMSFVLYREGVAAPLQYRHSAQPWADFTLLGARAPGTYSCYYHTPSAPYVLSQRSEVLVISWEDSGSSDYTRGNLVRLGLAGLVLISLGALVTFDWRSQNRAPAGIRP>sp|A6ND48|O14I1_HUMAN Olfactory receptor 14I1 OS=Homo sapiens OX=9606GN=OR14I1 PE=1 SV=1MDNLTKVTEFLLMEFSGIWELQVLHAGLFLLIYLAVLVGNLLIIAVITLDQHLHTPMYFFLKNLSVLDLCYISVTVPKSIRNSLTRRSSISYLGCVAQVYFFSAFASAELAFLTVMSYDRYVAICHPLQYRAVMTSGGCYQMAVTTWLSCFSYAAVHTGNMFREHVCRSSVIHQFFRDIPHVLALVSCEVFFVEFLTLALSSCLVLGCFILMMISYFQIFSTVLRIPSGQSRAKAFSTCSPQLIVIMLFLTTGLFAALGPIAKALSIQDLVIALTYTVLPPFLNPIIYSLRNKEIKTAMWRLFVKIYFLQK>sp|Q8NH00|OR2T4_HUMAN Olfactory receptor 2T4 OS=Homo sapiens OX=9606GN=OR2T4 PE=3 SV=2MDNITWMASHTGWSDFILMGLFRQSKHPMANITWMANHTGWSDFILLGLFRQSKHPALLCVVIFVVFLMALSGNAVLILLIHCDAHLHTPMYFFISQLSLMDMAYISVTVPKMLLDQVMGVNKISAPECGMQMFFYVTLAGSEFFLLATMAYDRYVAICHPLRYPVLMNHRVCLFLSSGCWFLGSVDGFTFTPITMTFPFRGSREIHHFFCEVPAVLNLSCSDTSLYEIFMYLCCVLMLLIPVVIISSSYLLILLTIHGMNSAEGRKKAFATCSSHLTVVILFYGAAIYTYMLPSSYHTPEKDMMVSVFYTILTPVVNPLIYSLRNKDVMGALKKMLTVEPAFQKAME>sp|Q9H341|O51M1_HUMAN Olfactory receptor 51M1 OS=Homo sapiens OX=9606GN=OR51M1 PE=3 SV=4MSVQYSLSPQFMLLSNITQFSPIFYLTSFPGLEGIKHWIFIPFFFMYMVAISGNCFILIIIKTNPRLHTPMYYLLSLLALTDLGLCVSTLPTTMGIFWFNSHSIYFGACQIQMFCIHSFSFMESSVLLMMSFDRLVAICHPLRYSVIITGQQVVRAGLIVIFRGPVATIPIVLLLKAFPYCGSVVLSHSFCLHQEVIQLACTDITFNNLYGLMVVVFTVMLDLVLIALSYGLILHTVAGLASQEEQRRAFQTCTAPLCAVLVFFVPMMGLSLVHRFGKHAPPAIHLLMANVYLFVPPMLNPIIYSIKTKEIHRAIIKFLGLKKASK>sp|Q9H339|O51B5_HUMAN Olfactory receptor 51B5 OS=Homo sapiens OX=9606GN=OR51B5 PE=2 SV=2MSSSGSSHPFLLTGFPGLEEAHHWISVFFLFMYISILFGNGTLLLLIKEDHNLHEPMYFFLAMLAATDLGLALTTMPTVLGVLWLDHREIGSAACFSQAYFIHSLSFLESGILLAMAYDRFIAICNPLRYTSVLTNTRVVKIGLGVLMRGFVSVVPPIRPLYFFLYCHSHVLSHAFCLHQDVIKLACADTTFNRLYPAVLVVFIFVLDYLIIFISYVLILKTVLSIASREERAKALITCVSHICCVLVFYVTVIGLSLIHRFGKQVPHIVHLIMSYAYFLFPPLMNPITYSVKTKQIQNAILHLFTTHRIGT>sp|A6NH00|OR2T8_HUMAN Olfactory receptor 2T8 OS=Homo sapiens OX=9606GN=OR2T8 PE=3 SV=1MENGSYTSYFILLGLFNHTRAHQVLFMMVLSIVLTSLFGNSLMILLIHWDHRLHTPMYFLLSQLSLMDVMLVSTTVPKMAADYLTGSKAISRAGCGAQIFFLPTLGGGECFLLAAMAYDRYAAVCHPLRYPTLMSWQLCLRMNLSCWLLGAADGLLQAVATLSFPYCGAHEIDHFFCETPVLVRLACADTSVFENAMYICCVLMLLVPFSLILSSYGLILAAVLHMRSTEARKKAFATCSSHVAVVGLFYGAAIFTYMRPKSHRSTNHDKVVSAFYTMFTPLLNPLIYSVKNSEVKGALTRCMGRCVALSRE>sp|Q06190|P2R3A_HUMAN Serine/threonine-protein phosphatase 2A regulatorysubunit B'' subunit alpha OS=Homo sapiens OX=9606 GN=PPP2R3A PE=1 SV=1MAATYRLVVSTVNHYSSVVIDRRFEQAIHYCTGTCHTFTHGIDCIVVHHSVCADLLHIPVSQFKDADLNSMFLPHENGLSSAEGDYPQQAFTGIPRVKRGSTFQNTYNLKDIAGEAISFASGKIKEFSFEKLKNSNHAAYRKGRKVKSDSFNRRSVDLDLLCGHYNNDGNAPSFGLLRSSSVEEKPLSHRNSLDTNLTSMFLQNFSEEDLVTQILEKHKIDNFSSGTDIKMCLDILLKCSEDLKKCTDIIKQCIKKKSGSSISEGSGNDTISSSETVYMNVMTRLASYLKKLPFEFMQSGNNEALDLTELISNMPSLQLTPFSPVFGTEQPPKYEDVVQLSASDSGRFQTIELQNDKPNSRKMDTVQSIPNNSTNSLYNLEVNDPRTLKAVQVQSQSLTMNPLENVSSDDLMETLYIEEESDGKKALDKGQKTENGPSHELLKVNEHRAEFPEHATHLKKCPTPMQNEIGKIFEKSFVNLPKEDCKSKVSKFEEGDQRDFTNSSSQEEIDKLLMDLESFSQKMETSLREPLAKGKNSNFLNSHSQLTGQTLVDLEPKSKVSSPIEKVSPSCLTRIIETNGHKIEEEDRALLLRILESIEDFAQELVECKSSRGSLSQEKEMMQILQETLTTSSQANLSVCRSPVGDKAKDTTSAVLIQQTPEVIKIQNKPEKKPGTPLPPPATSPSSPRPLSPVPHVNNVVNAPLSINIPRFYFPEGLPDTCSNHEQTLSRIETAFMDIEEQKADIYEMGKIAKVCGCPLYWKAPMFRAAGGEKTGFVTAQSFIAMWRKLLNNHHDDASKFICLLAKPNCSSLEQEDFIPLLQDVVDTHPGLTFLKDAPEFHSRYITTVIQRIFYTVNRSWSGKITSTEIRKSNFLQTLALLEEEEDINQITDYFSYEHFYVIYCKFWELDTDHDLYISQADLSRYNDQASSSRIIERIFSGAVTRGKTIQKEGRMSYADFVWFLISEEDKRNPTSIEYWFRCMDVDGDGVLSMYELEYFYEEQCERMEAMGIEPLPFHDLLCQMLDLVKPAVDGKITLRDLKRCRMAHIFYDTFFNLEKYLDHEQRDPFAVQKDVENDGPEPSDWDRFAAEEYETLVAEESAQAQFQEGFEDYETDEPASPSEFGNKSNKILSASLPEKCGKLQSVDEE>sp|Q06190-2|P2R3A_HUMAN Isoform PR72 of Serine/threonine-proteinphosphatase 2A regulatory subunit B'' subunit alpha OS=Homo sapiensOX=9606 GN=PPP2R3AMMIKETSLRRDPDLRGELAFLARGCDFVLPSRFKKRLKSFQQTQIQNKPEKKPGTPLPPPATSPSSPRPLSPVPHVNNVVNAPLSINIPRFYFPEGLPDTCSNHEQTLSRIETAFMDIEEQKADIYEMGKIAKVCGCPLYWKAPMFRAAGGEKTGFVTAQSFIAMWRKLLNNHHDDASKFICLLAKPNCSSLEQEDFIPLLQDVVDTHPGLTFLKDAPEFHSRYITTVIQRIFYTVNRSWSGKITSTEIRKSNFLQTLALLEEEEDINQITDYFSYEHFYVIYCKFWELDTDHDLYISQADLSRYNDQASSSRIIERIFSGAVTRGKTIQKEGRMSYADFVWFLISEEDKRNPTSIEYWFRCMDVDGDGVLSMYELEYFYEEQCERMEAMGIEPLPFHDLLCQMLDLVKPAVDGKITLRDLKRCRMAHIFYDTFFNLEKYLDHEQRDPFAVQKDVENDGPEPSDWDRFAAEEYETLVAEESAQAQFQEGFEDYETDEPASPSEFGNKSNKILSASLPEKCGKLQSVDEE>sp|Q06190-3|P2R3A_HUMAN Isoform 3 of Serine/threonine-proteinphosphatase 2A regulatory subunit B'' subunit alpha OS=Homo sapiensOX=9606 GN=PPP2R3AMDIEEQKADIYEMGKIAKVCGCPLYWKAPMFRAAGGEKTGFVTAQSFIAMWRKLLNNHHDDASKFICLLAKPNCSSLEQEDFIPLLQDVVDTHPGLTFLKDAPEFHSRYITTVIQRIFYTVNRSWSGKITSTEIRKSNFLQTLALLEEEEDINQITDYFSYEHFYVIYCKFWELDTDHDLYISQADLSRYNDQASSSRIIERIFSGAVTRGKTIQKEGRMSYADFVWFLISEEDKRNPTSIEYWFRCMDVDGDGVLSMYELEYFYEEQCERMEAMGIEPLPFHDLLCQMLDLVKPAVDGKITLRDLKRCRMAHIFYDTFFNLEKYLDHEQRDPFAVQKDVENDGPEPSDWDRFAAEEYETLVAEESAQAQFQEGFEDYETDEPASPSEFGNKSNKILSASLPEKCGKLQSVDEE>sp|Q7L8S5|OTU6A_HUMAN OTU domain-containing protein 6A OS=Homo sapiensOX=9606 GN=OTUD6A PE=1 SV=1MDDPKSEQQRILRRHQRERQELQAQIRSLKNSVPKTDKTKRKQLLQDVARMEAEMAQKHRQELEKFQDDSSIESVVEDLAKMNLENRPPRSSKAHRKRERMESEERERQESIFQAEMSEHLAGFKREEEEKLAAILGARGLEMKAIPADGHCMYRAIQDQLVFSVSVEMLRCRTASYMKKHVDEFLPFFSNPETSDSFGYDDFMIYCDNIVRTTAWGGQLELRALSHVLKTPIEVIQADSPTLIIGEEYVKKPIILVYLRYAYSLGEHYNSVTPLEAGAAGGVLPRLL>sp|P37231|PPARG_HUMAN Peroxisome proliferator-activated receptor gammaOS=Homo sapiens OX=9606 GN=PPARG PE=1 SV=3MGETLGDSPIDPESDSFTDTLSANISQEMTMVDTEMPFWPTNFGISSVDLSVMEDHSHSFDIKPFTTVDFSSISTPHYEDIPFTRTDPVVADYKYDLKLQEYQSAIKVEPASPPYYSEKTQLYNKPHEEPSNSLMAIECRVCGDKASGFHYGVHACEGCKGFFRRTIRLKLIYDRCDLNCRIHKKSRNKCQYCRFQKCLAVGMSHNAIRFGRMPQAEKEKLLAEISSDIDQLNPESADLRALAKHLYDSYIKSFPLTKAKARAILTGKTTDKSPFVIYDMNSLMMGEDKIKFKHITPLQEQSKEVAIRIFQGCQFRSVEAVQEITEYAKSIPGFVNLDLNDQVTLLKYGVHEIIYTMLASLMNKDGVLISEGQGFMTREFLKSLRKPFGDFMEPKFEFAVKFNALELDDSDLAIFIAVIILSGDRPGLLNVKPIEDIQDNLLQALELQLKLNHPESSQLFAKLLQKMTDLRQIVTEHVQLLQVIKKTETDMSLHPLLQEIYKDLY>sp|P37231-2|PPARG_HUMAN Isoform 1 of Peroxisome proliferator-activatedreceptor gamma OS=Homo sapiens OX=9606 GN=PPARGMTMVDTEMPFWPTNFGISSVDLSVMEDHSHSFDIKPFTTVDFSSISTPHYEDIPFTRTDPVVADYKYDLKLQEYQSAIKVEPASPPYYSEKTQLYNKPHEEPSNSLMAIECRVCGDKASGFHYGVHACEGCKGFFRRTIRLKLIYDRCDLNCRIHKKSRNKCQYCRFQKCLAVGMSHNAIRFGRMPQAEKEKLLAEISSDIDQLNPESADLRALAKHLYDSYIKSFPLTKAKARAILTGKTTDKSPFVIYDMNSLMMGEDKIKFKHITPLQEQSKEVAIRIFQGCQFRSVEAVQEITEYAKSIPGFVNLDLNDQVTLLKYGVHEIIYTMLASLMNKDGVLISEGQGFMTREFLKSLRKPFGDFMEPKFEFAVKFNALELDDSDLAIFIAVIILSGDRPGLLNVKPIEDIQDNLLQALELQLKLNHPESSQLFAKLLQKMTDLRQIVTEHVQLLQVIKKTETDMSLHPLLQEIYKDLY>sp|P37231-3|PPARG_HUMAN Isoform 3 of Peroxisome proliferator-activatedreceptor gamma OS=Homo sapiens OX=9606 GN=PPARGMTMVDTEMPFWPTNFGISSVDLSVMEDHSHSFDIKPFTTVDFSSISTPHYEDIPFTRTDPVVADYKYDLKLQEYQSAIKVEPASPPYYSEKTQLYNKPHEEPSNSLMAIECRVCGDKASGFHYGVHACEGCKGFFRRTIRLKLIYDRCDLNCRIHKKSRNKCQYCRFQKCLAVGMSHNEELQKDSY>sp|P11465|PSG2_HUMAN Pregnancy-specific beta-1-glycoprotein 2 OS=Homosapiens OX=9606 GN=PSG2 PE=2 SV=2MGPLSAPPCTEHIKWKGLLVTASLLNFWNLPTTAQVTIEAQPPKVSEGKDVLLLVHNLPQNLTGYIWYKGQIRDLYHYITSYVVDGQIIIYGPAYSGRETAYSNASLLIQNVTREDAGSYTLHIIKRGDGTRGVTGYFTFTLYLETPKPSISSSNLNPREAMETVILTCDPETPDTSYQWWMNGQSLPMTHRFQLSETNRTLFLFGVTKYTAGPYECEIRNSGSASRSDPVTLNLLHGPDLPRIHPSYTNYRSGDNLYLSCFANSNPPAQYSWTINGKFQQSGQNLFIPQITTKHSGLYVCSVRNSATGEESSTSLTVKVSASTRIGLLPLLNPT>sp|A6NJY4|T238L_HUMAN Transmembrane protein 238-like OS=Homo sapiensOX=9606 GN=TMEM238L PE=4 SV=3MLLGSLWGRCHPGRCALFLILALLLDAVGLVLLLLGILAPLSSWDFFIYTGALILALSLLLWIIWYSLNIEVSPEKLDL>sp|Q9BVK8|TM147_HUMAN Transmembrane protein 147 OS=Homo sapiens OX=9606GN=TMEM147 PE=1 SV=1MTLFHFGNCFALAYFPYFITYKCSGLSEYNAFWKCVQAGVTYLFVQLCKMLFLATFFPTWEGGIYDFIGEFMKASVDVADLIGLNLVMSRNAGKGEYKIMVAALGWATAELIMSRCIPLWVGARGIEFDWKYIQMSIDSNISLVHYIVASAQVWMITRYDLYHTFRPAVLLLMFLSVYKAFVMETFVHLCSLGSWAALLARAVVTGLLALSTLALYVAVVNVHS>sp|Q9BVK8-2|TM147_HUMAN Isoform 2 of Transmembrane protein 147 OS=Homosapiens OX=9606 GN=TMEM147MLFLATFFPTWEGGIYDFIGEFMKASVDVADLIGLNLVMSRNAGKGEYKIMVAALGWATAELIMSRCIPLWVGARGIEFDWKYIQMSIDSNISLVHYIVASAQVWMITRYDLYHTFRPAVLLLMFLSVYKAFVMETFVHLCSLGSWAALLARAVVTGLLALSTLALYVAVVNVHS>sp|Q96DN5|TBC31_HUMAN TBC1 domain family member 31 OS=Homo sapiensOX=9606 GN=TBC1D31 PE=1 SV=2MQSTDLGNKESGKIWHRKPSPATRDGIIVNIIHNTSDYHPKVLRFLNVAFDGTGDCLIAGDHQGNIYVFDLHGNRFNLVQRTAQACTALAFNLRRKSEFLVALADYSIKCFDTVTKELVSWMRGHESSVFSISVHASGKYAITTSSDTAQLWDLDTFQRKRKLNIRQSVGIQKVFFLPLSNTILSCFKDNSIFAWECDTLFCKYQLPAPPESSSILYKVFAVTRDGRILAAGGKSNHLHLWCLEARQLFRIIQMPTKVRAIRHLEFLPDSFDAGSNQVLGVLSQDGIMRFINMQTCKLLFEIGSLDEGISSSAISPHGRYIASIMENGSLNIYSVQALTQEINKPPPPLVKVIEDLPKNKLSSSDLKMKVTSGRVQQPAKSRESKMQTRILKQDLTGDFESKKNELPDGLNKKRLQILLKGYGEYPTKYRMFIWRSLLQLPENHTAFSTLIDKGTHVAFLNLQKKYPIKSRKLLRVLQRTLSALAHWSVIFSDTPYLPLLAFPFVKLFQNNQLICFEVIATLIINWCQHWFEYFPNPPINILSMIENVLAFHDKELLQHFIDHDITSQLYAWPLLETVFSEVLTREEWLKLFDNIFSNHPSFLLMTVVAYNICSRTPLLSCNLKDDFEFFFHHRNNLDINVVIRQVYHLMETTPTDIHPDSMLNVFVALTKGQYPVFNQYPKFIVDYQTQERERIRNDELDYLRERQTVEDMQAKVDQQRVEDEAWYQKQELLRKAEETRREMLLQEEEKMIQQRQRLAAVKRELKVKEMHLQDAARRRFLKLQQDQQEMELRRLDDEIGRKVYMRDREIAATARDLEMRQLELESQKRLYEKNLTENQEALAKEMRADADAYRRKVDLEEHMFHKLIEAGETQSQKTQKVIKENLAKAEQACLNTDWQIQSLHKQKCDDLQRNKCYQEVAKLLRENRRKEIEIINAMVEEEAKKWKEAEGKEFRLRSAKKASALSDASRKWFLKQEINAAVEHAENPCHKEEPRFQNEQDSSCLPRTSQLNDSSEMDPSTQISLNRRAVEWDTTGQNLIKKVRNLRQRLTARARHRCQTPHLLAA>sp|Q96DN5-2|TBC31_HUMAN Isoform 2 of TBC1 domain family member 31OS=Homo sapiens OX=9606 GN=TBC1D31MQSTDLGNKESGKIWHRKPSPATRDGIIVNIIHNTSDYHPKVLRFLNVAFDGTGDCLIAGDHQGNIYVFDLHGNRFNLVQRTAQACTALAFNLRRKSEFLVALADYSIKCFDTVTKELVSWMRGHESSVFSISVHASGKYAITTSSDTAQLWDLDTFQRKRKLNIRQSVGIQKVFFLPLSNTILSCFKDNSIFAWECDTLFCKYQLPAPPESSSILYKVFAVTRDGRILAAGGKSNHLHLWCLEARQLFRIIQMPTKVRAIRHLEFLPDSFDAGSNQVLGVLSQDGIMRFINMQTCKLLFEIGSLDEGISSSAISPHGRYIASIMENGSLNIYSVQALTQEINKPPPPLVKVIEDLPKNKLSSSDLKMKVTSGRVQQPAKSRESKMQTRILKQDLTGDFESKKNELPDGLNKKRLQILLKGYGEYPTKYRMFIWRSLLQLPENHTAFSTLIDKGTHVAFLNLQKKYPIKSRKLLRVLQRTLSALAHWSVIFSDTPYLPLLAFPFVKLFQNNQLICFEVIATLIINWCQHWFEYFPNPPINILSMIENVLAFHDKELLQHFIDHDITSQLYAWPLLETVFSEVLTREEWLKLFDNIFSNHPSFLLMTVVAYNICSRTPLLSCNLKDDFEFFFHHRNNLDINVVIRQVYHLMETTPTDIHPDSMLNVFVALTKGQYPVFNQYPKFIVDYQTQERERIRNDELDYLRERQTVEDMQAKVDQQRVEDEAWYQKQELLRKAEETRREMLLQEEEKMIQQRQRLAAVKRELKVKEMHLQDAARRRFLKLQQDQQEMELRRLDDEIGRKVYMRDREIAATARDLEMRQLELESQKRLYEKNLTENQEALAKEMRADADAYRRKVDLEEHMFHKLIEAGETQSQKTQKWKEAEGKEFRLRSAKKASALSDASRKWFLKQEINAAVEHAENPCHKEEPRFQNEQDSSCLPRTSQLNDSSEMDPSTQISLNRRAVEWDTTGQNLIKKVRNLRQRLTARARHRCQTPHLLAA>sp|Q96DN5-3|TBC31_HUMAN Isoform 3 of TBC1 domain family member 31OS=Homo sapiens OX=9606 GN=TBC1D31MQSTDLGNKESGKIWHRKPSPATRDGIIVNIIHNTSDYHPKVLRFLNVAFDGTGDCLIAGDHQGNIYVFDLHGNRFNLVQRTAQACTALAFNLRRKSEFLVALADYSIKCFDTVTKELVSWMRGHESSVFSISVHASGKYAITTSSDTAQLWDLDTFQRKRKLNIRQSVGIQKVFFLPLSNTILSCFKDNSIFAWECDTLFCKYQLPAPPESSSILYKVFAVTRDGRILAAGGKSNHLHLWCLEARQLFRIIQMPTKVRAIRHLEFLPDSFDAGSNQVLGVLSQDGIMRFINMQTCKLLFEIGSLDEGISSSAISPHGRYIASIMENGSLNIYSVQALTQEINKPPPPLVKVIEDLPKNKLSSSDLKMKVTSGRVQQPAKSRESKMQTRILKQDLTGDFESKKNELPDGLNKKRLQILLKGYGEYPTKYRMFIWRSLLQLPENHTAFSTLIDKGTHVAFLNLQKKYPIKSRKLLRVLQRTLSALAHWSVIFSDTPYLPLLAFPFVKLFQNNQLICFEVIATLIINWCQHWFEYFPNPPINILSMIENVLAFHDKELLQHFIDHDITSQLYAWPLLETVFSEVLTREEWLKLFDNIFSNHPSFLLMTVVAYNICSRTPLLSCNLKDDFEFFFHHRNNLDINVVIRQVYHLMETTPTDIHPDSMLNVFVALTKGQYPVFNQYPKFIVDYQTQERERIRNDELDYLRERQTVEDMQAKVDQQRVEDEAWYQKQELLRKAEETRREMLLQEEEKMIQQRQRLAAVKRELKVKEMHLQDAARRRFLKLQQDQQEMELRRLDDEIGRKNLTENQEALAKEMRADADAYRRKVDLEEHMFHKLIEAGETQSQKTQKWKEAEGKEFRLRSAKKASALSDASRKWFLKQEINAAVEHAENPCHKEEPRFQNEQDSSCLPRTSQLNDSSEMDPSTQISLNRRAVEWDTTGQNLIKKVRNLRQRLTARARHRCQTPHLLAA>sp|A6NGA9|TM202_HUMAN Transmembrane protein 202 OS=Homo sapiens OX=9606GN=TMEM202 PE=4 SV=1MERREHLTLTFHSPEVPKIKGNRKYQRPTVPAKKHPSASMSCQRQQQLMDQAHIYIRTLCGSLCSFSLLMLIAMSPLNWVQFLVIKNGLELYAGLWTLCNHELCWSHTPKPPYYLQYSRAFFLISVFTILTGLGWLFSSWILNRGSMTTNLDLKVSMLSFISATCLLLCLNLFVAQVHWHTRDAMESDLLWTYYLNWCSDIFYMFAGIISLLNYLTSRSPACDENVTVIPTERSRLGVGPVTTVSPAKDEGPRSEMESLSVREKNLPKSGLWW>sp|Q6ZT07|TBCD9_HUMAN TBC1 domain family member 9 OS=Homo sapiensOX=9606 GN=TBC1D9 PE=2 SV=2MWVNPEEVLLANALWITERANPYFILQRRKGHAGDGGGGGGLAGLLVGTLDVVLDSSARVAPYRILYQTPDSLVYWTIACGGSRKEITEHWEWLEQNLLQTLSIFENENDITTFVRGKIQGIIAEYNKINDVKEDDDTEKFKEAIVKFHRLFGMPEEEKLVNYYSCSYWKGKVPRQGWMYLSINHLCFYSFLMGREAKLVIRWVDITQLEKNATLLLPDVIKVSTRSSEHFFSVFLNINETFKLMEQLANIAMRQLLDNEGFEQDRSLPKLKRKSPKKVSALKRDLDARAKSERYRALFRLPKDEKLDGHTDCTLWTPFNKMHILGQMFVSTNYICFTSKEENLCSLIIPLREVTIVEKADSSSVLPSPLSISTRNRMTFLFANLKDRDFLVQRISDFLQQTTSKIYSDKEFAGSYNSSDDEVYSRPSSLVSSSPQRSTSSDADGERQFNLNGNSVPTATQTLMTMYRRRSPEEFNPKLAKEFLKEQAWKIHFAEYGQGICMYRTEKTRELVLKGIPESMRGELWLLLSGAINEKATHPGYYEDLVEKSMGKYNLATEEIERDLHRSLPEHPAFQNEMGIAALRRVLTAYAFRNPNIGYCQAMNIVTSVLLLYAKEEEAFWLLVALCERMLPDYYNTRVVGALVDQGVFEELARDYVPQLYDCMQDLGVISTISLSWFLTLFLSVMPFESAVVVVDCFFYEGIKVIFQLALAVLDANVDKLLNCKDDGEAMTVLGRYLDSVTNKDSTLPPIPHLHSLLSDDVEPYPEVDIFRLIRTSYEKFGTIRADLIEQMRFKQRLKVIQTLEDTTKRNVVRTIVTETSFTIDELEELYALFKAEHLTSCYWGGSSNALDRHDPSLPYLEQYRIDFEQFKGMFALLFPWACGTHSDVLASRLFQLLDENGDSLINFREFVSGLSAACHGDLTEKLKLLYKMHVLPEPSSDQDEPDSAFEATQYFFEDITPECTHVVGLDSRSKQGADDGFVTVSLKPDKGKRANSQENRNYLRLWTPENKSKSKNAKDLPKLNQGQFIELCKTMYNMFSEDPNEQELYHATAAVTSLLLEIGEVGKLFVAQPAKEGGSGGSGPSCHQGIPGVLFPKKGPGQPYVVESVEPLPASLAPDSEEHSLGGQMEDIKLEDSSPRDNGACSSMLISDDDTKDDSSMSSYSVLSAGSHEEDKLHCEDIGEDTVLVRSGQGTAALPRSTSLDRDWAITFEQFLASLLTEPALVKYFDKPVCMMARITSAKNIRMMGKPLTSASDYEISAMSG>sp|Q9BVW5|TIPIN_HUMAN TIMELESS-interacting protein OS=Homo sapiensOX=9606 GN=TIPIN PE=1 SV=2MLEPQENGVIDLPDYEHVEDETFPPFPPPASPERQDGEGTEPDEESGNGAPVRVPPKRTVKRNIPKLDAQRLISERGLPALRHVFDKAKFKGKGHEAEDLKMLIRHMEHWAHRLFPKLQFEDFIDRVEYLGSKKEVQTCLKRIRLDLPILHEDFVSNNDEVAENNEHDVTSTELDPFLTNLSESEMFASELSRSLTEEQQQRIERNKQLALERRQAKLLSNSQTLGNDMLMNTPRAHTVEEVNTDEDQKEESNGLNEDILDNPCNDAIANTLNEEETLLDQSFKNVQQQLDATSRNITEAR>sp|Q9C030|TRIM6_HUMAN Tripartite motif-containing protein 6 OS=Homosapiens OX=9606 GN=TRIM6 PE=1 SV=1MTSPVLVDIREEVTCPICLELLTEPLSIDCGHSFCQACITPNGRESVIGQEGERSCPVCQTSYQPGNLRPNRHLANIVRRLREVVLGPGKQLKAVLCADHGEKLQLFCQEDGKVICWLCERSQEHRGHHTFLVEEVAQEYQEKFQESLKKLKNEEQEAEKLTAFIREKKTSWKNQMEPERCRIQTEFNQLRNILDRVEQRELKKLEQEEKKGLRIIEEAENDLVHQTQSLRELISDLERRCQGSTMELLQDVSDVTERSEFWTLRKPEALPTKLRSMFRAPDLKRMLRVCRELTDVQSYWVDVTLNPHTANLNLVLAKNRRQVRFVGAKVSGPSCLEKHYDCSVLGSQHFSSGKHYWEVDVAKKTAWILGVCSNSLGPTFSFNHFAQNHSAYSRYQPQSGYWVIGLQHNHEYRAYEDSSPSLLLSMTVPPRRVGVFLDYEAGTVSFYNVTNHGFPIYTFSKYYFPTTLCPYFNPCNCVIPMTLRRPSS>sp|Q9C030-2|TRIM6_HUMAN Isoform 2 of Tripartite motif-containing protein6 OS=Homo sapiens OX=9606 GN=TRIM6MCGSERILQAGNILEIRVGQAGARRVATMTSPVLVDIREEVTCPICLELLTEPLSIDCGHSFCQACITPNGRESVIGQEGERSCPVCQTSYQPGNLRPNRHLANIVRRLREVVLGPGKQLKAVLCADHGEKLQLFCQEDGKVICWLCERSQEHRGHHTFLVEEVAQEYQEKFQESLKKLKNEEQEAEKLTAFIREKKTSWKNQMEPERCRIQTEFNQLRNILDRVEQRELKKLEQEEKKGLRIIEEAENDLVHQTQSLRELISDLERRCQGSTMELLQDVSDVTERSEFWTLRKPEALPTKLRSMFRAPDLKRMLRVCRELTDVQSYWVDVTLNPHTANLNLVLAKNRRQVRFVGAKVSGPSCLEKHYDCSVLGSQHFSSGKHYWEVDVAKKTAWILGVCSNSLGPTFSFNHFAQNHSAYSRYQPQSGYWVIGLQHNHEYRAYEDSSPSLLLSMTVPPRRVGVFLDYEAGTVSFYNVTNHGFPIYTFSKYYFPTTLCPYFNPCNCVIPMTLRRPSS>sp|Q9C030-3|TRIM6_HUMAN Isoform 3 of Tripartite motif-containing protein6 OS=Homo sapiens OX=9606 GN=TRIM6MEPERCRIQTEFNQLRNILDRVEQRELKKLEQEEKKGLRIIEEAENDLVHQTQSLRELISDLERRCQGSTMELLQDVSDVTERSEFWTLRKPEALPTKLRSMFRAPDLKRMLRVCRELTDVQSYWVDVTLNPHTANLNLVLAKNRRQVRFVGAKVSGPSCLEKHYDCSVLGSQHFSSGKHYWEVDVAKKTAWILGVCSNSLGPTFSFNHFAQNHSAYSRYQPQSGYWVIGLQHNHEYRAYEDSSPSLLLSMTVPPRRVGVFLDYEAGTVSFYNVTNHGFPIYTFSKYYFPTTLCPYFNPCNCVIPMTLRRPSS>sp|Q6ZP80|TM182_HUMAN Transmembrane protein 182 OS=Homo sapiens OX=9606GN=TMEM182 PE=1 SV=2MRLNIAIFFGALFGALGVLLFLVAFGSDYWLLATEVGRCSGEKNIENVTFHHEGFFWRCWFNGIVEENDSNIWKFWYTNQPPSKNCTHAYLSPYPFMRGEHNSTSYDSAVIYRGFWAVLMLLGVVAVVIASFLIICAAPFASHFLYKAGGGSYIAAGILFSLVVMLYVIWVQAVADMESYRNMKMKDCLDFTPSVLYGWSFFLAPAGIFFSLLAGLLFLVVGWHIQIHH>sp|Q6ZP80-2|TM182_HUMAN Isoform 2 of Transmembrane protein 182 OS=Homosapiens OX=9606 GN=TMEM182MRGEHNSTSYDSAVIYRGFWAVLMLLGVVAVVIASFLIICAAPFASHFLYKAGGGSYIAAGILFSLVVMLYVIWVQAVADMESYRNMKMKDCLDFTPSVLYGWSFFLAPAGIFFSLLAGLLFLVVGWHIQIHH>sp|Q6ZP80-3|TM182_HUMAN Isoform 3 of Transmembrane protein 182 OS=Homosapiens OX=9606 GN=TMEM182MLLGVVAVVIASFLIICAAPFASHFLYKAGGGSYIAAGILFSLVVMLYVIWVQAVADMESYRNMKMKDCLDFTPSVLYGWSFFLAPAGIFFSLLAGLLFLVVGWHIQIHH>sp|Q9NUR3|TM74B_HUMAN Transmembrane protein 74B OS=Homo sapiens OX=9606GN=TMEM74B PE=2 SV=1MPPAQGYEFAAAKGPRDELGPSFPMASPPGLELKTLSNGPQAPRRSAPLGPVAPTREGVENACFSSEEHETHFQNPGNTRLGSSPSPPGGVSSLPRSQRDDLSLHSEEGPALEPVSRPVDYGFVSALVFLVSGILLVVTAYAIPREARVNPDTVTAREMERLEMYYARLGSHLDRCIIAGLGLLTVGGMLLSVLLMVSLCKGELYRRRTFVPGKGSRKTYGSINLRMRQLNGDGGQALVENEVVQVSETSHTLQRS>sp|Q6ZMR5|TM11A_HUMAN Transmembrane protease serine 11A OS=Homo sapiensOX=9606 GN=TMPRSS11A PE=1 SV=1MMYRTVGFGTRSRNLKPWMIAVLIVLSLTVVAVTIGLLVHFLVFDQKKEYYHGSFKILDPQINNNFGQSNTYQLKDLRETTENLVSQVDEIFIDSAWKKNYIKNQVVRLTPEEDGVKVDVIMVFQFPSTEQRAVREKKIQSILNQKIRNLRALPINASSVQVNAMSSSTGELTVQASCGKRVVPLNVNRIASGVIAPKAAWPWQASLQYDNIHQCGATLISNTWLVTAAHCFQKYKNPHQWTVSFGTKINPPLMKRNVRRFIIHEKYRSAAREYDIAVVQVSSRVTFSDDIRRICLPEASASFQPNLTVHITGFGALYYGGESQNDLREARVKIISDDVCKQPQVYGNDIKPGMFCAGYMEGIYDACRGDSGGPLVTRDLKDTWYLIGIVSWGDNCGQKDKPGVYTQVTYYRNWIASKTGI>sp|Q6ZMR5-2|TM11A_HUMAN Isoform 2 of Transmembrane protease serine 11AOS=Homo sapiens OX=9606 GN=TMPRSS11AMMYRTVGFGTRSRNLKPWMIAVLIVLSLTVVAVTIGLLVHFLVFDQKKEYYHGSFKILDPQINNNFGQSNTYQLKDLRETTENLVDEIFIDSAWKKNYIKNQVVRLTPEEDGVKVDVIMVFQFPSTEQRAVREKKIQSILNQKIRNLRALPINASSVQVNAMSSSTGELTVQASCGKRVVPLNVNRIASGVIAPKAAWPWQASLQYDNIHQCGATLISNTWLVTAAHCFQKYKNPHQWTVSFGTKINPPLMKRNVRRFIIHEKYRSAAREYDIAVVQVSSRVTFSDDIRRICLPEASASFQPNLTVHITGFGALYYGGESQNDLREARVKIISDDVCKQPQVYGNDIKPGMFCAGYMEGIYDACRGDSGGPLVTRDLKDTWYLIGIVSWGDNCGQKDKPGVYTQVTYYRNWIASKTGI>sp|P32971|TNFL8_HUMAN Tumor necrosis factor ligand superfamily member 8OS=Homo sapiens OX=9606 GN=TNFSF8 PE=1 SV=1MDPGLQQALNGMAPPGDTAMHVPAGSVASHLGTTSRSYFYLTTATLALCLVFTVATIMVLVVQRTDSIPNSPDNVPLKGGNCSEDLLCILKRAPFKKSWAYLQVAKHLNKTKLSWNKDGILHGVRYQDGNLVIQFPGLYFIICQLQFLVQCPNNSVDLKLELLINKHIKKQALVTVCESGMQTKHVYQNLSQFLLDYLQVNTTISVNVDTFQYIDTSTFPLENVLSIFLYSNSD>sp|Q86XT4|TRI50_HUMAN E3 ubiquitin-protein ligase TRIM50 OS=Homo sapiensOX=9606 GN=TRIM50 PE=1 SV=1MAWQVSLLELEDWLQCPICLEVFKEPLMLQCGHSYCKGCLVSLSCHLDAELRCPVCRQAVDGSSSLPNVSLARVIEALRLPGDPEPKVCVHHRNPLSLFCEKDQELICGLCGLLGSHQHHPVTPVSTVYSRMKEELAALISELKQEQKKVDELIAKLVNNRTRIVNESDVFSWVIRREFQELHHLVDEEKARCLEGIGGHTRGLVASLDMQLEQAQGTRERLAQAECVLEQFGNEDHHKFIRKFHSMASRAEMPQARPLEGAFSPISFKPGLHQADIKLTVWKRLFRKVLPAPEPLKLDPATAHPLLELSKGNTVVQCGLLAQRRASQPERFDYSTCVLASRGFSCGRHYWEVVVGSKSDWRLGVIKGTASRKGKLNRSPEHGVWLIGLKEGRVYEAFACPRVPLPVAGHPHRIGLYLHYEQGELTFFDADRPDDLRPLYTFQADFQGKLYPILDTCWHERGSNSLPMVLPPPSGPGPLSPEQPTKL>sp|Q86XT4-2|TRI50_HUMAN Isoform Beta of E3 ubiquitin-protein ligaseTRIM50 OS=Homo sapiens OX=9606 GN=TRIM50MAWQVSLLELEDWLQCPICLEVFKEPLMLQCGHSYCKGCLVSLSCHLDAELRCPVCRQAVDGSSSLPNVSLARVIEALRLPGDPEPKVCVHHRNPLSLFCEKDQELICGLCGLLGSHQHHPVTPVSTVYSRMKEELAALISELKQEQKKVDELIAKLVNNRTRIVNESDVFSWVIRREFQELHHLVDEEKARCLEGIGGHTRGLVASLDMQLEQAQGTRERLAQAECVLEQFGNEDHHKFIRFHSMASRAEMPQARPLEGAFSPISFKPGLHQADIKLTVWKRLFRKVLPAPEPLKLDPATAHPLLELSKGNTVVQCGLLAQRRASQPERFDYSTCVLASRGFSCGRHYWEVVVGSKSDWRLGVIKGTASRKGKLNRSPEHGVWLIGLKEGRVYEAFACPRVPLPVAGHPHRIGLYLHYEQGELTFFDADRPDDLRPLYTFQADFQGKLYPILDTCWHERGSNSLPMVLPPPSGPGPLSPEQPTKL>sp|Q8N2M4|TM86A_HUMAN Lysoplasmalogenase-like protein TMEM86A OS=Homosapiens OX=9606 GN=TMEM86A PE=1 SV=1MVSPVTVVKSEGPKLVPFFKATCVYFVLWLPSSSPSWVSTLIKCLPIFCLWLFLLAHGLGFLLAHPSATRIFVGLVFSAVGDAFLIWQDQGYFVHGLLMFAVTHMFYASAFGMQPLALRTGLVMAALSGLCYALLYPCLSGAFTYLVGVYVALIGFMGWRAMAGLRLAGADWRWTELAAGSGALFFIISDLTIALNKFCFPVPYSRALIMSTYYVAQMLVALSAVESREPVEHYRLTKAN>sp|Q9BRZ2|TRI56_HUMAN E3 ubiquitin-protein ligase TRIM56 OS=Homo sapiensOX=9606 GN=TRIM56 PE=1 SV=3MVSHGSSPSLLEALSSDFLACKICLEQLRAPKTLPCLHTYCQDCLAQLADGGRVRCPECRETVPVPPEGVASFKTNFFVNGLLDLVKARACGDLRAGKPACALCPLVGGTSTGGPATARCLDCADDLCQACADGHRCTRQTHTHRVVDLVGYRAGWYDEEARERQAAQCPQHPGEALRFLCQPCSQLLCRECRLDPHLDHPCLPLAEAVRARRPGLEGLLAGVDNNLVELEAARRVEKEALARLREQAARVGTQVEEAAEGVLRALLAQKQEVLGQLRAHVEAAEEAARERLAELEGREQVARAAAAFARRVLSLGREAEILSLEGAIAQRLRQLQGCPWAPGPAPCLLPQLELHPGLLDKNCHLLRLSFEEQQPQKDGGKDGAGTQGGEESQSRREDEPKTERQGGVQPQAGDGAQTPKEEKAQTTREEGAQTLEEDRAQTPHEDGGPQPHRGGRPNKKKKFKGRLKSISREPSPALGPNLDGSGLLPRPIFYCSFPTRMPGDKRSPRITGLCPFGPREILVADEQNRALKRFSLNGDYKGTVPVPEGCSPCSVAALQSAVAFSASARLYLINPNGEVQWRRALSLSQASHAVAALPSGDRVAVSVAGHVEVYNMEGSLATRFIPGGKASRGLRALVFLTTSPQGHFVGSDWQQNSVVICDGLGQVVGEYKGPGLHGCQPGSVSVDKKGYIFLTLREVNKVVILDPKGSLLGDFLTAYHGLEKPRVTTMVDGRYLVVSLSNGTIHIFRVRSPDS>sp|Q9BRZ2-2|TRI56_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM56OS=Homo sapiens OX=9606 GN=TRIM56MVSHGSSPSLLEALSSDFLACKICLEQLRAPKTLPCLHTYCQDCLAQLADGGRVRCPECRETVPVPPEGVASFKTNFFVNGLLDLVKARACGDLRAGKPACALCPLVGGTSTGGPATARCLDCADDLCQACADGHRCTRQTHTHRVVDLVGYRAGWYDEEARERQAAQCPQHPGEALRFLCQPCSQLLCRECRLDPHLDHPCLPLAEAVRARRPGLEGLLAGVDNNLVELEAARRVEKEALARLREQAARVGTQVEEAAEGVLRALLAQKQENHLNPGGGSCSELRSHHCTPAWVTRMKLHLKKKKKK>sp|Q9BRZ2-3|TRI56_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM56OS=Homo sapiens OX=9606 GN=TRIM56MVSHGSSPSLLEALSSDFLACKICLEQLRAPKTLPCLHTYCQDCLAQLADGGRVRCPECRETVPVPPEGVASFKTNFFVNGLLDLVKARACGDLRAGKPACALCPLVGGTSTGGPATARCLDCADDLCQACADGHRCTRQTHTHRVVDLVGYRAGWYDEEARERQAAQCPQHPGEALRFLCQPCSQLLCRECRLDPHLDHPCLPLAEAVRARRPGLEGLLAGVDNNLVELEAARRVEKEALARLREQAARVGTQVEEACLLRTESCKAE>sp|Q9H2K2|TNKS2_HUMAN Poly [ADP-ribose] polymerase tankyrase-2 OS=Homosapiens OX=9606 GN=TNKS2 PE=1 SV=1MSGRRCAGGGAACASAAAEAVEPAARELFEACRNGDVERVKRLVTPEKVNSRDTAGRKSTPLHFAAGFGRKDVVEYLLQNGANVQARDDGGLIPLHNACSFGHAEVVNLLLRHGADPNARDNWNYTPLHEAAIKGKIDVCIVLLQHGAEPTIRNTDGRTALDLADPSAKAVLTGEYKKDELLESARSGNEEKMMALLTPLNVNCHASDGRKSTPLHLAAGYNRVKIVQLLLQHGADVHAKDKGDLVPLHNACSYGHYEVTELLVKHGACVNAMDLWQFTPLHEAASKNRVEVCSLLLSYGADPTLLNCHNKSAIDLAPTPQLKERLAYEFKGHSLLQAAREADVTRIKKHLSLEMVNFKHPQTHETALHCAAASPYPKRKQICELLLRKGANINEKTKEFLTPLHVASEKAHNDVVEVVVKHEAKVNALDNLGQTSLHRAAYCGHLQTCRLLLSYGCDPNIISLQGFTALQMGNENVQQLLQEGISLGNSEADRQLLEAAKAGDVETVKKLCTVQSVNCRDIEGRQSTPLHFAAGYNRVSVVEYLLQHGADVHAKDKGGLVPLHNACSYGHYEVAELLVKHGAVVNVADLWKFTPLHEAAAKGKYEICKLLLQHGADPTKKNRDGNTPLDLVKDGDTDIQDLLRGDAALLDAAKKGCLARVKKLSSPDNVNCRDTQGRHSTPLHLAAGYNNLEVAEYLLQHGADVNAQDKGGLIPLHNAASYGHVDVAALLIKYNACVNATDKWAFTPLHEAAQKGRTQLCALLLAHGADPTLKNQEGQTPLDLVSADDVSALLTAAMPPSALPSCYKPQVLNGVRSPGATADALSSGPSSPSSLSAASSLDNLSGSFSELSSVVSSSGTEGASSLEKKEVPGVDFSITQFVRNLGLEHLMDIFEREQITLDVLVEMGHKELKEIGINAYGHRHKLIKGVERLISGQQGLNPYLTLNTSGSGTILIDLSPDDKEFQSVEEEMQSTVREHRDGGHAGGIFNRYNILKIQKVCNKKLWERYTHRRKEVSEENHNHANERMLFHGSPFVNAIIHKGFDERHAYIGGMFGAGIYFAENSSKSNQYVYGIGGGTGCPVHKDRSCYICHRQLLFCRVTLGKSFLQFSAMKMAHSPPGHHSVTGRPSVNGLALAEYVIYRGEQAYPEYLITYQIMRPEGMVDG>sp|Q15399|TLR1_HUMAN Toll-like receptor 1 OS=Homo sapiens OX=9606GN=TLR1 PE=1 SV=3MTSIFHFAIIFMLILQIRIQLSEESEFLVDRSKNGLIHVPKDLSQKTTILNISQNYISELWTSDILSLSKLRILIISHNRIQYLDISVFKFNQELEYLDLSHNKLVKISCHPTVNLKHLDLSFNAFDALPICKEFGNMSQLKFLGLSTTHLEKSSVLPIAHLNISKVLLVLGETYGEKEDPEGLQDFNTESLHIVFPTNKEFHFILDVSVKTVANLELSNIKCVLEDNKCSYFLSILAKLQTNPKLSNLTLNNIETTWNSFIRILQLVWHTTVWYFSISNVKLQGQLDFRDFDYSGTSLKALSIHQVVSDVFGFPQSYIYEIFSNMNIKNFTVSGTRMVHMLCPSKISPFLHLDFSNNLLTDTVFENCGHLTELETLILQMNQLKELSKIAEMTTQMKSLQQLDISQNSVSYDEKKGDCSWTKSLLSLNMSSNILTDTIFRCLPPRIKVLDLHSNKIKSIPKQVVKLEALQELNVAFNSLTDLPGCGSFSSLSVLIIDHNSVSHPSADFFQSCQKMRSIKAGDNPFQCTCELGEFVKNIDQVSSEVLEGWPDSYKCDYPESYRGTLLKDFHMSELSCNITLLIVTIVATMLVLAVTVTSLCSYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSGHDSFWVKNELLPNLEKEGMQICLHERNFVPGKSIVENIITCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNSLILILLEPIPQYSIPSSYHKLKSLMARRTYLEWPKEKSKRGLFWANLRAAINIKLTEQAKK>sp|P19438|TNR1A_HUMAN Tumor necrosis factor receptor superfamily member1A OS=Homo sapiens OX=9606 GN=TNFRSF1A PE=1 SV=1MGLSTVPDLLLPLVLLELLVGIYPSGVIGLVPHLGDREKRDSVCPQGKYIHPQNNSICCTKCHKGTYLYNDCPGPGQDTDCRECESGSFTASENHLRHCLSCSKCRKEMGQVEISSCTVDRDTVCGCRKNQYRHYWSENLFQCFNCSLCLNGTVHLSCQEKQNTVCTCHAGFFLRENECVSCSNCKKSLECTKLCLPQIENVKGTEDSGTTVLLPLVIFFGLCLLSLLFIGLMYRYQRWKSKLYSIVCGKSTPEKEGELEGTTTKPLAPNPSFSPTPGFTPTLGFSPVPSSTFTSSSTYTPGDCPNFAAPRREVAPPYQGADPILATALASDPIPNPLQKWEDSAHKPQSLDTDDPATLYAVVENVPPLRWKEFVRRLGLSDHEIDRLELQNGRCLREAQYSMLATWRRRTPRREATLELLGRVLRDMDLLGCLEDIEEALCGPAALPPAPSLLR>sp|P19438-2|TNR1A_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 1A OS=Homo sapiens OX=9606 GN=TNFRSF1AMGQVEISSCTVDRDTVCGCRKNQYRHYWSENLFQCFNCSLCLNGTVHLSCQEKQNTVCTCHAGFFLRENECVSCSNCKKSLECTKLCLPQIENVKGTEDSGTTVLLPLVIFFGLCLLSLLFIGLMYRYQRWKSKLYSIVCGKSTPEKEGELEGTTTKPLAPNPSFSPTPGFTPTLGFSPVPSSTFTSSSTYTPGDCPNFAAPRREVAPPYQGADPILATALASDPIPNPLQKWEDSAHKPQSLDTDDPATLYAVVENVPPLRWKEFVRRLGLSDHEIDRLELQNGRCLREAQYSMLATWRRRTPRREATLELLGRVLRDMDLLGCLEDIEEALCGPAALPPAPSLLR>sp|P19438-4|TNR1A_HUMAN Isoform 4 of Tumor necrosis factor receptorsuperfamily member 1A OS=Homo sapiens OX=9606 GN=TNFRSF1AMGLSTVPDLLLPLVLLELLVGIYPSGVIGLVPHLGDREKRDSVCPQGKYIHPQNNSICCTKCHKGTYLYNDCPGPGQDTDCRECESGSFTASENHLRHCLSCSKCRKEMGQVEISSCTVDRDTVCGCRKNQYRHYWSENLFQCFNCSLCLNGTVHLSCQEKQNTVCTCHAGFFLRENECVSCSKHHSAVAPGHFLWSLPFIPPLHWFNVSLPTVEVQALLHCLWEIDT>sp|P19438-3|TNR1A_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 1A OS=Homo sapiens OX=9606 GN=TNFRSF1AMYRYQRWKSKLYSIVCGKSTPEKEGELEGTTTKPLAPNPSFSPTPGFTPTLGFSPVPSSTFTSSSTYTPGDCPNFAAPRREVAPPYQGADPILATALASDPIPNPLQKWEDSAHKPQSLDTDDPATLYAVVENVPPLRWKEFVRRLGLSDHEIDRLELQNGRCLREAQYSMLATWRRRTPRREATLELLGRVLRDMDLLGCLEDIEEALCGPAALPPAPSLLR>sp|P19438-5|TNR1A_HUMAN Isoform 5 of Tumor necrosis factor receptorsuperfamily member 1A OS=Homo sapiens OX=9606 GN=TNFRSF1AMGLSTVPDLLLPLVLLELLVGIYPSGVIGLVPHLGDREKRDSVCPQGKYIHPQNNSICCTKCHKGTYLYNDCPGPGQDTDCRECESGSFTASENHLRHCLSCSKCRKEMGQVEISSCTVDRDTVCGCRKNQYRHYWSENLFQCFNCSLCLNGTVHLSCQEKQNTVCTCHAGFFLRENECVSCSKVLLCRPGWNAVARSRLTATSASQIQAILLLQPPK>sp|P05543|THBG_HUMAN Thyroxine-binding globulin OS=Homo sapiens OX=9606GN=SERPINA7 PE=1 SV=2MSPFLYLVLLVLGLHATIHCASPEGKVTACHSSQPNATLYKMSSINADFAFNLYRRFTVETPDKNIFFSPVSISAALVMLSFGACCSTQTEIVETLGFNLTDTPMVEIQHGFQHLICSLNFPKKELELQIGNALFIGKHLKPLAKFLNDVKTLYETEVFSTDFSNISAAKQEINSHVEMQTKGKVVGLIQDLKPNTIMVLVNYIHFKAQWANPFDPSKTEDSSSFLIDKTTTVQVPMMHQMEQYYHLVDMELNCTVLQMDYSKNALALFVLPKEGQMESVEAAMSSKTLKKWNRLLQKGWVDLFVPKFSISATYDLGATLLKMGIQHAYSENADFSGLTEDNGLKLSNAAHKAVLHIGEKGTEAAAVPEVELSDQPENTFLHPIIQIDRSFMLLILERSTRSILFLGKVVNPTEA>sp|Q92956|TNR14_HUMAN Tumor necrosis factor receptor superfamily member14 OS=Homo sapiens OX=9606 GN=TNFRSF14 PE=1 SV=3MEPPGDWGPPPWRSTPKTDVLRLVLYLTFLGAPCYAPALPSCKEDEYPVGSECCPKCSPGYRVKEACGELTGTVCEPCPPGTYIAHLNGLSKCLQCQMCDPAMGLRASRNCSRTENAVCGCSPGHFCIVQDGDHCAACRAYATSSPGQRVQKGGTESQDTLCQNCPPGTFSPNGTLEECQHQTKCSWLVTKAGAGTSSSHWVWWFLSGSLVIVIVCSTVGLIICVKRRKPRGDVVKVIVSVQRKRQEAEGEATVIEALQAPPDVTTVAVEETIPSFTGRSPNH>sp|Q92956-2|TNR14_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 14 OS=Homo sapiens OX=9606 GN=TNFRSF14MVSRPPRTPLSPSSWTPAMGLRASRNCSRTENAVCGCSPGHFCIVQDGDHCAACRAYATSSPGQRVQKGGTESQDTLCQNCPPGTFSPNGTLEECQHQTKCSWLVTKAGAGTSSSHWVWWFLSGSLVIVIVCSTVGLIICVKRRKPRGDVVKVIVSVQRKRQEAEGEATVIEALQAPPDVTTVAVEETIPSFTGRSPNH>sp|Q9Y6Q6|TNR11_HUMAN Tumor necrosis factor receptor superfamily member11A OS=Homo sapiens OX=9606 GN=TNFRSF11A PE=1 SV=1MAPRARRRRPLFALLLLCALLARLQVALQIAPPCTSEKHYEHLGRCCNKCEPGKYMSSKCTTTSDSVCLPCGPDEYLDSWNEEDKCLLHKVCDTGKALVAVVAGNSTTPRRCACTAGYHWSQDCECCRRNTECAPGLGAQHPLQLNKDTVCKPCLAGYFSDAFSSTDKCRPWTNCTFLGKRVEHHGTEKSDAVCSSSLPARKPPNEPHVYLPGLIILLLFASVALVAAIIFGVCYRKKGKALTANLWHWINEACGRLSGDKESSGDSCVSTHTANFGQQGACEGVLLLTLEEKTFPEDMCYPDQGGVCQGTCVGGGPYAQGEDARMLSLVSKTEIEEDSFRQMPTEDEYMDRPSQPTDQLLFLTEPGSKSTPPFSEPLEVGENDSLSQCFTGTQSTVGSESCNCTEPLCRTDWTPMSSENYLQKEVDSGHCPHWAASPSPNWADVCTGCRNPPGEDCEPLVGSPKRGPLPQCAYGMGLPPEEEASRTEARDQPEDGADGRLPSSARAGAGSGSSPGGQSPASGNVTGNSNSTFISSGQVMNFKGDIIVVYVSQTSQEGAAAAAEPMGRPVQEETLARRDSFAGNGPRFPDPCGGPEGLREPEKASRPVQEQGGAKA>sp|Q9Y6Q6-2|TNR11_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 11A OS=Homo sapiens OX=9606 GN=TNFRSF11AMAPRARRRRPLFALLLLCALLARLQVALQIAPPCTSEKHYEHLGRCCNKCEPGKYMSSKCTTTSDSVCLPCGPDEYLDSWNEEDKCLLHKVCDTGKALVAVVAGNSTTPRRCACTAGYHWSQDCECCRRNTECAPGLGAQHPLQLNKDTVCKPCLAGYFSDAFSSTDKCRPWTNCTFLGKRVEHHGTEKSDAVCSSSLPARKPPNGNVTGNSNSTFISSGQVMNFKGDIIVVYVSQTSQEGAAAAAEPMGRPVQEETLARRDSFAGNGPRFPDPCGGPEGLREPEKASRPVQEQGGAKA>sp|Q9Y6Q6-3|TNR11_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 11A OS=Homo sapiens OX=9606 GN=TNFRSF11AMAPRARRRRPLFALLLLCALLARLQVALQIAPPCTSEKHYEHLGRCCNKCEPGKYMSSKCTTTSDSVCLPCGPDEYLDSWNEEDKCLLHKVCDTGKALVAVVAGNSTTPRRCACTAGYHWSQDCECCRRNTECAPGLGAQHPLQLNKDTVCKPCLAGYFSDAFSSTDKCRPWTNCTFLGKRVEHHGTEKSDAVCSSSLPARKPPNEPHVYLPGLIILLLFASVALVAAIIFGVCYRKKGKALTGNVTGNSNSTFISSGQVMNFKGDIIVVYVSQTSQEGAAAAAEPMGRPVQEETLARRDSFAGNGPRFPDPCGGPEGLREPEKASRPVQEQGGAKA>sp|Q9Y6Q6-4|TNR11_HUMAN Isoform 4 of Tumor necrosis factor receptorsuperfamily member 11A OS=Homo sapiens OX=9606 GN=TNFRSF11AMAPRARRRRPLFALLLLCALLARLQVALQIAPPCTSEKHYEHLGRCCNKCEPGKYMSSKCTTTSDSVCLPCGPDEYLDSWNEEDKCLLHKVCDTGKALVAVVAGNSTTPRRCACTAGYHWSQDCECCRRNTECAPGLGAQHPLQLNKDTVCKPCLAGYFSDAFSSTDKCRPWTNCTFLGKRVEHHGTEKSDAVCSSSLPARKPPNEPHVYLPGLIILLLFASVALVAAIIFGVCYRKKGKALTANLWHWINEACGRLSGDKEM>sp|Q9Y6Q6-5|TNR11_HUMAN Isoform 5 of Tumor necrosis factor receptorsuperfamily member 11A OS=Homo sapiens OX=9606 GN=TNFRSF11AMAPRARRRRPLFALLLLCALLARLQVALQIAPPCTSEKHYEHLGRCCNKCEPGKYMSSKCTTTSDSVCLPCGPDEYLDSWNEEDKCLLHKVCDTGKALVAVVAGNSTTPRRCACTAGYHWSQDCECCRRNTECAPGLGAQHPLQLNKDTVCKPCLAGYFSDAFSSTDKCRPWTNCTFLGKRVEHHGTEKSDAVCSSSLPARKPPNEPHVYLPGLIILLLFASVALVAAIIFGVCYRKKGKALTANLWHWINEACGRLSGDKESSGDSCVSTHTANFGQQGACEGVLLLTLEEKTFPEDMCYPDQGGVCQGTCVGGGPYAQGEDARMLSLVSKTEIEEDSFRQMPTEDEYMDRPSQPTDQLLFLTEPGSKSTPPFSEPLEVGENDSLSQCFTGTQSTVGSESCNCTEPLCRTDWTPMSSENYLQKEVDSGHCPHWAASPSPNWADVCTGCRNPPGEDCEPLVGSPKRGPLPQCAYGMGLPPEEEASRTEARDQPEDGADGRLPSSARAGAGSGSSPGGQSPASD>sp|Q9Y6Q6-6|TNR11_HUMAN Isoform RANK-e5a of Tumor necrosis factorreceptor superfamily member 11A OS=Homo sapiens OX=9606 GN=TNFRSF11AMAPRARRRRPLFALLLLCALLARLQVALQIAPPCTSEKHYEHLGRCCNKCEPGKYMSSKCTTTSDSVCLPCGPDEYLDSWNEEDKCLLHKVCDTGKALVAVVAGNSTTPRRCACTAGYHWSQDCECCRRNTECAPGLGAQHPCYFSDAFSSTDKCRPWTNCTFLGKRVEHHGTEKSDAVCSSSLPARKPPNEPHVYLPGLIILLLFASVALVAAIIFGVCYRKKGKALTANLWHWINEACGRLSGDKESSGDSCVSTHTANFGQQGACEGVLLLTLEEKTFPEDMCYPDQGGVCQGTCVGGGPYAQGEDARMLSLVSKTEIEEDSFRQMPTEDEYMDRPSQPTDQLLFLTEPGSKSTPPFSEPLEVGENDSLSQCFTGTQSTVGSESCNCTEPLCRTDWTPMSSENYLQKEVDSGHCPHWAASPSPNWADVCTGCRNPPGEDCEPLVGSPKRGPLPQCAYGMGLPPEEEASRTEARDQPEDGADGRLPSSARAGAGSGSSPGGQSPASGNVTGNSNSTFISSGQVMNFKGDIIVVYVSQTSQEGAAAAAEPMGRPVQEETLARRDSFAGNGPRFPDPCGGPEGLREPEKASRPVQEQGGAKA>sp|A6NDI0|TR49B_HUMAN Putative tripartite motif-containing protein 49BOS=Homo sapiens OX=9606 GN=TRIM49B PE=2 SV=1MNSGILQVFQRELICPICMNYFIDPVTIDCGHSFCRPCFYLNWKDSPFLVQCSECTKSTGQINLKTNIHFKKMASLARKVSLWLFLSSEEQMCGTHRETKKMFCEVDRSLLCLLCSSSQEHRDHRHCPIESAAEEHQEKLLQKMQSLWEKACENHRNLNVETTRTRCWKDYVNLRLEAIRAEYQKMPAFHHEEEKHNLEMLKKKGKDIFHRLHLSKAKMAHRREILRGMYEELNEMCHKPDVELLQAFGDILHRSESVLLHMPQPLNPELSAGPITGLRDRLNQFRVHITLHHEEANSDIFLCEILRSMCIGCDHQDVPYFTATPRSFLAWGAQTFTSGKYYWEVHVGDSWNWAFGVCNMYWKEKNQNEKIDGEDGLFLLGCVKNDIQRSLFTTSPLLLQYIPRPTSRVGLFLDCEAKTVSFVDVNQSSLIYTIPNCSFSPPLRPIFCCIHF>sp|P00750|TPA_HUMAN Tissue-type plasminogen activator OS=Homo sapiensOX=9606 GN=PLAT PE=1 SV=1MDAMKRGLCCVLLLCGAVFVSPSQEIHARFRRGARSYQVICRDEKTQMIYQQHQSWLRPVLRSNRVEYCWCNSGRAQCHSVPVKSCSEPRCFNGGTCQQALYFSDFVCQCPEGFAGKCCEIDTRATCYEDQGISYRGTWSTAESGAECTNWNSSALAQKPYSGRRPDAIRLGLGNHNYCRNPDRDSKPWCYVFKAGKYSSEFCSTPACSEGNSDCYFGNGSAYRGTHSLTESGASCLPWNSMILIGKVYTAQNPSAQALGLGKHNYCRNPDGDAKPWCHVLKNRRLTWEYCDVPSCSTCGLRQYSQPQFRIKGGLFADIASHPWQAAIFAKHRRSPGERFLCGGILISSCWILSAAHCFQERFPPHHLTVILGRTYRVVPGEEEQKFEVEKYIVHKEFDDDTYDNDIALLQLKSDSSRCAQESSVVRTVCLPPADLQLPDWTECELSGYGKHEALSPFYSERLKEAHVRLYPSSRCTSQHLLNRTVTDNMLCAGDTRSGGPQANLHDACQGDSGGPLVCLNDGRMTLVGIISWGLGCGQKDVPGVYTKVTNYLDWIRDNMRP>sp|P00750-2|TPA_HUMAN Isoform 2 of Tissue-type plasminogen activatorOS=Homo sapiens OX=9606 GN=PLATMDAMKRGLCCVLLLCGAVFVSPSQEIHARFRRGARSYQVICRDEKTQMIYQQHQSWLRPVLRSNRVEYCWCNSGRAQCHSVPVKSCSEPRCFNGGTCQQALYFSDFVCQCPEGFAGKCCEIDTRATCYEDQGISYRGTWSTAESGAECTNWNSSALAQKPYSGRRPDAIRLGLGNHNYCRNPDRDSKPWCYVFKAGKYSSEFCSTPACSEGNSDCYFGNGSAYRGTHSLTESGASCLPWNSMILIGKVYTAQNPSAQALGLGKHNYCRTGRSVSSPATASMRPCPLSIRSG>sp|P00750-3|TPA_HUMAN Isoform 3 of Tissue-type plasminogen activatorOS=Homo sapiens OX=9606 GN=PLATMDAMKRGLCCVLLLCGAVFVSPSQEIHARFRRGARSYQGCSEPRCFNGGTCQQALYFSDFVCQCPEGFAGKCCEIDTRATCYEDQGISYRGTWSTAESGAECTNWNSSALAQKPYSGRRPDAIRLGLGNHNYCRNPDRDSKPWCYVFKAGKYSSEFCSTPACSEGNSDCYFGNGSAYRGTHSLTESGASCLPWNSMILIGKVYTAQNPSAQALGLGKHNYCRNPDGDAKPWCHVLKNRRLTWEYCDVPSCSTCGLRQYSQPQFRIKGGLFADIASHPWQAAIFAKHRRSPGERFLCGGILISSCWILSAAHCFQERFPPHHLTVILGRTYRVVPGEEEQKFEVEKYIVHKEFDDDTYDNDIALLQLKSDSSRCAQESSVVRTVCLPPADLQLPDWTECELSGYGKHEALSPFYSERLKEAHVRLYPSSRCTSQHLLNRTVTDNMLCAGDTRSGGPQANLHDACQGDSGGPLVCLNDGRMTLVGIISWGLGCGQKDVPGVYTKVTNYLDWIRDNMRP>sp|P00750-4|TPA_HUMAN Isoform 4 of Tissue-type plasminogen activatorOS=Homo sapiens OX=9606 GN=PLATMASCRDEKTQMIYQQHQSWLRPVLRSNRVEYCWCNSGRAQCSEGNSDCYFGNGSAYRGTHSLTESGASCLPWNSMILIGKVYTAQNPSAQALGLGKHNYCRNPDGDAKPWCHVLKNRRLTWEYCDVPSCSTCGLRQYSQPQFRIKGGLFADIASHPWQAAIFAKHRRSPGERFLCGGILISSCWILSAAHCFQERFPPHHLTVILGRTYRVVPGEEEQKFEVEKYIVHKEFDDDTYDNDIALLQLKSDSSRCAQESSVVRTVCLPPADLQLPDWTECELSGYGKHEALSPFYSERLKEAHVRLYPSSRCTSQHLLNRTVTDNMLCAGDTRSGGPQANLHDACQGDSGGPLVCLNDGRMTLVGIISWGLGCGQKDVPGVYTKVTNYLDWIRDNMRP>sp|Q9HD45|TM9S3_HUMAN Transmembrane 9 superfamily member 3 OS=Homosapiens OX=9606 GN=TM9SF3 PE=1 SV=2MRPLPGALGVAAAAALWLLLLLLPRTRADEHEHTYQDKEEVVLWMNTVGPYHNRQETYKYFSLPFCVGSKKSISHYHETLGEALQGVELEFSGLDIKFKDDVMPATYCEIDLDKEKRDAFVYAIKNHYWYQMYIDDLPIWGIVGEADENGEDYYLWTYKKLEIGFNGNRIVDVNLTSEGKVKLVPNTKIQMSYSVKWKKSDVKFEDRFDKYLDPSFFQHRIHWFSIFNSFMMVIFLVGLVSMILMRTLRKDYARYSKEEEMDDMDRDLGDEYGWKQVHGDVFRPSSHPLIFSSLIGSGCQIFAVSLIVIIVAMIEDLYTERGSMLSTAIFVYAATSPVNGYFGGSLYARQGGRRWIKQMFIGAFLIPAMVCGTAFFINFIAIYYHASRAIPFGTMVAVCCICFFVILPLNLVGTILGRNLSGQPNFPCRVNAVPRPIPEKKWFMEPAVIVCLGGILPFGSIFIEMYFIFTSFWAYKIYYVYGFMMLVLVILCIVTVCVTIVCTYFLLNAEDYRWQWTSFLSAASTAIYVYMYSFYYYFFKTKMYGLFQTSFYFGYMAVFSTALGIMCGAIGYMGTSAFVRKIYTNVKID>sp|Q96BF3|TMIG2_HUMAN Transmembrane and immunoglobulin domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=TMIGD2 PE=1 SV=2MGSPGMVLGLLVQIWALQEASSLSVQQGPNLLQVRQGSQATLVCQVDQATAWERLRVKWTKDGAILCQPYITNGSLSLGVCGPQGRLSWQAPSHLTLQLDPVSLNHSGAYVCWAAVEIPELEEAEGNITRLFVDPDDPTQNRNRIASFPGFLFVLLGVGSMGVAAIVWGAWFWGRRSCQQRDSGNSPGNAFYSNVLYRPRGAPKKSEDCSGEGKDQRGQSIYSTSFPQPAPRQPHLASRPCPSPRPCPSPRPGHPVSMVRVSPRPSPTQQPRPKGFPKVGEE>sp|Q96BF3-2|TMIG2_HUMAN Isoform 2 of Transmembrane and immunoglobulindomain-containing protein 2 OS=Homo sapiens OX=9606 GN=TMIGD2MGSPGMVLGLLVQIWALQEASSLSVQQGPNLLQVRQGSQATLVCQVDQATAWERLRVKWTKDGAILCQPYITNGSLSLGVCGPQGRLSWQAPSHLTLQLDPVSLNHSGAYVCWAAVEIPELEEAEGNITRLFVDPDDPTQNRNRIASFPGFLFVLLGVGSMGVAAIVWGAWFWGRRSCQQRDSGNAFYSNVLYRPRGAPKKSEDCSGEGKDQRGQSIYSTSFPQPAPRQPHLASRPCPSPRPCPSPRPGHPVSMVRVSPRPSPTQQPRPKGFPKVGEE>sp|Q8N5M4|TTC9C_HUMAN Tetratricopeptide repeat protein 9C OS=Homosapiens OX=9606 GN=TTC9C PE=1 SV=1MEKRLQEAQLYKEEGNQRYREGKYRDAVSRYHRALLQLRGLDPSLPSPLPNLGPQGPALTPEQENILHTTQTDCYNNLAACLLQMEPVNYERVREYSQKVLERQPDNAKALYRAGVAFFHLQDYDQARHYLLAAVNRQPKDANVRRYLQLTQSELSSYHRKEKQLYLGMFG>sp|Q8N5M4-2|TTC9C_HUMAN Isoform 2 of Tetratricopeptide repeat protein 9COS=Homo sapiens OX=9606 GN=TTC9CMLNKEEELELLEALWSFSTSPAHSLLLPGRGGAGPIERRKPVSQAFSRPQQFLSRALLEFFGKSHPPPHRLFRKSLNVGLHYSHIPFLTTCLHFLRKRLQKGEVGLSVETSKPQVPVGGLSRKKVPQEPWATVMEKRLQEAQLYKEEGNQRYREGKYRDAVSRYHRALLQLRGLDPSLPSPLPNLGPQGPALTPEQENILHTTQTDCYNNLAVVK>sp|Q86WT1|TT30A_HUMAN Tetratricopeptide repeat protein 30A OS=Homosapiens OX=9606 GN=TTC30A PE=2 SV=3MAGLSGAQIPDGEFTALVYRLIRDARYAEAVQLLGRELQRSPRSRAGLSLLGYCYYRLQEFALAAECYEQLGQLHPELEQYRLYQAQALYKACLYPEATRVAFLLLDNPAYHSRVLRLQAAIKYSEGDLPGSRSLVEQLLSGEGGEESGGDNETDGQVNLGCLLYKEGQYEAACSKFSATLQASGYQPDLSYNLALAYYSSRQYASALKHIAEIIERGIRQHPELGVGMTTEGFDVRSVGNTLVLHQTALVEAFNLKAAIEYQLRNYEVAQETLTDMPPRAEEELDPVTLHNQALMNMDARPTEGFEKLQFLLQQNPFPPETFGNLLLLYCKYEYFDLAADVLAENAHLTYKFLTPYLYDFLDALITCQTAPEEAFIKLDGLAGMLTEQLRRLTKQVQEARHNRDDEAIKKAVNEYDETMEKYIPVLMAQAKIYWNLENYPMVEKVFRKSVEFCNDHDVWKLNVAHVLFMQENKYKEAIGFYEPIVKKHYDNILNVSAIVLANLCVSYIMTSQNEEAEELMRKIEKEEEQLSYDDPNRKMYHLCIVNLVIGTLYCAKGNYEFGISRVIKSLEPYNKKLGTDTWYYAKRCFLSLLENMSKHMIVIHDSVIQECVQFLGHCELYGTNIPAVIEQPLEEERMHVGKNTVTDESRQLKALIYEIIGWNK>sp|Q9BXU7|UBP26_HUMAN Ubiquitin carboxyl-terminal hydrolase 26 OS=Homosapiens OX=9606 GN=USP26 PE=1 SV=1MAALFLRGFVQIGNCKTGISKSKEAFIEAVERKKKDRLVLYFKSGKYSTFRLSDNIQNVVLKSYRGNQNHLHLTLQNNNGLFIEGLSSTDAEQLKIFLDRVHQNEVQPPVRPGKGGSVFSSTTQKEINKTSFHKVDEKSSSKSFEIAKGSGTGVLQRMPLLTSKLTLTCGELSENQHKKRKRMLSSSSEMNEEFLKENNSVEYKKSKADCSRCVSYNREKQLKLKELEENKKLECESSCIMNATGNPYLDDIGLLQALTEKMVLVFLLQQGYSDGYTKWDKLKLFFELFPEKICHGLPNLGNTCYMNAVLQSLLSIPSFADDLLNQSFPWGKIPLNALTMCLARLLFFKDTYNIEIKEMLLLNLKKAISAAAEIFHGNAQNDAHEFLAHCLDQLKDNMEKLNTIWKPKSEFGEDNFPKQVFADDPDTSGFSCPVITNFELELLHSIACKACGQVILKTELNNYLSINLPQRIKAHPSSIQSTFDLFFGAEELEYKCAKCEHKTSVGVHSFSRLPRILIVHLKRYSLNEFCALKKNDQEVIISKYLKVSSHCNEGTRPPLPLSEDGEITDFQLLKVIRKMTSGNISVSWPATKESKDILAPHIGSDKESEQKKGQTVFKGASRRQQQKYLGKNSKPNELESVYSGDRAFIEKEPLAHLMTYLEDTSLCQFHKAGGKPASSPGTPLSKVDFQTVPENPKRKKYVKTSKFVAFDRIINPTKDLYEDKNIRIPERFQKVSEQTQQCDGMRICEQAPQQALPQSFPKPGTQGHTKNLLRPTKLNLQKSNRNSLLALGSNKNPRNKDILDKIKSKAKETKRNDDKGDHTYRLISVVSHLGKTLKSGHYICDAYDFEKQIWFTYDDMRVLGIQEAQMQEDRRCTGYIFFYMHNEIFEEMLKREENAQLNSKEVEETLQKE>sp|P25874|UCP1_HUMAN Mitochondrial brown fat uncoupling protein 1OS=Homo sapiens OX=9606 GN=UCP1 PE=1 SV=3MGGLTASDVHPTLGVQLFSAGIAACLADVITFPLDTAKVRLQVQGECPTSSVIRYKGVLGTITAVVKTEGRMKLYSGLPAGLQRQISSASLRIGLYDTVQEFLTAGKETAPSLGSKILAGLTTGGVAVFIGQPTEVVKVRLQAQSHLHGIKPRYTGTYNAYRIIATTEGLTGLWKGTTPNLMRSVIINCTELVTYDLMKEAFVKNNILADDVPCHLVSALIAGFCATAMSSPVDVVKTRFINSPPGQYKSVPNCAMKVFTNEGPTAFFKGLVPSFLRLGSWNVIMFVCFEQLKRELSKSRQTMDCAT>sp|Q712K3|UB2R2_HUMAN Ubiquitin-conjugating enzyme E2 R2 OS=Homo sapiensOX=9606 GN=UBE2R2 PE=1 SV=1MAQQQMTSSQKALMLELKSLQEEPVEGFRITLVDESDLYNWEVAIFGPPNTLYEGGYFKAHIKFPIDYPYSPPTFRFLTKMWHPNIYENGDVCISILHPPVDDPQSGELPSERWNPTQNVRTILLSVISLLNEPNTFSPANVDASVMFRKWRDSKGKDKEYAEIIRKQVSATKAEAEKDGVKVPTTLAEYCIKTKVPSNDNSSDLLYDDLYDDDIDDEDEEEEDADCYDDDDSGNEES>sp|C9JVI0|U17LB_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 11 OS=Homo sapiens OX=9606 GN=USP17L11 PE=3 SV=1MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQTNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSTTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|Q9P275|UBP36_HUMAN Ubiquitin carboxyl-terminal hydrolase 36 OS=Homosapiens OX=9606 GN=USP36 PE=1 SV=4MPIVDKLKEALKPGRKDSADDGELGKLLASSAKKVLLQKIEFEPASKSFSYQLEALKSKYVLLNPKTEGASRHKSGDDPPARRQGSEHTYESCGDGVPAPQKVLFPTERLSLRWERVFRVGAGLHNLGNTCFLNATIQCLTYTPPLANYLLSKEHARSCHQGSFCMLCVMQNHIVQAFANSGNAIKPVSFIRDLKKIARHFRFGNQEDAHEFLRYTIDAMQKACLNGCAKLDRQTQATTLVHQIFGGYLRSRVKCSVCKSVSDTYDPYLDVALEIRQAANIVRALELFVKADVLSGENAYMCAKCKKKVPASKRFTIHRTSNVLTLSLKRFANFSGGKITKDVGYPEFLNIRPYMSQNNGDPVMYGLYAVLVHSGYSCHAGHYYCYVKASNGQWYQMNDSLVHSSNVKVVLNQQAYVLFYLRIPGSKKSPEGLISRTGSSSLPGRPSVIPDHSKKNIGNGIISSPLTGKRQDSGTMKKPHTTEEIGVPISRNGSTLGLKSQNGCIPPKLPSGSPSPKLSQTPTHMPTILDDPGKKVKKPAPPQHFSPRTAQGLPGTSNSNSSRSGSQRQGSWDSRDVVLSTSPKLLATATANGHGLKGNDESAGLDRRGSSSSSPEHSASSDSTKAPQTPRSGAAHLCDSQETNCSTAGHSKTPPSGADSKTVKLKSPVLSNTTTEPASTMSPPPAKKLALSAKKASTLWRATGNDLRPPPPSPSSDLTHPMKTSHPVVASTWPVHRARAVSPAPQSSSRLQPPFSPHPTLLSSTPKPPGTSEPRSCSSISTALPQVNEDLVSLPHQLPEASEPPQSPSEKRKKTFVGEPQRLGSETRLPQHIREATAAPHGKRKRKKKKRPEDTAASALQEGQTQRQPGSPMYRREGQAQLPAVRRQEDGTQPQVNGQQVGCVTDGHHASSRKRRRKGAEGLGEEGGLHQDPLRHSCSPMGDGDPEAMEESPRKKKKKKRKQETQRAVEEDGHLKCPRSAKPQDAVVPESSSCAPSANGWCPGDRMGLSQAPPVSWNGERESDVVQELLKYSSDKAYGRKVLTWDGKMSAVSQDAIEDSRQARTETVVDDWDEEFDRGKEKKIKKFKREKRRNFNAFQKLQTRRNFWSVTHPAKAASLSYRR>sp|Q9H0E7|UBP44_HUMAN Ubiquitin carboxyl-terminal hydrolase 44 OS=Homosapiens OX=9606 GN=USP44 PE=1 SV=2MLAMDTCKHVGQLQLAQDHSSLNPQKWHCVDCNTTESIWACLSCSHVACGRYIEEHALKHFQESSHPVALEVNEMYVFCYLCDDYVLNDNTTGDLKLLRRTLSAIKSQNYHCTTRSGRFLRSMGTGDDSYFLHDGAQSLLQSEDQLYTALWHRRRILMGKIFRTWFEQSPIGRKKQEEPFQEKIVVKREVKKRRQELEYQVKAELESMPPRKSLRLQGLAQSTIIEIVSVQVPAQTPASPAKDKVLSTSENEISQKVSDSSVKRRPIVTPGVTGLRNLGNTCYMNSVLQVLSHLLIFRQCFLKLDLNQWLAMTASEKTRSCKHPPVTDTVVYQMNECQEKDTGFVCSRQSSLSSGLSGGASKGRKMELIQPKEPTSQYISLCHELHTLFQVMWSGKWALVSPFAMLHSVWRLIPAFRGYAQQDAQEFLCELLDKIQRELETTGTSLPALIPTSQRKLIKQVLNVVNNIFHGQLLSQVTCLACDNKSNTIEPFWDLSLEFPERYQCSGKDIASQPCLVTEMLAKFTETEALEGKIYVCDQCNSKRRRFSSKPVVLTEAQKQLMICHLPQVLRLHLKRFRWSGRNNREKIGVHVGFEEILNMEPYCCRETLKSLRPECFIYDLSAVVMHHGKGFGSGHYTAYCYNSEGGFWVHCNDSKLSMCTMDEVCKAQAYILFYTQRVTENGHSKLLPPELLLGSQHPNEDADTSSNEILS>sp|Q3SY77|UD3A2_HUMAN UDP-glucuronosyltransferase 3A2 OS=Homo sapiensOX=9606 GN=UGT3A2 PE=2 SV=1MAGQRVLLLVGFLLPGVLLSEAAKILTISTVGGSHYLLMDRVSQILQDHGHNVTMLNHKRGPFMPDFKKEEKSYQVISWLAPEDHQREFKKSFDFFLEETLGGRGKFENLLNVLEYLALQCSHFLNRKDIMDSLKNENFDMVIVETFDYCPFLIAEKLGKPFVAILSTSFGSLEFGLPIPLSYVPVFRSLLTDHMDFWGRVKNFLMFFSFCRRQQHMQSTFDNTIKEHFTEGSRPVLSHLLLKAELWFINSDFAFDFARPLLPNTVYVGGLMEKPIKPVPQDLENFIAKFGDSGFVLVTLGSMVNTCQNPEIFKEMNNAFAHLPQGVIWKCQCSHWPKDVHLAANVKIVDWLPQSDLLAHPSIRLFVTHGGQNSIMEAIQHGVPMVGIPLFGDQPENMVRVEAKKFGVSIQLKKLKAETLALKMKQIMEDKRYKSAAVAASVILRSHPLSPTQRLVGWIDHVLQTGGATHLKPYVFQQPWHEQYLLDVFVFLLGLTLGTLWLCGKLLGMAVWWLRGARKVKET>sp|Q3SY77-2|UD3A2_HUMAN Isoform 2 of UDP-glucuronosyltransferase 3A2OS=Homo sapiens OX=9606 GN=UGT3A2MAGQRVLLLVGFLLPGVLLSEAAKILTISTVDFKKEEKSYQVISWLAPEDHQREFKKSFDFFLEETLGGRGKFENLLNVLEYLALQCSHFLNRKDIMDSLKNENFDMVIVETFDYCPFLIAEKLGKPFVAILSTSFGSLEFGLPIPLSYVPVFRSLLTDHMDFWGRVKNFLMFFSFCRRQQHMQSTFDNTIKEHFTEGSRPVLSHLLLKAELWFINSDFAFDFARPLLPNTVYVGGLMEKPIKPVPQDLENFIAKFGDSGFVLVTLGSMVNTCQNPEIFKEMNNAFAHLPQGVIWKCQCSHWPKDVHLAANVKIVDWLPQSDLLAHPSIRLFVTHGGQNSIMEAIQHGVPMVGIPLFGDQPENMVRVEAKKFGVSIQLKKLKAETLALKMKQIMEDKRYKSAAVAASVILRSHPLSPTQRLVGWIDHVLQTGGATHLKPYVFQQPWHEQYLLDVFVFLLGLTLGTLWLCGKLLGMAVWWLRGARKVKET>sp|Q86VQ3|TXND2_HUMAN Thioredoxin domain-containing protein 2 OS=Homosapiens OX=9606 GN=TXNDC2 PE=1 SV=4MDVDKELGMESVKAGASGKPEMRLGTQEETSEGDANESSLLVLSSNVPLLALEFLEIAQAKEKAFLPMVSHTFHMRTEESDASQEGDDLPKSSANTSHPKQDDSPKSSEETIQPKEGDIPKAPEETIQSKKEDLPKSSEKAIQPKESNIPKSSAKPIQPKLGNIPKASVKPSQPKEGDIPKAPEETIQSKKEDLPKSSEEAIQPKEGDIPKSSAKPIQPKLGNIAKTSVKPSQPKESDIPKSPEETIQPKEGDIPKSSAKPIQPKLGNIPKASVKPSQPKEGDISKSPEEAIQPKEGDLPKSLEEAIQPKEGDIPKSPEEAIQPKEGDIPKSLEEAIQPKEGDIPKSPEETIQPKKGDIPKSPEEAIQPKEGDIPKSPKQAIQPKEGDIPKSLEEAIPPKEIDIPKSPEETIQPKEDDSPKSLEEATPSKEGDILKPEEETMEFPEGDKVKVILSKEDFEASLKEAGERLVAVDFSATWCGPCRTIRPFFHALSVKHEDVVFLEVDADNCEEVVRECAIMCVPTFQFYKKEEKVDELCGALKEKLEAVIAELK>sp|Q86VQ3-2|TXND2_HUMAN Isoform 2 of Thioredoxin domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=TXNDC2MVSHTFHMRTEESDASQEGDDLPKSSANTSHPKQDDSPKSSEETIQPKEGDIPKAPEETIQSKKEDLPKSSEKAIQPKESNIPKSSAKPIQPKLGNIPKASVKPSQPKEGDIPKAPEETIQSKKEDLPKSSEEAIQPKEGDIPKSSAKPIQPKLGNIAKTSVKPSQPKESDIPKSPEETIQPKEGDIPKSSAKPIQPKLGNIPKASVKPSQPKEGDISKSPEEAIQPKEGDLPKSLEEAIQPKEGDIPKSPEEAIQPKEGDIPKSLEEAIQPKEGDIPKSPEETIQPKKGDIPKSPEEAIQPKEGDIPKSPKQAIQPKEGDIPKSLEEAIPPKEIDIPKSPEETIQPKEDDSPKSLEEATPSKEGDILKPEEETMEFPEGDKVKVILSKEDFEASLKEAGERLVAVDFSATWCGPCRTIRPFFHALSVKHEDVVFLEVDADNCEEVVRECAIMCVPTFQFYKKEEKVDELCGALKEKLEAVIAELK>sp|Q86VQ3-3|TXND2_HUMAN Isoform 3 of Thioredoxin domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=TXNDC2MDVDKELGMESVKAGASGKPEMRLGTQEETSEGDANESSLLVLSSNVPLLALEFLEIAQAKEKAFLPMVSHTFHMRTEESDASQEGDDLPKSSANTSHPKQDDSPKSSEETIQPKEGDIPKAPEETIQSKKEDLPKSSEKAIQPKESNIPKSSAKPIQPKLGNIPKASVKPSQPKEGDIPKAPEETIQSKKEDLPKSSEEAIQPKEGDIPKSSAKPIQPKLGNIAKTSVKPSQPKESDIPKSPEETIQPKEGDIPKSSAKPIQPKLGNIPKASVKPSQPKEGDISKSPEEAIQPKEGDLPKSLEEAIQPKEGDIPKSLEEAIQPKEGDIPKSPEETIQPKKGDIPKSPEEAIQPKEGDIPKSPKQAIQPKEGDIPKSLEEAIPPKEIDIPKSPEETIQPKEDDSPKSLEEATPSKEGDILKPEEETMEFPEGDKVKVILSKEDFEASLKEAGERLVAVDFSATWCGPCRTIRPFFHALSVKHEDVVFLEVDADNCEEVVRECAIMCVPTFQFYKKEEKVDELCGALKEKLEAVIAELK>sp|A0A0A0MS01|TVG10_HUMAN Probable non-functional T cell receptor gammavariable 10 OS=Homo sapiens OX=9606 GN=TRGV10 PE=1 SV=2MSLLEAFAFSSWALGLGLSKVEQFQLSISTEVKKSIDIPCKISSTRFETDVIHWYRQKPNQALEHLIYIVSTKSAARRSMGKTSNKVEARKNSQTLTSILTIKSVEKEDMAVYYCAAWD>sp|O43818|U3IP2_HUMAN U3 small nucleolar RNA-interacting protein 2OS=Homo sapiens OX=9606 GN=RRP9 PE=1 SV=1MSATAAARKRGKPASGAGAGAGAGKRRRKADSAGDRGKSKGGGKMNEEISSDSESESLAPRKPEEEEEEELEETAQEKKLRLAKLYLEQLRQQEEEKAEARAFEEDQVAGRLKEDVLEQRGRLQKLVAKEIQAPASADIRVLRGHQLSITCLVVTPDDSAIFSAAKDCSIIKWSVESGRKLHVIPRAKKGAEGKPPGHSSHVLCMAISSDGKYLASGDRSKLILIWEAQSCQHLYTFTGHRDAVSGLAFRRGTHQLYSTSHDRSVKVWNVAENSYVETLFGHQDAVAALDALSRECCVTAGGRDGTVRVWKIPEESQLVFYGHQGSIDCIHLINEEHMVSGADDGSVALWGLSKKRPLALQREAHGLRGEPGLEQPFWISSVAALLNTDLVATGSHSSCVRLWQCGEGFRQLDLLCDIPLVGFINSLKFSSSGDFLVAGVGQEHRLGRWWRIKEARNSVCIIPLRRVPVPPAAGS>sp|O60656|UD19_HUMAN UDP-glucuronosyltransferase 1A9 OS=Homo sapiensOX=9606 GN=UGT1A9 PE=1 SV=1MACTGWTSPLPLCVCLLLTCGFAEAGKLLVVPMDGSHWFTMRSVVEKLILRGHEVVVVMPEVSWQLGRSLNCTVKTYSTSYTLEDLDREFKAFAHAQWKAQVRSIYSLLMGSYNDIFDLFFSNCRSLFKDKKLVEYLKESSFDAVFLDPFDNCGLIVAKYFSLPSVVFARGILCHYLEEGAQCPAPLSYVPRILLGFSDAMTFKERVRNHIMHLEEHLLCHRFFKNALEIASEILQTPVTEYDLYSHTSIWLLRTDFVLDYPKPVMPNMIFIGGINCHQGKPLPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|O60656-2|UD19_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A9OS=Homo sapiens OX=9606 GN=UGT1A9MACTGWTSPLPLCVCLLLTCGFAEAGKLLVVPMDGSHWFTMRSVVEKLILRGHEVVVVMPEVSWQLGRSLNCTVKTYSTSYTLEDLDREFKAFAHAQWKAQVRSIYSLLMGSYNDIFDLFFSNCRSLFKDKKLVEYLKESSFDAVFLDPFDNCGLIVAKYFSLPSVVFARGILCHYLEEGAQCPAPLSYVPRILLGFSDAMTFKERVRNHIMHLEEHLLCHRFFKNALEIASEILQTPVTEYDLYSHTSIWLLRTDFVLDYPKPVMPNMIFIGGINCHQGKPLPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|Q5VYS8|TUT7_HUMAN Terminal uridylyltransferase 7 OS=Homo sapiensOX=9606 GN=TUT7 PE=1 SV=1MGDTAKPYFVKRTKDRGTMDDDDFRRGHPQQDYLIIDDHAKGHGSKMEKGLQKKKITPGNYGNTPRKGPCAVSSNPYAFKNPIYSQPAWMNDSHKDQSKRWLSDEHTGNSDNWREFKPGPRIPVINRQRKDSFQENEDGYRWQDTRGCRTVRRLFHKDLTSLETTSEMEAGSPENKKQRSRPRKPRKTRNEENEQDGDLEGPVIDESVLSTKELLGLQQAEERLKRDCIDRLKRRPRNYPTAKYTCRLCDVLIESIAFAHKHIKEKRHKKNIKEKQEEELLTTLPPPTPSQINAVGIAIDKVVQEFGLHNENLEQRLEIKRIMENVFQHKLPDCSLRLYGSSCSRLGFKNSDVNIDIQFPAIMSQPDVLLLVQECLKNSDSFIDVDADFHARVPVVVCREKQSGLLCKVSAGNENACLTTKHLTALGKLEPKLVPLVIAFRYWAKLCSIDRPEEGGLPPYVFALMAIFFLQQRKEPLLPVYLGSWIEGFSLSKLGNFNLQDIEKDVVIWEHTDSAAGDTGITKEEAPRETPIKRGQVSLILDVKHQPSVPVGQLWVELLRFYALEFNLADLVISIRVKELVSRELKDWPKKRIAIEDPYSVKRNVARTLNSQPVFEYILHCLRTTYKYFALPHKITKSSLLKPLNAITCISEHSKEVINHHPDVQTKDDKLKNSVLAQGPGATSSAANTCKVQPLTLKETAESFGSPPKEEMGNEHISVHPENSDCIQADVNSDDYKGDKVYHPETGRKNEKEKVGRKGKHLLTVDQKRGEHVVCGSTRNNESESTLDLEGFQNPTAKECEGLATLDNKADLDGESTEGTEELEDSLNHFTHSVQGQTSEMIPSDEEEEDDEEEEEEEEPRLTINQREDEDGMANEDELDNTYTGSGDEDALSEEDDELGEAAKYEDVKECGKHVERALLVELNKISLKEENVCEEKNSPVDQSDFFYEFSKLIFTKGKSPTVVCSLCKREGHLKKDCPEDFKRIQLEPLPPLTPKFLNILDQVCIQCYKDFSPTIIEDQAREHIRQNLESFIRQDFPGTKLSLFGSSKNGFGFKQSDLDVCMTINGLETAEGLDCVRTIEELARVLRKHSGLRNILPITTAKVPIVKFFHLRSGLEVDISLYNTLALHNTRLLSAYSAIDPRVKYLCYTMKVFTKMCDIGDASRGSLSSYAYTLMVLYFLQQRNPPVIPVLQEIYKGEKKPEIFVDGWNIYFFDQIDELPTYWSECGKNTESVGQLWLGLLRFYTEEFDFKEHVISIRRKSLLTTFKKQWTSKYIVIEDPFDLNHNLGAGLSRKMTNFIMKAFINGRRVFGIPVKGFPKDYPSKMEYFFDPDVLTEGELAPNDRCCRICGKIGHFMKDCPMRRKVRRRRDQEDALNQRYPENKEKRSKEDKEIHNKYTEREVSTKEDKPIQCTPQKAKPMRAAADLGREKILRPPVEKWKRQDDKDLREKRCFICGREGHIKKECPQFKGSSGSLSSKYMTQGKASAKRTQQES>sp|Q5VYS8-2|TUT7_HUMAN Isoform 2 of Terminal uridylyltransferase 7OS=Homo sapiens OX=9606 GN=TUT7MGDTAKPYFVKRTKDRGTMDDDDFRRGHPQQDYLIIDDHAKGHGSKMEKGLQKKKITPGNYGNTPRKGPCAVSSNPYAFKNPIYSQPAWMNDSHKDQSKRWLSDEHTGNSDNWREFKPGPRIPVINRQRKDSFQENEDGYRWQDTRGCRTVRRLFHKDLTSLETTSEMEAGSPENKKQRSRPRKPRKTRNEENEQDGDLEGPVIDESVLSTKELLGLQQAEERLKRDCIDRLKRRPRNYPTAKYTCRLCDVLIESIAFAHKHIKEKRHKKNIKEKQEEELLTTLPPPTPSQINAVGIAIDKVVQEFGLHNENLEQRLEIKRIMENVFQHKLPDCSLRLYGSSCSRLGFKNSDVNIDIQFPAIMSQPDVLLLVQECLKNSDSFIDVDADFHARVPVVVCREKQSGLLCKVSAGNENACLTTKHLTALGKLEPKLVPLVIAFRYWAKLCSIDRPEEGGLPPYVFALMAIFFLQQRKEPLLPVYLGSWIEGFSLSKLGNFNLQDIEKDVVIWEHTDSAAGDTGITKEEAPRETPIKRGQVSLILDVKHQPSVPVGQLWVELLRFYALEFNLADLVISIRVKELVSRELKDWPKKRIAIEGISKCLSYSPPLFFLKVPV>sp|Q5VYS8-3|TUT7_HUMAN Isoform 3 of Terminal uridylyltransferase 7OS=Homo sapiens OX=9606 GN=TUT7MGDTAKPYFVKRTKDRGTMDDDDFRRGHPQQDYLIIDDHAKGHGSKMEKGLQKKKITPGNYGNTPRKGPCAVSSNPYAFKNPIYSQPAWMNDSHKDQSKRWLSDEHTGNSDNWREFKPGPRIPVINRQRKDSFQENEDGYRWQDTRGCRTVRRLFHKDLTSLETTSEMEAGSPENKKQRSRPRKPRKTRNEENEQDGDLEGPVIDESVLSTKELLGLQQAEERLKRDCIDRLKRRPRNYPTAKYTCRLCDVLIESIAFAHKHIKEKRHKKNIKEKQEEELLTTLPPPTPSQINAVGIAIDKVVQEFGLHNENLEQRLEIKRIMENVFQHKLPDCSLRLYGSSCSRLGFKNSDVNIDIQFPAIMSQPDVLLLVQECLKNSDSFIDVDADFHARVPVVVCREKQSGLLCKVSAGNENACLTTKHLTALGKLEPKLVPLVIAFRYWAKLCSIDRPEEGGLPPYVFALMAIFFLQQRKEPLLPVYLGSWIEGFSLSKLGNFNLQDIEKDVVIWEHTDSAAGDTGITKEEAPRETPIKRGQVVSSLLCR>sp|Q5VYS8-4|TUT7_HUMAN Isoform 4 of Terminal uridylyltransferase 7OS=Homo sapiens OX=9606 GN=TUT7MGDTAKPYFVKRTKDRGTMDDDDFRRGHPQQDYLIIDDHAKGHGSKMEKGLQKKKITPGNYGNTPRKGPCAVSSNPYAFKNPIYSQPAWMNDSHKDQSKRWLSDEHTGNSDNWREFKPGPRIPVINRQRKDSFQENEDGYRWQDTRGCRTVRRLFHKDLTSLETTSEMEAGSPENKKQRSRPRKPRKTRNEENEQDGDLEGPVIDESVLSTKELLGLQQAEERLKRDCIDRLKRRPRNYPTAKYTCRLCDVLIESIAFAHKHIKEKRHKKNIKEKQEEELLTTLPPPTPSQINAVGIAIDKVVQEFGLHNENLEQRLEIKRIMENVFQHKLPDCSLRLYGSSCSRLGFKNSDVNIDIQFPAIIEGFSLSKLGNFNLQDIEKDVVIWEHTDSAAGDTGITKEEAPRETPIKRGQVSLILDVKHQPSVPVGQLWVELLRFYALEFNLADLVISIRVKELVSRELKDWPKKRIAIEDPYSVKRNVARTLNSQPVFEYILHCLRTTYKYFALPHKITKSSLLKPLNAITCISEHSKEVINHHPDVQTKDDKLKNSVLAQGPGATSSAANTCKVQPLTLKETAESFGSPPKEEMGNEHISVHPENSDCIQADVNSDDYKGDKVYHPETGRKNEKEKVGRKGKHLLTVDQKRGEHVVCGSTRNNESESTLDLEGFQNPTAKECEGLATLDNKADLDGESTEGTEELEDSLNHFTHSVQGQTSEMIPSDEEEEDDEEEEEEEEPRLTINQREDEDGMANEDELDNTYTGSGDEDALSEEDDELGEAAKYEDVKECGKHVERALLVELNKISLKEENVCEEKNSPVDQSDFFYEFSKLIFTKGKGLDCVRTIEELARVLRKHSGLRNILPITTAKVPIVKFFHLRSGLEVDISLYNTLALHNTRLLSAYSAIDPRVKYLCYTMKVFTKMCDIGDASRGSLSSYAYTLMVLYFLQQRNPPVIPVLQEIYKGEKKPEIFVDGWNIYFFDQIDELPTYWSECGKNTESVGQLWLGLLRFYTEEFDFKEHVISIRRKSLLTTFKKQWTSKYIVIEDPFDLNHNLGAGLSRKMTNFIMKAFINGRRVFGIPVKGFPKDYPSKMEYFFDPDVLTEGELAPNDRCCRICGKIGHFMKDCPMRRKVRRRRDQEDALNQRYPENKEKRSKEDKEIHNKYTEREVSTKEDKPIQCTPQKAKPMRAAADLGREKILRPPVEKWKRQDDKDLREKRCFICGREGHIKKECPQFKGSSGSLSSKYMTQGKASAKRTQQES>sp|Q5VYS8-5|TUT7_HUMAN Isoform 5 of Terminal uridylyltransferase 7OS=Homo sapiens OX=9606 GN=TUT7MGDTAKPYFVKRTKDRGTMDDDDFRRGHPQQDYLIIDDHAKGHGSKMEKGLQKKKITPGNYGNTPRKGPCAVSSNPYAFKNPIYSQPAWMNDSHKDQSKRWLSDEHTGNSDNWREFKPGPRIPVINRQRKDSFQENEDGYRWQDTRGCRTVRRLFHKDLTSLETTSEMEAGSPENKKQRSRPRKPRKTRNEENEQDGDLEGPVIDESVLSTKELLGLQQAEERLKRDCIDRLKRRPRNYPTAKYTCRLCDVLIESIAFAHKHIKEKRHKKNIKEKQEEELLTTLPPPTPSQINAVGIAIDKVVQEFGLHNENLEQRLEIKRIMENVFQHKLPDCSLRLYGSSCSRLGFKNSDVNIDIQFPAIMSQPDVLLLVQECLKNSDSFIDVDADFHARVPVVVCREKQRSHFFKLFIY>sp|Q5VYS8-6|TUT7_HUMAN Isoform 6 of Terminal uridylyltransferase 7OS=Homo sapiens OX=9606 GN=TUT7MGDTAKPYFVKRTKDRGTMDDDDFRRGHPQQDYLIIDDHAKGHGSKMEKGLQKKKITPGNYGNTPRKGPCAVSSNPYAFKNPIYSQPAWMNDSHKDQSKRWLSDEHTGNSDNWREFKPGPRIPVINRQRKDSFQENEDGYRWQDTRGCRTVRRLFHKDLTSLETTSEMEAGSPENKKQRSRPRKPRKTRNEENEQDGDLEGPVIDESVLSTKELLGLQQAEERLKRDCIDRLKRRPRNYPTAKYTCRLCDVLIESIAFAHKHIKEKRHKKNIKEKQEEELLTTLPPPTPSQINAVGIAIDKVVQEFGLHNENLEQRLEIKRIMENVFQHKLPDCSLRLYGSSCSRLGFKNSDVNIDIQFPAIMSQPDVLLLVQECLKNSDSFIDVDADFHARVPVVVCREKQSGLLCKVSAGNENACLTTKHLTALGKLEPKLVPLVIAFRYWAKLCSIDRPEEGGLPPYVFALMAIFFLQQRKEPLLPVYLGSWIEGFSLSKLGNFNLQDIEKDVVIWEHTDSAAGDTGITKEEAPRETPIKRGQVSLILDVKHQPSVPVGQLWVELLRFYALEFNLADLVISIRVKELVSRELKDWPKKRIAIEDPYSVKRNVARTLNSQPVFEYILHCLRTTYKYFALPHKITKSSLLKPLNAITCISEHSKEVINHHPDVQTKDDKLKNSVLAQGPGATSSAANTCKVQPLTLKETAESFGSPPKEEMGNEHISVHPENSDCIQADVNSDDYKGDKVYHPETGRKNEKEKVGRKGKHLLTVDQKRGEHVVCGSTRNNESESTLDLEGFQNPTAKECEGLATLDNKADLDGESTEGTEELEDSLNHFTHSVQGQTSEMIPSDEEEEDDEEEEEEEEPRLTINQREDEDGMANEDELDNTYTGSGDEDALSEEDDELGEAAKYEDVKECGKHVERALLVELNKISLKEENVCEEKNSPVDQSDFFYEFSKLIFTKGKSPTVVCSLCKREGHLKKDCPEDFKRIQLEPLPPLTPKFLNILDQVCIQCYKDFSPTIIEDQAREHIRQNLESFIRQDFPGTKLSLFGSSKNGFGFKQSDLDVCMTINGLETAEGLDCVRTIEELARVLRKHSGLRNILPITTAKVPIVKFFHLRSGLEVDISLYNTLALHNTRLLSAYSAIDPRVKYLCYTMKVFTKIYKGEKKPEIFVDGWNIYFFDQIDELPTYWSECGKNTESVGQLWLGLLRFYTEEFDFKEHVISIRRKSLLTTFKKQWTSKYIVIEDPFDLNHNLGAGLSRKMTNFIMKAFINGRRVFGIPVKGFPKDYPSKMEYFFDPDVLTEGELAPNDRCCRICGKIGHFMKDCPMRRKVRRRRDQEDALNQRYPENKEKRSKEDKEIHNKYTEREVSTKEDKPIQCTPQKAKPMRAAADLGREKILRPPVEKWKRQDDKDLREKRCFICGREGHIKKECPQFKGSSGSLSSKYMTQGKASAKRTQQES>sp|Q8NEY4|VATC2_HUMAN V-type proton ATPase subunit C 2 OS=Homo sapiensOX=9606 GN=ATP6V1C2 PE=1 SV=2MSEFWLISAPGDKENLQALERMNTVTSKSNLSYNTKFAIPDFKVGTLDSLVGLSDELGKLDTFAESLIRRMAQSVVEVMEDSKGKVQEHLLANGVDLTSFVTHFEWDMAKYPVKQPLVSVVDTIAKQLAQIEMDLKSRTAAYNTLKTNLENLEKKSMGNLFTRTLSDIVSKEDFVLDSEYLVTLLVIVPKPNYSQWQKTYESLSDMVVPRSTKLITEDKEGGLFTVTLFRKVIEDFKTKAKENKFTVREFYYDEKEIEREREEMARLLSDKKQQYQTSCVALKKGSSTFPDHKVKVTPLGNPDRPAAGQTDRERESEGEGEGPLLRWLKVNFSEAFIAWIHIKALRVFVESVLRYGLPVNFQAVLLQPHKKSSTKRLREVLNSVFRHLDEVAATSILDASVEIPGLQLNNQDYFPYVYFHIDLSLLD>sp|Q8NEY4-2|VATC2_HUMAN Isoform 2 of V-type proton ATPase subunit C 2OS=Homo sapiens OX=9606 GN=ATP6V1C2MSEFWLISAPGDKENLQALERMNTVTSKSNLSYNTKFAIPDFKVGTLDSLVGLSDELGKLDTFAESLIRRMAQSVVEVMEDSKGKVQEHLLANGVDLTSFVTHFEWDMAKYPVKQPLVSVVDTIAKQLAQIEMDLKSRTAAYNTLKTNLENLEKKSMGNLFTRTLSDIVSKEDFVLDSEYLVTLLVIVPKPNYSQWQKTYESLSDMVVPRSTKLITEDKEGGLFTVTLFRKVIEDFKTKAKENKFTVREFYYDEKEIEREREEMARLLSDKKQQYGPLLRWLKVNFSEAFIAWIHIKALRVFVESVLRYGLPVNFQAVLLQPHKKSSTKRLREVLNSVFRHLDEVAATSILDASVEIPGLQLNNQDYFPYVYFHIDLSLLD>sp|P00749|UROK_HUMAN Urokinase-type plasminogen activator OS=Homosapiens OX=9606 GN=PLAU PE=1 SV=2MRALLARLLLCVLVVSDSKGSNELHQVPSNCDCLNGGTCVSNKYFSNIHWCNCPKKFGGQHCEIDKSKTCYEGNGHFYRGKASTDTMGRPCLPWNSATVLQQTYHAHRSDALQLGLGKHNYCRNPDNRRRPWCYVQVGLKPLVQECMVHDCADGKKPSSPPEELKFQCGQKTLRPRFKIIGGEFTTIENQPWFAAIYRRHRGGSVTYVCGGSLISPCWVISATHCFIDYPKKEDYIVYLGRSRLNSNTQGEMKFEVENLILHKDYSADTLAHHNDIALLKIRSKEGRCAQPSRTIQTICLPSMYNDPQFGTSCEITGFGKENSTDYLYPEQLKMTVVKLISHRECQQPHYYGSEVTTKMLCAADPQWKTDSCQGDSGGPLVCSLQGRMTLTGIVSWGRGCALKDKPGVYTRVSHFLPWIRSHTKEENGLAL>sp|P00749-2|UROK_HUMAN Isoform 2 of Urokinase-type plasminogen activatorOS=Homo sapiens OX=9606 GN=PLAUMVFHLRTRYEQANCDCLNGGTCVSNKYFSNIHWCNCPKKFGGQHCEIDKSKTCYEGNGHFYRGKASTDTMGRPCLPWNSATVLQQTYHAHRSDALQLGLGKHNYCRNPDNRRRPWCYVQVGLKPLVQECMVHDCADGKKPSSPPEELKFQCGQKTLRPRFKIIGGEFTTIENQPWFAAIYRRHRGGSVTYVCGGSLISPCWVISATHCFIDYPKKEDYIVYLGRSRLNSNTQGEMKFEVENLILHKDYSADTLAHHNDIALLKIRSKEGRCAQPSRTIQTICLPSMYNDPQFGTSCEITGFGKENSTDYLYPEQLKMTVVKLISHRECQQPHYYGSEVTTKMLCAADPQWKTDSCQGDSGGPLVCSLQGRMTLTGIVSWGRGCALKDKPGVYTRVSHFLPWIRSHTKEENGLAL>sp|Q9H320|VCX1_HUMAN Variable charge X-linked protein 1 OS=Homo sapiensOX=9606 GN=VCX PE=2 SV=1MSPKPRASGPPAKATEAGKRKSSSQPSPSDPKKKTTKVAKKGKAVRRGRRGKKGAATKMAAVTAPEAESAPAAPGPSDQPSQELPQHELPPEEPVSEGTQHDPLSQEAELEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEMEEPLSQESQVEEPPSQESEMEELPSV>sp|P56703|WNT3_HUMAN Proto-oncogene Wnt-3 OS=Homo sapiens OX=9606GN=WNT3 PE=1 SV=2MEPHLLGLLLGLLLGGTRVLAGYPIWWSLALGQQYTSLGSQPLLCGSIPGLVPKQLRFCRNYIEIMPSVAEGVKLGIQECQHQFRGRRWNCTTIDDSLAIFGPVLDKATRESAFVHAIASAGVAFAVTRSCAEGTSTICGCDSHHKGPPGEGWKWGGCSEDADFGVLVSREFADARENRPDARSAMNKHNNEAGRTTILDHMHLKCKCHGLSGSCEVKTCWWAQPDFRAIGDFLKDKYDSASEMVVEKHRESRGWVETLRAKYSLFKPPTERDLVYYENSPNFCEPNPETGSFGTRDRTCNVTSHGIDGCDLLCCGRGHNTRTEKRKEKCHCIFHWCCYVSCQECIRIYDVHTCK>sp|O94967|WDR47_HUMAN WD repeat-containing protein 47 OS=Homo sapiensOX=9606 GN=WDR47 PE=1 SV=1MTAEETVNVKEVEIIKLILDFLNSKKLHISMLALEKESGVINGLFSDDMLFLRQLILDGQWDEVLQFIQPLECMEKFDKKRFRYIILKQKFLEALCVNNAMSAEDEPQHLEFTMQEAVQCLHALEEYCPSKDDYSKLCLLLTLPRLTNHAEFKDWNPSTARVHCFEEACVMVAEFIPADRKLSEAGFKASNNRLFQLVMKGLLYECCVEFCQSKATGEEITESEVLLGIDLLCGNGCDDLDLSLLSWLQNLPSSVFSCAFEQKMLNIHVDKLLKPTKAAYADLLTPLISKLSPYPSSPMRRPQSADAYMTRSLNPALDGLTCGLTSHDKRISDLGNKTSPMSHSFANFHYPGVQNLSRSLMLENTECHSIYEESPERDTPVDAQRPIGSEILGQSSVSEKEPANGAQNPGPAKQEKNELRDSTEQFQEYYRQRLRYQQHLEQKEQQRQIYQQMLLEGGVNQEDGPDQQQNLTEQFLNRSIQKLGELNIGMDGLGNEVSALNQQCNGSKGNGSNGSSVTSFTTPPQDSSQRLTHDASNIHTSTPRNPGSTNHIPFLEESPCGSQISSEHSVIKPPLGDSPGSLSRSKGEEDDKSKKQFVCINILEDTQAVRAVAFHPAGGLYAVGSNSKTLRVCAYPDVIDPSAHETPKQPVVRFKRNKHHKGSIYCVAWSPCGQLLATGSNDKYVKVLPFNAETCNATGPDLEFSMHDGTIRDLAFMEGPESGGAILISAGAGDCNIYTTDCQRGQGLHALSGHTGHILALYTWSGWMIASGSQDKTVRFWDLRVPSCVRVVGTTFHGTGSAVASVAVDPSGRLLATGQEDSSCMLYDIRGGRMVQSYHPHSSDVRSVRFSPGAHYLLTGSYDMKIKVTDLQGDLTKQLPIMVVGEHKDKVIQCRWHTQDLSFLSSSADRTVTLWTYNG>sp|O94967-2|WDR47_HUMAN Isoform 2 of WD repeat-containing protein 47OS=Homo sapiens OX=9606 GN=WDR47MTAEETVNVKEVEIIKLILDFLNSKKLHISMLALEKESGVINGLFSDDMLFLRFRYIILKQKFLEALCVNNAMSAEDEPQHLEFTMQEAVQCLHALEEYCPSKDDYSKLCLLLTLPRLTNHAEFKDWNPSTARVHCFEEACVMVAEFIPADRKLSEAGFKASNNRLFQLVMKGLLYECCVEFCQSKATGEEITESEVLLGIDLLCGNGCDDLDLSLLSWLQNLPSSVFSCAFEQKMLNIHVDKLLKPTKAAYADLLTPLISKLSPYPSSPMRRPQSADAYMTRSLNPALDGLTCGLTSHDKRISDLGNKTSPMSHSFANFHYPGVQNLSRSLMLENTECHSIYEESPERDTPVDAQRPIGSEILGQSSVSEKEPANGAQNPGPAKQEKNELRDSTEQFQEYYRQRLRYQQHLEQKEQQRQIYQQMLLEGGVNQEDGPDQQQNLTEQFLNRSIQKLGELNIGMDGLGNEVSALNQQCNGSKGNGSNGSSVTSFTTPPQDSSQRLTHDASNIHTSTPRNPGSTNHIPFLEESPCGSQISSEHSVIKPPLGDSPGSLSRSKGEEDDKSKKQFVCINILEDTQAVRAVAFHPAGGLYAVGSNSKTLRVCAYPDVIDPSAHETPKQPVVRFKRNKHHKGSIYCVAWSPCGQLLATGSNDKYVKVLPFNAETCNATGPDLEFSMHDGTIRDLAFMEGPESGGAILISAGAGDCNIYTTDCQRGQGLHALSGHTGHILALYTWSGWMIASGSQDKTVRFWDLRVPSCVRVVGTTFHGTGSAVASVAVDPSGRLLATGQEDSSCMLYDIRGGRMVQSYHPHSSDVRSVRFSPGAHYLLTGSYDMKIKVTDLQGDLTKQLPIMVVGEHKDKVIQCRWHTQDLSFLSSSADRTVTLWTYNG>sp|O94967-3|WDR47_HUMAN Isoform 3 of WD repeat-containing protein 47OS=Homo sapiens OX=9606 GN=WDR47MTAEETVNVKEVEIIKLILDFLNSKKLHISMLALEKESGVINGLFSDDMLFLRQLILDGQWDEVLQFIQPLECMEKFDKKRFRYIILKQKFLEALCVNNAMSAEDEPQHLEFTMQEAVQCLHALEEYCPSKDDYSKLCLLLTLPRLTNHAEFKDWNPSTARVHCFEEACVMVAEFIPADRKLSEAGFKASNNRLFQLVMKGLLYECCVEFCQSKATGEEITESEVLLGIDLLCGNGCDDLDLSLLSWLQNLPSSVFSCAFEQKMLNIHVDKLLKPTKAAYADLLTPLISKLSPYPSSPMRRPQSADAYMTRSLNPALDGLTCGLTSHDKRISDLGNKTSPMSHSFANFHYPGVQNLSRSLMLENTECHSIYEESPERSDTPVDAQRPIGSEILGQSSVSEKEPANGAQNPGPAKQEKNELRDSTEQFQEYYRQRLRYQQHLEQKEQQRQIYQQMLLEGGVNQEDGPDQQQNLTEQFLNRSIQKLGELNIGMDGLGNEVSALNQQCNGSKGNGSNGSSVTSFTTPPQDSSQRLTHDASNIHTSTPRNPGSTNHIPFLEESPCGSQISSEHSVIKPPLGDSPGSLSRSKGEEDDKSKKQFVCINILEDTQAVRAVAFHPAGGLYAVGSNSKTLRVCAYPDVIDPSAHETPKQPVVRFKRNKHHKGSIYCVAWSPCGQLLATGSNDKYVKVLPFNAETCNATGPDLEFSMHDGTIRDLAFMEGPESGGAILISAGAGDCNIYTTDCQRGQGLHALSGHTGHILALYTWSGWMIASGSQDKTVRFWDLRVPSCVRVVGTTFHGTGSAVASVAVDPSGRLLATGQEDSSCMLYDIRGGRMVQSYHPHSSDVRSVRFSPGAHYLLTGSYDMKIKVTDLQGDLTKQLPIMVVGEHKDKVIQCRWHTQDLSFLSSSADRTVTLWTYNG>sp|O94967-4|WDR47_HUMAN Isoform 4 of WD repeat-containing protein 47OS=Homo sapiens OX=9606 GN=WDR47MTAEETVNVKEVEIIKLILDFLNSKKLHISMLALEKESGVINGLFSDDMLFLRQLILDGQWDEVLQFIQPLECMEKFDKKRFRYIILKQKFLEALCVNNAMSAEDEPQHVRFLFLKLEFTMQEAVQCLHALEEYCPSKDDYSKLCLLLTLPRLTNHAEFKDWNPSTARVHCFEEACVMVAEFIPADRKLSEAGFKASNNRLFQLVMKGLLYECCVEFCQSKATGEEITESEVLLGIDLLCGNGCDDLDLSLLSWLQNLPSSVFSCAFEQKMLNIHVDKLLKPTKAAYADLLTPLISKLSPYPSSPMRRPQSADAYMTRSLNPALDGLTCGLTSHDKRISDLGNKTSPMSHSFANFHYPGVQNLSRSLMLENTECHSIYEESPERSDTPVDAQRPIGSEILGQSSVSEKEPANGAQNPGPAKQEKNELRDSTEQFQEYYRQRLRYQQHLEQKEQQRQIYQQMLLEGGVNQEDGPDQQQNLTEQFLNRSIQKLGELNIGMDGLGNEVSALNQQCNGSKGNGSNGSSVTSFTTPPQDSSQRLTHDASNIHTSTPRNPGSTNHIPFLEESPCGSQISSEHSVIKPPLGDSPGSLSRSKGEEDDKSKKQFVCINILEDTQAVRAVAFHPAGGLYAVGSNSKTLRVCAYPDVIDPSAHETPKQPVVRFKRNKHHKGSIYCVAWSPCGQLLATGSNDKYVKVLPFNAETCNATGPDLEFSMHDGTIRDLAFMEGPESGGAILISAGAGDCNIYTTDCQRGQGLHALSGHTGHILALYTWSGWMIASGSQDKTVRFWDLRVPSCVRVVGTTFHGTGSAVASVAVDPSGRLLATGQEDSSCMLYDIRGGRMVQSYHPHSSDVRSVRFSPGAHYLLTGSYDMKIKVTDLQGDLTKQLPIMVVGEHKDKVIQCRWHTQDLSFLSSSADRTVTLWTYNG>sp|P0C1S8|WEE2_HUMAN Wee1-like protein kinase 2 OS=Homo sapiens OX=9606GN=WEE2 PE=1 SV=2MDDKDIDKELRQKLNFSYCEETEIEGQKKVEESREASSQTPEKGEVQDSEAKGTPPWTPLSNVHELDTSSEKDKESPDQILRTPVSHPLKCPETPAQPDSRSKLLPSDSPSTPKTMLSRLVISPTGKLPSRGPKHLKLTPAPLKDEMTSLALVNINPFTPESYKKLFLQSGGKRKIRGDLEEAGPEEGKGGLPAKRCVLRETNMASRYEKEFLEVEKIGVGEFGTVYKCIKRLDGCVYAIKRSMKTFTELSNENSALHEVYAHAVLGHHPHVVRYYSSWAEDDHMIIQNEYCNGGSLQAAISENTKSGNHFEEPKLKDILLQISLGLNYIHNSSMVHLDIKPSNIFICHKMQSESSGVIEEVENEADWFLSANVMYKIGDLGHATSINKPKVEEGDSRFLANEILQEDYRHLPKADIFALGLTIAVAAGAESLPTNGAAWHHIRKGNFPDVPQELSESFSSLLKNMIQPDAEQRPSAAALARNTVLRPSLGKTEELQQQLNLEKFKTATLERELREAQQAQSPQGYTHHGDTGVSGTHTGSRSTKRLVGGKSARSSSFTSGEREPLH>sp|Q8TAT8|YK045_HUMAN Putative uncharacterized protein LOC644613 OS=Homosapiens OX=9606 PE=5 SV=2MTERRRALSLAAVVDSINLACVVVSRDWLSLVPAFFYSPPPGGSFSGIKRESRRKRPSRNEIYGGGVLEQEVRMRRWSKTASPPVSLHHRPLGPARKP>sp|Q9HAA7|YG046_HUMAN Putative uncharacterized protein FLJ11871 OS=Homosapiens OX=9606 PE=5 SV=1MLFGIRILVNTPSPLVTGLHHYNPSIHRDQGECANQWRKGPGSAHLAGLAGRCSLINTPSPLVTGLQRYNPSMDRAQGMCASLEEEAGLCKPLWAWWELQSHKHSQTSHHRAAGLQSQHAPGSGRVRITGGKV>sp|P98182|ZN200_HUMAN Zinc finger protein 200 OS=Homo sapiens OX=9606GN=ZNF200 PE=1 SV=2MMAAKVVPMPPKPKQSFILRVPPDSKLGQDLLRDATNGPKTIHQLVLEHFLTFLPKPSLVQPSQKVKETLVIMKDVSSSLQNRVHPRPLVKLLPKGVQKEQETVSLYLKANPEELVVFEDLNVFHCQEECVSLDPTQQLTSEKEDDSSVGEMMLLAVNGSNPEGEDPEREPVENEDYREKSSDDDEMDSSLVSQQPPDNQEKERLNTSIPQKRKMRNLLVTIENDTPLEELSKYVDISIIALTRNRRTRRWYTCPLCGKQFNESSYLISHQRTHTGEKPYDCNHCGKSFNHKTNLNKHERIHTGEKPYSCSQCGKNFRQNSHRSRHEGIHIREKIFKCPECGKTFPKNEEFVLHLQSHEAERPYGCKKCGRRFGRLSNCTRHEKTHSACKTRKQK>sp|P98182-2|ZN200_HUMAN Isoform 2 of Zinc finger protein 200 OS=Homosapiens OX=9606 GN=ZNF200MMAAKVVPMPPKPKQSFILRVPPDSKLGQDLLRDATNGPKTIHQLVLEHFLTFLPKPSLVQPSQKVKETLVIMKDVSSSLQNRVHPRPLVKLLPKGVQKEQETVSLYLKANPELVVFEDLNVFHCQEECVSLDPTQQLTSEKEDDSSVGEMMLLAVNGSNPEGEDPEREPVENEDYREKSSDDDEMDSSLVSQQPPDNQEKERLNTSIPQKRKMRNLLVTIENDTPLEELSKYVDISIIALTRNRRTRRWYTCPLCGKQFNESSYLISHQRTHTGEKPYDCNHCGKSFNHKTNLNKHERIHTGEKPYSCSQCGKNFRQNSHRSRHEGIHIREKIFKCPECGKTFPKNEEFVLHLQSHEAERPYGCKKCGRRFGRLSNCTRHEKTHSACKTRKQK>sp|P98182-3|ZN200_HUMAN Isoform 3 of Zinc finger protein 200 OS=Homosapiens OX=9606 GN=ZNF200MMAAKVVPMPPKPKQSFILRVPPDSKLGQDLLRDATNGPKTIHQLVLEHFLTFLPKPSLVQPSQKVKETLVIMKDVSSSLQNRVHPRPLVKLLPKGVQKEQETVSLYLKANPEELVVFEDLNVFHCQEECVSLDPTQQLTSEKEDDSSVGEMMLLVNGSNPEGEDPEREPVENEDYREKSSDDDEMDSSLVSQQPPDNQEKERLNTSIPQKRKMRNLLVTIENDTPLEELSKYVDISIIALTRNRRTRRWYTCPLCGKQFNESSYLISHQRTHTGEKPYDCNHCGKSFNHKTNLNKHERIHTGEKPYSCSQCGKNFRQNSHRSRHEGIHIREKIFKCPECGKTFPKNEEFVLHLQSHEAERPYGCKKCGRRFGRLSNCTRHEKTHSACKTRKQK>sp|Q96BR9|ZBT8A_HUMAN Zinc finger and BTB domain-containing protein 8AOS=Homo sapiens OX=9606 GN=ZBTB8A PE=1 SV=2MEISSHQSHLLQQLNEQRRQDVFCDCSILVEGKVFKAHRNVLFASSGYFKMLLSQNSKETSQPTTATFQAFSPDTFTVILDFVYSGKLSLTGQNVIEVMSAASFLQMTDVISVCKTFIKSSLDISEKEKDRYFSLSDKDANSNGVERSSFYSGGWQEGSSSPRSHLSPEQGTGIISGKSWNKYNYHPASQKNTQQPLAKHEPRKESIKKTKHLRLSQPSEVTHYKSSKREVRTSDSSSHVSQSEEQAQIDAEMDSTPVGYQYGQGSDVTSKSFPDDLPRMRFKCPYCTHVVKRKADLKRHLRCHTGERPYPCQACGKRFSRLDHLSSHFRTIHQACKLICRKCKRHVTDLTGQVVQEGTRRYRLCNECLAEFGIDSLPIDLEAEQHLMSPSDGDKDSRWHLSEDENRSYVEIVEDGSGDLVIQQVDDSEEEEEKEIKPNIR>sp|Q96BR9-2|ZBT8A_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 8A OS=Homo sapiens OX=9606 GN=ZBTB8AMEISSHQSHLLQQLNEQRRQDVFCDCSILVEGKVFKAHRNVLFASSGYFKMLLSQNSKETSQPTTATFQAFSPDTFTVILDFVYSGKLSLTGQNVIEVMSAASFLQMTDVISVCKTFIKSSLDISEKEKDRYFSLSDKDANSNGVERSSFYSGGWQEGSSSPRSHLSPEQGTGIISGKSWNKYNYHPASQKNTQQPLAKHEPRKESIKKTKHLRLSQPSEVTHYKSSKREVRTSDSSSHVSQSEEQAQIDAEMDSTPVGYQYGQGSDVTSKSFPDDLPRMRFKCPYCTHVVKRKADLKRHLRCHTGERPYPCQACGKRFSRLDHLSSHFRTMEIRIPD>sp|Q5W150|YT011_HUMAN Putative uncharacterized protein MGC163334 OS=Homosapiens OX=9606 PE=1 SV=1MDCKSPKRANICPHLPGGGLFSTPPSQAAWRTLLTALCFPGPTCTGPMREGPRAVYNPPRAHRNSSDNCVMKHLLCAGDKNGTRRHALPSPLEGSFQPGRQIPPPQTPSTDPQTLPLSFRSLLRCHQLCAASLPPSLKLP>sp|Q9HCK0|ZBT26_HUMAN Zinc finger and BTB domain-containing protein 26OS=Homo sapiens OX=9606 GN=ZBTB26 PE=1 SV=2MSERSDLLHFKFENYGDSMLQKMNKLREENKFCDVTVLIDDIEVQGHKIVFAAGSPFLRDQFLLNDSREVKISILQSSEVGRQLLLSCYSGVLEFPEMELVNYLTAASFLQMSHIVERCTQALWKFIKPKQPMDSKEGCEPQSASPQSKEQQGDARGSPKQDSPCIHPSEDSMDMEDSDIQIVKVESIGDVSEVRSKKDQNQFISSEPTALHSSEPQHSLINSTVENRVSEIEQNHLHNYALSYTGSDNIIMASKDVFGPNIRGVDKGLQWHHQCPKCTRVFRHLENYANHLKMHKLFMCLLCGKTFTQKGNLHRHMRVHAGIKPFQCKICGKTFSQKCSLQDHLNLHSGDKPHKCNYCDMVFAHKPVLRKHLKQLHGKNSFDNANERNVQDLTVDFDSFACTTVTDSKGCQPQPDATQVLDAGKLAQAVLNLRNDSTCVN>sp|O75290|Z780A_HUMAN Zinc finger protein 780A OS=Homo sapiens OX=9606GN=ZNF780A PE=1 SV=3MVHGSVTFRDVAIDFSQEEWECLQPDQRTLYRDVMLENYSHLISLGSSISKPDVITLLEQEKEPWMVVRKETSRRYPDLELKYGPEKVSPENDTSEVNLPKQVIKQISTTLGIEAFYFRNDSEYRQFEGLQGYQEGNINQKMISYEKLPTHTPHASLICNTHKPYECKECGKYFSRSANLIQHQSIHTGEKPFECKECGKAFRLHIQFTRHQKFHTGEKPFECNECGKAFSLLTLLNRHKNIHTGEKLFECKECGKSFNRSSNLVQHQSIHSGVKPYECKECGKGFNRGAHLIQHQKIHSNEKPFVCKECGMAFRYHYQLIEHCQIHTGEKPFECKECGKAFTLLTKLVRHQKIHTGEKPFECRECGKAFSLLNQLNRHKNIHTGEKPFECKECGKSFNRSSNLVQHQSIHAGIKPYECKECGKGFNRGAHLIQHQKIHSNEKPFVCRECEMAFRYHCQLIEHSRIHTGDKPFECQDCGKAFNRGSSLVQHQSIHTGEKPYECKECGKAFRLYLQLSQHQKTHTGEKPFECKECGKFFRRGSNLNQHRSIHTGKKPFECKECGKAFRLHMHLIRHQKLHTGEKPFECKECGKAFRLHMQLIRHQKLHTGEKPFECKECGKVFSLPTQLNRHKNIHTGEKAS>sp|O75290-2|Z780A_HUMAN Isoform 2 of Zinc finger protein 780A OS=Homosapiens OX=9606 GN=ZNF780AMGRSPRKIDQFCNSSNMVHGSVTFRDVAIDFSQEEWECLQPDQRTLYRDVMLENYSHLISLGSSISKPDVITLLEQEKEPWMVVRKETSRRYPDLELKYGPEKVSPENDTSEVNLPKQISSLASKPSFTAIHIQRRIHCRICIAFGYLSLVYCSLEIL>sp|O75290-3|Z780A_HUMAN Isoform 3 of Zinc finger protein 780A OS=Homosapiens OX=9606 GN=ZNF780AMVHGSVTFRDVAIDFSQEEWECLQPDQRTLYRDVMLENYSHLISLAGSSISKPDVITLLEQEKEPWMVVRKETSRRYPDLELKYGPEKVSPENDTSEVNLPKQVIKQISTTLGIEAFYFRNDSEYRQFEGLQGYQEGNINQKMISYEKLPTHTPHASLICNTHKPYECKECGKYFSRSANLIQHQSIHTGEKPFECKECGKAFRLHIQFTRHQKFHTGEKPFECNECGKAFSLLTLLNRHKNIHTGEKLFECKECGKSFNRSSNLVQHQSIHSGVKPYECKECGKGFNRGAHLIQHQKIHSNEKPFVCKECGMAFRYHYQLIEHCQIHTGEKPFECKECGKAFTLLTKLVRHQKIHTGEKPFECRECGKAFSLLNQLNRHKNIHTGEKPFECKECGKSFNRSSNLVQHQSIHAGIKPYECKECGKGFNRGAHLIQHQKIHSNEKPFVCRECEMAFRYHCQLIEHSRIHTGDKPFECQDCGKAFNRGSSLVQHQSIHTGEKPYECKECGKAFRLYLQLSQHQKTHTGEKPFECKECGKFFRRGSNLNQHRSIHTGKKPFECKECGKAFRLHMHLIRHQKLHTGEKPFECKECGKAFRLHMQLIRHQKLHTGEKPFECKECGKVFSLPTQLNRHKNIHTGEKAS>sp|Q5SVZ6|ZMYM1_HUMAN Zinc finger MYM-type protein 1 OS=Homo sapiensOX=9606 GN=ZMYM1 PE=1 SV=1MKEPLLGGECDKAVASQLGLLDEIKTEPDNAQEYCHRQQSRTQENELKINAVFSESASQLTAGIQLSLASSGVNKMLPSVSTTAIQVSCAGCKKILQKGQTAYQRKGSAQLFCSIPCITEYISSASSPVPSKRTCSNCSKDILNPKDVISVQLEDTTSCKTFCSLSCLSSYEEKRKPFVTICTNSILTKCSMCQKTAIIQYEVKYQNVKHNLCSNACLSKFHSANNFIMNCCENCGTYCYTSSSLSHILQMEGQSHYFNSSKSITAYKQKPAKPLISVPCKPLKPSDEMIETTSDLGKTELFCSINCFSAYSKAKMESSSVSVVSVVHDTSTELLSPKKDTTPVISNIVSLADTDVALPIMNTDVLQDTVSSVTATADVIVDLSKSSPSEPSNAVASSSTEQPSVSPSSSVFSQHAIGSSTEVQKDNMKSMKISDELCHPKCTSKVQKVKGKSRSIKKSCCADFECLENSKKDVAFCYSCQLFCQKYFSCGRESFATHGTSNWKKTLEKFRKHEKSEMHLKSLEFWREYQFCDGAVSDDLSIHSKQIEGNKKYLKLIIENILFLGKQCLPLRGNDQSVSSVNKGNFLELLEMRAKDKGEETFRLMNSQVDFYNSTQIQSDIIEIIKTEMLQDIVNEINDSSAFSIICDETINSAMKEQLSICVRYPQKSSKAILIKERFLGFVDTEEMTGTHLHRTIKTYLQQIGVDMDKIHGQAYDSTTNLKIKFNKIAAEFKKEEPRALYIHCYAHFLDLSIIRFCKEVKELRSALKTLSSLFNTICMSGEMLANFRNIYRLSQNKTCKKHISQSCWTVHDRTLLSVIDSLPEIIETLEVIASHSSNTSFADELSHLLTLVSKFEFVFCLKFLYRVLSVTGILSKELQNKTIDIFSLSSKIEAILECLSSERNDVYFKTIWDGTEEICQKITCKGFKVEKPSLQKRRKIQKSVDLGNSDNMFFPTSTEEQYKINIYYQGLDTILQNLKLCFSEFDYCKIKQISELLFKWNEPLNETTAKHVQEFYKLDEDIIPELRFYRHYAKLNFVIDDSCINFVSLGCLFIQHGLHSNIPCLSKLLYIALSWPITSASTENSFSTLPRLKTYLCNTMGQEKLTGPALMAVEQELVNKLMEPERLNEIVEKFISQMKEI>sp|Q9C0B9|ZCHC2_HUMAN Zinc finger CCHC domain-containing protein 2OS=Homo sapiens OX=9606 GN=ZCCHC2 PE=1 SV=6MLRMKLPLKPTHPAEPPPEAEEPEADARPGAKAPSRRRRDCRPPPPPPPPAGPSRGPLPPPPPPRGLGPPVAGGAAAGAGMPGGGGGPSAALREQERVYEWFGLVLGSAQRLEFMCGLLDLCNPLELRFLGSCLEDLARKDYHYLRDSEAKANGLSDPGPLADFREPAVRSRLIVYLALLGSENREAAGRLHRLLPQVDSVLKSLRAARGEGSRGGAEDERGEDGDGEQDAEKDGSGPEGGIVEPRVGGGLGSRAQEELLLLFTMASLHPAFSFHQRVTLREHLERLRAALRGGPEDAEVEVEPCKFAGPRAQNNSAHGDYMQNNESSLIEQAPIPQDGLTVAPHRAQREAVHIEKIMLKGVQRKRADKYWEYTFKVNWSDLSVTTVTKTHQELQEFLLKLPKELSSETFDKTILRALNQGSLKREERRHPDLEPILRQLFSSSSQAFLQSQKVHSFFQSISSDSLHSINNLQSSLKTSKILEHLKEDSSEASSQEEDVLQHAIIHKKHTGKSPIVNNIGTSCSPLDGLTMQYSEQNGIVDWRKQSCTTIQHPEHCVTSADQHSAEKRSLSSINKKKGKPQTEKEKIKKTDNRLNSRINGIRLSTPQHAHGGTVKDVNLDIGSGHDTCGETSSESYSSPSSPRHDGRESFESEEEKDRDTDSNSEDSGNPSTTRFTGYGSVNQTVTVKPPVQIASLGNENGNLLEDPLNSPKYQHISFMPTLHCVMHNGAQKSEVVVPAPKPADGKTIGMLVPSPVAISAIRESANSTPVGILGPTACTGESEKHLELLASPLPIPSTFLPHSSTPALHLTVQRLKLPPPQGSSESCTVNIPQQPPGSLSIASPNTAFIPIHNPGSFPGSPVATTDPITKSASQVVGLNQMVPQIEGNTGTVPQPTNVKVVLPAAGLSAAQPPASYPLPGSPLAAGVLPSQNSSVLSTAATSPQPASAGISQAQATVPPAVPTHTPGPAPSPSPALTHSTAQSDSTSYISAVGNTNANGTVVPPQQMGSGPCGSCGRRCSCGTNGNLQLNSYYYPNPMPGPMYRVPSFFTLPSICNGSYLNQAHQSNGNQLPFFLPQTPYANGLVHDPVMGSQANYGMQQMAGFGRFYPVYPAPNVVANTSGSGPKKNGNVSCYNCGVSGHYAQDCKQSSMEANQQGTYRLRYAPPLPPSNDTLDSAD>sp|Q9C0B9-2|ZCHC2_HUMAN Isoform 2 of Zinc finger CCHC domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=ZCCHC2MQNNESSLIEQAPIPQDGLTVAPHRAQREAVHIEKIMLKGVQRKRADKYWEYTFKVNWSDLSVTTVTKTHQELQEFLLKLPKELSSETFDKTILRALNQGSLKREERRHPDLEPILRQLFSSSSQAFLQSQKVHSFFQSISSDSLHSINNLQSSLKTSKILEHLKEDSSEASSQEEDVLQHAIIHKKHTGKSPIVNNIGTSCSPLDGLTMQYSEQNGIVDWRKQSCTTIQHPEHCVTSADQHSAEKRSLSSINKKKGKPQTEKEKIKKTDNRLNSRINGIRLSTPQHAHGGTVKDVNLDIGSGHDTCGETSSESYSSPSSPRHDGRESFESEEEKDRDTDSNSEDSGNPSTTRFTGYGSVNQTVTVKPPVQIASLGNENGNLLEDPLNSPKYQHISFMPTLHCVMHNGAQKSEVVVPAPKPADGKTIGMLVPSPVAISAIRESANSTPVGILGPTACTGESEKHLELLASPLPIPSTFLPHSSTPALHLTVQRLKLPPPQGSSESCTVNIPQQPPGSLSIASPNTAFIPIHNPGSFPGSPVATTDPITKSASQVVGLNQMVPQIEGNTGTVPQPTNVKVVLPAAGLSAAQPPASYPLPGSPLAAGVLPSQNSSVLSTAATSPQPASAGISQAQATVPPAVPTHTPGPAPSPSPALTHSTAQSDSTSYISAVGNTNANGTVVPPQQMGSGPCGSCGRRCSCGTNGNLQLNSYYYPNPMPGPMYRVPSFFTLPSICNGSYLNQAHQSNGNQLPFFLPQTPYANGLVHDPVMGSQANYGMQQMAGFGRFYPVYPAPNVVANTSGSGPKKNGNVSCYNCGVSGHYAQDCKQSSMEANQQGTYRLRYAPPLPPSNDTLDSAD>sp|Q6ZW05|PTHD4_HUMAN Patched domain-containing protein 4 OS=Homosapiens OX=9606 GN=PTCHD4 PE=2 SV=3MCFLRRPGAPASWIWWRMLRQVLRRGLQSFCHRLGLCVSRHPVFFLTVPAVLTITFGLSALNRFQPEGDLERLVAPSHSLAKIERSLASSLFPLDQSKSQLYSDLHTPGRYGRVILLSPTGDNILLQAEGILQTHRAVLEMKDGRNSFIGHQLGGVVEVPNSKDQRVKSARAIQITYYLQTYGSATQDLIGEKWENEFCKLIRKLQEEHQELQLYSLASFSLWRDFHKTSILARSKVLVSLVLILTTATLSSSMKDCLRSKPFLGLLGVLTVCISIITAAGIFFITDGKYNSTLLGIPFFAMGHGTKGVFELLSGWRRTKENLPFKDRIADAYSDVMVTYTMTSSLYFITFGMGASPFTNIEAVKVFCQNMCVSILLNYFYIFSFFGSCLVFAGQLEQNRYHSIFCCKIPSAEYLDRKPVWFQTVMSDGHQQTSHHETNPYQHHFIQHFLREHYNEWITNIYVKPFVVILYLIYASFSFMGCLQISDGANIINLLASDSPSVSYAMVQQKYFSNYSPVIGFYVYEPLEYWNSSVQDDLRRLCSGFTAVSWVEQYYQFLKVSNVSANNKSDFISVLQSSFLKKPEFQHFRNDIIFSKAGDESNIIASRLYLVARTSRDKQKEITEVLEKLRPLSLSKSIRFIVFNPSFVFMDHYSLSVTVPVLIAGFGVLLVLILTFFLVIHPLGNFWLILSVTSIELGVLGLMTLWNVDMDCISILCLIYTLNFAIDHCAPLLFTFVLATEHTRTQCIKSSLQDHGTAILQNVTSFLIGLVPLLFVPSNLTFTLFKCLLLTGGCTLLHCFVILPVFLTFFPPSKKHHKKKKRAKRKEREEIECIEIQENPDHVTTV>sp|Q6ZW05-2|PTHD4_HUMAN Isoform 2 of Patched domain-containing protein 4OS=Homo sapiens OX=9606 GN=PTCHD4MLRQVLRRGLQSFCHRLGLCVSRHPVFFLTVPAVLTITFGLSALNRFQPEGDLERLVAPSHSLAKIERSLASSLFPLDQSKSQLYSDLHTPGRYGRVILLSPTGDNILLQAEGILQTHRAVLEMKDGRNSFIGHQLGGVVEVPNSKDQRVKSARAIQITYYLQTYGSATQDLIGEKWENEFCKLIRKLQEEHQELQLYSLASFSLWRDFHKTSILARSKVLVSLVLILTTATLSSSMKDCLRSKPFLGLLGVLTVCISIITAAGIFFITDGKYNSTLLGIPFFAMGISTEFTSS>sp|Q6ZW05-3|PTHD4_HUMAN Isoform 3 of Patched domain-containing protein 4OS=Homo sapiens OX=9606 GN=PTCHD4MRRPGAPASWIWWRMLRQVLRRGLQSFCHRLGLCVSRHPVFFLTVPAVLTITFGLSALNRFQPEGDLERLVAPSHSLAKIERSLASSLFPLDQSKSQLYSDLHTPGRYGRVILLSPTGDNILLQAEGILQTHRAVLEMKDGRNSFIGHQLGGVVEVPNSKDQRVKSARAIQITYYLQTYGSATQDLIGEKWENEFCKLIRKLQEEHQELQLYSLASFSLWRDFHKTSILARSKVLVSLVLILTTATLSSSMKDCLRSKPFLGLLGVLTVCISIITAAGIFFITDGKYNSTLLGIPFFAMGHGTKGVFELLSGWRRTKENLPFKDRIADAYSDVMVTYTMTSSLYFITFGMGASPFTNIEAVKVFCQNMCVSILLNYFYIFSFFGSCLVFAGQLEQNRYHSIFCCKIPSAEYLDRKPVWFQTVMSDGHQQTSHHETNPYQHHFIQHFLREHYNEWITNIYVKPFVVILYLIYASFSFMGCLQISDGANIINLLASDSPSVSYAMVQQKYFSNYSPVIGFYVYEPLEYWNSSVQDDLRRLCSGFTAVSWVEQYYQFLKVSNVSANNKSDFISVLQSSFLKKPEFQHFRNDIIFSKAGDESNIIASRLYLVARTSRDKQKEITEVLEKLRPLSLSKSIRFIVFNPSFVFMDHYSLSVTVPVLIAGFGVLLVLILTFFLVIHPLGNFWLILSVTSIELGVLGLMTLWNVDMDCISILCLIYTLNFAIDHCAPLLFTFVLATEHTRTQCIKSSLQDHGTAILQNVTSFLIGLVPLLFVPSNLTFTLFKCLLLTGGCTLLHCFVILPVFLTFFPPSKKHHKKKKRAKRKEREEIECIEIQENPDHVTTV>sp|Q6ZW05-4|PTHD4_HUMAN Isoform 4 of Patched domain-containing protein 4OS=Homo sapiens OX=9606 GN=PTCHD4MKDCLRSKPFLGLLGVLTVCISIITAAGIFFITDGKYNSTLLGIPFFAMGHGTKGVFELLSGWRRTKENLPFKDRIADAYSDVMVTYTMTSSLYFITFGMGASPFTNIEAVKVFCQNMCVSILLNYFYIFSFFGSCLVFAGQLEQNRYHSIFCCKIPSAEYLDRKPVWFQTVMSDGHQQTSHHETNPYQHHFIQHFLREHYNEWITNIYVKPFVVILYLIYASFSFMGCLQISDGANIINLLASDSPSVSYAMVQQKYFSNYSPVIGFYVYEPLEYWNSSVQDDLRRLCSGFTAVSWVEQYYQFLKVSNVSANNKSDFISVLQSSFLKKPEFQHFRNDIIFSKAGDESNIIASRLYLVARTSRDKQKEITEVLEKLRPLSLSKSIRFIVFNPSFVFMDHYSLSVTVPVLIAGFGVLLVLILTFFLVIHPLGNFWLILSVTSIELGVLGLMTLWNVDMDCISILCLIYTLNFAIDHCAPLLFTFVLATEHTRTQCIKSSLQDHGTAILQNVTSFLIGLVPLLFVPSNLTFTLFKCLLLTGGCTLLHCFVILPVFLTFFPPSKKHHKKKKRAKRKEREEIECIEIQENPDHVTTV>sp|Q8WUA2|PPIL4_HUMAN Peptidyl-prolyl cis-trans isomerase-like 4 OS=Homosapiens OX=9606 GN=PPIL4 PE=1 SV=1MAVLLETTLGDVVIDLYTEERPRACLNFLKLCKIKYYNYCLIHNVQRDFIIQTGDPTGTGRGGESIFGQLYGDQASFFEAEKVPRIKHKKKGTVSMVNNGSDQHGSQFLITTGENLDYLDGVHTVFGEVTEGMDIIKKINETFVDKDFVPYQDIRINHTVILDDPFDDPPDLLIPDRSPEPTREQLDSGRIGADEEIDDFKGRSAEEVEEIKAEKEAKTQAILLEMVGDLPDADIKPPENVLFVCKLNPVTTDEDLEIIFSRFGPIRSCEVIRDWKTGESLCYAFIEFEKEEDCEKAFFKMDNVLIDDRRIHVDFSQSVAKVKWKGKGGKYTKSDFKEYEKEQDKPPNLVLKDKVKPKQDTKYDLILDEQAEDSKSSHSHTSKKHKKKTHHCSEEKEDEDYMPIKNTNQDIYREMGFGHYEEEESCWEKQKSEKRDRTQNRSRSRSRERDGHYSNSHKSKYQTDLYERERSKKRDRSRSPKKSKDKEKSKYR>sp|P0DTF9|PTIP2_HUMAN PTTG1IP family member 2 OS=Homo sapiens OX=9606GN=PTTG1IP2 PE=3 SV=1MCWLRAWGQILLPVFLSLFLIQLLISFSENGFIHSPRNNQKPRDGNEEECAVKKSCQLCTEDKKCVWCSEEKACKKYCFPYFGCRFSSIYWLNCKVDMFGIMMLLLIAVLITGFVWYCCAYHFYLQDLNRNRVYFYGRRETVPIHDRSATVYDE>sp|P51665|PSMD7_HUMAN 26S proteasome non-ATPase regulatory subunit 7OS=Homo sapiens OX=9606 GN=PSMD7 PE=1 SV=2MPELAVQKVVVHPLVLLSVVDHFNRIGKVGNQKRVVGVLLGSWQKKVLDVSNSFAVPFDEDDKDDSVWFLDHDYLENMYGMFKKVNARERIVGWYHTGPKLHKNDIAINELMKRYCPNSVLVIIDVKPKDLGLPTEAYISVEEVHDDGTPTSKTFEHVTSEIGAEEAEEVGVEHLLRDIKDTTVGTLSQRITNQVHGLKGLNSKLLDIRSYLEKVATGKLPINHQIIYQLQDVFNLLPDVSLQEFVKAFYLKTNDQMVVVYLASLIRSVVALHNLINNKIANRDAEKKEGQEKEESKKDRKEDKEKDKDKEKSDVKKEEKKEKK>sp|O60895|RAMP2_HUMAN Receptor activity-modifying protein 2 OS=Homosapiens OX=9606 GN=RAMP2 PE=1 SV=2MASLRVERAGGPRLPRTRVGRPAALRLLLLLGAVLNPHEALAQPLPTTGTPGSEGGTVKNYETAVQFCWNHYKDQMDPIEKDWCDWAMISRPYSTLRDCLEHFAELFDLGFPNPLAERIIFETHQIHFANCSLVQPTFSDPPEDVLLAMIIAPICLIPFLITLVVWRSKDSEAQA>sp|O60895-2|RAMP2_HUMAN Isoform 2 of Receptor activity-modifying protein2 OS=Homo sapiens OX=9606 GN=RAMP2MASLRVERAGGPRLPRTRVGRPAALRLLLLLGAVLNPHEALAQPLPTTGTPGSEASVPTGGTVKNYETAVQFCWNHYKDQMDPIEKDWCDWAMISRPYSTLRDCLEHFAELFDLGFPNPLAERIIFETHQIHFANCSLVQPTFSDPPEDVLLAMIIAPICLIPFLITLVVWRSKDSEAQA>sp|Q9NXS2|QPCTL_HUMAN Glutaminyl-peptide cyclotransferase-like proteinOS=Homo sapiens OX=9606 GN=QPCTL PE=1 SV=2MRSGGRGRPRLRLGERGLMEPLLPPKRRLLPRVRLLPLLLALAVGSAFYTIWSGWHRRTEELPLGRELRVPLIGSLPEARLRRVVGQLDPQRLWSTYLRPLLVVRTPGSPGNLQVRKFLEATLRSLTAGWHVELDPFTASTPLGPVDFGNVVATLDPRAARHLTLACHYDSKLFPPGSTPFVGATDSAVPCALLLELAQALDLELSRAKKQAAPVTLQLLFLDGEEALKEWGPKDSLYGSRHLAQLMESIPHSPGPTRIQAIELFMLLDLLGAPNPTFYSHFPRTVRWFHRLRSIEKRLHRLNLLQSHPQEVMYFQPGEPFGSVEDDHIPFLRRGVPVLHLISTPFPAVWHTPADTEVNLHPPTVHNLCRILAVFLAEYLGL>sp|Q9NXS2-3|QPCTL_HUMAN Isoform 2 of Glutaminyl-peptidecyclotransferase-like protein OS=Homo sapiens OX=9606 GN=QPCTLMRSGGRGRPRLRLGERGLMEPLLPPKRRLLPRVRLLPLLLALAVGSAFYTIWSGWHRRTEELPLGRELRVPLIGSLPEARLRRVVGQLDPQRLWSTYLRPLLVVRTPGSPGNLQVRKAAPVTLQLLFLDGEEALKEWGPKDSLYGSRHLAQLMESIPHSPGPTRIQAIELFMLLDLLGAPNPTFYSHFPRTVRWFHRLRSIEKRLHRLNLLQSHPQEVMYFQPGEPFGSVEDDHIPFLRRGVPVLHLISTPFPAVWHTPADTEVNLHPPTVHNLCRILAVFLAEYLGL>sp|Q2TAL8|QRIC1_HUMAN Transcriptional regulator QRICH1 OS=Homo sapiensOX=9606 GN=QRICH1 PE=1 SV=1MNNSLENTISFEEYIRVKARSVPQHRMKEFLDSLASKGPEALQEFQQTATTTMVYQQGGNCIYTDSTEVAGSLLELACPVTTSVQPQTQQEQQIQVQQPQQVQVQVQVQQSPQQVSAQLSPQLTVHQPTEQPIQVQVQIQGQAPQSAAPSIQTPSLQSPSPSQLQAAQIQVQHVQAAQQIQAAEIPEEHIPHQQIQAQLVAGQSLAGGQQIQIQTVGALSPPPSQQGSPREGERRVGTASVLQPVKKRKVDMPITVSYAISGQPVATVLAIPQGQQQSYVSLRPDLLTVDSAHLYSATGTITSPTGETWTIPVYSAQPRGDPQQQSITHIAIPQEAYNAVHVSGSPTALAAVKLEDDKEKMVGTTSVVKNSHEEVVQTLANSLFPAQFMNGNIHIPVAVQAVAGTYQNTAQTVHIWDPQQQPQQQTPQEQTPPPQQQQQQLQVTCSAQTVQVAEVEPQSQPQPSPELLLPNSLKPEEGLEVWKNWAQTKNAELEKDAQNRLAPIGRRQLLRFQEDLISSAVAELNYGLCLMTREARNGEGEPYDPDVLYYIFLCIQKYLFENGRVDDIFSDLYYVRFTEWLHEVLKDVQPRVTPLGYVLPSHVTEEMLWECKQLGAHSPSTLLTTLMFFNTKYFLLKTVDQHMKLAFSKVLRQTKKNPSNPKDKSTSIRYLKALGIHQTGQKVTDDMYAEQTENPENPLRCPIKLYDFYLFKCPQSVKGRNDTFYLTPEPVVAPNSPIWYSVQPISREQMGQMLTRILVIREIQEAIAVANASTMH>sp|A1KZ92|PXDNL_HUMAN Peroxidasin-like protein OS=Homo sapiens OX=9606GN=PXDNL PE=1 SV=3MEPRLFCWTTLFLLAGWCLPGLPCPSRCLCFKSTVRCMHLMLDHIPQVPQQTTVLDLRFNRIREIPGSAFKKLKNLNTLLLNNNHIRKISRNAFEGLENLLYLYLYKNEIHALDKQTFKGLISLEHLYIHFNQLEMLQPETFGDLLRLERLFLHNNKLSKIPAGSFSNLDSLKRLRLDSNALVCDCDLMWLGELLQGFAQHGHTQAAATCEYPRRLHGRAVASVTVEEFNCQSPRITFEPQDVEVPSGNTVYFTCRAEGNPKPEIIWIHNNHSLDLEDDTRLNVFDDGTLMIRNTRESDQGVYQCMARNSAGEAKTQSAMLRYSSLPAKPSFVIQPQDTEVLIGTSTTLECMATGHPHPLITWTRDNGLELDGSRHVATSSGLYLQNITQRDHGRFTCHANNSHGTVQAAANIIVQAPPQFTVTPKDQVVLEEHAVEWLCEADGNPPPVIVWTKTGGQLPVEGQHTVLSSGTLRIDRAAQHDQGQYECQAVSSLGVKKVSVQLTVKPKALAVFTQLPQDTSVEVGKNINISCHAQGEPQPIITWNKEGVQITESGKFHVDDEGTLTIYDAGFPDQGRYECVARNSFGLAVTNMFLTVTAIQGRQAGDDFVESSILDAVQRVDSAINSTRRHLFSQKPHTSSDLLAQFHYPRDPLIVEMARAGEIFEHTLQLIRERVKQGLTVDLEGKEFRYNDLVSPRSLSLIANLSGCTARRPLPNCSNRCFHAKYRAHDGTCNNLQQPTWGAALTAFARLLQPAYRDGIRAPRGLGLPVGSRQPLPPPRLVATVWARAAAVTPDHSYTRMLMHWGWFLEHDLDHTVPALSTARFSDGRPCSSVCTNDPPCFPMNTRHADPRGTHAPCMLFARSSPACASGRPSATVDSVYAREQINQQTAYIDGSNVYGSSERESQALRDPSVPRGLLKTGFPWPPSGKPLLPFSTGPPTECARQEQESPCFLAGDHRANEHLALAAMHTLWFREHNRMATELSALNPHWEGNTVYQEARKIVGAELQHITYSHWLPKVLGDPGTRMLRGYRGYNPNVNAGIINSFATAAFRFGHTLINPILYRLNATLGEISEGHLPFHKALFSPSRIIKEGGIDPVLRGLFGVAAKWRAPSYLLSPELTQRLFSAAYSAAVDSAATIIQRGRDHGIPPYVDFRVFCNLTSVKNFEDLQNEIKDSEIRQKLRKLYGSPGDIDLWPALMVEDLIPGTRVGPTLMCLFVTQFQRLRDGDRFWYENPGVFTPAQLTQLKQASLSRVLCDNGDSIQQVQADVFVKAEYPQDYLNCSEIPKVDLRVWQDCCADCRSRGQFRAVTQESQKKRSAQYSYPVDKDMELSHLRSRQQDKIYVGEDARNVTVLAKTKFSQDFSTFAAEIQETITALREQINKLEARLRQAGCTDVRGVPRKAEERWMKEDCTHCICESGQVTCVVEICPPAPCPSPELVKGTCCPVCRDRGMPSDSPEKR>sp|A1KZ92-2|PXDNL_HUMAN Isoform 2 of Peroxidasin-like protein OS=Homosapiens OX=9606 GN=PXDNLMEPRLFCWTTLFLLAGWCLPGLPCPSRCLCFKSTVRCMHLMLDHIPQVPQQTTVLDLRFNRIREIPGSAFKKLKNLNTLLLNNNHIRKISRNAFEGLENLLYLYLYKNEIHALDKQTFKGLISLEHLYIHFNQLEMLQPETFGDLLRLERLFLHNNKLSKIPAGSFSNLDSLKRLRLDSNALVCDCDLMWLGELLQGFAQHGHTQAAATCEYPRRLHGRAVASVTVEEFNCQSPRITFEPQDVEVPSGNTVYFTCRAEGNPKPEIIWIHNNHSLDLEDDTRLNVFDDGTLMIRNTRESDQGVYQCMARNSAGEAKTQSAMLRYSSLPAKPSFVIQPQDTEVLIGTSTTLECMATGHPHPLITWTRDNGLELDGSRHVATSSGLYLQNITQRDHGRFTCHANNSHGTVQAAANIIVQAPPQFTVTPKDQVVLEEHAVEWLCEADGNPPPVIVWTKTGGQLPVEGQHTVLSSGTLRIDRAAQHDQGQYECQAVSSLGVKKVSVQLTVKPKALAVFTQLPQDTSVEVGKNINISCHAQGEPQPIITWNKEGVQITESGKFHVDDEGTLTIYDAGFPDQGRYECVARNSFGLAVTNMFLTVTAIQGRQAGDDFVESSILDAVQRVDSAINSTRRHLFSQKPHTSSDLLAQFHYPRDPLIVEMARAGEIFEHTLQLIRERVKQGLTVDLEGKEFRYNDLVSPRSLSLIANLSGCTARRPLPNCSNRCFHAKYRAHDGTCNNLQQPTWGAALTAFARLLQPAYRDGIRAPRGLGLPVGSRQPLPPPRLVATVWARAAAVTPDHSYTRMLMHWGWFLEHDLDHTVPALSTARFSDGRPCSSVCTNDPPCFPMNTRHADPRGTHAPCMLFARSSPACASGRPSATVDSVYAREQINQQTAYIDGSNVYGSSERESQALRDPSVPRGLLKTGFPWPPSGKPLLPFSTGPPTECARQEQESPCFLAGDHRANEHLALAAMHTLWFREHNRMATELSALNPHWEGNTVYQEARKIVGAELQHITYSHWLPKVLGDPGTRMLRGYRGYNPNVNAGIINSFATAAFRFGHTLINPILYRLNATLGEISEGHLPFHKALFSPSRIIKEGGIDPVLRGLFGVAAKWRAPSYLLSPELTQRLFSAAYSAAVDSAATIIQRGRDHGIPPYVDFRVFCNLTSVKNFEDLQNEIKDSEIRQKLRKLYGSPGDIDLWPALMVEDLIPGTRVGPTLMCLFVTQFQRLRDGDRFWYENPGVFTPAQLTQLKQASLSRVLCDNGDSIQQVQADVFVKAEYPQDYLNCSEIPKVDLRVWQDCCADKQAGGTPEAGRVYRC>sp|A1KZ92-3|PXDNL_HUMAN Isoform PMR1 of Peroxidasin-like protein OS=Homosapiens OX=9606 GN=PXDNLMLMHWGWFLEHDLDHTVPALSTARFSDGRPCSSVCTNDPPCFPMNTRHADPRGTHAPCMLFARSSPACASGRPSATVDSVYAREQINQQTAYIDGSNVYGSSERESQALRDPSVPRGLLKTGFPWPPSGKPLLPFSTGPPTECARQEQESPCFLAGDHRANEHLALAAMHTLWFREHNRMATELSALNPHWEGNTVYQEARKIVGAELQHITYSHWLPKVLGDPGTRMLRGYRGYNPNVNAGIINSFATAAFRFGHTLINPILYRLNATLGEISEGHLPFHKALFSPSRIIKEGGIDPVLRGLFGVAAKWRAPSYLLSPELTQRLFSAAYSAAVDSAATIIQRGRDHGIPPYVDFRVFCNLTSVKNFEDLQNEIKDSEIRQKLRKLYGSPGDIDLWPALMVEDLIPGTRVGPTLMCLFVTQFQRLRDGDRFWYENPGVFTPAQLTQLKQASLSRVLCDNGDSIQQVQADVFVKAEYPQDYLNCSEIPKVDLRVWQDCCADKQAGGTPEAGRVYRC>sp|P10276|RARA_HUMAN Retinoic acid receptor alpha OS=Homo sapiensOX=9606 GN=RARA PE=1 SV=2MASNSSSCPTPGGGHLNGYPVPPYAFFFPPMLGGLSPPGALTTLQHQLPVSGYSTPSPATIETQSSSSEEIVPSPPSPPPLPRIYKPCFVCQDKSSGYHYGVSACEGCKGFFRRSIQKNMVYTCHRDKNCIINKVTRNRCQYCRLQKCFEVGMSKESVRNDRNKKKKEVPKPECSESYTLTPEVGELIEKVRKAHQETFPALCQLGKYTTNNSSEQRVSLDIDLWDKFSELSTKCIIKTVEFAKQLPGFTTLTIADQITLLKAACLDILILRICTRYTPEQDTMTFSDGLTLNRTQMHNAGFGPLTDLVFAFANQLLPLEMDDAETGLLSAICLICGDRQDLEQPDRVDMLQEPLLEALKVYVRKRRPSRPHMFPKMLMKITDLRSISAKGAERVITLKMEIPGSMPPLIQEMLENSEGLDTLSGQPGGGGRDGGGLAPPPGSCSPSLSPSSNRSSPATHSP>sp|P10276-2|RARA_HUMAN Isoform Alpha-2 of Retinoic acid receptor alphaOS=Homo sapiens OX=9606 GN=RARAMYESVEVGGPTPNPFLVVDFYNQNRACLLPEKGLPAPGPYSTPLRTPLWNGSNHSIETQSSSSEEIVPSPPSPPPLPRIYKPCFVCQDKSSGYHYGVSACEGCKGFFRRSIQKNMVYTCHRDKNCIINKVTRNRCQYCRLQKCFEVGMSKESVRNDRNKKKKEVPKPECSESYTLTPEVGELIEKVRKAHQETFPALCQLGKYTTNNSSEQRVSLDIDLWDKFSELSTKCIIKTVEFAKQLPGFTTLTIADQITLLKAACLDILILRICTRYTPEQDTMTFSDGLTLNRTQMHNAGFGPLTDLVFAFANQLLPLEMDDAETGLLSAICLICGDRQDLEQPDRVDMLQEPLLEALKVYVRKRRPSRPHMFPKMLMKITDLRSISAKGAERVITLKMEIPGSMPPLIQEMLENSEGLDTLSGQPGGGGRDGGGLAPPPGSCSPSLSPSSNRSSPATHSP>sp|P10276-3|RARA_HUMAN Isoform Alpha-1-deltaBC of Retinoic acid receptoralpha OS=Homo sapiens OX=9606 GN=RARAMASNSSSCPTPGGGHLNGYPVPPYAFFFPPMLGGLSPPGALTTLQHQLPVSGYSTPSPATVRNDRNKKKKEVPKPECSESYTLTPEVGELIEKVRKAHQETFPALCQLGKYTTNNSSEQRVSLDIDLWDKFSELSTKCIIKTVEFAKQLPGFTTLTIADQITLLKAACLDILILRICTRYTPEQDTMTFSDGLTLNRTQMHNAGFGPLTDLVFAFANQLLPLEMDDAETGLLSAICLICGDRQDLEQPDRVDMLQEPLLEALKVYVRKRRPSRPHMFPKMLMKITDLRSISAKGAERVITLKMEIPGSMPPLIQEMLENSEGLDTLSGQPGGGGRDGGGLAPPPGSCSPSLSPSSNRSSPATHSP>sp|Q9BQ04|RBM4B_HUMAN RNA-binding protein 4B OS=Homo sapiens OX=9606GN=RBM4B PE=1 SV=1MVKLFIGNLPREATEQEIRSLFEQYGKVLECDIIKNYGFVHIEDKTAAEDAIRNLHHYKLHGVNINVEASKNKSKASTKLHVGNISPTCTNQELRAKFEEYGPVIECDIVKDYAFVHMERAEDAVEAIRGLDNTEFQGKRMHVQLSTSRLRTAPGMGDQSGCYRCGKEGHWSKECPVDRTGRVADFTEQYNEQYGAVRTPYTMGYGESMYYNDAYGALDYYKRYRVRSYEAVAAAAAASAYNYAEQTMSHLPQVQSTTVTSHLNSTSVDPYDRHLLPNSGAAATSAAMAAAAATTSSYYGRDRSPLRRAAAMLPTVGEGYGYGPESELSQASAATRNSLYDMARYEREQYVDRARYSAF>sp|Q70E73|RAPH1_HUMAN Ras-associated and pleckstrin homology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1 PE=1 SV=3MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSKARMESMNRPYTSLVPPLSPQPKIVTPYTASQPSPPLPPPPPPPPPPPPPPPPPPPPLPSQSAPSAGSAAPMFVKYSTITRLQNASQHSGALFKPPTPPVMQSQSVKPQILVPPNGVVPPPPPPPPPPTPGSAMAQLKPAPCAPSLPQFSAPPPPLKIHQVQHITQVAPPTPPPPPPIPAPLPPQAPPKPLVTIPAPTSTKTVAPVVTQAAPPTPTPPVPPAKKQPAFPASYIPPSPPTPPVPVPPPTLPKQQSFCAKPPPSPLSPVPSVVKQIASQFPPPPTPPAMESQPLKPVPANVAPQSPPAVKAKPKWQPSSIPVPSPDFPPPPPESSLVFPPPPPSPVPAPPPPPPPTASPTPDKSGSPGKKTSKTSSPGGKKPPPTPQRNSSIKSSSGAEHPEPKRPSVDSLVSKFTPPAESGSPSKETLPPPAAPPKPGKLNLSGVNLPGVLQQGCVSAKAPVLSGRGKDSVVEFPSPPSDSDFPPPPPETELPLPPIEIPAVFSGNTSPKVAVVNPQPQQWSKMSVKKAPPPTRPKRNDSTRLTQAEISEQPTMATVVPQVPTSPKSSLSVQPGFLADLNRTLQRKSITRHGSLSSRMSRAEPTATMDDMALPPPPPELLSDQQKAGYGGSHISGYATLRRGPPPAPPKRDQNTKLSRDW>sp|Q70E73-2|RAPH1_HUMAN Isoform RMO1 of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSKVTASF>sp|Q70E73-3|RAPH1_HUMAN Isoform RMO1a of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEHAISLRCSSKQAKRHIDFTEEQAELTPEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSKVTASF>sp|Q70E73-4|RAPH1_HUMAN Isoform RMO1b of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEHSYLDRETSLLLRNIAGKPSHLLTKEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSKVTASF>sp|Q70E73-5|RAPH1_HUMAN Isoform RMO1c of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSK>sp|Q70E73-6|RAPH1_HUMAN Isoform RMO1ab of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEHAISLRCSSKQAKRHIDFTEEQAELTPHSYLDRETSLLLRNIAGKPSHLLTKEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSKVTASF>sp|Q70E73-7|RAPH1_HUMAN Isoform RMO1ac of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEHAISLRCSSKQAKRHIDFTEEQAELTPEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSK>sp|Q70E73-8|RAPH1_HUMAN Isoform RMO1bc of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEHSYLDRETSLLLRNIAGKPSHLLTKEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSK>sp|Q70E73-9|RAPH1_HUMAN Isoform RMO1abc of Ras-associated and pleckstrinhomology domains-containing protein 1 OS=Homo sapiens OX=9606 GN=RAPH1MEQLSDEEIDHGAEEDSDKEDQDLDKMFGAWLGELDKLTQSLDSDKPMEPVKRSPLRQETNMANFSYRFSIYNLNEALNQGETVDLDALMADLCSIEQELSSIGSGNSKRQITETKATQKLPVSRHTLKHGTLKGLSSSSNRIAKPSHASYSLDDVTAQLEQASLSMDEAAQQSVLEDTKPLVTNQHRRTASAGTVSDAEVHSISNSSHSSITSAASSMDSLDIDKVTRPQELDLTHQGQPITEHAISLRCSSKQAKRHIDFTEEQAELTPHSYLDRETSLLLRNIAGKPSHLLTKEEQAAKLKAEKIRVALEKIKEAQVKKLVIRVHMSDDSSKTMMVDERQTVRQVLDNLMDKSHCGYSLDWSLVETVSELQMERIFEDHENLVENLLNWTRDSQNKLIFMERIEKYALFKNPQNYLLGKKETAEMADRNKEVLLEECFCGSSVTVPEIEGVLWLKDDGKKSWKKRYFLLRASGIYYVPKGKAKVSRDLVCFLQLDHVNVYYGQDYRNKYKAPTDYCLVLKHPQIQKKSQYIKYLCCDDVRTLHQWVNGIRIAKYGKQLYMNYQEALKRTESAYDWTSLSSSSIKSGSSSSSIPESQSNHSNQSDSGVSDTQPAGHVRSQSIVSSVFSEAWKRGTQLEESSK>sp|Q96IZ5|RBM41_HUMAN RNA-binding protein 41 OS=Homo sapiens OX=9606GN=RBM41 PE=1 SV=2MKRVNSCVKSDEHVLEELETEGERQLKSLLQHQLDTSVSIEECMSKKESFAPGTMYKPFGKEAAGTMTLSQFQTLHEKDQETASLRELGLNETEILIWKSHVSGEKKTKLRATPEAIQNRLQDIEERISERQRILCLPQRFAKSKQLTRREMEIEKSLFQGADRHSFLKALYYQDEPQKKNKGDPMNNLESFYQEMIMKKRLEEFQLMRGEPFASHSLVSATSVGDSGTAESPSLLQDKGKQAAQGKGPSLHVANVIDFSPEQCWTGPKKLTQPIEFVPEDEIQRNRLSEEEIRKIPMFSSYNPGEPNKVLYLKNLSPRVTERDLVSLFARFQEKKGPPIQFRMMTGRMRGQAFITFPNKEIAWQALHLVNGYKLHGKILVIEFGKNKKQRSNLQATSLISCATGSTTEISGS>sp|Q96IZ5-2|RBM41_HUMAN Isoform 2 of RNA-binding protein 41 OS=Homosapiens OX=9606 GN=RBM41MKRVNSCVKSDEHVLEELETEGERQLKSLLQHQLDTSVSIEECMSKKESFAPGTMYKPFGKEAAGTMTLSQFQTLHEKDQETASLRELGLNETEILIWKSHVSGEKKTKLRATPEAIQNRLQDIEERISERQRILCLPQRFAKSKQLTRREMEIEKSLFQGADRHSFLKALYYQDEPQKKNKGDPMNNLESFYQEMIMKKRLEEFQLMRGEPFASHSLVSATSVGDSGTAESPSLLQDKGKQAAQGKGPSLHVANVIDFSPEQCWTGPKKLTQPIEFVPEDEIQRNRLSEEEIRKIPMFSSYNPGEPNKVLYLKNLSPRVTERDLVSLFARFQEKKGPPIQFRMMTGRMRGQAFITFPNKEIAWQALHLVNGYKLHGKILVIEFGKNKKQRSNLQATSLISCATG>sp|Q96IZ5-3|RBM41_HUMAN Isoform 3 of RNA-binding protein 41 OS=Homosapiens OX=9606 GN=RBM41MKRVNSCVKSDEHVLEELETEGERQLKSLLQHQLDTSVSIEECMSKKESFAPGTMYKPFGKEAAGTMTLSQFQTLHEKDQETASLRELGLNETEILIWKSHVSGEKKTKLRATPEAIQNRLQDIEERISERQRILCLPQRFAKSKQLTRREMEIEKSLFQGADRHSFLKALYYQAYHKKTSADKYMTSMKRKIKLGTKDEPQKKNKGDPMNNLESFYQEMIMKKRLEEFQLMRGLTSFPREDFQNLSYEGTTSVLGAKWQKRTGRTSTFSILLVSLLSETVFTSSAMYGIPHLLTMSLKFSTRIGKLSFTP>sp|Q96T37|RBM15_HUMAN RNA-binding protein 15 OS=Homo sapiens OX=9606GN=RBM15 PE=1 SV=2MRTAGRDPVPRRSPRWRRAVPLCETSAGRRVTQLRGDDLRRPATMKGKERSPVKAKRSRGGEDSTSRGERSKKLGGSGGSNGSSSGKTDSGGGSRRSLHLDKSSSRGGSREYDTGGGSSSSRLHSYSSPSTKNSSGGGESRSSSRGGGGESRSSGAASSAPGGGDGAEYKTLKISELGSQLSDEAVEDGLFHEFKRFGDVSVKISHLSGSGSGDERVAFVNFRRPEDARAAKHARGRLVLYDRPLKIEAVYVSRRRSRSPLDKDTYPPSASVVGASVGGHRHPPGGGGGQRSLSPGGAALGYRDYRLQQLALGRLPPPPPPPLPRDLERERDYPFYERVRPAYSLEPRVGAGAGAAPFREVDEISPEDDQRANRTLFLGNLDITVTESDLRRAFDRFGVITEVDIKRPSRGQTSTYGFLKFENLDMSHRAKLAMSGKIIIRNPIKIGYGKATPTTRLWVGGLGPWVPLAALAREFDRFGTIRTIDYRKGDSWAYIQYESLDAAHAAWTHMRGFPLGGPDRRLRVDFADTEHRYQQQYLQPLPLTHYELVTDAFGHRAPDPLRGARDRTPPLLYRDRDRDLYPDSDWVPPPPPVRERSTRTAATSVPAYEPLDSLDRRRDGWSLDRDRGDRDLPSSRDQPRKRRLPEESGGRHLDRSPESDRPRKRHCAPSPDRSPELSSSRDRYNSDNDRSSRLLLERPSPIRDRRGSLEKSQGDKRDRKNSASAERDRKHRTTAPTEGKSPLKKEDRSDGSAPSTSTASSKLKSPSQKQDGGTAPVASASPKLCLAWQGMLLLKNSNFPSNMHLLQGDLQVASSLLVEGSTGGKVAQLKITQRLRLDQPKLDEVTRRIKVAGPNGYAILLAVPGSSDSRSSSSSAASDTATSTQRPLRNLVSYLKQKQAAGVISLPVGGNKDKENTGVLHAFPPCEFSQQFLDSPAKALAKSEEDYLVMIIVRGFGFQIGVRYENKKRENLALTLL>sp|Q96T37-2|RBM15_HUMAN Isoform 2 of RNA-binding protein 15 OS=Homosapiens OX=9606 GN=RBM15MRTAGRDPVPRRSPRWRRAVPLCETSAGRRVTQLRGDDLRRPATMKGKERSPVKAKRSRGGEDSTSRGERSKKLGGSGGSNGSSSGKTDSGGGSRRSLHLDKSSSRGGSREYDTGGGSSSSRLHSYSSPSTKNSSGGGESRSSSRGGGGESRSSGAASSAPGGGDGAEYKTLKISELGSQLSDEAVEDGLFHEFKRFGDVSVKISHLSGSGSGDERVAFVNFRRPEDARAAKHARGRLVLYDRPLKIEAVYVSRRRSRSPLDKDTYPPSASVVGASVGGHRHPPGGGGGQRSLSPGGAALGYRDYRLQQLALGRLPPPPPPPLPRDLERERDYPFYERVRPAYSLEPRVGAGAGAAPFREVDEISPEDDQRANRTLFLGNLDITVTESDLRRAFDRFGVITEVDIKRPSRGQTSTYGFLKFENLDMSHRAKLAMSGKIIIRNPIKIGYGKATPTTRLWVGGLGPWVPLAALAREFDRFGTIRTIDYRKGDSWAYIQYESLDAAHAAWTHMRGFPLGGPDRRLRVDFADTEHRYQQQYLQPLPLTHYELVTDAFGHRAPDPLRGARDRTPPLLYRDRDRDLYPDSDWVPPPPPVRERSTRTAATSVPAYEPLDSLDRRRDGWSLDRDRGDRDLPSSRDQPRKRRLPEESGGRHLDRSPESDRPRKRHCAPSPDRSPELSSSRDRYNSDNDRSSRLLLERPSPIRDRRGSLEKSQGDKRDRKNSASAERDRKHRTTAPTEGKSPLKKEDRSDGSAPSTSTASSKLKSPSQKQDGGTAPVASASPKLCLAWQGMLLLKNSNFPSNMHLLQGDLQVASSLLVEGSTGGKVAQLKITQRLRLDQPKLDEVTRRIKVAGPNGYAILLAVPGSSDSRSSSSSAASDTATSTQRPLRNLVSYLKQKQAAGVISLPVGGNKDKENTGVLHAFPPCEFSQQFLDSPAKALAKSEEDYLVMIIVRGAS>sp|Q96T37-3|RBM15_HUMAN Isoform 3 of RNA-binding protein 15 OS=Homosapiens OX=9606 GN=RBM15MRTAGRDPVPRRSPRWRRAVPLCETSAGRRVTQLRGDDLRRPATMKGKERSPVKAKRSRGGEDSTSRGERSKKLGGSGGSNGSSSGKTDSGGGSRRSLHLDKSSSRGGSREYDTGGGSSSSRLHSYSSPSTKNSSGGGESRSSSRGGGGESRSSGAASSAPGGGDGAEYKTLKISELGSQLSDEAVEDGLFHEFKRFGDVSVKISHLSGSGSGDERVAFVNFRRPEDARAAKHARGRLVLYDRPLKIEAVYVSRRRSRSPLDKDTYPPSASVVGASVGGHRHPPGGGGGQRSLSPGGAALGYRDYRLQQLALGRLPPPPPPPLPRDLERERDYPFYERVRPAYSLEPRVGAGAGAAPFREVDEISPEDDQRANRTLFLGNLDITVTESDLRRAFDRFGVITEVDIKRPSRGQTSTYGFLKFENLDMSHRAKLAMSGKIIIRNPIKIGYGKATPTTRLWVGGLGPWVPLAALAREFDRFGTIRTIDYRKGDSWAYIQYESLDAAHAAWTHMRGFPLGGPDRRLRVDFADTEHRYQQQYLQPLPLTHYELVTDAFGHRAPDPLRGARDRTPPLLYRDRDRDLYPDSDWVPPPPPVRERSTRTAATSVPAYEPLDSLDRRRDGWSLDRDRGDRDLPSSRDQPRKRRLPEESGGRHLDRSPESDRPRKRHCAPSPDRSPELSSSRDRYNSDNDRSSRLLLERPSPIRDRRGSLEKSQGDKRDRKNSASAERDRKHRTTAPTEGKSPLKKEDRSDGSAPSTSTASSKLKSPSQKQDGGTAPVASASPKLCLAWQGMLLLKNSNFPSNMHLLQGDLQVASSLLVEGSTGGKVAQLKITQRLRLDQPKLDEVTRRIKVAGPNGYAILLAVPGSSDSRSSSSSAASDTATSTQRPLRNLVSYLKQKQAAGVISLPVGGNKDKENTGVLHAFPPCEFSQQFLDSPAKALAKSEEDYLVMIIVRAKLVEQRMKIWNSKL>sp|Q96T37-4|RBM15_HUMAN Isoform 4 of RNA-binding protein 15 OS=Homosapiens OX=9606 GN=RBM15MKGKERSPVKAKRSRGGEDSTSRGERSKKLGGSGGSNGSSSGKTDSGGGSRRSLHLDKSSSRGGSREYDTGGGSSSSRLHSYSSPSTKNSSGGGESRSSSRGGGGESRSSGAASSAPGGGDGAEYKTLKISELGSQLSDEAVEDGLFHEFKRFGDVSVKISHLSGSGSGDERVAFVNFRRPEDARAAKHARGRLVLYDRPLKIEAVYVSRRRSRSPLDKDTYPPSASVVGASVGGHRHPPGGGGGQRSLSPGGAALGYRDYRLQQLALGRLPPPPPPPLPRDLERERDYPFYERVRPAYSLEPRVGAGAGAAPFREVDEISPEDDQRANRTLFLGNLDITVTESDLRRAFDRFGVITEVDIKRPSRGQTSTYGFLKFENLDMSHRAKLAMSGKIIIRNPIKIGYGKATPTTRLWVGGLGPWVPLAALAREFDRFGTIRTIDYRKGDSWAYIQYESLDAAHAAWTHMRGFPLGGPDRRLRVDFADTEHRYQQQYLQPLPLTHYELVTDAFGHRAPDPLRGARDRTPPLLYRDRDRDLYPDSDWVPPPPPVRERSTRTAATSVPAYEPLDSLDRRRDGWSLDRDRGDRDLPSSRDQPRKRRLPEESGGRHLDRSPESDRPRKRHCAPSPDRSPELSSSRDRYNSDNDRSSRLLLERPSPIRDRRGSLEKSQGDKRDRKNSASAERDRKHRTTAPTEGKSPLKKEDRSDGSAPSTSTASSKLKSPSQKQDGGTAPVASASPKLCLAWQGMLLLKNSNFPSNMHLLQGDLQVASSLLVEGSTGGKVAQLKITQRLRLDQPKLDEVTRRIKVAGPNGYAILLAVPGSSDSRSSSSSAASDTATSTQRPLRNLVSYLKQKQAAGVISLPVGGNKDKENTGVLHAFPPCEFSQQFLDSPAKALAKSEEDYLVMIIVRGAS>sp|Q6ZP01|RBM44_HUMAN RNA-binding protein 44 OS=Homo sapiens OX=9606GN=RBM44 PE=2 SV=3MMQATAVVETASGKGYHSNGGNLQKDKPSNPKKENLLLSSNGCDEVKLTFPDDDWNSSTLEQRANNKEISNIDKMDLLEPFFSVSQDTNTESTQFQSSELEDSTDYAFLNKTYSIPYSESKLKKESLTPLSSELDPEVQKKEEVFFNILEHQDKTVGLERIYNISDANYRESAEDTQKHDTDEDSQQEYHSAEEQEYISNHLSFDQTKALDISNPEVVELGNSGYEVKCASNVEDNRVNSGSGSIISFDSLDVYGQEESLHVSKFQNSVMLREYHDLKHEKYKEQETNSMYHTVFDGSVLRSNSPGNQESQSKSGSLSPQKVLKMKIYTENMKSQINEGKDFCGNKIVENKILLHLENPSTLPQDKALETLLQPCKDCQTSWTSVFDDSIISACGYYESLQNTADSALDFSAMLPKIAVRDNQAIEDNTSLKVAHSSTTKKTCFHNIGEMCTKSLTDAASCTVTINQTVDVSTDFRACFTTSRATSARPSVVSTSSNTEITMMNKKRPDEWQNEKQKSVACSTDWSYSEDCIDTQMAITKGSGKSLSVDSLKPNGNFLNKDFLELRKACGITDLKKHPEREFQLFKDTEKDLPSMCCQKIMQRAIKAELHLLNVHYQMCRRHCCDIYKLVMENREGLNMNLSSNSAKKELGSALLSLLGDLKVRYVTLKEKIHKGIPLEELPPLSLESKLLSTFSTFASRLMKKETHVFSEADAEQDNQRAHDVDVSSNLKKTLSQMSLSSDNSHATQNISPKKDDFKNGDINADFSQLKLGDKDCRHYQETSEDWSDAKESLTGVDVSGTQGNQVEQDTWNLDLTGEMKNVEPSQRDKGYLIHVGGLCPSVSEADLRSHFQKYQVSEISIYDSTNYRYASLAFTKNSDAKIAVKEMNGIEINGKSVNVWPVKILGEYTSPLSSKNGNRISSNNLEKSTNKQIHSEFSISRLPRTRPRQLGSEQDSEVFPSDQGVKKNCKQIESAKLLPDTPVQFIPPNTLNLRSFTKIIKRLAELHPEVSRDHIINALQEVRIRHKGFLNGLSITTIVEMTSSLLKNSASS>sp|Q8TC12|RDH11_HUMAN Retinol dehydrogenase 11 OS=Homo sapiens OX=9606GN=RDH11 PE=1 SV=2MVELMFPLLLLLLPFLLYMAAPQIRKMLSSGVCTSTVQLPGKVVVVTGANTGIGKETAKELAQRGARVYLACRDVEKGELVAKEIQTTTGNQQVLVRKLDLSDTKSIRAFAKGFLAEEKHLHVLINNAGVMMCPYSKTADGFEMHIGVNHLGHFLLTHLLLEKLKESAPSRIVNVSSLAHHLGRIHFHNLQGEKFYNAGLAYCHSKLANILFTQELARRLKGSGVTTYSVHPGTVQSELVRHSSFMRWMWWLFSFFIKTPQQGAQTSLHCALTEGLEILSGNHFSDCHVAWVSAQARNETIARRLWDVSCDLLGLPID>sp|Q8TC12-2|RDH11_HUMAN Isoform 2 of Retinol dehydrogenase 11 OS=Homosapiens OX=9606 GN=RDH11MVELMFPLLLLLLPFLLYMAAPQIRKMLSSGVCTSTVQLPGKVVVVTGANTGARVYLACRDVEKGELVAKEIQTTTGNQQVLVRKLDLSDTKSIRAFAKGFLAEEKHLHVLINNAGVMMCPYSKTADGFEMHIGVNHLGHFLLTHLLLEKLKESAPSRIVNVSSLAHHLGRIHFHNLQGEKFYNAGLAYCHSKLANILFTQELARRLKGSGVTTYSVHPGTVQSELVRHSSFMRWMWWLFSFFIKTPQQGAQTSLHCALTEGLEILSGNHFSDCHVAWVSAQARNETIARRLWDVSCDLLGLPID>sp|Q8TC12-3|RDH11_HUMAN Isoform 3 of Retinol dehydrogenase 11 OS=Homosapiens OX=9606 GN=RDH11MVELMFPLLLLLLPFLLYMAAPQIRKMLSSGVCTSTVQLPGKVVVVTGANTGIGKETAKELAQRGARVYLACRDVEKGELVAKEIQTTTGNQQVLVRKLDLSDTKSIRAFAKGFLAEEKHLHVLINNAGVMMCPYSKTADGFEMHIGVNHLGSGVTTYSVHPGTVQSELVRHSSFMRWMWWLFSFFIKTPQQGAQTSLHCALTEGLEILSGNHFSDCHVAWVSAQARNETIARRLWDVSCDLLGLPID>sp|Q09MP3|R51A2_HUMAN RAD51-associated protein 2 OS=Homo sapiens OX=9606GN=RAD51AP2 PE=1 SV=1MSLPQPTPRMAELRKPTSSLTPPEDPDSQPPSSKRLCLEEPGGVFKAGWRLPLVPRLSEAEKVWELSPRPFKGLLVSTNAIFDNSTDSCVEKSVSGKQICNLKCSNLKFQMSSCLQSPPSQSPDSDLRASGRSEAGLHDREAFSVHRSNSSKAGVSQLLPSTSIHDIHGIRNENRKQQFVQGRDNVHKENPFLDVTFYKETKSPFHEIKNRCKANSVVPSNKRENNISSSVLKISKSQNQPSLEIAKPSYFRDSGTISVPQFPMDLNSKMSSVYLKEIAKKKNDKKEAYVRDFTNIYWSQNRPDVKKQKLQNDKKTVEAENIFSKCYENDYPSLSSQNTCKRKDLISSNYCNCSSIQCNVRDSRKNFAILENANWEEAECLDSYVLTRLEKSQNWDCNVRHILRRNRGNCWIINNCKTKCENMKKTEEKWNWLLLLEIDLLSKEDYHCAKVINAYEEQSKLLVREILGSQTALITTVWLNGKGENDNTLQLRYNTTQKVFHVNNPFESFIIEIFYFHKSISGNKKDNSILTCCNILKCKKQIGIIGIQNLITRNMNTNIKNGILSIYLQDSVSEPLDILLKTNIAFLLNNFDSLTRIENDFELEEECIFKCMLYLKYPKNIVENHTAYLVKILTSSRLLEDNMKPMLKKRKLFRTEQVFEKSKKKLINSFSMTTQNTGFPIFETYEKIPLLMDFDDMDEISLIREITCQNMSCPQQVVNVENWAHYNSSTVKAHGNSCPQFIQNNRGYINENFYEVNMHSQDLNMERKQGHNKISNFDCEHIFEDLCNVRQQAIPASHNIIHNEETHTTSITQVLNFWNLLSEIEEKKYDLILKEEVKVTAESLTNSCQVHKDTKIEKEEKDSFFPMDDMFSVQSVSLISKEVNVEENKYVNQNYVTNTNEYESILPEREIANSKDFHRKNDSALYINHQFETGLSEGNDECFQDLAAKYLSTEALTIVKDFEMKRKFDLVLEELRMFHEISRENELLSTVETNNGQENYFGENDAEKVKMEIEKDLKMVVVNKIRASSSFHDTIAGPNMGKSHQSLFKWKTVPNNGEQEVPNESCYPSRSEEELLYSTSEKDCETPLPKRPAFLPDECKEEFNYLLRGGSHFPHGISRVRPLKTCSRPIRIGLSRKARIKQLHPYLKQMCYGNLKENF>sp|Q8N3Y7|RDHE2_HUMAN Epidermal retinol dehydrogenase 2 OS=Homo sapiensOX=9606 GN=SDR16C5 PE=1 SV=2MSFNLQSSKKLFIFLGKSLFSLLEAMIFALLPKPRKNVAGEIVLITGAGSGLGRLLALQFARLGSVLVLWDINKEGNEETCKMAREAGATRVHAYTCDCSQKEGVYRVADQVKKEVGDVSILINNAGIVTGKKFLDCPDELMEKSFDVNFKAHLWTYKAFLPAMIANDHGHLVCISSSAGLSGVNGLADYCASKFAAFGFAESVFVETFVQKQKGIKTTIVCPFFIKTGMFEGCTTGCPSLLPILEPKYAVEKIVEAILQEKMYLYMPKLLYFMMFLKSFLPLKTGLLIADYLGILHAMDGFVDQKKKL>sp|Q8N3Y7-2|RDHE2_HUMAN Isoform 2 of Epidermal retinol dehydrogenase 2OS=Homo sapiens OX=9606 GN=SDR16C5MSFNLQSSKKLFIFLGKSLFSLLEAMIFALLPKPRKNVAGEIVLITGAGSGLGRLLALQFARLGSVLVLWDINKEGNEETCKMAREAGATRVHAYTCDCSQKEGVYRVADQTYKAFLPAMIANDHGHLVCISSSAGLSGVNGLADYCASKFAAFGFAESVFVETFVQKQKGIKTTIVCPFFIKTGMFEGCTTGCPSLLPILEPKYAVEKIVEAILQEKMYLYMPKLLYFMMFLKSFLPLKTGLLIADYLGILHAMDGFVDQKKKL>sp|P51151|RAB9A_HUMAN Ras-related protein Rab-9A OS=Homo sapiens OX=9606GN=RAB9A PE=1 SV=1MAGKSSLFKVILLGDGGVGKSSLMNRYVTNKFDTQLFHTIGVEFLNKDLEVDGHFVTMQIWDTAGQERFRSLRTPFYRGSDCCLLTFSVDDSQSFQNLSNWKKEFIYYADVKEPESFPFVILGNKIDISERQVSTEEAQAWCRDNGDYPYFETSAKDATNVAAAFEEAVRRVLATEDRSDHLIQTDTVNLHRKPKPSSSCC>sp|Q96QF0|RAB3I_HUMAN Rab-3A-interacting protein OS=Homo sapiens OX=9606GN=RAB3IP PE=1 SV=1MGLKKMKGLSYDEAFAMANDPLEGFHEVNLASPTSPDLLGVYESGTQEQTTSPSVIYRPHPSALSSVPIQANALDVSELPTQPVYSSPRRLNCAEISSISFHVTDPAPCSTSGVTAGLTKLTTRKDNYNAEREFLQGATITEACDGSDDIFGLSTDSLSRLRSPSVLEVREKGYERLKEELAKAQRELKLKDEECERLSKVRDQLGQELEELTASLFEEAHKMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEADLSLYNEFRLWKDEPTMDRTCPFLDKIYQEDIFPCLTFSKSELASAVLEAVENNTLSIEPVGLQPIRFVKASAVECGGPKKCALTGQSKSCKHRIKLGDSSNYYYISPFCRYRITSVCNFFTYIRYIQQGLVKQQDVDQMFWEVMQLRKEMSLAKLGYFKEEL>sp|Q96QF0-2|RAB3I_HUMAN Isoform 1 of Rab-3A-interacting protein OS=Homosapiens OX=9606 GN=RAB3IPMANDPLEGFHEVNLASPTSPDLLGVYESGTQEQTTSPSVIYRPHPSALSSVPIQANALDVSELPTQPVYSSPRRLNCAEISSISFHVTDPAPCSTSGVTAGLTKLTTRKDNYNAEREFLQGATITEACDGSDDIFGLSTDSLSRLRSPSVLEVREKGYERLKEELAKAQRELKLKDEECERLSKVRDQLGQELEELTASLFEEAHKMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEADLSLYNEFRLWKDEPTMDRTCPFLDKIYQEDIFPCLTFSKSELASAVLEAVENNTLSIEPVGLQPIRFVKASAVECGGPKKCALTGQSKSCKHRIKLGDSSNYYYISPFCRYRITSVCNFFTYIRYIQQGLVKQQDVDQMFWEVMQLRKEMSLAKLGYFKEEL>sp|Q96QF0-3|RAB3I_HUMAN Isoform 3 of Rab-3A-interacting protein OS=Homosapiens OX=9606 GN=RAB3IPMANDPLEGFHEVNLASPTSPDLLGVYESGTQEQTTSPSVIYRPHPSALSSVPIQANALDVSELPTQPVYSSPRRLNCAEISSISFHVTDPAPCSTSGVTAGLTKLTTRKDNYNAEREFLQGATITEACDGSDDIFGLSTDSLSRLRSPSVLEVREKGYERLKEELAKAQRELKLKDEECERLSKVRDQLGQELEELTASLFEEAHKMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEADLSLYNEFRLWKDEPTMDRTCPFLDKIYQEDIFPCLTFSKSELASAVLEAVENNTLSIEPVGLQPIRFVKASAVECGGPKSLLYVTFLHTFDTFSRDS>sp|Q96QF0-4|RAB3I_HUMAN Isoform 4 of Rab-3A-interacting protein OS=Homosapiens OX=9606 GN=RAB3IPMGLKKMKGLSYDEAFAMANDPLEGFHEVNLASPTSPDLLGVYESGTQEQTTSPSVIYRPHPSALSSVPIQANALDVSELPTQPVYSSPRRLNCAEISSISFHVTDPAPCSTSGVTAGLTKLTTRKDNYNAEREFLQGATITEACDGSDDIFGLSTDSLSRLRSPSVLEVREKGYERLKEELAKAQRELKLKDEECERLSKVRDQLGQELEELTASLFEEAHKMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEADLSLYNEFRLWKDEPTMDRTCPFLDKIYQEDIFPCLTFSKSELASAVLEAVENNTLSIEPVGLQPIRFVKASAVECGGPKSLLYVTFLHTFDTFSRDS>sp|Q96QF0-5|RAB3I_HUMAN Isoform 5 of Rab-3A-interacting protein OS=Homosapiens OX=9606 GN=RAB3IPMANDPLEGFHEVNLASPTSPDLLGVYESGTQEQTTSPSVIYRPHPSALSSVPIQANALDVSELPTQPVYSSPRRLNCAEISSISFHVTDPAPCSTSGVTAGLTKLTTRKDNYNAEREFLQGATITEACDGSDDIFGLSTDSLSRLRSPSVLEVREKGYERLKEELAKAQRELKLKDEECERLSKVRDQLGQELEELTASLFEEAHKMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEKMCSHWPE>sp|Q96QF0-6|RAB3I_HUMAN Isoform 6 of Rab-3A-interacting protein OS=Homosapiens OX=9606 GN=RAB3IPMGLKKMKGLSYDEAFAMANDPLEGFHEVNLASPTSPDLLGVYESGTQEQTTSPSVIYRPHPSALSSVPIQANALDVSELPTQPVYSSPRRLNCAEISSISFHVTDPAPCSTSGVTAGLTKLTTRKDNYNAEREFLQGATITEACDGSDDIFGLSTDSLSRLRSPSVLEVREKGYERLKEELAKAQRELKLKDEECERLSKVRDQLGQELEELTASLFEEAHKMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEKMCSHWPE>sp|Q96QF0-7|RAB3I_HUMAN Isoform 7 of Rab-3A-interacting protein OS=Homosapiens OX=9606 GN=RAB3IPMANDPLEGFHEVNLASPTSPDLLGVYESGTQEQTTSPSVIYRPHPSALSSVPIQANALDVSELPTQPVYSSPRRLNCAEISSISFHVTDPAPCSTSGVTAGLTKLTTRKDNYNAEREFLQGATITEACDGSDDIFGLSTDSLSRLRSPSVLEVREKGYERLKEELAKAQRELKLKDEECERLSKVRDQLGQELEELTASLFEEAHKMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEVTHQGLSPLTLLILVSSHH>sp|Q96QF0-8|RAB3I_HUMAN Isoform 8 of Rab-3A-interacting protein OS=Homosapiens OX=9606 GN=RAB3IPMVREANIKQATAEKQLKEAQGKIDVLQAEVAALKTLVLSSSPTSPTQEPLPGGKTPFKKGHTRNKSTSSAMSGSHQDLSVIQPIVKDCKEADLSLYNEFRLWKDEPTMDRTCPFLDKIYQEDIFPCLTFSKSELASAVLEAVENNTLSIEPVGLQPIRFVKASAVECGGPKKCALTGQSKSCKHRIKLGDSSNYYYISPFCRYRITSVCNFFTYIRYIQQGLVKQQDVDQMFWEVMQLRKEMSLAKLGYFKEEL>sp|P83731|RL24_HUMAN 60S ribosomal protein L24 OS=Homo sapiens OX=9606GN=RPL24 PE=1 SV=1MKVELCSFSGYKIYPGHGRRYARTDGKVFQFLNAKCESAFLSKRNPRQINWTVLYRRKHKKGQSEEIQKKRTRRAVKFQRAITGASLADIMAKRNQKPEVRKAQREQAIRAAKEAKKAKQASKKTAMAAAKAPTKAAPKQKIVKPVKVSAPRVGGKR>sp|Q9H426|RIMS4_HUMAN Regulating synaptic membrane exocytosis protein 4OS=Homo sapiens OX=9606 GN=RIMS4 PE=1 SV=3MERSQSRLSLSASFEALAIYFPCMNSFDDEDAGDSRRLKGAIQRSTETGLAVEMPSRTLRQASHESIEDSMNSYGSEGNLNYGGVCLASDAQFSDFLGSMGPAQFVGRQTLATTPMGDVEIGLQERNGQLEVDIIQARGLTAKPGSKTLPAAYIKAYLLENGICIAKKKTKVARKSLDPLYNQVLLFPESPQGKVLQVIVWGNYGRMERKQFMGVARVLLEELDLTTLAVGWYKLFPTSSMVDPATGPLLRQASQLSLESTVGPCGERS>sp|Q9H426-2|RIMS4_HUMAN Isoform 2 of Regulating synaptic membraneexocytosis protein 4 OS=Homo sapiens OX=9606 GN=RIMS4MERSQSRLSLSASFEALAIYFPCMNSFDDEDAEGDSRRLKGAIQRSTETGLAVEMPSRTLRQASHESIEDSMNSYGSEGNLNYGGVCLASDAQFSDFLGSMGPAQFVGRQTLATTPMGDVEIGLQERNGQLEVDIIQARGLTAKPGSKTLPAAYIKAYLLENGICIAKKKTKVARKSLDPLYNQVLLFPESPQGKVLQVIVWGNYGRMERKQFMGVARVLLEELDLTTLAVGWYKLFPTSSMVDPATGPLLRQASQLSLESTVGPCGERS>sp|Q8TB24|RIN3_HUMAN Ras and Rab interactor 3 OS=Homo sapiens OX=9606GN=RIN3 PE=1 SV=4MIRHAGAPARGDPTGPVPVVGKGEEEEEEDGMRLCLPANPKNCLPHRRGISILEKLIKTCPVWLQLSLGQAEVARILHRVVAGMFLVRRDSSSKQLVLCVHFPSLNESSAEVLEYTIKEEKSILYLEGSALVFEDIFRLIAFYCVSRDLLPFTLRLPQAILEASSFTDLETIANLGLGFWDSSLNPPQERGKPAEPPRDRAPGFPLVSSLRPTAHDANCACEIELSVGNDRLWFVNPIFIEDCSSALPTDQPPLGNCPARPLPPTSDATSPTSRWAPRRPPPPPPVLPLQPCSPAQPPVLPALAPAPACPLPTSPPVPAPHVTPHAPGPPDHPNQPPMMTCERLPCPTAGLGPLREEAMKPGAASSPLQQVPAPPLPAKKNLPTAPPRRRVSERVSLEDQSPGMAAEGDQLSLPPQGTSDGPEDTPRESTEQGQDTEVKASDPHSMPELPRTAKQPPVPPPRKKRISRQLASTLPAPLENAELCTQAMALETPTPGPPREGQSPASQAGTQHPPAQATAHSQSSPEFKGSLASLSDSLGVSVMATDQDSYSTSSTEEELEQFSSPSVKKKPSMILGKARHRLSFASFSSMFHAFLSNNRKLYKKVVELAQDKGSYFGSLVQDYKVYSLEMMARQTSSTEMLQEIRTMMTQLKSYLLQSTELKALVDPALHSEEELEAIVESALYKCVLKPLKEAINSCLHQIHSKDGSLQQLKENQLVILATTTTDLGVTTSVPEVPMMEKILQKFTSMHKAYSPEKKISILLKTCKLIYDSMALGNPGKPYGADDFLPVLMYVLARSNLTEMLLNVEYMMELMDPALQLGEGSYYLTTTYGALEHIKSYDKITVTRQLSVEVQDSIHRWERRRTLNKARASRSSVQDFICVSYLEPEQQARTLASRADTQAQALCAQCAEKFAVERPQAHRLFVLVDGRCFQLADDALPHCIKGYLLRSEPKRDFHFVYRPLDGGGGGGGGSPPCLVVREPNFL>sp|Q8TB24-4|RIN3_HUMAN Isoform 4 of Ras and Rab interactor 3 OS=Homosapiens OX=9606 GN=RIN3MIRHAGAPARGDPTGPVPVVGKGEEEEEEDGMRLCLPANPKNCLPHRRGISILEKLIKTCPVWLQLSLGQAEVARILHRVVAGMFLVRRDSSSKQLVLCVHFPSLNESSAEVLEYTIKEEKSILYLEGSALVFEDIFRLIAFYCVSRDLLPFTLRLPQAILEASSFTDLETIANLGLGFWDSSLNPPQERGKPAEPPRDRAPGFPLVSSLRPTAHDANCACEIELSVGNDRLWFVNPIFIEDCSSALPTDQPPLGNCPARPLPPTSDATSPTSRWAPRRPPPPPPVLPLQPCSPAQPPVLPALAPAPACPLPTSPPVPAPHVTPHAPGPPDHPNQPPMMTCERLPCPTAGLGPLREEAMKPGAASSPLQQVPAPPLPAKKNLPTAPPRRRVSERVSLEDQSPGMAAEGDQLSLPPQGTSDGPEDTPRESTEQGQDTEVKASDPHSMPELPRTAKQPPVPPPRKKRISRQLASTLPAPLENAELCTQAMALETPTPGPPREGQSPASQAGTQHPPAQATAHSQSSPEFKGSLASLSDSLGVSVMATDQDSYSTSSTEEELEQFSSPSVKKKPSMILGKARHRLSFASFSSMFHAFLSNNRKLYKKVVELAQDKGSYFGSLVQDYKVYSLEMMARQTSSTEMLQEIRTMMTQLKSYLLQSTELKALVDPALHSEEELEAIVESALYKCVLKPLKEAINSCLHQIHSKDGSLQQLKENQLVILATTTTDLGVTTSVPEVPMMEKILQKFTSMHKAYSPEKKISILLKTCKLIYDSMALGNPGKPYGADDFLPVLMYVLARSNLTEMLLNVEYMMELMDPALQLGEGSYYLTTTYGALEHIKSYDKITVTRQLSVEVQDSIHRWERRRTLNKARASRSSVQVRPESGRGPVGPCPRHHPCCLLAKEP>sp|P18621|RL17_HUMAN 60S ribosomal protein L17 OS=Homo sapiens OX=9606GN=RPL17 PE=1 SV=3MVRYSLDPENPTKSCKSRGSNLRVHFKNTRETAQAIKGMHIRKATKYLKDVTLQKQCVPFRRYNGGVGRCAQAKQWGWTQGRWPKKSAEFLLHMLKNAESNAELKGLDVDSLVIEHIQVNKAPKMRRRTYRAHGRINPYMSSPCHIEMILTEKEQIVPKPEEEVAQKKKISQKKLKKQKLMARE>sp|P18621-2|RL17_HUMAN Isoform 2 of 60S ribosomal protein L17 OS=Homosapiens OX=9606 GN=RPL17MHIRKATKYLKDVTLQKQCVPFRRYNGGVGRCAQAKQWGWTQGRWPKKSAEFLLHMLKNAESNAELKGLDVDSLVIEHIQVNKAPKMRRRTYRAHGRINPYMSSPCHIEMILTEKEQIVPKPEEEVAQKKKISQKKLKKQKLMARE>sp|P18621-3|RL17_HUMAN Isoform 3 of 60S ribosomal protein L17 OS=Homosapiens OX=9606 GN=RPL17MVRYSLDPENPTKSCKSRGSNLRVHFKNTRETAQAIKGMHIRKATKYLKDVTLQKQCVPFRRYNGGVGRCAQAKQWGWTQGRWPKKSAEFLLHMLKNAESNAELKGLDVDSLVIEHIQVNKAPKMRRRTYRAHGRINPYMSSPCHIEMILTEKEQIVPKPEEEVAQKKKLRSSSLGKWCAFLVSSFQFCSGSTKNSWSHIYTLWFPPSLVVYGLRKQYKNPMIQTKAK>sp|P62899|RL31_HUMAN 60S ribosomal protein L31 OS=Homo sapiens OX=9606GN=RPL31 PE=1 SV=1MAPAKKGGEKKKGRSAINEVVTREYTINIHKRIHGVGFKKRAPRALKEIRKFAMKEMGTPDVRIDTRLNKAVWAKGIRNVPYRIRVRLSRKRNEDEDSPNKLYTLVTYVPVTTFKNLQTVNVDEN>sp|P62899-2|RL31_HUMAN Isoform 2 of 60S ribosomal protein L31 OS=Homosapiens OX=9606 GN=RPL31MAPAKKGGEKKKGRSAINEVVTREYTINIHKRIHGVGFKKRAPRALKEIRKFAMKEMGTPDVRIDTRLNKAVWAKGIRNVPYRIRVRLSRKRNEDEDSPNKLYTLVTYVPVTTFKISVLNSVTVAKSP>sp|P62899-3|RL31_HUMAN Isoform 3 of 60S ribosomal protein L31 OS=Homosapiens OX=9606 GN=RPL31MAPAKKGGEKKKGRSAINEVVTREYTINIHKRIHGVGFKKRAPRALKEIRKFAMKEMGTPDVRIDTRLNKAVWAKGIRNVPYRIRVRLSRKRNEDEDSPNKLYTLVTYVPVTTFKSKFSIP>sp|Q7L3T8|SYPM_HUMAN Probable proline--tRNA ligase, mitochondrialOS=Homo sapiens OX=9606 GN=PARS2 PE=1 SV=1MEGLLTRCRALPALATCSRQLSGYVPCRFHHCAPRRGRRLLLSRVFQPQNLREDRVLSLQDKSDDLTCKSQRLMLQVGLIYPASPGCYHLLPYTVRAMEKLVRVIDQEMQAIGGQKVNMPSLSPAELWQATNRWDLMGKELLRLRDRHGKEYCLGPTHEEAITALIASQKKLSYKQLPFLLYQVTRKFRDEPRPRFGLLRGREFYMKDMYTFDSSPEAAQQTYSLVCDAYCSLFNKLGLPFVKVQADVGTIGGTVSHEFQLPVDIGEDRLAICPRCSFSANMETLDLSQMNCPACQGPLTKTKGIEVGHTFYLGTKYSSIFNAQFTNVCGKPTLAEMGCYGLGVTRILAAAIEVLSTEDCVRWPSLLAPYQACLIPPKKGSKEQAASELIGQLYDHITEAVPQLHGEVLLDDRTHLTIGNRLKDANKFGYPFVIIAGKRALEDPAHFEVWCQNTGEVAFLTKDGVMDLLTPVQTV>sp|Q96BW9|TAM41_HUMAN Phosphatidate cytidylyltransferase, mitochondrialOS=Homo sapiens OX=9606 GN=TAMM41 PE=1 SV=2MALQTLQSSWVTFRKILSHFPEELSLAFVYGSGVYRQAGPSSDQKNAMLDFVFTVDDPVAWHSKNLKKNWSHYSFLKVLGPKIITSIQNNYGAGVYYNSLIMCNGRLIKYGVISTNVLIEDLLNWNNLYIAGRLQKPVKIISVNEDVTLRSALDRNLKSAVTAAFLMLPESFSEEDLFIEIAGLSYSGDFRMVVGEDKTKVLNIVKPNIAHFRELYGSILQENPQVVYKSQQGWLEIDKSPEGQFTQLMTLPKTLQQQINHIMDPPGKNRDVEETLFQVAHDPDCGDVVRLGLSAIVRPSSIRQSTKGIFTAGKSFGNPCVTYLLTEWLPHSWLQCKALYLLGACEMLSFDGHKLGYCSKVQTGITAAEPGGRTMSDHWQCCWKLYCPSEFSETLPVCRVFPSYCFIYQSYRCIGLQKQQHLCSPSSSPSLRQLLPSVLVGYFCCYCHFSKW>sp|Q96BW9-2|TAM41_HUMAN Isoform 2 of Phosphatidate cytidylyltransferase,mitochondrial OS=Homo sapiens OX=9606 GN=TAMM41MALQTLQSSWVTFRKILSHFPEELSLAFVYGSGVYRQAGPSSDQKNAMLDFVFTVDDPVAWHSKNLKKNWSHYSFLKVLGPKIITSIQNNYGAGVYYNSLIMCNGRLIKYGVISTNVLIEDLLNWNNLYIAGRLQKPVKIISVNEDVTLRSALDRNLKSAVTAAFLMLPESFSEEDLFIEIAGLSYSGDFRMVVGEDKTKVLNIVKPNIAHFRELYGSILQENPQVVYKSQQGWLEIDKSPEGQFTQLMTLPKTLQQQINHIMDPPGKNRDVEETLFQVAHDPDCGDVVRLGLKKSVIYSSLKLHKMWKGWLRKTS>sp|Q96BW9-3|TAM41_HUMAN Isoform 3 of Phosphatidate cytidylyltransferase,mitochondrial OS=Homo sapiens OX=9606 GN=TAMM41MALQTLQSSWVTFRKILSHFPEELSLAFVYGSGVYRQAGPSSDQKNAMLDFVFTVDDPVAWHSKNLKKNWSHYSFLKVLGPKIITSIQNNYGAGVYYNSLIMCNGRLIKYGVISTNVLIEDLLNWNNLYIAGRLQKPVKIISVNEDVTLRSALDRNLKSAVTAAFLMLPESFSEEDLFIEIAGLSYSGDFRMVVGEDKTKVLNIVKPNIAHFRELYGSILQENPQVVYKSQQGWLEIDKSPEGQFTQLMTLPKTLQQQINHIMDPPGKNRDVEETLFQVAHDPDCGDVVRLGLSAIVRPSSIRQSTKGIFTAGLKKSVIYSSLKLHKMWKGWLRKTS>sp|P22105|TENX_HUMAN Tenascin-X OS=Homo sapiens OX=9606 GN=TNXB PE=1SV=5MMPAQYALTSSLVLLVLLSTARAGPFSSRSNVTLPAPRPPPQPGGHTVGAGVGSPSSQLYEHTVEGGEKQVVFTHRINLPPSTGCGCPPGTEPPVLASEVQALRVRLEILEELVKGLKEQCTGGCCPASAQAGTGQTDVRTLCSLHGVFDLSRCTCSCEPGWGGPTCSDPTDAEIPPSSPPSASGSCPDDCNDQGRCVRGRCVCFPGYTGPSCGWPSCPGDCQGRGRCVQGVCVCRAGFSGPDCSQRSCPRGCSQRGRCEGGRCVCDPGYTGDDCGMRSCPRGCSQRGRCENGRCVCNPGYTGEDCGVRSCPRGCSQRGRCKDGRCVCDPGYTGEDCGTRSCPWDCGEGGRCVDGRCVCWPGYTGEDCSTRTCPRDCRGRGRCEDGECICDTGYSGDDCGVRSCPGDCNQRGRCEDGRCVCWPGYTGTDCGSRACPRDCRGRGRCENGVCVCNAGYSGEDCGVRSCPGDCRGRGRCESGRCMCWPGYTGRDCGTRACPGDCRGRGRCVDGRCVCNPGFTGEDCGSRRCPGDCRGHGLCEDGVCVCDAGYSGEDCSTRSCPGGCRGRGQCLDGRCVCEDGYSGEDCGVRQCPNDCSQHGVCQDGVCICWEGYVSEDCSIRTCPSNCHGRGRCEEGRCLCDPGYTGPTCATRMCPADCRGRGRCVQGVCLCHVGYGGEDCGQEEPPASACPGGCGPRELCRAGQCVCVEGFRGPDCAIQTCPGDCRGRGECHDGSCVCKDGYAGEDCGEEVPTIEGMRMHLLEETTVRTEWTPAPGPVDAYEIQFIPTTEGASPPFTARVPSSASAYDQRGLAPGQEYQVTVRALRGTSWGLPASKTITTMIDGPQDLRVVAVTPTTLELGWLRPQAEVDRFVVSYVSAGNQRVRLEVPPEADGTLLTDLMPGVEYVVTVTAERGRAVSYPASVRANTGSSPLGLLGTTDEPPPSGPSTTQGAQAPLLQQRPQELGELRVLGRDETGRLRVVWTAQPDTFAYFQLRMRVPEGPGAHEEVLPGDVRQALVPPPPPGTPYELSLHGVPPGGKPSDPIIYQGIMDKDEEKPGKSSGPPRLGELTVTDRTSDSLLLRWTVPEGEFDSFVIQYKDRDGQPQVVPVEGPQRSAVITSLDPGRKYKFVLYGFVGKKRHGPLVAEAKILPQSDPSPGTPPHLGNLWVTDPTPDSLHLSWTVPEGQFDTFMVQYRDRDGRPQVVPVEGPERSFVVSSLDPDHKYRFTLFGIANKKRYGPLTADGTTAPERKEEPPRPEFLEQPLLGELTVTGVTPDSLRLSWTVAQGPFDSFMVQYKDAQGQPQAVPVAGDENEVTVPGLDPDRKYKMNLYGLRGRQRVGPESVVAKTAPQEDVDETPSPTELGTEAPESPEEPLLGELTVTGSSPDSLSLFWTVPQGSFDSFTVQYKDRDGRPRAVRVGGKESEVTVGGLEPGHKYKMHLYGLHEGQRVGPVSAVGVTAPQQEETPPATESPLEPRLGELTVTDVTPNSVGLSWTVPEGQFDSFIVQYKDKDGQPQVVPVAADQREVTVYNLEPERKYKMNMYGLHDGQRMGPLSVVIVTAPLPPAPATEASKPPLEPRLGELTVTDITPDSVGLSWTVPEGEFDSFVVQYKDRDGQPQVVPVAADQREVTIPDLEPSRKYKFLLFGIQDGKRRSPVSVEAKTVARGDASPGAPPRLGELWVTDPTPDSLRLSWTVPEGQFDSFVVQFKDKDGPQVVPVEGHERSVTVTPLDAGRKYRFLLYGLLGKKRHGPLTADGTTEARSAMDDTGTKRPPKPRLGEELQVTTVTQNSVGLSWTVPEGQFDSFVVQYKDRDGQPQVVPVEGSLREVSVPGLDPAHRYKLLLYGLHHGKRVGPISAVAITAGREETETETTAPTPPAPEPHLGELTVEEATSHTLHLSWMVTEGEFDSFEIQYTDRDGQLQMVRIGGDRNDITLSGLESDHRYLVTLYGFSDGKHVGPVHVEALTVPEEEKPSEPPTATPEPPIKPRLGELTVTDATPDSLSLSWTVPEGQFDHFLVQYRNGDGQPKAVRVPGHEEGVTISGLEPDHKYKMNLYGFHGGQRMGPVSVVGVTAAEEETPSPTEPSMEAPEPAEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQVVRVGGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSAVGVTAPEEESPDAPLAKLRLGQMTVRDITSDSLSLSWTVPEGQFDHFLVQFKNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPVSAVGLTAPGKDEEMAPASTEPPTPEPPIKPRLEELTVTDATPDSLSLSWTVPEGQFDHFLVQYKNGDGQPKATRVPGHEDRVTISGLEPDNKYKMNLYGFHGGQRVGPVSAIGVTAAEEETPSPTEPSMEAPEPPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQVVRVGGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSTVGVTAPQEDVDETPSPTEPGTEAPGPPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQAVRVGGQESKVTVRGLEPGRKYKMHLYGLHEGRRLGPVSAVGVTEDEAETTQAVPTMTPEPPIKPRLGELTMTDATPDSLSLSWTVPEGQFDHFLVQYRNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPISVIGVTAAEEETPSPTELSTEAPEPPEEPLLGELTVTGSSPDSLSLSWTIPQGHFDSFTVQYKDRDGRPQVMRVRGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSTVGVTAPEDEAETTQAVPTTTPEPPNKPRLGELTVTDATPDSLSLSWMVPEGQFDHFLVQYRNGDGQPKVVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPISVIGVTAAEEETPAPTEPSTEAPEPPEEPLLGELTVTGSSPDSLSLSWTIPQGRFDSFTVQYKDRDGRPQVVRVRGEESEVTVGGLEPGCKYKMHLYGLHEGQRVGPVSAVGVTAPKDEAETTQAVPTMTPEPPIKPRLGELTVTDATPDSLSLSWMVPEGQFDHFLVQYRNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPVSAIGVTEEETPSPTEPSTEAPEAPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGQPQVVRVRGEESEVTVGGLEPGRKYKMHLYGLHEGQRVGPVSTVGITAPLPTPLPVEPRLGELAVAAVTSDSVGLSWTVAQGPFDSFLVQYRDAQGQPQAVPVSGDLRAVAVSGLDPARKYKFLLFGLQNGKRHGPVPVEARTAPDTKPSPRLGELTVTDATPDSVGLSWTVPEGEFDSFVVQYKDKDGRLQVVPVAANQREVTVQGLEPSRKYRFLLYGLSGRKRLGPISADSTTAPLEKELPPHLGELTVAEETSSSLRLSWTVAQGPFDSFVVQYRDTDGQPRAVPVAADQRTVTVEDLEPGKKYKFLLYGLLGGKRLGPVSALGMTAPEEDTPAPELAPEAPEPPEEPRLGVLTVTDTTPDSMRLSWSVAQGPFDSFVVQYEDTNGQPQALLVDGDQSKILISGLEPSTPYRFLLYGLHEGKRLGPLSAEGTTGLAPAGQTSEESRPRLSQLSVTDVTTSSLRLNWEAPPGAFDSFLLRFGVPSPSTLEPHPRPLLQRELMVPGTRHSAVLRDLRSGTLYSLTLYGLRGPHKADSIQGTARTLSPVLESPRDLQFSEIRETSAKVNWMPPPSRADSFKVSYQLADGGEPQSVQVDGQARTQKLQGLIPGARYEVTVVSVRGFEESEPLTGFLTTVPDGPTQLRALNLTEGFAVLHWKPPQNPVDTYDVQVTAPGAPPLQAETPGSAVDYPLHDLVLHTNYTATVRGLRGPNLTSPASITFTTGLEAPRDLEAKEVTPRTALLTWTEPPVRPAGYLLSFHTPGGQNQEILLPGGITSHQLLGLFPSTSYNARLQAMWGQSLLPPVSTSFTTGGLRIPFPRDCGEEMQNGAGASRTSTIFLNGNRERPLNVFCDMETDGGGWLVFQRRMDGQTDFWRDWEDYAHGFGNISGEFWLGNEALHSLTQAGDYSMRVDLRAGDEAVFAQYDSFHVDSAAEYYRLHLEGYHGTAGDSMSYHSGSVFSARDRDPNSLLISCAVSYRGAWWYRNCHYANLNGLYGSTVDHQGVSWYHWKGFEFSVPFTEMKLRPRNFRSPAGGG>sp|P22105-1|TENX_HUMAN Isoform 3 of Tenascin-X OS=Homo sapiens OX=9606GN=TNXBMMPAQYALTSSLVLLVLLSTARAGPFSSRSNVTLPAPRPPPQPGGHTVGAGVGSPSSQLYEHTVEGGEKQVVFTHRINLPPSTGCGCPPGTEPPVLASEVQALRVRLEILEELVKGLKEQCTGGCCPASAQAGTGQTDVRTLCSLHGVFDLSRCTCSCEPGWGGPTCSDPTDAEIPPSSPPSASGSCPDDCNDQGRCVRGRCVCFPGYTGPSCGWPSCPGDCQGRGRCVQGVCVCRAGFSGPDCSQRSCPRGCSQRGRCEGGRCVCDPGYTGDDCGMRSCPRGCSQRGRCENGRCVCNPGYTGEDCGVRSCPRGCSQRGRCKDGRCVCDPGYTGEDCGTRSCPWDCGEGGRCVDGRCVCWPGYTGEDCSTRTCPRDCRGRGRCEDGECICDTGYSGDDCGVRSCPGDCNQRGRCEDGRCVCWPGYTGTDCGSRACPRDCRGRGRCENGVCVCNAGYSGEDCGVRSCPGDCRGRGRCESGRCMCWPGYTGRDCGTRACPGDCRGRGRCVDGRCVCNPGFTGEDCGSRRCPGDCRGHGLCEDGVCVCDAGYSGEDCSTRSCPGGCRGRGQCLDGRCVCEDGYSGEDCGVRQCPNDCSQHGVCQDGVCICWEGYVSEDCSIRTCPSNCHGRGRCEEGRCLCDPGYTGPTCATRMCPADCRGRGRCVQGVCLCHVGYGGEDCGQEEPPASACPGGCGPRELCRAGQCVCVEGFRGPDCAIQTCPGDCRGRGECHDGSCVCKDGYAGEDCGEEVPTIEGMRMHLLEETTVRTEWTPAPGPVDAYEIQFIPTTEGASPPFTARVPSSASAYDQRGLAPGQEYQVTVRALRGTSWGLPASKTITTMIDGPQDLRVVAVTPTTLELGWLRPQAEVDRFVVSYVSAGNQRVRLEVPPEADGTLLTDLMPGVEYVVTVTAERGRAVSYPASVRANTGSSPLGLLGTTDEPPPSGPSTTQGAQAPLLQQRPQELGELRVLGRDETGRLRVVWTAQPDTFAYFQLRMRVPEGPGAHEEVLPGDVRQALVPPPPPGTPYELSLHGVPPGGKPSDPIIYQGIMDKDEEKPGKSSGPPRLGELTVTDRTSDSLLLRWTVPEGEFDSFVIQYKDRDGQPQVVPVEGPQRSAVITSLDPGRKYKFVLYGFVGKKRHGPLVAEAKILPQSDPSPGTPPHLGNLWVTDPTPDSLHLSWTVPEGQFDTFMVQYRDRDGRPQVVPVEGPERSFVVSSLDPDHKYRFTLFGIANKKRYGPLTADGTTAPERKEEPPRPEFLEQPLLGELTVTGVTPDSLRLSWTVAQGPFDSFMVQYKDAQGQPQAVPVAGDENEVTVPGLDPDRKYKMNLYGLRGRQRVGPESVVAKTAPQEDVDETPSPTELGTEAPESPEEPLLGELTVTGSSPDSLSLFWTVPQGSFDSFTVQYKDRDGRPRAVRVGGKESEVTVGGLEPGHKYKMHLYGLHEGQRVGPVSAVGVTAPQQEETPPATESPLEPRLGELTVTDVTPNSVGLSWTVPEGQFDSFIVQYKDKDGQPQVVPVAADQREVTVYNLEPERKYKMNMYGLHDGQRMGPLSVVIVTAPLPPAPATEASKPPLEPRLGELTVTDITPDSVGLSWTVPEGEFDSFVVQYKDRDGQPQVVPVAADQREVTIPDLEPSRKYKFLLFGIQDGKRRSPVSVEAKTVARGDASPGAPPRLGELWVTDPTPDSLRLSWTVPEGQFDSFVVQFKDKDGPQVVPVEGHERSVTVTPLDAGRKYRFLLYGLLGKKRHGPLTADGTTEARSAMDDTGTKRPPKPRLGEELQVTTVTQNSVGLSWTVPEGQFDSFVVQYKDRDGQPQVVPVEGSLREVSVPGLDPAHRYKLLLYGLHHGKRVGPISAVAITAGREETETETTAPTPPAPEPHLGELTVEEATSHTLHLSWMVTEGEFDSFEIQYTDRDGQLQMVRIGGDRNDITLSGLESDHRYLVTLYGFSDGKHVGPVHVEALTVPEEEKPSEPPTATPEPPIKPRLGELTVTDATPDSLSLSWTVPEGQFDHFLVQYRNGDGQPKAVRVPGHEEGVTISGLEPDHKYKMNLYGFHGGQRMGPVSVVGVTAAEEETPSPTEPSMEAPEPAEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQVVRVGGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSAVGVTAPEEESPDAPLAKLRLGQMTVRDITSDSLSLSWTVPEGQFDHFLVQFKNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPVSAVGLTAPGKDEEMAPASTEPPTPEPPIKPRLEELTVTDATPDSLSLSWTVPEGQFDHFLVQYKNGDGQPKATRVPGHEDRVTISGLEPDNKYKMNLYGFHGGQRVGPVSAIGVTAAEEETPSPTEPSMEAPEPPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQVVRVGGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSTVGVTAPQEDVDETPSPTEPGTEAPGPPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQAVRVGGQESKVTVRGLEPGRKYKMHLYGLHEGRRLGPVSAVGVTEDEAETTQAVPTMTPEPPIKPRLGELTMTDATPDSLSLSWTVPEGQFDHFLVQYRNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPISVIGVTAAEEETPSPTELSTEAPEPPEEPLLGELTVTGSSPDSLSLSWTIPQGHFDSFTVQYKDRDGRPQVMRVRGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSTVGVTEDEAETTQAVPTTTPEPPNKPRLGELTVTDATPDSLSLSWMVPEGQFDHFLVQYRNGDGQPKVVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPISVIGVTAAEEETPAPTEPSTEAPEPPEEPLLGELTVTGSSPDSLSLSWTIPQGRFDSFTVQYKDRDGRPQVVRVRGEESEVTVGGLEPGCKYKMHLYGLHEGQRVGPVSAVGVTAPKDEAETTQAVPTMTPEPPIKPRLGELTVTDATPDSLSLSWMVPEGQFDHFLVQYRNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPVSAIGVTEEETPSPTEPSTEAPEAPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGQPQVVRVRGEESEVTVGGLEPGRKYKMHLYGLHEGQRVGPVSTVGITAPLPTPLPVEPRLGELAVAAVTSDSVGLSWTVAQGPFDSFLVQYRDAQGQPQAVPVSGDLRAVAVSGLDPARKYKFLLFGLQNGKRHGPVPVEARTAPDTKPSPRLGELTVTDATPDSVGLSWTVPEGEFDSFVVQYKDKDGRLQVVPVAANQREVTVQGLEPSRKYRFLLYGLSGRKRLGPISADSTTAPLEKELPPHLGELTVAEETSSSLRLSWTVAQGPFDSFVVQYRDTDGQPRAVPVAADQRTVTVEDLEPGKKYKFLLYGLLGGKRLGPVSALGMTAPEEDTPAPELAPEAPEPPEEPRLGVLTVTDTTPDSMRLSWSVAQGPFDSFVVQYEDTNGQPQALLVDGDQSKILISGLEPSTPYRFLLYGLHEGKRLGPLSAEGTTGLAPAGQTSEESRPRLSQLSVTDVTTSSLRLNWEAPPGAFDSFLLRFGVPSPSTLEPHPRPLLQRELMVPGTRHSAVLRDLRSGTLYSLTLYGLRGPHKADSIQGTARTLSPVLESPRDLQFSEIRETSAKVNWMPPPSRADSFKVSYQLADGGEPQSVQVDGQARTQKLQGLIPGARYEVTVVSVRGFEESEPLTGFLTTVPDGPTQLRALNLTEGFAVLHWKPPQNPVDTYDVQVTAPGAPPLQAETPGSAVDYPLHDLVLHTNYTATVRGLRGPNLTSPASITFTTGLEAPRDLEAKEVTPRTALLTWTEPPVRPAGYLLSFHTPGGQNQEILLPGGITSHQLLGLFPSTSYNARLQAMWGQSLLPPVSTSFTTGGLRIPFPRDCGEEMQNGAGASRTSTIFLNGNRERPLNVFCDMETDGGGWLVFQRRMDGQTDFWRDWEDYAHGFGNISGEFWLGNEALHSLTQAGDYSMRVDLRAGDEAVFAQYDSFHVDSAAEYYRLHLEGYHGTAGDSMSYHSGSVFSARDRDPNSLLISCAVSYRGAWWYRNCHYANLNGLYGSTVDHQGVSWYHWKGFEFSVPFTEMKLRPRNFRSPAGGG>sp|P22105-2|TENX_HUMAN Isoform XB-short of Tenascin-X OS=Homo sapiensOX=9606 GN=TNXBMRLSWSVAQGPFDSFVVQYEDTNGQPQALLVDGDQSKILISGLEPSTPYRFLLYGLHEGKRLGPLSAEGTTGLAPAGQTSEESRPRLSQLSVTDVTTSSLRLNWEAPPGAFDSFLLRFGVPSPSTLEPHPRPLLQRELMVPGTRHSAVLRDLRSGTLYSLTLYGLRGPHKADSIQGTARTLSPVLESPRDLQFSEIRETSAKVNWMPPPSRADSFKVSYQLADGGEPQSVQVDGQARTQKLQGLIPGARYEVTVVSVRGFEESEPLTGFLTTVPDGPTQLRALNLTEGFAVLHWKPPQNPVDTYDVQVTAPGAPPLQAETPGSAVDYPLHDLVLHTNYTATVRGLRGPNLTSPASITFTTGLEAPRDLEAKEVTPRTALLTWTEPPVRPAGYLLSFHTPGGQNQEILLPGGITSHQLLGLFPSTSYNARLQAMWGQSLLPPVSTSFTTGGLRIPFPRDCGEEMQNGAGASRTSTIFLNGNRERPLNVFCDMETDGGGWLVFQRRMDGQTDFWRDWEDYAHGFGNISGEFWLGNEALHSLTQAGDYSMRVDLRAGDEAVFAQYDSFHVDSAAEYYRLHLEGYHGTAGDSMSYHSGSVFSARDRDPNSLLISCAVSYRGAWWYRNCHYANLNGLYGSTVDHQGVSWYHWKGFEFSVPFTEMKLRPRNFRSPAGGG>sp|P22105-4|TENX_HUMAN Isoform 5 of Tenascin-X OS=Homo sapiens OX=9606GN=TNXBMMPAQYALTSSLVLLVLLSTARAGPFSSRSNVTLPAPRPPPQPGGHTVGAGVGSPSSQLYEHTVEGGEKQVVFTHRINLPPSTGCGCPPGTEPPVLASEVQALRVRLEILEELVKGLKEQCTGGCCPASAQAGTGEQGQTDVRTLCSLHGVFDLSRCTCSCEPGWGGPTCSDPTDAEIPPSSPPSASGSCPDDCNDQGRCVRGRCVCFPGYTGPSCGWPSCPGDCQGRGRCVQGVCVCRAGFSGPDCSQRSCPRGCSQRGRCEGGRCVCDPGYTGDDCGMRSCPRGCSQRGRCENGRCVCNPGYTGEDCGVRSCPRGCSQRGRCKDGRCVCDPGYTGEDCGTRSCPWDCGEGGRCVDGRCVCWPGYTGEDCSTRTCPRDCRGRGRCEDGECICDTGYSGDDCGVRSCPGDCNQRGRCEDGRCVCWPGYTGTDCGSRACPRDCRGRGRCENGVCVCNAGYSGEDCGVRSCPGDCRGRGRCESGRCMCWPGYTGRDCGTRACPGDCRGRGRCVDGRCVCNPGFTGEDCGSRRCPGDCRGHGLCEDGVCVCDAGYSGEDCSTRSCPGGCRGRGQCLDGRCVCEDGYSGEDCGVRQCPNDCSQHGVCQDGVCICWEGYVSEDCSIRTCPSNCHGRGRCEEGRCLCDPGYTGPTCATRMCPADCRGRGRCVQGVCLCHVGYGGEDCGQEEPPASACPGGCGPRELCRAGQCVCVEGFRGPDCAIQTCPGDCRGRGECHDGSCVCKDGYAGEDCGEEVPTIEGMRMHLLEETTVRTEWTPAPGPVDAYEIQFIPTTEGASPPFTARVPSSASAYDQRGLAPGQEYQVTVRALRGTSWGLPASKTITTMIDGPQDLRVVAVTPTTLELGWLRPQAEVDRFVVSYVSAGNQRVRLEVPPEADGTLLTDLMPGVEYVVTVTAERGRAVSYPASVRANTGSSPLGLLGTTDEPPPSGPSTTQGAQAPLLQQRPQELGELRVLGRDETGRLRVVWTAQPDTFAYFQLRMRVPEGPGAHEEVLPGDVRQALVPPPPPGTPYELSLHGVPPGGKPSDPIIYQGIMDKDEEKPGKSSGPPRLGELTVTDRTSDSLLLRWTVPEGEFDSFVIQYKDRDGQPQVVPVEGPQRSAVITSLDPGRKYKFVLYGFVGKKRHGPLVAEAKILPQSDPSPGTPPHLGNLWVTDPTPDSLHLSWTVPEGQFDTFMVQYRDRDGRPQVVPVEGPERSFVVSSLDPDHKYRFTLFGIANKKRYGPLTADGTTAPERKEEPPRPEFLEQPLLGELTVTGVTPDSLRLSWTVAQGPFDSFMVQYKDAQGQPQAVPVAGDENEVTVPGLDPDRKYKMNLYGLRGRQRVGPESVVAKTAPQEDVDETPSPTELGTEAPESPEEPLLGELTVTGSSPDSLSLFWTVPQGSFDSFTVQYKDRDGRPRAVRVGGKESEVTVGGLEPGHKYKMHLYGLHEGQRVGPVSAVGVTAPQQEETPPATESPLEPRLGELTVTDVTPNSVGLSWTVPEGQFDSFIVQYKDKDGQPQVVPVAADQREVTVYNLEPERKYKMNMYGLHDGQRMGPLSVVIVTAPLPPAPATEASKPPLEPRLGELTVTDITPDSVGLSWTVPEGEFDSFVVQYKDRDGQPQVVPVAADQREVTIPDLEPSRKYKFLLFGIQDGKRRSPVSVEAKTVARGDASPGAPPRLGELWVTDPTPDSLRLSWTVPEGQFDSFVVQFKDKDGPQVVPVEGHERSVTVTPLDAGRKYRFLLYGLLGKKRHGPLTADGTTEARSAMDDTGTKRPPKPRLGEELQVTTVTQNSVGLSWTVPEGQFDSFVVQYKDRDGQPQVVPVEGSLREVSVPGLDPAHRYKLLLYGLHHGKRVGPISAVAITAGREETETETTAPTPPAPEPHLGELTVEEATSHTLHLSWMVTEGEFDSFEIQYTDRDGQLQMVRIGGDRNDITLSGLESDHRYLVTLYGFSDGKHVGPVHVEALTVPEEEKPSEPPTATPEPPIKPRLGELTVTDATPDSLSLSWTVPEGQFDHFLVQYRNGDGQPKAVRVPGHEEGVTISGLEPDHKYKMNLYGFHGGQRMGPVSVVGVTAAEEETPSPTEPSMEAPEPAEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQVVRVGGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSAVGVTAPEEESPDAPLAKLRLGQMTVRDITSDSLSLSWTVPEGQFDHFLVQFKNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPVSAVGLTAPGKDEEMAPASTEPPTPEPPIKPRLEELTVTDATPDSLSLSWTVPEGQFDHFLVQYKNGDGQPKATRVPGHEDRVTISGLEPDNKYKMNLYGFHGGQRVGPVSAIGVTAAEEETPSPTEPSMEAPEPPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQVVRVGGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSTVGVTAPQEDVDETPSPTEPGTEAPGPPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGRPQAVRVGGQESKVTVRGLEPGRKYKMHLYGLHEGRRLGPVSAVGVTEDEAETTQAVPTMTPEPPIKPRLGELTMTDATPDSLSLSWTVPEGQFDHFLVQYRNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPISVIGVTAAEEETPSPTELSTEAPEPPEEPLLGELTVTGSSPDSLSLSWTIPQGHFDSFTVQYKDRDGRPQVMRVRGEESEVTVGGLEPGRKYKMHLYGLHEGRRVGPVSTVGVTEDEAETTQAVPTTTPEPPNKPRLGELTVTDATPDSLSLSWMVPEGQFDHFLVQYRNGDGQPKVVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPISVIGVTAAEEETPAPTEPSTEAPEPPEEPLLGELTVTGSSPDSLSLSWTIPQGRFDSFTVQYKDRDGRPQVVRVRGEESEVTVGGLEPGCKYKMHLYGLHEGQRVGPVSAVGVTAPKDEAETTQAVPTMTPEPPIKPRLGELTVTDATPDSLSLSWMVPEGQFDHFLVQYRNGDGQPKAVRVPGHEDGVTISGLEPDHKYKMNLYGFHGGQRVGPVSAIGVTEEETPSPTEPSTEAPEAPEEPLLGELTVTGSSPDSLSLSWTVPQGRFDSFTVQYKDRDGQPQVVRVRGEESEVTVGGLEPGRKYKMHLYGLHEGQRVGPVSTVGITAPLPTPLPVEPRLGELAVAAVTSDSVGLSWTVAQGPFDSFLVQYRDAQGQPQAVPVSGDLRAVAVSGLDPARKYKFLLFGLQNGKRHGPVPVEARTAPDTKPSPRLGELTVTDATPDSVGLSWTVPEGEFDSFVVQYKDKDGRLQVVPVAANQREVTVQGLEPSRKYRFLLYGLSGRKRLGPISADSTTAPLEKELPPHLGELTVAEETSSSLRLSWTVAQGPFDSFVVQYRDTDGQPRAVPVAADQRTVTVEDLEPGKKYKFLLYGLLGGKRLGPVSALGMTAPEEDTPAPELAPEAPEPPEEPRLGVLTVTDTTPDSMRLSWSVAQGPFDSFVVQYEDTNGQPQALLVDGDQSKILISGLEPSTPYRFLLYGLHEGKRLGPLSAEGTTGLAPAGQTSEESRPRLSQLSVTDVTTSSLRLNWEAPPGAFDSFLLRFGVPSPSTLEPHPRPLLQRELMVPGTRHSAVLRDLRSGTLYSLTLYGLRGPHKADSIQGTARTLSPVLESPRDLQFSEIRETSAKVNWMPPPSRADSFKVSYQLADGGEPQSVQVDGQARTQKLQGLIPGARYEVTVVSVRGFEESEPLTGFLTTVPDGPTQLRALNLTEGFAVLHWKPPQNPVDTYDVQVTAPGAPPLQAETPGSAVDYPLHDLVLHTNYTATVRGLRGPNLTSPASITFTTGLEAPRDLEAKEVTPRTALLTWTEPPVRPAGYLLSFHTPGGQNQEILLPGGITSHQLLGLFPSTSYNARLQAMWGQSLLPPVSTSFTTGGLRIPFPRDCGEEMQNGAGASRTSTIFLNGNRERPLNVFCDMETDGGGWLVFQRRMDGQTDFWRDWEDYAHGFGNISGEFWLGNEALHSLTQAGDYSMRVDLRAGDEAVFAQYDSFHVDSAAEYYRLHLEGYHGTAGDSMSYHSGSVFSARDRDPNSLLISCAVSYRGAWWYRNCHYANLNGLYGSTVDHQGVSWYHWKGFEFSVPFTEMKLRPRNFRSPAGGG>sp|O15455|TLR3_HUMAN Toll-like receptor 3 OS=Homo sapiens OX=9606GN=TLR3 PE=1 SV=1MRQTLPCIYFWGGLLPFGMLCASSTTKCTVSHEVADCSHLKLTQVPDDLPTNITVLNLTHNQLRRLPAANFTRYSQLTSLDVGFNTISKLEPELCQKLPMLKVLNLQHNELSQLSDKTFAFCTNLTELHLMSNSIQKIKNNPFVKQKNLITLDLSHNGLSSTKLGTQVQLENLQELLLSNNKIQALKSEELDIFANSSLKKLELSSNQIKEFSPGCFHAIGRLFGLFLNNVQLGPSLTEKLCLELANTSIRNLSLSNSQLSTTSNTTFLGLKWTNLTMLDLSYNNLNVVGNDSFAWLPQLEYFFLEYNNIQHLFSHSLHGLFNVRYLNLKRSFTKQSISLASLPKIDDFSFQWLKCLEHLNMEDNDIPGIKSNMFTGLINLKYLSLSNSFTSLRTLTNETFVSLAHSPLHILNLTKNKISKIESDAFSWLGHLEVLDLGLNEIGQELTGQEWRGLENIFEIYLSYNKYLQLTRNSFALVPSLQRLMLRRVALKNVDSSPSPFQPLRNLTILDLSNNNIANINDDMLEGLEKLEILDLQHNNLARLWKHANPGGPIYFLKGLSHLHILNLESNGFDEIPVEVFKDLFELKIIDLGLNNLNTLPASVFNNQVSLKSLNLQKNLITSVEKKVFGPAFRNLTELDMRFNPFDCTCESIAWFVNWINETHTNIPELSSHYLCNTPPHYHGFPVRLFDTSSCKDSAPFELFFMINTSILLIFIFIVLLIHFEGWRISFYWNVSVHRVLGFKEIDRQTEQFEYAAYIIHAYKDKDWVWEHFSSMEKEDQSLKFCLEERDFEAGVFELEAIVNSIKRSRKIIFVITHHLLKDPLCKRFKVHHAVQQAIEQNLDSIILVFLEEIPDYKLNHALCLRRGMFKSHCILNWPVQKERIGAFRHKLQVALGSKNSVH>sp|O15455-2|TLR3_HUMAN Isoform 2 of Toll-like receptor 3 OS=Homo sapiensOX=9606 GN=TLR3MLDLSYNNLNVVGNDSFAWLPQLEYFFLEYNNIQHLFSHSLHGLFNVRYLNLKRSFTKQSISLASLPKIDDFSFQWLKCLEHLNMEDNDIPGIKSNMFTGLINLKYLSLSNSFTSLRTLTNETFVSLAHSPLHILNLTKNKISKIESDAFSWLGHLEVLDLGLNEIGQELTGQEWRGLENIFEIYLSYNKYLQLTRNSFALVPSLQRLMLRRVALKNVDSSPSPFQPLRNLTILDLSNNNIANINDDMLEGLEKLEILDLQHNNLARLWKHANPGGPIYFLKGLSHLHILNLESNGFDEIPVEVFKDLFELKIIDLGLNNLNTLPASVFNNQVSLKSLNLQKNLITSVEKKVFGPAFRNLTELDMRFNPFDCTCESIAWFVNWINETHTNIPELSSHYLCNTPPHYHGFPVRLFDTSSCKDSAPFELFFMINTSILLIFIFIVLLIHFEGWRISFYWNVSVHRVLGFKEIDRQTEQFEYAAYIIHAYKDKDWVWEHFSSMEKEDQSLKFCLEERDFEAGVFELEAIVNSIKRSRKIIFVITHHLLKDPLCKRFKVHHAVQQAIEQNLDSIILVFLEEIPDYKLNHALCLRRGMFKSHCILNWPVQKERIGAFRHKLQVALGSKNSVH>sp|Q8NFZ5|TNIP2_HUMAN TNFAIP3-interacting protein 2 OS=Homo sapiensOX=9606 GN=TNIP2 PE=1 SV=1MSRDPGSGGWEEAPRAAAALCTLYHEAGQRLRRLQDQLAARDALIARLRARLAALEGDAAPSLVDALLEQVARFREQLRRQEGGAAEAQMRQEIERLTERLEEKEREMQQLLSQPQHEREKEVVLLRRSMAEGERARAASDVLCRSLANETHQLRRTLTATAHMCQHLAKCLDERQHAQRNVGERSPDQSEHTDGHTSVQSVIEKLQEENRLLKQKVTHVEDLNAKWQRYNASRDEYVRGLHAQLRGLQIPHEPELMRKEISRLNRQLEEKINDCAEVKQELAASRTARDAALERVQMLEQQILAYKDDFMSERADRERAQSRIQELEEKVASLLHQVSWRQDSREPDAGRIHAGSKTAKYLAADALELMVPGGWRPGTGSQQPEPPAEGGHPGAAQRGQGDLQCPHCLQCFSDEQGEELLRHVAECCQ>sp|Q8NFZ5-2|TNIP2_HUMAN Isoform 2 of TNFAIP3-interacting protein 2OS=Homo sapiens OX=9606 GN=TNIP2MQQLLSQPQHEREKEVVLLRRSMAEGERARAASDVLCRSLANETHQLRRTLTATAHMCQHLAKCLDERQHAQRNVGERSPDQSEHTDGHTSVQSVIEKLQEENRLLKQKVTHVEDLNAKWQRYNASRDEYVRGLHAQLRGLQIPHEPELMRKEISRLNRQLEEKINDCAEVKQELAASRTARDAALERVQMLEQQILAYKDDFMSERADRERAQSRIQELEEKVASLLHQVSWRQDSREPDAGRIHAGSKTAKYLAADALELMVPGGWRPGTGSQQPEPPAEGGHPGAAQRGQGDLQCPHCLQCFSDEQGEELLRHVAECCQ>sp|P50616|TOB1_HUMAN Protein Tob1 OS=Homo sapiens OX=9606 GN=TOB1 PE=1SV=1MQLEIQVALNFIISYLYNKLPRRRVNIFGEELERLLKKKYEGHWYPEKPYKGSGFRCIHIGEKVDPVIEQASKESGLDIDDVRGNLPQDLSVWIDPFEVSYQIGEKGPVKVLYVDDNNENGCELDKEIKNSFNPEAQVFMPISDPASSVSSSPSPPFGHSAAVSPTFMPRSTQPLTFTTATFAATKFGSTKMKNSGRSNKVARTSPINLGLNVNDLLKQKAISSSMHSLYGLGLGSQQQPQQQQQPAQPPPPPPPPQQQQQQKTSALSPNAKEFIFPNMQGQGSSTNGMFPGDSPLNLSPLQYSNAFDVFAAYGGLNEKSFVDGLNFSLNNMQYSNQQFQPVMAN>sp|Q7Z2V1|TNT_HUMAN Protein TNT OS=Homo sapiens OX=9606 GN=C16orf82 PE=2SV=1MSLVPGQHCSPSHTRLHLTSPITMGTEPATQNTEFSKGSLIYGVTSPQRGHSQHSEASQGPLSLDKPLQLPPIFLEGEKGESSVQNEQEGEPSLQSPSLELQSPAWPRHAGVAQEPLKVSSSYLSDTQSSESHVSSVQHPRPEEGSHASLSSGYAGDKEGSDISLVGSHRRVRLNRRLNTQAASNQTSQLGSIDPPSSLKSRLTGPAHSTKQTGGKE>sp|Q8IWR1|TRI59_HUMAN Tripartite motif-containing protein 59 OS=Homosapiens OX=9606 GN=TRIM59 PE=1 SV=1MHNFEEELTCPICYSIFEDPRVLPCSHTFCRNCLENILQASGNFYIWRPLRIPLKCPNCRSITEIAPTGIESLPVNFALRAIIEKYQQEDHPDIVTCPEHYRQPLNVYCLLDKKLVCGHCLTIGQHHGHPIDDLQSAYLKEKDTPQKLLEQLTDTHWTDLTHLIEKLKEQKSHSEKMIQGDKEAVLQYFKELNDTLEQKKKSFLTALCDVGNLINQEYTPQIERMKEIREQQLELMALTISLQEESPLKFLEKVDDVRQHVQILKQRPLPEVQPVEIYPRVSKILKEEWSRTEIGQIKNVLIPKMKISPKRMSCSWPGKDEKEVEFLKILNIVVVTLISVILMSILFFNQHIITFLSEITLIWFSEASLSVYQSLSNSLHKVKNILCHIFYLLKEFVWKIVSH>sp|Q9Y3C4|TPRKB_HUMAN EKC/KEOPS complex subunit TPRKB OS=Homo sapiensOX=9606 GN=TPRKB PE=1 SV=1MQLTHQLDLFPECRVTLLLFKDVKNAGDLRRKAMEGTIDGSLINPTVIVDPFQILVAANKAVHLYKLGKMKTRTLSTEIIFNLSPNNNISEALKKFGISANDTSILIVYIEEGEKQINQEYLISQVEGHQVSLKNLPEIMNITEVKKIYKLSSQEESIGTLLDAIICRMSTKDVL>sp|Q9Y3C4-2|TPRKB_HUMAN Isoform 2 of EKC/KEOPS complex subunit TPRKBOS=Homo sapiens OX=9606 GN=TPRKBMQLTHQLDLFPECRIVDPFQILVAANKAVHLYKLGKMKTRTLSTEIIFNLSPNNNISEALKKFGISANDTSILIVYIEEGEKQINQEYLISQVEGHQVSLKNLPEIMNITEVKKIYKLSSQEESIGTLLDAIICRMSTKDVL>sp|Q9Y3C4-3|TPRKB_HUMAN Isoform 3 of EKC/KEOPS complex subunit TPRKBOS=Homo sapiens OX=9606 GN=TPRKBMQLTHQLDLFPECRVTLLLFKDVKNAGDLRRKAMEGTIDGSLINPTVFHSCCPGWSAMARSWLTATSASRVQAIVLPQPPELLGLQIVDPFQILVAANKAVHLYKLGKMKTRTLSTEIIFNLSPNNNISEALKKFGISANDTSILIVYIEEGEKQINQEYLISQVEGHQVSLKNLPEIMNITEVKKIYKLSSQEESIGTLLDAIICRMSTKDVL>sp|Q9NP84|TNR12_HUMAN Tumor necrosis factor receptor superfamily member12A OS=Homo sapiens OX=9606 GN=TNFRSF12A PE=1 SV=1MARGSLRRLLRLLVLGLWLALLRSVAGEQAPGTAPCSRGSSWSADLDKCMDCASCRARPHSDFCLGCAAAPPAPFRLLWPILGGALSLTFVLGLLSGFLVWRRCRRREKFTTPIEETGGEGCPAVALIQ>sp|Q9NP84-2|TNR12_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 12A OS=Homo sapiens OX=9606 GN=TNFRSF12AMARGSLRRLLRLLVLGLWLALLRSVAGEQAPGAAAPPAPFRLLWPILGGALSLTFVLGLLSGFLVWRRCRRREKFTTPIEETGGEGCPAVALIQ>sp|Q8NDV7|TNR6A_HUMAN Trinucleotide repeat-containing gene 6A proteinOS=Homo sapiens OX=9606 GN=TNRC6A PE=1 SV=2MRELEAKATKDVERNLSRDLVQEEEQLMEEKKKKKDDKKKKEAAQKKATEQKIKVPEQIKPSVSQPQPANSNNGTSTATSTNNNAKRATANNQQPQQQQQQQQPQQQQPQQQPQPQPQQQQPQQQPQALPRYPREVPPRFRHQEHKQLLKRGQHFPVIAANLGSAVKVLNSQSESSALTNQQPQNNGEVQNSKNQSDINHSTSGSHYENSQRGPVSSTSDSSTNCKNAVVSDLSEKEAWPSAPGSDPELASECMDADSASSSESERNITIMASGNTGGEKDGLRNSTGLGSQNKFVVGSSSNNVGHGSSTGPWGFSHGAIISTCQVSVDAPESKSESSNNRMNAWGTVSSSSNGGLNPSTLNSASNHGAWPVLENNGLALKGPVGSGSSGINIQCSTIGQMPNNQSINSKVSGGSTHGTWGSLQETCESEVSGTQKVSFSGQPQNITTEMTGPNNTTNFMTSSLPNSGSVQNNELPSSNTGAWRVSTMNHPQMQAPSGMNGTSLSHLSNGESKSGGSYGTTWGAYGSNYSGDKCSGPNGQANGDTVNATLMQPGVNGPMGTNFQVNTNKGGGVWESGAANSQSTSWGSGNGANSGGSRRGWGTPAQNTGTNLPSVEWNKLPSNQHSNDSANGNGKTFTNGWKSTEEEDQGSATSQTNEQSSVWAKTGGTVESDGSTESTGRLEEKGTGESQSRDRRKIDQHTLLQSIVNRTDLDPRVLSNSGWGQTPIKQNTAWDTETSPRGERKTDNGTEAWGSSATQTFNSGACIDKTSPNGNDTSSVSGWGDPKPALRWGDSKGSNCQGGWEDDSAATGMVKSNQWGNCKEEKAAWNDSQKNKQGWGDGQKSSQGWSVSASDNWGETSRNNHWGEANKKSSSGGSDSDRSVSGWNELGKTSSFTWGNNINPNNSSGWDESSKPTPSQGWGDPPKSNQSLGWGDSSKPVSSPDWNKQQDIVGSWGIPPATGKPPGTGWLGGPIPAPAKEEEPTGWEEPSPESIRRKMEIDDGTSAWGDPSKYNYKNVNMWNKNVPNGNSRSDQQAQVHQLLTPASAISNKEASSGSGWGEPWGEPSTPATTVDNGTSAWGKPIDSGPSWGEPIAAASSTSTWGSSSVGPQALSKSGPKSMQDGWCGDDMPLPGNRPTGWEEEEDVEIGMWNSNSSQELNSSLNWPPYTKKMSSKGLSGKKRRRERGMMKGGNKQEEAWINPFVKQFSNISFSRDSPEENVQSNKMDLSGGMLQDKRMEIDKHSLNIGDYNRTVGKGPGSRPQISKESSMERNPYFDKDGIVADESQNMQFMSSQSMKLPPSNSALPNQALGSIAGLGMQNLNSVRQNGNPSMFGVGNTAAQPRGMQQPPAQPLSSSQPNLRAQVPPPLLSPQVPVSLLKYAPNNGGLNPLFGPQQVAMLNQLSQLNQLSQISQLQRLLAQQQRAQSQRSVPSGNRPQQDQQGRPLSVQQQMMQQSRQLDPNLLVKQQTPPSQQQPLHQPAMKSFLDNVMPHTTPELQKGPSPINAFSNFPIGLNSNLNVNMDMNSIKEPQSRLRKWTTVDSISVNTSLDQNSSKHGAISSGFRLEESPFVPYDFMNSSTSPASPPGSIGDGWPRAKSPNGSSSVNWPPEFRPGEPWKGYPNIDPETDPYVTPGSVINNLSINTVREVDHLRDRNSGSSSSLNTTLPSTSAWSSIRASNYNVPLSSTAQSTSARNSDSKLTWSPGSVTNTSLAHELWKVPLPPKNITAPSRPPPGLTGQKPPLSTWDNSPLRIGGGWGNSDARYTPGSSWGESSSGRITNWLVLKNLTPQIDGSTLRTLCMQHGPLITFHLNLPHGNALVRYSSKEEVVKAQKSLHMCVLGNTTILAEFASEEEISRFFAQSQSLTPSPGWQSLGSSQSRLGSLDCSHSFSSRTDLNHWNGAGLSGTNCGDLHGTSLWGTPHYSTSLWGPPSSSDPRGISSPSPINAFLSVDHLGGGGESM>sp|Q8NDV7-2|TNR6A_HUMAN Isoform 2 of Trinucleotide repeat-containinggene 6A protein OS=Homo sapiens OX=9606 GN=TNRC6AMDADSASSSESERNITIMASGNTGGEKDGLRNSTGLGSQNKFVVGSSSNNVGHGSSTGPWGFSHGAIISTCQVSVDAPESKSESSNNRMNAWGTVSSSSNGGLNPSTLNSASNHGAWPVLENNGLALKGPVGSGSSGINIQCSTIGQMPNNQSINSKVSGGSTHGTWGSLQETCESEVSGTQKVSFSGQPQNITTEMTGPNNTTNFMTSSLPNSGSVQNNELPSSNTGAWRVSTMNHPQMQAPSGMNGTSLSHLSNGESKSGGSYGTTWGAYGSNYSGDKCSGPNGQANGDTVNATLMQPGVNGPMGTNFQVNTNKGGGVWESGAANSQSTSWGSGNGANSGGSRRGWGTPAQNTGTNLPSVEWNKLPSNQHSNDSANGNGKTFTNGWKSTEEEDQGSATSQTNEQSSVWAKTGGTVESDGSTESTGRLEEKGTGESQSRDRRKIDQHTLLQSIVNRTDLDPRVLSNSGWGQTPIKQNTAWDTETSPRGERKTDNGTEAWGSSATQTFNSGACIDKTSPNGNDTSSVSGWGDPKPALRWGDSKGSNCQGGWEDDSAATGMVKSNQWGNCKEEKAAWNDSQKNKQGWGDGQKSSQGWSVSASDNWGETSRNNHWGEANKKSSSGGSDSDRSVSGWNELGKTSSFTWGNNINPNNSSGWDESSKPTPSQGWGDPPKSNQSLGWGDSSKPVSSPDWNKQQDIVGSWGIPPATGKPPGTGWLGGPIPAPAKEEEPTGWEEPSPESIRRKMEIDDGTSAWGDPSKYNYKNVNMWNKNVPNGNSRSDQQAQVHQLLTPASAISNKEASSGSGWGEPWGEPSTPATTVDNGTSAWGKPIDSGPSWGEPIAAASSTSTWGSSSVGPQALSKSGPKSMQDGWCGDDMPLPGNRPTGWEEEEDVEIGMWNSNSSQELNSSLNWPPYTKKMSSKGLSGKKRRRERGMMKGGNKQEEAWINPFVKQFSNISFSRDSPEENVQSNKMDLSGGMLQDKRMEIDKHSLNIGDYNRTVGKGPGSRPQISKESSMERNPYFDKDGIVADESQNMQFMSSQSMKLPPSNSALPNQALGSIAGLGMQNLNSVRQNGNPSMFGVGNTAAQPRGMQQPPAQPLSSSQPNLRAQVPPPLLSPQVPVSLLKYAPNNGGLNPLFGPQQVAMLNQLSQLNQLSQISQLQRLLAQQQRAQSQRSVPSGNRPQQDQQGRPLSVQQQMMQQSRQLDPNLLVKQQTPPSQQQPLHQPAMKSFLDNVMPHTTPELQKGPSPINAFSNFPIGLNSNLNVNMDMNSIKEPQSRLRKWTTVDSISVNTSLDQNSSKHGAISSGFRLEESPFVPYDFMNSSTSPASPPGSIGDGWPRAKSPNGSSSVNWPPEFRPGEPWKGYPNIDPETDPYVTPGSVINNLSINTVREVDHLRDRNSGSSSSLNTTLPSTSAWSSIRASNYNVPLSSTAQSTSARNSDSKLTWSPGSVTNTSLAHELWKVPLPPKNITAPSRPPPGLTGQKPPLSTWDNSPLRIGGGWGNSDARYTPGSSWGESSSGRITNWLVLKNLTPQIDGSTLRTLCMQHGPLITFHLNLPHGNALVRYSSKEEVVKAQKSLHMCVLGNTTILAEFASEEEISRFFAQSQSLTPSPGWQSLGSSQSRLGSLDCSHSFSSRTDLNHWNGAGLSGTNCGDLHGTSLWGTPHYSTSLWGPPSSSDPRGISSPSPINAFLSVDHLGGGGESM>sp|Q8NDV7-3|TNR6A_HUMAN Isoform 3 of Trinucleotide repeat-containinggene 6A protein OS=Homo sapiens OX=9606 GN=TNRC6AMLQDKRMEIDKHSLNIGDYNRTVGKGPGSRPQISKESSMERNPYFDKNGNPSMFGVGNTAAQPRGMQQPPAQPLSSSQPNLRAQVPPPLLSPQVPVSLLKYAPNNGGLNPLFGPQQVAMLNQLSQLNQLSQISQLQRLLAQQQRAQSQRSVPSGNRPQQDQQGRPLSVQQQMMQQSRQLDPNLLVKQQTPPSQQQPLHQPAMKSFLDNVMPHTTPELQKGPSPINAFSNFPIGLNSNLNVNMDMNSIKEPQSRLRKWTTVDSISVNTSLDQNSSKHGAISSGFRLEESPFVPYDFMNSSTSPASPPGSIGDGWPRAKSPNGSSSVNWPP>sp|Q8NDV7-4|TNR6A_HUMAN Isoform 4 of Trinucleotide repeat-containinggene 6A protein OS=Homo sapiens OX=9606 GN=TNRC6AMQHGPLITFHLNLPHGNALVRYSSKEEVVKAQKSLHMCVLGNTTILAEFASEEEISRFFAQSQSLTPSPGWQSLGSSQSRLGSLDCSHSFSSRTDLNHWNGAGLSGTNCGDLHGTSLWGTPHYSTSLWGPPSSSDPRGISSPSPINAFLSVDHLGGGGESM>sp|Q8NDV7-5|TNR6A_HUMAN Isoform 5 of Trinucleotide repeat-containinggene 6A protein OS=Homo sapiens OX=9606 GN=TNRC6AMAYFGGTLYWLIFSTPFLLLGLVPEQIKPSVSQPQPANSNNGTSTATSTNNNAKRATANNQQPQQQQQQQQPQQQQPQQQPQPQPQQQQPQQQPQALPRYPREVPPRFRHQEHKQLLKRGQHFPVIAANLGSAVKVLNSQSESSALTNQQPQNNGEVQNSKNQSDINHSTSGSHYENSQRGPVSSTSDSSTNCKNAVVSDLSEKEAWPSAPGSDPELASECMDADSASSSESERNITIMASGNTGGEKDGLRNSTGLGSQNKFVVGSSSNNVGHGSSTGPWGFSHGAIISTCQVSVDAPESKSESSNNRMNAWGTVSSSSNGGLNPSTLNSASNHGAWPVLENNGLALKGPVGSGSSGINIQCSTIGQMPNNQSINSKVSGGSTHGTWGSLQETCESEVSGTQKVSFSGQPQNITTEMTGPNNTTNFMTSSLPNSGSVQNNELPSSNTGAWRVSTMNHPQMQAPSGMNGTSLSHLSNGESKSGGSYGTTWGAYGSNYSGDKCSGPNGQANGDTVNATLMQPGVNGPMGTNFQVNTNKGGGVWESGAANSQSTSWGSGNGANSGGSRRGWGTPAQNTGTNLPSVEWNKLPSNQHSNDSANGNGKTFTNGWKSTEEEDQGSATSQTNEQSSVWAKTGGTVESDGSTESTGRLEEKGTGESQSRDRRKIDQHTLLQSIVNRTDLDPRVLSNSGWGQTPIKQNTAWDTETSPRGERKTDNGTEAWGSSATQTFNSGACIDKTSPNGNDTSSVSGWGDPKPALRWGDSKGSNCQGGWEDDSAATGMVKSNQWGNCKEEKAAWNDSQKNKQGWGDGQKSSQGWSVSASDNWGETSRNNHWGEANKKSSSGGSDSDRSVSGWNELGKTSSFTWGNNINPNNSSGWDESSKPTPSQGWGDPPKSNQSLGWGDSSKPVSSPDWNKQQDIVGSWGIPPATGKPPGTGWLGGPIPAPAKEEEPTGWEEPSPESIRRKMEIDDGTSAWGDPSKYNYKNVNMWNKNVPNGNSRSDQQAQVHQLLTPASAISNKEASSGSGWGEPWGEPSTPATTVDNGTSAWGKPIDSGPSWGEPIAAASSTSTWGSSSVGPQALSKSGPKSMQDGWCGDDMPLPGNRPTGWEEEEDVEIGMWNSNSSQELNSSLNWPPYTKKMSSKGLSGKKRRRERGMMKGGNKQEEAWINPFVKQFSNISFSRDSPEENVQSNKMDLSGGMLQDKRMEIDKHSLNIGDYNRTVGKGPGSRPQISKESSMERNPYFDKDGIVADESQNMQFMSSQSMKLPPSNSALPNQALGSIAGLGMQNLNSVRQNGNPSMFGVGNTAAQPRGMQQPPAQPLSSSQPNLRAQVPPPLLSPQVPVSLLKYAPNNGGLNPLFGPQQVAMLNQLSQLNQLSQISQLQRLLAQQQRAQSQRSVPSGNRPQQDQQGRPLSVQQQMMQQSRQLDPNLLVKQQTPPSQQQPLHQPAMKSFLDNVMPHTTPELQKGPSPINAFSNFPIGLNSNLNVNMDMNSIKEPQSRLRKWTTVDSISVNTSLDQNSSKHGAISSGFRLEESPFVPYDFMNSSTSPASPPGSIGDGWPRAKSPNGSSSVNWPPEFRPGEPWKGYPNIDPETDPYVTPGSVINNLSINTVREVDHLRDRNSGSSSSLNTTLPSTSAWSSIRASNYNVPLSSTAQSTSARNSDSKLTWSPGSVTNTSLAHELWKVPLPPKNITAPSRPPPGLTGQKPPLSTWDNSPLRIGGGWGNSDARYTPGSSWGESSSGRITNWLVLKNLTPQIDGSTLRTLCMQHGPLITFHLNLPHGNALVRYSSKEEVVKAQKSLHMCVLGNTTILAEFASEEEISRFFAQSQSLTPSPGWQSLGSSQSRLGSLDCSHSFSSRTDLNHWNGAGLSGTNCGDLHGTSLWGTPHYSTSLWGPPSSSDPRGISSPSPINAFLSVDHLGGGGESM>sp|Q8NDV7-6|TNR6A_HUMAN Isoform 6 of Trinucleotide repeat-containinggene 6A protein OS=Homo sapiens OX=9606 GN=TNRC6AMRELEAKATKDVERNLSRDLVQEEEQLMEEKKKKKDDKKKKEAAQKKATEQKIKVPEQIKPSVSQPQPANSNNGTSTATSTNNNAKRATANNQQPQQQQQQQQPQQQQPQQQPQPQPQQQQPQQQPQALPRYPREVPPRFRHQEHKQLLKRGQHFPVIAANLGSAVKVLNSQSESSALTNQQPQNNGEVQNSKNQSDINHSTSGSHYENSQRGPVSSTSDSSTNCKNAVVSDLSEKEAWPSAPGSDPELASECMDADSASSSESERNITIMASGNTGGEKDGLRNSTGLGSQNKFVVGSSSNNVGHGSSTGPWGFSHGAIISTCQVSVDAPESKSESSNNRMNAWGTVSSSSNGGLNPSTLNSASNHGAWPVLENNGLALKGPVGSGSSGINIQCSTIGQMPNNQSINSKVSGGSTHGTWGSLQETCESEVSGTQKVSFSGQPQNITTEMTGPNNTTNFMTSSLPNSGSVQNNELPSSNTGAWRVSTMNHPQMQAPSGMNGTSLSHLSNGESKSGGSYGTTWGAYGSNYSGDKCSGPNGQANGDTVNATLMQPGVNGPMGTNFQVNTNKGGGVWESGAANSQSTSWGSGNGANSGGSRRGWGTPAQNTGTNLPSVEWNKLPSNQHSNDSANGNGKTFTNGWKSTEEEDQGSATSQTNEQSSVWAKTGGTVESDGSTESTGRLEEKGTGESQSRDRRKIDQHTLLQSIVNRTDLDPRVLSNSGWGQTPIKQNTAWDTETSPRGERKTDNGTEAWGSSATQTFNSGACIDKTSPNGNDTSSVSGWGDPKPALRWGDSKGSNCQGGWEDDSAATGMVKSNQWGNCKEEKAAWNDSQKNKQGWGDGQKSSQGWSVSASDNWGETSRNNHWGEANKKSSSGGSDSDRSVSGWNELGKTSSFTWGNNINPNNSSGWDESSKPTPSQGWGDPPKSNQSLGWGDSSKPVSSPDWNKQQDIVGSWGIPPATGKPPGTGWLGGPIPAPAKEEEPTGWEEPSPESIRRKMEIDDGTSAWGDPSKYNYKNVNMWNKNVPNGNSRSDQQAQVHQLLTPASAISNKEASSGSGWGEPWGEPSTPATTVDNGTSAWGKPIDSGPSWGEPIAAASSTSTWGSSSVGPQALSKSGPKSMQDGWCGDDMPLPGNRPTGWEEEEDVEIGMWNSNSSQELNSSLNWPPYTKKMSSKGLSGKKRRRERGMMKGGNKQEEAWINPFVKQFSNISFSRDSPEENVQSNKMDLSGGMLQDKRMEIDKHSLNIGDYNRTVGKGPGSRPQISKESSMERNPYFDKNGNPSMFGVGNTAAQPRGMQQPPAQPLSSSQPNLRAQVPPPLLSPQVPVSLLKYAPNNGGLNPLFGPQQVAMLNQLSQLNQLSQISQLQRLLAQQQRAQSQRSVPSGNRPQQDQQGRPLSVQQQMMQQSRQLDPNLLVKQQTPPSQQQPLHQPAMKSFLDNVMPHTTPELQKGPSPINAFSNFPIGLNSNLNVNMDMNSIKEPQSRLRKWTTVDSISVNTSLDQNSSKHGAISSGFRLEESPFVPYDFMNSSTSPASPPGSIGDGWPRAKSPNGSSSVNWPPEFRPGEPWKGYPNIDPETDPYVTPGSVINNLSINTVREVDHLRDRNSGSSSSLNTTLPSTSAWSSIRASNYNVPLSSTAQSTSARNSDSKLTWSPGSVTNTSLAHELWKVPLPPKNITAPSRPPPGLTGQKPPLSTWDNSPLRIGGGWGNSDARYTPGSSWGESSSGRITNWLVLKNLTPQIDGSTLRTLCMQHGPLITFHLNLPHGNALVRYSSKEEVVKAQKSLHMCVLGNTTILAEFASEEEISRFFAQSQSLTPSPGWQSLGSSQSRLGSLDCSHSFSSRTDLNHWNGAGLSGTNCGDLHGTSLWGTPHYSTSLWGPPSSSDPRGISSPSPINAFLSVDHLGGGGESM>sp|Q96A98|TIP39_HUMAN Tuberoinfundibular peptide of 39 residues OS=Homosapiens OX=9606 GN=PTH2 PE=1 SV=1METRQVSRSPRVRLLLLLLLLLVVPWGVRTASGVALPPVGVLSLRPPGRAWADPATPRPRRSLALADDAAFRERARLLAALERRHWLNSYMHKLLVLDAP>sp|O75509|TNR21_HUMAN Tumor necrosis factor receptor superfamily member21 OS=Homo sapiens OX=9606 GN=TNFRSF21 PE=1 SV=1MGTSPSSSTALASCSRIARRATATMIAGSLLLLGFLSTTTAQPEQKASNLIGTYRHVDRATGQVLTCDKCPAGTYVSEHCTNTSLRVCSSCPVGTFTRHENGIEKCHDCSQPCPWPMIEKLPCAALTDRECTCPPGMFQSNATCAPHTVCPVGWGVRKKGTETEDVRCKQCARGTFSDVPSSVMKCKAYTDCLSQNLVVIKPGTKETDNVCGTLPSFSSSTSPSPGTAIFPRPEHMETHEVPSSTYVPKGMNSTESNSSASVRPKVLSSIQEGTVPDNTSSARGKEDVNKTLPNLQVVNHQQGPHHRHILKLLPSMEATGGEKSSTPIKGPKRGHPRQNLHKHFDINEHLPWMIVLFLLLVLVVIVVCSIRKSSRTLKKGPRQDPSAIVEKAGLKKSMTPTQNREKWIYYCNGHGIDILKLVAAQVGSQWKDIYQFLCNASEREVAAFSNGYTADHERAYAALQHWTIRGPEASLAQLISALRQHRRNDVVEKIRGLMEDTTQLETDKLALPMSPSPLSPSPIPSPNAKLENSALLTVEPSPQDKNKGFFVDESEPLLRCDSTSSGSSALSRNGSFITKEKKDTVLRQVRLDPCDLQPIFDDMLHFLNPEELRVIEEIPQAEDKLDRLFEIIGVKSQEASQTLLDSVYSHLPDLL>sp|A0A1B0GX56|TRDV1_HUMAN T cell receptor delta variable 1 OS=Homosapiens OX=9606 GN=TRDV1 PE=1 SV=1MLFSSLLCVFVAFSYSGSSVAQKVTQAQSSVSMPVRKAVTLNCLYETSWWSYYIFWYKQLPSKEMIFLIRQGSDEQNAKSGRYSVNFKKAAKSVALTISALQLEDSAKYFCALGE>sp|A2RU14|TM218_HUMAN Transmembrane protein 218 OS=Homo sapiens OX=9606GN=TMEM218 PE=1 SV=1MAGTVLGVGAGVFILALLWVAVLLLCVLLSRASGAARFSVIFLFFGAVIITSVLLLFPRAGEFPAPEVEVKIVDDFFIGRYVLLAFLSAIFLGGLFLVLIHYVLEPIYAKPLHSY>sp|Q92544|TM9S4_HUMAN Transmembrane 9 superfamily member 4 OS=Homosapiens OX=9606 GN=TM9SF4 PE=1 SV=2MATAMDWLPWSLLLFSLMCETSAFYVPGVAPINFHQNDPVEIKAVKLTSSRTQLPYEYYSLPFCQPSKITYKAENLGEVLRGDRIVNTPFQVLMNSEKKCEVLCSQSNKPVTLTVEQSRLVAERITEDYYVHLIADNLPVATRLELYSNRDSDDKKKEKDVQFEHGYRLGFTDVNKIYLHNHLSFILYYHREDMEEDQEHTYRVVRFEVIPQSIRLEDLKADEKSSCTLPEGTNSSPQEIDPTKENQLYFTYSVHWEESDIKWASRWDTYLTMSDVQIHWFSIINSVVVVFFLSGILSMIIIRTLRKDIANYNKEDDIEDTMEESGWKLVHGDVFRPPQYPMILSSLLGSGIQLFCMILIVIFVAMLGMLSPSSRGALMTTACFLFMFMGVFGGFSAGRLYRTLKGHRWKKGAFCTATLYPGVVFGICFVLNCFIWGKHSSGAVPFPTMVALLCMWFGISLPLVYLGYYFGFRKQPYDNPVRTNQIPRQIPEQRWYMNRFVGILMAGILPFGAMFIELFFIFSAIWENQFYYLFGFLFLVFIILVVSCSQISIVMVYFQLCAEDYRWWWRNFLVSGGSAFYVLVYAIFYFVNKLDIVEFIPSLLYFGYTALMVLSFWLLTGTIGFYAAYMFVRKIYAAVKID>sp|Q6F5E7|TR3N_HUMAN Putative uncharacterized protein TXNRD3NB OS=Homosapiens OX=9606 GN=TXNRD3NB PE=5 SV=1MRDLSERRLGQPELKAEQQMPLEPVRARLSVGLACCCSHTTAEASSLEHGDKVFGQGFPSPLEEIKRLLKISRALQARSVPSTQEKAKCLSGEPGQPEGKGQETYPGPGKVEGKAEPAMRKDDVCPGMKCISG>sp|Q5JTV8|TOIP1_HUMAN Torsin-1A-interacting protein 1 OS=Homo sapiensOX=9606 GN=TOR1AIP1 PE=1 SV=2MAGDGRRAEAVREGWGVYVTPRAPIREGRGRLAPQNGGSSDAPAYRTPPSRQGRREVRFSDEPPEVYGDFEPLVAKERSPVGKRTRLEEFRSDSAKEEVRESAYYLRSRQRRQPRPQETEEMKTRRTTRLQQQHSEQPPLQPSPVMTRRGLRDSHSSEEDEASSQTDLSQTISKKTVRSIQEAPVSEDLVIRLRRPPLRYPRYEATSVQQKVNFSEEGETEEDDQDSSHSSVTTVKARSRDSDESGDKTTRSSSQYIESFWQSSQSQNFTAHDKQPSVLSSGYQKTPQEWAPQTARIRTRMQNDSILKSELGNQSPSTSSRQVTGQPQNASFVKRNRWWLLPLIAALASGSFWFFSTPEVETTAVQEFQNQMNQLKNKYQGQDEKLWKRSQTFLEKHLNSSHPRSQPAILLLTAARDAEEALRCLSEQIADAYSSFRSVRAIRIDGTDKATQDSDTVKLEVDQELSNGFKNGQNAAVVHRFESFPAGSTLIFYKYCDHENAAFKDVALVLTVLLEEETLGTSLGLKEVEEKVRDFLKVKFTNSNTPNSYNHMDPDKLNGLWSRISHLVLPVQPENALKRGICL>sp|Q5JTV8-2|TOIP1_HUMAN Isoform 2 of Torsin-1A-interacting protein 1OS=Homo sapiens OX=9606 GN=TOR1AIP1MAGDGRRAEAVREGWGVYVTPRAPIREGRGRLAPQNGGSSDAPAYRTPPSRQGRREVRFSDEPPEVYGDFEPLVAKERSPVGKRTRLEEFRSDSAKEEVRESAYYLRSRQRRQPRPQETEEMKTRRTTRLQQQHSEQPPLQPSPVMTRRGLRDSHSSEEDEASSQTDLSQTISKKTVRSIQEAPAVSEDLVIRLRRPPLRYPRYEATSVQQKVNFSEEGETEEDDQDSSHSSVTTVKARSRDSDESGDKTTRSSSQYIESFWQSSQSQNFTAHDKQPSVLSSGSTLIFYKYCDHENAAFKDVALVLTVLLEEETLGTSLGLKEVEEKVRDFLKVKFTNSNTPNSYNHMDPDKLNGLWSRISHLVLPVQPENALKRGICL>sp|Q5JTV8-3|TOIP1_HUMAN Isoform 3 of Torsin-1A-interacting protein 1OS=Homo sapiens OX=9606 GN=TOR1AIP1MAGDGRRAEAVREGWGVYVTPRAPIREGRGRLAPQNGGSSDAPAYRTPPSRQGRREVRFSDEPPEVYGDFEPLVAKERSPVGKRTRLEEFRSDSAKEEVRESAYYLRSRQRRQPRPQETEEMKTRRTTRLQQQHSEQPPLQPSPVMTRRGLRDSHSSEEDEASSQTDLSQTISKKTVRSIQEAPAVSEDLVIRLRRPPLRYPRYEATSVQQKVNFSEEGETEEDDQDSSHSSVTTVKARSRDSDESGDKTTRSSSQYIESFWQSSQSQNFTAHDKQPSVLSSGYQKTPQEWAPQTARIRTRMQNDSILKSELGNQSPSTSSRQVTGQPQNASFVKRNRWWLLPLIAALASGSFWFFSTPEVETTAVQEFQNQMNQLKNKYQGQDEKLWKRSQTFLEKHLNSSHPRSQPAILLLTAARDAEEALRCLSEQIADAYSSFRSVRAIRIDGTDKATQDSDTVKLEVDQELSNGFKNGQNAAVVHRFESFPAGSTLIFYKYCDHENAAFKDVALVLTVLLEEETLGTSLGLKEVEEKVRDFLKVKFTNSNTPNSYNHMDPDKLNGLWSRISHLVLPVQPENALKRGICL>sp|Q8N609|TR1L1_HUMAN Translocating chain-associated membrane protein 1-like 1 OS=Homo sapiens OX=9606 GN=TRAM1L1 PE=1 SV=2MGLRKKSTKNPPVLSQEFILQNHADIVSCVGMFFLLGLVFEGTAEASIVFLTLQHSVAVPAAEEQATGSKSLYYYGVKDLATVFFYMLVAIIIHATIQEYVLDKINKRMQFTKAKQNKFNESGQFSVFYFFSCIWGTFILISENCLSDPTLIWKARPHSMMTFQMKFFYISQLAYWFHAFPELYFQKTKKQDIPRQLVYIGLHLFHITGAYLLYLNHLGLLLLVLHYFVELLSHMCGLFYFSDEKYQKGISLWAIVFILGRLVTLIVSVLTVGFHLAGSQNRNPDALTGNVNVLAAKIAVLSSSCTIQAYVTWNLITLWLQRWVEDSNIQASCMKKKRSRSSKKRTENGVGVETSNRVDCPPKRKEKSS>sp|Q9BVS5|TR61B_HUMAN tRNA (adenine(58)-N(1))-methyltransferase,mitochondrial OS=Homo sapiens OX=9606 GN=TRMT61B PE=1 SV=2MLMAWCRGPVLLCLRQGLGTNSFLHGLGQEPFEGARSLCCRSSPRDLRDGEREHEAAQRKAPGAESCPSLPLSISDIGTGCLSSLENLRLPTLREESSPRELEDSSGDQGRCGPTHQGSEDPSMLSQAQSATEVEERHVSPSCSTSRERPFQAGELILAETGEGETKFKKLFRLNNFGLLNSNWGAVPFGKIVGKFPGQILRSSFGKQYMLRRPALEDYVVLMKRGTAITFPKDINMILSMMDINPGDTVLEAGSGSGGMSLFLSKAVGSQGRVISFEVRKDHHDLAKKNYKHWRDSWKLSHVEEWPDNVDFIHKDISGATEDIKSLTFDAVALDMLNPHVTLPVFYPHLKHGGVCAVYVVNITQVIELLDGIRTCELALSCEKISEVIVRDWLVCLAKQKNGILAQKVESKINTDVQLDSQEKIGVKGELFQEDDHEESHSDFPYGSFPYVARPVHWQPGHTAFLVKLRKVKPQLN>sp|Q9Y2S6|TMA7_HUMAN Translation machinery-associated protein 7 OS=Homosapiens OX=9606 GN=TMA7 PE=1 SV=1MSGREGGKKKPLKQPKKQAKEMDEEDKAFKQKQKEEQKKLEELKAKAAGKGPLATGGIKKSGKK>sp|C9J1S8|TR49D_HUMAN Tripartite motif-containing protein 49D OS=Homosapiens OX=9606 GN=TRIM49D1 PE=2 SV=1MNSGISQVFQRELTCPICLNYFIDPVTIDCGHSFCRPCFYLNWQDIPILTQCFECLKTTQQRNLKTNIRLKKMASRARKASLWLFLSSEEQMCGTHRETKKIFCEVDRSLLCLLCSSSLEHRYHRHCPAEWAAEEHREKLLKKMQSLWEKVCENQRNLNVETTRISHWKDYVNVRLEAIRAEYQKMPAFHHEEEKHNLEMLKKKGKDIFHRLHLSKAKMAHRREILRGTYAELMKMCHKPDVELLQAFGDILHRSESVLLHMPQPLNLELRAGPITGLRDRLNQFRVDITLPHNEANSHIFRRGDLRSICIGCDRQNAPHITATPTSFLAWGAQTFTSGKYYWEVHVGDSWNWAFGVCNKYWKGTNQNGNIHGEEGLFSLGCVKNDIQCSLFTTSPLTLQYVPRPTNHVGLFLDCEARTVSFVDVNQSSPIHTIPNCSFSPPLRPIFCCVHL>sp|Q5SWH9|TMM69_HUMAN Transmembrane protein 69 OS=Homo sapiens OX=9606GN=TMEM69 PE=1 SV=1MLRFIQKFSQASSKILKYSFPVGLRTSRTDILSLKMSLQQNFSPCPRPWLSSSFPAYMSKTQCYHTSPCSFKKQQKQALLARPSSTITYLTDSPKPALCVTLAGLIPFVAPPLVMLMTKTYIPILAFTQMAYGASFLSFLGGIRWGFALPEGSPAKPDYLNLASSAAPLFFSWFAFLISERLSEAIVTVIMGMGVAFHLELFLLPHYPNWFKALRIVVTLLATFSFIITLVVKSSFPEKGHKRPGQV>sp|P62995|TRA2B_HUMAN Transformer-2 protein homolog beta OS=Homo sapiensOX=9606 GN=TRA2B PE=1 SV=1MSDSGEQNYGERESRSASRSGSAHGSGKSARHTPARSRSKEDSRRSRSKSRSRSESRSRSRRSSRRHYTRSRSRSRSHRRSRSRSYSRDYRRRHSHSHSPMSTRRRHVGNRANPDPNCCLGVFGLSLYTTERDLREVFSKYGPIADVSIVYDQQSRRSRGFAFVYFENVDDAKEAKERANGMELDGRRIRVDFSITKRPHTPTPGIYMGRPTYGSSRRRDYYDRGYDRGYDDRDYYSRSYRGGGGGGGGWRAAQDRDQIYRRRSPSPYYSRGGYRSRSRSRSYSPRRY>sp|P62995-2|TRA2B_HUMAN Isoform 2 of Transformer-2 protein homolog betaOS=Homo sapiens OX=9606 GN=TRA2BMSDSGEQNYGERVNVEEGKCGSRHLTSFINEYLKLRNK>sp|P62995-3|TRA2B_HUMAN Isoform 3 of Transformer-2 protein homolog betaOS=Homo sapiens OX=9606 GN=TRA2BMSTRRRHVGNRANPDPNCCLGVFGLSLYTTERDLREVFSKYGPIADVSIVYDQQSRRSRGFAFVYFENVDDAKEAKERANGMELDGRRIRVDFSITKRPHTPTPGIYMGRPTYGSSRRRDYYDRGYDRGYDDRDYYSRSYRGGGGGGGGWRAAQDRDQIYRRRSPSPYYSRGGYRSRSRSRSYSPRRY>sp|Q8N2U0|TM256_HUMAN Transmembrane protein 256 OS=Homo sapiens OX=9606GN=TMEM256 PE=3 SV=1MAGPAAAFRRLGALSGAAALGFASYGAHGAQFPDAYGKELFDKANKHHFLHSLALLGVPHCRKPLWAGLLLASGTTLFCTSFYYQALSGDPSIQTLAPAGGTLLLLGWLALAL>sp|A0A087WTH1|TM265_HUMAN Transmembrane protein 265 OS=Homo sapiensOX=9606 GN=TMEM265 PE=3 SV=1MEDEEKAVEILGNTEAAHPPSPIRCCWLRLRCLAATSIICGCSCLGVMALVFAIKAEERHKAGRSEEAVRWGARARKLILASFAVWLAVLILGPLLLWLLSYAIAQAE>sp|Q96KB5|TOPK_HUMAN Lymphokine-activated killer T-cell-originatedprotein kinase OS=Homo sapiens OX=9606 GN=PBK PE=1 SV=3MEGISNFKTPSKLSEKKKSVLCSTPTINIPASPFMQKLGFGTGVNVYLMKRSPRGLSHSPWAVKKINPICNDHYRSVYQKRLMDEAKILKSLHHPNIVGYRAFTEANDGSLCLAMEYGGEKSLNDLIEERYKASQDPFPAAIILKVALNMARGLKYLHQEKKLLHGDIKSSNVVIKGDFETIKICDVGVSLPLDENMTVTDPEACYIGTEPWKPKEAVEENGVITDKADIFAFGLTLWEMMTLSIPHINLSNDDDDEDKTFDESDFDDEAYYAALGTRPPINMEELDESYQKVIELFSVCTNEDPKDRPSAAHIVEALETDV>sp|Q96KB5-2|TOPK_HUMAN Isoform 2 of Lymphokine-activated killer T-cell-originated protein kinase OS=Homo sapiens OX=9606 GN=PBKMEGISNFKTPSKLSEKKKSVLCSTPTINIPASPFMQKLGFGTGVNVYLMKRSPRGLSHSPWAVKKINPICNDHYRSVYQKRLMDEAKILKSLHHPNIVGYRAFTEANDGSLCLAMEYGGEKSLNDLIEERYKASQDPFPAAIILKVALNMARGLKYLHQEKKLLHGDIKSSNVVIKGDFETIKICDVGVSLPLDENMTAPAFITILLVSVTDPEACYIGTEPWKPKEAVEENGVITDKADIFAFGLTLWEMMTLSIPHINLSNDDDDEDKTFDESDFDDEAYYAALGTRPPINMEELDESYQKVIELFSVCTNEDPKDRPSAAHIVEALETDV>sp|Q9NS56|TOPRS_HUMAN E3 ubiquitin-protein ligase Topors OS=Homo sapiensOX=9606 GN=TOPORS PE=1 SV=1MGSQPPLGSPLSREEGEAPPPAPASEGRRRSRRVRLRGSCRHRPSFLGCRELAASAPARPAPASSEIMASAAKEFKMDNFSPKAGTSKLQQTVPADASPDSKCPICLDRFDNVSYLDRCLHKFCFRCVQEWSKNKAECPLCKQPFDSIFHSVRAEDDFKEYVLRPSYNGSFVTPDRRFRYRTTLTRERNASVYSPSGPVNRRTTTPPDSGVLFEGLGISTRPRDVEIPQFMRQIAVRRPTTADERSLRKIQEQDIINFRRTLYRAGARVRNIEDGGRYRDISAEFFRRNPACLHRLVPWLKRELTVLFGAHGSLVNIVQHIIMSNVTRYDLESQAFVSDLRPFLLNRTEHFIHEFISFARSPFNMAAFDQHANYDCPAPSYEEGSHSDSSVITISPDEAETQELDINVATVSQAPWDDETPGPSYSSSEQVHVTMSSLLNTSDSSDEELVTGGATSQIQGVQTNDDLNNDSDDSSDNCVIVGFVKPLAERTPELVELSSDSEDLGSYEKMETVKTQEQEQSYSSGDSDVSRCSSPHSVLGKDEQINKGHCDSSTRIKSKKEEKRSTSLSSPRNLNSSVRGDRVYSPYNHRHRKRGRSRSSDSRSQSRSGHDQKNHRKHHGKKRMKSKRSRSRESSRPRGRRDKKRSRTRDSSWSRRSQTLSLSSESTSRSRSRSSDHGKRRSRSRNRDRYYLRNNYGSRYKWEYTYYSRNKDRDGYESSYRRRTLSRAHYSRQSSSPEFRVQSFSERTNARKKNNHSERKYYYYERHRSRSLSSNRSRTASTGTDRVRNEKPGGKRKYKTRHLEGTNEVAQPSREFASKAKDSHYQKSSSKLDGNYKNESDTFSDSRSSDRETKHKRRKRKTRSLSVEIVYEGKATDTTKHHKKKKKKHKKKHKKHHGDNASRSPVVITIDSDSDKDSEVKEDTECDNSGPQDPLQNEFLAPSLEPFETKDVVTIEAEFGVLDKECDIATLSNNLNNANKTVDNIPPLAASVEQTLDVREESTFVSDLENQPSNIVSLQTEPSRQLPSPRTSLMSVCLGRDCDMS>sp|Q9NS56-2|TOPRS_HUMAN Isoform 2 of E3 ubiquitin-protein ligase ToporsOS=Homo sapiens OX=9606 GN=TOPORSMIMASAAKEFKMDNFSPKAGTSKLQQTVPADASPDSKCPICLDRFDNVSYLDRCLHKFCFRCVQEWSKNKAECPLCKQPFDSIFHSVRAEDDFKEYVLRPSYNGSFVTPDRRFRYRTTLTRERNASVYSPSGPVNRRTTTPPDSGVLFEGLGISTRPRDVEIPQFMRQIAVRRPTTADERSLRKIQEQDIINFRRTLYRAGARVRNIEDGGRYRDISAEFFRRNPACLHRLVPWLKRELTVLFGAHGSLVNIVQHIIMSNVTRYDLESQAFVSDLRPFLLNRTEHFIHEFISFARSPFNMAAFDQHANYDCPAPSYEEGSHSDSSVITISPDEAETQELDINVATVSQAPWDDETPGPSYSSSEQVHVTMSSLLNTSDSSDEELVTGGATSQIQGVQTNDDLNNDSDDSSDNCVIVGFVKPLAERTPELVELSSDSEDLGSYEKMETVKTQEQEQSYSSGDSDVSRCSSPHSVLGKDEQINKGHCDSSTRIKSKKEEKRSTSLSSPRNLNSSVRGDRVYSPYNHRHRKRGRSRSSDSRSQSRSGHDQKNHRKHHGKKRMKSKRSRSRESSRPRGRRDKKRSRTRDSSWSRRSQTLSLSSESTSRSRSRSSDHGKRRSRSRNRDRYYLRNNYGSRYKWEYTYYSRNKDRDGYESSYRRRTLSRAHYSRQSSSPEFRVQSFSERTNARKKNNHSERKYYYYERHRSRSLSSNRSRTASTGTDRVRNEKPGGKRKYKTRHLEGTNEVAQPSREFASKAKDSHYQKSSSKLDGNYKNESDTFSDSRSSDRETKHKRRKRKTRSLSVEIVYEGKATDTTKHHKKKKKKHKKKHKKHHGDNASRSPVVITIDSDSDKDSEVKEDTECDNSGPQDPLQNEFLAPSLEPFETKDVVTIEAEFGVLDKECDIATLSNNLNNANKTVDNIPPLAASVEQTLDVREESTFVSDLENQPSNIVSLQTEPSRQLPSPRTSLMSVCLGRDCDMS>sp|Q96JJ7|TMX3_HUMAN Protein disulfide-isomerase TMX3 OS=Homo sapiensOX=9606 GN=TMX3 PE=1 SV=2MAAWKSWTALRLCATVVVLDMVVCKGFVEDLDESFKENRNDDIWLVDFYAPWCGHCKKLEPIWNEVGLEMKSIGSPVKVGKMDATSYSSIASEFGVRGYPTIKLLKGDLAYNYRGPRTKDDIIEFAHRVSGALIRPLPSQQMFEHMQKRHRVFFVYVGGESPLKEKYIDAASELIVYTYFFSASEEVVPEYVTLKEMPAVLVFKDETYFVYDEYEDGDLSSWINRERFQNYLAMDGFLLYELGDTGKLVALAVIDEKNTSVEHTRLKSIIQEVARDYRDLFHRDFQFGHMDGNDYINTLLMDELTVPTVVVLNTSNQQYFLLDRQIKNVEDMVQFINNILDGTVEAQGGDSILQRLKRIVFDAKSTIVSIFKSSPLMGCFLFGLPLGVISIMCYGIYTADTDGGYIEERYEVSKSENENQEQIEESKEQQEPSSGGSVVPTVQEPKDVLEKKKD>sp|Q96JJ7-2|TMX3_HUMAN Isoform 2 of Protein disulfide-isomerase TMX3OS=Homo sapiens OX=9606 GN=TMX3MAAWKSWTALRLCATVVVLDMVVCKGFVEDLDESFKENRNDDIWLVDFYAPWCGHCKKLEPIWNEVGLEMKSIGSPVKVGKMDATSYSSIASEFGVRGYPTIKLLKGDLAYNYRGPRTKDDIIEFAHRVSGALIRPLPSQQMFEHMQKRHRVFFVYVGGESPLKEKYIDAASELIVYTYFFSASEEVVPEVIFKI>sp|Q96HA7|TONSL_HUMAN Tonsoku-like protein OS=Homo sapiens OX=9606GN=TONSL PE=1 SV=2MSLERELRQLSKAKAKAQRAGQRREEAALCHQLGELLAGHGRYAEALEQHWQELQLRERADDPLGCAVAHRKIGERLAEMEDYPAALQHQHQYLELAHSLRNHTELQRAWATIGRTHLDIYDHCQSRDALLQAQAAFEKSLAIVDEELEGTLAQGELNEMRTRLYLNLGLTFESLQQTALCNDYFRKSIFLAEQNHLYEDLFRARYNLGTIHWRAGQHSQAMRCLEGARECAHTMRKRFMESECCVVIAQVLQDLGDFLAAKRALKKAYRLGSQKPVQRAAICQNLQHVLAVVRLQQQLEEAEGRDPQGAMVICEQLGDLFSKAGDFPRAAEAYQKQLRFAELLDRPGAERAIIHVSLATTLGDMKDHHGAVRHYEEELRLRSGNVLEEAKTWLNIALSREEAGDAYELLAPCFQKALSCAQQAQRPQLQRQVLQHLHTVQLRLQPQEAPETETRLRELSVAEDEDEEEEAEEAAATAESEALEAGEVELSEGEDDTDGLTPQLEEDEELQGHLGRRKGSKWNRRNDMGETLLHRACIEGQLRRVQDLVRQGHPLNPRDYCGWTPLHEACNYGHLEIVRFLLDHGAAVDDPGGQGCEGITPLHDALNCGHFEVAELLLERGASVTLRTRKGLSPLETLQQWVKLYRRDLDLETRQKARAMEMLLQAAASGQDPHSSQAFHTPSSLLFDPETSPPLSPCPEPPSNSTRLPEASQAHVRVSPGQAAPAMARPRRSRHGPASSSSSSEGEDSAGPARPSQKRPRCSATAQRVAAWTPGPASNREAATASTSRAAYQAAIRGVGSAQSRLGPGPPRGHSKALAPQAALIPEEECLAGDWLELDMPLTRSRRPRPRGTGDNRRPSSTSGSDSEESRPRARAKQVRLTCMQSCSAPVNAGPSSLASEPPGSPSTPRVSEPSGDSSAAGQPLGPAPPPPIRVRVQVQDHLFLIPVPHSSDTHSVAWLAEQAAQRYYQTCGLLPRLTLRKEGALLAPQDLIPDVLQSNDEVLAEVTSWDLPPLTDRYRRACQSLGQGEHQQVLQAVELQGLGLSFSACSLALDQAQLTPLLRALKLHTALRELRLAGNRLGDKCVAELVAALGTMPSLALLDLSSNHLGPEGLRQLAMGLPGQATLQSLEELDLSMNPLGDGCGQSLASLLHACPLLSTLRLQACGFGPSFFLSHQTALGSAFQDAEHLKTLSLSYNALGAPALARTLQSLPAGTLLHLELSSVAAGKGDSDLMEPVFRYLAKEGCALAHLTLSANHLGDKAVRDLCRCLSLCPSLISLDLSANPEISCASLEELLSTLQKRPQGLSFLGLSGCAVQGPLGLGLWDKIAAQLRELQLCSRRLCAEDRDALRQLQPSRPGPGECTLDHGSKLFFRRL>sp|Q96HA7-2|TONSL_HUMAN Isoform 2 of Tonsoku-like protein OS=Homosapiens OX=9606 GN=TONSLMSLERELRQLSKAKAKAQRAGQRREEAALCHQLGELLAGHGRYAEALEQHWQELQLRERADDPLGCAVAHRKIGERLAEMEDYPAALQHQHQYLELAHSLRNHTELQRAWATIGRTHLDIYDHCQSRDALLQAQAAFEKSLAIVDEELEGTLAQGELNEMRTRLYLNLGLTFESLQQTALCNDYFRKSIFLAEQNHLYEDLFRARYNLGTIHWRAGQHSQAMRCLEGARECAHTMRKRFMESECCVVIAQVLQDLGDFLAAKRALKKAYRLGSQKPVQRAAICQNLQHVLAVVRLQQQLEEAEGRDPQGAMVICEQLGDLFSKAGDFPRAAEAYQKQLRFAELLDRPGAERAIIHVSLATTLGDMKDHHGAVRHYEEELRLRSGNVLEEAKTWLNIALSREEAGDAYELLAPCFQKALSCAQQAQRPQLQRQVLQHLHTVQLRLQPQEAPETETRLRELSVAEDEDEEEEAEEAAATAESEALEAGEVELSEGEDDTDGLTPQLEEDEELQGHLGRRKGSKWNRRNDMGETLLHRACIEGQLRRVQDLVRQGHPLNPRDYCGWTPLHEACNYGHLEIVRFLLDHGAAVDDPGGQGCEGITPLHDALNCGHFEVAELLLERGASVTLRTRKASARWRRCSSGVKLYRRDLDLETRQKARAMEMLLQAAASGQDPHSSQAFHTPSSLLFDPETSPPLSPCPEPPSNSTRLPEASQAHVRVSPGQAAPAMARPRRSRHGPASSSSSSEGEDSAGPARPSQKRPRCSATAQRVAAWTPGPASNREAATASTSRAAYQAAIRGVGSAQSRLGPGPPRGHSKALAPQAALIPEEECLAGDWLELDMPLTRSRRPRPRGTGDNRRPSSTSGSDSEESRPRARAKQVRLTCMQSCSAPVNAGPSSLASEPPGSPSTPRVSEPSGDSSAAGQPLGPAPPPPIRVRVQVQDHLFLIPVPHSSDTHSVAWLAEQAAQRYYQTCGLLPRLTLRKEGALLAPQDLIPDVLQSNDEVLAEVTSWDLPPLTDRYRRACQSLGQGEHQQVLQAVELQGLGLSFSACSLALDQAQLTPLLRALKLHTALRELRLAGNRLGDKCVAELVAALGTMPSLALLDLSSNHLGPEGLRQLAMGLPGQATLQSLEELDLSMNPLGDGCGQSLASLLHACPLLSTLRLQACGFGPSFFLSHQTALGSAFQDAEHLKTLSLSYNALGAPALARTLQSLPAGTLLHLELSSVAAGKGDSDLMEPVFRYLAKEGCALAHLTLSANHLGDKAVRDLCRCLSLCPSLISLDLSANPEISCASLEELLSTLQKRPQGLSFLGLSGCAVQGPLGLGLWDKIAAQLRELQLCSRRLCAEDRDALRQLQPSRPGPGECTLDHGSKLFFRRL>sp|Q9BQ50|TREX2_HUMAN Three prime repair exonuclease 2 OS=Homo sapiensOX=9606 GN=TREX2 PE=1 SV=2MSEAPRAETFVFLDLEATGLPSVEPEIAELSLFAVHRSSLENPEHDESGALVLPRVLDKLTLCMCPERPFTAKASEITGLSSEGLARCRKAGFDGAVVRTLQAFLSRQAGPICLVAHNGFDYDFPLLCAELRRLGARLPRDTVCLDTLPALRGLDRAHSHGTRARGRQGYSLGSLFHRYFRAEPSAAHSAEGDVHTLLLIFLHRAAELLAWADEQARGWAHIEPMYLPPDDPSLEA>sp|Q9BQ50-1|TREX2_HUMAN Isoform 1 of Three prime repair exonuclease 2OS=Homo sapiens OX=9606 GN=TREX2MGRAGSPLPRSSWPRMDDCGSRSRCSPTLCSSLRTCYPRGNITMSEAPRAETFVFLDLEATGLPSVEPEIAELSLFAVHRSSLENPEHDESGALVLPRVLDKLTLCMCPERPFTAKASEITGLSSEGLARCRKAGFDGAVVRTLQAFLSRQAGPICLVAHNGFDYDFPLLCAELRRLGARLPRDTVCLDTLPALRGLDRAHSHGTRARGRQGYSLGSLFHRYFRAEPSAAHSAEGDVHTLLLIFLHRAAELLAWADEQARGWAHIEPMYLPPDDPSLEA>sp|P02787|TRFE_HUMAN Serotransferrin OS=Homo sapiens OX=9606 GN=TF PE=1SV=3MRLAVGALLVCAVLGLCLAVPDKTVRWCAVSEHEATKCQSFRDHMKSVIPSDGPSVACVKKASYLDCIRAIAANEADAVTLDAGLVYDAYLAPNNLKPVVAEFYGSKEDPQTFYYAVAVVKKDSGFQMNQLRGKKSCHTGLGRSAGWNIPIGLLYCDLPEPRKPLEKAVANFFSGSCAPCADGTDFPQLCQLCPGCGCSTLNQYFGYSGAFKCLKDGAGDVAFVKHSTIFENLANKADRDQYELLCLDNTRKPVDEYKDCHLAQVPSHTVVARSMGGKEDLIWELLNQAQEHFGKDKSKEFQLFSSPHGKDLLFKDSAHGFLKVPPRMDAKMYLGYEYVTAIRNLREGTCPEAPTDECKPVKWCALSHHERLKCDEWSVNSVGKIECVSAETTEDCIAKIMNGEADAMSLDGGFVYIAGKCGLVPVLAENYNKSDNCEDTPEAGYFAIAVVKKSASDLTWDNLKGKKSCHTAVGRTAGWNIPMGLLYNKINHCRFDEFFSEGCAPGSKKDSSLCKLCMGSGLNLCEPNNKEGYYGYTGAFRCLVEKGDVAFVKHQTVPQNTGGKNPDPWAKNLNEKDYELLCLDGTRKPVEEYANCHLARAPNHAVVTRKDKEACVHKILRQQQHLFGSNVTDCSGNFCLFRSETKDLLFRDDTVCLAKLHDRNTYEKYLGEEYVKAVGNLRKCSTSSLLEACTFRRP>sp|Q8NEW7|TMIE_HUMAN Transmembrane inner ear expressed protein OS=Homosapiens OX=9606 GN=TMIE PE=1 SV=2MAGWPGAGPLCVLGGAALGVCLAGVAGQLVEPSTAPPKPKPPPLTKETVVFWDMRLWHVVGIFSLFVLSIIITLCCVFNCRVPRTRKEIEARYLQRKAAKMYTDKLETVPPLNELTEVPGEDKKKKKKKKKDSVDTVAIKVEEDEKNEAKKKKGEK>sp|Q86YD3|TMM25_HUMAN Transmembrane protein 25 OS=Homo sapiens OX=9606GN=TMEM25 PE=1 SV=1MALPPGPAALRHTLLLLPALLSSGWGELEPQIDGQTWAERALRENERHAFTCRVAGGPGTPRLAWYLDGQLQEASTSRLLSVGGEAFSGGTSTFTVTAHRAQHELNCSLQDPRSGRSANASVILNVQFKPEIAQVGAKYQEAQGPGLLVVLFALVRANPPANVTWIDQDGPVTVNTSDFLVLDAQNYPWLTNHTVQLQLRSLAHNLSVVATNDVGVTSASLPAPGLLATRVEVPLLGIVVAAGLALGTLVGFSTLVACLVCRKEKKTKGPSRHPSLISSDSNNLKLNNVRLPRENMSLPSNLQLNDLTPDSRAVKPADRQMAQNNSRPELLDPEPGGLLTSQGFIRLPVLGYIYRVSSVSSDEIWL>sp|Q86YD3-2|TMM25_HUMAN Isoform 2 of Transmembrane protein 25 OS=Homosapiens OX=9606 GN=TMEM25MALPPGPAALRHTLLLLPALLSSGWGELEPQIDGQTWAERALRENERHAFTCRVAGGPGTPRLAWYLDGQLQEASTSRLLSVGGEAFSGGTSTFTVTAHRAQHELNCSLQDPRSGRSANASVILNVQFKPEIAQVGAKYQEAQGPGLLVVLFALVRANPPANVTWIDQDGPVTVNTSDFLVLDAQNYPWLTNHTVQLQLRSLAHNLSVVATNDVGVTSASLPAPGPSRHPSLISSDSNNLKLNNVRLPRENMSLPSNLQLNDLTPDSRAVKPADRQMAQNNSRPELLDPEPGGLLTSQGFIRLPVLGYIYRVSSVSSDEIWL>sp|Q86YD3-3|TMM25_HUMAN Isoform 3 of Transmembrane protein 25 OS=Homosapiens OX=9606 GN=TMEM25MALPPGPAALRHTLLLLPALLSSVKPEIAQVGAKYQEAQGPGLLVVLFALVRANPPANVTWIDQDGPVTVNTSDFLVLDAQNYPWLTNHTVQLQLRSLAHNLSVVATNDVGVTSASLPAPGPSRHPSLISSDSNNLKLNNVRLPRENMSLPSNLQLNDLTPDSRAVKPADRQMAQNNSRPELLDPEPGGLLTSQGFIRLPVLGYIYRVSSVSSDEIWL>sp|Q86YD3-4|TMM25_HUMAN Isoform 4 of Transmembrane protein 25 OS=Homosapiens OX=9606 GN=TMEM25MALPPGPAALRHTLLLLPALLSSGWGELEPQIDGQTWAERALRENERHAFTCRVAGGPGTPRLAWYLDGQLQEASTSRLLSVGGEAFSGGTSTFTVTAHRAQHELNCSLQDPRSGRSANASVILNVQFKPEIAQVGAKYQEAQGPGLLVVLFALVRANPPANVTWIDQDGPVTVNTSDFLVLDAQNYPWLTNHTVQLQLRSLAHNLSVVATNDVGVTSASLPAPGLLATRVEVPLLGIVVAAGLALGTLVGFSTLVACLVCRKEKKTKGPSRHPSLISSDSNNLKLNNVRLPRENMSLPSNLQLNDLTPDSRAVKPADRQMAQNNSRPELLDPEPGGLLTSQGRRNQDKDA>sp|Q86YD3-5|TMM25_HUMAN Isoform 5 of Transmembrane protein 25 OS=Homosapiens OX=9606 GN=TMEM25MALPPGPAALRHTLLLLPALLSSGWGELEPQIDGQTWAERALRENERHAFTCRVAGGPGTPRLAWYLDGQLQEASTSRLLSVGGEAFSGGTSTFTVTAHRAQHELNCSLQDPRSGRSANASVILNVQFKPEIAQVGAKYQEAQGPGLLVVLFALVRANPPANVTWIDQDGPVTVNTSDFLVLDAQNYPWLTNHTVQLQLRSLAHNLSVVATNDVGVTSASLPAPGPSRHPSLISSDSNNLKLNNVRLPRENMSLPSNLQLNDLTPDSRVKPADRQMAQNNSRPELLDPEPGGLLTSQGRRNQDKDA>sp|Q9BTV4|TMM43_HUMAN Transmembrane protein 43 OS=Homo sapiens OX=9606GN=TMEM43 PE=1 SV=1MAANYSSTSTRREHVKVKTSSQPGFLERLSETSGGMFVGLMAFLLSFYLIFTNEGRALKTATSLAEGLSLVVSPDSIHSVAPENEGRLVHIIGALRTSKLLSDPNYGVHLPAVKLRRHVEMYQWVETEESREYTEDGQVKKETRYSYNTEWRSEIINSKNFDREIGHKNPSAMAVESFMATAPFVQIGRFFLSSGLIDKVDNFKSLSLSKLEDPHVDIIRRGDFFYHSENPKYPEVGDLRVSFSYAGLSGDDPDLGPAHVVTVIARQRGDQLVPFSTKSGDTLLLLHHGDFSAEEVFHRELRSNSMKTWGLRAAGWMAMFMGLNLMTRILYTLVDWFPVFRDLVNIGLKAFAFCVATSLTLLTVAAGWLFYRPLWALLIAGLALVPILVARTRVPAKKLE>sp|Q15661|TRYB1_HUMAN Tryptase alpha/beta-1 OS=Homo sapiens OX=9606GN=TPSAB1 PE=1 SV=1MLNLLLLALPVLASRAYAAPAPGQALQRVGIVGGQEAPRSKWPWQVSLRVHGPYWMHFCGGSLIHPQWVLTAAHCVGPDVKDLAALRVQLREQHLYYQDQLLPVSRIIVHPQFYTAQIGADIALLELEEPVNVSSHVHTVTLPPASETFPPGMPCWVTGWGDVDNDERLPPPFPLKQVKVPIMENHICDAKYHLGAYTGDDVRIVRDDMLCAGNTRRDSCQGDSGGPLVCKVNGTWLQAGVVSWGEGCAQPNRPGIYTRVTYYLDWIHHYVPKKP>sp|Q15661-2|TRYB1_HUMAN Isoform 2 of Tryptase alpha/beta-1 OS=Homosapiens OX=9606 GN=TPSAB1MLNLLLLALPVLASRAYAAPAPGQALQRVGIVGGQEAPRSKWPWQVSLRVHGPYWMHFCGGSLIHPQWVLTAAHCVGPVQLREQHLYYQDQLLPVSRIIVHPQFYTAQIGADIALLELEEPVNVSSHVHTVTLPPASETFPPGMPCWVTGWGDVDNDERLPPPFPLKQVKVPIMENHICDAKYHLGAYTGDDVRIVRDDMLCAGNTRRDSCQGDSGGPLVCKVNGTWLQAGVVSWGEGCAQPNRPGIYTRVTYYLDWIHHYVPKKP>sp|Q6P2H8|TMM53_HUMAN Transmembrane protein 53 OS=Homo sapiens OX=9606GN=TMEM53 PE=2 SV=1MASAELDYTIEIPDQPCWSQKNSPSPGGKEAETRQPVVILLGWGGCKDKNLAKYSAIYHKRGCIVIRYTAPWHMVFFSESLGIPSLRVLAQKLLELLFDYEIEKEPLLFHVFSNGGVMLYRYVLELLQTRRFCRLRVVGTIFDSAPGDSNLVGALRALAAILERRAAMLRLLLLVAFALVVVLFHVLLAPITALFHTHFYDRLQDAGSRWPELYLYSRADEVVLARDIERMVEARLARRVLARSVDFVSSAHVSHLRDYPTYYTSLCVDFMRNCVRC>sp|Q6P2H8-2|TMM53_HUMAN Isoform 2 of Transmembrane protein 53 OS=Homosapiens OX=9606 GN=TMEM53MVFFSESLGIPSLRVLAQKLLELLFDYEIEKEPLLFHVFSNGGVMLYRYVLELLQTRRFCRLRVVGTIFDSAPGDSNLVGALRALAAILERRAAMLRLLLLVAFALVVVLFHVLLAPITALFHTHFYDRLQDAGSRWPELYLYSRADEVVLARDIERMVEARLARRVLARSVDFVSSAHVSHLRDYPTYYTSLCVDFMRNCVRC>sp|A0A0B4J1U4|TRGV5_HUMAN T cell receptor gamma variable 5 OS=Homosapiens OX=9606 GN=TRGV5 PE=1 SV=1MRWALLVLLAFLSPASQKSSNLEGGTKSVTRPTRSSAEITCDLTVINAFYIHWYLHQEGKAPQRLLYYDVSNSKDVLESGLSPGKYYTHTPRRWSWILILRNLIENDSGVYYCATWDR>sp|P35030|TRY3_HUMAN Trypsin-3 OS=Homo sapiens OX=9606 GN=PRSS3 PE=1SV=2MCGPDDRCPARWPGPGRAVKCGKGLAAARPGRVERGGAQRGGAGLELHPLLGGRTWRAARDADGCEALGTVAVPFDDDDKIVGGYTCEENSLPYQVSLNSGSHFCGGSLISEQWVVSAAHCYKTRIQVRLGEHNIKVLEGNEQFINAAKIIRHPKYNRDTLDNDIMLIKLSSPAVINARVSTISLPTTPPAAGTECLISGWGNTLSFGADYPDELKCLDAPVLTQAECKASYPGKITNSMFCVGFLEGGKDSCQRDSGGPVVCNGQLQGVVSWGHGCAWKNRPGVYTKVYNYVDWIKDTIAANS>sp|P35030-2|TRY3_HUMAN Isoform 2 of Trypsin-3 OS=Homo sapiens OX=9606GN=PRSS3MELHPLLGGRTWRAARDADGCEALGTVAVPFDDDDKIVGGYTCEENSLPYQVSLNSGSHFCGGSLISEQWVVSAAHCYKTRIQVRLGEHNIKVLEGNEQFINAAKIIRHPKYNRDTLDNDIMLIKLSSPAVINARVSTISLPTTPPAAGTECLISGWGNTLSFGADYPDELKCLDAPVLTQAECKASYPGKITNSMFCVGFLEGGKDSCQRDSGGPVVCNGQLQGVVSWGHGCAWKNRPGVYTKVYNYVDWIKDTIAANS>sp|P35030-3|TRY3_HUMAN Isoform 3 of Trypsin-3 OS=Homo sapiens OX=9606GN=PRSS3MNPFLILAFVGAAVAVPFDDDDKIVGGYTCEENSLPYQVSLNSGSHFCGGSLISEQWVVSAAHCYKTRIQVRLGEHNIKVLEGNEQFINAAKIIRHPKYNRDTLDNDIMLIKLSSPAVINARVSTISLPTTPPAAGTECLISGWGNTLSFGADYPDELKCLDAPVLTQAECKASYPGKITNSMFCVGFLEGGKDSCQRDSGGPVVCNGQLQGVVSWGHGCAWKNRPGVYTKVYNYVDWIKDTIAANS>sp|P35030-4|TRY3_HUMAN Isoform 4 of Trypsin-3 OS=Homo sapiens OX=9606GN=PRSS3MHMRETSGFTLKKGRSAPLVFHPPDALIAVPFDDDDKIVGGYTCEENSLPYQVSLNSGSHFCGGSLISEQWVVSAAHCYKTRIQVRLGEHNIKVLEGNEQFINAAKIIRHPKYNRDTLDNDIMLIKLSSPAVINARVSTISLPTTPPAAGTECLISGWGNTLSFGADYPDELKCLDAPVLTQAECKASYPGKITNSMFCVGFLEGGKDSCQRDSGGPVVCNGQLQGVVSWGHGCAWKNRPGVYTKVYNYVDWIKDTIAANS>sp|P35030-5|TRY3_HUMAN Isoform 5 of Trypsin-3 OS=Homo sapiens OX=9606GN=PRSS3MGPAGEVAVPFDDDDKIVGGYTCEENSLPYQVSLNSGSHFCGGSLISEQWVVSAAHCYKTRIQVRLGEHNIKVLEGNEQFINAAKIIRHPKYNRDTLDNDIMLIKLSSPAVINARVSTISLPTTPPAAGTECLISGWGNTLSFGADYPDELKCLDAPVLTQAECKASYPGKITNSMFCVGFLEGGKDSCQRDSGGPVVCNGQLQGVVSWGHGCAWKNRPGVYTKVYNYVDWIKDTIAANS>sp|Q9Y4R7|TTLL3_HUMAN Tubulin monoglycylase TTLL3 OS=Homo sapiensOX=9606 GN=TTLL3 PE=2 SV=2MNRLRNAKIYVERAVKQKKIFTIQGCYPVIRCLLRRRGWVEKKMVHRSGPTLLPPQKDLDSSAMGDSDTTEDEDEDEDEEFQPSQLFDFDDLLKFDDLDGTHALMVGLCLNLRNLPWFDEVDANSFFPRCYCLGAEDDKKAFIEDFWLTAARNVLKLVVKSEWKSYPIQAVEEEASGDKQPKKQEKNPVLVSPEFVDEALCACEEYLSNLAHMDIDKDLEAPLYLTPEGWSLFLQRYYQVVHEGAELRHLDTQVQRCEDILQQLQAVVPQIDMEGDRNIWIVKPGAKSRGRGIMCMDHLEEMLKLVNGNPVVMKDGKWVVQKYIERPLLIFGTKFDLRQWFLVTDWNPLTVWFYRDSYIRFSTQPFSLKNLDNSVHLCNNSIQKHLENSCHRHPLLPPDNMWSSQRFQAHLQEMGAPNAWSTIIVPGMKDAVIHALQTSQDTVQCRKASFELYGADFVFGEDFQPWLIEINASPTMAPSTAVTARLCAGVQADTLRVVIDRMLDRNCDTGAFELIYKQPAVEVPQYVGIRLLVEGFTIKKPMAMCHRRMGVRPAVPLLTQRGSGEARHHFPSLHTKAQLPSPHVLRHQGQVLRRQHSKLVGTKALSTTGKALRTLPTAKVFISLPPNLDFKVAPSILKPRKAPALLCLRGPQLEVPCCLCPLKSEQFLAPVGRSRPKANSRPDCDKPRAEACPMKRLSPLKPLPLVGTFQRRRGLGDMKLGKPLLRFPTALVLDPTPNKKKQVKYLGLDSIAVGGSRVDGARPCTPGSTARA>sp|Q9Y4R7-2|TTLL3_HUMAN Isoform 2 of Tubulin monoglycylase TTLL3 OS=Homosapiens OX=9606 GN=TTLL3MDIDKDLEAPLYLTPEGWSLFLQRYYQVVHEGAELRHLDTQVQRCEDILQQLQAVVPQIDMEGDRNIWIVKPGAKSRGRGIMCMDHLEEMLKLVNGNPVVMKDGKWVVQKYIERPLLIFGTKFDLRQWFLVTDWNPLTVWFYRDSYIRFSTQPFSLKNLDNSVHLCNNSIQKHLENSCHRHPLLPPDNMWSSQRFQAHLQEMGAPNAWSTIIVPGMKDAVIHALQTSQDTVQCRKASFELYGADFVFGEDFQPWLIEINASPTMAPSTAVTARLCAGVQADTLRVVIDRMLDRNCDTGAFELIYKQPVTTSPASTPRPSCLLPMYSDTRARSSDDSTASWWALRPCRPQARP>sp|Q9Y4R7-5|TTLL3_HUMAN Isoform 3 of Tubulin monoglycylase TTLL3 OS=Homosapiens OX=9606 GN=TTLL3MDIDKDLEAPLYLTPEGWSLFLQRYYQVVHEGAELRHLDTQVQRCEDILQQLQAVVPQIDMEGDRNIWIVKPGAKSRGRGIMCMDHLEEMLKLVNGNPVVMKDGKWVVQKYIERPLLIFGTKFDLRQWFLVTDWNPLTVWFYRDSYIRFSTQPFSLKNLDNSVHLCNNSIQKHLENSCHRHPLLPPDNMWSSQRFQAHLQEMGAPNAWSTIIVPGMKDAVIHALQTSQDTVQCRKASFELYGADFVFGEDFQPWLIEINASPTMAPSTAVTARLCAGVQADTLRVVIDRMLDRNCDTGAFELIYKQPAVEVPQYVGIRLLVEGFTIKKPMAMCHRRMGVRPAVPLLTQRGSGEARHHFPSLHTKAQLPSPHVLRHQGQVLRRQHSKLVGTKALSTTGKALRTLPTAKVFISLPPNLDFKVAPSILKPRKVGLDL>sp|Q9Y4R7-6|TTLL3_HUMAN Isoform 4 of Tubulin monoglycylase TTLL3 OS=Homosapiens OX=9606 GN=TTLL3MEGDRNIWIVKPGAKSRGRGIMCMDHLEEMLKLVNGNPVVMKDGKWVVQKYIERPLLIFGTKFDLRQWFLVTDWNPLTVWFYRDSYIRFSTQPFSLKNLDNSVHLCNNSIQKHLENSCHRHPLLPPDNMWSSQRFQAHLQEMGAPNAWSTIIVPGMKDAVIHALQTSQDTVQCRKASFELYGADFVFGEDFQPWLIEINASPTMAPSTAVTARLCAGVQADTLRVVIDRMLDRNCDTGAFELIYKQPVTTSPASTPRPSCLLPMYSDTRARSSDDSTASWWALRPCRPQARP>sp|P01222|TSHB_HUMAN Thyrotropin subunit beta OS=Homo sapiens OX=9606GN=TSHB PE=1 SV=2MTALFLMSMLFGLTCGQAMSFCIPTEYTMHIERRECAYCLTINTTICAGYCMTRDINGKLFLPKYALSQDVCTYRDFIYRTVEIPGCPLHVAPYFSYPVALSCKCGKCNTDYSDCIHEAIKTNYCTKPQKSYLVGFSV>sp|P01222-2|TSHB_HUMAN Isoform 2 of Thyrotropin subunit beta OS=Homosapiens OX=9606 GN=TSHBMLSFLFFPQDINGKLFLPKYALSQDVCTYRDFIYRTVEIPGCPLHVAPYFSYPVALSCKCGKCNTDYSDCIHEAIKTNYCTKPQKSYLVGFSV>sp|Q9BXA6|TSSK6_HUMAN Testis-specific serine/threonine-protein kinase 6OS=Homo sapiens OX=9606 GN=TSSK6 PE=1 SV=1MSGDKLLSELGYKLGRTIGEGSYSKVKVATSKKYKGTVAIKVVDRRRAPPDFVNKFLPRELSILRGVRHPHIVHVFEFIEVCNGKLYIVMEAAATDLLQAVQRNGRIPGVQARDLFAQIAGAVRYLHDHHLVHRDLKCENVLLSPDERRVKLTDFGFGRQAHGYPDLSTTYCGSAAYASPEVLLGIPYDPKKYDVWSMGVVLYVMVTGCMPFDDSDIAGLPRRQKRGVLYPEGLELSERCKALIAELLQFSPSARPSAGQVARNCWLRAGDSG>sp|Q8NG11|TSN14_HUMAN Tetraspanin-14 OS=Homo sapiens OX=9606 GN=TSPAN14PE=1 SV=1MHYYRYSNAKVSCWYKYLLFSYNIIFWLAGVVFLGVGLWAWSEKGVLSDLTKVTRMHGIDPVVLVLMVGVVMFTLGFAGCVGALRENICLLNFFCGTIVLIFFLELAVAVLAFLFQDWVRDRFREFFESNIKSYRDDIDLQNLIDSLQKANQCCGAYGPEDWDLNVYFNCSGASYSREKCGVPFSCCVPDPAQKVVNTQCGYDVRIQLKSKWDESIFTKGCIQALESWLPRNIYIVAGVFIAISLLQIFGIFLARTLISDIEAVKAGHHF>sp|Q8NG11-2|TSN14_HUMAN Isoform 2 of Tetraspanin-14 OS=Homo sapiensOX=9606 GN=TSPAN14MHYYRYSNAKVSCWYKYLLFSYNIIFWGVLSDLTKVTRMHGIDPVVLVLMVGVVMFTLGFAGCVGALRENICLLNFFCGTIVLIFFLELAVAVLAFLFQDWVRDRFREFFESNIKSYRDDIDLQNLIDSLQKANQCCGAYGPEDWDLNVYFNCSGASYSREKCGVPFSCCVPDPAQKVVNTQCGYDVRIQLKSKWDESIFTKGCIQALESWLPRNIYIVAGVFIAISLLQIFGIFLARTLISDIEAVKAGHHF>sp|Q8NG11-3|TSN14_HUMAN Isoform 3 of Tetraspanin-14 OS=Homo sapiensOX=9606 GN=TSPAN14MHYYRYSNAKVSCWYKYLLFSYNIIFWNQCCGAYGPEDWDLNVYFNCSGASYSREKCGVPFSCCVPDPAQKVVNTQCGYDVRIQLKSKWDESIFTKGCIQALESWLPRNIYIVAGVFIAISLLQIFGIFLARTLISDIEAVKAGHHF>sp|Q8NFU3|TSTD1_HUMAN Thiosulfate:glutathione sulfurtransferase OS=Homosapiens OX=9606 GN=TSTD1 PE=1 SV=3MAGAPTVSLPELRSLLASGRARLFDVRSREEAAAGTIPGALNIPVSELESALQMEPAAFQALYSAEKPKLEDEHLVFFCQMGKRGLQATQLARSLGYTGARNYAGAYREWLEKES>sp|Q8NFU3-2|TSTD1_HUMAN Isoform 2 of Thiosulfate:glutathionesulfurtransferase OS=Homo sapiens OX=9606 GN=TSTD1MAGVSELESALQMEPAAFQALYSAEKPKLEDEHLVFFCQMGKRGLQATQLARSLGYTGARNYAGAYREWLEKES>sp|Q8NFU3-3|TSTD1_HUMAN Isoform 3 of Thiosulfate:glutathionesulfurtransferase OS=Homo sapiens OX=9606 GN=TSTD1MAGAPTVSLPELRSLLASGRARLFDVRSREEAAAGTIPGALNIPVSELESALQMEPAAFQALYSAEKPKLEDEHLVFFCQMGKRGLQATQLARSLGYTGYGEVWLLAGR>sp|Q8NFU3-4|TSTD1_HUMAN Isoform 4 of Thiosulfate:glutathionesulfurtransferase OS=Homo sapiens OX=9606 GN=TSTD1MAGGCRAPSSAPTVSLPELRSLLASGRARLFDVRSREEAAAGTIPGALNIPVSELESALQMEPAAFQALYSAEKPKLEDEHLVFFCQMGKRGLQATQLARSLGYTGARNYAGAYREWLEKES>sp|Q9UMW8|UBP18_HUMAN Ubl carboxyl-terminal hydrolase 18 OS=Homo sapiensOX=9606 GN=USP18 PE=1 SV=1MSKAFGLLRQICQSILAESSQSPADLEEKKEEDSNMKREQPRERPRAWDYPHGLVGLHNIGQTCCLNSLIQVFVMNVDFTRILKRITVPRGADEQRRSVPFQMLLLLEKMQDSRQKAVRPLELAYCLQKCNVPLFVQHDAAQLYLKLWNLIKDQITDVHLVERLQALYTIRVKDSLICVDCAMESSRNSSMLTLPLSLFDVDSKPLKTLEDALHCFFQPRELSSKSKCFCENCGKKTRGKQVLKLTHLPQTLTIHLMRFSIRNSQTRKICHSLYFPQSLDFSQILPMKRESCDAEEQSGGQYELFAVIAHVGMADSGHYCVYIRNAVDGKWFCFNDSNICLVSWEDIQCTYGNPNYHWQETAYLLVYMKMEC>sp|Q9UMW8-2|UBP18_HUMAN Isoform 2 of Ubl carboxyl-terminal hydrolase 18OS=Homo sapiens OX=9606 GN=USP18MAESSQSPADLEEKKEEDSNMKREQPRERPRAWDYPHGLVGLHNIGQTCCLNSLIQVFVMNVDFTRILKRITVPRGADEQRRSVPFQMLLLLEKMQDSRQKAVRPLELAYCLQKCNVPLFVQHDAAQLYLKLWNLIKDQITDVHLVERLQALYTIRVKDSLICVDCAMESSRNSSMLTLPLSLFDVDSKPLKTLEDALHCFFQPRELSSKSKCFCENCGKKTRGKQVLKLTHLPQTLTIHLMRFSIRNSQTRKICHSLYFPQSLDFSQILPMKRESCDAEEQSGGQYELFAVIAHVGMADSGHYCVYIRNAVDGKWFCFNDSNICLVSWEDIQCTYGNPNYHWQETAYLLVYMKMEC>sp|P35503|UD13_HUMAN UDP-glucuronosyltransferase 1A3 OS=Homo sapiensOX=9606 GN=UGT1A3 PE=1 SV=1MATGLQVPLPWLATGLLLLLSVQPWAESGKVLVVPIDGSHWLSMREVLRELHARGHQAVVLTPEVNMHIKEENFFTLTTYAISWTQDEFDRHVLGHTQLYFETEHFLKKFFRSMAMLNNMSLVYHRSCVELLHNEALIRHLNATSFDVVLTDPVNLCAAVLAKYLSIPTVFFLRNIPCDLDFKGTQCPNPSSYIPRLLTTNSDHMTFMQRVKNMLYPLALSYICHAFSAPYASLASELFQREVSVVDILSHASVWLFRGDFVMDYPRPIMPNMVFIGGINCANRKPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|P35503-3|UD13_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A3OS=Homo sapiens OX=9606 GN=UGT1A3MATGLQVPLPWLATGLLLLLSVQPWAESGKVLVVPIDGSHWLSMREVLRELHARGHQAVVLTPEVNMHIKEENFFTLTTYAISWTQDEFDRHVLGHTQLYFETEHFLKKFFRSMAMLNNMSLVYHRSCVELLHNEALIRHLNATSFDVVLTDPVNLCAAVLAKYLSIPTVFFLRNIPCDLDFKGTQCPNPSSYIPRLLTTNSDHMTFMQRVKNMLYPLALSYICHAFSAPYASLASELFQREVSVVDILSHASVWLFRGDFVMDYPRPIMPNMVFIGGINCANRKPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|Q9Y5T5|UBP16_HUMAN Ubiquitin carboxyl-terminal hydrolase 16 OS=Homosapiens OX=9606 GN=USP16 PE=1 SV=1MGKKRTKGKTVPIDDSSETLEPVCRHIRKGLEQGNLKKALVNVEWNICQDCKTDNKVKDKAEEETEEKPSVWLCLKCGHQGCGRNSQEQHALKHYLTPRSEPHCLVLSLDNWSVWCYVCDNEVQYCSSNQLGQVVDYVRKQASITTPKPAEKDNGNIELENKKLEKESKNEQEREKKENMAKENPPMNSPCQITVKGLSNLGNTCFFNAVMQNLSQTPVLRELLKEVKMSGTIVKIEPPDLALTEPLEINLEPPGPLTLAMSQFLNEMQETKKGVVTPKELFSQVCKKAVRFKGYQQQDSQELLRYLLDGMRAEEHQRVSKGILKAFGNSTEKLDEELKNKVKDYEKKKSMPSFVDRIFGGELTSMIMCDQCRTVSLVHESFLDLSLPVLDDQSGKKSVNDKNLKKTVEDEDQDSEEEKDNDSYIKERSDIPSGTSKHLQKKAKKQAKKQAKNQRRQQKIQGKVLHLNDICTIDHPEDSEYEAEMSLQGEVNIKSNHISQEGVMHKEYCVNQKDLNGQAKMIESVTDNQKSTEEVDMKNINMDNDLEVLTSSPTRNLNGAYLTEGSNGEVDISNGFKNLNLNAALHPDEINIEILNDSHTPGTKVYEVVNEDPETAFCTLANREVFNTDECSIQHCLYQFTRNEKLRDANKLLCEVCTRRQCNGPKANIKGERKHVYTNAKKQMLISLAPPVLTLHLKRFQQAGFNLRKVNKHIKFPEILDLAPFCTLKCKNVAEENTRVLYSLYGVVEHSGTMRSGHYTAYAKARTANSHLSNLVLHGDIPQDFEMESKGQWFHISDTHVQAVPTTKVLNSQAYLLFYERIL>sp|Q9Y5T5-2|UBP16_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 16 OS=Homo sapiens OX=9606 GN=USP16MGKKRTKGKTVPIDDSSETLEPVCRHIRKGLEQGNLKKALVNVEWNICQDCKTDNKVKDKAEEETEEKPSVWLCLKCGHQGCGRNSQEQHALKHYLTPRSEPHCLVLSLDNWSVWCYVCDNEVQYCSSNQLGQVVDYVRKQASITTPKPEKDNGNIELENKKLEKESKNEQEREKKENMAKENPPMNSPCQITVKGLSNLGNTCFFNAVMQNLSQTPVLRELLKEVKMSGTIVKIEPPDLALTEPLEINLEPPGPLTLAMSQFLNEMQETKKGVVTPKELFSQVCKKAVRFKGYQQQDSQELLRYLLDGMRAEEHQRVSKGILKAFGNSTEKLDEELKNKVKDYEKKKSMPSFVDRIFGGELTSMIMCDQCRTVSLVHESFLDLSLPVLDDQSGKKSVNDKNLKKTVEDEDQDSEEEKDNDSYIKERSDIPSGTSKHLQKKAKKQAKKQAKNQRRQQKIQGKVLHLNDICTIDHPEDSEYEAEMSLQGEVNIKSNHISQEGVMHKEYCVNQKDLNGQAKMIESVTDNQKSTEEVDMKNINMDNDLEVLTSSPTRNLNGAYLTEGSNGEVDISNGFKNLNLNAALHPDEINIEILNDSHTPGTKVYEVVNEDPETAFCTLANREVFNTDECSIQHCLYQFTRNEKLRDANKLLCEVCTRRQCNGPKANIKGERKHVYTNAKKQMLISLAPPVLTLHLKRFQQAGFNLRKVNKHIKFPEILDLAPFCTLKCKNVAEENTRVLYSLYGVVEHSGTMRSGHYTAYAKARTANSHLSNLVLHGDIPQDFEMESKGQWFHISDTHVQAVPTTKVLNSQAYLLFYERIL>sp|Q9Y5T5-3|UBP16_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 16 OS=Homo sapiens OX=9606 GN=USP16MGSVAVEPVCRHIRKGLEQGNLKKALVNVEWNICQDCKTDNKVKDKAEEETEEKPSVWLCLKCGHQGCGRNSQEQHALKHYLTPRSEPHCLVLSLDNWSVWCYVCDNEVQYCSSNQLGQVVDYVRKQASITTPKPEKDNGNIELENKKLEKESKNEQEREKKENMAKENPPMNSPCQITVKGLSNLGNTCFFNAVMQNLSQTPVLRELLKEVKMSGTIVKIEPPDLALTEPLEINLEPPGPLTLAMSQFLNEMQETKKGVVTPKELFSQVCKKAVRFKGYQQQDSQELLRYLLDGMRAEEHQRVSKGILKAFGNSTEKLDEELKNKVKDYEKKKSMPSFVDRIFGGELTSMIMCDQCRTVSLVHESFLDLSLPVLDDQSGKKSVNDKNLKKTVEDEDQDSEEEKDNDSYIKERSDIPSGTSKHLQKKAKKQAKKQAKNQRRQQKIQGKVLHLNDICTIDHPEDSEYEAEMSLQGEVNIKSNHISQEGVMHKEYCVNQKDLNGQAKMIESVTDNQKSTEEVDMKNINMDNDLEVLTSSPTRNLNGAYLTEGSNGEVDISNGFKNLNLNAALHPDEINIEILNDSHTPGTKVYEVVNEDPETAFCTLANREVFNTDECSIQHCLYQFTRNEKLRDANKLLCEVCTRRQCNGPKANIKGERKHVYTNAKKQMLISLAPPVLTLHLKRFQQAGFNLRKVNKHIKFPEILDLAPFCTLKCKNVAEENTRVLYSLYGVVEHSGTMRSGHYTAYAKARTANSHLSNLVLHGDIPQDFEMESKGQWFHISDTHVQAVPTTKVLNSQAYLLFYERIL>sp|Q9Y5T5-4|UBP16_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase 16 OS=Homo sapiens OX=9606 GN=USP16MRAEEHQRVSKGILKAFGNSTEKLDEELKNKVKDYEKKKSMPSFVDRIFGGELTSMIMCDQCRTVSLVHESFLDLSLPVLDDQSGKKSVNDKNLKKTVEDEDQDSEEEKDNDSYIKERSDIPSGTSKHLQKKAKKQAKKQAKNQRRQQKIQGKVLHLNDICTIDHPEDSEYEAEMSLQGEVNIKSNHISQEGVMHKEYCVNQKDLNGQAKMIESVTDNQKSTEEVDMKNINMDNDLEVLTSSPTRNLNGAYLTEGSNGEVDISNGFKNLNLNAALHPDEINIEILNDSHTPGTKVYEVVNEDPETAFCTLANREVFNTDECSIQHCLYQFTRNEKLRDANKLLCEVCTRRQCNGPKANIKGERKHVYTNAKKQMLISLAPPVLTLHLKRFQQAGFNLRKVNKHIKFPEILDLAPFCTLKCKNVAEENTRVLYSLYGVVEHSGTMRSGHYTAYAKARTANSHLSNLVLHGDIPQDFEMESKGQWFHISDTHVQAVPTTKVLNSQAYLLFYERIL>sp|Q9Y5T5-5|UBP16_HUMAN Isoform 5 of Ubiquitin carboxyl-terminalhydrolase 16 OS=Homo sapiens OX=9606 GN=USP16MGKKRTKGKTVPIDDSSETLEPVCRHIRKGLEQGNLKKALVNVEWNICQDCKTDNKVKDKAEEETEEKPSVWLCLKCGHQGCGRNSQEQHALKHYLTPRSEPHCLVLSLDNWSVWCYVCDNEVQYCSSNQLGQVVDYVRKQASITTPKPAEKDNGNIELENKKLEKESKNEQEREKKENMAKENPPMNSPCQITVKGLSNLGNTCFFNAVMQNLSQTPVLRELLKEVKMSGTIVKIEPPDLALTEPLEINLEPPGPLTLAMSQFLNEMQETKKGVVTPKELFSQVCKKAVRFKGYQQQDSQELLRYLLDGMRAEEHQRVSKGILKAFGNSTEKLDEELKNKVKDYEKKKSMPSFVDRIFGGELTSMIMCDQCRTVSLVHESFLDLSLPVLDDQVRLLNLFYSSRFFFL>sp|Q9Y385|UB2J1_HUMAN Ubiquitin-conjugating enzyme E2 J1 OS=Homo sapiensOX=9606 GN=UBE2J1 PE=1 SV=2METRYNLKSPAVKRLMKEAAELKDPTDHYHAQPLEDNLFEWHFTVRGPPDSDFDGGVYHGRIVLPPEYPMKPPSIILLTANGRFEVGKKICLSISGHHPETWQPSWSIRTALLAIIGFMPTKGEGAIGSLDYTPEERRALAKKSQDFCCEGCGSAMKDVLLPLKSGSDSSQADQEAKELARQISFKAEVNSSGKTISESDLNHSFSLTDLQDDIPTTFQGATASTSYGLQNSSAASFHQPTQPVAKNTSMSPRQRRAQQQSQRRLSTSPDVIQGHQPRDNHTDHGGSAVLIVILTLALAALIFRRIYLANEYIFDFEL>sp|O00322|UPK1A_HUMAN Uroplakin-1a OS=Homo sapiens OX=9606 GN=UPK1A PE=1SV=1MASAAAAEAEKGSPVVVGLLVVGNIIILLSGLSLFAETIWVTADQYRVYPLMGVSGKDDVFAGAWIAIFCGFSFFMVASFGVGAALCRRRSMVLTYLVLMLIVYIFECASCITSYTHRDYMVSNPSLITKQMLTFYSADTDQGQELTRLWDRVMIEQECCGTSGPMDWVNFTSAFRAATPEVVFPWPPLCCRRTGNFIPLNEEGCRLGHMDYLFTKGCFEHIGHAIDSYTWGISWFGFAILMWTLPVMLIAMYFYTML>sp|O00322-2|UPK1A_HUMAN Isoform 2 of Uroplakin-1a OS=Homo sapiensOX=9606 GN=UPK1AMASAAAAEAEKGSPVVVGLLVVGNIIILLSGLSLFAETIWVTADQYRVYPLMGVSGKDDVFAGAWIAIFCGFSFFMVASFGVGAALCRRRSMVLTYLVLMLIVYIFECASCITSYTHRDYMVSNPSLITKQMLTFYSADTDQGQELTRLWDRVMIEQECCGTSGPMDWVNFTSAFRAATPEVVFPWPPLCCRRTGNFIPLNEEGCRLGHMDYLFTKAGVQWHNLSSLQRLPPGFKGFSHLSFQSSWDYRAASNTSATPSTATRGVSRGLGLPS>sp|Q13564|ULA1_HUMAN NEDD8-activating enzyme E1 regulatory subunitOS=Homo sapiens OX=9606 GN=NAE1 PE=1 SV=1MAQLGKLLKEQKYDRQLRLWGDHGQEALESAHVCLINATATGTEILKNLVLPGIGSFTIIDGNQVSGEDAGNNFFLQRSSIGKNRAEAAMEFLQELNSDVSGSFVEESPENLLDNDPSFFCRFTVVVATQLPESTSLRLADVLWNSQIPLLICRTYGLVGYMRIIIKEHPVIESHPDNALEDLRLDKPFPELREHFQSYDLDHMEKKDHSHTPWIVIIAKYLAQWYSETNGRIPKTYKEKEDFRDLIRQGILKNENGAPEDEENFEEAIKNVNTALNTTQIPSSIEDIFNDDRCINITKQTPSFWILARALKEFVAKEGQGNLPVRGTIPDMIADSGKYIKLQNVYREKAKKDAAAVGNHVAKLLQSIGQAPESISEKELKLLCSNSAFLRVVRCRSLAEEYGLDTINKDEIISSMDNPDNEIVLYLMLRAVDRFHKQQGRYPGVSNYQVEEDIGKLKSCLTGFLQEYGLSVMVKDDYVHEFCRYGAAEPHTIAAFLGGAAAQEVIKIITKQFVIFNNTYIYSGMSQTSATFQL>sp|Q13564-2|ULA1_HUMAN Isoform 2 of NEDD8-activating enzyme E1regulatory subunit OS=Homo sapiens OX=9606 GN=NAE1MDAQQTKTNEARLWGDHGQEALESAHVCLINATATGTEILKNLVLPGIGSFTIIDGNQVSGEDAGNNFFLQRSSIGKNRAEAAMEFLQELNSDVSGSFVEESPENLLDNDPSFFCRFTVVVATQLPESTSLRLADVLWNSQIPLLICRTYGLVGYMRIIIKEHPVIESHPDNALEDLRLDKPFPELREHFQSYDLDHMEKKDHSHTPWIVIIAKYLAQWYSETNGRIPKTYKEKEDFRDLIRQGILKNENGAPEDEENFEEAIKNVNTALNTTQIPSSIEDIFNDDRCINITKQTPSFWILARALKEFVAKEGQGNLPVRGTIPDMIADSGKYIKLQNVYREKAKKDAAAVGNHVAKLLQSIGQAPESISEKELKLLCSNSAFLRVVRCRSLAEEYGLDTINKDEIISSMDNPDNEIVLYLMLRAVDRFHKQQGRYPGVSNYQVEEDIGKLKSCLTGFLQEYGLSVMVKDDYVHEFCRYGAAEPHTIAAFLGGAAAQEVIKIITKQFVIFNNTYIYSGMSQTSATFQL>sp|Q13564-3|ULA1_HUMAN Isoform 3 of NEDD8-activating enzyme E1regulatory subunit OS=Homo sapiens OX=9606 GN=NAE1MEFLQELNSDVSGSFVEESPENLLDNDPSFFCRFTVVVATQLPESTSLRLADVLWNSQIPLLICRTYGLVGYMRIIIKEHPVIESHPDNALEDLRLDKPFPELREHFQSYDLDHMEKKDHSHTPWIVIIAKYLAQWYSETNGRIPKTYKEKEDFRDLIRQGILKNENGAPEDEENFEEAIKNVNTALNTTQIPSSIEDIFNDDRCINITKQTPSFWILARALKEFVAKEGQGNLPVRGTIPDMIADSGKYIKLQNVYREKAKKDAAAVGNHVAKLLQSIGQAPESISEKELKLLCSNSAFLRVVRCRSLAEEYGLDTINKDEIISSMDNPDNEIVLYLMLRAVDRFHKQQGRYPGVSNYQVEEDIGKLKSCLTGFLQEYGLSVMVKDDYVHEFCRYGAAEPHTIAAFLGGAAAQEVIKIITKQFVIFNNTYIYSGMSQTSATFQL>sp|Q13564-4|ULA1_HUMAN Isoform 4 of NEDD8-activating enzyme E1regulatory subunit OS=Homo sapiens OX=9606 GN=NAE1MAQLGKLLKEQKYDRQLRLWGDHGQEALESAHVCLINATATGTEILKNLVLPGNVGIGSFTIIDGNQVSGEDAGNNFFLQRSSIGKNRAEAAMEFLQELNSDVSGSFVEESPENLLDNDPSFFCRFTVVVATQLPESTSLRLADVLWNSQIPLLICRTYGLVGYMRIIIKEHPVIESHPDNALEDLRLDKPFPELREHFQSYDLDHMEKKDHSHTPWIVIIAKYLAQWYSETNGRIPKTYKEKEDFRDLIRQGILKNENGAPEDEENFEEAIKNVNTALNTTQIPSSIEDIFNDDRCINITKQTPSFWILARALKEFVAKEGQGNLPVRGTIPDMIADSGKYIKLQNVYREKAKKDAAAVGNHVAKLLQSIGQAPESISEKELKLLCSNSAFLRVVRCRSLAEEYGLDTINKDEIISSMDNPDNEIVLYLMLRAVDRFHKQQGRYPGVSNYQVEEDIGKLKSCLTGFLQEYGLSVMVKDDYVHEFCRYGAAEPHTIAAFLGGAAAQEVIKIITKQFVIFNNTYIYSGMSQTSATFQL>sp|Q96C45|ULK4_HUMAN Serine/threonine-protein kinase ULK4 OS=Homosapiens OX=9606 GN=ULK4 PE=1 SV=2MENFILYEEIGRGSKTVVYKGRRKGTINFVAILCTDKCKRPEITNWVRLTREIKHKNIVTFHEWYETSNHLWLVVELCTGGSLKTVIAQDENLPEDVVREFGIDLISGLHHLHKLGILFCDISPRKILLEGPGTLKFSNFCLAKVEGENLEEFFALVAAEEGGGDNGENVLKKSMKSRVKGSPVYTAPEVVRGADFSISSDLWSLGCLLYEMFSGKPPFFSESISELTEKILCEDPLPPIPKDSSRPKASSDFINLLDGLLQRDPQKRLTWTRLLQHSFWKKAFAGADQESSVEDLSLSRNTMECSGPQDSKELLQNSQSRQAKGHKSGQPLGHSFRLENPTEFRPKSTLEGQLNESMFLLSSRPTPRTSTAVEVSPGEDMTHCSPQKTSPLTKITSGHLSQQDLESQMRELIYTDSDLVVTPIIDNPKIMKQPPVKFDAKILHLPTYSVDKLLFLKDQDWNDFLQQVCSQIDSTEKSMGASRAKLNLLCYLCVVAGHQEVATRLLHSPLFQLLIQHLRIAPNWDIRAKVAHVIGLLASHTAELQENTPVVEAIVLLTELIRENFRNSKLKQCLLPTLGELIYLVATQEEKKKNPRECWAVPLAAYTVLMRCLREGEERVVNHMAAKIIENVCTTFSAQSQGFITGEIGPILWYLFRHSTADSLRITAVSALCRITRHSPTAFQNVIEKVGLNSVINSLASAICKVQQYMLTLFAAMLSCGIHLQRLIQEKGFVSTIIRLLDSPSTCIRAKAFLVLLYILIYNREMLLLSCQARLVMYIERDSRKTTPGKEQQSGNEYLSKCLDLLICHIVQELPRILGDILNSLANVSGRKHPSTVQVKQLKLCLPLMPVVLHLVTSQVFRPQVVTEEFLFSYGTILSHIKSVDSGETNIDGAIGLTASEEFIKITLSAFEAIIQYPILLKDYRSTVVDYILPPLVSLVQSQNVEWRLFSLRLLSETTSLLVNQEFGDGKEKASVDSDSNLLALIRDVLLPQYEHILLEPDPVPAYALKLLVAMTEHNPTFTRLVEESKLIPLIFEVTLEHQESILGNTMQSVIALLSNLVACKDSNMELLYEQGLVSHICNLLTETATLCLDVDNKNNNEMAAPLLFSLLDILHSMLTYTSGIVRLALQAQKSGSGEDPQAAEDLLLLNRPLTDLISLLIPLLPNEDPEIFDVSSKCLSILVQLYGGENPDSLSPENVEIFAHLLTSKEDPKEQKLLLRILRRMITSNEKHLESLKNAGSLLRALERLAPGSGSFADSAVAPLALEILQAVGH>sp|P0DTE4|UD2A1_HUMAN UDP-glucuronosyltransferase 2A1 OS=Homo sapiensOX=9606 GN=UGT2A1 PE=1 SV=1MLNNLLLFSLQISLIGTTLGGNVLIWPMEGSHWLNVKIIIDELIKKEHNVTVLVASGALFITPTSNPSLTFEIYRVPFGKERIEGVIKDFVLTWLENRPSPSTIWRFYQEMAKVIKDFHMVSQEICDGVLKNQQLMAKLKKSKFEVLVSDPVFPCGDIVALKLGIPFMYSLRFSPASTVEKHCGKVPYPPSYVPAVLSELTDQMSFTDRIRNFISYHLQDYMFETLWKSWDSYYSKALGRPTTLCETMGKAEIWLIRTYWDFEFPRPYLPNFEFVGGLHCKPAKPLPKEMEEFIQSSGKNGVVVFSLGSMVKNLTEEKANLIASALAQIPQKVLWRYKGKKPATLGNNTQLFDWIPQNDLLGHPKTKAFITHGGTNGIYEAIYHGVPMVGVPMFADQPDNIAHMKAKGAAVEVNLNTMTSVDLLSALRTVINEPSYKENAMRLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVIGFLLVCVTTAIFLVIQCCLFSCQKFGKIGKKKKRE>sp|P0DTE4-4|UD2A1_HUMAN Isoform 2 of UDP-glucuronosyltransferase 2A1OS=Homo sapiens OX=9606 GN=UGT2A1MLNNLLLFSLQISLIGTTLGGNVLIWPMEGSHWLNVKIIIDELIKKEHNVTVLVASGALFITPTSNPSLTFEIYRVPFGKERIEGVIKDFVLTWLENRPSPSTIWRFYQEMAKVIKDFHMVSQEICDGVLKNQQLMAKLKKSKFEVLVSDPVFPCGDIVALKLGIPFMYSLRFSPASTVEKHCGKVPYPPSYVPAVLSELTDQMSFTDRIRNFISYHLQDYMFETLWKSWDSYYSKALDGSHWLNIKIILEELIQRNHNVTVLASSATLFINSNPDSPVNFEVIPVSYKKSNIDSLIEHMIMLWIDHRPTPLTIWAFYKELGKLLDTFFQINIQLCDGVLKNPKLMARLQKGGFDVLVADPVTICGDLVALKLGIPFMYTLRFSPASTVERHCGKIPAPVSYVPAALSELTDQMTFGERIKNTISYSLQDYIFQSYWGEWNSYYSKILGRPTTLCETMGKAEIWLIRTYWDFEFPRPYLPNFEFVGGLHCKPAKPLPKVLWRYKGKKPATLGNNTQLFDWIPQNDLLGHPKTKAFITHGGTNGIYEAIYHGVPMVGVPMFADQPDNIAHMKAKGAAVEVNLNTMTSVDLLSALRTVINEPSYKENAMRLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVIGFLLVCVTTAIFLVIQCCLFSCQKFGKIGKKKKRE>sp|P0DTE4-5|UD2A1_HUMAN Isoform 3 of UDP-glucuronosyltransferase 2A1OS=Homo sapiens OX=9606 GN=UGT2A1MLNNLLLFSLQISLIGTTLGGNVLIWPMEGSHWLNVKIIIDELIKKEHNVTVLVASGALFITPTSNPSLTFEIYRVPFGKERIEGVIKDFVLTWLENRPSPSTIWRFYQEMAKVIKDFHMVSQEICDGVLKNQQLMAKLKKSKFEVLVSDPVFPCGDIVALKLGIPFMYSLRFSPASTVEKHCGKVPYPPSYVPAVLSELTDQMSFTDRIRNFISYHLQDYMFETLWKSWDSYYSKALGGLLLCCPGWSAVADLGSLQPLLPGFKRFSRLSLHCSWDYRLPAGRPTTLCETMGKAEIWLIRTYWDFEFPRPYLPNFEFVGGLHCKPAKPLPKVLWRYKGKKPATLGNNTQLFDWIPQNDLLGHPKTKAFITHGGTNGIYEAIYHGVPMVGVPMFADQPDNIAHMKAKGAAVEVNLNTMTSVDLLSALRTVINEPSYKENAMRLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVIGFLLVCVTTAIFLVIQCCLFSCQKFGKIGKKKKRE>sp|O14907|TX1B3_HUMAN Tax1-binding protein 3 OS=Homo sapiens OX=9606GN=TAX1BP3 PE=1 SV=2MSYIPGQPVTAVVQRVEIHKLRQGENLILGFSIGGGIDQDPSQNPFSEDKTDKGIYVTRVSEGGPAEIAGLQIGDKIMQVNGWDMTMVTHDQARKRLTKRSEEVVRLLVTRQSLQKAVQQSMLS>sp|Q5T124|UBX11_HUMAN UBX domain-containing protein 11 OS=Homo sapiensOX=9606 GN=UBXN11 PE=1 SV=2MSSPLASLSKTRKVPLPSEPMNPGRRGIRIYGDEDEVDMLSDGCGSEEKISVPSCYGGIGAPVSRQVPASHDSELMAFMTRKLWDLEQQVKAQTDEILSKDQKIAALEDLVQTLRPHPAEATLQRQEELETMCVQLQRQVREMERFLSDYGLQWVGEPMDQEDSESKTVSEHGERDWMTAKKFWKPGDSLAPPEVDFDRLLASLQDLSELVVEGDTQVTPVPGGARLRTLEPIPLKLYRNGIMMFDGPFQPFYDPSTQRCLRDILDGFFPSELQRLYPNGVPFKVSDLRNQVYLEDGLDPFPGEGRVVGRQLMHKALDRVEEHPGSRMTAEKFLNRLPKFVIRQGEVIDIRGPIRDTLQNCCPLPARIQEIVVETPTLAAERERSQESPNTPAPPLSMLRIKSENGEQAFLLMMQPDNTIGDVRALLAQARVMDASAFEIFSTFPPTLYQDDTLTLQAAGLVPKAALLLRARRAPKSSLKFSPGPCPGPGPGPSPGPGPGPSPGPGPGPSPCPGPSPSPQ>sp|Q5T124-2|UBX11_HUMAN Isoform 2 of UBX domain-containing protein 11OS=Homo sapiens OX=9606 GN=UBXN11MSSPLASLSKTRKVPLPSEPMNPGRRGIRIYGDVPASHDSELMAFMTRKLWDLEQQVKAQTDEILSKDQKIAALEDLVQTLRPHPAEATLQRQEELETMCVQLQRQVREMERFLSDYGLQWVGEPMDQEDSESKTVSEHGERDWMTAKKFWKPGDSLAPPEVDFDRLLASLQDLSELVVEGDTQVTPVPGGARLRTLEPIPLKLYRNGIMMFDGPFQPFYDPSTQRCLRDILDGFFPSELQRLYPNGVPFKVSDLRNQVYLEDGLDPFPGEGRVVGRQLMHKALDRVEEHPGSRMTAEKFLNRLPKFVIRQGEVIDIRGPIRDTLQNCCPLPARIQEIVVETPTLAAERERSQESPNTPAPPLSMLRIKSENGEQAFLLMMQPDNTIGDVRALLAQARVMDASAFEIFSTFPPTLYQDDTLTLQAAGLVPKAALLLRARRAPKSSLKFSPGPCPGPGPGPSPGPGPGPSPGPGPGPSPCPGPSPSPQ>sp|Q5T124-3|UBX11_HUMAN Isoform 3 of UBX domain-containing protein 11OS=Homo sapiens OX=9606 GN=UBXN11MSSPLASLSKTRKVPLPSEPMNPGRRGIRIYGDEDEVDMLSDGCGSEEKISVPSCYGGIGAPVSRQGDSLAPPEVDFDRLLASLQDLSELVVEGDTQVTPVPGGARLRTLEPIPLKLYRNGIMMFDGPFQPFYDPSTQRCLRDILDGFFPSELQRLYPNGVPFKVSDLRNQVYLEDGLDPFPGEGRVVGRQLMHKALDRVEEHPGSRMTAEKFLNRLPKFVIRQGEVIDIRGPIRDTLQNCCPLPARIQEIVVETPTLAAERERSQESPNTPAPPLSMLRIKSENGEQAFLLMMQPDNTIGDVRALLAQARVMDASAFEIFSTFPPTLYQDDTLTLQAAGLVPKAALLLRARRAPKSSLKFSPGPCPGPGPGPSPGPGPGPSPGPGPGPSPCPGPSPSPQ>sp|Q5T124-4|UBX11_HUMAN Isoform 4 of UBX domain-containing protein 11OS=Homo sapiens OX=9606 GN=UBXN11MLSDGCGSEEKISVPSCYGGIGAPVSRQVPASHDSELMAFMTRKLWDLEQQVKAQTDEILSKDQKIAALEDLVQTLRPHPAEATLQRQEELETMCVQLQRQVREMERFLSDYGLQWVGEPMDQEDSESKTVSEHGERDWMTAKKFWKPGDSLAPPEVDFDRLLASLQDLSELVVEGDTQVTPVPGGARLRTLEPIPLKLYRNGIMMFDGPFQPFYDPSTQRCLRDILDGFFPSELQRLYPNGVPFKVSDLRNQVYLEDGLDPFPGEGRVVGRQLMHKALDRVEEHPGSRMTAEKFLNRLPKFVIRQGEVIDIRGPIRDTLQNCCPLPARIQEIVVETPTLAAERERSQESPNTPAPPLSMLRIKSENGEQAFLLMMQPDNTIGDVRALLAQARVMDASAFEIFSTFPPTLYQDDTLTLQAAGLVPKAALLLRARRAPKSSLKFSPGPCPGPGPGPSPGPGPGPSPGPGPGPSPCPGPSPSPQ>sp|Q5T124-5|UBX11_HUMAN Isoform 5 of UBX domain-containing protein 11OS=Homo sapiens OX=9606 GN=UBXN11MHKALDRVEEHPGSRMTAEKFLNRLPKFVIRQGEVIDIRGPIRDTLQNCCPLPARIQEIVVETPTLAAERERSQESPNTPAPPLSMLRIKSENGEQAFLLMMQPDNTIGDVRALLAQARVMDASAFEIFSTFPPTLYQDDTLTLQAAGLVPKAALLLRARRAPKSSLKFSPGPCPGPGPGPSPGPGPGPSPGPGPGPSPCPGPSPSPQ>sp|Q5T124-6|UBX11_HUMAN Isoform 6 of UBX domain-containing protein 11OS=Homo sapiens OX=9606 GN=UBXN11MSSPLASLSKTRKVPLPSEPMNPGRRGIRIYGDEDEVDMLSDGCGSEEKISVPSCYGGIGAPVSRQVPASHDSELMAFMTRKLWDLEQQVKAQTDEILSKDQKIAALEDLVQTLRPHPAEATLQRQEELETMCVQLQRQVREMERFLSDYGLQWVGEPMDQEDSESKTVSEHGERDWMTAKKFWKPGDSLAPPEVDFDRLLASLQDLSELVVEGDTQVTPVPGGARLRTLEPIPLKLYRNGIMMFDGPFQPFYDPSTQRCLRDILDGFFPSELQRLYPNGVPFKVISCSSNHTFGDFEGSGDTQPPQTPPILRGSRCTPWGTPV>sp|Q5T124-7|UBX11_HUMAN Isoform 7 of UBX domain-containing protein 11OS=Homo sapiens OX=9606 GN=UBXN11MSSPLASLSKTRKVPLPSEPMNPGRRGIRIYGDVPASHDSELMAFMTRKLWDLEQQVKAQTDEILSKDQKIAALEDLVQTLRPHPAEATLQRQEELETMCVQLQRQVREMERFLSDYGLQWVGEPMDQEDSESKTVSEHGERDWMTAKKFWKPGDSLAPPEVDFDRLLASLQDLSELVVEGDTQVTPVPGGARLRTLEPIPLKLYRNGIMMFDGPFQPFYDPSTQRCLRDILDGFFPSELQRLYPNGVPFKVISCSSNHTFGDFEGSGDTQPPQTPPILRGSRCTPWGTPV>sp|Q5T124-8|UBX11_HUMAN Isoform 8 of UBX domain-containing protein 11OS=Homo sapiens OX=9606 GN=UBXN11MAFMTRKLWDLEQQVKAQTDEILSKDQKIAALEDLVQTLRPHPAEATLQRQEELETMCVQLQRQVREMERFLSDYGLQWVGEPMDQEDSESKTVSEHGERDWMTAKKFWKPGDSLAPPEVDFDRLLASLQDLSELVVEGDTQVTPVPGGARLRTLEPIPLKLYRNGIMMFDGPFQPFYDPSTQRCLRDILDGFFPSELQRLYPNGVPFKVSDLRNQVYLEDGLDPFPGEGRVVGRQLMHKALDRVEEHPGSRMTAEKFLNRLPKFVIRQGEVIDIRGPIRDTLQNCCPLPARIQEIVVETPTLAAERERSQESPNTPAPPLSMLRIKSENGEQAFLLMMQPDNTIGDVRALLAQARVMDASAFEIFSTFPPTLYQDDTLTLQAAGLVPKAALLLRARRAPKSSLKFSPGPCPGPGPGPSPGPGPGPSPGPGPGPSPCPGPSPSPQ>sp|Q6RSH7|VHLL_HUMAN von Hippel-Lindau-like protein OS=Homo sapiensOX=9606 GN=VHLL PE=1 SV=1MPWRAGNGVGLEAQAGTQEAGPEEYCQEELGAEEEMAARAAWPVLRSVNSRELSRIIICNHSPRIVLPVWLNYYGKLLPYLTLLPGRDFRIHNFRSHPWLFRDARTHDKLLVNQTELFVPSSNVNGQPVFANITLQCIP>sp|Q6ZRX8|YL004_HUMAN Putative uncharacterized protein FLJ45999 OS=Homosapiens OX=9606 PE=5 SV=1MSPTTGPQPNPRAWECHHTTGPQPNPRAWECHRMKGPQPNPRAWECHLRRVHNLTPEPGNVTIRGVHILTPEPGNVTIRGVHNLTPEPGNVTERGVHNLTPEPGNVTERGVHNLIPEPGNVTVKRGPQPNPRAWECHRTRGPQPNPRAWECHRTRGPQPNPRAWECHR>sp|O15231|ZN185_HUMAN Zinc finger protein 185 OS=Homo sapiens OX=9606GN=ZNF185 PE=1 SV=3MSISALGGRTKGKPLPPGEEERNNVLKQMKVRTTLKGDKSWITKQDESEGRTIELPSGRSRATSFSSAGEVPKPRPPSTRAPTGYIIRGVFTKPIDSSSQPQQQFPKANGTPKSAASLVRTANAGPPRPSSSGYKMTTEDYKKLAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRRSEAASGVLRRTAPREHSYVLSAAKKSTGPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNSADGGRTKASRAIWIECLPSMPSPAGSQELSSRGEEIVRLQILTPRAGLRLVAPDVEGMRSSPGNKDKEAPCSRELQRDLAGEEAFRAPNTDAARSSAQLSDGNVGSGATGSRPEGLAAVDIGSERGSSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-2|ZN185_HUMAN Isoform 2 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MQRQAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRRSEAASGVLRRTAPREHSYVLSAAKKSTGSPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNSSRGEEIVRLQILTPRAGLRLVAPDVEGMSSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-3|ZN185_HUMAN Isoform 3 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MSISALGGRTKGKPLPPGEEERNNVLKQMKVRTTLKGDKSWITKQDESEGRTIELPSGRSRATSFSSAGEVPKPRPPSTRAPTGYIIRGVFTKPIDSSSQPQQQFPKANGTPKSAASLVRTANAGPPRPSSSGYKMTTEDYKKLAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRRSEAASGVLRRTAPREHSYVLSAAKKSTGSPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNSADGGRTKASRAIWIECLPSMPSPAGSQELSSRGEEIVRLQILTPRAGLRLVAPDVEGMRSSPGNKDKEAPCSRELQRDLAGEEAFRAPNTDAARSSAQLSDGNVGSGATGSRPEGLAAVDIGSERGSSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-4|ZN185_HUMAN Isoform 4 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MSISALGGRTKGKPLPPGEEERNNVLKQMKVRTTLKGDKSWITKQDESEGRTIELPSGRSRATSFSSAGEVPKPRPPSTRAPTGYIIRGVFTKPIDSSSQPQQQFPKANGTPKSAASLVRTANAGPPRPSSSGYKMTTEDYKKLAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRRSEAASGVLRRTAPREHSYVLSAAKKSTGPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNRSSPGNKDKEAPCSRELQRDLAGEEAFRAPNTDAARSSAQLSDGNVGSGATGSRPEGLAAVDIGSERGSSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-5|ZN185_HUMAN Isoform 5 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MTTEDYKKLAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRSSPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNRSSPGNKDKEAPCSRELQRDLAGEEAFRAPNTDAARSSAQLSDGNVGSGATGSRPEGLAAVDIGSERGSSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-6|ZN185_HUMAN Isoform 6 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MSISALGGRTKGKPLPPGEEERNNVLKQMKVRTTLKGDKSWITKQDESEGRTIELPSGRSRATSFSSAGEVPKPRPPSTRAPTGYIIRGVFTKPIDSSSQPQQQFPKANGTPKSAASLVRTANAGPPRPSSSGYKMTTEDYKKLAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRRSEAASGVLRRTAPREHSYVLSAAKKSTGPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNSADGGRTKASRAIWIECLPSMPSPAGSQELSSRGEEIVRLQILTPRAGLRLVAPDVEGMRSSPGNKDKEAPCSRELQRDLAGEEAFRAPNTDAARSSAQLSDGNVGSGATGSRPEGLAAVDIGSERGRLCAAASFASFLEDQDGHSANSQSCKPRPAAISSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-7|ZN185_HUMAN Isoform 7 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MSISALGGRTKGKPLPPGEEERNNVLKQMKVRTTLKGDKSWITKQDESEGRTIELPSGRSRATSFSSAGEVPKPRPPSTRAPTGYIIRGVFTKPIDSSSQPQQQFPKANGTPKSAASLVRTANAGPPRPSSSGYKMTTEDYKKLAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRRSEAASGVLRRTAPREHSYVLSAAKKSTGPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNSADGGRTKASRAIWIECLPSMPSPAGSQELRSSPGNKDKEAPCSRELQRDLAGEEAFRAPNTDAARSSAQLSDGNVGSGATGSRPEGLAAVDIGSERGSSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-8|ZN185_HUMAN Isoform 8 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MSISALGGRTKGKPLPPGEEERNNVLKQMKVRTTLKGDKSWITKQDESEGRTIELPSGRSRATSFSSAGEVPKPRPPSTRAPTGYIIRGVFTKPIDSSSQPQQQFPKANGTPKSAASLVRTANAGPPRPSSSGYKMTTEDYKKLAPYNIRRSSTSGDTEEEEEEEVVPFSSDEQKRRSEAASGVLRRTAPREHSYVLSAAKKSTGPTQETQAPFIAKRVEVVEEDGPSEKSQDPPALARSTPGSNSADGGRTKASRAIWIECLPSMPSPAGSQELRSSPGNKDKEAPCSRELQRDLAGEEAFRAPNTDAARSSAQLSDGNVGSGATGSRPEGLAAVDIGSERGRLCAAASFASFLEDQDGHSANSQSCKPRPAAISSSATSVSAVPADRKSNSTAAQEDAKADPKGALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|O15231-9|ZN185_HUMAN Isoform 9 of Zinc finger protein 185 OS=Homosapiens OX=9606 GN=ZNF185MAARDELGLGGDSLEAMPVPAARGRPRITNGPEELAAPSPAALADYEGKDVATRVGEAWQERPGAPRGGQGDPAVPAQQPADPSTPERQSSPSGSEQLVRRESCGSSVLTDFEGKDVATKVGEAWQDRPGAPRGGQGDPAVPTQQPADPSTPEQQNSPSGSEQFVRRESCTSRVRSPSSCMVTVTVTATSEQPHIYIPAPASELDSSSTTKGILFVKEYVNASEVSSGKPVSARYSNVSSIEDSFAMEKKPPCGSTPYSERTTGGICTYCNREIRDCPKITLEHLGICCHEYCFKCGICSKPMGDLLDQIFIHRDTIHCGKCYEKLF>sp|Q16600|ZN239_HUMAN Zinc finger protein 239 OS=Homo sapiens OX=9606GN=ZNF239 PE=1 SV=3MASTITGSQDCIVNHRGEVDGEPELDISPCQQWGEASSPISRNRDSVMTLQSGCFENIESETYLPLKVSSQIDTQDSSVKFCKNEPQDHQESRRLFVMEESTERKVIKGESCSENLQVKLVSDGQELASPLLNGEATCQNGQLKESLDPIDCNCKDIHGWKSQVVSCSQQRAHTEEKPCDHNNCGKILNTSPDGHPYEKIHTAEKQYECSQCGKNFSQSSELLLHQRDHTEEKPYKCEQCGKGFTRSSSLLIHQAVHTDEKPYKCDKCGKGFTRSSSLLIHHAVHTGEKPYKCDKCGKGFSQSSKLHIHQRVHTGEKPYECEECGMSFSQRSNLHIHQRVHTGERPYKCGECGKGFSQSSNLHIHRCIHTGEKPYQCYECGKGFSQSSDLRIHLRVHTGEKPYHCGKCGKGFSQSSKLLIHQRVHTGEKPYECSKCGKGFSQSSNLHIHQRVHKKDPR>sp|Q9UIE0|ZN230_HUMAN Zinc finger protein 230 OS=Homo sapiens OX=9606GN=ZNF230 PE=1 SV=3MTTFKEAVTFKDVAVFFTEEELGLLDPAQRKLYQDVMLENFTNLLSVGHQPFHPFHFLREEKFWMMETATQREGNSGGKTIAEAGPHEDCPCQQIWEQTASDLTQSQDSIINNSHFFEQGDVPSQVEAGLSIIHTGQKPSQNGKCKQSFSDVAIFDPPQQFHSGEKSHTCNECGKSFCYISALRIHQRVHLREKLSKCDMRGKEFSQSSCLQTRERVHTGEKPFKCEQCGKGFRCRAILQVHCKLHTGEKPYICEKCGRAFIHDFQLQKHQIIHTGEKPFKCEICGKSFCLRSSLNRHCMVHTAEKLYKSEECGKGFTDSLDLHKHQIIHTGQKPYNCKECGKSFRWSSYLLIHQRIHSGEKPYRCEECGKGYISKSGLNLHQRVHTGERPYNCKECGKSFSRASSILNHKKLHCRKKPFKCEDCGKRLVHRSFCKDQQGDHNGENSSKCEDCGKRYKRRLNLDIILSLFLNDM>sp|O60844|ZG16_HUMAN Zymogen granule membrane protein 16 OS=Homo sapiensOX=9606 GN=ZG16 PE=1 SV=2MLTVALLALLCASASGNAIQARSSSYSGEYGGGGGKRFSHSGNQLDGPITALRVRVNTYYIVGLQVRYGKVWSDYVGGRNGDLEEIFLHPGESVIQVSGKYKWYLKKLLFVTDKGRYLSFGKDSGTSFNAVPLHPNTVLRFISGRSGSLIDAIGLHWDVYPSSCSRC>sp|Q9UDV7|ZN282_HUMAN Zinc finger protein 282 OS=Homo sapiens OX=9606GN=ZNF282 PE=1 SV=3MQFVSTRPQPQQLGIQGLGLDSGSWSWAQALPPEEVCHQEPALRGEMAEGMPPMQAQEWDMDARRPMPFQFPPFPDRAPVFPDRMMREPQLPTAEISLWTVVAAIQAVERKVDAQASQLLNLEGRTGTAEKKLADCEKTAVEFGNHMESKWAVLGTLLQEYGLLQRRLENLENLLRNRNFWVLRLPPGSKGEAPKVPVTFVDIAVYFSEDEWKNLDEWQKELYNNLVKENYKTLMSLDAEGSVPKPDAPVQAEPREEPCVWEQRHPEEREIPMDPEAGAEPLVPAQDASSQVKREDTLCVRGQRGLEERAIPTESITDSPISAQDLLSRIKQEEHQCVWDQQDLADRDIPTDPNSESLISAHDILSWIKQEEQPYPWGPRDSMDGELGLDSGPSDSLLMVKNPPPAPPQPQPQPQPPQPQLQSQPQPQSLPPIAVAENPGGPPSRGLLDDGFQVLPGERGSGEAPPGGDRSTGGGGGDGGGGGGGAEAGTGAGGGCGSCCPGGLRRSLLLHGARSKPYSCPECGKSFGVRKSLIIHHRSHTKERPYECAECEKSFNCHSGLIRHQMTHRGERPYKCSECEKTYSRKEHLQNHQRLHTGERPFQCALCGKSFIRKQNLLKHQRIHTGERPYTCGECGKSFRYKESLKDHLRVHSGGPGPGAPRQLPPPPERD>sp|Q9UDV7-2|ZN282_HUMAN Isoform 2 of Zinc finger protein 282 OS=Homosapiens OX=9606 GN=ZNF282MQFVSTRPQPQQLGIQGLGLDSGSWSWAQALPPEEVCHQEPALRGEMAEGMPPMQAQEWDMDARRPMPFQFPPFPDRAPVFPDRMMREPQLPTAEISLWTVVAAIQAVERKVDAQASQLLNLEGRTGTAEKKLADCEKTAVEFGNHMESKWAVLGTLLQEYGLLQRRLENLENLLRNRNFWVLRLPPGSKGEAPKVPVTFVDIAVYFSEDEWKNLDEWQKELYNNLVKENYKTLMSLDAEGSVPKPDAPVQAEPREEPCVWEQRHPEEREIPMDPEAGAEPLVPAQDASSQVKREDTLCVRGQRGLEERAIPTESITDSPISAQDLLSRIKQEEHQCVWDQQDLADRDIPTDPNSESLISAHDILSWIKQEEQPYPWGPRDSMDGELGLDSGPSDSLLMVKNPPPAPPQPQPQPQPPQPQLQSQPQPQSLPPIAVAENPGGPPSRGLLDDGFQPHQGAALRVR>sp|Q6UX98|ZDH24_HUMAN Probable palmitoyltransferase ZDHHC24 OS=Homosapiens OX=9606 GN=ZDHHC24 PE=1 SV=1MGQPWAAGSTDGAPAQLPLVLTALWAAAVGLELAYVLVLGPGPPPLGPLARALQLALAAFQLLNLLGNVGLFLRSDPSIRGVMLAGRGLGQGWAYCYQCQSQVPPRSGHCSACRVCILRRDHHCRLLGRCVGFGNYRPFLCLLLHAAGVLLHVSVLLGPALSALLRAHTPLHMAALLLLPWLMLLTGRVSLAQFALAFVTDTCVAGALLCGAGLLFHGMLLLRGQTTWEWARGQHSYDLGPCHNLQAALGPRWALVWLWPFLASPLPGDGITFQTTADVGHTAS>sp|P49910|ZN165_HUMAN Zinc finger protein 165 OS=Homo sapiens OX=9606GN=ZNF165 PE=1 SV=1MATEPKKAAAQNSPEDEGLLIVKIEEEEFIHGQDTCLQRSELLKQELCRQLFRQFCYQDSPGPREALSRLRELCCQWLKPEIHTKEQILELLVLEQFLTILPGDLQAWVHEHYPESGEEAVTILEDLERGTDEAVLQVQAHEHGQEIFQKKVSPPGPALNVKLQPVETKAHFDSSEPQLLWDCDNESENSRSMPKLEIFEKIESQRIISGRISGYISEASGESQDICKSAGRVKRQWEKESGESQRLSSAQDEGFGKILTHKNTVRGEIISHDGCERRLNLNSNEFTHQKSCKHGTCDQSFKWNSDFINHQIIYAGEKNHQYGKSFKSPKLAKHAAVFSGDKTHQCNECGKAFRHSSKLARHQRIHTGERCYECNECGKSFAESSDLTRHRRIHTGERPFGCKECGRAFNLNSHLIRHQRIHTREKPYECSECGKTFRVSSHLIRHFRIHTGEKPYECSECGRAFSQSSNLSQHQRIHMRENLLM>sp|O15060|ZBT39_HUMAN Zinc finger and BTB domain-containing protein 39OS=Homo sapiens OX=9606 GN=ZBTB39 PE=1 SV=1MGMRIKLQSTNHPNNLLKELNKCRLSETMCDVTIVVGSRSFPAHKAVLACAAGYFQNLFLNTGLDAARTYVVDFITPANFEKVLSFVYTSELFTDLINVGVIYEVAERLGMEDLLQACHSTFPDLESTARAKPLTSTSESHSGTLSCPSAEPAHPLGELRGGGDYLGADRNYVLPSDAGGSYKEEEKNVASDANHSLHLPQPPPPPPKTEDHDTPAPFTSIPSMMTQPLLGTVSTGIQTSTSSCQPYKVQSNGDFSKNSFLTPDNAVDITTGTNSCLSNSEHSKDPGFGQMDELQLEDLGDDDLQFEDPAEDIGTTEEVIELSDDSEDELAFGENDNRENKAMPCQVCKKVLEPNIQLIRQHARDHVDLLTGNCKVCETHFQDRNSRVTHVLSHIGIFLFSCDMCETKFFTQWQLTLHRRDGIFENNIIVHPNDPLPGKLGLFSGAASPELKCAACGKVLAKDFHVVRGHILDHLNLKGQACSVCDQRHLNLCSLMWHTLSHLGISVFSCSVCANSFVDWHLLEKHMAVHQSLEDALFHCRLCSQSFKSEAAYRYHVSQHKCNSGLDARPGFGLQHPALQKRKLPAEEFLGEELALQGQPGNSKYSCKVCGKRFAHTSEFNYHRRIHTGEKPYQCKVCHKFFRGRSTIKCHLKTHSGALMYRCTVCGHYSSTLNLMSKHVGVHKGSLPPDFTIEQTFMYIIHSKEADKNPDS>sp|A8MU10|YQ047_HUMAN Putative uncharacterized protein ENSP00000381562OS=Homo sapiens OX=9606 PE=4 SV=1MGSIPSKPCNNPEGPLLQGMEAADWTGIGVCLPPGGARGHIYCCTRLCHQRAASAHRSLLLPRTVQTGGTEREKPGPGQRKRGAHCSACKRSSTRPS>sp|Q9Y2Y4|ZBT32_HUMAN Zinc finger and BTB domain-containing protein 32OS=Homo sapiens OX=9606 GN=ZBTB32 PE=1 SV=1MSLPPIRLPSPYGSDRLVQLAARLRPALCDTLITVGSQEFPAHSLVLAGVSQQLGRRGQWALGEGISPSTFAQLLNFVYGESVELQPGELRPLQEAARALGVQSLEEACWRARGDRAKKPDPGLKKHQEEPEKPSRNPERELGDPGEKQKPEQVSRTGGREQEMLHKHSPPRGRPEMAGATQEAQQEQTRSKEKRLQAPVGQRGADGKHGVLTWLRENPGGSEESLRKLPGPLPPAGSLQTSVTPRPSWAEAPWLVGGQPALWSILLMPPRYGIPFYHSTPTTGAWQEVWREQRIPLSLNAPKGLWSQNQLASSSPTPGSLPQGPAQLSPGEMEESDQGHTGALATCAGHEDKAGCPPRPHPPPAPPARSRPYACSVCGKRFSLKHQMETHYRVHTGEKPFSCSLCPQRSRDFSAMTKHLRTHGAAPYRCSLCGAGCPSLASMQAHMRGHSPSQLPPGWTIRSTFLYSSSRPSRPSTSPCCPSSSTT>sp|O75362|ZN217_HUMAN Zinc finger protein 217 OS=Homo sapiens OX=9606GN=ZNF217 PE=1 SV=1MQSKVTGNMPTQSLLMYMDGPEVIGSSLGSPMEMEDALSMKGTAVVPFRATQEKNVIQIEGYMPLDCMFCSQTFTHSEDLNKHVLMQHRPTLCEPAVLRVEAEYLSPLDKSQVRTEPPKEKNCKENEFSCEVCGQTFRVAFDVEIHMRTHKDSFTYGCNMCGRRFKEPWFLKNHMRTHNGKSGARSKLQQGLESSPATINEVVQVHAAESISSPYKICMVCGFLFPNKESLIEHRKVHTKKTAFGTSSAQTDSPQGGMPSSREDFLQLFNLRPKSHPETGKKPVRCIPQLDPFTTFQAWQLATKGKVAICQEVKESGQEGSTDNDDSSSEKELGETNKGSCAGLSQEKEKCKHSHGEAPSVDADPKLPSSKEKPTHCSECGKAFRTYHQLVLHSRVHKKDRRAGAESPTMSVDGRQPGTCSPDLAAPLDENGAVDRGEGGSEDGSEDGLPEGIHLDKNDDGGKIKHLTSSRECSYCGKFFRSNYYLNIHLRTHTGEKPYKCEFCEYAAAQKTSLRYHLERHHKEKQTDVAAEVKNDGKNQDTEDALLTADSAQTKNLKRFFDGAKDVTGSPPAKQLKEMPSVFQNVLGSAVLSPAHKDTQDFHKNAADDSADKVNKNPTPAYLDLLKKRSAVETQANNLICRTKADVTPPPDGSTTHNLEVSPKEKQTETAADCRYRPSVDCHEKPLNLSVGALHNCPAISLSKSLIPSITCPFCTFKTFYPEVLMMHQRLEHKYNPDVHKNCRNKSLLRSRRTGCPPALLGKDVPPLSSFCKPKPKSAFPAQSKSLPSAKGKQSPPGPGKAPLTSGIDSSTLAPSNLKSHRPQQNVGVQGAATRQQQSEMFPKTSVSPAPDKTKRPETKLKPLPVAPSQPTLGSSNINGSIDYPAKNDSPWAPPGRDYFCNRSASNTAAEFGEPLPKRLKSSVVALDVDQPGANYRRGYDLPKYHMVRGITSLLPQDCVYPSQALPPKPRFLSSSEVDSPNVLTVQKPYGGSGPLYTCVPAGSPASSSTLEGKRPVSYQHLSNSMAQKRNYENFIGNAHYRPNDKKT>sp|Q9H8U3|ZFAN3_HUMAN AN1-type zinc finger protein 3 OS=Homo sapiensOX=9606 GN=ZFAND3 PE=1 SV=1MGDAGSERSKAPSLPPRCPCGFWGSSKTMNLCSKCFADFQKKQPDDDSAPSTSNSQSDLFSEETTSDNNNTSITTPTLSPSQQPLPTELNVTSPSKEECGPCTDTAHVSLITPTKRSCGTDSQSENEASPVKRPRLLENTERSEETSRSKQKSRRRCFQCQTKLELVQQELGSCRCGYVFCMLHRLPEQHDCTFDHMGRGREEAIMKMVKLDRKVGRSCQRIGEGCS>sp|Q96SE7|ZN347_HUMAN Zinc finger protein 347 OS=Homo sapiens OX=9606GN=ZNF347 PE=1 SV=2MALTQGQVTFRDVAIEFSQEEWTCLDPAQRTLYRDVMLENYRNLASLGISCFDLSIISMLEQGKEPFTLESQVQIAGNPDGWEWIKAVITALSSEFVMKDLLHKGKSNTGEVFQTVMLERQESQDIEGCSFREVQKNTHGLEYQCRDAEGNYKGVLLTQEGNLTHGRDEHDKRDARNKLIKNQLGLSLQSHLPELQLFQYEGKIYECNQVEKSFNNNSSVSPPQQMPYNVKTHISKKYLKDFISSLLLTQGQKANNWGSPYKSNGCGMVFPQNSHLASHQRSHTKEKPYKCYECGKAFRTRSNLTTHQVIHTGEKRYKCNECGKVFSRNSQLSQHQKIHTGEKPYKCNECGKVFTQNSHLVRHRGIHTGEKPYKCNECGKAFRARSSLAIHQATHSGEKPYKCNECGKVFTQNSHLTNHWRIHTGEKPYKCNECGKAFGVRSSLAIHLVIHTGEKPYKCHECGKVFRRNSHLARHQLIHTGEKPYKCNECGKAFRAHSNLTTHQVIHTGEKPYKCNECGKVFTQNSHLANHQRIHTGVKPYMCNECGKAFSVYSSLTTHQVIHTGEKPYKCNECGKVFTQNSHLARHRGIHTGEKPYKCNECGKVFRHNSYLSRHQRIHTGEKPYKYNEYGKAFSEHSNLTTHQVIHTGEKPYKCNECGKVFTQNSHLARHRRVHTGGKPYQCNECGKAFSQTSKLARHQRVHTGEKPYECNQCGKAFSVRSSLTTHQAIHTGKKPYKCNECGKVFTQNSHLARHRGIHTGEKPYKCNECGKAFSQTSKLARHQRIHTGEKPYECGKPFSICSSLTTHQTIHTGGKPYKCNVWKVLKSEFKPCKPSQNS>sp|Q96SE7-2|ZN347_HUMAN Isoform 2 of Zinc finger protein 347 OS=Homosapiens OX=9606 GN=ZNF347MALTQGQVTFRDVAIEFSQEEWTCLDPAQRTLYRDVMLENYRNLASLAGISCFDLSIISMLEQGKEPFTLESQVQIAGNPDGWEWIKAVITALSSEFVMKDLLHKGKSNTGEVFQTVMLERQESQDIEGCSFREVQKNTHGLEYQCRDAEGNYKGVLLTQEGNLTHGRDEHDKRDARNKLIKNQLGLSLQSHLPELQLFQYEGKIYECNQVEKSFNNNSSVSPPQQMPYNVKTHISKKYLKDFISSLLLTQGQKANNWGSPYKSNGCGMVFPQNSHLASHQRSHTKEKPYKCYECGKAFRTRSNLTTHQVIHTGEKRYKCNECGKVFSRNSQLSQHQKIHTGEKPYKCNECGKVFTQNSHLVRHRGIHTGEKPYKCNECGKAFRARSSLAIHQATHSGEKPYKCNECGKVFTQNSHLTNHWRIHTGEKPYKCNECGKAFGVRSSLAIHLVIHTGEKPYKCHECGKVFRRNSHLARHQLIHTGEKPYKCNECGKAFRAHSNLTTHQVIHTGEKPYKCNECGKVFTQNSHLANHQRIHTGVKPYMCNECGKAFSVYSSLTTHQVIHTGEKPYKCNECGKVFTQNSHLARHRGIHTGEKPYKCNECGKVFRHNSYLSRHQRIHTGEKPYKYNEYGKAFSEHSNLTTHQVIHTGEKPYKCNECGKVFTQNSHLARHRRVHTGGKPYQCNECGKAFSQTSKLARHQRVHTGEKPYECNQCGKAFSVRSSLTTHQAIHTGKKPYKCNECGKVFTQNSHLARHRGIHTGEKPYKCNECGKAFSQTSKLARHQRIHTGEKPYECGKPFSICSSLTTHQTIHTGGKPYKCNVWKVLKSEFKPCKPSQNS>sp|B4DXR9|ZN732_HUMAN Zinc finger protein 732 OS=Homo sapiens OX=9606GN=ZNF732 PE=2 SV=1MELLTFRDVAIEFSPEEWKCLDPAQQNLYRDVMLENYRNLISLGVAISNPDLVIYLEQRKEPYKVKIHETVAKHPAVCSHFTQDFLPVQGIEDSFHKLILRRYEKCGHENLELRKSCKRKVQKGGYNEFNQCLSTIQSKIFQCNVHVKVFSTFSNSNQRRIRHTGEKHFKECGKSFQKFSDLTQHQGIHAGEKPYTCEECGKDFKWYLIFNEYEIIHTGEKPFTCEECGNIFTTSSNFAKHKVHTGEKSYKYEECGKAFNRSSTLTKHKRIHAEEKPFTCEECGKIITSSSNVAKHKKIHTGEKLYKCQECGKVFNRSTTLTKHNRIHTGEKPYTCEECGKAFSRSSVLNEHKRIHTGEKPYKCEQCGKAFRQSATLNKHKSIHTGEKPYTCEECGKAFSRFTTLNEHKRIHTGERPHKCEECGKAFGWSTDLNKHKIIHTGEKPYKCEECGKAFGWSAYLSKHKKIHTGEKPYRCEECGKAFLCSRALNKHKTIHTGEKPYECEECGKAFGWSTYLSKHKKIHTGEKPYRCEECGKAFRRSRVLNKYKTIHTGDKTPKCKGCGKAFKWSSYLNQHNKIYTGEKL>sp|Q9NQX6|ZN331_HUMAN Zinc finger protein 331 OS=Homo sapiens OX=9606GN=ZNF331 PE=1 SV=1MAQGLVTFADVAIDFSQEEWACLNSAQRDLYWDVMLENYSNLVSLDLESAYENKSLPTEKNIHEIRASKRNSDRRSKSLGRNWICEGTLERPQRSRGRYVNQMIINYVKRPATREGTPPRTHQRHHKENSFECKDCGKAFSRGYQLSQHQKIHTGEKPYECKECKKAFRWGNQLTQHQKIHTGEKPYECKDCGKAFRWGSSLVIHKRIHTGEKPYECKDCGKAFRRGDELTQHQRFHTGEKDYECKDCGKTFSRVYKLIQHKRIHSGEKPYECKDCGKAFICGSSLIQHKRIHTGEKPYECQECGKAFTRVNYLTQHQKIHTGEKPHECKECGKAFRWGSSLVKHERIHTGEKPYKCTECGKAFNCGYHLTQHERIHTGETPYKCKECGKAFIYGSSLVKHERIHTGVKPYGCTECGKSFSHGHQLTQHQKTHSGAKSYECKECGKACNHLNHLREHQRIHNS>sp|Q9P1D8|YP008_HUMAN Putative uncharacterized protein PRO2289 OS=Homosapiens OX=9606 GN=PRO2289 PE=5 SV=1MMITRGWEGWGRRGARGAGTGTGLGGPGTPESSVTPPEFPLPPATRITPNFPNTLDPAISRSSS>sp|Q6UXQ8|YO002_HUMAN Putative uncharacterized protein UNQ6190/PRO20217OS=Homo sapiens OX=9606 GN=UNQ6190/PRO20217 PE=5 SV=1MAGVRARAPLPLALLLSLPAAPGGRDPSASRARFPQRLGRAPCFEVGLRKPPPPPLLSPPSFSSGSSRPLQRPRGPKDGAGRKVCAKLVKRLPGESGSCEDGQSAPAQPPRRRTGTRACPPRAPLWR>sp|A8MX80|YM017_HUMAN Putative UPF0607 protein ENSP00000383144 OS=Homosapiens OX=9606 PE=3 SV=2MRLCLIPRNTGTPQRVLPPVVWSTPSRKKPVLSARNSMMFGHLSPMRIPHLRGKFNLQLPSLDEQVIPARLPKTEVRAEEPKEATEVKDQVETQEQEDNKRGPCSNGEAASTSRPLETQGNLTSSWYNPRPLEGNVHLKSLTEKNQTDKAQVHAVSFYSKGHGVASSHSPAGGILPFGRPDSLPTVLPAPVPGCSLWPEKAALKVLGKDYLPSSPGLLMVGEDMQPKDPAALGSSRSSPPKAAGHRSHKRKLSGPPLQLQPTPPLQLRWDRDEGPPPAKLPCLSPEALLVGQASQREGHLQQGNMHKNMRVLSRTSKFRRLRQLLRRRKKRRQGRCGGSRL>sp|Q4V348|Z658B_HUMAN Zinc finger protein 658B OS=Homo sapiens OX=9606GN=ZNF658B PE=2 SV=1MMNLEKNFDKTTLFNHMRTDKRGKCSDLNEYGTSCDKTTAVEYNKVHMAMTHYECNERGINFSRKSPLTQSQRTITGWSAFESNKCEENFSQSSAHIVHQKTQAGDKFGEHNECTDALYQKLDFTAHQRIHTDFTAHQKFYLSDEHGKCRKSFYWKAHLIQHERPHSGEKTYQYEECAKSFCSSSHPIQHPGTYVGFKLYECNECGKAFCQNSNLSKHLRIHTKEKPCDNNGCGRSYKSPLIGHQKTDAEMELCGGSEYGKTSHLKGHQRILMGEKPYECIECGKTFSKTSHLRAHQRIHTGEKPYECVECEKTFSHKTHLSVHQRVHTGEKPYECNDCGKSFTYNSALRAHQRIHTGEKPYECSDCEKTFAHNSALRAHHRIHTGEKPYECNECGRSFAHISVLKAHQRIHTREKPYECNECGRSFTYNSALRAHQRIHTGRKPYECSDCEKTFAHNSALKIHQRIHTGEKPYKCNECEKTFAHNSALRAHQNIHTGEKLYECSECGKTFFQKTRLSTHRRIHTGEKPYECSKCGKTFSQKSYLSGHERIHTGEKPYECNVCGKTFVYKAALIVHQRIHTGEKPYECNECGKTFSQRTHLCAHQRIHTGEKPYECNECGKTFADNSALRAHHRIHTGEKPYECNDCGKTFSKTSHLRAHLRTRSGEKPYECSECGKTFSEKSYVSAHQRVHTGEKPYECNVCGKPFAHNSTLRVHQRIHTGEKSYECNDCGKTFSQKSHLSAHQRIHTGEKPYECNECGKAFAQNSTLRVHQRIHTGEKPYECDECGKTFVRKAALRVHHTRMHTREKTLACNGFGKS>sp|Q75MW2|ZN767_HUMAN Protein ZNF767 OS=Homo sapiens OX=9606 GN=ZNF767PPE=5 SV=1MEEAAAAPISPWTMAATIQAMERKIESQAAHLLSLEGQTGMAEKKLADCEKTAVEFGNQLEGKWAVLGTLLQEYGLLQRRLENVENLLHNRNFWILRLPPGSKGESPKTTPSPSPRSSPRLNKGRSPATGAALTPRFQMFLWTPVQMQKLRPSRD>sp|Q75MW2-2|ZN767_HUMAN Isoform 2 of Protein ZNF767 OS=Homo sapiensOX=9606 GN=ZNF767PMEEAAAAPISPWTMAATIQAMERKIESQAAHLLSLEGQTGMAEKKLADCEKTAVEFGNQLEGKWAVLGTLLQEYGLLQRRLENVENLLHNRNFWILRLPPGSKGESPKVPMTFDDVAV>sp|Q9H7X3|ZN696_HUMAN Zinc finger protein 696 OS=Homo sapiens OX=9606GN=ZNF696 PE=1 SV=2MEPGGEPTGAKESSTLMESLAAVKAAFLAQAPSGSRSAEVQAAQSTEPAAEAGAPEGEGHRGGPPRALGSLGLCENQEARERPGGSPRGPVTSEKTGGQSGLESDVPPNAGPGAEGGGSWKGRPFPCGACGRSFKCSSDAAKHRSIHSGEKPYECSDCGKAFIHSSHVVRHQRAHSGERPYACAECGKAFGQSFNLLRHQRVHTGEKPYACADCGKAFGQRSDAAKHRRTHTGERLYACGECGKRFLHSSNVVRHRRTHHGENPYECRECGQAFSQSSNLLQHQRVHTGERPFACQDCGRAFSRSSFLREHRRIHTGEKPHQCGHCGRAFRALSGFFRHQRLHTGEKPFRCTECGRAFRLSFHLIQHRRVHGAE>sp|Q96DT7|ZBT10_HUMAN Zinc finger and BTB domain-containing protein 10OS=Homo sapiens OX=9606 GN=ZBTB10 PE=1 SV=2MSFSEMNRRTLAFRGGGLVTASGGGSTNNNAGGEASAWPPQPQPRQPPPPAPPALQPPNGRGADEEVELEGLEPQDLEASAGPAAGAAEEAKELLLPQDAGGPTSLGGGAGGPLLAERNRRTLAFRGGGGGGLGNNGSSRGRPETSVWPLRHFNGRGPATVDLELDALEGKELMQDGASLSDSTEDEEEGASLGDGSGAEGGSCSSSRRSGGDGGDEVEGSGVGAGEGETVQHFPLARPKSLMQKLQCSFQTSWLKDFPWLRYSKDTGLMSCGWCQKTPADGGSVDLPPVGHDELSRGTRNYKKTLLLRHHVSTEHKLHEANAQESEIPSEEGYCDFNSRPNENSYCYQLLRQLNEQRKKGILCDVSIVVSGKIFKAHKNILVAGSRFFKTLYCFSNKESPNQNNTTHLDIAAVQGFSVILDFLYSGNLVLTSQNAIEVMTVASYLQMSEVVQTCRNFIKDALNISIKSEAPESVVVDYNNRKPVNRDGLSSSRDQKIASFWATRNLTNLASNVKIENDGCNVDEGQIENYQMNDSSWVQDGSPEMAENESEGQTKVFIWNNMGSQGIQETGKTRRKNQTTKRFIYNIPPNNETNLEDCSVMQPPVAYPEENTLLIKEEPDLDGALLSGPDGDRNVNANLLAEAGTSQDGGDAGTSHDFKYGLMPGPSNDFKYGLIPGTSNDFKYGLIPGASNDFKYGLLPESWPKQETWENGESSLIMNKLKCPHCSYVAKYRRTLKRHLLIHTGVRSFSCDICGKLFTRREHVKRHSLVHKKDKKYKCMVCKKIFMLAASVGIRHGSRRYGVCVDCADKSQPGGQEGVDQGQDTEFPRDEEYEENEVGEADEELVDDGEDQNDPSRWDESGEVCMSLDD>sp|Q96DT7-2|ZBT10_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 10 OS=Homo sapiens OX=9606 GN=ZBTB10MSFSEMNRRTLAFRGGGLVTASGGGSTNNNAGGEASAWPPQPQPRQPPPPAPPALQPPNGRGADEEVELEGLEPQDLEASAGPAAGAAEEAKELLLPQDAGGPTSLGGGAGGPLLAERNRRTLAFRGGGGGGLGNNGSSRGRPETSVWPLRHFNGRGPATVDLELDALEGKELMQDGASLSDSTEDEEEGASLGDGSGAEGGSCSSSRRSGGDGGDEVEGSGVGAGEGETVQHFPLARPKSLMQKLQCSFQTSWLKDFPWLRYSKDTGLMSCGWCQKTPADGGSVDLPPVGHDELSRGTRNYKKTLLLRHHVSTEHKLHEANAQESEIPSEEGYCDFNSRPNENSYCYQLLRQLNEQRKKGILCDVSIVVSGKIFKAHKNILVAGSRFFKTLYCFSNKESPNQNNTTHLDIAAVQGFSVILDFLYSGNLVLTSQNAIEVMTVASYLQMSEVVQTCRNFIKDALNISIKSEAPESVVVDYNNRKPVNRDGLSSSRDQKIASFWATRNLTNLASNVKIENDGCNVDEGQIENYQMNDSSWVQDGSPEMAENESEGQTKVFIWNNMGSQGIQETGKTRRKNQTTKRFIYNIPPNNETNLEDCSVMQPPVAYPEENTLLIKEEPDLDGALLSGPDGDRNVNANLLAEAGTSQDGGDAGTSHDFKYGLMPGASNDFKYGLLPESWPKQETWENGESSLIMNKLKCPHCSYVAKYRRTLKRHLLIHTGVRSFSCDICGKLFTRREHVKRHSLVHKKDKKYKCMVCKKIFMLAASVGIRHGSRRYGVCVDCADKSQPGGQEGVDQGQDTEFPRDEEYEENEVGEADEELVDDGEDQNDPSRWDESGEVCMSLDD>sp|Q96DT7-3|ZBT10_HUMAN Isoform 3 of Zinc finger and BTB domain-containing protein 10 OS=Homo sapiens OX=9606 GN=ZBTB10MQDGASLSDSTEDEEEGASLGDGSGAEGGSCSSSRRSGGDGGDEVEGSGVGAGEGETVQHFPLARPKSLMQKLQCSFQTSWLKDFPWLRYSKDTGLMSCGWCQKTPADGGSVDLPPVGHDELSRGTRNYKKTLLLRHHVSTEHKLHEANAQESEIPSEEGYCDFNSRPNENSYCYQLLRQLNEQRKKGILCDVSIVVSGKIFKAHKNILVAGSRFFKTLYCFSNKESPNQNNTTHLDIAAVQGFSVILDFLYSGNLVLTSQNAIEVMTVASYLQMSEVVQTCRNFIKDALNISIKSEAPESVVVDYNNRKPVNRDGLSSSRDQKIASFWATRNLTNLASNVKIENDGCNVDEGQIENYQMNDSSWVQDGSPEMAENESEGQTKVFIWNNMGSQGIQETGKTRRKNQTTKRFIYNIPPNNETNLEDCSVMQPPVAYPEENTLLIKEEPDLDGALLSGPDGDRNVNANLLAEAGTSQDGGDAGTSHDFKYGLMPGPSNDFKYGLIPGTSNDFKYGLIPGASNDFKYGLLPESWPKQETWENGESSLIMNKLKCPHCSYVAKYRRTLKRHLLIHTGVRSFSCDICGKLFTRREHVKRHSLVHKKDKKYKCMVCKKIFMLAASVGIRHGSRRYGVCVDCADKSQPGGQEGVDQGQDTEFPRDEEYEENEVGEADEELVDDGEDQNDPSRWDESGEVCMSLDD>sp|Q96DT7-4|ZBT10_HUMAN Isoform 4 of Zinc finger and BTB domain-containing protein 10 OS=Homo sapiens OX=9606 GN=ZBTB10MTRLERSSHRTVICKVPGELVAREGKCASRARESEIPSEEGYCDFNSRPNENSYCYQLLRQLNEQRKKGILCDVSIVVSGKIFKAHKNILVAGSRFFKTLYCFSNKESPNQNNTTHLDIAAVQGFSVILDFLYSGNLVLTSQNAIEVMTVASYLQMSEVVQTCRNFIKDALNISIKSEAPESVVVDYNNRKPVNRDGLSSSRDQKIASFWATRNLTNLASNVKIENDGCNVDEGQIENYQMNDSSWVQDGSPEMAENESEGQTKVFIWNNMGSQGIQETGKTRRKNQTTKRFIYNIPPNNETNLEDCSVMQPPVAYPEENTLLIKEEPDLDGALLSGPDGDRNVNANLLAEAGTSQDGGDAGTSHDFKYGLMPGPSNDFKYGLIPGTSNDFKYGLIPGASNDFKYGLLPESWPKQETWENGESSLIMNKLKCPHCSYVAKYRRTLKRHLLIHTGVRSFSCDICGKLFTRREHVKRHSLVHKKDKKYKCMVCKKIFMLAASVGIRHGSRRYGVCVDCADKSQPGGQEGVDQGQDTEFPRDEEYEENEVGEADEELVDDGEDQNDPSRWDESGEVCMSLDD>sp|Q5EBM4|ZN542_HUMAN Putative zinc finger protein 542 OS=Homo sapiensOX=9606 GN=ZNF542P PE=5 SV=2MLENYQNLVWLGLSISKSVISLLEKRKLPWIMAKEEIRGPLPGYFKVSEMTISQEPKAKTRTLFGKDVPGAEIKELSAKRAINEVLSQFDTVIKCTRNVCKECGNLYCHNMQLTLHKRNHTQKKCNQCLDCGKYFTRQSTLIQHQRIHTGERPYKCNECIKTFNQRAHLT>sp|Q5EBM4-2|ZN542_HUMAN Isoform 2 of Putative zinc finger protein 542OS=Homo sapiens OX=9606 GN=ZNF542PMLENYQNLVWLGLSISKSVISLLEKRKLPWIMAKEEIRGPLPDVPGAEIKELSAKRAINEVLSQFDTVIKCTRNVCKECGNLYCHNMQLTLHKRNHTQKKCNQCLDCGKYFTRQSTLIQHQRIHTGERPYKCNECIKTFNQRAHLT>sp|Q9NWS9|ZN446_HUMAN Zinc finger protein 446 OS=Homo sapiens OX=9606GN=ZNF446 PE=1 SV=1MPSPLGPPCLPVMDPETTLEEPETARLRFRGFCYQEVAGPREALARLRELCCQWLQPEAHSKEQMLEMLVLEQFLGTLPPEIQAWVRGQRPGSPEEAAALVEGLQHDPGQLLGWITAHVLKQEVLPAAQKTEEPLGSPHPSGTVESPGEGPQDTRIEGSVQLSCSVKEEPNVDGQEVAPSSPPLAAQSPEGNHGHQEPASTSFHPPRIQEEWGLLDRSQKELYWDAMLEKYGTVVSLGLPPHQPEAQAQSELGMLLTGTGVCRSLRSGNESEGPPGCPEAQPPQGPGPAAWEGLSGAATPAPTVRPGTPPVPTQPTPAETRLEPAATPRKPYTCEQCGRGFDWKSVFVIHHRTHTSGPGVQSPGLATGESTEKPPQGEVAFPHHPRRSLTGPRSYPCEECGCSFSWKSQLVIHRKSHTGQRRHFCSDCGRAFDWKSQLVIHRKGHRPEVP>sp|Q9NWS9-2|ZN446_HUMAN Isoform 2 of Zinc finger protein 446 OS=Homosapiens OX=9606 GN=ZNF446MPSPLGPPCLPVMDPETTLEEPETARLRFRGFCYQEVAGPREALARLRELCCQWLQPEAHSKEQMLEMLVLEQFLGTLPPEIQAWVRGQRPGSPEEAAALVEGLQHDPGQLLGWITAHVLKQEVLPAAQKTEEPLGSPHPSGTVESPGEGPQDTRIEGSVQLSCSVKEEPNVDGQEVAPSSPPLAAQSPEGNHGHQEPASTSFHPPRIQEEWGLLDRSQKELYWDAMLEKYGTVVSLGLPPHQPEAQAQSELGMLLTGTGVCRSLRSGNESEGPPGCPEAQPPQGPGPAAWEGLSGAATPAPTVRPGTPPVPTQPTPAETRLEPAATPRKPYTCEQCGRGFDWKSVFVIHHRTHTSGPGVQSPGLATGESTEKPPQGEVAFPHHPRRSLTGPRSYPCEECGCSFSWKSQLVIHRKSHRPEVP>sp|Q96SQ5|ZN587_HUMAN Zinc finger protein 587 OS=Homo sapiens OX=9606GN=ZNF587 PE=1 SV=1MAAAVPRRPTQQGTVTFEDVAVNFSQEEWCLLSEAQRCLYRDVMLENLALISSLGCWCGSKDEEAPCKQRISVQRESQSRTPRAGVSPKKAHPCEMCGLILEDVFHFADHQETHHKQKLNRSGACGKNLDDTAYLHQHQKQHIGEKFYRKSVREASFVKKRKLRVSQEPFVFREFGKDVLPSSGLCQEEAAVEKTDSETMHGPPFQEGKTNYSCGKRTKAFSTKHSVIPHQKLFTRDGCYVCSDCGKSFSRYVSFSNHQRDHTAKGPYDCGECGKSYSRKSSLIQHQRVHTGQTAYPCEECGKSFSQKGSLISHQLVHTGEGPYECRECGKSFGQKGNLIQHQQGHTGERAYHCGECGKSFRQKFCFINHQRVHTGERPYKCGECGKSFGQKGNLVHHQRGHTGERPYECKECGKSFRYRSHLTEHQRLHTGERPYNCRECGKLFNRKYHLLVHERVHTGERPYACEVCGKLFGNKHSVTIHQRIHTGERPYECSECGKSFLSSSALHVHKRVHSGQKPYKCSECGKSFSECSSLIKHRRIHTGERPYECTKCGKTFQRSSTLLHHQSSHRRKAL>sp|Q96SQ5-2|ZN587_HUMAN Isoform 2 of Zinc finger protein 587 OS=Homosapiens OX=9606 GN=ZNF587MAAAVPRRPTQGTVTFEDVAVNFSQEEWCLLSEAQRCLYRDVMLENLALISSLGCWCGSKDEEAPCKQRISVQRESQSRTPRAGVSPKKAHPCEMCGLILEDVFHFADHQETHHKQKLNRSGACGKNLDDTAYLHQHQKQHIGEKFYRKSVREASFVKKRKLRVSQEPFVFREFGKDVLPSSGLCQEEAAVEKTDSETMHGPPFQEGKTNYSCGKRTKAFSTKHSVIPHQKLFTRDGCYVCSDCGKSFSRYVSFSNHQRDHTAKGPYDCGECGKSYSRKSSLIQHQRVHTGQTAYPCEECGKSFSQKGSLISHQLVHTGEGPYECRECGKSFGQKGNLIQHQQGHTGERAYHCGECGKSFRQKFCFINHQRVHTGERPYKCGECGKSFGQKGNLVHHQRGHTGERPYECKECGKSFRYRSHLTEHQRLHTGERPYNCRECGKLFNRKYHLLVHERVHTGERPYACEVCGKLFGNKHSVTIHQRIHTGERPYECSECGKSFLSSSALHVHKRVHSGQKPYKCSECGKSFSECSSLIKHRRIHTGERPYECTKCGKTFQRSSTLLHHQSSHRRKAL>sp|Q15619|OR1C1_HUMAN Olfactory receptor 1C1 OS=Homo sapiens OX=9606GN=OR1C1 PE=2 SV=4MEKRNLTVVREFVLLGLPSSAEQQHLLSVLFLCMYLATTLGNMLIIATIGFDSHLHSPMYFFLSNLAFVDICFTSTTVPQMVVNILTGTKTISFAGCLTQLFFFVSFVNMDSLLLCVMAYDRYVAICHPLHYTARMNLCLCVQLVAGLWLVTYLHALLHTVLIAQLSFCASNIIHHFFCDLNPLLQLSCSDVSFNVMIIFAVGGLLALTPLVCILVSYGLIFSTVLKITSTQGKQRAVSTCSCHLSVVVLFYGTAIAVYFSPSSPHMPESDTLSTIMYSMVAPMLNPFIYTLRNRDMKRGLQKMLLKCTVFQQQ>sp|Q9H4B0|OSGP2_HUMAN Probable tRNA N6-adenosinethreonylcarbamoyltransferase, mitochondrial OS=Homo sapiens OX=9606GN=OSGEPL1 PE=2 SV=2MLILTKTAGVFFKPSKRKVYEFLRSFNFHPGTLFLHKIVLGIETSCDDTAAAVVDETGNVLGEAIHSQTEVHLKTGGIVPPAAQQLHRENIQRIVQEALSASGVSPSDLSAIATTIKPGLALSLGVGLSFSLQLVGQLKKPFIPIHHMEAHALTIRLTNKVEFPFLVLLISGGHCLLALVQGVSDFLLLGKSLDIAPGDMLDKVARRLSLIKHPECSTMSGGKAIEHLAKQGNRFHFDIKPPLHHAKNCDFSFTGLQHVTDKIIMKKEKEEGIEKGQILSSAADIAATVQHTMACHLVKRTHRAILFCKQRDLLPQNNAVLVASGGVASNFYIRRALEILTNATQCTLLCPPPRLCTDNGIMIAWNGIERLRAGLGILHDIEGIRYEPKCPLGVDISKEVGEASIKVPQLKMEI>sp|Q9H4B0-2|OSGP2_HUMAN Isoform 2 of Probable tRNA N6-adenosinethreonylcarbamoyltransferase, mitochondrial OS=Homo sapiens OX=9606GN=OSGEPL1MLILTKTAGVFFKPSKRKVYEFLRSFNFHPGTLFLHKIVLGIETSCDDTAAAVVDETGNVLGEAIHSQTEVHLKTGGIVPPAAQQLHRENIQRIVQEALSASGVSPSDLSAIATTIKPGLALSLGVGLSFSLQLVGQLKKPFIPIHHMEAHALTIRLTNKVEFPFLVLLISGGHCLLALVQGVSDFLLLGKSLDIAPGDMLDKVARRLSLIKHPECSTMSGGKAIEHLAKQGNRFHFDIKPPLHHAKNCDFSFTGLQHVTDKIIMKKEKEEGIEKGQILSSAADIAATVQHTMACHLVKRTHRAILFCKQRDLLPQNNAVLVASGGVASNFYIRRALEILTNATQCTLLCPPPRLCTDNGIMIA>sp|Q9H4B0-3|OSGP2_HUMAN Isoform 3 of Probable tRNA N6-adenosinethreonylcarbamoyltransferase, mitochondrial OS=Homo sapiens OX=9606GN=OSGEPL1MLILTKTAGVFFKPSKRKVYEFLRSFNFHPGTLFLHKIVLGIETSCDDTAAAVVDETGNVLGEAIHSQTEVHLKTGGIVPPAAQQLHRENIQRIVQEALSASGVSPSDLSAIATTIKPGLALSLGVGLSFSLQLVGQLKKPFIPIHHMEAHALTIRLTNKVEFPFLVLLISGGHCLLALVQGVSDFLLLGKSLDIAPGDMLDKVARRLSLIKHPECSTMSGGKAIEHLAKQGNRFHFDIKPPLHHAKNCDFSFTGLQHVTDKIIMKKEKEEGIFLISKVEQINIPGLCLKIAAHFCRY>sp|Q8NFH4|NUP37_HUMAN Nucleoporin Nup37 OS=Homo sapiens OX=9606 GN=NUP37PE=1 SV=1MKQDASRNAAYTVDCEDYVHVVEFNPFENGDSGNLIAYGGNNYVVIGTCTFQEEEADVEGIQYKTLRTFHHGVRVDGIAWSPETRLDSLPPVIKFCTSAADMKIRLFTSDLQDKNEYKVLEGHTDFINGLVFDPKEGQEIASVSDDHTCRIWNLEGVQTAHFVLHSPGMSVCWHPEETFKLMVAEKNGTIRFYDLLAQQAILSLESEQVPLMSAHWCLKNTFKVGAVAGNDWLIWDITRSSYPQNKRPVHMDRACLFRWSTISENLFATTGYPGKMASQFQIHHLGHPQPILMGSVAVGSGLSWHRTLPLCVIGGDHKLLFWVTEV>sp|Q9Y5N6|ORC6_HUMAN Origin recognition complex subunit 6 OS=Homosapiens OX=9606 GN=ORC6 PE=1 SV=1MGSELIGRLAPRLGLAEPDMLRKAEEYLRLSRVKCVGLSARTTETSSAVMCLDLAASWMKCPLDRAYLIKLSGLNKETYQSCLKSFECLLGLNSNIGIRDLAVQFSCIEAVNMASKILKSYESSLPQTQQVDLDLSRPLFTSAALLSACKILKLKVDKNKMVATSGVKKAIFDRLCKQLEKIGQQVDREPGDVATPPRKRKKIVVEAPAKEMEKVEEMPHKPQKDEDLTQDYEEWKRKILENAASAQKATAE>sp|Q8N1F7|NUP93_HUMAN Nuclear pore complex protein Nup93 OS=Homo sapiensOX=9606 GN=NUP93 PE=1 SV=2MDTEGFGELLQQAEQLAAETEGISELPHVERNLQEIQQAGERLRSRTLTRTSQETADVKASVLLGSRGLDISHISQRLESLSAATTFEPLEPVKDTDIQGFLKNEKDNALLSAIEESRKRTFGMAEEYHRESMLVEWEQVKQRILHTLLASGEDALDFTQESEPSYISDVGPPGRSSLDNIEMAYARQIYIYNEKIVNGHLQPNLVDLCASVAELDDKSISDMWTMVKQMTDVLLTPATDALKNRSSVEVRMEFVRQALAYLEQSYKNYTLVTVFGNLHQAQLGGVPGTYQLVRSFLNIKLPAPLPGLQDGEVEGHPVWALIYYCMRCGDLLAASQVVNRAQHQLGEFKTWFQEYMNSKDRRLSPATENKLRLHYRRALRNNTDPYKRAVYCIIGRCDVTDNQSEVADKTEDYLWLKLNQVCFDDDGTSSPQDRLTLSQFQKQLLEDYGESHFTVNQQPFLYFQVLFLTAQFEAAVAFLFRMERLRCHAVHVALVLFELKLLLKSSGQSAQLLSHEPGDPPCLRRLNFVRLLMLYTRKFESTDPREALQYFYFLRDEKDSQGENMFLRCVSELVIESREFDMILGKLENDGSRKPGVIDKFTSDTKPIINKVASVAENKGLFEEAAKLYDLAKNADKVLELMNKLLSPVVPQISAPQSNKERLKNMALSIAERYRAQGISANKFVDSTFYLLLDLITFFDEYHSGHIDRAFDIIERLKLVPLNQESVEERVAAFRNFSDEIRHNLSEVLLATMNILFTQFKRLKGTSPSSSSRPQRVIEDRDSQLRSQARTLITFAGMIPYRTSGDTNARLVQMEVLMN>sp|Q8N1F7-2|NUP93_HUMAN Isoform 2 of Nuclear pore complex protein Nup93OS=Homo sapiens OX=9606 GN=NUP93MAEEYHRESMLVEWEQVKQRILHTLLASGEDALDFTQESEPSYISDVGPPGRSSLDNIEMAYARQIYIYNEKIVNGHLQPNLVDLCASVAELDDKSISDMWTMVKQMTDVLLTPATDALKNRSSVEVRMEFVRQALAYLEQSYKNYTLVTVFGNLHQAQLGGVPGTYQLVRSFLNIKLPAPLPGLQDGEVEGHPVWALIYYCMRCGDLLAASQVVNRAQHQLGEFKTWFQEYMNSKDRRLSPATENKLRLHYRRALRNNTDPYKRAVYCIIGRCDVTDNQSEVADKTEDYLWLKLNQVCFDDDGTSSPQDRLTLSQFQKQLLEDYGESHFTVNQQPFLYFQVLFLTAQFEAAVAFLFRMERLRCHAVHVALVLFELKLLLKSSGQSAQLLSHEPGDPPCLRRLNFVRLLMLYTRKFESTDPREALQYFYFLRDEKDSQGENMFLRCVSELVIESREFDMILGKLENDGSRKPGVIDKFTSDTKPIINKVASVAENKGLFEEAAKLYDLAKNADKVLELMNKLLSPVVPQISAPQSNKERLKNMALSIAERYRAQGISANKFVDSTFYLLLDLITFFDEYHSGHIDRAFDIIERLKLVPLNQESVEERVAAFRNFSDEIRHNLSEVLLATMNILFTQFKRLKGTSPSSSSRPQRVIEDRDSQLRSQARTLITFAGMIPYRTSGDTNARLVQMEVLMN>sp|Q8NGD5|OR4KE_HUMAN Olfactory receptor 4K14 OS=Homo sapiens OX=9606GN=OR4K14 PE=3 SV=1MDPQNYSLVSEFVLHGLCTSRHLQNFFFIFFFGVYVAIMLGNLLILVTVISDPCLHSSPMYFLLGNLAFLDMWLASFATPKMIRDFLSDQKLISFGGCMAQIFFLHFTGGAEMVLLVSMAYDRYVAICKPLHYMTLMSWQTCIRLVLASWVVGFVHSISQVAFTVNLPYCGPNEVDSFFCDLPLVIKLACMDTYVLGIIMISDSGLLSLSCFLLLLISYTVILLAIRQRAAGSTSKALSTCSAHIMVVTLFFGPCIFVYVRPFSRFSVDKLLSVFYTIFTPLLNPIIYTLRNEEMKAAMKKLQNRRVTFQ>sp|Q8NH64|O51A7_HUMAN Olfactory receptor 51A7 OS=Homo sapiens OX=9606GN=OR51A7 PE=2 SV=1MSVLNNSEVKLFLLIGIPGLEHAHIWFSIPICLMYLLAIMGNCTILFIIKTEPSLHEPMYYFLAMLAVSDMGLSLSSLPTMLRVFLFNAMGISPNACFAQEFFIHGFTVMESSVLLIMSLDRFLAIHNPLRYSSILTSNRVAKMGLILAIRSILLVIPFPFTLRRLKYCQKNLLSHSYCLHQDTMKLACSDNKTNVIYGFFIALCTMLDLALIVLSYVLILKTILSIASLAERLKALNTCVSHICAVLTFYVPIITLAAMHHFAKHKSPLVVILIADMFLLVPPLMNPIVYCVKTRQIWEKILGKLLNVCGR>sp|Q8NGK1|O51G1_HUMAN Olfactory receptor 51G1 OS=Homo sapiens OX=9606GN=OR51G1 PE=2 SV=1MTILLNSSLQRATFFLTGFQGLEGLHGWISIPFCFIYLTVILGNLTILHVICTDATLHGPMYYFLGMLAVTDLGLCLSTLPTVLGIFWFDTREIGIPACFTQLFFIHTLSSMESSVLLSMSIDRYVAVCNPLHDSTVLTPACIVKMGLSSVLRSALLILPLPFLLKRFQYCHSHVLAHAYCLHLEIMKLACSSIIVNHIYGLFVVACTVGVDSLLIFLSYALILRTVLSIASHQERLRALNTCVSHICAVLLFYIPMIGLSLVHRFGEHLPRVVHLFMSYVYLLVPPLMNPIIYSIKTKQIRQRIIKKFQFIKSLRCFWKD>sp|Q7RTS6|OTOP2_HUMAN Proton channel OTOP2 OS=Homo sapiens OX=9606GN=OTOP2 PE=1 SV=3MSEELAQGPKESPPAPRAGPREVWKKGGRLLSVLLAVNVLLLACTLISGGAFNKVAVYDTDVFALLTAMMLLATLWILFYLLRTVRCPCAVPYRDAHAGPIWLRGGLVLFGICTLIMDVFKTGYYSSFFECQSAIKILHPLIQAVFVIIQTYFLWVSAKDCVHVHLDLTWCGLMFTLTTNLAIWMAAVVDESVHQSHSYSSSHSNASHARLISDQHADNPVGGDSCLCSTAVCQIFQQGYFYLYPFNIEYSLFASTMLYVMWKNVGRFLASTPGHSHTPTPVSLFRETFFAGPVLGLLLFVVGLAVFIIYEVQVSGDGSRTRQALVIYYSFNIVCLGLTTLVSLSGSIIYRFDRRAMDHHKNPTRTLDVALLMGAALGQYAISYYSIVAVVAGTPQDLLAGLNLTHALLMIAQHTFQNMFIIESLHRGPPGAEPHSTHPKEPCQDLTFTNLDALHTLSACPPNPGLVSPSPSDQREAVAIVSTPRSQWRRQCLKDISLFLLLCNVILWIMPAFGARPHFSNTVEVDFYGYSLWAVIVNICLPFGIFYRMHAVSSLLEVYVLS>sp|Q8NGI9|OR5A2_HUMAN Olfactory receptor 5A2 OS=Homo sapiens OX=9606GN=OR5A2 PE=2 SV=1MAVGRNNTIVTKFILLGLSDHPQMKIFLFMLFLGLYLLTLAWNLSLIALIKMDSHLHMPMYFFLSNLSFLDICYVSSTAPKMLSDIITEQKTISFVGCATQYFVFCGMGLTECFLLAAMAYDRYAAICNPLLYTVLISHTLCLKMVVGAYVGGFLSSFIETYSVYQHDFCGPYMINHFFCDLPPVLALSCSDTFTSEVVTFIVSVVVGIVSVLVVLISYGYIVAAVVKISSATGRTKAFSTCASHLTAVTLFYGSGFFMYMRPSSSYSLNRDKVVSIFYALVIPVVNPIIYSFRNKEIKNAMRKAMERDPGISHGGPFIFMTLG>sp|Q8NGZ4|OR2G3_HUMAN Olfactory receptor 2G3 OS=Homo sapiens OX=9606GN=OR2G3 PE=2 SV=1MGLGNESSLMDFILLGFSDHPRLEAVLFVFVLFFYLLTLVGNFTIIIISYLDPPLHTPMYFFLSNLSLLDICFTTSLAPQTLVNLQRPKKTITYGGCVAQLYISLALGSTECILLADMALDRYIAVCKPLHYVVIMNPRLCQQLASISWLSGLASSLIHATFTLQLPLCGNHRLDHFICEVPALLKLACVDTTVNELVLFVVSVLFVVIPPALISISYGFITQAVLRIKSVEARHKAFSTCSSHLTVVIIFYGTIIYVYLQPSDSYAQDQGKFISLFYTMVTPTLNPIIYTLRNKDMKEALRKLLSGKL>sp|Q96R69|OR4F4_HUMAN Olfactory receptor 4F4 OS=Homo sapiens OX=9606GN=OR4F4 PE=2 SV=2MVTEFIFLGLSDSQELQTFLFMLFFVFYGGIVFGNLLIVITVVSDSHLHSPMYFLLANLSLIDLSLSSVTAPKMITDFFSQRKVISFKGCLVQIFLLHFFGGSEMVILIAMGFDRYIAICKPLHYTTIMCGNACVGIMAVAWGIGFLHSVSQLAFAVHLPFCGPNEVDSFYCDLPRVIKLACTDTYRLDIMVIANSGVLTVCSFVLLIISYTIILMTIQHCPLDKSSKALSTLTAHITVVLLFFGPCVFIYAWPFPIKSLDKFLAVFYSVITPLLNPIIYTLRNKDMKTAIRRLRKWDAHSSVKF>sp|A6NMZ5|O4C45_HUMAN Olfactory receptor 4C45 OS=Homo sapiens OX=9606GN=OR4C45 PE=3 SV=1MNNVIEFILLGLTHNPELQKFLFVMFLITYLITLAGNLFISVIIFISPALGSPMYSFPSYLFIIDIFCSSSIAPKMNFDLISEKNTISFNGCMTQLFTEHFFYYYYYYTLTEIILLSVMAYDHYVAIRKPLHYATIMSQPMCGFLMVVAGILGFVHGGIQTLFIAQLPFCGPNVINHFMCDLVPLLELACTDTHTLGPLIAANSGSLCFLIFSMLVASYVIILCFLRTHSSEGRRKALSSCASHIFIVILFFVPFSYLYLRPTSFPTDKAVTVFCTLFTPMLNPLIYTLKNKEVKNVIKKLWKQIMTTDDK>sp|Q6ZW49|PAXI1_HUMAN PAX-interacting protein 1 OS=Homo sapiens OX=9606GN=PAXIP1 PE=1 SV=2MSDQAPKVPEEMFREVKYYAVGDIDPQVIQLLKAGKAKEVSYNALASHIISEDGDNPEVGEAREVFDLPVVKPSWVILSVQCGTLLPVNGFSPESCQIFFGITACLSQVSSEDRSALWALVTFYGGDCQLTLNKKCTHLIVPEPKGEKYECALKRASIKIVTPDWVLDCVSEKTKKDEAFYHPRLIIYEEEEEEEEEEEEVENEEQDSQNEGSTDEKSSPASSQEGSPSGDQQFSPKSNTEKSKGELMFDDSSDSSPEKQERNLNWTPAEVPQLAAAKRRLPQGKEPGLINLCANVPPVPGNILPPEVRGNLMAAGQNLQSSERSEMIATWSPAVRTLRNITNNADIQQMNRPSNVAHILQTLSAPTKNLEQQVNHSQQGHTNANAVLFSQVKVTPETHMLQQQQQAQQQQQQHPVLHLQPQQIMQLQQQQQQQISQQPYPQQPPHPFSQQQQQQQQAHPHQFSQQQLQFPQQQLHPPQQLHRPQQQLQPFQQQHALQQQFHQLQQHQLQQQQLAQLQQQHSLLQQQQQQQIQQQQLQRMHQQQQQQQMQSQTAPHLSQTSQALQHQVPPQQPPQQQQQQQPPPSPQQHQLFGHDPAVEIPEEGFLLGCVFAIADYPEQMSDKQLLATWKRIIQAHGGTVDPTFTSRCTHLLCESQVSSAYAQAIRERKRCVTAHWLNTVLKKKKMVPPHRALHFPVAFPPGGKPCSQHIISVTGFVDSDRDDLKLMAYLAGAKYTGYLCRSNTVLICKEPTGLKYEKAKEWRIPCVNAQWLGDILLGNFEALRQIQYSRYTAFSLQDPFAPTQHLVLNLLDAWRVPLKVSAELLMSIRLPPKLKQNEVANVQPSSKRARIEDVPPPTKKLTPELTPFVLFTGFEPVQVQQYIKKLYILGGEVAESAQKCTHLIASKVTRTVKFLTAISVVKHIVTPEWLEECFRCQKFIDEQNYILRDAEAEVLFSFSLEESLKRAHVSPLFKAKYFYITPGICPSLSTMKAIVECAGGKVLSKQPSFRKLMEHKQNSSLSEIILISCENDLHLCREYFARGIDVHNAEFVLTGVLTQTLDYESYKFN>sp|Q6ZW49-1|PAXI1_HUMAN Isoform 2 of PAX-interacting protein 1 OS=Homosapiens OX=9606 GN=PAXIP1MVFLQNHVRFFLESLPAFLRVLIQAGALCWSLPELSQGEVGKGACPAEVGKHRDHLPSSDPVLMQAEASVVMCWVSSEDRSALWALVTFYGGDCQLTLNKKCTHLIVPEPKGEKYECALKRASIKIVTPDWVLDCVSEKTKKDEAFYHPRLIIYEEEEEEEEEEEEVENEEQDSQNEGSTDEKSSPASSQEGSPSGDQQFSPKSNTEKSKGELMFDDSSDSSPEKQERNLNWTPAEVPQLAAAKRRLPQGKEPGLINLCANVPPVPGNILPPEVRGNLMAAGQNLQSSERSEMIATWSPAVRTLRNITNNADIQQMNRPSNVAHILQTLSAPTKNLEQQVNHSQQGHTNANAVLFSQVKVTPETHMLQQQQQAQQQQQQHPVLHLQPQQIMQLQQQQQQQISQQPYPQQPPHPFSQQQQQQQQAHPHQFSQQQLQFPQQQLHPPQQLHRPQQQLQPFQQQHALQQQFHQLQQHQLQQQQLAQLQQQHSLLQQQQQQQIQQQQLQRMHQQQQQQQMQSQTAPHLSQTSQALQHQVPPQQPPQQQQQQQPPPSPQQHQLFGHDPAVEIPEEGFLLGCVFAIADYPEQMSDKQLLATWKRIIQAHGGTVDPTFTSRCTHLLCESQVSSAYAQAIRERKRCVTAHWLNTVLKKKKMVPPHRALHFPVAFPPGGKPCSQHIISVTGFVDSDRDDLKLMAYLAGAKYTGYLCRSNTVLICKEPTGLKYEKAKEWRIPCVNAQWLGDILLGNFEALRQIQYSRYTAFSLQDPFAPTQHLVLNLLDAWRVPLKVSAELLMSIRLPPKLKQNEVANVQPSSKRARIEDVPPPTKKLTPELTPFVLFTGFEPVQVQQYIKKLYILGGEVAESAQKCTHLIASKVTRTVKFLTAISVVKHIVTPEWLEECFRCQKFIDEQNYILRDAEAEVLFSFSLEESLKRAHVSPLFKAKYFYITPGICPSLSTMKAIVECAGGKVLSKQPSFRKLMEHKQNSSLSEIILISCENDLHLCREYFARGIDVHNAEFVLTGVLTQTLDYESYKFN>sp|Q6ZW49-2|PAXI1_HUMAN Isoform 3 of PAX-interacting protein 1 OS=Homosapiens OX=9606 GN=PAXIP1MFDDSSDSSPEKQERNLNWTPAEVPQLAAAKRRLPQGKEPGLINLCANVPPVPGNILPPEVRGNLMAAGQNLQSSERSEMIATWSPAVRTLRNITNNADIQQMNRPSNVAHILQTLSAPTKNLEQQVNHSQQGHTNANAVLFSQVKVTPETHMLQQQQQAQQQQQQHPVLHLQPQQIMQLQQQQQQQISQQPYPQQPPHPFSQQQQQQQQAHPHQFSQQQLQFPQQQLHPPQQLHRPQQQLQPFQQQHALQQQFHQLQQHQLQQQQLAQLQQQHSLLQQQQQQQIQQQQLQRMHQQQQQQQMQSQTAPHLSQTSQALQHQVPPQQPPQQQQQQQPPPSPQQHQLFGHDPAVEIPEEGFLLGCVFAIADYPEQMSDKQLLATWKRIIQAHGGTVDPTFTSRCTHLLCESQVSSAYAQAIRERKRCVTAHWLNTVLKKKKMVPPHRALHFPVAFPPGGKPCSQHIISVTGFVDSDRDDLKLMAYLAGAKYTGYLCRSNTVLICKEPTGLKYEKAKEWRIPCVNAQWLGDILLGNFEALRQIQYSRYTAFSLQDPFAPTQHLVLNLLDAWRVPLKVSAELLMSIRLPPKLKQNEVANVQPSSKRARIEDVPPPTKKLTPELTPFVLFTGFEPVQVQQYIKKLYILGGEVAESAQKCTHLIASKVTRTVKFLTAISVVKHIVTPEWLEECFRCQKFIDEQNYILRDAEAEVLFSFSLEESLKRAHVSPLFKAKYFYITPGICPSLSTMKAIVECAGGKVLSKQPSFRKLMEHKQNSSLSEIILISCENDLHLCREYFARGIDVHNAEFVLTGVLTQTLDYESYKFN>sp|Q86WC6|PPR27_HUMAN Protein phosphatase 1 regulatory subunit 27OS=Homo sapiens OX=9606 GN=PPP1R27 PE=1 SV=1MPSRTARYARYSPRQRRRRMLADRSVRFPNDVLFLDHIRQGDLEQVGRFIRTRKVSLATIHPSGLAALHEAVLSGNLECVKLLVKYGADIHQRDEAGWTPLHIACSDGYPDIARYLISLGADRDATNDDGDLPSDLIDPDYKELVELFKGTTMD>sp|P10619|PPGB_HUMAN Lysosomal protective protein OS=Homo sapiensOX=9606 GN=CTSA PE=1 SV=2MIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSSLDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYAGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNSGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWDMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKMEVQRRPWLVKYGDSGEQIAGFVKEFSHIAFLTIKGAGHMVPTDKPLAAFTMFSRFLNKQPY>sp|P10619-2|PPGB_HUMAN Isoform 2 of Lysosomal protective protein OS=Homosapiens OX=9606 GN=CTSAMIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSSLDGLLTEHGPFLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYAGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNSGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWDMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKMEVQRRPWLVKYGDSGEQIAGFVKEFSHIAFLTIKGAGHMVPTDKPLAAFTMFSRFLNKQPY>sp|Q13522|PPR1A_HUMAN Protein phosphatase 1 regulatory subunit 1AOS=Homo sapiens OX=9606 GN=PPP1R1A PE=1 SV=2MEQDNSPRKIQFTVPLLEPHLDPEAAEQIRRRRPTPATLVLTSDQSSPEIDEDRIPNPHLKSTLAMSPRQRKKMTRITPTMKELQMMVEHHLGQQQQGEEPEGAAESTETQESRPPGIPDTEVESRLGTSGTAKKTAECIPKTHERGSKEPSTKEPSTHIPPLDSKGANSV>sp|Q6NUP7|PP4R4_HUMAN Serine/threonine-protein phosphatase 4 regulatorysubunit 4 OS=Homo sapiens OX=9606 GN=PPP4R4 PE=1 SV=1MHPPPPAAAMDFSQNSLFGYMEDLQELTIIERPVRRSLKTPEEIERLTVDEDLSDIERAVYLLSAGQDVQGTSVIANLPFLMRQNPTETLRRVLPKVREALHVAGVEMQLTAAMSFLTILQDESVSIHAYTHSFLQVILLHLEHRDTGVSNAWLETLLSVIEVLPKETLRHEILNPLVSKAQLSQTVQSRLVSCKILGKLTNKFDAHTIKREILPLVKSLCQDVEYEVRSCMCRQLENIAQGIGTELTKSVVLPELIELSRDEGSSVRLAAFETLVNLLDIFDTDDRSQTILPLVKSFCEKSFKADESILISLSFHLGKLCHGLYGIFTPDQHLRFLEFYKKLCTLGLQQENGHNENQIPPQILEQEKKYISVRKNCAYNFPAMIVFVDPKNFHMELYSTFFCLCHDPEVPVRYTIAICFYEVSKLLNSGVYLIHKELITLLQDESLEVLDALIDHLPEILELMSTGGESSVQENKLSSLPDLIPALTAAEQRAAASLKWRTHEKLLQKYACLPHVISSDQIYYRFLQRMFTIMMTNNVLPVQKAASRTLCIFLRYNRKQEQRHEVIQKLIEQLGQGKSYWNRLRFLDTCEFIIEIFSKSFFCKYFFLPAIELTHDPVANVRMKLCYLLPKVKSTLKIPADKHLLQQLEMCVRKLLCQEKDKDVLAIVKRTVLELDRMEMSMDAFQKKFYEKDLLDQEKEREELLLLEMEQLEKEKQQNDGRPMSDKMFEKKRRDTKTPTQSLPKNIPISVPGPSSVTPSTSKEIKKSKLIRSQSFNNQAFHAKYGNLEKCASKSSTTGYTTSVSGLGKTSVLSLADDSFRTRNASSVPSSFSPNTPLPSTSRGTGNSVDPKSSGSKDTQPRKATLKSRKSNP>sp|Q6NUP7-2|PP4R4_HUMAN Isoform 2 of Serine/threonine-proteinphosphatase 4 regulatory subunit 4 OS=Homo sapiens OX=9606 GN=PPP4R4MHPPPPAAAMDFSQNSLFGYMEDLQELTIIERPVRRSLKTPEEIERLTVDEDLSDIERAVYLLSAGQDVQGTSVIANLPFLMRQNPTETLRRVLPKVRVHEDAHLFIQRVWISHMFVQRV>sp|P11464|PSG1_HUMAN Pregnancy-specific beta-1-glycoprotein 1 OS=Homosapiens OX=9606 GN=PSG1 PE=1 SV=1MGTLSAPPCTQRIKWKGLLLTASLLNFWNLPTTAQVTIEAEPTKVSEGKDVLLLVHNLPQNLTGYIWYKGQMRDLYHYITSYVVDGEIIIYGPAYSGRETAYSNASLLIQNVTREDAGSYTLHIIKGDDGTRGVTGRFTFTLHLETPKPSISSSNLNPRETMEAVSLTCDPETPDASYLWWMNGQSLPMTHSLKLSETNRTLFLLGVTKYTAGPYECEIRNPVSASRSDPVTLNLLPKLPKPYITINNLNPRENKDVLNFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIRDRYGGIRSDPVTLNVLYGPDLPRIYPSFTYYRSGEVLYLSCSADSNPPAQYSWTINEKFQLPGQKLFIRHITTKHSGLYVCSVRNSATGKESSKSMTVEVSDWTVP>sp|P11464-2|PSG1_HUMAN Isoform 2 of Pregnancy-specific beta-1-glycoprotein 1 OS=Homo sapiens OX=9606 GN=PSG1MGTLSAPPCTQRIKWKGLLLTASLLNFWNLPTTAQVTIEAEPTKVSEGKDVLLLVHNLPQNLTGYIWYKGQMRDLYHYITSYVVDGEIIIYGPAYSGRETAYSNASLLIQNVTREDAGSYTLHIIKGDDGTRGVTGRFTFTLHLETPKPSISSSNLNPRETMEAVSLTCDPETPDASYLWWMNGQSLPMTHSLKLSETNRTLFLLGVTKYTAGPYECEIRNPVSASRSDPVTLNLLPKLPKPYITINNLNPRENKDVLNFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIRDRYGGIRSDPVTLNVLYGPDLPRIYPSFTYYRSGEVLYLSCSADSNPPAQYSWTINEKFQLPGQKLFIRHITTKHSGLYVCSVRNSATGKESSKSMTVEVSAYSSSINYTSGNRN>sp|P11464-3|PSG1_HUMAN Isoform 3 of Pregnancy-specific beta-1-glycoprotein 1 OS=Homo sapiens OX=9606 GN=PSG1MGTLSAPPCTQRIKWKGLLLTASLLNFWNLPTTAQVTIEAEPTKVSEGKDVLLLVHNLPQNLTGYIWYKGQMRDLYHYITSYVVDGEIIIYGPAYSGRETAYSNASLLIQNVTREDAGSYTLHIIKGDDGTRGVTGRFTFTLHLETPKPSISSSNLNPRETMEAVSLTCDPETPDASYLWWMNGQSLPMTHSLKLSETNRTLFLLGVTKYTAGPYECEIRNPVSASRSDPVTLNLLPKLPKPYITINNLNPRENKDVLNFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIRDRYGGIRSDPVTLNVLYGPDLPRIYPSFTYYRSGEVLYLSCSADSNPPAQYSWTINEKFQLPGQKLFIRHITTKHSGLYVCSVRNSATGKESSKSMTVEVSEAL>sp|P11464-4|PSG1_HUMAN Isoform 4 of Pregnancy-specific beta-1-glycoprotein 1 OS=Homo sapiens OX=9606 GN=PSG1MGTLSAPPCTQRIKWKGLLLTASLLNFWNLPTTAQVTIEAEPTKVSEGKDVLLLVHNLPQNLTGYIWYKGQMRDLYHYITSYVVDGEIIIYGPAYSGRETAYSNASLLIQNVTREDAGSYTLHIIKGDDGTRGVTGRFTFTLHLETPKPSISSSNLNPRETMEAVSLTCDPETPDASYLWWMNGQSLPMTHSLKLSETNRTLFLLGVTKYTAGPYECEIRNPVSASRSDPVTLNLLPKLPKPYITINNLNPRENKDVLNFTCEPKSENYTYIWWLNGQSLPVSPRVKRPIENRILILPSVTRNETGPYQCEIRDRYGGIRSDPVTLNVLYGPDLPRIYPSFTYYRSGEVLYLSCSADSNPPAQYSWTINEKFQLPGQKLFIRHITTKHSGLYVCSVRNSATGKESSKSMTVEVSGKWIPASLAIGF>sp|P23468|PTPRD_HUMAN Receptor-type tyrosine-protein phosphatase deltaOS=Homo sapiens OX=9606 GN=PTPRD PE=1 SV=2MVHVARLLLLLLTFFLRTDAETPPRFTRTPVDQTGVSGGVASFICQATGDPRPKIVWNKKGKKVSNQRFEVIEFDDGSGSVLRIQPLRTPRDEAIYECVASNNVGEISVSTRLTVLREDQIPRGFPTIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDTSNNNGRIKQLRSESIGGTPIRGALQIEQSEESDQGKYECVATNSAGTRYSAPANLYVRELREVRRVPPRFSIPPTNHEIMPGGSVNITCVAVGSPMPYVKWMLGAEDLTPEDDMPIGRNVLELNDVRQSANYTCVAMSTLGVIEAIAQITVKALPKPPGTPVVTESTATSITLTWDSGNPEPVSYYIIQHKPKNSEELYKEIDGVATTRYSVAGLSPYSDYEFRVVAVNNIGRGPPSEPVLTQTSEQAPSSAPRDVQARMLSSTTILVQWKEPEEPNGQIQGYRVYYTMDPTQHVNNWMKHNVADSQITTIGNLVPQKTYSVKVLAFTSIGDGPLSSDIQVITQTGVPGQPLNFKAEPESETSILLSWTPPRSDTIANYELVYKDGEHGEEQRITIEPGTSYRLQGLKPNSLYYFRLAARSPQGLGASTAEISARTMQSKPSAPPQDISCTSPSSTSILVSWQPPPVEKQNGIITEYSIKYTAVDGEDDKPHEILGIPSDTTKYLLEQLEKWTEYRITVTAHTDVGPGPESLSVLIRTNEDVPSGPPRKVEVEAVNSTSVKVSWRSPVPNKQHGQIRGYQVHYVRMENGEPKGQPMLKDVMLADAQWEFDDTTEHDMIISGLQPETSYSLTVTAYTTKGDGARSKPKLVSTTGAVPGKPRLVINHTQMNTALIQWHPPVDTFGPLQGYRLKFGRKDMEPLTTLEFSEKEDHFTATDIHKGASYVFRLSARNKVGFGEEMVKEISIPEEVPTGFPQNLHSEGTTSTSVQLSWQPPVLAERNGIITKYTLLYRDINIPLLPMEQLIVPADTTMTLTGLKPDTTYDVKVRAHTSKGPGPYSPSVQFRTLPVDQVFAKNFHVKAVMKTSVLLSWEIPENYNSAMPFKILYDDGKMVEEVDGRATQKLIVNLKPEKSYSFVLTNRGNSAGGLQHRVTAKTAPDVLRTKPAFIGKTNLDGMITVQLPEVPANENIKGYYIIIVPLKKSRGKFIKPWESPDEMELDELLKEISRKRRSIRYGREVELKPYIAAHFDVLPTEFTLGDDKHYGGFTNKQLQSGQEYVFFVLAVMEHAESKMYATSPYSDPVVSMDLDPQPITDEEEGLIWVVGPVLAVVFIICIVIAILLYKRKRAESDSRKSSIPNNKEIPSHHPTDPVELRRLNFQTPGMASHPPIPILELADHIERLKANDNLKFSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVLLSAIEGIPGSDYVNANYIDGYRKQNAYIATQGSLPETFGDFWRMIWEQRSATVVMMTKLEERSRVKCDQYWPSRGTETHGLVQVTLLDTVELATYCVRTFALYKNGSSEKREVRQFQFTAWPDHGVPEHPTPFLAFLRRVKTCNPPDAGPMVVHCSAGVGRTGCFIVIDAMLERIKHEKTVDIYGHVTLMRAQRNYMVQTEDQYIFIHDALLEAVTCGNTEVPARNLYAYIQKLTQIETGENVTGMELEFKRLASSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWEHNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDQYQFSYRAALEYLGSFDHYAT>sp|P23468-2|PTPRD_HUMAN Isoform 2 of Receptor-type tyrosine-proteinphosphatase delta OS=Homo sapiens OX=9606 GN=PTPRDMVHVARLLLLLLTFFLRTDAETPPRFTRTPVDQTGVSGGVASFICQATGDPRPKIVWNKKGKKVSNQRFEVIEFDDGSGSVLRIQPLRTPRDEAIYECVASNNVGEISVSTRLTVLREDQIPRGFPTIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDTSNNNGRIKQLRSGALQIEQSEESDQGKYECVATNSAGTRYSAPANLYVEVRRVPPRFSIPPTNHEIMPGGSVNITCVAVGSPMPYVKWMLGAEDLTPEDDMPIGRNVLELNDVRQSANYTCVAMSTLGVIEAIAQITVKALPKPPGTPVVTESTATSITLTWDSGNPEPVSYYIIQHKPKNSEELYKEIDGVATTRYSVAGLSPYSDYEFRVVAVNNIGRGPPSEPVLTQTSEQAPSSAPRDVQARMLSSTTILVQWKEPEEPNGQIQGYRVYYTMDPTQHVNNWMKHNVADSQITTIGNLVPQKTYSVKVLAFTSIGDGPLSSDIQVITQTGVPGQPLNFKAEPESETSILLSWTPPRSDTIANYELVYKDGEHGEEQRITIEPGTSYRLQGLKPNSLYYFRLAARSPQGLGASTAEISARTMQSKPSAPPQDISCTSPSSTSILVSWQPPPVEKQNGIITEYSIKYTAVDGEDDKPHEILGIPSDTTKYLLEQLEKWTEYRITVTAHTDVGPGPESLSVLIRTNEDVPSGPPRKVEVEAVNSTSVKVSWRSPVPNKQHGQIRGYQVHYVRMENGEPKGQPMLKDVMLADAQDMIISGLQPETSYSLTVTAYTTKGDGARSKPKLVSTTGAVPGKPRLVINHTQMNTALIQWHPPVDTFGPLQGYRLKFGRKDMEPLTTLEFSEKEDHFTATDIHKGASYVFRLSARNKVGFGEEMVKEISIPEEVPTGFPQNLHSEGTTSTSVQLSWQPPVLAERNGIITKYTLLYRDINIPLLPMEQLIVPADTTMTLTGLKPDTTYDVKVRAHTSKGPGPYSPSVQFRTLPVDQVFAKNFHVKAVMKTSVLLSWEIPENYNSAMPFKILYDDGKMVEEVDGRATQKLIVNLKPEKSYSFVLTNRGNSAGGLQHRVTAKTAPDVLRTKPAFIGKTNLDGMITVQLPEVPANENIKGYYIIIVPLKKSRGKFIKPWESPDEMELDELLKEISRKRRSIRYGREVELKPYIAAHFDVLPTEFTLGDDKHYGGFTNKQLQSGQEYVFFVLAVMEHAESKMYATSPYSDPVVSMDLDPQPITDEEEGLIWVVGPVLAVVFIICIVIAILLYKRKRAESDSRKSSIPNNKEIPSHHPTDPVELRRLNFQTPGMASHPPIPILELADHIERLKANDNLKFSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVLLSAIEGIPGSDYVNANYIDGYRKQNAYIATQGSLPETFGDFWRMIWEQRSATVVMMTKLEERSRVKCDQYWPSRGTETHGLVQVTLLDTVELATYCVRTFALYKNGSSEKREVRQFQFTAWPDHGVPEHPTPFLAFLRRVKTCNPPDAGPMVVHCSAGVGRTGCFIVIDAMLERIKHEKTVDIYGHVTLMRAQRNYMVQTEDQYIFIHDALLEAVTCGNTEVPARNLYAYIQKLTQIETGENVTGMELEFKRLASSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWEHNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDQYQFSYRAALEYLGSFDHYAT>sp|P23468-3|PTPRD_HUMAN Isoform 3 of Receptor-type tyrosine-proteinphosphatase delta OS=Homo sapiens OX=9606 GN=PTPRDMVHVARLLLLLLTFFLRTDAETPPRFTRTPVDQTGVSGGVASFICQATGDPRPKIVWNKKGKKVSNQRFEVIEFDDGSGSVLRIQPLRTPRDEAIYECVASNNVGEISVSTRLTVLREDQIPRGFPTIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDTSNNNGRIKQLRSESIGGTPIRGALQIEQSEESDQGKYECVATNSAGTRYSAPANLYVRELREVRRVPPRFSIPPTNHEIMPGGSVNITCVAVGSPMPYVKWMLGAEDLTPEDDMPIGRNVLELNDVRQSANYTCVAMSTLGVIEAIAQITVKALPKPPGTPVVTESTATSITLTWDSGNPEPVSYYIIQHKPKNSEELYKEIDGVATTRYSVAGLSPYSDYEFRVVAVNNIGRGPPSEPVLTQTSEQAPSSAPRDVQARMLSSTTILVQWKEPEEPNGQIQGYRVYYTMDPTQHVNNWMKHNVADSQITTIGNLVPQKTYSVKVLAFTSIGDGPLSSDIQVITQTGVPGQPLNFKAEPESETSILLSWTPPRSDTIANYELVYKDGEHGEEQRITIEPGTSYRLQGLKPNSLYYFRLAARSPQGLGASTAEISARTMQSKKGYYIIIVPLKKSRGKFIKPWESPDEMELDELLKEISRKRRSIRYGREVELKPYIAAHFDVLPTEFTLGDDKHYGGFTNKQLQSGQEYVFFVLAVMEHAESKMYATSPYSDPVVSMDLDPQPITDEEEGLIWVVGPVLAVVFIICIVIAILLYKRKRAESDSRKSSIPNNKEIPSHHPTDPVELRRLNFQTPGMASHPPIPILELADHIERLKANDNLKFSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVLLSAIEGIPGSDYVNANYIDGYRKQNAYIATQGSLPETFGDFWRMIWEQRSATVVMMTKLEERSRVKCDQYWPSRGTETHGLVQVTLLDTVELATYCVRTFALYKNGSSEKREVRQFQFTAWPDHGVPEHPTPFLAFLRRVKTCNPPDAGPMVVHCSAGVGRTGCFIVIDAMLERIKHEKTVDIYGHVTLMRAQRNYMVQTEDQYIFIHDALLEAVTCGNTEVPARNLYAYIQKLTQIETGENVTGMELEFKRLASSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWEHNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDQYQFSYRAALEYLGSFDHYAT>sp|P23468-4|PTPRD_HUMAN Isoform 4 of Receptor-type tyrosine-proteinphosphatase delta OS=Homo sapiens OX=9606 GN=PTPRDMVHVARLLLLLLTFFLRTDAETPPRFTRTPVDQTGVSGGVASFICQATGDPRPKIVWNKKGKKVSNQRFEVIEFDDGSGSVLRIQPLRTPRDEAIYECVASNNVGEISVSTRLTVLREDQIPRGFPTIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDTSNNNGRIKQLRSESIGALQIEQSEESDQGKYECVATNSAGTRYSAPANLYVRVRRVPPRFSIPPTNHEIMPGGSVNITCVAVGSPMPYVKWMLGAEDLTPEDDMPIGRNVLELNDVRQSANYTCVAMSTLGVIEAIAQITVKALPKPPGTPVVTESTATSITLTWDSGNPEPVSYYIIQHKPKNSEELYKEIDGVATTRYSVAGLSPYSDYEFRVVAVNNIGRGPPSEPVLTQTSEQAPSSAPRDVQARMLSSTTILVQWKEPEEPNGQIQGYRVYYTMDPTQHVNNWMKHNVADSQITTIGNLVPQKTYSVKVLAFTSIGDGPLSSDIQVITQTGVPGQPLNFKAEPESETSILLSWTPPRSDTIANYELVYKDGEHGEEQRITIEPGTSYRLQGLKPNSLYYFRLAARSPQGLGASTAEISARTMQSMFAKNFHVKAVMKTSVLLSWEIPENYNSAMPFKILYDDGKMVEEVDGRATQKLIVNLKPEKSYSFVLTNRGNSAGGLQHRVTAKTAPDVLRTKPAFIGKTNLDGMITVQLPEVPANENIKGYYIIIVPLKKSRGKFIKPWESPDEMELDELLKEISRKRRSIRYGREVELKPYIAAHFDVLPTEFTLGDDKHYGGFTNKQLQSGQEYVFFVLAVMEHAESKMYATSPYSDPVVSMDLDPQPITDEEEGLIWVVGPVLAVVFIICIVIAILLYKRKRAESDSRKSSIPNNKEIPSHHPTDPVELRRLNFQTPGSDDSGYPGNLHSSSMASHPPIPILELADHIERLKANDNLKFSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVLLSAIEGIPGSDYVNANYIDGYRKQNAYIATQGSLPETFGDFWRMIWEQRSATVVMMTKLEERSRVKCDQYWPSRGTETHGLVQVTLLDTVELATYCVRTFALYKNGSSEKREVRQFQFTAWPDHGVPEHPTPFLAFLRRVKTCNPPDAGPMVVHCSAGVGRTGCFIVIDAMLERIKHEKTVDIYGHVTLMRAQRNYMVQTEDQYIFIHDALLEAVTCGNTEVPARNLYAYIQKLTQIETGENVTGMELEFKRLASSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWEHNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDQYQFSYRAALEYLGSFDHYAT>sp|P23468-5|PTPRD_HUMAN Isoform 5 of Receptor-type tyrosine-proteinphosphatase delta OS=Homo sapiens OX=9606 GN=PTPRDMVHVARLLLLLLTFFLRTDAETPPRFTRTPVDQTGVSGGVASFICQATGDPRPKIVWNKKGKKVSNQRFEVIEFDDGSGSVLRIQPLRTPRDEAIYECVASNNVGEISVSTRLTVLREDQIPRGFPTIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDTSNNNGRIKQLRSESIGGTPIRGALQIEQSEESDQGKYECVATNSAGTRYSAPANLYVRELREVRRVPPRFSIPPTNHEIMPGGSVNITCVAVGSPMPYVKWMLGAEDLTPEDDMPIGRNVLELNDVRQSANYTCVAMSTLGVIEAIAQITVKALPKPPGTPVVTESTATSITLTWDSGNPEPVSYYIIQHKPKNSEELYKEIDGVATTRYSVAGLSPYSDYEFRVVAVNNIGRGPPSEPVLTQTSEQAPSSAPRDVQARMLSSTTILVQWKEPEEPNGQIQGYRVYYTMDPTQHVNNWMKHNVADSQITTIGNLVPQKTYSVKVLAFTSIGDGPLSSDIQVITQTGVPGQPLNFKAEPESETSILLSWTPPRSDTIANYELVYKDGEHGEEQRITIEPGTSYRLQGLKPNSLYYFRLAARSPQGLGASTAEISARTMQSMFAKNFHVKAVMKTSVLLSWEIPENYNSAMPFKILYDDGKMVEEVDGRATQKLIVNLKPEKSYSFVLTNRGNSAGGLQHRVTAKTAPDVLRTKPAFIGKTNLDGMITVQLPEVPANENIKGYYIIIVPLKKSRGKFIKPWESPDEMELDELLKEISRKRRSIRYGREVELKPYIAAHFDVLPTEFTLGDDKHYGGFTNKQLQSGQEYVFFVLAVMEHAESKMYATSPYSDPVVSMDLDPQPITDEEEGLIWVVGPVLAVVFIICIVIAILLYKSKPDRKRAESDSRKSSIPNNKEIPSHHPTDPVELRRLNFQTPGMASHPPIPILELADHIERLKANDNLKFSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVLLSAIEGIPGSDYVNANYIDGYRKQNAYIATQGSLPETFGDFWRMIWEQRSATVVMMTKLEERSRVKCDQYWPSRGTETHGLVQVTLLDTVELATYCVRTFALYKNGSSEKREVRQFQFTAWPDHGVPEHPTPFLAFLRRVKTCNPPDAGPMVVHCSAGVGRTGCFIVIDAMLERIKHEKTVDIYGHVTLMRAQRNYMVQTEDQYIFIHDALLEAVTCGNTEVPARNLYAYIQKLTQIETGENVTGMELEFKRLASSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWEHNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDQYQFSYRAALEYLGSFDHYAT>sp|P23468-6|PTPRD_HUMAN Isoform 6 of Receptor-type tyrosine-proteinphosphatase delta OS=Homo sapiens OX=9606 GN=PTPRDMVHVARLLLLLLTFFLRTDAETPPRFTRTPVDQTGVSGGVASFICQATGDPRPKIVWNKKGKKVSNQRFEVIEFDDGSGSVLRIQPLRTPRDEAIYECVASNNVGEISVSTRLTVLREDQIPRGFPTIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDTSNNNGRIKQLRSESIGGTPIRGALQIEQSEESDQGKYECVATNSAGTRYSAPANLYVRELREVRRVPPRFSIPPTNHEIMPGGSVNITCVAVGSPMPYVKWMLGAEDLTPEDDMPIGRNVLELNDVRQSANYTCVAMSTLGVIEAIAQITVKALPKPPGTPVVTESTATSITLTWDSGNPEPVSYYIIQHKPKNSEELYKEIDGVATTRYSVAGLSPYSDYEFRVVAVNNIGRGPPSEPVLTQTSEQAPSSAPRDVQARMLSSTTILVQWKEPEEPNGQIQGYRVYYTMDPTQHVNNWMKHNVADSQITTIGNLVPQKTYSVKVLAFTSIGDGPLSSDIQVITQTGVPGQPLNFKAEPESETSILLSWTPPRSDTIANYELVYKDGEHGEEQRITIEPGTSYRLQGLKPNSLYYFRLAARSPQGLGASTAEISARTMQSMFAKNFHVKAVMKTSVLLSWEIPENYNSAMPFKILYDDGKMVEEVDGRATQKLIVNLKPEKSYSFVLTNRGNSAGGLQHRVTAKTAPDVLRTKPAFIGKTNLDGMITVQLPEVPANENIKGYYIIIVPLKKSRGKFIKPWESPDEMELDELLKEISRKRRSIRYGREVELKPYIAAHFDVLPTEFTLGDDKHYGGFTNKQLQSGQEYVFFVLAVMEHAESKMYATSPYSDPVVSMDLDPQPITDEEEGLIWVVGPVLAVVFIICIVIAILLYKSSKPDRKRAESDSRKSSIPNNKEIPSHHPTDPVELRRLNFQTPGMASHPPIPILELADHIERLKANDNLKFSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVLLSAIEGIPGSDYVNANYIDGYRKQNAYIATQGSLPETFGDFWRMIWEQRSATVVMMTKLEERSRVKCDQYWPSRGTETHGLVQVTLLDTVELATYCVRTFALYKNGSSEKREVRQFQFTAWPDHGVPEHPTPFLAFLRRVKTCNPPDAGPMVVHCSAGVGRTGCFIVIDAMLERIKHEKTVDIYGHVTLMRAQRNYMVQTEDQYIFIHDALLEAVTCGNTEVPARNLYAYIQKLTQIETGENVTGMELEFKRLASSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWEHNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDQYQFSYRAALEYLGSFDHYAT>sp|P23468-7|PTPRD_HUMAN Isoform 7 of Receptor-type tyrosine-proteinphosphatase delta OS=Homo sapiens OX=9606 GN=PTPRDMVHVARLLLLLLTFFLRTDAETPPRFTRTPVDQTGVSGGVASFICQATGDPRPKIVWNKKGKKVSNQRFEVIEFDDGSGSVLRIQPLRTPRDEAIYECVASNNVGEISVSTRLTVLREDQIPRGFPTIDMGPQLKVVERTRTATMLCAASGNPDPEITWFKDFLPVDTSNNNGRIKQLRSGGTPIRGALQIEQSEESDQGKYECVATNSAGTRYSAPANLYVRELREVRRVPPRFSIPPTNHEIMPGGSVNITCVAVGSPMPYVKWMLGAEDLTPEDDMPIGRNVLELNDVRQSANYTCVAMSTLGVIEAIAQITVKALPKPPGTPVVTESTATSITLTWDSGNPEPVSYYIIQHKPKNSEELYKEIDGVATTRYSVAGLSPYSDYEFRVVAVNNIGRGPPSEPVLTQTSEQAPSSAPRDVQARMLSSTTILVQWKEPEEPNGQIQGYRVYYTMDPTQHVNNWMKHNVADSQITTIGNLVPQKTYSVKVLAFTSIGDGPLSSDIQVITQTGVPGQPLNFKAEPESETSILLSWTPPRSDTIANYELVYKDGEHGEEQRITIEPGTSYRLQGLKPNSLYYFRLAARSPQGLGASTAEISARTMQSMFAKNFHVKAVMKTSVLLSWEIPENYNSAMPFKILYDDGKMVEEVDGRATQKLIVNLKPEKSYSFVLTNRGNSAGGLQHRVTAKTAPDVLRTKPAFIGKTNLDGMITVQLPEVPANENIKGYYIIIVPLKKSRGKFIKPWESPDEMELDELLKEISRKRRSIRYGREVELKPYIAAHFDVLPTEFTLGDDKHYGGFTNKQLQSGQEYVFFVLAVMEHAESKMYATSPYSDPVVSMDLDPQPITDEEEGLIWVVGPVLAVVFIICIVIAILLYKSKPDRKRAESDSRKSSIPNNKEIPSHHPTDPVELRRLNFQTPGMASHPPIPILELADHIERLKANDNLKFSQEYESIDPGQQFTWEHSNLEVNKPKNRYANVIAYDHSRVLLSAIEGIPGSDYVNANYIDGYRKQNAYIATQGSLPETFGDFWRMIWEQRSATVVMMTKLEERSRVKCDQYWPSRGTETHGLVQVTLLDTVELATYCVRTFALYKNGSSEKREVRQFQFTAWPDHGVPEHPTPFLAFLRRVKTCNPPDAGPMVVHCSAGVGRTGCFIVIDAMLERIKHEKTVDIYGHVTLMRAQRNYMVQTEDQYIFIHDALLEAVTCGNTEVPARNLYAYIQKLTQIETGENVTGMELEFKRLASSKAHTSRFISANLPCNKFKNRLVNIMPYESTRVCLQPIRGVEGSDYINASFIDGYRQQKAYIATQGPLAETTEDFWRMLWEHNSTIVVMLTKLREMGREKCHQYWPAERSARYQYFVVDPMAEYNMPQYILREFKVTDARDGQSRTVRQFQFTDWPEQGVPKSGEGFIDFIGQVHKTKEQFGQDGPISVHCSAGVGRTGVFITLSIVLERMRYEGVVDIFQTVKMLRTQRPAMVQTEDQYQFSYRAALEYLGSFDHYAT>sp|Q96NR3|PTHD1_HUMAN Patched domain-containing protein 1 OS=Homosapiens OX=9606 GN=PTCHD1 PE=2 SV=2MLRQVLHRGLRTCFSRLGHFIASHPVFFASAPVLISILLGASFSRYQVEESVEHLLAPQHSLAKIERNLVNSLFPVNRSKHRLYSDLQTPGRYGRVIVTSFQKANMLDQHHTDLILKLHAAVTKIQVPRPGFNYTFAHICILNNDKTCIVDDIVHVLEELKNARATNRTNFAITYPITHLKDGRAVYNGHQLGGVTVHSKDRVKSAEAIQLTYYLQSINSLNDMVAERWESSFCDTVRLFQKSNSKVKMYPYTSSSLREDFQKTSRVSERYLVTSLILVVTMAILCCSMQDCVRSKPWLGLLGLVTISLATLTAAGIINLTGGKYNSTFLGVPFVMLGHGLYGTFEMLSSWRKTREDQHVKERTAAVYADSMLSFSLTTAMYLVTFGIGASPFTNIEAARIFCCNSCIAIFFNYLYVLSFYGSSLVFTGYIENNYQHSIFCRKVPKPEALQEKPAWYRFLLTARFSEDTAEGEEANTYESHLLVCFLKRYYCDWITNTYVKPFVVLFYLIYISFALMGYLQVSEGSDLSNIVATATQTIEYTTAQQKYFSNYSPVIGFYIYESIEYWNTSVQEDVLEYTKGFVRISWFESYLNYLRKLNVSTGLPKKNFTDMLRNSFLKAPQFSHFQEDIIFSKKYNDEVDVVASRMFLVAKTMETNREELYDLLETLRRLSVTSKVKFIVFNPSFVYMDRYASSLGAPLHNSCISALFLLFFSAFLVADSLINVWITLTVVSVEFGVIGFMTLWKVELDCISVLCLIYGINYTIDNCAPMLSTFVLGKDFTRTKWVKNALEVHGVAILQSYLCYIVGLIPLAAVPSNLTCTLFRCLFLIAFVTFFHCFAILPVILTFLPPSKKKRKEKKNPENREEIECVEMVDIDSTRVVDQITTV>sp|Q96NR3-2|PTHD1_HUMAN Isoform 2 of Patched domain-containing protein 1OS=Homo sapiens OX=9606 GN=PTCHD1MLDQHHTDLILKLHAAVTKIQVPRPGFNYTFAHICILNNDKTCIVDDIVHVLEELKNARATNRTNFAITYPITHLKDGRAVYNGHQLGGVTVHSKDRVKSAEAIQLTYYLQSINSLNDMVAERWESSFCDTVRLFQKSNSKVKMYPYTSSSLREDFQKTSRVSERYLVTSLILVVTMAILCCSMQDCVRSKPWLGLLGLVTISLATLTAAGIINLTGGKYNSTFLGVPFVMLGHGLYGTFEMLSSWRKTREDQHVKERTAAVYADSMLSFSLTTAMYLVTFGIGASPFTNIEAARIFCCNSCIAIFFNYLYVLSFYGSSLVFTGYIENNYQHSIFCRKVPKPEALQEKPAWYRFLLTARFSEDTAEGEEANTYESHLLVCFLKRYYCDWITNTYVKPFVVLFYLIYISFALMGYLQVSEGSDLSNIVATATQTIEYTTAQQKYFSNYSPVIGFYIYESIEYWNTSVQEDVLEYTKGFVRISWFESYLNYLRKLNVSTGLPKKNFTDMLRNSFLKAPQFSHFQEDIIFSKKYNDEVDVVASRMFLVAKTMETNREELYDLLETLRRLSVTSKVKFIVFNPSFVYMDRYASSLGAPLHNSCISALFLLFFSAFLVADSLINVWITLTVVSVEFGVIGFMTLWKVELDCISVLCLIYGINYTIDNCAPMLSTFVLGKDFTRTKWVKNALEVHGVAILQSYLCYIVGLIPLAAVPSNLTCTLFRCLFLIAFVTFFHCFAILPVILTFLPPSKKKRKEKKNPENREEIECVEMVDIDSTRVVDQITTV>sp|Q96NR3-3|PTHD1_HUMAN Isoform 3 of Patched domain-containing protein 1OS=Homo sapiens OX=9606 GN=PTCHD1MLDQHHTDLILKLHAAVTKIQVPRPGFNYTFAHICILNNDKTCIVDDIVHVLEELKNARATNRTNFAITYPITHLKDGRAVYNGHQLGGVTVHSKDRVKSAEAIQLTYYLQSINSLNDMVAERWESSFCDTVRLFQKSNSKVKMYPYTSSSLREDFQKTSRVSERYLVTSLILVVTMAILCCSMQDCVRSKPWLGLLGLVTISLATLTAAGIINLTGGKYNSTFLGVPFVMLGNYYSSFFCFRLLVVLTRFLKGQE>sp|Q6UX71|PXDC2_HUMAN Plexin domain-containing protein 2 OS=Homo sapiensOX=9606 GN=PLXDC2 PE=1 SV=1MARFPKADLAAAGVMLLCHFFTDQFQFADGKPGDQILDWQYGVTQAFPHTEEEVEVDSHAYSHRWKRNLDFLKAVDTNRASVGQDSPEPRSFTDLLLDDGQDNNTQIEEDTDHNYYISRIYGPSDSASRDLWVNIDQMEKDKVKIHGILSNTHRQAARVNLSFDFPFYGHFLREITVATGGFIYTGEVVHRMLTATQYIAPLMANFDPSVSRNSTVRYFDNGTALVVQWDHVHLQDNYNLGSFTFQATLLMDGRIIFGYKEIPVLVTQISSTNHPVKVGLSDAFVVVHRIQQIPNVRRRTIYEYHRVELQMSKITNISAVEMTPLPTCLQFNRCGPCVSSQIGFNCSWCSKLQRCSSGFDRHRQDWVDSGCPEESKEKMCENTEPVETSSRTTTTVGATTTQFRVLTTTRRAVTSQFPTSLPTEDDTKIALHLKDNGASTDDSAAEKKGGTLHAGLIIGILILVLIVATAILVTVYMYHHPTSAASIFFIERRPSRWPAMKFRRGSGHPAYAEVEPVGEKEGFIVSEQC>sp|Q6UX71-2|PXDC2_HUMAN Isoform 2 of Plexin domain-containing protein 2OS=Homo sapiens OX=9606 GN=PLXDC2MARFPKADLAAAGVMLLCHFFTDQFQFADGKPGDQILDWQYGVTQAFPHTEEEVEVDSHAYSHRWKRNLDFLKAVDTNRASVGQDSPEPRSFTDLLLDDGQDNNTQIERVNLSFDFPFYGHFLREITVATGGFIYTGEVVHRMLTATQYIAPLMANFDPSVSRNSTVRYFDNGTALVVQWDHVHLQDNYNLGSFTFQATLLMDGRIIFGYKEIPVLVTQISSTNHPVKVGLSDAFVVVHRIQQIPNVRRRTIYEYHRVELQMSKITNISAVEMTPLPTCLQFNRCGPCVSSQIGFNCSWCSKLQRCSSGFDRHRQDWVDSGCPEESKEKMCENTEPVETSSRTTTTVGATTTQFRVLTTTRRAVTSQFPTSLPTEDDTKIALHLKDNGASTDDSAAEKKGGTLHAGLIIGILILVLIVATAILVTVYMYHHPTSAASIFFIERRPSRWPAMKFRRGSGHPAYAEVEPVGEKEGFIVSEQC>sp|Q6UX71-3|PXDC2_HUMAN Isoform 3 of Plexin domain-containing protein 2OS=Homo sapiens OX=9606 GN=PLXDC2MCENTEPVETSSRTTTTVGATTTQFRVLTTTRRAVTSQFPTSLPTEDDTKIALHLKDNGASTDDSAAEKKGGTLHAGLIIGILILVLIVATAILVTVYMYHHPTSAASIFFIERRPSRWPAMKFRRGSGHPAYAEVEPVGEKEGFIVSEQC>sp|P50876|R144A_HUMAN E3 ubiquitin-protein ligase RNF144A OS=Homosapiens OX=9606 GN=RNF144A PE=1 SV=2MTTTRYRPTWDLALDPLVSCKLCLGEYPVEQMTTIAQCQCIFCTLCLKQYVELLIKEGLETAISCPDAACPKQGHLQENEIECMVAAEIMQRYKKLQFEREVLFDPCRTWCPASTCQAVCQLQDVGLQTPQPVQCKACRMEFCSTCKASWHPGQGCPETMPITFLPGETSAAFKMEEDDAPIKRCPKCKVYIERDEGCAQMMCKNCKHAFCWYCLESLDDDFLLIHYDKGPCRNKLGHSRASVIWHRTQVVGIFAGFGLLLLVASPFLLLATPFVLCCKCKCSKGDDDPLPT>sp|Q8TD07|RAE1E_HUMAN Retinoic acid early transcript 1E OS=Homo sapiensOX=9606 GN=RAET1E PE=1 SV=1MRRISLTSSPVRLLLFLLLLLIALEIMVGGHSLCFNFTIKSLSRPGQPWCEAQVFLNKNLFLQYNSDNNMVKPLGLLGKKVYATSTWGELTQTLGEVGRDLRMLLCDIKPQIKTSDPSTLQVEMFCQREAERCTGASWQFATNGEKSLLFDAMNMTWTVINHEASKIKETWKKDRGLEKYFRKLSKGDCDHWLREFLGHWEAMPEPTVSPVNASDIHWSSSSLPDRWIILGAFILLVLMGIVLICVWWQNGEWQAGLWPLRTS>sp|Q8TD07-2|RAE1E_HUMAN Isoform 2 of Retinoic acid early transcript 1EOS=Homo sapiens OX=9606 GN=RAET1EMRRISLTSSPVRLLLFLLLLLIALEIMYNSDNNMVKPLGLLGKKVYATSTWGELTQTLGEVGRDLRMLLCDIKPQIKTSDPSTLQVEMFCQREAERCTGASWQFATNGEKSLLFDAMNMTWTVINHEASKIKETWKKDRGLEKYFRKLSKGDCDHWLREFLGHWEAMPEPTVSPVNASDIHWSSSSLPDRWIILGAFILLVLMGIVLICVWWQNGEWQAGLWPLRTS>sp|Q8TD07-3|RAE1E_HUMAN Isoform 3 of Retinoic acid early transcript 1EOS=Homo sapiens OX=9606 GN=RAET1EMRRISLTSSPVRLLLFLLLLLIALEIMVGGHSLCFNFTIKSLSRPGQPWCEAQVFLNKNLFLQYNSDNNMVKPLGLLGKKVYATSTWGELTQTLGEVGRDLRMLLCDIKPQIKTSDPSTLQVEMFCQREAERCTGASWQFATNGEKSLLFDAMNMTWTVINHEASKIKETWKKDRGLEKYFRKLSKGDCDHWLREFLGHWEAMPEPTGRRST>sp|Q8TD07-4|RAE1E_HUMAN Isoform 4 of Retinoic acid early transcript 1EOS=Homo sapiens OX=9606 GN=RAET1EMRRISLTSSPVRLLLFLLLLLIALEIMVGGHSLCFNFTIKSLSRPGQPWCEAQVFLNKNLFLQYNSDNNMVKPLGLLGKKVYATSTWGELTQTLGEVGRDLRMLLCDIKPQIKTSDPSTLQVEMFCQREAERCTGASWQFATNGEKSLLFDAMNMTWTVINHEASKIKETWKKDRGLEKYFRKLSKGDCDHWLREFLGHWEAMPEPTGN>sp|Q8TD07-5|RAE1E_HUMAN Isoform 5 of Retinoic acid early transcript 1EOS=Homo sapiens OX=9606 GN=RAET1EMRRISLTSSPVRLLLFLLLLLIALEIMVGGHSLCFNFTIKSLSRPGQPWCEAQVFLNKNLFLQYNSDNNMVKPLGLLGKKVYATSTWGELTQTLGEVGRDLRMLLCDIKPQIKTSDPSTLQVEMFCQREAERCTGASWQFATNGEKSLLFDAMNMTWTVINHEAMSPVNASDIHWSSSSLPDRWIILGAFILLVLMGIVLICVWWQNGEWQAGLWPLRTS>sp|Q8TD07-6|RAE1E_HUMAN Isoform 6 of Retinoic acid early transcript 1EOS=Homo sapiens OX=9606 GN=RAET1EMRRISLTSSPVRLLLFLLLLLIALEIMVGECPEHKNWLRTRRREKGGHSLCFNFTIKSLSRPGQPWCEAQVFLNKNLFLQYNSDNNMVKPLGLLGKKVYATSTWGELTQTLGEVGRDLRMLLCDIKPQIKTSDPSTLQVEMFCQREAERCTGASWQFATNGEKSLLFDAMNMTWTVINHEASKIKETWKKDRGLEKYFRKLSKGDCDHWLREFLGHWEAMPEPTVSPVNASDIHWSSSSLPDRWIILGAFILLVLMGIVLICVWWQNGEWQAGLWPLRTS>sp|Q5U651|RAIN_HUMAN Ras-interacting protein 1 OS=Homo sapiens OX=9606GN=RASIP1 PE=1 SV=1MLSGERKEGGSPRFGKLHLPVGLWINSPRKQLAKLGRRWPSAASVKSSSSDTGSRSSEPLPPPPPHVELRRVGAVKAAGGASGSRAKRISQLFRGSGTGTTGSSGAGGPGTPGGAQRWASEKKLPELAAGVAPEPPLATRATAPPGVLKIFGAGLASGANYKSVLATARSTARELVAEALERYGLAGSPGGGPGESSCVDAFALCDALGRPAAAGVGSGEWRAEHLRVLGDSERPLLVQELWRARPGWARRFELRGREEARRLEQEAFGAADSEGTGAPSWRPQKNRSRAASGGAALASPGPGTGSGAPAGSGGKERSENLSLRRSVSELSLQGRRRRQQERRQQALSMAPGAADAQIGTADPGDFDQLTQCLIQAPSNRPYFLLLQGYQDAQDFVVYVMTREQHVFGRGGNSSGRGGSPAPYVDTFLNAPDILPRHCTVRAGPEHPAMVRPSRGAPVTHNGCLLLREAELHPGDLLGLGEHFLFMYKDPRTGGSGPARPPWLPARPGATPPGPGWAFSCRLCGRGLQERGEALAAYLDGREPVLRFRPREEEALLGEIVRAAAAGSGDLPPLGPATLLALCVQHSARELELGHLPRLLGRLARLIKEAVWEKIKEIGDRQPENHPEGVPEVPLTPEAVSVELRPLMLWMANTTELLSFVQEKVLEMEKEADQEDPQLCNDLELCDEAMALLDEVIMCTFQQSVYYLTKTLYSTLPALLDSNPFTAGAELPGPGAELGAMPPGLRPTLGVFQAALELTSQCELHPDLVSQTFGYLFFFSNASLLNSLMERGQGRPFYQWSRAVQIRTNLDLVLDWLQGAGLGDIATEFFRKLSMAVNLLCVPRTSLLKASWSSLRTDHPTLTPAQLHHLLSHYQLGPGRGPPAAWDPPPAEREAVDTGDIFESFSSHPPLILPLGSSRLRLTGPVTDDALHRELRRLRRLLWDLEQQELPANYRHGPPVATSP>sp|Q9UKL0|RCOR1_HUMAN REST corepressor 1 OS=Homo sapiens OX=9606GN=RCOR1 PE=1 SV=2MPAMVEKGPEVSGKRRGRNNAAASASAAAASAAASAACASPAATAASGAAASSASAAAASAAAAPNNGQNKSLAAAAPNGNSSSNSWEEGSSGSSSDEEHGGGGMRVGPQYQAVVPDFDPAKLARRSQERDNLGMLVWSPNQNLSEAKLDEYIAIAKEKHGYNMEQALGMLFWHKHNIEKSLADLPNFTPFPDEWTVEDKVLFEQAFSFHGKTFHRIQQMLPDKSIASLVKFYYSWKKTRTKTSVMDRHARKQKREREESEDELEEANGNNPIDIEVDQNKESKKEVPPTETVPQVKKEKHSTQAKNRAKRKPPKGMFLSQEDVEAVSANATAATTVLRQLDMELVSVKRQIQNIKQTNSALKEKLDGGIEPYRLPEVIQKCNARWTTEEQLLAVQAIRKYGRDFQAISDVIGNKSVVQVKNFFVNYRRRFNIDEVLQEWEAEHGKEETNGPSNQKPVKSPDNSIKMPEEEDEAPVLDVRYASAS>sp|P18124|RL7_HUMAN 60S ribosomal protein L7 OS=Homo sapiens OX=9606GN=RPL7 PE=1 SV=1MEGVEEKKKEVPAVPETLKKKRRNFAELKIKRLRKKFAQKMLRKARRKLIYEKAKHYHKEYRQMYRTEIRMARMARKAGNFYVPAEPKLAFVIRIRGINGVSPKVRKVLQLLRLRQIFNGTFVKLNKASINMLRIVEPYIAWGYPNLKSVNELIYKRGYGKINKKRIALTDNALIARSLGKYGIICMEDLIHEIYTVGKRFKEANNFLWPFKLSSPRGGMKKKTTHFVEGGDAGNREDQINRLIRRMN>sp|Q8NHW5|RLA0L_HUMAN 60S acidic ribosomal protein P0-like OS=Homosapiens OX=9606 GN=RPLP0P6 PE=5 SV=1MPREDRATWKSNYFLKIIQLLDDYPKCFIVGADNVGSKQMQQIRMSLRGKVVVLMGKNTMMRKAIRGHLENNPALEKLLPHIWGNVGFVFTKEDLTEIRDMLLANKVPAAARAGAIAPCEVTVPAQNTGLGPEKTSFFQALGITTKISRGTIEILSDVQLIKTGDKVGASEATLLNMLNISPFSFGLVIQQVFDNGSIYNPEVLDKTEETLHSRFLEGVRNVASVCLQTGYPTVASVPHSIINGYKRVLALSVETDYTFPLAENVKAFLADPSAFVAAAPVAADTTAAPAAAAAPAKVEAKEESEESDEDMGFGLFD>sp|P05388|RLA0_HUMAN 60S acidic ribosomal protein P0 OS=Homo sapiensOX=9606 GN=RPLP0 PE=1 SV=1MPREDRATWKSNYFLKIIQLLDDYPKCFIVGADNVGSKQMQQIRMSLRGKAVVLMGKNTMMRKAIRGHLENNPALEKLLPHIRGNVGFVFTKEDLTEIRDMLLANKVPAAARAGAIAPCEVTVPAQNTGLGPEKTSFFQALGITTKISRGTIEILSDVQLIKTGDKVGASEATLLNMLNISPFSFGLVIQQVFDNGSIYNPEVLDITEETLHSRFLEGVRNVASVCLQIGYPTVASVPHSIINGYKRVLALSVETDYTFPLAEKVKAFLADPSAFVAAAPVAAATTAAPAAAAAPAKVEAKEESEESDEDMGFGLFD>sp|P05388-2|RLA0_HUMAN Isoform 2 of 60S acidic ribosomal protein P0OS=Homo sapiens OX=9606 GN=RPLP0MPREDRATWKSNYFLKIIQLLDDYPKCFIVGADNVGSKQMQQIRMSLRGKAVVLMGKNTMMRKAIRGHLENNPALEKLLPHIRGNVGFVFTKEDLTEIRDMLLANKVPAAARAGAIAPCEVTVPAQNTGLGPEKTSFFQALGITTKISRGTIEILGVRNVASVCLQIGYPTVASVPHSIINGYKRVLALSVETDYTFPLAEKVKAFLADPSAFVAAAPVAAATTAAPAAAAAPAKVEAKEESEESDEDMGFGLFD>sp|A8MWL7|TM14D_HUMAN Transmembrane protein 14DP OS=Homo sapiens OX=9606GN=TMEM14DP PE=5 SV=2MEKPLFPLVPLHWFGFGYTALVVSGGIVGYVKTGRAPSLAAGLLFGSLAGVGAYQLYQDPRNVWDFLAATSVTFVGIMGMRSYYYGKFMPVGLIAGASLLMAAKVGVRMLMTSD>sp|Q6NUQ4|TM214_HUMAN Transmembrane protein 214 OS=Homo sapiens OX=9606GN=TMEM214 PE=1 SV=2MATKTAGVGRWEVVKKGRRPGVGAGAGGRGGGRNRRALGEANGVWKYDLTPAIQTTSTLYERGFENIMKRQNKEQVPPPAVEPKKPGNKKQPKKVATPPNQNQKQGRFRSLEEALKALDVADLQKELDKSQSVFSGNPSIWLKDLASYLNYKLQAPLSEPTLSQHTHDYPYSLVSRELRGIIRGLLAKAAGSLELFFDHCLFTMLQELDKTPGESLHGYRICIQAILQDKPKIATANLGKFLELLRSHQSRPAKCLTIMWALGQAGFANLTEGLKVWLGIMLPVLGIKSLSPFAITYLDRLLLMHPNLTKGFGMIGPKDFFPLLDFAYMPNNSLTPSLQEQLCQLYPRLKVLAFGAKPDSTLHTYFPSFLSRATPSCPPEMKKELLSSLTECLTVDPLSASVWRQLYPKHLSQSSLLLEHLLSSWEQIPKKVQKSLQETIQSLKLTNQELLRKGSSNNQDVVTCDMACKGLLQQVQGPRLPWTRLLLLLLVFAVGFLCHDLRSHSSFQASLTGRLLRSSGFLPASQQACAKLYSYSLQGYSWLGETLPLWGSHLLTVVRPSLQLAWAHTNATVSFLSAHCASHLAWFGDSLTSLSQRLQIQLPDSVNQLLRYLRELPLLFHQNVLLPLWHLLLEALAWAQEHCHEACRGEVTWDCMKTQLSEAVHWTWLCLQDITVAFLDWALALISQQ>sp|Q6NUQ4-2|TM214_HUMAN Isoform 2 of Transmembrane protein 214 OS=Homosapiens OX=9606 GN=TMEM214MATKTAGVGRWEVVKKGRRPGVGAGAGGRGGGRNRRALGEANGVWKYDLTPAIQTTSTLYERGFENIMKRQNKEQVPPPAVEPKKPGNKKQPKKVATPPNQNQKQGRFRSLEEALKALDVADLQKELDKSQSVFSGNPSIWLKDLASYLNYKLQAPLSEPTLSQHTHGESLHGYRICIQAILQDKPKIATANLGKFLELLRSHQSRPAKCLTIMWALGQAGFANLTEGLKVWLGIMLPVLGIKSLSPFAITYLDRLLLMHPNLTKGFGMIGPKDFFPLLDFAYMPNNSLTPSLQEQLCQLYPRLKVLAFGAKPDSTLHTYFPSFLSRATPSCPPEMKKELLSSLTECLTVDPLSASVWRQLYPKHLSQSSLLLEHLLSSWEQIPKKVQKSLQETIQSLKLTNQELLRKGSSNNQDVVTCDMACKGLLQQVQGPRLPWTRLLLLLLVFAVGFLCHDLRSHSSFQASLTGRLLRSSGFLPASQQACAKLYSYSLQGYSWLGETLPLWGSHLLTVVRPSLQLAWAHTNATVSFLSAHCASHLAWFGDSLTSLSQRLQIQLPDSVNQLLRYLRELPLLFHQNVLLPLWHLLLEALAWAQEHCHEACRGEVTWDCMKTQLSEAVHWTWLCLQDITVAFLDWALALISQQ>sp|Q96HH4|TM169_HUMAN Transmembrane protein 169 OS=Homo sapiens OX=9606GN=TMEM169 PE=2 SV=1MEEPTAVEGQVQLPSPHQGSLRKAVAAALALDGESTMGHRKKKRKESRPESIIIYRSDNEKTDEEPGESEGGDQPKEEEGDDFLDYPVDDDMWNLPLDSRYVTLTGTITRGKKKGQMVDIHVTLTEKELQELTKPKESSRETTPEGRMACQMGADRGPHVVLWTLICLPVVFILSFVVSFYYGTITWYNIFLVYNEERTFWHKISYCPCLVLFYPVLIMAMASSLGLYAAVVQLSWSWEAWWQAARDMEKGFCGWLCSKLGLEDCSPYSIVELLESDNISSTLSNKDPIQEVETSTV>sp|Q14134|TRI29_HUMAN Tripartite motif-containing protein 29 OS=Homosapiens OX=9606 GN=TRIM29 PE=1 SV=2MEAADASRSNGSSPEARDARSPSGPSGSLENGTKADGKDAKTTNGHGGEAAEGKSLGSALKPGEGRSALFAGNEWRRPIIQFVESGDDKNSNYFSMDSMEGKRSPYAGLQLGAAKKPPVTFAEKGELRKSIFSESRKPTVSIMEPGETRRNSYPRADTGLFSRSKSGSEEVLCDSCIGNKQKAVKSCLVCQASFCELHLKPHLEGAAFRDHQLLEPIRDFEARKCPVHGKTMELFCQTDQTCICYLCMFQEHKNHSTVTVEEAKAEKETELSLQKEQLQLKIIEIEDEAEKWQKEKDRIKSFTTNEKAILEQNFRDLVRDLEKQKEEVRAALEQREQDAVDQVKVIMDALDERAKVLHEDKQTREQLHSISDSVLFLQEFGALMSNYSLPPPLPTYHVLLEGEGLGQSLGNFKDDLLNVCMRHVEKMCKADLSRNFIERNHMENGGDHRYVNNYTNSFGGEWSAPDTMKRYSMYLTPKGGVRTSYQPSSPGRFTKETTQKNFNNLYGTKGNYTSRVWEYSSSIQNSDNDLPVVQGSSSFSLKGYPSLMRSQSPKAQPQTWKSGKQTMLSHYRPFYVNKGNGIGSNEAP>sp|Q14134-2|TRI29_HUMAN Isoform Beta of Tripartite motif-containingprotein 29 OS=Homo sapiens OX=9606 GN=TRIM29MEAADASRSNGSSPEARDARSPSGPSGSLENGTKADGKDAKTTNGHGGEAAEGKSLGSALKPGEGRSALFAGNEWRRPIIQFVESGDDKNSNYFSMDSMEGKRSPYAGLQLGAAKKPPVTFAEKGELRKSIFSESRKPTVSIMEPGETRRNSYPRADTGLFSRSKSGSEEVLCDSCIGNKQKAVKSCLVCQASFCELHLKPHLEGAAFRDHQLLEPIRDFEARKCPVHGKTMELFCQTDQTCICYLCMFQEHKNHSTVTVEEAKAEKETELSLQKEQLQLKIIEIEDEAEKWQKEKDRIKSFTTNEKAILEQNFRDLVRDLEKQKEEVRAALEQREQDAVDQVKVIMDALDERAKVLHEDKQTREQLHSISDSVLFLQEFGALMSNYSLPPPLPTYHVLLEGEGLGQSLGNFKDDLLNVCMRHVEKMCKADLSRNFIERNHMENGGDHRYVNNYTNSFGGEWSAPDTMKRYSMYLTPKGGVRTSYQPSSPGRFTKETTQKNFNNLYGTKGNYTSRVWEYSSSIQNSDNDLPVVQGSSSFSLKGYPSLMRSQSPKAQPQTWKSGKQTMLVV>sp|Q13049|TRI32_HUMAN E3 ubiquitin-protein ligase TRIM32 OS=Homo sapiensOX=9606 GN=TRIM32 PE=1 SV=2MAAAAASHLNLDALREVLECPICMESFTEEQLRPKLLHCGHTICRQCLEKLLASSINGVRCPFCSKITRITSLTQLTDNLTVLKIIDTAGLSEAVGLLMCRSCGRRLPRQFCRSCGLVLCEPCREADHQPPGHCTLPVKEAAEERRRDFGEKLTRLRELMGELQRRKAALEGVSKDLQARYKAVLQEYGHEERRVQDELARSRKFFTGSLAEVEKSNSQVVEEQSYLLNIAEVQAVSRCDYFLAKIKQADVALLEETADEEEPELTASLPRELTLQDVELLKVGHVGPLQIGQAVKKPRTVNVEDSWAMEATASAASTSVTFREMDMSPEEVVASPRASPAKQRGPEAASNIQQCLFLKKMGAKGSTPGMFNLPVSLYVTSQGEVLVADRGNYRIQVFTRKGFLKEIRRSPSGIDSFVLSFLGADLPNLTPLSVAMNCQGLIGVTDSYDNSLKVYTLDGHCVACHRSQLSKPWGITALPSGQFVVTDVEGGKLWCFTVDRGSGVVKYSCLCSAVRPKFVTCDAEGTVYFTQGLGLNLENRQNEHHLEGGFSIGSVGPDGQLGRQISHFFSENEDFRCIAGMCVDARGDLIVADSSRKEILHFPKGGGYSVLIREGLTCPVGIALTPKGQLLVLDCWDHCIKIYSYHLRRYSTP>sp|Q6ZWK6|TM11F_HUMAN Transmembrane protease serine 11F OS=Homo sapiensOX=9606 GN=TMPRSS11F PE=2 SV=2MMYAPVEFSEAEFSRAEYQRKQQFWDSVRLALFTLAIVAIIGIAIGIVTHFVVEDDKSFYYLASFKVTNIKYKENYGIRSSREFIERSHQIERMMSRIFRHSSVGGRFIKSHVIKLSPDEQGVDILIVLIFRYPSTDSAEQIKKKIEKALYQSLKTKQLSLTINKPSFRLTPIDSKKMRNLLNSRCGIRMTSSNMPLPASSSTQRIVQGRETAMEGEWPWQASLQLIGSGHQCGASLISNTWLLTAAHCFWKNKDPTQWIATFGATITPPAVKRNVRKIILHENYHRETNENDIALVQLSTGVEFSNIVQRVCLPDSSIKLPPKTSVFVTGFGSIVDDGPIQNTLRQARVETISTDVCNRKDVYDGLITPGMLCAGFMEGKIDACKGDSGGPLVYDNHDIWYIVGIVSWGQSCALPKKPGVYTRVTKYRDWIASKTGM>sp|O60507|TPST1_HUMAN Protein-tyrosine sulfotransferase 1 OS=Homosapiens OX=9606 GN=TPST1 PE=1 SV=1MVGKLKQNLLLACLVISSVTVFYLGQHAMECHHRIEERSQPVKLESTRTTVRTGLDLKANKTFAYHKDMPLIFIGGVPRSGTTLMRAMLDAHPDIRCGEETRVIPRILALKQMWSRSSKEKIRLDEAGVTDEVLDSAMQAFLLEIIVKHGEPAPYLCNKDPFALKSLTYLSRLFPNAKFLLMVRDGRASVHSMISRKVTIAGFDLNSYRDCLTKWNRAIETMYNQCMEVGYKKCMLVHYEQLVLHPERWMRTLLKFLQIPWNHSVLHHEEMIGKAGGVSLSKVERSTDQVIKPVNVGALSKWVGKIPPDVLQDMAVIAPMLAKLGYDPYANPPNYGKPDPKIIENTRRVYKGEFQLPDFLKEKPQTEQVE>sp|Q8NCL8|TM116_HUMAN Transmembrane protein 116 OS=Homo sapiens OX=9606GN=TMEM116 PE=2 SV=1MKHTQSGQSTSPLVIDYTCRVCQMAFVFSSLIPLLLMTPVFCLGNTSECFQNFSQSHKCILMHSPPSAMAELPPSANTSVCSTLYFYGIAIFLGSFVLSLLTIMVLLIRAQTLYKKFVKSTGFLGSEQWAVIHIVDQRVRFYPVAFFCCWGPAVILMIIKLTKPQDTKLHMALYVLQALTATSQGLLNCGVYGWTQHKFHQLKQEARRDADTQTPLLCSQKRFYSRGLNSLESTLTFPASTSTIF>sp|Q8NCL8-2|TM116_HUMAN Isoform 2 of Transmembrane protein 116 OS=Homosapiens OX=9606 GN=TMEM116MATLSVIGSSSLIAYAVFHNIQKSPEIRPLFYLSFCDLLLGLCWLTETLLYGASVANKDIICYNLQAVGQIFYISSFLYTVNYIWYLYTELRMKHTQSGQSTSPLVIDYTCRVCQMAFVFSSLIPLLLMTPVFCLGNTSECFQNFSQSHKCILMHSPPSAMAELPPSANTSVCSTLYFYGIAIFLGSFVLSLLTIMVLLIRAQTLYKKFVKSTGFLGSEQWAVIHIVDQRVRFYPVAFFCCWGPAVILMIIKLTKPQDTKLHMALYVLQALTATSQGLLNCGVYGWTQHKFHQLKQEARRDADTQTPLLCSQKRFYSRGLNSLESTLTFPASTSTIF>sp|Q8NCL8-3|TM116_HUMAN Isoform 3 of Transmembrane protein 116 OS=Homosapiens OX=9606 GN=TMEM116MATLSVIGSSSLIAYAVFHNIQKSPEIRPLFYLSFCDLLLGLCWLTETLLYGASVANKDIICYNLQAVGQVIDYTCRVCQMAFVFSSLIPLLLMTPVFCLGNTSECFQNFSQSHKCILMHSPPSAMAELPPSANTSVCSTLYFYGIAIFLGSFVLSLLTIMVLLIRAQTLYKKFVKSTGFLGSEQWAVIHIVDQRVRFYPVAFFCCWGPAVILMIIKLTKPQDTKLHMALYVLQALTATSQGLLNCGVYGWTQHKFHQLKQEARRDADTQTPLLCSQKRFYSRGLNSLESTLTFPASTSTIF>sp|Q14106|TOB2_HUMAN Protein Tob2 OS=Homo sapiens OX=9606 GN=TOB2 PE=1SV=2MQLEIKVALNFIISYLYNKLPRRRADLFGEELERLLKKKYEGHWYPEKPLKGSGFRCVHIGEMVDPVVELAAKRSGLAVEDVRANVPEELSVWIDPFEVSYQIGEKGAVKVLYLDDSEGCGAPELDKEIKSSFNPDAQVFVPIGSQDSSLSNSPSPSFGQSPSPTFIPRSAQPITFTTASFAATKFGSTKMKKGGGAASGGGVASSGAGGQQPPQQPRMARSPTNSLLKHKSLSLSMHSLNFITANPAPQSQLSPNAKEFVYNGGGSPSLFFDAADGQGSGTPGPFGGSGAGTCNSSSFDMAQVFGGGANSLFLEKTPFVEGLSYNLNTMQYPSQQFQPVVLAN>sp|Q14106-2|TOB2_HUMAN Isoform 2 of Protein Tob2 OS=Homo sapiens OX=9606GN=TOB2MQLEIKVALNFIISYLYNKLPRRRADLFGEELERLLKKKYEGHWYPEKPLKGSGFRCVHIGEMVDPVVELAAKRSGLAVEDVRANVPEELSVWIDPFEVSYQIGEKGAVKVLYLDDSEGCGAPELDKEIKSSFNPDAQVFVPIGSQDSSLSNSPSPSFGQSPSPTFIPRSAQPITFTTASFAATKFGSTKMKKGGGAASGGGVASSGAGGQQPPQQPRMARSPTNSLLKHKSLSLSMHSLNFITDYNHDQ>sp|O43715|TRIA1_HUMAN TP53-regulated inhibitor of apoptosis 1 OS=Homosapiens OX=9606 GN=TRIAP1 PE=1 SV=1MNSVGEACTDMKREYDQCFNRWFAEKFLKGDSSGDPCTDLFKRYQQCVQKAIKEKEIPIEGLEFMGHGKEKPENSS>sp|Q6UXF1|TM108_HUMAN Transmembrane protein 108 OS=Homo sapiens OX=9606GN=TMEM108 PE=1 SV=2MKRSLQALYCQLLSFLLILALTEALAFAIQEPSPRESLQVLPSGTPPGTMVTAPHSSTRHTSVVMLTPNPDGPPSQAAAPMATPTPRAEGHPPTHTISTIAATVTAPHSESSLSTGPAPAAMATTSSKPEGRPRGQAAPTILLTKPPGATSRPTTAPPRTTTRRPPRPPGSSRKGAGNSSRPVPPAPGGHSRSKEGQRGRNPSSTPLGQKRPLGKIFQIYKGNFTGSVEPEPSTLTPRTPLWGYSSSPQPQTVAATTVPSNTSWAPTTTSLGPAKDKPGLRRAAQGGGSTFTSQGGTPDATAASGAPVSPQAAPVPSQRPHHGDPQDGPSHSDSWLTVTPGTSRPLSTSSGVFTAATGPTPAAFDTSVSAPSQGIPQGASTTPQAPTHPSRVSESTISGAKEETVATLTMTDRVPSPLSTVVSTATGNFLNRLVPAGTWKPGTAGNISHVAEGDKPQHRATICLSKMDIAWVILAISVPISSCSVLLTVCCMKRKKKTANPENNLSYWNNTITMDYFNRHAVELPREIQSLETSEDQLSEPRSPANGDYRDTGMVLVNPFCQETLFVGNDQVSEI>sp|Q6UXF1-2|TM108_HUMAN Isoform 2 of Transmembrane protein 108 OS=Homosapiens OX=9606 GN=TMEM108MKRSLQALYCQLLSFLLILALTEALAFAIQEPSPRESLQVLPSGTPPGTMVTAPHSSTRHTSVVMLTPNPDGPPSQAAAPMATPTPRAEGHPPTHTISTIAATVTAPHSESSLSTGPAPAAMATTSSKPEGRPRGQAAPTILLTKPPGATSRPTTAPPRTTTRRPPRPPGSSRKGAGNSSRPVPPAPGGHSRSKEGQRGRNPSSTPLGQKRPLGKIFQIYKGNFTGSVEPEPSTLTPRTPLWGYSSSPQPQTVAATTVPSNTSWAPTTTSLGPAKDKPGLRRAAQGGGSTFTSQGGTPDATAASGAPVSPQAAPVPSQRPHHGDPQDGPSHSDSWLTVTPGTSRPLSTSSGVFTAATGPTPAAFDTSVSAPSQGIPQGASTTPQAPTHPSRVSESTISGAKEETVATLTMTDRVPSPLSTVVSTATGNFLNRLVPAGTWKPGTAGNISHVAEGDKPQHRATICLSKMDIAWVILAISVPISSCSDPI>sp|Q9NS68|TNR19_HUMAN Tumor necrosis factor receptor superfamily member19 OS=Homo sapiens OX=9606 GN=TNFRSF19 PE=1 SV=1MALKVLLEQEKTFFTLLVLLGYLSCKVTCESGDCRQQEFRDRSGNCVPCNQCGPGMELSKECGFGYGEDAQCVTCRLHRFKEDWGFQKCKPCLDCAVVNRFQKANCSATSDAICGDCLPGFYRKTKLVGFQDMECVPCGDPPPPYEPHCASKVNLVKIASTASSPRDTALAAVICSALATVLLALLILCVIYCKRQFMEKKPSWSLRSQDIQYNGSELSCFDRPQLHEYAHRACCQCRRDSVQTCGPVRLLPSMCCEEACSPNPATLGCGVHSAASLQARNAGPAGEMVPTFFGSLTQSICGEFSDAWPLMQNPMGGDNISFCDSYPELTGEDIHSLNPELESSTSLDSNSSQDLVGGAVPVQSHSENFTAATDLSRYNNTLVESASTQDALTMRSQLDQESGAVIHPATQTSLQVRQRLGSL>sp|Q9NS68-2|TNR19_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 19 OS=Homo sapiens OX=9606 GN=TNFRSF19MALKVLLEQEKTFFTLLVLLGYLSCKVTCESGDCRQQEFRDRSGNCVPCNQCGPGMELSKECGFGYGEDAQCVTCRLHRFKEDWGFQKCKPCLDCAVVNRFQKANCSATSDAICGDCLPGFYRKTKLVGFQDMECVPCGDPPPPYEPHCASKVNLVKIASTASSPRDTALAAVICSALATVLLALLILCVIYCKRQFMEKKPSWSLRSQDIQYNGSELSCFDRPQLHEYAHRACCQCRRDSVQTCGPVRLLPSMCCEEACSPNPATLGCGVHSAASLQARNAGPAGEMVPTFFGSLTQSICGEFSDAWPLMQNPMGGDNISFCDSYPELTGEDIHSLNPELESSTSLDSNSSQDLVGGAVPVQSHSENFTAATDLSRYNNTLVESASTQDALTMRSQLDQESGAVIHPATQTSLQEA>sp|Q9NS68-3|TNR19_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 19 OS=Homo sapiens OX=9606 GN=TNFRSF19MECVPCGDPPPPYEPHCASKVNLVKIASTASSPRDTALAAVICSALATVLLALLILCVIYCKRQFMEKKPSWSLRSQDIQYNGSELSCFDRPQLHEYAHRACCQCRRDSVQTCGPVRLLPSMCCEEACSPNPATLGCGVHSAASLQARNAGPAGEMVPTFFGSLTQSICGEFSDAWPLMQNPMGGDNISFCDSYPELTGEDIHSLNPELESSTSLDSNSSQDLVGGAVPVQSHSENFTAATDLSRYNNTLVESASTQDALTMRSQLDQESGAVIHPATQTSLQEA>sp|Q8NE00|TM104_HUMAN Transmembrane protein 104 OS=Homo sapiens OX=9606GN=TMEM104 PE=1 SV=2MAGEITETGELYSSYVGLVYMFNLIVGTGALTMPKAFATAGWLVSLVLLVFLGFMSFVTTTFVIEAMAAANAQLHWKRMENLKEEEDDDSSTASDSDVLIRDNYERAEKRPILSVQRRGSPNPFEITDRVEMGQMASMFFNKVGVNLFYFCIIVYLYGDLAIYAAAVPFSLMQVTCSATGNDSCGVEADTKYNDTDRCWGPLRRVDAYRIYLAIFTLLLGPFTFFDVQKTKYLQILTSLMRWIAFAVMIVLALIRIGHGQGEGHPPLADFSGVRNLFGVCVYSFMCQHSLPSLITPVSSKRHLTRLVFLDYVLILAFYGLLSFTAIFCFRGDSLMDMYTLNFARCDVVGLAAVRFFLGLFPVFTISTNFPIIAVTLRNNWKTLFHREGGTYPWVVDRVVFPTITLVPPVLVAFCTHDLESLVGITGAYAGTGIQYVIPAFLVYHCRRDTQLAFGCGVSNKHRSPFRHTFWVGFVLLWAFSCFIFVTANIILSETKL>sp|Q8NE00-2|TM104_HUMAN Isoform 2 of Transmembrane protein 104 OS=Homosapiens OX=9606 GN=TMEM104MAGEITETGELYSSYVGLVYMFNLIVGTGALTMPKAFATAGWLVSLVLLVFLGFMSFVTTTFVIEAMAAANAQLHWKRMENLKEEEDDDSSTASDSDVLIRDNYERAEKRPILSVQRRGSPNPFEITDRVEMGQMASMFFNKVGVNLFYFCIIVYLYGDLAIYAAAVPFSLMQVTCSATGNDSCGVEADTKYNDTDRCWGPLRRVDAYRIYLAIFTLLLGPFTFFDVQKTKYLQILTSLMRWIDGPPGSVMGRAEEDASPAWPRSRCRCGGKLKLNSLYPTSATCMAPDAPGAGQVKVGVNFLCLPPHRSTRPT>sp|A0JD36|TRDV2_HUMAN T cell receptor delta variable 2 OS=Homo sapiensOX=9606 GN=TRDV2 PE=1 SV=1MQRISSLIHLSLFWAGVMSAIELVPEHQTVPVSIGVPATLRCSMKGEAIGNYYINWYRKTQGNTMTFIYREKDIYGPGFKDNFQGDIDIAKNLAVLKILAPSERDEGSYYCACDT>sp|A6NGJ6|TRI64_HUMAN Tripartite motif-containing protein 64 OS=Homosapiens OX=9606 GN=TRIM64 PE=2 SV=4MDSDDLQVFQNELICCICVNYFIDPVTIDCGHSFCRPCLCLCSEEGRAPMRCPSCRKISEKPNFNTNVVLKKLSSLARQTRPQNINSSDNICVLHEETKELFCEADKRLLCGPCSESPEHMAHSHSPIGWAAEECREKLIKEMDYLWEINQETRNNLNQETRTFHSLKDYVSVRKRIITIQYQKMPIFLDEEEQRHLQALEREAEELFQQLQDSQVRMTQHLERMKDMYRELWETCHVPDVELLQDVRNVSARTDLAQMQKPQPVNPELTSWCITGVLDMLNNFRVDSALSTEMIPCYISLSEDVRYVIFGDDHLSAPTDPQGVDSFAVWGAQAFTSGKHYWEVDVTLSSNWILGVCQDSRTADANFVIDSDERFFLISSKRSNHYSLSTNSPPLIQYVQRPLGQVGVFLDYDNGSVSFFDVSKGSLIYGFPPSSFSSPLRPFFCFGCT>sp|O14763|TR10B_HUMAN Tumor necrosis factor receptor superfamily member10B OS=Homo sapiens OX=9606 GN=TNFRSF10B PE=1 SV=2MEQRGQNAPAASGARKRHGPGPREARGARPGPRVPKTLVLVVAAVLLLVSAESALITQQDLAPQQRAAPQQKRSSPSEGLCPPGHHISEDGRDCISCKYGQDYSTHWNDLLFCLRCTRCDSGEVELSPCTTTRNTVCQCEEGTFREEDSPEMCRKCRTGCPRGMVKVGDCTPWSDIECVHKESGTKHSGEVPAVEETVTSSPGTPASPCSLSGIIIGVTVAAVVLIVAVFVCKSLLWKKVLPYLKGICSGGGGDPERVDRSSQRPGAEDNVLNEIVSILQPTQVPEQEMEVQEPAEPTGVNMLSPGESEHLLEPAEAERSQRRRLLVPANEGDPTETLRQCFDDFADLVPFDSWEPLMRKLGLMDNEIKVAKAEAAGHRDTLYTMLIKWVNKTGRDASVHTLLDALETLGERLAKQKIEDHLLSSGKFMYLEGNADSAMS>sp|O14763-3|TR10B_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 10B OS=Homo sapiens OX=9606 GN=TNFRSF10BMEQRGQNAPAASGARKRHGPGPREARGARPGPRVPKTLVLVVAAVLLLVSAESALITQQDLAPQQRAAPQQKRSSPSEGLCPPGHHISEDGRDCISCKYGQDYSTHWNDLLFCLRCTR>sp|O14763-2|TR10B_HUMAN Isoform Short of Tumor necrosis factor receptorsuperfamily member 10B OS=Homo sapiens OX=9606 GN=TNFRSF10BMEQRGQNAPAASGARKRHGPGPREARGARPGPRVPKTLVLVVAAVLLLVSAESALITQQDLAPQQRAAPQQKRSSPSEGLCPPGHHISEDGRDCISCKYGQDYSTHWNDLLFCLRCTRCDSGEVELSPCTTTRNTVCQCEEGTFREEDSPEMCRKCRTGCPRGMVKVGDCTPWSDIECVHKESGIIIGVTVAAVVLIVAVFVCKSLLWKKVLPYLKGICSGGGGDPERVDRSSQRPGAEDNVLNEIVSILQPTQVPEQEMEVQEPAEPTGVNMLSPGESEHLLEPAEAERSQRRRLLVPANEGDPTETLRQCFDDFADLVPFDSWEPLMRKLGLMDNEIKVAKAEAAGHRDTLYTMLIKWVNKTGRDASVHTLLDALETLGERLAKQKIEDHLLSSGKFMYLEGNADSAMS>sp|Q309B1|TR16L_HUMAN Tripartite motif-containing protein 16-likeprotein OS=Homo sapiens OX=9606 GN=TRIM16L PE=1 SV=3MQFGELLAAVRKAQANVMLFLEEKEQAALSQANGIKAHLEYRSAEMEKSKQELETMAAISNTVQFLEEYCKFKNTEDITFPSVYIGLKDKLSGIRKVITESTVHLIQLLENYKKKLQEFSKEEEYDIRTQVSAIVQRKYWTSKPEPSTREQFLQYVHDITFDPDTAHKYLRLQEENRKVTNTTPWEHPYPDLPSRFLHWRQVLSQQSLYLHRYYFEVEIFGAGTYVGLTCKGIDQKGEERSSCISGNNFSWSLQWNGKEFTAWYSDMETPLKAGPFWRLGVYIDFPGGILSFYGVEYDSMTLVHKFACKFSEPVYAAFWLSKKENAIRIVDLGEEPEKPAPSLVGTAP>sp|Q309B1-2|TR16L_HUMAN Isoform 2 of Tripartite motif-containing protein16-like protein OS=Homo sapiens OX=9606 GN=TRIM16LMQFGELLAAVRKAQANVMLFLEEKEQAALSQANGIKAHLEYRSAEMEKSKQELETMAAISNTVQFLEMCMTSRSTRTQHTSISGCRRRTARSPTPRPGSIPTRTSPAGSCTGGRCCPSRVCTCTGTILRWRSSGQAPMLA>sp|A6NMA1|TR5OS_HUMAN Putative uncharacterized protein TRPC5OS OS=Homosapiens OX=9606 GN=TRPC5OS PE=4 SV=1MDSVLIHVLIDGLVACVAQLIRIADELLQFILQVQEVPYVEENGRAEETEADAPLPEEPSLPDLPDLSDLDSILTPREDEDLIFDIDQAMLDMDNLYEDTVSGINDDLTGD>sp|Q9NS69|TOM22_HUMAN Mitochondrial import receptor subunit TOM22homolog OS=Homo sapiens OX=9606 GN=TOMM22 PE=1 SV=3MAAAVAAAGAGEPQSPDELLPKGDAEKPEEELEEDDDEELDETLSERLWGLTEMFPERVRSAAGATFDLSLFVAQKMYRFSRAALWIGTTSFMILVLPVVFETEKLQMEQQQQLQQRQILLGPNTGLSGGMPGALPSLPGKI>sp|A0A075B700|TJA31_HUMAN T cell receptor alpha joining 31 OS=Homosapiens OX=9606 GN=TRAJ31 PE=4 SV=2NNNARLMFGDGTQLVVKP>sp|A0A075B6Y3|TJA3_HUMAN T cell receptor alpha joining 3 OS=Homo sapiensOX=9606 GN=TRAJ3 PE=4 SV=2GYSSASKIIFGSGTRLSIRP>sp|Q8WY98|TM234_HUMAN Transmembrane protein 234 OS=Homo sapiens OX=9606GN=TMEM234 PE=1 SV=1MAASLGQVLALVLVAALWGGTQPLLKRASAGLQRVHEPTWAQQLLQEMKTLFLNTEYLMPFLLNQCGSLLYYLTLASTDLTLAVPICNSLAIIFTLIVGKALGEDIGGKRAVAGMVLTVIGISLCITSSVPWTAELQLHGKGQLQTLSQKCKREASGTQSERFG>sp|Q8WY98-2|TM234_HUMAN Isoform 2 of Transmembrane protein 234 OS=Homosapiens OX=9606 GN=TMEM234MAASLGQVLALVLVAALWGGTQPLLKRASAGLQRVHEPTWAQQLLQEMKTLFLNTEYLMPFLLNQCGSLLYYLTLASTDLTLAVPICNSLAIIFTLIVGKALGEDIGGKRKLDYCECGTQLCGSRHTCVSSFPEPISPEWVRTRPFPILPFPLQLFCFLVAIRVPFPWTVWRKTEAGVWD>sp|Q8WY98-3|TM234_HUMAN Isoform 3 of Transmembrane protein 234 OS=Homosapiens OX=9606 GN=TMEM234MAASLGQVLALVLVAALWGGTQPLLKRASAGLQRVHEPTWAQQLLQEMKTLFLNTEYLMPFLLNQCGSLLYYLTLASTDLTLAVPICNSLAIIFTLIVGKALGEDIGGKRAVAGMVLTVIGISLCITSSVSKTQGQQSTL>sp|Q8WY98-4|TM234_HUMAN Isoform 4 of Transmembrane protein 234 OS=Homosapiens OX=9606 GN=TMEM234MAASLGQVLALVLVAALWGGTQPLLKRASAGLQRVHEPTWAQQLLQEMKTLFLNTEYLMPFLLNQCGSLLYYLTLASTGWSQTSEFRSSCWNPGKH>sp|C9JQI7|TM232_HUMAN Transmembrane protein 232 OS=Homo sapiens OX=9606GN=TMEM232 PE=2 SV=2MNMPVNKSPMINTCGGISSPYHEELWKLNFQHLSGERGHKSRPTFSITKEFILRFNQTQNSKEKEELLELARKIILRCKRKLGLKTLGSGRHVHLPAAWTEVIYLAQCKGEIQDESLNMLYASLDHASFDYDHLPALFFVAESVLYRLCCDASLKTYLYSVEIKLAKIGYLVFLRLFIFFLHGHLESFKQHLLRLQPYLYALSFSGASYHKYPNIFSNVQFILKASEIIGKRELRSESIFRPVEDKKRYENTDSDMGGYEINHLLWHCVAAWSCVQNNSPQLNNVLEHLVFHKTQLQKKCWLDSVLALLVLGEAAKLNMACLKALMDVVRDFVSSIMSVQNQEESCKVDDFSWAWNVVYIYTVILAEICLYAATSDLRKTALIGFCHCKSSQKNILYLDKSVPPELKETSILSLLEYFSSKMSENCDQVVWTGYYGLVYNLVKISWELQGDEEQDGLRNMIWQTLQKTKDYEEDVRIQNAINIAQAELNDPTDPFTRYSTNISSNVGEEVFSKYIGWRIANTLSKLFFPPIEAHFLPLKKPSIKKDQTKYPNKKLESVKKQVLHFTVREHPSVSEIPMFPYPDFFTKADKELAKIIDHHWQEELKIREKEDAICKAQELKDKKLAEKNHFQEVMKKREEKLHKQTKPYELPYRKEVI>sp|C9JQI7-2|TM232_HUMAN Isoform 1 of Transmembrane protein 232 OS=Homosapiens OX=9606 GN=TMEM232MNMPVNKSPMINTCGGISSPYHEELWKLNFQHLSGERGHKSRPTFSITKEFILRFNQTQNSKEKEELLELARKIILRCKRKLGLKTLGSGRHVHLPAAWTEVIYLAQCKGEIQDESLNMLYASLDHASFDYDHLPALFFVAESVLYRLCCDASLKTYLYSVEIKLAKIGYLVFLRLFIFFLHGHLESFKQHLLRLQPYLYALSFSGASYHKYPNIFSNVQFILKASEIIGKRELRSESIFRPVEDKKRYENTDSDMGGYEINHLLWHCVAAWSCVQNNSPQLNNVLEHLVFHKTQLQKKCWLDSVLALLVLGEAAKLNMACLKALMDVVRDFVSSIMSVQNQEESCKVDDFSWAWNVVYIYTVILAEICLYAATSDLRKTALIGFCHCKSSQKNILYLDKSVPPELKETSILSLLEYFSSKMSENCDQVVWTGYYGLVYNLVKISWELQGDEEQDGLRNMIWQTLQKTKDYEEDVRIQNAINIAQGTSFCIRNSHVSISRFLHQGR>sp|O43399|TPD54_HUMAN Tumor protein D54 OS=Homo sapiens OX=9606GN=TPD52L2 PE=1 SV=2MDSAGQDINLNSPNKGLLSDSMTDVPVDTGVAARTPAVEGLTEAEEEELRAELTKVEEEIVTLRQVLAAKERHCGELKRRLGLSTLGELKQNLSRSWHDVQVSSAYVKTSEKLGEWNEKVTQSDLYKKTQETLSQAGQKTSAALSTVGSAISRKLGDMRNSATFKSFEDRVGTIKSKVVGDRENGSDNLPSSAGSGDKPLSDPAPF>sp|O43399-2|TPD54_HUMAN Isoform 2 of Tumor protein D54 OS=Homo sapiensOX=9606 GN=TPD52L2MDSAGQDINLNSPNKGLLSDSMTDVPVDTGVAARTPAVEGLTEAEEEELRAELTKVEEEIVTLRQVLAAKERHCGELKRRLGLSTLGELKQNLSRSWHDVQVSSAYKKTQETLSQAGQKTSAALSTVGSAISRKLGDMRNSATFKSFEDRVGTIKSKVVGDRENGSDNLPSSAGSGDKPLSDPAPF>sp|O43399-3|TPD54_HUMAN Isoform 3 of Tumor protein D54 OS=Homo sapiensOX=9606 GN=TPD52L2MDSAGQDINLNSPNKGLLSDSMTDVPVDTGVAARTPAVEGLTEAEEEELRAELTKVEEEIVTLRQVLAAKERHCGELKRRLGLSTLGELKQNLSRSWHDVQVSSAYKKTQETLSQAGQKTSAALSTVGSAISRKLGDMRAHPFSHSFSSYSIRHSISMPAMRNSATFKSFEDRVGTIKSKVVGDRENGSDNLPSSAGSGDKPLSDPAPF>sp|O43399-4|TPD54_HUMAN Isoform 4 of Tumor protein D54 OS=Homo sapiensOX=9606 GN=TPD52L2MDSAGQDINLNSPNKGLLSDSMTDVPVDTGVAARTPAVEGLTEAEEEELRAELTKVEEEIVTLRQVLAAKERHCGELKRRLGLSTLGELKQNLSRSWHDVQVSSAYKKTQETLSQAGQKTSAALSTVGSAISRKLGDMSSYSIRHSISMPAMRNSATFKSFEDRVGTIKSKVVGDRENGSDNLPSSAGSGDKPLSDPAPF>sp|O43399-5|TPD54_HUMAN Isoform 5 of Tumor protein D54 OS=Homo sapiensOX=9606 GN=TPD52L2MDSAGQDINLNSPNKGLLSDSMTDVPVDTGVAARTPAVEGLTEAEEEELRAELTKVEEEIVTLRQVLAAKERHCGELKRRLGLSTLGELKQNLSRSWHDVQVSSAYVKTSEKLGEWNEKVTQSDLYKKTQETLSQAGQKTSAALSTVGSAISRKLGDMSSYSIRHSISMPAMRNSATFKSFEDRVGTIKSKVVGDRENGSDNLPSSAGSGDKPLSDPAPF>sp|O43399-6|TPD54_HUMAN Isoform 6 of Tumor protein D54 OS=Homo sapiensOX=9606 GN=TPD52L2MDSAGQGVAARTPAVEGLTEAEEEELRAELTKVEEEIVTLRQVLAAKERHCGELKRRLGLSTLGELKQNLSRSWHDVQVSSAYKKTQETLSQAGQKTSAALSTVGSAISRKLGDMRNSATFKSFEDRVGTIKSKVVGDRENGSDNLPSSAGSGDKPLSDPAPF>sp|O43399-7|TPD54_HUMAN Isoform 7 of Tumor protein D54 OS=Homo sapiensOX=9606 GN=TPD52L2MDSAGQDINLNSPNKGLLSDSMTDVPVDTGVAARTPAVEGLTEAEEEELRAELTKVEEEIVTLRQVLAAKERHCGELKRRLGLSTLGELKQNLSRSWHDVQVSSAYVKTSEKLGEWNEKVTQSDLYKKTQETLSQAGQKTSAALSTVGSAISRKLGDMRAHPFSHSFSSYSIRHSISMPAMRNSATFKSFEDRVGTIKSKVVGDRENGSDNLPSSAGSGDKPLSDPAPF>sp|Q7RTY8|TMPS7_HUMAN Transmembrane protease serine 7 OS=Homo sapiensOX=9606 GN=TMPRSS7 PE=2 SV=3MDKENSDVSAAPADLKISNISVQVVSAQKKLPVRRPPLPGRRLPLPGRRPPQRPIGKAKPKKQSKKKVPFWNVQNKIILFTVFLFILAVIAWTLLWLYISKTESKDAFYFAGMFRITNIEFLPEYRQKESREFLSVSRTVQQVINLVYTTSAFSKFYEQSVVADVSSNNKGGLLVHFWIVFVMPRAKGHIFCEDCVAAILKDSIQTSIINRTSVGSLQGLAVDMDSVVLNAGLRSDYSSTIGSDKGCSQYFYAEHLSLHYPLEISAASGRLMCHFKLVAIVGYLIRLSIKSIQIEADNCVTDSLTIYDSLLPIRSSILYRICEPTRTLMSFVSTNNLMLVTFKSPHIRRLSGIRAYFEVIPEQKCENTVLVKDITGFEGKISSPYYPSYYPPKCKCTWKFQTSLSTLGIALKFYNYSITKKSMKGCEHGWWEINEHMYCGSYMDHQTIFRVPSPLVHIQLQCSSRLSDKPLLAEYGSYNISQPCPVGSFRCSSGLCVPQAQRCDGVNDCFDESDELFCVSPQPACNTSSFRQHGPLICDGFRDCENGRDEQNCTQSIPCNNRTFKCGNDICFRKQNAKCDGTVDCPDGSDEEGCTCSRSSSALHRIIGGTDTLEGGWPWQVSLHFVGSAYCGASVISREWLLSAAHCFHGNRLSDPTPWTAHLGMYVQGNAKFVSPVRRIVVHEYYNSQTFDYDIALLQLSIAWPETLKQLIQPICIPPTGQRVRSGEKCWVTGWGRRHEADNKGSLVLQQAEVELIDQTLCVSTYGIITSRMLCAGIMSGKRDACKGDSGGPLSCRRKSDGKWILTGIVSWGHGSGRPNFPGVYTRVSNFVPWIHKYVPSLL>sp|Q7RTY8-2|TMPS7_HUMAN Isoform 2 of Transmembrane protease serine 7OS=Homo sapiens OX=9606 GN=TMPRSS7MFRITNIEFLPEYRQKESREFLSVSRTVQQVINLVYTTSAFSKFYEQSVVADVSNNKGGLLVHFWIVFVMPRAKGHIFCEDCVAAILKDSIQTSIINRTSVGSLQGLAVDMDSVVLNDKGCSQYFYAEHLSLHYPLEISAASGRLMCHFKLVAIVGYLIRLSIKSIQIEADNCVTDSLTIYDSLLPIRSSILYRICEPTRTLMSFVSTNNLMLVTFKSPHIRRLSGIRAYFEVIPEQKCENTVLVKDITGFEGKISSPYYPSYYPPKCKCTWKFQTSLSTLGIALKFYNYSITKKSMKGCEHGWWEINEHMYCGSYMDHQTIFRVPSPLVHIQLQCSSRLSDKPLLAEYGSYNISQPCPVGSFRCSSGLCVPQAQRCDGVNDCFDESDELFCVSPQPACNTSSFRQHGPLICDGFRDCENGRDEQNCTQSIPCNNRTFKCGNDICFRKQNAKCDGTVDCPDGSDEEGCTCSRSSSALHRIIGGTDTLEGGWPWQVSLHFVGSAYCGASVISREWLLSAAHCFHGNRLSDPTPWTAHLGMYVQGNAKFVSPVRRIVVHEYYNSQTFDYDIALLQLSIAWPETLKQLIQPICIPPTGQRVRSGEKCWVTGWGRRHEADNKGSLVLQQAEVELIDQTLCVSTYGIITSRMLCAGIMSGKRDACKGDSGGPLSCRRKSDGKWILTGIVSWGHGSGRPNFPGVYTRVSNFVPWIHKYVPSLL>sp|Q7RTY8-3|TMPS7_HUMAN Isoform 3 of Transmembrane protease serine 7OS=Homo sapiens OX=9606 GN=TMPRSS7MCHFKLVAIVGYLIRLSIKSIQIEADNCVTDSLTIYDSLLPIRSSILYRICEPTRTLMSFVSTNNLMLVTFKSPHIRRLSGIRAYFEVIPEQKCENTVLVKDITGFEGKISSPYYPSYYPPKCKCTWKFQTSLSTLGIALKFYNYSITKKSMKGCEHGWWEINEHMYCGSYMDHQTIFRVPSPLVHIQLQCSSRLSDKPLLAEYGSYNISQPCPVGSFRCSSGLCVPQAQRCDGVNDCFDESDELFCVSPQPACNTSSFRQHGPLICDGFRDCENGRDEQNCTQSIPCNNRTFKCGNDICFRKQNAKCDGTVDCPDGSDEEGCTCSRSSSALHRIIGGTDTLEGGWPWQVSLHFVGSAYCGASVISREWLLSAAHCFHGNRLSDPTPWTAHLGMYVQGNAKFVSPVRRIVVHEYYNSQTFDYDIALLQLSIAWPETLKQLIQPICIPPTGQRVRSGEKCWVTGWGRRHEADNKGSLVLQQAEVELIDQTLCVSTYGIITSRMLCAGIMSGKRDACKGDSGGPLSCRRKSDGKWILTGIVSWGHGSGRPNFPGVYTRVSNFVPWIHKYVPSLL>sp|Q5SV17|TM240_HUMAN Transmembrane protein 240 OS=Homo sapiens OX=9606GN=TMEM240 PE=1 SV=2MSMSANTMIFMILGASVVMAIACLMDMNALLDRFHNYILPHLRGEDRVCHCNCGRHHIHYVIPYDGDQSVVDASENYFVTDSVTKQEIDLMLGLLLGFCISWFLVWMDGVLHCAVRAWRAGRRYDGSWTWLPKLCSLRELGRRPHRPFEEAAGNMVHVKQKLYHNGHPSPRHL>sp|P51854|TKTL1_HUMAN Transketolase-like protein 1 OS=Homo sapiensOX=9606 GN=TKTL1 PE=1 SV=2MADAEARAEFPEEARPDRGTLQVLQDMASRLRIHSIRATCSTSSGHPTSCSSSSEIMSVLFFYIMRYKQSDPENPDNDRFVLAKRLSFVDVATGWLGQGLGVACGMAYTGKYFDRASYRVFCLMSDGESSEGSVWEAMAFASYYSLDNLVAIFDVNRLGHSGALPAEHCINIYQRRCEAFGWNTYVVDGRDVEALCQVFWQASQVKHKPTAVVAKTFKGRGTPSIEDAESWHAKPMPRERADAIIKLIESQIQTSRNLDPQPPIEDSPEVNITDVRMTSPPDYRVGDKIATRKACGLALAKLGYANNRVVVLDGDTRYSTFSEIFNKEYPERFIECFMAEQNMVSVALGCASRGRTIAFASTFAAFLTRAFDHIRIGGLAESNINIIGSHCGVSVGDDGASQMALEDIAMFRTIPKCTIFYPTDAVSTEHAVALAANAKGMCFIRTTRPETMVIYTPQERFEIGQAKVLRHCVSDKVTVIGAGITVYEALAAADELSKQDIFIRVIDLFTIKPLDVATIVSSAKATEGRIITVEDHYPQGGIGEAVCAAVSMDPDIQVHSLAVSGVPQSGKSEELLDMYGISARHIIVAVKCMLLN>sp|P51854-1|TKTL1_HUMAN Isoform 2 of Transketolase-like protein 1OS=Homo sapiens OX=9606 GN=TKTL1MSVLFFYIMRYKQSDPENPDNDRFVLAKRLSFVDVATGWLGQGLGVACGMAYTGKYFDRASYRVFCLMSDGESSEGSVWEAMAFASYYSLDNLVAIFDVNRLGHSGALPAEHCINIYQRRCEAFGWNTYVVDGRDVEALCQVFWQASQVKHKPTAVVAKTFKGRGTPSIEDAESWHAKPMPRERADAIIKLIESQIQTSRNLDPQPPIEDSPEVNITDVRMTSPPDYRVGDKIATRKACGLALAKLGYANNRVVVLDGDTRYSTFSEIFNKEYPERFIECFMAEQNMVSVALGCASRGRTIAFASTFAAFLTRAFDHIRIGGLAESNINIIGSHCGVSVGDDGASQMALEDIAMFRTIPKCTIFYPTDAVSTEHAVALAANAKGMCFIRTTRPETMVIYTPQERFEIGQAKGVSMLQDSWSSVISYQKVLRHCVSDKVTVIGAGITVYEALAAADELSKQDIFIRVIDLFTIKPLDVATIVSSAKATEGRIITVEDHYPQGGIGEAVCAAVSMDPDIQVHSLAVSGVPQSGKSEELLDMYGISARHIIVAVKCMLLN>sp|P51854-4|TKTL1_HUMAN Isoform 4 of Transketolase-like protein 1OS=Homo sapiens OX=9606 GN=TKTL1MSVLFFYIMRYKQSDPENPDNDRFVLAKRLSFVDVATGWLGQGLGVACGMAYTGKYFDRASYRVFCLMSDGESSEGSVWEAMAFASYYSLDNLVAIFDVNRLGHSGALPAEHCINIYQRRCEAFGWNTYVVDGRDVEALCQVFWQASQVKHKPTAVVAKTFKGRGTPSIEDAESWHAKPMPRERADAIIKLIESQIQTSRNLDPQPPIEDSPEVNITDVRMTSPPDYRVGDKIATRKACGLALAKLGYANNRVVVLDGDTRYSTFSEIFNKEYPERFIECFMAEQNMVSVALGCASRGRTIAFASTFAAFLTRAFDHIRIGGLAESNINIIGSHCGVSVGDDGASQMALEDIAMFRTIPKCTIFYPTDAVSTEHAVALAANAKGMCFIRTTRPETMVIYTPQERFEIGQAKVLRHCVSDKVTVIGAGITVYEALAAADELSKQDIFIRVIDLFTIKPLDVATIVSSAKATEGRIITVEDHYPQGGIGEAVCAAVSMDPDIQVHSLAVSGVPQSGKSEELLDMYGISARHIIVAVKCMLLN>sp|Q8WUH6|TM263_HUMAN Transmembrane protein 263 OS=Homo sapiens OX=9606GN=TMEM263 PE=1 SV=1MNQTDKNQQEIPSYLNDEPPEGSMKDHPQQQPGMLSRVTGGIFSVTKGAVGATIGGVAWIGGKSLEVTKTAVTTVPSMGIGLVKGGVSAVAGGVTAVGSAVVNKVPLTGKKKDKSD>sp|Q92547|TOPB1_HUMAN DNA topoisomerase 2-binding protein 1 OS=Homosapiens OX=9606 GN=TOPBP1 PE=1 SV=3MSRNDKEPFFVKFLKSSDNSKCFFKALESIKEFQSEEYLQIITEEEALKIKENDRSLYICDPFSGVVFDHLKKLGCRIVGPQVVIFCMHHQRCVPRAEHPVYNMVMSDVTISCTSLEKEKREEVHKYVQMMGGRVYRDLNVSVTHLIAGEVGSKKYLVAANLKKPILLPSWIKTLWEKSQEKKITRYTDINMEDFKCPIFLGCIICVTGLCGLDRKEVQQLTVKHGGQYMGQLKMNECTHLIVQEPKGQKYECAKRWNVHCVTTQWFFDSIEKGFCQDESIYKTEPRPEAKTMPNSSTPTSQINTIDSRTLSDVSNISNINASCVSESICNSLNSKLEPTLENLENLDVSAFQAPEDLLDGCRIYLCGFSGRKLDKLRRLINSGGGVRFNQLNEDVTHVIVGDYDDELKQFWNKSAHRPHVVGAKWLLECFSKGYMLSEEPYIHANYQPVEIPVSHKPESKAALLKKKNSSFSKKDFAPSEKHEQADEDLLSQYENGSSTVVEAKTSEARPFNDSTHAEPLNDSTHISLQEENQSSVSHCVPDVSTITEEGLFSQKSFLVLGFSNENESNIANIIKENAGKIMSLLSRTVADYAVVPLLGCEVEATVGEVVTNTWLVTCIDYQTLFDPKSNPLFTPVPVMTGMTPLEDCVISFSQCAGAEKESLTFLANLLGASVQEYFVRKSNAKKGMFASTHLILKERGGSKYEAAKKWNLPAVTIAWLLETARTGKRADESHFLIENSTKEERSLETEITNGINLNSDTAEHPGTRLQTHRKTVVTPLDMNRFQSKAFRAVVSQHARQVAASPAVGQPLQKEPSLHLDTPSKFLSKDKLFKPSFDVKDALAALETPGRPSQQKRKPSTPLSEVIVKNLQLALANSSRNAVALSASPQLKEAQSEKEEAPKPLHKVVVCVSKKLSKKQSELNGIAASLGADYRWSFDETVTHFIYQGRPNDTNREYKSVKERGVHIVSEHWLLDCAQECKHLPESLYPHTYNPKMSLDISAVQDGRLCNSRLLSAVSSTKDDEPDPLILEENDVDNMATNNKESAPSNGSGKNDSKGVLTQTLEMRENFQKQLQEIMSATSIVKPQGQRTSLSRSGCNSASSTPDSTRSARSGRSRVLEALRQSRQTVPDVNTEPSQNEQIIWDDPTAREERARLASNLQWPSCPTQYSELQVDIQNLEDSPFQKPLHDSEIAKQAVCDPGNIRVTEAPKHPISEELETPIKDSHLIPTPQAPSIAFPLANPPVAPHPREKIITIEETHEELKKQYIFQLSSLNPQERIDYCHLIEKLGGLVIEKQCFDPTCTHIVVGHPLRNEKYLASVAAGKWVLHRSYLEACRTAGHFVQEEDYEWGSSSILDVLTGINVQQRRLALAAMRWRKKIQQRQESGIVEGAFSGWKVILHVDQSREAGFKRLLQSGGAKVLPGHSVPLFKEATHLFSDLNKLKPDDSGVNIAEAAAQNVYCLRTEYIADYLMQESPPHVENYCLPEAISFIQNNKELGTGLSQKRKAPTEKNKIKRPRVH>sp|Q9Y320|TMX2_HUMAN Thioredoxin-related transmembrane protein 2 OS=Homosapiens OX=9606 GN=TMX2 PE=1 SV=1MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWREVEILMFLSAIVMMKNRRSITVEQHIGNIFMFSKVANTILFFRLDIRMGLLYITLCIVFLMTCKPPLYMGPEYIKYFNDKTIDEELERDKRVTWIVEFFANWSNDCQSFAPIYADLSLKYNCTGLNFGKVDVGRYTDVSTRYKVSTSPLTKQLPTLILFQGGKEAMRRPQIDKKGRAVSWTFSEENVIREFNLNELYQRAKKLSKAGDNIPEEQPVASTPTTVSDGENKKDK>sp|Q9Y320-2|TMX2_HUMAN Isoform 2 of Thioredoxin-related transmembraneprotein 2 OS=Homo sapiens OX=9606 GN=TMX2MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWREVEILMFLSAIVMMKNRRSMFLMTCKPPLYMGPEYIKYFNDKTIDEELERDKRVTWIVEFFANWSNDCQSFAPIYADLSLKYNCTGLNFGKVDVGRYTDVSTRYKVSTSPLTKQLPTLILFQGGKEAMRRPQIDKKGRAVSWTFSEENVIREFNLNELYQRAKKLSKAGDNIPEEQPVASTPTTVSDGENKKDK>sp|Q5JU69|TOR2A_HUMAN Torsin-2A OS=Homo sapiens OX=9606 GN=TOR2A PE=2SV=1MAAATRGCRPWGSLLGLLGLVSAAAAAWDLASLRCTLGAFCECDFRPDLPGLECDLAQHLAGQHLAKALVVKALKAFVRDPAPTKPLVLSLHGWTGTGKSYVSSLLAHYLFQGGLRSPRVHHFSPVLHFPHPSHIERYKKDLKSWVQGNLTACGRSLFLFDEMDKMPPGLMEVLRPFLGSSWVVYGTNYRKAIFIFISNTGGKQINQVALEAWRSRRDREEILLQELEPVISRAVLDNPHHGFSNSGIMEERLLDAVVPFLPLQRHHVRHCVLNELAQLGLEPRDEVVQAVLDSTTFFPEDEQLFSSNGCKTVASRIAFFL>sp|Q5JU69-2|TOR2A_HUMAN Isoform 2 of Torsin-2A OS=Homo sapiens OX=9606GN=TOR2AMAAATRGCRPWGSLLGLLGLVSAAAAAWDLASLRCTLGAFCECDFRPDLPGLECDLAQHLAGQHLAKALVVKALKAFVRDPAPTKPLVLSLHGWTGTGKSYVSSLLAHYLFQGGLRSPRVHHFSPVLHFPHPSHIERYKKDLKSWVQGNLTACGRSLFLFDEMDKMPPGLMEVLRPFLGSSWVVYGTNYRKAIFIFIRWGPALQWAQWGGHFSEVQLYSLSLCSQQNPVPHGLSWAFPVPSATLRDDIVIPPG>sp|Q5JU69-5|TOR2A_HUMAN Isoform 3 of Torsin-2A OS=Homo sapiens OX=9606GN=TOR2AMAAATRGCRPWGSLLGLLGLVSAAAAAWDLASLRCTLGAFCECDFRPDLPEGSEELGPREPHCLWPLPLPLR>sp|Q8WWA1|TMM40_HUMAN Transmembrane protein 40 OS=Homo sapiens OX=9606GN=TMEM40 PE=1 SV=2METSASSSQPQDNSQVHRETEDVDYGETDFHKQDGKAGLFSQEQYERNKSSSSSSSSSSSSSSSSSSSSSESNDEDQQPRATGKHRRSLGAGYPHGNGSPGPGHGEPDVLKDELQLYGDAPGEVVPSGESGLRRRGSDPASGEVEASQLRRLNIKKDDEFFHFVLLCFAIGALLVCYHYYADWFMSLGVGLLTFASLETVGIYFGLVYRIHSVLQGFIPLFQKFRLTGFRKTD>sp|Q8WWA1-2|TMM40_HUMAN Isoform 2 of Transmembrane protein 40 OS=Homosapiens OX=9606 GN=TMEM40METSASSSQPQDNSQVHRETEDVDYGETDFHKQDGKAGLFSQEQYERNKSSSSSSSSSSSSSSSSSSSSSGPGHGEPDVLKDELQLYGDAPGEVVPSGESGLRRRGSDPASGEVEASQLRRLNIKKDDEFFHFVLLCFAIGALLVCYHYYADWFMSLGVGLLTFASLETVGIYFGLVYRIHSVLQGFIPLFQKFRLTGFRKTD>sp|Q8WWA1-3|TMM40_HUMAN Isoform 3 of Transmembrane protein 40 OS=Homosapiens OX=9606 GN=TMEM40METSASSSQPQDNSQVHRETEDVDCPGHGEPDVLKDELQLYGDAPGEVVPSGESGLRRRGSDPASGEVEASQLRRLNIKKDDEFFHFVLLCFAIGALLVCYHYYADWFMSLGVGLLTFASLETVGIYFGLVYRIHSVLQGFIPLFQKFRLTGFRKTD>sp|Q9Y6L7|TLL2_HUMAN Tolloid-like protein 2 OS=Homo sapiens OX=9606GN=TLL2 PE=1 SV=1MPRATALGALVSLLLLLPLPRGAGGLGERPDATADYSELDGEEGTEQQLEHYHDPCKAAVFWGDIALDEDDLKLFHIDKARDWTKQTVGATGHSTGGLEEQASESSPDTTAMDTGTKEAGKDGRENTTLLHSPGTLHAAAKTFSPRVRRATTSRTERIWPGGVIPYVIGGNFTGSQRAIFKQAMRHWEKHTCVTFIERTDEESFIVFSYRTCGCCSYVGRRGGGPQAISIGKNCDKFGIVAHELGHVVGFWHEHTRPDRDQHVTIIRENIQPGQEYNFLKMEAGEVSSLGETYDFDSIMHYARNTFSRGVFLDTILPRQDDNGVRPTIGQRVRLSQGDIAQARKLYKCPACGETLQDTTGNFSAPGFPNGYPSYSHCVWRISVTPGEKIVLNFTSMDLFKSRLCWYDYVEVRDGYWRKAPLLGRFCGDKIPEPLVSTDSRLWVEFRSSSNILGKGFFAAYEATCGGDMNKDAGQIQSPNYPDDYRPSKECVWRITVSEGFHVGLTFQAFEIERHDSCAYDYLEVRDGPTEESALIGHFCGYEKPEDVKSSSNRLWMKFVSDGSINKAGFAANFFKEVDECSWPDHGGCEHRCVNTLGSYKCACDPGYELAADKKMCEVACGGFITKLNGTITSPGWPKEYPTNKNCVWQVVAPAQYRISLQFEVFELEGNDVCKYDFVEVRSGLSPDAKLHGRFCGSETPEVITSQSNNMRVEFKSDNTVSKRGFRAHFFSDKDECAKDNGGCQHECVNTFGSYLCRCRNGYWLHENGHDCKEAGCAHKISSVEGTLASPNWPDKYPSRRECTWNISSTAGHRVKLTFNEFEIEQHQECAYDHLEMYDGPDSLAPILGRFCGSKKPDPTVASGSSMFLRFYSDASVQRKGFQAVHSTECGGRLKAEVQTKELYSHAQFGDNNYPSEARCDWVIVAEDGYGVELTFRTFEVEEEADCGYDYMEAYDGYDSSAPRLGRFCGSGPLEEIYSAGDSLMIRFRTDDTINKKGFHARYTSTKFQDALHMKK>sp|Q96DA6|TIM14_HUMAN Mitochondrial import inner membrane translocasesubunit TIM14 OS=Homo sapiens OX=9606 GN=DNAJC19 PE=1 SV=3MASTVVAVGLTIAAAGFAGRYVLQAMKHMEPQVKQVFQSLPKSAFSGGYYRGGFEPKMTKREAALILGVSPTANKGKIRDAHRRIMLLNHPDKGGSPYIAAKINEAKDLLEGQAKK>sp|Q96DA6-2|TIM14_HUMAN Isoform 2 of Mitochondrial import inner membranetranslocase subunit TIM14 OS=Homo sapiens OX=9606 GN=DNAJC19MKHMEPQVKQVFQSLPKSAFSGGYYRGGFEPKMTKREAALILGVSPTANKGKIRDAHRRIMLLNHPDKGGSPYIAAKINEAKDLLEGQAKK>sp|Q8NHH1|TTL11_HUMAN Tubulin polyglutamylase TTLL11 OS=Homo sapiensOX=9606 GN=TTLL11 PE=1 SV=2MAAAASVTGRVTWAASPMRSLGLGRRLSLPGPRLDAVTAAVNPSLSDHGNGLGRGTRGSGCSGGSLVADWGGGAAAAAAVALALAPALSTMRRGSSESELAARWEAEAVAAAKAAAKAEAEATAETVAEQVRVDAGAAGEPECKAGEEQPKVLAPAPAQPSAAEEGNTQVLQRPPPTLPPSKPKPVQGLCPHGKPRDKGRSCKRSSGHGSGENGSQRPVTVDSSKARTSLDALKISIRQLKWKEFPFGRRLPCDIYWHGVSFHDNDIFSGQVNKFPGMTEMVRKITLSRAVRTMQNLFPEEYNFYPRSWILPDEFQLFVAQVQMVKDDDPSWKPTFIVKPDGGCQGDGIYLIKDPSDIRLAGTLQSRPAVVQEYICKPLLIDKLKFDIRLYVLLKSLDPLEIYIAKDGLSRFCTEPYQEPTPKNLHRIFMHLTNYSLNIHSGNFIHSDSASTGSKRTFSSILCRLSSKGVDIKKVWSDIISVVIKTVIALTPELKVFYQSDIPTGRPGPTCFQILGFDILLMKNLKPILLEVNANPSMRIEHEHELSPGVFENVPSLVDEEVKVAVIRDTLRLMDPLKKKRENQSQQLEKPFAGKEDALDGELTSAPDCNANPEAHLPSICLKQVFPKYAKQFNYLRLVDRMANLFIRFLGIKGTMKLGPTGFRTFIRSCKLSSSSLSMAAVDILYIDITRRWNSMTLDQRDSGMCLQAFVEAFFFLAQRKFKMLPLHEQVASLIDLCEYHLSLLDEKRLVCGRGVPSGGRPPHRGPPQEPSPSAQPAGDNPPPRTSCANKLSHPRHTLS>sp|Q8NHH1-2|TTL11_HUMAN Isoform 2 of Tubulin polyglutamylase TTLL11OS=Homo sapiens OX=9606 GN=TTLL11MAAAASVTGRVTWAASPMRSLGLGRRLSLPGPRLDAVTAAVNPSLSDHGNGLGRGTRGSGCSGGSLVADWGGGAAAAAAVALALAPALSTMRRGSSESELAARWEAEAVAAAKAAAKAEAEATAETVAEQVRVDAGAAGEPECKAGEEQPKVLAPAPAQPSAAEEGNTQVLQRPPPTLPPSKPKPVQGLCPHGKPRDKGRSCKRSSGHGSGENGSQRPVTVDSSKARTSLDALKISIRQLKWKEFPFGRRLPCDIYWHGVSFHDNDIFSGQVNKFPGMTEMVRKITLSRAVRTMQNLFPEEYNFYPRSWILPDEFQLFVAQVQMVKDDDPSWKPTFIVKPDGGCQGDGIYLIKDPSDIRLAGTLQSRPAVVQEYICKPLLIDKLKFDIRLYVLLKSLDPLEIYIAKDGLSRFCTEPYQEPTPKNLHRIFMHLTNYSLNIHSGNFIHSDSASTGSKRTFSSILCRLSSKGVDIKKVWSDIISVVIKTVIALTPELKVFYQSDIPTGRPGPTCFQVTIASSQPAFPALTGLKRALWLRVG>sp|Q9UJT2|TSKS_HUMAN Testis-specific serine kinase substrate OS=Homosapiens OX=9606 GN=TSKS PE=1 SV=3MASVVVKTIWQSKEIHEAGDTPTGVESCSQLVPEAPRRVTSRAKGIPKKKKAVSFHGVEPQMSHQPMHWCLNLKRSSACTNVSLLNLAAMEPTDSTGTDSTVEDLSGQLTLAGPPASPTLPWDPDDADITEILSGVNSGLVRAKDSITSLKEKTNRVNQHVQSLQSECSVLSENLERRRQEAEELEGYCIQLKENCWKVTRSVEDAEIKTNVLKQNSALLEEKLRYLQQQLQDETPRRQEAELQEPEEKQEPEEKQEPEEKQKPEAGLSWNSLGPAATSQGCPGPPGSPDKPSRPHGLVPAGWGMGPRAGEGPYVSEQELQKLFTGIEELRREVSSLTARWHQEEGAVQEALRLLGGLGGRVDGFLGQWERAQREQAQTARDLQELRGRADELCTMVERSAVSVASLRSELEGLGPLKPILEEFGRQFQNSRRGPDLSMNLDRSHQGNCARCASQGSQLSTESLQQLLDRALTSLVDEVKQRGLTPACPSCQRLHKKILELERQALAKHVRAEALSSTLRLAQDEALRAKNLLLTDKMKPEEKMATLDHLHLKMCSLHDHLSNLPLEGSTGTMGGGSSAGTPPKQGGSAPEQ>sp|Q9UJT2-2|TSKS_HUMAN Isoform 2 of Testis-specific serine kinasesubstrate OS=Homo sapiens OX=9606 GN=TSKSMGDSCPAVTFRSQKENRAGLQEKLRYLQQQLQDETPRRQEAELQEPEEKQEPEEKQKPEAGLSWNSLGPAATSQGCPGPPGSPDKPSRPHGLVPAGWGMGPRAGEGPYVSEQELQKLFTGIEELRREVSSLTARWHQEEGAVQEALRLLGGLGGRVDGFLGQWERAQREQAQTARDLQELRGRADELCTMVERSAVSVASLRSELEGLGPLKPILEEFGRQFQNSRRGPDLSMNLDRSHQGNCARCASQGSQLSTESLQQLLDRALTSLVDEVKQRGLTPACPSCQRLHKKILELERQALAKHVRAEALSSTLRLAQDEALRAKNLLLTDKMKPEEKMATLDHLHLKMCSLHDHLSNLPLEGSTGTMGGGSSAGTPPKQGGSAPEQ>sp|P54855|UDB15_HUMAN UDP-glucuronosyltransferase 2B15 OS=Homo sapiensOX=9606 GN=UGT2B15 PE=1 SV=3MSLKWTSVFLLIQLSCYFSSGSCGKVLVWPTEYSHWINMKTILEELVQRGHEVTVLTSSASTLVNASKSSAIKLEVYPTSLTKNYLEDSLLKILDRWIYGVSKNTFWSYFSQLQELCWEYYDYSNKLCKDAVLNKKLMMKLQESKFDVILADALNPCGELLAELFNIPFLYSLRFSVGYTFEKNGGGFLFPPSYVPVVMSELSDQMIFMERIKNMIHMLYFDFWFQIYDLKKWDQFYSEVLGRPTTLFETMGKAEMWLIRTYWDFEFPRPFLPNVDFVGGLHCKPAKPLPKEMEEFVQSSGENGIVVFSLGSMISNMSEESANMIASALAQIPQKVLWRFDGKKPNTLGSNTRLYKWLPQNDLLGHPKTKAFITHGGTNGIYEAIYHGIPMVGIPLFADQHDNIAHMKAKGAALSVDIRTMSSRDLLNALKSVINDPVYKENVMKLSRIHHDQPMKPLDRAVFWIEFVMRHKGAKHLRVAAHNLTWIQYHSLDVIAFLLACVATVIFIITKFCLFCFRKLAKKGKKKKRD>sp|Q6P3X3|TTC27_HUMAN Tetratricopeptide repeat protein 27 OS=Homosapiens OX=9606 GN=TTC27 PE=1 SV=1MWTPELAILRGFPTEAERQQWKQEGVVGSESGSFLQLLLEGNYEAIFLNSMTQNIFNSTTTAEEKIDSYLEKQVVTFLDYSTDLDTTERQQLIFLLGVSSLQLFVQSNWTGPPVDLHPQDFLSSVLFQQFSEVKGLDAFVLSLLTLDGESIYSLTSKPILLLLARIILVNVRHKLTAIQSLPWWTLRCVNIHQHLLEERSPLLFTLAENCIDQVMKLQNLFVDDSGRYLAIQFHLECAYVFLYYYEYRKAKDQLDIAKDISQLQIDLTGALGKRTRFQENYVAQLILDVRREGDVLSNCEFTPAPTPQEHLTKNLELNDDTILNDIKLADCEQFQMPDLCAEEIAIILGICTNFQKNNPVHTLTEVELLAFTSCLLSQPKFWAIQTSALILRTKLEKGSTRRVERAMRQTQALADQFEDKTTSVLERLKIFYCCQVPPHWAIQRQLASLLFELGCTSSALQIFEKLEMWEDVVICYERAGQHGKAEEILRQELEKKETPSLYCLLGDVLGDHSCYDKAWELSRYRSARAQRSKALLHLRNKEFQECVECFERSVKINPMQLGVWFSLGCAYLALEDYQGSAKAFQRCVTLEPDNAEAWNNLSTSYIRLKQKVKAFRTLQEALKCNYEHWQIWENYILTSTDVGEFSEAIKAYHRLLDLRDKYKDVQVLKILVRAVIDGMTDRSGDVATGLKGKLQELFGRVTSRVTNDGEIWRLYAHVYGNGQSEKPDENEKAFQCLSKAYKCDTQSNCWEKDITSFKEVVQRALGLAHVAIKCSKNKSSSQEAVQMLSSVRLNLRGLLSKAKQLFTDVATGEMSRELADDITAMDTLVTELQDLSNQFRNQY>sp|Q9BZA0|TTY10_HUMAN Putative transcript Y 10 protein OS=Homo sapiensOX=9606 GN=TTTY10 PE=5 SV=1MKLQTLMDWEEAHEKNRKNKRKAEALVAALQTCRVQDPPGTSTDCYLLPVLKPGHFKKNCPSHKKKPP>sp|O75310|UDB11_HUMAN UDP-glucuronosyltransferase 2B11 OS=Homo sapiensOX=9606 GN=UGT2B11 PE=1 SV=1MTLKWTSVLLLIHLSCYFSSGSCGKVLVWAAEYSHWMNMKTILKELVQRGHEVTVLASSASILFDPNDASTLKFEVYPTSLTKTEFENIIMQQVKRWSDIRKDSFWLYFSQEQEILWELYDIFRNFCKDVVSNKKVMKKLQESRFDIVFADAVFPCGELLAALLNIRFVYSLRFTPGYTIERHSGGLIFPPSYIPIVMSKLSDQMTFMERVKNMIYVLYFDFWFQMSDMKKWDQFYSEVLGRPTTLFETMGKADIWLMRNSWSFQFPHPFLPNVDFVGGFHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSVISNMTAERANVIATALAKIPQKVLWRFDGNKPDALGLNTRLYKWIPQNDLLGHPKTRAFITHGGANGIYEAIYHGIPMVGIPLFFDQPDNIAHMKAKGAAVRLDFNTMSSTDLLNALKTVINDPLYKENIMKLSRIQHDQPVKPLDRAVFWIEFVMPHKGAKHLRVAAHDLTWFQYHSLDVIGFLLACVATVIFIITKFCLFCFWKFARKGKKGKRD>sp|Q7Z4L5|TT21B_HUMAN Tetratricopeptide repeat protein 21B OS=Homosapiens OX=9606 GN=TTC21B PE=1 SV=2MDSQELKTLINYYCQERYFHHVLLVASEGIKRYGSDPVFRFYHAYGTLMEGKTQEALREFEAIKNKQDVSLCSLLALIYAHKMSPNPDREAILESDARVKEQRKGAGEKALYHAGLFLWHIGRHDKAREYIDRMIKISDGSKQGHVLKAWLDITRGKEPYTKKALKYFEEGLQDGNDTFALLGKAQCLEMRQNYSGALETVNQIIVNFPSFLPAFVKKMKLQLALQDWDQTVETAQRLLLQDSQNVEALRMQALYYVCREGDIEKASTKLENLGNTLDAMEPQNAQLFYNITLAFSRTCGRSQLILQKIQTLLERAFSLNPQQSEFATELGYQMILQGRVKEALKWYKTAMTLDETSVSALVGFIQCQLIEGQLQDADQQLEFLNEIQQSIGKSAELIYLHAVLAMKKNKRQEEVINLLNDVLDTHFSQLEGLPLGIQYFEKLNPDFLLEIVMEYLSFCPMQPASPGQPLCPLLRRCISVLETVVRTVPGLLQTVFLIAKVKYLSGDIEAAFNNLQHCLEHNPSYADAHLLLAQVYLSQEKVKLCSQSLELCLSYDFKVRDYPLYHLIKAQSQKKMGEIADAIKTLHMAMSLPGMKRIGASTKSKDRKTEVDTSHRLSIFLELIDVHRLNGEQHEATKVLQDAIHEFSGTSEEVRVTIANADLALAQGDIERALSILQNVTAEQPYFIEAREKMADIYLKHRKDKMLYITCFREIAERMANPRSFLLLGDAYMNILEPEEAIVAYEQALNQNPKDGTLASKMGKALIKTHNYSMAITYYEAALKTGQKNYLCYDLAELLLKLKWYDKAEKVLQHALAHEPVNELSALMEDGRCQVLLAKVYSKMEKLGDAITALQQARELQARVLKRVQMEQPDAVPAQKHLAAEICAEIAKHSVAQRDYEKAIKFYREALVHCETDNKIMLELARLYLAQDDPDSCLRQCALLLQSDQDNEAATMMMADLMFRKQDYEQAVFHLQQLLERKPDNYMTLSRLIDLLRRCGKLEDVPRFFSMAEKRNSRAKLEPGFQYCKGLYLWYTGEPNDALRHFNKARKDRDWGQNALYNMIEICLNPDNETVGGEVFENLDGDLGNSTEKQESVQLAVRTAEKLLKELKPQTVQGHVQLRIMENYCLMATKQKSNVEQALNTFTEIAASEKEHIPALLGMATAYMILKQTPRARNQLKRIAKMNWNAIDAEEFEKSWLLLADIYIQSAKYDMAEDLLKRCLRHNRSCCKAYEYMGYIMEKEQAYTDAALNYEMAWKYSNRTNPAVGYKLAFNYLKAKRYVDSIDICHQVLEAHPTYPKIRKDILDKARASLRP>sp|Q7Z4L5-2|TT21B_HUMAN Isoform 2 of Tetratricopeptide repeat protein21B OS=Homo sapiens OX=9606 GN=TTC21BMDSQELKTLINYYCQERYFHHVLLVASEGIKRYGSDPVFRFYHAYGTLMEGKTQEALREFEAIKNKQDVSLCSLLALIYAHKMSPNPDREAILESDARVKEQRKGAGEKALYHAGLFLWHIGRHDKAREYIDRMIKISDGSKQGHVLKAWLDITRGKEPYTKKALKYFEEGLQDGNDTFALLGKAQCLEMRQNYSGALETVNQIIVNFPSFLPAFVKKMKLQLALQDWDQTVETAQRLLLQDSQNVEALRMQALYYVCREGDIEKASTKLENLGNTLDAMEPQNAQLFYNITLAFSRTCGRSQLILQKIQTLLERAFSLNPQQSEFATELGYQMILQGRVKEALKWYKTAMTLDETSVSALVGFIQCQLIEGQLQDADQQLEFLNEIQQSIGKSAELIYLHAVLAMKKNKRQEEVINLLNDVLDTHFSQLEGLPLGIQYFEKLNPDFLLEIVMEYLSFCPMQVSNYGTYFQGCVYLMFYERT>sp|P0C672|TSN19_HUMAN Tetraspanin-19 OS=Homo sapiens OX=9606 GN=TSPAN19PE=3 SV=1MLRNNKTIIIKYFLNLINGAFLVLGLLFMGFGAWLLLDRNNFLTAFDENNHFIVPISQILIGMGSSTVLFCLLGYIGIHNEIRWLLIVYAVLITWTFAVQVVLSAFIITKKEEVQQLWHDKIDFVISEYGSKDKPEDITKWTILNALQKTLQCCGQHNYTDWIKNKNKENSGQVPCSCTKSTLRKWFCDEPLNATYLEGCENKISAWYNVNVLTLIGINFGLLTSEVFQVSLTVCFFKNIKNIIHAEM>sp|Q70J99|UN13D_HUMAN Protein unc-13 homolog D OS=Homo sapiens OX=9606GN=UNC13D PE=1 SV=1MATLLSHPQQRPPFLRQAIKIRRRRVRDLQDPPPQMAPEIQPPSHHFSPEQRALLYEDALYTVLHRLGHPEPNHVTEASELLRYLQEAFHVEPEEHQQTLQRVRELEKPIFCLKATVKQAKGILGKDVSGFSDPYCLLGIEQGVGVPGGSPGSRHRQKAVVRHTIPEEETHRTQVITQTLNPVWDETFILEFEDITNASFHLDMWDLDTVESVRQKLGELTDLHGLRRIFKEARKDKGQDDFLGNVVLRLQDLRCREDQWYPLEPRTETYPDRGQCHLQFQLIHKRRATSASRSQPSYTVHLHLLQQLVSHEVTQHEAGSTSWDGSLSPQAATVLFLHATQKDLSDFHQSMAQWLAYSRLYQSLEFPSSCLLHPITSIEYQWIQGRLKAEQQEELAASFSSLLTYGLSLIRRFRSVFPLSVSDSPARLQSLLRVLVQMCKMKAFGELCPNTAPLPQLVTEALQTGTTEWFHLKQQHHQPMVQGIPEAGKALLGLVQDVIGDLHQCQRTWDKIFHNTLKIHLFSMAFRELQWLVAKRVQDHTTVVGDVVSPEMGESLFQLYISLKELCQLRMSSSERDGVLALDNFHRWFQPAIPSWLQKTYNEALARVQRAVQMDELVPLGELTKHSTSAVDLSTCFAQISHTARQLDWPDPEEAFMITVKFVEDTCRLALVYCSLIKARARELSSGQKDQGQAANMLCVVVNDMEQLRLVIGKLPAQLAWEALEQRVGAVLEQGQLQNTLHAQLQSALAGLGHEIRTGVRTLAEQLEVGIAKHIQKLVGVRESVLPEDAILPLMKFLEVELCYMNTNLVQENFSSLLTLLWTHTLTVLVEAAASQRSSSLASNRLKIALQNLEICFHAEGCGLPPKALHTATFQALQRDLELQAASSRELIRKYFCSRIQQQAETTSEELGAVTVKASYRASEQKLRVELLSASSLLPLDSNGSSDPFVQLTLEPRHEFPELAARETQKHKKDLHPLFDETFEFLVPAEPCRKAGACLLLTVLDYDTLGADDLEGEAFLPLREVPGLSGSEEPGEVPQTRLPLTYPAPNGDPILQLLEGRKGDREAQVFVRLRRHRAKQASQHALRPAP>sp|Q70J99-2|UN13D_HUMAN Isoform 2 of Protein unc-13 homolog D OS=Homosapiens OX=9606 GN=UNC13DMATLLSHPQQRPPFLRQAIKIRRRRVRDLQDPPPQMAPEIQPPSHHFSPEQRALLYEDALYTVLHRLGHPEPNHVTEASELLRYLQEAFHVEPEEHQQTLQRVRELEKPIFCLKATVKQAKGILGKDVSGFSDPYCLLGIEQGVGVPGGSPGSRHRQKAVVRHTIPEEETHRTQVITQTLNPVWDETFILEFEDITNASFHLDMWDLDTVESVRQKLGELTDLHGLRRIFKEARKDKGQDDFLGNVVLRLQDLRCREDQWYPLEPRTETYPDRGQCHLQFQLIHKRVGRVLGQWPCPALAAVCWVAGLAAPSVRPCLLTEASLQRATSASRSQPSYTVHLHLLQQLVSHEVTQHEVLPSWGWA>sp|Q70J99-3|UN13D_HUMAN Isoform 3 of Protein unc-13 homolog D OS=Homosapiens OX=9606 GN=UNC13DMATLLSHPQQRPPFLRQAIKIRRRRVRDLQDPPPQMAPEIQPPSHHFSPEQRALLYEDALYTVLHRLGHPEPNHVTEASELLRYLQEAFHVEPEEHQQTLQRVRELEKPIFCLKATVKQAKGILGKDVSGFSDPYCLLGIEQGVGVPGGSPGSRHRQKAVVRHTIPEEETHRTQVITQTLNPVWDETFILEFEDITNASFHLDMWDLDTVESVRQKLGELTDLHGLRRIFKEARKDKGQDDFLGNVVLRLQDLRCREDQWYPLEPRTETYPDRGQCHLQFQLIHKRRATSASRSQPSYTVHLHLLQQLVSHEVTQHEAGSTSWDGSLSPQAATVLFLHATQKDLSDFHQSMAQWLAYSRLYQSLEFPSSCLLHPITSIEYQWIQGRLKAEQQEELAASFSSLLTYGLSLIRRFRSVFPLSVSDSPARLQSLLRVLVQMCKMKAFGELCPNTAPLPQLVTEALQTGTTEWFHLKQQHHQPMVQGIPEAGKALLGLVQDVIGDLHQCQRTWDKIFHNTLKIHLFSMAFRELQWLVAKRVQDHTTVVGDVVSPEMGESLFQLYISLKELCQLRMSSSERDGVLALDNFHRWFQPAIPSWLQKTYNEALARVQRAVQMDELVPLGELTKHSTSAVDLSTCFAQISHTARQLDWPDPEEAFMITVKFVEDTCRLALVYCSLIKARARELSSGQKDQGQAANMLCVVVNDMEQLRLVIGKLPAQLAWEALEQRVGAVLEQGQLQNTLHAQLQSALAGLGHEIRTGVRTLAEQLEVGIAKHIQKLVGVRESVLPEDAILPLMKFLEVELCYMNTNLVQENFSSLLTLLWTHTLTVLVEAAASQRSSSLASNRLKIALQNLEICFHAEGCGLPPKALHTATFQALQRDLELQAASSRELIRKYFCSRIQQQAETTSEELGAVTVKASYRASEQKLRVELLSASSLLPLDSNGSSDPFVQLTLEPRHEFPELAARETQKHKKDLHPLFDETFEFLVPAEPCRKAGACLLLTVLDYDTLGADDLEGEAFLPLREVPGLSGSEEPGEVPQTRLPLTYPAPNGDPILQLLEGRKGDREAQVFVRLRRHRAKQGIGPSVSWPWPICLLAFLFQPLGWGPGSLGPGLQAQSLLEKGEGTLPKMRLQLPWGEGGGHY>sp|Q8N2C7|UNC80_HUMAN Protein unc-80 homolog OS=Homo sapiens OX=9606GN=UNC80 PE=1 SV=2MVKRKSSEGQEQDGGRGIPLPIQTFLWRQTSAFLRPKLGKQYEASCVSFERVLVENKLHGLSPALSEAIQSISRWELVQAALPHVLHCTATLLSNRNKLGHQDKLGVAETKLLHTLHWMLLEAPQDCNNERFGGTDRGSSWGGSSSAFIHQVENQGSPGQPCQSSSNDEEENNRRKIFQNSMATVELFVFLFAPLVHRIKESDLTFRLASGLVIWQPMWEHRQPGVSGFTALVKPIRNIITAKRSSPINSQSRTCESPNQDARHLEGLQVVCETFQSDSISPKATISGCHRGNSFDGSLSSQTSQERGPSHSRASLVIPPCQRSRYATYFDVAVLRCLLQPHWSEEGTQWSLMYYLQRLRHMLEEKPEKPPEPDIPLLPRPRSSSMVAAAPSLVNTHKTQDLTMKCNEEEKSLSSEAFSKVSLTNLRRSAVPDLSSDLGMNIFKKFKSRKEDRERKGSIPFHHTGKRRPRRMGVPFLLHEDHLDVSPTRSTFSFGSFSGLGEDRRGIEKGGWQTTILGKLTRRGSSDAATEMESLSARHSHSHHTLVSDLPDPSNSHGENTVKEVRSQISTITVATFNTTLASFNVGYADFFNEHMRKLCNQVPIPEMPHEPLACANLPRSLTDSCINYSYLEDTEHIDGTNNFVHKNGMLDLSVVLKAVYLVLNHDISSRICDVALNIVECLLQLGVVPCVEKNRKKSENKENETLEKRPSEGAFQFKGVSGSSTCGFGGPAVSGAGDGGGEEGGGGDGGGGGGDGGGGGGGGGGPYEKNDKNQEKDESTPVSNHRLALTMLIKIVKSLGCAYGCGEGHRGLSGDRLRHQVFRENAQNCLTKLYKLDKMQFRQTMRDYVNKDSLNNVVDFLHALLGFCMEPVTDNKAGFGNNFTTVDNKSTAQNVEGIIVSAMFKSLITRCASTTHELHSPENLGLYCDIRQLVQFIKEAHGNVFRRVALSALLDSAEKLAPGKKVEENEQESKPAGSKRSEAGSIVDKGQVSSAPEECRSFMSGRPSQTPEHDEQMQGANLGRKDFWRKMFKSQSAASDTSSQSEQDTSECTTAHSGTTSDRRARSRSRRISLRKKLKLPIGKRNWLKRSSLSGLADGVEDLLDISSVDRLSFIRQSSKVKFTSAVKLSEGGPGSGMENGRDEEENFFKRLGCHSFDDHLSPNQDGGKSKNVVNLGAIRQGMKRFQFLLNCCEPGTIPDASILAAALDLEAPVVARAALFLECARFVHRCNRGNWPEWMKGHHVNITKKGLSRGRSPIVGNKRNQKLQWNAAKLFYQWGDAIGVRLNELCHGESESPANLLGLIYDEETKRRLRKEDEEEDFLDDSTVNPSKCGCPFALKMAACQLLLEITTFLRETFSCLPRPRTEPLVDLESCRLRLDPELDRHRYERKISFAGVLDENEDSKDSLHSSSHTLKSDAGVEEKKEGSPWSASEPSIEPEGMSNAGAEENYHRNMSWLHVMILLCNQQSFICTHVDYCHPHCYLHHSRSCARLVRAIKLLYGDSVDSLRESSNISSVALRGKKQKECSDKSCLRTPSLKKRVSDANLEGKKDSGMLKYIRLQVMSLSPAPLSLLIKAAPILTEEMYGDIQPAAWELLLSMDEHMAGAAAAMFLLCAVKVPEAVSDMLMSEFHHPETVQRLNAVLKFHTLWRFRYQVWPRMEEGAQQIFKIPPPSINFTLPSPVLGMPSVPMFDPPWVPQCSGSVQDPINEDQSKSFSARAVSRSHQRAEHILKNLQQEEEKKRLGREASLITAIPITQEACYEPTCTPNSEPEEEVEEVTNLASRRLSVSPSCTSSTSHRNYSFRRGSVWSVRSAVSAEDEEHTTEHTPNHHVPQPPQAVFPACICAAVLPIVHLMEDGEVREDGVAVSAVAQQVLWNCLIEDPSTVLRHFLEKLTISNRQDELMYMLRKLLLNIGDFPAQTSHILFNYLVGLIMYFVRTPCEWGMDAISATLTFLWEVVGYVEGLFFKDLKQTMKKEQCEVKLLVTASMPGTKTLVVHGQNECDIPTQLPVHEDTQFEALLKECLEFFNIPESQSTHYFLMDKRWNLIHYNKTYVRDIYPFRRSVSPQLNLVHMHPEKGQELIQKQVFTRKLEEVGRVLFLISLTQKIPTAHKQSHVSMLQEDLLRLPSFPRSAIDAEFSLFSDPQAGKELFGLDTLQKSLWIQLLEEMFLGMPSEFPWGDEIMLFLNVFNGALILHPEDSALLRQYAATVINTAVHFNHLFSLSGYQWILPTMLQVYSDYESNPQLRQAIEFACHQFYILHRKPFVLQLFASVAPLLEFPDAANNGPSKGVSAQCLFDLLQSLEGETTDILDILELVKAEKPLKSLDFCYGNEDLTFSISEAIKLCVTVVAYAPESFRSLQMLMVLEALVPCYLQKLKRQTSQVETVPAAREEIAATAALATSLQALLYSVEVLTRPMTAPQMSRCDQGHKGTTTANHTMSSGVNTRYQEQGAKLHFIRENLHLLEEGQGIPREELDERIAREEFRRPRESLLNICTEFYKHCGPRLKILQNLAGEPRVIALELLDVKSHMRLAEIAHSLLKLAPYDTQTMESRGLRRYIMEMLPITDWTAEAVRPALILILKRLDRMFNKIHKMPTLRRQVEWEPASNLIEGVCLTLQRQPIISFLPHLRSLINVCVNLVMGVVGPSSVADGLPLLHLSPYLSPPLPFSTAVVRLVALQIQALKEDFPLSHVISPFTNQERREGMLLNLLIPFVLTVGSGSKDSPWLEQPEVQLLLQTVINVLLPPRIISTSRSKNFMLESSPAHCSTPGDAGKDLRREGLAESTSQAAYLALKVILVCFERQLGSQWYWLSLQVKEMALRKVGGLALWDFLDFIVRTRIPIFVLLRPFIQCKLLAQPAENHEELSARQHIADQLERRFIPRPLCKSSLIAEFNSELKILKEAVHSGSAYQGKTSISTVGTSTSAYRLSLATMSRSNTGTGTVWEQDSEPSQQASQDTLSRTDEEDEENDSISMPSVVSEQEAYLLSAIGRRRFSSHVSSMSVPQAEVGMLPSQSEPNVLDDSQGLAAEGSLSRVASIQSEPGQQNLLVQQPLGRKRGLRQLRRPLLSRQKTQTEPRNRQGARLSTTRRSIQPKTKPSADQKRSVTFIEAQPEPAAAPTDALPATGQLQGCSPAPSRKPEAMDEPVLTSSPAIVVADLHSVSPKQSENFPTEEGEKEEDTEAQGATAHSPLSAQLSDPDDFTGLETSSLLQHGDTVLHISEENGMENPLLSSQFTFTPTELGKTDAVLDESHV>sp|Q8N2C7-2|UNC80_HUMAN Isoform 2 of Protein unc-80 homolog OS=Homosapiens OX=9606 GN=UNC80MVKRKSSEGQEQDGGRGIPLPIQTFLWRQTSAFLRPKLGKQYEASCVSFERVLVENKLHGLSPALSEAIQSISRWELVQAALPHVLHCTATLLSNRNKLGHQDKLGVAETKLLHTLHWMLLEAPQDCNNERFGGTDRGSSWGGSSSAFIHQVENQGSPGQPCQSSSNDEEENNRRKIFQNSMATVELFVFLFAPLVHRIKESDLTFRLASGLVIWQPMWEHRQPGVSGFTALVKPIRNIITAKRSSPINSQSRTCESPNQDARHLEGLQVVCETFQSDSISPKATISGCHRGNSFDGSLSSQTSQERGPSHSRASLVIPPCQRSRYATYFDVAVLRCLLQPHWSEEGTQWSLMYYLQRLRHMLEEKPEKPPEPDIPLLPRPRSSSMVAAAPSLVNTHKTQDLTMKCNEEEKSLSSEAFSKVSLTNLRRSAVPDLSSDLGMNIFKKFKSRKEDRERKGSIPFHHTGKRRPRRMGVPFLLHEDHLDVSPTRSTFSFGSFSGLGEDRRGIEKGGWQTTILGKLTRRGSSDAATEMESLSARHSHSHHTLVSDLPDPSNSHGENTVKEVRSQISTITVATFNTTLASFNVGYADFFNEHMRKLCNQVPIPEMPHEPLACANLPRSLTDSCINYSYLEDTEHIDGTNNFVHKNGMLDLSVVLKAVYLVLNHDISSRICDVALNIVECLLQLGVVPCVEKNRKKSENKENETLEKRPSEGAFQFKGVSGSSTCGFGGPAVSGAGDGGGEEGGGGDGGGGGGDGGGGGGGGGGPYEKNDKNQEKDESTPVSNHRLALTMLIKIVKSLGCAYGCGEGHRGLSGDRLRHQVFRENAQNCLTKLYKLDKMQFRQTMRDYVNKDSLNNVVDFLHALLGFCMEPVTDNKAGFGNNFTTVDNKSTAQNVEGIIVSAMFKSLITRCASTTHELHSPENLGLYCDIRQLVQFIKEAHGNVFRRVALSALLDSAEKLAPGKKVEENEQESKPAGSKRSEAGSIVDKGQVSSAPEECRSFMSGRPSQTPEHDEQMQGANLGRKDFWRKMFKSQSAASDTSSQSEQDTSECTTAHSGTTSDRRARSRSRRISLRKKLKLPIGKRNWLKRSSLSGLADGVEDLLDISSVDRLSFIRQSSKVKFTSAVKLSEGGPGSGMENGRDEEENFFKRLGCHSFDDHLSPNQDGGKSKNVVNLGAIRQGMKRFQFLLNCCEPGTIPDASILAAALDLEAPVVARAALFLECARFVHRCNRGNWPEWMKGHHVNITKKGLSRGRSPIVGNKRNQKLQWNAAKLFYQWGDAIGVRLNELCHGESESPANLLGLIYDEETKRRLRKEDEEEDFLDDSTVNPSKCGCPFALKMAACQLLLEITTFLRETFSCLPRPRTEPLVDLESCRLRLDPELDRHRYERKISFAGVLDENEDSKDSLHSSSHTLKSDAGVEEKKEGSPWSASEPSIEPEGMSNAGAEENYHRNMSWLHVMILLCNQQSFICTHVDYCHPHCYLHHSRSCARLVRAIKLLYGDSVDSLRESSNISSVALRGKKQKECSDKSCLRTPSLKKRVSDANLEGKKDSGMLKYIRLQVMSLSPAPLSLLIKAAPILTEEMYGDIQPAAWELLLSMDEHMAGAAAAMFLLCAVKVPEAVSDMLMSEFHHPETVQRLNAVLKFHTLWRFRYQVWPRMEEGAQQIFKIPPPSINFTLPSPVLGMPSVPMFDPPWVPQCSGSVQDPINEDQSKSFSARAVSRSHQRAEHILKNLQQEEEKKRLGREASLITAIPITQEACYEPTCTPNSEPEEEVEEVTNLASRRLSVSPSCTSSTSHRNYSFRRGSVWSVRSAVSAEDEEHTTEHTPNHHVPQPPQAVFPACICAAVLPIVHLMEDGEVREDGVAVSAVAQQVLWNCLIEDPSTVLRHFLEKLTISNRQDELMYMLRKLLLNIGDFPAQTSHILFNYLVGLIMYFVRTPCEWGMDAISATLTFLWEVVGYVEGLFFKDLKQTMKKEQCEVKLLVTASMPGTKTLVVHGQNECDIPTQLPVHEDTQFEALLKECLEFFNIPESQSTHYFLMDKRWNLIHYNKTYVRDIYPFRRSVSPQLNLVHMHPEKGQELIQKQVFTRKLEEVGRVLFLISLTQKIPTAHKQSHVSMLQEDLLRLPSFPRSAIDAEFSLFSDPQAGKELFGLDTLQKSLWIQLLEEMFLGMPSEFPWGDEIMLFLNVFNGALILHPEDSALLRQYAATVINTAVHFNHLFSLSGYQWILPTMLQVYSDYESNPQLRQAIEFACHQFYILHRKPFVLQLFASVAPLLEFPDAANNGPSKGVSAQCLFDLLQSLEGETTDILDILELVKAEKPLKSLDFCYGNEDLTFSISEAIKLCVTVVAYAPESFRSLQMLMVLEALVPCYLQKLKRQTSQVETVPAAREEIAATAALATSLQALLYSVEVLTRPMTAPQMSRCDQGHKGTTTANHTMSSGVNTRYQEQGAKLHFIRENLHLLEEGQGIPREELDERIAREEFRRPRESLLNICTEFYKHCGPRLKILQNLAGEPRVIALELLDVKSHMRLAEIAHSLLKLAPYDTQTMESRGLRRYIMEMLPITDWTAEAVRPALILILKRLDRMFNKIHKMPTLR>sp|Q8N2C7-3|UNC80_HUMAN Isoform 3 of Protein unc-80 homolog OS=Homosapiens OX=9606 GN=UNC80MVKRKSSEGQEQDGGRGIPLPIQTFLWRQTSAFLRPKLGKQYEASCVSFERVLVENKLHGLSPALSEAIQSISRWELVQAALPHVLHCTATLLSNRNKLGHQDKLGVAETKLLHTLHWMLLEAPQDCNNERFGGTDRGSSWGGSSSAFIHQVENQGSPGQPCQSSSNDEEENNRRKIFQNSMATVELFVFLFAPLVHRIKESDLTFRLASGLVIWQPMWEHRQPGVSGFTALVKPIRNIITAKRSSPINSQSRTCESPNQDARHLEGLQVVCETFQSDSISPKATISGCHRGNSFDGSLSSQTSQERGPSHSRSTFHFPP>sp|Q8N2C7-4|UNC80_HUMAN Isoform 4 of Protein unc-80 homolog OS=Homosapiens OX=9606 GN=UNC80MVKRKSSEGQEQDGGRGIPLPIQTFLWRQTSAFLRPKLGKQYEASCVSFERVLVENKLHGLSPALSEAIQSISRWELVQAALPHVLHCTATLLSNRNKLGHQDKLGVAETKLLHTLHWMLLEAPQDCNNERFGGTDRGSSWGGSSSAFIHQVENQGSPGQPCQSSSNDEEENNRRKIFQNSMATVELFVFLFAPLVHRIKESDLTFRLASGLVIWQPMWEHRQPGVSGFTALVKPIRNIITAKRSSPINSQSRTCESPNQDARHLEGLQVVCETFQSDSISPKATISGCHRGNSFDGSLSSQTSQERGPSHSRASLVIPPCQRSRYATYFDVAVLRCLLQPHWSEEGTQWSLMYYLQRLRHMLEEKPEKPPEPDIPLLPRPRSSSMVAAAPSLVNTHKTQDLTMKCNEEEKSLSSEAFSKVSLTNLRRSAVPDLSSDLGMNIFKKFKSRKEDRERKGSIPFHHTGKRRPRRMGVPFLLHEDHLDVSPTRSTFSFGSFSGLGEDRRGIEKGGWQTTILGKLTRRGSSDAATEMESLSARHSHSHHTLVSDLPDPSNSHGENTVKEVRSQISTITVATFNTTLASFNVGYADFFNEHMRKLCNQVPIPEMPHEPLACANLPRSLTDSCINYSYLEDTEHIDGTNNFVHKNGMLDLSVVLKAVYLVLNHDISSRICDVALNIVECLLQLGVVPCVEKNRKKSENKENETLEKRPSEGAFQFKGVSGSSTCGFGGPAVSGAGDGGGEEGGGGDGGGGGGDGGGGGGGGGGPYEKNDKNQEKDESTPVSNHRLALTMLIKIVKSLGCAYGCGEGHRGLSGDRLRHQVFRENAQNCLTKLYKLDKMQFRQTMRDYVNKDSLNNVVDFLHALLGFCMEPVTDNKAGFGNNFTTVDNKSTAQNVEGIIVSAMFKSLITRCASTTHELHSPENLGLYCDIRQLVQFIKEAHGNVFRRVALSALLDSAEKLAPGKKVEENEQESKPAGSKRSEAGSIVDKGQVSSAPEECRSFMSGRPSQTPEHDEQMQGANLGRKDFWRKMFKSQSAASDTSSQSEQDTSECTTAHSGTTSDRRARSRSRRISLRKKLKLPIGKRNWLKRSSLSGLADGVEDLLDISSVDRLSFIRQSSKVKFTSAVKLSEGGPGSGMENGRDEEENFFKRLGCHSFDDHLSPNQDGGKSKNVVNLGAIRQGMKRFQFLLNCCEPGTIPDASILAAALDLEAPVVARAALFLECARFVHRCNRGNWPEWMKGHHVNITKKGLSRGRSPIVGNKRNQKLQWNAAKLFYQWGDAIGVRLNELCHGESESPANLLGLIYDEETKRRLRKEDEEEDFLDDSTVNPSKCGCPFALKMAACQLLLEITTFLRETFSCLPRPRTEPLVDLESCRLRLDPELDRHRYERKISFAGVLDENEDSKDSLHSSSHTLKSDAGVEEKKEGSPWSASEPSIEPEGMSNAGAEENYHRNMSWLHVMILLCNQQSFICTHVDYCHPHCYLHHSRSCARLVRAIKLLYGDSVDSLRESSNISSVALRGKKQKECSDKSCLRTPSLKKRVSDANLEGKKDSGMLKYIRLQVMSLSPAPLSLLIKAAPILTEEMYGDIQPAAWELLLSMDEHMAGAAAAMFLLCAVKVPEAVSDMLMSEFHHPETVQRLNAVLKFHTLWRFRYQVWPRMEEGAQQIFKIPPPSINFTLPSPVLGMPSVPMFDPPWVPQCSGSVQDPINEDQSKSFSARAVSRSHQRAEHILKNLQQEEEKKRLGREASLITAIPITQEACYEPTCTPNSEPEEEVEEVTNLASRRLSVSPSCTSSTSHRNYSFRRGSVWSVRSAVSAEDEEHTTEHTPNHHVPQPPQAVFPACICAAVLPIVHLMEDGEVREDGVAVSAVAQQVLWNCLIEDPSTVLRHFLEKLTISNRQDELMYMLRKLLLNIGDFPAQTSHILFNYLVGLIMYFVRTPCEWGMDAISATLTFLWEVVGYVEGLFFKDLKQTMKKEQCEVKLLVTASMPGTKTLVVHGQNECDIPTQLPVHEDTQFEALLKECLEFFNIPESQSTHYFLMDKRWNLIHYNKTYVRDIYPFRRSVSPQLNLVHMHPEKGQELIQKQVFTRKLEEVGRVLFLISLTQKIPTAHKQSHVSMLQEDLLRLPSFPRSAIDAEFSLFSDPQAGKELFGLDTLQKSLWIQLLEEMFLGMPSEFPWGDEIMLFLNVFNGALILHPEDSALLRQYAATVINTAVHFNHLFSLSGYQWILPTMLQVYSDYESNPQLRQAIEFACHQFYILHRKPFVLQLFASVAPLLEFPDAANNGPSKGVSAQCLFDLLQSLEGETTDILDILELVKAEKPLKSLDFCYGNEDLTFSISEAIKLCVTVVAYAPESFRSLQMLMVLEALVPCYLQKLKRQTSQVETVPAAREEIAATAALATSLQALLYSVEVLTRPMTAPQMSRCDQGHKGTTTANHTMSSGVNTRYQEQGAKLHFIRENLHLLEEGQGIPREELDERIAREEFRRPRESLLNICTEFYKHCGPRLKILQNLAGEPRVIALELLDVKSHMRLAEIAHSLLKLAPYDTQTMESRGLRRYIMEMLPITDWTAEAVRPALILILKRLDRMFNKIHKMPTLRRQVEWEPASNLIEGVCLTLQRQPIISFLPHLRSLINVCVNLVMGVVGPSSVADGLPLLHLSPYLSPPLPFSTAVVRLVALQIQALKEDFPLSHVISPFTNQERREGMLLNLLIPFVLTVGSGSKDSPWLEQPEVQLLLQTVINVLLPPRIISTSRSKNFMLESSPAHCSTPGDAGKDLRREGLAESTSQAAYLALKVILVCFERQLGSQWYWLSLQVKEMALRKVGGLALWDFLDFIVRTRIPIFVLLRPFIQCKLLAQPAENHEELSARQHIADQLERRFIPRPLCKSSLIAEFNSELKILKEAVHSGSAYQGKTSISTVGTSTSAYRLSLATMSRSNTGTGTVWEQDSEPSQQASQDTLSRTDEEDEENDSISMPSVVSEQEAYLLSAIGRRRFSSHVSSMSVPQAEVGMLPSQR>sp|Q8N2C7-5|UNC80_HUMAN Isoform 5 of Protein unc-80 homolog OS=Homosapiens OX=9606 GN=UNC80MESRGLRRYIMEMLPITDWTAEAVRPALILILKRLDRMFNKIHKMPTLRRQVEWEPASNLIEGVCLTLQRQPIISFLPHLRSLINVCVNLVMGVVGPSSVADGLPLLHLSPYLSPPLPFSTAVVRLVALQIQALKEDFPLSHVISPFTNQERREGMLLNLLIPFVLTVGSGSKDSPWLEQPEVQLLLQTVINVLLPPRIISTSRSKNFMLESSPAHCSTPGDAGKDLRREGLAESTSQAAYLALKVILVCFERQLGSQWYWLSLQVKEMALRKVGGLALWDFLDFIVRTRIPIFVLLRPFIQCKLLAQPAENHEELSARQHIADQLERRFIPRPLCKSSLIAEFNSELKILKEAVHSGSAYQGKTSISTVGTSTSAYRLSLATMSRSNTGTGTVWEQDSEPSQQASQDTLSRTDEEDEENDSISMPSVVSEQEAYLLSAIGRRRFSSHVSSMSVPQAEVGMLPSQRVASIQSEPGQQNLLVQQPLGRKRGLRQLRRPLLSRQKTQTEPRNRQGARLSTTRRSIQPKTKPSADQKRSVTFIEAQPEPAAAPTDALPATGQLQGCSPAPSRKPEAMDEPVLTSSPAIVVADLHSVSPKQSENFPTEEGEKEEDTEAQGATAHSPLSAQLSDPDDFTGLETSSLLQHGDTVLHISEENGMENPLLSSQFTFTPTELGKTDAVLDESHV>sp|Q8N2C7-6|UNC80_HUMAN Isoform 6 of Protein unc-80 homolog OS=Homosapiens OX=9606 GN=UNC80MESRGLRRYIMEMLPITDWTAEAVRPALILILKRLDRMFNKIHKMPTLRRQVEWEPASNLIEGVCLTLQRQPIISFLPHLRSLINVCVNLVMGVVGPSSVADGLPLLHLSPYLSPPLPFSTAVVRLVALQIQALKEDFPLSHVISPFTNQERREGMLLNLLIPFVLTVGSGSKDSPWLEQPEVQLLLQTVINVLLPPRIISTSRSKNFMLESSPAHCSTPGDAGKDLRREGLAESTSQAAYLALKVILVCFERQLGSQWYWLSLQVKEMALRKVGGLALWDFLDFIVRTRIPIFVLLRPFIQCKLLAQPAENHEELSARQHIADQLERRFIPRPLCKSSLIAEFNSELKILKEAVHSGSAYQGKTSISTVGTSTSAYRLSLATMSRSNTGTGTVWEQDSEPSQQASQDTLSRTDEEDEENDSISMPSVVSEQEAYLLSAIGRRRFSSHVSSMSVPQAEVGMLPSQR>sp|Q8N2C7-7|UNC80_HUMAN Isoform 7 of Protein unc-80 homolog OS=Homosapiens OX=9606 GN=UNC80MVKRKSSEGQEQDGGRGIPLPIQTFLWRQTSAFLRPKLGKQYEASCVSFERVLVENKLHGLSPALSEAIQSISRWELVQAALPHVLHCTATLLSNRNKLGHQDKLGVAETKLLHTLHWMLLEAPQDCNNERFGGTDRGSSWGGSSSAFIHQVENQGSPGQPCQSSSNDEEENNRRKIFQNSMATVELFVFLFAPLVHRIKESDLTFRLASGLVIWQPMWEHRQPGVSGFTALVKPIRNIITAKRSSPINSQSRTCESPNQDARHLEGLQVVCETFQSDSISPKATISGCHRGNSFDGSLSSQTSQERGPSHSRASLVIPPCQRSRYATYFDVAVLRCLLQPHWSEEGTQWSLMYYLQRLRHMLEEKPEKPPEPDIPLLPRPRSSSMVAAAPSLVNTHKTQDLTMKCNEEEKSLSSEAFSKVSLTNLRRSAVPDLSSDLGMNIFKKFKSRKEDRERKGSIPFHHTGKRRPRRMGVPFLLHEDHLDVSPTRSTFSFGSFSGLGEDRRGIEKGGWQTTILGKLTRRGSSDAATEMESLSARHSHSHHTLVSDLPDPSNSHGENTVKEVRSQISTITVATFNTTLASFNVGYADFFNEHMRKLCNQVPIPEMPHEPLACANLPRSLTDSCINYSYLEDTEHIDGTNNFVHKNGMLDLSVVLKAVYLVLNHDISSRICDVALNIVECLLQLGVVPCVEKNRKKSENKENETLEKRPSEGAFQFKGVSGSSTCGFGGPAVSGAGDGGGEEGGGGDGGGGGGDGGGGGGGGGGPYEKNDKNQEKDESTPVSNHRLALTMLIKIVKSLGCAYGCGEGHRGLSGDRLRHQAQNCLTKLYKLDKMQFRQTMRDYVNKDSLNNVVDFLHALLGFCMEPVTDNKAGFGNNFTTVDNKSTAQNVEGIIVSAMFKSLITRCASTTHELHSPENLGLYCDIRQLVQFIKEAHGNVFRRVALSALLDSAEKLAPGKKVEENEQESKPAGSKRSEAGSIVDKGQVSSAPEECRSFMSGRPSQTPEHDEQMQGANLGRKDFWRKMFKSQSAASDTSSQSEQDTSECTTAHSGTTSDRRARSRSRRISLRKKLKLPIGKRNWLKRSSLSGLADGVEDLLDISSVDRLSFIRQSSKVKFTSAVKLSEGGPGSGMENGRDEEENFFKRLGCHSFDDHLSPNQDGGKSKNVVNLGAIRQGMKRFQFLLNCCEPGTIPDASILAAALDLEAPVVARAALFLECARFVHRCNRGNWPEWMKGHHVNITKKGLSRGRSPIVGNKRNQKLQWNAAKLFYQWGDAIGVRLNELCHGESESPANLLGLIYDEETKRRLRKEDEEEDFLDDSTVNPSKCGCPFALKMAACQLLLEITTFLRETFSCLPRPRTEPLVDLESCRLRLDPELDRHRYERKISFAGVLDENEDSKDSLHSSSHTLKSDAGVEEKKEGSPWSASEPSIEPEGMSNAGAEENYHRNMSWLHVMILLCNQQSFICTHVDYCHPHCYLHHSRSCARLVRAIKLLYGDSVDSLRESSNISSVALRGKKQKECSDKSCLRTPSLKKRVSDANLEGKKDSGMLKYIRLQVMSLSPAPLSLLIKAAPILTEEMYGDIQPAAWELLLSMDEHMAGAAAAMFLLCAVKVPEAVSDMLMSEFHHPETVQRLNAVLKFHTLWRFRYQVWPRMEEGAQQIFKIPPPSINFTLPSPVLGMPSVPMFDPPWVPQCSGSVQDPINEDQSKSFSARAVSRSHQRAEHILKNLQQEEEKKRLGREASLITAIPITQEACYEPTCTPNSEPEEEVEEVTNLASRRLSVSPSCTSSTSHRNYSFRRGSVWSVRSAVSAEDEEHTTEHTPNHHVPQPPQAVFPACICAAVLPIVHLMEDGEVREDGVAVSAVAQQVLWNCLIEDPSTVLRHFLEKLTISNRQDELMYMLRKLLLNIGDFPAQTSHILFNYLVGLIMYFVRTPCEWGMDAISATLTFLWEVVGYVEGLFFKDLKQTMKKEQCEVKLLVTASMPGTKTLVVHGQNECDIPTQLPVHEDTQFEALLKECLEFFNIPESQSTHYFLMDKRWNLIHYNKTYVRDIYPFRRSVSPQLNLVHMHPEKGQELIQKQVFTRKLEEVGRVLFLISLTQKIPTAHKQSHVSMLQEDLLRLPSFPRSAIDAEFSLFSDPQAGKELFGLDTLQKSLWIQLLEEMFLGMPSEFPWGDEIMLFLNVFNGALILHPEDSALLRQYAATVINTAVHFNHLFSLSGYQWILPTMLQVYSDYESNPQLRQAIEFACHQFYILHRKPFVLQLFASVAPLLEFPDAANNGPSKGVSAQCLFDLLQSLEGETTDILDILELVKAEKPLKSLDFCYGNEDLTFSISEAIKLCVTVVAYAPESFRSLQMLMVLEALVPCYLQKLKRQTSQVETVPAAREEIAATAALATSLQALLYSVEVLTRPMTAPQMSRCDQGHKGTTTANHTMSSGVNTRYQEQGAKLHFIRENLHLLEEGQGIPREELDERIAREEFRRPRESLLNICTEFYKHCGPRLKILQNLAGEPRVIALELLDVKSHMRLAEIAHSLLKLAPYDTQTMESRGLRRYIMEMLPITDWTAEAVRPALILILKRLDRMFNKIHKMPTLRRQVEWEPASNLIEGVCLTLQRQPIISFLPHLRSLINVCVNLVMGVVGPSSVADGLPLLHLSPYLSPPLPFSTAVVRLVALQIQALKEDFPLSHVISPFTNQERREGMLLNLLIPFVLTVGSGSKDSPWLEQPEVQLLLQTVINVLLPPRIISTSRSKNFMLESSPAHCSTPGDAGKDLRREGLAESTSQAAYLALKVILVCFERQLGSQWYWLSLQVKEMALRKVGGLALWDFLDFIVRTRIPIFVLLRPFIQCKLLAQPAENHEELSARQHIADQLERRFIPRPLCKSSLIAEFNSELKILKEAVHSGSAYQGKTSISTVGTSTSAYRLSLATMSRSNTGTGTVWEQDSEPSQQASQDTLSRTDEEDEENDSISMPSVVSEQEAYLLSAIGRRRFSSHVSSMSVPQAEVGMLPSQRVASIQSEPGQQNLLVQQPLGRKRGLRQLRRPLLSRQKTQTEPRNRQGARLSTTRRSIQPKTKPSADQKRSVTFIEAQPEPAAAPTDALPATGQLQGCSPAPSRKPEAMDEPVLTSSPAIVVADLHSVSPKQSENFPTEEGEKEEDTEAQGATAHSPLSAQLSDPDDFTGLETSSLLQHGDTVLHISEENGMENPLLSSQFTFTPTELGKTDAVLDESHV>sp|Q9Y5K5|UCHL5_HUMAN Ubiquitin carboxyl-terminal hydrolase isozyme L5OS=Homo sapiens OX=9606 GN=UCHL5 PE=1 SV=3MTGNAGEWCLMESDPGVFTELIKGFGCRGAQVEEIWSLEPENFEKLKPVHGLIFLFKWQPGEEPAGSVVQDSRLDTIFFAKQVINNACATQAIVSVLLNCTHQDVHLGETLSEFKEFSQSFDAAMKGLALSNSDVIRQVHNSFARQQMFEFDTKTSAKEEDAFHFVSYVPVNGRLYELDGLREGPIDLGACNQDDWISAVRPVIEKRIQKYSEGEIRFNLMAIVSDRKMIYEQKIAELQRQLAEEEPMDTDQGNSMLSAIQSEVAKNQMLIEEEVQKLKRYKIENIRRKHNYLPFIMELLKTLAEHQQLIPLVEKAKEKQNAKKAQETK>sp|Q9Y5K5-2|UCHL5_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase isozyme L5 OS=Homo sapiens OX=9606 GN=UCHL5MTGNAGEWCLMESDPGVFTELIKGFGCRGAQVEEIWSLEPENFEKLKPVHGLIFLFKWQPGEEPAGSVVQDSRLDTIFFAKQVINNACATQAIVSVLLNCTHQDVHLGETLSEFKEFSQSFDAAMKGLALSNSDVIRQVHNSFARQQMFEFDTKTSAKEEDAFHFVSYVPVNGRLYELDGLREGPIDLGACNQDDWISAVRPVIEKRIQKYSEGEIRFNLMAIVSDRKMIYEQKIAELQRQLAEEPMDTDQGNSMLSAIQSEVAKNQMLIEEEVQKLKRYKIENIRRKHNYLPFIMELLKTLAEHQQLIPLVEKGK>sp|Q9Y5K5-3|UCHL5_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase isozyme L5 OS=Homo sapiens OX=9606 GN=UCHL5MTGNAGEWCLMESDPGVFTELIKGFGCRGAQVEEIWSLEPENFEKLKPVHGLIFLFKWQPGEEPAGSVVQDSRLDTIFFAKQVINNACATQAIVSVLLNCTHQDVHLGETLSEFKEFSQSFDAAMKGLALSNSDVIRQVHNSFARQQMFEFDTKTSAKEEDAFHFVSYVPVNGRLYELDGLREGPIDLGACNQDDWISAVRPVIEKRIQKYSEGEIRFNLMAIVSDRKMIYEQKIAELQRQLAEEPMDTDQGNSMLSAIQSEVAKNQMLIEEEVQKLKRYKIENIRRKHNYLPFIMELLKTLAEHQQLIPLVEKAKEKQNAKKAQETK>sp|Q9Y5K5-4|UCHL5_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase isozyme L5 OS=Homo sapiens OX=9606 GN=UCHL5MTGNAGEWCLMESDPGVFTELIKGFGCRGAQVEEIWSLEPENFEKLKPVHGLIFLFKWQPGEEPAGSVVQDSRLDTIFFAKQVINNACATQAIVSVLLNCTHQDVHLGETLSEFKEFSQSFDAAMKGLALSNSDVIRQVHNSFARQQMFEFDTKTSAKEEDAFHFVSYVPVNGRLYELDGLREGPIDLGACNQDDWISAVRPVIEKRIQKYSEGEIRFNLMAIVSDRKMIYEQKIAELQRQLAEEPMDTDQGNSMLSAIQSEVAKNQMLIEEEVQKLKRYKIENIRRKHNYLPFIMELLKTLAEHQQLIPLVEKFEKHFEKTLLGK>sp|C9JPN9|UL17C_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 12 OS=Homo sapiens OX=9606 GN=USP17L12 PE=3 SV=1MEEDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSNRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKMLTLLTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQPNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLKLSSTTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|P29597|TYK2_HUMAN Non-receptor tyrosine-protein kinase TYK2 OS=Homosapiens OX=9606 GN=TYK2 PE=1 SV=3MPLRHWGMARGSKPVGDGAQPMAAMGGLKVLLHWAGPGGGEPWVTFSESSLTAEEVCIHIAHKVGITPPCFNLFALFDAQAQVWLPPNHILEIPRDASLMLYFRIRFYFRNWHGMNPREPAVYRCGPPGTEASSDQTAQGMQLLDPASFEYLFEQGKHEFVNDVASLWELSTEEEIHHFKNESLGMAFLHLCHLALRHGIPLEEVAKKTSFKDCIPRSFRRHIRQHSALTRLRLRNVFRRFLRDFQPGRLSQQMVMVKYLATLERLAPRFGTERVPVCHLRLLAQAEGEPCYIRDSGVAPTDPGPESAAGPPTHEVLVTGTGGIQWWPVEEEVNKEEGSSGSSGRNPQASLFGKKAKAHKAVGQPADRPREPLWAYFCDFRDITHVVLKEHCVSIHRQDNKCLELSLPSRAAALSFVSLVDGYFRLTADSSHYLCHEVAPPRLVMSIRDGIHGPLLEPFVQAKLRPEDGLYLIHWSTSHPYRLILTVAQRSQAPDGMQSLRLRKFPIEQQDGAFVLEGWGRSFPSVRELGAALQGCLLRAGDDCFSLRRCCLPQPGETSNLIIMRGARASPRTLNLSQLSFHRVDQKEITQLSHLGQGTRTNVYEGRLRVEGSGDPEEGKMDDEDPLVPGRDRGQELRVVLKVLDPSHHDIALAFYETASLMSQVSHTHLAFVHGVCVRGPENIMVTEYVEHGPLDVWLRRERGHVPMAWKMVVAQQLASALSYLENKNLVHGNVCGRNILLARLGLAEGTSPFIKLSDPGVGLGALSREERVERIPWLAPECLPGGANSLSTAMDKWGFGATLLEICFDGEAPLQSRSPSEKEHFYQRQHRLPEPSCPQLATLTSQCLTYEPTQRPSFRTILRDLTRLQPHNLADVLTVNPDSPASDPTVFHKRYLKKIRDLGEGHFGKVSLYCYDPTNDGTGEMVAVKALKADCGPQHRSGWKQEIDILRTLYHEHIIKYKGCCEDQGEKSLQLVMEYVPLGSLRDYLPRHSIGLAQLLLFAQQICEGMAYLHAQHYIHRDLAARNVLLDNDRLVKIGDFGLAKAVPEGHEYYRVREDGDSPVFWYAPECLKEYKFYYASDVWSFGVTLYELLTHCDSSQSPPTKFLELIGIAQGQMTVLRLTELLERGERLPRPDKCPCEVYHLMKNCWETEASFRPTFENLIPILKTVHEKYQGQAPSVFSVC>sp|O43914|TYOBP_HUMAN TYRO protein tyrosine kinase-binding proteinOS=Homo sapiens OX=9606 GN=TYROBP PE=1 SV=1MGGLEPCSRLLLLPLLLAVSGLRPVQAQAQSDCSCSTVSPGVLAGIVMGDLVLTVLIALAVYFLGRLVPRGRGAAEAATRKQRITETESPYQELQGQRSDVYSDLNTQRPYYK>sp|O43914-2|TYOBP_HUMAN Isoform 2 of TYRO protein tyrosine kinase-binding protein OS=Homo sapiens OX=9606 GN=TYROBPMGGLEPCSRLLLLPLLLAVSGLRPVQAQAQSDCSCSTVSPGVLAGIVMGDLVLTVLIALAVYFLGRLVPRGRGAAEATRKQRITETESPYQELQGQRSDVYSDLNTQRPYYK>sp|O43914-3|TYOBP_HUMAN Isoform 3 of TYRO protein tyrosine kinase-binding protein OS=Homo sapiens OX=9606 GN=TYROBPMGGLEPCSRLLLLPLLLAVSDCSCSTVSPGVLAGIVMGDLVLTVLIALAVYFLGRLVPRGRGAAEAATRKQRITETESPYQELQGQRSDVYSDLNTQRPYYK>sp|Q53HI1|UNC50_HUMAN Protein unc-50 homolog OS=Homo sapiens OX=9606GN=UNC50 PE=1 SV=2MLPSTSVNSLVQGNGVLNSRDAARHTAGAKRYKYLRRLFRFRQMDFEFAAWQMLYLFTSPQRVYRNFHYRKQTKDQWARDDPAFLVLLSIWLCVSTIGFGFVLDMGFFETIKLLLWVVLIDCVGVGLLIATLMWFISNKYLVKRQSRDYDVEWGYAFDVHLNAFYPLLVILHFIQLFFINHVILTDTFIGYLVGNTLWLVAVGYYIYVTFLGYSALPFLKNTVILLYPFAPLILLYGLSLALGWNFTHTLCSFYKYRVK>sp|P0CG47|UBB_HUMAN Polyubiquitin-B OS=Homo sapiens OX=9606 GN=UBB PE=1SV=1MQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGMQIFVKTLTGKTITLEVEPSDTIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGGC>sp|Q9P2U7|VGLU1_HUMAN Vesicular glutamate transporter 1 OS=Homo sapiensOX=9606 GN=SLC17A7 PE=2 SV=1MEFRQEEFRKLAGRALGKLHRLLEKRQEGAETLELSADGRPVTTQTRDPPVVDCTCFGLPRRYIIAIMSGLGFCISFGIRCNLGVAIVSMVNNSTTHRGGHVVVQKAQFSWDPETVGLIHGSFFWGYIVTQIPGGFICQKFAANRVFGFAIVATSTLNMLIPSAARVHYGCVIFVRILQGLVEGVTYPACHGIWSKWAPPLERSRLATTAFCGSYAGAVVAMPLAGVLVQYSGWSSVFYVYGSFGIFWYLFWLLVSYESPALHPSISEEERKYIEDAIGESAKLMNPLTKFSTPWRRFFTSMPVYAIIVANFCRSWTFYLLLISQPAYFEEVFGFEISKVGLVSALPHLVMTIIVPIGGQIADFLRSRRIMSTTNVRKLMNCGGFGMEATLLLVVGYSHSKGVAISFLVLAVGFSGFAISGFNVNHLDIAPRYASILMGISNGVGTLSGMVCPIIVGAMTKHKTREEWQYVFLIASLVHYGGVIFYGVFASGEKQPWAEPEEMSEEKCGFVGHDQLAGSDDSEMEDEAEPPGAPPAPPPSYGATHSTFQPPRPPPPVRDY>sp|Q9P2U7-2|VGLU1_HUMAN Isoform 2 of Vesicular glutamate transporter 1OS=Homo sapiens OX=9606 GN=SLC17A7MSGLGFCISFGIRCNLGVAIVSMVNNSTTHRGGHVVVQKAQFSWDPETVGLIHGSFFWGYIVTQIPGGFICQKFAANRVFGFAIVATSTLNMLIPSAARVHYGCVIFVRILQGLVEGVTYPACHGIWSKWAPPLERSRLATTAFCGSYAGAVVAMPLAGVLVQYSGWSSVFYVYGSFGIFWYLFWLLVSYESPALHPSISEEERKYIEDAIGESAKLMNPLTKFSTPWRRFFTSMPVYAIIVANFCRSWTFYLLLISQPAYFEEVFGFEISKVGLVSALPHLVMTIIVPIGGQIADFLRSRRIMSTTNVRKLMNCGGFGMEATLLLVVGYSHSKGVAISFLVLAVGFSGFAISGFNVNHLDIAPRYASILMGISNGVGTLSGMVCPIIVGAMTKHKTREEWQYVFLIASLVHYGGVIFYGVFASGEKQPWAEPEEMSEEKCGFVGHDQLAGSDDSEMEDEAEPPGAPPAPPPSYGATHSTFQPPRPPPPVRDY>sp|Q9P2U7-3|VGLU1_HUMAN Isoform 3 of Vesicular glutamate transporter 1OS=Homo sapiens OX=9606 GN=SLC17A7MGSQLALAGLLEKRQEGAETLELSADGRPVTTQTRDPPVVDCTCFGLPRRYIIAIMSGLGFCISFGIRCNLGVAIVSMVNNSTTHRGGHVVVQKAQFSWDPETVGLIHGSFFWGYIVTQIPGGFICQKFAANRVFGFAIVATSTLNMLIPSAARVHYGCVIFVRILQGLVEGVTYPACHGIWSKWAPPLERSRLATTAFCGSYAGAVVAMPLAGVLVQYSGWSSVFYVYGSFGIFWYLFWLLVSYESPALHPSISEEERKYIEDAIGESAKLMNPLTKFSTPWRRFFTSMPVYAIIVANFCRSWTFYLLLISQPAYFEEVFGFEISKVGLVSALPHLVMTIIVPIGGQIADFLRSRRIMSTTNVRKLMNCGGFGMEATLLLVVGYSHSKGVAISFLVLAVGFSGFAISGFNVNHLDIAPRYASILMGISNGVGTLSGMVCPIIVGAMTKHKTREEWQYVFLIASLVHYGGVIFYGVFASGEKQPWAEPEEMSEEKCGFVGHDQLAGSDDSEMEDEAEPPGAPPAPPPSYGATHSTFQPPRPPPPVRDY>sp|Q9Y6F9|WNT6_HUMAN Protein Wnt-6 OS=Homo sapiens OX=9606 GN=WNT6 PE=1SV=2MLPPLPSRLGLLLLLLLCPAHVGGLWWAVGSPLVMDPTSICRKARRLAGRQAELCQAEPEVVAELARGARLGVRECQFQFRFRRWNCSSHSKAFGRILQQDIRETAFVFAITAAGASHAVTQACSMGELLQCGCQAPRGRAPPRPSGLPGTPGPPGPAGSPEGSAAWEWGGCGDDVDFGDEKSRLFMDARHKRGRGDIRALVQLHNNEAGRLAVRSHTRTECKCHGLSGSCALRTCWQKLPPFREVGARLLERFHGASRVMGTNDGKALLPAVRTLKPPGRADLLYAADSPDFCAPNRRTGSPGTRGRACNSSAPDLSGCDLLCCGRGHRQESVQLEENCLCRFHWCCVVQCHRCRVRKELSLCL>sp|Q9Y277|VDAC3_HUMAN Voltage-dependent anion-selective channel protein3 OS=Homo sapiens OX=9606 GN=VDAC3 PE=1 SV=1MCNTPTYCDLGKAAKDVFNKGYGFGMVKIDLKTKSCSGVEFSTSGHAYTDTGKASGNLETKYKVCNYGLTFTQKWNTDNTLGTEISWENKLAEGLKLTLDTIFVPNTGKKSGKLKASYKRDCFSVGSNVDIDFSGPTIYGWAVLAFEGWLAGYQMSFDTAKSKLSQNNFALGYKAADFQLHTHVNDGTEFGGSIYQKVNEKIETSINLAWTAGSNNTRFGIAAKYMLDCRTSLSAKVNNASLIGLGYTQTLRPGVKLTLSALIDGKNFSAGGHKVGLGFELEA>sp|Q9Y277-2|VDAC3_HUMAN Isoform 2 of Voltage-dependent anion-selectivechannel protein 3 OS=Homo sapiens OX=9606 GN=VDAC3MCNTPTYCDLGKAAKDVFNKGYGFGMVKIDLKTKSCSGVMEFSTSGHAYTDTGKASGNLETKYKVCNYGLTFTQKWNTDNTLGTEISWENKLAEGLKLTLDTIFVPNTGKKSGKLKASYKRDCFSVGSNVDIDFSGPTIYGWAVLAFEGWLAGYQMSFDTAKSKLSQNNFALGYKAADFQLHTHVNDGTEFGGSIYQKVNEKIETSINLAWTAGSNNTRFGIAAKYMLDCRTSLSAKVNNASLIGLGYTQTLRPGVKLTLSALIDGKNFSAGGHKVGLGFELEA>sp|O43915|VEGFD_HUMAN Vascular endothelial growth factor D OS=Homosapiens OX=9606 GN=VEGFD PE=1 SV=1MYREWVVVNVFMMLYVQLVQGSSNEHGPVKRSSQSTLERSEQQIRAASSLEELLRITHSEDWKLWRCRLRLKSFTSMDSRSASHRSTRFAATFYDIETLKVIDEEWQRTQCSPRETCVEVASELGKSTNTFFKPPCVNVFRCGGCCNEESLICMNTSTSYISKQLFEISVPLTSVPELVPVKVANHTGCKCLPTAPRHPYSIIRRSIQIPEEDRCSHSKKLCPIDMLWDSNKCKCVLQEENPLAGTEDHSHLQEPALCGPHMMFDEDRCECVCKTPCPKDLIQHPKNCSCFECKESLETCCQKHKLFHPDTCSCEDRCPFHTRPCASGKTACAKHCRFPKEKRAAQGPHSRKNP>sp|P11684|UTER_HUMAN Uteroglobin OS=Homo sapiens OX=9606 GN=SCGB1A1 PE=1SV=1MKLAVTLTLVTLALCCSSASAEICPSFQRVIETLLMDTPSSYEAAMELFSPDQDMREAGAQLKKLVDTLPQKPRESIIKLMEKIAQSSLCN>sp|Q8N398|VW5B2_HUMAN von Willebrand factor A domain-containing protein5B2 OS=Homo sapiens OX=9606 GN=VWA5B2 PE=2 SV=3MPGLYCPSSWTPLPLTDSWVRACANGPCLSVRARLTYRNPQPQPVDGVFVYPLAEAEVVSGFEAEAAGRRVSFQLQSRRRSQAACCRALGPGLGTPTPRRCAQGHLVLDLAQARSTLVLPTGIIAAAGTMTVTLHSSRELPSRPDGVLHVALPTVLTPLAPPGPPGPPRPPGLCDDSPTSCFGVGSLQEEGLAWEELAAPRDVFSGPARCPAPYTFSFEMLVTGPCLLAGLESPSHALRADAPPHASSAATICVTLAEGHHCDRALEILLHPSEPHQPHLMLEGGSLSSAEYEARVRARRDFQRLQRRDSDGDRQVWFLQRRFHKDILLNPVLALSFCPDLSSKPGHLGTATRELLFLLDSSSVAHKDAIVLAVKSLPPQTLINLAVFGTLVQPLFPESRPCSDDAVQLICESIETLQVPSGPPDVLAALDWAVGQPQHRAYPRQLFLLTAASPMAATTHRTLELMRWHRGTARCFSFGLGPTCHQLLQGLSALSRGQAYFLRPGQRLQPMLVQALRKALEPALSDISVDWFVPDTVEALLTPREIPALYPGDQLLGYCSLFRVDGFRSRPPGGQEPGWQSSGGSVFPSPEEAPSAASPGTEPTGTSEPLGTGTVSAELSSPWAARDSEQSTDALTDPVTDPGPNPSDTAIWRRIFQSSYIREQYVLTHCSASPEPGPGSTGSSESPGSQGPGSPEGSAPLEPPSQQGCRSLAWGEPAGSRSCPLPAPTPAPFKVGALSTEVLGRQHRAALAGRSLSSPPGRANQVPGRPRKPSLGAILDGPSPEPGQQLGQGLDDSGNLLSPAPMDWDMLMEPPFLFTAVPPSGELAPPAVPPQAPRCHVVIRGLCGEQPMCWEVGVGLETLWGPGDGSQPPSPPVREAAWDQALHRLTAASVVRDNEQLALRGGAETTADRGHARRCWLRALQTSKVSSAPSCFTCPVAVDATTREVLPGALQVCSSEPAEPPGTPPASHSHLDAAPLPTVVYSKGLQRGSPAGAWDSDQNGNSKRALGDPATPTEGPRRPPPRPPCRLSMGRRHKLCSPDPGQANNSEGSDHDYLPLVRLQEAPGSFRLDAPFCAAVRISQERLCRASPFAVHRASLSPTSASLPWALLGPGVGQGDSATASCSPSPSSGSEGPGQVDSGRGSDTEASEGAEGLGGTDLRGRTWATAVALAWLEHRCAAAFDEWELTAAKADCWLRAQHLPDGLDLAALKAAARGLFLLLRHWDQNLQLHLLCYSPANV>sp|Q5T9L3|WLS_HUMAN Protein wntless homolog OS=Homo sapiens OX=9606GN=WLS PE=1 SV=2MAGAIIENMSTKKLCIVGGILLVFQIIAFLVGGLIAPGPTTAVSYMSVKCVDARKNHHKTKWFVPWGPNHCDKIRDIEEAIPREIEANDIVFSVHIPLPHMEMSPWFQFMLFILQLDIAFKLNNQIRENAEVSMDVSLAYRDDAFAEWTEMAHERVPRKLKCTFTSPKTPEHEGRYYECDVLPFMEIGSVAHKFYLLNIRLPVNEKKKINVGIGEIKDIRLVGIHQNGGFTKVWFAMKTFLTPSIFIIMVWYWRRITMMSRPPVLLEKVIFALGISMTFINIPVEWFSIGFDWTWMLLFGDIRQGIFYAMLLSFWIIFCGEHMMDQHERNHIAGYWKQVGPIAVGSFCLFIFDMCERGVQLTNPFYSIWTTDIGTELAMAFIIVAGICLCLYFLFLCFMVFQVFRNISGKQSSLPAMSKVRRLHYEGLIFRFKFLMLITLACAAMTVIFFIVSQVTEGHWKWGGVTVQVNSAFFTGIYGMWNLYVFALMFLYAPSHKNYGEDQSNGDLGVHSGEELQLTTTITHVDGPTEIYKLTRKEAQE>sp|Q5T9L3-2|WLS_HUMAN Isoform 2 of Protein wntless homolog OS=Homosapiens OX=9606 GN=WLSMAGAIIENMSTKKLCIVGGILLVFQIIAFLVGGLIGPTTAVSYMSVKCVDARKNHHKTKWFVPWGPNHCDKIRDIEEAIPREIEANDIVFSVHIPLPHMEMSPWFQFMLFILQLDIAFKLNNQIRENAEVSMDVSLAYRDDAFAEWTEMAHERVPRKLKCTFTSPKTPEHEGRYYECDVLPFMEIGSVAHKFYLLNIRLPVNEKKKINVGIGEIKDIRLVGIHQNGGFTKVWFAMKTFLTPSIFIIMVWYWRRITMMSRPPVLLEKVIFALGISMTFINIPVEWFSIGFDWTWMLLFGDIRQGIFYAMLLSFWIIFCGEHMMDQHERNHIAGYWKQVGPIAVGSFCLFIFDMCERGVQLTNPFYSIWTTDIGTELAMAFIIVAGICLCLYFLFLCFMVFQVFRNISGKQSSLPAMSKVRRLHYEGLIFRFKFLMLITLACAAMTVIFFIVSQVTEGHWKWGGVTVQVNSAFFTGIYGMWNLYVFALMFLYAPSHKNYGEDQSNGMQLPCKSREDCALFVSELYQELFSASKYSFINDNAASGI>sp|Q5T9L3-3|WLS_HUMAN Isoform 3 of Protein wntless homolog OS=Homosapiens OX=9606 GN=WLSMAGAIIENMSTKKLCIVGGILLVFQIIAFLVGGLIGENAEVSMDVSLAYRDDAFAEWTEMAHERVPRKLKCTFTSPKTPEHEGRYYECDVLPFMEIGSVAHKFYLLNIRLPVNEKKKINVGIGEIKDIRLVGIHQNGGFTKVWFAMKTFLTPSIFIIMVWYWRRITMMSRPPVLLEKVIFALGISMTFINIPVEWFSIGFDWTWMLLFGDIRQGIFYAMLLSFWIIFCGEHMMDQHERNHIAGYWKQVGPIAVGSFCLFIFDMCERGVQLTNPFYSIWTTDIGTELAMAFIIVAGICLCLYFLFLCFMVFQVFRNISGKQSSLPAMSKVRRLHYEGLIFRFKFLMLITLACAAMTVIFFIVSQVTEGHWKWGGVTVQVNSAFFTGIYGMWNLYVFALMFLYAPSHKNYGEDQSNGDLGVHSGEELQLTTTITHVDGPTEIYKLTRKEAQE>sp|Q6UX68|XKR5_HUMAN XK-related protein 5 OS=Homo sapiens OX=9606GN=XKR5 PE=2 SV=2MHARLLGLSALLQAAEQSARLYTVAYYFTTGRLLWGWLALAVLLPGFLVQALSYLWFRADGHPGHCSLMMLHLLQLGVWKRHWDAALTSLQKELEAPHRGWLQLQEADLSALRLLEALLQTGPHLLLQTYVFLASDFTDIVPGVSTLFSWSSLSWALVSYTRFMGFMKPGHLAMPWAALFCQQLWRMGMLGTRVLSLVLFYKAYHFWVFVVAGAHWLVMTFWLVAQQSDIIDSTCHWRLFNLLVGAVYILCYLSFWDSPSRNRMVTFYMVMLLENIILLLLATDFLQGASWTSLQTIAGVLSGFLIGSVSLVIYYSLLHPKSTDIWQGCLRKSCGIAGGDKTERRDSPRATDLAGKRTESSGSCQGASYEPTILGKPPTPEQVPPEAGLGTQVAVEDSFLSHHHWLWVKLALKTGNVSKINAAFGDNSPAYCPPAWGLSQQDYLQRKALSAQQELPSSSRDPSTLENSSAFEGVPKAEADPLETSSYVSFASDQQDEAPTQNPAATQGEGTPKEGADAVSGTQGKGTGGQQRGGEGQQSSTLYFSATAEVATSSQQEGSPATLQTAHSGRRLGKSSPAQPASPHPVGLAPFPDTMADISPILGTGPCRGFCPSAGFPGRTLSISELEEPLEPKRELSHHAAVGVWVSLPQLRTAHEPCLTSTPKSESIQTDCSCREQMKQEPSFFI>sp|Q6UX68-3|XKR5_HUMAN Isoform 2 of XK-related protein 5 OS=Homo sapiensOX=9606 GN=XKR5MHARLLGLSALLQAAEQSARLYTVAYYFTTGRLLWGWLALAVLLPGFLVQALSYLWFRADGHPGHCSLMMLHLLQLGVWKRPQIHL>sp|Q96NR7|WWAS2_HUMAN Putative uncharacterized protein WWC2-AS2 OS=Homosapiens OX=9606 GN=WWC2-AS2 PE=5 SV=1MTSAETASRAAESGGTPVRPCSRPHRAPSPAAPSRPGAPAAGPRKLLVPGLPCLVRGGWPWTRPDSSPFRPAARPRMSPHRSPAVARRCGRPRRRDPRRRRTPALPRPWPGRGGPGRSLLHRHLFIQQLLRTCWPALPRDRTPAPGGTMPGAALAGPGRQASGSPAPQSEGAPPRPWTPLQPGLHHRPPSSSSGLLSSFF>sp|P61129|ZC3H6_HUMAN Zinc finger CCCH domain-containing protein 6OS=Homo sapiens OX=9606 GN=ZC3H6 PE=1 SV=2MTDSEHAGHDREDGELEDGEIDDAGFEEIQEKEAKENEKQKSEKAYRKSRKKHKKEREKKKSKRRKREKHKHNSPSSDDSSDYSLDSDVEHTESSHKKRTGFYRDYDIPFTQRGHISGSYITSKKGQHNKKFKSKEYDEYSTYSDDNFGNYSDDNFGNYGQETEEDFANQLKQYRQAKETSNIALGSSFSKESGKKQRMKGVQQGIEQRVKSFNVGRGRGLPKKIKRKERGGRTNKGPNVFSVSDDFQEYNKPGKKWKVMTQEFINQHTVEHKGKQICKYFLEGRCIKGDQCKFDHDAELEKRKEICKFYLQGYCTKGENCIYMHNEFPCKFYHSGAKCYQGDNCKFSHDDLTKETKKLLDKVLNTDEELINEDERELEELRKRGITPLPKPPPGVGLLPTPPEHFPFSDPEDDFQTDFSDDFRKIPSLFEIVVKPTVDLAHKIGRKPPAFYTSASPPGPQFQGSSPHPQHIYSSGSSPGPGPNMSQGHSSPVMHPGSPGHHPCAGPPGLPVPQSPPLPPGPPEIVGPQNQAGVLVQPDTSLTPPSMGGAYHSPGFPGHVMKVPRENHCSPGSSYQQSPGEMQLNTNYESLQNPAEFYDNYYAQHSIHNFQPPNNSGDGMWHGEFAQQQPPVVQDSPNHGSGSDGSSTRTGHGPLPVPGLLPAVQRALFVRLTQRYQEDEEQTSTQPHRAPSKEEDDTVNWYSSSEEEEGSSVKSILKTLQKQTETLRNQQQPSTELSTPTDPRLAKEKSKGNQVVDPRLRTIPRQDIRKPSESAPLDLRLAWDPRKLRGNGSGHIGSSVGGAKFDLHHANAGTNVKHKRGDDDDEDTERELREKAFLIPLDASPGIMLQDPRSQLRQFSHIKMDITLTKPNFAKHIVWAPEDLLPVPLPKPDPVSSINLPLPPLIADQRLNRLWNTKSDLHQNTVSIDPKLAAKAKINTTNREGYLEQFGDSHGSGAKLGDPRLQKNFDPRLHRLPNTESHQVVMKDSHASKGAPHLPRSNPGSSQPSGAGTSNSGSGALPPYAPKLSSSAGLPLGTSTSVLSGISLYDPRDHGSSSTSELATASSGENSKNQKKSGGLKSSDKTEPSPGEAILPQKPSPNVGVTLEGPADPQADVPRSSGKVQVPAVHSLPVQALTGLIRPQYSDPRQARQPGQGSPTPDNDPGRETDDKSLKEVFKTFDPTASPFC>sp|Q96P53|WDFY2_HUMAN WD repeat and FYVE domain-containing protein 2OS=Homo sapiens OX=9606 GN=WDFY2 PE=1 SV=2MAAEIQPKPLTRKPILLQRMEGSQEVVNMAVIVPKEEGVISVSEDRTVRVWLKRDSGQYWPSVYHAMPSPCSCMSFNPETRRLSIGLDNGTISEFILSEDYNKMTPVKNYQAHQSRVTMILFVLELEWVLSTGQDKQFAWHCSESGQRLGGYRTSAVASGLQFDVETRHVFIGDHSGQVTILKLEQENCTLVTTFRGHTGGVTALCWDPVQRVLFSGSSDHSVIMWDIGGRKGTAIELQGHNDRVQALSYAQHTRQLISCGGDGGIVVWNMDVERQETPEWLDSDSCQKCDQPFFWNFKQMWDSKKIGLRQHHCRKCGKAVCGKCSSKRSSIPLMGFEFEVRVCDSCHEAITDEERAPTATFHDSKHNIVHVHFDATRGWLLTSGTDKVIKLWDMTPVVS>sp|Q0VG73|YC023_HUMAN Putative uncharacterized protein LOC152225 OS=Homosapiens OX=9606 PE=5 SV=1MNNSFNKEDRMSSDTMVGSCDRQTKNGAKWHGGVSSLLDFTLIYIQLSTSFQNAGHSFKKQHICSDFEVMDELSCAVYGNKFYYLLPTLTHPSIQ>sp|Q5PR19|YI024_HUMAN Putative UPF0607 protein LOC392364 OS=Homo sapiensOX=9606 PE=2 SV=3MAPAPVPALGTLGCYRFLFNPRQHLGPSFPARRYGAPRRLCFLPQNTGTPLRVLPSVFWSPPSRKKPVLSARNSRMFGHLSPVRIPHLRGKFNLRLPSLDEQVIPARLPKMEVRAEEPKEATEVKDQVETQEQEDNKRGPCSNGEAASTSRPLETQGNPTSPRYNPRPLEGNVQLKSLTENNQTDKAQVHAVSFYSKGHGVASSHSPAGGFPRGRTPPARQHG>sp|O75152|ZC11A_HUMAN Zinc finger CCCH domain-containing protein 11AOS=Homo sapiens OX=9606 GN=ZC3H11A PE=1 SV=3MPNQGEDCYFFFYSTCTKGDSCPFRHCEAAIGNETVCTLWQEGRCFRQVCRFRHMEIDKKRSEIPCYWENQPTGCQKLNCAFHHNRGRYVDGLFLPPSKTVLPTVPESPEEEVKASQLSVQQNKLSVQSNPSPQLRSVMKVESSENVPSPTHPPVVINAADDDEDDDDQFSEEGDETKTPTLQPTPEVHNGLRVTSVRKPAVNIKQGECLNFGIKTLEEIKSKKMKEKSKKQGEGSSGVSSLLLHPEPVPGPEKENVRTVVRTVTLSTKQGEEPLVRLSLTERLGKRKFSAGGDSDPPLKRSLAQRLGKKVEAPETNIDKTPKKAQVSKSLKERLGMSADPDNEDATDKVNKVGEIHVKTLEEILLERASQKRGELQTKLKTEGPSKTDDSTSGARSSSTIRIKTFSEVLAEKKHRQQEAERQKSKKDTTCIKLKIDSEIKKTVVLPPIVASRGQSEEPAGKTKSMQEVHIKTLEEIKLEKALRVQQSSESSTSSPSQHEATPGARRLLRITKRTGMKEEKNLQEGNEVDSQSSIRTEAKEASGETTGVDITKIQVKRCETMREKHMQKQQEREKSVLTPLRGDVASCNTQVAEKPVLTAVPGITRHLTKRLPTKSSQKVEVETSGIGDSLLNVKCAAQTLEKRGKAKPKVNVKPSVVKVVSSPKLAPKRKAVEMHAAVIAAVKPLSSSSVLQEPPAKKAAVAVVPLVSEDKSVTVPEAENPRDSLVLPPTQSSSDSSPPEVSGPSSSQMSMKTRRLSSASTGKPPLSVEDDFEKLIWEISGGKLEAEIDLDPGKDEDDLLLELSEMIDS>sp|Q5T1R4|ZEP3_HUMAN Transcription factor HIVEP3 OS=Homo sapiens OX=9606GN=HIVEP3 PE=2 SV=1MDPEQSVKGTKKAEGSPRKRLTKGEAIQTSVSSSVPYPGSGTAATQESPAQELLAPQPFPGPSSVLREGSQEKTGQQQKPPKRPPIEASVHISQLPQHPLTPAFMSPGKPEHLLEGSTWQLVDPMRPGPSGSFVAPGLHPQSQLLPSHASIIPPEDLPGVPKVFVPRPSQVSLKPTEEAHKKERKPQKPGKYICQYCSRPCAKPSVLQKHIRSHTGERPYPCGPCGFSFKTKSNLYKHRKSHAHRIKAGLASGMGGEMYPHGLEMERIPGEEFEEPTEGESTDSEEETSATSGHPAELSPRPKQPLLSSGLYSSGSHSSSHERCSLSQSSTAQSLEDPPPFVEPSSEHPLSHKPEDTHTIKQKLALRLSERKKVIDEQAFLSPGSKGSTESGYFSRSESAEQQVSPPNTNAKSYAEIIFGKCGRIGQRTAMLTATSTQPLLPLSTEDKPSLVPLSVPRTQVIEHITKLITINEAVVDTSEIDSVKPRRSSLSRRSSMESPKSSLYREPLSSHSEKTKPEQSLLSLQHPPSTAPPVPLLRSHSMPSAACTISTPHHPFRGSYSFDDHITDSEALSHSSHVFTSHPRMLKRQPAIELPLGGEYSSEEPGPSSKDTASKPSDEVEPKESELTKKTKKGLKTKGVIYECNICGARYKKRDNYEAHKKYYCSELQIAKPISAGTHTSPEAEKSQIEHEPWSQMMHYKLGTTLELTPLRKRRKEKSLGDEEEPPAFESTKSQFGSPGPSDAARNLPLESTKSPAEPSKSVPSLEGPTGFQPRTPKPGSGSESGKERRTTSKEISVIQHTSSFEKSDSLEQPSGLEGEDKPLAQFPSPPPAPHGRSAHSLQPKLVRQPNIQVPEILVTEEPDRPDTEPEPPPKEPEKTEEFQWPQRSQTLAQLPAEKLPPKKKRLRLAEMAQSSGESSFESSVPLSRSPSQESNVSLSGSSRSASFERDDHGKAEAPSPSSDMRPKPLGTHMLTVPSHHPHAREMRRSASEQSPNVSHSAHMTETRSKSFDYGSLSLTGPSAPAPVAPPARVAPPERRKCFLVRQASLSRPPESELEVAPKGRQESEEPQPSSSKPSAKSSLSQISSAATSHGGPPGGKGPGQDRPPLGPTVPYTEALQVFHHPVAQTPLHEKPYLPPPVSLFSFQHLVQHEPGQSPEFFSTQAMSSLLSSPYSMPPLPPSLFQAPPLPLQPTVLHPGQLHLPQLMPHPANIPFRQPPSFLPMPYPTSSALSSGFFLPLQSQFALQLPGDVESHLPQIKTSLAPLATGSAGLSPSTEYSSDIRLPPVAPPASSSAPTSAPPLALPACPDTMVSLVVPVRVQTNMPSYGSAMYTTLSQILVTQSQGSSATVALPKFEEPPSKGTTVCGADVHEVGPGPSGLSEEQSRAFPTPYLRVPVTLPERKGTSLSSESILSLEGSSSTAGGSKRVLSPAGSLELTMETQQQKRVKEEEASKADEKLELVKPCSVVLTSTEDGKRPEKSHLGNQGQGRRELEMLSSLSSDPSDTKEIPPLPHPALSHGTAPGSEALKEYPQPSGKPHRRGLTPLSVKKEDSKEQPDLPSLAPPSSLPLSETSSRPAKSQEGTDSKKVLQFPSLHTTTNVSWCYLNYIKPNHIQHADRRSSVYAGWCISLYNPNLPGVSTKAALSLLRSKQKVSKETYTMATAPHPEAGRLVPSSSRKPRMTEVHLPSLVSPEGQKDLARVEKEEERRGEPEEDAPASQRGEPARIKIFEGGYKSNEEYVYVRGRGRGKYVCEECGIRCKKPSMLKKHIRTHTDVRPYVCKHCHFAFKTKGNLTKHMKSKAHSKKCQETGVLEELEAEEGTSDDLFQDSEGREGSEAVEEHQFSDLEDSDSDSDLDEDEDEDEEESQDELSRPSSEAPPPGPPHALRADSSPILGPQPPDAPASGTEATRGSSVSEAERLTASSCSMSSQSMPGLPWLGPAPLGSVEKDTGSALSYKPVSPRRPWSPSKEAGSRPPLARKHSLTKNDSSPQRCSPAREPQASAPSPPGLHVDPGRGMGALPCGSPRLQLSPLTLCPLGRELAPRAHVLSKLEGTTDPGLPRYSPTRRWSPGQAESPPRSAPPGKWALAGPGSPSAGEHGPGLGLDPRVLFPPAPLPHKLLSRSPETCASPWQKAESRSPSCSPGPAHPLSSRPFSALHDFHGHILARTEENIFSHLPLHSQHLTRAPCPLIPIGGIQMVQARPGAHPTLLPGPTAAWVSGFSGGGSDLTGAREAQERGRWSPTESSSASVSPVAKVSKFTLSSELEGGDYPKERERTGGGPGRPPDWTPHGTGAPAEPTPTHSPCTPPDTLPRPPQGRRAAQSWSPRLESPRAPTNPEPSATPPLDRSSSVGCLAEASARFPARTRNLSGEPRTRQDSPKPSGSGEPRAHPHQPEDRVPPNA>sp|Q5T1R4-2|ZEP3_HUMAN Isoform 2 of Transcription factor HIVEP3 OS=Homosapiens OX=9606 GN=HIVEP3MDPEQSVKGTKKAEGSPRKRLTKGEAIQTSVSSSVPYPGSGTAATQESPAQELLAPQPFPGPSSVLREGSQEKTGQQQKPPKRPPIEASVHISQLPQHPLTPAFMSPGKPEHLLEGSTWQLVDPMRPGPSGSFVAPGLHPQSQLLPSHASIIPPEDLPGVPKVFVPRPSQVSLKPTEEAHKKERKPQKPGKYICQYCSRPCAKPSVLQKHIRSHTGERPYPCGPCGFSFKTKSNLYKHRKSHAHRIKAGLASGMGGEMYPHGLEMERIPGEEFEEPTEGESTDSEEETSATSGHPAELSPRPKQPLLSSGLYSSGSHSSSHERCSLSQSSTAQSLEDPPPFVEPSSEHPLSHKPEDTHTIKQKLALRLSERKKVIDEQAFLSPGSKGSTESGYFSRSESAEQQVSPPNTNAKSYAEIIFGKCGRIGQRTAMLTATSTQPLLPLSTEDKPSLVPLSVPRTQVIEHITKLITINEAVVDTSEIDSVKPRRSSLSRRSSMESPKSSLYREPLSSHSEKTKPEQSLLSLQHPPSTAPPVPLLRSHSMPSAACTISTPHHPFRGSYSFDDHITDSEALSHSSHVFTSHPRMLKRQPAIELPLGGEYSSEEPGPSSKDTASKPSDEVEPKESELTKKTKKGLKTKGVIYECNICGARYKKRDNYEAHKKYYCSELQIAKPISAGTHTSPEAEKSQIEHEPWSQMMHYKLGTTLELTPLRKRRKEKSLGDEEEPPAFESTKSQFGSPGPSDAARNLPLESTKSPAEPSKSVPSLEGPTGFQPRTPKPGSGSESGKERRTTSKEISVIQHTSSFEKSDSLEQPSGLEGEDKPLAQFPSPPPAPHGRSAHSLQPKLVRQPNIQVPEILVTEEPDRPDTEPEPPPKEPEKTEEFQWPQRSQTLAQLPAEKLPPKKKRLRLAEMAQSSGESSFESSVPLSRSPSQESNVSLSGSSRSASFERDDHGKAEAPSPSSDMRPKPLGTHMLTVPSHHPHAREMRRSASEQSPNVSHSAHMTETRSKSFDYGSLSLTGPSAPAPVAPPARVAPPERRKCFLVRQASLSRPPESELEVAPKGRQESEEPQPSSSKPSAKSSLSQISSAATSHGGPPGGKGPGQDRPPLGPTVPYTEALQVFHHPVAQTPLHEKPYLPPPVSLFSFQHLVQHEPGQSPEFFSTQAMSSLLSSPYSMPPLPPSLFQAPPLPLQPTVLHPGQLHLPQLMPHPANIPFRQPPSFLPMPYPTSSALSSGFFLPLQSQFALQLPGDVESHLPQIKTSLAPLATGSAGLSPSTEYSSDIRLPPVAPPASSSAPTSAPPLALPACPDTMVSLVVPVRVQTNMPSYGSAMYTTLSQILVTQSQGSSATVALPKFEEPPSKGTTVCGADVHEVGPGPSGLSEEQSRAFPTPYLRVPVTLPERKGTSLSSESILSLEGSSSTAGGSKRVLSPAGSLELTMETQQQKRVKEEEASKADEKLELVKPCSVVLTSTEDGKRPEKSHLGNQGQGRRELEMLSSLSSDPSDTKEIPPLPHPALSHGTAPGSEALKEYPQPSGKPHRRGLTPLSVKKEDSKEQPDLPSLAPPSSLPLSETSSRPAKSQEGTDSKKVLQFPSLHTTTNVSWCYLNYIKPNHIQHADRRSSVYAGWCISLYNPNLPGVSTKAALSLLRSKQKVSKETYTMATAPHPEAGRLVPSSSRKPRMTEVHLPSLVSPEGQKDLARVEKEEERRGEPEEDAPASQRGEPARIKIFEGGYKSNEEYVYVRGRGRGKYVCEECGIRCKKPSMLKKHIRTHTDVRPYVCKHCHFAFKTKGNLTKHMKSKAHSKKCQETGVLEELEAEEGTSDDLFQDSEGREGSEAVEEHQFSDLEDSDSDSDLDEDEDEDEEESQDELSRPSSEAPPPGPPHALRADSSPILGPQPPDAPASGTEATRGSSVSEAERLTASSCSMSSQSMPGLPWLGPAPLGSVEKDTGSALSYKPVSPRRPWSPSKEAGSRPPLARKHSLTKNDSSPQRCSPAREPQASAPSPPGLHVDPGRGMGALPCGSPRLQLSPLTLCPLGRELAPRAHVLSKLEGTTDPGLPRYSPTRRWSPGQAESPPRSAPPGKWALAGPGSPSAGEHGPGLGLDPRVLFPPAPLPHKLLSRSPETCASPWKAESRSPSCSPGPAHPLSSRPFSALHDFHGHILARTEENIFSHLPLHSQHLTRAPCPLIPIGGIQMVQARPGAHPTLLPGPTAAWVSGFSGGGSDLTGAREAQERGRWSPTESSSASVSPVAKVSKFTLSSELEGGDYPKERERTGGGPGRPPDWTPHGTGAPAEPTPTHSPCTPPDTLPRPPQGRRAAQSWSPRLESPRAPTNPEPSATPPLDRSSSVGCLAEASARFPARTRNLSGEPRTRQDSPKPSGSGEPRAHPHQPEDRVPPNA>sp|Q86TJ5|ZN554_HUMAN Zinc finger protein 554 OS=Homo sapiens OX=9606GN=ZNF554 PE=1 SV=1MVTCAHLGRRARLPAAQPSACPGTCFSQEERMAAGYLPRWSQELVTFEDVSMDFSQEEWELLEPAQKNLYREVMLENYRNVVSLEALKNQCTDVGIKEGPLSPAQTSQVTSLSSWTGYLLFQPVASSHLEQREALWIEEKGTPQASCSDWMTVLRNQDSTYKKVALQEEPASGINMIKLIREDGGWKQLEDSHEDPQGLLSQKASLHVVAVPQEKATAWHGFGENGNLSPALVLSQGSSKGNHLCGSELDITSLASDSVLNHHQLGYADRRPCESNECGNAIRQNSHFIQHGGKMFVYLENGQSLNHGMALTIHNKINTAEKPFECHQCGKVFNRRHSLSEHQRIHTGEKPYECQECGRAFTHSSTLTRHLRTHTGEKPYGCGECGKAFNRISSLTQHQRIHTGEKPYKCEDCGKSFCQSSYLILHKRTHTGEKPYECSECGKAFSDRSSLNQHERTHTGENPYECKQCGRAFSQRSSLVRHERTHTGEKPYRCQECGKAFSQSSSLVTHQKTHSSQKTYKIIDCGKAFYQNRHLIGY>sp|Q7Z3V5|ZN571_HUMAN Zinc finger protein 571 OS=Homo sapiens OX=9606GN=ZNF571 PE=2 SV=3MPHLLVTFRDVAIDFSQEEWECLDPAQRDLYRDVMLENYSNLISLDLESSCVTKKLSPEKEIYEMESLQWENMGKRINHHLQYNGLGDNMECKGNLEGQEASQEGLYMCVKITCEEKATESHSTSSTFHRIIPTKEKLYKCKECRQGFSYLSCLIQHEENHNIEKCSEVKKHRNTFSKKPSYIQHQRIQTGEKPYECMECGKAFGRTSDLIQHQKIHTNEKPYQCNACGKAFIRGSQLTEHQRVHTGEKPYECKKCGKAFSYCSQYTLHQRIHSGEKPYECKDCGKAFILGSQLTYHQRIHSGEKPYECKECGKAFILGSHLTYHQRVHTGEKPYICKECGKAFLCASQLNEHQRIHTGEKPYECKECGKTFFRGSQLTYHLRVHSGERPYKCKECGKAFISNSNLIQHQRIHTGEKPYKCKECGKAFICGKQLSEHQRIHTGEKPFECKECGKAFIRVAYLTQHEKIHGEKHYECKECGKTFVRATQLTYHQRIHTGEKPYKCKECDKAFIYGSQLSEHQRIHRGEKPYECKQCGKAFIRGSHLTEHLRTHTGEKPYECKECGRAFSRGSELTLHQRIHTGEKPYTCVQCGKDFRCPSQLTQHTRLHN>sp|Q6NX49|ZN544_HUMAN Zinc finger protein 544 OS=Homo sapiens OX=9606GN=ZNF544 PE=1 SV=1MEARSMLVPPQASVCFEDVAMAFTQEEWEQLDLAQRTLYREVTLETWEHIVSLGLFLSKSDVISQLEQEEDLCRAEQEAPRDWKATLEENRLNSEKDRAREELSHHVEVYRSGPEEPPSLVLGKVQDQSNQLREHQENSLRFMVLTSERLFAQREHCELELGGGYSLPSTLSLLPTTLPTSTGFPKPNSQVKELKQNSAFINHEKNGADGKHCESHQCARAFCQSIYLSKLGNVETGKKNPYEYIVSGDSLNYGSSLCFHGRTFSVKKSDDCKDYGNLFSHSVSLNEQKPVHFGKSQYECDECRETCSESLCLVQTERSGPGETPFRCEERCAAFPMASSFSDCNIIQTTEKPSVCNQCGKSFSCCKLIHQRTHTGEKPFECTQCGKSFSQSYDLVIHQRTHTGEKPYECDLCGKSFTQRSKLITHQRIHTGEKPYQCIECRKSFRWNSNLIVHQRIHTGEKPYECTHCGKSFSQSYELVTHKRTHTGEKPFKCTQCGKSFSQKYDLVVHQRTHTGEKPYECNLCGKSFSQSSKLITHQRIHTGEKPYQCIECGKSFRWNSNLVIHQRIHTGEKPYDCTHCGKSFSQSYQLVAHKRTHTGEKPYECNECGKAFNRSTQLIRHLQIHTGEKPYKCNQCNKAFARSSYLVMHQRTHTGEKPFECSQCGKAFSGSSNLLSHHRIHSGEKPYECSDCGKSFRQQSQLVVHRRTHTGEKP>sp|P62277|RS13_HUMAN 40S ribosomal protein S13 OS=Homo sapiens OX=9606GN=RPS13 PE=1 SV=2MGRMHAPGKGLSQSALPYRRSVPTWLKLTSDDVKEQIYKLAKKGLTPSQIGVILRDSHGVAQVRFVTGNKILRILKSKGLAPDLPEDLYHLIKKAVAVRKHLERNRKDKDAKFRLILIESRIHRLARYYKTKRVLPPNWKYESSTASALVA>sp|P62244|RS15A_HUMAN 40S ribosomal protein S15a OS=Homo sapiens OX=9606GN=RPS15A PE=1 SV=2MVRMNVLADALKSINNAEKRGKRQVLIRPCSKVIVRFLTVMMKHGYIGEFEIIDDHRAGKIVVNLTGRLNKCGVISPRFDVQLKDLEKWQNNLLPSRQFGFIVLTTSAGIMDHEEARRKHTGGKILGFFF>sp|Q9HCB6|SPON1_HUMAN Spondin-1 OS=Homo sapiens OX=9606 GN=SPON1 PE=1SV=2MRLSPAPLKLSRTPALLALALPLAAALAFSDETLDKVPKSEGYCSRILRAQGTRREGYTEFSLRVEGDPDFYKPGTSYRVTLSAAPPSYFRGFTLIALRENREGDKEEDHAGTFQIIDEEETQFMSNCPVAVTESTPRRRTRIQVFWIAPPAGTGCVILKASIVQKRIIYFQDEGSLTKKLCEQDSTFDGVTDKPILDCCACGTAKYRLTFYGNWSEKTHPKDYPRRANHWSAIIGGSHSKNYVLWEYGGYASEGVKQVAELGSPVKMEEEIRQQSDEVLTVIKAKAQWPAWQPLNVRAAPSAEFSVDRTRHLMSFLTMMGPSPDWNVGLSAEDLCTKECGWVQKVVQDLIPWDAGTDSGVTYESPNKPTIPQEKIRPLTSLDHPQSPFYDPEGGSITQVARVVIERIARKGEQCNIVPDNVDDIVADLAPEEKDEDDTPETCIYSNWSPWSACSSSTCDKGKRMRQRMLKAQLDLSVPCPDTQDFQPCMGPGCSDEDGSTCTMSEWITWSPCSISCGMGMRSRERYVKQFPEDGSVCTLPTEETEKCTVNEECSPSSCLMTEWGEWDECSATCGMGMKKRHRMIKMNPADGSMCKAETSQAEKCMMPECHTIPCLLSPWSEWSDCSVTCGKGMRTRQRMLKSLAELGDCNEDLEQVEKCMLPECPIDCELTEWSQWSECNKSCGKGHVIRTRMIQMEPQFGGAPCPETVQRKKCRIRKCLRNPSIQKLRWREARESRRSEQLKEESEGEQFPGCRMRPWTAWSECTKLCGGGIQERYMTVKKRFKSSQFTSCKDKKEIRACNVHPC>sp|O60687|SRPX2_HUMAN Sushi repeat-containing protein SRPX2 OS=Homosapiens OX=9606 GN=SRPX2 PE=1 SV=1MASQLTQRGALFLLFFLTPAVTPTWYAGSGYYPDESYNEVYAEEVPQAPALDYRVPRWCYTLNIQDGEATCYSPKGGNYHSSLGTRCELSCDRGFRLIGRRSVQCLPSRRWSGTAYCRQMRCHALPFITSGTYTCTNGVLLDSRCDYSCSSGYHLEGDRSRICMEDGRWSGGEPVCVDIDPPKIRCPHSREKMAEPEKLTARVYWDPPLVKDSADGTITRVTLRGPEPGSHFPEGEHVIRYTAYDRAYNRASCKFIVKVQVRRCPTLKPPQHGYLTCTSAGDNYGATCEYHCDGGYDRQGTPSRVCQSSRQWSGSPPICAPMKINVNVNSAAGLLDQFYEKQRLLIISAPDPSNRYYKMQISMLQQSTCGLDLRHVTIIELVGQPPQEVGRIREQQLSANIIEELRQFQRLTRSYFNMVLIDKQGIDRDRYMEPVTPEEIFTFIDDYLLSNQELTQRREQRDICE>sp|Q14162|SREC_HUMAN Scavenger receptor class F member 1 OS=Homo sapiensOX=9606 GN=SCARF1 PE=1 SV=3MGLGLLLPLLLLWTRGTQGSELDPKGQHVCVASSPSAELQCCAGWRQKDQECTIPICEGPDACQKDEVCVKPGLCRCKPGFFGAHCSSRCPGQYWGPDCRESCPCHPHGQCEPATGACQCQADRWGARCEFPCACGPHGRCDPATGVCHCEPGWWSSTCRRPCQCNTAAARCEQATGACVCKPGWWGRRCSFRCNCHGSPCEQDSGRCACRPGWWGPECQQQCECVRGRCSAASGECTCPPGFRGARCELPCPAGSHGVQCAHSCGRCKHNEPCSPDTGSCESCEPGWNGTQCQQPCLPGTFGESCEQQCPHCRHGEACEPDTGHCQRCDPGWLGPRCEDPCPTGTFGEDCGSTCPTCVQGSCDTVTGDCVCSAGYWGPSCNASCPAGFHGNNCSVPCECPEGLCHPVSGSCQPGSGSRDTALIAGSLVPLLLLFLGLACCACCCWAPRSDLKDRPARDGATVSRMKLQVWGTLTSLGSTLPCRSLSSHKLPWVTVSHHDPEVPFNHSFIEPPSAGWATDDSFSSDPESGEADEVPAYCVPPQEGMVPVAQAGSSEASLAAGAFPPPEDASTPFAIPRTSSLARAKRPSVSFAEGTKFAPQSRRSSGELSSPLRKPKRLSRGAQSGPEGREAEESTGPEEAEAPESFPAAASPGDSATGHRRPPLGGRTVAEHVEAIEGSVQESSGPVTTIYMLAGKPRGSEGPVRSVFRHFGSFQKGQAEAKVKRAIPKPPRQALNRKKGSPGLASGSVGQSPNSAPKAGLPGATGPMAVRPEEAVRGLGAGTESSRRAQEPVSGCGSPEQDPQKQAEEERQEEPEYENVVPISRPPEP>sp|Q14162-2|SREC_HUMAN Isoform 2 of Scavenger receptor class F member 1OS=Homo sapiens OX=9606 GN=SCARF1MGLGLLLPLLLLWTRGTQGSELDPKGQHVCVASSPSAELQCCAGWRQKDQECTIPICEGPDACQKDEVCVKPGLCRCKPGFFGAHCSSRCPGQYWGPDCRESCPCHPHGQCEPATGACQCQADRWGARCEFPCACGPHGRCDPATGVCHCEPGWWSSTCRRPCQCNTAAARCEQATGACVCKPGWWGRRCSFRCNCHGSPCEQDSGRCACRPGWWGPECQQQCECVRGRCSAASGECTCPPGFRGARCELPCPAGSHGVQCAHSCGRCKHNEPCSPDTGSCESCEPGWNGTQCQQPCLPGTFGESCEQQCPHCRHGEACEPDTGHCQRCSGSRDTALIAGSLVPLLLLFLGLACCACCCWAPRSDLKDRPARDGATVSRMKLQVWGTLTSLGSTLPCRSLSSHKLPWVTVSHHDPEVPFNHSFIEPPSAGWATDDSFSSDPESGEADEVPAYCVPPQEGMVPVAQAGSSEASLAAGAFPPPEDASTPFAIPRTSSLARAKRPSVSFAEGTKFAPQSRRSSGELSSPLRKPKRLSRGAQSGPEGREAEESTGPEEAEAPESFPAAASPGDSATGHRRPPLGGRTVAEHVEAIEGSVQESSGPVTTIYMLAGKPRGSEGPVRSVFRHFGSFQKGQAEAKVKRAIPKPPRQALNRKKGSPGLASGSVGQSPNSAPKAGLPGATGPMAVRPEEAVRGLGAGTESSRRAQEPVSGCGSPEQDPQKQAEEERQEEPEYENVVPISRPPEP>sp|Q14162-3|SREC_HUMAN Isoform 3 of Scavenger receptor class F member 1OS=Homo sapiens OX=9606 GN=SCARF1MGLGLLLPLLLLWTRGTQGSELDPKGQHVCVASSPSAELQCCAGWRQKDQECTIPICEGPDACQKDEVCVKPGLCRCKPGFFGAHCSSRCPGQYWGPDCRESCPCHPHGQCEPATGACQCQADRWGARCEFPCACGPHGRCDPATGVCHCEPGWWSSTCRRPCQCNTAAARCEQATGACVCKPGWWGRRCSFRCNCHGSPCEQDSGRCACRPGWWGPECQQQCECVRGRCSAASGECTCPPGFRGARCELPCPAGSHGVQCAHSCGRCKHNEPCSPDTGSCESCEPGWNGTQCQQPCLPGTFGESCEQQCPHCRHGEACEPDTGHCQRCDPGWLGPRCEDPCPTGTFGEDCGSTCPTCVQGSCDTVTGDCVCSAGYWGPSCNASCPAGFHGNNCSVPCECPEGLCHPVSGSCQPGSGSRDTALIAGSLVPLLLLFLGLACCACCCWAPRSDLKDRPARDGATVSRMKLQVWGTLTSLGSTLPCRSLSSHKLPWVTASSSRPLPAGPLMTPSHPILSLERQMRFLPTVCHPKKGWSLWPRQGRQRPAWLQVLSRPLRTPPRHSPSRAPPA>sp|Q14162-4|SREC_HUMAN Isoform 4 of Scavenger receptor class F member 1OS=Homo sapiens OX=9606 GN=SCARF1MGLGLLLPLLLLWTRGTQGSELDPKGQHVCVASSPSAELQCCAGWRQKDQECTIPICEGPDACQKDEVCVKPGLCRCKPGFFGAHCSSRCPGQYWGPDCRESCPCHPHGQCEPATGACQCQADRWGARCEFPCACGPHGRCDPATGVCHCEPGWWSSTCRRPCQCNTAAARCEQATGACVCKPGWWGRRCSFRCNCHGSPCEQDSGRCACRPGWWGPECQQQCECVRGRCSAASGECTCPPGFRGARCELPCPAGSHGVQCAHSCGRCKHNEPCSPDTGSCESCEPGWNGTQCQQPCLPGTFGESCEQQCPHCRHGEACEPDTGHCQRCDPGWLGPR>sp|Q14162-5|SREC_HUMAN Isoform 5 of Scavenger receptor class F member 1OS=Homo sapiens OX=9606 GN=SCARF1MGLGLLLPLLLLWTRGTQGSELDPKGQHVCVASSPSAELQCCAGWRQKDQECTIPICEGPDACQKDEVCVKPGLCRCKPGFFGAHCSSRCPGQYWGPDCRESCPCHPHGQCEPATGACQCQADRWGARCEFPCACGPHGRCDPATGVCHCEPGWWSSTCRRPCQCNTAAARCEQATGACVCKPGWWGRRCSFRCNCHGSPCEQDSGRCACRPGWWGPECQQQCECVRGRCSAASGECTCPPGFRGARCELPCPAGSHGVQCAHSCGRCKHNEPCSPDTGSCESCEPGWNGTQCQQPCLPGTFGESCEQQCPHCRHGEACEPDTGHCQRCDPGWLGPRGPVIL>sp|Q9UQ90|SPG7_HUMAN Paraplegin OS=Homo sapiens OX=9606 GN=SPG7 PE=1SV=2MAVLLLLLRALRRGPGPGPRPLWGPGPAWSPGFPARPGRGRPYMASRPPGDLAEAGGRALQSLQLRLLTPTFEGINGLLLKQHLVQNPVRLWQLLGGTFYFNTSRLKQKNKEKDKSKGKAPEEDEEERRRRERDDQMYRERLRTLLVIAVVMSLLNALSTSGGSISWNDFVHEMLAKGEVQRVQVVPESDVVEVYLHPGAVVFGRPRLALMYRMQVANIDKFEEKLRAAEDELNIEAKDRIPVSYKRTGFFGNALYSVGMTAVGLAILWYVFRLAGMTGREGGFSAFNQLKMARFTIVDGKMGKGVSFKDVAGMHEAKLEVREFVDYLKSPERFLQLGAKVPKGALLLGPPGCGKTLLAKAVATEAQVPFLAMAGPEFVEVIGGLGAARVRSLFKEARARAPCIVYIDEIDAVGKKRSTTMSGFSNTEEEQTLNQLLVEMDGMGTTDHVIVLASTNRADILDGALMRPGRLDRHVFIDLPTLQERREIFEQHLKSLKLTQSSTFYSQRLAELTPGFSGADIANICNEAALHAAREGHTSVHTLNFEYAVERVLAGTAKKSKILSKEEQKVVAFHESGHALVGWMLEHTEAVMKVSITPRTNAALGFAQMLPRDQHLFTKEQLFERMCMALGGRASEALSFNEVTSGAQDDLRKVTRIAYSMVKQFGMAPGIGPISFPEAQEGLMGIGRRPFSQGLQQMMDHEARLLVAKAYRHTEKVLQDNLDKLQALANALLEKEVINYEDIEALIGPPPHGPKKMIAPQRWIDAQREKQDLGEEETEETQQPPLGGEEPTWPK>sp|Q9UQ90-2|SPG7_HUMAN Isoform 2 of Paraplegin OS=Homo sapiens OX=9606GN=SPG7MAVLLLLLRALRRGPGPGPRPLWGPGPAWSPGFPARPGRGRPYMASRPPGDLAEAGGRALQSLQLRLLTPTFEGINGLLLKQHLVQNPVRLWQLLGGTFYFNTSRLKQKNKEKDKSKGKAPEEDEEERRRRERDDQMYRERLRTLLVIAVVMSLLNALSTSGGSISWNDFVHEMLAKGEVQRVQVVPESDVVEVYLHPGAVVFGRPRLALMYRMQVANIDKFEEKLRAAEDELNIEAKDRIPVSYKRTGFFGNALYSVGMTAVGLAILWYVFRLAGMTGREGGFSAFNQLKMARFTIVDGKMGKGVSFKDVAGMHEAKLEVREFVDYLKSPERFLQLGAKVPKGALLLGPPGCGKTLLAKAVATEAQVPFLAMAGPEFVEVIGGLGAARVRSLFKEARARAPCIVYIDEIDAVGKKRSTTMSGFSNTEEEQTLNQLLVEMDGASLDQLPSQGTMRKLRGKTPACSCLTEPTGSRRAMEGHSLCWGCLLH>sp|Q7Z699|SPRE1_HUMAN Sprouty-related, EVH1 domain-containing protein 1OS=Homo sapiens OX=9606 GN=SPRED1 PE=1 SV=2MSEETATSDNDNSYARVRAVVMTRDDSSGGWLPLGGSGLSSVTVFKVPHQEENGCADFFIRGERLRDKMVVLECMLKKDLIYNKVTPTFHHWKIDDKKFGLTFQSPADARAFDRGIRRAIEDISQGCPESKNEAEGADDLQANEEDSSSSLVKDHLFQQETVVTSEPYRSSNIRPSPFEDLNARRVYMQSQANQITFGQPGLDIQSRSMEYVQRQISKECGSLKSQNRVPLKSIRHVSFQDEDEIVRINPRDILIRRYADYRHPDMWKNDLERDDADSSIQFSKPDSKKSDYLYSCGDETKLSSPKDSVVFKTQPSSLKIKKSKRRKEDGERSRCVYCQERFNHEENVRGKCQDAPDPIKRCIYQVSCMLCAESMLYHCMSDSEGDFSDPCSCDTSDDKFCLRWLALVALSFIVPCMCCYVPLRMCHRCGEACGCCGGKHKAAG>sp|O60701|UGDH_HUMAN UDP-glucose 6-dehydrogenase OS=Homo sapiens OX=9606GN=UGDH PE=1 SV=1MFEIKKICCIGAGYVGGPTCSVIAHMCPEIRVTVVDVNESRINAWNSPTLPIYEPGLKEVVESCRGKNLFFSTNIDDAIKEADLVFISVNTPTKTYGMGKGRAADLKYIEACARRIVQNSNGYKIVTEKSTVPVRAAESIRRIFDANTKPNLNLQVLSNPEFLAEGTAIKDLKNPDRVLIGGDETPEGQRAVQALCAVYEHWVPREKILTTNTWSSELSKLAANAFLAQRISSINSISALCEATGADVEEVATAIGMDQRIGNKFLKASVGFGGSCFQKDVLNLVYLCEALNLPEVARYWQQVIDMNDYQRRRFASRIIDSLFNTVTDKKIAILGFAFKKDTGDTRESSSIYISKYLMDEGAHLHIYDPKVPREQIVVDLSHPGVSEDDQVSRLVTISKDPYEACDGAHAVVICTEWDMFKELDYERIHKKMLKPAFIFDGRRVLDGLHNELQTIGFQIETIGKKVSSKRIPYAPSGEIPKFSLQDPPNKKPKV>sp|O60701-2|UGDH_HUMAN Isoform 2 of UDP-glucose 6-dehydrogenase OS=Homosapiens OX=9606 GN=UGDHMFEIKKICCIGAGYVGGPTCSVIAHMCPEIRVTVVDVNESRINAWNSPTLPIYEPGLKEVVESCRGKNLFFSTNIDDAIKEADLVFISVLSNPEFLAEGTAIKDLKNPDRVLIGGDETPEGQRAVQALCAVYEHWVPREKILTTNTWSSELSKLAANAFLAQRISSINSISALCEATGADVEEVATAIGMDQRIGNKFLKASVGFGGSCFQKDVLNLVYLCEALNLPEVARYWQQVIDMNDYQRRRFASRIIDSLFNTVTDKKIAILGFAFKKDTGDTRESSSIYISKYLMDEGAHLHIYDPKVPREQIVVDLSHPGVSEDDQVSRLVTISKDPYEACDGAHAVVICTEWDMFKELDYERIHKKMLKPAFIFDGRRVLDGLHNELQTIGFQIETIGKKVSSKRIPYAPSGEIPKFSLQDPPNKKPKV>sp|O60701-3|UGDH_HUMAN Isoform 3 of UDP-glucose 6-dehydrogenase OS=Homosapiens OX=9606 GN=UGDHMGKGRAADLKYIEACARRIVQNSNGYKIVTEKSTVPVRAAESIRRIFDANTKPNLNLQVLSNPEFLAEGTAIKDLKNPDRVLIGGDETPEGQRAVQALCAVYEHWVPREKILTTNTWSSELSKLAANAFLAQRISSINSISALCEATGADVEEVATAIGMDQRIGNKFLKASVGFGGSCFQKDVLNLVYLCEALNLPEVARYWQQVIDMNDYQRRRFASRIIDSLFNTVTDKKIAILGFAFKKDTGDTRESSSIYISKYLMDEGAHLHIYDPKVPREQIVVDLSHPGVSEDDQVSRLVTISKDPYEACDGAHAVVICTEWDMFKELDYERIHKKMLKPAFIFDGRRVLDGLHNELQTIGFQIETIGKKVSSKRIPYAPSGEIPKFSLQDPPNKKPKV>sp|P07814|SYEP_HUMAN Bifunctional glutamate/proline--tRNA ligase OS=Homosapiens OX=9606 GN=EPRS1 PE=1 SV=5MATLSLTVNSGDPPLGALLAVEHVKDDVSISVEEGKENILHVSENVIFTDVNSILRYLARVATTAGLYGSNLMEHTEIDHWLEFSATKLSSCDSFTSTINELNHCLSLRTYLVGNSLSLADLCVWATLKGNAAWQEQLKQKKAPVHVKRWFGFLEAQQAFQSVGTKWDVSTTKARVAPEKKQDVGKFVELPGAEMGKVTVRFPPEASGYLHIGHAKAALLNQHYQVNFKGKLIMRFDDTNPEKEKEDFEKVILEDVAMLHIKPDQFTYTSDHFETIMKYAEKLIQEGKAYVDDTPAEQMKAEREQRIDSKHRKNPIEKNLQMWEEMKKGSQFGQSCCLRAKIDMSSNNGCMRDPTLYRCKIQPHPRTGNKYNVYPTYDFACPIVDSIEGVTHALRTTEYHDRDEQFYWIIEALGIRKPYIWEYSRLNLNNTVLSKRKLTWFVNEGLVDGWDDPRFPTVRGVLRRGMTVEGLKQFIAAQGSSRSVVNMEWDKIWAFNKKVIDPVAPRYVALLKKEVIPVNVPEAQEEMKEVAKHPKNPEVGLKPVWYSPKVFIEGADAETFSEGEMVTFINWGNLNITKIHKNADGKIISLDAKLNLENKDYKKTTKVTWLAETTHALPIPVICVTYEHLITKPVLGKDEDFKQYVNKNSKHEELMLGDPCLKDLKKGDIIQLQRRGFFICDQPYEPVSPYSCKEAPCVLIYIPDGHTKEMPTSGSKEKTKVEATKNETSAPFKERPTPSLNNNCTTSEDSLVLYNRVAVQGDVVRELKAKKAPKEDVDAAVKQLLSLKAEYKEKTGQEYKPGNPPAEIGQNISSNSSASILESKSLYDEVAAQGEVVRKLKAEKSPKAKINEAVECLLSLKAQYKEKTGKEYIPGQPPLSQSSDSSPTRNSEPAGLETPEAKVLFDKVASQGEVVRKLKTEKAPKDQVDIAVQELLQLKAQYKSLIGVEYKPVSATGAEDKDKKKKEKENKSEKQNKPQKQNDGQRKDPSKNQGGGLSSSGAGEGQGPKKQTRLGLEAKKEENLADWYSQVITKSEMIEYHDISGCYILRPWAYAIWEAIKDFFDAEIKKLGVENCYFPMFVSQSALEKEKTHVADFAPEVAWVTRSGKTELAEPIAIRPTSETVMYPAYAKWVQSHRDLPIKLNQWCNVVRWEFKHPQPFLRTREFLWQEGHSAFATMEEAAEEVLQILDLYAQVYEELLAIPVVKGRKTEKEKFAGGDYTTTIEAFISASGRAIQGGTSHHLGQNFSKMFEIVFEDPKIPGEKQFAYQNSWGLTTRTIGVMTMVHGDNMGLVLPPRVACVQVVIIPCGITNALSEEDKEALIAKCNDYRRRLLSVNIRVRADLRDNYSPGWKFNHWELKGVPIRLEVGPRDMKSCQFVAVRRDTGEKLTVAENEAETKLQAILEDIQVTLFTRASEDLKTHMVVANTMEDFQKILDSGKIVQIPFCGEIDCEDWIKKTTARDQDLEPGAPSMGAKSLCIPFKPLCELQPGAKCVCGKNPAKYYTLFGRSY>sp|Q93075|TATD2_HUMAN Putative deoxyribonuclease TATDN2 OS=Homo sapiensOX=9606 GN=TATDN2 PE=1 SV=2MASERGKVKHNWSSTSEGCPRKRSCLREPCDVAPSSRPAQRSASRSGGPSSPKRLKAQKEDDVACSRRLSWGSSRRRNNSSSSFSPHFLGPGVGGAASKGCLIRNTRGFLSSGGSPLRPANASLEEMASLEEEACSLKVDSKDSSHNSTNSEFAAEAEGQNDTIEEPNKVQKRKRDRLRDQGSTMIYLKAIQGILGKSMPKRKGEAATRAKPSAAEHPSHGEGPARSEGPAKTAEGAARSVTVTAAQKEKDATPEVSMEEDKTVPERSSFYDRRVVIDPQEKPSEEPLGDRRTVIDKCSPPLEFLDDSDSHLEIQKHKDREVVMEHPSSGSDWSDVEEISTVRFSQEEPVSLKPSAVPEPSSFTTDYVMYPPHLYSSPWCDYASYWTSSPKPSSYPSTGSSSNDAAQVGKSSRSRMSDYSPNSTGSVQNTSRDMEASEEGWSQNSRSFRFSRSSEEREVKEKRTFQEEMPPRPCGGHASSSLPKSHLEPSLEEGFIDTHCHLDMLYSKLSFQGTFTKFRKIYSSSFPKEFQGCISDFCDPRTLTDCLWEELLKEDLVWGAFGCHPHFARYYSESQERNLLQALRHPKAVAFGEMGLDYSYKCTTPVPEQHKVFERQLQLAVSLKKPLVIHCREADEDLLEIMKKFVPPDYKIHRHCFTGSYPVIEPLLKYFPNMSVGFTAVLTYSSAWEAREALRQIPLERIIVETDAPYFLPRQVPKSLCQYAHPGLALHTVREIARVKDQPLSLTLAALRENTSRLYSL>sp|A2VDJ0|T131L_HUMAN Transmembrane protein 131-like OS=Homo sapiensOX=9606 GN=TMEM131L PE=1 SV=2MAGLRRPQPGCYCRTAAAVNLLLGVFQVLLPCCRPGGAQGQAIEPLPNVVELWQAEEGELLLPTQGDSEEGLEEPSQEQSFSDKLFSGKGLHFQPSVLDFGIQFLGHPVAKILHAYNPSRDSEVVVNSVFAAAGHFHVPPVPCRVIPAMGKTSFRIIFLPTEEGSIESSLFINTSSYGVLSYHVSGIGTRRISTEGSAKQLPNAYFLLPKVQSIQLSQMQAETTNTSLLQVQLECSLHNKVCQQLKGCYLESDDVLRLQMSIMVTMENFSKEFEENTQHLLDHLSIVYVATDESETSDDSAVNMYILHSGNSLIWIQDIRHFSQRDALSLQFEPVLLPTSTTNFTKIASFTCKATSCDSGIIEDVKKTTHTPTLKACLFSSVAQGYFRMDSSATQFHIETHENTSGLWSIWYRNHFDRSVVLNDVFLSKETKHMLKILNFTGPLFLPPGCWNIFSLKLAVKDIAINLFTNVFLTTNIGAIFAIPLQIYSAPTKEGSLGFEVIAHCGMHYFMGKSKAGNPNWNGSLSLDQSTWNVDSELANKLYERWKKYKNGDVCKRNVLGTTRFAHLKKSKESESFVFFLPRLIAEPGLMLNFSATALRSRMIKYFVVQNPSSWPVSLQLLPLSLYPKPEALVHLLHRWFGTDMQMINFTTGEFQLTEACPYLGTHSEESRFGILHLHLQPLEMKRVGVVFTPADYGKVTSLILIRNNLTVIDMIGVEGFGARELLKVGGRLPGAGGSLRFKVPESTLMDCRRQLKDSKQILSITKNFKVENIGPLPITVSSLKINGYNCQGYGFEVLDCHQFSLDPNTSRDISIVFTPDFTSSWVIRDLSLVTAADLEFRFTLNVTLPHHLLPLCADVVPGPSWEESFWRLTVFFVSLSLLGVILIAFQQAQYILMEFMKTRQRQNASSSSQQNNGPMDVISPHSYKSNCKNFLDTYGPSDKGRGKNCLPVNTPQSRIQNAAKRSPATYGHSQKKHKCSVYYSKHKTSTAAASSTSTTTEEKQTSPLGSSLPAAKEDICTDAMRENWISLRYASGINVNLQKNLTLPKNLLNKEENTLKNTIVFSNPSSECSMKEGIQTCMFPKETDIKTSENTAEFKERELCPLKTSKKLPENHLPRNSPQYHQPDLPEISRKNNGNNQQVPVKNEVDHCENLKKVDTKPSSEKKIHKTSREDMFSEKQDIPFVEQEDPYRKKKLQEKREGNLQNLNWSKSRTCRKNKKRGVAPVSRPPEQSDLKLVCSDFERSELSSDINVRSWCIQESTREVCKADAEIASSLPAAQREAEGYYQKPEKKCVDKFCSDSSSDCGSSSGSVRASRGSWGSWSSTSSSDGDKKPMVDAQHFLPAGDSVSQNDFPSEAPISLNLSHNICNPMTVNSLPQYAEPSCPSLPAGPTGVEEDKGLYSPGDLWPTPPVCVTSSLNCTLENGVPCVIQESAPVHNSFIDWSATCEGQFSSAYCPLELNDYNAFPEENMNYANGFPCPADVQTDFIDHNSQSTWNTPPNMPAAWGHASFISSPPYLTSTRSLSPMSGLFGSIWAPQSDVYENCCPINPTTEHSTHMENQAVVCKEYYPGFNPFRAYMNLDIWTTTANRNANFPLSRDSSYCGNV>sp|A2VDJ0-2|T131L_HUMAN Isoform 2 of Transmembrane protein 131-likeOS=Homo sapiens OX=9606 GN=TMEM131LMLLVLECVLFSVAQGYFRMDSSATQFHIETHENTSGLWSIWYRNHFDRSVVLNDVFLSKETKHMLKILNFTGPLFLPPGCWNIFSLKLAVKDIAINLFTNVFLTTNIGAIFAIPLQIYSAPTKEGSLGFEVIAHCGMHYFMGKSKAGNPNWNGSLSLDQSTWNVDSELANKLYERWKKYKNGDVCKRNVLGTTRFAHLKKSKESESFVFFLPRLIAEPGLMLNFSATALRSRMIKYFVVQNPSSWPVSLQLLPLSLYPKPEALVHLLHRWFGTDMQMINFTTGEFQLTEACPYLGTHSEESRFGILHLHLQPLEMKRVGVVFTPADYGKVTSLILIRNNLTVIDMIGVEGFGARELLKVGGRLPGAGGSLRFKVPESTLMDCRRQLKDSKQILSITKNFKVENIGPLPITVSSLKINGYNCQGYGFEVLDCHQFSLDPNTSRDISIVFTPDFTSSWVIRDLSLVTAADLEFRFTLNVTLPHHLLPLCADVVPGPSWEESFWRLTVFFVSLSLLGVILIAFQQAQYILMEFMKTRQRQNASSSSQQNNGPMDVISPHSYKSNCKNFLDTYGPSDKGRGKNCLPVNTPQSRIQNAAKRSPATYGHSQKKHKCSVYYSKHKTSTAAASSTSTTTEEKQTSPLGSSLPAAKEDICTDAMRENWISLRYASGINVNLQKNLTLPKNLLNKEENTLKNTIVFSNPSSECSMKEGIQTCMFPKETDIKTSENTAEFKERELCPLKTSKKLPENHLPRNSPQYHQPDLPEISRKNNGNNQQVPVKNEVDHCENLKKVDTKPSSEKKIHKTSREDMFSEKQDIPFVEQEDPYRKKKLQEKREGNLQNLNWSKSRTCRKNKKRGVAPVSRPPEQSDLKLVCSDFERSELSSDINVRSWCIQESTREVCKADAEIASSLPAAQREAEGYYQKPEKKCVDKFCSDSSSDCGSSSGSVRASRGSWGSWSSTSSSDGDKKPMVDAQHFLPAGDSVSQNDFPSEAPISLNLSHNICNPMTVNSLPQYAEPSCPSLPAGPTGVEEDKGLYSPGDLWPTPPVCVTSSLNCTLENGVPCVIQESAPVHNSFIDWSATCEGQFSSAYCPLELNDYNAFPEENMNYANGFPCPADVQTDFIDHNSQSTWNTPPNMPAAWGHASFISSPPYLTSTRSLSPMSGLFGSIWAPQSDVYENCCPINPTTEHSTHMENQAVVCKEYYPGFNPFRAYMNLDIWTTTANRNANFPLSRDSSYCGNV>sp|A2VDJ0-3|T131L_HUMAN Isoform 3 of Transmembrane protein 131-likeOS=Homo sapiens OX=9606 GN=TMEM131LMAGLRRPQPGCYCRTAAAVNLLLGVFQVLLPCCRPGGAQGQAIEPLPNVVELWQAEEGELLLPTQGDSEEGLEEPSQEQSFSDKLFSGKGLHFQPSVLDFGIQFLGHPVAKILHAYNPSRDSEVVVNSVFAAAGHFHVPPVPCRVIPAMGKTSFRIIFLPTEEGSIESSLFINTSSYGVLSYHVSGIGTRRISTEGSAKQLPNAYFLLPKVQSIQLSQMQAETTNTSLLQVQLECSLHNKVCQQLKGCYLESDDVLRLQMSIMVTMENFSKEFEENTQHLLDHLSIVYVATDESETSDDSAVNMYILHSGNSLIWIQDIRHFSQRDALSLQFEPVLLPTSTTNFTKIASFTCKAATSCDSGIIEDVKKTTHTPTLKACLFSSVAQGYFRMDSSATQFHIETHENTSGLWSIWYRNHFDRSVVLNDVFLSKETKHMLKILNFTGPLFLPPGCWNIFSLKLAVKDIAINLFTNVFLTTNIGAIFAIPLQIYSAPTKEGSLGFEVIAHCGMHYFMGKSKAGNPNWNGSLSLDQSTWNVDSELANKLYERWKKYKNGDVCKFGTDMQMINFTTGEFQLTEACPYLGTHSEESRFGILHLHLQPLEMKRVGVVFTPADYGKVTSLILIRNNLTVIDMIGVEGFGARELLKVGGRLPGAGGSLRFKVPESTLMDCRRQLKDSKQILSITKNFKVENIGPLPITVSSLKINGYNCQGYGFEVLDCHQFSLDPNTSRDISIVFTPDFTSSWVIRDLSLVTAADLEFRFTLNVTLPHHLLPLCADVVPGPSWEESFWRLTVFFVSLSLLGVILIAFQQAQYILMEFMKTRQRQNASSSSQQNNGPMDVISPHSYKSNCKNFLDTYGPSDKGRGKNCLPVNTPQSRIQNAAKRSPATYGHSQKKHKCSVYYSKHKTSTAAASSTSTTTEEKQTSPLGSSLPAAKEDICTDAMRENWISLRYASGINVNLQKNLTLPKNLLNKEENTLKNTIVFSNPSSECSMKEGIQTCMFPKETDIKTSENTAEFKERELCPLKTSKKLPENHLPRNSPQYHQPDLPEISRKNNGNNQQVPVKNEVDHCENLKKVDTKPSSEKKIHKTSREDMFSEKQDIPFVEQEDPYRKKKLQEKREGNLQNLNWSKSRTCRKNKKRGVAPVSRPPEQSDLKLVCSDFERSELSSDINVRSWCIQESTREVCKADAEIASSLPAAQREAEGYYQKPEKKCVDKFCSDSSSDCGSSSGSVRASRGSWGSWSSTSSSDGDKKPMVDAQHFLPAGDSVSQNDFPSEAPISLNLSHNICNPMTVNSLPQYAEPSCPSLPAGPTGVEEDKGLYSPGDLWPTPPVCVTSSLNCTLENGVPCVIQESAPVHNSFIDWSATCEGQFSSAYCPLELNDYNAFPEENMNYANGFPCPADVQTDFIDHNSQSTWNTPPNMPAAWGHASFISSPPYLTSTRSLSPMSGLFGSIWAPQSDVYENCCPINPTTEHSTHMENQAVVCKEYYPGFNPFRAYMNLDIWTTTANRNANFPLSRDSSYCGNV>sp|A2VDJ0-5|T131L_HUMAN Isoform 4 of Transmembrane protein 131-likeOS=Homo sapiens OX=9606 GN=TMEM131LMAGLRRPQPGCYCRTAAAVNLLLGVFQVLLPCCRPGGAQGQAIEPLPNVVELWQAEEGELLLPTQGDSEEGLEEPSQEQSFSDKLFSGKGLHFQPSVLDFGIQFLGHPVAKILHAYNPSRDSEVVVNSVFAAAGHFHVPPVPCRVIPAMGKTSFRIIFLPTEEGSIESSLFINTSSYGVLSYHVSGIGTRRISTEGSAKQLPNAYFLLPKVQSIQLSQMQAETTNTSLLQVQLECSLHNKVCQQLKGCYLESDDVLRLQMSIMVTMENFSKEFEENTQHLLDHLSIVYVATDESETSDDSAVNMYILHSGNSLIWIQDIRHFSQRDALSLQFEPVLLPTSTTNFTKIASFTCKAATSCDSGIIEDVKKTTHTPTLKACLFSSVAQGYFRMDSSATQFHIETHENTSGLWSIWYRNHFDRSVVLNDVFLSKETKHMLKILNFTGPLFLPPGCWNIFSLKLAVKDIAINLFTNVFLTTNIGAIFAIPLQIYSAPTKEGSLGFEVIAHCGMHYFMGKSKAGNPNWNGSLSLDQSTWNVDSELANKLYERWKKYKNGDVCKRNVLGTTRFAHLKKSKESESFVFFLPRLIAEPGLMLNFSATALRSRMIKYFVVQNPSSWPVSLQLLPLSLYPKPEALVHLLHRWFGTDMQMINFTTGEFQLTEACPYLGTHSEESRFGILHLHLQPLEMKRVGVVFTPADYGKVTSLILIRNNLTVIDMIGVEGFGARELLKVGGRLPGAGGSLRFKVPESTLMDCRRQLKDSKQILSITKNFKVENIGPLPITVSSLKINGYNCQGYGFEVLDCHQFSLDPNTSRDISIVFTPDFTSSWVIRDLSLVTAADLEFRFTLNVTLPHHLLPLCADVVPGPSWEESFWRLTVFFVSLSLLGVILIAFQQAQYILMEFMKTRQRQNASSSSQQNNGPMDVISPHSYKSNCKNFLDTYGPSDKGRGKNCLPVNTPQSRIQNAAKRSPATYGHSQKKHKCSVYYSKHKTSTAAASSTSTTTEEKQTSPLGSSLPAAKEDICTDAMRENWISLRYASGINVNLQKNLTLPKNLLNKEENTLKNTIVFSNPSSECSMKEGIQTCMFPKETDIKTSENTAEFKERELCPLKTSKKLPENHLPRNSPQYHQPDLPEISRKNNGNNQQVPVKNEVDHCENLKKVDTKPSSEKKIHKTSREDMFSEKQDIPFVEQEDPYRKKKLQEKREGNLQNLNWSKSRTCRKNKKRGVAPVSRPPEQSDLKLVCSDFERSELSSDINVRSWCIQESTREVCKADAEIASSLPAAQREAEGYYQKPEKKCVDKFCSDSSSDCGSSSGSVRASRGSWGSWSSTSSSDGDKKPMVDAQHFLPAGDSVSQNDFPSEAPISLNLSHNICNPMTVNSLPQYAEPSCPSLPAGPTGVEEDKGLYSPGDLWPTPPVCVTSSLNCTLENGVPCVIQESAPVHNSFIDWSATCEGQFSSAYCPLELNDYNAFPEENMNYANGFPCPADVQTDFIDHNSQSTWNTPPNMPAAWGHASFISSPPYLTSTRSLSPMSGLFGSIWAPQSDVYENCCPINPTTEHSTHMENQAVVCKEYYPGFNPFRAYMNLDIWTTTANRNANFPLSRDSSYCGNV>sp|A2VDJ0-6|T131L_HUMAN Isoform 5 of Transmembrane protein 131-likeOS=Homo sapiens OX=9606 GN=TMEM131LMGKTSFRIIFLPTEEGSIESSLFINTSSYGVLSYHVSGIGTRRISTEGSAKQLPNAYFLLPKVQSIQLSQMQAETTNTSLLQVQLECSLHNKVCQQLKGCYLESDDVLRLQMSIMVTMENFSKEFEENTQHLLDHLSIVYVATDESETSDDSAVNMYILHSGNSLIWIQDIRHFSQRDALSLQFEPVLLPTSTTNFTKIASFTCKAATSCDSGIIEDVKKTTHTPTLKACLFSSVAQGYFRMDSSATQFHIETHENTSGLWSIWYRNHFDRSVVLNDVFLSKETKHMLKILNFTGPLFLPPGCWNIFSLKLAVKDIAINLFTNVFLTTNIGAIFAIPLQIYSAPTKEGSLGFEVIAHCGMHYFMGKSKAGNPNWNGSLSLDQSTWNVDSELANKLYERWKKYKNGDVCKRNVLGTTRFAHLKKSKESESFVFFLPRLIAEPGLMLNFSATALRSRMIKYFVVQNPSSWPVSLQLLPLSLYPKPEALVHLLHRWFGTDMQMINFTTGEFQLTEACPYLGTHSEESRFGILHLHLQPLEMKRVGVVFTPADYGKVTSLILIRNNLTVIDMIGVEGFGARELLKVGGRLPGAGGSLRFKVPESTLMDCRRQLKDSKQILSITKNFKVENIGPLPITVSSLKINGYNCQGYGFEVLDCHQFSLDPNTSRDISIVFTPDFTSSWVIRDLSLVTAADLEFRFTLNVTLPHHLLPLCADVVPGPSWEESFWRLTVFFVSLSLLGVILIAFQQAQYILMEFMKTRQRQNASSSSQQNNGPMDVISPHSYKSNCKNFLDTYGPSDKGRGKNCLPVNTPQSRIQNAAKRSPATYGHSQKKHKCSVYYSKHKTSTAAASSTSTTTEEKQTSPLGSSLPAAKEDICTDAMRENWISLRYASGINVNLQKNLTLPKNLLNKEENTLKNTIVFSNPSSECSMKEGIQTCMFPKETDIKTSENTAEFKERELCPLKTSKKLPENHLPRNSPQYHQPDLPEISRKNNGNNQQVPVKNEVDHCENLKKVDTKPSSEKKIHKTSREDMFSEKQDIPFVEQEDPYRKKKLQEKREGNLQNLNWSKSRTCRKNKKRGVAPVSRPPEQSDLKLVCSDFERSELSSDINVRSWCIQESTREVCKADAEIASSLPAAQREAEGYYQKPEKKCVDKFCSDSSSDCGSSSGSVRASRGSWGSWSSTSSSDGDKKPMVDAQHFLPAGDSVSQNDFPSEAPISLNLSHNICNPMTVNSLPQYAEPSCPSLPAGPTGVEEDKGLYSPGDLWPTPPVCVTSSLNCTLENGVPCVIQESAPVHNSFIDWSATCEGQFSSAYCPLELNDYNAFPEENMNYANGFPCPADVQTDFIDHNSQSTWNTPPNMPAAWGHASFISSPPYLTSTRSLSPMSGLFGSIWAPQSDVYENCCPINPTTEHSTHMENQAVVCKEYYPGFNPFRAYMNLDIWTTTANRNANFPLSRDSSYCGNV>sp|Q13509|TBB3_HUMAN Tubulin beta-3 chain OS=Homo sapiens OX=9606GN=TUBB3 PE=1 SV=2MREIVHIQAGQCGNQIGAKFWEVISDEHGIDPSGNYVGDSDLQLERISVYYNEASSHKYVPRAILVDLEPGTMDSVRSGAFGHLFRPDNFIFGQSGAGNNWAKGHYTEGAELVDSVLDVVRKECENCDCLQGFQLTHSLGGGTGSGMGTLLISKVREEYPDRIMNTFSVVPSPKVSDTVVEPYNATLSIHQLVENTDETYCIDNEALYDICFRTLKLATPTYGDLNHLVSATMSGVTTSLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTARGSQQYRALTVPELTQQMFDAKNMMAACDPRHGRYLTVATVFRGRMSMKEVDEQMLAIQSKNSSYFVEWIPNNVKVAVCDIPPRGLKMSSTFIGNSTAIQELFKRISEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATAEEEGEMYEDDEEESEAQGPK>sp|Q13509-2|TBB3_HUMAN Isoform 2 of Tubulin beta-3 chain OS=Homo sapiensOX=9606 GN=TUBB3MDSVRSGAFGHLFRPDNFIFGQSGAGNNWAKGHYTEGAELVDSVLDVVRKECENCDCLQGFQLTHSLGGGTGSGMGTLLISKVREEYPDRIMNTFSVVPSPKVSDTVVEPYNATLSIHQLVENTDETYCIDNEALYDICFRTLKLATPTYGDLNHLVSATMSGVTTSLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTARGSQQYRALTVPELTQQMFDAKNMMAACDPRHGRYLTVATVFRGRMSMKEVDEQMLAIQSKNSSYFVEWIPNNVKVAVCDIPPRGLKMSSTFIGNSTAIQELFKRISEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATAEEEGEMYEDDEEESEAQGPK>sp|A6NHL2|TBAL3_HUMAN Tubulin alpha chain-like 3 OS=Homo sapiens OX=9606GN=TUBAL3 PE=1 SV=2MRECLSIHIGQAGIQIGDACWELYCLEHGIQPNGVVLDTQQDQLENAKMEHTNASFDTFFCETRAGKHVPRALFVDLEPTVIDGIRTGQHRSLFHPEQLLSGKEDAANNYARGRYSVGSEVIDLVLERTRKLAEQCGGLQGFLIFRSFGGGTGSGFTSLLMERLTGEYSRKTKLEFSVYPAPRISTAVVEPYNSVLTTHSTTEHTDCTFMVDNEAVYDICHRKLGVECPSHASINRLVVQVVSSITASLRFEGPLNVDLIEFQTNLVPYPRIHFPMTAFAPIVSADKAYHEQFSVSDITTACFESSNQLVKCDPRLGKYMACCLLYRGDVVPKEVNAAIAATKSRHSVQFVDWCPTGFKVGINNRPPTVMPGGDLAKVHRSICMLSNTTAIVEAWARLDHKFDLMYAKRAFLHWYLREGMEEAEFLEAREDLAALERDYEEVAQSF>sp|A6NHL2-2|TBAL3_HUMAN Isoform 2 of Tubulin alpha chain-like 3 OS=Homosapiens OX=9606 GN=TUBAL3MDQLENAKMEHTNASFDTFFCETRAGKHVPRALFVDLEPTVIDGIRTGQHRSLFHPEQLLSGKEDAANNYARGRYSVGSEVIDLVLERTRKLAEQCGGLQGFLIFRSFGGGTGSGFTSLLMERLTGEYSRKTKLEFSVYPAPRISTAVVEPYNSVLTTHSTTEHTDCTFMVDNEAVYDICHRKLGVECPSHASINRLVVQVVSSITASLRFEGPLNVDLIEFQTNLVPYPRIHFPMTAFAPIVSADKAYHEQFSVSDITTACFESSNQLVKCDPRLGKYMACCLLYRGDVVPKEVNAAIAATKSRHSVQFVDWCPTGFKVGINNRPPTVMPGGDLAKVHRSICMLSNTTAIVEAWARLDHKFDLMYAKRAFLHWYLREGMEEAEFLEAREDLAALERDYEEVAQSF>sp|P10636|TAU_HUMAN Microtubule-associated protein tau OS=Homo sapiensOX=9606 GN=MAPT PE=1 SV=5MAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKESPLQTPTEDGSEEPGSETSDAKSTPTAEDVTAPLVDEGAPGKQAAAQPHTEIPEGTTAEEAGIGDTPSLEDEAAGHVTQEPESGKVVQEGFLREPGPPGLSHQLMSGMPGAPLLPEGPREATRQPSGTGPEDTEGGRHAPELLKHQLLGDLHQEGPPLKGAGGKERPGSKEEVDEDRDVDESSPQDSPPSKASPAQDGRPPQTAAREATSIPGFPAEGAIPLPVDFLSKVSTEIPASEPDGPSVGRAKGQDAPLEFTFHVEITPNVQKEQAHSEEHLGRAAFPGAPGEGPEARGPSLGEDTKEADLPEPSEKQPAAAPRGKPVSRVPQLKARMVSKSKDGTGSDDKKAKTSTRSSAKTLKNRPCLSPKHPTPGSSDPLIQPSSPAVCPEPPSSPKYVSSVTSRTGSSGAKEMKLKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIINKKLDLSNVQSKCGSKDNIKHVPGGGSVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-2|TAU_HUMAN Isoform Fetal-tau of Microtubule-associatedprotein tau OS=Homo sapiens OX=9606 GN=MAPTMAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKAEEAGIGDTPSLEDEAAGHVTQARMVSKSKDGTGSDDKKAKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-3|TAU_HUMAN Isoform Tau-A of Microtubule-associated proteintau OS=Homo sapiens OX=9606 GN=MAPTMLRALQQRKREAGIGDTPSLEDEAAGHVTQARMVSKSKDGTGSDDKKAKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-4|TAU_HUMAN Isoform Tau-B of Microtubule-associated proteintau OS=Homo sapiens OX=9606 GN=MAPTMAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKESPLQTPTEDGSEEPGSETSDAKSTPTAEAEEAGIGDTPSLEDEAAGHVTQARMVSKSKDGTGSDDKKAKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-5|TAU_HUMAN Isoform Tau-C of Microtubule-associated proteintau OS=Homo sapiens OX=9606 GN=MAPTMAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKESPLQTPTEDGSEEPGSETSDAKSTPTAEDVTAPLVDEGAPGKQAAAQPHTEIPEGTTAEEAGIGDTPSLEDEAAGHVTQARMVSKSKDGTGSDDKKAKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-6|TAU_HUMAN Isoform Tau-D of Microtubule-associated proteintau OS=Homo sapiens OX=9606 GN=MAPTMAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKAEEAGIGDTPSLEDEAAGHVTQARMVSKSKDGTGSDDKKAKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIINKKLDLSNVQSKCGSKDNIKHVPGGGSVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-7|TAU_HUMAN Isoform Tau-E of Microtubule-associated proteintau OS=Homo sapiens OX=9606 GN=MAPTMAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKESPLQTPTEDGSEEPGSETSDAKSTPTAEAEEAGIGDTPSLEDEAAGHVTQARMVSKSKDGTGSDDKKAKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIINKKLDLSNVQSKCGSKDNIKHVPGGGSVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-8|TAU_HUMAN Isoform Tau-F of Microtubule-associated proteintau OS=Homo sapiens OX=9606 GN=MAPTMAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKESPLQTPTEDGSEEPGSETSDAKSTPTAEDVTAPLVDEGAPGKQAAAQPHTEIPEGTTAEEAGIGDTPSLEDEAAGHVTQARMVSKSKDGTGSDDKKAKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIINKKLDLSNVQSKCGSKDNIKHVPGGGSVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|P10636-9|TAU_HUMAN Isoform Tau-G of Microtubule-associated proteintau OS=Homo sapiens OX=9606 GN=MAPTMAEPRQEFEVMEDHAGTYGLGDRKDQGGYTMHQDQEGDTDAGLKESPLQTPTEDGSEEPGSETSDAKSTPTAEDVTAPLVDEGAPGKQAAAQPHTEIPEGTTAEEAGIGDTPSLEDEAAGHVTQEPESGKVVQEGFLREPGPPGLSHQLMSGMPGAPLLPEGPREATRQPSGTGPEDTEGGRHAPELLKHQLLGDLHQEGPPLKGAGGKERPGSKEEVDEDRDVDESSPQDSPPSKASPAQDGRPPQTAAREATSIPGFPAEGAIPLPVDFLSKVSTEIPASEPDGPSVGRAKGQDAPLEFTFHVEITPNVQKEQAHSEEHLGRAAFPGAPGEGPEARGPSLGEDTKEADLPEPSEKQPAAAPRGKPVSRVPQLKARMVSKSKDGTGSDDKKAKTSTRSSAKTLKNRPCLSPKHPTPGSSDPLIQPSSPAVCPEPPSSPKYVSSVTSRTGSSGAKEMKLKGADGKTKIATPRGAAPPGQKGQANATRIPAKTPPAPKTPPSSATKQVQRRPPPAGPRSERGEPPKSGDRSGYSSPGSPGTPGSRSRTPSLPTPPTREPKKVAVVRTPPKSPSSAKSRLQTAPVPMPDLKNVKSKIGSTENLKHQPGGGKVQIINKKLDLSNVQSKCGSKDNIKHVPGGGSVQIVYKPVDLSKVTSKCGSLGNIHHKPGGGQVEVKSEKLDFKDRVQSKIGSLDNITHVPGGGNKKIETHKLTFRENAKAKTDHGAEIVYKSPVVSGDTSPRHLSNVSSTGSIDMVDSPQLATLADEVSASLAKQGL>sp|Q12788|TBL3_HUMAN Transducin beta-like protein 3 OS=Homo sapiensOX=9606 GN=TBL3 PE=1 SV=2MAETAAGVGRFKTNYAVERKIEPFYKGGKAQLDQTGQHLFCVCGTRVNILEVASGAVLRSLEQEDQEDITAFDLSPDNEVLVTASRALLLAQWAWQEGSVTRLWKAIHTAPVATMAFDPTSTLLATGGCDGAVRVWDIVRHYGTHHFRGSPGVVHLVAFHPDPTRLLLFSSATDAAIRVWSLQDRSCLAVLTAHYSAVTSLAFSADGHTMLSSGRDKICIIWDLQSCQATRTVPVFESVEAAVLLPEEPVSQLGVKSPGLYFLTAGDQGTLRVWEAASGQCVYTQAQPPGPGQELTHCTLAHTAGVVLTATADHNLLLYEARSLRLQKQFAGYSEEVLDVRFLGPEDSHVVVASNSPCLKVFELQTSACQILHGHTDIVLALDVFRKGWLFASCAKDQSVRIWRMNKAGQVMCVAQGSGHTHSVGTVCCSRLKESFLVTGSQDCTVKLWPLPKALLSKNTAPDNGPILLQAQTTQRCHDKDINSVAIAPNDKLLATGSQDRTAKLWALPQCQLLGVFSGHRRGLWCVQFSPMDQVLATASADGTIKLWALQDFSCLKTFEGHDASVLKVAFVSRGTQLLSSGSDGLVKLWTIKNNECVRTLDAHEDKVWGLHCSRLDDHALTGASDSRVILWKDVTEAEQAEEQARQEEQVVRQQELDNLLHEKRYLRALGLAISLDRPHTVLTVIQAIRRDPEACEKLEATMLRLRRDQKEALLRFCVTWNTNSRHCHEAQAVLGVLLRREAPEELLAYEGVRAALEALLPYTERHFQRLSRTLQAAAFLDFLWHNMKLPVPAAAPTPWETHKGALP>sp|Q9BUZ4|TRAF4_HUMAN TNF receptor-associated factor 4 OS=Homo sapiensOX=9606 GN=TRAF4 PE=1 SV=1MPGFDYKFLEKPKRRLLCPLCGKPMREPVQVSTCGHRFCDTCLQEFLSEGVFKCPEDQLPLDYAKIYPDPELEVQVLGLPIRCIHSEEGCRWSGPLRHLQGHLNTCSFNVIPCPNRCPMKLSRRDLPAHLQHDCPKRRLKCEFCGCDFSGEAYESHEGMCPQESVYCENKCGARMMRRLLAQHATSECPKRTQPCTYCTKEFVFDTIQSHQYQCPRLPVACPNQCGVGTVAREDLPGHLKDSCNTALVLCPFKDSGCKHRCPKLAMARHVEESVKPHLAMMCALVSRQRQELQELRRELEELSVGSDGVLIWKIGSYGRRLQEAKAKPNLECFSPAFYTHKYGYKLQVSAFLNGNGSGEGTHLSLYIRVLPGAFDNLLEWPFARRVTFSLLDQSDPGLAKPQHVTETFHPDPNWKNFQKPGTWRGSLDESSLGFGYPKFISHQDIRKRNYVRDDAVFIRAAVELPRKILS>sp|Q9BUZ4-2|TRAF4_HUMAN Isoform 2 of TNF receptor-associated factor 4OS=Homo sapiens OX=9606 GN=TRAF4MPGFDYKFLEKPKRRLLCPLCGKPMREPVQVSTCGHRFCDTCLQEFLSEGVFKCPEDQLPLDYAKIYPDPELEVQVLGLPIRCIHSEEGCRWSGPLRHLQGHLNTCSFNVIPCPNRCPMKLSRRDLPAHLQHDCPKRRLKCEFCGCDFSGEAYESHESSLGFGYPKFISHQDIRKRNYVRDDAVFIRAAVELPRKILS>sp|Q8NBT3|TM145_HUMAN Transmembrane protein 145 OS=Homo sapiens OX=9606GN=TMEM145 PE=2 SV=2MEPLRAPALRRLLPPLLLLLLSLPPRARAKYVRGNLSSKEDWVFLTRFCFLSDYGRLDFRFRYPEAKCCQNILLYFDDPSQWPAVYKAGDKDCLAKESVIRPENNQVINLTTQYAWSGCQVVSEEGTRYLSCSSGRSFRSGDGLQLEYEMVLTNGKSFWTRHFSADEFGILETDVTFLLIFILIFFLSCYFGYLLKGRQLLHTTYKMFMAAAGVEVLSLLFFCIYWGQYATDGIGNESVKILAKLLFSSSFLIFLLMLILLGKGFTVTRGRISHAGSVKLSVYMTLYTLTHVVLLIYEAEFFDPGQVLYTYESPAGYGLIGLQVAAYVWFCYAVLVSLRHFPEKQPFYVPFFAAYTLWFFAVPVMALIANFGIPKWAREKIVNGIQLGIHLYAHGVFLIMTRPSAANKNFPYHVRTSQIASAGVPGPGGSQSADKAFPQHVYGNVTFISDSVPNFTELFSIPPPATSPLPRAAPDSGLPLFRDLRPPGPLRDL>sp|Q9BYX2|TBD2A_HUMAN TBC1 domain family member 2A OS=Homo sapiensOX=9606 GN=TBC1D2 PE=1 SV=3MEGAGENAPESSSSAPGSEESARDPQVPPPEEESGDCARSLEAVPKKLCGYLSKFGGKGPIRGWKSRWFFYDERKCQLYYSRTAQDANPLDSIDLSSAVFDCKADAEEGIFEIKTPSRVITLKAATKQAMLYWLQQLQMKRWEFHNSPPAPPATPDAALAGNGPVLHLELGQEEAELEEFLCPVKTPPGLVGVAAALQPFPALQNISLKHLGTEIQNTMHNIRGNKQAQGTGHEPPGEDSPQSGEPQREEQPLASDASTPGREPEDSPKPAPKPSLTISFAQKAKRQNNTFPFFSEGITRNRTAQEKVAALEQQVLMLTKELKSQKELVKILHKALEAAQQEKRASSAYLAAAEDKDRLELVRHKVRQIAELGRRVEALEQERESLAHTASLREQQVQELQQHVQLLMDKNHAKQQVICKLSEKVTQDFTHPPDQSPLRPDAANRDFLSQQGKIEHLKDDMEAYRTQNCFLNSEIHQVTKIWRKVAEKEKALLTKCAYLQARNCQVESKYLAGLRRLQEALGDEASECSELLRQLVQEALQWEAGEASSDSIELSPISKYDEYGFLTVPDYEVEDLKLLAKIQALESRSHHLLGLEAVDRPLRERWAALGDLVPSAELKQLLRAGVPREHRPRVWRWLVHLRVQHLHTPGCYQELLSRGQAREHPAARQIELDLNRTFPNNKHFTCPTSSFPDKLRRVLLAFSWQNPTIGYCQGLNRLAAIALLVLEEEESAFWCLVAIVETIMPADYYCNTLTASQVDQRVLQDLLSEKLPRLMAHLGQHHVDLSLVTFNWFLVVFADSLISNILLRVWDAFLYEGTKVVFRYALAIFKYNEKEILRLQNGLEIYQYLRFFTKTISNSRKLMNIAFNDMNPFRMKQLRQLRMVHRERLEAELRELEQLKAEYLERRASRRRAVSEGCASEDEVEGEA>sp|Q9BYX2-2|TBD2A_HUMAN Isoform 2 of TBC1 domain family member 2AOS=Homo sapiens OX=9606 GN=TBC1D2MEGAGENAPESSSSAPGSEESARDPQVPPPEEESGDCARSLEAVPKKLCGYLSKFGGKGPIRGWKSRWFFYDERKCQLYYSRTAQDANPLDSIDLSSAVFDCKADAEEGIFEIKTPSRVITLKAATKQAMLYWLQQLQMKRWEFHNSPPAPPATPDAALAGNGPVLHLELGQEEAELEEFLCPVKTPPGLVGVAAALQPFPALQNISLKHLGTEIQNTMHNIRGNKQAQGTGHEPPGEDSPQSGEPQREEQPLASDASTPGREPEDSPKPAPKPSLTISFAQKAKRQNNTFPFFSEGITRNRTAQEKVAALEQQVLMLTKELKSQKELVKILHKALEAAQQEKRASSAYLAAAEDKDRLELVRHKVRQIAELGRRVEALEQERESLAHTASLREQQVQELQQHVQLLMDKNHAKQQVICKLSEKVTQDFTHPPDQSPLRPDAANRDFLSQQGKIEHLKDDMEAYRTQNCFLNSEIHQVTKIWRKVAEKEKALLTKCAYLQARNCQVESKYLAGLRRLQEALGDEASECSELLRQLVQEALQWEAGEASSDSIELSPISKYDEYGFLTVPDYEVEDLKLLAKIQALESRSHHLLGLEAVDRPLRERWAALGDLVPSAELKQLLRAGVPREHRPRVWRWLVHLRVQHLHTPGCYQELLSRGQAREHPAARQIELDLNRTFPNNKHFTCPTSSFPDKLRRVLLAFSWQNPTIGYCQGLNRLAAIALLVLEEEESAFWCLVAIVETIMPADYYCNTLTASQVDQRVLQDLLSEKLPRLMAHLGQHHVDLSLVTFNWFLVVFADSLISNILLRVWDAFLYEGTKYNEKEILRLQNGLEIYQYLRFFTKTISNSRKLMNIAFNDMNPFRMKQLRQLRMVHRERLEAELRELEQLKAEYLERRASRRRAVSEGCASEDEVEGEA>sp|Q9BYX2-3|TBD2A_HUMAN Isoform 3 of TBC1 domain family member 2AOS=Homo sapiens OX=9606 GN=TBC1D2MEGAGENAPESSSSAPGSEESARDPQVPPPEEESGDCARSLEAVPKKLCGYLSKFGGKGPIRGWKSRWFFYDERKCQLYYSRTAQDANPLDSIDLSSAVFDCKADAEEGIFEIKTPSRVITLKAATKQAMLYWLQQLQMKRWEFHNSPPAPPATPDAALAGNGPVLHLELGQEEAELEEFLCPVKTPPGLVGVAAALQPFPALQNISLKHLGTEIQNTMHNIRGNKQAQGTGHEPPGEDSPQSGEPQREEQPLASDASTPGREPEDSPKPAPKPSLTISFAQKAKRQNNTFPFFSEGITRNRTAQEKVAALEQQVLMLTKELKSQKELVKILHKALEAAQQEKRASSAYLAAAEDKDRLELVRHKVRQIAELGRRVEALEQERESLAHTASLREQQVQELQQHVQLLMDKNHAKQQVICKLSEKVTQDFTHPPDQSPLRPDAANRDFLSQQGKIEHLKDDMEAYRTQNCFLNSEIHQVTKIWRKVAEKEKALLTKCAYLQARNCQVESKYLAGLRRLQEALGDEASECSELLRQLVQEALQWEAGEASSDSIELSPISKYDEYGFLTVPDYEVEDLKLLAKIQALESRSHHLLGLEAVDRPLRERWAALGDLVPSAELKQLLRAGVPREHRPRVWRWLVHLRVQHLHTPGCYQELLSRGQAREHPAARQIELDLNRTFPNNKHFTCPTSSFPDKLRRVLLAFSWQNPTIGYCQGLNRLAAIALLVLEEEESAFWCLVAIVETIMPADYYCNTLTASQVDQRVLQDLLSEKLPRLMAHLGQHHVDLSLVTFNWFLVVFADSLISNILLRVWDAFLYEGTKVVFRYALAIFKYNEKEILRLQNGLEIYQYLRFFTKTISNSR>sp|Q9BYX2-4|TBD2A_HUMAN Isoform 4 of TBC1 domain family member 2AOS=Homo sapiens OX=9606 GN=TBC1D2MHNIRGNKQAQGTGHEPPGEDSPQSGEPQREEQPLASDASTPGREPEDSPKPAPKPSLTISFAQKAKRQNNTFPFFSEGITRNRTAQEKVAALEQQVLMLTKELKSQKELVKILHKALEAAQQEKRASSAYLAAAEDKDRLELVRHKVRQIAELGRRVEALEQERESLAHTASLREQQVQELQQHVQLLMDKNHAKQQVICKLSEKVTQDFTHPPDQSPLRPDAANRDFLSQQGKIEHLKDDMEAYRTQNCFLNSEIHQVTKIWRKVAEKEKALLTKCAYLQARNCQVESKYLAGLRRLQEALGDEASECSELLRQLVQEALQWEAGEASSDSIELSPISKYDEYGFLTVPDYEVEDLKLLAKIQALESRSHHLLGLEAVDRPLRERWAALGDLVPSAELKQLLRAGVPREHRPRVWRWLVHLRVQHLHTPGCYQELLSRGQAREHPAARQIELDLNRTFPNNKHFTCPTSSFPDKLRRVLLAFSWQNPTIGYCQGLNRLAAIALLVLEEEESAFWCLVAIVETIMPADYYCNTLTASQVDQRVLQDLLSEKLPRLMAHLGQHHVDLSLVTFNWFLVVFADSLISNILLRVWDAFLYEGTKVVFRYALAIFKYNEKEILRLQNGLEIYQYLRFFTKTISNSRKLMNIAFNDMNPFRMKQLRQLRMVHRERLEAELRELEQLKAEYLERRASRRRAVSEGCASEDEVEGEA>sp|Q9BYX2-5|TBD2A_HUMAN Isoform 5 of TBC1 domain family member 2AOS=Homo sapiens OX=9606 GN=TBC1D2MPIPWTASTSPLRPDAANRDFLSQQGKIEHLKDDMEAYRTQNCFLNSEIHQVTKIWRKVAEKEKALLTKCAYLQARNCQVESKYLAGLRRLQEALGDEASECSELLRQLVQEALQWEAGEASSDSIELSPISKYDEYGFLTVPDYEVEDLKLLAKIQALESRSHHLLGLEAVDRPLRERWAALGDLVPSAELKQLLRAGVPREHRPRVWRWLVHLRVQHLHTPGCYQELLSRGQAREHPAARQIELDLNRTFPNNKHFTCPTSSFPDKLRRVLLAFSWQNPTIGYCQGLNRLAAIALLVLEEEESAFWCLVAIVETIMPADYYCNTLTASQVDQRVLQDLLSEKLPRLMAHLGQHHVDLSLVTFNWFLVVFADSLISNILLRVWDAFLYEGTKVVFRYALAIFKYNEKEILRLQNGLEIYQYLRFFTKTISNSRKLMNIAFNDMNPFRMKQLRQLRMVHRERLEAELRELEQLKAEYLERRASRRRAVSEGCASEDEVEGEA>sp|Q9BYX2-6|TBD2A_HUMAN Isoform 6 of TBC1 domain family member 2AOS=Homo sapiens OX=9606 GN=TBC1D2MEAYRTQNCFLNSEIHQVTKIWRKVAEKEKALLTKCAYLQARNCQVESKYLAGLRRLQEALGDEASECSELLRQLVQEALQWEAGEASSDSIELSPISKYDEYGFLTVPDYEVEDLKLLAKIQALESRSHHLLGLEAVDRPLRERWAALGDLVPSAELKQLLRAGVPREHRPRVWRWLVHLRVQHLHTPGCYQELLSRGQAREHPAARQIELDLNRTFPNNKHFTCPTSSFPDKLRRVLLAFSWQNPTIGYCQGLNRLAAIALLVLEEEESAFWCLVAIVETIMPADYYCNTLTASQVDQRVLQDLLSEKLPRLMAHLGQHHVDLSLVTFNWFLVVFADSLISNILLRVWDAFLYEGTKVVFRYALAIFKYNEKEILRLQNGLEIYQYLRFFTKTISNSRKLMNIAFNDMNPFRMKQLRQLRMVHRERLEAELRELEQLKAEYLERRASRRRAVSEGCASEDEVEGEA>sp|P40225|TPO_HUMAN Thrombopoietin OS=Homo sapiens OX=9606 GN=THPO PE=1SV=1MELTELLLVVMLLLTARLTLSSPAPPACDLRVLSKLLRDSHVLHSRLSQCPEVHPLPTPVLLPAVDFSLGEWKTQMEETKAQDILGAVTLLLEGVMAARGQLGPTCLSSLLGQLSGQVRLLLGALQSLLGTQLPPQGRTTAHKDPNAIFLSFQHLLRGKVRFLMLVGGSTLCVRRAPPTTAVPSRTSLVLTLNELPNRTSGLLETNFTASARTTGSGLLKWQQGFRAKIPGLLNQTSRSLDQIPGYLNRIHELLNGTRGLFPGPSRRTLGAPDISSGTSDTGSLPPNLQPGYSPSPTHPPTGQYTLFPLPPTLPTPVVQLHPLLPDPSAPTPTPTSPLLNTSYTHSQNLSQEG>sp|P40225-2|TPO_HUMAN Isoform 2 of Thrombopoietin OS=Homo sapiensOX=9606 GN=THPOMELTELLLVVMLLLTARLTLSSPAPPACDLRVLSKLLRDSHVLHSRLSQCPEVHPLPTPVLLPAVDFSLGEWKTQMEETKAQDILGAVTLLLEGVMAARGQLGPTCLSSLLGQLSGQVRLLLGALQSLLGTQGRTTAHKDPNAIFLSFQHLLRGKVRFLMLVGGSTLCVRRAPPTTAVPSRTSLVLTLNELPNRTSGLLETNFTASARTTGSGLLKWQQGFRAKIPGLLNQTSRSLDQIPGYLNRIHELLNGTRGLFPGPSRRTLGAPDISSGTSDTGSLPPNLQPGYSPSPTHPPTGQYTLFPLPPTLPTPVVQLHPLLPDPSAPTPTPTSPLLNTSYTHSQNLSQEG>sp|P40225-3|TPO_HUMAN Isoform 3 of Thrombopoietin OS=Homo sapiensOX=9606 GN=THPOMELTELLLVVMLLLTARLTLSSPAPPACDLRVLSKLLRDSHVLHSRLSQCPEVHPLPTPVLLPAVDFSLGEWKTQMEETKAQDILGAVTLLLEGVMAARGQLGPTCLSSLLGQLSGQVRLLLGALQSLLGTQLPPQGRTTAHKDPNAIFLSFQHLLRGKTSGLLETNFTASARTTGSGLLKWQQGFRAKIPGLLNQTSRSLDQIPGYLNRIHELLNGTRGLFPGPSRRTLGAPDISSGTSDTGSLPPNLQPGYSPSPTHPPTGQYTLFPLPPTLPTPVVQLHPLLPDPSAPTPTPTSPLLNTSYTHSQNLSQEG>sp|Q6UW68|TM205_HUMAN Transmembrane protein 205 OS=Homo sapiens OX=9606GN=TMEM205 PE=1 SV=1MEEGGNLGGLIKMVHLLVLSGAWGMQMWVTFVSGFLLFRSLPRHTFGLVQSKLFPFYFHISMGCAFINLCILASQHAWAQLTFWEASQLYLLFLSLTLATVNARWLEPRTTAAMWALQTVEKERGLGGEVPGSHQGPDPYRQLREKDPKYSALRQNFFRYHGLSSLCNLGCVLSNGLCLAGLALEIRSL>sp|Q5VWI1|TCRGL_HUMAN Transcription elongation regulator 1-like proteinOS=Homo sapiens OX=9606 GN=TCERG1L PE=2 SV=2MQAGARFQRRRRQLQQQQPRRRQPLLWPMDAEPPPPPPWVWMVPGSAGLLRLSAGVVVPPVLLASAPPPAAPLLPGLPGWPAPSEPVLPLLPLPSAPDSAAAAAAHPFPALHGQWLFGGHSPSLGLPPSSTVELVPVFPHLCPSALATPIGKSWIDKRIPNCKIFFNNSFALDSTWIHPEESRFFHGHEKPRLLANQVAVSLSRPAPASRPLPTVVLAPQPIPGGCHNSLKVTSSPAIAIATAAAAAMVSVDPENLRGPSPSSVQPRHFLTLAPIKIPLRTSPVSDTRTERGRVARPPALMLRAQKSRDGDKEDKEPPPMLGGGEDSTARGNRPVASTPVPGSPWCVVWTGDDRVFFFNPTMHLSVWEKPMDLKDRGDLNRIIEDPPHKRKLEAPATDNSDGSSSEDNREDQDVKTKRNRTEGCGSPKPEEAKREDKGTRTPPPQILLPLEERVTHFRDMLLERGVSAFSTWEKELHKIVFDPRYLLLNSEERKQIFEQFVKTRIKEEYKEKKSKLLLAKEEFKKLLEESKVSPRTTFKEFAEKYGRDQRFRLVQKRKDQEHFFNQFILILKKRDKENRLRLRKMR>sp|Q4V9L6|TM119_HUMAN Transmembrane protein 119 OS=Homo sapiens OX=9606GN=TMEM119 PE=1 SV=1MVSAAAPSLLILLLLLLGSVPATDARSVPLKATFLEDVAGSGEAEGSSASSPSLPPPWTPALSPTSMGPQPITLGGPSPPTNFLDGIVDFFRQYVMLIAVVGSLAFLLMFIVCAAVITRQKQKASAYYPSSFPKKKYVDQSDRAGGPRAFSEVPDRAPDSRPEEALDSSRQLQADILAATQNLKSPTRAALGGGDGARMVEGRGAEEEEKGSQEGDQEVQGHGVPVETPEAQEEPCSGVLEGAVVAGEGQGELEGSLLLAQEAQGPVGPPESPCACSSVHPSV>sp|Q96A61|TRI52_HUMAN E3 ubiquitin-protein ligase TRIM52 OS=Homo sapiensOX=9606 GN=TRIM52 PE=1 SV=1MAGYATTPSPMQTLQEEAVCAICLDYFKDPVSISCGHNFCRGCVTQLWSKEDEEDQNEEEDEWEEEEDEEAVGAMDGWDGSIREVLYRGNADEELFQDQDDDELWLGDSGITNWDNVDYMWDEEEEEEEEDQDYYLGGLRPDLRIDVYREEEILEAYDEDEDEELYPDIHPPPSLPLPGQFTCPQCRKSFTRRSFRPNLQLANMVQIIRQMCPTPYRGNRSNDQGMCFKHQEALKLFCEVDKEAICVVCRESRSHKQHSVLPLEEVVQEYQEIKLETTLVGILQIEQESIHSKAYNQ>sp|Q96A61-2|TRI52_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM52OS=Homo sapiens OX=9606 GN=TRIM52MAGYATTPSPMQTLQEEAVCAICLDYFKDPVSISCGHNFCRGCVTQLWSKEDEEDQNEEEDEWEEEEDEEAVGAMDGWDGSIREVLYRGNADEELFQDQDDDELWLGDSGITNWDNVDYMWDEEEEEEEEDQDYYLGGLRPDLRIDVYREEEILEAYDEDEDEELYPDIHPPPSLPLPGQFTCPQCRKSFTRRSFRPNLQLANMVQIIRQMCPTPYRGNRSNDQGMCFKHQEALKLFCEVDKEAICVVCRESRSHKQHSVLPLEEVVQEYQVREMRECGGMKGVER>sp|Q9NV29|TM100_HUMAN Transmembrane protein 100 OS=Homo sapiens OX=9606GN=TMEM100 PE=1 SV=2MTEEPIKEILGAPKAHMAATMEKSPKSEVVITTVPLVSEIQLMAATGGTELSCYRCIIPFAVVVFIAGIVVTAVAYSFNSHGSIISIFGLVVLSSGLFLLASSALCWKVRQRSKKAKRRESQTALVANQRSLFA>sp|Q5EBN2|TRI61_HUMAN Putative tripartite motif-containing protein 61OS=Homo sapiens OX=9606 GN=TRIM61 PE=2 SV=1MEFVTALADLRAEASCPICLDYLKDPVTISCGHNFCLSCIIMSWKDLHDSFPCPFCHFCCPERKFISNPQLGSLTEIAKQLQIRSKKRKRQEEKHVCKKHNQVLTFFCQKDLELLCPRCSLSTDHQHHCVWPIKKAASYHRKKLEEYNAPWKERVELIEKVITMQTRKSLELKKKMESPSVTRLECSCTISAHFNLRLPGSSDSSASGS>sp|B3SHH9|TM114_HUMAN Transmembrane protein 114 OS=Homo sapiens OX=9606GN=TMEM114 PE=1 SV=2MRVHLGGLAGAAALTGALSFVLLAAAIGTDFWYIIDTERLERTGPGAQDLLGSINRSQPEPLSSHSGLWRTCRVQSPCTPLMNPFRLENVTVSESSRQLLTMHGTFVILLPLSLILMVFGGMTGFLSFLLQAYLLLLLTGILFLFGAMVTLAGISVYIAYSAAAFREALCLLEEKALLDQVDISFGWSLALGWISFIAELLTGAAFLAAARELSLRRRQDQAI>sp|Q92994|TF3B_HUMAN Transcription factor IIIB 90 kDa subunit OS=Homosapiens OX=9606 GN=BRF1 PE=1 SV=1MTGRVCRGCGGTDIELDAARGDAVCTACGSVLEDNIIVSEVQFVESSGGGSSAVGQFVSLDGAGKTPTLGGGFHVNLGKESRAQTLQNGRRHIHHLGNQLQLNQHCLDTAFNFFKMAVSRHLTRGRKMAHVIAACLYLVCRTEGTPHMLLDLSDLLQVNVYVLGKTFLLLARELCINAPAIDPCLYIPRFAHLLEFGEKNHEVSMTALRLLQRMKRDWMHTGRRPSGLCGAALLVAARMHDFRRTVKEVISVVKVCESTLRKRLTEFEDTPTSQLTIDEFMKIDLEEECDPPSYTAGQRKLRMKQLEQVLSKKLEEVEGEISSYQDAIEIELENSRPKAKGGLASLAKDGSTEDTASSLCGEEDTEDEELEAAASHLNKDLYRELLGGAPGSSEAAGSPEWGGRPPALGSLLDPLPTAASLGISDSIRECISSQSSDPKDASGDGELDLSGIDDLEIDRYILNESEARVKAELWMRENAEYLREQREKEARIAKEKELGIYKEHKPKKSCKRREPIQASTAREAIEKMLEQKKISSKINYSVLRGLSSAGGGSPHREDAQPEHSASARKLSRRRTPASRSGADPVTSVGKRLRPLVSTQPAKKVATGEALLPSSPTLGAEPARPQAVLVESGPVSYHADEEADEEEPDEEDGEPCVSALQMMGSNDYGCDGDEDDGY>sp|Q92994-2|TF3B_HUMAN Isoform 2 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MTALRLLQRMKRDWMHTGRRPSGLCGAALLVAARMHDFRRTVKEVISVVKVCESTLRKRLTEFEDTPTSQLTIDEFMKIDLEEECDPPIEEGGQTEAREPPQASSWEGPSTTRRRSQLWHGCPGCGRGGFTLCP>sp|Q92994-3|TF3B_HUMAN Isoform 3 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MTALRLLQRMKRDWMHTGRRPSGLCGAALLVAARMHDFRRTVKEVISVVKVCESTLRKRLTEFEDTPTSQLTIDEFMKIDLEEECDPPSYTAGQRKLRMKQLEQVLSKKLEEVEGEISSYQDAIEIELENSRPKAKGGLASLAKDGSTEDTASSLCGEEDTEDEELEAAASHLNKDLYRELLGGAPGSSEAAGSPEWGGRPPALGSLLDPLPTAASLGISDSIRECISSQSSDPKDASGDGELDLSGIDDLEIDRYILNESEARVKAELWMRENAEYLREQREKEARIAKEKELGIYKEHKPKKSCKRREPIQASTAREAIEKMLEQKKISSKINYSVLRGLSSAGGGSPHREDAQPEHSASARKLSRRRTPASRSGADPVTSVGKRLRPLVSTQPAKKVATGEALLPSSPTLGAEPARPQAVLVESGPVSYHADEEADEEEPDEEDGEPCVSALQMMGSNDYGCDGDEDDGY>sp|Q92994-4|TF3B_HUMAN Isoform 4 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MTGRVCRGCGGTDIELDAARGDAVCTACGSVLEDNIIVSEVQFVESSGGGSSAVGQFVSLDGAGKTPTLGGGFHVNLGKESRAQTLQNGRRHIHHLGNQLQLNQHCLDTAFNFFKMAVSRHLTRGRKMAHVIAACLYLVCRTEGTPHMLLDLSDLLQVDSLRPASFPTWGCDLGVVTRVVTGVYPRCASRISVAGLCCLPSQEVLVCRMRGLHDMGVTVRDLWECGSPWQEGHLPMLGTVGC>sp|Q92994-5|TF3B_HUMAN Isoform 5 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MTGRVCRGCGGTDIELDAARGDAVCTACGSVLEDNIIVSEVQFVESSGGGSSAVGQFVSLDGRRHIHHLGNQLQLNQHCLDTAFNFFKMAVSRHLTRGRKMAHVIAACLYLVCRTEGTPHMLLDLSDLLQVNVYVLGKTFLLLARELCINAPAIDPCLYIPRFAHLLEFGEKNHEVSMTALRLLQRMKRDWMHTGRRPSGLCGAALLVAARMHDFRRTVKEVISVVKVCESTLRKRLTEFEDTPTSQLTIDEFMKIDLEEECDPPSYTAGQRKLRMKQLEQVLSKKLEEVEGEISSYQDAIEIELENSRPKAKGGLASLAKDGSTEDTASSLCGEEDTEDEELEAAASHLNKDLYRELLGGAPGSSEAAGSPEWGGRPPALGSLLDPLPTAASLGISDSIRECISSQSSDPKDASGDGELDLSGIDDLEIDRYILNESEARVKAELWMRENAEYLREQREKEARIAKEKELGIYKEHKPKKSCKRREPIQASTAREAIEKMLEQKKISSKINYSVLRGLSSAGGGSPHREDAQPEHSASARKLSRRRTPASRSGADPVTSVGKRLRPLVSTQPAKKVATGEALLPSSPTLGAEPARPQAVLVESGPVSYHADEEADEEEPDEEDGEPCVSALQMMGSNDYGCDGDEDDGY>sp|Q92994-6|TF3B_HUMAN Isoform 6 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MTGRVCRGCGGTDIELDAARGDAVCTACGSVLEDNIIVSEVQFVESSGGGSSAVGQFVSLDGAGKTPTLGGGFHVNLGKESRAQTLQNGRRHIHHLGNQLQLNQHCLDTAFNFFKMAVSRHLTRGRKMAHVIAACLYLVCRTEGTPHMLLDLSDLLQVDSLRPASFPTWGCDLGVVTRVVTGVYPRCLHASQWPVCAACPVRKFWSVG>sp|Q92994-7|TF3B_HUMAN Isoform 7 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MAVSRHLTRGRKMAHVIAACLYLVCRTEGTPHMLLDLSDLLQVNVYVLGKTFLLLARELCINAPAIDPCLYIPRFAHLLEFGEKNHEVSMTALRLLQRMKRDWMHTGRRPSGLCGAALLVAARMHDFRRTVKEVISVVKVCESTLRKRLTEFEDTPTSQLTIDEFMKIDLEEECDPPSYTAGQRKLRMKQLEQVLSKKLEEVEGEISSYQDAIEIELENSRPKAKGGLASLAKDGSTEDTASSLCGEEDTEDEELEAAASHLNKDLYRELLGGAPGSSEAAGSPEWGGRPPALGSLLDPLPTAASLGISDSIRECISSQSSDPKDASGDGELDLSGIDDLEIDRYILNESEARVKAELWMRENAEYLREQREKEARIAKEKELGIYKEHKPKKSCKRREPIQASTAREAIEKMLEQKKISSKINYSVLRGLSSAGGGSPHREDAQPEHSASARKLSRRRTPASRSGADPVTSVGKRLRPLVSTQPAKKVATGEALLPSSPTLGAEPARPQAVLVESGPVSYHADEEADEEEPDEEDGEPCVSALQMMGSNDYGCDGDEDDGY>sp|Q92994-8|TF3B_HUMAN Isoform 8 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MAVSRHLTRGRKMAHVIAACLYLVCRTEGTPHMLLDLSDLLQVNVYVLGKTFLLLARELCINAPAIDPCLYIPRFAHLLEFGEKNHEVSMTALRLLQRMKRDWMHTGRRPSGLCGAALLVAARMHDFRRTVKEVISVVKVCESTLRKRLTEFEDTPTSQLTIDEFMKIDLEEECDPPSYTAGQRKLRMKQLEQVLSKKLEEVEGEISSYQDAIEIELENSRPKAKGGLASLAKDGSTEDTASSLCGEEDTEDEELEAAASHLNKDLYRELLGGAPGSSEAAGSPEWGGRPPALGSLLDPLPTAASLGISDSIRECISSQSSDPKDASGDGELDLSGIDDLEIDRRDLSMPRCAKAKSQPHFPVLAQYILNESEARVKAELWMRENAEYLREQREKEARIAKEKELGIYKEHKPKKSCKRREPIQASTAREAIEKMLEQKKISSKINYSVLRGLSSAGGGSPHREDAQPEHSASARKLSRRRTPASRSGADPVTSVGKRLRPLVSTQPAKKVATGEALLPSSPTLGAEPARPQAVLVESGPVSYHADEEADEEEPDEEDGEPCVSALQMMGSNDYGCDGDEDDGY>sp|Q92994-9|TF3B_HUMAN Isoform 9 of Transcription factor IIIB 90 kDasubunit OS=Homo sapiens OX=9606 GN=BRF1MHDFRRTVKEVISVVKVCESTLRKRLTEFEDTPTSQLTIDEFMKIDLEEECDPPSYTAGQRKLRMKQLEQVLSKKLEEVEGEISSYQDAIEIELENSRPKAKGGLASLAKDGSTEDTASSLCGEEDTEDEELEAAASHLNKDLYRELLGGAPGSSEAAGSPEWGGRPPALGSLLDPLPTAASLGISDSIRECISSQSSDPKDASGDGELDLSGIDDLEIDRYILNESEARVKAELWMRENAEYLREQREKEARIAKEKELGIYKEHKPKKSCKRREPIQASTAREAIEKMLEQKKISSKINYSVLRGLSSAGGGSPHREDAQPEHSASARKLSRRRTPASRSGADPVTSVGKRLRPLVSTQPAKKVATGEALLPSSPTLGAEPARPQAVLVESGPVSYHADEEADEEEPDEEDGEPCVSALQMMGSNDYGCDGDEDDGY>sp|Q6PJ69|TRI65_HUMAN Tripartite motif-containing protein 65 OS=Homosapiens OX=9606 GN=TRIM65 PE=1 SV=3MAAQLLEEKLTCAICLGLYQDPVTLPCGHNFCGACIRDWWDRCGKACPECREPFPDGAELRRNVALSGVLEVVRAGPARDPGPDPGPGPDPAARCPRHGRPLELFCRTEGRCVCSVCTVRECRLHERALLDAERLKREAQLRASLEVTQQQATQAEGQLLELRKQSSQIQNSACILASWVSGKFSSLLQALEIQHTTALRSIEVAKTQALAQARDEEQRLRVHLEAVARHGCRIRELLEQVDEQTFLQESQLLQPPGPLGPLTPLQWDEDQQLGDLKQLLSRLCGLLLEEGSHPGAPAKPVDLAPVEAPGPLAPVPSTVCPLRRKLWQNYRNLTFDPVSANRHFYLSRQDQQVKHCRQSRGPGGPGSFELWQVQCAQSFQAGHHYWEVRASDHSVTLGVSYPQLPRCRLGPHTDNIGRGPCSWGLCVQEDSLQAWHNGEAQRLPGVSGRLLGMDLDLASGCLTFYSLEPQTQPLYTFHALFNQPLTPVFWLLEGRTLTLCHQPGAVFPLGPQEEVLS>sp|O75764|TCEA3_HUMAN Transcription elongation factor A protein 3OS=Homo sapiens OX=9606 GN=TCEA3 PE=1 SV=2MGQEEELLRIAKKLEKMVARKNTEGALDLLKKLHSCQMSIQLLQTTRIGVAVNGVRKHCSDKEVVSLAKVLIKNWKRLLDSPGPPKGEKGEEREKAKKKEKGLECSDWKPEAGLSPPRKKREDPKTRRDSVDSKSSASSSPKRPSVERSNSSKSKAESPKTPSSPLTPTFASSMCLLAPCYLTGDSVRDKCVEMLSAALKADDDYKDYGVNCDKMASEIEDHIYQELKSTDMKYRNRVRSRISNLKDPRNPGLRRNVLSGAISAGLIAKMTAEEMASDELRELRNAMTQEAIREHQMAKTGGTTTDLFQCSKCKKKNCTYNQVQTRSADEPMTTFVLCNECGNRWKFC>sp|O75764-2|TCEA3_HUMAN Isoform 2 of Transcription elongation factor Aprotein 3 OS=Homo sapiens OX=9606 GN=TCEA3MGQEEELLRIAKKLEKMVARKNTEGALDLLKKLHSCQMSIQLLQTTRIGVAVNGVRKHCSDKEVVSLAKVLIKNWKRLLDSPGPPKGEKGEEREKAKKKEKGLECSDWKPEAGLSPPRKKREDPKTRRDSVDSKSSASSSPKRPSVERACSLMQ>sp|P13726|TF_HUMAN Tissue factor OS=Homo sapiens OX=9606 GN=F3 PE=1 SV=1METPAWPRVPRPETAVARTLLLGWVFAQVAGASGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREIFYIIGAVVFVVIILVIILAISLHKCRKAGVGQSWKENSPLNVS>sp|P13726-2|TF_HUMAN Isoform 2 of Tissue factor OS=Homo sapiens OX=9606GN=F3METPAWPRVPRPETAVARTLLLGWVFAQVAGASGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKYSTSLELWYLWSSSLSSSWLYLYTSVERQEWGRAGRRTPH>sp|Q99805|TM9S2_HUMAN Transmembrane 9 superfamily member 2 OS=Homosapiens OX=9606 GN=TM9SF2 PE=1 SV=1MSARLPVLSPPRWPRLLLLSLLLLGAVPGPRRSGAFYLPGLAPVNFCDEEKKSDECKAEIELFVNRLDSVESVLPYEYTAFDFCQASEGKRPSENLGQVLFGERIEPSPYKFTFNKKETCKLVCTKTYHTEKAEDKQKLEFLKKSMLLNYQHHWIVDNMPVTWCYDVEDGQRFCNPGFPIGCYITDKGHAKDACVISSDFHERDTFYIFNHVDIKIYYHVVETGSMGARLVAAKLEPKSFKHTHIDKPDCSGPPMDISNKASGEIKIAYTYSVSFEEDDKIRWASRWDYILESMPHTHIQWFSIMNSLVIVLFLSGMVAMIMLRTLHKDIARYNQMDSTEDAQEEFGWKLVHGDIFRPPRKGMLLSVFLGSGTQILIMTFVTLFFACLGFLSPANRGALMTCAVVLWVLLGTPAGYVAARFYKSFGGEKWKTNVLLTSFLCPGIVFADFFIMNLILWGEGSSAAIPFGTLVAILALWFCISVPLTFIGAYFGFKKNAIEHPVRTNQIPRQIPEQSFYTKPLPGIIMGGILPFGCIFIQLFFILNSIWSHQMYYMFGFLFLVFIILVITCSEATILLCYFHLCAEDYHWQWRSFLTSGFTAVYFLIYAVHYFFSKLQITGTASTILYFGYTMIMVLIFFLFTGTIGFFACFWFVTKIYSVVKVD>sp|Q9UKU6|TRHDE_HUMAN Thyrotropin-releasing hormone-degrading ectoenzymeOS=Homo sapiens OX=9606 GN=TRHDE PE=2 SV=1MGEDDAALRAGSRGLSDPWADSVGVRPRTTERHIAVHKRLVLAFAVSLVALLAVTMLAVLLSLRFDECGASATPGADGGPSGFPERGGNGSLPGSARRNHHAGGDSWQPEAGGVASPGTTSAQPPSEEEREPWEPWTQLRLSGHLKPLHYNLMLTAFMENFTFSGEVNVEIACRNATRYVVLHASRVAVEKVQLAEDRAFGAVPVAGFFLYPQTQVLVVVLNRTLDAQRNYNLKIIYNALIENELLGFFRSSYVLHGERRFLGVTQFSPTHARKAFPCFDEPIYKATFKISIKHQATYLSLSNMPVETSVFEEDGWVTDHFSQTPLMSTYYLAWAICNFTYRETTTKSGVVVRLYARPDAIRRGSGDYALHITKRLIEFYEDYFKVPYSLPKLDLLAVPKHPYAAMENWGLSIFVEQRILLDPSVSSISYLLDVTMVIVHEICHQWFGDLVTPVWWEDVWLKEGFAHYFEFVGTDYLYPGWNMEKQRFLTDVLHEVMLLDGLASSHPVSQEVLQATDIDRVFDWIAYKKGAALIRMLANFMGHSVFQRGLQDYLTIHKYGNAARNDLWNTLSEALKRNGKYVNIQEVMDQWTLQMGYPVITILGNTTAENRIIITQQHFIYDISAKTKALKLQNNSYLWQIPLTIVVGNRSHVSSEAIIWVSNKSEHHRITYLDKGSWLLGNINQTGYFRVNYDLRNWRLLIDQLIRNHEVLSVSNRAGLIDDAFSLARAGYLPQNIPLEIIRYLSEEKDFLPWHAASRALYPLDKLLDRMENYNIFNEYILKQVATTYIKLGWPKNNFNGSLVQASYQHEELRREVIMLACSFGNKHCHQQASTLISDWISSNRNRIPLNVRDIVYCTGVSLLDEDVWEFIWMKFHSTTAVSEKKILLEALTCSDDRNLLNRLLNLSLNSEVVLDQDAIDVIIHVARNPHGRDLAWKFFRDKWKILNTRYGEALFMNSKLISGVTEFLNTEGELKELKNFMKNYDGVAAASFSRAVETVEANVRWKMLYQDELFQWLGKALRH>sp|Q13641|TPBG_HUMAN Trophoblast glycoprotein OS=Homo sapiens OX=9606GN=TPBG PE=1 SV=1MPGGCSRGPAAGDGRLRLARLALVLLGWVSSSSPTSSASSFSSSAPFLASAVSAQPPLPDQCPALCECSEAARTVKCVNRNLTEVPTDLPAYVRNLFLTGNQLAVLPAGAFARRPPLAELAALNLSGSRLDEVRAGAFEHLPSLRQLDLSHNPLADLSPFAFSGSNASVSAPSPLVELILNHIVPPEDERQNRSFEGMVVAALLAGRALQGLRRLELASNHFLYLPRDVLAQLPSLRHLDLSNNSLVSLTYVSFRNLTHLESLHLEDNALKVLHNGTLAELQGLPHIRVFLDNNPWVCDCHMADMVTWLKETEVVQGKDRLTCAYPEKMRNRVLLELNSADLDCDPILPPSLQTSYVFLGIVLALIGAIFLLVLYLNRKGIKKWMHNIRDACRDHMEGYHYRYEINADPRLTNLSSNSDV>sp|A6NLI5|TR64C_HUMAN Tripartite motif-containing protein 64C OS=Homosapiens OX=9606 GN=TRIM64C PE=3 SV=4MDSDTLRVFQNELICCICVNYFIDPVTTDCVHSFCRPCLCLCSEEGRAPMRCPLCRKISEKPNFNTNVALKKLASLARQTRPQNINSSDNICVLHEETKELFCEADKRLLCGPCSESPEHMAHSHSPIGWAAEECRVQKLIKEMDYLWKINQETQNNLNQETSKFCSLVDYVSLRKVIITIQYQKMHIFLDEEEQRHLQALEREAKELFQQLQDSQVRMTQHLEGMKDMYRELWETYHMPDVELLQDVGNISARTDLAQMPKPQPVNPELTSWCITGVLDMLNNFRVDNALSTEMTPCYISLSEDVRRVIFGDDHRSAPMDPQGVESFAVWCAQAFTSGKHYWEVDVTHSSNWILGVCRDSRTADTNIVIDSDKTFFSISSKTSNHYSLSTNSPPLIQYVQRPLGWVGVFLDYDNGSVSFFDVSKGSLIYGFPPSSFSSPLRPFFCFGCT>sp|Q8TDI8|TMC1_HUMAN Transmembrane channel-like protein 1 OS=Homosapiens OX=9606 GN=TMC1 PE=1 SV=2MSPKKVQIKVEEKEDETEESSSEEEEEVEDKLPRRESLRPKRKRTRDVINEDDPEPEPEDEETRKAREKERRRRLKRGAEEEEIDEEELERLKAELDEKRQIIATVKCKPWKMEKKIEVLKEAKKFVSENEGALGKGKGKRWFAFKMMMAKKWAKFLRDFENFKAACVPWENKIKAIESQFGSSVASYFLFLRWMYGVNMVLFILTFSLIMLPEYLWGLPYGSLPRKTVPRAEEASAANFGVLYDFNGLAQYSVLFYGYYDNKRTIGWMNFRLPLSYFLVGIMCIGYSFLVVLKAMTKNIGDDGGGDDNTFNFSWKVFTSWDYLIGNPETADNKFNSITMNFKEAITEEKAAQVEENVHLIRFLRFLANFFVFLTLGGSGYLIFWAVKRSQEFAQQDPDTLGWWEKNEMNMVMSLLGMFCPTLFDLFAELEDYHPLIALKWLLGRIFALLLGNLYVFILALMDEINNKIEEEKLVKANITLWEANMIKAYNASFSENSTGPPFFVHPADVPRGPCWETMVGQEFVRLTVSDVLTTYVTILIGDFLRACFVRFCNYCWCWDLEYGYPSYTEFDISGNVLALIFNQGMIWMGSFFAPSLPGINILRLHTSMYFQCWAVMCCNVPEARVFKASRSNNFYLGMLLLILFLSTMPVLYMIVSLPPSFDCGPFSGKNRMFEVIGETLEHDFPSWMAKILRQLSNPGLVIAVILVMVLAIYYLNATAKGQKAANLDLKKKMKMQALENKMRNKKMAAARAAAAAGRQ>sp|Q6P589|TP8L2_HUMAN Tumor necrosis factor alpha-induced protein 8-likeprotein 2 OS=Homo sapiens OX=9606 GN=TNFAIP8L2 PE=1 SV=1MESFSSKSLALQAEKKLLSKMAGRSVAHLFIDETSSEVLDELYRVSKEYTHSRPQAQRVIKDLIKVAIKVAVLHRNGSFGPSELALATRFRQKLRQGAMTALSFGEVDFTFEAAVLAGLLTECRDVLLELVEHHLTPKSHGRIRHVFDHFSDPGLLTALYGPDFTQHLGKICDGLRKLLDEGKL>sp|Q9BUB7|TMM70_HUMAN Transmembrane protein 70, mitochondrial OS=Homosapiens OX=9606 GN=TMEM70 PE=1 SV=2MLFLALGSPWAVELPLCGRRTALCAAAALRGPRASVSRASSSSGPSGPVAGWSTGPSGAARLLRRPGRAQIPVYWEGYVRFLNTPSDKSEDGRLIYTGNMARAVFGVKCFSYSTSLIGLTFLPYIFTQNNAISESVPLPIQIIFYGIMGSFTVITPVLLHFITKGYVIRLYHEATTDTYKAITYNAMLAETSTVFHQNDVKIPDAKHVFTTFYAKTKSLLVNPVLFPNREDYIHLMGYDKEEFILYMEETSEEKRHKDDK>sp|Q9BUB7-2|TMM70_HUMAN Isoform 2 of Transmembrane protein 70,mitochondrial OS=Homo sapiens OX=9606 GN=TMEM70MARAVFGVKCFSYSTSLIGLTFLPYIFTQNNAISESVPLPIQIIFYGIMGSFTVITPVLLHFITKGYVIRLYHEATTDTYKAITYNAMLAETSTVFHQNDVKIPDAKHVFTTFYAKTKSLLVNPVLFPNREDYIHLMGYDKEEFILYMEETSEEKRHKDDK>sp|Q9BUB7-3|TMM70_HUMAN Isoform 3 of Transmembrane protein 70,mitochondrial OS=Homo sapiens OX=9606 GN=TMEM70MLFLALGSPWAVELPLCGRRTALCAAAALRGPRASVSRASSSSGPSGPVAGWSTGPSGAARLLRRPGRAQIPVYWEGYVRFLNTPSDKSEDGRLIYTGNMARAVFGK>sp|A5PLN9|TPC13_HUMAN Trafficking protein particle complex subunit 13OS=Homo sapiens OX=9606 GN=TRAPPC13 PE=1 SV=2MEVNPPKQEHLLALKVMRLTKPTLFTNIPVTCEEKDLPGDLFNQLMRDDPSTVNGAEVLMLGEMLTLPQNFGNIFLGETFSSYISVHNDSNQVVKDILVKADLQTSSQRLNLSASNAAVAELKPDCCIDDVIHHEVKEIGTHILVCAVSYTTQAGEKMYFRKFFKFQVLKPLDVKTKFYNAESDLSSVTDEVFLEAQIQNMTTSPMFMEKVSLEPSIMYNVTELNSVSQAGECVSTFGSRAYLQPMDTRQYLYCLKPKNEFAEKAGIIKGVTVIGKLDIVWKTNLGERGRLQTSQLQRMAPGYGDVRLSLEAIPDTVNLEEPFHITCKITNCSERTMDLVLEMCNTNSIHWCGISGRQLGKLHPSSSLCLALTLLSSVQGLQSISGLRLTDTFLKRTYEYDDIAQVCVVSSAIKVES>sp|A5PLN9-2|TPC13_HUMAN Isoform 2 of Trafficking protein particlecomplex subunit 13 OS=Homo sapiens OX=9606 GN=TRAPPC13MEVNPPKQEHLLALKVMRLTKPTLFTNIPVTCEEKDLPGDLFNQLMRDDPSTVNGAEVLMLGEMLTLPQNFGNIFLGETFSSYISVHNDSNQVVKDILVKADLQTSSQRLNLSASNAAVAELKPDCCIDDVIHHEVKEIGTHILVCAVSYTTQAGEKMYFRKFFKFQVLKPLDVKTKFYNAETDEVFLEAQIQNMTTSPMFMEKVSLEPSIMYNVTELNSVSQAGECVSTFGSRAYLQPMDTRQYLYCLKPKNEFAEKAGIIKGVTVIGKLDIVWKTNLGERGRLQTSQLQRMAPGYGDVRLSLEAIPDTVNLEEPFHITCKITNCSERTMDLVLEMCNTNSIHWCGISGRQLGKLHPSSSLCLALTLLSSVQGLQSISGLRLTDTFLKRTYEYDDIAQVCVVSSAIKVES>sp|A5PLN9-4|TPC13_HUMAN Isoform 3 of Trafficking protein particlecomplex subunit 13 OS=Homo sapiens OX=9606 GN=TRAPPC13MEVNPPKQEHLLALKVMRLTKPTLFTNIPVTCEEKDLPGDLFNQLMRDDPSTVNGAEVLMLGEMLTLPQNFGNIFLGETFSSYISVHNDSNQVVKDILVKADLQTSSQRLNLSASNAAVAELKPDCCIDDVIHHEVKEIGTHILVCAVSYTTQAGEKMYFRKFFKFQVLKPLDVKTKFYNAETDEVFLEAQIQNMTTSPMFMEKVSLEPSIMYNVTELNSVSQAGECVSTFGSRAYLQPMDTRQYLYCLKPKNEFAEKAGIIKGVTVIGKLDIVWKTNLGERGRLQTSQLQRMAPGYGDVRLSLEAIPDTVNLEEPFHITCKITNCSSERTMDLVLEMCNTNSIHWCGISGRQLGKLHPSSSLCLALTLLSSVQGLQSISGLRLTDTFLKRTYEYDDIAQVCVVSSAIKVES>sp|A5PLN9-5|TPC13_HUMAN Isoform 4 of Trafficking protein particlecomplex subunit 13 OS=Homo sapiens OX=9606 GN=TRAPPC13MEVNPPKQEHLLALKVMRLTKPTLFTNIPVTCEEKDLPGDLFNQLMRDDPSTVNGAEVLMLGEMLTLPQNFGNIFLGETFSSYISVHNDSNQVVKDILVKADLQTSSQRLNLSASNAAVAELKPDCCIDDVIHHEVKEIGTHILVCAVSYTTQAGEKMYFRKFFKFQVLKPLDVKTKFYNAESDLSSVTDEVFLEAQIQNMTTSPMFMEKVSLEPSIMYNVTELNSVSQAGECVSTFGSRAYLQPMDTRQYLYCLKPKNEFAEKAGIIKGVTVIGKLDIVWKTNLGERGRLQTSQLQRMAPGYGDVRLSLEAIPDTVNLEEPFHITCKITNCSSERTMDLVLEMCNTNSIHWCGISGRQLGKLHPSSSLCLALTLLSSVQGLQSISGLRLTDTFLKRTYEYDDIAQVCVVSSAIKVES>sp|A5PLN9-7|TPC13_HUMAN Isoform 5 of Trafficking protein particlecomplex subunit 13 OS=Homo sapiens OX=9606 GN=TRAPPC13MEVNPPKQEHLLALKVMRLTKPTLFTNIPVTCEEKDLPGDLFNQLMRDDPSTVNGAEVLMLGEMLTLPQNFGNIFLGETFSSYISVHNDSNQVVKDILVKADLQTSSQRLNLSASNAAVAELKPDCCIDDVIHHEVKEIGTHILVCAVSYTTQAGEKMYFRKFFKFQVLKPLDVKTKFYNAETDEVFLEAQIQNMTTSPMFMEKVSLEPSIMYNVTELNSVSQAGECVSTFGSRAYLQPMDTRQYLYCLKPKNEFAEKAGIIKGVTVIGKLDIVWKTNLGERGRLQTSQLQRMVSLEKTSLGFWCVKDR>sp|Q8WZ42|TITIN_HUMAN Titin OS=Homo sapiens OX=9606 GN=TTN PE=1 SV=4MTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEIKKKVTEKKVVIPKKEEAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-2|TITIN_HUMAN Isoform 2 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEIKKKVTEKKVVIPKKEEAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-3|TITIN_HUMAN Isoform 3 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-4|TITIN_HUMAN Isoform 4 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEIKKKVTEKKVVIPKKEEAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVFEEPEESPSAPPKKPEVPPVRVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-5|TITIN_HUMAN Isoform 5 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPREVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-6|TITIN_HUMAN Isoform 6 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKELFSEGESEHSERDTRDAFSDSEDIDHKSMAAKRYASRISSTSSWPEYFKPSFTQKLTFKYVLEGEPVVFTCRLIACPTPEMTWFHNNRPIPTGLRRIIKAESDLHHHSSSLEIKRVQDRDSGSYRLLAINSEGSAESTASLLVIQKGQDEKYLEFLKRAERTHENVEALVERGEDRIKVDLRFTGSPFNKKQDVEQKGMMRTIHFKTMSSAKKTDYMYDEEYLESKSDIRGWLNVGESFLDKETKVKLQRLREARKTLMEKKKLSLLDTSSEISSRTLRSEASDKDILFSREDMKIRSMSDLAESYKVDHSAESIVQNPHALSNQMDQNIESEELPTSFQTIVDEEIFQTEIRMSQEALVKESLPKDHLYGEILVNENTQARGQLEEIMANTTIGESSTYITNVCEKEEVYETPENVSQAITPHASESFGTLVNVEESEEIASERIKKDDLRELQLSASTRIDEFKTEQKEENMRFFENSFRKRPQRCPPSFLQEIESQEVYEGDSCNFVCHFQGYPQPIVTWYNNDMPIPRNQNFIIHSLENYSILTLSSVHHQNEGSITCVLFNQYGTVKTTSMLKVKAKQKHDVKAHKVPVFHDYLDEEEELALVFDQAKGAHPSMSQEGQTNLHLLKTNPPVPPSGDTELLSFPVEIQVTAATPIPEQDKESKEVFQTEELEPKAMPQDQVTQSPKHRFVFLSDITNEPPKMLQEMPKHARCREGDSIILECLISGEPQPVVTWFQNGVLLKQNQKFQFEEVNCSHQLYIKDVNSQDSGKYKCVAENNSGAVESVSDLTVEPVTYRENSQFENIGEIYGKYSRDQQLQDQGESVRAHFYDYPAGPFTPWTNVKEYSVRDYFQSLETIEQIDQKEQVRCIPSREKIPRFVHGASRTIKISKPIRAEFIQCQAEGKERHVSEKSKLHQAEGTVYPFVDDFSDVTIKKEIRNNFGKLGRSEKENVQECAQSDYLPNIHSERISDSYNTKDSSAIVYEESLGEEIHYPGKKVKHRIIEFEKLHVEKGVLEKRPTRTSIVNPPQKKIDDKAFSLKQRESRSSNLNANMYQAEKMSPNTESDSSNIAINLKLLSSQTHKEFDAQEREQQEKISLIDKPAISKRAEHESPITFDLKQFHTQIKHTDVKFQELDSGQPEEAYFKIQHPADTENIVFDLKQMYSHIGDPALEFQGQETREQQEIHYKEKIPSPETLQPDTHNISKSVQNNVFASQEISSSQELSNRTMVEKSSIDENSISLEKEVRHVQEQNLDILKTDLSLKSFSEEIYSESCALLPTSSADIEETDLSEKSCPLENGGRSSISHLKKAASEEKPLGVGEMEEECTLEPELAAFPKQDGGTQEYTDATLEDHRGDVQEADTLHRQLSLSQCFPLLMTEEQQNPGEQISTNIHASGEEKCYEEVQVQNEASFSTLEGEMIETSFSQNIPKLDEAHTTEAAESETSLTQYLLAAGKREVPETKDTRDQAKLVQSESITSMEVEEVTFNTVYEYYNQKQESLGRPLSPESDISIGVGSTTSEEISELDQFYTPPSSVEYFESPKSPDLYFNPSDITKQSSIHSGGETVERYSTPLGEVAERYSTPSEGEVGERYSTPPGETLERYSTPPGETLERYSTPPGETLERYSTPPGETLERYSTPPGETLERYSTPPGEALERYSIPTGGPNPTGTFKTYPSKIEREDGTPNEHFYTPTEERGSAYEIWRSDSFGTPNEAIEPKDNEMPPSFIEPLTKRKVYENTTLGFIVEVEGLPVPGVKWYRNKSLLEPDERIKMERVGNVCSLEISNIQKGEGGEYMCHAVNIIGEAKSFANVDIMPQEERVVALPPPVTHQHVMEFDLEHTTSSRTPSPQEIVLEVELSEKDVKEFEKQVKIVTVPEFTPDHKSMIVSLDVLPFNFVDPNMDSREGEDKELKIDLEVFEMPPRFIMPICDFKIPENSDAVFKCSVIGIPTPEVKWYKEYMCIEPDNIKYVISEEKGSHTLKIRNVCLSDSATYRCRAVNCVGEAICRGFLTMGDSEIFAVIAKKSKVTLSSLMEELVLKSNYTDSFFEFQVVEGPPRFIKGISDCYAPIGTAAYFQCLVRGSPRPTVYWYKDGKLVQGRRFTVEESGTGFHNLFITSLVKSDEGEYRCVATNKSGMAESFAALTLT>sp|Q8WZ42-7|TITIN_HUMAN Isoform 7 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEVQALDRQSSGKDVRESTKSQAVADSSFTKEESKISQKEIKSFQGSSYEYEVQVFESVSQSSIHTAASVQDTQLCHTASLSQIAESTELSKECAKESTGEAPKIFLHLQDVTVKCGDTAQFLCVLKDDSFIDVTWTHEGAKIEESERLKQSQNGNIQFLTICNVQLVDQGLYSCIVHNDCGERTTSAVLSVEGAPESILHERIEQEIEMEMKAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEIKKKVTEKKVVIPKKEEAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-8|TITIN_HUMAN Isoform 8 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEGFSKFEENTSNSQWHVSLSVSFKKEPLGQKPSFIQPLSSLRVHNGETVRFHARVSGIPKPEIQWFHNQQLILPTKDVVFHFEESTGMALMLIVDAYSEHAGQYSCKAANSAGEATCAATLTVTPKAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEIKKKVTEKKVVIPKKEEAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-9|TITIN_HUMAN Isoform 9 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEVQALDRQSSGKDVRESAKSQAVADSSFTKEESKISQKEIKSFQGSSYEYEVQVFESVSQSSIHTAASVQDTQLCHTASLSQIAESTELSKECAKESTGEAPKIFLHLQDVTVKCGDTAQFLCVLKDDSFIDVTWTHEGAKIEESERLKQSQNGNIQFLTICNVQLVDQGLYSCIVHNDCGERTTSAVLSVEGAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-10|TITIN_HUMAN Isoform 10 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEGFSKFEENTSNSQWHVSLSVSFKKEPLGQKPSFIQPLSSLRVHNGETVRFHARVSGIPKPEIQWFHNQQLILPTKDVVFHFEESTGMALMLIVDAYSEHAGQYSCKAANSAGEATCAATLTVTPKAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-11|TITIN_HUMAN Isoform 11 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEIKKKVTEKKVVIPKKEEAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-12|TITIN_HUMAN Isoform 12 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEGFSKFEENTSNSQWHVSLSVSFKKEPLGQKPSFIQPLSSLRVHNGETVRFHARVSGIPKPEIQWFHNQQLILPTKDVVFHFEESTGMALMLIVDAYSEHAGQYSCKAANSAGEATCAATLTVTPKVQALDRQSSGKDVRESAKSQAVADSSFTKEESKISQKEIKSFQGSSYEYEVQVFESVSQSSIHTAASVQDTQLCHTASLSQIAESTELSKECAKESTGEAPKIFLHLQDVTVKCGDTAQFLCVLKDDSFIDVTWTHEGAKIEESERLKQSQNGNIQFLTICNVQLVDQGLYSCIVHNDCGERTTSAVLSVEGAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEVPKKPVPEKKVPVPAPKKVEPPPPPKVPEIKKKVTEKKVVIPKKEEAPPAKVSVVPKKPEPEKKVPPPGLKKAVAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKAPEVPKKIVPEEKVREAVLKKPEVPPAKVPGMPKKSVQEEKSPIVISEDTEMYIYEASEEAVLEEKVLVTQPQKTKPKLAKVPEPPKKVVPEDKIYVTIPKKRETPATKEPDTTRGIFPEVEPPEAIPEIPEHPPTEEFEVFKEVIPEGETPIVKRRKTPSPTVPESPREIVPVKETPMAAPLEIEIPPTKAPEAMKEVVPEMKIFEDVPEEPETPRMKTPEAPQEIIPAKTVPSKKREPPSVKVPEALQEIVPEKKTLVVPLRKPEVLPDEVPEALREVVPEKKVHPPQRAEVVPVKVHEAPKEIIPEKKVSVVPPKKPEVPPVKVPEASKEVIREEKVPLAPPKEPEVPPVKVPEPPKEVVPEKKAPVAPPKEPEVPPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKLPEAIPPKPESPPPEVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVLEKKASVAVPKKPEAPRAKVPEAAQEVVPEKKIPKAPIKKPEAPAVTVPEVPQEATEKEIPVAPPKKPEAPIVPVPEAQEVVPEKKVPKAPPTKPEAPPATVPEVPQEIVPEKKTLVLPKKPEVPPVTVPEAPKEVVLEKKVPSAPPKKPEVPPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVLEKKASVAVPKKPEAPRAKVPEAAQEVVPEKKIPKAPIKKPEAPAVTVPEVPQEAAEKEIPVAPPKKPEAPIVPVPEAQEVVPEKKVPKAPPTKPEAPPATVPEVPQEIVPEKKTLVLPKKPEVPPVTVPEAPKEVVLEKKVPSTPPKKPEVPPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVLEKKVSVAVPKKPEAPRAKVPEAAQEVVPEKKIPKAPIKKPEAPAVTVPEVPQEAAEKEIPVAPPKKPEAPIVPVPEAQEVVPEKKVPKAPPTKPEAPPATVPEVPQEIVPEKKTLVLPKKPEVPPVTVPEAPKEVVLEKKVPLAPPKKPEVPPVKVPEAPKEVVPEKKVPVTPPKKPEVPPVKVPEAPIEVVPEKKMPLAPPKKPEVPPVKVPEAPKEVVPEKKVPSAPPKKPEVPPVKVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEMPKKVVPVKKVPTVKKPETPAAKVPEVPKKLVPVKKEPVPVTKKPEVLPEKVPKVPEKIIPEKEVSVPIPAEPEVPPAEVEETPEEIIYEEKASITIGRKETPPVEEREIEKYIKPEEPEPEPQPEEIPVKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q8WZ42-13|TITIN_HUMAN Isoform 13 of Titin OS=Homo sapiens OX=9606GN=TTNMTTQAPTFTQPLQSVVVLEGSTATFEAHISGFPVPEVSWFRDGQVISTSTLPGVQISFSDGRAKLTIPAVTKANSGRYSLKATNGSGQATSTAELLVKAETAPPNFVQRLQSMTVRQGSQVRLQVRVTGIPTPVVKFYRDGAEIQSSLDFQISQEGDLYSLLIAEAYPEDSGTYSVNATNSVGRATSTAELLVQGEEEVPAKKTKTIVSTAQISESRQTRIEKKIEAHFDARSIATVEMVIDGAAGQQLPHKTPPRIPPKPKSRSPTPPSIAAKAQLARQQSPSPIRHSPSPVRHVRAPTPSPVRSVSPAARISTSPIRSVRSPLLMRKTQASTVATGPEVPPPWKQEGYVASSSEAEMRETTLTTSTQIRTEERWEGRYGVQEQVTISGAAGAAASVSASASYAAEAVATGAKEVKQDADKSAAVATVVAAVDMARVREPVISAVEQTAQRTTTTAVHIQPAQEQVRKEAEKTAVTKVVVAADKAKEQELKSRTKEVITTKQEQMHVTHEQIRKETEKTFVPKVVISAAKAKEQETRISEEITKKQKQVTQEAIRQETEITAASMVVVATAKSTKLETVPGAQEETTTQQDQMHLSYEKIMKETRKTVVPKVIVATPKVKEQDLVSRGREGITTKREQVQITQEKMRKEAEKTALSTIAVATAKAKEQETILRTRETMATRQEQIQVTHGKVDVGKKAEAVATVVAAVDQARVREPREPGHLEESYAQQTTLEYGYKERISAAKVAEPPQRPASEPHVVPKAVKPRVIQAPSETHIKTTDQKGMHISSQIKKTTDLTTERLVHVDKRPRTASPHFTVSKISVPKTEHGYEASIAGSAIATLQKELSATSSAQKITKSVKAPTVKPSETRVRAEPTPLPQFPFADTPDTYKSEAGVEVKKEVGVSITGTTVREERFEVLHGREAKVTETARVPAPVEIPVTPPTLVSGLKNVTVIEGESVTLECHISGYPSPTVTWYREDYQIESSIDFQITFQSGIARLMIREAFAEDSGRFTCSAVNEAGTVSTSCYLAVQVSEEFEKETTAVTEKFTTEEKRFVESRDVVMTDTSLTEEQAGPGEPAAPYFITKPVVQKLVEGGSVVFGCQVGGNPKPHVYWKKSGVPLTTGYRYKVSYNKQTGECKLVISMTFADDAGEYTIVVRNKHGETSASASLLEEADYELLMKSQQEMLYQTQVTAFVQEPKVGETAPGFVYSEYEKEYEKEQALIRKKMAKDTVVVRTYVEDQEFHISSFEERLIKEIEYRIIKTTLEELLEEDGEEKMAVDISESEAVESGFDSRIKNYRILEGMGVTFHCKMSGYPLPKIAWYKDGKRIKHGERYQMDFLQDGRASLRIPVVLPEDEGIYTAFASNIKGNAICSGKLYVEPAAPLGAPTYIPTLEPVSRIRSLSPRSVSRSPIRMSPARMSPARMSPARMSPARMSPGRRLEETDESQLERLYKPVFVLKPVSFKCLEGQTARFDLKVVGRPMPETFWFHDGQQIVNDYTHKVVIKEDGTQSLIIVPATPSDSGEWTVVAQNRAGRSSISVILTVEAVEHQVKPMFVEKLKNVNIKEGSRLEMKVRATGNPNPDIVWLKNSDIIVPHKYPKIRIEGTKGEAALKIDSTVSQDSAWYTATAINKAGRDTTRCKVNVEVEFAEPEPERKLIIPRGTYRAKEIAAPELEPLHLRYGQEQWEEGDLYDKEKQQKPFFKKKLTSLRLKRFGPAHFECRLTPIGDPTMVVEWLHDGKPLEAANRLRMINEFGYCSLDYGVAYSRDSGIITCRATNKYGTDHTSATLIVKDEKSLVEESQLPEGRKGLQRIEELERMAHEGALTGVTTDQKEKQKPDIVLYPEPVRVLEGETARFRCRVTGYPQPKVNWYLNGQLIRKSKRFRVRYDGIHYLDIVDCKSYDTGEVKVTAENPEGVIEHKVKLEIQQREDFRSVLRRAPEPRPEFHVHEPGKLQFEVQKVDRPVDTTETKEVVKLKRAERITHEKVPEESEELRSKFKRRTEEGYYEAITAVELKSRKKDESYEELLRKTKDELLHWTKELTEEEKKALAEEGKITIPTFKPDKIELSPSMEAPKIFERIQSQTVGQGSDAHFRVRVVGKPDPECEWYKNGVKIERSDRIYWYWPEDNVCELVIRDVTAEDSASIMVKAINIAGETSSHAFLLVQAKQLITFTQELQDVVAKEKDTMATFECETSEPFVKVKWYKDGMEVHEGDKYRMHSDRKVHFLSILTIDTSDAEDYSCVLVEDENVKTTAKLIVEGAVVEFVKELQDIEVPESYSGELECIVSPENIEGKWYHNDVELKSNGKYTITSRRGRQNLTVKDVTKEDQGEYSFVIDGKKTTCKLKMKPRPIAILQGLSDQKVCEGDIVQLEVKVSLESVEGVWMKDGQEVQPSDRVHIVIDKQSHMLLIEDMTKEDAGNYSFTIPALGLSTSGRVSVYSVDVITPLKDVNVIEGTKAVLECKVSVPDVTSVKWYLNDEQIKPDDRVQAIVKGTKQRLVINRTHASDEGPYKLIVGRVETNCNLSVEKIKIIRGLRDLTCTETQNVVFEVELSHSGIDVLWNFKDKEIKPSSKYKIEAHGKIYKLTVLNMMKDDEGKYTFYAGENMTSGKLTVAGGAISKPLTDQTVAESQEAVFECEVANPDSKGEWLRDGKHLPLTNNIRSESDGHKRRLIIAATKLDDIGEYTYKVATSKTSAKLKVEAVKIKKTLKNLTVTETQDAVFTVELTHPNVKGVQWIKNGVVLESNEKYAISVKGTIYSLRIKNCAIVDESVYGFRLGRLGASARLHVETVKIIKKPKDVTALENATVAFEVSVSHDTVPVKWFHKSVEIKPSDKHRLVSERKVHKLMLQNISPSDAGEYTAVVGQLECKAKLFVETLHITKTMKNIEVPETKTASFECEVSHFNVPSMWLKNGVEIEMSEKFKIVVQGKLHQLIIMNTSTEDSAEYTFVCGNDQVSATLTVTPIMITSMLKDINAEEKDTITFEVTVNYEGISYKWLKNGVEIKSTDKCQMRTKKLTHSLNIRNVHFGDAADYTFVAGKATSTATLYVEARHIEFRKHIKDIKVLEKKRAMFECEVSEPDITVQWMKDDQELQITDRIKIQKEKYVHRLLIPSTRMSDAGKYTVVAGGNVSTAKLFVEGRDVRIRSIKKEVQVIEKQRAVVEFEVNEDDVDAHWYKDGIEINFQVQERHKYVVERRIHRMFISETRQSDAGEYTFVAGRNRSSVTLYVNAPEPPQVLQELQPVTVQSGKPARFCAVISGRPQPKISWYKEEQLLSTGFKCKFLHDGQEYTLLLIEAFPEDAAVYTCEAKNDYGVATTSASLSVEVPEVVSPDQEMPVYPPAIITPLQDTVTSEGQPARFQCRVSGTDLKVSWYSKDKKIKPSRFFRMTQFEDTYQLEIAEAYPEDEGTYTFVASNAVGQVSSTANLSLEAPESILHERIEQEIEMEMKEFSSSFLSAEEEGLHSAELQLSKINETLELLSESPVYPTKFDSEKEGTGPIFIKEVSNADISMGDVATLSVTVIGIPKPKIQWFFNGVLLTPSADYKFVFDGDDHSLIILFTKLEDEGEYTCMASNDYGKTICSAYLKINSKGEGHKDTETESAVAKSLEKLGGPCPPHFLKELKPIRCAQGLPAIFEYTVVGEPAPTVTWFKENKQLCTSVYYTIIHNPNGSGTFIVNDPQREDSGLYICKAENMLGESTCAAELLVLLEDTDMTDTPCKAKSTPEAPEDFPQTPLKGPAVEALDSEQEIATFVKDTILKAALITEENQQLSYEHIAKANELSSQLPLGAQELQSILEQDKLTPESTREFLCINGSIHFQPLKEPSPNLQLQIVQSQKTFSKEGILMPEEPETQAVLSDTEKIFPSAMSIEQINSLTVEPLKTLLAEPEGNYPQSSIEPPMHSYLTSVAEEVLSPKEKTVSDTNREQRVTLQKQEAQSALILSQSLAEGHVESLQSPDVMISQVNYEPLVPSEHSCTEGGKILIESANPLENAGQDSAVRIEEGKSLRFPLALEEKQVLLKEEHSDNVVMPPDQIIESKREPVAIKKVQEVQGRDLLSKESLLSGIPEEQRLNLKIQICRALQAAVASEQPGLFSEWLRNIEKVEVEAVNITQEPRHIMCMYLVTSAKSVTEEVTIIIEDVDPQMANLKMELRDALCAIIYEEIDILTAEGPRIQQGAKTSLQEEMDSFSGSQKVEPITEPEVESKYLISTEEVSYFNVQSRVKYLDATPVTKGVASAVVSDEKQDESLKPSEEKEESSSESGTEEVATVKIQEAEGGLIKEDGPMIHTPLVDTVSEEGDIVHLTTSITNAKEVNWYFENKLVPSDEKFKCLQDQNTYTLVIDKVNTEDHQGEYVCEALNDSGKTATSAKLTVVKRAAPVIKRKIEPLEVALGHLAKFTCEIQSAPNVRFQWFKAGREIYESDKCSIRSSKYISSLEILRTQVVDCGEYTCKASNEYGSVSCTATLTVTEAYPPTFLSRPKSLTTFVGKAAKFICTVTGTPVIETIWQKDGAALSPSPNWRISDAENKHILELSNLTIQDRGVYSCKASNKFGADICQAELIIIDKPHFIKELEPVQSAINKKVHLECQVDEDRKVTVTWSKDGQKLPPGKDYKICFEDKIATLEIPLAKLKDSGTYVCTASNEAGSSSCSATVTVREPPSFVKKVDPSYLMLPGESARLHCKLKGSPVIQVTWFKNNKELSESNTVRMYFVNSEAILDITDVKVEDSGSYSCEAVNDVGSDSCSTEIVIKEPPSFIKTLEPADIVRGTNALLQCEVSGTGPFEISWFKDKKQIRSSKKYRLFSQKSLVCLEIFSFNSADVGEYECVVANEVGKCGCMATHLLKEPPTFVKKVDDLIALGGQTVTLQAAVRGSEPISVTWMKGQEVIREDGKIKMSFSNGVAVLIIPDVQISFGGKYTCLAENEAGSQTSVGELIVKEPAKIIERAELIQVTAGDPATLEYTVAGTPELKPKWYKDGRPLVASKKYRISFKNNVAQLKFYSAELHDSGQYTFEISNEVGSSSCETTFTVLDRDIAPFFTKPLRNVDSVVNGTCRLDCKIAGSLPMRVSWFKDGKEIAASDRYRIAFVEGTASLEIIRVDMNDAGNFTCRATNSVGSKDSSGALIVQEPPSFVTKPGSKDVLPGSAVCLKSTFQGSTPLTIRWFKGNKELVSGGSCYITKEALESSLELYLVKTSDSGTYTCKVSNVAGGVECSANLFVKEPATFVEKLEPSQLLKKGDATQLACKVTGTPPIKITWFANDREIKESSKHRMSFVESTAVLRLTDVGIEDSGEYMCEAQNEAGSDHCSSIVIVKESPYFTKEFKPIEVLKEYDVMLLAEVAGTPPFEITWFKDNTILRSGRKYKTFIQDHLVSLQILKFVAADAGEYQCRVTNEVGSSICSARVTLREPPSFIKKIESTSSLRGGTAAFQATLKGSLPITVTWLKDSDEITEDDNIRMTFENNVASLYLSGIEVKHDGKYVCQAKNDAGIQRCSALLSVKEPATITEEAVSIDVTQGDPATLQVKFSGTKEITAKWFKDGQELTLGSKYKISVTDTVSILKIISTEKKDSGEYTFEVQNDVGRSSCKARINVLDLIIPPSFTKKLKKMDSIKGSFIDLECIVAGSHPISIQWFKDDQEISASEKYKFSFHDNTAFLEISQLEGTDSGTYTCSATNKAGHNQCSGHLTVKEPPYFVEKPQSQDVNPNTRVQLKALVGGTAPMTIKWFKDNKELHSGAARSVWKDDTSTSLELFAAKATDSGTYICQLSNDVGTATSKATLFVKEPPQFIKKPSPVLVLRNGQSTTFECQITGTPKIRVSWYLDGNEITAIQKHGISFIDGLATFQISGARVENSGTYVCEARNDAGTASCSIELKVKEPPTFIRELKPVEVVKYSDVELECEVTGTPPFEVTWLKNNREIRSSKKYTLTDRVSVFNLHITKCDPSDTGEYQCIVSNEGGSCSCSTRVALKEPPSFIKKIENTTTVLKSSATFQSTVAGSPPISITWLKDDQILDEDDNVYISFVDSVATLQIRSVDNGHSGRYTCQAKNESGVERCYAFLLVQEPAQIVEKAKSVDVTEKDPMTLECVVAGTPELKVKWLKDGKQIVPSRYFSMSFENNVASFRIQSVMKQDSGQYTFKVENDFGSSSCDAYLRVLDQNIPPSFTKKLTKMDKVLGSSIHMECKVSGSLPISAQWFKDGKEISTSAKYRLVCHERSVSLEVNNLELEDTANYTCKVSNVAGDDACSGILTVKEPPSFLVKPGRQQAIPDSTVEFKAILKGTPPFKIKWFKDDVELVSGPKCFIGLEGSTSFLNLYSVDASKTGQYTCHVTNDVGSDSCTTMLLVTEPPKFVKKLEASKIVKAGDSSRLECKIAGSPEIRVVWFRNEHELPASDKYRMTFIDSVAVIQMNNLSTEDSGDFICEAQNPAGSTSCSTKVIVKEPPVFSSFPPIVETLKNAEVSLECELSGTPPFEVVWYKDKRQLRSSKKYKIASKNFHTSIHILNVDTSDIGEYHCKAQNEVGSDTCVCTVKLKEPPRFVSKLNSLTVVAGEPAELQASIEGAQPIFVQWLKEKEEVIRESENIRITFVENVATLQFAKAEPANAGKYICQIKNDGGMRENMATLMVLEPAVIVEKAGPMTVTVGETCTLECKVAGTPELSVEWYKDGKLLTSSQKHKFSFYNKISSLRILSVERQDAGTYTFQVQNNVGKSSCTAVVDVSDRAVPPSFTRRLKNTGGVLGASCILECKVAGSSPISVAWFHEKTKIVSGAKYQTTFSDNVCTLQLNSLDSSDMGNYTCVAANVAGSDECRAVLTVQEPPSFVKEPEPLEVLPGKNVTFTSVIRGTPPFKVNWFRGARELVKGDRCNIYFEDTVAELELFNIDISQSGEYTCVVSNNAGQASCTTRLFVKEPAAFLKRLSDHSVEPGKSIILESTYTGTLPISVTWKKDGFNITTSEKCNIVTTEKTCILEILNSTKRDAGQYSCEIENEAGRDVCGALVSTLEPPYFVTELEPLEAAVGDSVSLQCQVAGTPEITVSWYKGDTKLRPTPEYRTYFTNNVATLVFNKVNINDSGEYTCKAENSIGTASSKTVFRIQERQLPPSFARQLKDIEQTVGLPVTLTCRLNGSAPIQVCWYRDGVLLRDDENLQTSFVDNVATLKILQTDLSHSGQYSCSASNPLGTASSSARLTAREPKKSPFFDIKPVSIDVIAGESADFECHVTGAQPMRITWSKDNKEIRPGGNYTITCVGNTPHLRILKVGKGDSGQYTCQATNDVGKDMCSAQLSVKEPPKFVKKLEASKVAKQGESIQLECKISGSPEIKVSWFRNDSELHESWKYNMSFINSVALLTINEASAEDSGDYICEAHNGVGDASCSTALTVKAPPVFTQKPSPVGALKGSDVILQCEISGTPPFEVVWVKDRKQVRNSKKFKITSKHFDTSLHILNLEASDVGEYHCKATNEVGSDTCSCSVKFKEPPRFVKKLSDTSTLIGDAVELRAIVEGFQPISVVWLKDRGEVIRESENTRISFIDNIATLQLGSPEASNSGKYICQIKNDAGMRECSAVLTVLEPARIIEKPEPMTVTTGNPFALECVVTGTPELSAKWFKDGRELSADSKHHITFINKVASLKIPCAEMSDKGLYSFEVKNSVGKSNCTVSVHVSDRIVPPSFIRKLKDVNAILGASVVLECRVSGSAPISVGWFQDGNEIVSGPKCQSSFSENVCTLNLSLLEPSDTGIYTCVAANVAGSDECSAVLTVQEPPSFEQTPDSVEVLPGMSLTFTSVIRGTPPFKVKWFKGSRELVPGESCNISLEDFVTELELFEVQPLESGDYSCLVTNDAGSASCTTHLFVKEPATFVKRLADFSVETGSPIVLEATYTGTPPISVSWIKDEYLISQSERCSITMTEKSTILEILESTIEDYAQYSCLIENEAGQDICEALVSVLEPPYFIEPLEHVEAVIGEPATLQCKVDGTPEIRISWYKEHTKLRSAPAYKMQFKNNVASLVINKVDHSDVGEYSCKADNSVGAVASSAVLVIKARKLPPFFARKLKDVHETLGFPVAFECRINGSEPLQVSWYKDGVLLKDDANLQTSFVHNVATLQILQTDQSHIGQYNCSASNPLGTASSSAKLILSEHEVPPFFDLKPVSVDLALGESGTFKCHVTGTAPIKITWAKDNREIRPGGNYKMTLVENTATLTVLKVGKGDAGQYTCYASNIAGKDSCSAQLGVQEPPRFIKKLEPSRIVKQDEFTRYECKIGGSPEIKVLWYKDETEIQESSKFRMSFVDSVAVLEMHNLSVEDSGDYTCEAHNAAGSASSSTSLKVKEPPIFRKKPHPIETLKGADVHLECELQGTPPFHVSWYKDKRELRSGKKYKIMSENFLTSIHILNVDAADIGEYQCKATNDVGSDTCVGSIALKAPPRFVKKLSDISTVVGKEVQLQTTIEGAEPISVVWFKDKGEIVRESDNIWISYSENIATLQFSRVEPANAGKYTCQIKNDAGMQECFATLSVLEPATIVEKPESIKVTTGDTCTLECTVAGTPELSTKWFKDGKELTSDNKYKISFFNKVSGLKIINVAPSDSGVYSFEVQNPVGKDSCTASLQVSDRTVPPSFTRKLKETNGLSGSSVVMECKVYGSPPISVSWFHEGNEISSGRKYQTTLTDNTCALTVNMLEESDSGDYTCIATNMAGSDECSAPLTVREPPSFVQKPDPMDVLTGTNVTFTSIVKGTPPFSVSWFKGSSELVPGDRCNVSLEDSVAELELFDVDTSQSGEYTCIVSNEAGKASCTTHLYIKAPAKFVKRLNDYSIEKGKPLILEGTFTGTPPISVTWKKNGINVTPSQRCNITTTEKSAILEIPSSTVEDAGQYNCYIENASGKDSCSAQILILEPPYFVKQLEPVKVSVGDSASLQCQLAGTPEIGVSWYKGDTKLRPTTTYKMHFRNNVATLVFNQVDINDSGEYICKAENSVGEVSASTFLTVQEQKLPPSFSRQLRDVQETVGLPVVFDCAISGSEPISVSWYKDGKPLKDSPNVQTSFLDNTATLNIFKTDRSLAGQYSCTATNPIGSASSSARLILTEGKNPPFFDIRLAPVDAVVGESADFECHVTGTQPIKVSWAKDSREIRSGGKYQISYLENSAHLTVLKVDKGDSGQYTCYAVNEVGKDSCTAQLNIKERLIPPSFTKRLSETVEETEGNSFKLEGRVAGSQPITVAWYKNNIEIQPTSNCEITFKNNTLVLQVRKAGMNDAGLYTCKVSNDAGSALCTSSIVIKEPKKPPVFDQHLTPVTVSEGEYVQLSCHVQGSEPIRIQWLKAGREIKPSDRCSFSFASGTAVLELRDVAKADSGDYVCKASNVAGSDTTKSKVTIKDKPAVAPATKKAAVDGRLFFVSEPQSIRVVEKTTATFIAKVGGDPIPNVKWTKGKWRQLNQGGRVFIHQKGDEAKLEIRDTTKTDSGLYRCVAFNEHGEIESNVNLQVDERKKQEKIEGDLRAMLKKTPILKKGAGEEEEIDIMELLKNVDPKEYEKYARMYGITDFRGLLQAFELLKQSQEEETHRLEIEEIERSERDEKEFEELVSFIQQRLSQTEPVTLIKDIENQTVLKDNDAVFEIDIKINYPEIKLSWYKGTEKLEPSDKFEISIDGDRHTLRVKNCQLKDQGNYRLVCGPHIASAKLTVIEPAWERHLQDVTLKEGQTCTMTCQFSVPNVKSEWFRNGRILKPQGRHKTEVEHKVHKLTIADVRAEDQGQYTCKYEDLETSAELRIEAEPIQFTKRIQNIVVSEHQSATFECEVSFDDAIVTWYKGPTELTESQKYNFRNDGRCHYMTIHNVTPDDEGVYSVIARLEPRGEARSTAELYLTTKEIKLELKPPDIPDSRVPIPTMPIRAVPPEEIPPVVAPPIPLLLPTPEEKKPPPKRIEVTKKAVKKDAKKVVAKPKEMTPREEIVKKPPPPTTLIPAKAPEIIDVSSKAEEVKIMTITRKKEVQKEKEAVYEKKQAVHKEKRVFIESFEEPYDELEVEPYTEPFEQPYYEEPDEDYEEIKVEAKKEVHEEWEEDFEEGQEYYEREEGYDEGEEEWEEAYQEREVIQVQKEVYEESHERKVPAKVPEKKAPPPPKVIKKPVIEKIEKTSRRMEEEKVQVTKVPEVSKKIVPQKPSRTPVQEEVIEVKVPAVHTKKMVISEEKMFFASHTEEEVSVTVPEVQKEIVTEEKIHVAISKRVEPPPKVPELPEKPAPEEVAPVPIPKKVEPPAPKVPEVPKKPVPEEKKPVPVPKKEPAAPPKVPEVPKKPVPEEKIPVPVAKKKEAPPAKVPEVQKGVVTEEKITIVTQREESPPPAVPEIPKKKVPEERKPVPRKEEEVPPPPKVPALPKKPVPEEKVAVPVPVAKKAPPPRAEVSKKTVVEEKRFVAEEKLSFAVPQRVEVTRHEVSAEEEWSYSEEEEGVSISVYREEEREEEEEAEVTEYEVMEEPEEYVVEEKLHIISKRVEAEPAEVTERQEKKIVLKPKIPAKIEEPPPAKVPEAPKKIVPEKKVPAPVPKKEKVPPPKVPEEPKKPVPEKKVPPKVIKMEEPLPAKVTERHMQITQEEKVLVAVTKKEAPPKARVPEEPKRAVPEEKVLKLKPKREEEPPAKVTEFRKRVVKEEKVSIEAPKREPQPIKEVTIMEEKERAYTLEEEAVSVQREEEYEEYEEYDYKEFEEYEPTEEYDQYEEYEEREYERYEEHEEYITEPEKPIPVKPVPEEPVPTKPKAPPAKVLKKAVPEEKVPVPIPKKLKPPPPKVPEEPKKVFEEKIRISITKREKEQVTEPAAKVPMKPKRVVAEEKVPVPRKEVAPPVRVPEVPKELEPEEVAFEEEVVTHVEEYLVEEEEEYIHEEEEFITEEEVVPVIPVKVPEVPRKPVPEEKKPVPVPKKKEAPPAKVPEVPKKPEEKVPVLIPKKEKPPPAKVPEVPKKPVPEEKVPVPVPKKVEAPPAKVPEVPKKPVPEKKVPVPAPKKVEAPPAKVPEVPKKLIPEEKKPTPVPKKVEAPPPKVPKKREPVPVPVALPQEEEVLFEEEIVPEEEVLPEEEEVLPEEEEVLPEEEEVLPEEEEIPPEEEEVPPEEEYVPEEEEFVPEEEVLPEVKPKVPVPAPVPEIKKKVTEKKVVIPKKEEAPPAKVPEVPKKVEEKRIILPKEEEVLPVEVTEEPEEEPISEEEIPEEPPSIEEVEEVAPPRVPEVIKKAVPEAPTPVPKKVEAPPAKVSKKIPEEKVPVPVQKKEAPPAKVPEVPKKVPEKKVLVPKKEAVPPAKGRTVLEEKVSVAFRQEVVVKERLELEVVEAEVEEIPEEEEFHEVEEYFEEGEFHEVEEFIKLEQHRVEEEHRVEKVHRVIEVFEAEEVEVFEKPKAPPKGPEISEKIIPPKKPPTKVVPRKEPPAKVPEVPKKIVVEEKVRVPEEPRVPPTKVPEVLPPKEVVPEKKVPVPPAKKPEAPPPKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKAAVPEKKVPEAIPPKPESPPPEVPEAPKEVVPEKKVPAAPPKKPEVTPVKVPEAPKEVVPEKKVPVPPPKKPEVPPTKVPEVPKVAVPEKKVPEAIPPKPESPPPEVFEEPEEVALEEPPAEVVEEPEPAAPPQVTVPPKKPVPEKKAPAVVAKKPELPPVKVPEVPKEVVPEKKVPLVVPKKPEAPPAKVPEVPKEVVPEKKVAVPKKPEVPPAKVPEVPKKPVLEEKPAVPVPERAESPPPEVYEEPEEIAPEEEIAPEEEKPVPVAEEEEPEVPPPAVPEEPKKIIPEKKVPVIKKPEAPPPKEPEMPKKVVPVKKVPTVKKPETPAAKVPEVPKKLVPVKKEPVPVTKKPEVLPEKVPKVPEKIIPEKEVSVPIPAEPEVPPAEVEETPEEIIYEEKASITIGRKETPPVEEREIEKYIKPEEPEPEPQPEEIPVKEPEPEKVIEKPKLKPRPPPPPPAPPKEDVKEKIFQLKAIPKKKVPEKPQVPEKVELTPLKVPGGEKKVRKLLPERKPEPKEEVVLKSVLRKRPEEEEPKVEPKKLEKVKKPAVPEPPPPKPVEEVEVPTVTKRERKIPEPTKVPEIKPAIPLPAPEPKPKPEAEVKTIKPPPVEPEPTPIAAPVTVPVVGKKAEAKAPKEEAAKPKGPIKGVPKKTPSPIEAERRKLRPGSGGEKPPDEAPFTYQLKAVPLKFVKEIKDIILTESEFVGSSAIFECLVSPSTAITTWMKDGSNIRESPKHRFIADGKDRKLHIIDVQLSDAGEYTCVLRLGNKEKTSTAKLVVEELPVRFVKTLEEEVTVVKGQPLYLSCELNKERDVVWRKDGKIVVEKPGRIVPGVIGLMRALTINDADDTDAGTYTVTVENANNLECSSCVKVVEVIRDWLVKPIRDQHVKPKGTAIFACDIAKDTPNIKWFKGYDEIPAEPNDKTEILRDGNHLYLKIKNAMPEDIAEYAVEIEGKRYPAKLTLGEREVELLKPIEDVTIYEKESASFDAEISEADIPGQWKLKGELLRPSPTCEIKAEGGKRFLTLHKVKLDQAGEVLYQALNAITTAILTVKEIELDFAVPLKDVTVPERRQARFECVLTREANVIWSKGPDIIKSSDKFDIIADGKKHILVINDSQFDDEGVYTAEVEGKKTSARLFVTGIRLKFMSPLEDQTVKEGETATFVCELSHEKMHVVWFKNDAKLHTSRTVLISSEGKTHKLEMKEVTLDDISQIKAQVKELSSTAQLKVLEADPYFTVKLHDKTAVEKDEITLKCEVSKDVPVKWFKDGEEIVPSPKYSIKADGLRRILKIKKADLKDKGEYVCDCGTDKTKANVTVEARLIKVEKPLYGVEVFVGETAHFEIELSEPDVHGQWKLKGQPLTASPDCEIIEDGKKHILILHNCQLGMTGEVSFQAANAKSAANLKVKELPLIFITPLSDVKVFEKDEAKFECEVSREPKTFRWLKGTQEITGDDRFELIKDGTKHSMVIKSAAFEDEAKYMFEAEDKHTSGKLIIEGIRLKFLTPLKDVTAKEKESAVFTVELSHDNIRVKWFKNDQRLHTTRSVSMQDEGKTHSITFKDLSIDDTSQIRVEAMGMSSEAKLTVLEGDPYFTGKLQDYTGVEKDEVILQCEISKADAPVKWFKDGKEIKPSKNAVIKADGKKRMLILKKALKSDIGQYTCDCGTDKTSGKLDIEDREIKLVRPLHSVEVMETETARFETEISEDDIHANWKLKGEALLQTPDCEIKEEGKIHSLVLHNCRLDQTGGVDFQAANVKSSAHLRVKPRVIGLLRPLKDVTVTAGETATFDCELSYEDIPVEWYLKGKKLEPSDKVVPRSEGKVHTLTLRDVKLEDAGEVQLTAKDFKTHANLFVKEPPVEFTKPLEDQTVEEGATAVLECEVSRENAKVKWFKNGTEILKSKKYEIVADGRVRKLVIHDCTPEDIKTYTCDAKDFKTSCNLNVVPPHVEFLRPLTDLQVREKEMARFECELSRENAKVKWFKDGAEIKKGKKYDIISKGAVRILVINKCLLDDEAEYSCEVRTARTSGMLTVLEEEAVFTKNLANIEVSETDTIKLVCEVSKPGAEVIWYKGDEEIIETGRYEILTEGRKRILVIQNAHLEDAGNYNCRLPSSRTDGKVKVHELAAEFISKPQNLEILEGEKAEFVCSISKESFPVQWKRDDKTLESGDKYDVIADGKKRVLVVKDATLQDMGTYVVMVGAARAAAHLTVIEKLRIVVPLKDTRVKEQQEVVFNCEVNTEGAKAKWFRNEEAIFDSSKYIILQKDLVYTLRIRDAHLDDQANYNVSLTNHRGENVKSAANLIVEEEDLRIVEPLKDIETMEKKSVTFWCKVNRLNVTLKWTKNGEEVPFDNRVSYRVDKYKHMLTIKDCGFPDEGEYIVTAGQDKSVAELLIIEAPTEFVEHLEDQTVTEFDDAVFSCQLSREKANVKWYRNGREIKEGKKYKFEKDGSIHRLIIKDCRLDDECEYACGVEDRKSRARLFVEEIPVEIIRPPQDILEAPGADVVFLAELNKDKVEVQWLRNNMVVVQGDKHQMMSEGKIHRLQICDIKPRDQGEYRFIAKDKEARAKLELAAAPKIKTADQDLVVDVGKPLTMVVPYDAYPKAEAEWFKENEPLSTKTIDTTAEQTSFRILEAKKGDKGRYKIVLQNKHGKAEGFINLKVIDVPGPVRNLEVTETFDGEVSLAWEEPLTDGGSKIIGYVVERRDIKRKTWVLATDRAESCEFTVTGLQKGGVEYLFRVSARNRVGTGEPVETDNPVEARSKYDVPGPPLNVTITDVNRFGVSLTWEPPEYDGGAEITNYVIELRDKTSIRWDTAMTVRAEDLSATVTDVVEGQEYSFRVRAQNRIGVGKPSAATPFVKVADPIERPSPPVNLTSSDQTQSSVQLKWEPPLKDGGSPILGYIIERCEEGKDNWIRCNMKLVPELTYKVTGLEKGNKYLYRVSAENKAGVSDPSEILGPLTADDAFVEPTMDLSAFKDGLEVIVPNPITILVPSTGYPRPTATWCFGDKVLETGDRVKMKTLSAYAELVISPSERSDKGIYTLKLENRVKTISGEIDVNVIARPSAPKELKFGDITKDSVHLTWEPPDDDGGSPLTGYVVEKREVSRKTWTKVMDFVTDLEFTVPDLVQGKEYLFKVCARNKCGPGEPAYVDEPVNMSTPATVPDPPENVKWRDRTANSIFLTWDPPKNDGGSRIKGYIVERCPRGSDKWVACGEPVAETKMEVTGLEEGKWYAYRVKALNRQGASKPSRPTEEIQAVDTQEAPEIFLDVKLLAGLTVKAGTKIELPATVTGKPEPKITWTKADMILKQDKRITIENVPKKSTVTIVDSKRSDTGTYIIEAVNVCGRATAVVEVNVLDKPGPPAAFDITDVTNESCLLTWNPPRDDGGSKITNYVVERRATDSEVWHKLSSTVKDTNFKATKLIPNKEYIFRVAAENMYGVGEPVQASPITAKYQFDPPGPPTRLEPSDITKDAVTLTWCEPDDDGGSPITGYWVERLDPDTDKWVRCNKMPVKDTTYRVKGLTNKKKYRFRVLAENLAGPGKPSKSTEPILIKDPIDPPWPPGKPTVKDVGKTSVRLNWTKPEHDGGAKIESYVIEMLKTGTDEWVRVAEGVPTTQHLLPGLMEGQEYSFRVRAVNKAGESEPSEPSDPVLCREKLYPPSPPRWLEVINITKNTADLKWTVPEKDGGSPITNYIVEKRDVRRKGWQTVDTTVKDTKCTVTPLTEGSLYVFRVAAENAIGQSDYTEIEDSVLAKDTFTTPGPPYALAVVDVTKRHVDLKWEPPKNDGGRPIQRYVIEKKERLGTRWVKAGKTAGPDCNFRVTDVIEGTEVQFQVRAENEAGVGHPSEPTEILSIEDPTSPPSPPLDLHVTDAGRKHIAIAWKPPEKNGGSPIIGYHVEMCPVGTEKWMRVNSRPIKDLKFKVEEGVVPDKEYVLRVRAVNAIGVSEPSEISENVVAKDPDCKPTIDLETHDIIVIEGEKLSIPVPFRAVPVPTVSWHKDGKEVKASDRLTMKNDHISAHLEVPKSVRADAGIYTITLENKLGSATASINVKVIGLPGPCKDIKASDITKSSCKLTWEPPEFDGGTPILHYVLERREAGRRTYIPVMSGENKLSWTVKDLIPNGEYFFRVKAVNKVGGGEYIELKNPVIAQDPKQPPDPPVDVEVHNPTAEAMTITWKPPLYDGGSKIMGYIIEKIAKGEERWKRCNEHLVPILTYTAKGLEEGKEYQFRVRAENAAGISEPSRATPPTKAVDPIDAPKVILRTSLEVKRGDEIALDASISGSPYPTITWIKDENVIVPEEIKKRAAPLVRRRKGEVQEEEPFVLPLTQRLSIDNSKKGESQLRVRDSLRPDHGLYMIKVENDHGIAKAPCTVSVLDTPGPPINFVFEDIRKTSVLCKWEPPLDDGGSEIINYTLEKKDKTKPDSEWIVVTSTLRHCKYSVTKLIEGKEYLFRVRAENRFGPGPPCVSKPLVAKDPFGPPDAPDKPIVEDVTSNSMLVKWNEPKDNGSPILGYWLEKREVNSTHWSRVNKSLLNALKANVDGLLEGLTYVFRVCAENAAGPGKFSPPSDPKTAHDPISPPGPPIPRVTDTSSTTIELEWEPPAFNGGGEIVGYFVDKQLVGTNEWSRCTEKMIKVRQYTVKEIREGADYKLRVSAVNAAGEGPPGETQPVTVAEPQEPPAVELDVSVKGGIQIMAGKTLRIPAVVTGRPVPTKVWTKEEGELDKDRVVIDNVGTKSELIIKDALRKDHGRYVITATNSCGSKFAAARVEVFDVPGPVLDLKPVVTNRKMCLLNWSDPEDDGGSEITGFIIERKDAKMHTWRQPIETERSKCDITGLLEGQEYKFRVIAKNKFGCGPPVEIGPILAVDPLGPPTSPERLTYTERTKSTITLDWKEPRSNGGSPIQGYIIEKRRHDKPDFERVNKRLCPTTSFLVENLDEHQMYEFRVKAVNEIGESEPSLPLNVVIQDDEVPPTIKLRLSVRGDTIKVKAGEPVHIPADVTGLPMPKIEWSKNETVIEKPTDALQITKEEVSRSEAKTELSIPKAVREDKGTYTVTASNRLGSVFRNVHVEVYDRPSPPRNLAVTDIKAESCYLTWDAPLDNGGSEITHYVIDKRDASRKKAEWEEVTNTAVEKRYGIWKLIPNGQYEFRVRAVNKYGISDECKSDKVVIQDPYRLPGPPGKPKVLARTKGSMLVSWTPPLDNGGSPITGYWLEKREEGSPYWSRVSRAPITKVGLKGVEFNVPRLLEGVKYQFRAMAINAAGIGPPSEPSDPEVAGDPIFPPGPPSCPEVKDKTKSSISLGWKPPAKDGGSPIKGYIVEMQEEGTTDWKRVNEPDKLITTCECVVPNLKELRKYRFRVKAVNEAGESEPSDTTGEIPATDIQEEPEVFIDIGAQDCLVCKAGSQIRIPAVIKGRPTPKSSWEFDGKAKKAMKDGVHDIPEDAQLETAENSSVIIIPECKRSHTGKYSITAKNKAGQKTANCRVKVMDVPGPPKDLKVSDITRGSCRLSWKMPDDDGGDRIKGYVIEKRTIDGKAWTKVNPDCGSTTFVVPDLLSEQQYFFRVRAENRFGIGPPVETIQRTTARDPIYPPDPPIKLKIGLITKNTVHLSWKPPKNDGGSPVTHYIVECLAWDPTGTKKEAWRQCNKRDVEELQFTVEDLVEGGEYEFRVKAVNAAGVSKPSATVGPVTVKDQTCPPSIDLKEFMEVEEGTNVNIVAKIKGVPFPTLTWFKAPPKKPDNKEPVLYDTHVNKLVVDDTCTLVIPQSRRSDTGLYTITAVNNLGTASKEMRLNVLGRPGPPVGPIKFESVSADQMTLSWFPPKDDGGSKITNYVIEKREANRKTWVHVSSEPKECTYTIPKLLEGHEYVFRIMAQNKYGIGEPLDSEPETARNLFSVPGAPDKPTVSSVTRNSMTVNWEEPEYDGGSPVTGYWLEMKDTTSKRWKRVNRDPIKAMTLGVSYKVTGLIEGSDYQFRVYAINAAGVGPASLPSDPATARDPIAPPGPPFPKVTDWTKSSADLEWSPPLKDGGSKVTGYIVEYKEEGKEEWEKGKDKEVRGTKLVVTGLKEGAFYKFRVRAVNIAGIGEPGEVTDVIEMKDRLVSPDLQLDASVRDRIVVHAGGVIRIIAYVSGKPPPTVTWNMNERTLPQEATIETTAISSSMVIKNCQRSHQGVYSLLAKNEAGERKKTIIVDVLDVPGPVGTPFLAHNLTNESCKLTWFSPEDDGGSPITNYVIEKRESDRRAWTPVTYTVTRQNATVQGLIQGKAYFFRIAAENSIGMGPFVETSEALVIREPITVPERPEDLEVKEVTKNTVTLTWNPPKYDGGSEIINYVLESRLIGTEKFHKVTNDNLLSRKYTVKGLKEGDTYEYRVSAVNIVGQGKPSFCTKPITCKDELAPPTLHLDFRDKLTIRVGEAFALTGRYSGKPKPKVSWFKDEADVLEDDRTHIKTTPATLALEKIKAKRSDSGKYCVVVENSTGSRKGFCQVNVVDRPGPPVGPVSFDEVTKDYMVISWKPPLDDGGSKITNYIIEKKEVGKDVWMPVTSASAKTTCKVSKLLEGKDYIFRIHAENLYGISDPLVSDSMKAKDRFRVPDAPDQPIVTEVTKDSALVTWNKPHDGGKPITNYILEKRETMSKRWARVTKDPIHPYTKFRVPDLLEGCQYEFRVSAENEIGIGDPSPPSKPVFAKDPIAKPSPPVNPEAIDTTCNSVDLTWQPPRHDGGSKILGYIVEYQKVGDEEWRRANHTPESCPETKYKVTGLRDGQTYKFRVLAVNAAGESDPAHVPEPVLVKDRLEPPELILDANMAREQHIKVGDTLRLSAIIKGVPFPKVTWKKEDRDAPTKARIDVTPVGSKLEIRNAAHEDGGIYSLTVENPAGSKTVSVKVLVLDKPGPPRDLEVSEIRKDSCYLTWKEPLDDGGSVITNYVVERRDVASAQWSPLSATSKKKSHFAKHLNEGNQYLFRVAAENQYGRGPFVETPKPIKALDPLHPPGPPKDLHHVDVDKTEVSLVWNKPDRDGGSPITGYLVEYQEEGTQDWIKFKTVTNLECVVTGLQQGKTYRFRVKAENIVGLGLPDTTIPIECQEKLVPPSVELDVKLIEGLVVKAGTTVRFPAIIRGVPVPTAKWTTDGSEIKTDEHYTVETDNFSSVLTIKNCLRRDTGEYQITVSNAAGSKTVAVHLTVLDVPGPPTGPINILDVTPEHMTISWQPPKDDGGSPVINYIVEKQDTRKDTWGVVSSGSSKTKLKIPHLQKGCEYVFRVRAENKIGVGPPLDSTPTVAKHKFSPPSPPGKPVVTDITENAATVSWTLPKSDGGSPITGYYMERREVTGKWVRVNKTPIADLKFRVTGLYEGNTYEFRVFAENLAGLSKPSPSSDPIKACRPIKPPGPPINPKLKDKSRETADLVWTKPLSDGGSPILGYVVECQKPGTAQWNRINKDELIRQCAFRVPGLIEGNEYRFRIKAANIVGEGEPRELAESVIAKDILHPPEVELDVTCRDVITVRVGQTIRILARVKGRPEPDITWTKEGKVLVREKRVDLIQDLPRVELQIKEAVRADHGKYIISAKNSSGHAQGSAIVNVLDRPGPCQNLKVTNVTKENCTISWENPLDNGGSEITNFIVEYRKPNQKGWSIVASDVTKRLIKANLLANNEYYFRVCAENKVGVGPTIETKTPILAINPIDRPGEPENLHIADKGKTFVYLKWRRPDYDGGSPNLSYHVERRLKGSDDWERVHKGSIKETHYMVDRCVENQIYEFRVQTKNEGGESDWVKTEEVVVKEDLQKPVLDLKLSGVLTVKAGDTIRLEAGVRGKPFPEVAWTKDKDATDLTRSPRVKIDTRADSSKFSLTKAKRSDGGKYVVTATNTAGSFVAYATVNVLDKPGPVRNLKIVDVSSDRCTVCWDPPEDDGGCEIQNYILEKCETKRMVWSTYSATVLTPGTTVTRLIEGNEYIFRVRAENKIGTGPPTESKPVIAKTKYDKPGRPDPPEVTKVSKEEMTVVWNPPEYDGGKSITGYFLEKKEKHSTRWVPVNKSAIPERRMKVQNLLPDHEYQFRVKAENEIGIGEPSLPSRPVVAKDPIEPPGPPTNFRVVDTTKHSITLGWGKPVYDGGAPIIGYVVEMRPKIADASPDEGWKRCNAAAQLVRKEFTVTSLDENQEYEFRVCAQNQVGIGRPAELKEAIKPKEILEPPEIDLDASMRKLVIVRAGCPIRLFAIVRGRPAPKVTWRKVGIDNVVRKGQVDLVDTMAFLVIPNSTRDDSGKYSLTLVNPAGEKAVFVNVRVLDTPGPVSDLKVSDVTKTSCHVSWAPPENDGGSQVTHYIVEKREADRKTWSTVTPEVKKTSFHVTNLVPGNEYYFRVTAVNEYGPGVPTDVPKPVLASDPLSEPDPPRKLEVTEMTKNSATLAWLPPLRDGGAKIDGYITSYREEEQPADRWTEYSVVKDLSLVVTGLKEGKKYKFRVAARNAVGVSLPREAEGVYEAKEQLLPPKILMPEQITIKAGKKLRIEAHVYGKPHPTCKWKKGEDEVVTSSHLAVHKADSSSILIIKDVTRKDSGYYSLTAENSSGTDTQKIKVVVMDAPGPPQPPFDISDIDADACSLSWHIPLEDGGSNITNYIVEKCDVSRGDWVTALASVTKTSCRVGKLIPGQEYIFRVRAENRFGISEPLTSPKMVAQFPFGVPSEPKNARVTKVNKDCIFVAWDRPDSDGGSPIIGYLIERKERNSLLWVKANDTLVRSTEYPCAGLVEGLEYSFRIYALNKAGSSPPSKPTEYVTARMPVDPPGKPEVIDVTKSTVSLIWARPKHDGGSKIIGYFVEACKLPGDKWVRCNTAPHQIPQEEYTATGLEEKAQYQFRAIARTAVNISPPSEPSDPVTILAENVPPRIDLSVAMKSLLTVKAGTNVCLDATVFGKPMPTVSWKKDGTLLKPAEGIKMAMQRNLCTLELFSVNRKDSGDYTITAENSSGSKSATIKLKVLDKPGPPASVKINKMYSDRAMLSWEPPLEDGGSEITNYIVDKRETSRPNWAQVSATVPITSCSVEKLIEGHEYQFRICAENKYGVGDPVFTEPAIAKNPYDPPGRCDPPVISNITKDHMTVSWKPPADDGGSPITGYLLEKRETQAVNWTKVNRKPIIERTLKATGLQEGTEYEFRVTAINKAGPGKPSDASKAAYARDPQYPPGPPAFPKVYDTTRSSVSLSWGKPAYDGGSPIIGYLVEVKRADSDNWVRCNLPQNLQKTRFEVTGLMEDTQYQFRVYAVNKIGYSDPSDVPDKHYPKDILIPPEGELDADLRKTLILRAGVTMRLYVPVKGRPPPKITWSKPNVNLRDRIGLDIKSTDFDTFLRCENVNKYDAGKYILTLENSCGKKEYTIVVKVLDTPGPPVNVTVKEISKDSAYVTWEPPIIDGGSPIINYVVQKRDAERKSWSTVTTECSKTSFRVANLEEGKSYFFRVFAENEYGIGDPGETRDAVKASQTPGPVVDLKVRSVSKSSCSIGWKKPHSDGGSRIIGYVVDFLTEENKWQRVMKSLSLQYSAKDLTEGKEYTFRVSAENENGEGTPSEITVVARDDVVAPDLDLKGLPDLCYLAKENSNFRLKIPIKGKPAPSVSWKKGEDPLATDTRVSVESSAVNTTLIVYDCQKSDAGKYTITLKNVAGTKEGTISIKVVGKPGIPTGPIKFDEVTAEAMTLKWAPPKDDGGSEITNYILEKRDSVNNKWVTCASAVQKTTFRVTRLHEGMEYTFRVSAENKYGVGEGLKSEPIVARHPFDVPDAPPPPNIVDVRHDSVSLTWTDPKKTGGSPITGYHLEFKERNSLLWKRANKTPIRMRDFKVTGLTEGLEYEFRVMAINLAGVGKPSLPSEPVVALDPIDPPGKPEVINITRNSVTLIWTEPKYDGGHKLTGYIVEKRDLPSKSWMKANHVNVPECAFTVTDLVEGGKYEFRIRAKNTAGAISAPSESTETIICKDEYEAPTIVLDPTIKDGLTIKAGDTIVLNAISILGKPLPKSSWSKAGKDIRPSDITQITSTPTSSMLTIKYATRKDAGEYTITATNPFGTKVEHVKVTVLDVPGPPGPVEISNVSAEKATLTWTPPLEDGGSPIKSYILEKRETSRLLWTVVSEDIQSCRHVATKLIQGNEYIFRVSAVNHYGKGEPVQSEPVKMVDRFGPPGPPEKPEVSNVTKNTATVSWKRPVDDGGSEITGYHVERREKKSLRWVRAIKTPVSDLRCKVTGLQEGSTYEFRVSAENRAGIGPPSEASDSVLMKDAAYPPGPPSNPHVTDTTKKSASLAWGKPHYDGGLEITGYVVEHQKVGDEAWIKDTTGTALRITQFVVPDLQTKEKYNFRISAINDAGVGEPAVIPDVEIVEREMAPDFELDAELRRTLVVRAGLSIRIFVPIKGRPAPEVTWTKDNINLKNRANIENTESFTLLIIPECNRYDTGKFVMTIENPAGKKSGFVNVRVLDTPGPVLNLRPTDITKDSVTLHWDLPLIDGGSRITNYIVEKREATRKSYSTATTKCHKCTYKVTGLSEGCEYFFRVMAENEYGIGEPTETTEPVKASEAPSPPDSLNIMDITKSTVSLAWPKPKHDGGSKITGYVIEAQRKGSDQWTHITTVKGLECVVRNLTEGEEYTFQVMAVNSAGRSAPRESRPVIVKEQTMLPELDLRGIYQKLVIAKAGDNIKVEIPVLGRPKPTVTWKKGDQILKQTQRVNFETTATSTILNINECVRSDSGPYPLTARNIVGEVGDVITIQVHDIPGPPTGPIKFDEVSSDFVTFSWDPPENDGGVPISNYVVEMRQTDSTTWVELATTVIRTTYKATRLTTGLEYQFRVKAQNRYGVGPGITSACIVANYPFKVPGPPGTPQVTAVTKDSMTISWHEPLSDGGSPILGYHVERKERNGILWQTVSKALVPGNIFKSSGLTDGIAYEFRVIAENMAGKSKPSKPSEPMLALDPIDPPGKPVPLNITRHTVTLKWAKPEYTGGFKITSYIVEKRDLPNGRWLKANFSNILENEFTVSGLTEDAAYEFRVIAKNAAGAISPPSEPSDAITCRDDVEAPKIKVDVKFKDTVILKAGEAFRLEADVSGRPPPTMEWSKDGKELEGTAKLEIKIADFSTNLVNKDSTRRDSGAYTLTATNPGGFAKHIFNVKVLDRPGPPEGPLAVTEVTSEKCVLSWFPPLDDGGAKIDHYIVQKRETSRLAWTNVASEVQVTKLKVTKLLKGNEYIFRVMAVNKYGVGEPLESEPVLAVNPYGPPDPPKNPEVTTITKDSMVVCWGHPDSDGGSEIINYIVERRDKAGQRWIKCNKKTLTDLRYKVSGLTEGHEYEFRIMAENAAGISAPSPTSPFYKACDTVFKPGPPGNPRVLDTSRSSISIAWNKPIYDGGSEITGYMVEIALPEEDEWQIVTPPAGLKATSYTITGLTENQEYKIRIYAMNSEGLGEPALVPGTPKAEDRMLPPEIELDADLRKVVTIRACCTLRLFVPIKGRPAPEVKWARDHGESLDKASIESTSSYTLLIVGNVNRFDSGKYILTVENSSGSKSAFVNVRVLDTPGPPQDLKVKEVTKTSVTLTWDPPLLDGGSKIKNYIVEKRESTRKAYSTVATNCHKTSWKVDQLQEGCSYYFRVLAENEYGIGLPAETAESVKASERPLPPGKITLMDVTRNSVSLSWEKPEHDGGSRILGYIVEMQTKGSDKWATCATVKVTEATITGLIQGEEYSFRVSAQNEKGISDPRQLSVPVIAKDLVIPPAFKLLFNTFTVLAGEDLKVDVPFIGRPTPAVTWHKDNVPLKQTTRVNAESTENNSLLTIKDACREDVGHYVVKLTNSAGEAIETLNVIVLDKPGPPTGPVKMDEVTADSITLSWGPPKYDGGSSINNYIVEKRDTSTTTWQIVSATVARTTIKACRLKTGCEYQFRIAAENRYGKSTYLNSEPTVAQYPFKVPGPPGTPVVTLSSRDSMEVQWNEPISDGGSRVIGYHLERKERNSILWVKLNKTPIPQTKFKTTGLEEGVEYEFRVSAENIVGIGKPSKVSECYVARDPCDPPGRPEAIIVTRNSVTLQWKKPTYDGGSKITGYIVEKKELPEGRWMKASFTNIIDTHFEVTGLVEDHRYEFRVIARNAAGVFSEPSESTGAITARDEVDPPRISMDPKYKDTIVVHAGESFKVDADIYGKPIPTIQWIKGDQELSNTARLEIKSTDFATSLSVKDAVRVDSGNYILKAKNVAGERSVTVNVKVLDRPGPPEGPVVISGVTAEKCTLAWKPPLQDGGSDIINYIVERRETSRLVWTVVDANVQTLSCKVTKLLEGNEYTFRIMAVNKYGVGEPLESEPVVAKNPFVVPDAPKAPEVTTVTKDSMIVVWERPASDGGSEILGYVLEKRDKEGIRWTRCHKRLIGELRLRVTGLIENHDYEFRVSAENAAGLSEPSPPSAYQKACDPIYKPGPPNNPKVIDITRSSVFLSWSKPIYDGGCEIQGYIVEKCDVSVGEWTMCTPPTGINKTNIEVEKLLEKHEYNFRICAINKAGVGEHADVPGPIIVEEKLEAPDIDLDLELRKIINIRAGGSLRLFVPIKGRPTPEVKWGKVDGEIRDAAIIDVTSSFTSLVLDNVNRYDSGKYTLTLENSSGTKSAFVTVRVLDTPSPPVNLKVTEITKDSVSITWEPPLLDGGSKIKNYIVEKREATRKSYAAVVTNCHKNSWKIDQLQEGCSYYFRVTAENEYGIGLPAQTADPIKVAEVPQPPGKITVDDVTRNSVSLSWTKPEHDGGSKIIQYIVEMQAKHSEKWSECARVKSLQAVITNLTQGEEYLFRVVAVNEKGRSDPRSLAVPIVAKDLVIEPDVKPAFSSYSVQVGQDLKIEVPISGRPKPTITWTKDGLPLKQTTRINVTDSLDLTTLSIKETHKDDGGQYGITVANVVGQKTASIEIVTLDKPDPPKGPVKFDDVSAESITLSWNPPLYTGGCQITNYIVQKRDTTTTVWDVVSATVARTTLKVTKLKTGTEYQFRIFAENRYGQSFALESDPIVAQYPYKEPGPPGTPFATAISKDSMVIQWHEPVNNGGSPVIGYHLERKERNSILWTKVNKTIIHDTQFKAQNLEEGIEYEFRVYAENIVGVGKASKNSECYVARDPCDPPGTPEPIMVKRNEITLQWTKPVYDGGSMITGYIVEKRDLPDGRWMKASFTNVIETQFTVSGLTEDQRYEFRVIAKNAAGAISKPSDSTGPITAKDEVELPRISMDPKFRDTIVVNAGETFRLEADVHGKPLPTIEWLRGDKEIEESARCEIKNTDFKALLIVKDAIRIDGGQYILRASNVAGSKSFPVNVKVLDRPGPPEGPVQVTGVTSEKCSLTWSPPLQDGGSDISHYVVEKRETSRLAWTVVASEVVTNSLKVTKLLEGNEYVFRIMAVNKYGVGEPLESAPVLMKNPFVLPGPPKSLEVTNIAKDSMTVCWNRPDSDGGSEIIGYIVEKRDRSGIRWIKCNKRRITDLRLRVTGLTEDHEYEFRVSAENAAGVGEPSPATVYYKACDPVFKPGPPTNAHIVDTTKNSITLAWGKPIYDGGSEILGYVVEICKADEEEWQIVTPQTGLRVTRFEISKLTEHQEYKIRVCALNKVGLGEATSVPGTVKPEDKLEAPELDLDSELRKGIVVRAGGSARIHIPFKGRPTPEITWSREEGEFTDKVQIEKGVNYTQLSIDNCDRNDAGKYILKLENSSGSKSAFVTVKVLDTPGPPQNLAVKEVRKDSAFLVWEPPIIDGGAKVKNYVIDKRESTRKAYANVSSKCSKTSFKVENLTEGAIYYFRVMAENEFGVGVPVETVDAVKAAEPPSPPGKVTLTDVSQTSASLMWEKPEHDGGSRVLGYVVEMQPKGTEKWSIVAESKVCNAVVTGLSSGQEYQFRVKAYNEKGKSDPRVLGVPVIAKDLTIQPSLKLPFNTYSIQAGEDLKIEIPVIGRPRPNISWVKDGEPLKQTTRVNVEETATSTVLHIKEGNKDDFGKYTVTATNSAGTATENLSVIVLEKPGPPVGPVRFDEVSADFVVISWEPPAYTGGCQISNYIVEKRDTTTTTWHMVSATVARTTIKITKLKTGTEYQFRIFAENRYGKSAPLDSKAVIVQYPFKEPGPPGTPFVTSISKDQMLVQWHEPVNDGGTKIIGYHLEQKEKNSILWVKLNKTPIQDTKFKTTGLDEGLEYEFKVSAENIVGIGKPSKVSECFVARDPCDPPGRPEAIVITRNNVTLKWKKPAYDGGSKITGYIVEKKDLPDGRWMKASFTNVLETEFTVSGLVEDQRYEFRVIARNAAGNFSEPSDSSGAITARDEIDAPNASLDPKYKDVIVVHAGETFVLEADIRGKPIPDVVWSKDGKELEETAARMEIKSTIQKTTLVVKDCIRTDGGQYILKLSNVGGTKSIPITVKVLDRPGPPEGPLKVTGVTAEKCYLAWNPPLQDGGANISHYIIEKRETSRLSWTQVSTEVQALNYKVTKLLPGNEYIFRVMAVNKYGIGEPLESGPVTACNPYKPPGPPSTPEVSAITKDSMVVTWARPVDDGGTEIEGYILEKRDKEGVRWTKCNKKTLTDLRLRVTGLTEGHSYEFRVAAENAAGVGEPSEPSVFYRACDALYPPGPPSNPKVTDTSRSSVSLAWSKPIYDGGAPVKGYVVEVKEAAADEWTTCTPPTGLQGKQFTVTKLKENTEYNFRICAINSEGVGEPATLPGSVVAQERIEPPEIELDADLRKVVVLRASATLRLFVTIKGRPEPEVKWEKAEGILTDRAQIEVTSSFTMLVIDNVTRFDSGRYNLTLENNSGSKTAFVNVRVLDSPSAPVNLTIREVKKDSVTLSWEPPLIDGGAKITNYIVEKRETTRKAYATITNNCTKTTFRIENLQEGCSYYFRVLASNEYGIGLPAETTEPVKVSEPPLPPGRVTLVDVTRNTATIKWEKPESDGGSKITGYVVEMQTKGSEKWSTCTQVKTLEATISGLTAGEEYVFRVAAVNEKGRSDPRQLGVPVIARDIEIKPSVELPFHTFNVKAREQLKIDVPFKGRPQATVNWRKDGQTLKETTRVNVSSSKTVTSLSIKEASKEDVGTYELCVSNSAGSITVPITIIVLDRPGPPGPIRIDEVSCDSITISWNPPEYDGGCQISNYIVEKKETTSTTWHIVSQAVARTSIKIVRLTTGSEYQFRVCAENRYGKSSYSESSAVVAEYPFSPPGPPGTPKVVHATKSTMLVTWQVPVNDGGSRVIGYHLEYKERSSILWSKANKILIADTQMKVSGLDEGLMYEYRVYAENIAGIGKCSKSCEPVPARDPCDPPGQPEVTNITRKSVSLKWSKPHYDGGAKITGYIVERRELPDGRWLKCNYTNIQETYFEVTELTEDQRYEFRVFARNAADSVSEPSESTGPIIVKDDVEPPRVMMDVKFRDVIVVKAGEVLKINADIAGRPLPVISWAKDGIEIEERARTEIISTDNHTLLTVKDCIRRDTGQYVLTLKNVAGTRSVAVNCKVLDKPGPPAGPLEINGLTAEKCSLSWGRPQEDGGADIDYYIVEKRETSHLAWTICEGELQMTSCKVTKLLKGNEYIFRVTGVNKYGVGEPLESVAIKALDPFTVPSPPTSLEITSVTKESMTLCWSRPESDGGSEISGYIIERREKNSLRWVRVNKKPVYDLRVKSTGLREGCEYEYRVYAENAAGLSLPSETSPLIRAEDPVFLPSPPSKPKIVDSGKTTITIAWVKPLFDGGAPITGYTVEYKKSDDTDWKTSIQSLRGTEYTISGLTTGAEYVFRVKSVNKVGASDPSDSSDPQIAKEREEEPLFDIDSEMRKTLIVKAGASFTMTVPFRGRPVPNVLWSKPDTDLRTRAYVDTTDSRTSLTIENANRNDSGKYTLTIQNVLSAASLTLVVKVLDTPGPPTNITVQDVTKESAVLSWDVPENDGGAPVKNYHIEKREASKKAWVSVTNNCNRLSYKVTNLQEGAIYYFRVSGENEFGVGIPAETKEGVKITEKPSPPEKLGVTSISKDSVSLTWLKPEHDGGSRIVHYVVEALEKGQKNWVKCAVAKSTHHVVSGLRENSEYFFRVFAENQAGLSDPRELLLPVLIKEQLEPPEIDMKNFPSHTVYVRAGSNLKVDIPISGKPLPKVTLSRDGVPLKATMRFNTEITAENLTINLKESVTADAGRYEITAANSSGTTKAFINIVVLDRPGPPTGPVVISDITEESVTLKWEPPKYDGGSQVTNYILLKRETSTAVWTEVSATVARTMMKVMKLTTGEEYQFRIKAENRFGISDHIDSACVTVKLPYTTPGPPSTPWVTNVTRESITVGWHEPVSNGGSAVVGYHLEMKDRNSILWQKANKLVIRTTHFKVTTISAGLIYEFRVYAENAAGVGKPSHPSEPVLAIDACEPPRNVRITDISKNSVSLSWQQPAFDGGSKITGYIVERRDLPDGRWTKASFTNVTETQFIISGLTQNSQYEFRVFARNAVGSISNPSEVVGPITCIDSYGGPVIDLPLEYTEVVKYRAGTSVKLRAGISGKPAPTIEWYKDDKELQTNALVCVENTTDLASILIKDADRLNSGCYELKLRNAMGSASATIRVQILDKPGPPGGPIEFKTVTAEKITLLWRPPADDGGAKITHYIVEKRETSRVVWSMVSEHLEECIITTTKIIKGNEYIFRVRAVNKYGIGEPLESDSVVAKNAFVTPGPPGIPEVTKITKNSMTVVWSRPIADGGSDISGYFLEKRDKKSLGWFKVLKETIRDTRQKVTGLTENSDYQYRVCAVNAAGQGPFSEPSEFYKAADPIDPPGPPAKIRIADSTKSSITLGWSKPVYDGGSAVTGYVVEIRQGEEEEWTTVSTKGEVRTTEYVVSNLKPGVNYYFRVSAVNCAGQGEPIEMNEPVQAKDILEAPEIDLDVALRTSVIAKAGEDVQVLIPFKGRPPPTVTWRKDEKNLGSDARYSIENTDSSSLLTIPQVTRNDTGKYILTIENGVGEPKSSTVSVKVLDTPAACQKLQVKHVSRGTVTLLWDPPLIDGGSPIINYVIEKRDATKRTWSVVSHKCSSTSFKLIDLSEKTPFFFRVLAENEIGIGEPCETTEPVKAAEVPAPIRDLSMKDSTKTSVILSWTKPDFDGGSVITEYVVERKGKGEQTWSHAGISKTCEIEVSQLKEQSVLEFRVFAKNEKGLSDPVTIGPITVKELIITPEVDLSDIPGAQVTVRIGHNVHLELPYKGKPKPSISWLKDGLPLKESEFVRFSKTENKITLSIKNAKKEHGGKYTVILDNAVCRIAVPITVITLGPPSKPKGPIRFDEIKADSVILSWDVPEDNGGGEITCYSIEKRETSQTNWKMVCSSVARTTFKVPNLVKDAEYQFRVRAENRYGVSQPLVSSIIVAKHQFRIPGPPGKPVIYNVTSDGMSLTWDAPVYDGGSEVTGFHVEKKERNSILWQKVNTSPISGREYRATGLVEGLDYQFRVYAENSAGLSSPSDPSKFTLAVSPVDPPGTPDYIDVTRETITLKWNPPLRDGGSKIVGYSIEKRQGNERWVRCNFTDVSECQYTVTGLSPGDRYEFRIIARNAVGTISPPSQSSGIIMTRDENVPPIVEFGPEYFDGLIIKSGESLRIKALVQGRPVPRVTWFKDGVEIEKRMNMEITDVLGSTSLFVRDATRDHRGVYTVEAKNASGSAKAEIKVKVQDTPGKVVGPIRFTNITGEKMTLWWDAPLNDGCAPITHYIIEKRETSRLAWALIEDKCEAQSYTAIKLINGNEYQFRVSAVNKFGVGRPLDSDPVVAQIQYTVPDAPGIPEPSNITGNSITLTWARPESDGGSEIQQYILERREKKSTRWVKVISKRPISETRFKVTGLTEGNEYEFHVMAENAAGVGPASGISRLIKCREPVNPPGPPTVVKVTDTSKTTVSLEWSKPVFDGGMEIIGYIIEMCKADLGDWHKVNAEACVKTRYTVTDLQAGEEYKFRVSAINGAGKGDSCEVTGTIKAVDRLTAPELDIDANFKQTHVVRAGASIRLFIAYQGRPTPTAVWSKPDSNLSLRADIHTTDSFSTLTVENCNRNDAGKYTLTVENNSGSKSITFTVKVLDTPGPPGPITFKDVTRGSATLMWDAPLLDGGARIHHYVVEKREASRRSWQVISEKCTRQIFKVNDLAEGVPYYFRVSAVNEYGVGEPYEMPEPIVATEQPAPPRRLDVVDTSKSSAVLAWLKPDHDGGSRITGYLLEMRQKGSDFWVEAGHTKQLTFTVERLVEKTEYEFRVKAKNDAGYSEPREAFSSVIIKEPQIEPTADLTGITNQLITCKAGSPFTIDVPISGRPAPKVTWKLEEMRLKETDRVSITTTKDRTTLTVKDSMRGDSGRYFLTLENTAGVKTFSVTVVVIGRPGPVTGPIEVSSVSAESCVLSWGEPKDGGGTEITNYIVEKRESGTTAWQLVNSSVKRTQIKVTHLTKYMEYSFRVSSENRFGVSKPLESAPIIAEHPFVPPSAPTRPEVYHVSANAMSIRWEEPYHDGGSKIIGYWVEKKERNTILWVKENKVPCLECNYKVTGLVEGLEYQFRTYALNAAGVSKASEASRPIMAQNPVDAPGRPEVTDVTRSTVSLIWSAPAYDGGSKVVGYIIERKPVSEVGDGRWLKCNYTIVSDNFFTVTALSEGDTYEFRVLAKNAAGVISKGSESTGPVTCRDEYAPPKAELDARLHGDLVTIRAGSDLVLDAAVGGKPEPKIIWTKGDKELDLCEKVSLQYTGKRATAVIKFCDRSDSGKYTLTVKNASGTKAVSVMVKVLDSPGPCGKLTVSRVTQEKCTLAWSLPQEDGGAEITHYIVERRETSRLNWVIVEGECPTLSYVVTRLIKNNEYIFRVRAVNKYGPGVPVESEPIVARNSFTIPSPPGIPEEVGTGKEHIIIQWTKPESDGGNEISNYLVDKREKKSLRWTRVNKDYVVYDTRLKVTSLMEGCDYQFRVTAVNAAGNSEPSEASNFISCREPSYTPGPPSAPRVVDTTKHSISLAWTKPMYDGGTDIVGYVLEMQEKDTDQWYRVHTNATIRNTEFTVPDLKMGQKYSFRVAAVNVKGMSEYSESIAEIEPVERIEIPDLELADDLKKTVTIRAGASLRLMVSVSGRPPPVITWSKQGIDLASRAIIDTTESYSLLIVDKVNRYDAGKYTIEAENQSGKKSATVLVKVYDTPGPCPSVKVKEVSRDSVTITWEIPTIDGGAPVNNYIVEKREAAMRAFKTVTTKCSKTLYRISGLVEGTMYYFRVLPENIYGIGEPCETSDAVLVSEVPLVPAKLEVVDVTKSTVTLAWEKPLYDGGSRLTGYVLEACKAGTERWMKVVTLKPTVLEHTVTSLNEGEQYLFRIRAQNEKGVSEPRETVTAVTVQDLRVLPTIDLSTMPQKTIHVPAGRPVELVIPIAGRPPPAASWFFAGSKLRESERVTVETHTKVAKLTIRETTIRDTGEYTLELKNVTGTTSETIKVIILDKPGPPTGPIKIDEIDATSITISWEPPELDGGAPLSGYVVEQRDAHRPGWLPVSESVTRSTFKFTRLTEGNEYVFRVAATNRFGIGSYLQSEVIECRSSIRIPGPPETLQIFDVSRDGMTLTWYPPEDDGGSQVTGYIVERKEVRADRWVRVNKVPVTMTRYRSTGLTEGLEYEHRVTAINARGSGKPSRPSKPIVAMDPIAPPGKPQNPRVTDTTRTSVSLAWSVPEDEGGSKVTGYLIEMQKVDQHEWTKCNTTPTKIREYTLTHLPQGAEYRFRVLACNAGGPGEPAEVPGTVKVTEMLEYPDYELDERYQEGIFVRQGGVIRLTIPIKGKPFPICKWTKEGQDISKRAMIATSETHTELVIKEADRGDSGTYDLVLENKCGKKAVYIKVRVIGSPNSPEGPLEYDDIQVRSVRVSWRPPADDGGADILGYILERREVPKAAWYTIDSRVRGTSLVVKGLKENVEYHFRVSAENQFGISKPLKSEEPVTPKTPLNPPEPPSNPPEVLDVTKSSVSLSWSRPKDDGGSRVTGYYIERKETSTDKWVRHNKTQITTTMYTVTGLVPDAEYQFRIIAQNDVGLSETSPASEPVVCKDPFDKPSQPGELEILSISKDSVTLQWEKPECDGGKEILGYWVEYRQSGDSAWKKSNKERIKDKQFTIGGLLEATEYEFRVFAENETGLSRPRRTAMSIKTKLTSGEAPGIRKEMKDVTTKLGEAAQLSCQIVGRPLPDIKWYRFGKELIQSRKYKMSSDGRTHTLTVMTEEQEDEGVYTCIATNEVGEVETSSKLLLQATPQFHPGYPLKEKYYGAVGSTLRLHVMYIGRPVPAMTWFHGQKLLQNSENITIENTEHYTHLVMKNVQRKTHAGKYKVQLSNVFGTVDAILDVEIQDKPDKPTGPIVIEALLKNSAVISWKPPADDGGSWITNYVVEKCEAKEGAEWQLVSSAISVTTCRIVNLTENAGYYFRVSAQNTFGISDPLEVSSVVIIKSPFEKPGAPGKPTITAVTKDSCVVAWKPPASDGGAKIRNYYLEKREKKQNKWISVTTEEIRETVFSVKNLIEGLEYEFRVKCENLGGESEWSEISEPITPKSDVPIQAPHFKEELRNLNVRYQSNATLVCKVTGHPKPIVKWYRQGKEIIADGLKYRIQEFKGGYHQLIIASVTDDDATVYQVRATNQGGSVSGTASLEVEVPAKIHLPKTLEGMGAVHALRGEVVSIKIPFSGKPDPVITWQKGQDLIDNNGHYQVIVTRSFTSLVFPNGVERKDAGFYVVCAKNRFGIDQKTVELDVADVPDPPRGVKVSDVSRDSVNLTWTEPASDGGSKITNYIVEKCATTAERWLRVGQARETRYTVINLFGKTSYQFRVIAENKFGLSKPSEPSEPTITKEDKTRAMNYDEEVDETREVSMTKASHSSTKELYEKYMIAEDLGRGEFGIVHRCVETSSKKTYMAKFVKVKGTDQVLVKKEISILNIARHRNILHLHESFESMEELVMIFEFISGLDIFERINTSAFELNEREIVSYVHQVCEALQFLHSHNIGHFDIRPENIIYQTRRSSTIKIIEFGQARQLKPGDNFRLLFTAPEYYAPEVHQHDVVSTATDMWSLGTLVYVLLSGINPFLAETNQQIIENIMNAEYTFDEEAFKEISIEAMDFVDRLLVKERKSRMTASEALQHPWLKQKIERVSTKVIRTLKHRRYYHTLIKKDLNMVVSAARISCGGAIRSQKGVSVAKVKVASIEIGPVSGQIMHAVGEEGGHVKYVCKIENYDQSTQVTWYFGVRQLENSEKYEITYEDGVAILYVKDITKLDDGTYRCKVVNDYGEDSSYAELFVKGVREVYDYYCRRTMKKIKRRTDTMRLLERPPEFTLPLYNKTAYVGENVRFGVTITVHPEPHVTWYKSGQKIKPGDNDKKYTFESDKGLYQLTINSVTTDDDAEYTVVARNKYGEDSCKAKLTVTLHPPPTDSTLRPMFKRLLANAECQEGQSVCFEIRVSGIPPPTLKWEKDGQPLSLGPNIEIIHEGLDYYALHIRDTLPEDTGYYRVTATNTAGSTSCQAHLQVERLRYKKQEFKSKEEHERHVQKQIDKTLRMAEILSGTESVPLTQVAKEALREAAVLYKPAVSTKTVKGEFRLEIEEKKEERKLRMPYDVPEPRKYKQTTIEEDQRIKQFVPMSDMKWYKKIRDQYEMPGKLDRVVQKRPKRIRLSRWEQFYVMPLPRITDQYRPKWRIPKLSQDDLEIVRPARRRTPSPDYDFYYRPRRRSLGDISDEELLLPIDDYLAMKRTEEERLRLEEELELGFSASPPSRSPPHFELSSLRYSSPQAHVKVEETRKDFRYSTYHIPTKAEASTSYAELRERHAQAAYRQPKQRQRIMAEREDEELLRPVTTTQHLSEYKSELDFMSKEEKSRKKSRRQREVTEITEIEEEYEISKHAQRESSSSASRLLRRRRSLSPTYIELMRPVSELIRSRPQPAEEYEDDTERRSPTPERTRPRSPSPVSSERSLSRFERSARFDIFSRYESMKAALKTQKTSERKYEVLSQQPFTLDHAPRITLRMRSHRVPCGQNTRFILNVQSKPTAEVKWYHNGVELQESSKIHYTNTSGVLTLEILDCHTDDSGTYRAVCTNYKGEASDYATLDVTGGDYTTYASQRRDEEVPRSVFPELTRTEAYAVSSFKKTSEMEASSSVREVKSQMTETRESLSSYEHSASAEMKSAALEEKSLEEKSTTRKIKTTLAARILTKPRSMTVYEGESARFSCDTDGEPVPTVTWLRKGQVLSTSARHQVTTTKYKSTFEISSVQASDEGNYSVVVENSEGKQEAEFTLTIQKARVTEKAVTSPPRVKSPEPRVKSPEAVKSPKRVKSPEPSHPKAVSPTETKPTPTEKVQHLPVSAPPKITQFLKAEASKEIAKLTCVVESSVLRAKEVTWYKDGKKLKENGHFQFHYSADGTYELKINNLTESDQGEYVCEISGEGGTSKTNLQFMGQAFKSIHEKVSKISETKKSDQKTTESTVTRKTEPKAPEPISSKPVIVTGLQDTTVSSDSVAKFAVKATGEPRPTAIWTKDGKAITQGGKYKLSEDKGGFFLEIHKTDTSDSGLYTCTVKNSAGSVSSSCKLTIKAIKDTEAQKVSTQKTSEITPQKKAVVQEEISQKALRSEEIKMSEAKSQEKLALKEEASKVLISEEVKKSAATSLEKSIVHEEITKTSQASEEVRTHAEIKAFSTQMSINEGQRLVLKANIAGATDVKWVLNGVELTNSEEYRYGVSGSDQTLTIKQASHRDEGILTCISKTKEGIVKCQYDLTLSKELSDAPAFISQPRSQNINEGQNVLFTCEISGEPSPEIEWFKNNLPISISSNVSISRSRNVYSLEIRNASVSDSGKYTIKAKNFRGQCSATASLMVLPLVEEPSREVVLRTSGDTSLQGSFSSQSVQMSASKQEASFSSFSSSSASSMTEMKFASMSAQSMSSMQESFVEMSSSSFMGISNMTQLESSTSKMLKAGIRGIPPKIEALPSDISIDEGKVLTVACAFTGEPTPEVTWSCGGRKIHSQEQGRFHIENTDDLTTLIIMDVQKQDGGLYTLSLGNEFGSDSATVNIHIRSI>sp|Q9NZQ9|TMOD4_HUMAN Tropomodulin-4 OS=Homo sapiens OX=9606 GN=TMOD4PE=1 SV=1MSSYQKELEKYRDIDEDEILRTLSPEELEQLDCELQEMDPENMLLPAGLRQRDQTKKSPTGPLDREALLQYLEQQALEVKERDDLVPFTGEKKGKPYIQPKREIPAEEQITLEPELEEALAHATDAEMCDIAAILDMYTLMSNKQYYDALCSGEICNTEGISSVVQPDKYKPVPDEPPNPTNIEEILKRVRSNDKELEEVNLNNIQDIPIPMLSELCEAMKANTYVRSFSLVATRSGDPIANAVADMLRENRSLQSLNIESNFISSTGLMAVLKAVRENATLTELRVDNQRQWPGDAVEMEMATVLEQCPSIVRFGYHFTQQGPRARAAQAMTRNNELRRQQKKR>sp|Q9NZQ9-2|TMOD4_HUMAN Isoform 2 of Tropomodulin-4 OS=Homo sapiensOX=9606 GN=TMOD4MSSYQKELEKYRDIDEDEILRTLSPEELEQLDCELQEMDPENMLLPAGLRQRDQTKKSPTGPLDREALLQYLEQQALEVKERDDLVPFTGEKKGVVQPDKYKPVPDEPPNPTNIEEILKRVRSNDKELEEVNLNNIQDIPIPMLSELCEAMKANTYVRSFSLVATRSGDPIANAVADMLRENRSLQSLNIESNFISSTGLMAVLKAVRENATLTELRVDNQRQWPGDAVEMEMATVLEQCPSIVRFGYHFTQQGPRARAAQAMTRNNELRRQQKKR>sp|Q9NYL9|TMOD3_HUMAN Tropomodulin-3 OS=Homo sapiens OX=9606 GN=TMOD3PE=1 SV=1MALPFRKDLEKYKDLDEDELLGNLSETELKQLETVLDDLDPENALLPAGFRQKNQTSKSTTGPFDREHLLSYLEKEALEHKDREDYVPYTGEKKGKIFIPKQKPVQTFTEEKVSLDPELEEALTSASDTELCDLAAILGMHNLITNTKFCNIMGSSNGVDQEHFSNVVKGEKILPVFDEPPNPTNVEESLKRTKENDAHLVEVNLNNIKNIPIPTLKDFAKALETNTHVKCFSLAATRSNDPVATAFAEMLKVNKTLKSLNVESNFITGVGILALIDALRDNETLAELKIDNQRQQLGTAVELEMAKMLEENTNILKFGYQFTQQGPRTRAANAITKNNDLVRKRRVEGDHQ>sp|Q16890|TPD53_HUMAN Tumor protein D53 OS=Homo sapiens OX=9606GN=TPD52L1 PE=1 SV=1MEAQAQGLLETEPLQGTDEDAVASADFSSMLSEEEKEELKAELVQLEDEITTLRQVLSAKERHLVEIKQKLGMNLMNELKQNFSKSWHDMQTTTAYKKTHETLSHAGQKATAAFSNVGTAISKKFGDMSYSIRHSISMPAMRNSPTFKSFEERVETTVTSLKTKVGGTNPNGGSFEEVLSSTAHASAQSLAGGSRRTKEEELQC>sp|Q16890-2|TPD53_HUMAN Isoform 2 of Tumor protein D53 OS=Homo sapiensOX=9606 GN=TPD52L1MEAQAQGLLETEPLQGTDEDAVASADFSSMLSEEEKEELKAELVQLEDEITTLRQVLSAKERHLVEIKQKLGMNLMNELKQNFSKSWHDMQTTTAYKKTHETLSHAGQKATAAFSNVGTAISKKFGDMSYSIRHSISMPAMRRK>sp|Q16890-3|TPD53_HUMAN Isoform 3 of Tumor protein D53 OS=Homo sapiensOX=9606 GN=TPD52L1MEAQAQGLLETEPLQGTDEDAVASADFSSMLSEEEKEELKAELVQLEDEITTLRQVLSAKERHLVEIKQKLGMNLMNELKQNFSKSWHDMQTTTAYKKTHETLSHAGQKATAAFSNVGTAISKKFGDMRRK>sp|Q16890-4|TPD53_HUMAN Isoform 4 of Tumor protein D53 OS=Homo sapiensOX=9606 GN=TPD52L1MLSEEEKEELKAELVQLEDEITTLRQVLSAKERHLVEIKQKLGMNLMNELKQNFSKSWHDMQTTTAYKKTHETLSHAGQKATAAFSNVGTAISKKFGDMRRK>sp|Q16890-5|TPD53_HUMAN Isoform 5 of Tumor protein D53 OS=Homo sapiensOX=9606 GN=TPD52L1MLSEEEKEELKAELVQLEDEITTLRQVLSAKERHLVEIKQKLGMNLMNELKQNFSKSWHDMQTTTAYKKTHETLSHAGQKATAAFSNVGTAISKKFGDMSYSIRHSISMPAMRNSPTFKSFEERVETTVTSLKTKVGGTNPNGGSFEEVLSSTAHASAQSLAGGSRRTKEEELQC>sp|Q9BU79|TM243_HUMAN Transmembrane protein 243 OS=Homo sapiens OX=9606GN=TMEM243 PE=1 SV=1MEDFATRTYGTSGLDNRPLFGETSAKDRIINLVVGSLTSLLILVTLISAFVFPQLPPKPLNIFFAVCISLSSITACILIYWYRQGDLEPKFRKLIYYIIFSIIMLCICANLYFHDVGR>sp|O94826|TOM70_HUMAN Mitochondrial import receptor subunit TOM70OS=Homo sapiens OX=9606 GN=TOMM70 PE=1 SV=1MAASKPVEAAVVAAAVPSSGSGVGGGGTAGPGTGGLPRWQLALAVGAPLLLGAGAIYLWSRQQRRREARGRGDASGLKRNSERKTPEGRASPAPGSGHPEGPGAHLDMNSLDRAQAAKNKGNKYFKAGKYEQAIQCYTEAISLCPTEKNVDLSTFYQNRAAAFEQLQKWKEVAQDCTKAVELNPKYVKALFRRAKAHEKLDNKKECLEDVTAVCILEGFQNQQSMLLADKVLKLLGKEKAKEKYKNREPLMPSPQFIKSYFSSFTDDIISQPMLKGEKSDEDKDKEGEALEVKENSGYLKAKQYMEEENYDKIISECSKEIDAEGKYMAEALLLRATFYLLIGNANAAKPDLDKVISLKEANVKLRANALIKRGSMYMQQQQPLLSTQDFNMAADIDPQNADVYHHRGQLKILLDQVEEAVADFDECIRLRPESALAQAQKCFALYRQAYTGNNSSQIQAAMKGFEEVIKKFPRCAEGYALYAQALTDQQQFGKADEMYDKCIDLEPDNATTYVHKGLLQLQWKQDLDRGLELISKAIEIDNKCDFAYETMGTIEVQRGNMEKAIDMFNKAINLAKSEMEMAHLYSLCDAAHAQTEVAKKYGLKPPTL>sp|Q7Z410|TMPS9_HUMAN Transmembrane protease serine 9 OS=Homo sapiensOX=9606 GN=TMPRSS9 PE=1 SV=2MEPTVADVHLVPRTTKEVPALDAACCRAASIGVVATSLVVLTLGVLLAFLSTQGFHVDHTAELRGIRWTSSLRRETSDYHRTLTPTLEALLHFLLRPLQTLSLGLEEELLQRGIRARLREHGISLAAYGTIVSAELTGRHKGPLAERDFKSGRCPGNSFSCGNSQCVTKVNPECDDQEDCSDGSDEAHCECGLQPAWRMAGRIVGGMEASPGEFPWQASLRENKEHFCGAAIINARWLVSAAHCFNEFQDPTKWVAYVGATYLSGSEASTVRAQVVQIVKHPLYNADTADFDVAVLELTSPLPFGRHIQPVCLPAATHIFPPSKKCLISGWGYLKEDFLVKPEVLQKATVELLDQALCASLYGHSLTDRMVCAGYLDGKVDSCQGDSGGPLVCEEPSGRFFLAGIVSWGIGCAEARRPGVYARVTRLRDWILEATTKASMPLAPTMAPAPAAPSTAWPTSPESPVVSTPTKSMQALSTVPLDWVTVPKLQECGARPAMEKPTRVVGGFGAASGEVPWQVSLKEGSRHFCGATVVGDRWLLSAAHCFNHTKVEQVRAHLGTASLLGLGGSPVKIGLRRVVLHPLYNPGILDFDLAVLELASPLAFNKYIQPVCLPLAIQKFPVGRKCMISGWGNTQEGNATKPELLQKASVGIIDQKTCSVLYNFSLTDRMICAGFLEGKVDSCQGDSGGPLACEEAPGVFYLAGIVSWGIGCAQVKKPGVYTRITRLKGWILEIMSSQPLPMSPPSTTRMLATTSPRTTAGLTVPGATPSRPTPGAASRVTGQPANSTLSAVSTTARGQTPFPDAPEATTHTQLPDCGLAPAALTRIVGGSAAGRGEWPWQVSLWLRRREHRCGAVLVAERWLLSAAHCFDVYGDPKQWAAFLGTPFLSGAEGQLERVARIYKHPFYNLYTLDYDVALLELAGPVRRSRLVRPICLPEPAPRPPDGTRCVITGWGSVREGGSMARQLQKAAVRLLSEQTCRRFYPVQISSRMLCAGFPQGGVDSCSGDAGGPLACREPSGRWVLTGVTSWGYGCGRPHFPGVYTRVAAVRGWIGQHIQE>sp|Q9H0I9|TKTL2_HUMAN Transketolase-like protein 2 OS=Homo sapiensOX=9606 GN=TKTL2 PE=2 SV=1MMANDAKPDVKTVQVLRDTANRLRIHSIRATCASGSGQLTSCCSAAEVVSVLFFHTMKYKQTDPEHPDNDRFILSRGHAAPILYAAWVEVGDISESDLLNLRKLHSDLERHPTPRLPFVDVATGSLGQGLGTACGMAYTGKYLDKASYRVFCLMGDGESSEGSVWEAFAFASHYNLDNLVAVFDVNRLGQSGPAPLEHGADIYQNCCEAFGWNTYLVDGHDVEALCQAFWQASQVKNKPTAIVAKTFKGRGIPNIEDAENWHGKPVPKERADAIVKLIESQIQTNENLIPKSPVEDSPQISITDIKMTSPPAYKVGDKIATQKTYGLALAKLGRANERVIVLSGDTMNSTFSEIFRKEHPERFIECIIAEQNMVSVALGCATRGRTIAFAGAFAAFFTRAFDQLRMGAISQANINLIGSHCGVSTGEDGVSQMALEDLAMFRSIPNCTVFYPSDAISTEHAIYLAANTKGMCFIRTSQPETAVIYTPQENFEIGQAKVVRHGVNDKVTVIGAGVTLHEALEAADHLSQQGISVRVIDPFTIKPLDAATIISSAKATGGRVITVEDHYREGGIGEAVCAAVSREPDILVHQLAVSGVPQRGKTSELLDMFGISTRHIIAAVTLTLMK>sp|Q71RG4|TMUB2_HUMAN Transmembrane and ubiquitin-like domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=TMUB2 PE=1 SV=2MISRHLQNNLMSVDPASSQAMELSDVTLIEGVGNEVMVVAGVVVLILALVLAWLSTYVADSGSNQLLGAIVSAGDTSVLHLGHVDHLVAGQGNPEPTELPHPSEGNDEKAEEAGEGRGDSTGEAGAGGGVEPSLEHLLDIQGLPKRQAGAGSSSPEAPLRSEDSTCLPPSPGLITVRLKFLNDTEELAVARPEDTVGALKSKYFPGQESQMKLIYQGRLLQDPARTLRSLNITDNCVIHCHRSPPGSAVPGPSASLAPSATEPPSLGVNVGSLMVPVFVVLLGVVWYFRINYRQFFTAPATVSLVGVTVFFSFLVFGMYGR>sp|Q71RG4-2|TMUB2_HUMAN Isoform 2 of Transmembrane and ubiquitin-likedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=TMUB2MELSDVTLIEGVGNEVMVVAGVVVLILALVLAWLSTYVADSGSNQLLGAIVSAGDTSVLHLGHVDHLVAGQGNPEPTELPHPSEGNDEKAEEAGEGRGDSTGEAGAGGGVEPSLEHLLDIQGLPKRQAGAGSSSPEAPLRSEDSTCLPPSPGLITVRLKFLNDTEELAVARPEDTVGALKSKYFPGQESQMKLIYQGRLLQDPARTLRSLNITDNCVIHCHRSPPGSAVPGPSASLAPSATEPPSLGVNVGSLMVPVFVVLLGVVWYFRINYRQFFTAPATVSLVGVTVFFSFLVFGMYGR>sp|Q71RG4-3|TMUB2_HUMAN Isoform 3 of Transmembrane and ubiquitin-likedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=TMUB2MELSDVTLIEGVGNEVMVVAGVVVLILALVLAWLSTYVADSGSNQLLGAIVSAGDTSVLHLGHVDHLVAGQGNPEPTELPHPSEGNDEKAEEAGEGRGDSTGEAGAGGGVEPSLEHLLDIQGLPKRQAGAGSSSPEAPLRSEDSTCLPPSPGLITVRLKFLNDTEELAVARPEDTVGALKR>sp|Q71RG4-4|TMUB2_HUMAN Isoform 4 of Transmembrane and ubiquitin-likedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=TMUB2MELSDVTLIEGVGNEVMVVAGVVVLILALVLAWLSTYVADSGSNQLLGAIVSAGDTSVLHLGHVDHLVAGQGNPEPTELPHPSEANTSLDKKAR>sp|Q7Z6W1|TMCO2_HUMAN Transmembrane and coiled-coil domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=TMCO2 PE=1 SV=1MSTSSSSSWDNLLESLSLSTVWNWIQASFLGETSAPQQTSLGLLDNLAPAVQIILRISFLILLGIGIYALWKRSIQSIQKTLLFVITLYKLYKKGSHIFEALLANPEGSGLRIQDNNNLFLSLGLQEKILKKLKTVENKMKNLEGIIVAQKPATKRDCSSEPYCSCSDCQSPLSTSGFTSPI>sp|Q0VDI3|TM267_HUMAN Transmembrane protein 267 OS=Homo sapiens OX=9606GN=TMEM267 PE=1 SV=1MASETEKTHALLQTCSTESLISSLGLGAFCLVADRLLQFSTIQQNDWLRALSDNAVHCVIGMWSWAVVTGIKKKTDFGEIILAGFLASVIDVDHFFLAGSMSLKAALTLPRRPFLHCSTVIPVVVLTLKFTMHLFKLKDSWCFLPWMLFISWTSHHIRDGIRHGLWICPFGKTSPLPFWLYVIITSSLPHICSFVMYLTGTRQMMSSKHGVRIDV>sp|P0DPE3|TMDD1_HUMAN Transmembrane and death domain protein 1 OS=Homosapiens OX=9606 GN=TMDD1 PE=3 SV=1MAARTLASALVLTLWVWALAPAGAVDAMGPHAAVRLAELLTPEECGHFRSLLEAPEPDVEAELSRLSEDRLARPEPLNTTSGSPSRRRRREAAEDPAGRVAGPGEVSDGCREALAAWLAPQAASLSWDRLARALRRSGRPDVARELGKNLHQQATLQLRKFGQRFLPRPGAAARVPFAPAPRPRRAAVPAPDWDALQLIVERLPQPLYERSPMGWAGPLALGLLTGFVGALGTGALVVLLTLWITGGDGDRASPGSPGPLATVQGWWETKLLLPKERRAPPGAWAADGPDSPSPHSALALSCKMGAQSWGSGALDGL>sp|Q86UE8|TLK2_HUMAN Serine/threonine-protein kinase tousled-like 2OS=Homo sapiens OX=9606 GN=TLK2 PE=1 SV=2MMEELHSLDPRRQELLEARFTGVGVSKGPLNSESSNQSLCSVGSLSDKEVETPEKKQNDQRNRKRKAEPYETSQGKGTPRGHKISDYFEFAGGSAPGTSPGRSVPPVARSSPQHSLSNPLPRRVEQPLYGLDGSAAKEATEEQSALPTLMSVMLAKPRLDTEQLAQRGAGLCFTFVSAQQNSPSSTGSGNTEHSCSSQKQISIQHRQTQSDLTIEKISALENSKNSDLEKKEGRIDDLLRANCDLRRQIDEQQKMLEKYKERLNRCVTMSKKLLIEKSKQEKMACRDKSMQDRLRLGHFTTVRHGASFTEQWTDGYAFQNLIKQQERINSQREEIERQRKMLAKRKPPAMGQAPPATNEQKQRKSKTNGAENETPSSGNTELKDTAPALGAHSLLRLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRIHNEDNSQFKDHPTLNDRYLLLHLLGRGGFSEVYKAFDLTEQRYVAVKIHQLNKNWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDSFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIIMQIVNALKYLNEIKPPIIHYDLKPGNILLVNGTACGEIKITDFGLSKIMDDDSYNSVDGMELTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFYQCLYGRKPFGHNQSQQDILQENTILKATEVQFPPKPVVTPEAKAFIRRCLAYRKEDRIDVQQLACDPYLLPHIRKSVSTSSPAGAAIASTSGASNNSSSN>sp|Q86UE8-2|TLK2_HUMAN Isoform 2 of Serine/threonine-protein kinasetousled-like 2 OS=Homo sapiens OX=9606 GN=TLK2MMEELHSLDPRRQELLEARFTGVGVSKGPLNSESSNQSLCSVGSLSDKEVETPEKKQNDQRNRKRKAEPYETSQGKGTPRGHKISDYFEFAGGSAPGTSPGRSVPPVARSSPQHSLSNPLPRRVEQPLYGLDGSAAKEATEEQSALPTLMSVMLAKPRLDTEQLAQRGAGLCFTFVSAQQNSPSSTGSGNTEHSCSSQKQISIQHRQTQSDLTIEKISALENSKNSDLEKKEGRIDDLLRANCDLRRQIDEQQKMLEKYKERLNRCVTMSKKLLIEKSKQEKMACRDKSMQDRLRLGHFTTVRHGASFTEQWTDGYAFQNLIKQQERINSQREEIERQRKMLAKRKPPAMGQAPPATNEQKQRKSKTNGAENETLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRIHNEDNSQFKDHPTLNDRYLLLHLLGRGGFSEVYKAFDLTEQRYVAVKIHQLNKNWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDSFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIIMQIVNALKYLNEIKPPIIHYDLKPGNILLVNGTACGEIKITDFGLSKIMDDDSYNSVDGMELTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFYQCLYGRKPFGHNQSQQDILQENTILKATEVQFPPKPVVTPEAKAFIRRCLAYRKEDRIDVQQLACDPYLLPHIRKSVSTSSPAGAAIASTSGASNNSSSN>sp|Q86UE8-3|TLK2_HUMAN Isoform 3 of Serine/threonine-protein kinasetousled-like 2 OS=Homo sapiens OX=9606 GN=TLK2MMEELHSLDPRRQELLEARFTGVGVSKGPLNSESSNQSLCSVGSLSDKEVETPEKKQNDQRNRKRKAEPYETSQGKGTPRGHKISDYFERRVEQPLYGLDGSAAKEATEEQSALPTLMSVMLAKPRLDTEQLAQRGAGLCFTFVSAQQNSPSSTGSGNTEHSCSSQKQISIQHRQTQSDLTIEKISALENSKNSDLEKKEGRIDDLLRANCDLRRQIDEQQKMLEKYKERLNRCVTMSKKLLIEKSKQEKMACRDKSMQDRLRLGHFTTVRHGASFTEQWTDGYAFQNLIKQQERINSQREEIERQRKMLAKRKPPAMGQAPPATNEQKQRKSKTNGAENETLTLAEYHEQEEIFKLRLGHLKKEEAEIQAELERLERVRNLHIRELKRIHNEDNSQFKDHPTLNDRYLLLHLLGRGGFSEVYKAFDLTEQRYVAVKIHQLNKNWRDEKKENYHKHACREYRIHKELDHPRIVKLYDYFSLDTDSFCTVLEYCEGNDLDFYLKQHKLMSEKEARSIIMQIVNALKYLNEIKPPIIHYDLKPGNILLVNGTACGEIKITDFGLSKIMDDDSYNSVDGMELTSQGAGTYWYLPPECFVVGKEPPKISNKVDVWSVGVIFYQCLYGRKPFGHNQSQQDILQENTILKATEVQFPPKPVVTPEAKAFIRRCLAYRKEDRIDVQQLACDPYLLPHIRKSVSTSSPAGAAIASTSGASNNSSSN>sp|Q8WWH5|TRUB1_HUMAN Probable tRNA pseudouridine synthase 1 OS=Homosapiens OX=9606 GN=TRUB1 PE=1 SV=1MAASEAAVVSSPSLKTDTSPVLETAGTVAAMAATPSARAAAAVVAAAARTGSEARVSKAALATKLLSLSGVFAVHKPKGPTSAELLNRLKEKLLAEAGMPSPEWTKRKKQTLKIGHGGTLDSAARGVLVVGIGSGTKMLTSMLSGSKRYTAIGELGKATDTLDSTGRVTEEKPYDKITQEDIEGILQKFTGNIMQVPPLYSALKKDGQRLSTLMKRGEVVEAKPARPVTVYSISLQKFQPPFFTLDVECGGGFYIRSLVSDIGKELSSCANVLELTRTKQGPFTLEEHALPEDKWTIDDIAQSLEHCSSLFPAELALKKSKPESNEQVLSCEYITLNEPKREDDVIKTC>sp|Q96HH6|TMM19_HUMAN Transmembrane protein 19 OS=Homo sapiens OX=9606GN=TMEM19 PE=1 SV=1MTDLNDNICKRYIKMITNIVILSLIICISLAFWIISMTASTYYGNLRPISPWRWLFSVVVPVLIVSNGLKKKSLDHSGALGGLVVGFILTIANFSFFTSLLMFFLSSSKLTKWKGEVKKRLDSEYKEGGQRNWVQVFCNGAVPTELALLYMIENGPGEIPVDFSKQYSASWMCLSLLAALACSAGDTWASEVGPVLSKSSPRLITTWEKVPVGTNGGVTVVGLVSSLLGGTFVGIAYFLTQLIFVNDLDISAPQWPIIAFGGLAGLLGSIVDSYLGATMQYTGLDESTGMVVNSPTNKARHIAGKPILDNNAVNLFSSVLIALLLPTAAWGFWPRG>sp|Q96HH6-2|TMM19_HUMAN Isoform 2 of Transmembrane protein 19 OS=Homosapiens OX=9606 GN=TMEM19MTDLNDNICKRYIKMITNIVILSLIICISLAFWIISMTASTYYGNLRPISPWRWLFSVVVPVLIVSNGLKKKSLDHSGALGGLVVGFILTIANFSFFTSLLMFFLSSSKLTKWKGEVKKRLDSEYKEGGQRNWVQVFCNGAVPTELALLYMIENGPGEIPVDFSKQYSASWMCLSLLAALACSAGDTWASEVGPVLSKSSPRLITTWEKVPVGTNGGVTVVGLVSSLLGGTFVGIAYFLTQLIFVNDLDISAPQWPIIAFGGLAGLLGSIVDSYLGATMQYTGKNIPSFLQLIGMLKK>sp|O95900|TRUB2_HUMAN Mitochondrial mRNA pseudouridine synthase TRUB2OS=Homo sapiens OX=9606 GN=TRUB2 PE=1 SV=1MGSAGLSRLHGLFAVYKPPGLKWKHLRDTVELQLLKGLNARKPPAPKQRVRFLLGPMEGSEEKELTLTATSVPSFINHPLVCGPAFAHLKVGVGHRLDAQASGVLVLGVGHGCRLLTDMYNAHLTKDYTVRGLLGKATDDFREDGRLVEKTTYDHVTREKLDRILAVIQGSHQKALVMYSNLDLKTQEAYEMAVRGLIRPMNKSPMLITGIRCLYFAPPEFLLEVQCMHETQKELRKLVHEIGLELKTTAVCTQVRRTRDGFFTLDSALLRTQWDLTNIQDAIRAATPQVAAELEKSLSPGLDTKQLPSPGWSWDSQGPSSTLGLERGAGQ>sp|O95900-2|TRUB2_HUMAN Isoform 2 of Mitochondrial mRNA pseudouridinesynthase TRUB2 OS=Homo sapiens OX=9606 GN=TRUB2MEGSEEKELTLTATSVPSFINHPLVCGPAFAHLKVGVGHRLDAQASGVLVLGVGHGCRLLTDMYNAHLTKDYTVRGLLGKATDDFREDGRLVEKTTYDHVTREKLDRILAVIQGSHQKALVMYSNLDLKTQEAYEMAVRGLIRPMNKSPMLITGIRCLYFAPPEFLLEVQCMHETQKELRKLVHEIGLELKTTAVCTQVRRTRDGFFTLDSALLRTQWDLTNIQDAIRAATPQVAAELEKSLSPGLDTKQLPSPGWSWDSQGPSSTLGLERGAGQ>sp|Q9Y606|TRUA_HUMAN tRNA pseudouridine synthase A OS=Homo sapiensOX=9606 GN=PUS1 PE=1 SV=3MGLQLRALLGAFGRWTLRLGPRPSCSPRMAGNAEPPPAGAACPQDRRSCSGRAGGDRVWEDGEHPAKKLKSGGDEERREKPPKRKIVLLMAYSGKGYHGMQRNVGSSQFKTIEDDLVSALVRSGCIPENHGEDMRKMSFQRCARTDKGVSAAGQVVSLKVWLIDDILEKINSHLPSHIRILGLKRVTGGFNSKNRCDARTYCYLLPTFAFAHKDRDVQDETYRLSAETLQQVNRLLACYKGTHNFHNFTSQKGPQDPSACRYILEMYCEEPFVREGLEFAVIRVKGQSFMMHQIRKMVGLVVAIVKGYAPESVLERSWGTEKVDVPKAPGLGLVLERVHFEKYNQRFGNDGLHEPLDWAQEEGKVAAFKEEHIYPTIIGTERDERSMAQWLSTLPIHNFSATALTAGGTGAKVPSPLEGSEGDGDTD>sp|Q9Y606-2|TRUA_HUMAN Isoform 2 of tRNA pseudouridine synthase AOS=Homo sapiens OX=9606 GN=PUS1MAGNAEPPPAGAACPQDRRSCSGRAGGDRVWEDGEHPAKKLKSGGDEERREKPPKRKIVLLMAYSGKGYHGMQRNVGSSQFKTIEDDLVSALVRSGCIPENHGEDMRKMSFQRCARTDKGVSAAGQVVSLKVWLIDDILEKINSHLPSHIRILGLKRVTGGFNSKNRCDARTYCYLLPTFAFAHKDRDVQDETYRLSAETLQQVNRLLACYKGTHNFHNFTSQKGPQDPSACRYILEMYCEEPFVREGLEFAVIRVKGQSFMMHQIRKMVGLVVAIVKGYAPESVLERSWGTEKVDVPKAPGLGLVLERVHFEKYNQRFGNDGLHEPLDWAQEEGKVAAFKEEHIYPTIIGTERDERSMAQWLSTLPIHNFSATALTAGGTGAKVPSPLEGSEGDGDTD>sp|Q92574|TSC1_HUMAN Hamartin OS=Homo sapiens OX=9606 GN=TSC1 PE=1 SV=2MAQQANVGELLAMLDSPMLGVRDDVTAVFKENLNSDRGPMLVNTLVDYYLETSSQPALHILTTLQEPHDKHLLDRINEYVGKAATRLSILSLLGHVIRLQPSWKHKLSQAPLLPSLLKCLKMDTDVVVLTTGVLVLITMLPMIPQSGKQHLLDFFDIFGRLSSWCLKKPGHVAEVYLVHLHASVYALFHRLYGMYPCNFVSFLRSHYSMKENLETFEEVVKPMMEHVRIHPELVTGSKDHELDPRRWKRLETHDVVIECAKISLDPTEASYEDGYSVSHQISARFPHRSADVTTSPYADTQNSYGCATSTPYSTSRLMLLNMPGQLPQTLSSPSTRLITEPPQATLWSPSMVCGMTTPPTSPGNVPPDLSHPYSKVFGTTAGGKGTPLGTPATSPPPAPLCHSDDYVHISLPQATVTPPRKEERMDSARPCLHRQHHLLNDRGSEEPPGSKGSVTLSDLPGFLGDLASEEDSIEKDKEEAAISRELSEITTAEAEPVVPRGGFDSPFYRDSLPGSQRKTHSAASSSQGASVNPEPLHSSLDKLGPDTPKQAFTPIDLPCGSADESPAGDRECQTSLETSIFTPSPCKIPPPTRVGFGSGQPPPYDHLFEVALPKTAHHFVIRKTEELLKKAKGNTEEDGVPSTSPMEVLDRLIQQGADAHSKELNKLPLPSKSVDWTHFGGSPPSDEIRTLRDQLLLLHNQLLYERFKRQQHALRNRRLLRKVIKAAALEEHNAAMKDQLKLQEKDIQMWKVSLQKEQARYNQLQEQRDTMVTKLHSQIRQLQHDREEFYNQSQELQTKLEDCRNMIAELRIELKKANNKVCHTELLLSQVSQKLSNSESVQQQMEFLNRQLLVLGEVNELYLEQLQNKHSDTTKEVEMMKAAYRKELEKNRSHVLQQTQRLDTSQKRILELESHLAKKDHLLLEQKKYLEDVKLQARGQLQAAESRYEAQKRITQVFELEILDLYGRLEKDGLLKKLEEEKAEAAEAAEERLDCCNDGCSDSMVGHNEEASGHNGETKTPRPSSARGSSGSRGGGGSSSSSSELSTPEKPPHQRAGPFSSRWETTMGEASASIPTTVGSLPSSKSFLGMKARELFRNKSESQCDEDGMTSSLSESLKTELGKDLGVEAKIPLNLDGPHPSPPTPDSVGQLHIMDYNETHHEHS>sp|Q92574-2|TSC1_HUMAN Isoform 2 of Hamartin OS=Homo sapiens OX=9606GN=TSC1MAQQANVGELLAMLDSPMLGVRDDVTAVFKENLNSDRGPMLVNTLVDYYLETSSQPALHILTTLQEPHDKMDTDVVVLTTGVLVLITMLPMIPQSGKQHLLDFFDIFGRLSSWCLKKPGHVAEVYLVHLHASVYALFHRLYGMYPCNFVSFLRSHYSMKENLETFEEVVKPMMEHVRIHPELVTGSKDHELDPRRWKRLETHDVVIECAKISLDPTEASYEDGYSVSHQISARFPHRSADVTTSPYADTQNSYGCATSTPYSTSRLMLLNMPGQLPQTLSSPSTRLITEPPQATLWSPSMVCGMTTPPTSPGNVPPDLSHPYSKVFGTTAGGKGTPLGTPATSPPPAPLCHSDDYVHISLPQATVTPPRKEERMDSARPCLHRQHHLLNDRGSEEPPGSKGSVTLSDLPGFLGDLASEEDSIEKDKEEAAISRELSEITTAEAEPVVPRGGFDSPFYRDSLPGSQRKTHSAASSSQGASVNPEPLHSSLDKLGPDTPKQAFTPIDLPCGSADESPAGDRECQTSLETSIFTPSPCKIPPPTRVGFGSGQPPPYDHLFEVALPKTAHHFVIRKTEELLKKAKGNTEEDGVPSTSPMEVLDRLIQQGADAHSKELNKLPLPSKSVDWTHFGGSPPSDEIRTLRDQLLLLHNQLLYERFKRQQHALRNRRLLRKVIKAAALEEHNAAMKDQLKLQEKDIQMWKVSLQKEQARYNQLQEQRDTMVTKLHSQIRQLQHDREEFYNQSQELQTKLEDCRNMIAELRIELKKANNKVCHTELLLSQVSQKLSNSESVQQQMEFLNRQLLVLGEVNELYLEQLQNKHSDTTKEVEMMKAAYRKELEKNRSHVLQQTQRLDTSQKRILELESHLAKKDHLLLEQKKYLEDVKLQARGQLQAAESRYEAQKRITQVFELEILDLYGRLEKDGLLKKLEEEKAEAAEAAEERLDCCNDGCSDSMVGHNEEASGHNGETKTPRPSSARGSSGSRGGGGSSSSSSELSTPEKPPHQRAGPFSSRWETTMGEASASIPTTVGSLPSSKSFLGMKARELFRNKSESQCDEDGMTSSLSESLKTELGKDLGVEAKIPLNLDGPHPSPPTPDSVGQLHIMDYNETHHEHS>sp|Q8N7F7|UBL4B_HUMAN Ubiquitin-like protein 4B OS=Homo sapiens OX=9606GN=UBL4B PE=1 SV=1MFLTVKLLLGQRCSLKVSGQESVATLKRLVSRRLKVPEEQQHLLFRGQLLEDDKHLSDYCIGPNASINVIMQPLEKMALKEAHQPQTQPLWHQLGLVLAKHFEPQDAKAVLQLLRQEHEERLQKISLEHLEQLAQYLLAEEPHVEPAGERELEAKARPQSSCDMEEKEEAAADQ>sp|Q9BXA7|TSSK1_HUMAN Testis-specific serine/threonine-protein kinase 1OS=Homo sapiens OX=9606 GN=TSSK1B PE=1 SV=1MDDAAVLKRRGYLLGINLGEGSYAKVKSAYSERLKFNVAIKIIDRKKAPADFLEKFLPREIEILAMLNHCSIIKTYEIFETSHGKVYIVMELAVQGDLLELIKTRGALHEDEARKKFHQLSLAIKYCHDLDVVHRDLKCDNLLLDKDFNIKLSDFSFSKRCLRDDSGRMALSKTFCGSPAYAAPEVLQGIPYQPKVYDIWSLGVILYIMVCGSMPYDDSNIKKMLRIQKEHRVNFPRSKHLTGECKDLIYHMLQPDVNRRLHIDEILSHCWMQPKARGSPSVAINKEGESSRGTEPLWTPEPGSDKKSATKLEPEGEAQPQAQPETKPEGTAMQMSRQSEILGFPSKPSTMETEEGPPQQPPETRAQ>sp|Q9ULT0|TTC7A_HUMAN Tetratricopeptide repeat protein 7A OS=Homosapiens OX=9606 GN=TTC7A PE=1 SV=3MAAKGAHGSYLKVESELERCRAEGHWDRMPELVRQLQTLSMPGGGGNRRGSPSAAFTFPDTDDFGKLLLAEALLEQCLKENHAKIKDSMPLLEKNEPKMSEAKNYLSSILNHGRLSPQYMCEAMLILGKLHYVEGSYRDAISMYARAGIDDMSMENKPLYQMRLLSEAFVIKGLSLERLPNSIASRFRLTEREEEVITCFERASWIAQVFLQELEKTTNNSTSRHLKGCHPLDYELTYFLEAALQSAYVKNLKKGNIVKGMRELREVLRTVETKATQNFKVMAAKHLAGVLLHSLSEECYWSPLSHPLPEFMGKEESSFATQALRKPHLYEGDNLYCPKDNIEEALLLLLISESMATRDVVLSRVPEQEEDRTVSLQNAAAIYDLLSITLGRRGQYVMLSECLERAMKFAFGEFHLWYQVALSMVACGKSAYAVSLLRECVKLRPSDPTVPLMAAKVCIGSLRWLEEAEHFAMMVISLGEEAGEFLPKGYLALGLTYSLQATDATLKSKQDELHRKALQTLERAQQLAPSDPQVILYVSLQLALVRQISSAMEQLQEALKVRKDDAHALHLLALLFSAQKHHQHALDVVNMAITEHPENFNLMFTKVKLEQVLKGPEEALVTCRQVLRLWQTLYSFSQLGGLEKDGSFGEGLTMKKQSGMHLTLPDAHDADSGSRRASSIAASRLEEAMSELTMPSSVLKQGPMQLWTTLEQIWLQAAELFMEQQHLKEAGFCIQEAAGLFPTSHSVLYMRGRLAEVKGNLEEAKQLYKEALTVNPDGVRIMHSLGLMLSRLGHKSLAQKVLRDAVERQSTCHEAWQGLGEVLQAQGQNEAAVDCFLTALELEASSPVLPFSIIPREL>sp|Q9ULT0-3|TTC7A_HUMAN Isoform 2 of Tetratricopeptide repeat protein 7AOS=Homo sapiens OX=9606 GN=TTC7AMAAKGAHGSYLKVESELERCRAEGHWDRMPELVRQLQTLSMPGGGGNRRGSPSAAFTFPDTDDFGKLLLAEALLEQCLKENHAKIKDSMPLLEKNEPKMSEAKNYLSSILNHGRLSGLAVLLRLVSNSWAQAILLLQPPEALGLQE>sp|Q9ULT0-4|TTC7A_HUMAN Isoform 3 of Tetratricopeptide repeat protein 7AOS=Homo sapiens OX=9606 GN=TTC7AMAAKGAHGSYLKVESELERCRAEGHWDRMPELVRQLQTLSMPGGGGNRRGSPSAAFTFPDTDDFGKLLLAEALLEQCLKENHAKIKDSMPLLEKNEPKMSEAKNYLSSILNHGRLSPQYMCEAMLILGKLHYVEGSYRDAISMYARAGIDDMSMENKPLYQMRLLSEAFVIKGLSLERLPNSIASRFRLTEREEEVITCFERASWIAQVFLQELEKTTNNSTSRHLKGCHPLDYELTYFLEAALQSAYVKNLKKGNIVKGMRELREVLRTVETKATQNFKVMAAKHLAGVLLHSLSEECYWSPLSHPLPEFMGKEESSFATQALRKPHLYEGDNLYCPKDNIEEALLLLLISESMATRDVVLSRVPEQEEDRTVSLQNAAAIYDLLSITLGRRGQYVMLSECLERAMKFAFGEFHLWYQVALSMVACGKSAYAVSLLRECVKLRPSDPTVPLMAAKVCIGSLRWLEEAEHFAMMVISLGEEAGEFLPKGYLALGLTYSLQATDATLKSKQDELHRKALQTLERAQQLAPSDPQVILYVSLQLALVRQISSAMEQLQEALKVRKDDAHALHLLALLFSAQKHHQHALDVVNMAITEHPENFNLMFTKVKLEQVLKGPEEALVTCRQVLRLWQTLYSFSQLGDFRSPEGFQTPQRNICNSEIYRGGGLEKDGSFGEGLTMKKQSGMHLTLPDAHDADSGSRRASSIAASRLEEAMSELTMPSSVLKQGPMQLWTTLEQIWLQAAELFMEQQHLKEAGFCIQEAAGLFPTSHSVLYMRGRLAEVKGNLEEAKQLYKEALTVNPDGVRIMHSLGLMLSRLGHKSLAQKVLRDAVERQSTCHEAWQGLGEVLQAQGQNEAAVDCFLTALELEASSPVLPFSIIPREL>sp|Q13454|TUSC3_HUMAN Tumor suppressor candidate 3 OS=Homo sapiensOX=9606 GN=TUSC3 PE=1 SV=1MGARGAPSRRRQAGRRLRYLPTGSFPFLLLLLLLCIQLGGGQKKKENLLAEKVEQLMEWSSRRSIFRMNGDKFRKFIKAPPRNYSMIVMFTALQPQRQCSVCRQANEEYQILANSWRYSSAFCNKLFFSMVDYDEGTDVFQQLNMNSAPTFMHFPPKGRPKRADTFDLQRIGFAAEQLAKWIADRTDVHIRVFRPPNYSGTIALALLVSLVGGLLYLRRNNLEFIYNKTGWAMVSLCIVFAMTSGQMWNHIRGPPYAHKNPHNGQVSYIHGSSQAQFVAESHIILVLNAAITMGMVLLNEAATSKGDVGKRRIICLVGLGLVVFFFSFLLSIFRSKYHGYPYSDLDFE>sp|Q13454-2|TUSC3_HUMAN Isoform 2 of Tumor suppressor candidate 3OS=Homo sapiens OX=9606 GN=TUSC3MGARGAPSRRRQAGRRLRYLPTGSFPFLLLLLLLCIQLGGGQKKKENLLAEKVEQLMEWSSRRSIFRMNGDKFRKFIKAPPRNYSMIVMFTALQPQRQCSVCRQANEEYQILANSWRYSSAFCNKLFFSMVDYDEGTDVFQQLNMNSAPTFMHFPPKGRPKRADTFDLQRIGFAAEQLAKWIADRTDVHIRVFRPPNYSGTIALALLVSLVGGLLYLRRNNLEFIYNKTGWAMVSLCIVFAMTSGQMWNHIRGPPYAHKNPHNGQVSYIHGSSQAQFVAESHIILVLNAAITMGMVLLNEAATSKGDVGKRRIICLVGLGLVVFFFSFLLSIFRSKYHGYPYSFLIK>sp|O00526|UPK2_HUMAN Uroplakin-2 OS=Homo sapiens OX=9606 GN=UPK2 PE=1SV=2MAPLLPIRTLPLILILLALLSPGAADFNISSLSGLLSPALTESLLVALPPCHLTGGNATLMVRRANDSKVVTSSFVVPPCRGRRELVSVVDSGAGFTVTRLSAYQVTNLVPGTKFYISYLVKKGTATESSREIPMSTLPRRNMESIGLGMARTGGMVVITVLLSVAMFLLVLGFIIALALGSRK>sp|Q8N8Y2|VA0D2_HUMAN V-type proton ATPase subunit d 2 OS=Homo sapiensOX=9606 GN=ATP6V0D2 PE=1 SV=1MLEGAELYFNVDHGYLEGLVRGCKASLLTQQDYINLVQCETLEDLKIHLQTTDYGNFLANHTNPLTVSKIDTEMRKRLCGEFEYFRNHSLEPLSTFLTYMTCSYMIDNVILLMNGALQKKSVKEILGKCHPLGRFTEMEAVNIAETPSDLFNAILIETPLAPFFQDCMSENALDELNIELLRNKLYKSYLEAFYKFCKNHGDVTAEVMCPILEFEADRRAFIITLNSFGTELSKEDRETLYPTFGKLYPEGLRLLAQAEDFDQMKNVADHYGVYKPLFEAVGGSGGKTLEDVFYEREVQMNVLAFNRQFHYGVFYAYVKLKEQEIRNIVWIAECISQRHRTKINSYIPIL>sp|P21281|VATB2_HUMAN V-type proton ATPase subunit B, brain isoformOS=Homo sapiens OX=9606 GN=ATP6V1B2 PE=1 SV=3MALRAMRGIVNGAAPELPVPTGGPAVGAREQALAVSRNYLSQPRLTYKTVSGVNGPLVILDHVKFPRYAEIVHLTLPDGTKRSGQVLEVSGSKAVVQVFEGTSGIDAKKTSCEFTGDILRTPVSEDMLGRVFNGSGKPIDRGPVVLAEDFLDIMGQPINPQCRIYPEEMIQTGISAIDGMNSIARGQKIPIFSAAGLPHNEIAAQICRQAGLVKKSKDVVDYSEENFAIVFAAMGVNMETARFFKSDFEENGSMDNVCLFLNLANDPTIERIITPRLALTTAEFLAYQCEKHVLVILTDMSSYAEALREVSAAREEVPGRRGFPGYMYTDLATIYERAGRVEGRNGSITQIPILTMPNDDITHPIPDLTGYITEGQIYVDRQLHNRQIYPPINVLPSLSRLMKSAIGEGMTRKDHADVSNQLYACYAIGKDVQAMKAVVGEEALTSDDLLYLEFLQKFERNFIAQGPYENRTVFETLDIGWQLLRIFPKEMLKRIPQSTLSEFYPRDSAKH>sp|Q9UBK9|UXT_HUMAN Protein UXT OS=Homo sapiens OX=9606 GN=UXT PE=1 SV=1MATPPKRRAVEATGEKVLRYETFISDVLQRDLRKVLDHRDKVYEQLAKYLQLRNVIERLQEAKHSELYMQVDLGCNFFVDTVVPDTSRIYVALGYGFFLELTLAEALKFIDRKSSLLTELSNSLTKDSMNIKAHIHMLLEGLRELQGLQNFPEKPHH>sp|Q9UBK9-2|UXT_HUMAN Isoform 1 of Protein UXT OS=Homo sapiens OX=9606GN=UXTMVFPLPTPQEPIMATPPKRRAVEATGEKVLRYETFISDVLQRDLRKVLDHRDKVYEQLAKYLQLRNVIERLQEAKHSELYMQVDLGCNFFVDTVVPDTSRIYVALGYGFFLELTLAEALKFIDRKSSLLTELSNSLTKDSMNIKAHIHMLLEGLRELQGLQNFPEKPHH>sp|Q8TED0|UTP15_HUMAN U3 small nucleolar RNA-associated protein 15homolog OS=Homo sapiens OX=9606 GN=UTP15 PE=1 SV=3MAGYKPVAIQTYPILGEKITQDTLYWNNYKTPVQIKEFGAVSKVDFSPQPPYNYAVTASSRIHIYGRYSQEPIKTFSRFKDTAYCATFRQDGRLLVAGSEDGGVQLFDISGRAPLRQFEGHTKAVHTVDFTADKYHVVSGADDYTVKLWDIPNSKEILTFKEHSDYVRCGCASKLNPDLFITGSYDHTVKMFDARTSESVLSVEHGQPVESVLLFPSGGLLVSAGGRYVKVWDMLKGGQLLVSLKNHHKTVTCLCLSSSGQRLLSGSLDRKVKVYSTTSYKVVHSFDYAASILSLALAHEDETIVVGMTNGILSVKHRKSEAKKESLPRRRRPAYRTFIKGKNYMKQRDDILINRPAKKHLELYDRDLKHFRISKALDRVLDPTCTIKTPEITVSIIKELNRRGVLANALAGRDEKEISHVLNFLIRNLSQPRFAPVLINAAEIIIDIYLPVIGQSPVVDKKFLLLQGLVEKEIDYQRELLETLGMMDMLFATMRRKEGTSVLEHTSDGFPENKKIES>sp|Q8TED0-2|UTP15_HUMAN Isoform 2 of U3 small nucleolar RNA-associatedprotein 15 homolog OS=Homo sapiens OX=9606 GN=UTP15MFDARTSESVLSVEHGQPVESVLLFPSGGLLVSAGGRYVKVWDMLKGGQLLVSLKNHHKTVTCLCLSSSGQRLLSGSLDRKVKVYSTTSYKVVHSFDYAASILSLALAHEDETIVVGMTNGILSVKHRKSEAKKESLPRRRRPAYRTFIKGKNYMKQRDDILINRPAKKHLELYDRDLKHFRISKALDRVLDPTCTIKTPEITVSIIKELNRRGVLANALAGRDEKEISHVLNFLIRNLSQPRFAPVLINAAEIIIDIYLPVIGQSPVVDKKFLLLQGLVEKEIDYQRELLETLGMMDMLFATMRRKEGTSVLEHTSDGFPENKKIES>sp|Q8TED0-3|UTP15_HUMAN Isoform 3 of U3 small nucleolar RNA-associatedprotein 15 homolog OS=Homo sapiens OX=9606 GN=UTP15MAGYKPVAIQTYPILGEKITQDTLYWNNYKPPYNYAVTASSRIHIYGRYSQEPIKTFSRFKDTAYCATFRQDGRLLVAGSEDGGVQLFDISGRAPLRQFEGHTKAVHTVDFTADKYHVVSGADDYTVKLWDIPNSKEILTFKEHSDYVRCGCASKLNPDLFITGSYDHTVKMFDARTSESVLSVEHGQPVESVLLFPSGGLLVSAGGRYVKVWDMLKGGQLLVSLKNHHKTVTCLCLSSSGQRLLSGSLDRKVKVYSTTSYKVVHSFDYAASILSLALAHEDETIVVGMTNGILSVKHRKSEAKKESLPRRRRPAYRTFIKGKNYMKQRDDILINRPAKKHLELYDRDLKHFRISKALDRVLDPTCTIKTPEITVSIIKELNRRGVLANALAGRDEKEISHVLNFLIRNLSQPRFAPVLINAAEIIIDIYLPVIGQSPVVDKKFLLLQGLVEKEIDYQRELLETLGMMDMLFATMRRKEGTSVLEHTSDGFPENKKIES>sp|Q96LB4|VATG3_HUMAN V-type proton ATPase subunit G 3 OS=Homo sapiensOX=9606 GN=ATP6V1G3 PE=1 SV=1MTSQSQGIHQLLQAEKRAKDKLEEAKKRKGKRLKQAKEEAMVEIDQYRMQRDKEFRLKQSKIMGSQNNLSDEIEEQTLGKIQELNGHYNKYMESVMNQLLSMVCDMKPEIHVNYRATN>sp|Q96LB4-3|VATG3_HUMAN Isoform 3 of V-type proton ATPase subunit G 3OS=Homo sapiens OX=9606 GN=ATP6V1G3MTSQSQGIHQLLQAEKRAKDKLEEAKKILHLLFLKRRDWDCFWKRKAIEASQGGSNGRN>sp|Q96LB4-4|VATG3_HUMAN Isoform 4 of V-type proton ATPase subunit G 3OS=Homo sapiens OX=9606 GN=ATP6V1G3MTSQSQGIHQLLQAEKRAKDKLEEAKKKTGTASGKGKRLKQAKEEAMVEIDQYRMQRDKEFRLKQSKIMGSQNNLSDEIEEQTLGKIQELNGHYNKYMESVMNQLLSMVCDMKPEIHVNYRATN>sp|Q6PCB0|VWA1_HUMAN von Willebrand factor A domain-containing protein 1OS=Homo sapiens OX=9606 GN=VWA1 PE=1 SV=1MLPWTALGLALSLRLALARSGAERGPPASAPRGDLMFLLDSSASVSHYEFSRVREFVGQLVAPLPLGTGALRASLVHVGSRPYTEFPFGQHSSGEAAQDAVRASAQRMGDTHTGLALVYAKEQLFAEASGARPGVPKVLVWVTDGGSSDPVGPPMQELKDLGVTVFIVSTGRGNFLELSAAASAPAEKHLHFVDVDDLHIIVQELRGSILDAMRPQQLHATEITSSGFRLAWPPLLTADSGYYVLELVPSAQPGAARRQQLPGNATDWIWAGLDPDTDYDVALVPESNVRLLRPQILRVRTRPGEAGPGASGPESGAGPAPTQLAALPAPEEAGPERIVISHARPRSLRVSWAPALGSAAALGYHVQFGPLRGGEAQRVEVPAGRNCTTLQGLAPGTAYLVTVTAAFRSGRESALSAKACTPDGPRPRPRPVPRAPTPGTASREP>sp|Q6PCB0-2|VWA1_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 1 OS=Homo sapiens OX=9606 GN=VWA1MRPQQLHATEITSSGFRLAWPPLLTADSGYYVLELVPSAQPGAARRQQLPGNATDWIWAGLDPDTDYDVALVPESNVRLLRPQILRVRTRPGEAGPGASGPESGAGPAPTQLAALPAPEEAGPERIVISHARPRSLRVSWAPALGSAAALGYHVQFGPLRGGEAQRVEVPAGRNCTTLQGLAPGTAYLVTVTAAFRSGRESALSAKACTPDGPRPRPRPVPRAPTPGTASREP>sp|Q6PCB0-3|VWA1_HUMAN Isoform 3 of von Willebrand factor A domain-containing protein 1 OS=Homo sapiens OX=9606 GN=VWA1MLPWTALGLALSLRLALARSGAERGAQGPGRHRVHCQHRPRQLPGAVSRCLSPCREAPALCGRG>sp|P47989|XDH_HUMAN Xanthine dehydrogenase/oxidase OS=Homo sapiensOX=9606 GN=XDH PE=1 SV=4MTADKLVFFVNGRKVVEKNADPETTLLAYLRRKLGLSGTKLGCGEGGCGACTVMLSKYDRLQNKIVHFSANACLAPICSLHHVAVTTVEGIGSTKTRLHPVQERIAKSHGSQCGFCTPGIVMSMYTLLRNQPEPTMEEIENAFQGNLCRCTGYRPILQGFRTFARDGGCCGGDGNNPNCCMNQKKDHSVSLSPSLFKPEEFTPLDPTQEPIFPPELLRLKDTPRKQLRFEGERVTWIQASTLKELLDLKAQHPDAKLVVGNTEIGIEMKFKNMLFPMIVCPAWIPELNSVEHGPDGISFGAACPLSIVEKTLVDAVAKLPAQKTEVFRGVLEQLRWFAGKQVKSVASVGGNIITASPISDLNPVFMASGAKLTLVSRGTRRTVQMDHTFFPGYRKTLLSPEEILLSIEIPYSREGEYFSAFKQASRREDDIAKVTSGMRVLFKPGTTEVQELALCYGGMANRTISALKTTQRQLSKLWKEELLQDVCAGLAEELHLPPDAPGGMVDFRCTLTLSFFFKFYLTVLQKLGQENLEDKCGKLDPTFASATLLFQKDPPADVQLFQEVPKGQSEEDMVGRPLPHLAADMQASGEAVYCDDIPRYENELSLRLVTSTRAHAKIKSIDTSEAKKVPGFVCFISADDVPGSNITGICNDETVFAKDKVTCVGHIIGAVVADTPEHTQRAAQGVKITYEELPAIITIEDAIKNNSFYGPELKIEKGDLKKGFSEADNVVSGEIYIGGQEHFYLETHCTIAVPKGEAGEMELFVSTQNTMKTQSFVAKMLGVPANRIVVRVKRMGGGFGGKETRSTVVSTAVALAAYKTGRPVRCMLDRDEDMLITGGRHPFLARYKVGFMKTGTVVALEVDHFSNVGNTQDLSQSIMERALFHMDNCYKIPNIRGTGRLCKTNLPSNTAFRGFGGPQGMLIAECWMSEVAVTCGMPAEEVRRKNLYKEGDLTHFNQKLEGFTLPRCWEECLASSQYHARKSEVDKFNKENCWKKRGLCIIPTKFGISFTVPFLNQAGALLHVYTDGSVLLTHGGTEMGQGLHTKMVQVASRALKIPTSKIYISETSTNTVPNTSPTAASVSADLNGQAVYAACQTILKRLEPYKKKNPSGSWEDWVTAAYMDTVSLSATGFYRTPNLGYSFETNSGNPFHYFSYGVACSEVEIDCLTGDHKNLRTDIVMDVGSSLNPAIDIGQVEGAFVQGLGLFTLEELHYSPEGSLHTRGPSTYKIPAFGSIPIEFRVSLLRDCPNKKAIYASKAVGEPPLFLAASIFFAIKDAIRAARAQHTGNNVKELFRLDSPATPEKIRNACVDKFTTLCVTGVPENCKPWSVRV>sp|Q641Q2|WAC2A_HUMAN WASH complex subunit 2A OS=Homo sapiens OX=9606GN=WASHC2A PE=1 SV=3MMNRTTPDQELAPASEPVWERPWSVEEIRRSSQSWSLAADAGLLQFLQEFSQQTISRTHEIKKQVDGLIRETKATDCRLHNVFNDFLMLSNTQFIENRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNRHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAVGRVDEEPTTLPSGEAKPRKTLKEKKERRTPSDDEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEAPQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSMKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTGKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSSSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASKLKGASLLPGKLPTLVSLFDDEDEEDNLFGGTAAKKQTLCLQAQREEKAKASELSKKKASALLFSSDEEDQWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDEEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKKKETVSEAPPLLFSDEEEKEAQLGVKSVDKKVESAKESLKFGRTDVAESEKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGRDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLVQEKKRVVKKDHSVDSFKNQKHPESIQGSKEKGIWKPETPQDSSGLAPFKTKEPSTRIGKIQANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSETEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDRSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSNSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSSGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|Q641Q2-2|WAC2A_HUMAN Isoform 2 of WASH complex subunit 2A OS=Homosapiens OX=9606 GN=WASHC2AMMNRTTPDQELAPASEPVWERPWSVEEIRRSSQSWSLAADAGLLQFLQEFSQQTISRTHEIKKQVDGLIRETKATDCRLHNVFNDFLMLSNTQFIENRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNRHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAVGRVDEEPTTLPSGEAKPRKTLKEKKERRTPSDDEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEAPQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSMKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTGKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSSSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASKLKGASLLPGKLPTLVSLFDDEDEEDNLFGGTAAKKQTLCLQAQREEKAKASELSKKKASALLFSSDEEDQWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDEEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKKKETVSEAPPLLFSDEEEKEAQLGVKSVDKKVESAKESLKFGRTDVAESEKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGRDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLVQEKKRVVKKDHSVDSFKNQKHPESIQGSKEKGIWKPETPQANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSETEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDRSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSNSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSSGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|A6NIX2|WTIP_HUMAN Wilms tumor protein 1-interacting protein OS=Homosapiens OX=9606 GN=WTIP PE=1 SV=3MQRSRAGADEAALLLAGLALRELEPGCGSPGRGRRGPRPGPGDEAAPALGRRGKGSGGPEAGADGLSRGERGPRRAAVPELSAQPAGSPRASLAGSDGGGGGGSARSSGISLGYDQRHGSPRSGRSDPRPGPGPPSVGSARSSVSSLGSRGSAGAYADFLPPGACPAPARSPEPAGPAPFPLPALPLPPGREGGPSAAERRLEALTRELERALEARTARDYFGICIKCGLGIYGAQQACQAMGSLYHTDCFTCDSCGRRLRGKAFYNVGEKVYCQEDFLYSGFQQTADKCSVCGHLIMEMILQALGKSYHPGCFRCSVCNECLDGVPFTVDVENNIYCVRDYHTVFAPKCASCARPILPAQGCETTIRVVSMDRDYHVACYHCEDCGLQLSGEEGRRCYPLAGHLLCRRCHLRRLQPGPLPSPTVHVTEL>sp|P51811|XK_HUMAN Membrane transport protein XK OS=Homo sapiens OX=9606GN=XK PE=1 SV=5MKFPASVLASVFLFVAETTAALSLSSTYRSGGDRMWQALTLLFSLLPCALVQLTLLFVHRDLSRDRPLVLLLHLLQLGPLFRCFEVFCIYFQSGNNEEPYVSITKKRQMPKNGLSEEIEKEVGQAEGKLITHRSAFSRASVIQAFLGSAPQLTLQLYISVMQQDVTVGRSLLMTISLLSIVYGALRCNILAIKIKYDEYEVKVKPLAYVCIFLWRSFEIATRVVVLVLFTSVLKTWVVVIILINFFSFFLYPWILFWCSGSPFPENIEKALSRVGTTIVLCFLTLLYTGINMFCWSAVQLKIDSPDLISKSHNWYQLLVYYMIRFIENAILLLLWYLFKTDIYMYVCAPLLVLQLLIGYCTAILFMLVFYQFFHPCKKLFSSSVSEGFQRWLRCFCWACRQQKPCEPIGKEDLQSSRDRDETPSSSKTSPEPGQFLNAEDLCSA>sp|Q9H6D3|XKR8_HUMAN XK-related protein 8 OS=Homo sapiens OX=9606GN=XKR8 PE=1 SV=1MPWSSRGALLRDLVLGVLGTAAFLLDLGTDLWAAVQYALGGRYLWAALVLALLGLASVALQLFSWLWLRADPAGLHGSQPPRRCLALLHLLQLGYLYRCVQELRQGLLVWQQEEPSEFDLAYADFLALDISMLRLFETFLETAPQLTLVLAIMLQSGRAEYYQWVGICTSFLGISWALLDYHRALRTCLPSKPLLGLGSSVIYFLWNLLLLWPRVLAVALFSALFPSYVALHFLGLWLVLLLWVWLQGTDFMPDPSSEWLYRVTVATILYFSWFNVAEGRTRGRAIIHFAFLLSDSILLVATWVTHSSWLPSGIPLQLWLPVGCGCFFLGLALRLVYYHWLHPSCCWKPDPDQVDGARSLLSPEGYQLPQNRRMTHLAQKFFPKAKDEAASPVKG>sp|P02774|VTDB_HUMAN Vitamin D-binding protein OS=Homo sapiens OX=9606GN=GC PE=1 SV=2MKRVLVLLLAVAFGHALERGRDYEKNKVCKEFSHLGKEDFTSLSLVLYSRKFPSGTFEQVSQLVKEVVSLTEACCAEGADPDCYDTRTSALSAKSCESNSPFPVHPGTAECCTKEGLERKLCMAALKHQPQEFPTYVEPTNDEICEAFRKDPKEYANQFMWEYSTNYGQAPLSLLVSYTKSYLSMVGSCCTSASPTVCFLKERLQLKHLSLLTTLSNRVCSQYAAYGEKKSRLSNLIKLAQKVPTADLEDVLPLAEDITNILSKCCESASEDCMAKELPEHTVKLCDNLSTKNSKFEDCCQEKTAMDVFVCTYFMPAAQLPELPDVELPTNKDVCDPGNTKVMDKYTFELSRRTHLPEVFLSKVLEPTLKSLGECCDVEDSTTCFNAKGPLLKKELSSFIDKGQELCADYSENTFTEYKKKLAERLKAKLPDATPTELAKLVNKHSDFASNCCSINSPPLYCDSEIDAELKNIL>sp|P02774-2|VTDB_HUMAN Isoform 2 of Vitamin D-binding protein OS=Homosapiens OX=9606 GN=GCMAALKHQPQEFPTYVEPTNDEICEAFRKDPKEYANQFMWEYSTNYGQAPLSLLVSYTKSYLSMVGSCCTSASPTVCFLKERLQLKHLSLLTTLSNRVCSQYAAYGEKKSRLSNLIKLAQKVPTADLEDVLPLAEDITNILSKCCESASEDCMAKELPEHTVKLCDNLSTKNSKFEDCCQEKTAMDVFVCTYFMPAAQLPELPDVELPTNKDVCDPGNTKVMDKYTFELSRRTHLPEVFLSKVLEPTLKSLGECCDVEDSTTCFNAKGPLLKKELSSFIDKGQELCADYSENTFTEYKKKLAERLKAKLPDATPTELAKLVNKHSDFASNCCSINSPPLYCDSEIDAELKNIL>sp|P02774-3|VTDB_HUMAN Isoform 3 of Vitamin D-binding protein OS=Homosapiens OX=9606 GN=GCMLWSWSEERGGAARLSGRKMKRVLVLLLAVAFGHALERGRDYEKNKVCKEFSHLGKEDFTSLSLVLYSRKFPSGTFEQVSQLVKEVVSLTEACCAEGADPDCYDTRTSALSAKSCESNSPFPVHPGTAECCTKEGLERKLCMAALKHQPQEFPTYVEPTNDEICEAFRKDPKEYANQFMWEYSTNYGQAPLSLLVSYTKSYLSMVGSCCTSASPTVCFLKERLQLKHLSLLTTLSNRVCSQYAAYGEKKSRLSNLIKLAQKVPTADLEDVLPLAEDITNILSKCCESASEDCMAKELPEHTVKLCDNLSTKNSKFEDCCQEKTAMDVFVCTYFMPAAQLPELPDVELPTNKDVCDPGNTKVMDKYTFELSRRTHLPEVFLSKVLEPTLKSLGECCDVEDSTTCFNAKGPLLKKELSSFIDKGQELCADYSENTFTEYKKKLAERLKAKLPDATPTELAKLVNKHSDFASNCCSINSPPLYCDSEIDAELKNIL>sp|Q6PJT7|ZC3HE_HUMAN Zinc finger CCCH domain-containing protein 14OS=Homo sapiens OX=9606 GN=ZC3H14 PE=1 SV=1MEIGTEISRKIRSAIKGKLQELGAYVDEELPDYIMVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPSNKSNFSRGDERRHEAAVPPLAIPSARPEKRDSRVSTSSQESKTTNVRQTYDDGAATRLMSTVKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQGTQQRQLLSRLQIDPVMAETLQMSQDYYDMESMVHADTRSFILKKPKLSEEVVVAPNQESGMKTADSLRVLSGHLMQTRDLVQPDKPASPKFIVTLDGVPSPPGYMSDQEEDMCFEGMKPVNQTAASNKGLRGLLHPQQLHLLSRQLEDPNGSFSNAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPAVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-2|ZC3HE_HUMAN Isoform 2 of Zinc finger CCCH domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MEIGTEISRKIRSAIKGKLQELGAYVDEELPDYIMVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPSNKSNFSRGDERRHEAAVPPLAIPSARPEKRDSRVSTSSQESKTTNVRQTYDDGAATRLMSTVKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQGTQQRQLLSRLQIDPVMAETLQMSQDYYDMESMVHADTRSFILKKPKLSEEVVVAPNQESGMKTADSLRVLSGHLMQTRDLVQPDKPASPKFIVTLDGVPSPPGYMSDQEEDMCFEGMKPVNQTAASNKGLRGLLHPQQLHLLSRQLEDPNGSFSNAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-3|ZC3HE_HUMAN Isoform 3 of Zinc finger CCCH domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MEIGTEISRKIRSAIKGKLQELGAYVDEELPDYIMVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPSNKSNFSRGDERRHEAAVPPLAIPSARPEKRDSRVSTSSQESKTTNVRQTYDDGAATRLMSTVKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-4|ZC3HE_HUMAN Isoform 4 of Zinc finger CCCH domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPSNKSNFSRGDERRHEAAVPPLAIPSARPEKRDSRVSTSSQESKTTNVRQTYDDGAATRLMSTVKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQGTQQRQLLSRLQIDPVMAETLQMSQAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPAVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-5|ZC3HE_HUMAN Isoform 5 of Zinc finger CCCH domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MEIGTEISRKIRSAIKGKLQELGAYVDEELPDYIMVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPSNKSNFSRGDERRHEAAVPPLAIPSARPEKRDSRVSTSSQESKTTNVRQTYDDGAATRLMSTVKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQDYYDMESMVHADTRSFILKKPKLSEEVVVAPNQESGMKTADSLRVLSGHLMQTRDLVQPDKPASPKFIVTLDGVPSPPGYMSDQEEDMCFEGMKPVNQTAASNKGLRGLLHPQQLHLLSRQLEDPNGSFSNAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPAVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-6|ZC3HE_HUMAN Isoform 6 of Zinc finger CCCH domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MRMSSKFPSPPLPIFLPPEPVDLGSITSSSCSLNELDNISHLLRKISADINEIKGMKAAILTVEANLFDLNVRVSKNEAKISSLEVKMNEYSTTYECNRQFEDQEEDTESQSRTTDVKIIGFLRNVEKGTQQRQLLSRLQIDPVMAETLQMSQAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-8|ZC3HE_HUMAN Isoform 8 of Zinc finger CCCH domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MRMSSKFPSPPLPIFLPPEPVDLGSITSSSCSLNELDNISHLLRKISADINEIKGMKAAILTVEANLFDLNVRVSKNEAKISSLEVKMNEYSTTYECNRQFEDQEEDTESQSRTTDVKIIGFLRNVEKAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPAVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-9|ZC3HE_HUMAN Isoform 9 of Zinc finger CCCH domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MEIGTEISRKIRSAIKGKLQELGAYVDEELPDYIMVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPSNKSNFSRGDERRHEAAVPPLAIPSARPEKRDSRVSTSSQESKTTNVRQTYDDGAATRLMSTVKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQGTQQRQLLSRLQIDPVMAETLQMSQDYYDMESMVHADTRSFILKKPKLSEEVVVAPNQESGMKTADSLRVLSGHLMQTRDLVQPDKPASPKFIVTLDGVPSPPGYMSDQEEDMCFEGMKPVNQTAASNKGLRGLLHPQQLHLLSRQLEDPNAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-10|ZC3HE_HUMAN Isoform 10 of Zinc finger CCCH domain-containing protein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MEIGTEISRKIRSAIKGKLQELGAYVDEELPDYIMVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPSNKSNFSRGDERRHEAAVPPLAIPSAKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPAVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|Q6PJT7-11|ZC3HE_HUMAN Isoform 11 of Zinc finger CCCH domain-containing protein 14 OS=Homo sapiens OX=9606 GN=ZC3H14MEIGTEISRKIRSAIKGKLQELGAYVDEELPDYIMVMVANKKSQDQMTEDLSLFLGNNTIRFTVWLHGVLDKLRSVTTEPSSLKSSDTNIFDSNVPPLAIPSARPEKRDSRVSTSSQESKTTNVRQTYDDGAATRLMSTVKPLREPAPSEDVIDIKPEPDDLIDEDLNFVQENPLSQKKPTVTLTYGSSRPSIEIYRPPASRNADSGVHLNRLQFQQQQNSIHAAKQLDMQSSWVYETGRLCEPEVLNSLEETYSPFFRNNSEKMSMEDENFRKRKLPVVSSVVKVKKFNHDGEEEEEDDDYGSRTGSISSSVSVPAKPERRPSLPPSKQANKNLILKAISEAQESVTKTTNYSTVPQKQTLPVAPRTRTSQEELLAEVVQGQSRTPRISPPIKEEETKGDSVEKNQGTQQRQLLSRLQIDPVMAETLQMSQAEMSELSVAQKPEKLLERCKYWPACKNGDECAYHHPISPCKAFPNCKFAEKCLFVHPNCKYDAKCTKPDCPFTHVSRRIPVLSPKPVAPPAPPSSSQLCRYFPACKKMECPFYHPKHCRFNTQCTRPDCTFYHPTINVPPRHALKWIRPQTSE>sp|P23025|XPA_HUMAN DNA repair protein complementing XP-A cells OS=Homosapiens OX=9606 GN=XPA PE=1 SV=1MAAADGALPEAAALEQPAELPASVRASIERKRQRALMLRQARLAARPYSATAAAATGGMANVKAAPKIIDTGGGFILEEEEEEEQKIGKVVHQPGPVMEFDYVICEECGKEFMDSYLMNHFDLPTCDNCRDADDKHKLITKTEAKQEYLLKDCDLEKREPPLKFIVKKNPHHSQWGDMKLYLKLQIVKRSLEVWGSQEALEEAKEVRQENREKMKQKKFDKKVKELRRAVRSSVWKRETIVHQHEYGPEENLEDDMYRKTCTMCGHELTYEKM>sp|Q9HAV4|XPO5_HUMAN Exportin-5 OS=Homo sapiens OX=9606 GN=XPO5 PE=1SV=1MAMDQVNALCEQLVKAVTVMMDPNSTQRYRLEALKFCEEFKEKCPICVPCGLRLAEKTQVAIVRHFGLQILEHVVKFRWNGMSRLEKVYLKNSVMELIANGTLNILEEENHIKDALSRIVVEMIKREWPQHWPDMLIELDTLSKQGETQTELVMFILLRLAEDVVTFQTLPPQRRRDIQQTLTQNMERIFSFLLNTLQENVNKYQQVKTDTSQESKAQANCRVGVAALNTLAGYIDWVSMSHITAENCKLLEILCLLLNEQELQLGAAECLLIAVSRKGKLEDRKPLMVLFGDVAMHYILSAAQTADGGGLVEKHYVFLKRLCQVLCALGNQLCALLGADSDVETPSNFGKYLESFLAFTTHPSQFLRSSTQMTWGALFRHEILSRDPLLLAIIPKYLRASMTNLVKMGFPSKTDSPSCEYSRFDFDSDEDFNAFFNSSRAQQGEVMRLACRLDPKTSFQMAGEWLKYQLSTFLDAGSVNSCSAVGTGEGSLCSVFSPSFVQWEAMTLFLESVITQMFRTLNREEIPVNDGIELLQMVLNFDTKDPLILSCVLTNVSALFPFVTYRPEFLPQVFSKLFSSVTFETVEESKAPRTRAVRNVRRHACSSIIKMCRDYPQLVLPNFDMLYNHVKQLLSNELLLTQMEKCALMEALVLISNQFKNYERQKVFLEELMAPVASIWLSQDMHRVLSDVDAFIAYVGTDQKSCDPGLEDPCGLNRARMSFCVYSILGVVKRTCWPTDLEEAKAGGFVVGYTSSGNPIFRNPCTEQILKLLDNLLALIRTHNTLYAPEMLAKMAEPFTKALDMLDAEKSAILGLPQPLLELNDSPVFKTVLERMQRFFSTLYENCFHILGKAGPSMQQDFYTVEDLATQLLSSAFVNLNNIPDYRLRPMLRVFVKPLVLFCPPEHYEALVSPILGPLFTYLHMRLSQKWQVINQRSLLCGEDEAADENPESQEMLEEQLVRMLTREVMDLITVCCVSKKGADHSSAPPADGDDEEMMATEVTPSAMAELTDLGKCLMKHEDVCTALLITAFNSLAWKDTLSCQRTTSQLCWPLLKQVLSGTLLADAVTWLFTSVLKGLQMHGQHDGCMASLVHLAFQIYEALRPRYLEIRAVMEQIPEIQKDSLDQFDCKLLNPSLQKVADKRRKDQFKRLIAGCIGKPLGEQFRKEVHIKNLPSLFKKTKPMLETEVLDNDGGGLATIFEP>sp|Q8N8H1|ZN321_HUMAN Putative protein ZNF321 OS=Homo sapiens OX=9606GN=ZNF321P PE=5 SV=3MMKEFSSTAQGNTEVIHTGTLQRHESHHIRDFCFQEIEKDIHNFEFQWQEEERNGHEAPMTEIKELTGSTDRHDQRHAGNKPIKDQLGSSFHSHLPELHIFQPEWKIGNQVEKSIINASLILTSQRISCSPKTRISNNYGNNSLHSSLPIQKLGSTHERKIFPM>sp|Q86XK7|VSIG1_HUMAN V-set and immunoglobulin domain-containing protein1 OS=Homo sapiens OX=9606 GN=VSIG1 PE=1 SV=1MVFAFWKVFLILSCLAGQVSVVQVTIPDGFVNVTVGSNVTLICIYTTTVASREQLSIQWSFFHKKEMEPISIYFSQGGQAVAIGQFKDRITGSNDPGNASITISHMQPADSGIYICDVNNPPDFLGQNQGILNVSVLVKPSKPLCSVQGRPETGHTISLSCLSALGTPSPVYYWHKLEGRDIVPVKENFNPTTGILVIGNLTNFEQGYYQCTAINRLGNSSCEIDLTSSHPEVGIIVGALIGSLVGAAIIISVVCFARNKAKAKAKERNSKTIAELEPMTKINPRGESEAMPREDATQLEVTLPSSIHETGPDTIQEPDYEPKPTQEPAPEPAPGSEPMAVPDLDIELELEPETQSELEPEPEPEPESEPGVVVEPLSEDEKGVVKA>sp|Q86XK7-2|VSIG1_HUMAN Isoform 2 of V-set and immunoglobulin domain-containing protein 1 OS=Homo sapiens OX=9606 GN=VSIG1MVFAFWKVFLILSCLAGQVSVVQVTIPDGFVNVTVGSNVTLICIYTTTVASREQLSIQWSFFHKKEMEPISHSSCLSTEGMEEKAVSQCLKMTHARDARGRCSWTSEIYFSQGGQAVAIGQFKDRITGSNDPGNASITISHMQPADSGIYICDVNNPPDFLGQNQGILNVSVLVKPSKPLCSVQGRPETGHTISLSCLSALGTPSPVYYWHKLEGRDIVPVKENFNPTTGILVIGNLTNFEQGYYQCTAINRLGNSSCEIDLTSSHPEVGIIVGALIGSLVGAAIIISVVCFARNKAKAKAKERNSKTIAELEPMTKINPRGESEAMPREDATQLEVTLPSSIHETGPDTIQEPDYEPKPTQEPAPEPAPGSEPMAVPDLDIELELEPETQSELEPEPEPEPESEPGVVVEPLSEDEKGVVKA>sp|Q5T750|XP32_HUMAN Skin-specific protein 32 OS=Homo sapiens OX=9606GN=XP32 PE=1 SV=1MCDQQKQPQFPPSCVKGSGLGAGQGSNGASVKCPVPCQTQTVCVTGPAPCPTQTYVKYQVPCQTQTYVKCPAPCQRTYVKYPTPCQTYVKCPAPCQTTYVKCPTPCQTYVKCPAPCQMTYIKSPAPCQTQTCYVQGASPCQSYYVQAPASGSTSQYCVTDPCSAPCSTSYCCLAPRTFGVSPLRRWIQRPQNCNTGSSGCCENSGSSGCCGSGGCGCSCGCGSSGCCCLGIIPMRSRGPACCDHEDDCCC>sp|Q6FIF0|ZFAN6_HUMAN AN1-type zinc finger protein 6 OS=Homo sapiensOX=9606 GN=ZFAND6 PE=1 SV=2MAQETNHSQVPMLCSTGCGFYGNPRTNGMCSVCYKEHLQRQNSSNGRISPPATSVSSLSESLPVQCTDGSVPEAQSALDSTSSSMQPSPVSNQSLLSESVASSQLDSTSVDKAVPETEDVQASVSDTAQQPSEEQSKSLEKPKQKKNRCFMCRKKVGLTGFECRCGNVYCGVHRYSDVHNCSYNYKADAAEKIRKENPVVVGEKIQKI>sp|Q6FIF0-2|ZFAN6_HUMAN Isoform 2 of AN1-type zinc finger protein 6OS=Homo sapiens OX=9606 GN=ZFAND6MAQETNHSQVPMLCSTGCGFYGNPRTNGMCSVCYKEHLQRQNSSNGRISPPVQCTDGSVPEAQSALDSTSSSMQPSPVSNQSLLSESVASSQLDSTSVDKAVPETEDVQASVSDTAQQPSEEQSKSLEKPKQKKNRCFMCRKKVGLTGFECRCGNVYCGVHRYSDVHNCSYNYKADAAEKIRKENPVVVGEKIQKI>sp|O60481|ZIC3_HUMAN Zinc finger protein ZIC 3 OS=Homo sapiens OX=9606GN=ZIC3 PE=1 SV=1MTMLLDGGPQFPGLGVGSFGAPRHHEMPNREPAGMGLNPFGDSTHAAAAAAAAAAFKLSPAAAHDLSSGQSSAFTPQGSGYANALGHHHHHHHHHHHTSQVPSYGGAASAAFNSTREFLFRQRSSGLSEAASGGGQHGLFAGSASSLHAPAGIPEPPSYLLFPGLHEQGAGHPSPTGHVDNNQVHLGLRGELFGRADPYRPVASPRTDPYAAGAQFPNYSPMNMNMGVNVAAHHGPGAFFRYMRQPIKQELSCKWIDEAQLSRPKKSCDRTFSTMHELVTHVTMEHVGGPEQNNHVCYWEECPREGKSFKAKYKLVNHIRVHTGEKPFPCPFPGCGKIFARSENLKIHKRTHTGEKPFKCEFEGCDRRFANSSDRKKHMHVHTSDKPYICKVCDKSYTHPSSLRKHMKVHESQGSDSSPAASSGYESSTPPAIASANSKDTTKTPSAVQTSTSHNPGLPPNFNEWYV>sp|O60481-2|ZIC3_HUMAN Isoform 2 of Zinc finger protein ZIC 3 OS=Homosapiens OX=9606 GN=ZIC3MTMLLDGGPQFPGLGVGSFGAPRHHEMPNREPAGMGLNPFGDSTHAAAAAAAAAAFKLSPAAAHDLSSGQSSAFTPQGSGYANALGHHHHHHHHHHHTSQVPSYGGAASAAFNSTREFLFRQRSSGLSEAASGGGQHGLFAGSASSLHAPAGIPEPPSYLLFPGLHEQGAGHPSPTGHVDNNQVHLGLRGELFGRADPYRPVASPRTDPYAAGAQFPNYSPMNMNMGVNVAAHHGPGAFFRYMRQPIKQELSCKWIDEAQLSRPKKSCDRTFSTMHELVTHVTMEHVGGPEQNNHVCYWEECPREGKSFKAKYKLVNHIRVHTGEKPFPCPFPGCGKIFARSENLKIHKRTHTGEKPFKCEFEGCDRRFANSSDRKKHMHVHTSDKPYICKVCDKSYTHPSSLRKHMKCCPAWYPGQSLIPDEELDTDVGMQQPALHNTTYPKCRVNAEPTVQEMIY>sp|Q9H4Z2|ZN335_HUMAN Zinc finger protein 335 OS=Homo sapiens OX=9606GN=ZNF335 PE=1 SV=1MEENEVESSSDAAPGPGRPEEPSESGLGVGTSEAVSADSSDAAAAPGQAEADDSGVGQSSDRGSRSQEEVSESSSSADPLPNSYLPDSSSVSHGPVAGVTGGPPALVHSSALPDPNMLVSDCTASSSDLGSAIDKIIESTIGPDLIQNCITVTSAEDGGAETTRYLILQGPDDGAPMTSPMSSSTLAHSLAAIEALADGPTSTSTCLEAQGGPSSPVQLPPASGAEEPDLQSLEAMMEVVVVQQFKCKMCQYRSSTKATLLRHMRERHFRPVAAAAAAAGKKGRLRKWSTSTKSQEEEGPEEEDDDDIVDAGAIDDLEEDSDYNPAEDEPRGRQLRLQRPTPSTPRPRRRPGRPRKLPRLEISDLPDGVEGEPLVSSQSGQSPPEPQDPEAPSSSGPGHLVAMGKVSRTPVEAGVSQSDAENAAPSCPDEHDTLPRRRGRPSRRFLGKKYRKYYYKSPKPLLRPFLCRICGSRFLSHEDLRFHVNSHEAGDPQLFKCLQCSYRSRRWSSLKEHMFNHVGSKPYKCDECSYTSVYRKDVIRHAAVHSRDRKKRPDPTPKLSSFPCPVCGRVYPMQKRLTQHMKTHSTEKPHMCDKCGKSFKKRYTFKMHLLTHIQAVANRRFKCEFCEFVCEDKKALLNHQLSHVSDKPFKCSFCPYRTFREDFLLSHVAVKHTGAKPFACEYCHFSTRHKKNLRLHVRCRHASSFEEWGRRHPEEPPSRRRPFFSLQQIEELKQQHSAAPGPPPSSPGPPEIPPEATTFQSSEAPSLLCSDTLGGATIIYQQGAEESTAMATQTALDLLLNMSAQRELGGTALQVAVVKSEDVEAGLASPGGQPSPEGATPQVVTLHVAEPGGGAAAESQLGPPDLPQITLAPGPFGGTGYSVITAPPMEEGTSAPGTPYSEEPAGEAAQAVVVSDTLKEAGTHYIMATDGTQLHHIELTADGSISFPSPDALASGAKWPLLQCGGLPRDGPEPPSPAKTHCVGDSQSSASSPPATSKALGLAVPPSPPSAATAASKKFSCKICAEAFPGRAEMESHKRAHAGPGAFKCPDCPFSARQWPEVRAHMAQHSSLRPHQCSQCSFASKNKKDLRRHMLTHTKEKPFACHLCGQRFNRNGHLKFHIQRLHSPDGRKSGTPTARAPTQTPTQTIILNSDDETLATLHTALQSSHGVLGPERLQQALSQEHIIVAQEQTVTNQEEAAYIQEITTADGQTVQHLVTSDNQVQYIISQDGVQHLLPQEYVVVPEGHHIQVQEGQITHIQYEQGAPFLQESQIQYVPVSPGQQLVTQAQLEAAAHSAVTAVADAAMAQAQGLFGTDETVPEHIQQLQHQGIEYDVITLADD>sp|Q9H4Z2-2|ZN335_HUMAN Isoform 2 of Zinc finger protein 335 OS=Homosapiens OX=9606 GN=ZNF335MATSSMPESERNVATKASGAPMTSPMSSSTLAHSLAAIEALADGPTSTSTCLEAQGGPSSPVQLPPASGAEEPDLQSLEAMMEVVVVQQFKCKMCQYRSSTKATLLRHMRERHFRPVAAAAAAAGKKGRLRKWSTSTKSQEEEGPEEEDDDDIVDAGAIDDLEEDSDYNPAEDEPRGRQLRLQRPTPSTPRPRRRPGRPRKLPRLEISDLPDGVEGEPLVSSQSGQSPPEPQDPEAPSSSGPGHLVAMGKVSRTPVEAGVSQSDAENAAPSCPDEHDTLPRRRGRPSRRFLGKKYRKYYYKSPKPLLRPFLCRICGSRFLSHEDLRFHVNSHEAGDPQLFKCLQCSYRSRRWSSLKEHMFNHVGSKPYKCDECSYTSVYRKDVIRHAAVHSRDRKKRPDPTPKLSSFPCPVCGRVYPMQKRLTQHMKTHSTEKPHMCDKCGKSFKKRYTFKMHLLTHIQAVANRRFKCEFCEFVCEDKKALLNHQLSHVSDKPFKCSFCPYRTFREDFLLSHVAVKHTGAKPFACEYCHFSTRHKKNLRLHVRCRHASSFEEWGRRHPEEPPSRRRPFFSLQQIEELKQQHSAAPGPPPSSPGPPEIPPEATTFQSSEAPSLLCSDTLGGATIIYQQGAEESTAMATQTALDLLLNMSAQRELGGTALQVAVVKSEDVEAGLASPGGQPSPEGATPQVVTLHVAEPGGGAAAESQLGPPDLPQITLAPGPFGGTGYSVITAPPMEEGTSAPGTPYSEEPAGEAAQAVVVSDTLKEAGTHYIMATDGTQLHHIELTADGSISFPSPDALASGAKWPLLQCGGLPRDGPEPPSPAKTHCVGDSQSSASSPPATSKALGLAVPPSPPSAATAASKKFSCKICAEAFPGRAEMESHKRAHAGPGAFKCPDCPFSARQWPEVRAHMAQHSSLRPHQCSQCSFASKNKKDLRRHMLTHTKEKPFACHLCGQRFNRNGHLKFHIQRLHSPDGRKSGTPTARAPTQTPTQTIILNSDDETLATLHTALQSSHGVLGPERLQQALSQEHIIVAQEQTVTNQEEAAYIQEITTADGQTVQHLVTSDNQVQYIISQDGVQHLLPQEYVVVPEGHHIQVQEGQITHIQYEQGAPFLQESQIQYVPVSPGQQLVTQAQLEAAAHSAVTAVADAAMAQAQGLFGTDETVPEHIQQLQHQGIEYDVITLADD>sp|Q8TBK6|ZCH10_HUMAN Zinc finger CCHC domain-containing protein 10OS=Homo sapiens OX=9606 GN=ZCCHC10 PE=1 SV=1MATPMHRLIARRQAFDTELQPVKTFWILIQPSIVISEANKQHVRCQKCLEFGHWTYECTGKRKYLHRPSRTAELKKALKEKENRLLLQQSIGETNVERKAKKKRSKSVTSSSSSSSDSSASDSSSESEETSTSSSSEDSDTDESSSSSSSSASSTTSSSSSDSDSDSSSSSSSSTSTDSSSDDEPPKKKKKK>sp|Q8TBK6-2|ZCH10_HUMAN Isoform 2 of Zinc finger CCHC domain-containingprotein 10 OS=Homo sapiens OX=9606 GN=ZCCHC10MATPMHRLIARRQAEANKQHVRCQKCLEFGHWTYECTGKRKYLHRPSRTAELKKALKEKENRLLLQQSIGETNVERKAKKKRSKSVTSSSSSSSDSSASDSSSESEETSTSSSSEDSDTDESSSSSSSSASSTTSSSSSDSDSDSSSSSSSSTSTDSSSDDEPPKKKKKK>sp|Q5T742|ZFAS1_HUMAN Uncharacterized protein ZNF22-AS1 OS=Homo sapiensOX=9606 GN=ZNF22-AS1 PE=5 SV=3MVPGPPESVVRFFLWFCFLLPPTRKASCDPRDLKSCNRPCVWSRLLKPNSSLSNLETAYFPQILRFLRPWYFSRSHLNYHQKAPARWEWLYSIYRKGTKAQRRNVLRSPCAPPQPSWPCSVI>sp|Q8N9L1|ZIC4_HUMAN Zinc finger protein ZIC 4 OS=Homo sapiens OX=9606GN=ZIC4 PE=2 SV=3MRYKTSLVMRKRLRLYRNTLKESSSSSGHHGPQLTAASSPSVFPGLHEEPPQASPSRPLNGLLRLGLPGDMYARPEPFPPGPAARSDALAAAAALHGYGGMNLTVNLAAPHGPGAFFRYMRQPIKQELICKWLAADGTATPSLCSKTFSTMHELVTHVTVEHVGGPEQANHICFWEECPRQGKPFKAKYKLVNHIRVHTGEKPFPCPFPGCGKVFARSENLKIHKRTHTGEKPFRCEFEGCERRFANSSDRKKHSHVHTSDKPYTCKVRGCDKCYTHPSSLRKHMKVHGRSPPPSSGYDSATPSALVSPSSDCGHKSQVASSAAVAARTADLSE>sp|Q8N9L1-2|ZIC4_HUMAN Isoform 2 of Zinc finger protein ZIC 4 OS=Homosapiens OX=9606 GN=ZIC4MRYKTSLVMRKRLRLYRNTLKESSSSSGHHGPQLTAASSPSVFPGLHEEPPQASPSRPLNGLLRLGLPGDMYARPEPFPPGPAARSDALAAAAALHGYGGMNLTVNLAAPHGPGAFFRYMRQPIKQELICKWLAADGTATPSLCSKTFSTMHELVTHVTVEHVGGPEQANHICFWEECPRQGKPFKAKYKLVNHIRVHTGEKPFPCPFPGCGKVFARSENLKIHKRTHTGQYSALSVACGPSGEAGPRVWISSSPN>sp|Q8N9L1-3|ZIC4_HUMAN Isoform 3 of Zinc finger protein ZIC 4 OS=Homosapiens OX=9606 GN=ZIC4MPPFCRNAKLGLLSFLICAGRSLLPLGKNAFWLERIENNNTLWEKAQSQKMRYKTSLVMRKRLRLYRNTLKESSSSSGHHGPQLTAASSPSVFPGLHEEPPQASPSRPLNGLLRLGLPGDMYARPEPFPPGPAARSDALAAAAALHGYGGMNLTVNLAAPHGPGAFFRYMRQPIKQELICKWLAADGTATPSLCSKTFSTMHELVTHVTVEHVGGPEQANHICFWEECPRQGKPFKAKYKLVNHIRVHTGEKPFPCPFPGCGKVFARSENLKIHKRTHTGEKPFRCEFEGCERRFANSSDRKKHSHVHTSDKPYTCKVRGCDKCYTHPSSLRKHMKVHGRSPPPSSGYDSATPSALVSPSSDCGHKSQVASSAAVAARTADLSE>sp|Q8N9L1-4|ZIC4_HUMAN Isoform 4 of Zinc finger protein ZIC 4 OS=Homosapiens OX=9606 GN=ZIC4MRYKTSLVMRKRLRLYRNTLKESSEKPFRCEFEGCERRFANSSDRKKHSHVHTSDKPYTCKVRGCDKCYTHPSSLRKHMKVHGRSPPPSSGYDSATPSALVSPSSDCGHKSQVASSAAVAARTADLSE>sp|Q8N9L1-5|ZIC4_HUMAN Isoform 5 of Zinc finger protein ZIC 4 OS=Homosapiens OX=9606 GN=ZIC4MNGPCQSLRKAEGLLEGCTSAVTVFRKLPLDSKAQSQKMRYKTSLVMRKRLRLYRNTLKESSSSSGHHGPQLTAASSPSVFPGLHEEPPQASPSRPLNGLLRLGLPGDMYARPEPFPPGPAARSDALAAAAALHGYGGMNLTVNLAAPHGPGAFFRYMRQPIKQELICKWLAADGTATPSLCSKTFSTMHELVTHVTVEHVGGPEQANHICFWEECPRQGKPFKAKYKLVNHIRVHTGEKPFPCPFPGCGKVFARSENLKIHKRTHTGEKPFRCEFEGCERRFANSSDRKKHSHVHTSDKPYTCKVRGCDKCYTHPSSLRKHMKVHGRSPPPSSGYDSATPSALVSPSSDCGHKSQVASSAAVAARTADLSE>sp|Q9Y3M9|ZN337_HUMAN Zinc finger protein 337 OS=Homo sapiens OX=9606GN=ZNF337 PE=1 SV=2MGPQGARRQAFLAFGDVTVDFTQKEWRLLSPAQRALYREVTLENYSHLVSLGILHSKPELIRRLEQGEVPWGEERRRRPGPCAGIYAEHVLRPKNLGLAHQRQQQLQFSDQSFQSDTAEGQEKEKSTKPMAFSSPPLRHAVSSRRRNSVVEIESSQGQRENPTEIDKVLKGIENSRWGAFKCAERGQDFSRKMMVIIHKKAHSRQKLFTCRECHQGFRDESALLLHQNTHTGEKSYVCSVCGRGFSLKANLLRHQRTHSGEKPFLCKVCGRGYTSKSYLTVHERTHTGEKPYECQECGRRFNDKSSYNKHLKAHSGEKPFVCKECGRGYTNKSYFVVHKRIHSGEKPYRCQECGRGFSNKSHLITHQRTHSGEKPFACRQCKQSFSVKGSLLRHQRTHSGEKPFVCKDCERSFSQKSTLVYHQRTHSGEKPFVCRECGQGFIQKSTLVKHQITHSEEKPFVCKDCGRGFIQKSTFTLHQRTHSEEKPYGCRECGRRFRDKSSYNKHLRAHLGEKRFFCRDCGRGFTLKPNLTIHQRTHSGEKPFMCKQCEKSFSLKANLLRHQWTHSGERPFNCKDCGRGFILKSTLLFHQKTHSGEKPFICSECGQGFIWKSNLVKHQLAHSGKQPFVCKECGRGFNWKGNLLTHQRTHSGEKPFVCNVCGQGFSWKRSLTRHHWRIHSKEKPFVCQECKRGYTSKSDLTVHERIHTGERPYECQECGRKFSNKSYYSKHLKRHLREKRFCTGSVGEASS>sp|Q9Y3M9-2|ZN337_HUMAN Isoform 2 of Zinc finger protein 337 OS=Homosapiens OX=9606 GN=ZNF337MGPQGARRQAFLAFGDVTVDFTQKEWRLLSPAQRALYREVTLENYSHLVSLGIYAEHVLRPKNLGLAHQRQQQLQFSDQSFQSDTAEGQEKEKSTKPMAFSSPPLRHAVSSRRRNSVVEIESSQGQRENPTEIDKVLKGIENSRWGAFKCAERGQDFSRKMMVIIHKKAHSRQKLFTCRECHQGFRDESALLLHQNTHTGEKSYVCSVCGRGFSLKANLLRHQRTHSGEKPFLCKVCGRGYTSKSYLTVHERTHTGEKPYECQECGRRFNDKSSYNKHLKAHSGEKPFVCKECGRGYTNKSYFVVHKRIHSGEKPYRCQECGRGFSNKSHLITHQRTHSGEKPFACRQCKQSFSVKGSLLRHQRTHSGEKPFVCKDCERSFSQKSTLVYHQRTHSGEKPFVCRECGQGFIQKSTLVKHQITHSEEKPFVCKDCGRGFIQKSTFTLHQRTHSEEKPYGCRECGRRFRDKSSYNKHLRAHLGEKRFFCRDCGRGFTLKPNLTIHQRTHSGEKPFMCKQCEKSFSLKANLLRHQWTHSGERPFNCKDCGRGFILKSTLLFHQKTHSGEKPFICSECGQGFIWKSNLVKHQLAHSGKQPFVCKECGRGFNWKGNLLTHQRTHSGEKPFVCNVCGQGFSWKRSLTRHHWRIHSKEKPFVCQECKRGYTSKSDLTVHERIHTGERPYECQECGRKFSNKSYYSKHLKRHLREKRFCTGSVGEASS>sp|Q9P243|ZFAT_HUMAN Zinc finger protein ZFAT OS=Homo sapiens OX=9606GN=ZFAT PE=1 SV=2METRAAENTAIFMCKCCNLFSPNQSELLSHVSEKHMEEGVNVDEIIIPLRPLSTPEPPNSSKTGDEFLVMKRKRGRPKGSTKKSSTEEELAENIVSPTEDSPLAPEEGNSLPPSSLECSKCCRKFSNTRQLRKHICIIVLNLGEEEGEAGNESDLELEKKCKEDDREKASKRPRSQKTEKVQKISGKEARQLSGAKKPIISVVLTAHEAIPGATKIVPVEAGPPETGATNSETTSADLVPRRGYQEYAIQQTPYEQPMKSSRLGPTQLKIFTCEYCNKVFKFKHSLQAHLRIHTNEKPYKCPQCSYASAIKANLNVHLRKHTGEKFACDYCSFTCLSKGHLKVHIERVHKKIKQHCRFCKKKYSDVKNLIKHIRDAHDPQDKKVKEALDELCLMTREGKRQLLYDCHICERKFKNELDRDRHMLVHGDKWPFACELCGHGATKYQALELHVRKHPFVYVCAVCRKKFVSSIRLRTHIKEVHGAAQEALVFTSSINQSFCLLEPGGDIQQEALGDQLQLVEEEFALQGVNALKEEACPGDTQLEEGRKEPEAPGEMPAPAVHLASPQAESTALPPCELETTVVSSSDLHSQEVVSDDFLLKNDTSSAEAHAAPEKPPDMQHRSSVQTQGEVITLLLSKAQSAGSDQESHGAQSPLGEGQNMAVLSAGDPDPSRCLRSNPAEASDLLPPVAGGGDTITHQPDSCKAAPEHRSGITAFMKVLNSLQKKQMNTSLCERIRKVYGDLECEYCGKLFWYQVHFDMHVRTHTREHLYYCSQCHYSSITKNCLKRHVIQKHSNILLKCPTDGCDYSTPDKYKLQAHLKVHTALDKRSYSCPVCEKSFSEDRLIKSHIKTNHPEVSMSTISEVLGRRVQLKGLIGKRAMKCPYCDFYFMKNGSDLQRHIWAHEGVKPFKCSLCEYATRSKSNLKAHMNRHSTEKTHLCDMCGKKFKSKGTLKSHKLLHTADGKQFKCTVCDYTAAQKPQLLRHMEQHVSFKPFRCAHCHYSCNISGSLKRHYNRKHPNEEYANVGTGELAAEVLIQQGGLKCPVCSFVYGTKWEFNRHLKNKHGLKVVEIDGDPKWETATEAPEEPSTQYLHITEAEEDVQGTQAAVAALQDLRYTSESGDRLDPTAVNILQQIIELGAETHDATALASVVAMAPGTVTVVKQVTEEEPSSNHTVMIQETVQQASVELAEQHHLVVSSDDVEGIETVTVYTQGGEASEFIVYVQEAMQPVEEQAVEQPAQEL>sp|Q9P243-2|ZFAT_HUMAN Isoform 2 of Zinc finger protein ZFAT OS=Homosapiens OX=9606 GN=ZFATMCKCCNLFSPNQSELLSHVSEKHMEEGVNVDEIIIPLRPLSTPEPPNSSKTGDEFLVMKRKRGRPKGSTKKSSTEEELAENIVSPTEDSPLAPEEGNSLPPSSLECSKCCRKFSNTRQLRKHICIIVLNLGEEEGEAGNESDLELEKKCKEDDREKASKRPRSQKTEKVQKISGKEARQLSGAKKPIISVVLTAHEAIPGATKIVPVEAGPPETGATNSETTSADLVPRRGYQEYAIQQTPYEQPMKSSRLGPTQLKIFTCEYCNKVFKFKHSLQAHLRIHTNEKPYKCPQCSYASAIKANLNVHLRKHTGEKFACDYCSFTCLSKGHLKVHIERVHKKIKQHCRFCKKKYSDVKNLIKHIRDAHDPQDKKVKEALDELCLMTREGKRQLLYDCHICERKFKNELDRDRHMLVHGDKWPFACELCGHGATKYQALELHVRKHPFVYVCAVCRKKFVSSIRLRTHIKEVHGAAQEALVFTSSINQSFCLLEPGGDIQQEALGDQLQLVEEEFALQGVNALKEEACPGDTQLEEGRKEPEAPGEMPAPAVHLASPQAESTALPPCELETTVVSSSDLHSQEVVSDDFLLKNDTSSAEAHAAPEKPPDMQHRSSVQTQGEVITLLLSKAQSAGSDQESHGAQSPLGEGQNMAVLSAGDPDPSRCLRSNPAEASDLLPPVAGGGDTITHQPDSCKAAPEHRSGITAFMKVLNSLQKKQMNTSLCERIRKVYGDLECEYCGKLFWYQVHFDMHVRTHTREHLYYCSQCHYSSITKNCLKRHVIQKHSNILLKCPTDGCDYSTPDKYKLQAHLKVHTALDKRSYSCPVCEKSFSEDRLIKSHIKTNHPEVSMSTISEVLGRRVQLKGLIGKRAMKCPYCDFYFMKNGSDLQRHIWAHEGVKPFKCSLCEYATRSKSNLKAHMNRHSTEKTHLCDMCGKKFKSKGTLKSHKLLHTADGKQFKCTVCDYTAAQKPQLLRHMEQHVSFKPFRCAHCHYSCNISGSLKRHYNRKHPNEEYANVGTGELAAEVLIQQGGLKCPVCSFVYGTKWEFNRHLKNKHGLKVVEIDGDPKWETATEAPEEPSTQYLHITEAEEDVQGTQAAVAALQDLRYTSESGDRLDPTAVNILQQIIELGAETHDATALASVVAMAPGTVTVVKQVTEEEPSSNHTVMIQETVQQASVELAEQHHLVVSSDDVEGIETVTVYTQGGEASEFIVYVQEAMQPVEEQAVEQPAQEL>sp|Q9P243-3|ZFAT_HUMAN Isoform 3 of Zinc finger protein ZFAT OS=Homosapiens OX=9606 GN=ZFATMCKCCNLFSPNQSELLSHVSEKHMEEGVNVDEIIIPLRPLSTPEPPNSSKTGDEFLVMKRKRGRPKGSTKKSSTEEELAENIVSPTEDSPLAPEEGNSLPPSSLECSKCCRKFSNTRQLRKHICIIVLNLGEEEGEAGNESDLELEKKCKEDDREKASKRPRSQKTEKVQKISGKEARQLSGAKKPIISVVLTAHEAIPGATKIVPVEAGPPETGATNSETTSADLVPRRGYQEYAIQQTPYEQPMKSSRLGPTQLKIFTCEYCNKVFKFKHSLQAHLRIHTNEKPYKCPQCSYASAIKANLNVHLRKHTGEKFACDYCSFTCLSKGHLKVHIERVHKKIKQHCRFCKKKYSDVKNLIKHIRDAHDPQDKKVKEALDELCLMTREGKRQLLYDCHICERKFKNELDRDRHMLVHGDKWPFACELCGHGATKYQALELHVRKHPFVYVCAVCRKKFVSSIRLRTHIKEVHGAAQEALVFTSSINQSFCLLEPGGDIQQEALGDQLQLVEEEFALQGVNALKEEACPGDTQLEEGRKEPEAPGEMPAPAVHLASPQAESTALPPCELETTVVSSSDLHSQEVVSDDFLLKNDTSSAEAHAAPEKPPDMQHRSSVQTQGEVITLLLSKAQSAGSDQESHGAQSPLGEGQNMAVLSAGDPDPSRCLRSNPAEASDLLPPVAGGGDTITHQPDSCKAAPEHRSGITAFMKVLNSLQKKQMNTSLCERIRKVYGDLECEYCGKLFWYQVHFDMHVRTHTREHLYYCSQCHYSSITKNCLKRHVIQKHSNILLKCPTDGCDYSTPDKYKLQAHLKVHTALVSSKPKRQPRLPWVLIAFSSLCLYVGVSAAGQP>sp|Q9P243-4|ZFAT_HUMAN Isoform 4 of Zinc finger protein ZFAT OS=Homosapiens OX=9606 GN=ZFATMETRAAENTAIFMCKCCNLFSPNQSELLSHVSEKHMEEGVNVDEIIIPLRPLSTPEPPNSSKTGDEFLVMKRKRGRPKGSTKKSSTEEELAENIVSPTEDSPLAPEEGNSLPPSSLECSKCCRKFSNTRQLRKHICIIVLNLGEEEGEAGATKIVPVEAGPPETGATNSETTSADLVPRRGYQEYAIQQTPYEQPMKSSRLGPTQLKIFTCEYCNKVFKFKHSLQAHLRIHTNEKPYKCPQCSYASAIKANLNVHLRKHTGEKFACDYCSFTCLSKGHLKVHIERVHKKIKQHCRFCKKKYSDVKNLIKHIRDAHDPQDKKVKEALDELCLMTREGKRQLLYDCHICERKFKNELDRDRHMLVHGDKWPFACELCGHGATKYQALELHVRKHPFVYVCAVCRKKFVSSIRLRTHIKEVHGAAQEALVFTSSINQSFCLLEPGGDIQQEALGDQLQLVEEEFALQGVNALKEEACPGDTQLEEGRKEPEAPGEMPAPAVHLASPQAESTALPPCELETTVVSSSDLHSQEVVSDDFLLKNDTSSAEAHAAPEKPPDMQHRSSVQTQGEVITLLLSKAQSAGSDQESHGAQSPLGEGQNMAVLSAGDPDPSRCLRSNPAEASDLLPPVAGGGDTITHQPDSCKAAPEHRSGITAFMKVLNSLQKKQMNTSLCERIRKVYGDLECEYCGKLFWYQVHFDMHVRTHTREHLYYCSQCHYSSITKNCLKRHVIQKHSNILLKCPTDGCDYSTPDKYKLQAHLKVHTALDKRSYSCPVCEKSFSEDRLIKSHIKTNHPEVSMSTISEVLGRRVQLKGLIGKRAMKCPYCDFYFMKNGSDLQRHIWAHEGVKPFKCSLCEYATRSKSNLKAHMNRHSTEKTHLCDMCGKKFKSKGTLKSHKLLHTADGKQFKCTVCDYTAAQKPQLLRHMEQHVSFKPFRCAHCHYSCNISGSLKRHYNRKHPNEEYANVGTGELAAEVLIQQGGLKCPVCSFVYGTKWEFNRHLKNKHGLKVVEIDGDPKWETATEAPEEPSTQYLHITEAEEDVQGTQAAVAALQDLRYTSESGDRLDPTAVNILQQIIELGAETHDATALASVVAMAPGTVTVVKQVTEEEPSSNHTVMIQETVQQASVELAEQHHLVVSSDDVEGIETVTVYTQGGEASEFIVYVQEAMQPVEEQAVEQPAQEL>sp|Q06730|ZN33A_HUMAN Zinc finger protein 33A OS=Homo sapiens OX=9606GN=ZNF33A PE=1 SV=3MNKVEQKSQESVSFKDVTVGFTQEEWQHLDPSQRALYRDVMLENYSNLVSVGYCVHKPEVIFRLQQGEEPWKQEEEFPSQSFPVWTADHLKERSQENQSKHLWEVVFINNEMLTKEQGDVIGIPFNVDVSSFPSRKMFCQCDSCGMSFNTVSELVISKINYLGKKSDEFNACGKLLLNIKHDETHTQEKNEVLKNRNTLSHHEETLQHEKIQTLEHNFEYSICQETLLEKAVFNTQKRENAEENNCDYNEFGRTLCDSSSLLFHQISPSRDNHYEFSDCEKFLCVKSTLSKPHGVSMKHYDCGESGNNFRRKLCLSHLQKGDKGEKHFECNECGKAFWEKSHLTRHQRVHTGQKPFQCNECEKAFWDKSNLTKHQRSHTGEKPFECNECGKAFSHKSALTLHQRTHTGEKPYQCNACGKTFCQKSDLTKHQRTHTGLKPYECYECGKSFRVTSHLKVHQRTHTGEKPFECLECGKSFSEKSNLTQHQRIHIGDKSYECNACGKTFYHKSLLTRHQIIHTGWKPYECYECGKTFCLKSDLTVHQRTHTGQKPFACPECGKFFSHKSTLSQHYRTHTGEKPYECHECGKIFYNKSYLTKHNRTHTGEKPYECNECGKAFYQKSQLTQHQRIHIGEKPYKCNECGKAFCHKSALIVHQRTHTQEKPYKCNECGKSFCVKSGLIFHERKHTGEKPYECNECGKFFRHKSSLTVHHRAHTGEKSCQCNECGKIFYRKSELAQHQRSHTGEKPYECNTCRKTFSQKSNLIVHQRRHIGENLMNEMDIRNFQPQVSLHNASEYSHCGESPDDILNVQ>sp|Q06730-2|ZN33A_HUMAN Isoform 2 of Zinc finger protein 33A OS=Homosapiens OX=9606 GN=ZNF33AMNKVEQKSQESVSFKDVTVGFTQEEWQHLDPSQRALYRDVMLENYSNLVSVGYCVHKPEVIFRLQQGEEPWKQEEEFPSQSFPEVWTADHLKERSQENQSKHLWEVVFINNEMLTKEQGDVIGIPFNVDVSSFPSRKMFCQCDSCGMSFNTVSELVISKINYLGKKSDEFNACGKLLLNIKHDETHTQEKNEVLKNRNTLSHHEETLQHEKIQTLEHNFEYSICQETLLEKAVFNTQKRENAEENNCDYNEFGRTLCDSSSLLFHQISPSRDNHYEFSDCEKFLCVKSTLSKPHGVSMKHYDCGESGNNFRRKLCLSHLQKGDKGEKHFECNECGKAFWEKSHLTRHQRVHTGQKPFQCNECEKAFWDKSNLTKHQRSHTGEKPFECNECGKAFSHKSALTLHQRTHTGEKPYQCNACGKTFCQKSDLTKHQRTHTGLKPYECYECGKSFRVTSHLKVHQRTHTGEKPFECLECGKSFSEKSNLTQHQRIHIGDKSYECNACGKTFYHKSLLTRHQIIHTGWKPYECYECGKTFCLKSDLTVHQRTHTGQKPFACPECGKFFSHKSTLSQHYRTHTGEKPYECHECGKIFYNKSYLTKHNRTHTGEKPYECNECGKAFYQKSQLTQHQRIHIGEKPYKCNECGKAFCHKSALIVHQRTHTQEKPYKCNECGKSFCVKSGLIFHERKHTGEKPYECNECGKFFRHKSSLTVHHRAHTGEKSCQCNECGKIFYRKSELAQHQRSHTGEKPYECNTCRKTFSQKSNLIVHQRRHIGENLMNEMDIRNFQPQVSLHNASEYSHCGESPDDILNVQ>sp|Q06730-3|ZN33A_HUMAN Isoform 3 of Zinc finger protein 33A OS=Homosapiens OX=9606 GN=ZNF33AMANATRRGSGVEQKSQESVSFKDVTVGFTQEEWQHLDPSQRALYRDVMLENYSNLVSVGYCVHKPEVIFRLQQGEEPWKQEEEFPSQSFPVWTADHLKERSQENQSKHLWEVVFINNEMLTKEQGDVIGIPFNVDVSSFPSRKMFCQCDSCGMSFNTVSELVISKINYLGKKSDEFNACGKLLLNIKHDETHTQEKNEVLKNRNTLSHHEETLQHEKIQTLEHNFEYSICQETLLEKAVFNTQKRENAEENNCDYNEFGRTLCDSSSLLFHQISPSRDNHYEFSDCEKFLCVKSTLSKPHGVSMKHYDCGESGNNFRRKLCLSHLQKGDKGEKHFECNECGKAFWEKSHLTRHQRVHTGQKPFQCNECEKAFWDKSNLTKHQRSHTGEKPFECNECGKAFSHKSALTLHQRTHTGEKPYQCNACGKTFCQKSDLTKHQRTHTGLKPYECYECGKSFRVTSHLKVHQRTHTGEKPFECLECGKSFSEKSNLTQHQRIHIGDKSYECNACGKTFYHKSLLTRHQIIHTGWKPYECYECGKTFCLKSDLTVHQRTHTGQKPFACPECGKFFSHKSTLSQHYRTHTGEKPYECHECGKIFYNKSYLTKHNRTHTGEKPYECNECGKAFYQKSQLTQHQRIHIGEKPYKCNECGKAFCHKSALIVHQRTHTQEKPYKCNECGKSFCVKSGLIFHERKHTGEKPYECNECGKFFRHKSSLTVHHRAHTGEKSCQCNECGKIFYRKSELAQHQRSHTGEKPYECNTCRKTFSQKSNLIVHQRRHIGENLMNEMDIRNFQPQVSLHNASEYSHCGESPDDILNVQ>sp|Q6PEW1|ZCH12_HUMAN Zinc finger CCHC domain-containing protein 12OS=Homo sapiens OX=9606 GN=ZCCHC12 PE=1 SV=2MASIIARVGNSRRLNAPLPPWAHSMLRSLGRSLGPIMASMADRNMKLFSGRVVPAQGEETFENWLTQVNGVLPDWNMSEEEKLKRLMKTLRGPAREVMRVLQATNPNLSVADFLRAMKLVFGESESSVTAHGKFFNTLQAQGEKASLYVIRLEVQLQNAIQAGIIAEKDANRTRLQQLLLGGELSRDLRLRLKDFLRMYANEQERLPNFLELIRMVREEEDWDDAFIKRKRPKRSESMVERAVSPVAFQGSPPIVIGSADCNVIEIDDTLDDSDEDVILVESQDPPLPSWGAPPLRDRARPQDEVLVIDSPHNSRAQFPSTSGGSGYKNNGPGEMRRARKRKHTIRCSYCGEEGHSKETCDNESDKAQVFENLIITLQELTHTEMERSRVAPGEYNDFSEPL>sp|Q96T25|ZIC5_HUMAN Zinc finger protein ZIC 5 OS=Homo sapiens OX=9606GN=ZIC5 PE=1 SV=2MFLKAGRGNKVPPVRVYGPDCVVLMEPPLSKRNPPALRLADLATAQVQPLQNMTGFPALAGPPAHSQLRAAVAHLRLRDLGADPGVATTPLGPEHMAQASTLGLSPPSQAFPAHPEAPAAAARAAALVAHPGAGSYPCGGGSSGAQPSAPPPPAPPLPPTPSPPPPPPPPPPPALSGYTTTNSGGGGSSGKGHSRDFVLRRDLSATAPAAAMHGAPLGGEQRSGTGSPQHPAPPPHSAGMFISASGTYAGPDGSGGPALFPALHDTPGAPGGHPHPLNGQMRLGLAAAAAAAAAELYGRAEPPFAPRSGDAHYGAVAAAAAAALHGYGAVNLNLNLAAAAAAAAAGPGPHLQHHAPPPAPPPPPAPAQHPHQHHPHLPGAAGAFLRYMRQPIKQELICKWIDPDELAGLPPPPPPPPPPPPPPPAGGAKPCSKTFGTMHELVNHVTVEHVGGPEQSSHVCFWEDCPREGKPFKAKYKLINHIRVHTGEKPFPCPFPGCGKVFARSENLKIHKRTHTGEKPFKCEFDGCDRKFANSSDRKKHSHVHTSDKPYYCKIRGCDKSYTHPSSLRKHMKIHCKSPPPSPGPLGYSSVGTPVGAPLSPVLDPARSHSSTLSPQVTNLNEWYVCQASGAPSHLHTPSSNGTTSETEDEEIYGNPEVVRTIH>sp|Q06732|ZN33B_HUMAN Zinc finger protein 33B OS=Homo sapiens OX=9606GN=ZNF33B PE=1 SV=2MNKVDQKFQGSVSFKDVTVGFTQEEWQHLDPSQRALYRDVMLENYSNLVSVGYCAHKPEVIFRLEQGEEPWRLEEEFPSQSFPEVWTADHLKERSQENQSKHLWEVVFINNEMLTKEQGNVIGIPFNMDVSSFPSRKMFCQYDSRGMSFNTVSELVISKINYLGKKSDEFNACGKLLLNIKHDETHTREKNEVLKNRNTLSHRENTLQHEKIQTLDHNFEYSICQETLLEKAVFNTRKRENAEENNCDYNEFGRTFCDSSSLLFHQIPPSKDSHYEFSDCEKFLCVKSTLSKHDGVPVKHYDCGESGNNFRRKLCLSQLQKGDKGEKHFECNECGKAFWEKSHLTRHQRVHTGEKHFQCNQCGKTFWEKSNLTKHQRSHTGEKPFECNECGKAFSHKSALTLHQRTHTGEKPYQCNACGKTFYQKSDLTKHQRTHTGQKPYECYECGKSFCMNSHLTVHQRTHTGEKPFECLECGKSFCQKSHLTQHQRTHIGDKPYECNACGKTFYHKSVLTRHQIIHTGLKPYECYECGKTFCLKSDLTIHQRTHTGEKPFACPECGKFFSHKSTLSQHYRTHTGEKPYECHECGKIFYNKSYLTKHNRTHTGEKPYECNECGKTFCQKSQLTQHQRIHIGEKPYECNECGKAFCHKSALIVHQRTHTQEKPYKCNECGKSFCVKSGLILHERKHTGEKPYECNECGKSFSHKSSLTVHHRAHTGEKSCQCNECGKIFYRKSDLAKHQRSHTGEKPYECNTCRKTFSQKSNLIVHQRTHIGEKPYE>sp|Q8WW36|ZCH13_HUMAN Zinc finger CCHC domain-containing protein 13OS=Homo sapiens OX=9606 GN=ZCCHC13 PE=1 SV=1MSSKDFFACGHSGHWARGCPRGGAGGRRGGGHGRGSQCGSTTLSYTCYCCGESGRNAKNCVLLGNICYNCGRSGHIAKDCKDPKRERRQHCYTCGRLGHLARDCDRQKEQKCYSCGKLGHIQKDCAQVKCYRCGEIGHVAINCSKARPGQLLPLRQIPTSSQGMSQ>sp|Q9BYN7|ZN341_HUMAN Zinc finger protein 341 OS=Homo sapiens OX=9606GN=ZNF341 PE=1 SV=2MAQAIFEALEGMDNQTVLAVQSLLDGQGAVPDPTGQSVNAPPAIQPLDDEDVFLCGKCKKQFNSLPAFMTHKREQCQGNAPALATVSLATNSIYPPSAAPTAVQQAPTPANRQISTYITVPPSPLIQTLVQGNILVSDDVLMSAMSAFTSLDQPMPQGPPPVQSSLNMHSVPSYLTQPPPPPPPPPPLPPPPPPQPPPPPPQSLGPPGRPNPGGNGVVEVYSAAAPLAGSGTVEIQALGMQPYPPLEVPNQCVEPPVYPTPTVYSPGKQGFKPKGPNPAAPMTSATGGTVATFDSPATLKTRRAKGARGLPEAAGKPKAQKLKCSYCDKSFTKNFDLQQHIRSHTGEKPFQCIACGRAFAQKSNVKKHMQTHKVWPPGHSGGTVSRNSVTVQVMALNPSRQEDEESTGLGQPLPGAPQPQALSTAGEEEGDKPESKQVVLIDSSYLCQFCPSKFSTYFQLKSHMTQHKNEQVYKCVVKSCAQTFPKLDTFLEHIKSHQEELSYRCHLCGKDFPSLYDLGVHQYSHSLLPQHSPKKDNAVYKCVKCVNKYSTPEALEHHLQTATHNFPCPHCQKVFPCERYLRRHLPTHGSGGRFKCQVCKKFFRREHYLKLHAHIHSGEKPYKCSVCESAFNRKDKLKRHMLIHEPFKKYKCPFSTHTGCSKEFNRPDKLKAHILSHSGMKLHKCALCSKSFSRRAHLAEHQRAHTGNYKFRCAGCAKGFSRHKYLKDHRCRLGPQKDKDLQTRRPPQRRAAPRSCGSGGRKVLTPLPDPLGLEELKDTGAGLVPEAVPGKPPFAEPDAVLSIVVGGAVGAETELVVPGHAEGLGSNLALAELQAGAEGPCAMLAVPVYIQASE>sp|Q9BYN7-2|ZN341_HUMAN Isoform 2 of Zinc finger protein 341 OS=Homosapiens OX=9606 GN=ZNF341MAQAIFEALEGMDNQTVLAVQSLLDGQGAVPDPTGQSVNAPPAIQPLDDEDVFLCGKCKKQFNSLPAFMTHKREQCQGNAPALATVSLATNSIYPPSAAPTAVQQAPTPANRQISTYITVPPSPLIQTLVQGNILVSDDVLMSAMSAFTSLDQPMPQGPPPVQSSLNMHSVPSYLTQPPPPPPPPPPLPPPPPPQPPPPPPQSLGPPGRPNPGGNGVVEVYSAAAPLAGSGTVEIQALGMQPYPPLEVPNQCVEPPVYPTPTVYSPGKQGFKPKGPNPAAPMTSATGGTVATFDSPATLKTRRAKAAGKPKAQKLKCSYCDKSFTKNFDLQQHIRSHTGEKPFQCIACGRAFAQKSNVKKHMQTHKVWPPGHSGGTVSRNSVTVQVMALNPSRQEDEESTGLGQPLPGAPQPQALSTAGEEEGDKPESKQVVLIDSSYLCQFCPSKFSTYFQLKSHMTQHKNEQVYKCVVKSCAQTFPKLDTFLEHIKSHQEELSYRCHLCGKDFPSLYDLGVHQYSHSLLPQHSPKKDNAVYKCVKCVNKYSTPEALEHHLQTATHNFPCPHCQKVFPCERYLRRHLPTHGSGGRFKCQVCKKFFRREHYLKLHAHIHSGEKPYKCSVCESAFNRKDKLKRHMLIHEPFKKYKCPFSTHTGCSKEFNRPDKLKAHILSHSGMKLHKCALCSKSFSRRAHLAEHQRAHTGNYKFRCAGCAKGFSRHKYLKDHRCRLGPQKDKDLQTRRPPQRRAAPRSCGSGGRKVLTPLPDPLGLEELKDTGAGLVPEAVPGKPPFAEPDAVLSIVVGGAVGAETELVVPGHAEGLGSNLALAELQAGAEGPCAMLAVPVYIQASE>sp|Q8WYQ9|ZCH14_HUMAN Zinc finger CCHC domain-containing protein 14OS=Homo sapiens OX=9606 GN=ZCCHC14 PE=1 SV=1MASNHPAFSFHQKQVLRQELTQIQSSLNGGGGHGGKGAPGPGGALPTCPACHKITPRTEAPVSSVSNSLENALHTSAHSTEESLPKRPLGKHSKVSVEKIDLKGLSHTKNDRNVECSFEVLWSDSSITSVTKSSSEVTEFISKLCQLYPEENLEKLIPCLAGPDAFYVERNHVDLDSGLRYLASLPSHVLKNDHVRRFLSTSSPPQQLQSPSPGNPSLSKVGTVMGVSGRPVCGVAGIPSSQSGAQHHGQHPAGSAAPLPHCSHAGSAGSALAYRTQMDTSPAILMPSSLQTPQTQEQNGILDWLRKLRLHKYYPVFKQLSMEKFLSLTEEDLNKFESLTMGAKKKLKTQLELEKEKSERRCLNPSAPPLVTSSGVARVPPTSHVGPVQSGRGSHAAELRVEVEQPHHQLPREGSSSEYSSSSSSPMGVQAREESSDSAEENDRRVEIHLESSDKEKPVMLLNHFTSSSARPTAQVLPVQNEASSNPSGHHPLPPQMLSAASHITPIRMLNSVHKPERGSADMKLLSSSVHSLLSLEERNKGSGPRSSMKVDKSFGSAMMDVLPASAPHQPVQVLSGLSESSSMSPTVSFGPRTKVVHASTLDRVLKTAQQPALVVETSTAATGTPSTVLHAARPPIKLLLSSSVPADSAISGQTSCPNNVQISVPPAIINPRTALYTANTKVAFSAMSSMPVGPLQGGFCANSNTASPSSHPSTSFANMATLPSCPAPSSSPALSSVPESSFYSSSGGGGSTGNIPASNPNHHHHHHHQQPPAPPQPAPPPPGCIVCTSCGCSGSCGSSGLTVSYANYFQHPFSGPSVFTFPFLPFSPMCSSGYVSAQQYGGGSTFPVVHAPYSSSGTPDPVLSGQSTFAVPPMQNFMAGTAGVYQTQGLVGSSNGSSHKKSGNLSCYNCGATGHRAQDCKQPSMDFNRPGTFRLKYAPPAESLDSTD>sp|Q8WYQ9-2|ZCH14_HUMAN Isoform 2 of Zinc finger CCHC domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=ZCCHC14MASNHPAFSFHQKQVLRQELTQIQSSLNGGGGHGGKGAPGPGGALPTCPACHKITPRTEAPVSSVSNSLENALHTSAHSTEESLPKRPLGKHSKVSVEKIDLKGLSHTKNDRNVECSFEVLWSDSSITSVTKSSSEVTEFISKLCQLYPEENLEKLIPCLAGPDAFYVERNHVDLDSGLRYLASLPSHVLKNDHVRRFLSTSSPPQQLQSPSPGNPSLSKVGTVMGVSGRPVCGVAGIPSSQSGAQHHGQHPAGSAAPLPHCSHAGSAGSALAYRTQMDTSPAILMPSSLQTPQTQEQNGILDWLRKLRLHKYYPVFKQLSMEKFLSLTEEDLNKFESLTMGAKKKLKTQLELEKEKSERRCLNPSAPPLVTSSGVARVPPTSHVGPVQSGRGSHAAELRVEVEQPHHQLPREGSSSEYSSSSSSPMGVQAREESSDSAEENDRRVEIHLESSDKEKPVMLLNHFTSSSARPTAQVLPVQNEASSNPSGHHPLPPQMLSAASHITPIRMLNSVHKPERGSADMKLLSSSVHSLLSLEERNKGSGPRSSMKVDKSFGSAMMDVLPASAPHQPVQVLSGLSESSSMSPTVSFGPRTKVVHASTLDRVLKTAQQPALVVETSTAATGTPSTVLHAARPPIKLLLSSSVPADSAISGQTSCPNNVQISVPPAIINPRTALYTANTKVAFSAMSSMPVGPLQGGFCANSNTASPSSHPSTSFANMATLPSCPAPSSSPALSSVPESSFYSSSGGGGSTGNIPASNPNHHHHHHHQQPPAPPQPAPPPPGCIVCTSCGCSGSCGSSGLTVSYANYFQHPFSGPSVFTFPFLPFSPMCSSGYVSAQQYGGGSTFPVVHAPYSSSGTPDPVLSGQSTFAVPPMQNFMAGTAGVYQTQGLVGSSNGSSHKKSGNLSCYNCGATGHRAQDCKQPSMDFNRPGKRAPWPRPPGSRRTSAHKCLVFMKSKLLSL>sp|Q6P1L6|ZN343_HUMAN Zinc finger protein 343 OS=Homo sapiens OX=9606GN=ZNF343 PE=1 SV=1MMLPYPSALGDQYWEEILLPKNGENVETMKKLTQNHKAKGLPSNDTDCPQKKEGKAQIVVPVTFRDVTVIFTEAEWKRLSPEQRNLYKEVMLENYRNLLSLAEPKPEIYTCSSCLLAFSCQQFLSQHVLQIFLGLCAENHFHPGNSSPGHWKQQGQQYSHVSCWFENAEGQERGGGSKPWSARTEERETSRAFPSPLQRQSASPRKGNMVVETEPSSAQRPNPVQLDKGLKELETLRFGAINCREYEPDHNLESNFITNPRTLLGKKPYICSDCGRSFKDRSTLIRHHRIHSMEKPYVCSECGRGFSQKSNLSRHQRTHSEEKPYLCRECGQSFRSKSILNRHQWTHSEEKPYVCSECGRGFSEKSSFIRHQRTHSGEKPYVCLECGRSFCDKSTLRKHQRIHSGEKPYVCRECGRGFSQNSDLIKHQRTHLDEKPYVCRECGRGFCDKSTLIIHERTHSGEKPYVCGECGRGFSRKSLLLVHQRTHSGEKHYVCRECRRGFSQKSNLIRHQRTHSNEKPYICRECGRGFCDKSTLIVHERTHSGEKPYVCSECGRGFSRKSLLLVHQRTHSGEKHYVCRECGRGFSHKSNLIRHQRTH>sp|Q6P1L6-2|ZN343_HUMAN Isoform 2 of Zinc finger protein 343 OS=Homosapiens OX=9606 GN=ZNF343MLENYRNLLSLAEPKPEIYTCSSCLLAFSCQQFLSQHVLQIFLGLCAENHFHPGNSSPGHWKQQGQQYSHVSCWFENAEGQERGGGSKPWSARTEERETSRAFPSPLQRQSASPRKGNMVVETEPSSAQRPNPVQLDKGLKELETLRFGAINCREYEPDHNLESNFITNPRTLLGKKPYICSDCGRSFKDRSTLIRHHRIHSMEKPYVCSECGRGFSQKSNLSRHQRTHSEEKPYLCRECGQSFRSKSILNRHQWTHSEEKPYVCSECGRGFSEKSSFIRHQRTHSGEKPYVCLECGRSFCDKSTLRKHQRIHSGEKPYVCRECGRGFSQNSDLIKHQRTHLDEKPYVCRECGRGFCDKSTLIIHERTHSGEKPYVCGECGRGFSRKSLLLVHQRTHSGEKHYVCRECRRGFSQKSNLIRHQRTHSNEKPYICRECGRGFCDKSTLIVHERTHSGEKPYVCSECGRGFSRKSLLLVHQRTHSGEKHYVCRECGRGFSHKSNLIRHQRTH>sp|Q6P1L6-3|ZN343_HUMAN Isoform 3 of Zinc finger protein 343 OS=Homosapiens OX=9606 GN=ZNF343MMLPYPSALGDQYWEEILLPKNGENVETMKKLTQNHKAKGLPSNDTDCPQKKEGKAQIVVPVTFRDVTVIFTEAEWKRLSPEQRNLYKEVMLENYRNLLSLGQEIETILANIVKSHLY>sp|Q14585|ZN345_HUMAN Zinc finger protein 345 OS=Homo sapiens OX=9606GN=ZNF345 PE=1 SV=1MENLTKHSIECSSFRGDWECKNQFERKQGSQEGHFSEMIFTPEDMPTFSIQHQRIHTDEKLLECKECGKDFSFVSVLVRHQRIHTGEKPYECKECGKAFGSGANLAYHQRIHTGEKPFECKECGKAFGSGSNLTHHQRIHTGEKPYECKECGKAFSFGSGLIRHQIIHSGEKPYECKECGKSFSFESALIRHHRIHTGEKPYECIDCGKAFGSGSNLTQHRRIHTGEKPYECKACGMAFSSGSALTRHQRIHTGEKPYICNECGKAFSFGSALTRHQRIHTGEKPYVCKECGKAFNSGSDLTQHQRIHTGEKPYECKECEKAFRSGSKLIQHQRMHTGEKPYECKECGKTFSSGSDLTQHHRIHTGEKPYECKECGKAFGSGSKLIQHQLIHTGERPYECKECGKSFSSGSALNRHQRIHTGEKPYECKECGKAFYSGSSLTQHQRIHTGEKLYECKNCGKAYGRDSEFQQHKKSHNGKKLCELETIN>sp|Q9C0A1|ZFHX2_HUMAN Zinc finger homeobox protein 2 OS=Homo sapiensOX=9606 GN=ZFHX2 PE=1 SV=3MATLNSASTTGTTPSPGHNAPSLPSDTFSSSTPSDPVTKDPPAASSTSENMRSSEPGGQLLESGCGLVPPKEIGEPQEGPDCGHFPPNDPGVEKDKEQEEEEEGLPPMDLSNHLFFTAGGEAYLVAKLSLPGGSELLLPKGFPWGEAGIKEEPSLPFLAYPPPSHLTALHIQHGFDPIQGFSSSDQILSHDTSAPSPAACEERHGAFWSYQLAPNPPGDPKDGPMGNSGGNHVAVFWLCLLCRLGFSKPQAFMDHTQSHGVKLTPAQYQGLSGSPAVLQEGDEGCKALISFLEPKLPARPSSDIPLDNSSTVNMEANVAQTEDGPPEAEVQALILLDEEVMALSPPSPPTATWDPSPTQAKESPVAAGEAGPDWFPEGQEEDGGLCPPLNQSSPTSKEGGTLPAPVGSPEDPSDPPQPYRLADDYTPAPAAFQGLSLSSHMSLLHSRNSCKTLKCPKCNWHYKYQQTLDVHMREKHPESNSHCSYCSAGGAHPRLARGESYNCGYKPYRCDVCNYSTTTKGNLSIHMQSDKHLANLQGFQAGPGGQGSPPEASLPPSAGDKEPKTKSSWQCKVCSYETNISRNLRIHMTSEKHMQNVLMLHQGLPLGLPPGLMGPGPPPPPGATPTSPPELFQYFGPQALGQPQTPLAGPGLRPDKPLEAQLLLNGFHHVGAPARKFPTSAPGSLSPDAHLPPSQLLGSSSDSLPTSPPPDDSLSLKVFRCLVCQAFSTDSLELLLYHCSIGRSLPEAEWKEVAGDTHRCKLCCYGTQLKANFQLHLKTDKHAQKYQLAAHLREGGGAMGTPSPASLGDGAPYGSVSPLHLRCNICDFESNSKEKMQLHARGAAHEENSQIYKFLLDMEGAEAGAELGLYHCLLCAWETPSRLAVLQHLRTPAHRDAQAQRRLQLLQNGPTTEEGLAALQSILSFSHGQLRTPGKAPVTPLAEPPTPEKDAQNKTEQLASEETENKTGPSRDSANQTTVYCCPYCSFLSPESSQVRAHTLSQHAVQPKYRCPLCQEQLVGRPALHFHLSHLHNVVPECVEKLLLVATTVEMTFTTKVLSAPTLSPLDNGQEPPTHGPEPTPSRDQAAEGPNLTPEASPDPLPEPPLASVEVPDKPSGSPGQPPSPAPSPVPEPDAQAEDVAPPPTMAEEEEGTTGELRSAEPAPADSRHPLTYRKTTNFALDKFLDPARPYKCTVCKESFTQKNILLVHYNSVSHLHKMKKAAIDPSAPARGEAGAPPTTTAATDKPFKCTVCRVSYNQSSTLEIHMRSVLHQTRSRGTKTDSKIEGPERSQEEPKEGETEGEVGTEKKGPDTSGFISGLPFLSPPPPPLDLHRFPAPLFTPPVLPPFPLVPESLLKLQQQQLLLPFYLHDLKVGPKLTLAGPAPVLSLPAATPPPPPQPPKAELAEREWERPPMAKEGNEAGPSSPPDPLPNEAARTAAKALLENFGFELVIQYNEGKQAVPPPPTPPPPEALGGGDKLACGACGKLFSNMLILKTHEEHVHRRFLPFEALSRYAAQFRKSYDSLYPPLAEPPKPPDGSLDSPVPHLGPPFLVPEPEAGGTRAPEERSRAGGHWPIEEEESSRGNLPPLVPAGRRFSRTKFTEFQTQALQSFFETSAYPKDGEVERLASLLGLASRVVVVWFQNARQKARKNACEGGSMPTGGGTGGASGCRRCHATFSCVFELVRHLKKCYDDQTLEEEEEEAERGEEEEEVEEEEVEEEQGLEPPAGPEGPLPEPPDGEELSQAEATKAGGKEPEEKATPSPSPAHTCDQCAISFSSQDLLTSHRRLHFLPSLQPSAPPQLLDLPLLVFGERNPLVAATSPMPGPPLKRKHEDGSLSPTGSEAGGGGEGEPPRDKRLRTTILPEQLEILYRWYMQDSNPTRKMLDCISEEVGLKKRVVQVWFQNTRARERKGQFRSTPGGVPSPAVKPPATATPASLPKFNLLLGKVDDGTGREAPKREAPAFPYPTATLASGPQPFLPPGKEATTPTPEPPLPLLPPPPPSEEEGPEEPPKASPESEACSLSAGDLSDSSASSLAEPESPGAGGTSGGPGGGTGVPDGMGQRRYRTQMSSLQLKIMKACYEAYRTPTMQECEVLGEEIGLPKRVIQVWFQNARAKEKKAKLQGTAAGSTGGSSEGLLAAQRTDCPYCDVKYDFYVSCRGHLFSRQHLAKLKEAVRAQLKSESKCYDLAPAPEAPPALKAPPATTPASMPLGAAPTLPRLAPVLLSGPALAQPPLGNLAPFNSGPAASSGLLGLATSVLPTTTVVQTAGPGRPLPQRPMPDQTNTSTAGTTDPVPGPPTEPLGDKVSSERKPVAGPTSSSNDALKNLKALKTTVPALLGGQFLPFPLPPAGGTAPPAVFGPQLQGAYFQQLYGMKKGLFPMNPMIPQTLIGLLPNALLQPPPQPPEPTATAPPKPPELPAPGEGEAGEVDELLTGSTGISTVDVTHRYLCRQCKMAFDGEAPATAHQRSFCFFGRGSGGSMPPPLRVPICTYHCLACEVLLSGREALASHLRSSAHRRKAAPPQGGPPISITNAATAASAAVAFAKEEARLPHTDSNPKTTTTSTLLAL>sp|Q9C0A1-2|ZFHX2_HUMAN Isoform 2 of Zinc finger homeobox protein 2OS=Homo sapiens OX=9606 GN=ZFHX2MATLNSASTTGTTPSPGHNAPSLPSDTFSSSTPSDPVTKDPPAASSTSENMRSSEPGGQLLESGCGLVPPKEIGEPQEGPDCGHFPPNDPGVEKDKEQEEEEEGLPPMDLSNHLFFTAGGEAYLVAKLSLPGGSELLLPKGFPWGEAGIKEEPSLPFLAYPPPSHLTALHIQHGFDPIQGFSSSDQILSHDTSAPSPAACEERHGAFWSYQLAPNPPGDPKDGPMGNSGGNHVAVFWLCLLCRLGFSKPQAFMDHTQSHGVKLTPAQYQGLSGSPAVLQEGDEGCKALISFLEPKLPARPSSDIPLDNSSTVNMEANVAQTEDGPPEAEVQALILLDEEVMALSPPSPPTATWDPSPTQAKESPVAAGEAGPDWFPEGQEEDGGLCPPLNQSSPTSKEGGTLPAPVGSPEDPSDPPQPYRLADDYTPAPAAFQGLSLSSHMSLLHSRNSCKTLKCPKCNWHYKYQQTLDVHMREKHPESNSHCSYCSAGGAHPRLARGESYNCGYKPYRCDVCNYSTTTKGNLSIHMQSDKHLANLQGFQAGPGGQGSPPEASLPPSAGDKEPKTKSSWQCKVCSYETNISRNLRIHMTSEKHMQNVLMLHQGLPLGLPPGLMGPGPPPPPGATPTSPPELFQYFGPQALGQPQTPLAGPGLRPDKPLEAQLLLNGFHHVGAPARKFPTSAPGSLSPDAHLPPSQLLGSSSDSLPTSPPPDDSLSLKVFRCLVCQAFSTDSLELLLYHCSIGRSLPEAEWKEVAGDTHRCKLCCYGTQLKANFQLHLKTDKHAQKYQLAAHLREGGGAMGTPSPASLGDGAPYGSVSPLHLRCNICDFESNSKEKMQLHARGAAHEENSQIYKRTETGLLIK>sp|Q8ND82|Z280C_HUMAN Zinc finger protein 280C OS=Homo sapiens OX=9606GN=ZNF280C PE=1 SV=1MDDDKPFQPKNISKMAELFMECEEEELEPWQKKVEETQDEDDDELIFVGEISSSKPAISNILNRGHSSSSSKGIKSEPHSPGIPEIFRTASQRCRDPPSNPVAASPRFHLVSKSSQSSVTVENASKPDFTKNSQVGSDNSSILLFDSTQESLPPSQDIPAIFREGMKNTSYVLKHPSTSKVNSVTPKKPKTSEDVPQINPSTSLPLIGSPPVTSSQVMLSKGTNTSSPYDAGADYLRACPKCNVQFNLLDPLKYHMKHCCPDMITKFLGVIVKSERPCDEDKTDSETGKLIMLVNEFYYGRHEGVTEKEPKTYTTFKCFSCSKVLKNNIRFMNHMKHHLELEKQNNESWENHTTCQHCYRQYPTPFQLQCHIESTHTPHEFSTICKICELSFETEHILLQHMKDTHKPGEMPYVCQVCQFRSSTFSDVEAHFRAAHENTKNLLCPFCLKVSKMATPYMNHYMKHQKKGVHRCPKCRLQFLTSKEKAEHKAQHRTFIKPKELEGLPPGAKVTIRASLGPLQSKLPTAPFGCAPGTSFLQVTPPTSQNTTARNPRKSNASRSKTSKLHATTSTASKVNTSKPRGRIAKSKAKPSYKQKRQRNRKNKMSLALKNIRCRRGIHKCIECHSKIKDFASHFSIYIHCSFCKYNTNCNKAFVNHMMSSHSNHPGKRFCIFKKHSGTLRGITLVCLKCDFLADSSGLDRMAKHLSQRKTHTCQVIIENVSKSTSTSEPTTGCSLK>sp|Q494X3|ZN404_HUMAN Zinc finger protein 404 OS=Homo sapiens OX=9606GN=ZNF404 PE=1 SV=2MARVPLTFSDVAIDFSQEEWEYLNSDQRDLYRDVMLENYTNLVSLDFNFTTESNKLSSEKRNYEVNAYHQETWKRNKTFNLMRFIFRTDPQYTIEFGRQQRPKVGCFSQMIFKKHKSLPLHKRNNTREKSYECKEYKKGFRKYLHLTEHLRDHTGVIPYECNECGKAFVVFQHFIRHRKIHTDLKPYECNGCEKAFRFYSQLIQHQIIHTGMKPYECKQCGKAFRRHSHLTEHQKIHVGLKPFECKECGETFRLYRHMCLHQKIHHGVKPYKCKECGKAFGHRSSLYQHKKIHSGEKPYKCEQCEKAFVRSYLLVEHQRSHTGEKPHECMECGKAFGKGSSLLKHKRIHSSEKLYDCKDCGKAFCRGSQLTQHQRIHTGEKPHECKECGKTFKLHSYLIQHQIIHTDLKPYECKQCGKAFSRVGDLKTHQSIHAGEKPYECKECGKTFRLNSQLIYHQTIHTGLKPYVCKECKKAFRSISGLSQHKRIHTGEKPYECKECDKAFNRSDRLTQHETIHTGVKPQKCKECGKAFSHCYQLSQHQRFHHGERLLM>sp|Q96NJ6|ZFP3_HUMAN Zinc finger protein 3 homolog OS=Homo sapiensOX=9606 GN=ZFP3 PE=1 SV=1MGTENKEVIPKEEISEESEPHGSLLEKFPKVVYQGHEFGAGCEEDMLEGHSRESMEEVIEQMSPQERDFPSGLMIFKKSPSSEKDRENNESERGCSPSPNLVTHQGDTTEGVSAFATSGQNFLEILESNKTQRSSVGEKPHTCKECGKAFNQNSHLIQHMRVHSGEKPFECKECGKTFGTNSSLRRHLRIHAGEKPFACNECGKAFIQSSHLIHHHRIHTGERPYKCEECGKAFSQNSALILHQRIHTGEKPYECNECGKTFRVSSQLIQHQRIHTEERYHECNECGKAFKHSSGLIRHQKIHTGEKPYLCNECGKGFGQSSELIRHQRIHTGDKPYECNECGKTFGQNSEIIRHIRIHTGEKPYVCKECGKAFRGNSELLRHERIHTGEKPYECFECGKAFRRTSHLIVHQRIHTGEKPHQCNECARTFWDNSELLLHQKIHIGEKPYECSECEKTFSQHSQLIIHQRIHTGEKPYECQECQKTFSRSSHLLRHQSVHCME>sp|Q9C0G0|ZN407_HUMAN Zinc finger protein 407 OS=Homo sapiens OX=9606GN=ZNF407 PE=1 SV=2MMDSENKPENDEDEKINKEAQDLTKLSSHNEDGGPVSDVIASFPENSMGKRGFSESSNSDSVVIGEDRNKHASKRRKLDEAEPLKSGKQGICRLETSESSVTEGGIALDETGKETFLSDCTVGGTCLPNALSPSCNFSTIDVVSLKTDTEKTSAQEMVSLDLERESPFPPKEISVSCTIGNVDTVLKCSICGHLFSSCSDLEKHAESHMQQPKEHTCCHCSHKAESSSALHMHIKQAHGPQKVFSCDLCGFQCSEENLLNAHYLGKTHLRRQNLAARGGFVQILTKQPFPKKSRTMATKNVHSKPRTSKSIAKNSDSKGLRNVGSTFKDFRGSISKQSGSSSELLVEMMPSRNTLSQEVEIVEEHVTSLGLAQNPENQSRKLDTLVTSEGLLEKLESTKNTLQAAHGNSVTSRPRPERNILVLGNSFRRRSSTFTLKGQAKKRFNLLGIKRGTSETQRMYMKHLRTQMKTHDAESVLKHLEACSSVQRVCVTTSETQEAEQGQGSARPPDSGLHSLTVKPASGSQTLCACTDCGQVATNRTDLEIHVKRCHAREMKFYCRTCDFSSMSRRDLDEHLHSNQHQQTASVLSCQCCSFISLDEINLRDHMKEKHNMHFLCTPCNLFFLSEKDVEEHKATEKHINSLVQPKTLQSSNSDLVLQTLPLSTLESENAKESMDDSGKASQEEPLKSRVSHGNEVRHSSKPQFQCKKCFYKTRSSTVLTRHIKLRHGQDYHFLCKACNLYSLSKEGMEKHIKRSKHLENAKKNNIGLSFEECIERVCIGANDKKEEFDVSGNGRIEGHIGVQLQEHSYLEKGMLASEELSQSGGSTKDDELASTTTPKRGRPKGNISRTCSHCGLLASSITNLTVHIRRKHSHQYSYLCKVCKYYTVTKGDMERHCATKKHKGRVEIEASGKHSSDIIVGPEGGSLEAGKKNAGSAVTMSDEHANKPAESPTSVLEKPDRGNSIEAEVENVFHSLDGEVNSHLLDKKEQISSEPEDFAQPGDVYSQRDVTGTGENKCLHCEFSAHSSASLELHVKRKHTKEFEFYCMACDYYAVTRREMTRHAATEKHKMKRQSYLNSANVEAGSADMSKNIIMPEEEHQQNSEEFQIISGQPSDTLKSRNAADCSILNENTNLDMSKVLCAADSVEVETEEESNFNEDHSFCETFQQAPVKDKVRKPEEMMSLTMSSNYGSPSRFQNENSGSSALNCETAKKNHEISNDAGELRVHCEGEGGNAGDGGGVVPHRHLCPVTLDGERSAESPVLVVTRITREQGNLESGGQNRVARGHGLEDLKGVQEDPVLGNKEILMNSQHETEFILEEDGPASDSTVESSDVYETIISIDDKGQAMYSFGRFDSSIIRIKNPEDGELIDQSEEGLIATGVRISELPLKDCAQGVKKKKSEGSSIGESTRIRCDDCGFLADGLSGLNVHIAMKHPTKEKHFHCLLCGKSFYTESNLHQHLASAGHMRNEQASVEELPEGGATFKCVKCTEPFDSEQNLFLHIKGQHEELLREVNKYIVEDTEQINREREENQGNVCKYCGKMCRSSNSMAFLAHIRTHTGSKPFKCKICHFATAQLGDARNHVKRHLGMREYKCHVCGVAFVMKKHLNTHLLGKHGVGTPKERKFTCHLCDRSFTEKWALNNHMKLHTGEKPFKCTWPTCHYSFLTASAMKDHYRTHTGEKSFLCDLCGFAGGTRHALTKHRRQHTGEKPFKCDECNFASTTQSHLTRHKRVHTGEKPYRCPWCDYRSNCAENIRKHILHTGKHEGVKMYNCPKCDYGTNVPVEFRNHLKEQHPDIENPDLAYLHAGIVSKSYECRLKGQGATFVETDSPFTAAALAEEPLVKEKPLRSSRRPAPPPEQVQQVIIFQGYDGEFALDPSVEETAAATLQTLAMAGQVARVVHITEDGQVIATSQSGAHVGSVVPGPILPEQLADGATQVVVVGGSMEGHGMDESLSPGGAVIQQVTKQEILNLSEAGVAPPEASSALDALLCAVTELGEVEGRAGLEEQGRPGAKDVLIQLPGQEVSHVAADPEAPEIQMFPQAQESPAAVEVLTQVVHPSAAMASQERAQVAFKKMVQGVLQFAVCDTAAAGQLVKDGVTQVVVSEEGAVHMVAGEGAQIIMQEAQGEHMDLVESDGEISQIIVTEELVQAMVQESSGGFSEGTTHYILTELPPGVQDEPGLYSHTVLETADSQELLQAGATLGTEAGAPSRAEQLASVVIYTQEGSSAAAAIQSQRESSELQEA>sp|Q9C0G0-2|ZN407_HUMAN Isoform 2 of Zinc finger protein 407 OS=Homosapiens OX=9606 GN=ZNF407MMDSENKPENDEDEKINKEAQDLTKLSSHNEDGGPVSDVIASFPENSMGKRGFSESSNSDSVVIGEDRNKHASKRRKLDEAEPLKSGKQGICRLETSESSVTEGGIALDETGKETFLSDCTVGGTCLPNALSPSCNFSTIDVVSLKTDTEKTSAQEMVSLDLERESPFPPKEISVSCTIGNVDTVLKCSICGHLFSSCSDLEKHAESHMQQPKEHTCCHCSHKAESSSALHMHIKQAHGPQKVFSCDLCGFQCSEENLLNAHYLGKTHLRRQNLAARGGFVQILTKQPFPKKSRTMATKNVHSKPRTSKSIAKNSDSKGLRNVGSTFKDFRGSISKQSGSSSELLVEMMPSRNTLSQEVEIVEEHVTSLGLAQNPENQSRKLDTLVTSEGLLEKLESTKNTLQAAHGNSVTSRPRPERNILVLGNSFRRRSSTFTLKGQAKKRFNLLGIKRGTSETQRMYMKHLRTQMKTHDAESVLKHLEACSSVQRVCVTTSETQEAEQGQGSARPPDSGLHSLTVKPASGSQTLCACTDCGQVATNRTDLEIHVKRCHAREMKFYCRTCDFSSMSRRDLDEHLHSNQHQQTASVLSCQCCSFISLDEINLRDHMKEKHNMHFLCTPCNLFFLSEKDVEEHKATEKHINSLVQPKTLQSSNSDLVLQTLPLSTLESENAKESMDDSGKASQEEPLKSRVSHGNEVRHSSKPQFQCKKCFYKTRSSTVLTRHIKLRHGQDYHFLCKACNLYSLSKEGMEKHIKRSKHLENAKKNNIGLSFEECIERVCIGANDKKEEFDVSGNGRIEGHIGVQLQEHSYLEKGMLASEELSQSGGSTKDDELASTTTPKRGRPKGNISRTCSHCGLLASSITNLTVHIRRKHSHQYSYLCKVCKYYTVTKGDMERHCATKKHKGRVEIEASGKHSSDIIVGPEGGSLEAGKKNAGSAVTMSDEHANKPAESPTSVLEKPDRGNSIEAEVENVFHSLDGEVNSHLLDKKEQISSEPEDFAQPGDVYSQRDVTGTGENKCLHCEFSAHSSASLELHVKRKHTKEFEFYCMACDYYAVTRREMTRHAATEKHKMKRQSYLNSANVEAGSADMSKNIIMPEEEHQQNSEEFQIISGQPSDTLKSRNAADCSILNENTNLDMSKVLCAADSVEVETEEESNFNEDHSFCETFQQAPVKDKVRKPEEMMSLTMSSNYGSPSRFQNENSGSSALNCETAKKNHEISNDAGELRVHCEGEGGNAGDGGGVVPHRHLCPVTLDGERSAESPVLVVTRITREQGNLESGGQNRVARGHGLEDLKGVQEDPVLGNKEILMNSQHETEFILEEDGPASDSTVESSDVYETIISIDDKGQAMYSFGRFDSSIIRIKNPEDGELIDQSEEGLIATGVRISELPLKDCAQGVKKKKSEGSSIGESTRIRCDDCGFLADGLSGLNVHIAMKHPTKEKHFHCLLCGKSFYTESNLHQHLASAGHMRNEQASVEELPEGGATFKCVKCTEPFDSEQNLFLHIKGQHEELLREVNKYIVEDTEQINREREENQGNVCKYCGKMCRSSNSMAFLAHIRTHTGSKPFKCKICHFATAQLGDARNHVKRHLGMREYKCHVCGVAFVMKKHLNTHLLGKHGVGTPKERKFTCHLCDRSFTEKWALNNHMKLHTGEKPFKCTWPTCHYSFLTASAMKDHYRTHTGEKSFLCDLCGFAGGTRHALTKHRRQHTGEKPFKCDECNFASTTQSHLTRHKRVHTGEKPYRCPWCDYRSNCAENIRKHILHTGKHEGVKMYNCPKCDYGTNVPVEFRNHLKEQHPDIENPDLAYLHAGKGQKL>sp|Q9C0G0-3|ZN407_HUMAN Isoform 3 of Zinc finger protein 407 OS=Homosapiens OX=9606 GN=ZNF407MMDSENKPENDEDEKINKEAQDLTKLSSHNEDGGPVSDVIASFPENSMGKRGFSESSNSDSVVIGEDRNKHASKRRKLDEAEPLKSGKQGICRLETSESSVTEGGIALDETGKETFLSDCTVGGTCLPNALSPSCNFSTIDVVSLKTDTEKTSAQEMVSLDLERESPFPPKEISVSCTIGNVDTVLKCSICGHLFSSCSDLEKHAESHMQQPKEHTCCHCSHKAESSSALHMHIKQAHGPQKVFSCDLCGFQCSEENLLNAHYLGKTHLRRQNLAARGGFVQILTKQPFPKKSRTMATKNVHSKPRTSKSIAKNSDSKGLRNVGSTFKDFRGSISKQSGSSSELLVEMMPSRNTLSQEVEIVEEHVTSLGLAQNPENQSRKLDTLVTSEGLLEKLESTKNTLQAAHGNSVTSRPRPERNILVLGNSFRRRSSTFTLKGQAKKRFNLLGIKRGTSETQRMYMKHLRTQMKTHDAESVLKHLEACSSVQRVCVTTSETQEAEQGQGSARPPDSGLHSLTVKPASGSQTLCACTDCGQVATNRTDLEIHVKRCHAREMKFYCRTCDFSSMSRRDLDEHLHSNQHQQTASVLSCQCCSFISLDEINLRDHMKEKHNMHFLCTPCNLFFLSEKDVEEHKATEKHINSLVQPKTLQSSNSDLVLQTLPLSTLESENAKESMDDSGKASQEEPLKSRVSHGNEVRHSSKPQFQCKKCFYKTRSSTVLTRHIKLRHGQDYHFLCKACNLYSLSKEGMEKHIKRSKHLENAKKNNIGLSFEECIERVCIGANDKKEEFDVSGNGRIEGHIGVQLQEHSYLEKGMLASEELSQSGGSTKDDELASTTTPKRGRPKGNISRTCSHCGLLASSITNLTVHIRRKHSHQYSYLCKVCKYYTVTKGDMERHCATKKHKGRVEIEASGKHSSDIIVGPEGGSLEAGKKNAGSAVTMSDEHANKPAESPTSVLEKPDRGNSIEAEVENVFHSLDGEVNSHLLDKKEQISSEPEDFAQPGDVYSQRDVTGTGENKCLHCEFSAHSSASLELHVKRKHTKEFEFYCMACDYYAVTRREMTRHAATEKHKMKRQSYLNSANVEAGSADMSKNIIMPEEEHQQNSEEFQIISGQPSDTLKSRNAADCSILNENTNLDMSKVLCAADSVEVETEEESNFNEDHSFCETFQQAPVKDKVRKPEEMMSLTMSSNYGSPSRFQNENSGSSALNCETAKKNHEISNDAGELRVHCEGEGGNAGDGGGVVPHRHLCPVTLDGERSAESPVLVVTRITREQGNLESGGQNRVARGHGLEDLKGVQEDPVLGNKEILMNSQHETEFILEEDGPASDSTVESSDVYETIISIDDKGQAMYSFGRFDSSIIRIKNPEDGELIDQSEEGLIATGVRISELPLKDCAQGVKKKKSEGSSIGESTRIRCDDCGFLADGLSGLNVHIAMKHPTKEKHFHCLLCGKSFYTESNLHQHLASAGHMRNEQASVEELPEGGATFKCVKCTEPFDSEQNLFLHIKGQHEELLREVNKYIVEDTEQINREREENQGNVCKYCGKMCRSSNSMAFLAHIRTHTGSKPFKCKICHFATAQLGDARNHVKRHLGMREYKCHVCGVAFVMKKHLNTHLLGKHGVGTPKERVKVAYRKIGTLPGIQNNRNASSASEAQSLCEHFS>sp|Q8N8Y5|ZFP41_HUMAN Zinc finger protein 41 homolog OS=Homo sapiensOX=9606 GN=ZFP41 PE=1 SV=1MEKPAGRKKKTPTPREEADVQKSALREEKVSGDRKPPERPTVPRKPRTEPCLSPEDEEHVFDAFDASFKDDFEGVPVFIPFQRKKPYECSECGRIFKHKTDHIRHQRVHTGEKPFKCAQCGKAFRHSSDVTKHQRTHTGEKPFKCGECGKAFNCGSNLLKHQKTHTGEKPYECTHCGKAFAYSSCLIRHQKRHPRKKP>sp|Q86U90|YRDC_HUMAN YrdC domain-containing protein, mitochondrialOS=Homo sapiens OX=9606 GN=YRDC PE=1 SV=1MSPARRCRGMRAAVAASVGLSEGPAGSRSGRLFRPPSPAPAAPGARLLRLPGSGAVQAASPERAGWTEALRAAVAELRAGAVVAVPTDTLYGLACAASCSAALRAVYRLKGRSEAKPLAVCLGRVADVYRYCRVRVPEGLLKDLLPGPVTLVMERSEELNKDLNPFTPLVGIRIPDHAFMQDLAQMFEGPLALTSANLSSQASSLNVEEFQDLWPQLSLVIDGGQIGDGQSPECRLGSTVVDLSVPGKFGIIRPGCALESTTAILQQKYGLLPSHASYL>sp|Q8TF45|ZN418_HUMAN Zinc finger protein 418 OS=Homo sapiens OX=9606GN=ZNF418 PE=1 SV=2MQGTVAFEDVAVNFSQEEWSLLSEVQRCLYHDVMLENWVLISSLGCWCGSEDEEAPSKKSISIQRVSQVSTPGAGVSPKKAHSCEMCGAILGDILHLADHQGTHHKQKLHRCEAWGNKLYDSSNRPHQNQYLGEKPYRSSVEEALFVKRCKFHVSEESSIFIQSGKDFLPSSGLLLQEATHTGEKSNSKPECESPFQWGDTHYSCGECMKHSSTKHVFVQQQRLPSREECYCWECGKSFSKYDSVSNHQRVHTGKRPYECGECGKSFSHKGSLVQHQRVHTGKRPYECGECGKSFSHKGSLVQHQRVHTGERPYECGECGKSFSQNGTLIKHQRVHTGERPYECEECGKCFTQKGNLIQHQRGHTSERPYECEECGKCFSQKGTLTEHHRVHTRERPYECGECGKSFSRKGHLRNHQRGHTGERPYECGECGKSFSRKGNLIQHQRSHTGERPYECRECRKLFRGKSHLIEHQRVHTGERPYECNECGKSFQDSSGFRVHQRVHTGEKPFECSECGKSFPQSCSLLRHRRVHTGERPYECGECGKSFHQSSSLLRHQKTHTAERPYECRECGKFFSSLLEHRRVHTGERPYECRECGKTFTRRSAHFKHQRLHTRGKPYECSECGKSFAETFSLTEHRRVHTGERPYECSECGKSFHRSSSLLRHQRVHTERSPYK>sp|O95780|ZN682_HUMAN Zinc finger protein 682 OS=Homo sapiens OX=9606GN=ZNF682 PE=2 SV=1MELLTFRDVTIEFSLEEWEFLNPAQQSLYRKVMLENYRNLVSLGLTVSKPELISRLEQRQEPWNVKRHETIAKPPAMSSHYTEDLLPEQCMQDSFQKVILRRYGSCGLEDLHLRKDGENVGECKDQKEIYNGLNQCLSTLPSKIFPYNKCVKVFSKSSNLNRENIRHTTEKLFKCMQCGKVFKSHSGLSYHKIIHTEEKLCICEECGKTFKWFSYLTKHKRIHTGEKPYKCEECGKAFNWCSSLTKHKRIHTGEKPYKCEECGKAFHWCSPFVRHKKIHTGEKPYTCEDCGRAFNRHSHLTKHKTIHTGKKPYKCKECGKAFNHCSLLTIHERTHTGEKPYKCEECGKAFNSSSILTEHKVIHSGEKPYKCEKCDKVFKRFSYLTKHKRIHTGEKPYKCEECGKAFNWSSILTEHKRIHTGEKPYNCEECGKAFNRCSHLTRHKKIHTAVKRYKCEECGKAFKRCSHLNEHKRVQRGEKSCKYKKCGEAFNHCSNLTT>sp|O95780-2|ZN682_HUMAN Isoform 2 of Zinc finger protein 682 OS=Homosapiens OX=9606 GN=ZNF682MSSHYTEDLLPEQCMQDSFQKVILRRYGSCGLEDLHLRKDGENVGECKDQKEIYNGLNQCLSTLPSKIFPYNKCVKVFSKSSNLNRENIRHTTEKLFKCMQCGKVFKSHSGLSYHKIIHTEEKLCICEECGKTFKWFSYLTKHKRIHTGEKPYKCEECGKAFNWCSSLTKHKRIHTGEKPYKCEECGKAFHWCSPFVRHKKIHTGEKPYTCEDCGRAFNRHSHLTKHKTIHTGKKPYKCKECGKAFNHCSLLTIHERTHTGEKPYKCEECGKAFNSSSILTEHKVIHSGEKPYKCEKCDKVFKRFSYLTKHKRIHTGEKPYKCEECGKAFNWSSILTEHKRIHTGEKPYNCEECGKAFNRCSHLTRHKKIHTAVKRYKCEECGKAFKRCSHLNEHKRVQRGEKSCKYKKCGEAFNHCSNLTT>sp|O95780-3|ZN682_HUMAN Isoform 3 of Zinc finger protein 682 OS=Homosapiens OX=9606 GN=ZNF682MLENYRNLVSLGLTVSKPELISRLEQRQEPWNVKRHETIAKPPAMSSHYTEDLLPEQCMQDSFQKVILRRYGSCGLEDLHLRKDGENVGECKDQKEIYNGLNQCLSTLPSKIFPYNKCVKVFSKSSNLNRENIRHTTEKLFKCMQCGKVFKSHSGLSYHKIIHTEEKLCICEECGKTFKWFSYLTKHKRIHTGEKPYKCEECGKAFNWCSSLTKHKRIHTGEKPYKCEECGKAFHWCSPFVRHKKIHTGEKPYTCEDCGRAFNRHSHLTKHKTIHTGKKPYKCKECGKAFNHCSLLTIHERTHTGEKPYKCEECGKAFNSSSILTEHKVIHSGEKPYKCEKCDKVFKRFSYLTKHKRIHTGEKPYKCEECGKAFNWSSILTEHKRIHTGEKPYNCEECGKAFNRCSHLTRHKKIHTAVKRYKCEECGKAFKRCSHLNEHKRVQRGEKSCKYKKCGEAFNHCSNLTT>sp|Q96GR4|ZDH12_HUMAN Palmitoyltransferase ZDHHC12 OS=Homo sapiensOX=9606 GN=ZDHHC12 PE=2 SV=2MAPWALLSPGVLVRTGHTVLTWGITLVLFLHDTELRQWEEQGELLLPLTFLLLVLGSLLLYLAVSLMDPGYVNVQPQPQEELKEEQTAMVPPAIPLRRCRYCLVLQPLRARHCRECRRCVRRYDHHCPWMENCVGERNHPLFVVYLALQLVVLLWGLYLAWSGLRFFQPWGQWLRSSGLLFATFLLLSLFSLVASLLLVSHLYLVASNTTTWEFISSHRIAYLRQRPSNPFDRGLTRNLAHFFCGWPSGSWETLWAEEEEEGSSPAV>sp|Q96GR4-2|ZDH12_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC12OS=Homo sapiens OX=9606 GN=ZDHHC12MAPWALLSPGVLVRTGHTVLTWGITLVLFLHDTELRQWEEQGELLLPLTFLLLVLGSLLLYLAVSLMDPGYVNVQPQPQEELKEEQTAMVPPAIPLRRCRYCLVLQPLRARHCRECRRCVRRYDHHCPWMENCVGERNHPLFVVYLALQLVVLLWGLYLAWSGLRFFQPWGQWLRSSGLLFATFLLLSHFFCGWPSGSWETLWAEEEEEGSSPAV>sp|Q96GR4-3|ZDH12_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC12OS=Homo sapiens OX=9606 GN=ZDHHC12MAPWALLSPGVLVRTGHTVLTWGITLVLFLHDTDKSADELLATHSHSWNQHLQAFAQPGTHFPTSNCTPTPPTPVLPGPASLCSPASPELRQWEEQGELLLPLTFLLLVLGSLLLYLAVSLMDPGYVNVQPQPQEELKEEQTAMVPPAIPLRRCRYCLVLQPLRARHCRECRRCVRRYDHHCPWMENCVGERNHPLFVVYLALQLVVLLWGLYLAWSGLRFFQPWGQWLRSSGLLFATFLLLSLFSLVASLLLVSHLYLVASNTTTWEFISSHRIAYLRQRPSNPFDRGLTRNLAHFFCGWPSGSWETLWAEEEEEGSSPAV>sp|Q9GZS3|WDR61_HUMAN WD repeat-containing protein 61 OS=Homo sapiensOX=9606 GN=WDR61 PE=1 SV=1MTNQYGILFKQEQAHDDAIWSVAWGTNKKENSETVVTGSLDDLVKVWKWRDERLDLQWSLEGHQLGVVSVDISHTLPIAASSSLDAHIRLWDLENGKQIKSIDAGPVDAWTLAFSPDSQYLATGTHVGKVNIFGVESGKKEYSLDTRGKFILSIAYSPDGKYLASGAIDGIINIFDIATGKLLHTLEGHAMPIRSLTFSPDSQLLVTASDDGYIKIYDVQHANLAGTLSGHASWVLNVAFCPDDTHFVSSSSDKSVKVWDVGTRTCVHTFFDHQDQVWGVKYNGNGSKIVSVGDDQEIHIYDCPI>sp|Q6ZR03|YU004_HUMAN Uncharacterized protein FLJ46757 OS=Homo sapiensOX=9606 PE=2 SV=1MPCRLLHQRETRSGGPRGPRHSAPTGPGWHNAPTLQSWEESHAPSRDPRDHQGSVEDTSLGGDAPADGVSPSVPPLQGLGKAAGPGGTGQAECQVVVATHRANLKPWDGRAAPLGKRTEEGRLSTSSCASVSRNKPDSVPQGDPVWPPESTGPALCAGEETEPQSSEGLAWGPWAQPWAPSLCPSQTGTASTASPQRASRLALQGPPGTILSLSSSSPCLPPSHCDPGAASSWAGLQSLKLLLQVSFQGAADGCSLRDANTNRKGPMHGSDFPPRLCLHSMSLWGSWGSRPPSPAHSREVAS>sp|P67809|YBOX1_HUMAN Y-box-binding protein 1 OS=Homo sapiens OX=9606GN=YBX1 PE=1 SV=3MSSEAETQQPPAAPPAAPALSAADTKPGTTGSGAGSGGPGGLTSAAPAGGDKKVIATKVLGTVKWFNVRNGYGFINRNDTKEDVFVHQTAIKKNNPRKYLRSVGDGETVEFDVVEGEKGAEAANVTGPGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNYQNSESGEKNEGSESAPEGQAQQRRPYRRRRFPPYYMRRPYGRRPQYSNPPVQGEVMEGADNQGAGEQGRPVRQNMYRGYRPRFRRGPPRQRQPREDGNEEDKENQGDETQGQQPPQRRYRRNFNYRRRRPENPKPQDGKETKAADPPAENSSAPEAEQGGAE>sp|P16989|YBOX3_HUMAN Y-box-binding protein 3 OS=Homo sapiens OX=9606GN=YBX3 PE=1 SV=4MSEAGEATTTTTTTLPQAPTEAAAAAPQDPAPKSPVGSGAPQAAAPAPAAHVAGNPGGDAAPAATGTAAAASLATAAGSEDAEKKVLATKVLGTVKWFNVRNGYGFINRNDTKEDVFVHQTAIKKNNPRKYLRSVGDGETVEFDVVEGEKGAEAANVTGPDGVPVEGSRYAADRRRYRRGYYGRRRGPPRNYAGEEEEEGSGSSEGFDPPATDRQFSGARNQLRRPQYRPQYRQRRFPPYHVGQTFDRRSRVLPHPNRIQAGEIGEMKDGVPEGAQLQGPVHRNPTYRPRYRSRGPPRPRPAPAVGEAEDKENQQATSGPNQPSVRRGYRRPYNYRRRPRPPNAPSQDGKEAKAGEAPTENPAPPTQQSSAE>sp|P16989-2|YBOX3_HUMAN Isoform 2 of Y-box-binding protein 3 OS=Homosapiens OX=9606 GN=YBX3MSEAGEATTTTTTTLPQAPTEAAAAAPQDPAPKSPVGSGAPQAAAPAPAAHVAGNPGGDAAPAATGTAAAASLATAAGSEDAEKKVLATKVLGTVKWFNVRNGYGFINRNDTKEDVFVHQTAIKKNNPRKYLRSVGDGETVEFDVVEGEKGAEAANVTGPDGVPVEGSRYAADRRRYRRGYYGRRRGPPRNAGEIGEMKDGVPEGAQLQGPVHRNPTYRPRYRSRGPPRPRPAPAVGEAEDKENQQATSGPNQPSVRRGYRRPYNYRRRPRPPNAPSQDGKEAKAGEAPTENPAPPTQQSSAE>sp|P16989-3|YBOX3_HUMAN Isoform 3 of Y-box-binding protein 3 OS=Homosapiens OX=9606 GN=YBX3MSEAGEATTTTTTTLPQAPTEAAAAAPQDPAPKSPVGSGAPQAAAPAPAAHVAGNPGGDAAPAATGTAAAASLATAAGSEDAEKKVLATKVLGTVKWFNVRNGYGFINRNDTKEDVFVHQTAIKKNNPRKYLRSVGDGETVEFDVVEGEKGAEAANVTGPDGVPVEGSRYAADRRRYRRGYYGRRRGPPRNYAGEEEEEGSGSSEGFDPPATDRQFSGARNQLRRPQYRPQYRQRRFPPYHVGQTFDRRSRVLPHPNRIQAGEIGEMKDGVPEGAQLQGPVHRNPTYRPRYRSRGPPRPRPAPAVGEAEDKENQQATSGPNQPSVRRGYRRPYNYRRRPPSS>sp|Q2M3W8|ZN181_HUMAN Zinc finger protein 181 OS=Homo sapiens OX=9606GN=ZNF181 PE=1 SV=1MPQVTFNDVAIDFTHEEWGWLSSAQRDLYKDVMVQNYENLVSVAGLSVTKPYVITLLEDGKEPWMMEKKLSKGMIPDWESRWENKELSTKKDNYDEDSPQTVIIEKVVKQSYEFSNSKKNLEYIEKLEGKHGSQVDHFRPAILTSRESPTADSVYKYNIFRSTFHSKSTLSEPQKISAEGNSHKYDILKKNLPKKSVIKNEKVNGGKKLLNSNKSGAAFSQGKSLTLPQTCNREKIYTCSECGKAFGKQSILNRHWRIHTGEKPYECRECGKTFSHGSSLTRHLISHSGEKPYKCIECGKAFSHVSSLTNHQSTHTGEKPYECMNCGKSFSRVSHLIEHLRIHTQEKLYECRICGKAFIHRSSLIHHQKIHTGEKPYECRECGKAFCCSSHLTRHQRIHTMEKQYECNKCLKVFSSLSFLVQHQSIHTEEKPFECQKCRKSFNQLESLNMHLRNHIRLKPYECSICGKAFSHRSSLLQHHRIHTGEKPYECIKCGKTFSCSSNLTVHQRIHTGEKPYKCNECGKAFSKGSNLTAHQRVHNGEKPNSVVSVEKPLDYMNHYTCEKSYRRETV>sp|Q2M3W8-2|ZN181_HUMAN Isoform 2 of Zinc finger protein 181 OS=Homosapiens OX=9606 GN=ZNF181MMEKKLSKGMIPDWESRWENKELSTKKDNYDEDSPQTVIIEKVVKQSYEFSNSKKNLEYIEKLEGKHGSQVDHFRPAILTSRESPTADSVYKYNIFRSTFHSKSTLSEPQKISAEGNSHKYDILKKNLPKKSVIKNEKVNGGKKLLNSNKSGAAFSQGKSLTLPQTCNREKIYTCSECGKAFGKQSILNRHWRIHTGEKPYECRECGKTFSHGSSLTRHLISHSGEKPYKCIECGKAFSHVSSLTNHQSTHTGEKPYECMNCGKSFSRVSHLIEHLRIHTQEKLYECRICGKAFIHRSSLIHHQKIHTGEKPYECRECGKAFCCSSHLTRHQRIHTMEKQYECNKCLKVFSSLSFLVQHQSIHTEEKPFECQKCRKSFNQLESLNMHLRNHIRLKPYECSICGKAFSHRSSLLQHHRIHTGEKPYECIKCGKTFSCSSNLTVHQRIHTGEKPYKCNECGKAFSKGSNLTAHQRVHNGEKPNSVVSVEKPLDYMNHYTCEKSYRRETV>sp|Q2M3W8-3|ZN181_HUMAN Isoform 3 of Zinc finger protein 181 OS=Homosapiens OX=9606 GN=ZNF181MPQVTFNDVAIDFTHEEWGWLSSAQRDLYKDVMVQNYENLVSVGLSVTKPYVITLLEDGKEPWMMEKKLSKGMIPDWESRWENKELSTKKDNYDEDSPQTVIIEKVVKQSYEFSNSKKNLEYIEKLEGKHGSQVDHFRPAILTSRESPTADSVYKYNIFRSTFHSKSTLSEPQKISAEGNSHKYDILKKNLPKKSVIKNEKVNGGKKLLNSNKSGAAFSQGKSLTLPQTCNREKIYTCSECGKAFGKQSILNRHWRIHTGEKPYECRECGKTFSHGSSLTRHLISHSGEKPYKCIECGKAFSHVSSLTNHQSTHTGEKPYECMNCGKSFSRVSHLIEHLRIHTQEKLYECRICGKAFIHRSSLIHHQKIHTGEKPYECRECGKAFCCSSHLTRHQRIHTMEKQYECNKCLKVFSSLSFLVQHQSIHTEEKPFECQKCRKSFNQLESLNMHLRNHIRLKPYECSICGKAFSHRSSLLQHHRIHTGEKPYECIKCGKTFSCSSNLTVHQRIHTGEKPYKCNECGKAFSKGSNLTAHQRVHNGEKPNSVVSVEKPLDYMNHYTCEKSYRRETV>sp|Q6ZN06|ZN813_HUMAN Zinc finger protein 813 OS=Homo sapiens OX=9606GN=ZNF813 PE=2 SV=2MALPQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCMMKEFSSTAQGNREVIHTGTLQRHESHHTGDFRFQEIDKDIHNLEFQWQEDERNSHEAPMTEIKKLTGSADRYDQRHAGNKPIKDQLGSSFHSHLPELHMFQTQGKIGNQVEKSINDASSISTSQRISCRPKTHISNNYGNNFRNSSLLTQKQEVHMREKSFQCNESGKAFNYSSLLRKHQIIHLGEKQYKCDVCGKVFNRKRNLVCHRRCHTGEKPYRCNECGKTFSQTYSLTCHRRLHTGEKPYKCEECDKAFSFKSNLKRHRRIHAGEKPYKCNECGKTFSQTSSLTCHRRLHTGEKPFKCNECGKTFSRKSSLTCHHRLHTGEKPYKCNECGKTFSQELTLKCHRRLHTGEKPYKCNECGKVFNKKANLARHHRLHSGEKPYKCTECVKTFSRNSALVIHKAIHIGEKRYKCNECGKTFSRISALVIHTAIHTGEKPYKCNECGKGFNRKTHLACHHRLHTGEKPYKCNECGKVFNRKTHLAHHHRLHTGDKPYKCNECGKVFNQKAHLARHHRLHTGEKPYKCNECGKVFNQKANLARHHRLHTGEKPYKFNECGKAFN>sp|O95409|ZIC2_HUMAN Zinc finger protein ZIC 2 OS=Homo sapiens OX=9606GN=ZIC2 PE=1 SV=2MLLDAGPQFPAIGVGSFARHHHHSAAAAAAAAAEMQDRELSLAAAQNGFVDSAAAHMGAFKLNPGAHELSPGQSSAFTSQGPGAYPGSAAAAAAAAALGPHAAHVGSYSGPPFNSTRDFLFRSRGFGDSAPGGGQHGLFGPGAGGLHHAHSDAQGHLLFPGLPEQHGPHGSQNVLNGQMRLGLPGEVFGRSEQYRQVASPRTDPYSAAQLHNQYGPMNMNMGMNMAAAAAHHHHHHHHHPGAFFRYMRQQCIKQELICKWIDPEQLSNPKKSCNKTFSTMHELVTHVSVEHVGGPEQSNHVCFWEECPREGKPFKAKYKLVNHIRVHTGEKPFPCPFPGCGKVFARSENLKIHKRTHTGEKPFQCEFEGCDRRFANSSDRKKHMHVHTSDKPYLCKMCDKSYTHPSSLRKHMKVHESSPQGSESSPAASSGYESSTPPGLVSPSAEPQSSSNLSPAAAAAAAAAAAAAAAVSAVHRGGGSGSGGAGGGSGGGSGSGGGGGGAGGGGGGSSGGGSGTAGGHSGLSSNFNEWYV>sp|A8MT70|ZBBX_HUMAN Zinc finger B-box domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZBBX PE=2 SV=3MNRKDFVVLPWGKPGNSVKLKYRNAQELRMEKVQLEFENQEMEKKLQEFRSTRNKEKEDRESSEYYWKSGKVGKLVNQSYMMSQNKGNVVKFSAGKVKLKLLKEQIQEPVKPTVNYKMANSSECEKPKINGKVCGQCENKAALLVCLECGEDYCSGCFAKVHQKGALKLHRTTLLQAKSQILFNVLDVAHQFIKDVNPDEPKEENNSTKETSKIQHKPKSVLLQRSSSEVEITTMKRAQRTKPRKSLLCEGSFDEEASAQSFQEVLSQWRTGNHDDNKKQNLHAAVKDSLEECEVQTNLKIWREPLNIELKEDILSYMEKLWLKKHRRTPQEQLFKMLPDTFPHPHETTGDAQCSQNENDEDSDGEETKVQHTALLLPVETLNIERPEPSLKIVELDDTYEEEFEEAENIVPYKVKLADADSQRSCAFHDCQKNSFPYENGIHQHHVFDKGKRDFLNLCLRNSSTYYKDNSKAETSNTDFDNIVDPDVYSSDIEKIEESTSFERNLKEKNIGLESNQKSDDSCVSLESKDTLLGRDLEKAPIEEKLSQDIKESLELSNLYKRPSFEESKTTKSSLLLQEIACRSKPITKQYQGLERFFIFDTNERLNLLPSHRLECNNSSTRITLAGQKSQRPSTANFPLSNSVKESSSCLSSSHPRSRSAAAQSSSRAASEISEIEYIDITDQNELSLDDTTDQHTLDNLEKELQVLRSLADTSEKLYSLTSEEFPDFSSQSLNISQISTDFLKTSHVRGPCGVEELSCSGRDTKIQSLLSLSESSTDEEEEDFLNKQHVITLPWSKST>sp|A8MT70-3|ZBBX_HUMAN Isoform 3 of Zinc finger B-box domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=ZBBXMEKVQLEFENQEMEKKLQEFRSTRNKEKEDRESSEYYWKSGKVGKLVNQSYMMSQNKGNVVKFSAGKVKLKLLKEQIQEPVKPTVNYKMANSSECEKPKINGKVCGQCENKAALLVCLECGEDYCSGCFAKVHQKGALKLHRTTLLQAKSQILFNVLDVAHQFIKDVNPDEPKEENNSTKETSKIQHKPKSVLLQRSSSEVEITTMKRAQRTKPRKSLLCEGSFDEEASAQSFQEVLSQWRTGNHDDNKKQNLHAAVKDSLEECEVQTNLKIWREPLNIELKEDILSYMEKLWLKKHRRTPQEQLFKMLPDTFPHPHETTGDAQCSQNENDEDSDGEETKVQHTALLLPVETLNIERPEPSLKIVELDDTYEEEFEEAENIVPYKVKLADADSQRSCAFHDCQKNSFPYENGIHQHHVFDKGKRDFLNLCLRNSSTYYKDNSKAETSNTDFDNIVDPDVYSSDIEKIEESTSFERNLKEKNIGLESNQKSDDSCVSLESKDTLLGRDLEKAPIEEKLSQDIKESLELSNLYKRPSFEESKTTKSSLLLQEIACRSKPITKQYQGLERFFIFDTNERLNLLPSHRLECNNSSTRITLAGQKSQRPSTANFPLSNSVKESSSCLSSSHPRSRSAAAQSSSRAASEISEIEYIDITDQNELSLDDTTDQHTLDNLEKELQVLRSLADTSEKLYSLTSEEFPDFSSQSLNISQISTDFLKTSHVRGPCGVEELSCSGRDTKIQSLLSLSESSTDEEEEDFLNKQHVITLPWSKST>sp|A8MT70-2|ZBBX_HUMAN Isoform 2 of Zinc finger B-box domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=ZBBXMNRKDFVVLPWGKPGNSVKLKYRNAQELRMEKVQLEFENQEMEKKLQEFRSTRNKEKEDRESSEYYWKSGKVGKLVNQSYMMSQNKGNVVKFSAGKVKLKLLKEQIQEPVKPTVNYKMANSSECEKPKINGKVCGQCENKAALLVCLECGEDYCSGCFAKVHQKGALKLHRTTLLQAKSQILFNVLDVAHQFIKDVNPDEPKEENNSTKETSKIQHKPKSVLLQRSSSEVEITTMKRAQRTKPRKSLLCEGSFDEEASAQSFQEVLSQWRTGNHDDNKKQNLHAAVKDSLEECEVQTNLKIWREPLNIELKEDILSYMEKLWLKKHRRTPQEQLFKMLPDTFPHPHETTGDAQCSQNENDEDSDGEETKVQHTALLLPVETLNIERPEPSLKIVELDDTYEEEFEEAENIVPYKVKLADADSQRSCAFHDCQKNSFPYENGIHQHHVFDKGKRDFLNLCLRNSSTYYKDNSKAETSNTDFDNIVDPDVYSSDIEKIEESTSFERNLKEKNIGLESNQKSDDSCVSLESKDTLLGRDLEKAPIEEKLSQDIKESLELSNLYKRPSFEESKTTKSSLLLQEIACRSKPITKQYQGLERFFIFDTNERLNLLPSHRLECNNSSTRITLAEDREWIPDHSLSEYADNAIVLGVLQGAQSPSSSRKQQKMGQKSQRPSTANFPLSNSVKESSSCLSSSHPRSRSAAAQSSSRAASEISEIEYIDITDQNELSLDDTTDQHTLDNLEKELQVLRSLADTSEKLYSLTSEEFPDFSSQSLNISQISTDFLKTSHVRGPCGVEELSCSGRDTKIQSLLSLSESSTDEEEEDFLNKQHVITLPWSKST>sp|Q8NB15|ZN511_HUMAN Zinc finger protein 511 OS=Homo sapiens OX=9606GN=ZNF511 PE=1 SV=2MQLPPALCARLAAGPGAAEPLPVERDPAAGAAPFRFVARPVRFPREHQFFEDGDVQRHLYLQDVIMQVADVPEKPRVPAFACQVAGCCQVFDALDDYEHHYHTLHGNVCSFCKRAFPSGHLLDAHILEWHDSLFQILSERQDMYQCLVEGCTEKFKTSRDRKDHMVRMHLYPADFRFDKPKKSRSPASAEAPGDSGERSEGEAMEICSEPVAASPAPAGERRIYRHRIPSTICFGQGAARGFKSNKKKTKQC>sp|Q8NB15-1|ZN511_HUMAN Isoform 1 of Zinc finger protein 511 OS=Homosapiens OX=9606 GN=ZNF511MQLPPALCARLAAGPGAAEPLPVERDPAAGAAPFRFVARPVRFPREHQFFEDGDVQRHLYLQDVIMQVADVPEKPRVPAFACQVAGCCQVFDALDDYEHHYHTLHGNVCSFCKRAFPSGHLLDAHILEWHDSLFQILSERQDMYQCLVEGCTEKFKTSRDRKDHMVRMHLYPADFRFDKPKKSRSPASAEAPGDSGERSEGEAMEICSEPVAASPAPAGERRIYRHRSVSELFLKPVLNMCSVLRILGCTWAAALLILNSER>sp|P17023|ZNF19_HUMAN Zinc finger protein 19 OS=Homo sapiens OX=9606GN=ZNF19 PE=1 SV=4MAAMPLKAQYQEMVTFEDVAVHFTKTEWTGLSPAQRALYRSVMLENFGNLTALGYPVPKPALISLLERGDMAWGLEAQDDPPAERTKNVCKDVETNIDSESTLIQGISEERDGMMSHGQLKSVPQRTDFPETRNVEKHQDIPTVKNIQGKVPRIPCARKPFICEECGKSFSYFSYYARHQRIHTGEKPFECSECGKAFNGNSSLIRHQRIHTGERPYQCEECGRAFNDNANLIRHQRIHSGDRPYYCTECGNSFTSSSEFVIHQRIHTGEKPYECNECGKAFVGNSPLLRHQKIHTGEKPYECNECGKSFGRTSHLSQHQRIHTGEKPYSCKVCGQAFNFHTKLTRHQRIHSEEKPFDCVDCGKAFSAQEQLKRHLRIHTQESSYVCDECGKALTSKRNLHQHQRIHTGEKPYECSKYEKAFGTSSQLGHLEHVYSGEKPVLDICRFGLPEFFTPFYW>sp|P17023-2|ZNF19_HUMAN Isoform 2 of Zinc finger protein 19 OS=Homosapiens OX=9606 GN=ZNF19MVTFEDVAVHFTKTEWTGLSPAQRALYRSVMLENFGNLTALGYPVPKPALISLLERGDMAWGLEAQDDPPAERTKNVCKDVETNIDSESTLIQGISEERDGMMSHGQLKSVPQRTDFPETRNVEKHQDIPTVKNIQGKVPRIPCARKPFICEECGKSFSYFSYYARHQRIHTGEKPFECSECGKAFNGNSSLIRHQRIHTGERPYQCEECGRAFNDNANLIRHQRIHSGDRPYYCTECGNSFTSSSEFVIHQRIHTGEKPYECNECGKAFVGNSPLLRHQKIHTGEKPYECNECGKSFGRTSHLSQHQRIHTGEKPYSCKVCGQAFNFHTKLTRHQRIHSEEKPFDCVDCGKAFSAQEQLKRHLRIHTQESSYVCDECGKALTSKRNLHQHQRIHTGEKPYECSKYEKAFGTSSQLGHLEHVYSGEKPVLDICRFGLPEFFTPFYW>sp|Q63HK3|ZKSC2_HUMAN Zinc finger protein with KRAB and SCAN domains 2OS=Homo sapiens OX=9606 GN=ZKSCAN2 PE=1 SV=2MAVALDSQIDAPLEVEGCLIMKVEKDPEWASEPILEGSDSSETFRKCFRQFCYEDVTGPHEAFSKLWELCCRWLKPEMRSKEQILELLVIEQFLTILPEKIQAWAQKQCPQSGEEAVALVVHLEKETGRLRQQVSSPVHREKHSPLGAAWEVADFQPEQVETQPRAVSREEPGSLHSGHQEQLNRKRERRPLPKNARPSPWVPALADEWNTLDQEVTTTRLPAGSQEPVKDVHVARGFSYRKSVHQIPAQRDLYRDFRKENVGNVVSLGSAVSTSNKITRLEQRKEPWTLGLHSSNKRSILRSNYVKEKSVHAIQVPARSAGKTWREQQQWGLEDEKIAGVHWSYEETKTFLAILKESRFYETLQACPRNSQVYGAVAEWLRECGFLRTPEQCRTKFKSLQKSYRKVRNGHMLEPCAFFEDMDALLNPAARAPSTDKPKEMIPVPRLKRIAISAKEHISLVEEEEAAEDSDDDEIGIEFIRKSEIHGAPVLFQNLSGVHWGYEETKTFLDILRETRFYEALQACHRKSKLYGAVAEQLRECGFLRTPEQCRTKFKSLQKSYRKVKNGHVLESCAFYKEMDALINSRASAPSPSTPEEVPSPSRQERGGIEVEPQEPTGWEPEETSQEAVIEDSCSERMSEEEIVQEPEFQGPPGLLQSPNDFEIGSSIKEDPTQIVYKDMEQHRALIEKSKRVVSQSTDPSKYRKRECISGRQWENLQGIRQGKPMSQPRDLGKAVVHQRPFVGKRPYRLLKYGESFGRSTRLMCRMTHHKENPYKCGVCGKCFGRSRSLIRHQRIHTGEKPFKCLDCGKSFNDSSNFGAHQRIHTGEKPYRCGECGKCFSQSSSLIIHQRTHTGEKPYQCGECGKSFTNSSHFSAHRRVHTGENPYKCVDCEKSFNNCTRFREHRRIHTGEKPYGCAQCGKRFSKSSVLTKHREVHVREKPLPHPPSLYCPENPHKGKTDEFRKTF>sp|Q63HK3-2|ZKSC2_HUMAN Isoform 2 of Zinc finger protein with KRAB andSCAN domains 2 OS=Homo sapiens OX=9606 GN=ZKSCAN2MAVALDSQIDAPLEVEGCLIMKVEKDPEWASEPILEGSDSSETFRKCFRQFCYEDVTGPHEAFSKLWELCCRWLKPEMRSKEQILELLVIEQFLTILPEKIQAWAQKQCPQSGEEAVALVVHLEKETGRLRQQVSSPVHREKHSPLGAAWEVADFQPEQVETQPRAVSREEPGSLHSGHQEQLNRKRERRPLPKNARPSPWVPALADEWNTLDQEVTTTRLPAGSQEPVKDVHVARGFSYRKSVHQIPAQRDLYRDFRKENVGNVVSLGSAVSTSNKITRLEQRKEPWTLGLHSSNKRSILRSNYVKEKSVHAIQVPARSAGKTWREQQQWGLEDEKIAGVHWSYEETKTFLAILKESRFYETLQACPRNSQVYGAVAEWLRECGFLRTPEQCRTKFKSLQKSYRKVRNGHMLEPCAFFEDMDALLNPAARAPSTDKPKEMIPVPRLKRIAISAKEHISLVEEEEAAEDSDDDEIGIEFIRKSEIHGAPVLFQNLSGKNCALFLW>sp|Q9H7R0|ZN442_HUMAN Zinc finger protein 442 OS=Homo sapiens OX=9606GN=ZNF442 PE=2 SV=1MIVFGGEDRSDLFLPDSQTNEERKQYDSVAFEDVAVNFTQEEWALLGPSQKSLYRDVMWETIRNLDCIGMKWEDTNIEDQHRNPRRSLRCHIIERFSESRQPDSTVNEKPPGVDPCKSSVCGEIMGCSFLNCYITFDAGHKPDECQEYGEKPHTHKQCGTAFNYHHSFQTQERPHTGKKRYDCKECGKTFSSSGNLRRHIIVQRGGGPYICKLCGKAFFWPSLFRMHERTHTGEKPYECKQCCKAFPIYSSYLRHERTHTGEKPYECKHCSKAFPDYSSYVRHERTHTGEKPYKCKRCGRAFSVSSSLRIHERTHTGEKPYECKQCGKAFHHLGSFQRHMIRHTGDGPHKCKICGKGFDCPSSLQSHERTHTGEKPYECKQCGKALSHHSSFRSHMIMHTGDGPHKCKVCGKAFIYPSVFQGHERTHTGEKPYECKECGKAFRISSSLRRHETTHTGEKPYKCKCGKAFIDFYSFQNHETTHTGEKPYECKECGKAFSCFTYLSQHRRTHMAEKPYECKTCKKAFSHFGNLKVHERIHTGEKPYECKECRKAFSWLTCLLRHERIHTGKKSYECQQCGKAFTRSRFLRGHEKTHTGEKMHECKECGKALSSLSSLHRHKRTHWRDTL>sp|Q9H7R0-2|ZN442_HUMAN Isoform 2 of Zinc finger protein 442 OS=Homosapiens OX=9606 GN=ZNF442MKWEDTNIEDQHRNPRRSLRCHIIERFSESRQPDSTVNEKPPGVDPCKSSVCGEIMGCSFLNCYITFDAGHKPDECQEYGEKPHTHKQCGTAFNYHHSFQTQERPHTGKKRYDCKECGKTFSSSGNLRRHIIVQRGGGPYICKLCGKAFFWPSLFRMHERTHTGEKPYECKQCCKAFPIYSSYLRHERTHTGEKPYECKHCSKAFPDYSSYVRHERTHTGEKPYKCKRCGRAFSVSSSLRIHERTHTGEKPYECKQCGKAFHHLGSFQRHMIRHTGDGPHKCKICGKGFDCPSSLQSHERTHTGEKPYECKQCGKALSHHSSFRSHMIMHTGDGPHKCKVCGKAFIYPSVFQGHERTHTGEKPYECKECGKAFRISSSLRRHETTHTGEKPYKCKCGKAFIDFYSFQNHETTHTGEKPYECKECGKAFSCFTYLSQHRRTHMAEKPYECKTCKKAFSHFGNLKVHERIHTGEKPYECKECRKAFSWLTCLLRHERIHTGKKSYECQQCGKAFTRSRFLRGHEKTHTGEKMHECKECGKALSSLSSLHRHKRTHWRDTL>sp|Q86UK7|ZN598_HUMAN E3 ubiquitin-protein ligase ZNF598 OS=Homo sapiensOX=9606 GN=ZNF598 PE=1 SV=1MAAAGGAEGRRAALEAAAAAAPERGGGSCVLCCGDLEATALGRCDHPVCYRCSTKMRVLCEQRYCAVCREELRQVVFGKKLPAFATIPIHQLQHEKKYDIYFADGKVYALYRQLLQHECPRCPELPPFSLFGDLEQHMRRQHELFCCRLCLQHLQIFTYERKWYSRKDLARHRMQGDPDDTSHRGHPLCKFCDERYLDNDELLKHLRRDHYFCHFCDSDGAQDYYSDYAYLREHFREKHFLCEEGRCSTEQFTHAFRTEIDLKAHRTACHSRSRAEARQNRHIDLQFSYAPRHSRRNEGVVGGEDYEEVDRYSRQGRVARAGTRGAQQSRRGSWRYKREEEDREVAAAVRASVAAQQQEEARRSEDQEEGGRPKKEEAAARGPEDPRGPRRSPRTQGEGPGPKETSTNGPVSQEAFSVTGPAAPGCVGVPGALPPPSPKLKDEDFPSLSASTSSSCSTAATPGPVGLALPYAIPARGRSAFQEEDFPALVSSVPKPGTAPTSLVSAWNSSSSSKKVAQPPLSAQATGSGQPTRKAGKGSRGGRKGGPPFTQEEEEDGGPALQELLSTRPTGSVSSTLGLASIQPSKVGKKKKVGSEKPGTTLPQPPPATCPPGALQAPEAPASRAEGPVAVVVNGHTEGPAPARSAPKEPPGLPRPLGSFPCPTPQEDFPALGGPCPPRMPPPPGFSAVVLLKGTPPPPPPGLVPPISKPPPGFSGLLPSPHPACVPSPATTTTTKAPRLLPAPRAYLVPENFRERNLQLIQSIRDFLQSDEARFSEFKSHSGEFRQGLISAAQYYKSCRDLLGENFQKVFNELLVLLPDTAKQQELLSAHTDFCNREKPLSTKSKKNKKSAWQATTQQAGLDCRVCPTCQQVLAHGDASSHQALHAARDDDFPSLQAIARIIT>sp|Q86UK7-2|ZN598_HUMAN Isoform 2 of E3 ubiquitin-protein ligase ZNF598OS=Homo sapiens OX=9606 GN=ZNF598MAAAGGAEGRRAALEAAAAAAPERGGGSCVLCCGDLEATALGRCDHPVCYRCSTKMRVLCEQRYCAVCREELRQVVFGKKLPAFATIPIHQLQHEKKYDIYFADGKVYALYRQLLQHECPRCPELPPFSLFGDLEQHMRRQHELFCCRLCLQHLQIFTYERKWYSRKDLARHRMQGDPDDTSHRGHPLCKFCDERYLDNDELLKHLRRDHYFCHFCDSDGAQDYYSDYAYLREHFREKHFLCEEGRCSTEQFTHAFRTEIDLKAHRTACHSRSRAEARQNRHIDLQFSYAPRHSRRNEGVVGGEDYEEVDRYSRQGRVARAGTRGAQQSRRGSWREEEDREVAAAVRASVAAQQQEEARRSEDQEEGGRPKKEEAAARGPEDPRGPRRSPRTQGEGPGPKETSTNGPVSQEAFSVTGPAAPGALPPPSPKLKDEDFPSLSASTSSSCSTAATPGPVGLALPYAIPARGRSAFQEEDFPALVSSVPKPGTAPTSLVSAWNSSSSSKKVAQPPLSAQATGSGQPTRKAGKGSRGGRKGGPPFTQEEEEEDGGPALQELLSTRPTGSVSSTLGLASIQPSKVGKKKKVGSEKPGTTLPQPPPATCPPGALQAPEAPASRAEGPVAVVVNGHTEGPAPARSAPKEPPGLPRPLGSFPCPTPQEDFPALGGPCPPRMPPPPGFSAVVLLKGTPPPPPPGLVPPISKPPPGFSGLLPSPHPACVPSPATTTTTKAPRLLPAPRAYLVPENFRERNLQLIQSIRDFLQSDEARFSEFKSHSGEFRQGLISAAQYYKSCRDLLGENFQKVFNELLVLLPDTAKQQELLSAHTDFCNREKPLSTKSKKNKKSAWQATTQQAGLDCRVCPTCQQVLAHGDASSHQALHAARDDDFPSLQAIARIIT>sp|Q86UK7-3|ZN598_HUMAN Isoform 3 of E3 ubiquitin-protein ligase ZNF598OS=Homo sapiens OX=9606 GN=ZNF598MAAAGGAEGRRAALEAAAAAAPERGGGSCVLCCGDLEATALGRCDHPVCYRCSTKMRVLCEQRYCAVCREELRQVVFGKKLPAFATIPIHQLQHEKKYDIYFADGKVYALYRQLLQHECPRCPELPPFSLFGDLEQHMRRQHELFCCRLCLQHLQIFTYERKWYSRKDLARHRMQGDPDDTSHRGHPLCKFCDERYLDNDELLKHLRRDHYFCHFCDSDGAQDYYSDYAYLREHFREKHFLCEEGRCSTEQFTHAFRTEIDLKAHRTACHSRSRAEARQNRHIDLQFSYAPRHSRRNEGVVGGEDYEEVDRYSRQGRVARAGTRGAQQSRRGSWRYKREEEDREVAAAVRASVAAQQQEEARRSEDQEEGGRPKKEEAAARGPEDPRGPRRSPRTQGEGPGPKETSTNGPVSQEAFSVTGPAAPGALPPPSPKLKDEDFPSLSASTSSSCSTAATPGPVGLALPYAIPARGRSAFQEEDFPALVSSVPKPGTAPTSLVSAWNSSSSSKKVAQPPLSAQATGSGQPTRKAGKGSRGGRKGGPPFTQEEEEDGGPALQELLSTRPTGSVSSTLGLASIQPSKVGKKKKVGSEKPGTTLPQPPPATCPPGALQAPEAPASRAEGPVAVVVNGHTEGPAPARSAPKEPPGLPRPLGSFPCPTPQEDFPALGGPCPPRMPPPPGFSAVVLLKGTPPPPPPGLVPPISKPPPGFSGLLPSPHPACVPSPATTTTTKAPRLLPAPRAYLVPENFRERNLQLIQSIRDFLQSDEARFSEFKSHSGEFRQGLISAAQYYKSCRDLLGENFQKVFNELLVLLPDTAKQQELLSAHTDFCNREKPLSTKSKKNKKSAWQATTQQAGLDCRVCPTCQQVLAHGDASSHQALHAARDDDFPSLQAIARIIT>sp|Q86UK7-4|ZN598_HUMAN Isoform 4 of E3 ubiquitin-protein ligase ZNF598OS=Homo sapiens OX=9606 GN=ZNF598MVGGCGQPQVGAGRAGMEPRGLIAVDQLCFPAPSALPPPSPKLKDEDFPSLSASTSSSCSTAATPGPVGLALPYAIPARGRSAFQEEDFPALVSSVPKPGTAPTSLVSAWNSSSSSKKVAQPPLSAQATGSGQPTRKAGKGSRGGRKGGPPFTQEEEEEDGGPALQELLSTRPTGSVSSTLGLASIQPSKVGKKKKVGSEKPGTTLPQPPPATCPPGALQAPEAPASRAEGPVAVVVNGHTEGPAPARSAPKEPPGLPRPLGSFPCPTPQEDFPALGGPCPPRMPPPPGFSAVVLLKGTPPPPPPGLVPPISKPPPGFSGLLPSPHPACVPSPATTTTTKA>sp|Q96ND8|ZN583_HUMAN Zinc finger protein 583 OS=Homo sapiens OX=9606GN=ZNF583 PE=2 SV=2MSKDLVTFGDVAVNFSQEEWEWLNPAQRNLYRKVMLENYRSLVSLGVSVSKPDVISLLEQGKEPWMVKKEGTRGPCPDWEYVFKNSEFSSKQETYEESSKVVTVGARHLSYSLDYPSLREDCQSEDWYKNQLGSQEVHLSQLIITHKEILPEVQNKEYNKSWQTFHQDTIFDIQQSFPTKEKAHKHEPQKKSYRKKSVEMKHRKVYVEKKLLKCNDCEKVFNQSSSLTLHQRIHTGEKPYACVECGKTFSQSANLAQHKRIHTGEKPYECKECRKAFSQNAHLAQHQRVHTGEKPYQCKECKKAFSQIAHLTQHQRVHTGERPFECIECGKAFSNGSFLAQHQRIHTGEKPYVCNVCGKAFSHRGYLIVHQRIHTGERPYECKECRKAFSQYAHLAQHQRVHTGEKPYECKVCRKAFSQIAYLDQHQRVHTGEKPYECIECGKAFSNSSSLAQHQRSHTGEKPYMCKECRKTFSQNAGLAQHQRIHTGEKPYECNVCGKAFSYSGSLTLHQRIHTGERPYECKDCRKSFRQRAHLAHHERIHTMESFLTLSSPSPSTSNQLPRPVGFIS>sp|Q6PF04|ZN613_HUMAN Zinc finger protein 613 OS=Homo sapiens OX=9606GN=ZNF613 PE=1 SV=2MIKSQESLTLEDVAVEFTWEEWQLLGPAQKDLYRDVMLENYSNLVSVGYQASKPDALFKLEQGEPWTVENEIHSQICPEIKKVDNHLQMHSQKQRCLKRVEQCHKHNAFGNIIHQRKSDFPLRQNHDTFDLHGKILKSNLSLVNQNKRYEIKNSVGVNGDGKSFLHAKHEQFHNEMNFPEGGNSVNTNSQFIKHQRTQNIDKPHVCTECGKAFLKKSRLIYHQRVHTGEKPHGCSICGKAFSRKSGLTEHQRNHTGEKPYECTECDKAFRWKSQLNAHQKIHTGEKSYICSDCGKGFIKKSRLINHQRVHTGEKPHGCSLCGKAFSKRSRLTEHQRTHTGEKPYECTECDKAFRWKSQLNAHQKAHTGEKSYICRDCGKGFIQKGNLIVHQRIHTGEKPYICNECGKGFIQKGNLLIHRRTHTGEKPYVCNECGKGFSQKTCLISHQRFHTGKTPFVCTECGKSCSHKSGLINHQRIHTGEKPYTCSDCGKAFRDKSCLNRHRRTHTGERPYGCSDCGKAFSHLSCLVYHKGMLHAREKCVGSVKLENPCSESHSLSHTRDLIQDKDSVNMVTLQMPSVAAQTSLTNSAFQAESKVAIVSQPVARSSVSADSRICTE>sp|Q6PF04-2|ZN613_HUMAN Isoform 2 of Zinc finger protein 613 OS=Homosapiens OX=9606 GN=ZNF613MLENYSNLVSVGYQASKPDALFKLEQGEPWTVENEIHSQICPEIKKVDNHLQMHSQKQRCLKRVEQCHKHNAFGNIIHQRKSDFPLRQNHDTFDLHGKILKSNLSLVNQNKRYEIKNSVGVNGDGKSFLHAKHEQFHNEMNFPEGGNSVNTNSQFIKHQRTQNIDKPHVCTECGKAFLKKSRLIYHQRVHTGEKPHGCSICGKAFSRKSGLTEHQRNHTGEKPYECTECDKAFRWKSQLNAHQKIHTGEKSYICSDCGKGFIKKSRLINHQRVHTGEKPHGCSLCGKAFSKRSRLTEHQRTHTGEKPYECTECDKAFRWKSQLNAHQKAHTGEKSYICRDCGKGFIQKGNLIVHQRIHTGEKPYICNECGKGFIQKGNLLIHRRTHTGEKPYVCNECGKGFSQKTCLISHQRFHTGKTPFVCTECGKSCSHKSGLINHQRIHTGEKPYTCSDCGKAFRDKSCLNRHRRTHTGERPYGCSDCGKAFSHLSCLVYHKGMLHAREKCVGSVKLENPCSESHSLSHTRDLIQDKDSVNMVTLQMPSVAAQTSLTNSAFQAESKVAIVSQPVARSSVSADSRICTE>sp|O15015|ZN646_HUMAN Zinc finger protein 646 OS=Homo sapiens OX=9606GN=ZNF646 PE=1 SV=2MEDTPPSLSCSDCQRHFPSLPELSRHRELLHPSPNQDSEEADSIPRPYRCQQCGRGYRHPGSLVNHRRTHETGLFPCTTCGKDFSNPMALKSHMRTHAPEGRRRHRPPRPKEATPHLQGETVSTDSWGQRLGSSEGWENQTKHTEETPDCESVPDPRAASGTWEDLPTRQREGLASHPGPEDGADGWGPSTNSARAPPLPIPASSLLSNLEQYLAESVVNFTGGQEPTQSPPAEEERRYKCSQCGKTYKHAGSLTNHRQSHTLGIYPCAICFKEFSNLMALKNHSRLHAQYRPYHCPHCPRVFRLPRELLEHQQSHEGERQEPRWEEKGMPTTNGHTDESSQDQLPSAQMLNGSAELSTSGELEDSGLEEYRPFRCGDCGRTYRHAGSLINHRKSHQTGVYPCSLCSKQLFNAAALKNHVRAHHRPRQGVGENGQPSVPPAPLLLAETTHKEEEDPTTTLDHRPYKCSECGRAYRHRGSLVNHRHSHRTGEYQCSLCPRKYPNLMALRNHVRVHCKAARRSADIGAEGAPSHLKVELPPDPVEAEAAPHTDQDHVCKHEEEATDITPAADKTAAHICSICGLLFEDAESLERHGLTHGAGEKENSRTETTMSPPRAFACRDCGKSYRHSGSLINHRQTHQTGDFSCGACAKHFHTMAAMKNHLRRHSRRRSRRHRKRAGGASGGREAKLLAAESWTRELEDNEGLESPQDPSGESPHGAEGNLESDGDCLQAESEGDKCGLERDETHFQGDKESGGTGEGLERKDASLLDNLDIPGEEGGGTHFCDSLTGVDEDQKPATGQPNSSSHSANAVTGWQAGAAHTCSDCGHSFPHATGLLSHRPCHPPGIYQCSLCPKEFDSLPALRSHFQNHRPGEATSAQPFLCCLCGMIFPGRAGYRLHRRQAHSSSGMTEGSEEEGEEEGVAEAAPARSPPLQLSEAELLNQLQREVEALDSAGYGHICGCCGQTYDDLGSLERHHQSQSSGTTADKAPSPLGVAGDAMEMVVDSVLEDIVNSVSGEGGDAKSQEGAGTPLGDSLCIQGGESLLEAQPRPFRCNQCGKTYRHGGSLVNHRKIHQTGDFLCPVCSRCYPNLAAYRNHLRNHPRCKGSEPQVGPIPEAAGSSELQVGPIPEGGSNKPQHMAEEGPGQAEVEKLQEELKVEPLEEVARVKEEVWEETTVKGEEIEPRLETAEKGCQTEASSERPFSCEVCGRSYKHAGSLINHRQSHQTGHFGCQACSKGFSNLMSLKNHRRIHADPRRFRCSECGKAFRLRKQLASHQRVHMERRGGGGTRKATREDRPFRCGQCGRTYRHAGSLLNHRRSHETGQYSCPTCPKTYSNRMALKDHQRLHSENRRRRAGRSRRTAVRCALCGRSFPGRGSLERHLREHEETEREPANGQGGLDGTAASEANLTGSQGLETQLGGAEPVPHLEDGVPRPGERSQSPIRAASSEAPEPLSWGAGKAGGWPVGGGLGNHSGGWVPQFLTRSEEPEDSVHRSPCHAGDCQLNGPTLSHMDSWDNRDNSSQLQPGSHSSCSQCGKTYCQSGSLLNHNTNKTDRHYCLLCSKEFLNPVATKSHSHNHIDAQTFACPDCGKAFESHQELASHLQAHARGHSQVPAQMEEARDPKAGTGEDQVVLPGQGKAQEAPSETPRGPGESVERARGGQAVTSMAAEDKERPFRCTQCGRSYRHAGSLLNHQKAHTTGLYPCSLCPKLLPNLLSLKNHSRTHTDPKRHCCSICGKAFRTAARLEGHGRVHAPREGPFTCPHCPRHFRRRISFVQHQQQHQEEWTVAGSGAPVAPVTGRGDLPLPPPPTPTTPLLDPSPQWPADLSFSL>sp|O15015-1|ZN646_HUMAN Isoform 1 of Zinc finger protein 646 OS=Homosapiens OX=9606 GN=ZNF646MEDTPPSLSCSDCQRHFPSLPELSRHRELLHPSPNQDSEEADSIPRPYRCQQCGRGYRHPGSLVNHRRTHETGLFPCTTCGKDFSNPMALKSHMRTHAPEGRRRHRPPRPKEATPHLQGETVSTDSWGQRLGSSEGWENQTKHTEETPDCESVPDPRAASGTWEDLPTRQREGLASHPGPEDGADGWGPSTNSARAPPLPIPASSLLSNLEQYLAESVVNFTGGQEPTQSPPAEEERRYKCSQCGKTYKHAGSLTNHRQSHTLGIYPCAICFKEFSNLMALKNHSRLHAQYRPYHCPHCPRVFRLPRELLEHQQSHEGERQEPRWEEKGMPTTNGHTDESSQDQLPSAQMLNGSAELSTSGELEDSGLEEYRPFRCGDCGRTYRHAGSLINHRKSHQTGVYPCSLCSKQLFNAAALKNHVRAHHRPRQGVGENGQPSVPPAPLLLAETTHKEEEDPTTTLDHRPYKCSECGRAYRHRGSLVNHRHSHRTGEYQCSLCPRKYPNLMALRNHVRVHCKAARRSADIGAEGAPSHLKVELPPDPVEAEAAPHTDQDHVCKHEEEATDITPAADKTAAHICSICGLLFEDAESLERHGLTHGAGEKENSRTETTMSPPRAFACRDCGKSYRHSGSLINHRQTHQTGDFSCGACAKHFHTMAAMKNHLRRHSRRRSRRHRKRAGGASGGREAKLLAAESWTRELEDNEGLESPQDPSGESPHGAEGNLESDGDCLQAESEGDKCGLERDETHFQGDKESGGTGEGLERKDASLLDNLDIPGEEGGGTHFCDSLTGVDEDQKPATGQPNSSSHSANAVTGWQAGAAHTCSDCGHSFPHATGLLSHRPCHPPGIYQCSLCPKEFDSLPALRSHFQNHRPGEATSAQPFLCCLCGMIFPGRAGYRLHRRQAHSSSGMTEGSEEEGEEEGVAEAAPARSPPLQLSEAELLNQLQREVEALDSAGYGHICGCCGQTYDDLGSLERHHQSQSSGTTADKAPSPLGVAGDAMEMVVDSVLEDIVNSVSGEGGDAKSQEGAGTPLGDSLCIQGGESLLEAQPRPFRCNQCGKTYRHGGSLVNHRKIHQTGDFLCPVCSRCYPNLAAYRNHLRNHPRCKGSEPQVGPIPEAAGSSELQVGPIPEGGSNKPQHMAEEGPGQAEVEKLQEELKVEPLEEVARVKEEVWEETTVKGEEIEPRLETAEKGCQTEASSERPFSCEVCGRSYKHAGSLINHRQSHQTGHFGCQACSKGFSNLMSLKNHRRIHADPRRFRCSECGKAFRLRKQLASHQRVHMERRGGGGTRKATREDRPFRCGQCGRTYRHAGSLLNHRRSHETGQYSCPTCPKTYSNRMALKDHQRLHSENRRRRAGRSRRTAVRCALCGRSFPGRGSLERHLREHEETEREPANGQGGLDGTAASEANLTGSQGLETQLGGAEPVPHLEDGVPRPGERSQSPIRAASSEAPEPLSWGAGKAGGWPVGGGLGNHSGGWVPQFLTRSEEPEDSVHRSPCHAGDCQLNGPTLSHMDSWDNRDNSSQLQPGSHSSCSQCGKTYCQSGSLLNHNTNKTDRHYCLLCSKEFLNPVATKSHSHNHIDAQTFACPDCGKAFESHQELASHLQAHARGHSQVPAQMEEARDPKAGTGEDQVVLPGQGKAQEAPSETPRGPGESVERARGGQAVTSMAAEDKERPFRCTQCGRSYRHAGSLLNHQKAHTTGLYPCSLCPKLLPNLLSLKNHSRTHTDPKRHCCSICGKAFRTAARLEGHGRVHAPREGPFTCPHCPRHFRRRISFVQHQQQHQEEWTVAGSGRGHEGSQEEVGTQWRGKSSPKVGGGARSERREPRGF>sp|Q9C0D3|ZY11B_HUMAN Protein zyg-11 homolog B OS=Homo sapiens OX=9606GN=ZYG11B PE=1 SV=2MPEDQAGAAMEEASPYSLLDICLNFLTTHLEKFCSARQDGTLCLQEPGVFPQEVADRLLRTMAFHGLLNDGTVGIFRGNQMRLKRACIRKAKISAVAFRKAFCHHKLVELDATGVNADITITDIISGLGSNKWIQQNLQCLVLNSLTLSLEDPYERCFSRLSGLRALSITNVLFYNEDLAEVASLPRLESLDISNTSITDITALLACKDRLKSLTMHHLKCLKMTTTQILDVVRELKHLNHLDISDDKQFTSDIALRLLEQKDILPNLVSLDVSGRKHVTDKAVEAFIQQRPSMQFVGLLATDAGYSEFLTGEGHLKVSGEANETQIAEALKRYSERAFFVREALFHLFSLTHVMEKTKPEILKLVVTGMRNHPMNLPVQLAASACVFNLTKQDLAAGMPVRLLADVTHLLLKAMEHFPNHQQLQKNCLLSLCSDRILQDVPFNRFEAAKLVMQWLCNHEDQNMQRMAVAIISILAAKLSTEQTAQLGTELFIVRQLLQIVKQKTNQNSVDTTLKFTLSALWNLTDESPTTCRHFIENQGLELFMRVLESFPTESSIQQKVLGLLNNIAEVQELHSELMWKDFIDHISSLLHSVEVEVSYFAAGIIAHLISRGEQAWTLSRSQRNSLLDDLHSAILKWPTPECEMVAYRSFNPFFPLLGCFTTPGVQLWAVWAMQHVCSKNPSRYCSMLIEEGGLQHLYNIKDHEHTDPHVQQIAVAILDSLEKHIVRHGRPPPCKKQPQARLN>sp|Q9C0D3-2|ZY11B_HUMAN Isoform 2 of Protein zyg-11 homolog B OS=Homosapiens OX=9606 GN=ZYG11BMWKDFIDHISSLLHSVEVEVSYFAAGIIAHLISRGEQAWTLSRSQRNSLLDDLHSAILKWPTPECEMVAYRSFNPFFPLLGCFTTPGVQLWAVWAMQHVCSKNPSRYCSMLIEEGGLQHLYNIKDHEHTDPHVQQIAVAILDSLEKHIVRHGRPPPCKKQPQARLN>sp|P63220|RS21_HUMAN 40S ribosomal protein S21 OS=Homo sapiens OX=9606GN=RPS21 PE=1 SV=1MQNDAGEFVDLYVPRKCSASNRIIGAKDHASIQMNVAEVDKVTGRFNGQFKTYAICGAIRRMGESDDSILRLAKADGIVSKNF>sp|Q6UXX9|RSPO2_HUMAN R-spondin-2 OS=Homo sapiens OX=9606 GN=RSPO2 PE=1SV=2MQFRLFSFALIILNCMDYSHCQGNRWRRSKRASYVSNPICKGCLSCSKDNGCSRCQQKLFFFLRREGMRQYGECLHSCPSGYYGHRAPDMNRCARCRIENCDSCFSKDFCTKCKVGFYLHRGRCFDECPDGFAPLEETMECVEGCEVGHWSEWGTCSRNNRTCGFKWGLETRTRQIVKKPVKDTILCPTIAESRRCKMTMRHCPGGKRTPKAKEKRNKKKKRKLIERAQEQHSVFLATDRANQ>sp|Q6UXX9-2|RSPO2_HUMAN Isoform 2 of R-spondin-2 OS=Homo sapiens OX=9606GN=RSPO2MRQYGECLHSCPSGYYGHRAPDMNRCARCRIENCDSCFSKDFCTKCKVGFYLHRGRCFDECPDGFAPLEETMECVEGCEVGHWSEWGTCSRNNRTCGFKWGLETRTRQIVKKPVKDTILCPTIAESRRCKMTMRHCPGGKRTPKAKEKRNKKKKRKLIERAQEQHSVFLATDRANQ>sp|Q6UXX9-3|RSPO2_HUMAN Isoform 3 of R-spondin-2 OS=Homo sapiens OX=9606GN=RSPO2MQFRLFSFALIILNCMDYSHCQGNRWRRSKRGCRIENCDSCFSKDFCTKCKVGFYLHRGRCFDECPDGFAPLEETMECVGCEVGHWSEWGTCSRNNRTCGFKWGLETRTRQIVKKPVKDTILCPTIAESRRCKMTMRHCPGGKRTPKAKEKRNKKKKRKLIERAQEQHSVFLATDRANQ>sp|Q96IZ7|RSRC1_HUMAN Serine/Arginine-related protein 53 OS=Homo sapiensOX=9606 GN=RSRC1 PE=1 SV=1MGRRSSDTEEESRSKRKKKHRRRSSSSSSSDSRTYSRKKGGRKSRSKSRSWSRDLQPRSHSYDRRRRHRSSSSSSYGSRRKRSRSRSRGRGKSYRVQRSRSKSRTRRSRSRPRLRSHSRSSERSSHRRTRSRSRDRERRKGRDKEKREKEKDKGKDKELHNIKRGESGNIKAGLEHLPPAEQAKARLQLVLEAAAKADEALKAKERNEEEAKRRKEEDQATLVEQVKRVKEIEAIESDSFVQQTFRSSKEVKKSVEPSEVKQATSTSGPASAVADPPSTEKEIDPTSIPTAIKYQDDNSLAHPNLFIEKADAEEKWFKRLIALRQERLMGSPVA>sp|Q96IZ7-2|RSRC1_HUMAN Isoform 2 of Serine/Arginine-related protein 53OS=Homo sapiens OX=9606 GN=RSRC1MGRRSSDTEEESRSKRKKKHRRRSSSSSSSDSRTYSRKKGGRKSRSKSRSWSRDLQPRSHSYDRRRRHRSSSSSSYGSRRKRSRSRSRGRGKSYRVQRSRSKSRTRRESGNIKAGLEHLPPAEQAKARLQLVLEAAAKADEALKAKERNEEEAKRRKEEDQATLVEQVKRVKEIEAIESDSFVQQTFRSSKEVKKSVEPSEVKQATSTSGPASAVADPPSTEKEIDPTSIPTAIKYQDDNSLAHPNLFIEKADAEEKWFKRLIALRQERLMGSPVA>sp|P62308|RUXG_HUMAN Small nuclear ribonucleoprotein G OS=Homo sapiensOX=9606 GN=SNRPG PE=1 SV=1MSKAHPPELKKFMDKKLSLKLNGGRHVQGILRGFDPFMNLVIDECVEMATSGQQNNIGMVVIRGNSIIMLEALERV>sp|Q8N2Y8|RUSC2_HUMAN AP-4 complex accessory subunit RUSC2 OS=Homosapiens OX=9606 GN=RUSC2 PE=1 SV=3MDSPPKLTGETLIVHHIPLVHCQVPDRQCCGGAGGGGGSTRPNPFCPPELGITQPDQDLGQADSLLFSSLHSTPGGTARSIDSTKSRSRDGRGPGAPKRHNPFLLQEGVGEPGLGDLYDDSIGDSATQQSFHLHGTGQPNFHLSSFQLPPSGPRVGRPWGTTRSRAGVVEGQEQEPVMTLDTQQCGTSHCCRPELEAETMELDECGGPGGSGSGGGASDTSGFSFDQEWKLSSDESPRNPGCSGSGDQHCRCSSTSSQSEAADQSMGYVSDSSCNSSDGVLVTFSTLYNKMHGTPRANLNSAPQSCSDSSFCSHSDPGAFYLDLQPSPFESKMSYESHHPESGGREGGYGCPHASSPELDANCNSYRPHCEPCPAVADLTACFQSQARLVVATQNYYKLVTCDLSSQSSPSPAGSSITSCSEEHTKISPPPGPGPDPGPSQPSEYYLFQKPEVQPEEQEAVSSSTQAAAAVGPTVLEGQVYTNTSPPNLSTGRQRSRSYDRSLQRSPPVRLGSLERMLSCPVRLSEGPAAMAGPGSPPRRVTSFAELAKGRKKTGGSGSPPLRVSVGDSSQEFSPIQEAQQDRGAPLDEGTCCSHSLPPMPLGPGMDLLGPDPSPPWSTQVCQGPHSSEMPPAGLRATGQGPLAQLMDPGPALPGSPANSHTQRDARARADGGGTESRPVLRYSKEQRPTTLPIQPFVFQHHFPKQLAKARALHSLSQLYSLSGCSRTQQPAPLAAPAAQVSVPAPSGEPQASTPRATGRGARKAGSEPETSRPSPLGSYSPIRSVGPFGPSTDSSASTSCSPPPEQPTATESLPPWSHSCPSAVRPATSQQPQKEDQKILTLTEYRLHGTGSLPPLGSWRSGLSRAESLARGGGEGSMATRPSNANHLSPQALKWREYRRKNPLGPPGLSGSLDRRSQEARLARRNPIFEFPGSLSAASHLNCRLNGQAVKPLPLTCPDFQDPFSLTEKPPAEFCLSPDGSSEAISIDLLQKKGLVKAVNIAVDLIVAHFGTSRDPGVKAKLGNSSVSPNVGHLVLKYLCPAVRAVLEDGLKAFVLDVIIGQRKNMPWSVVEASTQLGPSTKVLHGLYNKVSQFPELTSHTMRFNAFILGLLNIRSLEFWFNHLYNHEDIIQTHYQPWGFLSAAHTVCPGLFEELLLLLQPLALLPFSLDLLFQHRLLQSGQQQRQHKELLRVSQDLLLSAHSTLQLARARGQEGPGDVDRAAQGERVKGVGASEGGEEEEEEEETEEVAEAAGGSGRARWARGGQAGWWYQLMQSSQVYIDGSIEGSRFPRGSSNSSSEKKKGAGGGGPPQAPPPREGVVEGAEACPASEEALGRERGWPFWMGSPPDSVLAELRRSREREGPAASPAENEEGASEPSPGGIKWGHLFGSRKAQREARPTNRLPSDWLSLDKSMFQLVAQTVGSRREPEPKESLQEPHSPALPSSPPCEVQALCHHLATGPGQLSFHKGDILRVLGRAGGDWLRCSRGPDSGLVPLAYVTLTPTPSPTPGSSQN>sp|P51398|RT29_HUMAN 28S ribosomal protein S29, mitochondrial OS=Homosapiens OX=9606 GN=DAP3 PE=1 SV=1MMLKGITRLISRIHKLDPGRFLHMGTQARQSIAAHLDNQVPVESPRAISRTNENDPAKHGDQHEGQHYNISPQDLETVFPHGLPPRFVMQVKTFSEACLMVRKPALELLHYLKNTSFAYPAIRYLLYGEKGTGKTLSLCHVIHFCAKQDWLILHIPDAHLWVKNCRDLLQSSYNKQRFDQPLEASTWLKNFKTTNERFLNQIKVQEKYVWNKRESTEKGSPLGEVVEQGITRVRNATDAVGIVLKELKRQSSLGMFHLLVAVDGINALWGRTTLKREDKSPIAPEELALVHNLRKMMKNDWHGGAIVSALSQTGSLFKPRKAYLPQELLGKEGFDALDPFIPILVSNYNPKEFESCIQYYLENNWLQHEKAPTEEGKKELLFLSNANPSLLERHCAYL>sp|P51398-2|RT29_HUMAN Isoform 2 of 28S ribosomal protein S29,mitochondrial OS=Homo sapiens OX=9606 GN=DAP3MMLKGITRLISRIHKAKHGDQHEGQHYNISPQDLETVFPHGLPPRFVMQVKTFSEACLMVRKPALELLHYLKNTSFAYPAIRYLLYGEKGTGKTLSLCHVIHFCAKQDWLILHIPDAHLWVKNCRDLLQSSYNKQRFDQPLEASTWLKNFKTTNERFLNQIKVQEKYVWNKRESTEKGSPLGEVVEQGITRVRNATDAVGIVLKELKRQSSLGMFHLLVAVDGINALWGRTTLKREDKSPIAPEELALVHNLRKMMKNDWHGGAIVSALSQTGSLFKPRKAYLPQELLGKEGFDALDPFIPILVSNYNPKEFESCIQYYLENNWLQHEKAPTEEGKKELLFLSNANPSLLERHCAYL>sp|P51398-3|RT29_HUMAN Isoform 3 of 28S ribosomal protein S29,mitochondrial OS=Homo sapiens OX=9606 GN=DAP3MMLKGITRLISRIHKLDPGRFLHMGTQARQSIAAHLDNQVPVESPRAISRTNENDPVKTFSEACLMVRKPALELLHYLKNTSFAYPAIRYLLYGEKGTGKTLSLCHVIHFCAKQDWLILHIPDAHLWVKNCRDLLQSSYNKQRFDQPLEASTWLKNFKTTNERFLNQIKVQEKYVWNKRESTEKGSPLGEVVEQGITRVRNATDAVGIVLKELKRQSSLGMFHLLVAVDGINALWGRTTLKREDKSPIAPEELALVHNLRKMMKNDWHGGAIVSALSQTGSLFKPRKAYLPQELLGKEGFDALDPFIPILVSNYNPKEFESCIQYYLENNWLQHEKAPTEEGKKELLFLSNANPSLLERHCAYL>sp|Q96GQ5|RUSF1_HUMAN RUS family member 1 OS=Homo sapiens OX=9606GN=RUSF1 PE=1 SV=2MADDAGLETPLCSEQFGSGEARGCRAAADGSLQWEVGGWRWWGLSRAFTVKPEGRDAGEVGASGAPSPPLSGLQAVFLPQGFPDSVSPDYLPYQLWDSVQAFASSLSGSLATQAVLLGIGVGNAKATVSAATATWLVKDSTGMLGRIVFAWWKGSKLDCNAKQWRLFADILNDVAMFLEIMAPVYPICFTMTVSTSNLAKCIVSVAGGATRAALTVHQARRNNMADVSAKDSSQETLVNLAGLLVSLLMLPLVSGCPGFSLGCFFFLTALHIYANYRAVRALVMETLNEGRLRLVLKHYLQRGEVLDPTAANRMEPLWTGFWPAPSLSLGVPLHRLVSSVFELQQLVEGHQESYLLCWDQSQNQVQVVLNQKAGPKTILRAATHGLMLGALQGDGPLPAELEELRNRVRAGPKKESWVVVKETHEVLDMLFPKFLKGLQDAGWKTEKHQLEVDEWRATWLLSPEKKVL>sp|Q96GQ5-2|RUSF1_HUMAN Isoform 2 of RUS family member 1 OS=Homo sapiensOX=9606 GN=RUSF1MCLMGEGRMGRWGSWMTGYRKKGWIWCVWVMAEGERKRGDLSEAWIISVHWVAVQWLVGHACLCCPPPPLHCPLPHSVFELQQLVEGHQESYLLCWDQSQNQVQVVLNQKAGPKTILRAATHGLMLGALQGDGPLPAELEELRNRVRAGPKKESWVVVKETHEVLDMLFPKFLKGLQDAGWKTEKHQLEVDEWRATWLLSPEKKVL>sp|Q9Y2Q9|RT28_HUMAN 28S ribosomal protein S28, mitochondrial OS=Homosapiens OX=9606 GN=MRPS28 PE=1 SV=1MAALCRTRAVAAESHFLRVFLFFRPFRGVGTESGSESGSSNAKEPKTRAGGFASALERHSELLQKVEPLQKGSPKNVESFASMLRHSPLTQMGPAKDKLVIGRIFHIVENDLYIDFGGKFHCVCRRPEVDGEKYQKGTRVRLRLLDLELTSRFLGATTDTTVLEANAVLLGIQESKDSRSKEEHHEK>sp|Q6NW29|RWDD4_HUMAN RWD domain-containing protein 4 OS=Homo sapiensOX=9606 GN=RWDD4 PE=1 SV=3MSANEDQEMELEALRSIYEGDESFRELSPVSFQYRIGENGDPKAFLIEISWTETYPQTPPILSMNAFFNNTISSAVKQSILAKLQEAVEANLGTAMTYTLFEYAKDNKEQFMENHNPINSATSISNIISIETPNTAPSSKKKDKKEQLSKAQKRKLADKTDHKGELPRGWNWVDVVKHLSKTGSKDDE>sp|Q6NW29-2|RWDD4_HUMAN Isoform 2 of RWD domain-containing protein 4OS=Homo sapiens OX=9606 GN=RWDD4MTYTLFEYAKDNKEQFMENHNPINSATSISNIISIETPNTAPSSKKKDKKEQLSKAQKRKLADKTDHKGELPRGWNWVDVVKHLSKTGSKDDE>sp|Q9BZR6|RTN4R_HUMAN Reticulon-4 receptor OS=Homo sapiens OX=9606GN=RTN4R PE=1 SV=1MKRASAGGSRLLAWVLWLQAWQVAAPCPGACVCYNEPKVTTSCPQQGLQAVPVGIPAASQRIFLHGNRISHVPAASFRACRNLTILWLHSNVLARIDAAAFTGLALLEQLDLSDNAQLRSVDPATFHGLGRLHTLHLDRCGLQELGPGLFRGLAALQYLYLQDNALQALPDDTFRDLGNLTHLFLHGNRISSVPERAFRGLHSLDRLLLHQNRVAHVHPHAFRDLGRLMTLYLFANNLSALPTEALAPLRALQYLRLNDNPWVCDCRARPLWAWLQKFRGSSSEVPCSLPQRLAGRDLKRLAANDLQGCAVATGPYHPIWTGRATDEEPLGLPKCCQPDAADKASVLEPGRPASAGNALKGRVPPGDSPPGNGSGPRHINDSPFGTLPGSAEPPLTAVRPEGSEPPGFPTSGPRRRPGCSRKNRTRSHCRLGQAGSGGGGTGDSEGSGALPSLTCSLTPLGLALVLWTVLGPC>sp|Q9Y399|RT02_HUMAN 28S ribosomal protein S2, mitochondrial OS=Homosapiens OX=9606 GN=MRPS2 PE=1 SV=1MATSSAALPRILGAGARAPSRWLGFLGKATPRPARPSRRTLGSATALMIRESEDSTDFNDKILNEPLKHSDFFNVKELFSVRSLFDARVHLGHKAGCRHRFMEPYIFGSRLDHDIIDLEQTATHLQLALNFTAHMAYRKGIILFISRNRQFSYLIENMARDCGEYAHTRYFRGGMLTNARLLFGPTVRLPDLIIFLHTLNNIFEPHVAVRDAAKMNIPTVGIVDTNCNPCLITYPVPGNDDSPLAVHLYCRLFQTAITRAKEKRQQVEALYRLQGQKEPGDQGPAHPPGADMSHSL>sp|Q9NVS2|RT18A_HUMAN 39S ribosomal protein S18a, mitochondrial OS=Homosapiens OX=9606 GN=MRPS18A PE=1 SV=1MAALKALVSGCGRLLRGLLAGPAATSWSRLPARGFREVVETQEGKTTIIEGRITATPKESPNPPNPSGQCPICRWNLKHKYNYDDVLLLSQFIRPHGGMLPRKITGLCQEEHRKIEECVKMAHRAGLLPNHRPRLPEGVVPKSKPQLNRYLTRWAPGSVKPIYKKGPRWNRVRMPVGSPLLRDNVCYSRTPWKLYH>sp|Q9NVS2-2|RT18A_HUMAN Isoform 2 of 39S ribosomal protein S18a,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS18AMAALKALVSGCGRLLRGLLAGPAATSWSRLPARGFREVVETQEGKTTIIEGRITATPKESPNPPNPSGQCPICRWNLKHKYNYDDVLLLSQFIRPHGGMLPRKITGLCQEEHRKIEECVKMAHRAGRRPWGPRGAEGCRHSLPTQLPHVSAPPGRKVDIRSVNYTHHPMPTFPLPWAFPLAPSELQRELQRLSPLPRHSGLLPNHRPRLPEGVVPKSKPQLNRYLTRWAPGSVKPIYKKGPRWNRVRMPVGSPLLRDNVCYSRTPWKLYH>sp|Q9NVS2-3|RT18A_HUMAN Isoform 3 of 39S ribosomal protein S18a,mitochondrial OS=Homo sapiens OX=9606 GN=MRPS18AMAALKALVSGCGRLLRGLLAGPAATSWSRLPARGFREVVETQEGKTTIIEGRITATPKESPNPPNPSGQCPICRWNLKHKYNYDDVLLLSQFIRPHGGMLPRKITGLCQEEHRKIEECVKMAHRAGT>sp|P21453|S1PR1_HUMAN Sphingosine 1-phosphate receptor 1 OS=Homo sapiensOX=9606 GN=S1PR1 PE=1 SV=2MGPTSVPLVKAHRSSVSDYVNYDIIVRHYNYTGKLNISADKENSIKLTSVVFILICCFIILENIFVLLTIWKTKKFHRPMYYFIGNLALSDLLAGVAYTANLLLSGATTYKLTPAQWFLREGSMFVALSASVFSLLAIAIERYITMLKMKLHNGSNNFRLFLLISACWVISLILGGLPIMGWNCISALSSCSTVLPLYHKHYILFCTTVFTLLLLSIVILYCRIYSLVRTRSRRLTFRKNISKASRSSEKSLALLKTVIIVLSVFIACWAPLFILLLLDVGCKVKTCDILFRAEYFLVLAVLNSGTNPIIYTLTNKEMRRAFIRIMSCCKCPSGDSAGKFKRPIIAGMEFSRSKSDNSSHPQKDEGDNPETIMSSGNVNSSS>sp|Q5VWQ0|RSBN1_HUMAN Lysine-specific demethylase 9 OS=Homo sapiensOX=9606 GN=RSBN1 PE=1 SV=2MFISGRRTADKWRAEERLQCPAGSARAALARCADGGAVGPFKCVFVGEMAAQVGAVRVVRAVAAQEEPDKEGKEKPHAGVSPRGVKRQRRSSSGGSQEKRGRPSQEPPLAPPHRRRRSRQHPGPLPPTNAAPTVPGPVEPLLLPPPPPPSLAPAGPAVAAPLPAPSTSALFTFSPLTVSAAGPKHKGHKERHKHHHHRGPDGDPSSCGTDLKHKDKQENGERTGGVPLIKAPKRETPDENGKTQRADDFVLKKIKKKKKKKHREDMRGRRLKMYNKEVQTVCAGLTRISKEILTQGQINSTSGLNKESFRYLKDEQLCRLNLGMQEYRVPQGVQTPFMTHQEHSIRRNFLKTGTKFSNFIHEEHQSNGGALVLHAYMDELSFLSPMEMERFSEEFLALTFSENEKNAAYYALAIVHGAAAYLPDFLDYFAFNFPNTPVKMEILGKKDIETTTISNFHTQVNRTYCCGTYRAGPMRQISLVGAVDEEVGDYFPEFLDMLEESPFLKMTLPWGTLSSLRLQCRSQSDDGPIMWVRPGEQMIPTADMPKSPFKRRRSMNEIKNLQYLPRTSEPREVLFEDRTRAHADHVGQGFDWQSTAAVGVLKAVQFGEWSDQPRITKDVICFHAEDFTDVVQRLQLDLHEPPVSQCVQWVDEAKLNQMRREGIRYARIQLCDNDIYFIPRNVIHQFKTVSAVCSLAWHIRLKQYHPVVEATQNTESNSNMDCGLTGKRELEVDSQCVRIKTESEEACTEIQLLTTASSSFPPASELNLQQDQKTQPIPVLKVESRLDSDQQHNLQEHSTTSV>sp|Q5VWQ0-4|RSBN1_HUMAN Isoform 4 of Lysine-specific demethylase 9OS=Homo sapiens OX=9606 GN=RSBN1MFISGRRTADKWRAEERLQCPAGSARAALARCADGGAVGPFKCVFVGEMAAQVGAVRVVRAVAAQEEPDKEGKEKPHAGVSPRGVKRQRRSSSGGSQEKRGRPSQEPPLAPPHRRRRSRQHPGPLPPTNAAPTVPGPVEPLLLPPPPPPSLAPAGPAVAAPLPAPSTSALFTFSPLTVSAAGPKHKGHKERHKHHHHRGPDGDPSSCGTDLKHKDKQENGERTGGVPLIKAPKRETPDENGKTQRADDFVLKKIKKKKKKKHREDMRGRRLKMYNKEVQTVCAGLTRISKEILTQGQINSTSGLNKESFRYLKDEQLCRLNLGMQEYRVPQGVQTPFMTHQEHSIRRNFLKTGTKFSNFIHEEHQSNGGALVLHAYMDELSFLSPMEMERFSEEFLALTFSENEKNAAYYALAIVHGAAAYLPDFLDYFAFNFPNTPVKMEILGKKDIETTTISNFHTQ>sp|Q6PIS1|S23A3_HUMAN Solute carrier family 23 member 3 OS=Homo sapiensOX=9606 GN=SLC23A3 PE=2 SV=2MSRSPLNPSQLRSVGSQDALAPLPPPAPQNPSTHSWDPLCGSLPWGLSCLLALQHVLVMASLLCVSHLLLLCSLSPGGLSYSPSQLLASSFFSCGMSTILQTWMGSRLPLVQAPSLEFLIPALVLTSQKLPRAIQTPGNSSLMLHLCRGPSCHGLGHWNTSLQEVSGAVVVSGLLQGMMGLLGSPGHVFPHCGPLVLAPSLVVAGLSAHREVAQFCFTHWGLALLVILLMVVCSQHLGSCQFHVCPWRRASTSSTHTPLPVFRLLSVLIPVACVWIVSAFVGFSVIPQELSAPTKAPWIWLPHPGEWNWPLLTPRALAAGISMALAASTSSLGCYALCGRLLHLPPPPPHACSRGLSLEGLGSVLAGLLGSPMGTASSFPNVGKVGLIQAGSQQVAHLVGLLCVGLGLSPRLAQLLTTIPLPVVGGVLGVTQAVVLSAGFSSFYLADIDSGRNIFIVGFSIFMALLLPRWFREAPVLFSTGWSPLDVLLHSLLTQPIFLAGLSGFLLENTIPGTQLERGLGQGLPSPFTAQEARMPQKPREKAAQVYRLPFPIQNLCPCIPQPLHCLCPLPEDPGDEEGGSSEPEEMADLLPGSGEPCPESSREGFRSQK>sp|Q6PIS1-2|S23A3_HUMAN Isoform 2 of Solute carrier family 23 member 3OS=Homo sapiens OX=9606 GN=SLC23A3MSRSPLNPSQLRSVGSQDALAPLPPPAPQNPSTHSWDPLCGSLPWGLSCLLALQHVLVMASLLCVSHLLLLCSLSPGGLSYSPSQLLASSFFSCGMSTILQTWMGSRLPLVQAPSLEFLIPALVLTSQKLPRAIQTPGNSSLMLHLCRGPSCHGLGHWNTSLQEVSGAVVVSGLLQGMMGLLGSPGHVFPHCGPLVLAPSLVVAGLSAHREVAQFCFTHWGLALLTWAPASFMCAPGGELQRHQLTLLSLSSGSFRNCLPPPRHHGFGCLTQAGSQQVAHLVGLLCVGLGLSPRLAQLLTTIPLPVVGGVLGVTQAVVLSAGFSSFYLADIDSGRNIFIVGFSIFMALLLPRWFREAPVLFSTGWSPLDVLLHSLLTQPIFLAGLSGFLLENTIPGTQLERGLGQGLPSPFTAQEARMPQKPREKAAQVYRLPFPIQNLCPCIPQPLHCLCPLPEDPGDEEGGSSEPEEMADLLPGSGEPCPESSREGFRSQK>sp|Q6PIS1-5|S23A3_HUMAN Isoform 3 of Solute carrier family 23 member 3OS=Homo sapiens OX=9606 GN=SLC23A3MSRSPLNPSQLRSVGSQDALAPLPPPAPQNPSTHSWDPLCGSLPWGLSCLLALQHVLVMASLLCVSHLLLLCSLSPGGLSYSPSQLLASSFFSCGMSTILQTWMGSRLPLVQAPSLEFLIPALVLTSQKLPRAIQTPGNCEHRARARASLMLHLCRGPSCHGLGHWNTSLQEVSGAVVVSGLLQGMMGLLGSPGHVFPHCGPLVLAPSLVVAGLSAHREVAQFCFTHWGLALLVILLMVVCSQHLGSCQFHVCPWRRASTSSTHTPLPVFRLLSVLIPVACVWIVSAFVGFSVIPQELSAPTKAPWIWLPHPGEWNWPLLTPRALAAGISMALAASTSSLGCYALCGRLLHLPPPPPHACSRGLSLEGLGSVLAGLLGSPMGTASSFPNVGKVGLIQAGSQQVAHLVGLLCVGLGLSPRLAQLLTTIPLPVVGGVLGVTQAVVLSAGFSSFYLADIDSGRNIFIVGFSIFMALLLPRWFREAPVLFSTGWSPLDVLLHSLLTQPIFLAGLSGFLLENTIPGTQLERGLGQGLPSPFTAQEARMPQKPREKAAQVYRLPFPIQNLCPCIPQPLHCLCPLPEDPGDEEGGSSEPEEMADLLPGSGEPCPESSREGFRSQK>sp|Q9BZW2|S13A1_HUMAN Solute carrier family 13 member 1 OS=Homo sapiensOX=9606 GN=SLC13A1 PE=1 SV=1MKFFSYILVYRRFLFVVFTVLVLLPLPIVLHTKEAECAYTLFVVATFWLTEALPLSVTALLPSLMLPMFGIMPSKKVASAYFKDFHLLLIGVICLATSIEKWNLHKRIALKMVMMVGVNPAWLTLGFMSSTAFLSMWLSNTSTAAMVMPIAEAVVQQIINAEAEVEATQMTYFNGSTNHGLEIDESVNGHEINERKEKTKPVPGYNNDTGKISSKVELEKNSGMRTKYRTKKGHVTRKLTCLCIAYSSTIGGLTTITGTSTNLIFAEYFNTRYPDCRCLNFGSWFTFSFPAALIILLLSWIWLQWLFLGFNFKEMFKCGKTKTVQQKACAEVIKQEYQKLGPIRYQEIVTLVLFIIMALLWFSRDPGFVPGWSALFSEYPGFATDSTVALLIGLLFFLIPAKTLTKTTPTGEIVAFDYSPLITWKEFQSFMPWDIAILVGGGFALADGCEESGLSKWIGNKLSPLGSLPAWLIILISSLMVTSLTEVASNPATITLFLPILSPLAEAIHVNPLYILIPSTLCTSFAFLLPVANPPNAIVFSYGHLKVIDMVKAGLGVNIVGVAVVMLGICTWIVPMFDLYTYPSWAPAMSNETMP>sp|Q3KQZ1|S2535_HUMAN Solute carrier family 25 member 35 OS=Homo sapiensOX=9606 GN=SLC25A35 PE=1 SV=1MDFLMSGLAACGACVFTNPLEVVKTRMQLQGELQAPGTYQRHYRNVFHAFITIGKVDGLAALQKGLAPALLYQFLMNGIRLGTYGLAEAGGYLHTAEGTHSPARSAAAGAMAGVMGAYLGSPIYMVKTHLQAQAASEIAVGHQYKHQGMFQALTEIGQKHGLVGLWRGALGGLPRVIVGSSTQLCTFSSTKDLLSQWEIFPPQSWKLALVAAMMSGIAVVLAMAPFDVACTRLYNQPTDAQGKGLMYRGILDALLQTARTEGIFGMYKGIGASYFRLGPHTILSLFFWDQLRSLYYTDTK>sp|Q3KQZ1-2|S2535_HUMAN Isoform 2 of Solute carrier family 25 member 35OS=Homo sapiens OX=9606 GN=SLC25A35MDFLMSGLAACGACVFTNPLEVVKTRMQLQGELQAPGTYQRHYRNVFHAFITIGKVDGLAALQKGLAPALLYQFLMNGIRLGTYGLAEAGGYLHTAEGTHSPARSAAAGAMAGVMGAYLGSPIYMVKTHLQAQAASEIAVGHQYKHQGMFQALTEIGQKHGLVGLWRGALGGLPRVIVGSSTQLCTFSSTKDLLSQWEIFPPQSWKLALVAAMMSGIAVVLAMAPFDVACTRLYNQPTDAQGKGLMYRGILDALLQTARTEGIFGMYKEPSPQVLSNIMQCFSAFTGDQRC>sp|Q3KQZ1-3|S2535_HUMAN Isoform 3 of Solute carrier family 25 member 35OS=Homo sapiens OX=9606 GN=SLC25A35MDFLMSGLAACGACVFTNPLEVVKTRMQLQGELQAPGTYQRHYRNVFHAFITIGKVDGLAALQKGLAPALLYQFLMNGIRLGTYGLAEAGGYLHTAEGTHSPARSAAAGAMAGVMGAYLGSPIYMVKTHLQAQAASEIAVGHQYKHQGMFQALTEIGQKHGLVGLWRGALGGLPRVIVGSSTQLCTFSSTKDLLSQWEIFPPQSWKLALVAAMMSGIAVVLAMAPFDVACTRLYNQPTDAQGKGLMYRGILDALLQTARTEGIFEPSPQVLSNIMQCFSAFTGDQRC>sp|Q3KQZ1-4|S2535_HUMAN Isoform 4 of Solute carrier family 25 member 35OS=Homo sapiens OX=9606 GN=SLC25A35MDFLMSGLAACGACVFTNPLEVVKTRMQLQGELQAPGTYQRHYRNVFHAFITIGKVDGLAALQKGLAPALLYQFLMNGIRLGTYGLAEAGGYLHTAEGTHSPARSAAAGAMAGVMGAYLGSPIYMVKTHLQAQAASEIAVGHQYKHQGMFQALTEIGQKHGLVGLWRGALGGLPRVIVGSSTQLCTFSSTKDLLSQWEIFPPQSWKLALVAAMMSGIAVVLAMAPFDVACTRLYNQPTDAQGKNRVPKFSATSCSASAPLLGTKDVRIVKGQTGHQLFKVTQAPGCSPILLGTQS>sp|Q96FQ6|S10AG_HUMAN Protein S100-A16 OS=Homo sapiens OX=9606GN=S100A16 PE=1 SV=1MSDCYTELEKAVIVLVENFYKYVSKYSLVKNKISKSSFREMLQKELNHMLSDTGNRKAADKLIQNLDANHDGRISFDEYWTLIGGITGPIAKLIHEQEQQSSS>sp|Q8N1F8|S11IP_HUMAN Serine/threonine-protein kinase 11-interactingprotein OS=Homo sapiens OX=9606 GN=STK11IP PE=1 SV=4MTTAQRDSLLWKLAGLLRESGDVVLSGCSTLSLLTPTLQQLNHVFELHLGPWGPGQTGFVALPSHPADSPVILQLQFLFDVLQKTLSLKLVHVAGPGPTGPIKIFPFKSLRHLELRGVPLHCLHGLRGIYSQLETLICSRSLQALEELLSACGGDFCSALPWLALLSANFSYNALTALDSSLRLLSALRFLNLSHNQVQDCQGFLMDLCELHHLDISYNRLHLVPRMGPSGAALGVLILRGNELRSLHGLEQLRNLRHLDLAYNLLEGHRELSPLWLLAELRKLYLEGNPLWFHPEHRAATAQYLSPRARDAATGFLLDGKVLSLTDFQTHTSLGLSPMGPPLPWPVGSTPETSGGPDLSDSLSSGGVVTQPLLHKVKSRVRVRRASISEPSDTDPEPRTLNPSPAGWFVQQHPELELMSSFRERFGRNWLQYRSHLEPSGNPLPATPTTSAPSAPPASSQGPDTAPRPSPPQEEARGPQESPQKMSEEVRAEPQEEEEEKEGKEEKEEGEMVEQGEEEAGEEEEEEQDQKEVEAELCRPLLVCPLEGPEGVRGRECFLRVTSAHLFEVELQAARTLERLELQSLEAAEIEPEAQAQRSPRPTGSDLLPGAPILSLRFSYICPDRQLRRYLVLEPDAHAAVQELLAVLTPVTNVAREQLGEARDLLLGRFQCLRCGHEFKPEEPRMGLDSEEGWRPLFQKTESPAVCPNCGSDHVVLLAVSRGTPNRERKQGEQSLAPSPSASPVCHPPGHGDHLDRAKNSPPQAPSTRDHGSWSLSPPPERCGLRSVDHRLRLFLDVEVFSDAQEEFQCCLKVPVALAGHTGEFMCLVVVSDRRLYLLKVTGEMREPPASWLQLTLAVPLQDLSGIELGLAGQSLRLEWAAGAGRCVLLPRDARHCRAFLEELLDVLQSLPPAWRNCVSATEEEVTPQHRLWPLLEKDSSLEARQFFYLRAFLVEGPSTCLVSLLLTPSTLFLLDEDAAGSPAEPSPPAASGEASEKVPPSGPGPAVRVREQQPLSSLSSVLLYRSAPEDLRLLFYDEVSRLESFWALRVVCQEQLTALLAWIREPWEELFSIGLRTVIQEALALDR>sp|P21817|RYR1_HUMAN Ryanodine receptor 1 OS=Homo sapiens OX=9606GN=RYR1 PE=1 SV=3MGDAEGEDEVQFLRTDDEVVLQCSATVLKEQLKLCLAAEGFGNRLCFLEPTSNAQNVPPDLAICCFVLEQSLSVRALQEMLANTVEAGVESSQGGGHRTLLYGHAILLRHAHSRMYLSCLTTSRSMTDKLAFDVGLQEDATGEACWWTMHPASKQRSEGEKVRVGDDIILVSVSSERYLHLSTASGELQVDASFMQTLWNMNPICSRCEEGFVTGGHVLRLFHGHMDECLTISPADSDDQRRLVYYEGGAVCTHARSLWRLEPLRISWSGSHLRWGQPLRVRHVTTGQYLALTEDQGLVVVDASKAHTKATSFCFRISKEKLDVAPKRDVEGMGPPEIKYGESLCFVQHVASGLWLTYAAPDPKALRLGVLKKKAMLHQEGHMDDALSLTRCQQEESQAARMIHSTNGLYNQFIKSLDSFSGKPRGSGPPAGTALPIEGVILSLQDLIIYFEPPSEDLQHEEKQSKLRSLRNRQSLFQEEGMLSMVLNCIDRLNVYTTAAHFAEFAGEEAAESWKEIVNLLYELLASLIRGNRSNCALFSTNLDWLVSKLDRLEASSGILEVLYCVLIESPEVLNIIQENHIKSIISLLDKHGRNHKVLDVLCSLCVCNGVAVRSNQDLITENLLPGRELLLQTNLINYVTSIRPNIFVGRAEGTTQYSKWYFEVMVDEVTPFLTAQATHLRVGWALTEGYTPYPGAGEGWGGNGVGDDLYSYGFDGLHLWTGHVARPVTSPGQHLLAPEDVISCCLDLSVPSISFRINGCPVQGVFESFNLDGLFFPVVSFSAGVKVRFLLGGRHGEFKFLPPPGYAPCHEAVLPRERLHLEPIKEYRREGPRGPHLVGPSRCLSHTDFVPCPVDTVQIVLPPHLERIREKLAENIHELWALTRIEQGWTYGPVRDDNKRLHPCLVDFHSLPEPERNYNLQMSGETLKTLLALGCHVGMADEKAEDNLKKTKLPKTYMMSNGYKPAPLDLSHVRLTPAQTTLVDRLAENGHNVWARDRVGQGWSYSAVQDIPARRNPRLVPYRLLDEATKRSNRDSLCQAVRTLLGYGYNIEPPDQEPSQVENQSRCDRVRIFRAEKSYTVQSGRWYFEFEAVTTGEMRVGWARPELRPDVELGADELAYVFNGHRGQRWHLGSEPFGRPWQPGDVVGCMIDLTENTIIFTLNGEVLMSDSGSETAFREIEIGDGFLPVCSLGPGQVGHLNLGQDVSSLRFFAICGLQEGFEPFAINMQRPVTTWFSKGLPQFEPVPLEHPHYEVSRVDGTVDTPPCLRLTHRTWGSQNSLVEMLFLRLSLPVQFHQHFRCTAGATPLAPPGLQPPAEDEARAAEPDPDYENLRRSAGGWSEAENGKEGTAKEGAPGGTPQAGGEAQPARAENEKDATTEKNKKRGFLFKAKKVAMMTQPPATPTLPRLPHDVVPADNRDDPEIILNTTTYYYSVRVFAGQEPSCVWAGWVTPDYHQHDMSFDLSKVRVVTVTMGDEQGNVHSSLKCSNCYMVWGGDFVSPGQQGRISHTDLVIGCLVDLATGLMTFTANGKESNTFFQVEPNTKLFPAVFVLPTHQNVIQFELGKQKNIMPLSAAMFQSERKNPAPQCPPRLEMQMLMPVSWSRMPNHFLQVETRRAGERLGWAVQCQEPLTMMALHIPEENRCMDILELSERLDLQRFHSHTLRLYRAVCALGNNRVAHALCSHVDQAQLLHALEDAHLPGPLRAGYYDLLISIHLESACRSRRSMLSEYIVPLTPETRAITLFPPGRSTENGHPRHGLPGVGVTTSLRPPHHFSPPCFVAALPAAGAAEAPARLSPAIPLEALRDKALRMLGEAVRDGGQHARDPVGGSVEFQFVPVLKLVSTLLVMGIFGDEDVKQILKMIEPEVFTEEEEEEDEEEEGEEEDEEEKEEDEEETAQEKEDEEKEEEEAAEGEKEEGLEEGLLQMKLPESVKLQMCHLLEYFCDQELQHRVESLAAFAERYVDKLQANQRSRYGLLIKAFSMTAAETARRTREFRSPPQEQINMLLQFKDGTDEEDCPLPEEIRQDLLDFHQDLLAHCGIQLDGEEEEPEEETTLGSRLMSLLEKVRLVKKKEEKPEEERSAEESKPRSLQELVSHMVVRWAQEDFVQSPELVRAMFSLLHRQYDGLGELLRALPRAYTISPSSVEDTMSLLECLGQIRSLLIVQMGPQEENLMIQSIGNIMNNKVFYQHPNLMRALGMHETVMEVMVNVLGGGESKEIRFPKMVTSCCRFLCYFCRISRQNQRSMFDHLSYLLENSGIGLGMQGSTPLDVAAASVIDNNELALALQEQDLEKVVSYLAGCGLQSCPMLVAKGYPDIGWNPCGGERYLDFLRFAVFVNGESVEENANVVVRLLIRKPECFGPALRGEGGSGLLAAIEEAIRISEDPARDGPGIRRDRRREHFGEEPPEENRVHLGHAIMSFYAALIDLLGRCAPEMHLIQAGKGEALRIRAILRSLVPLEDLVGIISLPLQIPTLGKDGALVQPKMSASFVPDHKASMVLFLDRVYGIENQDFLLHVLDVGFLPDMRAAASLDTATFSTTEMALALNRYLCLAVLPLITKCAPLFAGTEHRAIMVDSMLHTVYRLSRGRSLTKAQRDVIEDCLMSLCRYIRPSMLQHLLRRLVFDVPILNEFAKMPLKLLTNHYERCWKYYCLPTGWANFGVTSEEELHLTRKLFWGIFDSLAHKKYDPELYRMAMPCLCAIAGALPPDYVDASYSSKAEKKATVDAEGNFDPRPVETLNVIIPEKLDSFINKFAEYTHEKWAFDKIQNNWSYGENIDEELKTHPMLRPYKTFSEKDKEIYRWPIKESLKAMIAWEWTIEKAREGEEEKTEKKKTRKISQSAQTYDPREGYNPQPPDLSAVTLSRELQAMAEQLAENYHNTWGRKKKQELEAKGGGTHPLLVPYDTLTAKEKARDREKAQELLKFLQMNGYAVTRGLKDMELDSSSIEKRFAFGFLQQLLRWMDISQEFIAHLEAVVSSGRVEKSPHEQEIKFFAKILLPLINQYFTNHCLYFLSTPAKVLGSGGHASNKEKEMITSLFCKLAALVRHRVSLFGTDAPAVVNCLHILARSLDARTVMKSGPEIVKAGLRSFFESASEDIEKMVENLRLGKVSQARTQVKGVGQNLTYTTVALLPVLTTLFQHIAQHQFGDDVILDDVQVSCYRTLCSIYSLGTTKNTYVEKLRPALGECLARLAAAMPVAFLEPQLNEYNACSVYTTKSPRERAILGLPNSVEEMCPDIPVLERLMADIGGLAESGARYTEMPHVIEITLPMLCSYLPRWWERGPEAPPSALPAGAPPPCTAVTSDHLNSLLGNILRIIVNNLGIDEASWMKRLAVFAQPIVSRARPELLQSHFIPTIGRLRKRAGKVVSEEEQLRLEAKAEAQEGELLVRDEFSVLCRDLYALYPLLIRYVDNNRAQWLTEPNPSAEELFRMVGEIFIYWSKSHNFKREEQNFVVQNEINNMSFLTADNKSKMAKAGDIQSGGSDQERTKKKRRGDRYSVQTSLIVATLKKMLPIGLNMCAPTDQDLITLAKTRYALKDTDEEVREFLHNNLHLQGKVEGSPSLRWQMALYRGVPGREEDADDPEKIVRRVQEVSAVLYYLDQTEHPYKSKKAVWHKLLSKQRRRAVVACFRMTPLYNLPTHRACNMFLESYKAAWILTEDHSFEDRMIDDLSKAGEQEEEEEEVEEKKPDPLHQLVLHFSRTALTEKSKLDEDYLYMAYADIMAKSCHLEEGGENGEAEEEVEVSFEEKQMEKQRLLYQQARLHTRGAAEMVLQMISACKGETGAMVSSTLKLGISILNGGNAEVQQKMLDYLKDKKEVGFFQSIQALMQTCSVLDLNAFERQNKAEGLGMVNEDGTVINRQNGEKVMADDEFTQDLFRFLQLLCEGHNNDFQNYLRTQTGNTTTINIIICTVDYLLRLQESISDFYWYYSGKDVIEEQGKRNFSKAMSVAKQVFNSLTEYIQGPCTGNQQSLAHSRLWDAVVGFLHVFAHMMMKLAQDSSQIELLKELLDLQKDMVVMLLSLLEGNVVNGMIARQMVDMLVESSSNVEMILKFFDMFLKLKDIVGSEAFQDYVTDPRGLISKKDFQKAMDSQKQFSGPEIQFLLSCSEADENEMINCEEFANRFQEPARDIGFNVAVLLTNLSEHVPHDPRLHNFLELAESILEYFRPYLGRIEIMGASRRIERIYFEISETNRAQWEMPQVKESKRQFIFDVVNEGGEAEKMELFVSFCEDTIFEMQIAAQISEPEGEPETDEDEGAGAAEAGAEGAEEGAAGLEGTAATAAAGATARVVAAAGRALRGLSYRSLRRRVRRLRRLTAREAATAVAALLWAAVTRAGAAGAGAAAGALGLLWGSLFGGGLVEGAKKVTVTELLAGMPDPTSDEVHGEQPAGPGGDADGEGASEGAGDAAEGAGDEEEAVHEAGPGGADGAVAVTDGGPFRPEGAGGLGDMGDTTPAEPPTPEGSPILKRKLGVDGVEEELPPEPEPEPEPELEPEKADAENGEKEEVPEPTPEPPKKQAPPSPPPKKEEAGGEFWGELEVQRVKFLNYLSRNFYTLRFLALFLAFAINFILLFYKVSDSPPGEDDMEGSAAGDVSGAGSGGSSGWGLGAGEEAEGDEDENMVYYFLEESTGYMEPALRCLSLLHTLVAFLCIIGYNCLKVPLVIFKREKELARKLEFDGLYITEQPEDDDVKGQWDRLVLNTPSFPSNYWDKFVKRKVLDKHGDIYGRERIAELLGMDLATLEITAHNERKPNPPPGLLTWLMSIDVKYQIWKFGVIFTDNSFLYLGWYMVMSLLGHYNNFFFAAHLLDIAMGVKTLRTILSSVTHNGKQLVMTVGLLAVVVYLYTVVAFNFFRKFYNKSEDEDEPDMKCDDMMTCYLFHMYVGVRAGGGIGDEIEDPAGDEYELYRVVFDITFFFFVIVILLAIIQGLIIDAFGELRDQQEQVKEDMETKCFICGIGSDYFDTTPHGFETHTLEEHNLANYMFFLMYLINKDETEHTGQESYVWKMYQERCWDFFPAGDCFRKQYEDQLS>sp|P21817-2|RYR1_HUMAN Isoform 2 of Ryanodine receptor 1 OS=Homo sapiensOX=9606 GN=RYR1MGDAEGEDEVQFLRTDDEVVLQCSATVLKEQLKLCLAAEGFGNRLCFLEPTSNAQNVPPDLAICCFVLEQSLSVRALQEMLANTVEAGVESSQGGGHRTLLYGHAILLRHAHSRMYLSCLTTSRSMTDKLAFDVGLQEDATGEACWWTMHPASKQRSEGEKVRVGDDIILVSVSSERYLHLSTASGELQVDASFMQTLWNMNPICSRCEEGFVTGGHVLRLFHGHMDECLTISPADSDDQRRLVYYEGGAVCTHARSLWRLEPLRISWSGSHLRWGQPLRVRHVTTGQYLALTEDQGLVVVDASKAHTKATSFCFRISKEKLDVAPKRDVEGMGPPEIKYGESLCFVQHVASGLWLTYAAPDPKALRLGVLKKKAMLHQEGHMDDALSLTRCQQEESQAARMIHSTNGLYNQFIKSLDSFSGKPRGSGPPAGTALPIEGVILSLQDLIIYFEPPSEDLQHEEKQSKLRSLRNRQSLFQEEGMLSMVLNCIDRLNVYTTAAHFAEFAGEEAAESWKEIVNLLYELLASLIRGNRSNCALFSTNLDWLVSKLDRLEASSGILEVLYCVLIESPEVLNIIQENHIKSIISLLDKHGRNHKVLDVLCSLCVCNGVAVRSNQDLITENLLPGRELLLQTNLINYVTSIRPNIFVGRAEGTTQYSKWYFEVMVDEVTPFLTAQATHLRVGWALTEGYTPYPGAGEGWGGNGVGDDLYSYGFDGLHLWTGHVARPVTSPGQHLLAPEDVISCCLDLSVPSISFRINGCPVQGVFESFNLDGLFFPVVSFSAGVKVRFLLGGRHGEFKFLPPPGYAPCHEAVLPRERLHLEPIKEYRREGPRGPHLVGPSRCLSHTDFVPCPVDTVQIVLPPHLERIREKLAENIHELWALTRIEQGWTYGPVRDDNKRLHPCLVDFHSLPEPERNYNLQMSGETLKTLLALGCHVGMADEKAEDNLKKTKLPKTYMMSNGYKPAPLDLSHVRLTPAQTTLVDRLAENGHNVWARDRVGQGWSYSAVQDIPARRNPRLVPYRLLDEATKRSNRDSLCQAVRTLLGYGYNIEPPDQEPSQVENQSRCDRVRIFRAEKSYTVQSGRWYFEFEAVTTGEMRVGWARPELRPDVELGADELAYVFNGHRGQRWHLGSEPFGRPWQPGDVVGCMIDLTENTIIFTLNGEVLMSDSGSETAFREIEIGDGFLPVCSLGPGQVGHLNLGQDVSSLRFFAICGLQEGFEPFAINMQRPVTTWFSKGLPQFEPVPLEHPHYEVSRVDGTVDTPPCLRLTHRTWGSQNSLVEMLFLRLSLPVQFHQHFRCTAGATPLAPPGLQPPAEDEARAAEPDPDYENLRRSAGGWSEAENGKEGTAKEGAPGGTPQAGGEAQPARAENEKDATTEKNKKRGFLFKAKKVAMMTQPPATPTLPRLPHDVVPADNRDDPEIILNTTTYYYSVRVFAGQEPSCVWAGWVTPDYHQHDMSFDLSKVRVVTVTMGDEQGNVHSSLKCSNCYMVWGGDFVSPGQQGRISHTDLVIGCLVDLATGLMTFTANGKESNTFFQVEPNTKLFPAVFVLPTHQNVIQFELGKQKNIMPLSAAMFQSERKNPAPQCPPRLEMQMLMPVSWSRMPNHFLQVETRRAGERLGWAVQCQEPLTMMALHIPEENRCMDILELSERLDLQRFHSHTLRLYRAVCALGNNRVAHALCSHVDQAQLLHALEDAHLPGPLRAGYYDLLISIHLESACRSRRSMLSEYIVPLTPETRAITLFPPGRSTENGHPRHGLPGVGVTTSLRPPHHFSPPCFVAALPAAGAAEAPARLSPAIPLEALRDKALRMLGEAVRDGGQHARDPVGGSVEFQFVPVLKLVSTLLVMGIFGDEDVKQILKMIEPEVFTEEEEEEDEEEEGEEEDEEEKEEDEEETAQEKEDEEKEEEEAAEGEKEEGLEEGLLQMKLPESVKLQMCHLLEYFCDQELQHRVESLAAFAERYVDKLQANQRSRYGLLIKAFSMTAAETARRTREFRSPPQEQINMLLQFKDGTDEEDCPLPEEIRQDLLDFHQDLLAHCGIQLDGEEEEPEEETTLGSRLMSLLEKVRLVKKKEEKPEEERSAEESKPRSLQELVSHMVVRWAQEDFVQSPELVRAMFSLLHRQYDGLGELLRALPRAYTISPSSVEDTMSLLECLGQIRSLLIVQMGPQEENLMIQSIGNIMNNKVFYQHPNLMRALGMHETVMEVMVNVLGGGESKEIRFPKMVTSCCRFLCYFCRISRQNQRSMFDHLSYLLENSGIGLGMQGSTPLDVAAASVIDNNELALALQEQDLEKVVSYLAGCGLQSCPMLVAKGYPDIGWNPCGGERYLDFLRFAVFVNGESVEENANVVVRLLIRKPECFGPALRGEGGSGLLAAIEEAIRISEDPARDGPGIRRDRRREHFGEEPPEENRVHLGHAIMSFYAALIDLLGRCAPEMHLIQAGKGEALRIRAILRSLVPLEDLVGIISLPLQIPTLGKDGALVQPKMSASFVPDHKASMVLFLDRVYGIENQDFLLHVLDVGFLPDMRAAASLDTATFSTTEMALALNRYLCLAVLPLITKCAPLFAGTEHRAIMVDSMLHTVYRLSRGRSLTKAQRDVIEDCLMSLCRYIRPSMLQHLLRRLVFDVPILNEFAKMPLKLLTNHYERCWKYYCLPTGWANFGVTSEEELHLTRKLFWGIFDSLAHKKYDPELYRMAMPCLCAIAGALPPDYVDASYSSKAEKKATVDAEGNFDPRPVETLNVIIPEKLDSFINKFAEYTHEKWAFDKIQNNWSYGENIDEELKTHPMLRPYKTFSEKDKEIYRWPIKESLKAMIAWEWTIEKAREGEEEKTEKKKTRKISQSAQTYDPREGYNPQPPDLSAVTLSRELQAMAEQLAENYHNTWGRKKKQELEAKGGGTHPLLVPYDTLTAKEKARDREKAQELLKFLQMNGYAVTRGLKDMELDSSSIEKRFAFGFLQQLLRWMDISQEFIAHLEAVVSSGRVEKSPHEQEIKFFAKILLPLINQYFTNHCLYFLSTPAKVLGSGGHASNKEKEMITSLFCKLAALVRHRVSLFGTDAPAVVNCLHILARSLDARTVMKSGPEIVKAGLRSFFESASEDIEKMVENLRLGKVSQARTQVKGVGQNLTYTTVALLPVLTTLFQHIAQHQFGDDVILDDVQVSCYRTLCSIYSLGTTKNTYVEKLRPALGECLARLAAAMPVAFLEPQLNEYNACSVYTTKSPRERAILGLPNSVEEMCPDIPVLERLMADIGGLAESGARYTEMPHVIEITLPMLCSYLPRWWERGPEAPPSALPAGAPPPCTAVTSDHLNSLLGNILRIIVNNLGIDEASWMKRLAVFAQPIVSRARPELLQSHFIPTIGRLRKRAGKVVSEEEQLRLEAKAEAQEGELLVRDEFSVLCRDLYALYPLLIRYVDNNRAQWLTEPNPSAEELFRMVGEIFIYWSKSHNFKREEQNFVVQNEINNMSFLTADNKSKMAKSGGSDQERTKKKRRGDRYSVQTSLIVATLKKMLPIGLNMCAPTDQDLITLAKTRYALKDTDEEVREFLHNNLHLQGKVEGSPSLRWQMALYRGVPGREEDADDPEKIVRRVQEVSAVLYYLDQTEHPYKSKKAVWHKLLSKQRRRAVVACFRMTPLYNLPTHRACNMFLESYKAAWILTEDHSFEDRMIDDLSKAGEQEEEEEEVEEKKPDPLHQLVLHFSRTALTEKSKLDEDYLYMAYADIMAKSCHLEEGGENGEAEEEVEVSFEEKQMEKQRLLYQQARLHTRGAAEMVLQMISACKGETGAMVSSTLKLGISILNGGNAEVQQKMLDYLKDKKEVGFFQSIQALMQTCSVLDLNAFERQNKAEGLGMVNEDGTVINRQNGEKVMADDEFTQDLFRFLQLLCEGHNNDFQNYLRTQTGNTTTINIIICTVDYLLRLQESISDFYWYYSGKDVIEEQGKRNFSKAMSVAKQVFNSLTEYIQGPCTGNQQSLAHSRLWDAVVGFLHVFAHMMMKLAQDSSQIELLKELLDLQKDMVVMLLSLLEGNVVNGMIARQMVDMLVESSSNVEMILKFFDMFLKLKDIVGSEAFQDYVTDPRGLISKKDFQKAMDSQKQFSGPEIQFLLSCSEADENEMINCEEFANRFQEPARDIGFNVAVLLTNLSEHVPHDPRLHNFLELAESILEYFRPYLGRIEIMGASRRIERIYFEISETNRAQWEMPQVKESKRQFIFDVVNEGGEAEKMELFVSFCEDTIFEMQIAAQISEPEGEPETDEDEGAGAAEAGAEGAEEGAAGLEGTAATAAAGATARVVAAAGRALRGLSYRSLRRRVRRLRRLTAREAATAVAALLWAAVTRAGAAGAGAAAGALGLLWGSLFGGGLVEGAKKVTVTELLAGMPDPTSDEVHGEQPAGPGGDADGEGASEGAGDAAEGAGDEEEAVHEAGPGGADGAVAVTDGGPFRPEGAGGLGDMGDTTPAEPPTPEGSPILKRKLGVDGVEEELPPEPEPEPEPELEPEKADAENGEKEEVPEPTPEPPKKQAPPSPPPKKEEAGGEFWGELEVQRVKFLNYLSRNFYTLRFLALFLAFAINFILLFYKVSDSPPGEDDMEGSAAGDVSGAGSGGSSGWGLGAGEEAEGDEDENMVYYFLEESTGYMEPALRCLSLLHTLVAFLCIIGYNCLKVPLVIFKREKELARKLEFDGLYITEQPEDDDVKGQWDRLVLNTPSFPSNYWDKFVKRKVLDKHGDIYGRERIAELLGMDLATLEITAHNERKPNPPPGLLTWLMSIDVKYQIWKFGVIFTDNSFLYLGWYMVMSLLGHYNNFFFAAHLLDIAMGVKTLRTILSSVTHNGKQLVMTVGLLAVVVYLYTVVAFNFFRKFYNKSEDEDEPDMKCDDMMTCYLFHMYVGVRAGGGIGDEIEDPAGDEYELYRVVFDITFFFFVIVILLAIIQGLIIDAFGELRDQQEQVKEDMETKCFICGIGSDYFDTTPHGFETHTLEEHNLANYMFFLMYLINKDETEHTGQESYVWKMYQERCWDFFPAGDCFRKQYEDQLS>sp|P21817-3|RYR1_HUMAN Isoform 3 of Ryanodine receptor 1 OS=Homo sapiensOX=9606 GN=RYR1MGDAEGEDEVQFLRTDDEVVLQCSATVLKEQLKLCLAAEGFGNRLCFLEPTSNAQNVPPDLAICCFVLEQSLSVRALQEMLANTVEAGVESSQGGGHRTLLYGHAILLRHAHSRMYLSCLTTSRSMTDKLAFDVGLQEDATGEACWWTMHPASKQRSEGEKVRVGDDIILVSVSSERYLHLSTASGELQVDASFMQTLWNMNPICSRCEEGFVTGGHVLRLFHGHMDECLTISPADSDDQRRLVYYEGGAVCTHARSLWRLEPLRISWSGSHLRWGQPLRVRHVTTGQYLALTEDQGLVVVDASKAHTKATSFCFRISKEKLDVAPKRDVEGMGPPEIKYGESLCFVQHVASGLWLTYAAPDPKALRLGVLKKKAMLHQEGHMDDALSLTRCQQEESQAARMIHSTNGLYNQFIKSLDSFSGKPRGSGPPAGTALPIEGVILSLQDLIIYFEPPSEDLQHEEKQSKLRSLRNRQSLFQEEGMLSMVLNCIDRLNVYTTAAHFAEFAGEEAAESWKEIVNLLYELLASLIRGNRSNCALFSTNLDWLVSKLDRLEASSGILEVLYCVLIESPEVLNIIQENHIKSIISLLDKHGRNHKVLDVLCSLCVCNGVAVRSNQDLITENLLPGRELLLQTNLINYVTSIRPNIFVGRAEGTTQYSKWYFEVMVDEVTPFLTAQATHLRVGWALTEGYTPYPGAGEGWGGNGVGDDLYSYGFDGLHLWTGHVARPVTSPGQHLLAPEDVISCCLDLSVPSISFRINGCPVQGVFESFNLDGLFFPVVSFSAGVKVRFLLGGRHGEFKFLPPPGYAPCHEAVLPRERLHLEPIKEYRREGPRGPHLVGPSRCLSHTDFVPCPVDTVQIVLPPHLERIREKLAENIHELWALTRIEQGWTYGPVRDDNKRLHPCLVDFHSLPEPERNYNLQMSGETLKTLLALGCHVGMADEKAEDNLKKTKLPKTYMMSNGYKPAPLDLSHVRLTPAQTTLVDRLAENGHNVWARDRVGQGWSYSAVQDIPARRNPRLVPYRLLDEATKRSNRDSLCQAVRTLLGYGYNIEPPDQEPSQVENQSRCDRVRIFRAEKSYTVQSGRWYFEFEAVTTGEMRVGWARPELRPDVELGADELAYVFNGHRGQRWHLGSEPFGRPWQPGDVVGCMIDLTENTIIFTLNGEVLMSDSGSETAFREIEIGDGFLPVCSLGPGQVGHLNLGQDVSSLRFFAICGLQEGFEPFAINMQRPVTTWFSKGLPQFEPVPLEHPHYEVSRVDGTVDTPPCLRLTHRTWGSQNSLVEMLFLRLSLPVQFHQHFRCTAGATPLAPPGLQPPAEDEARAAEPDPDYENLRRSAGGWSEAENGKEGTAKEGAPGGTPQAGGEAQPARAENEKDATTEKNKKRGFLFKAKKVAMMTQPPATPTLPRLPHDVVPADNRDDPEIILNTTTYYYSVRVFAGQEPSCVWAGWVTPDYHQHDMSFDLSKVRVVTVTMGDEQGNVHSSLKCSNCYMVWGGDFVSPGQQGRISHTDLVIGCLVDLATGLMTFTANGKESNTFFQVEPNTKLFPAVFVLPTHQNVIQFELGKQKNIMPLSAAMFQSERKNPAPQCPPRLEMQMLMPVSWSRMPNHFLQVETRRAGERLGWAVQCQEPLTMMALHIPEENRCMDILELSERLDLQRFHSHTLRLYRAVCALGNNRVAHALCSHVDQAQLLHALEDAHLPGPLRAGYYDLLISIHLESACRSRRSMLSEYIVPLTPETRAITLFPPGRSTENGHPRHGLPGVGVTTSLRPPHHFSPPCFVAALPAAGAAEAPARLSPAIPLEALRDKALRMLGEAVRDGGQHARDPVGGSVEFQFVPVLKLVSTLLVMGIFGDEDVKQILKMIEPEVFTEEEEEEDEEEEGEEEDEEEKEEDEEETAQEKEDEEKEEEEAAEGEKEEGLEEGLLQMKLPESVKLQMCHLLEYFCDQELQHRVESLAAFAERYVDKLQANQRSRYGLLIKAFSMTAAETARRTREFRSPPQEQINMLLQFKDGTDEEDCPLPEEIRQDLLDFHQDLLAHCGIQLDGEEEEPEEETTLGSRLMSLLEKVRLVKKKEEKPEEERSAEESKPRSLQELVSHMVVRWAQEDFVQSPELVRAMFSLLHRQYDGLGELLRALPRAYTISPSSVEDTMSLLECLGQIRSLLIVQMGPQEENLMIQSIGNIMNNKVFYQHPNLMRALGMHETVMEVMVNVLGGGESKEIRFPKMVTSCCRFLCYFCRISRQNQRSMFDHLSYLLENSGIGLGMQGSTPLDVAAASVIDNNELALALQEQDLEKVVSYLAGCGLQSCPMLVAKGYPDIGWNPCGGERYLDFLRFAVFVNGESVEENANVVVRLLIRKPECFGPALRGEGGSGLLAAIEEAIRISEDPARDGPGIRRDRRREHFGEEPPEENRVHLGHAIMSFYAALIDLLGRCAPEMHLIQAGKGEALRIRAILRSLVPLEDLVGIISLPLQIPTLGKDGALVQPKMSASFVPDHKASMVLFLDRVYGIENQDFLLHVLDVGFLPDMRAAASLDTATFSTTEMALALNRYLCLAVLPLITKCAPLFAGTEHRAIMVDSMLHTVYRLSRGRSLTKAQRDVIEDCLMSLCRYIRPSMLQHLLRRLVFDVPILNEFAKMPLKLLTNHYERCWKYYCLPTGWANFGVTSEEELHLTRKLFWGIFDSLAHKKYDPELYRMAMPCLCAIAGALPPDYVDASYSSKAEKKATVDAEGNFDPRPVETLNVIIPEKLDSFINKFAEYTHEKWAFDKIQNNWSYGENIDEELKTHPMLRPYKTFSEKDKEIYRWPIKESLKAMIAWEWTIEKAREGEEEKTEKKKTRKISQSAQTYDPREGYNPQPPDLSAVTLSRELQAMAEQLAENYHNTWGRKKKQELEAKGGGTHPLLVPYDTLTAKEKARDREKAQELLKFLQMNGYAVTRGLKDMELDSSSIEKRFAFGFLQQLLRWMDISQEFIAHLEAVVSSGRVEKSPHEQEIKFFAKILLPLINQYFTNHCLYFLSTPAKVLGSGGHASNKEKEMITSLFCKLAALVRHRVSLFGTDAPAVVNCLHILARSLDARTVMKSGPEIVKAGLRSFFESASEDIEKMVENLRLGKVSQARTQVKGVGQNLTYTTVALLPVLTTLFQHIAQHQFGDDVILDDVQVSCYRTLCSIYSLGTTKNTYVEKLRPALGECLARLAAAMPVAFLEPQLNEYNACSVYTTKSPRERAILGLPNSVEEMCPDIPVLERLMADIGGLAESGARYTEMPHVIEITLPMLCSYLPRWWERGPEAPPSALPAGAPPPCTAVTSDHLNSLLGNILRIIVNNLGIDEASWMKRLAVFAQPIVSRARPELLQSHFIPTIGRLRKRAGKVVSEEEQLRLEAKAEAQEGELLVRDEFSVLCRDLYALYPLLIRYVDNNRAQWLTEPNPSAEELFRMVGEIFIYWSKSHNFKREEQNFVVQNEINNMSFLTADNKSKMAKAGDIQSGGSDQERTKKKRRGDRYSVQTSLIVATLKKMLPIGLNMCAPTDQDLITLAKTRYALKDTDEEVREFLHNNLHLQGKVEGSPSLRWQMALYRGVPGREEDADDPEKIVRRVQEVSAVLYYLDQTEHPYKSKKAVWHKLLSKQRRRAVVACFRMTPLYNLPTHRACNMFLESYKAAWILTEDHSFEDRMIDDLSKAGEQEEEEEEVEEKKPDPLHQLVLHFSRTALTEKSKLDEDYLYMAYADIMAKSCHLEEGGENGEAEEEVEVSFEEKQMEKQRLLYQQARLHTRGAAEMVLQMISACKGETGAMVSSTLKLGISILNGGNAEVQQKMLDYLKDKKEVGFFQSIQALMQTCSVLDLNAFERQNKAEGLGMVNEDGTVGEKVMADDEFTQDLFRFLQLLCEGHNNDFQNYLRTQTGNTTTINIIICTVDYLLRLQESISDFYWYYSGKDVIEEQGKRNFSKAMSVAKQVFNSLTEYIQGPCTGNQQSLAHSRLWDAVVGFLHVFAHMMMKLAQDSSQIELLKELLDLQKDMVVMLLSLLEGNVVNGMIARQMVDMLVESSSNVEMILKFFDMFLKLKDIVGSEAFQDYVTDPRGLISKKDFQKAMDSQKQFSGPEIQFLLSCSEADENEMINCEEFANRFQEPARDIGFNVAVLLTNLSEHVPHDPRLHNFLELAESILEYFRPYLGRIEIMGASRRIERIYFEISETNRAQWEMPQVKESKRQFIFDVVNEGGEAEKMELFVSFCEDTIFEMQIAAQISEPEGEPETDEDEGAGAAEAGAEGAEEGAAGLEGTAATAAAGATARVVAAAGRALRGLSYRSLRRRVRRLRRLTAREAATAVAALLWAAVTRAGAAGAGAAAGALGLLWGSLFGGGLVEGAKKVTVTELLAGMPDPTSDEVHGEQPAGPGGDADGEGASEGAGDAAEGAGDEEEAVHEAGPGGADGAVAVTDGGPFRPEGAGGLGDMGDTTPAEPPTPEGSPILKRKLGVDGVEEELPPEPEPEPEPELEPEKADAENGEKEEVPEPTPEPPKKQAPPSPPPKKEEAGGEFWGELEVQRVKFLNYLSRNFYTLRFLALFLAFAINFILLFYKVSDSPPGEDDMEGSAAGDVSGAGSGGSSGWGLGAGEEAEGDEDENMVYYFLEESTGYMEPALRCLSLLHTLVAFLCIIGYNCLKVPLVIFKREKELARKLEFDGLYITEQPEDDDVKGQWDRLVLNTPSFPSNYWDKFVKRKVLDKHGDIYGRERIAELLGMDLATLEITAHNERKPNPPPGLLTWLMSIDVKYQIWKFGVIFTDNSFLYLGWYMVMSLLGHYNNFFFAAHLLDIAMGVKTLRTILSSVTHNGKQLVMTVGLLAVVVYLYTVVAFNFFRKFYNKSEDEDEPDMKCDDMMTCYLFHMYVGVRAGGGIGDEIEDPAGDEYELYRVVFDITFFFFVIVILLAIIQGLIIDAFGELRDQQEQVKEDMETKCFICGIGSDYFDTTPHGFETHTLEEHNLANYMFFLMYLINKDETEHTGQESYVWKMYQERCWDFFPAGDCFRKQYEDQLS>sp|Q9UP95|S12A4_HUMAN Solute carrier family 12 member 4 OS=Homo sapiensOX=9606 GN=SLC12A4 PE=1 SV=2MPHFTVVPVDGPRRGDYDNLEGLSWVDYGERAELDDSDGHGNHRESSPFLSPLEASRGIDYYDRNLALFEEELDIRPKVSSLLGKLVSYTNLTQGAKEHEEAESGEGTRRRAAEAPSMGTLMGVYLPCLQNIFGVILFLRLTWMVGTAGVLQALLIVLICCCCTLLTAISMSAIATNGVVPAGGSYFMISRSLGPEFGGAVGLCFYLGTTFAAAMYILGAIEILLTYIAPPAAIFYPSGAHDTSNATLNNMRVYGTIFLTFMTLVVFVGVKYVNKFASLFLACVIISILSIYAGGIKSIFDPPVFPVCMLGNRTLSRDQFDICAKTAVVDNETVATQLWSFFCHSPNLTTDSCDPYFMLNNVTEIPGIPGAAAGVLQENLWSAYLEKGDIVEKHGLPSADAPSLKESLPLYVVADIATSFTVLVGIFFPSVTGIMAGSNRSGDLRDAQKSIPVGTILAIITTSLVYFSSVVLFGACIEGVVLRDKYGDGVSRNLVVGTLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIAKDNIIPFLRVFGHGKVNGEPTWALLLTALIAELGILIASLDMVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKYYHWALSFLGMSLCLALMFVSSWYYALVAMLIAGMIYKYIEYQGAEKEWGDGIRGLSLSAARYALLRLEEGPPHTKNWRPQLLVLLKLDEDLHVKYPRLLTFASQLKAGKGLTIVGSVIQGSFLESYGEAQAAEQTIKNMMEIEKVKGFCQVVVASKVREGLAHLIQSCGLGGMRHNSVVLGWPYGWRQSEDPRAWKTFIDTVRCTTAAHLALLVPKNIAFYPSNHERYLEGHIDVWWIVHDGGMLMLLPFLLRQHKVWRKCRMRIFTVAQMDDNSIQMKKDLAVFLYHLRLEAEVEVVEMHNSDISAYTYERTLMMEQRSQMLRQMRLTKTEREREAQLVKDRHSALRLESLYSDEEDESAVGADKIQMTWTRDKYMTETWDPSHAPDNFRELVHIKPDQSNVRRMHTAVKLNEVIVTRSHDARLVLLNMPGPPRNSEGDENYMEFLEVLTEGLERVLLVRGGGREVITIYS>sp|Q9UP95-2|S12A4_HUMAN Isoform 2 of Solute carrier family 12 member 4OS=Homo sapiens OX=9606 GN=SLC12A4MPHFTVVPVDGPRRGDYDNLEGLSWVDYGERAELDDSDGHGNHRESSPFLSPLEASRGIDYYDRNLALFEEELDIRPKVSSLLGKLVSYTNLTQGAKEHEEAESGEGTRRRAAEAPSMGTLMGVYLPCLQNIFGVILFLRLTWMVGTAGVLQALLIVLICCCCTLLTAISMSAIATNGVVPAGGSYFMISRSLGPEFGGAVGLCFYLGTTFAAAMYILGAIEILLTYIAPPAAIFYPSGAHDTSNATLNNMRVYGTIFLTFMTLVVFVGVKYVNKFASLFLACVIISILSIYAGGIKSIFDPPVFPVCMLGNRTLSRDQFDICAKTAVVDNETVATQLWSFFCHSPNLTTDSCDPYFMLNNVTEIPGIPGAAAGVLQENLWSAYLEKGDIVEKHGLPSADAPSLKESLPLYVVADIATSFTVLVGIFFPSVTGIMAGSNRSGDLRDAQKSIPVGTILAIITTSLVYFSSVVLFGACIEGVVLRDKYGDGVSRNLVVGTLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIAKDNIIPFLRVFGHGKVNGEPTWALLLTALIAELGILIASLDMVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKYYHWALSFLGMSLCLALMFVSSWYYALVAMLIAGMIYKYIEYQGAEKEWGDGIRGLSLSAARYALLRLEEGPPHTKNWRPQLLVLLKLDEDLHVKYPRLLTFASQLKAGKGLTIVGSVIQGSFLESYGEAQAAEQTIKNMMEIEKVKGFCQVVVASKVREGLAHLIQSCGLGGMRHNSVVLGWPYGWRQSEDPRAWKTFIDTVRCTTAAHLALLVPKNIAFYPSNHERYLEGHIDVWWIVHDGGMLMLLPFLLRQHKVWRKCRMRIFTVAQMDDNSIQMKKDLAVFLYHLRLEAEVEVVEMHNSDISAYTYERTLMMEQRSQMLRQMRLTKTEREREAQLVKDRHSALRLESLYSDEEDESAVGADKIQMTWTRDKYMTETWDPSHAPDNFRELVHIKPDQSNVRRMHTAVKLNEVIVTRSHDARLVLLNMPGPPRNSEGDENCIPLWRGRQLGGG>sp|Q9UP95-3|S12A4_HUMAN Isoform 3 of Solute carrier family 12 member 4OS=Homo sapiens OX=9606 GN=SLC12A4MPHFTVVPVDGPRRGDYDNLEGLSWVDYGERAELDDSDGHGNHRESSPFLSPLEASRGIDYYDRNLALFEEELDIRPKVSSLLGKLVSYTNLTQGAKEHEEAESGEGTRRRAAEAPSMGTLMGVYLPCLQNIFGVILFLRLTWMVGTAGVLQALLIVLICCCCTLLTAISMSAIATNGVVPAGGSYFMISRSLGPEFGGAVGLCFYLGTTFAAAMYILGAIEILLTYIAPPAAIFYPSGAHDTSNATLNNMRVYGTIFLTFMTLVVFVGVKYVNKFASLFLACVIISILSIYAGGIKSIFDPPVFPVCMLGNRTLSRDQFDICAKTAVVDNETVATQLWSFFCHSPNLTTDSCDPYFMLNNVTEIPGIPGAAAGVLQENLWSAYLEKGDIVEKHGLPSADAPSLKESLPLYVVADIATSFTVLVGIFFPSVTGIMAGSNRSGDLRDAQKSIPVGTILAIITTSLVYFSSVVLFGACIEGVVLRDKYGDGVSRNLVVGTLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIAKDNIIPFLRVFGHGKVNGEPTWALLLTALIAELGILIASLDMVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKYYHWALSFLGMSLCLALMFVSSWYYALVAMLIAGMIYKYIEYQGAEKEWGDGIRGLSLSAARYALLRLEEGPPHTKNWRPQLLVLLKLDEDLHVKYPRLLTFASQLKAGKGLTIVGSVIQGSFLESYGEAQAAEQTIKNMMEIEKVKGFCQVVVASKVREGLAHLIQSCGLGGMRHNSVVLGWPYGWRQSEDPRAWKTFIDTVRCTTAAHLALLVPKNIAFYPSNHERYLEGHIDVWWIVHDGGMLMLLPFLLRQHKVWRKCRMRIFTVAQMDDNSIQMKKDLAVFLYHLRLEAEVEVVEMHNSDISAYTYERTLMMEQRSQMLRQMRLTKTEREREAQLVKDRHSALRLESLYSDEEDESAVGADKIQMTWTRDKYMTETWDPSHAPDNFRELVHIKP>sp|Q9UP95-4|S12A4_HUMAN Isoform 4 of Solute carrier family 12 member 4OS=Homo sapiens OX=9606 GN=SLC12A4MPHFTVVPVDGPRRGDYDNLEGLSWVDYGERAELDDSDGHGNHRESSPFLSPLEASRGIDYYDRNLALFEEELDIRPKVSSLLGKLVSYTNLTQGAKEHEEAESGEGTRRRAAEAPSMGTLMGVYLPCLQNIFGVILFLRLTWMVGTAGVLQALLIVLICCCCTLLTAISMSAIATNGVVPAGGSYFMISRSLGPEFGGAVGLCFYLGTTFAAAMYILGAIEILLTYIAPPAAIFYPSGAHDTSNATLNNMRVYGTIFLTFMTLVVFVGVKYVNKFASLFLACVIISILSIYAGGIKSIFDPPVFPVCMLGNRTLSRDQFDICAKTAVVDNETVATQLWSFFCHSPNLTTDSCDPYFMLNNVTEIPGIPGAAAGVLQENLWSAYLEKGDIVEKHGLPSADAPSLKESLPLYVVADIATSFTVLVGIFFPSVTGIMAGSNRSGDLRDAQKSIPVGTILAIITTSLVYFSSVVLFGACIEGVVLRDKYGDGVSRNLVVGTLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIAKDNIIPFLRVFGHGKVNGEPTWALLLTALIAELGILIASLDMVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKYYHWALSFLGMSLCLALMFVSSWYYALVAMLIAGMIYKYIEYQGAEKEWGDGIRGLSLSAARYALLRLEEGPPHTKNWRPQLLVLLKLDEDLHVKYPRLLTFASQLKAGKGLTIVGSVIQGSFLESYGEAQAAEQTPCAALRLPTWPCSCPRTSPSTPATTSATWRAT>sp|Q9UP95-5|S12A4_HUMAN Isoform 5 of Solute carrier family 12 member 4OS=Homo sapiens OX=9606 GN=SLC12A4MGDTLSPGHGNHRESSPFLSPLEASRGIDYYDRNLALFEEELDIRPKVSSLLGKLVSYTNLTQGAKEHEEAESGEGTRRRAAEAPSMGTLMGVYLPCLQNIFGVILFLRLTWMVGTAGVLQALLIVLICCCCTLLTAISMSAIATNGVVPAGGSYFMISRSLGPEFGGAVGLCFYLGTTFAAAMYILGAIEILLTYIAPPAAIFYPSGAHDTSNATLNNMRVYGTIFLTFMTLVVFVGVKYVNKFASLFLACVIISILSIYAGGIKSIFDPPVFPVCMLGNRTLSRDQFDICAKTAVVDNETVATQLWSFFCHSPNLTTDSCDPYFMLNNVTEIPGIPGAAAGVLQENLWSAYLEKGDIVEKHGLPSADAPSLKESLPLYVVADIATSFTVLVGIFFPSVTGIMAGSNRSGDLRDAQKSIPVGTILAIITTSLVYFSSVVLFGACIEGVVLRDKYGDGVSRNLVVGTLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIAKDNIIPFLRVFGHGKVNGEPTWALLLTALIAELGILIASLDMVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKYYHWALSFLGMSLCLALMFVSSWYYALVAMLIAGMIYKYIEYQGAEKEWGDGIRGLSLSAARYALLRLEEGPPHTKNWRPQLLVLLKLDEDLHVKYPRLLTFASQLKAGKGLTIVGSVIQGSFLESYGEAQAAEQTIKNMMEIEKVKGFCQVVVASKVREGLAHLIQSCGLGGMRHNSVVLGWPYGWRQSEDPRAWKTFIDTVRCTTAAHLALLVPKNIAFYPSNHERYLEGHIDVWWIVHDGGMLMLLPFLLRQHKVWRKCRMRIFTVAQMDDNSIQMKKDLAVFLYHLRLEAEVEVVEMHNSDISAYTYERTLMMEQRSQMLRQMRLTKTEREREAQLVKDRHSALRLESLYSDEEDESAVGADKIQMTWTRDKYMTETWDPSHAPDNFRELVHIKPDQSNVRRMHTAVKLNEVIVTRSHDARLVLLNMPGPPRNSEGDENYMEFLEVLTEGLERVLLVRGGGREVITIYS>sp|Q9UP95-6|S12A4_HUMAN Isoform 6 of Solute carrier family 12 member 4OS=Homo sapiens OX=9606 GN=SLC12A4MAAEGAVCGFVYLEGTAWAVPEDTEPLASCTLGHGNHRESSPFLSPLEASRGIDYYDRNLALFEEELDIRPKVSSLLGKLVSYTNLTQGAKEHEEAESGEGTRRRAAEAPSMGTLMGVYLPCLQNIFGVILFLRLTWMVGTAGVLQALLIVLICCCCTLLTAISMSAIATNGVVPAGGSYFMISRSLGPEFGGAVGLCFYLGTTFAAAMYILGAIEILLTYIAPPAAIFYPSGAHDTSNATLNNMRVYGTIFLTFMTLVVFVGVKYVNKFASLFLACVIISILSIYAGGIKSIFDPPVFPVCMLGNRTLSRDQFDICAKTAVVDNETVATQLWSFFCHSPNLTTDSCDPYFMLNNVTEIPGIPGAAAGVLQENLWSAYLEKGDIVEKHGLPSADAPSLKESLPLYVVADIATSFTVLVGIFFPSVTGIMAGSNRSGDLRDAQKSIPVGTILAIITTSLVYFSSVVLFGACIEGVVLRDKYGDGVSRNLVVGTLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIAKDNIIPFLRVFGHGKVNGEPTWALLLTALIAELGILIASLDMVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKYYHWALSFLGMSLCLALMFVSSWYYALVAMLIAGMIYKYIEYQGAEKEWGDGIRGLSLSAARYALLRLEEGPPHTKNWRPQLLVLLKLDEDLHVKYPRLLTFASQLKAGKGLTIVGSVIQGSFLESYGEAQAAEQTIKNMMEIEKVKGFCQVVVASKVREGLAHLIQSCGLGGMRHNSVVLGWPYGWRQSEDPRAWKTFIDTVRCTTAAHLALLVPKNIAFYPSNHERYLEGHIDVWWIVHDGGMLMLLPFLLRQHKVWRKCRMRIFTVAQMDDNSIQMKKDLAVFLYHLRLEAEVEVVEMHNSDISAYTYERTLMMEQRSQMLRQMRLTKTEREREAQLVKDRHSALRLESLYSDEEDESAVGADKIQMTWTRDKYMTETWDPSHAPDNFRELVHIKPDQSNVRRMHTAVKLNEVIVTRSHDARLVLLNMPGPPRNSEGDENYMEFLEVLTEGLERVLLVRGGGREVITIYS>sp|Q9UP95-7|S12A4_HUMAN Isoform 7 of Solute carrier family 12 member 4OS=Homo sapiens OX=9606 GN=SLC12A4MRAGGACRPGAAGTAAGTAAGGWDGGCGGAEPARCLTSPWCQWTGRGAATMTTSRGSVGWTTGSAPSWMTRTEELDIRPKVSSLLGKLVSYTNLTQGAKEHEEAESGEGTRRRAAEAPSMGTLMGVYLPCLQNIFGVILFLRLTWMVGTAGVLQALLIVLICCCCTLLTAISMSAIATNGVVPAGGSYFMISRSLGPEFGGAVGLCFYLGTTFAAAMYILGAIEILLTYIAPPAAIFYPSGAHDTSNATLNNMRVYGTIFLTFMTLVVFVGVKYVNKFASLFLACVIISILSIYAGGIKSIFDPPVFPVCMLGNRTLSRDQFDICAKTAVVDNETVATQLWSFFCHSPNLTTDSCDPYFMLNNVTEIPGIPGAAAGVLQENLWSAYLEKGDIVEKHGLPSADAPSLKESLPLYVVADIATSFTVLVGIFFPSVTGIMAGSNRSGDLRDAQKSIPVGTILAIITTSLVYFSSVVLFGACIEGVVLRDKYGDGVSRNLVVGTLAWPSPWVIVIGSFFSTCGAGLQSLTGAPRLLQAIAKDNIIPFLRVFGHGKVNGEPTWALLLTALIAELGILIASLDMVAPILSMFFLMCYLFVNLACAVQTLLRTPNWRPRFKYYHWALSFLGMSLCLALMFVSSWYYALVAMLIAGMIYKYIEYQGAEKEWGDGIRGLSLSAARYALLRLEEGPPHTKNWRPQLLVLLKLDEDLHVKYPRLLTFASQLKAGKGLTIVGSVIQGSFLESYGEAQAAEQTIKNMMEIEKVKGFCQVVVASKVREGLAHLIQSCGLGGMRHNSVVLGWPYGWRQSEDPRAWKTFIDTVRCTTAAHLALLVPKNIAFYPSNHERYLEGHIDVWWIVHDGGMLMLLPFLLRQHKVWRKCRMRIFTVAQMDDNSIQMKKDLAVFLYHLRLEAEVEVVEMHNSDISAYTYERTLMMEQRSQMLRQMRLTKTEREREAQLVKDRHSALRLESLYSDEEDESAVGADKIQMTWTRDKYMTETWDPSHAPDNFRELVHIKPDQSNVRRMHTAVKLNEVIVTRSHDARLVLLNMPGPPRNSEGDENYMEFLEVLTEGLERVLLVRGGGREVITIYS>sp|Q92736|RYR2_HUMAN Ryanodine receptor 2 OS=Homo sapiens OX=9606GN=RYR2 PE=1 SV=3MADGGEGEDEIQFLRTDDEVVLQCTATIHKEQQKLCLAAEGFGNRLCFLESTSNSKNVPPDLSICTFVLEQSLSVRALQEMLANTVEKSEGQVDVEKWKFMMKTAQGGGHRTLLYGHAILLRHSYSGMYLCCLSTSRSSTDKLAFDVGLQEDTTGEACWWTIHPASKQRSEGEKVRVGDDLILVSVSSERYLHLSYGNGSLHVDAAFQQTLWSVAPISSGSEAAQGYLIGGDVLRLLHGHMDECLTVPSGEHGEEQRRTVHYEGGAVSVHARSLWRLETLRVAWSGSHIRWGQPFRLRHVTTGKYLSLMEDKNLLLMDKEKADVKSTAFTFRSSKEKLDVGVRKEVDGMGTSEIKYGDSVCYIQHVDTGLWLTYQSVDVKSVRMGSIQRKAIMHHEGHMDDGISLSRSQHEESRTARVIRSTVFLFNRFIRGLDALSKKAKASTVDLPIESVSLSLQDLIGYFHPPDEHLEHEDKQNRLRALKNRQNLFQEEGMINLVLECIDRLHVYSSAAHFADVAGREAGESWKSILNSLYELLAALIRGNRKNCAQFSGSLDWLISRLERLEASSGILEVLHCVLVESPEALNIIKEGHIKSIISLLDKHGRNHKVLDVLCSLCVCHGVAVRSNQHLICDNLLPGRDLLLQTRLVNHVSSMRPNIFLGVSEGSAQYKKWYYELMVDHTEPFVTAEATHLRVGWASTEGYSPYPGGGEEWGGNGVGDDLFSYGFDGLHLWSGCIARTVSSPNQHLLRTDDVISCCLDLSAPSISFRINGQPVQGMFENFNIDGLFFPVVSFSAGIKVRFLLGGRHGEFKFLPPPGYAPCYEAVLPKEKLKVEHSREYKQERTYTRDLLGPTVSLTQAAFTPIPVDTSQIVLPPHLERIREKLAENIHELWVMNKIELGWQYGPVRDDNKRQHPCLVEFSKLPEQERNYNLQMSLETLKTLLALGCHVGISDEHAEDKVKKMKLPKNYQLTSGYKPAPMDLSFIKLTPSQEAMVDKLAENAHNVWARDRIRQGWTYGIQQDVKNRRNPRLVPYTLLDDRTKKSNKDSLREAVRTLLGYGYNLEAPDQDHAARAEVCSGTGERFRIFRAEKTYAVKAGRWYFEFETVTAGDMRVGWSRPGCQPDQELGSDERAFAFDGFKAQRWHQGNEHYGRSWQAGDVVGCMVDMNEHTMMFTLNGEILLDDSGSELAFKDFDVGDGFIPVCSLGVAQVGRMNFGKDVSTLKYFTICGLQEGYEPFAVNTNRDITMWLSKRLPQFLQVPSNHEHIEVTRIDGTIDSSPCLKVTQKSFGSQNSNTDIMFYRLSMPIECAEVFSKTVAGGLPGAGLFGPKNDLEDYDADSDFEVLMKTAHGHLVPDRVDKDKEATKPEFNNHKDYAQEKPSRLKQRFLLRRTKPDYSTSHSARLTEDVLADDRDDYDFLMQTSTYYYSVRIFPGQEPANVWVGWITSDFHQYDTGFDLDRVRTVTVTLGDEKGKVHESIKRSNCYMVCAGESMSPGQGRNNNGLEIGCVVDAASGLLTFIANGKELSTYYQVEPSTKLFPAVFAQATSPNVFQFELGRIKNVMPLSAGLFKSEHKNPVPQCPPRLHVQFLSHVLWSRMPNQFLKVDVSRISERQGWLVQCLDPLQFMSLHIPEENRSVDILELTEQEELLKFHYHTLRLYSAVCALGNHRVAHALCSHVDEPQLLYAIENKYMPGLLRAGYYDLLIDIHLSSYATARLMMNNEYIVPMTEETKSITLFPDENKKHGLPGIGLSTSLRPRMQFSSPSFVSISNECYQYSPEFPLDILKSKTIQMLTEAVKEGSLHARDPVGGTTEFLFVPLIKLFYTLLIMGIFHNEDLKHILQLIEPSVFKEAATPEEESDTLEKELSVDDAKLQGAGEEEAKGGKRPKEGLLQMKLPEPVKLQMCLLLQYLCDCQVRHRIEAIVAFSDDFVAKLQDNQRFRYNEVMQALNMSAALTARKTKEFRSPPQEQINMLLNFKDDKSECPCPEEIRDQLLDFHEDLMTHCGIELDEDGSLDGNSDLTIRGRLLSLVEKVTYLKKKQAEKPVESDSKKSSTLQQLISETMVRWAQESVIEDPELVRAMFVLLHRQYDGIGGLVRALPKTYTINGVSVEDTINLLASLGQIRSLLSVRMGKEEEKLMIRGLGDIMNNKVFYQHPNLMRALGMHETVMEVMVNVLGGGESKEITFPKMVANCCRFLCYFCRISRQNQKAMFDHLSYLLENSSVGLASPAMRGSTPLDVAAASVMDNNELALALREPDLEKVVRYLAGCGLQSCQMLVSKGYPDIGWNPVEGERYLDFLRFAVFCNGESVEENANVVVRLLIRRPECFGPALRGEGGNGLLAAMEEAIKIAEDPSRDGPSPNSGSSKTLDTEEEEDDTIHMGNAIMTFYSALIDLLGRCAPEMHLIHAGKGEAIRIRSILRSLIPLGDLVGVISIAFQMPTIAKDGNVVEPDMSAGFCPDHKAAMVLFLDRVYGIEVQDFLLHLLEVGFLPDLRAAASLDTAALSATDMALALNRYLCTAVLPLLTRCAPLFAGTEHHASLIDSLLHTVYRLSKGCSLTKAQRDSIEVCLLSICGQLRPSMMQHLLRRLVFDVPLLNEHAKMPLKLLTNHYERCWKYYCLPGGWGNFGAASEEELHLSRKLFWGIFDALSQKKYEQELFKLALPCLSAVAGALPPDYMESNYVSMMEKQSSMDSEGNFNPQPVDTSNITIPEKLEYFINKYAEHSHDKWSMDKLANGWIYGEIYSDSSKVQPLMKPYKLLSEKEKEIYRWPIKESLKTMLAWGWRIERTREGDSMALYNRTRRISQTSQVSVDAAHGYSPRAIDMSNVTLSRDLHAMAEMMAENYHNIWAKKKKMELESKGGGNHPLLVPYDTLTAKEKAKDREKAQDILKFLQINGYAVSRGFKDLELDTPSIEKRFAYSFLQQLIRYVDEAHQYILEFDGGSRGKGEHFPYEQEIKFFAKVVLPLIDQYFKNHRLYFLSAASRPLCSGGHASNKEKEMVTSLFCKLGVLVRHRISLFGNDATSIVNCLHILGQTLDARTVMKTGLESVKSALRAFLDNAAEDLEKTMENLKQGQFTHTRNQPKGVTQIINYTTVALLPMLSSLFEHIGQHQFGEDLILEDVQVSCYRILTSLYALGTSKSIYVERQRSALGECLAAFAGAFPVAFLETHLDKHNIYSIYNTKSSRERAALSLPTNVEDVCPNIPSLEKLMEEIVELAESGIRYTQMPHVMEVILPMLCSYMSRWWEHGPENNPERAEMCCTALNSEHMNTLLGNILKIIYNNLGIDEGAWMKRLAVFSQPIINKVKPQLLKTHFLPLMEKLKKKAATVVSEEDHLKAEARGDMSEAELLILDEFTTLARDLYAFYPLLIRFVDYNRAKWLKEPNPEAEELFRMVAEVFIYWSKSHNFKREEQNFVVQNEINNMSFLITDTKSKMSKAAVSDQERKKMKRKGDRYSMQTSLIVAALKRLLPIGLNICAPGDQELIALAKNRFSLKDTEDEVRDIIRSNIHLQGKLEDPAIRWQMALYKDLPNRTDDTSDPEKTVERVLDIANVLFHLEQKSKRVGRRHYCLVEHPQRSKKAVWHKLLSKQRKRAVVACFRMAPLYNLPRHRAVNLFLQGYEKSWIETEEHYFEDKLIEDLAKPGAEPPEEDEGTKRVDPLHQLILLFSRTALTEKCKLEEDFLYMAYADIMAKSCHDEEDDDGEEEVKSFEEKEMEKQKLLYQQARLHDRGAAEMVLQTISASKGETGPMVAATLKLGIAILNGGNSTVQQKMLDYLKEKKDVGFFQSLAGLMQSCSVLDLNAFERQNKAEGLGMVTEEGSGEKVLQDDEFTCDLFRFLQLLCEGHNSDFQNYLRTQTGNNTTVNIIISTVDYLLRVQESISDFYWYYSGKDVIDEQGQRNFSKAIQVAKQVFNTLTEYIQGPCTGNQQSLAHSRLWDAVVGFLHVFAHMQMKLSQDSSQIELLKELMDLQKDMVVMLLSMLEGNVVNGTIGKQMVDMLVESSNNVEMILKFFDMFLKLKDLTSSDTFKEYDPDGKGVISKRDFHKAMESHKHYTQSETEFLLSCAETDENETLDYEEFVKRFHEPAKDIGFNVAVLLTNLSEHMPNDTRLQTFLELAESVLNYFQPFLGRIEIMGSAKRIERVYFEISESSRTQWEKPQVKESKRQFIFDVVNEGGEKEKMELFVNFCEDTIFEMQLAAQISESDLNERSANKEESEKERPEEQGPRMAFFSILTVRSALFALRYNILTLMRMLSLKSLKKQMKKVKKMTVKDMVTAFFSSYWSIFMTLLHFVASVFRGFFRIICSLLLGGSLVEGAKKIKVAELLANMPDPTQDEVRGDGEEGERKPLEAALPSEDLTDLKELTEESDLLSDIFGLDLKREGGQYKLIPHNPNAGLSDLMSNPVPMPEVQEKFQEQKAKEEEKEEKEETKSEPEKAEGEDGEKEEKAKEDKGKQKLRQLHTHRYGEPEVPESAFWKKIIAYQQKLLNYFARNFYNMRMLALFVAFAINFILLFYKVSTSSVVEGKELPTRSSSENAKVTSLDSSSHRIIAVHYVLEESSGYMEPTLRILAILHTVISFFCIIGYYCLKVPLVIFKREKEVARKLEFDGLYITEQPSEDDIKGQWDRLVINTQSFPNNYWDKFVKRKVMDKYGEFYGRDRISELLGMDKAALDFSDAREKKKPKKDSSLSAVLNSIDVKYQMWKLGVVFTDNSFLYLAWYMTMSVLGHYNNFFFAAHLLDIAMGFKTLRTILSSVTHNGKQLVLTVGLLAVVVYLYTVVAFNFFRKFYNKSEDGDTPDMKCDDMLTCYMFHMYVGVRAGGGIGDEIEDPAGDEYEIYRIIFDITFFFFVIVILLAIIQGLIIDAFGELRDQQEQVKEDMETKCFICGIGNDYFDTVPHGFETHTLQEHNLANYLFFLMYLINKDETEHTGQESYVWKMYQERCWEFFPAGDCFRKQYEDQLN>sp|Q92736-2|RYR2_HUMAN Isoform 2 of Ryanodine receptor 2 OS=Homo sapiensOX=9606 GN=RYR2MADGGEGEDEIQFLRTDDEVVLQCTATIHKEQQKLCLAAEGFGNRLCFLESTSNSKNVPPDLSICTFVLEQSLSVRALQEMLANTVEKSEGQVDVEKWKFMMKTAQGGGHRTLLYGHAILLRHSYSGMYLCCLSTSRSSTDKLAFDVGLQEDTTGEACWWTIHPASKQRSEGEKVRVGDDLILVSVSSERYLHLSYGNGSLHVDAAFQQTLWSVAPISSGSEAAQGYLIGGDVLRLLHGHMDECLTVPSGEHGEEQRRTVHYEGGAVSVHARSLWRLETLRVAWSGSHIRWGQPFRLRHVTTGKYLSLMEDKNLLLMDKEKADVKSTAFTFRSSKEKLDVGVRKEVDGMGTSEIKYGDSVCYIQHVDTGLWLTYQSVDVKSVRMGSIQRKAIMHHEGHMDDGISLSRSQHEESRTARVIRSTVFLFNRFIRGLDALSKKAKASTVDLPIESVSLSLQDLIGYFHPPDEHLEHEDKQNRLRALKNRQNLFQEEGMINLVLECIDRLHVYSSAAHFADVAGREAGESWKSILNSLYELLAALIRGNRKNCAQFSGSLDWLISRLERLEASSGILEVLHCVLVESPEALNIIKEGHIKSIISLLDKHGRNHKVLDVLCSLCVCHGVAVRSNQHLICDNLLPGRDLLLQTRLVNHVSSMRPNIFLGVSEGSAQYKKWYYELMVDHTEPFVTAEATHLRVGWASTEGYSPYPGGGEEWGGNGVGDDLFSYGFDGLHLWSGCIARTVSSPNQHLLRTDDVISCCLDLSAPSISFRINGQPVQGMFENFNIDGLFFPVVSFSAGIKVRFLLGGRHGEFKFLPPPGYAPCYEAVLPKEKLKVEHSREYKQERTYTRDLLGPTVSLTQAAFTPIPVDTSQIVLPPHLERIREKLAENIHELWVMNKIELGWQYGPVRDDNKRQHPCLVEFSKLPEQERNYNLQMSLETLKTLLALGCHVGISDEHAEDKVKKMKLPKNYQLTSGYKPAPMDLSFIKLTPSQEAMVDKLAENAHNVWARDRIRQGWTYGIQQDVKNRRNPRLVPYTLLDDRTKKSNKDSLREAVRTLLGYGYNLEAPDQDHAARAEVCSGTGERFRIFRAEKTYAVKAGRWYFEFETVTAGDMRVGWSRPGCQPDQELGSDERAFAFDGFKAQRWHQGNEHYGRSWQAGDVVGCMVDMNEHTMMFTLNGEILLDDSGSELAFKDFDVGDGFIPVCSLGVAQVGRMNFGKDVSTLKYFTICGLQEGYEPFAVNTNRDITMWLSKRLPQFLQVPSNHEHIEVTRIDGTIDSSPCLKVTQKSFGSQNSNTDIMFYRLSMPIECAEVFSKTVAGGLPGAGLFGPKNDLEDYDADSDFEVLMKTAHGHLVPDRVDKDKEATKPEFNNHKDYAQEKPSRLKQRFLLRRTKPDYSTSHSARLTEDVLADDRDDYDFLMQTSTYYYSVRIFPGQEPANVWVGWITSDFHQYDTGFDLDRVRTVTVTLGDEKGKVHESIKRSNCYMVCAGESMSPGQGRNNNGLEIGCVVDAASGLLTFIANGKELSTYYQVEPSTKLFPAVFAQATSPNVFQFELGRIKNVMPLSAGLFKSEHKNPVPQCPPRLHVQFLSHVLWSRMPNQFLKVDVSRISERQGWLVQCLDPLQFMSLHIPEENRSVDILELTEQEELLKFHYHTLRLYSAVCALGNHRVAHALCSHVDEPQLLYAIENKYMPGLLRAGYYDLLIDIHLSSYATARLMMNNEYIVPMTEETKSITLFPDENKKHGLPGIGLSTSLRPRMQFSSPSFVSISNECYQYSPEFPLDILKSKTIQMLTEAVKEGSLHARDPVGGTTEFLFVPLIKLFYTLLIMGIFHNEDLKHILQLIEPSVFKEAATPEEESDTLEKELSVDDAKLQGAGEEEAKGGKRPKEGLLQMKLPEPVKLQMCLLLQYLCDCQVRHRIEAIVAFSDDFVAKLQDNQRFRYNEVMQALNMSAALTARKTKEFRSPPQEQINMLLNFKDDKSECPCPEEIRDQLLDFHEDLMTHCGIELDEDGSLDGNSDLTIRGRLLSLVEKVTYLKKKQAEKPVESDSKKSSTLQQLISETMVRWAQESVIEDPELVRAMFVLLHRQYDGIGGLVRALPKTYTINGVSVEDTINLLASLGQIRSLLSVRMGKEEEKLMIRGLGDIMNNKVFYQHPNLMRALGMHETVMEVMVNVLGGGESKEITFPKMVANCCRFLCYFCRISRQNQKAMFDHLSYLLENSSVGLASPAMRGSTPLDVAAASVMDNNELALALREPDLEKVVRYLAGCGLQSCQMLVSKGYPDIGWNPVEGERYLDFLRFAVFCNGESVEENANVVVRLLIRRPECFGPALRGEGGNGLLAAMEEAIKIAEDPSRDGPSPNSGSSKTLDTEEEEDDTIHMGNAIMTFYSALIDLLGRCAPEMHLIHAGKGEAIRIRSILRSLIPLGDLVGVISIAFQMPTIAKDGNVVEPDMSAGFCPDHKAAMVLFLDRVYGIEVQDFLLHLLEVGFLPDLRAAASLDTAALSATDMALALNRYLCTAVLPLLTRCAPLFAGTEHHASLIDSLLHTVYRLSKGCSLTKAQRDSIEVCLLSICGQLRPSMMQHLLRRLVFDVPLLNEHAKMPLKLLTNHYERCWKYYCLPGGWGNFGAASEEELHLSRKLFWGIFDALSQKKYEQELFKLALPCLSAVAGALPPDYMESNYVSMMEKQSSMDSEGNFNPQPVDTSNITIPEKLEYFINKYAEHSHDKWSMDKLANGWIYGEIYSDSSKVQPLMKPYKLLSEKEKEIYRWPIKESLKTMLAWGWRIERTREGDSMALYNRTRRISQTSQVSVDAAHGYSPRAIDMSNVTLSRDLHAMAEMMAENYHNIWAKKKKMELESKGGGNHPLLVPYDTLTAKEKAKDREKAQDILKFLQINGYAVSRGFKDLELDTPSIEKRFAYSFLQQLIRYVDEAHQYILEFDGGSRGKGEHFPYEQEIKFFAKVVLPLIDQYFKNHRLYFLSAASRPLCSGGHASNKEKEMVTSLFCKLGVLVRHRISLFGNDATSIVNCLHILGQTLDARTVMKTGLESVKSALRAFLDNAAEDLEKTMENLKQGQFTHTRNQPKGVTQIINYTTVALLPMLSSLFEHIGQHQFGEDLILEDVQVSCYRILTSLYALGTSKSIYVERQRSALGECLAAFAGAFPVAFLETHLDKHNIYSIYNTKSSRERAALSLPTNVEDVCPNIPSLEKLMEEIVELAESGIRYTQMPHVMEVILPMLCSYMSRWWEHGPENNPERAEMCCTALNSEHMNTLLGNILKIIYNNLGIDEGAWMKRLAVFSQPIINKVKPQLLKTHFLPLMEKLKKKAATVVSEEDHLKAEARGDMSEAELLILDEFTTLARDLYAFYPLLIRFVDYNRAKWLKEPNPEAEELFRMVAEVFIYWSKSHNFKREEQNFVVQNEINNMSFLITDTKSKMSKAAVSDQERKKMKRKGDRYSMQTSLIVAALKRLLPIGLNICAPGDQELIALAKNRFSLKDTEDEVRDIIRSNIHLQGKLEDPAIRWQMALYKDLPNRTDDTSDPEKTVERVLDIANVLFHLEQKSKRVGRRHYCLVEHPQRSKKAVWHKLLSKQRKRAVVACFRMAPLYNLPRHRAVNLFLQGYEKSWIETEEHYFEDKLIEDLAKPGAEPPEEDEGTKRVDPLHQLILLFSRTALTEKCKLEEDFLYMAYADIMAKSCHDEEDDDGEEEVKSFEVTGSQRSKEKEMEKQKLLYQQARLHDRGAAEMVLQTISASKGETGPMVAATLKLGIAILNGGNSTVQQKMLDYLKEKKDVGFFQSLAGLMQSCSVLDLNAFERQNKAEGLGMVTEEGSGEKVLQDDEFTCDLFRFLQLLCEGHNSDFQNYLRTQTGNNTTVNIIISTVDYLLRVQESISDFYWYYSGKDVIDEQGQRNFSKAIQVAKQVFNTLTEYIQGPCTGNQQSLAHSRLWDAVVGFLHVFAHMQMKLSQDSSQIELLKELMDLQKDMVVMLLSMLEGNVVNGTIGKQMVDMLVESSNNVEMILKFFDMFLKLKDLTSSDTFKEYDPDGKGVISKRDFHKAMESHKHYTQSETEFLLSCAETDENETLDYEEFVKRFHEPAKDIGFNVAVLLTNLSEHMPNDTRLQTFLELAESVLNYFQPFLGRIEIMGSAKRIERVYFEISESSRTQWEKPQVKESKRQFIFDVVNEGGEKEKMELFVNFCEDTIFEMQLAAQISESDLNERSANKEESEKERPEEQGPRMAFFSILTVRSALFALRYNILTLMRMLSLKSLKKQMKKVKKMTVKDMVTAFFSSYWSIFMTLLHFVASVFRGFFRIICSLLLGGSLVEGAKKIKVAELLANMPDPTQDEVRGDGEEGERKPLEAALPSEDLTDLKELTEESDLLSDIFGLDLKREGGQYKLIPHNPNAGLSDLMSNPVPMPEVQEKFQEQKAKEEEKEEKEETKSEPEKAEGEDGEKEEKAKEDKGKQKLRQLHTHRYGEPEVPESAFWKKIIAYQQKLLNYFARNFYNMRMLALFVAFAINFILLFYKVSTSSVVEGKELPTRSSSENAKVTSLDSSSHRIIAVHYVLEESSGYMEPTLRILAILHTVISFFCIIGYYCLKVPLVIFKREKEVARKLEFDGLYITEQPSEDDIKGQWDRLVINTQSFPNNYWDKFVKRKVMDKYGEFYGRDRISELLGMDKAALDFSDAREKKKPKKDSSLSAVLNSIDVKYQMWKLGVVFTDNSFLYLAWYMTMSVLGHYNNFFFAAHLLDIAMGFKTLRTILSSVTHNGKQLVLTVGLLAVVVYLYTVVAFNFFRKFYNKSEDGDTPDMKCDDMLTCYMFHMYVGVRAGGGIGDEIEDPAGDEYEIYRIIFDITFFFFVIVILLAIIQGLIIDAFGELRDQQEQVKEDMETKCFICGIGNDYFDTVPHGFETHTLQEHNLANYLFFLMYLINKDETEHTGQESYVWKMYQERCWEFFPAGDCFRKQYEDQLN>sp|O95932|TGM3L_HUMAN Protein-glutamine gamma-glutamyltransferase 6OS=Homo sapiens OX=9606 GN=TGM6 PE=1 SV=3MAGIRVTKVDWQRSRNGAAHHTQEYPCPELVVRRGQSFSLTLELSRALDCEEILIFTMETGPRASEALHTKAVFQTSELERGEGWTAAREAQMEKTLTVSLASPPSAVIGRYLLSIRLSSHRKHSNRRLGEFVLLFNPWCAEDDVFLASEEERQEYVLSDSGIIFRGVEKHIRAQGWNYGQFEEDILNICLSILDRSPGHQNNPATDVSCRHNPIYVTRVISAMVNSNNDRGVVQGQWQGKYGGGTSPLHWRGSVAILQKWLKGRYKPVKYGQCWVFAGVLCTVLRCLGIATRVVSNFNSAHDTDQNLSVDKYVDSFGRTLEDLTEDSMWNFHVWNESWFARQDLGPSYNGWQVLDATPQEESEGVFRCGPASVTAIREGDVHLAHDGPFVFAEVNADYITWLWHEDESRERVYSNTKKIGRCISTKAVGSDSRVDITDLYKYPEGSRKERQVYSKAVNRLFGVEASGRRIWIRRAGGRCLWRDDLLEPATKPSIAGKFKVLEPPMLGHDLRLALCLANLTSRAQRVRVNLSGATILYTRKPVAEILHESHAVRLGPQEEKRIPITISYSKYKEDLTEDKKILLAAMCLVTKGEKLLVEKDITLEDFITIKVLGPAMVGVAVTVEVTVVNPLIERVKDCALMVEGSGLLQEQLSIDVPTLEPQERASVQFDITPSKSGPRQLQVDLVSPHFPDIKGFVIVHVATAK>sp|O95932-2|TGM3L_HUMAN Isoform 2 of Protein-glutamine gamma-glutamyltransferase 6 OS=Homo sapiens OX=9606 GN=TGM6MAGIRVTKVDWQRSRNGAAHHTQEYPCPELVVRRGQSFSLTLELSRALDCEEILIFTMETGPRASEALHTKAVFQTSELERGEGWTAAREAQMEKTLTVSLASPPSAVIGRYLLSIRLSSHRKHSNRRLGEFVLLFNPWCAEDDVFLASEEERQEYVLSDSGIIFRGVEKHIRAQGWNYGQFEEDILNICLSILDRSPGHQNNPATDVSCRHNPIYVTRVISAMVNSNNDRGVVQGQWQGKYGGGTSPLHWRGSVAILQKWLKGRYKPVKYGQCWVFAGVLCTVLRCLGIATRVVSNFNSAHDTDQNLSVDKYVDSFGRTLEDLTEDSMWNFHVWNESWFARQDLGPSYNGWQVLDATPQEESEGVFRCGPASVTAIREGDVHLAHDGPFVFAEVNADYITWLWHEDESRERVYSNTKKIGRCISTKAVGSDSRVDITDLYKYPEGSRKERQVYSKAVNRLFGVEASGRRIWIRRAGGRCLWRDDLLEPATKPSIAGKFKVLEPPMLGHDLRLALCLANLTSRAQRVRVNLSGATILYTRKPVAEILHESHAVRLGPQEEKRIPITISYSKYKEDLTEDKKILLAAMCLVTKGEKLLVEKDITLEDFITIKRAYPGASGEGLSPV>sp|Q86W42|THOC6_HUMAN THO complex subunit 6 homolog OS=Homo sapiensOX=9606 GN=THOC6 PE=1 SV=1MERAVPLAVPLGQTEVFQALQRLHMTIFSQSVSPCGKFLAAGNNYGQIAIFSLSSALSSEAKEESKKPVVTFQAHDGPVYSMVSTDRHLLSAGDGEVKAWLWAEMLKKGCKELWRRQPPYRTSLEVPEINALLLVPKENSLILAGGDCQLHTMDLETGTFTRVLRGHTDYIHCLALRERSPEVLSGGEDGAVRLWDLRTAKEVQTIEVYKHEECSRPHNGRWIGCLATDSDWMVCGGGPALTLWHLRSSTPTTIFPIRAPQKHVTFYQDLILSAGQGRCVNQWQLSGELKAQVPGSSPGLLSLSLNQQPAAPECKVLTAAGNSCRVDVFTNLGYRAFSLSF>sp|Q86W42-2|THOC6_HUMAN Isoform 2 of THO complex subunit 6 homologOS=Homo sapiens OX=9606 GN=THOC6MTIFSQSVSPCGKFLAAGNNYGQIAIFSLSSALSSEAKEESKKPVVTFQAHDGPVYSMVSTDRHLLSAGDGEVKAWLWAEMLKKGCKELWRRQPPYRTSLEVPEINALLLVPKENSLILAGGDCQLHTMDLETGTFTRVLRGHTDYIHCLALRERSPEVLSGGEDGAVRLWDLRTAKEVQTIEVYKHEECSRPHNGRWIGCLATDSDWMVCGGGPALTLWHLRSSTPTTIFPIRAPQKHVTFYQDLILSAGQGRCVNQWQLSGELKAQVPGSSPGLLSLSLNQQPAAPECKVLTAAGNSCRVDVFTNLGYRAFSLSF>sp|Q86W42-3|THOC6_HUMAN Isoform 3 of THO complex subunit 6 homologOS=Homo sapiens OX=9606 GN=THOC6MERAVPLAVPLGQTEVFQALQRLHMTIFSQSVSPCGKFLAAGNNYGQIAIFSLSSALSSEAKEESKKPVVTFQAHDGPVYSMVSTDRHLLSAGDGEVKAWLWAEMLKKGCKELWRRQPPYRTSLEVPEINALLLVPKENSLILAGGDCQLHTMDLETGTFTRVLRGHTDYIHCLALRERSPEVLSGGEDGAVRLWDLRTAKEVQTIEVYKHEECSRPHNGRWIGCLATDSDWMVCGGGPALTLWHLRSSTPTTIFPIRAPQKHVTFYQDLVLTAAGNSCRVDVFTNLGYRAFSLSF>sp|Q96KG9|SCYL1_HUMAN N-terminal kinase-like protein OS=Homo sapiensOX=9606 GN=SCYL1 PE=1 SV=1MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSSTDRAMRIRLLQQMEQFIQYLDEPTVNTQIFPHVVHGFLDTNPAIREQTVKSMLLLAPKLNEANLNVELMKHFARLQAKDEQGPIRCNTTVCLGKIGSYLSASTRHRVLTSAFSRATRDPFAPSRVAGVLGFAATHNLYSMNDCAQKILPVLCGLTVDPEKSVRDQAFKAIRSFLSKLESVSEDPTQLEEVEKDVHAASSPGMGGAAASWAGWAVTGVSSLTSKLIRSHPTTAPTETNIPQRPTPEGVPAPAPTPVPATPTTSGHWETQEEDKDTAEDSSTADRWDDEDWGSLEQEAESVLAQQDDWSTGGQVSRASQVSNSDHKSSKSPESDWSSWEAEGSWEQGWQEPSSQEPPPDGTRLASEYNWGGPESSDKGDPFATLSARPSTQPRPDSWGEDNWEGLETDSRQVKAELARKKREERRREMEAKRAERKVAKGPMKLGARKLD>sp|Q96KG9-2|SCYL1_HUMAN Isoform 2 of N-terminal kinase-like proteinOS=Homo sapiens OX=9606 GN=SCYL1MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSSTDRAMRIRLLQQMEQFIQYLDEPTVNTQIFPHVVHGFLDTNPAIREQTVKSMLLLAPKLNEANLNVELMKHFARLQAKDEQGPIRCNTTVCLGKIGSYLSASTRHRVLTSAFSRATRDPFAPSRVAGVLGFAATHNLYSMNDCAQKILPVLCGLTVDPEKSVRDQAFKAIRSFLSKLESVSEDPTQLEEVEKDVHAASSPGMGGAAASWAGWAVTGVSSLTSKLIRSHPTTAPTETNIPQRPTPEGHWETQEEDKDTAEDSSTADRWDDEDWGSLEQEAESVLAQQDDWSTGGQVSRASQVSNSDHKSSKSPESDWSSWEAEGSWEQGWQEPSSQEPPPDGTRLASEYNWGGPESSDKGDPFATLSARPSTQPRPDSWGEDNWEGLETDSRQVKAELARKKREERRREMEAKRAERKVAKGPMKLGARKLD>sp|Q96KG9-3|SCYL1_HUMAN Isoform 3 of N-terminal kinase-like proteinOS=Homo sapiens OX=9606 GN=SCYL1MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSSTDRAMRIRLLQQMEQFIQYLDEPTVNTQIFPHVVHGFLDTNPAIREQTVKSMLLLAPKLNEANLNVELMKHFARLQAKDEQGPIRCNTTVCLGKIGSYLSASTRHRVLTSAFSRATRDPFAPSRVAGVLGFAATHNLYSMNDCAQKILPVLCGLTVDPEKSVRDQAFKAIRSFLSKLESVSEDPTQLEEVEKDVHAASSPGMGGAAASWAGWAVTGVSSLTSKLIRSHPTTAPTETNIPQRPTPEGHWETQEPPPDGTRLASEYNWGGPESSDKGDPFATLSARPSTQPRPDSWGEDNWEGLETDSRQVKAELARKKREERRREMEAKRAERKVAKGPMKLGARKLD>sp|Q96KG9-4|SCYL1_HUMAN Isoform 4 of N-terminal kinase-like proteinOS=Homo sapiens OX=9606 GN=SCYL1MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSSTDRAMRIRLLQQMEQFIQYLDEPTVNTQIFPHVVHGFLDTNPAIREQTVKSMLLLAPKLNEANLNVELMKHFARLQAKDEQGPIRCNTTVCLGKIGSYLSASTRHRVLTSAFSRATRDPFAPSRVAGVLGFAATHNLYSMNDCAQKILPVLCGLTVDPEKSVRDQAFKAIRSFLSKLESVSEDPTQLEEVEKDVHAASSPGMGGAAASWAGWAVTGVSSLTSKLIRSHPTTAPTETNIPQRPTPEGVPAPAPTPVPATPTTSGHWETQEEDKDTAEDSSTADRWDDEDWGSLEQEAESVLAQQDDWSTGGQVSRASQVSNSDHKSSKSPESDWSSWEAEGSWEQGWQEPSSQEPPPDGTRLASEYNWGGPESSDKGDPFATLSARPSTQDRSRLSWPGRSARSGGGRWRPNAPRGRWPRAP>sp|Q96KG9-5|SCYL1_HUMAN Isoform 5 of N-terminal kinase-like proteinOS=Homo sapiens OX=9606 GN=SCYL1MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSSTDRAMRIRLLQQMEQFIQYLDEPTVNTQIFPHVVHGFLDTNPAIREQTVKSMLLLAPKLNEANLNVELMKHFARLQAKDEQGPIRCNTTVCLGKIGSYLSASTRHRVLTSAFSRATRDPFAPSRVAGVLGFAATHNLYSMNDCAQKILPVLCGLTVDPEKSVRDQAFKAIRSFLSKLESVSEDPTQLEEVEKDVHAASSPGMGGAAASWAGWAVTGVSSLTSKLIRSHPTTAPTETNIPQRPSRPARRPLGDAGGGQGHSRGQQHC>sp|Q96KG9-6|SCYL1_HUMAN Isoform 6 of N-terminal kinase-like proteinOS=Homo sapiens OX=9606 GN=SCYL1MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSSTDRAMRIRLLQQMEQFIQYLDEPTVNTQIFPHVVHGFLDTNPAIREQTVKSMLLLAPKLNEANLNVELMKHFARLQAKDEQGPIRCNTTVCLGKIGSYLSASTRHRVLTSAFSRATRDPFAPSRVAGVLGFAATHNLYSMNDCAQKILPVLCGLTVDPEKSVRDQAFKAIRSFLSKLESVSEDPTQLEEVEKDVHAASSPGMGGAAASWAGWAVTGVSSLTSKLIRSHPTTAPTETNIPQRPTPEGVPAPAPTPVPATPTTSGHWETQEEDKDTAEDSSTADRWDDEDWGSLEQEAESVLAQQDDWSTGGQVSRASQSPTGAAGKLRAPGNRAGRSQAPRSHLLTVHGWPASITGVAQSPATRATPSLPCLHVPAPSRGQTLGVRTTGRASRLTVDRSRLSWPGRSARSGGGRWRPNAPRGRWPRAP>sp|Q9NSC2|SALL1_HUMAN Sal-like protein 1 OS=Homo sapiens OX=9606GN=SALL1 PE=1 SV=2MSRRKQAKPQHFQSDPEVASLPRRDGDTEKGQPSRPTKSKDAHVCGRCCAEFFELSDLLLHKKNCTKNQLVLIVNENPASPPETFSPSPPPDNPDEQMNDTVNKTDQVDCSDLSEHNGLDREESMEVEAPVANKSGSGTSSGSHSSTAPSSSSSSSSSSGGGGSSSTGTSAITTSLPQLGDLTTLGNFSVINSNVIIENLQSTKVAVAQFSQEARCGGASGGKLAVPALMEQLLALQQQQIHQLQLIEQIRHQILLLASQNADLPTSSSPSQGTLRTSANPLSTLSSHLSQQLAAAAGLAQSLASQSASISGVKQLPPIQLPQSSSGNTIIPSNSGSSPNMNILAAAVTTPSSEKVASSAGASHVSNPAVSSSSSPAFAISSLLSPASNPLLPQQASANSVFPSPLPNIGTTAEDLNSLSALAQQRKSKPPNVTAFEAKSTSDEAFFKHKCRFCAKVFGSDSALQIHLRSHTGERPFKCNICGNRFSTKGNLKVHFQRHKEKYPHIQMNPYPVPEHLDNIPTSTGIPYGMSIPPEKPVTSWLDTKPVLPTLTTSVGLPLPPTLPSLIPFIKTEEPAPIPISHSATSPPGSVKSDSGGPESATRNLGGLPEEAEGSTLPPSGGKSEESGMVTNSVPTASSSVLSSPAADCGPAGSATTFTNPLLPLMSEQFKAKFPFGGLLDSAQASETSKLQQLVENIDKKATDPNECIICHRVLSCQSALKMHYRTHTGERPFKCKICGRAFTTKGNLKTHYSVHRAMPPLRVQHSCPICQKKFTNAVVLQQHIRMHMGGQIPNTPVPDSYSESMESDTGSFDEKNFDDLDNFSDENMEDCPEGSIPDTPKSADASQDSLSSSPLPLEMSSIAALENQMKMINAGLAEQLQASLKSVENGSIEGDVLTNDSSSVGGDMESQSAGSPAISESTSSMQALSPSNSTQEFHKSPSIEEKPQRAVPSEFANGLSPTPVNGGALDLTSSHAEKIIKEDSLGILFPFRDRGKFKNTACDICGKTFACQSALDIHYRSHTKERPFICTVCNRGFSTKGNLKQHMLTHQMRDLPSQLFEPSSNLGPNQNSAVIPANSLSSLIKTEVNGFVHVSPQDSKDTPTSHVPSGPLSSSATSPVLLPALPRRTPKQHYCNTCGKTFSSSSALQIHERTHTGEKPFACTICGRAFTTKGNLKVHMGTHMWNSTPARRGRRLSVDGPMTFLGGNPVKFPEMFQKDLAARSGSGDPSSFWNQYAAALSNGLAMKANEISVIQNGGIPPIPGSLGSGNSSPVSGLTGNLERLQNSEPNAPLAGLEKMASSENGTNFRFTRFVEDSKEIVTS>sp|Q9NSC2-2|SALL1_HUMAN Isoform 2 of Sal-like protein 1 OS=Homo sapiensOX=9606 GN=SALL1MNDTVNKTDQVDCSDLSEHNGLDREESMEVEAPVANKSGSGTSSGSHSSTAPSSSSSSSSSSGGGGSSSTGTSAITTSLPQLGDLTTLGNFSVINSNVIIENLQSTKVAVAQFSQEARCGGASGGKLAVPALMEQLLALQQQQIHQLQLIEQIRHQILLLASQNADLPTSSSPSQGTLRTSANPLSTLSSHLSQQLAAAAGLAQSLASQSASISGVKQLPPIQLPQSSSGNTIIPSNSGSSPNMNILAAAVTTPSSEKVASSAGASHVSNPAVSSSSSPAFAISSLLSPASNPLLPQQASANSVFPSPLPNIGTTAEDLNSLSALAQQRKSKPPNVTAFEAKSTSDEAFFKHKCRFCAKVFGSDSALQIHLRSHTGERPFKCNICGNRFSTKGNLKVHFQRHKEKYPHIQMNPYPVPEHLDNIPTSTGIPYGMSIPPEKPVTSWLDTKPVLPTLTTSVGLPLPPTLPSLIPFIKTEEPAPIPISHSATSPPGSVKSDSGGPESATRNLGGLPEEAEGSTLPPSGGKSEESGMVTNSVPTASSSVLSSPAADCGPAGSATTFTNPLLPLMSEQFKAKFPFGGLLDSAQASETSKLQQLVENIDKKATDPNECIICHRVLSCQSALKMHYRTHTGERPFKCKICGRAFTTKGNLKTHYSVHRAMPPLRVQHSCPICQKKFTNAVVLQQHIRMHMGGQIPNTPVPDSYSESMESDTGSFDEKNFDDLDNFSDENMEDCPEGSIPDTPKSADASQDSLSSSPLPLEMSSIAALENQMKMINAGLAEQLQASLKSVENGSIEGDVLTNDSSSVGGDMESQSAGSPAISESTSSMQALSPSNSTQEFHKSPSIEEKPQRAVPSEFANGLSPTPVNGGALDLTSSHAEKIIKEDSLGILFPFRDRGKFKNTACDICGKTFACQSALDIHYRSHTKERPFICTVCNRGFSTKGNLKQHMLTHQMRDLPSQLFEPSSNLGPNQNSAVIPANSLSSLIKTEVNGFVHVSPQDSKDTPTSHVPSGPLSSSATSPVLLPALPRRTPKQHYCNTCGKTFSSSSALQIHERTHTGEKPFACTICGRAFTTKGNLKVHMGTHMWNSTPARRGRRLSVDGPMTFLGGNPVKFPEMFQKDLAARSGSGDPSSFWNQYAAALSNGLAMKANEISVIQNGGIPPIPGSLGSGNSSPVSGLTGNLERLQNSEPNAPLAGLEKMASSENGTNFRFTRFVEDSKEIVTS>sp|Q9BXA9|SALL3_HUMAN Sal-like protein 3 OS=Homo sapiens OX=9606GN=SALL3 PE=1 SV=2MSRRKQAKPQHLKSDEELLPPDGAPEHAAPGEGAEDADSGPESRSGGEETSVCEKCCAEFFKWADFLEHQRSCTKLPPVLIVHEDAPAPPPEDFPEPSPASSPSERAESEAAEEAGAEGAEGEARPVEKEAEPMDAEPAGDTRAPRPPPAAPAPPTPAYGAPSTNVTLEALLSTKVAVAQFSQGARAAGGSGAGGGVAAAAVPLILEQLMALQQQQIHQLQLIEQIRSQVALMQRPPPRPSLSPAAAPSAPGPAPSQLPGLAALPLSAGAPAAAIAGSGPAAPAAFEGAQPLSRPESGASTPGGPAEPSAPAAPSAAPAPAAPAPAPAPQSAASSQPQSASTPPALAPGSLLGAAPGLPSPLLPQTSASGVIFPNPLVSIAATANALDPLSALMKHRKGKPPNVSVFEPKASAEDPFFKHKCRFCAKVFGSDSALQIHLRSHTGERPFKCNICGNRFSTKGNLKVHFQRHKEKYPHIQMNPYPVPEYLDNVPTCSGIPYGMSLPPEKPVTTWLDSKPVLPTVPTSVGLQLPPTVPGAHGYADSPSATPASRSPQRPSPASSECASLSPGLNHVESGVSATAESPQSLLGGPPLTKAEPVSLPCTNARAGDAPVGAQASAAPTSVDGAPTSLGSPGLPAVSEQFKAQFPFGGLLDSMQTSETSKLQQLVENIDKKMTDPNQCVICHRVLSCQSALKMHYRTHTGERPFKCKICGRAFTTKGNLKTHFGVHRAKPPLRVQHSCPICQKKFTNAVVLQQHIRMHMGGQIPNTPLPEGFQDAMDSELAYDDKNAETLSSYDDDMDENSMEDDAELKDAATDPAKPLLSYAGSCPPSPPSVISSIAALENQMKMIDSVMSCQQLTGLKSVENGSGESDRLSNDSSSAVGDLESRSAGSPALSESSSSQALSPAPSNGESFRSKSPGLGAPEEPQEIPLKTERPDSPAAAPGSGGAPGRAGIKEEAPFSLLFLSRERGKCPSTVCGVCGKPFACKSALEIHYRSHTKERPFVCALCRRGCSTMGNLKQHLLTHRLKELPSQLFDPNFALGPSQSTPSLISSAAPTMIKMEVNGHGKAMALGEGPPLPAGVQVPAGPQTVMGPGLAPMLAPPPRRTPKQHNCQSCGKTFSSASALQIHERTHTGEKPFGCTICGRAFTTKGNLKVHMGTHMWNNAPARRGRRLSVENPMALLGGDALKFSEMFQKDLAARAMNVDPSFWNQYAAAITNGLAMKNNEISVIQNGGIPQLPVSLGGSALPPLGSMASGMDKARTGSSPPIVSLDKASSETAASRPFTRFIEDNKEIGIN>sp|Q9BXA9-2|SALL3_HUMAN Isoform 1 of Sal-like protein 3 OS=Homo sapiensOX=9606 GN=SALL3MSRRKQAKPQHLKSDEELLPPDGAPEHAAPGEGAEDADSGPESRSGGEETSVCEKCCAEFFKWADFLEHQRSCTKLPPVLIVHEDAPAPPPEDFPEPSPASSPSERAESEAAEEAGAEGAEGEARPVEKEAEPMDAEPAGDTRAPRPPPAAPAPPTPAYGAPSTNVTLEALLSTKVAVAQFSQGARAAGGSGAGGGVAAAAVPLILEQLMALQQQQIHQLQLIEQIRSQVALMQRPPPRPSLSPAAAPSAPGPAPSQLPGLAALPLSAGAPAAAIAGSGPAAPAAFEGAQPLSRPESGASTPGGPAEPSAPAAPSAAPAPAAPAPAPAPQSAASSQPQSASTPPALAPGSLLGAAPGLPSPLLPQTSASGVIFPNPLVSIAATANALDPLSALMKHRKGKPPNVSVFEPKASAEDPFFKHKCRFCAKVFGSDSALQIHLRSHTGERPFKCNICGNRFSTKGNLKVHFQRHKEKYPHIQMNPYPVPEYLDNVPTCSGIPYGMSLPPEKPVTTWLDSKPVLPTVPTSVGLQLPPTVPGAHGYADSPSATPASRSPQRPSPASSECASLSPGLNHVESGVSATAESPQSLLGGPPLTKAEPVSLPCTNARAGDAPVGAQASAAPTSVDGAPTSLGSPGLPAVSEQFKAQFPFGGLLDSMQTSETSKLQQLVENIDKKMTDPNQCVICHRVLSCQSALKMHYRTHTGERPFKCKICGRAFTTKGNLKTHFGVHRAKPPLRVQHSCPICQKKFTNAVVLQQHIRMHMGGQIPNTPLPEGFQDAMDSELAYDDKNAETLSSYDDDMDENSMEDDAELKDAATDPAKPLLSYAGSCPPSPPSVISSIAALENQMKMIDSVMSCQQLTGLKSVENGSGESDRLSNDSSSAVGDLESRSAGSPALSESSSSQALSPAPSNGESFRSKSPGLGAPEEPQEIPLKTERPDSPAAAPGSGGAPGRAGIKEEAPFSLLFLSRERGPSQSTPSLISSAAPTMIKMEVNGHGKAMALGEGPPLPAGVQVPAGPQTVMGPGLAPMLAPPPRRTPKQHNCQSCGKTFSSASALQIHERTHTGEKPFGCTICGRAFTTKGNLKVHMGTHMWNNAPARRGRRLSVENPMALLGGDALKFSEMFQKDLAARAMNVDPSFWNQYAAAITNGLAMKNNEISVIQNGGIPQLPVSLGGSALPPLGSMASGMDKARTGSSPPIVSLDKASSETAASRPFTRFIEDNKEIGIN>sp|Q9BXA9-3|SALL3_HUMAN Isoform 2 of Sal-like protein 3 OS=Homo sapiensOX=9606 GN=SALL3MDAEPAGDTRAPRPPPAAPAPPTPAYGAPSTNVTLEALLSTKVAVAQFSQGARAAGGSGAGGGVAAAAVPLILEQLMALQQQQIHQLQLIEQIRSQVALMQRPPPRPSLSPAAAPSAPGPAPSQLPGLAALPLSAGAPAAAIAGSGPAAPAAFEGAQPLSRPESGASTPGGPAEPSAPAAPSAAPAPAAPAPAPAPQSAASSQPQSASTPPALAPGSLLGAAPGLPSPLLPQTSASGVIFPNPLVSIAATANALDPLSALMKHRKGKPPNVSVFEPKASAEDPFFKHKCRFCAKVFGSDSALQIHLRSHTGERPFKCNICGNRFSTKGNLKVHFQRHKEKYPHIQMNPYPVPEYLDNVPTCSGIPYGMSLPPEKPVTTWLDSKPVLPTVPTSVGLQLPPTVPGAHGYADSPSATPASRSPQRPSPASSECASLSPGLNHVESGVSATAESPQSLLGGPPLTKAEPVSLPCTNARAGDAPVGAQASAAPTSVDGAPTSLGSPGLPAVSEQFKAQFPFGGLLDSMQTSETSKLQQLVENIDKKMTDPNQCVICHRVLSCQSALKMHYRTHTGERPFKCKICGRAFTTKGNLKTHFGVHRAKPPLRVQHSCPICQKKFTNAVVLQQHIRMHMGGQIPNTPLPEGFQDAMDSELAYDDKNAETLSSYDDDMDENSMEDDAELKDAATDPAKPLLSYAGSCPPSPPSVISSIAALENQMKMIDSVMSCQQLTGLKSVENGSGESDRLSNDSSSAVGDLESRSAGSPALSESSSSQALSPAPSNGESFRSKSPGLGAPEEPQEIPLKTERPDSPAAAPGSGGAPGRAGIKEEAPFSLLFLSRERGPSQSTPSLISSAAPTMIKMEVNGHGKAMALGEGPPLPAGVQVPAGPQTVMGPGLAPMLAPPPRRTPKQHNCQSCGKTFSSASALQIHERTHTGEKPFGCTICGRAFTTKGNLKVHMGTHMWNNAPARRGRRLSVENPMALLGGDALKFSEMFQKDLAARAMNVDPSFWNQYAAAITNGLAMKNNEISVIQNGGIPQLPVSLGGSALPPLGSMASGMDKARTGSSPPIVSLDKASSETAASRPFTRFIEDNKEIGIN>sp|Q9BXA9-4|SALL3_HUMAN Isoform 4 of Sal-like protein 3 OS=Homo sapiensOX=9606 GN=SALL3MDAEPAGDTRAPRPPPAAPAPPTPAYGAPSTNVTLEALLSTKVAVAQFSQGARAAGGSGAGGGVAAAAVPLILEQLMALQQQQIHQLQLIEQIRSQVALMQRPPPRPSLSPAAAPSAPGPAPSQLPGLAALPLSAGAPAAAIAGSGPAAPAAFEGAQPLSRPESGASTPGGPAEPSAPAAPSAAPAPAAPAPAPAPQSAASSQPQSASTPPALAPGSLLGAAPGLPSPLLPQTSASGVIFPNPLVSIAATANALDPLSALMKHRKGKPPNVSVFEPKASAEDPFFKHKCRFCAKVFGSDSALQIHLRSHTGERPFKCNICGNRFSTKGNLKVHFQRHKEKYPHIQMNPYPVPEYLDNVPTCSGIPYGMSLPPEKPVTTWLDSKPVLPTVPTSVGLQLPPTVPGAHGYADSPSATPASRSPQRPSPASSECASLSPGLNHVESGVSATAESPQSLLGGPPLTKAEPVSLPCTNARAGDAPVGAQASAAPTSVDGAPTSLGSPGLPAVSEQFKAQFPFGGLLDSMQTSETSKLQQLVENIDKKMTDPNQCVICHRVLSCQSALKMHYRTHTGERPFKCKICGRAFTTKGNLKTHFGVHRAKPPLRVQHSCPICQKKFTNAVVLQQHIRMHMGGQIPNTPLPEGFQDAMDSELAYDDKNAETLSSYDDDMDENSMEDDAELKDAATDPAKPLLSYAGSCPPSPPSVISSIAALENQMKMIDSVMSCQQLTGLKSVENGSGESDRLSNDSSSAVGDLESRSAGSPALSESSSSQALSPAPSNGESFRSKSPGLGAPEEPQEIPLKTERPDSPAAAPGSGGAPGRAGIKEEAPFSLLFLSRERGKCPSTVCGVCGKPFACKSALEIHYRSHTKERPFVCALCRRGCSTMGNLKQHLLTHRLKELPSQLFDPNFALGPSQSTPSLISSAAPTMIKMEVNGHGKAMALGEGPPLPAGVQVPAGPQTVMGPGLAPMLAPPPRRTPKQHNCQSCGKTFSSASALQIHERTHTGEKPFGCTICGRAFTTKGNLKVHMGTHMWNNAPARRGRRLSVENPMALLGGDALKFSEMFQKDLAARAMNVDPSFWNQYAAAITNGLAMKNNEISVIQNGGIPQLPVSLGGSALPPLGSMASGMDKARTGSSPPIVSLDKASSETAASRPFTRFIEDNKEIGIN>sp|O95754|SEM4F_HUMAN Semaphorin-4F OS=Homo sapiens OX=9606 GN=SEMA4FPE=2 SV=2MPASAARPRPGPGQPTASPFPLLLLAVLSGPVSGRVPRSVPRTSLPISEADSCLTRFAVPHTYNYSVLLVDPASHTLYVGARDTIFALSLPFSGERPRRIDWMVPEAHRQNCRKKGKKEDECHNFVQILAIANASHLLTCGTFAFDPKCGVIDVSRFQQVERLESGRGKCPFEPAQRSAAVMAGGVLYAATVKNYLGTEPIITRAVGRAEDWIRTDTLPSWLNAPAFVAAVALSPAEWGDEDGDDEIYFFFTETSRAFDSYERIKVPRVARVCAGDLGGRKTLQQRWTTFLKADLLCPGPEHGRASSVLQDVAVLRPELGAGTPIFYGIFSSQWEGATISAVCAFRPQDIRTVLNGPFRELKHDCNRGLPVVDNDVPQPRPGECITNNMKLRHFGSSLSLPDRVLTFIRDHPLMDRPVFPADGHPLLVTTDTAYLRVVAHRVTSLSGKEYDVLYLGTEDGHLHRAVRIGAQLSVLEDLALFPEPQPVENMKLYHSWLLVGSRTEVTQVNTTNCGRLQSCSECILAQDPVCAWSFRLDECVAHAGEHRGLVQDIESADVSSLCPKEPGERPVVFEVPVATAAHVVLPCSPSSAWASCVWHQPSGVTALTPRRDGLEVVVTPGAMGAYACECQEGGAAHVVAAYSLVWGSQRDAPSRAHTVGAGLAGFFLGILAASLTLILIGRRQQRRRQRELLARDKVGLDLGAPPSGTTSYSQDPPSPSPEDERLPLALAKRGSGFGGFSPPFLLDPCPSPAHIRLTGAPLATCDETSI>sp|O95754-2|SEM4F_HUMAN Isoform Short of Semaphorin-4F OS=Homo sapiensOX=9606 GN=SEMA4FMPASAARPRPGPGQPTASPFPLLLLAVLSGPVSGRVPRSVPRTSLPISEADSCLTRFAVPHTYNYSVLLVDPASHTLYVGARDTIFALSLPFSGERPRRIDWMVPEAHRQNCRKKGKKEGDLGGRKTLQQRWTTFLKADLLCPGPEHGRASSVLQDVAVLRPELGAGTPIFYGIFSSQWEGATISAVCAFRPQDIRTVLNGPFRELKHDCNRGLPVVDNDVPQPRPGECITNNMKLRHFGSSLSLPDRVLTFIRDHPLMDRPVFPADGHPLLVTTDTAYLRVVAHRVTSLSGKEYDVLYLGTEDGHLHRAVRIGAQLSVLEDLALFPEPQPVENMKLYHSWLLVGSRTEVTQVNTTNCGRLQSCSECILAQDPVCAWSFRLDECVAHAGEHRGLVQDIESADVSSLCPKEPGERPVVFEVPVATAAHVVLPCSPSSAWASCVWHQPSGVTALTPRRDGLEVVVTPGAMGAYACECQEGGAAHVVAAYSLVWGSQRDAPSRAHTVGAGLAGFFLGILAASLTLILIGRRQQRRRQRELLARDKVGLDLGAPPSGTTSYSQDPPSPSPEDERLPLALAKRGSGFGGFSPPFLLDPCPSPAHIRLTGAPLATCDETSI>sp|P35499|SCN4A_HUMAN Sodium channel protein type 4 subunit alphaOS=Homo sapiens OX=9606 GN=SCN4A PE=1 SV=4MARPSLCTLVPLGPECLRPFTRESLAAIEQRAVEEEARLQRNKQMEIEEPERKPRSDLEAGKNLPMIYGDPPPEVIGIPLEDLDPYYSNKKTFIVLNKGKAIFRFSATPALYLLSPFSVVRRGAIKVLIHALFSMFIMITILTNCVFMTMSDPPPWSKNVEYTFTGIYTFESLIKILARGFCVDDFTFLRDPWNWLDFSVIMMAYLTEFVDLGNISALRTFRVLRALKTITVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALVGLQLFMGNLRQKCVRWPPPFNDTNTTWYSNDTWYGNDTWYGNEMWYGNDSWYANDTWNSHASWATNDTFDWDAYISDEGNFYFLEGSNDALLCGNSSDAGHCPEGYECIKTGRNPNYGYTSYDTFSWAFLALFRLMTQDYWENLFQLTLRAAGKTYMIFFVVIIFLGSFYLINLILAVVAMAYAEQNEATLAEDKEKEEEFQQMLEKFKKHQEELEKAKAAQALEGGEADGDPAHGKDCNGSLDTSQGEKGAPRQSSSGDSGISDAMEELEEAHQKCPPWWYKCAHKVLIWNCCAPWLKFKNIIHLIVMDPFVDLGITICIVLNTLFMAMEHYPMTEHFDNVLTVGNLVFTGIFTAEMVLKLIAMDPYEYFQQGWNIFDSIIVTLSLVELGLANVQGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKIALDCNLPRWHMHDFFHSFLIVFRILCGEWIETMWDCMEVAGQAMCLTVFLMVMVIGNLVVLNLFLALLLSSFSADSLAASDEDGEMNNLQIAIGRIKLGIGFAKAFLLGLLHGKILSPKDIMLSLGEADGAGEAGEAGETAPEDEKKEPPEEDLKKDNHILNHMGLADGPPSSLELDHLNFINNPYLTIQVPIASEESDLEMPTEEETDTFSEPEDSKKPPQPLYDGNSSVCSTADYKPPEEDPEEQAEENPEGEQPEECFTEACVQRWPCLYVDISQGRGKKWWTLRRACFKIVEHNWFETFIVFMILLSSGALAFEDIYIEQRRVIRTILEYADKVFTYIFIMEMLLKWVAYGFKVYFTNAWCWLDFLIVDVSIISLVANWLGYSELGPIKSLRTLRALRPLRALSRFEGMRVVVNALLGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFYYCINTTTSERFDISEVNNKSECESLMHTGQVRWLNVKVNYDNVGLGYLSLLQVATFKGWMDIMYAAVDSREKEEQPQYEVNLYMYLYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKLGGKDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPQNKIQGMVYDLVTKQAFDITIMILICLNMVTMMVETDNQSQLKVDILYNINMIFIIIFTGECVLKMLALRQYYFTVGWNIFDFVVVILSIVGLALSDLIQKYFVSPTLFRVIRLARIGRVLRLIRGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYSIFGMSNFAYVKKESGIDDMFNFETFGNSIICLFEITTSAGWDGLLNPILNSGPPDCDPNLENPGTSVKGDCGNPSIGICFFCSYIIISFLIVVNMYIAIILENFNVATEESSEPLGEDDFEMFYETWEKFDPDATQFIAYSRLSDFVDTLQEPLRIAKPNKIKLITLDLPMVPGDKIHCLDILFALTKEVLGDSGEMDALKQTMEEKFMAANPSKVSYEPITTTLKRKHEEVCAIKIQRAYRRHLLQRSMKQASYMYRHSHDGSGDDAPEKEGLLANTMSKMYGHENGNSSSPSPEEKGEAGDAGPTMGLMPISPSDTAWPPAPPPGQTVRPGVKESLV>sp|Q9NY46|SCN3A_HUMAN Sodium channel protein type 3 subunit alphaOS=Homo sapiens OX=9606 GN=SCN3A PE=1 SV=2MAQALLVPPGPESFRLFTRESLAAIEKRAAEEKAKKPKKEQDNDDENKPKPNSDLEAGKNLPFIYGDIPPEMVSEPLEDLDPYYINKKTFIVMNKGKAIFRFSATSALYILTPLNPVRKIAIKILVHSLFSMLIMCTILTNCVFMTLSNPPDWTKNVEYTFTGIYTFESLIKILARGFCLEDFTFLRDPWNWLDFSVIVMAYVTEFVSLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCLQWPPSDSAFETNTTSYFNGTMDSNGTFVNVTMSTFNWKDYIGDDSHFYVLDGQKDPLLCGNGSDAGQCPEGYICVKAGRNPNYGYTSFDTFSWAFLSLFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFLGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFQQMLEQLKKQQEEAQAVAAASAASRDFSGIGGLGELLESSSEASKLSSKSAKEWRNRRKKRRQREHLEGNNKGERDSFPKSESEDSVKRSSFLFSMDGNRLTSDKKFCSPHQSLLSIRGSLFSPRRNSKTSIFSFRGRAKDVGSENDFADDEHSTFEDSESRRDSLFVPHRHGERRNSNVSQASMSSRMVPGLPANGKMHSTVDCNGVVSLVGGPSALTSPTGQLPPEGTTTETEVRKRRLSSYQISMEMLEDSSGRQRAVSIASILTNTMEELEESRQKCPPCWYRFANVFLIWDCCDAWLKVKHLVNLIVMDPFVDLAITICIVLNTLFMAMEHYPMTEQFSSVLTVGNLVFTGIFTAEMVLKIIAMDPYYYFQEGWNIFDGIIVSLSLMELGLSNVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINDDCTLPRWHMNDFFHSFLIVFRVLCGEWIETMWDCMEVAGQTMCLIVFMLVMVIGNLVVLNLFLALLLSSFSSDNLAATDDDNEMNNLQIAVGRMQKGIDYVKNKMRECFQKAFFRKPKVIEIHEGNKIDSCMSNNTGIEISKELNYLRDGNGTTSGVGTGSSVEKYVIDENDYMSFINNPSLTVTVPIAVGESDFENLNTEEFSSESELEESKEKLNATSSSEGSTVDVVLPREGEQAETEPEEDLKPEACFTEGCIKKFPFCQVSTEEGKGKIWWNLRKTCYSIVEHNWFETFIVFMILLSSGALAFEDIYIEQRKTIKTMLEYADKVFTYIFILEMLLKWVAYGFQTYFTNAWCWLDFLIVDVSLVSLVANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFYHCVNMTTGNMFDISDVNNLSDCQALGKQARWKNVKVNFDNVGAGYLALLQVATFKGWMDIMYAAVDSRDVKLQPVYEENLYMYLYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPANKFQGMVFDFVTRQVFDISIMILICLNMVTMMVETDDQGKYMTLVLSRINLVFIVLFTGEFVLKLVSLRHYYFTIGWNIFDFVVVILSIVGMFLAEMIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYAIFGMSNFAYVKKEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLAPILNSAPPDCDPDTIHPGSSVKGDCGNPSVGIFFFVSYIIISFLVVVNMYIAVILENFSVATEESAEPLSEDDFEMFYEVWEKFDPDATQFIEFSKLSDFAAALDPPLLIAKPNKVQLIAMDLPMVSGDRIHCLDILFAFTKRVLGESGEMDALRIQMEDRFMASNPSKVSYEPITTTLKRKQEEVSAAIIQRNFRCYLLKQRLKNISSNYNKEAIKGRIDLPIKQDMIIDKLNGNSTPEKTDGSSSTTSPPSYDSVTKPDKEKFEKDKPEKESKGKEVRENQK>sp|Q9NY46-2|SCN3A_HUMAN Isoform 2 of Sodium channel protein type 3subunit alpha OS=Homo sapiens OX=9606 GN=SCN3AMAQALLVPPGPESFRLFTRESLAAIEKRAAEEKAKKPKKEQDNDDENKPKPNSDLEAGKNLPFIYGDIPPEMVSEPLEDLDPYYINKKTFIVMNKGKAIFRFSATSALYILTPLNPVRKIAIKILVHSLFSMLIMCTILTNCVFMTLSNPPDWTKNVEYTFTGIYTFESLIKILARGFCLEDFTFLRDPWNWLDFSVIVMAYVTEFVSLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCLQWPPSDSAFETNTTSYFNGTMDSNGTFVNVTMSTFNWKDYIGDDSHFYVLDGQKDPLLCGNGSDAGQCPEGYICVKAGRNPNYGYTSFDTFSWAFLSLFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFLGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFQQMLEQLKKQQEEAQAVAAASAASRDFSGIGGLGELLESSSEASKLSSKSAKEWRNRRKKRRQREHLEGNNKGERDSFPKSESEDSVKRSSFLFSMDGNRLTSDKKFCSPHQSLLSIRGSLFSPRRNSKTSIFSFRGRAKDVGSENDFADDEHSTFEDSESRRDSLFVPHRHGERRNSNGTTTETEVRKRRLSSYQISMEMLEDSSGRQRAVSIASILTNTMEELEESRQKCPPCWYRFANVFLIWDCCDAWLKVKHLVNLIVMDPFVDLAITICIVLNTLFMAMEHYPMTEQFSSVLTVGNLVFTGIFTAEMVLKIIAMDPYYYFQEGWNIFDGIIVSLSLMELGLSNVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINDDCTLPRWHMNDFFHSFLIVFRVLCGEWIETMWDCMEVAGQTMCLIVFMLVMVIGNLVVLNLFLALLLSSFSSDNLAATDDDNEMNNLQIAVGRMQKGIDYVKNKMRECFQKAFFRKPKVIEIHEGNKIDSCMSNNTGIEISKELNYLRDGNGTTSGVGTGSSVEKYVIDENDYMSFINNPSLTVTVPIAVGESDFENLNTEEFSSESELEESKEKLNATSSSEGSTVDVVLPREGEQAETEPEEDLKPEACFTEGCIKKFPFCQVSTEEGKGKIWWNLRKTCYSIVEHNWFETFIVFMILLSSGALAFEDIYIEQRKTIKTMLEYADKVFTYIFILEMLLKWVAYGFQTYFTNAWCWLDFLIVDVSLVSLVANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFYHCVNMTTGNMFDISDVNNLSDCQALGKQARWKNVKVNFDNVGAGYLALLQVATFKGWMDIMYAAVDSRDVKLQPVYEENLYMYLYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPANKFQGMVFDFVTRQVFDISIMILICLNMVTMMVETDDQGKYMTLVLSRINLVFIVLFTGEFVLKLVSLRHYYFTIGWNIFDFVVVILSIVGMFLAEMIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYAIFGMSNFAYVKKEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLAPILNSAPPDCDPDTIHPGSSVKGDCGNPSVGIFFFVSYIIISFLVVVNMYIAVILENFSVATEESAEPLSEDDFEMFYEVWEKFDPDATQFIEFSKLSDFAAALDPPLLIAKPNKVQLIAMDLPMVSGDRIHCLDILFAFTKRVLGESGEMDALRIQMEDRFMASNPSKVSYEPITTTLKRKQEEVSAAIIQRNFRCYLLKQRLKNISSNYNKEAIKGRIDLPIKQDMIIDKLNGNSTPEKTDGSSSTTSPPSYDSVTKPDKEKFEKDKPEKESKGKEVRENQK>sp|Q9NY46-3|SCN3A_HUMAN Isoform 3 of Sodium channel protein type 3subunit alpha OS=Homo sapiens OX=9606 GN=SCN3AMAQALLVPPGPESFRLFTRESLAAIEKRAAEEKAKKPKKEQDNDDENKPKPNSDLEAGKNLPFIYGDIPPEMVSEPLEDLDPYYINKKTFIVMNKGKAIFRFSATSALYILTPLNPVRKIAIKILVHSLFSMLIMCTILTNCVFMTLSNPPDWTKNVEYTFTGIYTFESLIKILARGFCLEDFTFLRDPWNWLDFSVIVMAYVTEFVDLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCLQWPPSDSAFETNTTSYFNGTMDSNGTFVNVTMSTFNWKDYIGDDSHFYVLDGQKDPLLCGNGSDAGQCPEGYICVKAGRNPNYGYTSFDTFSWAFLSLFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFLGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFQQMLEQLKKQQEEAQAVAAASAASRDFSGIGGLGELLESSSEASKLSSKSAKEWRNRRKKRRQREHLEGNNKGERDSFPKSESEDSVKRSSFLFSMDGNRLTSDKKFCSPHQSLLSIRGSLFSPRRNSKTSIFSFRGRAKDVGSENDFADDEHSTFEDSESRRDSLFVPHRHGERRNSNVSQASMSSRMVPGLPANGKMHSTVDCNGVVSLVGGPSALTSPTGQLPPEGTTTETEVRKRRLSSYQISMEMLEDSSGRQRAVSIASILTNTMEELEESRQKCPPCWYRFANVFLIWDCCDAWLKVKHLVNLIVMDPFVDLAITICIVLNTLFMAMEHYPMTEQFSSVLTVGNLVFTGIFTAEMVLKIIAMDPYYYFQEGWNIFDGIIVSLSLMELGLSNVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINDDCTLPRWHMNDFFHSFLIVFRVLCGEWIETMWDCMEVAGQTMCLIVFMLVMVIGNLVVLNLFLALLLSSFSSDNLAATDDDNEMNNLQIAVGRMQKGIDYVKNKMRECFQKAFFRKPKVIEIHEGNKIDSCMSNNTGIEISKELNYLRDGNGTTSGVGTGSSVEKYVIDENDYMSFINNPSLTVTVPIAVGESDFENLNTEEFSSESELEESKEKLNATSSSEGSTVDVVLPREGEQAETEPEEDLKPEACFTEGCIKKFPFCQVSTEEGKGKIWWNLRKTCYSIVEHNWFETFIVFMILLSSGALAFEDIYIEQRKTIKTMLEYADKVFTYIFILEMLLKWVAYGFQTYFTNAWCWLDFLIVDVSLVSLVANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFYHCVNMTTGNMFDISDVNNLSDCQALGKQARWKNVKVNFDNVGAGYLALLQVATFKGWMDIMYAAVDSRDVKLQPVYEENLYMYLYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPANKFQGMVFDFVTRQVFDISIMILICLNMVTMMVETDDQGKYMTLVLSRINLVFIVLFTGEFVLKLVSLRHYYFTIGWNIFDFVVVILSIVGMFLAEMIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYAIFGMSNFAYVKKEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLAPILNSAPPDCDPDTIHPGSSVKGDCGNPSVGIFFFVSYIIISFLVVVNMYIAVILENFSVATEESAEPLSEDDFEMFYEVWEKFDPDATQFIEFSKLSDFAAALDPPLLIAKPNKVQLIAMDLPMVSGDRIHCLDILFAFTKRVLGESGEMDALRIQMEDRFMASNPSKVSYEPITTTLKRKQEEVSAAIIQRNFRCYLLKQRLKNISSNYNKEAIKGRIDLPIKQDMIIDKLNGNSTPEKTDGSSSTTSPPSYDSVTKPDKEKFEKDKPEKESKGKEVRENQK>sp|Q9NY46-4|SCN3A_HUMAN Isoform 4 of Sodium channel protein type 3subunit alpha OS=Homo sapiens OX=9606 GN=SCN3AMAQALLVPPGPESFRLFTRESLAAIEKRAAEEKAKKPKKEQDNDDENKPKPNSDLEAGKNLPFIYGDIPPEMVSEPLEDLDPYYINKKTFIVMNKGKAIFRFSATSALYILTPLNPVRKIAIKILVHSLFSMLIMCTILTNCVFMTLSNPPDWTKNVEYTFTGIYTFESLIKILARGFCLEDFTFLRDPWNWLDFSVIVMAYVTEFVDLGNVSALRTFRVLRALKTISVIPGLKTIVGALIQSVKKLSDVMILTVFCLSVFALIGLQLFMGNLRNKCLQWPPSDSAFETNTTSYFNGTMDSNGTFVNVTMSTFNWKDYIGDDSHFYVLDGQKDPLLCGNGSDAGQCPEGYICVKAGRNPNYGYTSFDTFSWAFLSLFRLMTQDYWENLYQLTLRAAGKTYMIFFVLVIFLGSFYLVNLILAVVAMAYEEQNQATLEEAEQKEAEFQQMLEQLKKQQEEAQAVAAASAASRDFSGIGGLGELLESSSEASKLSSKSAKEWRNRRKKRRQREHLEGNNKGERDSFPKSESEDSVKRSSFLFSMDGNRLTSDKKFCSPHQSLLSIRGSLFSPRRNSKTSIFSFRGRAKDVGSENDFADDEHSTFEDSESRRDSLFVPHRHGERRNSNGTTTETEVRKRRLSSYQISMEMLEDSSGRQRAVSIASILTNTMEELEESRQKCPPCWYRFANVFLIWDCCDAWLKVKHLVNLIVMDPFVDLAITICIVLNTLFMAMEHYPMTEQFSSVLTVGNLVFTGIFTAEMVLKIIAMDPYYYFQEGWNIFDGIIVSLSLMELGLSNVEGLSVLRSFRLLRVFKLAKSWPTLNMLIKIIGNSVGALGNLTLVLAIIVFIFAVVGMQLFGKSYKECVCKINDDCTLPRWHMNDFFHSFLIVFRVLCGEWIETMWDCMEVAGQTMCLIVFMLVMVIGNLVVLNLFLALLLSSFSSDNLAATDDDNEMNNLQIAVGRMQKGIDYVKNKMRECFQKAFFRKPKVIEIHEGNKIDSCMSNNTGIEISKELNYLRDGNGTTSGVGTGSSVEKYVIDENDYMSFINNPSLTVTVPIAVGESDFENLNTEEFSSESELEESKEKLNATSSSEGSTVDVVLPREGEQAETEPEEDLKPEACFTEGCIKKFPFCQVSTEEGKGKIWWNLRKTCYSIVEHNWFETFIVFMILLSSGALAFEDIYIEQRKTIKTMLEYADKVFTYIFILEMLLKWVAYGFQTYFTNAWCWLDFLIVDVSLVSLVANALGYSELGAIKSLRTLRALRPLRALSRFEGMRVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFYHCVNMTTGNMFDISDVNNLSDCQALGKQARWKNVKVNFDNVGAGYLALLQVATFKGWMDIMYAAVDSRDVKLQPVYEENLYMYLYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKFGGQDIFMTEEQKKYYNAMKKLGSKKPQKPIPRPANKFQGMVFDFVTRQVFDISIMILICLNMVTMMVETDDQGKYMTLVLSRINLVFIVLFTGEFVLKLVSLRHYYFTIGWNIFDFVVVILSIVGMFLAEMIEKYFVSPTLFRVIRLARIGRILRLIKGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYAIFGMSNFAYVKKEAGIDDMFNFETFGNSMICLFQITTSAGWDGLLAPILNSAPPDCDPDTIHPGSSVKGDCGNPSVGIFFFVSYIIISFLVVVNMYIAVILENFSVATEESAEPLSEDDFEMFYEVWEKFDPDATQFIEFSKLSDFAAALDPPLLIAKPNKVQLIAMDLPMVSGDRIHCLDILFAFTKRVLGESGEMDALRIQMEDRFMASNPSKVSYEPITTTLKRKQEEVSAAIIQRNFRCYLLKQRLKNISSNYNKEAIKGRIDLPIKQDMIIDKLNGNSTPEKTDGSSSTTSPPSYDSVTKPDKEKFEKDKPEKESKGKEVRENQK>sp|P48643|TCPE_HUMAN T-complex protein 1 subunit epsilon OS=Homo sapiensOX=9606 GN=CCT5 PE=1 SV=1MASMGTLAFDEYGRPFLIIKDQDRKSRLMGLEALKSHIMAAKAVANTMRTSLGPNGLDKMMVDKDGDVTVTNDGATILSMMDVDHQIAKLMVELSKSQDDEIGDGTTGVVVLAGALLEEAEQLLDRGIHPIRIADGYEQAARVAIEHLDKISDSVLVDIKDTEPLIQTAKTTLGSKVVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVGGRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGFDDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIEEAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMNPALGIDCLHKGTNDMKQQHVIETLIGKKQQISLATQMVRMILKIDDIRKPGESEE>sp|P48643-2|TCPE_HUMAN Isoform 2 of T-complex protein 1 subunit epsilonOS=Homo sapiens OX=9606 GN=CCT5MAAKAVANTMRTSLGPNVLAGALLEEAEQLLDRGIHPIRIADGYEQAARVAIEHLDKISDSVLVDIKDTEPLIQTAKTTLGSKVVNSCHRQMAEIAVNAVLTVADMERRDVDFELIKVEGKVGGRLEDTKLIKGVIVDKDFSHPQMPKKVEDAKIAILTCPFEPPKPKTKHKLDVTSVEDYKALQKYEKEKFEEMIQQIKETGANLAICQWGFDDEANHLLLQNNLPAVRWVGGPEIELIAIATGGRIVPRFSELTAEKLGFAGLVQEISFGTTKDKMLVIEQCKNSRAVTIFIRGGNKMIIEEAKRSLHDALCVIRNLIRDNRVVYGGGAAEISCALAVSQEADKCPTLEQYAMRAFADALEVIPMALSENSGMNPIQTMTEVRARQVKEMNPALGIDCLHKGTNDMKQQHVIETLIGKKQQISLATQMVRMILKIDDIRKPGESEE>sp|Q70HW3|SAMC_HUMAN S-adenosylmethionine mitochondrial carrier proteinOS=Homo sapiens OX=9606 GN=SLC25A26 PE=1 SV=2MDRPGFVAALVAGGVAGVSVDLILFPLDTIKTRLQSPQGFSKAGGFHGIYAGVPSAAIGSFPNAAAFFITYEYVKWFLHADSSSYLTPMKHMLAASAGEVVACLIRVPSEVVKQRAQVSASTRTFQIFSNILYEEGIQGLYRGYKSTVLREIPFSLVQFPLWESLKALWSWRQDHVVDSWQSAVCGAFAGGFAAAVTTPLDVAKTRITLAKAGSSTADGNVLSVLHGVWRSQGLAGLFAGVFPRMAAISLGGFIFLGAYDRTHSLLLEVGRKSP>sp|Q70HW3-2|SAMC_HUMAN Isoform 2 of S-adenosylmethionine mitochondrialcarrier protein OS=Homo sapiens OX=9606 GN=SLC25A26MKHMLAASAGEVVACLIRVPSEVVKQRAQVSASTRTFQIFSNILYEEGIQGLYRGYKSTVLREIPFSLVQFPLWESLKALWSWRQDHVVDSWQSAVCGAFAGGFAAAVTTPLDVAKTRITLAKAGSSTADGNVLSVLHGVWRSQGLAGLFAGVFPRMAAISLGGFIFLGAYDRTHSLLLEVGRKSP>sp|Q70HW3-3|SAMC_HUMAN Isoform 3 of S-adenosylmethionine mitochondrialcarrier protein OS=Homo sapiens OX=9606 GN=SLC25A26MKHMLAASAGEVVACLIRVPSEVVKQRAQVSASTRTFQIFSNILYEEGIQGLYRGYKSTVLREEED>sp|Q7Z3H4|SAMD7_HUMAN Sterile alpha motif domain-containing protein 7OS=Homo sapiens OX=9606 GN=SAMD7 PE=1 SV=1MAVNPLLTPTGQQTIPLIPSPFGPPTVDRDVLPSTVAPTDPRQFCVPSQFGSSVLPNTNMANVLSSRIYPGWGILPPESIKAVARRNEMIQRHHTARTEMEMYAIYQQRRMEKINPKGLAGLGIPFLYGSSVPAAPAAYHGRSMLPAGDLHFHRSTLRNLQGNPMLAATAPHFEESWGQRCRRLRKNTGNQKALDSDAESSKSQAEEKILGQTHAVPYEEDHYAKDPDIEAPSNQKSSETNEKPTTALANTCGELEPTHRKPWGSHTTTLKAKAWDDGKEEASEQIFATCDEKNGVCPPVPRPSLPGTHALVTIGGNLSLDEDIQKWTVDDVHSFIRSLPGCSDYAQVFKDHAIDGETLPLLTEEHLRGTMGLKLGPALKIQSQVSQHVGSMFYKKTLSFPIRQAFDQPADTSPLLDPNSWSDTMNIFCPQDTIIPKGIERGSMRN>sp|Q8WTV0|SCRB1_HUMAN Scavenger receptor class B member 1 OS=Homosapiens OX=9606 GN=SCARB1 PE=1 SV=1MGCSAKARWAAGALGVAGLLCAVLGAVMIVMVPSLIKQQVLKNVRIDPSSLSFNMWKEIPIPFYLSVYFFDVMNPSEILKGEKPQVRERGPYVYREFRHKSNITFNNNDTVSFLEYRTFQFQPSKSHGSESDYIVMPNILVLGAAVMMENKPMTLKLIMTLAFTTLGERAFMNRTVGEIMWGYKDPLVNLINKYFPGMFPFKDKFGLFAELNNSDSGLFTVFTGVQNISRIHLVDKWNGLSKVDFWHSDQCNMINGTSGQMWPPFMTPESSLEFYSPEACRSMKLMYKESGVFEGIPTYRFVAPKTLFANGSIYPPNEGFCPCLESGIQNVSTCRFSAPLFLSHPHFLNADPVLAEAVTGLHPNQEAHSLFLDIHPVTGIPMNCSVKLQLSLYMKSVAGIGQTGKIEPVVLPLLWFAESGAMEGETLHTFYTQLVLMPKVMHYAQYVLLALGCVLLLVPVICQIRSQVGAGQRAARADSHSLACWGKGASDRTLWPTAAWSPPPAAVLRLCRSGSGHCWGLRSTLASFACRVATTLPVLEGLGPSLGGGTGS>sp|Q8WTV0-2|SCRB1_HUMAN Isoform 1 of Scavenger receptor class B member 1OS=Homo sapiens OX=9606 GN=SCARB1MGCSAKARWAAGALGVAGLLCAVLGAVMIVMVPSLIKQQVLKNVRIDPSSLSFNMWKEIPIPFYLSVYFFDVMNPSEILKGEKPQVRERGPYVYREFRHKSNITFNNNDTVSFLEYRTFQFQPSKSHGSESDYIVMPNILVLGAAVMMENKPMTLKLIMTLAFTTLGERAFMNRTVGEIMWGYKDPLVNLINKYFPGMFPFKDKFGLFAELNNSDSGLFTVFTGVQNISRIHLVDKWNGLSKVDFWHSDQCNMINGTSGQMWPPFMTPESSLEFYSPEACRSMKLMYKESGVFEGIPTYRFVAPKTLFANGSIYPPNEGFCPCLESGIQNVSTCRFSAPLFLSHPHFLNADPVLAEAVTGLHPNQEAHSLFLDIHPVTGIPMNCSVKLQLSLYMKSVAGIGQTGKIEPVVLPLLWFAESGAMEGETLHTFYTQLVLMPKVMHYAQYVLLALGCVLLLVPVICQIRSQEKCYLFWSSSKKGSKDKEAIQAYSESLMTSAPKGSVLQEAKL>sp|Q8WTV0-3|SCRB1_HUMAN Isoform 2 of Scavenger receptor class B member 1OS=Homo sapiens OX=9606 GN=SCARB1MGCSAKARWAAGALGVAGLLCAVLGAVMIVMVPSLIKQQVLKGAAVMMENKPMTLKLIMTLAFTTLGERAFMNRTVGEIMWGYKDPLVNLINKYFPGMFPFKDKFGLFAELNNSDSGLFTVFTGVQNISRIHLVDKWNGLSKVDFWHSDQCNMINGTSGQMWPPFMTPESSLEFYSPEACRSMKLMYKESGVFEGIPTYRFVAPKTLFANGSIYPPNEGFCPCLESGIQNVSTCRFSAPLFLSHPHFLNADPVLAEAVTGLHPNQEAHSLFLDIHPVTGIPMNCSVKLQLSLYMKSVAGIGQTGKIEPVVLPLLWFAESGAMEGETLHTFYTQLVLMPKVMHYAQYVLLALGCVLLLVPVICQIRSQEKCYLFWSSSKKGSKDKEAIQAYSESLMTSAPKGSVLQEAKL>sp|Q8WTV0-4|SCRB1_HUMAN Isoform 4 of Scavenger receptor class B member 1OS=Homo sapiens OX=9606 GN=SCARB1MALQPSWNVRIDPSSLSFNMWKEIPIPFYLSVYFFDVMNPSEILKGEKPQVRERGPYVYREFRHKSNITFNNNDTVSFLEYRTFQFQPSKSHGSESDYIVMPNILVLGAAVMMENKPMTLKLIMTLAFTTLGERAFMNRTVGEIMWGYKDPLVNLINKYFPGMFPFKDKFGLFAELNNSDSGLFTVFTGVQNISRIHLVDKWNGLSKVDFWHSDQCNMINGTSGQMWPPFMTPESSLEFYSPEACRSMKLMYKESGVFEGIPTYRFVAPKTLFANGSIYPPNEGFCPCLESGIQNVSTCRFSAPLFLSHPHFLNADPVLAEAVTGLHPNQEAHSLFLDIHPVTGIPMNCSVKLQLSLYMKSVAGIGQTGKIEPVVLPLLWFAESGAMEGETLHTFYTQLVLMPKVMHYAQYVLLALGCVLLLVPVICQIRSQEKCYLFWSSSKKGSKDKEAIQAYSESLMTSAPKGSVLQEAKL>sp|Q8WTV0-5|SCRB1_HUMAN Isoform 5 of Scavenger receptor class B member 1OS=Homo sapiens OX=9606 GN=SCARB1MGCSAKARWAAGALGVAGLLCAVLGAVMIVMVPSLIKQQVLKNVRIDPSSLSFNMWKEIPIPFYLSVYFFDVMNPSEILKGEKPQVRERGPYVYREFRHKSNITFNNNDTVSFLEYRTFQFQPSKSHGSESDYIVMPNILVLGAAVMMENKPMTLKLIMTLAFTTLGERAFMNRTVGEIMWGYKDPLVNLINKYFPGMFPFKDKFGLFAELNNSDSGLFTVFTGVQNISRIHLVDKWNGLSKVDFWHSDQCNMINGTSGQMWPPFMTPESSLEFYSPEACRSMKLMYKESGVFEGIPTYRFVAPKTLFANGSIYPPNEGFCPCLESGIQNVSTCRFSAPLFLSHPHFLNADPVLAEAVTGLHPNQEAHSLFLDIHPVTGIPMNCSVKLQLSLYMKSVAGIGQTGKIEPVVLPLLWFAESGAMEGETLHTFYTQLVLMPKVMHYAQYVLLALGCVLLLVPVICQIRSQGPEDTVSQPGLAAGPDRPPSPYTPLLPDSPSGQPPSPTA>sp|Q8N357|S35F6_HUMAN Solute carrier family 35 member F6 OS=Homo sapiensOX=9606 GN=SLC35F6 PE=1 SV=1MAWTKYQLFLAGLMLVTGSINTLSAKWADNFMAEGCGGSKEHSFQHPFLQAVGMFLGEFSCLAAFYLLRCRAAGQSDSSVDPQQPFNPLLFLPPALCDMTGTSLMYVALNMTSASSFQMLRGAVIIFTGLFSVAFLGRRLVLSQWLGILATIAGLVVVGLADLLSKHDSQHKLSEVITGDLLIIMAQIIVAIQMVLEEKFVYKHNVHPLRAVGTEGLFGFVILSLLLVPMYYIPAGSFSGNPRGTLEDALDAFCQVGQQPLIAVALLGNISSIAFFNFAGISVTKELSATTRMVLDSLRTVVIWALSLALGWEAFHALQILGFLILLIGTALYNGLHRPLLGRLSRGRPLAEESEQERLLGGTRTPINDAS>sp|Q6ICL7|S35E4_HUMAN Solute carrier family 35 member E4 OS=Homo sapiensOX=9606 GN=SLC35E4 PE=1 SV=1MCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWIFTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHHPLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQSALLQEERLDAVTLLYATSLPSFCLLAGAALVLEAGVAPPPTAGDSRLWACILLSCLLSVLYNLASFSLLALTSALTVHVLGNLTVVGNLILSRLLFGSRLSALSYVGIALTLSGMFLYHNCEFVASWAARRGLWRRDQPSKGL>sp|Q6ICL7-2|S35E4_HUMAN Isoform 2 of Solute carrier family 35 member E4OS=Homo sapiens OX=9606 GN=SLC35E4MCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWIFTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHHPLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQSLSFQICKMELMIPMERVRMRSAGQGQE>sp|P50443|S26A2_HUMAN Sulfate transporter OS=Homo sapiens OX=9606GN=SLC26A2 PE=1 SV=2MSSESKEQHNVSPRDSAEGNDSYPSGIHLELQRESSTDFKQFETNDQCRPYHRILIERQEKSDTNFKEFVIKKLQKNCQCSPAKAKNMILGFLPVLQWLPKYDLKKNILGDVMSGLIVGILLVPQSIAYSLLAGQEPVYGLYTSFFASIIYFLLGTSRHISVGIFGVLCLMIGETVDRELQKAGYDNAHSAPSLGMVSNGSTLLNHTSDRICDKSCYAIMVGSTVTFIAGVYQVAMGFFQVGFVSVYLSDALLSGFVTGASFTILTSQAKYLLGLNLPRTNGVGSLITTWIHVFRNIHKTNLCDLITSLLCLLVLLPTKELNEHFKSKLKAPIPIELVVVVAATLASHFGKLHENYNSSIAGHIPTGFMPPKVPEWNLIPSVAVDAIAISIIGFAITVSLSEMFAKKHGYTVKANQEMYAIGFCNIIPSFFHCFTTSAALAKTLVKESTGCHTQLSGVVTALVLLLVLLVIAPLFYSLQKSVLGVITIVNLRGALRKFRDLPKMWSISRMDTVIWFVTMLSSALLSTEIGLLVGVCFSIFCVILRTQKPKSSLLGLVEESEVFESVSAYKNLQIKPGIKIFRFVAPLYYINKECFKSALYKQTVNPILIKVAWKKAAKRKIKEKVVTLGGIQDEMSVQLSHDPLELHTIVIDCSAIQFLDTAGIHTLKEVRRDYEAIGIQVLLAQCNPTVRDSLTNGEYCKKEEENLLFYSVYEAMAFAEVSKNQKGVCVPNGLSLSSD>sp|Q8IUW3|SPA2L_HUMAN Spermatogenesis-associated protein 2-like proteinOS=Homo sapiens OX=9606 GN=SPATA2L PE=1 SV=1MGSSSLSEDYRQCLERELRRGRAGVCGDPSLRAVLWQILVEDFDLHGALQDDALALLTDGLWGRADLAPALRGLARAFELLELAAVHLYLLPWRKEFTTIKTFSGGYVHVLKGVLSDDLLLKSFQKMGYVRRDSHRLMVTALPPACQLVQVALGCFALRLECEILGEVLAQLGTSVLPAEELLQARRASGDVASCVAWLQQRLAQDEEPPPLPPRGSPAAYRAPLDLYRDLQEDEGSEDASLYGEPSPGPDSPPAELAYRPPLWEQSAKLWGTGGRAWEPPAEELPQASSPPYGALEEGLEPEPSAFSFLSLRRELSRPGDLATPESSAAASPRRIRAEGVPASAYRSVSEPPGYQAHSCLSPGALPTLCCDTCRQLHAAHCAALPACRPGHSLRVLLGDAQRRLWLQRAQMDTLLYNSPGARP>sp|Q8IUW3-2|SPA2L_HUMAN Isoform 2 of Spermatogenesis-associated protein2-like protein OS=Homo sapiens OX=9606 GN=SPATA2LMGSSSLSEDYRQCLERELRRGRAGVCGDPSLRAVLWQILVEDFDLHGALQDDALALLTDGLWGRADLAPALRGLARAFELLELAAVHLYLLPWRKEFTTIKTFSGGYVHVLKGVLSDDLLLKSFQKMGYVRRDSHRLMLCWSQSAGLCRVHG>sp|Q3SY56|SP6_HUMAN Transcription factor Sp6 OS=Homo sapiens OX=9606GN=SP6 PE=1 SV=1MLTAVCGSLGSQHTEAPHASPPRLDLQPLQTYQGHTSPEAGDYPSPLQPGELQSLPLGPEVDFSQGYELPGASSRVTCEDLESDSPLAPGPFSKLLQPDMSHHYESWFRPTHPGAEDGSWWDLHPGTSWMDLPHTQGALTSPGHPGALQAGLGGYVGDHQLCAPPPHPHAHHLLPAAGGQHLLGPPDGAKALEVAAPESQGLDSSLDGAARPKGSRRSVPRSSGQTVCRCPNCLEAERLGAPCGPDGGKKKHLHNCHIPGCGKAYAKTSHLKAHLRWHSGDRPFVCNWLFCGKRFTRSDELQRHLQTHTGTKKFPCAVCSRVFMRSDHLAKHMKTHEGAKEEAAGAASGEGKAGGAVEPPGGKGKREAEGSVAPSN>sp|P32745|SSR3_HUMAN Somatostatin receptor type 3 OS=Homo sapiensOX=9606 GN=SSTR3 PE=1 SV=1MDMLHPSSVSTTSEPENASSAWPPDATLGNVSAGPSPAGLAVSGVLIPLVYLVVCVVGLLGNSLVIYVVLRHTASPSVTNVYILNLALADELFMLGLPFLAAQNALSYWPFGSLMCRLVMAVDGINQFTSIFCLTVMSVDRYLAVVHPTRSARWRTAPVARTVSAAVWVASAVVVLPVVVFSGVPRGMSTCHMQWPEPAAAWRAGFIIYTAALGFFGPLLVICLCYLLIVVKVRSAGRRVWAPSCQRRRRSERRVTRMVVAVVALFVLCWMPFYVLNIVNVVCPLPEEPAFFGLYFLVVALPYANSCANPILYGFLSYRFKQGFRRVLLRPSRRVRSQEPTVGPPEKTEEEDEEEEDGEESREGGKGKEMNGRVSQITQPGTSGQERPPSRVASKEQQLLPQEASTGEKSSTMRISYL>sp|Q8IW70|T151B_HUMAN Transmembrane protein 151B OS=Homo sapiens OX=9606GN=TMEM151B PE=2 SV=2MSPPGSAAGESAAGGGGGGGGPGVSEELTAAAAAAAADEGPAREEQRPIQPSFTKSLCRESHWKCLLLSLLMYGCLGAVAWCHVTTVTRLTFSSAYQGNSLMYHDSPCSNGYVYIPLAFLLMLYAVYLVECWHCQARHELQHRVDVSSVRERVGRMQQATPCIWWKAISYHYVRRTRQVTRYRNGDAYTTTQVYHERVNTHVAEAEFDYARCGVRDVSKTLVGLEGAPATRLRFTKCFSFASVEAENAYLCQRARFFAENEGLDDYMEAREGMHLKNVDFREFMVAFPDPARPPWYACSSAFWAAALLTLSWPLRVLAEYRTAYAHYHVEKLFGLEGPGSASSAGGGLSPSDELLPPLTHRLPRVNTVDSTELEWHIRSNQQLVPSYSEAVLMDLAGLGTRCGGAGGGYAPSCRYGGVGGPGAAGVAPYRRSCEHCQRAVSSSSIFSRSALSICASPRAGPGPGGGAGCGGSRFSLGRLYGSRRSCLWRSRSGSVNEASCPTEQTRLSSQASMGDDEDDDEEEAGPPPPYHDALYFPVLIVHRQEGCLGHSHRPLHRHGSCVETSL>sp|Q8IW70-2|T151B_HUMAN Isoform 2 of Transmembrane protein 151B OS=Homosapiens OX=9606 GN=TMEM151BMSPPGSAAGESAAGGGGGGGGPGVSEELTAAAAAAAADEGPAREEQRPIQPSFTKSLCRESHWKCLLLSLLMYGCLGAVAWCHVTTVTRLTFSSAYQGNSLMYHDSPCSNGYVYIPLAFLLMLYAVYLVECWHCQARHELQHRVDVSSVRERVGRMQQATPCIWWKAISYHYVRRTRQVTRYRNGDAYTTTQVPGCLGSQVVPLRSPWRNAQLDAGSDEEPA>sp|Q3SY00|T10IP_HUMAN Testis-specific protein 10-interacting proteinOS=Homo sapiens OX=9606 GN=TSGA10IP PE=1 SV=2MGQDTDMLNTYQQLVRTPSVRPGQDVRLQAPGTRTGLLKLLSTVSQDKQGCLGSGDGVPNQDLQQRSQSSRQTAKKDRKPRGQSKKGQGSEESEDHFPLLPRKPSFPFQWAWESIATDVRAVLQPSSPTPGHQALPMPSSFSQRQSRRKSTANLPEAHGCCWKTEAQNLKARQQLGAWGGVSIPTGKGELGSEPPSGLQLPGRRPGSGSASDKQVQLQSLGAEEAERGLSSGVLPQRPRRGSISEEEQFSEATEEAEEGEHRTPCRRRAGCQRKGQISGEEASDEGEVQGQSQGSSPSFNNLRRRQWRKTRAKELQGPWDLEKLHRQLQRDLDCGPQKLPWKTLRAAFQASKRNGKAYASGYDETFVSANLPNRTFHKRQEATRSLLQAWERQRQEERQQAELRRARTQHVQRQVAHCLAAYAPRGSRGPGAAQRKLEELRRQERQRFAEYQAELQGIQHRVQARPFLFQQAMQANARLTVTRRFSQVLSALGLDEEQLLSEAGKVDREGTPRKPRSHRSMGVRMEHSPQRPPRTEPTGSQPDRHYNPSLDPECSP>sp|Q3SY00-2|T10IP_HUMAN Isoform 2 of Testis-specific protein 10-interacting protein OS=Homo sapiens OX=9606 GN=TSGA10IPMGQDTDMLNTYQQLVRTPSVRPGQDVRLQAPGTRTGLLKLLSTVSQDKQGCLGSGDGVPNQDLQQRSQSSRQTAKKDRKPRGQSKKGQGSEESEDHFPLLPRKPSFPFQWAWESIATDVRAVLQPSSPTPGHQALPMPSSFSQRQSRRKSTANLPEAHGCCWKTEAQNLKARQQLGAWGGVSIPTGKGELGSEPPSGLQLPGRRPGSGSASDKQVQLQSLGAEEAERGLSSGVLPQRPRRGSISEEEQFSEATEEAEEGEHRTPCRRRAGCQRKGQISGEEASDEGEVQGQSQGSSPSFNNLRRRQWRKTRAKELQGPWDLEKLHRQLQRDLDCGSHQEPAAGLGAAAAGGAAAGRAAAGPDTACTAAGGPLPGSLRTQREPGPWGGPAQAGGAEAPGATALC>sp|Q14C87|T132D_HUMAN Transmembrane protein 132D OS=Homo sapiens OX=9606GN=TMEM132D PE=1 SV=1MCPSEMGTLWHHWSPVLISLAALFSKVTEGRGILESIQRFSLLPTYLPVTYHINNADVSFFLKEANQDIMRNSSLQSRVESFLIYKSRRLPVLNASYGPFSIEQVVPQDLMLPSNPFGFTNKFSLNWKLKAHILRDKVYLSRPKVQVLFHIMGRDWDDRSAGEKLPCLRVFAFRETREVRGSCRLQGDLGLCVAELELLSSWFSPPTVVAGRRKSVDQPEGTPVELYYTVHPGGERGDCVREDARRSNGIRTGHSDIDESGPPLQRIGSIFLYQTHRKPSLRELRLDNSVAIHYIPKTVRKGDVLTFPVSISRNSTEDRFTLRAKVKKGVNIIGVRASSPSIWDVKERTDYTGKYAPAVIVCQKKAAGSENSADGASYEVMQIDVEVEEPGDLPATQLVTWQVEYPGEITSDLGVSKIYVSPKDLIGVVPLAMEAEILNTAILTGKTVAVPVKVVSVEDDGTVTELLESVECRSSDEDVIKVSDRCDYVFVNGKEMKGKVNVVVNFTYQHLSSPLEMTVWVPRLPLQIEVSDTELNQIKGWRVPIVSSRRPAGDSEEEEDDERRGRGCTLQYQHAMVRVLTQFVAEAAGPGGHLAHLLGSDWQVDITELINDFMQVEEPRIAKLQGGQILMGQELGMTTIQILSPLSDTILAEKTITVLDEKVTITDLGVQLVTGLSLSLQLSPGSNRAIFATAVAQELLQRPKQEAAISCWVQFSDGSVTPLDIYDGKDFSLMATSLDEKVVSIHQDPKFKWPIIAAETEGQGTLVKVEMVISESCQKSKRKSVLAVGTANIKVKFGQNDANPNTSDSRHTGAGVHMENNVSDRRPKKPSQEWGSQEGQYYGSSSMGLMEGRGTTTDRSILQKKKGQESLLDDNSHLQTIPSDLTSFPAQVDLPRSNGEMDGNDLMQASKGLSDLEIGMYALLGVFCLAILVFLINCVTFALKYRHKQVPFEEQEGMSHSHDWVGLSNRTELLENHINFASSQDEQITAIDRGMDFEESKYLLSTNSQKSINGQLFKPLGPIIIDGKDQKSEPPTSPTSKRKRVKFTTFTAVSSDDEYPTRNSIVMSSEDDIKWVCQDLDPGDCKELHNYMERLHENV>sp|Q14C87-2|T132D_HUMAN Isoform 2 of Transmembrane protein 132D OS=Homosapiens OX=9606 GN=TMEM132DMQRDESSPFPPLFSLTSSQVSDRCDYVFVNGKEMKGKVNVVVNFTYQHLSSPLEMTVWVPRLPLQIEVSDTELNQIKGWRVPIVSSRRPAGDSEEEEDDERRGRGCTLQYQHAMVRVLTQFVAEAAGPGGHLAHLLGSDWQVDITELINDFMQVEEPRIAKLQGGQILMGQELGMTTIQILSPLSDTILAEKTITVLDEKVTITDLGVQLVTGLSLSLQLSPGSNRAIFATAVAQELLQRPKQEAAISCWVQFSDGSVTPLDIYDGKDFSLMATSLDEKVVSIHQDPKFKWPIIAAETEGQGTLVKVEMVISESCQKSKRKSVLAVGTANIKVKFGQNDANPNTSDSRHTGAGVHMENNVSDRRPKKPSQEWGSQEGQYYGSSSMGLMEGRGTTTDRSILQKKKGQESLLDDNSHLQTIPSDLTSFPAQVDLPRSNGEMDGNDLMQASKGLSDLEIGMYALLGVFCLAILVFLINCVTFALKYRHKQVPFEEQEGMSHSHDWVGLSNRTELLENHINFASSQDEQITAIDRGMDFEESKYLLSTNSQKSINGQLFKPLGPIIIDGKDQKSEPPTSPTSKRKRVKFTTFTAVSSDDEYPTRNSIVMSSEDDIKWVCQDLDPGDCKELHNYMERLHENV>sp|Q5T011|SZT2_HUMAN KICSTOR complex protein SZT2 OS=Homo sapiensOX=9606 GN=SZT2 PE=1 SV=3MASERPEPEVEEAGQVFLLMKKDYRISRNVRLAWFLSHLHQTVQATPQEMLLQSEQELEVLSVLPPGWQPDEPVVPRPFLLVPSTRVTFLAWQYRFVIELDLSPSTGIVDDSTGEILFDEVFHALSRCLGGLLRPFRVPGSCIDFQPEIYVTIQAYSSIIGLQSHQVLVQGCLLDPSQREVFLQQIYEQLCLFEDKVATMLQQQYDPQSQAEDQSPDSGDLLGRKVGVSMVTADLGLVSMIRQGILALQLLPSNSSAGIIVITDGVTSVPDVAVCETLLNQLRSGTVACSFVQVGGVYSYDCSFGHVPNVELMKFIAMATFGSYLSTCPEPEPGNLGLTVYHRAFLLYSFLRSGEALNPEYYCGSQHRLFNEHLVSASSNPALALRRKKHTEKEVPADLVSTVSVRLREGYSVREVTLAKGGSQLEVKLVLLWKHNMRIEYVAMAPWPLEPEGPRVTRVEVTMEGGYDILHDVSCALRQPIRSLYRTHVIRRFWNTLQSINQTDQMLAHLQSFSSVPEHFTLPDSTKSGVPLFYIPPGSTTPVLSLQPSGSDSSHAQFAAYWKPVLSMDANSWQRWLHMHRLVLILEHDTPIPKHLHTPGSNGRYSTIQCRISHSSLTSLLRDWSSFVLVEGYSYVKLLSSAPDQPPNSFYMVRIISKAPCMVLRLGFPIGTPAPARHKIVSGLREEILRLRFPHRVQSKEPTPKVKRKGLGGAGGGSSPSKSPPVLGPQQALSDRPCLVVLHKPLDKLLIRYEKLPLDYRAPFLLTLEPPGPLPLVSGRSASSSLASLSRYLYHQRWLWSVPSGLAPALPLSAIAQLLSILTEVRLSEGFHFACSGEGIINMVLELPIQNEPPGQAAAEEKHTCVVQYILFPPHSTSTKDSFSTDDDNDVEVEALEGDSELNLVTEVWVEPQYGRVGPGPGIWKHLQDLTYSEIPQALHPRDAACIGSMLSFEYLIQLCQSKEWGPLPPEPRVSDGLDQGGDTCVHEIPFHFDLMGLLPQCQQLQMFFLLLAREPEGVPFAEGSCPANDMVLCLLHSCLGQELSDREIPLTPVDQAAFLSEVLRRTCHVPGAEGPLLGVHGIPKEQAVGSTQATGDSAFTSLSVGLPETLKPLISAQPPQWRCYARLVNPQHVFLTFLPATFSDVQRLAACGLEGPPQEETKPKFGDWSGAPSLKDLGGTGIKATKSHVPVLSVTLASDNAQNQGELSPPFRRDLQAYAGRQASQTESADGPRTRCPVYIYSCSLEALREQMVGMQPPQAPRDLIFRTQFLDHPSPSSAWMEPRYKEAANHCALLQEHAQRCYVRGLFRSLQQAQSVTSQDLLTAVDACEELLQEIDITPFLLALCGHTWGLPHAPPSPGPLSPGPFSSSMEEGAEPRERAILASESSIETEDLSEPEFQSTRVPGIPDPGPEISLTDVCQLRGEAHGALHSVIQEKFLEISRLHFRTVPSNPHYFFYCPPSSRREDEGPRDTVDRKISDLEFSEAELMGEEGDTSACCVVTESDPELEVEYRESRESDLGPAGLDSASLSDVDTVNPDEDSFSILGGDSPTGPESFLHDLPPLFLHLTCSVRLRGQHSSVPVCSLPTCLGQVLSSLEGPPVGGRVPLRDLSVTLDVFMLTLPLEVELPTASDPQHHRSTSESSASFPRSPGQPSSLRSDDGLGPPLPPPEEERHPGLSNLATPHRLAIETTMNEIRWLLEDEMVGALRRGGIPQSPALHRAAAHIHSSPGRSTCLRQTLPLSFVFGPERSLTQFKEEFRRLHLPGHVLLEDPDSGFFFVAAGQQPGGSHGEPSSAAWAWHSHEDRAEGIEGETLTASPQAPGSPEDSEGVPLISLPRVPQGGSQPGPSRGLSLMSSQGSVDSDHLGYDGGSSGSDSEGPNDTLGEKAPFTLRTPPGPAPPQPSLSGLPGPCLPDFWLIVRVLQDRVEVYAHARSLIREDGGPGTECRHLQQLLVRRVGEICREVNQRLLLQDLHDSHVCNSLLVAESEEDLWRSETPFHSRQRAPLPSDDYAADESCAPRGYLAATMQFVPGHFSCDVVWGTVIRVHSRLKMGPSMGVSRAIQALRSVLNAFSVVNRKNMFVYQERATKAVYYLRLLETSCSDRPWKGDALPPSLALSRSQEPIYSEEASGPRSPLDMVSSRSSDAARPVGQVDRHIQLLVHGVGQAGPEITDELVRVLCRRLDEATLDVITVMLVRNCKLTPADVEFIQPPGSLPSEVLHLALPTSCRPWLPALAWYLRQNLLIFLHSPKYTDSNSRNHFQHPLPPQGGLPDLDIYLYNKPGGQGTGGKGVACITLAFVDEGGAPLSLALWPPSSPGPPDPLREEEFEQLTQVIRCPVVVDSSSAQNGAPRLRLDVWEKGNISIVQLEEKLRGAARQALADAIIELQLLPASLCTEDTPTGSLRNGSLETKSSAGRASTFPPAPVPGEPVTPPSKAGRRSFWDMLSKTECGDLGSPKTTDDIVLDRPEDTRGRRRHKTESVRTPGGAERAPGSDSGAQRQKRRTTQLEEGEVGTLHPVFARVAQRWMEFMVQIGCASVSRSSAHMVSRFLLPSILSEFTALVTSMAGDTSVRIFEQHLGSEPEIFGPCSPGQLGPSPRPAAERHLLLLGRNFLQWRRPTQQAAKAMQRFEPGGDGSSGRNAPRQRLLLLEVVDKKLQLLTYNWAPDLGAALGRALVRLVQWQNARAHLIFCLLSQKLGLFHHYGQLDFPVRDEKEPNPFLLPTMEVETLIRSASPPLSREQGRLSGSSRGGGPLPLDTFPFDEALRDITAARPSSVLGPVPRPPDPVTYHGQQFLEIKMAERRELERQMKMENLFVTWQQRSTPATMPISAGELETLKQSSRLVHYCATAMLFDPAAWLHGPPETSGPPDGQRRHRPESGSGSREAPTSCESLDVSPPGAREEPWLKELSLAFLQQYVQYLQSIGFVLVPLRPPSPARSTSRPRAMAILGTEGRGSFSCPKTKTDGSPKSTSSPVTTYHLQRALPGGIILMELAFQGCYFCVKQFALECSRIPMGQAVNSQLSMLFTEECDKVRDLMHVHSFSYDFHLRLVHQHVLGAHLVLRHGYHLTTFLRHFLAHHPDGPHFGRNHIYQGTLELPTPLIAAHQLYNYVADHASSYHMKPLRMARPGGPEHNEYALVSAWHSSGSYLDSEGLRHQDDFDVSLLVCHCAAPFEEQGEAERHVLRLQFFVVLTSQRELFPRLTADMRRFRKPPRLPPEPEAPGSSAGSPGEASGLILAPGPAPLFPPLAAEVGMARARLAQLVRLAGGHCRRDTLWKRLFLLEPPGPDRLRLGGRLALAELEELLEAVHAKSIGDIDPQLDCFLSMTVSWYQSLIKVLLSRFPQSCRHFQSPDLGTQYLVVLNQKFTDCFVLVFLDSHLGKTSLTVVFREPFPVQPQDSESPPAQLVSTYHHLESVINTACFTLWTRLL>sp|Q5T011-4|SZT2_HUMAN Isoform 2 of KICSTOR complex protein SZT2 OS=Homosapiens OX=9606 GN=SZT2MASERPEPEVEEAGQVFLLMKKDYRISRNVRLAWFLSHLHQTVQATPQEMLLQSEQELEVLSVLPPGWQPDEPVVPRPFLLVPSTRVTFLAWQYRFVIELDLSPSTGIVDDSTGEILFDEVFHALSRCLGGLLRPFRVPGSCIDFQPEIYVTIQAYSSIIGLQSHQVLVQGCLLDPSQREVFLQQIYEQLCLFEDKVATMLQQQYDPQSQAEDQSPDSGDLLGRKVGVSMVTADLGLVSMIRQGILALQLLPSNSSAGIIVITDGVTSVPDVAVCETLLNQLRSGTVACSFVQVGGVYSYDCSFGHVPNVELMKFIAMATFGSYLSTCPEPEPGNLGLTVYHRAFLLYSFLRSGEALNPEYYCGSQHRLFNEHLVSASSNPALALRRKKHTEKEVPADLVSTVSVRLREGYSVREVTLAKGGSQLEVKLVLLWKHNMRIEYVAMAPWPLEPEGPRVTRVEVTMEGGYDILHDVSCALRQPIRSLYRTHVIRRFWNTLQSINQTDQMLAHLQSFSSVPEHFTLPDSTKSGVPLFYIPPGSTTPVLSLQPSGSDSSHAQFAAYWKPVLSMDANSWQRWLHMHRLVLILEHDTPIPKHLHTPGSNGRYSTIQCRISHSSLTSLLRDWSSFVLVEGYSYVKLLSSAPDQPPNSFYMVRIISKAPCMVLRLGFPIGTPAPARHKIVSGLREEILRLRFPHRVQSKEPTPKVKRKGLGGAGGGSSPSKSPPVLGPQQALSDRPCLVVLHKPLDKLLIRYEKLPLDYRAPFLLTLEPPGPLPLVSGRSASSSLASLSRYLYHQRWLWSVPSGLAPALPLSAIAQLLSILTEVRLSEGFHFACSGEGIINMVLELPIQNEPPGQAAAEEKHTCVVQYILFPPHSTSTKDSFSTDDDNDVEVEALEGDSELNLVTEVWVEPQYGRVGPGPGIWKHLQDLTYSEIPQALHPRDAACIGSMLSFEYLIQLCQSKEWGPLPPEPRVSDGLDQGGDTCVHEIPFHFDLMGLLPQCQQLQMFFLLLARAAWGRS>sp|Q5T011-5|SZT2_HUMAN Isoform 3 of KICSTOR complex protein SZT2 OS=Homosapiens OX=9606 GN=SZT2MASERPEPEVEEAGQVFLLMKKDYRISRNVRLAWFLSHLHQTVQATPQEMLLQSEQELEVLSVLPPGWQPDEPVVPRPFLLVPSTRVTFLAWQYRFVIELDLSPSTGIVDDSTGEILFDEVFHALSRCLGGLLRPFRVPGSCIDFQPEIYVTIQAYSSIIGLQSHQVLVQGCLLDPSQREVFLQQIYEQLCLFEDKVATMLQQQYDPQSQAEDQSPDSGDLLGRKVGVSMVTADLGLVSMIRQGILALQLLPSNSSAGIIVITDGVTSVPDVAVCETLLNQLRSGTVACSFVQVGGVYSYDCSFGHVPNVELMKFIAMATFGSYLSTCPEPEPGNLGLTVYHRAFLLYSFLRSGEALNPEYYCGSQHRLFNEHLVSASSNPALALRRKKHTEKEVPADLVSTVSVRLREGYSVREVTLAKGGSQLEVKLVLLWKHNMRIEYVAMAPWPLEPEGPRVTRVEVTMEGGYDILHDVSCALRQPIRSLYRTHVIRRFWNTLQSINQTDQMLAHLQSFSSVPEHFTLPDSTKSGVPLFYIPPGSTTPVLSLQPSGSDSSHAQFAAYWKPVLSMDANSWQRWLHMHRLVLILEHDTPIPKHLHTPGSNGRYSTIQCRISHSSLTSLLRDWSSFVLVEGYSYVKLLSSAPDQPPNSFYMVRIISKAPCMVLRLGFPIGTPAPARHKIVSGLREEILRLRFPHRVQSKEPTPKVKRKGLGGAGGGSSPSKSPPVLGPQQALSDRPCLVVLHKPLDKLLIRYEKLPLDYRAPFLLTLEPPGPLPLVSGRSASSSLASLSRYLYHQRWLWSVPSGLAPALPLSAIAQLLSILTEVRLSEGFHFACSGEGIINMVLELPIQNEPPGQAAAEEKHTCVVQYILFPPHSTSTKDSFSTDDDNDVEVEALEGDSELNLVTEVWVEPQYGRVGPGPGIWKHLQDLTYSEIPQALHPRDAACIGSMLSFEYLIQLCQSKEWGPLPPEPRVSDGLDQGGDTCVHEIPFHFDLMGLLPQCQQLQMFFLLLARGAEGPLLGVHGIPKEQAVGSTQATGDSAFTSLSVGLPETLKPLISAQPPQWRCYARLVNPQHVFLTFLPATFSDVQRLAACGLEGPPQEETKPKFGDWSGAPSLKDLGGTGIKATKSHVPVLSVTLASDNAQNQGELSPPFRRDLQAYAGRQASQTESADGPRTRCPVYIYSCSLEALREQMVGMQPPQAPRDLIFRTQFLDHPSPSSAWMEPRYKEAANHCALLQEHAQRCYVRGLFRSLQQAQSVTSQDLLTAVDACEELLQEIDITPFLLALCGHTWGLPHAPPSPGPLSPGPFSSSMEEGAEPRERAILASESSIETEDLSEPEFQSTRVPGIPDPGPEISLTDVCQLRGEAHGALHSVIQEKFLEISRLHFRTVPSNPHYFFYCPPSSRREDEGPRDTVDRKISDLEFSEAELMGEEGDTSACCVVTESDPELEVEYRESRESDLGPAGLDSASLSDVDTVNPDEDSFSILGGDSPTGPESFLHDLPPLFLHLTCSVRLRGQHSSVPVCSLPTCLGQVLSSLEGPPVGGRVPLRDLSVTLDVFMLTLPLEVELPTASDPQHHRSTSESSASFPRSPGQPSSLRSDDGLGPPLPPPEEERHPGLSNLATPHRLAIETTMNEIRWLLEDEMVGALRRGGIPQSPALHRAAAHIHSSPGRSTCLRQTLPLSFVFGPERSLTQFKEEFRRLHLPGHVLLEDPDSGFFFVAAGQQPGGSHGEPSSAAWAWHSHEDRAEGIEGETLTASPQAPGSPEDSEGVPLISLPRVPQGGSQPGPSRGLSLMSSQGSVDSDHLGYDGGSSGSDSEGPNDTLGEKAPFTLRTPPGPAPPQPSLSGLPGPCLPDFWLIVRVLQDRVEVYAHARSLIREDGGPGTECRHLQQLLVRRVGEICREVNQRLLLQDLHDSHVCNSLLVAESEEDLWRSETPFHSRQRAPLPSDDYAADESCAPRGYLAATMQFVPGHFSCDVVWGTVIRVHSRLKMGPSMGVSRAIQALRSVLNAFSVVNRKNMFVYQERATKAVYYLRLLETSCSDRPWKGDALPPSLALSRSQEPIYSEEASGPRSPLDMVSSRSSDAARPVGQVDRHIQLLVHGVGQAGPEITDELVRVLCRRLDEATLDVITVMLVRNCKLTPADVEFIQPPGSLPSEVLHLALPTSCRPWLPALAWYLRQNLLIFLHSPKYTDSNSRNHFQHPLPPQGGLPDLDIYLYNKPGGQGTGGKGVACITLAFVDEGGAPLSLALWPPSSPGPPDPLREEEFEQLTQVIRCPVVVDSSSAQNGAPRLRLDVWEKGNISIVQLEEKLRGAARQALADAIIELQLLPASLCTEDTPTGSLRNGSLETKSSAGRASTFPPAPVPGEPVTPPSKAGRRSFWDMLSKTECGDLGSPKTTDDIVLDRPEDTRGRRRHKTESVRTPGGAERAPGSDSGAQRQKRRTTQLEEGEVGTLHPVFARVAQRWMEFMVQIGCASVSRSSAHMVSRFLLPSILSEFTALVTSMAGDTSVRIFEQHLGSEPEIFGPCSPGQLGPSPRPAAERHLLLLGRNFLQWRRPTQQAAKAMQRFEPGGDGSSGRNAPRQRLLLLEVVDKKLQLLTYNWAPDLGAALGRALVRLVQWQNARAHLIFCLLSQKLGLFHHYGQLDFPVRDEKEPNPFLLPTMEVETLIRSASPPLSREQGRLSGSSRGGGPLPLDTFPFDEALRDITAARPSSVLGPVPRPPDPVTYHGQQFLEIKMAERRELERQMKMENLFVTWQQRSTPATMPISAGELETLKQSSRLVHYCATAMLFDPAAWLHGPPETSGPPDGQRRHRPESGSGSREAPTSCESLDVSPPGAREEPWLKELSLAFLQQYVQYLQSIGFVLVPLRPPSPARSTSRPRAMAILGTEGRGSFSCPKTKTDGSPKSTSSPVTTYHLQRALPGGIILMELAFQGCYFCVKQFALECSRIPMGQAVNSQLSMLFTEECDKVRDLMHVHSFSYDFHLRLVHQHVLGAHLVLRHGYHLTTFLRHFLAHHPDGPHFGRNHIYQGTLELPTPLIAAHQLYNYVADHASSYHMKPLRMARPGGPEHNEYALVSAWHSSGSYLDSEGLRHQDDFDVSLLVCHCAAPFEEQGEAERHVLRLQFFVVLTSQRELFPRLTADMRRFRKPPRLPPEPEAPGSSAGSPGEASGLILAPGPAPLFPPLAAEVGMARARLAQLVRLAGGHCRRDTLWKRLFLLEPPGPDRLRLGGRLALAELEELLEAVHAKSIGDIDPQLDCFLSMTVSWYQSLIKVLLSRFPQSCRHFQSPDLGTQYLVVLNQKFTDCFVLVFLDSHLGKTSLTVVFREPFPVQPQDSESPPAQLVSTYHHLESVINTACFTLWTRLL>sp|Q5T011-7|SZT2_HUMAN Isoform 4 of KICSTOR complex protein SZT2 OS=Homosapiens OX=9606 GN=SZT2MASERPEPEVEEAGQVFLLMKKDYRISRNVRLAWFLSHLHQTVQATPQEMLSEQELEVLSVLPPGWQPDEPVVPRPFLLVPSTRVTFLAWQYRFVIELDLSPSTGIVDDSTGEILFDEVFHALSRCLGGLLRPFRVPGSCIDFQPEIYVTIQAYSSIIGLQSHQRQGFTMLARLPSNF>sp|Q15170|TCAL1_HUMAN Transcription elongation factor A protein-like 1OS=Homo sapiens OX=9606 GN=TCEAL1 PE=1 SV=3MDKPRKENEEEPQSAPKTDEERPPVEHSPEKQSPEEQSSEEQSSEEEFFPEELLPELLPEMLLSEERPPQEGLSRKDLFEGRPPMEQPPCGVGKHKLEEGSFKERLARSRPQFRGDIHGRNLSNEEMIQAADELEEMKRVRNKLMIMHWKAKRSRPYPI>sp|Q13885|TBB2A_HUMAN Tubulin beta-2A chain OS=Homo sapiens OX=9606GN=TUBB2A PE=1 SV=1MREIVHIQAGQCGNQIGAKFWEVISDEHGIDPTGSYHGDSDLQLERINVYYNEAAGNKYVPRAILVDLEPGTMDSVRSGPFGQIFRPDNFVFGQSGAGNNWAKGHYTEGAELVDSVLDVVRKESESCDCLQGFQLTHSLGGGTGSGMGTLLISKIREEYPDRIMNTFSVMPSPKVSDTVVEPYNATLSVHQLVENTDETYSIDNEALYDICFRTLKLTTPTYGDLNHLVSATMSGVTTCLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTSRGSQQYRALTVPELTQQMFDSKNMMAACDPRHGRYLTVAAIFRGRMSMKEVDEQMLNVQNKNSSYFVEWIPNNVKTAVCDIPPRGLKMSATFIGNSTAIQELFKRISEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATADEQGEFEEEEGEDEA>sp|O75347|TBCA_HUMAN Tubulin-specific chaperone A OS=Homo sapiensOX=9606 GN=TBCA PE=1 SV=3MADPRVRQIKIKTGVVKRLVKEKVMYEKEAKQQEEKIEKMRAEDGENYDIKKQAEILQESRMMIPDCQRRLEAAYLDLQRILENEKDLEEAEEYKEARLVLDSVKLEA>sp|O75347-2|TBCA_HUMAN Isoform 2 of Tubulin-specific chaperone A OS=Homosapiens OX=9606 GN=TBCAMADPRVRQIKIKTGVVKRLVKEKVMYEKEAKQQEEKIEKMRAEDGENYDIKKQAEILQESRMMIPDCQRRLEAAYLDLQRILVSKDFCVMFKFFFSIQYMESQKFKYLTLRTSWQYFLFTCPLYRYILK>sp|Q9BZK7|TBL1R_HUMAN F-box-like/WD repeat-containing protein TBL1XR1OS=Homo sapiens OX=9606 GN=TBL1XR1 PE=1 SV=1MSISSDEVNFLVYRYLQESGFSHSAFTFGIESHISQSNINGALVPPAALISIIQKGLQYVEAEVSINEDGTLFDGRPIESLSLIDAVMPDVVQTRQQAYRDKLAQQQAAAAAAAAAAASQQGSAKNGENTANGEENGAHTIANNHTDMMEVDGDVEIPPNKAVVLRGHESEVFICAWNPVSDLLASGSGDSTARIWNLSENSTSGSTQLVLRHCIREGGQDVPSNKDVTSLDWNSEGTLLATGSYDGFARIWTKDGNLASTLGQHKGPIFALKWNKKGNFILSAGVDKTTIIWDAHTGEAKQQFPFHSAPALDVDWQSNNTFASCSTDMCIHVCKLGQDRPIKTFQGHTNEVNAIKWDPTGNLLASCSDDMTLKIWSMKQDNCVHDLQAHNKEIYTIKWSPTGPGTNNPNANLMLASASFDSTVRLWDVDRGICIHTLTKHQEPVYSVAFSPDGRYLASGSFDKCVHIWNTQTGALVHSYRGTGGIFEVCWNAAGDKVGASASDGSVCVLDLRK>sp|O95379|TFIP8_HUMAN Tumor necrosis factor alpha-induced protein 8OS=Homo sapiens OX=9606 GN=TNFAIP8 PE=1 SV=1MHSEAEESKEVATDVFNSKNLAVQAQKKILGKMVSKSIATTLIDDTSSEVLDELYRVTREYTQNKKEAEKIIKNLIKTVIKLAILYRNNQFNQDELALMEKFKKKVHQLAMTVVSFHQVDYTFDRNVLSRLLNECREMLHQIIQRHLTAKSHGRVNNVFDHFSDCEFLAALYNPFGNFKPHLQKLCDGINKMLDEENI>sp|O95379-2|TFIP8_HUMAN Isoform 2 of Tumor necrosis factor alpha-inducedprotein 8 OS=Homo sapiens OX=9606 GN=TNFAIP8MAVATDVFNSKNLAVQAQKKILGKMVSKSIATTLIDDTSSEVLDELYRVTREYTQNKKEAEKIIKNLIKTVIKLAILYRNNQFNQDELALMEKFKKKVHQLAMTVVSFHQVDYTFDRNVLSRLLNECREMLHQIIQRHLTAKSHGRVNNVFDHFSDCEFLAALYNPFGNFKPHLQKLCDGINKMLDEENI>sp|O95379-3|TFIP8_HUMAN Isoform 3 of Tumor necrosis factor alpha-inducedprotein 8 OS=Homo sapiens OX=9606 GN=TNFAIP8MATDVFNSKNLAVQAQKKILGKMVSKSIATTLIDDTSSEVLDELYRVTREYTQNKKEAEKIIKNLIKTVIKLAILYRNNQFNQDELALMEKFKKKVHQLAMTVVSFHQVDYTFDRNVLSRLLNECREMLHQIIQRHLTAKSHGRVNNVFDHFSDCEFLAALYNPFGNFKPHLQKLCDGINKMLDEENI>sp|O95379-4|TFIP8_HUMAN Isoform 4 of Tumor necrosis factor alpha-inducedprotein 8 OS=Homo sapiens OX=9606 GN=TNFAIP8MTLPRYCEVVLLIAHGEKMLKLVATDVFNSKNLAVQAQKKILGKMVSKSIATTLIDDTSSEVLDELYRVTREYTQNKKEAEKIIKNLIKTVIKLAILYRNNQFNQDELALMEKFKKKVHQLAMTVVSFHQVDYTFDRNVLSRLLNECREMLHQIIQRHLTAKSHGRVNNVFDHFSDCEFLAALYNPFGNFKPHLQKLCDGINKMLDEENI>sp|Q9NVG8|TBC13_HUMAN TBC1 domain family member 13 OS=Homo sapiensOX=9606 GN=TBC1D13 PE=1 SV=3MSSLHKSRIADFQDVLKEPSIALEKLRELSFSGIPCEGGLRCLCWKILLNYLPLERASWTSILAKQRELYAQFLREMIIQPGIAKANMGVSREDVTFEDHPLNPNPDSRWNTYFKDNEVLLQIDKDVRRLCPDISFFQRATDYPCLLILDPQNEFETLRKRVEQTTLKSQTVARNRSGVTNMSSPHKNSVPSSLNEYEVLPNGCEAHWEVVERILFIYAKLNPGIAYVQGMNEIVGPLYYTFATDPNSEWKEHAEADTFFCFTNLMAEIRDNFIKSLDDSQCGITYKMEKVYSTLKDKDVELYLKLQEQNIKPQFFAFRWLTLLLSQEFLLPDVIRIWDSLFADDNRFDFLLLVCCAMLMLIREQLLEGDFTVNMRLLQDYPITDVCQILQKAKELQDSK>sp|Q9NVG8-2|TBC13_HUMAN Isoform 2 of TBC1 domain family member 13OS=Homo sapiens OX=9606 GN=TBC1D13MSSLHKSRIADFQDVLKEPSIALEKLRELSFSGIPCEGGLRCLCWKILLNYLPLERASWTSILAKQRELYAQFLREMIIQPGIAKANMGVSREDVTFEDHPLNPNPDSRWNTYFKDNEVLLQIDKDVRRLCPDISFFQRATDYPCLLILDPQNEFETLRKRVEQTTLKSQTVARNRSGVTNQEQNIKPQFFAFRWLTLLLSQEFLLPDVIRIWDSLFADDNRFDFLLLVCCAMLMLIREQLLEGDFTVNMRLLQDYPITDVCQILQKAKELQDSK>sp|Q9NVG8-3|TBC13_HUMAN Isoform 3 of TBC1 domain family member 13OS=Homo sapiens OX=9606 GN=TBC1D13MSSPHKNSVPSSLNEYEVLPNGCEAHWEVVERILFIYAKLNPGIAYVQGMNEIVGPLYYTFATDPNSEWKEHAEADTFFCFTNLMAEIRDNFIKSLDDSQCGITYKMEKVYSTLKDKDVELYLKLQEQNIKPQFFAFRWLTLLLSQEFLLPDVIRIWDSLFADDNRFDFLLLVCCAMLMLIREQLLEGDFTVNMRLLQDYPITDVCQILQKAKELQDSK>sp|Q86TI0|TBCD1_HUMAN TBC1 domain family member 1 OS=Homo sapiensOX=9606 GN=TBC1D1 PE=1 SV=2MEPITFTARKHLLSNEVSVDFGLQLVGSLPVHSLTTMPMLPWVVAEVRRLSRQSTRKEPVTKQVRLCVSPSGLRCEPEPGRSQQWDPLIYSSIFECKPQRVHKLIHNSHDPSYFACLIKEDAVHRQSICYVFKADDQTKVPEIISSIRQAGKIARQEELHCPSEFDDTFSKKFEVLFCGRVTVAHKKAPPALIDECIEKFNHVSGSRGSESPRPNPPHAAPTGSQEPVRRPMRKSFSQPGLRSLAFRKELQDGGLRSSGFFSSFEESDIENHLISGHNIVQPTDIEENRTMLFTIGQSEVYLISPDTKKIALEKNFKEISFCSQGIRHVDHFGFICRESSGGGGFHFVCYVFQCTNEALVDEIMMTLKQAFTVAAVQQTAKAPAQLCEGCPLQSLHKLCERIEGMNSSKTKLELQKHLTTLTNQEQATIFEEVQKLRPRNEQRENELIISFLRCLYEEKQKEHIHIGEMKQTSQMAAENIGSELPPSATRFRLDMLKNKAKRSLTESLESILSRGNKARGLQEHSISVDLDSSLSSTLSNTSKEPSVCEKEALPISESSFKLLGSSEDLSSDSESHLPEEPAPLSPQQAFRRRANTLSHFPIECQEPPQPARGSPGVSQRKLMRYHSVSTETPHERKDFESKANHLGDSGGTPVKTRRHSWRQQIFLRVATPQKACDSSSRYEDYSELGELPPRSPLEPVCEDGPFGPPPEEKKRTSRELRELWQKAILQQILLLRMEKENQKLQASENDLLNKRLKLDYEEITPCLKEVTTVWEKMLSTPGRSKIKFDMEKMHSAVGQGVPRHHRGEIWKFLAEQFHLKHQFPSKQQPKDVPYKELLKQLTSQQHAILIDLGRTFPTHPYFSAQLGAGQLSLYNILKAYSLLDQEVGYCQGLSFVAGILLLHMSEEEAFKMLKFLMFDMGLRKQYRPDMIILQIQMYQLSRLLHDYHRDLYNHLEEHEIGPSLYAAPWFLTMFASQFPLGFVARVFDMIFLQGTEVIFKVALSLLGSHKPLILQHENLETIVDFIKSTLPNLGLVQMEKTINQVFEMDIAKQLQAYEVEYHVLQEELIDSSPLSDNQRMDKLEKTNSSLRKQNLDLLEQLQVANGRIQSLEATIEKLLSSESKLKQAMLTLELERSALLQTVEELRRRSAEPSDREPECTQPEPTGD>sp|Q86TI0-2|TBCD1_HUMAN Isoform 2 of TBC1 domain family member 1 OS=Homosapiens OX=9606 GN=TBC1D1MEPITFTARKHLLSNEVSVDFGLQLVGSLPVHSLTTMPMLPWVVAEVRRLSRQSTRKEPVTKQVRLCVSPSGLRCEPEPGRSQQWDPLIYSSIFECKPQRVHKLIHNSHDPSYFACLIKEDAVHRQSICYVFKADDQTKVPEIISSIRQAGKIARQEELHCPSEFDDTFSKKFEVLFCGRVTVAHKKAPPALIDECIEKFNHVSGSRGSESPRPNPPHAAPTGSQEPVRRPMRKSFSQPGLRSLAFRKELQDGGLRSSGFFSSFEESDIENHLISGHNIVQPTDIEENRTMLFTIGQSEVYLISPDTKKIALEKNFKEISFCSQGIRHVDHFGFICRESSGGGGFHFVCYVFQCTNEALVDEIMMTLKQAFTVAAVQQTAKAPAQLCEGCPLQSLHKLCERIEGMNSSKTKLELQKHLTTLTNQEQATIFEEVQKLRPRNEQRENELIISFLRCLYEEKQKEHIHIGEMKQTSQMAAENIGSELPPSATRFRLDMLKNKAKRSLTESLESILSRGNKARGLQEHSISVDLDSSLSSTLSNTSKEPSVCEKEALPISESSFKLLGSSEDLSSDSESHLPEEPAPLSPQQAFRRRANTLSHFPIECQEPPQPARGSPGVSQRKLMRYHSVSTETPHERNVDPSPVGESKHRPGQSSAPAPPPRLNPSASSPNFFKYLKHNSSGEQSGNAVPKSISYRNALRKKLHSSSSVPNFLKFLAPVDENNTSDFMNTKRDFESKANHLGDSGGTPVKTRRHSWRQQIFLRVATPQKACDSSSRYEDYSELGELPPRSPLEPVCEDGPFGPPPEEKKRTSRELRELWQKAILQQILLLRMEKENQKLQASENDLLNKRLKLDYEEITPCLKEVTTVWEKMLSTPGRSKIKFDMEKMHSAVGQGVPRHHRGEIWKFLAEQFHLKHQFPSKQQPKDVPYKELLKQLTSQQHAILIDLGRTFPTHPYFSAQLGAGQLSLYNILKAYSLLDQEVGYCQGLSFVAGILLLHMSEEEAFKMLKFLMFDMGLRKQYRPDMIILQMEKTINQVFEMDIAKQLQAYEVEYHVLQEELIDSSPLSDNQRMDKLEKTNSSLRKQNLDLLEQLQVANGRIQSLEATIEKLLSSESKLKQAMLTLELERSALLQTVEELRRRSAEPSDREPECTQPEPTGD>sp|Q9UFV1|TBC29_HUMAN Putative TBC1 domain family member 29 OS=Homosapiens OX=9606 GN=TBC1D29P PE=5 SV=1MGHLDKEGLCTQGSSFSWLLRVLNDGISLGLTPCLWDMYLLEGEQMLMLITSIAFKVQRSLYEETNKETWGPATPRALKGTGRARPICESLHSSLQALTASESSRGPSLLQTPPRVPGQQALSRGDKGISVSLSLPSLPSRRGRCGRIIG>sp|Q8WV44|TRI41_HUMAN E3 ubiquitin-protein ligase TRIM41 OS=Homo sapiensOX=9606 GN=TRIM41 PE=1 SV=3MAAVAMTPNPVQTLQEEAVCAICLDYFTDPVSIGCGHNFCRVCVTQLWGGEDEEDRDELDREEEEEDGEEEEVEAVGAGAGWDTPMRDEDYEGDMEEEVEEEEEGVFWTSGMSRSSWDNMDYVWEEEDEEEDLDYYLGDMEEEDLRGEDEEDEEEVLEEVEEEDLDPVTPLPPPPAPRRCFTCPQCRKSFPRRSFRPNLQLANMVQVIRQMHPTPGRGSRVTDQGICPKHQEALKLFCEVDEEAICVVCRESRSHKQHSVVPLEEVVQEYKAKLQGHVEPLRKHLEAVQKMKAKEERRVTELKSQMKSELAAVASEFGRLTRFLAEEQAGLERRLREMHEAQLGRAGAAASRLAEQAAQLSRLLAEAQERSQQGGLRLLQDIKETFNRCEEVQLQPPEVWSPDPCQPHSHDFLTDAIVRKMSRMFCQAARVDLTLDPDTAHPALMLSPDRRGVRLAERRQEVADHPKRFSADCCVLGAQGFRSGRHYWEVEVGGRRGWAVGAARESTHHKEKVGPGGSSVGSGDASSSRHHHRRRRLHLPQQPLLQREVWCVGTNGKRYQAQSSTEQTLLSPSEKPRRFGVYLDYEAGRLGFYNAETLAHVHTFSAAFLGERVFPFFRVLSKGTRIKLCP>sp|Q8WV44-2|TRI41_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM41OS=Homo sapiens OX=9606 GN=TRIM41MAAVAMTPNPVQTLQEEAVCAICLDYFTDPVSIGCGHNFCRVCVTQLWGGEDEEDRDELDREEEEEDGEEEEVEAVGAGAGWDTPMRDEDYEGDMEEEVEEEEEGVFWTSGMSRSSWDNMDYVWEEEDEEEDLDYYLGDMEEEDLRGEDEEDEEEVLEEVEEEDLDPVTPLPPPPAPRRCFTCPQCRKSFPRRSFRPNLQLANMVQVIRQMHPTPGRGSRVTDQGICPKHQEALKLFCEVDEEAICVVCRESRSHKQHSVVPLEEVVQEYKAKLQGHVEPLRKHLEAVQKMKAKEERRVTELKSQMKSELAAVASEFGRLTRFLAEEQAGLERRLREMHEAQLGRAGAAASRLAEQAAQLSRLLAEAQERSQQGGLRLLQDIKETFNRCEEVQLQPPEVWSPDPCQPHSHDFLTDAIVRKMSRMFCQAARVDLTLDPDTAHPALMLSPDRRGVRLAERRQEVADHPKRFSADCCVLGAQGFRSGRHYWEEPKEPSWPPAQPSLTYYVCPTDRPEFSFT>sp|Q8WV44-3|TRI41_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM41OS=Homo sapiens OX=9606 GN=TRIM41MSRMFCQAARVDLTLDPDTAHPALMLSPDRRGVRLAERRQEVADHPKRFSADCCVLGAQGFRSGRHYWEVEVGGRRGWAVGAARESTHHKEKVGPGGSSVGSGDASSSRHHHRRRRLHLPQQPLLQREVWCVGTNGKRYQAQSSTEQTLLSPSEKPRRFGVYLDYEAGRLGFYNAETLAHVHTFSAAFLGERVFPFFRVLSKGTRIKLCP>sp|Q8WV44-4|TRI41_HUMAN Isoform 4 of E3 ubiquitin-protein ligase TRIM41OS=Homo sapiens OX=9606 GN=TRIM41MAAVAMTPNPVQTLQEEAVCAICLDYFTDPVSIGCGHNFCRVCVTQLWGGEDEEDRDELDREEEEEDGEEEEVEAVGAGAGWDTPMRDEDYEGDMEEEVEEEEEGVFWTSGMSRSSWDNMDYVWEEEDEEEDLDYYLGDMEEEDLRGEDEEDEEEVLEEVEEEDLDPVTPLPPPPAPRRCFTCPQCRKSFPRRSFRPNLQLANMVQVIRQMHPTPGRGSRVTDQGICPKHQEALKLFCEVDEEAICVVCRESRSHKQHSVVPLEEVVQEYKAKLQGHVEPLRKHLEAVQKMKAKEERRVTELKSQMKSELAAVASEFGRLTRFLAEEQAGLERRLREMHEAQLGRAGAAASRLAEQAAQLSRLLAEAQERSQQGGLRLLQV>sp|Q9Y5U5|TNR18_HUMAN Tumor necrosis factor receptor superfamily member18 OS=Homo sapiens OX=9606 GN=TNFRSF18 PE=1 SV=1MAQHGAMGAFRALCGLALLCALSLGQRPTGGPGCGPGRLLLGTGTDARCCRVHTTRCCRDYPGEECCSEWDCMCVQPEFHCGDPCCTTCRHHPCPPGQGVQSQGKFSFGFQCIDCASGTFSGGHEGHCKPWTDCTQFGFLTVFPGNKTHNAVCVPGSPPAEPLGWLTVVLLAVAACVLLLTSAQLGLHIWQLRSQCMWPRETQLLLEVPPSTEDARSCQFPEEERGERSAEEKGRLGDLWV>sp|Q9Y5U5-2|TNR18_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 18 OS=Homo sapiens OX=9606 GN=TNFRSF18MAQHGAMGAFRALCGLALLCALSLGQRPTGGPGCGPGRLLLGTGTDARCCRVHTTRCCRDYPGEECCSEWDCMCVQPEFHCGDPCCTTCRHHPCPPGQGVQSQGKFSFGFQCIDCASGTFSGGHEGHCKPWTDCCWRCRRRPKTPEAASSPRKSGASDRQRRRGGWETCGCEPGRPPGPPTAASPSPGAPQAAGALRSALGRALLPWQQKWVQEGGSDQRPGPCSSAAAAGPCRRERETQSWPPSSLAGPDGVGS>sp|Q9Y5U5-3|TNR18_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 18 OS=Homo sapiens OX=9606 GN=TNFRSF18MAQHGAMGAFRALCGLALLCALSLGQRPTGGPGCGPGRLLLGTGTDARCCRVHTTRCCRDYPGEECCSEWDCMCVQPEFHCGDPCCTTCRHHPCPPGQGVQSQGKFSFGFQCIDCASGTFSGGHEGHCKPWTDCTQFGFLTVFPGNKTHNAVCVPGSPPAEPLGWLTVVLLAVAACVLLLTSAQLGLHIWQLRKTQLLLEVPPSTEDARSCQFPEEERGERSAEEKGRLGDLWV>sp|Q9C019|TRI15_HUMAN Tripartite motif-containing protein 15 OS=Homosapiens OX=9606 GN=TRIM15 PE=1 SV=1MPATPSLKVVHELPACTLCAGPLEDAVTIPCGHTFCRLCLPALSQMGAQSSGKILLCPLCQEEEQAETPMAPVPLGPLGETYCEEHGEKIYFFCENDAEFLCVFCREGPTHQAHTVGFLDEAIQPYRDRLRSRLEALSTERDEIEDVKCQEDQKLQVLLTQIESKKHQVETAFERLQQELEQQRCLLLARLRELEQQIWKERDEYITKVSEEVTRLGAQVKELEEKCQQPASELLQDVRVNQSRCEMKTFVSPEAISPDLVKKIRDFHRKILTLPEMMRMFSENLAHHLEIDSGVITLDPQTASRSLVLSEDRKSVRYTRQKKSLPDSPLRFDGLPAVLGFPGFSSGRHRWQVDLQLGDGGGCTVGVAGEGVRRKGEMGLSAEDGVWAVIISHQQCWASTSPGTDLPLSEIPRGVRVALDYEAGQVTLHNAQTQEPIFTFTASFSGKVFPFFAVWKKGSCLTLKG>sp|Q9C019-2|TRI15_HUMAN Isoform 2 of Tripartite motif-containing protein15 OS=Homo sapiens OX=9606 GN=TRIM15MPATPSLKVVHELPACTLCAGPLEDAVTIPCGHTFCRLCLPALSQMGAQSSGKILLCPLCQEEEQAETPMAPVPLGPLGETYCEEHGEKIYFFCENDAEFLCTSECRTTDGFGCA>sp|Q9C037|TRIM4_HUMAN E3 ubiquitin-protein ligase TRIM4 OS=Homo sapiensOX=9606 GN=TRIM4 PE=1 SV=2MEAEDIQEELTCPICLDYFQDPVSIECGHNFCRGCLHRNWAPGGGPFPCPECRHPSAPAALRPNWALARLTEKTQRRRLGPVPPGLCGRHWEPLRLFCEDDQRPVCLVCRESQEHQTHAMAPIDEAFESYRTGNFDIHVDEWKRRLIRLLLYHFKQEEKLLKSQRNLVAKMKKVMHLQDVEVKNATQWKDKIKSQRMRISTEFSKLHNFLVEEEDLFLQRLNKEEEETKKKLNENTLKLNQTIASLKKLILEVGEKSQAPTLELLQNPKEVLTRSEIQDVNYSLEAVKVKTVCQIPLMKEMLKRFQVAVNLAEDTAHPKLVFSQEGRYVKNTASASSWPVFSSAWNYFAGWRNPQKTAFVERFQHLPCVLGKNVFTSGKHYWEVESRDSLEVAVGVCREDVMGITDRSKMSPDVGIWAIYWSAAGYWPLIGFPGTPTQQEPALHRVGVYLDRGTGNVSFYSAVDGVHLHTFSCSSVSRLRPFFWLSPLASLVIPPVTDRK>sp|Q9C037-2|TRIM4_HUMAN Isoform Beta of E3 ubiquitin-protein ligaseTRIM4 OS=Homo sapiens OX=9606 GN=TRIM4MEAEDIQEELTCPICLDYFQDPVSIECGHNFCRGCLHRNWAPGGGPFPCPECRHPSAPAALRPNWALARLTEKTQRRRLGPVPPGLCGRHWEPLRLFCEDDQRPVCLVCRESQEHQTHAMAPIDEAFESYREKLLKSQRNLVAKMKKVMHLQDVEVKNATQWKDKIKSQRMRISTEFSKLHNFLVEEEDLFLQRLNKEEEETKKKLNENTLKLNQTIASLKKLILEVGEKSQAPTLELLQNPKEVLTRSEIQDVNYSLEAVKVKTVCQIPLMKEMLKRFQVAVNLAEDTAHPKLVFSQEGRYVKNTASASSWPVFSSAWNYFAGWRNPQKTAFVERFQHLPCVLGKNVFTSGKHYWEVESRDSLEVAVGVCREDVMGITDRSKMSPDVGIWAIYWSAAGYWPLIGFPGTPTQQEPALHRVGVYLDRGTGNVSFYSAVDGVHLHTFSCSSVSRLRPFFWLSPLASLVIPPVTDRK>sp|Q9C037-3|TRIM4_HUMAN Isoform Gamma of E3 ubiquitin-protein ligaseTRIM4 OS=Homo sapiens OX=9606 GN=TRIM4MEAEDIQEELTCPICLDYFQDPVSIECGHNFCRGCLHRNWAPGGGPFPCPECRHPSAPAALRPNWALARLTEKTQRRRLGPVPPGLCGRHWEPLRLFCEDDQRPVCLVCRESQEHQTHAMAPIDEAFESYREKLLKSQRNLVAKMKKVMHLQDVEVKNATQWKDKIKSQRMRISTEFSKLHNFLVEEEDLFLQRLNKEEEETKKKLNENTLKLNQTIASLKKLILEVGEKSQAPTLELLQNPKEVLTRSEIQDVNYSLEAVKVKTVCQIPLMKEMLKRFQATKIKTQKQNRHNM>sp|Q9NW97|TMM51_HUMAN Transmembrane protein 51 OS=Homo sapiens OX=9606GN=TMEM51 PE=1 SV=1MMAQSKANGSHYALTAIGLGMLVLGVIMAMWNLVPGFSAAEKPTAQGSNKTEVGGGILKSKTFSVAYVLVGAGVMLLLLSICLSIRDKRKQRQGEDLAHVQHPTGAGPHAQEEDSQEEEEEDEEAASRYYVPSYEEVMNTNYSEARGEEQNPRLSISLPSYESLTGLDETTPTSTRADVEASPGNPPDRQNSKLAKRLKPLKVRRIKSEKLHLKDFRINLPDKNVPPPSIEPLTPPPQYDEVQEKAPDTRPPD>sp|P57088|TMM33_HUMAN Transmembrane protein 33 OS=Homo sapiens OX=9606GN=TMEM33 PE=1 SV=2MADTTPNGPQGAGAVQFMMTNKLDTAMWLSRLFTVYCSALFVLPLLGLHEAASFYQRALLANALTSALRLHQRLPHFQLSRAFLAQALLEDSCHYLLYSLIFVNSYPVTMSIFPVLLFSLLHAATYTKKVLDARGSNSLPLLRSVLDKLSANQQNILKFIACNEIFLMPATVFMLFSGQGSLLQPFIYYRFLTLRYSSRRNPYCRTLFNELRIVVEHIIMKPACPLFVRRLCLQSIAFISRLAPTVP>sp|Q86YW5|TRML1_HUMAN Trem-like transcript 1 protein OS=Homo sapiensOX=9606 GN=TREML1 PE=1 SV=2MGLTLLLLLLLGLEGQGIVGSLPEVLQAPVGSSILVQCHYRLQDVKAQKVWCRFLPEGCQPLVSSAVDRRAPAGRRTFLTDLGGGLLQVEMVTLQEEDAGEYGCMVDGARGPQILHRVSLNILPPEEEEETHKIGSLAENAFSDPAGSANPLEPSQDEKSIPLIWGAVLLVGLLVAAVVLFAVMAKRKQGNRLGVCGRFLSSRVSGMNPSSVVHHVSDSGPAAELPLDVPHIRLDSPPSFDNTTYTSLPLDSPSGKPSLPAPSSLPPLPPKVLVCSKPVTYATVIFPGGNKGGGTSCGPAQNPPNNQTPSS>sp|Q86YW5-2|TRML1_HUMAN Isoform 2 of Trem-like transcript 1 proteinOS=Homo sapiens OX=9606 GN=TREML1MGLTLLLLLLLGLEGQGIVGSLPEVLQAPVGSSILVQCHYRLQDVKAQKVWCRFLPEGCQPLVSSAVDRRAPAGRRTFLTDLGGGLLQVEMVTLQEEDAGEYGCMVDGARGPQILHRVSLNILPPEEEEETHKIGSLAENAFSDPAGSANPLEPSQDEKSIPLIWGAVLLVGLLVAAVVLFAVMAKRKQESLLSGPPRQ>sp|Q86YW5-3|TRML1_HUMAN Isoform 3 of Trem-like transcript 1 proteinOS=Homo sapiens OX=9606 GN=TREML1MGLTLLLLLLLGLEEEEEETHKIGSLAENAFSDPAGSANPLEPSQDEKSIPLIWGAVLLVGLLVAAVVLFAVMAKRKQGNRLGVCGRFLSSRVSGMNPSSVVHHVSDSGPAAELPLDVPHIRLDSPPSFDNTTYTSLPLDSPSGKPSLPAPSSLPPLPPKVLVCSKPVTYATVIFPGGNKGGGTSCGPAQNPPNNQTPSS>sp|Q99614|TTC1_HUMAN Tetratricopeptide repeat protein 1 OS=Homo sapiensOX=9606 GN=TTC1 PE=1 SV=1MGEKSENCGVPEDLLNGLKVTDTQEAECAGPPVPDPKNQHSQSKLLRDDEAHLQEDQGEEECFHDCSASFEEEPGADKVENKSNEDVNSSELDEEYLIELEKNMSDEEKQKRREESTRLKEEGNEQFKKGDYIEAESSYSRALEMCPSCFQKERSILFSNRAAARMKQDKKEMAINDCSKAIQLNPSYIRAILRRAELYEKTDKLDEALEDYKSILEKDPSIHQAREACMRLPKQIEERNERLKEEMLGKLKDLGNLVLRPFGLSTENFQIKQDSSTGSYSINFVQNPNNNR>sp|P51784|UBP11_HUMAN Ubiquitin carboxyl-terminal hydrolase 11 OS=Homosapiens OX=9606 GN=USP11 PE=1 SV=3MAVAPRLFGGLCFRFRDQNPEVAVEGRLPISHSCVGCRRERTAMATVAANPAAAAAAVAAAAAVTEDREPQHEELPGLDSQWRQIENGESGRERPLRAGESWFLVEKHWYKQWEAYVQGGDQDSSTFPGCINNATLFQDEINWRLKEGLVEGEDYVLLPAAAWHYLVSWYGLEHGQPPIERKVIELPNIQKVEVYPVELLLVRHNDLGKSHTVQFSHTDSIGLVLRTARERFLVEPQEDTRLWAKNSEGSLDRLYDTHITVLDAALETGQLIIMETRKKDGTWPSAQLHVMNNNMSEEDEDFKGQPGICGLTNLGNTCFMNSALQCLSNVPQLTEYFLNNCYLEELNFRNPLGMKGEIAEAYADLVKQAWSGHHRSIVPHVFKNKVGHFASQFLGYQQHDSQELLSFLLDGLHEDLNRVKKKEYVELCDAAGRPDQEVAQEAWQNHKRRNDSVIVDTFHGLFKSTLVCPDCGNVSVTFDPFCYLSVPLPISHKRVLEVFFIPMDPRRKPEQHRLVVPKKGKISDLCVALSKHTGISPERMMVADVFSHRFYKLYQLEEPLSSILDRDDIFVYEVSGRIEAIEGSREDIVVPVYLRERTPARDYNNSYYGLMLFGHPLLVSVPRDRFTWEGLYNVLMYRLSRYVTKPNSDDEDDGDEKEDDEEDKDDVPGPSTGGSLRDPEPEQAGPSSGVTNRCPFLLDNCLGTSQWPPRRRRKQLFTLQTVNSNGTSDRTTSPEEVHAQPYIAIDWEPEMKKRYYDEVEAEGYVKHDCVGYVMKKAPVRLQECIELFTTVETLEKENPWYCPSCKQHQLATKKLDLWMLPEILIIHLKRFSYTKFSREKLDTLVEFPIRDLDFSEFVIQPQNESNPELYKYDLIAVSNHYGGMRDGHYTTFACNKDSGQWHYFDDNSVSPVNENQIESKAAYVLFYQRQDVARRLLSPAGSSGAPASPACSSPPSSEFMDVN>sp|O60636|TSN2_HUMAN Tetraspanin-2 OS=Homo sapiens OX=9606 GN=TSPAN2PE=1 SV=2MGRFRGGLRCIKYLLLGFNLLFWLAGSAVIAFGLWFRFGGAIKELSSEDKSPEYFYVGLYVLVGAGALMMAVGFFGCCGAMRESQCVLGSFFTCLLVIFAAEVTTGVFAFIGKGVAIRHVQTMYEEAYNDYLKDRGKGNGTLITFHSTFQCCGKESSEQVQPTCPKELLGHKNCIDEIETIISVKLQLIGIVGIGIAGLTIFGMIFSMVLCCAIRNSRDVI>sp|O60636-2|TSN2_HUMAN Isoform 2 of Tetraspanin-2 OS=Homo sapiensOX=9606 GN=TSPAN2MGRFRGGLRCIKYLLLGFNLLFWLAGSAVIAFGLWFRFGGAIKELSSEDKSPEYFYVGLYVLVGAGALMMAVGFFGCCGAMRESQCVLGSFFTCLLVIFAAEVTTGVFAFIGKGVAIRHVQTMYEEAYNDYLKDRGKGNGTLITFHSTFQCCGKESSEQVQPTCPKELLGHKIFGMIFSMVLCCAIRNSRDVI>sp|Q9BZ98|TTY12_HUMAN Putative transcript Y 12 protein OS=Homo sapiensOX=9606 GN=TTTY12 PE=5 SV=1MIDPETRHKAFLKAWPWQNSTITFVPGLAICHYSSVQVPRRGAILPMLYALCYVKMPSFQHGPGRMYHLTCDWPRKMSLSCHVCRAHFRD>sp|Q8WU66|TSEAR_HUMAN Thrombospondin-type laminin G domain and EARrepeat-containing protein OS=Homo sapiens OX=9606 GN=TSPEAR PE=1 SV=2MSALLSLCFVLPLAAPGHGTQGWEPCTDLRPLDILAEVVPSDGATSGIRIVQVHGARGLQLSVAAPRTMSFPASRIFSQCDLFPEEFSIVVTLRVPNLPPKRNEYLLTVVAEESDLLLLGLRLSPAQLHFLFLREDTAGAWQTRVSFRSPALVDGRWHTLVLAVSAGVFSLTTDCGLPVDIMADVPFPATLSVKGARFFVGSRRRAKGLFMGLVRQLVLLPGSDATPRLCPSRNAPLAVLSIPRVLQALTGKPEDNEVLKYPYETNIRVTLGPQPPCTEVEDAQFWFDASRKGLYLCVGNEWVSVLAAKERLDYVEEHQNLSTNSETLGIEVFRIPQVGLFVATANRKATSAVYKWTEEKFVSYQNIPTHQAQAWRHFTIGKKIFLAVANFEPDEKGQEFSVIYKWSHRKLKFTPYQSIATHSARDWEAFEVDGEHFLAVANHREGDNHNIDSVIYKWNPATRLFEANQTIATSGAYDWEFFSVGPYSFLVVANTFNGTSTKVHSHLYIRLLGSFQLFQSFPTFGAADWEVFQIGERIFLAVANSHSYDVEMQVQNDSYVINSVIYELNVTAQAFVKFQDILTCSALDWEFFSVGEDYFLVVANSFDGRTFSVNSIIYRWQGYEGFVAVHSLPTVGCRDWEAFSTTAGAYLIYSSAKEPLSRVLRLRTR>sp|Q8WU66-2|TSEAR_HUMAN Isoform 2 of Thrombospondin-type laminin Gdomain and EAR repeat-containing protein OS=Homo sapiens OX=9606GN=TSPEARMSALLSLCFVLPLAAPGHGTQGWEPCTDLRPLDILAEVVPSDGATSGIRIVQVHGARGLQLSVAAPRTMSFPASRIFSQCDLFPEEFSIVVTLRVPNLPPKRNEYLLTVVAEESDLLLLGLRLSPAQLHFLFLREDTAGAWQTRVSFRSPALVDGRWHTLVLAVSAGVFSLTTDCGLPVDIMADVPFPATLSVKGARFFVGSRRRAKGLFMGLVRQLVLLPGSDATPRLCPSRNAPLAVLSIPRVLQALTGKPEDNEVLKYPYETNIRVTLGPQPPCTEVEDAQFWFDASRKGLYLCVGNEWVSVLAAKERLDYVEEHQNLSTNSETLGIEVFRIPQVGLFVATANRKATSAVYKWTEEKFVSYQNIPTHQAQAWRHFTIGKKIFLAVANFEPDEKGQEFSVIYKWSHRKLKFTPYQSIATHSARDWEAFEVDGEHFLAVANHREGDNHNIDSVIYKWNPATRLFEANQTIATSGAYDWEFFSVGPYSFLVVANTFNGTSTKVHSHLYIRLLGSFQLFQSFPTFGAADWEVFQIGERIFLAVANSHSYDVEMQVQNDSYVINSVIYELNVTAQAFVKFQDILTCSGGRRGLHARRAEG>sp|Q5SRN2|TSBP1_HUMAN Testis-expressed basic protein 1 OS=Homo sapiensOX=9606 GN=TSBP1 PE=2 SV=3MTVLEITLAVILTLLGLAILAILLTRWARCKQSEMYISRYSSEQSARLLDYEDGRGSRHAYSTQSDTSYDNRERSKRDYTPSTNSLVSMASKFSLGQTELILLLMCFILALSRSSIGSIKCLQTTEEPPSRTAGAMMQFTAPIPGATGPIKLSQKTIVQTPGPIVQYPGSNAGPPSAPRGPPMAPIIISQRTARIPQVHTMDSSGKITLTPVVILTGYMDEELAKKSCSKIQILKCGGTARSQNSREENKEALKNDIIFTNSVESLKSAHIKEPEREGKGTDLEKDKIGMEVKVDSDAGIPKRQETQLKISEMSIPQGQGAQIKKSVSDVPRGQESQVKKSESGVPKGQEAQVTKSGLVVLKGQEAQVEKSEMGVPRRQESQVKKSQSGVSKGQEAQVKKRESVVLKGQEAQVEKSELKVPKGQEGQVEKTEADVPKEQEVQEKKSEAGVLKGPESQVKNTEVSVPETLESQVKKSESGVLKGQEAQEKKESFEDKGNNDKEKERDAEKDPNKKEKGDKNTKGDKGKDKVKGKRESEINGEKSKGSKRAKANTGRKYNKKVEE>sp|Q5SRN2-2|TSBP1_HUMAN Isoform 2 of Testis-expressed basic protein 1OS=Homo sapiens OX=9606 GN=TSBP1MTVLEITLAVILTLLGLAILAILLTRWARCKQSEMYISRYSSEQSARLLDYEDGRGSRHAYSTQSDTSYDNRERSKRDYTPSTNSLALSRSSIALPQGSMSSIKCLQTTEEPPSRTAGAMMQFTAPIPGATGPIKLSQKTIVQTPGPIVQYPGSNVRSHPHTITGPPSAPRGPPMAPIIISQRTASQLAAPIRIPQVHTMDSSGKITLTPVVILTGYMDEELAKKSCSKIQILKCGGTARSQNSREENKEALKNDIIFTNSVESLKSAHIKEPEREGKGTDLEKDKIGMEVKVDSDAGIPKRQETQLKISEMSIPQGQGAQIKKSVSDVPRGQESQVKKSESGVPKGQEAQVTKSGLVVLKGQEAQVEKSEMGVPRRQESQVKKSQSGVSKGQEAQVKKRESVVLKGQEAQVEKSELKVPKGQEGQVEKTEADVPKEQEVQEKKSEAGVLKGPESQVKNTEVSVPETLESQVKKSESGVLKGQEAQEKKESFEDKGNNDKEKERDAEKDPNKKEKGDKNTKGDKGKDKVKGKRESEINGEKSKGSKRAKANTGRKYNKKVEE>sp|Q5SRN2-3|TSBP1_HUMAN Isoform 3 of Testis-expressed basic protein 1OS=Homo sapiens OX=9606 GN=TSBP1MTVLEITLAVILTLLGLAILAILLTRWARCKQSEMYISRYSSEQSARLLDYEDGRGSRHAYSTQSDTSYDNRERSKRDYTPSTNSLALSRSSIALPQGSMSSIKCLQTTEEPPSRTAGAMMQFTAPIPGATGPIKLSQKTIVQTPGPIVQYPGSNAGPPSAPRGPPMAPIIISQRTASQLAAPIIISQRTARIPQVHTMDSSGKITLTPVVILTGYMDEELAKKSCSKIQILKCGGTARSQNSREENKEALKNDIIFTNSVESLKSAHIKEPEREGKGTDLEKDKIGMEVKVDSDAGIPKRQETQLKISEMSIPQGQGAQIKKSVSDVPRGQESQVKKSESGVPKGQEAQVTKSGLVVLKGQEAQVEKSEMGVPRRQESQVKKSQSGVSKGQEAQVKKRESVVLKGQEAQVEKSELKVPKGQEGQVEKTEADVPKEQEVQEKKSEAGVLKGPESQVKNTEVSVPETLESQVKKSESGVLKGQEAQEKKESFEDKGNNDKEKERDAEKDPNKKEKGDKNTKGDKGKDKVKGKRESEINGEKSKGSKRAKANTGRKYNKKVEE>sp|P0CV99|TSPY4_HUMAN Testis-specific Y-encoded protein 4 OS=Homosapiens OX=9606 GN=TSPY4 PE=3 SV=1MRPEGSLTYRVPERLRQGFCGVGRAAQALVCASAKEGTAFRMEAVQEGAAGVESEQAALGEEAVLLLDDIMAEVEVVAEVEVVAEEEGLVERREEAQRAQQAVPGPGPMTPESALEELLAVQVELEPVNAQARKAFSRQREKMERRRKPHLDRRGAVIQSVPGFWANVIANHPQMSALITDEDEDMLSYMVSLEVEEEKHPVHLCKIMLFFRSNPYFQNKVITKEYLVNITEYRASHSTPIEWYPDYEVEAYRRRHHNSSLNFFNWFSDHNFAGSNKIAEILCKDLWRNPLQYYKRMKPPEEGTETSGDSQLLS>sp|Q9NYU1|UGGG2_HUMAN UDP-glucose:glycoprotein glucosyltransferase 2OS=Homo sapiens OX=9606 GN=UGGT2 PE=1 SV=4MAPAKATNVVRLLLGSTALWLSQLGSGTVAASKSVTAHLAAKWPETPLLLEASEFMAEESNEKFWQFLETVQELAIYKQTESDYSYYNLILKKAGQFLDNLHINLLKFAFSIRAYSPAIQMFQQIAADEPPPDGCNAFVVIHKKHTCKINEIKKLLKKAASRTRPYLFKGDHKFPTNKENLPVVILYAEMGTRTFSAFHKVLSEKAQNEEILYVLRHYIQKPSSRKMYLSGYGVELAIKSTEYKALDDTQVKTVTNTTVEDETETNEVQGFLFGKLKEIYSDLRDNLTAFQKYLIESNKQMMPLKVWELQDLSFQAASQIMSAPVYDSIKLMKDISQNFPIKARSLTRIAVNQHMREEIKENQKDLQVRFKIQPGDARLFINGLRVDMDVYDAFSILDMLKLEGKMMNGLRNLGINGEDMSKFLKLNSHIWEYTYVLDIRHSSIMWINDLENDDLYITWPTSCQKLLKPVFPGSVPSIRRNFHNLVLFIDPAQEYTLDFIKLADVFYSHEVPLRIGFVFILNTDDEVDGANDAGVALWRAFNYIAEEFDISEAFISIVHMYQKVKKDQNILTVDNVKSVLQNTFPHANIWDILGIHSKYDEERKAGASFYKMTGLGPLPQALYNGEPFKHEEMNIKELKMAVLQRMMDASVYLQREVFLGTLNDRTNAIDFLMDRNNVVPRINTLILRTNQQYLNLISTSVTADVEDFSTFFFLDSQDKSAVIAKNMYYLTQDDESIISAVTLWIIADFDKPSGRKLLFNALKHMKTSVHSRLGIIYNPTSKINEENTAISRGILAAFLTQKNMFLRSFLGQLAKEEIATAIYSGDKIKTFLIEGMDKNAFEKKYNTVGVNIFRTHQLFCQDVLKLRPGEMGIVSNGRFLGPLDEDFYAEDFYLLEKITFSNLGEKIKGIVENMGINANNMSDFIMKVDALMSSVPKRASRYDVTFLRENHSVIKTNPQENDMFFNVIAIVDPLTREAQKMAQLLVVLGKIINMKIKLFMNCRGRLSEAPLESFYRFVLEPELMSGANDVSSLGPVAKFLDIPESPLLILNMITPEGWLVETVHSNCDLDNIHLKDTEKTVTAEYELEYLLLEGQCFDKVTEQPPRGLQFTLGTKNKPAVVDTIVMAHHGYFQLKANPGAWILRLHQGKSEDIYQIVGHEGTDSQADLEDIIVVLNSFKSKILKVKVKKETDKIKEDILTDEDEKTKGLWDSIKSFTVSLHKENKKEKDVLNIFSVASGHLYERFLRIMMLSVLRNTKTPVKFWLLKNYLSPTFKEVIPHMAKEYGFRYELVQYRWPRWLRQQTERQRIIWGYKILFLDVLFPLAVDKIIFVDADQIVRHDLKELRDFDLDGAPYGYTPFCDSRREMDGYRFWKTGYWASHLLRRKYHISALYVVDLKKFRRIGAGDRLRSQYQALSQDPNSLSNLDQDLPNNMIYQVAIKSLPQDWLWCETWCDDESKQRAKTIDLCNNPKTKESKLKAAARIVPEWVEYDAEIRQLLDHLENKKQDTILTHDEL>sp|Q9NYU1-2|UGGG2_HUMAN Isoform 2 of UDP-glucose:glycoproteinglucosyltransferase 2 OS=Homo sapiens OX=9606 GN=UGGT2MAPAKATNVVRLLLGSTALWLSQLGSGTVAASKSVTAHLAAKWPETPLLLEASEFMAEESNEKFWQFLETVQELAIYKQTESDYSYYNLILKKAGQFLDNLHINLLKFAFSIRAYSPAIQMFQQIAADEPPPDGCNAFVVIHKKHTCKINEIKKLLKKAASRTRPYLFKGDHKFPTNKENLPVVILYAEMGTRTFSAFHKVLSEKAQNEEILYVLRHYIQKPSSRKMYLSGYGVELAIKSTEYKALDDTQVKTVTNTTVEDETETNEVQGFLFGKLKS>sp|A0A1B0GUS4|UB2L5_HUMAN Ubiquitin-conjugating enzyme E2 L5 OS=Homosapiens OX=9606 GN=UBE2L5 PE=2 SV=1MAASRRLMKELEEIRKCGMENFRNIQVDEANLLTWQGLIVPDNPPYNKGAFRIEINFPAEYPFKPPRITFKTKIYHPNIDEKGQVCLPVISAENWKPATKTDQVIQSLIALVNDPQPEHPLRADLAEEYSNDRKKFCKNAEEFTKKYGEKRPVD>sp|Q9BZF9|UACA_HUMAN Uveal autoantigen with coiled-coil domains andankyrin repeats OS=Homo sapiens OX=9606 GN=UACA PE=1 SV=2MKSLKSRLRRQDVPGPASSGAAAASAHAADWNKYDDRLMKAAERGDVEKVTSILAKKGVNPGKLDVEGRSVFHVVTSKGNLECLNAILIHGVDITTSDTAGRNALHLAAKYGHALCLQKLLQYNCPTEHADLQGRTALHDAAMADCPSSIQLLCDHGASVNAKDVDGRTPLVLATQMSRPTICQLLIDRGADVNSRDKQNRTALMLGCEYGCRDAVEVLIKNGADISLLDALGHDSSYYARIGDNLDILTLLKTASENTNKGRELWKKGPSLQQRNLTHMQDEVNVKSHQREHQNIQDLEIENEDLKERLRKIQQEQRILLDKVNGLQLQLNEEVMVADDLESEREKLKSLLAAKEKQHEESLRTIEALKNRFKYFESDHLGSGSHFSNRKEDMLLKQGQMYMADSQCTSPGIPAHMQSRSMLRPLELSLPSQTSYSENEILKKELEAMRTFCESAKQDRLKLQNELAHKVAECKALALECERVKEDSDEQIKQLEDALKDVQKRMYESEGKVKQMQTHFLALKEHLTSEAASGNHRLTEELKDQLKDLKVKYEGASAEVGKLRNQIKQNEMIVEEFKRDEGKLIEENKRLQKELSMCEMEREKKGRKVTEMEGQAKELSAKLALSIPAEKFENMKSSLSNEVNEKAKKLVEMEREHEKSLSEIRQLKRELENVKAKLAQHVKPEEHEQVKSRLEQKSGELGKKITELTLKNQTLQKEIEKVYLDNKLLKEQAHNLTIEMKNHYVPLKVSEDMKKSHDAIIDDLNRKLLDVTQKYTEKKLEMEKLLLENDSLSKDVSRLETVFVPPEKHEKEIIALKSNIVELKKQLSELKKKCGEDQEKIHALTSENTNLKKMMSNQYVPVKTHEEVKMTLNDTLAKTNRELLDVKKKFEDINQEFVKIKDKNEILKRNLENTQNQIKAEYISLAEHEAKMSSLSQSMRKVQDSNAEILANYRKGQEEIVTLHAEIKAQKKELDTIQECIKVKYAPIVSFEECERKFKATEKELKDQLSEQTQKYSVSEEEVKKNKQENDKLKKEIFTLQKDLRDKTVLIEKSHEMERALSRKTDELNKQLKDLSQKYTEVKNVKEKLVEENAKQTSEILAVQNLLQKQHVPLEQVEALKKSLNGTIENLKEELKSMQRCYEKEQQTVTKLHQLLENQKNSSVPLAEHLQIKEAFEKEVGIIKASLREKEEESQNKMEEVSKLQSEVQNTKQALKKLETREVVDLSKYKATKSDLETQISSLNEKLANLNRKYEEVCEEVLHAKKKEISAKDEKELLHFSIEQEIKDQKERCDKSLTTITELQRRIQESAKQIEAKDNKITELLNDVERLKQALNGLSQLTYTSGNPTKRQSQLIDTLQHQVKSLEQQLADADRQHQEVIAIYRTHLLSAAQGHMDEDVQEALLQIIQMRQGLVC>sp|Q9BZF9-2|UACA_HUMAN Isoform 2 of Uveal autoantigen with coiled-coildomains and ankyrin repeats OS=Homo sapiens OX=9606 GN=UACAMMNCWFSCTPKNRHAADWNKYDDRLMKAAERGDVEKVTSILAKKGVNPGKLDVEGRSVFHVVTSKGNLECLNAILIHGVDITTSDTAGRNALHLAAKYGHALCLQKLLQYNCPTEHADLQGRTALHDAAMADCPSSIQLLCDHGASVNAKDVDGRTPLVLATQMSRPTICQLLIDRGADVNSRDKQNRTALMLGCEYGCRDAVEVLIKNGADISLLDALGHDSSYYARIGDNLDILTLLKTASENTNKGRELWKKGPSLQQRNLTHMQDEVNVKSHQREHQNIQDLEIENEDLKERLRKIQQEQRILLDKVNGLQLQLNEEVMVADDLESEREKLKSLLAAKEKQHEESLRTIEALKNRFKYFESDHLGSGSHFSNRKEDMLLKQGQMYMADSQCTSPGIPAHMQSRSMLRPLELSLPSQTSYSENEILKKELEAMRTFCESAKQDRLKLQNELAHKVAECKALALECERVKEDSDEQIKQLEDALKDVQKRMYESEGKVKQMQTHFLALKEHLTSEAASGNHRLTEELKDQLKDLKVKYEGASAEVGKLRNQIKQNEMIVEEFKRDEGKLIEENKRLQKELSMCEMEREKKGRKVTEMEGQAKELSAKLALSIPAEKFENMKSSLSNEVNEKAKKLVEMEREHEKSLSEIRQLKRELENVKAKLAQHVKPEEHEQVKSRLEQKSGELGKKITELTLKNQTLQKEIEKVYLDNKLLKEQAHNLTIEMKNHYVPLKVSEDMKKSHDAIIDDLNRKLLDVTQKYTEKKLEMEKLLLENDSLSKDVSRLETVFVPPEKHEKEIIALKSNIVELKKQLSELKKKCGEDQEKIHALTSENTNLKKMMSNQYVPVKTHEEVKMTLNDTLAKTNRELLDVKKKFEDINQEFVKIKDKNEILKRNLENTQNQIKAEYISLAEHEAKMSSLSQSMRKVQDSNAEILANYRKGQEEIVTLHAEIKAQKKELDTIQECIKVKYAPIVSFEECERKFKATEKELKDQLSEQTQKYSVSEEEVKKNKQENDKLKKEIFTLQKDLRDKTVLIEKSHEMERALSRKTDELNKQLKDLSQKYTEVKNVKEKLVEENAKQTSEILAVQNLLQKQHVPLEQVEALKKSLNGTIENLKEELKSMQRCYEKEQQTVTKLHQLLENQKNSSVPLAEHLQIKEAFEKEVGIIKASLREKEEESQNKMEEVSKLQSEVQNTKQALKKLETREVVDLSKYKATKSDLETQISSLNEKLANLNRKYEEVCEEVLHAKKKEISAKDEKELLHFSIEQEIKDQKERCDKSLTTITELQRRIQESAKQIEAKDNKITELLNDVERLKQALNGLSQLTYTSGNPTKRQSQLIDTLQHQVKSLEQQLADADRQHQEVIAIYRTHLLSAAQGHMDEDVQEALLQIIQMRQGLVC>sp|P47985|UCRI_HUMAN Cytochrome b-c1 complex subunit Rieske,mitochondrial OS=Homo sapiens OX=9606 GN=UQCRFS1 PE=1 SV=2MLSVASRSGPFAPVLSATSRGVAGALRPLVQATVPATPEQPVLDLKRPFLSRESLSGQAVRRPLVASVGLNVPASVCYSHTDIKVPDFSEYRRLEVLDSTKSSRESSEARKGFSYLVTGVTTVGVAYAAKNAVTQFVSSMSASADVLALAKIEIKLSDIPEGKNMAFKWRGKPLFVRHRTQKEIEQEAAVELSQLRDPQHDLDRVKKPEWVILIGVCTHLGCVPIANAGDFGGYYCPCHGSHYDASGRIRLGPAPLNLEVPTYEFTSDDMVIVG>sp|Q13404|UB2V1_HUMAN Ubiquitin-conjugating enzyme E2 variant 1 OS=Homosapiens OX=9606 GN=UBE2V1 PE=1 SV=2MAATTGSGVKVPRNFRLLEELEEGQKGVGDGTVSWGLEDDEDMTLTRWTGMIIGPPRTIYENRIYSLKIECGPKYPEAPPFVRFVTKINMNGVNSSNGVVDPRAISVLAKWQNSYSIKVVLQELRRLMMSKENMKLPQPPEGQCYSN>sp|Q13404-1|UB2V1_HUMAN Isoform 1 of Ubiquitin-conjugating enzyme E2variant 1 OS=Homo sapiens OX=9606 GN=UBE2V1MAYKFRTHSPEALEQLYPWECFVFCLIIFGTFTNQIHKWSHTYFGLPRWVTLLQDWHVILPRKHHRIHHVSPHETYFCITTGVKVPRNFRLLEELEEGQKGVGDGTVSWGLEDDEDMTLTRWTGMIIGPPRTIYENRIYSLKIECGPKYPEAPPFVRFVTKINMNGVNSSNGVVDPRAISVLAKWQNSYSIKVVLQELRRLMMSKENMKLPQPPEGQCYSN>sp|Q13404-2|UB2V1_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2variant 1 OS=Homo sapiens OX=9606 GN=UBE2V1MPGEVQASYLKSQSKLSDEGRLEPRKFHCKGSKSPSQFRLLEELEEGQKGVGDGTVSWGLEDDEDMTLTRWTGMIIGPPRTIYENRIYSLKIECGPKYPEAPPFVRFVTKINMNGVNSSNGVVDPRAISVLAKWQNSYSIKVVLQELRRLMMSKENMKLPQPPEGQCYSN>sp|Q13404-6|UB2V1_HUMAN Isoform 4 of Ubiquitin-conjugating enzyme E2variant 1 OS=Homo sapiens OX=9606 GN=UBE2V1MKEDLNLENFTAKTIYENRIYSLKIECGPKYPEAPPFVRFVTKINMNGVNSSNGVVDPRAISVLAKWQNSYSIKVVLQELRRLMMSKENMKLPQPPEGQCYSN>sp|Q13404-7|UB2V1_HUMAN Isoform 5 of Ubiquitin-conjugating enzyme E2variant 1 OS=Homo sapiens OX=9606 GN=UBE2V1MPGEVQASYLKSQSKLSDEGRLEPRKFHCKGVKVPRNFRLLEELEEGQKGVGDGTVSWGLEDDEDMTLTRWTGMIIGPPRTIYENRIYSLKIECGPKYPEAPPFVRFVTKINMNGVNSSNGVVDPRAISVLAKWQNSYSIKVVLQELRRLMMSKENMKLPQPPEGQCYSN>sp|Q13404-8|UB2V1_HUMAN Isoform 6 of Ubiquitin-conjugating enzyme E2variant 1 OS=Homo sapiens OX=9606 GN=UBE2V1MAATTGSGVKVPRNFRLLEELEEGQKGVGDGTVSWGLEDDEDMTLTRWTGMIIGPPRVDPRAISVLAKWQNSYSIKVVLQELRRLMMSKENMKLPQPPEGQCYSN>sp|Q9HAC8|UBTD1_HUMAN Ubiquitin domain-containing protein 1 OS=Homosapiens OX=9606 GN=UBTD1 PE=1 SV=1MGNCVGRQRRERPAAPGHPRKRAGRNEPLKKERLKWKSDYPMTDGQLRSKRDEFWDTAPAFEGRKEIWDALKAAAYAAEANDHELAQAILDGASITLPHGTLCECYDELGNRYQLPIYCLSPPVNLLLEHTEEESLEPPEPPPSVRREFPLKVRLSTGKDVRLSASLPDTVGQLKRQLHAQEGIEPSWQRWFFSGKLLTDRTRLQETKIQKDFVIQVIINQPPPPQD>sp|Q04323|UBXN1_HUMAN UBX domain-containing protein 1 OS=Homo sapiensOX=9606 GN=UBXN1 PE=1 SV=2MAELTALESLIEMGFPRGRAEKALALTGNQGIEAAMDWLMEHEDDPDVDEPLETPLGHILGREPTSSEQGGLEGSGSAAGEGKPALSEEERQEQTKRMLELVAQKQREREEREEREALERERQRRRQGQELSAARQRLQEDEMRRAAEERRREKAEELAARQRVREKIERDKAERAKKYGGSVGSQPPPVAPEPGPVPSSPSQEPPTKREYDQCRIQVRLPDGTSLTQTFRAREQLAAVRLYVELHRGEELGGGQDPVQLLSGFPRRAFSEADMERPLQELGLVPSAVLIVAKKCPS>sp|Q04323-2|UBXN1_HUMAN Isoform 2 of UBX domain-containing protein 1OS=Homo sapiens OX=9606 GN=UBXN1MAELTALESLIEMGFPRGRAEKALALTGNQGIEAAMDWLMEHEDDPDVDEPLETPLGHILGREPTSSEQGGLEGSGSAAGEGKPALSEEERQEQTKRMLELVAQKQREREEREEREALERERQRRRQGQELSAARQRLQEDEMRRAAEERRREKAEELAARQRVREKIERDKAERAKKYGGSVGSQPPPVAPEPGPVPSSPSQEPPTKREYDQCRIQVRLPDGTSLTQTFRAREQLAAVRLYVELHRGEELGGGQDPVQLLSGFPRRAFSEADMERPLQELGMAARLETRTRNWGSREACLGKGGMQREGAL>sp|P38435|VKGC_HUMAN Vitamin K-dependent gamma-carboxylase OS=Homosapiens OX=9606 GN=GGCX PE=1 SV=2MAVSAGSARTSPSSDKVQKDKAELISGPRQDSRIGKLLGFEWTDLSSWRRLVTLLNRPTDPASLAVFRFLFGFLMVLDIPQERGLSSLDRKYLDGLDVCRFPLLDALRPLPLDWMYLVYTIMFLGALGMMLGLCYRISCVLFLLPYWYVFLLDKTSWNNHSYLYGLLAFQLTFMDANHYWSVDGLLNAHRRNAHVPLWNYAVLRGQIFIVYFIAGVKKLDADWVEGYSMEYLSRHWLFSPFKLLLSEELTSLLVVHWGGLLLDLSAGFLLFFDVSRSIGLFFVSYFHCMNSQLFSIGMFSYVMLASSPLFCSPEWPRKLVSYCPRRLQQLLPLKAAPQPSVSCVYKRSRGKSGQKPGLRHQLGAAFTLLYLLEQLFLPYSHFLTQGYNNWTNGLYGYSWDMMVHSRSHQHVKITYRDGRTGELGYLNPGVFTQSRRWKDHADMLKQYATCLSRLLPKYNVTEPQIYFDIWVSINDRFQQRIFDPRVDIVQAAWSPFQRTSWVQPLLMDLSPWRAKLQEIKSSLDNHTEVVFIADFPGLHLENFVSEDLGNTSIQLLQGEVTVELVAEQKNQTLREGEKMQLPAGEYHKVYTTSPSPSCYMYVYVNTTELALEQDLAYLQELKEKVENGSETGPLPPELQPLLEGEVKGGPEPTPLVQTFLRRQQRLQEIERRRNTPFHERFFRFLLRKLYVFRRSFLMTCISLRNLILGRPSLEQLAQEVTYANLRPFEAVGELNPSNTDSSHSNPPESNPDPVHSEF>sp|P38435-2|VKGC_HUMAN Isoform 2 of Vitamin K-dependent gamma-carboxylase OS=Homo sapiens OX=9606 GN=GGCXMAVSAGSARTSPSSGFLMVLDIPQERGLSSLDRKYLDGLDVCRFPLLDALRPLPLDWMYLVYTIMFLGALGMMLGLCYRISCVLFLLPYWYVFLLDKTSWNNHSYLYGLLAFQLTFMDANHYWSVDGLLNAHRRNAHVPLWNYAVLRGQIFIVYFIAGVKKLDADWVEGYSMEYLSRHWLFSPFKLLLSEELTSLLVVHWGGLLLDLSAGFLLFFDVSRSIGLFFVSYFHCMNSQLFSIGMFSYVMLASSPLFCSPEWPRKLVSYCPRRLQQLLPLKAAPQPSVSCVYKRSRGKSGQKPGLRHQLGAAFTLLYLLEQLFLPYSHFLTQGYNNWTNGLYGYSWDMMVHSRSHQHVKITYRDGRTGELGYLNPGVFTQSRRWKDHADMLKQYATCLSRLLPKYNVTEPQIYFDIWVSINDRFQQRIFDPRVDIVQAAWSPFQRTSWVQPLLMDLSPWRAKLQEIKSSLDNHTEVVFIADFPGLHLENFVSEDLGNTSIQLLQGEVTVELVAEQKNQTLREGEKMQLPAGEYHKVYTTSPSPSCYMYVYVNTTELALEQDLAYLQELKEKVENGSETGPLPPELQPLLEGEVKGGPEPTPLVQTFLRRQQRLQEIERRRNTPFHERFFRFLLRKLYVFRRSFLMTCISLRNLILGRPSLEQLAQEVTYANLRPFEAVGELNPSNTDSSHSNPPESNPDPVHSEF>sp|B1ANS9|WDR64_HUMAN WD repeat-containing protein 64 OS=Homo sapiensOX=9606 GN=WDR64 PE=2 SV=1MDIRKEKRLNMALQMSNFKKALNRFEKLVEQTAAQKRDERAGLFIHKEDAIGYDKFYASVQKLFGPDVKNQDVKRFYRKLCNNTDASADWCEIFGYFSSEEDPIASQLDEENLVFFVSRKRRILISGSRRRDVIKSIVKIPHLDLLITATQKGLITVFNNQDTSWITGCDYLLQLKRIVATTERTIIVWDYKAQGSSQENYFVIKPMDHCLLCVCVVPLPDHLCRDDILLGDDGGFVNRFTVNSDDFGIKQAKSKRKLQNQVLDSKNFKSVKRKLHNDWVMKIRYISALNCFGSCSLDSNHSLVLESLKRLEDNLPVREFSMPRGANTFCYCVKANVIVTGGDDKVIRLWHPNISTKPVGKLVGHMFSIAEIVTNEKDQHVVSLSSAKVFRVWDIQTLSLLQVFHDSQGGPGDMQIYSMIYDANHGMLITGSSVMDMYPLTRMIQDTKQVPHTHEREINVMLYNKYFHQVLTICSESIIRVWELETGLQVYQILEPHGFNTEVTSAAVDESGFLFATGAYNGTVRIWDFGSGQEMKVLPEGKDWKEDEHCLRRLIFLKAQEKHQQLVLALERNGTIKMIQGKEDDIYLMVIWELPDVVPFLQDGKHAVHLRMSTRDRNMAIPFPDVELIVERNFSQPTDNPTMDLLRVNCIDLLQVEGYNLIAAGTLNGVIILWNFVTSTVKKVYRPEDCFTVNPDLHPKHFKINDILFLFRTPECARRSSQDSICSSSQCESSKGPQSSKGSKQSIHDSEVKGEQTDVMVGKQQPMDKKHPGIANLPEAQPPILVTAHEDGHLRLWTLEGRLLKDMLPFTKHSAISLTSLYTDSCTRILLAGNVEGHVILCNISSFLDPPHDEKKFKQLLSWRAHSLEIIQVIYVEEKQVVLTASIDGSVRLWHALNGHYCGYFGQRRLFELSQTRDFILPCDVTEYPIEIKEESKFTEKQKYEYPLIFDREKWRKMSSVSLLFKRTPPKAFEVEQDFKFFKSLSSPKIRRYPLEGFVTENREAGIVFGSLPIYSISSPTSLRFLPLIGVEAQKDSSDGITGKKKGGHVQREKAPRRRSLKKNLVPQINLASSFFPAIPK>sp|B1ANS9-2|WDR64_HUMAN Isoform 2 of WD repeat-containing protein 64OS=Homo sapiens OX=9606 GN=WDR64MDIRKEKRLNMALQMSNFKKALNRFEKLVEQTAAQKRDERAGLFIHKEDAIGYDKFYASVQKLFGPDVKNQDVKRFYRKLCNNTDASADWCEIFGYFSSEEDPIASQLDEENLVFFVSRKRRILISGSRRRDVIKSIVKIPHLDLLITATQKGLITVFNNQDTSWITGCDYLLQLKRIVATTERTIIVWDYKAQGSSQENYFVIKPMDHCLLCVCVVPLPDHLCRDDILLGDDGGFVNRFTVNSDDFGIKQAKSKRKLQNQVLDSKNFKSVKRKLHNDWVMKIRYISALNCFGSCSLDSNHSLVLESLKRLEDNLPVREFSMPRGANTFCYCVKANVIVTGGDDKVIRLWHPNISTKPVGKLVGHMFSIAEIVTNEKDQHVVSLSSAKVFRVWDIQTLSLLQVFHDSQGGPGDMQIYSMIYDANHGMLITGSSVMDMYPLTRMIQDTKQVPHTHEREINVMLYNKYFHQVLTICSESIIRVWELETGLQVYQILEPHGFNTEVTSAAVDESGFLFATGAYNGTVRIWDFGSGQEMKVLPEGKDWKEDEHCLRRLIFLKAQEKHQQLVLALERNGTIKMIQGKEDDIYLMVIWELPDVVPFLQDGKHAVHLRMSTRDRNMAIPFPDVELIVERNFSQPTDNPTMDLLRVNCIDLLQVEGYNLIAAGTLNEGHVILCNISSFLDPPHDEKKFKQLLSWRAHSLEIIQVIYVEEKQVVLTASIDGSVRLWHALNGHYCGYFGQRRLFELSQTRDFILPCDVTEYPIEIKEESKFTEKQKYEYPLIFDREKWRKMSSVSLLFKRTPPKAFEVEQDFKFFKSLSSPKIRRYPLEGFVTENREAGIVFGSLPIYSISSPTSLRFLPLIGVEAQKDSSDGITGKKKGGHVQREKAPRRRSLKKNLVPQINLASSFFPAIPK>sp|Q96AX1|VP33A_HUMAN Vacuolar protein sorting-associated protein 33AOS=Homo sapiens OX=9606 GN=VPS33A PE=1 SV=1MAAHLSYGRVNLNVLREAVRRELREFLDKCAGSKAIVWDEYLTGPFGLIAQYSLLKEHEVEKMFTLKGNRLPAADVKNIIFFVRPRLELMDIIAENVLSEDRRGPTRDFHILFVPRRSLLCEQRLKDLGVLGSFIHREEYSLDLIPFDGDLLSMESEGAFKECYLEGDQTSLYHAAKGLMTLQALYGTIPQIFGKGECARQVANMMIRMKREFTGSQNSIFPVFDNLLLLDRNVDLLTPLATQLTYEGLIDEIYGIQNSYVKLPPEKFAPKKQGDGGKDLPTEAKKLQLNSAEELYAEIRDKNFNAVGSVLSKKAKIISAAFEERHNAKTVGEIKQFVSQLPHMQAARGSLANHTSIAELIKDVTTSEDFFDKLTVEQEFMSGIDTDKVNNYIEDCIAQKHSLIKVLRLVCLQSVCNSGLKQKVLDYYKREILQTYGYEHILTLHNLEKAGLLKPQTGGRNNYPTIRKTLRLWMDDVNEQNPTDISYVYSGYAPLSVRLAQLLSRPGWRSIEEVLRILPGPHFEERQPLPTGLQKKRQPGENRVTLIFFLGGVTFAEIAALRFLSQLEDGGTEYVIATTKLMNGTSWIEALMEKPF>sp|Q6ZQT0|YD023_HUMAN Putative uncharacterized protein FLJ45035 OS=Homosapiens OX=9606 PE=5 SV=1MFARLCPVSETFGRLCPVSETFARLCPVSETFARLCPVSETFARLCPVSETFGRLCPVSEMFGRLSPVSETFGRLCPVSETFGRLCPVSEMFARLCPVSETFGRLSPVSEMFGRLCPVSEMFGRLCPVSEMFGRLCPVIT>sp|A6NM28|ZFP92_HUMAN Zinc finger protein 92 homolog OS=Homo sapiensOX=9606 GN=ZFP92 PE=2 SV=3MAAILLTTRPKVPVSFEDVSVYFTKTEWKLLDLRQKVLYKRVMLENYSHLVSLGFSFSKPHLISQLERGEGPWVADIPRTWATAGLHIGDRTQSKTSTSTQKHSGRQLPGADPQGGKEGQAARSSVLQRGAQGLGQSSAAGPQGPKGAEKRYLCQQCGKAFSRSSNLIKHRIIHSGEKPYACPECGKLFRRSFALLEHQRIHSGEKPYACPECSKTFTRSSNLIKHQVIHSGERPFACGDCGKLFRRSFALLEHARVHSGERPYACPECGKAFSRSSNLIEHQRTHRGEKPYACGQCAKAFKGVSQLIHHQRSHSGERPFACRECGKAFRGRSGLSQHRRVHSGEKPYECSDCGKAFGRRANLFKHQAVHGARRPAKAETARRLAGPGSTGPGSAVAATSPPRPSTAARPSRPSRR>sp|Q49AA0|ZFP69_HUMAN Zinc finger protein 69 homolog OS=Homo sapiensOX=9606 GN=ZFP69 PE=2 SV=2MPQQLLITLPTEASTWVKLQHPKKAVEGAPLWEDVTKMFEGEALLSQDAEDVKTQRESLEDEVTPGLPTAESQELLTFKDISIDFTQEEWGQLAPAHQNLYREVMLENYSNLVSVGYQLSKPSVISQLEKGEEPWMAEKEGPGDPSSDLKSKIETIESTAKSTISQERLYHGIMMESFMRDDIIYSTLRKVSTYDDVLERHQETCMRDVRQAILTHKKRVQETNKFGENIIVHSNVIIEQRHHKYDTPTKRNTYKLDLINHPTSYIRTKTYECNICEKIFKQPIHLTEHMRIHTGEKPFRCKECGRAFSQSASLSTHQRIHTGEKPFECEECGKAFRHRSSLNQHHRTHTGEKPYVCDKCQKAFSQNISLVQHLRTHSGEKPFTCNECGKTFRQIRHLSEHIRIHTGEKPYACTACCKTFSHRAYLTHHQRIHTGERPYKCKECGKAFRQRIHLSNHKTVHTGVKAYECNRCGKAYRHDSSFKKHQRHHTGEKPYECNECGKAFSYNSSLSRHHEIHRRNAFRNKV>sp|Q14590|ZN235_HUMAN Zinc finger protein 235 OS=Homo sapiens OX=9606GN=ZNF235 PE=2 SV=3MTKFQEAVTFKDVAVAFTEEELGLLDSAQRKLYRDVMLENFRNLVSVGHQSFKPDMISQLEREEKLWMKELQTQRGKHSGDRNQNEMATLHKAGLRCFSLGELSCWQIKRHIASKLARSQDSMINIEGKSSQFPKHHDSPCQVGAGESIQASVDDNCLVNHIGDHSSIIENQEFPTGKVPNSWSKIYLNETQNYQRSCKQTQMKNKLCIFAPYVDIFSCISHHHDDNIVHKRDKVHSNSDCGKDTLKVSPLTQRSIHTGQKTYQGNECEEAFNDSSSLELHKQVHLGKKSPACSTHEKDTSYSSGIPVQQSVRTGKKRYWCHECGKGFSQSSNLQTHQRVHTGEKPYTCHECGKSFNQSSHLYAHLPIHTGEKPYRCDSCGKGFSRSTDLNIHCRVHTGEKPYKCEVCGKGFTQRSHLQAHERIHTGEKPYKCGDCGKRFSCSSNLHTHQRVHTEEKPYKCDECGKCFSLSFNLHSHQRVHTGEKPYKCEECGKGFSSASSFQSHQRVHTGEKPFRCNVCGKGFSQSSYFQAHQRVHTGEKPYKCEVCGKRFNWSLNLHNHQRVHTGEKPYKCEECGKGFSQASNLQAHQSVHTGEKPFKCDACQKRFSQASHLQAHQRVHTGEKPYKCDTCGKAFSQRSNLQVHQIIHTGEKPFKCEECGKEFSWSAGLSAHQRVHTGEKPYTCQQCGKGFSQASHFHTHQRVHTGERPYICDVCCKGFSQRSHLIYHQRVHTGGNL>sp|Q14590-2|ZN235_HUMAN Isoform 2 of Zinc finger protein 235 OS=Homosapiens OX=9606 GN=ZNF235MTKFQEAVTFKDVAVAFTEEELGLLDSAQRKLYRDVMLENFRNLVSVGHQSFKPDMISQLEREEKLWMKELQTQRGDRNQNEMATLHKAGLRCFSLGELSCWQIKRHIASKLARSQDSMINIEGKSSQFPKHHDSPCQVGAGESIQASVDDNCLVNHIGDHSSIIENQEFPTGKVPNSWSKIYLNETQNYQRSCKQTQMKNKLCIFAPYVDIFSCISHHHDDNIVHKRDKVHSNSDCGKDTLKVSPLTQRSIHTGQKTYQGNECEEAFNDSSSLELHKQVHLGKKSPACSTHEKDTSYSSGIPVQQSVRTGKKRYWCHECGKGFSQSSNLQTHQRVHTGEKPYTCHECGKSFNQSSHLYAHLPIHTGEKPYRCDSCGKGFSRSTDLNIHCRVHTGEKPYKCEVCGKGFTQRSHLQAHERIHTGEKPYKCGDCGKRFSCSSNLHTHQRVHTEEKPYKCDECGKCFSLSFNLHSHQRVHTGEKPYKCEECGKGFSSASSFQSHQRVHTGEKPFRCNVCGKGFSQSSYFQAHQRVHTGEKPYKCEVCGKRFNWSLNLHNHQRVHTGEKPYKCEECGKGFSQASNLQAHQSVHTGEKPFKCDACQKRFSQASHLQAHQRVHTGEKPYKCDTCGKAFSQRSNLQVHQIIHTGEKPFKCEECGKEFSWSAGLSAHQRVHTGEKPYTCQQCGKGFSQASHFHTHQRVHTGERPYICDVCCKGFSQRSHLIYHQRVHTGGNL>sp|Q9NYT6|ZN226_HUMAN Zinc finger protein 226 OS=Homo sapiens OX=9606GN=ZNF226 PE=2 SV=2MNMFKEAVTFKDVAVAFTEEELGLLGPAQRKLYRDVMVENFRNLLSVGHPPFKQDVSPIERNEQLWIMTTATRRQGNLGEKNQSKLITVQDRESEEELSCWQIWQQIANDLTRCQDSMINNSQCHKQGDFPYQVGTELSIQISEDENYIVNKADGPNNTGNPEFPILRTQDSWRKTFLTESQRLNRDQQISIKNKLCQCKKGVDPIGWISHHDGHRVHKSEKSYRPNDYEKDNMKILTFDHNSMIHTGQKSYQCNECKKPFSDLSSFDLHQQLQSGEKSLTCVERGKGFCYSPVLPVHQKVHVGEKLKCDECGKEFSQGAHLQTHQKVHVIEKPYKCKQCGKGFSRRSALNVHCKVHTAEKPYNCEECGRAFSQASHLQDHQRLHTGEKPFKCDACGKSFSRNSHLQSHQRVHTGEKPYKCEECGKGFICSSNLYIHQRVHTGEKPYKCEECGKGFSRPSSLQAHQGVHTGEKSYICTVCGKGFTLSSNLQAHQRVHTGEKPYKCNECGKSFRRNSHYQVHLVVHTGEKPYKCEICGKGFSQSSYLQIHQKAHSIEKPFKCEECGQGFNQSSRLQIHQLIHTGEKPYKCEECGKGFSRRADLKIHCRIHTGEKPYNCEECGKVFRQASNLLAHQRVHSGEKPFKCEECGKSFGRSAHLQAHQKVHTGDKPYKCDECGKGFKWSLNLDMHQRVHTGEKPYKCGECGKYFSQASSLQLHQSVHTGEKPYKCDVCGKVFSRSSQLQSHQRVHTGEKPYKCEICGKSFSWRSNLTVHHRIHVGDKSYKSNRGGKNIRESTQEKKSIK>sp|Q9NYT6-2|ZN226_HUMAN Isoform 2 of Zinc finger protein 226 OS=Homosapiens OX=9606 GN=ZNF226MNMFKEAVTFKDVAVAFTEEELGLLGPAQRKLYRDVMVENFRNLLSVGHPPFKQDVSPIERNEQLWIMTTATRRQGNLDTLLVKALLLYDLAQT>sp|P17010|ZFX_HUMAN Zinc finger X-chromosomal protein OS=Homo sapiensOX=9606 GN=ZFX PE=2 SV=2MDEDGLELQQEPNSFFDATGADGTHMDGDQIVVEVQETVFVSDVVDSDITVHNFVPDDPDSVVIQDVIEDVVIEDVQCPDIMEEADVSETVIIPEQVLDSDVTEEVSLAHCTVPDDVLASDITSASMSMPEHVLTGDSIHVSDVGHVGHVGHVEHVVHDSVVEAEIVTDPLTTDVVSEEVLVADCASEAVIDANGIPVDQQDDDKGNCEDYLMISLDDAGKIEHDGSSGMTMDTESEIDPCKVDGTCPEVIKVYIFKADPGEDDLGGTVDIVESEPENDHGVELLDQNSSIRVPREKMVYMTVNDSQPEDEDLNVAEIADEVYMEVIVGEEDAAAAAAAAAVHEQQMDDNEIKTFMPIAWAAAYGNNSDGIENRNGTASALLHIDESAGLGRLAKQKPKKRRRPDSRQYQTAIIIGPDGHPLTVYPCMICGKKFKSRGFLKRHMKNHPEHLAKKKYRCTDCDYTTNKKISLHNHLESHKLTSKAEKAIECDECGKHFSHAGALFTHKMVHKEKGANKMHKCKFCEYETAEQGLLNRHLLAVHSKNFPHICVECGKGFRHPSELKKHMRIHTGEKPYQCQYCEYRSADSSNLKTHVKTKHSKEMPFKCDICLLTFSDTKEVQQHALIHQESKTHQCLHCDHKSSNSSDLKRHIISVHTKDYPHKCDMCDKGFHRPSELKKHVAAHKGKKMHQCRHCDFKIADPFVLSRHILSVHTKDLPFRCKRCRKGFRQQSELKKHMKTHSGRKVYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEYCKKGFRRPSEKNQHIMRHHKEVGLP>sp|P17010-2|ZFX_HUMAN Isoform 2 of Zinc finger X-chromosomal proteinOS=Homo sapiens OX=9606 GN=ZFXMTMDTESEIDPCKVDGTCPEVIKVYIFKADPGEDDLGGTVDIVESEPENDHGVELLDQNSSIRVPREKMVYMTVNDSQPEDEDLNVAEIADEVYMEVIVGEEDAAAAAAAAAVHEQQMDDNEIKTFMPIAWAAAYGNNSDGIENRNGTASALLHIDESAGLGRLAKQKPKKRRRPDSRQYQTAIIIGPDGHPLTVYPCMICGKKFKSRGFLKRHMKNHPEHLAKKKYRCTDCDYTTNKKISLHNHLESHKLTSKAEKAIECDECGKHFSHAGALFTHKMVHKEKGANKMHKCKFCEYETAEQGLLNRHLLAVHSKNFPHICVECGKGFRHPSELKKHMRIHTGEKPYQCQYCEYRSADSSNLKTHVKTKHSKEMPFKCDICLLTFSDTKEVQQHALIHQESKTHQCLHCDHKSSNSSDLKRHIISVHTKDYPHKCDMCDKGFHRPSELKKHVAAHKGKKMHQCRHCDFKIADPFVLSRHILSVHTKDLPFRCKRCRKGFRQQSELKKHMKTHSGRKVYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEYCKKGFRRPSEKNQHIMRHHKEVGLP>sp|P17010-3|ZFX_HUMAN Isoform 3 of Zinc finger X-chromosomal proteinOS=Homo sapiens OX=9606 GN=ZFXMDEDGLELQQEPNSFFDATDRVSFCHPGWSTVAPSGSTATSASQAQVICSASRVTGATGADGTHMDGDQIVVEVQETVFVSDVVDSDITVHNFVPDDPDSVVIQDVIEDVVIEDVQCPDIMEEADVSETVIIPEQVLDSDVTEEVSLAHCTVPDDVLASDITSASMSMPEHVLTGDSIHVSDVGHVGHVGHVEHVVHDSVVEAEIVTDPLTTDVVSEEVLVADCASEAVIDANGIPVDQQDDDKGNCEDYLMISLDDAGKIEHDGSSGMTMDTESEIDPCKVDGTCPEVIKVYIFKADPGEDDLGGTVDIVESEPENDHGVELLDQNSSIRVPREKMVYMTVNDSQPEDEDLNVAEIADEVYMEVIVGEEDAAAAAAAAAVHEQQMDDNEIKTFMPIAWAAAYGNNSDGIENRNGTASALLHIDESAGLGRLAKQKPKKRRRPDSRQYQTAIIIGPDGHPLTVYPCMICGKKFKSRGFLKRHMKNHPEHLAKKKYRCTDCDYTTNKKISLHNHLESHKLTSKAEKAIECDECGKHFSHAGALFTHKMVHKEKGANKMHKCKFCEYETAEQGLLNRHLLAVHSKNFPHICVECGKGFRHPSELKKHMRIHTGEKPYQCQYCEYRSADSSNLKTHVKTKHSKEMPFKCDICLLTFSDTKEVQQHALIHQESKTHQCLHCDHKSSNSSDLKRHIISVHTKDYPHKCDMCDKGFHRPSELKKHVAAHKGKKMHQCRHCDFKIADPFVLSRHILSVHTKDLPFRCKRCRKGFRQQSELKKHMKTHSGRKVYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEYCKKGFRRPSEKNQHIMRHHKEVGLP>sp|Q96KR1|ZFR_HUMAN Zinc finger RNA-binding protein OS=Homo sapiensOX=9606 GN=ZFR PE=1 SV=2MIPICPVVSFTYVPSRLGEDAKMATGNYFGFTHSGAAAAAAAAQYSQQPASGVAYSHPTTVASYTVHQAPVAAHTVTAAYAPAAATVAVARPAPVAVAAAATAAAYGGYPTAHTATDYGYTQRQQEAPPPPPPATTQNYQDSYSYVRSTAPAVAYDSKQYYQQPTATAAAVAAAAQPQPSVAETYYQTAPKAGYSQGATQYTQAQQTRQVTAIKPATPSPATTTFSIYPVSSTVQPVAAAATVVPSYTQSATYSTTAVTYSGTSYSGYEAAVYSAASSYYQQQQQQQKQAAAAAAAAAATAAWTGTTFTKKAPFQNKQLKPKQPPKPPQIHYCDVCKISCAGPQTYKEHLEGQKHKKKEAALKASQNTSSSNSSTRGTQNQLRCELCDVSCTGADAYAAHIRGAKHQKVVKLHTKLGKPIPSTEPNVVSQATSSTAVSASKPTASPSSIAANNCTVNTSSVATSSMKGLTTTGNSSLNSTSNTKVSAVPTNMAAKKTSTPKINFVGGNKLQSTGNKAEDIKGTECVKSTPVTSAVQIPEVKQDTVSEPVTPASLAALQSDVQPVGHDYVEEVRNDEGKVIRFHCKLCECSFNDPNAKEMHLKGRRHRLQYKKKVNPDLQVEVKPSIRARKIQEEKMRKQMQKEEYWRRREEEERWRMEMRRYEEDMYWRRMEEEQHHWDDRRRMPDGGYPHGPPGPLGLLGVRPGMPPQPQGPAPLRRPDSSDDRYVMTKHATIYPTEEELQAVQKIVSITERALKLVSDSLSEHEKNKNKEGDDKKEGGKDRALKGVLRVGVLAKGLLLRGDRNVNLVLLCSEKPSKTLLSRIAENLPKQLAVISPEKYDIKCAVSEAAIILNSCVEPKMQVTITLTSPIIREENMREGDVTSGMVKDPPDVLDRQKCLDALAALRHAKWFQARANGLQSCVIIIRILRDLCQRVPTWSDFPSWAMELLVEKAISSASSPQSPGDALRRVFECISSGIILKGSPGLLDPCEKDPFDTLATMTDQQREDITSSAQFALRLLAFRQIHKVLGMDPLPQMSQRFNIHNNRKRRRDSDGVDGFEAEGKKDKKDYDNF>sp|Q8N966|ZDH22_HUMAN Palmitoyltransferase ZDHHC22 OS=Homo sapiensOX=9606 GN=ZDHHC22 PE=1 SV=2MLALRLLNVVAPAYFLCISLVTFVLQLFLFLPSMREDPAAARLFSPALLHGALFLFLSANALGNYVLVIQNSPDDLGACQGASARKTPCPSPSTHFCRVCARVTLRHDHHCFFTGNCIGSRNMRNFVLFCLYTSLACLYSMVAGVAYISAVLSISFAHPLAFLTLLPTSISQFFSGAVLGSEMFVILMLYLWFAIGLACAGFCCHQLLLILRGQTRHQVRKGVAVRARPWRKNLQEVFGKRWLLGLLVPMFNVGSESSKQQDK>sp|Q9NR11|ZN302_HUMAN Zinc finger protein 302 OS=Homo sapiens OX=9606GN=ZNF302 PE=1 SV=1MSQVTFSDVAIDFSHEEWACLDSAQRDLYKDVMVQNYENLVSVGLSVTKPYVIMLLEDGKEPWMMEKKLSKAYPFPLSHSVPASVNFGFSALFEHCSEVTEIFELSELCVFWVLHFLSNSPNSTVEAFSRSKKKKKKKKKRQCFAFLIYFRLGIKMGKQGIINKEGYLYEDSPQPVTMEKVVKQSYEFSNSNKNLEYTECDTFRSTFHSKSTLSEPQNNSAEGNSHKYDILKKNLSKKSVIKSERINGGKKLLNSNKSGAAFNQSKSLTLPQTCNREKIYTCSECGKAFGKQSILSRHWRIHTGEKPYECRECGKTFSHGSSLTRHQISHSGEKPYKCIECGKAFSHGSSLTNHQSTHTGEKPYECMNCGKSFSRVSLLIQHLRIHTQEKRYECRICGKAFIHSSSLIHHQKSHTGEKPYECRECGKAFCCSSHLTQHQRIHSMKKKYECNKCLKVFSSFSFLVQHQSIHTEEKPFEV>sp|Q9NR11-2|ZN302_HUMAN Isoform 2 of Zinc finger protein 302 OS=Homosapiens OX=9606 GN=ZNF302MSQVTFSDVAIDFSHEEWACLDSAQRDLYKDVMVQNYENLVSVGLSVTKPYVIMLLEDGKEPWMMEKKLSKDWESRWENKELSTKKDIYDEDSPQPVTMEKVVKQSYEFSNSNKNLEYTECDTFRSTFHSKSTLSEPQNNSAEGNSHKYDILKKNLSKKSVIKSERINGGKKLLNSNKSGAAFNQSKSLTLPQTCNREKIYTCSECGKAFGKQSILSRHWRIHTGEKPYECRECGKTFSHGSSLTRHQISHSGEKPYKCIECGKAFSHGSSLTNHQSTHTGEKPYECMNCGKSFSRVSLLIQHLRIHTQEKRYECRICGKAFIHSSSLIHHQKSHTGEKPYECRECGKAFCCSSHLTQHQRIHSMKKKYECNKCLKVFSSFSFLVQHQSIHTEEKPFEV>sp|A8MUV8|ZN727_HUMAN Putative zinc finger protein 727 OS=Homo sapiensOX=9606 GN=ZNF727 PE=5 SV=3MRVLTFRDVAVEFSPEEWECLDSAQQRLYRDVMLENYGNLFSLGLAIFKPDLITYLEQRKEPWNARRQKTVAKHPAGSLHFTAEILLEHDINDSFQKVILRKSGSCDLNTLRLKKDYQRVGNCKGQKSSYNGIHQCLSATRSKTCQYNKCGKAFGLCSIFTEHKKIFSREKCYKCEECGKDCRLSDFTIQKRIHTADRSYKCEECGKACKKFSNLTEHNRVHTGKKPYKCEECGKTFTCSSALTKHKRNHTGDRPYKCEECHKAFRCCSDLTKHKRIHTGEKPYKCKECHKAFRCCSDLTKHKRIHTGEKPYKCNECGKAFMWISALSQHNRIHTGEKPYICEECGKAFTYSSTLISHKRIHMELRPYKCEECGKTFKWFSDLTNHKRIHTGEKPYKCEECGKSFTCSSNLIKHKRIHMEVRPYKCEECGKTFKWFPDLTNHKRIHTGEKPYKCEECGKTFTCSSSLIKHKRSHTGDRPTSAKNVAKPLGGSQTLLNIR>sp|Q9ULJ6|ZMIZ1_HUMAN Zinc finger MIZ domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZMIZ1 PE=1 SV=3MNSMDRHIQQTNDRLQCIKQHLQNPANFHNAATELLDWCGDPRAFQRPFEQSLMGCLTVVSRVAAQQGFDLDLGYRLLAVCAANRDKFTPKSAALLSSWCEELGRLLLLRHQKSRQSDPPGKLPMQPPLSSMSSMKPTLSHSDGSFPYDSVPWQQNTNQPPGSLSVVTTVWGVTNTSQSQVLGNPMANANNPMNPGGNPMASGMTTSNPGLNSPQFAGQQQQFSAKAGPAQPYIQQSMYGRPNYPGSGGFGASYPGGPNAPAGMGIPPHTRPPADFTQPAAAAAAAAVAAAAATATATATATVAALQETQNKDINQYGPMGPTQAYNSQFMNQPGPRGPASMGGSMNPASMAAGMTPSGMSGPPMGMNQPRPPGISPFGTHGQRMPQQTYPGPRPQSLPIQNIKRPYPGEPNYGNQQYGPNSQFPTQPGQYPAPNPPRPLTSPNYPGQRMPSQPSSGQYPPPTVNMGQYYKPEQFNGQNNTFSGSSYSNYSQGNVNRPPRPVPVANYPHSPVPGNPTPPMTPGSSIPPYLSPSQDVKPPFPPDIKPNMSALPPPPANHNDELRLTFPVRDGVVLEPFRLEHNLAVSNHVFHLRPTVHQTLMWRSDLELQFKCYHHEDRQMNTNWPASVQVSVNATPLTIERGDNKTSHKPLHLKHVCQPGRNTIQITVTACCCSHLFVLQLVHRPSVRSVLQGLLKKRLLPAEHCITKIKRNFSSVAASSGNTTLNGEDGVEQTAIKVSLKCPITFRRIQLPARGHDCKHVQCFDLESYLQLNCERGTWRCPVCNKTALLEGLEVDQYMWGILNAIQHSEFEEVTIDPTCSWRPVPIKSDLHIKDDPDGIPSKRFKTMSPSQMIMPNVMEMIAALGPGPSPYPLPPPPGGTNSNDYSSQGNNYQGHGNFDFPHGNPGGTSMNDFMHGPPQLSHPPDMPNNMAALEKPLSHPMQETMPHAGSSDQPHPSIQQGLHVPHPSSQSGPPLHHSGAPPPPPSQPPRQPPQAAPSSHPHSDLTFNPSSALEGQAGAQGASDMPEPSLDLLPELTNPDELLSYLDPPDLPSNSNDDLLSLFENN>sp|Q9ULJ6-2|ZMIZ1_HUMAN Isoform 2 of Zinc finger MIZ domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=ZMIZ1RPPPAGPQAPEGARAGSRPVQLLALLSSWCEELGRLLLLRHQKSRQSDPPGKLPMQPPLSSMSSMKPTLSHSDGSFPYDSVPWQQNTNQPPGSLSVVTTVWGVTNTSQSQVLGNPMANANNPMNPGGNPMASGMTTSNPGLNSPQFAGQQQQFSAKAGPAQPYIQQSMYGRPNYPGSGGFGASYPGGPNAPAGMGIPPHTRPPADFTQPAAAAAAAAVAAAAATATATATATVAALQETQNKDINQYGPMGPTQAYNSQFMNQPGPRGPASMGGSMNPASMAAGMTPSGMSGPPMGMNQPRPPGISPFGTHGQRMPQQTYPGPRPQSLPIQNIKRPYPGEPNYGNQQYGPNSQFPTQPGQYPAPNPPRPLTSPNYPGQRMPSQPSSGQYPPPTVNMGQYYKPEQFNGQNNTFSGSSYSNYSQGNVNRPPRPVPVANYPHSPVPGNPTPPMTPGSSIPPYLSPSQDVKPPFPPDIKPNMSALPPPPANHNDELRLTFPVRDGVVLEPFRLEHNLAVSNHVFHLRPTVHQTLMWRSDLELQFKCYHHEDRQMNTNWPASVQVSVNATPLTIERGDNKTSHKPLHLKHVCQPGRNTIQITVTACCCSHLFVLQLVHRPSVRSVLQGLLKKRLLPAEHCITKIKRNFSSVAASSGNTTLNGEDGVEQTAIKVSLKCPITFRRIQLPARGHDCKHVQCFDLESYLQLNCERGTWRCPVCNKTALLEGLEVDQYMWGILNAIQHSEFEEVTIDPTCSWRPVPIKSDLHIKDDPDGIPSKRFKTMSPSQMIMPNVMEMIAALGPGPSPYPLPPPPGGTNSNDYSSQGNNYQGHGNFDFPHGNPGGTSMNDFMHGPPQLSHPPDMPNNMAALEKPLSHPMQETMPHAGSSDQPHPSIQQGLHVPHPSSQSGPPLHHSGAPPPPPSQPPRQPPQAAPSSHPHSDLTFNPSSALEGQAGAQGASDMPEPSLDLLPELTNPDELLSYLDPPDLPSNSNDDLLSLFENN>sp|Q96MN9|ZN488_HUMAN Zinc finger protein 488 OS=Homo sapiens OX=9606GN=ZNF488 PE=1 SV=1MPEWPPCLSVAPALVITMAAGKGAPLSPSAENRWRLSEPELGRGCKPVLLEKTNRLGPEAAVGRAGRDVGSAELALLVAPGKPRPGKPLPPKTRGEQRQSAFTELPRMKDRQVDAQAQEREHDDPTGQPGAPQLTQNIPRGPAGSKVFSVWPSGARSEQRSAFSKPTKRPAERPELTSVFPAGESADALGELSGLLNTTDLACWGRLSTPKLLVGDLWNLQALPQNAPLCSTFLGAPTLWLEHTQAQVPPPSSSSTTSWALLPPTLTSLGLSTQNWCAKCNLSFRLTSDLVFHMRSHHKKEHAGPDPHSQKRREEALACPVCQEHFRERHHLSRHMTSHS>sp|Q96MN9-2|ZN488_HUMAN Isoform 2 of Zinc finger protein 488 OS=Homosapiens OX=9606 GN=ZNF488MKDRQVDAQAQEREHDDPTGQPGAPQLTQNIPRGPAGSKVFSVWPSGARSEQRSAFSKPTKRPAERPELTSVFPAGESADALGELSGLLNTTDLACWGRLSTPKLLVGDLWNLQALPQNAPLCSTFLGAPTLWLEHTQAQVPPPSSSSTTSWALLPPTLTSLGLSTQNWCAKCNLSFRLTSDLVFHMRSHHKKEHAGPDPHSQKRREEALACPVCQEHFRERHHLSRHMTSHS>sp|Q7Z2W4|ZCCHV_HUMAN Zinc finger CCCH-type antiviral protein 1 OS=Homosapiens OX=9606 GN=ZC3HAV1 PE=1 SV=3MADPEVCCFITKILCAHGGRMALDALLQEIALSEPQLCEVLQVAGPDRFVVLETGGEAGITRSVVATTRARVCRRKYCQRPCDNLHLCKLNLLGRCNYSQSERNLCKYSHEVLSEENFKVLKNHELSGLNKEELAVLLLQSDPFFMPEICKSYKGEGRQQICNQQPPCSRLHICDHFTRGNCRFPNCLRSHNLMDRKVLAIMREHGLNPDVVQNIQDICNSKHMQKNPPGPRAPSSHRRNMAYRARSKSRDRFFQGSQEFLASASASAERSCTPSPDQISHRASLEDAPVDDLTRKFTYLGSQDRARPPSGSSKATDLGGTSQAGTSQRFLENGSQEDLLHGNPGSTYLASNSTSAPNWKSLTSWTNDQGARRKTVFSPTLPAARSSLGSLQTPEAVTTRKGTGLLSSDYRIINGKSGTQDIQPGPLFNNNADGVATDITSTRSLNYKSTSSGHREISSPRIQDAGPASRDVQATGRIADDADPRVALVNDSLSDVTSTTSSRVDDHDSEEICLDHLCKGCPLNGSCSKVHFHLPYRWQMLIGKTWTDFEHMETIEKGYCNPGIHLCSVGSYTINFRVMSCDSFPIRRLSTPSSVTKPANSVFTTKWIWYWKNESGTWIQYGEEKDKRKNSNVDSSYLESLYQSCPRGVVPFQAGSRNYELSFQGMIQTNIASKTQKDVIRRPTFVPQWYVQQMKRGPDHQPAKTSSVSLTATFRPQEDFCFLSSKKYKLSEIHHLHPEYVRVSEHFKASMKNFKIEKIKKIENSELLDKFTWKKSQMKEEGKLLFYATSRAYVESICSNNFDSFLHETHENKYGKGIYFAKDAIYSHKNCPYDAKNVVMFVAQVLVGKFTEGNITYTSPPPQFDSCVDTRSNPSVFVIFQKDQVYPQYVIEYTEDKACVIS>sp|Q7Z2W4-2|ZCCHV_HUMAN Isoform 2 of Zinc finger CCCH-type antiviralprotein 1 OS=Homo sapiens OX=9606 GN=ZC3HAV1MADPEVCCFITKILCAHGGRMALDALLQEIALSEPQLCEVLQVAGPDRFVVLETGGEAGITRSVVATTRARVCRRKYCQRPCDNLHLCKLNLLGRCNYSQSERNLCKYSHEVLSEENFKVLKNHELSGLNKEELAVLLLQSDPFFMPEICKSYKGEGRQQICNQQPPCSRLHICDHFTRGNCRFPNCLRSHNLMDRKVLAIMREHGLNPDVVQNIQDICNSKHMQKNPPGPRAPSSHRRNMAYRARSKSRDRFFQGSQEFLASASASAERSCTPSPDQISHRASLEDAPVDDLTRKFTYLGSQDRARPPSGSSKATDLGGTSQAGTSQRFLENGSQEDLLHGNPGSTYLASNSTSAPNWKSLTSWTNDQGARRKTVFSPTLPAARSSLGSLQTPEAVTTRKGTGLLSSDYRIINGKSGTQDIQPGPLFNNNADGVATDITSTRSLNYKSTSSGHREISSPRIQDAGPASRDVQATGRIADDADPRVALVNDSLSDVTSTTSSRVDDHDSEEICLDHLCKGCPLNGSCSKVHFHLPYRWQMLIGKTWTDFEHMETIEKGYCNPGIHLCSVGSYTINFRVMSCDSFPIRRLSTPSSVTKPANSVFTTKWIWYWKNESGTWIQYGEEKDKRKNSNVDSSYLESLYQSCPRGVVPFQAGSRNYELSFQGMIQTNIASKTQKDVIRRPTFVPQWYVQQMKRGPE>sp|Q7Z2W4-3|ZCCHV_HUMAN Isoform 3 of Zinc finger CCCH-type antiviralprotein 1 OS=Homo sapiens OX=9606 GN=ZC3HAV1MADPEVCCFITKILCAHGGRMALDALLQEIALSEPQLCEVLQVAGPDRFVVLETGGEAGITRSVVATTRARVCRRKYCQRPCDNLHLCKLNLLGRCNYSQSERNLCKYSHEVLSEENFKVLKNHELSGLNKEELAVLLLQSDPFFMPEICKSYKGEGRQQICNQQPPCSRLHICDHFTRGNCRFPNCLRSHNLMDRKVLAIMREHGLNPDVVQNIQDICNSKHMQKNPPGPRAPSSHRRNMAYRARSKSRDRFFQGSQEFLASASASAERSCTPSPDQISHRASLEDAPVDDLTRKFTYLGSQDRARPPSGSSKATDLGGTSQAGTSQRFLENGSQEDLLHGNPGSTYLASNSTSAPNWKSLTSWTNDQGARRKTVFSPTLPAARSSLGSLQTPEAVTTRKGTGLLSSDYRIINGKSGTQDIQPGPLFNNNADGVATDITSTRSLNYKSTSSGHREISSPRIQDAGPASRDVQATGRIADDADPRVALVNGKYKGKTLWASTFVHDIPNGSSQVVDKTTDVEKTGATGFGLTMAVKAEKDMLCTGSQSLRNLVPTTPGESTAPAQVSTLPQSPAALSSSNRAAVWGAQGQNCTQVPVSSASELTRKTTGSAQCKSLKDKGASVS>sp|Q7Z2W4-4|ZCCHV_HUMAN Isoform 4 of Zinc finger CCCH-type antiviralprotein 1 OS=Homo sapiens OX=9606 GN=ZC3HAV1MLIGKTWTDFEHMETIEKGYCNPGIHLCSVGSYTINFRVMSCDSFPIRRLSTPSSVTKPANSVFTTKWIWYWKNESGTWIQYGEEKDKRKNSNVDSSYLESLYQSCPRGVVPFQAGSRNYELSFQGMIQTNIASKTQKDVIRRPTFVPQWYVQQMKRGPDHQPAKTSSVSLTATFRPQEDFCFLSSKKYKLSEIHHLHPEYVRVSEHFKASMKNFKIEKIKKIENSELLDKFTWKKSQMKEEGKLLFYATSRAYVESICSNNFDSFLHETHENKYGKGIYFAKDAIYSHKNCPYDAKNVVMFVAQVLVGKFTEGNITYTSPPPQFDSCVDTRSNPSVFVIFQKDQVYPQYVIEYTEDKACVIS>sp|Q7Z2W4-5|ZCCHV_HUMAN Isoform 5 of Zinc finger CCCH-type antiviralprotein 1 OS=Homo sapiens OX=9606 GN=ZC3HAV1MLIGKTWTDFEHMETIEKGYCNPGIHLCSVGSYTINFRVMSCDSFPIRRLSTPSSVTKPANSVFTTKWIWYWKNESGTWIQYGEEKDKRKNSNVDSSYLESLYQSCPRGVVPFQAGSRNYELSFQGMIQTNIASKTQKDVIRRPTFVPQWYVQQMKRGPE>sp|Q8IVP9|ZN547_HUMAN Zinc finger protein 547 OS=Homo sapiens OX=9606GN=ZNF547 PE=1 SV=2MAEMNPAQGHVVFEDVAIYFSQEEWGHLDEAQRLLYRDVMLENLALLSSLGCCHGAEDEEAPLEPGVSVGVSQVMAPKPCLSTQNTQPCETCSSLLKDILRLAEHDGTHPEQGLYTCPAHLHQHQKEQIREKLSRGDGGRPTFVKNHRVHMAGKTFLCSECGKAFSHKHKLSDHQKIHTGERTYKCSKCGILFMERSTLNRHQRTHTGERPYECNECGKAFLCKSHLVRHQTIHSGERPYECSECGKLFMWSSTLITHQRVHTGKRPYGCSECGKFFKCNSNLFRHYRIHTGKRSYGCSECGKFFMERSTLSRHQRVHTGERPYECNECGKFFSLKSVLIQHQRVHTGERPYECSECGKAFLTKSHLICHQTVHTAAKQCSECGKFFRYNSTLLRHQKVHTG>sp|Q8IVP9-2|ZN547_HUMAN Isoform 2 of Zinc finger protein 547 OS=Homosapiens OX=9606 GN=ZNF547MAEMNPAQGHVVFEDVAIYFSQEEWGHLDEAQRLLYRDVMLENLALLSSLGCCHGAEDEEAPLEPGVSVGVSQVMAPKPCLSTQNTQPCETCSSLLKDILRLAEHDGTHPEQGLYTCPAHLHQHQKEQIREKLSRGDGGRPTFVKNHRVHMAGKTFLCSECGKAFSHKHKLSDHQKIHTGERTYKCSKCGILFMERSTLNRHQRTHTGERPYECNECGKAFLCKSHLVRHQTIHSGERPYECSECGKLFMWSSTLITHQRVHTGKRPYGCSECGKFFKCNSNLFRHYRIHTGKRSYGCSECGKFFMERSTLSRHQRVHTGERPYECNECGKFFSLKSVLIQHQRVYTEEESFQ>sp|Q96JM2|ZN462_HUMAN Zinc finger protein 462 OS=Homo sapiens OX=9606GN=ZNF462 PE=1 SV=3MEVLQCDGCDFRAPSYEDLKAHIQDVHTAFLQPTDVAEDNVNELRCGSVNASNQTEVEFSSIKDEFAIAEDLSGQNATSLGTGGYYGHSPGYYGQHIAANPKPTNKFFQCKFCVRYFRSKNLLIEHTRKVHGAQAEGSSSGPPVPGSLNYNIMMHEGFGKVFSCQFCTYKSPRRARIIKHQKMYHKNNLKETTAPPPAPAPMPDPVVPPVSLQDPCKELPAEVVERSILESMVKPLTKSRGNFCCEWCSYQTPRRERWCDHMMKKHRSMVKILSSLRQQQEGTNLPDVPNKSAPSPTSNSTYLTMNAASREIPNTTVSNFRGSMGNSIMRPNSSASKFSPMSYPQMKPKSPHNSGLVNLTERSRYGMTDMTNSSADLETNSMLNDSSSDEELNEIDSENGLSAMDHQTSGLSAEQLMGSDGNKLLETKGIPFRRFMNRFQCPFCPFLTMHRRSISRHIENIHLSGKTAVYKCDECPFTCKSSLKLGAHKQCHTGTTSDWDAVNSQSESISSSLNEGVVSYESSSINGRKSGVMLDPLQQQQPPQPPPPPPPPPPSQPQPLQQPQPPQLQPPHQVPPQPQTQPPPTQQPQPPTQAAPLHPYKCTMCNYSTTTLKGLRVHQQHKHSFCDNLPKFEGQPSSLPLENETDSHPSSSNTVKKSQTSILGLSSKNNFVAKASRKLANDFPLDLSPVKKRTRIDEIASNLQSKINQTKQQEDAVINVEDDEEEEEDNEVEIEVELDREEEPTEPIIEVPTSFSAQQIWVRDTSEPQKEPNFRNITHDYNATNGAEIELTLSEDEEDYYGSSTNLKDHQVSNTALLNTQTPIYGTEHNSENTDFGDSGRLYYCKHCDFNNKSARSVSTHYQRMHPYIKFSFRYILDPNDHSAVYRCLECYIDYTNFEDLQQHYGEHHPEAMNVLNFDHSDLIYRCRFCSYTSPNVRSLMPHYQRMHPTVKINNAMIFSSYVVEQQEGLNTESQTLREILNSAPKNMATSTPVARGGGLPATFNKNTPKTFTPECENQKDPLVNTVVVYDCDVCSFASPNMHSVLVHYQKKHPEEKASYFRIQKTMRMVSVDRGSALSQLSFEVGAPMSPKMSNMGSPPPPQPPPPDLSTELYYCKHCSYSNRSVVGVLVHYQKRHPEIKVTAKYIRQAPPTAAMMRGVEGPQGSPRPPAPIQQLNRSSSERDGPPVENEMFFCQHCDYGNRTVKGVLIHYQKKHRDFKANADVIRQHTATIRSLCDRNQKKPASCVLVSPSNLERDKTKLRALKCRQCSYTSPYFYALRKHIKKDHPALKATVTSIMRWAFLDGLIEAGYHCEWCIYSHTEPNGLLLHYQRRHPEHYVDYTYMATKLWAGPDPSPPSLTMPAEAKTYRCRDCVFEAVSIWDITNHYQAFHPWAMNGDESVLLDIIKEKDAVEKPILSSEELAGPVNCENSIPTPFPEQEAECPEDARLSPEKSLQLASANPAISSTPYQCTVCQSEYNNLHGLLTHYGKKHPGMKVKAADFAQDIDINPGAVYKCRHCPYINTRIHGVLTHYQKRHPSIKVTAEDFVHDVEQSADISQNDVEETSRIFKQGYGAYRCKLCPYTHGTLEKLKIHYEKYHNQPEFDVFSQSPPKLPVPLEPEMTTEVSPSQVSITEEEVGEEPVSTSHFSTSHLVSHTVFRCQLCKYFCSTRKGIARHYRIKHNNVRAQPEGKNNLFKCALCAYTNPIRKGLAAHYQKRHDIDAYYTHCLAASRTISDKPNKVIIPSPPKDDSPQLSEELRRAVEKKKCSLCSFQSFSKKGIVSHYMKRHPGVFPKKQHASKLGGYFTAVYADEHEKPTLMEEEERGNFEKAEVEGEAQEIEWLPFRCIKCFKLSFSTAELLCMHYTDHHSRDLKRDFIILGNGPRLQNSTYQCKHCDSKLQSTAELTSHLNIHNEEFQKRAKRQERRKQLLSKQKYADGAFADFKQERPFGHLEEVPKIKERKVVGYKCKFCVEVHPTLRAICNHLRKHVQYGNVPAVSAAVKGLRSHERSHLALAMFTREDKYSCQYCSFVSAFRHNLDRHMQTHHGHHKPFRCKLCSFKSSYNSRLKTHILKAHAGEHAYKCSWCSFSTMTISQLKEHSLKVHGKALTLPRPRIVSLLSSHSHHSSQKATPAEEVEDSNDSSYSEPPDVQQQLNHYQSAALARNNSRVSPVPLSGAAAGTEQKTEAVLHCEFCEFSSGYIQSIRRHYRDKHGGKKLFKCKDCSFYTGFKSAFTMHVEAGHSAVPEEGPKDLRCPLCLYHTKYKRNMIDHIVLHREERVVPIEVCRSKLSKYLQGVVFRCDKCTFTCSSDESLQQHIEKHNELKPYKCQLCYYETKHTEELDSHLRDEHKVSRNFELVGRVNLDQLEQMKEKMESSSSDDEDKEEEMNSKAEDRELMRFSDHGAALNTEKRFPCEFCGRAFSQGSEWERHVLRHGMALNDTKQVSREEIHPKEIMENSVKMPSIEEKEDDEAIGIDFSLKNETVAICVVTADKSLLENAEAKKE>sp|Q96JM2-2|ZN462_HUMAN Isoform 2 of Zinc finger protein 462 OS=Homosapiens OX=9606 GN=ZNF462MMRGVEGPQGSPRPPAPIQQLNRSSSERDGPPVENEMFFCQHCDYGNRTVKGVLIHYQKKHRDFKANADVIRQHTATIRSLCDRNQKKPASCVLVSPSNLERDKTKLRALKCRQCSYTSPYFYALRKHIKKDHPALKATVTSIMRWAFLDGLIEAGYHCEWCIYSHTEPNGLLLHYQRRHPEHYVDYTYMATKLWAGPDPSPPSLTMPAEAKTYRCRDCVFEAVSIWDITNHYQAFHPWAMNGDESVLLDIIKEKDAVEKPILSSEELAGPVNCENSIPTPFPEQEAECPEDARLSPEKSLQLASANPAISSTPYQCTVCQSEYNNLHGLLTHYGKKHPGMKVKAADFAQDIDINPGAVYKCRHCPYINTRIHGVLTHYQKRHPSIKVTAEDFVHDVEQSADISQNDVEETSRIFKQGYGAYRCKLCPYTHGTLEKLKIHYEKYHNQPEFDVFSQSPPKLPVPLEPEMTTEVSPSQVSITEEEVGEEPVSTSHFSTSHLVSHTVFRCQLCKYFCSTRKGIARHYRIKHNNVRAQPEGKNNLFKCALCAYTNPIRKGLAAHYQKRHDIDAYYTHCLAASRTISDKPNKVIIPSPPKDDSPQLSEELRRAVEKKKCSLCSFQSFSKKGIVSHYMKRHPGVFPKKQHASKLGGYFTAVYADEHEKPTLMEEEERGNFEKAEVEGEAQEIEWLPFRCIKCFKLSFSTAELLCMHYTDHHSRDLKRDFIILGNGPRLQNSTYQCKHCDSKLQSTAELTSHLNIHNEEFQKRAKRQERRKQLLSKQKYADGAFADFKQERPFGHLEEVPKIKERKVVGYKCKFCVEVHPTLRAICNHLRKHVQYGNVPAVSAAVKQEADDPAHLFLDGLEAAKDASGALVGRVDGEHCLLDGMLEDETRPGGYHCSQCDRVLMSMQGLRSHERSHLALAMFTREDKYSCQYCSFVSAFRHNLDRHMQTHHGHHKPFRCKLCSFKSSYNSRLKTHILKAHAGEHAYKCSWCSFSTMTISQLKEHSLKVHGKALTLPRPRIVSLLSSHSHHSSQKATPAEEVEDSNDSSYSEPPDVQQQLNHYQSAALARNNSRVSPVPLSGAAAGTEQKTEAVLHCEFCEFSSGYIQSIRRHYRDKHGGKKLFKCKDCSFYTGFKSAFTMHVEAGHSAVPEEGPKDLRCPLCLYHTKYKRNMIDHIVLHREERVVPIEVCRSKLSKYLQGVVFRCDKCTFTCSSDESLQQHIEKHNELKPYKCQLCYYETKHTEELDSHLRDEHKVSRNFELVGRVNLDQLEQMKEKMESSSSDDEDKEEEMNSKAEDRELMRFSDHGAALNTEKRFPCEFCGRAFSQGSEWERHVLRHGMALNDTKQVSREEIHPKEIMENSVKMPSIEEKEDDEAIGIDFSLKNETVAICVVTADKSLLENAEAKKE>sp|Q96JM2-3|ZN462_HUMAN Isoform 3 of Zinc finger protein 462 OS=Homosapiens OX=9606 GN=ZNF462MEVLQCDGCDFRAPSYEDLKAHIQDVHTAFLQPTDVAEDNVNELRCGSVNASNQTEVEFSSIKDEFAIAEDLSGQNATSLGTGGYYGHSPGYYGQHIAANPKPTNKFFQCKFCVRYFRSKNLLIEHTRKVHGAQAEGSSSGPPVPGSLNYNIMMHEGFGKVFSCQFCTYKSPRRARIIKHQKMYHKNNLKETTAPPPAPAPMPDPVVPPVSLQDPCKELPAEVVERSILESMVKPLTKSRGNFCCEWCSYQTPRRERWCDHMMKKHRSMVKILSSLRQQQEGTNLPDVPNKSAPSPTSNSTYLTMNAASREIPNTTVSNFRGSMGNSIMRPNSSASKFSPMSYPQMKPKSPHNSGLVNLTERSRYGMTDMTNSSADLETNSMLNDSSSDEELNEIDSENGLSAMDHQTSGLSAEQLMGSDGNKLLETKGIPFRRFMNRFQCPFCPFLTMHRRSISRHIENIHLSGKTAVYKCDECPFTCKSSLKLGAHKQCHTGTTSDWDAVNSQSESISSSLNEGVVSYESSSINGRKSGVMLDPLQQQQPPQPPPPPPPPPPSQPQPLQQPQPPQLQPPHQVPPQPQTQPPPTQQPQPPTQAAPLHPYKCTMCNYSTTTLKGLRVHQQHKHSFCDNLPKFEGQPSSLPLENETDSHPSSSNTVKKSQTSILGLSSKNNFVAKASRKLANDFPLDLSPVKKRTRIDEIASNLQSKINQTKQQEDAVINVEDDEEEEEDNEVEIEVELDREEEPTEPIIEVPTSFSAQQIWVRDTSEPQKEPNFRNITHDYNATNGAEIELTLSEDEEDYYGSSTNLKDHQVSNTALLNTQTPIYGTEHNSENTDFGDSGRLYYCKHCDFNNKSARSVSTHYQRMHPYIKFSFRYILDPNDHSAVYRCLECYIDYTNFEDLQQHYGEHHPEAMNVLNFDHSDLIYRCRFCSYTSPNVRSLMPHYQRMHPTVKINNAMIFSSYVVEQQEGLNTESQTLREILNSAPKNMATSTPVARGGGLPATFNKNTPKTFTPECENQKDPLVNTVVVYDCDVCSFASPNMHSVLVHYQKKHPEEKASYFRIQKTMRMVSVDRGSALSQLSFEVGAPMSPKMSNMGSPPPPQPPPPDLSTELYYCKHCSYSNRSVVGVLVHYQKRHPEIKVTAKYIRQAPPTAAMMRGVEGPQGSPRPPAPIQQLNRSSSERDGPPVENEMFFCQHCDYGNRTVKGVLIHYQKKHRDFKANADVIRQHTATIRSLCDRNQKKPASCVLVSPSNLERDKTKLRALKCRQCSYTSPYFYALRKHIKKDHPALKATVTSIMRWAFLDGLIEAGYHCEWCIYSHTEPNGLLLHYQRRHPEHYVDYTYMATKLWAGPDPSPPSLTMPAEAKTYRCRDCVFEAVSIWDITNHYQAFHPWAMNGDESVLLDIIKEKDAVEKPILSSEELAGPVNCENSIPTPFPEQEAECPEDARLSPEKSLQLASANPAISSTPYQCTVCQSEYNNLHGLLTHYGKKHPGMKVKAADFAQDIDINPGAVYKCRHCPYINTRIHGVLTHYQKRHPSIKVTAEDFVHDVEQSADISQNDVEETSRIFKQGYGAYRCKLCPYTHGTLEKLKIHYEKYHNQPEFDVFSQSPPKLPVPLEPEMTTEVSPSQVSITEEEVGEEPVSTSHFSTSHLVSHTVFRCQLCKYFCSTRKGIARHYRIKHNNVRAQPEGKNNLFKCALCAYTNPIRKGLAAHYQKRHDIDAYYTHCLAASRTISDKPNKVIIPSPPKDDSPQLSEELRRAVEKKKCSLCSFQSFSKKGIVSHYMKRHPGVFPKKQHASKLGGYFTAVYADEHEKPTLMEEEERGNFEKAEVEGEAQEIEWLPFRCIKCFKLSFSTAELLCMHYTDHHSRDLKRDFIILGNGPRLQNSTYQCKHCDSKLQSTAELTSHLNIHNEEFQKRAKRQERRKQLLSKQKYADGAFADFKQERPFGHLEEVPKIKERKVVGYKCKFCVEVHPTLRAICNHLRKHVQYGNVPAVSAAVKEADDPAHLFLDGLEAAKDASGALVGRVDGEHCLLDGMLEDETRPGGYHCSQCDRVLMSMQGLRSHERSHLALAMFTREDKYSCQYCSFVSAFRHNLDRHMQTHHGHHKPFRCKLCSFKSSYNSRLKTHILKAHAGEHAYKCSWCSFSTMTISQLKEHSLKVHGKALTLPRPRIVSLLSSHSHHSSQKATPAEEVEDSNDSSYSEPPDVQQQLNHYQSAALARNNSRVSPVPLSGAAAGTEQKTEAVLHCEFCEFSSGYIQSIRRHYRDKHGGKKLFKCKDCSFYTGFKSAFTMHVEAGHSAVPEEGPKDLRCPLCLYHTKYKRNMIDHIVLHREERVVPIEVCRSKLSKYLQGVVFRCDKCTFTCSSDESLQQHIEKHNELKPYKCQLCYYETKHTEELDSHLRDEHKVSRNFELVGRVNLDQLEQMKEKMESSSSDDEDKEEEMNSKAEDRELMRFSDHGAALNTEKRFPCEFCGRAFSQGSEWERHVLRHGMALNDTKQVSREEIHPKEIMENSVKMPSIEEKEDDEAIGIDFSLKNETVAICVVTADKSLLENAEAKKE>sp|Q96CK0|ZN653_HUMAN Zinc finger protein 653 OS=Homo sapiens OX=9606GN=ZNF653 PE=1 SV=1MAERALEPEAEAEAEAGAGGEAAAEEGAAGRKARGRPRLTESDRARRRLESRKKYDVRRVYLGEAHGPWVDLRRRSGWSDAKLAAYLISLERGQRSGRHGKPWEQVPKKPKRKKRRRRNVNCLKNVVIWYEDHKHRCPYEPHLAELDPTFGLYTTAVWQCEAGHRYFQDLHSPLKPLSDSDPDSDKVGNGLVAGSSDSSSSGSASDSEESPEGQPVKAAAAAAAATPTSPVGSSGLITQEGVHIPFDVHHVESLAEQGTPLCSNPAGNGPEALETVVCVPVPVQVGAGPSALFENVPQEALGEVVASCPMPGMVPGSQVIIIAGPGYDALTAEGIHLNMAAGSGVPGSGLGEEVPCAMMEGVAAYTQTEPEGSQPSTMDATAVAGIETKKEKEDLCLLKKEEKEEPVAPELATTVPESAEPEAEADGEELDGSDMSAIIYEIPKEPEKRRRSKRSRVMDADGLLEMFHCPYEGCSQVYVALSSFQNHVNLVHRKGKTKVCPHPGCGKKFYLSNHLRRHMIIHSGVREFTCETCGKSFKRKNHLEVHRRTHTGETPLQCEICGYQCRQRASLNWHMKKHTAEVQYNFTCDRCGKRFEKLDSVKFHTLKSHPDHKPT>sp|Q9BXS9|S26A6_HUMAN Solute carrier family 26 member 6 OS=Homo sapiensOX=9606 GN=SLC26A6 PE=1 SV=1MGLADASGPRDTQALLSATQAMDLRRRDYHMERPLLNQEHLEELGRWGSAPRTHQWRTWLQCSRARAYALLLQHLPVLVWLPRYPVRDWLLGDLLSGLSVAIMQLPQGLAYALLAGLPPVFGLYSSFYPVFIYFLFGTSRHISVGTFAVMSVMVGSVTESLAPQALNDSMINETARDAARVQVASTLSVLVGLFQVGLGLIHFGFVVTYLSEPLVRGYTTAAAVQVFVSQLKYVFGLHLSSHSGPLSLIYTVLEVCWKLPQSKVGTVVTAAVAGVVLVVVKLLNDKLQQQLPMPIPGELLTLIGATGISYGMGLKHRFEVDVVGNIPAGLVPPVAPNTQLFSKLVGSAFTIAVVGFAIAISLGKIFALRHGYRVDSNQELVALGLSNLIGGIFQCFPVSCSMSRSLVQESTGGNSQVAGAISSLFILLIIVKLGELFHDLPKAVLAAIIIVNLKGMLRQLSDMRSLWKANRADLLIWLVTFTATILLNLDLGLVVAVIFSLLLVVVRTQMPHYSVLGQVPDTDIYRDVAEYSEAKEVRGVKVFRSSATVYFANAEFYSDALKQRCGVDVDFLISQKKKLLKKQEQLKLKQLQKEEKLRKQAASPKGASVSINVNTSLEDMRSNNVEDCKMMQVSSGDKMEDATANGQEDSKAPDGSTLKALGLPQPDFHSLILDLGALSFVDTVCLKSLKNIFHDFREIEVEVYMAACHSPVVSQLEAGHFFDASITKKHLFASVHDAVTFALQHPRPVPDSPVSVTRL>sp|Q9BXS9-2|S26A6_HUMAN Isoform 2 of Solute carrier family 26 member 6OS=Homo sapiens OX=9606 GN=SLC26A6MGLADASGPRDTQALLSATQAMDLRRRDYHMERPLLNQEHLEELGRWGSAPRTHQWRTWLQCSRARAYALLLQHLPVLVWLPRYPVRDWLLGDLLSGLSVAIMQLPQGLAYALLAGLPPVFGLYSSFYPVFIYFLFGTSRHISVGTFAVMSVMVGSVTESLAPQALNDSMINETARDAARVQVASTLSVLVGLFQVGLGLIHFGFVVTYLSEPLVRGYTTAAAVQVFVSQLKYVFGLHLSSHSGPLSLIYTVLEVCWKLPQSKVGTVVTAAVAGVVLVVVKLLNDKLQQQLPMPIPGELLTLIGATGISYGMGLKHRFEVDVVGNIPAGLVPPVAPNTQLFSKLVGSAFTIAVVGFAIAISLGKIFALRHGYRVDSNQELVALGLSNLIGGIFQCFPVSCSMSRSLVQESTGGNSQVAGAISSLFILLIIVKLGELFHDLPKAVLAAIIIVNLKGMLRQLSDMRSLWKANRADLLIWLVTFTATILLNLDLGLVVAVIFSLLLVVVRTQMPHYSVLGQVPDTDIYRDVAEYSEAKEVRGVKVFRSSATVYFANAEFYSDALKQRCGVDVDFLISQKKKLLKKQEQLKLKQLQKEEKLRKQAGPLLSACLAPQQVSSGDKMEDATANGQEDSKAPDGSTLKALGLPQPDFHSLILDLGALSFVDTVCLKSLKNIFHDFREIEVEVYMAACHSPVVSQLEAGHFFDASITKKHLFASVHDAVTFALQHPRPVPDSPVSVTRL>sp|Q9BXS9-3|S26A6_HUMAN Isoform 3 of Solute carrier family 26 member 6OS=Homo sapiens OX=9606 GN=SLC26A6MGLADASGPRDTQALLSATQAMDLRRRDYHMERPLLNQEHLEELGRWGSAPRTHQWRTWLQCSRARAYALLLQHLPVLVWLPRYPVRDWLLGDLLSGLSVAIMQLPQGLAYALLAGLPPVFGLYSSFYPVFIYFLFGTSRHISVGTFAVMSVMVGSVTESLAPQALNDSMINETARDAARVQVASTLSVLVGLFQVGLGLIHFGFVVTYLSEPLVRGYTTAAAVQVFVSQLKYVFGLHLSSHSGPLSLIYTVLEVCWKLPQSKVGTVVTAAVAGVVLVVVKLLNDKLQQQLPMPIPGELLTLIGATGISYGMGLKHRFEVDVVGNIPAGLVPPVAPNTQLFSKLVGSAFTIAVVGFAIAISLGKIFALRHGYRVDSNQELVALGLSNLIGGIFQCFPVSCSMSRSLVQESTGGNSQVAGAISSLFILLIIVKLGELFHDLPKAVLAAIIIVNLKGMLRQLSDMRSLWKANRADLLIWLVTFTATILLNLDLGLVVAVIFSLLLVVVRTQMPHYSVLGQVPDTDIYRDVAEYSEAKEVRGVKVFRSSATVYFANAEFYSDALKQRCGVDVDFLISQKKKLLKKQEQLKLKQLQKEEKLRKQAASPKGASVSINVNTSLEDMRSNNVEDCKMMVSSGDKMEDATANGQEDSKAPDGSTLKALGLPQPDFHSLILDLGALSFVDTVCLKSLKNIFHDFREIEVEVYMAACHSPVVSQLEAGHFFDASITKKHLFASVHDAVTFALQHPRPVPDSPVSVTRL>sp|Q9BXS9-4|S26A6_HUMAN Isoform 4 of Solute carrier family 26 member 6OS=Homo sapiens OX=9606 GN=SLC26A6MDLRRRDYHMERPLLNQEHLEELGRWGSAPRTHQWRTWLQCSRARAYALLLQHLPVLVWLPRYPVRDWLLGDLLSGLSVAIMQLPQGLAYALLAGLPPVFGLYSSFYPVFIYFLFGTSRHISVGTFAVMSVMVGSVTESLAPQALNDSMINETARDAARVQVASTLSVLVGLFQVGLGLIHFGFVVTYLSEPLVRGYTTAAAVQVFVSQLKYVFGLHLSSHSGPLSLIYTVLEVCWKLPQSKVGTVVTAAVAGVVLVVVKLLNDKLQQQLPMPIPGELLTLIGATGISYGMGLKHRFEVDVVGNIPAGLVPPVAPNTQLFSKLVGSAFTIAVVGFAIAISLGKIFALRHGYRVDSNQELVALGLSNLIGGIFQCFPVSCSMSRSLVQESTGGNSQVAGAISSLFILLIIVKLGELFHDLPKAVLAAIIIVNLKGMLRQLSDMRSLWKANRADLLIWLVTFTATILLNLDLGLVVAVIFSLLLVVVRTQMPHYSVLGQVPDTDIYRDVAEYSEAKEVRGVKVFRSSATVYFANAEFYSDALKQRCGVDVDFLISQKKKLLKKQEQLKLKQLQKEEKLRKQAASPKGASVSINVNTSLEDMRSNNVEDCKMMVSSGDKMEDATANGQEDSKAPDGSTLKALGLPQPDFHSLILDLGALSFVDTVCLKSLKNIFHDFREIEVEVYMAACHSPVVSQLEAGHFFDASITKKHLFASVHDAVTFALQHPRPVPDSPVSVTRL>sp|Q9BXS9-5|S26A6_HUMAN Isoform 5 of Solute carrier family 26 member 6OS=Homo sapiens OX=9606 GN=SLC26A6MDLRRRDYHMERPLLNQEHLEELGRWGSAPRTHQWRTWLQCSRARAYALLLQHLPVLVWLPRYPVRDWLLGDLLSGLSVAIMQLPQGLAYALLAGLPPVFGLYSSFYPVFIYFLFGTSRHISVGTFAVMSVMVGSVTESLAPQALNDSMINETARDAARVQVASTLSVLVGLFQVGLGLIHFGFVVTYLSEPLVRGYTTAAAVQVFVSQLKYVFGLHLSSHSGPLSLIYTVLEVCWKLPQSKLIGATGISYGMGLKHRFEVDVVGNIPAGLVPPVAPNTQLFSKLVGSAFTIAVVGFAIAISLGKIFALRHGYRVDSNQELVALGLSNLIGGIFQCFPVSCSMSRSLVQESTGGNSQVAGAISSLFILLIIVKLGELFHDLPKAVLAAIIIVNLKGMLRQLSDMRSLWKANRADLLIWLVTFTATILLNLDLGLVVAVIFSLLLVVVRTQMPHYSVLGQVPDTDIYRDVAEYSEAKEVRGVKVFRSSATVYFANAEFYSDALKQRCGVDVDFLISQKKKLLKKQEQLKLKQLQKEEKLRKQAASPKGASVSINVNTSLEDMRSNNVEDCKMMVSSGDKMEDATANGQEDSKAPDGSTLKALGLPQPDFHSLILDLGALSFVDTVCLKSLKNIFHDFREIEVEVYMAACHSPVVSQLEAGHFFDASITKKHLFASVHDAVTFALQHPRPVPDSPVSVTRL>sp|Q9BXS9-6|S26A6_HUMAN Isoform 6 of Solute carrier family 26 member 6OS=Homo sapiens OX=9606 GN=SLC26A6MDLRRRDYHMERPLLNQEHLEELGRWGSAPRTHQWRTWLQCSRARAYALLLQHLPVLVWLPRYPVRDWLLGDLLSGLSVAIMQLPQGLAYALLAGLPPVFGLYSSFYPVFIYFLFGTSRHISVGTFAVMSVMVGSVTESLAPQALNDSMINETARDAARVQVASTLSVLVGLFQVGLGLIHFGFVVTYLSEPLVRGYTTAAAVQVFVSQLKYVFGLHLSSHSGPLSLIYTVLEVCWKLPQSKVGTVVTAAVAGVVLVVVKLLNDKLQQQLPMPIPGELLTLIGATGISYGMGLKHRFEVDVVGNIPAGLVPPVAPNTQLFSKLVGSAFTIAVVGFAIAISLGKIFALRHGYRVDSNQELVALGLSNLIGGIFQCFPVSCSMSRSLVQESTGGNSQVAGAISSLFILLIIVKLGELFHDLPKAVLAAIIIVNLKGMLRQLSDMRSLWKANRADLLIWLVTFTATILLNLDLGLVVAVIFSLLLVVVRTQMPHYSVLGQVPDTDIYRDVAEYSEAKEVRGVKVFRSSATVYFANAEFYSDALKQRCGVDVDFLISQKKKLLKKQEQLKLKQLQKEEKLRKQAASPKGASVSINVNTSLEDMRSNNVEDCKMMVRLEVGKEVTAVSCRDAGSTCLMRNAMDPAAVGSRVLRRWQEEWGGWVRYSSGSVVICHRI>sp|Q9BXS9-7|S26A6_HUMAN Isoform 7 of Solute carrier family 26 member 6OS=Homo sapiens OX=9606 GN=SLC26A6MGLADASGPRDTQALLSATQAMDLRRRDYHMERPLLNQEHLEELGRWGSAPRTHQWRTWLQCSRARAYALLLQHLPVLVWLPRYPVRDWLLGDLLSGLSVAIMQLPQGLAYALLAGLPPVFGLYSSFYPVFIYFLFGTSRHISVATPGPLPLLTAPGRPTGGAGPDPLRLRGHLPVRTSCPRLYHSCSCAGLRLTAQVCVWPPSEQPLWATVPHLLLEVCWKLPQSKVGTVVTAAVAGVVLVVVKLLNDKLQQQLPMPIPGELLTLIGATGISYGMGLKHRFEVDVVGNIPAGLVPPVAPNTQLFSKLVGSAFTIAVVGFAIAISLGKIFALRHGYRVDSNQELVALGLSNLIGGIFQCFPVSCSMSRSLVQESTGGNSQVAGAISSLFILLIIVKLGELFHDLPKAVLAAIIIVNLKGMLRQLSDMRSLWKANRADLLIWLVTFTATILLNLDLGLVVAVIFSLLLVVVRTQMPHYSVLGQVPDTDIYRDVAEYSEAKEVRGVKVFRSSATVYFANAEFYSDALKQRCGVDVDFLISQKKKLLKKQEQLKLKQLQKEEKLRKQAASPKGASVSINVNTSLEDMRSNNVEDCKMMQVSSGDKMEDATANGQEDSKAPDGSTLKALGLPQPDFHSLILDLGALSFVDTVCLKSLKNIFHDFREIEVEVYMAACHSPVVSQLEAGHFFDASITKKHLFASVHDAVTFALQHPRPVPDSPVSVTRL>sp|O60248|SOX15_HUMAN Protein SOX-15 OS=Homo sapiens OX=9606 GN=SOX15PE=1 SV=1MALPGSSQDQAWSLEPPAATAAASSSSGPQEREGAGSPAAPGTLPLEKVKRPMNAFMVWSSAQRRQMAQQNPKMHNSEISKRLGAQWKLLDEDEKRPFVEEAKRLRARHLRDYPDYKYRPRRKAKSSGAGPSRCGQGRGNLASGGPLWGPGYATTQPSRGFGYRPPSYSTAYLPGSYGSSHCKLEAPSPCSLPQSDPRLQGELLPTYTHYLPPGSPTPYNPPLAGAPMPLTHL>sp|O60248-2|SOX15_HUMAN Isoform 2 of Protein SOX-15 OS=Homo sapiensOX=9606 GN=SOX15MALPGSSQDQAWSLEPPAATAAASSSSGPQEREGAGSPAAPGTLPLEKVKRPMNAFMVWSSAQRRQMAQQNPKMHNSEISKRLGAQWKLLDEDEKRPFVEEAKRLRARHLRDYPDYKYRPRRKAKSSGAGPSRCGQGRGNLASGGPLWGPGYATTQPSRGFGYRPPSYSTAYLPGSYG>sp|Q13884|SNTB1_HUMAN Beta-1-syntrophin OS=Homo sapiens OX=9606 GN=SNTB1PE=1 SV=3MAVAAAAAAAGPAGAGGGRAQRSGLLEVLVRDRWHKVLVNLSEDALVLSSEEGAAAYNGIGTATNGSFCRGAGAGHPGAGGAQPPDSPAGVRTAFTDLPEQVPESISNQKRGVKVLKQELGGLGISIKGGKENKMPILISKIFKGLAADQTQALYVGDAILSVNGADLRDATHDEAVQALKRAGKEVLLEVKYMREATPYVKKGSPVSEIGWETPPPESPRLGGSTSDPPSSQSFSFHRDRKSIPLKMCYVTRSMALADPENRQLEIHSPDAKHTVILRSKDSATAQAWFSAIHSNVNDLLTRVIAEVREQLGKTGIAGSREIRHLGWLAEKVPGESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATRLVHSGPGKGSPQAGVDLSFATRTGTRQGIETHLFRAETSRDLSHWTRSIVQGCHNSAELIAEISTACTYKNQECRLTIHYENGFSITTEPQEGAFPKTIIQSPYEKLKMSSDDGIRMLYLDFGGKDGEIQLDLHSCPKPIVFIIHSFLSAKITRLGLVA>sp|Q13884-2|SNTB1_HUMAN Isoform 2 of Beta-1-syntrophin OS=Homo sapiensOX=9606 GN=SNTB1MAVAAAAAAAGPAGAGGGRAQRSGLLEVLVRDRWHKVLVNLSEDALVLSSEEGAAAYNGIGTATNGSFCRGAGAGHPGAGGAQPPDSPAGVRTAFTDLPEQVPESISNQKRGVKVLKQELGGLGISIKGGKENKMPILISKIFKGLAADQTQALYVGDAILSVNGADLRDATHDEAVQALKRAGKEVLLEVKYMREATPYVKKGSPVSEIGWETPPPESPRLGGSTSDPPSSQSFSFHRDRKSIPLKMCYVTRSMALADPENRQLEIHSPDAKHTVILRSKDSATAQAWFSAIHSNVNDLLTRVIAEVREQLGKTGIAGSREIRHLGWLAEKVPGESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATSPHP>sp|Q8NBT2|SPC24_HUMAN Kinetochore protein Spc24 OS=Homo sapiens OX=9606GN=SPC24 PE=1 SV=2MAAFRDIEEVSQGLLSLLGANRAEAQQRRLLGRHEQVVERLLETQDGAEKQLREILTMEKEVAQSLLNAKEQVHQGGVELQQLEAGLQEAGEEDTRLKASLLYLTRELEELKEIEADLERQEKEVDEDTTVTIPSAVYVAQLYHQVSKIEWDYECEPGMVKGIHHGPSVAQPIHLDSTQLSRKFISDYLWSLVDTEW>sp|Q8NBT2-2|SPC24_HUMAN Isoform 2 of Kinetochore protein Spc24 OS=Homosapiens OX=9606 GN=SPC24MAAFRDIEEVSQGLLSLLGANRAEAQQRRLLGRHEQVVERLLETQDGAEKQLREILTMEKEVAQSLLNAKELERQEKEVDEDTTVTIPSAVYVAQLYHQVSKIEWDYECEPGMVKGIHHGPSVAQPIHLDSTQLSRKFISDYLWSLVDTEW>sp|Q8WVK2|SNR27_HUMAN U4/U6.U5 small nuclear ribonucleoprotein 27 kDaprotein OS=Homo sapiens OX=9606 GN=SNRNP27 PE=1 SV=1MGRSRSRSPRRERRRSRSTSRERERRRRERSRSRERDRRRSRSRSPHRRRSRSPRRHRSTSPSPSRLKERRDEEKKETKETKSKERQITEEDLEGKTEEEIEMMKLMGFASFDSTKGKKVDGSVNAYAINVSQKRKYRQYMNRKGGFNRPLDFIA>sp|Q9NXA8|SIR5_HUMAN NAD-dependent protein deacylase sirtuin-5,mitochondrial OS=Homo sapiens OX=9606 GN=SIRT5 PE=1 SV=2MRPLQIVPSRLISQLYCGLKPPASTRNQICLKMARPSSSMADFRKFFAKAKHIVIISGAGVSAESGVPTFRGAGGYWRKWQAQDLATPLAFAHNPSRVWEFYHYRREVMGSKEPNAGHRAIAECETRLGKQGRRVVVITQNIDELHRKAGTKNLLEIHGSLFKTRCTSCGVVAENYKSPICPALSGKGAPEPGTQDASIPVEKLPRCEEAGCGGLLRPHVVWFGENLDPAILEEVDRELAHCDLCLVVGTSSVVYPAAMFAPQVAARGVPVAEFNTETTPATNRFRFHFQGPCGTTLPEALACHENETVS>sp|Q9NXA8-2|SIR5_HUMAN Isoform 2 of NAD-dependent protein deacylasesirtuin-5, mitochondrial OS=Homo sapiens OX=9606 GN=SIRT5MRPLQIVPSRLISQLYCGLKPPASTRNQICLKMARPSSSMADFRKFFAKAKHIVIISGAGVSAESGVPTFRGAGGYWRKWQAQDLATPLAFAHNPSRVWEFYHYRREVMGSKEPNAGHRAIAECETRLGKQGRRVVVITQNIDELHRKAGTKNLLEIHGSLFKTRCTSCGVVAENYKSPICPALSGKGAPEPGTQDASIPVEKLPRCEEAGCGGLLRPHVVWFGENLDPAILEEVDRELAHCDLCLVVGTSSVVYPAAMFAPQVAARGVPVAEFNTETTPATNRFSHLISISSLIIIKN>sp|Q9NXA8-3|SIR5_HUMAN Isoform 3 of NAD-dependent protein deacylasesirtuin-5, mitochondrial OS=Homo sapiens OX=9606 GN=SIRT5MRPLQIVPSRLISQLYCGLKPPASTRNQICLKMARPSSSMADFRKFFAKAKHIVIISGAGVSAESGVPTFRGAGGYWRKWQAQDLATPLAFAHNPSRVWEFYHYRREVMGSKEPNAGHRAIAECETRLGKQGRRVVVITQNIDELHRKAGTKNLLEIHGSLFKTRCTSCGVVAENYKSPICPALSGKGCEEAGCGGLLRPHVVWFGENLDPAILEEVDRELAHCDLCLVVGTSSVVYPAAMFAPQVAARGVPVAEFNTETTPATNRFRFHFQGPCGTTLPEALACHENETVS>sp|Q9NXA8-4|SIR5_HUMAN Isoform 4 of NAD-dependent protein deacylasesirtuin-5, mitochondrial OS=Homo sapiens OX=9606 GN=SIRT5MGSKEPNAGHRAIAECETRLGKQGRRVVVITQNIDELHRKAGTKNLLEIHGSLFKTRCTSCGVVAENYKSPICPALSGKGAPEPGTQDASIPVEKLPRCEEAGCGGLLRPHVVWFGENLDPAILEEVDRELAHCDLCLVVGTSSVVYPAAMFAPQVAARGVPVAEFNTETTPATNRFRFHFQGPCGTTLPEALACHENETVS>sp|Q9UIG8|SO3A1_HUMAN Solute carrier organic anion transporter familymember 3A1 OS=Homo sapiens OX=9606 GN=SLCO3A1 PE=1 SV=3MQGKKPGGSSGGGRSGELQGDEAQRNKKKKKKVSCFSNIKIFLVSECALMLAQGTVGAYLVSVLTTLERRFNLQSADVGVIASSFEIGNLALILFVSYFGARGHRPRLIGCGGIVMALGALLSALPEFLTHQYKYEAGEIRWGAEGRDVCAANGSGGDEGPDPDLICRNRTATNMMYLLLIGAQVLLGIGATPVQPLGVSYIDDHVRRKDSSLYIGILFTMLVFGPACGFILGSFCTKIYVDAVFIDTSNLDITPDDPRWIGAWWGGFLLCGALLFFSSLLMFGFPQSLPPHSEPAMESEQAMLSEREYERPKPSNGVLRHPLEPDSSASCFQQLRVIPKVTKHLLSNPVFTCIILAACMEIAVVAGFAAFLGKYLEQQFNLTTSSANQLLGMTAIPCACLGIFLGGLLVKKLSLSALGAIRMAMLVNLVSTACYVSFLFLGCDTGPVAGVTVPYGNSTAPGSALDPYSPCNNNCECQTDSFTPVCGADGITYLSACFAGCNSTNLTGCACLTTVPAENATVVPGKCPSPGCQEAFLTFLCVMCICSLIGAMAQTPSVIILIRTVSPELKSYALGVLFLLLRLLGFIPPPLIFGAGIDSTCLFWSTFCGEQGACVLYDNVVYRYLYVSIAIALKSFAFILYTTTWQCLRKNYKRYIKNHEGGLSTSEFFASTLTLDNLGRDPVPANQTHRTKFIYNLEDHEWCENMESVL>sp|Q9UIG8-2|SO3A1_HUMAN Isoform 2 of Solute carrier organic aniontransporter family member 3A1 OS=Homo sapiens OX=9606 GN=SLCO3A1MQGKKPGGSSGGGRSGELQGDEAQRNKKKKKKVSCFSNIKIFLVSECALMLAQGTVGAYLVSVLTTLERRFNLQSADVGVIASSFEIGNLALILFVSYFGARGHRPRLIGCGGIVMALGALLSALPEFLTHQYKYEAGEIRWGAEGRDVCAANGSGGDEGPDPDLICRNRTATNMMYLLLIGAQVLLGIGATPVQPLGVSYIDDHVRRKDSSLYIGILFTMLVFGPACGFILGSFCTKIYVDAVFIDTSNLDITPDDPRWIGAWWGGFLLCGALLFFSSLLMFGFPQSLPPHSEPAMESEQAMLSEREYERPKPSNGVLRHPLEPDSSASCFQQLRVIPKVTKHLLSNPVFTCIILAACMEIAVVAGFAAFLGKYLEQQFNLTTSSANQLLGMTAIPCACLGIFLGGLLVKKLSLSALGAIRMAMLVNLVSTACYVSFLFLGCDTGPVAGVTVPYGNSTAPGSALDPYSPCNNNCECQTDSFTPVCGADGITYLSACFAGCNSTNLTGCACLTTVPAENATVVPGKCPSPGCQEAFLTFLCVMCICSLIGAMAQTPSVIILIRTVSPELKSYALGVLFLLLRLLGFIPPPLIFGAGIDSTCLFWSTFCGEQGACVLYDNVVYRYLYVSIAIALKSFAFILYTTTWQCLRKNYKRYIKNHEGGLSTSTEYQDIETEKTCPESHSPSEDSFVRS>sp|Q9UIG8-3|SO3A1_HUMAN Isoform 3 of Solute carrier organic aniontransporter family member 3A1 OS=Homo sapiens OX=9606 GN=SLCO3A1MNVSVLTTLERRFNLQSADVGVIASSFEIGNLALILFVSYFGARGHRPRLIGCGGIVMALGALLSALPEFLTHQYKYEAGEIRWGAEGRDVCAANGSGGDEGPDPDLICRNRTATNMMYLLLIGAQVLLGIGATPVQPLGVSYIDDHVRRKDSSLYIGILFTMLVFGPACGFILGSFCTKIYVDAVFIDTSNLDITPDDPRWIGAWWGGFLLCGALLFFSSLLMFGFPQSLPPHSEPAMESEQAMLSEREYERPKPSNGVLRHPLEPDSSASCFQQLRVIPKVTKHLLSNPVFTCIILAACMEIAVVAGFAAFLGKYLEQQFNLTTSSANQLLGMTAIPCACLGIFLGGLLVKKLSLSALGAIRMAMLVNLVSTACYVSFLFLGCDTGPVAGVTVPYGNSTAPGSALDPYSPCNNNCECQTDSFTPVCGADGITYLSACFAGCNSTNLTGCACLTTVPAENATVVPGKCPSPGCQEAFLTFLCVMCICSLIGAMAQTPSVIILIRTVSPELKSYALGVLFLLLRLLGFIPPPLIFGAGIDSTCLFWSTFCGEQGACVLYDNVVYRYLYVSIAIALKSFAFIL>sp|Q9UIG8-4|SO3A1_HUMAN Isoform 4 of Solute carrier organic aniontransporter family member 3A1 OS=Homo sapiens OX=9606 GN=SLCO3A1MFGFPQSLPPHSEPAMESEQAMLSEREYERPKPSNGVLRHPLEPDSSASCFQQLRVIPKVTKHLLSNPVFTCIILAACMEIAVVAGFAAFLGKYLEQQFNLTTSSANQLLGMTAIPCACLGIFLGGLLVKKLSLSALGAIRMAMLVNLVSTACYVSFLFLGCDTGPVAGVTVPYGNSTAPGSALDPYSPCNNNCECQTDSFTPVCGADGITYLSACFAGCNSTNLTGCACLTTVPAENATVVPGKCPSPGCQEAFLTFLCVMCICSLIGAMAQTPSVIILIRTVSPELKSYALGVLFLLLRLLGFIPPPLIFGAGIDSTCLFWSTFCGEQGACVLYDNVVYRYLYVSIAIALKSFAFILYTTTWQCLRKNYKRYIKNHEGGLSTSEFFASTLTLDNLGRDPVPANQTHRTKFIYNLEDHEWCENMESVL>sp|Q9NRH2|SNRK_HUMAN SNF-related serine/threonine-protein kinase OS=Homosapiens OX=9606 GN=SNRK PE=1 SV=2MAGFKRGYDGKIAGLYDLDKTLGRGHFAVVKLARHVFTGEKVAVKVIDKTKLDTLATGHLFQEVRCMKLVQHPNIVRLYEVIDTQTKLYLILELGDGGDMFDYIMKHEEGLNEDLAKKYFAQIVHAISYCHKLHVVHRDLKPENVVFFEKQGLVKLTDFGFSNKFQPGKKLTTSCGSLAYSAPEILLGDEYDAPAVDIWSLGVILFMLVCGQPPFQEANDSETLTMIMDCKYTVPSHVSKECKDLITRMLQRDPKRRASLEEIENHPWLQGVDPSPATKYNIPLVSYKNLSEEEHNSIIQRMVLGDIADRDAIVEALETNRYNHITATYFLLAERILREKQEKEIQTRSASPSNIKAQFRQSWPTKIDVPQDLEDDLTATPLSHATVPQSPARAADSVLNGHRSKGLCDSAKKDDLPELAGPALSTVPPASLKPTASGRKCLFRVEEDEEEDEEDKKPMSLSTQVVLRRKPSVTNRLTSRKSAPVLNQIFEEGESDDEFDMDENLPPKLSRLKMNIASPGTVHKRYHRRKSQGRGSSCSSSETSDDDSESRRRLDKDSGFTYSWHRRDSSEGPPGSEGDGGGQSKPSNASGGVDKASPSENNAGGGSPSSGSGGNPTNTSGTTRRCAGPSNSMQLASRSAGELVESLKLMSLCLGSQLHGSTKYIIDPQNGLSFSSVKVQEKSTWKMCISSTGNAGQVPAVGGIKFFSDHMADTTTELERIKSKNLKNNVLQLPLCEKTISVNIQRNPKEGLLCASSPASCCHVI>sp|Q9NRH2-2|SNRK_HUMAN Isoform 2 of SNF-related serine/threonine-proteinkinase OS=Homo sapiens OX=9606 GN=SNRKMAGFKRGYDGKIAGLYDLDKTLGRGHFAVVKLARHVFTGEKVAVKVIDKTKLDTLATGHLFQEVRCMKLVQHPNIVRLYEVIDTQTKLYLILELGDGGDMFDYIMKHEEGLNEDLAKKYFAQIVHAISYCHKLHVVHRDLKPENVVFFEKQGLVKLTDFGFSNKFQPGKKLTTSCGSLAYSAPEILLGDEYDAPAVDIWSLGVILFMLVCGQPPFQEANDSETLTMIMDCKYTVPSHVSKECKE>sp|Q86U17|SPA11_HUMAN Serpin A11 OS=Homo sapiens OX=9606 GN=SERPINA11PE=2 SV=2MGPAWLWLLGTGILASVHCQPLLAHGDKSLQGPQPPRHQLSEPAPAYHRITPTITNFALRLYKELAADAPGNIFFSPVSISTTLALLSLGAQANTSALILEGLGFNLTETPEADIHQGFRSLLHTLALPSPKLELKVGNSLFLDKRLKPRQHYLDSIKELYGAFAFSANFTDSVTTGRQINDYLRRQTYGQVVDCLPEFSQDTFMVLANYIFFKAKWKHPFSRYQTQKQESFFVDERTSLQVPMMHQKEMHRFLYDQDLACTVLQIEYRGNALALLVLPDPGKMKQVEAALQPQTLRKWGQLLLPSLLDLHLPRFSISGTYNLEDILPQIGLTNILNLEADFSGVTGQLNKTISKVSHKAMVDMSEKGTEAGAASGLLSQPPSLNTMSDPHAHFNRPFLLLLWEVTTQSLLFLGKVVNPVAG>sp|Q8NCR6|SMRP1_HUMAN Spermatid-specific manchette-related protein 1OS=Homo sapiens OX=9606 GN=SMRP1 PE=1 SV=2MFLFSRKTRTPISTYSDSYRAPTSIKEVYKDPPLCAWEANKFLTPGLTHTMERHVDPEALQKMAKCAVQDYTYRGSISGHPYLPEKYWLSQEEADKCSPNYLGSDWYNTWRMEPYNSSCCNKYTTYLPRLPKEARMETAVRGMPLECPPRPERLNAYEREVMVNMLNSLSRNQQLPRITPRCGCVDPLPGRLPFHGYESACSGRHYCLRGMDYYASGAPCTDRRLRPWCREQPTMCTSLRAPARNAVCCYNSPAVILPISEP>sp|Q8NCR6-2|SMRP1_HUMAN Isoform 2 of Spermatid-specific manchette-related protein 1 OS=Homo sapiens OX=9606 GN=SMRP1METAVRGMPLECPPRPERLNAYEREVMVNMLNSLSRNQQLPRITPRCGCVDPLPGRLPFHGYESACSGRHYCLRGMDYYASGAPCTDRRLRPWCREQPTVRFAGLRPPQPGSTPHKPRPRTPPPSSPASFRAGPQPALAPRCTLSRPCRVPPSGSKA>sp|Q8NCR6-3|SMRP1_HUMAN Isoform 3 of Spermatid-specific manchette-related protein 1 OS=Homo sapiens OX=9606 GN=SMRP1METAVRGMPLECPPRPERLNAYEREVMVNMLNSLSRNQQLPRITPRCGCVPPYEHRPGMQCAVTTPPPSYYPYPNLRWDTSHFKKSGGPQRNNYVIHPEFVSETYPDYRCW>sp|Q8NCR6-4|SMRP1_HUMAN Isoform 4 of Spermatid-specific manchette-related protein 1 OS=Homo sapiens OX=9606 GN=SMRP1METAVRGMPLECPPRPERLNAYEREVMVNMLNSLSRNQQLPRITPRCGCVDPLPGRLPFHGYESACSGRHYCLRGMDYYASGAPCTDRRLRPWCREQPTVRCVPPYEHRPGMQCAVTTPPPSYYPYPNLRWDTSHFKKSGGPQRNNYVIHPEFVSETYPDYRCW>sp|Q8NCR6-5|SMRP1_HUMAN Isoform 5 of Spermatid-specific manchette-related protein 1 OS=Homo sapiens OX=9606 GN=SMRP1METAVRGMPLECPPRPERLNAYEREVMVNMLNSLSRNQQLPRITPRCGCVDPLPGRLPFHGYESACSGRHYCLRGMDYYASGAPCTDRRLRPWCREQPTMCTSLRAPARNAVCCYNSPAVILPISEP>sp|P04278|SHBG_HUMAN Sex hormone-binding globulin OS=Homo sapiensOX=9606 GN=SHBG PE=1 SV=2MESRGPLATSRLLLLLLLLLLRHTRQGWALRPVLPTQSAHDPPAVHLSNGPGQEPIAVMTFDLTKITKTSSSFEVRTWDPEGVIFYGDTNPKDDWFMLGLRDGRPEIQLHNHWAQLTVGAGPRLDDGRWHQVEVKMEGDSVLLEVDGEEVLRLRQVSGPLTSKRHPIMRIALGGLLFPASNLRLPLVPALDGCLRRDSWLDKQAEISASAPTSLRSCDVESNPGIFLPPGTQAEFNLRDIPQPHAEPWAFSLDLGLKQAAGSGHLLALGTPENPSWLSLHLQDQKVVLSSGSGPGLDLPLVLGLPLQLKLSMSRVVLSQGSKMKALALPPLGLAPLLNLWAKPQGRLFLGALPGEDSSTSFCLNGLWAQGQRLDVDQALNRSHEIWTHSCPQSPGNGTDASH>sp|P04278-2|SHBG_HUMAN Isoform 2 of Sex hormone-binding globulin OS=Homosapiens OX=9606 GN=SHBGPRFKGSPAVLFKLTYAVITCFSLRLTHPPRPWSAHDPPAVHLSNGPGQEPIAVMTFDLTKITKTSSSFEVRTWDPEGVIFYGDTNPKDDWFMLGLRDGRPEIQLHNHWAQLTVGAGPRLDDGRWHQVEVKMEGDSVLLEVDGEEVLRLRQVSGPLTSKRHPIMRIALGGLLFPASNLRLPLVPALDGCLRRDSWLDKQAEISASAPTSLRSCDVESNPGIFLPPGTQAEFNLRDIPQPHAEPWAFSLDLGLKQAAGSGHLLALGTPENPSWLSLHLQDQEKTLPPLFA>sp|P04278-3|SHBG_HUMAN Isoform 3 of Sex hormone-binding globulin OS=Homosapiens OX=9606 GN=SHBGMESRGPLATSRLLLLLLLLLLRHTRQGWALRPVLPTQSAHDPPAVHLSNGPGQEPIAVMTFDLTKITKTSSSFEVRTWDPEGVIFYGDTNPKDDWFMLGLRDGRPEIQLHNHWAQLTVGAGPRLDDGRWHQVEVKMEGDSVLLEVDGEEVLRLRQVSGPLTSKRHPIMRIALGGLLFPASNLRLPLVPALDGCLRRDSWLDKQAEISASAPTSLRSCDVESNPGIFLPPGTQAEFNLRDIPQPHAEPWAFSLDLGLKQAAGSGHLLALGTPENPSWLSLHLQDQEKTLPPLFA>sp|P04278-4|SHBG_HUMAN Isoform 4 of Sex hormone-binding globulin OS=Homosapiens OX=9606 GN=SHBGMESRGPLATSRLLLLLLLLLLRHTRQGWALRPVLPTQSAHDPPAVHLSNGPGQEPIAVMTFDLTKITKTSSSFEVRTWDPEGVIFYGDTNPKDDWFMLGLRDGRPEIQLHNHWAQLTVGAGPRLDDGRWHQVEVKMEGDSVLLEVDGEEVLRLRQVSGPLTSKRHPIMRIALGGLLFPASNLRLPLVPALDGCLRRDSWLDKQAEISASAPTSLRSCDVESNPGIFLPPGTQAEFNLRGEDSSTSFCLNGLWAQGQRLDVDQALNRSHEIWTHSCPQSPGNGTDASH>sp|P04278-5|SHBG_HUMAN Isoform 5 of Sex hormone-binding globulin OS=Homosapiens OX=9606 GN=SHBGMESRGPLATSRLLLLLLLLLLRHTRQGWALRPVLPTQSAHDPPAVHLSNGPGQEPIAVMTFDLTKITKTSSSFEVRTWDPEGVIFYGDTNPKDDWFMLGLRDGRPEIQLHNHWAQLTVGAGPRLDDGRWHQVEVKMEGDSVLLEVDGEEVLRLRQVSGPLTSKRHPIMRIALGGLLFPASNLRLPAEISASAPTSLRSCDVESNPGIFLPPGTQAEFNLRDIPQPHAEPWAFSLDLGLKQAAGSGHLLALGTPENPSWLSLHLQDQKVVLSSGSGPGLDLPLVLGLPLQLKLSMSRVVLSQGSKMKALALPPLGLAPLLNLWAKPQGRLFLGALPGEDSSTSFCLNGLWAQGQRLDVDQALNRSHEIWTHSCPQSPGNGTDASH>sp|P38935|SMBP2_HUMAN DNA-binding protein SMUBP-2 OS=Homo sapiensOX=9606 GN=IGHMBP2 PE=1 SV=3MASAAVESFVTKQLDLLELERDAEVEERRSWQENISLKELQSRGVCLLKLQVSSQRTGLYGRLLVTFEPRRYGSAAALPSNSFTSGDIVGLYDAANEGSQLATGILTRVTQKSVTVAFDESHDFQLSLDRENSYRLLKLANDVTYRRLKKALIALKKYHSGPASSLIEVLFGRSAPSPASEIHPLTFFNTCLDTSQKEAVLFALSQKELAIIHGPPGTGKTTTVVEIILQAVKQGLKVLCCAPSNIAVDNLVERLALCKQRILRLGHPARLLESIQQHSLDAVLARSDSAQIVADIRKDIDQVFVKNKKTQDKREKSNFRNEIKLLRKELKEREEAAMLESLTSANVVLATNTGASADGPLKLLPESYFDVVVIDECAQALEASCWIPLLKARKCILAGDHKQLPPTTVSHKAALAGLSLSLMERLAEEYGARVVRTLTVQYRMHQAIMRWASDTMYLGQLTAHSSVARHLLRDLPGVAATEETGVPLLLVDTAGCGLFELEEEDEQSKGNPGEVRLVSLHIQALVDAGVPARDIAVVSPYNLQVDLLRQSLVHRHPELEIKSVDGFQGREKEAVILSFVRSNRKGEVGFLAEDRRINVAVTRARRHVAVICDSRTVNNHAFLKTLVEYFTQHGEVRTAFEYLDDIVPENYSHENSQGSSHAATKPQGPATSTRTGSQRQEGGQEAAAPARQGRKKPAGKSLASEAPSQPSLNGGSPEGVESQDGVDHFRAMIVEFMASKKMQLEFPPSLNSHDRLRVHQIAEEHGLRHDSSGEGKRRFITVSKRAPRPRAALGPPAGTGGPAPLQPVPPTPAQTEQPPREQRGPDQPDLRTLHLERLQRVRSAQGQPASKEQQASGQQKLPEKKKKKAKGHPATDLPTEEDFEALVSAAVKADNTCGFAKCTAGVTTLGQFCQLCSRRYCLSHHLPEIHGCGERARAHARQRISREGVLYAGSGTKNGSLDPAKRAQLQRRLDKKLSELSNQRTSRRKERGT>sp|Q7Z614|SNX20_HUMAN Sorting nexin-20 OS=Homo sapiens OX=9606 GN=SNX20PE=1 SV=1MASPEHPGSPGCMGPITQCTARTQQEAPATGPDLPHPGPDGHLDTHSGLSSNSSMTTRELQQYWQNQKCRWKHVKLLFEIASARIEERKVSKFVVYQIIVIQTGSFDNNKAVLERRYSDFAKLQKALLKTFREEIEDVEFPRKHLTGNFAEEMICERRRALQEYLGLLYAIRCVRRSREFLDFLTRPELREAFGCLRAGQYPRALELLLRVLPLQEKLTAHCPAAAVPALCAVLLCHRDLDRPAEAFAAGERALQRLQAREGHRYYAPLLDAMVRLAYALGKDFVTLQERLEESQLRRPTPRGITLKELTVREYLH>sp|Q7Z614-2|SNX20_HUMAN Isoform 2 of Sorting nexin-20 OS=Homo sapiensOX=9606 GN=SNX20MASPEHPGSPGCMGPITQCTARTQQEAPATGPDLPHPGPDGHLDTHSGLSSNSSMTTRELQQYWQNQKCRWKHVKLLFEIASARIEERKVSKFVVYQIIVIQTGSFDNNKAVLERRYSDFVTLQERLEESQLRRPTPRGITLKELTVREYLH>sp|Q7Z614-3|SNX20_HUMAN Isoform 3 of Sorting nexin-20 OS=Homo sapiensOX=9606 GN=SNX20MASPEHPGSPGCMGPITQCTARTQQEAPATGPDLPHPGPDGHLDTHSGLSSNSSMTTRELQQYWQNQKCRWKHVKLLFEIASARIEERKVSKFVMGKSRPGEMTYPGSRGETGTAPEPDPRCPRQSDML>sp|Q7Z614-4|SNX20_HUMAN Isoform 4 of Sorting nexin-20 OS=Homo sapiensOX=9606 GN=SNX20MASPEHPGSPGCMGPITQCTARTQQEAPATGPDLPHPGPDGHLDTHSGLSSNSSMTTRELQQYWQNQKCRWKHVKLLFEIASARIEERKVSKFVAPAPDATP>sp|Q9H4L7|SMRCD_HUMAN SWI/SNF-related matrix-associated actin-dependentregulator of chromatin subfamily A containing DEAD/H box 1 OS=Homosapiens OX=9606 GN=SMARCAD1 PE=1 SV=2MNLFNLDRFRFEKRNKIEEAPEATPQPSQPGPSSPISLSAEEENAEGEVSRANTPDSDITEKTEDSSVPETPDNERKASISYFKNQRGIQYIDLSSDSEDVVSPNCSNTVQEKTFNKDTVIIVSEPSEDEESQGLPTMARRNDDISELEDLSELEDLKDAKLQTLKELFPQRSDNDLLKLIESTSTMDGAIAAALLMFGDAGGGPRKRKLSSSSEPYEEDEFNDDQSIKKTRLDHGEESNESAESSSNWEKQESIVLKLQKEFPNFDKQELREVLKEHEWMYTEALESLKVFAEDQDMQYVSQSEVPNGKEVSSRSQNYPKNATKTKLKQKFSMKAQNGFNKKRKKNVFNPKRVVEDSEYDSGSDVGSSLDEDYSSGEEVMEDGYKGKILHFLQDASIGELTLIPQCSQKKAQKITELRPFNSWEALFTKMSKTNGLSEDLIWHCKTLIQERDVVIRLMNKCEDISNKLTKQVTMLTGNGGGWNIEQPSILNQSLSLKPYQKVGLNWLALVHKHGLNGILADEMGLGKTIQAIAFLAYLYQEGNNGPHLIVVPASTIDNWLREVNLWCPTLKVLCYYGSQEERKQIRFNIHSRYEDYNVIVTTYNCAISSSDDRSLFRRLKLNYAIFDEGHMLKNMGSIRYQHLMTINANNRLLLTGTPVQNNLLELMSLLNFVMPHMFSSSTSEIRRMFSSKTKSADEQSIYEKERIAHAKQIIKPFILRRVKEEVLKQLPPKKDRIELCAMSEKQEQLYLGLFNRLKKSINNLEKNTEMCNVMMQLRKMANHPLLHRQYYTAEKLKEMSQLMLKEPTHCEANPDLIFEDMEVMTDFELHVLCKQYRHINNFQLDMDLILDSGKFRVLGCILSELKQKGDRVVLFSQFTMMLDILEVLLKHHQHRYLRLDGKTQISERIHLIDEFNTDMDIFVFLLSTKAGGLGINLTSANVVILHDIDCNPYNDKQAEDRCHRVGQTKEVLVIKLISQGTIEESMLKINQQKLKLEQDMTTVDEGDEGSMPADIATLLKTSMGL>sp|Q9H4L7-2|SMRCD_HUMAN Isoform 2 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily A containing DEAD/H box1 OS=Homo sapiens OX=9606 GN=SMARCAD1MNLFNLDRFRFEKRNKIEEAPEATPQPSQPGPSSPISLSAEEENAEGEVSRANTPDSDITEKTEDSSVPETPDNERKASISYFKNQRGIQYIDLSSDSEDVVSPNCSNTVQEKTFNKDTVIIVSEPSEDEESQGLPTMARRNDDISELEDLSELEDLKDAKLQTLKELFPQRSDNDLLKLIESTSTMDGAIAAALLMFGDAGGGPRKRKLSSSSEPYEEDEFNDDQSIKKTRLDHGEESNESAESSSNWEKQESIVLKLQKEFPNFDKQELREVLKEHEWMYTEALESLKVFAEDQDMQYVSQSEVPNGKEVSSRSQNYPKNATKTKLKQKFSMKAQNGFNKKRKKNVFNPKRVVEDSEYDSGSDVGSSLDEDYSSGEEVMEDGYKGKILHFLQDASIGELTLIPQCSQKKAQKITELRPFNSWEALFTKMSKTNGLSEDLIWHCKTLIQERDVVIRLMNKCEDISNKLTKQVTMLTGNGGGWNIEQPSILNQSLSLKPYQKVGLNWLALVHKHGLNGILADEMGLGKTIQAIAFLAYLYQEGNNGPHLIVVPASTIDNWLREVNLWCPTLKVLCYYGSQEERKQIRFNIHSRYEDYNVIVTTYNCAISSSDDRSLFRRLKLNYAIFDEGHMLKNMGSIRYQHLMTINANNRLLLTGTPVQNNLLELMSLLNFVMPHMFSSSTSEIRRMFSSKTKSADEQSIYEKERIAHAKQIIKPFILRRVKEEVLKQLPPKKDRIELCAMSEKQEQLYLGLFNRLKKSINNLVTEKNTEMCNVMMQLRKMANHPLLHRQYYTAEKLKEMSQLMLKEPTHCEANPDLIFEDMEVMTDFELHVLCKQYRHINNFQLDMDLILDSGKFRVLGCILSELKQKGDRVVLFSQFTMMLDILEVLLKHHQHRYLRLDGKTQISERIHLIDEFNTDMDIFVFLLSTKAGGLGINLTSANVVILHDIDCNPYNDKQAEDRCHRVGQTKEVLVIKLISQGTIEESMLKINQQKLKLEQDMTTVDEGDEGSMPADIATLLKTSMGL>sp|Q9H4L7-3|SMRCD_HUMAN Isoform 3 of SWI/SNF-related matrix-associatedactin-dependent regulator of chromatin subfamily A containing DEAD/H box1 OS=Homo sapiens OX=9606 GN=SMARCAD1MSKTNGLSEDLIWHCKTLIQERDVVIRLMNKCEDISNKLTKQVTMLTGNGGGWNIEQPSILNQSLSLKPYQKVGLNWLALVHKHGLNGILADEMGLGKTIQAIAFLAYLYQEGNNGPHLIVVPASTIDNWLREVNLWCPTLKVLCYYGSQEERKQIRFNIHSRYEDYNVIVTTYNCAISSSDDRSLFRRLKLNYAIFDEGHMLKNMGSIRYQHLMTINANNRLLLTGTPVQNNLLELMSLLNFVMPHMFSSSTSEIRRMFSSKTKSADEQSIYEKERIAHAKQIIKPFILRRVKEEVLKQLPPKKDRIELCAMSEKQEQLYLGLFNRLKKSINNLEKNTEMCNVMMQLRKMANHPLLHRQYYTAEKLKEMSQLMLKEPTHCEANPDLIFEDMEVMTDFELHVLCKQYRHINNFQLDMDLILDSGKFRVLGCILSELKQKGDRVVLFSQFTMMLDILEVLLKHHQHRYLRLDGKTQISERIHLIDEFNTDMDIFVFLLSTKAGGLGINLTSANVVILHDIDCNPYNDKQAEDRCHRVGQTKEVLVIKLISQGTIEESMLKINQQKLKLEQDMTTVDEGDEGSMPADIATLLKTSMGL>sp|O75368|SH3L1_HUMAN SH3 domain-binding glutamic acid-rich-like proteinOS=Homo sapiens OX=9606 GN=SH3BGRL PE=1 SV=1MVIRVYIASSSGSTAIKKKQQDVLGFLEANKIGFEEKDIAANEENRKWMRENVPENSRPATGYPLPPQIFNESQYRGDYDAFFEARENNAVYAFLGLTAPPGSKEAEVQAKQQA>sp|Q8WU79|SMAP2_HUMAN Stromal membrane-associated protein 2 OS=Homosapiens OX=9606 GN=SMAP2 PE=1 SV=1MTGKSVKDVDRYQAVLANLLLEEDNKFCADCQSKGPRWASWNIGVFICIRCAGIHRNLGVHISRVKSVNLDQWTQEQIQCMQEMGNGKANRLYEAYLPETFRRPQIDPAVEGFIRDKYEKKKYMDRSLDINAFRKEKDDKWKRGSEPVPEKKLEPVVFEKVKMPQKKEDPQLPRKSSPKSTAPVMDLLGLDAPVACSIANSKTSNTLEKDLDLLASVPSPSSSGSRKVVGSMPTAGSAGSVPENLNLFPEPGSKSEEIGKKQLSKDSILSLYGSQTPQMPTQAMFMAPAQMAYPTAYPSFPGVTPPNSIMGSMMPPPVGMVAQPGASGMVAPMAMPAGYMGGMQASMMGVPNGMMTTQQAGYMAGMAAMPQTVYGVQPAQQLQWNLTQMTQQMAGMNFYGANGMMNYGQSMSGGNGQAANQTLSPQMWK>sp|Q8WU79-2|SMAP2_HUMAN Isoform 2 of Stromal membrane-associated protein2 OS=Homo sapiens OX=9606 GN=SMAP2MIFKGPRWASWNIGVFICIRCAGIHRNLGVHISRVKSVNLDQWTQEQIQCMQEMGNGKANRLYEAYLPETFRRPQIDPAVEGFIRDKYEKKKYMDRSLDINAFRKEKDDKWKRGSEPVPEKKLEPVVFEKVKMPQKKEDPQLPRKSSPKSTAPVMDLLGLDAPVACSIANSKTSNTLEKDLDLLASVPSPSSSGSRKVVGSMPTAGSAGSVPENLNLFPEPGSKSEEIGKKQLSKDSILSLYGSQTPQMPTQAMFMAPAQMAYPTAYPSFPGVTPPNSIMGSMMPPPVGMVAQPGASGMVAPMAMPAGYMGGMQASMMGVPNGMMTTQQAGYMAGMAAMPQTVYGVQPAQQLQWNLTQMTQQMAGMNFYGANGMMNYGQSMSGGNGQAANQTLSPQMWK>sp|Q8WU79-3|SMAP2_HUMAN Isoform 3 of Stromal membrane-associated protein2 OS=Homo sapiens OX=9606 GN=SMAP2MQEMGNGKANRLYEAYLPETFRRPQIDPAVEGFIRDKYEKKKYMDRSLDINAFRKEKDDKWKRGSEPVPEKKLEPVVFEKVKMPQKKEDPQLPRKSSPKSTAPVMDLLGLDAPVACSIANSKTSNTLEKDLDLLASVPSPSSSGSRKVVGSMPTAGSAGSVPENLNLFPEPGSKSEEIGKKQLSKDSILSLYGSQTPQMPTQAMFMAPAQMAYPTAYPSFPGVTPPNSIMGSMMPPPVGMVAQPGASGMVAPMAMPAGYMGGMQASMMGVPNGMMTTQQAGYMAGMAAMPQTVYGVQPAQQLQWNLTQMTQQMAGMNFYGANGMMNYGQSMSGGNGQAANQTLSPQMWK>sp|O75556|SG2A1_HUMAN Mammaglobin-B OS=Homo sapiens OX=9606 GN=SCGB2A1PE=1 SV=1MKLLMVLMLAALLLHCYADSGCKLLEDMVEKTINSDISIPEYKELLQEFIDSDAAAEAMGKFKQCFLNQSHRTLKNFGLMMHTVYDSIWCNMKSN>sp|Q9HD40|SPCS_HUMAN O-phosphoseryl-tRNA(Sec) selenium transferaseOS=Homo sapiens OX=9606 GN=SEPSECS PE=1 SV=2MNRESFAAGERLVSPAYVRQGCEARRSHEHLIRLLLEKGKCPENGWDESTLELFLHELAIMDSNNFLGNCGVGEREGRVASALVARRHYRFIHGIGRSGDISAVQPKAAGSSLLNKITNSLVLDIIKLAGVHTVANCFVVPMATGMSLTLCFLTLRHKRPKAKYIIWPRIDQKSCFKSMITAGFEPVVIENVLEGDELRTDLKAVEAKVQELGPDCILCIHSTTSCFAPRVPDRLEELAVICANYDIPHIVNNAYGVQSSKCMHLIQQGARVGRIDAFVQSLDKNFMVPVGGAIIAGFNDSFIQEISKMYPGRASASPSLDVLITLLSLGSNGYKKLLKERKEMFSYLSNQIKKLSEAYNERLLHTPHNPISLAMTLKTLDEHRDKAVTQLGSMLFTRQVSGARVVPLGSMQTVSGYTFRGFMSHTNNYPCAYLNAASAIGMKMQDVDLFIKRLDRCLKAVRKERSKESDDNYDKTEDVDIEEMALKLDNVLLDTYQDASS>sp|Q9HD40-2|SPCS_HUMAN Isoform 2 of O-phosphoseryl-tRNA(Sec) seleniumtransferase OS=Homo sapiens OX=9606 GN=SEPSECSMNRESFAAGERLVSPAYVRQGCEARRSHEHLIRLLLEKVHSWHWTIR>sp|Q9HD40-3|SPCS_HUMAN Isoform 3 of O-phosphoseryl-tRNA(Sec) seleniumtransferase OS=Homo sapiens OX=9606 GN=SEPSECSMQCDDLGSLQPPPPGFTPFACLSLPSSWDYRRPPPHPGKCPENGWDESTLELFLHELAIMDSNNFLGNCGVGEREGRVASALVARRHYRFIHGIGRSGDISAVQPKAAGSSLLNKITNSLVLDIIKLAGVHTVANCFVVPMATGMSLTLCFLTLRHKRPKAKYIIWPRIDQKSCFKSMITAGFEPVVIENVLEGDELRTDLKAVEAKVQELGPDCILCIHSTTSCFAPRVPDRLEELAVICANYDIPHIVNNAYGVQSSKCMHLIQQGARVGRIDAFVQSLDKNFMVPVGGAIIAGFNDSFIQEISKMYPGRASASPSLDVLITLLSLGSNGYKKLLKERKEMFSYLSNQIKKLSEAYNERLLHTPHNPISLAMTLKTLDEHRDKAVTQLGSMLFTRQVSGARVVPLGSMQTVSGYTFRGFMSHTNNYPCAYLNAASAIGMKMQDVDLFIKRLDRCLKAVRKERSKESDDNYDKTEDVDIEEMALKLDNVLLDTYQDASS>sp|Q8N0X7|SPART_HUMAN Spartin OS=Homo sapiens OX=9606 GN=SPART PE=1 SV=1MEQEPQNGEPAEIKIIREAYKKAFLFVNKGLNTDELGQKEEAKNYYKQGIGHLLRGISISSKESEHTGPGWESARQMQQKMKETLQNVRTRLEILEKGLATSLQNDLQEVPKLYPEFPPKDMCEKLPEPQSFSSAPQHAEVNGNTSTPSAGAVAAPASLSLPSQSCPAEAPPAYTPQAAEGHYTVSYGTDSGEFSSVGEEFYRNHSQPPPLETLGLDADELILIPNGVQIFFVNPAGEVSAPSYPGYLRIVRFLDNSLDTVLNRPPGFLQVCDWLYPLVPDRSPVLKCTAGAYMFPDTMLQAAGCFVGVVLSSELPEDDRELFEDLLRQMSDLRLQANWNRAEEENEFQIPGRTRPSSDQLKEASGTDVKQLDQGNKDVRHKGKRGKRAKDTSSEEVNLSHIVPCEPVPEEKPKELPEWSEKVAHNILSGASWVSWGLVKGAEITGKAIQKGASKLRERIQPEEKPVEVSPAVTKGLYIAKQATGGAAKVSQFLVDGVCTVANCVGKELAPHVKKHGSKLVPESLKKDKDGKSPLDGAMVVAASSVQGFSTVWQGLECAAKCIVNNVSAETVQTVRYKYGYNAGEATHHAVDSAVNVGVTAYNINNIGIKAMVKKTATQTGHTLLEDYQIVDNSQRENQEGAANVNVRGEKDEQTKEVKEAKKKDK>sp|Q9HBX3|SNIT1_HUMAN Uncharacterized protein encoded by SND1-IT1OS=Homo sapiens OX=9606 GN=SND1-IT1 PE=4 SV=1MSHHPHSLRNSCLIRMDLLYWQFTIYTITFCFSHLSGRLTLSAQHISHRPCLLSYSLLFWKVHHLFLEGFPCSPRLDEMSFHQFPQHPVHVSVVHLPIVYKGSMTQVSPH>sp|Q8TEV9|SMCR8_HUMAN Guanine nucleotide exchange protein SMCR8 OS=Homosapiens OX=9606 GN=SMCR8 PE=1 SV=2MISAPDVVAFTKEEEYEEEPYNEPALPEEYSVPLFPFASQGANPWSKLSGAKFSRDFILISEFSEQVGPQPLLTIPNDTKVFGTFDLNYFSLRIMSVDYQASFVGHPPGSAYPKLNFVEDSKVVLGDSKEGAFAYVHHLTLYDLEARGFVRPFCMAYISADQHKIMQQFQELSAEFSRASECLKTGNRKAFAGELEKKLKDLDYTRTVLHTETEIQKKANDKGFYSSQAIEKANELASVEKSIIEHQDLLKQIRSYPHRKLKGHDLCPGEMEHIQDQASQASTTSNPDESADTDLYTCRPAYTPKLIKAKSTKCFDKKLKTLEELCDTEYFTQTLAQLSHIEHMFRGDLCYLLTSQIDRALLKQQHITNFLFEDFVEVDDRMVEKQESIPSKPSQDRPPSSSLEECPIPKVLISVGSYKSSVESVLIKMEQELGDEEYKEVEVTELSSFDPQENLDYLDMDMKGSISSGESIEVLGTEKSTSVLSKSDSQASLTVPLSPQVVRSKAVSHRTISEDSIEVLSTCPSEALIPDDFKASYPSAINEEESYPDGNEGAIRFQASISPPELGETEEGSIENTPSQIDSSCCIGKESDGQLVLPSTPAHTHSDEDGVVSSPPQRHRQKDQGFRVDFSVENANPSSRDNSCEGFPAYELDPSHLLASRDISKTSLDNYSDTTSYVSSVASTSSDRIPSAYPAGLSSDRHKKRAGQNALKFIRQYPFAHPAIYSLLSGRTLVVLGEDEAIVRKLVTALAIFVPSYGCYAKPVKHWASSPLHIMDFQKWKLIGLQRVASPAGAGTLHALSRYSRYTSILDLDNKTLRCPLYRGTLVPRLADHRTQIKRGSTYYLHVQSMLTQLCSKAFLYTFCHHLHLPTHDKETEELVASRQMSFLKLTLGLVNEDVRVVQYLAELLKLHYMQESPGTSHPMLRFDYVPSFLYKI>sp|Q8TEV9-2|SMCR8_HUMAN Isoform 2 of Guanine nucleotide exchange proteinSMCR8 OS=Homo sapiens OX=9606 GN=SMCR8MISAPDVVAFTKEEEYEEEPYNEPALPEEYSVPLFPFASQGANPWSKLSGAKFSRDFILISEFSEQVGPQPLLTIPNDTKVFGTFDLNYFSLRIMSVDYQASFVGHPPGSAYPKLNFVEDSKVVLGDSKEGAFAYVHHLTLYDLEARGFVRPFCMAYISADQHKIMQQFQELSAEFSRASECLKTGNRKAFAGELEKKLKDLDYTRTVLHTETEIQKKANDKGFYSSQAIEKANELASVEKSIIEHQDLLKQIRSYPHRKLKGHDLCPGEMEHIQDQASQASTTSNPDESADTDLYTCRPAYTPKLIKAKSTKCFDKKLKTLEELCDTEYFTQTLAQLSHIEHMFRGDLCYLLTSQIDRALLKQQHITNFLFEDFVEVDDRMVEKQESIPSKPSQDRPPSSSLEECPIPKVLISVGSYKSSVESVLIKMEQELGDEEYKEVEVTELSSFDPQENLDYLDMDMKGSISSGESIEVLGTEKSTSVLSKSDSQASLTVPLSPQVVRSKAVSHRTISEDSIEVLSTCPSEALIPDDFKASYPSAINEEESYPDGNEGAIRFQASISPPELGETEEGSIENTPSQIDSSCCIGKESDGQLVLPSTPAHTHSDEDGVVSSPPQRHRQKDQGFRVDFSVENANPSSRDNSCEGFPAYELDPSHLLASRDISKTSLDNYSDTTSYVSSVASTSSDRIPSAYPAGLSSDRHKKRAGQNALKFIRQYPFAHPAIYSLLSGRTLVVLGEDEAIVRKLVTALAIFVPSYGCYAKPVKHWASSPLHIMDFQKWKLIGLQR>sp|O60264|SMCA5_HUMAN SWI/SNF-related matrix-associated actin-dependentregulator of chromatin subfamily A member 5 OS=Homo sapiens OX=9606GN=SMARCA5 PE=1 SV=1MSSAAEPPPPPPPESAPSKPAASIASGGSNSSNKGGPEGVAAQAVASAASAGPADAEMEEIFDDASPGKQKEIQEPDPTYEEKMQTDRANRFEYLLKQTELFAHFIQPAAQKTPTSPLKMKPGRPRIKKDEKQNLLSVGDYRHRRTEQEEDEELLTESSKATNVCTRFEDSPSYVKWGKLRDYQVRGLNWLISLYENGINGILADEMGLGKTLQTISLLGYMKHYRNIPGPHMVLVPKSTLHNWMSEFKRWVPTLRSVCLIGDKEQRAAFVRDVLLPGEWDVCVTSYEMLIKEKSVFKKFNWRYLVIDEAHRIKNEKSKLSEIVREFKTTNRLLLTGTPLQNNLHELWSLLNFLLPDVFNSADDFDSWFDTNNCLGDQKLVERLHMVLRPFLLRRIKADVEKSLPPKKEVKIYVGLSKMQREWYTRILMKDIDILNSAGKMDKMRLLNILMQLRKCCNHPYLFDGAEPGPPYTTDMHLVTNSGKMVVLDKLLPKLKEQGSRVLIFSQMTRVLDILEDYCMWRNYEYCRLDGQTPHDERQDSINAYNEPNSTKFVFMLSTRAGGLGINLATADVVILYDSDWNPQVDLQAMDRAHRIGQTKTVRVFRFITDNTVEERIVERAEMKLRLDSIVIQQGRLVDQNLNKIGKDEMLQMIRHGATHVFASKESEITDEDIDGILERGAKKTAEMNEKLSKMGESSLRNFTMDTESSVYNFEGEDYREKQKIAFTEWIEPPKRERKANYAVDAYFREALRVSEPKAPKAPRPPKQPNVQDFQFFPPRLFELLEKEILFYRKTIGYKVPRNPELPNAAQAQKEEQLKIDEAESLNDEELEEKEKLLTQGFTNWNKRDFNQFIKANEKWGRDDIENIAREVEGKTPEEVIEYSAVFWERCNELQDIEKIMAQIERGEARIQRRISIKKALDTKIGRYKAPFHQLRISYGTNKGKNYTEEEDRFLICMLHKLGFDKENVYDELRQCIRNSPQFRFDWFLKSRTAMELQRRCNTLITLIERENMELEEKEKAEKKKRGPKPSTQKRKMDGAPDGRGRKKKLKL>sp|Q5TCZ1|SPD2A_HUMAN SH3 and PX domain-containing protein 2A OS=Homosapiens OX=9606 GN=SH3PXD2A PE=1 SV=1MLAYCVQDATVVDVEKRRNPSKHYVYIINVTWSDSTSQTIYRRYSKFFDLQMQLLDKFPIEGGQKDPKQRIIPFLPGKILFRRSHIRDVAVKRLKPIDEYCRALVRLPPHISQCDEVFRFFEARPEDVNPPKEDYGSSKRKSVWLSSWAESPKKDVTGADATAEPMILEQYVVVSNYKKQENSELSLQAGEVVDVIEKNESGWWFVSTSEEQGWVPATYLEAQNGTRDDSDINTSKTGEVSKRRKAHLRRLDRRWTLGGMVNRQHSREEKYVTVQPYTSQSKDEIGFEKGVTVEVIRKNLEGWWYIRYLGKEGWAPASYLKKAKDDLPTRKKNLAGPVEIIGNIMEISNLLNKKASGDKETPPAEGEGHEAPIAKKEISLPILCNASNGSAVGVPDRTVSRLAQGSPAVARIAPQRAQISSPNLRTRPPPRRESSLGFQLPKPPEPPSVEVEYYTIAEFQSCISDGISFRGGQKAEVIDKNSGGWWYVQIGEKEGWAPASYIDKRKKPNLSRRTSTLTRPKVPPPAPPSKPKEAEEGPTGASESQDSPRKLKYEEPEYDIPAFGFDSEPELSEEPVEDRASGERRPAQPHRPSPASSLQRARFKVGESSEDVALEEETIYENEGFRPYAEDTLSARGSSGDSDSPGSSSLSLTRKNSPKSGSPKSSSLLKLKAEKNAQAEMGKNHSSASFSSSITINTTCCSSSSSSSSSLSKTSGDLKPRSASDAGIRGTPKVRAKKDADANAGLTSCPRAKPSVRPKPFLNRAESQSQEKMDISTLRRQLRPTGQLRGGLKGSKSEDSELPPQTASEAPSEGSRRSSSDLITLPATTPPCPTKKEWEGPATSYMTCSAYQKVQDSEISFPAGVEVQVLEKQESGWWYVRFGELEGWAPSHYLVLDENEQPDPSGKELDTVPAKGRQNEGKSDSLEKIERRVQALNTVNQSKKATPPIPSKPPGGFGKTSGTPAVKMRNGVRQVAVRPQSVFVSPPPKDNNLSCALRRNESLTATDGLRGVRRNSSFSTARSAAAEAKGRLAERAASQGSDSPLLPAQRNSIPVSPVRPKPIEKSQFIHNNLKDVYVSIADYEGDEETAGFQEGVSMEVLERNPNGWWYCQILDGVKPFKGWVPSNYLEKKN>sp|Q5TCZ1-2|SPD2A_HUMAN Isoform 2 of SH3 and PX domain-containingprotein 2A OS=Homo sapiens OX=9606 GN=SH3PXD2AMILEQYVVVSNYKKQENSELSLQAGEVVDVIEKNESGWWFVSTSEEQGWVPATYLEAQNGTRDDSDINTSKTGEEEKYVTVQPYTSQSKDEIGFEKGVTVEVIRKNLEGWWYIRYLGKEGWAPASYLKKAKDDLPTRKKNLAGPVEIIGNIMEISNLLNKKASGDKETPPAEGEGHEAPIAKKEISLPILCNASNGSAVGVPDRTVSRLAQGSPAVARIAPQRAQISSPNLRTRPPPRRESSLGFQLPKPPEPPSVEVEYYTIAEFQSCISDGISFRGGQKAEVIDKNSGGWWYVQIGEKEGWAPASYIDKRKKPNLSRRTSTLTRPKVPPPAPPSKPKEAEEGPTGASESQDSPRKLKYEEPEYDIPAFGFDSEPELSEEPVEDRASGERRPAQPHRPSPASSLQRARFKVGESSEDVALEEETIYENEGFRPYAEDTLSARGSSGDSDSPGSSSLSLTRKNSPKSGSPKSSSLLKLKAEKNAQAEMGKNHSSASFSSSITINTTCCSSSSSSSSSLSKTSGDLKPRSASDAGIRGTPKVRAKKDADANAGLTSCPRAKPSVRPKPFLNRAESQSQEKMDISTLRRQLRPTGQLRGGLKGSKSEDSELPPQTASEAPSEGSRRSSSDLITLPATTPPCPTKKEWEGPATSYMTCSAYQKVQDSEISFPAGVEVQVLEKQESGWWYVRFGELEGWAPSHYLVLDENEQPDPSGKELDTVPAKGRQNEGKSDSLEKIERRVQALNTVNQSKKATPPIPSKPPGGFGKTSGTPAVKMRNGVRQVAVRPQSVFVSPPPKDNNLSCALRRNESLTATDGLRGVRRNSSFSTARSAAAEAKGRLAERAASQGSDSPLLPAQRNSIPVSPVRPKPIEKSQFIHNNLKDVYVSIADYEGDEETAGFQEGVSMEVLERNPNGWWYCQILDGVKPFKGWVPSNYLEKKN>sp|Q5TCZ1-3|SPD2A_HUMAN Isoform 3 of SH3 and PX domain-containingprotein 2A OS=Homo sapiens OX=9606 GN=SH3PXD2AMLAYCVQDATVVDVEKRRNPSKHYVYIINVTWSDSTSQTIYRRYSKFFDLQMQLLDKFPIEGGQKDPKQRIIPFLPGKILFRRSHIRDVAVKRLKPIDEYCRALVRLPPHISQCDEVFRFFEARPEDVNPPKEDYGSSKRKSVWLSSWAESPKKDVTGADATAEPMILEQYVVVSNYKKQENSELSLQAGEVVDVIEKNESGWWFVSTSEEQGWVPATYLEAQNGTRDDSDINTSKTGEEEKYVTVQPYTSQSKDEIGFEKGVTVEVIRKNLEGWWYIRYLGKEGWAPASYLKKAKDDLPTRKKNLAGPVEIIGNIMEISNLLNKKASGDKETPPAEGEGHEAPIAKKEISLPILCNASNGSAVGVPDRTVSRLAQGSPAVARIAPQRAQISSPNLRTRPPPRRESSLGFQLPKPPEPPSVEVEYYTIAEFQSCISDGISFRGGQKAEVIDKNSGGWWYVQIGEKEGWAPASYIDKRKKPNLSRRTSTLTRPKVPPPAPPSKPKEAEEGPTGASESQDSPRKLKYEEPEYDIPAFGFDSEPELSEEPVEDRASGERRPAQPHRPSPASSLQRARFKVGESSEDVALEEETIYENEGFRPYAEDTLSARGSSGDSDSPGSSSLSLTRKNSPKSGSPKSSSLLKLKAEKNAQAEMGKNHSSASFSSSITINTTCCSSSSSSSSSLSKTSGDLKPRSASDAGIRGTPKVRAKKDADANAGLTSCPRAKPSVRPKPFLNRAESQSQEKMDISTLRRQLRPTGQLRGGLKGSKSEDSELPPQTASEAPSEGSRRSSSDLITLPATTPPCPTKKEWEGPATSYMTCSAYQKVQDSEISFPAGVEVQVLEKQESGWWYVRFGELEGWAPSHYLVLDENEQPDPSGKELDTVPAKGRQNEGKSDSLEKIERRVQALNTVNQSKKATPPIPSKPPGGFGKTSGTPAVKMRNGVRQVAVRPQSVFVSPPPKDNNLSCALRRNESLTATDGLRGVRRNSSFSTARSAAAEAKGRLAERAASQGSDSPLLPAQRNSIPVSPVRPKPIEKSQFIHNNLKDVYVSIADYEGDEETAGFQEGVSMEVLERNPNGWWYCQILDGVKPFKGWVPSNYLEKKN>sp|Q96ES7|SGF29_HUMAN SAGA-associated factor 29 OS=Homo sapiens OX=9606GN=SGF29 PE=1 SV=1MALVSADSRIAELLTELHQLIKQTQEERSRSEHNLVNIQKTHERMQTENKISPYYRTKLRGLYTTAKADAEAECNILRKALDKIAEIKSLLEERRIAAKIAGLYNDSEPPRKTMRRGVLMTLLQQSAMTLPLWIGKPGDKPPPLCGAIPASGDYVARPGDKVAARVKAVDGDEQWILAEVVSYSHATNKYEVDDIDEEGKERHTLSRRRVIPLPQWKANPETDPEALFQKEQLVLALYPQTTCFYRALIHAPPQRPQDDYSVLFEDTSYADGYSPPLNVAQRYVVACKEPKKK>sp|O95347|SMC2_HUMAN Structural maintenance of chromosomes protein 2OS=Homo sapiens OX=9606 GN=SMC2 PE=1 SV=2MHIKSIILEGFKSYAQRTEVNGFDPLFNAITGLNGSGKSNILDSICFLLGISNLSQVRASNLQDLVYKNGQAGITKASVSITFDNSDKKQSPLGFEVHDEITVTRQVVIGGRNKYLINGVNANNTRVQDLFCSVGLNVNNPHFLIMQGRITKVLNMKPPEILSMIEEAAGTRMYEYKKIAAQKTIEKKEAKLKEIKTILEEEITPTIQKLKEERSSYLEYQKVMREIEHLSRLYIAYQFLLAEDTKVRSAEELKEMQDKVIKLQEELSENDKKIKALNHEIEELEKRKDKETGGILRSLEDALAEAQRVNTKSQSAFDLKKKNLACEESKRKELEKNMVEDSKTLAAKEKEVKKITDGLHALQEASNKDAEALAAAQQHFNAVSAGLSSNEDGAEATLAGQMMACKNDISKAQTEAKQAQMKLKHAQQELKNKQAEVKKMDSGYRKDQEALEAVKRLKEKLEAEMKKLNYEENKEESLLEKRRQLSRDIGRLKETYEALLARFPNLRFAYKDPEKNWNRNCVKGLVASLISVKDTSATTALELVAGERLYNVVVDTEVTGKKLLERGELKRRYTIIPLNKISARCIAPETLRVAQNLVGPDNVHVALSLVEYKPELQKAMEFVFGTTFVCDNMDNAKKVAFDKRIMTRTVTLGGDVFDPHGTLSGGARSQAASILTKFQELKDVQDELRIKENELRALEEELAGLKNTAEKYRQLKQQWEMKTEEADLLQTKLQQSSYHKQQEELDALKKTIEESEETLKNTKEIQRKAEEKYEVLENKMKNAEAERERELKDAQKKLDCAKTKADASSKKMKEKQQEVEAITLELEELKREHTSYKQQLEAVNEAIKSYESQIEVMAAEVAKNKESVNKAQEEVTKQKEVITAQDTVIKAKYAEVAKHKEQNNDSQLKIKELDHNISKHKREAEDGAAKVSKMLKDYDWINAERHLFGQPNSAYDFKTNNPKEAGQRLQKLQEMKEKLGRNVNMRAMNVLTEAEERYNDLMKKKRIVENDKSKILTTIEDLDQKKNQALNIAWQKVNKDFGSIFSTLLPGANAMLAPPEGQTVLDGLEFKVALGNTWKENLTELSGGQRSLVALSLILSMLLFKPAPIYILDEVDAALDLSHTQNIGQMLRTHFTHSQFIVVSLKEGMFNNANVLFKTKFVDGVSTVARFTQCQNGKISKEAKSKAKPPKGAHVEV>sp|O95347-2|SMC2_HUMAN Isoform 2 of Structural maintenance ofchromosomes protein 2 OS=Homo sapiens OX=9606 GN=SMC2MHIKSIILEGFKSYAQRTEVNGFDPLFNAITGLNGSGKSNILDSICFLLGISNLSQVRASNLQDLVYKNGQAGITKASVSITFDNSDKKQSPLGFEVHDEITVTRQVVIGGRNKYLINGVNANNTRVQDLFCSVGLNVNNPHFLIMQGRITKVLNMKPPEILSMIEEAAGTRMYEYKKIAAQKTIEKKEAKLKEIKTILEEEITPTIQKLKEERSSYLEYQKVMREIEHLSRLYIAYQFLLAEDTKVRSAEELKEMQDKVIKLQEELSENDKKIKALNHEIEELEKRKDKETGGILRSLEDALAEAQRVNTKSQSAFDLKKKNLACEESKRKELEKNMVEDSKTLAAKEKEVKKITDGLHALQEASNKDAEALAAAQQHFNAVSAGLSSNEDGAEATLAGQMMACKNDISKAQTEAKQAQMKLKHAQQELKNKQAEVKKMDSGYRKDQEALEAVKRLKEKLEAEMKKLNYEENKEESLLEKRRQLSRDIGRLKETYEALLARFPNLRFAYKDPEKNWNRNCVKGLVASLISVKDTSATTALELVAGERLYNVVVDTEVTGKKLLERGELKRRYTIIPLNKISARCIAPETLRVAQNLVGPDNVHVALSLVEYKPELQKAMEFVFGTTFVCDNMDNAKKVAFDKRIMTRTVTLGGDVFDPHGTLSGGARSQAASILTKFQELKDVQDELRIKENELRALEEELAGLKNTAEKYRQLKQQWEMKTEEADLLQTKLQQSSYHKQQEELDALKKTIEESEETLKNTKEIQRKAEEKYEVLENKMKNAEAERERELKDAQKKLDCAKTKADASSKKMKEKQQEVEAITLELEELKREHTSYKQQLEAVNEAIKSYESQIEVMAAEVAKNKESVNKAQEEVTKQKEVITAQDTVIKAKYAEVAKHKEQNNDSQLKIKELDHNISKHKREAEDGAAKVSKMLKDYDWINAERHLFGQPNSAYDFKTNNPKEAGQRLQKLQEMKEKLGRNVNMRAMNVLTEAEERYNDLMKKKRIVENDKSKILTTIEDLDQKKNQALNIAWQKVNKDFGSIFSTLLPGANAMLAPPEGQTVLDGLEFKVALGNTWKENLTELSGGQRQKQQNHTTG>sp|O75093|SLIT1_HUMAN Slit homolog 1 protein OS=Homo sapiens OX=9606GN=SLIT1 PE=1 SV=4MALTPGWGSSAGPVRPELWLLLWAAAWRLGASACPALCTCTGTTVDCHGTGLQAIPKNIPRNTERLELNGNNITRIHKNDFAGLKQLRVLQLMENQIGAVERGAFDDMKELERLRLNRNQLHMLPELLFQNNQALSRLDLSENAIQAIPRKAFRGATDLKNLQLDKNQISCIEEGAFRALRGLEVLTLNNNNITTIPVSSFNHMPKLRTFRLHSNHLFCDCHLAWLSQWLRQRPTIGLFTQCSGPASLRGLNVAEVQKSEFSCSGQGEAGRVPTCTLSSGSCPAMCTCSNGIVDCRGKGLTAIPANLPETMTEIRLELNGIKSIPPGAFSPYRKLRRIDLSNNQIAEIAPDAFQGLRSLNSLVLYGNKITDLPRGVFGGLYTLQLLLLNANKINCIRPDAFQDLQNLSLLSLYDNKIQSLAKGTFTSLRAIQTLHLAQNPFICDCNLKWLADFLRTNPIETSGARCASPRRLANKRIGQIKSKKFRCSAKEQYFIPGTEDYQLNSECNSDVVCPHKCRCEANVVECSSLKLTKIPERIPQSTAELRLNNNEISILEATGMFKKLTHLKKINLSNNKVSEIEDGAFEGAASVSELHLTANQLESIRSGMFRGLDGLRTLMLRNNRISCIHNDSFTGLRNVRLLSLYDNQITTVSPGAFDTLQSLSTLNLLANPFNCNCQLAWLGGWLRKRKIVTGNPRCQNPDFLRQIPLQDVAFPDFRCEEGQEEGGCLPRPQCPQECACLDTVVRCSNKHLRALPKGIPKNVTELYLDGNQFTLVPGQLSTFKYLQLVDLSNNKISSLSNSSFTNMSQLTTLILSYNALQCIPPLAFQGLRSLRLLSLHGNDISTLQEGIFADVTSLSHLAIGANPLYCDCHLRWLSSWVKTGYKEPGIARCAGPQDMEGKLLLTTPAKKFECQGPPTLAVQAKCDLCLSSPCQNQGTCHNDPLEVYRCACPSGYKGRDCEVSLDSCSSGPCENGGTCHAQEGEDAPFTCSCPTGFEGPTCGVNTDDCVDHACANGGVCVDGVGNYTCQCPLQYEGKACEQLVDLCSPDLNPCQHEAQCVGTPDGPRCECMPGYAGDNCSENQDDCRDHRCQNGAQCMDEVNSYSCLCAEGYSGQLCEIPPHLPAPKSPCEGTECQNGANCVDQGNRPVCQCLPGFGGPECEKLLSVNFVDRDTYLQFTDLQNWPRANITLQVSTAEDNGILLYNGDNDHIAVELYQGHVRVSYDPGSYPSSAIYSAETINDGQFHTVELVAFDQMVNLSIDGGSPMTMDNFGKHYTLNSEAPLYVGGMPVDVNSAAFRLWQILNGTGFHGCIRNLYINNELQDFTKTQMKPGVVPGCEPCRKLYCLHGICQPNATPGPMCHCEAGWVGLHCDQPADGPCHGHKCVHGQCVPLDALSYSCQCQDGYSGALCNQAGALAEPCRGLQCLHGHCQASGTKGAHCVCDPGFSGELCEQESECRGDPVRDFHQVQRGYAICQTTRPLSWVECRGSCPGQGCCQGLRLKRRKFTFECSDGTSFAEEVEKPTKCGCALCA>sp|O75093-2|SLIT1_HUMAN Isoform 2 of Slit homolog 1 protein OS=Homosapiens OX=9606 GN=SLIT1MALTPGWGSSAGPVRPELWLLLWAAAWRLGASACPALCTCTGTTVDCHGTGLQAIPKNIPRNTERLELNGNNITRIHKNDFAGLKQLRVLQLMENQIGAVERGAFDDMKELERLRLNRNQLHMLPELLFQNNQALSRLDLSENAIQAIPRKAFRGATDLKNLQLDKNQISCIEEGAFRALRGLEVLTLNNNNITTIPVSSFNHMPKLRTFRLHSNHLFCDCHLAWLSQWLRQRPTIGLFTQCSGPASLRGLNVAEVQKSEFSCSGQGEAGRVPTCTLSSGSCPAMCTCSNGIVDCRGKGLTAIPANLPETMTEIRLELNGIKSIPPGAFSPYRKLRRIRPLSFCSPCRDLSNNQIAEIAPDAFQGLRSLNSLVLYGNKITDLPRGVFGGLYTLQLLLLNANKINCIRPDAFQDLQNLSLLSLYDNKIQSLAKGTFTSLRAIQTLHLAQNPFICDCNLKWLADFLRTNPIETSGARCASPRRLANKRIGQIKSKKFRCSAKEQYFIPGTEDYQLNSECNSDVVCPHKCRCEANVVECSSLKLTKIPERIPQSTAELRLNNNEISILEATGMFKKLTHLKKINLSNNKVSEIEDGAFEGAASVSELHLTANQLESIRSGMFRGLDGLRTLMLRNNRISCIHNDSFTGLRNVRLLSLYDNQITTVSPGAFDTLQSLSTLNLLANPFNCNCQLAWLGGWLRKRKIVTGNPRCQNPDFLRQIPLQDVAFPDFRCEEGQEEGGCLPRPQCPQECACLDTVVRCSNKHLRALPKGIPKNVTELYLDGNQFTLVPGQLSTFKYLQLVILSYNALQCIPPLAFQ>sp|Q8NEY3|SPAT4_HUMAN Spermatogenesis-associated protein 4 OS=Homosapiens OX=9606 GN=SPATA4 PE=1 SV=1MAAAGQEKGYLTQTAAALDKSPSLSPQLAAPIRGRPKKCLVYPHAPKSSRLSRSVLRWLQGLDLSFFPRNINRDFSNGFLIAEIFCIYYPWELELSSFENGTSLKVKLDNWAQLEKFLARKKFKLPKELIHGTIHCKAGVPEILIEEVYTLLTHREIKSIQDDFVNFTDYSYQMRLPLVSRSTVSKSIKDNIRLSELLSNPNMLTNELKAEFLILLHMLQRKLGRKLNPEWFDVKPTVGEVTLNHLPAQASGRRYNLKVKRGRVVPVLPNIGSGGSSHREIHVKQAGQHSYYSAMKPIRNMDKKP>sp|P62314|SMD1_HUMAN Small nuclear ribonucleoprotein Sm D1 OS=Homosapiens OX=9606 GN=SNRPD1 PE=1 SV=1MKLVRFLMKLSHETVTIELKNGTQVHGTITGVDVSMNTHLKAVKMTLKNREPVQLETLSIRGNNIRYFILPDSLPLDTLLVDVEPKVKSKKREAVAGRGRGRGRGRGRGRGRGRGGPRR>sp|Q96EA4|SPDLY_HUMAN Protein Spindly OS=Homo sapiens OX=9606 GN=SPDL1PE=1 SV=2MEADIITNLRCRLKEAEEERLKAAQYGLQLVESQNELQNQLDKCRNEMMTMTESYEQEKYTLQREVELKSRMLESLSCECEAIKQQQKMHLEKLEEQLSRSHGQEVNELKTKIEKLKVELDEARLSEKQLKHQVDHQKELLSCKSEELRVMSERVQESMSSEMLALQIELTEMESMKTTLKEEVNELQYRQEQLELLITNLMRQVDRLKEEKEEREKEAVSYYNALEKARVANQDLQVQLDQALQQALDPNSKGNSLFAEVEDRRAAMERQLISMKVKYQSLKKQNVFNREQMQRMKLQIATLLQMKGSQTEFEQQERLLAMLEQKNGEIKHLLGEIRNLEKFKNLYDSMESKPSVDSGTLEDNTYYTDLLQMKLDNLNKEIESTKGELSIQRMKALFESQRALDIERKLFANERCLQLSESENMKLRAKLDELKLKYEPEETVEVPVLKKRREVLPVDITTAKDACVNNSALGGEVYRLPPQKEETQSCPNSLEDNNLQLEKSVSIYTPVVSLSPHKNLPVDMQLKKEKKCVKLIGVPADAEALSERSGNTPNSPRLAAESKLQTEVKEGKETSSKLEKETCKKLHPILYVSSKSTPETQCPQQ>sp|Q96EA4-2|SPDLY_HUMAN Isoform 2 of Protein Spindly OS=Homo sapiensOX=9606 GN=SPDL1MEADIITNLRCRLKEAEEERLKAAQYGLQLVESQNELQNQLDKCRNEMMTMTESYEQEKYTLQREVELKSRMLESLSCECEAIKQQQKMHLEKLEEQLSRSHGQEVNELKTKIEKLKVELDEARLSEKQLKHQVDHQKELLSCKSEELRVMSERVQESMSSEMLALQIELTEMESMKVKYQSLKKQNVFNREQMQRMKLQIATLLQMKGSQTEFEQQERLLAMLEQKNGEIKHLLGEIRNLEKFKNLYDSMESKPSVDSGTLEDNTYYTDLLQMKLDNLNKEIESTKGELSIQRMKALFESQRALDIERKLFANERCLQLSESENMKLRAKLDELKLKYEPEETVEVPVLKKRREVLPVDITTAKDACVNNSALGGEVYRLPPQKEETQSCPNSLEDNNLQLEKSVSIYTPVVSLSPHKNLPVDMQLKKEKKCVKLIGVPADAEALSERSGNTPNSPRLAAESKLQTEVKEGKETSSKLEKETCKKLHPILYVSSKSTPETQCPQQ>sp|Q96EA4-3|SPDLY_HUMAN Isoform 3 of Protein Spindly OS=Homo sapiensOX=9606 GN=SPDL1MEADIITNLRCRLKEAEEERLKAAQYGLQLVESQNELQNQLDKCRNEMMTMTESYEQEKYTLQREVELKSRMLESLSCECEAIKQQQKMHLEKLEEQLSRSHGQEVNELQYRQEQLELLITNLMRQVDRLKEEKEEREKEAVSYYNALEKARVANQDLQVQLDQALQQALDPNSKGNSLFAEVEDRRAAMERQLISMKVKYQSLKKQNVFNREQMQRMKLQIATLLQMKGSQTEFEQQERLLAMLEQKNGEIKHLLGEIRNLEKFKNLYDSMESKPSVDSGTLEDNTYYTDLLQMKLDNLNKEIESTKGELSIQRMKALFESQRALDIERKLFANERCLQLSESENMKLRAKLDELKLKYEPEETVEVPVLKKRREVLPVDITTAKDACVNNSALGGEVYRLPPQKEETQSCPNSLEDNNLQLEKSVSIYTPVVSLSPHKNLPVDMQLKKEKKCVKLIGVPADAEALSERSGNTPNSPRLAAESKLQTEVKEGKETSSKLEKETCKKLHPILYVSSKSTPETQCPQQ>sp|Q9UM00|TMCO1_HUMAN Calcium load-activated calcium channel OS=Homosapiens OX=9606 GN=TMCO1 PE=1 SV=2MPRKRKCDLRAVRVGLLLGGGGVYGSRFRFTFPGCRALSPWRVRVQRRRCEMSTMFADTLLIVFISVCTALLAEGITWVLVYRTDKYKRLKAEVEKQSKKLEKKKETITESAGRQQKKKIERQEEKLKNNNRDLSMVRMKSMFAIGFCFTALMGMFNSIFDGRVVAKLPFTPLSYIQGLSHRNLLGDDTTDCSFIFLYILCTMSIRQNIQKILGLAPSRAATKQAGGFLGPPPPSGKFS>sp|Q9UM00-2|TMCO1_HUMAN Isoform 2 of Calcium load-activated calciumchannel OS=Homo sapiens OX=9606 GN=TMCO1MPRKRKCDLRAVRVGLLLGGGGVYGSRFRFTFPGCRALSPWRVRVQRRRCEMSTMFADTLLIVFISVCTALLAEGITWVLVYRTDKYKRLKAEVEKQSKKLEKKKETITESAGRLSMVRMKSMFAIGFCFTALMGMFNSIFDGRVVAKLPFTPLSYIQGLSHRNLLGDDTTDCSFIFLYILCTMSIRQNIQKILGLAPSRAATKQAGGFLGPPPPSGKFS>sp|Q9UM00-1|TMCO1_HUMAN Isoform 3 of Calcium load-activated calciumchannel OS=Homo sapiens OX=9606 GN=TMCO1MSTMFADTLLIVFISVCTALLAEGITWVLVYRTDKYKRLKAEVEKQSKKLEKKKETITESAGRQQKKKIERQEEKLKNNNRDLSMVRMKSMFAIGFCFTALMGMFNSIFDGRVVAKLPFTPLSYIQGLSHRNLLGDDTTDCSFIFLYILCTMSIRQNIQKILGLAPSRAATKQAGGFLGPPPPSGKFS>sp|O75494|SRS10_HUMAN Serine/arginine-rich splicing factor 10 OS=Homosapiens OX=9606 GN=SRSF10 PE=1 SV=1MSRYLRPPNTSLFVRNVADDTRSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNSRPTGRPRRSRSHSDNDRFKHRNRSFSRSKSNSRSRSKSQPKKEMKAKSRSRSASHTKTRGTSKTDSKTHYKSGSRYEKESRKKEPPRSKSQSRSQSRSRSKSRSRSWTSPKSSGH>sp|O75494-2|SRS10_HUMAN Isoform 2 of Serine/arginine-rich splicingfactor 10 OS=Homo sapiens OX=9606 GN=SRSF10MSRYLRPPNTSLFVRNVADDTRSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNRPTGRPRRSRSHSDNDRFKHRNRSFSRSKSNSRSRSKSQPKKEMKAKSRSRSASHTKTRGTSKTDSKTHYKSGSRYEKESRKKEPPRSKSQSRSQSRSRSKSRSRSWTSPKSSGH>sp|O75494-3|SRS10_HUMAN Isoform 3 of Serine/arginine-rich splicingfactor 10 OS=Homo sapiens OX=9606 GN=SRSF10MSRYLRPPNTSLFVRNVADDTRSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNSRPTGRPRRSRSHSDNDRPNCSWNTQYSSAYYTSRKI>sp|O75494-4|SRS10_HUMAN Isoform 4 of Serine/arginine-rich splicingfactor 10 OS=Homo sapiens OX=9606 GN=SRSF10MSRYLRPPNTSLFVRNVADDTRSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNSRPTGRPRRSRSHSDNDSQVSKKKNER>sp|O75494-5|SRS10_HUMAN Isoform 5 of Serine/arginine-rich splicingfactor 10 OS=Homo sapiens OX=9606 GN=SRSF10MSRYLRPPNTSLFVRNVADDTRSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRKPNCSWNTQYSSAYYTSRKI>sp|O75494-6|SRS10_HUMAN Isoform 6 of Serine/arginine-rich splicingfactor 10 OS=Homo sapiens OX=9606 GN=SRSF10MSRYLRPPNTSLFVRNVADDTRSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHNLDRKWICGRQIEIQFAQGDRKTPNQMKAKEGRNVYSSSRYDDYDRYRRSRSRSYERRRSRSRSFDYNYRRSYSPRNRPTGRPRRSRSHSDNDRPNCSWNTQYSSAYYTSRKI>sp|Q92783|STAM1_HUMAN Signal transducing adapter molecule 1 OS=Homosapiens OX=9606 GN=STAM PE=1 SV=3MPLFATNPFDQDVEKATSEMNTAEDWGLILDICDKVGQSRTGPKDCLRSIMRRVNHKDPHVAMQALTLLGACVSNCGKIFHLEVCSRDFASEVSNVLNKGHPKVCEKLKALMVEWTDEFKNDPQLSLISAMIKNLKEQGVTFPAIGSQAAEQAKASPALVAKDPGTVANKKEEEDLAKAIELSLKEQRQQSTTLSTLYPSTSSLLTNHQHEGRKVRAIYDFEAAEDNELTFKAGEIITVLDDSDPNWWKGETHQGIGLFPSNFVTADLTAEPEMIKTEKKTVQFSDDVQVETIEPEPEPAFIDEDKMDQLLQMLQSTDPSDDQPDLPELLHLEAMCHQMGPLIDEKLEDIDRKHSELSELNVKVMEALSLYTKLMNEDPMYSMYAKLQNQPYYMQSSGVSGSQVYAGPPPSGAYLVAGNAQMSHLQSYSLPPEQLSSLSQAVVPPSANPALPSQQTQAAYPNTMVSSVQGNTYPSQAPVYSPPPAATAAAATADVTLYQNAGPNMPQVPNYNLTSSTLPQPGGSQQPPQPQQPYSQKALL>sp|Q92783-2|STAM1_HUMAN Isoform 2 of Signal transducing adapter molecule1 OS=Homo sapiens OX=9606 GN=STAMMPLFATNPFDQDVEKATSEMNTAEDWGLILDICDKVGQSRTGPKDCLRSIMRRVNHKDPHVAMQALTLLGACVSNCGKIFHLEVCSRDFASEVSNVLNKGHPKVCEKLKALMVEWTDEFKNDPQLSLISAMIKNLKEQGVTFPAIGSQAAEQAKASPALVAKDPGTVANKKEEEDLAKAIELSLKEQRQQSTTLSTLYPSTSSLLTNHQHEGRKVRAIYDFEAAEDNELTFKAGEIITVLDDSDPNWWKGETHQGIGLFPSNFVTADLTAEPEMIKTEKKTVQFSDDVQVETIEPEPEPAFIDEDKMDQLLQMLQSTDPSDDQPDLPELLHLEAMCHQMGPLIDEKLEDIDRKHSELSELNVKVMEALSLYTKLMNEDPMYSMYAKLQNQPGSGPTIRKPSPS>sp|Q16384|SSX1_HUMAN Protein SSX1 OS=Homo sapiens OX=9606 GN=SSX1 PE=1SV=2MNGDDTFAKRPRDDAKASEKRSKAFDDIATYFSKKEWKKMKYSEKISYVYMKRNYKAMTKLGFKVTLPPFMCNKQATDFQGNDFDNDHNRRIQVEHPQMTFGRLHRIIPKIMPKKPAEDENDSKGVSEASGPQNDGKQLHPPGKANISEKINKRSGPKRGKHAWTHRLRERKQLVIYEEISDPEEDDE>sp|O14662|STX16_HUMAN Syntaxin-16 OS=Homo sapiens OX=9606 GN=STX16 PE=1SV=3MATRRLTDAFLLLRNNSIQNRQLLAEQVSSHITSSPLHSRSIAAELDELADDRMALVSGISLDPEAAIGVTKRPPPKWVDGVDEIQYDVGRIKQKMKELASLHDKHLNRPTLDDSSEEEHAIEITTQEITQLFHRCQRAVQALPSRARACSEQEGRLLGNVVASLAQALQELSTSFRHAQSGYLKRMKNREERSQHFFDTSVPLMDDGDDNTLYHRGFTEDQLVLVEQNTLMVEEREREIRQIVQSISDLNEIFRDLGAMIVEQGTVLDRIDYNVEQSCIKTEDGLKQLHKAEQYQKKNRKMLVILILFVIIIVLIVVLVGVKSR>sp|O14662-2|STX16_HUMAN Isoform A of Syntaxin-16 OS=Homo sapiens OX=9606GN=STX16MATRRLTDAFLLLRNNSIQNRQLLAEQLADDRMALVSGISLDPEAAIGVTKRPPPKWVDGVDEIQYDVGRIKQKMKELASLHDKHLNRPTLDDSSEEEHAIEITTQEITQLFHRCQRAVQALPSRARACSEQEGRLLGNVVASLAQALQELSTSFRHAQSGYLKRMKNREERSQHFFDTSVPLMDDGDDNTLYHRGFTEDQLVLVEQNTLMVEEREREIRQIVQSISDLNEIFRDLGAMIVEQGTVLDRIDYNVEQSCIKTEDGLKQLHKAEQYQKKNRKMLVILILFVIIIVLIVVLVGVKSR>sp|O14662-3|STX16_HUMAN Isoform C of Syntaxin-16 OS=Homo sapiens OX=9606GN=STX16MATRRLTDAFLLLRNNSIQNRQLLAEQELDELADDRMALVSGISLDPEAAIGVTKRPPPKWVDGVDEIQYDVGRIKQKMKELASLHDKHLNRPTLDDSSEEEHAIEITTQEITQA>sp|O14662-4|STX16_HUMAN Isoform D of Syntaxin-16 OS=Homo sapiens OX=9606GN=STX16MATRRLTDAFLLLRNNSIQNRQLLAEQELDELADDRMALVSGISLDPEAAIGVTKRPPPKWVDGVDEIQYDVGRIKQKMKELASLHDKHLNRPTLDDSSEEEHAIEITTQEITQLFHRCQRAVQALPSRARACSEQEGRLLGNVVASLAQALQELSTSFRHAQSGYLKRMKNREERSQHFFDTSVPLMDDGDDNTLYHRGFTEDQLVLVEQNTLMVEEREREIRQIVQSISDLNEIFRDLGAMIVEQGTVLDRIDYNVEQSCIKTEDGLKQLHKAEQYQKKNRKMLVILILFVIIIVLIVVLVGVKSR>sp|O14662-5|STX16_HUMAN Isoform E of Syntaxin-16 OS=Homo sapiens OX=9606GN=STX16MATRRLTDAFLLLRNNSIQNRQLLAEQVSSHITSSPLHSRSIAALADDRMALVSGISLDPEAAIGVTKRPPPKWVDGVDEIQYDVGRIKQKMKELASLHDKHLNRPTLDDSSEEEHAIEITTQEITQLFHRCQRAVQALPSRARACSEQEGRLLGNVVASLAQALQELSTSFRHAQSGYLKRMKNREERSQHFFDTSVPLMDDGDDNTLYHRGFTEDQLVLVEQNTLMVEEREREIRQIVQSISDLNEIFRDLGAMIVEQGTVLDRIDYNVEQSCIKTEDGLKQLHKAEQYQKKNRKMLVILILFVIIIVLIVVLVGVKSR>sp|O14662-6|STX16_HUMAN Isoform 6 of Syntaxin-16 OS=Homo sapiens OX=9606GN=STX16MALVSGISLDPEAAIGVTKRPPPKWVDGVDEIQYDVGRIKQKMKELASLHDKHLNRPTLDDSSEEEHAIEITTQEITQLFHRCQRAVQALPSRARACSEQEGRLLGNVVASLAQALQELSTSFRHAQSGYLKRMKNREERSQHFFDTSVPLMDDGDDNTLYHRGFTEDQLVLVEQNTLMVEEREREIRQIVQSISDLNEIFRDLGAMIVEQGTVLDRIDYNVEQSCIKTEDGLKQLHKAEQYQKKNRKMLVILILFVIIIVLIVVLVGVKSR>sp|Q7RTT4|SSX8_HUMAN Putative protein SSX8 OS=Homo sapiens OX=9606GN=SSX8P PE=5 SV=2MNGDDAFAKRPRDDDKASEKRSKAFNDIATYFSKKEWEKMKYSEKISYVYMKRNYEAMTKLGFNVTLPPFMCNKQATDFQGNYFDNDRNRRIQVERPQMTFGRLQRIIPKIMPKKPAEEGNDSKGVSEASGPQNDGKQLAPGKANTSEKINKRSGPKRGRHAWTHRLRERNQLVIYEEIRDPEEDDE>sp|Q99909|SSX3_HUMAN Protein SSX3 OS=Homo sapiens OX=9606 GN=SSX3 PE=1SV=2MNGDDTFARRPTVGAQIPEKIQKAFDDIAKYFSKEEWEKMKVSEKIVYVYMKRKYEAMTKLGFKAILPSFMRNKRVTDFQGNDFDNDPNRGNQVQRPQMTFGRLQGIFPKIMPKKPAEEGNVSKEVPEASGPQNDGKQLCPPGKPTTSEKINMISGPKRGEHAWTHRLRERKQLVIYEEISDPEEDDE>sp|Q99909-2|SSX3_HUMAN Isoform 2 of Protein SSX3 OS=Homo sapiens OX=9606GN=SSX3MNGDDTFARRPTVGAQIPEKIQKAFDDIAKYFSKEEWEKMKVSEKIVYVYMKRKYEAMTKLGFKAILPSFMRNKRVTDFQGNDFDNDPNRGNQVQRPQMTFGRLQGIFPKIMPKKPAEEGNVSKEVPEASGPQNDGKQLCPPGKPTTSEKINMISGVLQRYCRFGSRPLQ>sp|O94768|ST17B_HUMAN Serine/threonine-protein kinase 17B OS=Homosapiens OX=9606 GN=STK17B PE=1 SV=1MSRRRFDCRSISGLLTTTPQIPIKMENFNNFYILTSKELGRGKFAVVRQCISKSTGQEYAAKFLKKRRRGQDCRAEILHEIAVLELAKSCPRVINLHEVYENTSEIILILEYAAGGEIFSLCLPELAEMVSENDVIRLIKQILEGVYYLHQNNIVHLDLKPQNILLSSIYPLGDIKIVDFGMSRKIGHACELREIMGTPEYLAPEILNYDPITTATDMWNIGIIAYMLLTHTSPFVGEDNQETYLNISQVNVDYSEETFSSVSQLATDFIQSLLVKNPEKRPTAEICLSHSWLQQWDFENLFHPEETSSSSQTQDHSVRSSEDKTSKSSCNGTCGDREDKENIPEDSSMVSKRFRFDDSLPNPHELVSDLLC>sp|P50226|ST1A2_HUMAN Sulfotransferase 1A2 OS=Homo sapiens OX=9606GN=SULT1A2 PE=1 SV=2MELIQDISRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKVPGIPSGMETLKNTPAPRLLKTHLPLALLPQTLLDQKVKVVYVARNAKDVAVSYYHFYHMAKVYPHPGTWESFLEKFMAGEVSYGSWYQHVQEWWELSRTHPVLYLFYEDMKENPKREIQKILEFVGRSLPEETVDLMVEHTSFKEMKKNPMTNYTTVRREFMDHSISPFMRKGMAGDWKTTFTVAQNERFDADYAKKMAGCSLSFRSEL>sp|Q14140|SRTD2_HUMAN SERTA domain-containing protein 2 OS=Homo sapiensOX=9606 GN=SERTAD2 PE=1 SV=1MLGKGGKRKFDEHEDGLEGKIVSPCDGPSKVSYTLQRQTIFNISLMKLYNHRPLTEPSLQKTVLINNMLRRIQEELKQEGSLRPMFTPSSQPTTEPSDSYREAPPAFSHLASPSSHPCDLGSTTPLEACLTPASLLEDDDDTFCTSQAMQPTAPTKLSPPALLPEKDSFSSALDEIEELCPTSTSTEAATAATDSVKGTSSEAGTQKLDGPQESRADDSKLMDSLPGNFEITTSTGFLTDLTLDDILFADIDTSMYDFDPCTSSSGTASKMAPVSADDLLKTLAPYSSQPVTPSQPFKMDLTELDHIMEVLVGS>sp|Q6IMI6|ST1C3_HUMAN Sulfotransferase 1C3 OS=Homo sapiens OX=9606GN=SULT1C3 PE=1 SV=1MAKIEKNAPTMEKKPELFNIMEVDGVPTLILSKEWWEKVCNFQAKPDDLILATYPKSGTTWMHEILDMILNDGDVEKCKRAQTLDRHAFLELKFPHKEKPDLEFVLEMSSPQLIKTHLPSHLIPPSIWKENCKIVYVARNPKDCLVSYYHFHRMASFMPDPQNLEEFYEKFMSGKVVGGSWFDHVKGWWAAKDMHRILYLFYEDIKKDPKREIEKILKFLEKDISEEILNKIIYHTSFDVMKQNPMTNYTTLPTSIMDHSISPFMRKGMPGDWKNYFTVAQNEEFDKDYQKKMAGSTLTFRTEI>sp|Q6IMI6-2|ST1C3_HUMAN Isoform 2 of Sulfotransferase 1C3 OS=Homosapiens OX=9606 GN=SULT1C3MAKIEKNAPTMEKKPELFNIMEVDGVPTLILSKEWWEKVCNFQAKPDDLILATYPKSGTTWMHEILDMILNDGDVEKCKRAQTLDRHAFLELKFPHKEKPDLEFVLEMSSPQLIKTHLPSHLIPPSIWKENCKIVYVARNPKDCLVSYYHFHRMASFMPDPQNLEEFYEKFMSGKVVGGSWFDHVKGWWAAKDMHRILYLFYEDIKKNPKHEIHKVLEFLEKTWSGDVINKIVHHTSFDVMKDNPMANHTAVPAHIFNHSISKFMRKGMPGDWKNHFTVALNENFDKHYEKKMAGSTLNFCLEI>sp|O00338|ST1C2_HUMAN Sulfotransferase 1C2 OS=Homo sapiens OX=9606GN=SULT1C2 PE=1 SV=1MALTSDLGKQIKLKEVEGTLLQPATVDNWSQIQSFEAKPDDLLICTYPKAGTTWIQEIVDMIEQNGDVEKCQRAIIQHRHPFIEWARPPQPSGVEKAKAMPSPRILKTHLSTQLLPPSFWENNCKFLYVARNAKDCMVSYYHFQRMNHMLPDPGTWEEYFETFINGKVVWGSWFDHVKGWWEMKDRHQILFLFYEDIKRDPKHEIRKVMQFMGKKVDETVLDKIVQETSFEKMKENPMTNRSTVSKSILDQSISSFMRKGTVGDWKNHFTVAQNERFDEIYRRKMEGTSINFCMEL>sp|O00338-2|ST1C2_HUMAN Isoform Long of Sulfotransferase 1C2 OS=Homosapiens OX=9606 GN=SULT1C2MALTSDLGKQIKLKEVEGTLLQPATVDNWSQIQSFEAKPDDLLICTYPKAGTTWIQEIVDMIEQNGDVEKCQRAIIQHRHPFIEWARPPQPSETGFHHVAQAGLKLLSSSNPPASTSQSAKITDLLPPSFWENNCKFLYVARNAKDCMVSYYHFQRMNHMLPDPGTWEEYFETFINGKVVWGSWFDHVKGWWEMKDRHQILFLFYEDIKRDPKHEIRKVMQFMGKKVDETVLDKIVQETSFEKMKENPMTNRSTVSKSILDQSISSFMRKGTVGDWKNHFTVAQNERFDEIYRRKMEGTSINFCMEL>sp|O15400|STX7_HUMAN Syntaxin-7 OS=Homo sapiens OX=9606 GN=STX7 PE=1SV=4MSYTPGVGGDPAQLAQRISSNIQKITQCSVEIQRTLNQLGTPQDSPELRQQLQQKQQYTNQLAKETDKYIKEFGSLPTTPSEQRQRKIQKDRLVAEFTTSLTNFQKVQRQAAEREKEFVARVRASSRVSGSFPEDSSKERNLVSWESQTQPQVQVQDEEITEDDLRLIHERESSIRQLEADIMDINEIFKDLGMMIHEQGDVIDSIEANVENAEVHVQQANQQLSRAADYQRKSRKTLCIIILILVIGVAIISLIIWGLNH>sp|O15400-2|STX7_HUMAN Isoform 2 of Syntaxin-7 OS=Homo sapiens OX=9606GN=STX7MSYTPGVGGDPAQLAQRISSNIQKITQCSVEIQRTLNQLGTPQDSPELRQQLQQKQQYTNQLAKETDKYIKEFGSLPTTPSEQRQRKIQKDRLVAEFTTSLTNFQKVQRQAAEREKEFVARVRASSRVSGSFPEDSSKERNLVSWESQTQPQVQVQDEEITEDDLRLIHERESSIRQLEADIMDINEIFKDLGMMIHEQGDVIDSIEANVENAEVHVQQANQQLSRAADYQKKDSCMLM>sp|A6NGC4|TLCD2_HUMAN TLC domain-containing protein 2 OS=Homo sapiensOX=9606 GN=TLCD2 PE=3 SV=3MAPTGLLVAGASFLAFRGLHWGLRRLPTPESAARDRWQWWNLCVSLAHSLLSGTGALLGLSLYPQMAADPIHGHPRWALVLVAVSVGYFLADGADLLWNQTLGKTWDLLCHHLVVVSCLSTAVLSGHYVGFSMVSLLLELNSACLHLRKLLLLSRQAPSLAFSVTSWASLATLALFRLVPLGWMSLWLFRQHHQVPLALVTLGGIGLVTVGIMSIILGIRILVNDVLQSRPHPPSPGHEKTRGTRTRRDNGPVTSNSSTLSLKD>sp|Q9GZU3|TM39B_HUMAN Transmembrane protein 39B OS=Homo sapiens OX=9606GN=TMEM39B PE=1 SV=1MGGRRGPNRTSYCRNPLCEPGSSGGSSGSHTSSASVTSVRSRTRSSSGTGLSSPPLATQTVVPLQHCKIPELPVQASILFELQLFFCQLIALFVHYINIYKTVWWYPPSHPPSHTSLNFHLIDFNLLMVTTIVLGRRFIGSIVKEASQRGKVSLFRSILLFLTRFTVLTATGWSLCRSLIHLFRTYSFLNLLFLCYPFGMYIPFLQLNCDLRKTSLFNHMASMGPREAVSGLAKSRDYLLTLRETWKQHTRQLYGPDAMPTHACCLSPSLIRSEVEFLKMDFNWRMKEVLVSSMLSAYYVAFVPVWFVKNTHYYDKRWSCELFLLVSISTSVILMQHLLPASYCDLLHKAAAHLGCWQKVDPALCSNVLQHPWTEECMWPQGVLVKHSKNVYKAVGHYNVAIPSDVSHFRFHFFFSKPLRILNILLLLEGAVIVYQLYSLMSSEKWHQTISLALILFSNYYAFFKLLRDRLVLGKAYSYSASPQRDLDHRFS>sp|Q9GZU3-2|TM39B_HUMAN Isoform 2 of Transmembrane protein 39B OS=Homosapiens OX=9606 GN=TMEM39BMGGRRGPNRTSYCRNPLCEPGSSGGSSGSHTSSASVTSVRSRTRSSSGTGLSSPPLATQTVVPLQHCKIPELPVQASILFELQLFFCQLIALFVHYINIYKTVWWYPPSHPPSHTSLNFHLIDFNLLMVTTIVLGRRFIGSIVKEVWDVHSVPAAELRPPQDKPLQPHGLHGAPGGGQWPGKEPGLPPDTAGDVEAAHKTAVWPGRHAHPCLLPVTQPHPQ>sp|Q9GZU3-3|TM39B_HUMAN Isoform 3 of Transmembrane protein 39B OS=Homosapiens OX=9606 GN=TMEM39BMKNFHLIDFNLLMVTTIVLGRRFIGSIVKEASQRGKVSLFRSILLFLTRFTVLTATGWSLCRSLIHLFRTYSFLNLLFLCYPFGMYIPFLQLNCDLRKTSLFNHMASMGPREAVSGLAKSRDYLLTLRETWKQHTRQLYGPDAMPTHACCLSPSLIRSEVEFLKMDFNWRMKEVLVSSMLSAYYVAFVPVWFVKNTHYYDKRWSCELFLLVSISTSVILMQHLLPASYCDLLHKAAAHLGCWQKVDPALCSNVLQHPWTEECMWPQGVLVKHSKNVYKAVGHYNVAIPSDVSHFRFHVSLLPGEGGLGPERVGGSAGQECDVIARESYFQYFPNPKEDSAHM>sp|Q9GZU3-4|TM39B_HUMAN Isoform 4 of Transmembrane protein 39B OS=Homosapiens OX=9606 GN=TMEM39BMYIPFLQLNCDLRKTSLFNHMASMGPREAVSGLAKSRDYLLTLRETWKQHTRQLYGPDAMPTHACCLSPSLIRSEVEFLKMDFNWRMKEVLVSSMLSAYYVAFVPVWFVKNTHYYDKRWSCELFLLVSISTSVILMQHLLPASYCDLLHKAAAHLGCWQKVDPALCSNVLQHPWTEECMWPQGVLVKHSKNVYKAVGHYNVAIPSDVSHFRFHFFFSKPLRILNILLLLEGAVIVYQLYSLMSSEKWHQTISLALILFSNYYAFFKLLRDRLVLGKAYSYSASPQRDLDHRFS>sp|Q12846|STX4_HUMAN Syntaxin-4 OS=Homo sapiens OX=9606 GN=STX4 PE=1SV=2MRDRTHELRQGDDSSDEEDKERVALVVHPGTARLGSPDEEFFHKVRTIRQTIVKLGNKVQELEKQQVTILATPLPEESMKQELQNLRDEIKQLGREIRLQLKAIEPQKEEADENYNSVNTRMRKTQHGVLSQQFVELINKCNSMQSEYREKNVERIRRQLKITNAGMVSDEELEQMLDSGQSEVFVSNILKDTQVTRQALNEISARHSEIQQLERSIRELHDIFTFLATEVEMQGEMINRIEKNILSSADYVERGQEHVKTALENQKKARKKKVLIAICVSITVVLLAVIIGVTVVG>sp|Q12846-2|STX4_HUMAN Isoform 2 of Syntaxin-4 OS=Homo sapiens OX=9606GN=STX4MGMTARTKRTRSGSRWWCTRARHGWGARTRSSSTSPLGHPPQVRTIRQTIVKLGNKVQELEKQQVTILATPLPEESMKQELQNLRDEIKQLGREIRLQLKAIEPQKEEADENYNSVNTRMRKTQHGVLSQQFVELINKCNSMQSEYREKNVERIRRQLKITNAGMVSDEELEQMLDSGQSEVFVSNILKDTQVTRQALNEISARHSEIQQLERSIRELHDIFTFLATEVEMQGEMINRIEKNILSSADYVERGQEHVKTALENQKKARKKKVLIAICVSITVVLLAVIIGVTVVG>sp|Q16629|SRSF7_HUMAN Serine/arginine-rich splicing factor 7 OS=Homosapiens OX=9606 GN=SRSF7 PE=1 SV=1MSRYGRYGGETKVYVGNLGTGAGKGELERAFSYYGPLRTVWIARNPPGFAFVEFEDPRDAEDAVRGLDGKVICGSRVRVELSTGMPRRSRFDRPPARRPFDPNDRCYECGEKGHYAYDCHRYSRRRRSRSRSRSHSRSRGRRYSRSRSRSRGRRSRSASPRRSRSISLRRSRSASLRRSRSGSIKGSRYFQSPSRSRSRSRSISRPRSSRSKSRSPSPKRSRSPSGSPRRSASPERMD>sp|Q16629-2|SRSF7_HUMAN Isoform 2 of Serine/arginine-rich splicingfactor 7 OS=Homo sapiens OX=9606 GN=SRSF7MSRYGRYGGETKVYVGNLGTGAGKGELERAFSYYGPLRTVWIARNPPGFAFVEFEDPRDAEDAVRGLDGKVICGSRVRVELSTGMPRRSRFDRPPARRPFDPNDRCYECGEKGHYAYDCHRYSRRRRSRAENLRR>sp|Q16629-3|SRSF7_HUMAN Isoform 3 of Serine/arginine-rich splicingfactor 7 OS=Homo sapiens OX=9606 GN=SRSF7MSRYGRYGGETKVYVGNLGTGAGKGELERAFSYYGPLRTVWIARNPPGFAFVEFEDPRDAEDAVRGLDGKVICGSRVRVELSTGMPRRSRFDRPPARRPFDPNDRCYECGEKGHYAYDCHRYSRRRRSRYLF>sp|Q16629-4|SRSF7_HUMAN Isoform 4 of Serine/arginine-rich splicingfactor 7 OS=Homo sapiens OX=9606 GN=SRSF7MSRYGRYGGETKVYVGNLGTGAGKGELERAFSYYGPLRTVWIARNPPGFAFVEFEDPRDAEDAVRGLDGKVICGSRVRVELSTGMPRRSRFDRPPARRPFDPNDRCYECGEKGHYAYDCHRYSRRRRSRSRSRSHSRSRGRRYSRSRSRSRGRRSRSASPRRSRSISLRRSRSASLRRSRSGSIKGSRYFQSPSRSRSRSRSISRPRSSRSPSGSPRRSASPERMD>sp|Q96MV1|TLCD4_HUMAN TLC domain-containing protein 4 OS=Homo sapiensOX=9606 GN=TLCD4 PE=1 SV=1MEINTKLLISVTCISFFTFQLLFYFVSYWFSAKVSPGFNSLSFKKKIEWNSRVVSTCHSLVVGIFGLYIFLFDEATKADPLWGGPSLANVNIAIASGYLISDLSIIILYWKVIGDKFFIMHHCASLYAYYLVLKNGVLAYIGNFRLLAELSSPFVNQRWFFEALKYPKFSKAIVINGILMTVVFFIVRIASMLPHYGFMYSVYGTEPYIRLGVLIQLSWVISCVVLDVMNVMWMIKISKGCIKVISHIRQEKAKNSLQNGKLD>sp|Q6IMI4|ST6B1_HUMAN Sulfotransferase 6B1 OS=Homo sapiens OX=9606GN=SULT6B1 PE=2 SV=2MADKSKFIEYIDEALEKSKETALSHLFFTYQGIPYPITMCTSETFQALDTFEARHDDIVLASYPKCGSNWILHIVSELIYAVSKKKYKYPEFPVLECGDSEKYQRMKGFPSPRILATHLHYDKLPGSIFENKAKILVIFRNPKDTAVSFLHFHNDVPDIPSYGSWDEFFRQFMKGQVSWGRYFDFAINWNKHLDGDNVKFILYEDLKENLAAGIKQIAEFLGFFLTGEQIQTISVQSTFQAMRAKSQDTHGAVGPFLFRKGEVGDWKNLFSEIQNQEMDEKFKECLAGTSLGAKLKYESYCQG>sp|Q6IMI4-2|ST6B1_HUMAN Isoform 2 of Sulfotransferase 6B1 OS=Homosapiens OX=9606 GN=SULT6B1MADKSKFIEYIDEALEKSKETALSHLFFTYQGIPYPITMCTSETFQALDTFEARHDDIVLASYPKCGSNWILHIVSELIYAVSKKKYKYPEFPVLECGDSEKYQNLAAGIKQIAEFLGFFLTGEQIQTISVQSTFQAMRAKSQDTHGAVGPFLFRKGEVGDWKNLFSEIQNQEMDEKFKECLAGTSLGAKLKYESYCQG>sp|O00204|ST2B1_HUMAN Sulfotransferase 2B1 OS=Homo sapiens OX=9606GN=SULT2B1 PE=1 SV=2MDGPAEPQIPGLWDTYEDDISEISQKLPGEYFRYKGVPFPVGLYSLESISLAENTQDVRDDDIFIITYPKSGTTWMIEIICLILKEGDPSWIRSVPIWERAPWCETIVGAFSLPDQYSPRLMSSHLPIQIFTKAFFSSKAKVIYMGRNPRDVVVSLYHYSKIAGQLKDPGTPDQFLRDFLKGEVQFGSWFDHIKGWLRMKGKDNFLFITYEELQQDLQGSVERICGFLGRPLGKEALGSVVAHSTFSAMKANTMSNYTLLPPSLLDHRRGAFLRKGVCGDWKNHFTVAQSEAFDRAYRKQMRGMPTFPWDEDPEEDGSPDPEPSPEPEPKPSLEPNTSLEREPRPNSSPSPSPGQASETPHPRPS>sp|O00204-2|ST2B1_HUMAN Isoform 2 of Sulfotransferase 2B1 OS=Homosapiens OX=9606 GN=SULT2B1MASPPPFHSQKLPGEYFRYKGVPFPVGLYSLESISLAENTQDVRDDDIFIITYPKSGTTWMIEIICLILKEGDPSWIRSVPIWERAPWCETIVGAFSLPDQYSPRLMSSHLPIQIFTKAFFSSKAKVIYMGRNPRDVVVSLYHYSKIAGQLKDPGTPDQFLRDFLKGEVQFGSWFDHIKGWLRMKGKDNFLFITYEELQQDLQGSVERICGFLGRPLGKEALGSVVAHSTFSAMKANTMSNYTLLPPSLLDHRRGAFLRKGVCGDWKNHFTVAQSEAFDRAYRKQMRGMPTFPWDEDPEEDGSPDPEPSPEPEPKPSLEPNTSLEREPRPNSSPSPSPGQASETPHPRPS>sp|P0CL83|ST3L1_HUMAN Putative STAG3-like protein 1 OS=Homo sapiensOX=9606 GN=STAG3L1 PE=5 SV=1MIFSMLRKLPKVTCRDVLPEIRAICIEEIGCWMQSYSTSFLTDSYLKYIGWTLHDKHREVRVKCVKALKGLYGNRDLTARLELFTGRFKDWMVSMIVDREYSVAVEAVRLLILILKLFYPECEIRTMGGREQRQSPGAQRTFFQLLLSFFVESKLHDHAAYLVDNLWDCAGTQLKDWEGLTSLLLEKDQSTCHMEPGPGTFHLLG>sp|P09430|STP1_HUMAN Spermatid nuclear transition protein 1 OS=Homosapiens OX=9606 GN=TNP1 PE=1 SV=2MSTSRKLKSHGMRRSKSRSPHKGVKRGGSKRKYRKGNLKSRKRGDDANRNYRSHL>sp|P61956|SUMO2_HUMAN Small ubiquitin-related modifier 2 OS=Homo sapiensOX=9606 GN=SUMO2 PE=1 SV=3MADEKPKEGVKTENNDHINLKVAGQDGSVVQFKIKRHTPLSKLMKAYCERQGLSMRQIRFRFDGQPINETDTPAQLEMEDEDTIDVFQQQTGGVY>sp|P61956-2|SUMO2_HUMAN Isoform 2 of Small ubiquitin-related modifier 2OS=Homo sapiens OX=9606 GN=SUMO2MADEKPKEGVKTENNDHINLKVAGQDGSVVQFKIKRHTPLSKLMKAYCERQLEMEDEDTIDVFQQQTGGVY>sp|O75716|STK16_HUMAN Serine/threonine-protein kinase 16 OS=Homo sapiensOX=9606 GN=STK16 PE=1 SV=4MGHALCVCSRGTVIIDNKRYLFIQKLGEGGFSYVDLVEGLHDGHFYALKRILCHEQQDREEAQREADMHRLFNHPNILRLVAYCLRERGAKHEAWLLLPFFKRGTLWNEIERLKDKGNFLTEDQILWLLLGICRGLEAIHAKGYAHRDLKPTNILLGDEGQPVLMDLGSMNQACIHVEGSRQALTLQDWAAQRCTISYRAPELFSVQSHCVIDERTDVWSLGCVLYAMMFGEGPYDMVFQKGDSVALAVQNQLSIPQSPRHSSALRQLLNSMMTVDPHQRPHIPLLLSQLEALQPPAPGQHTTQI>sp|Q15831|STK11_HUMAN Serine/threonine-protein kinase STK11 OS=Homosapiens OX=9606 GN=STK11 PE=1 SV=1MEVVDPQQLGMFTEGELMSVGMDTFIHRIDSTEVIYQPRRKRAKLIGKYLMGDLLGEGSYGKVKEVLDSETLCRRAVKILKKKKLRRIPNGEANVKKEIQLLRRLRHKNVIQLVDVLYNEEKQKMYMVMEYCVCGMQEMLDSVPEKRFPVCQAHGYFCQLIDGLEYLHSQGIVHKDIKPGNLLLTTGGTLKISDLGVAEALHPFAADDTCRTSQGSPAFQPPEIANGLDTFSGFKVDIWSAGVTLYNITTGLYPFEGDNIYKLFENIGKGSYAIPGDCGPPLSDLLKGMLEYEPAKRFSIRQIRQHSWFRKKHPPAEAPVPIPPSPDTKDRWRSMTVVPYLEDLHGADEDEDLFDIEDDIIYTQDFTVPGQVPEEEASHNGQRRGLPKAVCMNGTEAAQLSTKSRAEGRAPNPARKACSASSKIRRLSACKQQ>sp|Q15831-2|STK11_HUMAN Isoform 2 of Serine/threonine-protein kinaseSTK11 OS=Homo sapiens OX=9606 GN=STK11MEVVDPQQLGMFTEGELMSVGMDTFIHRIDSTEVIYQPRRKRAKLIGKYLMGDLLGEGSYGKVKEVLDSETLCRRAVKILKKKKLRRIPNGEANVKKEIQLLRRLRHKNVIQLVDVLYNEEKQKMYMVMEYCVCGMQEMLDSVPEKRFPVCQAHGYFCQLIDGLEYLHSQGIVHKDIKPGNLLLTTGGTLKISDLGVAEALHPFAADDTCRTSQGSPAFQPPEIANGLDTFSGFKVDIWSAGVTLYNITTGLYPFEGDNIYKLFENIGKGSYAIPGDCGPPLSDLLKGMLEYEPAKRFSIRQIRQHSWFRKKHPPAEAPVPIPPSPDTKDRWRSMTVVPYLEDLHGADEDEDLFDIEDDIIYTQDFTVPGGEEASEAGLRAERGLQKSEGSDLSGEEASRPAPQ>sp|P55854|SUMO3_HUMAN Small ubiquitin-related modifier 3 OS=Homo sapiensOX=9606 GN=SUMO3 PE=1 SV=2MSEEKPKEGVKTENDHINLKVAGQDGSVVQFKIKRHTPLSKLMKAYCERQGLSMRQIRFRFDGQPINETDTPAQLEMEDEDTIDVFQQQTGGVPESSLAGHSF>sp|P55854-2|SUMO3_HUMAN Isoform 2 of Small ubiquitin-related modifier 3OS=Homo sapiens OX=9606 GN=SUMO3MSEEKPKEGVKTENDHINLKVAGQDGSVVQFKIKRHTPLSKLMKAYCERQVRHLAPPQSLPVCALVLCVPGIPRARASRGWTQMQLPEGLSMRQIRFRFDGQPINETDTPAQLEMEDEDTIDVFQQQTGGVPESSLAGHSF>sp|O75683|SURF6_HUMAN Surfeit locus protein 6 OS=Homo sapiens OX=9606GN=SURF6 PE=1 SV=3MASLLAKDAYLQSLAKKICSHSAPEQQARTRAGKTQGSETAGPPKKKRKKTQKKFRKREEKAAEHKAKSLGEKSPAASGARRPEAAKEEAAWASSSAGNPADGLATEPESVFALDVLRQRLHEKIQEARGQGSAKELSPAALEKRRRRKQERDRKKRKRKELRAKEKARKAEEATEAQEVVEATPEGACTEPREPPGLIFNKVEVSEDEPASKAQRRKEKRQRVKGNLTPLTGRNYRQLLERLQARQSRLDELRGQDEGKAQELEAKMKWTNLLYKAEGVKIRDDERLLQEALKRKEKRRAQRQRRWEKRTAGVVEKMQQRQDRRRQNLRRKKAARAERRLLRARKKGRILPQDLERAGLV>sp|Q04725|TLE2_HUMAN Transducin-like enhancer protein 2 OS=Homo sapiensOX=9606 GN=TLE2 PE=1 SV=2MYPQGRHPTPLQSGQPFKFSILEICDRIKEEFQFLQAQYHSLKLECEKLASEKTEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLSGICAQIIPFLTQEHQQQVLQAVERAKQVTVGELNSLIGQQLQPLSHHAPPVPLTPRPAGLVGGSATGLLALSGALAAQAQLAAAVKEDRAGVEAEGSRVERAPSRSASPSPPESLVEEERPSGPGGGGKQRADEKEPSGPYESDEDKSDYNLVVDEDQPSEPPSPATTPCGKVPICIPARRDLVDSPASLASSLGSPLPRAKELILNDLPASTPASKSCDSSPPQDASTPGPSSASHLCQLAAKPAPSTDSVALRSPLTLSSPFTTSFSLGSHSTLNGDLSVPSSYVSLHLSPQVSSSVVYGRSPVMAFESHPHLRGSSVSSSLPSIPGGKPAYSFHVSADGQMQPVPFPSDALVGAGIPRHARQLHTLAHGEVVCAVTISGSTQHVYTGGKGCVKVWDVGQPGAKTPVAQLDCLNRDNYIRSCKLLPDGRSLIVGGEASTLSIWDLAAPTPRIKAELTSSAPACYALAVSPDAKVCFSCCSDGNIVVWDLQNQTMVRQFQGHTDGASCIDISDYGTRLWTGGLDNTVRCWDLREGRQLQQHDFSSQIFSLGHCPNQDWLAVGMESSNVEILHVRKPEKYQLHLHESCVLSLKFASCGRWFVSTGKDNLLNAWRTPYGASIFQSKESSSVLSCDISRNNKYIVTGSGDKKATVYEVVY>sp|Q04725-2|TLE2_HUMAN Isoform 2 of Transducin-like enhancer protein 2OS=Homo sapiens OX=9606 GN=TLE2MQRHYVMYYEMSYGLNIEMHKQAEIVKRLSGICAQIIPFLTQEHQQQVLQAVERAKQVTVGELNSLIGSASPSPPESLVEEERPSGPGGGGKQRADEKEPSGPYESDEDKSDYNLVVDEDQPSEPPSPATTPCGKVPICIPARRDLVDSPASLASSLGSPLPRAKELILNDLPASTPASKSCDSSPPQDASTPGPSSASHLCQLAAKPAPSTDSVALRSPLTLSSPFTTSFSLGSHSTLNGDLSVPSSYVSLHLSPQVSSSVVYGRSPVMAFESHPHLRGSSVSSSLPSIPGGKPAYSFHVSADGQMQPVPFPSDALVGAGIPRHARQLHTLAHGEVVCAVTISGSTQHVYTGGKGCVKVWDVGQPGAKTPVAQLDCLNRDNYIRSCKLLPDGRSLIVGGEASTLSIWDLAAPTPRIKAELTSSAPACYALAVSPDAKVCFSCCSDGNIVVWDLQNQTMVRQFQGHTDGASCIDISDYGTRLWTGGLDNTVRCWDLREGRQLQQHDFSSQIFSLGHCPNQDWLAVGMESSNVEILHVRKPEKYQLHLHESCVLSLKFASCGRWFVSTGKDNLLNAWRTPYGASIFQSKESSSVLSCDISRNNKYIVTGSGDKKATVYEVVY>sp|Q04725-3|TLE2_HUMAN Isoform 3 of Transducin-like enhancer protein 2OS=Homo sapiens OX=9606 GN=TLE2MVQSRLTATSASQDSPASGLQTPLQSGQPFKFSILEICDRIKEEFQFLQAQYHSLKLECEKLASEKTEMQRHYVMYYEMSYGLNIEMHKQAEIVKRLSGICAQIIPFLTQEHQQQVLQAVERAKQVTVGELNSLIGQQQLQPLSHHAPPVPLTPRPAGLVGGSATGLLALSGALAAQAQLAAAVKEDRAGVEAEGSRVERAPSRSASPSPPESLVEEERPSGPGGGGKQRADEKEPSGPYESDEDKSDYNLVVDEDQPSEPPSPATTPCGKVPICIPARRDLVDSPASLASSLGSPLPRAKELILNDLPASTPASKSCDSSPPQDASTPGPSSASHLCQLAAKPAPSTDSVALRSPLTLSSPFTTSFSLGSHSTLNGDLSVPSSYVSLHLSPQVSSSVVYGRSPVMAFESHPHLRGSSVSSSLPSIPGGKPAYSFHVSADGQMQPVPFPSDALVGAGIPRHARQLHTLAHGEVVCAVTISGSTQHVYTGGKGCVKVWDVGQPGAKTPVAQLDCLNRDNYIRSCKLLPDGRSLIVGGEASTLSIWDLAAPTPRIKAELTSSAPACYALAVSPDAKVCFSCCSDGNIVVWDLQNQTMVRQFQGHTDGASCIDISDYGTRLWTGGLDNTVRCWDLREGRQLQQHDFSSQIFSLGHCPNQDWLAVGMESSNVEILHVRKPEKYQLHLHESCVLSLKFASCVQGVVLSPEL>sp|O60279|SUSD5_HUMAN Sushi domain-containing protein 5 OS=Homo sapiensOX=9606 GN=SUSD5 PE=1 SV=3MTAEGPSPPARWHRRLPGLWAAALLLLGLPRLSVRADGKFFVLESQNGSQGLQLEAARLSCKSRGAHLASADELRRVVQDCSFAVCTTGWLADGTLGTTVCSKGSGEQQIMRAVDVRIESNPVPGGTYSALCIKDEEKPCGDPPSFPHTILQGRTGLEMGDELLYVCAPGHIMGHRETAFTLLCNSCGEWYGLVQACGKDEAEAHIDYEDNFPDDRSVSFRELMEDSRTEADEDRGQGDSSEEAPKQDRLVSISVGRENIARDKVFVPTTGLPGAGSSVPADSPGSRLLQKHLFWFPAEAFHKPGLEKEVDDDTKKQFSAGDNHSGVKLVPGEPETKVIYGNTDGPSGPFVGKNDSKAGDPVVSSSDESWLDGYPVTEGAWRKTEAEEEEDGDRGDGSVGLDENVLVTPDQPILVEVKKPKSSTLTPSEGMTHSSVLPSQMLDVEALALRPVNASETEGIGDGDLTKYQSTLPWRFITEESPMATLSYELTSSTLEILTVNTVKQTPNHIPSTIMATTQPPVETTVPEIQDSFPYLLSEDFFGQEGPGPGASEELHPTLESCVGDGCPGLSRGPVIATIVTVLCLLLLLAGVGMVWGYRKCQHKSSVYKLNVGQRQARHYHQQIEMEKV>sp|O43278|SPIT1_HUMAN Kunitz-type protease inhibitor 1 OS=Homo sapiensOX=9606 GN=SPINT1 PE=1 SV=2MAPARTMARARLAPAGIPAVALWLLCTLGLQGTQAGPPPAPPGLPAGADCLNSFTAGVPGFVLDTNASVSNGATFLESPTVRRGWDCVRACCTTQNCNLALVELQPDRGEDAIAACFLINCLYEQNFVCKFAPREGFINYLTREVYRSYRQLRTQGFGGSGIPKAWAGIDLKVQPQEPLVLKDVENTDWRLLRGDTDVRVERKDPNQVELWGLKEGTYLFQLTVTSSDHPEDTANVTVTVLSTKQTEDYCLASNKVGRCRGSFPRWYYDPTEQICKSFVYGGCLGNKNNYLREEECILACRGVQGGPLRGSSGAQATFPQGPSMERRHPVCSGTCQPTQFRCSNGCCIDSFLECDDTPNCPDASDEAACEKYTSGFDELQRIHFPSDKGHCVDLPDTGLCKESIPRWYYNPFSEHCARFTYGGCYGNKNNFEEEQQCLESCRGISKKDVFGLRREIPIPSTGSVEMAVAVFLVICIVVVVAILGYCFFKNQRKDFHGHHHHPPPTPASSTVSTTEDTEHLVYNHTTRPL>sp|O43278-2|SPIT1_HUMAN Isoform 2 of Kunitz-type protease inhibitor 1OS=Homo sapiens OX=9606 GN=SPINT1MAPARTMARARLAPAGIPAVALWLLCTLGLQGTQAGPPPAPPGLPAGADCLNSFTAGVPGFVLDTNASVSNGATFLESPTVRRGWDCVRACCTTQNCNLALVELQPDRGEDAIAACFLINCLYEQNFVCKFAPREGFINYLTREVYRSYRQLRTQGFGGSGIPKAWAGIDLKVQPQEPLVLKDVENTDWRLLRGDTDVRVERKDPNQVELWGLKEGTYLFQLTVTSSDHPEDTANVTVTVLSTKQTEDYCLASNKVGRCRGSFPRWYYDPTEQICKSFVYGGCLGNKNNYLREEECILACRGVQGPSMERRHPVCSGTCQPTQFRCSNGCCIDSFLECDDTPNCPDASDEAACEKYTSGFDELQRIHFPSDKGHCVDLPDTGLCKESIPRWYYNPFSEHCARFTYGGCYGNKNNFEEEQQCLESCRGISKKDVFGLRREIPIPSTGSVEMAVAVFLVICIVVVVAILGYCFFKNQRKDFHGHHHHPPPTPASSTVSTTEDTEHLVYNHTTRPL>sp|Q96L08|SUSD3_HUMAN Sushi domain-containing protein 3 OS=Homo sapiensOX=9606 GN=SUSD3 PE=1 SV=1MRWAAATLRGKARPRGRAGVTTPAPGNRTGTCAKLRLPPQATFQVLRGNGASVGTVLMFRCPSNHQMVGSGLLTCTWKGSIAEWSSGSPVCKLVPPHETFGFKVAVIASIVSCAIILLMSMAFLTCCLLKCVKKSKRRRSNRSAQLWSQLKDEDLETVQAAYLGLKHFNKPVSGPSQAHDNHSFTTDHGESTSKLASVTRSVDKDPGIPRALSLSGSSSSPQAQVMVHMANPRQPLPASGLATGMPQQPAAYALG>sp|Q96L08-2|SUSD3_HUMAN Isoform 2 of Sushi domain-containing protein 3OS=Homo sapiens OX=9606 GN=SUSD3MKNIGLVMEWEIPEIICTCAKLRLPPQATFQVLRGNGASVGTVLMFRCPSNHQMVGSGLLTCTWKGSIAEWSSGSPVCKLVPPHETFGFKVAVIASIVSCAIILLMSMAFLTCCLLKCVKKSKRRRSNRSAQLWSQLKDEDLETVQAAYLGLKHFNKPVSGPSQAHDNHSFTTDHGESTSKLASVTRSVDKDPGIPRALSLSGSSSSPQAQVMVHMANPRQPLPASGLATGMPQQPAAYALG>sp|Q96L08-3|SUSD3_HUMAN Isoform 3 of Sushi domain-containing protein 3OS=Homo sapiens OX=9606 GN=SUSD3MSMAFLTCCLLKCVKKSKRRRSNRSAQLWSQLKDEDLETVQAAYLGLKHFNKPVSGPSQAHDNHSFTTDHGESTSKLASVTRSVDKDPGIPRALSLSGSSSSPQAQVMVHMANPRQPLPASGLATGMPQQPAAYALG>sp|Q5T0L3|SPT46_HUMAN Spermatogenesis-associated protein 46 OS=Homosapiens OX=9606 GN=SPATA46 PE=1 SV=3MENFSLLSISGPPISSSALSAFPDIMFSRATSLPDIAKTAVPTEASSPAQALPPQYQSIIVRQGIQNTALSPDCSLGDTQHGEKLRRNCTIYRPWFSPYSYFVCADKESQLEAYDFPEVQQDEGKWDNCLSEDMAENICSSSSSPENTCPREATKKSRHGLDSITSQDILMASRWHPAQQNGYKCVACCRMYPTLDFLKSHIKRGFREGFSCKVYYRKLKALWSKEQKARLGDRLSSGSCQAFNSPAEHLRQIGGEAYLCL>sp|Q9Y2K9|STB5L_HUMAN Syntaxin-binding protein 5-like OS=Homo sapiensOX=9606 GN=STXBP5L PE=1 SV=2MKKFNFRKVLDGLTASSPGSGSSSGSNSGGGAGSGSVHPAGTAGVLREEIQETLTSEYFQICKTVRHGFPHQPTALAFDPVQKILAIGTRTGAIRILGRPGVDCYCQHESGAAVLQLQFLINEGALVSASSDDTLHLWNLRQKRPAILHSLKFNRERITYCHLPFQSKWLYVGTERGNTHIVNIESFILSGYVIMWNKAIELSTKTHPGPVVHLSDSPRDEGKLLIGYENGTVVFWDLKSKRAELRVYYDEAIHSIDWHHEGKQFMCSHSDGSLTLWNLKSPSRPFQTTIPHGKSQREGRKSESCKPILKVEYKTCKNSEPFIIFSGGLSYDKACRRPSLTIMHGKAITVLEMDHPIVEFLTLCETPYPNEFQEPYAVVVLLEKDLIVVDLTQSNFPIFENPYPMDIHESPVTCTAYFADCPPDLILVLYSIGVKHKKQGYSNKEWPISGGAWNLGAQTYPEIIITGHADGSIKFWDASAITLQMLYKLKTSKVFEKQKVGEGKQTCEIVEEDPFAIQMIYWCPESRIFCVSGVSAYVIIYKFSRHEITTEIVSLEVRLQYDVEDIITPEPETSPPFPDLSAQLPSSRSLSGSTNTVASEGVTKDSIPCLNVKTRPVRMPPGYQAELVIQLVWVDGEPPQQITSLAVSSAYGIVAFGNCNGLAVVDFIQKTVLLSMGTIDLYRSSDLYQRQPRSPRKNKQFIADNFCMRGLSNFYPDLTKRIRTSYQSLTELNDSPVPLELERCKSPTSDHVNGHCTSPTSQSCSSGKRLSSADVSKVNRWGPGRPPFRKAQSAACMEISLPVTTEENRENSYNRSRSSSISSIDKDSKEAITALYFMDSFARKNDSTISPCLFVGTSLGMVLIISLNLPLADEQRFTEPVMVLPSGTFLSLKGAVLTFSCMDRMGGLMQPPYEVWRDPNNIDENEKSWRRKVVMNSSSASQEIGDHQYTIICSEKQAKVFSLPSQTCLYVHNITETSFILQANVVVMCSSACLACFCANGHIMIMSLPSLRPMLDVNYLPLTDMRIARTFCFTNEGQALYLVSPTEIQRLTYSQEMCDNLQDMLGDLFTPIETPEAQNRGFLKGLFGGSGQTFDREELFGEASAGKASRSLAQHIPGPGSIEGMKGAAGGVMGELTRARIALDERGQRLGELEEKTAGMMTSAEAFSKHAHELMLKYKDKKWYQF>sp|Q9Y2K9-2|STB5L_HUMAN Isoform 2 of Syntaxin-binding protein 5-likeOS=Homo sapiens OX=9606 GN=STXBP5LMKKFNFRKVLDGLTASSPGSGSSSGSNSGGGAGSGSVHPAGTAGVLREEIQETLTSEYFQICKFGMVFLISPQH>sp|Q9NUV7|SPTC3_HUMAN Serine palmitoyltransferase 3 OS=Homo sapiensOX=9606 GN=SPTLC3 PE=1 SV=3MANPGGGAVCNGKLHNHKKQSNGSQSRNCTKNGIVKEAQQNGKPHFYDKLIVESFEEAPLHVMVFTYMGYGIGTLFGYLRDFLRNWGIEKCNAAVERKEQKDFVPLYQDFENFYTRNLYMRIRDNWNRPICSAPGPLFDLMERVSDDYNWTFRFTGRVIKDVINMGSYNFLGLAAKYDESMRTIKDVLEVYGTGVASTRHEMGTLDKHKELEDLVAKFLNVEAAMVFGMGFATNSMNIPALVGKGCLILSDELNHTSLVLGARLSGATIRIFKHNNTQSLEKLLRDAVIYGQPRTRRAWKKILILVEGVYSMEGSIVHLPQIIALKKKYKAYLYIDEAHSIGAVGPTGRGVTEFFGLDPHEVDVLMGTFTKSFGASGGYIAGRKDLVDYLRVHSHSAVYASSMSPPIAEQIIRSLKLIMGLDGTTQGLQRVQQLAKNTRYFRQRLQEMGFIIYGNENASVVPLLLYMPGKVAAFARHMLEKKIGVVVVGFPATPLAEARARFCVSAAHTREMLDTVLEALDEMGDLLQLKYSRHKKSARPELYDETSFELED>sp|Q9NUV7-2|SPTC3_HUMAN Isoform 2 of Serine palmitoyltransferase 3OS=Homo sapiens OX=9606 GN=SPTLC3MANPGGGAVCNGKLHNHKKQSNGSQSRNCTKNGIVKEAQQNGKPHFYDKLIVESFEEAPLHVMVFTYMGYGIGTLFGYLRDFLRNWGIEKCNAAVERKEQKVRMRTSLDLCQCLLLSKVFSEVVMQVQILESMRCSGTIQGKFHSSPPPKPHYPWAYGPVFTNISWATTICHIPN>sp|Q9HD15|SRA1_HUMAN Steroid receptor RNA activator 1 OS=Homo sapiensOX=9606 GN=SRA1 PE=1 SV=1MTRCPAGQAEVEMAELYVKPGNKERGWNDPPQFSYGLQTQAGGPRRSLLTKRVAAPQDGSPRVPASETSPGPPPMGPPPPSSKAPRSPPVGSGPASGVEPTSFPVESEAVMEDVLRPLEQALEDCRGHTRKQVCDDISRRLALLQEQWAGGKLSIPVKKRMALLVQELSSHRWDAADDIHRSLMVDHVTEVSQWMVGVKRLIAEKRSLFSEEAANEEKSAATAEKNHTIPGFQQAS>sp|Q496J9|SV2C_HUMAN Synaptic vesicle glycoprotein 2C OS=Homo sapiensOX=9606 GN=SV2C PE=1 SV=1MEDSYKDRTSLMKGAKDIAREVKKQTVKKVNQAVDRAQDEYTQRSYSRFQDEEDDDDYYPAGETYNGEANDDEGSSEATEGHDEDDEIYEGEYQGIPSMNQAKDSIVSVGQPKGDEYKDRRELESERRADEEELAQQYELIIQECGHGRFQWALFFVLGMALMADGVEVFVVGFVLPSAETDLCIPNSGSGWLGSIVYLGMMVGAFFWGGLADKVGRKQSLLICMSVNGFFAFLSSFVQGYGFFLFCRLLSGFGIGGAIPTVFSYFAEVLAREKRGEHLSWLCMFWMIGGIYASAMAWAIIPHYGWSFSMGSAYQFHSWRVFVIVCALPCVSSVVALTFMPESPRFLLEVGKHDEAWMILKLIHDTNMRARGQPEKVFTVNKIKTPKQIDELIEIESDTGTWYRRCFVRIRTELYGIWLTFMRCFNYPVRDNTIKLTIVWFTLSFGYYGLSVWFPDVIKPLQSDEYALLTRNVERDKYANFTINFTMENQIHTGMEYDNGRFIGVKFKSVTFKDSVFKSCTFEDVTSVNTYFKNCTFIDTVFDNTDFEPYKFIDSEFKNCSFFHNKTGCQITFDDDYSAYWIYFVNFLGTLAVLPGNIVSALLMDRIGRLTMLGGSMVLSGISCFFLWFGTSESMMIGMLCLYNGLTISAWNSLDVVTVELYPTDRRATGFGFLNALCKAAAVLGNLIFGSLVSITKSIPILLASTVLVCGGLVGLCLPDTRTQVLM>sp|Q9BXN6|SPNXD_HUMAN Sperm protein associated with the nucleus on the Xchromosome D OS=Homo sapiens OX=9606 GN=SPANXD PE=1 SV=1MDKQSSAGGVKRSVPCDSNEANEMMPETSSGYSDPQPAPKKLKTSESSTILVVRYRRNFKRTSPEELVNDHARKNRINPLQMEEEEFMEIMVEIPAK>sp|Q8NEF9|SRFB1_HUMAN Serum response factor-binding protein 1 OS=Homosapiens OX=9606 GN=SRFBP1 PE=1 SV=1MAQPGTLNLNNEVVKMRKEVKRIRVLVIRKLVRSVGRLKSKKGTEDALLKNQRRAQRLLEEIHAMKELKPDIVTKSALGDDINFEKIFKKPDSTATERAIARLAVHPLLKKKIDVLKAAVQAFKEARQNVAEVESSKNASEDNHSENTLYSNDNGSNLQREATVISEQKVKETKILAKKPIHNSKEKIAKMEHGPKAVTIANSPSKPSEKDSVVSLESQKTPADPKLKTLSQTKKNKGSDSSLSGNSDGGEEFCEEEKEYFDDSTEERFYKQSSMSEDSDSGDDFFIGKVRRTRKKESSCHSSVKEQKPLEKVFLKEDTGETHGDTRNDKIKPSTETRKLESVFFHSLSGSKSSRRNFKEQAPKTRSLDFPQNEPQIKNQFNKKLSGRLENTKQQLQLPLHPSWEASRRRKEQQSNIAVFQGKKITFDD>sp|Q12772|SRBP2_HUMAN Sterol regulatory element-binding protein 2OS=Homo sapiens OX=9606 GN=SREBF2 PE=1 SV=2MDDSGELGGLETMETLTELGDELTLGDIDEMLQFVSNQVGEFPDLFSEQLCSSFPGSGGSGSSSGSSGSSSSSSNGRGSSSGAVDPSVQRSFTQVTLPSFSPSAASPQAPTLQVKVSPTSVPTTPRATPILQPRPQPQPQPQTQLQQQTVMITPTFSTTPQTRIIQQPLIYQNAATSFQVLQPQVQSLVTSSQVQPVTIQQQVQTVQAQRVLTQTANGTLQTLAPATVQTVAAPQVQQVPVLVQPQIIKTDSLVLTTLKTDGSPVMAAVQNPALTALTTPIQTAALQVPTLVGSSGTILTTMPVMMGQEKVPIKQVPGGVKQLEPPKEGERRTTHNIIEKRYRSSINDKIIELKDLVMGTDAKMHKSGVLRKAIDYIKYLQQVNHKLRQENMVLKLANQKNKLLKGIDLGSLVDNEVDLKIEDFNQNVLLMSPPASDSGSQAGFSPYSIDSEPGSPLLDDAKVKDEPDSPPVALGMVDRSRILLCVLTFLCLSFNPLTSLLQWGGAHDSDQHPHSGSGRSVLSFESGSGGWFDWMMPTLLLWLVNGVIVLSVFVKLLVHGEPVIRPHSRSSVTFWRHRKQADLDLARGDFAAAAGNLQTCLAVLGRALPTSRLDLACSLSWNVIRYSLQKLRLVRWLLKKVFQCRRATPATEAGFEDEAKTSARDAALAYHRLHQLHITGKLPAGSACSDVHMALCAVNLAECAEEKIPPSTLVEIHLTAAMGLKTRCGGKLGFLASYFLSRAQSLCGPEHSAVPDSLRWLCHPLGQKFFMERSWSVKSAAKESLYCAQRNPADPIAQVHQAFCKNLLERAIESLVKPQAKKKAGDQEEESCEFSSALEYLKLLHSFVDSVGVMSPPLSRSSVLKSALGPDIICRWWTSAITVAISWLQGDDAAVRSHFTKVERIPKALEVTESPLVKAIFHACRAMHASLPGKADGQQSSFCHCERASGHLWSSLNVSGATSDPALNHVVQLLTCDLLLSLRTALWQKQASASQAVGETYHASGAELAGFQRDLGSLRRLAHSFRPAYRKVFLHEATVRLMAGASPTRTHQLLEHSLRRRTTQSTKHGEVDAWPGQRERATAILLACRHLPLSFLSSPGQRAVLLAEAARTLEKVGDRRSCNDCQQMIVKLGGGTAIAAS>sp|Q12772-2|SRBP2_HUMAN Isoform 2 of Sterol regulatory element-bindingprotein 2 OS=Homo sapiens OX=9606 GN=SREBF2MDDSGELGGLETMETLTELGDELTLGDIDEMLQFVSNQVGEFPDLFSEQLCSSFPGSGGSGSSSGSSGSSSSSSNGRGSSSGAVDPSVQRSFTQVTLPSFSPSAASPQAPTLQVKVSPTSVPTTPRATPILQPRPQPQPQPQTQLQQQTVMITPTFSTTPQTRIIQQPLIYQNAATSFQVLQPQVQSLVTSSQVQPVTIQQQVQTVQAQRVLTQTANGTLQTLAPATVQTVAAPQVQQVPVLVQPQIIKTDSLVLTTLKTDGSPVMAAVQNPALTTPIQTAALQVPTLVGSSGTILTTMPVMMGQEKVPIKQVPGGVKQLEPPKEGERRTTHNIIEKRYRSSINDKIIELKDLVMGTDAKMHKSGVLRKAIDYIKYLQQVNHKLRQENMVLKLANQKNKLLKGIDLGSLVDNEVDLKIEDFNQNVLLMSPPASDSGSQAGFSPYSIDSEPGSPLLDDAKVKDEPDSPPVALGMVDRSRILLCVLTFLCLSFNPLTSLLQWGGAHDSDQHPHSGSGRSVLSFESGSGGWFDWMMPTLLLWLVNGVIVLSVFVKLLVHGEPVIRPHSRSSVTFWRHRKQADLDLARGVYGKKSGATHSIEEELNIHISRGTRTRTLLSSRRFCSCCRQPTNLPGSFGPGTAHLPPGPGLQPLLERDPLQPAEATPGALAAQESLPVPAGHASH>sp|A7MD48|SRRM4_HUMAN Serine/arginine repetitive matrix protein 4OS=Homo sapiens OX=9606 GN=SRRM4 PE=1 SV=2MASVQQGEKQLFEKFWRGTFKAVATPRPESIIVASITARKPLPRTEPQNNPVVPAQDGPSEKLGQHLATEPLGTNSWERDKTCRELGATRGHSASHDKDLTPPPSSRGKKKKKKSTRKKRRRSSSYSPSPVKKKKKKSSKKHKRRRSFSKKRRHSSSSPKSKRRDEKRHKKQSRSRPRKSHRHRHHRCPSRSQSSESRPSSCESRHRGRSPEEGQKSRRRHSRRCSKTLCKDSPEAQSSRPPSQPLQMLGYLSARGVITGSGSAADLFTKTASPLTTSRGRSQEYDSGNDTSSPPSTQTSSARSRGQEKGSPSGGLSKSRELNSGNTSDSGNSFTTSSPQNKGAMLENLSPTSRGRESRGFQSPCLECAEVKKSSLVPSTARSSPMKGCSRSSSYASTRSSSHSSRSPNPRASPRYTQSRSTSSEKRSYSRSPSYSSKSGKRSPPSRSSRSRRSPSYSRYSPSRERDPKYSEKDSQQRERERARRRRRSYSPMRKRRRDSPSHLEARRITSARKRPIPYYRPSPSSSGSLSSTSSWYSSSSSRSASRSYSRSRSRSRSRRRSRTRTSSSSSSRSPSPGSRSRSRSRSRSRSRSRSQSRSYSSADSYSSTRR>sp|P43308|SSRB_HUMAN Translocon-associated protein subunit beta OS=Homosapiens OX=9606 GN=SSR2 PE=1 SV=1MRLLSFVVLALFAVTQAEEGARLLASKSLLNRYAVEGRDLTLQYNIYNVGSSAALDVELSDDSFPPEDFGIVSGMLNVKWDRIAPASNVSHTVVLRPLKAGYFNFTSATITYLAQEDGPVVIGSTSAPGQGGILAQREFDRRFSPHFLDWAAFGVMTLPSIGIPLLLWYSSKRKYDTPKTKKN>sp|Q08945|SSRP1_HUMAN FACT complex subunit SSRP1 OS=Homo sapiens OX=9606GN=SSRP1 PE=1 SV=1MAETLEFNDVYQEVKGSMNDGRLRLSRQGIIFKNSKTGKVDNIQAGELTEGIWRRVALGHGLKLLTKNGHVYKYDGFRESEFEKLSDFFKTHYRLELMEKDLCVKGWNWGTVKFGGQLLSFDIGDQPVFEIPLSNVSQCTTGKNEVTLEFHQNDDAEVSLMEVRFYVPPTQEDGVDPVEAFAQNVLSKADVIQATGDAICIFRELQCLTPRGRYDIRIYPTFLHLHGKTFDYKIPYTTVLRLFLLPHKDQRQMFFVISLDPPIKQGQTRYHFLILLFSKDEDISLTLNMNEEEVEKRFEGRLTKNMSGSLYEMVSRVMKALVNRKITVPGNFQGHSGAQCITCSYKASSGLLYPLERGFIYVHKPPVHIRFDEISFVNFARGTTTTRSFDFEIETKQGTQYTFSSIEREEYGKLFDFVNAKKLNIKNRGLKEGMNPSYDEYADSDEDQHDAYLERMKEEGKIREENANDSSDDSGEETDESFNPGEEEEDVAEEFDSNASASSSSNEGDSDRDEKKRKQLKKAKMAKDRKSRKKPVEVKKGKDPNAPKRPMSAYMLWLNASREKIKSDHPGISITDLSKKAGEIWKGMSKEKKEEWDRKAEDARRDYEKAMKEYEGGRGESSKRDKSKKKKKVKVKMEKKSTPSRGSSSKSSSRQLSESFKSKEFVSSDESSSGENKSKKKRRRSEDSEEEELASTPPSSEDSASGSDE>sp|P49590|SYHM_HUMAN Histidine--tRNA ligase, mitochondrial OS=Homosapiens OX=9606 GN=HARS2 PE=1 SV=1MPLLGLLPRRAWASLLSQLLRPPCASCTGAVRCQSQVAEAVLTSQLKAHQEKPNFIIKTPKGTRDLSPQHMVVREKILDLVISCFKRHGAKGMDTPAFELKETLTEKYGEDSGLMYDLKDQGGELLSLRYDLTVPFARYLAMNKVKKMKRYHVGKVWRRESPTIVQGRYREFCQCDFDIAGQFDPMIPDAECLKIMCEILSGLQLGDFLIKVNDRRIVDGMFAVCGVPESKFRAICSSIDKLDKMAWKDVRHEMVVKKGLAPEVADRIGDYVQCHGGVSLVEQMFQDPRLSQNKQALEGLGDLKLLFEYLTLFGIADKISFDLSLARGLDYYTGVIYEAVLLQTPTQAGEEPLNVGSVAAGGRYDGLVGMFDPKGHKVPCVGLSIGVERIFYIVEQRMKTKGEKVRTTETQVFVATPQKNFLQERLKLIAELWDSGIKAEMLYKNNPKLLTQLHYCESTGIPLVVIIGEQELKEGVIKIRSVASREEVAIKRENFVAEIQKRLSES>sp|P49590-2|SYHM_HUMAN Isoform 2 of Histidine--tRNA ligase,mitochondrial OS=Homo sapiens OX=9606 GN=HARS2MPLLGLLPRRAWASLLSQLLRPPCASCTGAVRCQSQGTRDLSPQHMVVREKILDLVISCFKRHGAKGMDTPAFELKETLTEKYGEDSGLMYDLKDQGGELLSLRYDLTVPFARYLAMNKVKKMKRYHVGKVWRRESPTIVQGRYREFCQCDFDIAGQFDPMIPDAECLKIMCEILSGLQLGDFLIKVNDRRIVDGMFAVCGVPESKFRAICSSIDKLDKMAWKDVRHEMVVKKGLAPEVADRIGDYVQCHGGVSLVEQMFQDPRLSQNKQALEGLGDLKLLFEYLTLFGIADKISFDLSLARGLDYYTGVIYEAVLLQTPTQAGEEPLNVGSVAAGGRYDGLVGMFDPKGHKVPCVGLSIGVERIFYIVEQRMKTKGEKVRTTETQVFVATPQKNFLQERLKLIAELWDSGIKAEMLYKNNPKLLTQLHYCESTGIPLVVIIGEQELKEGVIKIRSVASREEVAIKRENFVAEIQKRLSES>sp|Q86UD7|TBC26_HUMAN TBC1 domain family member 26 OS=Homo sapiensOX=9606 GN=TBC1D26 PE=2 SV=3MEMDGDPYNLPAQGQGNIIITKYEQGHRAGAAVDLGHEQVDVRKYTNNLGIVHEMELPHVSALEVKQRRKESKRTNKWQKMLADWTKYRSTKKLSQRVYKVIPLAVRGRAWSLLLDIDRIKSQNPGKYKVMKEKGKRSSRIIHCIQLDVSHTLQKHMMFIQRFGVKQQELCDILVAYSAYNPEVGYHRDLSRITAILLLCLPEEDAFWALTQLLAGERHSLWYSTAQILPGSRGSYRTRSRCCTSPSQRS>sp|Q86UD7-2|TBC26_HUMAN Isoform 2 of TBC1 domain family member 26OS=Homo sapiens OX=9606 GN=TBC1D26MEMDGDPYNLPAQGQGNIIITKYEQGHRAGAAVDLGHEQVDVRKYTNNLGIVHEMELPHVSALEVKQRRKESKRTNKWQKMLADWTKYRSTKKLSQRVYKVIPLAVRGRAWSLLLDIDRIKSQNPGKYKVMKEKGKRSSRIIHCIQLDVSHTLQKHMMFIQRFGVKQQELCDILVAYSAYNPVSIPGQRYSWDMCPYSQAWVSLGGVATS>sp|Q86UD7-3|TBC26_HUMAN Isoform 3 of TBC1 domain family member 26OS=Homo sapiens OX=9606 GN=TBC1D26MEMDGDPYNLPAQGQGNIIITKYEQGHRAGAAVDLGHEQVDVRKYTNNLGIVHEMELPHVSALEVKVRACACCVGGCFRDWESGGR>sp|Q96GX1|TECT2_HUMAN Tectonic-2 OS=Homo sapiens OX=9606 GN=TCTN2 PE=2SV=1MGFQPPAALLLRLFLLQGILRLLWGDLAFIPPFIRMSGPAVSASLVGDTEGVTVSLAVLQDEAGILPIPTCGVLNNETEDWSVTVIPGAKVLEVTVRWKRGLDWCSSNETDSFSESPCILQTLLVSASHNSSCSAHLLIQVEIYANSSLTHNASENVTVIPNQVYQPLGPCPCNLTAGACDVRCCCDQECSSNLTTLFRRSCFTGVFGGDVNPPFDQLCSAGTTTRGVPDWFPFLCVQSPLANTPFLGYFYHGAVSPKQDSSFEVYVDTDAKDFADFGYKQGDPIMTVKKAYFTIPQVSLAGQCMQNAPVAFLHNFDVKCVTNLELYQERDGIINAKIKNVALGGIVTPKVIYEEATDLDKFITNTETPLNNGSTPRIVNVEEHYIFKWNNNTISEINVKIFRAEINAHQKGIMTQRFVVKFLSYNSGNEEELSGNPGYQLGKPVRALNINRMNNVTTLHLWQSAGRGLCTSATFKPILFGENVLSGCLLEVGINENCTQLRENAVERLDSLIQATHVAMRGNSDYADLSDGWLEIIRVDAPDPGADPLASSVNGMCLDIPAHLSIRILISDAGAVEGITQQEILGVETRFSSVNWQYQCGLTCEHKADLLPISASVQFIKIPAQLPHPLTRFQINYTEYDCNRNEVCWPQLLYPWTQYYQGELHSQCVAKGLLLLLFLTLALFLSNPWTRICKAYS>sp|Q96GX1-2|TECT2_HUMAN Isoform 2 of Tectonic-2 OS=Homo sapiens OX=9606GN=TCTN2MGFQPPAALLLRLFLLQGILRLLWGDLAFIPPFIRMSGPAVSASLVGDTEGVTVSLAVLQDEAGILPIPTCGVLNNETEDWSVTVIPGAVLEVTVRWKRGLDWCSSNETDSFSESPCILQTLLVSASHNSSCSAHLLIQVEIYANSSLTHNASENVTVIPNQVYQPLGPCPCNLTAGACDVRCCCDQECSSNLTTLFRRSCFTGVFGGDVNPPFDQLCSAGTTTRGVPDWFPFLCVQSPLANTPFLGYFYHGAVSPKQDSSFEVYVDTDAKDFADFGYKQGDPIMTVKKAYFTIPQVSLAGQCMQNAPVAFLHNFDVKCVTNLELYQERDGIINAKIKNVALGGIVTPKVIYEEATDLDKFITNTETPLNNGSTPRIVNVEEHYIFKWNNNTISEINVKIFRAEINAHQKGIMTQRFVVKFLSYNSGNEEELSGNPGYQLGKPVRALNINRMNNVTTLHLWQSAGRGLCTSATFKPILFGENVLSGCLLEVGINENCTQLRENAVERLDSLIQATHVAMRGNSDYADLSDGWLEIIRVDAPDPGADPLASSVNGMCLDIPAHLSIRILISDAGAVEGITQQEILGVETRFSSVNWQYQCGLTCEHKADLLPISASVQFIKIPAQLPHPLTRFQINYTEYDCNRNEVCWPQLLYPWTQYYQGELHSQCVAKGLLLLLFLTLALFLSNPWTRICKAYS>sp|O60907|TBL1X_HUMAN F-box-like/WD repeat-containing protein TBL1XOS=Homo sapiens OX=9606 GN=TBL1X PE=1 SV=3MTELAGASSSCCHRPAGRGAMQSVLHHFQRLRGREGGSHFINTSSPRGEAKMSITSDEVNFLVYRYLQESGFSHSAFTFGIESHISQSNINGTLVPPAALISILQKGLQYVEAEISINEDGTVFDGRPIESLSLIDAVMPDVVQTRQQAFREKLAQQQASAAAAAAAATAAATAATTTSAGVSHQNPSKNREATVNGEENRAHSVNNHAKPMEIDGEVEIPSSKATVLRGHESEVFICAWNPVSDLLASGSGDSTARIWNLNENSNGGSTQLVLRHCIREGGHDVPSNKDVTSLDWNTNGTLLATGSYDGFARIWTEDGNLASTLGQHKGPIFALKWNRKGNYILSAGVDKTTIIWDAHTGEAKQQFPFHSAPALDVDWQNNTTFASCSTDMCIHVCRLGCDRPVKTFQGHTNEVNAIKWDPSGMLLASCSDDMTLKIWSMKQEVCIHDLQAHNKEIYTIKWSPTGPATSNPNSNIMLASASFDSTVRLWDIERGVCTHTLTKHQEPVYSVAFSPDGKYLASGSFDKCVHIWNTQSGNLVHSYRGTGGIFEVCWNARGDKVGASASDGSVCVLDLRK>sp|O60907-2|TBL1X_HUMAN Isoform 2 of F-box-like/WD repeat-containingprotein TBL1X OS=Homo sapiens OX=9606 GN=TBL1XMSITSDEVNFLVYRYLQESGFSHSAFTFGIESHISQSNINGTLVPPAALISILQKGLQYVEAEISINEDGTVFDGRPIESLSLIDAVMPDVVQTRQQAFREKLAQQQASAAAAAAAATAAATAATTTSAGVSHQNPSKNREATVNGEENRAHSVNNHAKPMEIDGEVEIPSSKATVLRGHESEVFICAWNPVSDLLASGSGDSTARIWNLNENSNGGSTQLVLRHCIREGGHDVPSNKDVTSLDWNTNGTLLATGSYDGFARIWTEDGNLASTLGQHKGPIFALKWNRKGNYILSAGVDKTTIIWDAHTGEAKQQFPFHSAPALDVDWQNNTTFASCSTDMCIHVCRLGCDRPVKTFQGHTNEVNAIKWDPSGMLLASCSDDMTLKIWSMKQEVCIHDLQAHNKEIYTIKWSPTGPATSNPNSNIMLASASFDSTVRLWDIERGVCTHTLTKHQEPVYSVAFSPDGKYLASGSFDKCVHIWNTQSGNLVHSYRGTGGIFEVCWNARGDKVGASASDGSVCVLDLRK>sp|O43711|TLX3_HUMAN T-cell leukemia homeobox protein 3 OS=Homo sapiensOX=9606 GN=TLX3 PE=1 SV=3MEAPASAQTPHPHEPISFGIDQILNSPDQDSAPAPRGPDGASYLGGPPGGRPGATYPSLPASFAGLGAPFEDAGSYSVNLSLAPAGVIRVPAHRPLPGAVPPPLPSALPAMPSVPTVSSLGGLNFPWMESSRRFVKDRFTAAAALTPFTVTRRIGHPYQNRTPPKRKKPRTSFSRVQICELEKRFHRQKYLASAERAALAKSLKMTDAQVKTWFQNRRTKWRRQTAEEREAERQQASRLMLQLQHDAFQKSLNDSIQPDPLCLHNSSLFALQNLQPWEEDSSKVPAVTSLV>sp|Q8WUU8|TM174_HUMAN Transmembrane protein 174 OS=Homo sapiens OX=9606GN=TMEM174 PE=1 SV=1MEQGSGRLEDFPVNVFSVTPYTPSTADIQVSDDDKAGATLLFSGIFLGLVGITFTVMGWIKYQGVSHFEWTQLLGPVLLSVGVTFILIAVCKFKMLSCQLCKESEERVPDSEQTPGGPSFVFTGINQPITFHGATVVQYIPPPYGSPEPMGINTSYLQSVVSPCGLITSGGAAAAMSSPPQYYTIYPQDNSAFVVDEGCLSFTDGGNHRPNPDVDQLEETQLEEEACACFSPPPYEEIYSLPR>sp|Q8WUU8-2|TM174_HUMAN Isoform 2 of Transmembrane protein 174 OS=Homosapiens OX=9606 GN=TMEM174MEQGSGRLEDFPVNVFSVTPYTPSTADIQVSDDDKAGATLLFSGIFLGLVGITFTVMGWIKYQGVSHFEWTQLLGPVLLSVGVTFILIAVCKFKMLSCQLCKESEERVPDSEQTPGGPSFVFTGINQPITFHGATVVQYIPPPYGSPEPMGINTSYLQSVVSPCGLITSGGAAAAMSSPPQYYTIYPQDNSAFVVDEGCLSFTDGGNHRYGPILMLTS>sp|O95407|TNF6B_HUMAN Tumor necrosis factor receptor superfamily member6B OS=Homo sapiens OX=9606 GN=TNFRSF6B PE=1 SV=1MRALEGPGLSLLCLVLALPALLPVPAVRGVAETPTYPWRDAETGERLVCAQCPPGTFVQRPCRRDSPTTCGPCPPRHYTQFWNYLERCRYCNVLCGEREEEARACHATHNRACRCRTGFFAHAGFCLEHASCPPGAGVIAPGTPSQNTQCQPCPPGTFSASSSSSEQCQPHRNCTALGLALNVPGSSSHDTLCTSCTGFPLSTRVPGAEECERAVIDFVAFQDISIKRLQRLLQALEAPEGWGPTPRAGRAALQLKLRRRLTELLGAQDGALLVRLLQALRVARMPGLERSVRERFLPVH>sp|Q9BYV6|TRI55_HUMAN Tripartite motif-containing protein 55 OS=Homosapiens OX=9606 GN=TRIM55 PE=1 SV=2MSASLNYKSFSKEQQTMDNLEKQLICPICLEMFTKPVVILPCQHNLCRKCASDIFQASNPYLPTRGGTTMASGGRFRCPSCRHEVVLDRHGVYGLQRNLLVENIIDIYKQESTRPEKKSDQPMCEEHEEERINIYCLNCEVPTCSLCKVFGAHKDCQVAPLTHVFQRQKSELSDGIAILVGSNDRVQGVISQLEDTCKTIEECCRKQKQELCEKFDYLYGILEERKNEMTQVITRTQEEKLEHVRALIKKYSDHLENVSKLVESGIQFMDEPEMAVFLQNAKTLLKKISEASKAFQMEKIEHGYENMNHFTVNLNREEKIIREIDFYREDEDEEEEEGGEGEKEGEGEVGGEAVEVEEVENVQTEFPGEDENPEKASELSQVELQAAPGALPVSSPEPPPALPPAADAPVTQGEVVPTGSEQTTESETPVPAAAETADPLFYPSWYKGQTRKATTNPPCTPGSEGLGQIGPPGSEDSNVRKAEVAAAAASERAAVSGKETSAPAATSQIGFEAPPLQGQAAAPASGSGADSEPARHIFSFSWLNSLNE>sp|Q9BYV6-2|TRI55_HUMAN Isoform 2 of Tripartite motif-containing protein55 OS=Homo sapiens OX=9606 GN=TRIM55MSASLNYKSFSKEQQTMDNLEKQLICPICLEMFTKPVVILPCQHNLCRKCASDIFQASNPYLPTRGGTTMASGGRFRCPSCRHEVVLDRHGVYGLQRNLLVENIIDIYKQESTRPEKKSDQPMCEEHEEERINIYCLNCEVPTCSLCKVFGAHKDCQVAPLTHVFQRQKSELSDGIAILVGSNDRVQGVISQLEDTCKTIEECCRKQKQELCEKFDYLYGILEERKNEMTQVITRTQEEKLEHVRALIKKYSDHLENVSKLVESGIQFMDEPEMAVFLQNAKTLLKKISEASKAFQMEKIEHGYENMNHFTVNLNREEKIIREIDFYREDEDEEEEEGGEGEKEGEGEVGGEAVEVEEVENVQTEFPGEDENPEKASELSQVELQAAPGALPVSSPEPPPALPPAADAPVTQIGFEAPPLQGQAAAPASGSGADSEPARHIFSFSWLNSLNE>sp|Q9BYV6-3|TRI55_HUMAN Isoform 3 of Tripartite motif-containing protein55 OS=Homo sapiens OX=9606 GN=TRIM55MSASLNYKSFSKEQQTMDNLEKQLICPICLEMFTKPVVILPCQHNLCRKCASDIFQASNPYLPTRGGTTMASGGRFRCPSCRHEVVLDRHGVYGLQRNLLVENIIDIYKQESTRPEKKSDQPMCEEHEEERINIYCLNCEVPTCSLCKVFGAHKDCQVAPLTHVFQRQKSELSDGIAILVGSNDRVQGVISQLEDTCKTIEECCRKQKQELCEKFDYLYGILEERKNEMTQVITRTQEEKLEHVRALIKKYSDHLENVSKLVESGIQFMDEPEMAVFLQNAKTLLKKISEASKAFQMEKIEHGYENMNHFTVNLNREEKIIREIDFYREDEDEEEEEGGEGEKEGEGEVGGEAVEVEEVENVQTEFPGEDENPEKASELSQVELQAAPGALPVSSPEPPPALPPAADAPVTQGEVVPTGSEQTTESETPVPAAAETADPLFYPSWYKGQTRKATTNPPCTPGSEGLGQIGPPGSEDSNVRKAEVAAAAASERAAVSGKETSAPAATSQELVICLALLAFLILHYIWSQIQCLIFTLMDWI>sp|Q9BYV6-4|TRI55_HUMAN Isoform 4 of Tripartite motif-containing protein55 OS=Homo sapiens OX=9606 GN=TRIM55MSASLNYKSFSKEQQTMDNLEKQLICPICLEMFTKPVVILPCQHNLCRKCASDIFQASNPYLPTRGGTTMASGGRFRCPSCRHEVVLDRHGVYGLQRNLLVENIIDIYKQESTRPEKKSDQPMCEEHEEERINIYCLNCEVPTCSLCKVFGAHKDCQVAPLTHVFQRQKSELSDGIAILVGSNDRVQGVISQLEDTCKTIEIGFEAPPLQGQAAAPASGSGADSEPARHIFSFSWLNSLNE>sp|Q13061|TRDN_HUMAN Triadin OS=Homo sapiens OX=9606 GN=TRDN PE=1 SV=4MTEITAEGNASTTTTVIDSKNGSVPKSPGKVLKRTVTEDIVTTFSSPAAWLLVIALIITWSAVAIVMFDLVDYKNFSASSIAKIGSDPLKLVRDAMEETTDWIYGFFSLLSDIISSEDEEDDDGDEDTDKGEIDEPPLRKKEIHKDKTEKQEKPERKIQTKVTHKEKEKGKEKVREKEKPEKKATHKEKIEKKEKPETKTLAKEQKKAKTAEKSEEKTKKEVKGGKQEKVKQTAAKVKEVQKTPSKPKEKEDKEKAAVSKHEQKDQYAFCRYMIDIFVHGDLKPGQSPAIPPPLPTEQASRPTPASPALEEKEGEKKKAEKKVTSETKKKEKEDIKKKSEKETAIDVEKKEPGKASETKQGTVKIAAQAAAKKDEKKEDSKKTKKPAEVEQPKGKKQEKKEKHVEPAKSPKKEHSVPSDKQVKAKTERAKEEIGAVSIKKAVPGKKEEKTTKTVEQEIRKEKSGKTSSILKDKEPIKGKEEKVPASLKEKEPETKKDEKMSKAGKEVKPKPPQLQGKKEEKPEPQIKKEAKPAISEKVQIHKQDIVKPEKTVSHGKPEEKVLKQVKAVTIEKTAKPKPTKKAEHREREPPSIKTDKPKPTPKGTSEVTESGKKKTEISEKESKEKADMKHLREEKVSTRKESLQLHNVTKAEKPARVSKDVEDVPASKKAKEGTEDVSPTKQKSPISFFQCVYLDGYNGYGFQFPFTPADRPGESSGQANSPGQKQQGQ>sp|Q13061-2|TRDN_HUMAN Isoform 2 of Triadin OS=Homo sapiens OX=9606GN=TRDNMTEITAEGNASTTTTVIDSKNGSVPKSPGKVLKRTVTEDIVTTFSSPAAWLLVIALIITWSAVAIVMFDLVDYKNFSASSIAKIGSDPLKLVRDAMEETTDWIYGFFSLLSDIISSEDEEDDDGDEDTDKGEIDEPPLRKKEIHKDKTEKQEKPERKIQTKVTHKEKEKGKEKVREKEKPEKKATHKEKIEKKEKPETKTLAKEQKKAKTAEKSEEKTKKEVKGGKQEKVKQTAAKVKEVQKTPSKPKEKEDKEKAAVSKHEQKGQSPAIPPPLPTEQASRPTPASPALEGKYFFFS>sp|Q13061-3|TRDN_HUMAN Isoform 3 of Triadin OS=Homo sapiens OX=9606GN=TRDNMTEITAEGNASTTTTVIDSKNGSVPKSPGKVLKRTVTEDIVTTFSSPAAWLLVIALIITWSAVAIVMFDLVDYKNFSASSIAKIGSDPLKLVRDAMEETTDWIYGFFSLLSDIISSEDEEDDDGDEDTDKGEIDEPPLRKKEIHKDKTEKQEKPERKIQTKEVGHSS>sp|Q8IWZ5|TRI42_HUMAN Tripartite motif-containing protein 42 OS=Homosapiens OX=9606 GN=TRIM42 PE=1 SV=2METAMCVCCPCCTWQRCCPQLCSCLCCKFIFTSERNCTCFPCPYKDERNCQFCHCTCSESPNCHWCCCSWANDPNCKCCCTASSNLNCYYYESRCCRNTIITFHKGRLRSIHTSSKTALRTGSSDTQVDEVKSIPANSHLVNHLNCPMCSRLRLHSFMLPCNHSLCEKCLRQLQKHAEVTENFFILICPVCDRSHCMPYSNKMQLPENYLHGRLTKRYMQEHGYLKWRFDRSSGPILCQVCRNKRIAYKRCITCRLNLCNDCLKAFHSDVAMQDHVFVDTSAEEQDEKICIHHPSSRIIEYCRNDNKLLCTFCKFSFHNGHDTISLIDACSERAASLFSAIAKFKAVRYEIDNDLMEFNILKNSFKADKEAKRKEIRNGFLKLRSILQEKEKIIMEQIENLEVSRQKEIEKYVYVTTMKVNEMDGLIAYSKEALKETGQVAFLQSAKILVDQIEDGIQTTYRPDPQLRLHSINYVPLDFVELSSAIHELFPTGPKKVRSSGDSLPSPYPVHSETMIARKVTFSTHSLGNQHIYQRSSSMLSFSNTDKKAKVGLEACGRAQSATPAKPTDGLYTYWSAGADSQSVQNSSSFHNWYSFNDGSVKTPGPIVIYQTLVYPRAAKVYWTCPAEDVDSFEMEFYEVITSPPNNVQMELCGQIRDIMQQNLELHNLTPNTEYVFKVRAINDNGPGQWSDICKVVTPDGHGKNRAKWGLLKNIQSALQKHF>sp|Q8IWZ5-2|TRI42_HUMAN Isoform 2 of Tripartite motif-containing protein42 OS=Homo sapiens OX=9606 GN=TRIM42METAMCVCCPCCTWQRCCPQLCSCLCCKFIFTSERNCTCFPCPYKDERNCQFCHCTCSESPNCHWCCCSWANDPNCKCCCTASSNLNCYYYESRCCRNTIITFHKGRLRSIHTSSKTALRTGSSDTQVDEVKSIPANSHLVNHLNCPMCSRLRLHSFMLPCNHSLCEKCLRQLQKHAEVTENFFILICPVCDRSHCMPYSNKMQLPENYLHGRLTKRYMQEHGYLKWRFDRSSGPILCQVCRNKRIAYKRCITCRLNLCNDCLKAFHSDVAMQDHVFVDTSAEEQDEKICIHHPSSRIIEYCRNDNKLLCTFCKFSFHNGHDTISLIDACSERAASLFSAIAKFKAGPPLFHSFSLTSSSGTHGEDGVG>sp|O60235|TM11D_HUMAN Transmembrane protease serine 11D OS=Homo sapiensOX=9606 GN=TMPRSS11D PE=1 SV=1MYRPARVTSTSRFLNPYVVCFIVVAGVVILAVTIALLVYFLAFDQKSYFYRSSFQLLNVEYNSQLNSPATQEYRTLSGRIESLITKTFKESNLRNQFIRAHVAKLRQDGSGVRADVVMKFQFTRNNNGASMKSRIESVLRQMLNNSGNLEINPSTEITSLTDQAAANWLINECGAGPDLITLSEQRILGGTEAEEGSWPWQVSLRLNNAHHCGGSLINNMWILTAAHCFRSNSNPRDWIATSGISTTFPKLRMRVRNILIHNNYKSATHENDIALVRLENSVTFTKDIHSVCLPAATQNIPPGSTAYVTGWGAQEYAGHTVPELRQGQVRIISNDVCNAPHSYNGAILSGMLCAGVPQGGVDACQGDSGGPLVQEDSRRLWFIVGIVSWGDQCGLPDKPGVYTRVTAYLDWIRQQTGI>sp|Q96A04|TSACC_HUMAN TSSK6-activating co-chaperone protein OS=Homosapiens OX=9606 GN=TSACC PE=1 SV=1MERHTSHPNRKVPAKEEANAVPLCRAKPSPSYINLQASSPPATFLNIQTTKLPSVDHKPKECLGLLECMYANLQLQTQLAQQQMAVLEHLQASVTQLAPGRGSNNSSLPALSPNPLLNHLPQFSK>sp|P26651|TTP_HUMAN mRNA decay activator protein ZFP36 OS=Homo sapiensOX=9606 GN=ZFP36 PE=1 SV=1MDLTAIYESLLSLSPDVPVPSDHGGTESSPGWGSSGPWSLSPSDSSPSGVTSRLPGRSTSLVEGRSCGWVPPPPGFAPLAPRLGPELSPSPTSPTATSTTPSRYKTELCRTFSESGRCRYGAKCQFAHGLGELRQANRHPKYKTELCHKFYLQGRCPYGSRCHFIHNPSEDLAAPGHPPVLRQSISFSGLPSGRRTSPPPPGLAGPSLSSSSFSPSSSPPPPGDLPLSPSAFSAAPGTPLARRDPTPVCCPSCRRATPISVWGPLGGLVRTPSVQSLGSDPDEYASSGSSLGGSDSPVFEAGVFAPPQPVAAPRRLPIFNRISVSE>sp|Q8TAM2|TTC8_HUMAN Tetratricopeptide repeat protein 8 OS=Homo sapiensOX=9606 GN=TTC8 PE=1 SV=2MSSEMEPLLLAWSYFRRRKFQLCADLCTQMLEKSPYDQEPDPELPVHQAAWILKARALTEMVYIDEIDVDQEGIAEMMLDENAIAQVPRPGTSLKLPGTNQTGGPSQAVRPITQAGRPITGFLRPSTQSGRPGTMEQAIRTPRTAYTARPITSSSGRFVRLGTASMLTSPDGPFINLSRLNLTKYSQKPKLAKALFEYIFHHENDVKTIHLEDVVLHLGIYPFLLRNKNHIEKNALDLAALSTEHSQYKDWWWKVQIGKCYYRLGMYREAEKQFKSALKQQEMVDTFLYLAKVYVSLDQPVTALNLFKQGLDKFPGEVTLLCGIARIYEEMNNMSSAAEYYKEVLKQDNTHVEAIACIGSNHFYSDQPEIALRFYRRLLQMGIYNGQLFNNLGLCCFYAQQYDMTLTSFERALSLAENEEEAADVWYNLGHVAVGIGDTNLAHQCFRLALVNNNNHAEAYNNLAVLEMRKGHVEQARALLQTASSLAPHMYEPHFNFATISDKIGDLQRSYVAAQKSEAAFPDHVDTQHLIKQLRQHFAML>sp|Q8TAM2-2|TTC8_HUMAN Isoform 2 of Tetratricopeptide repeat protein 8OS=Homo sapiens OX=9606 GN=TTC8MSSEMEPLLLAWSYFRRRKFQLCADLCTQMLEKSPYDQEMNNMSSAAEYYKEVLKQDNTHVEAIACIGSNHFYSDQPEIALRFYRRLLQMGIYNGQLFNNLGLCCFYAQQYDMTLTSFERALSLAENEEEAADVWYNLGHVAVGIGDTNLAHQCFRLALVNNNNHAEAYNNLAVLEMRKGHVEQARALLQTASSLAPHMYEPHFNFATISDKIGDLQRSYVAAQKSEAAFPDHVDTQHLIKQLRQHFAML>sp|Q8TAM2-3|TTC8_HUMAN Isoform 3 of Tetratricopeptide repeat protein 8OS=Homo sapiens OX=9606 GN=TTC8MSSEMEPLLLAWSYFRRRKFQLCADLCTQMLEKSPYDQEPDPELPVHQAAWILKARALTEMVYIDEIDVDQEGIAEMMLDENAIAQVPRPGTSLKLPGTNQTGGPSQAVRPITQAGRPITGFLRPSTQSGRPGTMEQAIRTPRTAYTARPITSSSGRFVRLGTALFEYIFHHENDVKTALDLAALSTEHSQYKDWWWKVQIGKCYYRLGMYREAEKQFKSALKQQEMVDTFLYLAKVYVSLDQPVTALNLFKQGLDKFPGEVTLLCGIARIYEEMNNMSSAAEYYKEVLKQDNTHVEAIACIGSNHFYSDQPEIALRFYRRLLQMGIYNGQLFNNLGLCCFYAQQYDMTLTSFERALSLAENEEEAADVWYNLGHVAVGIGDTNLAHQCFRLALVNNNNHAEAYNNLAVLEMRKGHVEQARALLQTASSLAPHMYEPHFNFATISDKIGDLQRSYVAAQKSEAAFPDHVDTQHLIKQLRQHFAML>sp|Q8TAM2-4|TTC8_HUMAN Isoform 4 of Tetratricopeptide repeat protein 8OS=Homo sapiens OX=9606 GN=TTC8MSSEMEPLLLAWSYFRRRKFQLCADLCTQMLEKSPYDQEPDPELPVHQAAWILKARALTEMVYIDEIDVDQEGIAEMMLDENAIAQVPRPGTSLKLPGTNQTGGPSQAVRPITQAGRPITGFLRPSTQSGRPGTMEQAIRTPRTAYTARPITSSSGRFVRLGTASMLTSPDGPFINLSRLNLTKYSQKPKLAKALFEYIFHHENDVKTALDLAALSTEHSQYKDWWWKVQIGKCYYRLGMYREAEKQFKSALKQQEMVDTFLYLAKVYVSLDQPVTALNLFKQGLDKFPGEVTLLCGIARIYEEMNNMSSAAEYYKEVLKQDNTHVEAIACIGSNHFYSDQPEIALRFYRRLLQMGIYNGQLFNNLGLCCFYAQQYDMTLTSFERALSLAENEEEAADVWYNLGHVAVGIGDTNLAHQCFRLALVNNNNHAEAYNNLAVLEMRKGHVEQARALLQTASSLAPHMYEPHFNFATISDKIGDLQRSYVAAQKSEAAFPDHVDTQHLIKQLRQHFAML>sp|Q8TAM2-6|TTC8_HUMAN Isoform 5 of Tetratricopeptide repeat protein 8OS=Homo sapiens OX=9606 GN=TTC8MSSEMEPLLLAWSYFRRRKFQLCADLCTQMLEKSPYDQEPDPELPVHQAAWILKARALTEMVYIDEIDVDQEGIAEMMLDENAIAQVPRPGTSLKLPGTNQTGGPSQAVRPITQAGRPITGFLRPSTQSGRPGTMEQAIRTPRTAYTARPITSSSGRFVRLGTASMLTSPDGPFINLSRLNLTKYSQKPKLAKVCT>sp|Q6PF05|TT23L_HUMAN Tetratricopeptide repeat protein 23-like OS=Homosapiens OX=9606 GN=TTC23L PE=1 SV=2MQASPIRIPTVSNDIDWDFCFHMSQQTEIPAHQQTDELYPTGGCGESEEETKAKEKEKAIDCMSHPKEKLAQSQKKVAQLIKEKMNTQANKELIRCVILSRIIFGDHHWKCARALANLAYGYLTLRGLPVQAKKHATSAKNTLLTWKANTTSNKEKEEILEALVKLYYTLGVAWLLQNRGREAYFNLQKAERNMKELKELYKGGVCELQVSENDLTLALGRASLAIHRLNLALAYFEKAIGDVIAAKGDRTSDLISLYEEAAQIEQLRRNHNQAIQYLQQAHSVCVSLFTEVSPKTAEMSALLAKAYAMSGEAQHRDAVEIYFIRSINAYRATLGSEDFETLSTTEEFCKWLVQNGEKQDK>sp|Q6PF05-2|TT23L_HUMAN Isoform 2 of Tetratricopeptide repeat protein23-like OS=Homo sapiens OX=9606 GN=TTC23LMQASPIRIPTVSNDIDWDFCFHMSQQTEIPAHQQTDELYPTGGCGESEEETKAKEKEKAIDCMSHPKEKLAQSQKKVAQLIKEKMNTQANKELIRCVILSRIIFGDHHWKCARALANLAYGYLTLRGLPVQAKKHATSAKNTLLTWKANTTSNKEKEEILEALVKLYYTLGVAWLLQNRGREAYFNLQKAERNMKELKELYKGGVCELQVSENDLTLALGRASLAIHRLNLALAYFEKAIGDVIAAKGDRTSDLISLYEEAAQIEQLRRNHNQAIQYLQQMLLRYIS>sp|Q6PF05-3|TT23L_HUMAN Isoform 3 of Tetratricopeptide repeat protein23-like OS=Homo sapiens OX=9606 GN=TTC23LMQASPIRIPTVSNDIDWDFCFHMSQQTEIPAHQQTDELYPTGGCGESEEETKAKEKEKAIDCMSHPKEKLAQSQKKVAQLIKEKMNTQANKELIRCVILSRIIFGDHHWKCARALANLAYGYLTLRGLPVQAKKHATSAKNTLLTWKANTTSNKEKEEILEALVKLYYTLGVAWLLQNRGREAYFNLQKAERNMKELKELYKGGVCELQVSENDLTLALGRASLAIHRLNLALAYFEKAIGDVIAAKGDRTSDLISLYEEAAQIEQLRRNHNQAIQYLQQAHSVCVSLFTEVSPKTAEMSALLAKAYAMSGEAQHRDAVEIYFIRSINAYRATLGSEDFETLSTTEEFCKWLVQNGEKQIFQKRRYKHDHKRHEKMFNPISHRGNANENHHTDTRVV>sp|Q8IX04|UEVLD_HUMAN Ubiquitin-conjugating enzyme E2 variant 3 OS=Homosapiens OX=9606 GN=UEVLD PE=1 SV=2MEFDCEGLRRLLGKYKFRDLTVEELRNVNVFFPHFKYSMDTYVFKDSSQKDLLNFTGTIPVMYQGNTYNIPIRFWILDSHPFAPPICFLKPTANMGILVGKHVDAQGRIYLPYLQNWSHPKSVIVGLIKEMIAKFQEELPMYSLSSSDEARQVDLLAYIAKITEGVSDTNSKSWANHENKTVNKITVVGGGELGIACTLAISAKGIADRLVLLDLSEGTKGATMDLEIFNLPNVEISKDLSASAHSKVVIFTVNSLGSSQSYLDVVQSNVDMFRALVPALGHYSQHSVLLVASQPVEIMTYVTWKLSTFPANRVIGIGCNLDSQRLQYIITNVLKAQTSGKEVWVIGEQGEDKVLTWSGQEEVVSHTSQVQLSNRAMELLRVKGQRSWSVGLSVADMVDSIVNNKKKVHSVSALAKGYYDINSEVFLSLPCILGTNGVSEVIKTTLKEDTVTEKLQSSASSIHSLQQQLKL>sp|Q8IX04-2|UEVLD_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2variant 3 OS=Homo sapiens OX=9606 GN=UEVLDMEFDCEGLRRLLGKYKFRDLTVEELRNVNVFFPHFKYSMDTYVFKDSSQKDLLNFTGTIPVMYQGNTYNIPIRFWILDSHPFAPPICFLKPTANMGILVGKHVDAQGRIYLPYLQNWSHPKSVIVGLIKEMIAKFQEELPMYSLSSSDEARQVDLLAYIAKITEGVSDTNSKSWANHENKTVNKITVVGGGELGIACTLAISAKGIADRLVLLDLSEGTKGATMDLEIFNLPNVEISKDLSASAHSKVVIFTVNSLGSSQSYLDVVQSNVDMFRALVPALGHYSQHSVLLVASQPVEIMTYVTWKLSTFPANRVIGIGCNLDSQRLQYIITNVLKAQTSGKEVWVIGEQGEDKVLTWSGQEEVVSHTSQVQLSNRDIMI>sp|Q8IX04-3|UEVLD_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2variant 3 OS=Homo sapiens OX=9606 GN=UEVLDMEFDCEGLRRLLGKYKFRDLTVEELRNVNVFFPHFKYSMDTYGNTYNIPIRFWILDSHPFAPPICFLKPTANMGILVGKHVDAQGRIYLPYLQNWSHPKSVIVGLIKEMIAKFQEELPMYSLSSSDEARQVDLLAYIAKITEGVSDTNSKSWANHENKTVNKITVVGGGELGIACTLAISAKGIADRLVLLDLSEGTKGATMDLEIFNLPNVEISKDLSASAHSKVVIFTVNSLGSSQSYLDVVQSNVDMFRALVPALGHYSQHSVLLVASQPVEIMTYVTWKLSTFPANRVIGIGCNLDSQRLQYIITNVLKAQTSGKEVWVIGEQGEDKVLTWSGQEEVVSHTSQVQLSNRDIMI>sp|Q8IX04-4|UEVLD_HUMAN Isoform 4 of Ubiquitin-conjugating enzyme E2variant 3 OS=Homo sapiens OX=9606 GN=UEVLDMDTYVFKDSSQKDLLNFTGTIPVMYQGNTYNIPIRFWILDSHPFAPPICFLKPTANMGILVGKHVDAQGRIYLPYLQNWSHPKSVIVGLIKEMIAKFQEELPMYSLSSSDEARQVDLLAYIAKITEGVSDTNSKSWANHENKTVNKITVVGGGELGIACTLAISAKGIADRLVLLDLSEGTKGATMDLEIFNLPNVEISKDLSASAHSKVVIFTVNSLGSSQSYLDVVQSNVDMFRALVPALGHYSQHSVLLVASQPVEIMTYVTWKLSTFPANRVIGIGCNLDSQRLQYIITNVLKAQTSGKEVWVIGEQGEDKVLTWSGQEEVVSHTSQVQLSNRDIMI>sp|Q8IX04-5|UEVLD_HUMAN Isoform 5 of Ubiquitin-conjugating enzyme E2variant 3 OS=Homo sapiens OX=9606 GN=UEVLDMEFDCEGLRRLLGKYKFRDLTVEELRNVNVFFPHFKYSMDTYVFKDSSQKDLLNFTGTIPVMYQGNTYNIPIRFWILDSHPFAPPICFLKPTANMGILVGKHVDAQGRIYLPYLQNWSHPKSVIVGLIKEMIAKFQEELPMYSLSSSDEARQVDLLAYIAKITEGVSDTNSKSWANHENKTVNKITVVGGGELGIACTLAISAKVESRSVTQAGV>sp|Q8IX04-6|UEVLD_HUMAN Isoform 6 of Ubiquitin-conjugating enzyme E2variant 3 OS=Homo sapiens OX=9606 GN=UEVLDMEFDCEGLRRLLGKYKFRDLTVEELRNVNVFFPHFKYSMDTYGNTYNIPIRFWILDSHPFAPPICFLKPTANMGILVGKHVDAQGRIYLPYLQNWSHPKSVIVGLIKEMIAKFQEELPMYSLSSSDEARQVDLLAYIAKITEGVSDTNSKSWANHENKTVNKITVVGGGELGIACTLAISAKGIADRLVLLDLSEGTKGATMDLEIFNLPNVEISKDLSASAHSKVVIFTVNSLGSSQSYLDVVQSNVDMFRALVPALGHYSQHSVLLVASQPVEIMTYVTWKLSTFPANRVIGIGCNLDSQRLQYIITNVLKAQTSGKEVWVIGEQGEDKVLTWSGQEEVVSHTSQVQLSNRAMELLRVKGQRSWSVGLSVADMVDSIVNNKKKVHSVSALAKGYYDINSEVFLSLPCILGTNGVSEVIKTTLKEDTVTEKLQSSASSIHSLQQQLKL>sp|Q8IX04-7|UEVLD_HUMAN Isoform 7 of Ubiquitin-conjugating enzyme E2variant 3 OS=Homo sapiens OX=9606 GN=UEVLDMEFDCEGLRRLLGKYKFRDLTVEELRNVNVFFPHFKYSMDTYVFKDSSQKDLLNFTGTIPVMYQGVSDTNSKSWANHENKTVNKITVVGGGELGIACTLAISAKGIADRLVLLDLSEGTKGATMDLEIFNLPNVEISKVEIMTYVTWKLSTFPANRVIGIGCNLDSQRLQYIITNVLKAQTSGKEVWVIGEQGEDKGIL>sp|Q9P2D8|UNC79_HUMAN Protein unc-79 homolog OS=Homo sapiens OX=9606GN=UNC79 PE=2 SV=4MSTKAEQFASKIRYLQEYHNRVLHNIYPVPSGTDIANTLKYFSQTLLSILSRTGKKENQDASNLTVPMTMCLFPVPFPLTPSLRPQVSSINPTVTRSLLYSVLRDAPSERGPQSRDAQLSDYPSLDYQGLYVTLVTLLDLVPLLQHGQHDLGQSIFYTTTCLLPFLNDDILSTLPYTMISTLATFPPFLHKDIIEYLSTSFLPMAILGSSRREGVPAHVNLSASSMLMIAMQYTSNPVYHCQLLECLMKYKQEVWKDLLYVIAYGPSQVKPPAVQMLFHYWPNLKPPGAISEYRGLQYTAWNPIHCQHIECHNAINKPAVKMCIDPSLSVALGDKPPPLYLCEECSERIAGDHSEWLIDVLLPQAEISAICQKKNCSSHVRRAVVTCFSAGCCGRHGNRPVRYCKRCHSNHHSNEVGAAAETHLYQTSPPPINTRECGAEELVCAVEAVISLLKEAEFHAEQREHELNRRRQLGLSSSHHSLDNADFDNKDDDKHDQRLLSQFGIWFLVSLCTPSENTPTESLARLVAMVFQWFHSTAYMMDDEVGSLVEKLKPQFVTKWLKTVCDVRFDVMVMCLLPKPMEFARVGGYWDKSCSTVTQLKEGLNRILCLIPYNVINQSVWECIMPEWLEAIRTEVPDNQLKEFREVLSKMFDIELCPLPFSMEEMFGFISCRFTGYPSSVQEQALLWLHVLSELDIMVPLQLLISMFSDGVNSVKELANQRKSRVSELAGNLASRRVSVASDPGRRVQHNMLSPFHSPFQSPFRSPLRSPFRSPFKNFGHPGGRTIDFDCEDDEMNLNCFILMFDLLLKQMELQDDGITMGLEHSLSKDIISIINNVFQAPWGGSHTCQKDEKAIECNLCQSSILCYQLACELLERLAPKEESRLVEPTDSLEDSLLSSRPEFIIGPEGEEEENPASKHGENPGNCTEPVEHAAVKNDTERKFCYQQLPVTLRLIYTIFQEMAKFEEPDILFNMLNCLKILCLHGECLYIARKDHPQFLAYIQDHMLIASLWRVVKSEFSQLSSLAVPLLLHALSLPHGADIFWTIINGNFNSKDWKMRFEAVEKVAVICRFLDIHSVTKNHLLKYSLAHAFCCFLTAVEDVNPAVATRAGLLLDTIKRPALQGLCLCLDFQFDTVVKDRPTILSKLLLLHFLKQDIPALSWEFFVNRFETLSLEAQLHLDCNKEFPFPTTITAVRTNVANLSDAALWKIKRARFARNRQKSVRSLRDSVKGPVESKRALSLPETLTSKIRQQSPENDNTIKDLLPEDAGIDHQTVHQLITVLMKFMAKDESSAESDISSAKAFNTVKRHLYVLLGYDQQEGCFMIAPQKMRLSTCFNAFIAGIAQVMDYNINLGKHLLPLVVQVLKYCSCPQLRHYFQQPPRCSLWSLKPHIRQMWLKALLVILYKYPYRDCDISKILLHLIHITVNTLNAQYHSCKPHATAGPLYSDNSNISRYSEKEKGEIELAEYRETGALQDSLLHCVREESIPKKKLRSFKQKSLDIGNADSLLFTLDEHRRKSCIDRCDIEKPPTQAAYIAQRPNDPGRSRQNSATRPDNSEIPENPAMEGFPDARRPVIPEVRLNCMETFEVKVDSPVKPAPKEDLDLIDLSSDSTSGPEKHSILSTSDSDSLVFEPLPPLRIVESDEEEETMNQGDDGPSGKNAASSPSVPSHPSVLSLSTAPLVQVSVEDCSKDFSSKDSGNNQSAGNTDSALITLEDPMDAEGSSKPEELPEFSCGSPLTLKQKRDLLQKSFALPEMSLDDHPDPGTEGEKPGELMPSSGAKTVLLKVPEDAENPTESEKPDTSAESDTEQNPERKVEEDGAEESEFKIQIVPRQRKQRKIAVSAIQREYLDISFNILDKLGEQKDPDPSTKGLSTLEMPRESSSAPTLDAGVPETSSHSSISTQYRQMKRGSLGVLTMSQLMKRQLEHQSSAPHNISNWDTEQIQPGKRQCNVPTCLNPDLEGQPLRMRGATKSSLLSAPSIVSMFVPAPEEFTDEQPTVMTDKCHDCGAILEEYDEETLGLAIVVLSTFIHLSPDLAAPLLLDIMQSVGRLASSTTFSNQAESMMVPGNAAGVAKQFLRCIFHQLAPNGIFPQLFQSTIKDGTFLRTLASSLMDFNELSSIAALSQLLEGLNNKKNLPAGGAMIRCLENIATFMEALPMDSPSSLWTTISNQFQTFFAKLPCVLPLKCSLDSSLRIMICLLKIPSTNATRSLLEPFSKLLSFVIQNAVFTLAYLVELCGLCYRAFTKERDKFYLSRSVVLELLQALKLKSPLPDTNLLLLVQFICADAGTKLAESTILSKQMIASVPGCGTAAMECVRQYINEVLDFMADMHTLTKLKSHMKTCSQPLHEDTFGGHLKVGLAQIAAMDISRGNHRDNKAVIRYLPWLYHPPSAMQQGPKEFIECVSHIRLLSWLLLGSLTHNAVCPNASSPCLPIPLDAGSHVADHLIVILIGFPEQSKTSVLHMCSLFHAFIFAQLWTVYCEQSAVATNLQNQNEFSFTAILTALEFWSRVTPSILQLMAHNKVMVEMVCLHVISLMEALQECNSTIFVKLIPMWLPMIQSNIKHLSAGLQLRLQAIQNHVNHHSLRTLPGSGQSSAGLAALRKWLQCTQFKMAQVEIQSSEAASQFYPL>sp|Q9P2D8-2|UNC79_HUMAN Isoform 2 of Protein unc-79 homolog OS=Homosapiens OX=9606 GN=UNC79MISTLATFPPFLHKDIIEYLSTSFLPMAILGSSRREGVPAHVNLSASSMLMIAMQYTSNPVYHCQLLECLMKYKQEVWKDLLYVIAYGPSQVKPPAVQMLFHYWPNLKPPGAISEYRGLQYTAWNPIHCQHIECHNAINKPAVKMCIDPSLSVALGDKPPPLYLCEECSERIAGDHSEWLIDVLLPQAEISAICQKKNCSSHVRRAVVTCFSAGCCGRHGNRPVRYCKRCHSNHHSNEVGAAAETHLYQTSPPPINTRECGAEELVCAVEAVISLLKEAEFHAEQREHELNRRRQLGLSSSHHSLDNADFDNKDDDKHDQRLLSQFGIWFLVSLCTPSENTPTESLARLVAMVFQWFHSTAYMMDDEVGSLVEKLKPQFVTKWLKTVCDVRFDVMVMCLLPKPMEFARVGGYWDKSCSTVTQLKEGLNRILCLIPYNVINQSVWECIMPEWLEAIRTEVPDNQLKEFREVLSKMFDIELCPLPFSMEEMFGFISCRFTGYPSSVQEQALLWLHVLSELDIMVPLQLLISMFSDGVNSVKELANQRKSRVSELAGNLASRRVSVASDPGRRVQHNMLSPFHSPFQSPFRSPLRSPFRSPFKNFGHPGGRTIDFDCEDDEMNLNCFILMFDLLLKQMELQDDGITMGLEHSLSKDIISIINNVFQAPWGGSHTCQKDEKAIECNLCQSSILCYQLACELLERLAPKEESRLVEPTDSLEDSLLSSRPEFIIGPEGEEEENPASKHGENPGNCTEPVEHAAVKNDTERKFCYQQLPVTLRLIYTIFQEMAKFEEPDILFNMLNCLKILCLHGECLYIARKDHPQFLAYIQDHMLIASLWRVVKSEFSQLSSLAVPLLLHALSLPHGADIFWTIINGNFNSKDWKMRFEAVEKVAVICRFLDIHSVTKNHLLKYSLAHAFCCFLTAVEDVNPAVATRAGLLLDTIKRPALQGLCLCLDFQFDTVVKDRPTILSKLLLLHFLKQDIPALSWEFFVNRFETLSLEAQLHLDCNKEFPFPTTITAVRTNVANLSDAALWKIKRARFARNRQKSVRSLRDSVKGPVESKRALSLPETLTSKIRQQSPENDNTIKDLLPEDAGIDHQTVHQLITVLMKFMAKDESSAESDISSAKAFNTVKRHLYVLLGYDQQEGCFMIAPQKMRLSTCFNAFIAGIAQVMDYNINLGKHLLPLVVQVLKYCSCPQLRHYFQQPPRCSLWSLKPHIRQMWLKALLVILYKYPYRDCDISKILLHLIHITVNTLNAQYHSCKPHATAGPLYSDNSNISRYSEKEKGEIELAEYRETGALQDSLLHCVREESIPKKKLRSFKQKSLDIGNADSLLFTLDEHRRKSCIDRCDIEKPPTQAAYIAQRPNDPGRSRQNSATRPDNSEIPENPAMEGFPDARRPVIPEVRLNCMETFEVKVDSPVKPAPKEDLDLIDLSSDSTSGPEKHSILSTSDSDSLVFEPLPPLRIVESDEEEETMNQGDDGPSGKNAASSPSVPSHPSVLSLSTAPLVQVSVEDCSKDFSSKDSGNNQSAGNTDSALITLEDPMDAEGSSKPEELPEFSCGSPLTLKQKRDLLQKSFALPEMSLDDHPDPGTEGEKPGELMPSSGAKTVLLKVPEDAENPTESEKPDTSAESDTEQNPERKVEEDGAEESEFKIQIVPRQRKQRKIAVSAIQREYLDISFNILDKLGEQKDPDPSTKGLSTLEMPRESSSAPTLDAGVPETSSHSSISTQYRQMKRGSLGVLTMSQLMKRQLEHQSSAPHNISNWDTEQIQPGKRQCNVPTCLNPDLEGQPLRMRGATKSSLLSAPSIVSMFVPAPEEFTDEQPTVMTDKCHDCGAILEEYDEETLGLAIVVLSTFIHLSPDLAAPLLLDIMQSVGRLASSTTFSNQAESMMVPGNAAGVAKQFLRCIFHQLAPNGIFPQLFQSTIKDGTFLRTLASSLMDFNELSSIAALSQLLEGLNNKKNLPAGGAMIRCLENIATFMEALPMDSPSSLWTTISNQFQTFFAKLPCVLPLKCSLDSSLRIMICLLKIPSTNATRSLLEPFSKLLSFVIQNAVFTLAYLVELCGLCYRAFTKERDKFYLSRSVVLELLQALKLKSPLPDTNLLLLVQFICADAGTKLAESTILSKQMIASVPGCGTAAMECVRQYINEVLDFMADMHTLTKLKSHMKTCSQPLHEDTFGGHLKVGLAQIAAMDISRGNHRDNKAVIRYLPWLYHPPSAMQQGPKEFIECVSHIRLLSWLLLGSLTHNAVCPNASSPCLPIPLDAGSHVADHLIVILIGFPEQSKTSVLHMCSLFHAFIFAQLWTVYCEQSAVATNLQNQNEFSFTAILTALEFWSRVTPSILQLMAHNKVMVEMVCLHVISLMEALQECNSTIFVKLIPMWLPMIQSNIKHLSAGLQLRLQAIQNHVNHHSLRTLPGSGQSSAGLAALRKWLQCTQFKMAQVEIQSSEAASQFYPL>sp|Q9P2D8-3|UNC79_HUMAN Isoform 3 of Protein unc-79 homolog OS=Homosapiens OX=9606 GN=UNC79MSTKAEQFASKIRYLQEYHNRVLHNIYPVPSGTDIANTLKYFSQTLLSILSRTGKKENQDASNLTVPMTMCLFPVPFPLTPSLRPQVSSINPTVTRSLLYSVLRDAPSERGPQSRDAQLSDYPSLDYQGLYVTLVTLLDLVPLLQHGQHDLGQSIFYTTTCLLPFLNDDILSTLPYTMISTLATFPPFLHKDIIEYLSTSFLPMAILGSSRREGVPAHVNLSASSMLMIAMQYTSNPVYHCQLLECLMKYKQEVWKDLLYVIAYGPSQVKPPAVQMLFHYWPNLKPPGAISEYRGLQYTAWNPIHCQHIECHNAINKPAVKMCIDPSLSVALGDKPPPLYLCEECSERIAGDHSEWLIDVLLPQAEISAICQKKNCSSHVRRAVVTCFSAGCCGRHGNRPVRYCKRCHSNHHSNEVGAAAETHLYQTSPPPINTRECGAEELVCAVEAVISLLKEAEFHAEQREHELNRRRQLGLSSSHHSLDNADFDNKDDDKHDQRLLSQFGIWFLVSLCTPSENTPTESLARLVAMVFQWFHSTAYMMDDEVGSLVEKLKPQFVTKWLKTVCDVRFDVMVMCLLPKPMEFARVGGYWDKSCSTVTQLKEGLNRILCLIPYNVINQSVWECIMPEWLEAIRTEVPDNQLKEFREVLSKMFDIELCPLPFSMEEMFGFISCRFTGYPSSVQEQALLWLHVLSELDIMVPLQLLISMFSDGVNSVKELANQRKSRVSELAGNLASRRVSVASDPGRRVQHNMLSPFHSPFQSPFRSPLRSPFRSPFKNFGHPGGRTIDFDCEDDEMNLNCFILMFDLLLKQMELQDDGITMGLEHSLSKDIISIINNVFQAPWGGSHTCQKDEKAIECNLCQSSILCYQLACELLERLAPKEESRLVEPTDSLEDSLLSSRPEFIIGPEGEEEENPASKHGENPGNCTEPVEHAAVKNDTERKFCYQQLPVTLRLIYTIFQEMAKFEEPDILFNMLNCLKILCLHGECLYIARKDHPQFLAYIQDHMLIASLWRVVKSEFSQLSSLAVPLLLHALSLPHGADIFWTIINGNFNSKDWKMRFEAVEKVAVICRFLDIHSVTKNHLLKYSLAHAFCCFLTAVEDVNPAVATRAGLLLDTIKRPALQGLCLCLDFQFDTVVKDRPTILSKLLLLHFLKQDIPALSWEFFVNRFETLSLEAQLHLDCNKEFPFPTTITAVRTNVANLSDAALWKIKRARFARNRQKSVRSLRDSVKGPVESKRALSLPETLTSKIPMRLTRHEQSAPALGGTPEQTPGQQSPENDNTIKDLLPEDAGIDHQTVHQLITVLMKFMAKDESSAESDISSAKAFNTVKRHLYVLLGYDQQEGCFMIAPQKMRLSTCFNAFIAGIAQVMDYNINLGKHLLPLVVQVLKYCSCPQLRHYFQQPPRCSLWSLKPHIRQMWLKALLVILYKYPYRDCDISKILLHLIHITVNTLNAQYHSCKPHATAGPLYSDNSNISRYSEKEKGEIELAEYRETGALQDSLLHCVREESIPKKKLRSFKQKSLDIGNADSLLFTLDEHRRKSCIDRCDIEKPPTQAAYIAQRPNDPGRSRQNSATRPDNSEIPENPAMEGFPDARRPVIPEVRLNCMETFEVKVDSPVKPAPKEDLDLIDLSSDSTSGPEKHSILSTSDSDSLVFEPLPPLRIVESDEEEETMNQGDDGPSGKNAASSPSVPSHPSVLSLSTAPLVQVSVEDCSKDFSSKDSGNNQSAGNTDSALITLEDPMDAEGSSKPEELPEFSCGSPLTLKQKRDLLQKSFALPEMSLDDHPDPGTEGEKPGELMPSSGAKTVLLKVPEDAENPTESEKPDTSAESDTEQNPERKVEEDGAEESEFKIQIVPRQRKQRKIAVSAIQREYLDISFNILDKLGEQKDPDPSTKGLSTLEMPRESSSAPTLDAGVPETSSHSSISTQYRQMKRGSLGVLTMSQLMKRQLEHQSSAPHNISNWDTEQIQPGKRQCNVPTCLNPDLEGQPLRMRGATKSSLLSAPSIVSMFVPAPEEFTDEQPTVMTDKCHDCGAILEEYDEETLGLAIVVLSTFIHLSPDLAAPLLLDIMQSVGRLASSTTFSNQAESMMVPGNAAGVAKQFLRCIFHQLAPNGIFPQLFQSTIKDGTFLRTLASSLMDFNELSSIAALSQLLEGLNNKKNLPAGGAMIRCLENIATFMEALPMDSPSSLWTTISNQFQTFFAKLPCVLPLKCSLDSSLRIMICLLKIPSTNATRSLLEPFSKLLSFVIQNAVFTLAYLVELCGLCYRAFTKERDKFYLSRSVVLELLQALKLKSPLPDTNLLLLVQFICADAGTKLAESTILSKQMIASVPGCGTAAMECVRQYINEVLDFMADMHTLTKLKSHMKTCSQPLHEDTFGGHLKVGLAQIAAMDISRGNHRDNKAVIRYLPWLYHPPSAMQQGPKEFIECVSHIRLLSWLLLGSLTHNAVCPNASSPCLPIPLDAGSHVADHLIVILIGFPEQSKTSVLHMCSLFHAFIFAQLWTVYCEQSAVATNLQNQNEFSFTAILTALEFWSRVTPSILQLMAHNKVMVEMVCLHVISLMEALQECNSTIFVKLIPMWLPMIQSNIKHLSAGLQLRLQAIQNHVNHHSLRTLPGSGQSSAGLAALRKWLQCTQFKMAQVEIQSSEAASQFYPL>sp|Q92890|UFD1_HUMAN Ubiquitin recognition factor in ER-associateddegradation protein 1 OS=Homo sapiens OX=9606 GN=UFD1 PE=1 SV=3MFSFNMFDHPIPRVFQNRFSTQYRCFSVSMLAGPNDRSDVEKGGKIIMPPSALDQLSRLNITYPMLFKLTNKNSDRMTHCGVLEFVADEGICYLPHWMMQNLLLEEGGLVQVESVNLQVATYSKFQPQSPDFLDITNPKAVLENALRNFACLTTGDVIAINYNEKIYELRVMETKPDKAVSIIECDMNVDFDAPLGYKEPERQVQHEESTEGEADHSGYAGELGFRAFSGSGNRLDGKKKGVEPSPSPIKPGDIKRGIPNYEFKLGKITFIRNSRPLVKKVEEDEAGGRFVAFSGEGQSLRKKGRKP>sp|Q92890-1|UFD1_HUMAN Isoform Long of Ubiquitin recognition factor inER-associated degradation protein 1 OS=Homo sapiens OX=9606 GN=UFD1MFSFNMFDHPIPRVFQNRFSTQYRCFSVSMLAGPNDRSDVEKGGKIIMPPSALDQLSRLNITYPMLFKLTNKNSDRMTHCGVLEFVADEGICYLPHWMMQNLLLEEDGLVQLETVNLQVATYSKSKFCYLPHWMMQNLLLEEGGLVQVESVNLQVATYSKFQPQSPDFLDITNPKAVLENALRNFACLTTGDVIAINYNEKIYELRVMETKPDKAVSIIECDMNVDFDAPLGYKEPERQVQHEESTEGEADHSGYAGELGFRAFSGSGNRLDGKKKGVEPSPSPIKPGDIKRGIPNYEFKLGKITFIRNSRPLVKKVEEDEAGGRFVAFSGEGQSLRKKGRKP>sp|Q92890-3|UFD1_HUMAN Isoform 3 of Ubiquitin recognition factor in ER-associated degradation protein 1 OS=Homo sapiens OX=9606 GN=UFD1MFSFNMFDHPIPRVFQNRFSTQYRCFSVSMLAGPNDRSDVEKGGKIIMPPSALDQLSRLNITYPMLFKLTNKNSDRMTHCGVLEFVADEGICYLPHWMMQNLLLEEGGLVQVESVNLQVATYSKFQPQSPDFLDITNPKAVLENALRNFACLTTGDVIAINYNEKIYELRVMETKPDKAVSIIECDMNVDFDAPLGYKEPERQVQHEESTEGEADHSGYAGELGFRAFSGSGNRLDGKKKGVEPSPSPIKPGDIKRGIPNYEFKLG>sp|O94782|UBP1_HUMAN Ubiquitin carboxyl-terminal hydrolase 1 OS=Homosapiens OX=9606 GN=USP1 PE=1 SV=1MPGVIPSESNGLSRGSPSKKNRLSLKFFQKKETKRALDFTDSQENEEKASEYRASEIDQVVPAAQSSPINCEKRENLLPFVGLNNLGNTCYLNSILQVLYFCPGFKSGVKHLFNIISRKKEALKDEANQKDKGNCKEDSLASYELICSLQSLIISVEQLQASFLLNPEKYTDELATQPRRLLNTLRELNPMYEGYLQHDAQEVLQCILGNIQETCQLLKKEEVKNVAELPTKVEEIPHPKEEMNGINSIEMDSMRHSEDFKEKLPKGNGKRKSDTEFGNMKKKVKLSKEHQSLEENQRQTRSKRKATSDTLESPPKIIPKYISENESPRPSQKKSRVKINWLKSATKQPSILSKFCSLGKITTNQGVKGQSKENECDPEEDLGKCESDNTTNGCGLESPGNTVTPVNVNEVKPINKGEEQIGFELVEKLFQGQLVLRTRCLECESLTERREDFQDISVPVQEDELSKVEESSEISPEPKTEMKTLRWAISQFASVERIVGEDKYFCENCHHYTEAERSLLFDKMPEVITIHLKCFAASGLEFDCYGGGLSKINTPLLTPLKLSLEEWSTKPTNDSYGLFAVVMHSGITISSGHYTASVKVTDLNSLELDKGNFVVDQMCEIGKPEPLNEEEARGVVENYNDEEVSIRVGGNTQPSKVLNKKNVEAIGLLGGQKSKADYELYNKASNPDKVASTAFAENRNSETSDTTGTHESDRNKESSDQTGINISGFENKISYVVQSLKEYEGKWLLFDDSEVKVTEEKDFLNSLSPSTSPTSTPYLLFYKKL>sp|Q6H3X3|ULBP5_HUMAN UL-16 binding protein 5 OS=Homo sapiens OX=9606GN=RAET1G PE=1 SV=1MAAAASPAFLLRLPLLLLLSSWCRTGLADPHSLCYDITVIPKFRPGPRWCAVQGQVDEKTFLHYDCGSKTVTPVSPLGKKLNVTTAWKAQNPVLREVVDILTEQLLDIQLENYIPKEPLTLQARMSCEQKAEGHGSGSWQLSFDGQIFLLFDSENRMWTTVHPGARKMKEKWENDKDMTMSFHYISMGDCTGWLEDFLMGMDSTLEPSAGAPPTMSSGTAQPRATATTLILCCLLIMCLLICSRHSLTQSHGHHPQSLQPPPHPPLLHPTWLLRRVLWSDSYQIAKRPLSGGHVTRVTLPIIGDDSHSLPCPLALYTINNGAARYSEPLQVSIS>sp|Q6H3X3-2|ULBP5_HUMAN Isoform 2 of UL-16 binding protein 5 OS=Homosapiens OX=9606 GN=RAET1GMAAAASPAFLLRLPLLLLLSSWCRTGLADPHSLCYDITVIPKFRPGPRWCAVQGQVDEKTFLHYDCGSKTVTPVSPLGKKLNVTTAWKAQNPVLREVVDILTEQLLDIQLENYIPKEPLTLQARMSCEQKAEGHGSGSWQLSFDGQIFLLFDSENRMWTTVHPGARKMKEKWENDKDMTMSFHYISMGDCTGWLEDFLMGMDSTLEPSAGGTV>sp|Q6H3X3-3|ULBP5_HUMAN Isoform 3 of UL-16 binding protein 5 OS=Homosapiens OX=9606 GN=RAET1GMAAAASPAFLLRLPLLLLLSSWCRTGLADPHSLCYDITVIPKFRPGPRWCAVQGQVDEKTFLHYDCGSKTVTPVSPLGKKLNVTTAWKAQNPVLREVVDILTEQLLDIQLENYIPKENRMWTTVHPGARKMKEKWENDKDMTMSFHYISMGDCTGWLEDFLMGMDSTLEPSAGAPP>sp|Q70EK8|UBP53_HUMAN Inactive ubiquitin carboxyl-terminal hydrolase 53OS=Homo sapiens OX=9606 GN=USP53 PE=1 SV=2MAWVKFLRKPGGNLGKVYQPGSMLSLAPTKGLLNEPGQNSCFLNSAVQVLWQLDIFRRSLRVLTGHVCQGDACIFCALKTIFAQFQHSREKALPSDNIRHALAESFKDEQRFQLGLMDDAAECFENMLERIHFHIVPSRDADMCTSKSCITHQKFAMTLYEQCVCRSCGASSDPLPFTEFVRYISTTALCNEVERMLERHERFKPEMFAELLQAANTTDDYRKCPSNCGQKIKIRRVLMNCPEIVTIGLVWDSEHSDLTEAVVRNLATHLYLPGLFYRVTDENAKNSELNLVGMICYTSQHYCAFAFHTKSSKWVFFDDANVKEIGTRWKDVVSKCIRCHFQPLLLFYANPDGTAVSTEDALRQVISWSHYKSVAENMGCEKPVIHKSDNLKENGFGDQAKQRENQKFPTDNISSSNRSHSHTGVGKGPAKLSHIDQREKIKDISRECALKAIEQKNLLSSQRKDLEKGQRKDLGRHRDLVDEDLSHFQSGSPPAPNGFKQHGNPHLYHSQGKGSYKHDRVVPQSRASAQIISSSKSQILAPGEKITGKVKSDNGTGYDTDSSQDSRDRGNSCDSSSKSRNRGWKPMRETLNVDSIFSESEKRQHSPRHKPNISNKPKSSKDPSFSNWPKENPKQKGLMTIYEDEMKQEIGSRSSLESNGKGAEKNKGLVEGKVHGDNWQMQRTESGYESSDHISNGSTNLDSPVIDGNGTVMDISGVKETVCFSDQITTSNLNKERGDCTSLQSQHHLEGFRKELRNLEAGYKSHEFHPESHLQIKNHLIKRSHVHEDNGKLFPSSSLQIPKDHNAREHIHQSDEQKLEKPNECKFSEWLNIENSERTGLPFHVDNSASGKRVNSNEPSSLWSSHLRTVGLKPETAPLIQQQNIMDQCYFENSLSTECIIRSASRSDGCQMPKLFCQNLPPPLPPKKYAITSVPQSEKSESTPDVKLTEVFKATSHLPKHSLSTASEPSLEVSTHMNDERHKETFQVRECFGNTPNCPSSSSTNDFQANSGAIDAFCQPELDSISTCPNETVSLTTYFSVDSCMTDTYRLKYHQRPKLSFPESSGFCNNSLS>sp|P13051|UNG_HUMAN Uracil-DNA glycosylase OS=Homo sapiens OX=9606GN=UNG PE=1 SV=2MIGQKTLYSFFSPSPARKRHAPSPEPAVQGTGVAGVPEESGDAAAIPAKKAPAGQEEPGTPPSSPLSAEQLDRIQRNKAAALLRLAARNVPVGFGESWKKHLSGEFGKPYFIKLMGFVAEERKHYTVYPPPHQVFTWTQMCDIKDVKVVILGQDPYHGPNQAHGLCFSVQRPVPPPPSLENIYKELSTDIEDFVHPGHGDLSGWAKQGVLLLNAVLTVRAHQANSHKERGWEQFTDAVVSWLNQNSNGLVFLLWGSYAQKKGSAIDRKRHHVLQTAHPSPLSVYRGFFGCRHFSKTNELLQKSGKKPIDWKEL>sp|P13051-2|UNG_HUMAN Isoform 1 of Uracil-DNA glycosylase OS=Homosapiens OX=9606 GN=UNGMGVFCLGPWGLGRKLRTPGKGPLQLLSRLCGDHLQAIPAKKAPAGQEEPGTPPSSPLSAEQLDRIQRNKAAALLRLAARNVPVGFGESWKKHLSGEFGKPYFIKLMGFVAEERKHYTVYPPPHQVFTWTQMCDIKDVKVVILGQDPYHGPNQAHGLCFSVQRPVPPPPSLENIYKELSTDIEDFVHPGHGDLSGWAKQGVLLLNAVLTVRAHQANSHKERGWEQFTDAVVSWLNQNSNGLVFLLWGSYAQKKGSAIDRKRHHVLQTAHPSPLSVYRGFFGCRHFSKTNELLQKSGKKPIDWKEL>sp|Q495M9|USH1G_HUMAN Usher syndrome type-1G protein OS=Homo sapiensOX=9606 GN=USH1G PE=1 SV=1MNDQYHRAARDGYLELLKEATRKELNAPDEDGMTPTLWAAYHGNLESLRLIVSRGGDPDKCDIWGNTPLHLAASNGHLHCLSFLVSFGANIWCLDNDYHTPLDMAAMKGHMECVRYLDSIAAKQSSLNPKLVGKLKDKAFREAERRIRECAKLQRRHHERMERRYRRELAERSDTLSFSSLTSSTLSRRLQHLALGSHLPYSQATLHGTARGKTKMQKKLERRKQGGEGTFKVSEDGRKSARSLSGLQLGSDVMFVRQGTYANPKEWGRAPLRDMFLSDEDSVSRATLAAEPAHSEVSTDSGHDSLFTRPGLGTMVFRRNYLSSGLHGLGREDGGLDGVGAPRGRLQSSPSLDDDSLGSANSLQDRSCGEELPWDELDLGLDEDLEPETSPLETFLASLHMEDFAALLRQEKIDLEALMLCSDLDLRSISVPLGPRKKILGAVRRRRQAMERPPALEDTEL>sp|Q7L8A9|VASH1_HUMAN Tubulinyl-Tyr carboxypeptidase 1 OS=Homo sapiensOX=9606 GN=VASH1 PE=1 SV=1MPGGKKVAGGGSSGATPTSAAATAPSGVRRLETSEGTSAQRDEEPEEEGEEDLRDGGVPFFVNRGGLPVDEATWERMWKHVAKIHPDGEKVAQRIRGATDLPKIPIPSVPTFQPSTPVPERLEAVQRYIRELQYNHTGTQFFEIKKSRPLTGLMDLAKEMTKEALPIKCLEAVILGIYLTNSMPTLERFPISFKTYFSGNYFRHIVLGVNFAGRYGALGMSRREDLMYKPPAFRTLSELVLDFEAAYGRCWHVLKKVKLGQSVSHDPHSVEQIEWKHSVLDVERLGRDDFRKELERHARDMRLKIGKGTGPPSPTKDRKKDVSSPQRAQSSPHRRNSRSERRPSGDKKTSEPKAMPDLNGYQIRV>sp|Q7L8A9-2|VASH1_HUMAN Isoform 2 of Tubulinyl-Tyr carboxypeptidase 1OS=Homo sapiens OX=9606 GN=VASH1MPGGKKVAGGGSSGATPTSAAATAPSGVRRLETSEGTSAQRDEEPEEEGEEDLRDGGVPFFVNRGGLPVDEATWERMWKHVAKIHPDGEKVAQRIRGATDLPKIPIPSVPTFQPSTPVPERLEAVQRYIRELQYNHTGTQFFEIKKSRPLTGLMDLAKEMTKEALPIKCLEAVILGMYPSSPEGEGSGLLWASASCSESEGGVG>sp|Q9UID3|VPS51_HUMAN Vacuolar protein sorting-associated protein 51homolog OS=Homo sapiens OX=9606 GN=VPS51 PE=1 SV=2MAAAAAAGPSPGSGPGDSPEGPEGEAPERRRKAHGMLKLYYGLSEGEAAGRPAGPDPLDPTDLNGAHFDPEVYLDKLRRECPLAQLMDSETDMVRQIRALDSDMQTLVYENYNKFISATDTIRKMKNDFRKMEDEMDRLATNMAVITDFSARISATLQDRHERITKLAGVHALLRKLQFLFELPSRLTKCVELGAYGQAVRYQGRAQAVLQQYQHLPSFRAIQDDCQVITARLAQQLRQRFREGGSGAPEQAECVELLLALGEPAEELCEEFLAHARGRLEKELRNLEAELGPSPPAPDVLEFTDHGGSGFVGGLCQVAAAYQELFAAQGPAGAEKLAAFARQLGSRYFALVERRLAQEQGGGDNSLLVRALDRFHRRLRAPGALLAAAGLADAATEIVERVARERLGHHLQGLRAAFLGCLTDVRQALAAPRVAGKEGPGLAELLANVASSILSHIKASLAAVHLFTAKEVSFSNKPYFRGEFCSQGVREGLIVGFVHSMCQTAQSFCDSPGEKGGATPPALLLLLSRLCLDYETATISYILTLTDEQFLVQDQFPVTPVSTLCAEARETARRLLTHYVKVQGLVISQMLRKSVETRDWLSTLEPRNVRAVMKRVVEDTTAIDVQVGLLYEEGVRKAQSSDSSKRTFSVYSSSRQQGRYAPSYTPSAPMDTNLLSNIQKLFSERIDVFSPVEFNKVSVLTGIIKISLKTLLECVRLRTFGRFGLQQVQVDCHFLQLYLWRFVADEELVHLLLDEVVASAALRCPDPVPMEPSVVEVICERG>sp|Q9UID3-2|VPS51_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 51 homolog OS=Homo sapiens OX=9606 GN=VPS51MKNDFRKMEDEMDRLATNMAVITDFSARISATLQDRHERITKLAGVHALLRKLQFLFELPSRLTKCVELGAYGQAVRYQGRAQAVLQQYQHLPSFRAIQDDCQVITARLAQQLRQRFREGGSGAPEQAECVELLLALGEPAEELCEEFLAHARGRLEKELRNLEAELGPSPPAPDVLEFTDHGGSGFVGGLCQVAAAYQELFAAQGPAGAEKLAAFARQLGSRYFALVERRLAQEQGGGDNSLLVRALDRFHRRLRAPGALLAAAGLADAATEIVERVARERLGHHLQGLRAAFLGCLTDVRQALAAPRVAGKEGPGLAELLANVASSILSHIKASLAAVHLFTAKEVSFSNKPYFRGEFCSQGVREGLIVGFVHSMCQTAQSFCDSPGEKGGATPPALLLLLSRLCLDYETATISYILTLTDEQFLVQDQFPVTPVSTLCAEARETARRLLTHYVKVQGLVISQMLRKSVETRDWLSTLEPRNVRAVMKRVVEDTTAIDVQVGLLYEEGVRKAQSSDSSKRTFSVYSSSRQQGRYAPSYTPSAPMDTNLLSNIQKLFSERIDVFSPVEFNKVSVLTGIIKISLKTLLECVRLRTFGRFGLQQVQVDCHFLQLYLWRFVADEELVHLLLDEVVASAALRCPDPVPMEPSVVEVICERG>sp|B2RXF5|ZBT42_HUMAN Zinc finger and BTB domain-containing protein 42OS=Homo sapiens OX=9606 GN=ZBTB42 PE=1 SV=2MEFPEHGGRLLGRLRQQRELGFLCDCTVLVGDARFPAHRAVLAACSVYFHLFYRDRPAGSRDTVRLNGDIVTAPAFGRLLDFMYEGRLDLRSLPVEDVLAAASYLHMYDIVKVCKGRLQEKDRSLDPGNPAPGAEPAQPPCPWPVWTADLCPAARKAKLPPFGVKAALPPRASGPPPCQVPEESDQALDLSLKSGPRQERVHPPCVLQTPLCSQRQPGAQPLVKDERDSLSEQEESSSSRSPHSPPKPPPVPAAKGLVVGLQPLPLSGEGSRELELGAGRLASEDELGPGGPLCICPLCSKLFPSSHVLQLHLSAHFRERDSTRARLSPDGVAPTCPLCGKTFSCTYTLKRHERTHSGEKPYTCVQCGKSFQYSHNLSRHTVVHTREKPHACRWCERRFTQSGDLYRHVRKFHCGLVKSLLV>sp|Q8NDW4|ZN248_HUMAN Zinc finger protein 248 OS=Homo sapiens OX=9606GN=ZNF248 PE=1 SV=1MNKSQEQVSFKDVCVDFTQEEWYLLDPAQKILYRDVILENYSNLVSVGYCITKPEVIFKIEQGEEPWILEKGFPSQCHPERKWKVDDVLESSQENEDDHFWELLFHNNKTVSVENGDRGSKTFNLGTDPVSLRNYPYKICDSCEMNLKNISGLIISKKNCSRKKPDEFNVCEKLLLDIRHEKIPIGEKSYKYDQKRNAINYHQDLSQPSFGQSFEYSKNGQGFHDEAAFFTNKRSQIGETVCKYNECGRTFIESLKLNISQRPHLEMEPYGCSICGKSFCMNLRFGHQRALTKDNPYEYNEYGEIFCDNSAFIIHQGAYTRKILREYKVSDKTWEKSALLKHQIVHMGGKSYDYNENGSNFSKKSHLTQLRRAHTGEKTFECGECGKTFWEKSNLTQHQRTHTGEKPYECTECGKAFCQKPHLTNHQRTHTGEKPYECKQCGKTFCVKSNLTEHQRTHTGEKPYECNACGKSFCHRSALTVHQRTHTGEKPFICNECGKSFCVKSNLIVHQRTHTGEKPYKCNECGKTFCEKSALTKHQRTHTGEKPYECNACGKTFSQRSVLTKHQRIHTRVKALSTS>sp|Q8NDW4-2|ZN248_HUMAN Isoform 2 of Zinc finger protein 248 OS=Homosapiens OX=9606 GN=ZNF248MNKSQEQVSFKDVCVDFTQEEWYLLDPAQKILYRDVILENYSNLVSVGYCITKPEVIFKIEQGEEPWILEKGFPSQCHPERKWKVDDVLESSQENEDDHFWELLFHNNKTWNLKLIKVE>sp|O14628|ZN195_HUMAN Zinc finger protein 195 OS=Homo sapiens OX=9606GN=ZNF195 PE=1 SV=2MTLLTFRDVAIEFSLEEWKCLDLAQQNLYRDVMLENYRNLFSVGLTVCKPGLITCLEQRKEPWNVKRQEAADGHPEMGFHHATQACLELLGSSDLPASASQSAGITGVNHRAQPGLNVSVDKFTALCSPGVLQTVKWFLEFRCIFSLAMSSHFTQDLLPEQGIQDAFPKRILRGYGNCGLDNLYLRKDWESLDECKLQKDYNGLNQCSSTTHSKIFQYNKYVKIFDNFSNLHRRNISNTGEKPFKCQECGKSFQMLSFLTEHQKIHTGKKFQKCGECGKTFIQCSHFTEPENIDTGEKPYKCQECNNVIKTCSVLTKNRIYAGGEHYRCEEFGKVFNQCSHLTEHEHGTEEKPCKYEECSSVFISCSSLSNQQMILAGEKLSKCETWYKGFNHSPNPSKHQRNEIGGKPFKCEECDSIFKWFSDLTKHKRIHTGEKPYKCDECGKAYTQSSHLSEHRRIHTGEKPYQCEECGKVFRTCSSLSNHKRTHSEEKPYTCEECGNIFKQLSDLTKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEECGRVFMWFSDITKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEKCGKAFTQFSHLTVHESIHT>sp|O14628-4|ZN195_HUMAN Isoform 4 of Zinc finger protein 195 OS=Homosapiens OX=9606 GN=ZNF195MTLLTFRDVAIEFSLEEWKCLDLAQQNLYRDVMLENYRNLFSVGLTVCKPGLITCLEQRKEPWNVKRQEAADGHPAMSSHFTQDLLPEQGIQDAFPKRILRGYGNCGLDNLYLRKDWESLDECKLQKDYNGLNQCSSTTHSKIFQYNKYVKIFDNFSNLHRRNISNTGEKPFKCQECGKSFQMLSFLTEHQKIHTGKKFQKCGECGKTFIQCSHFTEPENIDTGEKPYKCQECNNVIKTCSVLTKNRIYAGGEHYRCEEFGKVFNQCSHLTEHEHGTEEKPCKYEECSSVFISCSSLSNQQMILAGEKLSKCETWYKGFNHSPNPSKHQRNEIGGKPFKCEECDSIFKWFSDLTKHKRIHTGEKPYKCDECGKAYTQSSHLSEHRRIHTGEKPYQCEECGKVFRTCSSLSNHKRTHSEEKPYTCEECGNIFKQLSDLTKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEECGRVFMWFSDITKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEKCGKAFTQFSHLTVHESIHT>sp|O14628-5|ZN195_HUMAN Isoform 5 of Zinc finger protein 195 OS=Homosapiens OX=9606 GN=ZNF195MTLLTFRDVAIEFSLEEWKCLDLAQQNLYRDVMLENYRNLFSVGLTVCKPGLITCLEQRKEPWNVKRQEAADGHPEMGFHHATQACLELLGSSDLPASASQSAGITGVNHRAQPGLNVSVDKFTAMSSHFTQDLLPEQGIQDAFPKRILRGYGNCGLDNLYLRKDWESLDECKLQKDYNGLNQCSSTTHSKIFQYNKYVKIFDNFSNLHRRNISNTGEKPFKCQECGKSFQMLSFLTEHQKIHTGKKFQKCGECGKTFIQCSHFTEPENIDTGEKPYKCQECNNVIKTCSVLTKNRIYAGGEHYRCEEFGKVFNQCSHLTEHEHGTEEKPCKYEECSSVFISCSSLSNQQMILAGEKLSKCETWYKGFNHSPNPSKHQRNEIGGKPFKCEECDSIFKWFSDLTKHKRIHTGEKPYKCDECGKAYTQSSHLSEHRRIHTGEKPYQCEECGKVFRTCSSLSNHKRTHSEEKPYTCEECGNIFKQLSDLTKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEECGRVFMWFSDITKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEKCGKAFTQFSHLTVHESIHT>sp|O14628-6|ZN195_HUMAN Isoform 6 of Zinc finger protein 195 OS=Homosapiens OX=9606 GN=ZNF195MAGAQTLLTFRDVAIEFSLEEWKCLDLAQQNLYRDVMLENYRNLFSVGLTVCKPGLITCLEQRKEPWNVKRQEAADGHPEMGFHHATQACLELLGSSDLPASASQSAGITGVNHRAQPGLNVSVDKFTAMSSHFTQDLLPEQGIQDAFPKRILRGYGNCGLDNLYLRKDWESLDECKLQKDYNGLNQCSSTTHSKIFQYNKYVKIFDNFSNLHRRNISNTGEKPFKCQECGKSFQMLSFLTEHQKIHTGKKFQKCGECGKTFIQCSHFTEPENIDTGEKPYKCQECNNVIKTCSVLTKNRIYAGGEHYRCEEFGKVFNQCSHLTEHEHGTEEKPCKYEECSSVFISCSSLSNQQMILAGEKLSKCETWYKGFNHSPNPSKHQRNEIGGKPFKCEECDSIFKWFSDLTKHKRIHTGEKPYKCDECGKAYTQSSHLSEHRRIHTGEKPYQCEECGKVFRTCSSLSNHKRTHSEEKPYTCEECGNIFKQLSDLTKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEECGRVFMWFSDITKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEKCGKAFTQFSHLTVHESIHT>sp|O14628-7|ZN195_HUMAN Isoform 7 of Zinc finger protein 195 OS=Homosapiens OX=9606 GN=ZNF195MAGAQTLLTFRDVAIEFSLEEWKCLDLAQQNLYRDVMLENYRNLFSVGLTVCKPGLITCLEQRKEPWNVKRQEAADGHPAMSSHFTQDLLPEQGIQDAFPKRILRGYGNCGLDNLYLRKDWESLDECKLQKDYNGLNQCSSTTHSKIFQYNKYVKIFDNFSNLHRRNISNTGEKPFKCQECGKSFQMLSFLTEHQKIHTGKKFQKCGECGKTFIQCSHFTEPENIDTGEKPYKCQECNNVIKTCSVLTKNRIYAGGEHYRCEEFGKVFNQCSHLTEHEHGTEEKPCKYEECSSVFISCSSLSNQQMILAGEKLSKCETWYKGFNHSPNPSKHQRNEIGGKPFKCEECDSIFKWFSDLTKHKRIHTGEKPYKCDECGKAYTQSSHLSEHRRIHTGEKPYQCEECGKVFRTCSSLSNHKRTHSEEKPYTCEECGNIFKQLSDLTKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEECGRVFMWFSDITKHKKTHTGEKPYKCDECGKNFTQSSNLIVHKRIHTGEKPYKCEKCGKAFTQFSHLTVHESIHT>sp|O14628-8|ZN195_HUMAN Isoform 8 of Zinc finger protein 195 OS=Homosapiens OX=9606 GN=ZNF195MAGAQTLLTFRDVAIEFSLEEWKCLDLAQQNLYRDVMLENYRNLFSVGLTVCKPGLITCLEQRKEPWNVKRQEAADGHPGIFFVVTMEII>sp|Q6ZS49|YQ050_HUMAN Putative uncharacterized protein FLJ45831 OS=Homosapiens OX=9606 PE=5 SV=1MEISCTSQGFFFLKEHSSGVSSVKAAQMPGRTLYRSLCSCVFPLHSPTRPPSPASAPKGFLLLSPTSSNASKLMPYYLFHRSRGVDNSKISVLILLGCELEQTKKKKLGPATALGNSGRVE>sp|Q96H79|ZCCHL_HUMAN Zinc finger CCCH-type antiviral protein 1-likeOS=Homo sapiens OX=9606 GN=ZC3HAV1L PE=1 SV=2MAEPTVCSFLTKVLCAHGGRMFLKDLRGHVELSEARLRDVLQRAGPERFLLQEVETQEGLGDAEAEAAAGAVGGGGTSAWRVVAVSSVRLCARYQRGECQACDQLHFCRRHMLGKCPNRDCWSTCTLSHDIHTPVNMQVLKSHGLFGLNENQLRILLLQNDPCLLPEVCLLYNKGEALYGYCNLKDKCNKFHVCKSFVKGECKLQTCKRSHQLIHAASLKLLQDQGLNIPSVVNFQIISTYKHMKLHKMLENTDNSSPSTEHSQGLEKQGVHAAGAAEAGPLASVPAQSAKKPCPVSCEK>sp|Q96H79-2|ZCCHL_HUMAN Isoform 2 of Zinc finger CCCH-type antiviralprotein 1-like OS=Homo sapiens OX=9606 GN=ZC3HAV1LMAEPTVCSFLTKVLCAHGGRMFLKDLRGHVELSEARLRDVLQRAGPERFLLQEVETQEGLGDAEAEAAAGAVGGGGTSAWRVVAVSGTIGACHHTQLIFLGF>sp|Q96PE6|ZIM3_HUMAN Zinc finger imprinted 3 OS=Homo sapiens OX=9606GN=ZIM3 PE=1 SV=1MNNSQGRVTFEDVTVNFTQGEWQRLNPEQRNLYRDVMLENYSNLVSVGQGETTKPDVILRLEQGKEPWLEEEEVLGSGRAEKNGDIGGQIWKPKDVKESLAREVPSINKETLTTQKGVECDGSKKILPLGIDDVSSLQHYVQNNSHDDNGYRKLVGNNPSKFVGQQLKCNACRKLFSSKSRLQSHLRRHACQKPFECHSCGRAFGEKWKLDKHQKTHAEERPYKCENCGNAYKQKSNLFQHQKMHTKEKPYQCKTCGKAFSWKSSCINHEKIHNAKKSYQCNECEKSFRQNSTLIQHKKVHTGQKPFQCTDCGKAFIYKSDLVKHQRIHTGEKPYKCSICEKAFSQKSNVIDHEKIHTGKRAYECDLCGNTFIQKKNLIQHKKIHTGEKPYECNRCGKAFFQKSNLHSHQKTHSGERTYRCSECGKTFIRKLNLSLHKKTHTGQKPYGCSECGKAFADRSYLVRHQKRIHSR>sp|Q8IYI8|ZN440_HUMAN Zinc finger protein 440 OS=Homo sapiens OX=9606GN=ZNF440 PE=1 SV=1MDPVAFKDVAVNFTQEEWALLDISQRKLYREVMLETFRNLTSLGKRWKDQNIEYEHQNPRRNFRSLIEEKVNEIKDDSHCGETFTPVPDDRLNFQEKKASPEVKSCESFVCGEVGLGNSSFNMNIRGDIGHKAYEYQEYGPKPCKCQQPKKAFRYRPSFRTQERDHTGEKPNACKVCGKTFISHSSVRRHMVMHSGDGPYKCKFCGKAFHCLRLYLIHERIHTGEKPCECKQCGKSFSYSATHRIHKRTHTGEKPYEYQECGKAFHSPRSYRRHERIHMGEKAYQCKECGKAFTCPRYVRIHERTHSRKNLYECKQCGKALSSLTSFQTHVRLHSGERPYECKICGKDFCSVNSFQRHEKIHSGEKPYKCKQCGKAFPHSSSLRYHERTHTGEKPYECKQCGKAFRSASHLRVHGRTHTGEKPYECKECGKAFRYVNNLQSHERTQTHIRIHSGERRYKCKICGKGFYCPKSFQRHEKTHTGEKLYECKQRSVVPSVVPVPFDIMKGLTLERSPINASNVGKPSELCQSFECMVGLTLKRNPMSVSNDGKPSDLPHTFEYVVGHTMERSPMHVRNVGNPSDLPRTFEFMKGHKHT>sp|P17041|ZNF32_HUMAN Zinc finger protein 32 OS=Homo sapiens OX=9606GN=ZNF32 PE=1 SV=2MFGFPTATLLDCHGRYAQNVAFFNVMTEAHHKYDHSEATGSSSWDIQNSFRREKLEQKSPDSKTLQEDSPGVRQRVYECQECGKSFRQKGSLTLHERIHTGQKPFECTHCGKSFRAKGNLVTHQRIHTGEKPYQCKECGKSFSQRGSLAVHERLHTGQKPYECAICQRSFRNQSNLAVHRRVHSGEKPYRCDQCGKAFSQKGSLIVHIRVHTGLKPYACTQCRKSFHTRGNCILHGKIHTGETPYLCGQCGKSFTQRGSLAVHQRSCSQRLTL>sp|Q9H609|ZN576_HUMAN Zinc finger protein 576 OS=Homo sapiens OX=9606GN=ZNF576 PE=1 SV=1MEDPNPEENMKQQDSPKERSPQSPGGNICHLGAPKCTRCLITFADSKFQERHMKREHPADFVAQKLQGVLFICFTCARSFPSSKALITHQRSHGPAAKPTLPVATTTAQPTFPCPDCGKTFGQAVSLRRHRQMHEVRAPPGTFACTECGQDFAQEAGLHQHYIRHARGEL>sp|Q9BTK2|YX002_HUMAN Putative uncharacterized protein LOC642776 OS=Homosapiens OX=9606 PE=5 SV=2MEGGMAAYPVATRESRCRRGRIGVQPSPERRSEVVGPFPLARSLS>sp|Q49AG3|ZBED5_HUMAN Zinc finger BED domain-containing protein 5OS=Homo sapiens OX=9606 GN=ZBED5 PE=2 SV=2MIAPLLCILSYNFNTFAILNVYSKLTMFCTTNSLPMDLLLKQGSLKQEVESFCYQIVSESNDQKVGILQSEDKQLQPSVSKKSEGELSRVKFISNSNKITFSKKPKRRKYDESYLSFGFTYFGNRDAPHAQCVLCKKILSNSSLAPSKLRRHLETKHAAYKDKDISFFKQHLDSPENNKPPTPKIVNTDNESATEASYNVSYHIALSGEAHTIGELLIKPCAKDVVMRMFDEQYSKKIDAVQLSNSTVARRIKDLAADIEEELVCRLKICDGFSLQLDESADVSGLAVLLVFVRYRFNKSIEEDLLLCESLQSNATGEEIFNCINSFMQKHEIEWEKCVDVCSDASRAVDGKIAEAVTLIKYVAPESTSSHCLLYRHALAVKIMPTSLKNVLDQAVQIINYIKARPHQSRLLKILCEEMGAQHTALLLNTEVRWLSRGKVLVRLFELRRELLVFMDSAFRLSDCLTNSSWLLRLAYLADIFTKLNEVNLSMQGKNVTVFTVFDKMSSLLRKLEFWASSVEEENFDCFPTLSDFLTEINSTVDKDICSAIVQHLRGLRATLLKYFPVTNDNNAWVRNPFTVTVKPASLVARDYESLIDLTSDSQVKQNFSELSLNDFWSSLIQEYPSIARRAVRVLLPFATMHLCETGFSYYAATKTKYRKRLDAAPHMRIRLSNITPNIKRICDKKTQKHCSH>sp|Q9UID6|ZN639_HUMAN Zinc finger protein 639 OS=Homo sapiens OX=9606GN=ZNF639 PE=1 SV=1MNEYPKKRKRKTLHPSRYSDSSGISRIADGFNGIFSDHCYSVCSMRQPDLKYFDNKDDDSDTETSNDLPKFADGIKARNRNQNYLVPSPVLRILDHTAFSTEKSADIVICDEECDSPESVNQQTQEESPIEVHTAEDVPIAVEVHAISEDYDIETENNSSESLQDQTDEEPPAKLCKILDKSQALNVTAQQKWPLLRANSSGLYKCELCEFNSKYFSDLKQHMILKHKRTDSNVCRVCKESFSTNMLLIEHAKLHEEDPYICKYCDYKTVIFENLSQHIADTHFSDHLYWCEQCDVQFSSSSELYLHFQEHSCDEQYLCQFCEHETNDPEDLHSHVVNEHACKLIELSDKYNNGEHGQYSLLSKITFDKCKNFFVCQVCGFRSRLHTNVNRHVAIEHTKIFPHVCDDCGKGFSSMLEYCKHLNSHLSEGIYLCQYCEYSTGQIEDLKIHLDFKHSADLPHKCSDCLMRFGNERELISHLPVHETT>sp|Q15973|ZN124_HUMAN Zinc finger protein 124 OS=Homo sapiens OX=9606GN=ZNF124 PE=1 SV=2MSGHPGSWEMNSVAFEDVAVNFTQEEWALLDPSQKNLYRDVMQETFRNLASIGNKGEDQSIEDQYKNSSRNLRHIISHSGNNPYGCEECGKKPCTCKQCQKTSLSVTRVHRDTVMHTGNGHYGCTICEKVFNIPSSFQIHQRNHTGEKPYECMECGKALGFSRSLNRHKRIHTGEKRYECKQCGKAFSRSSHLRDHERTHTGEKPYECKHCGKAFRYSNCLHYHERTHTGEKPYVCMECGKAFSCLSSLQGHIKAHAGEEPYPCKQCGKAFRYASSLQKHEKTHIAQKPYVCNNCGKGFRCSSSLRDHERTHTGEKPYECQKCGKAFSRASTLWKHKKTHTGEKPYKCKKM>sp|Q15973-4|ZN124_HUMAN Isoform 2 of Zinc finger protein 124 OS=Homosapiens OX=9606 GN=ZNF124MSGHPGSWEMNSVAFEDVAVNFTQEEWALLDPSQKNLYRDVMQETFRNLASIGNKGEDQSIEDQYKNSSRNLSSFQIHQRNHTGEKPYECMECGKALGFSRSLNRHKRIHTGEKRYECKQCGKAFSRSSHLRDHERTHTGEKPYECKHCGKAFRYSNCLHYHERTHTGEKPYVCMECGKAFSCLSSLQGHIKAHAGEEPYPCKQCGKAFRYASSLQKHEKTHIAQKPYVCNNCGKGFRCSSSLRDHERTHTGEKPYECQKCGKAFSRASTLWKHKKTHTGEKPYKCKKM>sp|Q15973-1|ZN124_HUMAN Isoform 3 of Zinc finger protein 124 OS=Homosapiens OX=9606 GN=ZNF124MNALCVKNSSYVHSSLHRHIISHSGNNPYGCEECGKKPCTCKQCQKTSLSVTRVHRDTVMHTGNGHYGCTICEKVFNIPSSFQIHQRNHTGEKPYECMECGKALGFSRSLNRHKRIHTGEKRYECKQCGKAFSRSSHLRDHERTHTGEKPYECKHCGKAFRYSNCLHYHERTHTGEKPYVCMECGKAFSCLSSLQGHIKAHAGEEPYPCKQCGKAFRYASSLQKHEKTHIAQKPYVCNNCGKGFRCSSSLRDHERTHTGEKPYECQKCGKAFSRASTLWKHKKTHTGEKPYKCKKM>sp|Q15973-2|ZN124_HUMAN Isoform 4 of Zinc finger protein 124 OS=Homosapiens OX=9606 GN=ZNF124MNALCVKNSSYVHSSLHRHIISHSGNNPYGCEECGKKPCTCKQCQKTSLSVTRVHRDTVMHTGNGHYGCTICEKVFNIPSSFQIHQRNHTGEKPYECMECGKALGFSRSLNRHKRIHTGEKRYECKQCGKAFSRASTLWKHKKTHTGEKPYKCKKM>sp|Q15973-5|ZN124_HUMAN Isoform 5 of Zinc finger protein 124 OS=Homosapiens OX=9606 GN=ZNF124MSGHPGSWEMNSVAFEDVAVNFTQEEWALLDPSQKNLYRDVMQETFRNLASIGNKGEDQSIEDQYKNSSRNLR>sp|Q5EBL2|ZN628_HUMAN Zinc finger protein 628 OS=Homo sapiens OX=9606GN=ZNF628 PE=1 SV=3MSGVMVGSHADMAPASTAEGAGEKPGPAAPAPAAQYECGECGKSFRWSSRLLHHQRTHTGERPYKCPDCPKAFKGSSALLYHQRGHTGERPYQCPDCPKAFKRSSLLQIHRSVHTGLRAFICGQCGLAFKWSSHYQYHLRQHTGERPYPCPDCPKAFKNSSSLRRHRHVHTGERPYTCGVCGKSFTQSTNLRQHQRVHTGERPFRCPLCPKTFTHSSNLLLHQRTHGAAPAPGTASAAPPPQSREPGKVFVCDAYLQRHLQPHSPPAPPAPPPPPPPVVPELFLAAAETTVELVYRCDGCEQGFSSEELLLEHQPCPGPDAAPQPQEAPAEAPKADQPPSPLPQPPPPAAAPAPGFACLPCGKSFRTVAGLSRHQHSHGAAGGQAFRCGSCDGSFPQLASLLAHQQCHVEEAAAGRPPPQAEAAEVTCPQEPLAPAAPVPPPPPSAPASAERPYKCAECGKSFKGSSGLRYHLRDHTGERPYQCGECGKAFKRSSLLAIHQRVHTGLRAFTCGQCGLTFKWSSHYQYHLRLHSGERPYACGECGKAFRNTSCLRRHRHVHTGERPHACGVCGKSFAQTSNLRQHQRVHTGERPFRCPLCPKTFTHSSNLLLHQRTHSAERPFTCPICGRGFVMAAYLQRHLRTHAPANTPPSTTAPAAGPQPPAPLAAARAPPATQDVHVLPHLQATLSLEVAGGTAQAPSLGPAAPNSQTFLLVQTAQGLQLIPSSVQPPTPPPPPAPPKLILLPSSSAGAGGGRARQGPRAVGKAGQGAGVVWLPGPGGLGVQGAASAGASGTGQSLIVLQNVGGGEAGPQEMSGVQLQPLRPAPEVTTVQLQPAQEVTTVQLQPAQEVTTVQLQPAQEVTTVQLQPVAGQLSNSSGGAVATEAPNLLVVQSGAAEELLTGPGPGEAGDGEASTGVVQDVLFETLQTDEGLQSVLVLSGADGEQTRLCVQEVETLPPGLTEPPATGPPGQKLLIIRSAPATELLDSSNTGGGTATLQLLAPPPSGPASGPAGLPGAPASQMVQVVPAGAGPGVMTPQGLPSIQIVQTLPAVQLVHTF>sp|Q9UEG4|ZN629_HUMAN Zinc finger protein 629 OS=Homo sapiens OX=9606GN=ZNF629 PE=1 SV=2MEPETALWGPDLQGPEQSPNDAHRGAESENEEESPRQESSGEEIIMGDPAQSPESKDSTEMSLERSSQDPSVPQNPPTPLGHSNPLDHQIPLDPPAPEVVPTPSDWTKACEASWQWGALTTWNSPPVVPANEPSLRELVQGRPAGAEKPYICNECGKSFSQWSKLLRHQRIHTGERPNTCSECGKSFTQSSHLVQHQRTHTGEKPYKCPDCGKCFSWSSNLVQHQRTHTGEKPYKCTECEKAFTQSTNLIKHQRSHTGEKPYKCGECRRAFYRSSDLIQHQATHTGEKPYKCPECGKRFGQNHNLLKHQKIHAGEKPYRCTECGKSFIQSSELTQHQRTHTGEKPYECLECGKSFGHSSTLIKHQRTHLREDPFKCPVCGKTFTLSATLLRHQRTHTGERPYKCPECGKSFSVSSNLINHQRIHRGERPYICADCGKSFIMSSTLIRHQRIHTGEKPYKCSDCGKSFIRSSHLIQHRRTHTGEKPYKCPECGKSFSQSSNLITHVRTHMDENLFVCSDCGKAFLEAHELEQHRVIHERGKTPARRAQGDSLLGLGDPSLLTPPPGAKPHKCLVCGKGFNDEGIFMQHQRIHIGENPYKNADGLIAHAAPKPPQLRSPRLPFRGNSYPGAAEGRAEAPGQPLKPPEGQEGFSQRRGLLSSKTYICSHCGESFLDRSVLLQHQLTHGNEKPFLFPDYRIGLGEGAGPSPFLSGKPFKCPECKQSFGLSSELLLHQKVHAGGKSSQKSPELGKSSSVLLEHLRSPLGARPYRCSDCRASFLDRVALTRHQETHTQEKPPNPEDPPPEAVTLSTDQEGEGETPTPTESSSHGEGQNPKTLVEEKPYLCPECGAGFTEVAALLLHRSCHPGVSL>sp|Q03938|ZNF90_HUMAN Zinc finger protein 90 OS=Homo sapiens OX=9606GN=ZNF90 PE=2 SV=3MGPLEFRDVAIEFSLEEWHCLDTAQQNLYRDVMLENYRHLVFLGIVVTKPDLITCLEQGKKPFTVKRHEMIAKSPVMCFHFAQDLCPEQSLKDSFQKVIVTRYEKREYGNLELKKGCESVDEGKVHKRGYNGLNQCLTATQSKVFQCDTYVKVSHIFSNSNRHKIRDTGKKPFKCIECGKAFNQSSTLATHKKIHTGEITCKCEECGKAFNRSSHLTSHKRIHTGEKRYKCEDCGKELKYSSTLTAHKRIHTGEKRYKCEDCGKELKYSSTLTAHKRIHTGEKPYKCDKCGRAFISSSILYVHKISHTEEKPYKCEECGKAFKLSSILSTHKRIHTGEKPYKCEECGKAFRRSLVLRTHKRIHTGEKPYKCDKCGKAFISSSLLYKHKISHSEKKPYKCEECGKAFKRSSTLTIHKISHTEEKPYKCQECDKVFKRSSALSTHKIIHSGEKPYKCEECGKAFKRSSNLTTHKISHTEEKLYKCQECDKAFKYSSALSTHKIIHSGENPYKCEECGKAFKRSSVLSKHKIIHTGAKPYKCEECGKAFKRSSQLTSHKISHTGEKPYKCEECGKAFNLSSDLNTHKRIHIGQKAYIVKNMANL>sp|Q8IWY8|ZSC29_HUMAN Zinc finger and SCAN domain-containing protein 29OS=Homo sapiens OX=9606 GN=ZSCAN29 PE=1 SV=2MMAKSALRENGTNSETFRQRFRRFHYQEVAGPREAFSQLWELCCRWLRPEVRTKEQIVELLVLEQFLTVLPGEIQNWVQEQCPENGEEAVTLVEDLEREPGRPRSSVTVSVKGQEVRLEKMTPPKSSQELLSVRQESVEPQPRGVPKKERARSPDLGPQEQMNPKEKLKPFQRSGLPFPKSGVVSRLEQGEPWIPDLLGSKEKELPSGSHIGDRRVHADLLPSKKDRRSWVEQDHWSFEDEKVAGVHWGYEETRTLLAILSQTEFYEALRNCHRNSQVYGAVAERLREYGFLRTLEQCRTKFKGLQKSYRKVKSGHPPETCPFFEEMEALMSAQVIALPSNGLEAAASHSGLVGSDAETEEPGQRGWQHEEGAEEAVAQESDSDDMDLEATPQDPNSAAPVVFRSPGGVHWGYEETKTYLAILSETQFYEALRNCHRNSQLYGAVAERLWEYGFLRTPEQCRTKFKSLQTSYRKVKNGQAPETCPFFEEMDALVSVRVAAPPNDGQEETASCPVQGTSEAEAQKQAEEADEATEEDSDDDEEDTEIPPGAVITRAPVLFQSPRGFEAGFENEDNSKRDISEEVQLHRTLLARSERKIPRYLHQGKGNESDCRSGRQWAKTSGEKRGKLTLPEKSLSEVLSQQRPCLGERPYKYLKYSKSFGPNSLLMHQVSHQVENPYKCADCGKSFSRSARLIRHRRIHTGEKPYKCLDCGKSFRDSSNFITHRRIHTGEKPYQCGECGKCFNQSSSLIIHQRTHTGEKPYQCEECGKSFNNSSHFSAHRRIHTGERPHVCPDCGKSFSKSSDLRAHHRTHTGEKPYGCHDCGKCFSKSSALNKHGEIHAREKLLTQSAPK>sp|Q8IWY8-2|ZSC29_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 29 OS=Homo sapiens OX=9606 GN=ZSCAN29MTPPKSSQELLSVRQESVEPQPRGVPKKERARSPDLGPQEQMNPKEKLKPFQRSGLPFPKSGVVSRLEQGEPWIPDLLGSKEKELPSGSHIGDRRVHADLLPSKKDRRSWVEQDHWSFEDEKVAGVHWGYEETRTLLAILSQTEFYEALRNCHRNSQVYGAVAERLREYGFLRTLEQCRTKFKGLQKSYRKVKSGHPPETCPFFEEMEALMSAQVIALPSNGLEAAASHSGLVGSDAETEEPGQRGWQHEEGAEEAVAQESDSDDMDLEATPQDPNSAAPVVFRSPGGVHWGYEETKTYLAILSETQFYEALRNCHRNSQLYGAVAERLWEYGFLRTPEQCRTKFKSLQTSYRKVKNGQAPETCPFFEEMDALVSVRVAAPPNDGQEETASCPVQGTSEAEAQKQAEEADEATEEDSDDDEEDTEIPPGAVITRAPVLFQSPRGFEAGFENEDNSKRDISEEVQLHRTLLARSERKIPRYLHQGKGNESDCRSGRQWAKTSGEKRGKLTLPEKSLSEVLSQQRPCLGERPYKYLKYSKSFGPNSLLMHQVSHQVENPYKCADCGKSFSRSARLIRHRRIHTGEKPYKCLDCGKSFRDSSNFITHRRIHTGEKPYQCGECGKCFNQSSSLIIHQRTHTGEKPYQCEECGKSFNNSSHFSAHRRIHTGERPHVCPDCGKSFSKSSDLRAHHRTHTGEKPYGCHDCGKCFSKSSALNKHGEIHAREKLLTQSAPK>sp|Q8IWY8-3|ZSC29_HUMAN Isoform 3 of Zinc finger and SCAN domain-containing protein 29 OS=Homo sapiens OX=9606 GN=ZSCAN29MMAKSALRENGTNSETFRQRFRRFHYQEVAGPREAFSQLWELCCRWLRPEVRTKEQIVELLVLEQFLTVLPGEIQNWVQEQCPENGEEAVTLVEDLEREPGRPRSSVTVSVKGQEVRLEKMTPPKSSQELLSVRQESVEPQPRGVPKKERARSPDLGPQEQMNPKEKLKPFQRSGLPFPKSGVVSRLEQGEPWIPDLLGSKEKELPSGSHIGDRRVHADLLPSKKDRRSWVEQDHWSFEDEKVAGVHWGYEETRTLLAILSQTEFYEALRNCHRNSQVYGAVAERLREYGFLRTLEQCRTKFKGLQKSYRKVKSGHPPETCPFFEEMEALMSAQVIALPSNGLEAAASHSGLVGSDAETEEPGQRGWQHEEGAEEAVAQESDSDDMDLEATPQDPNSAAPVVFRSPGGVHWGYEETKTYLAILSETQFYEALRNCHRNSQLYGAVAERLWEYGFLRTPEQCRTKFKSLQTSYRKVKNGQAPETCPFFEEMDALVLKLDLRMKIIQNGIFLRKYNCIGHYLQDLKGKFPGIFIRVKAMRVTVDQEDSGQRPQGRKEEN>sp|Q8IWY8-4|ZSC29_HUMAN Isoform 4 of Zinc finger and SCAN domain-containing protein 29 OS=Homo sapiens OX=9606 GN=ZSCAN29MMAKSALRENGTNSETFRQRFRRFHYQEVAGPREAFSQLWELCCRWLRPEVRTKEQIVELLVLEQFLTVLPGEIQNWVQEQCPENGEEAVTLVEDLEREPGRPRSSVTVSVKGQEVRLEKMTPPKSSQELLSVRQESVEPQPRGVPKKERARSPDLGPQEQMNPKEKLKPFQRSGFEAGFENEDNSKRDISEEVQLHRTLLARSERKIPRYLHQGKGNESDCRSGRQWAKTSGEKRGKLTLPEKSLSEVLSQQRPCLGERPYKYLKYSKSFGPNSLLMHQVSHQVENPYKCADCGKSFSRSARLIRHRRIHTGEKPYKCLDCGKSFRDSSNFITHRRIHTGEKPYQCGECGKCFNQSSSLIIHQRTHTGEKPYQCEECGKSFNNSSHFSAHRRIHTGERPHVCPDCGKSFSKSSDLRAHHRTHTGEKPYGCHDCGKCFSKSSALNKHGEIHAREKLLTQSAPK>sp|Q9Y6M5|ZNT1_HUMAN Zinc transporter 1 OS=Homo sapiens OX=9606GN=SLC30A1 PE=1 SV=3MGCWGRNRGRLLCMLALTFMFMVLEVVVSRVTSSLAMLSDSFHMLSDVLALVVALVAERFARRTHATQKNTFGWIRAEVMGALVNAIFLTGLCFAILLEAIERFIEPHEMQQPLVVLGVGVAGLLVNVLGLCLFHHHSGFSQDSGHGHSHGGHGHGHGLPKGPRVKSTRPGSSDINVAPGEQGPDQEETNTLVANTSNSNGLKLDPADPENPRSGDTVEVQVNGNLVREPDHMELEEDRAGQLNMRGVFLHVLGDALGSVIVVVNALVFYFSWKGCSEGDFCVNPCFPDPCKAFVEIINSTHASVYEAGPCWVLYLDPTLCVVMVCILLYTTYPLLKESALILLQTVPKQIDIRNLIKELRNVEGVEEVHELHVWQLAGSRIIATAHIKCEDPTSYMEVAKTIKDVFHNHGIHATTIQPEFASVGSKSSVVPCELACRTQCALKQCCGTLPQAPSGKDAEKTPAVSISCLELSNNLEKKPRRTKAENIPAVVIEIKNMPNKQPESSL>sp|Q86XI8|ZSWM9_HUMAN Uncharacterized protein ZSWIM9 OS=Homo sapiensOX=9606 GN=ZSWIM9 PE=1 SV=2MERPEPPPGTAAGQEEQELRERAFFSWAEFSRFFDAWCQQRLALFFVKSSMHLARCRWASAPPLYTLIDVLKYSYVRLVCKDVRAPSRPAVGPPQPGCPAFIIVKLSPLRDRLVVTECQLTHSHPACPLEFAYYFRPGHLLANACLPVRTTNKISKQFVAPADVRRLLSYCKGRDHGVLDALHVLEGLFRTDPEAKVKLVFVEDQAVVETVFFLTSRTRALLRRFPRMLLVDRLPGLQGALDLLAVLCVDGSGRARQAACCVARPGTPSLLRFALASLLQSAPDVKGRVRCLTAGPEVAAQLPAVRQLLPCARVQICRAQGLETLFSKAQELGGAGREDPGLWSRLCRLAGASSPAAYDEALAELHAHGPAAFVDYFERNWEPRRDMWVRFRAFEAARDLDACALVRGHRRRLLRRLSPSRGVAQCLRDLVAMQWADAAGEAVPEGPDGGGPWLEDEPGRGAQGENERVRGLETGDWGGAPKEGSIWRGAQMEKEWARALETRDWGGAQFEGEKGRALQIRDWRGGRLENQKPRGLEGGVLRGSKLEKGHLRGPEIRDWRGPQLEGEKDWGLEGYVWRGSQLEDQALRGLEGYTWRVAQLEDRRSTTDLRGTQFDYERGKGESTEDR>sp|Q86XI8-2|ZSWM9_HUMAN Isoform 2 of Uncharacterized protein ZSWIM9OS=Homo sapiens OX=9606 GN=ZSWIM9MERPEPPPGTAAGQEEQELRERAFFSWAEFSRFFDAWCQQRLALFFVKSSMHLARCRWASAPPLYTLIDVLKYSYVRLVCKDVRAPSRPAVGPPQPGCPAFIIVKLSPLRDRLVVTECQLTHSHPACPLEFAYYFRPGHLLANACLPVRTTNKISKQFVAPADVRRLLSYCKGRDHGVLDALHVLEGLFRTDPEAKVKLVFVEDQAVVETVFFLTSRTRALLRRFPRMLLVDRLPGLQGALDLLAVLCVDGSGRARQAACCVARPGTPSLLRFALASLLQSAPDVKGRVRCLTAGPEVAAQLPAVRQLLPCARVQICRAQGLETLFSKAQELGGAGREDPGLWSRLCRLAGASSPAAYDEALAELHAHGPAAFVDYFERNWEPRRDMWVRFRAFEAARDLDACALVRGHRRRLLRRLSPSRGVAQCLRDLVAMQWADAAGEAVPEGPDGGGPWLEDEPGRGAQGENERVRGLETGDWGGAPKEGSIWRGAQMEKEWARALETRDWGGAQFEGEKGRALQIRDWRGGRLENQKPRGLEGGVLRGSKLEKGHLRGPEIRDWRGPQLEGEKDWGLEGYVWRGSQLEDQALRGLEGYTWRVAQLEDRRSTTDLRGTQFDYERVRSLEGSPWRGAQLHDERAGGLRTAEWKGPQSEVEKGRGLEVRNLRGIPLEKSLELAPENGDQRGPQWEDERRRGPEIAEERGARVGVKRRRGLEDIVLVQLGDTRVTGMENGDGGGARSVGPKSRAGRGMEWGDAGGRCLGLGNGVVSGTPVGTVLEGSPEWAAARSEHLAAGDGLQEGGEDGPREPKRLCRPPGEEEVDWEPLAKFRAACGPELADLVAEELAFARQHGTRGFHWTGAGFALKDGTSDFFLDGALTRCSCSIHAARRLPCRHLFAARLLTGAALFHMDLLRDCWGRAPEP>sp|Q9UGI0|ZRAN1_HUMAN Ubiquitin thioesterase ZRANB1 OS=Homo sapiensOX=9606 GN=ZRANB1 PE=1 SV=2MSERGIKWACEYCTYENWPSAIKCTMCRAQRPSGTIITEDPFKSGSSDVGRDWDPSSTEGGSSPLICPDSSARPRVKSSYSMENANKWSCHMCTYLNWPRAIRCTQCLSQRRTRSPTESPQSSGSGSRPVAFSVDPCEEYNDRNKLNTRTQHWTCSVCTYENWAKAKRCVVCDHPRPNNIEAIELAETEEASSIINEQDRARWRGSCSSGNSQRRSPPATKRDSEVKMDFQRIELAGAVGSKEELEVDFKKLKQIKNRMKKTDWLFLNACVGVVEGDLAAIEAYKSSGGDIARQLTADEVRLLNRPSAFDVGYTLVHLAIRFQRQDMLAILLTEVSQQAAKCIPAMVCPELTEQIRREIAASLHQRKGDFACYFLTDLVTFTLPADIEDLPPTVQEKLFDEVLDRDVQKELEEESPIINWSLELATRLDSRLYALWNRTAGDCLLDSVLQATWGIYDKDSVLRKALHDSLHDCSHWFYTRWKDWESWYSQSFGLHFSLREEQWQEDWAFILSLASQPGASLEQTHIFVLAHILRRPIIVYGVKYYKSFRGETLGYTRFQGVYLPLLWEQSFCWKSPIALGYTRGHFSALVAMENDGYGNRGAGANLNTDDDVTITFLPLVDSERKLLHVHFLSAQELGNEEQQEKLLREWLDCCVTEGGVLVAMQKSSRRRNHPLVTQMVEKWLDRYRQIRPCTSLSDGEEDEDDEDE>sp|Q9BR11|ZSWM1_HUMAN Zinc finger SWIM domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZSWIM1 PE=2 SV=2MLERLKAPWSAALQRKYFDLGIWTAPISPMALTMLNGLLIKDSSPPMLLHQVNKTAQLDTFNYQSCFMQSVFDHFPEILFIHRTYNPRGKVLYTFLVDGPRVQLEGHLARAVYFAIPAKEDTEGLAQMFQVFKKFNPAWERVCTILVDPHFLPLPILAMEFPTAEVLLSAFHICKFLQAKFYQLSLERPVERLLLTSLQSTMCSATAGNLRKLYTLLSNCIPPAKLPELHSHWLLNDRIWLAHRWRSRAESSHYFQSLEVTTHILSQFFGTTPSEKQGMASLFRYMQQNSADKANFNQGLCAQNNHAPSDTIPESPKLEQLVESHIQHSLNAICTGPAAQLCLGELAVVQKSTHLIGSGSEKMNIQILEDTHKVQPQPPASCSCYFNQAFHLPCRHILAMLSARRQVLQPDMLPAQWTAGCATSLDSILGSKWSETLDKHLAVTHLTEEVGQLLQHCTKEEFERRYSTLRELADSWIGPYEQVQL>sp|A6NJL1|ZSA5B_HUMAN Zinc finger and SCAN domain-containing protein 5BOS=Homo sapiens OX=9606 GN=ZSCAN5B PE=1 SV=1MAANWTLSWGQGGPCNSPGSDTPRSVASPETQLGNHDRNPETWHMNFRMFSCPEESDPIQALRKLTELCHLWLRPDLHTKEQILDMLVMEQFMISMPQELQVLVKVNGVQSCKDLEDLLRNNRRPKKWSIVNLLGKEYLMLNSDVEMAEAPASVRDDPRDVSSQWASSVNQMHPGTGQARREQQILPRVAALSRRQGEDFLLHKSIDVTGDPNSPRPKQTLEKDLKENREENPGLSSPEPQLPKSPNLVRAKEGKEPQKRASVENVDADTPSACVVEREALTHSGNRGDALNLSSPKRSKPDASSISQEEPQGEATPVGNRESPGQAEINPVHSPGPAGPVSHPDGQEAKALPPFACDVCNKSFKYFSQLSIHRRSHTGDRPFQCDLCRKRFLQPSDLRVHQRVHTGERPYMCDVCQKRFAHESTLQGHKRIHTGERPFKCKYCSKVFSHKGNLNVHQRTHSGEKPYKCPTCQKAFRQLGTFKRHLKTHRETTSQ>sp|Q9HCJ5|ZSWM6_HUMAN Zinc finger SWIM domain-containing protein 6OS=Homo sapiens OX=9606 GN=ZSWIM6 PE=1 SV=2MAERGQQPPPAKRLCCRPGGGGGGGGSSGGGGGAGGGYSSACRPGPRAGGAAAAAACGGGAALGLLPPGKTQSPESLLDIAARRVAEKWPFQRVEERFERIPEPVQRRIVYWSFPRSEREICMYSSFNTGGGAAGGPGDDSGGGGGAGGGGGGGSSSSPAATSAAATSAAAAAAAAAAAAAAAAGAGAPSVGAAGAADGGDETRLPFRRGIALLESGCVDNVLQVGFHLSGTVTEPAIQSEPETVCNVAISFDRCKITSVTCSCGNKDIFYCAHVVALSLYRIRKPDQVKLHLPISETLFQMNRDQLQKFVQYLITVHHTEVLPTAQKLADEILSQNSEINQVHGAPDPTAGASIDDENCWHLDEEQVQEQVKLFLSQGGYHGSGKQLNLLFAKVREMLKMRDSNGARMLTLITEQFMADPRLSLWRQQGTAMTDKYRQLWDELGALWMCIVLNPHCKLEQKASWLKQLKKWNSVDVCPWEDGNHGSELPNLTNALPQGANANQDSSNRPHRTVFTRAIEACDLHWQDSHLQHIISSDLYTNYCYHDDTENSLFDSRGWPLWHEHVPTACARVDALRSHGYPREALRLAIAIVNTLRRQQQKQLEMFRTQKKELPHKNITSITNLEGWVGHPLDPVGTLFSSLMEACRIDDENLSGFSDFTENMGQCKSLEYQHLPAHKFLEEGESYLTLAVEVALIGLGQQRIMPDGLYTQEKVCRNEEQLISKLQEIELDDTLVKIFRKQAVFLLEAGPYSGLGEIIHRESVPMHTFAKYLFTSLLPHDAELAYKIALRAMRLLVLESTAPSGDLTRPHHIASVVPNRYPRWFTLSHIESQQCELASTMLTAAKGDVRRLETVLESIQKNIHSSSHIFKLAQDAFKIATLMDSLPDITLLKVSLELGLQVMRMTLSTLNWRRREMVRWLVTCATEVGVYALDSIMQTWFTLFTPTEATSIVATTVMSNSTIVRLHLDCHQQEKLASSARTLALQCAMKDPQNCALSALTLCEKDHIAFETAYQIVLDAATTGMSYTQLFTIARYMEHRGYPMRAYKLATLAMTHLNLSYNQDTHPAINDVLWACALSHSLGKNELAAIIPLVVKSVKCATVLSDILRRCTLTTPGMVGLHGRRNSGKLMSLDKAPLRQLLDATIGAYINTTHSRLTHISPRHYSEFIEFLSKARETFLMAHDGHIQFTQFIDNLKQIYKGKKKLMMLVRERFG>sp|Q19AV6|ZSWM7_HUMAN Zinc finger SWIM domain-containing protein 7OS=Homo sapiens OX=9606 GN=ZSWIM7 PE=1 SV=1MAVVLPAVVEELLSEMAAAVQESARIPDEYLLSLKFLFGSSATQALDLVDRQSITLISSPSGRRVYQVLGSSSKTYTCLASCHYCSCPAFAFSVLRKSDSILCKHLLAVYLSQVMRTCQQLSVSDKQLTDILLMEKKQEA>sp|Q6V9R5|ZN562_HUMAN Zinc finger protein 562 OS=Homo sapiens OX=9606GN=ZNF562 PE=2 SV=2MSAFDMSHGFFPREPICPFEEKTKIGTMVEDHRSNSYQDSVTFDDVAVEFTPEEWALLDTTQKYLYRDVMLENYMNLASVDFFFCLTSEWEIQPRTKRSSLQQGFLKNQIFTGIQMQTRSYSGWKLCENCGEVFSEQFCLKTHMRAQNGGNTFEGNCYGKDSISVHKEASIGQELSKFNPCGKVFTLTPGLAVHLEILNGRQPYKCKECGKGFKYFASLDNHMGIHIGEKLCEFQECERAITTSSHLKQCVAVHTGKKSEKTKNCGKSFTNFSQLSAHAKTHKGEKSFECKECGRSFRNSSSFNVHIQIHTGIKPHKCTECGKAFTRSTHLTQHVRTHTGIKPYECKECGQAFTQYTGLAIHIRNHTGEKPYQCKECGKAFNRSSTLTQHRRIHTGEKPYECVECGKTFITSSHRSKHLKTHSGER>sp|Q6V9R5-2|ZN562_HUMAN Isoform 2 of Zinc finger protein 562 OS=Homosapiens OX=9606 GN=ZNF562MSAFDMSHDFFFCLTSEWEIQPRTKRSSLQQGFLKNQIFTGIQMQTRSYSGWKLCENCGEVFSEQFCLKTHMRAQNGGNTFEGNCYGKDSISVHKEASIGQELSKFNPCGKVFTLTPGLAVHLEILNGRQPYKCKECGKGFKYFASLDNHMGIHIGEKLCEFQECERAITTSSHLKQCVAVHTGKKSEKTKNCGKSFTNFSQLSAHAKTHKGEKSFECKECGRSFRNSSSFNVHIQIHTGIKPHKCTECGKAFTRSTHLTQHVRTHTGIKPYECKECGQAFTQYTGLAIHIRNHTGEKPYQCKECGKAFNRSSTLTQHRRIHTGEKPYECVECGKTFITSSHRSKHLKTHSGER>sp|Q8N3U1|YS014_HUMAN Putative uncharacterized protein LOC400692 OS=Homosapiens OX=9606 PE=2 SV=2MPDASLGSLGITWCFLESPLEVSSGRFGLARLLGSQDHGDDPAERGRTATDAWGPSRWGQSPGNGGGYCDASPPSALAPGDRAWALPASPSSGAPASQHCCLEKAGTRTKASPVWGRDGNTWN>sp|Q16587|ZNF74_HUMAN Zinc finger protein 74 OS=Homo sapiens OX=9606GN=ZNF74 PE=1 SV=3MEIPAPEPEKTALSSQDPALSLKENLEDISGWGLPEARSKESVSFKDVAVDFTQEEWGQLDSPQRALYRDVMLENYQNLLALGPPLHKPDVISHLERGEEPWSMQREVPRGPCPEWELKAVPSQQQGICKEEPAQEPIMERPLGGAQAWGRQAGALQRSQAAPWAPAPAMVWDVPVEEFPLRCPLFAQQRVPEGGPLLDTRKNVQATEGRTKAPARLCAGENASTPSEPEKFPQVRRQRGAGAGEGEFVCGECGKAFRQSSSLTLHRRWHSREKAYKCDECGKAFTWSTNLLEHRRIHTGEKPFFCGECGKAFSCHSSLNVHQRIHTGERPYKCSACEKAFSCSSLLSMHLRVHTGEKPYRCGECGKAFNQRTHLTRHHRIHTGEKPYQCGSCGKAFTCHSSLTVHEKIHSGDKPFKCSDCEKAFNSRSRLTLHQRTHTGEKPFKCADCGKGFSCHAYLLVHRRIHSGEKPFKCNECGKAFSSHAYLIVHRRIHTGEKPFDCSQCWKAFSCHSSLIVHQRIHTGEKPYKCSECGRAFSQNHCLIKHQKIHSGEKSFKCEKCGEMFNWSSHLTEHQRLHSEGKPLAIQFNKHLLSTYYVPGSLLGAGDAGLRDVDPIDALDVAKLLCVVPPRAGRNFSLGSKPRN>sp|Q16587-2|ZNF74_HUMAN Isoform 1 of Zinc finger protein 74 OS=Homosapiens OX=9606 GN=ZNF74MLENYQNLLALGPPLHKPDVISHLERGEEPWSMQREVPRGPCPEWELKAVPSQQQGICKEEPAQEPIMERPLGGAQAWGRQAGALQRSQAAPWAPAPAMVWDVPVEEFPLRCPLFAQQRVPEGGPLLDTRKNVQATEGRTKAPARLCAGENASTPSEPEKFPQVRRQRGAGAGEGEFVCGECGKAFRQSSSLTLHRRWHSREKAYKCDECGKAFTWSTNLLEHRRIHTGEKPFFCGECGKAFSCHSSLNVHQRIHTGERPYKCSACEKAFSCSSLLSMHLRVHTGEKPYRCGECGKAFNQRTHLTRHHRIHTGEKPYQCGSCGKAFTCHSSLTVHEKIHSGDKPFKCSDCEKAFNSRSRLTLHQRTHTGEKPFKCADCGKGFSCHAYLLVHRRIHSGEKPFKCNECGKAFSSHAYLIVHRRIHTGEKPFDCSQCWKAFSCHSSLIVHQRIHTGEKPYKCSECGRAFSQNHCLIKHQKIHSGEKSFKCEKCGEMFNWSSHLTEHQRLHSEGKPLAIQFNKHLLSTYYVPGSLLGAGDAGLRDVDPIDALDVAKLLCVVPPRAGRNFSLGSKPRN>sp|Q16587-3|ZNF74_HUMAN Isoform 3 of Zinc finger protein 74 OS=Homosapiens OX=9606 GN=ZNF74MEIPAPEPEKTALSSQDPALSLKENLEDISGWGLPEARSKESVSFKDVAVDFTQEEWGQLDSPQRALYRDVMLENYQNLLALEWELKAVPSQQQGICKEEPAQEPIMERPLGGAQAWGRQAGALQRSQAAPWAPAPAMVWDVPVEEFPLRCPLFAQQRVPEGGPLLDTRKNVQATEGRTKAPARLCAGENASTPSEPEKFPQVRRQRGAGAGEGEFVCGECGKAFRQSSSLTLHRRWHSREKAYKCDECGKAFTWSTNLLEHRRIHTGEKPFFCGECGKAFSCHSSLNVHQRIHTGERPYKCSACEKAFSCSSLLSMHLRVHTGEKPYRCGECGKAFNQRTHLTRHHRIHTGEKPYQCGSCGKAFTCHSSLTVHEKIHSGDKPFKCSDCEKAFNSRSRLTLHQRTHTGEKPFKCADCGKGFSCHAYLLVHRRIHSGEKPFKCNECGKAFSSHAYLIVHRRIHTGEKPFDCSQCWKAFSCHSSLIVHQRIHTGEKPYKCSECGRAFSQNHCLIKHQKIHSGEKSFKCEKCGEMFNWSSHLTEHQRLHSEGKPLAIQFNKHLLSTYYVPGSLLGAGDAGLRDVDPIDALDVAKLLCVVPPRAGRNFSLGSKPRN>sp|Q16587-4|ZNF74_HUMAN Isoform 4 of Zinc finger protein 74 OS=Homosapiens OX=9606 GN=ZNF74MPSPPFSPRAGPPLHKPDVISHLERGEEPWSMQREVPRGPCPEWELKAVPSQQQGICKEEPAQEPIMERPLGGAQAWGRQAGALQRSQAAPWAPAPAMVWDVPVEEFPLRCPLFAQQRVPEGGPLLDTRKNVQATEGRTKAPARLCAGENASTPSEPEKFPQVRRQRGAGAGEGEFVCGECGKAFRQSSSLTLHRRWHSREKAYKCDECGKAFTWSTNLLEHRRIHTGEKPFFCGECGKAFSCHSSLNVHQRIHTGERPYKCSACEKAFSCSSLLSMHLRVHTGEKPYRCGECGKAFNQRTHLTRHHRIHTGEKPYQCGSCGKAFTCHSSLTVHEKIHSGDKPFKCSDCEKAFNSRSRLTLHQRTHTGEKPFKCADCGKGFSCHAYLLVHRRIHSGEKPFKCNECGKAFSSHAYLIVHRRIHTGEKPFDCSQCWKAFSCHSSLIVHQRIHTGEKPYKCSECGRAFSQNHCLIKHQKIHSGEKSFKCEKCGEMFNWSSHLTEHQRLHSEGKPLAIQFNKHLLSTYYVPGSLLGAGDAGLRDVDPIDALDVAKLLCVVPPRAGRNFSLGSKPRN>sp|Q16587-5|ZNF74_HUMAN Isoform 5 of Zinc finger protein 74 OS=Homosapiens OX=9606 GN=ZNF74MEIPAPEPEKTGIGEFQGCGCGLHPGGVGSTRLPSEGLVPGCDVGELPEPSCPRTSTAQARCDLSSGTRRGAMEHAEGSPQRALSRMGAEGGALSTAGHLQRRTGPGAHHGAAPRRGAGVGAPGRCSAEESGCALGARTCHGLGRPCRGIPPQVSPLRPATRSRGGTLAGHTQERPGH>sp|Q15937|ZNF79_HUMAN Zinc finger protein 79 OS=Homo sapiens OX=9606GN=ZNF79 PE=1 SV=2MLEEGVLPSPGPALPQEENTGEEGMAAGLLTAGPRGSTFFSSVTVAFAQERWRCLVSTPRDRFKEGIPGKSRSLVLLGLPVSQPGMNSQLEQREGAWMLEGEDLRSPSPGWKIISGSPPEQALSEASFQDPCVEMPPGDSDHGTSDLEKSFNLRPVLSPQQRVPVEARPRKCETHTESFKNSEILKPHRAKPYACNECGKAFSYCSSLSQHQKSHTGEKPYECSECGKAFSQSSSLIQHQRIHTGEKPYKCSECGRAFSQNANLTKHQRTHTGEKPYRCSECEKAFSDCSALVQHQRIHTGEKPYECSDCGKAFRHSANLTNHQRTHTGEKPYKCSECGKAFSYCAAFIQHQRIHTGEKPYRCAACGKAFSQSANLTNHQRTHTGEKPYKCSECGKAFSQSTNLIIHQKTHTGEKPYKCNECGKFFSESSALIRHHIIHTGEKPYECNECGKAFNQSSSLSQHQRIHTGVKPYECSECGKAFRCSSAFVRHQRLHAGE>sp|Q86YE8|ZN573_HUMAN Zinc finger protein 573 OS=Homo sapiens OX=9606GN=ZNF573 PE=2 SV=4MFPVLEPHQVGLIRSYNSKTMTCFQELVTFRDVAIDFSRQEWEYLDPNQRDLYRDVMLENYRNLVSLGGHSISKPVVVDLLERGKEPWMILREETQFTDLDLQCEIISYIEVPTYETDISSTQLQSIYKREKLYECKKCQKKFSSGYQLILHHRFHVIERPYECKECGKNFRSGYQLTLHQRFHTGEKPYECTECGKNFRSGYQLTVHQRFHTGEKTYECRQCGKAFIYASHIVQHERIHTGGKPYECQECGRAFSQGGHLRIHQRVHTGEKPYKCKECGKTFSRRSNLVEHGQFHTDEKPYICEKCGKAFRRGHQLTVHQRVHTGKKPYECKECGKGYTTASYFLLHQRIHKGGKPYECKECKKTFTLYRNLTRHQNIHTGEKLFECKQCGKTYTTGSKLFQHQKTHTGEKPYECKECGKAFSLYGYLKQHQKIHTGMKHFECKECKKTFTLYRNLTRHQNIHTGKKLFECQECGKAYSTGSNLIQHRKTHTGEKPYKCKECGKTFSLHGYLNQHQKIHTGMKPYECKVCRKTFTFYRNLTLHQSIHTDEKPFECKECGKTFRRSSHLTAHQSIHADKKPYECKECGKAFKMYGYLTQHQKIHTGGKPYECKECGKAFSRASNLVQHERIHTGEKPYVCKQCGKTFRYGSALKAHQRIHRSIKV>sp|Q86YE8-2|ZN573_HUMAN Isoform 2 of Zinc finger protein 573 OS=Homosapiens OX=9606 GN=ZNF573MILREETQFTDLDLQCEIISYIEVPTYETDISSTQLQSIYKREKLYECKKCQKKFSSGYQLILHHRFHVIERPYECKECGKNFRSGYQLTLHQRFHTGEKPYECTECGKNFRSGYQLTVHQRFHTGEKTYECRQCGKAFIYASHIVQHERIHTGGKPYECQECGRAFSQGGHLRIHQRVHTGEKPYKCKECGKTFSRRSNLVEHGQFHTDEKPYICEKCGKAFRRGHQLTVHQRVHTGKKPYECKECGKGYTTASYFLLHQRIHKGGKPYECKECKKTFTLYRNLTRHQNIHTGEKLFECKQCGKTYTTGSKLFQHQKTHTGEKPYECKECGKAFSLYGYLKQHQKIHTGMKHFECKECKKTFTLYRNLTRHQNIHTGKKLFECQECGKAYSTGSNLIQHRKTHTGEKPYKCKECGKTFSLHGYLNQHQKIHTGMKPYECKVCRKTFTFYRNLTLHQSIHTDEKPFECKECGKTFRRSSHLTAHQSIHADKKPYECKECGKAFKMYGYLTQHQKIHTGGKPYECKECGKAFSRASNLVQHERIHTGEKPYVCKQCGKTFRYGSALKAHQRIHRSIKV>sp|Q86YE8-3|ZN573_HUMAN Isoform 3 of Zinc finger protein 573 OS=Homosapiens OX=9606 GN=ZNF573MESCSVAQAGVQWPDLSSLQPPPPRFKQFSCHSLQVAGITDLDLQCEIISYIEVPTYETDISSTQLQSIYKREKLYECKKCQKKFSSGYQLILHHRFHVIERPYECKECGKNFRSGYQLTLHQRFHTGEKPYECTECGKNFRSGYQLTVHQRFHTGEKTYECRQCGKAFIYASHIVQHERIHTGGKPYECQECGRAFSQGGHLRIHQRVHTGEKPYKCKECGKTFSRRSNLVEHGQFHTDEKPYICEKCGKAFRRGHQLTVHQRVHTGKKPYECKECGKGYTTASYFLLHQRIHKGGKPYECKECKKTFTLYRNLTRHQNIHTGEKLFECKQCGKTYTTGSKLFQHQKTHTGEKPYECKECGKAFSLYGYLKQHQKIHTGMKHFECKECKKTFTLYRNLTRHQNIHTGKKLFECQECGKAYSTGSNLIQHRKTHTGEKPYKCKECGKTFSLHGYLNQHQKIHTGMKPYECKVCRKTFTFYRNLTLHQSIHTDEKPFECKECGKTFRRSSHLTAHQSIHADKKPYECKECGKAFKMYGYLTQHQKIHTGGKPYECKECGKAFSRASNLVQHERIHTGEKPYVCKQCGKTFRYGSALKAHQRIHRSIKV>sp|Q86YE8-4|ZN573_HUMAN Isoform 4 of Zinc finger protein 573 OS=Homosapiens OX=9606 GN=ZNF573MLENYRNLVSLDLDLQCEIISYIEVPTYETDISSTQLQSIYKREKLYECKKCQKKFSSGYQLILHHRFHVIERPYECKECGKNFRSGYQLTLHQRFHTGEKPYECTECGKNFRSGYQLTVHQRFHTGEKTYECRQCGKAFIYASHIVQHERIHTGGKPYECQECGRAFSQGGHLRIHQRVHTGEKPYKCKECGKTFSRRSNLVEHGQFHTDEKPYICEKCGKAFRRGHQLTVHQRVHTGKKPYECKECGKGYTTASYFLLHQRIHKGGKPYECKECKKTFTLYRNLTRHQNIHTGEKLFECKQCGKTYTTGSKLFQHQKTHTGEKPYECKECGKAFSLYGYLKQHQKIHTGMKHFECKECKKTFTLYRNLTRHQNIHTGKKLFECQECGKAYSTGSNLIQHRKTHTGEKPYKCKECGKTFSLHGYLNQHQKIHTGMKPYECKVCRKTFTFYRNLTLHQSIHTDEKPFECKECGKTFRRSSHLTAHQSIHADKKPYECKECGKAFKMYGYLTQHQKIHTGGKPYECKECGKAFSRASNLVQHERIHTGEKPYVCKQCGKTFRYGSALKAHQRIHRSIKV>sp|Q8N1G0|ZN687_HUMAN Zinc finger protein 687 OS=Homo sapiens OX=9606GN=ZNF687 PE=1 SV=1MGDMKTPDFDDLLAAFDIPDIDANEAIHSGPEENEGPGGPGKPEPGVGSESEDTAAASAGDGPGVPAQASDHGLPPPDISVVSVIVKNTVCPEQSEALAGGSAGDGAQAAGVTKEGPVGPHRMQNGFGSPEPSLPGTPHSPAPPSGGTWKEKGMEGKTPLDLFAHFGPEPGDHSDPLPPSAPSPTREGALTPPPFPSSFELAQENGPGMQPPVSSPPLGALKQESCSPHHPQVLAQQGSGSSPKATDIPASASPPPVAGVPFFKQSPGHQSPLASPKVPVCQPLKEEDDDEGPVDKSSPGSPQSPSSGAEAADEDSNDSPASSSSRPLKVRIKTIKTSCGNITRTVTQVPSDPDPPAPLAEGAFLAEASLLKLSPATPTSEGPKVVSVQLGDGTRLKGTVLPVATIQNASTAMLMAASVARKAVVLPGGTATSPKMIAKNVLGLVPQALPKADGRAGLGTGGQKVNGASVVMVQPSKTATGPSTGGGTVISRTQSSLVEAFNKILNSKNLLPAYRPNLSPPAEAGLALPPTGYRCLECGDAFSLEKSLARHYDRRSMRIEVTCNHCARRLVFFNKCSLLLHAREHKDKGLVMQCSHLVMRPVALDQMVGQPDITPLLPVAVPPVSGPLALPALGKGEGAITSSAITTVAAEAPVLPLSTEPPAAPATSAYTCFRCLECKEQCRDKAGMAAHFQQLGPPAPGATSNVCPTCPMMLPNRCSFSAHQRMHKNRPPHVCPECGGNFLQANFQTHLREACLHVSRRVGYRCPSCSVVFGGVNSIKSHIQTSHCEVFHKCPICPMAFKSGPSAHAHLYSQHPSFQTQQAKLIYKCAMCDTVFTHKPLLSSHFDQHLLPQRVSVFKCPSCPLLFAQKRTMLEHLKNTHQSGRLEETAGKGAGGALLTPKTEPEELAVSQGGAAPATEESSSSSEEEEVPSSPEPPRPAKRPRRELGSKGLKGGGGGPGGWTCGLCHSWFPERDEYVAHMKKEHGKSVKKFPCRLCERSFCSAPSLRRHVRVNHEGIKRVYPCRYCTEGKRTFSSRLILEKHVQVRHGLQLGAQSPGRGTTLARGSSARAQGPGRKRRQSSDSCSEEPDSTTPPAKSPRGGPGSGGHGPLRYRSSSSTEQSLMMGLRVEDGAQQCLDCGLCFASPGSLSRHRFISHKKRRGVGKASALGLGDGEEEAPPSRSDPDGGDSPLPASGGPLTCKVCGKSCDSPLNLKTHFRTHGMAFIRARQGAVGDN>sp|Q8N1G0-2|ZN687_HUMAN Isoform 2 of Zinc finger protein 687 OS=Homosapiens OX=9606 GN=ZNF687MGDMKTPDFDDLLAAFDIPDIDANEAIHSGPEENEGPGGPGKPEPGVGSESEDTAAASAGDGPGVPAQASDHGLPPPDISVVSVIVKNTVCPEQSEALAGGSAGDGAQAAGVTKEGPVGPHRMQNGFGSPEPSLPGTPHSPAPPSGGTWKEKGMEGKTPLDLFAHFGPEPGDHSDPLPPSAPSPTREGALTPPPFPSSFELAQENGPGMQPPVSSPPLGALKQESCSPHHPQVLAQQGSGSSPKATDIPASASPPPVAGVPFFKQSPGHQSPLASPKVPVCQPLKEEDDDEGPVDKSSPGSPQSPSSGAEAADEDSNDSPASSSSRPLKVRIKTIKTSCGNITRTVTQVPSDPDPPAPLAEGAFLAEASLLKLSPATPTSEGPKVVSVQLGDGTRLKGTVLPVATIQNASTAMLMAASVARKAVVLPGGTATSPKMIAKNVLGLVPQALPKADGRAGLGTGGQKVNGASVVMVQPSKTATGPSTGGGTVISRTQSSLVEAFNKILNSKNLLPAYRPNLSPPAEAGLALPPTGYRCLECGDAFSLEKSLARHYDRRSMRIEVTCNHCARRLVFFNKCSLLLHAREHKDKGLVMQCSHLVMRPVALDQMVGQPDITPLLPVAVPPVSGPLALPALGKGEGAITSSAITTVAAEAPVLPLSTEPPAAPATSAYTCFRCLECKEQCRDKAGMAAHFQQLGPPAPGATSNVCPTCPMMLPNRCSFSAHQRMHKNRPPHVCPECGGNFLQANFQTHLREACLHVSRRVGYRCPSCSVVFGGVNSIKSHIQTSHCEVFHKCPICPMAFKSGPSAHAHLYSQHPSFQTQQAKLIYKCAMCDTVFTHKPLLSSHFDQHLLPQRVSVFKCPSCPLLFAQKRTMLEHLKNTHQSGRLEETAGKGAGGALLTPKTEPEELAVSQGGAAPATEESSSSSEEEEVPSSPEPPRPAKRPRRELGSKGLKGGGGGPGGWTCGLCHSWFPERDEYVAHMKKEHGKSVKKFPCRLCERSFCSAPSLRRHVRVNHEGIKRVYPCRSKGPGLRAVPLLPSCPLPFQVLHRGKTHLQQPPDPRETCPGPARLAAWGPVPWPGDHLGSGFQCQSPGARSETPPVF>sp|Q8NEK5|ZN548_HUMAN Zinc finger protein 548 OS=Homo sapiens OX=9606GN=ZNF548 PE=1 SV=2MNLTEGRVVFEDVAIYFSQEEWGHLDEAQRLLYRDVMLENLALLSSLGSWHGAEDEEAPSQQGFSVGVSEVTASKPCLSSQKVHPSETCGPPLKDILCLVEHNGIHPEQHIYICEAELFQHPKQQIGENLSRGDDWIPSFGKNHRVHMAEEIFTCMEGWKDLPATSCLLQHQGPQSEWKPYRDTEDREAFQTGQNDYKCSECGKTFTCSYSFVEHQKIHTGERSYECNKCGKFFKYSANFMKHQTVHTSERTYECRECGKSFMYNYRLMRHKRVHTGERPYECNTCGKFFRYSSTFVRHQRVHTGERPYECRECGKFFMDSSTLIKHQRVHTGERPYKCNDCGKFFRYISTLIRHQRIHTGERPYECSVCGELFRYNSSLVKHWRNHTGERPYKCSECGKSFRYHCRLIRHQRVHTGERPYECSECGKFFRYNSNLIKHWRNHTGERPYECRECGKAFSHKHILVEHQKIHSGERPYECSECQKAFIRKSHLVHHQKIHSEERLVCSMNVGNSLAKTPTSLNIRDFTMEKVYH>sp|Q8NEK5-2|ZN548_HUMAN Isoform 2 of Zinc finger protein 548 OS=Homosapiens OX=9606 GN=ZNF548MNLTEGPLAMAEMDPTQGRVVFEDVAIYFSQEEWGHLDEAQRLLYRDVMLENLALLSSLGSWHGAEDEEAPSQQGFSVGVSEVTASKPCLSSQKVHPSETCGPPLKDILCLVEHNGIHPEQHIYICEAELFQHPKQQIGENLSRGDDWIPSFGKNHRVHMAEEIFTCMEGWKDLPATSCLLQHQGPQSEWKPYRDTEDREAFQTGQNDYKCSECGKTFTCSYSFVEHQKIHTGERSYECNKCGKFFKYSANFMKHQTVHTSERTYECRECGKSFMYNYRLMRHKRVHTGERPYECNTCGKFFRYSSTFVRHQRVHTGERPYECRECGKFFMDSSTLIKHQRVHTGERPYKCNDCGKFFRYISTLIRHQRIHTGERPYECSVCGELFRYNSSLVKHWRNHTGERPYKCSECGKSFRYHCRLIRHQRVHTGERPYECSECGKFFRYNSNLIKHWRNHTGERPYECRECGKAFSHKHILVEHQKIHSGERPYECSECQKAFIRKSHLVHHQKIHSEERLVCSMNVGNSLAKTPTSLNIRDFTMEKVYH>sp|Q03924|ZN117_HUMAN Zinc finger protein 117 OS=Homo sapiens OX=9606GN=ZNF117 PE=2 SV=5MKRHEMVAKHLVMFYYFAQHLWPEQNIRDSFQKVTLRRYRKCGYENLQLRKGCKSVVECKQHKGDYSGLNQCLKTTLSKIFQCNKYVEVFHKISNSNRHKMRHTENKHFKCKECRKTFCMLSHLTQHKRIQTRVNFYKCEAYGRAFNWSSTLNKHKRIHTGEKPYKCKECGKAFNQTSHLIRHKRIHTEEKPYKCEECGKAFNQSSTLTTHNIIHTGEIPYKCEKCVRAFNQASKLTEHKLIHTGEKRYECEECGKAFNRSSKLTEHKYIHTGEKLYKCEECGKAFNQSSTLTTHKRIHSGEKPYKCEECGKAFKQFSNLTDHKKIHTGEKPYKCEECGKAFNQLSNLTRHKVIHTGEKPYKCGECGKAFNQSSALNTHKIIHTGENPHKCRESGKVFHLSSKLSTCKKIHTGEKLYKCEECGKAFNRSSTLIGHKRIHTGEKPYKCEECGKAFNQSSTLTTHKIIHTEEKQYKCDECGKAST>sp|Q9BY31|ZN717_HUMAN Zinc finger protein 717 OS=Homo sapiens OX=9606GN=ZNF717 PE=2 SV=3MFPVFSGCFQELQEKNKSLELVSFEEVAVHFTWEEWQDLDDAQRTLYRDVMLETYSSLVSLGHYITKPEMIFKLEQGAEPWIVEETPNLRLSAVQIIDDLIERSHESHDRFFWQIVITNSNTSTQERVELGKTFNLNSNHVLNLIINNGNSSGMKPGQFNDCQNMLFPIKPGETQSGEKPHVCDITRRSHRHHEHLTQHHKIQTLLQTFQCNEQGKTFNTEAMFFIHKRVHIVQTFGKYNEYEKACNNSAVIVQVITQVGQPTCCRKSDFTKHQQTHTGEKPYECVECEKPSISKSDLMLQCKMPTEEKPYACNWCEKLFSYKSSLIIHQRIHTGEKPYGCNECGKTFRRKSFLTLHERTHTGDKPYKCIECGKTFHCKSLLTLHHRTHSGEKPYQCSECGKTFSQKSYLTIHHRTHTGEKPYACDHCEEAFSHKSRLTVHQRTHTGEKPYECNECGKPFINKSNLRLHQRTHTGEKPYECNECGKTFHRKSFLTIHQWTHTGEKPYECNECGKTFRCKSFLTVHQRTHAGEKPYACNECGKTYSHKSYLTVHHRTHTGEKPYECNECGKSFHCKSFLTIHQRTHAGKKPYECNECEKTFINKLNLGIHKRTHTGERPYECNECGKTFRQKSNLSTHQGTHTGEKPYVCNECGKTFHRKSFLTIHQRTHTGKNRMDVMNVEKLFVRNHTLLYIRELTPGKSPMNVMNVENPFIRRQIFRSIKVFTRGRNPMNVANVEKPCQKSVLTVHHRTHTGEKPYECNECGKTFCHKSNLSTHQGTHSGEKPYECDECRKTFYDKTVLTIHQRTHTGEKPFECKECRKTFSQKSKLFVHHRTHTGEKPFRCNECRKTFSQKSGLSIHQRTHTGEKPYECKECGKTFCQKSHLSRHQQTHIGEKSDVAEAGYVFPQNHSFFP>sp|Q69YN4|VIR_HUMAN Protein virilizer homolog OS=Homo sapiens OX=9606GN=VIRMA PE=1 SV=2MAVDSAMELLFLDTFKHPSAEQSSHIDVVRFPCVVYINEVRVIPPGVRAHSSLPDNRAYGETSPHTFQLDLFFNNVSKPSAPVFDRLGSLEYDENTSIIFRPNSKVNTDGLVLRGWYNCLTLAIYGSVDRVISHDRDSPPPPPPPPPPPQPQPSLKRNPKHADGEKEDQFNGSPPRPQPRGPRTPPGPPPPDDDEDDPVPLPVSGDKEEDAPHREDYFEPISPDRNSVPQEGQYSDEGEVEEEQQEEGEEDEDDVDVEEEEDEDEDDRRTVDSIPEEEEEDEEEEGEEDEEGEGDDGYEQISSDEDGIADLERETFKYPNFDVEYTAEDLASVPPMTYDPYDRELVPLLYFSCPYKTTFEIEISRMKDQGPDKENSGAIEASVKLTELLDLYREDRGAKWVTALEEIPSLIIKGLSYLQLKNTKQDSLGQLVDWTMQALNLQVALRQPIALNVRQLKAGTKLVSSLAECGAQGVTGLLQAGVISGLFELLFADHVSSSLKLNAFKALDSVISMTEGMEAFLRGRQNEKSGYQKLLELILLDQTVRVVTAGSAILQKCHFYEVLSEIKRLGDHLAEKTSSLPNHSEPDHDTDAGLERTNPEYENEVEASMDMDLLESSNISEGEIERLINLLEEVFHLMETAPHTMIQQPVKSFPTMARITGPPERDDPYPVLFRYLHSHHFLELVTLLLSIPVTSAHPGVLQATKDVLKFLAQSQKGLLFFMSEYEATNLLIRALCHFYDQDEEEGLQSDGVIDDAFALWLQDSTQTLQCITELFSHFQRCTASEETDHSDLLGTLHNLYLITFNPVGRSAVGHVFSLEKNLQSLITLMEYYSKEALGDSKSKKSVAYNYACILILVVVQSSSDVQMLEQHAASLLKLCKADENNAKLQELGKWLEPLKNLRFEINCIPNLIEYVKQNIDNLMTPEGVGLTTALRVLCNVACPPPPVEGQQKDLKWNLAVIQLFSAEGMDTFIRVLQKLNSILTQPWRLHVNMGTTLHRVTTISMARCTLTLLKTMLTELLRGGSFEFKDMRVPSALVTLHMLLCSIPLSGRLDSDEQKIQNDIIDILLTFTQGVNEKLTISEETLANNTWSLMLKEVLSSILKVPEGFFSGLILLSELLPLPLPMQTTQVIEPHDISVALNTRKLWSMHLHVQAKLLQEIVRSFSGTTCQPIQHMLRRICVQLCDLASPTALLIMRTVLDLIVEDLQSTSEDKEKQYTSQTTRLLALLDALASHKACKLAILHLINGTIKGDERYAEIFQDLLALVRSPGDSVIRQQCVEYVTSILQSLCDQDIALILPSSSEGSISELEQLSNSLPNKELMTSICDCLLATLANSESSYNCLLTCVRTMMFLAEHDYGLFHLKSSLRKNSSALHSLLKRVVSTFSKDTGELASSFLEFMRQILNSDTIGCCGDDNGLMEVEGAHTSRTMSINAAELKQLLQSKEESPENLFLELEKLVLEHSKDDDNLDSLLDSVVGLKQMLESSGDPLPLSDQDVEPVLSAPESLQNLFNNRTAYVLADVMDDQLKSMWFTPFQAEEIDTDLDLVKVDLIELSEKCCSDFDLHSELERSFLSEPSSPGRTKTTKGFKLGKHKHETFITSSGKSEYIEPAKRAHVVPPPRGRGRGGFGQGIRPHDIFRQRKQNTSRPPSMHVDDFVAAESKEVVPQDGIPPPKRPLKVSQKISSRGGFSGNRGGRGAFHSQNRFFTPPASKGNYSRREGTRGSSWSAQNTPRGNYNESRGGQSNFNRGPLPPLRPLSSTGYRPSPRDRASRGRGGLGPSWASANSGSGGSRGKFVSGGSGRGRHVRSFTR>sp|Q69YN4-2|VIR_HUMAN Isoform 2 of Protein virilizer homolog OS=Homosapiens OX=9606 GN=VIRMAMAVDSAMELLFLDTFKHPSAEQSSHIDVVRFPCVVYINEVRVIPPGVRAHSSLPDNRAYGETSPHTFQLDLFFNNVSKPSAPVFDRLGSLEYDENTSIIFRPNSKVNTDGLVLRGWYNCLTLAIYGSVDRVISHDRDSPPPPPPPPPPPQPQPSLKRNPKHADGEKEDQFNGSPPRPQPRGPRTPPGPPPPDDDEDDPVPLPVSGDKEEDAPHREDYFEPISPDRNSVPQEGQYSDEGEVEEEQQEEGEEDEDDVDVEEEEDEDEDDRRTVDSIPEEEEEDEEEEGEEDEEGEGDDGYEQISSDEDGIADLERETFKYPNFDVEYTAEDLASVPPMTYDPYDRELVPLLYFSCPYKTTFEIEISRMKDQGPDKENSGAIEASVKLTELLDLYREDRGAKWVTALEEIPSLIIKGLSYLQLKNTKQDSLGQLVDWTMQALNLQVALRQPIALNVRQLKAGTKLVSSLAECGAQGVTGLLQAGVISGLFELLFADHVSSSLKLNAFKALDSVISMTEGMEAFLRGRQNEKSGYQKLLELILLDQTVRVVTAGSAILQKCHFYEVLSEIKRLGDHLAEKTSSLPNHSEPDHDTDAGLERTNPEYENEVEASMDMDLLESSNISEGEIERLINLLEEVFHLMETAPHTMIQQPVKSFPTMARITGPPERDDPYPVLFRYLHSHHFLELVTLLLSIPVTSAHPGVLQATKDVLKFLAQSQKGLLFFMSEYEATNLLIRALCHFYDQDEEEGLQSDGVIDDAFALWLQDSTQTLQCITELFSHFQRCTASEETDHSDLLGTLHNLYLITFNPVGRSAVGHVFSLEKNLQSLITLMEYYSKEALGDSKSKKSVAYNYACILILVVVQSSSDVQMLEQHAASLLKLCKADENNAKLQELGKWLEPLKNLRFEINCIPNLIEYVKQNIDNLMTPEGVGLTTALRVLCNVACPPPPVEGQQKDLKWNLAVIQLFSAEGMDTFIRVLQKLNSILTQPWRLHVNMGTTLHRVTTISMARCTLTLLKTMLTELLRGGSFEFKDMRVPSALVTLHMLLCSIPLSGRLDSDEQKIQNDIIDILLTFTQGVNEKLTISEETLANNTWSLMLKEVLSSILKVPEGFFSGLILLSELLPLPLPMQTTQVIEPHDISVALNTRKLWSMHLHVQAKLLQEIVRSFSGTTCQPIQHMLRRICVQLCDLASPTALLIMRTVLDLIVEDLQSTSEDKEKQYTSQTTRLLALLDALASHKACKLAILHLINGTIKGDERYAEIFQDLLALVRSPGDSVIRQQCVEYVTSILQSLCDQDIALILPSSSEGSISELEQLSNSLPNKELMTSICDCLLATLANSESSYNCLLTCVRTMMFLAEHDYGLFHLKRDAVEMIMVSWK>sp|Q69YN4-3|VIR_HUMAN Isoform 3 of Protein virilizer homolog OS=Homosapiens OX=9606 GN=VIRMAMAVDSAMELLFLDTFKHPSAEQSSHIDVVRFPCVVYINEVRVIPPGVRAHSSLPDNRAYGETSPHTFQLDLFFNNVSKPSAPVFDRLGSLEYDENTSIIFRPNSKVNTDGLVLRGWYNCLTLAIYGSVDRVISHDRDSPPPPPPPPPPPQPQPSLKRNPKHADGEKEDQFNGSPPRPQPRGPRTPPGPPPPDDDEDDPVPLPVSGDKEEDAPHREDYFEPISPDRNSVPQEGQYSDEGEVEEEQQEEGEEDEDDVDVEEEEDEDEDDRRTVDSIPEEEEEDEEEEGEEDEEGEGDDGYEQISSDEDGIADLERETFKYPNFDVEYTAEDLASVPPMTYDPYDRELVPLLYFSCPYKTTFEIEISRMKDQGPDKENSGAIEASVKLTELLDLYREDRGAKWVTALEEIPSLIIKGLSYLQLKNTKQDSLGQLVDWTMQALNLQVALRQPIALNVRQLKAGTKLVSSLAECGAQGVTGLLQAGVISGLFELLFADHVSSSLKLNAFKALDSVISMTEGMEAFLRGRQNEKSGYQKLLELILLDQTVRVVTAGSAILQKCHFYEVLSEIKRLGDHLAEKTSSLPNHSEPDHDTDAGLERTNPEYENEVEASMDMDLLESSNISEGEIERLINLLEEVFHLMETAPHTMIQQPVKSFPTMARITGPPERDDPYPVLFRYLHSHHFLELVTLLLSIPVTSAHPGVLQATKDVLKFLAQSQKGLLFFMSEYEATNLLIRALCHFYDQDEEEGLQSDGVIDDAFALWLQDSTQTLQCITELFSHFQRCTASEETDHSDLLGTLHNLYLITFNPVGRSAVGHVFSLEKNLQSLITLMEYYSKEALGDSKSKKSVAYNYACILILVVVQSSSDVQMLEQHAASLLKLCKADENNAKLQELGKWLEPLKNLRFEINCIPNLIEYVKQNIDNLMTPEGVGLTTALRVLCNVACPPPPVEGQQKDLKWNLAVIQLFSAEGMDTFIRVLQKLNSILTQPWRLHVNMGTTLHRVTTISMARCTLTLLKTMLTELLRGGSFEFKDMRVPSALVTLHMLLCSIPLSGRLDSDEQKIQNDIIDILLTFTQGVNEKLTISEETLANNTWSLMLKEVLSSILKVPEGFFSGLILLSELLPLPLPMQTTQVIEPHDISVALNTRKLWSMHLHVQAKLLQEIVRSFSGTTCQPIQHMLRRICVQLCDLASPTALLIMRTVLDLIVEDLQSTSEDKEKQYTSQTTRLLALLDALASHKACKLAILHLINGTIKGDERYAEIFQDLLALVRSPGDSVIRQQCVEYVTSILQSLCDQDIALILPSSSEGSISELEQLSNSLPNKELMTSICDCLLATLANSESSYNCLLTCVRTMMFLAEHDYGLFHLKSSLRKNSSALHSLLKRVVSTFSKDTGELASSFLEFMRQILNSDTIGCCGDDNGLMEVEGAHTSRTMSINAAELKQLLQSKEESPENLFLELEKLVLEHSKDDDNLDSLLDSVVGLKQMLESSGDPLPLSDQDVEPVLSAPESLQNLFNNRTAYVLADVMDDQLKSMWFTPFQAEEIDTDLDLVKVDLIELSEKCCSDFDLHSELERSFLSEPSSPGRTKTTKGFKLGKHKHETFITSSGKSEYIEPAKRAHVVPPPRGRGRGGFGQGIRPHDIFRQRKQNTSRPPSMHVDDFVAAESKEVVPQDGIPPPKRPLKVSQKEQEAPVGVLRILLEEITMKVVEARAILTEALFHHYDPLVLQVTAQVLGTVLLEVVGDLDLPGLVQIAAVEAQEESLLVEAVVEVVMYAPLHDKNPFGNILTVYEHFTRTIKIRH>sp|Q69YN4-4|VIR_HUMAN Isoform 4 of Protein virilizer homolog OS=Homosapiens OX=9606 GN=VIRMAMAVDSAMELLFLDTFKHPSAEQSSHIDVVRFPCVVYINEVRVIPPGVRAHSSLPDNRAYGETSPHTFQLDLFFNNVSKPSAPVFDRLGSLEYDENTSIIFRPNSKVNTDGLVLRGWYNCLTLAIYGSVDRVISHDRDSPPPPPPPPPPPQPQPSLKRNPKHADGEKEDQFNGSPPRPQPRGPRTPPGPPPPDDDEDDPVPLPVSGDKEEDAPHREDYFEPISPDRNSVPQEGQYSDEGEVEEEQQEEGEEDEDDVDVEEEEDEDEDDRRTVDSIPEEEEEDEEEEGEEDEEGEGDDGYEQISSDEDGIADLERETFKYPNFDVEYTAEDLASVPPMTYDPYDRELVPLLYFSCPYKTTFEIEISRMKDQGPDKENSGAIEASVKLTELLDLYREDRGAKWVTALEEIPSLIIKGLSYLQLKNTKQDSLGQLVDWTMQALNLQVALRQPIALNVRQLKAGTKLVSSLAECGAQGVTGLLQAGVISGLFELLFADHVSSSLKLNAFKALDSVISMTEGMEAFLRGRQNEKSGYQKLLELILLDQTVRVVTAGSAILQKCHFYEVLSEIKRLGDHLAEKTSSLPNHSEPDHDTDAGLERTNPEYENEVEASMDMDLLESSNISEGEIERLINLLEEVFHLMETAPHTMIQQPVKSFPTMARITGPPERDDPYPVLFRYLHSHHFLELVTLLLSIPVTSAHPGVLQATKDVLKFLAQSQKGLLFFMSEYEATNLLIRALCHFYDQDEEEGLQSDGVIDDAFALWLQDSTQTLQCITELFSHFQRCTASEETDHSDLLGTLHNLYLITFNPVGRSAVGHVFSLEKNLQSLITLMEYYSKEALGDSKSKKSVAYNYACILILVVVQSSSDVQMLEQHAASLLKLCKADENNAKLQELGKWLEPLKNLRFEINCIPNLIEYVKQNIDNLMTPEGVGLTTALRVLCNVACPPPPVEGQQKDLKWNLAVIQLFSAEGMDTFIRVLQKLNSILTQPWRLHVNMGTTLHRVTTISMARCTLTLLKTMLTELLRGGSFEFKDMRVPSALVTLHMLLCSIPLSGRLDSDEQKIQNDIIDILLTFTQGVNEKLTISEETLANNTWSLMLKEVLSSILKVPEGFFSGLILLSELLPLPLPMQTTQVSLPYNMHLINDCSNTF>sp|Q9P1Q0|VPS54_HUMAN Vacuolar protein sorting-associated protein 54OS=Homo sapiens OX=9606 GN=VPS54 PE=1 SV=2MASSHSSSPVPQGSSSDVFFKIEVDPSKHIRPVPSLPDVCPKEPTGDSHSLYVAPSLVTDQHRWTVYHSKVNLPAALNDPRLAKRESDFFTKTWGLDFVDTEVIPSFYLPQISKEHFTVYQQEISQREKIHERCKNICPPKDTFERTLLHTHDKSRTDLEQVPKIFMKPDFALDDSLTFNSVLPWSHFNTAGGKGNRDAASSKLLQEKLSHYLDIVEVNIAHQISLRSEAFFHAMTSQHELQDYLRKTSQAVKMLRDKIAQIDKVMCEGSLHILRLALTRNNCVKVYNKLKLMATVHQTQPTVQVLLSTSEFVGALDLIATTQEVLQQELQGIHSFRHLGSQLCELEKLIDKMMIAEFSTYSHSDLNRPLEDDCQVLEEERLISLVFGLLKQRKLNFLEIYGEKMVITAKNIIKQCVINKVSQTEEIDTDVVVKLADQMRMLNFPQWFDLLKDIFSKFTIFLQRVKATLNIIHSVVLSVLDKNQRTRELEEISQQKNAAKDNSLDTEVAYLIHEGMFISDAFGEGELTPIAVDTTSQRNASPNSEPCSSDSVSEPECTTDSSSSKEHTSSSAIPGGVDIMVSEDMKLTDSELGKLANNIQELLYSASDICHDRAVKFLMSRAKDGFLEKLNSMEFITLSRLMETFILDTEQICGRKSTSLLGALQSQAIKFVNRFHEERKTKLSLLLDNERWKQADVPAEFQDLVDSLSDGKIALPEKKSGATEERKPAEVLIVEGQQYAVVGTVLLLIRIILEYCQCVDNIPSVTTDMLTRLSDLLKYFNSRSCQLVLGAGALQVVGLKTITTKNLALSSRCLQLIVHYIPVIRAHFEARLPPKQYSMLRHFDHITKDYHDHIAEISAKLVAIMDSLFDKLLSKYEVKAPVPSACFRNICKQMTKMHEAIFDLLPEEQTQMLFLRINASYKLHLKKQLSHLNVINDGGPQNGLVTADVAFYTGNLQALKGLKDLDLNMAEIWEQKR>sp|Q9P1Q0-2|VPS54_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 54 OS=Homo sapiens OX=9606 GN=VPS54MASSHSSSPVPQGSSSDVFFKIEVDPSKHIRPVPSLPDVCPKEPTGDSHSLYVAPSLVTDQHRWTVYHSKVNLPAALNDPRLAKRESDFFTKTWGLDFVDTEVIPSFYLPQISKEHFTVYQQEISQREKIHERCKNICPPKDTFERTLLHTHDKSRTDLEQVPKIFMKPDFALDDSLTFNSVLPWSHFNTAGGKGNRDAASSKLLQEKLSHYLDIVEVNIAHQISLRSEAFFHAMTSQHELQDYLRKTSQAVKMLRDKIAQIDKVMCEGSLHILRLALTRNNCVKVYNKLKLMATVHQTQPTVQVLLSTSEFVGALDLIATTQEVLQQELQGIHSFRHLGSQLCELEKLIDKMMIAEFSTYSHSDLNRPLEDDCQVLEEERLISLVFGLLKQRKLNFLEIYGEKMVITAKNIIKQCVINKVSQTEEIDTDVVVKLADQMRMLNFPQWFDLLKDIFSKFTIFLQRVKATLNIIHSVVLSVLDKNQRTRELEEISQQKNAAKDNSLDTEVAYLIHEGMFISDAFGEGELTPIAVDTTSQRNASPNSEPCSSDSVSEPECTTDSSSSKEHTSSSAIPGGVDIMVSEDMKLTDSELGKLANNIQELLYSASDICHDRAVKFLMSRAKDGFLEKLNSMEFITLSRLMETFILDTEQICGRKSTSLLGALQSQAIKFVNRFHEERKTKLSLLLDNERWKQADVPAEFQDLVDSLSDGKIALPEKKSGATEERKPAEVLIVEGQQYAVVGTVLLLIRIILEYCQCVDNIPSVTTDMLTRLSDLLKYFNSRSCQLVLGAGALQVVGLKTITTKNLALSSRCLQLIVHYIPVIRAHFEARLPPKQYSMLRHFDHITKDYHDHIAEISAKLVAIMDSLFDKLLSKYEVKAPVPSACFRNICKQMTKMHEAIFDLLPEEQTQMLFLRINASYKLHLKKQLSHLNVINDGGPQNGLVTADVAFYTGNLQALKGLKIWT>sp|Q9P1Q0-3|VPS54_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 54 OS=Homo sapiens OX=9606 GN=VPS54MLPTKNRIKREKIHERCKNICPPKDTFERTLLHTHDKSRTDLEQVPKIFMKPDFALDDSLTFNSVLPWSHFNTAGGKGNRDAASSKLLQEKLSHYLDIVEVNIAHQISLRSEAFFHAMTSQHELQDYLRKTSQAVKMLRDKIAQIDKVMCEGSLHILRLALTRNNCVKVYNKLKLMATVHQTQPTVQVLLSTSEFVGALDLIATTQEVLQQELQGIHSFRHLGSQLCELEKLIDKMMIAEFSTYSHSDLNRPLEDDCQVLEECVINKVSQTEEIDTDVVVKLADQMRMLNFPQWFDLLKDIFSKFTIFLQRVKATLNIIHSVVLSVLDKNQRTRELEEISQQKNAAKDNSLDTEVAYLIHEGMFISDAFGEGELTPIAVDTTSQRNASPNSEPCSSDSVSEPECTTDSSSSKEHTSSSAIPGGVDIMVSEDMKLTDSELGKLANNIQELLYSASDICHDRAVKFLMSRAKDGFLEKLNSMEFITLSRLMETFILDTEQICGRKSTSLLGALQSQAIKFVNRFHEERKTKLSLLLDNERWKQADVPAEFQDLVDSLSDGKIALPEKKSGATEERKPAEVLIVEGQQYAVVGTVLLLIRIILEYCQCVDNIPSVTTDMLTRLSDLLKYFNSRSCQLVLGAGALQVVGLKTITTKNLALSSRCLQLIVHYIPVIRAHFEARLPPKQYSMLRHFDHITKDYHDHIAEISAKLVAIMDSLFDKLLSKYEVKAPVPSACFRNICKQMTKMHEAIFDLLPEEQTQMLFLRINASYKLHLKKQLSHLNVINDGGPQNGLVTADVAFYTGNLQALKGLKDLDLNMAEIWEQKR>sp|Q9P1Q0-4|VPS54_HUMAN Isoform 4 of Vacuolar protein sorting-associatedprotein 54 OS=Homo sapiens OX=9606 GN=VPS54MASSHSSSPVPQGSSSDVFFKIEVDPSKHIRPVPSLPDVCPKEPTVTDQHRWTVYHSKVNLPAALNDPRLAKRESDFFTKTWGLDFVDTEVIPSFYLPQISKEHFTVYQQEISQREKIHERCKNICPPKDTFERTLLHTHDKSRTDLEQVPKIFMKPDFALDDSLTFNSVLPWSHFNTAGGKGNRDAASSKLLQEKLSHYLDIVEVNIAHQISLRSEAFFHAMTSQHELQDYLRKTSQAVKMLRDKIAQIDKVMCEGSLHILRLALTRNNCVKVYNKLKLMATVHQTQPTVQVLLSTSEFVGALDLIATTQEVLQQELQGIHSFRHLGSQLCELEKLIDKMMIAEFSTYSHSDLNRPLEDDCQVLEEERLISLVFGLLKQRKLNFLEIYGEKMVITAKNIIKQCVINKVSQTEEIDTDVVVKLADQMRMLNFPQWFDLLKDIFSKFTIFLQRVKATLNIIHSVVLSVLDKNQRTRELEEISQQKNAAKDNSLDTEVAYLIHEGMFISDAFGEGELTPIAVDTTSQRNASPNSEPCSSDSVSEPECTTDSSSSKEHTSSSAIPGGVDIMVSEDMKLTDSELGKLANNIQELLYSASDICHDRAVKFLMSRAKDGFLEKLNSMEFITLSRLMETFILDTEQICGRKSTSLLGALQSQAIKFVNRFHEERKTKLSLLLDNERWKQADVPAEFQDLVDSLSDGKIALPEKKSGATEERKPAEVLIVEGQQYAVVGTVLLLIRIILEYCQCVDNIPSVTTDMLTRLSDLLKYFNSRSCQLVLGAGALQVVGLKTITTKNLALSSRCLQLIVHYIPVIRAHFEARLPPKQYSMLRHFDHITKDYHDHIAEISAKLVAIMDSLFDKLLSKYEVKAPVPSACFRNICKQMTKMHEAIFDLLPEEQTQMLFLRINASYKLHLKKQLSHLNVINDGGPQNGLVTADVAFYTGNLQALKGLKDLDLNMAEIWEQKR>sp|Q9P1Q0-5|VPS54_HUMAN Isoform 5 of Vacuolar protein sorting-associatedprotein 54 OS=Homo sapiens OX=9606 GN=VPS54MLRHFDHITKDYHDHIAEISAKLVAIMDSLFDKLLSKYEVKAPVPSACFRNICKQMTKMHEAIFDLLPEEQTQMLFLRINASYKLHLKKQLSHLNVINDGGPQNGLVTADVAFYTGNLQALKGLKDLDLNMAEIWEQKR>sp|Q9Y4E6|WDR7_HUMAN WD repeat-containing protein 7 OS=Homo sapiensOX=9606 GN=WDR7 PE=1 SV=2MAGNSLVLPIVLWGRKAPTHCISAVLLTDDGATIVTGCHDGQICLWDLSVELQINPRALLFGHTASITCLSKACASSDKQYIVSASESGEMCLWDVSDGRCIEFTKLACTHTGIQFYQFSVGNQREGRLLCHGHYPEILVVDATSLEVLYSLVSKISPDWISSMSIIRSHRTQEDTVVALSVTGILKVWIVTSEISDMQDTEPIFEEESKPIYCQNCQSISFCAFTQRSLLVVCSKYWRVFDAGDYSLLCSGPSENGQTWTGGDFVSSDKVIIWTENGQSYIYKLPASCLPASDSFRSDVGKAVENLIPPVQHILLDRKDKELLICPPVTRFFYGCREYFHKLLIQGDSSGRLNIWNISDTADKQGSEEGLAMTTSISLQEAFDKLNPCPAGIIDQLSVIPNSNEPLKVTASVYIPAHGRLVCGREDGSIVIVPATQTAIVQLLQGEHMLRRGWPPHRTLRGHRNKVTCLLYPHQVSARYDQRYLISGGVDFSVIIWDIFSGEMKHIFCVHGGEITQLLVPPENCSARVQHCICSVASDHSVGLLSLREKKCIMLASRHLFPIQVIKWRPSDDYLVVGCSDGSVYVWQMDTGALDRCVMGITAVEILNACDEAVPAAVDSLSHPAVNLKQAMTRRSLAALKNMAHHKLQTLATNLLASEASDKGNLPKYSHNSLMVQAIKTNLTDPDIHVLFFDVEALIIQLLTEEASRPNTALISPENLQKASGSSDKGGSFLTGKRAAVLFQQVKETIKENIKEHLLDDEEEDEEIMRQRREESDPEYRSSKSKPLTLLEYNLTMDTAKLFMSCLHAWGLNEVLDEVCLDRLGMLKPHCTVSFGLLSRGGHMSLMLPGYNQPACKLSHGKTEVGRKLPASEGVGKGTYGVSRAVTTQHLLSIISLANTLMSMTNATFIGDHMKKGPTRPPRPSTPDLSKARGSPPTSSNIVQGQIKQVAAPVVSARSDADHSGSDPPSAPALHTCFLVNEGWSQLAAMHCVMLPDLLGLDKFRPPLLEMLARRWQDRCLEVREAAQALLLAELRRIEQAGRKEAIDAWAPYLPQYIDHVISPGVTSEAAQTITTAPDASGPEAKVQEEEHDLVDDDITTGCLSSVPQMKKISTSYEERRKQATAIVLLGVIGAEFGAEIEPPKLLTRPRSSSQIPEGFGLTSGGSNYSLARHTCKALTFLLLQPPSPKLPPHSTIRRTAIDLIGRGFTVWEPYMDVSAVLMGLLELCADAEKQLANITMGLPLSPAADSARSARHALSLIATARPPAFITTIAKEVHRHTALAANTQSQQNMHTTTLARAKGEILRVIEILIEKMPTDVVDLLVEVMDIIMYCLEGSLVKKKGLQECFPAICRFYMVSYYERNHRIAVGARHGSVALYDIRTGKCQTIHGHKGPITAVAFAPDGRYLATYSNTDSHISFWQMNTSLLGSIGMLNSAPQLRCIKTYQVPPVQPASPGSHNALKLARLIWTSNRNVILMAHDGKEHRFMV>sp|Q9Y4E6-2|WDR7_HUMAN Isoform 2 of WD repeat-containing protein 7OS=Homo sapiens OX=9606 GN=WDR7MAGNSLVLPIVLWGRKAPTHCISAVLLTDDGATIVTGCHDGQICLWDLSVELQINPRALLFGHTASITCLSKACASSDKQYIVSASESGEMCLWDVSDGRCIEFTKLACTHTGIQFYQFSVGNQREGRLLCHGHYPEILVVDATSLEVLYSLVSKISPDWISSMSIIRSHRTQEDTVVALSVTGILKVWIVTSEISDMQDTEPIFEEESKPIYCQNCQSISFCAFTQRSLLVVCSKYWRVFDAGDYSLLCSGPSENGQTWTGGDFVSSDKVIIWTENGQSYIYKLPASCLPASDSFRSDVGKAVENLIPPVQHILLDRKDKELLICPPVTRFFYGCREYFHKLLIQGDSSGRLNIWNISDTADKQGSEEGLAMTTSISLQEAFDKLNPCPAGIIDQLSVIPNSNEPLKVTASVYIPAHGRLVCGREDGSIVIVPATQTAIVQLLQGEHMLRRGWPPHRTLRGHRNKVTCLLYPHQVSARYDQRYLISGGVDFSVIIWDIFSGEMKHIFCVHGGEITQLLVPPENCSARVQHCICSVASDHSVGLLSLREKKCIMLASRHLFPIQVIKWRPSDDYLVVGCSDGSVYVWQMDTGALDRCVMGITAVEILNACDEAVPAAVDSLSHPAVNLKQAMTRRSLAALKNMAHHKLQTLATNLLASEASDKGNLPKYSHNSLMVQAIKTNLTDPDIHVLFFDVEALIIQLLTEEASRPNTALISPENLQKASGSSDKGGSFLTGKRAAVLFQQVKETIKENIKEHLLDDEEEDEEIMRQRREESDPEYRSSKSKPLTLLEYNLTMDTAKLFMSCLHAWGLNEVLDEVCLDRLGMLKPHCTVSFGLLSRGGHMSLMLPGYNQPACKLSHGKTEVGRKLPASEGVGKGTYGVSRAVTTQHLLSIISLANTLMSMTNATFIGDHMKKGPTRPPRPSTPDLSKARGSPPTSSNIVQGQIKQGWSQLAAMHCVMLPDLLGLDKFRPPLLEMLARRWQDRCLEVREAAQALLLAELRRIEQAGRKEAIDAWAPYLPQYIDHVISPGVTSEAAQTITTAPDASGPEAKVQEEEHDLVDDDITTGCLSSVPQMKKISTSYEERRKQATAIVLLGVIGAEFGAEIEPPKLLTRPRSSSQIPEGFGLTSGGSNYSLARHTCKALTFLLLQPPSPKLPPHSTIRRTAIDLIGRGFTVWEPYMDVSAVLMGLLELCADAEKQLANITMGLPLSPAADSARSARHALSLIATARPPAFITTIAKEVHRHTALAANTQSQQNMHTTTLARAKGEILRVIEILIEKMPTDVVDLLVEVMDIIMYCLEGSLVKKKGLQECFPAICRFYMVSYYERNHRIAVGARHGSVALYDIRTGKCQTIHGHKGPITAVAFAPDGRYLATYSNTDSHISFWQMNTSLLGSIGMLNSAPQLRCIKTYQVPPVQPASPGSHNALKLARLIWTSNRNVILMAHDGKEHRFMV>sp|P55808|XG_HUMAN Glycoprotein Xg OS=Homo sapiens OX=9606 GN=XG PE=2SV=1MESWWGLPCLAFLCFLMHARGQRDFDLADALDDPEPTKKPNSDIYPKPKPPYYPQPENPDSGGNIYPRPKPRPQPQPGNSGNSGGYFNDVDRDDGRYPPRPRPRPPAGGGGGGYSSYGNSDNTHGGDHHSTYGNPEGNMVAKIVSPIVSVVVVTLLGAAASYFKLNNRRNCFRTHEPENV>sp|P55808-2|XG_HUMAN Isoform 2 of Glycoprotein Xg OS=Homo sapiensOX=9606 GN=XGMESWWGLPCLAFLCFLMHARGQRDFDLADALDDPEPTKKPNSDIYPKPKPPYYPQPENPDSGGNIYPRPKPRPQPQPGNSGNSGGSYFNDVDRDDGRYPPRPRPRPPAGGGGGGYSSYGNSDNTHGGDHHSTYGNPEGNMVAKIVSPIVSVVVVTLLGAAASYFKLNNRRNCFRTHEPENV>sp|P55808-3|XG_HUMAN Isoform 3 of Glycoprotein Xg OS=Homo sapiensOX=9606 GN=XGMESWWGLPCLAFLCFLMHARGQRDFDLADALDDPEPTKKPNSDIYPKPKPPYYPQPENPDSGGNIYPRPKPRPQPQPGNSGNSGGYFNDVDRDDGRYPPRPRPRPPAGGGGGGYSSYGNSDNTHGRGGYRLNSRYGNTYGGDHHSTYGNPEGNMVAKIVSPIVSVVVVTLLGAAASYFKLNNRRNCFRTHEPENV>sp|Q52M93|Z585B_HUMAN Zinc finger protein 585B OS=Homo sapiens OX=9606GN=ZNF585B PE=2 SV=1MPASWTSPQKSSALAPEDHGSSYEGSVSFRDVAIDFSREEWRHLDLSQRNLYRDVMLETYSHLLSVGYQVPKPEVVMLEQGKEPWALQGERPRHSCPGEKLWDHNQHRKIIGYKPASSQDQKIYSGEKSYECAEFGKSFTWKSQFKVHLKVPTGEKLYVCIECGRAFVQKPEFITHQKTHMREKPYKCNECGKSFFQVSSLFRHHRIHTGEKLYECSECGKGFPYNSDLSIHEKIHTGERHHECTDCGKAFTQKSTLKIHQKIHTGERSYICIECGQAFIQKTQLIAHRRIHSGEKPYECNNCGKSFISKSQLQVHQRVHTRVKPYICTEYGKVFSNNSNLITHEKIQSREKSSICTECGKAFTYRSELIIHQRIHTGEKPYECSDCGRAFTQKSALTVHQRIHTGEKSYICMKCGLAFIRKAHLITHQIIHTGEKPYKCGHCGKLFTSKSQLHVHKRIHTGEKPYVCNKCGKAFTNRSNLITHQKTHTGEKSYICSKCGKAFTQRSDLITHQRIHTGEKPYECNTCGKAFTQKSNLNIHQKIHTGERQYECHECGKAFNQKSILIVHQKIHTGEKPYVCTECGRAFIRKSNFITHQRIHTGEKPYECSDCGKSFTSKSQLLVHQPVHTGEKPYVCAECGKAFSGRSNLSKHQKTHTGEKPYICSECGKTFRQKSELITHHRIHTGEKPYECSDCGKSFTKKSQLQVHQRIHTGEKPYVCAECGKAFSNRSNLNKHQTTHTGDKPYKCGICGKGFVQKSVFSVHQSSHA>sp|Q9NSJ1|Z355P_HUMAN Putative zinc finger protein 355P OS=Homo sapiensOX=9606 GN=ZNF355P PE=5 SV=2MRDEVAEKEKADINVTLVFQGYENTPIMVCVDGIVFSKPDLVTCLEQRKKPWSMKHPGLTQHNIVHTGDKPYKCKDCGKIFKWSSNLTIHQRIHSGEKPYKCEECGKAFKQSSKLNEHMRAHTGEKFYKCEECGKAFKHPSGLTLHKRIHTGENPYKFEECDKAFYWVLSFTKHMIIHRGEKPYKYQECGKAFKWSSNLTIHKRIHTGEKPCKCEECGKACKQSLGLTIQKRIHTEEKPYKCEECGSSNLTIYKKIHAGEKPYNCEKCGKAFYCSSNLIQNNIVHAEEKHYKCQECGKAFKKSLDLNVHKIIHSGEKPYRYEECGKITHSGEESYKCEECGKGFYCSSSLTKHMIVHTEEKLYKCEECGKAFKWSSELTIHQRIRTEEKPYKCEECVRVFKHSSKLNEHKRNHTGEKPYKCEACGKAF>sp|Q8TAQ5|ZN420_HUMAN Zinc finger protein 420 OS=Homo sapiens OX=9606GN=ZNF420 PE=1 SV=1MARKLVMFRDVAIDFSQEEWECLDSAQRDLYRDVMLENYSNLVSLDLPSRCASKDLSPEKNTYETELSQWEMSDRLENCDLEESNSRDYLEAKGKMEKQQENQKEYFRQGMIIYDKMSIFNQHTYLSQHSRCHSTEKPYKCKECGKAFRRASHLTQHQSIHTGEKPYECKQCGKAFSRDSQLSLHQRLHTGEKPYACKECGKAFTQSSQLILHHRIHTGEKPYKCEECGKAFIRSSQLTRHQKVHTGEKPYECKECGKAFTQNSQLTLHQRLHTGEKLYECKECRKVFTQLSQLILHKRIHTGEKPYECKECGKAFICGSQLSQHQKIHNGEKPYECKECGRAFIRGSLLMQHQRIHTGEKPYKCEECGKAFIRGSQLTQHQRIHTNEKPYECKECGKMFSHGSQLTQHQRIHTGEKPYQCKECGKAFNRGSLLTRHQRIHTGEKPYECKECGKTFSRGSELTQHERIHTGEKPYECKECGKSFIRGSQLTQHQRIHTGEKPYECKECRMAFTQSSHLSQHQRLHTGEKPYVCNECGKAFARGLLLIQHQRIHTGEKPYQCKECGKAFIRGSQLTQHQRIHTGEKPYECKECGKAFSHGSQLTLHQRIHTGEKPYECRECRKAFTQSSHLSRHQRIHTGEKPYQCKECGKAFTRGSQLTQHQRIHISEKSFEYKECGIDFSHGSQVYM>sp|Q8TAQ5-2|ZN420_HUMAN Isoform 2 of Zinc finger protein 420 OS=Homosapiens OX=9606 GN=ZNF420MARKLVMFRDVAIDFSQEEWECLDSAQRDLYRDVMLENYSNLVSLDLPSRCASKDLSPEKNTYETELSQWEMSDRLENCDLEESNSRDYLEAKGKMEKQQENQKEYFRQGMIIYDKMSIFNQHTYLSQHSRCHSTEKPYKCKECGKAFRRASHLTQHQSIHTGEKPYECKQCGKAFSRDSQLSLHQRLHTGEKPYACKECGKAFTQSSQLILHHRIHTGEKPYKCEECGKAFIRSSQLTRHQKVHTGEKPYECKECGKAFTQNSQLTLHQRLHTGEKLYECKECRKVFTQLSQLILHKRIHTGEKPYECKECGKAFICGSQLSQHQKIHNGEKPYECKECGRAFIRGSLLMQHQRIHTGEKPYKCEECGKAFIRGSQLTQHQRIHTNEKPYECKECGKMFSHGSQLTQHQRIHTGEKPYQCKECGKAFNRGSLLTRHQRIHTGEKPYECKECGKTFSRGSELTQHERIHTAFLAGQQDRSDIYMSRRFTKSIFPVFFSVPTMWTSKLELRYSHGDFENGIWVLWIMEQKYRRSLQP>sp|A8MQ14|ZN850_HUMAN Zinc finger protein 850 OS=Homo sapiens OX=9606GN=ZNF850 PE=3 SV=2MNMEGLVMFQDLSIDFSQEEWECLDAAQKDLYRDVMMENYSSLVSLGLSIPKPDVISLLEQGKEPWMVSRDVLGGWCRDSEFRCKTKDSCLPKEIYEVTSSQWVRMEKCHSLVGSSVRDDWECKGQFQHQDINQERYLEKAIMTYETTPTFCLQTSLTLHHRIHPGEKLYKSTECMAFKYGSELTQQQETHTGEKLYKCKECGKAFHHFSYLVKHQRIHTGEKPCACKEYGKAFISGSHLIQHQKMYTDERPHECQESVKAFRPSAHLIQHWRIHTGDKPYECKECGKSFTSGSTLNQHQQIHTGEKPYHCKQCGKSFTVGSTLIRHQQIHTGEKPYDCKECGKSFASGSALIRHQRIHTGEKPYDCKECGKSFTFHSALIRHQRIHTGEKPYDCKECGKSFTFRSGLIGHQAIHTGEKPYDCKECGKSFTAGSTLIQHQRIHTGEKPYDCKECGKSFASGSALLQHQRIHTGEKPYCCKECGKSFTFRSTRNRHQRIHTGEKPYNCKECGKSFASGSALLQHQRIHTGEKPYHCKECGKSFTFRSGLIGHQAVHTGEKPYDCKECGKSFTSRSALIQHQRIHTGEKPYHCKECGKSFTVGSTLLQHQQIHTGEKPYDCKECGKAFRLRLRLTQHQQIHTGEKPYQCQECGKAFVSVSGLTQHHRIHTGEKPYECPDCGKAFRQRTYLNQHRRIHTGEKPYECKECGKSFTFCSGLIQHQQNHTDEKPYDGKECGKSFTSHSTLIQHQQIHTGEKPYDCKECGKSFTSHSTLIQHQQIHTGEKLYDCKECGKSFTSHSTLIQHQPLHTGEKPYHCKECGKSFTLRSALIQHRPVHTGEKRYSCKECGKSFTSRSTLIEHQRIHTGEKPYHCKECGKSFAFRSAIIQHRRIHTGEKPYDCKECGKAFRRRSKLTQHQRIHTGEKPYRCHECGKAFVRFSGLTKHHSIHTGEKPYECKTCGKSFRQRTHLTLHQRIHTGDRPYECKECGKSFTCGSELIRHQRTHTGEKPYDCKECGKAFRCPSQLSQHKRIHTGEKTYQCPECGKAFFYASGLSRHQSVHTGEKPYECKTCGKAFKQLTQLTRHQRIHDLT>sp|P52736|ZN133_HUMAN Zinc finger protein 133 OS=Homo sapiens OX=9606GN=ZNF133 PE=1 SV=2MAFRDVAVDFTQDEWRLLSPAQRTLYREVMLENYSNLVSLGISFSKPELITQLEQGKETWREEKKCSPATCPADPEPELYLDPFCPPGFSSQKFPMQHVLCNHPPWIFTCLCAEGNIQPGDPGPGDQEKQQQASEGRPWSDQAEGPEGEGAMPLFGRTKKRTLGAFSRPPQRQPVSSRNGLRGVELEASPAQSGNPEETDKLLKRIEVLGFGTVNCGECGLSFSKMTNLLSHQRIHSGEKPYVCGVCEKGFSLKKSLARHQKAHSGEKPIVCRECGRGFNRKSTLIIHERTHSGEKPYMCSECGRGFSQKSNLIIHQRTHSGEKPYVCRECGKGFSQKSAVVRHQRTHLEEKTIVCSDCGLGFSDRSNLISHQRTHSGEKPYACKECGRCFRQRTTLVNHQRTHSKEKPYVCGVCGHSFSQNSTLISHRRTHTGEKPYVCGVCGRGFSLKSHLNRHQNIHSGEKPIVCKDCGRGFSQQSNLIRHQRTHSGEKPMVCGECGRGFSQKSNLVAHQRTHSGERPYVCRECGRGFSHQAGLIRHKRKHSREKPYMCRQCGLGFGNKSALITHKRAHSEEKPCVCRECGQGFLQKSHLTLHQMTHTGEKPYVCKTCGRGFSLKSHLSRHRKTTSVHHRLPVQPDPEPCAGQPSDSLYSL>sp|P52736-2|ZN133_HUMAN Isoform 2 of Zinc finger protein 133 OS=Homosapiens OX=9606 GN=ZNF133MAFRDVAVDFTQDEWRLLSPAQRTLYREVMLENYSNLVSLGISFSKPELITQLEQGKETWREEKKCSPATCPDPEPELYLDPFCPPGFSSQKFPMQHVLCNHPPWIFTCLCAEGNIQPGDPGPGDQEKQQQASEGRPWSDQAEGPEGEGAMPLFGRTKKRTLGAFSRPPQRQPVSSRNGLRGVELEASPAQSGNPEETDKLLKRIEVLGFGTVNCGECGLSFSKMTNLLSHQRIHSGEKPYVCGVCEKGFSLKKSLARHQKAHSGEKPIVCRECGRGFNRKSTLIIHERTHSGEKPYMCSECGRGFSQKSNLIIHQRTHSGEKPYVCRECGKGFSQKSAVVRHQRTHLEEKTIVCSDCGLGFSDRSNLISHQRTHSGEKPYACKECGRCFRQRTTLVNHQRTHSKEKPYVCGVCGHSFSQNSTLISHRRTHTGEKPYVCGVCGRGFSLKSHLNRHQNIHSGEKPIVCKDCGRGFSQQSNLIRHQRTHSGEKPMVCGECGRGFSQKSNLVAHQRTHSGERPYVCRECGRGFSHQAGLIRHKRKHSREKPYMCRQCGLGFGNKSALITHKRAHSEEKPCVCRECGQGFLQKSHLTLHQMTHTGEKPYVCKTCGRGFSLKSHLSRHRKTTSVHHRLPVQPDPEPCAGQPSDSLYSL>sp|P52736-3|ZN133_HUMAN Isoform 3 of Zinc finger protein 133 OS=Homosapiens OX=9606 GN=ZNF133MQHVLCNHPPWIFTCLCAEGNIQPGDPGPGDQEKQQQASEGRPWSDQAEGPEGEGAMPLFGRTKKRTLGAFSRPPQRQPVSSRNGLRGVELEASPAQSGNPEETDKLLKRIEVLGFGTVNCGECGLSFSKMTNLLSHQRIHSGEKPYVCGVCEKGFSLKKSLARHQKAHSGEKPIVCRECGRGFNRKSTLIIHERTHSGEKPYMCSECGRGFSQKSNLIIHQRTHSGEKPYVCRECGKGFSQKSAVVRHQRTHLEEKTIVCSDCGLGFSDRSNLISHQRTHSGEKPYACKECGRCFRQRTTLVNHQRTHSKEKPYVCGVCGHSFSQNSTLISHRRTHTGEKPYVCGVCGRGFSLKSHLNRHQNIHSGEKPIVCKDCGRGFSQQSNLIRHQRTHSGEKPMVCGECGRGFSQKSNLVAHQRTHSGERPYVCRECGRGFSHQAGLIRHKRKHSREKPYMCRQCGLGFGNKSALITHKRAHSEEKPCVCRECGQGFLQKSHLTLHQMTHTGEKPYVCKTCGRGFSLKSHLSRHRKTTSVHHRLPVQPDPEPCAGQPSDSLYSL>sp|P52736-4|ZN133_HUMAN Isoform 4 of Zinc finger protein 133 OS=Homosapiens OX=9606 GN=ZNF133MCNGRKTVLADPEPELYLDPFCPPGFSSQKFPMQHVLCNHPPWIFTCLCAEGNIQPGDPGPGDQEKQQQASEGRPWSDQAEGPEGEGAMPLFGRTKKRTLGAFSRPPQRQPVSSRNGLRGVELEASPAQSGNPEETDKLLKRIEVLGFGTVNCGECGLSFSKMTNLLSHQRIHSGEKPYVCGVCEKGFSLKKSLARHQKAHSGEKPIVCRECGRGFNRKSTLIIHERTHSGEKPYMCSECGRGFSQKSNLIIHQRTHSGEKPYVCRECGKGFSQKSAVVRHQRTHLEEKTIVCSDCGLGFSDRSNLISHQRTHSGEKPYACKECGRCFRQRTTLVNHQRTHSKEKPYVCGVCGHSFSQNSTLISHRRTHTGEKPYVCGVCGRGFSLKSHLNRHQNIHSGEKPIVCKDCGRGFSQQSNLIRHQRTHSGEKPMVCGECGRGFSQKSNLVAHQRTHSGERPYVCRECGRGFSHQAGLIRHKRKHSREKPYMCRQCGLGFGNKSALITHKRAHSEEKPCVCRECGQGFLQKSHLTLHQMTHTGEKPYVCKTCGRGFSLKSHLSRHRKTTSVHHRLPVQPDPEPCAGQPSDSLYSL>sp|P52736-5|ZN133_HUMAN Isoform 5 of Zinc finger protein 133 OS=Homosapiens OX=9606 GN=ZNF133MAHMAFRDVAVDFTQDEWRLLSPAQRTLYREVMLENYSNLVSLGISFSKPELITQLEQGKETWREEKKCSPATCPADPEPELYLDPFCPPGFSSQKFPMQHVLCNHPPWIFTCLCAEGNIQPGDPGPGDQEKQQQASEGRPWSDQAEGPEGEGAMPLFGRTKKRTLGAFSRPPQRQPVSSRNGLRGVELEASPAQSGNPEETDKLLKRIEVLGFGTVNCGECGLSFSKMTNLLSHQRIHSGEKPYVCGVCEKGFSLKKSLARHQKAHSGEKPIVCRECGRGFNRKSTLIIHERTHSGEKPYMCSECGRGFSQKSNLIIHQRTHSGEKPYVCRECGKGFSQKSAVVRHQRTHLEEKTIVCSDCGLGFSDRSNLISHQRTHSGEKPYACKECGRCFRQRTTLVNHQRTHSKEKPYVCGVCGHSFSQNSTLISHRRTHTGEKPYVCGVCGRGFSLKSHLNRHQNIHSGEKPIVCKDCGRGFSQQSNLIRHQRTHSGEKPMVCGECGRGFSQKSNLVAHQRTHSGERPYVCRECGRGFSHQAGLIRHKRKHSREKPYMCRQCGLGFGNKSALITHKRAHSEEKPCVCRECGQGFLQKSHLTLHQMTHTGEKPYVCKTCGRGFSLKSHLSRHRKTTSVHHRLPVQPDPEPCAGQPSDSLYSL>sp|P51504|ZNF80_HUMAN Zinc finger protein 80 OS=Homo sapiens OX=9606GN=ZNF80 PE=1 SV=2MSPKRDGLGTGDGLHSQVLQEQVSTGDNLHECDSQGPSKDTLVREGKTYKCKECGSVFNKNSLLVRHQQIHTGVKPYECQECGKAFPEKVDFVRPMRIHTGEKPCKCVECGKVFNRRSHLLCYRQIHTGEKPYECSECGKTFSYHSVFIQHRVTHTGEKLFGCKECGKTFYYNSSLTRHMKIHTGEKPCKCSECGKTFTYRSVFFRHSMTHTAGKPYECKECGKGFYYSYSLTRHTRSHTGEKPYECLEHRKDFGYHSAFAQQSKIHSGGKNL>sp|Q2M218|ZN630_HUMAN Zinc finger protein 630 OS=Homo sapiens OX=9606GN=ZNF630 PE=2 SV=1MIESQEPVTFEDVAVDFTQEEWQQLNPAQKTLHRDVMLETYNHLVSVGCSGIKPDVIFKLEHGKDPWIIESELSRWIYPDRVKGLESSQQIISGELLFQREILERAPKDNSLYSVLKIWHIDNQMDRYQGNQDRVLRQVTVISRETLTDEMGSKYSAFGKMFNRCTDLAPLSQKFHKFDSCENSLKSNSDLLNYNRSYARKNPTKRFRCGRPPKYNASCSVPEKEGFIHTGMEPYGDSQCEKVLSHKQAHVQYKKFQAREKPNVCSMCGKAFIKKSQLIIHQRIHTGEKPYVCGDCRKAFSEKSHLIVHQRIHTGEKPYECTKYGRAFSRKSPFTVHQRVHTGEKPYECFECPKAFSQKSHLIIHQRVHTREKPFECSECRKAFCEMSHLFIHQITHTGKKPYECTECGKTFPRKTQLIIHQRTHTGEKPYKCGECGKTFCQQSHLIGHQRIHTGEKPYVCTDCGKAFSQKSHLTGHQRLHTGEKPYMCTECGKSFSQKSPLIIHQRIHTGEKPYQCGECGKTFSQKSLLIIHLRVHTGEKPYECTECGRAFSLKSHLILHQRGHTGEKPYECSECGKAFCGKSPLIIHQKTHPREKTPECAESGMTFFWKSQMITYQRRHTGEKPSRCSDCGKAFCQHVYFTGHQNPYRKDTLYIC>sp|Q2M218-2|ZN630_HUMAN Isoform 2 of Zinc finger protein 630 OS=Homosapiens OX=9606 GN=ZNF630MIESQEEWQQLNPAQKTLHRDVMLETYNHLVSVGCSGIKPDVIFKLEHGKDPWIIESELSRWIYPDRVKGLESSQQIISGELLFQREILERAPKDNSLYSVLKIWHIDNQMDRYQGNQDRVLRQVTVISRETLTDEMGSKYSAFGKMFNRCTDLAPLSQKFHKFDSCENSLKSNSDLLNYNRSYARKNPTKRFRCGRPPKYNASCSVPEKEGFIHTGMEPYGDSQCEKVLSHKQAHVQYKKFQAREKPNVCSMCGKAFIKKSQLIIHQRIHTGEKPYVCGDCRKAFSEKSHLIVHQRIHTGEKPYECTKYGRAFSRKSPFTVHQRVHTGEKPYECFECPKAFSQKSHLIIHQRVHTREKPFECSECRKAFCEMSHLFIHQITHTGKKPYECTECGKTFPRKTQLIIHQRTHTGEKPYKCGECGKTFCQQSHLIGHQRIHTGEKPYVCTDCGKAFSQKSHLTGHQRLHTGEKPYMCTECGKSFSQKSPLIIHQRIHTGEKPYQCGECGKTFSQKSLLIIHLRVHTGEKPYECTECGRAFSLKSHLILHQRGHTGEKPYECSECGKAFCGKSPLIIHQKTHPREKTPECAESGMTFFWKSQMITYQRRHTGEKPSRCSDCGKAFCQHVYFTGHQNPYRKDTLYIC>sp|Q6UXI7|VITRN_HUMAN Vitrin OS=Homo sapiens OX=9606 GN=VIT PE=2 SV=1MRTVVLTMKASVIEMFLVLLVTGVHSNKETAKKIKRPKFTVPQINCDVKAGKIIDPEFIVKCPAGCQDPKYHVYGTDVYASYSSVCGAAVHSGVLDNSGGKILVRKVAGQSGYKGSYSNGVQSLSLPRWRESFIVLESKPKKGVTYPSALTYSSSKSPAAQAGETTKAYQRPPIPGTTAQPVTLMQLLAVTVAVATPTTLPRPSPSAASTTSIPRPQSVGHRSQEMDLWSTATYTSSQNRPRADPGIQRQDPSGAAFQKPVGADVSLGLVPKEELSTQSLEPVSLGDPNCKIDLSFLIDGSTSIGKRRFRIQKQLLADVAQALDIGPAGPLMGVVQYGDNPATHFNLKTHTNSRDLKTAIEKITQRGGLSNVGRAISFVTKNFFSKANGNRSGAPNVVVVMVDGWPTDKVEEASRLARESGINIFFITIEGAAENEKQYVVEPNFANKAVCRTNGFYSLHVQSWFGLHKTLQPLVKRVCDTDRLACSKTCLNSADIGFVIDGSSSVGTGNFRTVLQFVTNLTKEFEISDTDTRIGAVQYTYEQRLEFGFDKYSSKPDILNAIKRVGYWSGGTSTGAAINFALEQLFKKSKPNKRKLMILITDGRSYDDVRIPAMAAHLKGVITYAIGVAWAAQEELEVIATHPARDHSFFVDEFDNLHQYVPRIIQNICTEFNSQPRN>sp|Q6UXI7-2|VITRN_HUMAN Isoform 2 of Vitrin OS=Homo sapiens OX=9606GN=VITMRTVVLTMKASVIEMFLVLLVTGVHSNKETAKKIKRPKFTVPQINCDVKAGKIIDPEFIVKCPAGCQDPKYHVYGTDVYASYSSVCGAAVHSGVLDNSGGKILVRKVAGQSGYKGSYSNGVQSLSLPRWRESFIVLESKPKKGVTYPSALTYSSSKSPAAQAGETTKAYQRPPIPGTTAQPVTLMQLLAVTVAVATPTTLPRPSPSAASTTSIPRPQSVGHRSQEMDLWSTATYTSSQNRPRADPGLVPKEELSTQSLEPVSLGDPNCKIDLSFLIDGSTSIGKRRFRIQKQLLADVAQALDIGPAGPLMGVVQYGDNPATHFNLKTHTNSRDLKTAIEKITQRGGLSNVGRAISFVTKNFFSKANGNRSGAPNVVVVMVDGWPTDKVEEASRLARESGINIFFITIEGAAENEKQYVVEPNFANKAVCRTNGFYSLHVQSWFGLHKTLQPLVKRVCDTDRLACSKTCLNSADIGFVIDGSSSVGTGNFRTVLQFVTNLTKEFEISDTDTRIGAVQYTYEQRLEFGFDKYSSKPDILNAIKRVGYWSGGTSTGAAINFALEQLFKKSKPNKRKLMILITDGRSYDDVRIPAMAAHLKGVITYAIGVAWAAQEELEVIATHPARDHSFFVDEFDNLHQYVPRIIQNICTEFNSQPRN>sp|Q6UXI7-3|VITRN_HUMAN Isoform 3 of Vitrin OS=Homo sapiens OX=9606GN=VITMRTVVLTMKASVIEMFLVLLVTGVHSNKETAKKIKRPKFTVPQINCDVKAGKIIDPEFIVKCPAGCQDPKYHVYGTDVYASYSSVCGAAVHSGVLDNSGGKILVRKVAGQSGYKGSYSNGVQSLSLPRWRESFIVLESKPKKGVTYPSALTYSSSKSPAAQAGKCSRVIESKPSESMNTRRVLGDSGEINILTGQAPLALAIF>sp|Q6UXI7-4|VITRN_HUMAN Isoform 4 of Vitrin OS=Homo sapiens OX=9606GN=VITMRTVVLTMKASVIEMFLVLLVTGVHSNKETAKKIKRPKFTVPQINCDVKAGKIIDPEFIVKCPAGCQDPKYHVYGTDVYASYSSVCGAAVHSGVLDNSGGKILVRKVAGQSGYKGSYSNGVQSLSLPRWRESFIVLESKPKKGVTYPSALTYSSSKSPAAQAGETTKAYQRPPIPGTTAQPVTLMQLLAVTVAVATPTTLPRPSPSAASTTSIPRPQSVGHRSQEMDLWSTATYTSSQNRPRADPGIQRQDPSGAAFQKPVGADVSLGEMDSWKPGSVLLDEGLVPKEELSTQSLEPVSLGDPNCKIDLSFLIDGSTSIGKRRFRIQKQLLADVAQALDIGPAGPLMGVVQYGDNPATHFNLKTHTNSRDLKTAIEKITQRGGLSNVGRAISFVTKNFFSKANGNRSGAPNVVVVMVDGWPTDKVEEASRLARESGINIFFITIEGAAENEKQYVVEPNFANKAVCRTNGFYSLHVQSWFGLHKTLQPLVKRVCDTDRLACSKTCLNSADIGFVIDGSSSVGTGNFRTVLQFVTNLTKEFEISDTDTRIGAVQYTYEQRLEFGFDKYSSKPDILNAIKRVGYWSGGTSTGAAINFALEQLFKKSKPNKRKLMILITDGRSYDDVRIPAMAAHLKGVITYAIGVAWAAQEELEVIATHPARDHSFFVDEFDNLHQYVPRIIQNICTEFNSQPRN>sp|Q6UXI7-5|VITRN_HUMAN Isoform 5 of Vitrin OS=Homo sapiens OX=9606GN=VITMRTVVLTMKASVIEMFLVLLVTGVHSNKETAKKIKRPKFTVPQINCDVKAGKIIDPEFIVKCPAGCQDPKYHVYGTDVYASYSSVCGAAVHSGVLDNSGGKILVRKVAGQSGYKGSYSNGVQSLSLPRWRESFIVLESKPKKGVTYPSALTYSSSKSPAAQAGETTKAYQRPPIPGTTAQPVTLMQLLAVTVAVATPTTLPRPSPSAASTTSIPRPQSVGHRSQEMDLWSTATYTSSQNRPRADPGIQRQDPSGAAFQKPVGADVSLDCKIDLSFLIDGSTSIGKRRFRIQKQLLADVAQALDIGPAGPLMGVVQYGDNPATHFNLKTHTNSRDLKTAIEKITQRGGLSNVGRAISFVTKNFFSKANGNRSGAPNVVVVMVDGWPTDKVEEASRLARESGINIFFITIEGAAENEKQYVVEPNFANKAVCRTNGFYSLHVQSWFGLHKTLQPLVKRVCDTDRLACSKTCLNSADIGFVIDGSSSVGTGNFRTVLQFVTNLTKEFEISDTDTRIGAVQYTYEQRLEFGFDKYSSKPDILNAIKRVGYWSGGTSTGAAINFALEQLFKKSKPNKRKLMILITDGRSYDDVRIPAMAAHLKGVITYAIGVAWAAQEELEVIATHPARDHSFFVDEFDNLHQYVPRIIQNICTEFNSQPRN>sp|Q92558|WASF1_HUMAN Wiskott-Aldrich syndrome protein family member 1OS=Homo sapiens OX=9606 GN=WASF1 PE=1 SV=1MPLVKRNIDPRHLCHTALPRGIKNELECVTNISLANIIRQLSSLSKYAEDIFGELFNEAHSFSFRVNSLQERVDRLSVSVTQLDPKEEELSLQDITMRKAFRSSTIQDQQLFDRKTLPIPLQETYDVCEQPPPLNILTPYRDDGKEGLKFYTNPSYFFDLWKEKMLQDTEDKRKEKRKQKQKNLDRPHEPEKVPRAPHDRRREWQKLAQGPELAEDDANLLHKHIEVANGPASHFETRPQTYVDHMDGSYSLSALPFSQMSELLTRAEERVLVRPHEPPPPPPMHGAGDAKPIPTCISSATGLIENRPQSPATGRTPVFVSPTPPPPPPPLPSALSTSSLRASMTSTPPPPVPPPPPPPATALQAPAVPPPPAPLQIAPGVLHPAPPPIAPPLVQPSPPVARAAPVCETVPVHPLPQGEVQGLPPPPPPPPLPPPGIRPSSPVTVTALAHPPSGLHPTPSTAPGPHVPLMPPSPPSQVIPASEPKRHPSTLPVISDARSVLLEAIRKGIQLRKVEEQREQEAKHERIENDVATILSRRIAVEYSDSEDDSEFDEVDWLE>sp|P07947|YES_HUMAN Tyrosine-protein kinase Yes OS=Homo sapiens OX=9606GN=YES1 PE=1 SV=3MGCIKSKENKSPAIKYRPENTPEPVSTSVSHYGAEPTTVSPCPSSSAKGTAVNFSSLSMTPFGGSSGVTPFGGASSSFSVVPSSYPAGLTGGVTIFVALYDYEARTTEDLSFKKGERFQIINNTEGDWWEARSIATGKNGYIPSNYVAPADSIQAEEWYFGKMGRKDAERLLLNPGNQRGIFLVRESETTKGAYSLSIRDWDEIRGDNVKHYKIRKLDNGGYYITTRAQFDTLQKLVKHYTEHADGLCHKLTTVCPTVKPQTQGLAKDAWEIPRESLRLEVKLGQGCFGEVWMGTWNGTTKVAIKTLKPGTMMPEAFLQEAQIMKKLRHDKLVPLYAVVSEEPIYIVTEFMSKGSLLDFLKEGDGKYLKLPQLVDMAAQIADGMAYIERMNYIHRDLRAANILVGENLVCKIADFGLARLIEDNEYTARQGAKFPIKWTAPEAALYGRFTIKSDVWSFGILQTELVTKGRVPYPGMVNREVLEQVERGYRMPCPQGCPESLHELMNLCWKKDPDERPTFEYIQSFLEDYFTATEPQYQPGENL>sp|Q75L30|YG027_HUMAN Putative uncharacterized protein FLJ92257 OS=Homosapiens OX=9606 PE=5 SV=1MATFPGQVSTYFLAAWTGPGPATHWPLYAQLMPHSGLSRPSSCPGTSSPGPKLPQVGLSRPSCCLPAFSPGLALPPGCIYKTNSCLTTTFYGSAPAQLLPAFVGPKLPQVKLFRPTFCLAVACTDPALA>sp|Q8N1X5|YF001_HUMAN Uncharacterized protein FLJ37310 OS=Homo sapiensOX=9606 PE=2 SV=1MAAAGVTAKAGGGTSAAAASLIRARSPAWPRRAVSCSLARGTGAPKCGSDSTPPPPLPRRRSRARRGHLGNGDRPSAGATVGGEGQASQIGGGGGGGGGRRNATGRGRRRRQGGAGSAVKCRRDSVLEPGLASSPGVAPAGGSGGLWSGAGLCSGLGARGFPGGRRSGRDAG>sp|A6NC05|YD286_HUMAN Glutaredoxin-like protein C5orf63 OS=Homo sapiensOX=9606 GN=C5orf63 PE=2 SV=3MLWFQGNSMQLARSSFGLFLRNCSASKTTLPVLTLFTKDPCPLCDEAKEVLKPYENRQPYKDQKLPGTRRRRSPSSPSHPHMASQSGKRYNLTLNQVLSFDYDMGLDAPKTISSDCGAFYCLRMFKSPDMTCCFYPKQ>sp|A6NC05-2|YD286_HUMAN Isoform 2 of Glutaredoxin-like protein C5orf63OS=Homo sapiens OX=9606 GN=C5orf63MLWFQGNSMQLARSSFGLFLRNCSASKTTLPVLTLFTKDPCPLCDEAKEVLKPYENRFILQEVNITLPENSVWYERYKFDIPVFHLNGQFLMMHRVNTSKLEKQLLKLEQQSTGG>sp|Q9UL36|ZN236_HUMAN Zinc finger protein 236 OS=Homo sapiens OX=9606GN=ZNF236 PE=1 SV=2MGLCGLLERCWLHHDPDGVLTLNAENTNYAYQVPNFHKCEICLLSFPKESQFQRHMRDHERNDKPHRCDQCPQTFNVEFNLTLHKCTHSGEDPTCPVCNKKFSRVASLKAHIMLHEKEENLICSECGDEFTLQSQLAVHMEEHRQELAGTRQHACKACKKEFETSSELKEHMKTHYKIRVSSTRSYNRNIDRSGFTYSCPHCGKTFQKPSQLTRHIRIHTGERPFKCSECGKAFNQKGALQTHMIKHTGEKPHACAFCPAAFSQKGNLQSHVQRVHSEVKNGPTYNCTECSCVFKSLGSLNTHISKMHMGGPQNSTSSTETAHVLTATLFQTLPLQQTEAQATSASSQPSSQAVSDVIQQLLELSEPAPVESGQSPQPGQQLSITVGINQDILQQALENSGLSSIPAAAHPNDSCHAKTSAPHAQNPDVSSVSNEQTDPTDAEQEKEQESPEKLDKKEKKMIKKKSPFLPGSIREENGVRWHVCPYCAKEFRKPSDLVRHIRIHTHEKPFKCPQCFRAFAVKSTLTAHIKTHTGIKAFKCQYCMKSFSTSGSLKVHIRLHTGVRPFACPHCDKKFRTSGHRKTHIASHFKHTELRKMRHQRKPAKVRVGKTNIPVPDIPLQEPILITDLGLIQPIPKNQFFQSYFNNNFVNEADRPYKCFYCHRAYKKSCHLKQHIRSHTGEKPFKCSQCGRGFVSAGVLKAHIRTHTGLKSFKCLICNGAFTTGGSLRRHMGIHNDLRPYMCPYCQKTFKTSLNCKKHMKTHRYELAQQLQQHQQAASIDDSTVDQQSMQASTQMQVEIESDELPQTAEVVAANPEAMLDLEPQHVVGTEEAGLGQQLADQPLEADEDGFVAPQDPLRGHVDQFEEQSPAQQSFEPAGLPQGFTVTDTYHQQPQFPPVQQLQDSSTLESQALSTSFHQQSLLQAPSSDGMNVTTRLIQESSQEELDLQAQGSQFLEDNEDQSRRSYRCDYCNKGFKKSSHLKQHVRSHTGEKPYKCKLCGRGFVSSGVLKSHEKTHTGVKAFSCSVCNASFTTNGSLTRHMATHMSMKPYKCPFCEEGFRTTVHCKKHMKRHQTVPSAVSATGETEGGDICMEEEEEHSDRNASRKSRPEVITFTEEETAQLAKIRPQESATVSEKVLVQSAAEKDRISELRDKQAELQDEPKHANCCTYCPKSFKKPSDLVRHVRIHTGEKPYKCDECGKSFTVKSTLDCHVKTHTGQKLFSCHVCSNAFSTKGSLKVHMRLHTGAKPFKCPHCELRFRTSGRRKTHMQFHYKPDPKKARKPMTRSSSEGLQPVNLLNSSSTDPNVFIMNNSVLTGQFDQNLLQPGLVGQAILPASVSAGGDLTVSLTDGSLATLEGIQLQLAANLVGPNVQISGIDAASINNITLQIDPSILQQTLQQGNLLAQQLTGEPGLAPQNSSLQTSDSTVPASVVIQPISGLSLQPTVTSANLTIGPLSEQDSVLTTNSSGTQDLTQVMTSQGLVSPSGGPHEITLTINNSSLSQVLAQAAGPTATSSSGSPQEITLTISELNTTSGSLPSTTPMSPSAISTQNLVMSSSGVGGDASVTLTLADTQGMLSGGLDTVTLNITSQGQQFPALLTDPSLSGQGGAGSPQVILVSHTPQSASAACEEIAYQVAGVSGNLAPGNQPEKEGRAHQCLECDRAFSSAAVLMHHSKEVHGRERIHGCPVCRKAFKRATHLKEHMQTHQAGPSLSSQKPRVFKCDTCEKAFAKPSQLERHSRIHTGERPFHCTLCEKAFNQKSALQVHMKKHTGERPYKCAYCVMGFTQKSNMKLHMKRAHSYAGALQESAGHPEQDGEELSRTLHLEEVVQEAAGEWQALTHVF>sp|Q9UL36-2|ZN236_HUMAN Isoform A of Zinc finger protein 236 OS=Homosapiens OX=9606 GN=ZNF236MGLCGLLERCWLHHDPDGVLTLNAENTNYAYQVPNFHKCEICLLSFPKESQFQRHMRDHERNDKPHRCDQCPQTFNVEFNLTLHKCTHSGEDPTCPVCNKKFSRVASLKAHIMLHEKEENLICSECGDEFTLQSQLAVHMEEHRQELAGTRQHACKACKKEFETSSELKEHMKTHYKIRVSSTRSYNRNIDRSGFTYSCPHCGKTFQKPSQLTRHIRIHTGERPFKCSECGKAFNQKGALQTHMIKHTGEKPHACAFCPAAFSQKGNLQSHVQRVHSEVKNGPTYNCTECSCVFKSLGSLNTHISKMHMGGPQNSTSSTETAHVLTATLFQTLPLQQTEAQATSASSQPSSQAVSDVIQQLLELSEPAPVESGQSPQPGQQLSITVGINQDILQQALENSGLSSIPAAAHPNDSCHAKTSAPHAQNPDVSSVSNEQTDPTDAEQEKEQESPEKLDKKEKKMIKKKSPFLPGSIREENGVRWHVCPYCAKEFRKPSDLVRHIRIHTHEKPFKCPQCFRAFAVKSTLTAHIKTHTGIKAFKCQYCMKSFSTSGSLKVHIRLHTGVRPFACPHCDKKFRTSGHRKTHIASHFKHTELRKMRHQRKPAKVRVGKTNIPVPDIPLQEPILITDLGLIQPIPKNQFFQSYFNNNFVNEADRPYKCFYCHRAYKKSCHLKQHIRSHTGEKPFKCSQCGRGFVSAGVLKAHIRTHTGLKSFKCLICNGAFTTGGSLRRHMGIHNDLRPYMCPYCQKTFKTSLNCKKHMKTHRYELAQQLQQHQQAASIDDSTVDQQSMQASTQMQVEIESDELPQTAEVVAANPEAMLDLEPQHVVGTEEAGLGQQLADQPLEADEDGFVAPQDPLRGHVDQFEEQSPAQQSFEPAGLPQGFTVTDTYHQQPQFPPVQQLQDSSTLESQALSTSFHQQSLLQAPSSDGMNVTTRLIQESSQEELDLQAQGSQFLEDNEDQSRRSYRCDYCNKGFKKSSHLKQHVRSHTGEKPYKCKLCGRGFVSSGVLKSHEKTHTGVKAFSCSVCNASFTTNGSLTRHMATHMSMKPYKCPFCEEGFRTTVHCKKHMKRHQTVPSAVSATGETEGGDICMEEEEEHSDRNASRKSRPEVITFTEEETAQLAKIRPQESATVSEKVLVQSAAEKDRISELRDKQAELQDEPKHANCCTYCPKSFKKPSDLVRHVRIHTGEKPYKCDECGKSFTVKSTLDCHVKTHTGQKLFSCHVCSNAFSTKGSLKVHMRLHTGAKPFKCPHCELRFRTSGRRKTHMQFHYKPDPKKARKPMTRSSSEGLQPVNLLNSSSTDPNVFIMNNSVLTGQFDQNLLQPGLVGQAILPASVSAGGDLTVSLTDGSLATLEGIQLQLAANLVGPNVQISGIDAASINNITLQIDPSILQQTLQQGNLLAQQLTGEPGLAPQNSSLQTSDSTVPASVVIQPISGLSLQPTVTSANLTIGPLSEQDSVLTTNSSGTQDLTQVMTSQGLVSPSGGPHEITLTINNSSLSQVLAQAAGPTATSSSGSPQEITLTISGSRSVQHSVGPQECGSVEALYLENSSDKT>sp|Q14592|ZN460_HUMAN Zinc finger protein 460 OS=Homo sapiens OX=9606GN=ZNF460 PE=1 SV=2MAAAWMAPAQESVTFEDVAVTFTQEEWGQLDVTQRALYVEVMLETCGLLVALGDSTKPETVEPIPSHLALPEEVSLQEQLAQGVPRYSYLGQAMDQDGPSEMQEYFLRPGTDPQSEKLHGKMSLEHEGLATADGICSMMIQNQVSPEDALYGFDSYGPVTDSLIHEGENSYKFEEMFNENCFLVQHEQILPRVKPYDCPECGKAFGKSKHLLQHHIIHTGEKPYKCLECGKDFNRRSHLTRHQRTHNGDKPFVCSECGRTFNRGSHLTRHQRVHSGEKPFVCNECGKAFTYRSNFVLHNKSHNEKKPFACSECGKGFYESTALIQHFIIHTGERPFKCLECGKAFNCRSHLKQHERIHTGEKPFVCSQCGKAFTHYSTYVLHERAHTGEKPFECKECGKAFSIRKDLIRHFNIHTGEKPYECLQCGKAFTRMSGLTRHQWIHTGEKPYVCIQCGKAFCRTTNLIRHFSIHTGEKPYECVECGKAFNRRSPLTRHQRIHTAEKSHEPIQSGNVSCESTDLIQHSIIHTESSPVSAVNMETPSIAAHSSSLDINGFIVEETLPL>sp|Q14592-2|ZN460_HUMAN Isoform 2 of Zinc finger protein 460 OS=Homosapiens OX=9606 GN=ZNF460MLETCGLLVALGDSTKPETVEPIPSHLALPEEVSLQEQLAQGVPRYSYLGQAMDQDGPSEMQEYFLRPGTDPQSEKLHGKMSLEHEGLATADGICSMMIQNQVSPEDALYGFDSYGPVTDSLIHEGENSYKFEEMFNENCFLVQHEQILPRVKPYDCPECGKAFGKSKHLLQHHIIHTGEKPYKCLECGKDFNRRSHLTRHQRTHNGDKPFVCSECGRTFNRGSHLTRHQRVHSGEKPFVCNECGKAFTYRSNFVLHNKSHNEKKPFACSECGKGFYESTALIQHFIIHTGERPFKCLECGKAFNCRSHLKQHERIHTGEKPFVCSQCGKAFTHYSTYVLHERAHTGEKPFECKECGKAFSIRKDLIRHFNIHTGEKPYECLQCGKAFTRMSGLTRHQWIHTGEKPYVCIQCGKAFCRTTNLIRHFSIHTGEKPYECVECGKAFNRRSPLTRHQRIHTAEKSHEPIQSGNVSCESTDLIQHSIIHTESSPVSAVNMETPSIAAHSSSLDINGFIVEETLPL>sp|Q9Y493|ZAN_HUMAN Zonadhesin OS=Homo sapiens OX=9606 GN=ZAN PE=2 SV=5MVPPVWTLLLLVGAALFRKEKPPDQKLVVRSSRDNYVLTQCDFEDDAKPLCDWSQVSADDEDWVRASGPSPTGSTGAPGGYPNGEGSYLHMESNSFHRGGVARLLSPDLWEQGPLCVHFAHHMFGLSWGAQLRLLLLSGEEGRRPDVLWKHWNTQRPSWMLTTVTVPAGFTLPTRLMFEGTRGSTAYLDIALDALSIRRGSCNRVCMMQTCSFDIPNDLCDWTWIPTASGAKWTQKKGSSGKPGVGPDGDFSSPGSGCYMLLDPKNARPGQKAVLLSPVSLSSGCLSFSFHYILRGQSPGAALHIYASVLGSIRKHTLFSGQPGPNWQAVSVNYTAVGRIQFAVVGVFGKTPEPAVAVDATSIAPCGEGFPQCDFEDNAHPFCDWVQTSGDGGHWALGHKNGPVHGMGPAGGFPNAGGHYIYLEADEFSQAGQSVRLVSRPFCAPGDICVEFAYHMYGLGEGTMLELLLGSPAGSPPIPLWKRVGSQRPYWQNTSVTVPSGHQQPMQLIFKGIQGSNTASVVAMGFILINPGTCPVKVLPELPPVSPVSSTGPSETTGLTENPTISTKKPTVSIEKPSVTTEKPTVPKEKPTIPTEKPTISTEKPTIPSEKPNMPSEKPTIPSEKPTILTEKPTIPSEKPTIPSEKPTISTEKPTVPTEEPTTPTEETTTSMEEPVIPTEKPSIPTEKPSIPTEKPTISMEETIISTEKPTISPEKPTIPTEKPTIPTEKSTISPEKPTTPTEKPTIPTEKPTISPEKPTTPTEKPTISPEKLTIPTEKPTIPTEKPTIPTEKPTISTEEPTTPTEETTISTEKPSIPMEKPTLPTEETTTSVEETTISTEKLTIPMEKPTISTEKPTIPTEKPTISPEKLTIPTEKLTIPTEKPTIPIEETTISTEKLTIPTEKPTISPEKPTISTEKPTIPTEKPTIPTEETTISTEKLTIPTEKPTISPEKLTIPTEKPTISTEKPTIPTEKLTIPTEKPTIPTEKPTIPTEKLTALRPPHPSPTATGLAALVMSPHAPSTPMTSVILGTTTTSRSSTERCPPNARYESCACPASCKSPRPSCGPLCREGCVCNPGFLFSDNHCIQASSCNCFYNNDYYEPGAEWFSPNCTEHCRCWPGSRVECQISQCGTHTVCQLKNGQYGCHPYAGTATCLVYGDPHYVTFDGRHFGFMGKCTYILAQPCGNSTDPFFRVTAKNEEQGQEGVSCLSKVYVTLPESTVTLLKGRRTLVGGQQVTLPAIPSKGVFLGASGRFVELQTEFGLRVRWDGDQQLYVTVSSTYSGKLCGLCGNYDGNSDNDHLKLDGSPAGDKEELGNSWQTDQDEDQECQKYQVVNSPSCDSSLQSSMSGPGFCGRLVDTHGPFETCLLHVKAASFFDSCMLDMCGFQGLQHLLCTHMSTMTTTCQDAGHAVKPWREPHFCPMACPPNSKYSLCAKPCPDTCHSGFSGMFCSDRCVEACECNPGFVLSGLECIPRSQCGCLHPAGSYFKVGERWYKPGCKELCVCESNNRIRCQPWRCRAQEFCGQQDGIYGCHAQGAATCTASGDPHYLTFDGALHHFMGTCTYVLTRPCWSRSQDSYFVVSATNENRGGILEVSYIKAVHVTVFDLSISLLRGCKVMLNGHRVALPVWLAQGRVTIRLSSNLVLLYTNFGLQVRYDGSHLVEVTVPSSYGGQLCGLCGNYNNNSLDDNLRPDRKLAGDSMQLGAAWKLPESSEPGCFLVGGKPSSCQENSMADAWNKNCAILINPQGPFSQCHQVVPPQSSFASCVHGQCGTKGDTTALCRSLQAYASLCAQAGQAPAWRNRTFCPMRCPPGSSYSPCSSPCPDTCSSINNPRDCPKALPCAESCECQKGHILSGTSCVPLGQCGCTDPAGSYHPVGERWYTENTCTRLCTCSVHNNITCFQSTCKPNQICWALDGLLHCRASGVGVCQLPGESHYVSFDGSNHSIPDACTLVLVKVCHPAMALPFFKISAKHEKEEGGTEAFRLHEVYIDIYDAQVTLQKGHRVLINSKQVTLPAISQIPGVSVKSSSIYSIVNIKIGVQVKFDGNHLLEIEIPTTYYGKVCGMCGNFNDEEEDELMMPSDEVANSDSEFVNSWKDKDIDPSCQSLLVDEQQIPAEQQENPSGNCRAADLRRAREKCEAALRAPVWAQCASRIDLTPFLVDCANTLCEFGGLYQALCQALQAFGATCQSQGLKPPLWRNSSFCPLECPAYSSYTNCLPSCSPSCWDLDGRCEGAKVPSACAEGCICQPGYVLSEDKCVPRSQCGCKDAHGGSIPLGKSWVSSGCTEKCVCTGGAIQCGDFRCPSGSHCQLTSDNSNSNCVSDKSEQCSVYGDPRYLTFDGFSYRLQGRMTYVLIKTVDVLPEGVEPLLVEGRNKMDPPRSSIFLQEVITTVYGYKVQLQAGLELVVNNQKMAVPYRPNEHLRVTLWGQRLYLVTDFELVVSFGGRKNAVISLPSMYEGLVSGLCGNYDKNRKNDMMLPSGALTQNLNTFGNSWEVKTEDALLRFPRAIPAEEEGQGAELGLRTGLQVSECSPEQLASNSTQACRVLADPQGPFAACHQTVAPEPFQEHCVLDLCSAQDPREQEELRCQVLSGHGVSSRYHISELYDTLPSILCQPGRPRGLRGPLRGRLRQHPRLCLQWHPEPPLADCGCTSNGIYYQLGSSFLTEDCSQRCTCASSRILLCEPFSCRAGEVCTLGNHTQGCFPESPCLQNPCQNDGQCREQGATFTCECEVGYGGGLCMEPRDAPPPRKPASNLVGVLLGLLVPVVVVLLAVTRECIYRTRRKREKTQEGDRLARLVDTDTVLDCAC>sp|Q9Y493-2|ZAN_HUMAN Isoform 1 of Zonadhesin OS=Homo sapiens OX=9606GN=ZANMVPPVWTLLLLVGAALFRKEKPPDQKLVVRSSRDNYVLTQCDFEDDAKPLCDWSQVSADDEDWVRASGPSPTGSTGAPGGYPNGEGSYLHMESNSFHRGGVARLLSPDLWEQGPLCVHFAHHMFGLSWGAQLRLLLLSGEEGRRPDVLWKHWNTQRPSWMLTTVTVPAGFTLPTRLMFEGTRGSTAYLDIALDALSIRRGSCNRVCMMQTCSFDIPNDLCDWTWIPTASGAKWTQKKGSSGKPGVGPDGDFSSPGSGCYMLLDPKNARPGQKAVLLSPVSLSSGCLSFSFHYILRGQSPGAALHIYASVLGSIRKHTLFSGQPGPNWQAVSVNYTAVGRIQFAVVGVFGKTPEPAVAVDATSIAPCGEGFPQCDFEDNAHPFCDWVQTSGDGGHWALGHKNGPVHGMGPAGGFPNAGGHYIYLEADEFSQAGQSVRLVSRPFCAPGDICVEFAYHMYGLGEGTMLELLLGSPAGSPPIPLWKRVGSQRPYWQNTSVTVPSGHQQPMQLIFKGIQGSNTASVVAMGFILINPGTCPVKVLPELPPVSPVSSTGPSETTGLTENPTISTKKPTVSIEKPSVTTEKPTVPKEKPTIPTEKPTISTEKPTIPSEKPNMPSEKPTIPSEKPTILTEKPTIPSEKPTIPSEKPTISTEKPTVPTEEPTTPTEETTTSMEEPVIPTEKPSIPTEKPSIPTEKPTISMEETIISTEKPTISPEKPTIPTEKPTIPTEKSTISPEKPTTPTEKPTIPTEKPTISPEKPTTPTEKPTISPEKLTIPTEKPTIPTEKPTIPTEKPTISTEEPTTPTEETTISTEKPSIPMEKPTLPTEETTTSVEETTISTEKLTIPMEKPTISTEKPTIPTEKPTISPEKLTIPTEKLTIPTEKPTIPIEETTISTEKLTIPTEKPTISPEKPTISTEKPTIPTEKPTIPTEETTISTEKLTIPTEKPTISPEKLTIPTEKPTISTEKPTIPTEKLTIPTEKPTIPTEKPTIPTEKLTALRPPHPSPTATGLAALVMSPHAPSTPMTSVILGTTTTSRSSTERCPPNARYESCACPASCKSPRPSCGPLCREGCVCNPGFLFSDNHCIQASSCNCFYNNDYYEPGAEWFSPNCTEHCRCWPGSRVECQISQCGTHTVCQLKNGQYGCHPYAGTATCLVYGDPHYVTFDGRHFGFMGKCTYILAQPCGNSTDPFFRVTAKNEEQGQEGVSCLSKVYVTLPESTVTLLKGRRTLVGGQQVTLPAIPSKGVFLGASGRFVELQTEFGLRVRWDGDQQLYVTVSSTYSGKLCGLCGNYDGNSDNDHLKLDGSPAGDKEELGNSWQTDQDEDQECQKYQVVNSPSCDSSLQSSMSGPGFCGRLVDTHGPFETCLLHVKAASFFDSCMLDMCGFQGLQHLLCTHMSTMTTTCQDAGHAVKPWREPHFCPMACPPNSKYSLCAKPCPDTCHSGFSGMFCSDRCVEACECNPGFVLSGLECIPRSQCGCLHPAGSYFKVGERWYKPGCKELCVCESNNRIRCQPWRCRAQEFCGQQDGIYGCHAQGAATCTASGDPHYLTFDGALHHFMGTCTYVLTRPCWSRSQDSYFVVSATNENRGGILEVSYIKAVHVTVFDLSISLLRGCKVMLNGHRVALPVWLAQGRVTIRLSSNLVLLYTNFGLQVRYDGSHLVEVTVPSSYGGQLCGLCGNYNNNSLDDNLRPDRKLAGDSMQLGAAWKLPESSEPGCFLVGGKPSSCQENSMADAWNKNCAILINPQGPFSQCHQVVPPQSSFASCVHGQCGTKGDTTALCRSLQAYASLCAQAGQAPAWRNRTFCPMRCPPGSSYSPCSSPCPDTCSSINNPRDCPKALPCAESCECQKGHILSGTSCVPLGQCGCTDPAGSYHPVGERWYTENTCTRLCTCSVHNNITCFQSTCKPNQICWALDGLLHCRASGVGVCQLPGESHYVSFDGSNHSIPDACTLVLVKVCHPAMALPFFKISAKHEKEEGGTEAFRLHEVYIDIYDAQVTLQKGHRVLINSKQVTLPAISQIPGVSVKSSSIYSIVNIKIGVQVKFDGNHLLEIEIPTTYYGKVCGMCGNFNDEEEDELMMPSDEVANSDSEFVNSWKDKDIDPSCQSLLVDEQQIPAEQQENPSGNCRAADLRRAREKCEAALRAPVWAQCASRIDLTPFLVDCANTLCEFGGLYQALCQALQAFGATCQSQGLKPPLWRNSSFCPLECPAYSSYTNCLPSCSPSCWDLDGRCEGAKVPSACAEGCICQPGYVLSEDKCVPRSQCGCKDAHGGSIPLGKSWVSSGCTEKCVCTGGAIQCGDFRCPSGSHCQLTSDNSNSNCVSDKSEQCSVYGDPRYLTFDGFSYRLQGRMTYVLIKTVDVLPEGVEPLLVEGRNKMDPPRSSIFLQEVITTVYGYKVQLQAGLELVVNNQKMAVPYRPNEHLRVTLWGQRLYLVTDFELVVSFGGRKNAVISLPSMYEGLVSGLCGNYDKNRKNDMMLPSGALTQNLNTFGNSWEVKTEDALLRFPRAIPAEEEGQGAELGLRTGLQVSECSPEQLASNSTQACRVLADPQGPFAACHQTVAPEPFQEHCVLDLCSAQDPREQEELRCQVLSGYAILCQEAGAALAGWRDRTLCAMECPAGTIYQSCMTPCPASCANLADPGDCEGPCVEGCASIPGYAYSGTQSLPWLTVAAPAMASTTRSELAAGGPGEQRRQGEPDQGWNWNVSSWPFPFLAGQQLSD>sp|Q9Y493-3|ZAN_HUMAN Isoform 2 of Zonadhesin OS=Homo sapiens OX=9606GN=ZANMVPPVWTLLLLVGAALFRKEKPPDQKLVVRSSRDNYVLTQCDFEDDAKPLCDWSQVSADDEDWVRASGPSPTGSTGAPGGYPNGEGSYLHMESNSFHRGGVARLLSPDLWEQGPLCVHFAHHMFGLSWGAQLRLLLLSGEEGRRPDVLWKHWNTQRPSWMLTTVTVPAGFTLPTRLMFEGTRGSTAYLDIALDALSIRRGSCNRVCMMQTCSFDIPNDLCDWTWIPTASGAKWTQKKGSSGKPGVGPDGDFSSPGSGCYMLLDPKNARPGQKAVLLSPVSLSSGCLSFSFHYILRGQSPGAALHIYASVLGSIRKHTLFSGQPGPNWQAVSVNYTAVGRIQFAVVGVFGKTPEPAVAVDATSIAPCGEGFPQCDFEDNAHPFCDWVQTSGDGGHWALGHKNGPVHGMGPAGGFPNAGGHYIYLEADEFSQAGQSVRLVSRPFCAPGDICVEFAYHMYGLGEGTMLELLLGSPAGSPPIPLWKRVGSQRPYWQNTSVTVPSGHQQPMQLIFKGIQGSNTASVVAMGFILINPGTCPVKVLPELPPVSPVSSTGPSETTGLTENPTISTKKPTVSIEKPSVTTEKPTVPKEKPTIPTEKPTISTEKPTIPSEKPNMPSEKPTIPSEKPTILTEKPTIPSEKPTIPSEKPTISTEKPTVPTEEPTTPTEETTTSMEEPVIPTEKPSIPTEKPSIPTEKPTISMEETIISTEKPTISPEKPTIPTEKPTIPTEKSTISPEKPTTPTEKPTIPTEKPTISPEKPTTPTEKPTISPEKLTIPTEKPTIPTEKPTIPTEKPTISTEEPTTPTEETTISTEKPSIPMEKPTLPTEETTTSVEETTISTEKLTIPMEKPTISTEKPTIPTEKPTISPEKLTIPTEKLTIPTEKPTIPIEETTISTEKLTIPTEKPTISPEKPTISTEKPTIPTEKPTIPTEETTISTEKLTIPTEKPTISPEKLTIPTEKPTISTEKPTIPTEKLTIPTEKPTIPTEKPTIPTEKLTALRPPHPSPTATGLAALVMSPHAPSTPMTSVILGTTTTSRSSTERCPPNARYESCACPASCKSPRPSCGPLCREGCVCNPGFLFSDNHCIQASSCNCFYNNDYYEPGAEWFSPNCTEHCRCWPGSRVECQISQCGTHTVCQLKNGQYGCHPYAGTATCLVYGDPHYVTFDGRHFGFMGKCTYILAQPCGNSTDPFFRVTAKNEEQGQEGVSCLSKVYVTLPESTVTLLKGRRTLVGGQQVTLPAIPSKGVFLGASGRFVELQTEFGLRVRWDGDQQLYVTVSSTYSGKLCGLCGNYDGNSDNDHLKLDGSPAGDKEELGNSWQTDQDEDQECQKYQVVNSPSCDSSLQSSMSGPGFCGRLVDTHGPFETCLLHVKAASFFDSCMLDMCGFQGLQHLLCTHMSTMTTTCQDAGHAVKPWREPHFCPMACPPNSKYSLCAKPCPDTCHSGFSGMFCSDRCVEACECNPGFVLSGLECIPRSQCGCLHPAGSYFKVGERWYKPGCKELCVCESNNRIRCQPWRCRAQEFCGQQDGIYGCHAQGAATCTASGDPHYLTFDGALHHFMGTCTYVLTRPCWSRSQDSYFVVSATNENRGGILEVSYIKAVHVTVFDLSISLLRGCKVMLNGHRVALPVWLAQGRVTIRLSSNLVLLYTNFGLQVRYDGSHLVEVTVPSSYGGQLCGLCGNYNNNSLDDNLRPDRKLAGDSMQLGAAWKLPESSEPGCFLVGGKPSSCQENSMADAWNKNCAILINPQGPFSQCHQVVPPQSSFASCVHGQCGTKGDTTALCRSLQAYASLCAQAGQAPAWRNRTFCPMRCPPGSSYSPCSSPCPDTCSSINNPRDCPKALPCAESCECQKGHILSGTSCVPLGQCGCTDPAGSYHPVGERWYTENTCTRLCTCSVHNNITCFQSTCKPNQICWALDGLLHCRASGVGVCQLPGESHYVSFDGSNHSIPDACTLVLVKVCHPAMALPFFKISAKHEKEEGGTEAFRLHEVYIDIYDAQVTLQKGHRVLINSKQVTLPAISQIPGVSVKSSSIYSIVNIKIGVQVKFDGNHLLEIEIPTTYYGKVCGMCGNFNDEEEDELMMPSDEVANSDSEFVNSWKDKDIDPSCQSLLVDEQQIPAEQQENPSGNCRAADLRRAREKCEAALRAPVWAQCASRIDLTPFLVDCANTLCEFGGLYQALCQALQAFGATCQSQGLKPPLWRNSSFCPLECPAYSSYTNCLPSCSPSCWDLDGRCEGAKVPSACAEGCICQPGYVLSEDKCVPRSQCGCKDAHGGSIPLGKSWVSSGCTEKCVCTGGAIQCGDFRCPSGSHCQLTSDNSNSNCVSDKSEQCSVYGDPRYLTFDGFSYRLQGRMTYVLIKTVDVLPEGVEPLLVEGRNKMDPPRSSIFLQEVITTVYGYKVQLQAGLELVVNNQKMAVPYRPNEHLRVTLWGQRLYLVTDFELVVSFGGRKNAVISLPSMYEGLVSGLCGNYDKNRKNDMMLPSGALTQNLNTFGNSWEVKTEDALLRFPRAIPAEEEGQGAELGLRTGLQVSECSPEQLASNSTQACRVLADPQGPFAACHQTVAPEPFQEHCVLDLCSAQDPREQEELRCQVLSGYAILCQEAGAALAGWRDRTLCAMECPAGTIYQSCMTPCPASCANLADPGDCEGPCVEGCASIPGYAYSGTQSLPWLTVAAPAMASTTSWAAAF>sp|Q9Y493-4|ZAN_HUMAN Isoform 4 of Zonadhesin OS=Homo sapiens OX=9606GN=ZANMVPPVWTLLLLVGAALFRKEKPPDQKLVVRSSRDNYVLTQCDFEDDAKPLCDWSQVSADDEDWVRASGPSPTGSTGAPGGYPNGEGSYLHMESNSFHRGGVARLLSPDLWEQGPLCVHFAHHMFGLSWGAQLRLLLLSGEEGRRPDVLWKHWNTQRPSWMLTTVTVPAGFTLPTRLMFEGTRGSTAYLDIALDALSIRRGSCNRVCMMQTCSFDIPNDLCDWTWIPTASGAKWTQKKGSSGKPGVGPDGDFSSPGSGCYMLLDPKNARPGQKAVLLSPVSLSSGCLSFSFHYILRGQSPGAALHIYASVLGSIRKHTLFSGQPGPNWQAVSVNYTAVGRIQFAVVGVFGKTPEPAVAVDATSIAPCGEGFPQCDFEDNAHPFCDWVQTSGDGGHWALGHKNGPVHGMGPAGGFPNAGGHYIYLEADEFSQAGQSVRLVSRPFCAPGDICVEFAYHMYGLGEGTMLELLLGSPAGSPPIPLWKRVGSQRPYWQNTSVTVPSGHQQPMQLIFKGIQGSNTASVVAMGFILINPGTCPVKVLPELPPVSPVSSTGPSETTGLTENPTISTKKPTVSIEKPSVTTEKPTVPKEKPTIPTEKPTISTEKPTIPSEKPNMPSEKPTIPSEKPTILTEKPTIPSEKPTIPSEKPTISTEKPTVPTEEPTTPTEETTTSMEEPVIPTEKPSIPTEKPSIPTEKPTISMEETIISTEKPTISPEKPTIPTEKPTIPTEKSTISPEKPTTPTEKPTIPTEKPTISPEKPTTPTEKPTISPEKLTIPTEKPTIPTEKPTIPTEKPTISTEEPTTPTEETTISTEKPSIPMEKPTLPTEETTTSVEETTISTEKLTIPMEKPTISTEKPTIPTEKPTISPEKLTIPTEKLTIPTEKPTIPIEETTISTEKLTIPTEKPTISPEKPTISTEKPTIPTEKPTIPTEETTISTEKLTIPTEKPTISPEKLTIPTEKPTISTEKPTIPTEKLTIPTEKPTIPTEKPTIPTEKLTALRPPHPSPTATGLAALVMSPHAPSTPMTSVILGTTTTSRSSTERCPPNARYESCACPASCKSPRPSCGPLCREGCVCNPGFLFSDNHCIQASSCNCFYNNDYYEPGAEWFSPNCTEHCRCWPGSRVECQISQCGTHTVCQLKNGQYGCHPYAGTATCLVYGDPHYVTFDGRHFGFMGKCTYILAQPCGNSTDPFFRVTAKNEEQGQEGVSCLSKVYVTLPESTVTLLKGRRTLVGGQQVTLPAIPSKGVFLGASGRFVELQTEFGLRVRWDGDQQLYVTVSSTYSGKLCGLCGNYDGNSDNDHLKLDGSPAGDKEELGNSWQTDQDEDQECQKYQVVNSPSCDSSLQSSMSGPGFCGRLVDTHGPFETCLLHVKAASFFDSCMLDMCGFQGLQHLLCTHMSTMTTTCQDAGHAVKPWREPHFCPMACPPNSKYSLCAKPCPDTCHSGFSGMFCSDRCVEACECNPGFVLSGLECIPRSQCGCLHPAGSYFKVGERWYKPGCKELCVCESNNRIRCQPWRCRAQEFCGQQDGIYGCHAQGAATCTASGDPHYLTFDGALHHFMGTCTYVLTRPCWSRSQDSYFVVSATNENRGGILEVSYIKAVHVTVFDLSISLLRGCKVMLNGHRVALPVWLAQGRVTIRLSSNLVLLYTNFGLQVRYDGSHLVEVTVPSSYGGQLCGLCGNYNNNSLDDNLRPDRKLAGDSMQLGAAWKLPESSEPGCFLVGGKPSSCQENSMADAWNKNCAILINPQGPFSQCHQVVPPQSSFASCVHGQCGTKGDTTALCRSLQAYASLCAQAGQAPAWRNRTFCPMRCPPGSSYSPCSSPCPDTCSSINNPRDCPKALPCAESCECQKGHILSGTSCVPLGQCGCTDPAGSYHPVGERWYTENTCTRLCTCSVHNNITCFQSTCKPNQICWALDGLLHCRASGVGVCQLPGESHYVSFDGSNHSIPDACTLVLVKVCHPAMALPFFKISAKHEKEEGGTEAFRLHEVYIDIYDAQVTLQKGHRVLINSKQVTLPAISQIPGVSVKSSSIYSIVNIKIGVQVKFDGNHLLEIEIPTTYYGKVCGMCGNFNDEEEDELMMPSDEVANSDSEFVNSWKDKDIDPSCQSLLVDEQQIPAEQQENPSGNCRAADLRRAREKCEAALRAPVWAQCASRIDLTPFLVDCANTLCEFGGLYQALCQALQAFGATCQSQGLKPPLWRNSSFCPLECPAYSSYTNCLPSCSPSCWDLDGRCEGAKVPSACAEGCICQPGYVLSEDKCVPRSQCGCKDAHGGSIPLGKSWVSSGCTEKCVCTGGAIQCGDFRCPSGSHCQLTSDNSNSNCVSDKSEQCSVYGDPRYLTFDGFSYRLQGRMTYVLIKTVDVLPEGVEPLLVEGRNKMDPPRSSIFLQEVITTVYGYKVQLQAGLELVVNNQKMAVPYRPNEHLRVTLWGQRLYLVTDFELVVSFGGRKNAVISLPSMYEGLVSGLCGNYDKNRKNDMMLPSGALTQNLNTFGNSWEVKTEDALLRFPRAIPAEEEGQGAELGLRTGLQVSECSPEQLASNSTQACRVLADPQGPFAACHQTVAPEPFQEHCVLDLCSAQDPREQEELRCQVLSGYAILCQEAGAALAGWRDRTLCAGQQLSD>sp|Q9Y493-5|ZAN_HUMAN Isoform 5 of Zonadhesin OS=Homo sapiens OX=9606GN=ZANMVPPVWTLLLLVGAALFRKEKPPDQKLVVRSSRDNYVLTQCDFEDDAKPLCDWSQVSADDEDWVRASGPSPTGSTGAPGGYPNGEGSYLHMESNSFHRGGVARLLSPDLWEQGPLCVHFAHHMFGLSWGAQLRLLLLSGEEGRRPDVLWKHWNTQRPSWMLTTVTVPAGFTLPTRLMFEGTRGSTAYLDIALDALSIRRGSCNRVCMMQTCSFDIPNDLCDWTWIPTASGAKWTQKKGSSGKPGVGPDGDFSSPGSGCYMLLDPKNARPGQKAVLLSPVSLSSGCLSFSFHYILRGQSPGAALHIYASVLGSIRKHTLFSGQPGPNWQAVSVNYTAVGRIQFAVVGVFGKTPEPAVAVDATSIAPCGEGFPQCDFEDNAHPFCDWVQTSGDGGHWALGHKNGPVHGMGPAGGFPNAGGHYIYLEADEFSQAGQSVRLVSRPFCAPGDICVEFAYHMYGLGEGTMLELLLGSPAGSPPIPLWKRVGSQRPYWQNTSVTVPSGHQQPMQLIFKGIQGSNTASVVAMGFILINPGTCPVKVLPELPPVSPVSSTGPSETTGLTENPTISTKKPTVSIEKPSVTTEKPTVPKEKPTIPTEKPTISTEKPTIPSEKPNMPSEKPTIPSEKPTILTEKPTIPSEKPTIPSEKPTISTEKPTVPTEEPTTPTEETTTSMEEPVIPTEKPSIPTEKPSIPTEKPTISMEETIISTEKPTISPEKPTIPTEKPTIPTEKSTISPEKPTTPTEKPTIPTEKPTISPEKPTTPTEKPTISPEKLTIPTEKPTIPTEKPTIPTEKPTISTEEPTTPTEETTISTEKPSIPMEKPTLPTEETTTSVEETTISTEKLTIPMEKPTISTEKPTIPTEKPTISPEKLTIPTEKLTIPTEKPTIPIEETTISTEKLTIPTEKPTISPEKPTISTEKPTIPTEKPTIPTEETTISTEKLTIPTEKPTISPEKLTIPTEKPTISTEKPTIPTEKLTIPTEKPTIPTEKPTIPTEKLTALRPPHPSPTATGLAALVMSPHAPSTPMTSVILGTTTTSRSSTERCPPNARYESCACPASCKSPRPSCGPLCREGCVCNPGFLFSDNHCIQASSCNCFYNNDYYEPGAEWFSPNCTEHCRCWPGSRVECQISQCGTHTVCQLKNGQYGCHPYAGTATCLVYGDPHYVTFDGRHFGFMGKCTYILAQPCGNSTDPFFRVTAKNEEQGQEGVSCLSKVYVTLPESTVTLLKGRRTLVGGQQVTLPAIPSKGVFLGASGRFVELQTEFGLRVRWDGDQQLYVTVSSTYSGKLCGLCGNYDGNSDNDHLKLDGSPAGDKEELGNSWQTDQDEDQECQKYQVVNSPSCDSSLQSSMSGPGFCGRLVDTHGPFETCLLHVKAASFFDSCMLDMCGFQGLQHLLCTHMSTMTTTCQDAGHAVKPWREPHFCPMACPPNSKYSLCAKPCPDTCHSGFSGMFCSDRCVEACECNPGFVLSGLECIPRSQCGCLHPAGSYFKVGERWYKPGCKELCVCESNNRIRCQPWRCRAQEFCGQQDGIYGCHAQGAATCTASGDPHYLTFDGALHHFMGTCTYVLTRPCWSRSQDSYFVVSATNENRGGILEVSYIKAVHVTVFDLSISLLRGCKVMLNGHRVALPVWLAQGRVTIRLSSNLVLLYTNFGLQVRYDGSHLVEVTVPSSYGGQLCGLCGNYNNNSLDDNLRPDRKLAGDSMQLGAAWKLPESSEPGCFLVGGKPSSCQENSMADAWNKNCAILINPQGPFSQCHQVVPPQSSFASCVHGQCGTKGDTTALCRSLQAYASLCAQAGQAPAWRNRTFCPMRCPPGSSYSPCSSPCPDTCSSINNPRDCPKALPCAESCECQKGHILSGTSCVPLGQCGCTDPAGSYHPVGERWYTENTCTRLCTCSVHNNITCFQSTCKPNQICWALDGLLHCRASGVGVCQLPGESHYVSFDGSNHSIPDACTLVLVKVCHPAMALPFFKISAKHEKEEGGTEAFRLHEVYIDIYDAQVTLQKGHRVLINSKQVTLPAISQIPGVSVKSSSIYSIVNIKIGVQVKFDGNHLLEIEIPTTYYGKVCGMCGNFNDEEEDELMMPSDEVANSDSEFVNSWKDKDIDPSCQSLLVDEQQIPAEQQENPSGNCRAADLRRAREKCEAALRAPVWAQCASRIDLTPFLVDCANTLCEFGGLYQALCQALQAFGATCQSQGLKPPLWRNSSFCPLECPAYSSYTNCLPSCSPSCWDLDGRCEGAKVPSACAEGCICQPGYVLSEDKCVPRSQCGCKDAHGGSIPLGKSWVSSGCTEKCVCTGGAIQCGDFRCPSGSHCQLTSDNSNSNCVSDKSEQCSVYGDPRYLTFDGFSYRLQGRMTYVLIKTVDVLPEGVEPLLVEGRNKMDPPRSSIFLQEVITTVYGYKVQLQAGLELVVNNQKMAVPYRPNEHLRVTLWGQRLYLVTDFELVVSFGGRKNAVISLPSMYEGLVSGLCGNYDKNRKNDMMLPSGALTQNLNTFGNSWEVKTEDALLRFPRAIPAEEEGQGAELGLRTGLQVSECSPEQLASNSTQACRVLADPQGPFAACHQTVAPEPFQEHCVLDLCSAQDPREQEELRCQVLSGWAAAF>sp|Q9Y493-6|ZAN_HUMAN Isoform 6 of Zonadhesin OS=Homo sapiens OX=9606GN=ZANMVPPVWTLLLLVGAALFRKEKPPDQKLVVRSSRDNYVLTQCDFEDDAKPLCDWSQVSADDEDWVRASGPSPTGSTGAPGGYPNGEGSYLHMESNSFHRGGVARLLSPDLWEQGPLCVHFAHHMFGLSWGAQLRLLLLSGEEGRRPDVLWKHWNTQRPSWMLTTVTVPAGFTLPTRLMFEGTRGSTAYLDIALDALSIRRGSCNRVCMMQTCSFDIPNDLCDWTWIPTASGAKWTQKKGSSGKPGVGPDGDFSSPGSGCYMLLDPKNARPGQKAVLLSPVSLSSGCLSFSFHYILRGQSPGAALHIYASVLGSIRKHTLFSGQPGPNWQAVSVNYTAVGRIQFAVVGVFGKTPEPAVAVDATSIAPCGEGFPQCDFEDNAHPFCDWVQTSGDGGHWALGHKNGPVHGMGPAGGFPNAGGHYIYLEADEFSQAGQSVRLVSRPFCAPGDICVEFAYHMYGLGEGTMLELLLGSPAGSPPIPLWKRVGSQRPYWQNTSVTVPSGHQQPMQLIFKGIQGSNTASVVAMGFILINPGTCPVKVLPELPPVSPVSSTGPSETTGLTENPTISTKKPTVSIEKPSVTTEKPTVPKEKPTIPTEKPTISTEKPTIPSEKPNMPSEKPTIPSEKPTILTEKPTIPSEKPTIPSEKPTISTEKPTVPTEEPTTPTEETTTSMEEPVIPTEKPSIPTEKPSIPTEKPTISMEETIISTEKPTISPEKPTIPTEKPTIPTEKSTISPEKPTTPTEKPTIPTEKPTISPEKPTTPTEKPTISPEKLTIPTEKPTIPTEKPTIPTEKPTISTEEPTTPTEETTISTEKPSIPMEKPTLPTEETTTSVEETTISTEKLTIPMEKPTISTEKPTIPTEKPTISPEKLTIPTEKLTIPTEKPTIPIEETTISTEKLTIPTEKPTISPEKPTISTEKPTIPTEKPTIPTEETTISTEKLTIPTEKPTISPEKLTIPTEKPTISTEKPTIPTEKLTIPTEKPTIPTEKPTIPTEKLTALRPPHPSPTATGLAALVMSPHAPSTPMTSVILGTTTTSRSSTERCPPNARYESCACPASCKSPRPSCGPLCREGCVCNPGFLFSDNHCIQASSCNCFYNNDYYEPGAEWFSPNCTEHCRCWPGSRVECQISQCGTHTVCQLKNGQYGCHPYAGTATCLVYGDPHYVTFDGRHFGFMGKCTYILAQPCGNSTDPFFRVTAKNEEQGQEGVSCLSKVYVTLPESTVTLLKGRRTLVGGQQVTLPAIPSKGVFLGASGRFVELQTEFGLRVRWDGDQQLYVTVSSTYSGKLCGLCGNYDGNSDNDHLKLDGSPAGDKEELGNSWQTDQDEDQECQKYQVVNSPSCDSSLQSSMSGPGFCGRLVDTHGPFETCLLHVKAASFFDSCMLDMCGFQGLQHLLCTHMSTMTTTCQDAGHAVKPWREPHFCPMACPPNSKYSLCAKPCPDTCHSGFSGMFCSDRCVEACECNPGFVLSGLECIPRSQCGCLHPAGSYFKVGERWYKPGCKELCVCESNNRIRCQPWRCRAQEFCGQQDGIYGCHAQGAATCTASGDPHYLTFDGALHHFMGTCTYVLTRPCWSRSQDSYFVVSATNENRGGILEVSYIKAVHVTVFDLSISLLRGCKVMLNGHRVALPVWLAQGRVTIRLSSNLVLLYTNFGLQVRYDGSHLVEVTVPSSYGGQLCGLCGNYNNNSLDDNLRPDRKLAGDSMQLGAAWKLPESSEPGCFLVGGKPSSCQENSMADAWNKNCAILINPQGPFSQCHQVVPPQSSFASCVHGQCGTKGDTTALCRSLQAYASLCAQAGQAPAWRNRTFCPMRCPPGSSYSPCSSPCPDTCSSINNPRDCPKALPCAESCECQKGHILSGTSCVPLGQCGCTDPAGSYHPVGERWYTENTCTRLCTCSVHNNITCFQSTCKPNQICWALDGLLHCRASGVGVCQLPGESHYVSFDGSNHSIPDACTLVLVKVCHPAMALPFFKISAKHEKEEGGTEAFRLHEVYIDIYDAQVTLQKGHRVLINSKQVTLPAISQIPGVSVKSSSIYSIVNIKIGVQVKFDGNHLLEIEIPTTYYGKVCGMCGNFNDEEEDELMMPSDEVANSDSEFVNSWKDKDIDPSCQSLLVDEQQIPAEQQENPSGNCRAADLRRAREKCEAALRAPVWAQCASRIDLTPFLVDCANTLCEFGGLYQALCQALQAFGATCQSQGLKPPLWRNSSFCPLECPAYSSYTNCLPSCSPSCWDLDGRCEGAKVPSACAEGCICQPGYVLSEDKCVPRSQCGCKDAHGGSIPLGKSWVSSGCTEKCVCTGGAIQCGDFRCPSGSHCQLTSDNSNSNCVSDKSEQCSVYGDPRYLTFDGFSYRLQGRMTYVLIKTVDVLPEGVEPLLVEGRNKMDPPRSSIFLQEVITTVYGYKVQLQAGLELVVNNQKMAVPYRPNEHLRVTLWGQRLYLVTDFELVVSFGGRKNAVISLPSMYEGLVSGLCGNYDKNRKNDMMLPSGALTQNLNTFGNSWEVKTEDALLRFPRAIPAEEEGQGAELGLRTGLQVSECSPEQLASNSTQACRVLADPQGPFAACHQTVAPEPFQEHCVLDLCSAQDPREQEELRCQVLSGYAILCQEAGAALAGWRDRTLCESPCLQNPCQNDGQCREQGATFTCECEVGYGGGLCMEPRDAPPPRKPASNLVGVLLGLLVPVVVVLLAVTRECIYRTRRKREKTQEGDRLARLVDTDTVLDCAC>sp|Q9Y493-7|ZAN_HUMAN Isoform 7 of Zonadhesin OS=Homo sapiens OX=9606GN=ZANMVPPVWTLLLLVGAALFRKEKPPDQKLVVRSSRDNYVLTQCDFEDDAKPLCDWSQVSADDEDWVRASGPSPTGSTGAPGGYPNGEGSYLHMESNSFHRGGVARLLSPDLWEQGPLCVHFAHHMFGLSWGAQLRLLLLSGEEGRRPDVLWKHWNTQRPSWMLTTVTVPAGFTLPTRLMFEGTRGSTAYLDIALDALSIRRGSCNRVCMMQTCSFDIPNDLCDWTWIPTASGAKWTQKKGSSGKPGVGPDGDFSSPGSGCYMLLDPKNARPGQKAVLLSPVSLSSGCLSFSFHYILRGQSPGAALHIYASVLGSIRKHTLFSGQPGPNWQAVSVNYTAVGRIQFAVVGVFGKTPEPAVAVDATSIAPCGEGFPQCDFEDNAHPFCDWVQTSGDGGHWALGHKNGPVHGMGPAGGFPNAGGHYIYLEADEFSQAGQSVRLVSRPFCAPGDICVEFAYHMYGLGEGTMLELLLGSPAGSPPIPLWKRVGSQRPYWQNTSVTVPSGHQQPMQLIFKGIQGSNTASVVAMGFILINPGTCPVKVLPELPPVSPVSSTGPSETTGLTENPTISTKKPTVSIEKPSVTTEKPTVPKEKPTIPTEKPTISTEKPTIPSEKPNMPSEKPTIPSEKPTILTEKPTIPSEKPTIPSEKPTISTEKPTVPTEEPTTPTEETTTSMEEPVIPTEKPSIPTEKPSIPTEKPTISMEETIISTEKPTISPEKPTIPTEKPTIPTEKSTISPEKPTTPTEKPTIPTEKPTISPEKPTTPTEKPTISPEKLTIPTEKPTIPTEKPTIPTEKPTISTEEPTTPTEETTISTEKPSIPMEKPTLPTEETTTSVEETTISTEKLTIPMEKPTISTEKPTIPTEKPTISPEKLTIPTEKLTIPTEKPTIPIEETTISTEKLTIPTEKPTISPEKPTISTEKPTIPTEKPTIPTEETTISTEKLTIPTEKPTISPEKLTIPTEKPTISTEKPTIPTEKLTIPTEKPTIPTEKPTIPTEKLTALRPPHPSPTATGLAALVMSPHAPSTPMTSVILGTTTTSRSSTERCPPNARYESCACPASCKSPRPSCGPLCREGCVCNPGFLFSDNHCIQASSCNCFYNNDYYEPGAEWFSPNCTEHCRCWPGSRVECQISQCGTHTVCQLKNGQYGCHPYAGTATCLVYGDPHYVTFDGRHFGFMGKCTYILAQPCGNSTDPFFRVTAKNEEQGQEGVSCLSKVYVTLPESTVTLLKGRRTLVGGQQVTLPAIPSKGVFLGASGRFVELQTEFGLRVRWDGDQQLYVTVSSTYSGKLCGLCGNYDGNSDNDHLKLDGSPAGDKEELGNSWQTDQDEDQECQKYQVVNSPSCDSSLQSSMSGPGFCGRLVDTHGPFETCLLHVKAASFFDSCMLDMCGFQGLQHLLCTHMSTMTTTCQDAGHAVKPWREPHFCPMACPPNSKYSLCAKPCPDTCHSGFSGMFCSDRCVEACECNPGFVLSGLECIPRSQCGCLHPAGSYFKVGERWYKPGCKELCVCESNNRIRCQPWRCRAQEFCGQQDGIYGCHAQGAATCTASGDPHYLTFDGALHHFMGTCTYVLTRPCWSRSQDSYFVVSATNENRGGILEVSYIKAVHVTVFDLSISLLRGCKVMLNGHRVALPVWLAQGRVTIRLSSNLVLLYTNFGLQVRYDGSHLVEVTVPSSYGGQLCGLCGNYNNNSLDDNLRPDRKLAGDSMQLGAAWKLPESSEPGCFLVGGKPSSCQENSMADAWNKNCAILINPQGPFSQCHQVVPPQSSFASCVHGQCGTKGDTTALCRSLQAYASLCAQAGQAPAWRNRTFCPMRCPPGSSYSPCSSPCPDTCSSINNPRDCPKALPCAESCECQKGHILSGTSCVPLGQCGCTDPAGSYHPVGERWYTENTCTRLCTCSVHNNITCFQSTCKPNQICWALDGLLHCRASGVGVCQLPGESHYVSFDGSNHSIPDACTLVLVKVCHPAMALPFFKISAKHEKEEGGTEAFRLHEVYIDIYDAQVTLQKGHRVLINSKQVTLPAISQIPGVSVKSSSIYSIVNIKIGVQVKFDGNHLLEIEIPTTYYGKVCGMCGNFNDEEEDELMMPSDEVANSDSEFVNSWKDKDIDPSCQSLLVDEQQIPAEQQENPSGNCRAADLRRAREKCEAALRAPVWAQCASRIDLTPFLVDCANTLCEFGGLYQALCQALQAFGATCQSQGLKPPLWRNSSFCPLECPAYSSYTNCLPSCSPSCWDLDGRCEGAKVPSACAEGCICQPGYVLSEDKCVPRSQCGCKDAHGGSIPLGKSWVSSGCTEKCVCTGGAIQCGDFRCPSGSHCQLTSDNSNSNCVSDKSEQCSVYGDPRYLTFDGFSYRLQGRMTYVLIKTVDVLPEGVEPLLVEGRNKMDPPRSSIFLQEVITTVYGYKVQLQAGLELVVNNQKMAVPYRPNEHLRVTLWGQRLYLVTDFELVVSFGGRKNAVISLPSMYEGLVSGLCGNYDKNRKNDMMLPSGALTQNLNTFGNSWEVKTEDALLRFPRAIPAEEEGQGAELGLRTGLQVSECSPEQLASNSTQACRVLADPQGPFAACHQTVAPEPFQEHCVLDLCSAQDPREQEELRCQVLSGYAILCQEAGAALAGWRDRTLCAMECPAGTIYQSCMTPCPASCANLADPGDCEGPCVEGCADPRLCLQWHPEPPLADCGCTSNGIYYQVRAGSRRPWGAEAPRRARPGMELERLLLALPFLAGQQFLTEDCSQRCTCASSRILLCEPFSCRAGEVCTLGNHTQGCFPESPCLQNPCQNDGQCREQGATFTCECEVGYGGGLCMEPRDAPPPRKPASNLVGVLLGLLVPVVVVLLAVTRECIYRTRRKREKTQEGDRLARLVDTDTVLDCAC>sp|P13682|ZNF35_HUMAN Zinc finger protein 35 OS=Homo sapiens OX=9606GN=ZNF35 PE=1 SV=4MTAELREAMALAPWGPVKVKKEEEEEENFPGQASSQQVHSENIKVWAPVQGLQTGLDGSEEEEKGQNISWDMAVVLKATQEAPAASTLGSYSLPGTLAKSEILETHGTMNFLGAETKNLQLLVPKTEICEEAEKPLIISERIQKADPQGPELGEACEKGNMLKRQRIKREKKDFRQVIVNDCHLPESFKEEENQKCKKSGGKYSLNSGAVKNPKTQLGQKPFTCSVCGKGFSQSANLVVHQRIHTGEKPFECHECGKAFIQSANLVVHQRIHTGQKPYVCSKCGKAFTQSSNLTVHQKIHSLEKTFKCNECEKAFSYSSQLARHQKVHITEKCYECNECGKTFTRSSNLIVHQRIHTGEKPFACNDCGKAFTQSANLIVHQRSHTGEKPYECKECGKAFSCFSHLIVHQRIHTAEKPYDCSECGKAFSQLSCLIVHQRIHSGDLPYVCNECGKAFTCSSYLLIHQRIHNGEKPYTCNECGKAFRQRSSLTVHQRTHTGEKPYECEKCGAAFISNSHLMRHHRTHLVE>sp|P52740|ZN132_HUMAN Zinc finger protein 132 OS=Homo sapiens OX=9606GN=ZNF132 PE=2 SV=2MALPSPQVLMGLPALLMGPAQHTSWPCGSAVPTLKSMVTFEDVAVYFSQEEWELLDAAQRHLYHSVMLENLELVTSLGSWHGVEGEGAHPKQNVSVEVLQVRIPNADPSTKKANSCDMCGPFLKDILHLAEHQGTQSEEKPYTCGACGRDFWLNANLHQHQKEHSGGKPFRWYKDRDALMKSSKVHLSENPFTCREGGKVILGSCDLLQLQAVDSGQKPYSNLGQLPEVCTTQKLFECSNCGKAFLKSSTLPNHLRTHSEEIPFTCPTGGNFLEEKSILGNKKFHTGEIPHVCKECGKAFSHSSKLRKHQKFHTEVKYYECIACGKTFNHKLTFVHHQRIHSGERPYECDECGKAFSNRSHLIRHEKVHTGERPFECLKCGRAFSQSSNFLRHQKVHTQVRPYECSQCGKSFSRSSALIQHWRVHTGERPYECSECGRAFNNNSNLAQHQKVHTGERPFECSECGRDFSQSSHLLRHQKVHTGERPFECCDCGKAFSNSSTLIQHQKVHTGQRPYECSECRKSFSRSSSLIQHWRIHTGEKPYECSECGKAFAHSSTLIEHWRVHTKERPYECNECGKFFSQNSILIKHQKVHTGEKPYKCSECGKFFSRKSSLICHWRVHTGERPYECSECGRAFSSNSHLVRHQRVHTQERPYECIQCGKAFSERSTLVRHQKVHTRERTYECSQCGKLFSHLCNLAQHKKIHT>sp|P52740-2|ZN132_HUMAN Isoform 2 of Zinc finger protein 132 OS=Homosapiens OX=9606 GN=ZNF132MCGPFLKDILHLAEHQGTQSEEKPYTCGACGRDFWLNANLHQHQKEHSGGKPFRWYKDRDALMKSSKVHLSENPFTCREGGKVILGSCDLLQLQAVDSGQKPYSNLGQLPEVCTTQKLFECSNCGKAFLKSSTLPNHLRTHSEEIPFTCPTGGNFLEEKSILGNKKFHTGEIPHVCKECGKAFSHSSKLRKHQKFHTEVKYYECIACGKTFNHKLTFVHHQRIHSGERPYECDECGKAFSNRSHLIRHEKVHTGERPFECLKCGRAFSQSSNFLRHQKVHTQVRPYECSQCGKSFSRSSALIQHWRVHTGERPYECSECGRAFNNNSNLAQHQKVHTGERPFECSECGRDFSQSSHLLRHQKVHTGERPFECCDCGKAFSNSSTLIQHQKVHTGQRPYECSECRKSFSRSSSLIQHWRIHTGEKPYECSECGKAFAHSSTLIEHWRVHTKERPYECNECGKFFSQNSILIKHQKVHTGEKPYKCSECGKFFSRKSSLICHWRVHTGERPYECSECGRAFSSNSHLVRHQRVHTQERPYECIQCGKAFSERSTLVRHQKVHTRERTYECSQCGKLFSHLCNLAQHKKIHT>sp|A6NP61|ZAR1L_HUMAN ZAR1-like protein OS=Homo sapiens OX=9606 GN=ZAR1LPE=2 SV=2MERFVRVPYGLYQGYGSTVPLGQPGLSGHKQPDWRQNMGPPTFLARPGLLVPANAPDYCIDPYKRAQLKAILSQMNPSLSPRLCKPNTKEVGVQVSPRVDKAVQCSLGPRTLSSCSPWDGRDPQEPLPACGVTSPATGRRGLIRLRRDGDEAESKALPGPAEASQPQPPSRRSGADRQEEPGQLEESGEKDAPCPQETKSKQVPGDAASEPLRRPNFQFLEPKYGYFHCKDCKTRWESAYVWCISGTNKVYFKQLCCKCQKSFNPYRVEAIQCQTCSKSHCSCPQKKRHIDLRRPHRQELCGRCKDKRFSCGNIYSFKYVM>sp|P0CJ79|ZN888_HUMAN Zinc finger protein 888 OS=Homo sapiens OX=9606GN=ZNF888 PE=3 SV=2MALPQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCMMEFSSIGKGNTEVIHTGTLQRLASHHIGECCFQEIEKDIHDFVFQWQEDETNGHEAPMTEIKELTGSTDQYDQRHAGNKPIKYQLGSSFHSHLPELHIFQPEGKIGNQLEKSINNASSVSTSQRISCRPKTHISNNYGNNFFHSSLLTQKQDVHRKEKSFQFNESGKSFNCSSLFKKHQIIHLGEKQYKCDVCGKDFNQKRYLAHHRRCHTGEKPYMCNKCGKVFNKKAYLARHYRRHTGEKPYKCNECGKTFSDKSALLVHKTIHTGEKPYKCNECGKVFNQQSNLARHHRVHTGEKPYQCKECDKVFSRKSYLERHRRIHTGEKPYKCKVCDKAFRHDSHLAQHIVIHTREKPYKCNECGKTFGENSALLVHKTIHTGEKPYKCNECGKVFNQQSNLARHHRLHTGEKPYKCKECDKVFSRKSHLERHRRIHTGEKPYKCKVCDKAFRRDSHLAQHTVIHTGEKPYKCNECGKTFVQNSSLVMHKVIHTGEKRYKCNECGKSFNHKSSLAYHHRLHTGEKPYKCNECGKVFRTQSQLACHHRLHTGEKPYKCEECDKVFNIKSHLEIHRRVHTGEKPYKCRVCDKAFGRDSYLAQHQRVHTGEKPYKCKVCDKAFKCYSHLAQHTRIHTGEKPFKCSECGKAFRAQSTLIHHQAIHGVGKLD>sp|Q6IQ21|ZN770_HUMAN Zinc finger protein 770 OS=Homo sapiens OX=9606GN=ZNF770 PE=1 SV=1MMAENNLKMLKIQQCVVANKLPRNRPYVCNICFKHFETPSKLARHYLIHTGQKPFECDVCHKTFRQLVHLERHQLTHSLPFKCSICQRHFKNLKTFVKHQQLHNETYQNNVKQVRRLLEAKQEKSMYGVYNTFTTEERWALHPCSKSDPMYSMKRRKNIHACTICGKMFPSQSKLDRHVLIHTGQRPFKCVLCTKSFRQSTHLKIHQLTHSEERPFQCCFCQKGFKIQSKLLKHKQIHTRNKAFRALLLKKRRTESRPLPNKLNANQGGFENGEIGESEENNPLDVHSIYIVPFQCPKCEKCFESEQILNEHSCFAARSGKIPSRFKRSYNYKTIVKKILAKLKRARSKKLDNFQSEKKVFKKSFLRNCDLISGEQSSEQTQRTFVGSLGKHGTYKTIGNRKKKTLTLPFSWQNMGKNLKGILTTENILSIDNSVNKKDLSICGSSGEEFFNNCEVLQCGFSVPRENIRTRHKICPCDKCEKVFPSISKLKRHYLIHTGQRPFGCNICGKSFRQSAHLKRHEQTHNEKSPYASLCQVEFGNFNNLSNHSGNNVNYNASQQCQAPGVQKYEVSESDQMSGVKAESQDFIPGSTGQPCLPNVLLESEQSNPFCSYSEHQEKNDVFLYRCSVCAKSFRSPSKLERHYLIHAGQKPFECSVCGKTFRQAPHWKRHQLTHFKERPQGKVVALDSVM>sp|Q8IZN3|ZDH14_HUMAN Palmitoyltransferase ZDHHC14 OS=Homo sapiensOX=9606 GN=ZDHHC14 PE=1 SV=1MPPGGGGPMKDCEYSQISTHSSSPMESPHKKKKIAARRKWEVFPGRNKFFCNGRIMMARQTGVFYLTLVLILVTSGLFFAFDCPYLAVKITPAIPAVAGILFFFVMGTLLRTSFSDPGVLPRATPDEAADLERQIDIANGTSSGGYRPPPRTKEVIINGQTVKLKYCFTCKIFRPPRASHCSLCDNCVERFDHHCPWVGNCVGKRNYRFFYMFILSLSFLTVFIFAFVITHVILRSQQTGFLNALKDSPASVLEAVVCFFSVWSIVGLSGFHTYLISSNQTTNEDIKGSWSNKRGKENYNPYSYGNIFTNCCVALCGPISPSLIDRRGYIQPDTPQPAAPSNGITMYGATQSQSDMCDQDQCIQSTKFVLQAAATPLLQSEPSLTSDELHLPGKPGLGTPCASLTLGPPTPPASMPNLAEATLADVMPRKDEHMGHQFLTPDEAPSPPRLLAAGSPLAHSRTMHVLGLASQDSLHEDSVRGLVKLSSV>sp|Q8IZN3-2|ZDH14_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC14OS=Homo sapiens OX=9606 GN=ZDHHC14MPPGGGGPMKDCEYSQISTHSSSPMESPHKKKKIAARRKWEVFPGRNKFFCNGRIMMARQTGVFYLTLVLILVTSGLFFAFDCPYLAVKITPAIPAVAGILFFFVMGTLLRTSFSDPGVLPRATPDEAADLERQIDIANGTSSGGYRPPPRTKEVIINGQTVKLKYCFTCKIFRPPRASHCSLCDNCVERFDHHCPWVGNCVGKRNYRFFYMFILSLSFLTVFIFAFVITHVILRSQQTGFLNALKDSPASVLEAVVCFFSVWSIVGLSGFHTYLISSNQTTNEDIKGSWSNKRGKENYNPYSYGNIFTNCCVALCGPISPSLIDRRGYIQPDTPQPAAPSNGITMYGATQSQSDMAAATPLLQSEPSLTSDELHLPGKPGLGTPCASLTLGPPTPPASMPNLAEATLADVMPRKDEHMGHQFLTPDEAPSPPRLLAAGSPLAHSRTMHVLGLASQDSLHEDSVRGLVKLSSV>sp|Q9P1C3|YN010_HUMAN Putative uncharacterized protein PRO2829 OS=Homosapiens OX=9606 GN=PRO2829 PE=5 SV=1MVRPHLLKKKILGRVWWLMPVVLALWEAEVGGSLEVRSLRPAWPTW>sp|Q96NG8|ZN582_HUMAN Zinc finger protein 582 OS=Homo sapiens OX=9606GN=ZNF582 PE=2 SV=1MSLGSELFRDVAIVFSQEEWQWLAPAQRDLYRDVMLETYSNLVSLGLAVSKPDVISFLEQGKEPWMVERVVSGGLCPVLESRYDTKELFPKQHVYEVESPQWEIMESLTSYGLECSSFQDDWECRNQFDRQQGNPDRHFHQMIIRHEEMPTFDQHASLTFYQKIHTREKPFGYNKCRKDFWQKELLINHQGIYTNEKPYKCKECGKAFKYGSRLIQHENIHSGKKPYECKECGKAFNSGSNFIQHQRVHTGEKPYECKDCEKAFSRSSQLIEHQRTHTGEKPYQCKECGKAFNRISHLKVHYRIHTGEKPYACKECGKTFSHRSQLIQHQTVHTGRKLYECKECGKAFNQGSTLIRHQRIHTGEKPYECKVCGKAFRVSSQLKQHQRIHTGEKPYQCKVCGRAFKRVSHLTVHYRIHTGEKPYECKECGKAFSHCSQLIHHQVIHTEKKPYEYKECEKTLSHDSTTVQPQRMHNRETHVNIINVEKPSISSYPLLIIREFMLASNHMNGSNGESPLA>sp|Q8N988|ZN557_HUMAN Zinc finger protein 557 OS=Homo sapiens OX=9606GN=ZNF557 PE=1 SV=2MAAVVLPPTAASQREGHTEGGELVNELLKSWLKGLVTFEDVAVEFTQEEWALLDPAQRTLYRDVMLENCRNLASLGNQVDKPRLISQLEQEDKVMTEERGILSGTCPDVENPFKAKGLTPKLHVFRKEQSRNMKMERNHLGATLNECNQCFKVFSTKSSLTRHRKIHTGERPYGCSECGKSYSSRSYLAVHKRIHNGEKPYECNDCGKTFSSRSYLTVHKRIHNGEKPYECSDCGKTFSNSSYLRPHLRIHTGEKPYKCNQCFREFRTQSIFTRHKRVHTGEGHYVCNQCGKAFGTRSSLSSHYSIHTGEYPYECHDCGRTFRRRSNLTQHIRTHTGEKPYTCNECGKSFTNSFSLTIHRRIHNGEKSYECSDCGKSFNVLSSVKKHMRTHTGKKPYECNYCGKSFTSNSYLSVHTRMHNRQM>sp|Q8N988-2|ZN557_HUMAN Isoform 2 of Zinc finger protein 557 OS=Homosapiens OX=9606 GN=ZNF557MAAVVLPPTAALSSLFPASQREGHTEGGELVNELLKSWLKGLVTFEDVAVEFTQEEWALLDPAQRTLYRDVMLENCRNLASLGNQVDKPRLISQLEQEDKVMTEERGILSGTCPDVENPFKAKGLTPKLHVFRKEQSRNMKMERNHLGATLNECNQCFKVFSTKSSLTRHRKIHTGERPYGCSECGKSYSSRSYLAVHKRIHNGEKPYECNDCGKTFSSRSYLTVHKRIHNGEKPYECSDCGKTFSNSSYLRPHLRIHTGEKPYKCNQCFREFRTQSIFTRHKRVHTGEGHYVCNQCGKAFGTRSSLSSHYSIHTGEYPYECHDCGRTFRRRSNLTQHIRTHTGEKPYTCNECGKSFTNSFSLTIHRRIHNGEKSYECSDCGKSFNVLSSVKKHMRTHTGKKPYECNYCGKSFTSNSYLSVHTRMHNRQM>sp|Q9ULT6|ZNRF3_HUMAN E3 ubiquitin-protein ligase ZNRF3 OS=Homo sapiensOX=9606 GN=ZNRF3 PE=1 SV=3MRPRSGGRPGATGRRRRRLRRRPRGLRCSRLPPPPPLPLLLGLLLAAAGPGAARAKETAFVEVVLFESSPSGDYTTYTTGLTGRFSRAGATLSAEGEIVQMHPLGLCNNNDEEDLYEYGWVGVVKLEQPELDPKPCLTVLGKAKRAVQRGATAVIFDVSENPEAIDQLNQGSEDPLKRPVVYVKGADAIKLMNIVNKQKVARARIQHRPPRQPTEYFDMGIFLAFFVVVSLVCLILLVKIKLKQRRSQNSMNRLAVQALEKMETRKFNSKSKGRREGSCGALDTLSSSSTSDCAICLEKYIDGEELRVIPCTHRFHRKCVDPWLLQHHTCPHCRHNIIEQKGNPSAVCVETSNLSRGRQQRVTLPVHYPGRVHRTNAIPAYPTRTSMDSHGNPVTLLTMDRHGEQSLYSPQTPAYIRSYPPLHLDHSLAAHRCGLEHRAYSPAHPFRRPKLSGRSFSKAACFSQYETMYQHYYFQGLSYPEQEGQSPPSLAPRGPARAFPPSGSGSLLFPTVVHVAPPSHLESGSTSSFSCYHGHRSVCSGYLADCPGSDSSSSSSSGQCHCSSSDSVVDCTEVSNQGVYGSCSTFRSSLSSDYDPFIYRSRSPCRASEAGGSGSSGRGPALCFEGSPPPEELPAVHSHGAGRGEPWPGPASPSGDQVSTCSLEMNYSSNSSLEHRGPNSSTSEVGLEASPGAAPDLRRTWKGGHELPSCACCCEPQPSPAGPSAGAAGSSTLFLGPHLYEGSGPAGGEPQSGSSQGLYGLHPDHLPRTDGVKYEGLPCCFYEEKQVARGGGGGSGCYTEDYSVSVQYTLTEEPPPGCYPGARDLSQRIPIIPEDVDCDLGLPSDCQGTHSLGSWGGTRGPDTPRPHRGLGATREEERALCCQARALLRPGCPPEEAGAVRANFPSALQDTQESSTTATEAAGPRSHSADSSSPGA>sp|Q9ULT6-2|ZNRF3_HUMAN Isoform 2 of E3 ubiquitin-protein ligase ZNRF3OS=Homo sapiens OX=9606 GN=ZNRF3MHPLGLCNNNDEEDLYEYGWVGVVKLEQPELDPKPCLTVLGKAKRAVQRGATAVIFDVSENPEAIDQLNQGSEDPLKRPVVYVKGADAIKLMNIVNKQKVARARIQHRPPRQPTEYFDMGIFLAFFVVVSLVCLILLVKIKLKQRRSQNSMNRLAVQALEKMETRKFNSKSKGRREGSCGALDTLSSSSTSDCAICLEKYIDGEELRVIPCTHRFHRKCVDPWLLQHHTCPHCRHNIIEQKGNPSAVCVETSNLSRGRQQRVTLPVHYPGRVHRTNAIPAYPTRTSMDSHGNPVTLLTMDRHGEQSLYSPQTPAYIRSYPPLHLDHSLAAHRCGLEHRAYSPAHPFRRPKLSGRSFSKAACFSQYETMYQHYYFQGLSYPEQEGQSPPSLAPRGPARAFPPSGSGSLLFPTVVHVAPPSHLESGSTSSFSCYHGHRSVCSGYLADCPGSDSSSSSSSGQCHCSSSDSVVDCTEVSNQGVYGSCSTFRSSLSSDYDPFIYRSRSPCRASEAGGSGSSGRGPALCFEGSPPPEELPAVHSHGAGRGEPWPGPASPSGDQVSTCSLEMNYSSNSSLEHRGPNSSTSEVGLEASPGAAPDLRRTWKGGHELPSCACCCEPQPSPAGPSAGAAGSSTLFLGPHLYEGSGPAGGEPQSGSSQGLYGLHPDHLPRTDGVKYEGLPCCFYEEKQVARGGGGGSGCYTEDYSVSVQYTLTEEPPPGCYPGARDLSQRIPIIPEDVDCDLGLPSDCQGTHSLGSWGGTRGPDTPRPHRGLGATREEERALCCQARALLRPGCPPEEAGAVRANFPSALQDTQESSTTATEAAGPRSHSADSSSPGA>sp|Q05996|ZP2_HUMAN Zona pellucida sperm-binding protein 2 OS=Homosapiens OX=9606 GN=ZP2 PE=1 SV=1MACRQRGGSWSPSGWFNAGWSTYRSISLFFALVTSGNSIDVSQLVNPAFPGTVTCDEREITVEFPSSPGTKKWHASVVDPLGLDMPNCTYILDPEKLTLRATYDNCTRRVHGGHQMTIRVMNNSAALRHGAVMYQFFCPAMQVEETQGLSASTICQKDFMSFSLPRVFSGLADDSKGTKVQMGWSIEVGDGARAKTLTLPEAMKEGFSLLIDNHRMTFHVPFNATGVTHYVQGNSHLYMVSLKLTFISPGQKVIFSSQAICAPDPVTCNATHMTLTIPEFPGKLKSVSFENQNIDVSQLHDNGIDLEATNGMKLHFSKTLLKTKLSEKCLLHQFYLASLKLTFLLRPETVSMVIYPECLCESPVSIVTGELCTQDGFMDVEVYSYQTQPALDLGTLRVGNSSCQPVFEAQSQGLVRFHIPLNGCGTRYKFEDDKVVYENEIHALWTDFPPSKISRDSEFRMTVKCSYSRNDMLLNINVESLTPPVASVKLGPFTLILQSYPDNSYQQPYGENEYPLVRFLRQPIYMEVRVLNRDDPNIKLVLDDCWATSTMDPDSFPQWNVVVDGCAYDLDNYQTTFHPVGSSVTHPDHYQRFDMKAFAFVSEAHVLSSLVYFHCSALICNRLSPDSPLCSVTCPVSSRHRRATGATEAEKMTVSLPGPILLLSDDSSFRGVGSSDLKASGSSGEKSRSETGEEVGSRGAMDTKGHKTAGDVGSKAVAAVAAFAGVVATLGFIYYLYEKRTVSNH>sp|Q05996-2|ZP2_HUMAN Isoform 2 of Zona pellucida sperm-binding protein2 OS=Homo sapiens OX=9606 GN=ZP2MACRQRGGSWSPSGWFNAGWSTYRSISLFFALVTSGNSIDVSQLVNPAFPGTVTCDEREITVEFPSSPGTKKWHASVVDPLGLDMPNCTYILDPEKLTLRATYDNCTRRVHGGHQMTIRVMNNSAALRHGAVMYQFFCPAMQVEETQGLSASTICQKDFMSFSLPRVFSGLADDSKGTKVQMGWSIEVGDGARAKTLTLPEAMKEGFSLLIDNHRMTFHVPFNATGVTHYVQGNSHLYMVSLKLTFISPGQKVIFSSQAICAPDPVTCNATHMTLTIPEFPGKLKSVSFENQNIDVSQLHDNGIDLEATNGMKLHFSKTLLKTKLSEKCLLHQFYLASLKLTFLLRPETVSMVIYPECLCESPVSIVTGELCTQDGFMDVEVYSYQTQPALDLGTLRVGNSSCQPVFEAQSQGLVRFHIPLNGCGTRYKFEDDKVVYENEIHALWTDFPPSKISRDSEFRNDMLLNINVESLTPPVASVKLGPFTLILQSYPDNSYQQPYGENEYPLVRFLRQPIYMEVRVLNRDDPNIKLVLDDCWATSTMDPDSFPQWNVVVDGCAYDLDNYQTTFHPVGSSVTHPDHYQRFDMKAFAFVSEAHVLSSLVYFHCSALICNRLSPDSPLCSVTCPVSSRHRRATGATEAEKMTVSLPGPILLLSDDSSFRGVGSSDLKASGSSGEKSRSETGEEVGSRGAMDTKGHKTAGDVGSKAVAAVAAFAGVVATLGFIYYLYEKRTVSNH>sp|Q0IIN9|ZNFS1_HUMAN Putative uncharacterized protein ZNF252P-AS1OS=Homo sapiens OX=9606 GN=ZNF252P-AS1 PE=5 SV=1MLRQSCSFPVTSLPALGGVCGREGAGAEVPPAACGCEGRDPDTERSCGRSSTGGCSPCSGPGPSSPRTSRGALSPSLGRLFPHLQVVIKLRIQLAPAVHLALPTCSLLTSSPPLEGCCHRLNEEAEVQRGFRPIAVELEFENQPLGAETRLRNGRRAGVKRSEGRGQVRPGQVRSTGPEGGLTRMERKAARLQWDSGSIKMSENEQLWEEP>sp|P17040|ZSC20_HUMAN Zinc finger and SCAN domain-containing protein 20OS=Homo sapiens OX=9606 GN=ZSCAN20 PE=1 SV=3MAMALELQAQASPQPEPEELLIVKLEEDSWGSESKLWEKDRGSVSGPEASRQRFRQFQYRDAAGPHEAFSQLWALCCRWLRPEIRLKEQILELLVLEQFLTILPREVQTWVQARHPESGEEAVALVEDWHRETRTAGQSGLELHTEETRPLKTGEEAQSFQLQPVDPWPEGQSQKKGVKNTCPDLPNHLNAEVAPQPLKESAVLTPRVPTLPKMGSVGDWEVTAESQEALGPGKHAEKELCKDPPGDDCGNSVCLGVPVSKPSNTSEKEQGPEFWGLSLINSGKRSTADYSLDNEPAQALTWRDSRAWEEQYQWDVEDMKVSGVHWGYEETKTFLAILSESPFSEKLRTCHQNRQVYRAIAEQLRARGFLRTLEQCRYRVKNLLRNYRKAKSSHPPGTCPFYEELEALVRARTAIRATDGPGEAVALPRLGYSDAEMDEQEEGGWDPEEMAEDCNGAGLVNVESTQGPRIAGAPALFQSRIAGVHWGYEETKAFLAILSESPFSEKLRTCHQNSQVYRAIAERLCALGFLRTLEQCRYRFKNLLRSYRKAKSSHPPGTCPFYEELDSLMRARAAVRAMGTVREAAGLPRCGQSSAETDAQEAWGEVANEDAVKPSTLCPKAPDMGFEMRHEDEDQISEQDIFEGLPGALSKCPTEAVCQPLDWGEDSENENEDEGQWGNPSQEQWQESSSEEDLEKLIDHQGLYLAEKPYKCDTCMKSFSRSSHFIAHQRIHTGEKPYKCLECGKNFSDRSNLNTHQRIHTGEKPYKCLECGKSFSDHSNLITHQRIHTGEKPYKCGECWKSFNQSSNLLKHQRIHLGGNPDQCSEPGGNFAQSPSFSAHWRNSTEETAPEQPQSISKDLNSPGPHSTNSGEKLYECSECGRSFSKSSALISHQRIHTGEKPYECAECGKSFSKSSTLANHQRTHTGEKPYKCVDCGKCFSERSKLITHQRVHTGEKPYKCLECGKFFRDRSNLITHQRIHTGEKPYKCRECGKCFNQSSSLIIHQRIHTGEKPYKCTECGKDFNNSSHFSAHRRTHAGGKAS>sp|P17040-2|ZSC20_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 20 OS=Homo sapiens OX=9606 GN=ZSCAN20MAMALELQAQASPQPEPEELLIVKLELLVLEQFLTILPREVQTWVQARHPESGEEAVALVEDWHRETRTAGQSGLELHTEETRPLKTGEEAQSFQLQPVDPWPEGQSQKKGVKNTCPDLPNHLNAEVAPQPLKESAVLTPRVPTLPKMGSVGDWEVTAESQEALGPGKHAEKELCKDPPGDDCGNSVCLGVPVSKPSNTSEKEQGPEFWGLSLINSGKRSTADYSLDNEPAQALTWRDSRAWEEQYQWDVEDMKVSGVHWGYEETKTFLAILSESPFSEKLRTCHQNRQVYRAIAEQLRARGFLRTLEQCRYRVKNLLRNYRKAKSSHPPGTCPFYEELEALVRARTAIRATDGPGEAVALPRLGYSDAEMDEQEEGGWDPEEMAEDCNGAGLVNVESTQGPRIAGAPALFQSRIAGVHWGYEETKAFLAILSESPFSEKLRTCHQNSQVYRAIAERLCALGFLRTLEQCRYRFKNLLRSYRKAKSSHPPGTCPFYEELDSLMRARAAVRAMGTVREAAGLPRCGQSSAETDAQEAWGEVANEDAVKPSTLCPKAPDMGFEMRHEDEDQISEQDIFEGLPGALSKCPTEAVCQPLDWGEDSENENEDEGQWGNPSQEQWQESSSEEDLEKLIDHQGLYLAEKPYKCDTCMKSFSRSSHFIAHQRIHTGEKPYKCLECGKNFSDRSNLNTHQRIHTGEKPYKCLECGKSFSDHSNLITHQRIHTGEKPYKCGECWKSFNQSSNLLKHQRIHLGGNPDQCSEPGGNFAQSPSFSAHWRNSTEETAPEQPQSISKDLNSPGPHSTNSGEKLYECSECGRSFSKSSALISHQRIHTGEKPYECAECGKSFSKSSTLANHQRTHTGEKPYKCVDCGKCFSERSKLITHQRVHTGEKPYKCLECGKFFRDRSNLITHQRIHTGEKPYKCRECGKCFNQSSSLIIHQRIHTGEKPYKCTECGKDFNNSSHFSAHRRTHAGGKAS>sp|P17040-3|ZSC20_HUMAN Isoform 3 of Zinc finger and SCAN domain-containing protein 20 OS=Homo sapiens OX=9606 GN=ZSCAN20MAMALELQAQASPQPEPEELLIVKLEEDSWGSESKLWEKDRGSVSGPEASRQRFRQFQYRDAAGPHEAFSQLWALCCRWLRPEIRLKEQILELLVLEQFLTILPREVQTWVQARHPESGEEAVALVEDWHRETRTAGQSGLELHTEETRPLKTGEEAQSFQLQPVDPWPEGQSQKKGVKNTCPDLPNHLNAEVAPQPLKESAVLTPRVPTLPKMGSVGDWEVTAESQEALGPGKHAEKELCKDPPGDDCGNSVCLGVPVSKPSNTSEKEQGPEFWGLSLINSGKRSTADYSLDNEPAQALTWRDSRAWEEQYQWDVEDMKVSGVHWGYEETKTFLAILSESPFSEKLRTCHQNRQVYRAIAEQLRARGFLRTLEQCRYRVKNLLRNYRKAKSSHPPGTCPFYEELEALVRARTAIRATDGPGEAVALPRLGYSDAEMDEQEEGGWDPEEMAEDCNGAGLVNVESTQGPRIAGAPALFQSRIGVHWGYEETKAFLAILSESPFSEKLRTCHQNSQVYRAIAERLCALGFLRTLEQCRYRFKNLLRSYRKAKSSHPPGTCPFYEELDSLMRARAAVRAMGTVREAAGLPRCGQSSAETDAQEAWGEVANEDAVKPSTLCPKAPDMGFEMRHEDEDQISEQDIFEGLPGALSKCPTEAVCQPLDWGEDSENENEDEGQWGNPSQEQWQESSSEEDLEKLIDHQGLYLAEKPYKCDTCMKSFSRSSHFIAHQRIHTGEKPYKCLECGKNFSDRSNLNTHQRIHTGEKPYKCLECGKSFSDHSNLITHQRIHTGEKPYKCGECWKSFNQSSNLLKHQRIHLGGNPDQCSEPGGNFAQSPSFSAHWRNSTEETAPEQPQSISKDLNSPGPHSTNSGEKLYECSECGRSFSKSSALISHQRIHTGEKPYECAECGKSFSKSSTLANHQRTHTGEKPYKCVDCGKCFSERSKLITHQRVHTGEKPYKCLECGKFFRDRSNLITHQRIHTGEKPYKCRECGKCFNQSSSLIIHQRIHTGEKPYKCTECGKDFNNSSHFSAHRRTHAGGKAS>sp|P17040-4|ZSC20_HUMAN Isoform 4 of Zinc finger and SCAN domain-containing protein 20 OS=Homo sapiens OX=9606 GN=ZSCAN20MAMALELQAQASPQPEPEELLIVKLEEDSWGSESKLWEKDRGSVSGPEASRQRFRQFQYRDAAGPHEAFSQLWALCCRWLRPEIRLKEQILELLVLEQFLTILPREVQTWVQARHPESGEEAVALVEDWHRETRTAGQSGLELHTEETRPLKTGEEAQSFQLQPVDPWPEGQSQKKGVKNTCPDLPNHLNAEVAPQPLKESGVPVSKPSNTSEKEQGPEFWGLSLINSGKRSTADYSLDNEPAQALTWRDSRAWEEQYQWDVEDMKVSGVHWGYEETKTFLAILSESPFSEKLRTCHQNRQVYRAIAEQLRARGFLRTLEQCRYRVKNLLRNYRKAKSSHPPGTCPFYEELEALVRARTAIRATDGPGEAVALPRLGYSDAEMDEQEEGGWDPEEMAEDCNGAGLVNVESTQGPRIAGAPALFQSRIGKNMGV>sp|Q99726|ZNT3_HUMAN Zinc transporter 3 OS=Homo sapiens OX=9606GN=SLC30A3 PE=1 SV=2MEPSPAAGGLETTRLVSPRDRGGAGGSLRLKSLFTEPSEPLPEESKPVEMPFHHCHRDPLPPPGLTPERLHARRQLYAACAVCFVFMAGEVVGGYLAHSLAIMTDAAHLLADVGSMMGSLFSLWLSTRPATRTMTFGWHRSETLGALASVVSLWMVTGILLYLAFVRLLHSDYHIEGGAMLLTASIAVCANLLMAFVLHQAGPPHSHGSRGAEYAPLEEGPEEPLPLGNTSVRAAFVHVLGDLLQSFGVLAASILIYFKPQYKAADPISTFLFSICALGSTAPTLRDVLRILMEGTPRNVGFEPVRDTLLSVPGVRATHELHLWALTLTYHVASAHLAIDSTADPEAVLAEASSRLYSRFGFSSCTLQVEQYQPEMAQCLRCQEPPQA>sp|Q8TCW7|ZPLD1_HUMAN Zona pellucida-like domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZPLD1 PE=2 SV=2MEQIWLLLLLTIRVLPGSAQFNGYNCDANLHSRFPAERDISVYCGVQAITMKINFCTVLFSGYSETDLALNGRHGDSHCRGFINNNTFPAVVIFIINLSTLEGCGNNLVVSTIPGVSAYGNATSVQVGNISGYIDTPDPPTIISYLPGLLYKFSCSYPLEYLVNNTQLASSSAAISVRENNGTFVSTLNLLLYNDSTYNQQLIIPSIGLPLKTKVFAAVQATNLDGRWNVLMDYCYTTPSGNPNDDIRYDLFLSCDKDPQTTVIENGRSQRGRFSFEVFRFVKHKNQKMSTVFLHCVTKLCRADDCPFLMPICSHRERRDAGRRTTWSPQSSSGSAVLSAGPIITRSDETPTNNSQLGSPSMPPFQLNAITSALISGMVILGVTSFSLLLCSLALLHRKGPTSLVLNGIRNPVFD>sp|Q8TCW7-2|ZPLD1_HUMAN Isoform 2 of Zona pellucida-like domain-containing protein 1 OS=Homo sapiens OX=9606 GN=ZPLD1MMLRFSMCRGNDEGFAMEQIWLLLLLTIRVLPGSAQFNGYNCDANLHSRFPAERDISVYCGVQAITMKINFCTVLFSGYSETDLALNGRHGDSHCRGFINNNTFPAVVIFIINLSTLEGCGNNLVVSTIPGVSAYGNATSVQVGNISGYIDTPDPPTIISYLPGLLYKFSCSYPLEYLVNNTQLASSSAAISVRENNGTFVSTLNLLLYNDSTYNQQLIIPSIGLPLKTKVFAAVQATNLDGRWNVLMDYCYTTPSGNPNDDIRYDLFLSCDKDPQTTVIENGRSQRGRFSFEVFRFVKHKNQKMSTVFLHCVTKLCRADDCPFLMPICSHRERRDAGRRTTWSPQSSSGSAVLSAGPIITRSDETPTNNSQLGSPSMPPFQLNAITSALISGMVILGVTSFSLLLCSLALLHRKGPTSLVLNGIRNPVFD>sp|P63316|TNNC1_HUMAN Troponin C, slow skeletal and cardiac musclesOS=Homo sapiens OX=9606 GN=TNNC1 PE=1 SV=1MDDIYKAAVEQLTEEQKNEFKAAFDIFVLGAEDGCISTKELGKVMRMLGQNPTPEELQEMIDEVDEDGSGTVDFDEFLVMMVRCMKDDSKGKSEEELSDLFRMFDKNADGYIDLDELKIMLQATGETITEDDIEELMKDGDKNNDGRIDYDEFLEFMKGVE>sp|Q8IYL2|TRM44_HUMAN Probable tRNA (uracil-O(2)-)-methyltransferaseOS=Homo sapiens OX=9606 GN=TRMT44 PE=1 SV=2MAEVGRTGISYPGALLPQGFWAAVEVWLERPQVANKRLCGARLEARWSAALPCAEARGPGTSAGSEQKERGPGPGQGSPGGGPGPRSLSGPEQGTACCELEEAQGQCQQEEAQREAASVPLRDSGHPGHAEGREGDFPAADLDSLWEDFSQSLARGNSELLAFLTSSGAGSQPEAQRELDVVLRTVIPKTSPHCPLTTPRREIVVQDVLNGTITFLPLEEDDEGNLKVKMSNVYQIQLSHSKEEWFISVLIFCPERWHSDGIVYPKPTWLGEELLAKLAKWSVENKKSDFKSTLSLISIMKYSKAYQELKEKYKEMVKVWPEVTDPEKFVYEDVAIAAYLLILWEEERAERRLTARQSFVDLGCGNGLLVHILSSEGHPGRGIDVRRRKIWDMYGPQTQLEEDAITPNDKTLFPDVDWLIGNHSDELTPWIPVIAARSSYNCRFFVLPCCFFDFIGRYSRRQSKKTQYREYLDFIKEVGFTCGFHVDEDCLRIPSTKRVCLVGKSRTYPSSREASVDEKRTQYIKSRRGCPVSPPGWELSPSPRWVAAGSAGHCDGQQALDARVGCVTRAWAAEHGAGPQAEGPWLPGFHPREKAERVRNCAALPRDFIDQVVLQVANLLLGGKQLNTRSSRNGSLKTWNGGESLSLAEVANELDTETLRRLKRECGGLQTLLRNSHQVFQVVNGRVHIRDWREETLWKTKQPEAKQRLLSEACKTRLCWFFMHHPDGCALSTDCCPFAHGPAELRPPRTTPRKKIS>sp|Q8IYL2-2|TRM44_HUMAN Isoform 2 of Probable tRNA (uracil-O(2)-)-methyltransferase OS=Homo sapiens OX=9606 GN=TRMT44MCIKFSSVIAKKNERWHSDGIVYPKPTWLGEELLAKLAKWSVENKKSDFKSTLSLISIMKYSKAYQELKEKYKEMVKVWPEVTDPEKFVYEDVAIAAYLLILWEEERAERRLTARQSFVDLGCGNGLLVHILSSEGHPGRGIDVRRRKIWDMYGPQTQLEEDAITPNDKTLFPDVDWLIGNHSDELTPWIPVIAARSSYNCRFFVLPCCFFDFIGRYSRRQSKKTQYREYLDFIKEVGFTCGFHVDEDCLRIPSTKRVCLVGKSRTYPSSREASVDEKRTQYIKSRRGCPVSPPGWELSPSPRWVAAGSAGHCDGQQALDARVGCVTRAWAAEHGAGPQAEGPWLPGFHPREKAERVRNCAALPRDFIDQVVLQVANLLLGGKQLNTRSSRNGSLKTWNGGGKLSTILGRG>sp|Q8IYL2-3|TRM44_HUMAN Isoform 3 of Probable tRNA (uracil-O(2)-)-methyltransferase OS=Homo sapiens OX=9606 GN=TRMT44MYGPQTQLEEDAITPNDKTLFPDVDWLIGNHSDELTPWIPVIAARSSYNCRFFVLPCCFFDFIGRYSRRQSKKTQYREYLDFIKEVGFTCGFHVDEDCLRIPSTKRVCLVGKSRTYPSSREASVDEKRTQYIKSRRGCPVSPPGWELSPSPRWVAAGSAGHCDGQQALDARVGCVTRAWAAEHGAGPQAEGPWLPGFHPREKAERVRNCAALPRDFIDQVVLQVANLLLGGKQLNTRSSRNGSLKTWNGGESLSLAEVANELDTETLRRLKRECGGLQTLLRNSHQVFQVVNGRVHIRDWREETLWKTKQPEAKQRLLSEACKTRLCWFFMHHPDGCALSTDCCPFAHGPAELRPPRTTPRKKIS>sp|Q9Y2C9|TLR6_HUMAN Toll-like receptor 6 OS=Homo sapiens OX=9606GN=TLR6 PE=1 SV=2MTKDKEPIVKSFHFVCLMIIIVGTRIQFSDGNEFAVDKSKRGLIHVPKDLPLKTKVLDMSQNYIAELQVSDMSFLSELTVLRLSHNRIQLLDLSVFKFNQDLEYLDLSHNQLQKISCHPIVSFRHLDLSFNDFKALPICKEFGNLSQLNFLGLSAMKLQKLDLLPIAHLHLSYILLDLRNYYIKENETESLQILNAKTLHLVFHPTSLFAIQVNISVNTLGCLQLTNIKLNDDNCQVFIKFLSELTRGSTLLNFTLNHIETTWKCLVRVFQFLWPKPVEYLNIYNLTIIESIREEDFTYSKTTLKALTIEHITNQVFLFSQTALYTVFSEMNIMMLTISDTPFIHMLCPHAPSTFKFLNFTQNVFTDSIFEKCSTLVKLETLILQKNGLKDLFKVGLMTKDMPSLEILDVSWNSLESGRHKENCTWVESIVVLNLSSNMLTDSVFRCLPPRIKVLDLHSNKIKSVPKQVVKLEALQELNVAFNSLTDLPGCGSFSSLSVLIIDHNSVSHPSADFFQSCQKMRSIKAGDNPFQCTCELREFVKNIDQVSSEVLEGWPDSYKCDYPESYRGSPLKDFHMSELSCNITLLIVTIGATMLVLAVTVTSLCIYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSEHDSAWVKSELVPYLEKEDIQICLHERNFVPGKSIVENIINCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNNLILILLEPIPQNSIPNKYHKLKALMTQRTYLQWPKEKSKRGLFWANIRAAFNMKLTLVTENNDVKS>sp|Q9Y2C9-2|TLR6_HUMAN Isoform 2 of Toll-like receptor 6 OS=Homo sapiensOX=9606 GN=TLR6MTKDKEPIVKSFHFVCLMIIIVGTRIQFSDGNEFAVDKSKRGLIHVPKDLPLKTKVLDMSQNYIAELQVSDMSFLSELTVLRLSHNRIQLLDLSVFKFNQDLEYLDLSHNQLQKISCHPIVSFRHLDLSFNDFKALPICKEFGNLSQLNFLGLSAMKLQKLDLLPIAHLHLSYILLDLRNYYIKENETESLQILNAKTLHLVFHPTSLFAIQVNISVNTLGCLQLTNIKLNDDNCQVFIKFLSELTRGSTLLNFTLNHIETTWKCLVRVFQFLWPKPVEYLNIYNLTIIESIREEDFTYSKTTLKALTIEHITNQVFLFSQTALYTVFSEMNIMMLTISDTPFIHMLCPHAPSTFKFLNFTQNVFTDSIFEKCSTLVKLETLIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNNLILILLEPIPQNSIPNKYHKLKALMTQRTYLQWPKEKSKRGLFWANIRAAFNMKLTLVTENNDVKS>sp|Q6P9F5|TRI40_HUMAN E3 ubiquitin ligase TRIM40 OS=Homo sapiens OX=9606GN=TRIM40 PE=1 SV=3MIPLQKDNQEEGVCPICQESLKEAVSTNCGHLFCRVCLTQHVEKASASGVFCCPLCRKPCSEEVLGTGYICPNHQKRVCRFCEESRLLLCVECLVSPEHMSHHELTIENALSHYKERLNRRSRKLRKDIAELQRLKAQQEKKLQALQFQVDHGNHRLEAGPESQHQTREQLGALPQQWLGQLEHMPAEAARILDISRAVTQLRSLVIDLERTAKELDTNTLKNAGDLLNRSAPQKLEVIYPQLEKGVSELLLQPPQKL>sp|Q6P9F5-2|TRI40_HUMAN Isoform 2 of E3 ubiquitin ligase TRIM40 OS=Homosapiens OX=9606 GN=TRIM40MIPLQKDNQEEGVCPICQESLKEAVSTNCGHLFCRVCLTQHVEKASASGVFCCPLCRKPCSEEVLGTGYICPNHQKRVCRFCEESRLLLCVECLVSPEHMSHHELTIENALSHYKERLNRRSRKLRKDIAELQRLKAQQEKKLQALQQWLGQLEHMPAEAARILDISRAVTQLRSLVIDLERTAKELDTNTLKNAGDLLNRSAPQKLEVIYPQLEKGVSELLLQPPQKL>sp|Q9C026|TRIM9_HUMAN E3 ubiquitin-protein ligase TRIM9 OS=Homo sapiensOX=9606 GN=TRIM9 PE=1 SV=1MEEMEEELKCPVCGSFYREPIILPCSHNLCQACARNILVQTPESESPQSHRAAGSGVSDYDYLDLDKMSLYSEADSGYGSYGGFASAPTTPCQKSPNGVRVFPPAMPPPATHLSPALAPVPRNSCITCPQCHRSLILDDRGLRGFPKNRVLEGVIDRYQQSKAAALKCQLCEKAPKEATVMCEQCDVFYCDPCRLRCHPPRGPLAKHRLVPPAQGRVSRRLSPRKVSTCTDHELENHSMYCVQCKMPVCYQCLEEGKHSSHEVKALGAMWKLHKSQLSQALNGLSDRAKEAKEFLVQLRNMVQQIQENSVEFEACLVAQCDALIDALNRRKAQLLARVNKEHEHKLKVVRDQISHCTVKLRQTTGLMEYCLEVIKENDPSGFLQISDALIRRVHLTEDQWGKGTLTPRMTTDFDLSLDNSPLLQSIHQLDFVQVKASSPVPATPILQLEECCTHNNSATLSWKQPPLSTVPADGYILELDDGNGGQFREVYVGKETMCTVDGLHFNSTYNARVKAFNKTGVSPYSKTLVLQTSEVAWFAFDPGSAHSDIILSNDNLTVTCSSYDDRVVLGKTGFSKGIHYWELTVDRYDNHPDPAFGVARMDVMKDVMLGKDDKAWAMYVDNNRSWFMHNNSHTNRTEGGITKGATIGVLLDLNRKNLTFFINDEQQGPIAFDNVEGLFFPAVSLNRNVQVTLHTGLPVPDFYSSRASIA>sp|Q9C026-4|TRIM9_HUMAN Isoform 4 of E3 ubiquitin-protein ligase TRIM9OS=Homo sapiens OX=9606 GN=TRIM9MEEMEEELKCPVCGSFYREPIILPCSHNLCQACARNILVQTPESESPQSHRAAGSGVSDYDYLDLDKMSLYSEADSGYGSYGGFASAPTTPCQKSPNGVRVFPPAMPPPATHLSPALAPVPRNSCITCPQCHRSLILDDRGLRGFPKNRVLEGVIDRYQQSKAAALKCQLCEKAPKEATVMCEQCDVFYCDPCRLRCHPPRGPLAKHRLVPPAQGRVSRRLSPRKVSTCTDHELENHSMYCVQCKMPVCYQCLEEGKHSSHEVKALGAMWKLHKSQLSQALNGLSDRAKEAKEFLVQLRNMVQQIQENSVEFEACLVAQCDALIDALNRRKAQLLARVNKEHEHKLKVVRDQISHCTVKLRQTTGLMEYCLEVIKENDPSGFLQISDALIRRVHLTEDQWGKGTLTPRMTTDFDLSLDNSPLLQSIHQLDFVQVKVPATPILQLEECCTHNNSATLSWKQPPLSTVPADGYILELDDGNGGQFREVYVGKETMCTVDGLHFNSTYNARVKAFNKTGVSPYSKTLVLQTSEDTDSEEQTLPFPVPSERLPLRRMSPFSSTLNLQPSFPGRSYFDFRSSPHQLSLHSSLQSLNAPGCNFETQSAPYSQLVDIKKLLAVAWFAFDPGSAHSDIILSNDNLTVTCSSYDDRVVLGKTGFSKGIHYWELTVDRYDNHPDPAFGVARMDVMKDVMLGKDDKAWAMYVDNNRSWFMHNNSHTNRTEGGITKGATIGVLLDLNRKNLTFFINDEQQGPIAFDNVEGLFFPAVSLNRNVQVSTLPLRLNSCCWLPVQRLPRAVQSNRREGS>sp|Q9C026-5|TRIM9_HUMAN Isoform 5 of E3 ubiquitin-protein ligase TRIM9OS=Homo sapiens OX=9606 GN=TRIM9MEEMEEELKCPVCGSFYREPIILPCSHNLCQACARNILVQTPESESPQSHRAAGSGVSDYDYLDLDKMSLYSEADSGYGSYGGFASAPTTPCQKSPNGVRVFPPAMPPPATHLSPALAPVPRNSCITCPQCHRSLILDDRGLRGFPKNRVLEGVIDRYQQSKAAALKCQLCEKAPKEATVMCEQCDVFYCDPCRLRCHPPRGPLAKHRLVPPAQGRVSRRLSPRKVSTCTDHELENHSMYCVQCKMPVCYQCLEEGKHSSHEVKALGAMWKLHKSQLSQALNGLSDRAKEAKEFLVQLRNMVQQIQENSVEFEACLVAQCDALIDALNRRKAQLLARVNKEHEHKLKVVRDQISHCTVKLRQTTGLMEYCLEVIKENDPSGFLQISDALIRRVHLTEDQWGKGTLTPRMTTDFDLSLDNSPLLQSIHQLDFVQVKASSPVPATPILQLEECCTHNNSATLSWKQPPLSTVPADGYILELDDGNGGQFREVYVGKETMCTVDGLHFNSTYNARVKAFNKTGVSPYSKTLVLQTSEGKALQQYPSERELRGI>sp|Q8IYM9|TRI22_HUMAN E3 ubiquitin-protein ligase TRIM22 OS=Homo sapiensOX=9606 GN=TRIM22 PE=1 SV=1MDFSVKVDIEKEVTCPICLELLTEPLSLDCGHSFCQACITAKIKESVIISRGESSCPVCQTRFQPGNLRPNRHLANIVERVKEVKMSPQEGQKRDVCEHHGKKLQIFCKEDGKVICWVCELSQEHQGHQTFRINEVVKECQEKLQVALQRLIKEDQEAEKLEDDIRQERTAWKNYIQIERQKILKGFNEMRVILDNEEQRELQKLEEGEVNVLDNLAAATDQLVQQRQDASTLISDLQRRLRGSSVEMLQDVIDVMKRSESWTLKKPKSVSKKLKSVFRVPDLSGMLQVLKELTDVQYYWVDVMLNPGSATSNVAISVDQRQVKTVRTCTFKNSNPCDFSAFGVFGCQYFSSGKYYWEVDVSGKIAWILGVHSKISSLNKRKSSGFAFDPSVNYSKVYSRYRPQYGYWVIGLQNTCEYNAFEDSSSSDPKVLTLFMAVPPCRIGVFLDYEAGIVSFFNVTNHGALIYKFSGCRFSRPAYPYFNPWNCLVPMTVCPPSS>sp|Q8IYM9-2|TRI22_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM22OS=Homo sapiens OX=9606 GN=TRIM22MDFSVKVDIEKEVTCPICLELLTEPLSLDCGHSFCQACITAKIKESVIISRGESSCPVCQTRFQPGNLRPNRHLANIVERVKEVKMSPQEGQKRDVCEHHGKKLQIFCKEDGKVICWVCELSQEHQGHQTFRINEVVKECQEKLQVALQRLIKEDQEAEKLEDDIRQERTAWKIERQKILKGFNEMRVILDNEEQRELQKLEEGEVNVLDNLAAATDQLVQQRQDASTLISDLQRRLRGSSVEMLQDVIDVMKRSESWTLKKPKSVSKKLKSVFRVPDLSGMLQVLKELTDVQYYWVDVMLNPGSATSNVAISVDQRQVKTVRTCTFKNSNPCDFSAFGVFGCQYFSSGKYYWEVDVSGKIAWILGVHSKISSLNKRKSSGFAFDPSVNYSKVYSRYRPQYGYWVIGLQNTCEYNAFEDSSSSDPKVLTLFMAVPPCRIGVFLDYEAGIVSFFNVTNHGALIYKFSGCRFSRPAYPYFNPWNCLVPMTVCPPSS>sp|Q13507|TRPC3_HUMAN Short transient receptor potential channel 3OS=Homo sapiens OX=9606 GN=TRPC3 PE=1 SV=3MREKGRRQAVRGPAFMFNDRGTSLTAEEERFLDAAEYGNIPVVRKMLEESKTLNVNCVDYMGQNALQLAVGNEHLEVTELLLKKENLARIGDALLLAISKGYVRIVEAILNHPGFAASKRLTLSPCEQELQDDDFYAYDEDGTRFSPDITPIILAAHCQKYEVVHMLLMKGARIERPHDYFCKCGDCMEKQRHDSFSHSRSRINAYKGLASPAYLSLSSEDPVLTALELSNELAKLANIEKEFKNDYRKLSMQCKDFVVGVLDLCRDSEEVEAILNGDLESAEPLEVHRHKASLSRVKLAIKYEVKKFVAHPNCQQQLLTIWYENLSGLREQTIAIKCLVVLVVALGLPFLAIGYWIAPCSRLGKILRSPFMKFVAHAASFIIFLGLLVFNASDRFEGITTLPNITVTDYPKQIFRVKTTQFTWTEMLIMVWVLGMMWSECKELWLEGPREYILQLWNVLDFGMLSIFIAAFTARFLAFLQATKAQQYVDSYVQESDLSEVTLPPEIQYFTYARDKWLPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVLFIMVFFAFMIGMFILYSYYLGAKVNAAFTTVEESFKTLFWSIFGLSEVTSVVLKYDHKFIENIGYVLYGIYNVTMVVVLLNMLIAMINSSYQEIEDDSDVEWKFARSKLWLSYFDDGKTLPPPFSLVPSPKSFVYFIMRIVNFPKCRRRRLQKDIEMGMGNSKSRLNLFTQSNSRVFESHSFNSILNQPTRYQQIMKRLIKRYVLKAQVDKENDEVNEGELKEIKQDISSLRYELLEDKSQATEELAILIHKLSEKLNPSMLRCE>sp|Q13507-2|TRPC3_HUMAN Isoform 2 of Short transient receptor potentialchannel 3 OS=Homo sapiens OX=9606 GN=TRPC3MSTKVRKCKEQARVTFPAPEEEEDEGEDEGAEPQRRRRGWRGVNGGLEPRSAPSQREPHGYCPPPFSHGPDLSMEGSPSLRRMTVMREKGRRQAVRGPAFMFNDRGTSLTAEEERFLDAAEYGNIPVVRKMLEESKTLNVNCVDYMGQNALQLAVGNEHLEVTELLLKKENLARIGDALLLAISKGYVRIVEAILNHPGFAASKRLTLSPCEQELQDDDFYAYDEDGTRFSPDITPIILAAHCQKYEVVHMLLMKGARIERPHDYFCKCGDCMEKQRHDSFSHSRSRINAYKGLASPAYLSLSSEDPVLTALELSNELAKLANIEKEFKNDYRKLSMQCKDFVVGVLDLCRDSEEVEAILNGDLESAEPLEVHRHKASLSRVKLAIKYEVKKFVAHPNCQQQLLTIWYENLSGLREQTIAIKCLVVLVVALGLPFLAIGYWIAPCSRLGKILRSPFMKFVAHAASFIIFLGLLVFNASDRFEGITTLPNITVTDYPKQIFRVKTTQFTWTEMLIMVWVLGMMWSECKELWLEGPREYILQLWNVLDFGMLSIFIAAFTARFLAFLQATKAQQYVDSYVQESDLSEVTLPPEIQYFTYARDKWLPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVLFIMVFFAFMIGMFILYSYYLGAKVNAAFTTVEESFKTLFWSIFGLSEVTSVVLKYDHKFIENIGYVLYGIYNVTMVVVLLNMLIAMINSSYQEIEDDSDVEWKFARSKLWLSYFDDGKTLPPPFSLVPSPKSFVYFIMRIVNFPKCRRRRLQKDIEMGMGNSKSRLNLFTQSNSRVFESHSFNSILNQPTRYQQIMKRLIKRYVLKAQVDKENDEVNEGELKEIKQDISSLRYELLEDKSQATEELAILIHKLSEKLNPSMLRCE>sp|Q13507-3|TRPC3_HUMAN Isoform 3 of Short transient receptor potentialchannel 3 OS=Homo sapiens OX=9606 GN=TRPC3MEGSPSLRRMTVMREKGRRQAVRGPAFMFNDRGTSLTAEEERFLDAAEYGNIPVVRKMLEESKTLNVNCVDYMGQNALQLAVGNEHLEVTELLLKKENLARIGDALLLAISKGYVRIVEAILNHPGFAASKRLTLSPCEQELQDDDFYAYDEDGTRFSPDITPIILAAHCQKYEVVHMLLMKGARIERPHDYFCKCGDCMEKQRHDSFSHSRSRINAYKGLASPAYLSLSSEDPVLTALELSNELAKLANIEKEFKNDYRKLSMQCKDFVVGVLDLCRDSEEVEAILNGDLESAEPLEVHRHKASLSRVKLAIKYEVKKFVAHPNCQQQLLTIWYENLSGLREQTIAIKCLVVLVVALGLPFLAIGYWIAPCSRLGKILRSPFMKFVAHAASFIIFLGLLVFNASDRFEGITTLPNITVTDYPKQIFRVKTTQFTWTEMLIMVWVLGMMWSECKELWLEGPREYILQLWNVLDFGMLSIFIAAFTARFLAFLQATKAQQYVDSYVQESDLSEVTLPPEIQYFTYARDKWLPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVLFIMVFFAFMIGMFILYSYYLGAKVNAAFTTVEESFKTLFWSIFGLSEVTSVVLKYDHKFIENIGYVLYGIYNVTMVVVLLNMLIAMINSSYQEIEDDSDVEWKFARSKLWLSYFDDGKTLPPPFSLVPSPKSFVYFIMRIVNFPKCRRRRLQKDIEMGMGNSKSRLNLFTQSNSRVFESHSFNSILNQPTRYQQIMKRLIKRYVLKAQVDKENDEVNEGELKEIKQDISSLRYELLEDKSQATEELAILIHKLSEKLNPSMLRCE>sp|P49746|TSP3_HUMAN Thrombospondin-3 OS=Homo sapiens OX=9606 GN=THBS3PE=1 SV=1METQELRGALALLLLCFFTSASQDLQVIDLLTVGESRQMVAVAEKIRTALLTAGDIYLLSTFRLPPKQGGVLFGLYSRQDNTRWLEASVVGKINKVLVRYQREDGKVHAVNLQQAGLADGRTHTVLLRLRGPSRPSPALHLYVDCKLGDQHAGLPALAPIPPAEVDGLEIRTGQKAYLRMQGFVESMKIILGGSMARVGALSECPFQGDESIHSAVTNALHSILGEQTKALVTQLTLFNQILVELRDDIRDQVKEMSLIRNTIMECQVCGFHEQRSHCSPNPCFRGVDCMEVYEYPGYRCGPCPPGLQGNGTHCSDINECAHADPCFPGSSCINTMPGFHCEACPRGYKGTQVSGVGIDYARASKQVCNDIDECNDGNNGGCDPNSICTNTVGSFKCGPCRLGFLGNQSQGCLPARTCHSPAHSPCHIHAHCLFERNGAVSCQCNVGWAGNGNVCGTDTDIDGYPDQALPCMDNNKHCKQDNCLLTPNSGQEDADNDGVGDQCDDDADGDGIKNVEDNCRLFPNKDQQNSDTDSFGDACDNCPNVPNNDQKDTDGNGEGDACDNDVDGDGIPNGLDNCPKVPNPLQTDRDEDGVGDACDSCPEMSNPTQTDADSDLVGDVCDTNEDSDGDGHQDTKDNCPQLPNSSQLDSDNDGLGDECDGDDDNDGIPDYVPPGPDNCRLVPNPNQKDSDGNGVGDVCEDDFDNDAVVDPLDVCPESAEVTLTDFRAYQTVVLDPEGDAQIDPNWVVLNQGMEIVQTMNSDPGLAVGYTAFNGVDFEGTFHVNTVTDDDYAGFLFSYQDSGRFYVVMWKQTEQTYWQATPFRAVAQPGLQLKAVTSVSGPGEHLRNALWHTGHTPDQVRLLWTDPRNVGWRDKTSYRWQLLHRPQVGYIRVKLYEGPQLVADSGVIIDTSMRGGRLGVFCFSQENIIWSNLQYRCNDTVPEDFEPFRRQLLQGRV>sp|P49746-2|TSP3_HUMAN Isoform 2 of Thrombospondin-3 OS=Homo sapiensOX=9606 GN=THBS3METQELRGALALLLLCFFTSASQDLQVIDLLTVGESRQMVAVAEKIRTALLTAGDIYLLSTFRLPPKQGGVLFGLYSRQDNTRWLEASVVGKINKVTNALHSILGEQTKALVTQLTLFNQILVELRDDIRDQVKEMSLIRNTIMECQVCGFHEQRSHCSPNPCFRGVDCMEVYEYPGYRCGPCPPGLQGNGTHCSDINECAHADPCFPGSSCINTMPGFHCEACPRGYKGTQVSGVGIDYARASKQVCNDIDECNDGNNGGCDPNSICTNTVGSFKCGPCRLGFLGNQSQGCLPARTCHSPAHSPCHIHAHCLFERNGAVSCQCNVGWAGNGNVCGTDTDIDGYPDQALPCMDNNKHCKQDNCLLTPNSGQEDADNDGVGDQCDDDADGDGIKNVEDNCRLFPNKDQQNSDTDSFGDACDNCPNVPNNDQKDTDGNGEGDACDNDVDGDGIPNGLDNCPKVPNPLQTDRDEDGVGDACDSCPEMSNPTQTDADSDLVGDVCDTNEDSDGDGHQDTKDNCPQLPNSSQLDSDNDGLGDECDGDDDNDGIPDYVPPGPDNCRLVPNPNQKDSDGNGVGDVCEDDFDNDAVVDPLDVCPESAEVTLTDFRAYQTVVLDPEGDAQIDPNWVVLNQGMEIVQTMNSDPGLAVGYTAFNGVDFEGTFHVNTVTDDDYAGFLFSYQDSGRFYVVMWKQTEQTYWQATPFRAVAQPGLQLKAVTSVSGPGEHLRNALWHTGHTPDQVRLLWTDPRNVGWRDKTSYRWQLLHRPQVGYIRVKLYEGPQLVADSGVIIDTSMRGGRLGVFCFSQENIIWSNLQYRCNDTVPEDFEPFRRQLLQGRV>sp|O95859|TSN12_HUMAN Tetraspanin-12 OS=Homo sapiens OX=9606 GN=TSPAN12PE=1 SV=1MAREDSVKCLRCLLYALNLLFWLMSISVLAVSAWMRDYLNNVLTLTAETRVEEAVILTYFPVVHPVMIAVCCFLIIVGMLGYCGTVKRNLLLLAWYFGSLLVIFCVELACGVWTYEQELMVPVQWSDMVTLKARMTNYGLPRYRWLTHAWNFFQREFKCCGVVYFTDWLEMTEMDWPPDSCCVREFPGCSKQAHQEDLSDLYQEGCGKKMYSFLRGTKQLQVLRFLGISIGVTQILAMILTITLLWALYYDRREPGTDQMMSLKNDNSQHLSCPSVELLKPSLSRIFEHTSMANSFNTHFEMEEL>sp|O95859-2|TSN12_HUMAN Isoform 2 of Tetraspanin-12 OS=Homo sapiensOX=9606 GN=TSPAN12MAHKLLLVPVQWSDMVTLKARMTNYGLPRYRWLTHAWNFFQREFKCCGVVYFTDWLEMTEMDWPPDSCCVREFPGCSKQAHQEDLSDLYQEGCGKKMYSFLRGTKQLQVLRFLGISIGVTQILAMILTITLLWALYYDRREPGTDQMMSLKNDNSQHLSCPSVELLKPSLSRIFEHTSMANSFNTHFEMEEL>sp|Q86V25|VASH2_HUMAN Tubulinyl-Tyr carboxypeptidase 2 OS=Homo sapiensOX=9606 GN=VASH2 PE=1 SV=2MTGSAADTHRCPHPKGAKGTRSRSSHARPVSLATSGGSEEEDKDGGVLFHVNKSGFPIDSHTWERMWMHVAKVHPKGGEMVGAIRNAAFLAKPSIPQVPNYRLSMTIPDWLQAIQNYMKTLQYNHTGTQFFEIRKMRPLSGLMETAKEMTRESLPIKCLEAVILGIYLTNGQPSIERFPISFKTYFSGNYFHHVVLGIYCNGRYGSLGMSRRAELMDKPLTFRTLSDLIFDFEDSYKKYLHTVKKVKIGLYVPHEPHSFQPIEWKQLVLNVSKMLRADIRKELEKYARDMRMKILKPASAHSPTQVRSRGKSLSPRRRQASPPRRLGRREKSPALPEKKVADLSTLNEVGYQIRI>sp|Q86V25-2|VASH2_HUMAN Isoform 2 of Tubulinyl-Tyr carboxypeptidase 2OS=Homo sapiens OX=9606 GN=VASH2MWMHVAKVHPKGGEMVGAIRNAAFLAKPSIPQVPNYRLSMTIPDWLQAIQNYMKTLQYNHTGTQFFEIRKMRPLSGLMETAKEMTRESLPIKCLEAVILGIYLTNGQPSIERFPISFKTYFSGNYFHHVVLGIYCNGRYGSLGMSRRAELMDKPLTFRTLSDLIFDFEDSYKKYLHTVKKVKIGLYVPHEPHSFQPIEWKQLVLNVSKMLRADIRKELEKYARDMRMKILKPASAHSPTQVRSRGKSLSPRRRQASPPRRLGRREKSPALPEKKVADLSTLNEVGYQIRI>sp|Q86V25-3|VASH2_HUMAN Isoform 3 of Tubulinyl-Tyr carboxypeptidase 2OS=Homo sapiens OX=9606 GN=VASH2METAKEMTRESLPIKCLEAVILGIYLTNGQPSIERFPISFKTYFSGNYFHHVVLGIYCNGRYGSLGMSRRAELMDKPLTFRTLSDLIFDFEDSYKKYLHTVKKVKIGLYVPHEPHSFQPIEWKQLVLNVSKMLRADIRKELEKYARDMRMKGLCSH>sp|Q86V25-4|VASH2_HUMAN Isoform 4 of Tubulinyl-Tyr carboxypeptidase 2OS=Homo sapiens OX=9606 GN=VASH2MTGSAADTHRCPHPKGAKGTRSRSSHARPVSLATSGGSEEEDKDGGVLFHVNKSGFPIDSHTWERMWMHVAKVHPKGGEMVGAIRNAAFLAKPSIPQVPNYRLSMTIPDWLQAIQNYMKTLQYNHTGTQFFEIRKMRPLSGLMETAKEMTRESLPIKCLEAVILGITHS>sp|Q86V25-5|VASH2_HUMAN Isoform 5 of Tubulinyl-Tyr carboxypeptidase 2OS=Homo sapiens OX=9606 GN=VASH2MTGSAADTHRCPHPKGAKGTRSRSSHARPVSLATSGGSEEEDKDGGVLFHVNKSGFPIDSHTWERMWMHVAKVHPKGGEMVGAIRNAAFLAKPSIPQVPNYRLSMTIPDWLQAIQNYMKTLHYLTNGQPSIERFPISFKTYFSGNYFHHVVLGIYCNGRYGSLGMSRRAELMDKPLTFRTLSDLIFDFEDSYKKYLHTVKKVKIGLYVPHEPHSFQPIEWKQLVLNVSKMLRADIRKELEKYARDMRMKILKPASAHSPTQVRSRGKSLSPRRRQASPPRRLGRREKSPALPEKKVADLSTLNEVGYQIRI>sp|Q86V25-6|VASH2_HUMAN Isoform 6 of Tubulinyl-Tyr carboxypeptidase 2OS=Homo sapiens OX=9606 GN=VASH2MTIPDWLQAIQNYMKTLQYNHTGTQFFEIRKMRPLSGLMETAKEMTRESLPIKCLEAVILGIYLTNGQPSIERFPISFKTYFSGNYFHHVVLGIYCNGRYGSLGMSRRAELMDKPLTFRTLSDLIFDFEDSYKKYLHTVKKVKIGLYVPHEPHSFQPIEWKQLVLNVSKMLRADIRKELEKYARDMRMKILKPASAHSPTQVRSRGKSLSPRRRQASPPRRLGRREKSPALPEKKVADLSTLNEVGYQIRI>sp|Q8IV63|VRK3_HUMAN Inactive serine/threonine-protein kinase VRK3OS=Homo sapiens OX=9606 GN=VRK3 PE=1 SV=2MISFCPDCGKSIQAAFKFCPYCGNSLPVEEHVGSQTFVNPHVSSFQGSKRGLNSSFETSPKKVKWSSTVTSPRLSLFSDGDSSESEDTLSSSERSKGSGSRPPTPKSSPQKTRKSPQVTRGSPQKTSCSPQKTRQSPQTLKRSRVTTSLEALPTGTVLTDKSGRQWKLKSFQTRDNQGILYEAAPTSTLTCDSGPQKQKFSLKLDAKDGRLFNEQNFFQRAAKPLQVNKWKKLYSTPLLAIPTCMGFGVHQDKYRFLVLPSLGRSLQSALDVSPKHVLSERSVLQVACRLLDALEFLHENEYVHGNVTAENIFVDPEDQSQVTLAGYGFAFRYCPSGKHVAYVEGSRSPHEGDLEFISMDLHKGCGPSRRSDLQSLGYCMLKWLYGFLPWTNCLPNTEDIMKQKQKFVDKPGPFVGPCGHWIRPSETLQKYLKVVMALTYEEKPPYAMLRNNLEALLQDLRVSPYDPIGLPMVP>sp|Q8IV63-2|VRK3_HUMAN Isoform 2 of Inactive serine/threonine-proteinkinase VRK3 OS=Homo sapiens OX=9606 GN=VRK3MISFCPDCGKSIQAAFKFCPYCGNSLPVEEHVGSQTFVNPHVSSFQGSKRGLNSSFETSPKKVKWSSTVTSPRLSLFSDGDSSESEDTLSSSERSKGSGSRPPTPKSSPQKTRKSPQVTRGSPQKTSCSPQKTRQSPQTLKRSRVTTSLEALPTGTVLTDKSGRQWKLKSFQTRDNQGILYEAAPTSTLTCDSGPQKQKFSLKLDAKDGRLFNEQNFFQRAAKPLQVNKWKKLYSTPLLAIPTCMGFGVHQDKYRFLVLPSLGRSLQSALDVSPKHVLSERSVLQVACRLLDALEFLHENEYVHGNVTAENIFVDPEDQSQVTLAGYGFAFRYCPSGKHVAYVEGSRSPHEGDLEFISMDLHKGCGPSRRSDLQSLGYCMLKWLYGFLPWTNCLPNTEDIMKQKQKLPWDSF>sp|Q8IV63-3|VRK3_HUMAN Isoform 3 of Inactive serine/threonine-proteinkinase VRK3 OS=Homo sapiens OX=9606 GN=VRK3MISFCPDCGKSIQAAFKFCPYCGNSLPVEEHVGSQTFVNPHVSSFQGSGSRPPTPKSSPQKTRKSPQVTRGSPQKTSCSPQKTRQSPQTLKRSRVTTSLEALPTGTVLTDKSGRQWKLKSFQTRDNQGILYEAAPTSTLTCDSGPQKQKFSLKLDAKDGRLFNEQNFFQRAAKPLQVNKWKKLYSTPLLAIPTCMGFGVHQDKYRFLVLPSLGRSLQSALDVSPKHVLSERSVLQVACRLLDALEFLHENEYVHGNVTAENIFVDPEDQSQVTLAGYGFAFRYCPSGKHVAYVEGSRSPHEGDLEFISMDLHKGCGPSRRSDLQSLGYCMLKWLYGFLPWTNCLPNTEDIMKQKQKFVDKPGPFVGPCGHWIRPSETLQKYLKVVMALTYEEKPPYAMLRNNLEALLQDLRVSPYDPIGLPMVP>sp|Q8N8F6|YIPF7_HUMAN Protein YIPF7 OS=Homo sapiens OX=9606 GN=YIPF7PE=1 SV=2MDLLKISHTKLHLLEDLSIKNKQRMSNLAQFDSDFYQSNFTIDNQEQSGNDSNAYGNLYGSRKQQAGEQPQPASFVPSEMLMSSGYAGQFFQPASNSDYYSQSPYIDSFDEEPPLLEELGIHFDHIWQKTLTVLNPMKPVDGSIMNETDLTGPILFCVALGATLLLAGKVQFGYVYGMSAIGCLVIHALLNLMSSSGVSYGCVASVLGYCLLPMVILSGCAMFFSLQGIFGIMSSLVIIGWCSLSASKIFIAALHMEGQQLLVAYPCAILYGLFALLTIF>sp|Q8N8F6-2|YIPF7_HUMAN Isoform 2 of Protein YIPF7 OS=Homo sapiensOX=9606 GN=YIPF7MDLLKISHTKLHLLEDLSIKNKQRMSNLAQFDSDFYQSNFTIDNQEQSGNDSNAYGNLYGSRKQQAGEQPQPASFVPSEMLMSSGYAGQFFQPASNSDYYSQSPYIDSFDEEPPLLEELGIHFDHIWQKTLTVLNPMKPVDGSIMNETDLTGPILFCVALGATLLLVMCHRKHQILMLVLSSAGFEAICINIRETVSPYIVNFLSERE>sp|Q8N8F6-3|YIPF7_HUMAN Isoform 3 of Protein YIPF7 OS=Homo sapiensOX=9606 GN=YIPF7MDLLKISHTKLHLLEDLSIKNKQRMSNLAQFDSDFYQSNFTIDNQEQSGNDSNAYGNLYGSRKTWNPF>sp|Q8N8F6-4|YIPF7_HUMAN Isoform 4 of Protein YIPF7 OS=Homo sapiensOX=9606 GN=YIPF7MDLLKISHTKLHLLEDLSIKNKQRMSNLAQFDSDFYQSNFTIDNQEQSGNDSNAYGNLYGSRKQQAGEQPQPASFVPSEMLMSSGYAGQFFQPASNSDYYSQSPYIDSFDEEPPLLEDKNLESILITYGKKL>sp|Q6ZV60|YL023_HUMAN Putative uncharacterized protein encoded byLINC00173 OS=Homo sapiens OX=9606 GN=LINC00173 PE=5 SV=1MSFSPYSTMITVCVCFNSRVQLTVPSFTAWLRSRYSKALFMVLRRAAQEKDKGVCQGWHCVKKWACKGRIPGQPLQPQPLGPYLRSLSQHPATQTPRPQARASSRYLELHRSQNRGGSEFKFWFCYCLIACCRDSISSSGKWE>sp|Q6ZVU0|YK022_HUMAN Putative uncharacterized protein FLJ42102 OS=Homosapiens OX=9606 PE=5 SV=1MVTKWWGQDPPVQLRSQLMLWIMELILWKFQSSVVGSSVVTWKISDVAGPHGDHSCSLQHLEQIIGSVSNYPRYTGSRSCDRGENPVSLSKRIKCTWMLGASGFPPRCPSGRDHSRDHPGKSQVPALELANQLAAWGLWSSVVKSWGFRAGETEAPISALSSAHA>sp|P13994|YJU2B_HUMAN Probable splicing factor YJU2B OS=Homo sapiensOX=9606 GN=YJU2B PE=1 SV=2MGERKGVNKYYPPDFNPEKHGSLNRYHNSHPLRERARKLSQGILIIRFEMPYNIWCDGCKNHIGMGVRYNAEKKKVGNYYTTPIYRFRMKCHLCVNYIEMQTDPANCDYVIVSGAQRKEERWDMADNEQVLTTEHEKKQKLETDAMFRLEHGEADRSTLKKALPTLSHIQEAQSAWKDDFALNSMLRRRFREKKKAIQEEEERDQALQAKASLTIPLVPETEDDRKLAALLKFHTLDSYEDKQKLKRTEIISRSWFPSAPGSASSSKVSGVLKKLAQSRRTALATSPITVGDLGIVRRRSRDVPESPQHAADTPKSGEPRVPEEAAQDRPMSPGDCPPETTETPKCSSPRGQEGSRQDKPLSPAGSSQEAADTPDTRHPCSLGSSLVADYSDSESE>sp|Q9GZM5|YIPF3_HUMAN Protein YIPF3 OS=Homo sapiens OX=9606 GN=YIPF3PE=1 SV=1MATTAAPAGGARNGAGPEWGGFEENIQGGGSAVIDMENMDDTSGSSFEDMGELHQRLREEEVDADAADAAAAEEEDGEFLGMKGFKGQLSRQVADQMWQAGKRQASRAFSLYANIDILRPYFDVEPAQVRSRLLESMIPIKMVNFPQKIAGELYGPLMLVFTLVAILLHGMKTSDTIIREGTLMGTAIGTCFGYWLGVSSFIYFLAYLCNAQITMLQMLALLGYGLFGHCIVLFITYNIHLHALFYLFWLLVGGLSTLRMVAVLVSRTVGPTQRLLLCGTLAALHMLFLLYLHFAYHKVVEGILDTLEGPNIPPIQRVPRDIPAMLPAARLPTTVLNATAKAVAVTLQSH>sp|Q8NAP3|ZBT38_HUMAN Zinc finger and BTB domain-containing protein 38OS=Homo sapiens OX=9606 GN=ZBTB38 PE=1 SV=2MTVMSLSRDLKDDFHSDTVLSILNEQRIRGILCDVTIIVEDTKFKAHSNVLAASSLYFKNIFWSHTICISSHVLELDDLKAEVFTEILNYIYSSTVVVKRQETVTDLAAAGKKLGISFLEDLTDRNFSNSPGPYVFCITEKGVVKEEKNEKRHEEPAITNGPRITNAFSIIETENSNNMFSPLDLRASFKKVSDSMRTASLCLERTDVCHEAEPVRTLAEHSYAVSSVAEAYRSQPVREHDGSSPGNTGKENCEALAAKPKTCRKPKTFSIPQDSDSATENIPPPPVSNLEVNQERSPQPAAVLTRSKSPNNEGDVHFSREDENQSSDVPGPPAAEVPPLVYNCSCCSKAFDSSTLLSAHMQLHKPTQEPLVCKYCNKQFTTLNRLDRHEQICMRSSHMPIPGGNQRFLENYPTIGQNGGSFTGPEPLLSENRIGEFSSTGSTLPDTDHMVKFVNGQMLYSCVVCKRSYVTLSSLRRHANVHSWRRTYPCHYCNKVFALAEYRTRHEIWHTGERRYQCIFCLETFMTYYILKNHQKSFHAIDHRLSISKKTANGGLKPSVYPYKLYRLLPMKCKRAPYKSYRNSSYENARENSQMNESAPGTYVVQNPHSSELPTLNFQDTVNTLTNSPAIPLETSACQDIPTSANVQNAEGTKWGEEALKMDLDNNFYSTEVSVSSTENAVSSDLRAGDVPVLSLSNSSENAASVISYSGSAPSVIVHSSQFSSVIMHSNAIAAMTSSNHRAFSDPAVSQSLKDDSKPEPDKVGRFASRPKSIKEKKKTTSHTRGEIPEESNYVADPGGSLSKTTNIAEETSKIETYIAKPALPGTSTNSNVAPLCQITVKIGNEAIVKRHILGSKLFYKRGRRPKYQMQEEPLPQGNDPEPSGDSPLGLCQSECMEMSEVFDDASDQDSTDKPWRPYYNYKPKKKSRQLKKMRKVNWRKEHGNRSPSHKCKYPAELDCAVGKAPQDKPFEEEETKEMPKLQCELCDGDKAVGAGNQGRPHRHLTSRPYACELCAKQFQSPSTLKMHMRCHTGEKPYQCKTCGRCFSVQGNLQKHERIHLGLKEFVCQYCNKAFTLNETLKIHERIHTGEKRYHCQFCFQRFLYLSTKRNHEQRHIREHNGKGYACFQCPKICKTAAALGMHQKKHLFKSPSQQEKIGDVCHENSNPLENQHFIGSEDNDQKDNIQTGVENVVL>sp|Q6ZRG5|YQ015_HUMAN Putative uncharacterized protein FLJ43944 OS=Homosapiens OX=9606 PE=5 SV=1MMRWNFSPEDLSSIFRNNSTLPKITVKNVDIEFTIPTAVTIEVEPSPVQQDNPPISSEQADFSLAQPDSPSLPLESPEESESSAQQEATAQTPNPPKEVEPSPVQQEFPAEPTEPAKEVEPSATQQEASGHPLKSTKEVNPPPKQEIPAQPSEPPEKVELSPVLQQAPTQLLEPLKKVECSPVQQAVPAQSSEPSIVVEPSPVQQIAHLCLQSSLRKWNPL>sp|Q9NYG2|ZDHC3_HUMAN Palmitoyltransferase ZDHHC3 OS=Homo sapiensOX=9606 GN=ZDHHC3 PE=1 SV=2MMLIPTHHFRNIERKPEYLQPEKCVPPPYPGPVGTMWFIRDGCGIACAIVTWFLVLYAEFVVLFVMLIPSRDYVYSIINGIVFNLLAFLALASHCRAMLTDPGAVPKGNATKEFIESLQLKPGQVVYKCPKCCSIKPDRAHHCSVCKRCIRKMDHHCPWVNNCVGENNQKYFVLFTMYIALISLHALIMVGFHFLHCFEEDWTKCSSFSPPTTVILLILLCFEGLLFLIFTSVMFGTQVHSICTDETGIEQLKKEERRWAKKTKWMNMKAVFGHPFSLGWASPFATPDQGKADPYQYVV>sp|Q9NYG2-2|ZDHC3_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC3 OS=Homosapiens OX=9606 GN=ZDHHC3MMLIPTHHFRNIERKPEYLQPEKCVPPPYPGPVGTMWFIRDGCGIACAIVTWFLVLYAEFVVLFVMLIPSRDYVYSIINGIVFNLLAFLALASHCRAMLTDPGAVPKGNATKEFIESLQLKPGQVVYKCPKCCSIKPDRAHHCSVCKRCIRKMDHHCPWVNNCVGENNQKYFVLFTMYIALISLHALIMVGFHFLHCFEEDWTTYGLNREEMAETGISLHEKMQPLNFSSTECSSFSPPTTVILLILLCFEGLLFLIFTSVMFGTQVHSICTDETGIEQLKKEERRWAKKTKWMNMKAVFGHPFSLGWASPFATPDQGKADPYQYVV>sp|P08048|ZFY_HUMAN Zinc finger Y-chromosomal protein OS=Homo sapiensOX=9606 GN=ZFY PE=1 SV=3MDEDEFELQPQEPNSFFDGIGADATHMDGDQIVVEIQEAVFVSNIVDSDITVHNFVPDDPDSVVIQDVVEDVVIEEDVQCSDILEEADVSENVIIPEQVLDSDVTEEVSLPHCTVPDDVLASDITSTSMSMPEHVLTSESMHVCDIGHVEHMVHDSVVEAEIITDPLTSDIVSEEVLVADCAPEAVIDASGISVDQQDNDKASCEDYLMISLDDAGKIEHDGSTGVTIDAESEMDPCKVDSTCPEVIKVYIFKADPGEDDLGGTVDIVESEPENDHGVELLDQNSSIRVPREKMVYMTVNDSQQEDEDLNVAEIADEVYMEVIVGEEDAAVAAAAAAVHEQQIDEDEMKTFVPIAWAAAYGNNSDGIENRNGTASALLHIDESAGLGRLAKQKPKKKRRPDSRQYQTAIIIGPDGHPLTVYPCMICGKKFKSRGFLKRHMKNHPEHLAKKKYHCTDCDYTTNKKISLHNHLESHKLTSKAEKAIECDECGKHFSHAGALFTHKMVHKEKGANKMHKCKFCEYETAEQGLLNRHLLAVHSKNFPHICVECGKGFRHPSELRKHMRIHTGEKPYQCQYCEYRSADSSNLKTHIKTKHSKEMPFKCDICLLTFSDTKEVQQHTLVHQESKTHQCLHCDHKSSNSSDLKRHVISVHTKDYPHKCEMCEKGFHRPSELKKHVAVHKGKKMHQCRHCDFKIADPFVLSRHILSVHTKDLPFRCKRCRKGFRQQNELKKHMKTHSGRKVYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEYCKKGFRRPSEKNQHIMRHHKEVGLP>sp|P08048-2|ZFY_HUMAN Isoform 2 of Zinc finger Y-chromosomal proteinOS=Homo sapiens OX=9606 GN=ZFYMDEDEFELQPQEPNSFFDGIVDDAGKIEHDGSTGVTIDAESEMDPCKVDSTCPEVIKVYIFKADPGEDDLGGTVDIVESEPENDHGVELLDQNSSIRVPREKMVYMTVNDSQQEDEDLNVAEIADEVYMEVIVGEEDAAVAAAAAAVHEQQIDEDEMKTFVPIAWAAAYGNNSDGIENRNGTASALLHIDESAGLGRLAKQKPKKKRRPDSRQYQTAIIIGPDGHPLTVYPCMICGKKFKSRGFLKRHMKNHPEHLAKKKYHCTDCDYTTNKKISLHNHLESHKLTSKAEKAIECDECGKHFSHAGALFTHKMVHKEKGANKMHKCKFCEYETAEQGLLNRHLLAVHSKNFPHICVECGKGFRHPSELRKHMRIHTGEKPYQCQYCEYRSADSSNLKTHIKTKHSKEMPFKCDICLLTFSDTKEVQQHTLVHQESKTHQCLHCDHKSSNSSDLKRHVISVHTKDYPHKCEMCEKGFHRPSELKKHVAVHKGKKMHQCRHCDFKIADPFVLSRHILSVHTKDLPFRCKRCRKGFRQQNELKKHMKTHSGRKVYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEYCKKGFRRPSEKNQHIMRHHKEVGLP>sp|P08048-3|ZFY_HUMAN Isoform 3 of Zinc finger Y-chromosomal proteinOS=Homo sapiens OX=9606 GN=ZFYMDGDQIVVEIQEAVFVSNIVDSDITVHNFVPDDPDSVVIQDVVEDVVIEEDVQCSDILEEADVSENVIIPEQVLDSDVTEEVSLPHCTVPDDVLASDITSTSMSMPEHVLTSESMHVCDIGHVEHMVHDSVVEAEIITDPLTSDIVSEEVLVADCAPEAVIDASGISVDQQDNDKASCEDYLMISLDDAGKIEHDGSTGVTIDAESEMDPCKVDSTCPEVIKVYIFKADPGEDDLGGTVDIVESEPENDHGVELLDQNSSIRVPREKMVYMTVNDSQQEDEDLSNNSDGIENRNGTASALLHIDESAGLGRLAKQKPKKKRRPDSRQYQTAIIIGPDGHPLTVYPCMICGKKFKSRGFLKRHMKNHPEHLAKKKYHCTDCDYTTNKKISLHNHLESHKLTSKAEKAIECDECGKHFSHAGALFTHKMVHKEKGANKMHKCKFCEYETAEQGLLNRHLLAVHSKNFPHICVECGKGFRHPSELRKHMRIHTGEKPYQCQYCEYRSADSSNLKTHIKTKHSKEMPFKCDICLLTFSDTKEVQQHTLVHQESKTHQCLHCDHKSSNSSDLKRHVISVHTKDYPHKCEMCEKGFHRPSELKKHVAVHKGKKMHQCRHCDFKIADPFVLSRHILSVHTKDLPFRCKRCRKGFRQQNELKKHMKTHSGRKVYQCEYCEYSTTDASGFKRHVISIHTKDYPHRCEYCKKGFRRPSEKNQHIMRHHKEVGLP>sp|Q9UJW8|ZN180_HUMAN Zinc finger protein 180 OS=Homo sapiens OX=9606GN=ZNF180 PE=1 SV=2MRACAGSTREAGSGAQDLSTLLCLEESMEEQDEKPPEPPKACAQDSFLPQEIIIKVEGEDTGSLTIPSQEGVNFKIVTVDFTREEQGTWNPAQRTLDRDVILENHRDLVSWDLATAVGKKDSTSKQRIFDEEPANGVKIERFTRDDPWLSSCEEVDDCKDQLEKQQEKQEILLQEVAFTQRKAVIHERVCKSDETGEKSGLNSSLFSSPVIPIRNHFHKHVSHAKKWHLNAAVNSHQKINENETLYENNECGKPPQSIHLIQFTRTQTKDKCYGFSDRIQSFCHGTPLHIHEKIHGGGKTFDFKECGQVLNPKISHNEQQRIPFEESQYKCSETSHSSSLTQNMRNNSEEKPFECNQCGKSFSWSSHLVAHQRTHTGEKPYECSECGKSFSRSSHLVSHQRTHTGEKPYRCNQCGKSFSQSYVLVVHQRTHTGEKPYECNQCGKSFRQSYKLIAHQRTHTGEKPYECNQCGKSFIQSYKLIAHQRIHTGEKPYECNQCGKSFSQSYKLVAHQRTHTGEKPFECNQCGKSFSWSSQLVAHQRTHTGEKPYECSECGKSFNRSSHLVMHQRIHTGEKPYECNQCGKSFSQSYVLVVHQRTHTGEKPYECSQCGKSFRQSSCLTQHQRTHTGEKPFECNQCGKTFSLSARLIVHQRTHTGEKPFTCIQCGKAFINSYKLIRHQATHTEEKLYECN>sp|Q9UJW8-2|ZN180_HUMAN Isoform 2 of Zinc finger protein 180 OS=Homosapiens OX=9606 GN=ZNF180MEEQDEKPPEPPKACAQDSFLPQEIIIKVEGEDTGSLTIPSQEGVNFKIVTVDFTREEQGTWNPAQRTLDRDVILENHRDLVSWDLATAVGKKDSTSKQRIFDEEPANGVKIERFTRDDPWLSSCEEVDDCKDQLEKQQEKQEILLQEVAFTQRKAVIHERVCKSDETGEKSGLNSSLFSSPVIPIRNHFHKHVSHAKKWHLNAAVNSHQKINENETLYENNECGKPPQSIHLIQFTRTQTKDKCYGFSDRIQSFCHGTPLHIHEKIHGGGKTFDFKECGQVLNPKISHNEQQRIPFEESQYKCSETSHSSSLTQNMRNNSEEKPFECNQCGKSFSWSSHLVAHQRTHTGEKPYECSECGKSFSRSSHLVSHQRTHTGEKPYRCNQCGKSFSQSYVLVVHQRTHTGEKPYECNQCGKSFRQSYKLIAHQRTHTGEKPYECNQCGKSFIQSYKLIAHQRIHTGEKPYECNQCGKSFSQSYKLVAHQRTHTGEKPFECNQCGKSFSWSSQLVAHQRTHTGEKPYECSECGKSFNRSSHLVMHQRIHTGEKPYECNQCGKSFSQSYVLVVHQRTHTGEKPYECSQCGKSFRQSSCLTQHQRTHTGEKPFECNQCGKTFSLSARLIVHQRTHTGEKPFTCIQCGKAFINSYKLIRHQATHTEEKLYECN>sp|Q9UJW8-3|ZN180_HUMAN Isoform 3 of Zinc finger protein 180 OS=Homosapiens OX=9606 GN=ZNF180MRACAGSTREAGSGAQDLSTLLCLEESMEEQDEKPPEPPKACAQEGVNFKIVTVDFTREEQGTWNPAQRTLDRDVILENHRDLVSWDLATAVGKKDSTSKQRIFDEEPANGVKIERFTRDDPWLSSCEEVDDCKDQLEKQQEKQEILLQEVAFTQRKAVIHERVCKSDETGEKSGLNSSLFSSPVIPIRNHFHKHVSHAKKWHLNAAVNSHQKINENETLYENNECGKPPQSIHLIQFTRTQTKDKCYGFSDRIQSFCHGTPLHIHEKIHGGGKTFDFKECGQVLNPKISHNEQQRIPFEESQYKCSETSHSSSLTQNMRNNSEEKPFECNQCGKSFSWSSHLVAHQRTHTGEKPYECSECGKSFSRSSHLVSHQRTHTGEKPYRCNQCGKSFSQSYVLVVHQRTHTGEKPYECNQCGKSFRQSYKLIAHQRTHTGEKPYECNQCGKSFIQSYKLIAHQRIHTGEKPYECNQCGKSFSQSYKLVAHQRTHTGEKPFECNQCGKSFSWSSQLVAHQRTHTGEKPYECSECGKSFNRSSHLVMHQRIHTGEKPYECNQCGKSFSQSYVLVVHQRTHTGEKPYECSQCGKSFRQSSCLTQHQRTHTGEKPFECNQCGKTFSLSARLIVHQRTHTGEKPFTCIQCGKAFINSYKLIRHQATHTEEKLYECN>sp|Q9UJW8-4|ZN180_HUMAN Isoform 4 of Zinc finger protein 180 OS=Homosapiens OX=9606 GN=ZNF180MRRVYAGSWKRCAAQDLSTLLCLEESMEEQDEKPPEPPKACAQDSFLPQEIIIKVEGEDTGSLTIPSQEGVNFKIVTVDFTREEQGTWNPAQRTLDRDVILENHRDLVSWDLATAVGKKDSTSKQRIFDEEPANGVKIERFTRDDPWLSSCEEVDDCKDQLEKQQEKQEILLQEVAFTQRKAVIHERVCKSDETGEKSGLNSSLFSSPVIPIRNHFHKHVSHAKKWHLNAAVNSHQKINENETLYENNECGKPPQSIHLIQFTRTQTKDKCYGFSDRIQSFCHGTPLHIHEKIHGGGKTFDFKECGQVLNPKISHNEQQRIPFEESQYKCSETSHSSSLTQNMRNNSEEKPFECNQCGKSFSWSSHLVAHQRTHTGEKPYECSECGKSFSRSSHLVSHQRTHTGEKPYRCNQCGKSFSQSYVLVVHQRTHTGEKPYECNQCGKSFRQSYKLIAHQRTHTGEKPYECNQCGKSFIQSYKLIAHQRIHTGEKPYECNQCGKSFSQSYKLVAHQRTHTGEKPFECNQCGKSFSWSSQLVAHQRTHTGEKPYECSECGKSFNRSSHLVMHQRIHTGEKPYECNQCGKSFSQSYVLVVHQRTHTGEKPYECSQCGKSFRQSSCLTQHQRTHTGEKPFECNQCGKTFSLSARLIVHQRTHTGEKPFTCIQCGKAFINSYKLIRHQATHTEEKLYECN>sp|A6NK53|ZN233_HUMAN Zinc finger protein 233 OS=Homo sapiens OX=9606GN=ZNF233 PE=2 SV=3MTKFQEMVTFKDVAVVFTREELGLLDLAQRKLYQDVMLENFRNLLSVGYQPFKLDVILQLGKEDKLRMMETEIQGDGCSGHKNQNEIDTLQEVRLRFLSYEDLICWQIWEQFTSKLTSNQDLIINLQGKRSKLLKQGDSPCQVWTGESSQVSEDENYVIKLQGESSNSIKNQELPLRTTWDFWRKMYLREPQNYQSRCQQIDVKNKLCKCDHCVRQRIAHQHDDHGVHKREKAFSHNNCGKDCVKESSQHSIIQSGEQTSDENGKGLSVGSNLELHQQLHLRDKPHVNVEYGKGIGYSSGLPRHQCFHIGEKCYRNGDSGEGFSQGSHLQPHQRVSTGENLYRCQVYARSSNQNSCLPSHELTHPGEKLCTCGRCGKGFHHSLDFDIHCVDSAGERACKCDVYDKGFSQTSQLQAHQRGHSRDKTYKWEVSDRIFNRNSGLHQRVHTGEKPYKCEVCDKGFSKASNLQAHQRIHTGEKPYKCDVCDKNFSRNSHLQAHQRVHTGEKPYKCDTCGKDFSQISHLQAHQRVHKGEKPYKCETCGKGFSQSSHLQDHQQVHTGENPYKCDVCGKGFSWSSHLQAHQRVHTGEKPYKCEECRKGFIWNSYLHVHQRIHTGEKPYKCGMCGKSFSQTSHLQAHQRVHTGEKPYKCFVCGKGFSKSSLSSDSSESP>sp|Q96SR6|ZN382_HUMAN Zinc finger protein 382 OS=Homo sapiens OX=9606GN=ZNF382 PE=2 SV=3MPLQGSVSFKDVTVDFTQEEWQQLDPAQKALYRDVMLENYCHFVSVGFHMAKPDMIRKLEQGEELWTQRIFPSYSYLEEDGKTEDVLVKFKEYQDRHSRPLIFINHKKLIKERSNIYGKTFTLGKNRISKTILCEYKPDGKVLKNISELVIRNISPIKEKFGDSTGWEKSLLNTKHEKIHPAVNLHKQTERVLSGKQELIQHQKVQAPEQPFDHNECEKSFLMKGMLFTHTRAHRGERTFEYNKDGIAFIEKSSLSVHPSNLMEKKPSAYNKYGKFLCRKPVFIMPQRPQTEEKPFHCPYCGNNFRRKSYLIEHQRIHTGEKPYVCNQCGKAFRQKTALTLHEKTHIEGKPFICIDCGKSFRQKATLTRHHKTHTGEKAYECPQCGSAFRKKSYLIDHQRTHTGEKPYQCNECGKAFIQKTTLTVHQRTHTGEKPYICNECGKSFCQKTTLTLHQRIHTGEKPYICNECGKSFRQKAILTVHHRIHTGEKSNGCPQCGKAFSRKSNLIRHQKTHTGEKPYECKQCGKFFSCKSNLIVHQKTHKVETTGIQ>sp|Q96SR6-2|ZN382_HUMAN Isoform 2 of Zinc finger protein 382 OS=Homosapiens OX=9606 GN=ZNF382MSQGSVSFKDVTVDFTQEEWQQLDPAQKALYRDVMLENYCHFVSVGFHMAKPDMIRKLEQGEELWTQRIFPSYSYLEEDGKTEDVLVKFKEYQDRHSRPLIFINHKKLIKERSNIYGKTFTLGKNRISKTILCEYKPDGKVLKNISELVIRNISPIKEKFGDSTGWEKSLLNTKHEKIHPAVNLHKQTERVLSGKQELIQHQKVQAPEQPFDHNECEKSFLMKGMLFTHTRAHRGERTFEYNKDGIAFIEKSSLSVHPSNLMEKKPSAYNKYGKFLCRKPVFIMPQRPQTEEKPFHCPYCGNNFRRKSYLIEHQRIHTGEKPYVCNQCGKAFRQKTALTLHEKTHIEGKPFICIDCGKSFRQKATLTRHHKTHTGEKAYECPQCGSAFRKKSYLIDHQRTHTGEKPYQCNECGKAFIQKTTLTVHQRTHTGEKPYICNECGKSFCQKTTLTLHQRIHTGEKPYICNECGKSFRQKAILTVHHRIHTGEKSNGCPQCGKAFSRKSNLIRHQKTHTGEKPYECKQCGKFFSCKSNLIVHQKTHKVETTGIQ>sp|Q96SR6-3|ZN382_HUMAN Isoform 3 of Zinc finger protein 382 OS=Homosapiens OX=9606 GN=ZNF382MPLQGSVSFKDVTVDFTQEEWQQLDPAQKALYRDVMLENYCHFVSVGFHMAKPDMIRKLEQGEELWTQRIFPSYSYLEDGKTEDVLVKFKEYQDRHSRPLIFINHKKLIKERSNIYGKTFTLGKNRISKTILCEYKPDGKVLKNISELVIRNISPIKEKFGDSTGWEKSLLNTKHEKIHPAVNLHKQTERVLSGKQELIQHQKVQAPEQPFDHNECEKSFLMKGMLFTHTRAHRGERTFEYNKDGIAFIEKSSLSVHPSNLMEKKPSAYNKYGKFLCRKPVFIMPQRPQTEEKPFHCPYCGNNFRRKSYLIEHQRIHTGEKPYVCNQCGKAFRQKTALTLHEKTHIEGKPFICIDCGKSFRQKATLTRHHKTHTGEKAYECPQCGSAFRKKSYLIDHQRTHTGEKPYQCNECGKAFIQKTTLTVHQRTHTGEKPYICNECGKSFCQKTTLTLHQRIHTGEKPYICNECGKSFRQKAILTVHHRIHTGEKSNGCPQCGKAFSRKSNLIRHQKTHTGEKPYECKQCGKFFSCKSNLIVHQKTHKVETTGIQ>sp|Q8TBF4|ZCRB1_HUMAN Zinc finger CCHC-type and RNA-binding motif-containing protein 1 OS=Homo sapiens OX=9606 GN=ZCRB1 PE=1 SV=2MSGGLAPSKSTVYVSNLPFSLTNNDLYRIFSKYGKVVKVTIMKDKDTRKSKGVAFILFLDKDSAQNCTRAINNKQLFGRVIKASIAIDNGRAAEFIRRRNYFDKSKCYECGESGHLSYACPKNMLGEREPPKKKEKKKKKKAPEPEEEIEEVEESEDEGEDPALDSLSQAIAFQQAKIEEEQKKWKPSSGVPSTSDDSRRPRIKKSTYFSDEEELSD>sp|Q8WU90|ZC3HF_HUMAN Zinc finger CCCH domain-containing protein 15OS=Homo sapiens OX=9606 GN=ZC3H15 PE=1 SV=1MPPKKQAQAGGSKKAEQKKKEKIIEDKTFGLKNKKGAKQQKFIKAVTHQVKFGQQNPRQVAQSEAEKKLKKDDKKKELQELNELFKPVVAAQKISKGADPKSVVCAFFKQGQCTKGDKCKFSHDLTLERKCEKRSVYIDARDEELEKDTMDNWDEKKLEEVVNKKHGEAEKKKPKTQIVCKHFLEAIENNKYGWFWVCPGGGDICMYRHALPPGFVLKKDKKKEEKEDEISLEDLIERERSALGPNVTKITLESFLAWKKRKRQEKIDKLEQDMERRKADFKAGKALVISGREVFEFRPELVNDDDEEADDTRYTQGTGGDEVDDSVSVNDIDLSLYIPRDVDETGITVASLERFSTYTSDKDENKLSEASGGRAENGERSDLEEDNEREGTENGAIDAVPVDENLFTGEDLDELEEELNTLDLEE>sp|Q8WU90-2|ZC3HF_HUMAN Isoform 2 of Zinc finger CCCH domain-containingprotein 15 OS=Homo sapiens OX=9606 GN=ZC3H15MYRHALPPGFVLKKDKKKEEKEDEISLEDLIERERSALGPNVTKITLESFLAWKKRKRQEKIDKLEQDMERRKADFKAGKALVISGREVFEFRPELVNDDDEEADDTRYTQGTGGDEVRGSFVPHLLMLIERNNRKYHNMVKSHQHQSHSAWVQILTPTMGN>sp|Q9BX82|ZN471_HUMAN Zinc finger protein 471 OS=Homo sapiens OX=9606GN=ZNF471 PE=2 SV=1MNVEVVKVMPQDLVTFKDVAIDFSQEEWQWMNPAQKRLYRSMMLENYQSLVSLGLCISKPYVISLLEQGREPWEMTSEMTRSPFSDWESIYVTQELPLKQFMYDDACMEGITSYGLECSTFEENWKWEDLFEKQMGSHEMFSKKEIITHKETITKETEFKYTKFGKCIHLENIEESIYNHTSDKKSFSKNSMVIKHKKVYVGKKLFKCNECDKTFTHSSSLTVHFRIHTGEKPYACEECGKAFKQRQHLAQHHRTHTGEKLFECKECRKAFKQSEHLIQHQRIHTGEKPYKCKECRKAFRQPAHLAQHQRIHTGEKPYECKECGKAFSDGSSFARHQRCHTGKRPYECIECGKAFRYNTSFIRHWRSYHTGEKPFNCIDCGKAFSVHIGLILHRRIHTGEKPYKCGVCGKTFSSGSSRTVHQRIHTGEKPYECDICGKDFSHHASLTQHQRVHSGEKPYECKECGKAFRQNVHLVSHLRIHTGEKPYECKECGKAFRISSQLATHQRIHTGEKPYECIECGNAFKQRSHLAQHQKTHTGEKPYECNECGKAFSQTSNLTQHQRIHTGEKPYKCTECGKAFSDSSSCAQHQRLHTGQRPYQCFECGKAFRRKLSLICHQRSHTGEEP>sp|Q9BX82-2|ZN471_HUMAN Isoform 2 of Zinc finger protein 471 OS=Homosapiens OX=9606 GN=ZNF471MNVEVVKVMPQDLVTFKDVAIDFSQEEWQWMNPAQKRLYRSMMLENYQSLVSLGLCISKPYVISLLEQGREPWEMTSEMTRSPFSEFILVKNHMHVRNVEKPSSKGNTLLNITEHILERNSLNVKNVGKPSNKVNTLFSIKEFILEKNHINVRNAEKPSDSLHTLLSIREFILERNPMNVKNVAKPSVMARLLLDIRDVTLAKDPMNVLSVGRLLGITHLLFVTGGVIILERSLLIALIVGKPSVFT>sp|Q7Z2F6|ZN720_HUMAN Putative protein ZNF720 OS=Homo sapiens OX=9606GN=ZNF720 PE=1 SV=1MGLLTFRDVAIEFSREEWEHLDSDQKLLYGDVMLENYGNLVSLGLAVSKPDLITFLEQRKEPWNVKSAETVAIQPDIFSHDTQGLLRKKLIEASFQKVILDGYGSCGPQNLNLRKEWESEGKIILW>sp|Q7Z2F6-2|ZN720_HUMAN Isoform 2 of Putative protein ZNF720 OS=Homosapiens OX=9606 GN=ZNF720MVNVPDIFSHDTQGLLRKKLIEASFQKVILDGYGSCGPQNLNLRKEWESEGKCEGHNGYYDGHTKCKTTTYNKNLTVTGGQKHEKTQFMSVAFSKPCVSVSKCQHQFLKLTFSFKGNLDNPNSDLVHVSNNHLNQLKYRTGVNVQSNISEKERFKNEEVISKYDQFDGSLLKVCFTNK>sp|O60384|ZN861_HUMAN Putative zinc finger protein 861 OS=Homo sapiensOX=9606 GN=ZNF861P PE=5 SV=1MWLSTSPYRKGSQCGEAFSQIPGHNLNKKTPPGVKPPESHVCGEVGVGYPSTERHIRDRLGRKPCEYQECRQKAYTCKPCGNAFRFHHSFHIHERPHSGENLYEC>sp|Q96MU6|ZN778_HUMAN Zinc finger protein 778 OS=Homo sapiens OX=9606GN=ZNF778 PE=1 SV=3MAAPDLAHGGHVSRDSVCLHEEQTQAAGMVAGWLINCYQDAVTFDDVAVDFTQEEWTLLDPSQRDLYRDVMLENYENLASVEWRLKTKGPALRQDRSWFRASNETQTARSHNGGQLCDRTQCGEAFSEHSGLSTHVRTQNTGDSCVSNHYERDFFIPCQKTLFKIGEQFSVLGQCGKAFSSTPNVVSQQACTRDRSLDYSSCGEVFLNQSYLQARAGSHNGEETWKWKPCGKALTHSMGCATPVEMHAVRNPHVCRECGKAFRYTAYLTGRVQVHPGEKPCELEECGKASPVSSSLTQHVRIHAAEKPCECKECGKAFTGLSGLSKHVQTDPGQKPYECKDCGKACGGFYLLNEHGKTHTREKPFACVVCGKYFRNSSCLNNHVRIHTGIKPYTCSYCGKAFTVRCGLTRHVRTHTGEKPYTCKDCGKAFCTSSGLTEHVRTHTGEKPYECKDCGKSFTVSSSLTEHARIHTGEKPYECKQCGKAFTGRSGLTKHMRTHTGEKPYECKDCGKAYNRVYLLNEHVKTHTEEKPFICTVCRKSFRNSSCLNKHIQIHTGIKPYECKDCGKTFTVSSSLTEHIRTHTGEKPYECKVCGKAFTTSSHLIVHIRTHTGEKPYICKECGKAFASSSHLIEHRRTHTGEKPYICNECGKAFRASSHLHKHGRIHTGQKPYKCKECGKAYNRFYLLKEHLKTYTEEQVFVCKDCGKSFKNSSCLNHHTQIHTDEKPF>sp|Q96MU6-2|ZN778_HUMAN Isoform 2 of Zinc finger protein 778 OS=Homosapiens OX=9606 GN=ZNF778MLENYENLASVGHHLFQPSVIYWLEQEEELRAGRRAVLQEWRLKTKGPALRQDRSWFRASNETQTARSHNGGQLCDRTQCGEAFSEHSGLSTHVRTQNTGDSCVSNHYERDFFIPCQKTLFKIGEQFSVLGQCGKAFSSTPNVVSQQACTRDRSLDYSSCGEVFLNQSYLQARAGSHNGEETWKWKPCGKALTHSMGCATPVEMHAVRNPHVCRECGKAFRYTAYLTGRVQVHPGEKPCELEECGKASPVSSSLTQHVRIHAAEKPCECKECGKAFTGLSGLSKHVQTDPGQKPYECKDCGKACGGFYLLNEHGKTHTREKPFACVVCGKYFRNSSCLNNHVRIHTGIKPYTCSYCGKAFTVRCGLTRHVRTHTGEKPYTCKDCGKAFCTSSGLTEHVRTHTGEKPYECKDCGKSFTVSSSLTEHARIHTGEKPYECKQCGKAFTGRSGLTKHMRTHTGEKPYECKDCGKAYNRVYLLNEHVKTHTEEKPFICTVCRKSFRNSSCLNKHIQIHTGIKPYECKDCGKTFTVSSSLTEHIRTHTGEKPYECKVCGKAFTTSSHLIVHIRTHTGEKPYICKECGKAFASSSHLIEHRRTHTGEKPYICNECGKAFRASSHLHKHGRIHTGQKPYKCKECGKAYNRFYLLKEHLKTYTEEQVFVCKDCGKSFKNSSCLNHHTQIHTDEKPF>sp|Q6ZSR3|YO027_HUMAN Putative uncharacterized protein FLJ45275,mitochondrial OS=Homo sapiens OX=9606 PE=5 SV=1MGWRFPSPSPRQASPVAPLLAAPTAVRSCSHCSGQREAISSHPLQLETPELGVCLPWHWEGWRQVRKITPSLPQPPGSQVPLEVTFHVRATLPHFRGGETKARRAREEGKLPSLGNAPAPRRRSVAWPAAEGSCAAPESSPPASEASLPAPESSLLVAGSGDLCADSF>sp|Q8WV37|ZN480_HUMAN Zinc finger protein 480 OS=Homo sapiens OX=9606GN=ZNF480 PE=1 SV=2MLCDEKAQKRRKRKAKESGMALPQGHLTFRDVAIEFSQAEWKCLDPAQRALYKDVMLENYRNLVSLGISLPDLNINSMLEQRREPWSGESEVKIAKNSDGRECIKGVNTGSSYALGSNAEDKPIKKQLGVSFHLHLSELELFPDERVINGCNQVENFINHSSSVSCLQEMSSSVKTPIFNRNDFDDSSFLPQEQKVHLREKPYECNEHSKVFRVSSSLTKHQVIHTVEKPYKCNSCGKVFSRNSHLAEHCRIHTGEKPYKCNVCGKVFSYNSNFARHQRIHTREKPYECNECGKVFSNNSYLARHQRIHAEEKPYKCNECGKGFSHKSSLANHWRIYTGEKPYKCDECGKAFYRIALLVRHQKIHTGEKPYKCNECGKVFIQNSHLAQHWRIHTGEKPYKCNECGKVFNQLSNLARHRRIHTGEKPYKCNECGKAFSEYSGLSAHLVIHTGEKPYKCSECGKAFRHKLSLTNHQRIHTGERPYKCNECGKVFNRIAHLARHRKIHTGEKPYKCNECGKAFSRISYLAQHWTIHMG>sp|Q8WV37-2|ZN480_HUMAN Isoform 2 of Zinc finger protein 480 OS=Homosapiens OX=9606 GN=ZNF480MLEQRREPWSGESEVKIAKNSDGRECIKGVNTGSSYALGSNAEDKPIKKQLGVSFHLHLSELELFPDERVINGCNQVENFINHSSSVSCLQEMSSSVKTPIFNRNDFDDSSFLPQEQKVHLREKPYECNEHSKVFRVSSSLTKHQVIHTVEKPYKCNSCGKVFSRNSHLAEHCRIHTGEKPYKCNVCGKVFSYNSNFARHQRIHTREKPYECNECGKVFSNNSYLARHQRIHAEEKPYKCNECGKGFSHKSSLANHWRIYTGEKPYKCDECGKAFYRIALLVRHQKIHTGEKPYKCNECGKVFIQNSHLAQHWRIHTGEKPYKCNECGKVFNQLSNLARHRRIHTGEKPYKCNECGKAFSEYSGLSAHLVIHTGEKPYKCSECGKAFRHKLSLTNHQRIHTGERPYKCNECGKVFNRIAHLARHRKIHTGEKPYKCNECGKAFSRISYLAQHWTIHMG>sp|Q8WV37-3|ZN480_HUMAN Isoform 3 of Zinc finger protein 480 OS=Homosapiens OX=9606 GN=ZNF480MSSSVKTPIFNRNDFDDSSFLPQEQKVHLREKPYECNEHSKVFRVSSSLTKHQVIHTVEKPYKCNSCGKVFSRNSHLAEHCRIHTGEKPYKCNVCGKVFSYNSNFARHQRIHTREKPYECNECGKVFSNNSYLARHQRIHAEEKPYKCNECGKGFSHKSSLANHWRIYTGEKPYKCDECGKAFYRIALLVRHQKIHTGEKPYKCNECGKVFIQNSHLAQHWRIHTGEKPYKCNECGKVFNQLSNLARHRRIHTGEKPYKCNECGKAFSEYSGLSAHLVIHTGEKPYKCSECGKAFRHKLSLTNHQRIHTGERPYKCNECGKVFNRIAHLARHRKIHTGEKPYKCNECGKAFSRISYLAQHWTIHMG>sp|Q9NW07|ZN358_HUMAN Zinc finger protein 358 OS=Homo sapiens OX=9606GN=ZNF358 PE=1 SV=2MRRSVLVRNPGHKGLRPVYEELDSDSEDLDPNPEDLDPVSEDPEPDPEDLNTVPEDVDPSYEDLEPVSEDLDPDAEAPGSEPQDPDPMSSSFDLDPDVIGPVPLILDPNSDTLSPGDPKVDPISSGLTATPQVLATSPAVLPAPASPPRPFSCPDCGRAFRRSSGLSQHRRTHSGEKPYRCPDCGKSFSHGATLAQHRGIHTGARPYQCAACGKAFGWRSTLLKHRSSHSGEKPHHCPVCGKAFGHGSLLAQHLRTHGGPRPHKCPVCAKGFGQGSALLKHLRTHTGERPYPCPQCGKAFGQSSALLQHQRTHTAERPYRCPHCGKAFGQSSNLQHHLRIHTGERPYACPHCSKAFGQSSALLQHLHVHSGERPYRCQLCGKAFGQASSLTKHKRVHEGAAAAAAAAAAAAAAAAAGLGLGPGLSPASMMRPGQVSLLGPDAVSVLGSGLGLSPGTSSGRNPDPGSGPGTLPDPSSKPLPGSRSTPSPTPVESSDPKAGHDAGPDLVPSPDLDPVPSPDPDPVPSPDPNPVSCPDPCSPTRGTVSPALPTGESPEWVQEQGALLGPDG>sp|P17019|ZN708_HUMAN Zinc finger protein 708 OS=Homo sapiens OX=9606GN=ZNF708 PE=1 SV=5MKRHEMAAKPPAMCSHFAKDLRPEQYIKNSFQQVILRRYGKCGYQKGCKSVDEHKLHKGGHKGLNRCVTTTQSKIVQCDKYVKVFHKYSNAKRHKIRHTGKNPFKCKECGKSFCMLSQLTQHEIIHTGEKPYKCEECGKAFKKSSNLTNHKIIHTGEKPYKCEECGKAFNQSSTLTRHKIIHTGEKLYKCEECGKAFNRSSNLTKHKIVHTGEKPYKCEECGKAFKQSSNLTNHKKIHTGEKPYKCGECGKAFTLSSHLTTHKRIHTGEKPYKCEECGKAFSVFSTLTKHKIIHTEEKPYKCEECGKAFNRSSHLTNHKVIHTGEKPYKCEECGKAFTKSSTLTYHKVIHTGKKPYKCEECGKAFSIFSILTKHKVIHTEDKPYKCEECGKTFNYSSNFTNHKKIHTGEKPYKCEECGKSFILSSHLTTHKIIHTGEKPYKCKECGKAFNQSSTLMKHKIIHTGEKPYKCEECGKAFNQSPNLTKHKRIHTKEKPYKCK>sp|Q8N9Z0|ZN610_HUMAN Zinc finger protein 610 OS=Homo sapiens OX=9606GN=ZNF610 PE=2 SV=2MLCDEEAQKRKAKESGMALPQGRLTFMDVAIEFSQEEWKSLDPGQRALYRDVMLENYRNLVFLGICLPDLSIISMLKQRREPLILQSQVKIVKNTDGRECVRSVNTGRSCVLGSNAENKPIKNQLGLTLEAHLSELQLFQAGRKIYRSNQVEKFTNHRSSVSPLQKISSSFTTHIFNKYRNDLIDFPLLPQEEKAYIRGKSYEYECSEDGEVFRVRASLTNHQVIHTAEKPYKCTECGKVFSRNSHLVEHWRIHTGQKPYKCSECDKVFNRNSNLARHQRIHTGEKPHKCNECGKAFRECSGLTTHLVIHTGEKPYKCNECGKNFRHKFSLTNHQRSHTAEKPYKCNECGKVFSLLSYLARHQIIHSTEKPYKCNECGRAFHKRPGLMAHLLIHTGEKPYKCNECDKVFGRKLYLTNHQRIHTGERPYKCNACGKVFNQNPHLSRHRKIHAGENSLRTLQME>sp|Q8N9Z0-2|ZN610_HUMAN Isoform 2 of Zinc finger protein 610 OS=Homosapiens OX=9606 GN=ZNF610MLCDEEAQKRKAKESGMALPQGRLTFMDVAIEFSQEEWKSLDPGQRALYRDVMLENYRNLVFLGRSCVLGSNAENKPIKNQLGLTLEAHLSELQLFQAGRKIYRSNQVEKFTNHRSSVSPLQKISSSFTTHIFNKYRNDLIDFPLLPQEEKAYIRGKSYEYECSEDGEVFRVRASLTNHQVIHTAEKPYKCTECGKVFSRNSHLVEHWRIHTGQKPYKCSECDKVFNRNSNLARHQRIHTGEKPHKCNECGKAFRECSGLTTHLVIHTGEKPYKCNECGKNFRHKFSLTNHQRSHTAEKPYKCNECGKVFSLLSYLARHQIIHSTEKPYKCNECGRAFHKRPGLMAHLLIHTGEKPYKCNECDKVFGRKLYLTNHQRIHTGERPYKCNACGKVFNQNPHLSRHRKIHAGENSLRTLQME>sp|Q8WXB4|ZN606_HUMAN Zinc finger protein 606 OS=Homo sapiens OX=9606GN=ZNF606 PE=2 SV=1MAAINPWASWGALTDQSWGMTAVDPWASWALCPQYPAWHVEGSLEEGRRATGLPAAQVQEPVTFKDVAVDFTQEEWGQLDLVQRTLYRDVMLETYGHLLSVGNQIAKPEVISLLEQGEEPWSVEQACPQRTCPEWVRNLESKALIPAQSIFEEEQSHGMKLERYIWDDPWFSRLEVLGCKDQLEMYHMNQSTAMRQMVFMQKQVLSQRSSEFCGLGAEFSQNLNFVPSQRVSQIEHFYKPDTHAQSWRCDSAIMYADKVTCENNDYDKTVYQSIQPIYPARIQTGDNLFKCTDAVKSFNHIIHFGDHKGIHTGEKLYEYKECHQIFNQSPSFNEHPRLHVGENQYNYKEYENIFYFSSFMEHQKIGTVEKAYKYNEWEKVFGYDSFLTQHTSTYTAEKPYDYNECGTSFIWSSYLIQHKKTHTGEKPYECDKCGKVFRNRSALTKHERTHTGIKPYECNKCGKAFSWNSHLIVHKRIHTGEKPYVCNECGKSFNWNSHLIGHQRTHTGEKPFECTECGKSFSWSSHLIAHMRMHTGEKPFKCDECEKAFRDYSALSKHERTHSGAKPYKCTECGKSFSWSSHLIAHQRTHTGEKPYNCQECGKAFRERSALTKHEIIHSGIKPYECNKCGKSCSQMAHLVRHQRTHTGEKPYECNKCGKSFSQSCHLVAHRRIHTGEKPYKCNQCERSFNCSSHLIAHRRTHTGEKPYRCNECGKAFNESSSLIVHLRNHTGEKPYKCNHCEKAFCKNSSLIIHQRMHSGEKRFICSECGKAFSGHSALLQHQRNHSEEKLN>sp|Q8N2I2|ZN619_HUMAN Zinc finger protein 619 OS=Homo sapiens OX=9606GN=ZNF619 PE=2 SV=1MGQPAPYAEGPIQGGDAGELCKCDFLVSISIPQTRSDIPAGARRSSMGPRSLDTCWGRGPERHVHRLECNGVIFTHRNLCLPGGKTKTENEEKTAQLNISKESESHRLIVEGLLMDVPQHPDFKDRLEKSQLHDTGNKTKIGDCTDLTVQDHESSTTEREEIARKLEESSVSTHLITKQGFAKEQVFYKCGECGSYYNPHSDFHLHQRVHTNEKPYTCKECGKTFRYNSKLSRHQKIHTGEKPYSCEECGQAFSQNSHLLQHQKLHGGQRPYECTDCGKTFSYNSKLIRHQRIHTGEKPFKCKECGKAFSCSYDCIIHERIHNGEKPYECKECGKSLSSNSVLIQHQRIHTGEKPYECKECGKAFHRSSVFLQHQRFHTGEQLYKCNECWKTFSCSSRFIVHQRIHNGEKPYECQECGKTFSQKITLVQHQRVHTGEKPYECKECGKAFRWNASFIQHQKWHTRKKLINGTGLSAVKPYCPCAILSPLPPQHTCSALAPPGPPLSSSHAVVLPPSVPFFLLLPSSEKANPSPVQIAHFFQDLAFPGKSSLQSPNPLSHSL>sp|Q8N2I2-2|ZN619_HUMAN Isoform 2 of Zinc finger protein 619 OS=Homosapiens OX=9606 GN=ZNF619MKPGVISHAPDSVVPAAFPFPKPDLIFQLEQGEAAWGPDPWTLAGGEALRGMCTGGKTKTENEEKTAQLNISKESESHRLIVEGLLMDVPQHPDFKDRLEKSQLHDTGNKTKIGDCTDLTVQDHESSTTEREEIARKLEESSVSTHLITKQGFAKEQVFYKCGECGSYYNPHSDFHLHQRVHTNEKPYTCKECGKTFRYNSKLSRHQKIHTGEKPYSCEECGQAFSQNSHLLQHQKLHGGQRPYECTDCGKTFSYNSKLIRHQRIHTGEKPFKCKECGKAFSCSYDCIIHERIHNGEKPYECKECGKSLSSNSVLIQHQRIHTGEKPYECKECGKAFHRSSVFLQHQRFHTGEQLYKCNECWKTFSCSSRFIVHQRIHNGEKPYECQECGKTFSQKITLVQHQRVHTGEKPYECKECGKAFRWNASFIQHQKWHTRKKLINGTGLSAVKPYCPCAILSPLPPQHTCSALAPPGPPLSSSHAVVLPPSVPFFLLLPSSEKANPSPVQIAHFFQDLAFPGKSSLQSPNPLSHSL>sp|Q8N2I2-3|ZN619_HUMAN Isoform 3 of Zinc finger protein 619 OS=Homosapiens OX=9606 GN=ZNF619MLQTVWFQGLGRNLLFQEPVTFEDVAVYFTQNEWASLHPTQRALYREVMLENYANVTSLSAFPFPKPDLIFQLEQGEAAWGPDPWTLAGGEALRGMCTGGKTKTENEEKTAQLNISKESESHRLIVEGLLMDVPQHPDFKDRLEKSQLHDTGNKTKIGDCTDLTVQDHESSTTEREEIARKLEESSVSTHLITKQGFAKEQVFYKCGECGSYYNPHSDFHLHQRVHTNEKPYTCKECGKTFRYNSKLSRHQKIHTGEKPYSCEECGQAFSQNSHLLQHQKLHGGQRPYECTDCGKTFSYNSKLIRHQRIHTGEKPFKCKECGKAFSCSYDCIIHERIHNGEKPYECKECGKSLSSNSVLIQHQRIHTGEKPYECKECGKAFHRSSVFLQHQRFHTGEQLYKCNECWKTFSCSSRFIVHQRIHNGEKPYECQECGKTFSQKITLVQHQRVHTGEKPYECKECGKAFRWNASFIQHQKWHTRKKLINGTGLSAVKPYCPCAILSPLPPQHTCSALAPPGPPLSSSHAVVLPPSVPFFLLLPSSEKANPSPVQIAHFFQDLAFPGKSSLQSPNPLSHSL>sp|Q8N2I2-4|ZN619_HUMAN Isoform 4 of Zinc finger protein 619 OS=Homosapiens OX=9606 GN=ZNF619MLQTVWFQGLGRNLLFQEPVTFEDVAVYFTQNEWASLHPTQRALYREVMLENYANVTSLYPTAGGFPLDTERTEKVPGALSSFLPSSSSLELILALLPMSAFPFPKPDLIFQLEQGEAAWGPDPWTLAGGEALRGMCTGGKTKTENEEKTAQLNISKESESHRLIVEGLLMDVPQHPDFKDRLEKSQLHDTGNKTKIGDCTDLTVQDHESSTTEREEIARKLEESSVSTHLITKQGFAKEQVFYKCGECGSYYNPHSDFHLHQRVHTNEKPYTCKECGKTFRYNSKLSRHQKIHTGEKPYSCEECGQAFSQNSHLLQHQKLHGGQRPYECTDCGKTFSYNSKLIRHQRIHTGEKPFKCKECGKAFSCSYDCIIHERIHNGEKPYECKECGKSLSSNSVLIQHQRIHTGEKPYECKECGKAFHRSSVFLQHQRFHTGEQLYKCNECWKTFSCSSRFIVHQRIHNGEKPYECQECGKTFSQKITLVQHQRVHTGEKPYECKECGKAFRWNASFIQHQKWHTRKKLINGTGLSAVKPYCPCAILSPLPPQHTCSALAPPGPPLSSSHAVVLPPSVPFFLLLPSSEKANPSPVQIAHFFQDLAFPGKSSLQSPNPLSHSL>sp|Q5JVG8|ZN506_HUMAN Zinc finger protein 506 OS=Homo sapiens OX=9606GN=ZNF506 PE=2 SV=2MGPLQFRDVAIEFSLEEWHCLDAAQRNLYRDVMLENYRNLIFLGIVVSKPNLITCLEQGKKPLTMKRHEMIAKPPVMYSHFAQDLWSEQSIKDSFQKVILRRYEKCRHDNLQLKKGCESVDECPVHKRGYNGLKQCLATTQRKIFQCDEYVKFLHKFSNSNKHKIRDTGKKSFKCIEYGKTFNQSSTRTTYKKIDAGEKRYKCEECGKAYKQSSHLTTHKKIHTGEKPYKCEECGKAYKQSCNLTTHKIIHTGEKPYRCRECGKAFNHPATLFSHKKIHTGEKPYKCDKCGKAFISSSTLTKHEIIHTGEKPYKCEECGKAFNRSSNLTKHKRIHTGDVPYKCDECGKTFTWYSSLSKHKRAHTGEKPYKCEECGKAFTAFSTLTEHKIIHTGEKPYKCEECGKAFNWSSALNKHKKIHIRQKPCIVKNVENLLNVPQPLISIR>sp|Q5JVG8-2|ZN506_HUMAN Isoform 2 of Zinc finger protein 506 OS=Homosapiens OX=9606 GN=ZNF506MGPLQFRDVAIEFSLEEWHCLDAAQRNLYRDVMLENYRNLIFLVMYSHFAQDLWSEQSIKDSFQKVILRRYEKCRHDNLQLKKGCESVDECPVHKRGYNGLKQCLATTQRKIFQCDEYVKFLHKFSNSNKHKIRDTGKKSFKCIEYGKTFNQSSTRTTYKKIDAGEKRYKCEECGKAYKQSSHLTTHKKIHTGEKPYKCEECGKAYKQSCNLTTHKIIHTGEKPYRCRECGKAFNHPATLFSHKKIHTGEKPYKCDKCGKAFISSSTLTKHEIIHTGEKPYKCEECGKAFNRSSNLTKHKRIHTGDVPYKCDECGKTFTWYSSLSKHKRAHTGEKPYKCEECGKAFTAFSTLTEHKIIHTGEKPYKCEECGKAFNWSSALNKHKKIHIRQKPCIVKNVENLLNVPQPLISIR>sp|Q96JF6|ZN594_HUMAN Zinc finger protein 594 OS=Homo sapiens OX=9606GN=ZNF594 PE=2 SV=3MKEWKSKMEISEEKKSARAASEKLQRQITQECELVETSNSEDRLLKHWVSPLKDAMRHLPSQESGIREMHIIPQKAIVGEIGHGCNEGEKILSAGESSHRYEVSGQNFKQKSGLTEHQKIHNINKTYECKECEKTFNRSSNLIIHQRIHTGNKPYVCNECGKDSNQSSNLIIHQRIHTGKKPYICHECGKDFNQSSNLVRHKQIHSGGNPYECKECGKAFKGSSNLVLHQRIHSRGKPYLCNKCGKAFSQSTDLIIHHRIHTGEKPYECYDCGQMFSQSSHLVPHQRIHTGEKPLKCNECEKAFRQHSHLTEHQRLHSGEKPYECHRCGKTFSGRTAFLKHQRLHAGEKIEECEKTFSKDEELREEQRIHQEEKAYWCNQCGRNFQGTSDLIRHQVTHTGEKPYECKECGKTFNQSSDLLRHHRIHSGEKPCVCSKCGKSFRGSSDLIRHHRVHTGEKPYECSECGKAFSQRSHLVTHQKIHTGEKPYQCTECGKAFRRRSLLIQHRRIHSGEKPYECKECGKLFIWRTAFLKHQSLHTGEKLECEKTFSQDEELRGEQKIHQEAKAYWCNQCGRAFQGSSDLIRHQVTHTREKPYECKECGKTFNQSSDLLRHHRIHSGEKPYVCNKCGKSFRGSSDLIKHHRIHTGEKPYECSECGKAFSQRSHLATHQKIHTGEKPYQCSECGNAFRRRSLLIQHRRLHSGEKPYECKECGKLFMWHTAFLKHQRLHAGEKLEECEKTFSKDEELRKEQRTHQEKKVYWCNQCSRTFQGSSDLIRHQVTHTREKPYECKECGKTQSELRPSETS>sp|A8K0R7|ZN839_HUMAN Zinc finger protein 839 OS=Homo sapiens OX=9606GN=ZNF839 PE=2 SV=1MLLPTTIQPQTARKSQLPRGNSCLVGLHIASPQLLRVQPLVRTEPQSCFLSDLCQPPAQGFVQRPLPALQVVPAKRVPAPKAPDEQGSMLTPLSASDPLAVTSLSSSSAHPFISNLHTRHTEKLKKSLKVKTRSGRVSRPPKYKAKDYKFIKTEDLADGHLSDSDDYSELCVEEDEDQRERHALFDLSSCSLRPKSFKCQTCEKSYIGKGGLARHFKLNPGHGQLDPEMVLSEKASGSTLRGCTEERTLSLTSLGLSMPADPCEGGARSCLVTESARGGLQNGQSVDVEETLPSEPENGALLRSERYQGPRRRACSETLAESRTAVLQQRRAAQLPGGPAAAGEQRASPSKARLKEFLQQCDREDLVELALPQLAQVVTVYEFLLMKVEKDHLAKPFFPAIYKEFEELHKMVKKMCQDYLSSSGLCSQETLEINNDKVAESLGITEFLRKKEIHPDNLGPKHLSRDMDGEQLEGASSEKREREAAEEGLASVKRPRREALSNDTTESLAANSRGREKPRPLHALAAGFSPPVNVTVSPRSEESHTTTVSGGNGSVFQAGPQLQALANLEARRGSIGAALSSRDVSGLPVYAQSGEPRRLTQAQVAAFPGENALEHSSDQDTWDSLRSPGFCSPLSSGGGAESLPPGGPGHAEAGHLGKVCDFHLNHQQPSPTSVLPTEVAAPPLEKILSVDSVAVDCAYRTVPKPGPQPGPHGSLLTEGCLRSLSGDLNRFPCGMEVHSGQRELESVVAVGEAMAFEISNGSHELLSQGQKQIFIQTSDGLILSPPGTIVSQEEDIVTVTDAEGRACGWAR>sp|A8K0R7-2|ZN839_HUMAN Isoform 2 of Zinc finger protein 839 OS=Homosapiens OX=9606 GN=ZNF839MLLPTTIQPQTARKSQLPRGNSCLVGLHIASPQLLRVQPLVRTEPQSCFLSDLCQPPAQGFVQRPLPALQVVPAKRVPAPKAPDEQGSMLTPLSASDPLAVTSLSSSSAHPFISNLHTRHTEKLKKSLKVKTRSGRVSRPPKYKAKDYKFIKTEDLADGHLSDSDDYSELCVEEDEDQRERHALFDLSSCSLRPKSFKCQTCEKSYIGKGGLARHFKLNPGHGQLDPEMVLSEKASGSTLRGCTEERTLSLTSLGLSMPADPCEGGARSCLVTESARGGLQNGQSVDVEETLPSEPENGALLRSERYQGPRRRACSETLAESRTAVLQQRRAAQLPGGPAAAGEQRASPSKARLKEFLQQCDREDLVELALPQLAQVVTVYEFLLMKVEKDHLAKPFFPAIYKEFEELHKMVKKMCQDYLSSSGLCSQETLEINNDKVAESLGITEFLRKKEIHPDNLGPKHLSRDMDGEQLEGASSEKREREAAEEGLASVKRPRREALSNDTTESLAANSRGREKPRPLHALAAGEGFSPPVNVTVSPRSEESHTTTVSGGNGSVFQAGPQLQALANLEARRGSIGAALSSRDVSGLPVYAQSGEPRRLTQAQVAAFPGENALEHSSDQDTWDSLRSPGFCSPLSSGGGAESLPPGGPGHAEAGHLGKVCDFHLNHQQPSPTSVLPTEVAAPPLEKILSVDSVAVDCAYRTVPKPGPQPGPHGSLLTEGCLRSLSGDLNRFPCGMEVHSGQRELESVVAVGEAMAFEISNGSHELLSQGQKQIFIQTSDGLILSPPGTIVSQEEDIVTVTDAEGRACGWAR>sp|A8K0R7-5|ZN839_HUMAN Isoform 3 of Zinc finger protein 839 OS=Homosapiens OX=9606 GN=ZNF839MADAEPEAGGGSEDGGGGGGPAPPGQSGSVARVAPLGPEQLRQVLEQVTKAQPPPPPPPFVLRDAARRLRDAAQQAALQRGRGTEPPRLPRLLPPQQLEAICVKVTSGETKGQERPMLLPTTIQPQTARKSQLPRGNSCLVGLHIASPQLLRVQPLVRTEPQSCFLSDLCQPPAQGFVQRPLPALQVVPAKRVPAPKAPDEQGSMLTPLSASDPLAVTSLSSSSAHPFISNLHTRHTEKLKKSLKVKTRSGRVSRPPKYKAKDYKFIKTEDLADGHLSDSDDYSELCVEEDEDQRERHALFDLSSCSLRPKSFKCQTCEKSYIGKGGLARHFKLNPGHGQLDPEMVLSEKASGSTLRGCTEERTLSLTSLGLSMPADPCEGGARSCLVTESARGGLQNGQSVDVEETLPSEPENGALLRSERYQGPRRRACSETLAESRTAVLQQRRAAQLPGGPAAAGEQRASPSKARLKEFLQQCDREDLVELALPQLAQVVTVYEFLLMKVEKDHLAKPFFPAIYKEFEELHKMVKKMCQDYLSSSGLCSQETLEINNDKVAESLGITEFLRKKEIHPDNLGPKHLSRDMDGEQLEGASSEKREREAAEEGLASVKRPRREALSNDTTESLAANSRGREKPRPLHALAAGFSPPVNVTVSPRSEESHTTTVSGGNGSVFQAGPQLQALANLEARRGSIGAALSSRDVSGLPVYAQSGEPRRLTQAQVAAFPGENALEHSSDQDTWDSLRSPGFCSPLSSGGGAESLPPGGPGHAEAGHLGKVCDFHLNHQQPSPTSVLPTEVAAPPLEKILSVDSVAVDCAYRTVPKPGPQPGPHGSLLTEGCLRSLSGDLNRFPCGMEVHSGQRELESVVAVGEAMAFEISNGSHELLSQGQKQIFIQTSDGLILSPPGTIVSQEEDIVTVTDAEGRACGWAR>sp|O75373|ZN737_HUMAN Zinc finger protein 737 OS=Homo sapiens OX=9606GN=ZNF737 PE=2 SV=3MGPLQFRDVAIEFSLEEWHCLDTAQRNLYRNVMLENYRNLVFLGIVVSKPDLITCLEQGKKPLTMKKHEMVANPSVTCSHFARDLWPEQSIKDSFQKVTLRRYENYGHDNLQFKKGCESVDECKVHKRGYNGLNQYLTTTQSKIFQCDKYVKVIHKFSNSNRHKIRHTGKKPFKCIECGKAFNQSSTLTTHKKIHTGEKPFKCEECGKAFNWSSHLTTHKRIHTGEKRYKCEDCGKAFSRFSYLTAHKIIHSGEKPYKCEECGKAFKRSSNLTTHKIIHTGEKPYKCEECGKAFKRSSILTAHKIIHSGEKPYKCEECGKAFKHPSVLTTHKRIHTGEKPYKCEECGRAFKYFSSLTTHKIIHSGEKPYKCEECGKAFNWSSHLTTHKRIHTGEKPYKCEECGEAFKYSSSLTTHKIIHTGQQPFKCEECGKAFKCFSILTTHKRIHTGEKPYKCEECGKAFNSSSHLTAHKRIHTGEKPYKCERCGKAFKRSFILTRHKRIHTGEKPYKCEECGKGFKCPSTLTTHKVIHTGEKL>sp|O43361|ZN749_HUMAN Zinc finger protein 749 OS=Homo sapiens OX=9606GN=ZNF749 PE=1 SV=2MNLTEDCMVFEDVAIYFSQEEWGILNDAQRHLHSNVMLENFALLSSVGCWHGAKDEEVPSKQCVSVRVLQVTIPKPALSTLKAQPCKMCSSILKDILHLAEHDGTHPEQGLYTCAAEHDLHQKEQIREKLTRSDEWRPSFVNHSAHVGERNFTCTQGGKDFTASSDLLQQQVLNSGWKLYRDTQDGEAFQGEQNDFNSSQGGKDFCHQHGLFEHQKTHNGERPYEFSECGELFRYNSNLIKYQQNHAGERPYEGTEYGKTFIRKSNLVQHQKIHSEGFLSKRSDPIEHQEILSRPTPYECTQCGKAFLTQAHLVGHQKTHTGEQPYECNKCGKFFMYNSKLIRHQKVHTGERRYECSECGKLFMDSFTLGRHQRVHTGERPFECSICGKFFSHRSTLNMHQRVHAGKRLYKCSECGKAFSLKHNVVQHLKIHTGERPYECTECEKAFVRKSHLVQHQKIHTDAFSKRSDLIQHKRIDIRPRPYTCSECGKAFLTQAHLVGHQKIHTGERPYECTQCAKAFVRKSHLVQHEKIHTDAFSKRSDLIQHKRIDLRPRPYVCSECGKAFLTQAHLDGHQKIQTGERRYECNECGKFFLDSYKLVIHQRIHTGEKPYKCSKCGKFFRYRCTLSRHQKVHTGERPYECSECGKFFRDSYKLIIHQRVHTGEKPYECSNCGKFLRYRSTFIKHHKVCTGEKPHECSKCRELFRTKSSLIIHQQSHTGESPFKLRECGKDFNKCNTGQRQKTHTGERSYECGESSKVFKYNSSLIKHQIIHTGKRP>sp|Q6AW86|Z324B_HUMAN Zinc finger protein 324B OS=Homo sapiens OX=9606GN=ZNF324B PE=1 SV=1MTFEDVAVYFSQEEWGLLDTAQRALYRHVMLENFTLVTSLGLSTSRPRVVIQLERGEEPWVPSGKDMTLARNTYGRLNSGSWSLTEDRDVSGEWPRAFPDTPPGMTTSVFPVADACHSVKSLQRQPGASPSQERKPTGVSVIYWERLLLGSRSDQASISLRLTSPLRPPKSSRPREKTFTEYRVPGRQPRTPERQKPCAQEVPGRAFGNASDLKAASGGRDRRMGAAWQEPHRLLGGQEPSTWDELGEALHAGEKSFECRACSKVFVKSSDLLKHLRTHTGERPYECTQCGKAFSQTSHLTQHQRIHSGETPYACPVCGKAFRHSSSLVRHQRIHTAEKSFRCSECGKAFSHGSNLSQHRKIHAGGRPYACAQCGRRFCRNSHLIQHERTHTGEKPFVCALCGAAFSQGSSLFLHQRVHTGEKPFACAQCGRSFSRSSNLTQHQLLHTGERPFRCVDCGKGFAKGAVLLSHRRIHTGEKPFVCTQCGRAFRERPALLHHQRIHTTEKTNAAAPDCTPGPGFLQGHHRKVRRGGKPSPVLKPAKV>sp|Q6AW86-2|Z324B_HUMAN Isoform 2 of Zinc finger protein 324B OS=Homosapiens OX=9606 GN=ZNF324BMGVPTAVSATPVRADASSKPQPLLQSQPHLFFFPKLLSRLLGSPLPVHSAGPGPLLTRMPQATTVSLRLGSWSLTEDRDVSGEWPRAFPDTPPGMTTSVFPVADACHSVKSLQRQPGASPSQERKPTGVSVIYWERLLLGSRSDQASISLRLTSPLRPPKSSRPREKTFTEYRVPGRQPRTPERQKPCAQEVPGRAFGNASDLKAASGGRDRRMGAAWQEPHRLLGGQEPSTWDELGEALHAGEKSFECRACSKVFVKSSDLLKHLRTHTGERPYECTQCGKAFSQTSHLTQHQRIHSGETPYACPVCGKAFRHSSSLVRHQRIHTAEKSFRCSECGKAFSHGSNLSQHRKIHAGGRPYACAQCGRRFCRNSHLIQHERTHTGEKPFVCALCGAAFSQGSSLFLHQRVHTGEKPFACAQCGRSFSRSSNLTQHQLLHTGERPFRCVDCGKGFAKGAVLLSHRRIHTGEKPFVCTQCGRAFRERPALLHHQRIHTTEKTNAAAPDCTPGPGFLQGHHRKVRRGGKPSPVLKPAKV>sp|Q9H707|ZN552_HUMAN Zinc finger protein 552 OS=Homo sapiens OX=9606GN=ZNF552 PE=1 SV=2MAAAALRFPVQGTVTFEDVAVKFTQEEWNLLSEAQRCLYRDVTLENLALMSSLGCWCGVEDEAAPSKQSIYIQRETQVRTPMAGVSPKKAHPCEMCGPILGDILHVADHQGTHHKQKLHRCEAWGNKLYDSGNFHQHQNEHIGEKPYRGSVEEALFAKRCKLHVSGESSVFSESGKDFLLRSGLLQQEATHTGKSNSKTECVSLFHGGKSHYSCGGCMKHFSTKDILSQHERLLPTEEPSVWCECGKSSSKYDSFSNHQGVHTREKPYTCGICGKLFNSKSHLLVHQRIHTGEKPYECEVCQKFFRHKYHLIAHQRVHTGERPYECSDCGKSFTHSSTFRVHKRVHTGQKPYECSECGKSFAESSSLTKHRRVHTGEKPYGCSECEKKFRQISSLRHHQRVHKRKGL>sp|Q9P0T4|ZN581_HUMAN Zinc finger protein 581 OS=Homo sapiens OX=9606GN=ZNF581 PE=1 SV=1MLVLPSPCPQPLAFSSVETMEGPPRRTCRSPEPGPSSSIGSPQASSPPRPNHYLLIDTQGVPYTVLVDEESQREPGASGAPGQKKCYSCPVCSRVFEYMSYLQRHSITHSEVKPFECDICGKAFKRASHLARHHSIHLAGGGRPHGCPLCPRRFRDAGELAQHSRVHSGERPFQCPHCPRRFMEQNTLQKHTRWKHP>sp|Q8N883|ZN614_HUMAN Zinc finger protein 614 OS=Homo sapiens OX=9606GN=ZNF614 PE=1 SV=2MIKTQESLTLEDVAVEFSWEEWQLLDTAQKNLYRDVMVENYNHLVSLGYQTSKPDVLSKLAHGQEPWTTDAKIQNKNCPGIGKVDSHLQEHSPNQRLLKSVQQCNGQNTLRNIVHLSKTHFPIVQNHDTFDLYRKNLKSSLSLINQKRRHGINNPVEFIGGEKTLLHGKHERTHTKTRFSENAKCIHTKFQVFKHQRTQKIEKPHACIECEQTFLRKSQLIYHENICIQENPGSGQCEKLSRSVLFTKHLKTNTTDKICIPNEYRKGSTVKSSLITHQQTHTEEKSYMCSECGKGFTMKRYLIAHQRTHSGEKPYVCKECGKGFTVKSNLIVHQRTHTGEKPYICSECGKGFTMKRYLVVHQRTHTGEKPYMCSECGKGFTVKSNLIVHQRSHTGEKSYICSECGKGFTVKRTLVIHQRTHTGEKSYICNECGKGFTTKRTLIIHQRTHTGEKPYECNECGKAFSQKICLIQHERCHTGKTPFVCTECGKSYSHKYGLITHQRIHTGEKPYECNECGKAFTTKSVLNVHQRTHTGERPYGCSDCEKAFSHLSNLVKHKKMHTREMGRISQVENSCNGESQLLPYK>sp|Q8N883-2|ZN614_HUMAN Isoform 2 of Zinc finger protein 614 OS=Homosapiens OX=9606 GN=ZNF614MIKTQESLTLEDVAVEFSWEEWQLLDTAQKNLYRDVMVENYNHLVSLGYQTSKPDVLSKLAHGQEPWTTDAKIQNKNCPGIGKVDSHLQEHSPNQRLLKSVQQCNGQNTLRNIVHLSKTHFPIVQNHDTFDLYRKNLKSSLSLINQKRRHGINNPVEFIGETGSLERPRQADHLRSEVQDQPGQRGETLCLLKIHTKN>sp|A4D1E1|Z804B_HUMAN Zinc finger protein 804B OS=Homo sapiens OX=9606GN=ZNF804B PE=2 SV=2MACYLVISSRHLSNGHYRGIKGVFRGPLCKNGSPSPDFAEKKSTAKALEDVKANFYCELCDKQYHKHQEFDNHINSYDHAHKQRLKELKQREFARNVASKSWKDEKKQEKALKRLHQLAELRQQSECVSGNGPAYKAPRVAIEKQLQQGIFPIKNGRKVSCMKSALLLKGKNLPRIISDKQRSTMPNRHQLQSDRRCLFGNQVLQTSSDLSNANHRTGVSFTFSKKVHLKLESSASVFSENTEETHDCNKSPIYKTKQTADKCKCCRFANKDTHLTKEKEVNISPSHLESVLHNTISINSKILQDKHDSIDETLEDSIGIHASFSKSNIHLSDVDFTPTSREKETRNTLKNTLENCVNHPCQANASFSPPNIYNHSDARISECLDEFSSLEPSEQKSTVHLNPNSRIENREKSLDKTERVSKNVQRLVKEACTHNVASKPLPFLHVQSKDGHTTLQWPTELLLFTKTEPCISYGCNPLYFDFKLSRNTKEDHNLEDLKTELGKKPLELKTKRESQVSGLTEDQQKLIQEDYQYPKPKTMIANPDWEKFQRKYNLDYSDSEPNKSEYTFSANDLEMKNPKVPLYLNTSLKDCAGKNNSSENKLKEASRAHWQGCRKAVLNDIDEDLSFPSYISRFKKHKLIPCSPHLEFEDERQFNCKSSPCTVGGHSDHGKDFSVILKSNHISMTSKVSGCGNQRYKRYSPQSCLSRYSSSLDTSPSSMSSLRSTCSSHRFNGNSRGNLLCFHKREHHSVERHKRKCLKHNCFYLSDDITKSSQMQSEPQKERNCKLWESFKNEKYSKRRYCHCRERQKLGKNQQQFSGLKSTRIIYCDSNSQISCTGSSKKPPNCQGTQHDRLDSYSIEKMYYLNKSKRNQESLGSPHICDLGKVRPMKCNSGNISCLLKNCSSGPSETTESNTAEGERTPLTAKILLERVQAKKCQEQSSNVEISSNSCKSELEAPSQVPCTIQLAPSGCNRQALPLSEKIQYASESRNDQDSAIPRTTEKDKSKSSHTNNFTILADTDCDNHLSKGIIHLVTESQSLNIKRDATTKEQSKPLISEIQPFIQSCDPVPNEFPGAFPSNKYTGVTDSTETQEDQINLDLQDVSMHINHVEGNINSYYDRTMQKPDKVEDGLEMCHKSISPPLIQQPITFSPDEIDKYKILQLQAQQHMQKQLLSKHLRVLPAAGPTAFSPASTVQTVPVHQHTSITTIHHTFLQHFAVSASLSSHSSHLPIAHLHPLSQAHFSPISFSTLTPTIIPAHPTFLAGHPLHLVAATPFHPSHITLQPLPPTAFIPTLFGPHLNPATTSIIHLNPLIQPVFQGQDFCHHSCSSQMQQLNEVKEALNVSTHLN>sp|Q6NXT4|ZNT6_HUMAN Zinc transporter 6 OS=Homo sapiens OX=9606GN=SLC30A6 PE=1 SV=2MGTIHLFRKPQRSFFGKLLREFRLVAADRRSWKILLFGVINLICTGFLLMWCSSTNSIALTAYTYLTIFDLFSLMTCLISYWVTLRKPSPVYSFGFERLEVLAVFASTVLAQLGALFILKESAERFLEQPEIHTGRLLVGTFVALCFNLFTMLSIRNKPFAYVSEAASTSWLQEHVADLSRSLCGIIPGLSSIFLPRMNPFVLIDLAGAFALCITYMLIEINNYFAVDTASAIAIALMTFGTMYPMSVYSGKVLLQTTPPHVIGQLDKLIREVSTLDGVLEVRNEHFWTLGFGSLAGSVHVRIRRDANEQMVLAHVTNRLYTLVSTLTVQIFKDDWIRPALLSGPVAANVLNFSDHHVIPMPLLKGTDDLNPVTSTPAKPSSPPPEFSFNTPGKNVNPVILLNTQTRPYGFGLNHGHTPYSSMLNQGLGVPGIGATQGLRTGFTNIPSRYGTNNRIGQPRP>sp|Q6NXT4-2|ZNT6_HUMAN Isoform 2 of Zinc transporter 6 OS=Homo sapiensOX=9606 GN=SLC30A6MGTIHLFRKPQRSFFGKLLREFRLVAADRRSWKILLFGVINLICTGFLLMWCSSTNSIALTAYTYLTIFDLFRDGVSPFWLGWSQTPDLKWSTHLGLPKCWDNRRELPCLSNSLMTCLISYWVTLRKPSPVYSFGFERLEVLAVFASTVLAQLGALFILKESAERFLEQPEIHTGRLLVGTFVALCFNLFTMLSIRNKPFAYVSEAASTSWLQEHVADLSRSLCGIIPGLSSIFLPRMNPFVLIDLAGAFALCITYMLIEINNYFAVDTASAIAIALMTFGTMYPMSVYSGKVLLQTTPPHVIGQLDKLIREVSTLDGVLEVRNEHFWTLGFGSLAGSVHVRIRRDANEQMVLAHVTNRLYTLVSTLTVQIFKDDWIRPALLSGPVAANVLNFSDHHVIPMPLLKGTDDLNPVTSTPAKPSSPPPEFSFNTPGKNVNPVILLNTQTRPYGFGLNHGHTPYSSMLNQGLGVPGIGATQGLRTGFTNIPSRYGTNNRIGQPRP>sp|Q6NXT4-4|ZNT6_HUMAN Isoform 4 of Zinc transporter 6 OS=Homo sapiensOX=9606 GN=SLC30A6MSWKILLFGVINLICTGFLLMWCSSTNSIALTAYTYLTIFDLFSLMTCLISYWVTLRKPSPVYSFGFERLEVLAVFASTVLAQLGALFILKESAERFLEQPEIHTGRLLVGTFVALCFNLFTMLSIRNKPFAYVSEAASTSWLQEHVADLSRSLCGIIPGLSSIFLPRMNPFVLIDLAGAFALCITYMLIEINNYFAVDTASAIAIALMTFGTMYPMSVYSGKVLLQTTPPHVIGQLDKLIREVSTLDGVLEVRNEHFWTLGFGSLAGSVHVRIRRDANEQMVLAHVTNRLYTLVSTLTVQIFKDDWIRPALLSGPVAANVLNFSDHHVIPMPLLKGTDDLNPVTSTPAKPSSPPPEFSFNTPGKNVNPVILLNTQTRPYGFGLNHGHTPYSSMLNQGLGVPGIGATQGLRTGFTNIPSRYGTNNRIGQPRP>sp|Q6NXT4-3|ZNT6_HUMAN Isoform 3 of Zinc transporter 6 OS=Homo sapiensOX=9606 GN=SLC30A6MGTIHLFRKPQRSFFGKLLREFRLVAADRRSWKILLFGVINLICTGFLLMWCSSTNSIALTAYTYLTIFDLFSLMTCLISYWVTLRKPSPVYSFGFERLEVLAVFASTVLAQLGALFILKESAERFLEQPEIHTGRLLVGTFVALCFNLFTMLSIRNKPFAYVSEAASTSWLQEHVADLSRSLCGIIPGLSSIFLPRMNPFVLIDLAGAFALCITYMLIEINNYFAVDTASAIAIALMTFGTMYPMSVYSGKVLLQTTPPHVIGQLDKLIREAGSVHVRIRRDANEQMVLAHVTNRLYTLVSTLTVQIFKDDWIRPALLSGPVAANVLNFSDHHVIPMPLLKGTDDLNPVTSTPAKPSSPPPEFSFNTPGKNVNPVILLNTQTRPYGFGLNHGHTPYSSMLNQGLGVPGIGATQGLRTGFTNIPSRYGTNNRIGQPRP>sp|P17098|ZNF8_HUMAN Zinc finger protein 8 OS=Homo sapiens OX=9606GN=ZNF8 PE=1 SV=2MDPEDEGVAGVMSVGPPAARLQEPVTFRDVAVDFTQEEWGQLDPTQRILYRDVMLETFGHLLSIGPELPKPEVISQLEQGTELWVAERGTTQGCHPAWEPRSESQASRKEEGLPEEEPSHVTGREGFPTDAPYPTTLGKDRECQSQSLALKEQNNLKQLEFGLKEAPVQDQGYKTLRLRENCVLSSSPNPFPEISRGEYLYTYDSQITDSEHNSSLVSQQTGSPGKQPGENSDCHRDSSQAIPITELTKSQVQDKPYKCTDCGKSFNHNAHLTVHKRIHTGERPYMCKECGKAFSQNSSLVQHERIHTGDKPYKCAECGKSFCHSTHLTVHRRIHTGEKPYECQDCGRAFNQNSSLGRHKRTHTGEKPYTCSVCGKSFSRTTCLFLHLRTHTEERPYECNHCGKGFRHSSSLAQHQRKHAGEKPFECRQRLIFEQTPALTKHEWTEALGCDPPLSQDERTHRSDRPFKCNQCGKCFIQSSHLIRHQITHTREEQPHGRSRRREQSSSRNSHLVQHQHPNSRKSSAGGAKAGQPESRALALFDIQKIMQEKNPVHVIGVEEPSVGASMLFDIREST>sp|Q9BRI3|ZNT2_HUMAN Zinc transporter 2 OS=Homo sapiens OX=9606GN=SLC30A2 PE=1 SV=1MEAKEKQHLLDARPAIRSYTGSLWQEGAGWIPLPRPGLDLQAIELAAQSNHHCHAQKGPDSHCDPKKGKAQRQLYVASAICLLFMIGEVVEILGALVSVLSIWVVTGVLVYLAVERLISGDYEIDGGTMLITSGCAVAVNIIMGLTLHQSGHGHSHGTTNQQEENPSVRAAFIHVIGDFMQSMGVLVAAYILYFKPEYKYVDPICTFVFSILVLGTTLTILRDVILVLMEGTPKGVDFTAVRDLLLSVEGVEALHSLHIWALTVAQPVLSVHIAIAQNTDAQAVLKTASSRLQGKFHFHTVTIQIEDYSEDMKDCQACQGPSD>sp|Q9BRI3-2|ZNT2_HUMAN Isoform 2 of Zinc transporter 2 OS=Homo sapiensOX=9606 GN=SLC30A2MEAKEKQHLLDARPAIRSYTGSLWQEGAGWIPLPRPGLDLQAIELAAQSNHHCHAQKGPDSHCDPKKGKAQRQLYVASAICLLFMIGEVVGGYLAHSLAVMTDAAHLLTDFASMLISLFSLWMSSRPATKTMNFGWQRAEILGALVSVLSIWVVTGVLVYLAVERLISGDYEIDGGTMLITSGCAVAVNIIMGLTLHQSGHGHSHGTTNQQEENPSVRAAFIHVIGDFMQSMGVLVAAYILYFKPEYKYVDPICTFVFSILVLGTTLTILRDVILVLMEGTPKGVDFTAVRDLLLSVEGVEALHSLHIWALTVAQPVLSVHIAIAQNTDAQAVLKTASSRLQGKFHFHTVTIQIEDYSEDMKDCQACQGPSD>sp|Q6ZTR6|ZNFDT_HUMAN Putative uncharacterized protein ZNF516-DT OS=Homosapiens OX=9606 GN=ZNF516-DT PE=5 SV=1MRVPPAGTWALRPIWTEMGTPLRGSQAPGRIVLLLLVITPQWRWIPSKTPNVAPRSNQRCNPGGYLSGGVSLCASHSQPAALPNLGRLQKKLLQTRCKGRRMCPKAGDQTGGAFCMCDVSGGGGECVSGSGGGGESGRKTGTTSAMKDPRVLKCKLRVTNDLH>sp|P47901|V1BR_HUMAN Vasopressin V1b receptor OS=Homo sapiens OX=9606GN=AVPR1B PE=1 SV=1MDSGPLWDANPTPRGTLSAPNATTPWLGRDEELAKVEIGVLATVLVLATGGNLAVLLTLGQLGRKRSRMHLFVLHLALTDLAVALFQVLPQLLWDITYRFQGPDLLCRAVKYLQVLSMFASTYMLLAMTLDRYLAVCHPLRSLQQPGQSTYLLIAAPWLLAAIFSLPQVFIFSLREVIQGSGVLDCWADFGFPWGPRAYLTWTTLAIFVLPVTMLTACYSLICHEICKNLKVKTQAWRVGGGGWRTWDRPSPSTLAATTRGLPSRVSSINTISRAKIRTVKMTFVIVLAYIACWAPFFSVQMWSVWDKNAPDEDSTNVAFTISMLLGNLNSCCNPWIYMGFNSHLLPRPLRHLACCGGPQPRMRRRLSDGSLSSRHTTLLTRSSCPATLSLSLSLTLSGRPRPEESPRDLELADGEGTAETIIF>sp|Q92575|UBXN4_HUMAN UBX domain-containing protein 4 OS=Homo sapiensOX=9606 GN=UBXN4 PE=1 SV=2MLWFQGAIPAAIATAKRSGAVFVVFVAGDDEQSTQMAASWEDDKVTEASSNSFVAIKIDTKSEACLQFSQIYPVVCVPSSFFIGDSGIPLEVIAGSVSADELVTRIHKVRQMHLLKSETSVANGSQSESSVSTPSASFEPNNTCENSQSRNAELCEIPPTSDTKSDTATGGESAGHATSSQEPSGCSDQRPAEDLNIRVERLTKKLEERREEKRKEEEQREIKKEIERRKTGKEMLDYKRKQEEELTKRMLEERNREKAEDRAARERIKQQIALDRAERAARFAKTKEEVEAAKAAALLAKQAEMEVKRESYARERSTVARIQFRLPDGSSFTNQFPSDAPLEEARQFAAQTVGNTYGNFSLATMFPRREFTKEDYKKKLLDLELAPSASVVLLPAGRPTASIVHSSSGDIWTLLGTVLYPFLAIWRLISNFLFSNPPPTQTSVRVTSSEPPNPASSSKSEKREPVRKRVLEKRGDDFKKEGKIYRLRTQDDGEDENNTWNGNSTQQM>sp|P35968|VGFR2_HUMAN Vascular endothelial growth factor receptor 2OS=Homo sapiens OX=9606 GN=KDR PE=1 SV=2MQSKVLLAVALWLCVETRAASVGLPSVSLDLPRLSIQKDILTIKANTTLQITCRGQRDLDWLWPNNQSGSEQRVEVTECSDGLFCKTLTIPKVIGNDTGAYKCFYRETDLASVIYVYVQDYRSPFIASVSDQHGVVYITENKNKTVVIPCLGSISNLNVSLCARYPEKRFVPDGNRISWDSKKGFTIPSYMISYAGMVFCEAKINDESYQSIMYIVVVVGYRIYDVVLSPSHGIELSVGEKLVLNCTARTELNVGIDFNWEYPSSKHQHKKLVNRDLKTQSGSEMKKFLSTLTIDGVTRSDQGLYTCAASSGLMTKKNSTFVRVHEKPFVAFGSGMESLVEATVGERVRIPAKYLGYPPPEIKWYKNGIPLESNHTIKAGHVLTIMEVSERDTGNYTVILTNPISKEKQSHVVSLVVYVPPQIGEKSLISPVDSYQYGTTQTLTCTVYAIPPPHHIHWYWQLEEECANEPSQAVSVTNPYPCEEWRSVEDFQGGNKIEVNKNQFALIEGKNKTVSTLVIQAANVSALYKCEAVNKVGRGERVISFHVTRGPEITLQPDMQPTEQESVSLWCTADRSTFENLTWYKLGPQPLPIHVGELPTPVCKNLDTLWKLNATMFSNSTNDILIMELKNASLQDQGDYVCLAQDRKTKKRHCVVRQLTVLERVAPTITGNLENQTTSIGESIEVSCTASGNPPPQIMWFKDNETLVEDSGIVLKDGNRNLTIRRVRKEDEGLYTCQACSVLGCAKVEAFFIIEGAQEKTNLEIIILVGTAVIAMFFWLLLVIILRTVKRANGGELKTGYLSIVMDPDELPLDEHCERLPYDASKWEFPRDRLKLGKPLGRGAFGQVIEADAFGIDKTATCRTVAVKMLKEGATHSEHRALMSELKILIHIGHHLNVVNLLGACTKPGGPLMVIVEFCKFGNLSTYLRSKRNEFVPYKTKGARFRQGKDYVGAIPVDLKRRLDSITSSQSSASSGFVEEKSLSDVEEEEAPEDLYKDFLTLEHLICYSFQVAKGMEFLASRKCIHRDLAARNILLSEKNVVKICDFGLARDIYKDPDYVRKGDARLPLKWMAPETIFDRVYTIQSDVWSFGVLLWEIFSLGASPYPGVKIDEEFCRRLKEGTRMRAPDYTTPEMYQTMLDCWHGEPSQRPTFSELVEHLGNLLQANAQQDGKDYIVLPISETLSMEEDSGLSLPTSPVSCMEEEEVCDPKFHYDNTAGISQYLQNSKRKSRPVSVKTFEDIPLEEPEVKVIPDDNQTDSGMVLASEELKTLEDRTKLSPSFGGMVPSKSRESVASEGSNQTSGYQSGYHSDDTDTTVYSSEEAELLKLIEIGVQTGSTAQILQPDSGTTLSSPPV>sp|P35968-2|VGFR2_HUMAN Isoform 2 of Vascular endothelial growth factorreceptor 2 OS=Homo sapiens OX=9606 GN=KDRMQSKVLLAVALWLCVETRAASVGLPSVSLDLPRLSIQKDILTIKANTTLQITCRGQRDLDWLWPNNQSGSEQRVEVTECSDGLFCKTLTIPKVIGNDTGAYKCFYRETDLASVIYVYVQDYRSPFIASVSDQHGVVYITENKNKTVVIPCLGSISNLNVSLCARYPEKRFVPDGNRISWDSKKGFTIPSYMISYAGMVFCEAKINDESYQSIMYIVVVVGYRIYDVVLSPSHGIELSVGEKLVLNCTARTELNVGIDFNWEYPSSKHQHKKLVNRDLKTQSGSEMKKFLSTLTIDGVTRSDQGLYTCAASSGLMTKKNSTFVRVHEKPFVAFGSGMESLVEATVGERVRIPAKYLGYPPPEIKWYKNGIPLESNHTIKAGHVLTIMEVSERDTGNYTVILTNPISKEKQSHVVSLVVYVPPQIGEKSLISPVDSYQYGTTQTLTCTVYAIPPPHHIHWYWQLEEECANEPSQAVSVTNPYPCEEWRSVEDFQGGNKIEVNKNQFALIEGKNKTVSTLVIQAANVSALYKCEAVNKVGRGERVISFHVTRGPEITLQPDMQPTEQESVSLWCTADRSTFENLTWYKLGPQPLPIHVGELPTPVCKNLDTLWKLNATMFSNSTNDILIMELKNASLQDQGDYVCLAQDRKTKKRHCVVRQLTVLGRETILDHCAEAVGMP>sp|P35968-3|VGFR2_HUMAN Isoform 3 of Vascular endothelial growth factorreceptor 2 OS=Homo sapiens OX=9606 GN=KDRMQSKVLLAVALWLCVETRAASVGLPSVSLDLPRLSIQKDILTIKANTTLQITCRGQRDLDWLWPNNQSGSEQRVEVTECSDGLFCKTLTIPKVIGNDTGAYKCFYRETDLASVIYVYVQDYRSPFIASVSDQHGVVYITENKNKTVVIPCLGSISNLNVSLCARYPEKRFVPDGNRISWDSKKGFTIPSYMISYAGMVFCEAKINDESYQSIMYIVVVVGYRIYDVVLSPSHGIELSVGEKLVLNCTARTELNVGIDFNWEYPSSKHQHKKLVNRDLKTQSGSEMKKFLSTLTIDGVTRSDQGLYTCAASSGLMTKKNSTFVRVHEKPFVAFGSGMESLVEATVGERVRIPAKYLGYPPPEIKWYKNGIPLESNHTIKAGHVLTIMEVSERDTGNYTVILTNPISKEKQSHVVSLVVYVPPQIGEKSLISPVDSYQYGTTQTLTCTVYAIPPPHHIHWYWQLEEECANEPSQAVSVTNPYPCEEWRSVEDFQGGNKIEVNKNQFALIEGKNKTVSTLVIQAANVSALYKCEAVNKVGRGERVISFHVTRGPEITLQPDMQPTEQESVSLWCTADRSTFENLTWYKLGPQPLPIHVGELPTPVCKNLDTLWKLNATMFSNSTNDILIMELKNASLQDQGDYVCLAQDRKTKKRHCVVRQLTVLERVAPTITGNLENQTTSIGESIEVSCTASGNPPPQIMWFKDNETLVEDSE>sp|Q8N2B8|YB035_HUMAN Putative uncharacterized protein FLJ33534 OS=Homosapiens OX=9606 PE=2 SV=1MGLLSQRKWTLSGSQQTGCVALTVPSFPWVASRMHYGRKQVSWIIFLKIGAGCQVHVGHDCSTLRRQQGAPWSFASSFRPAASPLAPPSPGVSGLFPPHERWSGGSQTRCGKCVKMQILGSTLKLFRHPPSQVTRLWGRHHLKTPAPFLQSPGIQLNPGKVPASLLRLATWKPL>sp|Q8N2B8-2|YB035_HUMAN Isoform 2 of Putative uncharacterized proteinFLJ33534 OS=Homo sapiens OX=9606MGLLSQRKWTLSGSQQTGCVALTVPSFPWVASRMHYGRKQVSWIIFLKIGAGCQVHVGHDCSTLRRQQGAPWSFASSFRPAASPLAPPSPGVSAAALWLCLFCALRVLG>sp|Q6UXP9|YO001_HUMAN Putative uncharacterized protein UNQ9370/PRO34162OS=Homo sapiens OX=9606 GN=UNQ9370/PRO34162 PE=5 SV=1MIFMQILEPQEVPSFLMICQRRSPAMHRTCTDHAPLAIAQVWLWVSLAKAGSNRRGPGRAEGTFFSLLAALHAAQHFPNLPTAPGGASQSNIVSPELTPKPTTALKHAECLLDLNSHSLYRKPRPKAAVYLNLSLPLKSVHRLSLKKSFGFGKRDFENNSVFIVDSGGTCAGLLPGYIGWC>sp|Q8N4W9|ZN808_HUMAN Zinc finger protein 808 OS=Homo sapiens OX=9606GN=ZNF808 PE=1 SV=2MLREEAAQKRKGKESGMALPQGRLTFRDVAIEFSLAEWKFLNPAQRALYREVMLENYRNLEAVDISSKHMMKEVLSTGQGNREVIHTGTLQRHQSYHIGDFCFQEIEKEIHNIEFQCQEDERNGHEAPTTKIKKLTGSTDQHDHRHAGNKPIKDQLGSSFYSHLPELHIFQIKGEIANQLEKSTSDASSVSTSQRISCRPQIHISNNYGNNPLNSSLLPQKQEVHMREKSFPCNESGKAFNCSSLLRKHQIPHLGDKQYKCDVCGKLFNHKQYLACHRRCHTGEKPYKCKECGKSFSYKSSLTCHHRLHTGVKPYKCNECGKVFRQNSALVIHKAIHTGEKPYKCNECGKAFNQQSHLSRHQRLHTGVKPYKCKICEKAFACHSYLANHTRIHSGEKTYKCNECGKAFNHQSSLARHHILHTGEKPYKCEECDKVFSQKSTLERHKRIHTGEKPYKCKVCDTAFTCNSQLARHRRIHTGEKTYKCNECRKTFSRRSSLLCHRRLHSGEKPYKCNQCGNTFRHRASLVYHRRLHTLEKSYKCTVCNKVFMRNSVLAVHTRIHTAKKPYKCNECGKAFNQQSHLSRHRRLHTGEKPYKCEACDKVFGQKSALESHKRIHTGEKPYRCQVCDTAFTWNSQLARHTRIHTGEKTYKCNECGKTFSYKSSLVWHRRLHGGEKSYKCKVCDKAFVCRSYVAKHTRIHSGMKPYKCNECSKTFSNRSSLVCHRRIHSGEKPYKCSECSKTFSQKATLLCHRRLHSGEKPYKCNDCGNTFRHWSSLVYHRRLHTGEKSYKCTVCDKAFVRNSYLARHIRIHTAEKPYKCNECGKAFNEQSHLSRHHRIHTGEKPYKCEACDKVFSRKSHLKRHRIIHTGEKPYKCNECGKAFSDRSTLIHHQAIHGIGKFD>sp|Q8N4W9-2|ZN808_HUMAN Isoform 2 of Zinc finger protein 808 OS=Homosapiens OX=9606 GN=ZNF808MMKEVLSTGQGNREVIHTGTLQRHQSYHIGDFCFQEIEKEIHNIEFQCQEDERNGHEAPTTKIKKLTGSTDQHDHRHAGNKPIKDQLGSSFYSHLPELHIFQIKGEIANQLEKSTSDASSVSTSQRISCRPQIHISNNYGNNPLNSSLLPQKQEVHMREKSFPCNESGKAFNCSSLLRKHQIPHLGDKQYKCDVCGKLFNHKQYLACHRRCHTGEKPYKCKECGKSFSYKSSLTCHHRLHTGVKPYKCNECGKVFRQNSALVIHKAIHTGEKPYKCNECGKAFNQQSHLSRHQRLHTGVKPYKCKICEKAFACHSYLANHTRIHSGEKTYKCNECGKAFNHQSSLARHHILHTGEKPYKCEECDKVFSQKSTLERHKRIHTGEKPYKCKVCDTAFTCNSQLARHRRIHTGEKTYKCNECRKTFSRRSSLLCHRRLHSGEKPYKCNQCGNTFRHRASLVYHRRLHTLEKSYKCTVCNKVFMRNSVLAVHTRIHTAKKPYKCNECGKAFNQQSHLSRHRRLHTGEKPYKCEACDKVFGQKSALESHKRIHTGEKPYRCQVCDTAFTWNSQLARHTRIHTGEKTYKCNECGKTFSYKSSLVWHRRLHGGEKSYKCKVCDKAFVCRSYVAKHTRIHSGMKPYKCNECSKTFSNRSSLVCHRRIHSGEKPYKCSECSKTFSQKATLLCHRRLHSGEKPYKCNDCGNTFRHWSSLVYHRRLHTGEKSYKCTVCDKAFVRNSYLARHIRIHTAEKPYKCNECGKAFNEQSHLSRHHRIHTGEKPYKCEACDKVFSRKSHLKRHRIIHTGEKPYKCNECGKAFSDRSTLIHHQAIHGIGKFD>sp|Q15928|ZN141_HUMAN Zinc finger protein 141 OS=Homo sapiens OX=9606GN=ZNF141 PE=1 SV=1MELLTFRDVAIEFSPEEWKCLDPDQQNLYRDVMLENYRNLVSLGVAISNPDLVTCLEQRKEPYNVKIHKIVARPPAMCSHFTQDHWPVQGIEDSFHKLILRRYEKCGHDNLQLRKGCKSLNECKLQKGGYNEFNECLSTTQSKILQCKASVKVVSKFSNSNKRKTRHTGEKHFKECGKSFQKFSHLTQHKVIHAGEKPYTCEECGKAFKWSLIFNEHKRIHTGEKPFTCEECGSIFTTSSHFAKHKIIHTGEKPYKCEECGKAFNRFTTLTKHKRIHAGEKPITCEECRKIFTSSSNFAKHKRIHTGEKPYKCEECGKAFNRSTTLTKHKRIHTGEKPYTCEECGKAFRQSSKLNEHKKVHTGERPYKCDECGKAFGRSRVLNEHKKIHTGEKPYKCEECGKAFRRSTDRSQHKKIHSADKPYKCKECDKAFKQFSLLSQHKKIHTVDKPYKCKDCDKAFKRFSHLNKHKKIHT>sp|Q8N9W7|YO010_HUMAN Putative transmembrane protein FLJ36131 OS=Homosapiens OX=9606 PE=5 SV=1MYVSISFLLGLSHLVLCCLLTFIVNFYLPPESIDFEFMAHNWSKGRSPSSTLGLSWFKAGFRFSDGWSMFYSFGLPGVALPGSPPRSHLLPGTQILIRSFQPCESAKHSARLSSLLTTTSYSVS>sp|P0CG31|Z286B_HUMAN Putative zinc finger protein 286B OS=Homo sapiensOX=9606 GN=ZNF286B PE=5 SV=1METDLAEMPEKGVLSSQDSPHFQEKSTEEGEVAALRLTARSQAAAAAAAPGSRSLRGVHVPPPLHPAPAREEIKSTCSLKACFSLSLTLTYYRTAFLLSTENEGNLHFQCPSDVETRPQSKDSTSVQDFSKAESCKVAIIDRLTRNSVYDSNLEAALECENWLEKQQGNQERHLREMFTHMNSLSEETDHEHDVYWKSFNQKSVLITEDRVPKGSYAFHTLEKSLKQKSNLMKKQRTYKEKKPHKCNDCGELFTCHSVHIQHQRVHTGEKPYTCNECGKSFSHRANLTKHQRTHTRILFECRECKKTFTESSSLATHQRIHVGERPYECNECGKGFNRSTHLVQHQLIHTGVRPYECNECDKAFIHSSALIKHQRTHTGEKPYKCQECGKAFSHCSSLTKHQRVHTGEKPYECSECGKTFSQSTHLVQHQRIHTGEKPYECSECGKTFSQSSNFAKHQRIHIGKKPYKCSECGKAFIHSSALIQHQRTHTGEKPFRCNECGKSFKCSSSLIRHQRVHTEEQP>sp|Q6P2D0|ZFP1_HUMAN Zinc finger protein 1 homolog OS=Homo sapiensOX=9606 GN=ZFP1 PE=1 SV=2MNKSQGSVSFTDVTVDFTQEEWEQLDPSQRILYMDVMLENYSNLLSVEVWKADDQMERDHRNPDEQARQFLILKNQTPIEERGDLFGKALNLNTDFVSLRQVPYKYDLYEKTLKYNSDLLNSNRSYAGKQTDECNEFGKALLYLKQEKTHSGVEYSEYNKSGKALSHKAAIFKHQKIKNLVQPFICTYCDKAFSFKSLLISHKRIHTGEKPYECNVCKKTFSHKANLIKHQRIHTGEKPFECPECGKAFTHQSNLIVHQRAHMEKKPYECSECGKTFAQKFELTTHQRIHTGERPYECNECAKTFFKKSNLIIHQKIHTGEKRYECSECGKSFIQNSQLIIHMRTHTGEKPYECTECGKTFSQRSTLRLHLRIHTGEKPYECSECGKAFSRKSRLSVHQRVHIGEKP>sp|Q6P2D0-2|ZFP1_HUMAN Isoform 2 of Zinc finger protein 1 homologOS=Homo sapiens OX=9606 GN=ZFP1MERDHRNPDEQARQFLILKNQTPIEERGDLFGKALNLNTDFVSLRQVPYKYDLYEKTLKYNSDLLNSNRSYAGKQTDECNEFGKALLYLKQEKTHSGVEYSEYNKSGKALSHKAAIFKHQKIKNLVQPFICTYCDKAFSFKSLLISHKRIHTGEKPYECNVCKKTFSHKANLIKHQRIHTGEKPFECPECGKAFTHQSNLIVHQRAHMEKKPYECSECGKTFAQKFELTTHQRIHTGERPYECNECAKTFFKKSNLIIHQKIHTGEKRYECSECGKSFIQNSQLIIHMRTHTGEKPYECTECGKTFSQRSTLRLHLRIHTGEKPYECSECGKAFSRKSRLSVHQRVHIGEKP>sp|P52743|ZN137_HUMAN Putative zinc finger protein 137 OS=Homo sapiensOX=9606 GN=ZNF137P PE=5 SV=1MNVARFLVEKHTLHVIIDFILSKVSNQQSNLAQHQRVYTGEKPYKCNEWGKALSGKSSLFYHQAIHGVGKLCKCNDCHKVFSNATTIANHWRIHNEDRSYKCNKCGKIFRHRSYLAVYQRTHTGEKPYKYHDCGKVFSQASSYAKHRRIHTGEKPHKCDDCGKVLTSRSHLIRHQRIHTGQKSYKCLKCGKVFSLWALHAEHQKIHF>sp|P17014|ZNF12_HUMAN Zinc finger protein 12 OS=Homo sapiens OX=9606GN=ZNF12 PE=1 SV=3MNKSLGPVSFKDVAVDFTQEEWQQLDPEQKITYRDVMLENYSNLVSVGYHIIKPDVISKLEQGEEPWIVEGEFLLQSYPDEVWQTDDLIERIQEEENKPSRQTVFIETLIEERGNVPGKTFDVETNPVPSRKIAYKNSLCDSCEKCLTSVSEYISSDGSYARMKADECSGCGKSLLHIKLEKTHPGDQAYEFNQNGEPYTLNEESLYQKIRILEKPFEYIECQKAFQKDTVFVNHMEEKPYKWNGSEIAFLQMSDLTVHQTSHMEMKPYECSECGKSFCKKSKFIIHQRTHTGEKPYECNQCGKSFCQKGTLTVHQRTHTGEKPYECNECGKNFYQKLHLIQHQRTHSGEKPYECSYCGKSFCQKTHLTQHQRTHSGERPYVCHDCGKTFSQKSALNDHQKIHTGVKLYKCSECGKCFCRKSTLTTHLRTHTGEKPYECNECGKFFSRLSYLTVHYRTHSGEKPYECNECGKTFYLNSALMRHQRVHTGEKPYECNECGKLFSQLSYLTIHHRTHSGVKPYECSECGKTFYQNSALCRHRRIHKGEKPYECYICGKFFSQMSYLTIHHRIHSGEKPYECSECGKTFCQNSALNRHQRTHTGEKAYECYECGKCFSQMSYLTIHHRIHSGEKPFECNECGKAFSRMSYLTVHYRTHSGEKPYECTECGKKFYHKSAFNSHQRIHRRGNMNVIDVGRLL>sp|P17014-2|ZNF12_HUMAN Isoform 2 of Zinc finger protein 12 OS=Homosapiens OX=9606 GN=ZNF12MNKSLGPVSFKDVAVDFTQEEWQQLDPEQKITYRDVMLENYSNLVSVGYHIIKPDVISKLEQGEEPWIVEGEFLLQSYPDEVWQTDDLIERIQEEENKPSRQTVFIETLIEERGNVPGKTFDVETNPVPSRKIAYKNSLCDSCEKCLTSVSEYISSDGSYARMKADECSGCGKSLLHIKLEKTHPGDQAYEFNQNGEPYTLNEESLYQKIRILEKPFEYIECQKAFQKDTVFVNHMEEKPYKWNGSEIAFLQMSDLTVHQTSHMEMKPYECSECGKSFCKKSKFIIHQRTHTGEKPYECNQCGKSFCQKGTLTVHQRTHTGEKPYECNECGKNFYQKLHLIQHQRTHSGEKPYECSYCGKSFCQKTHLTQHQRTHSGERPYVCHDCGKTFSQKSALNDHQKIHTGVKLYKCSECGKCFCRKSTLTTHLRTHTGEKPYECNECGKFFSRLSYLTVHYRTHSGEKPYECTECGKKFYHKSAFNSHQRIHRRGNMNVIDVGRLL>sp|P17014-3|ZNF12_HUMAN Isoform 3 of Zinc finger protein 12 OS=Homosapiens OX=9606 GN=ZNF12MEEKPYKWNGSEIAFLQMSDLTVHQTSHMEMKPYECSECGKSFCKKSKFIIHQRTHTGEKPYECNQCGKSFCQKGTLTVHQRTHTGEKPYECNECGKNFYQKLHLIQHQRTHSGEKPYECSYCGKSFCQKTHLTQHQRTHSGERPYVCHDCGKTFSQKSALNDHQKIHTGVKLYKCSECGKCFCRKSTLTTHLRTHTGEKPYECNECGKFFSRLSYLTVHYRTHSGEKPYECNECGKTFYLNSALMRHQRVHTGEKPYECNECGKLFSQLSYLTIHHRTHSGVKPYECSECGKTFYQNSALCRHRRIHKGEKPYECYICGKFFSQMSYLTIHHRIHSGEKPYECSECGKTFCQNSALNRHQRTHTGEKAYECYECGKCFSQMSYLTIHHRIHSGEKPFECNECGKAFSRMSYLTVHYRTHSGEKPYECTECGKKFYHKSAFNSHQRIHRRGNMNVIDVGRLL>sp|P17014-4|ZNF12_HUMAN Isoform 4 of Zinc finger protein 12 OS=Homosapiens OX=9606 GN=ZNF12MLENYSNLVSVGYHIIKPDVISKLEQGEEPWIVEGEFLLQSYPDEVWQTDDLIERIQEEENKPSRQTVFIETLIEEREYISSDGSYARMKADECSGCGKSLLHIKLEKTHPGDQAYEFNQNGEPYTLNEESLYQKIRILEKPFEYIECQKAFQKDTVFVNHMEEKPYKWNGSEIAFLQMSDLTVHQTSHMEMKPYECSECGKSFCKKSKFIIHQRTHTGEKPYECNQCGKSFCQKGTLTVHQRTHTGEKPYECNECGKNFYQKLHLIQHQRTHSGEKPYECSYCGKSFCQKTHLTQHQRTHSGERPYVCHDCGKTFSQKSALNDHQKIHTGVKLYKCSECGKCFCRKSTLTTHLRTHTGEKPYECNECGKFFSRLSYLTVHYRTHSGEKPYECNECGKTFYLNSALMRHQRVHTGEKPYECNECGKLFSQLSYLTIHHRTHSGVKPYECSECGKTFYQNSALCRHRRIHKGEKPYECYICGKFFSQMSYLTIHHRIHSGEKPYECSECGKTFCQNSALNRHQRTHTGEKAYECYECGKCFSQMSYLTIHHRIHSGEKPFECNECGKAFSRMSYLTVHYRTHSGEKPYECTECGKKFYHKSAFNSHQRIHRRGNMNVIDVGRLL>sp|P17014-5|ZNF12_HUMAN Isoform 5 of Zinc finger protein 12 OS=Homosapiens OX=9606 GN=ZNF12MNKSLGPVSFKDVAVDFTQEEWQQLDPEQKITYRDVMLENYSNLVSVGYHIIKPDVISKLEQGEEPWIVEGEFLLQSYPDEVWQTDDLIERIQEEENKPSRQTVFIETLIEEREYISSDGSYARMKADECSGCGKSLLHIKLEKTHPGDQAYEFNQNGEPYTLNEESLYQKIRILEKPFEYIECQKAFQKDTVFVNHMEEKPYKWNGSEIAFLQMSDLTVHQTSHMEMKPYECSECGKSFCKKSKFIIHQRTHTGEKPYECNQCGKSFCQKGTLTVHQRTHTGEKPYECNECGKNFYQKLHLIQHQRTHSGEKPYECSYCGKSFCQKTHLTQHQRTHSGERPYVCHDCGKTFSQKSALNDHQKIHTGVKLYKCSECGKCFCRKSTLTTHLRTHTGEKPYECNECGKFFSRLSYLTVHYRTHSGEKPYECNECGKTFYLNSALMRHQRVHTGEKPYECNECGKLFSQLSYLTIHHRTHSGVKPYECSECGKTFYQNSALCRHRRIHKGEKPYECYICGKFFSQMSYLTIHHRIHSGEKPYECSECGKTFCQNSALNRHQRTHTGEKAYECYECGKCFSQMSYLTIHHRIHSGEKPFECNECGKAFSRMSYLTVHYRTHSGEKPYECTECGKKFYHKSAFNSHQRIHRRGNMNVIDVGRLL>sp|Q9Y2A4|ZN443_HUMAN Zinc finger protein 443 OS=Homo sapiens OX=9606GN=ZNF443 PE=2 SV=2MASVALEDVAVNFTREEWALLGPCQKNLYKDVMQETIRNLDCVVMKWKDQNIEDQYRYPRKNLRCRMLERFVESKDGTQCGETSSQIQDSIVTKNTLPGVGPCESSMRGEKVMGHSSLNCYIRVGAGHKPHEYHECGEKPDTHKQRGKAFSYHNSFQTHERLHTGKKPYDCKECGKSFSSLGNLQRHMAVQRGDGPYKCKLCGKAFFWPSLLHMHERTHTGEKPYECKQCSKAFSFYSSYLRHERTHTGEKPYECKQCSKAFPFYSSYLRHERTHTGEKPYKCKQCSKAFPDSSSCLIHERTHTGEKPYTCKQCGKAFSVSGSLQRHETTHSAEKPYACQQCGKAFHHLGSFQRHMIRHTGNGPHKCKICGKGFDCPSSLQSHERTHTGEKPYECKQCGKALSHRSSFRSHMIMHTGDGPHKCKVCGKAFVYPSVFQRHERTHTAEKPYKCKQCGKAYRISSSLRRHETTHTGEKPYKCKLGKACIDFCSFQNHKTTHTGEKPYECKECGKAFSRFRYLSRHKRTHTGEKPYECKTCRKAFGHYDNLKVHERIHSGEKPYECKECGKAFSWLTCFLRHERIHMREKSYECPQCGKAFTHSRFLQGHEKTHTGENPYECKECGKAFASLSSLHRHKKTHWKKTHTGENPYECKECGKAFASLSSLHRHKKTH>sp|Q9UJL9|ZF69B_HUMAN Zinc finger protein 69 homolog B OS=Homo sapiensOX=9606 GN=ZFP69B PE=1 SV=2MLQQLLITLPTEASTWVKLRHPKAATERVALWEDVTKMFKAEALLSQDADETQGESLESRVTLGSLTAESQELLTFKDVSVDFTQEEWGQLAPAHRNLYREVMLENYGNLVSVGCQLSKPGVISQLEKGEEPWLMERDISGVPSSDLKSKTKTKESALQNDISWEELHCGLMMERFTKGSSMYSTLGRISKCNKLESQQENQRMGKGQIPLMCKKTFTQERGQESNRFEKRINVKSEVMPGPIGLPRKRDRKYDTPGKRSRYNIDLVNHSRSYTKMKTFECNICEKIFKQLIHLTEHMRIHTGEKPFRCKECGKAFSQSSSLIPHQRIHTGEKPYECKECGKTFRHPSSLTQHVRIHTGEKPYECRVCEKAFSQSIGLIQHLRTHVREKPFTCKDCGKAFFQIRHLRQHEIIHTGVKPYICNVCSKTFSHSTYLTQHQRTHTGERPYKCKECGKAFSQRIHLSIHQRVHTGVKPYECSHCGKAFRHDSSFAKHQRIHTGEKPYDCNECGKAFSCSSSLIRHCKTHLRNTFSNVV>sp|Q9UJL9-2|ZF69B_HUMAN Isoform 2 of Zinc finger protein 69 homolog BOS=Homo sapiens OX=9606 GN=ZFP69BMLENYGNLVSVGCQLSKPGVISQLEKGEEPWLMERDISGVPSSDLKSKTKTKESALQNDISWEELHCGLMMERFTKGSSMYSTLGRISKCNKLESQQENQRMGKGQIPLMCKKTFTQERGQESNRFEKRINVKSEVMPGPIGLPRKRDRKYDTPGKRSRYNIDLVNHSRSYTKMKTFECNICEKIFKQLIHLTEHMRIHTGEKPFRCKECGKAFSQSSSLIPHQRIHTGEKPYECKECGKTFRHPSSLTQHVRIHTGEKPYECRVCEKAFSQSIGLIQHLRTHVREKPFTCKDCGKAFFQIRHLRQHEIIHTGVKPYICNVCSKTFSHSTYLTQHQRTHTGERPYKCKECGKAFSQRIHLSIHQRVHTGVKPYECSHCGKAFRHDSSFAKHQRIHTGEKPYDCNECGKAFSCSSSLIRHCKTHLRNTFSNVV>sp|Q7Z398|ZN550_HUMAN Zinc finger protein 550 OS=Homo sapiens OX=9606GN=ZNF550 PE=1 SV=2MAETKDAAQMLVTFKDVAVTFTREEWRQLDLAQRTLYREVMLETCGLLVSLGHRVPKPELVHLLEHGQELWIVKRGLSHATCAGDRAQVHTREPTTYPPVLSERAFLRGSLTLESSTSSDSRLGRARDEEGLLEMQKGKVTPETDLHKETHLGKVSLEGEGLGTDDGLHSRALQEWLSADVLHECDSQQPGKDALIHAGTNPYKCKQCGKGFNRKWYLVRHQRVHTGMKPYECNACGKAFSQSSTLIRHYLIHTGEKPYKCLECGKAFKRRSYLMQHHPIHTGEKPYECSQCRKAFTHRSTFIRHNRTHTGEKPFECKECEKAFSNRAHLIQHYIIHTGEKPYDCMACGKAFRCSSELIQHQRIHTGEKPYECTQCGKAFHRSTYLIQHSVIHTGEMPYKCIECGKAFKRRSHLLQHQRVHT>sp|Q7Z398-2|ZN550_HUMAN Isoform 2 of Zinc finger protein 550 OS=Homosapiens OX=9606 GN=ZNF550MAETKDAAQMLVTFKDVAVTFTREEWRQLDLAQRTLYREVMLETCGLLVSLGDRAQVHTREPTTYPPVLSERAFLRGSLTLESSTSSDSRLGRARDEEGLLEMQKGKVTPETDLHKETHLGKVSLEGEGLGTDDGLHSRALQEWLSADVLHECDSQQPGKDALIHAGTNPYKCKQCGKGFNRKWYLVRHQRVHTGMKPYECNACGKAFSQSSTLIRHYLIHTGEKPYKCLECGKAFKRRSYLMQHHPIHTGEKPYECSQCRKAFTHRSTFIRHNRTHTGEKPFECKECEKAFSNRAHLIQHYIIHTGEKPYDCMACGKAFRCSSELIQHQRIHTGEKPYECTQCGKAFHRSTYLIQHSVIHTGEMPYKCIECGKAFKRRSHLLQHQRVHT>sp|P22415|USF1_HUMAN Upstream stimulatory factor 1 OS=Homo sapiensOX=9606 GN=USF1 PE=1 SV=1MKGQQKTAETEEGTVQIQEGAVATGEDPTSVAIASIQSAATFPDPNVKYVFRTENGGQVMYRVIQVSEGQLDGQTEGTGAISGYPATQSMTQAVIQGAFTSDDAVDTEGTAAETHYTYFPSTAVGDGAGGTTSGSTAAVVTTQGSEALLGQATPPGTGQFFVMMSPQEVLQGGSQRSIAPRTHPYSPKSEAPRTTRDEKRRAQHNEVERRRRDKINNWIVQLSKIIPDCSMESTKSGQSKGGILSKACDYIQELRQSNHRLSEELQGLDQLQLDNDVLRQQVEDLKNKNLLLRAQLRHHGLEVVIKNDSN>sp|P22415-2|USF1_HUMAN Isoform 2 of Upstream stimulatory factor 1OS=Homo sapiens OX=9606 GN=USF1MYRVIQVSEGQLDGQTEGTGAISGYPATQSMTQAVIQGAFTSDDAVDTEGTAAETHYTYFPSTAVGDGAGGTTSGSTAAVVTTQGSEALLGQATPPGTGQFFVMMSPQEVLQGGSQRSIAPRTHPYSPKSEAPRTTRDEKRRAQHNEVERRRRDKINNWIVQLSKIIPDCSMESTKSGQSKGGILSKACDYIQELRQSNHRLSEELQGLDQLQLDNDVLRQQVEDLKNKNLLLRAQLRHHGLEVVIKNDSN>sp|Q15904|VAS1_HUMAN V-type proton ATPase subunit S1 OS=Homo sapiensOX=9606 GN=ATP6AP1 PE=1 SV=2MMAAMATARVRMGPRCAQALWRMPWLPVFLSLAAAAAAAAAEQQVPLVLWSSDRDLWAPAADTHEGHITSDLQLSTYLDPALELGPRNVLLFLQDKLSIEDFTAYGGVFGNKQDSAFSNLENALDLAPSSLVLPAVDWYAVSTLTTYLQEKLGASPLHVDLATLRELKLNASLPALLLIRLPYTASSGLMAPREVLTGNDEVIGQVLSTLKSEDVPYTAALTAVRPSRVARDVAVVAGGLGRQLLQKQPVSPVIHPPVSYNDTAPRILFWAQNFSVAYKDQWEDLTPLTFGVQELNLTGSFWNDSFARLSLTYERLFGTTVTFKFILANRLYPVSARHWFTMERLEVHSNGSVAYFNASQVTGPSIYSFHCEYVSSLSKKGSLLVARTQPSPWQMMLQDFQIQAFNVMGEQFSYASDCASFFSPGIWMGLLTSLFMLFIFTYGLHMILSLKTMDRFDDHKGPTISLTQIV>sp|Q6ZS81|WDFY4_HUMAN WD repeat- and FYVE domain-containing protein 4OS=Homo sapiens OX=9606 GN=WDFY4 PE=1 SV=3MEAEDLSKAEDRNEDPGSKNEGQLAAVQPDVPHGGQSSSPTALWDMLERKFLEYQQLTHKSPIERQKSLLSLLPLFLKAWEHSVGIICFPSLQRLAEDVSDQLAQQLQKALVGKPAEQARLAAGQLLWWKGDVDQDGYLLLKSVYVLTGTDSETLGRVAESGLPALLLQCLYLFFVFPLDKDELLESDLQVQKMFVQMLLNICSDSQGLEGLLSGSELQSLLIATTCLREHSCCFWKEPTFCVLRAISKAQNLSIIQYLQATDCVRLSLQNLSRLTDTLPAPEVSEAVSLILGFVKDSYPVSSALFLEFENSEGYPLLLKVLLRYDGLTQSEVDPHLEELLGLVVWLTTCGRSELKVFDSITYPQLEGFKFHHEASGVTVKNLQAFQVLQNVFHKASDSVLCIQVLSVIRTMWAWNARNFFLLEWTLQPISQFVEIMPLKPAPVQEHFFQLLEALVFELHYVPHEILRKVQHLIKESPGPSCTLMALQSILSIAGGDPLFTDIFRDSGLLGLLLAQLRKQAKIMRKSGNKVSTPGVQDPERELTCVMLRIVVTLLKGSVRNAVVLKDHGMVPFIKIFLDDECYREASLSILEQLSAINAEEYMSIIVGALCSSTQGELQLKLDLLKSLLRILVTPKGRAAFRVSSGFNGLLSLLSDLEGSLQEPPLQAWGAVSPRQTLELVLYTLCAVSAALHWDPVNGYFFRRNGLFEKLAEDLCLLGCFGALEEEGNLLRSWVDTKARPFADLLGTAFSSSGSLPPRIQSCLQILGFLDSMASGTLHLRGDLKESLRTKQGPVVDVQKGETGSDPQRNFKQWPDLEERMDEGDAAIMHPGVVCIMVRLLPRLYHEDHPQLSEEIQCSLASHIQSLVKSEKNRQVMCEAGLLGTLMASCHRALVTSGSPLHSRLIRIFEKLASQAIEPDVLRQFLGLGIPSSLSATTKILDSSHTHRGNPGCSGSQTAQGLAEGPWPAAPDAGLHPGVTQAPQPLGESQDSTTALQTALSLISMTSPRNLQPQRAALAPSFVEFDMSVEGYGCLFIPTLSTVMGTSTEYSVSGGIGTGATRPFPPPGGLTFSCWFLISRHGAATEGHPLRFLTLVRHLARTEQPFVCFSVSLCPDDLSLVVSTEEKEFQPLDVMEPEDDSEPSAGCQLQVRCGQLLACGQWHHLAVVVTKEMKRHCTVSTCLDGQVIGSAKMLYIQALPGPFLSMDPSAFVDVYGYIATPRVWKQKSSLIWRLGPTYLFEEAISMETLEVINKLGPRYCGNFQAVHVQGEDLDSEATPFVAEERVSFGLHIASSSITSVADIRNAYNEVDSRLIAKEMNISSRDNAMPVFLLRNCAGHLSGSLRTIGAVAVGQLGVRVFHSSPAASSLDFIGGPAILLGLISLATDDHTMYAAVKVLHSVLTSNAMCDFLMQHICGYQIMAFLLRKKASLLNHRIFQLILSVAGTVELGFRSSAITNTGVFQHILCNFELWMNTADNLELSLFSHLLEILQSPREGPRNAEAAHQAQLIPKLIFLFNEPSLIPSKISTIIGILACQLRGHFSTQDLLRIGLFVVYTLKPSSVNERQICMDGALDPSLPAGSQTSGKTIWLRNQLLEMLLSVISSPQLHLSSESKEEMFLKLGPDWFLLLLQGHLHASTTVLALKLLLYFLASPSLRTRFRDGLCAGSWVERSTEGVDIVMDNLKSQSPLPEQSPCLLPGFRVLNDFLAHHVHIPEVYLIVSTFFLQTPLTELMDGPKDSLDAMLQWLLQRHHQEEVLQAGLCTEGALLLLEMLKATMSQPLAGSEDGAWAQTFPASVLQFLSLVHRTYPQDPAWRAPEFLQTLAIAAFPLGAQKGVGAESTRNTSSPEAAAEGDSTVEGLQAPTKAHPARRKLREFTQLLLRELLLGASSPKQWLPLEVLLEASPDHATSQQKRDFQSEVLLSAMELFHMTSGGDAAMFRDGKEPQPSAEAAAAPSLANISCFTQKLVEKLYSGMFSADPRHILLFILEHIMVVIETASSQRDTVLSTLYSSLNKVILYCLSKPQQSLSECLGLLSILGFLQEHWDVVFATYNSNISFLLCLMHCLLLLNERSYPEGFGLEPKPRMSTYHQVFLSPNEDVKEKREDLPSLSDVQHNIQKTVQTLWQQLVAQRQQTLEDAFKIDLSVKPGEREVKIEEVTPLWEETMLKAWQHYLASEKKSLASRSNVAHHSKVTLWSGSLSSAMKLMPGRQAKDPECKTEDFVSCIENYRRRGQELYASLYKDHVQRRKCGNIKAANAWARIQEQLFGELGLWSQGEETKPCSPWELDWREGPARMRKRIKRLSPLEALSSGRHKESQDKNDHISQTNAENQDELTLREAEGEPDEVGVDCTQLTFFPALHESLHSEDFLELCRERQVILQELLDKEKVTQKFSLVIVQGHLVSEGVLLFGHQHFYICENFTLSPTGDVYCTRHCLSNISDPFIFNLCSKDRSTDHYSCQCHSYADMRELRQARFLLQDIALEIFFHNGYSKFLVFYNNDRSKAFKSFCSFQPSLKGKATSEDTLSLRRYPGSDRIMLQKWQKRDISNFEYLMYLNTAAGRTCNDYMQYPVFPWVLADYTSETLNLANPKIFRDLSKPMGAQTKERKLKFIQRFKEVEKTEGDMTVQCHYYTHYSSAIIVASYLVRMPPFTQAFCALQGGSFDVADRMFHSVKSTWESASRENMSDVRELTPEFFYLPEFLTNCNGVEFGCMQDGTVLGDVQLPPWADGDPRKFISLHRKALESDFVSANLHHWIDLIFGYKQQGPAAVDAVNIFHPYFYGDRMDLSSITDPLIKSTILGFVSNFGQVPKQLFTKPHPARTAAGKPLPGKDVSTPVSLPGHPQPFFYSLQSLRPSQVTVKDMYLFSLGSESPKGAIGHIVSTEKTILAVERNKVLLPPLWNRTFSWGFDDFSCCLGSYGSDKVLMTFENLAAWGRCLCAVCPSPTTIVTSGTSTVVCVWELSMTKGRPRGLRLRQALYGHTQAVTCLAASVTFSLLVSGSQDCTCILWDLDHLTHVTRLPAHREGISAITISDVSGTIVSCAGAHLSLWNVNGQPLASITTAWGPEGAITCCCLMEGPAWDTSQIIITGSQDGMVRVWKTEDVKMSVPGRPAGEEPPAQPPSPRGHKWEKNLALSRELDVSIALTGKPSKTSPAVTALAVSRNHTKLLVGDERGRIFCWSADG>sp|Q6ZS81-2|WDFY4_HUMAN Isoform 2 of WD repeat- and FYVE domain-containing protein 4 OS=Homo sapiens OX=9606 GN=WDFY4MEAEDLSKAEDRNEDPGSKNEGQLAAVQPDVPHGGQSSSPTALWDMLERKFLEYQQLTHKSPIERQKSLLSLLPLFLKAWEHSVGIICFPSLQRLAEDVSDQLAQQLQKALVGKPAEQARLAAGQLLWWKGDVDQDGYLLLKSVYVLTGTDSETLGRVAESGLPALLLQCLYLFFVFPLDKDELLESDLQVQKMFVQMLLNICSDSQGLEGLLSGSELQSLLIATTCLREHSCCFWKEPTFCVLRAISKAQNLSIIQYLQATDCVRLSLQNLSRLTDTLPAPEVSEAVSLILGFVKDSYPVSSALFLEFENSEGYPLLLKVLLRYDGLTQSEVDPHLEELLGLVVWLTTCGRSELKVFDSITYPQLEGFKFHHEASGVTVKNLQAFQVLQNVFHKASDSVLCIQVLSVIRTMWAWNARNFFLLEWTLQPISQFVEIMPLKPAPVQEHFFQLLEALVFELHYVPHEILRKVQHLIKESPGPSCTLMALQSILSIAGGDPLFTDIFRDSGLLGLLLAQLRKQAKIMRKSGNKVSTPGVQDPERELTCVMLRIVVTLLKGSVRNAVVLKDHGMVPFIKIFLDDECYREASLSILEQLSAINAEEYMSIIVGALCSSTQGELQLKLDLLKVISSPPLRLASLWICTKRSTFAQAFVFM>sp|Q6ZS81-3|WDFY4_HUMAN Isoform 3 of WD repeat- and FYVE domain-containing protein 4 OS=Homo sapiens OX=9606 GN=WDFY4MEAEDLSKAEDRNEDPGSKNEGQLAAVQPDVPHGGQSSSPTALWDMLERKFLEYQQLTHKSPIERQKSLLSLLPLFLKAWEHSVGIICFPSLQRLAEDVSDQLAQQLQKALVGKPAEQARLAAGQLLWWKGDVDQDGYLLLKSVYVLTGTDSETLGRVAESGLPALLLQCLYLFFVFPLDKDELLESDLQVQKMFVQMLLNICSDSQGLEGLLSGSELQSLLIATTCLREHSCCFWKEPTFCVLRAISKAQNLSIIQYLQATDCVRLSLQNLSRLTDTLPAPEVSEAVSLILGFVKDSYPVSSALFLEFENSEGYPLLLKVLLRYDGLTQSEVDPHLEELLGLVVWLTTCGRSELKVFDSITYPQLEGFKFHHEASGVTVKNLQAFQVLQNVFHKASDSVLCIQVLSVIRTMWAWNARNFFLLEWTLQPISQFVEIMPLKPAPVQEHFFQLLEALVFELHYVPHEILRKVQHLIKESPGPSCTLMALQSILSIAGGDPLFTDIFRDSGLLGLLLAQLRKQAKIMRKSGNKVSTPGVQDPERELTCVMLRIVVTLLKGSVRNAVVLKDHGMVPFIKIFLDDECYREASLSILEQLSAINAEEYMSIIVGALCSSTQGELQLKLDLLKSLLRILVTPKGRAAFRVSSGFNGLLSLLSDLEGSLQEPPLQAWGAVSPRQTLELVLYTLCAVSAALHWDPVNGYFFRRNGLFEKLAEDLCLLGCFGALEEEGNLLRSWVDTKARPFADLLGTAFSSSGSLPPRIQSCLQILGFLDSMASGTLHLRGDLKESLRTKQGPVVDVQKGETGSDPQRNFKQWPDLEERMDEGDAAIMHPGVVCIMVRLLPRLYHEDHPQLSEEIQCSLASHIQSLVKSEKNRQVMCEAGLLGTLMASCHRALVTSGSPLHSRLIRIFEKLASQAIEPDVLRQFLGLGIPSSLSATTKILDSSHTHRGNPGCSGSQTAQGLAEGPWPAAPDAGLHPGVTQAPQPLGESQDSTTALQTALSLISMTFPACWKPNIWKDNLAQKPVAGDAAQCNIFPPASSVL>sp|Q6ZS81-4|WDFY4_HUMAN Isoform 4 of WD repeat- and FYVE domain-containing protein 4 OS=Homo sapiens OX=9606 GN=WDFY4MEAEDLSKAEDRNEDPGSKNEGQLAAVQPDVPHGGQSSSPTALWDMLERKFLEYQQLTHKSPIERQKSLLSLLPLFLKAWEHSVGIICFPSLQRLAEDVSDQLAQQLQKALVGKPAEQARLAAGQLLWWKGDVDQDGYLLLKSVYVLTGTDSETLGRVAESGLPALLLQCLYLFFVFPLDKDELLESDLQVQKMFVQMLLNICSDSQGLEGLLSGSELQSLLIATTCLREHSCCFWKEPTFCVLRAISKAQNLSIIQYLQATDCVRLSLQNLSRLTDTLPAPEVSEAVSLILGFVKDSYPVSSALFLEFENSEGYPLLLKVLLRYDGLTQSEVDPHLEELLGLVVWLTTCGRSELKVFDSITYPQLEGFKFHHEASGVTVKNLQAFQVLQNVFHKASDSVLCIQVLSVIRTMWAWNARNFFLLEWTLQPISQFVEIMPLKPAPVQEHFFQLLEALVFELHYVPHEILRKVQHLIKESPGPSCTLMALQSILSIAGGDPLFTDIFRDSGLLGLLLAQLRKQAKIMRKSGNKVSTPGVQDPERELTCVMLRIVVTLLKGSVRNAVVLKDHGMVPFIKIFLDDECYREASLSILEQLSAINAEEYMSIIVGALCSSTQGELQLKLDLLKSLLRILVTPKGRAAFRVSSGFNGLLSLLSDLEGSLQEPPLQAWGAVSPRQTLELVLYTLCAVSAALHWDPVNGYFFRRNGLFEKLAEDLCLLGCFGALEEEGNLLRSWVDTKARPFADLLGTAFSSSGSLPPRIQSCLQILGFLDSMASGTLHLRGDLKESLRTKQGPVVDVQKGETGSDPQRNFKQWPDLEERMDEGDAAIMHPGVVCIMVRLLPRLYHEDHPQLSEEIQCSLASHIQSLVKSEKNRQVMCEAGLLGTLMASCHRALVTSGSPLHSRLIRIFEKLASQAIEPDVLRQFLGLGIPSSLSATTKILDSSHTHRGNPGCSGSQTAQGLAEGPWPAAPDAGLHPGVTQAPQPLGESQDSTTALQTALSLISMTSPRNLQPQRAALAPSFVEFDMSVEGYGCLFIPTLSTVMGTSTEYSVSGGIGTGATRPFPPPGGLTFSCWFLISRHGAATEGHPLRFLTLVRHLARTEQPFVCFSVSLCPDDLSLVVSTEEKEFQPLDVMEPEDDSEPSAGCQLQVRCGQLLACGQWHHLAVVVTKEMKRHCTVSTCLDGQVIGSAKMLYIQALPGPFLSMDPSAFVDVYGYIATPRVWKQKSSLIWRLGPTYLFEEAISMETLEVINKLGPRYCGNFQAVHVQGEDLDSEATPFVAEERVSFGLHIASSSITSVADIRNAYNEVDSRLIAKEMNISSRDNAMPVFLLRNCAGHLSGSLRTIGAVAVGQLGVRVFHSSPAASSLDFIGGPAILLGLISLATDDHTMYAAVKVLHSVLTSNAMCDFLMQHICGYQIMAFLLRKKASLLNHRIFQLILSVAGTVELGFRSSAITNTGVFQHILCNFELWMNTADNLELSLFSHLLEILQSPREGPRNAEAAHQAQLIPKLIFLFNEPSLIPSKISTIIGILACQLRGHFSTQDLLRIGLFVVYTLKPSSVNERQICMDGALDPSLPAGSQTSGKTIWLRNQLLEMLLSVISSPQLHLSSESKEEMFLKLGPDWFLLLLQGHLHASTTVLALKLLLYFLASPSLRTRFRDGLCAGSWVERSTEGVDIVMDNLKSQSPLPEQSPCLLPGFRVLNDFLAHHVHIPEVYLIVSTFFLQTPLTELMDGPKDSLDAMLQWLLQRHHQEEVLQAGLCTEGALLLLEMLKATMSQPLAGSEDGAWAQTFPASVLQFLSLVHRTYPQDPAWRAPEFLQTLAIAAFPLGAQKGVGAESTRNTSSPEAAAEGDSTVEGLQAPTKAHPARRKLREFTQLLLRELLLGASSPKQWLPLEVLLEASPDHATSQQKRDFQSEVLLSAMELFHMTSGGDAAMFRDGKEPQPSAEAAAAPSLANISCFTQKLVEKLYSGMFSADPRHILLFILEHIMVVIETASSQRDTVLSTLYSSLNKVILYCLSKPQQSLSECLGLLSILGFLQEHWDVVFATYNSNISFLLCLMHCLLLLNERSYPEGFGLEPKPRMSTYHQVFLSPNEDVKEKREDLPSLSDVQHNIQKTVQTLWQQLVAQRQQTLEDAFKIDLSVKPGEREVKIEEVTPLWEETMLKAWQHYLASEKKSLASRSNVAHHSKVTLWSGSLSSAMKLMPGRQAKDPECKTEDFVSCIENYRRRGQELYASLYKDHVQRRKCGNIKAANAWARIQEQLFGELGLWSQGEETKPCSPWELDWREGPARMRKRIKRLSPLEALSSGRHKESQDKNDHISQTNAENQDELTLREAEGEPDEVGVDCTQLTFFPALHESLHSEDFLELCRERQVILQELLDKEKVTQKFSLVIVQGHLVSEGVLLFGHQHFYICENFTLSPTGDVYCTRHCLSNISDPFIFNLCSKDRSTDHYSCQCHSYADMRELRQARFLLQDIALEIFFHNGYSKFLVFYNNDRSKAFKSFCSFQPSLKGKATSEDTLSLRRYPGSDRIMLQKWQKRDISNFEYLMYLNTAAGRTCNDYMQYPVFPWVLADYTSETLNLANPKIFRDLSKPMGAQTKERKLKFIQRFKEVEKTEGDMTVQCHYYTHYSSAIIVASYLVRMPPFTQAFCALQGGSFDVADRMFHSVKSTWESASRENMSDVRELTPEFFYLPEFLTNCNGVEFGCMQDGTVLGDVQLPPWADGDPRKFISLHRKALESDFVSANLHHWIDLIFGYKQQGPAAVDAVNIFHPYFYGDRMDLSSITDPLIKSTILGFVSNFGQVPKQLFTKPHPARTAAGKPLPGKDVSTPVSLPGHPQPFFYSLQSLRPSQVTVKDMYLFSLGSESPKGAIGHIVSTEKTILAVERNKVLLPPLWNRTFSWGFDDFSCCLGSYGSDKVLMTFENLAAWGRCLCAVCPSPTTIVTSGTSTVVCVWELSMTKGRPRGLRLRQALYGHTQAVTCLAASVTFSLLVSGSQDCTCILWDLDHLTHVTRLPAHREGISAITISDVSGTIVSCAGAHLSLWNVNGQPLASITTAWGPEGAITCCCLMEGPAWDTSQIIITGSQDGMVRVWKTEDVKMSVPGLQMGRKREAAEALAQQCQAEGGRGDWGLSSAYRRNPQGLLPHSSQGRASGNHSSAAQPSPWPMGLL>sp|Q6ZS81-5|WDFY4_HUMAN Isoform 5 of WD repeat- and FYVE domain-containing protein 4 OS=Homo sapiens OX=9606 GN=WDFY4MEAEDLSKAEDRNEDPGSKNEGQLAAVQPDVPHGGQSSSPTALWDMLERKFLEYQQLTHKSPIERQKSLLSLLPLFLKAWEHSVGIICFPSLQRLAEDVSDQLAQQLQKALVGKPAEQARLAAGQLLWWKGDVDQDGYLLLKSVYVLTGTDSETLGRVAESGLPALLLQCLYLFFVFPLDKDELLESDLQVQKMFVQMLLNICSDSQGLEGLLSGSELQSLLIATTCLREHSCCFWKEPTFCVLRAISKAQNLSIIQYLQATDCVRLSLQNLSRLTDTLPAPEVSEAVSLILGFVKDSYPVSSALFLEFENSEGYPLLLKVLLRYDGLTQSEVDPHLEELLGLVVWLTTCGRSELKVFDSITYPQLEGFKFHHEASGVTVKNLQAFQVLQNVFHKASDSVLCIQVLSVIRTMWAWNARNFFLLEWTLQPISQFVEIMPLKPAPVQEHFFQLLEALVFELHYVPHEILRKVQHLIKESPGPSCTLMALQSILSIAGGDPLFTDIFRDSGLLGLLLAQLRKQAKIMRKSGNKVSTPGVQDPERELTCVMLRIVVTLLKGSVRNAVVLKDHGMVPFIKIFLDDECYREASLSILEQLSAINAEEYMSIIVGALCSSTQGELQLKLDLLKSLLRILVTPKGRAAFRVSSGFNGLLSLLSDLEGSLQEPPLQAWGAVSPRQTLELVLYTLCAVSAALHWDPVNGYFFRRNGLFEKLAEDLCLLGCFGALEEEGNLLRSWVDTKARPFADLLGTAFSSSGSLPPRIQSCLQILGFLDSMASGTLHLRGDLKESLRTKQGPVVDVQKGETGSDPQRNFKQWPDLEERMDEGDAAIMHPGVVCIMVRLLPRLYHEDHPQLSEEIQCSLASHIQSLVKSEKNRQVMCEAGLLGTLMASCHRALVTSGSPLHSRLIRIFEKLASQAIEPDVLRQFLGLGIPSSLSATTKILDSSHTHRGNPGCSGSQTAQGLAEGPWPAAPDAGLHPGVTQAPQPLGESQDSTTALQTALSLISMTSPRNLQPQRAALAPSFVEFDMSVEGYGCLFIPTLSTVMGTSTEYSVSGGIGTGATRPFPPPGGLTFSCWFLISRHGAATEGHPLRFLTLVRHLARTEQPFVCFSVSLCPDDLSLVVSTEEKEFQPLDVMEPEDDSEPSAGCQLQVRCGQLLACGQWHHLAVVVTKEMKRHCTVSTCLDGQVIGSAKMLYIQALPGPFLSMDPSAFVDVYGYIATPRVWKQKSSLIWRLGPTYLFEEAISMETLEVINKLGPRYCGNFQAVHVQGEDLDSEATPFVAEERVSFGLHIASSSITSVADIRNAYNEVDSRLIAKEMNISSRDNAMPVFLLRNCAGHLSGSLRTIGAVAVGQLGVRVFHSSPAASSLDFIGGPAILLGLISLATDDHTMYAAVKVLHSVLTSNAMCDFLMQHICGYQIMAFLLRKKASLLNHRIFQLILSVAGTVELGFRSSAITNTGVFQHILCNFELWMNTADNLELSLFSHLLEILQSPREGPRNAEAAHQAQLIPKLIFLFNEPSLIPSKISTIIGILACQLRGHFSTQDLLRIGLFVVYTLKPSSVNERQICMDGALDPSLPAGSQTSGKTIWLRNQLLEMLLSVISSPQLHLSSESKEEMFLKLGPDWFLLLLQGHLHASTTVLALKLLLYFLASPSLRTRFRDGLCAGSWVERSTEGVDIVMDNLKSQSPLPEQSPCLLPGFRVLNDFLAHHVHIPEVYLIVSTFFLQTPLTELMDGPKDSLDAMLQWLLQRHHQEEVLQAGLCTEGALLLLEMLKATMSQPLAGSEDGAWAQTFPASVLQFLSLVHRTYPQDPAWRAPEFLQTLAIAAFPLGAQKGVGAESTRNTSSPEAAAEGDSTVEGLQAPTKAHPARRKLREFTQLLLRELLLGASSPKQWLPLEVLLEASPDHATSQQKRDFQSEVLLSAMELFHMTSGGDAAMFRDGKEPQPSAEAAAAPSLANISCFTQKLVEKLYSGMFSADPRHILLFILEHIMVVIETASSQRDTVLSTLYSSLNKVILYCLSKPQQSLSECLGLLSILGFLQEHWDVVFATYNSNISFLLCLMHCLLLLNERSYPEGFGLEPKPRMSTYHQVFLSPNEDVKEKREDLPSLSDVQHNIQKTVQTLWQQLVAQRQQTLEDAFKIDLSVKPGEREVKIEEVTPLWEETMLKAWQHYLASEKKSLASRSNVAHHSKVTLWSGSLSSAMKLMPGRQAKDPECKTEDFVSCIENYRRRGQELYASLYKDHVQRRKCGNIKAANAWARIQEQLFGELGLWSQGEETKPCSPWELDWREGPARMRKRIKRLSPLEALSSGRHKESQDKNDHISQTNAENQDELTLREAEGEPDEVGVDCTQLTFFPALHESLHSEDFLELCRERQVILQELLDKEKVTQKFSLVIVQGHLVSEGVLLFGHQHFYICENFTLSPTGDVYCTRHCLSNISDPFIFNLCSKDRSTDHYSCQCHSYADMRELRQARFLLQDIALEIFFHNGYSKFLVFYNNDRSKAFKSFCSFQPSLKGKATSEDTLSLRRYPGSDRIMLQKWQKRDISNFEYLMYLNTAAGRTCNDYMQYPVFPWVLADYTSETLNLANPKIFRDLSKPMGAQTKERKLKFIQRFKEVEKTEGDMTVQCHYYTHYSSAIIVASYLVRMPPFTQAFCALQGGSFDVADRMFHSVKSTWESASRENMSDVRELTPEFFYLPEFLTNCNGVEFGCMQDGTVLGDVQLPPWADGDPRKFISLHRKALESDFVSANLHHWIDLIFGYKQQGPAAVDAVNIFHPYFYGDRMDLSSITDPLIKSTILGFVSNFGQVPKQLFTKPHPARTAAGKPLPGKDVSTPVSLPGHPQPFFYSLQSLRPSQVTVKGDSLAMHCLVSCPRVVPSVAGFLWRSSTTYLGKVLGTDFEWLHLQSQPDSRGVSSLGSV>sp|Q6P280|ZN529_HUMAN Zinc finger protein 529 OS=Homo sapiens OX=9606GN=ZNF529 PE=1 SV=2MANSSFIGDHVHGAPHAVMPEVEFPDQFFTVLTMDHELVTLRDVVINFSQEEWEYLDSAQRNLYWDVMMENYSNLLSLDLESRNETKHLSVGKDIIQNTGSQWEVMESSKLCGLEGSIFRNDWQSKSKIDLQGPEVGYFSQMKIISENVPSYKTHESLTLPRRTHDSEKPYEYKEYEKVFSCDLEFDEYQKIHTGGKNYECNQCWKTFGIDNSSMLQLNIHTGVKPCKYMEYGNTCSFYKDFNVYQKIHNEKFYKCKEYRRTFERVGKVTPLQRVHDGEKHFECSFCGKSFRVHAQLTRHQKIHTDEKTYKCMECGKDFRFHSQLTEHQRIHTGEKPYKCMHCEKVFRISSQLIEHQRIHTGEKPYACKECGKAFGVCRELARHQRIHTGKKPYECKACGKVFRNSSSLTRHQRIHTGEKPYKCKECEKAFGVGSELTRHERIHSGQKPYECKECGKFFRLTSALIQHQRIHSGEKPYECKVCGKAFRHSSALTEHQRIHTGEKPYECKACGKAFRHSSSFTKHQRIHTDDKPYECKECGNSFSVVGHLTCQPKIYTGEKSFD>sp|Q9BSG1|ZNF2_HUMAN Zinc finger protein 2 OS=Homo sapiens OX=9606GN=ZNF2 PE=1 SV=5MAAVSPTTRCQESVTFEDVAVVFTDEEWSRLVPIQRDLYKEVMLENYNSIVSLGLPVPQPDVIFQLKRGDKPWMVDLHGSEEREWPESVSLDWETKPEIHDASDKKSEGSLRECLGRQSPLCPKFEVHTPNGRMGTEKQSPSGETRKKSLSRDKGLRRRSALSREILTKERHQECSDCGKTFFDHSSLTRHQRTHTGEKPYDCRECGKAFSHRSSLSRHLMSHTGESPYECSVCSKAFFDRSSLTVHQRIHTGEKPFQCNECGKAFFDRSSLTRHQRIHTGESPYECHQCGKAFSQKSILTRHQLIHTGRKPYECNECGKAFYGVSSLNRHQKAHAGDPRYQCNECGKAFFDRSSLTQHQKIHTGDKPYECSECGKAFSQRCRLTRHQRVHTGEKPFECTVCGKVFSSKSSVIQHQRRYAKQGID>sp|Q9BSG1-3|ZNF2_HUMAN Isoform 3 of Zinc finger protein 2 OS=Homosapiens OX=9606 GN=ZNF2MLENYNSIVSLGLPVPQPDVIFQLKRGDKPWMVDLHGSEEREWPESVSLDWETKPEIHDASDKKSEGSLRECLGRQSPLCPKFEVHTPNGRMGTEKQSPSGETRKKSLSRDKGLRRRSALSREILTKERHQECSDCGKTFFDHSSLTRHQRTHTGEKPYDCRECGKAFSHRSSLSRHLMSHTGESPYECSVCSKAFFDRSSLTVHQRIHTGEKPFQCNECGKAFFDRSSLTRHQRIHTGESPYECHQCGKAFSQKSILTRHQLIHTGRKPYECNECGKAFYGVSSLNRHQKAHAGDPRYQCNECGKAFFDRSSLTQHQKIHTGDKPYECSECGKAFSQRCRLTRHQRVHTGEKPFECTVCGKVFSSKSSVIQHQRRYAKQGID>sp|Q9BSG1-4|ZNF2_HUMAN Isoform 4 of Zinc finger protein 2 OS=Homosapiens OX=9606 GN=ZNF2MAAVSPTTRCQESVTFEDVAVVFTDEEWSRLVPIQRDLYKEVMLENYNSIVSLDWETKPEIHDASDKKSEGSLRECLGRQSPLCPKFEVHTPNGRMGTEKQSPSGETRKKSLSRDKGLRRRSALSREILTKERHQECSDCGKTFFDHSSLTRHQRTHTGEKPYDCRECGKAFSHRSSLSRHLMSHTGESPYECSVCSKAFFDRSSLTVHQRIHTGEKPFQCNECGKAFFDRSSLTRHQRIHTGESPYECHQCGKAFSQKSILTRHQLIHTGRKPYECNECGKAFYGVSSLNRHQKAHAGDPRYQCNECGKAFFDRSSLTQHQKIHTGDKPYECSECGKAFSQRCRLTRHQRVHTGEKPFECTVCGKVFSSKSSVIQHQRRYAKQGID>sp|Q86YH2|Z280B_HUMAN Zinc finger protein 280B OS=Homo sapiens OX=9606GN=ZNF280B PE=1 SV=2MEQSCEEEKEPEPQKNIQETKQVDDEDAELIFVGVEHVNEDAELIFVGVTSNSKPVVSNILNRVTPGSWSRRKKYDHLRKDTARKLQPKSHETVTSEAVTVLPASQLESRSTDSPIIIEPLSKPDYRNSSPQVVPNNSSELPSPLITFTDSLHHPVSTALSVGGINESPRVSKQLSTFEVNSINPKRAKLRDGIIEGNSSASFPSDTFHTMNTQQSTPSNNVHTSLSHVQNGAPFPAAFPKDNIHFKPINTNLDRENELAKTDILSLTSQNKTFDPKKENPIVLLSDFYYGQHKGEGQPEQKTHTTFKCLSCVKVLKNVKFMNHVKHHLEFEKQRNDSWENHTTCQHCHRQFPTPFQLQCHIENVHTAQEPSTVCKICELSFETDQVLLQHMKDHHKPGEMPYVCQVCHYRSSVFADVETHFRTCHENTKNLLCPFCLKIFKTATPYMCHYRGHWGKSAHQCSKCRLQFLTFKEKMEHKTQCHQMFKKPKQLEGLPPETKVTIQVSLEPLQPGSVDVASITVSTSDSEPSLPRSKSKISKKSH>sp|Q96N38|ZN714_HUMAN Zinc finger protein 714 OS=Homo sapiens OX=9606GN=ZNF714 PE=2 SV=3MNVMLENYKNLVFLAGIAVSKQDPITSLEQEKEPWNMKICEMVDESPAMCSSFTRDLWPEQDIKDSFQQVILRRHGKCEHENLQLRKGSANVVECKVYKKGYELNQCLTTTQSKIFPCDKYIKVFHKIFNSNRHKTRHTGEKPFKCKKCDESFCMLLHLHQHKRIHIRENSYQCEECDKVFKRFSTLTRHKRVHTGEKPFKCEECGKAFKHSSTLTTHKMIHTGEKPYRCEECGKAFYHSSHLTTHKVIHTGEKPFKCEECGKAFNHPSALTTHKFIHVKEKPYKCEECDKAFNRFSYLTKHKIIHSGEKSYKCEQCGKGFNWSSTLTKHKRIHTGEKPYKCEECGKAFNVSSHLTTHKMIHTGEKPYKCEECGKAFNHSSKLTIHKIIHTGEKPYKCEECGKAFNQSSNLTKHKIIHTGEKLYKCEECGKAFNRSSNLTTHKRIHTGEKPYKCEECGKAFNRSSNLTKHNIIHTGEKSYKCEECGKAFNQSSTLTKHRKIQQGMVAHACNPNTLRGLGEQIARSGVQDQPGQHGKTPSLLKIQKFAGCGGRRL>sp|Q96N38-2|ZN714_HUMAN Isoform 2 of Zinc finger protein 714 OS=Homosapiens OX=9606 GN=ZNF714MNVMLENYKNLVFLAGIAVSKQDPITSLEQEKEPWNMKICEMVDESPAMCSSFTRDLWPEQDIKDSFQQVILRRHGKCEHENLQLRKGSANVVECKVYKKGYELNQCLTTTQSKIFPCDKYIKVFHKIFNSNRHKTRHTGEKPFKCKKCDESFCMLLHLHQHKRIHIRENSYQCEECDKVFKRFSTLTRHKRVHTGEKPFKCEECGKAFKHSSTLTTHKMIHTGEKPYRCEECGKAFYHSSHLTTHKVIHTGEKPFKCEECGKAFNHPSALTTHKFIHVKEKPYKCEECDKAFNRFSYLTKHKIIHSGEKSYKCEQCGKGFNWSSTLTKHKRIHTGEKPYKCEECGKAFNVSSHLTTHKMIHTGEKPYKCEECGKAFNHSSKLTIHKIIHTGEKPYKCEECGKAFNQSSNLTKHKIIHTGEKLYKCEECGKAFNRSSNLTTHKRIHTGEKPYKCEECGKAFNRSSNLTKHNIIHTGEKSYKCEECGKAFNQSSTLTKHRKIQQGMVAHACNPNTLGGQGRWIT>sp|Q96N38-3|ZN714_HUMAN Isoform 3 of Zinc finger protein 714 OS=Homosapiens OX=9606 GN=ZNF714MLLHLHQHKRIHIRENSYQCEECDKVFKRFSTLTRHKRVHTGEKPFKCEECGKAFKHSSTLTTHKMIHTGEKPYRCEECGKAFYHSSHLTTHKVIHTGEKPFKCEECGKAFNHPSALTTHKFIHVKEKPYKCEECDKAFNRFSYLTKHKIIHSGEKSYKCEQCGKGFNWSSTLTKHKRIHTGEKPYKCEECGKAFNVSSHLTTHKMIHTGEKPYKCEECGKAFNHSSKLTIHKIIHTGEKPYKCEECGKAFNQSSNLTKHKIIHTGEKLYKCEECGKAFNRSSNLTTHKRIHTGEKPYKCEECGKAFNRSSNLTKHNIIHTGEKSYKCEECGKAFNQSSTLTKHRKIQQGMVAHACNPNTLRGLGEQIARSGVQDQPGQHGKTPSLLKIQKFAGCGGRRL>sp|Q5CZA5|ZN805_HUMAN Zinc finger protein 805 OS=Homo sapiens OX=9606GN=ZNF805 PE=2 SV=3MAMALTDPAQVSVTFDDVAVTFTQEEWGQLDLAQRTLYQEVMLENCGLLVSLGCPVPRPELIYHLEHGQEPWTRKEDLSQGTCPGDKGKPKSTEPTTCELALSEGISFWGQLTQGASGDSQLGQPKDQDGFSEMQGERLRPGLDSQKEKLPGKMSPKHDGLGTADSVCSRIIQDRVSLGDDVHDCDSHGSGKNPVIQEEENIFKCNECEKVFNKKRLLARHERIHSGVKPYECTECGKTFSKSTYLLQHHMVHTGEKPYKCMECGKAFNRKSHLTQHQRIHSGEKPYKCSECGKAFTHRSTFVLHNRSHTGEKPFVCKECGKAFRDRPGFIRHYIIHSGENPYECFECGKVFKHRSYLMWHQQTHTGEKPYECSECGKAFCESAALIHHYVIHTGEKPFECLECGKAFNHRSYLKRHQRIHTGEKPYVCSECGKAFTHCSTFILHKRAHTGEKPFECKECGKAFSNRADLIRHFSIHTGEKPYECMECGKAFNRRSGLTRHQRIHSGEKPYECIECGKTFCWSTNLIRHSIIHTGEKPYECSECGKAFSRSSSLTQHQRMHTGRNPISVTDVGRPFTSGQTSVNIQELLLGKNFLNVTTEENLLQEEASYMASDRTYQRETPQVSSL>sp|Q5CZA5-2|ZN805_HUMAN Isoform 2 of Zinc finger protein 805 OS=Homosapiens OX=9606 GN=ZNF805MQGERLRPGLDSQKEKLPGKMSPKHDGLGTADSVCSRIIQDRVSLGDDVHDCDSHGSGKNPVIQEEENIFKCNECEKVFNKKRLLARHERIHSGVKPYECTECGKTFSKSTYLLQHHMVHTGEKPYKCMECGKAFNRKSHLTQHQRIHSGEKPYKCSECGKAFTHRSTFVLHNRSHTGEKPFVCKECGKAFRDRPGFIRHYIIHSGENPYECFECGKVFKHRSYLMWHQQTHTGEKPYECSECGKAFCESAALIHHYVIHTGEKPFECLECGKAFNHRSYLKRHQRIHTGEKPYVCSECGKAFTHCSTFILHKRAHTGEKPFECKECGKAFSNRADLIRHFSIHTGEKPYECMECGKAFNRRSGLTRHQRIHSGEKPYECIECGKTFCWSTNLIRHSIIHTGEKPYECSECGKAFSRSSSLTQHQRMHTGRNPISVTDVGRPFTSGQTSVNIQELLLGKNFLNVTTEENLLQEEASYMASDRTYQRETPQVSSL>sp|Q96ME7|ZN512_HUMAN Zinc finger protein 512 OS=Homo sapiens OX=9606GN=ZNF512 PE=1 SV=2MSSRLGAVPATSGPTTFKQQRSTRIVGAKNSRTQCSIKDNSFQYTIPHDDSLSGSSSASSCEPVSDFPASFRKSTYWMKMRRIKPAATSHVEGSGGVSAKGKRKPRQEEDEDYREFPQKKHKLYGRKQRPKTQPNPKSQARRIRKEPPVYAAGSLEEQWYLEIVDKGSVSCPTCQAVGRKTIEGLKKHMENCKQEMFTCHHCGKQLRSLAGMKYHVMANHNSLPILKAGDEIDEPSERERLRTVLKRLGKLRCMRESCSSSFTSIMGYLYHVRKCGKGAAELEKMTLKCHHCGKPYRSKAGLAYHLRSEHGPISFFPESGQPECLKEMNLESKSGGRVQRRSAKIAVYHLQELASAELAKEWPKRKVLQDLVPDDRKLKYTRPGLPTFSQEVLHKWKTDIKKYHRIQCPNQGCEAVYSSVSGLKAHLGSCTLGNFVAGKYKCLLCQKEFVSESGVKYHINSVHAEDWFVVNPTTTKSFEKLMKIKQRQQEEEKRRQQHRSRRSLRRRQQPGIELPETELSLRVGKDQRRNNEELVVSASCKEPEQEPVPAQFQKVKPPKTNHKRGRK>sp|Q96ME7-2|ZN512_HUMAN Isoform 2 of Zinc finger protein 512 OS=Homosapiens OX=9606 GN=ZNF512MKMRRIKPAATSHVEGSGGVSAKGKRKPRQEEDEDYREFPQKKHKLYGRKQRPKTQPNPKSQARRIRKEPPVYAAGSLEEQWYLEIVDKGSVSCPTCQAVGRKTIEGLKKHMENCKQEMFTCHHCGKQLRSLAGMKYHVMANHNSLPILKAGDEIDEPSERERLRTVLKRLGKLRCMRESCSSSFTSIMGYLYHVRKCGKGAAELEKMTLKCHHCGKPYRSKAGLAYHLRSEHGPISFFPESGQPECLKEMNLESKSGGRVQRRSAKIAVYHLQELASAELAKEWPKRKVLQDLVPDDRKLKYTRPGLPTFSQEVLHKWKTDIKKYHRIQCPNQGCEAVYSSVSGLKAHLGSCTLGNFVAGKYKCLLCQKEFVSESGVKYHINSVHAEDWFVVNPTTTKSFEKLMKIKQRQQEEEKRRQQHRSRRSLRRRQQPGIELPETELSLRVGKDQRRNNEELVVSASCKEPEQEPVPAQFQKVKPPKTNHKRGRK>sp|Q96ME7-3|ZN512_HUMAN Isoform 3 of Zinc finger protein 512 OS=Homosapiens OX=9606 GN=ZNF512MSSRLGAVPATSGPTTFKQQRSTRIVGAKNRTQCSIKDNSFQYTIPHDDSLSGSSSASSCEPVSDFPASFRKSTYWMKMRRIKPAATSHVEGSGGVSAKGKRKPRQEEDEDYREFPQKKHKLYGSLEEQWYLEIVDKGSVSCPTCQAVGRKTIEGLKKHMENCKQEMFTCHHCGKQLRSLAGMKYHVMANHNSLPILKAGDEIDEPSERERLRTVLKRLGKLRCMRESCSSSFTSIMGYLYHVRKCGKGAAELEKMTLKCHHCGKPYRSKAGLAYHLRSEHGPISFFPESGQPECLKEMNLESKSGGRVQRRSAKIAVYHLQELASAELAKEWPKRKVLQDLVPDDRKLKYTRPGLPTFSQEVLHKWKTDIKKYHRIQCPNQGCEAVYSSVSGLKAHLGSCTLGNFVAGKYKCLLCQKEFVSESGVKYHINSVHAEDWFVVNPTTTKSFEKLMKIKQRQQEEEKRRQQHRSRRSLRRRQQPGIELPETELSLRVGKDQRRNNEELVVSASCKEPEQEPVPAQFQKVKPPKTNHKRGRK>sp|P17020|ZNF16_HUMAN Zinc finger protein 16 OS=Homo sapiens OX=9606GN=ZNF16 PE=1 SV=3MPSLRTRREEAEMELSVPGPSPWTPAAQARVRDAPAVTHPGSAACGTPCCSDTELEAICPHYQQPDCDTRTEDKEFLHKEDIHEDLESQAEISENYAGDVSQVPELGDLCDDVSERDWGVPEGRRLPQSLSQEGDFTPAAMGLLRGPLGEKDLDCNGFDSRFSLSPNLMACQEIPTEERPHPYDMGGQSFQHSVDLTGHEGVPTAESPLICNECGKTFQGNPDLIQRQIVHTGEASFMCDDCGKTFSQNSVLKNRHRSHMSEKAYQCSECGKAFRGHSDFSRHQSHHSSERPYMCNECGKAFSQNSSLKKHQKSHMSEKPYECNECGKAFRRSSNLIQHQRIHSGEKPYVCSECGKAFRRSSNLIKHHRTHTGEKPFECGECGKAFSQSAHLRKHQRVHTGEKPYECNDCGKPFSRVSNLIKHHRVHTGEKPYKCSDCGKAFSQSSSLIQHRRIHTGEKPHVCNVCGKAFSYSSVLRKHQIIHTGEKPYRCSVCGKAFSHSSALIQHQGVHTGDKPYACHECGKTFGRSSNLILHQRVHTGEKPYECTECGKTFSQSSTLIQHQRIHNGLKPHECNQCGKAFNRSSNLIHHQKVHTGEKPYTCVECGKGFSQSSHLIQHQIIHTGERPYKCSECGKAFSQRSVLIQHQRIHTGVKPYDCAACGKAFSQRSKLIKHQLIHTRE>sp|Q7Z340|ZN551_HUMAN Zinc finger protein 551 OS=Homo sapiens OX=9606GN=ZNF551 PE=1 SV=3MPAPVGRRSPPSPRSSMAAVALRDSAQGMTFEDVAIYFSQEEWELLDESQRFLYCDVMLENFAHVTSLGYCHGMENEAIASEQSVSIQVRTSKGNTPTQKTHLSEIKMCVPVLKDILPAAEHQTTSPVQKSYLGSTSMRGFCFSADLHQHQKHYNEEEPWKRKVDEATFVTGCRFHVLNYFTCGEAFPAPTDLLQHEATPSGEEPHSSSSKHIQAFFNAKSYYKWGEYRKASSHKHTLVQHQSVCSEGGLYECSKCEKAFTCKNTLVQHQQIHTGQKMFECSECEESFSKKCHLILHKIIHTGERPYECSDREKAFIHKSEFIHHQRRHTGGVRHECGECRKTFSYKSNLIEHQRVHTGERPYECGECGKSFRQSSSLFRHQRVHSGERPYQCCECGKSFRQIFNLIRHRRVHTGEMPYQCSDCGKSFSCKSELIQHQRIHSGERPYECRECGKSFRQFSNLIRHRSIHTGDRPYECSECEKSFSRKFILIQHQRVHTGERPYECSECGKSFTRKSDLIQHRRIHTGTRPYECSECGKSFRQRSGLIQHRRLHTGERPYECSECGKSFSQSASLIQHQRVHTGERPYECSECGKSFSQSSSLIQHQRGHTGERPYECSQCGKPFTHKSDLIQHQRVHTGERPYECSECGKSFSRKSNLIRHRRVHTEERP>sp|Q7Z340-2|ZN551_HUMAN Isoform 2 of Zinc finger protein 551 OS=Homosapiens OX=9606 GN=ZNF551MENEAIASEQSVSIQVRTSKGNTPTQKTHLSEIKMCVPVLKDILPAAEHQTTSPVQKSYLGSTSMRGFCFSADLHQHQKHYNEEEPWKRKVDEATFVTGCRFHVLNYFTCGEAFPAPTDLLQHEATPSGEEPHSSSSKHIQAFFNAKSYYKWGEYRKASSHKHTLVQHQSVCSEGGLYECSKCEKAFTCKNTLVQHQQIHTGQKMFECSECEESFSKKCHLILHKIIHTGERPYECSDREKAFIHKSEFIHHQRRHTGGVRHECGECRKTFSYKSNLIEHQRVHTGERPYECGECGKSFRQSSSLFRHQRVHSGERPYQCCECGKSFRQIFNLIRHRRVHTGEMPYQCSDCGKSFSCKSELIQHQRIHSGERPYECRECGKSFRQFSNLIRHRSIHTGDRPYECSECEKSFSRKFILIQHQRVHTGERPYECSECGKSFTRKSDLIQHRRIHTGTRPYECSECGKSFRQRSGLIQHRRLHTGERPYECSECGKSFSQSASLIQHQRVHTGERPYECSECGKSFSQSSSLIQHQRGHTGERPYECSQCGKPFTHKSDLIQHQRVHTGERPYECSECGKSFSRKSNLIRHRRVHTEERP>sp|Q7Z340-3|ZN551_HUMAN Isoform 3 of Zinc finger protein 551 OS=Homosapiens OX=9606 GN=ZNF551MPAPVGRRSPPSPRSSMAAVALRDSAQGMTFEDVAIYFSQEEWELLDESQRFLYCDVMLENFAHVTSLGYCHGMENEAIASEQSVSIQVRTSKGNTPTQKTHLSEIKMCVPVLKDILPAAEHQTTSPVQKSYLGSTSMRGFCFSADLHQHQKHYNEEEPWKRKVDEATFVTGCRFHVLNYFTCGEAFPAPTDLLQHEATPSGEEPHSSSSKHIQAFFNAKSYYKWGEYRKASSHKHTLVQHQSVCSEGGLYECSKCEKAFTCKNTLVQHQQIHTGQKMFECSECEESFSKKCHLILHKIIHTGERPYECSDREKAFIHKSEFIHHQRRHTGGVRHECGECRKTFSYKSNLIEHQRVHTGERP>sp|Q15942|ZYX_HUMAN Zyxin OS=Homo sapiens OX=9606 GN=ZYX PE=1 SV=1MAAPRPSPAISVSVSAPAFYAPQKKFGPVVAPKPKVNPFRPGDSEPPPAPGAQRAQMGRVGEIPPPPPEDFPLPPPPLAGDGDDAEGALGGAFPPPPPPIEESFPPAPLEEEIFPSPPPPPEEEGGPEAPIPPPPQPREKVSSIDLEIDSLSSLLDDMTKNDPFKARVSSGYVPPPVATPFSSKSSTKPAAGGTAPLPPWKSPSSSQPLPQVPAPAQSQTQFHVQPQPQPKPQVQLHVQSQTQPVSLANTQPRGPPASSPAPAPKFSPVTPKFTPVASKFSPGAPGGSGSQPNQKLGHPEALSAGTGSPQPPSFTYAQQREKPRVQEKQHPVPPPAQNQNQVRSPGAPGPLTLKEVEELEQLTQQLMQDMEHPQRQNVAVNELCGRCHQPLARAQPAVRALGQLFHIACFTCHQCAQQLQGQQFYSLEGAPYCEGCYTDTLEKCNTCGEPITDRMLRATGKAYHPHCFTCVVCARPLEGTSFIVDQANRPHCVPDYHKQYAPRCSVCSEPIMPEPGRDETVRVVALDKNFHMKCYKCEDCGKPLSIEADDNGCFPLDGHVLCRKCHTARAQT>sp|Q15942-2|ZYX_HUMAN Isoform 2 of Zyxin OS=Homo sapiens OX=9606 GN=ZYXMTKNDPFKARVSSGYVPPPVATPFSSKSSTKPAAGGTAPLPPWKSPSSSQPLPQVPAPAQSQTQFHVQPQPQPKPQVQLHVQSQTQPVSLANTQPRGPPASSPAPAPKFSPVTPKFTPVASKFSPGAPGGSGSQPNQKLGHPEALSAGTGSPQPPSFTYAQQREKPRVQEKQHPVPPPAQNQNQVRSPGAPGPLTLKEVEELEQLTQQLMQDMEHPQRQNVAVNELCGRCHQPLARAQPAVRALGQLFHIACFTCHQCAQQLQGQQFYSLEGAPYCEGCYTDTLEKCNTCGEPITDRMLRATGKAYHPHCFTCVVCARPLEGTSFIVDQANRPHCVPDYHKQYAPRCSVCSEPIMPEPGRDETVRVVALDKNFHMKCYKCEDCGKPLSIEADDNGCFPLDGHVLCRKCHTARAQT>sp|Q9H7M6|ZSWM4_HUMAN Zinc finger SWIM domain-containing protein 4OS=Homo sapiens OX=9606 GN=ZSWIM4 PE=2 SV=3MEPPAAKRSRGCPAGPEERDAGAGAARGRGRPEALLDLSAKRVAESWAFEQVEERFSRVPEPVQKRIVFWSFPRSEREICMYSSLGYPPPEGEHDARVPFTRGLHLLQSGAVDRVLQVGFHLSGNIREPGSPGEPERLYHVSISFDRCKITSVSCGCDNRDLFYCAHVVALSLYRIRHAHQVELRLPISETLSQMNRDQLQKFVQYLISAHHTEVLPTAQRLADEILLLGSEINLVNGAPDPTAGAGIEDANCWHLDEEQIQEQVKQLLSNGGYYGASQQLRSMFSKVREMLRMRDSNGARMLILMTEQFLQDTRLALWRQQGAGMTDKCRQLWDELGALWVCVVLSPHCKPEERAGWLQLLSRWDKLDVCPLEEGNYSFDGPSLQPTMAPAPELLQKGSTCITNTEGWVGHPLDPIGCLCRALLEACRLEEETLTLYPDSGPEKRKVAYQHVPVPGSPGESYLVLALEVALLGLGQQRALPEGLYAQDKVVRNEEQLLALLEEVELDERLVQVLRKQAGLLLEGGPFSGFGEVLFRESVPMHTCARYLFTALLPHDPDLAYRLALRAMRLPILETAFPAGEPHPSPLDSIMSNRFPRWFILGHLETRQCELASTMLTAAKGDPKWLHTVLGSIQQNIHSPALLFKLAQDACKTATPVSAPPDTTLLGIALELGLQVMRMTLNVMTWRRREMVRWLVSCATEIGPQALMNIMQNWYSLFTPVEAATIVAVTGTTHATLLRLQLDTSRREELWACARTLALQCAMKDPQNCALPALTLCEKNHSAFEAAYQIVLDAAAGGLGHAHLFTVARYMEHRGLPLRAYKLATLALAQLSIAFNQDSHPAVNDVLWACSLSHSLGRHELSAIVPLIIRSIHCAPMLSDILRRWTLSAPGLGPLGARRAAKPLGADRAPLCQLLDAAVTAYITTSHSRLTHISPRHYGDFIEFLGKARETFLLAPDGHLQFSQFLENLKQTYKGKKKLMLLVRERFG>sp|Q96SZ4|ZSC10_HUMAN Zinc finger and SCAN domain-containing protein 10OS=Homo sapiens OX=9606 GN=ZSCAN10 PE=1 SV=1MGPRASLSRLRELCGHWLRPALHTKKQILELLVLEQFLSVLPPHLLGRLQGQPLRDGEEVVLLLEGIHREPSHAGPLDFSCNAGKSCPRADVTLEEKGCASQVPSHSPKKELPAEEPSVLGPSDEPPRPQPRAAQPAEPGQWRLPPSSKQPLSPGPQKTFQALQESSPQGPSPWPEESSRDQELAAVLECLTFEDVPENKAWPAHPLGFGSRTPDKEEFKQEEPKGAAWPTPILAESQADSPGVPGEPCAQSLGRGAAASGPGEDGSLLGSSEILEVKVAEGVPEPNPELQFICADCGVSFPQLSRLKAHQLRSHPAGRSFLCLCCGKSFGRSSILKLHMRTHTDERPHACHLCGHRFRQSSHLSKHLLTHSSEPAFLCAECGRGFQRRASLVQHLLAHAQDQKPPCAPESKAEAPPLTDVLCSHCGQSFQRRSSLKRHLRIHARDKDRRSSEGSGSRRRDSDRRPFVCSDCGKAFRRSEHLVAHRRVHTGERPFSCQACGRSFTQSSQLVSHQRVHTGEKPYACPQCGKRFVRRASLARHLLTHGGPRPHHCTQCGKSFGQTQDLARHQRSHTGEKPCRCSECGEGFSQSAHLARHQRIHTGEKPHACDTCGHRFRNSSNLARHRRSHTGERPYSCQTCGRSFRRNAHLRRHLATHAEPGQEQAEPPQECVECGKSFSRSCNLLRHLLVHTGARPYSCTQCGRSFSRNSHLLRHLRTHARETLY>sp|Q96SZ4-2|ZSC10_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 10 OS=Homo sapiens OX=9606 GN=ZSCAN10MRTHTDERPHACHLCGHRFRQSSHLSKHLLTHSSEPAFLCAECGRGFQRRASLVQHLLAHAQDQKPPCAPESKAEAPPLTDVLCSHCGQSFQRRSSLKRHLRIHARDKDRRSSEGSGSRRRDSDRRPFVCSDCGKAFRRSEHLVAHRRVHTGERPFSCQACGRSFTQSSQLVSHQRVHTGEKPYACPQCGKRFVRRASLARHLLTHGGPRPHHCTQCGKSFGQTQDLARHQRSHTGEKPCRCSECGEGFSQSAHLARHQRIHTGEKPHACDTCGHRFRNSSNLARHRRSHTGERPYSCQTCGRSFRRNAHLRRHLATHAEPGQEQAEPPQECVECGKSFSRSCNLLRHLLVHTGARPYSCTQCGRSFSRNSHLLRHLRTHARETLY>sp|Q96SZ4-3|ZSC10_HUMAN Isoform 3 of Zinc finger and SCAN domain-containing protein 10 OS=Homo sapiens OX=9606 GN=ZSCAN10MLPVSGGHGATGVPEPAPGALRPLAAAGSAHQETDPGAAGAGAVPECAASAPPGPPAGAAAQGWGGGGAAARGHPPGAQPRGAAGPQGPSPWPEESSRDQELAAVLECLTFEDVPENKAWPAHPLGFGSRTPDKEEFKQEEPKGAAWPTPILAESQADSPGVPGEPCAQSLGRGAAASGPGEDGSLLGSSEILEVKVAEGVPEPNPELQFICADCGVSFPQLSRLKAHQLRSHPAGRSFLCLCCGKSFGRSSILKLHMRTHTDERPHACHLCGHRFRQSSHLSKHLLTHSSEPAFLCAECGRGFQRRASLVQHLLAHAQDQKPPCAPESKAEAPPLTDVLCSHCGQSFQRRSSLKRHLRIHARDKDRRSSEGSGSRRRDSDRRPFVCSDCGKAFRRSEHLVAHRRVHTGERPFSCQACGRSFTQSSQLVSHQRVHTGEKPYACPQCGKRFVRRASLARHLLTHGGPRPHHCTQCGKSFGQTQDLARHQRSHTGEKPCRCSECGEGFSQSAHLARHQRIHTGEKPHACDTCGHRFRNSSNLARHRRSHTGERPYSCQTCGRSFRRNAHLRRHLATHAEPGQEQAEPPQECVECGKSFSRSCNLLRHLLVHTGARPYSCTQCGRSFSRNSHLLRHLRTHARETLY>sp|P09327|VILI_HUMAN Villin-1 OS=Homo sapiens OX=9606 GN=VIL1 PE=1 SV=4MTKLSAQVKGSLNITTPGLQIWRIEAMQMVPVPSSTFGSFFDGDCYIILAIHKTASSLSYDIHYWIGQDSSLDEQGAAAIYTTQMDDFLKGRAVQHREVQGNESEAFRGYFKQGLVIRKGGVASGMKHVETNSYDVQRLLHVKGKRNVVAGEVEMSWKSFNRGDVFLLDLGKLIIQWNGPESTRMERLRGMTLAKEIRDQERGGRTYVGVVDGENELASPKLMEVMNHVLGKRRELKAAVPDTVVEPALKAALKLYHVSDSEGNLVVREVATRPLTQDLLSHEDCYILDQGGLKIYVWKGKKANEQEKKGAMSHALNFIKAKQYPPSTQVEVQNDGAESAVFQQLFQKWTASNRTSGLGKTHTVGSVAKVEQVKFDATSMHVKPQVAAQQKMVDDGSGEVQVWRIENLELVPVDSKWLGHFYGGDCYLLLYTYLIGEKQHYLLYVWQGSQASQDEITASAYQAVILDQKYNGEPVQIRVPMGKEPPHLMSIFKGRMVVYQGGTSRTNNLETGPSTRLFQVQGTGANNTKAFEVPARANFLNSNDVFVLKTQSCCYLWCGKGCSGDEREMAKMVADTISRTEKQVVVEGQEPANFWMALGGKAPYANTKRLQEENLVITPRLFECSNKTGRFLATEIPDFNQDDLEEDDVFLLDVWDQVFFWIGKHANEEEKKAAATTAQEYLKTHPSGRDPETPIIVVKQGHEPPTFTGWFLAWDPFKWSNTKSYEDLKAELGNSRDWSQITAEVTSPKVDVFNANSNLSSGPLPIFPLEQLVNKPVEELPEGVDPSRKEEHLSIEDFTQAFGMTPAAFSALPRWKQQNLKKEKGLF>sp|P09327-2|VILI_HUMAN Isoform 2 of Villin-1 OS=Homo sapiens OX=9606GN=VIL1MTKLSAQVKGSLNITTPGLQIWRIEAMQMVPVPSSTFGSFFDGDCYIILAIHKTASSLSYDIHYWIGQDSSLDEQGAAAIYTTQMDDFLKGRAVQHREVQGNESEAFRGYFKQGLVIRKGGVASGMKHVETNSYDVQRLLHVKGKRNVVAGEVEMSWKSFNRGDVFLLDLGKLIIQWNGPESTRMERLRGMTLAKEIRDQERGGRTYVGVVDGENELASPKLMEVMNHVLGKRRELKAAVPDTVVEPALKAALKLYHVSDSEGNLVVREVATRPLTQDLLSHEDCYILDQGGLKIYVWKGKKANEQEKKGAMSHALNFIKAKQYPPSTQVEVQNDGAESAVFQQLFQKWTASNRTSGLGKTHTVGSVGEGQAGAVREPGSRSWARRATWSTTHPPSLTCIFNEDFYAGSGLVLADGDVDKL>sp|Q7Z739|YTHD3_HUMAN YTH domain-containing family protein 3 OS=Homosapiens OX=9606 GN=YTHDF3 PE=1 SV=1MSATSVDQRPKGQGNKVSVQNGSIHQKDAVNDDDFEPYLSSQTNQSNSYPPMSDPYMPSYYAPSIGFPYSLGEAAWSTAGDQPMPYLTTYGQMSNGEHHYIPDGVFSQPGALGNTPPFLGQHGFNFFPGNADFSTWGTSGSQGQSTQSSAYSSSYGYPPSSLGRAITDGQAGFGNDTLSKVPGISSIEQGMTGLKIGGDLTAAVTKTVGTALSSSGMTSIATNSVPPVSSAAPKPTSWAAIARKPAKPQPKLKPKGNVGIGGSAVPPPPIKHNMNIGTWDEKGSVVKAPPTQPVLPPQTIIQQPQPLIQPPPLVQSQLPQQQPQPPQPQQQQGPQPQAQPHQVQPQQQQLQNRWVAPRNRGAGFNQNNGAGSENFGLGVVPVSASPSSVEVHPVLEKLKAINNYNPKDFDWNLKNGRVFIIKSYSEDDIHRSIKYSIWCSTEHGNKRLDAAYRSLNGKGPLYLLFSVNGSGHFCGVAEMKSVVDYNAYAGVWSQDKWKGKFEVKWIFVKDVPNNQLRHIRLENNDNKPVTNSRDTQEVPLEKAKQVLKIIATFKHTTSIFDDFAHYEKRQEEEEAMRRERNRNKQ>sp|Q9Y2G7|ZFP30_HUMAN Zinc finger protein 30 homolog OS=Homo sapiensOX=9606 GN=ZFP30 PE=1 SV=1MARDLVMFRDVAVDFSQEEWECLNSYQRNLYRDVILENYSNLVSLAGCSISKPDVITLLEQGKEPWMVVRDEKRRWTLDLESRYDTKKLFQGKDIYEMNLSQWKVMERIKSCGLEEQESPHEVCFRQVTKTTSEKMPTYRKLTSLPLYQKSHNREKPYECGECGKAFRVRQQLTFHQRIHTGEKPYECKECGKAFRQCAHLSRHQRIHTSDKLYECKKCGKIFTCGSDLRVHQRIHIGEKPYECKECGKAFRVRGQLNLHQRIHTGEKPYECKECGKAFRQYAHLTRHQRLNIAEKCYECKECGQAFLCSTGLRLHHKLHTGEKPYECKECGKAFRVRQQLTLHQRIHTGEKPYDCKECGKTFSRGYHLTLHQRIHTGEKPYECKECQKFFRRYSELISHQGIHIGEKPYECKECGKAFRLFSQLTQHQSIHFGEKPFKCKECEKTFRLLSQLTQHQSIHTGEKPYDCKECGKAFRLHSSLIQHQRIHSGEKPYKCKECKKAFRQHSHLTYHQRIHNVT>sp|O96006|ZBED1_HUMAN E3 SUMO-protein ligase ZBED1 OS=Homo sapiensOX=9606 GN=ZBED1 PE=1 SV=1MENKSLESSQTDLKLVAHPRAKSKVWKYFGFDTNAEGCILQWKKIYCRICMAQIAYSGNTSNLSYHLEKNHPEEFCEFVKSNTEQMREAFATAFSKLKPESSQQPGQDALAVKAGHGYDSKKQQELTAAVLGLICEGLYPASIVDEPTFKVLLKTADPRYELPSRKYISTKAIPEKYGAVREVILKELAEATWCGISTDMWRSENQNRAYVTLAAHFLGLGAPNCLSMGSRCLKTFEVPEENTAETITRVLYEVFIEWGISAKVFGATTNYGKDIVKACSLLDVAVHMPCLGHTFNAGIQQAFQLPKLGALLSRCRKLVEYFQQSAVAMYMLYEKQKQQNVAHCMLVSNRVSWWGSTLAMLQRLKEQQFVIAGVLVEDSNNHHLMLEASEWATIEGLVELLQPFKQVAEMLSASRYPTISMVKPLLHMLLNTTLNIKETDSKELSMAKEVIAKELSKTYQETPEIDMFLNVATFLDPRYKRLPFLSAFERQQVENRVVEEAKGLLDKVKDGGYRPAEDKIFPVPEEPPVKKLMRTSTPPPASVINNMLAEIFCQTGGVEDQEEWHAQVVEELSNFKSQKVLGLNEDPLKWWSDRLALFPLLPKVLQKYWCVTATRVAPERLFGSAANVVSAKRNRLAPAHVDEQVFLYENARSGAEAEPEDQDEGEWGLDQEQVFSLGDGVSGGFFGIRDSSFL>sp|Q96K75|ZN514_HUMAN Zinc finger protein 514 OS=Homo sapiens OX=9606GN=ZNF514 PE=2 SV=1MTFEDVAVEFSQWEWGQLNPAQKDLYREVMLENFRNLAILGLLVSKPYVICQLEEGGEPFMVEREISTGAHSDWKRRSKSKESMPSWGISKEELFQVVSVEKHIQDVLQFSKLKAACGCDGQLEMQQIKQERHLKQMSTIHKSATTLSRDYKWNGFGRSLGLRSVLVNQHSILMGEGSYKCDTEFRQTLGGNNSQRTHPEKKSCKCNECGKSFHFQSELRRHQRCHTGEKPYECSDCGRAFGHISSLIKHQRTHTGEKPYECSECGRAFSQSSSLVLHYRFHTGEKPYKCNECGRAFGHTSSLIKHQRTHTGEKPYECRECGRTFSQSSSLIVHYRFHTGEKPYKCNKCGRAFSQSSSLTQHYRFHTGEKPYKCNECGRAFAHTASLIKHQRSHAGKKTL>sp|Q05516|ZBT16_HUMAN Zinc finger and BTB domain-containing protein 16OS=Homo sapiens OX=9606 GN=ZBTB16 PE=1 SV=2MDLTKMGMIQLQNPSHPTGLLCKANQMRLAGTLCDVVIMVDSQEFHAHRTVLACTSKMFEILFHRNSQHYTLDFLSPKTFQQILEYAYTATLQAKAEDLDDLLYAAEILEIEYLEEQCLKMLETIQASDDNDTEATMADGGAEEEEDRKARYLKNIFISKHSSEESGYASVAGQSLPGPMVDQSPSVSTSFGLSAMSPTKAAVDSLMTIGQSLLQGTLQPPAGPEEPTLAGGGRHPGVAEVKTEMMQVDEVPSQDSPGAAESSISGGMGDKVEERGKEGPGTPTRSSVITSARELHYGREESAEQVPPPAEAGQAPTGRPEHPAPPPEKHLGIYSVLPNHKADAVLSMPSSVTSGLHVQPALAVSMDFSTYGGLLPQGFIQRELFSKLGELAVGMKSESRTIGEQCSVCGVELPDNEAVEQHRKLHSGMKTYGCELCGKRFLDSLRLRMHLLAHSAGAKAFVCDQCGAQFSKEDALETHRQTHTGTDMAVFCLLCGKRFQAQSALQQHMEVHAGVRSYICSECNRTFPSHTALKRHLRSHTGDHPYECEFCGSCFRDESTLKSHKRIHTGEKPYECNGCGKKFSLKHQLETHYRVHTGEKPFECKLCHQRSRDYSAMIKHLRTHNGASPYQCTICTEYCPSLSSMQKHMKGHKPEEIPPDWRIEKTYLYLCYV>sp|Q05516-2|ZBT16_HUMAN Isoform PLZFA of Zinc finger and BTB domain-containing protein 16 OS=Homo sapiens OX=9606 GN=ZBTB16MDLTKMGMIQLQNPSHPTGLLCKANQMRLAGTLCDVVIMVDSQEFHAHRTVLACTSKMFEILFHRNSQHYTLDFLSPKTFQQILEYAYTATLQAKAEDLDDLLYAAEILEIEYLEEQCLKMLETIQASDDNDTEATMADGGAEEEEDRKARYLKNIFISKHSSEESGYASVAGQSLPGPMVDQSPSVSTSFGLSAMSPTKAAVDSLMTIGQSLLQGTLQPPAGPEEPTLAGGGRHPGVAEVKTEMMQVDEVPSQGFIQRELFSKLGELAVGMKSESRTIGEQCSVCGVELPDNEAVEQHRKLHSGMKTYGCELCGKRFLDSLRLRMHLLAHSAGAKAFVCDQCGAQFSKEDALETHRQTHTGTDMAVFCLLCGKRFQAQSALQQHMEVHAGVRSYICSECNRTFPSHTALKRHLRSHTGDHPYECEFCGSCFRDESTLKSHKRIHTGEKPYECNGCGKKFSLKHQLETHYRVHTGEKPFECKLCHQRSRDYSAMIKHLRTHNGASPYQCTICTEYCPSLSSMQKHMKGHKPEEIPPDWRIEKTYLYLCYV>sp|Q8TBZ5|ZN502_HUMAN Zinc finger protein 502 OS=Homo sapiens OX=9606GN=ZNF502 PE=1 SV=1MLNMQGAEERDIRRETCPGWVNKNKPALEQDVCKIDSSGIVVKRFQEDEYQDSTFEEKYACEGMKENSPREIAESCLFQEGGFGRITFIHKEAPPEIISQGYNFEKSLLLTSSLVTRLRVSTEESLHQWETSNIQTNDISDQSKCPTLCTQKKSWKCNECGKTFTQSSSLTQHQRTHTGERPYTCEECGKAFSRSSFLVQHQRIHTGVKPYGCEQCGKTFRCRSFLTQHQRIHTGEKPYKCNECGNSFRNHSHLTEHQRIHTGEKPYKCNRCGKAFNQNTHLIHHQRIHTGEKPYICSECGSSFRKHSNLTQHQRIHTGEKPHKCDECGKTFQTKANLSQHQRIHSGEKPYKCKECGKAFCQSPSLIKHQRIHTGEKPYKCKECGKAFTQSTPLTKHQRIHTGERPYKCSECGKAFIQSICLIRHQRSHTGEKPYKCNECGKGFNQNTCLTQHMRIHTGEKPYKCKECGKAFAHSSSLTEHHRTHTGEKLYKCSECEKTFRKYAHLSEHYRIHTGEKPYECIECGKFFRHSSVLFRHQKLHSGD>sp|Q9H7R5|ZN665_HUMAN Zinc finger protein 665 OS=Homo sapiens OX=9606GN=ZNF665 PE=2 SV=3MALPQGQLTFKDVAIEFSQEEWTCLDPAQKTLYRDVMLENYRNLVSLDISCKCVNTDLPPKGKNNMGEAFYTVKLERLESCDTVGLSFQEVQKNTYDFECQWKDDEGNYKTVLMLQKENLPGRRAQRDRRAAGNRHIENQLGVSFQSHLPELQQFQHEGKIYEYNQVEKSPNNRGKHYKCDECGKVFSQNSRLTSHKRIHTGEKPYQCNKCGKAFTVRSNLTIHQVIHTGEKPYKCNECGKVFSQPSNLAGHQRIHTGEKPYKCNECGKAFRAHSKLTTHQVIHTGEKPYKCKECGKCFTQNSHLASHRRIHTGEKPYKCNECGKAFSVRSSLTTHQTIHTGEKPYKCNECGKVFRHNSYLAKHRRIHTGEKPYKCNECGKAFSMHSNLTKHQIIHTGEKPFKCNECVKVFTQYSHLANHRRIHTGEKPYRCDECGKAFSVRSSLTTHQAIHTGEKPYKCNDCGKVFTQNSHLASHRGIHSGEKPYKCDECGKAFSQTSQLARHWRVHTGEKPYKCNECGKAFSVHSSLTIHQTIHTGQKPYKCNDCGKVFRHNSYLAIHQRIHTGEKPYKCNECGKAFSVHSNLATHQVIHTGEKPYKCNECGKVFTQNSHLANHRRIHTGEKPYRCNECGKAFSVRSTLTTHMAVHTGDKPYKCNQCGKVFTQNSNLAKHRRIHSG>sp|Q96SK2|TM209_HUMAN Transmembrane protein 209 OS=Homo sapiens OX=9606GN=TMEM209 PE=1 SV=2MMQGEAHPSASLIDRTIKMRKETEARKVVLAWGLLNVSMAGMIYTEMTGKLISSYYNVTYWPLWYIELALASLFSLNALFDFWRYFKYTVAPTSLVVSPGQQTLLGLKTAVVQTTPPHDLAATQIPPAPPSPSIQGQSVLSYSPSRSPSTSPKFTTSCMTGYSPQLQGLSSGGSGSYSPGVTYSPVSGYNKLASFSPSPPSPYPTTVGPVESSGLRSRYRSSPTVYNSPTDKEDYMTDLRTLDTFLRSEEEKQHRVKLGSPDSTSPSSSPTFWNYSRSMGDYAQTLKKFQYQLACRSQAPCANKDEADLSSKQAAEEVWARVAMNRQLLDHMDSWTAKFRNWINETILVPLVQEIESVSTQMRRMGCPELQIGEASITSLKQAALVKAPLIPTLNTIVQYLDLTPNQEYLFERIKELSQGGCMSSFRWNRGGDFKGRKWDTDLPTDSAIIMHVFCTYLDSRLPPHPKYPDGKTFTSQHFVQTPNKPDVTNENVFCIYQSAINPPHYELIYQRHVYNLPKGRNNMFHTLLMFLYIIKTKESGMLGRVNLGLSGVNILWIFGE>sp|Q96SK2-2|TM209_HUMAN Isoform 2 of Transmembrane protein 209 OS=Homosapiens OX=9606 GN=TMEM209MQGEAHPSASLIDRTIKMRKETEARKVVLAWGLLNVSMAGMIYTEMTGKLISSYYNVTYWPLWYIELALASLFSLNALFDFWRYFKYTVAPTSLVVSPGQQTLLGLKTAVVQTTPPHDLAATQIPPAPPSPSIQGQSVLSYSPSRSPSTSPKFTTSCMTGYSPQLQGLSSGGSGSYSPGVTYSPVSGYNKLASFSPSPPSPYPTTVGPVESSGLRSRYRSSPTVYNSPTDKEDYMTDLRTLDTFLRSEEEKQHRVKLGSPDSTSPSSSPTFWNYSRSMGDYAQTLKKFQYQLACRSQAPCANKDEADLSSKQAAEEVWARVAMNRQLLDHMDSWTAKFRNWINETILVPLVQEIESVSTQMRRMGCPELQIGEASITSLKQAALVKAPLIPTLNTIVQYLDLTPNQEYLFERIKELSQGGCMSSFRWNRGGDFKGRKWDTDLPTDSAIIMHVFCTYLDSRLPPHPKYPDGKTFTSQHFVQTPNKPDVTNENVFCIYQSAINPPHYELIYQRHVYNLPKGRNNMFHTLLMFLYIIKTKESGMLGRVNLGLSGVNILWIFGE>sp|Q96SK2-3|TM209_HUMAN Isoform 3 of Transmembrane protein 209 OS=Homosapiens OX=9606 GN=TMEM209MMQGEAHPSASLIDRTIKMRKETEARKVVLAWGLLNVSMAGMIYTEMTGKLISSYYNVTYWPLWYIELALASLFSLNALFDFWRYFKYTVAPTSLVVSPGQQTLLGLKTAVVQTTPPHDLAATQIPPAPPSPSIQGQSVLSYSPSRSPSTSPKFTTSCMTGYSPQLQGLSSGGSGSYSPGVTYSPVSGYNKLASFSPSPPSPYPTTVGPVESSGLRSRYRSSPTVYNSPTDKEDYMTDLRTLDTFLRSEEEKQHRVKLGSPDSTSPSSSPTFWNYSRSMGDYAQTLKKFQYQLACRSQAPCANKDEADLSSKQAAEEVWARVAMNRQLLDHMDSWTAKFRNWINETILVPLVQEIESVSTQMRRMGCPELQIGELSQGGCMSSFRWNRGGDFKGRKWDTDLPTDSAIIMHVFCTYLDSRLPPHPKYPDGKTFTSQHFVQTPNKPDVTNENVFCIYQSAINPPHYELIYQRHVYNLPKGRNNMFHTLLMFLYIIKTKESGMLGRVNLGLSGVNILWIFGE>sp|Q96SK2-4|TM209_HUMAN Isoform 4 of Transmembrane protein 209 OS=Homosapiens OX=9606 GN=TMEM209MMQGEAHPSASLIDRTIKMRKETEARKVVLAWGLLNVSMAGMIYTEMTGKLISSYYNVTYWPLWYIELALASLFSLNALFDFWRYFKYTVAPTSLVVSPGQQTLLGLKTAVVQTTPPHDLAATQIPPAPPSPSIQGQSVLSYSPSRSPSTSPKFTTSCMTGYSPQLQGLSSGGSGSYSPGVTYSPVSGYNKVMTLFSCLVTLF>sp|O14836|TR13B_HUMAN Tumor necrosis factor receptor superfamily member13B OS=Homo sapiens OX=9606 GN=TNFRSF13B PE=1 SV=1MSGLGRSRRGGRSRVDQEERFPQGLWTGVAMRSCPEEQYWDPLLGTCMSCKTICNHQSQRTCAAFCRSLSCRKEQGKFYDHLLRDCISCASICGQHPKQCAYFCENKLRSPVNLPPELRRQRSGEVENNSDNSGRYQGLEHRGSEASPALPGLKLSADQVALVYSTLGLCLCAVLCCFLVAVACFLKKRGDPCSCQPRSRPRQSPAKSSQDHAMEAGSPVSTSPEPVETCSFCFPECRAPTQESAVTPGTPDPTCAGRWGCHTRTTVLQPCPHIPDSGLGIVCVPAQEGGPGA>sp|O14836-2|TR13B_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 13B OS=Homo sapiens OX=9606 GN=TNFRSF13BMSGLGRSRRGGRSRVDQEERWSLSCRKEQGKFYDHLLRDCISCASICGQHPKQCAYFCENKLRSPVNLPPELRRQRSGEVENNSDNSGRYQGLEHRGSEASPALPGLKLSADQVALVYSTLGLCLCAVLCCFLVAVACFLKKRGDPCSCQPRSRPRQSPAKSSQDHAMEAGSPVSTSPEPVETCSFCFPECRAPTQESAVTPGTPDPTCAGRWGCHTRTTVLQPCPHIPDSGLGIVCVPAQEGGPGA>sp|O14836-3|TR13B_HUMAN Isoform 3 of Tumor necrosis factor receptorsuperfamily member 13B OS=Homo sapiens OX=9606 GN=TNFRSF13BMSGLGRSRRGGRSRVDQEERFPQGLWTGVAMRSCPEEQYWDPLLGTCMSCKTICNHQSQRTCAAFCRSLSCRKEQGKFYDHLLRDCISCASICGQHPKQCAYFCENKLRSPVNLPPELRRQRSGEVENNSDNSGRYQGLEHRGSEASPAPRGCPAPGTRKSFWDKENFQGEGFHLG>sp|Q969Q1|TRI63_HUMAN E3 ubiquitin-protein ligase TRIM63 OS=Homo sapiensOX=9606 GN=TRIM63 PE=1 SV=1MDYKSSLIQDGNPMENLEKQLICPICLEMFTKPVVILPCQHNLCRKCANDIFQAANPYWTSRGSSVSMSGGRFRCPTCRHEVIMDRHGVYGLQRNLLVENIIDIYKQECSSRPLQKGSHPMCKEHEDEKINIYCLTCEVPTCSMCKVFGIHKACEVAPLQSVFQGQKTELNNCISMLVAGNDRVQTIITQLEDSRRVTKENSHQVKEELSQKFDTLYAILDEKKSELLQRITQEQEKKLSFIEALIQQYQEQLDKSTKLVETAIQSLDEPGGATFLLTAKQLIKSIVEASKGCQLGKTEQGFENMDFFTLDLEHIADALRAIDFGTDEEEEEFIEEEDQEEEESTEGKEEGHQ>sp|Q969Q1-2|TRI63_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM63OS=Homo sapiens OX=9606 GN=TRIM63MDYKSSLIQDGNPMENLEKQLICPICLEMFTKPVVILPCQHNLCRKCANDIFQAANPYWTSRGSSVSMSGGRFRCPTCRHEVIMDRHGVYGLQRNLLVENIIDIYCLTCEVPTCSMCKVFGIHKACEVAPLQSVFQGQKTELNNCISMLVAGNDRVQTIITQLEDSRRVTKENSHQVKEELSQKFDTLYAILDEKKSELLQRITQEQEKKLSFIEALIQQYQEQLDKSTKLVETAIQSLDEPGGATFLLTAKQLIKSIVEASKGCQLGKTEQGFENMDFFTLDLEHIADALRAIDFGTDEEEEEFIEEEDQEEEESTEGKEEGHQ>sp|P13805|TNNT1_HUMAN Troponin T, slow skeletal muscle OS=Homo sapiensOX=9606 GN=TNNT1 PE=1 SV=4MSDTEEQEYEEEQPEEEAAEEEEEAPEEPEPVAEPEEERPKPSRPVVPPLIPPKIPEGERVDFDDIHRKRMEKDLLELQTLIDVHFEQRKKEEEELVALKERIERRRSERAEQQRFRTEKERERQAKLAEEKMRKEEEEAKKRAEDDAKKKKVLSNMGAHFGGYLVKAEQKRGKRQTGREMKVRILSERKKPLDIDYMGEEQLRARSAWLPPSQPSCPAREKAQELSDWIHQLESEKFDLMAKLKQQKYEINVLYNRISHAQKFRKGAGKGRVGGRWK>sp|P13805-2|TNNT1_HUMAN Isoform 2 of Troponin T, slow skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT1MSDTEEQEYEEEQPEEEAAEEEEEEEERPKPSRPVVPPLIPPKIPEGERVDFDDIHRKRMEKDLLELQTLIDVHFEQRKKEEEELVALKERIERRRSERAEQQRFRTEKERERQAKLAEEKMRKEEEEAKKRAEDDAKKKKVLSNMGAHFGGYLVKAEQKRGKRQTGREMKVRILSERKKPLDIDYMGEEQLREKAQELSDWIHQLESEKFDLMAKLKQQKYEINVLYNRISHAQKFRKGAGKGRVGGRWK>sp|P13805-3|TNNT1_HUMAN Isoform 3 of Troponin T, slow skeletal muscleOS=Homo sapiens OX=9606 GN=TNNT1MSDTEEQEYEEEQPEEEAAEEEEEAPEEPEPVAEPEEERPKPSRPVVPPLIPPKIPEGERVDFDDIHRKRMEKDLLELQTLIDVHFEQRKKEEEELVALKERIERRRSERAEQQRFRTEKERERQAKLAEEKMRKEEEEAKKRAEDDAKKKKVLSNMGAHFGGYLVKAEQKRGKRQTGREMKVRILSERKKPLDIDYMGEEQLREKAQELSDWIHQLESEKFDLMAKLKQQKYEINVLYNRISHAQKFRKGAGKGRVGGRWK>sp|Q6QAJ8|TM220_HUMAN Transmembrane protein 220 OS=Homo sapiens OX=9606GN=TMEM220 PE=1 SV=1MAPALWRACNGLMAAFFALAALVQVNDPDAEVWVVVYTIPAVLTLLVGLNPEVTGNVIWKSISAIHILFCTVWAVGLASYLLHRTQQNILHEEEGRELSGLVIITAWIILCHSSSKNPVGGRIQLAIAIVITLFPFISWVYIYINKEMRSSWPTHCKTVI>sp|Q6QAJ8-2|TM220_HUMAN Isoform 2 of Transmembrane protein 220 OS=Homosapiens OX=9606 GN=TMEM220MAPALWRACNGLMAAFFALAALVQVVYTIPAVLTLLVGLNPEVTGNVIWKSISAIHILFCTVWAVGLASYLLHRTQQNILHEEEGRELSGLVIITAWIILCHSSSKNPVGGRIQLAIAIVITLFPFISWVYIYINKEMRSSWPTHCKTVI>sp|O75663|TIPRL_HUMAN TIP41-like protein OS=Homo sapiens OX=9606GN=TIPRL PE=1 SV=2MMIHGFQSSHRDFCFGPWKLTASKTHIMKSADVEKLADELHMPSLPEMMFGDNVLRIQHGSGFGIEFNATDALRCVNNYQGMLKVACAEEWQESRTEGEHSKEVIKPYDWTYTTDYKGTLLGESLKLKVVPTTDHIDTEKLKAREQIKFFEEVLLFEDELHDHGVSSLSVKIRVMPSSFFLLLRFFLRIDGVLIRMNDTRLYHEADKTYMLREYTSRESKISSLMHVPPSLFTEPNEISQYLPIKEAVCEKLIFPERIDPNPADSQKSTQVE>sp|O75663-2|TIPRL_HUMAN Isoform 2 of TIP41-like protein OS=Homo sapiensOX=9606 GN=TIPRLMMIHGFQSSHRDFCFGPWKLTASKTHIMKSADVEKLADELHMPSLPEMMFGDNVLRIQHGSGFGIEFNATDALRCVNNYQGMLKVACAEEWQESRTEGEHSKEVIKPYDWTYTTDYKGTLLGESLKLKVVPTTDHIDTEKLKAREQIKFFEEVLLFEDELHDHGVSSLSVKIPGGGHL>sp|O14788|TNF11_HUMAN Tumor necrosis factor ligand superfamily member 11OS=Homo sapiens OX=9606 GN=TNFSF11 PE=1 SV=1MRRASRDYTKYLRGSEEMGGGPGAPHEGPLHAPPPPAPHQPPAASRSMFVALLGLGLGQVVCSVALFFYFRAQMDPNRISEDGTHCIYRILRLHENADFQDTTLESQDTKLIPDSCRRIKQAFQGAVQKELQHIVGSQHIRAEKAMVDGSWLDLAKRSKLEAQPFAHLTINATDIPSGSHKVSLSSWYHDRGWAKISNMTFSNGKLIVNQDGFYYLYANICFRHHETSGDLATEYLQLMVYVTKTSIKIPSSHTLMKGGSTKYWSGNSEFHFYSINVGGFFKLRSGEEISIEVSNPSLLDPDQDATYFGAFKVRDID>sp|O14788-2|TNF11_HUMAN Isoform 2 of Tumor necrosis factor ligandsuperfamily member 11 OS=Homo sapiens OX=9606 GN=TNFSF11MDPNRISEDGTHCIYRILRLHENADFQDTTLESQDTKLIPDSCRRIKQAFQGAVQKELQHIVGSQHIRAEKAMVDGSWLDLAKRSKLEAQPFAHLTINATDIPSGSHKVSLSSWYHDRGWAKISNMTFSNGKLIVNQDGFYYLYANICFRHHETSGDLATEYLQLMVYVTKTSIKIPSSHTLMKGGSTKYWSGNSEFHFYSINVGGFFKLRSGEEISIEVSNPSLLDPDQDATYFGAFKVRDID>sp|O14788-3|TNF11_HUMAN Isoform 3 of Tumor necrosis factor ligandsuperfamily member 11 OS=Homo sapiens OX=9606 GN=TNFSF11MFVALLGLGLGQVVCSVALFFYFRAQMDPNRISEDGTHCIYRILRLHENADFQDTTLESQDTKLIPDSCRRIKQAFQGAVQKELQHIVGSQHIRAEKAMVDGSWLDLAKRSKLEAQPFAHLTINATDIPSGSHKVSLSSWYHDRGWAKISNMTFSNGKLIVNQDGFYYLYANICFRHHETSGDLATEYLQLMVYVTKTSIKIPSSHTLMKGGSTKYWSGNSEFHFYSINVGGFFKLRSGEEISIEVSNPSLLDPDQDATYFGAFKVRDID>sp|Q96LD4|TRI47_HUMAN E3 ubiquitin-protein ligase TRIM47 OS=Homo sapiensOX=9606 GN=TRIM47 PE=1 SV=2MDGSGPFSCPICLEPLREPVTLPCGHNFCLACLGALWPHRGASGAGGPGGAARCPLCQEPFPDGLQLRKNHTLSELLQLRQGSGPGSGPGPAPALAPEPSAPSALPSVPEPSAPCAPEPWPAGEEPVRCDACPEGAALPAALSCLSCLASFCPAHLGPHERSPALRGHRLVPPLRRLEESLCPRHLRPLERYCRAERVCLCEACAAQEHRGHELVPLEQERALQEAEQSKVLSAVEDRMDELGAGIAQSRRTVALIKSAAVAERERVSRLFADAAAALQGFQTQVLGFIEEGEAAMLGRSQGDLRRQEEQRSRLSRARQNLSQVPEADSVSFLQELLALRLALEDGCGPGPGPPRELSFTKSSQAVRAVRDMLAVACVNQWEQLRGPGGNEDGPQKLDSEADAEPQDLESTNLLESEAPRDYFLKFAYIVDLDSDTADKFLQLFGTKGVKRVLCPINYPLSPTRFTHCEQVLGEGALDRGTYYWEVEIIEGWVSMGVMAEDFSPQEPYDRGRLGRNAHSCCLQWNGRSFSVWFHGLEAPLPHPFSPTVGVCLEYADRALAFYAVRDGKMSLLRRLKASRPRRGGIPASPIDPFQSRLDSHFAGLFTHRLKPAFFLESVDAHLQIGPLKKSCISVLKRR>sp|Q96LD4-2|TRI47_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM47OS=Homo sapiens OX=9606 GN=TRIM47MDELGAGIAQSRRTVALIKSAAVAERERVSRLFADAAAALQGFQTQVLGFIEEGEAAMLGRSQGDLRRQEEQRSRLSRARQNLSQVPEADSVSFLQELLALRLALEDGCGPGPGPPRELSFTKSSQAVRAVRDMLAVACVNQWEQLRGPGGNEDGPQKLDSEADAEPQDLESTNLLESEAPRDYFLKFAYIVDLDSDTADKFLQLFGTKGVKRVLCPINYPLSPTRFTHCEQVLGEGALDRGTYYWEVEIIEGWVSMGVMAEDFSPQEPYDRGRLGRNAHSCCLQWNGRSFSVWFHGLEAPLPHPFSPTVGVCLEYADRALAFYAVRDGKMSLLRRLKASRPRRGGIPASPIDPFQSRLDSHFAGLFTHRLKPAFFLESVDAHLQIGPLKKSCISVLKRR>sp|A6NCK2|TR43B_HUMAN Tripartite motif-containing protein 43B OS=Homosapiens OX=9606 GN=TRIM43B PE=3 SV=3MDSDFSHAFQKELTCVICLNYLVDPVTICCGHSFCRPCLCLSWEEAQSPANCPACREPSPKMDFKTNILLKNLVTIARKASLWQFLSSEKQICGTHRQTKKMFCDMDKSLLCLLCSNSQEHGAHKHYPIEEAAEEDREKLLKQMRILWKKIQENQRNLYEERRTAFLLRGDVVLRAQMIRNEYRKLHPVLHKEEKQHLERLNKEYQEIFQQLQRSWVKMDQKSKHLKEMYQELMEMCHKPEVELLQDLGDIVARSESVLLHMPQPVNPELTAGPITGLVYRLNRFRVEISFHFEVTNHNIRLFEDVRSWMFRRGPLNSDRSDYFAAWGARVFSFGKHYWELDVDNSCDWALGVCNNSWIRKNSTMVNSEDIFLLLCLKVDNHFNLLTTSPVFPHYIEKPLGRVGVFLDFESGSVSFLNVTKSSLIWSYPAGSLTFPVRPFFYTGHR>sp|Q9Y5L4|TIM13_HUMAN Mitochondrial import inner membrane translocasesubunit Tim13 OS=Homo sapiens OX=9606 GN=TIMM13 PE=1 SV=1MEGGFGSDFGGSGSGKLDPGLIMEQVKVQIAVANAQELLQRMTDKCFRKCIGKPGGSLDNSEQKCIAMCMDRYMDAWNTVSRAYNSRLQRERANM>sp|Q99603|TRGV9_HUMAN T cell receptor gamma variable 9 OS=Homo sapiensOX=9606 GN=TRGV9 PE=1 SV=1MLSLLHTSTLAVLGALCVYGAGHLEQPQISSTKTLSKTARLECVVSGITISATSVYWYRERPGEVIQFLVSISYDGTVRKESGIPSGKFEVDRIPETSTSTLTIHNVEKQDIATYYCALWEV>sp|Q8NEE8|TTC16_HUMAN Tetratricopeptide repeat protein 16 OS=Homosapiens OX=9606 GN=TTC16 PE=2 SV=2MTDSDEDALKVDQGPSRDIPKPWVIPAPKGILQHIFGTSHVFQSICDVKPKVTGLTVPLKVREYYSRGQQCLEQADWETAVLLFSRALHLDPQLVDFYALRAEAYLQLCDFSSAAQNLRRAYSLQQDNCKHLERLTFVLYLQGQCLFEQCAFLDALNVFSHAAELQPEKPCFRYRCMACLLALKQHQACLTLITNELKQDTTNADVYIFRARLYNFLQKPHLCYRDLHSALLLNPKHPQARMLLQKMVAQAQQARQDAGILAVQGKLQHALQRINRAIENNPLDPSLFLFRGTMYRRLQEFDGAVEDFLKVLDMVTEDQEDMVRQAQRQLLLTYNDFAVHCYRQGAYQEGVLLLNKALRDEQQEKGLYINRGDCFFQLGNLAFAEADYQQALALSPQDEGANTRMGLLQEKMGFCEQRRKQFQKAENHFSTAIRHNPQKAQYYLYRAKSRQLLQNIFGARQDVATVLLLNPKQPKLSLLMTNLFPGMSVEEVLSTQIAHLARLQLEQMVEGSLQAGSPQGIVGMLKRHELERQKALALQHSWKQGEPLIATSEELKATPEIPQVKPGSSEGEAEAPEEEEEKEKEKKEEKKSELIPSKVASLSDSYLDQTSSASSMSFRTTGTSETEMSAICQEYRSTSATAVTFSDSSLLKTQSSDSGNNREALSHGPRKIKATQGQRQSLSKTEPTQSQRRNSSKTKATIHKRNSSKTKATQSQRRNSSKTRATQGQGQSSSKTEATQGQRQSSSEIEATQGPRQEPSKTKTTRSPRQRPRKVKAARGRSWRPSKVDATQGRSRGLLRSSTKTEAFYDSNWSLSKTEYAQGQGQRSSKAEGAQGKSQGMSSTSSKAESTWGPSPSLSKTEVDQDLTYYEAV>sp|Q8NEE8-2|TTC16_HUMAN Isoform 2 of Tetratricopeptide repeat protein 16OS=Homo sapiens OX=9606 GN=TTC16MACLLALKQHQACLTLITNELKQDTTNADVYIFRARLYNFLQKPHLCYRDLHSALLLNPKHPQARMLLQKMVAQAQQARQDAGILAVQGKLQHALQRINRAIENNPLDPSLFLFRGTMYRRLQEFDGAVEDFLKVLDMVTEDQEDMVRQAQRQLLLTYNDFAVHCYRQGAYQEGVLLLNKALRDEQQEKGLYINRGGAQRPGHWGGGVRGSLAISKAPTGHLRPLGGRRKGERKEAREEEM>sp|Q9H1Z9|TSN10_HUMAN Tetraspanin-10 OS=Homo sapiens OX=9606 GN=TSPAN10PE=2 SV=1MEEGERSPLLSQETAGQKPLSVHRPPTSGCLGPVPREDQAEAWGCSCCPPETKHQALSGTPKKGPAPSLSPGSSCVKYLIFLSNFPFSLLGLLALAIGLWGLAVKGSLGSDLGGPLPTDPMLGLALGGLVVSAASLAGCLGALCENTCLLRGFSGGILAFLVLEAVAGALVVALWGPLQDSLEHTLRVAIAHYQDDPDLRFLLDQVQLGLRCCGAASYQDWQQNLYFNCSSPGVQACSLPASCCIDPREDGASVNDQCGFGVLRLDADAAQRVVYLEGCGPPLRRWLRANLAASGGYAIAVVLLQGAELLLAARLLGALAARSGAAYGPGAHGEDRAGPQSPSPGAPPAAKPARG>sp|Q5VTQ0|TT39B_HUMAN Tetratricopeptide repeat protein 39B OS=Homosapiens OX=9606 GN=TTC39B PE=1 SV=4MDAVLACRLRGRGNRVAALRPRPRPGGSAGPSPFALLCAGLSPEPRAGVGSEFPAWFLGGSSQRRNMALLGSRAELEADEDVFEDALETISISSHSDMATSSLHFASCDTQQAPRQRGASTVSSSSSTKVDLKSGLEECAVALNLFLSNKFTDALELLRPWAKESMYHALGYSTIVVLQAVLTFEQQDIQNGISAMKDALQTCQKYRKKYTVVESFSSLLSRGSLEQLSEEEMHAEICYAECLLQKAALTFVQDENMINFIKGGLKIRTSYQIYKECLSILHEIQKNKLQQEFFYEFEGGVKLGSGAFNLMLSLLPARIIRLLEFIGFSGNRELGLLQLREGASGRSMRSALCCLTILAFHTYISLILGTGEVNVAEAERLLAPFLQQFPNGSLVLFYHARIELLKGNLEEAQEVFQKCISVQEEWKQFHHLCYWELMWINVFQQNWMQAYYYSDLLCKESKWSKATYVFLKAAILSMLPEEDVVATNENVVTLFRQVDSLKQRIAGKSIPTEKFAVRKARRYSASLPAPVKLILPALEMMYVWNGFSIVSKRKDLSENLLVTVEKAEAALQSQNFNSFSVDDECLVKLLKGCCLKNLQRPLQAELCYNHVVESEKLLKYDHYLVPFTLFELASLYKSQGEIDKAIKFLETARNNYKDYSLESRLHFRIQAALHLWRKPSSD>sp|Q5VTQ0-2|TT39B_HUMAN Isoform 2 of Tetratricopeptide repeat protein39B OS=Homo sapiens OX=9606 GN=TTC39BMATSSLHFASCDTQQAPRQRGASTVSSSSSTKVDLKSGLEECAVALNLFLSNKFTDALELLRPWAKESMYHALGYSTIVVLQAVLTFEQQDIQNGISAMKDALQTCQKYRKKYTVVESFSSLLSRGSLEQLSEEEMHAEICYAECLLQKAALTFVQDENMINFIKGGLKIRTSYQIYKECLSILHEIQKNKLQQEFFYEFEGGVKLGSGAFNLMLSLLPARIIRLLEFIGFSGNRELGLLQLREGASGRSMRSALCCLTILAFHTYISLILGTGEVNVAEAERLLAPFLQQFPNGSLVLFYHARIELLKGNLEEAQEVFQKCISVQEEWKQFHHLCYWELMWINVFQQNWMQAYYYSDLLCKESKWSKATYVFLKAAILSMLPEEDVVATNENVVTLFRQVDSLKQRIAGKSIPTEKFAVRKARRYSASLPAPVKLILPALEMMYVWNGFSIVSKRKDLSENLLVTVEKAEAALQSQNFNSFSVDDECLVKLLKGCCLKNLQRPLQAELCYNHVVESEKLLKYDHYLVPFTLFELASLYKSQGEIDKAIKFLETARNNYKDYSLESRLHFRIQAALHLWRKPSSD>sp|Q5VTQ0-3|TT39B_HUMAN Isoform 3 of Tetratricopeptide repeat protein39B OS=Homo sapiens OX=9606 GN=TTC39BMDAVLACRLRGRGNRVAALRPRPRPGGSAGPSPFALLCAGLSPEPRAGVGSEFPAWFLGGSSQRRNMALLGSRAELEADEDVFEDALETISISSHSDMATSSLHFASCDTQQAPRQRGASTVSSSSSTKVDLKSGLEECAVALNLFLSNKFTDALELLRPWAKESMYHALGYSTIVVLQAVLTFEQQDIQNGISAMKDALQTCQKYRKKYTVVESFSSLLSRGSLEQLSEEEMHAEICYAECLLQKAALTFVQDENMINFIKGGLKIRTSYQIYKECLSILHEIQKNKLQQEFFYEFEGGVKLGSGAFNLMLSLLPARIIRLLEFIGFSGNRELGLLQLREGASGRSMRSALCCLTILAFHTYISLILGTGEVNVAEAERLLAPFLQQFPNVRSVFQSAQEVFQKCISVQEEWKQFHHLCYWELMWINVFQQNWMQAYYYSDLLCKESKWSKATYVFLKAAILSMLPEEDVVATNENVVTLFRQVDSLKQRIAGKSIPTEKFAVRKARRYSASLPAPVKLILPALEMMYVWNGFSIVSKRKDLSENLLVTVEKAEAALQSQNFNSFSVDDECLVKLLKGCCLKNLQRPLQAELCYNHVVESEKLLKYDHYLVPFTLFELASLYKSQGEIDKAIKFLETARNNYKDYSLESRLHFRIQAALHLWRKPSSD>sp|Q5VTQ0-4|TT39B_HUMAN Isoform 4 of Tetratricopeptide repeat protein39B OS=Homo sapiens OX=9606 GN=TTC39BMDAVLACRLRGRGNRVAALRPRPRPGGSAGPSPFALLCAGLSPEPRAGVGSEFPAWFLGGSSQRRNMALLGSRAELEADEDVFEDALETISISSHSDMATSSLHFASCDTQQAPRQRGASTVSSSSSTKVDLKSGLEECAVALNLFLSNKFTDALELLRPWAKESMYHALGYSTIVVLQAVLTFEQQDIQNGISAMKDALQTCQKKKYTVVESFSSLLSRGSLEQLSEEEMHAEICYAECLLQKAALTFVQDENMINFIKGGLKIRTSYQIYKECLSILHEIQKNKLQQEFFYEFEGGVKLGSGAFNLMLSLLPARIIRLLEFIGFSGNRELGLLQLREGASGRSMRSALCCLTILAFHTYISLILGTGEVNVAEAERLLAPFLQQFPNGSLVLFYHARIELLKGNLEEAQEVFQKCISVQEEWKQFHHLCYWELMWINVFQQNWMQAYYYSDLLCKESKWSKATYVFLKAAILSMLPEEDVVATNENVVTLFRQVDSLKQRIAGKSIPTEKFAVRKARRYSASLPAPVKLILPALEMMYVWNGFSIVSKRKDLSENLLVTVEKAEAALQSQNFNSFSVDDECLVKLLKGCCLKNLQRPLQAELCYNHVVESEKLLKYDHYLVPFTLFELASLYKSQGEIDKAIKFLETARNNYKDYSLESRLHFRIQAALHLWRKPSSD>sp|Q5VTQ0-5|TT39B_HUMAN Isoform 5 of Tetratricopeptide repeat protein39B OS=Homo sapiens OX=9606 GN=TTC39BMYHALGYSTIVVLQAVLTFEQQDIQNGISAMKDALQTCQKYRKKYTVVESFSSLLSRGSLEQLSEEEMHAEICYAECLLQKAALTFVQDENMINFIKGGLKIRTSYQIYKECLSILHEIQKNKLQQEFFYEFEGGVKLGSGAFNLMLSLLPARIIRLLEFIGFSGNRELGLLQLREGASGRSMRSALCCLTILAFHTYISLILGTGEVNVAEAERLLAPFLQQFPNGSLVLFYHARIELLKGNLEEAQEVFQKCISVQEEWKQFHHLCYWELMWINVFQQNWMQAYYYSDLLCKESKWSKATYVFLKAAILSMLPEEDVVATNENVVTLFRQVDSLKQRIAGKSIPTEKFAVRKARRYSASLPAPVKLILPALEMMYVWNGFSIVSKRKDLSENLLVTVEKAEAALQSQNFNSFSVDDECLVKLLKGCCLKNLQRPLQAELCYNHVVESEKLLKYDHYLVPFTLFELASLYKSQGEIDKAIKFLETARNNYKDYSLESRLHFRIQAALHLWRKPSSD>sp|Q5VTQ0-6|TT39B_HUMAN Isoform 6 of Tetratricopeptide repeat protein39B OS=Homo sapiens OX=9606 GN=TTC39BMDAVLACRLRGRGNRVAALRPRPRPGGSAGPSPFALLCAGLSPEPRAGVGSEFPAWFLGGSSQRRNMALLGSRAELEADEDVFEDALETISMAKESMYHALGYSTIVVLQAVLTFEQQDIQNGISAMKDALQTCQKYRKKYTVVESFSSLLSRGSLEQLSEEEMHAEICYAECLLQKAALTFVQDENMINFIKGGLKIRTSYQIYKECLSILHEIQKNKLQQEFFYEFEGGVKLGSGAFNLMLSLLPARIIRLLEFIGFSGNRELGLLQLREGASGRSMRSALCCLTILAFHTYISLILGTGEVNVAEAERLLAPFLQQFPNGSLVLFYHARIELLKGNLEEAQEVFQKCISVQEEWKQFHHLCYWELMWINVFQQNWMQAYYYSDLLCKESKWSKATYVFLKAAILSMLPEEDVVATNENVVTLFRQVDSLKQRIAGKSIPTEKFAVRKARRYSASLPAPVKLILPALEMMYVWNGFSIVSKRKDLSENLLVTVEKAEAALQSQNFNSFSVDDECLVKLLKGCCLKNLQRPLQAELCYNHVVESEKLLKYDHYLVPFTLFELASLYKSQGEIDKAIKFLETARNNYKDYSLESRLHFRIQAALHLWRKPSSD>sp|Q5VTQ0-7|TT39B_HUMAN Isoform 7 of Tetratricopeptide repeat protein39B OS=Homo sapiens OX=9606 GN=TTC39BMTFLWGWAGVLHRQVDSLKQRIAGKSIPTEKFAVRKARRYSASLPAPVKLILPALEMMYVWNGFSIVSKRKDLSENLLVTVEKAEAALQSQNFNSFSVDDECLVKLLKGCCLKNLQRPLQAELCYNHVVESEKLLKYDHYLVPFTLFELASLYKSQGEIDKAIKFLETARNNYKDYSLESRLHFRIQAALHLWRKPSSD>sp|Q96T88|UHRF1_HUMAN E3 ubiquitin-protein ligase UHRF1 OS=Homo sapiensOX=9606 GN=UHRF1 PE=1 SV=1MWIQVRTMDGRQTHTVDSLSRLTKVEELRRKIQELFHVEPGLQRLFYRGKQMEDGHTLFDYEVRLNDTIQLLVRQSLVLPHSTKERDSELSDTDSGCCLGQSESDKSSTHGEAAAETDSRPADEDMWDETELGLYKVNEYVDARDTNMGAWFEAQVVRVTRKAPSRDEPCSSTSRPALEEDVIYHVKYDDYPENGVVQMNSRDVRARARTIIKWQDLEVGQVVMLNYNPDNPKERGFWYDAEISRKRETRTARELYANVVLGDDSLNDCRIIFVDEVFKIERPGEGSPMVDNPMRRKSGPSCKHCKDDVNRLCRVCACHLCGGRQDPDKQLMCDECDMAFHIYCLDPPLSSVPSEDEWYCPECRNDASEVVLAGERLRESKKKAKMASATSSSQRDWGKGMACVGRTKECTIVPSNHYGPIPGIPVGTMWRFRVQVSESGVHRPHVAGIHGRSNDGAYSLVLAGGYEDDVDHGNFFTYTGSGGRDLSGNKRTAEQSCDQKLTNTNRALALNCFAPINDQEGAEAKDWRSGKPVRVVRNVKGGKNSKYAPAEGNRYDGIYKVVKYWPEKGKSGFLVWRYLLRRDDDEPGPWTKEGKDRIKKLGLTMQYPEGYLEALANREREKENSKREEEEQQEGGFASPRTGKGKWKRKSAGGGPSRAGSPRRTSKKTKVEPYSLTAQQSSLIREDKSNAKLWNEVLASLKDRPASGSPFQLFLSKVEETFQCICCQELVFRPITTVCQHNVCKDCLDRSFRAQVFSCPACRYDLGRSYAMQVNQPLQTVLNQLFPGYGNGR>sp|Q96T88-2|UHRF1_HUMAN Isoform 2 of E3 ubiquitin-protein ligase UHRF1OS=Homo sapiens OX=9606 GN=UHRF1MGVFAVPPLSSDTMWIQVRTMDGRQTHTVDSLSRLTKVEELRRKIQELFHVEPGLQRLFYRGKQMEDGHTLFDYEVRLNDTIQLLVRQSLVLPHSTKERDSELSDTDSGCCLGQSESDKSSTHGEAAAETDSRPADEDMWDETELGLYKVNEYVDARDTNMGAWFEAQVVRVTRKAPSRDEPCSSTSRPALEEDVIYHVKYDDYPENGVVQMNSRDVRARARTIIKWQDLEVGQVVMLNYNPDNPKERGFWYDAEISRKRETRTARELYANVVLGDDSLNDCRIIFVDEVFKIERPGEGSPMVDNPMRRKSGPSCKHCKDDVNRLCRVCACHLCGGRQDPDKQLMCDECDMAFHIYCLDPPLSSVPSEDEWYCPECRNDASEVVLAGERLRESKKKAKMASATSSSQRDWGKGMACVGRTKECTIVPSNHYGPIPGIPVGTMWRFRVQVSESGVHRPHVAGIHGRSNDGAYSLVLAGGYEDDVDHGNFFTYTGSGGRDLSGNKRTAEQSCDQKLTNTNRALALNCFAPINDQEGAEAKDWRSGKPVRVVRNVKGGKNSKYAPAEGNRYDGIYKVVKYWPEKGKSGFLVWRYLLRRDDDEPGPWTKEGKDRIKKLGLTMQYPEGYLEALANREREKENSKREEEEQQEGGFASPRTGKGKWKRKSAGGGPSRAGSPRRTSKKTKVEPYSLTAQQSSLIREDKSNAKLWNEVLASLKDRPASGSPFQLFLSKVEETFQCICCQELVFRPITTVCQHNVCKDCLDRSFRAQVFSCPACRYDLGRSYAMQVNQPLQTVLNQLFPGYGNGR>sp|P62068|UBP46_HUMAN Ubiquitin carboxyl-terminal hydrolase 46 OS=Homosapiens OX=9606 GN=USP46 PE=1 SV=1MTVRNIASICNMGTNASALEKDIGPEQFPINEHYFGLVNFGNTCYCNSVLQALYFCRPFRENVLAYKAQQKKKENLLTCLADLFHSIATQKKKVGVIPPKKFISRLRKENDLFDNYMQQDAHEFLNYLLNTIADILQEEKKQEKQNGKLKNGNMNEPAENNKPELTWVHEIFQGTLTNETRCLNCETVSSKDEDFLDLSVDVEQNTSITHCLRDFSNTETLCSEQKYYCETCCSKQEAQKRMRVKKLPMILALHLKRFKYMEQLHRYTKLSYRVVFPLELRLFNTSSDAVNLDRMYDLVAVVVHCGSGPNRGHYITIVKSHGFWLLFDDDIVEKIDAQAIEEFYGLTSDISKNSESGYILFYQSRE>sp|P62068-2|UBP46_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 46 OS=Homo sapiens OX=9606 GN=USP46MQQDAHEFLNYLLNTIADILQEEKKQEKQNGKLKNGNMNEPAENNKPELTWVHEIFQGTLTNETRCLNCETVSSKDEDFLDLSVDVEQNTSITHCLRDFSNTETLCSEQKYYCETCCSKQEAQKRMRVKKLPMILALHLKRFKYMEQLHRYTKLSYRVVFPLELRLFNTSSDAVNLDRMYDLVAVVVHCGSGPNRGHYITIVKSHGFWLLFDDDIVEVGLQIILQ>sp|P62068-3|UBP46_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 46 OS=Homo sapiens OX=9606 GN=USP46MNCFQGTNASALEKDIGPEQFPINEHYFGLVNFGNTCYCNSVLQALYFCRPFRENVLAYKAQQKKKENLLTCLADLFHSIATQKKKVGVIPPKKFISRLRKENDLFDNYMQQDAHEFLNYLLNTIADILQEEKKQEKQNGKLKNGNMNEPAENNKPELTWVHEIFQGTLTNETRCLNCETVSSKDEDFLDLSVDVEQNTSITHCLRDFSNTETLCSEQKYYCETCCSKQEAQKRMRVKKLPMILALHLKRFKYMEQLHRYTKLSYRVVFPLELRLFNTSSDAVNLDRMYDLVAVVVHCGSGPNRGHYITIVKSHGFWLLFDDDIVEKIDAQAIEEFYGLTSDISKNSESGYILFYQSRE>sp|P62068-4|UBP46_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase 46 OS=Homo sapiens OX=9606 GN=USP46MTVRNIASICNMGTNASALEKDIGPEQFPINEHYFGLVNALYFCRPFRENVLAYKAQQKKKENLLTCLADLFHSIATQKKKVGVIPPKKFISRLRKENDLFDNYMQQDAHEFLNYLLNTIADILQEEKKQEKQNGKLKNGNMNEPAENNKPELTWVHEIFQGTLTNETRCLNCETVSSKDEDFLDLSVDVEQNTSITHCLRDFSNTETLCSEQKYYCETCCSKQEAQKRMRVKKLPMILALHLKRFKYMEQLHRYTKLSYRVVFPLELRLFNTSSDAVNLDRMYDLVAVVVHCGSGPNRGHYITIVKSHGFWLLFDDDIVEKIDAQAIEEFYGLTSDISKNSESGYILFYQSRE>sp|P51965|UB2E1_HUMAN Ubiquitin-conjugating enzyme E2 E1 OS=Homo sapiensOX=9606 GN=UBE2E1 PE=1 SV=1MSDDDSRASTSSSSSSSSNQQTEKETNTPKKKESKVSMSKNSKLLSTSAKRIQKELADITLDPPPNCSAGPKGDNIYEWRSTILGPPGSVYEGGVFFLDITFTPEYPFKPPKVTFRTRIYHCNINSQGVICLDILKDNWSPALTISKVLLSICSLLTDCNPADPLVGSIATQYMTNRAEHDRMARQWTKRYAT>sp|P51965-2|UB2E1_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 E1OS=Homo sapiens OX=9606 GN=UBE2E1MKEVGRPREVRGRPGKSRIQKELADITLDPPPNCSAGPKGDNIYEWRSTILGPPGSVYEGGVFFLDITFTPEYPFKPPKVTFRTRIYHCNINSQGVICLDILKDNWSPALTISKVLLSICSLLTDCNPADPLVGSIATQYMTNRAEHDRMARQWTKRYAT>sp|P51965-3|UB2E1_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 E1OS=Homo sapiens OX=9606 GN=UBE2E1MSDDDSRASTSSSSSSSSNQQTEKETNTPKKKESKVSMSKNSKLLSTSAKSAGPKGDNIYEWRSTILGPPGSVYEGGVFFLDITFTPEYPFKPPKVTFRTRIYHCNINSQGVICLDILKDNWSPALTISKVLLSICSLLTDCNPADPLVGSIATQYMTNRAEHDRMARQWTKRYAT>sp|P01282|VIP_HUMAN VIP peptides OS=Homo sapiens OX=9606 GN=VIP PE=1SV=1MDTRNKAQLLVLLTLLSVLFSQTSAWPLYRAPSALRLGDRIPFEGANEPDQVSLKEDIDMLQNALAENDTPYYDVSRNARHADGVFTSDFSKLLGQLSAKKYLESLMGKRVSSNISEDPVPVKRHSDAVFTDNYTRLRKQMAVKKYLNSILNGKRSSEGESPDFPEELEK>sp|P01282-2|VIP_HUMAN Isoform 2 of VIP peptides OS=Homo sapiens OX=9606GN=VIPMDTRNKAQLLVLLTLLSVLFSQTSAWPLYRAPSALRLGDRIPFEGANEPDQVSLKEDIDMLQNALAENDTPYYDVSRNARHADGVFTSDFSKLLGQLSAKKYLESLMGKRVSNISEDPVPVKRHSDAVFTDNYTRLRKQMAVKKYLNSILNGKRSSEGESPDFPEELEK>sp|Q8TCN5|ZN507_HUMAN Zinc finger protein 507 OS=Homo sapiens OX=9606GN=ZNF507 PE=1 SV=2MEESSSVAMLVPDIGEQEAILTAESIISPSLEIDEQRKTKPDPLIHVIQKLSKIVENEKSQKCLLIGKKRPRSSAATHSLETQELCEIPAKVIQSPAADTRRAEMSQTNFTPDTLAQNEGKAMSYQCSLCKFLSSSFSVLKDHIKQHGQQNEVILMCSECHITSRSQEELEAHVVNDHDNDANIHTQSKAQQCVSPSSSLCRKTTERNETIPDIPVSVDNLQTHTVQTASVAEMGRRKWYAYEQYGMYRCLFCSYTCGQQRMLKTHAWKHAGEVDCSYPIFENENEPLGLLDSSAAAAPGGVDAVVIAIGESELSIHNGPSVQVQICSSEQLSSSSPLEQSAERGVHLSQSVTLDPNEEEMLEVISDAEENLIPDSLLTSAQKIISSSPNKKGHVNVIVERLPSAEETLSQKRFLMNTEMEEGKDLSLTEAQIGREGMDDVYRADKCTVDIGGLIIGWSSSEKKDELMNKGLATDENAPPGRRRTNSESLRLHSLAAEALVTMPIRAAELTRANLGHYGDINLLDPDTSQRQVDSTLAAYSKMMSPLKNSSDGLTSLNQSNSTLVALPEGRQELSDGQVKTGISMSLLTVIEKLRERTDQNASDDDILKELQDNAQCQPNSDTSLSGNNVVEYIPNAERPYRCRLCHYTSGNKGYIKQHLRVHRQRQPYQCPICEHIADNSKDLESHMIHHCKTRIYQCKQCEESFHYKSQLRNHEREQHSLPDTLSIATSNEPRISSDTADGKCVQEGNKSSVQKQYRCDVCDYTSTTYVGVRNHRRIHNSDKPYRCSLCGYVCSHPPSLKSHMWKHASDQNYNYEQVNKAINDAISQSGRVLGKSPGKTQLKSSEESADPVTGSSENAVSSSELMSQTPSEVLGTNENEKLSPTSNTSYSLEKISSLAPPSMEYCVLLFCCCICGFESTSKENLLDHMKEHEGEIVNIILNKDHNTALNTN>sp|Q8TCN5-2|ZN507_HUMAN Isoform 2 of Zinc finger protein 507 OS=Homosapiens OX=9606 GN=ZNF507MEESSSVAMLVPDIGEQEAILTAESIISPSLEIDEQRKTKPDPLIHVIQKLSKIVENEKSQKCLLIGKKRPRSSAATHSLETQELCEIPAKVIQSPAADTRRAEMSQTNFTPDTLAQNEGKAMSYQCSLCKFLSSSFSVLKDHIKQHGQQNEVILMCSECHITSRSQEELEAHVVNDHDNDANIHTQSKAQQCVSPSSSLCRKTTERNETIPDIPVSVDNLQTHTVQTASVAEMGRRKWYAYEQYGMYRCLFCSYTCGQQRMLKTHAWKHAGEVDCSYPIFENENEPLGLLDSSAAAAPGGVDAVVIAIGESELSIHNGPSVQVQICSSEQLSSSSPLEQSAERGVHLSQSVTLDPNEEEMLEVISDAEENLIPDSLLTSAQKIISSSPNKKGHVNVIVERLPSAEETLSQKRFLMNTEMEEGKDLSLTEAQIGREGMDDVYRADKCTVDIGGLIIGWSSSEKKDELMNKGLATDENAPPGRRRTNSESLRLHSLAAEALVTMPIRAAELTRANLGHYGDINLLDPDTSQRQVDSTLAAYSKMMSPLKNSSDGLTSLNQSNSTLVALPEGRQELSDGQVKTGISMSLLTVIEKLRERTDQNASDDDILKELQDNAQCQPNSDTSLSGNNVVEYIPNAERPYRCRLCHYTSGNKGYIKQHLRVHRQRQPYQCPICEHIADNSKDLESHMIHHCKTRIYQCKQCEESFHYKSQLRNHEREQHSLPDTLSIATSNEPRISSDTADGKCVQEGIYVFCYAGCSDLHMT>sp|Q9HCL3|ZFP14_HUMAN Zinc finger protein 14 homolog OS=Homo sapiensOX=9606 GN=ZFP14 PE=1 SV=2MAHGSVTFRDVAIDFSQEEWEFLDPAQRDLYRDVMWENYSNFISLGPSISKPDVITLLDEERKEPGMVVREGTRRYCPDLESRYRTNTLSPEKDIYEIYSFQWDIMERIKSYSLQGSIFRNDWECKSKIEGEKEQQEGYFGQVKITSEKMTTYKRHNFLTEYQIVHNGEKVYECKECRKTFIRRSTLSQHLRIHTGEKPYKCKECGQAFRQRAHLIRHHKLHTGEKPYECKECGKAFTVLQELTQHQRLHTGEKPYECKECGKAFRVHQQLARHQRIHTGEKPYECKDCGKTFRQCTHLTRHQRLHTAEKLYECKECGKAFVCGPDLRVHQKIHFGEKPYECKECGKAFRICQQLTVHQSIHTGEKPYECKECGKTFRLRQQLVRHQRIHTREKPYECMECWKTFSSYSQLISHQSIHIGERPYECEECGKAFRLLSQLTQHQSIHTGEKPYECKECRKPFRLLSQLTQHQSIHTGEKPYECKECGKAFRLYSFLTQHQRIHTGEKPYKCKECKKAFRQHSHLTQHQKIHNGI>sp|Q7Z7K2|ZN467_HUMAN Zinc finger protein 467 OS=Homo sapiens OX=9606GN=ZNF467 PE=1 SV=1MRETLEALSSLGFSVGQPEMAPQSEPREGSHNAQEQMSSSREERALGVCSGHEAPTPEEGAHTEQAEAPCRGQACSAQKAQPVGTCPGEEWMIRKVKVEDEDQEAEEEVEWPQHLSLLPSPFPAPDLGHLAAAYKLEPGAPGALSGLALSGWGPMPEKPYGCGECERRFRDQLTLRLHQRLHRGEGPCACPDCGRSFTQRAHMLLHQRSHRGERPFPCSECDKRFSKKAHLTRHLRTHTGERPYPCAECGKRFSQKIHLGSHQKTHTGERPFPCTECEKRFRKKTHLIRHQRIHTGERPYQCAQCARSFTHKQHLVRHQRVHQTAGPARPSPDSSASPHSTAPSPTPSFPGPKPFACSDCGLSFGWKKNLATHQCLHRSEGRPFGCDECALGATVDAPAAKPLASAPGGPGCGPGSDPVVPQRAPSGERSFFCPDCGRGFSHGQHLARHPRVHTGERPFACTQCDRRFGSRPNLVAHSRAHSGARPFACAQCGRRFSRKSHLGRHQAVHTGSRPHACAVCARSFSSKTNLVRHQAIHTGSRPFSCPQCGKSFSRKTHLVRHQLIHGEAAHAAPDAALAAPAWSAPPEVAPPPLFF>sp|Q5FWF6|ZN789_HUMAN Zinc finger protein 789 OS=Homo sapiens OX=9606GN=ZNF789 PE=1 SV=3MFPPARGKELLSFEDVAMYFTREEWGHLNWGQKDLYRDVMLENYRNMVLLGFQFPKPEMICQLENWDEQWILDLPRTGNRKASGSACPGSEARHKMKKLTPKQKFSEDLESYKISVVMQESAEKLSEKLHKCKEFVDSCRLTFPTSGDEYSRGFLQNLNLIQDQNAQTRWKQGRYDEDGKPFNQRSLLLGHERILTRAKSYECSECGKVIRRKAWFDQHQRIHFLENPFECKVCGQAFRQRSALTVHKQCHLQNKPYRCHDCGKCFRQLAYLVEHKRIHTKEKPYKCSKCEKTFSQNSTLIRHQVIHSGEKRHKCLECGKAFGRHSTLLCHQQIHSKPNTHKCSECGQSFGRNVDLIQHQRIHTKEEFFQCGECGKTFSFKRNLFRHQVIHTGSQPYQCVICGKSFKWHTSFIKHQGTHKGQIST>sp|Q5FWF6-2|ZN789_HUMAN Isoform 2 of Zinc finger protein 789 OS=Homosapiens OX=9606 GN=ZNF789MKKLTPKQKFSEDLESYKISVVMQESAEKLSEKLHKCKEFVDSCRLTFPTSGDEYSRGFLQNLNLIQDQNAQTRWKQGRYDEDGKPFNQRSLLLGHERILTRAKSYECSECGKVIRRKAWFDQHQRIHFLENPFECKVCGQAFRQRSALTVHKQCHLQNKPYRCHDCGKCFRQLAYLVEHKRIHTKEKPYKCSKCEKTFSQNSTLIRHQVIHSGEKRHKCLECGKAFGRHSTLLCHQQIHSKPNTHKCSECGQSFGRNVDLIQHQRIHTKEEFFQCGECGKTFSFKRNLFRHQVIHTGSQPYQCVICGKSFKWHTSFIKHQGTHKGQIST>sp|Q5FWF6-3|ZN789_HUMAN Isoform 3 of Zinc finger protein 789 OS=Homosapiens OX=9606 GN=ZNF789MFPPARGKELLSFEDVAMYFTREEWGHLNWGQKDLYRDVMLENYRNMVLLVYFQFDAAIPLC>sp|Q8IYN0|ZN100_HUMAN Zinc finger protein 100 OS=Homo sapiens OX=9606GN=ZNF100 PE=1 SV=2MDDPRYGMCPLKGASGCPGAERSLLVQSYFEKGPLTFRDVAIEFSLEEWQCLDSAQQGLYRKVMLENYRNLVFLAGIALTKPDLITCLEQGKEPWNIKRHEMVAKPPVICSHFPQDLWAEQDIKDSFQEAILKKYGKYGHDNLQLQKGCKSVDECKVHKEHDNKLNQCLITTQSNIFQCDPSAKVFHTFSNSNRHKIRHTRKKPFKCKKCEKSFCMLLHLTQHKRFHITENSYQCKDCGKAFNWFSTLTTHRRIHTGEKPYKCEECGKAFNRSSHLTTHKIIHTGEKPYRCEECGKAFNRSSHLTTHKRIHTGVKPYKCTECGKAFNRSSHLTTHRIIHTGEKPYKCEECGKAFNQSSTLTTHKITHAGEKPYKCEECGKAFYRFSYLTKHKTSHTGEKFYKCEECGKGFNWSSALTKHKRIHTGEKPYKCEECGKAFNESSNLTTHKMIHTGEKPYKCDECGKAFNRSSQLTAHKMIHTGEKPYKCEECGKAFNRSSTLTKHKITHTGEKSYKWEECGKDFNQSLSLIKQNNSYWRETLQM>sp|Q7Z570|Z804A_HUMAN Zinc finger protein 804A OS=Homo sapiens OX=9606GN=ZNF804A PE=2 SV=3MECYYIVISSTHLSNGHFRNIKGVFRGPLSKNGNKTLDYAEKENTIAKALEDLKANFYCELCDKQYYKHQEFDNHINSYDHAHKQRLKELKQREFARNVASKSRKDERKQEKALQRLHKLAELRKETVCAPGSGPMFKSTTVTVRENCNEISQRVVVDSVNNQQDFKYTLIHSEENTKDATTVAEDPESANNYTAKNNQVGDQAQGIHRHKIGFSFAFPKKASVKLESSAAAFSEYSDDASVGKGFSRKSRFVPSACHLQQSSPTDVLLSSEEKTNSFHPPEAMCRDKETVQTQEIKEVSSEKDALLLPSFCKFQLQLSSDADNCQNSVPLADQIPLESVVINEDIPVSGNSFELLGNKSTVLDMSNDCISVQATTEENVKHNEASTTEVENKNGPETLAPSNTEEVNITIHKKTNFCKRQCEPFVPVLNKHRSTVLQWPSEMLVYTTTKPSISYSCNPLCFDFKSTKVNNNLDKNKPDLKDLCSQQKQEDICMGPLSDYKDVSTEGLTDYEIGSSKNKCSQVTPLLADDILSSSCDSGKNENTGQRYKNISCKIRETEKYNFTKSQIKQDTLDEKYNKIRLKETHEYWFHKSRRKKKRKKLCQHHHMEKTKESETRCKMEAENSYTENAGKYLLEPISEKQYLAAEQLLDSHQLLDKRPKSESISLSDNEEMCKTWNTEYNTYDTISSKNHCKKNTILLNGQSNATMIHSGKHNLTYSRTYCCWKTKMSSCSQDHRSLVLQNDMKHMSQNQAVKRGYNSVMNESERFYRKRRQHSHSYSSDESLNRQNHLPEEFLRPPSTSVAPCKPKKKRRRKRGRFHPGFETLELKENTDYPVKDNSSLNPLDRLISEDKKEKMKPQEVAKIERNSEQTNQLRNKLSFHPNNLLPSETNGETEHLEMETTSGELSDVSNDPTTSVCVASAPTKEAIDNTLLEHKERSENINLNEKQIPFQVPNIERNFRQSQPKSYLCHYELAEALPQGKMNETPTEWLRYNSGILNTQPPLPFKEAHVSGHTFVTAEQILAPLALPEQALLIPLENHDKFKNVPCEVYQHILQPNMLANKVKFTFPPAALPPPSTPLQPLPLQQSLCSTSVTTIHHTVLQQHAAAAAAAAAAAAAGTFKVLQPHQQFLSQIPALTRTSLPQLSVGPVGPRLCPGNQPTFVAPPQMPIIPASVLHPSHLAFPSLPHALFPSLLSPHPTVIPLQPLF>sp|Q6NX45|ZN774_HUMAN Zinc finger protein 774 OS=Homo sapiens OX=9606GN=ZNF774 PE=1 SV=2MWLGTSGKSGLPGHCLENPLQECHPAQLEEWALKGISRPSVISQPEQKEEPWVLPLQNFEARKIPRESHTDCEHQVAKLNQDNSETAEQCGTSSERTNKDLSHTLSWGGNWEQGLELEGQHGTLPGEGQLESFSQERDLNKLLDGYVGEKPMCAECGKSFNQSSYLIRHLRTHTGERPYTCIECGKGFKQSSDLVTHRRTHTGEKPYQCKGCEKKFSDSSTLIKHQRTHTGERPYECPECGKTFGRKPHLIMHQRTHTGEKPYACLECHKSFSRSSNFITHQRTHTGVKPYRCNDCGESFSQSSDLIKHQRTHTGERPFKCPECGKGFRDSSHFVAHMSTHSGERPFSCPDCHKSFSQSSHLVTHQRTHTGERPFKCENCGKGFADSSALIKHQRIHTGERPYKCGECGKSFNQSSHFITHQRIHLGDRPYRCPECGKTFNQRSHFLTHQRTHTGEKPFHCSKCNKSFRQKAHLLCHQNTHLI>sp|Q9BR84|ZN559_HUMAN Zinc finger protein 559 OS=Homo sapiens OX=9606GN=ZNF559 PE=1 SV=1MVAGWLTNYSQDSVTFEDVAVDFTQEEWTLLDQTQRNLYRDVMLENYKNLVAVDWESHINTKWSAPQQNFLQGKTSSVVEMERNHFGEELFDFNQCEKALSEHSCLKTHRRTYFRKKTCECNQCEKAFRKPSIFTLHKKTDIGEELPNCNQCETAFSQHLHLVCKKTSQNLHLVCKKTHTQEKPYKCSDCEKGLPSSSHLRECVRIYGGERPYTHKEYVETFSHSTALFVHMQTQDGEKFYECKACGKPFTESSYLTQHLRTHSRVLPIEHKKFGKAFAFSPDLAKHIRLRTRGKHYVCNECGKEFTCFSKLNIHIRVHTGEKPYECNKCGKAFTDSSGLIKHRRTHTGEKPYECKECGKAFANSSHLTVHMRTHTGEKPYQCKECGKAFINSSSFKSHMQTHPGVKPYDCQQCGKAFIRSSFLIRHLRSHSAERPFECEECGKAFRYSSHLSQHKRIHTGERPYKCQKCGQAFSISSGLTVHMRTHTGERPFECQECGKAFTRSTYLIRHLRSHSVEKPYKECGQTFSNSSCLTECV>sp|Q9BR84-2|ZN559_HUMAN Isoform 2 of Zinc finger protein 559 OS=Homosapiens OX=9606 GN=ZNF559MVAGWLTNYSQDSVTFEDVAVDFTQEEWTLLDQTQRNLYRDVMLENYKNLVAVDWESHINTKWSAPQQNFLQGKTSSVVEMNSE>sp|Q96MF0|YO028_HUMAN Putative uncharacterized protein LOC100506887OS=Homo sapiens OX=9606 PE=5 SV=2MPFKTKYPNGFHFAYLPTGSTQFRSLLQGQDSASQGVCPCRLCGAVPVRDQARIQSRRITLANCQGQPSALRQVNELANSAQIESFLCFSQLPNAVCFGGHLSCEFRECGYCNINPHHSKQLKLNSVTREES>sp|P0CG23|ZN853_HUMAN Zinc finger protein 853 OS=Homo sapiens OX=9606GN=ZNF853 PE=2 SV=1MLHQPTPGNRGLTARMEVGPATETFVLELQCLEDGGPGPDTLSGGSGGSESQEEEEPQERNSSPQRPAVSAPVGASEIAEETRPGQRELQLQQLEQQPEPQQQPQHEQLQQPQPHLELQQQPQQDGQQQLSQLQQEKHQSVHHQELKPELQLMHQQQQLQPQQVQEQQRLQQQQEQLQTQQAQEQQVLQQQEQLQQQVQEQQLLQQQQEQLQQQQLLQQQEQLQQQQFQQQQEQLQQQQQLLLLQQQGQLQQQLLQQQQAQLQQQLLEQQQAQLQQQLLLQQQEQLQQQQQQQLLQQQQEQLQQQQLQPPPLEPEEEEEVELELMPVDLGSEQELEQQRQELERQQELERQQEQRQLQLKLQEELQQLEQQLEQQQQQLEQQEVQLELTPVELGAQQQEVQLELTPVQPELQLELVPAAGGGGAAVPGAPAAVVVAPPGYVVVQELMVLPAVAAPAVVAIPGPAGSAALTPARQRRRRRARDRPTICGECGKGFSRSTDLVRHQATHTGERPHRCGECGKGFSQHSNLVTHQRIHTGEKPYACSYCAKRFSESSALVQHQRTHTGERPYACGDCGKRFSVSSNLLRHRRTHSGERPYVCEDCGERFRHKVQIRRHERQLHGAGRSRGLGLLRASRPAALGGPARAEQAATATAPADKAL>sp|Q8IWR0|Z3H7A_HUMAN Zinc finger CCCH domain-containing protein 7AOS=Homo sapiens OX=9606 GN=ZC3H7A PE=1 SV=1MSNVSEERRKRQQNIKEGLQFIQSPLSYPGTQEQYAVYLRALVRNLFNEGNDVYREHDWNNSISQYTEALNIADYAKSEEILIPKEIIEKLYINRIACYSNMGFHDKVLEDCNIVLSLNASNCKALYRKSKALSDLGRYKKAYDAVAKCSLAVPQDEHVIKLTQELAQKLGFKIRKAYVRAELSLKSVPGDGATKALNHSVEDIEPDLLTPRQEAVPVVSLPAPSFSHEVGSELASVPVMPLTSILPLQVEESALPSAVLANGGKMPFTMPEAFLDDGDMVLGDELDDLLDSAPETNETVMPSALVRGPLQTASVSPSMPFSASLLGTLPIGARYAPPPSFSEFYPPLTSSLEDFCSSLNSFSMSESKRDLSTSTSREGTPLNNSNSSLLLMNGPGSLFASENFLGISSQPRNDFGNFFGSAVTKPSSSVTPRHPLEGTHELRQACQICFVKSGPKLMDFTYHANIDHKCKKDILIGRIKNVEDKSWKKIRPRPTKTNYEGPYYICKDVAAEEECRYSGHCTFAYCQEEIDVWTLERKGAFSREAFFGGNGKINLTVFKLLQEHLGEFIFLCEKCFDHKPRMISKRNKDNSTACSHPVTKHEFEDNKCLVHILRETTVKYSKIRSFHGQCQLDLCRHEVRYGCLREDECFYAHSLVELKVWIMQNETGISHDAIAQESKRYWQNLEANVPGAQVLGNQIMPGFLNMKIKFVCAQCLRNGQVIEPDKNRKYCSAKARHSWTKDRRAMRVMSIERKKWMNIRPLPTKKQMPLQFDLCNHIASGKKCQYVGNCSFAHSPEEREVWTYMKENGIQDMEQFYELWLKSQKNEKSEDIASQSNKENGKQIHMPTDYAEVTVDFHCWMCGKNCNSEKQWQGHISSEKHKEKVFHTEDDQYCWQHRFPTGYFSICDRYMNGTCPEGNSCKFAHGNAELHEWEERRDALKMKLNKARKDHLIGPNDNDFGKYSFLFKDLN>sp|Q8IWR0-2|Z3H7A_HUMAN Isoform 2 of Zinc finger CCCH domain-containingprotein 7A OS=Homo sapiens OX=9606 GN=ZC3H7AMKENGIQDMEQFYELWLKSQKNEKSEDIASQSNKENGKQIHMPTDYAEVTVDFHCWMCGKNCNSEKQWQGHISSEKHKEKVFHTEDDQYCWQHRFPTGYFSICDRYMNGTCPEGNSCKFAHGNAELHEWEERRDALKMKLNKARKDHLIGPNDNDFGKYSFLFKDLN>sp|Q8IZ26|ZNF34_HUMAN Zinc finger protein 34 OS=Homo sapiens OX=9606GN=ZNF34 PE=1 SV=3MLLLLSDQLLLTALRKPNPQAMAALFLSAPPQAEVTFEDVAVYLSREEWGRLGPAQRGLYRDVMLETYGNLVSLGVGPAGPKPGVISQLERGDEPWVLDVQGTSGKEHLRVNSPALGTRTEYKELTSQETFGEEDPQGSEPVEACDHISKSEGSLEKLVEQRGPRAVTLTNGESSRESGGNLRLLSRPVPDQRPHKCDICEQSFEQRSYLNNHKRVHRSKKTNTVRNSGEIFSANLVVKEDQKIPTGKKLHYCSYCGKTFRYSANLVKHQRLHTEEKPYKCDECGKAFSQSCEFINHRRMHSGEIPYRCDECGKTFTRRPNLMKHQRIHTGEKPYKCGECGKHFSAYSSLIYHQRIHTGEKPYKCNDCGKAFSDGSILIRHRRTHTGEKPFECKECGKGFTQSSNLIQHQRIHTGEKPYKCNECEKAFIQKTKLVEHQRSHTGEKPYECNDCGKVFSQSTHLIQHQRIHTGEKPYKCSECGKAFHNSSRLIHHQRLHHGEKPYRCSDCKKAFSQSTYLIQHRRIHTGEKPYKCSECGKAFRHSSNMCQHQRIHLREDFSM>sp|Q8N720|ZN655_HUMAN Zinc finger protein 655 OS=Homo sapiens OX=9606GN=ZNF655 PE=1 SV=3MEEIPAQEAAGSPRVQFQSLETQSECLSPEPQFVQDTDMEQGLTGDGETREENKLLIPKQKISEEVHSYKVRVGRLKHDITQVPETREVYKSEDRLERLQEILRKFLYLEREFRQITISKETFTSEKNNECHEPEKSFSLDSTIDADQRVLRIQNTDDNDKYDMSFNQNSASGKHEHLNLTEDFQSSECKESLMDLSHLNKWESIPNTEKSYKCDVCGKIFHQSSALTRHQRIHTREKPYKCKECEKSFSQSSSLSRHKRIHTREKPYKCEASDKSCEASDKSCSPSSGIIQHKKIHTRAKSYKCSSCERVFSRSVHLTQHQKIHKEMPCKCTVCGSDFCHTSYLLEHQRVHHEEKAYEYDEYGLAYIKQQGIHFREKPYTCSECGKDFRLNSHLIQHQRIHTGEKAHECNECGKAFSQTSCLIQHHKMHRKEKSYECNEYEGSFSHSSDLILQQEVLTRQKAFDCDVWEKNSSQRAHLVQHQSIHTKENS>sp|Q8N720-2|ZN655_HUMAN Isoform 2 of Zinc finger protein 655 OS=Homosapiens OX=9606 GN=ZNF655MEEIPAQEAAGSPRVQFQSLETQSECLSPEPQFVQDTDMEQGLTGAPPVPQVPALPREGSPGDQAAALLTARYQEFVTFEDVAVHLTREEWGYLDPVQRDLYREVMLENYGNVVSLGILLRLPTTRIHSVNSCPALSHTQASAFSGETLAVLTAGISKRWPKYRLPIDIARPCSETPFPRL>sp|Q8N720-3|ZN655_HUMAN Isoform 3 of Zinc finger protein 655 OS=Homosapiens OX=9606 GN=ZNF655MEEIPAQEAAGSPRVQFQSLETQSECLSPEPQFVQDTDMEQGLTGGFPISKPDGISQLEQDLQVFDLETKTREVLRDDCSDGETREENKLLIPKQKISEEVHSYKVRVGRLKHDITQVPETREVYKSEDRLERLQEILRKFLYLEREFRQITISKETFTSEKNNECHEPEKSFSLDSTIDADQRVLRIQNTDDNDKYDMSFNQNSASGKHEHLNLTEDFQSSECKESLMDLSHLNKWESIPNTEKSYKCDVCGKIFHQSSALTRHQRIHTREKPYKCKECEKSFSQSSSLSRHKRIHTREKPYKCEASDKSCEASDKSCSPSSGIIQHKKIHTRAKSYKCSSCERVFSRSVHLTQHQKIHKEMPCKCTVCGSDFCHTSYLLEHQRVHHEEKAYEYDEYGLAYIKQQGIHFREKPYTCSECGKDFRLNSHLIQHQRIHTGEKAHECNECGKAFSQTSCLIQHHKMHRKEKSYECNEYEGSFSHSSDLILQQEVLTRQKAFDCDVWEKNSSQRAHLVQHQSIHTKENS>sp|Q8N720-4|ZN655_HUMAN Isoform 4 of Zinc finger protein 655 OS=Homosapiens OX=9606 GN=ZNF655MEEIPAQEAAGSPRVQFQSLETQSECLSPEPQFVQDTDMEQGLTGGILLRLPTTRIHSVNSCPALSHTQASAFSGETLAVLTAGISKRWPKYRLPIDIARPCSETPFPRL>sp|Q7L945|ZN627_HUMAN Zinc finger protein 627 OS=Homo sapiens OX=9606GN=ZNF627 PE=1 SV=1MDSVAFEDVAVNFTLEEWALLDPSQKNLYRDVMRETFRNLASVGKQWEDQNIEDPFKIPRRNISHIPERLCESKEGGQGEETFSQIPDGILNKKTPGVKPCESSVCGEVGMGPSSLNRHIRDHTGREPNEYQEYGKKSYTRNQCGRALSYHRSFPVRERTHPGGKPYDCKECGETFISLVSIRRHMLTHRGGVPYKCKVCGKAFDYPSLFRIHERSHTGEKPYECKQCGKAFSCSSYIRIHERTHTGDKPYECKQCGKAFSCSKYIRIHERTHTGEKPYECKQCGKAFRCASSVRSHERTHTGEKLFECKECGKALTCLASVRRHMIKHTGNGPYKCKVCGKAFDFPSSFRIHERTHTGEKPYDCKQCGKAFSCSSSFRKHERIHTGEKPYKCTKCGKAFSRSSYFRIHERTHTGEKPYECKQCGKAFSRSTYFRVHEKIHTGEKPYENPNPNASVVPVLS>sp|Q12768|WASC5_HUMAN WASH complex subunit 5 OS=Homo sapiens OX=9606GN=WASHC5 PE=1 SV=1MLDFLAENNLCGQAILRIVSCGNAIIAELLRLSEFIPAVFRLKDRADQQKYGDIIFDFSYFKGPELWESKLDAKPELQDLDEEFRENNIEIVTRFYLAFQSVHKYIVDLNRYLDDLNEGVYIQQTLETVLLNEDGKQLLCEALYLYGVMLLVIDQKIEGEVRERMLVSYYRYSAARSSADSNMDDICKLLRSTGYSSQPGAKRPSNYPESYFQRVPINESFISMVIGRLRSDDIYNQVSAYPLPEHRSTALANQAAMLYVILYFEPSILHTHQAKMREIVDKYFPDNWVISIYMGITVNLVDAWEPYKAAKTALNNTLDLSNVREQASRYATVSERVHAQVQQFLKEGYLREEMVLDNIPKLLNCLRDCNVAIRWLMLHTADSACDPNNKRLRQIKDQILTDSRYNPRILFQLLLDTAQFEFILKEMFKQMLSEKQTKWEHYKKEGSERMTELADVFSGVKPLTRVEKNENLQAWFREISKQILSLNYDDSTAAGRKTVQLIQALEEVQEFHQLESNLQVCQFLADTRKFLHQMIRTINIKEEVLITMQIVGDLSFAWQLIDSFTSIMQESIRVNPSMVTKLRATFLKLASALDLPLLRINQANSPDLLSVSQYYSGELVSYVRKVLQIIPESMFTSLLKIIKLQTHDIIEVPTRLDKDKLRDYAQLGPRYEVAKLTHAISIFTEGILMMKTTLVGIIKVDPKQLLEDGIRKELVKRVAFALHRGLIFNPRAKPSELMPKLKELGATMDGFHRSFEYIQDYVNIYGLKIWQEEVSRIINYNVEQECNNFLRTKIQDWQSMYQSTHIPIPKFTPVDESVTFIGRLCREILRITDPKMTCHIDQLNTWYDMKTHQEVTSSRLFSEIQTTLGTFGLNGLDRLLCFMIVKELQNFLSMFQKIILRDRTVQDTLKTLMNAVSPLKSIVANSNKIYFSAIAKTQKIWTAYLEAIMKVGQMQILRQQIANELNYSCRFDSKHLAAALENLNKALLADIEAHYQDPSLPYPKEDNTLLYEITAYLEAAGIHNPLNKIYITTKRLPYFPIVNFLFLIAQLPKLQYNKNLGMVCRKPTDPVDWPPLVLGLLTLLKQFHSRYTEQFLALIGQFICSTVEQCTSQKIPEIPADVVGALLFLEDYVRYTKLPRRVAEAHVPNFIFDEFRTVL>sp|Q1RN00|YC018_HUMAN Putative uncharacterized protein LOC151760 OS=Homosapiens OX=9606 PE=2 SV=1MLPVQRRKLDPLLKKYRHHKKATRTKRRRKEKMEAQCSPVPPTPSTPPQSEEDEAVDKKPTLLSAQEDTPDLLHEDRLQYLQEEGSGVMHQECQIQSCELSVAQKPRPSSPAVTSLASPPLCFGSFLSCVCQTFSRSRKQKPPRRKGNNQAEAGGDAEVLRPGPAKPELSLSKTCSHLKLIELSFVFSFIVLSVCHCSS>sp|Q9BSR8|YIPF4_HUMAN Protein YIPF4 OS=Homo sapiens OX=9606 GN=YIPF4PE=1 SV=1MQPPGPPPAYAPTNGDFTFVSSADAEDLSGSIASPDVKLNLGGDFIKESTATTFLRQRGYGWLLEVEDDDPEDNKPLLEELDIDLKDIYYKIRCVLMPMPSLGFNRQVVRDNPDFWGPLAVVLFFSMISLYGQFRVVSWIITIWIFGSLTIFLLARVLGGEVAYGQVLGVIGYSLLPLIVIAPVLLVVGSFEVVSTLIKLFGVFWAAYSAASLLVGEEFKTKKPLLIYPIFLLYIYFLSLYTGV>sp|Q9NUD5|ZCHC3_HUMAN Zinc finger CCHC domain-containing protein 3OS=Homo sapiens OX=9606 GN=ZCCHC3 PE=1 SV=2MATGGGAEEERKRGRPQLLPPARPAARGEEADGGREKMGWAQVVKNLAEKKGEFREPRPPRREEESGGGGGSAGLGGPAGLAAPDLGDFPPAGRGDPKGRRRDPAGEAVDPRKKKGAAEAGRRKKAEAAAAAMATPARPGEAEDAAERPLQDEPAAAAGPGKGRFLVRICFQGDEGACPTRDFVVGALILRSIGMDPSDIYAVIQIPGSREFDVSFRSAEKLALFLRVYEEKREQEDCWENFVVLGRSKSSLKTLFILFRNETVDVEDIVTWLKRHCDVLAVPVKVTDRFGIWTGEYKCEIELRQGEGGVRHLPGAFFLGAERGYSWYKGQPKTCFKCGSRTHMSGSCTQDRCFRCGEEGHLSPYCRKGIVCNLCGKRGHAFAQCPKAVHNSVAAQLTGVAGH>sp|Q9NUD5-2|ZCHC3_HUMAN Isoform 2 of Zinc finger CCHC domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=ZCCHC3MATGGGAEEERKRGRPQLLPPARPAARGEEADGGREKMGWAQVVKNLADVSFRSAEKLALFLRVYEEKREQEDCWENFVVLGRSKSSLKTLFILFRNETVDVEDIVTWLKRHCDVLAVPVKVTDRFGIWTGEYKCEIELRQGEGGVRHLPGAFFLGAERGYSWYKGQPKTCFKCGSRTHMSGSCTQDRCFRCGEEGHLSPYCRKGIVCNLCGKRGHAFAQCPKAVHNSVAAQLTGVAGH>sp|Q96IR2|ZN845_HUMAN Zinc finger protein 845 OS=Homo sapiens OX=9606GN=ZNF845 PE=1 SV=3MALSQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDISSKCMMKEFSSTAQGNTEVIHTGTLQRHERHHIGDFCFQEMEKDIHDFEFQWKEDERNSHEAPMTEIKQLTGSTNRHDQRHAGNKPIKDQLGSSFHSHLPELHMFQTEGKIGNQVEKSINSASLVSTSQRISCRPKTHISKNYGNNFLNSSLLTQKQEVHMREKSFQCNESGKAFNYSSVLRKHQIIHLGAKQYKCDVCGKVFNQKRYLACHRRCHTGKKPYKCNDCGKTFSQELTLTCHHRLHTGEKHYKCSECGKTFSRNSALVIHKAIHTGEKSYKCNECGKTFSQTSYLVYHRRLHTGEKPYKCEECDKAFSFKSNLERHRKIHTGEKPYKCNECSRTFSRKSSLTRHRRLHTGEKPYKCNDCGKTFSQMSSLVYHRRLHTGEKPYKCEECDEAFSFKSNLERHRRIHTGEKPYKCNDCGKTFSQTSSLVYHRRLHTGEKPYKCEECDEAFSFKSNLERHRIIHTGEKLYKCNECGKTFSRKSSLTRHCRLHTGEKPYQCNECGKAFRGQSALIYHQAIHGIGKLYKCNDCHQVFSNATTIANHWRIHNEERSYKCNRCGKFFRHRSYLAVHWRTHSGEKPYKCEECDEAFSFKSNLQRHRRIHTGEKPYRCNECGKTFSRKSYLTCHRRLHTGEKPYKCNECGKTFGRNSALIIHKAIHTGEKPYKCNECGKAFSQKSSLTCHLRLHTGEKPYKCEECDKVFSRKSSLEKHRRIHTGEKPYKCKVCDKAFGRDSHLAQHTRIHTGEKPYKCNECGKNFRHNSALVIHKAIHSGEKPYKCNECGKTFRHNSALEIHKAIHTGEKPYKCSECGKVFNRKANLSRHHRLHTGEKPYKCNKCGKVFNQQAHLACHHRIHTGEKPYKCNECGKTFRHNSVLVIHKTIHTGEKPYKCNECGKVFNRKAKLARHHRIHTGKKH>sp|Q9H2Y7|ZN106_HUMAN Zinc finger protein 106 OS=Homo sapiens OX=9606GN=ZNF106 PE=1 SV=1MPVGRIECPSSPSFPRDISHECRVCGVTEVGLSAYAKHISGQLHKDNVDAQEREDDGKGEEEEEDYFDKELIQLIKQRKEQSRQDEPSNSNQEINSDDRRPQWRREDRIPYQDRESYSQPAWHHRGPPQRDWKWEKDGFNNTRKNSFPHSLRNGGGPRGRSGWHKGVAGGSSTWFHNHSNSGGGWLSNSGAVDWNHNGTGRNSSWLSEGTGGFSSWHMNNSNGNWKSSVRSTNNWNYSGPGDKFQPGRNRNSNCQMEDMTMLWNKKSNKSNKYSHDRYNWQRQENDKLGTVATYRGPSEGFTSDKFPSEGLLDFNFEQLESQTTKQADTATSKVSGKNGSAAREKPRRWTPYPSQKTLDLQSGLKDITGNKSEMIEKPLFDFSLITTGIQEPQTDETRNSPTQKTQKEIHTGSLNHKASSDSAASFEVVRQCPTAEKPEQEHTPNKMPSLKSPLLPCPATKSLSQKQDPKNISKNTKTNFFSPGEHSNPSNKPTVEDNHGPYISKLRSSCPHVLKGNKSTFGSQKQSGDNLNDTLRKAKEVLQCHESLQNPLLSTSKSTRNYAKASRNVEESEKGSLKIEFQVHALEDESDGETSDTEKHGTKIGTLGSATTELLSGSTRTADEKEEDDRILKTSRELSTSPCNPIVRQKESELQMTSAASPHPGLLLDLKTSLEDAQVDDSIKSHVSYETEGFESASLDAELQKSDISQPSGPLLPELSKLGFPASLQRDLTRHISLKSKTGVHLPEPNLNSARRIRNISGHRKSETEKESGLKPTLRQILNASRRNVNWEQVIQQVTKKKQELGKGLPRFGIEMVPLVQNEQEALDLDGEPDLSSLEGFQWEGVSISSSPGLARKRSLSESSVIMDRAPSVYSFFSEEGTGKENEPQQMVSPSNSLRAGQSQKATMHLKQEVTPRAASLRTGERAENVATQRRHSAQLSSDHIIPLMHLAKDLNSQERSIPPSENQNSQESNGEGNCLSSSASSALAISSLADAATDSSCTSGAEQNDGQSIRKKRRATGDGSSPELPSLERKNKRRKIKGKKERSQVDQLLNISLREEELSKSLQCMDNNLLQARAALQTAYVEVQRLLMLKQQITMEMSALRTHRIQILQGLQETYEPSEHPDQVPCSLTRERRNSRSQTSIDAALLPTPFFPLFLEPPSSHVSPSPTGASLQITTSPTFQTHGSVPAPDSSVQIKQEPMSPEQDENVNAVPPSSACNVSKELLEANREISDSCPVYPVITARLSLPESTESFHEPSQELKFSVEQRNTRNRENSPSSQSAGLSSINKEGEEPTKGNSGSEACTSSFLRLSFASETPLEKEPHSPADQPEQQAESTLTSAETRGSKKKKKLRKKKSLRAAHVPENSDTEQDVLTVKPVRKVKAGKLIKGGKVTTSTWEDSRTGREQESVRDEPDSDSSLEVLEIPNPQLEVVAIDSSESGEEKPDSPSKKDIWNSTEQNPLETSRSGCDEVSSTSEIGTRYKDGIPVSVAETQTVISSIKGSKNSSEISSEPGDDDEPTEGSFEGHQAAVNAIQIFGNLLYTCSADKTVRVYNLVSRKCIGVFEGHTSKVNCLLVTQTSGKNAALYTGSSDHTIRCYNVKSRECVEQLQLEDRVLCLHSRWRILYAGLANGTVVTFNIKNNKRLEIFECHGPRAVSCLATAQEGARKLLVVGSYDCTISVRDARNGLLLRTLEGHSKTILCMKVVNDLVFSGSSDQSVHAHNIHTGELVRIYKGHNHAVTVVNILGKVMVTACLDKFVRVYELQSHDRLQVYGGHKDMIMCMTIHKSMIYTGCYDGSIQAVRLNLMQNYRCWWHGCSLIFGVVDHLKQHLLTDHTNPNFQTLKCRWKNCDAFFTARKGSKQDAAGHIERHAEDDSKIDS>sp|Q9H2Y7-2|ZN106_HUMAN Isoform 2 of Zinc finger protein 106 OS=Homosapiens OX=9606 GN=ZNF106MVRERKCILCHIVYSSKKEMDEHMRSMLHHRELENLKGRFGIEMVPLVQNEQEALDLDGEPDLSSLEGFQWEGVSISSSPGLARKRSLSESSVIMDRAPSVYSFFSEEGTGKENEPQQMVSPSNSLRAGQSQKATMHLKQEVTPRAASLRTGERAENVATQRRHSAQLSSDHIIPLMHLAKDLNSQERSIPPSENQNSQESNGEGNCLSSSASSALAISSLADAATDSSCTSGAEQNDGQSIRKKRRATGDGSSPELPSLERKNKRRKIKGKKERSQVDQLLNISLREEELSKSLQCMDNNLLQARAALQTAYVEVQRLLMLKQQITMEMSALRTHRIQILQGLQETYEPSEHPDQVPCSLTRERRNSRSQTSIDAALLPTPFFPLFLEPPSSHVSPSPTGASLQITTSPTFQTHGSVPAPDSSVQIKQEPMSPEQDENVNAVPPSSACNVSKELLEANREISDSCPVYPVITARLSLPESTESFHEPSQELKFSVEQRNTRNRENSPSSQSAGLSSINKEGEEPTKGNSGSEACTSSFLRLSFASETPLEKEPHSPADQPEQQAESTLTSAETRGSKKKKKLRKKKSLRAAHVPENSDTEQDVLTVKPVRKVKAGKLIKGGKVTTSTWEDSRTGREQESVRDEPDSDSSLEVLEIPNPQLEVVAIDSSESGEEKPDSPSKKDIWNSTEQNPLETSRSGCDEVSSTSEIGTRYKDGIPVSVAETQTVISSIKGSKNSSEISSEPGDDDEPTEGSFEGHQAAVNAIQIFGNLLYTCSADKTVRVYNLVSRKCIGVFEGHTSKVNCLLVTQTSGKNAALYTGSSDHTIRCYNVKSRECVEQLQLEDRVLCLHSRWRILYAGLANGTVVTFNIKNNKRLEIFECHGPRAVSCLATAQEGARKLLVVGSYDCTISVRDARNGLLLRTLEGHSKTILCMKVVNDLVFSGSSDQSVHAHNIHTGELVRIYKGHNHAVTVVNILGKVMVTACLDKFVRVYELQSHDRLQVYGGHKDMIMCMTIHKSMIYTGCYDGSIQAVRLNLMQNYRCWWHGCSLIFGVVDHLKQHLLTDHTNPNFQTLKCRWKNCDAFFTARKGSKQDAAGHIERHAEDDSKIDS>sp|Q6UXU0|YS002_HUMAN Putative uncharacterized protein UNQ9165/PRO28630OS=Homo sapiens OX=9606 GN=UNQ9165/PRO28630 PE=2 SV=1MAALSRALGPLRTPAPPLWIGLFLVATGSQQSLAQPLPGNTTEATPRSLRASGSLCGPHAKAPYLCEATHEPAAARIRAQVPDTRWSRVGGQRFYSRVLSPLHRGPSGHTEASAQRSHMGKLKEPQPQDHKPGLGAS>sp|P36406|TRI23_HUMAN E3 ubiquitin-protein ligase TRIM23 OS=Homo sapiensOX=9606 GN=TRIM23 PE=1 SV=1MATLVVNKLGAGVDSGRQGSRGTAVVKVLECGVCEDVFSLQGDKVPRLLLCGHTVCHDCLTRLPLHGRAIRCPFDRQVTDLGDSGVWGLKKNFALLELLERLQNGPIGQYGAAEESIGISGESIIRCDEDEAHLASVYCTVCATHLCSECSQVTHSTKTLAKHRRVPLADKPHEKTMCSQHQVHAIEFVCLEEGCQTSPLMCCVCKEYGKHQGHKHSVLEPEANQIRASILDMAHCIRTFTEEISDYSRKLVGIVQHIEGGEQIVEDGIGMAHTEHVPGTAENARSCIRAYFYDLHETLCRQEEMALSVVDAHVREKLIWLRQQQEDMTILLSEVSAACLHCEKTLQQDDCRVVLAKQEITRLLETLQKQQQQFTEVADHIQLDASIPVTFTKDNRVHIGPKMEIRVVTLGLDGAGKTTILFKLKQDEFMQPIPTIGFNVETVEYKNLKFTIWDVGGKHKLRPLWKHYYLNTQAVVFVVDSSHRDRISEAHSELAKLLTEKELRDALLLIFANKQDVAGALSVEEITELLSLHKLCCGRSWYIQGCDARSGMGLYEGLDWLSRQLVAAGVLDVA>sp|P36406-2|TRI23_HUMAN Isoform Beta of E3 ubiquitin-protein ligaseTRIM23 OS=Homo sapiens OX=9606 GN=TRIM23MATLVVNKLGAGVDSGRQGSRGTAVVKVLECGVCEDVFSLQGDKVPRLLLCGHTVCHDCLTRLPLHGRAIRCPFDRQVTDLGDSGVWGLKKNFALLELLERLQNGPIGQYGAAEESIGISGESIIRCDEDEAHLASVYCTVCATHLCSECSQVTHSTKTLAKHRRVPLADKPHEKTMCSQHQVHAIEFVCLEEGCQTSPLMCCVCKEYGKHQGHKHSVLEPEANQIRASILDMAHCIRTFTEEISDYSRKLVGIVQHIEGGEQIVEDGIGMAHTEHVPGTAENARSCIRAYFYDLHETLCRQEEMALSVVDAHVREKLIWLRQQQEDMTILLSEVSAACLHCEKTLQQDDCRVVLAKQEITRLLETLQKQQQQFTEVADHIQLDASIPVTFTKDNRVHIGPKMEIRVVTLGLDGAGKTTILFKLKQDEFMQPIPTIGFNVETVEYKNLKFTIWDVGGKHKLRPLWKHYYLNTQAVVFVVDSSHRDRISEAHSELAKLLTEKELRDALLLIFANKQDVAGALSVEEITELLSLHKLCCGRSWYIQGCDARSVFQIICDQYTGKEVVTEKG>sp|P36406-3|TRI23_HUMAN Isoform Gamma of E3 ubiquitin-protein ligaseTRIM23 OS=Homo sapiens OX=9606 GN=TRIM23MATLVVNKLGAGVDSGRQGSRGTAVVKVLECGVCEDVFSLQGDKVPRLLLCGHTVCHDCLTRLPLHGRAIRCPFDRQVTDLGDSGVWGLKKNFALLELLERLQNGPIGQYGAAEESIGISGESIIRCDEDEAHLASVYCTVCATHLCSECSQVTHSTKTLAKHRRVPLADKPHEKTMCSQHQVHAIEFVCLEEGCQTSPLMCCVCKEYGKHQGHKHSVLEPEANQIRASILDMAHCIRTFTEEISDYSRKLVGIVQHIEGGEQIVEDGIGMAHTEHVPGTAENARSCIRAYFYDLHETLCRQEEMALSVVDAHVREKLIWLRQQQEDMTILLSEVSAACLHCEKTLQQDDCRVVLAKQEITRLLETLQKQQQQFTEVADHIQLDASIPVTFTKDNRVHIGPKMEIRVVTLGLDGAGKTTILFKLKQDEFMQPIPTIGFNVETVEYKNLKFTIWDVGGKHKLRPLWKHYYLNTQAVVFVVDSSHRDRISEAHSELAKLLTEKELRDALLLIFANKQDVAGALSVEEITELLSLHKLCCGRSCFSDNM>sp|Q9HCM9|TRI39_HUMAN E3 ubiquitin-protein ligase TRIM39 OS=Homo sapiensOX=9606 GN=TRIM39 PE=1 SV=2MAETSLLEAGASAASTAAALENLQVEASCSVCLEYLKEPVIIECGHNFCKACITRWWEDLERDFPCPVCRKTSRYRSLRPNRQLGSMVEIAKQLQAVKRKIRDESLCPQHHEALSLFCYEDQEAVCLICAISHTHRAHTVVPLDDATQEYKEKLQKCLEPLEQKLQEITRCKSSEEKKPGELKRLVESRRQQILREFEELHRRLDEEQQVLLSRLEEEEQDILQRLRENAAHLGDKRRDLAHLAAEVEGKCLQSGFEMLKDVKSTLEKNIPRKFGGSLSTICPRDHKALLGLVKEINRCEKVKTMEVTSVSIELEKNFSNFPRQYFALRKILKQLIADVTLDPETAHPNLVLSEDRKSVKFVETRLRDLPDTPRRFTFYPCVLATEGFTSGRHYWEVEVGDKTHWAVGVCRDSVSRKGELTPLPETGYWRVRLWNGDKYAATTTPFTPLHIKVKPKRVGIFLDYEAGTLSFYNVTDRSHIYTFTDTFTEKLWPLFYPGIRAGRKNAAPLTIRPPTDWE>sp|Q9HCM9-2|TRI39_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM39OS=Homo sapiens OX=9606 GN=TRIM39MAETSLLEAGASAASTAAALENLQVEASCSVCLEYLKEPVIIECGHNFCKACITRWWEDLERDFPCPVCRKTSRYRSLRPNRQLGSMVEIAKQLQAVKRKIRDESLCPQHHEALSLFCYEDQEAVCLICAISHTHRAHTVVPLDDATQEYKEKLQKCLEPLEQKLQEITRCKSSEEKKPGELKRLVESRRQQILREFEELHRRLDEEQQVLLSRLEEEEQDILQRLRENAAHLGDKRRDLAHLAAEVEGKCLQSGFEMLKDVKSTLEKCEKVKTMEVTSVSIELEKNFSNFPRQYFALRKILKQLIADVTLDPETAHPNLVLSEDRKSVKFVETRLRDLPDTPRRFTFYPCVLATEGFTSGRHYWEVEVGDKTHWAVGVCRDSVSRKGELTPLPETGYWRVRLWNGDKYAATTTPFTPLHIKVKPKRVGIFLDYEAGTLSFYNVTDRSHIYTFTDTFTEKLWPLFYPGIRAGRKNAAPLTIRPPTDWE>sp|Q8N616|TM148_HUMAN Putative uncharacterized protein encoded byLINC00311 OS=Homo sapiens OX=9606 GN=LINC00311 PE=5 SV=1MVAADQGRGWNPLDGPTWEVLAMPLPLGPATQVPALFSAALVPPVSSLRPNQMLDWQRLKTPHGAPVACSLGLSGEWVPTPCALSILALLGLQLDPLFGLWGCTRTLFWSEWARESRRP>sp|Q86UV6|TRI74_HUMAN Tripartite motif-containing protein 74 OS=Homosapiens OX=9606 GN=TRIM74 PE=1 SV=1MAWQVSLLELEDWLQCPICLEVFKESLMLQCGHSYCKGCLVSLSYHLDTKVRCPMCWQVVDGSSSLPNVSLAWVIEALRLPGDPEPKVCVHHRNPLSLFCEKDQELICGLCGLLGSHQHHPVTPVSTVCSRMKEELAALFSELKQEQKKVDELIAKLVKNRTRIVNESDVFSWVIRREFQELRHPVDEEKARCLEGIGGHTRGLVASLDMQLEQAQGTRERLAQAECVLEQFGNEDHHEFIWKFHSMASR>sp|Q86UV6-2|TRI74_HUMAN Isoform 2 of Tripartite motif-containing protein74 OS=Homo sapiens OX=9606 GN=TRIM74MAWQVSLLELEDWLQCPICLEVFKESLMLQCGHSYCKGCLVSLSYHLDTKVRCPMCWQVVDGSSSLPNVSLAWVIEALRLPGDPEPKVCVHHRNPLSLFCEKDQELICGLCGLLGSHQHHPVTPVSTVCSRMKEELAALFSELKQEQKKVDELIAKLVKNRTRIVNESDVFSWVIRREFQELRHPVDEEKARCLEGIGGHTRGLVASLDMQLEQAQGTRERLAQAECVLEQFGNEDHHEFIWFHSMASR>sp|Q7L0X0|TRIL_HUMAN TLR4 interactor with leucine rich repeats OS=Homosapiens OX=9606 GN=TRIL PE=1 SV=2MEAARALRLLLVVCGCLALPPLAEPVCPERCDCQHPQHLLCTNRGLRVVPKTSSLPSPHDVLTYSLGGNFITNITAFDFHRLGQLRRLDLQYNQIRSLHPKTFEKLSRLEELYLGNNLLQALAPGTLAPLRKLRILYANGNEISRLSRGSFEGLESLVKLRLDGNALGALPDAVFAPLGNLLYLHLESNRIRFLGKNAFAQLGKLRFLNLSANELQPSLRHAATFAPLRSLSSLILSANNLQHLGPRIFQHLPRLGLLSLRGNQLTHLAPEAFWGLEALRELRLEGNRLSQLPTALLEPLHSLEALDLSGNELSALHPATFGHLGRLRELSLRNNALSALSGDIFAASPALYRLDLDGNGWTCDCRLRGLKRWMGDWHSQGRLLTVFVQCRHPPALRGKYLDYLDDQQLQNGSCADPSPSASLTADRRRQPLPTAAGEEMTPPAGLAEELPPQPQLQQQGRFLAGVAWDGAARELVGNRSALRLSRRGPGLQQPSPSVAAAAGPAPQSLDLHKKPQRGRPTRADPALAEPTPTASPGSAPSPAGDPWQRATKHRLGTEHQERAAQSDGGAGLPPLVSDPCDFNKFILCNLTVEAVGADSASVRWAVREHRSPRPLGGARFRLLFDRFGQQPKFHRFVYLPESSDSATLRELRGDTPYLVCVEGVLGGRVCPVAPRDHCAGLVTLPEAGSRGGVDYQLLTLALLTVNALLVLLALAAWASRWLRRKLRARRKGGAPVHVRHMYSTRRPLRSMGTGVSADFSGFQSHRPRTTVCALSEADLIEFPCDRFMDSAGGGAGGSLRREDRLLQRFAD>sp|P68371|TBB4B_HUMAN Tubulin beta-4B chain OS=Homo sapiens OX=9606GN=TUBB4B PE=1 SV=1MREIVHLQAGQCGNQIGAKFWEVISDEHGIDPTGTYHGDSDLQLERINVYYNEATGGKYVPRAVLVDLEPGTMDSVRSGPFGQIFRPDNFVFGQSGAGNNWAKGHYTEGAELVDSVLDVVRKEAESCDCLQGFQLTHSLGGGTGSGMGTLLISKIREEYPDRIMNTFSVVPSPKVSDTVVEPYNATLSVHQLVENTDETYCIDNEALYDICFRTLKLTTPTYGDLNHLVSATMSGVTTCLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTSRGSQQYRALTVPELTQQMFDAKNMMAACDPRHGRYLTVAAVFRGRMSMKEVDEQMLNVQNKNSSYFVEWIPNNVKTAVCDIPPRGLKMSATFIGNSTAIQELFKRISEQFTAMFRRKAFLHWYTGEGMDEMEFTEAESNMNDLVSEYQQYQDATAEEEGEFEEEAEEEVA>sp|Q9NS93|TM7S3_HUMAN Transmembrane 7 superfamily member 3 OS=Homosapiens OX=9606 GN=TM7SF3 PE=2 SV=1MGFLQLLVVAVLASEHRVAGAAEVFGNSSEGLIEFSVGKFRYFELNRPFPEEAILHDISSNVTFLIFQIHSQYQNTTVSFSPTLLSNSSETGTASGLVFILRPEQSTCTWYLGTSGIQPVQNMAILLSYSERDPVPGGCNLEFDLDIDPNIYLEYNFFETTIKFAPANLGYARGVDPPPCDAGTDQDSRWRLQYDVYQYFLPENDLTEEMLLKHLQRMVSVPQVKASALKVVTLTANDKTSVSFSSLPGQGVIYNVIVWDPFLNTSAAYIPAHTYACSFEAGEGSCASLGRVSSKVFFTLFALLGFFICFFGHRFWKTELFFIGFIIMGFFFYILITRLTPIKYDVNLILTAVTGSVGGMFLVAVWWRFGILSICMLCVGLVLGFLISSVTFFTPLGNLKIFHDDGVFWVTFSCIAILIPVVFMGCLRILNILTCGVIGSYSVVLAIDSYWSTSLSYITLNVLKRALNKDFHRAFTNVPFQTNDFIILAVWGMLAVSGITLQIRRERGRPFFPPHPYKLWKQERERRVTNILDPSYHIPPLRERLYGRLTQIKGLFQKEQPAGERTPLLL>sp|Q9HCF6|TRPM3_HUMAN Transient receptor potential cation channelsubfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3 PE=2 SV=4MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRCLPFFSLDSRLFYSFWGSCQLDSVGIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRPKALKLLGMEDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-2|TRPM3_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRPKALKLLGMEDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-3|TRPM3_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKREYPGFGWIYFKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRPKALKLLGMEDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-4|TRPM3_HUMAN Isoform 4 of Transient receptor potential cationchannel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-5|TRPM3_HUMAN Isoform 5 of Transient receptor potential cationchannel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKREYPGFGWIYFKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-6|TRPM3_HUMAN Isoform 6 of Transient receptor potential cationchannel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRPKALKLLGMEDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDRKQVYDSHTPKSAPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-7|TRPM3_HUMAN Isoform 7 of Transient receptor potential cationchannel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRCLPFFSLDSRLFYSFWGSCQLDSVGIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-8|TRPM3_HUMAN Isoform 8 of Transient receptor potential cationchannel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-10|TRPM3_HUMAN Isoform 10 of Transient receptor potentialcation channel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MPEPWGTVYFLGIAQVFSFLFSWWNLEGVMNQADAPRPLNWTIRKLCHAAFLPSVRLLKAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRPKALKLLGMEDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAEHPLYSV>sp|Q9HCF6-11|TRPM3_HUMAN Isoform 11 of Transient receptor potentialcation channel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MGKKWRDAAEMERGCSDREDNAESRRRSRSASRGRFAESWKRLSSKQGSTKRSGLPSQQTPAQKSWIERAFYKRECVHIIPSTKDPHRCCCGRLIGQHVGLTPSISVLQNEKNESRLSRNDIQSEKWSISKHTQLSPTDAFGTIEFQGGGHSNKAMYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRCLPFFSLDSRLFYSFWGSCQLDSVGIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGGLINESLRDQLLVTIQKTFTYTRTQAQHLFIILMECMKKKELITVFRMGSEGHQDIDLAILTALLKGANASAPDQLSLALAWNRVDIARSQIFIYGQQWPVGSLEQAMLDALVLDRVDFVKLLIENGVSMHRFLTISRLEELYNTRHGPSNTLYHLVRDVKKGNLPPDYRISLIDIGLVIEYLMGGAYRCNYTRKRFRTLYHNLFGPKRPKALKLLGMEDDIPLRRGRKTTKKREEEVDIDLDDPEINHFPFPFHELMVWAVLMKRQKMALFFWQHGEEAMAKALVACKLCKAMAHEASENDMVDDISQELNHNSRDFGQLAVELLDQSYKQDEQLAMKLLTYELKNWSNATCLQLAVAAKHRDFIAHTCSQMLLTDMWMGRLRMRKNSGLKVILGILLPPSILSLEFKNKDDMPYMSQAQEIHLQEKEAEEPEKPTKEKEEEDMELTAMLGRNNGESSRKKDEEEVQSKHRLIPLGRKIYEFYNAPIVKFWFYTLAYIGYLMLFNYIVLVKMERWPSTQEWIVISYIFTLGIEKMREILMSEPGKLLQKVKVWLQEYWNVTDLIAILLFSVGMILRLQDQPFRSDGRVIYCVNIIYWYIRLLDIFGVNKYLGPYVMMIGKMMIDMMYFVIIMLVVLMSFGVARQAILFPNEEPSWKLAKNIFYMPYWMIYGEVFADQIDPPCGQNETREDGKIIQLPPCKTGAWIVPAIMACYLLVANILLVNLLIAVFNNTFFEVKSISNQVWKFQRYQLIMTFHERPVLPPPLIIFSHMTMIFQHLCCRWRKHESDPDERDYGLKLFITDDELKKVHDFEEQCIEEYFREKDDRFNSSNDERIRVTSERVENMSMRLEEVNEREHSMKASLQTVDIRLAQLEDLIGRMATALERLTGLERAESNKIRSRTSSDCTDAAYIVRQSSFNSQEGNTFKLQESIDPAGEETMSPTSPTLMPRMRSHSFYSVNMKDKGGIEKLESIFKERSLSLHRATSSHSVAKEPKAPAAPANTLAIVPDSRRPSSCIDIYVSAMDELHCDIDPLDNSVNILGLGEPSFSTPVPSTAPSSSAYATLAPTDRPPSRSIDFEDITSMDTRSFSSDYTHLPECQNPWDSEPPMYHTIERSKSSRYLATTPFLLEEAPIVKSHSFMFSPSRSYYANFGVPVKTAEYTSITDCIDTRCVNAPQAIADRAAFPGGLGDKVEDLTCCHPEREAELSHPSSDSEENEAKGRRATIAISSQEGDNSERTLSNNITVPKIERANSYSAEEPSAPYAHTRKSFSISDKLDRQRNTASLRNPFQRSKSSKPEGRGDSLSMRRLSRTSAFQSFESKHN>sp|Q9HCF6-12|TRPM3_HUMAN Isoform 12 of Transient receptor potentialcation channel subfamily M member 3 OS=Homo sapiens OX=9606 GN=TRPM3MYVRVSFDTKPDLLLHLMTKEWQLELPKLLISVHGGLQNFELQPKLKQVFGKGLIKAAMTTGAWIFTGGVNTGVIRHVGDALKDHASKSRGKICTIGIAPWGIVENQEDLIGRDVVRPYQTMSNPMSKLTVLNSMHSHFILADNGTTGKYGAEVKLRRQLEKHISLQKINTRIGQGVPVVALIVEGGPNVISIVLEYLRDTPPVPVVVCDGSGRASDILAFGHKYSEEGG>sp|P48995|TRPC1_HUMAN Short transient receptor potential channel 1OS=Homo sapiens OX=9606 GN=TRPC1 PE=1 SV=1MMAALYPSTDLSGASSSSLPSSPSSSSPNEVMALKDVREVKEENTLNEKLFLLACDKGDYYMVKKILEENSSGDLNINCVDVLGRNAVTITIENENLDILQLLLDYGCQSADALLVAIDSEVVGAVDILLNHRPKRSSRPTIVKLMERIQNPEYSTTMDVAPVILAAHRNNYEILTMLLKQDVSLPKPHAVGCECTLCSAKNKKDSLRHSRFRLDIYRCLASPALIMLTEEDPILRAFELSADLKELSLVEVEFRNDYEELARQCKMFAKDLLAQARNSRELEVILNHTSSDEPLDKRGLLEERMNLSRLKLAIKYNQKEFVSQSNCQQFLNTVWFGQMSGYRRKPTCKKIMTVLTVGIFWPVLSLCYLIAPKSQFGRIIHTPFMKFIIHGASYFTFLLLLNLYSLVYNEDKKNTMGPALERIDYLLILWIIGMIWSDIKRLWYEGLEDFLEESRNQLSFVMNSLYLATFALKVVAHNKFHDFADRKDWDAFHPTLVAEGLFAFANVLSYLRLFFMYTTSSILGPLQISMGQMLQDFGKFLGMFLLVLFSFTIGLTQLYDKGYTSKEQKDCVGIFCEQQSNDTFHSFIGTCFALFWYIFSLAHVAIFVTRFSYGEELQSFVGAVIVGTYNVVVVIVLTKLLVAMLHKSFQLIANHEDKEWKFARAKLWLSYFDDKCTLPPPFNIIPSPKTICYMISSLSKWICSHTSKGKVKRQNSLKEWRNLKQKRDENYQKVMCCLVHRYLTSMRQKMQSTDQATVENLNELRQDLSKFRNEIRDLLGFRTSKYAMFYPRN>sp|P48995-2|TRPC1_HUMAN Isoform Short of Short transient receptorpotential channel 1 OS=Homo sapiens OX=9606 GN=TRPC1MMAALYPSTDLSGASSSSLPSSPSSSSPNEVMALKDVREVKEENTLNEKLFLLACDKGDYYMVKKILEENSSGDLNINCVDVLGRNAVTITIENENLDILQLLLDYGCQKLMERIQNPEYSTTMDVAPVILAAHRNNYEILTMLLKQDVSLPKPHAVGCECTLCSAKNKKDSLRHSRFRLDIYRCLASPALIMLTEEDPILRAFELSADLKELSLVEVEFRNDYEELARQCKMFAKDLLAQARNSRELEVILNHTSSDEPLDKRGLLEERMNLSRLKLAIKYNQKEFVSQSNCQQFLNTVWFGQMSGYRRKPTCKKIMTVLTVGIFWPVLSLCYLIAPKSQFGRIIHTPFMKFIIHGASYFTFLLLLNLYSLVYNEDKKNTMGPALERIDYLLILWIIGMIWSDIKRLWYEGLEDFLEESRNQLSFVMNSLYLATFALKVVAHNKFHDFADRKDWDAFHPTLVAEGLFAFANVLSYLRLFFMYTTSSILGPLQISMGQMLQDFGKFLGMFLLVLFSFTIGLTQLYDKGYTSKEQKDCVGIFCEQQSNDTFHSFIGTCFALFWYIFSLAHVAIFVTRFSYGEELQSFVGAVIVGTYNVVVVIVLTKLLVAMLHKSFQLIANHEDKEWKFARAKLWLSYFDDKCTLPPPFNIIPSPKTICYMISSLSKWICSHTSKGKVKRQNSLKEWRNLKQKRDENYQKVMCCLVHRYLTSMRQKMQSTDQATVENLNELRQDLSKFRNEIRDLLGFRTSKYAMFYPRN>sp|Q96N46|TTC14_HUMAN Tetratricopeptide repeat protein 14 OS=Homosapiens OX=9606 GN=TTC14 PE=1 SV=1MDRDLLRQSLNCHGSSLLSLLRSEQQDNPHFRSLLGSAAEPARGPPPQHPLQGRKEKRVDNIEIQKFISKKADLLFALSWKSDAPATSEINEDSEDHYAIMPPLEQFMEIPSMDRRELFFRDIERGDIVIGRISSIREFGFFMVLICLGSGIMRDIAHLEITALCPLRDVPSHSNHGDPLSYYQTGDIIRAGIKDIDRYHEKLAVSLYSSSLPPHLSGIKLGVISSEELPLYYRRSVELNSNSLESYENVMQSSLGFVNPGVVEFLLEKLGIDESNPPSLMRGLQSKNFSEDDFASALRKKQSASWALKCVKIGVDYFKVGRHVDAMNEYNKALEIDKQNVEALVARGALYATKGSLNKAIEDFELALENCPTHRNARKYLCQTLVERGGQLEEEEKFLNAESYYKKALALDETFKDAEDALQKLHKYMQKSLELREKQAEKEEKQKTKKIETSAEKLRKLLKEEKRLKKKRRKSTSSSSVSSADESVSSSSSSSSSGHKRHKKHKRNRSESSRSSRRHSSRASSNQIDQNRKDECYPVPANTSASFLNHKQEVEKLLGKQDRLQYEKTQIKEKDRCPLSSSSLEIPDDFGGRSEDPRDFYNSYKTQAGSSKTEKPYKSERHFSSRRNSSDSFCRNSEDKIYGYRRFEKDIEGRKEHYRRWEPGSVRHSTSPASSEYSWKSVEKYKKYAHSGSRDFSRHEQRYRLNTNQGEYEREDNYGEDIKTEVPEEDALSSKEHSESSVKKNLPQNLLNIFNQIAEFEKEKGNKSKN>sp|Q96N46-2|TTC14_HUMAN Isoform 2 of Tetratricopeptide repeat protein 14OS=Homo sapiens OX=9606 GN=TTC14MDRDLLRQSLNCHGSSLLSLLRSEQQDNPHFRSLLGSAAEPARGPPPQHPLQGRKEKRVDNIEIQKFISKKADLLFALSWKSDAPATSEINEDSEDHYAIMPPLEQFMEIPSMDRRELFFRDIERGDIVIGRISSIREFGFFMVLICLGSGIMRDIAHLEITALCPLRDVPSHSNHGDPLSYYQTGDIIRAGIKDIDRYHEKLAVSLYSSSLPPHLSGIKLGVISSEELPLYYRRSVELNSNSLESYENVMQSSLGFVNPGVVEFLLEKLGIDESNPPSLMRGLQSKNFSEDDFASALRKKQSASWALKCVKIGVDYFKVGRHVDAMNEYNKALEIDKQNVEALVARGALYATKGSLNKAIEDFELALENCPTHRNARKYLCQTLVERGGQLEEEEKFLNAESYYKKALALDETFKDAEDALQKLHKYMQKSLELREKQAEKEEKQKTKKIETSAEKLRKLLKEEKRLKKKRRKSTSSSSVSSADESVSSSSSSSSSGHKRHKKHKRNRSESSRSSRRHSSRASSNQIDQNRKDECYPVPANTSASFLNHKQEVEKLLGKQDRLQYEKTQIKEKDRCPLSSSSLEIPDDFGVYSYLFKKLTIKQPQAGPSGDIPEEGIVIIDDSSIHVTDPEDLQVGQDMEVEDSGIDDPDHG>sp|Q96N46-3|TTC14_HUMAN Isoform 3 of Tetratricopeptide repeat protein 14OS=Homo sapiens OX=9606 GN=TTC14MDRDLLRQSLNCHGSSLLSLLRSEQQDNPHFRSLLGSAAEPARGPPPQHPLQGRKEKRVDNIEIQKFISKKADLLFALSWKSDAPATSEINEDSEDHYAIMPPLEQFMEIPSMDRRELFFRDIERGDIVIGRISSIREFGFFMVLICLGSGIMRDIAHLEITALCPLRDVPSHSNHGDPLSYYQTGDIIRAGIKDIDRYHEKLAVSLYSSSLPPHLSGIKLGVISSEELPLYYRRSVELNSNSLESYENVMQSSLGFVNPGVVEFLLEKLGIDESNPPSLMRGLQSKNFSEDDFASALRKKQSASWALKCVKIGVDYFKVGRHVDAMNEYNKALEIDKQNVEALVARGALYATKGSLNKAIEDFELALENCPTHRNARKYLCQTLVERGGQLEEEEKFLNAESYYKKALALDETFKDAEDALQKLHKYMQVIPYFLLEI>sp|Q5R3I4|TTC38_HUMAN Tetratricopeptide repeat protein 38 OS=Homosapiens OX=9606 GN=TTC38 PE=1 SV=1MAAASPLRDCQAWKDARLPLSTTSNEACKLFDATLTQYVKWTNDKSLGGIEGCLSKLKAADPTFVMGHAMATGLVLIGTGSSVKLDKELDLAVKTMVEISRTQPLTRREQLHVSAVETFANGNFPKACELWEQILQDHPTDMLALKFSHDAYFYLGYQEQMRDSVARIYPFWTPDIPLSSYVKGIYSFGLMETNFYDQAEKLAKEALSINPTDAWSVHTVAHIHEMKAEIKDGLEFMQHSETFWKDSDMLACHNYWHWALYLIEKGEYEAALTIYDTHILPSLQANDAMLDVVDSCSMLYRLQMEGVSVGQRWQDVLPVARKHSRDHILLFNDAHFLMASLGAHDPQTTQELLTTLRDASESPGENCQHLLARDVGLPLCQALVEAEDGNPDRVLELLLPIRYRIVQLGGSNAQRDVFNQLLIHAALNCTSSVHKNVARSLLMERDALKPNSPLTERLIRKAATVHLMQ>sp|Q8N831|TSYL6_HUMAN Testis-specific Y-encoded-like protein 6 OS=Homosapiens OX=9606 GN=TSPYL6 PE=1 SV=1MSLPESPHSPATLDYALEDPHQGQRSREKSKATEVMADMFDGRLEPIVFPPPRLPEEGVAPQDPADGGHTFHILVDAGRSHGAIKAGQEVTPPPAEGLEAASASLTTDGSLKNGFPGEETHGLGGEKALETCGAGRSESEVIAEGKAEDVKPEECAMFSAPVDEKPGGEEMDVAEENRAIDEVNREAGPGPGPGPLNVGLHLNPLESIQLELDSVNAEADRALLQVERRFGQIHEYYLEQRNDIIRNIPGFWVTAFRHHPQLSAMIRGQDAEMLSYLTNLEVKELRHPRTGCKFKFFFQRNPYFRNKLIVKVYEVRSFGQVVSFSTLIMWRRGHGPQSFIHRNRHVICSFFTWFSDHSLPESDRIAQIIKEDLWSNPLQYYLLGEDAHRARRRLVREPVEIPRPFGFQCG>sp|Q9Y2K6|UBP20_HUMAN Ubiquitin carboxyl-terminal hydrolase 20 OS=Homosapiens OX=9606 GN=USP20 PE=1 SV=2MGDSRDLCPHLDSIGEVTKEDLLLKSKGTCQSCGVTGPNLWACLQVACPYVGCGESFADHSTIHAQAKKHNLTVNLTTFRLWCYACEKEVFLEQRLAAPLLGSSSKFSEQDSPPPSHPLKAVPIAVADEGESESEDDDLKPRGLTGMKNLGNSCYMNAALQALSNCPPLTQFFLECGGLVRTDKKPALCKSYQKLVSEVWHKKRPSYVVPTSLSHGIKLVNPMFRGYAQQDTQEFLRCLMDQLHEELKEPVVATVALTEARDSDSSDTDEKREGDRSPSEDEFLSCDSSSDRGEGDGQGRGGGSSQAETELLIPDEAGRAISEKERMKDRKFSWGQQRTNSEQVDEDADVDTAMAALDDQPAEAQPPSPRSSSPCRTPEPDNDAHLRSSSRPCSPVHHHEGHAKLSSSPPRASPVRMAPSYVLKKAQVLSAGSRRRKEQRYRSVISDIFDGSILSLVQCLTCDRVSTTVETFQDLSLPIPGKEDLAKLHSAIYQNVPAKPGACGDSYAAQGWLAFIVEYIRRFVVSCTPSWFWGPVVTLEDCLAAFFAADELKGDNMYSCERCKKLRNGVKYCKVLRLPEILCIHLKRFRHEVMYSFKINSHVSFPLEGLDLRPFLAKECTSQITTYDLLSVICHHGTAGSGHYIAYCQNVINGQWYEFDDQYVTEVHETVVQNAEGYVLFYRKSSEEAMRERQQVVSLAAMREPSLLRFYVSREWLNKFNTFAEPGPITNQTFLCSHGGIPPHKYHYIDDLVVILPQNVWEHLYNRFGGGPAVNHLYVCSICQVEIEALAKRRRIEIDTFIKLNKAFQAEESPGVIYCISMQWFREWEAFVKGKDNEPPGPIDNSRIAQVKGSGHVQLKQGADYGQISEETWTYLNSLYGGGPEIAIRQSVAQPLGPENLHGEQKIEAETRAV>sp|Q03405|UPAR_HUMAN Urokinase plasminogen activator surface receptorOS=Homo sapiens OX=9606 GN=PLAUR PE=1 SV=1MGHPPLLPLLLLLHTCVPASWGLRCMQCKTNGDCRVEECALGQDLCRTTIVRLWEEGEELELVEKSCTHSEKTNRTLSYRTGLKITSLTEVVCGLDLCNQGNSGRAVTYSRSRYLECISCGSSDMSCERGRHQSLQCRSPEEQCLDVVTHWIQEGEEGRPKDDRHLRGCGYLPGCPGSNGFHNNDTFHFLKCCNTTKCNEGPILELENLPQNGRQCYSCKGNSTHGCSSEETFLIDCRGPMNQCLVATGTHEPKNQSYMVRGCATASMCQHAHLGDAFSMNHIDVSCCTKSGCNHPDLDVQYRSGAAPQPGPAHLSLTITLLMTARLWGGTLLWT>sp|Q03405-2|UPAR_HUMAN Isoform 2 of Urokinase plasminogen activatorsurface receptor OS=Homo sapiens OX=9606 GN=PLAURMGHPPLLPLLLLLHTCVPASWGLRCMQCKTNGDCRVEECALGQDLCRTTIVRLWEEGEELELVEKSCTHSEKTNRTLSYRTGLKITSLTEVVCGLDLCNQGNSGRAVTYSRSRYLECISCGSSDMSCERGRHQSLQCRSPEEQCLDVVTHWIQEGEEGRPKDDRHLRGCGYLPGCPGSNGFHNNDTFHFLKCCNTTKCNEGPILELENLPQNGRQCYSCKGNSTHGCSSEETFLIDCRGPMNQCLVATGTHERSLWGSWLPCKSTTALRPPCCEEAQATHV>sp|Q03405-3|UPAR_HUMAN Isoform 3 of Urokinase plasminogen activatorsurface receptor OS=Homo sapiens OX=9606 GN=PLAURMGHPPLLPLLLLLHTCVPASWGLRCMQCKTNGDCRVEECALGQDLCRTTIVRLWEEGEELELVEKSCTHSEKTNRTLSYRTGLKITSLTEVVCGLDLCNQGNSGRAVTYSRSRYLECISCGSSDMSCERGRHQSLQCRSPEEQCLDVVTHWIQEGEEVLELENLPQNGRQCYSCKGNSTHGCSSEETFLIDCRGPMNQCLVATGTHEPKNQSYMVRGCATASMCQHAHLGDAFSMNHIDVSCCTKSGCNHPDLDVQYRSGAAPQPGPAHLSLTITLLMTARLWGGTLLWT>sp|P61081|UBC12_HUMAN NEDD8-conjugating enzyme Ubc12 OS=Homo sapiensOX=9606 GN=UBE2M PE=1 SV=1MIKLFSLKQQKKEEESAGGTKGSSKKASAAQLRIQKDINELNLPKTCDISFSDPDDLLNFKLVICPDEGFYKSGKFVFSFKVGQGYPHDPPKVKCETMVYHPNIDLEGNVCLNILREDWKPVLTINSIIYGLQYLFLEPNPEDPLNKEAAEVLQNNRRLFEQNVQRSMRGGYIGSTYFERCLK>sp|C9J2P7|U17LF_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 15 OS=Homo sapiens OX=9606 GN=USP17L15 PE=3 SV=2MEDDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIDKNVQYPECLDMKLYMSQTNSGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSTTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQWSQWKYRPTRRGAHTHAHTQTHT>sp|O14530|TXND9_HUMAN Thioredoxin domain-containing protein 9 OS=Homosapiens OX=9606 GN=TXNDC9 PE=1 SV=2MEADASVDMFSKVLEHQLLQTTKLVEEHLDSEIQKLDQMDEDELERLKEKRLQALRKAQQQKQEWLSKGHGEYREIPSERDFFQEVKESENVVCHFYRDSTFRCKILDRHLAILSKKHLETKFLKLNVEKAPFLCERLHIKVIPTLALLKDGKTQDYVVGFTDLGNTDDFTTETLEWRLGSSDILNYSGNLMEPPFQNQKKFGTNFTKLEKKTIRGKKYDSDSDDD>sp|O14530-2|TXND9_HUMAN Isoform 2 of Thioredoxin domain-containingprotein 9 OS=Homo sapiens OX=9606 GN=TXNDC9MEADASVDMFSKVLEHQLLQTTKLVEEHLDSEIQKLDQMDEDELERLKEKRLQALRKAQQQKQEWLSKGHGEYREIPSERDFFQEVKESENVVCHFYRDSTFRCKILDRHLAILSKKHLETKFLKLNVEKAPFLCERLHIKVIPTLALLKDGKTQDYVVGFTDLGNTDDFTTETLEWRLGSSDILNYR>sp|P06133|UD2B4_HUMAN UDP-glucuronosyltransferase 2B4 OS=Homo sapiensOX=9606 GN=UGT2B4 PE=1 SV=2MSMKWTSALLLIQLSCYFSSGSCGKVLVWPTEFSHWMNIKTILDELVQRGHEVTVLASSASISFDPNSPSTLKFEVYPVSLTKTEFEDIIKQLVKRWAELPKDTFWSYFSQVQEIMWTFNDILRKFCKDIVSNKKLMKKLQESRFDVVLADAVFPFGELLAELLKIPFVYSLRFSPGYAIEKHSGGLLFPPSYVPVVMSELSDQMTFIERVKNMIYVLYFEFWFQIFDMKKWDQFYSEVLGRPTTLSETMAKADIWLIRNYWDFQFPHPLLPNVEFVGGLHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSMVSNTSEERANVIASALAKIPQKVLWRFDGNKPDTLGLNTRLYKWIPQNDLLGHPKTRAFITHGGANGIYEAIYHGIPMVGVPLFADQPDNIAHMKAKGAAVSLDFHTMSSTDLLNALKTVINDPLYKENAMKLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVTGFLLACVATVIFIITKCLFCVWKFVRTGKKGKRD>sp|P06133-2|UD2B4_HUMAN Isoform 2 of UDP-glucuronosyltransferase 2B4OS=Homo sapiens OX=9606 GN=UGT2B4MFFALLHVSSTNGLDAVFPFGELLAELLKIPFVYSLRFSPGYAIEKHSGGLLFPPSYVPVVMSELSDQMTFIERVKNMIYVLYFEFWFQIFDMKKWDQFYSEVLGRPTTLSETMAKADIWLIRNYWDFQFPHPLLPNVEFVGGLHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSMVSNTSEERANVIASALAKIPQKVLWRFDGNKPDTLGLNTRLYKWIPQNDLLGHPKTRAFITHGGANGIYEAIYHGIPMVGVPLFADQPDNIAHMKAKGAAVSLDFHTMSSTDLLNALKTVINDPLYKENAMKLSRIHHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVTGFLLACVATVIFIITKCLFCVWKFVRTGKKGKRD>sp|P06133-3|UD2B4_HUMAN Isoform 3 of UDP-glucuronosyltransferase 2B4OS=Homo sapiens OX=9606 GN=UGT2B4MSMKWTSALLLIQLSCYFSSGSCGKVLVWPTEFSHWMNIKTILDELVQRGHEVTVLASSASISFDPNSPSTLKFEVYPVSLTKTEFEDIIKQLVKRWAELPKDTFWSYFSQVQEIMWTFNDILRKFCKDIVSNKKLMKKLQESRFDVVLADAVFPFGELLAELLKIPFVYSLRFSPGYAIEKHSGGLLFPPSYVPVVMSELSDQMTFIERVKNMIYVLYFEFWFQIFDMKKWDQFYSEVLGRPTTLSETMAKADIWLIRNYWDFQFPHPLLPNVEFVGGLHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSMVSNTSEERANVIASALAKIPQKVLWRFDGNKPDTLGLNTRLYKWIPQNDLLDIKRML>sp|Q9H3M7|TXNIP_HUMAN Thioredoxin-interacting protein OS=Homo sapiensOX=9606 GN=TXNIP PE=1 SV=1MVMFKKIKSFEVVFNDPEKVYGSGEKVAGRVIVEVCEVTRVKAVRILACGVAKVLWMQGSQQCKQTSEYLRYEDTLLLEDQPTGENEMVIMRPGNKYEYKFGFELPQGPLGTSFKGKYGCVDYWVKAFLDRPSQPTQETKKNFEVVDLVDVNTPDLMAPVSAKKEKKVSCMFIPDGRVSVSARIDRKGFCEGDEISIHADFENTCSRIVVPKAAIVARHTYLANGQTKVLTQKLSSVRGNHIISGTCASWRGKSLRVQKIRPSILGCNILRVEYSLLIYVSVPGSKKVILDLPLVIGSRSGLSSRTSSMASRTSSEMSWVDLNIPDTPEAPPCYMDVIPEDHRLESPTTPLLDDMDGSQDSPIFMYAPEFKFMPPPTYTEVDPCILNNNVQ>sp|Q9H3M7-2|TXNIP_HUMAN Isoform 2 of Thioredoxin-interacting proteinOS=Homo sapiens OX=9606 GN=TXNIPMPPKHSLSHRCILSVTASLMATRFSFPSGENEMVIMRPGNKYEYKFGFELPQGPLGTSFKGKYGCVDYWVKAFLDRPSQPTQETKKNFEVVDLVDVNTPDLMAPVSAKKEKKVSCMFIPDGRVSVSARIDRKGFCEGDEISIHADFENTCSRIVVPKAAIVARHTYLANGQTKVLTQKLSSVRGNHIISGTCASWRGKSLRVQKIRPSILGCNILRVEYSLLIYVSVPGSKKVILDLPLVIGSRSGLSSRTSSMASRTSSEMSWVDLNIPDTPEAPPCYMDVIPEDHRLESPTTPLLDDMDGSQDSPIFMYAPEFKFMPPPTYTEVDPCILNNNVQ>sp|Q9NZI7|UBIP1_HUMAN Upstream-binding protein 1 OS=Homo sapiens OX=9606GN=UBP1 PE=1 SV=1MAWVLKMDEVIESGLVHDFDASLSGIGQELGAGAYSMSDVLALPIFKQEDSSLPLDGETEHPPFQYVMCAATSPAVKLHDETLTYLNQGQSYEIRMLDNRKMGDMPEINGKLVKSIIRVVFHDRRLQYTEHQQLEGWKWNRPGDRLLDLDIPMSVGIIDTRTNPSQLNAVEFLWDPAKRTSAFIQVHCISTEFTPRKHGGEKGVPFRIQVDTFKQNENGEYTDHLHSASCQIKVFKPKGADRKQKTDREKMEKRTAHEKEKYQPSYDTTILTEMRLEPIIEDAVEHEQKKSSKRTLPADYGDSLAKRGSCSPWPDAPTAYVNNSPSPAPTFTSPQQSTCSVPDSNSSSPNHQGDGASQTSGEQIQPSATIQETQQWLLKNRFSSYTRLFSNFSGADLLKLTKEDLVQICGAADGIRLYNSLKSRSVRPRLTIYVCREQPSSTVLQGQQQAASSASENGSGAPYVYHAIYLEEMIASEVARKLALVFNIPLHQINQVYRQGPTGIHILVSDQMVQNFQDESCFLFSTVKAESSDGIHIILK>sp|Q9NZI7-4|UBIP1_HUMAN Isoform 2 of Upstream-binding protein 1 OS=Homosapiens OX=9606 GN=UBP1MAWVLKMDEVIESGLVHDFDASLSGIGQELGAGAYSMSDVLALPIFKQEDSSLPLDGETEHPPFQYVMCAATSPAVKLHDETLTYLNQGQSYEIRMLDNRKMGDMPEINGKLVKSIIRVVFHDRRLQYTEHQQLEGWKWNRPGDRLLDLDIPMSVGIIDTRTNPSQLNAVEFLWDPAKRTSAFIQVHCISTEFTPRKHGGEKGVPFRIQVDTFKQNENGEYTDHLHSASCQIKVFKPKGADRKQKTDREKMEKRTAHEKEKYQPSYDTTILTECSPWPDAPTAYVNNSPSPAPTFTSPQQSTCSVPDSNSSSPNHQGDGASQTSGEQIQPSATIQETQQWLLKNRFSSYTRLFSNFSGADLLKLTKEDLVQICGAADGIRLYNSLKSRSVRPRLTIYVCREQPSSTVLQGQQQAASSASENGSGAPYVYHAIYLEEMIASEVARKLALVFNIPLHQINQVYRQGPTGIHILVSDQMVQNFQDESCFLFSTVKAESSDGIHIILK>sp|Q6ZT12|UBR3_HUMAN E3 ubiquitin-protein ligase UBR3 OS=Homo sapiensOX=9606 GN=UBR3 PE=2 SV=2MAAAAAAAVGGQQPSQPELPAPGLALDKAATAAHLKAALSRPDNRAGAEELQALLERVLSAERPLAAAAGGEDAAAAGGGGGPGAAEEEALEWCKCLLAGGGGYDEFCAAVRAYDPAALCGLVWTANFVAYRCRTCGISPCMSLCAECFHQGDHTGHDFNMFRSQAGGACDCGDSNVMRESGFCKRHQIKSSSNIPCVPKDLLMMSEFVLPRFIFCLIQYLREGYNEPAADGPSEKDLNKVLQLLEPQISFLEDLTKMGGAMRSVLTQVLTNQQNYKDLTSGLGENACVKKSHEKYLIALKSSGLTYPEDKLVYGVQEPSAGTSSLAVQGFIGATGTLGQVDSSDEDDQDGSQGLGKRKRVKLSSGTKDQSIMDVLKHKSFLEELLFWTIKYEFPQKMVTFLLNMLPDQEYKVAFTKTFVQHYAFIMKTLKKSHESDTMSNRIVHISVQLFSNEELARQVTEECQLLDIMVTVLLYMMESCLIKSELQDEENSLHVVVNCGEALLKNNTYWPLVSDFINILSHQSVAKRFLEDHGLLVTWMNFVSFFQGMNLNKRELNEHVEFESQTYYAAFAAELEACAQPMWGLLSHCKVRETQEYTRNVVRYCLEALQDWFDAINFVDEPAPNQVTFHLPLHRYYAMFLSKAVKCQELDLDSVLPDQEMLMKLMIHPLQIQASLAEIHSNMWVRNGLQIKGQAMTYVQSHFCNSMIDPDIYLLQVCASRLDPDYFISSVFERFKVVDLLTMASQHQNTVLDAEHERSMLEGALTFLVILLSLRLHLGMSDDEILRAEMVAQLCMNDRTHSSLLDLIPENPNPKSGIIPGSYSFESVLSAVADFKAPVFEPGGSMQQGMYTPKAEVWDQEFDPVMVILRTVYRRDVQSAMDRYTAFLKQSGKFPGNPWPPYKKRTSLHPSYKGLMRLLHCKTLHIVLFTLLYKILMDHQNLSEHVLCMVLYLIELGLENSAEEESDEEASVGGPERCHDSWFPGSNLVSNMRHFINYVRVRVPETAPEVKRDSPASTSSDNLGSLQNSGTAQVFSLVAERRKKFQEIINRSSSEANQVVRPKTSSKWSAPGSAPQLTTAILEIKESILSLLIKLHHKLSGKQNSYYPPWLDDIEILIQPEIPKYSHGDGITAVERILLKAASQSRMNKRIIEEICRKVTPPVPPKKVTAAEKKTLDKEERRQKARERQQKLLAEFASRQKSFMETAMDVDSPENDIPMEITTAEPQVSEAVYDCVICGQSGPSSEDRPTGLVVLLQASSVLGQCRDNVEPKKLPISEEEQIYPWDTCAAVHDVRLSLLQRYFKDSSCLLAVSIGWEGGVYVQTCGHTLHIDCHKSYMESLRNDQVLQGFSVDKGEFTCPLCRQFANSVLPCYPGSNVENNPWQRPSNKSIQDLIKEVEELQGRPGAFPSETNLSKEMESVMKDIKNTTQKKYRDYSKTPGSPDNDFLFMYSVARTNLELELIHRGGNLCSGGASTAGKRSCLNQLFHVLALHMRLYSIDSEYNPWRKLTQLEEMNPQLGYEEQQPEVPILYHDVTSLLLIQILMMPQPLRKDHFTCIVKVLFTLLYTQALAALSVKCSEEDRSAWKHAGALKKSTCDAEKSYEVLLSFVISELFKGKLYHEEGTQECAMVNPIAWSPESMEKCLQDFCLPFLRITSLLQHHLFGEDLPSCQEEEEFSVLASCLGLLPTFYQTEHPFISASCLDWPVPAFDIITQWCFEIKSFTERHAEQGKALLIQESKWKLPHLLQLPENYNTIFQYYHRKTCSVCTKVPKDPAVCLVCGTFVCLKGLCCKQQSYCECVLHSQNCGAGTGIFLLINASVIIIIRGHRFCLWGSVYLDAHGEEDRDLRRGKPLYICKERYKVLEQQWISHTFDHINKRWGPHYNGL>sp|Q6ZT12-2|UBR3_HUMAN Isoform 2 of E3 ubiquitin-protein ligase UBR3OS=Homo sapiens OX=9606 GN=UBR3MIASKQRQFTEVFRIMSSTFSQSRFLYAAVVTDSPENDIPMEITTAEPQVSEAVYDCVICGQSGPSSEDRPTGLVVLLQASSVLGQCRDNVEPKKLPISEEEQIYPWDTCAAVHDVRLSLLQRYFKDSSCLLAVSIGWEGGVYVQTCGHTLHIDCHKSYMESLRNDQVLQGFSVDKGEFTCPLCRQFANSVLPCYPGSNVENNPWQRPSNKSIQDLIKEVEELQGRPGAFPSETNLSKEMESVMKDIKNTTQKKYRDYSKTPGSPDNDFLFMYSVARTNLELELIHRGGNLCSGGASTAGKRSCLNQLFHVLALHMRLYSIDSEYNPWRKLTQLEEMNPQLGYEEQQPEVPILYHDVTSLLLIQILMMPQPLRKDHFTCIVKVLFTLLYTQALAALSVKCSEEDRSAWKHAGALKKSTCDAEKSYEVLLSFVISELFKGKLYHEEGTQECAMVNPIAWSPESMEKCLQDFCLPFLRITSLLQHHLFGEDLPSCQEEEEFSVLASCLGLLPTFYQTEHPFISASCLDWPVPAFDIITQWCFEIKSFTERHAEQGKALLIQESKWKLPHLLQLPENYNTIFQYYHRKTCSVCTKVPKDPAVCLVCGTFVCLKGLCCKQQSYCECVLHSQNCGAGTGIFLLINASVIIIIRGHRFCLWGSVYLDAHGEEDRDLRRGKPLYICKERYKVLEQQWISHTFDHINKRWGPHYNGL>sp|Q6ZT12-3|UBR3_HUMAN Isoform 3 of E3 ubiquitin-protein ligase UBR3OS=Homo sapiens OX=9606 GN=UBR3MRLYSIDSEYNPWRKLTQLEEMNPQLGYEEQQPEVPILYHDVTSLLLIQILMMPQPLRKDHFTCIVKVLFTLLYTQALAALSVKCSEEDRSAWKHAGALKKSTCDAEKSYEVLLSFVISELFKGKLYHEEGTQECAMVNPIAWSPESMEKCLQDFCLPFLRITSLLQHHLFGEDLPSCQEEEEFSVLASCLGLLPTFYQTEHPFISASCLDWPVPAFDIITQWCFEIKSFTERHAEQGKALLIQESKWKLPHLLQLPENYNTIFQYYHRKTCSVCTKVPKDPAVCLVCGTFVCLKGLCCKQQSYCECVLHSQNCGAGTGIFLLINASVIIIIRGHRFCLWGSVYLDAHGEEDRDLRRGKPLYICKERYKVLEQQWISHTFDHINKRWGPHYNGL>sp|Q6ZT12-4|UBR3_HUMAN Isoform 4 of E3 ubiquitin-protein ligase UBR3OS=Homo sapiens OX=9606 GN=UBR3MAAAAAAAVGGQQPSQPELPAPGLALDKAATAAHLKAALSRPDNRAGAEELQALLERVLSAERPLAAAAGGEDAAAAGGGGGPGAAEEEALEWCKCLLAGGGGYDEFCAAVRAYDPAALCGLVWTANFVAYRCRTCGISPCMSLCAECFHQGDHTGHDFNMFRSQAGGACDCGDSNVMRESGFCKRHQIKSSSNIPCVPKDLLMMSEFVLPRFIFCLIQYLREGYNEPAADGPSEKDLNKVLQLLEPQISFLEDLTKMGGAMRSVLTQVLTNQQNYKDLTSGLGENACVKKSHEKYLIALKSSGLTYPEDKLVYGVQEPSAGTSSLAVQGFIGATGTLGQVDSSDEDDQDGSQGLGKRKRVKLSSGTKDQSIMDVLKHKSFLEELLFWTIKYEFPQKMVTFLLNMLPDQEYKVAFTKTFVQHYAFIMKTLKKSHESDTMSNRIVHISVQLFSNEELARQVTEECQLLDIMVTVLLYMMESCLIKSELQDEENSLHVVVNCGEALLKNNTYWPLVSDFINILSHQSVAKRFLEDHGLLVTWMNFVSFFQGMNLNKRELNEHVEFESQTYYAAFAAELEACAQPMWGLLSHCKVRETQEYTRNVVRYCLEALQDWFDAINFVDEPAPNQVTFHLPLHRYYAMFLSKAVKCQELDLDSVLPDQEMLMKLMIHPLQIQASLAEIHSNMWVRNGLQIKGQAMTYVQSHFCNSMIDPDIYLLQVCASRLDPDYFISSVFERFKVVDLLTMASQHQNTVLDAEHERSMLEGALTFLVILLSLRLHLGMSDDEILRAEMVAQLCMNDRTHSSLLDLIPENPNPKSGIIPGSYSFESVLSAVADFKAPVFEPGGSMQQGMYTPKAEVWDQEFDPVMVILRTVYRRDVQSAMDRYTAFLKQSGKFPGNPWPPYKKRTSLHPSYKGLMRLLHCKTLHIVLFTLLYKILMDHQNLSEHVLCMVLYLIELGLENSAEEESDEEASVGGPERCHDSWFPGSNLVSNMRHFINYVRVRVPETAPEVKRDSPASTSSDNLGSLQNSGTAQVFSLVAERRKKFQEIINRSSSEANQVVRPKTSSKWSAPGSAPQLTTAILEIKESILSLLIKLHHKLSGKQNSYYPPWLDDIEILIQPEIPKYSHGDGITAVERILLKAASQSRMNKRIIEEICRKVTPPVPPKKVTAAEKKTLDKEERRQKARERQQKLLAEFASRQKSFMETAMDVDSPENDIPMEITTAEPQVSEAVYDCVICGQSGPSSEDRPTGLVVLLQASSVLGQCRDNVEPKKLPISEEEQIYPWDTCAAVHDVRLSLLQRYFKDSSCLLAVSIGWEGGVYVQTCGHTLHIDCHKSYMESLRNDQVLQGFSVDKGEFTCPLCRQFANSVLPCYPGSNVENNPWQRPSNKSIQDLIKEVEELQGRPGAFPSETNLSKEMESVMKDIKNTTQKKYRDYSKTPGSPDNDFLFMYSVARTNLELELIHRGGNLCSGGASTAGKRSCLNFCFIISPFTKSEIILCQYRKSHDKVYPKYQLFHVLALHMRLYSIDSEYNPWRKLTQLEEMNPQLGYEEQQPEVPILYHDVTSLLLIQILMMPQPLRKDHFTCIVKVLFTLLYTQALAALSVKCSEEDRSAWKHAGALKKSTCDAEKSYEVLLSFVISELFKGKLYHEEGTQECAMVNPIAWSPESMEKCLQDFCLPFLRITSLLQHHLFGEDLPSCQEEEEFSVLASCLGLLPTFYQTEHPFISASCLDWPVPAFDIITQWCFEIKSFTERHAEQGKALLIQESKWKLPHLLQLPENYNTIFQYYHRKTCSVCTKVPKDPAVCLVCGTFVCLKGLCCKQQSYCECVLHSQNCGAGTGIFLLINASVIIIIRGHRFCLWGSVYLDAHGEEDRDLRRGKPLYICKERYKVLEQQWISHTFDHINKRWGPHYNGL>sp|Q01081|U2AF1_HUMAN Splicing factor U2AF 35 kDa subunit OS=Homosapiens OX=9606 GN=U2AF1 PE=1 SV=3MAEYLASIFGTEKDKVNCSFYFKIGACRHGDRCSRLHNKPTFSQTIALLNIYRNPQNSSQSADGLRCAVSDVEMQEHYDEFFEEVFTEMEEKYGEVEEMNVCDNLGDHLVGNVYVKFRREEDAEKAVIDLNNRWFNGQPIHAELSPVTDFREACCRQYEMGECTRGGFCNFMHLKPISRELRRELYGRRRKKHRSRSRSRERRSRSRDRGRGGGGGGGGGGGGRERDRRRSRDRERSGRF>sp|Q01081-2|U2AF1_HUMAN Isoform 2 of Splicing factor U2AF 35 kDa subunitOS=Homo sapiens OX=9606 GN=U2AF1MAEYLASIFGTEKDKVNCSFYFKIGACRHGDRCSRLHNKPTFSQTILIQNIYRNPQNSAQTADGSHCAVSDVEMQEHYDEFFEEVFTEMEEKYGEVEEMNVCDNLGDHLVGNVYVKFRREEDAEKAVIDLNNRWFNGQPIHAELSPVTDFREACCRQYEMGECTRGGFCNFMHLKPISRELRRELYGRRRKKHRSRSRSRERRSRSRDRGRGGGGGGGGGGGGRERDRRRSRDRERSGRF>sp|Q01081-3|U2AF1_HUMAN Isoform 3 of Splicing factor U2AF 35 kDa subunitOS=Homo sapiens OX=9606 GN=U2AF1MAEYLASIFGTEKDKVNCSFYFKIGACRHGDRCSRLHNKPTFSQTILIQNIYRNPQNSAQTADGSHYHCPLEHLP>sp|Q01081-4|U2AF1_HUMAN Isoform 4 of Splicing factor U2AF 35 kDa subunitOS=Homo sapiens OX=9606 GN=U2AF1MQEHYDEFFEEVFTEMEEKYGEVEEMNVCDNLGDHLVGNVYVKFRREEDAEKAVIDLNNRWFNGQPIHAELSPVTDFREACCRQYEMGECTRGGFCNFMHLKPISRELRRELYGRRRKKHRSRSRSRERRSRSRDRGRGGGGGGGGGGGGRERDRRRSRDRERSGRF>sp|O75445|USH2A_HUMAN Usherin OS=Homo sapiens OX=9606 GN=USH2A PE=1 SV=3MNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKVSIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPNAHSNSASFIFGNHKSCFSSPPSPKLMASFTLAVWLKPEQQGVMCVIEKTVDGQIVFKLTISEKETMFYYRTVNGLQPPIKVMTLGRILVKKWIHLSVQVHQTKISFFINGVEKDHTPFNARTLSGSITDFASGTVQIGQSLNGLEQFVGRMQDFRLYQVALTNREILEVFSGDLLRLHAQSHCRCPGSHPRVHPLAQRYCIPNDAGDTADNRVSRLNPEAHPLSFVNDNDVGTSWVSNVFTNITQLNQGVTISVDLENGQYQVFYIIIQFFSPQPTEIRIQRKKENSLDWEDWQYFARNCGAFGMKNNGDLEKPDSVNCLQLSNFTPYSRGNVTFSILTPGPNYRPGYNNFYNTPSLQEFVKATQIRFHFHGQYYTTETAVNLRHRYYAVDEITISGRCQCHGHADNCDTTSQPYRCLCSQESFTEGLHCDRCLPLYNDKPFRQGDQVYAFNCKPCQCNSHSKSCHYNISVDPFPFEHFRGGGGVCDDCEHNTTGRNCELCKDYFFRQVGADPSAIDVCKPCDCDTVGTRNGSILCDQIGGQCNCKRHVSGRQCNQCQNGFYNLQELDPDGCSPCNCNTSGTVDGDITCHQNSGQCKCKANVIGLRCDHCNFGFKFLRSFNDVGCEPCQCNLHGSVNKFCNPHSGQCECKKEAKGLQCDTCRENFYGLDVTNCKACDCDTAGSLPGTVCNAKTGQCICKPNVEGRQCNKCLEGNFYLRQNNSFLCLPCNCDKTGTINGSLLCNKSTGQCPCKLGVTGLRCNQCEPHRYNLTIDNFQHCQMCECDSLGTLPGTICDPISGQCLCVPNRQGRRCNQCQPGFYISPGNATGCLPCSCHTTGAVNHICNSLTGQCVCQDASIAGQRCDQCKDHYFGFDPQTGRCQPCNCHLSGALNETCHLVTGQCFCKQFVTGSKCDACVPSASHLDVNNLLGCSKTPFQQPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTTEDQYPYSIQYFLDTDLLPYTKYSYYIETTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTWTTLSNQSGPIEKYILSCAPLAGGQPCVSYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTAQAPPQRLSPPKMQKISSTELHVEWSPPAELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFVESANENALKPPQTMTTITGLEPYTKYEFRVLAVNMAGSVSSAWVSERTGESAPVFMIPPSVFPLSSYSLNISWEKPADNVTRGKVVGYDINMLSEQSPQQSIPMAFSQLLHTAKSQELSYTVEGLKPYRIYEFTITLCNSVGCVTSASGAGQTLAAAPAQLRPPLVKGINSTTIHLRWFPPEELNGPSPIYQLERRESSLPALMTTMMKGIRFIGNGYCKFPSSTHPVNTDFTGIKASFRTKVPEGLIVFAASPGNQEEYFALQLKKGRLYFLFDPQGSPVEVTTTNDHGKQYSDGKWHEIIAIRHQAFGQITLDGIYTGSSAILNGSTVIGDNTGVFLGGLPRSYTILRKDPEIIQKGFVGCLKDVHFMKNYNPSAIWEPLDWQSSEEQINVYNSWEGCPASLNEGAQFLGAGFLELHPYMFHGGMNFEISFKFRTDQLNGLLLFVYNKDGPDFLAMELKSGILTFRLNTSLAFTQVDLLLGLSYCNGKWNKVIIKKEGSFISASVNGLMKHASESGDQPLVVNSPVYVGGIPQELLNSYQHLCLEQGFGGCMKDVKFTRGAVVNLASVSSGAVRVNLDGCLSTDSAVNCRGNDSILVYQGKEQSVYEGGLQPFTEYLYRVIASHEGGSVYSDWSRGRTTGAAPQSVPTPSRVRSLNGYSIEVTWDEPVVRGVIEKYILKAYSEDSTRPPRMPSASAEFVNTSNLTGILTGLLPFKNYAVTLTACTLAGCTESSHALNISTPQEAPQEVQPPVAKSLPSSLLLSWNPPKKANGIITQYCLYMDGRLIYSGSEENYIVTDLAVFTPHQFLLSACTHVGCTNSSWVLLYTAQLPPEHVDSPVLTVLDSRTIHIQWKQPRKISGILERYVLYMSNHTHDFTIWSVIYNSTELFQDHMLQYVLPGNKYLIKLGACTGGGCTVSEASEALTDEDIPEGVPAPKAHSYSPDSFNVSWTEPEYPNGVITSYGLYLDGILIHNSSELSYRAYGFAPWSLHSFRVQACTAKGCALGPLVENRTLEAPPEGTVNVFVKTQGSRKAHVRWEAPFRPNGLLTHSVLFTGIFYVDPVGNNYTLLNVTKVMYSGEETNLWVLIDGLVPFTNYTVQVNISNSQGSLITDPITIAMPPGAPDGVLPPRLSSATPTSLQVVWSTPARNNAPGSPRYQLQMRSGDSTHGFLELFSNPSASLSYEVSDLQPYTEYMFRLVASNGFGSAHSSWIPFMTAEDKPGPVVPPILLDVKSRMMLVTWQHPRKSNGVITHYNIYLHGRLYLRTPGNVTNCTVMHLHPYTAYKFQVEACTSKGCSLSPESQTVWTLPGAPEGIPSPELFSDTPTSVIISWQPPTHPNGLVENFTIERRVKGKEEVTTLVTLPRSHSMRFIDKTSALSPWTKYEYRVLMSTLHGGTNSSAWVEVTTRPSRPAGVQPPVVTVLEPDAVQVTWKPPLIQNGDILSYEIHMPDPHITLTNVTSAVLSQKVTHLIPFTNYSVTIVACSGGNGYLGGCTESLPTYVTTHPTVPQNVGPLSVIPLSESYVVISWQPPSKPNGPNLRYELLRRKIQQPLASNPPEDLNRWHNIYSGTQWLYEDKGLSRFTTYEYMLFVHNSVGFTPSREVTVTTLAGLPERGANLTASVLNHTAIDVRWAKPTVQDLQGEVEYYTLFWSSATSNDSLKILPDVNSHVIGHLKPNTEYWIFISVFNGVHSINSAGLHATTCDGEPQGMLPPEVVIINSTAVRVIWTSPSNPNGVVTEYSIYVNNKLYKTGMNVPGSFILRDLSPFTIYDIQVEVCTIYACVKSNGTQITTVEDTPSDIPTPTIRGITSRSLQIDWVSPRKPNGIILGYDLLWKTWYPCAKTQKLVQDQSDELCKAVRCQKPESICGHICYSSEAKVCCNGVLYNPKPGHRCCEEKYIPFVLNSTGVCCGGRIQEAQPNHQCCSGYYARILPGEVCCPDEQHNRVSVGIGDSCCGRMPYSTSGNQICCAGRLHDGHGQKCCGRQIVSNDLECCGGEEGVVYNRLPGMFCCGQDYVNMSDTICCSASSGESKAHIKKNDPVPVKCCETELIPKSQKCCNGVGYNPLKYVCSDKISTGMMMKETKECRILCPASMEATEHCGRCDFNFTSHICTVIRGSHNSTGKASIEEMCSSAEETIHTGSVNTYSYTDVNLKPYMTYEYRISAWNSYGRGLSKAVRARTKEDVPQGVSPPTWTKIDNLEDTIVLNWRKPIQSNGPIIYYILLRNGIERFRGTSLSFSDKEGIQPFQEYSYQLKACTVAGCATSSKVVAATTQGVPESILPPSITALSAVALHLSWSVPEKSNGVIKEYQIRQVGKGLIHTDTTDRRQHTVTGLQPYTNYSFTLTACTSAGCTSSEPFLGQTLQAAPEGVWVTPRHIIINSTTVELYWSLPEKPNGLVSQYQLSRNGNLLFLGGSEEQNFTDKNLEPNSRYTYKLEVKTGGGSSASDDYIVQTPMSTPEEIYPPYNITVIGPYSIFVAWIPPGILIPEIPVEYNVLLNDGSVTPLAFSVGHHQSTLLENLTPFTQYEIRIQACQNGSCGVSSRMFVKTPEAAPMDLNSPVLKALGSACIEIKWMPPEKPNGIIINYFIYRRPAGIEEESVLFVWSEGALEFMDEGDTLRPFTLYEYRVRACNSKGSVESLWSLTQTLEAPPQDFPAPWAQATSAHSVLLNWTKPESPNGIISHYRVVYQERPDDPTFNSPTVHAFTVKGTSHQAHLYGLEPFTTYRIGVVAANHAGEILSPWTLIQTLESSPSGLRNFIVEQKENGRALLLQWSEPMRTNGVIKTYNIFSDGFLEYSGLNRQFLFRRLDPFTLYTLTLEACTRAGCAHSAPQPLWTDEAPPDSQLAPTVHSVKSTSVELSWSEPVNPNGKIIRYEVIRRCFEGKAWGNQTIQADEKIVFTEYNTERNTFMYNDTGLQPWTQCEYKIYTWNSAGHTCSSWNVVRTLQAPPEGLSPPVISYVSMNPQKLLISWIPPEQSNGIIQSYRLQRNEMLYPFSFDPVTFNYTDEELLPFSTYSYALQACTSGGCSTSKPTSITTLEAAPSEVSPPDLWAVSATQMNVCWSPPTVQNGKITKYLVRYDNKESLAGQGLCLLVSHLQPYSQYNFSLVACTNGGCTASVSKSAWTMEALPENMDSPTLQVTGSESIEITWKPPRNPNGQIRSYELRRDGTIVYTGLETRYRDFTLTPGVEYSYTVTASNSQGGILSPLVKDRTSPSAPSGMEPPKLQARGPQEILVNWDPPVRTNGDIINYTLFIRELFERETKIIHINTTHNSFGMQSYIVNQLKPFHRYEIRIQACTTLGCASSDWTFIQTPEIAPLMQPPPHLEVQMAPGGFQPTVSLLWTGPLQPNGKVLYYELYRRQIATQPRKSNPVLIYNGSSTSFIDSELLPFTEYEYQVWAVNSAGKAPSSWTWCRTGPAPPEGLRAPTFHVISSTQAVVNISAPGKPNGIVSLYRLFSSSAHGAETVLSEGMATQQTLHGLQAFTNYSIGVEACTCFNCCSKGPTAELRTHPAPPSGLSSPQIGTLASRTASFRWSPPMFPNGVIHSYELQFHVACPPDSALPCTPSQIETKYTGLGQKASLGGLQPYTTYKLRVVAHNEVGSTASEWISFTTQKELPQYRAPFSVDSNLSVVCVNWSDTFLLNGQLKEYVLTDGGRRVYSGLDTTLYIPRTADKTFFFQVICTTDEGSVKTPLIQYDTSTGLGLVLTTPGKKKGSRSKSTEFYSELWFIVLMAMLGLILLAIFLSLILQRKIHKEPYIRERPPLVPLQKRMSPLNVYPPGENHMGLADTKIPRSGTPVSIRSNRSACVLRIPSQNQTSLTYSQGSLHRSVSQLMDIQDKKVLMDNSLWEAIMGHNSGLYVDEEDLMNAIKDFSSVTKERTTFTDTHL>sp|O75445-2|USH2A_HUMAN Isoform 2 of Usherin OS=Homo sapiens OX=9606GN=USH2AMNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKVSIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPNAHSNSASFIFGNHKSCFSSPPSPKLMASFTLAVWLKPEQQGVMCVIEKTVDGQIVFKLTISEKETMFYYRTVNGLQPPIKVMTLGRILVKKWIHLSVQVHQTKISFFINGVEKDHTPFNARTLSGSITDFASGTVQIGQSLNGLEQFVGRMQDFRLYQVALTNREILEVFSGDLLRLHAQSHCRCPGSHPRVHPLAQRYCIPNDAGDTADNRVSRLNPEAHPLSFVNDNDVGTSWVSNVFTNITQLNQGVTISVDLENGQYQVFYIIIQFFSPQPTEIRIQRKKENSLDWEDWQYFARNCGAFGMKNNGDLEKPDSVNCLQLSNFTPYSRGNVTFSILTPGPNYRPGYNNFYNTPSLQEFVKATQIRFHFHGQYYTTETAVNLRHRYYAVDEITISGRCQCHGHADNCDTTSQPYRCLCSQESFTEGLHCDRCLPLYNDKPFRQGDQVYAFNCKPCQCNSHSKSCHYNISVDPFPFEHFRGGGGVCDDCEHNTTGRNCELCKDYFFRQVGADPSAIDVCKPCDCDTVGTRNGSILCDQIGGQCNCKRHVSGRQCNQCQNGFYNLQELDPDGCSPCNCNTSGTVDGDITCHQNSGQCKCKANVIGLRCDHCNFGFKFLRSFNDVGCEPCQCNLHGSVNKFCNPHSGQCECKKEAKGLQCDTCRENFYGLDVTNCKACDCDTAGSLPGTVCNAKTGQCICKPNVEGRQCNKCLEGNFYLRQNNSFLCLPCNCDKTGTINGSLLCNKSTGQCPCKLGVTGLRCNQCEPHRYNLTIDNFQHCQMCECDSLGTLPGTICDPISGQCLCVPNRQGRRCNQCQPGFYISPGNATGCLPCSCHTTGAVNHICNSLTGQCVCQDASIAGQRCDQCKDHYFGFDPQTGRCQPCNCHLSGALNETCHLVTGQCFCKQFVTGSKCDACVPSASHLDVNNLLGCSKTPFQQPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTTEDQYPYSIQYFLDTDLLPYTKYSYYIETTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTWTTLSNQSGPIEKYILSCAPLAGGQPCVSYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTAQAPPQRLSPPKMQKISSTELHVEWSPPAELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFVESANENALKPPQTMTTITGLEPYTKYEFRVLAVNMAGSVSSAWVSERTGESAPVFMIPPSVFPLSSYSLNISWEKPADNVTRGKVVGYDINMLSEQSPQQSIPMAFSQLLHTAKSQELSYTVEGLKPYRIYEFTITLCNSVGCVTSASGAGQTLAAAPAQLRPPLVKGINSTTIHLRWFPPEELNGPSPIYQLERRESSLPALMTTMMKGIRFIGNGYCKFPSSTHPVNTDFTGKCV>sp|O75445-3|USH2A_HUMAN Isoform 3 of Usherin OS=Homo sapiens OX=9606GN=USH2AMNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKVSIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPNAHSNSASFIFGNHKSCFSSPPSPKLMASFTLAVWLKPEQQGVMCVIEKTVDGQIVFKLTISEKETMFYYRTVNGLQPPIKVMTLGRILVKKWIHLSVQVHQTKISFFINGVEKDHTPFNARTLSGSITDFASGTVQIGQSLNGLEQFVGRMQDFRLYQVALTNREILEVFSGDLLRLHAQSHCRCPGSHPRVHPLAQRYCIPNDAGDTADNRVSRLNPEAHPLSFVNDNDVGTSWVSNVFTNITQLNQGVTISVDLENGQYQVFYIIIQFFSPQPTEIRIQRKKENSLDWEDWQYFARNCGAFGMKNNGDLEKPDSVNCLQLSNFTPYSRGNVTFSILTPGPNYRPGYNNFYNTPSLQEFVKATQIRFHFHGQYYTTETAVNLRHRYYAVDEITISGRCQCHGHADNCDTTSQPYRCLCSQESFTEGLHCDRCLPLYNDKPFRQGDQVYAFNCKPCQCNSHSKSCHYNISVDPFPFEHFRGGGGVCDDCEHNTTGRNCELCKDYFFRQVGADPSAIDVCKPCDCDTVGTRNGSILCDQIGGQCNCKRHVSGRQCNQCQNGFYNLQELDPDGCSPCNCNTSGTVDGDITCHQNSGQCKCKANVIGLRCDHCNFGFKFLRSFNDVGCEPCQCNLHGSVNKFCNPHSGQCECKKEAKGLQCDTCRENFYGLDVTNCKACDCDTAGSLPGTVCNAKTGQCICKPNVEGRQCNKCLEGNFYLRQNNSFLCLPCNCDKTGTINGSLLCNKSTGQCPCKLGVTGLRCNQCEPHRYNLTIDNFQHCQMCECDSLGTLPGTICDPISGQCLCVPNRQGRRCNQCQPGFYISPGNATGCLPCSCHTTGAVNHICNSLTGQCVCQDASIAGQRCDQCKDHYFGFDPQTGRCQPCNCHLSGALNETCHLVTGQCFCKQFVTGSKCDACVPSASHLDVNNLLGCSKTPFQQPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTTEDQYPYSIQYFLDTDLLPYTKYSYYIETTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTWTTLSNQSGPIEKYILSCAPLAGGQPCVSYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTAQAPPQRLSPPKMQKISSTELHVEWSPPAELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFVESANENALKPPQTMTTITGLEPYTKYEFRVLAVNMAGSVSSAWVSERTGESAPVFMIPPSVFPLSSYSLNISWEKPADNVTRGKVVGYDINMLSEQSPQQSIPMAFSQLLHTAKSQELSYTVEGLKPYRIYEFTITLCNSVGCVTSASGAGQTLAAAPAQLRPPLVKGINSTTIHLRWFPPEELNGPSPIYQLERRESSLPALMTTMMKGIRFIGNGYCKFPSSTHPVNTDFTGIKASFRTKVPEGLIVFAASPGNQEEYFALQLKKGRLYFLFDPQGSPVEVTTTNDHGKQYSDGKWHEIIAIRHQAFGQITLDGIYTGSSAILNGSTVIGDNTGVFLGGLPRSYTILRKDPEIIQKGFVGCLKDVHFMKNYNPSAIWEPLDWQSSEEQINVYNSWEGCPASLNEGAQFLGAGFLELHPYMFHGGMNFEISFKFRTDQLNGLLLFVYNKDGPDFLAMELKSGILTFRLNTSLAFTQVDLLLGLSYCNGKWNKVIIKKEGSFISASVNGLMKHASESGDQPLVVNSPVYVGGIPQELLNSYQHLCLEQGFGGCMKDVKFTRGAVVNLASVSSGAVRVNLDGCLSTDSAVNCRGNDSILVYQGKEQSVYEGGLQPFTEYLYRVIASHEGGSVYSDWSRGRTTGAAPQSVPTPSRVRSLNGYSIEVTWDEPVVRGVIEKYILKAYSEDSTRPPRMPSASAEFVNTSNLTGILTGLLPFKNYAVTLTACTLAGCTESSHALNISTPQEAPQEVQPPVAKSLPSSLLLSWNPPKKANGIITQYCLYMDGRLIYSGSEENYIVTDLAVFTPHQFLLSACTHVGCTNSSWVLLYTAQLPPEHVDSPVLTVLDSRTIHIQWKQPRKISGILERYVLYMSNHTHDFTIWSVIYNSTELFQDHMLQYVLPGNKYLIKLGACTGGGCTVSEASEALTDEDIPEGVPAPKAHSYSPDSFNVSWTEPEYPNGVITSYGLYLDGILIHNSSELSYRAYGFAPWSLHSFRVQACTAKGCALGPLVENRTLEAPPEGTVNVFVKTQGSRKAHVRWEAPFRPNGLLTHSVLFTGIFYVDPVGNNYTLLNVTKVMYSGEETNLWVLIDGLVPFTNYTVQVNISNSQGSLITDPITIAMPPGAPDGVLPPRLSSATPTSLQVVWSTPARNNAPGSPRYQLQMRSGDSTHGFLELFSNPSASLSYEVSDLQPYTEYMFRLVASNGFGSAHSSWIPFMTAEDKPGPVVPPILLDVKSRMMLVTWQHPRKSNGVITHYNIYLHGRLYLRTPGNVTNCTVMHLHPYTAYKFQVEACTSKGCSLSPESQTVWTLPGAPEGIPSPELFSDTPTSVIISWQPPTHPNGLVENFTIERRVKGKEEVTTLVTLPRSHSMRFIDKTSALSPWTKYEYRVLMSTLHGGTNSSAWVEVTTRPSRPAGVQPPVVTVLEPDAVQVTWKPPLIQNGDILSYEIHMPDPHITLTNVTSAVLSQKVTHLIPFTNYSVTIVACSGGNGYLGGCTESLPTYVTTHPTVPQNVGPLSVIPLSESYVVISWQPPSKPNGPNLRYELLRRKIQQPLASNPPEDLNRWHNIYSGTQWLYEDKGLSRFTTYEYMLFVHNSVGFTPSREVTVTTLAGLPERGANLTASVLNHTAIDVRWAKPTVQDLQGEVEYYTLFWSSATSNDSLKILPDVNSHVIGHLKPNTEYWIFISVFNGVHSINSAGLHATTCDGEPQGMLPPEVVIINSTAVRVIWTSPSNPNGVVTEYSIYVNNKLYKTGMNVPGSFILRDLSPFTIYDIQVEVCTIYACVKSNGTQITTVEDTPSDIPTPTIRGITSRSLQIDWVSPRKPNGIILGYDLLWKTWYPCAKTQKLVQDQSDELCKAVRCQKPESICGHICYSSEAKVCCNGVLYNPKPGHRCCEEKYIPFVLNSTGVCCGGRIQEAQPNHQCCSGYYARILPGEVCCPDEQHNRVSVGIGDSCCGRMPYSTSGNQICCAGRLHDGHGQKCCGRQIVSNDLECCGGEEGVVYNRLPGMFCCGQDYVNMSDTICCSASSGESKAHIKKNDPVPVKCCETELIPKSQKCCNGVGYNPLKYVCSDKISTGMMMKETKECRILCPASMEATEHCGRCDFNFTSHICTVIRGSHNSTGKASIEEMCSSAEETIHTGSVNTYSYTDVNLKPYMTYEYRISAWNSYGRGLSKAVRARTKEDVPQGVSPPTWTKIDNLEDTIVLNWRKPIQSNGPIIYYILLRNGIERFRGTSLSFSDKEGIQPFQEYSYQLKACTVAGCATSSKVVAATTQGVPESILPPSITALSAVALHLSWSVPEKSNGVIKEYQIRQVGKGLIHTDTTDRRQHTVTGLQPYTNYSFTLTACTSAGCTSSEPFLGQTLQAAPEGVWVTPRHIIINSTTVELYWSLPEKPNGLVSQYQLSRNGNLLFLGGSEEQNFTDKNLEPNSRYTYKLEVKTGGGSSASDDYIVQTPMSTPEEIYPPYNITVIGPYSIFVAWIPPGILIPEIPVEYNVLLNDGSVTPLAFSVGHHQSTLLENLTPFTQYEIRIQACQNGSCGVSSRMFVKTPEAAPMDLNSPVLKALGSACIEIKWMPPEKPNGIIINYFIYRRPAGIEEESVLFVWSEGALEFMDEGDTLRPFTLYEYRVRACNSKGSVESLWSLTQTLEAPPQDFPAPWAQATSAHSVLLNWTKPESPNGIISHYRVVYQERPDDPTFNSPTVHAFTVKGTSHQAHLYGLEPFTTYRIGVVAANHAGEILSPWTLIQTLESSPSGLRNFIVEQKENGRALLLQWSEPMRTNGVIKTYNIFSDGFLEYSGLNRQFLFRRLDPFTLYTLTLEACTRAGCAHSAPQPLWTDEAPPDSQLAPTVHSVKSTSVELSWSEPVNPNGKIIRYEVIRRCFEGKAWGNQTIQADEKIVFTEYNTERNTFMYNDTGLQPWTQCEYKIYTWNSAGHTCSSWNVVRTLQAPPEGLSPPVISYVSMNPQKLLISWIPPEQSNGIIQSYRLQRNEMLYPFSFDPVTFNYTDEELLPFSTYSYALQACTSGGCSTSKPTSITTLEAAPSEVSPPDLWAVSATQMNVCWSPPTVQNGKITKYLVRYDNKESLAGQGLCLLVSHLQPYSQYNFSLVACTNGGCTASVSKSAWTMEALPENMDSPTLQVTGSESIEITWKPPRNPNGQIRSYELRRDGTIVYTGLETRYRDFTLTPGVEYSYTVTASNSQGGILSPLVKDRTSPSAPSGMEPPKLQARGPQEILVNWDPPVRTNGDIINYTLFIRELFERETKIIHINTTHNSFGMQSYIVNQLKPFHRYEIRIQACTTLGCASSDWTFIQTPEIAPLMQPPPHLEVQMAPGGFQPTVSLLWTGPLQPNGKVLYYELYRRQIATQPRKSNPVLIYNGSSTSFIDSELLPFTEYEYQVWAVNSAGKAPSSWTWCRTGPAPPEGLRAPTFHVISSTQAVVNISAPGKPNGIVSLYRLFSSSAHGAETVLSEGMATQQTLHGLQAFTNYSIGVEACTCFNCCSKGPTAELRTHPAPPSGLSSPQIGTLASRTASFRWSPPMFPNGVIHSYELQFHVACPPDSALPCTPSQIETKYTGLGQKASLGGLQPYTTYKLRVVAHNEVGSTASEWISFTTQKELPQYRAPFSVDSNLSVVCVNWSDTFLLNGQLKEYVLTDGGRRVYSGLDTTLYIPRTADKTFFFQVICTTDEGSVKTPLIQYDTSTGLGLVLTTPGKKKGSRSKSTEFYSELWFIVLMAMLGLILLAIFLSLILQRKIHKEPYIRERPPLVPLQKRMSPLNVYPPGENHMFDSVADISDVSSNVTLKSYTMHFEGLADTKIPRSGTPVSIRSNRSACVLRIPSQNQTSLTYSQGSLHRSVSQLMDIQDKKVLMDNSLWEAIMGHNSGLYVDEEDLMNAIKDFSSVTKERTTFTDTHL>sp|Q68DE3|USF3_HUMAN Basic helix-loop-helix domain-containing proteinUSF3 OS=Homo sapiens OX=9606 GN=USF3 PE=1 SV=4MPEMTENETPTKKQHRKKNRETHNAVERHRKKKINAGINRIGELIPCSPALKQSKNMILDQAFKYITELKRQNDELLLNGGNNEQAEEIKKLRKQLEEIQKENGRYIELLKANDICLYDDPTIHWKGNLKNSKVSVVIPSDQVQKKIIVYSNGNQPGGNSQGTAVQGITFNVSHNLQKQTANVVPVQRTCNLVTPVSISGVYPSENKPWHQTTVPALATNQPVPLCLPAAISAQSILELPTSESESNVLGATSGSLIAVSIESEPHQHHSLHTCLNDQNSSENKNGQENPKVLKKMTPCVTNIPHSSSATATKVHHGNKSCLSIQDFRGDFQNTFVVSVTTTVCSQPPRTAGDSSPMSISKSADLTSTATVVASSAPGVGKATIPISTLSGNPLDNGWTLSCSLPSSSVSTSDLKNINSLTRISSAGNTQTTWTTLQLAGNTIQPLSQTPSSAVTPVLNESGTSPTTSNHSRYVATDINLNNSFPADGQPVEQVVVTLPSCPSLPMQPLIAQPQVKSQPPKNILPLNSAMQVIQMAQPVGSAVNSAPTNQNVIILQPPSTTPCPTVMRAEVSNQTVGQQIVIIQAANQNPLPLLPAPPPGSVRLPINGANTVIGSNNSVQNVPTPQTFGGKHLVHILPRPSSLSASNSTQTFSVTMSNQQPQTISLNGQLFALQPVMSSSGTTNQTPMQIIQPTTSEDPNTNVALNTFGALASLNQSISQMAGQSCVQLSISQPANSQTAANSQTTTANCVSLTTTAAPPVTTDSSATLASTYNLVSTSSMNTVACLPNMKSKRLNKKPGGRKHLAANKSACPLNSVRDVSKLDCPNTEGSAEPPCNDGLLESFPAVLPSVSVSQANSVSVSASHSLGVLSSESLIPESVSKSKSAEKSSPPSQESVTSEHFAMAAAKSKDSTPNLQQETSQDKPPSSLALSDAAKPCASANVLIPSPSDPHILVSQVPGLSSTTSTTSTDCVSEVEIIAEPCRVEQDSSDTMQTTGLLKGQGLTTLLSDLAKKKNPQKSSLSDQMDHPDFSSENPKIVDSSVNLHPKQELLLMNNDDRDPPQHHSCLPDQEVINGSLINGRQADSPMSTSSGSSRSFSVASMLPETTREDVTSNATTNTCDSCTFVEQTDIVALAARAIFDQENLEKGRVGLQADIREVASKPSEASLLEGDPPFKSQIPKESGTGQAEATPNEFNSQGSIEATMERPLEKPSCSLGIKTSNASLQDSTSQPPSITSLSVNNLIHQSSISHPLASCAGLSPTSEQTTVPATVNLTVSSSSYGSQPPGPSLMTEYSQEQLNTMTSTIPNSQIQEPLLKPSHESRKDSAKRAVQDDLLLSSAKRQKHCQPAPLRLESMSLMSRTPDTISDQTQMMVSQIPPNSSNSVVPVSNPAHGDGLTRLFPPSNNFVTPALRQTEVQCGSQPSVAEQQQTQASQHLQALQQHVPAQGVSHLHSNHLYIKQQQQQQQQQQQQQQQQQAGQLRERHHLYQMQHHVPHAESSVHSQPHNVHQQRTLQQEVQMQKKRNLVQGTQTSQLSLQPKHHGTDQSRSKTGQPHPHHQQMQQQMQQHFGSSQTEKSCENPSTSRNHHNHPQNHLNQDIMHQQQDVGSRQQGSGVSSEHVSGHNPMQRLLTSRGLEQQMVSQPSIVTRSSDMTCTPHRPERNRVSSYSAEALIGKTSSNSEQRMGISIQGSRVSDQLEMRSYLDVPRNKSLAIHNMQGRVDHTVASDIRLSDCQTFKPSGASQQPQSNFEVQSSRNNEIGNPVSSLRSMQSQAFRISQNTGPPPIDRQKRLSYPPVQSIPTGNGIPSRDSENTCHQSFMQSLLAPHLSDQVIGSQRSLSEHQRNTQCGPSSAIEYNCPPTHENVHIRRESESQNRESCDMSLGAINTRNSTLNIPFSSSSSSGDIQGRNTSPNVSVQKSNPMRITESHATKGHMNPPVTTNMHGVARPALPHPSVSHGNGDQGPAVRQANSSVPQRSRHPLQDSSGSKIRQPERNRSGNQRQSTVFDPSLPHLPLSTGGSMILGRQQPATEKRGSIVRFMPDSPQVPNDNSGPDQHTLSQNFGFSFIPEGGMNPPINANASFIPQVTQPSATRTPALIPVDPQNTLPSFYPPYSPAHPTLSNDISIPYFPNQMFSNPSTEKVNSGSLNNRFGSILSPPRPVGFAQPSFPLLPDMPPMHMTNSHLSNFNMTSLFPEIATALPDGSAMSPLLTIANSSASDSSKQSSNRPAHNISHILGHDCSSAV>sp|P63027|VAMP2_HUMAN Vesicle-associated membrane protein 2 OS=Homosapiens OX=9606 GN=VAMP2 PE=1 SV=3MSATAATAPPAAPAGEGGPPAPPPNLTSNRRLQQTQAQVDEVVDIMRVNVDKVLERDQKLSELDDRADALQAGASQFETSAAKLKRKYWWKNLKMMIILGVICAIILIIIIVYFST>sp|P49767|VEGFC_HUMAN Vascular endothelial growth factor C OS=Homosapiens OX=9606 GN=VEGFC PE=1 SV=1MHLLGFFSVACSLLAAALLPGPREAPAAAAAFESGLDLSDAEPDAGEATAYASKDLEEQLRSVSSVDELMTVLYPEYWKMYKCQLRKGGWQHNREQANLNSRTEETIKFAAAHYNTEILKSIDNEWRKTQCMPREVCIDVGKEFGVATNTFFKPPCVSVYRCGGCCNSEGLQCMNTSTSYLSKTLFEITVPLSQGPKPVTISFANHTSCRCMSKLDVYRQVHSIIRRSLPATLPQCQAANKTCPTNYMWNNHICRCLAQEDFMFSSDAGDDSTDGFHDICGPNKELDEETCQCVCRAGLRPASCGPHKELDRNSCQCVCKNKLFPSQCGANREFDENTCQCVCKRTCPRNQPLNPGKCACECTESPQKCLLKGKKFHHQTCSCYRRPCTNRQKACEPGFSYSEEVCRCVPSYWKRPQMS>sp|O75695|XRP2_HUMAN Protein XRP2 OS=Homo sapiens OX=9606 GN=RP2 PE=1SV=4MGCFFSKRRKADKESRPENEEERPKQYSWDQREKVDPKDYMFSGLKDETVGRLPGTVAGQQFLIQDCENCNIYIFDHSATVTIDDCTNCIIFLGPVKGSVFFRNCRDCKCTLACQQFRVRDCRKLEVFLCCATQPIIESSSNIKFGCFQWYYPELAFQFKDAGLSIFNNTWSNIHDFTPVSGELNWSLLPEDAVVQDYVPIPTTEELKAVRVSTEANRSIVPISRGQRQKSSDESCLVVLFAGDYTIANARKLIDEMVGKGFFLVQTKEVSMKAEDAQRVFREKAPDFLPLLNKGPVIALEFNGDGAVEVCQLIVNEIFNGTKMFVSESKETASGDVDSFYNFADIQMGI>sp|Q05940|VMAT2_HUMAN Synaptic vesicular amine transporter OS=Homosapiens OX=9606 GN=SLC18A2 PE=1 SV=2MALSELALVRWLQESRRSRKLILFIVFLALLLDNMLLTVVVPIIPSYLYSIKHEKNATEIQTARPVHTASISDSFQSIFSYYDNSTMVTGNATRDLTLHQTATQHMVTNASAVPSDCPSEDKDLLNENVQVGLLFASKATVQLITNPFIGLLTNRIGYPIPIFAGFCIMFVSTIMFAFSSSYAFLLIARSLQGIGSSCSSVAGMGMLASVYTDDEERGNVMGIALGGLAMGVLVGPPFGSVLYEFVGKTAPFLVLAALVLLDGAIQLFVLQPSRVQPESQKGTPLTTLLKDPYILIAAGSICFANMGIAMLEPALPIWMMETMCSRKWQLGVAFLPASISYLIGTNIFGILAHKMGRWLCALLGMIIVGVSILCIPFAKNIYGLIAPNFGVGFAIGMVDSSMMPIMGYLVDLRHVSVYGSVYAIADVAFCMGYAIGPSAGGAIAKAIGFPWLMTIIGIIDILFAPLCFFLRSPPAKEEKMAILMDHNCPIKTKMYTQNNIQSYPIGEDEESESD>sp|Q05940-2|VMAT2_HUMAN Isoform 2 of Synaptic vesicular aminetransporter OS=Homo sapiens OX=9606 GN=SLC18A2MALSELALVRWLQESRRSRKLILFIVFLALLLDNMLLTVVVPIIPSYLYSIKHEKNATEIQTARPVHTASISDSFQSIFSYYDNSTMVTGNATRDLTLHQTATQHMVTNASAVPSDCPSEDKDLLNENVQVGLLFASKATVQLITNPFIGLLTNRIGYPIPIFAGFCIMFVSTIMFAFSSSYAFLLIARSLQGIGSSCSSVAGRCGMPE>sp|Q5GH76|XKR4_HUMAN XK-related protein 4 OS=Homo sapiens OX=9606GN=XKR4 PE=1 SV=1MAAKSDGRLKMKKSSDVAFTPLQNSDHSGSVQGLAPGLPSGSGAEDEEAAGGGCCPDGGGCSRCCCCCAGSGGSAGSGGSGGVAGPGGGGAGSAALCLRLGREQRRYSLWDCLWILAAVAVYFADVGTDVWLAVDYYLRGQRWWFGLTLFFVVLGSLSVQVFSFRWFVHDFSTEDSATAAAASSCPQPGADCKTVVGGGSAAGEGEARPSTPQRQASNASKSNIAAANSGSNSSGATRASGKHRSASCSFCIWLLQSLIHILQLGQIWRYFHTIYLGIRSRQSGENDRWRFYWKMVYEYADVSMLHLLATFLESAPQLVLQLCIIVQTHSLQALQGFTAAASLVSLAWALASYQKALRDSRDDKKPISYMAVIIQFCWHFFTIAARVITFALFASVFQLYFGIFIVLHWCIMTFWIVHCETEFCITKWEEIVFDMVVGIIYIFSWFNVKEGRTRCRLFIYYFVILLENTALSALWYLYKAPQIADAFAIPALCVVFSSFLTGVVFMLMYYAFFHPNGPRFGQSPSCACEDPAAAFTLPPDVATSTLRSISNNRSVVSDRDQKFAERDGCVPVFQVRPTAPSTPSSRPPRIEESVIKIDLFRNRYPAWERHVLDRSLRKAILAFECSPSPPRLQYKDDALIQERLEYETTL>sp|Q6P4I2|WDR73_HUMAN WD repeat-containing protein 73 OS=Homo sapiensOX=9606 GN=WDR73 PE=1 SV=1MDPGDDWLVESLRLYQDFYAFDLSGATRVLEWIDDKGVFVAGYESLKKNEILHLKLPLRLSVKENKGLFPERDFKVRHGGFSDRSIFDLKHVPHTRLLVTSGLPGCYLQVWQVAEDSDVIKAVSTIAVHEKEESLWPRVAVFSTLAPGVLHGARLRSLQVVDLESRKTTYTSDVSDSEELSSLQVLDADTFAFCCASGRLGLVDTRQKWAPLENRSPGPGSGGERWCAEVGSWGQGPGPSIASLGSDGRLCLLDPRDLCHPVSSVQCPVSVPSPDPELLRVTWAPGLKNCLAISGFDGTVQVYDATSWDGTRSQDGTRSQVEPLFTHRGHIFLDGNGMDPAPLVTTHTWHPCRPRTLLSATNDASLHVWDWVDLCAPR>sp|Q6UXR8|YS001_HUMAN Putative uncharacterized protein UNQ6493/PRO21345OS=Homo sapiens OX=9606 GN=UNQ6493/PRO21345 PE=5 SV=1MEPWWPRGTGANAPWVLVAVPPGLFPSLLGACCTLTSSSWLQPRFWGLGWRVEVGLEGAGGSSQNYQAALPSFFCLAASPASRPAIFGILAAEPPSASPQAPWPKPGCASPHGSHWPSILIC>sp|Q6P9A1|ZN530_HUMAN Zinc finger protein 530 OS=Homo sapiens OX=9606GN=ZNF530 PE=2 SV=2MAAALRAPTQQVFVAFEDVAIYFSQEEWELLDEMQRLLYRDVMLENFAVMASLGCWCGAVDEGTPSAESVSVEELSQGRTPKADTSTDKSHPCEICTPVLRDILQMIELHASPCGQKLYLGGASRDFWMSSNLHQLQKLDNGEKLFKVDGDQASFMMNCRFHVSGKPFTFGEVGRDFSATSGLLQHQVTPTIERPHSRIRHLRVPTGRKPLKYTESRKSFREKSVFIQHQRADSGERPYKCSECGKSFSQSSGFLRHRKAHGRTRTHECSECGKSFSRKTHLTQHQRVHTGERPYDCSECGKSFRQVSVLIQHQRVHTGERPYECSECGKSFSHSTNLYRHRSAHTSTRPYECSECGKSFSHSTNLFRHWRVHTGVRPYECSECGKAFSCNIYLIHHQRFHTGERPYVCSECGKSFGQKSVLIQHQRVHTGERPYECSECGKVFSQSSGLFRHRRAHTKTKPYECSECEKSFSCKTDLIRHQTVHTGERPYECSVCGKSFIRKTHLIRHQTVHTNERPYECDECGKSYSQSSALLQHRRVHTGERPYECRECGKSFTRKNHLIQHKTVHTGERPYECSECGKSFSQSSGLLRHRRVHVQ>sp|Q8IZC7|ZN101_HUMAN Zinc finger protein 101 OS=Homo sapiens OX=9606GN=ZNF101 PE=1 SV=1MDSVAFEDVAVNFTQEEWALLSPSQKNLYRDVTLETFRNLASVGIQWKDQDIENLYQNLGIKLRSLVERLCGRKEGNEHRETFSQIPDCHLNKKSQTGVKPCKCSVCGKVFLRHSFLDRHMRAHAGHKRSECGGEWRETPRKQKQHGKASISPSSGARRTVTPTRKRPYECKVCGKAFNSPNLFQIHQRTHTGKRSYKCREIVRAFTVSSFFRKHGKMHTGEKRYECKYCGKPIDYPSLFQIHVRTHTGEKPYKCKQCGKAFISAGYLRTHEIRSHALEKSHQCQECGKKLSCSSSLHRHERTHSGGKLYECQKCAKVFRCPTSLQAHERAHTGERPYECNKCGKTFNYPSCFRRHKKTHSGEKPYECTRCGKAFGWCSSLRRHEMTHTGEKPFDCKQCGKVFTFSNYLRLHERTHLAGRSQCFGRRQGDHLSPGV>sp|Q8IZC7-2|ZN101_HUMAN Isoform 2 of Zinc finger protein 101 OS=Homosapiens OX=9606 GN=ZNF101MRAHAGHKRSECGGEWRETPRKQKQHGKASISPSSGARRTVTPTRKRPYECKVCGKAFNSPNLFQIHQRTHTGKRSYKCREIVRAFTVSSFFRKHGKMHTGEKRYECKYCGKPIDYPSLFQIHVRTHTGEKPYKCKQCGKAFISAGYLRTHEIRSHALEKSHQCQECGKKLSCSSSLHRHERTHSGGKLYECQKCAKVFRCPTSLQAHERAHTGERPYECNKCGKTFNYPSCFRRHKKTHSGEKPYECTRCGKAFGWCSSLRRHEMTHTGEKPFDCKQCGKVFTFSNYLRLHERTHLAGRSQCFGRRQGDHLSPGV>sp|Q13105|ZBT17_HUMAN Zinc finger and BTB domain-containing protein 17OS=Homo sapiens OX=9606 GN=ZBTB17 PE=1 SV=3MDFPQHSQHVLEQLNQQRQLGLLCDCTFVVDGVHFKAHKAVLAACSEYFKMLFVDQKDVVHLDISNAAGLGQVLEFMYTAKLSLSPENVDDVLAVATFLQMQDIITACHALKSLAEPATSPGGNAEALATEGGDKRAKEEKVATSTLSRLEQAGRSTPIGPSRDLKEERGGQAQSAASGAEQTEKADAPREPPPVELKPDPTSGMAAAEAEAALSESSEQEMEVEPARKGEEEQKEQEEQEEEGAGPAEVKEEGSQLENGEAPEENENEESAGTDSGQELGSEARGLRSGTYGDRTESKAYGSVIHKCEDCGKEFTHTGNFKRHIRIHTGEKPFSCRECSKAFSDPAACKAHEKTHSPLKPYGCEECGKSYRLISLLNLHKKRHSGEARYRCEDCGKLFTTSGNLKRHQLVHSGEKPYQCDYCGRSFSDPTSKMRHLETHDTDKEHKCPHCDKKFNQVGNLKAHLKIHIADGPLKCRECGKQFTTSGNLKRHLRIHSGEKPYVCIHCQRQFADPGALQRHVRIHTGEKPCQCVMCGKAFTQASSLIAHVRQHTGEKPYVCERCGKRFVQSSQLANHIRHHDNIRPHKCSVCSKAFVNVGDLSKHIIIHTGEKPYLCDKCGRGFNRVDNLRSHVKTVHQGKAGIKILEPEEGSEVSVVTVDDMVTLATEALAATAVTQLTVVPVGAAVTADETEVLKAEISKAVKQVQEEDPNTHILYACDSCGDKFLDANSLAQHVRIHTAQALVMFQTDADFYQQYGPGGTWPAGQVLQAGELVFRPRDGAEGQPALAETSPTAPECPPPAE>sp|Q13105-2|ZBT17_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 17 OS=Homo sapiens OX=9606 GN=ZBTB17MDFPQHSQHVLEQLNQQRQLGLLCDCTFVVDGVHFKAHKAVLAACSEYFKMLFVDQKDVVHLDISNAAGLGQVLEFMYTAKLSLSPENVDDVLAVATFLQMQDIITACHALKSLAEPATSPGGNAEALATEGGDKRAKEEKVATSTLSRLEQAGRSTPIGPSRDLKEERGGQAQSAASGAEQTEKADAPREPPPVELKPDPTSGMAAAEAEAALSESSEQEMEVEPARKGEEEQKEQEEQEEEGAGPAEVKEEGSQLENGEAPEENENEESAGTDSGQELGSEARGLRSGTYGDRTESKAYGSVIHKCEDCGKEFTHTGNFKRHIRIHTGEKPFSCRECSKAFSDPAACKAHEKTHSPLKPYGCEECGKSYRLISLLNLHKKRHSGEARYRCEDCGKLFTTSGNLKRHQLVHSGEKPYQCDYCGRSFSDPTSKMRHLETHDTDKEHKCPHCDKKFNQVGNLKAHLKIHIADGPLKCRECGKQFTTSGNLKRHLRIHSGEKPYVCIHCQRQFADPGALQRHVRIHTGEKPCQCVMCGKAFTQASSLIAHVRQHTGEKPYVCERCGKRFVQSSQLANHIRHHDNIRPHKCSVCSKAFVNVGDLSKHIIIHTGEKPYLCDKCGRGFNRVDNLRSHVKTVHQGKAGIKILEPEEGSEVSVVTVDDMVTLATEALAATAVTQLTGPATLPAVVPVGAAVTADETEVLKAEISKAVKQVQEEDPNTHILYACDSCGDKFLDANSLAQHVRIHTAQALVMFQTDADFYQQYGPGGTWPAGQVLQAGELVFRPRDGAEGQPALAETSPTAPECPPPAE>sp|Q13105-3|ZBT17_HUMAN Isoform 3 of Zinc finger and BTB domain-containing protein 17 OS=Homo sapiens OX=9606 GN=ZBTB17MMCWPWPLSSKCRTSSRPAMPSSHLLSRLPALGEMRRPWPQKVCPVPSPGGDKRAKEEKVATSTLSRLEQAGRSTPIGPSRDLKEERGGQAQSAASGAEQTEKADAPREPPPVELKPDPTSGMAAAEAEAALSESSEQEMEVEPARKGEEEQKEQEEQEEEGAGPAEVKEEGSQLENGEAPEENENEESAGTDSGQELGSEARGLRSGTYGDRTESKAYGSVIHKCEDCGKEFTHTGNFKRHIRIHTGEKPFSCRECSKAFSDPAACKAHEKTHSPLKPYGCEECGKSYRLISLLNLHKKRHSGEARYRCEDCGKLFTTSGNLKRHQLVHSGEKPYQCDYCGRSFSDPTSKMRHLETHDTDKEHKCPHCDKKFNQVGNLKAHLKIHIADGPLKCRECGKQFTTSGNLKRHLRIHSGEKPYVCIHCQRQFADPGALQRHVRIHTGEKPCQCVMCGKAFTQASSLIAHVRQHTGEKPYVCERCGKRFVQSSQLANHIRHHDNIRPHKCSVCSKAFVNVGDLSKHIIIHTGEKPYLCDKCGRGFNRVDNLRSHVKTVHQGKAGIKILEPEEGSEVSVVTVDDMVTLATEALAATAVTQLTVVPVGAAVTADETEVLKAEISKAVKQVQEEDPNTHILYACDSCGDKFLDANSLAQHVRIHTAQALVMFQTDADFYQQYGPGGTWPAGQVLQAGELVFRPRDGAEGQPALAETSPTAPECPPPAE>sp|Q8NAF0|ZN579_HUMAN Zinc finger protein 579 OS=Homo sapiens OX=9606GN=ZNF579 PE=1 SV=2MDPQPPPPAQGSPPHRGRGRGRGRGRGRGRGRGRGGAGAPRAPLPCPTCGRLFRFPYYLSRHRLSHSGLRPHACPLCPKAFRRPAHLSRHLRGHGPQPPLRCAACPRTFPEPAQLRRHLAQEHAGGEVELAIERVAKETAEPSWGPQDEGSEPPTTAAAGATEEEAVAAWPETWPAGEPSTLAAPTSAAEPRESESEEAEAGAAELRAELALAAGRQEEKQVLLQADWTLLCLRCREAFATKGELKAHPCLRPEGEQEGEGGPPPRPKRHQCSICLKAFARPWSLSRHRLVHSTDRPFVCPDCGLAFRLASYLRQHRRVHGPLSLLAPLPAAGKKDDKASGARNSAKGPEGGEGAECGGASEGGEGQNGGDAAPARPPAGEPRFWCPECGKGFRRRAHLRQHGVTHSGARPFQCVRCQREFKRLADLARHAQVHAGGPAPHPCPRCPRRFSRAYSLLRHQRCHRAELERAAALQALQAQAPTSPPPPPPPLKAEQEEEGLPLPLANIKEEPPSPGTPPQSPPAPPVFLSASCFDSQDHSAFEMEEEEVDSKAHLRGLGGLAS>sp|Q96K58|ZN668_HUMAN Zinc finger protein 668 OS=Homo sapiens OX=9606GN=ZNF668 PE=1 SV=3MEVEAAEARSPAPGYKRSGRRYKCVSCTKTFPNAPRAARHAATHGPADCSEEVAEVKPKPETEAKAEEASGEKVSGSAAKPRPYACPLCPKAYKTAPELRSHGRSHTGEKPFPCPECGRRFMQPVCLRVHLASHAGELPFRCAHCPKAYGALSKLKIHQRGHTGERPYACADCGKSFADPSVFRKHRRTHAGLRPYSCERCGKAYAELKDLRNHERSHTGERPFLCSECGKSFSRSSSLTCHQRIHAAQKPYRCPACGKGFTQLSSYQSHERTHSGEKPFLCPRCGRMFSDPSSFRRHQRAHEGVKPYHCEKCGKDFRQPADLAMHRRVHTGDRPFKCLQCDKTFVASWDLKRHALVHSGQRPFRCEECGRAFAERASLTKHSRVHSGERPFHCNACGKSFVVSSSLRKHERTHRSSEAAGVPPAQELVVGLALPVGVAGESSAAPAAGAGLGDPPAGLLGLPPESGGVMATQWQVVGMTVEHVECQDAGVREAPGPLEGAGEAGGEEADEKPPQFVCRECKETFSTMTLLRRHERSHPELRPFPCTQCGKSFSDRAGLRKHSRTHSSVRPYTCPHCPKAFLSASDLRKHERTHPVPMGTPTPLEPLVALLGMPEEGPA>sp|Q96K58-2|ZN668_HUMAN Isoform 2 of Zinc finger protein 668 OS=Homosapiens OX=9606 GN=ZNF668MSEPGMLGRKDVWVPRETPFTKAMEVEAAEARSPAPGYKRSGRRYKCVSCTKTFPNAPRAARHAATHGPADCSEEVAEVKPKPETEAKAEEASGEKVSGSAAKPRPYACPLCPKAYKTAPELRSHGRSHTGEKPFPCPECGRRFMQPVCLRVHLASHAGELPFRCAHCPKAYGALSKLKIHQRGHTGERPYACADCGKSFADPSVFRKHRRTHAGLRPYSCERCGKAYAELKDLRNHERSHTGERPFLCSECGKSFSRSSSLTCHQRIHAAQKPYRCPACGKGFTQLSSYQSHERTHSGEKPFLCPRCGRMFSDPSSFRRHQRAHEGVKPYHCEKCGKDFRQPADLAMHRRVHTGDRPFKCLQCDKTFVASWDLKRHALVHSGQRPFRCEECGRAFAERASLTKHSRVHSGERPFHCNACGKSFVVSSSLRKHERTHRSSEAAGVPPAQELVVGLALPVGVAGESSAAPAAGAGLGDPPAGLLGLPPESGGVMATQWQVVGMTVEHVECQDAGVREAPGPLEGAGEAGGEEADEKPPQFVCRECKETFSTMTLLRRHERSHPELRPFPCTQCGKSFSDRAGLRKHSRTHSSVRPYTCPHCPKAFLSASDLRKHERTHPVPMGTPTPLEPLVALLGMPEEGPA>sp|P17039|ZNF30_HUMAN Zinc finger protein 30 OS=Homo sapiens OX=9606GN=ZNF30 PE=2 SV=5MAHKYVGLQYHGSVTFEDVAIAFSQQEWESLDSSQRGLYRDVMLENYRNLVSMGHSRSKPHVIALLEQWKEPEVTVRKDGRRWCTDLQLEDDTIGCKEMPTSENCPSFALHQKISRQKPRECQEYGKTLCQDSKPVQHERIHSSEKPNRCKECGKNFSNGHQLTIHQRLHVGEKPYKYEKCGKAFISGSAFVKHGRIHTGEKPLKCKQCGKTISGSYQLTVHKSIHTGKKPYECGECGKAFLVYGKLTRHQSTHTGEKPFGCEECGKAFSTFSYLVQHQRIHTSEKPYECKECGKAFSTSSPLAKHQRIHTGEKPYECKECGKSFTVYGQLTRHQSIHTGEKPFECKECGKAFRLSSFLHAHQRIHAEIKPYGCKECGRTFSRASYLVQHGRLHTGEKPYECKECGKAFSTGSYLVQHQRIHTGEKPYECKECGKAFISRHQLTVHQRVHTGEKPYECKECGKAFRVHVHLTQHRKIHTDVKPYECKECGKTFSRASYLVQHSRIHTGKKPYECKECGKAFSSGSYLVQHQRIHTGEKPYECNKCGKAFTVYGQLIGHQSVHTGEKPFECKECGKAFRLNSFLTEHQRVHTGEKPFKCKKCGKTFRYSSALKVHLRKHMSVIP>sp|P17039-2|ZNF30_HUMAN Isoform 2 of Zinc finger protein 30 OS=Homosapiens OX=9606 GN=ZNF30MAHKYVGLQYHGSVTFEDVAIAFSQQEWESLDSSQRGLYRDVMLENYRNLVSMAGHSRSKPHVIALLEQWKEPEVTVRKDGRRWCTDLQLEDDTIGCKEMPTSENCPSFALHQKISRQKPRECQEYGKTLCQDSKPVQHERIHSSEKPNRCKECGKNFSNGHQLTIHQRLHVGEKPYKYEKCGKAFISGSAFVKHGRIHTGEKPLKCKQCGKTISGSYQLTVHKSIHTGKKPYECGECGKAFLVYGKLTRHQSTHTGEKPFGCEECGKAFSTFSYLVQHQRIHTSEKPYECKECGKAFSTSSPLAKHQRIHTGEKPYECKECGKSFTVYGQLTRHQSIHTGEKPFECKECGKAFRLSSFLHAHQRIHAEIKPYGCKECGRTFSRASYLVQHGRLHTGEKPYECKECGKAFSTGSYLVQHQRIHTGEKPYECKECGKAFISRHQLTVHQRVHTGEKPYECKECGKAFRVHVHLTQHRKIHTDVKPYECKECGKTFSRASYLVQHSRIHTGKKPYECKECGKAFSSGSYLVQHQRIHTGEKPYECNKCGKAFTVYGQLIGHQSVHTGEKPFECKECGKAFRLNSFLTEHQRVHTGEKPFKCKKCGKTFRYSSALKVHLRKHMSVIP>sp|P17039-3|ZNF30_HUMAN Isoform 3 of Zinc finger protein 30 OS=Homosapiens OX=9606 GN=ZNF30MAHKYVGLQYHGSVTFEDVAIAFSQQEWESLDSSQRGLYRDVMLENYRNLVSMGHSRSKPHVIALLEQWKEPEVTVRKDGRRWCTG>sp|Q2M3X9|ZN674_HUMAN Zinc finger protein 674 OS=Homo sapiens OX=9606GN=ZNF674 PE=2 SV=1MAMSQESLTFKDVFVDFTLEEWQQLDSAQKNLYRDVMLENYSHLVSVGHLVGKPDVIFRLGPGDESWMADGGTPVRTCAGEDRPEVWEVDEQIDHYKESQDKFLWQAAFIGKETLKDESGQECKICRKIIYLNTDFVSVKQRLPKYYSWERCSKHHLNFLGQNRSYVRKKDDGCKAYWKVCLHYNLHKAQPAERFFDPNQRGKALHQKQALRKSQRSQTGEKLYKCTECGKVFIQKANLVVHQRTHTGEKPYECCECAKAFSQKSTLIAHQRTHTGEKPYECSECGKTFIQKSTLIKHQRTHTGEKPFVCDKCPKAFKSSYHLIRHEKTHIRQAFYKGIKCTTSSLIYQRIHTSEKPQCSEHGKASDEKPSPTKHWRTHTKENIYECSKCGKSFRGKSHLSVHQRIHTGEKPYECSICGKTFSGKSHLSVHHRTHTGEKPYECRRCGKAFGEKSTLIVHQRMHTGEKPYKCNECGKAFSEKSPLIKHQRIHTGERPYECTDCKKAFSRKSTLIKHQRIHTGEKPYKCSECGKAFSVKSTLIVHHRTHTGEKPYECRDCGKAFSGKSTLIKHQRSHTGDKNL>sp|Q2M3X9-2|ZN674_HUMAN Isoform 2 of Zinc finger protein 674 OS=Homosapiens OX=9606 GN=ZNF674MAMSQESLTFKDVFVDFTLEEWQQLDSAQKNLYRDVMLENYSHLVSVGHLVGKPDVIFRLGPGDESWMADGGTPVRTCAVWEVDEQIDHYKESQDKFLWQAAFIGKETLKDESGQECKICRKIIYLNTDFVSVKQRLPKYYSWERCSKHHLNFLGQNRSYVRKKDDGCKAYWKVCLHYNLHKAQPAERFFDPNQRGKALHQKQALRKSQRSQTGEKLYKCTECGKVFIQKANLVVHQRTHTGEKPYECCECAKAFSQKSTLIAHQRTHTGEKPYECSECGKTFIQKSTLIKHQRTHTGEKPFVCDKCPKAFKSSYHLIRHEKTHIRQAFYKGIKCTTSSLIYQRIHTSEKPQCSEHGKASDEKPSPTKHWRTHTKENIYECSKCGKSFRGKSHLSVHQRIHTGEKPYECSICGKTFSGKSHLSVHHRTHTGEKPYECRRCGKAFGEKSTLIVHQRMHTGEKPYKCNECGKAFSEKSPLIKHQRIHTGERPYECTDCKKAFSRKSTLIKHQRIHTGEKPYKCSECGKAFSVKSTLIVHHRTHTGEKPYECRDCGKAFSGKSTLIKHQRSHTGDKNL>sp|Q96KM6|Z512B_HUMAN Zinc finger protein 512B OS=Homo sapiens OX=9606GN=ZNF512B PE=1 SV=1MTDPFCVGGRRLPGSSKSGPGKDGSRKEVRLPMLHDPPKMGMPVVRGGQTVPGQAPLCFDPGSPASDKTEGKKKGRPKAENQALRDIPLSLMNDWKDEFKAHSRVKCPNSGCWLEFPSIYGLKYHYQRCQGGAISDRLAFPCPFCEAAFTSKTQLEKHRIWNHMDRPLPASKPGPISRPVTISRPVGVSKPIGVSKPVTIGKPVGVSKPIGISKPVSVGRPMPVTKAIPVTRPVPVTKPVTVSRPMPVTKAMPVTKPITVTKSVPVTKPVPVTKPITVTKLVTVTKPVPVTKPVTVSRPIVVSKPVTVSRPIAISRHTPPCKMVLLTRSENKAPRATGRNSGKKRAADSLDTCPIPPKQARPENGEYGPSSMGQSSAFQLSADTSSGSLSPGSRPSGGMEALKAAGPASPPEEDPERTKHRRKQKTPKKFTGEQPSISGTFGLKGLVKAEDKARVHRSKKQEGPGPEDARKKVPAAPITVSKEAPAPVAHPAPGGPEEQWQRAIHERGEAVCPTCNVVTRKTLVGLKKHMEVCQKLQDALKCQHCRKQFKSKAGLNYHTMAEHSAKPSDAEASEGGEQEERERLRKVLKQMGRLRCPQEGCGAAFSSLMGYQYHQRRCGKPPCEVDSPSFPCTHCGKTYRSKAGHDYHVRSEHTAPPPEEPTDKSPEAEDPLGVERTPSGRVRRTSAQVAVFHLQEIAEDELARDWTKRRMKDDLVPETARLNYTRPGLPTLNPQLLEAWKNEVKEKGHVNCPNDCCEAIYSSVSGLKAHLASCSKGAHLAGKYRCLLCPKEFSSESGVKYHILKTHAENWFRTSADPPPKHRSQDSLVPKKEKKKNLAGGKKRGRKPKERTPEEPVAKLPPRRDDWPPGCRDKGARGSTGRKVGVSKAPEK>sp|Q9Y2D9|ZN652_HUMAN Zinc finger protein 652 OS=Homo sapiens OX=9606GN=ZNF652 PE=1 SV=3MSHTASSCQELVENCAVHVAGMAQEDSRRGQVPSSFYHGANQELDLSTKVYKRESGSPYSVLVDTKMSKPHLHETEEQPYFRETRAVSDVHAVKEDRENSDDTEEEEEEVSYKREQIIVEVNLNNQTLNVSKGEKGVSSQSKETPVLKTSSEEEEEESEEEATDDSNDYGENEKQKKKEKIVEKVSVTQRRTRRAASVAAATTSPTPRTTRGRRKSVEPPKRKKRATKEPKAPVQKAKCEEKETLTCEKCPRVFNTRWYLEKHMNVTHRRMQICDKCGKKFVLESELSLHQQTDCEKNIQCVSCNKSFKKLWSLHEHIKIVHGYAEKKFSCEICEKKFYTMAHVRKHMVAHTKDMPFTCETCGKSFKRSMSLKVHSLQHSGEKPFRCENCDERFQYKYQLRSHMSIHIGHKQFMCQWCGKDFNMKQYFDEHMKTHTGEKPFICEICGKSFTSRPNMKRHRRTHTGEKPYPCDVCGQRFRFSNMLKAHKEKCFRVTSPVNVPPAVQIPLTTSPATPVPSVVNTATTPTPPINMNPVSTLPPRPIPHPFSHLHIHPHPHHPHHLPIPPVPHLPPPPALFKSEPLNHRGQSEDNFLRHLAEKNSSAQHH>sp|Q8NDP4|ZN439_HUMAN Zinc finger protein 439 OS=Homo sapiens OX=9606GN=ZNF439 PE=1 SV=1MLSLSPILLYTCEMFQDPVAFKDVAVNFTQEEWALLDISQKNLYREVMLETFWNLTSIGKKWKDQNIEYEYQNPRRNFRSVTEEKVNEIKEDSHCGETFTPVPDDRLNFQKKKASPEVKSCDSFVCEVGLGNSSSNMNIRGDTGHKACECQEYGPKPWKSQQPKKAFRYHPSLRTQERDHTGKKPYACKECGKNIIYHSSIQRHMVVHSGDGPYKCKFCGKAFHCLSLYLIHERTHTGEKPYECKQCGKSFSYSATHRIHERTHIGEKPYECQECGKAFHSPRSCHRHERSHMGEKAYQCKECGKAFMCPRYVRRHERTHSRKKLYECKQCGKALSSLTSFQTHIRMHSGERPYECKTCGKGFYSAKSFQRHEKTHSGEKPYKCKQCGKAFTRSGSFRYHERTHTGEKPYECKQCGKAFRSAPNLQLHGRTHTGEKPYQCKECGKAFRSASQLRIHRRIHTGEKPYECKKCGKAFRYVQNFRFHERTQTHKNALWRKTL>sp|Q8IZU2|WDR17_HUMAN WD repeat-containing protein 17 OS=Homo sapiensOX=9606 GN=WDR17 PE=2 SV=2MAWMTYISNWFEQDDWYEGLQRANMSQVRQVGLLAAGCQPWNKDVCAASGDRFAYCATLAIYIYQLDHRYNEFKLHAIMSEHKKTITAISWCPHNPDLFASGSTDNLVIIWNVAEQKVIAKLDSTKGIPASLSWCWNAEDVVAFVSHRGPLFIWTISGPDSGVIVHKDAHSFLSDICMFRWHTHQKGKVVFGHIDGSLSIFHPGNKNQKHVLRPESLEGTDEEDPVTALEWDPLSTDYLLVVNLHYGIRLVDSESLSCITTFNLPSAAASVQCLAWVPSAPGMFITGDSQVGVLRIWNVSRTTPIDNLKLKKTGFHCLHVLNSPPRKKFSVQSPTKNHYTSSTSEAVPPPTLTQNQAFSLPPGHAVCCFLDGGVGLYDMGAKKWDFLRDLGHVETIFDCKFKPDDPNLLATASFDGTIKVWDINTLTAVYTSPGNEGVIYSLSWAPGGLNCIAGGTSRNGAFIWNVQKGKIIQRFNEHGTNGIFCIAWSHKDSKRIATCSSDGFCIIRTIDGKVLHKYKHPAAVFGCDWSQNNKDMIATGCEDTNVRVYYVATSSDQPLKVFSGHTAKVFHVKWSPLREGILCSGSDDGTVRIWDYTQDACINILNGHTAPVRGLMWNTEIPYLLISGSWDYTIKVWDTREGTCVDTVYDHGADVYGLTCHPSRPFTMASCSRDSTVRLWSLTALVTPVQINILADRSWEEIIGNTDYAIEPGTPPLLCGKVSRDIRQEIEKLTANSQVKKLRWFSECLSPPGGSDNLWNLVAVIKGQDDSLLPQNYCKGIMHLKHLIKFRTSEAQELTTVKMSKFGGGIGVPAKEERLKEAAEIHLRLGQIQRYCELMVELGEWDKALSIAPGVSVKYWKKLMQRRADQLIQEDKDDVIPYCIAIGDVKKLVHFFMSRGQLKEALLVAQAACEGNMQPLHVSVPKGASYSDDIYKEDFNELLHKVSKELAEWYFQDGRAVLAACCHLAIDNIELAMAYLIRGNELELAVCVGTVLGESAAPATHYALELLARKCMMISVCFPCVGYSVPFCYVNRNLAADLLLMIPDNELHLIKLCAFYPGCTEEINDLHDKCKLPTVEECMQLAETARADDNIFETVKYYLLSQEPEKALPIGISFVKEYISSSDWTLDTIYPVLDLLSYIRTEKLLLHTCTEARNELLILCGYIGALLAIRRQYQSIVPALYEYTSQLLKRREVSVPLKIEYLSEELDAWRACTQSTNRSLEDSPYTPPSDSQRMIYATLLKRLKEESLKGIIGPDYVTGSNLPSHSDIHISCLTGLKIQGPVFFLEDGKSAISLNDALMWAKVNPFSPLGTGIRLNPF>sp|Q8IZU2-2|WDR17_HUMAN Isoform 2 of WD repeat-containing protein 17OS=Homo sapiens OX=9606 GN=WDR17MSQVRQVGLLAAGCQPWNKDVCAASGDRFAYCATLAIYIYQLDHRYNEFKLHAIMSEHKKTITAISWCPHNPDLFASGSTDNLVIIWNVAEQKVIAKLDSTKGIPASLSWCWNAEDVVAFVSHRGPLFIWTISGPDSGVIVHKDAHSFLSDICMFRWHTHQKGKVVFGHIDGSLSIFHPGNKNQKHVLRPESLEGTDEEDPVTALEWDPLSTDYLLVVNLHYGIRLVDSESLSCITTFNLPSAAASVQCLAWVPSAPGMFITGDSQVGVLRIWNVSRTTPIDNLKLKKTGFHCLHVLNSPPRKKFSVQSPTKNHYTSSTSEAVPPPTLTQNQAFSLPPGHAVCCFLDGGVGLYDMGAKKWDFLRDLGHVETIFDCKFKPDDPNLLATASFDGTIKVWDINTLTAVYTSPGNEGVIYSLSWAPGGLNCIAGGTSRNGAFIWNVQKGKIIQRFNEHGTNGIFCIAWSHKDSKRIATCSSDGFCIIRTIDGKVLHKYKHPAAVFGCDWSQNNKDMIATGCEDTNVRVYYVATSSDQPLKVFSGHTAKVFHVKWSPLREGILCSGSDDGTVRIWDYTQDACINILNGHTAPVRGLMWNTEIPYLLISGSWDYTIKVWDTREGTCVDTVYDHGADVYGLTCHPSRPFTMASCSRDSTVRLWSLTALVTPVQINILADRSWEEIIGNTDYAIEPGTPPLLCGKVSRDIRQEIEKLTANSQVKKLRWFSECLSPPGGSDNLWNLVAVIKGQDDSLLPQNYCKGIMHLKHLIKFRTSEAQELTTVKMSKFGGGIGVPAKEERLKEAAEIHLRLGQIQRYCELMVELGEWDKALSIAPGVSVKYWKKLMQRRADQLIQEDKDDVIPYCIAIGDVKKLVHFFMSRGQLKEALLVAQAACEGNMQPLHVSVPKGASYSDDIYKEDFNELLHKVSKELAEWYFQDGRAVLAACCHLAIDNIELAMAYLIRGNELELAVCVGTVLGESAAPATHYALELLARKCMMISVWNLAADLLLMIPDNELHLIKLCAFYPGCTEEINDLHDKCKLPTVEECMQLAETARADDNIFETVKYYLLSQEPEKALPIGISFVKEYISSSDWTLDTIYPVLDLLSYIRTEKLLLHTCTEARNELLILCGYIGALLAIRRQYQSIVPALYEYTSQLLKRREVSVPLKIEYLSEELDAWRACTQSTNRSLEDSPYTPPSDSQRMIYATLLKRLKEESLKGIIGPDYVTGSNLPSHSDIHISCLTGLKIQGPVFFLEDGKSAISLNDALMWAKVNPFSPLGTGIRLNPF>sp|Q9NX94|WBP1L_HUMAN WW domain binding protein 1-like OS=Homo sapiensOX=9606 GN=WBP1L PE=1 SV=2MPFLLGLRQDKEACVGTNNQSYICDTGHCCGQSQCCNYYYELWWFWLVWTIIIILSCCCVCHHRRAKHRLQAQQRQHEINLIAYREAHNYSALPFYFRFLPNYLLPPYEEVVNRPPTPPPPYSAFQLQQQQLLPPQCGPAGGSPPGIDPTRGSQGAQSSPLSEPSRSSTRPPSIADPDPSDLPVDRAATKAPGMEPSGSVAGLGELDPGAFLDKDAECREELLKDDSSEHGAPDSKEKTPGRHRRFTGDSGIEVCVCNRGHHDDDLKEFNTLIDDALDGPLDFCDSCHVRPPGDEEEGLCQSSEEQAREPGHPHLPRPPACLLLNTINEQDSPNSQSSSSPS>sp|Q9NX94-2|WBP1L_HUMAN Isoform 2 of WW domain binding protein 1-likeOS=Homo sapiens OX=9606 GN=WBP1LMERRRLLGGMALLLLQALPSPLSARAEPPQDKEACVGTNNQSYICDTGHCCGQSQCCNYYYELWWFWLVWTIIIILSCCCVCHHRRAKHRLQAQQRQHEINLIAYREAHNYSALPFYFRFLPNYLLPPYEEVVNRPPTPPPPYSAFQLQQQQLLPPQCGPAGGSPPGIDPTRGSQGAQSSPLSEPSRSSTRPPSIADPDPSDLPVDRAATKAPGMEPSGSVAGLGELDPGAFLDKDAECREELLKDDSSEHGAPDSKEKTPGRHRRFTGDSGIEVCVCNRGHHDDDLKEFNTLIDDALDGPLDFCDSCHVRPPGDEEEGLCQSSEEQAREPGHPHLPRPPACLLLNTINEQDSPNSQSSSSPS>sp|P63121|VP113_HUMAN Endogenous retrovirus group K member 113 Proprotein OS=Homo sapiens OX=9606 GN=HERVK_113 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGISTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGVEITMPAPLYSPTSQKIMTKMGYIPGKGLGKNEDGIKVPVEAKINQEREGIGYPF>sp|A8MUA0|YB057_HUMAN Putative UPF0607 protein ENSP00000381514 OS=Homosapiens OX=9606 PE=3 SV=1MRLCLIPWNTGTPQRVLPPVVWSPPSRKKPVLSARNSRMFGYLSPVRIPRLRGKFNLQLPSLDEQVIPARLPKMEVRAEEPKEATEVKDQVQTQEQEDNKRGPCSNGEAASTSRPLETQGNLTSSWYNPRPLEGNVHLKSLTENNQTDKAQVHAVSFYSKGHGVASSHSPAGGILPFGKPDPLPTVLPAPVPGCSLWPEKAALKVLGKDHLPSSPGLLTVGEDMQPKDPAALGSSRSSPPRAAGHRSRKRKLSGPPLQLQPTPPLQLRWERDERPPPAKLPCLSPEALLVGQASQREGRLQQGNMRKNMRVLSRTSKFRRLRQLLRRRKKRQQVRSISACT>sp|Q96C00|ZBTB9_HUMAN Zinc finger and BTB domain-containing protein 9OS=Homo sapiens OX=9606 GN=ZBTB9 PE=1 SV=1METPTPLPPVPASPTCNPAPRTIQIEFPQHSSSLLESLNRHRLEGKFCDVSLLVQGRELRAHKAVLAAASPYFHDKLLLGDAPRLTLPSVIEADAFEGLLQLIYSGRLRLPLDALPAHLLVASGLQMWQVVDQCSEILRELETSGGGISARGGNSYHALLSTTSSTGGWCIRSSPFQTPVQSSASTESPASTESPVGGEGSELGEVLQIQVEEEEEEEEDDDDEDQGSATLSQTPQPQRVSGVFPRPHGPHPLPMTATPRKLPEGESAPLELPAPPALPPKIFYIKQEPFEPKEEISGSGTQPGGAKEETKVFSGGDTEGNGELGFLLPSGPGPTSGGGGPSWKPVDLHGNEILSGGGGPGGAGQAVHGPVKLGGTPPADGKRFGCLCGKRFAVKPKRDRHIMLTFSLRPFGCGICNKRFKLKHHLTEHMKTHAGALHACPHCGRRFRVHACFLRHRDLCKGQGWATAHWTYK>sp|Q8NAP8|ZBT8B_HUMAN Zinc finger and BTB domain-containing protein 8BOS=Homo sapiens OX=9606 GN=ZBTB8B PE=1 SV=2MEMQSYYAKLLGELNEQRKRDFFCDCSIIVEGRIFKAHRNILFANSGYFRALLIHYIQDSGRHSTASLDIVTSDAFSIILDFLYSGKLDLCGENVIEVMSAASYLQMNDVVNFCKTYIRSSLDICRKMEKEAAVAAAVAAAAAAAAAAAAAAAHQVDSESPSSGREGTSCGTKSLVSSPAEGEKSVECLRESPCGDCGDCHPLELVVRDSLGGGSADSNLSTPPKRIEPKVEFDADEVEVDVGEQLQQYAAPLNLAHVEEALPSGQAVDLAYSNYHVKQFLEALLRNSAAPSKDDADHHFSRSLEGRPEGAGVAMSSMMDVQADWYGEDSGDVLVVPIKLHKCPFCPYTAKQKGILKRHIRSHTGERPYPCETCGKRFTRQEHLRSHALSVHRSNRPIICKGCRRTFTSHLSQGLRRFGLCDSCTCVTDTPDDDDDLMPINLSLVEASSESQEKSDTDNDWPIYVESGEENDPAGDDSDDKPQIQPNLSDRETLT>sp|Q8NAP8-2|ZBT8B_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 8B OS=Homo sapiens OX=9606 GN=ZBTB8BMEMQSYYAKLLGELNEQRKRDFFCDCSIIVEGRIFKAHRNILFANSGYFRALLIHYIQDSGRHSTASLDIVTSDAFSIILDFLYSGKLDLCGENVIEVMSAASYLQMNDVVNFCKTYIRSSLDICRKMEKEAAVAAAVAAAAAAAAAAAAAAAHQVDSESPSSGREGTSCGTKSLVSSPAEGEKSVECLRESPCGDCGDCHPLELVVRDSLGGGSADSNLSTPPKRIEPKVEFDADEVEVDVGEQLQQYAAPLNLAHVEEALPSGQAVDLAYSNYHVKQFLEALLRNSAAPSKDDADHHFSRSLEGRPEGAGVAMSSMMDVQADWYGEDSGDVLVVPIKLHKCPFCPYTAKQKGILKRHIRSHTGERPYPCETCGKRFTRQEHLRSHALSVHRSNRPIICKGCRRTFTSHLSQGLRRFGLCDSCTCVTDTPDDDDDLMPINLSLVEASSESQEKSDTDNDWPIYVESEIGSHYVAQASLELLALSQPPASASQSAGITDGVSLCCPGRSTVA>sp|O95365|ZBT7A_HUMAN Zinc finger and BTB domain-containing protein 7AOS=Homo sapiens OX=9606 GN=ZBTB7A PE=1 SV=1MAGGVDGPIGIPFPDHSSDILSGLNEQRTQGLLCDVVILVEGREFPTHRSVLAACSQYFKKLFTSGAVVDQQNVYEIDFVSAEALTALMDFAYTATLTVSTANVGDILSAARLLEIPAVSHVCADLLDRQILAADAGADAGQLDLVDQIDQRNLLRAKEYLEFFQSNPMNSLPPAAAAAAASFPWSAFGASDDDLDATKEAVAAAVAAVAAGDCNGLDFYGPGPPAERPPTGDGDEGDSNPGLWPERDEDAPTGGLFPPPVAPPAATQNGHYGRGGEEEAASLSEAAPEPGDSPGFLSGAAEGEDGDGPDVDGLAASTLLQQMMSSVGRAGAAAGDSDEESRADDKGVMDYYLKYFSGAHDGDVYPAWSQKVEKKIRAKAFQKCPICEKVIQGAGKLPRHIRTHTGEKPYECNICKVRFTRQDKLKVHMRKHTGEKPYLCQQCGAAFAHNYDLKNHMRVHTGLRPYQCDSCCKTFVRSDHLHRHLKKDGCNGVPSRRGRKPRVRGGAPDPSPGATATPGAPAQPSSPDARRNGQEKHFKDEDEDEDVASPDGLGRLNVAGAGGGGDSGGGPGAATDGNFTAGLA>sp|Q13360|ZN177_HUMAN Zinc finger protein 177 OS=Homo sapiens OX=9606GN=ZNF177 PE=1 SV=4MAAGWLTTWSQNSVTFQEVAVDFSQEEWALLDPAQKNLYKDVMLENFRNLASVGYQLCRHSLISKVDQEQLKTDERGILQGDCADWETQLKPKDTIAMQNIPGGKTSNGINTAENQPGEHSLECNHCGKFRKNTRFICTRYCKGEKCYKYIKYSKVFNHPSTLRSHVSIHIGEKTLEFTDCRKAFNQESSLRKHLRTPTGQKFQEYEQCDMSFSLHSSCSVREQIPTGEKGDECSDYGKISPLSVHTKTGSVEEGLECNEHEKTFTDPLSLQNCVRTHSGEMPYECSDCGKAFIFQSSLKKHMRSHTGEKPYECDHCGKSFSQSSHLNVHKRTHTGEKPYDCKECGKAFTVPSSLQKHVRTHTGEKPYECSDCGKAFIDQSSLKKHTRSHTGEKPYECNQCGKSFSTGSYLIVHKRTHTGEKTYECKECGKAFRNSSCLRVHVRTHTGEKPYKCIQCEKAFSTSTNLIMHKRIHNGQKLHE>sp|Q13360-2|ZN177_HUMAN Isoform 2 of Zinc finger protein 177 OS=Homosapiens OX=9606 GN=ZNF177MAAGWLTTWSQNSVTFQEVAVDFSQEEWALLDPAQKNLYKDVMLENFRNLASVGYQLCRHSLISKVDQEQLKTDERGILQGDCADWETQLKPKDTIAMQNIPGGKTSNGINTNCVRTHSGEMPYECSDCGKAFIFQSSLKKHMRSHTGEKPYECDHCGKSFSQSSHLNVHKRTHTGEKPYDCKECGKAFTVPSSLQKHVRTHTGEKPYECSDCGKAFIDQSSLKKHTRSHTGEKPYECNQCGKSFSTGSYLIVHKRTHTGEKTYECKECGKAFRNSSCLRVHVRTHTGEKPYKCIQCEKAFSTSTNLIMHKRIHNGQKLHE>sp|Q13360-3|ZN177_HUMAN Isoform 3 of Zinc finger protein 177 OS=Homosapiens OX=9606 GN=ZNF177MAAGWLTTWSQNSVTFQEVAVDFSQEEWALLDPAQKNLYKDVMLENFRNLASVGYQLCRHSLISKVDQEQLKTDERGILQGDCADWETQLKPKDTIAMQNIPGGKTSNGINTNPHGREFL>sp|P0C880|YT014_HUMAN Putative uncharacterized protein FLJ40606 OS=Homosapiens OX=9606 PE=5 SV=1MAAATETGQAAVPSRKRRRGRRPPASDPQTLARLAAGPWLPGTLTCPERTGGDAATRSARPPVLPPPPRPPQRRCRHLVSRAGTPRCACAGTASEGPRRGRAAILSVAGSAGSSHPACFRPPPLLPIRPCCSLWR>sp|P17025|ZN182_HUMAN Zinc finger protein 182 OS=Homo sapiens OX=9606GN=ZNF182 PE=2 SV=2MTPASASGEDSGSFYSWQKAKREQGLVTFEDVAVDFTQEEWQYLNPPQRTLYRDVMLETYSNLVFVGQQVTKPNLILKLEVEECPAEGKIPFWNFPEVCQVDEQIERQHQDDQDKCLLMQVGFSDKKTIITKSARDCHEFGNILHLSTNLVASIQRPDKHESFGNNMVDNLDLFSRSSAENKYDNGCAKLFFHTEYEKTNPGMKPYGYKECGKGLRRKKGLSLHQRIKNGEKPFECTACRKTFSKKSHLIVHWRTHTGEKPFGCTECGKAFSQKSQLIIHLRTHTGERPFECPECGKAFREKSTVIIHYRTHTGEKPYECNECGKAFTQKSNLIVHQKTHTGEKTYECTKCGESFIQKLDLIIHHSTHTGKKPHECNECKKTFSDKSTLIIHQRTHTGEKPHKCTECGKSFNEKSTLIVHQRTHTGEKPYECDVCGKTFTQKSNLGVHQRTHSGEKPFECNECEKAFSQKSYLMLHQRGHTGEKPYECNECEKAFSQKSYLIIHQRTHTEEKPYKCNECGKAFREKSKLIIHQRIHTGEKPYECPVCWKAFSQKSQLIIHQRTHTGEKPYACTECGKAFREKSTFTVHQRTHTGEKPYKCTECGKAFTQKSNLIVHQRTHAGKKAHGRGHTRKSKFMAH>sp|P17025-2|ZN182_HUMAN Isoform 2 of Zinc finger protein 182 OS=Homosapiens OX=9606 GN=ZNF182MAKPQGLVTFEDVAVDFTQEEWQYLNPPQRTLYRDVMLETYSNLVFVGQQVTKPNLILKLEVEECPAEGKIPFWNFPEVCQVDEQIERQHQDDQDKCLLMQVGFSDKKTIITKSARDCHEFGNILHLSTNLVASIQRPDKHESFGNNMVDNLDLFSRSSAENKYDNGCAKLFFHTEYEKTNPGMKPYGYKECGKGLRRKKGLSLHQRIKNGEKPFECTACRKTFSKKSHLIVHWRTHTGEKPFGCTECGKAFSQKSQLIIHLRTHTGERPFECPECGKAFREKSTVIIHYRTHTGEKPYECNECGKAFTQKSNLIVHQKTHTGEKTYECTKCGESFIQKLDLIIHHSTHTGKKPHECNECKKTFSDKSTLIIHQRTHTGEKPHKCTECGKSFNEKSTLIVHQRTHTGEKPYECDVCGKTFTQKSNLGVHQRTHSGEKPFECNECEKAFSQKSYLMLHQRGHTGEKPYECNECEKAFSQKSYLIIHQRTHTEEKPYKCNECGKAFREKSKLIIHQRIHTGEKPYECPVCWKAFSQKSQLIIHQRTHTGEKPYACTECGKAFREKSTFTVHQRTHTGEKPYKCTECGKAFTQKSNLIVHQRTHAGKKAHGRGHTRKSKFMAH>sp|Q8IXZ2|ZC3H3_HUMAN Zinc finger CCCH domain-containing protein 3OS=Homo sapiens OX=9606 GN=ZC3H3 PE=1 SV=3MEEKEILRRQIRLLQGLIDDYKTLHGNAPAPGTPAASGWQPPTYHSGRAFSARYPRPSRRGYSSHHGPSWRKKYSLVNRPPGPSDPPADHAVRPLHGARGGQPPVPQQHVLERQVQLSQGQNVVIKVKPPSKSGSASASGAQRGSLEEFEETPWSDQRPREGEGEPPRGQLQPSRPTRARGTCSVEDPLLVCQKEPGKPRMVKSVGSVGDSPREPRRTVSESVIAVKASFPSSALPPRTGVALGRKLGSHSVASCAPQLLGDRRVDAGHTDQPVPSGSVGGPARPASGPRQAREASLVVTCRTNKFRKNNYKWVAASSKSPRVARRALSPRVAAENVCKASAGMANKVEKPQLIADPEPKPRKPATSSKPGSAPSKYKWKASSPSASSSSSFRWQSEASSKDHASQLSPVLSRSPSGDRPAVGHSGLKPLSGETPLSAYKVKSRTKIIRRRSSTSLPGDKKSGTSPAATAKSHLSLRRRQALRGKSSPVLKKTPNKGLVQVTTHRLCRLPPSRAHLPTKEASSLHAVRTAPTSKVIKTRYRIVKKTPASPLSAPPFPLSLPSWRARRLSLSRSLVLNRLRPVASGGGKAQPGSPWWRSKGYRCIGGVLYKVSANKLSKTSGQPSDAGSRPLLRTGRLDPAGSCSRSLASRAVQRSLAIIRQARQRREKRKEYCMYYNRFGRCNRGERCPYIHDPEKVAVCTRFVRGTCKKTDGTCPFSHHVSKEKMPVCSYFLKGICSNSNCPYSHVYVSRKAEVCSDFLKGYCPLGAKCKKKHTLLCPDFARRGACPRGAQCQLLHRTQKRHSRRAATSPAPGPSDATARSRVSASHGPRKPSASQRPTRQTPSSAALTAAAVAAPPHCPGGSASPSSSKASSSSSSSSSPPASLDHEAPSLQEAALAAACSNRLCKLPSFISLQSSPSPGAQPRVRAPRAPLTKDSGKPLHIKPRL>sp|Q8IXZ2-2|ZC3H3_HUMAN Isoform 2 of Zinc finger CCCH domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=ZC3H3MEPGGEPTGAKESSTLMESLAGRLDPAGSCSRSLASRAVQRSLAIIRQARQRREKRKEYCMYYNRFGRCNRGERCPYIHDPEKVAVCTRFVRGTCKKTDGTCPFSHHVSKEKMPVCSYFLKGICSNSNCPYSHVYVSRKAEVCSDFLKGYCPLGAKCKKKHTLLCPDFARRGACPRGAQCQLLHRTQKRHSRRAATSPAPGPSDATARSRVSASHGPRKPSASQRPTRQTPSSAALTAAAVAAPPHCPGGSASPSSSKASSSSSSSSSPPASLDHEAPSLQEAALAAACSNRLCKLPSFISLQSSPSPGAQPRVRAPRAPLTKDSGKPLHIKPRL>sp|Q8N972|ZN709_HUMAN Zinc finger protein 709 OS=Homo sapiens OX=9606GN=ZNF709 PE=2 SV=1MDSVVFEDVAVNFTQEEWALLGPSQKKLYRDVMQETFVNLASIGENWEEKNIEDHKNQGRKLRSHMVERLCERKEGSQFGETISQTPNPKPNKKTFTRVKPYECSVCGKDYMCHSSLNRHMRSHTEHRSYEYHKYGEKSYECKECGKRFSFRSSFRIHERTHTGEKPYKCKQCGKAFSWPSSFQIHERTHTGEKPYECKECGKAFIYHTTFRGHMRMHTGEKPYKCKECGKTFSHPSSFRNHERTHSGEKPYECKQCGKAFRYYQTFQIHERTHTGEKPYQCKQCGKALSCPTSFRSHERIHTGEKPYKCKKCGKAFSFPSSFRKHERIHTGEKPYDCKECGKAFISLPSYRRHMIMHTGNGPYKCKECGKAFDCPSSFQIHERTHTGEKPYECKQCGKAFSCSSSFRMHERTHTGEKPHECKQCGKAFSCSSSVRIHERTHTGEKPYECKQCGKAFSCSSSFRMHERIHTGEKPYECKQCGKAFSFSSSFRMHERTHTGEKPYECKQCGKAFSCSSSFRMHERTHTGEKPYECKQCGKAFSCSSSIRIHERTHTGEKPYECKQCGKAFSCSSSVRMHERTHTGVKPYECKQCDKAFSCSRSFRIHERTHTGEKPYACQQCGKAFKCSRSFRIHERVHSGE>sp|Q86UP3|ZFHX4_HUMAN Zinc finger homeobox protein 4 OS=Homo sapiensOX=9606 GN=ZFHX4 PE=1 SV=1METCDSPPISRQENGQSTSKLCGTTQLDNEVPEKVAGMEPDRENSSTDDNLKTDERKSEALLGFSVENAAATQVTSAKEIPCNECATSFPSLQKYMEHHCPNARLPVLKDDNESEISELEDSDVENLTGEIVYQPDGSAYIIEDSKESGQNAQTGANSKLFSTAMFLDSLASAGEKSDQSASAPMSFYPQIINTFHIASSLGKPFTADQAFPNTSALAGVGPVLHSFRVYDLRHKREKDYLTSDGSAKNSCVSKDVPNNVDLSKFDGCVSDGKRKPVLMCFLCKLSFGYIRSFVTHAVHDHRMTLNDEEQKLLSNKCVSAIIQGIGKDKEPLISFLEPKKSTSVYPHFSTTNLIGPDPTFRGLWSAFHVENGDSLPAGFAFLKGSASTSSSAEQPLGITQMPKAEVNLGGLSSLVVNTPITSVSLSHSSSESSKMSESKDQENNCERPKESNVLHPNGECPVKSEPTEPGDEDEEDAYSNELDDEEVLGELTDSIGNKDFPLLNQSISPLSSSVLKFIEKGTSSSSATVSDDTEKKKQTAAVRASGSVASNYGISGKDFADASASKDSATAAHPSEIARGDEDSSATPHQHGFTPSTPGTPGPGGDGSPGSGIECPKCDTVLGSSRSLGGHMTMMHSRNSCKTLKCPKCNWHYKYQQTLEAHMKEKHPEPGGSCVYCKTGQPHPRLARGESYTCGYKPFRCEVCNYSTTTKGNLSIHMQSDKHLNNVQNLQNGNGEQVFGHSAPAPNTSLSGCGTPSPSKPKQKPTWRCEVCDYETNVARNLRIHMTSEKHMHNMMLLQQNMKQIQHNLHLGLAPAEAELYQYYLAQNIGLTGMKLENPADPQLMINPFQLDPATAAALAPGLGELSPYISDPALKLFQCAVCNKFTSDSLEALSVHVSSERSLPEEEWRAVIGDIYQCKLCNYNTQLKANFQLHCKTDKHMQKYQLVAHIKEGGKSNEWRLKCIAIGNPVHLKCNACDYYTNSVDKLRLHTTNHRHEAALKLYKHLQKQEGAVNPESCYYYCAVCDYTTKVKLNLVQHVRSVKHQQTEGLRKLQLHQQGLAPEEDNLSEIFFVKDCPPNELETASLGARTCDDDLTEQHEEAEGAIKPTAVAEDDEKDTSERDNSEGKNSNKDSVSVAGGTQPLLLAKEEDVATKRSKPTEDNKFCHEQFYQCPYCNYNSRDQSRIQMHVLSQHSVQPVICCPLCQDVLSNKMHLQLHLTHLHSVSPDCVEKLLMTVPVPDVMMPNSMLLPAAASEKSERDTPAAVTAEGSGKYSGESPMDDKSMAGLEDSKANVEVKNEEQKPTKEPLEVSEWNKNSSKDVKIPDTLQDQLNEQQKRQPLSVSDRHVYKYRCNHCSLAFKTMQKLQIHSQYHAIRAATMCNLCQRSFRTFQALKKHLEAGHPELSEAELQQLYASLPVNGELWAESETMSQDDHGLEQEMEREYEVDHEGKASPVGSDSSSIPDDMGSEPKRTLPFRKGPNFTMEKFLDPSRPYKCTVCKESFTQKNILLVHYNSVSHLHKLKKVLQEASSPVPQETNSNTDNKPYKCSICNVAYSQSSTLEIHMRSVLHQTKARAAKLEPSGHVAGGHSIAANVNSPGQGMLDSMSLAAVNSKDTHLDAKELNKKQTPDLISAQPAHHPPQSPAQIQMQLQHELQQQAAFFQPQFLNPAFLPHFPMTPEALLQFQQPQFLFPFYIPGTEFSLGPDLGLPGSATFGMPGMTGMAGSLLEDLKQQIQTQHHVGQTQLQILQQQAQQYQATQPQLQPQKQQQQPPPPQQQQQQQASKLLKQEQSNIVSADCQIMKDVPSYKEAEDISEKPEKPKQEFISEGEGLKEGKDTKKQKSLEPSIPPPRIASGARGNAAKALLENFGFELVIQYNENRQKVQKKGKSGEGENTDKLECGTCGKLFSNVLILKSHQEHVHGQFFPYAALEKFARQYREAYDKLYPISPSSPETPPPPPPPPPLPPAPPQPSSMGPVKIPNTVSTPLQAPPPTPPPPPPPPPPPPPPPPPPPPSAPPQVQLPVSLDLPLFPSIMMQPVQHPALPPQLALQLPQMDALSADLTQLCQQQLGLDPNFLRHSQFKRPRTRITDDQLKILRAYFDINNSPSEEQIQEMAEKSGLSQKVIKHWFRNTLFKERQRNKDSPYNFSNPPITVLEDIRIDPQPTSLEHYKSDASFSKRSSRTRFTDYQLRVLQDFFDTNAYPKDDEIEQLSTVLNLPTRVIVVWFQNARQKARKSYENQAETKDNEKRELTNERYIRTSNMQYQCKKCNVVFPRIFDLITHQKKQCYKDEDDDAQDESQTEDSMDATDQVVYKHCTVSGQTDAAKNAAAPAASSGSGTSTPLIPSPKPEPEKTSPKPEYPAEKPKQSDPSPPSQGTKPALPLASTSSDPPQASTAQPQPQPQPPKQPQLIGRPPSASQTPVPSSPLQISMTSLQNSLPPQLLQYQCDQCTVAFPTLELWQEHQHMHFLAAQNQFLHSPFLERPMDMPYMIFDPNNPLMTGQLLGSSLTQMPPQASSSHTTAPTTVAASLKRKLDDKEDNNCSEKEGGNSGEDQHRDKRLRTTITPEQLEILYEKYLLDSNPTRKMLDHIAREVGLKKRVVQVWFQNTRARERKGQFRAVGPAQSHKRCPFCRALFKAKSALESHIRSRHWNEGKQAGYSLPPSPLISTEDGGESPQKYIYFDYPSLPLTKIDLSSENELASTVSTPVSKTAELSPKNLLSPSSFKAECSEDVENLNAPPAEAGYDQNKTDFDETSSINTAISDATTGDEGNTEMESTTGSSGDVKPALSPKEPKTLDTLPKPATTPTTEVCDDKFLFSLTSPSIHFNDKDGDHDQSFYITDDPDDNADRSETSSIADPSSPNPFGSSNPFKSKSNDRPGHKRFRTQMSNLQLKVLKACFSDYRTPTMQECEMLGNEIGLPKRVVQVWFQNARAKEKKFKINIGKPFMINQGGTEGTKPECTLCGVKYSARLSIRDHIFSKQHISKVRETVGSQLDREKDYLAPTTVRQLMAQQELDRIKKASDVLGLTVQQPGMMDSSSLHGISLPTAYPGLPGLPPVLLPGMNGPSSLPGFPQNSNISAGMLGFPTSATSSPALSLSSAPTKPLLQTPPPPPPPPPPPPSSSLSGQQTEQQNKESEKKQTKPNKVKKIKEEELEATKPEKHPKKEEKISSALSVLGKVVGETHVDPIQLQALQNAIAGDPASFIGGQFLPYFIPGFASYFTPQLPGTVQGGYFPPVCGMESLFPYGPTMPQTLAGLSPGALLQQYQQYQQNLQESLQKQQKQQQEQQQKPVQAKTSKVESDQPQNSNDASETKEDKSTATESTKEEPQLESKSADFSDTYVVPFVKYEFICRKCQMMFTDEDAAVNHQKSFCYFGQPLIDPQETVLRVPVSKYQCLACDVAISGNEALSQHLQSSLHKEKTIKQAMRNAKEHVRLLPHSVCSPNPNTTSTSQSAASSNNTYPHLSCFSMKSWPNILFQASARRAASPPSSPPSLSLPSTVTSSLCSTSGVQTSLPTESCSDESDSELSQKLEDLDNSLEVKAKPASGLDGNFNSIRMDMFSV>sp|Q86UP3-2|ZFHX4_HUMAN Isoform 2 of Zinc finger homeobox protein 4OS=Homo sapiens OX=9606 GN=ZFHX4METCDSPPISRQENGQSTSKLCGTTQLDNEVPEKVAGMEPDRENSSTDDNLKTDERKSEALLGFSVENAAATQVTSAKEIPCNECATSFPSLQKYMEHHCPNARLPVLKDDNESEISELEDSDVENLTGEIVYQPDGSAYIIEDSKESGQNAQTGANSKLFSTAMFLDSLASAGEKSDQSASAPMSFYPQIINTFHIASSLGKPFTADQAFPNTSALAGVGPVLHSFRVYDLRHKREKDYLTSDGSAKNSCVSKDVPNNVDLSKFDGCVSDGKRKPVLMCFLCKLSFGYIRSFVTHAVHDHRMTLNDEEQKLLSNKCVSAIIQGIGKDKEPLISFLEPKKSTSVYPHFSTTNLIGPDPTFRGLWSAFHVENGDSLPAGFAFLKGSASTSSSAEQPLGITQMPKAEVNLGGLSSLVVNTPITSVSLSHSSSESSKMSESKDQENNCERPKESNVLHPNGECPVKSEPTEPGDEDEEDAYSNELDDEEVLGELTDSIGNKDFPLLNQSISPLSSSVLKFIEKGTSSSSATVSDDTEKKKQTAAVRASGSVASNYGISGKDFADASASKDSATAAHPSEIARGDEDSSATPHQHGFTPSTPGTPGPGGDGSPGSGIECPKCDTVLGSSRSLGGHMTMMHSRNSCKTLKCPKCNWHYKYQQTLEAHMKEKHPEPGGSCVYCKTGQPHPRLARGESYTCGYKPFRCEVCNYSTTTKGNLSIHMQSDKHLNNVQNLQNGNGEQVFGHSAPAPNTSLSGCGTPSPSKPKQKPTWRCEVCDYETNVARNLRIHMTSEKHMHNMMLLQQNMKQIQHNLHLGLAPAEAELYQYYLAQNIGLTGMKLENPADPQLMINPFQLDPATAAALAPGLVNNELPPEIRLASGQLMGDDLSLLTAGELSPYISDPALKLFQCAVCNKFTSDSLEALSVHVSSERSLPEEEWRAVIGDIYQCKLCNYNTQLKANFQLHCKTDKHMQKYQLVAHIKEGGKSNEWRLKCIAIGNPVHLKCNACDYYTNSVDKLRLHTTNHRHEAALKLYKHLQKQEGAVNPESCYYYCAVCDYTTKVKLNLVQHVRSVKHQQTEGLRKLQLHQQGLAPEEDNLSEIFFVKDCPPNELETASLGARTCDDDLTEQQLRSTSEEQSEEAEGAIKPTAVAEDDEKDTSERDNSEGKNSNKDSGIITPEKELKVSVAGGTQPLLLAKEEDVATKRSKPTEDNKFCHEQFYQCPYCNYNSRDQSRIQMHVLSQHSVQPVICCPLCQDVLSNKMHLQLHLTHLHSVSPDCVEKLLMTVPVPDVMMPNSMLLPAAASEKSERDTPAAVTAEGSGKYSGESPMDDKSMAGLEDSKANVEVKNEEQKPTKEPLEVSEWNKNSSKDVKIPDTLQDQLNEQQKRQPLSVSDRHVYKYRCNHCSLAFKTMQKLQIHSQYHAIRAATMCNLCQRSFRTFQALKKHLEAGHPELSEAELQQLYASLPVNGELWAESETMSQDDHGLEQEMEREYEVDHEGKASPVGSDSSSIPDDMGSEPKRTLPFRKGPNFTMEKFLDPSRPYKCTVCKESFTQKNILLVHYNSVSHLHKLKKVLQEASSPVPQETNSNTDNKPYKCSICNVAYSQSSTLEIHMRSVLHQTKARAAKLEPSGHVAGGHSIAANVNSPGQGMLDSMSLAAVNSKDTHLDAKELNKKQTPDLISAQPAHHPPQSPAQIQMQLQHELQQQAAFFQPQFLNPAFLPHFPMTPEALLQFQQPQFLFPFYIPGTEFSLGPDLGLPGSATFGMPGMTGMAGSLLEDLKQQIQTQHHVGQTQLQILQQQAQQYQATQPQLQPQKQQQQPPPPQQQQQQQASKLLKQEQSNIVSADCQIMKDVPSYKEAEDISEKPEKPKQEFISEGEGLKEGKDTKKQKSLEPSIPPPRIASGARGNAAKALLENFGFELVIQYNENRQKVQKKGKSGEGENTDKLECGTCGKLFSNVLILKSHQEHVHGQFFPYAALEKFARQYREAYDKLYPISPSSPETPPPPPPPPPLPPAPPQPSSMGPVKIPNTVSTPLQAPPPTPPPSAPPQVQLPVSLDLPLFPSIMMQPVQHPALPPQLALQLPQMDALSADLTQLCQQQLGLDPNFLRHSQFKRPRTRITDDQLKILRAYFDINNSPSEEQIQEMAEKSGLSQKVIKHWFRNTLFKERQRNKDSPYNFSNPPITVLEDIRIDPQPTSLEHYKSDASFSKRSSRTRFTDYQLRVLQDFFDTNAYPKDDEIEQLSTVLNLPTRVIVVWFQNARQKARKSYENQAETKDNEKRELTNERYIRTSNMQYQCKKCNVVFPRIFDLITHQKKQCYKDEDDDAQDESQTEDSMDATDQVVYKHCTVSGQTDAAKNAAAPAASSGSGTSTPLIPSPKPEPEKTSPKPEYPAEKPKQSDPSPPSQGTKPALPLASTSSDPPQASTAQPQPQPQPPKQPQLIGRPPSASQTPVPSSPLQISMTSLQNSLPPQLLQYQCDQCTVAFPTLELWQEHQHMHFLAAQNQFLHSPFLERPMDMPYMIFDPNNPLMTGQLLGSSLTQMPPQASSSHTTAPTTVAASLKRKLDDKEDNNCSEKEGGNSGEDQHRDKRLRTTITPEQLEILYEKYLLDSNPTRKMLDHIAREVGLKKRVVQVWFQNTRARERKGQFRAVGPAQSHKRCPFCRALFKAKSALESHIRSRHWNEGKQAGYSLPPSPLISTEDGGESPQKYIYFDYPSLPLTKIDLSSENELASTVSTPVSKTAELSPKNLLSPSSFKAECSEDVENLNAPPAEAGYDQNKTDFDETSSINTAISDATTGDEGNTEMESTTGSSGDVKPALSPKEPKTLDTLPKPATTPTTEVCDDKFLFSLTSPSIHFNDKDGDHDQSFYITDDPDDNADRSETSSIADPSSPNPFGSSNPFKSKSNDRPGHKRFRTQMSNLQLKVLKACFSDYRTPTMQECEMLGNEIGLPKRVVQVWFQNARAKEKKFKINIGKPFMINQGGTEGTKPECTLCGVKYSARLSIRDHIFSKQHISKVRETVGSQLDREKDYLAPTTVRQLMAQQELDRIKKASDVLGLTVQQPGMMDSSSLHGISLPTAYPGLPGLPPVLLPGMNGPSSLPGFPQNSNTLTPPGAGMLGFPTSATSSPALSLSSAPTKPLLQTPPPPPPPPPPPPSSSLSGQQTEQQNKESEKKQTKPNKVKKIKEEELEATKPEKHPKKEEKISSALSVLGKVVGETHVDPIQLQALQNAIAGDPASFIGGQFLPYFIPGFASYFTPQLPGTVQGGYFPPVCGMESLFPYGPTMPQTLAGLSPGALLQQYQQYQQNLQESLQKQQKQQQEQQQKPVQAKTSKVESDQPQNSNDASETKEDKSTATESTKEEPQLESKSADFSDTYVVPFVKYEFICRKCQMMFTDEDAAVNHQKSFCYFGQPLIDPQETVLRVPVSKYQCLACDVAISGNEALSQHLQSSLHKEKTIKQAMRNAKEHVRLLPHSVCSPNPNTTSTSQSAASSNNTYPHLSCFSMKSWPNILFQASARRAASPPSSPPSLSLPSTVTSSLCSTSGVQTSLPTESCSDESDSELSQKLEDLDNSLEVKAKPASGLDGNFNSIRMDMFSV>sp|Q86UP3-3|ZFHX4_HUMAN Isoform 3 of Zinc finger homeobox protein 4OS=Homo sapiens OX=9606 GN=ZFHX4METCDSPPISRQENGQSTSKLCGTTQLDNEVPEKVAGMEPDRENSSTDDNLKTDERKSEALLGFSVENAAATQVTSAKEIPCNECATSFPSLQKYMEHHCPNARLPVLKDDNESEISELEDSDVENLTGEIVYQPDGSAYIIEDSKESGQNAQTGANSKLFSTAMFLDSLASAGEKSDQSASAPMSFYPQIINTFHIASSLGKPFTADQAFPNTSALAGVGPVLHSFRVYDLRHKREKDYLTSDGSAKNSCVSKDVPNNVDLSKFDGCVSDGKRKPVLMCFLCKLSFGYIRSFVTHAVHDHRMTLNDEEQKLLSNKCVSAIIQGIGKDKEPLISFLEPKKSTSVYPHFSTTNLIGPDPTFRGLWSAFHVENGDSLPAGFAFLKGSASTSSSAEQPLGITQMPKAEVNLGGLSSLVVNTPITSVSLSHSSSESSKMSESKDQENNCERPKESNVLHPNGECPVKSEPTEPGDEDEEDAYSNELDDEEVLGELTDSIGNKDFPLLNQSISPLSSSVLKFIEKGTSSSSATVSDDTEKKKQTAAVRASGSVASNYGISGKDFADASASKDSATAAHPSEIARGDEDSSATPHQHGFTPSTPGTPGPGGDGSPGSGIECPKCDTVLGSSRSLGGHMTMMHSRNSCKTLKCPKCNWHYKYQQTLEAHMKEKHPEPGGSCVYCKTGQPHPRLARGESYTCGYKPFRCEVCNYSTTTKGNLSIHMQSDKHLNNVQNLQNGNGEQVFGHSAPAPNTSLSGCGTPSPSKPKQKPTWRCEVCDYETNVARNLRIHMTSEKHMHNMMLLQQNMKQIQHNLHLGLAPAEAELYQYYLAQNIGLTGMKLENPADPQLMINPFQLDPATAAALAPGLGELSPYISDPALKLFQCAVCNKFTSDSLEALSVHVSSERSLPEEEWRAVIGDIYQCKLCNYNTQLKANFQLHCKTDKHMQKYQLVAHIKEGGKSNEWRLKCIAIGNPVHLKCNACDYYTNSVDKLRLHTTNHRHEAALKLYKVSSDIHFRWHRVEKGINSFRAWSTSLQLKEKKREKTSKGRGHSF>sp|Q86UP3-4|ZFHX4_HUMAN Isoform 4 of Zinc finger homeobox protein 4OS=Homo sapiens OX=9606 GN=ZFHX4METCDSPPISRQENGQSTSKLCGTTQLDNEVPEKVAGMEPDRENSSTDDNLKTDERKSEALLGFSVENAAATQVTSAKEIPCNECATSFPSLQKYMEHHCPNARLPVLKDDNESEISELEDSDVENLTGEIVYQPDGSAYIIEDSKESGQNAQTGANSKLFSTAMFLDSLASAGEKSDQSASAPMSFYPQIINTFHIASSLGKPFTADQAFPNTSALAGVGPVLHSFRVYDLRHKREKDYLTSDGSAKNSCVSKDVPNNVDLSKFDGCVSDGKRKPVLMCFLCKLSFGYIRSFVTHAVHDHRMTLNDEEQKLLSNKCVSAIIQGIGKDKEPLISFLEPKKSTSVYPHFSTTNLIGPDPTFRGLWSAFHVENGDSLPAGFAFLKGSASTSSSAEQPLGITQMPKAEVNLGGLSSLVVNTPITSVSLSHSSSESSKMSESKDQENNCERPKESNVLHPNGECPVKSEPTEPGDEDEEDAYSNELDDEEVLGELTDSIGNKDFPLLNQSISPLSSSVLKFIEKGTSSSSATVSDDTEKKKQTAAVRASGSVASNYGISGKDFADASASKDSATAAHPSEIARGDEDSSATPHQHGFTPSTPGTPGPGGDGSPGSGIECPKCDTVLGSSRSLGGHMTMMHSRNSCKTLKCPKCNWHYKYQQTLEAHMKEKHPEPGGSCVYCKTGQPHPRLARGESYTCGYKPFRCEVCNYSTTTKGNLSIHMQSDKHLNNVQNLQNGNGEQVFGHSAPAPNTSLSGCGTPSPSKPKQKPTWRCEVCDYETNVARNLRIHMTSEKHMHNMMLLQQNMKQIQHNLHLGLAPAEAELYQYYLAQNIGLTGMKLENPADPQLMINPFQLDPATAAALAPGLGELSPYISDPALKLFQCAVCNKFTSDSLEALSVHVSSERSLPEEEWRAVIGDIYQCKLCNYNTQLKANFQLHCKTDKHMQKYQLVAHIKEGGKSNEWRLKCIAIGNPVHLKCNACDYYTNSVDKLRLHTTNHRHEAALKLYKHLQKQEGAVNPESCYYYCAVCDYTTKVKLNLVQHVRSVKHQQTEGLRKLQLHQQGLAPEEDNLSEIFFVKDCPPNELETASLGARTCDDDLTEQHEEAEGAIKPTAVAEDDEKDTSERDNSEGKNSNKDSVSVAGGTQPLLLAKEEDVATKRSKPTEDNKFCHEQFYQCPYCNYNSRDQSRIQMHVLSQHSVQPVICCPLCQDVLSNKMHLQLHLTHLHSVSPDCVEKLLMTVPVPDVMMPNSMLLPAAASEKSERDTPAAVTAEGSGKYSGESPMDDKSMAGLEDSKANVEVKNEEQKPTKEPLEVSEWNKNSSKDVKIPDTLQDQLNEQQKRQPLSVSDRHVYKYRCNHCSLAFKTMQKLQIHSQYHAIRAATMCNLCQRSFRTFQALKKHLEAGHPELSEAELQQLYASLPVNGELWAESETMSQDDHGLEQEMEREYEVDHEGKASPVGSDSSSIPDDMGSEPKRTLPFRKGPNFTMEKFLDPSRPYKCTVCKESFTQKNILLVHYNSVSHLHKLKKVLQEASSPVPQETNSNTDNKPYKCSICNVAYSQSSTLEIHMRSVLHQTKARAAKLEPSGHVAGGHSIAANVNSPGQGMLDSMSLAAVNSKDTHLDAKELNKKQTPDLISAQPAHHPPQSPAQIQMQLQHELQQQAAFFQPQFLNPAFLPHFPMTPEALLQFQQPQFLFPFYIPGTEFSLGPDLGLPGSATFGMPGMTGMAGSLLEDLKQQIQTQHHVGQTQLQILQQQAQQYQATQPQLQPQKQQQQPPPPQQQQQQQASKLLKQEQSNIVSADCQIMKDVPSYKEAEDISEKPEKPKQEFISEGEGLKEGKDTKKQKSLEPSIPPPRIASGARGNAAKALLENFGFELVIQYNENRQKVQKKGKSGEGENTDKLECGTCGKLFSNVLILKSHQEHVHGQFFPYAALEKFARQYREAYDKLYPISPSSPETPPPPPPPPPLPPAPPQPSSMGPVKIPNTVSTPLQAPPPTPPPPPPPPPPPPPPPPPPPPSAPPQVQLPVSLDLPLFPSIMMQPVQHPALPPQLALQLPQMDALSADLTQLCQQQLGLDPNFLRHSQFKRPRTRITDDQLKILRAYFDINNSPSEEQIQEMAEKSGLSQKVIKHWFRNTLFKERQRNKDSPYNFSNPPITVLEDIRIDPQPTSLEHYKSDASFSKRSSRTRFTDYQLRVLQDFFDTNAYPKDDEIEQLSTVLNLPTRVIVVWFQNARQKARKSYENQAETKDNEKRELTNERYIRTSNMQYQCKKCNVVFPRIFDLITHQKKQCYKDEDDDAQDESQTEDSMDATDQVVYKHCTVSGQTDAAKNAAAPAASSGSGTSTPLIPSPKPEPEKTSPKPEYPAEKPKQSDPSPPSQGTKPALPLASTSSDPPQASTAQPQPQPQPPKQPQLIGRPPSASQTPVPSSPLQISMTSLQNSLPPQLLQYQCDQCTVAFPTLELWQEHQHMHFLAAQNQFLHSPFLERPMDMPYMIFDPNNPLMTGQLLGSSLTQMPPQASSSHTTAPTTVAASLKRKLDDKEDNNCSEKEGGNSGEDQHRDKRLRTTITPEQLEILYEKYLLDSNPTRKMLDHIAREVGLKKRVVQVWFQNTRARERKGQFRAVGPAQSHKRCPFCRALFKAKSALESHIRSRHWNEGKQAGYSLPPSPLISTEDGGESPQKYIYFDYPSLPLTKIDLSSENELASTVSTPVSKTAELSPKNLLSPSSFKAECSEDVENLNAPPAEAGYDQNKTDFDETSSINTAISDATTGDEGNTEMESTTGSSGDVKPALSPKEPKTLDTLPKPATTPTTEVCDDKFLFSLTSPSIHFNDKDGDHDQSFYITDDPDDNADRSETSSIADPSSPNPFGSSNPFKSKSNDRPGHKRFRTQMSNLQLKVLKACFSDYRTPTMQECEMLGNEIGLPKRVVQVWFQNARAKEKKFKINIGKPFMINQGGTEGTKPECTLCGVKYSARLSIRDHIFSKQHISKVRETVGSQLDREKDYLAPTTVRQLMAQQELDRIKKASDVLGLTVQQPGMMDSSSLHGISLPTAYPGLPGLPPVLLPGMNGPSSLPGFPQNSNTLTPPGAGMLGFPTSATSSPALSLSSAPTKPLLQTPPPPPPPPPPPPSSSLSGQQTEQQNKESEKKQTKPNKVKKIKEEELEATKPEKHPKKEEKISSALSVLGKVVGETHVDPIQLQALQNAIAGDPASFIGGQFLPYFIPGFASYFTPQLPGTVQGGYFPPVCGMESLFPYGPTMPQTLAGLSPGALLQQYQQYQQNLQESLQKQQKQQQEQQQKPVQAKTSKVESDQPQNSNDASETKEDKSTATESTKEEPQLESKSADFSDTYVVPFVKYEFICRKCQMMFTDEDAAVNHQKSFCYFGQPLIDPQETVLRVPVSKYQCLACDVAISGNEALSQHLQSSLHKEKTIKQAMRNAKEHVRLLPHSVCSPNPNTTSTSQSAASSNNTYPHLSCFSMKSWPNILFQASARRAASPPSSPPSLSLPSTVTSSLCSTSGVQTSLPTESCSDESDSELSQKLEDLDNSLEVKAKPASGLDGNFNSIRMDMFSV>sp|Q86UP3-5|ZFHX4_HUMAN Isoform 5 of Zinc finger homeobox protein 4OS=Homo sapiens OX=9606 GN=ZFHX4METCDSPPISRQENGQSTSKLCGTTQLDNEVPEKVAGMEPDRENSSTDDNLKTDERKSEALLGFSVENAAATQVTSAKEIPCNECATSFPSLQKYMEHHCPNARLPVLKDDNESEISELEDSDVENLTGEIVYQPDGSAYIIEDSKESGQNAQTGANSKLFSTAMFLDSLASAGEKSDQSASAPMSFYPQIINTFHIASSLGKPFTADQAFPNTSALAGVGPVLHSFRVYDLRHKREKDYLTSDGSAKNSCVSKDVPNNVDLSKFDGCVSDGKRKPVLMCFLCKLSFGYIRSFVTHAVHDHRMTLNDEEQKLLSNKCVSAIIQGIGKDKEPLISFLEPKKSTSVYPHFSTTNLIGPDPTFRGLWSAFHVENGDSLPAGFAFLKGSASTSSSAEQPLGITQMPKAEVNLGGLSSLVVNTPITSVSLSHSSSESSKMSESKDQENNCERPKESNVLHPNGECPVKSEPTEPGDEDEEDAYSNELDDEEVLGELTDSIGNKDFPLLNQSISPLSSSVLKFIEKGTSSSSATVSDDTEKKKQTAAVRASGSVASNYGISGKDFADASASKDSATAAHPSEIARGDEDSSATPHQHGFTPSTPGTPGPGGDGSPGSGIECPKCDTVLGSSRSLGGHMTMMHSRNSCKTLKCPKCNWHYKYQQTLEAHMKEKHPEPGGSCVYCKTGQPHPRLARGESYTCGYKPFRCEVCNYSTTTKGNLSIHMQSDKHLNNVQNLQNGNGEQVFGHSAPAPNTSLSGCGTPSPSKPKQKPTWRCEVCDYETNVARNLRIHMTSEKHMHNMMLLQQNMKQIQHNLHLGLAPAEAELYQYYLAQNIGLTGMKLENPADPQLMINPFQLDPATAAALAPGLVNNELPPEIRLASGQLMGDDLSLLTAGELSPYISDPALKLFQCAVCNKFTSDSLEALSVHVSSERSLPEEEWRAVIGDIYQCKLCNYNTQLKANFQLHCKTDKHMQKYQLVAHIKEGGKSNEWRLKCIAIGNPVHLKCNACDYYTNSVDKLRLHTTNHRHEAALKLYKHLQKQEGAVNPESCYYYCAVCDYTTKVKLNLVQHVRSVKHQQTEGLRKLQLHQQGLAPEEDNLSEIFFVKDCPPNELETASLGARTCDDDLTEQQLRSTSEEQSEEAEGAIKPTAVAEDDEKDTSERDNSEGKNSNKDSGIITPEKELKVSVAGGTQPLLLAKEEDVATKRSKPTEDNKFCHEQFYQCPYCNYNSRDQSRIQMHVLSQHSVQPVICCPLCQDVLSNKMHLQLHLTHLHSVSPDCVEKLLMTVPVPDVMMPNSMLLPAAASEKSERDTPAAVTAEGSGKYSGESPMDDKSMAGLEDSKANVEVKNEEQKPTKEPLEVSEWNKNSSKDVKIPDTLQDQLNEQQKRQPLSVSDRHVYKYRCNHCSLAFKTMQKLQIHSQYHAIRAATMCNLCQRSFRTFQALKKHLEAGHPELSEAELQQLYASLPVNGELWAESETMSQDDHGLEQEMEREYEVDHEGKASPVGSDSSSIPDDMGSEPKRTLPFRKGPNFTMEKFLDPSRPYKCTVCKESFTQKNILLVHYNSVSHLHKLKKVLQEASSPVPQETNSNTDNKPYKCSICNVAYSQSSTLEIHMRSVLHQTKARAAKLEPSGHVAGGHSIAANVNSPGQGMLDSMSLAAVNSKDTHLDAKELNKKQTPDLISAQPAHHPPQSPAQIQMQLQHELQQQAAFFQPQFLNPAFLPHFPMTPEALLQFQQPQFLFPFYIPGTEFSLGPDLGLPGSATFGMPGMTGMAGSLLEDLKQQIQTQHHVGQTQLQILQQQAQQYQATQPQLQPQKQQQQPPPPQQQQQQQASKLLKQEQSNIVSADCQIMKDVPSYKEAEDISEKPEKPKQEFISEGEGLKEGKDTKKQKSLEPSIPPPRIASGARGNAAKALLENFGFELVIQYNENRQKVQKKGKSGEGENTDKLECGTCGKLFSNVLILKSHQEHVHGQFFPYAALEKFARQYREAYDKLYPISPSSPETPPPPPPPPPLPPAPPQPSSMGPVKIPNTVSTPLQAPPPTPPPPPPPPPPPPPPPPPPPPSAPPQVQLPVSLDLPLFPSIMMQPVQHPALPPQLALQLPQMDALSADLTQLCQQQLGLDPNFLRHSQFKRPRTRITDDQLKILRAYFDINNSPSEEQIQEMAEKSGLSQKVIKHWFRNTLFKERQRNKDSPYNFSNPPITVLEDIRIDPQPTSLEHYKSDASFSKRSSRTRFTDYQLRVLQDFFDTNAYPKDDEIEQLSTVLNLPTRVIVVWFQNARQKARKSYENQAETKDNEKRELTNERYIRTSNMQYQCKKCNVVFPRIFDLITHQKKQCYKDEDDDAQDESQTEDSMDATDQVVYKHCTVSGQTDAAKNAAAPAASSGSGTSTPLIPSPKPEPEKTSPKPEYPAEKPKQSDPSPPSQGTKPALPLASTSSDPPQASTAQPQPQPQPPKQPQLIGRPPSASQTPVPSSPLQISMTSLQNSLPPQLLQYQCDQCTVAFPTLELWQEHQHMHFLAAQNQFLHSPFLERPMDMPYMIFDPNNPLMTGQLLGSSLTQMPPQASSSHTTAPTTVAASLKRKLDDKEDNNCSEKEGGNSGEDQHRDKRLRTTITPEQLEILYEKYLLDSNPTRKMLDHIAREVGLKKRVVQVWFQNTRARERKGQFRAVGPAQSHKRCPFCRALFKAKSALESHIRSRHWNEGKQAGYSLPPSPLISTEDGGESPQKYIYFDYPSLPLTKIDLSSENELASTVSTPVSKTAELSPKNLLSPSSFKAECSEDVENLNAPPAEAGYDQNKTDFDETSSINTAISDATTGDEGNTEMESTTGSSGDVKPALSPKEPKTLDTLPKPATTPTTEVCDDKFLFSLTSPSIHFNDKDGDHDQSFYITDDPDDNADRSETSSIADPSSPNPFGSSNPFKSKSNDRPGHKRFRTQMSNLQLKVLKACFSDYRTPTMQECEMLGNEIGLPKRVVQVWFQNARAKEKKFKINIGKPFMINQGGTEGTKPECTLCGVKYSARLSIRDHIFSKQHISKVRETVGSQLDREKDYLAPTTVRQLMAQQELDRIKKASDVLGLTVQQPGMMDSSSLHGISLPTAYPGLPGLPPVLLPGMNGPSSLPGFPQNSNTLTPPGAGMLGFPTSATSSPALSLSSAPTKPLLQTPPPPPPPPPPPPSSSLSGQQTEQQNKESEKKQTKPNKVKKIKEEELEATKPEKHPKKEEKISSALSVLGKVVGETHVDPIQLQALQNAIAGDPASFIGGQFLPYFIPGFASYFTPQLPGTVQGGYFPPVCGMESLFPYGPTMPQTLAGLSPGALLQQYQQYQQNLQESLQKQQKQQQEQQQKPVQAKTSKVESDQPQNSNDASETKEDKSTATESTKEEPQLESKSADFSDTYVVPFVKYEFICRKCQMMFTDEDAAVNHQKSFCYFGQPLIDPQETVLRVPVSKYQCLACDVAISGNEALSQHLQSSLHKEKTIKQAMRNAKEHVRLLPHSVCSPNPNTTSTSQSAASSNNTYPHLSCFSMKSWPNILFQASARRAASPPSSPPSLSLPSTVTSSLCSTSGVQTSLPTESCSDESDSELSQKLEDLDNSLEVKAKPASGLDGNFNSIRMDMFSV>sp|P0DPD5|ZN723_HUMAN Zinc finger protein 723 OS=Homo sapiens OX=9606GN=ZNF723 PE=3 SV=1MGPLTFTDVAIKFSLEEWQFLDTAQQNLYRDVMLENYRNLVFLGVGVSKPDLITCLEQGKEPWNMKRHKMVAKPPVVCSHFAQDLWPEQGIKDSFQKVILRSYGKYGHDNLQLRKGCESVDECKMHKGGYDELKQCLTTTPSKIFQCDKYVKVFHKFSSSNSQKIRHTGNNSFKCKECGKSFCMLSHLTKHERNHTRVNCYKCEECGKAFSVPSKLNNHKRIHTGEKPYKCEECGKAFNVSSSLNNHKRIHTGEKPYKCEECGKTFNMFSSLNNHKRIHTGEKPYKCKECGKAFNVFSSLNNHKRIHTGEKPYKCEECGKAFNQPSHLATHKRIHTGEKLYKCEECGKAFSQSSHITTHKRIHTGEKPYKCEECGKAFKVSVHLTTHKRIHTGEKPYKCEECGKAFNQSSALTTHKIIHTGERPYKCKQCGKGFSQSSTLTKHKIIHTKEKPYKCEECGKAFNQYSTLNKHKIIHAREKPYKCEECGKAFNKSSILNRHKIIHTKEKSQTLKM>sp|Q401N2|ZACN_HUMAN Zinc-activated ligand-gated ion channel OS=Homosapiens OX=9606 GN=ZACN PE=1 SV=2MMALWSLLHLTFLGFSITLLLVHGQGFQGTAAIWPSLFNVNLSKKVQESIQIPNNGSAPLLVDVRVFVSNVFNVDILRYTMSSMLLLRLSWLDTRLAWNTSAHPRHAITLPWESLWTPRLTILEALWVDWRDQSPQARVDQDGHVKLNLALATETNCNFELLHFPRDHSNCSLSFYALSNTAMELEFQAHVVNEIVSVKREYVVYDLKTQVPPQQLVPCFQVTLRLKNTALKSIIALLVPAEALLLADVCGGLLPLRAIERIGYKVTLLLSYLVLHSSLVQALPSSSSCNPLLIYYFTILLLLLFLSTIETVLLAGLLARGNLGAKSGPSPAPRGEQREHGNPGPHPAEEPSRGVKGSQRSWPETADRIFFLVYVVGVLCTQFVFAGIWMWAACKSDAAPGEAAPHGRRPRL>sp|Q401N2-2|ZACN_HUMAN Isoform 2 of Zinc-activated ligand-gated ionchannel OS=Homo sapiens OX=9606 GN=ZACNMMALWSLLHLTFLGFSITLLLVHGQGFQGTAAIWPSLFNVNLSKKVQESIQIPNNGSAPLLVDVRVFVSNVFNVDILRYTMSSMLLLRLSWLDTRLAWNTSAHPRHAITLPWESLWTPRLTILEALWVDWRDQSPQARVDQDGHVKLNLALATETNCNFELLHFPRDHSNCSLSFYALSNTGADRAGAAGLRRGGGRWGRGTPRSVVQGQGAGQGEGAKADRRRTPRSVFRAVYPRLRRAAPALPLRPPLEWQPISVLSGSLRAPL>sp|Q401N2-3|ZACN_HUMAN Isoform 3 of Zinc-activated ligand-gated ionchannel OS=Homo sapiens OX=9606 GN=ZACNMMALWSLLHLTFLGFSITLLLVHGQGFQGTAAIWPSLFNVNLSKKVQESIQIPNNGSAPLLVDVRVFVSNVFNVSSVLPRATALHSHGDCSGSAPCSKARGSGCHGLTPGNHLKVQPPCINPSGDI>sp|Q6ZSA8|YS025_HUMAN Putative uncharacterized protein FLJ45684 OS=Homosapiens OX=9606 PE=5 SV=2METANGEEPPAGPPVSLHGRRLLRVGGACPTPLPVLQRLPPSALHHTLHCVPRRVCVSPLGQVTRIPPVRTVRRAPSGLLPQRRGGPSWWPPSGVARGGPSWWPPSGVVRGGPSSWPPSGVAEPREALGLP>sp|Q99592|ZBT18_HUMAN Zinc finger and BTB domain-containing protein 18OS=Homo sapiens OX=9606 GN=ZBTB18 PE=1 SV=1MEFPDHSRHLLQCLSEQRHQGFLCDCTVLVGDAQFRAHRAVLASCSMYFHLFYKDQLDKRDIVHLNSDIVTAPAFALLLEFMYEGKLQFKDLPIEDVLAAASYLHMYDIVKVCKKKLKEKATTEADSTKKEEDASSCSDKVESLSDGSSHIAGDLPSDEDEGEDEKLNILPSKRDLAAEPGNMWMRLPSDSAGIPQAGGEAEPHATAAGKTVASPCSSTESLSQRSVTSVRDSADVDCVLDLSVKSSLSGVENLNSSYFSSQDVLRSNLVQVKVEKEASCDESDVGTNDYDMEHSTVKESVSTNNRVQYEPAHLAPLREDSVLRELDREDKASDDEMMTPESERVQVEGGMESSLLPYVSNILSPAGQIFMCPLCNKVFPSPHILQIHLSTHFREQDGIRSKPAADVNVPTCSLCGKTFSCMYTLKRHERTHSGEKPYTCTQCGKSFQYSHNLSRHAVVHTREKPHACKWCERRFTQSGDLYRHIRKFHCELVNSLSVKSEALSLPTVRDWTLEDSSQELWK>sp|Q99592-2|ZBT18_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 18 OS=Homo sapiens OX=9606 GN=ZBTB18MCPKGYEDSMEFPDHSRHLLQCLSEQRHQGFLCDCTVLVGDAQFRAHRAVLASCSMYFHLFYKDQLDKRDIVHLNSDIVTAPAFALLLEFMYEGKLQFKDLPIEDVLAAASYLHMYDIVKVCKKKLKEKATTEADSTKKEEDASSCSDKVESLSDGSSHIAGDLPSDEDEGEDEKLNILPSKRDLAAEPGNMWMRLPSDSAGIPQAGGEAEPHATAAGKTVASPCSSTESLSQRSVTSVRDSADVDCVLDLSVKSSLSGVENLNSSYFSSQDVLRSNLVQVKVEKEASCDESDVGTNDYDMEHSTVKESVSTNNRVQYEPAHLAPLREDSVLRELDREDKASDDEMMTPESERVQVEGGMESSLLPYVSNILSPAGQIFMCPLCNKVFPSPHILQIHLSTHFREQDGIRSKPAADVNVPTCSLCGKTFSCMYTLKRHERTHSGEKPYTCTQCGKSFQYSHNLSRHAVVHTREKPHACKWCERRFTQSGDLYRHIRKFHCELVNSLSVKSEALSLPTVRDWTLEDSSQELWK>sp|Q9UDW3|ZMAT5_HUMAN Zinc finger matrin-type protein 5 OS=Homo sapiensOX=9606 GN=ZMAT5 PE=1 SV=1MGKRYFCDYCDRSFQDNLHNRKKHLNGLQHLKAKKVWYDMFRDAAAILLDEQNKRPCRKFLLTGQCDFGSNCRFSHMSERDLQELSIQVEEERRAREWLLDAPELPEGHLEDWLEKRAKRLSSAPSSRAEPIRTTVFQYPVGWPPVQELPPSLRAPPPGGWPLQPRVQWG>sp|Q86UQ0|ZN589_HUMAN Zinc finger protein 589 OS=Homo sapiens OX=9606GN=ZNF589 PE=1 SV=1MWAPREQLLGWTAEALPAKDSAWPWEEKPRYLGPVTFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLAESKPEVHTCPSCPLAFGSQQFLSQDELHNHPIPGFHAGNQLHPGNPCPEDQPQSQHPSDKNHRGAEAEDQRVEGGVRPLFWSTNERGALVGFSSLFQRPPISSWGGNRILEIQLSPAQNASSEEVDRISKRAETPGFGAVTFGECALAFNQKSNLFRQKAVTAEKSSDKRQSQVCRECGRGFSRKSQLIIHQRTHTGEKPYVCGECGRGFIVESVLRNHLSTHSGEKPYVCSHCGRGFSCKPYLIRHQRTHTREKSFMCTVCGRGFREKSELIKHQRIHTGDKPYVCRD>sp|Q86UQ0-2|ZN589_HUMAN Isoform 2 of Zinc finger protein 589 OS=Homosapiens OX=9606 GN=ZNF589MIDFQMLNQLCRTIINPSVIPCLKYCGDQIGPVTFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLESKPEVHTCPSCPLAFGSQQFLSQDELHNHPIPGFHAGNQLHPGNPCPEDQPQSQHPSDKNHRGAEAEDQRVEGGVRPLFWSTNERGALVGFSSLFQRPPISSWGGNRILEIQLSPAQNASSEEVDRISKRAETPGFGAVTFGECALAFNQKSNLFRQKAVTAEKSSDKRQSQVCRECGRGFSRKSQLIIHQRTHTGEKPYVCGECGRGFIVESVLRNHLSTHSGEKPYVCSHCGRGFSCKPYLIRHQRTHTREKSFMCTVCGRGFREKSELIKHQRIHTGDKPYVCRD>sp|Q86UQ0-3|ZN589_HUMAN Isoform 3 of Zinc finger protein 589 OS=Homosapiens OX=9606 GN=ZNF589MIDFQMLNQLCRTIINPSVIPCLKYCGDQIGPVTFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLESKPEVHTCPSCPLAFGSQQFLSQDELHNHPIPGFHAGNQLHPGNPCPEDQPQSQHPSDKNHRGAEAEDQRVEGGVRPLFWSTNERGALVGFSSLFQRPPISSWGGNRILEIQLSPAQNASSEEVDRISKRAETPGFGAVTFGECALAFNQKSNLFRQKAVTAEKSSDKRQSQVCRECGRGFSRKSQLIIHQRTHTGEKPYVCGECGRGFIVESVLRNHLSTHSGEKPYVCSHCGRGFSCKPYLIRHQRTHTREKSFMCTVCGRGFREKSELIKHQRCQVTVPLEEWSLHLTTSFCNCVLPLASMTLSCFIFFYISSLCCFLSYPTFRFYSEFSLQPYNLRDTFTRSPS>sp|Q6ZR54|YN009_HUMAN Putative uncharacterized protein FLJ46641 OS=Homosapiens OX=9606 PE=5 SV=1MGKLRPSRGRGFADVSQQIRVRNRPSWACRRGGPLGTLLANAGPSTVPVTPTAGSCQPSPLSPGGSDPPPPPRAHVSPQEAPLGQVPGAEWLPPTRGLLCKDVSSSPGPSFHLGGPGLPGHAGPCGPRARPAQGLAGRGGNVGEGSESPLGTLPCSVPASQQLLRGRSHLQGSLAALGEARGGGAAFSWGQEGP>sp|Q3MIS6|ZN528_HUMAN Zinc finger protein 528 OS=Homo sapiens OX=9606GN=ZNF528 PE=2 SV=1MALTQGPLKFMDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLGICLPDLSVTSMLEQKRDPWTLQSEEKIANDPDGRECIKGVNTERSSKLGSNAGNKPCKNQLGFTFQLHLSDLQLFQAERKISGCKHFEKPVSDNSSVSPLEKISSSVKSHLLNKYRNNFDHAPLLPQEQKAHIREKAYKCNEHGQVFRASASLTNQVIHNADNPYKCSECGKVFSCSSKLVIHRRMHTGEKPYKCHECGKLFSSNSNLSQHQRIHTGEKPYKCHECDKVFRSSSKLAQHQRIHTGEKPYKCHECDKVFNQIAHLVRHQKIHTGEKPYSCNKCGKVFSRHSYLAEHQTVHTGEKPYKCEECGKAFSVRSSLITHQLIHTGRKPYKCKECDKVFGRKCFLTSHQRIHTRERPYGCSQCGKIFSQKSDLIRHRKTHTDEKPYKCNKCGTAFREFSDLTAHFLIHSGEKPYECKECGKVFRYKSSLTSHHRIHTGEKPYKCNRCGKVFSRSSNLVCHQKIHTGEKPYKCNQCGKVFNQASYLTRHQIIHTGERPYRCSKCGKAFRGCSGLTAHLAIHTEKKSHECKECGKIFTQKSSLTNHHRIHIGEKPYKCTLCSKVFSHNSDLAQHQRVHS>sp|Q3MIS6-2|ZN528_HUMAN Isoform 2 of Zinc finger protein 528 OS=Homosapiens OX=9606 GN=ZNF528MHTGEKPYKCHECGKLFSSNSNLSQHQRIHTGEKPYKCHECDKVFRSSSKLAQHQRIHTGEKPYKCHECDKVFNQIAHLVRHQKIHTGEKPYSCNKCGKVFSRHSYLAEHQTVHTGEKPYKCEECGKAFSVRSSLITHQLIHTGRKPYKCKECDKVFGRKCFLTSHQRIHTRERPYGCSQCGKIFSQKSDLIRHRKTHTDEKPYKCNKCGTAFREFSDLTAHFLIHSGEKPYECKECGKVFRYKSSLTSHHRIHTGEKPYKCNRCGKVFSRSSNLVCHQKIHTGEKPYKCNQCGKVFNQASYLTRHQIIHTGERPYRCSKCGKAFRGCSGLTAHLAIHTEKKSHECKECGKIFTQKSSLTNHHRIHIGEKPYKCTLCSKVFSHNSDLAQHQRVHS>sp|Q5T619|ZN648_HUMAN Zinc finger protein 648 OS=Homo sapiens OX=9606GN=ZNF648 PE=1 SV=1MAQVDSQDRWGEASPLSSLTEEAHDTQMLSMNLESDDEDGGEAEKEGTADPVACPRGSSPVTHENPDLPWPHPLGKEEEKFSDSSSAGGMGQKPVEMSGKASWSRDVTKINETQGSPGASRALGSLPSGLAHKLLGQMQPLGDRLPAGDDGYSGANQDAVLDVPPSFPSNGKYLCAHKSVDTSAGNSSLLCFPRPGSNWDLPTQETHTPAQASATPASLAAAVLAKARNSRKVQNQAGRREGGEAEARPYRCLRGGRAFQKPSKPLSPAETRGGAAKRYACELCGKAYSHRGTLQQHRRLHTGERPYQCSFCDKAYTWSSDHRKHIRTHTGEKPYPCPDCGKAFVRSSDLRKHQRNMHSNNKPFPCSECGLTFNKPLSLLRHQRTHLGAKPFRCPACDREFAVASRMVEHQRVHSGERPFPCPTCGKCFTKSSNLSEHQTLHTGQRPFKCADCGVAFAQPSRLVRHQRIHTGERPFPCTQCGQAFARSSTLKRHQQIHSGEKGFLCAECGRAFRIASELAQHIRMHNGERPYQCEDCGQAFTRSNHLQRHRAKHGTCKKEPIPSSSDE>sp|Q9H4T2|ZSC16_HUMAN Zinc finger and SCAN domain-containing protein 16OS=Homo sapiens OX=9606 GN=ZSCAN16 PE=1 SV=2MTTALEPEDQKGLLIIKAEDHYWGQDSSSQKCSPHRRELYRQHFRKLCYQDAPGPREALTQLWELCRQWLRPECHTKEQILDLLVLEQFLSILPKDLQAWVRAHHPETGEEAVTVLEDLERELDEPGKQVPGNSERRDILMDKLAPLGRPYESLTVQLHPKKTQLEQEAGKPQRNGDKTRTKNEELFQKEDMPKDKEFLGEINDRLNKDTPQHPKSKDIIENEGRSEWQQRERRRYKCDECGKSFSHSSDLSKHRRTHTGEKPYKCDECGKAFIQRSHLIGHHRVHTGVKPYKCKECGKDFSGRTGLIQHQRIHTGEKPYECDECGRPFRVSSALIRHQRIHTANKLY>sp|Q96LW9|ZSC31_HUMAN Zinc finger and SCAN domain-containing protein 31OS=Homo sapiens OX=9606 GN=ZSCAN31 PE=1 SV=2MASTEEQYDLKIVKVEEDPIWDQETHLRGNNFSGQEASRQLFRQFCYQETPGPREALSRLRELCHQWLRPEIHTKEQILELLVLEQFLTILPEELQAWVREHHPESGEEAVAVVEDLEQELSEPGNQAPDHEHGHSEVLLEDVEHLKVKQEPTDIQLQPMVTQLRYESFCLHQFQEQDGESIPENQELASKQEILKEMEHLGDSKLQRDVSLDSKYRETCKRDSKAEKQQAHSTGERRHRCNECGKSFTKSSVLIEHQRIHTGEKPYECEECGKAFSRRSSLNEHRRSHTGEKPYQCKECGKAFSASNGLTRHRRIHTGEKPYECKVCGKAFLLSSCLVQHQRIHTGEKRYQCRECGKAFIQNAGLFQHLRVHTGEKPYQCSQCSKLFSKRTLLKKHQKIHTGERP>sp|Q96LW9-2|ZSC31_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 31 OS=Homo sapiens OX=9606 GN=ZSCAN31MVTQLRYESFCLHQFQEQDGESIPENQELASKQEILKEMEHLGDSKLQRDVSLDSKYRETCKRDSKAEKQQAHSTGERRHRCNECGKSFTKSSVLIEHQRIHTGEKPYECEECGKAFSRRSSLNEHRRSHTGEKPYQCKECGKAFSASNGLTRHRRIHTGEKPYECKVCGKAFLLSSCLVQHQRIHTGEKRYQCRECGKAFIQNAGLFQHLRVHTGEKPYQCSQCSKLFSKRTLLKKHQKIHTGERP>sp|Q9BV38|WDR18_HUMAN WD repeat-containing protein 18 OS=Homo sapiensOX=9606 GN=WDR18 PE=1 SV=2MAAPMEVAVCTDSAAPMWSCIVWELHSGANLLTYRGGQAGPRGLALLNGEYLLAAQLGKNYISAWELQRKDQLQQKIMCPGPVTCLTASPNGLYVLAGVAESIHLWEVSTGNLLVILSRHYQDVSCLQFTGDSSHFISGGKDCLVLVWSLCSVLQADPSRIPAPRHVWSHHALPITDLHCGFGGPLARVATSSLDQTVKLWEVSSGELLLSVLFDVSIMAVTMDLAEHHMFCGGSEGSIFQVDLFTWPGQRERSFHPEQDAGKVFKGHRNQVTCLSVSTDGSVLLSGSHDETVRLWDVQSKQCIRTVALKGPVTNAAILLAPVSMLSSDFRPSLPLPHFNKHLLGAEHGDEPRHGGLTLRLGLHQQGSEPSYLDRTEQLQAVLCSTMEKSVLGGQDQLRVRVTELEDEVRNLRKINRDLFDFSTRFITRPAK>sp|Q8N3P4|VPS8_HUMAN Vacuolar protein sorting-associated protein 8homolog OS=Homo sapiens OX=9606 GN=VPS8 PE=1 SV=3MENEPDHENVEQSLCAKTSEEELNKSFNLEASLSKFSYIDMDKELEFKNDLIDDKEFDIPQVDTPPTLESILNETDDEDESFILEDPTLLNIDTIDSHSYDTSSVASSDSGDRTNLKRKKKLPDSFSLHGSVMRHSLLKGISAQIVSAADKVDAGLPTAIAVSSLIAVGTSHGLALIFGKDQNQALRLCLGSTSVGGQYGAISALSINNDCSRLLCGFAKGQITMWDLASGKLLRSITDAHPPGTAILHIKFTDDPTLAICNDSGGSVFELTFKRVMGVRTCESRCLFSGSKGEVCCIEPLHSKPELKDHPITQFSLLAMASLTKILVIGLKPSLKVWMTFPYGRMDPSSVPLLAWHFVAVQNYVNPMLAFCRGDVVHFLLVKRDESGAIHVTKQKHLHLYYDLINFTWINSRTVVLLDSVEKLHVIDRQTQEELETVEISEVQLVYNSSHFKSLATGGNVSQALALVGEKACYQSISSYGGQIFYLGTKSVYVMMLRSWRERVDHLLKQDCLTEALALAWSFHEGKAKAVVGLSGDASKRKAIVADRMVEILFHYADRALKKCPDQGKIQVMEQHFQDMVPVIVDYCLLLQRKDLLFSQMYDKLSENSVAKGVFLECLEPYILSDKLVGITPQVMKDLIVHFQDKKLMENVEALIVHMDITSLDIQQVVLMCWENRLYDAMIYVYNRGMNEFISPMEKLFRVIAPPLNAGKTLTDEQVVMGNKLLVYISCCLAGRAYPLGDIPEDLVPLVKNQVFEFLIRLHSAEASPEEEIYPYIRTLLHFDTREFLNVLALTFEDFKNDKQAVEYQQRIVDILLKVMVENSDFTPSQVGCLFTFLARQLAKPDNTLFVNRTLFDQVLEFLCSPDDDSRHSERQQVLLELLQAGGIVQFEESRLIRMAEKAEFYQICEFMYEREHQYDKIIDCYLRDPLREEEVFNYIHNILSIPGHSAEEKQSVWQKAMDHIEELVSLKPCKAAELVATHFSGHIETVIKKLQNQVLLFKFLRSLLDPREGIHVNQELLQISPCITEQFIELLCQFNPTQVIETLQVLECYRLEETIQITQKYQLHEVTAYLLEKKGDIHGAFLIMLERLQSKLQEVTHQGENTKEDPSLKDVEDTMVETIALCQRNSHNLNQQQREALWFPLLEAMMAPQKLSSSAIPHLHSEALKSLTMQVLNSMAAFIALPSILQRILQDPVYGKGKLGEIQGLILGMLDTFNYEQTLLETTTSLLNQDLHWSLCNLRASVTRGLNPKQDYCSICLQQYKRRQEMADEIIVFSCGHLYHSFCLQNKECTVEFEGQTRWTCYKCSSSNKVGKLSENSSEIKKGRITPSQVKMSPSYHQSKGDPTAKKGTSEPVLDPQQIQAFDQLCRLYRGSSRLALLTELSQNRSSESYRPFSGSQSAPAFNSIFQNENFQLQLIPPPVTED>sp|Q8N3P4-2|VPS8_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 8 homolog OS=Homo sapiens OX=9606 GN=VPS8MENEPDHENVEQSLCAKTSEEELNKSFNLEASLSKFSYIDMDKELEFKNDLIDDKEFDIPQVDTPPTLESILNETDDEDESFILEDPTLLNIDTIDSHSYDTSSVASSDSGDRTNLKRKKKLPDSFSLHGSVMRHSLLKGISAQIVSAADKVDAGLPTAIAVSSLIAVGTSHGLALIFDQNQALRLCLGSTSVGGQYGAISALSINNDCSRLLCGFAKGQITMWDLASGKLLRSITDAHPPGTAILHIKFTDDPTLAICNDSGGSVFELTFKRVMGVRTCESRCLFSGSKGEVCCIEPLHSKPELKDHPITQFSLLAMASLTKILVIGLKPSLKVWMTFPYGRMDPSSVPLLAWHFVAVQNYVNPMLAFCRGDVVHFLLVKRDESGAIHVTKQKHLHLYYDLINFTWINSRTVVLLDSVEKLHVIDRQTQEELETVEISEVQLVYNSSHFKSLATGGNVSQALALVGEKACYQSISSYGGQIFYLGTKSVYVMMLRSWRERVDHLLKQDCLTEALALAWSFHEGKAKAVVGLSGDASKRKAIVADRMVEILFHYADRALKKCPDQGKIQVMEQHFQVVLMCWENRLYDAMIYVYNRGMNEFISPMEKLFRVIAPPLNAGKTLTDEQVVMGNKLLVYISCCLAGRAYPLGDIPEDLVPLVKNQVFEFLIRLHSAEASPEEEIYPYIRTLLHFDTREFLNVLALTFEDFKNDKQAVEYQQRIVDILLKVMVENSDFTPSQVGCLFTFLARQLAKPDNTLFVNRTLFDQVLEFLCSPDDDSRHSERQQVLLELLQAGGIVQFEESRLIRMAEKAEFYQICEFMYEREHQYDKIIDCYLRDPLREEEVFNYIHNILSIPGHSAEEKQSVWQKAMDHIEELVSLKPCKAAELVATHFSGHIETVIKKLQNQVLLFKFLRSLLDPREGIHVNQELLQISPCITEQFIELLCQFNPTQVIETLQVLECYRLEETIQITQKYQLHEVTAYLLEKKGDIHGAFLIMLERLQSKLQEVTHQGENTKEDPSLKDVEDTMVETIALCQRNSHNLNQQQREALWFPLLEAMMAPQKLSSSAIPHLHSEALKSLTMQVLNSMAAFIALPSILQRILQDPVYGKGKLGEIQGLILGMLDTFNYEQTLLETTTSLLNQDLHWSLCNLRASVTRGLNPKQDYCSICLQQYKRRQEMADEIIVFSCGHLYHSFCLQNKECTVEFEGQTRWTCYKCSSSNKVGKLSENSSEIKKGRITPSQVKMSPSYHQSKGDPTAKKGTSEPVLDPQQIQAFDQLCRLYRGSSRLALLTELSQNRSSESYRPFSGSQSAPAFNSIFQNENFQLQLIPPPVTED>sp|Q8N3P4-3|VPS8_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 8 homolog OS=Homo sapiens OX=9606 GN=VPS8MENEPDHENVEQSLCAKTSEEELNKSFNLEASLSKFSYIDMDKELEFKNDLIDDKEFDIPQVDTPPTLESILNETDDEDESFILEDPTLLNIDTIDSHSYDTSSVASSDSGDRTNLKRKKKLPDSFSLHGSVMRHSLLKGISAQIVSAADKVDAGLPTAIAVSSLIAVGTSHGLALIFDQNQALRLCLGSTSVGGQYGAISALSINNDCSRLLCGFAKGQITMWDLASGKLLRSITDAHPPGTAILHIKFTDDPTLAICNDSGGSVFELTFKRVMGVRTCESRCLFSGSKGEVCCIEPLHSKPELKDHPITQFSLLAMASLTKILVIGLKPSLKVWMTFPYGRMDPSSVPLLAWHFVAVQNYVNPMLAFCRGDVVHFLLVKRDESGAIHVTKQKHLHLYYDLINFTWINSRTVVLLDSVEKLHVIDRQTQEELETVEISEVQLVYNSSHFKSLATGGNVSQALALVGEKACYQSISSYGGQIFYLGTKSVYVMMLRSWRERVDHLLKQDCLTEALALAWSFHEGKAKAVVGLSGDASKRKAIVADRMVEILFHYADRALKKCPDQGKIQVMEQHFQDMVPVIVDYCLLLQRKDLLFSQMYDKLSENSVAKGVFLECLEPYILSDKLVGITPQVMKDLIVHFQDKKLMENVEALIVHMDITSLDIQQVVLMCWENRLYDAMIYVYNRGMNEFISPMEKLFRVIAPPLNAGKTLTDEQVVMGNKLLVYISCCLAGRAYPLGDIPEDLVPLVKNQVFEFLIRLHSAEASPEEEIYPYIRTLLHFDTREFLNVLALTFEDFKNDKQAVEYQQRIVDILLKVMVENSDFTPSQVGCLFTFLARQLAKPDNTLFVNRTLFDQVLEFLCSPDDDSRHSERQQVLLELLQAGGIVQFEESRLIRMAEKAEFYQICEFMYEREHQYDKIIDCYLRDPLREEEVFNYIHNILSIPGHSAEEKQSVWQKAMDHIEELVSLKPCKAAELVATHFSGHIETVIKKLQNQVLLFKFLRSLLDPREGIHVNQELLQISPCITEQFIELLCQFNPTQVIETLQVLECYRLEETIQITQKYQLHEVTAYLLEKKGDIHGAFLIMLERLQSKLQEVTHQGENTKEDPSLKDVEDTMVETIALCQRNSHNLNQQQREALWFPLLEAMMAPQKLSSSAIPHLHSEALKSLTMQVLNSMAAFIALPSILQRILQDPVYGKGKLGEIQGLILGMLDTFNYEQTLLETTTSLLNQDLHWSLCNLRASVTRGLNPKQDYCSICLQQYKRRQEMADEIIVFSCGHLYHSFCLQNKECTVEFEGQTRWTCYKCSSSNKVGKLSENSSEIKKGRITPSQVKMSPSYHQSKGDPTAKKGTSEPVLDPQQIQAFDQLCRLYRGSSRLALLTELSQNRSSESYRPFSGSQSAPAFNSIFQNENFQLQLIPPPVTED>sp|A8K0Z3|WASH1_HUMAN WASH complex subunit 1 OS=Homo sapiens OX=9606GN=WASHC1 PE=1 SV=2MTPVRMQHSLAGQTYAVPFIQPDLRREEAVQQMADALQYLQKVSGDIFSRISQQVEQSRSQVQAIGEKVSLAQAKIEKIKGSKKAIKVFSSAKYPAPGRLQEYGSIFTGAQDPGLQRRPRHRIQSKHRPLDERALQEKLKDFPVCVSTKPEPEDDAEEGLGGLPSNISSVSSLLLFNTTENLYKKYVFLDPLAGAVTKTHVMLGAETEEKLFDAPLSISKREQLEQQVPENYFYVPDLGQVPEIHVPSYLPDLPGIANDLMYSADLGPGIAPSAPGTIPELPTFHTEVAEPLKVDLQDGVLTPPPPPPPPPPAPEVLASAPPLPPSTAAPVGQGARQDDSSSSASPSVQGAPREVVDPSGGWATLLESIRQAGGIGKAKLRSMKERKLEKQQQKEQEQVRATSQGGHLMSDLFNKLVMRRKGISGKGPGAGEGPGGAFVRVSDSIPPLPPPQQPQAEEDEDDWES>sp|O95201|ZN205_HUMAN Zinc finger protein 205 OS=Homo sapiens OX=9606GN=ZNF205 PE=1 SV=2MSADGGGIQDTQDKETPPEVPDRGHPHQEMPSKLGEAVPSGDTQESLHIKMEPEEPHSEGASQEDGAQGAWGWAPLSHGSKEKALFLPGGALPSPRIPVLSREGRTRDRQMAAALLTAWSQMPVTFEDVALYLSREEWGRLDHTQQNFYRDVLQKKNGLSLGFPFSRPFWAPQAHGKGEASGSSRQAGDEKEWRGACTGAVEVGQRVQTSSVAALGNVKPFRTRAGRVQWGVPQCAQEAACGRSSGPAKDSGQPAEPDRTPDAAPPDPSPTEPQEYRVPEKPNEEEKGAPESGEEGLAPDSEVGRKSYRCEQCGKGFSWHSHLVTHRRTHTGEKPYACTDCGKRFGRSSHLIQHQIIHTGEKPYTCPACRKSFSHHSTLIQHQRIHTGEKPYVCDRCAKRFTRRSDLVTHQGTHTGAKPHKCPICAKCFTQSSALVTHQRTHTGVKPYPCPECGKCFSQRSNLIAHNRTHTGEKPYHCLDCGKSFSHSSHLTAHQRTHRGVRPYACPLCGKSFSRRSNLHRHEKIHTTGPKALAMLMLGAAAAGALATPPPAPT>sp|O43345|ZN208_HUMAN Zinc finger protein 208 OS=Homo sapiens OX=9606GN=ZNF208 PE=2 SV=2MGSLTFRDVAIEFSLEEWQCLDTAQQNLYRNVMLENYRNLVFLGIAAFKPDLIIFLEEGKESWNMKRHEMVEESPVICSHFAQDLWPEQGIEDSFQKVILRRYEKCGHENLHLKIGYTNVDECKVHKEGYNKLNQSLTTTQSKVFQRGKYANVFHKCSNSNRHKIRHTGKKHLQCKEYVRSFCMLSHLSQHKRIYTRENSYKCEEGGKAFNWSSTLTYYKSAHTGEKPYRCKECGKAFSKFSILTKHKVIHTGEKSYKCEECGKAFNQSAILTKHKIIHTGEKPNKCEECGKAFSKVSTLTTHKAIHAGEKPYKCKECGKAFSKVSTLITHKAIHAGEKPYKCKECGKAFSKFSILTKHKVIHTGEKPYKCEECGKAYKWPSTLSYHKKIHTGEKPYKCEECGKGFSMFSILTKHEVIHTGEKPYKCEECGKAFNWSSNLMEHKKIHTGETPYKCEECGKGFSMFSILTKHKVIHNGEKPYKCEECDKATHAGEKPYKCEECGKAFNWSSNLMEHKRIHTGEKPYKCEECGKSFSTFSILTKHKVIHTGEKPYKCEECGKAYKWSSTLSYHKKIHTVEKPYKCEECGKAFNQSAILIKHKRIHTGEKPYKCEECGKTFSKVSTLTTHKAIHAGEKPYKCKECGKTFIKVSTLTTHKAIHAGEKPYKCKECGKAFSKFSILTKHKVIHTGEKPYKCEECGKAFNWSSNLMEHKRIHTGEKPYKCEECGKSFSTFSVLTKHKVIHTGEKPYKCEECGKAYKWSSTLSYHKKIHTVEKPYKCEECGKAFNRSAILIKHKRIHTDEKPYKCEECGKTFSKVSTLTTHKAIHAGEKPYKCKECGKAFSKFSILTKHKVIHTGEKPYKCEECGKAYKWPSTLSYHKKIHTGEKPYKCEECGKGFSMFSILTKHEVIHTGEKPYKCEECGKAFSWLSVFSKHKKTHAGEKFYKCEACGKAYKSSSTLSYHKKIHTEEKPYKYEECGKGFSTFSILTKHKVIHTGEKPYKCEECGKAFNWSSNLMEHKKIHTGETPYKCEECDKAFSWPSSLTEHKATHAGEKPYKCEECGKAFSWPSRLTEHKATHAGEEPYKCEECGKAFNWSSNLMEHKRIHTGEKPYKCEECGKSFSTFSILTKHKVIHTGEKPYKCEECGKAYKWSSTLSYHKKIHTVEKPYKCEECGKGFVMFSILAKHKVIHTGEKLYKCEECGKAYKWPSTLRYHKKIHTGEKPYKCEECGKAFSTFSILTKHKVIHTGEKPYKCEECGKAFSWLSVFSKHKKIHTGEKL>sp|O43345-2|ZN208_HUMAN Isoform 2 of Zinc finger protein 208 OS=Homosapiens OX=9606 GN=ZNF208MGSLTFRDVAIEFSLEEWQCLDTAQQNLYRNVMLENYRNLVFLGIAAFKPDLIIFLEEGKESWNMKRHEMVEESPVICSHFAQDLWPEQGIEDSFQKVILRRYEKCGHENLHLKIGYTNVDECKVHKEGYNKLNQSLTTTQSKVFQRGKYANVFHKCSNSNRHKIRHTGKKHLQCKEYVRSFCMLSHLSQHKRIYTRENSYKCEEGGKAFNWSSTLTYYKSAHTGEKPYRCKECGKAFSKFSILTKHKVIHTGEKSYKCEECGKAFNQSAILTKHKIIHTGEKPNKCEECGKAFSKVSTLTTHKAIHAGEKPYKCKECGKAFSKVSTLITHKAIHAGEKPYKCKECGKAFSKFSILTKHKVIHTGEKPYKCEECGKAYKWPSTLSYHKKIHTGEKPYKCEECGKGFSMFSILTKHEVIHTGEKPYKCEECGKAFNWSSNLMEHKKIHTGETPYKCEECGKGFSWSSTLSYHKKIHTVEKPYKCEECGKAFNQSAILIKHKRIHTGEKPYKCEECGKTFSKVSTLTTHKAIHAGEKPYKCKECGKTFIKVSTLTTHKAIHAGEKPYKCKECGKAFSKFSILTKHKVIHTGEKPYKCEECGKAFNWSSNLMEHKRIHTGEKPYKCEECGKSFSTFSVLTKHKVIHTGEKPYKCEECGKAYKWSSTLSYHKKIHTVEKPYKCEECGKAFNRSAILIKHKRIHTDEKPYKCEECGKTFSKVSTLTTHKAIHAGEKPYKCKECGKAFSKFSILTKHKVIHTGEKPYKCEECGKAYKWPSTLSYHKKIHTGEKPYKCEECGKGFSMFSILTKHEVIHTGEKPYKCEECGKAFSWLSVFSKHKKTHAGEKFYKCEACGKAYNTFSILTKHKVIHTGEKPYKCEECGKAFNWSSNLMEHKKIHTGETPYKCEECDKAFSWPSSLTEHKATHAGEKPYKCEECGKAFSWPSRLTEHKATHAGEEPYKCEECGKAFNWSSNLMEHKRIHTGEKPYKCEECGKSFSTFSILTKHKVIHTGEKPYKCEECGKAYKWSSTLSYHKKIHTVEKPYKCEECGKGFVMFSILAKHKVIHTGEKLYKCEECGKAYKWPSTLRYHKKIHTGEKPYKCEECGKAFSTFSILTKHKVIHTGEKPYKCEECGKAFSWLSVFSKHKKIHTGVPNPPTHKKIHAGEKLYK>sp|Q9UL58|ZN215_HUMAN Zinc finger protein 215 OS=Homo sapiens OX=9606GN=ZNF215 PE=2 SV=2MQPLSKLMAISKPRNLSLREQREVLRADMSWQQETNPVVETHDSEASRQKFRHFQYLKVSGPHEALSQLWELCLQWLRPEIHTKKQIIELLVLEQFLAILPEEVRTWVNLQHPNNSKDMVTLIEDVIEMLEDEDMPCKDSALQMGSIKEKMKAGSRTGKPQEPVTFKDVVVEFSKEEWGQLDSAVKNLYRNVMLENFRNLNSLRKAHLLSKPFESLKLESKKKRWIMEKEIPRKTIFDMKSISGEESSHGVIMTRLTESGHPSSDAWKGENWLYRNQKKWDINLPQEAFIPETIYTEEEDFECSENKKSFDINSVSSICAIQVGIPSRKGSPKCDKFKTYFKFNLDSVGKQHSEYEYGNDLSLSTDIRHQKSHTTMNSYECYQCGKAFCRSSSLIRHQIIHTGEKPYKCSECGRFFNRRTNLTKHQKLHAEAKACTSNKCGKAFSKSEDSNNPTLHFGNNFYQCVNCGKSFNRSSSLIRHQMIHTGEKPFKCKECSKAFNRSSNLVKHQKLHTRDKS>sp|Q9UL58-2|ZN215_HUMAN Isoform 2 of Zinc finger protein 215 OS=Homosapiens OX=9606 GN=ZNF215MQPLSKLMAISKPRNLSLREQREVLRADMSWQQETNPVVETHDSEASRQKFRHFQYLKVSGPHEALSQLWELCLQWLRPEIHTKKQIIELLVLEQFLAILPEEVRTWVNLQHPNNSKDMVTLIEDVIEMLEDEDMPCKDSALQMGSIKEKMKAGSRTGKPQEPVTFKDVVVEFSKEEWGQLDSAVKNLYRNVMLENFRNLNSLRKAHLLSKPFESLKLESKKKRWIMEKEIPRKTIFDMKSISGEESSHGVIMTRLTESGHPSSDAWKDGVSLLLPRLEYNDAVSAHCNLHLWVQVILLPQPPE>sp|O95159|ZFPL1_HUMAN Zinc finger protein-like 1 OS=Homo sapiens OX=9606GN=ZFPL1 PE=1 SV=2MGLCKCPKRKVTNLFCFEHRVNVCEHCLVANHAKCIVQSYLQWLQDSDYNPNCRLCNIPLASRETTRLVCYDLFHWACLNERAAQLPRNTAPAGYQCPSCNGPIFPPTNLAGPVASALREKLATVNWARAGLGLPLIDEVVSPEPEPLNTSDFSDWSSFNASSTPGPEEVDSASAAPAFYSQAPRPPASPGRPEQHTVIHMGNPEPLTHAPRKVYDTRDDDRTPGLHGDCDDDKYRRRPALGWLARLLRSRAGSRKRPLTLLQRAGLLLLLGLLGFLALLALMSRLGRAAADSDPNLDPLMNPHIRVGPS>sp|Q6ZPA2|YS039_HUMAN Putative uncharacterized protein FLJ26174 OS=Homosapiens OX=9606 PE=2 SV=1MVPLFITSDSALTYSPLPEPPPTPALGGQRGPPTCQCPDFPYPVPPSEGCPSGRLLLSLHWDWGRGAGGSWSGGAWPGSPGWRLARGPAHGASAESLGPLGKALVTGWEGGWRGGQGGACSPWYFPIPAAL>sp|Q0D2J5|ZN763_HUMAN Zinc finger protein 763 OS=Homo sapiens OX=9606GN=ZNF763 PE=1 SV=2MDPVACEDVAVNFTQEEWALLDISQRKLYREVMLETFRNLTSIGKKWKDQNIEYEYQNPRRNFRSLIEGNVNEIKEDSHCGETFTQVPDDRLNFQEKKASPEAKSCDNFVCGEVGIGNSSFNMNIRGDIGHKAYEYQDYAPKPYKCQQPKKAFRYHPSFRTQERNHTGEKPYACKECGKTFISHSGIRRRMVMHSGDGPYKCKFCGKAVHCLRLYLIHERTHTGEKPYECKQCVKSFSYSATHRIHERTHTGEKPYECQQCGKAFHSSSSFQAHKRTHTGGKPYECKQCGKSFSWCHSFQIHERTHTGEKPCECSKCNKAFRSYRSYLRHKRSHTGEKPYQCKECRKAFTYPSSLRRHERTHSAKKPYECKQCGKALSYKFSNTPKNALWRKTL>sp|Q0D2J5-2|ZN763_HUMAN Isoform 2 of Zinc finger protein 763 OS=Homosapiens OX=9606 GN=ZNF763MMFQDPVACEDVAVNFTQEEWALLDISQRKLYREVMLETFRNLTSIGKKWKDQNIEYEYQNPRRNFRSLIEGNVNEIKEDSHCGETFTQVPDDRLNFQEKKASPEAKSCDNFVCGEVGIGNSSFNMNIRGDIGHKAYEYQDYAPKPYKCQQPKKAFRYHPSFRTQERNHTGEKPYACKECGKTFISHSGIRRRMVMHSGDGPYKCKFCGKAVHCLRLYLIHERTHTGEKPYECKQCVKSFSYSATHRIHERTHTGEKPYECQQCGKAFHSSSSFQAHKRTHTGGKPYECKQCGKSFSWCHSFQIHERTHTGEKPCECSKCNKAFRSYRSYLRHKRSHTGEKPYQCKECRKAFTYPSSLRRHERTHSAKKPYECKQCGKALSYKFSNTPKNALWRKTL>sp|Q0D2J5-3|ZN763_HUMAN Isoform 3 of Zinc finger protein 763 OS=Homosapiens OX=9606 GN=ZNF763MNIRGDIGHKAYEYQDYAPKPYKCQQPKKAFRYHPSFRTQERNHTGEKPYACKECGKTFISHSGIRRRMVMHSGDGPYKCKFCGKAVHCLRLYLIHERTHTGEKPYECKQCVKSFSYSATHRIHERTHTGEKPYECQQCGKAFHSSSSFQAHKRTHTGGKPYECKQCGKSFSWCHSFQIHERTHTGEKPCECSKCNKAFRSYRSYLRHKRSHTGEKPYQCKECRKAFTYPSSLRRHERTHSAKKPYECKQCGKALSYKFSNTPKNALWRKTL>sp|P86452|ZBED6_HUMAN Zinc finger BED domain-containing protein 6OS=Homo sapiens OX=9606 GN=ZBED6 PE=1 SV=1MSVCTLSVPVSSLSPGRRCNTFSDSGILGCVPINSNTDEEDVVEEKMVAEGVNKEAKQPAKKKRKKGLRIKGKRRRKKLILAKKFSKDLGSGRPVADAPALLASNDPEQDEESLFESNIEKQIYLPSTRAKTSIVWHFFHVDPQYTWRAICNLCEKSVSRGKPGSHLGTSTLQRHLQARHSPHWTRANKFGVASGEEDFTLDVSLSPSSGSNGSFEYIPTDPLDDNRMGKKHDKSASDALRAERGRFLIKSNIVKHALIPGTRAKTSAVWNFFYTDPQHISRAVCNICKRSVSRGRPGSHLGTSTLQRHLQATHPIHWAVANKDSGAVANGLDEAETERSDLLSDTLHGEKSTGSQDLTAEDLSDSDSDEPMLEVENRSESPIPVAEQGTLMRAQERETTCCGNPVSSHISQAIIQMIVEDMHPYNYFSTPAFQRFMQIVAPDYRLPSETYFFTKAVPQLYDCVREKIFLTLENVQSQKIHLTVDIWTHDPSTDYFIVTVHWVSLETASFLNNGRIPDFRKWAVLCVTGLAKDCLITNILQELNDQIGLWLSPNFLIPSFIVSDNSSNVVHAIKDGGFTHVPCFLHCLNMVIQDFFCEHKSIENMLVAARKTCHHFSHSVKARQILQEFQNDHQLPWKNLKQDETGHWISTFYMLKWLLEHCYSVHHSLGRASGVVLTSLQWTLMTYVCDILKPFEEATQKVSVKTAGLNQVLPLIHHLLLSLQKLREDFQVRGITQALNLVDSLSLKLETDTLLSAMLKSKPCILATLLDPCFKNSLEDFFPQGADLETYKQFLAEEVCNYMESSPEICQIPTSEASCPSVTVGADSFTSSLKEGTSSSGSVDSSAVDNVALGSKSFMFPSAVAVVDEYFKEKYSEFSGGDDPLIYWQRKISIWPALTQVAIQYLSCPMCSWQSECIFTKNSHFHPKQIMSLDFDNIEQLMFLKMNLKNVNYDYSTLVLSWDPEQNEVVQSSEKEILP>sp|Q6P9G9|ZN449_HUMAN Zinc finger protein 449 OS=Homo sapiens OX=9606GN=ZNF449 PE=1 SV=3MAVALGCAIQASLNQGSVFQEYDTDCEVFRQRFRQFQYREAAGPHEAFNKLWELCCQWLKPKMRSKEQILELLVLEQFLTILPTEIETWVREHCPENRERVVSLIEDLQRELEIPEQQVDMHDMLLEELAPVGTAHIPPTMHLESPALQVMGPAQEAPVAEAWIPQAGPPELNYGATGECQNFLDPGYPLPKLDMNFSLENREEPWVKELQDSKEMKQLLDSKIGFEIGIENEEDTSKQKKMETMYPFIVTLEGNALQGPILQKDYVQLENQWETPPEDLQTDLAKLVDQQNPTLGETPENSNLEEPLNPKPHKKKSPGEKPHRCPQCGKCFARKSQLTGHQRIHSGEEPHKCPECGKRFLRSSDLYRHQRLHTGERPYECTVCKKRFTRRSHLIGHQRTHSEEETYKCLECGKSFCHGSSLKRHLKTHTGEKPHRCHNCGKSFSRLTALTLHQRTHTEERPFKCNYCGKSFRQRPSLVIHLRIHTGEKPYKCTHCSKSFRQRAGLIMHQVTHFRGLI>sp|Q6P9G9-2|ZN449_HUMAN Isoform 2 of Zinc finger protein 449 OS=Homosapiens OX=9606 GN=ZNF449MAVALGCAIQASLNQGSVFQEYDTDCEVFRQRFRQFQYREAAGPHEAFNKLWELCCQWLKPKMRSKEQILELLVLEQFLTILPTEIETWVREHCPENRERVVSLIEDLQRELEIPEQQVRKECGIFVIGPKEVAEAAGTRPHICLYVIPQPQDFSRVLFLFLFC>sp|Q6P9G9-3|ZN449_HUMAN Isoform 3 of Zinc finger protein 449 OS=Homosapiens OX=9606 GN=ZNF449MAVALGCAIQASLNQGSVFQEYDTDCEVFRQRFRQFQYREAAGPHEAFNKLWELCCQWLKPKMRSKEQILELLVLEQFLTILPTEIETWVREHCPENRERVVSLIEDLQRELEIPEQQTFAAEYSHY>sp|Q8TAF7|ZN461_HUMAN Zinc finger protein 461 OS=Homo sapiens OX=9606GN=ZNF461 PE=1 SV=2MAHELVMFRDVAIDVSQEEWECLNPAQRNLYKEVMLENYSNLVSLGLSVSKPAVISSLEQGKEPWMVVREETGRWCPGTWKTWGFHNNFLDNNEATDINADLASRDEPQKLSPKRDIYETELSQWVNMEEFKSHSPERSIFSAIWEGNCHFEQHQGQEEGYFRQLMINHENMPIFSQHTLLTQEFYDREKISECKKCRKIFSYHLFFSHHKRTHSKELSECKECTEIVNTPCLFKQQTIQNGDKCNECKECWKAFVHCSQLKHLRIHNGEKRYECNECGKAFNYGSELTLHQRIHTGEKPYECKECGKAFRQRSQLTQHQRLHTGEKPYECKQCGKAFIRGFQLTEHLRLHTGEKPYECKECGKTFRHRSHLTIHQRIHTGEKPYECRECGKAFSYHSSFSHHQKIHSGKKPYECHECGKAFCDGLQLTLHQRIHTGEKPYECKECGKTFRQCSHLKRHQRIHTGEKPHECMICGKAFRLHSHLIQHQRIHTGEKPYECKECGKAFSYHSSFSHHQRIHSGKKPYQCGKAFNHRLQLNLHQTLHTGEKPVRFPLLPPHPSLAS>sp|Q8TAF7-2|ZN461_HUMAN Isoform 2 of Zinc finger protein 461 OS=Homosapiens OX=9606 GN=ZNF461MEEFKSHSPERSIFSAIWEGNCHFEQHQGQEEGYFRQLMINHENMPIFSQHTLLTQEFYDREKISECKKCRKIFSYHLFFSHHKRTHSKELSECKECTEIVNTPCLFKQQTIQNGDKCNECKECWKAFVHCSQLKHLRIHNGEKRYECNECGKAFNYGSELTLHQRIHTGEKPYECKECGKAFRQRSQLTQHQRLHTGEKPYECKQCGKAFIRGFQLTEHLRLHTGEKPYECKECGKTFRHRSHLTIHQRIHTGEKPYECRECGKAFSYHSSFSHHQKIHSGKKPYECHECGKAFCDGLQLTLHQRIHTGEKPYECKECGKTFRQCSHLKRHQRIHTGEKPHECMICGKAFRLHSHLIQHQRIHTGEKPYECKECGKAFSYHSSFSHHQRIHSGKKPYQCGKAFNHRLQLNLHQTLHTGEKPVRFPLLPPHPSLAS>sp|Q8TF20|ZN721_HUMAN Zinc finger protein 721 OS=Homo sapiens OX=9606GN=ZNF721 PE=1 SV=2MCSHFTQDFLPVQGIEDSFHKLILRRYEKCGHDNLQLRKGCKSMNVCKVQKGVYNGINKCLSNTQSKIFQCNARVKVFSKFANSNKDKTRHTGEKHFKCNECGKSFQKFSDLTQHKGIHAGEKPYTCEERGKDFGWYTDLNQHKKIHTGEKPYKCEECGKAFNRSTNLTAHKRIHNREKAYTGEDRDRAFGWSTNLNEYKKIHTGDKPYKCKECGKAFMHSSHLNKHEKIHTGEKPYKCKECGKVISSSSSFAKHKRIHTGEKPFKCLECGKAFNISTTLTKHRRIHTGEKPYTCEVCGKAFRQSANLYVHRRIHTGEKPYTCGECGKTFRQSANLYVHRRIHTGEKPYKCEDCGKAFGRYTALNQHKKIHTGEKPYKCEECGKAFNSSTNLTAHKRIHTREKPYTCEDRGRAFGLSTNLNEYKKIHTGDKPYKCKECGKAFIHSLHLNKHEKIHTGKKPYKCKQCGKVITSSSSFAKHKRIHTGEKPFECLECGKAFTSSTTLTKHRRIHTGEKPYTCEVCGKAFRQSAILYVHRRIHTGEKPYTCEECGKTFRQSANLYVHRRIHTGEKPYKCEECGKAFGRYTDLNQHKKIHTGEKLYKCEECGKDFVWYTDLNQQKKIYTGEKPYKCEECGKAFAPSTDLNQHTKILTGEQSYKCEECGKAFGWSIALNQHKKIHTGEKPYKCEECGKAFSRSRNLTTHRRVHTREKPYKCEDRGRSFGWSTNLNEYKKIHTGDKLYKCKECGKVFKQSSHLNRHEKIHTGKKPYKCKECGKVITSSSSFAKHKRIHTGEKPFKCLECGKAFTSSTTLTKHRRIHTGEKPYTCEECGKAFRQSAILYVHRRIHTGEKPYTCGECGKTFRQSANLYAHKKIHTGEKPYTCGDCGKTFRQSANLYAHKKIHTGDKTIQV>sp|Q8TF20-2|ZN721_HUMAN Isoform 2 of Zinc finger protein 721 OS=Homosapiens OX=9606 GN=ZNF721MLENYRNLVSLAMCSHFTQDFLPVQGIEDSFHKLILRRYEKCGHDNLQLRKGCKSMNVCKVQKGVYNGINKCLSNTQSKIFQCNARVKVFSKFANSNKDKTRHTGEKHFKCNECGKSFQKFSDLTQHKGIHAGEKPYTCEERGKDFGWYTDLNQHKKIHTGEKPYKCEECGKAFNRSTNLTAHKRIHNREKAYTGEDRDRAFGWSTNLNEYKKIHTGDKPYKCKECGKAFMHSSHLNKHEKIHTGEKPYKCKECGKVISSSSSFAKHKRIHTGEKPFKCLECGKAFNISTTLTKHRRIHTGEKPYTCEVCGKAFRQSANLYVHRRIHTGEKPYTCGECGKTFRQSANLYVHRRIHTGEKPYKCEDCGKAFGRYTALNQHKKIHTGEKPYKCEECGKAFNSSTNLTAHKRIHTREKPYTCEDRGRAFGLSTNLNEYKKIHTGDKPYKCKECGKAFIHSLHLNKHEKIHTGKKPYKCKQCGKVITSSSSFAKHKRIHTGEKPFECLECGKAFTSSTTLTKHRRIHTGEKPYTCEVCGKAFRQSAILYVHRRIHTGEKPYTCEECGKTFRQSANLYVHRRIHTGEKPYKCEECGKAFGRYTDLNQHKKIHTGEKLYKCEECGKDFVWYTDLNQQKKIYTGEKPYKCEECGKAFAPSTDLNQHTKILTGEQSYKCEECGKAFGWSIALNQHKKIHTGEKPYKCEECGKAFSRSRNLTTHRRVHTREKPYKCEDRGRSFGWSTNLNEYKKIHTGDKLYKCKECGKVFKQSSHLNRHEKIHTGKKPYKCKECGKVITSSSSFAKHKRIHTGEKPFKCLECGKAFTSSTTLTKHRRIHTGEKPYTCEECGKAFRQSAILYVHRRIHTGEKPYTCGECGKTFRQSANLYAHKKIHTGEKPYTCGDCGKTFRQSANLYAHKKIHTGDKTIQV>sp|Q96EG3|ZN837_HUMAN Zinc finger protein 837 OS=Homo sapiens OX=9606GN=ZNF837 PE=1 SV=2MEAPAQKAGQGGLPKADAQGASGAREKRPEEPRPLEEDRAGSRPTQKGDLRGAAGGRTTPPGGGSRGCSLGVSPGPGTRHSAGTRPLVREPCGPTSSQNPELVIPEGLQAREGPCRSPARGGDCSRNSCLAWHRGAPAGETPPVCDPCPERIQNHPRTQLCEVHTDCWPCQPGTGAPTCPRTPKPTSRGRNPLVEQPRACACGEAFAWRALRIPQERLQATEEPRPCARCGKRFRPNQQQQAGKSPPVCPECGQTSRPRPIVPDPPAQRLYACDECGKAFTRTSSLLQHQRIHTGERPYECAECGKAFVRCSGLYRHQKTHSAERHRRGPVLARRAFRLGCPPCGDYSERSPRRGSGAGEKPYECADCAKAFGLFSHLVEHRRVHTGEKPYACPECGKAFNQRSNLSRHQRTHSSAKPYACPLCEKAFKGRSGLVQHQRAHTGERPYGCSECGKTFRGCSELRQHERLHSGEKPYICRDCGKAFVRNCSLVRHLRTHTGERPYACGDCGRAFSQRSNLNEHRKRHGGRAAP>sp|P17026|ZNF22_HUMAN Zinc finger protein 22 OS=Homo sapiens OX=9606GN=ZNF22 PE=1 SV=3MRLAKPKAGISRSSSQGKAYENKRKTGRQRQKWGMTIRFDSSFSRLRRSLDDKPYKCTECEKSFSQSSTLFQHQKIHTGKKSHKCADCGKSFFQSSNLIQHRRIHTGEKPYKCDECGESFKQSSNLIQHQRIHTGEKPYQCDECGRCFSQSSHLIQHQRTHTGEKPYQCSECGKCFSQSSHLRQHMKVHKEEKPRKTRGKNIRVKTHLPSWKAGTGRKSVAGLR>sp|Q8N8P6|YX004_HUMAN Putative uncharacterized protein FLJ39060 OS=Homosapiens OX=9606 PE=2 SV=1MVDGRTRTIINDIFFTEPTPEMSSLPVRSHSSLSLNLVSLMVICRGIIKLVIHFRMYCPPRLKAKHIEPTLRPVPLKELRISHWPNECIRHSASVPMATGANGLETKDETKRNAEKCACSVFL>sp|Q6P3V2|Z585A_HUMAN Zinc finger protein 585A OS=Homo sapiens OX=9606GN=ZNF585A PE=2 SV=2MPANWTSPQKSSALAPEDHGSSYEGSVSFRDVAIDFSREEWRHLDPSQRNLYRDVMLETYSHLLSVGYQVPEAEVVMLEQGKEPWALQGERPRQSCPGEKLWDHNQCRKILSYKQVSSQPQKMYPGEKAYECAKFEKIFTQKSQLKVHLKVLAGEKLYVCIECGKAFVQKPEFIIHQKTHMREKPFKCNECGKSFFQVSSLFRHQRIHTGEKLYECSQCGKGFSYNSDLSIHEKIHTGERHHECTDCGKAFTQKSTLKMHQKIHTGERSYICIECGQAFIQKTHLIAHRRIHTGEKPYECSNCGKSFISKSQLQVHQRVHTRVKPYICTEYGKVFSNNSNLVTHKKVQSREKSSICTECGKAFTYRSELIIHQRIHTGEKPYECSDCGKAFTQKSALTVHQRIHTGEKSYICMKCGLAFIQKAHLIAHQIIHTGEKPHKCGHCGKLFTSKSQLHVHKRIHTGEKPYMCNKCGKAFTNRSNLITHQKTHTGEKSYICSKCGKAFTQRSDLITHQRIHTGEKPYECNTCGKAFTQKSHLNIHQKIHTGERQYECHECGKAFNQKSILIVHQKIHTGEKPYVCTECGRAFIRKSNFITHQRIHTGEKPYECSDCGKSFTSKSQLLVHQPVHTGEKPYVCAECGKAFSGRSNLSKHQKTHTGEKPYICSECGKTFRQKSELITHHRIHTGEKPYECSDCGKSFTKKSQLQVHQRIHTGEKPYVCAECGKAFTDRSNLNKHQTTHTGDKPYKCGICGKGFVQKSVFSVHQSSHA>sp|Q6P3V2-2|Z585A_HUMAN Isoform 2 of Zinc finger protein 585A OS=Homosapiens OX=9606 GN=ZNF585AMLETYSHLLSVGYQVPEAEVVMLEQGKEPWALQGERPRQSCPGEKLWDHNQCRKILSYKQVSSQPQKMYPGEKAYECAKFEKIFTQKSQLKVHLKVLAGEKLYVCIECGKAFVQKPEFIIHQKTHMREKPFKCNECGKSFFQVSSLFRHQRIHTGEKLYECSQCGKGFSYNSDLSIHEKIHTGERHHECTDCGKAFTQKSTLKMHQKIHTGERSYICIECGQAFIQKTHLIAHRRIHTGEKPYECSNCGKSFISKSQLQVHQRVHTRVKPYICTEYGKVFSNNSNLVTHKKVQSREKSSICTECGKAFTYRSELITHHRIHTGEKPYECSDCGKSFTKKSQLQVHQRIHTGEKPYVCAECGKAFTDRSNLNKHQTTHTGDKPYKCGICGKGFVQKSVFSVHQSSHA>sp|P52746|ZN142_HUMAN Zinc finger protein 142 OS=Homo sapiens OX=9606GN=ZNF142 PE=1 SV=4MTDPLLDSQPASSTGEMDGLCPELLLIPPPLSNRGILGPVQSPCPSRDPAPIPTEPGCLLVEATATEEGPGNMEIIVETVAGTLTPGAPGETPAPKLPPGEREPSQEAGTPLPGQETAEEENVEKEEKSDTQKDSQKAVDKGQGAQRLEGDVVSGTESLFKTHMCPECKRCFKKRTHLVEHLHLHFPDPSLQCPNCQKFFTSKSKLKTHLLRELGEKAHHCPLCHYSAVERNALNRHMASMHEDISNFYSDTYACPVCREEFRLSQALKEHLKSHTAAAAAEPLPLRCFQEGCSYAAPDRKAFIKHLKETHGVRAVECRHHSCPMLFATAEAMEAHHKSHYAFHCPHCDFACSNKHLFRKHKKQGHPGSEELRCTFCPFATFNPVAYQDHVGKMHAHEKIHQCPECNFATAHKRVLIRHMLLHTGEKPHKCELCDFTCRDVSYLSKHMLTHSNTKDYMCTECGYVTKWKHYLRVHMRKHAGDLRYQCNQCSYRCHRADQLSSHKLRHQGKSLMCEVCAFACKRKYELQKHMASQHHPGTPAPLYPCHYCSYQSRHKQAVLSHENCKHTRLREFHCALCDYRTFSNTTLLFHKRKAHGYVPGDQAWQLRYASQEPEGAMQGPTPPPDSEPSNQLSARPEGPGHEPGTVVDPSLDQALPEMSEEVNTGRQEGSEAPHGGDLGGSPSPAEVEEGSCTLHLEALGVELESVTEPPLEEVTETAPMEFRPLGLEGPDGLEGPELSSFEGIGTSDLSAEENPLLEKPVSEPSTNPPSLEEAPNNWVGTFKTTPPAETAPLPPLPESESLLKALRRQDKEQAEALVLEGRVQMVVIQGEGRAFRCPHCPFITRREKALNLHSRTGCQGRREPLLCPECGASFKQQRGLSTHLLKKCPVLLRKNKGLPRPDSPIPLQPVLPGTQASEDTESGKPPPASQEAELLLPKDAPLELPREPEETEEPLATVSGSPVPPAGNSLPTEAPKKHCFDPVPPAGNSSPTEAPKKHHLDPVPPAGNSSPTEALKKHRFEQGKFHCNSCPFLCSRLSSITSHVAEGCRGGRGGGGKRGTPQTQPDVSPLSNGDSAPPKNGSTESSSGDGDTVLVQKQKGARFSCPTCPFSCQQERALRTHQIRGCPLEESGELHCSLCPFTAPAATALRLHQKRRHPTAAPARGPRPHLQCGDCGFTCKQSRCMQQHRRLKHEGVKPHQCPFCDFSTTRRYRLEAHQSRHTGIGRIPCSSCPQTFGTNSKLRLHRLRVHDKTPTHFCPLCDYSGYLRHDITRHVNSCHQGTPAFACSQCEAQFSSETALKQHALRRHPEPAQPAPGSPAETTEGPLHCSRCGLLCPSPASLRGHTRKQHPRLECGACQEAFPSRLALDEHRRQQHFSHRCQLCDFAARERVGLVKHYLEQHEETSAAVAASDGDGDAGQPPLHCPFCDFTCRHQLVLDHHVKGHGGTRLYKCTDCAYSTKNRQKITWHSRIHTGEKPYHCHLCPYACADPSRLKYHMRIHKEERKYLCPECGYKCKWVNQLKYHMTKHTGLKPYQCPECEYCTNRADALRVHQETRHREARAFMCEQCGKAFKTRFLLRTHLRKHSEAKPYVCNVCHRAFRWAAGLRHHALTHTDRHPFFCRLCNYKAKQKFQVVKHVRRHHPDQADPNQGVGKDPTTPTVHLHDVQLEDPSPPAPAAPHTGPEG>sp|Q86T29|ZN605_HUMAN Zinc finger protein 605 OS=Homo sapiens OX=9606GN=ZNF605 PE=2 SV=1MIQSQISFEDVAVDFTLEEWQLLNPTQKNLYRDVMLENYSNLVFLEVWLDNPKMWLRDNQDNLKSMERGHKYDVFGKIFNSSINIVHVGLRSHKCGTGEKSLKCPFDLLIPKNNCERKKIDELNKKLLFCIKPGRTHGGIKYCDCSTCRKSSNEEPWLTANHITHTGVYLCMECGRFFNKKSQLVIHQRTHTGEKPYQCSECGKAFSQKSLLTVHQRTHSGEKPHGCSECQKAFSRKSLLILHQRIHTGEKPYGCSECGKAFSRKSQLKRHQITHTIEKPYSCSECGKAFSQKLKLITHQRAHTGEKPYPCSHCGKAFFWKSQLITHQRTHTGKKPYGCGECQKAFSRNSLLIRHQRIHTGEKPYECNECGEAFIRKPQLIKHQITHTGEKNYRCSDCEEAFFKKSELIRHQKIHLGEKPYGCIQCGKTFFGKSQLLTHHRTHTGEKPYECSECGKAFTQKSSLISHQRTHTGEKPYECSECRKTFSEKSSLIHHQRTHTGEKPFECSECRKAFAWKPQLLRHQRIHTGEKPYECSECGKAFVQKVQLIKHQRNHTGEKTYGCSDCAKAFFEKAQLIIHQRIHTGERPYKCGECGKSFTRKSHLMRHQRIHTGDKYYGCNECGTTFNRKSQLMIHQRNHII>sp|Q86T29-2|ZN605_HUMAN Isoform 2 of Zinc finger protein 605 OS=Homosapiens OX=9606 GN=ZNF605MIQSQISFEDVAVDFTLEEWQLLNPTQKNLYRDVMLENYSNLVFLGFQILKPDAMFKLEQQDPWIIGQEILNQNFSEVWLDNPKMWLRDNQDNLKSMERGHKYDVFGKIFNSSINIVHVGLRSHKCGTGEKSLKCPFDLLIPKNNCERKKIDELNKKLLFCIKPGRTHGGIKYCDCSTCRKSSNEEPWLTANHITHTGVYLCMECGRFFNKKSQLVIHQRTHTGEKPYQCSECGKAFSQKSLLTVHQRTHSGEKPHGCSECQKAFSRKSLLILHQRIHTGEKPYGCSECGKAFSRKSQLKRHQITHTIEKPYSCSECGKAFSQKLKLITHQRAHTGEKPYPCSHCGKAFFWKSQLITHQRTHTGKKPYGCGECQKAFSRNSLLIRHQRIHTGEKPYECNECGEAFIRKPQLIKHQITHTGEKNYRCSDCEEAFFKKSELIRHQKIHLGEKPYGCIQCGKTFFGKSQLLTHHRTHTGEKPYECSECGKAFTQKSSLISHQRTHTGEKPYECSECRKTFSEKSSLIHHQRTHTGEKPFECSECRKAFAWKPQLLRHQRIHTGEKPYECSECGKAFVQKVQLIKHQRNHTGEKTYGCSDCAKAFFEKAQLIIHQRIHTGERPYKCGECGKSFTRKSHLMRHQRIHTGDKYYGCNECGTTFNRKSQLMIHQRNHII>sp|Q8NC26|ZN114_HUMAN Zinc finger protein 114 OS=Homo sapiens OX=9606GN=ZNF114 PE=1 SV=1MSQDSVTFADVAVNFTKEEWTLLDPAQRNLYRDVMLENSRNLAFIDWATPCKTKDATPQPDILPKRTFPEANRVCLTSISSQHSTLREDWRCPKTEEPHRQGVNNVKPPAVAPEKDESPVSICEDHEMRNHSKPTCRLVPSQGDSIRQCILTRDSSIFKYNPVLNDSQKTHENNEDDGVLGWNIQWVPCGRKTELKSSTWTGSQNTVHHIRDEIDTGANRHQRNPFGKAFREDGSLRAHNTHGREKMYDFTQCENTSRNNSIHAMQMQLYTAETNKKDCQTGATSANAPNSGSHKSHCTGEKTHKCPECGRAFFYQSFLMRHMKIHTGEKPYECGKCGKAFRYSLHLNKHLRKHVVQKKPYECEECGKVIRESSKYTHIRSHTGEKPYKCKTCGKDFAKSSGLKKHLKTHKDEKPCE>sp|Q8NC26-2|ZN114_HUMAN Isoform 2 of Zinc finger protein 114 OS=Homosapiens OX=9606 GN=ZNF114MLENSRNLAFIDWATPCKTKDATPQPDILPKRTFPEANRVCLTSISSQHSTLREDWRCPKTEEPHRQGVNNVKPPAVAPEKDESPVSICEDHEMRNHSKPTCRLVPSQGDSIRQCILTRDSSIFKYNPVLNDSQKTHENNEDDGVLGWNIQWVPCGRKTELKSSTWTGSQNTVHHIRDEIDTGANRHQRNPFGKAFREDGSLRAHNTHGREKMYDFTQCENTSRNNSIHAMQMQLYTAETNKKDCQTGATSANAPNSGSHKSHCTGEKTHKCPECGRAFFYQSFLMRHMKIHTGEKPYECGKCGKAFRYSLHLNKHLRKHVVQKKPYECEECGKVIRESSKYTHIRSHTGEKPYKCKTCGKDFAKSSGLKKHLKTHKDEKPCE>sp|Q14966|ZN638_HUMAN Zinc finger protein 638 OS=Homo sapiens OX=9606GN=ZNF638 PE=1 SV=2MSRPRFNPRGDFPLQRPRAPNPSGMRPPGPFMRPGSMGLPRFYPAGRARGIPHRFAGHESYQNMGPQRMNVQVTQHRTDPRLTKEKLDFHEAQQKKGKPHGSRWDDEPHISASVAVKQSSVTQVTEQSPKVQSRYTKESASSILASFGLSNEDLEELSRYPDEQLTPENMPLILRDIRMRKMGRRLPNLPSQSRNKETLGSEAVSSNVIDYGHASKYGYTEDPLEVRIYDPEIPTDEVENEFQSQQNISASVPNPNVICNSMFPVEDVFRQMDFPGESSNNRSFFSVESGTKMSGLHISGGQSVLEPIKSVNQSINQTVSQTMSQSLIPPSMNQQPFSSELISSVSQQERIPHEPVINSSNVHVGSRGSKKNYQSQADIPIRSPFGIVKASWLPKFSHADAQKMKRLPTPSMMNDYYAASPRIFPHLCSLCNVECSHLKDWIQHQNTSTHIESCRQLRQQYPDWNPEILPSRRNEGNRKENETPRRRSHSPSPRRSRRSSSSHRFRRSRSPMHYMYRPRSRSPRICHRFISRYRSRSRSRSPYRIRNPFRGSPKCFRSVSPERMSRRSVRSSDRKKALEDVVQRSGHGTEFNKQKHLEAADKGHSPAQKPKTSSGTKPSVKPTSATKSDSNLGGHSIRCKSKNLEDDTLSECKQVSDKAVSLQRKLRKEQSLHYGSVLLITELPEDGCTEEDVRKLFQPFGKVNDVLIVPYRKEAYLEMEFKEAITAIMKYIETTPLTIKGKSVKICVPGKKKAQNKEVKKKTLESKKVSASTLKRDADASKAVEIVTSTSAAKTGQAKASVAKVNKSTGKSASSVKSVVTVAVKGNKASIKTAKSGGKKSLEAKKTGNVKNKDSNKPVTIPENSEIKTSIEVKATENCAKEAISDAALEATENEPLNKETEEMCVMLVSNLPNKGYSVEEVYDLAKPFGGLKDILILSSHKKAYIEINRKAAESMVKFYTCFPVLMDGNQLSISMAPENMNIKDEEAIFITLVKENDPEANIDTIYDRFVHLDNLPEDGLQCVLCVGLQFGKVDHHVFISNRNKAILQLDSPESAQSMYSFLKQNPQNIGDHMLTCSLSPKIDLPEVQIEHDPELEKESPGLKNSPIDESEVQTATDSPSVKPNELEEESTPSIQTETLVQQEEPCEEEAEKATCDSDFAVETLELETQGEEVKEEIPLVASASVSIEQFTENAEECALNQQMFNSDLEKKGAEIINPKTALLPSDSVFAEERNLKGILEESPSEAEDFISGITQTMVEAVAEVEKNETVSEILPSTCIVTLVPGIPTGDEKTVDKKNISEKKGNMDEKEEKEFNTKETRMDLQIGTEKAEKNEGRMDAEKVEKMAAMKEKPAENTLFKAYPNKGVGQANKPDETSKTSILAVSDVSSSKPSIKAVIVSSPKAKATVSKTENQKSFPKSVPRDQINAEKKLSAKEFGLLKPTSARSGLAESSSKFKPTQSSLTRGGSGRISALQGKLSKLDYRDITKQSQETEARPSIMKRDDSNNKTLAEQNTKNPKSTTGRSSKSKEEPLFPFNLDEFVTVDEVIEEVNPSQAKQNPLKGKRKETLKNVPFSELNLKKKKGKTSTPRGVEGELSFVTLDEIGEEEDAAAHLAQALVTVDEVIDEEELNMEEMVKNSNSLFTLDELIDQDDCISHSEPKDVTVLSVAEEQDLLKQERLVTVDEIGEVEELPLNESADITFATLNTKGNEGDTVRDSIGFISSQVPEDPSTLVTVDEIQDDSSDLHLVTLDEVTEEDEDSLADFNNLKEELNFVTVDEVGEEEDGDNDLKVELAQSKNDHPTDKKGNRKKRAVDTKKTKLESLSQVGPVNENVMEEDLKTMIERHLTAKTPTKRVRIGKTLPSEKAVVTEPAKGEEAFQMSEVDEESGLKDSEPERKRKKTEDSSSGKSVASDVPEELDFLVPKAGFFCPICSLFYSGEKAMTNHCKSTRHKQNTEKFMAKQRKEKEQNEAEERSSR>sp|Q14966-2|ZN638_HUMAN Isoform 2 of Zinc finger protein 638 OS=Homosapiens OX=9606 GN=ZNF638MSRPRFNPRGDFPLQRPRAPNPSGMRPPGPFMRPGSMGLPRFYPAGRARGIPHRFAGHESYQNMGPQRMNVQVTQHRTDPRLTKEKLDFHEAQQKKGKPHGSRWDDEPHISASVAVKQSSVTQVTEQSPKVQSRYTKESASSILASFGLSNEDLEELSRYPDEQLTPENMPLILRDIRMRKMGRRLPNLPSQSRNKETLGSEAVSSNVIDYGHASKYGYTEDPLEVRIYDPEIPTDEVENEFQSQQNISASVPNPNVICNSMFPVEDVFRQMDFPGESSNNRSFFSVESGTKMSGLHISGGQSVLEPIKSVNQSINQTVSQTMSQSLIPPSMNQQPFSSELISSVSQQERIPHEPVINSSNVHVGSRGSKKNYQSQADIPIRSPFGIVKASWLPKFSHADAQKMKRLPTPSMMNDYYAASPRIFPHLCSLCNVECSHLKDWIQHQNTSTHIESCRQLRQQYPDWNPEILPSRRNEGNRKENETPRRRSHSPSPRRSRRSSSSHRFRRSRSPMHYMYRPRSRSPRICHRFISRYRSRSRSRSPYRIRNPFRGSPKCFRSVSPERMSRRSVRSSDRKKALEDVVQRSGHGTEFNKQKHLEAADKGHSPAQKPKTSSGTKPSVKPTSATKSDSNLGGHSIRCKSKNLEDDTLSECKQVSDKAVSLQRKLRKEQSLHYGSVLLITELPEDGCTEEDVRKLFQPFGKVNDVLIVPYRKEAYLEMEFKEAITAIMKYIETTPLTIKGKSVKICVPGKKKAQNKEVKKKTLESKKVSASTLKRDADASKAVEIVTSTSAGLLPTGGGNNYPQIVLAPGLCH>sp|Q14966-3|ZN638_HUMAN Isoform 3 of Zinc finger protein 638 OS=Homosapiens OX=9606 GN=ZNF638MSRPRFNPRGDFPLQRPRAPNPSGMRPPGPFMRPGSMGLPRFYPAGRARGIPHRFAGHESYQNMGPQRMNVQVTQHRTDPRLTKEKLDFHEAQQKKGKPHGSRWDDEPHISASVAVKQSSVTQVTEQSPKVQSRYTKESASSILASFGLSNEDLEELSRYPDEQLTPENMPLILRDIRMRKMGRRLPNLPSQSRNKETLGSEAVSSNVIDYGHASKYGYTEDPLEVRIYDPEIPTDEVENEFQSQQNISASVPNPNVICNSMFPVEDVFRQMDFPGESSNNRSFFSVESGTKMSGLHISGGQSVLEPIKSVNQSINQTVSQTMSQSLIPPSMNQQPFSSELISSVSQQERIPHEPVINSSNVHVGSRGSKKNYQSQADIPIRSPFGIVKASWLPKFSHADAQKMKRLPTPSMMNDYYAASPRIFPHLCSLCNVECSHLKDWIQHQNTSTHIESCRQLRQQYPDWNPEILPSRRNEGNRKENETPRRRSHSPSPRRSRRSSSSHRFRRSRSPMHYMYRPRSRSPRICHRFISRYRSRSRSRSPYRIRNPFRGSPKCFRSVSPERMSRRSVRSSDRKKALEDVVQRSGHGTEFNKQKHLEAADKGHSPAQKPKTSSGTKPSVKPTSATKSDSNLGGHSIRCKSKNLEDDTLSECKQVSDKAVSLQRKLRKEQSLHYGSVLLITELPEDGCTEEDVRKLFQPFGKVNDVLIVPYRKEAYLEMEFKEAITAIMKYIETTPLTIKGKSVKICVPGKKKAQNKEVKKKTLESKKVSASTLKRDADASKAVEIVTSTSAAKTGQAKASVAKVNKSTGKSASSVKSVVTVAVKGNKASIKTAKSGGKKSLEAKKTGNVKNKDSNKPVTIPENSEIKTSIEVKATENCAKEAISDAALEATENEPLNKETEEMCVMLVSNLPNKGYSVEEVYDLAKPFGGLKDILILSSHKKAYIEINRKAAESMVKFYTCFPVLMDGNQLSISMAPENMNIKDEEAIFITLVKENDPEANIDTIYDRFVHLDNLPEDGLQCVLCVGLQFGKVDHHVFISNRNKAILQLDSPESAQSMYSFLKQNPQNIGDHMLTCSLSPKIDLPEVQIEHDPELEKESPGLKNSPIDESEVQTATDSPSVKPNELEEESTPSIQTETLVQQEEPCEEEAEKATCDSDFAVETLELETQGEEVKEEIPLVASASVSIEQFTENAEECALNQQMFNSDLEKKGAEIINPKTALLPSDSVFAEERNLKGILEESPSEAEDFISGITQTMVEAVAEVEKNETVSEILPSTCIVTLVPGIPTGDEKTVDKKNISEKKGNMDEKEEKEFNTKETRMDLQIGTEKAEKNEGRMDAEKVEKMAAMKEKPAENTLFKAYPNKGVGQANKPDETSKTSILAVSDVSSSKPSIKAVIVSSPKAKATVSKTENQKSFPKSVPRDQINAEKKLSAKEFGLLKPTSARSGLAESSSKFKPTQSSLTRGGSGRISALQGKLSKLDYRDITKQSQETEARPSIMKRDDSNNKTLAEQNTKNPKSTTGRSSKSKEEPLFPFNLDEFVTVDEVIEEVNPSQAKQNPLKGKRKETLKNVPFSELNLKKKKGKTSTPRGVEGELSFVTLDEIGEEEDAAAHLAQALVTVDEVIDEEELNMEEMVKNSNSLFTLDELIDQDDCISHSEPKDVTVLSVAEEQDLLKQERLVTVDEIGEVEELPLNESADITFATLNTKGNEGDTVRDSIGFISSQVPEDPSTLVTVDEIQDDSSDLHLVTLDEVTEEDEDSLADFNNLKEELNFVTVDEVGEEEDGDNDLKVELAQSKNDHPTDKKGNRKKRAVDTKKTKLESLSQVGPVNENVMEEDLKTMIERHLTAKTPTKRVRIGKTLPSEKAVVTEPAKGEEAFQMSEVDEESGLKDSEPERKRKKTEDSSSGKSVASDVPEGEKAMTNHCKSTRHKQNTEKFMAKQRKEKEQNEAEERSSR>sp|Q14966-4|ZN638_HUMAN Isoform 4 of Zinc finger protein 638 OS=Homosapiens OX=9606 GN=ZNF638MSRPRFNPRGDFPLQRPRAPNPSGMRPPGPFMRPGSMGLPRFYPAGRARGIPHRFAGHESYQNMGPQRMNVQVTQHRTDPRLTKEKLDFHEAQQKKGKPHGSRWDDEPHISASVAVKQSSVTQVTEQSPKVQSRYTKESASSILASFGLSNEDLEELSRYPDEQLTPENMPLILRDIRMRKMGRRLPNLPSQSRNKETLGSEAVSSNVIDYGHASKYGYTEDPLEVRIYDPEIPTDEVENEFQSQQNISASVPNPNVICNSMFPVEDVFRQMDFPGESSNNRSFFSVESGTKMSGLHISGGQSVLEPIKSVNQSINQTVSQTMSQSLIPPSMNQQPFSSELISSVSQQERIPHEPVINSSNVHVGSRGSKKNYQSQADIPIRSPFGIVKASWLPKFSHADAQKMKRLPTPSMMNDYYAASPRIFPHLCSLCNVECSHLKDWIQHQNTSTHIESCRQLRQQYPDWNPEILPSRRNEGNRKENETPRRRSHSPSPRRSRRSSSSHRFRRSRSPMHYMYRPRSRSPRICHRFISRYRSRSRSRSPYRIRNPFRGSPKCFRSVSPERMSRRSVRSSDRKKALEDVVQRSGHGTEFNKQKHLEAADKGHSPAQKPKTSSGTKPSVKPTSATKSDSNLGGHSIRCKSKNLEDDTLSECKQVSDKAVSLQRKLRKEQSLHYGSVLLITELPEDGCTEEDVRKLFQPFGKVNDVLIVPYRKEAYLEMEFKEAITAIMKYIETTPLTIKGKSVKICVPGKKKAQNKEVKKKTLESKKVSASTLKRDADASKAVEIVTSTSAAKTGQAKASVAKVNKSTGKSASSVKSVVTVAVKGNKASIKTAKSGGKKSLEAKKTGNVKNKDSNKPVTIPENSEIKTSIEVKATENCAKEAISDAALEATENEPLNKETEEMCVMLVSNLPNKGYSVEEVYDLAKPFGGLKDILILSSHKKAYIEINRKAAESMVKFYTCFPVLMDGNQLSISMAPENMNIKDEEAIFITLVKENDPEANIDTIYDRFVHLDNLPEDGLQCVLCVGLQFGKVDHHVFISNRNKAILQLDSPESAQSMYSFLKQNPQNIGDHMLTCSLSPKIDLPEVQIEHDPELEKERLWLSKTLRILKALLVEVPNLKRSHYFHLIWMNLLLWMRL>sp|Q14966-5|ZN638_HUMAN Isoform 5 of Zinc finger protein 638 OS=Homosapiens OX=9606 GN=ZNF638MCVMLVSNLPNKGYSVEEVYDLAKPFGGLKDILILSSHKKAYIEINRKAAESMVKFYTCFPVLMDGNQLSISMAPENMNIKDEEAIFITLVKENDPEANIDTIYDRFVHLDNLPEDGLQCVLCVGLQFGKVDHHVFISNRNKAILQLDSPESAQSMYSFLKQNPQNIGDHMLTCSLSPKIDLPEVQIEHDPELEKESPGLKNSPIDESEVQTATDSPSVKPNELEEESTPSIQTETLVQQEEPCEEEAEKATCDSDFAVETLELETQGEEVKEEIPLVASASVSIEQFTENAEECALNQQMFNSDLEKKGAEIINPKTALLPSDSVFAEERNLKGILEESPSEAEDFISGITQTMVEAVAEVEKNETVSEILPSTCIVTLVPGIPTGDEKTVDKKNISEKKGNMDEKEEKEFNTKETRMDLQIGTEKAEKNEGRMDAEKVEKMAAMKEKPAENTLFKAYPNKGVGQANKPDETSKTSILAVSDVSSSKPSIKAVIVSSPKAKATVSKTENQKSFPKSVPRDQINAEKKLSAKEFGLLKPTSARSGLAESSSKFKPTQSSLTRGGSGRISALQGKLSKLDYRDITKQSQETEARPSIMKRDDSNNKTLAEQNTKNPKSTTGRSSKSKEEPLFPFNLDEFVTVDEVIEEVNPSQAKQNPLKGKRKETLKNVPFSELNLKKKKGKTSTPRGVEGELSFVTLDEIGEEEDAAAHLAQALVTVDEVIDEEELNMEEMVKNSNSLFTLDELIDQDDCISHSEPKDVTVLSVAEEQDLLKQERLVTVDEIGEVEELPLNESADITFATLNTKGNEGDTVRDSIGFISSQVPEDPSTLVTVDEIQDDSSDLHLVTLDEVTEEDEDSLADFNNLKEELNFVTVDEVGEEEDGDNDLKVELAQSKNDHPTDKKGNRKKRAVDTKKTKLESLSQVGPVNENVMEEDLKTMIERHLTAKTPTKRVRIGKTLPSEKAVVTEPAKGEEAFQMSEVDEESGLKDSEPERKRKKTEDSSSGKSVASDVPEELDFLVPKAGFFCPICSLFYSGEKAMTNHCKSTRHKQNTEKFMAKQRKEKEQNEAEERSSR>sp|Q14966-6|ZN638_HUMAN Isoform 6 of Zinc finger protein 638 OS=Homosapiens OX=9606 GN=ZNF638MSRPRFNPRGDFPLQRPRAPNPSGMRPPGPFMRPGSMGLPRFYPAGRARGIPHRFAGHESYQNMGPQRMNVQVTQHRTDPRLTKEKLDFHEAQQKKGKPHGSRWDDEPHISASVAVKQSSVTQVTEQSPKVQSRYTKESASSILASFGLSNEDLEELSRYPDEQLTPENMPLILRDIRMRKMGRRLPNLPSQSRNKETLGSEAVSSNVIDYGHASKYGYTEDPLEVRIYDPEIPTDEVENEFQSQQNISASVPNPNVICNSMFPVEDVFRQMDFPGESSNNRSFFSVESGTKMSGLHISGGQSVLEPIKSVNQSINQTVSQTMSQSLIPPSMNQQPFSSELISSVSQQERIPHEPVINSSNVHVGSRGSKKNYQSQADIPIRSPFGIVKASWLPKFSHADAQKMKRLPTPSMMNDYYAASPRIFPHLCSLCNVECSHLKDWIQHQNTSTHIESCRQLRQQYPDWNPEILPSRRNEGNRKENETPRRRSHSPSPRRSRRSSSSHRFRRSRSPMHYMYRPRSRSPRICHRFISRYRSRSRSRSPYRIRNPFRGSPKCFRSVSPERMSRRSVRSSDRKKALEDVVQRSGHGTEFNKQKHLEAADKGHSPAQKPKTSSGTKPSVKPTSATKSDSNLGGHSIRCKSKNLEDDTLSECKQVSDKAVSLQRKLRKEQSLHYGSVLLITELPEDGCTEEDVRKLFQPFGKVNDVLIVPYRKEAYLEMEFKEAITAIMKYIETTPLTIKGKSVKICVPGKKKAQNKEVKKKTLESKKVSASTLKRDADASKAVEIVTSTSAESVDQTQQLVPLVRNTARDHDGTPENEGEETVQSALFGFQYDASDHTMAWLGPNTVPEVKEMILQDPQLQTTQLPQTTQAPDITWGMLKKTTYKAEQILLQTQKPFTPDNLFLALLSGDAKPEYEQ>sp|P52738|ZN140_HUMAN Zinc finger protein 140 OS=Homo sapiens OX=9606GN=ZNF140 PE=1 SV=2MSQGSVTFRDVAIDFSQEEWKWLQPAQRDLYRCVMLENYGHLVSLGLSISKPDVVSLLEQGKEPWLGKREVKRDLFSVSESSGEIKDFSPKNVIYDDSSQYLIMERILSQGPVYSSFKGGWKCKDHTEMLQENQGCIRKVTVSHQEALAQHMNISTVERPYGCHECGKTFGRRFSLVLHQRTHTGEKPYACKECGKTFSQISNLVKHQMIHTGKKPHECKDCNKTFSYLSFLIEHQRTHTGEKPYECTECGKAFSRASNLTRHQRIHIGKKQYICRKCGKAFSSGSELIRHQITHTGEKPYECIECGKAFRRFSHLTRHQSIHTTKTPYECNECRKAFRCHSFLIKHQRIHAGEKLYECDECGKVFTWHASLIQHTKSHTGEKPYACAECDKAFSRSFSLILHQRTHTGEKPYVCKVCNKSFSWSSNLAKHQRTHTLDNPYEYENSFNYHSFLTEHQ>sp|P52738-2|ZN140_HUMAN Isoform 2 of Zinc finger protein 140 OS=Homosapiens OX=9606 GN=ZNF140MERILSQGPVYSSFKGGWKCKDHTEMLQENQGCIRKVTVSHQEALAQHMNISTVERPYGCHECGKTFGRRFSLVLHQRTHTGEKPYACKECGKTFSQISNLVKHQMIHTGKKPHECKDCNKTFSYLSFLIEHQRTHTGEKPYECTECGKAFSRASNLTRHQRIHIGKKQYICRKCGKAFSSGSELIRHQITHTGEKPYECIECGKAFRRFSHLTRHQSIHTTKTPYECNECRKAFRCHSFLIKHQRIHAGEKLYECDECGKVFTWHASLIQHTKSHTGEKPYACAECDKAFSRSFSLILHQRTHTGEKPYVCKVCNKSFSWSSNLAKHQRTHTLDNPYEYENSFNYHSFLTEHQ>sp|Q8IYX0|ZN679_HUMAN Zinc finger protein 679 OS=Homo sapiens OX=9606GN=ZNF679 PE=1 SV=2MAKRPGSPGSREMGLLTFRDVVIEFSLEEWQCLDHAQQNLYRDVMLENYRNLVSLGIAVSKPDLITCLEQNKEPWNIKRNEMVTKHPVMCSHFTQDLPPELGIKDSLQKVIPRRYGKSGHDNLQVKTCKSMGECEVQKGGCNEVNQCLSTTQNKIFQTHKCVKVFGKFSNSNRHKTRHTGKKHFKCKKYGKSFCMVSQLHQHQIIHTRENSYQCEECGKPFNCSSTLSKHKRIHTGEKPYRCEECGKAFTWSSTLTKHRRIHTGEKPYTCEECGQAFSRSSTLANHKRIHTGEKPYTCEECGKAFSLSSSLTYHKRIHTGEKPYTCEECGKAFNCSSTLKKHKIIHTGEKPYKCKECGKAFAFSSTLNTHKRIHTGEEPYKCEECDKAFKWSSSLANHKSMHTGEKPYKCE>sp|Q9BS31|ZN649_HUMAN Zinc finger protein 649 OS=Homo sapiens OX=9606GN=ZNF649 PE=1 SV=1MTKAQESLTLEDVAVDFTWEEWQFLSPAQKDLYRDVMLENYSNLVSVGYQAGKPDALTKLEQGEPLWTLEDEIHSPAHPEIEKADDHLQQPLQNQKILKRTGQRYEHGRTLKSYLGLTNQSRRYNRKEPAEFNGDGAFLHDNHEQMPTEIEFPESRKPISTKSQFLKHQQTHNIEKAHECTDCGKAFLKKSQLTEHKRIHTGKKPHVCSLCGKAFYKKYRLTEHERAHRGEKPHGCSLCGKAFYKRYRLTEHERAHKGEKPYGCSECGKAFPRKSELTEHQRIHTGIKPHQCSECGRAFSRKSLLVVHQRTHTGEKPHTCSECGKGFIQKGNLNIHQRTHTGEKPYGCIDCGKAFSQKSCLVAHQRYHTGKTPFVCPECGQPCSQKSGLIRHQKIHSGEKPYKCSDCGKAFLTKTMLIVHHRTHTGERPYGCDECEKAYFYMSCLVKHKRIHSREKRGDSVKVENPSTASHSLSPSEHVQGKSPVNMVTVAMVAGQCEFAHILHS>sp|Q9UDY2|ZO2_HUMAN Tight junction protein ZO-2 OS=Homo sapiens OX=9606GN=TJP2 PE=1 SV=2MPVRGDRGFPPRRELSGWLRAPGMEELIWEQYTVTLQKDSKRGFGIAVSGGRDNPHFENGETSIVISDVLPGGPADGLLQENDRVVMVNGTPMEDVLHSFAVQQLRKSGKVAAIVVKRPRKVQVAALQASPPLDQDDRAFEVMDEFDGRSFRSGYSERSRLNSHGGRSRSWEDSPERGRPHERARSRERDLSRDRSRGRSLERGLDQDHARTRDRSRGRSLERGLDHDFGPSRDRDRDRSRGRSIDQDYERAYHRAYDPDYERAYSPEYRRGARHDARSRGPRSRSREHPHSRSPSPEPRGRPGPIGVLLMKSRANEEYGLRLGSQIFVKEMTRTGLATKDGNLHEGDIILKINGTVTENMSLTDARKLIEKSRGKLQLVVLRDSQQTLINIPSLNDSDSEIEDISEIESNRSFSPEERRHQYSDYDYHSSSEKLKERPSSREDTPSRLSRMGATPTPFKSTGDIAGTVVPETNKEPRYQEDPPAPQPKAAPRTFLRPSPEDEAIYGPNTKMVRFKKGDSVGLRLAGGNDVGIFVAGIQEGTSAEQEGLQEGDQILKVNTQDFRGLVREDAVLYLLEIPKGEMVTILAQSRADVYRDILACGRGDSFFIRSHFECEKETPQSLAFTRGEVFRVVDTLYDGKLGNWLAVRIGNELEKGLIPNKSRAEQMASVQNAQRDNAGDRADFWRMRGQRSGVKKNLRKSREDLTAVVSVSTKFPAYERVLLREAGFKRPVVLFGPIADIAMEKLANELPDWFQTAKTEPKDAGSEKSTGVVRLNTVRQIIEQDKHALLDVTPKAVDLLNYTQWFPIVIFFNPDSRQGVKTMRQRLNPTSNKSSRKLFDQANKLKKTCAHLFTATINLNSANDSWFGSLKDTIQHQQGEAVWVSEGKMEGMDDDPEDRMSYLTAMGADYLSCDSRLISDFEDTDGEGGAYTDNELDEPAEEPLVSSITRSSEPVQHEESIRKPSPEPRAQMRRAASSDQLRDNSPPPAFKPEPPKAKTQNKEESYDFSKSYEYKSNPSAVAGNETPGASTKGYPPPVAAKPTFGRSILKPSTPIPPQEGEEVGESSEEQDNAPKSVLGKVKIFEKMDHKARLQRMQELQEAQNARIEIAQKHPDIYAVPIKTHKPDPGTPQHTSSRPPEPQKAPSRPYQDTRGSYGSDAEEEEYRQQLSEHSKRGYYGQSARYRDTEL>sp|Q9UDY2-2|ZO2_HUMAN Isoform A2 of Tight junction protein ZO-2 OS=Homosapiens OX=9606 GN=TJP2MPVRGDRGFPPRRELSGWLRAPGMEELIWEQYTVTLQKDSKRGFGIAVSGGRDNPHFENGETSIVISDVLPGGPADGLLQENDRVVMVNGTPMEDVLHSFAVQQLRKSGKVAAIVVKRPRKVQVAALQASPPLDQDDRAFEVMDEFDGRSFRSGYSERSRLNSHGGRSRSWEDSPERGRPHERARSRERDLSRDRSRGRSLERGLDQDHARTRDRSRGRSLERGLDHDFGPSRDRDRDRSRGRSIDQDYERAYHRAYDPDYERAYSPEYRRGARHDARSRGPRSRSREHPHSRSPSPEPRGRPGPIGVLLMKSRANEEYGLRLGSQIFVKEMTRTGLATKDGNLHEGDIILKINGTVTENMSLTDARKLIEKSRGKLQLVVLRDSQQTLINIPSLNDSDSEIEDISEIESNRSFSPEERRHQYSDYDYHSSSEKLKERPSSREDTPSRLSRMGATPTPFKSTGDIAGTVVPETNKEPRYQEDPPAPQPKAAPRTFLRPSPEDEAIYGPNTKMVRFKKGDSVGLRLAGGNDVGIFVAGIQEGTSAEQEGLQEGDQILKVNTQDFRGLVREDAVLYLLEIPKGEMVTILAQSRADVYRDILACGRGDSFFIRSHFECEKETPQSLAFTRGEVFRVVDTLYDGKLGNWLAVRIGNELEKGLIPNKSRAEQMASVQNAQRDNAGDRADFWRMRGQRSGVKKNLRKSREDLTAVVSVSTKFPAYERVLLREAGFKRPVVLFGPIADIAMEKLANELPDWFQTAKTEPKDAGSEKSTGVVRLNTVRQIIEQDKHALLDVTPKAVDLLNYTQWFPIVIFFNPDSRQGVKTMRQRLNPTSNKSSRKLFDQANKLKKTCAHLFTATINLNSANDSWFGSLKDTIQHQQGEAVWVSEGKMEGMDDDPEDRMSYLTAMGADYLSCDSRLISDFEDTDGEGGAYTDNELDEPAEEPLVSSITRSSEPVQHEEIEIAQKHPDIYAVPIKTHKPDPGTPQHTSSRPPEPQKAPSRPYQDTRGSYGSDAEEEEYRQQLSEHSKRGYYGQSARYRDTEL>sp|Q9UDY2-5|ZO2_HUMAN Isoform A3 of Tight junction protein ZO-2 OS=Homosapiens OX=9606 GN=TJP2MPVRGDRGFPPRRELSGWLRAPGMEELIWEQYTVTLQKDSKRGFGIAVSGGRDNPHFENGETSIVISDVLPGGPADGLLQENDRVVMVNGTPMEDVLHSFAVQQLRKSGKVAAIVVKRPRKVQVAALQASPPLDQDDRAFEVMDEFDGRSFRSGYSERSRLNSHGGRSRSWEDSPERGRPHERARSRERDLSRDRSRGRSLERGLDQDHARTRDRSRGRSLERGLDHDFGPSRDRDRDRSRGRSIDQDYERAYHRAYDPDYERAYSPEYRRGARHDARSRGPRSRSREHPHSRSPSPEPRGRPGPIGVLLMKSRANEEYGLRLGSQIFVKEMTRTGLATKDGNLHEGDIILKINGTVTENMSLTDARKLIEKSRGKLQLVVLRDSQQTLINIPSLNDSDSEIEDISEIESNRSFSPEERRHQYSDYDYHSSSEKLKERPSSREDTPSRLSRMGATPTPFKSTGDIAGTVVPETNKEPRYQEDPPAPQPKAAPRTFLRPSPEDEAIYGPNTKMVRFKKGDSVGLRLAGGNDVGIFVAGIQEGTSAEQEGLQEGDQILKVNTQDFRGLVREDAVLYLLEIPKGEMVTILAQSRADVYRDILACGRGDSFFIRSHFECEKETPQSLAFTRGEVFRVVDTLYDGKLGNWLAVRIGNELEKGLIPNKSRAEQMASVQNAQRDNAGDRADFWRMRGQRSGVKKNLRKSREDLTAVVSVSTKFPAYERVLLREAGFKRPVVLFGPIADIAMEKLANELPDWFQTAKTEPKDAGSEKSTGVVRLNTVRQIIEQDKHALLDVTPKAVDLLNYTQWFPIVIFFNPDSRQGVKTMRQRLNPTSNKSSRKLFDQANKLKKTCAHLFTATINLNSANDSWFGSLKDTIQHQQGEAVWVSEGKMEGMDDDPEDRMSYLTAMGADYLSCDSRLISDFEDTDGEGGAYTDNELDEPAEEPLVSSITRSSEPVQHEEVRRGRPRAGTGEPGVFLALSWTAVCSGCCGRHS>sp|Q9UDY2-3|ZO2_HUMAN Isoform C1 of Tight junction protein ZO-2 OS=Homosapiens OX=9606 GN=TJP2MEELIWEQYTVTLQKDSKRGFGIAVSGGRDNPHFENGETSIVISDVLPGGPADGLLQENDRVVMVNGTPMEDVLHSFAVQQLRKSGKVAAIVVKRPRKVQVAALQASPPLDQDDRAFEVMDEFDGRSFRSGYSERSRLNSHGGRSRSWEDSPERGRPHERARSRERDLSRDRSRGRSLERGLDQDHARTRDRSRGRSLERGLDHDFGPSRDRDRDRSRGRSIDQDYERAYHRAYDPDYERAYSPEYRRGARHDARSRGPRSRSREHPHSRSPSPEPRGRPGPIGVLLMKSRANEEYGLRLGSQIFVKEMTRTGLATKDGNLHEGDIILKINGTVTENMSLTDARKLIEKSRGKLQLVVLRDSQQTLINIPSLNDSDSEIEDISEIESNRSFSPEERRHQYSDYDYHSSSEKLKERPSSREDTPSRLSRMGATPTPFKSTGDIAGTVVPETNKEPRYQEDPPAPQPKAAPRTFLRPSPEDEAIYGPNTKMVRFKKGDSVGLRLAGGNDVGIFVAGIQEGTSAEQEGLQEGDQILKVNTQDFRGLVREDAVLYLLEIPKGEMVTILAQSRADVYRDILACGRGDSFFIRSHFECEKETPQSLAFTRGEVFRVVDTLYDGKLGNWLAVRIGNELEKGLIPNKSRAEQMASVQNAQRDNAGDRADFWRMRGQRSGVKKNLRKSREDLTAVVSVSTKFPAYERVLLREAGFKRPVVLFGPIADIAMEKLANELPDWFQTAKTEPKDAGSEKSTGVVRLNTVRQIIEQDKHALLDVTPKAVDLLNYTQWFPIVIFFNPDSRQGVKTMRQRLNPTSNKSSRKLFDQANKLKKTCAHLFTATINLNSANDSWFGSLKDTIQHQQGEAVWVSEGKMEGMDDDPEDRMSYLTAMGADYLSCDSRLISDFEDTDGEGGAYTDNELDEPAEEPLVSSITRSSEPVQHEESIRKPSPEPRAQMRRAASSDQLRDNSPPPAFKPEPPKAKTQNKEESYDFSKSYEYKSNPSAVAGNETPGASTKGYPPPVAAKPTFGRSILKPSTPIPPQEGEEVGESSEEQDNAPKSVLGKVKIFEKMDHKARLQRMQELQEAQNARIEIAQKHPDIYAVPIKTHKPDPGTPQHTSSRPPEPQKAPSRPYQDTRGSYGSDAEEEEYRQQLSEHSKRGYYGQSARYRDTEL>sp|Q9UDY2-4|ZO2_HUMAN Isoform C2 of Tight junction protein ZO-2 OS=Homosapiens OX=9606 GN=TJP2MEELIWEQYTVTLQKDSKRGFGIAVSGGRDNPHFENGETSIVISDVLPGGPADGLLQENDRVVMVNGTPMEDVLHSFAVQQLRKSGKVAAIVVKRPRKVQVAALQASPPLDQDDRAFEVMDEFDGRSFRSGYSERSRLNSHGGRSRSWEDSPERGRPHERARSRERDLSRDRSRGRSLERGLDQDHARTRDRSRGRSLERGLDHDFGPSRDRDRDRSRGRSIDQDYERAYHRAYDPDYERAYSPEYRRGARHDARSRGPRSRSREHPHSRSPSPEPRGRPGPIGVLLMKSRANEEYGLRLGSQIFVKEMTRTGLATKDGNLHEGDIILKINGTVTENMSLTDARKLIEKSRGKLQLVVLRDSQQTLINIPSLNDSDSEIEDISEIESNRSFSPEERRHQYSDYDYHSSSEKLKERPSSREDTPSRLSRMGATPTPFKSTGDIAGTVVPETNKEPRYQEDPPAPQPKAAPRTFLRPSPEDEAIYGPNTKMVRFKKGDSVGLRLAGGNDVGIFVAGIQEGTSAEQEGLQEGDQILKVNTQDFRGLVREDAVLYLLEIPKGEMVTILAQSRADVYRDILACGRGDSFFIRSHFECEKETPQSLAFTRGEVFRVVDTLYDGKLGNWLAVRIGNELEKGLIPNKSRAEQMASVQNAQRDNAGDRADFWRMRGQRSGVKKNLRKSREDLTAVVSVSTKFPAYERVLLREAGFKRPVVLFGPIADIAMEKLANELPDWFQTAKTEPKDAGSEKSTGVVRLNTVRQIIEQDKHALLDVTPKAVDLLNYTQWFPIVIFFNPDSRQGVKTMRQRLNPTSNKSSRKLFDQANKLKKTCAHLFTATINLNSANDSWFGSLKDTIQHQQGEAVWVSEGKMEGMDDDPEDRMSYLTAMGADYLSCDSRLISDFEDTDGEGGAYTDNELDEPAEEPLVSSITRSSEPVQHEEIEIAQKHPDIYAVPIKTHKPDPGTPQHTSSRPPEPQKAPSRPYQDTRGSYGSDAEEEEYRQQLSEHSKRGYYGQSARYRDTEL>sp|Q9UDY2-6|ZO2_HUMAN Isoform 6 of Tight junction protein ZO-2 OS=Homosapiens OX=9606 GN=TJP2MKTAQALHRMWIQAVKKLRRWKGRAPGMEELIWEQYTVTLQKDSKRGFGIAVSGGRDNPHFENGETSIVISDVLPGGPADGLLQENDRVVMVNGTPMEDVLHSFAVQQLRKSGKVAAIVVKRPRKVQVAALQASPPLDQDDRAFEVMDEFDGRSFRSGYSERSRLNSHGGRSRSWEDSPERGRPHERARSRERDLSRDRSRGRSLERGLDQDHARTRDRSRGRSLERGLDHDFGPSRDRDRDRSRGRSIDQDYERAYHRAYDPDYERAYSPEYRRGARHDARSRGPRSRSREHPHSRSPSPEPRGRPGPIGVLLMKSRANEEYGLRLGSQIFVKEMTRTGLATKDGNLHEGDIILKINGTVTENMSLTDARKLIEKSRGKLQLVVLRDSQQTLINIPSLNDSDSEIEDISEIESNRSFSPEERRHQYSDYDYHSSSEKLKERPSSREDTPSRLSRMGATPTPFKSTGDIAGTVVPETNKEPRYQEDPPAPQPKAAPRTFLRPSPEDEAIYGPNTKMVRFKKGDSVGLRLAGGNDVGIFVAGIQEGTSAEQEGLQEGDQILKVNTQDFRGLVREDAVLYLLEIPKGEMVTILAQSRADVYRDILACGRGDSFFIRSHFECEKETPQSLAFTRGEVFRVVDTLYDGKLGNWLAVRIGNELEKGLIPNKSRAEQMASVQNAQRDNAGDRADFWRMRGQRSGVKKNLRKSREDLTAVVSVSTKFPAYERVLLREAGFKRPVVLFGPIADIAMEKLANELPDWFQTAKTEPKDAGSEKSTGVVRLNTVRQIIEQDKHALLDVTPKAVDLLNYTQWFPIVIFFNPDSRQGVKTMRQRLNPTSNKSSRKLFDQANKLKKTCAHLFTATINLNSANDSWFGSLKDTIQHQQGEAVWVSEGKMEGMDDDPEDRMSYLTAMGADYLSCDSRLISDFEDTDGEGGAYTDNELDEPAEEPLVSSITRSSEPVQHEEAKTQNKEESYDFSKSYEYKSNPSAVAGNETPGASTKGYPPPVAAKPTFGRSILKPSTPIPPQEGEEVGESSEEQDNAPKSVLGKVKIFEKMDHKARLQRMQELQEAQNARIEIAQKHPDIYAVPIKTHKPDPGTPQHTSSRPPEPQKAPSRPYQDTRGSYGSDAEEEEYRQQLSEHSKRGYYGQSARYRDTEL>sp|Q9UDY2-7|ZO2_HUMAN Isoform 7 of Tight junction protein ZO-2 OS=Homosapiens OX=9606 GN=TJP2MKTAQALHRMWIQAVKKLRRWKGRVSPSASSPLVFPNLSSWEGEGSKTILTAPGMEELIWEQYTVTLQKDSKRGFGIAVSGGRDNPHFENGETSIVISDVLPGGPADGLLQENDRVVMVNGTPMEDVLHSFAVQQLRKSGKVAAIVVKRPRKVQVAALQASPPLDQDDRAFEVMDEFDGRSFRSGYSERSRLNSHGGRSRSWEDSPERGRPHERARSRERDLSRDRSRGRSLERGLDQDHARTRDRSRGRSLERGLDHDFGPSRDRDRDRSRGRSIDQDYERAYHRAYDPDYERAYSPEYRRGARHDARSRGPRSRSREHPHSRSPSPEPRGRPGPIGVLLMKSRANEEYGLRLGSQIFVKEMTRTGLATKDGNLHEGDIILKINGTVTENMSLTDARKLIEKSRGKLQLVVLRDSQQTLINIPSLNDSDSEIEDISEIESNRSFSPEERRHQYSDYDYHSSSEKLKERPSSREDTPSRLSRMGATPTPFKSTGDIAGTVVPETNKEPRYQEDPPAPQPKAAPRTFLRPSPEDEAIYGPNTKMVRFKKGDSVGLRLAGGNDVGIFVAGIQEGTSAEQEGLQEGDQILKVNTQDFRGLVREDAVLYLLEIPKGEMVTILAQSRADVYRDILACGRGDSFFIRSHFECEKETPQSLAFTRGEVFRVVDTLYDGKLGNWLAVRIGNELEKGLIPNKSRAEQMASVQNAQRDNAGDRADFWRMRGQRSGVKKNLRKSREDLTAVVSVSTKFPAYERVLLREAGFKRPVVLFGPIADIAMEKLANELPDWFQTAKTEPKDAGSEKSTGVVRLNTVRQIIEQDKHALLDVTPKAVDLLNYTQWFPIVIFFNPDSRQGVKTMRQRLNPTSNKSSRKLFDQANKLKKTCAHLFTATINLNSANDSWFGSLKDTIQHQQGEAVWVSEGKMEGMDDDPEDRMSYLTAMGADYLSCDSRLISDFEDTDGEGGAYTDNELDEPAEEPLVSSITRSSEPVQHEESIRKPSPEPRAQMRRAASSDQLRDNSPPPAFKPEPPKAKTQNKEESYDFSKSYEYKSNPSAVAGNETPGASTKGYPPPVAAKPTFGRSILKPSTPIPPQEGEEVGESSEEQDNAPKSVLGKVKIFEKMDHKARLQRMQELQEAQNARIEIAQKHPDIYAVPIKTHKPDPGTPQHTSSRPPEPQKAPSRPYQDTRGSYGSDAEEEEYRQQLSEHSKRGYYGQSARYRDTEL>sp|Q6X784|ZPBP2_HUMAN Zona pellucida-binding protein 2 OS=Homo sapiensOX=9606 GN=ZPBP2 PE=2 SV=1MMRTCVLLSAVLWCLTGVQCPRFTLFNKKGFIYGKTGQPDKIYVELHQNSPVLICMDFKLSKKEIVDPTYLWIGPNEKTLTGNNRINITETGQLMVKDFLEPLSGLYTCTLSYKTVKAETQEEKTVKKRYDFMVFAYREPDYSYQMAVRFTTRSCIGRYNDVFFRVLKKILDSLISDLSCHVIEPSYKCHSVEIPEHGLIHELFIAFQVNPFAPGWKGACNGSVDCEDTTNHNILQARDRIEDFFRSQAYIFYHNFNKTLPAMHFVDHSLQVVRLDSCRPGFGKNERLHSNCASCCVVCSPATFSPDVNVTCQTCVSVLTYGAKSCPQTSNKNQQYED>sp|Q6X784-2|ZPBP2_HUMAN Isoform 2 of Zona pellucida-binding protein 2OS=Homo sapiens OX=9606 GN=ZPBP2MMRTCVLLSAVLWCLTGDKIYVELHQNSPVLICMDFKLSKKEIVDPTYLWIGPNEKTLTGNNRINITETGQLMVKDFLEPLSGLYTCTLSYKTVKAETQEEKTVKKRYDFMVFAYREPDYSYQMAVRFTTRSCIGRYNDVFFRVLKKILDSLISDLSCHVIEPSYKCHSVEIPEHGLIHELFIAFQVNPFAPGWKGACNGSVDCEDTTNHNILQARDRIEDFFRSQAYIFYHNFNKTLPAMHFVDHSLQVVRLDSCRPGFGKNERLHSNCASCCVVCSPATFSPDVNVTCQTCVSVLTYGAKSCPQTSNKNQQYED>sp|O95218|ZRAB2_HUMAN Zinc finger Ran-binding domain-containing protein2 OS=Homo sapiens OX=9606 GN=ZRANB2 PE=1 SV=2MSTKNFRVSDGDWICPDKKCGNVNFARRTSCNRCGREKTTEAKMMKAGGTEIGKTLAEKSRGLFSANDWQCKTCSNVNWARRSECNMCNTPKYAKLEERTGYGGGFNERENVEYIEREESDGEYDEFGRKKKKYRGKAVGPASILKEVEDKESEGEEEDEDEDLSKYKLDEDEDEDDADLSKYNLDASEEEDSNKKKSNRRSRSKSRSSHSRSSSRSSSPSSSRSRSRSRSRSSSSSQSRSRSSSRERSRSRGSKSRSSSRSHRGSSSPRKRSYSSSSSSPERNRKRSRSRSSSSGDRKKRRTRSRSPERRHRSSSGSSHSGSRSSSKKK>sp|O95218-2|ZRAB2_HUMAN Isoform 2 of Zinc finger Ran-binding domain-containing protein 2 OS=Homo sapiens OX=9606 GN=ZRANB2MSTKNFRVSDGDWICPDKKCGNVNFARRTSCNRCGREKTTEAKMMKAGGTEIGKTLAEKSRGLFSANDWQCKTCSNVNWARRSECNMCNTPKYAKLEERTGYGGGFNERENVEYIEREESDGEYDEFGRKKKKYRGKAVGPASILKEVEDKESEGEEEDEDEDLSKYKLDEDEDEDDADLSKYNLDASEEEDSNKKKSNRRSRSKSRSSHSRSSSRSSSPSSSRSRSRSRSRSSSSSQSRSRSSSRERSRSRGSKSRSSSRSHRGSSSPRKRSYSSSSSSPERNRKRSRSRSSSSGDRKKRRTRSRSPESQVIGENTKQP>sp|Q8IWU4|ZNT8_HUMAN Zinc transporter 8 OS=Homo sapiens OX=9606GN=SLC30A8 PE=1 SV=2MEFLERTYLVNDKAAKMYAFTLESVELQQKPVNKDQCPRERPEELESGGMYHCHSGSKPTEKGANEYAYAKWKLCSASAICFIFMIAEVVGGHIAGSLAVVTDAAHLLIDLTSFLLSLFSLWLSSKPPSKRLTFGWHRAEILGALLSILCIWVVTGVLVYLACERLLYPDYQIQATVMIIVSSCAVAANIVLTVVLHQRCLGHNHKEVQANASVRAAFVHALGDLFQSISVLISALIIYFKPEYKIADPICTFIFSILVLASTITILKDFSILLMEGVPKSLNYSGVKELILAVDGVLSVHSLHIWSLTMNQVILSAHVATAASRDSQVVRREIAKALSKSFTMHSLTIQMESPVDQDPDCLFCEDPCD>sp|Q8IWU4-2|ZNT8_HUMAN Isoform 2 of Zinc transporter 8 OS=Homo sapiensOX=9606 GN=SLC30A8MYHCHSGSKPTEKGANEYAYAKWKLCSASAICFIFMIAEVVGGHIAGSLAVVTDAAHLLIDLTSFLLSLFSLWLSSKPPSKRLTFGWHRAEILGALLSILCIWVVTGVLVYLACERLLYPDYQIQATVMIIVSSCAVAANIVLTVVLHQRCLGHNHKEVQANASVRAAFVHALGDLFQSISVLISALIIYFKPEYKIADPICTFIFSILVLASTITILKDFSILLMEGVPKSLNYSGVKELILAVDGVLSVHSLHIWSLTMNQVILSAHVATAASRDSQVVRREIAKALSKSFTMHSLTIQMESPVDQDPDCLFCEDPCD>sp|P10073|ZSC22_HUMAN Zinc finger and SCAN domain-containing protein 22OS=Homo sapiens OX=9606 GN=ZSCAN22 PE=1 SV=2MAIPKHSLSPVPWEEDSFLQVKVEEEEEASLSQGGESSHDHIAHSEAARLRFRHFRYEEASGPHEALAHLRALCCQWLQPEAHSKEQILELLVLEQFLGALPPEIQAWVGAQSPKSGEEAAVLVEDLTQVLDKRGWDPGAEPTEASCKQSDLGESEPSNVTETLMGGVSLGPAFVKACEPEGSSERSGLSGEIWTKSVTQQIHFKKTSGPYKDVPTDQRGRESGASRNSSSAWPNLTSQEKPPSEDKFDLVDAYGTEPPYTYSGKRSSKCRECRKMFQSASALEAHQKTHSRKTPYACSECGKAFSRSTHLAQHQVVHTGAKPHECKECGKAFSRVTHLTQHQRIHTGEKPYKCGECGKTFSRSTHLTQHQRVHTGERPYECDACGKAFSQSTHLTQHQRIHTGEKPYKCDACGRAFSDCSALIRHLRIHSGEKPYQCKVCPKAFAQSSSLIEHQRIHTGEKPYKCSDCGKAFSRSSALMVHLRIHITVLQ>sp|A8MXY4|ZNF99_HUMAN Zinc finger protein 99 OS=Homo sapiens OX=9606GN=ZNF99 PE=2 SV=3MGSLTFWDVTIEFALEEWQCLDMAQQNLYRNVMLENYRNLVFLGIAVSKLDLITCLKQGKEPWNMKRHEMVTKPPVISSHFTQDFWPDQSIKDSFQEIILRTYARCGHKNLRLRKDCESVNEGKMHEEAYNKLNQCWTTTQGKIFQCNKYVKVFHKYSNSNRYKIRHTKKKTFKCMKCSKSFFMLSHLIQHKRIHTRENIYKCEERGKAFKWFSTLIKHKIIHTEDKPYKYKKCGKAFNISSMFTKCKIIHTGKKPCKCEECGKVFNNSSTLMKHKIIHTGKKPYKCEECGKAFKQSSHLTRHKAIHTGEKPYKCEECGKAFNHFSALRKHQIIHTGKKPYKCEECGKAFSQSSTLRKHEIIHTEEKPYKYEECGKAFSNLSALRKHEIIHTGQKPYKCEECGKAFKWSSKLTVHKVIHTAEKPCKCEECGKAFKRFSALRKHKIIHTGKQPYKCEECSKAFSNFSALRKHEIIHTGEKPYKCEECGKAFKWSSKLTVHKVIHMEEKPCKCEECGKAFKHFSALRKHKIIHTGKKPYKCEECGKAFNNSSTLMKHKIIHTGKKPYKCEECGKAFKQSSHLTRHKAIHTGEKPYKCEECGKAFNHFSALRKHQIIHTGKKPYKCEECGKAFSQSSTLRKHEIIHTGEKPYKCEECGKAFKWSSHLTRHKVIHTEEKPYKCEECGKAFNHFSALRKHKIIHTGKKPYKCEECGKAFSQSSTLRKHEIIHTGEKPYKCEECGKAFKWSSKLTVHKVIHTAEKPCKCEECGKAFKHFSALRKHKIIHTGKKPYKCEECGKAFNNSSTLRKHEIIHTGEKSYKCEECGKAFQWSSKLTLHKVIHMERNPANVKNVAKLLNISQPLENMR>sp|O75717|WDHD1_HUMAN WD repeat and HMG-box DNA-binding protein 1OS=Homo sapiens OX=9606 GN=WDHD1 PE=1 SV=1MPATRKPMRYGHTEGHTEVCFDDSGSFIVTCGSDGDVRIWEDLDDDDPKFINVGEKAYSCALKSGKLVTAVSNNTIQVHTFPEGVPDGILTRFTTNANHVVFNGDGTKIAAGSSDFLVKIVDVMDSSQQKTFRGHDAPVLSLSFDPKDIFLASASCDGSVRVWQISDQTCAISWPLLQKCNDVINAKSICRLAWQPKSGKLLAIPVEKSVKLYRRESWSHQFDLSDNFISQTLNIVTWSPCGQYLAAGSINGLIIVWNVETKDCMERVKHEKGYAICGLAWHPTCGRISYTDAEGNLGLLENVCDPSGKTSSSKVSSRVEKDYNDLFDGDDMSNAGDFLNDNAVEIPSFSKGIINDDEDDEDLMMASGRPRQRSHILEDDENSVDISMLKTGSSLLKEEEEDGQEGSIHNLPLVTSQRPFYDGPMPTPRQKPFQSGSTPLHLTHRFMVWNSIGIIRCYNDEQDNAIDVEFHDTSIHHATHLSNTLNYTIADLSHEAILLACESTDELASKLHCLHFSSWDSSKEWIIDLPQNEDIEAICLGQGWAAAATSALLLRLFTIGGVQKEVFSLAGPVVSMAGHGEQLFIVYHRGTGFDGDQCLGVQLLELGKKKKQILHGDPLPLTRKSYLAWIGFSAEGTPCYVDSEGIVRMLNRGLGNTWTPICNTREHCKGKSDHYWVVGIHENPQQLRCIPCKGSRFPPTLPRPAVAILSFKLPYCQIATEKGQMEEQFWRSVIFHNHLDYLAKNGYEYEESTKNQATKEQQELLMKMLALSCKLEREFRCVELADLMTQNAVNLAIKYASRSRKLILAQKLSELAVEKAAELTATQVEEEEEEEDFRKKLNAGYSNTATEWSQPRFRNQVEEDAEDSGEADDEEKPEIHKPGQNSFSKSTNSSDVSAKSGAVTFSSQGRVNPFKVSASSKEPAMSMNSARSTNILDNMGKSSKKSTALSRTTNNEKSPIIKPLIPKPKPKQASAASYFQKRNSQTNKTEEVKEENLKNVLSETPAICPPQNTENQRPKTGFQMWLEENRSNILSDNPDFSDEADIIKEGMIRFRVLSTEERKVWANKAKGETASEGTEAKKRKRVVDESDETENQEEKAKENLNLSKKQKPLDFSTNQKLSAFAFKQE>sp|O75717-2|WDHD1_HUMAN Isoform 2 of WD repeat and HMG-box DNA-bindingprotein 1 OS=Homo sapiens OX=9606 GN=WDHD1MDSSQQKTFRGHDAPVLSLSFDPKDIFLASASCDGSVRVWQISDQTCAISWPLLQKCNDVINAKSICRLAWQPKSGKLLAIPVEKSVKLYRRESWSHQFDLSDNFISQTLNIVTWSPCGQYLAAGSINGLIIVWNVETKDCMERVKHEKGYAICGLAWHPTCGRISYTDAEGNLGLLENVCDPSGKTSSSKVSSRVEKDYNDLFDGDDMSNAGDFLNDNAVEIPSFSKGIINDDEDDEDLMMASGRPRQRSHILEDDENSVDISMLKTGSSLLKEEEEDGQEGSIHNLPLVTSQRPFYDGPMPTPRQKPFQSGSTPLHLTHRFMVWNSIGIIRCYNDEQDNAIDVEFHDTSIHHATHLSNTLNYTIADLSHEAILLACESTDELASKLHCLHFSSWDSSKEWIIDLPQNEDIEAICLGQGWAAAATSALLLRLFTIGGVQKEVFSLAGPVVSMAGHGEQLFIVYHRGTGFDGDQCLGVQLLELGKKKKQILHGDPLPLTRKSYLAWIGFSAEGTPCYVDSEGIVRMLNRGLGNTWTPICNTREHCKGKSDHYWVVGIHENPQQLRCIPCKGSRFPPTLPRPAVAILSFKLPYCQIATEKGQMEEQFWRSVIFHNHLDYLAKNGYEYEESTKNQATKEQQELLMKMLALSCKLEREFRCVELADLMTQNAVNLAIKYASRSRKLILAQKLSELAVEKAAELTATQVEEEEEEEDFRKKLNAGYSNTATEWSQPRFRNQVEEDAEDSGEADDEEKPEIHKPGQNSFSKSTNSSDVSAKSGAVTFSSQGRVNPFKVSASSKEPAMSMNSARSTNILDNMGKSSKKSTALSRTTNNEKSPIIKPLIPKPKPKQASAASYFQKRNSQTNKTEEVKEENLKNVLSETPAICPPQNTENQRPKTGFQMWLEENRSNILSDNPDFSDEADIIKEGMIRFRVLSTEERKVWANKAKGETASEGTEAKKRKRVVDESDETENQEEKAKENLNLSKKQKPLDFSTNQKLSAFAFKQE>sp|A6NDX5|ZN840_HUMAN Putative zinc finger protein 840 OS=Homo sapiensOX=9606 GN=ZNF840P PE=5 SV=5MSLMGHGKVEMLLYAVPLLKAPNCLSSSMQLPHGGGRHQELVRFRDVAVVFSPEEWDHLTPEQRNLYKDVMLDNCKYLASLGNWTYKAHVMSSLKQGKEPWMMEREVTGDPCPACQPALATFRALNESGNAFRQSFHHGEYRTHRTFVQHYECDDCGMAFGHVSQLTGHQKIHKVGETHEYGENTRGFRHRSSFTMLQRICTLYKHFECNQCGETFNRPSKVIQHQSMHSGLKPYKCDVCQKAFRFLSSLSIHQRFHVGNRVNLTRHQKTHTQRKPFSCNFCGKTFHRFSEKTQHLLIHTRKKYYTCNYCKKEFNPYSKFILHQRTHTGEKPHKCDVCEKSFKSISNLNKHQKTHTGEKPFSCNECKKTFAQRTDLARHQQIHTGKKSFICSSCKKTFVRLSDLTQHKGTHTGERPYQCTTCEKAFKYRSNFTKHQKTHSIGRPFACNECGKTYRLNWELNQHKKIHTGEKPYECGECGKRFNNNSNLNKHKKIHTGEKHFVCNQCGKAFSLNSKLSRHQRTHNKKENSSKSVSNLNKHQKTHAGEKPFPCNECKKAFAQRMDLARHQQIHTGRKPFICSSCKKTFVRLSDLTQHKGTHTGERPYQCTTCEKAFKYQSNFTKHQKTHSIGRPFTCNECGKTFRLNWKLNQHKKIHTGEKPYECGECGKCFNNNSNLSKHKKIHTGEKHFVCNQCGKAFSLNSKLSRHQITHNKKKP>sp|O43829|ZBT14_HUMAN Zinc finger and BTB domain-containing protein 14OS=Homo sapiens OX=9606 GN=ZBTB14 PE=1 SV=2MEFFISMSETIKYNDDDHKTLFLKTLNEQRLEGEFCDIAIVVEDVKFRAHRCVLAACSTYFKKLFKKLEVDSSSVIEIDFLRSDIFEEVLNYMYTAKISVKKEDVNLMMSSGQILGIRFLDKLCSQKRDVSSPDENNGQSKSKYCLKINRPIGDAADTQDDDVEEIGDQDDSPSDDTVEGTPPSQEDGKSPTTTLRVQEAILKELGSEEVRKVNCYGQEVESMETPESKDLGSQTPQALTFNDGMSEVKDEQTPGWTTAASDMKFEYLLYGHHREQIACQACGKTFSDEGRLRKHEKLHTADRPFVCEMCTKGFTTQAHLKEHLKIHTGYKPYSCEVCGKSFIRAPDLKKHERVHSNERPFACHMCDKAFKHKSHLKDHERRHRGEKPFVCGSCTKAFAKASDLKRHENNMHSERKQVTPSAIQSETEQLQAAAMAAEAEQQLETIACS>sp|O75467|Z324A_HUMAN Zinc finger protein 324A OS=Homo sapiens OX=9606GN=ZNF324 PE=2 SV=1MAFEDVAVYFSQEEWGLLDTAQRALYRRVMLDNFALVASLGLSTSRPRVVIQLERGEEPWVPSGTDTTLSRTTYRRRNPGSWSLTEDRDVSGEWPRAFPDTPPGMTTSVFPVAGACHSVKSLQRQRGASPSRERKPTGVSVIYWERLLLGSGSGQASVSLRLTSPLRPPEGVRLREKTLTEHALLGRQPRTPERQKPCAQEVPGRTFGSAQDLEAAGGRGHHRMGAVWQEPHRLLGGQEPSTWDELGEALHAGEKSFECRACSKVFVKSSDLLKHLRTHTGERPYECAQCGKAFSQTSHLTQHQRIHSGETPYACPVCGKAFRHSSSLVRHQRIHTAEKSFRCSECGKAFSHGSNLSQHRKIHAGGRPYACAQCGRRFCRNSHLIQHERTHTGEKPFVCALCGAAFSQGSSLFKHQRVHTGEKPFACPQCGRAFSHSSNLTQHQLLHTGERPFRCVDCGKAFAKGAVLLSHRRIHTGEKPFVCTQCGRAFRERPALFHHQRIHTGEKTVRRSRASLHPQARSVAGASSEGAPAKETEPTPASGPAAVSQPAEV>sp|Q8NAQ8|YP023_HUMAN Putative uncharacterized protein FLJ34945 OS=Homosapiens OX=9606 PE=2 SV=1MYSVLQLLKCLCSCWRKGPEGRRFQTEAAVCARPAWSPHPAGASEALGALPPPRQLVEKRRVSPPRRLDQSGRDGGAVAKCSLSRGLSPPGWTGRSLLRPWGSAAVLGSRAALACVLRPSRGVMPATIQSRR>sp|Q8NEP9|ZN555_HUMAN Zinc finger protein 555 OS=Homo sapiens OX=9606GN=ZNF555 PE=1 SV=4MDSVVFEDVAVDFTLEEWALLDSAQRDLYRDVMLETFQNLASVDDETQFKASGSVSQQDIYGEKIPKESKIATFTRNVSWASVLGKIWDSLSIEDQTTNQGRNLSRNHGLERLCESNDQCGEALSQIPHLNLYKKIPPGVKQYEYNTYGKVFMHRRTSLKSPITVHTGHKPYQCQECGQAYSCRSHLRMHVRTHNGERPYVCKLCGKTFPRTSSLNRHVRIHTAEKTYECKQCGKAFIDFSSLTSHLRSHTGEKPYKCKECGKAFSYSSTFRRHTITHTGEKPYKCKECAEAFSYSSTFRRHMISHTGEKPHKCKECGEAFSYSSAFRRHMITHTGEKPYECKQCGKTFIYLQSFRRHERIHTGEKPYECKQCGKTFIYPQSFRRHERTHGGEKPYECNQCGKAFSHPSSFRGHMRVHTGEKPYECKQCGKTFNWPISLRKHMRTHTREKPYECKQCGKAFSLSACFREHVRMHPEDKSYECKLCGKAFYCHISLQKHMRRHTAEKLYKCKQCGKAFSWPELLQQHVRTHTVEKPYECKECGKVFKWPSSLPIHMRLHTGEKPYQCKHCGKAFNCSSSLRRHVRIHTTEKQYKCNVGHPPANEFMCSASEKSHQERDLIKVVNMVLPL>sp|Q8NEP9-2|ZN555_HUMAN Isoform 2 of Zinc finger protein 555 OS=Homosapiens OX=9606 GN=ZNF555MDSVVFEDVAVDFTLEEWALLDSAQRDLYRDVMLETFQNLASVDDETQFKASGSVSQQDIYGEKIPKESKIATFTRNVSWASVLGKIWDSLSIEDQTTNQGRNLRNHGLERLCESNDQCGEALSQIPHLNLYKKIPPGVKQYEYNTYGKVFMHRRTSLKSPITVHTGHKPYQCQECGQAYSCRSHLRMHVRTHNGERPYVCKLCGKTFPRTSSLNRHVRIHTAEKTYECKQCGKAFIDFSSLTSHLRSHTGEKPYKCKECGKAFSYSSTFRRHTITHTGEKPYKCKECAEAFSYSSTFRRHMISHTGEKPHKCKECGEAFSYSSAFRRHMITHTGEKPYECKQCGKTFIYLQSFRRHERIHTGEKPYECKQCGKTFIYPQSFRRHERTHGGEKPYECNQCGKAFSHPSSFRGHMRVHTGEKPYECKQCGKTFNWPISLRKHMRTHTREKLYKCKQCGKVFKWPSSLPIHMRLHTGEKPYQCKHCGKAFNCSSSLRRHVRIHTTEKQYKCNVGHPPANEFMCSASEKSHQERDLIKVVNMVLPL>sp|Q8NEP9-4|ZN555_HUMAN Isoform 3 of Zinc finger protein 555 OS=Homosapiens OX=9606 GN=ZNF555MDSVVFEDVAVDFTLEEWALLDSAQRDLYRDVMLETFQNLASVDDETQFKASGSVSQQDIYGEKIPKESKIATFTRNVSWASVLGKIWDSLSIEDQTTNQGRNLRNHGLERLCESNDQCGEALSQIPHLNLYKKIPPGVKQYEYNTYGKVFMHRRTSLKSPITVHTGHKPYQCQECGQAYSCRSHLRMHVRTHNGERPYVCKLCGKTFPRTSSLNRHVRIHTAEKTYECKQCGKAFIDFSSLTSHLRSHTGEKPYKCKECGKAFSYSSTFRRHTITHTGEKPYKCKECAEAFSYSSTFRRHMISHTGEKPHKCKECGEAFSYSSAFRRHMITHTGEKPYECKQCGKTFIYLQSFRRHERIHTGEKPYECKQCGKTFIYPQSFRRHERTHGGEKPYECNQCGKAFSHPSSFRGHMRVHTGEKPYECKQCGKTFNWPISLRKHMRTHTREKPYECKQCGKAFSLSACFREHVRMHPEDKSYECKLCGKAFYCHISLQKHMRRHTAEKLYKCKQCGKAFSWPELLQQHVRTHTVEKPYECKECGKVFKWPSSLPIHMRLHTGEKPYQCKHCGKAFNCSSSLRRHVRIHTTEKQYKCNVGHPPANEFMCSASEKSHQERDLIKVVNMVLPL>sp|Q6ZNC4|ZN704_HUMAN Zinc finger protein 704 OS=Homo sapiens OX=9606GN=ZNF704 PE=1 SV=1MTFTFQSEDLKRDCGKKMSHQHVFSLAMEEDVKTADTKKASRILDHEKENTRSICLLEQKRKVVSSNIDVPPARKSSEELDMDKVTAAMVLTSLSTSPLVRSPPVRPNESLSGSWKEGGCVPSSTSSSGYWSWSAPSDQSNPSTPSPPLSADSFKPFRSPAQPDDGIDEAEASNLLFDEPIPRKRKNSMKVMFKCLWKNCGKVLSTAAGIQKHIRTIHLGRVGDSDYSDGEEDFYYTEIKLNTDSVADGLSSLAPVSPSQSLASPPTFPIPDSSRTETPCAKTETKLMTPLSRSAPTTLYLVHTDHAYQATPPVTIPGSAKFTPNGSSFSISWQSPPVTFTGIPVSPTHHPVGTGEQRQHAHTVLSSPPRGTVSLRKPRGEGKKCRKVYGMENRDMWCTACRWKKACQRFLD>sp|P51814|ZNF41_HUMAN Zinc finger protein 41 OS=Homo sapiens OX=9606GN=ZNF41 PE=1 SV=2MAANGDSPPWSPALAAEGRGSSCEVRRERTPEARIHSVKRYPDLSPGPKGRSSADHAALNSIVSLQASVSFEDVTVDFSKEEWQHLDPAQRRLYWDVTLENYSHLLSVGYQIPKSEAAFKLEQGEGPWMLEGEAPHQSCSGEAIGKMQQQGIPGGIFFHCERFDQPIGEDSLCSILEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|P51814-2|ZNF41_HUMAN Isoform 2 of Zinc finger protein 41 OS=Homosapiens OX=9606 GN=ZNF41MGTLPHGPRPWLQRDVAAHVSIVSLQASVSFEDVTVDFSKEEWQHLDPAQRRLYWDVTLENYSHLLSVGYQIPKSEAAFKLEQGEGPWMLEGEAPHQSCSGEAIGKMQQQGIPGGIFFHCERFDQPIGEDSLCSILEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|P51814-3|ZNF41_HUMAN Isoform 3 of Zinc finger protein 41 OS=Homosapiens OX=9606 GN=ZNF41MGTLPHGPRPWLQRDVAAHVSADHAALNSIVSLQASVSFEDVTVDFSKEEWQHLDPAQRRLYWDVTLENYSHLLSVGYQIPKSEAAFKLEQGEGPWMLEGEAPHQSCSGEAIGKMQQQGIPGGIFFHCERFDQPIGEDSLCSILEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|P51814-4|ZNF41_HUMAN Isoform 4 of Zinc finger protein 41 OS=Homosapiens OX=9606 GN=ZNF41MLEGEAPHQSCSGEAIGKMQQQGIPGGIFFHCERFDQPIGEDSLCSILEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|P51814-5|ZNF41_HUMAN Isoform 5 of Zinc finger protein 41 OS=Homosapiens OX=9606 GN=ZNF41MAANGDSPPWSPALAAEGRGSSCEVRRERTPEARIHSVKRYPDLSPGPKGRSSIVSLQASVSFEDVTVDFSKEEWQHLDPAQRRLYWDVTLENYSHLLSVGYQIPKSEAAFKLEQGEGPWMLEGEAPHQSCSGEAIGKMQQQGIPGGIFFHCERFDQPIGEDSLCSILEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|P51814-6|ZNF41_HUMAN Isoform 6 of Zinc finger protein 41 OS=Homosapiens OX=9606 GN=ZNF41MAANGDSPPWSPALAAEGRGSSCEASVSFEDVTVDFSKEEWQHLDPAQRRLYWDVTLENYSHLLSVGYQIPKSEAAFKLEQGEGPWMLEGEAPHQSCSGEAIGKMQQQGIPGGIFFHCERFDQPIGEDSLCSILEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|P51814-7|ZNF41_HUMAN Isoform 7 of Zinc finger protein 41 OS=Homosapiens OX=9606 GN=ZNF41MGTLPHGPRPWLQRDVAAHVSIVSLQASVSFEDVTVDFSKEEWQHLDPAQRRLYWDVTLENYSHLLSVGYQIPKSEAAFKLEQGEGPWMLEGEAPHQSCSEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|P51814-8|ZNF41_HUMAN Isoform 8 of Zinc finger protein 41 OS=Homosapiens OX=9606 GN=ZNF41MAANGDSPPWSPALAAEGRGSSCEASVSFEDVTVDFSKEEWQHLDPAQRRLYWDVTLENYSHLLSVGYQIPKSEAAFKLEQGEGPWMLEGEAPHQSCSEELWQDNDQLEQRQENQNNLLSHVKVLIKERGYEHKNIEKIIHVTTKLVPSIKRLHNCDTILKHTLNSHNHNRNSATKNLGKIFGNGNNFPHSPSSTKNENAKTGANSCEHDHYEKHLSHKQAPTHHQKIHPEEKLYVCTECVMGFTQKSHLFEHQRIHAGEKSRECDKSNKVFPQKPQVDVHPSVYTGEKPYLCTQCGKVFTLKSNLITHQKIHTGQKPYKCSECGKAFFQRSDLFRHLRIHTGEKPYECSECGKGFSQNSDLSIHQKTHTGEKHYECNECGKAFTRKSALRMHQRIHTGEKPYVCADCGKAFIQKSHFNTHQRIHTGEKPYECSDCGKSFTKKSQLHVHQRIHTGEKPYICTECGKVFTHRTNLTTHQKTHTGEKPYMCAECGKAFTDQSNLIKHQKTHTGEKPYKCNGCGKAFIWKSRLKIHQKSHIGERHYECKDCGKAFIQKSTLSVHQRIHTGEKPYVCPECGKAFIQKSHFIAHHRIHTGEKPYECSDCGKCFTKKSQLRVHQKIHTGEKPNICAECGKAFTDRSNLITHQKIHTREKPYECGDCGKTFTWKSRLNIHQKSHTGERHYECSKCGKAFIQKATLSMHQIIHTGKKPYACTECQKAFTDRSNLIKHQKMHSGEKRYKASD>sp|Q8N8Z8|ZN441_HUMAN Zinc finger protein 441 OS=Homo sapiens OX=9606GN=ZNF441 PE=1 SV=2MDSVAFEDVAINFTCEEWALLGPSQKSLYRDVMQETIRNLDCIGMIWQNHDIEEDQYKDLRRNLRCHMVERACEIKDNSQCGGPFTQTQDSIVNEKIPGVDPWESSECTDVLMGRSSLNCYVRVDSEHKPCEYQEYGEKPYTHTQCGTAFSYQPCFQIHERPQHGKKLYDCKECASFSSLENLQRHMAAHHGDGPRICKLCGNAFIWPSLFHMLRRTHTEEKPYEYEQCSTAFPAYSSTLRHERTHSGEKPYQCKQCGKAFSCSCYTQLYERTHTGEQSYECKQCGKAFYHLGSFQRHMIVHTGDGPHKCKICGKGFLSPSSVRRHKRTHTGEKPYECKYCGKAFSDCTGFRRHMITHTGDGPHKCKVCGKAFDSPSLCRRHETTHTGEKPYKCECGKAFSDFYYFRNHETTHTGEKPYKCKQCGKAFICCTYLQIHERIHTGERPYKCKQCGKAFRSSNYIRVHEKTHTGEKPYECKQCGKALSHLKSFQRHMIMHTGDGPHKCKICGKSFDSPSSFRRHERIHTGERPYKCKLCGKGFRSSSYIQLHERTHTGEKPYGCQQCGKALSDLSSFRRHMITHTGNGPHKCKICGKGFDYPSSVQRHERTHTGEKPYECKECGKAFSHSSYLRIHERVHTGEKPYKCKECGKPFHCPSAFHKHERTHSMEKPYKCKECGEAFHCISSFHKHEMTH>sp|Q8N8Z8-2|ZN441_HUMAN Isoform 2 of Zinc finger protein 441 OS=Homosapiens OX=9606 GN=ZNF441MIWQNHDIEEDQYKDLRRNLRCHMVERACEIKDNSQCGGPFTQTQDSIVNEKIPGVDPWESSECTDVLMGRSSLNCYVRVDSEHKPCEYQEYGEKPYTHTQCGTAFSYQPCFQIHERPQHGKKLYDCKECASFSSLENLQRHMAAHHGDGPRICKLCGNAFIWPSLFHMLRRTHTEEKPYEYEQCSTAFPAYSSTLRHERTHSGEKPYQCKQCGKAFSCSCYTQLYERTHTGEQSYECKQCGKAFYHLGSFQRHMIVHTGDGPHKCKICGKGFLSPSSVRRHKRTHTGEKPYECKYCGKAFSDCTGFRRHMITHTGDGPHKCKVCGKAFDSPSLCRRHETTHTGEKPYKCECGKAFSDFYYFRNHETTHTGEKPYKCKQCGKAFICCTYLQIHERIHTGERPYKCKQCGKAFRSSNYIRVHEKTHTGEKPYECKQCGKALSHLKSFQRHMIMHTGDGPHKCKICGKSFDSPSSFRRHERIHTGERPYKCKLCGKGFRSSSYIQLHERTHTGEKPYGCQQCGKALSDLSSFRRHMITHTGNGPHKCKICGKGFDYPSSVQRHERTHTGEKPYECKECGKAFSHSSYLRIHERVHTGEKPYKCKECGKPFHCPSAFHKHERTHSMEKPYKCKECGEAFHCISSFHKHEMTH>sp|Q9HCK1|ZDBF2_HUMAN DBF4-type zinc finger-containing protein 2 OS=Homosapiens OX=9606 GN=ZDBF2 PE=1 SV=3MQKRQGYCSYCRVQYNNLEQHLFSAQHRSLTRQSRRQICTSSLMERFLQDVLQHHPYHCQESSSTQDETHVNTGSSSEVVHLDDAFSEEEEEDEDKVEDEDATEERPSEVSEPIEELHSRPHKSQEGTQEVSVRPSVIQKLEKGQQQPLEFVHKIGASVRKCNLVDIGQATNNRSNLVRPPVICNAPASCLPESSNDRPVTANTTSLPPAAHLDSVSKCDPNKVEKYLEQPDGASRNPVPSSHVETTSFSYQKHKESNRKSLRMNSDKLVLWKDVKSQGKTLSAGLKFHERMGTKGSLRVKSPSKLAVNPNKTDMPSNKGIFEDTIAKNHEEFFSNMDCTQEEKHLVFNKTAFWEQKCSVSSEMKFDCISLQSASDQPQETAQDLSLWKEEQIDQEDNYESRGSEMSFDCSSSFHSLTDQSKVSAKEVNLSKEVRTDVQYKNNKSYVSKISSDCDDILHLVTNQSQMIVKEISLQNARHISLVDQSYESSSSETNFDCDASPQSTSDYPQQSVTEVNLPKEVHIGLVDKNYGSSSSEVSADSVFPLQSVVDRPPVAVTETKLRKKAHTSLVDNYGSSCSETSFDCDVSLESVVDHPQLTVKGRNLKGRQVHLKHKKRKPSSAKAHLDCDVSLGTVADESQRAVEKINLLKEKNADLMDMNCESHGPEMGFQADAQLADQSQVAEIERQKVDVDLENKSVQSSRSSLSSDSPASLYHSAHDEPQEALDEVNLKELNIDMEVRSYDCSSSELTFDSDPPLLSVTEQSHLDAEGKERHIDLEDESCESDSSEITFDSDIPLYSVIDQPEVAVYEEETVDLESKSNESCVSEITFDSDIPLHSGNDHPEVAVKEVIQKEEYIHLERKNDEPSGSEISSDSHAPLHSVTNSPEVAVKKLNPQKEEQVHLENKENEPIDSEVSLDYNIIFHSVTGRSEDPIKEISLHTKEHMYLENKSVFETSLDSDVPLQAATHKPEVIVKETWLQREKHAEFQGRSTEFSGSKTSLDSGVPHYSVTEPQVAVNKINRKKQYVLENKNDKCSGSEIILDSNVPPQSMTDQPQLAFLKEKHVNLKDKNSKSGDSKITFDSEQLQEAVKKIDQWKEEVIGLKNKINEPSTYKLIHHPDVSVQSVADQPKVAIKHVNLGNENHMYLEVKNSQYSCSEMNLDSGFLGQSIVNRPQITILEQEHIELEGKHNQCCGSEVSFDSDDPLQSVADRLRETVKEISLWKDEEVDTEDRRNEAKGFEIMYDSDVLQPVAGQPEEVVKEVSLWKEHVDLENKIVKPTDSRINFDSHEPLQSVTNKIPGANKEINLLREEHVCLDDKGYVPSDSEIIYVSNIPLQSVIKQPHILEEEHASLEDKSSNSYSPEESSDSNDSFQAAADELQKPVKEINLWKEDHIYLEDKSYKLGDFDVSYASHIPVQFVTDQSSVPVKEINLQKKDHNDLENKNCEVCGSEIKCHSCVHLQSEVDQPQVSYKEADLQKEEHVVMEEKTDQPSDSEMMYDSDVPFQIVVNQFPGSVKETHLPKVVLVDLVPGDSDYEVISDDIPLQLVTDPPQLTVKDISCINTECIDIEDKSCDFFGSEVRCNCKASTPSMTNQCKETFKIINRKKDYIILGEPSCQSCGSEMNFNVDASDQSMTYESQGPDEKMVKYIDSEDKSCGYNGSKGKFNLEDTSHRTTHRLQKAHKEASLRKDPRNAGLKGKSCQSSASAVDFGASSKSALHRRADKKKRSKLKHRDLEVSCEPDGFEMNFQCAPPLPSDTDQPQETVKKRHPCKKVSSDLKEKNHDSQSSSVLKVDSVRNLKKAKDVIEDNPDEPVLEALPHVPPSFVGKTWSQIMREDDIKINALVKEFREGRFHCYFDDDCETKKVSSKGKKKVTWADLQGKEDTAPTQAVSESDDIVCGISDIDDLSVALDKPCHRHPPAERPPKQKGRVASQCQTAKISHSTQTSCKNYPVMKRKIIRQEEDPPKSKCSRLQDDRKTKKKVKIGTVEFPASCTKVLKPMQPKALVCVLSSLNIKLKEGEGLPFPKMRHHSWDNDIRFICKYKRNIFDYYEPLIKQIVISPPLSVIVPEFERRNWVKIHFNRSNQNSSAGDNDADGQGSASAPLMAVPARYGFNSHQGTSDSSLFLEESKVLHARELPKKRNFQLTFLNHDVVKISPKSVRNKLLESQSKKKIHGKRVTTSSNKLGFPKKVYKPIILQQKPRKASEKQSIWIRTKPSDIIRKYISKYSVFLRHRYQSRSAFLGRYLKKKKSVVSRLKKAKRTAKVLLNSSVPPAGAEELSSAMANPPPKRPVRASCRVARRRKKTDESYHGRQKGPSTPVRAYDLRSSSCLQQRERMMTRLANKLRGNEVK>sp|Q3KNS6|ZN829_HUMAN Zinc finger protein 829 OS=Homo sapiens OX=9606GN=ZNF829 PE=1 SV=1MPHSPLISIPHVWCHPEEEERMHDELLQAVSKGPVMFRDVSIDFSQEEWECLDADQMNLYKEVMLENFSNLVSVGLSNSKPAVISLLEQGKEPWMVDRELTRGLCSDLESMCETKILSLKKRHFSQVIITREDMSTFIQPTFLIPPQKTMSEEKPWECKICGKTFNQNSQFIQHQRIHFGEKHYESKEYGKSFSRGSLVTRHQRIHTGKKPYECKECGKAFSCSSYFSQHQRIHTGEKPYECKECGKAFKYCSNLNDHQRIHTGEKPYECKVCGKAFTKSSQLFLHLRIHTGEKPYECKECGKAFTQHSRLIQHQRMHTGEKPYECKQCGKAFNSASTLTNHHRIHAGEKLYECEECRKAFIQSSELIQHQRIHTDEKPYECNECGKAFNKGSNLTRHQRIHTGEKPYDCKECGKAFGSRSDLIRHEGIHTG>sp|Q3KNS6-2|ZN829_HUMAN Isoform 2 of Zinc finger protein 829 OS=Homosapiens OX=9606 GN=ZNF829MNKEYGKSFSRGSLVTRHQRIHTGKKPYECKECGKAFSCSSYFSQHQRIHTGEKPYECKECGKAFKYCSNLNDHQRIHTGEKPYECKVCGKAFTKSSQLFLHLRIHTGEKPYECKECGKAFTQHSRLIQHQRMHTGEKPYECKQCGKAFNSASTLTNHHRIHAGEKLYECEECRKAFIQSSELIQHQRIHTDEKPYECNECGKAFNKGSNLTRHQRIHTGEKPYDCKECGKAFGSRSDLIRHEGIHTG>sp|Q3KNS6-3|ZN829_HUMAN Isoform 3 of Zinc finger protein 829 OS=Homosapiens OX=9606 GN=ZNF829MTGKGLGEDTEDRWGAGALGPCGRSGLKGGGCVWEAEAGGSRGQEIETILANMETSLRSGQIPTLDSSEHNLSPEPLELDRMPHSPLISIPHVWCHPEEEERMHDELLQAVSKGPVMFRDVSIDFSQEEWECLDADQMNLYKEVMLENFSNLVSVGLSNSKPAVISLLEQGKEPWMVDRELTRGLCSDLESMCETKILSLKKRHFSQVIITREDMSTFIQPTFLIPPQKTMSEEKPWECKICGKTFNQNSQFIQHQRIHFGEKHYESKEYGKSFSRGSLVTRHQRIHTGKKPYECKECGKAFSCSSYFSQHQRIHTGEKPYECKECGKAFKYCSNLNDHQRIHTGEKPYECKVCGKAFTKSSQLFLHLRIHTGEKPYECKECGKAFTQHSRLIQHQRMHTGEKPYECKQCGKAFNSASTLTNHHRIHAGEKLYECEECRKAFIQSSELIQHQRIHTDEKPYECNECGKAFNKGSNLTRHQRIHTGEKPYDCKECGKAFGSRSDLIRHEGIHTG>sp|Q8TCF1|ZFAN1_HUMAN AN1-type zinc finger protein 1 OS=Homo sapiensOX=9606 GN=ZFAND1 PE=1 SV=1MAELDIGQHCQVEHCRQRDFLPFVCDDCSGIFCLEHRSRESHGCPEVTVINERLKTDQHTSYPCSFKDCAERELVAVICPYCEKNFCLRHRHQSDHECEKLEIPKPRMAATQKLVKDIIDSKTGETASKRWKGAKNSETAAKVALMKLKMHADGDKSLPQTERIYFQVFLPKGSKEKSKPMFFCHRWSIGKAIDFAASLARLKNDNNKFTAKKLRLCHITSGEALPLDHTLETWIAKEDCPLYNGGNIILEYLNDEEQFCKNVESYLE>sp|Q8TCF1-2|ZFAN1_HUMAN Isoform 2 of AN1-type zinc finger protein 1OS=Homo sapiens OX=9606 GN=ZFAND1MAATQKLVKDIIDSKTGETASKRWKGAKNSETAAKVALMKLKMHADGDKSLPQTERIYFQVFLPKGSKEKSKPMFFCHRWSIGKAIDFAASLARLKNDNNKFTAKKLRLCHITSGEALPLDHTLETWIAKEDCPLYNGGNIILEYLNDEEQFCKNVESYLE>sp|Q8TCF1-3|ZFAN1_HUMAN Isoform 3 of AN1-type zinc finger protein 1OS=Homo sapiens OX=9606 GN=ZFAND1MAELDIGQHCQVEHCRQRDFLPFVCDDCSGIFCLEHRSRESHGCPEVTVINERLKTDQHTSYPCSFKDCAERELVAVICPYCEKNFCLRHRHQSDHECEKLEIPKPRMAATQKLVKDIIDSKTGETASKRWKGAKNSETAAKVALMKLKMHADGDKSLPQVFLPKGSKEKSKPMFFCHRWSIGKAIDFAASLARLKNDNNKFTAKKLRLCHITSGEALPLDHTLETWIAKEDCPLYNGGNIILEYLNDEEQFCKNVESYLE>sp|Q8TCF1-4|ZFAN1_HUMAN Isoform 4 of AN1-type zinc finger protein 1OS=Homo sapiens OX=9606 GN=ZFAND1MAELDIGQHCQVEHCRQRDFLPFVCDDCSGIFCLEHRSRESHGCPEVTVINERLKTDQHTSYPCSFKDCAERELVAVICPYCEKNFCLRHRHQSDHECEKLEIPKPRMAATQKLVKDIIDSKTGETASKRWKGAKNSETAAKVALMKLKMHADGDKSLPQTERIYFQVFLPKGSKEKSKPMFFCHRWSIGKAIDFAASLARLKNDNNKFTAKVTSHYNNISILIKVL>sp|Q8IWB7|WDFY1_HUMAN WD repeat and FYVE domain-containing protein 1OS=Homo sapiens OX=9606 GN=WDFY1 PE=1 SV=1MAAEIHSRPQSSRPVLLSKIEGHQDAVTAALLIPKEDGVITASEDRTIRVWLKRDSGQYWPSIYHTMASPCSAMAYHHDSRRIFVGQDNGAVMEFHVSEDFNKMNFIKTYPAHQNRVSAIIFSLATEWVISTGHDKCVSWMCTRSGNMLGRHFFTSWASCLQYDFDTQYAFVGDYSGQITLLKLEQNTCSVITTLKGHEGSVACLWWDPIQRLLFSGASDNSIIMWDIGGRKGRTLLLQGHHDKVQSLCYLQLTRQLVSCSSDGGIAVWNMDVSREEAPQWLESDSCQKCEQPFFWNIKQMWDTKTLGLRQHHCRKCGQAVCGKCSSKRSSYPVMGFEFQVRVCDSCYDSIKDEDRTSLATFHEGKHNISHMSMDIARGLMVTCGTDRIVKIWDMTPVVGCSLATGFSPH>sp|Q8IY57|YAF2_HUMAN YY1-associated factor 2 OS=Homo sapiens OX=9606GN=YAF2 PE=1 SV=3MGDKKSPTRPKRQPKPSSDEGYWDCSVCTFRNSAEAFKCMMCDVRKGTSTRKPRPVSQLVAQQVTQQFVPPTQSKKEKKDKVEKEKSEKETTSKKNSHKKTRPRLKNVDRSSAQHLEVTVGDLTVIITDFKEKTKSPPASSAASADQHSQSGSSSDNTERGMSRSSSPRGEASSLNGESH>sp|Q8IY57-5|YAF2_HUMAN Isoform 2 of YY1-associated factor 2 OS=Homosapiens OX=9606 GN=YAF2MGDKKSPTRPKRQPKPSSDEGYWDCSVCTFRNSAEAFKCMMCDVRKGTSTRSTLFEVIVSASRTKEPLKFPISGRKPRPVSQLVAQQVTQQFVPPTQSKKEKKDKVEKEKSEKETTSKKNSHKKTRPRLKNVDRSSAQHLEVTVGDLTVIITDFKEKTKSPPASSAASADQHSQSGSSSDNTERGMSRSSSPRGEASSLNGESH>sp|Q8IY57-3|YAF2_HUMAN Isoform 3 of YY1-associated factor 2 OS=Homosapiens OX=9606 GN=YAF2MGDKKSPTRKPRPVSQLVAQQVTQQFVPPTQSKKEKKDKVEKEKSEKETTSKKNSHKKTRPRLKNVDRSSAQHLEVTVGDLTVIITDFKEKTKSPPASSAASADQHSQSGSSSDNTERGMSRSSSPRGEASSLNGESH>sp|Q8IY57-4|YAF2_HUMAN Isoform 4 of YY1-associated factor 2 OS=Homosapiens OX=9606 GN=YAF2MGDKKSPTRPKRQPKPSSDEGYWDCSVCTFRNSAEAFKCMMCDVRKGTSTRDSKEGGKLVSYSTASLGVRGTLRNRVGGGSSEEKKQAEYLAPGRRRNIVHRGVGPGQRSGPSLKEA>sp|O43670|ZN207_HUMAN BUB3-interacting and GLEBS motif-containingprotein ZNF207 OS=Homo sapiens OX=9606 GN=ZNF207 PE=1 SV=1MGRKKKKQLKPWCWYCNRDFDDEKILIQHQKAKHFKCHICHKKLYTGPGLAIHCMQVHKETIDAVPNAIPGRTDIELEIYGMEGIPEKDMDERRRLLEQKTQESQKKKQQDDSDEYDDDDSAASTSFQPQPVQPQQGYIPPMAQPGLPPVPGAPGMPPGIPPLMPGVPPLMPGMPPVMPGMPPGMMPMGGMMPPGPGIPPLMPGMPPGMPPPVPRPGIPPMTQAQAVSAPGILNRPPAPTATVPAPQPPVTKPLFPSAGQMGTPVTSSSTASSNSESLSASSKALFPSTAQAQAAVQGPVGTDFKPLNSTPATTTEPPKPTFPAYTQSTASTTSTTNSTAAKPAASITSKPATLTTTSATSKLIHPDEDISLEERRAQLPKYQRNLPRPGQAPIGNPPVGPIGGMMPPQPGIPQQQGMRPPMPPHGQYGGHHQGMPGYLPGAMPPYGQGPPMVPPYQGGPPRPPMGMRPPVMSQGGRY>sp|O43670-2|ZN207_HUMAN Isoform 2 of BUB3-interacting and GLEBS motif-containing protein ZNF207 OS=Homo sapiens OX=9606 GN=ZNF207MGRKKKKQLKPWCWYCNRDFDDEKILIQHQKAKHFKCHICHKKLYTGPGLAIHCMQVHKETIDAVPNAIPGRTDIELEIYGMEGIPEKDMDERRRLLEQKTQESQKKKQQDDSDEYDDDDSAASTSFQPQPVQPQQGYIPPMAQPGLPPVPGAPGMPPGIPPLMPGVPPLMPGMPPVMPGMPPGLHHQRKYTQSFCGENIMMPMGGMMPPGPGIPPLMPGMPPGMPPPVPRPGIPPMTQAQAVSAPGILNRPPAPTATVPAPQPPVTKPLFPSAGQAQAAVQGPVGTDFKPLNSTPATTTEPPKPTFPAYTQSTASTTSTTNSTAAKPAASITSKPATLTTTSATSKLIHPDEDISLEERRAQLPKYQRNLPRPGQAPIGNPPVGPIGGMMPPQPGIPQQQGMRPPMPPHGQYGGHHQGMPGYLPGAMPPYGQGPPMVPPYQGGPPRPPMGMRPPVMSQGGRY>sp|O43670-3|ZN207_HUMAN Isoform 3 of BUB3-interacting and GLEBS motif-containing protein ZNF207 OS=Homo sapiens OX=9606 GN=ZNF207MGRKKKKQLKPWCWYCNRDFDDEKILIQHQKAKHFKCHICHKKLYTGLPPVPGAPGMPPGIPPLMPGVPPLMPGMPPVMPGMPPGLHHQRKYTQSFCGENIMMPMGGMMPPGPGIPPLMPGMPPGMPPPVPRPGIPPMTQAQAVSAPGILNRPPAPTATVPAPQPPVTKPLFPSAGQMGTPVTSSSTASSNSESLSASSKALFPSTAQAQAAVQGPVGTDFKPLNSTPATTTEPPKPTFPAYTQSTASTTSTTNSTAAKPAASITSKPATLTTTSATSKLIHPDEDISLEERRAQLPKYQRNLPRPGQAPIGNPPVGPIGGMMPPQPGIPQQQGMRPPMPPHGQYGGHHQGMPGYLPGAMPPYGQGPPMVPPYQGGPPRPPMGMRPPVMSQGGRY>sp|O43670-4|ZN207_HUMAN Isoform 4 of BUB3-interacting and GLEBS motif-containing protein ZNF207 OS=Homo sapiens OX=9606 GN=ZNF207MGRKKKKQLKPWCWYCNRDFDDEKILIQHQKAKHFKCHICHKKLYTGPGLAIHCMQVHKETIDAVPNAIPGRTDIELEIYGMEGIPEKDMDERRRLLEQKTQESQKKKQQDDSDEYDDDDSAASTSFQPQPVQPQQGYIPPMAQPGLPPVPGAPGMPPGIPPLMPGVPPLMPGMPPVMPGMPPGLHHQRKYTQSFCGENIMMPMGGMMPPGPGIPPLMPGMPPGMPPPVPRPGIPPMTQAQAVSAPGILNRPPAPTATVPAPQPPVTKPLFPSAGQMGTPVTSSSTASSNSESLSASSKALFPSTAQAQAAVQGPVGTDFKPLNSTPATTTEPPKPTFPAYTQSTASTTSTTNSTAAKPAASITSKPATLTTTSATSKLIHPDEDISLEERRAQLPKYQRNLPRPGQAPIGNPPVGPIGGMMPPQPGIPQQQGMRPPMPPHGQYGGHHQGMPGYLPGAMPPYGQGPPMVPPYQGGPPRPPMGMRPPVMSQGGRY>sp|Q13398|ZN211_HUMAN Zinc finger protein 211 OS=Homo sapiens OX=9606GN=ZNF211 PE=2 SV=2MLGFPPGRPQLPVQLRPQTRMATALRDPASGSVTFEDVAVYFSWEEWDLLDEAQKHLYFDVMLENFALTSSLGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q13398-2|ZN211_HUMAN Isoform 2 of Zinc finger protein 211 OS=Homosapiens OX=9606 GN=ZNF211MLENFALTSSLGLISSWSHVVAQLGLGEVPSVLHRMFMTPASARWDQRGPGLHEWHLGKGMSSGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q13398-3|ZN211_HUMAN Isoform 3 of Zinc finger protein 211 OS=Homosapiens OX=9606 GN=ZNF211MRTLRQREVEYFSKATQLVRGSTKDRGAQVPIATEVLFKLTQGSVTFEDVAVYFSWEEWDLLDEAQKHLYFDVMLENFALTSSLGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q13398-4|ZN211_HUMAN Isoform 4 of Zinc finger protein 211 OS=Homosapiens OX=9606 GN=ZNF211MISAYCNLHLLGSSDSPASASQVAGTTGMRHHAQGSVTFEDVAVYFSWEEWDLLDEAQKHLYFDVMLENFALTSSLGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q13398-5|ZN211_HUMAN Isoform 5 of Zinc finger protein 211 OS=Homosapiens OX=9606 GN=ZNF211MLENFALTSSLGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q13398-6|ZN211_HUMAN Isoform 6 of Zinc finger protein 211 OS=Homosapiens OX=9606 GN=ZNF211MATALRDPASGSVTFEDVAVYFSWEEWDLLDEAQKHLYFDVMLENFALTSSLGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q13398-7|ZN211_HUMAN Isoform 7 of Zinc finger protein 211 OS=Homosapiens OX=9606 GN=ZNF211MLGFPPGRPQLPVQLRPQTRMATALRDPASVPIATEVLFKLTQGSVTFEDVAVYFSWEEWDLLDEAQKHLYFDVMLENFALTSSLGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q13398-8|ZN211_HUMAN Isoform 8 of Zinc finger protein 211 OS=Homosapiens OX=9606 GN=ZNF211MLGFPPGRPQLPVQLRPQTRMATALRDPASVPIATEVLFKLTQGSVTFEDVAVYFSWEEWDLLDEAQKHLYFDVMLENFALTSSLGLISSWSHVVAQLGLGEVPSVLHRMFMTPASARWDQRGPGLHEWHLGKGMSSGCWCGVEHEETPSEQRISGERVPQFRTSKEGSSSQNADSCEICCLVLRDILHLAEHQGTNCGQKLHTCGKQFYISANLQQHQRQHITEAPFRSYVDTASFTQSCIVHVSEKPFTCREIRKDFLANMRFLHQDATQTGEKPNNSNKCAVAFYSGKSHHNWGKCSKAFSHIDTLVQDQRILTREGLFECSKCGKACTRRCNLIQHQKVHSEERPYECNECGKFFTYYSSFIIHQRVHTGERPYACPECGKSFSQIYSLNSHRKVHTGERPYECGECGKSFSQRSNLMQHRRVHTGERPYECSECGKSFSQNFSLIYHQRVHTGERPHECNECGKSFSRSSSLIHHRRLHTGERPYECSKCGKSFKQSSSFSSHRKVHTGERPYVCGECGKSFSHSSNLKNHQRVHTGERPVECSECSKSFSCKSNLIKHLRVHTGERPYECSECGKSFSQSSSLIQHRRVHTGKRPYQCSQCGKSFGCKSVLIQHQRVHIGEKP>sp|Q96K62|ZBT45_HUMAN Zinc finger and BTB domain-containing protein 45OS=Homo sapiens OX=9606 GN=ZBTB45 PE=1 SV=1MAAAEAVHHIHLQNFSRSLLETLNGQRLGGHFCDVTVRIREASLRAHRCVLAAGSPFFQDKLLLGHSEIRVPPVVPAQTVRQLVEFLYSGSLVVAQGEALQVLTAASVLRIQTVIDECTQIIARARAPGTSAPTPLPTPVPPPLAPAQLRHRLRHLLAARPPGHPGAAHSRKQRQPARLQLPAPPTPAKAEGPDADPSLSAAPDDRGDEDDEESDDETDGEDGEGGGPGEGQAPPSFPDCAAGFLTAAADSACEEPPAPTGLADYSGAGRDFLRGAGSAEDVFPDSYVSTWHDEDGAVPEGCPTETPVQPDCILSGSRPPGVKTPGPPVALFPFHLGAPGPPAPPPSAPSGPAPAPPPAFYPTLQPEAAPSTQLGEVPAPSAAPTTAPSGTPARTPGAEPPTYECSHCRKTFSSRKNYTKHMFIHSGEKPHQCAVCWRSFSLRDYLLKHMVTHTGVRAFQCAVCAKRFTQKSSLNVHMRTHRPERAPCPACGKVFSHRALLERHLAAHPAP>sp|Q9NQZ6|ZC4H2_HUMAN Zinc finger C4H2 domain-containing protein OS=Homosapiens OX=9606 GN=ZC4H2 PE=1 SV=1MADEQEIMCKLESIKEIRNKTLQMEKIKARLKAEFEALESEERHLKEYKQEMDLLLQEKMAHVEELRLIHADINVMENTIKQSENDLNKLLESTRRLHDEYKPLKEHVDALRMTLGLQRLPDLCEEEEKLSLDYFEKQKAEWQTEPQEPPIPESLAAAAAAAQQLQVARKQDTRQTATFRQQPPPMKACLSCHQQIHRNAPICPLCKAKSRSRNPKKPKRKQDE>sp|Q9NQZ6-2|ZC4H2_HUMAN Isoform 2 of Zinc finger C4H2 domain-containingprotein OS=Homo sapiens OX=9606 GN=ZC4H2MADEQEIMCKLESIKEIRNKTLQMEKIKARLKAEFEALESEERHLKEYKQEMDLLLQEKMAHVEELRLIHADINVMENTIKQSENDLNKLLESTRRLHDEYKPLKEHVDALRMTLGLQRLPDLCEEEEKLSLE>sp|Q9NQZ6-3|ZC4H2_HUMAN Isoform 3 of Zinc finger C4H2 domain-containingprotein OS=Homo sapiens OX=9606 GN=ZC4H2MEKIKARLKAEFEALESEERHLKEYKQEMDLLLQEKMAHVEELRLIHADINVMENTIKQSENDLNKLLESTRRLHDEYKPLKEHVDALRMTLGLQRLPDLCEEEEKLSLDYFEKQKAEWQTEPQEPPIPESLAAAAAAAQQLQVARKQDTRQTATFRQQPPPMKACLSCHQQIHRNAPICPLCKAKSRSRNPKKPKRKQDE>sp|Q9NQZ6-4|ZC4H2_HUMAN Isoform 4 of Zinc finger C4H2 domain-containingprotein OS=Homo sapiens OX=9606 GN=ZC4H2MADEQEIMCKLESIKEIRNKTLQMEKIKARLKAEFEALESEERHLKEYKQEMDLLLQEKMAHVEELRLIHADINVMENTIKQSENDLNKLLESTRRLHDEYKPLKEHVDALRMTLGLQRLPDLCEEEEKLSLEPACHVTSKFTGMHLYALFARPRVGPGTPKSRNGSRMNKEREST>sp|Q9NQZ6-5|ZC4H2_HUMAN Isoform 5 of Zinc finger C4H2 domain-containingprotein OS=Homo sapiens OX=9606 GN=ZC4H2MIHFHLIFLYVARNKTLQMEKIKARLKAEFEALESEERHLKEYKQEMDLLLQEKMAHVEELRLIHADINVMENTIKQSENDLNKLLESTRRLHDEYKPLKEHVDALRMTLGLQRLPDLCEEEEKLSLDYFEKQKAEWQTEPQEPPIPESLAAAAAAAQQLQVARKQDTRQTATFRQQPPPMKACLSCHQQIHRNAPICPLCKAKSRSRNPKKPKRKQDE>sp|P0CB33|ZN735_HUMAN Putative zinc finger protein 735 OS=Homo sapiensOX=9606 GN=ZNF735 PE=5 SV=1MAKRPGPPGSREMGLLTFRDIAIEFSLAEWQCLDHAQQNLYRDVMLENYRNLFSLGMTVSKPDLIACLEQNKEPQNIKRNEMAAKHPVTCSHFNQDLQPEQSIKDSLQKVIPRTYGKCGHENLQLKKCCKRVDECEVHKGGYNDLNQCLSNTQNKIFQTHKCVKVFSKFSNSNRHNARYTGKKHLKCKKYGKSFCMFSHLNQHQIIHTKEKSYKCEECGKSFNHSSSGTTHKRILTGEKPYRCEECGKAFRWPSNLTRHKRIHTGEKPYACEECGQAFRRSSTLTNHKRIHTGERPYKCEECGKAFSVSSALIYHKRIHTGEKPYTCEECGKAFNCSSTLKTHKIIHTGEKPYTCEECGRTFNCSSTVKAHKRIHTGEKPYKCEECDKAFKWHSSLAKHKIIHTGEKPYKCK>sp|Q6NZY4|ZCHC8_HUMAN Zinc finger CCHC domain-containing protein 8OS=Homo sapiens OX=9606 GN=ZCCHC8 PE=1 SV=2MAAEVYFGDLELFEPFDHPEESIPKPVHTRFKDDDGDEEDENGVGDAELRERLRQCEETIEQLRAENQELKRKLNILTRPSGILVNDTKLDGPILQILFMNNAISKQYHQEIEEFVSNLVKRFEEQQKNDVEKTSFNLLPQPSSIVLEEDHKVEESCAIKNNKEAFSVVGSVLYFTNFCLDKLGQPLLNENPQLSEGWEIPKYHQVFSHIVSLEGQEIQVKAKRPKPHCFNCGSEEHQMKDCPMPRNAARISEKRKEYMDACGEANNQNFQQRYHAEEVEERFGRFKPGVISEELQDALGVTDKSLPPFIYRMRQLGYPPGWLKEAELENSGLALYDGKDGTDGETEVGEIQQNKSVTYDLSKLVNYPGFNISTPRGIPDEWRIFGSIPMQACQQKDVFANYLTSNFQAPGVKSGNKRSSSHSSPGSPKKQKNESNSAGSPADMELDSDMEVPHGSQSSESFQFQPPLPPDTPPLPRGTPPPVFTPPLPKGTPPLTPSDSPQTRTASGAVDEDALTLEELEEQQRRIWAALEQAESVNSDSDVPVDTPLTGNSVASSPCPNELDLPVPEGKTSEKQTLDEPEVPEIFTKKSEAGHASSPDSEVTSLCQKEKAELAPVNTEGALLDNGSVVPNCDISNGGSQKLFPADTSPSTATKIHSPIPDMSKFATGITPFEFENMAESTGMYLRIRSLLKNSPRNQQKNKKASE>sp|Q6NZY4-2|ZCHC8_HUMAN Isoform 2 of Zinc finger CCHC domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=ZCCHC8MKDCPMPRNAARISEKRKEYMDACGEANNQNFQQRYHAEEVEERFGRFKPGVISEELQDALGVTDKSLPPFIYRMRQLGYPPGWLKEAELENSGLALYDGKDGTDGETEVGEIQQNKSVTYDLSKLVNYPGFNISTPRGIPDEWRIFGSIPMQACQQKDVFANYLTSNFQAPGVKSGNKRSSSHSSPGSPKKQKNESNSAGSPADMELDSDMEVPHGSQSSESFQFQPPLPPDTPPLPRGTPPPVFTPPLPKGTPPLTPSDSPQTRTASGAVDEDALTLEELEEQQRRIWAALEQAESVNSDSDVPVDTPLTGNSVASSPCPNELDLPVPEGKTSEKQTLDEPEVPEIFTKKSEAGHASSPDSEVTSLCQKEKAELAPVNTEGALLDNGSVVPNCDISNGGSQKLFPADTSPSTATKIHSPIPDMSKFATGITPFEFENMAESTGMYLRIRSLLKNSPRNQQKNKKASE>sp|P51815|ZN75D_HUMAN Zinc finger protein 75D OS=Homo sapiens OX=9606GN=ZNF75D PE=2 SV=2MAMRELNADSCSSPQMGAMWETSGSVKENSSQSKKYSTKIENLGPESACRHFWSFRYHEATGPLETISQLQKLCHQWLRPEIHSKEQILEMLVLEQFLSILPKETQNWVQKHHPQNVKQALVLVEFLQREPDGTKNEVTAHELGKEAVLLGGTAVAPGFKWKPAEPQPMGVFQKEYWNTYRVLQEQLGWNTHKETQPVYERAVHDQQMLALSEQKRIKHWKMASKLILPESLSLLTFEDVAVYFSEEEWQLLNPLEKTLYNDVMQDIYETVISLGLKLKNDTGNDHPISVSTSEIQTSGCEVSKKTRMKIAQKTMGRENPGDTHSVQKWHRAFPRKKRKKPATCKQELPKLMDLHGKGPTGEKPFKCQECGKSFRVSSDLIKHHRIHTGEKPYKCQQCDRRFRWSSDLNKHFMTHQGIKPYRCSWCGKSFSHNTNLHTHQRIHTGEKPFKCDECGKRFIQNSHLIKHQRTHTGEQPYTCSLCKRNFSRRSSLLRHQKLHRRREACLVSPN>sp|P51815-2|ZN75D_HUMAN Isoform 2 of Zinc finger protein 75D OS=Homosapiens OX=9606 GN=ZNF75DMAMRELNADSCSSPQMGAMWETSGSVKENSSQSKKYSTKIENLGPESACRHFWSFRYHEATGPLETISQLQKLCHQWLRPEIHSKEQILEMLVLEQFLSILPKETQNWVQKHHPQNVKQALVLVEFLQREPDGTKNESLLTFEDVAVYFSEEEWQLLNPLEKTLYNDVMQDIYETVISLGLKLKNDTGNDHPISVSTSEIQTSGCEVSKKTRMKIAQKTMGRENPGDTHSVQKWHRAFPRKKRKKPATCKQELPKLMDLHGKGPTGEKPFKCQECGKSFRVSSDLIKHHRIHTGEKPYKCQQCDRRFRWSSDLNKHFMTHQGIKPYRCSWCGKSFSHNTNLHTHQRIHTGEKPFKCDECGKRFIQNSHLIKHQRTHTGEQPYTCSLCKRNFSRRSSLLRHQKLHRRREACLVSPN>sp|Q8WTR7|ZN473_HUMAN Zinc finger protein 473 OS=Homo sapiens OX=9606GN=ZNF473 PE=1 SV=1MAEEFVTLKDVGMDFTLGDWEQLGLEQGDTFWDTALDNCQDLFLLDPPRPNLTSHPDGSEDLEPLAGGSPEATSPDVTETKNSPLMEDFFEEGFSQEIIEMLSKDGFWNSNFGEACIEDTWLDSLLGDPESLLRSDIATNGESPTECKSHELKRGLSPVSTVSTGEDSMVHNVSEKTLTPAKSKEYRGEFFSYSDHSQQDSVQEGEKPYQCSECGKSFSGSYRLTQHWITHTREKPTVHQECEQGFDRNASLSVYPKTHTGYKFYVCNEYGTTFSQSTYLWHQKTHTGEKPCKSQDSDHPPSHDTQPGEHQKTHTDSKSYNCNECGKAFTRIFHLTRHQKIHTRKRYECSKCQATFNLRKHLIQHQKTHAAKTTSECQECGKIFRHSSLLIEHQALHAGEEPYKCNERGKSFRHNSTLKIHQRVHSGEKPYKCSECGKAFHRHTHLNEHRRIHTGYRPHKCQECVRSFSRPSHLMRHQAIHTAEKPYSCAECKETFSDNNRLVQHQKMHTVKTPYECQECGERFICGSTLKCHESVHAREKQGFFVSGKILDQNPEQKEKCFKCNKCEKTFSCSKYLTQHERIHTRGVKPFECDQCGKAFGQSTRLIHHQRIHSRVRLYKWGEQGKAISSASLIKLQSFHTKEHPFKCNECGKTFSHSAHLSKHQLIHAGENPFKCSKCDRVFTQRNYLVQHERTHARKKPLVCNECGKTFRQSSCLSKHQRIHSGEKPYVCDYCGKAFGLSAELVRHQRIHTGEKPYVCQECGKAFTQSSCLSIHRRVHTGEKPYRCGECGKAFAQKANLTQHQRIHTGEKPYSCNVCGKAFVLSAHLNQHLRVHTQETLYQCQRCQKAFRCHSSLSRHQRVHNKQQYCL>sp|P17029|ZKSC1_HUMAN Zinc finger protein with KRAB and SCAN domains 1OS=Homo sapiens OX=9606 GN=ZKSCAN1 PE=1 SV=3MMTAESREATGLSPQAAQEKDGIVIVKVEEEDEEDHMWGQDSTLQDTPPPDPEIFRQRFRRFCYQNTFGPREALSRLKELCHQWLRPEINTKEQILELLVLEQFLSILPKELQVWLQEYRPDSGEEAVTLLEDLELDLSGQQVPGQVHGPEMLARGMVPLDPVQESSSFDLHHEATQSHFKHSSRKPRLLQSRALPAAHIPAPPHEGSPRDQAMASALFTADSQAMVKIEDMAVSLILEEWGCQNLARRNLSRDNRQENYGSAFPQGGENRNENEESTSKAETSEDSASRGETTGRSQKEFGEKRDQEGKTGERQQKNPEEKTRKEKRDSGPAIGKDKKTITGERGPREKGKGLGRSFSLSSNFTTPEEVPTGTKSHRCDECGKCFTRSSSLIRHKIIHTGEKPYECSECGKAFSLNSNLVLHQRIHTGEKPHECNECGKAFSHSSNLILHQRIHSGEKPYECNECGKAFSQSSDLTKHQRIHTGEKPYECSECGKAFNRNSYLILHRRIHTREKPYKCTKCGKAFTRSSTLTLHHRIHARERASEYSPASLDAFGAFLKSCV>sp|Q6NUN9|ZN746_HUMAN Zinc finger protein 746 OS=Homo sapiens OX=9606GN=ZNF746 PE=1 SV=1MAEAVAAPISPWTMAATIQAMERKIESQAARLLSLEGRTGMAEKKLADCEKTAVEFGNQLEGKWAVLGTLLQEYGLLQRRLENVENLLRNRNFWILRLPPGSKGESPKEWGKLEDWQKELYKHVMRGNYETLVSLDYAISKPEVLSQIEQGKEPCNWRRPGPKIPDVPVDPSPGSGPPVPAPDLLMQIKQEGELQLQEQQALGVEAWAAGQPDIGEEPWGLSQLDSGAGDISTDATSGVHSNFSTTIPPTSWQTDLPPHHPSSACSDGTLKLNTAASTEDVKIVIKTEVQEEEVVATPVHPTDLEAHGTLFGPGQATRFFPSPAQEGAWESQGSSFPSQDPVLGLREPARPERDMGELSPAVAQEETPPGDWLFGGVRWGWNFRCKPPVGLNPRTGPEGLPYSSPDNGEAILDPSQAPRPFNEPCKYPGRTKGFGHKPGLKKHPAAPPGGRPFTCATCGKSFQLQVSLSAHQRSCGAPDGSGPGTGGGGSGSGGGGGGSGGGSARDGSALRCGECGRCFTRPAHLIRHRMLHTGERPFPCTECEKRFTERSKLIDHYRTHTGVRPFTCTVCGKSFIRKDHLRKHQRNHAAGAKTPARGQPLPTPPAPPDPFKSPASKGPLASTDLVTDWTCGLSVLGPTDGGDM>sp|Q6NUN9-2|ZN746_HUMAN Isoform 2 of Zinc finger protein 746 OS=Homosapiens OX=9606 GN=ZNF746MAEAVAAPISPWTMAATIQAMERKIESQAARLLSLEGRTGMAEKKLADCEKTAVEFGNQLEGKWAVLGTLLQEYGLLQRRLENVENLLRNRNFWILRLPPGSKGESPKEWGKLEDWQKELYKHVMRGNYETLVSLDYAISKPEVLSQIEQGKEPCNWRRPGPKIPDVPVDPSPGSGPPVPAPDLLMQIKQEGELQLQEQQALGVEAWAAGQPDIGEEPWGLSQLDSGAGDISTDATSGVHSNFSTTIPPTSWQTDLPPHHPSSACSDGTLKLNTAASTEADVKIVIKTEVQEEEVVATPVHPTDLEAHGTLFGPGQATRFFPSPAQEGAWESQGSSFPSQDPVLGLREPARPERDMGELSPAVAQEETPPGDWLFGGVRWGWNFRCKPPVGLNPRTGPEGLPYSSPDNGEAILDPSQAPRPFNEPCKYPGRTKGFGHKPGLKKHPAAPPGGRPFTCATCGKSFQLQVSLSAHQRSCGAPDGSGPGTGGGGSGSGGGGGGSGGGSARDGSALRCGECGRCFTRPAHLIRHRMLHTGERPFPCTECEKRFTERSKLIDHYRTHTGVRPFTCTVCGKSFIRKDHLRKHQRNHAAGAKTPARGQPLPTPPAPPDPFKSPASKGPLASTDLVTDWTCGLSVLGPTDGGDM>sp|Q6NUN9-3|ZN746_HUMAN Isoform 3 of Zinc finger protein 746 OS=Homosapiens OX=9606 GN=ZNF746MQIKQEGELQLQEQQALGVEAWAAGQPDIGEEPWGLSQLDSGAGDISTDATSGVHSNFSTTIPPTSWQTDLPPHHPSSACSDGTLKLNTAASTEDVKIVIKTEVQEEEVVATPVHPTDLEAHGTLFGPGQATRFFPSPAQEGAWESQGSSFPSQDPVLGLREPARPERDMGELSPAVAQEETPPGDWLFGGVRWGWNFRCKPPVGLNPRTGPEGLPYSSPDNGEAILDPSQAPRPFNEPCKYPGRTKGFGHKPGLKKHPAAPPGGRPFTCATCGKSFQLQVSLSAHQRSCGAPDGSGPGTGGGGSGSGGGGGGSGGGSARDGSALRCGECGRCFTRPAHLIRHRMLHTGERPFPCTECEKRFTERSKLIDHYRTHTGVRPFTCTVCGKSFIRKDHLRKHQRNHAAGAKTPARGQPLPTPPAPPDPFKSPASKGPLASTDLVTDWTCGLSVLGPTDGGDM>sp|P36508|ZNF76_HUMAN Zinc finger protein 76 OS=Homo sapiens OX=9606GN=ZNF76 PE=1 SV=2MESLGLHTVTLSDGTTAYVQQAVKGEKLLEGQVIQLEDGTTAYIHQVTVQKEALSFEDGQPVQLEDGSMAYIHRTPREGYDPSTLEAVQLEDGSTAYIHHPVAVPSESTILAVQTEVGLEDLAAEDDEGFSADAVVALEQYASKVLHDSQIPRNGKGQQVGDRAFRCGYKGCGRLYTTAHHLKVHERAHTGDRPYRCDFPSCGKAFATGYGLKSHVRTHTGEKPYKCPEELCSKAFKTSGDLQKHVRTHTGERPFQCPFEGCGRSFTTSNIRKVHVRTHTGERPYTCPEPHCGRGFTSATNYKNHVRIHTGEKPYVCTVPGCGKRFTEYSSLYKHHVVHTHCKPYTCSTCGKTYRQTSTLAMHKRSAHGELEATEESEQALYEQQQLEAASAAEESPPPKRPRIAYLSEVKEERDDIPAQVAMVTEEDGAPQVALITQDGAQQVSLSPEDLQALGSAISMVTQHGSTTLTIPSPDADLATSGTHTVTMVSADGTQTQPVTIITSGAVVAEDSSVASLRHQQVALLATANGTHIAVQLEEQQTLEEAINVATAAMQQGAVTLETTVSESGC>sp|P36508-2|ZNF76_HUMAN Isoform 1 of Zinc finger protein 76 OS=Homosapiens OX=9606 GN=ZNF76MESLGLHTVTLSDGTTAYVQQAVKGEKLLEGQVIQLEDGTTAYIHQVTVQKEALSFEDGQPVQLEDGSMAYIHRTPREGYDPSTLEAVQLEDGSTAYIHHPVAVPSESTILAVQTEVGLEDLAAEDDEGFSADAVVALEQYASKVLHDSQIPRNGKGQQVGDRAFRCGYKGCGRLYTTAHHLKVHERAHTGDRPYRCDFPSCGKAFATGYGLKSHVRTHTGEKPYKCPEELCSKAFKTSGDLQKHVRTHTGERPFQCPFEGCGRSFTTSNIRKVHVRTHTGERPYTCPEPHCGRGFTSATNYKNHVRIHTGEKPYVCTVPGCGKRFTEYSSLYKHHVVHTHCKPYTCSTCGKTYRQTSTLAMHKRSAHGELEATEESEQALYEQQQLEAASAAEESPPPKRPRIAYLSEVKEERDDIPAQVAMVTEEDGAPQVALITQDGAQQVTIITSGAVVAEDSSVASLRHQQVALLATANGTHIAVQLEEQQTLEEAINVATAAMQQGAVTLETTVSESGC>sp|Q14202|ZMYM3_HUMAN Zinc finger MYM-type protein 3 OS=Homo sapiensOX=9606 GN=ZMYM3 PE=1 SV=2MDPSDFPSPFDPLTLPEKPLAGDLPVDMEFGEDLLESQTAPTRGWAPPGPSPSSGALDLLDTPAGLEKDPGVLDGATELLGLGGLLYKAPSPPEVDHGPEGTLAWDAGDQTLEPGPGGQTPEVVPPDPGAGANSCSPEGLLEPLAPDSPITLQSPHIEEEETTSIATARRGSPGQEEELPQGQPQSPNAPPSPSVGETLGDGINSSQTKPGGSSPPAHPSLPGDGLTAKASEKPPERKRSERVRRAEPPKPEVVDSTESIPVSDEDSDAMVDDPNDEDFVPFRPRRSPRMSLRSSVSQRAGRSAVGTKMTCAHCRTPLQKGQTAYQRKGLPQLFCSSSCLTTFSKKPSGKKTCTFCKKEIWNTKDSVVAQTGSGGSFHEFCTSVCLSLYEAQQQRPIPQSGDPADATRCSICQKTGEVLHEVSNGSVVHRLCSDSCFSKFRANKGLKTNCCDQCGAYIYTKTGSPGPELLFHEGQQKRFCNTTCLGAYKKKNTRVYPCVWCKTLCKNFEMLSHVDRNGKTSLFCSLCCTTSYKVKQAGLTGPPRPCSFCRRSLSDPCYYNKVDRTVYQFCSPSCWTKFQRTSPEGGIHLSCHYCHSLFSGKPEVLDWQDQVFQFCCRDCCEDFKRLRGVVSQCEHCRQEKLLHEKLRFSGVEKSFCSEGCVLLYKQDFTKKLGLCCITCTYCSQTCQRGVTEQLDGSTWDFCSEDCKSKYLLWYCKAARCHACKRQGKLLETIHWRGQIRHFCNQQCLLRFYSQQNQPNLDTQSGPESLLNSQSPESKPQTPSQTKVENSNTVRTPEENGNLGKIPVKTRSAPTAPTPPPPPPPATPRKNKAAMCKPLMQNRGVSCKVEMKSKGSQTEEWKPQVIVLPIPVPIFVPVPMHLYCQKVPVPFSMPIPVPVPMFLPTTLESTDKIVETIEELKVKIPSNPLEADILAMAEMIAEAEELDKASSDLCDLVSNQSAEGLLEDCDLFGPARDDVLAMAVKMANVLDEPGQDLEADFPKNPLDINPSVDFLFDCGLVGPEDVSTEQDLPRTMRKGQKRLVLSESCSRDSMSSQPSCTGLNYSYGVNAWKCWVQSKYANGETSKGDELRFGPKPMRIKEDILACSAAELNYGLAQFVREITRPNGERYEPDSIYYLCLGIQQYLLENNRMVNIFTDLYYLTFVQELNKSLSTWQPTLLPNNTVFSRVEEEHLWECKQLGVYSPFVLLNTLMFFNTKFFGLQTAEEHMQLSFTNVVRQSRKCTTPRGTTKVVSIRYYAPVRQRKGRDTGPGKRKREDEAPILEQRENRMNPLRCPVKFYEFYLSKCPESLRTRNDVFYLQPERSCIAESPLWYSVIPMDRSMLESMLNRILAVREIYEELGRPGEEDLD>sp|Q14202-2|ZMYM3_HUMAN Isoform 2 of Zinc finger MYM-type protein 3OS=Homo sapiens OX=9606 GN=ZMYM3MDPSDFPSPFDPLTLPEKPLAGDLPVDMEFGEDLLESQTAPTRGWAPPGPSPSSGALDLLDTPAGLEKDPGVLDGATELLGLGGLLYKAPSPPEVDHGPEGTLAWDAGDQTLEPGPGGQTPEVVPPDPGAGANSCSPEGLLEPLAPDSPITLQSPHIEEEETTSIATARRGSPGQEEELPQGQPQSPNAPPSPSVGETLGDGINSSQTKPGGSSPPAHPSLPGDGLTAKASEKPPERKRSERVRRAEPPKPEVVDSTESIPVSDEDSDAMVDDPNDEDFVPFRPRRSPRMSLRSSVSQRAGRSAVGTKMTCAHCRTPLQKGQTAYQRKGLPQLFCSSSCLTTFSKKPSGKKTCTFCKKEIWNTKDSVVAQTGSGGSFHEFCTSVCLSLYEAQQQRPIPQSGDPADATRCSICQKTGEVLHEVSNGSVVHRLCSDSCFSKFRANKGLKTNCCDQCGAYIYTKTGSPGPELLFHEGQQKRFCNTTCLGAYKKKNTRVYPCVWCKTLCKNFEMLSHVDRNGKTSLFCSLCCTTSYKVKQAGLTGPPRPCSFCRRSLSDPCYYNKVDRTVYQFCSPSCWTKFQRTSPEGGIHLSCHYCHSLFSGKPEVLDWQDQVFQFCCRDCCEDFKRLRGVVSQCEHCRQEKLLHEKLRFSGVEKSFCSEGCVLLYKQDFTKKLGLCCITCTYCSQTCQRGVTEQLDGSTWDFCSEDCKSKYLLWYCKAARCHACKRQGKLLETIHWRGQIRHFCNQQCLLRFYSQQNQPNLDTQSGPESLLNSQSPESKPQTPSQTKVENSNTIPVKTRSAPTAPTPPPPPPPATPRKNKAAMCKPLMQNRGVSCKVEMKSKGSQTEEWKPQVIVLPIPVPIFVPVPMHLYCQKVPVPFSMPIPVPVPMFLPTTLESTDKIVETIEELKVKIPSNPLEADILAMAEMIAEAEELDKASSDLCDLVSNQSAEGLLEDCDLFGPARDDVLAMAVKMANVLDEPGQDLEADFPKNPLDINPSVDFLFDCGLVGPEDVSTEQDLPRTMRKGQKRLVLSESCSRDSMSSQPSCTGLNYSYGVNAWKCWVQSKYANGETSKGDELRFGPKPMRIKEDILACSAAELNYGLAQFVREITRPNGERYEPDSIYYLCLGIQQYLLENNRMVNIFTDLYYLTFVQELNKSLSTWQPTLLPNNTVFSRVEEEHLWECKQLGVYSPFVLLNTLMFFNTKFFGLQTAEEHMQLSFTNVVRQSRKCTTPRGTTKVVSIRYYAPVRQRKGRDTGPGKRKREDEAPILEQRENRMNPLRCPVKFYEFYLSKCPESLRTRNDVFYLQPERSCIAESPLWYSVIPMDRSMLESMLNRILAVREIYEELGRPGEEDLD>sp|Q14202-3|ZMYM3_HUMAN Isoform 3 of Zinc finger MYM-type protein 3OS=Homo sapiens OX=9606 GN=ZMYM3MDPSDFPSPFDPLTLPEKPLAGDLPVDMEFGEDLLESQTAPTRGWAPPGPSPSSGALDLLDTPAGLEKDPGVLDGATELLGLGGLLYKAPSPPEVDHGPEGTLAWDAGDQTLEPGPGGQTPEVVPPDPGAGANSCSPEGLLEPLAPDSPITLQSPHIEEEETTSIATARRGSPGQEEELPQGQPQSPNAPPSPSVGETLGDGINSSQTKPGGSSPPAHPSLPGDGLTAKASEKPPERKRSERVRRAEPPKPEVVDSTESIPVSDEDSDAMVDDPNDEDFVPFRPRRSPRMSLRSSVSQRAGRSAVGTKMTCAHCRTPLQKGQTAYQRKGLPQLFCSSSCLTTFSKKPSGKKTCTFCKKEIWNTKDSVVAQTGSGGSFHEFCTSVCLSLYEAQQQRPIPQSGDPADATRCSICQKTGEVLHEVSNGSVVHRLCSDSCFSKFRANKGLKTNCCDQCGAYIYTKTGSPGPELLFHEGQQKRFCNTTCLGAYKKVGPRE>sp|Q99986|VRK1_HUMAN Serine/threonine-protein kinase VRK1 OS=Homosapiens OX=9606 GN=VRK1 PE=1 SV=1MPRVKAAQAGRQSSAKRHLAEQFAVGEIITDMAKKEWKVGLPIGQGGFGCIYLADMNSSESVGSDAPCVVKVEPSDNGPLFTELKFYQRAAKPEQIQKWIRTRKLKYLGVPKYWGSGLHDKNGKSYRFMIMDRFGSDLQKIYEANAKRFSRKTVLQLSLRILDILEYIHEHEYVHGDIKASNLLLNYKNPDQVYLVDYGLAYRYCPEGVHKEYKEDPKRCHDGTIEFTSIDAHNGVAPSRRGDLEILGYCMIQWLTGHLPWEDNLKDPKYVRDSKIRYRENIASLMDKCFPEKNKPGEIAKYMETVKLLDYTEKPLYENLRDILLQGLKAIGSKDDGKLDLSVVENGGLKAKTITKKRKKEIEESKEPGVEDTEWSNTQTEEAIQTRSRTRKRVQK>sp|Q9UK13|ZN221_HUMAN Zinc finger protein 221 OS=Homo sapiens OX=9606GN=ZNF221 PE=1 SV=4MISPSLELLHSGLCKFPEVEGKMTTFKEAVTFKDVAVVFTEEELGLLDPAQRKLYRDVMLENFRNLLSVGNQPFHQDTFHFLGKEKFWKMKTTSQREGNSGGKIQIEMETVPEAGPHEEWSCQQIWEQIASDLTRSQNSIRNSSQFFKEGDVPCQIEARLSISHVQQKPYRCNECKQSFSDVSVFDLHQQSHSGEKSHTCGECGKSFCYSPALHIHQRVHMGEKCYKCDVCGKEFNQSSHLQTHQRVHTGEKPFKCGQCGKGFHSRSALNVHCKLHTGEKPYNCEECGKAFIHDSQLQEHQRIHTGEKPFKCDICGKSFRVRSRLNRHSMVHTGEKPFRCDTCGKNFRQRSALNSHSMVHIEEKPYKCEQCGKGFICRRDFCKHQMVHTGEKPYNCKECGKTFRWSSCLLNHQQVHSGQKSFKCEECGKGFYTNSRRSSHQRSHNGEKPYNCEECGKDYKRRLDLEFHQRVHTGERPYNCKECGKSFGWASCLLKHQRLHSGEKPFKCEECGKRFTQSSQLHSHQTCHTGEKLYKCEQCEKGYNSKFNLDMHQRVHGGERPYNCKECGKSFGWASCLLKHQRLHSGEKPLKSGVWEEIYSEFTASFTSVSLCGRKAI>sp|Q9Y6R6|Z780B_HUMAN Zinc finger protein 780B OS=Homo sapiens OX=9606GN=ZNF780B PE=2 SV=1MVHGSVTFRDVAIDFSQEEWECLQPDQRTLYRDVMLENYSHLISLGSSISKPDVITLLEQEKEPWIVVSKETSRWYPDLESKYGPEKISPENDIFEINLPKHVIKQISKTLGLEAFYFRNDSEYRSRFEGRQGHQEGYINQKIISYEEMPAYTHASPIHNTHKPYECKECGKYFSCGSNLIQHQSIHTGEKPYKCKECGKAFQLHIQLTRHQKFHTGEKTFECKECGKAFNLPTQLNRHKNIHTVKKLFECKECGKSFNRSSNLTQHQSIHAGVKPYQCKECGKAFNRGSNLIQHQKIHSNEKPFVCRECEMAFRYHYQLIEHCRIHTGEKPFECKECRKAFTLLTKLVRHQKIHMGEKPFECRECGKAFSLLNQLNRHKNIHTGEKPFECKECGKSFNRSSNLIQHQSIHADVKPYECKECGKGFNRGANLIQHQKIHSNEKPFVCRECEMAFRYHYQLIQHCQIHTGGKPFECKECGKAFSLLTQLARHKNIHTGEKPFECKDCGKAFNRGSNLVQHQSIHTGEKPYECKECGKAFRLHLQLSQHEKTHTGEKPFECKECGKFFRRGSNLNQHRSIHTGKKPFECKECGKAFRLHMHLIRHQKFHTGEKPFECKECGKAFSLHTQLNHHKNIHTGEKPFKCKECGKSFNRVSNLVQHQSIHAGVKPYECKECGKGFSRVSNLIQHQKTHSSAKPFVCKECRKTFRYHYQLTEHYRIHTGEKPFECKECGKAFGLLTQLAQHQIIHTGEKPFKCKECGKAFNRGSNLVQPQSIHTGEKPYECKECGKAFRLHLQLSLHQKLVQVRNPLNVRNVGQPSDISSNLLNIRKFILG>sp|Q96NS1|YPEL4_HUMAN Protein yippee-like 4 OS=Homo sapiens OX=9606GN=YPEL4 PE=2 SV=1MPSCDPGPGPACLPTKTFRSYLPRCHRTYSCVHCRAHLAKHDELISKSFQGSHGRAYLFNSVVNVGCGPAEQRLLLTGLHSVADIFCESCKTTLGWKYEQAFETSQKYKEGKYIIEMSHMVKDNGWD>sp|Q9NU63|ZFP57_HUMAN Zinc finger protein 57 homolog OS=Homo sapiensOX=9606 GN=ZFP57 PE=1 SV=2MAAGEPRSLLFFQKPVTFEDVAVNFTQEEWDCLDASQRVLYQDVMSETFKNLTSVARIFLHKPELITKLEQEEEQWRETRVLQASQAGPPFFCYTCGKCFSRRSYLYSHQFVHNPKLTNSCSQCGKLFRSPKSLSYHRRMHLGERPFCCTLCDKTYCDASGLSRHRRVHLGYRPHSCSVCGKSFRDQSELKRHQKIHQNQEPVDGNQECTLRIPGTQAEFQTPIARSQRSIQGLLDVNHAPVARSQEPIFRTEGPMAQNQASVLKNQAPVTRTQAPITGTLCQDARSNSHPVKPSRLNVFCCPHCSLTFSKKSYLSRHQKAHLTEPPNYCFHCSKSFSSFSRLVRHQQTHWKQKSYLCPICDLSFGEKEGLMDHWRGYKGKDLCQSSHHKCRVILGQWLGFSHDVPTMAGEEWKHGGDQSPPRIHTPRRRGLREKACKGDKTKEAVSILKHK>sp|Q9NU63-2|ZFP57_HUMAN Isoform 2 of Zinc finger protein 57 homologOS=Homo sapiens OX=9606 GN=ZFP57MFEQLKPIEPRDCWREARVKKKPVTFEDVAVNFTQEEWDCLDASQRVLYQDVMSETFKNLTSVARIFLHKPELITKLEQEEEQWREFVHLPNTEGLSEGKKKELREQHPSLRDEGTSDDKVFLACRGAGQCPLSAPAGTMDRTRVLQASQAGPPFFCYTCGKCFSRRSYLYSHQFVHNPKLTNSCSQCGKLFRSPKSLSYHRRMHLGERPFCCTLCDKTYCDASGLSRHRRVHLGYRPHSCSVCGKSFRDQSELKRHQKIHQNQEPVDGNQECTLRIPGTQAEFQTPIARSQRSIQGLLDVNHAPVARSQEPIFRTEGPMAQNQASVLKNQAPVTRTQAPITGTLCQDARSNSHPVKPSRLNVFCCPHCSLTFSKKSYLSRHQKAHLTEPPNYCFHCSKSFSSFSRLVRHQQTHWKQKSYLCPICDLSFGEKEGLMDHWRGYKGKDLCQSSHHKCRVILGQWLGFSHDVPTMAGEEWKHGGDQSPPRIHTPRRRGLREKACKGDKTKEAVSILKHK>sp|Q9NU63-3|ZFP57_HUMAN Isoform 3 of Zinc finger protein 57 homologOS=Homo sapiens OX=9606 GN=ZFP57MFEQLKPIEPVQKTLPWVGEVAATLQEAMKRDCWREARVKKKPVTFEDVAVNFTQEEWDCLDASQRVLYQDVMSETFKNLTSVARIFLHKPELITKLEQEEEQWREFVHLPNTEGLSEGKKKELREQHPSLRDEGTSDDKVFLACRGAGQCPLSAPAGTMDRTRVLQASQAGPPFFCYTCGKCFSRRSYLYSHQFVHNPKLTNSCSQCGKLFRSPKSLSYHRRMHLGERPFCCTLCDKTYCDASGLSRHRRVHLGYRPHSCSVCGKSFRDQSELKRHQKIHQNQEPVDGNQECTLRIPGTQAEFQTPIARSQRSIQGLLDVNHAPVARSQEPIFRTEGPMAQNQASVLKNQAPVTRTQAPITGTLCQDARSNSHPVKPSRLNVFCCPHCSLTFSKKSYLSRHQKAHLTEPPNYCFHCSKSFSSFSRLVRHQQTHWKQKSYLCPICDLSFGEKEGLMDHWRGYKGKDLCQSSHHKCRVILGQWLGFSHDVPTMAGEEWKHGGDQSPPRIHTPRRRGLREKACKGDKTKEAVSILKHK>sp|Q6ZN79|Z705A_HUMAN Zinc finger protein 705A OS=Homo sapiens OX=9606GN=ZNF705A PE=2 SV=1MHSLKKVTFEDVAIDFTQEEWAMMDTSKRKLYRDVMLENISHLVSLGYQISKSYIILQLEQGKELWREGREFLQDQNPDRESALKKKHMISMHPITRKDASTSMTMENSLILEDPFECNDSGEDCTHSSTITQRLLTHSGKKPYVSKQCGKSLRNLFSPKPHKQIHTKGKSYQCNLCEKAYTNCFRLRRHKMTHTGERPYACHLCGKAFTQCSHLRRHEKTHTGERPYKCHQCGKAFIQSFNLRRHERTHLGKKCYECDKSGKAFSQSSGFRGNKIIHTGEKPHACLLCGKAFSLSSDLR>sp|O94892|ZN432_HUMAN Zinc finger protein 432 OS=Homo sapiens OX=9606GN=ZNF432 PE=1 SV=1MINAQELLTLEDVTVEFTWEEWQLLGPFQKDLYRDVMLEIYSNLLSMGYQVSKPDALSKLERGEEPWTMEDERHSRICPENNEVDDHLQDHLENQRMLKSVEQYHEHNAFGNTASQTKSLCLFRENHDTFELYIKTLKSNLSLVNQNKSCEINNSTKFSGDGKSFLHGNYEELYSAAKFSVSTKANSTKSQVSKHQRTHEIEKNHVCSECGKAFVKKSQLTDHERVHTGEKPYGCTLCAKVFSRKSRLNEHQRIHKREKSFICSECGKVFTMKSRLIEHQRTHTGEKPYICNECGKGFPGKRNLIVHQRNHTGEKSYICSECGKGFTGKSMLIIHQRTHTGEKPYICSECGKGFTTKHYVIIHQRNHTGEKPYICNECGKGFTMKSRMIEHQRTHTGEKPYICSECGKGFPRKSNLIVHQRNHTVEKSYLCSECGKGFTVKSMLIIHQRTHTGEKPYTCSECGKGFPLKSRLIVHQRTHTGEKPYRCSECGKGFIVNSGLMLHQRTHTGEKPYICNECGKGFAFKSNLVVHQRTHTGEKPFMCSECGKGFTMKRYLIVHQQIHTEEKSCICSECGRGFAKETELALHKQVHTGEKPYGCNECGKGFTMKSRLIVHQRTHTGEKPFVCSECRKAFSSKRNLIVHQRTHNGNKP>sp|Q9Y5V0|ZN706_HUMAN Zinc finger protein 706 OS=Homo sapiens OX=9606GN=ZNF706 PE=1 SV=1MARGQQKIQSQQKNAKKQAGQKKKQGHDQKAAAKAALIYTCTVCRTQMPDPKTFKQHFESKHPKTPLPPELADVQA>sp|O43379|WDR62_HUMAN WD repeat-containing protein 62 OS=Homo sapiensOX=9606 GN=WDR62 PE=1 SV=4MAAVGSGGYARNDAGEKLPSVMAGVPARRGQSSPPPAPPICLRRRTRLSTASEETVQNRVSLEKVLGITAQNSSGLTCDPGTGHVAYLAGCVVVILDPKENKQQHIFNTARKSLSALAFSPDGKYIVTGENGHRPAVRIWDVEEKNQVAEMLGHKYGVACVAFSPNMKHIVSMGYQHDMVLNVWDWKKDIVVASNKVSCRVIALSFSEDSSYFVTVGNRHVRFWFLEVSTETKVTSTVPLVGRSGILGELHNNIFCGVACGRGRMAGSTFCVSYSGLLCQFNEKRVLEKWINLKVSLSSCLCVSQELIFCGCTDGIVRIFQAHSLHYLANLPKPHYLGVDVAQGLEPSFLFHRKAEAVYPDTVALTFDPIHQWLSCVYKDHSIYIWDVKDINRVGKVWSELFHSSYVWNVEVYPEFEDQRACLPSGSFLTCSSDNTIRFWNLDSSPDSHWQKNIFSNTLLKVVYVENDIQHLQDMSHFPDRGSENGTPMDVKAGVRVMQVSPDGQHLASGDRSGNLRIHELHFMDELVKVEAHDAEVLCLEYSKPETGLTLLASASRDRLIHVLNVEKNYNLEQTLDDHSSSITAIKFAGNRDIQMISCGADKSIYFRSAQQGSDGLHFVRTHHVAEKTTLYDMDIDITQKYVAVACQDRNVRVYNTVNGKQKKCYKGSQGDEGSLLKVHVDPSGTFLATSCSDKSISVIDFYSGECIAKMFGHSEIITSMKFTYDCHHLITVSGDSCVFIWHLGPEITNCMKQHLLEIDHRQQQQHTNDKKRSGHPRQDTYVSTPSEIHSLSPGEQTEDDLEEECEPEEMLKTPSKDSLDPDPRCLLTNGKLPLWAKRLLGDDDVADGLAFHAKRSYQPHGRWAERAGQEPLKTILDAQDLDCYFTPMKPESLENSILDSLEPQSLASLLSESESPQEAGRGHPSFLPQQKESSEASELILYSLEAEVTVTGTDSQYCRKEVEAGPGDQQGDSYLRVSSDSPKDQSPPEDSGESEADLECSFAAIHSPAPPPDPAPRFATSLPHFPGCAGPTEDELSLPEGPSVPSSSLPQTPEQEKFLRHHFETLTESPCRALGDVEASEAEDHFFNPRLSISTQFLSSLQKASRFTHTFPPRATQCLVKSPEVKLMDRGGSQPRAGTGYASPDRTHVLAAGKAEETLEAWRPPPPCLTSLASCVPASSVLPTDRNLPTPTSAPTPGLAQGVHAPSTCSYMEATASSRARISRSISLGDSEGPIVATLAQPLRRPSSVGELASLGQELQAITTATTPSLDSEGQEPALRSWGNHEARANLRLTLSSACDGLLQPPVDTQPGVTVPAVSFPAPSPVEESALRLHGSAFRPSLPAPESPGLPAHPSNPQLPEARPGIPGGTASLLEPTSGALGLLQGSPARWSEPWVPVEALPPSPLELSRVGNILHRLQTTFQEALDLYRVLVSSGQVDTGQQQARTELVSTFLWIHSQLEAECLVGTSVAPAQALPSPGPPSPPTLYPLASPDLQALLEHYSELLVQAVRRKARGH>sp|O43379-2|WDR62_HUMAN Isoform 2 of WD repeat-containing protein 62OS=Homo sapiens OX=9606 GN=WDR62MAAVGSGGYARNDAGEKLPSVMAGVPARRGQSSPPPAPPICLRRRTRLSTASEETVQNRVSLEKVLGITAQNSSGLTCDPGTGHVAYLAGCVVVILDPKENKQQHIFNTARKSLSALAFSPDGKYIVTGENGHRPAVRIWDVEEKNQVAEMLGHKYGVACVAFSPNMKHIVSMGYQHDMVLNVWDWKKDIVVASNKVSCRVIALSFSEDSSYFVTVGNRHVRFWFLEVSTETKVTSTVPLVGRSGILGELHNNIFCGVACGRGRMAGSTFCVSYSGLLCQFNEKRVLEKWINLKVSLSSCLCVSQELIFCGCTDGIVRIFQAHSLHYLANLPKPHYLGVDVAQGLEPSFLFHRKAEAVYPDTVALTFDPIHQWLSCVYKDHSIYIWDVKDINRVGKVWSELFHSSYVWNVEVYPEFEDQRACLPSGSFLTCSSDNTIRFWNLDSSPDSHWQKNIFSNLAPALQMCGRGHSRQPNTPSPGEIAS>sp|O43379-3|WDR62_HUMAN Isoform 3 of WD repeat-containing protein 62OS=Homo sapiens OX=9606 GN=WDR62MAAVGSGGYARNDAGEKLPSVMAGVPARRGQSSPPPAPPICLRRRTRLSTASEETVQNRVSLEKVLGITAQNSSGLTCDPGTGHVAYLAGCVVVILDPKENKQQHIFNTARKSLSALAFSPDGKYIVTGENGHRPAVRIWDVEEKNQVAEMLGHKYGVACVAFSPNMKHIVSMGYQHDMVLNVWDWKKDIVVASNKVSCRVIALSFSEDSSYFVTVGNRHVRFWFLEVSTETKVTSTVPLVGRSGILGELHNNIFCGVACGRGRMAGSTFCVSYSGLLCQFNEKRVLEKWINLKVSLSSCLCVSQELIFCGCTDGIVRIFQAHSLHYLANLPKPHYLGVDVAQGLEPSFLFHRKAEAVYPDTVALTFDPIHQWLSCVYKDHSIYIWDVKDINRVGKVWSELFHSSYVWNVEALS>sp|O43379-4|WDR62_HUMAN Isoform 4 of WD repeat-containing protein 62OS=Homo sapiens OX=9606 GN=WDR62MAAVGSGGYARNDAGEKLPSVMAGVPARRGQSSPPPAPPICLRRRTRLSTASEETVQNRVSLEKVLGITAQNSSGLTCDPGTGHVAYLAGCVVVILDPKENKQQHIFNTARKSLSALAFSPDGKYIVTGENGHRPAVRIWDVEEKNQVAEMLGHKYGVACVAFSPNMKHIVSMGYQHDMVLNVWDWKKDIVVASNKVSCRVIALSFSEDSSYFVTVGNRHVRFWFLEVSTETKVTSTVPLVGRSGILGELHNNIFCGVACGRGRMAGSTFCVSYSGLLCQFNEKRVLEKWINLKVSLSSCLCVSQELIFCGCTDGIVRIFQAHSLHYLANLPKPHYLGVDVAQGLEPSFLFHRKAEAVYPDTVALTFDPIHQWLSCVYKDHSIYIWDVKDINRVGKVWSELFHSSYVWNVEVYPEFEDQRACLPSGSFLTCSSDNTIRFWNLDSSPDSHWQKNIFSNTLLKVVYVENDIQHLQDMSHFPDRGSENGTPMDVKAGVRVMQVSPDGQHLASGDRSGNLRIHELHFMDELVKVEAHDAEVLCLEYSKPETGLTLLASASRDRLIHVLNVEKNYNLEQTLDDHSSSITAIKFAGNRDIQMISCGADKSIYFRSAQQGSDGLHFVRTHHVAEKTTLYDMDIDITQKYVAVACQDRNVRVYNTVNGKQKKCYKGSQGDEGSLLKVHVDPSGTFLATSCSDKSISVIDFYSGECIAKMFGHSEIITSMKFTYDCHHLITVSGDSCVFIWHLGPEITNCMKQHLLEIDHRQQQQHTNDKKRSGHPRQDTYVSTPSEIHSLSPGEQTEDDLEEECEPEEMLKTPSKDSLDPDPRCLLTNGKLPLWAKRLLGDDDVADGLAFHAKRSYQPHGRWAERAGQEPLKTILDAQDLDCYFTPMKPESLENSILDSLEPQSLASLLSESESPQEAGRGHPSFLPQQKESSEASELILYSLEAEVTVTGTDSQYCRKEVEAGPGDQQGDSYLRVSSDSPKDQSPPEDSGESEADLECSFAAIHSPAPPPDPAPRFATSLPHFPGCAGPTEDELSLPEGPSVPSSSLPQTPEQEKFLRHHFETLTESPCRELFPAALGDVEASEAEDHFFNPRLSISTQFLSSLQKASRFTHTFPPRATQCLVKSPEVKLMDRGGSQPRAGTGYASPDRTHVLAAGKAEETLEAWRPPPPCLTSLASCVPASSVLPTDRNLPTPTSAPTPGLAQGVHAPSTCSYMEATASSRARISRSISLGDSEGPIVATLAQPLRRPSSVGELASLGQELQAITTATTPSLDSEGQEPALRSWGNHEARANLRLTLSSACDGLLQPPVDTQPGVTVPAVSFPAPSPVEESALRLHGSAFRPSLPAPESPGLPAHPSNPQLPEARPGIPGGTASLLEPTSGALGLLQGSPARWSEPWVPVEALPPSPLELSRVGNILHRLQTTFQEALDLYRVLVSSGQVDTGQQQARTELVSTFLWIHSQLEAECLVGTSVAPAQALPSPGPPSPPTLYPLASPDLQALLEHYSELLVQAVRRKARGH>sp|Q5VSD8|YI029_HUMAN Putative uncharacterized protein LOC401522 OS=Homosapiens OX=9606 PE=4 SV=2MKLAKTAVLDPATYTSFSPGLSTCSSSQPPGDRRKGLLGCVGSGHCPLPTPAQFPKVQRPPTLLGGKNTSTQTTLHPVI>sp|Q96NJ1|YI001_HUMAN Uncharacterized protein FLJ30774 OS=Homo sapiensOX=9606 PE=2 SV=1MRRERPELRDAEGRLRLRAGCLVTAWPRAPSGAGSWSMAAASPWPASWGFPDASSTVPSLCTEARAGRGGPATARSRVSADSQGGRAGSSSPSSALRLCCAGPSQAHPGPSPAVLPGRCGLLGSFPRPPAPQGRWGPSLG>sp|A6NLC8|YE016_HUMAN Putative TAF11-like protein ENSP00000332601OS=Homo sapiens OX=9606 PE=3 SV=2METGRQTGVSAEMFAMPRDLKGSKKDGIPEDLDGNLEEPRDQEGELRSEDVMDLTEGDNEASASAPPAAKRRKTDTKGKKERKPTVDAEEAQRMTTLLSAMSEEQLSRYEVCRRSAFPKACIAGLMRSITGRSVSENVAIAMAGIAKVFVGEVVEEALDVCEMWGEMPPLQPKHLREAVRRLKPKGLFPNSNYKKIMF>sp|Q6UXR6|YI004_HUMAN Putative uncharacterized protein UNQ6494/PRO21346OS=Homo sapiens OX=9606 GN=UNQ6494/PRO21346 PE=5 SV=1MQCWQQPFLRFLQQPFFLATASLAGSSSSFNVLIPKRDEDGDGEGPGDVTAGVSRAAGSPSGWEAPWVQQPRCCRRATPVCCAGQGPPRSLQQGGSEVLLGQLCSPEPDWLPSSGPKVAKQVFQVAAELLQHPEHFVPSSVPEGCVHKPGSTCDGSLKGRAYPSCVPKRDPEHSREESHPLSG>sp|A4D1N5|YG018_HUMAN Putative uncharacterized protein FLJ40288 OS=Homosapiens OX=9606 PE=2 SV=1MSSRRSSLSPWKCPWFVYCFERPISREAGPVVHQSPTVLYLHSELAARQTQGRLLPREPAAEDLRLSLPGGHAALGLFKLQGKDSYPHPPTVLLGEDLSSSGWNSWVFGILNISRDEEAIGILTTILQLRETESSAVKWTHTKHSRELGP>sp|A8MPS7|YDJC_HUMAN Carbohydrate deacetylase OS=Homo sapiens OX=9606GN=YDJC PE=1 SV=1MSRPRMRLVVTADDFGYCPRRDEGIVEAFLAGAVTSVSLLVNGAATESAAELARRHSIPTGLHANLSEGRPVGPARRGASSLLGPEGFFLGKMGFREAVAAGDVDLPQVREELEAQLSCFRELLGRAPTHADGHQHVHVLPGVCQVFAEALQAYGVRFTRLPLERGVGGCTWLEAPARAFACAVERDARAAVGPFSRHGLRWTDAFVGLSTCGRHMSAHRVSGALARVLEGTLAGHTLTAELMAHPGYPSVPPTGGCGEGPDAFSCSWERLHELRVLTAPTLRAQLAQDGVQLCALDDLDSKRPGEEVPCEPTLEPFLEPSLL>sp|A8MPS7-2|YDJC_HUMAN Isoform 2 of Carbohydrate deacetylase OS=Homosapiens OX=9606 GN=YDJCMSRPRMRLVVTADDFGYCPRRDEGIVEAFLAGAVTSVSLLVNGAATESAAELARRHSIPTGLHANLSEGRPVGPARRGASSLLGPEGFFLGKMGFREAVAAGDVDLPQVREELEAQLSCFRELLGRAPTHADGHQHVHVLPGGQTPSWA>sp|A8MPS7-3|YDJC_HUMAN Isoform 3 of Carbohydrate deacetylase OS=Homosapiens OX=9606 GN=YDJCMSRPRMRLVVTADDFGYCPRRDEGIVEAFLAGAVTSVSLLVNGAATESAAELARRHSIPTGLHANLSEGRPVGPARRGASSLLGPEGFFLGKMGFREAVAAGDVDLPQVRSRSYRRMLARTPRAPPGGCGRSSRPN>sp|Q9UK12|ZN222_HUMAN Zinc finger protein 222 OS=Homo sapiens OX=9606GN=ZNF222 PE=2 SV=2MAKLYEAVTFKDVAVIFTEEELGLLDPAQRKLYRDVMLENFRNLLSVGGKIQTEMETVPEAGTHEEFSCKQIWEQIASDLTRSQDTTISNSQLFEQDDNPSQIKARLSTVHTREKPFQGENCKQFFSDVSFFDLPQQLYSGEKSHTCDECGKSFCYISALHIHQRVHMGVKCYKCDVCGKEFSQSSRLQTHQRVHTGEKPFKCEQCGKGFRCRSALKVHCKLHMREKPYNCEKCGKAFMHNFQLQKHHRIHTGEKPFKCEICGKSFCLRSSLNRHCMVHTAEKLYKSEKYGRGFIDRLDLHKHQMIHMGQKPYNCKECGKSFKWSSYLLVHQRVHTGEKPYKCEECGKGYISKSGLDFHHRTHTGERSYNCDNCGKSFRHASSILNHKKLHCQRKPLKCEDCGKRLVCRSYCKDQQRDHSGENPSKCEDCGKRYKRRLNLDIILSLFLNDI>sp|Q9UK12-2|ZN222_HUMAN Isoform 2 of Zinc finger protein 222 OS=Homosapiens OX=9606 GN=ZNF222MIDSGEKKPGRRAEEAVTFKDVAVIFTEEELGLLDPAQRKLYRDVMLENFRNLLSVGHQPFHGDTFHFLREEKFWVMGTTSQREGNLGGKIQTEMETVPEAGTHEEFSCKQIWEQIASDLTRSQDTTISNSQLFEQDDNPSQIKARLSTVHTREKPFQGENCKQFFSDVSFFDLPQQLYSGEKSHTCDECGKSFCYISALHIHQRVHMGVKCYKCDVCGKEFSQSSRLQTHQRVHTGEKPFKCEQCGKGFRCRSALKVHCKLHMREKPYNCEKCGKAFMHNFQLQKHHRIHTGEKPFKCEICGKSFCLRSSLNRHCMVHTAEKLYKSEKYGRGFIDRLDLHKHQMIHMGQKPYNCKECGKSFKWSSYLLVHQRVHTGEKPYKCEECGKGYISKSGLDFHHRTHTGERSYNCDNCGKSFRHASSILNHKKLHCQRKPLKCEDCGKRLVCRSYCKDQQRDHSGENPSKCEDCGKRYKRRLNLDIILSLFLNDI>sp|Q14587|ZN268_HUMAN Zinc finger protein 268 OS=Homo sapiens OX=9606GN=ZNF268 PE=1 SV=2MATRVRTASIWVPPLQERNSSWDRIRKLQGQESILGQGTPGLQPLPGTPRQKQKSRRIEKVLEWLFISQEQPKITKSWGPLSFMDVFVDFTWEEWQLLDPAQKCLYRSVMLENYSNLVSLGYQHTKPDIIFKLEQGEELCMVQAQVPNQTCPNTVWKIDDLMDWHQENKDKLGSTAKSFECTTFGKLCLLSTKYLSRQKPHKCGTHGKSLKYIDFTSDYARNNPNGFQVHGKSFFHSKHEQTVIGIKYCESIESGKTVNKKSQLMCQQMYMGEKPFGCSCCEKAFSSKSYLLVHQQTHAEEKPYGCNECGKDFSSKSYLIVHQRIHTGEKLHECSECRKTFSFHSQLVIHQRIHTGENPYECCECGKVFSRKDQLVSHQKTHSGQKPYVCNECGKAFGLKSQLIIHERIHTGEKPYECNECQKAFNTKSNLMVHQRTHTGEKPYVCSDCGKAFTFKSQLIVHQGIHTGVKPYGCIQCGKGFSLKSQLIVHQRSHTGMKPYVCNECGKAFRSKSYLIIHTRTHTGEKLHECNNCGKAFSFKSQLIIHQRIHTGENPYECHECGKAFSRKYQLISHQRTHAGEKPYECTDCGKAFGLKSQLIIHQRTHTGEKPFECSECQKAFNTKSNLIVHQRTHTGEKPYSCNECGKAFTFKSQLIVHKGVHTGVKPYGCSQCAKTFSLKSQLIVHQRSHTGVKPYGCSECGKAFRSKSYLIIHMRTHTGEKPHECRECGKSFSFNSQLIVHQRIHTGENPYECSECGKAFNRKDQLISHQRTHAGEKPYGCSECGKAFSSKSYLIIHMRTHSGEKPYECNECGKAFIWKSLLIVHERTHAGVNPYKCSQCEKSFSGKLRLLVHQRMHTREKPYECSECGKAFIRNSQLIVHQRTHSGEKPYGCNECGKTFSQKSILSAHQRTHTGEKPCKCTECGKAFCWKSQLIMHQRTHVDDKH>sp|Q14587-2|ZN268_HUMAN Isoform 2 of Zinc finger protein 268 OS=Homosapiens OX=9606 GN=ZNF268MDWHQENKDKLGSTAKSFECTTFGKLCLLSTKYLSRQKPHKCGTHGKSLKYIDFTSDYARNNPNGFQVHGKSFFHSKHEQTVIGIKYCESIESGKTVNKKSQLMCQQMYMGEKPFGCSCCEKAFSSKSYLLVHQQTHAEEKPYGCNECGKDFSSKSYLIVHQRIHTGEKLHECSECRKTFSFHSQLVIHQRIHTGENPYECCECGKVFSRKDQLVSHQKTHSGQKPYVCNECGKAFGLKSQLIIHERIHTGEKPYECNECQKAFNTKSNLMVHQRTHTGEKPYVCSDCGKAFTFKSQLIVHQGIHTGVKPYGCIQCGKGFSLKSQLIVHQRSHTGMKPYVCNECGKAFRSKSYLIIHTRTHTGEKLHECNNCGKAFSFKSQLIIHQRIHTGENPYECHECGKAFSRKYQLISHQRTHAGEKPYECTDCGKAFGLKSQLIIHQRTHTGEKPFECSECQKAFNTKSNLIVHQRTHTGEKPYSCNECGKAFTFKSQLIVHKGVHTGVKPYGCSQCAKTFSLKSQLIVHQRSHTGVKPYGCSECGKAFRSKSYLIIHMRTHTGEKPHECRECGKSFSFNSQLIVHQRIHTGENPYECSECGKAFNRKDQLISHQRTHAGEKPYGCSECGKAFSSKSYLIIHMRTHSGEKPYECNECGKAFIWKSLLIVHERTHAGVNPYKCSQCEKSFSGKLRLLVHQRMHTREKPYECSECGKAFIRNSQLIVHQRTHSGEKPYGCNECGKTFSQKSILSAHQRTHTGEKPCKCTECGKAFCWKSQLIMHQRTHVDDKH>sp|Q14587-3|ZN268_HUMAN Isoform 3 of Zinc finger protein 268 OS=Homosapiens OX=9606 GN=ZNF268MVQAQVPNQTCPNTVWKIDDLMDWHQENKDKLGSTAKSFECTTFGKLCLLSTKYLSRQKPHKCGTHGKSLKYIDFTSDYAR>sp|Q14587-4|ZN268_HUMAN Isoform 4 of Zinc finger protein 268 OS=Homosapiens OX=9606 GN=ZNF268MATRVRTASIWGTNTPNLISSSSWNKEKSCVWCRPKFQIRPVQTQSGKLMILWIGIRKIKTSWEVWQKALNALHLENYVFLVQSIFQDKNLINVARMERV>sp|Q14587-6|ZN268_HUMAN Isoform 5 of Zinc finger protein 268 OS=Homosapiens OX=9606 GN=ZNF268MATRVRTASIWVPPLQERNSSWDRIRKLQGQESILGQGTPGLQPLPGTPRQKQKSRRIEKVLEWLFISQEQPKITKSWTQSGKLMILWIGIRKIKTSWEVRQKALNALHLENYVFLVQSIFQDKNLINVARMERV>sp|Q14587-7|ZN268_HUMAN Isoform 6 of Zinc finger protein 268 OS=Homosapiens OX=9606 GN=ZNF268MATRVRTASIWGTNTPNLISSSSWNKEKSCVWCRPKFQIRPVQF>sp|Q14587-8|ZN268_HUMAN Isoform 7 of Zinc finger protein 268 OS=Homosapiens OX=9606 GN=ZNF268MATRVRTASIWGPLSFMDVFVDFTWEEWQLLDPAQKCLYRSVMLENYSNLVSLGYQHTKPDIIFKLEQGEELCMVQAQVPNQTCPILKAGKSKAKVLAGLVSGEGPLCASKMTPCC>sp|Q96MU7|YTDC1_HUMAN YTH domain-containing protein 1 OS=Homo sapiensOX=9606 GN=YTHDC1 PE=1 SV=3MAADSREEKDGELNVLDDILTEVPEQDDELYNPESEQDKNEKKGSKRKSDRMESTDTKRQKPSVHSRQLVSKPLSSSVSNNKRIVSTKGKSATEYKNEEYQRSERNKRLDADRKIRLSSSASREPYKNQPEKTCVRKRDPERRAKSPTPDGSERIGLEVDRRASRSSQSSKEEVNSEEYGSDHETGSSGSSDEQGNNTENEEEGVEEDVEEDEEVEEDAEEDEEVDEDGEEEEEEEEEEEEEEEEEEEEYEQDERDQKEEGNDYDTRSEASDSGSESVSFTDGSVRSGSGTDGSDEKKKERKRARGISPIVFDRSGSSASESYAGSEKKHEKLSSSVRAVRKDQTSKLKYVLQDARFFLIKSNNHENVSLAKAKGVWSTLPVNEKKLNLAFRSARSVILIFSVRESGKFQGFARLSSESHHGGSPIHWVLPAGMSAKMLGGVFKIDWICRRELPFTKSAHLTNPWNEHKPVKIGRDGQEIELECGTQLCLLFPPDESIDLYQVIHKMRHKRRMHSQPRSRGRPSRREPVRDVGRRRPEDYDIHNSRKKPRIDYPPEFHQRPGYLKDPRYQEVDRRFSGVRRDVFLNGSYNDYVREFHNMGPPPPWQGMPPYPGMEQPPHHPYYQHHAPPPQAHPPYSGHHPVPHEARYRDKRVHDYDMRVDDFLRRTQAVVSGRRSRPRERDRERERDRPRDNRRDRERDRGRDRERERERLCDRDRDRGERGRYRR>sp|Q96MU7-2|YTDC1_HUMAN Isoform 2 of YTH domain-containing protein 1OS=Homo sapiens OX=9606 GN=YTHDC1MAADSREEKDGELNVLDDILTEVPEQDDELYNPESEQDKNEKKGSKRKSDRMESTDTKRQKPSVHSRQLVSKPLSSSVSNNKRIVSTKGKSATEYKNEEYQRSERNKRLDADRKIRLSSSASREPYKNQPEKTCVRKRDPERRAKSPTPDGSERIGLEVDRRASRSSQSSKEEVNSEEYGSDHETGSSGSSDEQGNNTENEEEGVEEDVEEDEEVEEDAEEDEEVDEDGEEEEEEEEEEEEEEEEEEEEYEQDERDQKEEGNDYDTRSEASDSGSESVSFTDGSVRSGSGTDGSDEKKKERKRARGISPIVFDRSGSSASESYADQTSKLKYVLQDARFFLIKSNNHENVSLAKAKGVWSTLPVNEKKLNLAFRSARSVILIFSVRESGKFQGFARLSSESHHGGSPIHWVLPAGMSAKMLGGVFKIDWICRRELPFTKSAHLTNPWNEHKPVKIGRDGQEIELECGTQLCLLFPPDESIDLYQVIHKMRHKRRMHSQPRSRGRPSRREPVRDVGRRRPEDYDIHNSRKKPRIDYPPEFHQRPGYLKDPRYQEVDRRFSGVRRDVFLNGSYNDYVREFHNMGPPPPWQGMPPYPGMEQPPHHPYYQHHAPPPQAHPPYSGHHPVPHEARYRDKRVHDYDMRVDDFLRRTQAVVSGRRSRPRERDRERERDRPRDNRRDRERDRGRDRERERERLCDRDRDRGERGRYRR>sp|Q9UNY5|ZN232_HUMAN Zinc finger protein 232 OS=Homo sapiens OX=9606GN=ZNF232 PE=1 SV=1MAVSLTAAETLALQGTQGQEKMMMMGPKEEEQSCEYETRLPGNHSTSQEIFRQRFRHLRYQETPGPREALSQLRVLCCEWLRPEKHTKEQILEFLVLEQFLTILPEELQSWVRGHHPKSGEEAVTVLEDLEKGLEPEPQVPGPAHGPAQEEPWEKKESLGAAQEALSIQLQPKETQPFPKSEQVYLHFLSVVTEDGPEPKDKGSLPQPPITEVESQVFSEKLATDTSTFEATSEGTLELQQRNPKAERLRWSPAQEESFRQMVVIHKEIPTGKKDHECSECGKTFIYNSHLVVHQRVHSGEKPYKCSDCGKTFKQSSNLGQHQRIHTGEKPFECNECGKAFRWGAHLVQHQRIHSGEKPYECNECGKAFSQSSYLSQHRRIHSGEKPFICKECGKAYGWCSELIRHRRVHARKEPSH>sp|Q9UNY5-2|ZN232_HUMAN Isoform Short of Zinc finger protein 232 OS=Homosapiens OX=9606 GN=ZNF232MAVSLTAAETLALQGTQGQEKMMMMGPKEEEQSCEYETRLPGNHSTSQEIFRQRFRHLRYQETPGPREALSQLRVLCCEWLRPEKHTKEQILEFLVLEQFLTILPEELQSWVRGHHPKSGEEAVTVLEDLEKGLEPEPQVPGPAHGPAQEEPWEKKESLGAAQEALSIQLQPKETQPFPKSVVTEDGPEPKDKGSLPQPPITEVESQVFSEKLATDTSTFEATSEGTLELQQRNPKAERLRWSPAQEESFRQMVVIHKEIPTGKKDHECSECGKTFIYNSHLVVHQRVHSGEKPYKCSDCGKTFKQSSNLGQHQRIHTGEKPFECNECGKAFRWGAHLVQHQRIHSGEKPYECNECGKAFSQSSYLSQHRRIHSGEKPFICKECGKAYGWCSELIRHRRVHARKEPSH>sp|Q504Y3|ZCPW2_HUMAN Zinc finger CW-type PWWP domain protein 2 OS=Homosapiens OX=9606 GN=ZCWPW2 PE=1 SV=1MDKEKLDVKIEYCNYAMDSSVENMYVNKVWVQCENENCLKWRLLSSEDSAKVDHDEPWYCFMNTDSRYNNCSISEEDFPEESQLHQCGFKIVYSQLPLGSLVLVKLQNWPSWPGILCPDRFKGKYVTYDPDGNVEEYHIEFLGDPHSRSWIKATFVGHYSITLKPEKCKNKKKWYKSALQEACLLYGYSHEQRLEMCCLSKLQDKSETHDKVAALVKKRKQTSKNNIEKKKPKFRKRKRKAILKCSFENVYSDDALSKENRVVCETEVLLKELEQMLQQALQPTATPDESEEGHGEEINMGEKLSKCSPEAPAGSLFENHYEEDYLVIDGIKLKAGECIEDITNKFKEIDALMSEF>sp|Q8N2G6|ZCH24_HUMAN Zinc finger CCHC domain-containing protein 24OS=Homo sapiens OX=9606 GN=ZCCHC24 PE=1 SV=1MSLLSAIDTSAASVYQPAQLLNWVYLSLQDTHQASAFDAFRPEPTAGAAPPELAFGKGRPEQLGSPLHSSYLNSFFQLQRGEALSNSVYKGASPYGSLNNIADGLSSLTEHFSDLTLTSEARKPSKRPPPNYLCHLCFNKGHYIKDCPQARPKGEGLTPYQGKKRCFGEYKCPKCKRKWMSGNSWANMGQECIKCHINVYPHKQRPLEKPDGLDVSDQSKEHPQHLCEKCKVLGYYCRRVQ>sp|Q8NDX6|ZN740_HUMAN Zinc finger protein 740 OS=Homo sapiens OX=9606GN=ZNF740 PE=1 SV=1MAQASLLACEGLAGVSLVPTAASKKMMLSQIASKQAENGERAGSPDVLRCSSQGHRKDSDKSRSRKDDDSLSEASHSKKTVKKVVVVEQNGSFQVKIPKNFVCEHCFGAFRSSYHLKRHILIHTGEKPFECDICDMRFIQKYHLERHKRVHSGEKPYQCERCHQCFSRTDRLLRHKRMCQGCQSKTSDGQFSL>sp|Q6ZWC4|YS043_HUMAN Putative uncharacterized protein LOC100128429OS=Homo sapiens OX=9606 PE=5 SV=1MCWGKHWPRPEGRNLACSKGSPGWRTAGQGSGSYGAATLGKGTEQRGVGALRRGLLSFTCFCLSNWTSGAGFSEMGRSRFEEGRLGYSSDVLSARPTMSPTEMLRSRALNLGAATVLRRHRAPQGTSSYQEGRRAHEATSAESDDDNGVQVLASLAVSCAQHSRHKDPVGTQLQQACAQVPTSRAPLWPCPSHRLMHSTDGPLDPEPLSTLLPAA>sp|B7Z6K7|ZN814_HUMAN Zinc finger protein 814 OS=Homo sapiens OX=9606GN=ZNF814 PE=1 SV=2MAAAATLRLSAQGTVTFEDVAVNFTWEEWNLLSEAQRCLYRDVTLENLALISSLGCWCGVEDEAAPSKQSIYIQRETQVRTPMAGVSPKKAHPCEMCGPILGDILHVADHQGTHHKQKLHRCEAWGNKLYDSGNFHQHQNEHIGEKPYRGSVEEALFAKRCKLHVSGESSVFSESGKDFLPRSGLLQQEASHTGEKSNSKTECVSPIQCGGAHYSCGESMKHFSTKHILSQHQRLLTREECYVCCECGKSFSKYASLSNHQRVHTEKKHECGECGKSFSKYVSFSNHQRVHTEKKHECGECGKSFSKYVSFSNHQRVHTGKRPYECGECGKSFSKYASFSNHQRVHTEKKHYECGECGKSFSKYVSFSNHQRVHTGKRPYECGECGKSFSKYASFSNHQRVHTDKKHYECGECGKSFSQKSSLIQHQRFHTGEKPYGCEECGKSFSSEGHLRSHQRVHAGERPFKCGECVKSFSHKRSLVHHQRVHSGERPYQCGECGKSFSQKGNLVLHQRVHTGARPYECGECGKSFSSKGHLRNHQQIHTGDRLYECGECGKSFSHKGTLILHQRVHPRERSYGCGECGKSFSSIGHLRSHQRVHTGERPYECGECGKSFSHKRSLVHHQRMHTGERPYKCGDCGKSFNEKGHLRNHQRVHTTERPFKCGECGKCFSHKGNLILHQHGHTGERPYVCRECGKLFKKKSHLLVHQRIHNGEKPYACEACQKFFRNKYQLIAHQRVHTGERPYECNDCGKSFTHSSTFCVHKRIHTGEKPYECSECGKSFAESSSFTKHKRVHTGEKPYECSECGKSFAESSSLTKHKRVHTGEKPYKCEKCGKLFNKKSHLLVHQSSHWRKAI>sp|Q6ZN55|ZN574_HUMAN Zinc finger protein 574 OS=Homo sapiens OX=9606GN=ZNF574 PE=1 SV=2MTEESEETVLYIEHRYVCSECNQLYGSLEEVLMHQNSHVPQQHFELVGVADPGVTVATDTASGTGLYQTLVQESQYQCLECGQLLMSPSQLLEHQELHLKMMAPQEAVPAEPSPKAPPLSSSTIHYECVDCKALFASQELWLNHRQTHLRATPTKAPAPVVLGSPVVLGPPVGQARVAVEHSYRKAEEGGEGATVPSAAATTTEVVTEVELLLYKCSECSQLFQLPADFLEHQATHFPAPVPESQEPALQQEVQASSPAEVPVSQPDPLPASDHSYELRNGEAIGRDRRGRRARRNNSGEAGGAATQELFCSACDQLFLSPHQLQQHLRSHREGVFKCPLCSRVFPSPSSLDQHLGDHSSESHFLCVDCGLAFGTEALLLAHRRAHTPNPLHSCPCGKTFVNLTKFLYHRRTHGVGGVPLPTTPVPPEEPVIGFPEPAPAETGEPEAPEPPVSEETSAGPAAPGTYRCLLCSREFGKALQLTRHQRFVHRLERRHKCSICGKMFKKKSHVRNHLRTHTGERPFPCPDCSKPFNSPANLARHRLTHTGERPYRCGDCGKAFTQSSTLRQHRLVHAQHFPYRCQECGVRFHRPYRLLMHRYHHTGEYPYKCRECPRSFLLRRLLEVHQLVVHAGRQPHRCPSCGAAFPSSLRLREHRCAAAAAQAPRRFECGTCGKKVGSAARLQAHEAAHAAAGPGEVLAKEPPAPRAPRATRAPVASPAALGSTATASPAAPARRRGLECSECKKLFSTETSLQVHRRIHTGERPYPCPDCGKAFRQSTHLKDHRRLHTGERPFACEVCGKAFAISMRLAEHRRIHTGERPYSCPDCGKSYRSFSNLWKHRKTHQQQHQAAVRQQLAEAEAAVGLAVMETAVEALPLVEAIEIYPLAEAEGVQISG>sp|Q6ZN55-2|ZN574_HUMAN Isoform 2 of Zinc finger protein 574 OS=Homosapiens OX=9606 GN=ZNF574MPRATWANSKERSWAESERGPRDTGNGGSKAERHIQEIETGRGGDRAKAHRRQRMRLRGTERASLGPGRRLGDSRGTDMPGARAQGLAAATEESEETVLYIEHRYVCSECNQLYGSLEEVLMHQNSHVPQQHFELVGVADPGVTVATDTASGTGLYQTLVQESQYQCLECGQLLMSPSQLLEHQELHLKMMAPQEAVPAEPSPKAPPLSSSTIHYECVDCKALFASQELWLNHRQTHLRATPTKAPAPVVLGSPVVLGPPVGQARVAVEHSYRKAEEGGEGATVPSAAATTTEVVTEVELLLYKCSECSQLFQLPADFLEHQATHFPAPVPESQEPALQQEVQASSPAEVPVSQPDPLPASDHSYELRNGEAIGRDRRGRRARRNNSGEAGGAATQELFCSACDQLFLSPHQLQQHLRSHREGVFKCPLCSRVFPSPSSLDQHLGDHSSESHFLCVDCGLAFGTEALLLAHRRAHTPNPLHSCPCGKTFVNLTKFLYHRRTHGVGGVPLPTTPVPPEEPVIGFPEPAPAETGEPEAPEPPVSEETSAGPAAPGTYRCLLCSREFGKALQLTRHQRFVHRLERRHKCSICGKMFKKKSHVRNHLRTHTGERPFPCPDCSKPFNSPANLARHRLTHTGERPYRCGDCGKAFTQSSTLRQHRLVHAQHFPYRCQECGVRFHRPYRLLMHRYHHTGEYPYKCRECPRSFLLRRLLEVHQLVVHAGRQPHRCPSCGAAFPSSLRLREHRCAAAAAQAPRRFECGTCGKKVGSAARLQAHEAAHAAAGPGEVLAKEPPAPRAPRATRAPVASPAALGSTATASPAAPARRRGLECSECKKLFSTETSLQVHRRIHTGERPYPCPDCGKAFRQSTHLKDHRRLHTGERPFACEVCGKAFAISMRLAEHRRIHTGERPYSCPDCGKSYRSFSNLWKHRKTHQQQHQAAVRQQLAEAEAAVGLAVMETAVEALPLVEAIEIYPLAEAEGVQISG>sp|Q9NXT0|ZN586_HUMAN Zinc finger protein 586 OS=Homo sapiens OX=9606GN=ZNF586 PE=2 SV=2MAAAAALRAPAQSSVTFEDVAVNFSLEEWSLLNEAQRCLYRDVMLETLTLISSLGCWHGGEDEAAPSKQSTCIHIYKDQGGHSGERPYECGEYRKLFKNKSCLTEPRRDHKHRNVRTGERPYECSKYGKLFHQKPTLHIHERFHTGQKTYECSECGKSFHQSSSLLQRQTLHTRERPYECIECGKAFAEKSSLINHRKVHSGAKRYECNECGKSFAYTSSLIKHRRIHTGERPYECSECGRSFAENSSLIKHLRVHTGERPYECVECGKSFRRSSSLLQHQRVHTRERPYECSECGKSFSLRSNLIHHQRVHTGERHECGQCGKSFSRKSSLIIHLRVHTGERPYECSDCGKSFAENSSLIKHLRVHTGERPYECIDCGKSFRHSSSFRRHQRVHTGMRPYK>sp|Q9NXT0-2|ZN586_HUMAN Isoform 2 of Zinc finger protein 586 OS=Homosapiens OX=9606 GN=ZNF586MAAAAALRAPAQVVGMEGKMRQHLLSRARVYIYTKTREVIVEKGLMSVGNIGNYLRTSPASLNPEEITNTGMFALEKGLMSAANMGNYFTKSLHSIFMRDFILGKRPMSAVSVENHFTKALHSCSVRHFTLEKGLMSVLNVGKPLLKSPVSLTTGKFTLEQSVMNAMNVGSPLLIHLVSLNTGGFTLERGLMSAVNVGDPLLKTPVLLNT>sp|Q9NXT0-3|ZN586_HUMAN Isoform 3 of Zinc finger protein 586 OS=Homosapiens OX=9606 GN=ZNF586MLETLTLISSLGCWHGGEDEAAPSKQSTCIHIYKDQGGHSGERPYECGEYRKLFKNKSCLTEPRRDHKHRNVRTGERPYECSKYGKLFHQKPTLHIHERFHTGQKTYECSECGKSFHQSSSLLQRQTLHTRERPYECIECGKAFAEKSSLINHRKVHSGAKRYECNECGKSFAYTSSLIKHRRIHTGERPYECSECGRSFAENSSLIKHLRVHTGERPYECVECGKSFRRSSSLLQHQRVHTRERPYECSECGKSFSLRSNLIHHQRVHTGERHECGQCGKSFSRKSSLIIHLRVHTGERPYECSDCGKSFAENSSLIKHLRVHTGERPYECIDCGKSFRHSSSFRRHQRVHTGMRPYK>sp|Q96PM9|Z385A_HUMAN Zinc finger protein 385A OS=Homo sapiens OX=9606GN=ZNF385A PE=1 SV=2MILGSLSRAGPLPLLRQPPIMQPPLDLKQILPFPLEPAPTLGLFSNYSTMDPVQKAVLSHTFGGPLLKTKRPVISCNICQIRFNSQSQAEAHYKGNRHARRVKGIEAAKTRGREPGVREPGDPAPPGSTPTNGDGVAPRPVSMENGLGPAPGSPEKQPGSPSPPSIPETGQGVTKGEGGTPAPASLPGGSKEEEEKAKRLLYCALCKVAVNSLSQLEAHNKGTKHKTILEARSGLGPIKAYPRLGPPTPGEPEAPAQDRTFHCEICNVKVNSEVQLKQHISSRRHRDGVAGKPNPLLSRHKKSRGAGELAGTLTFSKELPKSLAGGLLPSPLAVAAVMAAAAGSPLSLRPAPAAPLLQGPPITHPLLHPAPGPIRTAHGPILFSPY>sp|Q96PM9-1|Z385A_HUMAN Isoform 1 of Zinc finger protein 385A OS=Homosapiens OX=9606 GN=ZNF385AMQPPLDLKQILPFPLEPAPTLGLFSNYSTMDPVQKAVLSHTFGGPLLKTKRPVISCNICQIRFNSQSQAEAHYKGNRHARRVKGIEAAKTRGREPGVREPGDPAPPGSTPTNGDGVAPRPVSMENGLGPAPGSPEKQPGSPSPPSIPETGQGVTKGEGGTPAPASLPGGSKEEEEKAKRLLYCALCKVAVNSLSQLEAHNKGTKHKTILEARSGLGPIKAYPRLGPPTPGEPEAPAQDRTFHCEICNVKVNSEVQLKQHISSRRHRDGVAGKPNPLLSRHKKSRGAGELAGTLTFSKELPKSLAGGLLPSPLAVAAVMAAAAGSPLSLRPAPAAPLLQGPPITHPLLHPAPGPIRTAHGPILFSPY>sp|Q96PM9-2|Z385A_HUMAN Isoform 2 of Zinc finger protein 385A OS=Homosapiens OX=9606 GN=ZNF385AMQPPLDLKQILPFPLEPAPTLGLFSNYSTMDPVQKAVLSHTFGGPLLKTKRPVISCNICQIRFNSQSQAEAHYKGNRHARRVKGIEAAKTRGREPGVREPGDPAPPGSTPTNGDGVAPRPGTKHKTILEARSGLGPIKAYPRLGPPTPGEPEAPAQDRTFHCEICNVKVNSEVQLKQHISSRRHRDGVAGKPNPLLSRHKKSRGAGELAGTLTFSKELPKSLAGGLLPSPLAVAAVMAAAAGSPLSLRPAPAAPLLQGPPITHPLLHPAPGPIRTAHGPILFSPY>sp|Q96PM9-3|Z385A_HUMAN Isoform 3 of Zinc finger protein 385A OS=Homosapiens OX=9606 GN=ZNF385AMILGSLSRAGPLPLLRQPPIMQPPLDLKQILPFPLEPAPTLGLFSNYSTMDPVQKAVLSHTFGGPLLKTKRPVISCNICQIRFNSQSQAEAHYKGNRHARRVKGIEAAKTRGREPGVREPGDPAPPGSTPTNGDGVAPRPGTKHKTILEARSGLGPIKAYPRLGPPTPGEPEAPAQDRTFHCEICNVKVNSEVQLKQHISSRRHRDGVAGKPNPLLSRHKKSRGAGELAGTLTFSKELPKSLAGGLLPSPLAVAAVMAAAAGSPLSLRPAPAAPLLQGPPITHPLLHPAPGPIRTAHGPILFSPY>sp|O15195|VILL_HUMAN Villin-like protein OS=Homo sapiens OX=9606 GN=VILLPE=1 SV=3MDISKGLPGMQGGLHIWISENRKMVPVPEGAYGNFFEEHCYVILHVPQSPKATQGASSDLHYWVGKQAGAEAQGAAEAFQQRLQDELGGQTVLHREAQGHESDCFCSYFRPGIIYRKGGLASDLKHVETNLFNIQRLLHIKGRKHVSATEVELSWNSFNKGDIFLLDLGKMMIQWNGPKTSISEKARGLALTYSLRDRERGGGRAQIGVVDDEAKAPDLMQIMEAVLGRRVGSLRAATPSKDINQLQKANVRLYHVYEKGKDLVVLELATPPLTQDLLQEEDFYILDQGGFKIYVWQGRMSSLQERKAAFSRAVGFIQAKGYPTYTNVEVVNDGAESAAFKQLFRTWSEKRRRNQKLGGRDKSIHVKLDVGKLHTQPKLAAQLRMVDDGSGKVEVWCIQDLHRQPVDPKRHGQLCAGNCYLVLYTYQRLGRVQYILYLWQGHQATADEIEALNSNAEELDVMYGGVLVQEHVTMGSEPPHFLAIFQGQLVIFQERAGHHGKGQSASTTRLFQVQGTDSHNTRTMEVPARASSLNSSDIFLLVTASVCYLWFGKGCNGDQREMARVVVTVISRKNEETVLEGQEPPHFWEALGGRAPYPSNKRLPEEVPSFQPRLFECSSHMGCLVLAEVGFFSQEDLDKYDIMLLDTWQEIFLWLGEAASEWKEAVAWGQEYLKTHPAGRSPATPIVLVKQGHEPPTFIGWFFTWDPYKWTSHPSHKEVVDGSPAAASTISEITAEVNNLRLSRWPGNGRAGAVALQALKGSQDSSENDLVRSPKSAGSRTSSSVSSTSATINGGLRREQLMHQAVEDLPEGVDPARREFYLSDSDFQDIFGKSKEEFYSMATWRQRQEKKQLGFF>sp|O15195-2|VILL_HUMAN Isoform 2 of Villin-like protein OS=Homo sapiensOX=9606 GN=VILLMDISKGLPGMQGGLHIWISENRKMVPVPEGAYGNFFEEHCYVILHVPQSPKATQGASSDLHYWVGKQAGAEAQGAAEAFQQRLQDELGGQTVLHREAQGHESDCFCSYFRPGIIYRKGGLASDLKHVETNLFNIQRLLHIKGRKHVSATEVELSWNSFNKGDIFLLDLGKMMIQWNGPKTSISEKARGLALTYSLRDRERGGGRAQIGVVDDEAKAPDLMQIMEAVLGRRVGSLRAATPSKDINQLQKANVRLYHVYEKGKDLLQEEDFYILDQGGFKIYVWQGRMSSLQERKAAFSRAVGFIQAKGYPTYTNVEVVNDGAESAAFKQLFRTWSEKRRRNQKLGGRDKSIHVKLDVGKLHTQPKLAAQLRMVDDGSGKVEVWCIQDLHRQPVDPKRHGQLCAGNCYLVLYTYQRLGRVQYILYLWQGHQATADEIEALNSNAEELDVMYGGVLVQEHVTMGSEPPHFLAIFQGQLVIFQERAGHHGKGQSASTTRLFQVQGTDSHNTRTMEVPARASSLNSSDIFLLVTASVCYLWFGKGCNGDQREMARVVVTVISRKNEETVLEGQEPPHFWEALGGRAPYPSNKRLPEEVPSFQPRLFECSSHMGCLVLAEVGFFSQEDLDKYDIMLLDTWQEIFLWLGEAASEWKEAVAWGQEYLKTHPAGRSPATPIVLVKQGHEPPTFIGWFFTWDPYKWTSHPSHKEVVDGSPAAASTISEITAEVNNLRLSRWPGNGRAGAVALQALKGSQDSSENDLVRSPKSAGSRTSSSVSSTSATINGGLRREQLMHQAVEDLPEGVDPARREFYLSDSDFQDIFGKSKEEFYSMATWRQRQEKKQLGFF>sp|P41587|VIPR2_HUMAN Vasoactive intestinal polypeptide receptor 2OS=Homo sapiens OX=9606 GN=VIPR2 PE=1 SV=2MRTLLPPALLTCWLLAPVNSIHPECRFHLEIQEEETKCAELLRSQTEKHKACSGVWDNITCWRPANVGETVTVPCPKVFSNFYSKAGNISKNCTSDGWSETFPDFVDACGYSDPEDESKITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHCPDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWWVIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVAVLYCFLNSEVQCELKRKWRSRCPTPSASRDYRVCGSSFSRNGSEGALQFHRGSRAQSFLQTETSVI>sp|P41587-2|VIPR2_HUMAN Isoform 2 of Vasoactive intestinal polypeptidereceptor 2 OS=Homo sapiens OX=9606 GN=VIPR2MPLWEAPSDHPANPPATLQGHTSLPGCQEEPARDPQSGLPQITSESSSFSEGSLPSWSSGPAGAKLNASHEGIGSSSDGNGDSKAATERVVSAMDTVRRKHPEITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHCPDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWWVIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVAVLYCFLNSEVQCELKRKWRSRCPTPSASRDYRVCGSSFSRNGSEGALQFHRGSRAQSFLQTETSVI>sp|Q8N1W2|ZN710_HUMAN Zinc finger protein 710 OS=Homo sapiens OX=9606GN=ZNF710 PE=1 SV=2MEGFMDSGTQTDAVVVLSLAQAAVLGLVSENELFGATISAEAFYPDLGPELSGAAMGEPEPPGPDVYQLACNGRALEEPAEEEVLEVEAACEKHTRRKTRPPVRLVPKVKFEKVEEEEQEVYEVSVPGDDKDAGPAEAPAEAASGGCDALVQSSAVKMIDLSAFSRKPRTLRHLPRTPRPELNVAPYDPHFPAPARDGFPEPSMALPGPEALPTECGFEPPHLAPLSDPEAPSMESPEPVKPEQGFVWQEASEFEADTAGSTVERHKKAQLDRLDINVQIDDSYLVEAGDRQKRWQCRMCEKSYTSKYNLVTHILGHNGIKPHSCPHCSKLFKQPSHLQTHLLTHQGTRPHKCQVCHKAFTQTSHLKRHMLLHSEVKPYSCHFCGRGFAYPSELKAHEVKHESGRCHVCVECGLDFSTLTQLKRHLASHQGPTLYQCLECDKSFHYRSQLQNHMLKHQNVRPFVCTECGMEFSQIHHLKQHSLTHKGVKEFKCEVCGREFTLQANMKRHMLIHTSVRPYQCHICFKTFVQKQTLKTHMIVHSPVKPFKCKVCGKSFNRMYNLLGHMHLHAGSKPFKCPYCSSKFNLKGNLSRHMKVKHGVMDIGLDSQDPMMELTGTDPSELDGQQEMEDFEENAYSYASVDSSAEASVLTEQAMKEMAYYNVL>sp|Q86VK4|ZN410_HUMAN Zinc finger protein 410 OS=Homo sapiens OX=9606GN=ZNF410 PE=1 SV=2MLSDELESKPELLVQFVQNTSIPLGQGLVESEAKDITCLSLLPVTEASECSRLMLPDDTTNHSNSSKEVPSSAVLRSLRVNVGPDGEETRAQTVQKSPEFLSTSESSSLLQDLQPSDSTSFILLNLTRAGLGSSAEHLVFVQDEAEDSGNDFLSSESTDSSIPWFLRVQELAHDSLIAATRAQLAKNAKTSSNGENVHLGSGDGQSKDSGPLPQVEKKLKCTVEGCDRTFVWPAHFKYHLKTHRNDRSFICPAEGCGKSFYVLQRLKVHMRTHNGEKPFMCHESGCGKQFTTAGNLKNHRRIHTGEKPFLCEAQGCGRSFAEYSSLRKHLVVHSGEKPHQCQVCGKTFSQSGSRNVHMRKHHLQLGAAGSQEQEQTAEPLMGSSLLEEASVPSKNLVSMNSQPSLGGESLNLPNTNSILGVDDEVLAEGSPRSLSSVPDVTHHLVTMQSGRQSYEVSVLTAVNPQELLNQGDLTERRT>sp|Q86VK4-2|ZN410_HUMAN Isoform 2 of Zinc finger protein 410 OS=Homosapiens OX=9606 GN=ZNF410MLSDELESKPELLVQFVQNTSIPLGQGLVESEAKDITCLSLLPVTEASECSRLMLPDDTTNHSNSSKEVPSSAVLRSLRVNVGPDGEETRAQTVQKSPEFLSTSESSSLLQDLQPSDSTSFILLNLTRAGLGSSAEHLVFVQDEAEDSGNDFLSSESTDSSIPWFLRVQELAHDSLIAATRAQLAKNAKTSSNGENVHLGSGDGQSKDSGPLPQVEKKLKCTVEGCDRTFVWPAHFKYHLKTHRRLWEKLLCAAEAEGAHEDPQWREALYVP>sp|Q86VK4-3|ZN410_HUMAN Isoform 3 of Zinc finger protein 410 OS=Homosapiens OX=9606 GN=ZNF410MLSDELESKPELLVQFVQNTSIPLGQGLVESEAKDITCLSLLPVTEASECSRLMLPDDTTNHSNSSKEVPSSAVLRSLRVNVGPDGEETRAQTVQKSPEFLSTSESSSLLQDLQPSDSTSFILLNLTRAGLGSSAEHLVFVQDEAEDSGNDFLSSESTDSSIPWFLRVQELAHDSLIAATRAQLAKNAKTSSNGENVHLGSGDGQSKDSGPLPQVEKKLKCTVEGCDRTFVWPAHFKYHLKTHRNDRSFICPAEGCGKSFYVLQRLKVHMRTHNGEKPFMCHESGCGKQFTTAGNLKNHRRIHTGEKPFLCEAQGCGRSFAEYSSLRKHLVVHSGEKPHQCQVCGKTFSQSGSRNVHMRKHHLQLGAAGSQEQEQTEVLAEGSPRSLSSVPDVTHHLVTMQSGRQSYEVSVLTAVNPQELLNQGDLTERRT>sp|Q86VK4-4|ZN410_HUMAN Isoform 4 of Zinc finger protein 410 OS=Homosapiens OX=9606 GN=ZNF410MLSDELESKPELLVQFVQNTSIPLGQGLVESEAKDITCLSLLPVTEASECSRLMLPGLGSSAEHLVFVQDEAEDSGNDFLSSESTDSSIPWFLRVQELAHDSLIAATRAQLAKNAKTSSNGENVHLGSGDGQSKDSGPLPQVEKKLKCTVEGCDRTFVWPAHFKYHLKTHRNDRSFICPAEGCGKSFYVLQRLKVHMRTHNGEKPFMCHESGCGKQFTTAGNLKNHRRIHTGEKPFLCEAQGCGRSFAEYSSLRKHLVVHSGEKPHQCQVCGKTFSQSGSRNVHMRKHHLQLGAAGSQEQEQTAEPLMGSSLLEEASVPSKNLVSMNSQPSLGGESLNLPNTNSILGVDDEVLAEGSPRSLSSVPDVTHHLVTMQSGRQSYEVSVLTAVNPQELLNQGDLTERRT>sp|Q86VK4-5|ZN410_HUMAN Isoform 5 of Zinc finger protein 410 OS=Homosapiens OX=9606 GN=ZNF410MLSDELESKPELLVQFVQNTSIPLGQGLVESEAKDITCLSLLPVTEASECSRLMLPEPVPWREEDGKSGCSDLNDTTNHSNSSKEVPSSAVLRSLRVNVGPDGEETRAQTVQKSPEFLSTSESSSLLQDLQPSDSTSFILLNLTRAGLGSSAEHLVFVQDEAEDSGNDFLSSESTDSSIPWFLRVQELAHDSLIAATRAQLAKNAKTSSNGENVHLGSGDGQSKDSGPLPQVEKKLKCTVEGCDRTFVWPAHFKYHLKTHRNDRSFICPAEGCGKSFYVLQRLKVHMRTHNGEKPFMCHESGCGKQFTTAGNLKNHRRIHTGEKPFLCEAQGCGRSFAEYSSLRKHLVVHSGEKPHQCQVCGKTFSQSGSRNVHMRKHHLQLGAAGSQEQEQTAEPLMGSSLLEEASVPSKNLVSMNSQPSLGGESLNLPNTNSILGVDDEVLAEGSPRSLSSVPDVTHHLVTMQSGRQSYEVSVLTAVNPQESLAPLPRLECSGAFSAHCNLCLPGSSDSPASAS>sp|Q9UGR2|Z3H7B_HUMAN Zinc finger CCCH domain-containing protein 7BOS=Homo sapiens OX=9606 GN=ZC3H7B PE=1 SV=2MERQKRKADIEKGLQFIQSTLPLKQEEYEAFLLKLVQNLFAEGNDLFREKDYKQALVQYMEGLNVADYAASDQVALPRELLCKLHVNRAACYFTMGLYEKALEDSEKALGLDSESIRALFRKARALNELGRHKEAYECSSRCSLALPHDESVTQLGQELAQKLGLRVRKAYKRPQELETFSLLSNGTAAGVADQGTSNGLGSIDDIETDCYVDPRGSPALLPSTPTMPLFPHVLDLLAPLDSSRTLPSTDSLDDFSDGDVFGPELDTLLDSLSLVQGGLSGSGVPSELPQLIPVFPGGTPLLPPVVGGSIPVSSPLPPASFGLVMDPSKKLAASVLDALDPPGPTLDPLDLLPYSETRLDALDSFGSTRGSLDKPDSFMEETNSQDHRPPSGAQKPAPSPEPCMPNTALLIKNPLAATHEFKQACQLCYPKTGPRAGDYTYREGLEHKCKRDILLGRLRSSEDQTWKRIRPRPTKTSFVGSYYLCKDMINKQDCKYGDNCTFAYHQEEIDVWTEERKGTLNRDLLFDPLGGVKRGSLTIAKLLKEHQGIFTFLCEICFDSKPRIISKGTKDSPSVCSNLAAKHSFYNNKCLVHIVRSTSLKYSKIRQFQEHFQFDVCRHEVRYGCLREDSCHFAHSFIELKVWLLQQYSGMTHEDIVQESKKYWQQMEAHAGKASSSMGAPRTHGPSTFDLQMKFVCGQCWRNGQVVEPDKDLKYCSAKARHCWTKERRVLLVMSKAKRKWVSVRPLPSIRNFPQQYDLCIHAQNGRKCQYVGNCSFAHSPEERDMWTFMKENKILDMQQTYDMWLKKHNPGKPGEGTPISSREGEKQIQMPTDYADIMMGYHCWLCGKNSNSKKQWQQHIQSEKHKEKVFTSDSDASGWAFRFPMGEFRLCDRLQKGKACPDGDKCRCAHGQEELNEWLDRREVLKQKLAKARKDMLLCPRDDDFGKYNFLLQEDGDLAGATPEAPAAAATATTGE>sp|Q96GE5|ZN799_HUMAN Zinc finger protein 799 OS=Homo sapiens OX=9606GN=ZNF799 PE=2 SV=4MASVALEDVAVNFTREEWALLGPCQKNLYKDVMQETIRNLDCVGMKWKDQNIEDQYRYPRKNLRCRMLERFVESKDGTQCGETSSQIQDSIVTKNTLPGVGPYESRMSGEVIMGHSSLNCYIRVGAGHKPYEYHECGEKPDTHKQRGKAFSYHNSLQTHERLHTGKKPYNCKECGKSFSSLGNLQRHMAVQRGDGPYKCKLCGKAFFWPSLLHMHERTHTGEKPYECKQCSKAFSFYSSYLRHERTHTGEKLYECKQCSKAFPDYSSCLRHERTHTGKKPYTCKQCGKAFSASTSLRRHETTHTDEKPYACQQCGKAFHHLGSFQRHMVMHTRDGPHKCKICGKGFDCPSSLKSHERTHTGEKLYECKQCGKALSHSSSFRRHMTMHTGDGPHKCKICGKAFVYPSVFQRHEKTHTAEKPYKCKQCGKAYRISSSLRRHETTHTGEKPYKCKCGKAFIDFYSFQNHKTTHAGEKPYECKECGKAFSCFQYLSQHRRTHTGEKPYECNTCKKAFSHFGNLKVHERIHSGEKPYECKECGKAFSWLTCFLRHERIHMREKPYECQQCGKAFTHSRFLQGHEKTHTGENPYECKECGKAFASLSSLHRHKKTHWKKTHTGENPYGCKECGKAFASLSSLHRHKKTH>sp|Q96GE5-2|ZN799_HUMAN Isoform 2 of Zinc finger protein 799 OS=Homosapiens OX=9606 GN=ZNF799MDQASVALEDVAVNFTREEWALLGPCQKNLYKDVMQETIRNLDCVGMKWKDQNIEDQYRYPRKNLRCRMLERFVESKDGTQCGETSSQIQDSIVTKNTLPGVGPYESRMSGEVIMGHSSLNCYIRVGAGHKPYEYHECGEKPDTHKQRGKAFSYHNSLQTHERLHTGKKPYNCKECGKSFSSLGNLQRHMAVQRGDGPYKCKLCGKAFFWPSLLHMHERTHTGEKPYECKQCSKAFSFYSSYLRHERTHTGEKLYECKQCSKAFPDYSSCLRHERTHTGKKPYTCKQCGKAFSASTSLRRHETTHTDEKPYACQQCGKAFHHLGSFQRHMVMHTRDGPHKCKICGKGFDCPSSLKSHERTHTGEKLYECKQCGKALSHSSSFRRHMTMHTGDGPHKCKICGKAFVYPSVFQRHEKTHTAEKPYKCKQCGKAYRISSSLRRHETTHTGEKPYKCKCGKAFIDFYSFQNHKTTHAGEKPYECKECGKAFSCFQYLSQHRRTHTGEKPYECNTCKKAFSHFGNLKVHERIHSGEKPYECKECGKAFSWLTCFLRHERIHMREKPYECQQCGKAFTHSRFLQGHEKTHTGENPYECKECGKAFASLSSLHRHKKTHWKKTHTGENPYGCKECGKAFASLSSLHRHKKTH>sp|A6NN14|ZN729_HUMAN Zinc finger protein 729 OS=Homo sapiens OX=9606GN=ZNF729 PE=2 SV=4MPGAPGSLEMGPLTFRDVTIEFSLEEWQCLDTVQQNLYRDVMLENYRNLVFLGMAVFKPDLITCLKQGKEPWNMKRHEMVTKPPVMRSHFTQDLWPDQSTKDSFQEVILRTYARCGHKNLRLRKDCKSANEGKMHKEGYNKLNQCRTATQRKIFQCNKHMKVFHKYSNRNKVRHTKKKTFKCIKCSKSFFMLSCLIRHKRIHIRQNIYKCEERGKAFKSFSTLTKHKIIHTEDKPYKYKKCGNAFKFSSTFTKHKRIHTGETPFRCEECGKAFNQSSNLTDHKRIHTGEKTYKCEECGKAFKGSSNFNAHKVIHTAEKPYKCEDCGKTFNHFSALRKHKIIHTGKKPYKREECGKAFSQSSTLRKHEIIHTGEKPYKCEECGKAFKWSSKLTVHKVVHTGEKPYKCEECGKAFSQFSTLKKHKIIHTGKKPYKCEECGKAFNSSSTLMKHKIIHTGEKPYKCEECGKAFRQSSHLTRHKAIHTGEKPYKCEECGKAFNHFSDLRRHKIIHTGKKPYKCEECGKAFSQSSTLRNHQIIHTGEKPYKCEECGKAFKWSSKLTVHKVIHTGEKPCKCEECGKAFKHFSALRKHKVIHTREKLYKCEECGKAFNNSSILAKHKIIHTGKKPYKCEECGKAFRQSSHLTRHKAIHTGEKPYKCEECGKAFSHFSALRRHKIIHTGKKPYKCEECGKAFSHFSALRRHKIIHTGEKPYKCEECGKAFKWSSKLTVHKVIHTAEKPCKCEECGKSFKHFSALRKHKVIHTREKLYKCEECVKAFNSFSALMKHKVIHTGEKPYKCEECGKAFKWSSKLTVHKVIHTGEKPCKCEECGKAFKHFSALRKHKVIHTGKKPYKCEECGKAFSQSSSLRKHEIIHSGEKPYKCEECGKAFKWLSKLTVHKVIHTAEKPCKCEECGKAFKHFSALRKHKIIHTGKKPYKCEECGKAFNDSSTLMKHKIIHTGKKPYKCAECGKAFKQSSHLTRHKAIHTGEKPYKCEECGKDFNNSSTLKKHKLIHTREKLYKCEECVKAFNNFSALMKHKIIHTGEKPYKCEECGKAFKWSSKLTEHKVIHTGEKPCKCEECDKAFKHFSALRKHKVIHTGKKPYQCDECGKAFNNSSTLTKHKIIHTGEKPYKCEECGKAFSQSSILTKHKIIHSVEKPYKCEECGKAFNQSSHLTRHKTIHTGEKPYKCEECGKAFIQCSYLIRHKTIHTREKPTNVKKVPKLLSNPHTLLDKTIHTGEKPYKCEECAKAF>sp|O60765|Z354A_HUMAN Zinc finger protein 354A OS=Homo sapiens OX=9606GN=ZNF354A PE=1 SV=2MAAGQREARPQVSLTFEDVAVLFTRDEWRKLAPSQRNLYRDVMLENYRNLVSLGLPFTKPKVISLLQQGEDPWEVEKDGSGVSSLGSKSSHKTTKSTQTQDSSFQGLILKRSNRNVPWDLKLEKPYIYEGRLEKKQDKKGSFQIVSATHKKIPTIERSHKNTELSQNFSPKSVLIRQQILPREKTPPKCEIQGNSLKQNSQLLNQPKITADKRYKCSLCEKTFINTSSLRKHEKNHSGEKLFKCKECSKAFSQSSALIQHQITHTGEKPYICKECGKAFTLSTSLYKHLRTHTVEKSYRCKECGKSFSRRSGLFIHQKIHAEENPCKYNPGRKASSCSTSLSGCQRIHSRKKSYLCNECGNTFKSSSSLRYHQRIHTGEKPFKCSECGRAFSQSASLIQHERIHTGEKPYRCNECGKGFTSISRLNRHRIIHTGEKFYNCNECGKALSSHSTLIIHERIHTGEKPCKCKVCGKAFRQSSALIQHQRMHTGERPYKCNECGKTFRCNSSLSNHQRIHTGEKPYRCEECGISFGQSSALIQHRRIHTGEKPFKCNTCGKTFRQSSSRIAHQRIHTGEKPYECNTCGKLFNHRSSLTNHYKIHIEEDP>sp|Q92618|ZN516_HUMAN Zinc finger protein 516 OS=Homo sapiens OX=9606GN=ZNF516 PE=1 SV=1MDRNREAEMELRRGPSPTRAGRGHEVDGDKATCHTCCICGKSFPFQSSLSQHMRKHTGEKPYKCPYCDHRASQKGNLKIHIRSHRTGTLIQGHEPEAGEAPLGEMRASEGLDACASPTKSASACNRLLNGASQADGARVLNGASQADSGRVLLRSSKKGAEGSACAPGEAKAAVQCSFCKSQFERKKDLELHVHQAHKPFKCRLCSYATLREESLLSHIERDHITAQGPGSGEACVENGKPELSPGEFPCEVCGQAFSQTWFLKAHMKKHRGSFDHGCHICGRRFKEPWFLKNHMKAHGPKTGSKNRPKSELDPIATINNVVQEEVIVAGLSLYEVCAKCGNLFTNLDSLNAHNAIHRRVEASRTRAPAEEGAEGPSDTKQFFLQCLNLRPSAAGDSCPGTQAGRRVAELDPVNSYQAWQLATRGKVAEPAEYLKYGAWDEALAGDVAFDKDRREYVLVSQEKRKREQDAPAAQGPPRKRASGPGDPAPAGHLDPRSAARPNRRAAATTGQGKSSECFECGKIFRTYHQMVLHSRVHRRARRERDSDGDRAARARCGSLSEGDSASQPSSPGSACAAADSPGSGLADEAAEDSGEEGAPEPAPGGQPRRCCFSEEVTSTELSSGDQSHKMGDNASERDTGESKAGIAASVSILENSSRETSRRQEQHRFSMDLKMPAFHPKQEVPVPGDGVEFPSSTGAEGQTGHPAEKLSDLHNKEHSGGGKRALAPDLMPLDLSARSTRDDPSNKETASSLQAALVVHPCPYCSHKTYYPEVLWMHKRIWHRVSCNSVAPPWIQPNGYKSIRSNLVFLSRSGRTGPPPALGGKECQPLLLARFTRTQVPGGMPGSKSGSSPLGVVTKAASMPKNKESHSGGPCALWAPGPDGYRQTKPCHGQEPHGAATQGPLAKPRQEASSKPVPAPGGGGFSRSATPTPTVIARAGAQPSANSKPVEKFGVPPAGAGFAPTNKHSAPDSLKAKFSAQPQGPPPAKGEGGAPPLPPREPPSKAAQELRTLATCAAGSRGDAALQAQPGVAGAPPVLHSIKQEPVAEGHEKRLDILNIFKTYIPKDFATLYQGWGVSGPGLEHRGTLRTQARPGEFVCIECGKSFHQPGHLRAHMRAHSVVFESDGPRGSEVHTTSADAPKQGRDHSNTGTVQTVPLRKGT>sp|Q9UJN7|ZN391_HUMAN Zinc finger protein 391 OS=Homo sapiens OX=9606GN=ZNF391 PE=2 SV=2MESLRGNTAQGPTNEEDYKNEGQLSRQTKCPAQKKSSFENTVVRKVSVTLKEIFTGEEGPESSEFSLSPNLDAQQKIPKGHGSPISRKNSKDNSDLIKHQRLFSQRKPCKCNECEKAFSYQSDLLVHSRIHGGEKPFECNKCGKSFSRSTHLIEHQRTHTGEKPYECNECGKAFSRSTHLSLHQRIHTGEKPYECSECGKAFSRSTNLSQHQRTHTQERPYKCNECGKAFGDRSTIIQHQRIHTGENPYECSKCGKAFSWISSLTEHQRTHTGENPYECSECGKVFSRSSSLTEHQRIHSGEKPHECRVCGKGFSRSSSLIIHQRTHTGEKPYKCNDCGKAFCQSSTLIRHQHLHTKE>sp|P17036|ZNF3_HUMAN Zinc finger protein 3 OS=Homo sapiens OX=9606GN=ZNF3 PE=1 SV=3METQADLVSQEPQALLDSALPSKVPAFSDKDSLGDEMLAAALLKAKSQELVTFEDVAVYFIRKEWKRLEPAQRDLYRDVMLENYGNVFSLDRETRTENDQEISEDTRSHGVLLGRFQKDISQGLKFKEAYEREVSLKRPLGNSPGERLNRKMPDFGQVTVEEKLTPRGERSEKYNDFGNSFTVNSNLISHQRLPVGDRPHKCDECSKSFNRTSDLIQHQRIHTGEKPYECNECGKAFSQSSHLIQHQRIHTGEKPYECSDCGKTFSCSSALILHRRIHTGEKPYECNECGKTFSWSSTLTHHQRIHTGEKPYACNECGKAFSRSSTLIHHQRIHTGEKPYECNECGKAFSQSSHLYQHQRIHTGEKPYECMECGGKFTYSSGLIQHQRIHTGENPYECSECGKAFRYSSALVRHQRIHTGEKPLNGIGMSKSSLRVTTELNIREST>sp|P17036-2|ZNF3_HUMAN Isoform 2 of Zinc finger protein 3 OS=Homosapiens OX=9606 GN=ZNF3METQADLVSQEPQALLDSALPSKVPAFSDKDSLGDEMLAAALLKAKSQELVTFEDVAVYFIRKEWKRLEPAQRDLYRDVMLENYGNVFSLDWIHVCLTTQKVMLAWLTGTLSVAKGLCSSELASVEPPDTF>sp|Q15696|U2AFM_HUMAN U2 small nuclear ribonucleoprotein auxiliaryfactor 35 kDa subunit-related protein 2 OS=Homo sapiens OX=9606 GN=ZRSR2PE=1 SV=2MAAPEKMTFPEKPSHKKYRAALKKEKRKKRRQELARLRDSGLSQKEEEEDTFIEEQQLEEEKLLERERQRLHEEWLLREQKAQEEFRIKKEKEEAAKKRQEEQERKLKEQWEEQQRKEREEEEQKRQEKKEKEEALQKMLDQAENELENGTTWQNPEPPVDFRVMEKDRANCPFYSKTGACRFGDRCSRKHNFPTSSPTLLIKSMFTTFGMEQCRRDDYDPDASLEYSEEETYQQFLDFYEDVLPEFKNVGKVIQFKVSCNLEPHLRGNVYVQYQSEEECQAALSLFNGRWYAGRQLQCEFCPVTRWKMAICGLFEIQQCPRGKHCNFLHVFRNPNNEFWEANRDIYLSPDRTGSSFGKNSERRERMGHHDDYYSRLRGRRNPSPDHSYKRNGESERKSSRHRGKKSHKRTSKSRERHNSRSRGRNRDRSRDRSRGRGSRSRSRSRSRRSRRSRSQSSSRSRSRGRRRSGNRDRTVQSPKSK>sp|A0JD32|TV382_HUMAN T cell receptor alpha variable 38-2/delta variable8 OS=Homo sapiens OX=9606 GN=TRAV38-2DV8 PE=3 SV=1MACPGFLWALVISTCLEFSMAQTVTQSQPEMSVQEAETVTLSCTYDTSESDYYLFWYKQPPSRQMILVIRQEAYKQQNATENRFSVNFQKAAKSFSLKISDSQLGDAAMYFCAYRS>sp|P15313|VATB1_HUMAN V-type proton ATPase subunit B, kidney isoformOS=Homo sapiens OX=9606 GN=ATP6V1B1 PE=1 SV=3MAMEIDSRPGGLPGSSCNLGAAREHMQAVTRNYITHPRVTYRTVCSVNGPLVVLDRVKFAQYAEIVHFTLPDGTQRSGQVLEVAGTKAIVQVFEGTSGIDARKTTCEFTGDILRTPVSEDMLGRVFNGSGKPIDKGPVVMAEDFLDINGQPINPHSRIYPEEMIQTGISPIDVMNSIARGQKIPIFSAAGLPHNEIAAQICRQAGLVKKSKAVLDYHDDNFAIVFAAMGVNMETARFFKSDFEQNGTMGNVCLFLNLANDPTIERIITPRLALTTAEFLAYQCEKHVLVILTDMSSYAEALREVSAAREEVPGRRGFPGYMYTDLATIYERAGRVEGRGGSITQIPILTMPNDDITHPIPDLTGFITEGQIYVDRQLHNRQIYPPINVLPSLSRLMKSAIGEGMTRKDHGDVSNQLYACYAIGKDVQAMKAVVGEEALTSEDLLYLEFLQKFEKNFINQGPYENRSVFESLDLGWKLLRIFPKEMLKRIPQAVIDEFYSREGALQDLAPDTAL>sp|P21796|VDAC1_HUMAN Voltage-dependent anion-selective channel protein1 OS=Homo sapiens OX=9606 GN=VDAC1 PE=1 SV=2MAVPPTYADLGKSARDVFTKGYGFGLIKLDLKTKSENGLEFTSSGSANTETTKVTGSLETKYRWTEYGLTFTEKWNTDNTLGTEITVEDQLARGLKLTFDSSFSPNTGKKNAKIKTGYKREHINLGCDMDFDIAGPSIRGALVLGYEGWLAGYQMNFETAKSRVTQSNFAVGYKTDEFQLHTNVNDGTEFGGSIYQKVNKKLETAVNLAWTAGNSNTRFGIAAKYQIDPDACFSAKVNNSSLIGLGYTQTLKPGIKLTLSALLDGKNVNAGGHKLGLGLEFQA>sp|O95670|VATG2_HUMAN V-type proton ATPase subunit G 2 OS=Homo sapiensOX=9606 GN=ATP6V1G2 PE=1 SV=1MASQSQGIQQLLQAEKRAAEKVADARKRKARRLKQAKEEAQMEVEQYRREREHEFQSKQQAAMGSQGNLSAEVEQATRRQVQGMQSSQQRNRERVLAQLLGMVCDVRPQVHPNYRISA>sp|O95670-2|VATG2_HUMAN Isoform 2 of V-type proton ATPase subunit G 2OS=Homo sapiens OX=9606 GN=ATP6V1G2MASQSQGIQQLLQAEKRAAEKVADARKRKARRLKQATRRQVQGMQSSQQRNRERVLAQLLGMVCDVRPQVHPNYRISA>sp|O95670-3|VATG2_HUMAN Isoform 3 of V-type proton ATPase subunit G 2OS=Homo sapiens OX=9606 GN=ATP6V1G2MEVEQYRREREHEFQSKQQAAMGSQGNLSAEVEQATRRQVQGMQSSQQRNRERVLAQLLGMVCDVRPQVHPNYRISA>sp|Q7Z5L0|VMO1_HUMAN Vitelline membrane outer layer protein 1 homologOS=Homo sapiens OX=9606 GN=VMO1 PE=1 SV=1MERGAGAKLLPLLLLLRATGFTCAQTDGRNGYTAVIEVTSGGPWGDWAWPEMCPDGFFASGFSLKVEPPQGIPGDDTALNGIRLHCARGNVLGNTHVVESQSGSWGEWSEPLWCRGGAYLVAFSLRVEAPTTLGDNTAANNVRFRCSDGEELQGPGLSWGDFGDWSDHCPKGACGLQTKIQGPRGLGDDTALNDARLFCCRS>sp|Q7Z5L0-2|VMO1_HUMAN Isoform 2 of Vitelline membrane outer layerprotein 1 homolog OS=Homo sapiens OX=9606 GN=VMO1MERGAGAKLLPLLLLLRATGFTCAQTDGRNGYTAVIEVTSGGPWGDWAWPEMCPDGFFASGFSLKLGRME>sp|Q7Z5L0-3|VMO1_HUMAN Isoform 3 of Vitelline membrane outer layerprotein 1 homolog OS=Homo sapiens OX=9606 GN=VMO1MERGAGAKLLPLLLLLRATGFTCAQTDGRNGYTAVIEVTSGGPWGDWAWPEMCPDGFFASGFSLKVEPPQGIPGDDTALNGIRLHCARGNVLGNTHVLGRME>sp|Q7Z5L0-4|VMO1_HUMAN Isoform 4 of Vitelline membrane outer layerprotein 1 homolog OS=Homo sapiens OX=9606 GN=VMO1MERGAGAKLLPLLLLLRATGFTCAQTDGRNGYTAVIEVTSGGPWGDWAWPEMCPDGFFASGFSLKVEPPQGIPGDDTALNGIRLHCARGNVLGNTHVVESQSGRWGAGVEDPLG>sp|P63123|VPK18_HUMAN Endogenous retrovirus group K member 18 Proprotein OS=Homo sapiens OX=9606 GN=ERVK-18 PE=3 SV=1WASQVSENRPVCKAVIQGKQLEGLVDTGADVSIIALNQWPKNWPKQKTVTGLVGIVTASEVYQSTEILHCLGPHNQESTVQPMITSIPLNLWGRDLLQQWGAEITMTATLYSPMSQKIMTKMGYIPGKGLGKNEDGIKVPIEAKINHGREGTGYPF>sp|P54219|VMAT1_HUMAN Chromaffin granule amine transporter OS=Homosapiens OX=9606 GN=SLC18A1 PE=1 SV=1MLRTILDAPQRLLKEGRASRQLVLVVVFVALLLDNMLFTVVVPIVPTFLYDMEFKEVNSSLHLGHAGSSPHALASPAFSTIFSFFNNNTVAVEESVPSGIAWMNDTASTIPPPATEAISAHKNNCLQGTGFLEEEITRVGVLFASKAVMQLLVNPFVGPLTNRIGYHIPMFAGFVIMFLSTVMFAFSGTYTLLFVARTLQGIGSSFSSVAGLGMLASVYTDDHERGRAMGTALGGLALGLLVGAPFGSVMYEFVGKSAPFLILAFLALLDGALQLCILQPSKVSPESAKGTPLFMLLKDPYILVAAGSICFANMGVAILEPTLPIWMMQTMCSPKWQLGLAFLPASVSYLIGTNLFGVLANKMGRWLCSLIGMLVVGTSLLCVPLAHNIFGLIGPNAGLGLAIGMVDSSMMPIMGHLVDLRHTSVYGSVYAIADVAFCMGFAIGPSTGGAIVKAIGFPWLMVITGVINIVYAPLCYYLRSPPAKEEKLAILSQDCPMETRMYATQKPTKEFPLGEDSDEEPDHEE>sp|P54219-2|VMAT1_HUMAN Isoform 2 of Chromaffin granule aminetransporter OS=Homo sapiens OX=9606 GN=SLC18A1MLRTILDAPQRLLKEGRASRQLVLVVVFVALLLDNMLFTVVVPIVPTFLYDMEFKEVNSSLHLGHAGSSPHALASPAFSTIFSFFNNNTVAVEESVPSGIAWMNDTASTIPPPATEAISAHKNNCLQGTGFLEEEITRVGVLFASKAVMQLLVNPFVGPLTNRIGYHIPMFAGFVIMFLSTVMFAFSGTYTLLFVARTLQGIGSSFSSVAGLGMLASVYTDDHERGRAMGTALGGLALGLLVGAPFGSVMYEFVGKSAPFLILAFLALLDGALQLCILQPSKVSPESAKGTPLFMLLKDPYILVAAGSICFANMGVAILEPTLPIWMMQTMCSPKWQLGLAFLPASVSYLIGTNLFGVLANKMGRWLCSLIGMLVVGTSLLCVPLAHNIFGLIGPNAGLGLAIGMVDSSMMPIMGHLVDLRHTSVYGSVYAIADVAFCMGFAIGYSESGLPHGDPDVCNPEAHEGISSGGGQ>sp|P54219-3|VMAT1_HUMAN Isoform 3 of Chromaffin granule aminetransporter OS=Homo sapiens OX=9606 GN=SLC18A1MLRTILDAPQRLLKEGRASRQLVLVVVFVALLLDNMLFTVVVPIVPTFLYDMEFKEVNSSLHLGHAGSSPHALASPAFSTIFSFFNNNTVAVEESVPSGIAWMNDTASTIPPPATEAISAHKNNCLQGTGFLEEEITRVGVLFASKAVMQLLVNPFVGPLTNRIGYHIPMFAGFVIMFLSTVMFAFSGTYTLLFVARTLQGIGSSFSSVAGLGMLASVYTDDHERGRAMGTALGGLALGLLVGAPFGSVMYEFVGKSAPFLILAFLALLDGALQLCILQPSKVSPESAKGTPLFMLLKDPYILVAAGLAFLPASVSYLIGTNLFGVLANKMGRWLCSLIGMLVVGTSLLCVPLAHNIFGLIGPNAGLGLAIGMVDSSMMPIMGHLVDLRHTSVYGSVYAIADVAFCMGFAIGPSTGGAIVKAIGFPWLMVITGVINIVYAPLCYYLRSPPAKEEKLAILSQDCPMETRMYATQKPTKEFPLGEDSDEEPDHEE>sp|Q96NZ8|WFKN1_HUMAN WAP, Kazal, immunoglobulin, Kunitz and NTR domain-containing protein 1 OS=Homo sapiens OX=9606 GN=WFIKKN1 PE=1 SV=1MPALRPLLPLLLLLRLTSGAGLLPGLGSHPGVCPNQLSPNLWVDAQSTCERECSRDQDCAAAEKCCINVCGLHSCVAARFPGSPAAPTTAASCEGFVCPQQGSDCDIWDGQPVCRCRDRCEKEPSFTCASDGLTYYNRCYMDAEACLRGLHLHIVPCKHVLSWPPSSPGPPETTARPTPGAAPVPPALYSSPSPQAVQVGGTASLHCDVSGRPPPAVTWEKQSHQRENLIMRPDQMYGNVVVTSIGQLVLYNARPEDAGLYTCTARNAAGLLRADFPLSVVQREPARDAAPSIPAPAECLPDVQACTGPTSPHLVLWHYDPQRGGCMTFPARGCDGAARGFETYEACQQACARGPGDACVLPAVQGPCRGWEPRWAYSPLLQQCHPFVYGGCEGNGNNFHSRESCEDACPVPRTPPCRACRLRSKLALSLCRSDFAIVGRLTEVLEEPEAAGGIARVALEDVLKDDKMGLKFLGTKYLEVTLSGMDWACPCPNMTAGDGPLVIMGEVRDGVAVLDAGSYVRAASEKRVKKILELLEKQACELLNRFQD>sp|Q8TF30|WHAMM_HUMAN WASP homolog-associated protein with actin,membranes and microtubules OS=Homo sapiens OX=9606 GN=WHAMM PE=1 SV=2MEDEQPDSLEGWVPVREGLFAEPERHRLRFLVAWNGAEGKFAVTCHDRTAQQRRLREGARLGPEPEPKPEAAVSPSSWAGLLSAAGLRGAHRQLAALWPPLERCFPRLPPELDVGGGGAWGLGLGLWALLWPTRAGPGEAALQELCGQLERYLGAAADGCGGATVRDALFPAEGGAADCESPREFRERALRARWVEADARLRQVIQGHGKANTMVALMNVYQEEDEAYQELVTVATMFFQYLLQPFRAMREVATLCKLDILKSLDEDDLGPRRVVALEKEAEEWTRRAEEAVVSIQDITVNYFKETVKALAGMQKEMEQDAKRFGQAAWATAIPRLEKLQLMLARETLQLMRAKELCLNHKRAEIQGKMEDLPEQEKNTNVVDELEIQFYEIQLELYEVKFEILKNEEILLTTQLDSLKRLIKEKQDEVVYYDPCENPEELKVIDCVVGLQDDKNLEVKELRRQCQQLESKRGRICAKRASLRSRKDQCKENHRFRLQQAEESIRYSRQHHSIQMKRDKIKEEEQKKKEWINQERQKTLQRLRSFKDKRLAQSVRNTSGSEPVAPNLPSDLSQQMCLPASHAVSVIHPSSRKTRGVPLSEAGNVKSPKCQNCHGNIPVQVFVPVGDQTHSKSSEELSLPPPPPPPPPPPPPPPPPPPPLRALSSSSQAATHQNLGFRAPVKDDQPRPLVCESPAERPRDSLESFSCPGSMDEVLASLRHGRAPLRKVEVPAVRPPHASINEHILAAIRQGVKLKKVHPDLGPNPSSKPTSNRRTSDLERSIKAALQRIKRVSADSEEDSDEQDPGQWDG>sp|P63119|VPK21_HUMAN Endogenous retrovirus group K member 21 Proprotein OS=Homo sapiens OX=9606 GN=ERVK-21 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPTPLYSPTSQKIMTKMGYIPGKGLGKNEDGIKVPVEAKINQKREGIGYPF>sp|B2RUY7|VWC2L_HUMAN von Willebrand factor C domain-containing protein2-like OS=Homo sapiens OX=9606 GN=VWC2L PE=1 SV=1MALHIHEACILLLVIPGLVTSAAISHEDYPADEGDQISSNDNLIFDDYRGKGCVDDSGFVYKLGERFFPGHSNCPCVCALDGPVCDQPECPKIHPKCTKVEHNGCCPECKEVKNFCEYHGKNYKILEEFKPSPCEWCRCEPSNEVHCVVADCAVPECVNPVYEPEQCCPVCKNGPNCFAGTTIIPAGIEVKVDECNICHCHNGDWWKPAQCSKRECQGKQTV>sp|B2RUY7-2|VWC2L_HUMAN Isoform 2 of von Willebrand factor C domain-containing protein 2-like OS=Homo sapiens OX=9606 GN=VWC2LMALHIHEACILLLVIPGLVTSAAISHEDYPADEGDQISSNDNLIFDDYRGKGCVDDSGFVYKLGERFFPGHSNCPCVCALDGPVCDQPECPKIHPKCTKVEHNGCCPECKEVKNFCEYHGKNYKILEEFKVCVTLHIY>sp|Q9H269|VPS16_HUMAN Vacuolar protein sorting-associated protein 16homolog OS=Homo sapiens OX=9606 GN=VPS16 PE=1 SV=2MDCYTANWNPLGDSAFYRKYELYSMDWDLKEELRDCLVAAAPYGGPIALLRNPWRKEKAASVRPVLDIYSASGMPLASLLWKSGPVVSLGWSAEEELLCVQEDGAVLVYGLHGDFRRHFSMGNEVLQNRVLDARIFHTEFGSGVAILTGAHRFTLSANVGDLKLRRMPEVPGLQSAPSCWTVLCQDRVAHILLAVGPDLYLLDHAACSAVTPPGLAPGVSSFLQMAVSFTYRHLALFTDTGYIWMGTASLKEKLCEFNCNIRAPPKQMVWCSRPRSKERAVVVAWERRLMVVGDAPESIQFVLDEDSYLVPELDGVRIFSRSTHEFLHEVPAASEEIFKIASMAPGALLLEAQKEYEKESQKADEYLREIQELGQLTQAVQQCIEAAGHEHQPDMQKSLLRAASFGKCFLDRFPPDSFVHMCQDLRVLNAVRDYHIGIPLTYSQYKQLTIQVLLDRLVLRRLYPLAIQICEYLRLPEVQGVSRILAHWACYKVQQKDVSDEDVARAINQKLGDTPGVSYSDIAARAYGCGRTELAIKLLEYEPRSGEQVPLLLKMKRSKLALSKAIESGDTDLVFTVLLHLKNELNRGDFFMTLRNQPMALSLYRQFCKHQELETLKDLYNQDDNHQELGSFHIRASYAAEERIEGRVAALQTAADAFYKAKNEFAAKATEDQMRLLRLQRRLEDELGGQFLDLSLHDTVTTLILGGHNKRAEQLARDFRIPDKRLWWLKLTALADLEDWEELEKFSKSKKSPIGYLPFVEICMKQHNKYEAKKYASRVGPEQKVKALLLVGDVAQAADVAIEHRNEAELSLVLSHCTGATDGATADKIQRARAQAQKK>sp|Q9H269-2|VPS16_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 16 homolog OS=Homo sapiens OX=9606 GN=VPS16MDCYTANWNPLGDSAFYRKYELYSMDWDLKEELRDCLVAAAPYGGPIALLRNPWRKEKAASVRPVLDIYSASGMPLASLLWKSGPVVSLGWSAEEELLCVQEDGAVLVYGLHGDFRRHFSMGNEVLQNRVLDARIFHTEFGSGVAILTGAHRFTLSANVGDLKLRRMPEVPGLQSAPSCWTVLCQDRVAHILLAVGPDLYLLDHAACSAVTPPGLAPGVSSFLQMAVSFTYRHLALFTDTGYIWMGTASLKEKLCEFNCNIRAPPKQMVWCSRPRSKERAVVVAWERRLMVVGDAPESIQYKQLTIQVLLDRLVLRRLYPLAIQICEYLRLPEVQGVSRILAHWACYKVQQKDVSDEDVARAINQKLGDTPGVSYSDIAARAYGCGRTELAIKLLEYEPRSGEQVPLLLKMKRSKLALSKAIESGDTDLVFTVLLHLKNELNRGDFFMTLRNQPMALSLYRQFCKHQELETLKDLYNQDDNHQELGSFHIRASYAAEERIEGRVAALQTAADAFYKAKNEFAAKATEDQMRLLRLQRRLEDELGGQFLDLSLHDTVTTLILGGHNKRAEQLARDFRIPDKRLWWLKLTALADLEDWEELEKFSKSKKSPIGYLPFVEICMKQHNKYEAKKYASRVGPEQKVKALLLVGDVAQAADVAIEHRNEAELSLVLSHCTGATDGATADKIQRARAQAQKK>sp|Q9BYP7|WNK3_HUMAN Serine/threonine-protein kinase WNK3 OS=Homosapiens OX=9606 GN=WNK3 PE=1 SV=3MATDSGDPASTEDSEKPDGISFENRVPQVAATLTVEARLKEKNSTFSASGETVERKRFFRKSVEMTEDDKVAESSPKDERIKAAMNIPRVDKLPSNVLRGGQEVKYEQCSKSTSEISKDCFKEKNEKEMEEEAEMKAVATSPSGRFLKFDIELGRGAFKTVYKGLDTETWVEVAWCELQDRKLTKAEQQRFKEEAEMLKGLQHPNIVRFYDSWESILKGKKCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLMRTSFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTSGIKPASFNKVTDPEVKEIIEGCIRQNKSERLSIRDLLNHAFFAEDTGLRVELAEEDDCSNSSLALRLWVEDPKKLKGKHKDNEAIEFSFNLETDTPEEVAYEMVKSGFFHESDSKAVAKSIRDRVTPIKKTREKKPAGCLEERRDSQCKSMGNVFPQPQNTTLPLAPAQQTGAECEETEVDQHVRQQLLQRKPQQHCSSVTGDNLSEAGAASVIHSDTSSQPSVAYSSNQTMGSQMVSNIPQAEVNVPGQIYSSQQLVGHYQQVSGLQKHSKLTQPQILPLVQGQSTVLPVHVLGPTVVSQPQVSPLTVQKVPQIKPVSQPVGAEQQAALLKPDLVRSLNQDVATTKENVSSPDNPSGNGKQDRIKQRRASCPRPEKGTKFQLTVLQVSTSGDNMVECQLETHNNKMVTFKFDVDGDAPEDIADYMVEDNFVLESEKEKFVEELRAIVGQAQEILHVHFATERATGVDSITVDSNSSQTGSSEQVQINSTSTQTSNESAPQSSPVGRWRFCINQTIRNRETQSPPSLQHSMSAVPGRHPLPSPKNTSNKEISRDTLLTIENNPCHRALFTSKSEHKDVVDGKISECASVETKQPAILYQVEDNRQIMAPVTNSSSYSTTSVRAVPAECEGLTKQASIFIPVYPCHQTASQADALMSHPGESTQTSGNSLTTLAFDQKPQTLSVQQPAMDAEFISQEGETTVNTEASSPKTVIPTQTPGLEPTTLQPTTVLESDGERPPKLEFADNRIKTLDEKLRNLLYQEHSISSIYPESQKDTQSIDSPFSSSAEDTLSCPVTEVIAISHCGIKDSPVQSPNFQQTGSKLLSNVAASQPANISVFKRDLNVITSVPSELCLHEMSSDASLPGDPEAYPAAVSSGGAIHLQTGGGYFGLSFTCPSLKNPISKKSWTRKLKSWAYRLRQSTSFFKRSKVRQVETEEMRSAIAPDPIPLTRESTADTRALNRCKAMSGSFQRGRFQVITIPQQQSAKMTSFGIEHISVFSETNHSSEEAFIKTAKSQLVEIEPATQNPKTSFSYEKLQALQETCKENKGVPKQGDNFLSFSAACETDVSSVTPEKEFEETSATGSSMQSGSELLLKEREILTAGKQPSSDSEFSASLAGSGKSVAKTGPESNQCLPHHEEQAYAQTQSSLFYSPSSPMSSDDESEIEDEDLKVELQRLREKHIQEVVNLQTQQNKELQELYERLRSIKDSKTQSTEIPLPPASPRRPRSFKSKLRSRPQSLTHVDNGIVATGKSCLINELENPLCVESNAASCQQSPASKKGMFTDDLHKLVDDWTKEAVGNSLIKPSLNQLKQSQHKLETENWNKVSENTPSTMGYTSTWISSLSQIRGAVPTSLPQGLSLPSFPGPLSSYGMPHVCQYNAVAGAGYPVQWVGISGTTQQSVVIPAQSGGPFQPGMNMQAFPTSSVQNPATIPPGPK>sp|Q9BYP7-2|WNK3_HUMAN Isoform 2 of Serine/threonine-protein kinase WNK3OS=Homo sapiens OX=9606 GN=WNK3MATDSGDPASTEDSEKPDGISFENRVPQVAATLTVEARLKEKNSTFSASGETVERKRFFRKSVEMTEDDKVAESSPKDERIKAAMNIPRVDKLPSNVLRGGQEVKYEQCSKSTSEISKDCFKEKNEKEMEEEAEMKAVATSPSGRFLKFDIELGRGAFKTVYKGLDTETWVEVAWCELQDRKLTKAEQQRFKEEAEMLKGLQHPNIVRFYDSWESILKGKKCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLMRTSFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTSGIKPASFNKVTDPEVKEIIEGCIRQNKSERLSIRDLLNHAFFAEDTGLRVELAEEDDCSNSSLALRLWVEDPKKLKGKHKDNEAIEFSFNLETDTPEEVAYEMVKSGFFHESDSKAVAKSIRDRVTPIKKTREKKPAGCLEERRDSQCKSMGNVFPQPQNTTLPLAPAQQTGAECEETEVDQHVRQQLLQRKPQQHCSSVTGDNLSEAGAASVIHSDTSSQPSVAYSSNQTMGSQMVSNIPQAEVNVPGQIYSSQQLVGHYQQVSGLQKHSKLTQPQILPLVQGQSTVLPVHVLGPTVVSQPQVSPLTVQKVPQIKPVSQPVGAEQQAALLKPDLVRSLNQDVATTKENVSSPDNPSGNGKQDRIKQRRASCPRPEKGTKFQLTVLQVSTSGDNMVECQLETHNNKMVTFKFDVDGDAPEDIADYMVEDNFVLESEKEKFVEELRAIVGQAQEILHVHFATERATGVDSITVDSNSSQTGSSEQVQINSTSTQTSNESAPQSSPVGRWRFCINQTIRNRETQSPPSLQHSMSAVPGRHPLPSPKNTSNKEISRDTLLTIENNPCHRALFTSKSEHKDVVDGKISECASVETKQPAILYQVEDNRQIMAPVTNSSSYSTTSVRAVPAECEGLTKQASIFIPVYPCHQTASQADALMSHPGESTQTSGNSLTTLAFDQKPQTLSVQQPAMDAEFISQEGETTVNTEASSPKTVIPTQTPGLEPTTLQPTTVLESDGERPPKLEFADNRIKTLDEKLRNLLYQEHSISSIYPESQKDTQSIDSPFSSSAEDTLSCPVTEVIAISHCGIKDSPVQSPNFQQTGSKLLSNVAASQPANISVFKRDLNVITSVPSELCLHEMSSDASLPGDPEAYPAAVSSGGAIHLQTGGGYFGLSFTCPSLKNPISKKSWTRKLKSWAYRLRQSTSFFKRSKVRQVETEEMRSAIAPDPIPLTRESTADTRALNRCKAMSGSFQRGRFQVITIPQQQSAKMTSFGIEHISVFSETNHSSEEAFIKTAKSQLVEIEPATQNPKTSFSYEKLQALQETCKENKGVPKQGDNFLSFSAACETDVSSVTPEKEFEETSATGSSMQSGSELLLKEREILTAGKQPSSDSEFSASLAGSGKSVAKTGPESNQCLPHHEEQAYAQTQSSLFYSPSSPMSSDDESEIEDEDLKVELQRLREKHIQEVVNLQTQQNKELQELYERLRSIKDSKTQSTEIPLPPASPRRPRSFKSKLRSRPQSLTHVDNGIVATDPLCVESNAASCQQSPASKKGMFTDDLHKLVDDWTKEAVGNSLIKPSLNQLKQSQHKLETENWNKVSENTPSTMGYTSTWISSLSQIRGAVPTSLPQGLSLPSFPGPLSSYGMPHVCQYNAVAGAGYPVQWVGISGTTQQSVVIPAQSGGPFQPGMNMQAFPTSSVQNPATIPPGPK>sp|Q9BYP7-3|WNK3_HUMAN Isoform 3 of Serine/threonine-protein kinase WNK3OS=Homo sapiens OX=9606 GN=WNK3MATDSGDPASTEDSEKPDGISFENRVPQVAATLTVEARLKEKNSTFSASGETVERKRFFRKSVEMTEDDKVAESSPKDERIKAAMNIPRVDKLPSNVLRGGQEVKYEQCSKSTSEISKDCFKEKNEKEMEEEAEMKAVATSPSGRFLKFDIELGRGAFKTVYKGLDTETWVEVAWCELQDRKLTKAEQQRFKEEAEMLKGLQHPNIVRFYDSWESILKGKKCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLMRTSFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTSGIKPASFNKVTDPEVKEIIEGCIRQNKSERLSIRDLLNHAFFAEDTGLRVELAEEDDCSNSSLALRLWVEDPKKLKGKHKDNEAIEFSFNLETDTPEEVAYEMVKSGFFHESDSKAVAKSIRDRVTPIKKTREKKPAGCLEERRDSQCKSMGNVFPQPQNTTLPLAPAQQTGAECEETEVDQHVRQQLLQRKPQQHCSSVTGDNLSEAGAASVIHSDTSSQPSVAYSSNQTMGSQMVSNIPQAEVNVPGQIYSSQQLVGHYQQVSGLQKHSKLTQPQILPLVQGQSTVLPVHVLGPTVVSQPQVSPLTVQKVPQIKPVSQPVGAEQQAALLKPDLVRSLNQDVATTKENVSSPDNPSGNGKQDRIKQRRASCPRPEKGTKFQLTVLQVSTSGDNMVECQLETHNNKMVTFKFDVDGDAPEDIADYMVEDNFVLESEKEKFVEELRAIVGQAQEILHVHFATERATGVDSITVDSNSSQTGSSEQVQINSTSTQTSNESAPQSSPVGRWRFCINQTIRNRETQSPPSLQHSMSAVPGRHPLPSPKNTSNKEISRDTLLTIENNPCHRALFTSKSEHKDVVDGKISECASVETKQPAILYQVEDNRQIMAPVTNSSSYSTTSVRAVPAECEGLTKQASIFIPVYPCHQTASQADALMSHPGESTQTSGNSLTTLAFDQKPQTLSVQQPAMDAEFISQEGETTVNTEASSPKTVIPTQTPGLEPTTLQPTTVLESDGERPPKLEFADNRIKTLDEKLRNLLYQEHSISSIYPESQKDTQSIDSPFSSSAEDTLSCPVTEVIAISHCGIKDSPVQSPNFQQTGSKLLSNVAASQPANISVFKRDLNVITSVPSELCLHEMSSDASLPGDPEAYPAAVSSGGAIHLQTGVETEEMRSAIAPDPIPLTRESTADTRALNRCKAMSGSFQRGRFQVITIPQQQSAKMTSFGIEHISVFSETNHSSEEAFIKTAKSQLVEIEPATQNPKTSFSYEKLQALQETCKENKGVPKQGDNFLSFSAACETDVSSVTPEKEFEETSATGSSMQSGSELLLKEREILTAGKQPSSDSEFSASLAGSGKSVAKTGPESNQCLPHHEEQAYAQTQSSLFYSPSSPMSSDDESEIEDEDLKVELQRLREKHIQEVVNLQTQQNKELQELYERLRSIKDSKTQSTEIPLPPASPRRPRSFKSKLRSRPQSLTHVDNGIVATDPLCVESNAASCQQSPASKKGMFTDDLHKLVDDWTKEAVGNSLIKPSLNQLKQSQHKLETENWNKVSENTPSTMGYTSTWISSLSQIRGAVPTSLPQGLSLPSFPGPLSSYGMPHVCQYNAVAGAGYPVQWVGISGTTQQSVVIPAQSGGPFQPGMNMQAFPTSSVQNPATIPPGPK>sp|Q9BYP7-4|WNK3_HUMAN Isoform 4 of Serine/threonine-protein kinase WNK3OS=Homo sapiens OX=9606 GN=WNK3MATDSGDPASTEDSEKPDGISFENRVPQVAATLTVEARLKEKNSTFSASGETVERKRFFRKSVEMTEDDKVAESSPKDERIKAAMNIPRVDKLPSNVLRGGQEVKYEQCSKSTSEISKDCFKEKNEKEMEEEAEMKAVATSPSGRFLKFDIELGRGAFKTVYKGLDTETWVEVAWCELQDRKLTKAEQQRFKEEAEMLKGLQHPNIVRFYDSWESILKGKKCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLMRTSFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTSGIKPASFNKVTDPEVKEIIEGCIRQNKSERLSIRDLLNHAFFAEDTGLRVELAEEDDCSNSSLALRLWVEDPKKLKGKHKDNEAIEFSFNLETDTPEEVAYEMVKSGFFHESDSKAVAKSIRDRVTPIKKTREKKPAGCLEERRDSQCKSMGNVFPQPQNTTLPLAPAQQTGAECEETEVDQHVRQQLLQRKPQQHCSSVTGDNLSEAGAASVIHSDTSSQPSVAYSSNQTMGSQMVSNIPQAEVNVPGQIYSSQQLVGHYQQVSGLQKHSKLTQPQILPLVQGQSTVLPVHVLGPTVVSQPQVSPLTVQKVPQIKPVSQPVGAEQQAALLKPDLVRSLNQDVATTKENVSSPDNPSGNGKQDRIKQRRASCPRPEKGTKFQLTVLQVSTSGDNMVECQLETHNNKMVTFKFDVDGDAPEDIADYMVEDNFVLESEKEKFVEELRAIVGQAQEILHVHFATERATGVDSITVDSNSSQTGSSEQVQINSTSTQTSNESAPQSSPVGRWRFCINQTIRNRETQSPPSLQHSMSAVPGRHPLPSPKNTSNKEISRDTLLTIENNPCHRALFTSKSEHKDVVDGKISECASVETKQPAILYQVEDNRQIMAPVTNSSSYSTTSVRAVPAECEGLTKQASIFIPVYPCHQTASQADALMSHPGESTQTSGNSLTTLAFDQKPQTLSVQQPAMDAEFISQEGETTVNTEASSPKTVIPTQTPGLEPTTLQPTTVLESDGERPPKLEFADNRIKTLDEKLRNLLYQEHSISSIYPESQKDTQSIDSPFSSSAEDTLSCPVTEVIAISHCGIKDSPVQSPNFQQTGSKLLSNVAASQPANISVFKRDLNVITSVPSELCLHEMSSDASLPGDPEAYPAAVSSGGAIHLQTGVETEEMRSAIAPDPIPLTRESTADTRALNRCKAMSGSFQRGRFQVITIPQQQSAKMTSFGIEHISVFSETNHSSEEAFIKTAKSQLVEIEPATQNPKTSFSYEKLQALQETCKENKGVPKQGDNFLSFSAACETDVSSVTPEKEFEETSATGSSMQSGSELLLKEREILTAGKQPSSDSEFSASLAGSGKSVAKTGPESNQCLPHHEEQAYAQTQSSLFYSPSSPMSSDDESEIEDEDLKVELQRLREKHIQEVVNLQTQQNKELQELYERLRSIKDSKTQSTEIPLPPASPRRPRSFKSKLRSRPQSLTHVDNGIVATGKSCLINELENPLCVESNAASCQQSPASKKGMFTDDLHKLVDDWTKEAVGNSLIKPSLNQLKQSQHKLETENWNKVSENTPSTMGYTSTWISSLSQIRGAVPTSLPQGLSLPSFPGPLSSYGMPHVCQYNAVAGAGYPVQWVGISGTTQQSVVIPAQSGGPFQPGMNMQAFPTSSVQNPATIPPGPK>sp|Q96QK1|VPS35_HUMAN Vacuolar protein sorting-associated protein 35OS=Homo sapiens OX=9606 GN=VPS35 PE=1 SV=2MPTTQQSPQDEQEKLLDEAIQAVKVQSFQMKRCLDKNKLMDALKHASNMLGELRTSMLSPKSYYELYMAISDELHYLEVYLTDEFAKGRKVADLYELVQYAGNIIPRLYLLITVGVVYVKSFPQSRKDILKDLVEMCRGVQHPLRGLFLRNYLLQCTRNILPDEGEPTDEETTGDISDSMDFVLLNFAEMNKLWVRMQHQGHSRDREKRERERQELRILVGTNLVRLSQLEGVNVERYKQIVLTGILEQVVNCRDALAQEYLMECIIQVFPDEFHLQTLNPFLRACAELHQNVNVKNIIIALIDRLALFAHREDGPGIPADIKLFDIFSQQVATVIQSRQDMPSEDVVSLQVSLINLAMKCYPDRVDYVDKVLETTVEIFNKLNLEHIATSSAVSKELTRLLKIPVDTYNNILTVLKLKHFHPLFEYFDYESRKSMSCYVLSNVLDYNTEIVSQDQVDSIMNLVSTLIQDQPDQPVEDPDPEDFADEQSLVGRFIHLLRSEDPDQQYLILNTARKHFGAGGNQRIRFTLPPLVFAAYQLAFRYKENSKVDDKWEKKCQKIFSFAHQTISALIKAELAELPLRLFLQGALAAGEIGFENHETVAYEFMSQAFSLYEDEISDSKAQLAAITLIIGTFERMKCFSEENHEPLRTQCALAASKLLKKPDQGRAVSTCAHLFWSGRNTDKNGEELHGGKRVMECLKKALKIANQCMDPSLQVQLFIEILNRYIYFYEKENDAVTIQVLNQLIQKIREDLPNLESSEETEQINKHFHNTLEHLRLRRESPESEGPIYEGLIL>sp|Q8NBI6|XXLT1_HUMAN Xyloside xylosyltransferase 1 OS=Homo sapiensOX=9606 GN=XXYLT1 PE=1 SV=1MGLLRGGLPCARAMARLGAVRSHYCALLLAAALAVCAFYYLGSGRETFSSATKRLKEARAGAPAAPSPPALELARGSVAPAPGAKAKSLEGGGAGPVDYHLLMMFTKAEHNAALQAKARVALRSLLRLAKFEAHEVLNLHFVSEEASREVAKGLLRELLPPAAGFKCKVIFHDVAVLTDKLFPIVEAMQKHFSAGLGTYYSDSIFFLSVAMHQIMPKEILQIIQLDLDLKFKTNIRELFEEFDSFLPGAIIGIAREMQPVYRHTFWQFRHENPQTRVGGPPPEGLPGFNSGVMLLNLEAMRQSPLYSRLLEPAQVQQLADKYHFRGHLGDQDFFTMIGMEHPKLFHVLDCTWNRQLCTWWRDHGYSDVFEAYFRCEGHVKIYHGNCNTPIPED>sp|Q8NBI6-2|XXLT1_HUMAN Isoform 2 of Xyloside xylosyltransferase 1OS=Homo sapiens OX=9606 GN=XXYLT1MWPPRCKDPGRQSAEILQIIQLDLDLKFKTNIRELFEEFDSFLPGAIIGIAREMQPVYRHTFWQFRHENPQTRVGGPPPEGLPGFNSGVMLLNLEAMRQSPLYSRLLEPAQVQQLADKYHFRGHLGDQDFFTMIGMEHPKLFHVLDCTWNRQLCTWWRDHGYSDVFEAYFRCEGHVKIYHGNCNTPIPED>sp|Q8NBI6-3|XXLT1_HUMAN Isoform 3 of Xyloside xylosyltransferase 1OS=Homo sapiens OX=9606 GN=XXYLT1MNGMSVLMKETLKSSVTPSPYEETGERQPSVNWAVSPHQTQNQWARWSWTSQPLELHTFWQFRHENPQTRVGGPPPEGLPGFNSGVMLLNLEAMRQSPLYSRLLEPAQVQQLADKYHFRGHLGDQDFFTMIGMEHPKLFHVLDCTWNRQLCTWWRDHGYSDVFEAYFRCEGHVKIYHGNCNTPIPED>sp|Q9UPY5|XCT_HUMAN Cystine/glutamate transporter OS=Homo sapiensOX=9606 GN=SLC7A11 PE=1 SV=1MVRKPVVSTISKGGYLQGNVNGRLPSLGNKEPPGQEKVQLKRKVTLLRGVSIIIGTIIGAGIFISPKGVLQNTGSVGMSLTIWTVCGVLSLFGALSYAELGTTIKKSGGHYTYILEVFGPLPAFVRVWVELLIIRPAATAVISLAFGRYILEPFFIQCEIPELAIKLITAVGITVVMVLNSMSVSWSARIQIFLTFCKLTAILIIIVPGVMQLIKGQTQNFKDAFSGRDSSITRLPLAFYYGMYAYAGWFYLNFVTEEVENPEKTIPLAICISMAIVTIGYVLTNVAYFTTINAEELLLSNAVAVTFSERLLGNFSLAVPIFVALSCFGSMNGGVFAVSRLFYVASREGHLPEILSMIHVRKHTPLPAVIVLHPLTMIMLFSGDLDSLLNFLSFARWLFIGLAVAGLIYLRYKCPDMHRPFKVPLFIPALFSFTCLFMVALSLYSDPFSTGIGFVITLTGVPAYYLFIIWDKKPRWFRIMSEKITRTLQIILEVVPEEDKL>sp|Q8TA94|ZN563_HUMAN Zinc finger protein 563 OS=Homo sapiens OX=9606GN=ZNF563 PE=1 SV=1MDAVAFEDVAVNFTQEEWALLGPSQKNLYRYVMQETIRNLDCIRMIWEEQNTEDQYKNPRRNLRCHMVERFSESKDSSQCGETFSLIRDSIVNNSICPGEDPCQSAECEEVIMGHLSLNSHIRVDSGHKPHEYQEYGEKPHTHKQRGKAFSYHHSFQSRGRPHTGKKRYECKECGKTFSSRRNLRRHMVVQGGNRPYKCKLCGKAFFWPSLLRMHERTHTGEKPYECKQCSKAFPFYSSYRRHERMHTGEKPYECKQCSKALPDSSSYIRHERTHTGEKPYTCKQCGKAFSVSSSLRRHETTHSAEKPYECKQCGKTFHHLGSFQIHMKRHTGDRPHKCKICGKGFDRPSLVRYHERIHTGEKPYECKQCGKTLSHSSSFRRHMIMHTGGGPHKCKICGKAFVYPSVCQRHEKSHSGEKPYECKQCGKALSHSSSFRRHMVMHTGDGPNKCKVCGKAFVYPSVCQRHEKTHWRETI>sp|Q8TA94-2|ZN563_HUMAN Isoform 2 of Zinc finger protein 563 OS=Homosapiens OX=9606 GN=ZNF563MDAVAFEDVAVNFTQEEWALLGPSQKNLYRYVMQETIRNLDCIRMIWEEQNTEDQYKNPRRNLRCHMVERFSESKDSSQCGETFSLIRDSIVNNSICPGEDPCQSAECEEVIMGHLSLNSHIRVDSGHKPHEYQEYGEKPHTHKQRGKAFSYHHSFQSRGRPHTGKKRYECKECGKTFSSRRNLRRHMVVQGGNRPYKFPIEDMRECTLGRNRMNVSSVLKPCLIPVP>sp|A8MT65|ZN891_HUMAN Zinc finger protein 891 OS=Homo sapiens OX=9606GN=ZNF891 PE=2 SV=2MAVMDLSSPWALTKQDSACFHLRNAEEERMIAVFLTTWLQEPMTFKDVAVEFTQEEWMMLDSAQRSLYRDVMLENYRNLTSVEYQLYRLTVISPLDQEEIRNMKKRIPQAICPDQKIQPKTKESTVQKILWEEPSNAVKMIKLTMHNWSSTLREDWECHKIRKQHKIPGGHWRQMIYAPKKTVPQELFRDYHELEENSKLGSKLIFSQSIFTSKHCQKCYSEIGCLKHNSIINNYVKNSISEKLYESHECDTTLWHFQRNQTVQKEYTYSKHGMHFTHNMFPVPNNLHMAQNACECNKDETLCHQSSLKKQGQTHTEKKHECNQCGKAFKRISNLTLYKKSHMGEKQYECKECGKVFNDSSTLRRHVRTHTGEKPYECNQCGKAFSQKTSLKAHMRTHTGEKPYECNQCGKSFGTSSYLIVHKRIHTGEKLYECSECGKAFNTSSHLKVHKKIHTGENVYECSDCGKVFSGVSSLRMHIRTHTGEKPYECKECRKAFSVSSSLRRHVRIHTGEKPYECIQCGKAFSQSSSLIIHKRIHTERETL>sp|Q562E7|WDR81_HUMAN WD repeat-containing protein 81 OS=Homo sapiensOX=9606 GN=WDR81 PE=1 SV=2MAQGSGGREGALRTPAGGWHSPPSPDMQELLRSVERDLSIDPRQLAPAPGGTHVVALVPARWLASLRDRRLPLGPCPRAEGLGEAEVRTLLQRSVQRLPAGWTRVEVHGLRKRRLSYPLGGGLPFEDGSCGPETLTRFMQEVAAQNYRNLWRHAYHTYGQPYSHSPAPSAVPALDSVRQALQRVYGCSFLPVGETTQCPSYAREGPCPPRGSPACPSLLRAEALLESPEMLYVVHPYVQFSLHDVVTFSPAKLTNSQAKVLFILFRVLRAMDACHRQGLACGALSLYHIAVDEKLCSELRLDLSAYERPEEDENEEAPVARDEAGIVSQEEQGGQPGQPTGQEELRSLVLDWVHGRISNFHYLMQLNRLAGRRQGDPNYHPVLPWVVDFTTPHGRFRDLRKSKFRLNKGDKQLDFTYEMTRQAFVAGGAGGGEPPHVPHHISDVLSDITYYVYKARRTPRSVLCGHVRAQWEPHEYPASMERMQNWTPDECIPEFYTDPSIFRSIHPDMPDLDVPAWCSSSQEFVAAHRALLESREVSRDLHHWIDLTFGYKLQGKEAVKEKNVCLHLVDAHTHLASYGVVQLFDQPHPQRLAGAPALAPEPPLIPKLLVQTIQETTGREDFTENPGQLPNGVGRPVLEATPCEASWTRDRPVAGEDDLEQATEALDSISLAGKAGDQLGSSSQASPGLLSFSVASASRPGRRNKAAGADPGEGEEGRILLPEGFNPMQALEELEKTGNFLAKGLGGLLEVPEQPRVQPAVPLQCLLHRDMQALGVLLAEMVFATRVRTLQPDAPLWVRFQAVRGLCTRHPKEVPVSLQPVLDTLLQMSGPEVPMGAERGKLDQLFEYRPVSQGLPPPCPSQLLSPFSSVVPFPPYFPALHRFILLYQARRVEDEAQGRELVFALWQQLGAVLKDITPEGLEILLPFVLSLMSEEHTAVYTAWYLFEPVAKALGPKNANKYLLKPLIGAYESPCQLHGRFYLYTDCFVAQLMVRLGLQAFLTHLLPHVLQVLAGAEASQEESKDLAGAAEEEESGLPGAGPGSCAFGEEIPMDGEPPASSGLGLPDYTSGVSFHDQADLPETEDFQAGLYVTESPQPQEAEAVSLGRLSDKSSTSETSLGEERAPDEGGAPVDKSSLRSGDSSQDLKQSEGSEEEEEEEDSCVVLEEEEGEQEEVTGASELTLSDTVLSMETVVAGGSGGDGEEEEEALPEQSEGKEQKILLDTACKMVRWLSAKLGPTVASRHVARNLLRLLTSCYVGPTRQQFTVSSGESPPLSAGNIYQKRPVLGDIVSGPVLSCLLHIARLYGEPVLTYQYLPYISYLVAPGSASGPSRLNSRKEAGLLAAVTLTQKIIVYLSDTTLMDILPRISHEVLLPVLSFLTSLVTGFPSGAQARTILCVKTISLIALICLRIGQEMVQQHLSEPVATFFQVFSQLHELRQQDLKLDPAGRGEGQLPQVVFSDGQQRPVDPALLDELQKVFTLEMAYTIYVPFSCLLGDIIRKIIPNHELVGELAALYLESISPSSRNPASVEPTMPGTGPEWDPHGGGCPQDDGHSGTFGSVLVGNRIQIPNDSRPENPGPLGPISGVGGGGLGSGSDDNALKQELPRSVHGLSGNWLAYWQYEIGVSQQDAHFHFHQIRLQSFPGHSGAVKCVAPLSSEDFFLSGSKDRTVRLWPLYNYGDGTSETAPRLVYTQHRKSVFFVGQLEAPQHVVSCDGAVHVWDPFTGKTLRTVEPLDSRVPLTAVAVMPAPHTSITMASSDSTLRFVDCRKPGLQHEFRLGGGLNPGLVRALAISPSGRSVVAGFSSGFMVLLDTRTGLVLRGWPAHEGDILQIKAVEGSVLVSSSSDHSLTVWKELEQKPTHHYKSASDPIHTFDLYGSEVVTGTVSNKIGVCSLLEPPSQATTKLSSENFRGTLTSLALLPTKRHLLLGSDNGVIRLLA>sp|Q562E7-2|WDR81_HUMAN Isoform 2 of WD repeat-containing protein 81OS=Homo sapiens OX=9606 GN=WDR81MDGEPPASSGLGLPDYTSGVSFHDQADLPETEDFQAGLYVTESPQPQEAEAVSLGRLSDKSSTYQYLPYISYLVAPGSASGPSRLNSRKEAGLLAAVTLTQKIIVYLSDTTLMDILPRISHEVLLPVLSFLTSLVTGFPSGAQARTILCVKTISLIALICLRIGQEMVQQHLSEPVATFFQVFSQLHELRQQDLKLDPAGRGEGQLPQVVFSDGQQRPVDPALLDELQKVFTLEMAYTIYVPFSCLLGDIIRKIIPNHELVGELAALYLESISPSSRNPASVEPTMPGTGPEWDPHGGGCPQDDGHSGTFGSVLVGNRIQIPNDSRPENPGPLGPISGVGGGGLGSGSDDNALKQELPRSVHGLSGNWLAYWQYEIGVSQQDAHFHFHQIRLQSFPGHSGAVKCVAPLSSEDFFLSGSKDRTVRLWPLYNYGDGTSETAPRLVYTQHRKSVFFVGQLEAPQHVVSCDGAVHVWDPFTGKTLRTVEPLDSRVPLTAVAVMPAPHTSITMASSDSTLRFVDCRKPGLQHEFRLGGGLNPGLVRALAISPSGRSVVAGFSSGFMVLLDTRTGLVLRGWPAHEGDILQIKAVEGSVLVSSSSDHSLTVWKELEQKPTHHYKSASDPIHTFDLYGSEVVTGTVSNKIGVCSLLEPPSQATTKLSSENFRGTLTSLALLPTKRHLLLGSDNGVIRLLA>sp|Q562E7-3|WDR81_HUMAN Isoform 3 of WD repeat-containing protein 81OS=Homo sapiens OX=9606 GN=WDR81MDGEPPASSGLGLPDYTSGVSFHDQADLPETEDFQAGLYVTESPQPQEAEAVSLGRLSDKSSTSETSLGEERAPDEGGAPVDKSSLRSGDSSQDLKQSEGSEEEEEEEDSCVVLEEEEGEQEEVTGASELTLSDTVLSMETVVAGGSGGDGEEEEEALPEQSEGKEQKILLDTACKMVRWLSAKLGPTVASRHVARNLLRLLTSCYVGPTRQQFTVSSGESPPLSAGNIYQKRPVLGDIVSGPVLSCLLHIARLYGEPVLTYQYLPYISYLVAPGSASGPSRLNSRKEAGLLAAVTLTQKIIVYLSDTTLMDILPRISHEVLLPVLSFLTSLVTGFPSGAQARTILCVKTISLIALICLRIGQEMVQQHLSEPVATFFQVFSQLHELRQQDLKLDPAGRGEGQLPQVVFSDGQQRPVDPALLDELQKVFTLEMAYTIYVPFSCLLGDIIRKIIPNHELVGELAALYLESISPSSRNPASVEPTMPGTGPEWDPHGGGCPQDDGHSGTFGSVLVGNRIQIPNDSRPENPGPLGPISGVGGGGLGSGSDDNALKQELPRSVHGLSGNWLAYWQYEIGVSQQDAHFHFHQIRLQSFPGHSGAVKCVAPLSSEDFFLSGSKDRTVRLWPLYNYGDGTSETAPRLVYTQHRKSVFFVGQLEAPQHVVSCDGAVHVWDPFTGKTLRTVEPLDSRVPLTAVAVMPAPHTSITMASSDSTLRFVDCRKPGLQHEFRLGGGLNPGLVRALAISPSGRSVVAGFSSGFMVLLDTRTGLVLRGWPAHEGDILQIKAVEGSVLVSSSSDHSLTVWKELEQKPTHHYKSASDPIHTFDLYGSEVVTGTVSNKIGVCSLLEPPSQATTKLSSENFRGTLTSLALLPTKRHLLLGSDNGVIRLLA>sp|Q562E7-4|WDR81_HUMAN Isoform 4 of WD repeat-containing protein 81OS=Homo sapiens OX=9606 GN=WDR81MAQGSGGREGALRTPAGGWHSPPSPDMQELLRSVERDLSIDPRQLAPAPGGTHVVALVPARWLASLRDRRLPLGPCPRAEGLGEAEVRTLLQRSVQRLPAGWTRVEVHGLRKRRLSYPLGGGLPFEDGSCGPETLTRFMQEVAAQNYRNLWRHAYHTYGQPYSHSPAPSAVPALDSVRQALQRVYGCSFLPVGETTQCPSYAREGPCPPRGSPACPSLLRAEALLESPEMLYVVHPYVQFSLHDVVTFSPAKLTNSQAKVLFILFRVLRAMDACHRQGLACGALSLYHIAVDEKLCSELRLDLSAYERPEEDENEEAPVARDEAGIVSQEEQGGQPGQPTGQEELRSLVLDWVHGRISNFHYLMQLNRLAGRRQGDPNYHPVLPWVVDFTTPHGRFRDLRKSKFRLNKGDKQLDFTYEMTRQAFVAGGAGGGEPPHVPHHISDVLSDITYYVYKARRTPRSVLCGHVRAQWEPHEYPASMERMQNWTPDECIPEFYTDPSIFRSIHPDMPDLDVPAWCSSSQEFVAAHRALLESREVSRDLHHWIDLTFGYKLQGKEAVKEKNVCLHLVDAHTHLASYGVVQLFDQPHPQRLAGAPALAPEPPLIPKLLVQTIQETTGREDFTENPGQLPNGVGRPVLEATPCEASWTRDRPVAGEDDLEQATEALDSISLAGKAGDQLGSSSQASPGLLSFSVASASRPGRRNKAAGADPGEGEEGRILLPEGFNPMQALEELEKTGNFLAKGLGGLLEVPEQPRVQPAVPLQCLLHRDMQALGVLLAEMVFATRVRTLQPDAPLWVRFQAVRGLCTRHPKEVPVSLQPVLDTLLQMSGPEVPMGAERGKLDQLFEYRPVSQGLPPPCPSQLLSPFSSVVPFPPYFPALHRFILLYQARRVEDEAQGRELVFALWQQLGAVLKDITPEGLEILLPFVLSLMSEEHTAVYTAWYLFEPVAKALGPKNANKYLLKPLIGAYESPCQLHGRFYLYTDCFVAQLMVRLGLQAFLTHLLPHVLQVLAGAEASQEESKDLAGAAEEEESGLPGAGPGSCAFGEEIPMDGEPPASSGLGLPDYTSGVSFHDQADLPETEDFQAGLYVTESPQPQEAEAVSLGRLSDKSSTSETSLGEERAPDEGGAPVDKSSLRSGDSSQDLKQSEGSEEEEEEEDSCVVLEEEEGEQEEVTGASELTLSDTVLSMETVVAGGSGGDGEEEEEALPEQSEGKEQKILLDTACKMVRWLSAKLGPTVASRHVARNLLRLLTSCYVGPTRQQFTVSSGESPPLSAGNIYQKRPVLGDIVSGPVLSCLLHIARLYGEPVLTYQYLPYISYLVAPGSASGPSRLNSRKEAGLLAAVTLTQKIIVYLSDTTLMDILPRISHEVLLPVLSFLTSLVTGFPSGAQARTILCVKTISLIALICLRIGQEMVQQHLSEPVATFFQVFSQLHELRQQDLKLDPAGRGEGQLPQVVFSDGQQRPVDPALLDELQKVFTLEMAYTIYVPFSCLLGDIIRKIIPNHELVGELAALYLESISPSSRNPASVEPTMPGTGPEWDPHGGGCPQDDGHSGTFGSVLVGNRIQIPNDSRPENPGPLGPISGVGGGGLGSGSDDNALKQELPRSVHGLSGNWLAYWQYEIGVSQQDAHFHFHQIRLQSFPGHSGAVKCVAPLSSEDFFLSGSKDRTVRLWPLYNYGDGTSETAPRLVYTQHRKSVFFVGQLEAPQHVVSCDGAVHVWDPFTGKTLRTVEPLDSRVPLTAVAVMPAPHTSITMASSDSTLRFVDCRKPGLQVRGVQFPEHSPGSLGTWQGGETPQKQKARMLFWGPS>sp|Q562E7-5|WDR81_HUMAN Isoform 5 of WD repeat-containing protein 81OS=Homo sapiens OX=9606 GN=WDR81MLVRVVLSLTPSFPEPSALYTACKMVRWLSAKLGPTVASRHVARNLLRLLTSCYVGPTRQQFTVSSGESPPLSAGNIYQKRPVLGDIVSGPVLSCLLHIARLYGEPVLTYQYLPYISYLVAPGSASGPSRLNSRKEAGLLAAVTLTQKIIVYLSDTTLMDILPRISHEVLLPVLSFLTSLVTGFPSGAQARTILCVKTISLIALICLRIGQEMVQQHLSEPVATFFQVFSQLHELRQQDLKLDPAGRGEGQLPQVVFSDGQQRPVDPALLDELQKVFTLEMAYTIYVPFSCLLGDIIRKIIPNHELVGELAALYLESISPSSRNPASVEPTMPGTGPEWDPHGGGCPQDDGHSGTFGSVLVGNRIQIPNDSRPENPGPLGPISGVGGGGLGSGSDDNALKQELPRSVHGLSGNWLAYWQYEIGVSQQDAHFHFHQIRLQSFPGHSGAVKCVAPLSSEDFFLSGSKDRTVRLWPLYNYGDGTSETAPRLVYTQHRKSVFFVGQLEAPQHVVSCDGAVHVWDPFTGKTLRTVEPLDSRVPLTAVAVMPAPHTSITMASSDSTLRFVDCRKPGLQHEFRLGGGLNPGLVRALAISPSGRSVVAGFSSGFMVLLDTRTGLVLRGWPAHEGDILQIKAVEGSVLVSSSSDHSLTVWKELEQKPTHHYKSASDPIHTFDLYGSEVVTGTVSNKIGVCSLLEPPSQATTKLSSENFRGTLTSLALLPTKRHLLLGSDNGVIRLLA>sp|Q562E7-6|WDR81_HUMAN Isoform 6 of WD repeat-containing protein 81OS=Homo sapiens OX=9606 GN=WDR81MVRWLSAKLGPTVASRHVARNLLRLLTSCYVGPTRQQFTVSSGESPPLSAGNIYQKRPVLGDIVSGPVLSCLLHIARLYGEPVLTYQYLPYISYLVAPGSASGPSRLNSRKEAGLLAAVTLTQKIIVYLSDTTLMDILPRISHEVLLPVLSFLTSLVTGFPSGAQARTILCVKTISLIALICLRIGQEMVQQHLSEPVATFFQVFSQLHELRQQDLKLDPAGRGEGQLPQVVFSDGQQRPVDPALLDELQKVFTLEMAYTIYVPFSCLLGDIIRKIIPNHELVGELAALYLESISPSSRNPASVEPTMPGTGPEWDPHGGGCPQDDGHSGTFGSVLVGNRIQIPNDSRPENPGPLGPISGVGGGGLGSGSDDNALKQELPRSVHGLSGNWLAYWQYEIGVSQQDAHFHFHQIRLQSFPGHSGAVKCVAPLSSEDFFLSGSKDRTVRLWPLYNYGDGTSETAPRLVYTQHRKSVFFVGQLEAPQHVVSCDGAVHVWDPFTGKTLRTVEPLDSRVPLTAVAVMPAPHTSITMASSDSTLRFVDCRKPGLQHEFRLGGGLNPGLVRALAISPSGRSVVAGFSSGFMVLLDTRTGLVLRGWPAHEGDILQIKAVEGSVLVSSSSDHSLTVWKELEQKPTHHYKSASDPIHTFDLYGSEVVTGTVSNKIGVCSLLEPPSQATTKLSSENFRGTLTSLALLPTKRHLLLGSDNGVIRLLA>sp|Q7Z5H5|VN1R4_HUMAN Vomeronasal type-1 receptor 4 OS=Homo sapiensOX=9606 GN=VN1R4 PE=2 SV=2MASRYVAVGMILSQTVVGVLGSFSVLLHYLSFYCTGCRLRSTDLIVKHLIVANFLALRCKGVPQTMAAFGVRYFLNALGCKLVFYLHRVGRGVSIGTTCLLSVFQVITVSSRKSRWAKLKEKAPKHVGFSVLLCWIVCMLVNIIFPMYVTGKWNYTNITVNEDLGYCSGGGNNKIAQTLRAMLLSFPDVLCLGLMLWVSSSMVCILHRHKQRVQHIDRSDLSPRASPENRATQSILILVSTFVSSYTLSCLFQVCMALLDNPNSLLVNTSALMSVCFPTLSPFVLMSCDPSVYRFCFAWKR>sp|Q96KV7|WDR90_HUMAN WD repeat-containing protein 90 OS=Homo sapiensOX=9606 GN=WDR90 PE=1 SV=2MARAWQHPFLNVFRHFRVDEWKRSAKQGDVAVVTDKTLKGAVYRIRGSVSAANYIQLPKSSTQSLGLTGRYLYVLFRPLPSKHFVIHLDVSSKDNQVIRVSFSNLFKEFKSTATWLQFPLVLEARTPQRDLVGLAPSGARWTCLQLDLQDVLLVYLNRCYGHLKSIRLCASLLVRNLYTSDLCFEPAISGAQWAKLPVTPMPREMAFPVPKGESWHDRYIHVRFPSESLKVPSKPIEKSCSPPEAVLLGPGPQPLPCPVASSKPVRFSVSPVVQTPSPTASGRAALAPRPFPEVSLSQERSDASNADGPGFHSLEPWAQLEASDIHTAAAGTHVLTHESAEVPVARTGSCEGFLPDPVLRLKGVIGFGGHGTRQALWTPDGAAVVYPCHAVIVVLLVDTGEQRFFLGHTDKVSALALDGSSSLLASAQARAPSVMRLWDFQTGRCLCLFRSPMHVVCSLSFSDSGALLCGVGKDHHGRTMVVAWGTGQVGLGGEVVVLAKAHTDFDVQAFRVTFFDETRMASCGQGSVRLWRLRGGVLRSCPVDLGEHHALQFTDLAFKQARDGCPEPSAAMLFVCSRSGHILEIDCQRMVVRHARRLLPTRTPGGPHPQKQTFSSGPGIAISSLSVSPAMCAVGSEDGFLRLWPLDFSSVLLEAEHEGPVSSVCVSPDGLRVLSATSSGHLGFLDTLSRVYHMLARSHTAPVLALAMEQRRGQLATVSQDRTVRIWDLATLQQLYDFTSSEDAPCAVTFHPTRPTFFCGFSSGAVRSFSLEAAEVLVEHTCHRGAVTGLTATPDGRLLFSSCSQGSLAQYSCADPQWHVLRVAADMVCPDAPASPSALAVSRDGRLLAFVGPSRCTVTVMGSASLDELLRVDIGTLDLASSRLDSAMAVCFGPAALGHLLVSTSSNRVVVLDAVSGRIIRELPGVHPEPCPSLTLSEDARFLLIAAGRTIKVWDYATQASPGPQVYIGHSEPVQAVAFSPDQQQVLSAGDAVFLWDVLAPTESDQSFPGAPPACKTGPGAGPLEDAASRASELPRQQVPKPCQASPPRLGVCARPPEGGDGARDTRNSGAPRTTYLASCKAFTPARVSCSPHSAKGTCPPPASGGWLRLKAVVGYSGNGRANMVWRPDTGFFAYTCGRLVVVEDLHSGAQQHWSGHSAEISTLALSHSAQVLASASGRSSTTAHCQIRVWDVSGGLCQHLIFPHSTTVLALAFSPDDRLLVTLGDHDGRTLALWGTATYDLVSSTRLPEPVHGVAFNPWDAGELTCVGQGTVTFWLLQQRGADISLQVRREPVPEAVGAGELTSLCYGAPPLLYCGTSSGQVCVWDTRAGRCFLSWEADDGGIGLLLFSGSRLVSGSSTGRLRLWAVGAVSELRCKGSGASSVFMEHELVLDGAVVSASFDDSVDMGVVGTTAGTLWFVSWAEGTSTRLISGHRSKVNEVVFSPGESHCATCSEDGSVRVWALASMELVIQFQVLNQSCLCLAWSPPCCGRPEQQRLAAGYGDGSLRIFSVSRTAMELKMHPHPVALTTVAFSTDGQTVLSGDKDGLVAVSHPCTGTTFRVLSDHQGAPISTICVTCKECEDLGVEGTDLWLAASGDQRVSVWASDWLRNHCELVDWLSFPMPATTETQGHLPPSLAAFCPWDGALLMYVGPGVYKEVIIYNLCQKQVVEKIPLPFFAMSLSLSPGTHLLAVGFAECMLRLVDCAMGTAQDFAGHDNAVHLCRFTPSARLLFTAARNEILVWEVPGL>sp|Q96KV7-10|WDR90_HUMAN Isoform 2 of WD repeat-containing protein 90OS=Homo sapiens OX=9606 GN=WDR90MLWFGQPGPGGWNRKCLRPFTLPRGQHPQPSYGFPQVNEVVFSPGESHCATCSEDGSVRVWALASMELVIQFQVLNQSCLCLAWSPPCCGRPEQQRLAAGYGDGSLRIFSVSRTAMELKMHPHPVALTTVAFSTDGQTVLSGDKDGLVAVSHPCTGTTFRVLSDHQGAPISTICVTCKECEDLGVEGTDLWLAASGDQRVSVWASDWLRNHCELVDWLSFPMPATTEVNHAPGTVGGAGTHPPHRSMLRLCRLRATWHPPSLPSALGMGRS>sp|Q96KV7-3|WDR90_HUMAN Isoform 3 of WD repeat-containing protein 90OS=Homo sapiens OX=9606 GN=WDR90MARAWQHPFLNVFRHFRVDEWKRSAKQGDVAVVTDKTLKGAVYRIRGSVSAANYIQLPKSSTQSLGLTGRYLYVLFRPLPSKHFVIHLDVSSKDNQVIRVSFSNLFKEFKSTATWLQFPLVLEARTPQRDLVGLAPSGARWTCLQLDLQDVLLVYLNRCYGHLKSIRLCASLLVRNLYTSDLCFEPAISGAQWAKLPVTPMPREMAFPVPKGESWHDRYIHVRFPSESLKVPSKPIEKSCSPPEAVLLGPGPQPLPCPVASSKPVRFSVSPVVQTPSPTASGRAALAPRPFPEVSLSQERSDASNADGPGFHSLEPWAQLEASDIHTAAAGTHVLTHESAEVPVARTGSCEGFLPDPVLRLKGVIGFGGHGTRQALWTPDGAAVVYPCHAVIVVLLVDTGEQRFFLGHTDKVSALALDGSSSLLASAQARAPSVMRLWDFQTGRCLCLFRSPMHVVCSLSFSDSGALLCGVGKDHHGRTMVVAWGTGQVGLGGEVVVLAKAHTDFDVQAFRVTFFDETRMASCGQGSVRLWRLRGGVLRSCPVDLGEHHALQFTDLAFKQARDGCPEPSAAMLFVCSRSGHILEIDCQRMVVRHARRLLPTRTPGGPHPQKQTFSSGPGIAISSLSVSPAMCAVGSEDGFLRLWPLDFSSVLLEAGDAVGTLSQLPESLAWMLGRGRPSPRGSAVSRPGSWLHRVPRGQVAYPEPWGG>sp|Q96KV7-7|WDR90_HUMAN Isoform 4 of WD repeat-containing protein 90OS=Homo sapiens OX=9606 GN=WDR90MLWFGQPGPGGWNRKCLRPFTLPRGQHPQPSYGFPQVNEVVFSPGESHCATCSEDGSVRVWALASMELVIQFQVLNQSCLCLAWSPPCCGRPEQQRLAAGYGDGSLRIFSVSRTAMELKMHPHPVALTTVAFSTDGQTVLSGDKDGLVAVSHPCTGTTFRVLSDHQGAPISTICVTCKETQGHLPPSLAAFCPWDGALLMYVGPGVYKEVIIYNLCQKQVVEKIPLPFFAMSLSLSPGTHLLAVGFAECMLRLVDCAMGTAQDFAGHDNAVHLCRFTPSARLLFTAARNEILVWEVPGL>sp|Q96KV7-5|WDR90_HUMAN Isoform 5 of WD repeat-containing protein 90OS=Homo sapiens OX=9606 GN=WDR90MARAWQHPFLNVFRHFRVDEWKRSAKQGDVAVVTDKTLKGAVYRIRGSVSAANYIQLPKSSTQSLGLTGRYLYVLFRPLPSKHFVIHLDVSSKDNQVIRVSFSNLFKEFKSTATWLQFPLVLEARTPQRDLVGLAPSGARWTCLQLDLQDVLLVYLNRCYGHLKSIRLCASLLVRNLYTSDLCFEPAISGAQWAKLPVTPMPREMAFPVPKGESWHDRYIHVRFPSESLKVPSKPIEKSCSPPEAVLLGPGPQPLPCPVASSKPVRFSVSPVVQTPSPTAQSGRAALAPRPFPEVSLSQERSDASNADGPGFHSLEPWAQLEASDIHTAAAGTHVLTHESAEVPVARTGSCEGFLPDPVLRLKGVIGFGGHGTRQALWTPDGAAVVYPCHAVIVVLLVDTGEQRFFLGHTDKVSALALDGSSSLLASAQARAPSVMRLWDFQTGRCLCLFRSPMHVVCSLSFSDSGALLCGVGKDHHGRTMVVAWGTGQVGLGGEVVVLAKAHTDFDVQAFRVTFFDETRMASCGQGSVRLWRLRGGVLRSCPVDLGEHHALQFTDLAFKQARDGCPEPSAAMLFVCSRSGHILEIDCQRMVVRHARRLLPTRTPGGPHPQKQTFSSGPGIAISSLSVSPAMCAVGSEDGFLRLWPLDFSSVLLEAGDAVGTLSQLPESLAWMLGRGRPSPRGSAVSRPGSWLHRVPRGQVAYPEPWGG>sp|A6NHS1|YK042_HUMAN Putative uncharacterized protein ENSP00000347057OS=Homo sapiens OX=9606 PE=5 SV=3MVLLAGTRPQGGEARCMIPPPPSPLLGAQVEEDRTEFKEFQDFSSLPDTRSVASDDSLYPFQDEEEHGVEGVESVPEEGILEAWGSCGRWCGVG>sp|Q9H7S9|ZN703_HUMAN Zinc finger protein 703 OS=Homo sapiens OX=9606GN=ZNF703 PE=1 SV=1MSDSPAGSNPRTPESSGSGSGGGGKRPAVPAAVSLLPPADPLRQANRLPIRVLKMLSAHTGHLLHPEYLQPLSSTPVSPIELDAKKSPLALLAQTCSQIGKPDPPPSSKLNSVAAAANGLGAEKDPGRSAPGAASAAAALKQLGDSPAEDKSSFKPYSKGSGGGDSRKDSGSSSVSSTSSSSSSSPGDKAGFRVPSAACPPFPPHGAPVSASSSSSSPGGSRGGSPHHSDCKNGGGVGGGELDKKDQEPKPSPEPAAVSRGGGGEPGAHGGAESGASGRKSEPPSALVGAGHVAPVSPYKPGHSVFPLPPSSIGYHGSIVGAYAGYPSQFVPGLDPSKSGLVGGQLSGGLGLPPGKPPSSSPLTGASPPSFLQGLCRDPYCLGGYHGASHLGGSSCSTCSAHDPAGPSLKAGGYPLVYPGHPLQPAALSSSAAQAALPGHPLYTYGFMLQNEPLPHSCNWVAASGPCDKRFATSEELLSHLRTHTALPGAEKLLAAYPGASGLGSAAAAAAAAASCHLHLPPPAAPGSPGSLSLRNPHTLGLSRYHPYGKSHLSTAGGLAVPSLPTAGPYYSPYALYGQRLASASALGYQ>sp|Q70YC5|ZN365_HUMAN Protein ZNF365 OS=Homo sapiens OX=9606 GN=ZNF365PE=1 SV=3MQQKAFEESRYPWQESFENVAVCLPLRCPRCGDHTRFRSLSSLRAHLEFSHSYEERTLLTKCSLFPSLKDTDLVTSSELLKPGKLQSSGNVVKQKPSYVNLYSISHEHSKDRKPFEVVAERPVSYVQTYTAMDLHADSLDGTRSGPGLPTSDTKASFEAHVREKFNRMVEAVDRTIEKRIDKLTKELAQKTAELLEVRAAFVQLTQKKQEVQRRERALNRQVDVAVEMIAVLRQRLTESEEELLRKEEEVVTFNHFLEAAAEKEVQGKARLQDFIENLLQRVELAEKQLEYYQSQQASGFVRDLSGHVLTDISSNRKPKCLSRGHPHSVCNHPDLKAHFHPKGRNHLKKAKDDRASMQPAKAIHEQAESSRDLCRPPKKGELLGFGRKGNIRPKMAKKKPTAIVNII>sp|Q70YC5-2|ZN365_HUMAN Isoform 2 of Protein ZNF365 OS=Homo sapiensOX=9606 GN=ZNF365MQQKAFEESRYPWQESFENVAVCLPLRCPRCGDHTRFRSLSSLRAHLEFSHSYEERTLLTKCSLFPSLKDTDLVTSSELLKPGKLQSSGNVVKQKPSYVNLYSISHEHSKDRKPFEVVAERPVSYVQTYTAMDLHADSLDGTRSGPGLPTSDTKASFEAHVREKFNRMVEAVDRTIEKRIDKLTKELAQKTAELLEVRAAFVQLTQKKQEVQRRERALNRQVDVAVEMIAVLRQRLTESEEELLRKEEEVVTFNHFLEAAAEKEVQGKARLQDFIENLLQRVELAEKQLEYYQSQQASGFVRDLSGHVSWKGAGEARLVCQNDLELEESAIVE>sp|Q70YC5-3|ZN365_HUMAN Isoform 3 of Protein ZNF365 OS=Homo sapiensOX=9606 GN=ZNF365MQQKAFEESRYPWQESFENVAVCLPLRCPRCGDHTRFRSLSSLRAHLEFSHSYEERTLLTKCSLFPSLKDTDLVTSSELLKPGKLQSSGNVVKQKPSYVNLYSISHEHSKDRKPFEVVAERPVSYVQTYTAMDLHADSLDGTRSGPGLPTSDTKASFEAHVREKFNRMVEAVDRTIEKRIDKLTKELAQKTAELLEVRAAFVQLTQKKQEVQRRERALNRQVDVAVEMIAVLRQRLTESEEELLRKEEEVVTFNHFLEAAAEKEVQGKARLQDFIENLLQRVELAEKQLEYYQSQQASGFVRDLSGHVSWKGAGEARLVCQNDLELEIFGHINHHLSGLKDSHCLVFLQAPPVPWIILASFLWILGNPWTSSTATAGFSQIWVLFPFCGGTFHHNEKDVLGLQDFERESVSTSQSRNISLLTLGQLQNCVIGKLTIIDLLTEHLLGVRHGVICFPWGLPSSS>sp|Q70YC5-4|ZN365_HUMAN Isoform 5 of Protein ZNF365 OS=Homo sapiensOX=9606 GN=ZNF365MTMRPPQSCEPTFRVMQQKAFEESRYPWQESFENVAVCLPLRCPRCGDHTRFRSLSSLRAHLEFSHSYEERTLLTKCSLFPSLKDTDLVTSSELLKPGKLQSSGNVVKQKPSYVNLYSISHEHSKDRKPFEVVAERPVSYVQTYTAMDLHADSLDGTRSGPGLPTSDTKASFEAHVREKFNRMVEAVDRTIEKRIDKLTKELAQKTAELLEVRAAFVQLTQKKQEVQRRERALNRQVDVAVEMIAVLRQRLTESEEELLRKEEEVVTFNHFLEAAAEKEVQGKARLQDFIENLLQRVELAEKQLEYYQSQQASGFVRDLSGHVLTDISSNRKPKCLSRGHPHSVCNHPDLKAHFHPKGRNHLKKAKDDRASMQPAKAIHEQAESSRDLCRPPKKGELLGFGRKGNIRPKMAKKKPTAIVNII>sp|Q70YC5-5|ZN365_HUMAN Isoform 6 of Protein ZNF365 OS=Homo sapiensOX=9606 GN=ZNF365MQPAKAIHEQAESSRDLCRPPKKGELLGFGRKGNIRPKMAKKKPTAIVNII>sp|Q3KP31|ZN791_HUMAN Zinc finger protein 791 OS=Homo sapiens OX=9606GN=ZNF791 PE=1 SV=1MDSVAFEDVSVSFSQEEWALLAPSQKKLYRDVMQETFKNLASIGEKWEDPNVEDQHKNQGRNLRSHTGERLCEGKEGSQCAENFSPNLSVTKKTAGVKPYECTICGKAFMRLSSLTRHMRSHTGYELFEKPYKCKECEKAFSYLKSFQRHERSHTGEKPYKCKQCGKTFIYHQPFQRHERTHIGEKPYECKQCGKALSCSSSLRVHERIHTGEKPYECKQCGKAFSCSSSIRVHERTHTGEKPYACKECGKAFISHTSVLTHMITHNGDRPYKCKECGKAFIFPSFLRVHERIHTGEKPYKCKQCGKAFRCSTSIQIHERIHTGEKPYKCKECGKSFSARPAFRVHVRVHTGEKPYKCKECGKAFSRISYFRIHERTHTGEKPYECKKCGKTFNYPLDLKIHKRNHTGEKPYECKECAKTFISLENFRRHMITHTGDGPYKCRDCGKVFIFPSALRTHERTHTGEKPYECKQCGKAFSCSSYIRIHKRTHTGEKPYECKECGKAFIYPTSFQGHMRMHTGEKPYKCKECGKAFSLHSSFQRHTRIHNYEKPLECKQCGKAFSVSTSLKKHMRMHNR>sp|Q3KP31-2|ZN791_HUMAN Isoform 2 of Zinc finger protein 791 OS=Homosapiens OX=9606 GN=ZNF791MQETFKNLASIGEKWEDPNVEDQHKNQGRNLRSHTGERLCEGKEGSQCAENFSPNLSVTKKTAGVKPYECTICGKAFMRLSSLTRHMRSHTGYELFEKPYKCKECEKAFSYLKSFQRHERSHTGEKPYKCKQCGKTFIYHQPFQRHERTHIGEKPYECKQCGKALSCSSSLRVHERIHTGEKPYECKQCGKAFSCSSSIRVHERTHTGEKPYACKECGKAFISHTSVLTHMITHNGDRPYKCKECGKAFIFPSFLRVHERIHTGEKPYKCKQCGKAFRCSTSIQIHERIHTGEKPYKCKECGKSFSARPAFRVHVRVHTGEKPYKCKECGKAFSRISYFRIHERTHTGEKPYECKKCGKTFNYPLDLKIHKRNHTGEKPYECKECAKTFISLENFRRHMITHTGDGPYKCRDCGKVFIFPSALRTHERTHTGEKPYECKQCGKAFSCSSYIRIHKRTHTGEKPYECKECGKAFIYPTSFQGHMRMHTGEKPYKCKECGKAFSLHSSFQRHTRIHNYEKPLECKQCGKAFSVSTSLKKHMRMHNR>sp|Q15326|ZMY11_HUMAN Zinc finger MYND domain-containing protein 11OS=Homo sapiens OX=9606 GN=ZMYND11 PE=1 SV=2MARLTKRRQADTKAIQHLWAAIEIIRNQKQIANIDRITKYMSRVHGMHPKETTRQLSLAVKDGLIVETLTVGCKGSKAGIEQEGYWLPGDEIDWETENHDWYCFECHLPGEVLICDLCFRVYHSKCLSDEFRLRDSSSPWQCPVCRSIKKKNTNKQEMGTYLRFIVSRMKERAIDLNKKGKDNKHPMYRRLVHSAVDVPTIQEKVNEGKYRSYEEFKADAQLLLHNTVIFYGADSEQADIARMLYKDTCHELDELQLCKNCFYLSNARPDNWFCYPCIPNHELVWAKMKGFGFWPAKVMQKEDNQVDVRFFGHHHQRAWIPSENIQDITVNIHRLHVKRSMGWKKACDELELHQRFLREGRFWKSKNEDRGEEEAESSISSTSNEQLKVTQEPRAKKGRRNQSVEPKKEEPEPETEAVSSSQEIPTMPQPIEKVSVSTQTKKLSASSPRMLHRSTQTTNDGVCQSMCHDKYTKIFNDFKDRMKSDHKRETERVVREALEKLRSEMEEEKRQAVNKAVANMQGEMDRKCKQVKEKCKEEFVEEIKKLATQHKQLISQTKKKQWCYNCEEEAMYHCCWNTSYCSIKCQQEHWHAEHKRTCRRKR>sp|Q15326-2|ZMY11_HUMAN Isoform 2 of Zinc finger MYND domain-containingprotein 11 OS=Homo sapiens OX=9606 GN=ZMYND11MARLTKRRQADTKAIQHLWAAIEIIRNQKQIANIDRITKYMSRVHGMHPKETTRQLSLAVKDGLIVETLTVGCKGSKAGIEQEGYWLPGDEISIKKKNTNKQEMGTYLRFIVSRMKERAIDLNKKGKDNKHPMYRRLVHSAVDVPTIQEKVNEGKYRSYEEFKADAQLLLHNTVIFYGADSEQADIARMLYKDTCHELDELQLCKNCFYLSNARPDNWFCYPCIPNHELVWAKMKGFGFWPAKVMQKEDNQVDVRFFGHHHQRAWIPSENIQDITVNIHRLHVKRSMGWKKACDELELHQRFLREGRFWKSKNEDRGEEEAESSISSTSNEQLKVTQEPRAKKGRRNQSVEPKKEEPEPETEAVSSSQEIPTMPQPIEKVSVSTQTKKLSASSPRMLHRSTQTTNDGVCQSMCHDKYTKIFNDFKDRMKSDHKRETERVVREALEKLRSEMEEEKRQAVNKAVANMQGEMDRKCKQVKEKCKEEFVEEIKKLATQHKQLISQTKKKQWCYNCEEEAMYHCCWNTSYCSIKCQQEHWHAEHKRTCRRKR>sp|Q15326-3|ZMY11_HUMAN Isoform 3 of Zinc finger MYND domain-containingprotein 11 OS=Homo sapiens OX=9606 GN=ZMYND11MARLTKRRQADTKAIQHLWAAIEIIRNQKQIANIDRITKYMSRVHGMHPKETTRQLSLAVKDGLIVETLTVGCKGSKAGIEQEGYWLPGDEIDWETENHDWYCFECHLPGEVLICDLCFRVYHSKCLSDEFRLRDSSSPWQCPVCRSIKKKNTNKQEMGTYLRFIVSRMKERAIDLNKKGKDNKHPMYRRLVHSAVDVPTIQEKVNEGKYRSYEEFKADAQLLLHNTVIFYGADSEQADIARMLYKDTCHELDELQLCKNCFYLSNARPDNWFCYPCIPNHELVWAKMKGFGFWPAKVMQKEDNQVDVRFFGHHHQRAWIPSENIQDITVNIHRLHVKRSMGWKKACDELELHQRFLREGRFWKSKNEDRGEEEAESSISSTSNEQLKVTQEPRAKKGRRNQSVEPKKEEPEPETEAVSSSQEIPTMPQPIEKVSVSTQTKKLSASSPRMLHRSTQTTNDGVCQSMCHDKYTKIFNDFKDRMKSDHKRETERVVREALEKLRSEMEEEKRQAVNKAVANMQGEMDRKCKQVKEKCKEEFVEEIKKLATQHKQLISQTKKKQWVNTSLF>sp|Q15326-4|ZMY11_HUMAN Isoform 4 of Zinc finger MYND domain-containingprotein 11 OS=Homo sapiens OX=9606 GN=ZMYND11MARLTKRRQADTKAIQHLWAAIEIIRNQKQIANIDRITKYMSRVHGMHPKETTRQLSLAVKDGLIVETLTVGCKGSKAGIEQEGYWLPGDEISIKKKNTNKQEMGTYLRFIVSRMKERAIDLNKKGKDNKHPMYRRLVHSAVDVPTIQEKVNEGKYRSYEEFKADAQLLLHNTVIFYGADSEQADIARMLYKDTCHELDELQLCKNCFYLSNARPDNWFCYPCIPNHELVWAKMKGFGFWPAKVMQKEDNQVDVRFFGHHHQRAWIPSENIQDITVNIHRLHVKRSMGWKKACDELELHQRFLREGRFWKSKNEDRGEEEAESSISSTSNEQLKVTQEPRAKKGRRNQSVEPKKEEPEPETEAVSSSQEIPTMPQPIEKVSVSTQTKKLSASSPRMLHRSTQTTNDGVCQSMCHDKYTKIFNDFKDRMKSDHKRETERVVREALEKLRSEMEEEKRQAVNKAVANMQGEMDRKCKQVKEKCKEEFVEEIKKLATQHKQLISQTKKKQWVNTSLF>sp|Q15326-5|ZMY11_HUMAN Isoform 5 of Zinc finger MYND domain-containingprotein 11 OS=Homo sapiens OX=9606 GN=ZMYND11MARLTKRRQADTKAIQHLWAAIEIIRNQKQIANIDRITKYMSRVHGMHPKETTRQLSLAVKDGLIVETLTVGCKGSKAGIEQEGYWLPGDEISIKKKNTNKQEMGTYLRFIVSRMKERKVNEGKYRSYEEFKADAQLLLHNTVIFYGADSEQADIARMLYKDTCHELDELQLCKNCFYLSNARPDNWFCYPCIPNHELVWAKMKGFGFWPAKVMQKEDNQVDVRFFGHHHQRAWIPSENIQDITVNIHRLHVKRSMGWKKACDELELHQRFLREGRFWKSKNEDRGEEEAESSISSTSNEQLKVTQEPRAKKGRRNQSVEPKKEEPEPETEAVSSSQEIPTMPQPIEKVSVSTQTKKLSASSPRMLHRSTQTTNDGVCQSMCHDKYTKIFNDFKDRMKSDHKRETERVVREALEKLRSEMEEEKRQAVNKAVANMQGEMDRKCKQVKEKCKEEFVEEIKKLATQHKQLISQTKKKQWCYNCEEEAMYHCCWNTSYCSIKCQQEHWHAEHKRTCRRKR>sp|Q15326-6|ZMY11_HUMAN Isoform 6 of Zinc finger MYND domain-containingprotein 11 OS=Homo sapiens OX=9606 GN=ZMYND11MARLTKRRQADTKAIQHLWAAIEIIRNQKQIANIDRITKYMSRVHGMHPKETTRQLSLAVKDGLIVETLTVGCKGSKAGIEQEGYWLPGDEIDWETENHDWYCFECHLPGEVLICDLCFRVYHSKCLSDEFRLRDSSSPWQCPVCRSIKKKNTNKQEMGTYLRFIVSRMKERAIDLNKKGKDNKHPMYRRLVHSAVDVPTIQEKVNEGKYRSYEEFKADAQLLLHNTVIFYGDSEQADIARMLYKDTCHELDELQLCKNCFYLSNARPDNWFCYPCIPNHELVWAKMKGFGFWPAKVMQKEDNQVDVRFFGHHHQRAWIPSENIQDITVNIHRLHVKRSMGWKKACDELELHQRFLREGRFWKSKNEDRGEEEAESSISSTSNEQLKVTQEPRAKKGRRNQSVEPKKEEPEPETEAVSSSQEIPTMPQPIEKVSVSTQTKKLSASSPRMLHRSTQTTNDGVCQSMCHDKYTKIFNDFKDRMKSDHKRETERVVREALEKLRSEMEEEKRQAVNKAVANMQGEMDRKCKQVKEKCKEEFVEEIKKLATQHKQLISQTKKKQWVNTSLF>sp|Q9Y3S2|ZN330_HUMAN Zinc finger protein 330 OS=Homo sapiens OX=9606GN=ZNF330 PE=1 SV=1MPKKKTGARKKAENRREREKQLRASRSTIDLAKHPCNASMECDKCQRRQKNRAFCYFCNSVQKLPICAQCGKTKCMMKSSDCVIKHAGVYSTGLAMVGAICDFCEAWVCHGRKCLSTHACACPLTDAECVECERGVWDHGGRIFSCSFCHNFLCEDDQFEHQASCQVLEAETFKCVSCNRLGQHSCLRCKACFCDDHTRSKVFKQEKGKQPPCPKCGHETQETKDLSMSTRSLKFGRQTGGEEGDGASGYDAYWKNLSSDKYGDTSYHDEEEDEYEAEDDEEEEDEGRKDSDTESSDLFTNLNLGRTYASGYAHYEEQEN>sp|Q96IT1|ZN496_HUMAN Zinc finger protein 496 OS=Homo sapiens OX=9606GN=ZNF496 PE=1 SV=1MPTALCPRVLAPKESEEPRKMRSPPGENPSPQGELPSPESSRRLFRRFRYQEAAGPREALQRLWDLCGGWLRPERHTKEQILELLVLEQFLAILPREIQSWVRAQEPESGEQAVAAVEALEREPGRPWQWLKHCEDPVVIDDGDSPLDQEQEQLPVEPHSDLAKNQDAQPITLAQCLGLPSRPPSQLSGDPVLQDAFLLQEENVRDTQQVTTLQLPPSRVSPFKDMILCFSEEDWSLLDPAQTGFYGEFIIGEDYGVSMPPNDLAAQPDLSQGEENEPRVPELQDLQGKEVPQVSYLDSPSLQPFQVEERRKREELQVPEFQACPQTVVPQNTYPAGGNPRSLENSLDEEVTIEIVLSSSGDEDSQHGPYCTEELGSPTEKQRSLPASHRSSTEAGGEVQTSKKSYVCPNCGKIFRWRVNFIRHLRSRREQEKPHECSVCGELFSDSEDLDGHLESHEAQKPYRCGACGKSFRLNSHLLSHRRIHLQPDRLQPVEKREQAASEDADKGPKEPLENGKAKLSFQCCECGKAFQRHDHLARHRSHFHLKDKARPFQCRYCVKSFTQNYDLLRHERLHMKRRSKQALNSY>sp|Q96IT1-2|ZN496_HUMAN Isoform 2 of Zinc finger protein 496 OS=Homosapiens OX=9606 GN=ZNF496MPTALCPRVLAPKESEEPRKMRSPPGENPSPQGELPSPESSRRLFRRFRYQEAAGPREALQRLWDLCGGWLRPERHTKEQILELLVLEQFLAILPREIQSWVRAQEPESGEQAVAAVEALEREPGRPWQWLKHCEDPVVIDDGDSPLDQEQEQLPVEPHSDLAKNQDAQPITLAQCLGLPSRPPSQLSGDPVLQDAFLLQEENVRDTQQVTTLQLPPRIFQFNNHRSNGYILEMLGSGGKKAQIISVLSQIYVSRVSPFKDMILCFSEEDWSLLDPAQTGFYGEFIIGEDYGVSMPPNDLAAQPDLSQGEENEPRVPELQDLQGKEVPQVSYLDSPSLQPFQVEERRKREELQVPEFQACPQTVVPQNTYPAGGNPRSLENSLDEEVTIEIVLSSSGDEDSQHGPYCTEELGSPTEKQRSLPASHRSSTEAGGEVQTSKKSYVCPNCGKIFRWRVNFIRHLRSRREQEKPHECSVCGELFSDSEDLDGHLESHEAQKPYRCGACGKSFRLNSHLLSHRRIHLQPDRLQPVEKREQAASEDADKGPKEPLENGKAKLSFQCCECGKAFQRHDHLARHRSHFHLKDKARPFQCRYCVKSFTQNYDLLRHERLHMKRRSKQALNSY>sp|Q9Y330|ZBT12_HUMAN Zinc finger and BTB domain-containing protein 12OS=Homo sapiens OX=9606 GN=ZBTB12 PE=1 SV=1MASGVEVLRFQLPGHEAATLRNMNQLRAEERFCDVTIVADSLKFRGHKVILAACSPFLRDQFLLNPSSELQVSLMHSARIVADLLLSCYTGALEFAVRDIVNYLTAASYLQMEHVVEKCRNALSQFIEPKIGLKEDGVSEASLVSSISATKSLLPPARTPKPAPKPPPPPPLPPPLLRPVKLEFPLDEDLELKAEEEDEDEDEDVSDICIVKVESALEVAHRLKPPGGLGGGLGIGGSVGGHLGELAQSSVPPSTVAPPQGVVKACYSLSEDAEGEGLLLIPGGRASVGATSGLVEAAAVAMAARGAGGSLGAGGSRGPLPGGFSGGNPLKNIKCTKCPEVFQGVEKLVFHMRAQHFIFMCPRCGKQFNHSSNLNRHMNVHRGVKSHSCGICGKCFTQKSTLHDHLNLHSGARPYRCSYCDVRFAHKPAIRRHLKEQHGKTTAENVLEASVAEINVLIR>sp|Q9BS34|ZN670_HUMAN Zinc finger protein 670 OS=Homo sapiens OX=9606GN=ZNF670 PE=1 SV=1MDSVSFEDVAVAFTQEEWALLDPSQKNLYRDVMQEIFRNLASVGNKSEDQNIQDDFKNPGRNLSSHVVERLFEIKEGSQYGETFSQDSNLNLNKKVSTGVKPCECSVCGKVFICHSALHRHILSHIGNKLFECEECPEKLYHCKQCGKAFISLTSVDRHMVTHTSNGPYKGPVYEKPFDFPSVFQMPQSTYTGEKTYKCKHCDKAFNYSSYLREHERTHTGEKPYACKKCGKSFTFSSSLRQHERSHTGEKPYECKECGKAFSRSTYLGIHERTHTGEKPYECIKCGKAFRCSRVLRVHERTHSGEKPYECKQCGKAFKYSSNLCEHERTHTGVKPYGCKECGKSFTSSSALRSHERTHTGEKPYECKKCGKAFSCSSSLRKHERAYMW>sp|Q6AZW8|ZN660_HUMAN Zinc finger protein 660 OS=Homo sapiens OX=9606GN=ZNF660 PE=1 SV=1MRRKTRNFKHKTVKDNKVLTEGSDQESEKDNSQCCDPATNERVQAEKRQYVCTECGKAFSQSANLTVHERIHTGEKPYKCKECGKAFSHSSNLVVHRRIHTGLKPYTCSECGKSFSGKSHLIRHQGIHSGEKTYECKECGKAFSRSSGLISHHRVHTGEKPYSCIECGKAFSRSSNLTQHQRMHRGKKVYKCKECGKTCGSNTKIMDHQRIHTGEKPYECDECGKTFILRKTLNEHQRLHRREKPYKCNECGKAFTSNRNLVDHQRVHTGEKPYKCNECGKTFRQTSQVILHLRTHTKEKPYKCSECGKAYRYSSQLIQHQRKHNEEKETS>sp|Q9H8X9|ZDH11_HUMAN Palmitoyltransferase ZDHHC11 OS=Homo sapiensOX=9606 GN=ZDHHC11 PE=1 SV=1MDTRSGSQCSVTPEAILNNEKLVLPPRISRVNGWSLPLHYFQVVTWAVFVGLSSATFGIFIPFLPHAWKYIAYVVTGGIFSFHLVVHLIASCIDPADSNVRLMKNYSQPMPLFDRSKHAHVIQNQFCHLCKVTVNKKTKHCISCNKCVSGFDHHCKWINNCVGSRNYWFFFSTVASATAGMLCLIAILLYVLVQYLVNPGVLRTDPRYEDVKNMNTWLLFLPLFPVQVQTLIVVIIGMLVLLLDFLGLVHLGQLLIFHIYLKAKKMTTFEYLINNRKEESSKHQAVRKDPYVQMDKGVLQQGAGALGSSAQGVKAKSSLLIHKHLCHFCTSVNQDGDSTAREGDEDPCPSALGAKARNSRLICRRLCQFSTRVHPDGGSMAQEADDAPSISTLGLQQETTEPMKTDSAESED>sp|Q9H8X9-2|ZDH11_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC11OS=Homo sapiens OX=9606 GN=ZDHHC11MNTWLLFLPLFPVQVQTLIVVIIGMLVLLLDFLGLVHLGQLLIFHIYLSMSPTLSPRSPQGWVVRAAHLTPLLEYVPNPEPPTPGARVFVPRVRMCSGSASPRSEIMDKKGKSQEEIKSMRTQQAQQEAELTPRPAGVVPGA>sp|P23396|RS3_HUMAN 40S ribosomal protein S3 OS=Homo sapiens OX=9606GN=RPS3 PE=1 SV=2MAVQISKKRKFVADGIFKAELNEFLTRELAEDGYSGVEVRVTPTRTEIIILATRTQNVLGEKGRRIRELTAVVQKRFGFPEGSVELYAEKVATRGLCAIAQAESLRYKLLGGLAVRRACYGVLRFIMESGAKGCEVVVSGKLRGQRAKSMKFVDGLMIHSGDPVNYYVDTAVRHVLLRQGVLGIKVKIMLPWDPTGKIGPKKPLPDHVSIVEPKDEILPTTPISEQKGGKPEPPAMPQPVPTA>sp|P23396-2|RS3_HUMAN Isoform 2 of 40S ribosomal protein S3 OS=Homosapiens OX=9606 GN=RPS3MAVQISKKRKFVADGIFKAELNEFLTRELAEDGYSGVEVRVTPTRTEIIILATRTQNVLGEKGRRIRELTAVVQKRFGFPEGSVELKIMVMVTGYPLLPLKLYAEKVATRGLCAIAQAESLRYKLLGGLAVRRACYGVLRFIMESGAKGCEVVVSGKLRGQRAKSMKFVDGLMIHSGDPVNYYVDTAVRHVLLRQGVLGIKVKIMLPWDPTGKIGPKKPLPDHVSIVEPKDEILPTTPISEQKGGKPEPPAMPQPVPTA>sp|Q8WW01|SEN15_HUMAN tRNA-splicing endonuclease subunit Sen15 OS=Homosapiens OX=9606 GN=TSEN15 PE=1 SV=1MEERGDSEPTPGCSGLGPGGVRGFGDGGGAPSWAPEDAWMGTHPKYLEMMELDIGDATQVYVAFLVYLDLMESKSWHEVNCVGLPELQLICLVGTEIEGEGLQTVVPTPITASLSHNRIREILKASRKLQGDPDLPMSFTLAIVESDSTIVYYKLTDGFMLPDPQNISLRR>sp|Q8WW01-2|SEN15_HUMAN Isoform 2 of tRNA-splicing endonuclease subunitSen15 OS=Homo sapiens OX=9606 GN=TSEN15MEERGDSEPTPGCSGLGPGGVRGFGDGGGAPSWAPEDAWMGTHPKYLEMMELDIGDATQVYVAFLVYLDLMESKSWHEVNCVGLPELQLICLVGTEIEGEGLQTVVPTPITASLSHNRIFLLEDDIHVS>sp|Q8IZQ5|SELH_HUMAN Selenoprotein H OS=Homo sapiens OX=9606 GN=SELENOHPE=1 SV=2MAPRGRKRKAEAAVVAVAEKREKLANGGEGMEEATVVIEHCTSURVYGRNAAALSQALRLEAPELPVKVNPTKPRRGSFEVTLLRPDGSSAELWTGIKKGPPRKLKFPEPQEVVEELKKYLS>sp|P55735|SEC13_HUMAN Protein SEC13 homolog OS=Homo sapiens OX=9606GN=SEC13 PE=1 SV=3MVSVINTVDTSHEDMIHDAQMDYYGTRLATCSSDRSVKIFDVRNGGQILIADLRGHEGPVWQVAWAHPMYGNILASCSYDRKVIIWREENGTWEKSHEHAGHDSSVNSVCWAPHDYGLILACGSSDGAISLLTYTGEGQWEVKKINNAHTIGCNAVSWAPAVVPGSLIDHPSGQKPNYIKRFASGGCDNLIKLWKEEEDGQWKEEQKLEAHSDWVRDVAWAPSIGLPTSTIASCSQDGRVFIWTCDDASSNTWSPKLLHKFNDVVWHVSWSITANILAVSGGDNKVTLWKESVDGQWVCISDVNKGQGSVSASVTEGQQNEQ>sp|P55735-2|SEC13_HUMAN Isoform 2 of Protein SEC13 homolog OS=Homosapiens OX=9606 GN=SEC13MIHDAQMDYYGTRLATCSSDRSVKIFDVRNGGQILIADLRGHEGPVWQVAWAHPMYGNILASCSYDRKVIIWREENGTWEKSHEHAGHDSSVNSVCWAPHDYGLILACGSSDGAISLLTYTGEGQWEVKKINNAHTIGCNAVSWAPAVVPGSLIDHPSGQKPNYIKRFASGGCDNLIKLWKEEEDGQWKEEQKLEAHSDWVRDVAWAPSIGLPTSTIASCSQDGRVFIWTCDDASSNTWSPKLLHKFNDVVWHVSWSITANILAVSGGDNKVTLWKESVDGQWVCISDVNKGQGSVSASVTEGQQNEQ>sp|P55735-3|SEC13_HUMAN Isoform 3 of Protein SEC13 homolog OS=Homosapiens OX=9606 GN=SEC13MREPVLTWCVPLELLCSHPLPLSAFLKSQVKLYTYRACAGKDEMGKMVSVINTVDTSHEDMIHDAQMDYYGTRLATCSSDRSVKIFDVRNGGQILIADLRGHEGPVWQVAWAHPMYGNILASCSYDRKVIIWREENGTWEKSHEHAGHDSSVNSVCWAPHDYGLILACGSSDGAISLLTYTGEGQWEVKKINNAHTIGCNAVSWAPAVVPGSLIDHPSGQKPNYIKRFASGGCDNLIKLWKEEEDGQWKEEQKLEAHSDWVRDVAWAPSIGLPTSTIASCSQDGRVFIWTCDDASSNTWSPKLLHKFNDVVWHVSWSITANILAVSGGDNKVTLWKESVDGQWVCISDVNKGQGSVSASVTEGQQNEQ>sp|P55735-4|SEC13_HUMAN Isoform 4 of Protein SEC13 homolog OS=Homosapiens OX=9606 GN=SEC13MGKMVSVINTVDTSHEDMIHDAQMDYYGTRLATCSSDRSVKIFDVRNGGQILIADLRGHEGPVWQVAWAHPMYGNILASCSYDRKVIIWREENGTWEKSHEHAGHDSSVNSVCWAPHDYGLILACGSSDGAISLLTYTGEGQWEVKKINNAHTIGCNAVSWAPAVVPGSLIDHPSGQKPNYIKRFASGGCDNLIKLWKEEEDGQWKEEQKLEAHSDWVRDVAWAPSIGLPTSTIASCSQDGRVFIWTCDDASSNTWSPKLLHKFNDVVWHVSWSITANILAVSGGDNKVTLWKESVDGQWVCISDVNKGQGSVSASVTEGQQNEQ>sp|Q9UJQ7|SCP2D_HUMAN SCP2 sterol-binding domain-containing protein 1OS=Homo sapiens OX=9606 GN=SCP2D1 PE=2 SV=1MWKRSDHQPKIKAEDGPLVGQFEVLGSVPEPAMPHPLELSEFESFPVFQDIRLHIREVGAQLVKKVNAVFQLDITKNGKTILRWTIDLKNGSGDMYPGPARLPADTVFTIPESVFMELVLGKMNPQKAFLAGKFKVSGKVLLSWKLERVFKDWAKF>sp|Q9HBR0|S38AA_HUMAN Putative sodium-coupled neutral amino acidtransporter 10 OS=Homo sapiens OX=9606 GN=SLC38A10 PE=1 SV=2MTAAAASNWGLITNIVNSIVGVSVLTMPFCFKQCGIVLGALLLVFCSWMTHQSCMFLVKSASLSKRRTYAGLAFHAYGKAGKMLVETSMIGLMLGTCIAFYVVIGDLGSNFFARLFGFQVGGTFRMFLLFAVSLCIVLPLSLQRNMMASIQSFSAMALLFYTVFMFVIVLSSLKHGLFSGQWLRRVSYVRWEGVFRCIPIFGMSFACQSQVLPTYDSLDEPSVKTMSSIFASSLNVVTTFYVMVGFFGYVSFTEATAGNVLMHFPSNLVTEMLRVGFMMSVAVGFPMMILPCRQALSTLLCEQQQKDGTFAAGGYMPPLRFKALTLSVVFGTMVGGILIPNVETILGLTGATMGSLICFICPALIYKKIHKNALSSQVVLWVGLGVLVVSTVTTLSVSEEVPEDLAEEAPGGRLGEAEGLMKVEAARLSAQDPVVAVAEDGREKPKLPKEREELEQAQIKGPVDVPGREDGKEAPEEAQLDRPGQGIAVPVGEAHRHEPPVPHDKVVVDEGQDREVPEENKPPSRHAGGKAPGVQGQMAPPLPDSEREKQEPEQGEVGKRPGQAQALEEAGDLPEDPQKVPEADGQPAVQPAKEDLGPGDRGLHPRPQAVLSEQQNGLAVGGGEKAKGGPPPGNAAGDTGQPAEDSDHGGKPPLPAEKPAPGPGLPPEPREQRDVERAGGNQAASQLEEAGRAEMLDHAVLLQVIKEQQVQQKRLLDQQEKLLAVIEEQHKEIHQQRQEDEEDKPRQVEVHQEPGAAVPRGQEAPEGKARETVENLPPLPLDPVLRAPGGRPAPSQDLNQRSLEHSEGPVGRDPAGPPDGGPDTEPRAAQAKLRDGQKDAAPRAAGTVKELPKGPEQVPVPDPAREAGGPEERLAEEFPGQSQDVTGGSQDRKKPGKEVAATGTSILKEANWLVAGPGAETGDPRMKPKQVSRDLGLAADLPGGAEGAAAQPQAVLRQPELRVISDGEQGGQQGHRLDHGGHLEMRKARGGDHVPVSHEQPRGGEDAAVQEPRQRPEPELGLKRAVPGGQRPDNAKPNRDLKLQAGSDLRRRRRDLGPHAEGQLAPRDGVIIGLNPLPDVQVNDLRGALDAQLRQAAGGALQVVHSRQLRQAPGPPEES>sp|Q9HBR0-2|S38AA_HUMAN Isoform 2 of Putative sodium-coupled neutralamino acid transporter 10 OS=Homo sapiens OX=9606 GN=SLC38A10MTAAAASNWGLITNIVNSIVGVSVLTMPFCFKQCGIVLGALLLVFCSWMTHQSCMFLVKSASLSKRRTYAGLAFHAYGKAGKMLVETSMIGLMLGTCIAFYVVIGDLGSNFFARLFGFQVGGTFRMFLLFAVSLCIVLPLSLQRNMMASIQSFSAMALLFYTVFMFVIVLSSLKHGLFSGQWLRRVSYVRWEGVFRCIPIFGMSFACQSQVLPTYDSLDEPSVKTMSSIFASSLNVVTTFYVMVGFFGYVSFTEATAGNVLMHFPSNLVTEMLRVGFMMSVAVGFPMMILPCRQALSTLLCEQQQKDGTFAAGGYMPPLRFKALTLSVVFGTMVGGILIPNVETILGLTGATMGSLICFICPALIYKKIHKNALSSQVVLWVGLGVLVVSTVTTLSVSEEVPEDLAEEAPGGRLGEAEGLMKVEAARLSAQDPVVAVAEDGREKPKLPKEREELEQAQIKGPVDVPGREDGKEAPEEAQLDRPGQGIAVPVGEAHRHEPPVPHDKVVVDEGQDREVPEENKPPSRHAGGKAPGVQGQMAPPLPDSEREKQEPEQGEVGKRPGQAQALEEAGDLPEDPQKVPEADGQPAVQPAKEDLGPGDRGLHPRPQAVLSEQQNGLAVGGGEKAKGGPPPGNAAGDTGQPAEDSDHGGKPPLPAEKPAPGPGLPPEPREQRDVERAGGNQAASQLEGKASALQPPASGPGSGSPLPQPWGDAQVILGSPARPPFSFQPPAEQTPRRAFCSLPISSLLSGNLLSALLPFKHLRHRHMACDYRFISLAPL>sp|Q9HBR0-3|S38AA_HUMAN Isoform 3 of Putative sodium-coupled neutralamino acid transporter 10 OS=Homo sapiens OX=9606 GN=SLC38A10MLVETSMIGLMLGTCIAFYVVIGDLGSNFFARLFGFQVGGTFRMFLLFAVSLCIVLPLSLQRNMMASIQSFSAMALLFYTVFMFVIVLSSLKHGLFSGQWLRRVSYVRWEGVFRCIPIFGMSFACQSQVLPTYDSLDEPSVKTMSSIFASSLNVVTTFYVMVGFFGYVSFTEATAGNVLMHFPSNLVTEMLRVGFMMSVAVGFPMMILPCRQALSTLLCEQQQKDGTFAAGGYMPPLRFKALTLSVVFGTMVGGILIPNVETILGLTGATMGSLICFICPALIYKKIHKNALSSQVVLWVGLGVLVVSTVTTLSVSEEVPEDLAEEAPGGRLGEAEGLMKVEAARLSAQDPVVAVAEDGREKPKLPKEREELEQAQIKGPVDVPGREDGKEAPEEAQLDRPGQGIAVPVGEAHRHEPPVPHDKVVVDEGQDREVPEENKPPSRHAGGKAPGVQGQMAPPLPDSEREKQEPEQGEVGKRPGQAQALEEAGDLPEDPQKVPEADGQPAVQPAKEDLGPGDRGLHPRPQAVLSEQQNGLAVGGGEKAKGGPPPGNAAGDTGQPAEDSDHGGKPPLPAEKPAPGPGLPPEPREQRDVERAGGNQAASQLEEAGRAEMLDHAVLLQVIKEQQVQQKRLLDQQEKLLAVIEEQHKEIHQQRQEDEEDKPRQVEVHQEPGAAVPRGQEAPEGS>sp|O43511|S26A4_HUMAN Pendrin OS=Homo sapiens OX=9606 GN=SLC26A4 PE=1SV=1MAAPGGRSEPPQLPEYSCSYMVSRPVYSELAFQQQHERRLQERKTLRESLAKCCSCSRKRAFGVLKTLVPILEWLPKYRVKEWLLSDVISGVSTGLVATLQGMAYALLAAVPVGYGLYSAFFPILTYFIFGTSRHISVGPFPVVSLMVGSVVLSMAPDEHFLVSSSNGTVLNTTMIDTAARDTARVLIASALTLLVGIIQLIFGGLQIGFIVRYLADPLVGGFTTAAAFQVLVSQLKIVLNVSTKNYNGVLSIIYTLVEIFQNIGDTNLADFTAGLLTIVVCMAVKELNDRFRHKIPVPIPIEVIVTIIATAISYGANLEKNYNAGIVKSIPRGFLPPELPPVSLFSEMLAASFSIAVVAYAIAVSVGKVYATKYDYTIDGNQEFIAFGISNIFSGFFSCFVATTALSRTAVQESTGGKTQVAGIISAAIVMIAILALGKLLEPLQKSVLAAVVIANLKGMFMQLCDIPRLWRQNKIDAVIWVFTCIVSIILGLDLGLLAGLIFGLLTVVLRVQFPSWNGLGSIPSTDIYKSTKNYKNIEEPQGVKILRFSSPIFYGNVDGFKKCIKSTVGFDAIRVYNKRLKALRKIQKLIKSGQLRATKNGIISDAVSTNNAFEPDEDIEDLEELDIPTKEIEIQVDWNSELPVKVNVPKVPIHSLVLDCGAISFLDVVGVRSLRVIVKEFQRIDVNVYFASLQDYVIEKLEQCGFFDDNIRKDTFFLTVHDAILYLQNQVKSQEGQGSILETITLIQDCKDTLELIETELTEEELDVQDEAMRTLAS>sp|O43511-2|S26A4_HUMAN Isoform 2 of Pendrin OS=Homo sapiens OX=9606GN=SLC26A4MIAILALGKLLEPLQKSVLAAVVIANLKGMFMQLCDIPRLWRQNKIDAVIWVFTCIVSIILGLDLGLLAGLIFGLLTVVLRVQFPSWNGLGSIPSTDIYKSTKNYKNIEEPQGVKILRFSSPIFYGNVDGFKKCIKSTVGFDAIRVYNKRLKALRKIQKLIKSGQLRATKNGIISDAVSTNNAFEPDEDIEDLEELDIPTKEIEIQVDWNSELPVKVNVPKVPIHSLVLDCGAISFLDVVGVRSLRVIVKEFQRIDVNVYFASLQDYVIEKLEQCGFFDDNIRKDTFFLTVHDAILYLQNQVKSQEGQGSILETITLIQDCKDTLELIETELTEEELDVQDEAMRTLAS>sp|Q96RN1|S26A8_HUMAN Testis anion transporter 1 OS=Homo sapiens OX=9606GN=SLC26A8 PE=1 SV=1MAQLERSAISGFSSKSRRNSFAYDVKREVYNEETFQQEHKRKASSSGNMNINITTFRHHVQCRCSWHRFLRCVLTIFPFLEWMCMYRLKDWLLGDLLAGISVGLVQVPQGLTLSLLARQLIPPLNIAYAAFCSSVIYVIFGSCHQMSIGSFFLVSALLINVLKVSPFNNGQLVMGSFVKNEFSAPSYLMGYNKSLSVVATTTFLTGIIQLIMGVLGLGFIATYLPESAMSAYLAAVALHIMLSQLTFIFGIMISFHAGPISFFYDIINYCVALPKANSTSILVFLTVVVALRINKCIRISFNQYPIEFPMELFLIIGFTVIANKISMATETSQTLIDMIPYSFLLPVTPDFSLLPKIILQAFSLSLVSSFLLIFLGKKIASLHNYSVNSNQDLIAIGLCNVVSSFFRSCVFTGAIARTIIQDKSGGRQQFASLVGAGVMLLLMVKMGHFFYTLPNAVLAGIILSNVIPYLETISNLPSLWRQDQYDCALWMMTFSSSIFLGLDIGLIISVVSAFFITTVRSHRAKILLLGQIPNTNIYRSINDYREIITIPGVKIFQCCSSITFVNVYYLKHKLLKEVDMVKVPLKEEEIFSLFNSSDTNLQGGKICRCFCNCDDLEPLPRILYTERFENKLDPEASSINLIHCSHFESMNTSQTASEDQVPYTVSSVSQKNQGQQYEEVEEVWLPNNSSRNSSPGLPDVAESQGRRSLIPYSDASLLPSVHTIILDFSMVHYVDSRGLVVLRQICNAFQNANILILIAGCHSSIVRAFERNDFFDAGITKTQLFLSVHDAVLFALSRKVIGSSELSIDESETVIRETYSETDKNDNSRYKMSSSFLGSQKNVSPGFIKIQQPVEEESELDLELESEQEAGLGLDLDLDRELEPEMEPKAETETKTQTEMEPQPETEPEMEPNPKSRPRAHTFPQQRYWPMYHPSMASTQSQTQTRTWSVERRRHPMDSYSPEGNSNEDV>sp|Q96RN1-2|S26A8_HUMAN Isoform 2 of Testis anion transporter 1 OS=Homosapiens OX=9606 GN=SLC26A8MAQLERSAISGFSSKSRRNSFAYDVKREVYNEETFQQEHKRKASSSGNMNINITTFRHHVQCRCSWHRFLRCVLTIFPFLEWMCMYRLKDWLLGDLLAGISVGLVQVPQGLTLSLLARQLIPPLNIAYAAFCSSVIYVIFGSCHQMSIGSFFLVSALLINVLKVSPFNNGQLVMGSFVKNEFSAPSYLMGYNKSLSVVATTTFLTGIIQIIGFTVIANKISMATETSQTLIDMIPYSFLLPVTPDFSLLPKIILQAFSLSLVSSFLLIFLGKKIASLHNYSVNSNQDLIAIGLCNVVSSFFRSCVFTGAIARTIIQDKSGGRQQFASLVGAGVMLLLMVKMGHFFYTLPNAVLAGIILSNVIPYLETISNLPSLWRQDQYDCALWMMTFSSSIFLGLDIGLIISVVSAFFITTVRSHRAKILLLGQIPNTNIYRSINDYREIITIPGVKIFQCCSSITFVNVYYLKHKLLKEVDMVKVPLKEEEIFSLFNSSDTNLQGGKICRCFCNCDDLEPLPRILYTERFENKLDPEASSINLIHCSHFESMNTSQTASEDQVPYTVSSVSQKNQGQQYEEVEEVWLPNNSSRNSSPGLPDVAESQGRRSLIPYSDASLLPSVHTIILDFSMVHYVDSRGLVVLRQICNAFQNANILILIAGCHSSIVRAFERNDFFDAGITKTQLFLSVHDAVLFALSRKVIGSSELSIDESETVIRETYSETDKNDNSRYKMSSSFLGSQKNVSPGFIKIQQPVEEESELDLELESEQEAGLGLDLDLDRELEPEMEPKAETETKTQTEMEPQPETEPEMEPNPKSRPRAHTFPQQRYWPMYHPSMASTQSQTQTRTWSVERRRHPMDSYSPEGNSNEDV>sp|Q96RN1-3|S26A8_HUMAN Isoform 3 of Testis anion transporter 1 OS=Homosapiens OX=9606 GN=SLC26A8MVSLQLALSPQFASLVGAGVMLLLMVKMGHFFYTLPNAVLAGIILSNVIPYLETISNLPSLWRQDQYDCALWMMTFSSSIFLGLDIGLIISVVSAFFITTVRSHRAKILLLGQIPNTNIYRSINDYREIITIPGVKIFQCCSSITFVNVYYLKHKLLKEVDMVKVPLKEEEIFSLFNSSDTNLQGGKICRCFCNCDDLEPLPRILYTERFENKLDPEASSINLIHCSHFESMNTSQTASEDQVPYTVSSVSQKNQGQQYEEVEEVWLPNNSSRNSSPGLPDVAESQGRRSLIPYSDASLLPSVHTIILDFSMVHYVDSRGLVVLRQICNAFQNANILILIAGCHSSIVRAFERNDFFDAGITKTQLFLSVHDAVLFALSRKVIGSSELSIDESETVIRETYSETDKNDNSRYKMSSSFLGSQKNVSPGFIKIQQPVEEESELDLELESEQEAGLGLDLDLDRELEPEMEPKAETETKTQTEMEPQPETEPEMEPNPKSRPRAHTFPQQRYWPMYHPSMASTQSQTQTRTWSVERRRHPMDSYSPEGNSNEDV>sp|Q96RN1-4|S26A8_HUMAN Isoform 4 of Testis anion transporter 1 OS=Homosapiens OX=9606 GN=SLC26A8MAQLERSAISGFSSKSRRNSFAYDVKREVYNEETFQQEHKRKASSSGNMNINITTFRHHVQCRCSWHRFLRCVLTIFPFLEWMCMYRLKDWLLGDLLAGISVGLVQVPQGLTLSLLARQLIPPLNIAYAAFCSSVIYVIFGSCHQMSIGSFFLVSALLINVLKVSPFNNGQLVMGSFVKNEFSAPSYLMGYNKSLSVVATTTFLTGIIQLIMGVLGLGFIATYLPESAMSAYLAAVALHIMLSQLTFIFGIMISFHAGPISFFYDIINYCVALPKANSTSILVFLTVVVALRINKCIRISFNQYPIEFPMELFLIIGFTVIANKISMATETSQTLIDMIPYSFLLPVTPDFSLLPKIILQAFSLSLVSSFLLIFLGKKIASLHNYSVNSNQDLIAIGLCNVVSSFFRSCVFTGAIARTIIQDKSGGRQQFASLVGAGVMLLLMVKMGHFFYTLPNAVLAGIILSNVIPYLETISNLPSLWRQDQYDCALWMMTFSSSIFLGLDIGLIISVVSAFFITTVRSHRAKILLLGQIPNTNIYRSINDYREIITIPGVKIFQCCSSITFVNVYYLKHKLLKEVDMVKVPLKEEEIFSLFNSSDTNLQGGKICRCFCNCDDLEPLPRILYTERFENKLDPEASSINLIHCSHFESMNTSQTASEDQVPYTVSSVSQKNQGQQYEEVEEVWLPNNSSRNSSPGLPDVAESQGRRSLIPYSDASLLPSVHTIILDFSMVHYVDSRGLVVLRQVSTEEALAGALIPLLPSQPHPDPD>sp|Q96EE3|SEH1_HUMAN Nucleoporin SEH1 OS=Homo sapiens OX=9606 GN=SEH1LPE=1 SV=3MFVARSIAADHKDLIHDVSFDFHGRRMATCSSDQSVKVWDKSESGDWHCTASWKTHSGSVWRVTWAHPEFGQVLASCSFDRTAAVWEEIVGESNDKLRGQSHWVKRTTLVDSRTSVTDVKFAPKHMGLMLATCSADGIVRIYEAPDVMNLSQWSLQHEISCKLSCSCISWNPSSSRAHSPMIAVGSDDSSPNAMAKVQIFEYNENTRKYAKAETLMTVTDPVHDIAFAPNLGRSFHILAIATKDVRIFTLKPVRKELTSSGGPTKFEIHIVAQFDNHNSQVWRVSWNITGTVLASSGDDGCVRLWKANYMDNWKCTGILKGNGSPVNGSSQQGTSNPSLGSTIPSLQNSLNGSSAGRKHS>sp|Q96EE3-1|SEH1_HUMAN Isoform B of Nucleoporin SEH1 OS=Homo sapiensOX=9606 GN=SEH1LMFVARSIAADHKDLIHDVSFDFHGRRMATCSSDQSVKVWDKSESGDWHCTASWKTHSGSVWRVTWAHPEFGQVLASCSFDRTAAVWEEIVGESNDKLRGQSHWVKRTTLVDSRTSVTDVKFAPKHMGLMLATCSADGIVRIYEAPDVMNLSQWSLQHEISCKLSCSCISWNPSSSRAHSPMIAVGSDDSSPNAMAKVQIFEYNENTRKYAKAETLMTVTDPVHDIAFAPNLGRSFHILAIATKDVRIFTLKPVRKELTSSGGPTKFEIHIVAQFDNHNSQVWRVSWNITGTVLASSGDDGCVRLWKANYMDNWKCTGILKGNGSPVNGSSQQGTSNPSLGSTIPSLQNSLNGSSAGRYFFTPLDSPRAGSRWSSYAQLLPPPPPPLVEHSCDADTANLQYPHPRRRYLSRPLNPLPENEGI>sp|Q9BWV2|SPAT9_HUMAN Spermatogenesis-associated protein 9 OS=Homosapiens OX=9606 GN=SPATA9 PE=2 SV=2MPIKPVGWICGQVLKNFSGRIEGIQKAIMDLVDEFKDEFPTILRLSQSNQKREPAQKTSKIRMAIALAKINRATLIRGLNSISRSSKSVAKLLHPQLACRLLELRDISGRLLREVNAPRQPLYNIQVRKGSLFEIISFPAKTALTSIIYASYAALIYLAVCVNAVLKKVKNIFQEEESIRQNREESENCRKAFSEPVLSEPMFAEGEIKAKPYRSLPEKPDISDYPKLLANKQSNNIQVLHSVFDQSAEMNEQI>sp|Q9BWV2-2|SPAT9_HUMAN Isoform 2 of Spermatogenesis-associated protein9 OS=Homo sapiens OX=9606 GN=SPATA9MPIKPVGWICGQVLKNFSGRIEGIQKAIMDLVDEFKDEFPTILRLSQSNQVRKGSLFEIISFPAKTALTSIIYASYAALIYLAVCVNAVLKKVKNIFQEEESIRQNREESENCRKAFSEPVLSEPMFAEGEIKAKPYRSLPEKPDISDYPKLLANKQSNNIQVLHSVFDQSAEMNEQI>sp|Q9BWV2-3|SPAT9_HUMAN Isoform 3 of Spermatogenesis-associated protein9 OS=Homo sapiens OX=9606 GN=SPATA9MPIKPVGWICGQVLKNFSGRIEGIQKAIMDLVDEFKDEFPTILRLSQSNQKREPAQKTSKIRMAIALAKINRATLIRGLNSISRSSKSVAKLLHPQLACRLLELRDISGRLLREVNAPRQPLYNIQEKKMGLQLS>sp|Q9BYC2|SCOT2_HUMAN Succinyl-CoA:3-ketoacid coenzyme A transferase 2,mitochondrial OS=Homo sapiens OX=9606 GN=OXCT2 PE=2 SV=2MAALRLLASVLGRGVPAGGSGLALSQGCARCFATSPRLRAKFYADPVEMVKDISDGATVMIGGFGLCGIPENLIAALLRTRVKDLQVVSSNVGVEDFGLGLLLAARQVRRIVCSYVGENTLCESQYLAGELELELTPQGTLAERIRAGGAGVPAFYTPTGYGTLVQEGGAPIRYTPDGHLALMSQPREVREFNGDHFLLERAIRADFALVKGWKADRAGNVVFRRSARNFNVPMCKAADVTAVEVEEIVEVGAFPPEDIHVPNIYVDRVIKGQKYEKRIERLTILKEEDGDAGKEEDARTRIIRRAALEFEDGMYANLGIGIPLLASNFISPSMTVHLHSENGILGLGPFPTEDEVDADLINAGKQTVTVLPGGCFFASDDSFAMIRGGHIQLTMLGAMQVSKYGDLANWMIPGKKVKGMGGAMDLVSSQKTRVVVTMQHCTKDNTPKIMEKCTMPLTGKRCVDRIITEKAVFDVHRKKELTLRELWEGLTVDDIKKSTGCAFAVSPNLRPMQQVAP>sp|Q9H853|TBA4B_HUMAN Putative tubulin-like protein alpha-4B OS=Homosapiens OX=9606 GN=TUBA4B PE=5 SV=2MRHQQTERQDPSQPLSRQHGTYRQIFHPEQLITGKEDAANNYAWGHYTIGKEFIDLLLDRIRKLADQCTGLQGFLVFHSLGRGTGSDVTSFLMEWLSVNYGKKSKLGFSIYPAPQVSTAMVQPYNSILTTHTTLEHSDCAFMVDNKAIYDICHCNLDIERPTYTNLNRLISQIVSSITASLRFDGALNVDLTEFQTNLVSYLTSTSPWPPMHQSSLQKRYTTSSCWWQRLPMPALSLPTRW>sp|Q96P15|SPB11_HUMAN Serpin B11 OS=Homo sapiens OX=9606 GN=SERPINB11PE=2 SV=1MGSLSTANVEFCLDVFKELNSNNIGDNIFFSSLSLLYALSMVLLGARGETAEQLEKVLHFSHTVDSLKPGFKDSPKCSQAGRIHSEFGVEFSQINQPDSNCTLSIANRLYGTKTMAFHQQYLSCSEKWYQARLQTVDFEQSTEETRKMINAWVENKTNGKVANLFGKSTIDPSSVMVLVNIIYFKGQRQNKFQVRETVKSPFQLSEGKNVTVEMMYQIGTFKLAFVKEPQMQVLELPYVNNKLSMIILLPVGIANLKQIEKQLNSGTFHEWTSSSNMMEREVEVHLPRFKLEIKYELNSLLKPLGVTDLFNQVKADLSGMSPTKGLYLSKAIHKSYLDVSEEGTEAAAATGDSIAVKSLPMRAQFKANHPFLFFIRHTHTNTILFCGKLASP>sp|Q96P15-2|SPB11_HUMAN Isoform 2 of Serpin B11 OS=Homo sapiens OX=9606GN=SERPINB11MGSLSTANVEFCLDVFKELNSNNIGDNIFFSSLSLLYALSMVLLGARGETAEQLEKVLHFSHTVDSLKPGFKDSPKCSQAGRIHSEFGVEFSQINQPDSNCTLSIANRLYGTKTMAFHQGKNVTVEMMYQIGTFKLAFVKEPQMQVLELPYVNNKLSMIILLPVGIANLKQIEKQLNSGTFHEWTSSSNMMEREVEVHLPRFKLEIKYELNSLLKPLGVTDLFNQVKADLSGMSPTKGLYLSKAIHKSYLDVSEEGTEAAAATGDSIAVKSLPMRAQFKANHPFLFFIRHTHTNTILFCGKLASP>sp|Q96P15-3|SPB11_HUMAN Isoform 3 of Serpin B11 OS=Homo sapiens OX=9606GN=SERPINB11MGSLSTANVEFCLDVFKELNSNNIGDNIFFSSLSLLYALSMVLLGARGETAEQLEKIEKQLNSGTFHEWTSSSNMMEREVEVHLPRFKLEIKYELNSLLKPLGVTDLFNQVKADLSGMSPTKGLYLSKAIHKSYLDVSEEGTEAAAATGDSIAVKSLPMRAQFKANHPFLFFIRHTHTNTILFCGKLASP>sp|Q9UNH7|SNX6_HUMAN Sorting nexin-6 OS=Homo sapiens OX=9606 GN=SNX6PE=1 SV=1MMEGLDDGPDFLSEEDRGLKAINVDLQSDAALQVDISDALSERDKVKFTVHTKSSLPNFKQNEFSVVRQHEEFIWLHDSFVENEDYAGYIIPPAPPRPDFDASREKLQKLGEGEGSMTKEEFTKMKQELEAEYLAIFKKTVAMHEVFLCRVAAHPILRRDLNFHVFLEYNQDLSVRGKNKKEKLEDFFKNMVKSADGVIVSGVKDVDDFFEHERTFLLEYHNRVKDASAKSDRMTRSHKSAADDYNRIGSSLYALGTQDSTDICKFFLKVSELFDKTRKIEARVSADEDLKLSDLLKYYLRESQAAKDLLYRRSRSLVDYENANKALDKARAKNKDVLQAETSQQLCCQKFEKISESAKQELIDFKTRRVAAFRKNLVELAELELKHAKGNLQLLQNCLAVLNGDT>sp|Q9UNH7-2|SNX6_HUMAN Isoform 2 of Sorting nexin-6 OS=Homo sapiensOX=9606 GN=SNX6MTKEEFTKMKQELEAEYLAIFKKTVAMHEVFLCRVAAHPILRRDLNFHVFLEYNQDLSVRGKNKKEKLEDFFKNMVKSADGVIVSGVKDVDDFFEHERTFLLEYHNRVKDASAKSDRMTRSHKSAADDYNRIGSSLYALGTQDSTDICKFFLKVSELFDKTRKIEARVSADEDLKLSDLLKYYLRESQAAKDLLYRRSRSLVDYENANKALDKARAKNKDVLQAETSQQLCCQKFEKISESAKQELIDFKTRRVAAFRKNLVELAELELKHAKGNLQLLQNCLAVLNGDT>sp|Q16533|SNPC1_HUMAN snRNA-activating protein complex subunit 1 OS=Homosapiens OX=9606 GN=SNAPC1 PE=1 SV=1MGTPPGLQTDCEALLSRFQETDSVRFEDFTELWRNMKFGTIFCGRMRNLEKNMFTKEALALAWRYFLPPYTFQIRVGALYLLYGLYNTQLCQPKQKIRVALKDWDEVLKFQQDLVNAQHFDAAYIFRKLRLDRAFHFTAMPKLLSYRMKKKIHRAEVTEEFKDPSDRVMKLITSDVLEEMLNVHDHYQNMKHVISVDKSKPDKALSLIKDDFFDNIKNIVLEHQQWHKDRKNPSLKSKTNDGEEKMEGNSQETERCERAESLAKIKSKAFSVVIQASKSRRHRQVKLDSSDSDSASGQGQVKATRKKEKKERLKPAGRKMSLRNKGNVQNIHKEDKPLSLSMPVITEEEENESLSGTEFTASKKRRKH>sp|P50453|SPB9_HUMAN Serpin B9 OS=Homo sapiens OX=9606 GN=SERPINB9 PE=1SV=1METLSNASGTFAIRLLKILCQDNPSHNVFCSPVSISSALAMVLLGAKGNTATQMAQALSLNTEEDIHRAFQSLLTEVNKAGTQYLLRTANRLFGEKTCQFLSTFKESCLQFYHAELKELSFIRAAEESRKHINTWVSKKTEGKIEELLPGSSIDAETRLVLVNAIYFKGKWNEPFDETYTREMPFKINQEEQRPVQMMYQEATFKLAHVGEVRAQLLELPYARKELSLLVLLPDDGVELSTVEKSLTFEKLTAWTKPDCMKSTEVEVLLPKFKLQEDYDMESVLRHLGIVDAFQQGKADLSAMSAERDLCLSKFVHKSFVEVNEEGTEAAAASSCFVVAECCMESGPRFCADHPFLFFIRHNRANSILFCGRFSSP>sp|A6NDS4|TBC3B_HUMAN TBC1 domain family member 3B OS=Homo sapiensOX=9606 GN=TBC1D3B PE=2 SV=2MDVVEVAGSWWAQEREDIIMKYEKGHRAGLPEDKGPKPFRSYNNNVDHLGIVHETELPPLTAREAKQIRREISRKSKWVDMLGDWEKYKSSRKLIDRAYKGMPMNIRGPMWSVLLNIEEMKLKNPGRYQIMKEKGKRSSEHIQRIDRDISGTLRKHMFFRDRYGTKQRELLHILLAYEEYNPEVGYCRDLSHIAALFLLYLPEEDAFWALVQLLASERHSLQGFHSPNGGTVQGLQDQQEHVVATSQSKTMGHQDKKDLCGQCSPLGCLIRILIDGISLGLTLRLWDVYLVEGEQALMPITRIAFKVQQKRLTKTSRCGPWARFCNRFVDTWARDEDTVLKHLRASMKKLTRKQGDLPPPAKPEQGSSASRPVPASRGRKTLCKGDRQAPPGPPARFPRPIWSASPPRAPRSSTPCPGGAVREDTYPVGTQGVPSPALAQGGPQGSWRFLQWNSMPRLPTDLDVEGPWFRHYDFRQSCWVRAISQEDQLAPCWQAEHPAERVRSAFAAPSTDSDQGTPFRARDEQQCAPTSGPCLCGLHLESSQFPPGF>sp|P35610|SOAT1_HUMAN Sterol O-acyltransferase 1 OS=Homo sapiens OX=9606GN=SOAT1 PE=1 SV=3MVGEEKMSLRNRLSKSRENPEEDEDQRNPAKESLETPSNGRIDIKQLIAKKIKLTAEAEELKPFFMKEVGSHFDDFVTNLIEKSASLDNGGCALTTFSVLEGEKNNHRAKDLRAPPEQGKIFIARRSLLDELLEVDHIRTIYHMFIALLILFILSTLVVDYIDEGRLVLEFSLLSYAFGKFPTVVWTWWIMFLSTFSVPYFLFQHWATGYSKSSHPLIRSLFHGFLFMIFQIGVLGFGPTYVVLAYTLPPASRFIIIFEQIRFVMKAHSFVRENVPRVLNSAKEKSSTVPIPTVNQYLYFLFAPTLIYRDSYPRNPTVRWGYVAMKFAQVFGCFFYVYYIFERLCAPLFRNIKQEPFSARVLVLCVFNSILPGVLILFLTFFAFLHCWLNAFAEMLRFGDRMFYKDWWNSTSYSNYYRTWNVVVHDWLYYYAYKDFLWFFSKRFKSAAMLAVFAVSAVVHEYALAVCLSFFYPVLFVLFMFFGMAFNFIVNDSRKKPIWNVLMWTSLFLGNGVLLCFYSQEWYARQHCPLKNPTFLDYVRPRSWTCRYVF>sp|P35610-2|SOAT1_HUMAN Isoform 2 of Sterol O-acyltransferase 1 OS=Homosapiens OX=9606 GN=SOAT1MELKPFFMKEVGSHFDDFVTNLIEKSASLDNGGCALTTFSVLEGEKNNHRAKDLRAPPEQGKIFIARRSLLDELLEVDHIRTIYHMFIALLILFILSTLVVDYIDEGRLVLEFSLLSYAFGKFPTVVWTWWIMFLSTFSVPYFLFQHWATGYSKSSHPLIRSLFHGFLFMIFQIGVLGFGPTYVVLAYTLPPASRFIIIFEQIRFVMKAHSFVRENVPRVLNSAKEKSSTVPIPTVNQYLYFLFAPTLIYRDSYPRNPTVRWGYVAMKFAQVFGCFFYVYYIFERLCAPLFRNIKQEPFSARVLVLCVFNSILPGVLILFLTFFAFLHCWLNAFAEMLRFGDRMFYKDWWNSTSYSNYYRTWNVVVHDWLYYYAYKDFLWFFSKRFKSAAMLAVFAVSAVVHEYALAVCLSFFYPVLFVLFMFFGMAFNFIVNDSRKKPIWNVLMWTSLFLGNGVLLCFYSQEWYARQHCPLKNPTFLDYVRPRSWTCRYVF>sp|P35610-3|SOAT1_HUMAN Isoform 3 of Sterol O-acyltransferase 1 OS=Homosapiens OX=9606 GN=SOAT1MKEVGSHFDDFVTNLIEKSASLDNGGCALTTFSVLEGEKNNHRAKDLRAPPEQGKIFIARRSLLDELLEVDHIRTIYHMFIALLILFILSTLVVDYIDEGRLVLEFSLLSYAFGKFPTVVWTWWIMFLSTFSVPYFLFQHWATGYSKSSHPLIRSLFHGFLFMIFQIGVLGFGPTYVVLAYTLPPASRFIIIFEQIRFVMKAHSFVRENVPRVLNSAKEKSSTVPIPTVNQYLYFLFAPTLIYRDSYPRNPTVRWGYVAMKFAQVFGCFFYVYYIFERLCAPLFRNIKQEPFSARVLVLCVFNSILPGVLILFLTFFAFLHCWLNAFAEMLRFGDRMFYKDWWNSTSYSNYYRTWNVVVHDWLYYYAYKDFLWFFSKRFKSAAMLAVFAVSAVVHEYALAVCLSFFYPVLFVLFMFFGMAFNFIVNDSRKKPIWNVLMWTSLFLGNGVLLCFYSQEWYARQHCPLKNPTFLDYVRPRSWTCRYVF>sp|A0A087WVF3|TBC3D_HUMAN TBC1 domain family member 3D OS=Homo sapiensOX=9606 GN=TBC1D3D PE=2 SV=1MDVVEVAGSWWAQEREDIIMKYEKGHRAGLPEDKGPKPFRSYNNNVDHLGIVHETELPPLTAREAKQIRREISRKSKWVDMLGDWEKYKSSRKLIDRAYKGMPMNIRGPMWSVLLNTEEMKLKNPGRYQIMKEKGKRSSEHIQRIDRDVSGTLRKHIFFRDRYGTKQRELLHILLAYEEYNPEVGYCRDLSHIAALFLLYLPEEDAFWALVQLLASERHSLQGFHSPNGGTVQGLQDQQEHVVATSQPKTMGHQDKKDLCGQCSPLGCLIRILIDGISLGLTLRLWDVYLVEGEQALMPITRIAFKVQQKRLTKTSRCGPWARFCNRFVDTWARDEDTVLKHLRASMKKLTRKQGDLPPPAKPEQGSSASRPVPASRGGKTLCKGDRQAPPGPPARFPRPIWSASPPRAPRSSTPCPGGAVREDTYPVGTQGVPSPALAQGGPQGSWRFLQWNSMPRLPTDLDVEGPWFRHYDFRQSCWVRAISQEDQLAPCWQAEHPAERVRSAFAAPSTDSDQGTPFRARDEQQCAPTSGPCLCGLHLESSQFPPGF>sp|Q9BQ87|TBL1Y_HUMAN F-box-like/WD repeat-containing protein TBL1YOS=Homo sapiens OX=9606 GN=TBL1Y PE=1 SV=1MSITSDEVNFLVYRYLQESGFSHSAFTFGIESHISQSNINGTLVPPSALISILQKGLQYVEAEISINKDGTVFDSRPIESLSLIVAVIPDVVQMRQQAFGEKLTQQQASAAATEASAMAKAATMTPAAISQQNPPKNREATVNGEENGAHEINNHSKPMEIDGDVEIPPNKATVLRGHESEVFICAWNPVSDLLASGSGDSTARIWNLNENSNGGSTQLVLRHCIREGGHDVPSNKDVTSLDWNSDGTLLAMGSYDGFARIWTENGNLASTLGQHKGPIFALKWNKKGNYVLSAGVDKTTIIWDAHTGEAKQQFPFHSAPALDVDWQNNMTFASCSTDMCIHVCRLGCDHPVKTFQGHTNEVNAIKWDPSGMLLASCSDDMTLKIWSMKQDACVHDLQAHSKEIYTIKWSPTGPATSNPNSSIMLASASFDSTVRLWDVEQGVCTHTLMKHQEPVYSVAFSPDGKYLASGSFDKYVHIWNTQSGSLVHSYQGTGGIFEVCWNARGDKVGASASDGSVCVLDL>sp|P35237|SPB6_HUMAN Serpin B6 OS=Homo sapiens OX=9606 GN=SERPINB6 PE=1SV=3MDVLAEANGTFALNLLKTLGKDNSKNVFFSPMSMSCALAMVYMGAKGNTAAQMAQILSFNKSGGGGDIHQGFQSLLTEVNKTGTQYLLRMANRLFGEKSCDFLSSFRDSCQKFYQAEMEELDFISAVEKSRKHINTWVAEKTEGKIAELLSPGSVDPLTRLVLVNAVYFRGNWDEQFDKENTEERLFKVSKNEEKPVQMMFKQSTFKKTYIGEIFTQILVLPYVGKELNMIIMLPDETTDLRTVEKELTYEKFVEWTRLDMMDEEEVEVSLPRFKLEESYDMESVLRNLGMTDAFELGKADFSGMSQTDLSLSKVVHKSFVEVNEEGTEAAAATAAIMMMRCARFVPRFCADHPFLFFIQHSKTNGILFCGRFSSP>sp|Q9Y651|SOX21_HUMAN Transcription factor SOX-21 OS=Homo sapiensOX=9606 GN=SOX21 PE=2 SV=1MSKPVDHVKRPMNAFMVWSRAQRRKMAQENPKMHNSEISKRLGAEWKLLTESEKRPFIDEAKRLRAMHMKEHPDYKYRPRRKPKTLLKKDKFAFPVPYGLGGVADAEHPALKAGAGLHAGAGGGLVPESLLANPEKAAAAAAAAAARVFFPQSAAAAAAAAAAAAAGSPYSLLDLGSKMAEISSSSSGLPYASSLGYPTAGAGAFHGAAAAAAAAAAAAGGHTHSHPSPGNPGYMIPCNCSAWPSPGLQPPLAYILLPGMGKPQLDPYPAAYAAAL>sp|Q9NTG7|SIR3_HUMAN NAD-dependent protein deacetylase sirtuin-3,mitochondrial OS=Homo sapiens OX=9606 GN=SIRT3 PE=1 SV=2MAFWGWRAAAALRLWGRVVERVEAGGGVGPFQACGCRLVLGGRDDVSAGLRGSHGARGEPLDPARPLQRPPRPEVPRAFRRQPRAAAPSFFFSSIKGGRRSISFSVGASSVVGSGGSSDKGKLSLQDVAELIRARACQRVVVMVGAGISTPSGIPDFRSPGSGLYSNLQQYDLPYPEAIFELPFFFHNPKPFFTLAKELYPGNYKPNVTHYFLRLLHDKGLLLRLYTQNIDGLERVSGIPASKLVEAHGTFASATCTVCQRPFPGEDIRADVMADRVPRCPVCTGVVKPDIVFFGEPLPQRFLLHVVDFPMADLLLILGTSLEVEPFASLTEAVRSSVPRLLINRDLVGPLAWHPRSRDVAQLGDVVHGVESLVELLGWTEEMRDLVQRETGKLDGPDK>sp|Q9NTG7-2|SIR3_HUMAN Isoform 2 of NAD-dependent protein deacetylasesirtuin-3, mitochondrial OS=Homo sapiens OX=9606 GN=SIRT3MVGAGISTPSGIPDFRSPGSGLYSNLQQYDLPYPEAIFELPFFFHNPKPFFTLAKELYPGNYKPNVTHYFLRLLHDKGLLLRLYTQNIDGLERVSGIPASKLVEAHGTFASATCTVCQRPFPGEDIRADVMADRVPRCPVCTGVVKPDIVFFGEPLPQRFLLHVVDFPMADLLLILGTSLEVEPFASLTEAVRSSVPRLLINRDLVGPLAWHPRSRDVAQLGDVVHGVESLVELLGWTEEMRDLVQRETGKLDGPDK>sp|Q5JXA9|SIRB2_HUMAN Signal-regulatory protein beta-2 OS=Homo sapiensOX=9606 GN=SIRPB2 PE=2 SV=1MCSTMSAPTCLAHLPPCFLLLALVLVPSDASGQSSRNDWQVLQPEGPMLVAEGETLLLRCMVVGSCTDGMIKWVKVSTQDQQEIYNFKRGSFPGVMPMIQRTSEPLNCDYSIYIHNVTREHTGTYHCVRFDGLSEHSEMKSDEGTSVLVKGAGDPEPDLWIIQPQELVLGTTGDTVFLNCTVLGDGPPGPIRWFQGAGLSREAIYNFGGISHPKETAVQASNNDFSILLQNVSSEDAGTYYCVKFQRKPNRQYLSGQGTSLKVKAKSTSSKEAEFTSEPATEMSPTGLLVVFAPVVLGLKAITLAALLLALATSRRSPGQEDVKTTGPAGAMNTLAWSKGQE>sp|Q5JXA9-2|SIRB2_HUMAN Isoform 2 of Signal-regulatory protein beta-2OS=Homo sapiens OX=9606 GN=SIRPB2MCSTMSAPTCLAHLPPCFLLLALVLVPSDASGQSSRNDWQVLQPEGPMLVAEGAGDPEPDLWIIQPQELVLGTTGDTVFLNCTVLGDGPPGPIRWFQGAGLSREAIYNFGGISHPKETAVQASNNDFSILLQNVSSEDAGTYYCVKFQRKPNRQYLSGQGTSLKVKAKSTSSKEAEFTSEPATEMSPTGLL>sp|Q5JXA9-3|SIRB2_HUMAN Isoform 3 of Signal-regulatory protein beta-2OS=Homo sapiens OX=9606 GN=SIRPB2MCSTMSAPTCLAHLPPCFLLLALVLVPSDASGQSSRNDWQVLQPEGPMLVAEGAGDPEPDLWIIQPQELVLGTTGDTVFLNCTVLGDGPPGPIRWFQGAGLSREAIYNFGGISHPKETAVQASNNDFSILLQNVSSEDAGTYYCVKFQRKPNRQYLSGQGTSLKVKAKSTSSKEAEFTSEPATEMSPTGLLVVFAPVVLGLKAITLAALLLALATSRRSPGQEDVKTTGPAGAMNTLAWSKGQE>sp|Q99961|SH3G1_HUMAN Endophilin-A2 OS=Homo sapiens OX=9606 GN=SH3GL1PE=1 SV=1MSVAGLKKQFYKASQLVSEKVGGAEGTKLDDDFKEMEKKVDVTSKAVTEVLARTIEYLQPNPASRAKLTMLNTVSKIRGQVKNPGYPQSEGLLGECMIRHGKELGGESNFGDALLDAGESMKRLAEVKDSLDIEVKQNFIDPLQNLCEKDLKEIQHHLKKLEGRRLDFDYKKKRQGKIPDEELRQALEKFEESKEVAETSMHNLLETDIEQVSQLSALVDAQLDYHRQAVQILDELAEKLKRRMREASSRPKREYKPKPREPFDLGEPEQSNGGFPCTTAPKIAASSSFRSSDKPIRTPSRSMPPLDQPSCKALYDFEPENDGELGFHEGDVITLTNQIDENWYEGMLDGQSGFFPLSYVEVLVPLPQ>sp|Q99961-2|SH3G1_HUMAN Isoform 2 of Endophilin-A2 OS=Homo sapiensOX=9606 GN=SH3GL1MSVAGLKKQFYKASQLVSEKVGGAEGTKLDDDFKEMEKKVDVTSKAVTEVLARTIEYLQPNPGDALLDAGESMKRLAEVKDSLDIEVKQNFIDPLQNLCEKDLKEIQHHLKKLEGRRLDFDYKKKRQGKIPDEELRQALEKFEESKEVAETSMHNLLETDIEQVSQLSALVDAQLDYHRQAVQILDELAEKLKRRMREASSRPKREYKPKPREPFDLGEPEQSNGGFPCTTAPKIAASSSFRSSDKPIRTPSRSMPPLDQPSCKALYDFEPENDGELGFHEGDVITLTNQIDENWYEGMLDGQSGFFPLSYVEVLVPLPQ>sp|Q99961-3|SH3G1_HUMAN Isoform 3 of Endophilin-A2 OS=Homo sapiensOX=9606 GN=SH3GL1MSVAGLKKQFYKASQLVSEKVGGAEGTKLDDDFKEMEKKVDVTSKAVTEVLARTIEYLQPNPASRAKLTMLNTVSKIRGQNLCEKDLKEIQHHLKKLEGRRLDFDYKKKRQGKIPDEELRQALEKFEESKEVAETSMHNLLETDIEQVSQLSALVDAQLDYHRQAVQILDELAEKLKRRMREASSRPKREYKPKPREPFDLGEPEQSNGGFPCTTAPKIAASSSFRSSDKPIRTPSRSMPPLDQPSCKALYDFEPENDGELGFHEGDVITLTNQIDENWYEGMLDGQSGFFPLSYVEVLVPLPQ>sp|Q53GS9|SNUT2_HUMAN U4/U6.U5 tri-snRNP-associated protein 2 OS=Homosapiens OX=9606 GN=USP39 PE=1 SV=2MSGRSKRESRGSTRGKRESESRGSSGRVKRERDREREPEAASSRGSPVRVKREFEPASAREAPASVVPFVRVKREREVDEDSEPEREVRAKNGRVDSEDRRSRHCPYLDTINRSVLDFDFEKLCSISLSHINAYACLVCGKYFQGRGLKSHAYIHSVQFSHHVFLNLHTLKFYCLPDNYEIIDSSLEDITYVLKPTFTKQQIANLDKQAKLSRAYDGTTYLPGIVGLNNIKANDYANAVLQALSNVPPLRNYFLEEDNYKNIKRPPGDIMFLLVQRFGELMRKLWNPRNFKAHVSPHEMLQAVVLCSKKTFQITKQGDGVDFLSWFLNALHSALGGTKKKKKTIVTDVFQGSMRIFTKKLPHPDLPAEEKEQLLHNDEYQETMVESTFMYLTLDLPTAPLYKDEKEQLIIPQVPLFNILAKFNGITEKEYKTYKENFLKRFQLTKLPPYLIFCIKRFTKNNFFVEKNPTIVNFPITNVDLREYLSEEVQAVHKNTTYDLIANIVHDGKPSEGSYRIHVLHHGTGKWYELQDLQVTDILPQMITLSEAYIQIWKRRDNDETNQQGA>sp|Q53GS9-2|SNUT2_HUMAN Isoform 2 of U4/U6.U5 tri-snRNP-associatedprotein 2 OS=Homo sapiens OX=9606 GN=USP39MLTAVPSHLFSAKNGRVDSEDRRSRHCPYLDTINSFSPFPTGRGLKSHAYIHSVQFSHHVFLNLHTLKFYCLPDNYEIIDSSLEDITYVLKPTFTKQQIANLDKQAKLSRAYDGTTYLPGIVGLNNIKANDYANAVLQALSNVPPLRNYFLEEDNYKNIKRPPGDIMFLLVQRFGELMRKLWNPRNFKAHVSPHEMLQAVVLCSKKTFQITKQGDGVDFLSWFLNALHSALGGTKKKKKTIVTDVFQGSMRIFTKKLPHPDLPAEEKEQLLHNDEYQETMVESTFMYLTLDLPTAPLYKDEKEQLIIPQVPLFNILAKFNGITEKEYKTYKENFLKRFQLTKLPPYLIFCIKRFTKNNFFVEKNPTIVNFPITNVDLREYLSEEVQAVHKNTTYDLIANIVHDGKPSEGSYRIHVLHHGTGKWYELQDLQVTDILPQMITLSEAYIQIWKRRDNDETNQQGA>sp|Q53GS9-3|SNUT2_HUMAN Isoform 3 of U4/U6.U5 tri-snRNP-associatedprotein 2 OS=Homo sapiens OX=9606 GN=USP39MSGRSKRESRGSTRGKRESESRGSSGRVKRERDREREPEAASSRGSPVRVKREFEPASAREAPASVVPFVRVKREREVDEDSEPEREVRAKNGRVDSEDRRSRHCPYLDTINRSVLDFDFEKLCSISLSHINAYACLVCGKYFQGRGLKSHAYIHSVQFSHHVFLNLHTLKFYCLPDNYEIIDSSLEDITYVLKPTFTKQQIANLDKQAKLSRAYDGTTYLPGIVGLNNIKANDYANAVLQALSNVPPLRNYFLEEDNYKNIKRPPGDIMFLLVQRFGELMRKLWNPRNFKAHVSPHEMLQAVVLCSKKTFQITKQGDGVDFLSWFLNALHSALGGTKKKKKTIVTDVFQGSMRIFTKKLPHPDLPAEEKEQLLHNDEYQETMVESTFMYLTLDLPTAPLYKDEKEQLIIPQVPLFNILAKFNGITEKEYKTYKENFLKRFQLTKLPPYLIFCIKRFTKNNFFVEKNPTIVNFPITGQANGMNYKTSR>sp|O14544|SOCS6_HUMAN Suppressor of cytokine signaling 6 OS=Homo sapiensOX=9606 GN=SOCS6 PE=1 SV=2MKKISLKTLRKSFNLNKSKEETDFMVVQQPSLASDFGKDDSLFGSCYGKDMASCDINGEDEKGGKNRSKSESLMGTLKRRLSAKQKSKGKAGTPSGSSADEDTFSSSSAPIVFKDVRAQRPIRSTSLRSHHYSPAPWPLRPTNSEETCIKMEVRVKALVHSSSPSPALNGVRKDFHDLQSETTCQEQANSLKSSASHNGDLHLHLDEHVPVVIGLMPQDYIQYTVPLDEGMYPLEGSRSYCLDSSSPMEVSAVPPQVGGRAFPEDESQVDQDLVVAPEIFVDQSVNGLLIGTTGVMLQSPRAGHDDVPPLSPLLPPMQNNQIQRNFSGLTGTEAHVAESMRCHLNFDPNSAPGVARVYDSVQSSGPMVVTSLTEELKKLAKQGWYWGPITRWEAEGKLANVPDGSFLVRDSSDDRYLLSLSFRSHGKTLHTRIEHSNGRFSFYEQPDVEGHTSIVDLIEHSIRDSENGAFCYSRSRLPGSATYPVRLTNPVSRFMQVRSLQYLCRFVIRQYTRIDLIQKLPLPNKMKDYLQEKHY>sp|Q9H3U7|SMOC2_HUMAN SPARC-related modular calcium-binding protein 2OS=Homo sapiens OX=9606 GN=SMOC2 PE=1 SV=2MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNVVIPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEERVVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNNDKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQPRKQG>sp|Q9H3U7-2|SMOC2_HUMAN Isoform 2 of SPARC-related modular calcium-binding protein 2 OS=Homo sapiens OX=9606 GN=SMOC2MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKTVSLQIFSVLNSDDAAAPALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNVVIPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEERVVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNNDKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQPRKQG>sp|O15304|SIVA_HUMAN Apoptosis regulatory protein Siva OS=Homo sapiensOX=9606 GN=SIVA1 PE=1 SV=2MPKRSCPFADVAPLQLKVRVSQRELSRGVCAERYSQEVFEKTKRLLFLGAQAYLDHVWDEGCAVVHLPESPKPGPTGAPRAARGQMLIGPDGRLIRSLGQASEADPSGVASIACSSCVRAVDGKAVCGQCERALCGQCVRTCWGCGSVACTLCGLVDCSDMYEKVLCTSCAMFET>sp|O15304-2|SIVA_HUMAN Isoform 2 of Apoptosis regulatory protein SivaOS=Homo sapiens OX=9606 GN=SIVA1MPKRSCPFADVAPLQLKVRVSQRELSRGVCAERYSQEVFDPSGVASIACSSCVRAVDGKAVCGQCERALCGQCVRTCWGCGSVACTLCGLVDCSDMYEKVLCTSCAMFET>sp|Q2TAL5|SMTL2_HUMAN Smoothelin-like protein 2 OS=Homo sapiens OX=9606GN=SMTNL2 PE=2 SV=1MEPAPDAQEARTVREALGRYEAALEGAVRALHEDMRGLQRGVERRVAEAMRLAGPLARTVADLQRDNQRLQAQLERLTRQVEALGLASGMSPVPGTPGTPSPPPAPGVPDRAPRLGSARFASHATFSLSGRGQSLDHDEASESEMRKTSNSCIMENGHQPGAGPGDGPPEIAQNFSAPDPPRPRPVSLSLRLPHQPVTAITRVSDRFSGETSAAALSPMSAATLGGLNPSPSEVITPWTPSPSEKNSSFTWSVPSSGYGAVTASKHSNSPPLVTPPQSPVSPQPPAITQVHRQGERRRELVRSQTLPRTSEAQARKALFEKWEQETAAGKGKGEARARLKRSQSFGVASASSIKQILLEWCRSKTLGYQHVDLQNFSSSWSDGMAFCALVHSFFPDAFDYNSLSPTQRQKNFELAFTMAENLANCERLIEVEDMMVMGRKPDPMCVFTYVQSLYNHLRRFE>sp|Q2TAL5-2|SMTL2_HUMAN Isoform 2 of Smoothelin-like protein 2 OS=Homosapiens OX=9606 GN=SMTNL2MRKTSNSCIMENGHQPGAGPGDGPPEIAQNFSAPDPPRPRPVSLSLRLPHQPVTAITRVSDRFSGETSAAALSPMSAATLGGLNPSPSEVITPWTPSPSEKNSSFTWSVPSSGYGAVTASKHSNSPPLVTPPQSPVSPQPPAITQVHRQGERRRELVRSQTLPRTSEAQARKALFEKWEQETAAGKGKGEARARLKRSQSFGVASASSIKQILLEWCRSKTLGYQHVDLQNFSSSWSDGMAFCALVHSFFPDAFDYNSLSPTQRQKNFELAFTMAENLANCERLIEVEDMMVMGRKPDPMCVFTYVQSLYNHLRRFE>sp|O95295|SNAPN_HUMAN SNARE-associated protein Snapin OS=Homo sapiensOX=9606 GN=SNAPIN PE=1 SV=1MAGAGSAAVSGAGTPVAGPTGRDLFAEGLLEFLRPAVQQLDSHVHAVRESQVELREQIDNLATELCRINEDQKVALDLDPYVKKLLNARRRVVLVNNILQNAQERLRRLNHSVAKETARRRAMLDSGIYPPGSPGK>sp|P61009|SPCS3_HUMAN Signal peptidase complex subunit 3 OS=Homo sapiensOX=9606 GN=SPCS3 PE=1 SV=1MNTVLSRANSLFAFSLSVMAALTFGCFITTAFKDRSVPVRLHVSRIMLKNVEDFTGPRERSDLGFITFDITADLENIFDWNVKQLFLYLSAEYSTKNNALNQVVLWDKIVLRGDNPKLLLKDMKTKYFFFDDGNGLKGNRNVTLTLSWNVVPNAGILPLVTGSGHVSVPFPDTYEITKSY>sp|Q96BR1|SGK3_HUMAN Serine/threonine-protein kinase Sgk3 OS=Homosapiens OX=9606 GN=SGK3 PE=1 SV=1MQRDHTMDYKESCPSVSIPSSDEHREKKKRFTVYKVLVSVGRSEWFVFRRYAEFDKLYNTLKKQFPAMALKIPAKRIFGDNFDPDFIKQRRAGLNEFIQNLVRYPELYNHPDVRAFLQMDSPKHQSDPSEDEDERSSQKLHSTSQNINLGPSGNPHAKPTDFDFLKVIGKGSFGKVLLAKRKLDGKFYAVKVLQKKIVLNRKEQKHIMAERNVLLKNVKHPFLVGLHYSFQTTEKLYFVLDFVNGGELFFHLQRERSFPEHRARFYAAEIASALGYLHSIKIVYRDLKPENILLDSVGHVVLTDFGLCKEGIAISDTTTTFCGTPEYLAPEVIRKQPYDNTVDWWCLGAVLYEMLYGLPPFYCRDVAEMYDNILHKPLSLRPGVSLTAWSILEELLEKDRQNRLGAKEDFLEIQNHPFFESLSWADLVQKKIPPPFNPNVAGPDDIRNFDTAFTEETVPYSVCVSSDYSIVNASVLEADDAFVGFSYAPPSEDLFL>sp|Q96BR1-2|SGK3_HUMAN Isoform 2 of Serine/threonine-protein kinase Sgk3OS=Homo sapiens OX=9606 GN=SGK3MQRDHTMDYKESCPSVSIPSSDEHREKKKRFTVYKVLVSVGRSEWFVFRRYAEFDKLYNTLKKQFPAMALKIPAKRIFGDNFDPDFIKQRRAGLNEFIQNLVRYPELYNHPDVRAFLQMDSPKHQSDPSEDEDERSSQKLHSTSQNINLGPSGNPHAKPTDFDFLKVIGKGSFGKVLLAKRKLDGKFYAVKVLQKKIVLNRKEQKHIMAERNVLLKNVKHPFLVGLHYSFQTTEKLYFVLDFVNGGELFFHLQRERSFPEHRARFYAAEIASALGYLHSIKIVYRDLKPENILLDSVGHVVLTDFGLCKEGIAISDTTTTFCGTPEPPFYCRDVAEMYDNILHKPLSLRPGVSLTAWSILEELLEKDRQNRLGAKEDFLEIQNHPFFESLSWADLVQKKIPPPFNPNVAGPDDIRNFDTAFTEETVPYSVCVSSDYSIVNASVLEADDAFVGFSYAPPSEDLFL>sp|Q495Y7|SPDE7_HUMAN Putative speedy protein E7 OS=Homo sapiens OX=9606GN=SPDYE7P PE=5 SV=1MEWWDKSEESLEEEPRKVLAPEPEEIWVAEMLCGLKMKLKRRRVSLVLPEHHEAFNRLLEDPVIKRFLAWDKGLRVSDKYLLAMVIVYFSRAGLPSWQYQCIHFFLALYLANDMEEDDEDPKQNIFYFLYGKTRSRIPLLRKRRFQLCRCMNPRARKNRSQIVLFQKLRFQFFCSMSCRAWVSPEELEEIQAYDPEHWVWARDRARLS>sp|A8MWV9|SM34A_HUMAN Small integral membrane protein 34 OS=Homo sapiensOX=9606 GN=SMIM34 PE=2 SV=1MEWAKWTPHEASNQTQASTLLGLLLGDHTEGRNDTNSTRALKVPDGTSAAWYILTIIGIYAVIFVFRLASNILRKNDKSLEDVYYSNLTSELKMTGLQGKVAKCSTLSISNRAVLQPCQAHLGAKGGSSGPQTATPETP>sp|Q9H2G2|SLK_HUMAN STE20-like serine/threonine-protein kinase OS=Homosapiens OX=9606 GN=SLK PE=1 SV=1MSFFNFRKIFKLGSEKKKKQYEHVKRDLNPEDFWEIIGELGDGAFGKVYKAQNKETSVLAAAKVIDTKSEEELEDYMVEIDILASCDHPNIVKLLDAFYYENNLWILIEFCAGGAVDAVMLELERPLTESQIQVVCKQTLDALNYLHDNKIIHRDLKAGNILFTLDGDIKLADFGVSAKNTRTIQRRDSFIGTPYWMAPEVVMCETSKDRPYDYKADVWSLGITLIEMAEIEPPHHELNPMRVLLKIAKSEPPTLAQPSRWSSNFKDFLKKCLEKNVDARWTTSQLLQHPFVTVDSNKPIRELIAEAKAEVTEEVEDGKEEDEEEETENSLPIPASKRASSDLSIASSEEDKLSQNACILESVSEKTERSNSEDKLNSKILNEKPTTDEPEKAVEDINEHITDAQLEAMTELHDRTAVIKENEREKRPKLENLPDTEDQETVDINSVSEGKENNIMITLETNIEHNLKSEEEKDQEKQQMFENKLIKSEEIKDTILQTVDLVSQETGEKEANIQAVDSEVGLTKEDTQEKLGEDDKTQKDVISNTSDVIGTCEAADVAQKVDEDSAEDTQSNDGKEVVEVGQKLINKPMVGPEAGGTKEVPIKEIVEMNEIEEGKNKEQAINSSENIMDINEEPGTTEGEEITESSSTEEMEVRSVVADTDQKALGSEVQDASKVTTQIDKEKKEIPVSIKKEPEVTVVSQPTEPQPVLIPSININSDSGENKEEIGSLSKTETILPPESENPKENDNDSGTGSTADTSSIDLNLSISSFLSKTKDSGSISLQETRRQKKTLKKTRKFIVDGVEVSVTTSKIVTDSDSKTEELRFLRRQELRELRFLQKEEQRAQQQLNSKLQQQREQIFRRFEQEMMSKKRQYDQEIENLEKQQKQTIERLEQEHTNRLRDEAKRIKGEQEKELSKFQNMLKNRKKEVINEVEKAPKELRKELMKRRKEELAQSQHAQEQEFVQKQQQELDGSLKKIIQQQKAELANIERECLNNKQQLMRAREAAIWELEERHLQEKHQLLKQQLKDQYFMQRHQLLKRHEKETEQMQRYNQRLIEELKNRQTQERARLPKIQRSEAKTRMAMFKKSLRINSTATPDQDRDKIKQFAAQEEKRQKNERMAQHQKHENQMRDLQLQCEANVRELHQLQNEKCHLLVEHETQKLKELDEEHSQELKEWREKLRPRKKTLEEEFARKLQEQEVFFKMTGESECLNPSTQSRISKFYPIPSLHSTGS>sp|Q9H2G2-2|SLK_HUMAN Isoform 2 of STE20-like serine/threonine-proteinkinase OS=Homo sapiens OX=9606 GN=SLKMSFFNFRKIFKLGSEKKKKQYEHVKRDLNPEDFWEIIGELGDGAFGKVYKAQNKETSVLAAAKVIDTKSEEELEDYMVEIDILASCDHPNIVKLLDAFYYENNLWILIEFCAGGAVDAVMLELERPLTESQIQVVCKQTLDALNYLHDNKIIHRDLKAGNILFTLDGDIKLADFGVSAKNTRTIQRRDSFIGTPYWMAPEVVMCETSKDRPYDYKADVWSLGITLIEMAEIEPPHHELNPMRVLLKIAKSEPPTLAQPSRWSSNFKDFLKKCLEKNVDARWTTSQLLQHPFVTVDSNKPIRELIAEAKAEVTEEVEDGKEEDEEEETENSLPIPASKRASSDLSIASSEEDKLSQNACILESVSEKTERSNSEDKLNSKILNEKPTTDEPEKAVEDINEHITDAQLEAMTELHDRTAVIKENEREKRPKLENLPDTEDQETVDINSVSEGKENNIMITLETNIEHNLKSEEEKDQEKQQMFENKLIKSEEIKDTILQTVDLVSQETGEKEANIQAVDSEVGLTKEDTQEKLGEDDKTQKDVISNTSDVIGTCEAADVAQKVDEDSAEDTQSNDGKEVVEVGQKLINKPMVGPEAGGTKEVPIKEIVEMNEIEEGKNKEQAINSSENIMDINEEPGTTEGEEITESSSTEEMEVRSVVADTDQKALGSEVQDASKVTTQIDKEKKEIPVSIKKEPEVTVVSQPTEPQPVLIPSININSDSGENKEEIGSLSKTETILPPESENPKENDNDSGTGSTADTSSIDLNLSISSFLSKTKDSGSISLQETRRQKKTLKKTRKFIVDGVEVSVTTSKIVTDSDSKTEELRFLRRQELRELRFLQKEEQRAQQQLNSKLQQQREQIFRRFEQEMMSKKRQYDQEIENLEKQQKQTIERLEQEHTNRLRDEAKRIKGEQEKELSKFQNMLKNRKKEEQEFVQKQQQELDGSLKKIIQQQKAELANIERECLNNKQQLMRAREAAIWELEERHLQEKHQLLKQQLKDQYFMQRHQLLKRHEKETEQMQRYNQRLIEELKNRQTQERARLPKIQRSEAKTRMAMFKKSLRINSTATPDQDRDKIKQFAAQEEKRQKNERMAQHQKHENQMRDLQLQCEANVRELHQLQNEKCHLLVEHETQKLKELDEEHSQELKEWREKLRPRKKTLEEEFARKLQEQEVFFKMTGESECLNPSTQSRISKFYPIPSLHSTGS>sp|Q9BQ61|TRIR_HUMAN Telomerase RNA component interacting RNase OS=Homosapiens OX=9606 GN=TRIR PE=1 SV=1MAARGRRAEPQGREAPGPAGGGGGGSRWAESGSGTSPESGDEEVSGAGSSPVSGGVNLFANDGSFLELFKRKMEEEQRQRQEEPPPGPQRPDQSAAAAGPGDPKRKGGPGSTLSFVGKRRGGNKLALKTGIVAKKQKTEDEVLTSKGDAWAKYMAEVKKYKAHQCGDDDKTRPLVK>sp|O94876|TMCC1_HUMAN Transmembrane and coiled-coil domains protein 1OS=Homo sapiens OX=9606 GN=TMCC1 PE=1 SV=3MEPSGSEQLFEDPDPGGKSQDAEARKQTESEQKLSKMTHNALENINVIGQGLKHLFQHQRRRSSVSPHDVQQIQADPEPEMDLESQNACAEIDGVPTHPTALNRVLQQIRVPPKMKRGTSLHSRRGKPEAPKGSPQINRKSGQEMTAVMQSGRPRSSSTTDAPTSSAMMEIACAAAAAAAACLPGEEGTAERIERLEVSSLAQTSSAVASSTDGSIHTDSVDGTPDPQRTKAAIAHLQQKILKLTEQIKIAQTARDDNVAEYLKLANSADKQQAARIKQVFEKKNQKSAQTILQLQKKLEHYHRKLREVEQNGIPRQPKDVFRDMHQGLKDVGAKVTGFSEGVVDSVKGGFSSFSQATHSAAGAVVSKPREIASLIRNKFGSADNIPNLKDSLEEGQVDDAGKALGVISNFQSSPKYGSEEDCSSATSGSVGANSTTGGIAVGASSSKTNTLDMQSSGFDALLHEIQEIRETQARLEESFETLKEHYQRDYSLIMQTLQEERYRCERLEEQLNDLTELHQNEILNLKQELASMEEKIAYQSYERARDIQEALEACQTRISKMELQQQQQQVVQLEGLENATARNLLGKLINILLAVMAVLLVFVSTVANCVVPLMKTRNRTFSTLFLVVFIAFLWKHWDALFSYVERFFSSPR>sp|O94876-2|TMCC1_HUMAN Isoform 2 of Transmembrane and coiled-coildomains protein 1 OS=Homo sapiens OX=9606 GN=TMCC1MVQRFSLRRQLSKIERLEVSSLAQTSSAVASSTDGSIHTDSVDGTPDPQRTKAAIAHLQQKILKLTEQIKIAQTARDDNVAEYLKLANSADKQQAARIKQVFEKKNQKSAQTILQLQKKLEHYHRKLREVEQNGIPRQPKDVFRDMHQGLKDVGAKVTGFSEGVVDSVKGGFSSFSQATHSAAGAVVSKPREIASLIRNKFGSADNIPNLKDSLEEGQVDDAGKALGVISNFQSSPKYGSEEDCSSATSGSVGANSTTGGIAVGASSSKTNTLDMQSSGFDALLHEIQEIRETQARLEESFETLKEHYQRDYSLIMQTLQEERYRCERLEEQLNDLTELHQNEILNLKQELASMEEKIAYQSYERARDIQEALEACQTRISKMELQQQQQQVVQLEGLENATARNLLGKLINILLAVMAVLLVFVSTVANCVVPLMKTRNRTFSTLFLVVFIAFLWKHWDALFSYVERFFSSPR>sp|Q9UQ13|SHOC2_HUMAN Leucine-rich repeat protein SHOC-2 OS=Homo sapiensOX=9606 GN=SHOC2 PE=1 SV=2MSSSLGKEKDSKEKDPKVPSAKEREKEAKASGGFGKESKEKEPKTKGKDAKDGKKDSSAAQPGVAFSVDNTIKRPNPAPGTRKKSSNAEVIKELNKCREENSMRLDLSKRSIHILPSSIKELTQLTELYLYSNKLQSLPAEVGCLVNLMTLALSENSLTSLPDSLDNLKKLRMLDLRHNKLREIPSVVYRLDSLTTLYLRFNRITTVEKDIKNLSKLSMLSIRENKIKQLPAEIGELCNLITLDVAHNQLEHLPKEIGNCTQITNLDLQHNELLDLPDTIGNLSSLSRLGLRYNRLSAIPRSLAKCSALEELNLENNNISTLPESLLSSLVKLNSLTLARNCFQLYPVGGPSQFSTIYSLNMEHNRINKIPFGIFSRAKVLSKLNMKDNQLTSLPLDFGTWTSMVELNLATNQLTKIPEDVSGLVSLEVLILSNNLLKKLPHGLGNLRKLRELDLEENKLESLPNEIAYLKDLQKLVLTNNQLTTLPRGIGHLTNLTHLGLGENLLTHLPEEIGTLENLEELYLNDNPNLHSLPFELALCSKLSIMSIENCPLSHLPPQIVAGGPSFIIQFLKMQGPYRAMV>sp|Q9UQ13-2|SHOC2_HUMAN Isoform 2 of Leucine-rich repeat protein SHOC-2OS=Homo sapiens OX=9606 GN=SHOC2MSSSLGKEKDSKEKDPKVPSAKEREKEAKASGGFGKESKEKEPKTKGKDAKDGKKDSSAAQPGVAFSVDNTIKRPNPAPGTRKKSSNAEVIKELNKCREENSMRLDLSKRSIHILPSSIKELTQLTELYLYSNKLQSLPAEVGCLVNLMTLALSENSLTSLPDSLDNLKKLRMLDLRHNKLREIPSVVYRLDSLTTLYLRFNRITTVEKDIKNLSKLSMLSIRENKIKQLPAEIGNLSSLSRLGLRYNRLSAIPRSLAKCSALEELNLENNNISTLPESLLSSLVKLNSLTLARNCFQLYPVGGPSQFSTIYSLNMEHNRINKIPFGIFSRAKVLSKLNMKDNQLTSLPLDFGTWTSMVELNLATNQLTKIPEDVSGLVSLEVLILSNNLLKKLPHGLGNLRKLRELDLEENKLESLPNEIAYLKDLQKLVLTNNQLTTLPRGIGHLTNLTHLGLGENLLTHLPEEIGTLENLEELYLNDNPNLHSLPFELALCSKLSIMSIENCPLSHLPPQIVAGGPSFIIQFLKMQGPYRAMV>sp|Q96DU3|SLAF6_HUMAN SLAM family member 6 OS=Homo sapiens OX=9606GN=SLAMF6 PE=1 SV=3MLWLFQSLLFVFCFGPGNVVSQSSLTPLMVNGILGESVTLPLEFPAGEKVNFITWLFNETSLAFIVPHETKSPEIHVTNPKQGKRLNFTQSYSLQLSNLKMEDTGSYRAQISTKTSAKLSSYTLRILRQLRNIQVTNHSQLFQNMTCELHLTCSVEDADDNVSFRWEALGNTLSSQPNLTVSWDPRISSEQDYTCIAENAVSNLSFSVSAQKLCEDVKIQYTDTKMILFMVSGICIVFGFIILLLLVLRKRRDSLSLSTQRTQGPAESARNLEYVSVSPTNNTVYASVTHSNRETEIWTPRENDTITIYSTINHSKESKPTFSRATALDNVV>sp|Q96DU3-2|SLAF6_HUMAN Isoform 2 of SLAM family member 6 OS=Homosapiens OX=9606 GN=SLAMF6MLWLFQSLLFVFCFGPGNVVSQSSLTPLMVNGILGESVTLPLEFPAGEKVNFITWLFNETSLAFIVPHETKSPEIHVTNPKQGKRLNFTQSYSLQLSNLKMEDTGSYRAQISTKTSAKLSSYTLRILRQLRNIQVTNHSQLFQNMTCELHLTCSVEDADDNVSFRWEALGNTLSSQPNLTVSWDPRISSEQDYTCIAENAVSNLSFSVSAQKLCEDVKIQYTDTKMILFMVSGICIVFGFIILLLLVLRKRRDSLSLSTQRTQGPESARNLEYVSVSPTNNTVYASVTHSNRETEIWTPRENDTITIYSTINHSKESKPTFSRATALDNVV>sp|Q96DU3-3|SLAF6_HUMAN Isoform 3 of SLAM family member 6 OS=Homosapiens OX=9606 GN=SLAMF6MLWLFQSLLFVFCFGPGQLRNIQVTNHSQLFQNMTCELHLTCSVEDADDNVSFRWEALGNTLSSQPNLTVSWDPRISSEQDYTCIAENAVSNLSFSVSAQKLCEDVKIQYTDTKMILFMVSGICIVFGFIILLLLVLRKRRDSLSLSTQRTQGPAESARNLEYVSVSPTNNTVYASVTHSNRETEIWTPRENDTITIYSTINHSKESKPTFSRATALDNVV>sp|P11387|TOP1_HUMAN DNA topoisomerase 1 OS=Homo sapiens OX=9606 GN=TOP1PE=1 SV=2MSGDHLHNDSQIEADFRLNDSHKHKDKHKDREHRHKEHKKEKDREKSKHSNSEHKDSEKKHKEKEKTKHKDGSSEKHKDKHKDRDKEKRKEEKVRASGDAKIKKEKENGFSSPPQIKDEPEDDGYFVPPKEDIKPLKRPRDEDDADYKPKKIKTEDTKKEKKRKLEEEEDGKLKKPKNKDKDKKVPEPDNKKKKPKKEEEQKWKWWEEERYPEGIKWKFLEHKGPVFAPPYEPLPENVKFYYDGKVMKLSPKAEEVATFFAKMLDHEYTTKEIFRKNFFKDWRKEMTNEEKNIITNLSKCDFTQMSQYFKAQTEARKQMSKEEKLKIKEENEKLLKEYGFCIMDNHKERIANFKIEPPGLFRGRGNHPKMGMLKRRIMPEDIIINCSKDAKVPSPPPGHKWKEVRHDNKVTWLVSWTENIQGSIKYIMLNPSSRIKGEKDWQKYETARRLKKCVDKIRNQYREDWKSKEMKVRQRAVALYFIDKLALRAGNEKEEGETADTVGCCSLRVEHINLHPELDGQEYVVEFDFLGKDSIRYYNKVPVEKRVFKNLQLFMENKQPEDDLFDRLNTGILNKHLQDLMEGLTAKVFRTYNASITLQQQLKELTAPDENIPAKILSYNRANRAVAILCNHQRAPPKTFEKSMMNLQTKIDAKKEQLADARRDLKSAKADAKVMKDAKTKKVVESKKKAVQRLEEQLMKLEVQATDREENKQIALGTSKLNYLDPRITVAWCKKWGVPIEKIYNKTQREKFAWAIDMADEDYEF>sp|O14657|TOR1B_HUMAN Torsin-1B OS=Homo sapiens OX=9606 GN=TOR1B PE=1SV=2MLRAGWLRGAAALALLLAARVVAAFEPITVGLAIGAASAITGYLSYNDIYCRFAECCREERPLNASALKLDLEEKLFGQHLATEVIFKALTGFRNNKNPKKPLTLSLHGWAGTGKNFVSQIVAENLHPKGLKSNFVHLFVSTLHFPHEQKIKLYQDQLQKWIRGNVSACANSVFIFDEMDKLHPGIIDAIKPFLDYYEQVDGVSYRKAIFIFLSNAGGDLITKTALDFWRAGRKREDIQLKDLEPVLSVGVFNNKHSGLWHSGLIDKNLIDYFIPFLPLEYRHVKMCVRAEMRARGSAIDEDIVTRVAEEMTFFPRDEKIYSDKGCKTVQSRLDFH>sp|Q9BX73|TM2D2_HUMAN TM2 domain-containing protein 2 OS=Homo sapiensOX=9606 GN=TM2D2 PE=1 SV=1MVLGGCPVSYLLLCGQAALLLGNLLLLHCVSRSHSQNATAEPELTSAGAAQPEGPGGAASWEYGDPHSPVILCSYLPDEFIECEDPVDHVGNATASQELGYGCLKFGGQAYSDVEHTSVQCHALDGIECASPRTFLRENKPCIKYTGHYFITTLLYSFFLGCFGVDRFCLGHTGTAVGKLLTLGGLGIWWFVDLILLITGGLMPSDGSNWCTVY>sp|Q9BX73-2|TM2D2_HUMAN Isoform 2 of TM2 domain-containing protein 2OS=Homo sapiens OX=9606 GN=TM2D2MKKCLLPVLITCMQTAICKDRMMMIMILLVNYRPDEFIECEDPVDHVGNATASQELGYGCLKFGGQAYSDVEHTSVQCHALDGIECASPRTFLRENKPCIKYTGHYFITTLLYSFFLGCFGVDRFCLGHTGTAVGKLLTLGGLGIWWFVDLILLITGGLMPSDGSNWCTVY>sp|O60225|SSX5_HUMAN Protein SSX5 OS=Homo sapiens OX=9606 GN=SSX5 PE=1SV=3MNGDDAFVRRPRVGSQIPEKMQKAFDDIAKYFSEKEWEKMKASEKIIYVYMKRKYEAMTKLGFKATLPPFMRNKRVADFQGNDFDNDPNRGNQVEHPQMTFGRLQGIFPKITPEKPAEEGNDSKGVPEASGPQNNGKQLRPSGKLNTSEKVNKTSGPKRGKHAWTHRVRERKQLVIYEEISDPQEDDE>sp|O60225-2|SSX5_HUMAN Isoform 2 of Protein SSX5 OS=Homo sapiens OX=9606GN=SSX5MNGDDAFVRRPRVGSQIPEKMQKHPWRQVCDRGIHLVNLSPFWKVGREPASSIKALLCGRGEARAFDDIAKYFSEKEWEKMKASEKIIYVYMKRKYEAMTKLGFKATLPPFMRNKRVADFQGNDFDNDPNRGNQVEHPQMTFGRLQGIFPKITPEKPAEEGNDSKGVPEASGPQNNGKQLRPSGKLNTSEKVNKTSGPKRGKHAWTHRVRERKQLVIYEEISDPQEDDE>sp|O75558|STX11_HUMAN Syntaxin-11 OS=Homo sapiens OX=9606 GN=STX11 PE=1SV=1MKDRLAELLDLSKQYDQQFPDGDDEFDSPHEDIVFETDHILESLYRDIRDIQDENQLLVADVKRLGKQNARFLTSMRRLSSIKRDTNSIAKAIKARGEVIHCKLRAMKELSEAAEAQHGPHSAVARISRAQYNALTLTFQRAMHDYNQAEMKQRDNCKIRIQRQLEIMGKEVSGDQIEDMFEQGKWDVFSENLLADVKGARAALNEIESRHRELLRLESRIRDVHELFLQMAVLVEKQADTLNVIELNVQKTVDYTGQAKAQVRKAVQYEEKNPCRTLCCFCCPCLK>sp|P0DMM9|ST1A3_HUMAN Sulfotransferase 1A3 OS=Homo sapiens OX=9606GN=SULT1A3 PE=1 SV=1MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLINTYPKSGTTWVSQILDMIYQGGDLEKCNRAPIYVRVPFLEVNDPGEPSGLETLKDTPPPRLIKSHLPLALLPQTLLDQKVKVVYVARNPKDVAVSYYHFHRMEKAHPEPGTWDSFLEKFMAGEVSYGSWYQHVQEWWELSRTHPVLYLFYEDMKENPKREIQKILEFVGRSLPEETMDFMVQHTSFKEMKKNPMTNYTTVPQELMDHSISPFMRKGMAGDWKTTFTVAQNERFDADYAEKMAGCSLSFRSEL>sp|P0DMM9-2|ST1A3_HUMAN Isoform 2 of Sulfotransferase 1A3 OS=Homosapiens OX=9606 GN=SULT1A3MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLINTYPKSGTTWVSQILDMIYQGGDLEKCNRAPIYVRVPFLEVNDPGEPSGLETLKDTPPPRLIKSHLPLALLPQTLLDQKVKVVYVARNPKDVAVSYYHFHRMEKAHPEPGTWDSFLEKFMAGEGGLDWRKEGVKPRGGGYNVQQPCVGAPCPLL>sp|P0DMM9-3|ST1A3_HUMAN Isoform 3 of Sulfotransferase 1A3 OS=Homosapiens OX=9606 GN=SULT1A3MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLINTYPKSGTTWVSQILDMIYQGGDLEKCNRAPIYVRVPFLEVNDPGEPSGLETLKDTPPPRLIKSHLPLALLPQTLLDQKVKVVYVARNPKDVAVSYYHFHRMEKAHPEPGTWDSFLEKFMAGEVSYGSWYQHVQEWWELSRTHPVLYLFYEDMKEEPSAAQNPKREIQKILEFVGRSLPEETMDFMVQHTSFKEMKKNPMTNYTTVPQELMDHSISPFMRKGMAGDWKTTFTVAQNERFDADYAEKMAGCSLSFRSEL>sp|A0A1B0GWG4|SRTM2_HUMAN Serine-rich and transmembrane domain-containing 2 OS=Homo sapiens OX=9606 GN=SERTM2 PE=3 SV=2MMEAHFKYHGNLTGRAHFPTLATEVDTSSDKYSNLYMYVGLFLSLLAILLILLFTMLLRLKHVISPINSDSTESVPQFTDVEMQSRIPTP>sp|Q8WW62|TMED6_HUMAN Transmembrane emp24 domain-containing protein 6OS=Homo sapiens OX=9606 GN=TMED6 PE=2 SV=2MSPLLFGAGLVVLNLVTSARSQKTEPLSGSGDQPLFRGADRYDFAIMIPPGGTECFWQFAHQTGYFYFSYEVQRTVGMSHDRHVAATAHNPQGFLIDTSQGVRGQINFSTQETGFYQLCLSNQHNHFGSVQVYLNFGVFYEGPETDHKQKERKQLNDTLDAIEDGTQKVQNNIFHMWRYYNFARMRKMADFFLIQSNYNYVNWWSTAQSLVIILSGILQLYFLKRLFNVPTTTDTKKPRC>sp|Q9BSF4|TIM29_HUMAN Mitochondrial import inner membrane translocasesubunit Tim29 OS=Homo sapiens OX=9606 GN=TIMM29 PE=1 SV=2MAAAALRRFWSRRRAEAGDAVVAKPGVWARLGSWARALLRDYAEACRDASAEARARPGRAAVYVGLLGGAAACFTLAPSEGAFEEALLEASGTLLLLAPATRNRESEAFVQRLLWLRGRGRLRYVNLGLCSLVYEAPFDAQASLYQARCRYLQPRWTDFPGRVLDVGFVGRWWVLGAWMRDCDINDDEFLHLPAHLRVVGPQQLHSETNERLFDEKYKPVVLTDDQVDQALWEEQVLQKEKKDRLALSQAHSLVQAEAPR>sp|Q8TAV4|STML3_HUMAN Stomatin-like protein 3 OS=Homo sapiens OX=9606GN=STOML3 PE=1 SV=1MDSRVSSPEKQDKENFVGVNNKRLGVCGWILFSLSFLLVIITFPISIWMCLKIIKEYERAVVFRLGRIQADKAKGPGLILVLPCIDVFVKVDLRTVTCNIPPQEILTRDSVTTQVDGVVYYRIYSAVSAVANVNDVHQATFLLAQTTLRNVLGTQTLSQILAGREEIAHSIQTLLDDATELWGIRVARVEIKDVRIPVQLQRSMAAEAEATREARAKVLAAEGEMNASKSLKSASMVLAESPIALQLRYLQTLSTVATEKNSTIVFPLPMNILEGIGGVSYDNHKKLPNKA>sp|Q8TAV4-2|STML3_HUMAN Isoform 2 of Stomatin-like protein 3 OS=Homosapiens OX=9606 GN=STOML3MNSRGELVGVNNKRLGVCGWILFSLSFLLVIITFPISIWMCLKIIKEYERAVVFRLGRIQADKAKGPGLILVLPCIDVFVKVDLRTVTCNIPPQEILTRDSVTTQVDGVVYYRIYSAVSAVANVNDVHQATFLLAQTTLRNVLGTQTLSQILAGREEIAHSIQTLLDDATELWGIRVARVEIKDVRIPVQLQRSMAAEAEATREARAKVLAAEGEMNASKSLKSASMVLAESPIALQLRYLQTLSTVATEKNSTIVFPLPMNILEGIGGVSYDNHKKLPNKA>sp|Q8IWU6|SULF1_HUMAN Extracellular sulfatase Sulf-1 OS=Homo sapiensOX=9606 GN=SULF1 PE=1 SV=1MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYARGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEFEGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGPPTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEIEALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETHNFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYKQCNPRPKNLDVGNKDGGSYDLHRGQLWDGWEG>sp|Q9H668|STN1_HUMAN CST complex subunit STN1 OS=Homo sapiens OX=9606GN=STN1 PE=1 SV=2MQPGSSRCEEETPSLLWGLDPVFLAFAKLYIRDILDMKESRQVPGVFLYNGHPIKQVDVLGTVIGVRERDAFYSYGVDDSTGVINCICWKKLNTESVSAAPSAARELSLTSQLKKLQETIEQKTKIEIGDTIRVRGSIRTYREEREIHATTYYKVDDPVWNIQIARMLELPTIYRKVYDQPFHSSALEKEEALSNPGALDLPSLTSLLSEKAKEFLMENRVQSFYQQELEMVESLLSLANQPVIHSASSDQVNFKKDTTSKAIHSIFKNAIQLLQEKGLVFQKDDGFDNLYYVTREDKDLHRKIHRIIQQDCQKPNHMEKGCHFLHILACARLSIRPGLSEAVLQQVLELLEDQSDIVSTMEHYYTAF>sp|O43615|TIM44_HUMAN Mitochondrial import inner membrane translocasesubunit TIM44 OS=Homo sapiens OX=9606 GN=TIMM44 PE=1 SV=2MAAAALRSGWCRCPRRCLGSGIQFLSSHNLPHGSTYQMRRPGGELPLSKSYSSGNRKGFLSGLLDNVKQELAKNKEMKESIKKFRDEARRLEESDVLQEARRKYKTIESETVRTSEVLRKKLGELTGTVKESLHEVSKSDLGRKIKEGVEEAAKTAKQSAESVSKGGEKLGRTAAFRALSQGVESVKKEIDDSVLGQTGPYRRPQRLRKRTEFAGDKFKEEKVFEPNEEALGVVLHKDSKWYQQWKDFKENNVVFNRFFEMKMKYDESDNAFIRASRALTDKVTDLLGGLFSKTEMSEVLTEILRVDPAFDKDRFLKQCENDIIPNVLEAMISGELDILKDWCYEATYSQLAHPIQQAKALGLQFHSRILDIDNVDLAMGKMMEQGPVLIITFQAQLVMVVRNPKGEVVEGDPDKVLRMLYVWALCRDQDELNPYAAWRLLDISASSTEQIL>sp|Q9BXA5|SUCR1_HUMAN Succinate receptor 1 OS=Homo sapiens OX=9606GN=SUCNR1 PE=1 SV=2MLGIMAWNATCKNWLAAEAALEKYYLSIFYGIEFVVGVLGNTIVVYGYIFSLKNWNSSNIYLFNLSVSDLAFLCTLPMLIRSYANGNWIYGDVLCISNRYVLHANLYTSILFLTFISIDRYLIIKYPFREHLLQKKEFAILISLAIWVLVTLELLPILPLINPVITDNGTTCNDFASSGDPNYNLIYSMCLTLLGFLIPLFVMCFFYYKIALFLKQRNRQVATALPLEKPLNLVIMAVVIFSVLFTPYHVMRNVRIASRLGSWKQYQCTQVVINSFYIVTRPLAFLNSVINPVFYFLLGDHFRDMLMNQLRHNFKSLTSFSRWAHELLLSFREK>sp|Q8WXE9|STON2_HUMAN Stonin-2 OS=Homo sapiens OX=9606 GN=STON2 PE=1SV=1MTTLDHVIATHQSEWVSFNEEPPFPAHSQGGTEEHLPGLSSSPDQSESSSGENHVVDGGSQDHSHSEQDDSSEKMGLISEAASPPGSPEQPPPDLASAISNWVQFEDDTPWASTSPPHQETAETALPLTMPCWTCPSFDSLGRCPLTSESSWTTHSEDTSSPSFGCSYTDLQLINAEEQTSGQASGADSTDNSSSLQEDEEVEMEAISWQASSPAMNGHPAPPVTSARFPSWVTFDDNEVSCPLPPVTSPLKPNTPPSASVIPDVPYNSMGSFKKRDRPKSTLMNFSKVQKLDISSLNRTPSVTEASPWRATNPFLNETLQDVQPSPINPFSAFFEEQERRSQNSSISSTTGKSQRDSLIVIYQDAISFDDSSKTQSHSDAVEKLKQLQIDDPDHFGSATLPDDDPVAWIELDAHPPGSARSQPRDGWPMMLRIPEKKNIMSSRHWGPIFVKLTDTGYLQLYYEQGLEKPFREFKLEICHEISEPRLQNYDENGRIHSLRIDRVTYKEKKKYQPKPAVAHTAEREQVIKLGTTNYDDFLSFIHAVQDRLMDLPVLSMDLSTVGLNYLEEEITVDVRDEFSGIVSKGDNQILQHHVLTRIHILSFLSGLAECRLGLNDILVKGNEIVLRQDIMPTTTTKWIKLHECRFHGCVDEDVFHNSRVILFNPLDACRFELMRFRTVFAEKTLPFTLRTATSVNGAEVEVQSWLRMSTGFSANRDPLTQVPCENVMIRYPVPSEWVKNFRRESVLGEKSLKAKVNRGASFGSTSVSGSEPVMRVTLGTAKYEHAFNSIVWRINRLPDKNSASGHPHCFFCHLELGSDREVPSRFANHVNVEFSMPTTSASKASVRSISVEDKTDVRKWVNYSAHYSYQVALGSIWLMLPTPFVHPTTLPLLFLLAMLTMFAW>sp|Q8WXE9-3|STON2_HUMAN Isoform 2 of Stonin-2 OS=Homo sapiens OX=9606GN=STON2MTTLDHVIATHQSEWVSFNEEPPFPAHSQGGTEEHLPGLSSSPDQSESSSGENHVVDGGSQDHSHSEQDDSSEKMGLISEAASPPGSPEQPPPDLASAISNWVQFEDDTPWASTSPPHQETAETALPLTMPCWTCPSFDSLGRCPLTSESSWTTHSEDTSSPSFGCSYTDLQLINAEEQTSGQASGADSTDNSSSLQEDEEVEMEAISWQASSPAMNGHPAPPVTSARFPSWVTFDDNEVSCPLPPVTSPLKPNTPPSASVIPDVPYNSMGSFKKRDRPKSTLMNFSKVQKLDISSLNRTPSVTEASPWRATNPFLNETLQDVQPSPINPFSAFFEEQERRSQNSSISSTTGKSQRDSLIVIYQDAISFDDSSKTQSHSDAVEKLKQLQIDDPDHFGSATLPDDDPVAWIELDAHPPGSARSQPRDGWPMMLRIPEKKNIMSSRHWGPIFVKLTDTGYLQLYYEQGLEKPFREFKLEICHEISEPRLQNYDENGRIHSLRIDRVTYKEKKKYQPKPAVAHTAEREQVIKLGTTNYDDFLSFIHAVQDRLMDLPVLSMDLSTVGLNYLEEEITVDVRDEFSGIVSKGDNQILQHHVLTRIHILSFLSGLAECRLGLNDILVKGNEIVLRQDIMPTTTTKWIKLHECRFHGCVDEDVFHNSRVILFNPLDACRFELMRFRTVFAEKTLPFTLRTATSVNGAEVEVQSWLRMSTGFSANRDPLTQVPCENVMIRYPVPSEWVKNFRRESVLGEKSLKAKVNRGASFGSTSVSGSEPVMRVTLGTAKYEHAFNSIVWRINRLPDKNSASGHPHCFFCHLELGSDREVPSRFANHVNVEFSMPTTSASKASVRSISVEDKTDVRKWVNYSAHYSYQTTETDNLPNPLYCSCLPHTDLKRGSKRVVKIRWNASLEVPLASSIRTMV>sp|P0CL84|ST3L2_HUMAN Putative STAG3-like protein 2 OS=Homo sapiensOX=9606 GN=STAG3L2 PE=5 SV=1MIFSMLRKLPKVTCRDVLPEIRAICIEEIGCWMQSYSTSFLTDSYLKYIGWTLHDKHREVRVKCVKALKGLYGNRDLTARLELFTGRFKDWMVSMIVDREYSVAVEAVRLLILILKNMEGVLMDVDCESVYPIV>sp|P0CL84-2|ST3L2_HUMAN Isoform 2 of Putative STAG3-like protein 2OS=Homo sapiens OX=9606 GN=STAG3L2MQHREVRVKCVKALKGLYGNRDLTARLELFTGRFKDWMVSMIVDREYSVAVEAVRLLILILKNMEGVLMDVDCESVYPIV>sp|O94804|STK10_HUMAN Serine/threonine-protein kinase 10 OS=Homo sapiensOX=9606 GN=STK10 PE=1 SV=1MAFANFRRILRLSTFEKRKSREYEHVRRDLDPNEVWEIVGELGDGAFGKVYKAKNKETGALAAAKVIETKSEEELEDYIVEIEILATCDHPYIVKLLGAYYHDGKLWIMIEFCPGGAVDAIMLELDRGLTEPQIQVVCRQMLEALNFLHSKRIIHRDLKAGNVLMTLEGDIRLADFGVSAKNLKTLQKRDSFIGTPYWMAPEVVMCETMKDTPYDYKADIWSLGITLIEMAQIEPPHHELNPMRVLLKIAKSDPPTLLTPSKWSVEFRDFLKIALDKNPETRPSAAQLLEHPFVSSITSNKALRELVAEAKAEVMEEIEDGRDEGEEEDAVDAASTLENHTQNSSEVSPPSLNADKPLEESPSTPLAPSQSQDSVNEPCSQPSGDRSLQTTSPPVVAPGNENGLAVPVPLRKSRPVSMDARIQVAQEKQVAEQGGDLSPAANRSQKASQSRPNSSALETLGGEKLANGSLEPPAQAAPGPSKRDSDCSSLCTSESMDYGTNLSTDLSLNKEMGSLSIKDPKLYKKTLKRTRKFVVDGVEVSITTSKIISEDEKKDEEMRFLRRQELRELRLLQKEEHRNQTQLSNKHELQLEQMHKRFEQEINAKKKFFDTELENLERQQKQQVEKMEQDHAVRRREEARRIRLEQDRDYTRFQEQLKLMKKEVKNEVEKLPRQQRKESMKQKMEEHTQKKQLLDRDFVAKQKEDLELAMKRLTTDNRREICDKERECLMKKQELLRDREAALWEMEEHQLQERHQLVKQQLKDQYFLQRHELLRKHEKEREQMQRYNQRMIEQLKVRQQQEKARLPKIQRSEGKTRMAMYKKSLHINGGGSAAEQREKIKQFSQQEEKRQKSERLQQQQKHENQMRDMLAQCESNMSELQQLQNEKCHLLVEHETQKLKALDESHNQNLKEWRDKLRPRKKALEEDLNQKKREQEMFFKLSEEAECPNPSTPSKAAKFFPYSSADAS>sp|Q9Y3M8|STA13_HUMAN StAR-related lipid transfer protein 13 OS=Homosapiens OX=9606 GN=STARD13 PE=1 SV=2MFSQVPRTPASGCYYLNSMTPEGQEMYLRFDQTTRRSPYRMSRILARHQLVTKIQQEIEAKEACDWLRAAGFPQYAQLYEDSQFPINIVAVKNDHDFLEKDLVEPLCRRLNTLNKCASMKLDVNFQRKKGDDSDEEDLCISNKWTFQRTSRRWSRVDDLYTLLPRGDRNGSPGGTGMRNTTSSESVLTDLSEPEVCSIHSESSGGSDSRSQPGQCCTDNPVMLDAPLVSSSLPQPPRDVLNHPFHPKNEKPTRARAKSFLKRMETLRGKGAHGRHKGSGRTGGLVISGPMLQQEPESFKAMQCIQIPNGDLQNSPPPACRKGLPCSGKSSGESSPSEHSSSGVSTPCLKERKCHEANKRGGMYLEDLDVLAGTALPDAGDQSRMHEFHSQENLVVHIPKDHKPGTFPKALSIESLSPTDSSNGVNWRTGSISLGREQVPGAREPRLMASCHRASRVSIYDNVPGSHLYASTGDLLDLEKDDLFPHLDDILQHVNGLQEVVDDWSKDVLPELQTHDTLVGEPGLSTFPSPNQITLDFEGNSVSEGRTTPSDVERDVTSLNESEPPGVRDRRDSGVGASLTRPNRRLRWNSFQLSHQPRPAPASPHISSQTASQLSLLQRFSLLRLTAIMEKHSMSNKHGWTWSVPKFMKRMKVPDYKDKAVFGVPLIVHVQRTGQPLPQSIQQALRYLRSNCLDQVGLFRKSGVKSRIHALRQMNENFPENVNYEDQSAYDVADMVKQFFRDLPEPLFTNKLSETFLHIYQYVSKEQRLQAVQAAILLLADENREVLQTLLCFLNDVVNLVEENQMTPMNLAVCLAPSLFHLNLLKKESSPRVIQKKYATGKPDQKDLNENLAAAQGLAHMIMECDRLFEVPHELVAQSRNSYVEAEIHVPTLEELGTQLEESGATFHTYLNHLIQGLQKEAKEKFKGWVTCSSTDNTDLAFKKVGDGNPLKLWKASVEVEAPPSVVLNRVLRERHLWDEDFVQWKVVETLDRQTEIYQYVLNSMAPHPSRDFVVLRTWKTDLPKGMCTLVSLSVEHEEAQLLGGVRAVVMDSQYLIEPCGSGKSRLTHICRIDLKGHSPEWYSKGFGHLCAAEVARIRNSFQPLIAEGPETKI>sp|Q9Y3M8-2|STA13_HUMAN Isoform 2 of StAR-related lipid transfer protein13 OS=Homo sapiens OX=9606 GN=STARD13MLEPSSVLHANVNQAPLWCLVLRWCRECKDTVCGGKQKSRVNHTFQRREIEAKEACDWLRAAGFPQYAQLYEDSQFPINIVAVKNDHDFLEKDLVEPLCRRLNTLNKCASMKLDVNFQRKKGDDSDEEDLCISNKWTFQRTSRRWSRVDDLYTLLPRGDRNGSPGGTGMRNTTSSESVLTDLSEPEVCSIHSESSGGSDSRSQPGQCCTDNPVMLDAPLVSSSLPQPPRDVLNHPFHPKNEKPTRARAKSFLKRMETLRGKGAHGRHKGSGRTGGLVISGPMLQQEPESFKAMQCIQIPNGDLQNSPPPACRKGLPCSGKSSGESSPSEHSSSGVSTPCLKERKCHEANKRGGMYLEDLDVLAGTALPDAGDQSRMHEFHSQENLVVHIPKDHKPGTFPKALSIESLSPTDSSNGVNWRTGSISLGREQVPGAREPRLMASCHRASRVSIYDNVPGSHLYASTGDLLDLEKDDLFPHLDDILQHVNGLQEVVDDWSKDVLPELQTHDTLVGEPGLSTFPSPNQITLDFEGNSVSEGRTTPSDVERDVTSLNESEPPGVRDRRDSGVGASLTRPNRRLRWNSFQLSHQPRPAPASPHISSQTASQLSLLQRFSLLRLTAIMEKHSMSNKHGWTWSVPKFMKRMKVPDYKDKAVFGVPLIVHVQRTGQPLPQSIQQALRYLRSNCLDQVGLFRKSGVKSRIHALRQMNENFPENVNYEDQSAYDVADMVKQFFRDLPEPLFTNKLSETFLHIYQYVSKEQRLQAVQAAILLLADENREVLQTLLCFLNDVVNLVEENQMTPMNLAVCLAPSLFHLNLLKKESSPRVIQKKYATGKPDQKDLNENLAAAQGLAHMIMECDRLFEVPHELVAQSRNSYVEAEIHVPTLEELGTQLEESGATFHTYLNHLIQGLQKEAKEKFKGWVTCSSTDNTDLAFKKVGDGNPLKLWKASVEVEAPPSVVLNRVLRERHLWDEDFVQWKVVETLDRQTEIYQYVLNSMAPHPSRDFVVLRTWKTDLPKGMCTLVSLSVEHEEAQLLGGVRAVVMDSQYLIEPCGSGKSRLTHICRIDLKGHSPEWYSKGFGHLCAAEVARIRNSFQPLIAEGPETKI>sp|Q9Y3M8-3|STA13_HUMAN Isoform 3 of StAR-related lipid transfer protein13 OS=Homo sapiens OX=9606 GN=STARD13MKLDVNFQRKKGDDSDEEDLCISNKWTFQRTSRRWSRVDDLYTLLPRGDRNGSPGGTGMRNTTSSESVLTDLSEPEVCSIHSESSGGSDSRSQPGQCCTDNPVMLDAPLVSSSLPQPPRDVLNHPFHPKNEKPTRARAKSFLKRMETLRGKGAHGRHKGSGRTGGLVISGPMLQQEPESFKAMQCIQIPNGDLQNSPPPACRKGLPCSGKSSGESSPSEHSSSGVSTPCLKERKCHEANKRGGMYLEDLDVLAGTALPDAGDQSRMHEFHSQENLVVHIPKDHKPGTFPKALSIESLSPTDSSNGVNWRTGSISLGREQVPGAREPRLMASCHRASRVSIYDNVPGSHLYASTGDLLDLEKDDLFPHLDDILQHVNGLQEVVDDWSKDVLPELQTHDTLVGEPGLSTFPSPNQITLDFEGNSVSEGRTTPSDVERDVTSLNESEPPGVRDRRDSGVGASLTRPNRRLRWNSFQLSHQPRPAPASPHISSQTASQLSLLQRFSLLRLTAIMEKHSMSNKHGWTWSVPKFMKRMKVPDYKDKAVFGVPLIVHVQRTGQPLPQSIQQALRYLRSNCLDQVGLFRKSGVKSRIHALRQMNENFPENVNYEDQSAYDVADMVKQFFRDLPEPLFTNKLSETFLHIYQYVSKEQRLQAVQAAILLLADENREVLQTLLCFLNDVVNLVEENQMTPMNLAVCLAPSLFHLNLLKKESSPRVIQKKYATGKPDQKDLNENLAAAQGLAHMIMECDRLFEVPHELVAQSRNSYVEAEIHVPTLEELGTQLEESGATFHTYLNHLIQGLQKEAKEKFKGWVTCSSTDNTDLAFKKVGDGNPLKLWKASVEVEAPPSVVLNRVLRERHLWDEDFVQWKVVETLDRQTEIYQYVLNSMAPHPSRDFVVLRTWKTDLPKGMCTLVSLSVEHEEAQLLGGVRAVVMDSQYLIEPCGSGKSRLTHICRIDLKGHSPEWYSKGFGHLCAAEVARIRNSFQPLIAEGPETKI>sp|Q9Y3M8-4|STA13_HUMAN Isoform 4 of StAR-related lipid transfer protein13 OS=Homo sapiens OX=9606 GN=STARD13MSTGTQPKTKVLSDKRPKERVEIEAKEACDWLRAAGFPQYAQLYEDSQFPINIVAVKNDHDFLEKDLVEPLCRRLNTLNKCASMKLDVNFQRKKGDDSDEEDLCISNKWTFQRTSRRWSRVDDLYTLLPRGDRNGSPGGTGMRNTTSSESVLTDLSEPEVCSIHSESSGGSDSRSQPGQCCTDNPVMLDAPLVSSSLPQPPRDVLNHPFHPKNEKPTRARAKSFLKRMETLRGKGAHGRHKGSGRTGGLVISGPMLQQEPESFKAMQCIQIPNGDLQNSPPPACRKGLPCSGKSSGESSPSEHSSSGVSTPCLKERKCHEANKRGGMYLEDLDVLAGTALPDAGDQSRMHEFHSQENLVVHIPKDHKPGTFPKALSIESLSPTDSSNGVNWRTGSISLGREQVPGAREPRLMASCHRASRVSIYDNVPGSHLYASTGDLLDLEKDDLFPHLDDILQHVNGLQEVVDDWSKDVLPELQTHDTLVGEPGLSTFPSPNQITLDFEGNSVSEGRTTPSDVERDVTSLNESEPPGVRDRRDSGVGASLTRPNRRLRWNSFQLSHQPRPAPASPHISSQTASQLSLLQRFSLLRLTAIMEKHSMSNKHGWTWSVPKFMKRMKVPDYKDKAVFGVPLIVHVQRTGQPLPQSIQQALRYLRSNCLDQVGLFRKSGVKSRIHALRQMNENFPENVNYEDQSAYDVADMVKQFFRDLPEPLFTNKLSETFLHIYQYVSKEQRLQAVQAAILLLADENREVLQTLLCFLNDVVNLVEENQMTPMNLAVCLAPSLFHLNLLKKESSPRVIQKKYATGKPDQKDLNENLAAAQGLAHMIMECDRLFEVPHELVAQSRNSYVEAEIHVPTLEELGTQLEESGATFHTYLNHLIQGLQKEAKEKFKGWVTCSSTDNTDLAFKKVGDGNPLKLWKASVEVEAPPSVVLNRVLRERHLWDEDFVQWKVVETLDRQTEIYQYVLNSMAPHPSRDFVVLRTWKTDLPKGMCTLVSLSVEHEEAQLLGGVRAVVMDSQYLIEPCGSGKSRLTHICRIDLKGHSPEWYSKGFGHLCAAEVARIRNSFQPLIAEGPETKI>sp|Q9Y3M8-5|STA13_HUMAN Isoform 5 of StAR-related lipid transfer protein13 OS=Homo sapiens OX=9606 GN=STARD13MLEPSSVLHANVNQAPLWCLVLRWCRECKDTVCGGKQKSRVNHTFQRREIEAKEACDWLRAAGFPQYAQLYEDSQFPINIVAVKNDHDFLEKDLVEPLCRRLNTLNKCASMKLDVNFQRKKGDDSDEEDLCISNKWTFQRTSRRWSRVDDLYTLLPRGDRNGSPGGTGMRNTTSSESVLTDLSEPEVCSIHSESSGGSDSRSQPGQCCTDNPVMLDAPLVSSSLPQPPRDVLNHPFHPKNEKPTRARAKSFLKRMETLRGKGAHGRHKGSGRTGGLVISGPMLQQEPESFKAMQCIQIPNGDLQNSPPPACRKGLPCSGKSSGESSPSEHSSSGVSTPCLKERKCHEANKRGGMYLEDLDVLAGTALPDAGDQSRMHEFHSQENLVVHIPKDHKPGTFPKALSIESLSPTDSSNGVNWRTGSISLGREQVPGAREPRLMASCHRASRVSIYDNVPGSHLYASTGDLLDLEKDDLFPHLDDILQHVNGLQEVVDDWSKDVLPELQTHDTLVGEPGLSTFPSPNQITLDFEGNSVSEGRTTPSDVERDVTSLNESEPPGVRDRRDSGVGASLTRPNRRLRWNSFQLSHQPRPAPASPHISSQTASQLSLLQRFSLLRLTAIMEKHSMSNKHGWTWSVPKFMKRMKVPDYKDKAVFGVPLIVHVQRTGQPLPQSIQQALRYLRSNCLDQE>sp|Q5VZP5|STYL2_HUMAN Serine/threonine/tyrosine-interacting-like protein2 OS=Homo sapiens OX=9606 GN=STYXL2 PE=2 SV=1MATRKDTEEEQVVPSEEDEANVRAVQAHYLRSPSPSQYSMVSDAETESIFMEPIHLSSAIAAKQIINEELKPPGVRADAECPGMLESAEQLLVEDLYNRVREKMDDTSLYNTPCVLDLQRALVQDRQEAPWNEVDEVWPNVFIAEKSVAVNKGRLKRLGITHILNAAHGTGVYTGPEFYTGLEIQYLGVEVDDFPEVDISQHFRKASEFLDEALLTYRGKVLVSSEMGISRSAVLVVAYLMIFHNMAILEALMTVRKKRAIYPNEGFLKQLRELNEKLMEEREEDYGREGGSAEAEEGEGTGSMLGARVHALTVEEEDDSASHLSGSSLGKATQASKPLTLIDEEEEEKLYEQWKKGQGLLSDKVPQDGGGWRSASSGQGGEELEDEDVERIIQEWQSRNERYQAEGYRRWGREEEKEEESDAGSSVGRRRRTLSESSAWESVSSHDIWVLKQQLELNRPDHGRRRRADSMSSESTWDAWNERLLEIEKEASRRYHAKSKREEAADRSSEAGSRVREDDEDSVGSEASSFYNFCSRNKDKLTALERWKIKRIQFGFHKKDLGAGDSSGEPGAEEAVGEKNPSDVSLTAYQAWKLKHQKKVGSENKEEVVELSKGEDSALAKKRQRRLELLERSRQTLEESQSMASWEADSSTASGSIPLSAFWSADPSVSADGDTTSVLSTQSHRSHLSQAASNIAGCSTSNPTTPLPNLPVGPGDTISIASIQNWIANVVSETLAQKQNEMLLLSRSPSVASMKAVPAASCLGDDQVSMLSGHSSSSLGGCLLPQSQARPSSDMQSVLSCNTTLSSPAESCRSKVRGTSKPIFSLFADNVDLKELGRKEKEMQMELREKMSEYKMEKLASDNKRSSLFKKKKVKEDEDDGVGDGDEDTDSAIGSFRYSSRSNSQKPETDTCSSLAVCDHYASGSRVGKEMDSSINKWLSGLRTEEKPPFQSDWSGSSRGKYTRSSLLRETESKSSSYKFSKSQSEEQDTSSYHEANGNSVRSTSRFSSSSTREGREMHKFSRSTYNETSSSREESPEPYFFRRTPESSEREESPEPQRPNWARSRDWEDVEESSKSDFSEFGAKRKFTQSFMRSEEEGEKERTENREEGRFASGRRSQYRRSTDREEEEEMDDEAIIAAWRRRQEETRTKLQKRRED>sp|Q96L03|SPT17_HUMAN Spermatogenesis-associated protein 17 OS=Homosapiens OX=9606 GN=SPATA17 PE=1 SV=1MATLARLQARSSTVGNQYYFRNSVVDPFRKKENDAAVKIQSWFRGCQVRAYIRHLNRIVTIIQKWWRSFLGRKQYQLTVQVAYYTMMMNLYNAMAVRIQRRWRGYRVRKYLFNYYYLKEYLKVVSETNDAIRKALEEFAEMKEREEKKANLEREEKKRDYQARKMHYLLSTKQIPGIYNSPFRKEPDPWELQLQKAKPLTHRRPKVKQKDSTSLTDWLACTSARSFPRSEILPPINRKQCQGPFRDITEVLEQRYRPLEPTLRVAEPIDELKLAREELRREEWLQNVNDNMFLPFSSYHKNEKYIPSMHLSSKYGPISYKEQFRSENPKKWICDKDFQTVLPSFELFSKYGKLYSKAGQIV>sp|Q9BXB7|SPT16_HUMAN Spermatogenesis-associated protein 16 OS=Homosapiens OX=9606 GN=SPATA16 PE=1 SV=3MDAGSSRSLENAVNRIYHDQLVPKINTSKKMSTLAHPPNILEMSQEIKKNCGGKQVEITLERTKMTKGIKEKQSNDLEKAAFKRKAEGEEKPTRKKQAKITELDNQLITMPLPHIPLKNIMDVEMKLVYIDEMGVRYEFVESFMSTGSQPTCQAAEIVDPLSVHNFSFLPQIDKWLQVALKDASSCYRQKKYALAAGQFRTALELCSKGAVLGEPFDAPAEDIASVASFIETKLVTCYLRMRKPDLALNHAHRSIVLNPAYFRNHLRQATVFRCLERYSEAARSAMIADYMFWLGGGREESISKLIKLYWQAMIEEAITRAESFSVMYTPFATKIRADKIEKVKDAFTKTHPAYAEYMYTDLQALHMLPQTVDWSSFPPQQYLLTLGFKNKDDGKFLEKISSRKLPIFTEHKTPFGLTREDTVRQMETMGKRILPILDFIRSTQLNGSFPASSGVMEKLQYASLLSQLQRVKEQSQVINQAMAELATIPYLQDISQQEAELLQSLMADAMDTLEGRRNNNERVWNMIQKVGQIEDFLYQLEDSFLKTKKLRTARRQKTKMKRLQTVQQR>sp|Q9UK28|TM59L_HUMAN Transmembrane protein 59-like OS=Homo sapiensOX=9606 GN=TMEM59L PE=2 SV=1MAAVALMPPPLLLLLLLASPPAASAPSARDPFAPQLGDTQNCQLRCRDRDLGPQPSQAGLEGASESPYDRAVLISACERGCRLFSICRFVARSSKPNATQTECEAACVEAYVKEAEQQACSHGCWSQPAEPEPEQKRKVLEAPSGALSLLDLFSTLCNDLVNSAQGFVSSTWTYYLQTDNGKVVVFQTQPIVESLGFQGGRLQRVEVTWRGSHPEALEVHVDPVGPLDKVRKAKIRVKTSSKAKVESEEPQDNDFLSCMSRRSGLPRWILACCLFLSVLVMLWLSCSTLVTAPGQHLKFQPLTLEQHKGFMMEPDWPLYPPPSHACEDSLPPYKLKLDLTKL>sp|A4D263|SPT48_HUMAN Spermatogenesis-associated protein 48 OS=Homosapiens OX=9606 GN=SPATA48 PE=4 SV=2MDVEIQDTPGKISISKRSILSGTVENIDYPHYCDLLRKMNMPFVKGLENRHNYGRFEKKCNPAFLKFHPYPPSVLPDYHLHDPYPPPYGPHYPLFPLRDDVTLGDSCSGFMSPGGDADLNPGIGRTIPTLVDFSDVKPQHRVPRPDTGFQTTIKRQKILSEELQQNRRWNSREVPDISIRARLGGWTSPLKVTPLQPHHEGRSLSHIFTFDEEATCTDEGEPLVQTNKKCNAKDSFYKSSTQKAYEDVPWDKMLPPKLVPEETTLEKTADPISQCFTLKRYKGVPAITQMVGELWDRFQTRSFLAPVKPINFVSSSSRSKYIPLYTGHVQSTNADDVDNPLGDIASLAKQRYSKPLYTNTSRAANIPGYTGKVHFTATHPANSNIPSTTPSPDSELHRVFQKEMAVDLFRHQAPLSRLVTTVRPYNPFNKKDKETIDY>sp|Q537H7|SPT45_HUMAN Spermatogenesis-associated protein 45 OS=Homosapiens OX=9606 GN=SPATA45 PE=3 SV=1MASINRTIEIMKKHGVSKQHLLEEINKKRESNCLVERSNQVSLLRVQKRHFPDAYQSFTDTTTKEPVPNSGRSSWIKLSLLAHMERKHFPPKNNAIFG>sp|Q9P2P6|STAR9_HUMAN StAR-related lipid transfer protein 9 OS=Homosapiens OX=9606 GN=STARD9 PE=1 SV=3MANVQVAVRVRPLSKRETKEGGRIIVEVDGKVAKIRNLKVDNRPDGFGDSREKVMAFGFDYCYWSVNPEDPQYASQDVVFQDLGMEVLSGVAKGYNICLFAYGQTGSGKTYTMLGTPASVGLTPRICEGLFVREKDCASLPSSCRIKVSFLEIYNERVRDLLKQSGQKKSYTLRVREHPEMGPYVQGLSQHVVTNYKQVIQLLEEGIANRITAATHVHEASSRSHAIFTIHYTQAILENNLPSEMASKINLVDLAGSERADPSYCKDRIAEGANINKSLVTLGIVISTLAQNSQVFSSCQSLNSSVSNGGDSGILSSPSGTSSGGAPSRRQSYIPYRDSVLTWLLKDSLGGNSKTIMVATVSPAHTSYSETMSTLRYASSAKNIINKPRVNEDANLKLIRELREEIERLKALLLSFELRNFSSLSDENLKELVLQNELKIDQLTKDWTQKWNDWQALMEHYSVDINRRRAGVVIDSSLPHLMALEDDVLSTGVVLYHLKEGTTKIGRIDSDQEQDIVLQGQWIERDHCTITSACGVVVLRPARGARCTVNGREVTASCRLTQGAVITLGKAQKFRFNHPAEAAVLRQRRQVGEAAAGRGSLEWLDLDGDLAASRLGLSPLLWKERRALEEQCDEDHQTPRDGETSHRAQIQQQQSYVEDLRHQILAEEIRAAKELEFDQAWISQQIKENQQCLLREETWLASLQQQQQEDQVAEKELEASVALDAWLQTDPEIQPSPFVQSQKRVVHLQLLRRHTLRAAERNVRRKKVSFQLERIIKKQRLLEAQKRLEKLTTLCWLQDDSTQEPPYQVLSPDATVPRPPCRSKLTSCSSLSPQRLCSKHMPQLHSIFLSWDPSTTLPPRPDPTHQTSEKTSSEEHLPQAASYPARTGCLRKNGLHSSGHGQPCTARAALARKGASAPDACLTMSPNSVGIQEMEMGVKQPHQMVSQGLASLRKSANKLKPRHEPKIFTSTTQTRGAKGLADPSHTQAGWRKEGNLGTHKAAKGASCNSLYPHGPRQTAGHGKAVKTFWTEYKPPSPSRASKRHQRVLATRVRNITKKSSHLPLGSPLKRQQNTRDPDTMVPLTDFSPVMDHSREKDNDLSDTDSNYSLDSLSCVYAKALIEPLKPEERKWDFPEPENSESDDSQLSEDSLAEKRYQSPKNRLGGNRPTNNRGQPRTRTRASVRGFTAASDSDLLAQTHRSFSLDSLIDAEEELGEDQQEEPFPGSADEIPTETFWHLEDSSLPVMDQEAICRLGPINYRTAARLDAVLPMSSSFYLDPQFQPHCELQPHCELQPHCELQPHCEQAESQVEPSYSEQADSLQGMQLSRESPLMSMDSWFSCDSKINPSSPPGIVGSLCPSPDMQEFHSCKGERPGYWPNTEELKPSDAETVLPYSSKLHQGSTELLCSARDEHTASAADTSRLSLWGIQRLIQPGADGTFQGRCIPDMTQQGSSEASHNSSVSNVLAASATTLTHVGSTHERDWSALQQKYLLELSCPVLEAIGAPKPAYPYLEEDSGSLAQASSKGGDTLLPVGPRVSSNLNLNNFPVHLSRIRRLRAEKEQDSLNAKLEGVSDFFSTSEKEASYDETYSADLESLSASRSTNAQVFATENAIPDSMTEACEVKQNNLEECLQSCRKPGLMTSSDEDFFQKNACHSNVTTATKADHWSQGWAPLRKNSAVQPGQLSPDSHYPLEEEKTDCQESSKEAVRRHINVSFALPSGPELYLHSAPWNPLSSSLQPPLLETFYVTKSRDALTETALEIPACREVRVPSPPPREAWGFGHNHQALQGAYLKNNLPVLLQNQNSKIASSQQVTAEIPVDLNTREVIRESGKCPGNITEESHDSVYSSVTQNRHFLPSTSTKVCEFENQVVILNKKHSFPALEGGEVTAQSCCGASSDSTESGKSLLFRESEAREEEELDQNTVLRQTINVSLEKDMPGESAVSLKSRSVDRRVSSPVMVAQGGGPTPKWEGKNETGLLEKGLRPKDSSEEFKLPGTKPAYERFQLVACPQERNPSECKSQEMLNPNREPSGKKQNKRVNNTDEMARLIRSVMQLENGILEIESKQNKQVHASHTPGTDKELVFQDQKEQEKTDHAFRPDSSGNPLPSKDQPSSPRQTDDTVFRDSEAGAMEVNSIGNHPQVQKITPNPFRSREGVRESEPVREHTHPAGSDRPARDICDSLGKHTTCREFTNTSLHPQRMKALARALPLQPRLERSSKNNGQFVKASASLKGQPWGLGSLEELETVKGFQESQVAEHVSSSNQEEPKAQGKVEEMPMQRGGSLQEENKVTQKFPSLSQLCRDTFFRQETVSPLLSRTEFCTAPLHQDLSNTLPLNSPRWPRRCLHVPVALGISSLDCVLDLTMLKIHNSPLVTGVEHQDQSTETRSHSPEGNVRGRSSEAHTAWCGSVRSMAMGSHSQSGVPESIPLGTEDRISASTSPQDHGKDLRITLLGFSTSEDFASEAEVAVQKEIRVSSLNKVSSQPEKRVSFSLEEDSDQASKPRQKAEKETEDVGLTSGVSLAPVSLPRVPSPEPRLLEPSDHASMCLAILEEIRQAKAQRKQLHDFVARGTVLSYCETLLEPECSSRVAGRPQCKQIDQSSSDQTRNEGEAPGFHVASLSAEAGQIDLLPDERKVQATSLSADSFESLPNTETDREPWDPVQAFSHAAPAQDRKRRTGELRQFAGASEPFICHSSSSEIIEKKKDATRTPSSADPLAPDSPRSSAPVEEVRRVVSKKVVAALPSQAPYDDPRVTLHELSQSVPQETAEGIPPGSQDSSPEHQEPRTLDTTYGEVSDNLLVTAQGEKTAHFESQSVTCDVQNSTSASGPKQDHVQCPEASTGFEEGRASPKQDTILPGALTRVALEAPTQQCVQCKESVGSGLTEVCRAGSKHSRPIPLPDQRPSANPGGIGEEAPCRHPREALDGPVFSRNPEGSRTLSPSRGKESRTLPCRQPCSSQPVATHAYSSHSSTLLCFRDGDLGKEPFKAAPHTIHPPCVVPSRAYEMDETGEISRGPDVHLTHGLEPKDVNREFRLTESSTCEPSTVAAVLSRAQGCRSPSAPDVRTGSFSHSATDGSVGLIGVPEKKVAEKQASTELEAASFPAGMYSEPLRQFRDSSVGDQNAQVCQTNPEPPATTQGPHTLDLSEGSAESKLVVEPQHECLENTTRCFLEKPQFSTELRDHNRLDSQAKFVARLKHTCSPQEDSPWQEEEQHRDQASGGGEGFAQGVNPLPDEDGLDGCQILDAGREEVAVAKPPVSKILSQGFKDPATVSLRQNETPQPAAQRSGHLYTGREQPAPNHRGSLPVTTIFSGPKHSRSSPTPQFSVVGSSRSLQELNLSVEPPSPTDEDTQGPNRLWNPHLRGYSSGKSVARTSLQAEDSNQKASSRLDDGTTDHRHLKPATPPYPMPSTLSHMPTPDFTTSWMSGTLEQAQQGKREKLGVQVRPENWCSQMDKGMLHFGSSDISPYALPWRPEEPARISWKQYMSGSAVDVSCSQKPQGLTLSNVARCSSMDNGLEDQNSPFHSHLSTYANICDLSTTHSSTENAQGSNEAWEVFRGSSSIALGDPHIPTSPEGVAPTSGHDRRPQFRGPSGEADCLRSKPPLAKGSAAGPVDEIMLLYPSEAGCPVGQTRTNTFEQGTQTLGSRRHWSSTDISFAQPEASAVSAFDLASWTSMHNLSLHLSQLLHSTSELLGSLSQPDVARREQNTKRDIPDKAPQALMMDGSTQTTVDEGSQTDLTLPTLCLQTSEAEPQGANVILEGLGSDTSTVSQEEGDVPGVPQKREAEETAQKMAQLLYLQEESTPYKPQSPSIPSSHLRFQKAPVGQHLPSVSPSVSDAFLPPSSQPEESYCLVVSSPSPSSPHSPGLFPSTSEYPGDSRVQKKLGPTSALFVDRASSPILTLSASTQEPGLSPGSLTLSAPSTHPVEGHQKLDSSPDPVDAPRTPMDNYSQTTDELGGSQRGRSSLQRSNGRSFLELHSPHSPQQSPKLQFSFLGQHPQQLQPRTTIGVQSRLLPPPLRHRSQRLGNSFVPEKVASPEHCPLSGREPSQWQSRTENGGESSASPGEPQRTLDRPSSWGGLQHLSPCPVSELTDTAGLRGSALGLPQACQPEELLCFSCQMCMAPEHQHHSLRDLPVHNKFSNWCGVQKGSPGGLDMTEEELGASGDLSSEKQEQSPPQPPNDHSQDSEWSKREQIPLQVGAQNLSLSVELTEAKLHHGFGEADALLQVLQSGTGEALAADEPVTSTWKELYARQKKAIETLRRERAERLGNFCRTRSLSPQKQLSLLPNKDLFIWDLDLPSRRREYLQQLRKDVVETTRSPESVSRSAHTPSDIELMLQDYQQAHEEAKVEIARARDQLRERTEQEKLRIHQKIISQLLKEEDKLHTLANSSSLCTSSNGSLSSGMTSGYNSSPALSGQLQFPENMGHTNLPDSRDVWIGDERGGHSAVRKNSAYSHRASLGSCCCSPSSLSSLGTCFSSSYQDLAKHVVDTSMADVMAACSDNLHNLFSCQATAGWNYQGEEQAVQLYYKVFSPTRHGFLGAGVVSQPLSRVWAAVSDPTVWPLYYKPIQTARLHQRVTNSISLVYLVCNTTLCALKQPRDFCCVCVEAKEGHLSVMAAQSVYDTSMPRPSRKMVRGEILPSAWILQPITVEGKEVTRVIYLAQVELGAPGFPPQLLSSFIKRQPLVIARLASFLGR>sp|Q9P2P6-2|STAR9_HUMAN Isoform 2 of StAR-related lipid transfer protein9 OS=Homo sapiens OX=9606 GN=STARD9MANVQVAVRVRPLSKRETKEGGRIIVEVDGKVAKIRNLKVDNRPDGFGDSREKVMAFGFDYCYWSVNPEDPQYASQDVVFQDLGMEVLSGVAKGYNICLFAYGQTGSGKTYTMLGTPASVGLTPRICEGLFVREKDCASLPSSCRIKVSFLEIYNERVRDLLKQSGQKKSYTLRVREHPEMGPYVQGLSQHVVTNYKQVIQLLEEGIANRITAATHVHEASSRSHAIFTIHYTQAILENNLPSEMASKINLVDLAGSERADPSYCKDRIAEGANINKSLVTLGIVISTLGIF>sp|Q9P2P6-3|STAR9_HUMAN Isoform 3 of StAR-related lipid transfer protein9 OS=Homo sapiens OX=9606 GN=STARD9MEVLSGVAKGYNICLFAYGQTGSGKTYTMLGTPASVGLTPRICEGLFVREKDCASLPSSCRIKVSFLEIYNERVRDLLKQSGQKKSYTLRVREHPEMGPYVQGLSQHVVTNYKQVIQLLEEGIANRITAATHVHEASSRSHAIFTIHYTQAILENNLPSEMASKINLVDLAGSERADPSYCKDRIAEGANINKSLVTLGIVISTLAQNSQVFSSCQSLNSSVSNGGDSGILSSPSGTSSGGAPSRRQSYIPYRDSVLTWLLKDSLGGNSKTIMVASEWDARAGPVLGLVLYLRERAMAPVSGMPELDLCWDWYSISEKGPWPQ>sp|Q92502|STAR8_HUMAN StAR-related lipid transfer protein 8 OS=Homosapiens OX=9606 GN=STARD8 PE=1 SV=2MTLNNCASMKLEVHFQSKQNEDSEEEEQCTISSHWAFQQESKCWSPMGSSDLLAPPSPGLPATSSCESVLTELSATSLPVITVSLPPEPADLPLPGRAPSSSDRPLLSPTQGQEGPQDKAKKRHRNRSFLKHLESLRRKEKSGSQQAEPKHSPATSEKVSKASSFRSCRGFLSAGFYRAKNWAATSAGGSGANTRKAWEAWPVASFRHPQWTHRGDCLVHVPGDHKPGTFPRSLSIESLCPEDGHRLADWQPGRRWGCEGRRGSCGSTGSHASTYDNLPELYPAEPVMVGAEAEDEDDEESGGSYAHLDDILQHVWGLQQRVELWSRAMYPDLGPGDEEEEEATSSVEIATVEVKCQAEALSQMEVPAHGESPAWAQAEVQPAVLAPAQAPAEAEPVAQEEAEAPAPAPAPAPAQDSEQEAHSGGEPTFASSLSVEEGHSISDTVASSSELDSSGNSMNEAEAAGPLAGLQASMPRERRDSGVGASLTRPCRKLRWHSFQNSHRPSLNSESLEINRQFAGQINLLHKGSLLRLTAFMEKYTVPHKQGWVWSMPKFMRRNKTPDYRGQHVFGVPPLIHVQRTGQPLPQSIQQAMRYLRSQCLDQVGIFRKSGVKSRIQNLRQMNETSPDNVCYEGQSAYDVADLLKQYFRDLPEPIFTSKLTTTFLQIYQLLPKDQWLAAAQAATLLLPDENREVLQTLLYFLSDIASAEENQMTAGNLAVCLAPSIFHLNVSKKDSPSPRIKSKRSLIGRPGPRDLSDNMAATQGLSHMISDCKKLFQVPQDMVLQLCSSYSAAELSPPGPALAELRQAQAAGVSLSLYMEENIQDLLRDAAERFKGWMSVPGPQHTELACRKAPDGHPLRLWKASTEVAAPPAVVLHRVLRERALWDEDLLRAQVLEALMPGVELYHYVTDSMAPHPCRDFVVLRMWRSDLPRGGCLLVSQSLDPEQPVPESGVRALMLTSQYLMEPCGLGRSRLTHICRADLRGRSPDWYNKVFGHLCAMEVAKIRDSFPTLQAAGPETKL>sp|Q92502-2|STAR8_HUMAN Isoform 2 of StAR-related lipid transfer protein8 OS=Homo sapiens OX=9606 GN=STARD8MPLLDVFWSCFRKVKCFPLLQVKKNAEAEAKRACEWLQATGFPQYVQLFEEGSFPLDIGSVKKNHGFLDEDSLGALCRRLMTLNNCASMKLEVHFQSKQNEDSEEEEQCTISSHWAFQQESKCWSPMGSSDLLAPPSPGLPATSSCESVLTELSATSLPVITVSLPPEPADLPLPGRAPSSSDRPLLSPTQGQEGPQDKAKKRHRNRSFLKHLESLRRKEKSGSQQAEPKHSPATSEKVSKASSFRSCRGFLSAGFYRAKNWAATSAGGSGANTRKAWEAWPVASFRHPQWTHRGDCLVHVPGDHKPGTFPRSLSIESLCPEDGHRLADWQPGRRWGCEGRRGSCGSTGSHASTYDNLPELYPAEPVMVGAEAEDEDDEESGGSYAHLDDILQHVWGLQQRVELWSRAMYPDLGPGDEEEEEATSSVEIATVEVKCQAEALSQMEVPAHGESPAWAQAEVQPAVLAPAQAPAEAEPVAQEEAEAPAPAPAPAPAQDSEQEAHSGGEPTFASSLSVEEGHSISDTVASSSELDSSGNSMNEAEAAGPLAGLQASMPRERRDSGVGASLTRPCRKLRWHSFQNSHRPSLNSESLEINRQFAGQINLLHKGSLLRLTAFMEKYTVPHKQGWVWSMPKFMRRNKTPDYRGQHVFGVPPLIHVQRTGQPLPQSIQQAMRYLRSQCLDQVGIFRKSGVKSRIQNLRQMNETSPDNVCYEGQSAYDVADLLKQYFRDLPEPIFTSKLTTTFLQIYQLLPKDQWLAAAQAATLLLPDENREVLQTLLYFLSDIASAEENQMTAGNLAVCLAPSIFHLNVSKKDSPSPRIKSKRSLIGRPGPRDLSDNMAATQGLSHMISDCKKLFQVPQDMVLQLCSSYSAAELSPPGPALAELRQAQAAGVSLSLYMEENIQDLLRDAAERFKGWMSVPGPQHTELACRKAPDGHPLRLWKASTEVAAPPAVVLHRVLRERALWDEDLLRAQVLEALMPGVELYHYVTDSMAPHPCRDFVVLRMWRSDLPRGGCLLVSQSLDPEQPVPESGVRALMLTSQYLMEPCGLGRSRLTHICRADLRGRSPDWYNKVFGHLCAMEVAKIRDSFPTLQAAGPETKL>sp|Q56A73|SPIN4_HUMAN Spindlin-4 OS=Homo sapiens OX=9606 GN=SPIN4 PE=1SV=1MSPPTVPPMGVDGVSAYLMKKRHTHRKQRRKPTFLTRRNIVGCRIQHGWKEGNEPVEQWKGTVLEQVSVKPTLYIIKYDGKDSVYGLELHRDKRVLALEILPERVPTPRIDSRLADSLIGKAVEHVFEGEHGTKDEWKGMVLARAPVMDTWFYITYEKDPVLYMYTLLDDYKDGDLRIIPDSNYYFPTAEQEPGEVVDSLVGKQVEHAKDDGSKRTGIFIHQVVAKPSVYFIKFDDDIHIYVYGLVKTP>sp|Q76KD6|SPERI_HUMAN Speriolin OS=Homo sapiens OX=9606 GN=SPATC1 PE=2SV=2MSLLTNYEGLRHQIERLVRENEELKKLVRLIRENHELKSAIKTQAGGLGISGFTSGLGEATAGLSSRQNNGVFLPPSPAVANERVLEEVGIMALAPLAEMLTSLQPSATPGSLMSPLTGTLSTLLSGPAPTSQSSPLTSFLTSPIAGPLTGTLASSLGLPSTGTLTPSSLVAGPVAMSQSSPLIAPVMGTVAVSLSSPLLSSTATPPGVSQNLLANPMSNLVLPEAPRLRLAEPLRGGPTGPQSPACVVPTATTKVPLSTEPPQSTQDPEPLSMAFAGAPLQTSTPIGAMGTPAPKTAFSFNTSDTQAQPSAAQEQVVPASVPTSPTTSPTVTVLASAPALAPQVATSYTPSSTTHIAQGAPHPPSRMHNSPTQNLPVPHCPPHNAHSPPRTSSSPASVNDSRGPRTTEPSTKSMMEVERKLAHRKTSKFPENPRESKQLAWERLVGEIAFQLDRRILSSIFPERVRLYGFTVSNIPEKIIQASLNPSDHKLDEKLCQRLTQRYVSVMNRLQSLGYNGRVHPALTEQLVNAYGILRERPELAASEGGPYTVDFLQRVVVETVHPGMLADALLLLSCLSQLAHDDGKPMFIW>sp|Q76KD6-2|SPERI_HUMAN Isoform 2 of Speriolin OS=Homo sapiens OX=9606GN=SPATC1MSLLTNYEGLRHQIERLVRENEELKKLVRLIRENHELKSAIKTQAGGLGISGFTSGLGEATAGLSSRQNNGVFLPPSPAVANERVLEEVGIMALAPLAEMLTSLQPSATPGSLMSPLTGTLSTLLSGPAPTSQSSPLTSFLTSPIAGPLTGTLASSLGLPSTGTLTPSSLVAGPVAMSQSSPLIAPVMGTVAVSLSSPLLSSTATPPGVSQNLLANPMSNLVLPEAPRLRLAEPLRGGPTGPQSPACVVPTATTKVPLSTEPPQSTQDPEPLSMAFAGAPLQTSTPIGAMGTPAPKTAFSFNTSDTQAQPSAAQEQVVPASVPTSPTTSPTVTVLASAPALAPQVATSYTPSSTTHIAQGAPHPPSRMHNSPTQNLPVPHCPPHNAHSPPRTSSSPASVNDSRGPRTTEPSTKSMMEVERKLAHRKTSKFPENPRGFPEPQ>sp|Q9BUD6|SPON2_HUMAN Spondin-2 OS=Homo sapiens OX=9606 GN=SPON2 PE=1SV=3MENPSPAAALGKALCALLLATLGAAGQPLGGESICSARALAKYSITFTGKWSQTAFPKQYPLFRPPAQWSSLLGAAHSSDYSMWRKNQYVSNGLRDFAERGEAWALMKEIEAAGEALQSVHEVFSAPAVPSGTGQTSAELEVQRRHSLVSFVVRIVPSPDWFVGVDSLDLCDGDRWREQAALDLYPYDAGTDSGFTFSSPNFATIPQDTVTEITSSSPSHPANSFYYPRLKALPPIARVTLVRLRQSPRAFIPPAPVLPSRDNEIVDSASVPETPLDCEVSLWSSWGLCGGHCGRLGTKSRTRYVRVQPANNGSPCPELEEEAECVPDNCV>sp|Q8NCC5|SPX3_HUMAN Sugar phosphate exchanger 3 OS=Homo sapiens OX=9606GN=SLC37A3 PE=2 SV=2MAWPNVFQRGSLLSQFSHHHVVVFLLTFFSYSLLHASRKTFSNVKVSISEQWTPSAFNTSVELPVEIWSSNHLFPSAEKATLFLGTLDTIFLFSYAVGLFISGIVGDRLNLRWVLSFGMCSSALVVFVFGALTEWLRFYNKWLYCCLWIVNGLLQSTGWPCVVAVMGNWFGKAGRGVVFGLWSACASVGNILGACLASSVLQYGYEYAFLVTASVQFAGGIVIFFGLLVSPEEIGLSGIEAEENFEEDSHRPLINGGENEDEYEPNYSIQDDSSVAQVKAISFYQACCLPGVIPYSLAYACLKLVNYSFFFWLPFYLSNNFGWKEAEADKLSIWYDVGGIIGGTLQGFISDVLQKRAPVLALSLLLAVGSLIGYSRSPNDKSINALLMTVTGFFIGGPSNMISSAISADLGRQELIQRSSEALATVTGIVDGSGSIGAAVGQYLVSLIRDKLGWMWVFYFFILMTSCTIVFISPLIVREIFSLVLRRQAHILRE>sp|Q8NCC5-2|SPX3_HUMAN Isoform 2 of Sugar phosphate exchanger 3 OS=Homosapiens OX=9606 GN=SLC37A3MAWPNVFQRGSLLSQFSHHHVVVFLLTFFSYSLLHASRKTFSNVKVSISEQWTPSAFNTSVELPVEIWSSNHLFPSAEKATLFLGTLDTIFLFSYAVGLFISGIVGDRLNLRWVLSFGMCSSALVVFVFGALTEWLRFYNKWLYCCLWIVNGLLQSTGWPCVVAVMGNWFGKAGRGVVFGLWSACASVGNILGACLASSVLQYGYEYAFLVTASVQFAGGIVIFFGLLVSPEEIGLSGIEAEENFEEDSHRPLINGGENEDEYEPNYSIQDDSSVAQVKAISFYQACCLPGVIPYSLAYACLKLVNYSFFFWLPFYLSNNFGWKEAEADKLSIWYDVGGIIGGTLQGFISDVLQKRAPVLALSLLLAVGSLIGYSRFFIGGPSNMISSAISADLGRQELIQRSSEALATVTGIVDGSGSIGAAVGQYLVSLIRDKLGWMWVFYFFILMTSCTIVFISPLIVREIFSLVLRRQAHILRE>sp|Q8NCC5-3|SPX3_HUMAN Isoform 3 of Sugar phosphate exchanger 3 OS=Homosapiens OX=9606 GN=SLC37A3MAWPNVFQRGSLLSQFSHHHVVVFLLTFFSYSLLHASRKTFSNVKVSISEQWTPSAFNTSVELPVEIWSSNHLFPSAEKATLFLGTLDTIFLFSYAVGLFISGIVGDRLNLRWVLSFGMCSSALVVFVFGALTEWLRFYNKWLYCCLWIVNGLLQSTGWPCVVAVMGNWFGKAGRGVVFGLWSACASVGNILGACLASSVLQYGYEYAFLVTASVQFAGGIVIFFGLLVSPEEIGLSGIEAEENFEEDSHRPLINGGENEDEYEPNYSIQDDSSVAQVKAISFYQACCLPGVIPYSLAYACLKLVNYSFFFWLPFYLSNNFGWKEAEADKLSIWYDVGGIIVFSVSDPGQARMDVGFLLFHSHDKLYNCVYLAINSEGNILSRAKETGSHIEGVTGARETERTMSATSGPLGLRVCPNLGLSRSSSLILDCQASLNTASHLRC>sp|Q8N0X2|SPG16_HUMAN Sperm-associated antigen 16 protein OS=Homosapiens OX=9606 GN=SPAG16 PE=1 SV=2MAAQRGMPSSAVRVLEEALGMGLTAAGDARDTADAVAAEGAYYLEQVTITEASEDDYEYEEIPDDNFSIPEGEEDLAKAIQMAQEQATDTEILERKTVLPSKHAVPEVIEDFLCNFLIKMGMTRTLDCFQSEWYELIQKGVTELRTVGNVPDVYTQIMLLENENKNLKKDLKHYKQAADKAREDLLKIQKERDFHRMHHKRIVQEKNKLINDLKGLKLHYASYEPTIRVLHEKHHTLLKEKMLTSLERDKVVGQISGLQETLKKLQRGHSYHGPQIKVDHSREKENAPEGPTQKGLREAREQNKCKTKMKGNTKDSEFPIDMQPNPNLNVSKESLSPAKFDYKLKNIFRLHELPVSCVSMQPHKDILVSCGEDRLWKVLGLPKCNVLLTGFGHTDWLSDCCFHPSGDKLATSSGDTTVKLWDLCKGDCILTFEGHSRAVWSCTWHSCGNFVASSSLDKTSKIWDVNSERCRCTLYGHTDSVNSIEFFPFSNTLLTSSADKTLSIWDARTGICEQSLYGHMHSINDAIFDPRGHMIASCDACGVTKLWDFRKLLPIVSIDIGPSPGNEVNFDSSGRVLAQASGNGVIHLLDLKSGEIHKLMGHENEAHTVVFSHDGEILFSGGSDGTVRTWS>sp|Q8N0X2-2|SPG16_HUMAN Isoform 2 of Sperm-associated antigen 16 proteinOS=Homo sapiens OX=9606 GN=SPAG16MTILASQKVKKIWQKQFRWPKNRLQILKFCKAREDLLKIQKERDFHRMHHKRIVQEKNKLINDLKGLKLHYASYEPTIRVLHEKHHTLLKEKMLTSLERDKVVGQISGLQETLKKLQRGHSYHGPQIKVDHSREKENAPEGPTQKGLREAREQNKCKTKMKGNTKDSEFPIDMQPNPNLNVSKESLSPAKFDYKLKNIFRLHELPVSCVSMQPHKDILVSCGEDRLWKVLGLPKCNVLLTGFGHTDWLSDCCFHPSGDKLATSSGDTTVKLWDLCKGDCILTFEGHSRAVWSCTWHSCGNFVASSSLDKTSKIWDVNSERCRCTLYGHTDSVNSIEFFPFSNTLLTSSADKTLSIWDARTGICEQSLYGHMHSINDAIFDPRGHMIASCDACGVTKLWDFRKLLPIVSIDIGPSPGNEVNFDSSENTTYLYRPGAQIYYFQLS>sp|Q8N0X2-3|SPG16_HUMAN Isoform 3 of Sperm-associated antigen 16 proteinOS=Homo sapiens OX=9606 GN=SPAG16MGVGTKARASHWRRLLSLGATPEEPLLDFKIPDDNFSIPEGEEDLAKAIQMAQEQATDTEILERKTVLPSKHAVPEVIEDFLCNFLIKMGMTRTLDCFQSEWYELIQKGVTELRTVGNVPDVYTQIMLLENENKNLKKDLKHYKQAADKAREDLLKIQKERDFHRMHHKRIVQEKNKLINDLKGLKLHYASYEPTIRVLHEKHHTLLKEKMLTSLERDKVVGQISGLQETLKKLQRGHSYHGPQIKGKGCM>sp|Q8N0X2-4|SPG16_HUMAN Isoform 4 of Sperm-associated antigen 16 proteinOS=Homo sapiens OX=9606 GN=SPAG16MAAQRGMPSSAVRVLEEALGMGLTAAGDARDTADAVAAEGAYYLEQVTITEASEDDYEYEEIPDDNFSIPEGEEDLAKAIQMAQEQATDTEILERKTVLPSKHAVPEVIEDFLCNFLIKMGMTRTLDCFQSEWYELIQKGVTELRTVGNVPDVYTQIMLLENENKNLKKDLKHYKQAAEYVIF>sp|Q8N0X2-5|SPG16_HUMAN Isoform 5 of Sperm-associated antigen 16 proteinOS=Homo sapiens OX=9606 GN=SPAG16MAAQRGMPSSAVRVLEEALGMGLTAAGDARDTADAVAAEGAYYLEQVTITEASEDDYEYEEIPDDNFSIPEGEEDLAKAIQMAQEQATDTEILERKTVLPSKHAVPEVIEDFLCNFLIKMGMTRTLDCFQSEWYELIQKGVTELRTVGNVPDVYTQIMLLENENKNLKKDLKHYKQAADKAREDLLKIQKERDFHRMHHKRIVQEKNKLINDLKGLKLHYASYEPTIRVLHEKHHTLLKEKMLTSLERDKVVGQISGLQETLKKLQRGHSYHGPQIKVDHSREKENAPEGPTQKGLREAREQNKCKTKMKGNTKQWTGNSQTWNKTVPLQDTIGRRQENNSAHQHID>sp|P08240|SRPRA_HUMAN Signal recognition particle receptor subunit alphaOS=Homo sapiens OX=9606 GN=SRPRA PE=1 SV=2MLDFFTIFSKGGLVLWCFQGVSDSCTGPVNALIRSVLLQERGGNNSFTHEALTLKYKLDNQFELVFVVGFQKILTLTYVDKLIDDVHRLFRDKYRTEIQQQSALSLLNGTFDFQNDFLRLLREAEESSKIRAPTTMKKFEDSEKAKKPVRSMIETRGEKPKEKAKNSKKKGAKKEGSDGPLATSKPVPAEKSGLPVGPENGVELSKEELIRRKREEFIQKHGRGMEKSNKSTKSDAPKEKGKKAPRVWELGGCANKEVLDYSTPTTNGTPEAALSEDINLIRGTGSGGQLQDLDCSSSDDEGAAQNSTKPSATKGTLGGMFGMLKGLVGSKSLSREDMESVLDKMRDHLIAKNVAADIAVQLCESVANKLEGKVMGTFSTVTSTVKQALQESLVQILQPQRRVDMLRDIMDAQRRQRPYVVTFCGVNGVGKSTNLAKISFWLLENGFSVLIAACDTFRAGAVEQLRTHTRRLSALHPPEKHGGRTMVQLFEKGYGKDAAGIAMEAIAFARNQGFDVVLVDTAGRMQDNAPLMTALAKLITVNTPDLVLFVGEALVGNEAVDQLVKFNRALADHSMAQTPRLIDGIVLTKFDTIDDKVGAAISMTYITSKPIVFVGTGQTYCDLRSLNAKAVVAALMKA>sp|P08240-2|SRPRA_HUMAN Isoform 2 of Signal recognition particlereceptor subunit alpha OS=Homo sapiens OX=9606 GN=SRPRAMLDFFTIFSKGGLVLWCFQGVSDSCTGPVNALIRSVLLQVGFQKILTLTYVDKLIDDVHRLFRDKYRTEIQQQSALSLLNGTFDFQNDFLRLLREAEESSKIRAPTTMKKFEDSEKAKKPVRSMIETRGEKPKEKAKNSKKKGAKKEGSDGPLATSKPVPAEKSGLPVGPENGVELSKEELIRRKREEFIQKHGRGMEKSNKSTKSDAPKEKGKKAPRVWELGGCANKEVLDYSTPTTNGTPEAALSEDINLIRGTGSGGQLQDLDCSSSDDEGAAQNSTKPSATKGTLGGMFGMLKGLVGSKSLSREDMESVLDKMRDHLIAKNVAADIAVQLCESVANKLEGKVMGTFSTVTSTVKQALQESLVQILQPQRRVDMLRDIMDAQRRQRPYVVTFCGVNGVGKSTNLAKISFWLLENGFSVLIAACDTFRAGAVEQLRTHTRRLSALHPPEKHGGRTMVQLFEKGYGKDAAGIAMEAIAFARNQGFDVVLVDTAGRMQDNAPLMTALAKLITVNTPDLVLFVGEALVGNEAVDQLVKFNRALADHSMAQTPRLIDGIVLTKFDTIDDKVGAAISMTYITSKPIVFVGTGQTYCDLRSLNAKAVVAALMKA>sp|Q4G0T1|SRCRM_HUMAN Scavenger receptor cysteine-rich domain-containingprotein SCART1 OS=Homo sapiens OX=9606 PE=1 SV=2MRAALWTLGLGPLLLNLWAVPIGGPGALRLAYRHSTCDGVVLVRHHGAWGYVCNQEWTLAEASVVCRQLGCGPAVGAPKYVPLPGEMAQPWLHNVSCRGNESSLWECSLGSWCQSPCPHAWVVVALCSNGTFRELRLVKGRSPCAGLPEIRNVNGVDRLCVLHVEEAMVFCRELGCGPVLQAPRRDVGVVRKYLACRGTEPTIRSCRLDNNFRSGCDLRLDAEVVCSGHTEARLVGGEHPCAGRLEVTWGTVCDAALDLATAHVVCRELQCGAVVSTPEGARFGRGSGPVWTEAFRCAGNESLLFHCPRGRGSQCGHGHDAGLRCSEFRMVNGSSSCEGRVEFQVQGSWAPLCATHWDIADATVLCHQLNCGNAVAAPGGGHFGDGDAAIWPDAFHCEGTESYLWNCPVSTLGAPACAPGNTASAVCSGLAHALRLREGQSRCDGRVEVSLDGVWGRVLDDAWDLRGAGVVCRQLGCRGAQQAYDAPAPSRGSVQVALSRVRCLGTETRLTQCNVSATLQEPAGTSRDAGVVCSGEVGTASPMARRHGIPGALTLSLHREPQGAAGRGAGALHGGAWGTVCDDAWDLRDAHVVCRQLGCGRALSALGAAHFGAGAGRIWLDELGCQGHESALWQCPSAGWGRHDWRHKEDAGVFCSESVALRLRGGTCCCAGWLDVFYNGTWGAMCSNALKDLSLSIICKQLGCGVWGVGLAGEQALPLCGHRDRLGGQHRVPQAAQLHSVAMPFPPMAPALLRPSRAGLSEDRPQAAGEPLNCSSWLGCPEEGALRVRGGEDRCSGRVELWHAGSWGTVCDDGWDLADAEVVCRQLGCGRAVAALGAAAFGPGSGPVWLDEVGCRGSEASLWGCPAERWGRGDRAHEEDAGVRCWEPGPGPPLPAAPFRTFWVVSVVLGSLLGLLLLGLMAFLILPRVTQAMQRGLGRSEVSPGEAIYDVIGEMPPAGLYEEIMEAEAVLQDEEDGSVVKVDTEAAVSGEVSNLLEGQSIRAEGGHSRPVSQGYDEAAFPLEEMTL>sp|Q4G0T1-2|SRCRM_HUMAN Isoform Gamma of Scavenger receptor cysteine-rich domain-containing protein SCART1 OS=Homo sapiens OX=9606MRAALWTLGLGPLLLNLWAVPIGGPGALRLAYRHSTCDGVVLVRHHGAWGYVCNQEWTLAEASVVCRQLGCGPAVGAPKYVPLPGEMAQPWLHNVSCRGNESSLWECSLGSWCQSPCPHAWVVVALCSNGTFRELRLVKGRSPCAGLPEIRNVNGVDRLCVLHVEEAMVFCRELGCGPVLQAPRRDVGVVRKYLACRGTEPTIRSCRLDNNFRSGCDLRLDAEVVCSGEAAT>sp|Q4G0T1-3|SRCRM_HUMAN Isoform Alpha of Scavenger receptor cysteine-rich domain-containing protein SCART1 OS=Homo sapiens OX=9606MRAALWTLGLGPLLLNLWAVPIGGPGALRLAYRHSTCDGVVLVRHHGAWGYVCNQEWTLAEASVVCRQLGCGPAVGAPKYVPLPGEMAQPWLHNVSCRGNESSLWECSLGSWCQSPCPHAWVVVALCSNGTFRELRLVKGRSPCAGLPEIRNVNGVDRLCVLHVEEAMVFCRELGCGPVLQAPRRDVGVVRKYLACRGTEPTIRSCRLDNNFRSGCDLRLDAEVVCSEFRMVNGSSSCEGRVEFQVQGSWAPLCATHWDIADATVLCHQLNCGNAVAAPGGGHFGDGDAAIWPDAFHCEGTESYLWNCPVSTLGAPACAPGNTASAVCSGLAHALRLREGQSRCDGRVEVSLDGVWGRVLDDAWDLRGAGVVCRQLGCRGAQQAYDAPAPSRGSVQVALSRVRCLGTETRLTQCNVSATLQEPAGTSRDAGVVCSGEVGTASPMARRHGIPGALTLSLHREPQGAAGRGAGALHGGAWGTVCDDAWDLRDAHVVCRQLGCGRALSALGAAHFGAGAGRIWLDELGCQGHESALWQCPSAGWGRHDWRHKEDAGVFCSGLGRSEVSPGEAIYDVIGEMPPAGLYEEIMEAEAVLQDEEDGSVVKVDTEAAVSGEVSNLLEGQSIRAEGGHSRPVSQGYDEAAFPLEEMTL>sp|P51688|SPHM_HUMAN N-sulphoglucosamine sulphohydrolase OS=Homo sapiensOX=9606 GN=SGSH PE=1 SV=1MSCPVPACCALLLVLGLCRARPRNALLLLADDGGFESGAYNNSAIATPHLDALARRSLLFRNAFTSVSSCSPSRASLLTGLPQHQNGMYGLHQDVHHFNSFDKVRSLPLLLSQAGVRTGIIGKKHVGPETVYPFDFAYTEENGSVLQVGRNITRIKLLVRKFLQTQDDRPFFLYVAFHDPHRCGHSQPQYGTFCEKFGNGESGMGRIPDWTPQAYDPLDVLVPYFVPNTPAARADLAAQYTTVGRMDQGVGLVLQELRDAGVLNDTLVIFTSDNGIPFPSGRTNLYWPGTAEPLLVSSPEHPKRWGQVSEAYVSLLDLTPTILDWFSIPYPSYAIFGSKTIHLTGRSLLPALEAEPLWATVFGSQSHHEVTMSYPMRSVQHRHFRLVHNLNFKMPFPIDQDFYVSPTFQDLLNRTTAGQPTGWYKDLRHYYYRARWELYDRSRDPHETQNLATDPRFAQLLEMLRDQLAKWQWETHDPWVCAPDGVLEEKLSPQCQPLHNEL>sp|P35325|SPR2B_HUMAN Small proline-rich protein 2B OS=Homo sapiensOX=9606 GN=SPRR2B PE=2 SV=1MSYQQQQCKQPCQPPPVCPTPKCPEPCPPPKCPEPCPPPKCPQPCPPQQCQQKYPPVTPSPPCQPKYPPKSK>sp|P22528|SPR1B_HUMAN Cornifin-B OS=Homo sapiens OX=9606 GN=SPRR1B PE=1SV=2MSSQQQKQPCTPPPQLQQQQVKQPCQPPPQEPCIPKTKEPCHPKVPEPCHPKVPEPCQPKVPEPCHPKVPEPCPSIVTPAPAQQKTKQK>sp|P49903|SPS1_HUMAN Selenide, water dikinase 1 OS=Homo sapiens OX=9606GN=SEPHS1 PE=1 SV=2MSTRESFNPESYELDKSFRLTRFTELKGTGCKVPQDVLQKLLESLQENHFQEDEQFLGAVMPRLGIGMDTCVIPLRHGGLSLVQTTDYIYPIVDDPYMMGRIACANVLSDLYAMGVTECDNMLMLLGVSNKMTDRERDKVMPLIIQGFKDAAEEAGTSVTGGQTVLNPWIVLGGVATTVCQPNEFIMPDNAVPGDVLVLTKPLGTQVAVAVHQWLDIPEKWNKIKLVVTQEDVELAYQEAMMNMARLNRTAAGLMHTFNAHAATDITGFGILGHAQNLAKQQRNEVSFVIHNLPVLAKMAAVSKACGNMFGLMHGTCPETSGGLLICLPREQAARFCAEIKSPKYGEGHQAWIIGIVEKGNRTARIIDKPRIIEVAPQVATQNVNPTPGATS>sp|P49903-2|SPS1_HUMAN Isoform 2 of Selenide, water dikinase 1 OS=Homosapiens OX=9606 GN=SEPHS1MSTRESFNPESYELDKSFRLTRFTELKGTGCKVPQDVLQKLLESLQENHFQEDEQFLGAVMPRLGIGMDTCVIPLRHGGLSLVQTTDYIYPIVDDPYMMGRIACANVLSDLYAMGVTECDNMLMLLGVSNKMTDRERDKVMPLIIQGFKDAAEEAGTSVTGGQTVLNPWIVLGGVATTVCQPNEFIMPDNAVPGDVLVLTKPLGTQVAVAVHQWLDIPEKWNKIKLVVTQEDVELAYQEAMMNMARLNRTGGLLICLPREQAARFCAEIKSPKYGEGHQAWIIGIVEKGNRTARIIDKPRIIEVAPQVATQNVNPTPGATS>sp|P49903-3|SPS1_HUMAN Isoform 3 of Selenide, water dikinase 1 OS=Homosapiens OX=9606 GN=SEPHS1MDTCVIPLRHGGLSLVQTTDYIYPIVDDPYMMGRIACANVLSDLYAMGVTECDNMLMLLGVSNKMTDRERDKVMPLIIQGFKDAAEEAGTSVTGGQTVLNPWIVLGGVATTVCQPNEFIMPDNAVPGDVLVLTKPLGTQVAVAVHQWLDIPEKWNKIKLVVTQEDVELAYQEAMMNMARLNRTAAGLMHTFNAHAATDITGFGILGHAQNLAKQQRNEVSFVIHNLPVLAKMAAVSKACGNMFGLMHGTCPETSGGLLICLPREQAARFCAEIKSPKYGEGHQAWIIGIVEKGNRTARIIDKPRIIEVAPQVATQNVNPTPGATS>sp|P49903-4|SPS1_HUMAN Isoform 4 of Selenide, water dikinase 1 OS=Homosapiens OX=9606 GN=SEPHS1MSTRESFNPESYELDKSFRLTRFTELKGTGCKVPQDVLQKLLESLQENHFQEDEQFLGAVMPRLGIGMDTCVIPLRHGGLSLVQTTDYIYPIVDDPYMMGRIACANVLSDLYAMGVTECDNMLMLLGVSNKMTDRERDKVMPLIIQGFKDAAEEAGTSVTGGQTVLNPWIVLGGVATTVCQPNEFIMPDNAVPGDVLVLTKPLGTQVAVAVHQWLDIPEKWNKIKLVVTQEDVELAYQEAMMNMARLNRTAAGLMHTFNAHAATDITGFGILGHAQNLAKQQRNEVSFVIHNLPVLAKMAAVSKACGNMFGLMHGTCPETSDVQ>sp|Q9BPZ2|SPI2B_HUMAN Spindlin-2B OS=Homo sapiens OX=9606 GN=SPIN2B PE=1SV=1MKTPNAQEAEGQQTRAAAGRATGSANMTKKKVSQKKQRGRPSSQPRRNIVGCRISHGWKEGDEPITQWKGTVLDQVPINPSLYLVKYDGIDCVYGLELHRDERVLSLKILSDRVASSHISDANLANTIIGKAVEHMFEGEHGSKDEWRGMVLAQAPIMKAWFYITYEKDPVLYMYQLLDDYKEGDLRIMPESSESPPTEREPGGVVDGLIGKHVEYTKEDGSKRIGMVIHQVEAKPSVYFIKFDDDFHIYVYDLVKKS>sp|Q8TCT6|SPPL3_HUMAN Signal peptide peptidase-like 3 OS=Homo sapiensOX=9606 GN=SPPL3 PE=1 SV=2MAEQTYSWAYSLVDSSQVSTFLISILLIVYGSFRSLNMDFENQDKEKDSNSSSGSFNGNSTNNSIQTIDSTQALFLPIGASVSLLVMFFFFDSVQVVFTICTAVLATIAFAFLLLPMCQYLTRPCSPQNKISFGCCGRFTAAELLSFSLSVMLVLIWVLTGHWLLMDALAMGLCVAMIAFVRLPSLKVSCLLLSGLLIYDVFWVFFSAYIFNSNVMVKVATQPADNPLDVLSRKLHLGPNVGRDVPRLSLPGKLVFPSSTGSHFSMLGIGDIVMPGLLLCFVLRYDNYKKQASGDSCGAPGPANISGRMQKVSYFHCTLIGYFVGLLTATVASRIHRAAQPALLYLVPFTLLPLLTMAYLKGDLRRMWSEPFHSKSSSSRFLEV>sp|Q8TCT6-3|SPPL3_HUMAN Isoform 3 of Signal peptide peptidase-like 3OS=Homo sapiens OX=9606 GN=SPPL3MVKVATQPADNPLDVLSRKLHLGPNVGRDVPRLSLPGKLVFPSSTGSHFSMLGIGDIVMPGLLLCFVLRYDNYKKQASGDSCGAPGPANISGRMQKVSYFHCTLIGYFVGLLTATVASRIHRAAQPALLYLVPFTLLPLLTMAYLKGDLRRMWSEPFHSKSSSSRFLEV>sp|Q9C093|SPEF2_HUMAN Sperm flagellar protein 2 OS=Homo sapiens OX=9606GN=SPEF2 PE=1 SV=2MSEILCQWLNKELKVSRTVSPKSFAKAFSSGYLLGEVLHKFELQDDFSEFLDSRVSSAKLNNFSRLEPTLNLLGVQFDQNVAHGIITEKPGVATKLLYQLYIALQKKKKSGLTGVEMQTMQRLTNLRLQNMKSDTFQERLRHMIPRQTDFNLMRITYRFQEKYKHVKEDLAHLHFEKLERFQKLKEEQRCFDIEKQYLNRRRQNEIMAKIQAAIIQIPKPASNRTLKALEAQKMMKKKKEAEDVADEIKKFEALIKKDLQAKESASKTSLDTAGQTTTDLLNTYSDDEYIKKIQKRLEEDAFAREQREKRRRKLLMDQLIAHEAQEEAYREEQLINRLMRQSQQERRIAVQLMHVRHEKEVLWQNRIFREKQHEERRLKDFQDALDREAALAKQAKIDFEEQFLKEKRFHDQIAVERAQARYEKHYSVCAEILDQIVDLSTKVADYRMLTNNLIPYKLMHDWKELFFNAKPIYEQASVKTLPANPSREQLTELEKRDLLDTNDYEEYKNMVGEWALPEEMVDNLPPSNNCILGHILHRLAEKSLPPRAESTTPELPSFAVKGCLLGKTLSGKTTILRSLQKDFPIQILSIDTLVQEAIQAFHDNEKVSEVLPIQKNDEEDALPVLQEEIKESQDPQHVFSAGPVSDEVLPETEGETMLSANADKTPKAEEVKSSDSFLKLTTRAQLGAKSEQLLKKGKSIPDVLLVDIIVNAINEIPVNQDCILDGFPMTLNQAQLLEEALTGCNRNLTEVERKKAQKSTLAIDPATSKEIPLPSPAFDFVILLDVSDTSSMSRMNDIIAEELSYKTAHEDISQRVAAENQDKDGDQNLRDQIQHRIIGFLDNWPLLEQWFSEPENILIKINAEIDKESLCEKVKEILTTEIAKKKNKVEKKLEEKEAEKKAAASLAELPLPTPPPAPPPEPEKEKEIHQSHVASKTPTAKGKPQSEAPHGKQESLQEGKGKKGETALKRKGSPKGKSSGGKVPVKKSPADSTDTSPVAIVPQPPKPGSEEWVYVNEPVPEEMPLFLVPYWELIENSYINTIKTVLRHLREDQHTVLAYLYEIRTSFQEFLKRPDHKQDFVAQWQADFNSLPDDLWDDEETKAELHQRVNDLRDRLWDICDARKEEAEQERLDIINESWLQDTLGMTMNHFFSLMQAELNRFQDTKRLLQDYYWGMESKIPVEDNKRFTRIPLVQLDSKDNSESQLRIPLVPRISISLETVTPKPKTKSVLKGKMDNSLENVESNFEADEKLVMDTWQQASLAVSHMVAAEIHQRLMEEEKENQPADPKEKSPQMGANKKVKKEPPKKKQEDKKPKGKSPPMAEATPVIVTTEEIAEIKRKNELRVKIKEEHLAALQFEEIATQFRLELIKTKALALLEDLVTKVVDVYKLMEKWLGERYLNEMASTEKLTDVARYHIETSTKIQNELYLSQEDFFINGNIKVFPDPPPSIRPPPVEKEEDGTLTIEQLDSLRDQFLDMAPKGIIGNKAFTDILIDLVTLNLGTNNFPSNWMHLTQPELQELTSLLTVNSEFVDWRKFLLVTSMPWPIPLEEELLETLQKFKAVDKEQLGTITFEQYMQAGLWFTGDEDIKIPENPLEPLPFNRQEHLIEFFFRLFADYEKDPPQLDYTQMLLYFACHPDTVEGVYRALSVAVGTHVFQQVKASIPSAEKTSSTDAGPAEEFPEPEENAAREERKLKDDTEKREQKDEEIPENANNEKMSMETLLKVFKGGSEAQDSNRFASHLKIENIYAEGFIKTFQDLGAKNLEPIEVAVLLKHPFIQDLISNYSDYKFPDIKIILQRSEHVQGSDGERSPSRHTEEKK>sp|Q9C093-2|SPEF2_HUMAN Isoform 2 of Sperm flagellar protein 2 OS=Homosapiens OX=9606 GN=SPEF2MSEILCQWLNKELKVSRTVSPKSFAKAFSSGYLLGEVLHKFELQDDFSEFLDSRVSSAKLNNFSRLEPTLNLLGVQFDQNVAHGIITEKPGVATKLLYQLYIALQKKKKSGLTGVEMQTMQRLTNLRLQNMKSDTFQERLRHMIPRQTDFNLMRITYRFQEKYKHVKEDLAHLHFEKLERFQKLKEEQRCFDIEKQYLNRRRQNEIMAKIQAAIIQIPKPASNRTLKALEAQKMMKKKKEAEDVADEIKKFEALIKKDLQAKESASKTSLDTAGQTTTDLLNTYSDDEYIKKIQKRLEEDAFAREQREKRRRKLLMDQLIAHEAQEEAYREEQLINRLMRQSQQERRIAVQLMHVRHEKEVLWQNRIFREKQHEERRLKDFQDALDREAALAKQAKIDFEEQFLKEKRFHDQIAVERAQARYEKHYSVCAEILDQIVDLSTKVADYRMLTNNLIPYKLMHDWKELFFNAKPIYEQASVKTLPANPSREQLTELEKRDLLDTNDYEEYKNMVGEWALPEEMVDNLPPSNNCILGHILHRLAEKSLPPRAESTTPELPSFAVKGCLLGKTLSGKTTILRSLQKDFPIQILSIDTLVQEAIQAFHDNEKVSEVLPIQKNDEEDALPVLQEEIKESQDPQHVFSAGPVSDEVLPETEGANADKTPKAEEVKSSDSFLKLTTRAQLGAKSEQLLKKGKSIPDVLLVDIIVNAINEIPVNQDCILDGFPMTLNQAQLLEEALTGCNRNLTEVERKKAQKSTLAIDPATSKEIPLPSPAFDFVILLDVSDTSSMSRMNDIIAEELSYKTAHEDISQRVAAENQDKDGDQNLRDQIQHRIIGFLDNWPLLEQWFSEPENILIKINAEIDKESLCEKVKEILTTEIAKKKNKVEKKLEEKEAEKKAAASLAELPLPTPPPAPPPEPEKEKEIHQSHVASKTPTAKGKPQSEAPHGKQESLQEGKGKKGETALKRKGSPKGKSSGGKVPVKKSPADSTDTSPVAIVPQPPKPGSEEWVYVNEPVPEEMPLFLVPYWELIENSYINTIKTVLRHLREDQHTVLAYLYEIRTSFQEFLKRPDHKQDFVAQWQADFNSLPDDLWDDEETKAELHQRVNDLRDRLWDICDARKEEAEQERLDIINESWLQDTLGMTMNHFFSLMQAELNRFQDTKRLLQDYYWGMESKIPVEDNKRFTRIPLVQLDSKDNSESQLRIPLVPRISISLETVTPKPKTKSVLKGKMDNSLENVESNFEADEKLVMDTWQQASLAVSHMVAAEIHQRLMEEEKENQPADPKEKSPQMGANKKVKKEPPKKKQEDKKPKGKSPPMAEATPVIVTTEEIAEIKRKNELRVKIKEEHLAALQFEEIATQFRLELIKTKALALLEDLVTKVVDVYKLMEKWLGERYLNEMASTEKLTDVARYHIETSTKIQNELYLSQEDFFINGNIKVFPDPPPSIRPPPVEKEEDGTLTIEQLDSLRDQFLDMAPKGIIGNKAFTDILIDLVTLNLGTNNFPSNWMHLTQPELQELTSLLTVNSEFVDWRKFLLVTSMPWPIPLEEELLETLQKFKAVDKEQLGTITFEQYMQAGLWFTGDEDIKIPENPLEPLPFNRQEHLIEFFFRLFADYEKDPPQLDYTQMLLYFACHPDTVEGVYRALSVAVGTHVFQQVKASIPSAEKTSSTDAGPAEEFPEPEENAAREERKLKDDTEKREQKDEEIPENANNEKMSMETLLKVFKGGSEAQDSNRFASHLKIENIYAEGFIKTFQDLGAKNLEPIEVAVLLKHPFIQDLISNYSDYKFPVHIIYVVEMIVCAKGWAPLPSGKQCARWRN>sp|Q9C093-3|SPEF2_HUMAN Isoform 3 of Sperm flagellar protein 2 OS=Homosapiens OX=9606 GN=SPEF2MSEILCQWLNKELKVSRTVSPKSFAKAFSSGYLLGEVLHKFELQDDFSEFLDSRVSSAKLNNFSRLEPTLNLLGVQFDQNVAHGIITEKPGVATKLLYQLYIALQKKKKSGLTGVEMQTMQRLTNLRLQNMKSDTFQERLRHMIPRQTDFNLMRITYRFQEKYKHVKEDLAHLHFEKLERFQKLKEEQRCFDIEKQYLNRRRQNEIMAKIQAAIIQIPKPASNRTLKALEAQKMMKKKKEAEDVADEIKKFEALIKKDLQAKESASKTSLDTAGQTTTDLLNTYSDDEYIKKIQKRLEEDAFAREQREKRRRKLLMDQLIAHEAQEEAYREEQLINRLMRQSQQERRIAVQLMHVRHEKEVLWQNRIFREKQHEERRLKDFQDALDREAALAKQAKIDFEEQFLKEKRFHDQIAVERAQARYEKHYSVCAEILDQIVDLSTKVADYRMLTNNLIPYKLMHDWKELFFNAKPIYEQASVKTLPANPSREQLTELEKRDLLDTNDYEEYKVPTDMK>sp|Q9C093-4|SPEF2_HUMAN Isoform 4 of Sperm flagellar protein 2 OS=Homosapiens OX=9606 GN=SPEF2MPSQIGDRKWLHGLQAALQNFLKGYPAIVRQLHSAGRGKSDTSQKKPKELLESLLQADIVKFAHFLLDVMNVLSILSCVNKNRNSSIADIFATLESMLEMLQMYQTRLGPKERMVDSATHFHGNCLRGKENISAVRNIVLTHLIKRLQGCFRDASQNVVRATVIGSFKLWPTKINQEFGEKEVSILTAHYEPVLEAANVKLSEVDTEWSMLKLEIYARFQNIRKLTWDFVNSIYLHKYPNILTLVDLVLTLPASSAEAEHGFSQMKWTKSHMHAKIKAESIIGNKAFTDILIDLVTLNLGTNNFPSNWMHLTQPELQELTSLLTVNSEFVDWRKFLLVTSMPWPIPLEEELLETLQKFKAVDKEQLGTITFEQYMQAGLWFTGDEDIKIPENPLEPLPFNRQEHLIEFFFRLFADYEKDPPQLDYTQMLLYFACHPDTVEGVYRALSVAVGTHVFQQVKASIPSAEKTSSTDAGPAEEFPEPEENAAREERKLKDDTEKREQKDEEIPENANNEKMSMETLLKVFKGGSEAQDSNRFASHLKIENIYAEGFIKTFQDLGAKNLEPIEVAVLLKHPFIQDLISNYSDYKFPDIKIILQRSEHVQGSDGERSPSRHTEEKK>sp|Q9BRV3|SWET1_HUMAN Sugar transporter SWEET1 OS=Homo sapiens OX=9606GN=SLC50A1 PE=1 SV=1MEAGGFLDSLIYGACVVFTLGMFSAGLSDLRHMRMTRSVDNVQFLPFLTTEVNNLGWLSYGALKGDGILIVVNTVGAALQTLYILAYLHYCPRKRVVLLQTATLLGVLLLGYGYFWLLVPNPEARLQQLGLFCSVFTISMYLSPLADLAKVIQTKSTQCLSYPLTIATLLTSASWCLYGFRLRDPYIMVSNFPGIVTSFIRFWLFWKYPQEQDRNYWLLQT>sp|Q9BRV3-2|SWET1_HUMAN Isoform 2 of Sugar transporter SWEET1 OS=Homosapiens OX=9606 GN=SLC50A1MRGLHPWHVLRRPLGPQAHANDPECGQRPVPALSHHGSQRVVLLQTATLLGVLLLGYGYFWLLVPNPEARLQQLGLFCSVFTISMYLSPLADLAKVIQTKSTQCLSYPLTIATLLTSASWCLYGFRLRDPYIMVSNFPGIVTSFIRFWLFWKYPQEQDRNYWLLQT>sp|Q9BRV3-3|SWET1_HUMAN Isoform 3 of Sugar transporter SWEET1 OS=Homosapiens OX=9606 GN=SLC50A1MEAGGFLDSLIYGACVVFTLGMFSAGLSDLRHMRMTRSVDNVQFLPFLTTEVNNLGWLSYGALKGDGILIVVNTVGAALQTLYILAYLHYCPRKAKVIQTKSTQCLSYPLTIATLLTSASWCLYGFRLRDPYIMVSNFPGIVTSFIRFWLFWKYPQEQDRNYWLLQT>sp|Q9BZY9|TRI31_HUMAN E3 ubiquitin-protein ligase TRIM31 OS=Homo sapiensOX=9606 GN=TRIM31 PE=1 SV=2MASGQFVNKLQEEVICPICLDILQKPVTIDCGHNFCLKCITQIGETSCGFFKCPLCKTSVRKNAIRFNSLLRNLVEKIQALQASEVQSKRKEATCPRHQEMFHYFCEDDGKFLCFVCRESKDHKSHNVSLIEEAAQNYQGQIQEQIQVLQQKEKETVQVKAQGVHRVDVFTDQVEHEKQRILTEFELLHQVLEEEKNFLLSRIYWLGHEGTEAGKHYVASTEPQLNDLKKLVDSLKTKQNMPPRQLLEDIKVVLCRSEEFQFLNPTPVPLELEKKLSEAKSRHDSITGSLKKFKDQLQADRKKDENRFFKSMNKNDMKSWGLLQKNNHKMNKTSEPGSSSAGGRTTSGPPNHHSSAPSHSLFRASSAGKVTFPVCLLASYDEISGQGASSQDTKTFDVALSEELHAALSEWLTAIRAWFCEVPSS>sp|Q9BZY9-2|TRI31_HUMAN Isoform Beta of E3 ubiquitin-protein ligaseTRIM31 OS=Homo sapiens OX=9606 GN=TRIM31MASGQFVNKLQEEVICPICLDILQKPVTIDCGHNFCLKCITQIGETSCGFFKCPLCKTSVRKNAIRFNSLLRNLVEKIQALQASEVQSKRKEATCPRHQEMFHYFCEDDGKFLCFVCRESKDHKSHNVSLIEEAAQNYQGQIQEQIQVLQQKEKETVQVKAQGVHRVDVFTDQVEHEKQRILTEFELLHQVLEEEKNFLLSRIYWLGHEGTEAGKHYVASTEPQLNDLKKLVDSLKTKQNMPPRQLLENWRKNSVKQNQDTTPSQGA>sp|Q9HA65|TBC17_HUMAN TBC1 domain family member 17 OS=Homo sapiensOX=9606 GN=TBC1D17 PE=1 SV=2MEGAGYRVVFEKGGVYLHTSAKKYQDRDSLIAGVIRVVEKDNDVLLHWAPVEEAGDSTQILFSKKDSSGGDSCASEEEPTFDPDYEPDWAVISTVRPQLCHSEPTRGAEPSCPQGSWAFSVSLGELKSIRRSKPGLSWAYLVLVTQAGGSLPALHFHRGGTRALLRVLSRYLLLASSPQDSRLYLVFPHDSSALSNSFHHLQLFDQDSSNVVSRFLQDPYSTTFSSFSRVTNFFRGALQPQPEGAASDLPPPPDDEPEPGFEVISCVELGPRPTVERGPPVTEEEWARHVGPEGRLQQVPELKNRIFSGGLSPSLRREAWKFLLGYLSWEGTAEEHKAHIRKKTDEYFRMKLQWKSVSPEQERRNSLLHGYRSLIERDVSRTDRTNKFYEGPENPGLGLLNDILLTYCMYHFDLGYVQGMSDLLSPILYVIQNEVDAFWCFCGFMELVQGNFEESQETMKRQLGRLLLLLRVLDPLLCDFLDSQDSGSLCFCFRWLLIWFKREFPFPDVLRLWEVLWTGLPGPNLHLLVACAILDMERDTLMLSGFGSNEILKHINELTMKLSVEDVLTRAEALHRQLTACPELPHNVQEILGLAPPAEPHSPSPTASPLPLSPTRAPPTPPPSTDTAPQPDSSLEILPEEEDEGADS>sp|Q9HA65-2|TBC17_HUMAN Isoform 2 of TBC1 domain family member 17OS=Homo sapiens OX=9606 GN=TBC1D17MEGAGYRDNDVLLHWAPVEEAGDSTQILFSKKDSSGGDSCASEEEPTFDPDYEPDWAVISTVRPQLCHSEPTRGAEPSCPQGSWAFSVSLGELKSIRRSKPGLSWAYLVLVTQAGGSLPALHFHRGGTRALLRVLSRYLLLASSPQDSRLYLVFPHDSSALSNSFHHLQLFDQDSSNVVSRFLQDPYSTTFSSFSRVTNFFRGALQPQPEGAASDLPPPPDDEPEPGFEVISCVELGPRPTVERGPPVTEEEWARHVGPEGRLQQVPELKNRIFSGGLSPSLRREAWKFLLGYLSWEGTAEEHKAHIRKKTDEYFRMKLQWKSVSPEQERRNSLLHGYRSLIERDVSRTDRTNKFYEGPENPGLGLLNDILLTYCMYHFDLGYVQGMSDLLSPILYVIQNEVDAFWCFCGFMELVQGNFEESQETMKRQLGRLLLLLRVLDPLLCDFLDSQDSGSLCFCFRWLLIWFKREFPFPDVLRLWEVLWTGLPGPNLHLLVACAILDMERDTLMLSGFGSNEILKHINELTMKLSVEDVLTRAEALHRQLTACPELPHNVQEILGLAPPAEPHSPSPTASPLPLSPTRAPPTPPPSTDTAPQPDSSLEILPEEEDEGADS>sp|Q9HA65-3|TBC17_HUMAN Isoform 3 of TBC1 domain family member 17OS=Homo sapiens OX=9606 GN=TBC1D17MEGAGYRVVFEKGGVYLHTSAKKYQDRDSLIAGVIRVVEKDNDVLLHWAPVEEAGDSTQILFSKKDSSGGDSCASEEEPTFDPDYEPDWAVISTVRPQLCHSEPTRGAEPSCPQGSWAFSVSLGELKSIRRSKPGLSWAYLVLVTQAGGSLPALHFHRGGTRALLRVLSRYLLLASSPQDSRLYLVFPHDSSALSNSFHHLQLFDQDSSNVVSRFLQDPYSTTFSSFSRVTNFFRGALQPQPEGAASDLPPPPDDEPEPGFEVISCVELGPRPTVERGPPVTEEEWARHVGPEGRLQQVPELKNRIFSGGLSPSLRREAWKFLLGYLSWEGTAEEHKAHIRKKTDEYFRMKLQWKSVSPEQERRNSLLHGYRSLIERDVSRTDRTNKFYEGPENPGLGLLNDILLTYCMYHFDLGYVQGMSDLLSPILYVIQNEVDAFWCFCGFMELVQGNFEESQETMKRQLGRLLLLLRVLDPLLCDFLDSQDSGSLCFCFRWLLIWFKREFPFPDVLRLWEVLWTGLPGPNLHLLVACAILDMERDTLMLSGFGSNEILKHINELTMKLSVEDVLTRAEALHRQLTACPELPEEEDEGADS>sp|P36941|TNR3_HUMAN Tumor necrosis factor receptor superfamily member 3OS=Homo sapiens OX=9606 GN=LTBR PE=1 SV=1MLLPWATSAPGLAWGPLVLGLFGLLAASQPQAVPPYASENQTCRDQEKEYYEPQHRICCSRCPPGTYVSAKCSRIRDTVCATCAENSYNEHWNYLTICQLCRPCDPVMGLEEIAPCTSKRKTQCRCQPGMFCAAWALECTHCELLSDCPPGTEAELKDEVGKGNNHCVPCKAGHFQNTSSPSARCQPHTRCENQGLVEAAPGTAQSDTTCKNPLEPLPPEMSGTMLMLAVLLPLAFFLLLATVFSCIWKSHPSLCRKLGSLLKRRPQGEGPNPVAGSWEPPKAHPYFPDLVQPLLPISGDVSPVSTGLPAAPVLEAGVPQQQSPLDLTREPQLEPGEQSQVAHGTNGIHVTGGSMTITGNIYIYNGPVLGGPPGPGDLPATPEPPYPIPEEGDPGPPGLSTPHQEDGKAWHLAETEHCGATPSNRGPRNQFITHD>sp|P36941-2|TNR3_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 3 OS=Homo sapiens OX=9606 GN=LTBRMEATGISLASQLKVPPYASENQTCRDQEKEYYEPQHRICCSRCPPGTYVSAKCSRIRDTVCATCAENSYNEHWNYLTICQLCRPCDPVMGLEEIAPCTSKRKTQCRCQPGMFCAAWALECTHCELLSDCPPGTEAELKDEVGKGNNHCVPCKAGHFQNTSSPSARCQPHTRCENQGLVEAAPGTAQSDTTCKNPLEPLPPEMSGTMLMLAVLLPLAFFLLLATVFSCIWKSHPSLCRKLGSLLKRRPQGEGPNPVAGSWEPPKAHPYFPDLVQPLLPISGDVSPVSTGLPAAPVLEAGVPQQQSPLDLTREPQLEPGEQSQVAHGTNGIHVTGGSMTITGNIYIYNGPVLGGPPGPGDLPATPEPPYPIPEEGDPGPPGLSTPHQEDGKAWHLAETEHCGATPSNRGPRNQFITHD>sp|Q6AZZ1|TRI68_HUMAN E3 ubiquitin-protein ligase TRIM68 OS=Homo sapiensOX=9606 GN=TRIM68 PE=1 SV=1MDPTALVEAIVEEVACPICMTFLREPMSIDCGHSFCHSCLSGLWEIPGESQNWGYTCPLCRAPVQPRNLRPNWQLANVVEKVRLLRLHPGMGLKGDLCERHGEKLKMFCKEDVLIMCEACSQSPEHEAHSVVPMEDVAWEYKWELHEALEHLKKEQEEAWKLEVGERKRTATWKIQVETRKQSIVWEFEKYQRLLEKKQPPHRQLGAEVAAALASLQREAAETMQKLELNHSELIQQSQVLWRMIAELKERSQRPVRWMLQDIQEVLNRSKSWSLQQPEPISLELKTDCRVLGLREILKTYAADVRLDPDTAYSRLIVSEDRKRVHYGDTNQKLPDNPERFYRYNIVLGSQCISSGRHYWEVEVGDRSEWGLGVCKQNVDRKEVVYLSPHYGFWVIRLRKGNEYRAGTDEYPILSLPVPPRRVGIFVDYEAHDISFYNVTDCGSHIFTFPRYPFPGRLLPYFSPCYSIGTNNTAPLAICSLDGED>sp|Q6AZZ1-2|TRI68_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM68OS=Homo sapiens OX=9606 GN=TRIM68MQKLELKTDCRVLGLREILKTYAADVRLDPDTAYSRLIVSEDRKRVHYGDTNQKLPDNPERFYRYNIVLGSQCISSGRHYWEVEVGDRSEWGLGVCKQNVDRKEVVYLSPHYGFWVIRLRKGNEYRAGTDEYPILSLPVPPRRVGIFVDYEAHDISFYNVTDCGSHIFTFPRYPFPGRLLPYFSPCYSIGTNNTAPLAICSLDGED>sp|Q8NG06|TRI58_HUMAN E3 ubiquitin-protein ligase TRIM58 OS=Homo sapiensOX=9606 GN=TRIM58 PE=2 SV=2MAWAPPGERLREDARCPVCLDFLQEPVSVDCGHSFCLRCISEFCEKSDGAQGGVYACPQCRGPFRPSGFRPNRQLAGLVESVRRLGLGAGPGARRCARHGEDLSRFCEEDEAALCWVCDAGPEHRTHRTAPLQEAAGSYQVKLQMALELMRKELEDALTQEANVGKKTVIWKEKVEMQRQRFRLEFEKHRGFLAQEEQRQLRRLEAEERATLQRLRESKSRLVQQSKALKELADELQERCQRPALGLLEGVRGVLSRSKAVTRLEAENIPMELKTACCIPGRRELLRKFQVDVKLDPATAHPSLLLTADLRSVQDGEPWRDVPNNPERFDTWPCILGLQSFSSGRHYWEVLVGEGAEWGLGVCQDTLPRKGETTPSPENGVWALWLLKGNEYMVLASPSVPLLQLESPRCIGIFLDYEAGEISFYNVTDGSYIYTFNQLFSGLLRPYFFICDATPLILPPTTIAGSGNWASRDHLDPASDVRDDHL>sp|Q9H8W5|TRI45_HUMAN Tripartite motif-containing protein 45 OS=Homosapiens OX=9606 GN=TRIM45 PE=1 SV=2MSENRKPLLGFVSKLTSGTALGNSGKTHCPLCLGLFKAPRLLPCLHTVCTTCLEQLEPFSVVDIRGGDSDTSSEGSIFQELKPRSLQSQIGILCPVCDAQVDLPMGGVKALTIDHLAVNDVMLESLRGEGQGLVCDLCNDREVEKRCQTCKANLCHFCCQAHRRQKKTTYHTMVDLKDLKGYSRIGKPILCPVHPAEELRLFCEFCDRPVCQDCVVGEHREHPCDFTSNVIHKHGDSVWELLKGTQPHVEALEEALAQIHIINSALQKRVEAVAADVRTFSEGYIKAIEEHRDKLLKQLEDIRAQKENSLQLQKAQLEQLLADMRTGVEFTEHLLTSGSDLEILITKRVVVERLRKLNKVQYSTRPGVNDKIRFCPQEKAGQCRGYEIYGTINTKEVDPAKCVLQGEDLHRAREKQTASFTLLCKDAAGEIMGRGGDNVQVAVVPKDKKDSPVRTMVQDNKDGTYYISYTPKEPGVYTVWVCIKEQHVQGSPFTVMVRRKHRPHSGVFHCCTFCSSGGQKTARCACGGTMPGGYLGCGHGHKGHPGHPHWSCCGKFNEKSECTWTGGQSAPRSLLRTVAL>sp|Q9H8W5-2|TRI45_HUMAN Isoform 2 of Tripartite motif-containing protein45 OS=Homo sapiens OX=9606 GN=TRIM45MSENRKPLLGFVSKLTSGTALGNSGKTHCPLCLGLFKAPRLLPCLHTVCTTCLEQLEPFSVVDIRGGDSDTSSEGSIFQELKPRSLQSQIGILCPVCDAQVDLPMGGVKALTIDHLAVNDVMLESLRGEGQGLVCDLCNDREVEKRCQTCKANLCHFCCQAHRRQKKTTYHTMVDLKDLKGYSRIGKPILCPVHPAEELRLFCEFCDRPVCQDCVVGEHREHPCDFTSNVIHKHGDSVWELLKGTQPHVEALEEALAQIHIINSALQKRVEAVAADVRTFSEGYIKAIEEHRDKLLKQLEDIRAQKENSLQLQKAQLEQLLADMRTGVEFTEHLLTSGSDLEILITKRVVVERLRKLNKVQYSTRPGVNDKIRFCPQEKAGQCRGYEIYDLHRAREKQTASFTLLCKDAAGEIMGRGGDNVQVAVVPKDKKDSPVRTMVQDNKDGTYYISYTPKEPGVYTVWVCIKEQHVQGSPFTVMVRRKHRPHSGVFHCCTFCSSGGQKTARCACGGTMPGGYLGCGHGHKGHPGHPHWSCCGKFNEKSECTWTGGQSAPRSLLRTVAL>sp|Q5T6R2|TPT2L_HUMAN Putative phosphatidylinositol 3,4,5-trisphosphate3-phosphatase TPTE2P1 OS=Homo sapiens OX=9606 GN=TPTE2P1 PE=5 SV=1MPAAFPCVFPPQSLQVFPQMIVKVWEKQSLPLPGLRGSPVERLYLPRNELDNPHKQKAWKIYPPEFAVEILFGMVSVDSLLFVLSSPHWWLHLAQGSFWMSEGGFSLCHPGWSVVAQSLLTSTSAFCVRAILLPQPPE>sp|Q5T6R2-2|TPT2L_HUMAN Isoform 2 of Putative phosphatidylinositol3,4,5-trisphosphate 3-phosphatase TPTE2P1 OS=Homo sapiens OX=9606GN=TPTE2P1MPAAFPCVFPPQSLQVFPQMIVKVWEKQSLPLPGLRGSPVERLYLPRNELDNPHKQKAWKIYPPEFAVEILFGGFSLCHPGWSVVAQSLLTSTSAFCVRAILLPQPPE>sp|Q9UPN9|TRI33_HUMAN E3 ubiquitin-protein ligase TRIM33 OS=Homo sapiensOX=9606 GN=TRIM33 PE=1 SV=3MAENKGGGEAESGGGGSGSAPVTAGAAGPAAQEAEPPLTAVLVEEEEEEGGRAGAEGGAAGPDDGGVAAASSGSAQAASSPAASVGTGVAGGAVSTPAPAPASAPAPGPSAGPPPGPPASLLDTCAVCQQSLQSRREAEPKLLPCLHSFCLRCLPEPERQLSVPIPGGSNGDIQQVGVIRCPVCRQECRQIDLVDNYFVKDTSEAPSSSDEKSEQVCTSCEDNASAVGFCVECGEWLCKTCIEAHQRVKFTKDHLIRKKEDVSESVGASGQRPVFCPVHKQEQLKLFCETCDRLTCRDCQLLEHKEHRYQFLEEAFQNQKGAIENLLAKLLEKKNYVHFAATQVQNRIKEVNETNKRVEQEIKVAIFTLINEINKKGKSLLQQLENVTKERQMKLLQQQNDITGLSRQVKHVMNFTNWAIASGSSTALLYSKRLITFQLRHILKARCDPVPAANGAIRFHCDPTFWAKNVVNLGNLVIESKPAPGYTPNVVVGQVPPGTNHISKTPGQINLAQLRLQHMQQQVYAQKHQQLQQMRMQQPPAPVPTTTTTTQQHPRQAAPQMLQQQPPRLISVQTMQRGNMNCGAFQAHQMRLAQNAARIPGIPRHSGPQYSMMQPHLQRQHSNPGHAGPFPVVSVHNTTINPTSPTTATMANANRGPTSPSVTAIELIPSVTNPENLPSLPDIPPIQLEDAGSSSLDNLLSRYISGSHLPPQPTSTMNPSPGPSALSPGSSGLSNSHTPVRPPSTSSTGSRGSCGSSGRTAEKTSLSFKSDQVKVKQEPGTEDEICSFSGGVKQEKTEDGRRSACMLSSPESSLTPPLSTNLHLESELDALASLENHVKIEPADMNESCKQSGLSSLVNGKSPIRSLMHRSARIGGDGNNKDDDPNEDWCAVCQNGGDLLCCEKCPKVFHLTCHVPTLLSFPSGDWICTFCRDIGKPEVEYDCDNLQHSKKGKTAQGLSPVDQRKCERLLLYLYCHELSIEFQEPVPASIPNYYKIIKKPMDLSTVKKKLQKKHSQHYQIPDDFVADVRLIFKNCERFNEMMKVVQVYADTQEINLKADSEVAQAGKAVALYFEDKLTEIYSDRTFAPLPEFEQEEDDGEVTEDSDEDFIQPRRKRLKSDERPVHIK>sp|Q9UPN9-2|TRI33_HUMAN Isoform Beta of E3 ubiquitin-protein ligaseTRIM33 OS=Homo sapiens OX=9606 GN=TRIM33MAENKGGGEAESGGGGSGSAPVTAGAAGPAAQEAEPPLTAVLVEEEEEEGGRAGAEGGAAGPDDGGVAAASSGSAQAASSPAASVGTGVAGGAVSTPAPAPASAPAPGPSAGPPPGPPASLLDTCAVCQQSLQSRREAEPKLLPCLHSFCLRCLPEPERQLSVPIPGGSNGDIQQVGVIRCPVCRQECRQIDLVDNYFVKDTSEAPSSSDEKSEQVCTSCEDNASAVGFCVECGEWLCKTCIEAHQRVKFTKDHLIRKKEDVSESVGASGQRPVFCPVHKQEQLKLFCETCDRLTCRDCQLLEHKEHRYQFLEEAFQNQKGAIENLLAKLLEKKNYVHFAATQVQNRIKEVNETNKRVEQEIKVAIFTLINEINKKGKSLLQQLENVTKERQMKLLQQQNDITGLSRQVKHVMNFTNWAIASGSSTALLYSKRLITFQLRHILKARCDPVPAANGAIRFHCDPTFWAKNVVNLGNLVIESKPAPGYTPNVVVGQVPPGTNHISKTPGQINLAQLRLQHMQQQVYAQKHQQLQQMRMQQPPAPVPTTTTTTQQHPRQAAPQMLQQQPPRLISVQTMQRGNMNCGAFQAHQMRLAQNAARIPGIPRHSGPQYSMMQPHLQRQHSNPGHAGPFPVVSVHNTTINPTSPTTATMANANRGPTSPSVTAIELIPSVTNPENLPSLPDIPPIQLEDAGSSSLDNLLSRYISGSHLPPQPTSTMNPSPGPSALSPGSSGLSNSHTPVRPPSTSSTGSRGSCGSSGRTAEKTSLSFKSDQVKVKQEPGTEDEICSFSGGVKQEKTEDGRRSACMLSSPESSLTPPLSTNLHLESELDALASLENHVKIEPADMNESCKQSGLSSLVNGKSPIRSLMHRSARIGGDGNNKDDDPNEDWCAVCQNGGDLLCCEKCPKVFHLTCHVPTLLSFPSGDWICTFCRDIGKPEVEYDCDNLQHSKKGKTAQGLSPVDQRKCERLLLYLYCHELSIEFQEPVPASIPNYYKIIKKPMDLSTVKKKLQKKHSQHYQIPDDFVADVRLIFKNCERFNEADSEVAQAGKAVALYFEDKLTEIYSDRTFAPLPEFEQEEDDGEVTEDSDEDFIQPRRKRLKSDERPVHIK>sp|Q8IZ69|TRM2A_HUMAN tRNA (uracil-5-)-methyltransferase homolog AOS=Homo sapiens OX=9606 GN=TRMT2A PE=1 SV=2MSENLDNEGPKPMESCGQESSSALSCPTVSVPPAAPAALEEVEKEGAGAATGPGPQPGLYSYIRDDLFTSEIFKLELQNVPRHASFSDVRRFLGRFGLQPHKTKLFGQPPCAFVTFRSAAERDKALRVLHGALWKGRPLSVRLARPKADPMARRRRQEGESEPPVTRVADVVTPLWTVPYAEQLERKQLECEQVLQKLAKEIGSTNRALLPWLLEQRHKHNKACCPLEGVRPSPQQTEYRNKCEFLVGVGVDGEDNTVGCRLGKYKGGTCAVAAPFDTVHIPEATKQVVKAFQEFIRSTPYSAYDPETYTGHWKQLTVRTSRRHQAMAIAYFHPQKLSPEELAELKTSLAQHFTAGPGRASGVTCLYFVEEGQRKTPSQEGLPLEHVAGDRCIHEDLLGLTFRISPHAFFQVNTPAAEVLYTVIQDWAQLDAGSMVLDVCCGTGTIGLALARKVKRVIGVELCPEAVEDARVNAQDNELSNVEFHCGRAEDLVPTLVSRLASQHLVAILDPPRAGLHSKVILAIRRAKNLRRLLYVSCNPRAAMGNFVDLCRAPSNRVKGIPFRPVKAVAVDLFPQTPHCEMLILFERVEHPNGTGVLGPHSPPAQPTPGPPDNTLQETGTFPSS>sp|Q8IZ69-2|TRM2A_HUMAN Isoform 2 of tRNA (uracil-5-)-methyltransferasehomolog A OS=Homo sapiens OX=9606 GN=TRMT2AMSENLDNEGPKPMESCGQESSSALSCPTVSVPPAAPAALEEVEKEGAGAATGPGPQPGLYSYIRDDLFTSEIFKLELQNVPRHASFSDVRRFLGRFGLQPHKTKLFGQPPCAFVTFRSAAERDKALRVLHGALWKGRPLSVRLARPKADPMARRRRQEGESEPPVTRVADVVTPLWTVPYAEQLERKQLECEQVLQKLAKEIGSTNRALLPWLLEQRHKHNKACCPLEGVRPSPQQTEYRNKCEFLVGVGVDGEDNTVGCRLGKYKGGTCAVAAPFDTVHIPEATKQVVKAFQEFIRSTPYSAYDPETYTGHWKQLTVRTSRRHQAMAIAYFHPQKLSPEELAELKTSLAQHFTAGPGRASGVTCLYFVEEGQRKTPSQEGLPLEHVAGDRCIHEDLLGLTFRISPHAFFQVNTPAAEVLYTVIQDWAQLDAGSMVLDVCCGTGTIGLALARKVKRVIGVELCPEAVEDARVNAQDNELSNVEFHCGRAEDLVPTLVSRLASQHLVAILDPPRAGLHSKVILAIRRAKNLRRLLYVSCNPRAAMGNFVDAPLFPPQPLQSPI>sp|Q92519|TRIB2_HUMAN Tribbles homolog 2 OS=Homo sapiens OX=9606GN=TRIB2 PE=1 SV=1MNIHRSTPITIARYGRSRNKTQDFEELSSIRSAEPSQSFSPNLGSPSPPETPNLSHCVSCIGKYLLLEPLEGDHVFRAVHLHSGEELVCKVFDISCYQESLAPCFCLSAHSNINQITEIILGETKAYVFFERSYGDMHSFVRTCKKLREEEAARLFYQIASAVAHCHDGGLVLRDLKLRKFIFKDEERTRVKLESLEDAYILRGDDDSLSDKHGCPAYVSPEILNTSGSYSGKAADVWSLGVMLYTMLVGRYPFHDIEPSSLFSKIRRGQFNIPETLSPKAKCLIRSILRREPSERLTSQEILDHPWFSTDFSVSNSAYGAKEVSDQLVPDVNMEENLDPFFN>sp|Q9Y2L5|TPPC8_HUMAN Trafficking protein particle complex subunit 8OS=Homo sapiens OX=9606 GN=TRAPPC8 PE=1 SV=2MAQCVQSVQELIPDSFVPCVAALCSDEAERLTRLNHLSFAELLKPFSRLTSEVHMRDPNNQLHVIKNLKIAVSNIVTQPPQPGAIRKLLNDVVSGSQPAEGLVANVITAGDYDLNISATTPWFESYRETFLQSMPALDHEFLNHYLACMLVASSSEAEPVEQFSKLSQEQHRIQHNSDYSYPKWFIPNTLKYYVLLHDVSAGDEQRAESIYEEMKQKYGTQGCYLLKINSRTSNRASDEQIPDPWSQYLQKNSIQNQESYEDGPCTITSNKNSDNNLLSLDGLDNEVKDGLPNNFRAHPLQLEQSSDPSNSIDGPDHLRSASSLHETKKGNTGIIHGACLTLTDHDRIRQFIQEFTFRGLLPHIEKTIRQLNDQLISRKGLSRSLFSATKKWFSGSKVPEKSINDLKNTSGLLYPPEAPELQIRKMADLCFLVQHYDLAYSCYHTAKKDFLNDQAMLYAAGALEMAAVSAFLQPGAPRPYPAHYMDTAIQTYRDICKNMVLAERCVLLSAELLKSQSKYSEAAALLIRLTSEDSDLRSALLLEQAAHCFINMKSPMVRKYAFHMILAGHRFSKAGQKKHALRCYCQAMQVYKGKGWSLAEDHINFTIGRQSYTLRQLDNAVSAFRHILINESKQSAAQQGAFLREYLYVYKNVSQLSPDGPLPQLPLPYINSSATRVFFGHDRRPADGEKQAATHVSLDQEYDSESSQQWRELEEQVVSVVNKGVIPSNFHPTQYCLNSYSDNSRFPLAVVEEPITVEVAFRNPLKVLLLLTDLSLLWKFHPKDFSGKDNEEVKQLVTSEPEMIGAEVISEFLINGEESKVARLKLFPHHIGELHILGVVYNLGTIQGSMTVDGIGALPGCHTGKYSLSMSVRGKQDLEIQGPRLNNTKEEKTSVKYGPDRRLDPIITEEMPLLEVFFIHFPTGLLCGEIRKAYVEFVNVSKCPLTGLKVVSKRPEFFTFGGNTAVLTPLSPSASENCSAYKTVVTDATSVCTALISSASSVDFGIGTGSQPEVIPVPLPDTVLLPGASVQLPMWLRGPDEEGVHEINFLFYYESVKKQPKIRHRILRHTAIICTSRSLNVRATVCRSNSLENEEGRGGNMLVFVDVENTNTSEAGVKEFHIVQVSSSSKHWKLQKSVNLSENKDTKLASREKGKFCFKAIRCEKEEAATQSSEKYTFADIIFGNEQIISSASPCADFFYRSLSSELKKPQAHLPVHTEKQSTEDAVRLIQKCSEVDLNIVILWKAYVVEDSKQLILEGQHHVILRTIGKEAFSYPQKQEPPEMELLKFFRPENITVSSRPSVEQLSSLIKTSLHYPESFNHPFHQKSLCLVPVTLLLSNCSKADVDVIVDLRHKTTSPEALEIHGSFTWLGQTQYKLQLKSQEIHSLQLKACFVHTGVYNLGTPRVFAKLSDQVTVFETSQQNSMPALIIISNV>sp|Q9Y2L5-2|TPPC8_HUMAN Isoform 2 of Trafficking protein particlecomplex subunit 8 OS=Homo sapiens OX=9606 GN=TRAPPC8MAQCVQSVQELIPDSFVPCVAALCSDEAERLTRLNHLSFAELLKPFSRLTSEVHMRDPNNQLHVIKNLKIAVSNIVTQPPQPGAIRKLLNDVVSGSQPAEGLVANVITAGDYDLNISATTPWFESYRETFLQSMPALDHEFLNHYLACMLVASSSEAEPVEQFSKLSQEQHRIQHNSDYSYPKWFIPNTLKYYVLLHDVSAGDEQRAESIYEEMKQKYGTQGCYLLKINSRTSNRASDEQIPDPWSQYLQKNSIQNQESYEDGPCTITSNKNSDNNLLSLDGLDNEVKDGLPNNFRAHPLQLEQSSDPSNSIDGPDHLRSASSLHETKKGNTGIIHGACLTLTDHDRIRQFIQEFTFRGLLPHIEKTIRQLNDQLISRKGLSRSLFSATKKWFSGSKVPEKSINDLKNTSGLLYPPEAPELQIRKMADLCFLVQHYDLAYSCYHTAKKDFLNDQAMLYAAGALEMAAVSAFLQPGAPRPYPAHYMDTAIQTYRDICKNMVLAERCVLLSAELLKSQSKYSEAAALLIRLTSEDSDLRSALLLEQAAHCFINMKSPMVRKYAFHMILAGHRFSKAGQKKHALRCYCQAMQVYKGKGWSLAEDHINFTIGRQSYTLRQLDNAVSAFRHILINESKQSAAQQGAFLREYLYVYKNVSQLSPDGPLPQLPLPYINSSATRVFFGHDRRPADGEKQAATHVSLDQEYDSESSQQWRELEEQVVSVVNKGVIPSNFHPTQYCLNSYSDNSRFPLAVVEEPITVEVAFRNPLKVLLLLTDLSLLWKFHPKDFSGKDNEEVKQLVTSEPEMIGAEVISEFLINGEESKVARLKLFPHHIGELHILGVVYNLGTIQGSMTVDGIGALPGCHTGKYSLSMSVRGKQDLEIQGPRLNNTKEEKTSVKYGPDRRLDPIITEEMPLLETLALAQEVNQRDFGIGTGSQPEVIPVPLPDTVLLPGASVQLPMWLRGPDEEGVHEINFLFYYESVKKQPKIRHRILRHTAIICTSRSLNVRATVCRSNSLENEEGRGGNMLVFVDVENTNTSEAGVKEFHIVQVSSSSKHWKLQKSVNLSENKDTKLASREKGKFCFKAIRCEKEEAATQSSEKYTFADIIFGNEQIISSASPCADFFYRSLSSELKKPQAHLPVHTEKQSTEDAVRLIQKCSEVDLNIVILWKAYVVEDSKQLILEGQHHVILRTIGKEAFSYPQKQEPPEMELLKFFRPENITVSSRPSVEQLSSLIKTSLHYPESFNHPFHQKSLCLVPVTLLLSNCSKADVDVIVDLRHKTTSPEALEIHGSFTWLGQTQYKLQLKSQEIHSLQLKACFVHTGVYNLGTPRVFAKLSDQVTVFETSQQNSMPALIIISNV>sp|Q66K66|TM198_HUMAN Transmembrane protein 198 OS=Homo sapiens OX=9606GN=TMEM198 PE=1 SV=1MPGTVATLRFQLLPPEPDDAFWGAPCEQPLERRYQALPALVCIMCCLFGVVYCFFGYRCFKAVLFLTGLLFGSVVIFLLCYRERVLETQLSAGASAGIALGIGLLCGLVAMLVRSVGLFLVGLLLGLLLAAAALLGSAPYYQPGSVWGPLGLLLGGGLLCALLTLRWPRPLTTLATAVTGAALIATAADYFAELLLLGRYVVERLRAAPVPPLCWRSWALLALWPLLSLMGVLVQWRVTAEGDSHTEVVISRQRRRVQLMRIRQQEDRKEKRRKKRPPRAPLRGPRAPPRPGPPDPAYRRRPVPIKRFNGDVLSPSYIQSFRDRQTGSSLSSFMASPTDADYEYGSRGPLTACSGPPVRV>sp|Q6Q0C0|TRAF7_HUMAN E3 ubiquitin-protein ligase TRAF7 OS=Homo sapiensOX=9606 GN=TRAF7 PE=1 SV=1MSSGKSARYNRFSGGPSNLPTPDVTTGTRMETTFGPAFSAVTTITKADGTSTYKQHCRTPSSSSTLAYSPRDEEDSMPPISTPRRSDSAISVRSLHSESSMSLRSTFSLPEEEEEPEPLVFAEQPSVKLCCQLCCSVFKDPVITTCGHTFCRRCALKSEKCPVDNVKLTVVVNNIAVAEQIGELFIHCRHGCRVAGSGKPPIFEVDPRGCPFTIKLSARKDHEGSCDYRPVRCPNNPSCPPLLRMNLEAHLKECEHIKCPHSKYGCTFIGNQDTYETHLETCRFEGLKEFLQQTDDRFHEMHVALAQKDQEIAFLRSMLGKLSEKIDQLEKSLELKFDVLDENQSKLSEDLMEFRRDASMLNDELSHINARLNMGILGSYDPQQIFKCKGTFVGHQGPVWCLCVYSMGDLLFSGSSDKTIKVWDTCTTYKCQKTLEGHDGIVLALCIQGCKLYSGSADCTIIVWDIQNLQKVNTIRAHDNPVCTLVSSHNVLFSGSLKAIKVWDIVGTELKLKKELTGLNHWVRALVAAQSYLYSGSYQTIKIWDIRTLDCIHVLQTSGGSVYSIAVTNHHIVCGTYENLIHVWDIESKEQVRTLTGHVGTVYALAVISTPDQTKVFSASYDRSLRVWSMDNMICTQTLLRHQGSVTALAVSRGRLFSGAVDSTVKVWTC>sp|Q6Q0C0-2|TRAF7_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRAF7OS=Homo sapiens OX=9606 GN=TRAF7MPPISTPRRSDSAISVRSLHSESSMSLRSTFSLPEEEEEPEPLVFAEQPSVKLCCQLCCSVFKDPVITTCGHTFCRRCALKSEKCPVDNVKLTVVVNNIAVAEQIGELFIHCRHGCRVAGSGKPPIFEVDPRGCPFTIKLSARKDHEGSCDYRPVRCPNNPSCPPLLRMNLEAHLKECEHIKCPHSKYGCTFIGNQDTYETHLETCRFEGLKEFLQQTDDRFHEMHVALAQKDQEIAFLRSMLGKLSEKIDQLEKSLELKFDVLDENQSKLSEDLMEFRRDASMLNDELSHINARLNMGILGSYDPQQIFKCKGTFVGHQGPVWCLCVYSMGDLLFSGSSDKTIKVWDTCTTYKCQKTLEGHDGIVLALCIQGCKLYSGSADCTIIVWDIQNLQKVNTIRAHDNPVCTLVSSHNVLFSGSLKAIKVWDIVGTELKLKKELTGLNHWVRALVAAQSYLYSGSYQTIKIWDIRTLDCIHVLQTSGGSVYSIAVTNHHIVCGTYENLIHVWDIESKEQVRTLTGHVGTVYALAVISTPDQTKVFSASYDRSLRVWSMDNMICTQTLLRHQGSVTALAVSRGRLFSGAVDSTVKVWTC>sp|O75674|TM1L1_HUMAN TOM1-like protein 1 OS=Homo sapiens OX=9606GN=TOM1L1 PE=1 SV=2MAFGKSHRDPYATSVGHLIEKATFAGVQTEDWGQFMHICDIINTTQDGPKDAVKALKKRISKNYNHKEIQLTLSLIDMCVQNCGPSFQSLIVKKEFVKENLVKLLNPRYNLPLDIQNRILNFIKTWSQGFPGGVDVSEVKEVYLDLVKKGVQFPPSEAEAETARQETAQISSNPPTSVPTAPALSSVIAPKNSTVTLVPEQIGKLHSELDMVKMNVRVMSAILMENTPGSENHEDIELLQKLYKTGREMQERIMDLLVVVENEDVTVELIQVNEDLNNAILGYERFTRNQQRILEQNKNQKEATNTTSEPSAPSQDLLDLSPSPRMPRATLGELNTMNNQLSGLNFSLPSSDVTNNLKPSLHPQMNLLALENTEIPPFAQRTSQNLTSSHAYDNFLEHSNSVFLQPVSLQTIAAAPSNQSLPPLPSNHPAMTKSDLQPPNYYEVMEFDPLAPAVTTEAIYEEIDAHQHKGAQNDGD>sp|O75674-2|TM1L1_HUMAN Isoform 2 of TOM1-like protein 1 OS=Homo sapiensOX=9606 GN=TOM1L1MAFGKSHRDPYATSVGHLIEKATFAGVQTEDWGQFMHICDIINTTQDGPKDAVKALKKRISKNYNHKEIQLTLSLIDMCVQNCGPSFQSLIVKKEFVKENLVKLLNPRYNLPLDIQNRILNFIKTWSQGFPGGVDVSEVKEVYLDLVKKGVQFPPSEAEAETARQETAQISSNPPTSVPTAPALSSVIAPKNSTVTLVPEQIGKLHSELDMVKMNVRVMSAILMENTPGSENHEDIELLQKLYKTGREMQERIMDLLVVVENEDVTVELIQVNEDLNNAILGYERFTRNQQRILEQNKNQKEATNTTSEPSAPSQDLLDLSPSPRMPRATLGELNTMNNQLSGLSK>sp|O75674-3|TM1L1_HUMAN Isoform 3 of TOM1-like protein 1 OS=Homo sapiensOX=9606 GN=TOM1L1MCVQNCGPSFQSLIVKKEFVKENLVKLLNPRYNLPLDIQNRILNFIKTWSQGFPGGVDVSEVKEVYLDLVKKGVQFPPSEAEAETARQETAQISSNPPTSVPTAPALSSVIAPKNSTVTLVPEQIGKLHSELDMVKMNVRVMSAILMENTPGSENHEDIELLQKLYKTGREMQERIMDLLVVVENEDVTVELIQVNEDLNNAILGYERFTRNQQRILEQNKNQKEATNTTSEPSAPSQDLLDLSPSPRMPRATLGELNTMNNQLSGLNFSLPSSDVTNNLKPSLHPQMNLLALENTEIPPFAQRTSQNLTSSHAYDNFLEHSNSVFLQPVSLQTIAAAPSNQSLPPLPSNHPAMTKSDLQPPNYYEVMEFDPLAPAVTTEAIYEEIDAHQHKGAQNDGD>sp|Q6ZUK4|TMM26_HUMAN Transmembrane protein 26 OS=Homo sapiens OX=9606GN=TMEM26 PE=1 SV=1MEGLVFLNALATRLLFLLHSLVGVWRVTEVKKEPRYWLLALLNLLLFLETALTLKFKRGRGYKWFSPAIFLYLISIVPSLWLLELHHETQYCSIQAEGTSQNTSRKEDFNQTLTSNEQTSRADDLIETAKVFVNNLSTVCEKVWTLGLHQTFLLMLIIGRWLLPIGGGITRDQLSQLLLMFVGTAADILEFTSETLEEQNVRNSPALVYAILVIWTWSMLQFPLDLAVQNVVCPVSVTERGFPSLFFCQYSADLWNIGISVFIQDGPFLVVRLILMTYFKVINQMLVFFAAKNFLVVVLQLYRLVVLALAVRASLRSQSEGLKGEHGCRAQTSESGPSQRDWQNESKEGLAIPLRGSPVTSDDSHHTP>sp|Q6ZUK4-2|TMM26_HUMAN Isoform 2 of Transmembrane protein 26 OS=Homosapiens OX=9606 GN=TMEM26MEGLVFLNALATRLLFLLHSLVGVWRVTEVKKEPRYWLLALLNLLLFLETALTLKFKRGRGYKWFSPAIFLYLISIVPSLWLLELHHETQYCSIQAEGTSQNTSRKEDFNQTLTSNEQTSRADDLIETAKVFVNNLSTVCEKVWTLGLHQTFLLMLIIGRWLLPIGGGITRDQLSQLLLMFVGTAADILEFTSETLEEQNVRLCWKNSTNRRHTNPKWQLVLF>sp|P03979|TRGV3_HUMAN T cell receptor gamma variable 3 OS=Homo sapiensOX=9606 GN=TRGV3 PE=1 SV=2MRWALLVLLAFLSPASQKSSNLEGRTKSVTRQTGSSAEITCDLTVTNTFYIHWYLHQEGKAPQRLLYYDVSTARDVLESGLSPGKYYTHTPRRWSWILRLQNLIENDSGVYYCATWDR>sp|P01033|TIMP1_HUMAN Metalloproteinase inhibitor 1 OS=Homo sapiensOX=9606 GN=TIMP1 PE=1 SV=1MAPFEPLASGILLLLWLIAPSRACTCVPPHPQTAFCNSDLVIRAKFVGTPEVNQTTLYQRYEIKMTKMYKGFQALGDAADIRFVYTPAMESVCGYFHRSHNRSEEFLIAGKLQDGLLHITTCSFVAPWNSLSLAQRRGFTKTYTVGCEECTVFPCLSIPCKLQSGTHCLWTDQLLQGSEKGFQSRHLACLPREPGLCTWQSLRSQIA>sp|P35625|TIMP3_HUMAN Metalloproteinase inhibitor 3 OS=Homo sapiensOX=9606 GN=TIMP3 PE=1 SV=2MTPWLGLIVLLGSWSLGDWGAEACTCSPSHPQDAFCNSDIVIRAKVVGKKLVKEGPFGTLVYTIKQMKMYRGFTKMPHVQYIHTEASESLCGLKLEVNKYQYLLTGRVYDGKMYTGLCNFVERWDQLTLSQRKGLNYRYHLGCNCKIKSCYYLPCFVTSKNECLWTDMLSNFGYPGYQSKHYACIRQKGGYCSWYRGWAPPDKSIINATDP>sp|Q8NHM4|TRY6_HUMAN Putative trypsin-6 OS=Homo sapiens OX=9606GN=PRSS3P2 PE=5 SV=2MNPLLILAFVGAAVAVPFDDDDKIVGGYTCEENSVPYQVSLNSGSHFCGGSLISEQWVVSAGHCYKPHIQVRLGEHNIEVLEGNEQFINAAKIIRHPKYNRIILNNDIMLIKLSTPAVINAHVSTISLPTAPPAAGTECLISGWGNTLSSGADYPDELQCLDAPVLTQAKCKASYPLKITSNMFCVGFLEGGKDSCQGDSGGPVVCNGQLQGIVSWGYGCAQKRRPGVYTKVYNYVDWIKDTIAANS>sp|Q6NXR4|TTI2_HUMAN TELO2-interacting protein 2 OS=Homo sapiens OX=9606GN=TTI2 PE=1 SV=1MELDSALEAPSQEDSNLSEELSHSAFGQAFSKILHCLARPEARRGNVKDAVLKDLGDLIEATEFDRLFEGTGARLRGMPETLGQVAKALEKYAAPSKEEEGGGDGHSEAAEKAAQVGLLFLKLLGKVETAKNSLVGPAWQTGLHHLAGPVYIFAITHSLEQPWTTPRSREVAREVLTSLLQVTECGSVAGFLHGENEDEKGRLSVILGLLKPDLYKESWKNNPAIKHVFSWTLQQVTRPWLSQHLERVLPASLVISDDYQTENKILGVHCLHHIVLNVPAADLLQYNRAQVLYHAISNHLYTPEHHLIQAVLLCLLDLFPILEKTLHWKGDGARPTTHCDEVLRLILTHMEPEHRLLLRRTYARNLPAFVNRLGILTVRHLKRLERVIIGYLEVYDGPEEEARLKILETLKLLMQHTWPRVSCRLVVLLKALLKLICDVARDPNLTPESVKSALLQEATDCLILLDRCSQGRVKGLLAKIPQSCEDRKVVNYIRKVQQVSEGAPYNGT>sp|P35442|TSP2_HUMAN Thrombospondin-2 OS=Homo sapiens OX=9606 GN=THBS2PE=1 SV=2MVWRLVLLALWVWPSTQAGHQDKDTTFDLFSISNINRKTIGAKQFRGPDPGVPAYRFVRFDYIPPVNADDLSKITKIMRQKEGFFLTAQLKQDGKSRGTLLALEGPGLSQRQFEIVSNGPADTLDLTYWIDGTRHVVSLEDVGLADSQWKNVTVQVAGETYSLHVGCDLIDSFALDEPFYEHLQAEKSRMYVAKGSARESHFRGLLQNVHLVFENSVEDILSKKGCQQGQGAEINAISENTETLRLGPHVTTEYVGPSSERRPEVCERSCEELGNMVQELSGLHVLVNQLSENLKRVSNDNQFLWELIGGPPKTRNMSACWQDGRFFAENETWVVDSCTTCTCKKFKTICHQITCPPATCASPSFVEGECCPSCLHSVDGEEGWSPWAEWTQCSVTCGSGTQQRGRSCDVTSNTCLGPSIQTRACSLSKCDTRIRQDGGWSHWSPWSSCSVTCGVGNITRIRLCNSPVPQMGGKNCKGSGRETKACQGAPCPIDGRWSPWSPWSACTVTCAGGIRERTRVCNSPEPQYGGKACVGDVQERQMCNKRSCPVDGCLSNPCFPGAQCSSFPDGSWSCGSCPVGFLGNGTHCEDLDECALVPDICFSTSKVPRCVNTQPGFHCLPCPPRYRGNQPVGVGLEAAKTEKQVCEPENPCKDKTHNCHKHAECIYLGHFSDPMYKCECQTGYAGDGLICGEDSDLDGWPNLNLVCATNATYHCIKDNCPHLPNSGQEDFDKDGIGDACDDDDDNDGVTDEKDNCQLLFNPRQADYDKDEVGDRCDNCPYVHNPAQIDTDNNGEGDACSVDIDGDDVFNERDNCPYVYNTDQRDTDGDGVGDHCDNCPLVHNPDQTDVDNDLVGDQCDNNEDIDDDGHQNNQDNCPYISNANQADHDRDGQGDACDPDDDNDGVPDDRDNCRLVFNPDQEDLDGDGRGDICKDDFDNDNIPDIDDVCPENNAISETDFRNFQMVPLDPKGTTQIDPNWVIRHQGKELVQTANSDPGIAVGFDEFGSVDFSGTFYVNTDRDDDYAGFVFGYQSSSRFYVVMWKQVTQTYWEDQPTRAYGYSGVSLKVVNSTTGTGEHLRNALWHTGNTPGQVRTLWHDPRNIGWKDYTAYRWHLTHRPKTGYIRVLVHEGKQVMADSGPIYDQTYAGGRLGLFVFSQEMVYFSDLKYECRDI>sp|Q9UKR8|TSN16_HUMAN Tetraspanin-16 OS=Homo sapiens OX=9606 GN=TSPAN16PE=2 SV=1MAEIHTPYSSLKKLLSLLNGFVAVSGIILVGLGIGGKCGGASLTNVLGLSSAYLLHVGNLCLVMGCITVLLGCAGWYGATKESRGTLLFCILSMVIVLIMEVTAATVVLLFFPIVGDVALEHTFVTLRKNYRGYNEPDDYSTQWNLVMEKLKCCGVNNYTDFSGSSFEMTTGHTYPRSCCKSIGSVSCDGRDVSPNVIHQKGCFHKLLKITKTQSFTLSGSSLGAAVIQRWGSRYVAQAGLELLA>sp|Q9UKR8-2|TSN16_HUMAN Isoform 2 of Tetraspanin-16 OS=Homo sapiensOX=9606 GN=TSPAN16MAEIHTPYSSLKKLLSLLNGFVAVSGIILVGLGIGGKCGGASLTNVLGLSSAYLLHVGNLCLVMGCITVLLGCAGWYGATKESRGTLLFCILSMVIVLIMEVTAATVVLLFFPIVGDVALEHTFVTLRKNYRGYNEPDDYSTQWNLVMEKLKCCGVNNYTDFSGSSFEMTTGHTYPRSCCKSIGSVSCDGRDVSPNVIHQKGCFHKLLKITKTQSFTLSGSSLGAAVIQLPGILATLLLFIKLG>sp|Q9UKR8-3|TSN16_HUMAN Isoform 3 of Tetraspanin-16 OS=Homo sapiensOX=9606 GN=TSPAN16MAEIHTPYSSLKKLLSLLNGFVAVSGIILVGLGIGGKCGGASLTNVLGLSSAYLLHVGNLCLVMGCITVLLGCAGWYGATKESRGTLLFVGDVALEHTFVTLRKNYRGYNEPDDYSTQWNLVMEKLKCCGVNNYTDFSGSSFEMTTGHTYPRSCCKSIGSVSCDGRDVSPNVIHQKGCFHKLLKITKTQSFTLSGSSLGAAVIQLPGILATLLLFIKLG>sp|Q9UKR8-4|TSN16_HUMAN Isoform 4 of Tetraspanin-16 OS=Homo sapiensOX=9606 GN=TSPAN16MAEIHTPYSSLKKLLSLLNGFVAVSGIILVGLGIGGKCGGASLTNVLGLSSAYLLHVGNLCLVMGCITVLLGCAGWYGATKESRGTLLFCILSMVIVLIMEVTAATVVLLFFPIVGDVALEHTFVTLRKNYRGYNEPDDYSTQWNLVMEKGLSKYFFSSL>sp|Q8NBS9|TXND5_HUMAN Thioredoxin domain-containing protein 5 OS=Homosapiens OX=9606 GN=TXNDC5 PE=1 SV=2MPARPGRLLPLLARPAALTALLLLLLGHGGGGRWGARAQEAAAAAADGPPAADGEDGQDPHSKHLYTADMFTHGIQSAAHFVMFFAPWCGHCQRLQPTWNDLGDKYNSMEDAKVYVAKVDCTAHSDVCSAQGVRGYPTLKLFKPGQEAVKYQGPRDFQTLENWMLQTLNEEPVTPEPEVEPPSAPELKQGLYELSASNFELHVAQGDHFIKFFAPWCGHCKALAPTWEQLALGLEHSETVKIGKVDCTQHYELCSGNQVRGYPTLLWFRDGKKVDQYKGKRDLESLREYVESQLQRTETGATETVTPSEAPVLAAEPEADKGTVLALTENNFDDTIAEGITFIKFYAPWCGHCKTLAPTWEELSKKEFPGLAGVKIAEVDCTAERNICSKYSVRGYPTLLLFRGGKKVSEHSGGRDLDSLHRFVLSQAKDEL>sp|Q8NBS9-2|TXND5_HUMAN Isoform 2 of Thioredoxin domain-containingprotein 5 OS=Homo sapiens OX=9606 GN=TXNDC5MEDAKVYVAKVDCTAHSDVCSAQGVRGYPTLKLFKPGQEAVKYQGPRDFQTLENWMLQTLNEEPVTPEPEVEPPSAPELKQGLYELSASNFELHVAQGDHFIKFFAPWCGHCKALAPTWEQLALGLEHSETVKIGKVDCTQHYELCSGNQVRGYPTLLWFRDGKKVDQYKGKRDLESLREYVESQLQRTETGATETVTPSEAPVLAAEPEADKGTVLALTENNFDDTIAEGITFIKFYAPWCGHCKTLAPTWEELSKKEFPGLAGVKIAEVDCTAERNICSKYSVRGYPTLLLFRGGKKVSEHSGGRDLDSLHRFVLSQAKDEL>sp|Q6NUS8|UD3A1_HUMAN UDP-glucuronosyltransferase 3A1 OS=Homo sapiensOX=9606 GN=UGT3A1 PE=2 SV=1MVGQRVLLLVAFLLSGVLLSEAAKILTISTLGGSHYLLLDRVSQILQEHGHNVTMLHQSGKFLIPDIKEEEKSYQVIRWFSPEDHQKRIKKHFDSYIETALDGRKESEALVKLMEIFGTQCSYLLSRKDIMDSLKNENYDLVFVEAFDFCSFLIAEKLVKPFVAILPTTFGSLDFGLPSPLSYVPVFPSLLTDHMDFWGRVKNFLMFFSFSRSQWDMQSTFDNTIKEHFPEGSRPVLSHLLLKAELWFVNSDFAFDFARPLLPNTVYIGGLMEKPIKPVPQDLDNFIANFGDAGFVLVAFGSMLNTHQSQEVLKKMHNAFAHLPQGVIWTCQSSHWPRDVHLATNVKIVDWLPQSDLLAHPSIRLFVTHGGQNSVMEAIRHGVPMVGLPVNGDQHGNMVRVVAKNYGVSIRLNQVTADTLTLTMKQVIEDKRYKSAVVAASVILHSQPLSPAQRLVGWIDHILQTGGATHLKPYAFQQPWHEQYLIDVFVFLLGLTLGTMWLCGKLLGVVARWLRGARKVKKT>sp|Q6NUS8-2|UD3A1_HUMAN Isoform 2 of UDP-glucuronosyltransferase 3A1OS=Homo sapiens OX=9606 GN=UGT3A1MLHQSGKFLIPDIKEEEKSYQVIRWFSPEDHQKRIKKHFDSYIETALDGRKESEALVKLMEIFGTQCSYLLSRKDIMDSLKNENYDLVFVEAFDFCSFLIAEKLVKPFVAILPTTFGSLDFGLPSPLSYVPVFPSLLTDHMDFWGRVKNFLMFFSFSRSQWDMQSTFDNTIKEHFPEGSRPVLSHLLLKAELWFVNSDFAFDFARPLLPNTVYIGGLMEKPIKPVPQNGQPALFTTPSLFSSGVYPEPLRWL>sp|Q9NYU2|UGGG1_HUMAN UDP-glucose:glycoprotein glucosyltransferase 1OS=Homo sapiens OX=9606 GN=UGGT1 PE=1 SV=3MGCKGDASGACAAGALPVTGVCYKMGVLVVLTVLWLFSSVKADSKAITTSLTTKWFSTPLLLEASEFLAEDSQEKFWNFVEASQNIGSSDHDGTDYSYYHAILEAAFQFLSPLQQNLFKFCLSLRSYSATIQAFQQIAADEPPPEGCNSFFSVHGKKTCESDTLEALLLTASERPKPLLFKGDHRYPSSNPESPVVIFYSEIGSEEFSNFHRQLISKSNAGKINYVFRHYIFNPRKEPVYLSGYGVELAIKSTEYKAKDDTQVKGTEVNTTVIGENDPIDEVQGFLFGKLRDLHPDLEGQLKELRKHLVESTNEMAPLKVWQLQDLSFQTAARILASPVELALVVMKDLSQNFPTKARAITKTAVSSELRTEVEENQKYFKGTLGLQPGDSALFINGLHMDLDTQDIFSLFDVLRNEARVMEGLHRLGIEGLSLHNVLKLNIQPSEADYAVDIRSPAISWVNNLEVDSRYNSWPSSLQELLRPTFPGVIRQIRKNLHNMVFIVDPAHETTAELMNTAEMFLSNHIPLRIGFIFVVNDSEDVDGMQDAGVAVLRAYNYVAQEVDDYHAFQTLTHIYNKVRTGEKVKVEHVVSVLEKKYPYVEVNSILGIDSAYDRNRKEARGYYEQTGVGPLPVVLFNGMPFEREQLDPDELETITMHKILETTTFFQRAVYLGELPHDQDVVEYIMNQPNVVPRINSRILTAERDYLDLTASNNFFVDDYARFTILDSQGKTAAVANSMNYLTKKGMSSKEIYDDSFIRPVTFWIVGDFDSPSGRQLLYDAIKHQKSSNNVRISMINNPAKEISYENTQISRAIWAALQTQTSNAAKNFITKMAKEGAAEALAAGADIAEFSVGGMDFSLFKEVFESSKMDFILSHAVYCRDVLKLKKGQRAVISNGRIIGPLEDSELFNQDDFHLLENIILKTSGQKIKSHIQQLRVEEDVASDLVMKVDALLSAQPKGDPRIEYQFFEDRHSAIKLRPKEGETYFDVVAVVDPVTREAQRLAPLLLVLAQLINMNLRVFMNCQSKLSDMPLKSFYRYVLEPEISFTSDNSFAKGPIAKFLDMPQSPLFTLNLNTPESWMVESVRTPYDLDNIYLEEVDSVVAAEYELEYLLLEGHCYDITTGQPPRGLQFTLGTSANPVIVDTIVMANLGYFQLKANPGAWILRLRKGRSEDIYRIYSHDGTDSPPDADEVVIVLNNFKSKIIKVKVQKKADMVNEDLLSDGTSENESGFWDSFKWGFTGQKTEEVKQDKDDIINIFSVASGHLYERFLRIMMLSVLKNTKTPVKFWFLKNYLSPTFKEFIPYMANEYNFQYELVQYKWPRWLHQQTEKQRIIWGYKILFLDVLFPLVVDKFLFVDADQIVRTDLKELRDFNLDGAPYGYTPFCDSRREMDGYRFWKSGYWASHLAGRKYHISALYVVDLKKFRKIAAGDRLRGQYQGLSQDPNSLSNLDQDLPNNMIHQVPIKSLPQEWLWCETWCDDASKKRAKTIDLCNNPMTKEPKLEAAVRIVPEWQDYDQEIKQLQIRFQKEKETGALYKEKTKEPSREGPQKREEL>sp|Q9NYU2-2|UGGG1_HUMAN Isoform 2 of UDP-glucose:glycoproteinglucosyltransferase 1 OS=Homo sapiens OX=9606 GN=UGGT1MGVLVVLTVLWLFSSVKADSKAITTSLTTKWFSTPLLLEASEFLAEDSQEKFWNFVEASQNIGSSDHDGTDYSYYHAILEAAFQFLSPLQQNLFKFCLSLRSYSATIQAFQQIAADEPPPEGCNSFFSVHGKKTCESDTLEALLLTASERPKPLLFKGDHRYPSSNPESPVVIFYSEIGSEEFSNFHRQLISKSNAGKINYVFRHYIFNPRKEPVYLSGYGVELAIKSTEYKAKDDTQVKGTEVNTTVIGENDPIDEVQGFLFGKLRDLHPDLEGQLKELRKHLVESTNEMAPLKVWQLQDLSFQTAARILASPVELALVVMKDLSQNFPTKARAITKTAVSSELRTEVEENQKYFKGTLGLQPGDSALFINGLHMDLDTQDIFSLFDVLRNEARVMEGLHRLGIEGLSLHNVLKLNIQPSEADYAVDIRSPAISWVNNLEVDSRYNSWPSSLQELLRPTFPGVIRQIRKNLHNMVFIVDPAHETTAELMNTAEMFLSNHIPLRIGFIFVVNDSEDVDGMQDAGVAVLRAYNYVAQEVDDYHAFQTLTHIYNKVRTGEKVKVEHVVSVLEKKYPYVEVNSILGIDSAYDRNRKEARGYYEQTGVGPLPVVLFNGMPFEREQLDPDELETITMHKILETTTFFQRAVYLGELPHDQDVVEYIMNQPNVVPRINSRILTAERDYLDLTASNNFFVDDYARFTILDSQGKTAAVANSMNYLTKKGMSSKEIYDDSFIRPVTFWIVGDFDSPSGRQLLYDAIKHQKSSNNVRISMINNPAKEISYENTQISRAIWAALQTQTSNAAKNFITKMAKEGAAEALAAGADIAEFSVGGMDFSLFKEVFESSKMDFILSHAVYCRDVLKLKKGQRAVISNGRIIGPLEDSELFNQDDFHLLENIILKTSGQKIKSHIQQLRVEEDVASDLVMKVDALLSAQPKGDPRIEYQFFEDRHSAIKLRPKEGETYFDVVAVVDPVTREAQRLAPLLLVLAQLINMNLRVFMNCQSKLSDMPLKSFYRYVLEPEISFTSDNSFAKGPIAKFLDMPQSPLFTLNLNTPESWMVESVRTPYDLDNIYLEEVDSVVAAEYELEYLLLEGHCYDITTGQPPRGLQFTLGTSANPVIVDTIVMANLGYFQLKANPGAWILRLRKGRSEDIYRIYSHDGTDSPPDADEVVIVLNNFKSKIIKVKVQKKADMVNEDLLSDGTSENESGFWDSFKWGFTGQKTEEVKQDKDDIINIFSVASGHLYERFLRIMMLSVLKNTKTPVKFWFLKNYLSPTFKEFIPYMANEYNFQYELVQYKWPRWLHQQTEKQRIIWGYKILFLDVLFPLVVDKFLFVDADQIVRTDLKELRDFNLDGAPYGYTPFCDSRREMDGYRFWKSGYWASHLAGRKYHISALYVVDLKKFRKIAAGDRLRGQYQGLSQDPNSLSNLDQDLPNNMIHQVPIKSLPQEWLWCETWCDDASKKRAKTIDLCNNPMTKEPKLEAAVRIVPEWQDYDQEIKQLQIRFQKEKETGALYKEKTKEPSREGPQKREEL>sp|P16662|UD2B7_HUMAN UDP-glucuronosyltransferase 2B7 OS=Homo sapiensOX=9606 GN=UGT2B7 PE=1 SV=2MSVKWTSVILLIQLSFCFSSGNCGKVLVWAAEYSHWMNIKTILDELIQRGHEVTVLASSASILFDPNNSSALKIEIYPTSLTKTELENFIMQQIKRWSDLPKDTFWLYFSQVQEIMSIFGDITRKFCKDVVSNKKFMKKVQESRFDVIFADAIFPCSELLAELFNIPFVYSLSFSPGYTFEKHSGGFIFPPSYVPVVMSELTDQMTFMERVKNMIYVLYFDFWFEIFDMKKWDQFYSEVLGRPTTLSETMGKADVWLIRNSWNFQFPYPLLPNVDFVGGLHCKPAKPLPKEMEDFVQSSGENGVVVFSLGSMVSNMTEERANVIASALAQIPQKVLWRFDGNKPDTLGLNTRLYKWIPQNDLLGHPKTRAFITHGGANGIYEAIYHGIPMVGIPLFADQPDNIAHMKARGAAVRVDFNTMSSTDLLNALKRVINDPSYKENVMKLSRIQHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHDLTWFQYHSLDVIGFLLVCVATVIFIVTKCCLFCFWKFARKAKKGKND>sp|Q9GZL7|WDR12_HUMAN Ribosome biogenesis protein WDR12 OS=Homo sapiensOX=9606 GN=WDR12 PE=1 SV=2MAQLQTRFYTDNKKYAVDDVPFSIPAASEIADLSNIINKLLKDKNEFHKHVEFDFLIKGQFLRMPLDKHMEMENISSEEVVEIEYVEKYTAPQPEQCMFHDDWISSIKGAEEWILTGSYDKTSRIWSLEGKSIMTIVGHTDVVKDVAWVKKDSLSCLLLSASMDQTILLWEWNVERNKVKALHCCRGHAGSVDSIAVDGSGTKFCSGSWDKMLKIWSTVPTDEEDEMEESTNRPRKKQKTEQLGLTRTPIVTLSGHMEAVSSVLWSDAEEICSASWDHTIRVWDVESGSLKSTLTGNKVFNCISYSPLCKRLASGSTDRHIRLWDPRTKDGSLVSLSLTSHTGWVTSVKWSPTHEQQLISGSLDNIVKLWDTRSCKAPLYDLAAHEDKVLSVDWTDTGLLLSGGADNKLYSYRYSPTTSHVGA>sp|Q969T9|WBP2_HUMAN WW domain-binding protein 2 OS=Homo sapiens OX=9606GN=WBP2 PE=1 SV=1MALNKNHSEGGGVIVNNTESILMSYDHVELTFNDMKNVPEAFKGTKKGTVYLTPYRVIFLSKGKDAMQSFMMPFYLMKDCEIKQPVFGANYIKGTVKAEAGGGWEGSASYKLTFTAGGAIEFGQRMLQVASQASRGEVPSGAYGYSYMPSGAYVYPPPVANGMYPCPPGYPYPPPPPEFYPGPPMMDGAMGYVQPPPPPYPGPMEPPVSGPDVPSTPAAEAKAAEAAASAYYNPGNPHNVYMPTSQPPPPPYYPPEDKKTQ>sp|Q969T9-2|WBP2_HUMAN Isoform 2 of WW domain-binding protein 2 OS=Homosapiens OX=9606 GN=WBP2MALNKNHSEGGGVIVNNTESILMSYDHVELTFNDMKNVPEAFKGTKKGTVYLTPYRVIFLSKGKDAMQSFMMPFYLMKDCEIKQPVFGANYIKGTVKAEAGGGWEGSASYKLTFTAGGAIEFGQRMLQVASQEFYPGPPMMDGAMGYVQPPPPPYPGPMEPPVSGPDVPSTPAAEAKAAEAAASAYYNPGNPHNVYMPTSQPPPPPYYPPEDKKTQ>sp|P0C879|YJ018_HUMAN Putative uncharacterized protein FLJ43185 OS=Homosapiens OX=9606 PE=5 SV=1MYNPWQVGASLAPARAGPRPFPTPRARPPDCSGGHAPSGFPALGLRTAQRPRPFSSSPRSASGRLRGPRPVARGPAHSSSPTGLPAYLPPAAALDSQTSAPTVSPVTRPRVVARGKTPRVSLAGLETLSSLLHQQQLFD>sp|A1YPR0|ZBT7C_HUMAN Zinc finger and BTB domain-containing protein 7COS=Homo sapiens OX=9606 GN=ZBTB7C PE=2 SV=1MANDIDELIGIPFPNHSSEVLCSLNEQRHDGLLCDVLLVVQEQEYRTHRSVLAACSKYFKKLFTAGTLASQPYVYEIDFVQPEALAAILEFAYTSTLTITAGNVKHILNAARMLEIQCIVNVCLEIMEPGGDGGEEDDKEDDDDDEDDDDEEDEEEEEEEEEDDDDDTEDFADQENLPDPQDISCHQSPSKTDHLTEKAYSDTPRDFPDSFQAGSPGHLGVIRDFSIESLLRENLYPKANIPDRRPSLSPFAPDFFPHLWPGDFGAFAQLPEQPMDSGPLDLVIKNRKIKEEEKEELPPPPPPPFPNDFFKDMFPDLPGGPLGPIKAENDYGAYLNFLSATHLGGLFPPWPLVEERKLKPKASQQCPICHKVIMGAGKLPRHMRTHTGEKPYMCTICEVRFTRQDKLKIHMRKHTGERPYLCIHCNAKFVHNYDLKNHMRIHTGVRPYQCEFCYKSFTRSDHLHRHIKRQSCRMARPRRGRKPAAWRAASLLFGPGGPAPDKAAFVMPPALGEVGGHLGGAAVCLPGPSPAKHFLAAPKGALSLQELERQFEETQMKLFGRAQLEAERNAGGLLAFALAENVAAARPYFPLPDPWAAGLAGLPGLAGLNHVASMSEANN>sp|Q5HYM0|ZC12B_HUMAN Probable ribonuclease ZC3H12B OS=Homo sapiensOX=9606 GN=ZC3H12B PE=1 SV=3MTATAEVETPKMEKSASKEEKQQPKQDSTEQGNADSEEWMSSESDPEQISLKSSDNSKSCQPRDGQLKKKEMHSKPHRQLCRSPCLDRPSFSQSSILQDGKLDLEKEYQAKMEFALKLGYAEEQIQSVLNKLGPESLINDVLAELVRLGNKGDSEGQINLSLLVPRGPSSREIASPELSLEDEIDNSDNLRPVVIDGSNVAMSHGNKEEFSCRGIQLAVDWFLDKGHKDITVFVPAWRKEQSRPDAPITDQDILRKLEKEKILVFTPSRRVQGRRVVCYDDRFIVKLAFDSDGIIVSNDNYRDLQVEKPEWKKFIEERLLMYSFVNDKFMPPDDPLGRHGPSLENFLRKRPIVPEHKKQPCPYGKKCTYGHKCKYYHPERANQPQRSVADELRISAKLSTVKTMSEGTLAKCGTGMSSAKGEITSEVKRVAPKRQSDPSIRSVAMEPEEWLSIARKPEASSVPSLVTALSVPTIPPPKSHAVGALNTRSASSPVPGSSHFPHQKASLEHMASMQYPPILVTNSHGTPISYAEQYPKFESMGDHGYYSMLGDFSKLNINSMHNREYYMAEVDRGVYARNPNLCSDSRVSHTRNDNYSSYNNVYLAVADTHPEGNLKLHRSASQNRLQPFPHGYHEALTRVQSYGPEDSKQGPHKQSVPHLALHAQHPSTGTRSSCPADYPMPPNIHPGATPQPGRALVMTRMDSISDSRLYESNPVRQRRPPLCREQHASWDPLPCTTDSYGYHSYPLSNSLMQPCYEPVMVRSVPEKMEQLWRNPWVGMCNDSREHMIPEHQYQTYKNLCNIFPSNIVLAVMEKNPHTADAQQLAALIVAKLRAAR>sp|Q5HYM0-2|ZC12B_HUMAN Isoform 2 of Probable ribonuclease ZC3H12BOS=Homo sapiens OX=9606 GN=ZC3H12BMTATAEVETPKMEKSASKEEKQQPKQDSTEQGNADSEEWMSSESDPEQISLKSSDNSKSCQPRDGQLKKKEMHSKPHRQLCRSPCLDRPSFSQNHLLMMYWQSLSDLGTKVIQKGSSREIASPELSLEDEIDNSDNLRPVVIDGSNVAMSHGNKEEFSCRGIQLAVDWFLDKGHKDITVFVPAWRKEQSRPDAPITDQDILRKLEKEKILVFTPSRRVQGRRVVCYDDRFIVKLAFDSDGIIVSNDNYRDLQVEKPEWKKFIEERLLMYSFVNDKFMPPDDPLGRHGPSLENFLRKRPIVPEHKKQPCPYGKKCTYGHKCKYYHPERANQPQRSVADELRISAKLSTVKTMSEGTLAKCGTGMSSAKGEITSEVKRVAPKRQSDPSIRSVAMEPEEWLSIARKPEASSVPSLVTALSVPTIPPPKSHAVGALNTRSASSPVPGSSHFPHQKASLEHMASMQYPPILVTNSHGTPISYAEQYPKFESMGDHGYYSMLGDFSKLNINSMHNREYYMAEVDRGVYARNPNLCSDSRVSHTRNDNYSSYNNVYLAVADTHPEGNLKLHRSASQNRLQPFPHGYHEALTRVQSYGPEDSKQGPHKQSVPHLALHAQHPSTGTRSSCPADYPMPPNIHPGATPQPGRALVMTRMDSISDSRLYESNPVRQRRPPLCREQHASWDPLPCTTDSYGYHSYPLSNSLMQPCYEPVMVRSVPEKMEQLWRNPWVGMCNDSREHMIPEHQYQTYKNLCNIFPSNIVLAVMEKNPHTADAQQLAALIVAKLRAAR>sp|Q8N0Y2|ZN444_HUMAN Zinc finger protein 444 OS=Homo sapiens OX=9606GN=ZNF444 PE=1 SV=1MEVAVPVKQEAEGLALDSPWHRFRRFHLGDAPGPREALGLLRALCRDWLRPEVHTKEQMLELLVLEQFLSALPADTQAWVCSRQPQSGEEAVALLEELWGPAASPDGSSATRVPQDVTQGPGATGGKEDSGMIPLAGTAPGAEGPAPGDSQAVRPYKQEPSSPPLAPGLPAFLAAPGTTSCPECGKTSLKPAHLLRHRQSHSGEKPHACPECGKAFRRKEHLRRHRDTHPGSPGSPGPALRPLPAREKPHACCECGKTFYWREHLVRHRKTHSGARPFACWECGKGFGRREHVLRHQRIHGRAAASAQGAVAPGPDGGGPFPPWPLG>sp|Q8N0Y2-2|ZN444_HUMAN Isoform 2 of Zinc finger protein 444 OS=Homosapiens OX=9606 GN=ZNF444MEVAVPVKQEAEGLALDSPWHRFRRFHLGDAPGPREALGLLRALCRDWLRPEVHTKEQMLELLVLEQFLSALPADTQAWVCSRQPQSGEEAVALLEELWGPAASPDGSSATRVPQDVTQGPGATGGKEDSGMIPLGTAPGAEGPAPGDSQAVRPYKQEPSSPPLAPGLPAFLAAPGTTSCPECGKTSLKPAHLLRHRQSHSGEKPHACPECGKAFRRKEHLRRHRDTHPGSPGSPGPALRPLPAREKPHACCECGKTFYWREHLVRHRKTHSGARPFACWECGKGFGRREHVLRHQRIHGRAAASAQGAVAPGPDGGGPFPPWPLG>sp|P17030|ZNF25_HUMAN Zinc finger protein 25 OS=Homo sapiens OX=9606GN=ZNF25 PE=1 SV=2MNKFQGPVTLKDVIVEFTKEEWKLLTPAQRTLYKDVMLENYSHLVSVGYHVNKPNAVFKLKQGKEPWILEVEFPHRGFPEDLWSIHDLEARYQESQAGNSRNGELTKHQKTHTTEKACECKECGKFFCQKSALIVHQHTHSKGKSYDCDKCGKSFSKNEDLIRHQKIHTRDKTYECKECKKIFYHLSSLSRHLRTHAGEKPYECNQCEKSFYQKPHLTEHQKTHTGEKPFECTECGKFFYVKAYLMVHQKTHTGEKPYECKECGKAFSQKSHLTVHQRMHTGEKPYKCKECGKFFSRNSHLKTHQRSHTGEKPYECKECRKCFYQKSALTVHQRTHTGEKPFECNKCGKTFYYKSDLTKHQRKHTGEKPYECTECGKSFAVNSVLRLHQRTHTGEKPYACKECGKSFSQKSHFIIHQRKHTGEKPYECQECGETFIQKSQLTAHQKTHTKKRNAEK>sp|P17030-2|ZNF25_HUMAN Isoform 2 of Zinc finger protein 25 OS=Homosapiens OX=9606 GN=ZNF25MWNFLSRNGELTKHQKTHTTEKACECKECGKFFCQKSALIVHQHTHSKGKSYDCDKCGKSFSKNEDLIRHQKIHTRDKTYECKECKKIFYHLSSLSRHLRTHAGEKPYECNQCEKSFYQKPHLTEHQKTHTGEKPFECTECGKFFYVKAYLMVHQKTHTGEKPYECKECGKAFSQKSHLTVHQRMHTGEKPYKCKECGKFFSRNSHLKTHQRSHTGEKPYECKECRKCFYQKSALTVHQRTHTGEKPFECNKCGKTFYYKSDLTKHQRKHTGEKPYECTECGKSFAVNSVLRLHQRTHTGEKPYACKECGKSFSQKSHFIIHQRKHTGEKPYECQECGETFIQKSQLTAHQKTHTKKRNAEK>sp|Q8IUH4|ZDH13_HUMAN Palmitoyltransferase ZDHHC13 OS=Homo sapiensOX=9606 GN=ZDHHC13 PE=1 SV=3MEGPGLGSQCRNHSHGPHPPGFGRYGICAHENKELANAREALPLIEDSSNCDIVKATQYGIFERCKELVEAGYDVRQPDKENVSLLHWAAINNRLDLVKFYISKGAVVDQLGGDLNSTPLHWAIRQGHLPMVILLLQHGADPTLIDGEGFSSIHLAVLFQHMPIIAYLISKGQSVNMTDVNGQTPLMLSAHKVIGPEPTGFLLKFNPSLNVVDKIHQNTPLHWAVAAGNVNAVDKLLEAGSSLDIQNVKGETPLDMALQNKNQLIIHMLKTEAKMRANQKFRLWRWLQKCELFLLLMLSVITMWAIGYILDFNSDSWLLKGCLLVTLFFLTSLFPRFLVGYKNLVYLPTAFLLSSVFWIFMTWFILFFPDLAGAPFYFSFIFSIVAFLYFFYKTWATDPGFTKASEEEKKVNIITLAETGSLDFRTFCTSCLIRKPLRSLHCHVCNCCVARYDQHCLWTGRCIGFGNHHYYIFFLFFLSMVCGWIIYGSFIYLSSHCATTFKEDGLWTYLNQIVACSPWVLYILMLATFHFSWSTFLLLNQLFQIAFLGLTSHERISLQKQSKHMKQTLSLRKTPYNLGFMQNLADFFQCGCFGLVKPCVVDWTSQYTMVFHPAREKVLRSV>sp|Q8IUH4-2|ZDH13_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC13OS=Homo sapiens OX=9606 GN=ZDHHC13MTDVNGQTPLMLSAHKVIGPEPTGFLLKFNPSLNVVDKIHQNTPLHWAVAAGNVNAVDKLLEAGSSLDIQNVKGETPLDMALQNKNQLIIHMLKTEAKMRANQKFRLWRWLQKCELFLLLMLSVITMWAIGYILDFNSDSWLLKGCLLVTLFFLTSLFPRFLVGYKNLVYLPTAFLLSSVFWIFMTWFILFFPDLAGAPFYFSFIFSIVAFLYFFYKTWATDPGFTKASEEEKKVNIITLAETGSLDFRTFCTSCLIRKPLRSLHCHVCNCCVARYDQHCLWTGRCIGFGNHHYYIFFLFFLSMVCGWIIYGSFIYLSSHCATTFKEDGLWTYLNQIVACSPWVLYILMLATFHFSWSTFLLLNQLFQIAFLGLTSHERISLQKQSKHMKQTLSLRKTPYNLGFMQNLADFFQCGCFGLVKPCVVDWTSQYTMVFHPAREKVLRSV>sp|Q8IUH4-3|ZDH13_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC13OS=Homo sapiens OX=9606 GN=ZDHHC13MVILLLQHGADPTLIDGEGFSSIHLAVLFQHMPIIAYLISKGQSVNMTDVNGQTPLMLSAHKVIGPEPTGFLLKFNPSLNVVDKIHQNTPLHWAVAAGNVNAVDKLLEAGSSLDIQNVKGETPLDMALQNKNQLIIHMLKTEAKMRANQKFRLWRWLQKCELFLLLMLSVITMWAIGYILDFNSDSWLLKGCLLVTLFFLTSLFPRFLVGYKNLVYLPTAFLLSSVFWIFMTWFILFFPDLAGAPFYFSFIFSIVAFLYFFYKTWATDPGFTKASEEEKKVNIITLAETGSLDFRTFCTSCLIRKPLRSLHCHVCNCCVARYDQHCLWTGRCIGFGNHHYYIFFLFFLSMVCGWIIYGSFIYLSSHCATTFKEDGLWTYLNQIVACSPWVLYILMLATFHFSWSTFLLLNQLFQIAFLGLTSHERISLQKQSKHMKQTLSLRKTPYNLGFMQNLADFFQCGCFGLVKPCVVDWTSQYTMVFHPAREKVLRSV>sp|Q96PM5|ZN363_HUMAN RING finger and CHY zinc finger domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=RCHY1 PE=1 SV=1MAATAREDGASGQERGQRGCEHYDRGCLLKAPCCDKLYTCRLCHDNNEDHQLDRFKVKEVQCINCEKIQHAQQTCEECSTLFGEYYCDICHLFDKDKKQYHCENCGICRIGPKEDFFHCLKCNLCLAMNLQGRHKCIENVSRQNCPICLEDIHTSRVVAHVLPCGHLLHRTCYEEMLKEGYRCPLCMHSALDMTRYWRQLDDEVAQTPMPSEYQNMTVDILCNDCNGRSTVQFHILGMKCKICESYNTAQAGGRRISLDQQ>sp|Q96PM5-2|ZN363_HUMAN Isoform 2 of RING finger and CHY zinc fingerdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=RCHY1MAATAREDGASGQERGQRGCEHYDRGCLLKAPCCDKLYTCRLCHDNNEDHQLDRFKVKEVQCINCEKIQHAQQTCEECSTLFGEYYCDICHLFDKDKKQYHCENCGICRIGPKEDFFHCLKCNLCLAMNLQGRHKCIENVSRQNCPICLEDIHTSRVVAHVLPCGHLLHRGYRCPLCMHSALDMTRYWRQLDDEVAQTPMPSEYQNMTVDILCNDCNGRSTVQFHILGMKCKICESYNTAQAGGRRISLDQQ>sp|Q96PM5-3|ZN363_HUMAN Isoform 3 of RING finger and CHY zinc fingerdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=RCHY1MAATAREDGASGQERGQRGCEHYDRGCLLKAPCCDKLYTCRLCHDNNEDHQLDRFKVKEVQCINCEKIQHAQQTCEECSTLFGEYYCDICHLFDKDKKQYHCENCGICRIGPKEDFFHCLKCNLCLAMNLQGRHKCIENVSRQNCPICLEDIHTSRVVAHVLPCGHLLHRTCYEEMLKE>sp|Q96PM5-4|ZN363_HUMAN Isoform 4 of RING finger and CHY zinc fingerdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=RCHY1MAATAREDGASGQERGQRGCEHYDRGCLLKAPCCDKLYTCRLCHDNNEDHQLDRFKVKEVQCINCEKIQHAQQTCEECSTLFGEYYCDICHLFDKDKKQYHCENCGICRIGPKEDFFHCLKCNLCLAMNLQGRHKCIENVSRQNCPICLEDIHTSRVVAHVLPCGHLLHRTCYEEMLKEYDQVLETAG>sp|Q96PM5-5|ZN363_HUMAN Isoform 5 of RING finger and CHY zinc fingerdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=RCHY1MAATAREDGASGQERGQRGCEHYDRGCLLKAPCCDKLYTCRLCHDNNEDHQLDRFKVKEVQCINCEKNSTCPTDL>sp|Q96PM5-6|ZN363_HUMAN Isoform 6 of RING finger and CHY zinc fingerdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=RCHY1MAPAVKSEAPCCDKLYTCRLCHDNNEDHQLDRFKVKEVQCINCEKIQHAQQTCEECSTLFGEYYCDICHLFDKDKKQYHCENCGICRIGPKEDFFHCLKCNLCLAMNLQGRHKCIENVSRQNCPICLEDIHTSRVVAHVLPCGHLLHRTCYEEMLKEGYRCPLCMHSALDMTRYWRQLDDEVAQTPMPSEYQNMTVDILCNDCNGRSTVQFHILGMKCKICESYNTAQAGGRRISLDQQ>sp|Q96PM5-7|ZN363_HUMAN Isoform 7 of RING finger and CHY zinc fingerdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=RCHY1MAATAREDGASGQERGQRGCEHYDRGCLLKAQQTCEECSTLFGEYYCDICHLFDKDKKQYHCENCGICRIGPKEDFFHCLKCNLCLAMNLQGRHKCIENVSRQNCPICLEDIHTSRVVAHVLPCGHLLHRTCYEEMLKEGYRCPLCMHSALDMTRYWRQLDDEVAQTPMPSEYQNMTVDILCNDCNGRSTVQFHILGMKCKICESYNTAQAGGRRISLDQQ>sp|Q96PM5-8|ZN363_HUMAN Isoform 8 of RING finger and CHY zinc fingerdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=RCHY1MAATAREDGASGQERGQRGCEHYDRGCLLKAQQTCEECSTLFGEYYCDICHLFDKDKKQYHCENCGICRIGPKEDFFHCLKCNLCLAMNLQGRHKCIENVSRQNCPICLEDIHTSRVVAHVLPCGHLLHRGYRCPLCMHSALDMTRYWRQLDDEVAQTPMPSEYQNMTVDILCNDCNGRSTVQFHILGMKCKICESYNTAQAGGRRISLDQQ>sp|Q68DY9|ZN772_HUMAN Zinc finger protein 772 OS=Homo sapiens OX=9606GN=ZNF772 PE=1 SV=2MAAAEPMGPAQVPMNSEVIVDPIQGQVNFEDVFVYFSQEEWVLLDEAQRLLYRDVMLENFALMASLGHTSFMSHIVASLVMGSEPWVPDWVDMTLAVATETPGGSDPGCWHGMEDEEIPFEQSFSIGMSQIRIPKGGPSTQKAYPCGTCGLVLKDILHLAEHQETHPGQKPYMCVLCGKQFCFSANLHQHQKQHSGEKPFRSDKSRPFLLNNCAVQSMEMSFVTGEACKDFLASSSIFEHHAPHNEWKPHSNTKCEEASHCGKRHYKCSECGKTFSRKDSLVQHQRVHTGERPYECGECGKTFSRKPILAQHQRIHTGEMPYECGICGKVFNHSSNLIVHQRVHTGARPYKCSECGKAYSHKSTLVQHESIHTGERPYECSECGKYFGHKYRLIKHWSVHTGARPYECIACGKFFSQSSDLIAHQRVHNGEKPYVCSECGKAFSHKHVLVQHHRIHTGERPYKCSECGKAFRQRASLIRHWKIHTGERP>sp|Q68DY9-2|ZN772_HUMAN Isoform 2 of Zinc finger protein 772 OS=Homosapiens OX=9606 GN=ZNF772MEDEEIPFEQSFSIGMSQIRIPKGGPSTQKAYPCGTCGLVLKDILHLAEHQETHPGQKPYMCVLCGKQFCFSANLHQHQKQHSGEKPFRSDKSRPFLLNNCAVQSMEMSFVTGEACKDFLASSSIFEHHAPHNEWKPHSNTKCEEASHCGKRHYKCSECGKTFSRKDSLVQHQRVHTGERPYECGECGKTFSRKPILAQHQRIHTGEMPYECGICGKVFNHSSNLIVHQRVHTGARPYKCSECGKAYSHKSTLVQHESIHTGERPYECSECGKYFGHKYRLIKHWSVHTGARPYECIACGKFFSQSSDLIAHQRVHNGEKPYVCSECGKAFSHKHVLVQHHRIHTGERPYKCSECGKAFRQRASLIRHWKIHTGERP>sp|Q68DY9-3|ZN772_HUMAN Isoform 3 of Zinc finger protein 772 OS=Homosapiens OX=9606 GN=ZNF772MAAAEPMGPAQVPMNSEVIVDPIQGQVNFEDVFVYFSQEEWVLLDEAQRLLYRDVMLENFALMASLGCWHGMEDEEIPFEQSFSIGMSQIRIPKGGPSTQKAYPCGTCGLVLKDILHLAEHQETHPGQKPYMCVLCGKQFCFSANLHQHQKQHSGEKPFRSDKSRPFLLNNCAVQSMEMSFVTGEACKDFLASSSIFEHHAPHNEWKPHSNTKCEEASHCGKRHYKCSECGKTFSRKDSLVQHQRVHTGERPYECGECGKTFSRKPILAQHQRIHTGEMPYECGICGKVFNHSSNLIVHQRVHTGARPYKCSECGKAYSHKSTLVQHESIHTGERPYECSECGKYFGHKYRLIKHWSVHTGARPYECIACGKFFSQSSDLIAHQRVHNGEKPYVCSECGKAFSHKHVLVQHHRIHTGERPYKCSECGKAFRQRASLIRHWKIHTGERP>sp|Q9UL54|TAOK2_HUMAN Serine/threonine-protein kinase TAO2 OS=Homosapiens OX=9606 GN=TAOK2 PE=1 SV=2MPAGGRAGSLKDPDVAELFFKDDPEKLFSDLREIGHGSFGAVYFARDVRNSEVVAIKKMSYSGKQSNEKWQDIIKEVRFLQKLRHPNTIQYRGCYLREHTAWLVMEYCLGSASDLLEVHKKPLQEVEIAAVTHGALQGLAYLHSHNMIHRDVKAGNILLSEPGLVKLGDFGSASIMAPANSFVGTPYWMAPEVILAMDEGQYDGKVDVWSLGITCIELAERKPPLFNMNAMSALYHIAQNESPVLQSGHWSEYFRNFVDSCLQKIPQDRPTSEVLLKHRFVLRERPPTVIMDLIQRTKDAVRELDNLQYRKMKKILFQEAPNGPGAEAPEEEEEAEPYMHRAGTLTSLESSHSVPSMSISASSQSSSVNSLADASDNEEEEEEEEEEEEEEEGPEAREMAMMQEGEHTVTSHSSIIHRLPGSDNLYDDPYQPEITPSPLQPPAAPAPTSTTSSARRRAYCRNRDHFATIRTASLVSRQIQEHEQDSALREQLSGYKRMRRQHQKQLLALESRLRGEREEHSARLQRELEAQRAGFGAEAEKLARRHQAIGEKEARAAQAEERKFQQHILGQQKKELAALLEAQKRTYKLRKEQLKEELQENPSTPKREKAEWLLRQKEQLQQCQAEEEAGLLRRQRQYFELQCRQYKRKMLLARHSLDQDLLREDLNKKQTQKDLECALLLRQHEATRELELRQLQAVQRTRAELTRLQHQTELGNQLEYNKRREQELRQKHAAQVRQQPKSLKVRAGQRPPGLPLPIPGALGPPNTGTPIEQQPCSPGQEAVLDQRMLGEEEEAVGERRILGKEGATLEPKQQRILGEESGAPSPSPQKHGSLVDEEVWGLPEEIEELRVPSLVPQERSIVGQEEAGTWSLWGKEDESLLDEEFELGWVQGPALTPVPEEEEEEEEGAPIGTPRDPGDGCPSPDIPPEPPPTHLRPCPASQLPGLLSHGLLAGLSFAVGSSSGLLPLLLLLLLPLLAAQGGGGLQAALLALEVGLVGLGASYLLLCTALHLPSSLFLLLAQGTALGAVLGLSWRRGLMGVPLGLGAAWLLAWPGLALPLVAMAAGGRWVRQQGPRVRRGISRLWLRVLLRLSPMAFRALQGCGAVGDRGLFALYPKTNKDGFRSRLPVPGPRRRNPRTTQHPLALLARVWVLCKGWNWRLARASQGLASHLPPWAIHTLASWGLLRGERPTRIPRLLPRSQRQLGPPASRQPLPGTLAGRRSRTRQSRALPPWR>sp|Q9UL54-2|TAOK2_HUMAN Isoform 2 of Serine/threonine-protein kinaseTAO2 OS=Homo sapiens OX=9606 GN=TAOK2MPAGGRAGSLKDPDVAELFFKDDPEKLFSDLREIGHGSFGAVYFARDVRNSEVVAIKKMSYSGKQSNEKWQDIIKEVRFLQKLRHPNTIQYRGCYLREHTAWLVMEYCLGSASDLLEVHKKPLQEVEIAAVTHGALQGLAYLHSHNMIHRDVKAGNILLSEPGLVKLGDFGSASIMAPANSFVGTPYWMAPEVILAMDEGQYDGKVDVWSLGITCIELAERKPPLFNMNAMSALYHIAQNESPVLQSGHWSEYFRNFVDSCLQKIPQDRPTSEVLLKHRFVLRERPPTVIMDLIQRTKDAVRELDNLQYRKMKKILFQEAPNGPGAEAPEEEEEAEPYMHRAGTLTSLESSHSVPSMSISASSQSSSVNSLADASDNEEEEEEEEEEEEEEEGPEAREMAMMQEGEHTVTSHSSIIHRLPGSDNLYDDPYQPEITPSPLQPPAAPAPTSTTSSARRRAYCRNRDHFATIRTASLVSRQIQEHEQDSALREQLSGYKRMRRQHQKQLLALESRLRGEREEHSARLQRELEAQRAGFGAEAEKLARRHQAIGEKEARAAQAEERKFQQHILGQQKKELAALLEAQKRTYKLRKEQLKEELQENPSTPKREKAEWLLRQKEQLQQCQAEEEAGLLRRQRQYFELQCRQYKRKMLLARHSLDQDLLREDLNKKQTQKDLECALLLRQHEATRELELRQLQAVQRTRAELTRLQHQTELGNQLEYNKRREQELRQKHAAQVRQQPKSLKSKELQIKKQFQETCKIQTRQYKALRAHLLETTPKAQHKSLLKRLKEEQTRKLAILAEQYDQSISEMLSSQALRLDETQEAEFQALRQQLQQELELLNAYQSKIKIRTESQHERELRELEQRVALRRALLEQRVEEELLALQTGRSERIRSLLERQAREIEAFDAESMRLGFSSMALGGIPAEAAAQGYPAPPPAPAWPSRPVPRSGAHWSHGPPPPGMPPPAWRQPSLLAPPGPPNWLGPPTQSGTPRGGALLLLRNSPQPLRRAASGGSGSENVGPPAAAVPGPLSRSTSVASHILNGSSHFYS>sp|Q9UL54-3|TAOK2_HUMAN Isoform 3 of Serine/threonine-protein kinaseTAO2 OS=Homo sapiens OX=9606 GN=TAOK2MMGTSQGHVARKSRNWGLNPSRLSSIPLSSTPCHLSPSSLSPFSVAERKPPLFNMNAMSALYHIAQNESPVLQSGHWSEYFRNFVDSCLQKIPQDRPTSEVLLKHRFVLRERPPTVIMDLIQRTKDAVRELDNLQYRKMKKILFQEAPNGPGAEAPEEEEEAEPYMHRAGTLTSLESSHSVPSMSISASSQSSSVNSLADASDNEEEEEEEEEEEEEEEGPEAREMAMMQEGEHTVTSHSSIIHRLPGSDNLYDDPYQPEITPSPLQPPAAPAPTSTTSSARRRAYCRNRDHFATIRTASLVSRQIQEHEQDSALREQLSGYKRMRRQHQKQLLALESRLRGEREEHSARLQRELEAQRAGFGAEAEKLARRHQAIGEKEARAAQAEERKFQQHILGQQKKELAALLEAQKRTYKLRKEQLKEELQENPSTPKREKAEWLLRQKEQLQQCQAEEEAGLLRRQRQYFELQCRQYKRKMLLARHSLDQDLLREDLNKKQTQKDLECALLLRQHEATRELELRQLQAVQRTRAELTRLQHQTELGNQLEYNKRREQELRQKHAAQVRQQPKSLKVRAGQRPPGLPLPIPGALGPPNTGTPIEQQPCSPGQEAVLDQRMLGEEEEAVGERRILGKEGATLEPKQQRILGEESGAPSPSPQKHGSLVDEEVWGLPEEIEELRVPSLVPQERSIVGQEEAGTWSLWGKEDESLLDEEFELGWVQGPALTPVPEEEEEEEEGAPIGTPRDPGDGCPSPDIPPEPPPTHLRPCPASQLPGLLSHGLLAGLSFAVGSSSGLLPLLLLLLLPLLAAQGGGGLQAALLALEVGLVGLGASYLLLCTALHLPSSLFLLLAQGTALGAVLGLSWRRGLMGVPLGLGAAWLLAWPGLALPLVAMAAGGRWVRQQGPRVRRGISRLWLRVLLRLSPMAFRALQGCGAVGDRGLFALYPKTNKDGFRSRLPVPGPRRRNPRTTQHPLALLARVWVLCKGWNWRLARASQGLASHLPPWAIHTLASWGLLRGERPTRIPRLLPRSQRQLGPPASRQPLPGTLAGRRSRTRQSRALPPWR>sp|Q9UL54-4|TAOK2_HUMAN Isoform 4 of Serine/threonine-protein kinaseTAO2 OS=Homo sapiens OX=9606 GN=TAOK2MPAGGRAGSLKDPDVAELFFKDDPEKLFSDLREIGHGSFGAVYFARDVRNSEVVAIKKMSYSGKQSNEKWQDIIKEVRFLQKLRHPNTIQYRGCYLREHTAWLVMEYCLGSASDLLEVHKKPLQEVEIAAVTHGALQGLAYLHSHNMIHRDVKAGNILLSEPGLVKLGDFGSASIMAPANSFVGTPYWMAPEVILAMDEGQYDGKVDVWSLGITCIELAERKPPLFNMNAMSALYHIAQNESPVLQSGHWSEYFRNFVDSCLQKIPQDRPTSEVLLKHRFVLRERPPTVIMDLIQRTKDAVRELDNLQYRKMKKILFQEAPNGPGAEAPEEEEEAEPYMHRAGTLTSLESSHSVPSMSISASSQSSSVNSLADASDNEEEEEEEEEEEEEEEGPEAREMAMMQEGEHTVTSHSSIIHRLPGSDNLYDDPYQPEITPSPLQPPAAPAPTSTTSSARRRAYCRNRDHFATIRTASLVSRQIQEHEQDSALREQLSGYKRMRRQHQKQLLALESRLRGEREEHSARLQRELEAQRAGFGAEAEKLARRHQAIGEKEARAAQAEERKFQQHILGQQKKELAALLEAQKRTYKLRKEQLKEELQENPSTPKREKAEWLLRQKEQLQQCQAEEEAGLLRRQRQYFELQCRQYKRKMLLARHSLDQDLLREDLNKKQTQKDLECALLLRQHEATRELELRQLQAVQRTRAELTRLQHQTELGNQLEYNKRREQELRQKHAAQVRQQPKSLKERSIVGQEEAGTWSLWGKEDESLLDEEFELGWVQGPALTPVPEEEEEEEEGAPIGTPRDPGDGCPSPDIPPEPPPTHLRPCPASQLPGLLSHGLLAGLSFAVGSSSGLLPLLLLLLLPLLAAQGGGGLQAALLALEVGLVGLGASYLLLCTALHLPSSLFLLLAQGTALGAVLGLSWRRGLMGVPLGLGAAWLLAWPGLALPLVAMAAGGRWVRQQGPRVRRGISRLWLRVLLRLSPMAFRALQGCGAVGDRGLFALYPKTNKDGFRSRLPVPGPRRRNPRTTQHPLALLARVWVLCKGWNWRLARASQGLASHLPPWAIHTLASWGLLRGERPTRIPRLLPRSQRQLGPPASRQPLPGTLAGRRSRTRQSRALPPWR>sp|O75529|TAF5L_HUMAN TAF5-like RNA polymerase II p300/CBP-associatedfactor-associated factor 65 kDa subunit 5L OS=Homo sapiens OX=9606GN=TAF5L PE=1 SV=1MKRVRTEQIQMAVSCYLKRRQYVDSDGPLKQGLRLSQTAEEMAANLTVQSESGCANIVSAAPCQAEPQQYEVQFGRLRNFLTDSDSQHSHEVMPLLYPLFVYLHLNLVQNSPKSTVESFYSRFHGMFLQNASQKDVIEQLQTTQTIQDILSNFKLRAFLDNKYVVRLQEDSYNYLIRYLQSDNNTALCKVLTLHIHLDVQPAKRTDYQLYASGSSSRSENNGLEPPDMPSPILQNEAALEVLQESIKRVKDGPPSLTTICFYAFYNTEQLLNTAEISPDSKLLAAGFDNSCIKLWSLRSKKLKSEPHQVDVSRIHLACDILEEEDDEDDNAGTEMKILRGHCGPVYSTRFLADSSGLLSCSEDMSIRYWDLGSFTNTVLYQGHAYPVWDLDISPYSLYFASGSHDRTARLWSFDRTYPLRIYAGHLADVDCVKFHPNSNYLATGSTDKTVRLWSAQQGNSVRLFTGHRGPVLSLAFSPNGKYLASAGEDQRLKLWDLASGTLYKELRGHTDNITSLTFSPDSGLIASASMDNSVRVWDIRNTYCSAPADGSSSELVGVYTGQMSNVLSVQFMACNLLLVTGITQENQEH>sp|O75529-2|TAF5L_HUMAN Isoform 2 of TAF5-like RNA polymerase IIp300/CBP-associated factor-associated factor 65 kDa subunit 5L OS=Homosapiens OX=9606 GN=TAF5LMKRVRTEQIQMAVSCYLKRRQYVDSDGPLKQGLRLSQTAEEMAANLTVQSESGCANIVSAAPCQAEPQQYEVQFGRLRNFLTDSDSQHSHEVMPLLYPLFVYLHLNLVQNSPKSTVESFYSRFHGMFLQNASQKDVIEQLQTTQTIQDILSNFKLRAFLDNKYVVRLQEDSYNYLIRYLQSDNNTALCKVLTLHIHLDVQPAKRTDYQLYASGSSSRSENNGLEPPDMPSPILQNEAALEVLQESIKRVKDGPPSLTTICFYAFYNTEQLLNTAEISPDSKLLAAGFDNSCIKLWSLRSKKLKSEPHQVDVSRIHLACDILEEEV>sp|P59536|T2R41_HUMAN Taste receptor type 2 member 41 OS=Homo sapiensOX=9606 GN=TAS2R41 PE=1 SV=2MQAALTAFFVLLFSLLSLLGIAANGFIVLVLGREWLRYGRLLPLDMILISLGASRFCLQLVGTVHNFYYSAQKVEYSGGLGRQFFHLHWHFLNSATFWFCSWLSVLFCVKIANITHSTFLWLKWRFPGWVPWLLLGSVLISFIITLLFFWVNYPVYQEFLIRKFSGNMTYKWNTRIETYYFPSLKLVIWSIPFSVFLVSIMLLINSLRRHTQRMQHNGHSLQDPSTQAHTRALKSLISFLILYALSFLSLIIDAAKFISMQNDFYWPWQIAVYLCISVHPFILIFSNLKLRSVFSQLLLLARGFWVA>sp|P52657|T2AG_HUMAN Transcription initiation factor IIA subunit 2OS=Homo sapiens OX=9606 GN=GTF2A2 PE=1 SV=1MAYQLYRNTTLGNSLQESLDELIQSQQITPQLALQVLLQFDKAINAALAQRVRNRVNFRGSLNTYRFCDNVWTFVLNDVEFREVTELIKVDKVKIVACDGKNTGSNTTE>sp|Q8WV15|T255B_HUMAN Transmembrane protein 255B OS=Homo sapiens OX=9606GN=TMEM255B PE=1 SV=1MQPPVPGPLGLLDPAEGLSRRKKTSLWFVGSLLLVSVLIVTVGLAATTRTENVTVGGYYPGIILGFGSFLGIIGINLVENRRQMLVAAIVFISFGVVAAFCCAIVDGVFAAQHIEPRPLTTGRCQFYSSGVGYLYDVYQTEVTCHSLDGKCQLKVRSNTCYCCDLYACGSAEPSPAYYEFIGVSGCQDVLHLYRLLWASAVLNVLGLFLGIITAAVLGAFKDMVPLSQLAYGPAVPPQTLYNPAQQILAYAGFRLTPEPVPTCSSYPLPLQPCSRFPVAPSSALASSEDLQPPSPSSSGSGLPGQAPPCYAPTYFPPGEKPPPYAP>sp|P04216|THY1_HUMAN Thy-1 membrane glycoprotein OS=Homo sapiens OX=9606GN=THY1 PE=1 SV=2MNLAISIALLLTVLQVSRGQKVTSLTACLVDQSLRLDCRHENTSSSPIQYEFSLTRETKKHVLFGTVGVPEHTYRSRTNFTSKYNMKVLYLSAFTSKDEGTYTCALHHSGHSPPISSQNVTVLRDKLVKCEGISLLAQNTSWLLLLLLSLSLLQATDFMSL>sp|Q6ZMP0|THSD4_HUMAN Thrombospondin type-1 domain-containing protein 4OS=Homo sapiens OX=9606 GN=THSD4 PE=2 SV=2MVSHFMGSLSVLCFLLLLGFQFVCPQPSTQHRKVPQRMAAEGAPEDDGGGGAPGVWGAWGPWSACSRSCSGGVMEQTRPCLPRSYRLRGGQRPGAPARAFADHVVSAVRTSVPLHRSRDETPALAGTDASRQGPTVLRGSRHPQPQGLEVTGDRRSRTRGTIGPGKYGYGKAPYILPLQTDTAHTPQRLRRQKLSSRHSRSQGASSARHGYSSPAHQVPQHGPLYQSDSGPRSGLQAAEAPIYQLPLTHDQGYPAASSLFHSPETSNNHGVGTHGATQSFSQPARSTAISCIGAYRQYKLCNTNVCPESSRSIREVQCASYNNKPFMGRFYEWEPFAEVKGNRKCELNCQAMGYRFYVRQAEKVIDGTPCDQNGTAICVSGQCKSIGCDDYLGSDKVVDKCGVCGGDNTGCQVVSGVFKHALTSLGYHRVVEIPEGATKINITEMYKSNNYLALRSRSGRSIINGNWAIDRPGKYEGGGTMFTYKRPNEISSTAGESFLAEGPTNEILDVYMIHQQPNPGVHYEYVIMGTNAISPQVPPHRRPGEPFNGQMVTEGRSQEEGEQKGRNEEKEDLRGEAPEMFTSESAQTFPVRHPDRFSPHRPDNLVPPAPQPPRRSRDHNWKQLGTTECSTTCGKGSQYPIFRCVHRSTHEEAPESYCDSSMKPTPEEEPCNIFPCPAFWDIGEWSECSKTCGLGMQHRQVLCRQVYANRSLTVQPYRCQHLEKPETTSTCQLKICSEWQIRTDWTSCSVPCGVGQRTRDVKCVSNIGDVVDDEECNMKLRPNDIENCDMGPCAKSWFLTEWSERCSAECGAGVRTRSVVCMTNHVSSLPLEGCGNNRPAEATPCDNGPCTGKVEWFAGSWSQCSIECGSGTQQREVICVRKNADTFEVLDPSECSFLEKPPSQQSCHLKPCGAKWFSTEWSMCSKSCQGGFRVREVRCLSDDMTLSNLCDPQLKPEERESCNPQDCVPEVDENCKDKYYNCNVVVQARLCVYNYYKTACCASCTRVANRQTGFLGSR>sp|Q6ZMP0-2|THSD4_HUMAN Isoform 2 of Thrombospondin type-1 domain-containing protein 4 OS=Homo sapiens OX=9606 GN=THSD4MVSHFMGSLSVLCFLLLLGFQFVCPQPSTQHRKVPQRMAAEGAPEDDGGGGAPGVWGAWGPWSACSRSCSGGVMEQTRPCLPRSYRLRGGQRPGAPARAFADHVVSAVRTSVPLHRSRDETPALAGTDASRQGPTVLRGSRHPQPQGLEVTGDRRSRTRGTIGPGKYGYGKAPYILPLQTDTAHTPQRLRRQKLSSRHSRSQGASSARHGYSSPAHQVPQHGPLYQSDSGPRSGLQAAEAPIYQLPLTHDQGYPAASSLFHSPETSNNHGVGTHGATQSFSQPARSTAISCIGAYRQYKLCNTNVCPESSRSIREVQCASYNNKPFMGRFYEWEPFAEVKGNRKCELNCQAMGYRFYVRQAEKVIDGTPCDQNGTAICVSGQCKSIGCDDYLGSDKVVDKCGVCGGDNTGCQVVSGVFKHALTSLGYHRVVEIPEGATKINITEMYKSNNYLALRSRSGRSIINGNWAIDRPGKYEGGGTMFTYKRPNEISSTAGESFLAEGPTNEILDVYVSLDVSGLFFGF>sp|Q6ZMP0-3|THSD4_HUMAN Isoform 3 of Thrombospondin type-1 domain-containing protein 4 OS=Homo sapiens OX=9606 GN=THSD4MFVSYLILTLLHVQTAVLARPGGESIGCDDYLGSDKVVDKCGVCGGDNTGCQVVSGVFKHALTSLGYHRVVEIPEGATKINITEMYKSNKKKSHLKPATRGSQFSSVKVCSVPAACKLLGTPGRARQPVPAPRELEHDKNSPHCAYLSLYLTSLAQSSWRVFSLFSYVLIYLFSKYLAFNTLFALKRMALQRDRKEKTRAWCIFIKLCGREIQILPGPV>sp|Q6ZMP0-4|THSD4_HUMAN Isoform 4 of Thrombospondin type-1 domain-containing protein 4 OS=Homo sapiens OX=9606 GN=THSD4MFVSYLILTLLHVQTAVLARPGGESIGCDDYLGSDKVVDKCGVCGGDNTGCQVVSGVFKHALTSLGYHRVVEIPEGATKINITEMYKSNNYLALRSRSGRSIINGNWAIDRPGKYEGGGTMFTYKRPNEISSTAGESFLAEGPTNEILDVYMIHQQPNPGVHYEYVIMGTNAISPQVPPHRRPGEPFNGQMVTEGRSQEEGEQKGRNEEKEDLRGEAPEMFTSESAQTFPVRHPDRFSPHRPDNLVPPAPQPPRRSRDHNWKQLGTTECSTTCGKGSQYPIFRCVHRSTHEEAPESYCDSSMKPTPEEEPCNIFPCPAFWDIGEWSECSKTCGLGMQHRQVLCRQVYANRSLTVQPYRCQHLEKPETTSTCQLKICSEWQIRTDWTSCSVPCGVGQRTRDVKCVSNIGDVVDDEECNMKLRPNDIENCDMGPCAKSWFLTEWSERCSAECGAGVRTRSVVCMTNHVSSLPLEGCGNNRPAEATPCDNGPCTGKVEWFAGSWSQCSIECGSGTQQREVICVRKNADTFEVLDPSECSFLEKPPSQQSCHLKPCGAKWFSTEWSMCSKSCQGGFRVREVRCLSDDMTLSNLCDPQLKPEERESCNPQDCVPEVDENCKDKYYNCNVVVQARLCVYNYYKTACCASCTRVANRQTGFLGSR>sp|Q8IYF3|TEX11_HUMAN Testis-expressed protein 11 OS=Homo sapiensOX=9606 GN=TEX11 PE=1 SV=3MISAHCNLRLLCSSDSSASASQVAGTTEVVENLVTNDNSPNIPEAIDRLFSDIANINRESMAEITDIQIEEMAVNLWNWALTIGGGWLVNEEQKIRLHYVACKLLSMCEASFASEQSIQRLIMMNMRIGKEWLDAGNFLIADECFQAAVASLEQLYVKLIQRSSPEADLTMEKITVESDHFRVLSYQAESAVAQGDFQRASMCVLQCKDMLMRLPQMTSSLHHLCYNFGVETQKNNKYEESSFWLSQSYDIGKMDKKSTGPEMLAKVLRLLATNYLDWDDTKYYDKALNAVNLANKEHLSSPGLFLKMKILLKGETSNEELLEAVMEILHLDMPLDFCLNIAKLLMDHERESVGFHFLTIIHERFKSSENIGKVLILHTDMLLQRKEELLAKEKIEEIFLAHQTGRQLTAESMNWLHNILWRQAASSFEVQNYTDALQWYYYSLRFYSTDEMDLDFTKLQRNMACCYLNLQQLDKAKEAVAEAERHDPRNVFTQFYIFKIAVIEGNSERALQAIITLENILTDEESEDNDLVAERGSPTMLLSLAAQFALENGQQIVAEKALEYLAQHSEDQEQVLTAVKCLLRFLLPKIAEMPESEDKKKEMDRLLTCLNRAFVKLSQPFGEEALSLESRANEAQWFRKTAWNLAVQCDKDPVMMREFFILSYKMSQFCPSDQVILIARKTCLLMAVAVDLEQGRKASTAFEQTMFLSRALEEIQTCNDIHNFLKQTGTFSNDSCEKLLLLYEFEVRAKLNDPLLESFLESVWELPHLETKTFETIAIIAMEKPAHYPLIALKALKKALLLYKKEEPIDISQYSKCMHNLVNLSVPDGASNVELCPLEEVWGYFEDALSHISRTKDYPEMEILWLMVKSWNTGVLMFSRSKYASAEKWCGLALRFLNHLTSFKESYETQMNMLYSQLVEALSNNKGPVFHEHGYWSKSD>sp|Q8IYF3-2|TEX11_HUMAN Isoform 2 of Testis-expressed protein 11 OS=Homosapiens OX=9606 GN=TEX11MEILHLDMPLDFCLNIAKLLMDHERESVGFHFLTIIHERFKSSENIGKVLILHTDMLLQRKEELLAKEKIEEIFLAHQTGRQLTAESMNWLHNILWRQAASSFEVQNYTDALQWYYYSLRFYSTDEMDLDFTKLQRNMACCYLNLQQLDKAKEAVAEAERHDPRNVFTQFYIFKIAVIEGNSERALQAIITLENILTDEESEDNDLVAERGSPTMLLSLAAQFALENGQQIVAEKALEYLAQHSEDQEQVLTAVKCLLRFLLPKIAEMPESEDKKKEMDRLLTCLNRAFVKLSQPFGEEALSLESRANEAQWFRKTAWNLAVQCDKDPVMMREFFILSYKMSQFCPSDQVILIARKTCLLMAVAVDLEQGRKASTAFEQTMFLSRALEEIQTCNDIHNFLKQTGTFSNDSCEKLLLLYEFEVRAKLNDPLLESFLESVWELPHLETKTFETIAIIAMEKPAHYPLIALKALKKALLLYKKEEPIDISQYSKCMHNLVNLSVPDGASNVELCPLEEVWGYFEDALSHISRTKDYPEMEILWLMVKSWNTGVLMFSRSKYASAEKWCGLALRFLNHLTSFKESYETQMNMLYSQLVEALSNNKGPVFHEHGYWSKSD>sp|Q8IYF3-3|TEX11_HUMAN Isoform 3 of Testis-expressed protein 11 OS=Homosapiens OX=9606 GN=TEX11MDNDDFFSMDFKEVVENLVTNDNSPNIPEAIDRLFSDIANINRESMAEITDIQIEEMAVNLWNWALTIGGGWLVNEEQKIRLHYVACKLLSMCEASFASEQSIQRLIMMNMRIGKEWLDAGNFLIADECFQAAVASLEQLYVKLIQRSSPEADLTMEKITVESDHFRVLSYQAESAVAQGDFQRASMCVLQCKDMLMRLPQMTSSLHHLCYNFGVETQKNNKYEESSFWLSQSYDIGKMDKKSTGPEMLAKVLRLLATNYLDWDDTKYYDKALNAVNLANKEHLSSPGLFLKMKILLKGETSNEELLEAVMEILHLDMPLDFCLNIAKLLMDHERESVGFHFLTIIHERFKSSENIGKVLILHTDMLLQRKEELLAKEKIEEIFLAHQTGRQLTAESMNWLHNILWRQAASSFEVQNYTDALQWYYYSLRFYSTDEMDLDFTKLQRNMACCYLNLQQLDKAKEAVAEAERHDPRNVFTQFYIFKIAVIEGNSERALQAIITLENILTDEESEDNDLVAERGSPTMLLSLAAQFALENGQQIVAEKALEYLAQHSEDQEQVLTAVKCLLRFLLPKIAEMPESEDKKKEMDRLLTCLNRAFVKLSQPFGEEALSLESRANEAQWFRKTAWNLAVQCDKDPVMMREFFILSYKMSQFCPSDQVILIARKTCLLMAVAVDLEQGRKASTAFEQTMFLSRALEEIQTCNDIHNFLKQTGTFSNDSCEKLLLLYEFEVRAKLNDPLLESFLESVWELPHLETKTFETIAIIAMEKPAHYPLIALKALKKALLLYKKEEPIDISQYSKCMHNLVNLSVPDGASNVELCPLEEVWGYFEDALSHISRTKDYPEMEILWLMVKSWNTGVLMFSRSKYASAEKWCGLALRFLNHLTSFKESYETQMNMLYSQLVEALSNNKGPVFHEHGYWSKSD>sp|Q96N03|VTM2L_HUMAN V-set and transmembrane domain-containing protein2-like protein OS=Homo sapiens OX=9606 GN=VSTM2L PE=1 SV=1MGAPLAVALGALHYLALFLQLGGATRPAGHAPWDNHVSGHALFTETPHDMTARTGEDVEMACSFRGSGSPSYSLEIQWWYVRSHRDWTDKQAWASNQLKASQQEDAGKEATKISVVKVVGSNISHKLRLSRVKPTDEGTYECRVIDFSDGKARHHKVKAYLRVQPGENSVLHLPEAPPAAPAPPPPKPGKELRKRSVDQEACSL>sp|Q96N03-2|VTM2L_HUMAN Isoform 2 of V-set and transmembrane domain-containing protein 2-like protein OS=Homo sapiens OX=9606 GN=VSTM2LMGAPLAVALGALHYLALFLQLGGATRPAGHAPWDNHVSGHALFTETPHDMTARTGEDVEMACSFRGSGSPSYSLEIQWWYVRSHRDWTDKQAWASNQVVKVVGSNISHKLRLSRVKPTDEGTYECRVIDFSDGKARHHKVKAYLRVQPG>sp|Q96N03-3|VTM2L_HUMAN Isoform 3 of V-set and transmembrane domain-containing protein 2-like protein OS=Homo sapiens OX=9606 GN=VSTM2LMGAPLAVALGALHYLALFLQLGGATRPAGHAPWDNHVSGHGGQGGGQQHLPQAAPVPGEAHGRRHLRVPRHRLQRRQGPAPQGQGLPAGAARGELRPASARSPSRRARPAAPQARQGAEEALGGPGGLQPLD>sp|Q53QW1|TEX44_HUMAN Testis-expressed protein 44 OS=Homo sapiensOX=9606 GN=TEX44 PE=1 SV=1MALPGYPLGNVDDSRSKDSPAGEPQGQVPLTADVLAVSSSVASTDWQDIDQASFKTATPRAISTSGDKDKSAVVPEHGQKTPRKITPLLPSQNPSPLQVSMSLQNPAWDRQVQDARTSQSLVVFPSHLLGKDKMSQMASVPEREPESAPSAPSAELQSTQHMEAQPVESDADHVTAGANGQHGPQAASTTKSAEEKAEHPKAPHPEAEALPSDESPVAMGANVVDSLGDLQTWFFPPPPAGSVSPSPGPHEVALGRRPLDSSLYTASEENSYMRSMTSLLDRGEGSISSLADILVWSETTMGMAIATGFLDSGHSTVADLLHSSGPSLRSVPSLVGSVSSAFSSGLVSGTSSALRTITRVLETVEQRTVEGIRSAMRYLTSHLTPRQAQADPNYD>sp|Q9UMR3|TBX20_HUMAN T-box transcription factor TBX20 OS=Homo sapiensOX=9606 GN=TBX20 PE=1 SV=4MEFTASPKPQLSSRANAFSIAALMSSGGSKEKEATENTIKPLEQFVEKSSCAQPLGELTSLDAHGEFGGGSGSSPSSSSLCTEPLIPTTPIIPSEEMAKIACSLETKELWDKFHELGTEMIITKSGRRMFPTIRVSFSGVDPEAKYIVLMDIVPVDNKRYRYAYHRSSWLVAGKADPPLPARLYVHPDSPFTGEQLLKQMVSFEKVKLTNNELDQHGHIILNSMHKYQPRVHIIKKKDHTASLLNLKSEEFRTFIFPETVFTAVTAYQNQLITKLKIDSNPFAKGFRDSSRLTDIERESVESLIQKHSYARSPIRTYGGEEDVLGDESQTTPNRGSAFTTSDNLSLSSWVSSSSSFPGFQHPQSLTALGTSTASIATPIPHPIQGSLPPYSRLGMPLTPSAIASSMQGSGPTFPSFHMPRYHHYFQQGPYAAIQGLRHSSAVMTPFV>sp|O15178|TBXT_HUMAN T-box transcription factor T OS=Homo sapiensOX=9606 GN=TBXT PE=1 SV=1MSSPGTESAGKSLQYRVDHLLSAVENELQAGSEKGDPTERELRVGLEESELWLRFKELTNEMIVTKNGRRMFPVLKVNVSGLDPNAMYSFLLDFVAADNHRWKYVNGEWVPGGKPEPQAPSCVYIHPDSPNFGAHWMKAPVSFSKVKLTNKLNGGGQIMLNSLHKYEPRIHIVRVGGPQRMITSHCFPETQFIAVTAYQNEEITALKIKYNPFAKAFLDAKERSDHKEMMEEPGDSQQPGYSQWGWLLPGTSTLCPPANPHPQFGGALSLPSTHSCDRYPTLRSHRSSPYPSPYAHRNNSPTYSDNSPACLSMLQSHDNWSSLGMPAHPSMLPVSHNASPPTSSSQYPSLWSVSNGAVTPGSQAAAVSNGLGAQFFRGSPAHYTPLTHPVSAPSSSGSPLYEGAAAATDIVDSQYDAAAQGRLIASWTPVSPPSM>sp|O15178-2|TBXT_HUMAN Isoform 2 of T-box transcription factor T OS=Homosapiens OX=9606 GN=TBXTMSSPGTESAGKSLQYRVDHLLSAVENELQAGSEKGDPTERELRVGLEESELWLRFKELTNEMIVTKNGRRMFPVLKVNVSGLDPNAMYSFLLDFVAADNHRWKYVNGEWVPGGKPEPQAPSCVYIHPDSPNFGAHWMKAPVSFSKVKLTNKLNGGGQIMLNSLHKYEPRIHIVRVGGPQRMITSHCFPETQFIAVTAYQNEEITALKIKYNPFAKAFLDAKERSDHKEMMEEPGDSQQPGYSQSYSDNSPACLSMLQSHDNWSSLGMPAHPSMLPVSHNASPPTSSSQYPSLWSVSNGAVTPGSQAAAVSNGLGAQFFRGSPAHYTPLTHPVSAPSSSGSPLYEGAAAATDIVDSQYDAAAQGRLIASWTPVSPPSM>sp|Q13207|TBX2_HUMAN T-box transcription factor TBX2 OS=Homo sapiensOX=9606 GN=TBX2 PE=1 SV=3MREPALAASAMAYHPFHAPRPADFPMSAFLAAAQPSFFPALALPPGALAKPLPDPGLAGAAAAAAAAAAAAEAGLHVSALGPHPPAAHLRSLKSLEPEDEVEDDPKVTLEAKELWDQFHKLGTEMVITKSGRRMFPPFKVRVSGLDKKAKYILLMDIVAADDCRYKFHNSRWMVAGKADPEMPKRMYIHPDSPATGEQWMAKPVAFHKLKLTNNISDKHGFTILNSMHKYQPRFHIVRANDILKLPYSTFRTYVFPETDFIAVTAYQNDKITQLKIDNNPFAKGFRDTGNGRREKRKQLTLPSLRLYEEHCKPERDGAESDASSCDPPPAREPPTSPGAAPSPLRLHRARAEEKSCAADSDPEPERLSEERAGAPLGRSPAPDSASPTRLTEPERARERRSPERGKEPAESGGDGPFGLRSLEKERAEARRKDEGRKEAAEGKEQGLAPLVVQTDSASPLGAGHLPGLAFSSHLHGQQFFGPLGAGQPLFLHPGQFTMGPGAFSAMGMGHLLASVAGGGNGGGGGPGTAAGLDAGGLGPAASAASTAAPFPFHLSQHMLASQGIPMPTFGGLFPYPYTYMAAAAAAASALPATSAAAAAAAAAGSLSRSPFLGSARPRLRFSPYQIPVTIPPSTSLLTTGLASEGSKAAGGNSREPSPLPELALRKVGAPSRGALSPSGSAKEAANELQSIQRLVSGLESQRALSPGRESPK>sp|P05452|TETN_HUMAN Tetranectin OS=Homo sapiens OX=9606 GN=CLEC3B PE=1SV=3MELWGAYLLLCLFSLLTQVTTEPPTQKPKKIVNAKKDVVNTKMFEELKSRLDTLAQEVALLKEQQALQTVCLKGTKVHMKCFLAFTQTKTFHEASEDCISRGGTLGTPQTGSENDALYEYLRQSVGNEAEIWLGLNDMAAEGTWVDMTGARIAYKNWETEITAQPDGGKTENCAVLSGAANGKWFDKRCRDQLPYICQFGIV>sp|Q6PEX7|TEX38_HUMAN Testis-expressed protein 38 OS=Homo sapiensOX=9606 GN=TEX38 PE=2 SV=3MDSQQEDLRFPGMWVSLYFGILGLCSVITGGCIIFLHWRKNLRREEHAQQWVEVMRAATFTYSPLLYWINKRRRYGMNAAINTGPAPAVTKTETEVQNPDVLWDLDIPEGRSHADQDSNPKAEAPAPLQPALQLAPQQPQARSPFPLPIFQEVPFAPPLCNLPPLLNHSVSYPLATCPERNVLFHSLLNLAQEDHSFNAKPFPSEL>sp|Q96M34|TEX55_HUMAN Testis-specific expressed protein 55 OS=Homosapiens OX=9606 GN=TEX55 PE=1 SV=2MEEPPQEALAEPLKHESPAAPSSAGHTKGQEEDDQKNQAERKADNHTAHRIADQTALRVPSQAESSIFSQATNGVAEQNGHSTPGQAGRRASNPADVSDLRADDQVNQTPSEQTKGKASSQANNVQHEQSDGQVSGLTEERTAEQTERRLPTQAERRTSGQIDGRLAMPSDQRGSRQTDHRMAGQSERRASEQMDRRMSGEAERRTSEQITHRLSKLSERRPSVQIDSGSSVPSDQSPSVQIDSGSSVPSDQRPSVQIDRRMSGKVRRRSSEKTDYRLAGLADPGTSEQTDLRLYGLVDHKTSVKTHHQVYGQATELAEHQAIDQAHSNADQPPVDNAHYTESDQTDHLADRQANHKDQLSYYETRGQSEDRIFPQLGNSKEDKEADYRVQPCKFEDSQVDLNSKPSVEMETQNATTIPPYNPVDARFTSNFQAKDQALFPRLPSISSKLNYTSSQEKTQAIVTKSDEFSEIDQGKGYHIRNQTYRRFPSIVYEDPYQVSLQYMEKHHILQIFQQITENLVYEKPEDPLNFMLCQV>sp|P01266|THYG_HUMAN Thyroglobulin OS=Homo sapiens OX=9606 GN=TG PE=1SV=5MALVLEIFTLLASICWVSANIFEYQVDAQPLRPCELQRETAFLKQADYVPQCAEDGSFQTVQCQNDGRSCWCVGANGSEVLGSRQPGRPVACLSFCQLQKQQILLSGYINSTDTSYLPQCQDSGDYAPVQCDVQQVQCWCVDAEGMEVYGTRQLGRPKRCPRSCEIRNRRLLHGVGDKSPPQCSAEGEFMPVQCKFVNTTDMMIFDLVHSYNRFPDAFVTFSSFQRRFPEVSGYCHCADSQGRELAETGLELLLDEIYDTIFAGLDLPSTFTETTLYRILQRRFLAVQSVISGRFRCPTKCEVERFTATSFGHPYVPSCRRNGDYQAVQCQTEGPCWCVDAQGKEMHGTRQQGEPPSCAEGQSCASERQQALSRLYFGTSGYFSQHDLFSSPEKRWASPRVARFATSCPPTIKELFVDSGLLRPMVEGQSQQFSVSENLLKEAIRAIFPSRGLARLALQFTTNPKRLQQNLFGGKFLVNVGQFNLSGALGTRGTFNFSQFFQQLGLASFLNGGRQEDLAKPLSVGLDSNSSTGTPEAAKKDGTMNKPTVGSFGFEINLQENQNALKFLASLLELPEFLLFLQHAISVPEDVARDLGDVMETVLSSQTCEQTPERLFVPSCTTEGSYEDVQCFSGECWCVNSWGKELPGSRVRGGQPRCPTDCEKQRARMQSLMGSQPAGSTLFVPACTSEGHFLPVQCFNSECYCVDAEGQAIPGTRSAIGKPKKCPTPCQLQSEQAFLRTVQALLSNSSMLPTLSDTYIPQCSTDGQWRQVQCNGPPEQVFELYQRWEAQNKGQDLTPAKLLVKIMSYREAASGNFSLFIQSLYEAGQQDVFPVLSQYPSLQDVPLAALEGKRPQPRENILLEPYLFWQILNGQLSQYPGSYSDFSTPLAHFDLRNCWCVDEAGQELEGMRSEPSKLPTCPGSCEEAKLRVLQFIRETEEIVSASNSSRFPLGESFLVAKGIRLRNEDLGLPPLFPPREAFAEQFLRGSDYAIRLAAQSTLSFYQRRRFSPDDSAGASALLRSGPYMPQCDAFGSWEPVQCHAGTGHCWCVDEKGGFIPGSLTARSLQIPQCPTTCEKSRTSGLLSSWKQARSQENPSPKDLFVPACLETGEYARLQASGAGTWCVDPASGEELRPGSSSSAQCPSLCNVLKSGVLSRRVSPGYVPACRAEDGGFSPVQCDQAQGSCWCVMDSGEEVPGTRVTGGQPACESPRCPLPFNASEVVGGTILCETISGPTGSAMQQCQLLCRQGSWSVFPPGPLICSLESGRWESQLPQPRACQRPQLWQTIQTQGHFQLQLPPGKMCSADYADLLQTFQVFILDELTARGFCQIQVKTFGTLVSIPVCNNSSVQVGCLTRERLGVNVTWKSRLEDIPVASLPDLHDIERALVGKDLLGRFTDLIQSGSFQLHLDSKTFPAETIRFLQGDHFGTSPRTWFGCSEGFYQVLTSEASQDGLGCVKCPEGSYSQDEECIPCPVGFYQEQAGSLACVPCPVGRTTISAGAFSQTHCVTDCQRNEAGLQCDQNGQYRASQKDRGSGKAFCVDGEGRRLPWWETEAPLEDSQCLMMQKFEKVPESKVIFDANAPVAVRSKVPDSEFPVMQCLTDCTEDEACSFFTVSTTEPEISCDFYAWTSDNVACMTSDQKRDALGNSKATSFGSLRCQVKVRSHGQDSPAVYLKKGQGSTTTLQKRFEPTGFQNMLSGLYNPIVFSASGANLTDAHLFCLLACDRDLCCDGFVLTQVQGGAIICGLLSSPSVLLCNVKDWMDPSEAWANATCPGVTYDQESHQVILRLGDQEFIKSLTPLEGTQDTFTNFQQVYLWKDSDMGSRPESMGCRKDTVPRPASPTEAGLTTELFSPVDLNQVIVNGNQSLSSQKHWLFKHLFSAQQANLWCLSRCVQEHSFCQLAEITESASLYFTCTLYPEAQVCDDIMESNAQGCRLILPQMPKALFRKKVILEDKVKNFYTRLPFQKLMGISIRNKVPMSEKSISNGFFECERRCDADPCCTGFGFLNVSQLKGGEVTCLTLNSLGIQMCSEENGGAWRILDCGSPDIEVHTYPFGWYQKPIAQNNAPSFCPLVVLPSLTEKVSLDSWQSLALSSVVVDPSIRHFDVAHVSTAATSNFSAVRDLCLSECSQHEACLITTLQTQPGAVRCMFYADTQSCTHSLQGQNCRLLLREEATHIYRKPGISLLSYEASVPSVPISTHGRLLGRSQAIQVGTSWKQVDQFLGVPYAAPPLAERRFQAPEPLNWTGSWDASKPRASCWQPGTRTSTSPGVSEDCLYLNVFIPQNVAPNASVLVFFHNTMDREESEGWPAIDGSFLAAVGNLIVVTASYRVGVFGFLSSGSGEVSGNWGLLDQVAALTWVQTHIRGFGGDPRRVSLAADRGGADVASIHLLTARATNSQLFRRAVLMGGSALSPAAVISHERAQQQAIALAKEVSCPMSSSQEVVSCLRQKPANVLNDAQTKLLAVSGPFHYWGPVIDGHFLREPPARALKRSLWVEVDLLIGSSQDDGLINRAKAVKQFEESRGRTSSKTAFYQALQNSLGGEDSDARVEAAATWYYSLEHSTDDYASFSRALENATRDYFIICPIIDMASAWAKRARGNVFMYHAPENYGHGSLELLADVQFALGLPFYPAYEGQFSLEEKSLSLKIMQYFSHFIRSGNPNYPYEFSRKVPTFATPWPDFVPRAGGENYKEFSELLPNRQGLKKADCSFWSKYISSLKTSADGAKGGQSAESEEEELTAGSGLREDLLSLQEPGSKTYSK>sp|P01266-2|THYG_HUMAN Isoform 2 of Thyroglobulin OS=Homo sapiensOX=9606 GN=TGMALVLEIFTLLASICWVSANIFEYQVDAQPLRPCELQRETAFLKQADYVPQCAEDGSFQTVQCQNDGRSCWCVGANGSEVLGSRQPGRPVACLSFCQLQKQQILLSGYINSTDTSYLPQCQDSGDYAPVQCDVQQVQCWCVDAEGMEVYGTRQLGRPKRCPRSCEIRNRRLLHGVGDKSPPQCSAEGEFMPVQCKFVNTTDMMIFDLVHSYNRFPDAFVTFSSFQRRFPEVSGYCHCADSQGRELAETGLELLLDEIYDTIFAGLDLPSTFTETTLYRILQRRFLAVQSVISGRFRCPTKCEVERFTATSFGHPYVPSCRRNGDYQAVQCQTEGPCWCVDAQGKEMHGTRQQGEPPSCAEGQSCASERQQALSRLYFGTSGYFSQHDLFSSPEKRWASPRVARFATSCPPTIKELFVDSGLLRPMVEGQSQQFSVSENLLKEAIRAIFPSRGLARLALQFTTNPKRLQQNLFGGKFLVNVGQFNLSGALGTRGTFNFSQFFQQLGLASFLNGGRQEDLAKPLSVGLDSNSSTGTPEAAKKDGTMNKPTVGSFGFEINLQENQNALKFLASLLELPEFLLFLQHAISVPEDVARDLGDVMETVLSSQTCEQTPERLFVPSCTTEGSYEDVQCFSGECWCVNSWGKELPGSRVRGGQPRCPTDCEKQRARMQSLMGSQPAGSTLFVPACTSEGHFLPVQCFNSECYCVDAEGQAIPGTRSAIGKPKKCPTPCQLQSEQAFLRTVQALLSNSSMLPTLSDTYIPQCSTDGQWRQVQCNGPPEQVFELYQRWEAQNKGQDLTPAKLLVKIMSYREAASGNFSLFIQSLYEAGQQDVFPVLSQYPSLQDVPLAALEGKRPQPRENILLEPYLFWQILNGQLSQYPGSYSDFSTPLAHFDLRNCWCVDEAGQELEGMRSEPSKLPTCPGSCEEAKLRVLQFIRETEEIVSASNSSRFPLGESFLVAKGIRLRNEDLGLPPLFPPREAFAEQFLRGSDYAIRLAAQSTLSFYQRRRFSPDDSAGASALLRSGPYMPQCDAFGSWEPVQCHAGTGHCWCVDEKGGFIPGSLTARSLQIPQCPTTCEKSRTSGLLSSWKQARSQENPSPKDLFVPACLETGEYARLQASGAGTWCVDPASGEELRPGSSSSAQCPSLCNVLKSGVLSRRVSPGYVPACRAEDGGFSPVQCDQAQGSCWCVMDSGEEVPGTRVTGGQPACESPRCPLPFNASEVVGGTILCETISGPTGSAMQQCQLLCRQGSWSVFPPGPLICSLESGRWESQLPQPRACQRPQLWQTIQTQGHFQLQLPPGKMCSADYADLLQTFQVFILDELTARGFCQIQVKTFGTLVSIPVCNNSSVQVGCLTRERLGVNVTWKSRLEDIPVASLPDLHDIERALVGKDLLGRFTDLIQSGSFQLHLDSKTFPAETIRFLQGDHFGTSPRTWFGCSEGFYQVLTSEASQDGLGCVKCPEGSYSQDEECIPCPVGFYQEQAGSLACVPCPVGRTTISAGAFSQTHLMQKFEKVPESKVIFDANAPVAVRSKVPDSEFPVMQCLTDCTEDEACSFFTVSTTEPEISCDFYAWTSDNVACMTSDQKRDALGNSKATSFGSLRCQVKVRSHGQDSPAVYLKKGQGSTTTLQKRFEPTGFQNMLSGLYNPIVFSASGANLTDAHLFCLLACDRDLCCDGFVLTQVQGGAIICGLLSSPSVLLCNVKDWMDPSEAWANATCPGVTYDQESHQVILRLGDQEFIKSLTPLEGTQDTFTNFQQVYLWKDSDMGSRPESMGCRKDTVPRPASPTEAGLTTELFSPVDLNQVIVNGNQSLSSQKHWLFKHLFSAQQANLWCLSRCVQEHSFCQLAEITESASLYFTCTLYPEAQVCDDIMESNAQGCRLILPQMPKALFRKKVILEDKVKNFYTRLPFQKLMGISIRNKVPMSEKSISNGFFECERRCDADPCCTGFGFLNVSQLKGGEVTCLTLNSLGIQMCSEENGGAWRILDCGSPDIEVHTYPFGWYQKPIAQNNAPSFCPLVVLPSLTEKVSLDSWQSLALSSVVVDPSIRHFDVAHVSTAATSNFSAVRDLCLSECSQHEACLITTLQTQPGAVRCMFYADTQSCTHSLQGQNCRLLLREEATHIYRKPGISLLSYEASVPSVPISTHGRLLGRSQAIQVGTSWKQVDQFLGVPYAAPPLAERRFQAPEPLNWTGSWDASKPRASCWQPGTRTSTSPGVSEDCLYLNVFIPQNVAPNASVLVFFHNTMDREESEGWPAIDGSFLAAVGNLIVVTASYRVGVFGFLSSGSGEVSGNWGLLDQVAALTWVQTHIRGFGGDPRRVSLAADRGGADVASIHLLTARATNSQLFRRAVLMGGSALSPAAVISHERAQQQAIALAKEVSCPMSSSQEVVSCLRQKPANVLNDAQTKLLAVSGPFHYWGPVIDGHFLREPPARALKRSLWVEVDLLIGSSQDDGLINRAKAVKQFEESRGRTSSKTAFYQALQNSLGGEDSDARVEAAATWYYSLEHSTDDYASFSRALENATRDYFIICPIIDMASAWAKRARGNVFMYHAPENYGHGSLELLADVQFALGLPFYPAYEGQFSLEEKSLSLKIMQYFSHFIRSGNPNYPYEFSRKVPTFATPWPDFVPRAGGENYKEFSELLPNRQGLKKADCSFWSKYISSLKTSADGAKGGQSAESEEEELTAGSGLREDLLSLQEPGSKTYSK>sp|P21580|TNAP3_HUMAN Tumor necrosis factor alpha-induced protein 3OS=Homo sapiens OX=9606 GN=TNFAIP3 PE=1 SV=1MAEQVLPQALYLSNMRKAVKIRERTPEDIFKPTNGIIHHFKTMHRYTLEMFRTCQFCPQFREIIHKALIDRNIQATLESQKKLNWCREVRKLVALKTNGDGNCLMHATSQYMWGVQDTDLVLRKALFSTLKETDTRNFKFRWQLESLKSQEFVETGLCYDTRNWNDEWDNLIKMASTDTPMARSGLQYNSLEEIHIFVLCNILRRPIIVISDKMLRSLESGSNFAPLKVGGIYLPLHWPAQECYRYPIVLGYDSHHFVPLVTLKDSGPEIRAVPLVNRDRGRFEDLKVHFLTDPENEMKEKLLKEYLMVIEIPVQGWDHGTTHLINAAKLDEANLPKEINLVDDYFELVQHEYKKWQENSEQGRREGHAQNPMEPSVPQLSLMDVKCETPNCPFFMSVNTQPLCHECSERRQKNQNKLPKLNSKPGPEGLPGMALGASRGEAYEPLAWNPEESTGGPHSAPPTAPSPFLFSETTAMKCRSPGCPFTLNVQHNGFCERCHNARQLHASHAPDHTRHLDPGKCQACLQDVTRTFNGICSTCFKRTTAEASSSLSTSLPPSCHQRSKSDPSRLVRSPSPHSCHRAGNDAPAGCLSQAARTPGDRTGTSKCRKAGCVYFGTPENKGFCTLCFIEYRENKHFAAASGKVSPTASRFQNTIPCLGRECGTLGSTMFEGYCQKCFIEAQNQRFHEAKRTEEQLRSSQRRDVPRTTQSTSRPKCARASCKNILACRSEELCMECQHPNQRMGPGAHRGEPAPEDPPKQRCRAPACDHFGNAKCNGYCNECFQFKQMYG>sp|P0CG35|TB15B_HUMAN Thymosin beta-15B OS=Homo sapiens OX=9606GN=TMSB15B PE=1 SV=1MSDKPDLSEVEKFDRSKLKKTNTEEKNTLPSKETIQQEKECVQTS>sp|Q9NVR7|TBCC1_HUMAN TBCC domain-containing protein 1 OS=Homo sapiensOX=9606 GN=TBCCD1 PE=1 SV=1MDQSRVLLWVKAEPFIVGALQVPPPSKFSLHYLRKISTYVQIRATEGAYPRLYWSTWRHIACGKLQLAKDLAWLYFEIFDSLSMKTPEERLEWSEVLSNCMSEEEVEKQRNQLSVDTLQFLLFLYIQQLNKVSLRTSLIGEEWPSPRNKSQSPDLTEKSNCHNKNWNDYSHQAFVYDHLSDLLELLLDPKQLTASFHSTHSSLVSREAVVALSFLIEGTISRARKIYPLHELALWQPLHADSGFSKISKTFSFYKLETWLRSCLTGNPFGTSACLKSGKKLAWAHQVEGTTKRAKIACNTHVAPRMHRLVVMSQVYKQTLAKSSDTLAGAHVKIHRCNESFIYLLSPLRSVTIEKCRNSIFVLGPVGTTLHLHSCDNVKVIAVCHRLSISSTTGCIFHVLTPTRPLILSGNQTVTFAPFHTHYPMLEDHMARTGLATVPNYWDNPMVVCRENSDTRVFQLLPPCEFYVFIIPFEMEGDTTEIPGGLPSVYQKALGQREQKIQIWQKTVKEAHLTKDQRKQFQVLVENKFYEWLINTGHRQQLDSLVPPAAGSKQAAG>sp|Q9NVR7-2|TBCC1_HUMAN Isoform 2 of TBCC domain-containing protein 1OS=Homo sapiens OX=9606 GN=TBCCD1MTDRLKFGFGFHRFLVLSVDTLQFLLFLYIQQLNKVSLRTSLIGEEWPSPRNKSQSPDLTEKSNCHNKNWNDYSHQAFVYDHLSDLLELLLDPKQLTASFHSTHSSLVSREAVVALSFLIEGTISRARKIYPLHELALWQPLHADSGFSKISKTFSFYKLETWLRSCLTGNPFGTSACLKSGKKLAWAHQVEGTTKRAKIACNTHVAPRMHRLVVMSQVYKQTLAKSSDTLAGAHVKIHRCNESFIYLLSPLRSVTIEKCRNSIFVLGPVGTTLHLHSCDNVKVIAVCHRLSISSTTGCIFHVLTPTRPLILSGNQTVTFAPFHTHYPMLEDHMARTGLATVPNYWDNPMVVCRENSDTRVFQLLPPCEFYVFIIPFEMEGDTTEIPGGLPSVYQKALGQREQKIQIWQKTVKEAHLTKDQRKQFQVLVENKFYEWLINTGHRQQLDSLVPPAAGSKQAAG>sp|Q8IV31|TM139_HUMAN Transmembrane protein 139 OS=Homo sapiens OX=9606GN=TMEM139 PE=1 SV=1MVPMHLLGRLEKPLLLLCCASFLLGLALLGIKTDITPVAYFFLTLGGFFLFAYLLVRFLEWGLRSQLQSMQTESPGPSGNARDNEAFEVPVYEEAVVGLESQCRPQELDQPPPYSTVVIPPAPEEEQPSHPEGSRRAKLEQRRMASEGSMAQEGSPGRAPINLRLRGPRAVSTAPDLQSLAAVPTLEPLTPPPAYDVCFGHPDDDSVFYEDNWAPP>sp|Q9P2M4|TBC14_HUMAN TBC1 domain family member 14 OS=Homo sapiensOX=9606 GN=TBC1D14 PE=1 SV=3MTDGKLSTSTNGVAFMGILDGRPGNPLQNLQHVNLKAPRLLSAPEYGPKLKLRALEDRHSLQSVDSGIPTLEIGNPEPVPCSAVHVRRKQSDSDLIPERAFQSACALPSCAPPAPSSTEREQSVRKSSTFPRTGYDSVKLYSPTSKALTRSDDVSVCSVSSLGTELSTTLSVSNEDILDLVVTSSSSAIVTLENDDDPQFTNVTLSSIKETRGLHQQDCVHEAEEGSKLKILGPFSNFFARNLLARKQSARLDKHNDLGWKLFGKAPLRENAQKDSKRIQKEYEDKAGRPSKPPSPKQNVRKNLDFEPLSTTALILEDRPANLPAKPAEEAQKHRQQYEEMVVQAKKRELKEAQRRKKQLEERCRVEESIGNAVLTWNNEILPNWETMWCSRKVRDLWWQGIPPSVRGKVWSLAIGNELNITHELFDICLARAKERWRSLSTGGSEVENEDAGFSAADREASLELIKLDISRTFPNLCIFQQGGPYHDMLHSILGAYTCYRPDVGYVQGMSFIAAVLILNLDTADAFIAFSNLLNKPCQMAFFRVDHGLMLTYFAAFEVFFEENLPKLFAHFKKNNLTPDIYLIDWIFTLYSKSLPLDLACRIWDVFCRDGEEFLFRTALGILKLFEDILTKMDFIHMAQFLTRLPEDLPAEELFASIATIQMQSRNKKWAQVLTALQKDSREMEKGSPSLRH>sp|Q9P2M4-2|TBC14_HUMAN Isoform 2 of TBC1 domain family member 14OS=Homo sapiens OX=9606 GN=TBC1D14MEYEDKAGRPSKPPSPKQNVRKNLDFEPLSTTALILEDRPANLPAKPAEEAQKHRQQYEEMVVQAKKRELKEAQRRKKQLEERCRVEESIGNAVLTWNNEILPNWETMWCSRKVRDLWWQGIPPSVRGKVWSLAIGNELNITHELFDICLARAKERWRSLSTGGSEVENEDAGFSAADREASLELIKLDISRTFPNLCIFQQGGPYHDMLHSILGAYTCYRPDVGYVQGMSFIAAVLILNLDTADAFIAFSNLLNKPCQMAFFRVDHGLMLTYFAAFEVFFEENLPKLFAHFKKNNLTPDIYLIDWIFTLYSKSLPLDLACRIWDVFCRDGEEFLFRTALGILKLFEDILTKMDFIHMAQFLTRLPEDLPAEELFASIATIQMQSRNKKWAQVLTALQKDSREMEKGSPSLRH>sp|Q92609|TBCD5_HUMAN TBC1 domain family member 5 OS=Homo sapiensOX=9606 GN=TBC1D5 PE=1 SV=1MYHSLSETRHPLQPEEQEVGIDPLSSYSNKSGGDSNKNGRRTSSTLDSEGTFNSYRKEWEELFVNNNYLATIRQKGINGQLRSSRFRSICWKLFLCVLPQDKSQWISRIEELRAWYSNIKEIHITNPRKVVGQQDLMINNPLSQDEGSLWNKFFQDKELRSMIEQDVKRTFPEMQFFQQENVRKILTDVLFCYARENEQLLYKQGMHELLAPIVFVLHCDHQAFLHASESAQPSEEMKTVLNPEYLEHDAYAVFSQLMETAEPWFSTFEHDGQKGKETLMTPIPFARPQDLGPTIAIVTKVNQIQDHLLKKHDIELYMHLNRLEIAPQIYGLRWVRLLFGREFPLQDLLVVWDALFADGLSLGLVDYIFVAMLLYIRDALISSNYQTCLGLLMHYPFIGDVHSLILKALFLRDPKRNPRPVTYQFHPNLDYYKARGADLMNKSRTNAKGAPLNINKVSNSLINFGRKLISPAMAPGSAGGPVPGGNSSSSSSVVIPTRTSAEAPSHHLQQQQQQQRLMKSESMPVQLNKGLSSKNISSSPSVESLPGGREFTGSPPSSATKKDSFFSNISRSRSHSKTMGRKESEEELEAQISFLQGQLNDLDAMCKYCAKVMDTHLVNIQDVILQENLEKEDQILVSLAGLKQIKDILKGSLRFNQSQLEAEENEQITIADNHYCSSGQGQGRGQGQSVQMSGAIKQASSETPGCTDRGNSDDFILISKDDDGSSARGSFSGQAQPLRTLRSTSGKSQAPVCSPLVFSDPLMGPASASSSNPSSSPDDDSSKDSGFTIVSPLDI>sp|Q92609-2|TBCD5_HUMAN Isoform 2 of TBC1 domain family member 5 OS=Homosapiens OX=9606 GN=TBC1D5MYHSLSETRHPLQPEEQEVGIDPLSSYSNKSGGDSNKNGRRTSSTLDSEGTFNSYRKEWEELFVNNNYLATIRQKGINGQLRSSRFRSICWKLFLCVLPQDKSQWISRIEELRAWYSNIKEIHITNPRKVVGQQDLMINNPLSQDEGSLWNKFFQDKELRSMIEQDVKRTFPEMQFFQQENVRKILTDVLFCYARENEQLLYKQGMHELLAPIVFVLHCDHQAFLHASESAQPSEEMKTVLNPEYLEHDAYAVFSQLMETAEPWFSTFEHDGQKGKETLMTPIPFARPQDLGPTIAIVTKVNQIQDHLLKKHDIELYMHLNRLEIAPQIYGLRWVRLLFGREFPLQDLLVVWDALFADGLSLGLVDYIFVAMLLYIRDALISSNYQTCLGLLMHYPFIGDVHSLILKALFLRDPKRNPRPVTYQFHPNLDYYKARGADLMNKSRTNAKGAPLNINKVSNSLINFGRKLISPAMAPGSAGGPVPGGNSSSSSSVVIPTRTSAEAPSHHLQQQQQQQRLMKSESMPVQLNKGDVVTGSDAQVSVPVQTLTDLQGLSSKNISSSPSVESLPGGREFTGSPPSSATKKDSFFSNISRSRSHSKTMGRKESEEELEAQISFLQGQLNDLDAMCKYCAKVMDTHLVNIQDVILQENLEKEDQILVSLAGLKQIKDILKGSLRFNQSQLEAEENEQITIADNHYCSSGQGQGRGQGQSVQMSGAIKQASSETPGCTDRGNSDDFILISKDDDGSSARGSFSGQAQPLRTLRSTSGKSQAPVCSPLVFSDPLMGPASASSSNPSSSPDDDSSKDSGFTIVSPLDI>sp|O00206|TLR4_HUMAN Toll-like receptor 4 OS=Homo sapiens OX=9606GN=TLR4 PE=1 SV=2MMSASRLAGTLIPAMAFLSCVRPESWEPCVEVVPNITYQCMELNFYKIPDNLPFSTKNLDLSFNPLRHLGSYSFFSFPELQVLDLSRCEIQTIEDGAYQSLSHLSTLILTGNPIQSLALGAFSGLSSLQKLVAVETNLASLENFPIGHLKTLKELNVAHNLIQSFKLPEYFSNLTNLEHLDLSSNKIQSIYCTDLRVLHQMPLLNLSLDLSLNPMNFIQPGAFKEIRLHKLTLRNNFDSLNVMKTCIQGLAGLEVHRLVLGEFRNEGNLEKFDKSALEGLCNLTIEEFRLAYLDYYLDDIIDLFNCLTNVSSFSLVSVTIERVKDFSYNFGWQHLELVNCKFGQFPTLKLKSLKRLTFTSNKGGNAFSEVDLPSLEFLDLSRNGLSFKGCCSQSDFGTTSLKYLDLSFNGVITMSSNFLGLEQLEHLDFQHSNLKQMSEFSVFLSLRNLIYLDISHTHTRVAFNGIFNGLSSLEVLKMAGNSFQENFLPDIFTELRNLTFLDLSQCQLEQLSPTAFNSLSSLQVLNMSHNNFFSLDTFPYKCLNSLQVLDYSLNHIMTSKKQELQHFPSSLAFLNLTQNDFACTCEHQSFLQWIKDQRQLLVEVERMECATPSDKQGMPVLSLNITCQMNKTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQLCLHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVELYRLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSI>sp|O00206-2|TLR4_HUMAN Isoform 2 of Toll-like receptor 4 OS=Homo sapiensOX=9606 GN=TLR4MELNFYKIPDNLPFSTKNLDLSFNPLRHLGSYSFFSFPELQVLDLSRCEIQTIEDGAYQSLSHLSTLILTGNPIQSLALGAFSGLSSLQKLVAVETNLASLENFPIGHLKTLKELNVAHNLIQSFKLPEYFSNLTNLEHLDLSSNKIQSIYCTDLRVLHQMPLLNLSLDLSLNPMNFIQPGAFKEIRLHKLTLRNNFDSLNVMKTCIQGLAGLEVHRLVLGEFRNEGNLEKFDKSALEGLCNLTIEEFRLAYLDYYLDDIIDLFNCLTNVSSFSLVSVTIERVKDFSYNFGWQHLELVNCKFGQFPTLKLKSLKRLTFTSNKGGNAFSEVDLPSLEFLDLSRNGLSFKGCCSQSDFGTTSLKYLDLSFNGVITMSSNFLGLEQLEHLDFQHSNLKQMSEFSVFLSLRNLIYLDISHTHTRVAFNGIFNGLSSLEVLKMAGNSFQENFLPDIFTELRNLTFLDLSQCQLEQLSPTAFNSLSSLQVLNMSHNNFFSLDTFPYKCLNSLQVLDYSLNHIMTSKKQELQHFPSSLAFLNLTQNDFACTCEHQSFLQWIKDQRQLLVEVERMECATPSDKQGMPVLSLNITCQMNKTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQLCLHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVELYRLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSI>sp|O00206-3|TLR4_HUMAN Isoform 3 of Toll-like receptor 4 OS=Homo sapiensOX=9606 GN=TLR4MPLLNLSLDLSLNPMNFIQPGAFKEIRLHKLTLRNNFDSLNVMKTCIQGLAGLEVHRLVLGEFRNEGNLEKFDKSALEGLCNLTIEEFRLAYLDYYLDDIIDLFNCLTNVSSFSLVSVTIERVKDFSYNFGWQHLELVNCKFGQFPTLKLKSLKRLTFTSNKGGNAFSEVDLPSLEFLDLSRNGLSFKGCCSQSDFGTTSLKYLDLSFNGVITMSSNFLGLEQLEHLDFQHSNLKQMSEFSVFLSLRNLIYLDISHTHTRVAFNGIFNGLSSLEVLKMAGNSFQENFLPDIFTELRNLTFLDLSQCQLEQLSPTAFNSLSSLQVLNMSHNNFFSLDTFPYKCLNSLQVLDYSLNHIMTSKKQELQHFPSSLAFLNLTQNDFACTCEHQSFLQWIKDQRQLLVEVERMECATPSDKQGMPVLSLNITCQMNKTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQLCLHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVELYRLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSI>sp|Q96RU8|TRIB1_HUMAN Tribbles homolog 1 OS=Homo sapiens OX=9606GN=TRIB1 PE=1 SV=2MRVGPVRSAMSGASQPRGPALLFPATRGVPAKRLLDADDAAAVAAKCPRLSECSSPPDYLSPPGSPCSPQPPPAAPGAGGGSGSAPGPSRIADYLLLPLAEREHVSRALCIHTGRELRCKVFPIKHYQDKIRPYIQLPSHSNITGIVEVILGETKAYVFFEKDFGDMHSYVRSRKRLREEEAARLFKQIVSAVAHCHQSAIVLGDLKLRKFVFSTEERTQLRLESLEDTHIMKGEDDALSDKHGCPAYVSPEILNTTGTYSGKAADVWSLGVMLYTLLVGRYPFHDSDPSALFSKIRRGQFCIPEHISPKARCLIRSLLRREPSERLTAPEILLHPWFESVLEPGYIDSEIGTSDQIVPEYQEDSDISSFFC>sp|Q96RU8-2|TRIB1_HUMAN Isoform 2 of Tribbles homolog 1 OS=Homo sapiensOX=9606 GN=TRIB1MHSYVRSRKRLREEEAARLFKQIVSAVAHCHQSAIVLGDLKLRKFVFSTEERTQLRLESLEDTHIMKGEDDALSDKHGCPAYVSPEILNTTGTYSGKAADVWSLGVMLYTLLVGRYPFHDSDPSALFSKIRRGQFCIPEHISPKARCLIRSLLRREPSERLTAPEILLHPWFESVLEPGYIDSEIGTSDQIVPEYQEDSDISSFFC>sp|Q9BSI4|TINF2_HUMAN TERF1-interacting nuclear factor 2 OS=Homo sapiensOX=9606 GN=TINF2 PE=1 SV=1MATPLVAGPAALRFAAAASWQVVRGRCVEHFPRVLEFLRSLRAVAPGLVRYRHHERLCMGLKAKVVVELILQGRPWAQVLKALNHHFPESGPIVRDPKATKQDLRKILEAQETFYQQVKQLSEAPVDLASKLQELEQEYGEPFLAAMEKLLFEYLCQLEKALPTPQAQQLQDVLSWMQPGVSITSSLAWRQYGVDMGWLLPECSVTDSVNLAEPMEQNPPQQQRLALHNPLPKAKPGTHLPQGPSSRTHPEPLAGRHFNLAPLGRRRVQSQWASTRGGHKERPTVMLFPFRNLGSPTQVISKPESKEEHAIYTADLAMGTRAASTGKSKSPCQTLGGRALKENPVDLPATEQKENCLDCYMDPLRLSLLPPRARKPVCPPSLCSSVITIGDLVLDSDEEENGQGEGKESLENYQKTKFDTLIPTLCEYLPPSGHGAIPVSSCDCRDSSRPL>sp|Q9BSI4-2|TINF2_HUMAN Isoform 2 of TERF1-interacting nuclear factor 2OS=Homo sapiens OX=9606 GN=TINF2MATPLVAGPAALRFAAAASWQVVRGRCVEHFPRVLEFLRSLRAVAPGLVRYRHHERLCMGLKAKVVVELILQGRPWAQVLKALNHHFPESGPIVRDPKATKQDLRKILEAQETFYQQVKQLSEAPVDLASKLQELEQEYGEPFLAAMEKLLFEYLCQLEKALPTPQAQQLQDVLSWMQPGVSITSSLAWRQYGVDMGWLLPECSVTDSVNLAEPMEQNPPQQQRLALHNPLPKAKPGTHLPQGPSSRTHPEPLAGRHFNLAPLGRRRVQSQWASTRGGHKERPTVMLFPFRNLGSPTQVISKPESKEEHAIYTADLAMGTRAASTGKSKSPCQTLGGRALKENPVDLPATEQKE>sp|Q9BSI4-3|TINF2_HUMAN Isoform 3 of TERF1-interacting nuclear factor 2OS=Homo sapiens OX=9606 GN=TINF2MATPLVAGPAALRFAAAASWQVVRGRCVEHFPRVLEFLRSLRAVAPGLVRYRHHERLCMGLKAKVVVELILQGRPWAQVLKALNHHFPESGPIVRDPKATKQDLRKILEAQETFYQQVKQLSEAPVDLASKLQVRLV>sp|A6NNM8|TTL13_HUMAN Tubulin polyglutamylase TTLL13P OS=Homo sapiensOX=9606 GN=TTLL13P PE=1 SV=2MEPSTCRTMESEEDYVEEKESEKCVKEGVTNPSNSSQQALLKADYKALKNGVPSPIMATKIPKKVIAPVDTGDLEAGRRKRRRKRRSLAINLTNCKYESVRRAAQMCGLKEVGEDEEWTLYWTDCAVSLERVMDMKRFQKINHFPGMTEICRKDLLARNLNRMYKLYPSEYNIFPRTWCLPADYGDFQSYGRQRKARTYICKPDSGCQGRGIFITRNPREIKPGEHMICQQYISKPLLIDGFKFDMRVYVLITSCDPLRIFTYEEGLARFATTPYMEPSHNNLDNVCMHLTNYAINKHNENFVRDGAVGSKRKLSTLNIWLQEHSYNPGELWGDIEDIIIKTIISAHSVLRHNYRTCFPQYLNGGTCACFEILGFDILLDHKLKPWLLEVNHSPSFTTDSCLDQEVKDALLCDAMTLVNLRGCDKRKVMEEDKRRVKERLFQCYRQPRESRKEKTESSHVAMLDQERYEDSHLGKYRRIYPGPDTEKYARFFKHNGSLFQETAASKAREECARQQLEEIRLKQEQQETSGTKRQKARDQNQGESAGEKSRPRAGLQSLSTHLAYRNRNWEKELLPGQLDTMRPQEIVEEEELERMKALLQRETLIRSLGIVEQLTRLQHPGPQGQKKLHESRDRLGSQELKSMSLVLLVLLRGAATEQGAPHFLHPVLPHESIPRILGALPSMNAAIPHVPRYHLQPKNFNWTGEPAAINSCSLSMKKAGRCYFSSARIRLTSQGQASRRLEAINRVLAGSVPPTLTPKQGYFLQPERVASDSWTECTLPSMVNSEHRAAKVPLCPASAPMLQRSRALLNINQFR>sp|A6NNM8-2|TTL13_HUMAN Isoform 2 of Tubulin polyglutamylase TTLL13POS=Homo sapiens OX=9606 GN=TTLL13PMEPSTCRTMESEEDYVEEKESEKCVKEGVTNPSNSSQQALLKADYKALKNGVPSPIMATKIPKKVIAPVDTGDLEAGRRKRRRKRRSLAINLTNCKYESVRRAAQMCGLKEVGEDEEWTLYWTDCAVSLERVMDMKRFQKINHFPGMTEICRKDLLARNLNRMYKLYPSEYNIFPRTWCLPADYGDFQSYGRQRKARTYICKPDSGCQGRGIFITRNPREIKPGEHMICQQYISKPLLIDGFKFDMRVYVLITSCDPLRIFTYEEGLARFATTPYMEPSHNNLDNVCMHLTNYAINKHNENFVRDGAVGSKRKLSTLNIWLQEHSYNPGELWGDIEDIIIKTIISAHSVLRHNYRTCFPQYLNGGTCACFEILGFDILLDHKLKPWLLEVNHSPSFTTDSCLDQEVKDALLCDAMTLVNLRGCDKRKVMEEDKRRVKERLFQCYRQPRESRCARCLACV>sp|O60635|TSN1_HUMAN Tetraspanin-1 OS=Homo sapiens OX=9606 GN=TSPAN1PE=1 SV=2MQCFSFIKTMMILFNLLIFLCGAALLAVGIWVSIDGASFLKIFGPLSSSAMQFVNVGYFLIAAGVVVFALGFLGCYGAKTESKCALVTFFFILLLIFIAEVAAAVVALVYTTMAEHFLTLLVVPAIKKDYGSQEDFTQVWNTTMKGLKCCGFTNYTDFEDSPYFKENSAFPPFCCNDNVTNTANETCTKQKAHDQKVEGCFNQLLYDIRTNAVTVGGVAAGIGGLELAAMIVSMYLYCNLQ>sp|Q9NQE7|TSSP_HUMAN Thymus-specific serine protease OS=Homo sapiensOX=9606 GN=PRSS16 PE=2 SV=2MAVWLAQWLGPLLLVSLWGLLAPASLLRRLGEHIQQFQESSAQGLGLSLGPGAAALPKVGWLEQLLDPFNVSDRRSFLQRYWVNDQHWVGQDGPIFLHLGGEGSLGPGSVMRGHPAALAPAWGALVISLEHRFYGLSIPAGGLEMAQLRFLSSRLALADVVSARLALSRLFNISSSSPWICFGGSYAGSLAAWARLKFPHLIFASVASSAPVRAVLDFSEYNDVVSRSLMSTAIGGSLECRAAVSVAFAEVERRLRSGGAAQAALRTELSACGPLGRAENQAELLGALQALVGGVVQYDGQTGAPLSVRQLCGLLLGGGGNRSHSTPYCGLRRAVQIVLHSLGQKCLSFSRAETVAQLRSTEPQLSGVGDRQWLYQTCTEFGFYVTCENPRCPFSQLPALPSQLDLCEQVFGLSALSVAQAVAQTNSYYGGQTPGANKVLFVNGDTDPWHVLSVTQALGSSESTLLIRTGSHCLDMAPERPSDSPSLRLGRQNIFQQLQTWLKLAKESQIKGEV>sp|Q9H313|TTYH1_HUMAN Protein tweety homolog 1 OS=Homo sapiens OX=9606GN=TTYH1 PE=1 SV=1MGAPPGYRPSAWVHLLHQLPRADFQLRPVPSVFAPQEQEYQQALLLVAALAGLGLGLSLIFIAVYLIRFCCCRPPEPPGSKIPSPGGGCVTWSCIVALLAGCTGIGIGFYGNSETSDGVSQLSSALLHANHTLSTIDHLVLETVERLGEAVRTELTTLEEVLEPRTELVAAARGARRQAEAAAQQLQGLAFWQGVPLSPLQVAENVSFVEEYRWLAYVLLLLLELLVCLFTLLGLAKQSKWLVIVMTVMSLLVLVLSWGSMGLEAATAVGLSDFCSNPDPYVLNLTQEETGLSSDILSYYLLCNRAVSNPFQQRLTLSQRALANIHSQLLGLEREAVPQFPSAQKPLLSLEETLNVTEGNFHQLVALLHCRSLHKDYGAALRGLCEDALEGLLFLLLFSLLSAGALATALCSLPRAWALFPPSDDYDDTDDDDPFNPQESKRFVQWQSSI>sp|Q9H313-2|TTYH1_HUMAN Isoform 2 of Protein tweety homolog 1 OS=Homosapiens OX=9606 GN=TTYH1MGAPPGYRPSAWVHLLHQLPRADFQLRPVPSVFAPQEQEYQQALLLVAALAGLGLGLSLIFIAVYLIRFCCCRPPEPPGSKIPSPGGGCVTWSCIVALLAGCTGIGIGFYGNSETSDGVSQLSSALLHANHTLSTIDHLVLETVERLGEAVRTELTTLEEVLEPRTELVAAARGARRQAEAAAQQLQGLAFWQGVPLSPLQVAENVSFVEEYRWLAYVLLLLLELLVCLFTLLGLAKQSKWLVIVMTVMSLLVLVLSWGSMGLEAATAVGLSDFCSNPDPYVLNLTQEETGLSSDILSYYLLCNRAVSNPFQQRLTLSQRALANIHSQLLGLEREAVPQFPSAQKPLLSLEETLNVTEGNFHQLVALLHCRSLHKDYGAALRGLCEDALEGLLFLLLFSLLSAGALATALCSLPRAWALFPPSDDYDDTDDDDPFNPQQESKRFVQWQSSI>sp|Q9H313-3|TTYH1_HUMAN Isoform 3 of Protein tweety homolog 1 OS=Homosapiens OX=9606 GN=TTYH1MGAPPGYRPSAWVHLLHQLPRADFQLRPVPSVFAPQEQEYQQALLLVAALAGLGLGLSLIFIAVYLIRFCCCRPPEPPGSKIPSPGGGCVTWSCIVALLAGCTGIGIGFYGNSETSDGVSQLSSALLHANHTLSTIDHLVLETVERLGEAVRTELTTLEEVLEPRTELVAAARGARRQAEAAAQQLQGLAFWQGVPLSPLQVAENVSFVEEYRWLAYVLLLLLELLVCLFTLLGLAKQSKWLVIVMTVMSLLVLVLSWGSMGLEAATAVGLSDFCSNPDPYVLNLTQEETGLSSDILSYYLLCNRAVSNPFQQRLTLSQRALANIHSQLLGLEREAVPQFPSAQKPLLSLEETLNVTEGNFHQLVALLHCRSLHKDYGAALRGLCEDALEGLLFLLLFSLLSAGALATALCSLPRAWALFPPRNPSALCSGSRLSEPLLPAGLEPGSPLRSFPGCRRRPH>sp|Q9H313-4|TTYH1_HUMAN Isoform 4 of Protein tweety homolog 1 OS=Homosapiens OX=9606 GN=TTYH1MWLAYVLLLLLELLVCLFTLLGLAKQSKWLVIVMTVMSLLVLVLSWGSMGLEAATAVGLSDFCSNPDPYVLNLTQEETGLSSDILSYYLLCNRAVSNPFQQRLTLSQRALANIHSQLLGLEREAVPQFPSAQKPLLSLEETLNVTEGNFHQLVALLHCRSLHKDYGAALRGLCEDALEGLLFLLLFSLLSAGALATALCSLPRAWALFPPSDDYDDTDDDDPFNPQQESKRFVQWQSSI>sp|Q9H313-5|TTYH1_HUMAN Isoform 5 of Protein tweety homolog 1 OS=Homosapiens OX=9606 GN=TTYH1MEKVRLWRGSESRAAICTGIGIGFYGNSETSDGVSQLSSALLHANHTLSTIDHLTVERLGEAVRTELTTLEEVLEPRTELVAAARGARRQAEAAAQQLQGLAFWQGVPLSPLQVAENVSFVEEYRWLAYVLLLLLELLVCLFTLLGLAKQSKWLVIVMTVMSLLVLVLSWGSMGLEAATAVGLSDFCSNPDPYVLNLTQEETGLSSDILSYYLLCNRAVSNPFQQRLTLSQRALANIHSQLLGLEREAVPQFPSAQKPLLSLEETLNVTEGNFHQLVALLHCRSLHKVKPLPSQFLLPRGASVSTHRTTSSFSLDPCHCA>sp|Q5JXB2|UE2NL_HUMAN Putative ubiquitin-conjugating enzyme E2 N-likeOS=Homo sapiens OX=9606 GN=UBE2NL PE=1 SV=1MAELPHRIIKETQRLLAEPVPGIKAEPDESNARYFHVVIAGESKDSPFEGGTFKRELLLAEEYPMAAPKVRFMTKIYHPNVDKLERISLDILKDKWSPALQIRTVLLSIQALLNAPNPDDPLANDVVEQWKTNEAQAIETARAWTRLYAMNSI>sp|Q99598|TSNAX_HUMAN Translin-associated protein X OS=Homo sapiensOX=9606 GN=TSNAX PE=1 SV=1MSNKEGSGGFRKRKHDNFPHNQRREGKDVNSSSPVMLAFKSFQQELDARHDKYERLVKLSRDITVESKRTIFLLHRITSAPDMEDILTESEIKLDGVRQKIFQVAQELSGEDMHQFHRAITTGLQEYVEAVSFQHFIKTRSLISMDEINKQLIFTTEDNGKENKTPSSDAQDKQFGTWRLRVTPVDYLLGVADLTGELMRMCINSVGNGDIDTPFEVSQFLRQVYDGFSFIGNTGPYEVSKKLYTLKQSLAKVENACYALKVRGSEIPKHMLADVFSVKTEMIDQEEGIS>sp|P04818|TYSY_HUMAN Thymidylate synthase OS=Homo sapiens OX=9606GN=TYMS PE=1 SV=3MPVAGSELPRRPLPPAAQERDAEPRPPHGELQYLGQIQHILRCGVRKDDRTGTGTLSVFGMQARYSLRDEFPLLTTKRVFWKGVLEELLWFIKGSTNAKELSSKGVKIWDANGSRDFLDSLGFSTREEGDLGPVYGFQWRHFGAEYRDMESDYSGQGVDQLQRVIDTIKTNPDDRRIIMCAWNPRDLPLMALPPCHALCQFYVVNSELSCQLYQRSGDMGLGVPFNIASYALLTYMIAHITGLKPGDFIHTLGDAHIYLNHIEPLKIQLQREPRPFPKLRILRKVEKIDDFKAEDFQIEGYNPHPTIKMEMAV>sp|P04818-2|TYSY_HUMAN Isoform 2 of Thymidylate synthase OS=Homo sapiensOX=9606 GN=TYMSMPVAGSELPRRPLPPAAQERDAEPRPPHGELQYLGQIQHILRCGVRKDDRTGTGTLSVFGMQARYSLRDEFPLLTTKRVFWKGVLEELLWFIKGSTNAKELSSKGVKIWDANGSRDFLDSLGFSTREEGDLGPVYGFQWRHFGAEYRDMESDLPLMALPPCHALCQFYVVNSELSCQLYQRSGDMGLGVPFNIASYALLTYMIAHITGLKPGDFIHTLGDAHIYLNHIEPLKIQLQREPRPFPKLRILRKVEKIDDFKAEDFQIEGYNPHPTIKMEMAV>sp|P04818-3|TYSY_HUMAN Isoform 3 of Thymidylate synthase OS=Homo sapiensOX=9606 GN=TYMSMPVAGSELPRRPLPPAAQERDAEPRPPHGELQYLGQIQHILRCGVRKDDRTGTGTLSVFGMQARYSLRDYSGQGVDQLQRVIDTIKTNPDDRRIIMCAWNPRDLPLMALPPCHALCQFYVVNSELSCQLYQRSGDMGLGVPFNIASYALLTYMIAHITGLKPGDFIHTLGDAHIYLNHIEPLKIQLQREPRPFPKLRILRKVEKIDDFKAEDFQIEGYNPHPTIKMEMAV>sp|Q12792|TWF1_HUMAN Twinfilin-1 OS=Homo sapiens OX=9606 GN=TWF1 PE=1SV=3MSHQTGIQASEDVKEIFARARNGKYRLLKISIENEQLVIGSYSQPSDSWDKDYDSFVLPLLEDKQPCYILFRLDSQNAQGYEWIFIAWSPDHSHVRQKMLYAATRATLKKEFGGGHIKDEVFGTVKEDVSLHGYKKYLLSQSSPAPLTAAEEELRQIKINEVQTDVGVDTKHQTLQGVAFPISREAFQALEKLNNRQLNYVQLEIDIKNEIIILANTTNTELKDLPKRIPKDSARYHFFLYKHSHEGDYLESIVFIYSMPGYTCSIRERMLYSSCKSRLLEIVERQLQMDVIRKIEIDNGDELTADFLYEEVHPKQHAHKQSFAKPKGPAGKRGIRRLIRGPAETEATTD>sp|Q12792-3|TWF1_HUMAN Isoform 3 of Twinfilin-1 OS=Homo sapiens OX=9606GN=TWF1MSHQTGIQASEDVKEIFARARNGKYRLLKISIENEQLVIGSYSQPSDSWDKDYDSFVLPLLEDKQPCYILFRLDSQNAQGYEWIFIAWSPDHSHVRQKMLYAATRATLKKEFGGGHIKDEVFGTVKEDVSLHGYKKYLLSQSSPAPLTAAEEELRQIKINESPEDHIGVQTDVGVDTKHQTLQGVAFPISREAFQALEKLNNRQLNYVQLEIDIKNEIIILANTTNTELKDLPKRIPKDSARYHFFLYKHSHEGDYLESIVFIYSMPGYTCSIRERMLYSSCKSRLLEIVERQLQMDVIRKIEIDNGDELTADFLYEEVHPKQHAHKQSFAKPKGPAGKRGIRRLIRGPAETEATTD>sp|Q12792-4|TWF1_HUMAN Isoform 4 of Twinfilin-1 OS=Homo sapiens OX=9606GN=TWF1MLYAATRATLKKEFGGGHIKDEVFGTVKEDVSLHGYKKYLLSQSSPAPLTAAEEELRQIKINEVQTDVGVDTKHQTLQGVAFPISREAFQALEKLNNRQLNYVQLEIDIKNEIIILANTTNTELKDLPKRIPKDSARYHFFLYKHSHEGDYLESIVFIYSMPGYTCSIRERMLYSSCKSRLLEIVERQLQMDVIRKIEIDNGDELTADFLYEEVHPKQHAHKQSFAKPKGPAGKRGIRRLIRGPAETEATTD>sp|P0C7I0|U17L8_HUMAN Inactive ubiquitin carboxyl-terminal hydrolase 17-like protein 8 OS=Homo sapiens OX=9606 GN=USP17L8 PE=3 SV=1MEDDSLYLGGEWQFNHFSKLTSPRPDAAFAEIQRTSLPEKSPLSSETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYLNASLQCLTYTPPLANYMLSREHSQTCQRPKCCMLCTMQAHITWALHSPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGCWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVKQALEQLVKPEELNGENAYPCGLCLQRAPASNTLTLHTSAKVLILVLKRFCDVTGNKLAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHNGYYFSYVKAQEGQWYKMDDAEVTACSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRPATQGELKRDHPCLQVPELDEHLVERATEESTLDHWKFPQEQNKMKPEFNVRKVEGTLPPNVLVIHQSKYKCGMKNHHPEQQSSLLNLSSMNSTDQESMNTGTLASLQGRTRRSKGKNKHSKRSLLVCQ>sp|P62253|UB2G1_HUMAN Ubiquitin-conjugating enzyme E2 G1 OS=Homo sapiensOX=9606 GN=UBE2G1 PE=1 SV=3MTELQSALLLRRQLAELNKNPVEGFSAGLIDDNDLYRWEVLIIGPPDTLYEGGVFKAHLTFPKDYPLRPPKMKFITEIWHPNVDKNGDVCISILHEPGEDKYGYEKPEERWLPIHTVETIMISVISMLADPNGDSPANVDAAKEWREDRNGEFKRKVARCVRKSQETAFE>sp|Q6UXZ4|UNC5D_HUMAN Netrin receptor UNC5D OS=Homo sapiens OX=9606GN=UNC5D PE=1 SV=1MGRAAATAGGGGGARRWLPWLGLCFWAAGTAAARGTDNGEALPESIPSAPGTLPHFIEEPDDAYIIKSNPIALRCKARPAMQIFFKCNGEWVHQNEHVSEETLDESSGLKVREVFINVTRQQVEDFHGPEDYWCQCVAWSHLGTSKSRKASVRIAYLRKNFEQDPQGREVPIEGMIVLHCRPPEGVPAAEVEWLKNEEPIDSEQDENIDTRADHNLIIRQARLSDSGNYTCMAANIVAKRRSLSATVVVYVNGGWSSWTEWSACNVRCGRGWQKRSRTCTNPAPLNGGAFCEGMSVQKITCTSLCPVDGSWEVWSEWSVCSPECEHLRIRECTAPPPRNGGKFCEGLSQESENCTDGLCILDKKPLHEIKPQSIENASDIALYSGLGAAVVAVAVLVIGVTLYRRSQSDYGVDVIDSSALTGGFQTFNFKTVRQGNSLLLNSAMQPDLTVSRTYSGPICLQDPLDKELMTESSLFNPLSDIKVKVQSSFMVSLGVSERAEYHGKNHSRTFPHGNNHSFSTMHPRNKMPYIQNLSSLPTRTELRTTGVFGHLGGRLVMPNTGVSLLIPHGAIPEENSWEIYMSINQGEPSLQSDGSEVLLSPEVTCGPPDMIVTTPFALTIPHCADVSSEHWNIHLKKRTQQGKWEEVMSVEDESTSCYCLLDPFACHVLLDSFGTYALTGEPITDCAVKQLKVAVFGCMSCNSLDYNLRVYCVDNTPCAFQEVVSDERHQGGQLLEEPKLLHFKGNTFSLQISVLDIPPFLWRIKPFTACQEVPFSRVWCSNRQPLHCAFSLERYTPTTTQLSCKICIRQLKGHEQILQVQTSILESERETITFFAQEDSTFPAQTGPKAFKIPYSIRQRICATFDTPNAKGKDWQMLAQKNSINRNLSYFATQSSPSAVILNLWEARHQHDGDLDSLACALEEIGRTHTKLSNISESQLDEADFNYSRQNGL>sp|Q6UXZ4-2|UNC5D_HUMAN Isoform 2 of Netrin receptor UNC5D OS=Homosapiens OX=9606 GN=UNC5DMILVLVKALSDVCAGTSGFLLDFSSQTSPGTDNGEALPESIPSAPGTLPHFIEEPDDAYIIKSNPIALRCKARPAMQIFFKCNGEWVHQNEHVSEETLDESSGLKVREVFINVTRQQVEDFHGPEDYWCQCVAWSHLGTSKSRKASVRIAYLRKNFEQDPQGREVPIEGMIVLHCRPPEGVPAAEVEWLKNEEPIDSEQDENIDTRADHNLIIRQARLSDSGNYTCMAANIVAKRRSLSATVVVYVNGGWSSWTEWSACNVRCGRGWQKRSRTCTNPAPLNGGAFCEGMSVQKITCTSLCPVDGSWEVWSEWSVCSPECEHLRIRECTAPPPRNGGKFCEGLSQESENCTDGLCILDKKPLHEIKPQSIENASDIALYSGLGAAVVAVAVLVIGVTLYRRSQSDYGVDVIDSSALTGGFQTFNFKTVRQGNSLLLNSAMQPDLTVSRTYSGPICLQDPLDKELMTESSLFNPLSDIKVKVQSSFMVSLGVSERAEYHGKNHSRTFPHGNNHSFSTMHPRNKMPYIQNLSSLPTRTELRTTGVFGHLGGRLVMPNTGVSLLIPHGAIPEENSWEIYMSINQGEPSLQSDGSEVLLSPEVTCGPPDMIVTTPFALTIPHCADVSSEHWNIHLKKRTQQGKWEEVMSVEDESTSCYCLLDPFACHVLLDSFGTYALTGEPITDCAVKQLKVAVFGCMSCNSLDYNLRVYCVDNTPCAFQEVVSDERHQGGQLLEEPKLLHFKGNTFSLQISVLDIPPFLWRIKPFTACQEVPFSRVWCSNRQPLHCAFSLERYTPTTTQLSCKICIRQLKGHEQILQVQTSILESERETITFFAQEDSTFPAQTGPKAFKIPYSIRQRICATFDTPNAKGKDWQMLAQKNSINRNLSYFATQSSPSAVILNLWEARHQHDGDLDSLACALEEIGRTHTKLSNISESQLDEADFNYSRQNGL>sp|F5GYI3|UBA1L_HUMAN Ubiquitin-associated protein 1-like OS=Homosapiens OX=9606 GN=UBAP1L PE=2 SV=1MNALDGVPFKLPKGFVIGTEPLPGPELSVPACGEVLLGSMHDFSLERTALFWVEAAGQGPSPYQCGDPGTASAPPAWLLLVSPEHGLAPAPTTIRDPEAGHQERPEEEGEDEAEASSGSEEEPAPSSLQPGSPASPGPGRRLCSLDVLRGVRLELAGARRRLSEGKLVSRPRALLHGLRGHRALSLCPSPAQSPRSASPPGPAPQHPAAPASPPRPSTAGAIPPLRSHKPTVASLSPYTCLPPLGGAPQPLNPHKSHPDTAADLLSALSQEEQDLIGPVVALGYPLRRAIIALQKTGRQSLSQFLSYLSACDRLLRQGYEEGLVDEAMEMFQFSESQAGEFLRLWEQFSDMGFQQDRIKEVLLVHGNRREQALEELVACAQ>sp|P41226|UBA7_HUMAN Ubiquitin-like modifier-activating enzyme 7 OS=Homosapiens OX=9606 GN=UBA7 PE=1 SV=2MDALDASKLLDEELYSRQLYVLGSPAMQRIQGARVLVSGLQGLGAEVAKNLVLMGVGSLTLHDPHPTCWSDLAAQFLLSEQDLERSRAEASQELLAQLNRAVQVVVHTGDITEDLLLDFQVVVLTAAKLEEQLKVGTLCHKHGVCFLAADTRGLVGQLFCDFGEDFTVQDPTEAEPLTAAIQHISQGSPGILTLRKGANTHYFRDGDLVTFSGIEGMVELNDCDPRSIHVREDGSLEIGDTTTFSRYLRGGAITEVKRPKTVRHKSLDTALLQPHVVAQSSQEVHHAHCLHQAFCALHKFQHLHGRPPQPWDPVDAETVVGLARDLEPLKRTEEEPLEEPLDEALVRTVALSSAGVLSPMVAMLGAVAAQEVLKAISRKFMPLDQWLYFDALDCLPEDGELLPSPEDCALRGSRYDGQIAVFGAGFQEKLRRQHYLLVGAGAIGCELLKVFALVGLGAGNSGGLTVVDMDHIERSNLSRQFLFRSQDVGRPKAEVAAAAARGLNPDLQVIPLTYPLDPTTEHIYGDNFFSRVDGVAAALDSFQARRYVAARCTHYLKPLLEAGTSGTWGSATVFMPHVTEAYRAPASAAASEDAPYPVCTVRYFPSTAEHTLQWARHEFEELFRLSAETINHHQQAHTSLADMDEPQTLTLLKPVLGVLRVRPQNWQDCVAWALGHWKLCFHYGIKQLLRHFPPNKVLEDGTPFWSGPKQCPQPLEFDTNQDTHLLYVLAAANLYAQMHGLPGSQDWTALRELLKLLPQPDPQQMAPIFASNLELASASAEFGPEQQKELNKALEVWSVGPPLKPLMFEKDDDSNFHVDFVVAAASLRCQNYGIPPVNRAQSKRIVGQIIPAIATTTAAVAGLLGLELYKVVSGPRPRSAFRHSYLHLAENYLIRYMPFAPAIQTFHHLKWTSWDRLKVPAGQPERTLESLLAHLQEQHGLRVRILLHGSALLYAAGWSPEKQAQHLPLRVTELVQQLTGQAPAPGQRVLVLELSCEGDDEDTAFPPLHYEL>sp|Q96ET8|TV23C_HUMAN Golgi apparatus membrane protein TVP23 homolog COS=Homo sapiens OX=9606 GN=TVP23C PE=1 SV=3MLQQDSNDDTEDVSLFDAEEETTNRPRKAKIRHPVASFFHLFFRVSAIIVCLLCELLSSSFITCMVTIILLLSCDFWAVKNVTGRLMVGLRWWNHIDEDGKSHWVFESRKESSQENKTVSEAESRIFWLGLIACSVLWVIFAFSALFSFTVKWLRRSRHIAQTGLKVLGSRDPPASAFQSAGITGVSRCPGHPSRKFHQVDINSFTRITDRALYWKPAPRLSSPPLRAAPGNCQQMAPARLFLSLRLWAWRGGGESPNSRGTGEPGPKFHLASGMH>sp|Q96ET8-2|TV23C_HUMAN Isoform 2 of Golgi apparatus membrane proteinTVP23 homolog C OS=Homo sapiens OX=9606 GN=TVP23CMLQQDSNDDTEDVSLFDAEEETTNRPRKAKIRHPVASFFHLFFRVSAIIVCLLCELLSSSFITCMVTIILLLSCDFWAVKNVTGRLMVGLRWWNHIDEDGKSHWVFESRKESSQENKTVSEAESRIFWLGLIACSVLWVIFAFSALFSFTVKWLESEPVMLRNQ>sp|Q96ET8-3|TV23C_HUMAN Isoform 3 of Golgi apparatus membrane proteinTVP23 homolog C OS=Homo sapiens OX=9606 GN=TVP23CMLQQDSNDDTEDVSLFDAEEETTNRPRKAKIRHPVASFFHLFFRVSAIIVCLLCELLSSSFITCMVTIILLLSCDFWAVKNVTGRLMVGLRWWNHIDEDGKSHWVFESRKESSQENKTVSEAESRIFWLGLIACSVLWVIFAFSALFSFTVKWLAVVIMGVVLQGANLYGYIRCKVRSRKHLTSMATSYFGKQFLRQVSVFWM>sp|Q8N806|UBR7_HUMAN Putative E3 ubiquitin-protein ligase UBR7 OS=Homosapiens OX=9606 GN=UBR7 PE=1 SV=2MAGAEGAAGRQSELEPVVSLVDVLEEDEELENEACAVLGGSDSEKCSYSQGSVKRQALYACSTCTPEGEEPAGICLACSYECHGSHKLFELYTKRNFRCDCGNSKFKNLECKLLPDKAKVNSGNKYNDNFFGLYCICKRPYPDPEDEIPDEMIQCVVCEDWFHGRHLGAIPPESGDFQEMVCQACMKRCSFLWAYAAQLAVTKISTEDDGLVRNIDGIGDQEVIKPENGEHQDSTLKEDVPEQGKDDVREVKVEQNSEPCAGSSSESDLQTVFKNESLNAESKSGCKLQELKAKQLIKKDTATYWPLNWRSKLCTCQDCMKMYGDLDVLFLTDEYDTVLAYENKGKIAQATDRSDPLMDTLSSMNRVQQVELICEYNDLKTELKDYLKRFADEGTVVKREDIQQFFEEFQSKKRRRVDGMQYYCS>sp|Q9BXU3|TX13A_HUMAN Testis-expressed protein 13A OS=Homo sapiensOX=9606 GN=TEX13A PE=1 SV=1MALRPEDPSSGFRHSNVVAFINEKMARHTKGPEFYLENISLSWEKVEDKLRAILEDSEVPSEVKEACTWGSLALGVRFAHRQAQLQRHRVRWLHGFAKLHKSAAQALASDLKKLREQQETERKEAASRLRMAQTSLVEVQKERDKELVSPHEWEQGAGWPGLATAGGVCTEGAAEEEEEAAVAAAGAAGGKGAEEEQRDVEVVAAPVEAMAPPVEAGAAPMETQFPHVEARAASMETTEKLERILLQLLGDADQEKYTYWGQKEGDLRSVETATSYFSGTTNPWSRASSEPLPVQLPASYSYSYSSPFSSFSDIPTISPPQATVTAPVPPQLPSDWEAFDTSLWSDGGPHRIDHQEHPRDRRYSEPHQQRPPVYRRPGDWDCPWCNAVNFSRRDTCFDCGKGIWLQKPH>sp|Q15853|USF2_HUMAN Upstream stimulatory factor 2 OS=Homo sapiensOX=9606 GN=USF2 PE=1 SV=1MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLDGQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTAVSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVERRRRDKINNWIVQLSKIIPDCNADNSKTGASKGGILSKACDYIRELRQTNQRMQETFKEAERLQMDNELLRQQIEELKNENALLRAQLQQHNLEMVGEGTRQ>sp|Q15853-2|USF2_HUMAN Isoform USF2A-delta-H of Upstream stimulatoryfactor 2 OS=Homo sapiens OX=9606 GN=USF2MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLDGQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTAVSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVERRRRDKINNWIVQLSKIIPDCNADNSKTGAACDYIRELRQTNQRMQETFKEAERLQMDNELLRQQIEELKNENALLRAQLQQHNLEMVGEGTRQ>sp|Q15853-3|USF2_HUMAN Isoform USF2B of Upstream stimulatory factor 2OS=Homo sapiens OX=9606 GN=USF2MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTAVSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVERRRRDKINNWIVQLSKIIPDCNADNSKTGASKGGILSKACDYIRELRQTNQRMQETFKEAERLQMDNELLRQQIEELKNENALLRAQLQQHNLEMVGEGTRQ>sp|Q15853-4|USF2_HUMAN Isoform USF2c of Upstream stimulatory factor 2OS=Homo sapiens OX=9606 GN=USF2MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVERRRRDKINNWIVQLSKIIPDCNADNSKTGASKGGILSKACDYIRELRQTNQRMQETFKEAERLQMDNELLRQQIEELKNENALLRAQLQQHNLEMVGEGTRQ>sp|O00507|USP9Y_HUMAN Probable ubiquitin carboxyl-terminal hydrolaseFAF-Y OS=Homo sapiens OX=9606 GN=USP9Y PE=2 SV=2MTAITHGSPVGGNDSQGQVLDGQSQHLFQQNQTSSPDSSNENSVATPPPEEQGQGDAPPQHEDEEPAFPHTELANLDDMINRPRWVVPVLPKGELEVLLEAAIDLSVKGLDVKSEACQRFFRDGLTISFTKILMDEAVSGWKFEIHRCIINNTHRLVELCVAKLSQDWFPLLELLAMALNPHCKFHIYNGTRPCELISSNAQLPEDELFARSSDPRSPKGWLVDLINKFGTLNGFQILHDRFFNGSALNIQIIAALIKPFGQCYEFLSQHTLKKYFIPVIEIVPHLLENLTDEELKKEAKNEAKNDALSMIIKSLKNLASRISGQDETIKNLEIFRLKMILRLLQISSFNGKMNALNEINKVISSVSYYTHRHSNPEEEEWLTAERMAEWIQQNNILSIVLQDSLHQPQYVEKLEKILRFVIKEKALTLQDLDNIWAAQAGKHEAIVKNVHDLLAKLAWDFSPGQLDHLFDCFKASWTNASKKQREKLLELIRRLAEDDKDGVMAHKVLNLLWNLAQSDDVPVDIMDLALSAHIKILDYSCSQDRDAQKIQWIDHFIEELRTNDKWVIPALKQIREICSLFGEASQNLSQTQRSPHIFYRHDLINQLQQNHALVTLVAENLATYMNSIRLYAGDHEDYDPQTVRLGSRYSHVQEVQERLNFLRFLLKDGQLWLCAPQAKQIWKCLAENAVYLCDREACFKWYSKLMGDEPDLDPDINKDFFESNVLQLDPSLLTENGMKCFERFFKAVNCRERKLIAKRRSYMMDDLELIGLDYLWRVVIQSSDEIANRAIDLLKEIYTNLGPRLKANQVVIHEDFIQSCFDRLKASYDTLCVFDGDKNSINCARQEAIRMVRVLTVIKEYINECDSDYHKERMILPMSRAFRGKHLSLIVRFPNQGRQVDELDIWSHTNDTIGSVRRCIVNRIKANVAHKKIELFVGGELIDSEDDRKLIGQLNLKDKSLITAKLTQINFNMPSSPDSSSDSSTASPGNHRNHYNDGPNLEVESCLPGVIMSVHPRYISFLWQVADLGSNLNMPPLRDGARVLMKLMPPDRTAVEKLRAVCLDHAKLGEGKLSPPLDSLFFGPSASQVLYLTEVVYALLMPAGVPLTDGSSDFQVHFLKSGGLPLVLSMLIRNNFLPNTDMETRRGAYLNALKIAKLLLTAIGYGHVRAVAEACQPVVDGTDPITQINQVTHDQAVVLQSALQSIPNPSSECVLRNESILLAQEISNEASRYMPDICVIRAIQKIIWASACGALGLVFSPNEEITKIYQMTTNGSNKLEVEDEQVCCEALEVMTLCFALLPTALDALSKEKAWQTFIIDLLLHCPSKTVRQLAQEQFFLMCTRCCMGHRPLLFFITLLFTILGSTAREKGKYSGDYFTLLRHLLNYAYNGNINIPNAEVLLVSEIDWLKRIRDNVKNTGETGVEEPILEGHLGVTKELLAFQTSEKKYHFGCEKGGANLIKELIDDFIFPASKVYLQYLRSGELPAEQAIPVCSSPVTINAGFELLVALAIGCVRNLKQIVDCLTEMYYMGTAITTCEALTEWEYLPPVGPRPPKGFVGLKNAGATCYMNSVIQQLYMIPSIRNSILAIEGTGSDLHDDMFGDEKQDSESNVDPRDDVFGYPHQFEDKPALSKTEDRKEYNIGVLRHLQVIFGHLAASQLQYYVPRGFWKQFRLWGEPVNLREQHDALEFFNSLVDSLDEALKALGHPAILSKVLGGSFADQKICQGCPHRYECEESFTTLNVDIRNHQNLLDSLEQYIKGDLLEGANAYHCEKCDKKVDTVKRLLIKKLPRVLAIQLKRFDYDWERECAIKFNDYFEFPRELDMGPYTVAGVANLERDNVNSENELIEQKEQSDNETAGGTKYRLVGVLVHSGQASGGHYYSYIIQRNGKDDQTDHWYKFDDGDVTECKMDDDEEMKNQCFGGEYMGEVFDHMMKRMSYRRQKRWWNAYILFYEQMDMIDEDDEMIRYISELTIARPHQIIMSPAIERSVRKQNVKFMHNRLQYSLEYFQFVKKLLTCNGVYLNPAPGQDYLLPEAEEITMISIQLAARFLFTTGFHTKKIVRGPASDWYDALCVLLRHSKNVRFWFTHNVLFNVSNRFSEYLLECPSAEVRGAFAKLIVFIAHFSLQDGSCPSPFASPGPSSQACDNLSLSDHLLRATLNLLRREVSEHGHHLQQYFNLFVMYANLGVAEKTQLLKLNVPATFMLVSLDEGPGPPIKYQYAELGKLYSVVSQLIRCCNVSSTMQSSINGNPPLPNPFGDLNLSQPIMPIQQNVLDILFVRTSYVKKIIEDCSNSEDTIKLLRFCSWENPQFSSTVLSELLWQVAYSYTYELRPYLDLLFQILLIEDSWQTHRIHNALKGIPDDRDGLFDTIQRSKNHYQKRAYQCIKCMVALFSSCPVAYQILQGNGDLKRKWTWAVEWLGDELERRPYTGNPQYSYNNWSPPVQSNETANGYFLERSHSARMTLAKACELCPEEEPDDQDAPDEHEPSPSEDAPLYPHSPASQYQQNNHVHGQPYTGPAAHHLNNPQKTGQRTQENYEGNEEVSSPQMKDQ>sp|O00507-2|USP9Y_HUMAN Isoform Short of Probable ubiquitin carboxyl-terminal hydrolase FAF-Y OS=Homo sapiens OX=9606 GN=USP9YMTAITHGSPVGGNDSQGQVLDGQSQHLFQQNQTSSPDSSNENSVATPPPEEQGQGDAPPQHEDEEPAFPHTELANLDDMINRPRWVVPVLPKGELEVLLEAAIDLSVKGLDVKSEACQRFFRDGLTISFTKILMDEAVSGWKFEIHRCIINNTHRLVELCVAKLSQDWFPLLELLAMALNPHCKFHIYNGTRPCELISSNAQLPEDELFARSSDPRSPKGWLVDLINKFGTLNGFQILHDRFFNGSALNIQIIAALIKPFGQCYEFLSQHTLKKYFIPVIEIVPHLLENLTDEELKKEAKNEAKNDALSMIIKSLKNLASRISGQDETIKNLEIFRLKMILRLLQISSFNGKMNALNEINKVISSVSYYTHRHSNPEEEEWLTAERMAEWIQQNNILSIVLQDSLHQPQYVEKLEKILRFVIKEKALTLQDLDNIWAAQAGKHEAIVKNVHDLLAKLAWDFSPGQLDHLFDCFKASWTNASKKQREKLLELIRRLAEDDKDGVMAHKVLNLLWNLAQSDDVPVDIMDLALSAHIKILDYSCSQDRDAQKIQWIDHFIEELRTNDKWVIPALKQIREICSLFGEASQNLSQTQRSPHIFYRHDLINQLQQNHALVTLVAENLATYMNSIRLYAGDHEDYDPQTVRLGSRYSHVQEVQERLNFLRFLLKDGQLWLCAPQAKQIWKCLAENAVYLCDREACFKWYSKLMGDEPDLDPDINKDFFESNVLQLDPSLLTENGMKCFERFFKAVNCRERKLIAKRRSYMMDDLELIGLDYLWRVVIQSSDEIANRAIDLLKEIYTNLGPRLKANQVVIHEDFIQSCFDRLKASYDTLCVFDGDKNSINCARQEAIRMVRVLTVIKEYINECDSDYHKERMILPMSRAFRGKHLSLIVRFPNQGRQVDELDIWSHTNDTIGSVRRCIVNRIKANVAHKKIELFVGGELIDSEDDRKLIGQLNLKDKSLITAKLTQINFNMPSSPDSSSDSSTASPGNHRNHYNDGPNLEVESCLPGVIMSVHPRYISFLWQVADLGSNLNMPPLRDGARVLMKLMPPDRTAVEKLRAVCLDHAKLGEGKLSPPLDSLFFGPSASQVLYLTEVVYALLMPAGVPLTDGSSDFQVHFLKSGGLPLVLSMLIRNNFLPNTDMETRRGAYLNALKIAKLLLTAIGYGHVRAVAEACQPVVDGTDPITQINQVTHDQAVVLQSALQSIPNPSSECVLRNESILLAQEISNEASRYMPDICVIRAIQKIIWASACGALGLVFSPNEEITKIYQMTTNGSNKLEVEDEQVCCEALEVMTLCFALLPTALDALSKEKAWQTFIIDLLLHCPSKTVRQLAQEQFFLMCTRCCMGHRPLLFFITLLFTILGSTAREKGKYSGDYFTLLRHLLNYAYNGNINIPNAEVLLVSEIDWLKRIRDNVKNTGETGVEEPILEGHLGVTKELLAFQTSEKKYHFGCEKGGANLIKELIDDFIFPASKVYLQYLRSGELPAEQAIPVCSSPVTINAGFELLVALAIGCVRNLKQIVDCLTEMYYMGTAITTCEALTEWEYLPPVGPRPPKGFVGLKNAGATCYMNSVIQQLYMIPSIRNSILAIEGTGSDLHDDMFGDEKQDSESNVDPRDDVFGYPHQFEDKPALSKTEDRKEYNIGVLRHLQVIFGHLAASQLQYYVPRGFWKQFRLWGEPVNLREQHDALEFFNSLVDSLDEALKALGHPAILSKVLGGSFADQKICQGCPHRYECEESFTTLNVDIRNHQNLLDSLEQYIKGDLLEGANAYHCEKCDKKVDTVKRLLIKKLPRVLAIQLKRFDYDWERECAIKFNDYFEFPRELDMGPYTVAGVANLERDNVNSENELIEQKEQSDNETAGGTKYRLVGVLVHSGQASGGHYYSYIIQRNGKDDQTDHWYKFDDGDVTECKMDDDEEMKNQCFGGEYMGEVFDHMMKRMSYRRQKRWWNAYILFYEQMDMIDEDDEMIRYISELTIARPHQIIMSPAIERSVRKQNVKFMHNRLQYSLEYFQFVKKLLTCNGVYLNPAPGQDYLLPEAEEITMISIQLAARFLFTTGFHTKKIVRGPASD>sp|Q9BVJ6|UT14A_HUMAN U3 small nucleolar RNA-associated protein 14homolog A OS=Homo sapiens OX=9606 GN=UTP14A PE=1 SV=1MTANRLAESLLALSQQEELADLPKDYLLSESEDEGDNDGERKHQKLLEAISSLDGKNRRKLAERSEASLKVSEFNVSSEGSGEKLVLADLLEPVKTSSSLATVKKQLSRVKSKKTVELPLNKEEIERIHREVAFNKTAQVLSKWDPVVLKNRQAEQLVFPLEKEEPAIAPIEHVLSGWKARTPLEQEIFNLLHKNKQPVTDPLLTPVEKASLRAMSLEEAKMRRAELQRARALQSYYEAKARREKKIKSKKYHKVVKKGKAKKALKEFEQLRKVNPAAALEELEKIEKARMMERMSLKHQNSGKWAKSKAIMAKYDLEARQAMQEQLSKNKELTQKLQVASESEEEEGGTEDVEELLVPDVVNEVQMNADGPNPWMLRSCTSDTKEAATQEDPEQLPELEAHGVSESEGEERPVAEEEILLREFEERRSLRKRSELSQDAEPAGSQETKDSGSQEVLSELRVLSQKLKENHQSRKQKASSEGTIPQVQREEPAPEEEEPLLLQRPERVQTLEELEELGKEECFQNKELPRPVLEGQQSERTPNNRPDAPKEKKKKEQMIDLQNLLTTQSPSVKSLAVPTIEELEDEEERNHRQMIKEAFAGDDVIRDFLKEKREAVEASKPKDVDLTLPGWGEWGGVGLKPSAKKRRRFLIKAPEGPPRKDKNLPNVIINEKRNIHAAAHQVRVLPYPFTHHWQFERTIQTPIGSTWNTQRAFQKLTTPKVVTKPGHIINPIKAEDVGYRSSSRSDLSVIQRNPKRITTRHKKQLKKCSVD>sp|Q9BVJ6-2|UT14A_HUMAN Isoform 2 of U3 small nucleolar RNA-associatedprotein 14 homolog A OS=Homo sapiens OX=9606 GN=UTP14AMKGDFRKKKSEARTPLEQEIFNLLHKNKQPVTDPLLTPVEKASLRAMSLEEAKMRRAELQRARALQSYYEAKARREKKIKSKKYHKVVKKGKAKKALKEFEQLRKVNPAAALEELEKIEKARMMERMSLKHQNSGKWAKSKAIMAKYDLEARQAMQEQLSKNKELTQKLQVASESEEEEGGTEDVEELLVPDVVNEVQMNADGPNPWMLRSCTSDTKEAATQEDPEQLPELEAHGVSESEGEERPVAEEEILLREFEERRSLRKRSELSQDAEPAGSQETKDSGSQEVLSELRVLSQKLKENHQSRKQKASSEGTIPQVQREEPAPEEEEPLLLQRPERVQTLEELEELGKEECFQNKELPRPVLEGQQSERTPNNRPDAPKEKKKKEQMIDLQNLLTTQSPSVKSLAVPTIEELEDEEERNHRQMIKEAFAGDDVIRDFLKEKREAVEASKPKDVDLTLPGWGEWGGVGLKPSAKKRRRFLIKAPEGPPRKDKNLPNVIINEKRNIHAAAHQVRVLPYPFTHHWQFERTIQTPIGSTWNTQRAFQKLTTPKVVTKPGHIINPIKAEDVGYRSSSRSDLSVIQRNPKRITTRHKKQLKKCSVD>sp|Q9BVJ6-3|UT14A_HUMAN Isoform 3 of U3 small nucleolar RNA-associatedprotein 14 homolog A OS=Homo sapiens OX=9606 GN=UTP14AMTANRLAESLLALSQQEELADLPKDYLLSESEDEGDNDGERKHQKLLEAISSLDGKNRRKLAERSEASLKVSEFNVSSEGSGEKLVLADLLEPVKTSSSLATVKKQLSRVKSKKTVELPLNKEEIERARTPLEQEIFNLLHKNKQPVTDPLLTPVEKASLRAMSLEEAKMRRAELQRARALQSYYEAKARREKKIKSKKYHKVVKKGKAKKALKEFEQLRKVNPAAALEELEKIEKARMMERMSLKHQNSGKWAKSKAIMAKYDLEARQAMQEQLSKNKELTQKLQVASESEEEEGGTEDVEELLVPDVVNEVQMNADGPNPWMLRSCTSDTKEAATQEDPEQLPELEAHGVSESEGEERPVAEEEILLREFEERRSLRKRSELSQDAEPAGSQETKDSGSQEVLSELRVLSQKLKENHQSRKQKASSEGTIPQVQREEPAPEEEEPLLLQRPERVQTLEELEELGKEECFQNKELPRPVLEGQQSERTPNNRPDAPKEKKKKEQMIDLQNLLTTQSPSVKSLAVPTIEELEDEEERNHRQMIKEAFAGDDVIRDFLKEKREAVEASKPKDVDLTLPGWGEWGGVGLKPSAKKRRRFLIKAPEGPPRKDKNLPNVIINEKRNIHAAAHQVRVLPYPFTHHWQFERTIQTPIGSTWNTQRAFQKLTTPKVVTKPGHIINPIKAEDVGYRSSSRSDLSVIQRNPKRITTRHKKQLKKCSVD>sp|Q96JC1|VPS39_HUMAN Vam6/Vps39-like protein OS=Homo sapiens OX=9606GN=VPS39 PE=1 SV=2MHDAFEPVPILEKLPLQIDCLAAWEEWLLVGTKQGHLLLYRIRKDVVPADVASPESGSCNRFEVTLEKSNKNFSKKIQQIHVVSQFKILVSLLENNIYVHDLLTFQQITTVSKAKGASLFTCDLQHTETGEEVLRMCVAVKKKLQLYFWKDREFHELQGDFSVPDVPKSMAWCENSICVGFKRDYYLIRVDGKGSIKELFPTGKQLEPLVAPLADGKVAVGQDDLTVVLNEEGICTQKCALNWTDIPVAMEHQPPYIIAVLPRYVEIRTFEPRLLVQSIELQRPRFITSGGSNIIYVASNHFVWRLIPVPMATQIQQLLQDKQFELALQLAEMKDDSDSEKQQQIHHIKNLYAFNLFCQKRFDESMQVFAKLGTDPTHVMGLYPDLLPTDYRKQLQYPNPLPVLSGAELEKAHLALIDYLTQKRSQLVKKLNDSDHQSSTSPLMEGTPTIKSKKKLLQIIDTTLLKCYLHTNVALVAPLLRLENNHCHIEESEHVLKKAHKYSELIILYEKKGLHEKALQVLVDQSKKANSPLKGHERTVQYLQHLGTENLHLIFSYSVWVLRDFPEDGLKIFTEDLPEVESLPRDRVLGFLIENFKGLAIPYLEHIIHVWEETGSRFHNCLIQLYCEKVQGLMKEYLLSFPAGKTPVPAGEEEGELGEYRQKLLMFLEISSYYDPGRLICDFPFDGLLEERALLLGRMGKHEQALFIYVHILKDTRMAEEYCHKHYDRNKDGNKDVYLSLLRMYLSPPSIHCLGPIKLELLEPKANLQAALQVLELHHSKLDTTKALNLLPANTQINDIRIFLEKVLEENAQKKRFNQVLKNLLHAEFLRVQEERILHQQVKCIITEEKVCMVCKKKIGNSAFARYPNGVVVHYFCSKEVNPADT>sp|Q96JC1-2|VPS39_HUMAN Isoform 2 of Vam6/Vps39-like protein OS=Homosapiens OX=9606 GN=VPS39MHDAFEPVPILEKLPLQIDCLAAWEEWLLVGTKQGHLLLYRIRKDVGCNRFEVTLEKSNKNFSKKIQQIHVVSQFKILVSLLENNIYVHDLLTFQQITTVSKAKGASLFTCDLQHTETGEEVLRMCVAVKKKLQLYFWKDREFHELQGDFSVPDVPKSMAWCENSICVGFKRDYYLIRVDGKGSIKELFPTGKQLEPLVAPLADGKVAVGQDDLTVVLNEEGICTQKCALNWTDIPVAMEHQPPYIIAVLPRYVEIRTFEPRLLVQSIELQRPRFITSGGSNIIYVASNHFVWRLIPVPMATQIQQLLQDKQFELALQLAEMKDDSDSEKQQQIHHIKNLYAFNLFCQKRFDESMQVFAKLGTDPTHVMGLYPDLLPTDYRKQLQYPNPLPVLSGAELEKAHLALIDYLTQKRSQLVKKLNDSDHQSSTSPLMEGTPTIKSKKKLLQIIDTTLLKCYLHTNVALVAPLLRLENNHCHIEESEHVLKKAHKYSELIILYEKKGLHEKALQVLVDQSKKANSPLKGHERTVQYLQHLGTENLHLIFSYSVWVLRDFPEDGLKIFTEDLPEVESLPRDRVLGFLIENFKGLAIPYLEHIIHVWEETGSRFHNCLIQLYCEKVQGLMKEYLLSFPAGKTPVPAGEEEGELGEYRQKLLMFLEISSYYDPGRLICDFPFDGLLEERALLLGRMGKHEQALFIYVHILKDTRMAEEYCHKHYDRNKDGNKDVYLSLLRMYLSPPSIHCLGPIKLELLEPKANLQAALQVLELHHSKLDTTKALNLLPANTQINDIRIFLEKVLEENAQKKRFNQVLKNLLHAEFLRVQEERILHQQVKCIITEEKVCMVCKKKIGNSAFARYPNGVVVHYFCSKEVNPADT>sp|Q9UNX4|WDR3_HUMAN WD repeat-containing protein 3 OS=Homo sapiensOX=9606 GN=WDR3 PE=1 SV=1MGLTKQYLRYVASAVFGVIGSQKGNIVFVTLRGEKGRYVAVPACEHVFIWDLRKGEKILILQGLKQEVTCLCPSPDGLHLAVGYEDGSIRIFSLLSGEGNVTFNGHKAAITTLKYDQLGGRLASGSKDTDIIVWDVINESGLYRLKGHKDAITQALFLREKNLLVTSGKDTMVKWWDLDTQHCFKTMVGHRTEVWGLVLLSEEKRLITGASDSELRVWDIAYLQEIEDPEEPDPKKIKGSSPGIQDTLEAEDGAFETDEAPEDRILSCRKAGSIMREGRDRVVNLAVDKTGRILACHGTDSVLELFCILSKKEIQKKMDKKMKKARKKAKLHSSKGEEEDPEVNVEMSLQDEIQRVTNIKTSAKIKSFDLIHSPHGELKAVFLLQNNLVELYSLNPSLPTPQPVRTSRITIGGHRSDVRTLSFSSDNIAVLSAAADSIKIWNRSTLQCIRTMTCEYALCSFFVPGDRQVVIGTKTGKLQLYDLASGNLLETIDAHDGALWSMSLSPDQRGFVTGGADKSVKFWDFELVKDENSTQKRLSVKQTRTLQLDEDVLCVSYSPNQKLLAVSLLDCTVKIFYVDTLKFFLSLYGHKLPVICMDISHDGALIATGSADRNVKIWGLDFGDCHKSLFAHDDSVMYLQFVPKSHLFFTAGKDHKIKQWDADKFEHIQTLEGHHQEIWCLAVSPSGDYVVSSSHDKSLRLWERTREPLILEEEREMEREAEYEESVAKEDQPAVPGETQGDSYFTGKKTIETVKAAERIMEAIELYREETAKMKEHKAICKAAGKEVPLPSNPILMAYGSISPSAYVLEIFKGIKSSELEESLLVLPFSYVPDILKLFNEFIQLGSDVELICRCLFFLLRIHFGQITSNQMLVPVIEKLRETTISKVSQVRDVIGFNMAGLDYLKRECEAKSEVMFFADATSHLEEKKRKRKKREKLILTLT>sp|A8MWX3|WASH4_HUMAN Putative WAS protein family homolog 4 OS=Homosapiens OX=9606 GN=WASH4P PE=5 SV=1MSGVMCLKASDTWASGIRSQPQGCLGKWRSMRCKHTRMHLAHLGNSRQLISLGPPRTREDGSRISQQVEQSRSQVQAIGEKVSLAQAKIEKIKGSKKAIKVFSSAKYPAPERLQEYGSIFTDAQDPGLQRRPRHRIQSKQRPLDERALQEKLKDFPVCVSTKPEPEDDAEEGLGGLPSNISSVSSLLLFNTTENLYKKYVFLDPLAGAVTKTHVMLGAETEEKLFDAPLSISKREQLEQQVPENYFYVPDLGQVPEIDVPSYLPDLPGIANDLMYIADLGPGIAPSAPGTIPELPTFHTEVAEPLKVDLQDGVLTPPPPPPPPPPAPEVLASAPPLPPSTAAPVGQGARQDDSSSSASPSVQGAPREVVDPSGGWATLLESIRQAGGIGKAKLRSMKERKLEKQQQKEQEQVRATSQGGHLMSDLFNKLVMRRKGISGKGPGAGDGPGGAFARVSDSIPPLPPPQQPQAEDEDDWES>sp|Q9H6R7|WDCP_HUMAN WD repeat and coiled-coil-containing proteinOS=Homo sapiens OX=9606 GN=WDCP PE=1 SV=1MELGKGKLLRTGLNALHQAVHPIHGLAWTDGNQVVLTDLRLHSGEVKFGDSKVIGQFECVCGLSWAPPVADDTPVLLAVQHEKHVTVWQLCPSPMESSKWLTSQTCEIRGSLPILPQGCVWHPKCAILTVLTAQDVSIFPNVHSDDSQVKADINTQGRIHCACWTQDGLRLVVAVGSSLHSYIWDSAQKTLHRCSSCLVFDVDSHVCSITATVDSQVAIATELPLDKICGLNASETFNIPPNSKDMTPYALPVIGEVRSMDKEATDSETNSEVSVSSSYLEPLDLTHIHFNQHKSEGNSLICLRKKDYLTGTGQDSSHLVLVTFKKAVTMTRKVTIPGILVPDLIAFNLKAHVVAVASNTCNIILIYSVIPSSVPNIQQIRLENTERPKGICFLTDQLLLILVGKQKLTDTTFLPSSKSDQYAISLIVREIMLEEEPSITSGESQTTYSTFSAPLNKANRKKLIESLSPDFCHQNKGLLLTVNTSSQNGRPGRTLIKEIQSPLSSICDGSIALDAEPVTQPASLPRHSSTPDHTSTLEPPRLPQRKNLQSEKETYQLSKEVEILSRNLVEMQRCLSELTNRLHNGKKSSSVYPLSQDLPYVHIIYQKPYYLGPVVEKRAVLLCDGKLRLSTVQQTFGLSLIEMLHDSHWILLSADSEGFIPLTFTATQEIIIRDGSLSRSDVFRDSFSHSPGAVSSLKVFTGLAAPSLDTTGCCNHVDGMA>sp|Q9H6R7-2|WDCP_HUMAN Isoform 2 of WD repeat and coiled-coil-containingprotein OS=Homo sapiens OX=9606 GN=WDCPMELGKGKLLRTGLNALHQAVHPIHGLAWTDGNQVVLTDLRLHSGEVKFGDSKVIGQFECVCGLSWAPPVADDTPVLLAVQHEKHVTVWQLCPSPMESSKWLTSQTCEIRGSLPILPQGCVWHPKCAILTVLTAQDVSIFPNVHSDDSQVKADINTQGRIHCACWTQDGLRLVVAVGSSLHSYIWDSAQKTLHRCSSCLVFDVDSHVCSITATVDSQVAIATELPLDKICGLNASETFNIPPNSKDMTPYALPVIGEVRSMDKEATDSETNSEVSVSSSYLEPLDLTHIHFNQHKSEGNSLICLRKKDYLTGTGQDSSHLVLVTFKKAVTMTRKVTIPGILVPDLIAFNLKAHVVAVASNTCNIILIYSVIPSSVPNIQQIRLENTERPKGICFLTDQLLLILVGKQKLTDTTFLPSSKSDQYAISLIVREIMLEEEPSITSGESQTTYSTFSAPLNKANRKKLIESLSPDFCHQNKGLLLTVNTSSQNGRPGRTLIKEIQSPLSSICDGSIALDAEPVTQPASLPRHSSTPDHTSTLEPPRLPQRKNLQSEKETYQLSKEVEILSRNLVEMQRCLSELTNRLHNGKKSSSVYPLSQDLPYVHIIYQIPTGFFSLLTVRALSR>sp|Q9H6R7-3|WDCP_HUMAN Isoform 3 of WD repeat and coiled-coil-containingprotein OS=Homo sapiens OX=9606 GN=WDCPMGRPGRTLIKEIQSPLSSICDGSIALDAEPVTQPASLPRHSSTPDHTSTLEPPRLPQRKNLQSEKETYQLSKEVEILSRNLVEMQRCLSELTNRLHNGKKSSSVYPLSQDLPYVHIIYQKPYYLGPVVEKRAVLLCDGKLRLSTVQQTFGLSLIEMLHDSHWILLSADSEGFIPLTFTATQEIIIRDGSLSRSDVFRDSFSHSPGAVSSLKVFTGLAAPSLDTTGCCNHVDGMA>sp|Q6ZTI0|YK032_HUMAN Putative uncharacterized protein FLJ44636 OS=Homosapiens OX=9606 PE=5 SV=1MPLPGTPGPVTTSPQTPTPRPLTTDWRILSGKGSGGSARAVSKLRSSSSGNSLLRIRDLGVRKSQEEAAPPSPRPQSRAHAQTTNPYWADTNTRPGAHPPEHGGVAALPAQVVGQCHQEATED>sp|Q499Y3|YJ016_HUMAN Putative uncharacterized protein C10orf88-likeOS=Homo sapiens OX=9606 PE=2 SV=2MRAVSANYSTGSPAVKSRIELDRIQTIMESMGSKLSPGAQQLINMVRFQQWNCIPIEEQLQLVLGNAGYKQMTGLQCSSALGALDKLSSTPFPFRTGLTSGNVTENLQAYIDKSTQASSGENSTKLDECKIVPQNHSLLENDLKNATSPFLPKKANDNSNIPNSELLPFLQNLCSQVNYLLVGRKAE>sp|Q8N7P7|YH007_HUMAN Uncharacterized protein FLJ40521 OS=Homo sapiensOX=9606 PE=2 SV=1MTAVSSNRNPEDDGCLLEQEPRGRRLSPRTGTPRTTAVSSNRDPKNDGCLLKQEPRGRRLSPRTGAPGTTAVSSNRNPEDDGCLLKQEPRGRRLSPQTGTPRTTAVSSNRNPGDDGCLLKQGPRGRRLSPQTGTPGTTAVSSNRNPEDDGCLLKQEPRGRRLSPQTGTPGTTAVSSNRDHEDDGCLLKQESRGRRLSPQTGTPGTTAVSSNRNPEDDGCLLKQESRGRRLSPQTGTPGTTAVSSNRDPEDDGCLLKQGPRGRRLSPQTGTPRTTAVSSNRNPEDDGCLLKQGPRGRRLSPQTGIPRTTAVSSNRDPGEDGCLLKQESRGRRLSPQTGTTRTTAVSSKRNPEDDGCLLKQEPRGRRLSSLTGAPGTTAVSSNRDPRTTAVSSNRNPGDDGCLLKQGPRGRRLSPQTGTPGTTAVSSNRDPEDDGCLLKQEPQELRKPEADTAL>sp|Q9BWQ6|YIPF2_HUMAN Protein YIPF2 OS=Homo sapiens OX=9606 GN=YIPF2PE=1 SV=1MASADELTFHEFEEATNLLADTPDAATTSRSDQLTPQGHVAVAVGSGGSYGAEDEVEEESDKAALLQEQQQQQQPGFWTFSYYQSFFDVDTSQVLDRIKGSLLPRPGHNFVRHHLRNRPDLYGPFWICATLAFVLAVTGNLTLVLAQRRDPSIHYSPQFHKVTVAGISIYCYAWLVPLALWGFLRWRKGVQERMGPYTFLETVCIYGYSLFVFIPMVVLWLIPVPWLQWLFGALALGLSAAGLVFTLWPVVREDTRLVATVLLSVVVLLHALLAMGCKLYFFQSLPPENVAPPPQITSLPSNIALSPTLPQSLAPS>sp|Q9UHT4|YG001_HUMAN Putative uncharacterized protein PRO1854 OS=Homosapiens OX=9606 GN=PRO1854 PE=5 SV=1MNNHRANDKFFLYVCMYVCIREKILLYKTHWMTPIFLKVVINTRRIKHHFKIHVPSQFFILITITKY>sp|Q5TC79|ZBT37_HUMAN Zinc finger and BTB domain-containing protein 37OS=Homo sapiens OX=9606 GN=ZBTB37 PE=2 SV=1MEKGGNIQLEIPDFSNSVLSHLNQLRMQGRLCDIVVNVQGQAFRAHKVVLAASSPYFRDHMSLNEMSTVSISVIKNPTVFEQLLSFCYTGRICLQLADIISYLTAASFLQMQHIIDKCTQILEGIHFKINVAEVEAELSQTRTKHQERPPESHRVTPNLNRSLSPRHNTPKGNRRGQVSAVLDIRELSPPEESTSPQIIEPSSDVESREPILRINRAGQWYVETGVADRGGRSDDEVRVLGAVHIKTENLEEWLGPENQPSGEDGSSAEEVTAMVIDTTGHGSVGQENYTLGSSGAKVARPTSSEVDRFSPSGSVVPLTERHRARSESPGRMDEPKQPSSQVEESAMMGVSGYVEYLREQEVSERWFRYNPRLTCIYCAKSFNQKGSLDRHMRLHMGITPFVCRMCGKKYTRKDQLEYHIRKHTGNKPFHCHVCGKSFPFQAILNQHFRKNHPGCIPLEGPHSISPETTVTSRGQAEEESPSQEETVAPGEAVQGSVSTTGPD>sp|Q5TC79-2|ZBT37_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 37 OS=Homo sapiens OX=9606 GN=ZBTB37MEKGGNIQLEIPDFSNSVLSHLNQLRMQGRLCDIVVNVQGQAFRAHKVVLAASSPYFRDHMSLNEMSTVSISVIKNPTVFEQLLSFCYTGRICLQLADIISYLTAASFLQMQHIIDKCTQILEGIHFKINVAEVEAELSQTRTKHQERPPESHRVTPNLNRSLSPRHNTPKGNRRGQVSAVLDIRELSPPEESTSPQIIEPSSDVESREPILRINRAGQWYVETGVADRGGRSDDEVRVLGAVHIKTENLEEWLGPENQPSGEDGSSAEEVTAMVIDTTGHGSVGQENYTLGSSGAKVARPTSSEVDRFSPSGSVVPLTERHRARSESPGRMDEPKQPSSQVWSCGFRTALVVGGIATVYE>sp|Q5TC79-3|ZBT37_HUMAN Isoform 3 of Zinc finger and BTB domain-containing protein 37 OS=Homo sapiens OX=9606 GN=ZBTB37MEKGGNIQLEIPDFSNSVLSHLNQLRMQGRLCDIVVNVQGQAFRAHKVVLAASSPYFRDHMSLNEMSTVSISVIKNPTVFEQLLSFCYTGRICLQLADIISYLTAASFLQMQHIIDKCTQILEGIHFKINVAEVEAELSQTRTKHQERPPESHRVTPNLNRSLSPRHNTPKGNRRGQVSAVLDIRELSPPEESTSPQIIEPSSDVESREPILRINRAGQWYVETGVADRGGRSDDEVRVLGAVHIKTENLEEWLGPENQPSGEDGSSAEEVTAMVIDTTGHGSVGQENYTLGSSGAKVARPTSSEVDR>sp|P17032|ZN37A_HUMAN Zinc finger protein 37A OS=Homo sapiens OX=9606GN=ZNF37A PE=2 SV=3MITSQGSVSFRDVTVGFTQEEWQHLDPAQRTLYRDVMLENYSHLVSVGYCIPKPEVILKLEKGEEPWILEEKFPSQSHLELINTSRNYSIMKFNEFNKGGKCFCDEKHEIIHSEEEPSEYNKNGNSFWLNEDLIWHQKIKNWEQSFEYNECGKAFPENSLFLVHKRGYTGQKTCKYTEHGKTCDMSFFITHQQTHPRENHYGNECGENIFEESILLEHQSVYPFSQKLNLTPIQRTHSINNIIEYNECGTFFSEKLVLHLQQRTHTGEKPYECHECGKTFTQKSAHTRHQRTHTGGKPYECHECGKTFYKNSDLIKHQRIHTGERPYGCHECGKSFSEKSTLTQHQRTHTGEKPYECHECGKTFSFKSVLTVHQKTHTGEKPYECYACGKAFLRKSDLIKHQRIHTGEKPYECNECGKSFSEKSTLTKHLRTHTGEKPYECIQCGKFFCYYSGFTEHLRRHTGEKPFGCNECGKTFRQKSALIVHQRTHIRQKPYGCNQCGKSFCVKSKLIAHHRTHTGEKPYECNVCGKSFYVKSKLTVHQRIHLGRNPINVVNEGNYSG>sp|P0C7X2|ZN688_HUMAN Zinc finger protein 688 OS=Homo sapiens OX=9606GN=ZNF688 PE=1 SV=1MAPPPAPLLAPRPGETRPGCRKPGTVSFADVAVYFSPEEWGCLRPAQRALYRDVMQETYGHLGALGFPGPKPALISWMEQESEAWSPAAQDPEKGERLGGARRGDVPNRKEEEPEEVPRAKGPRKAPVKESPEVLVERNPDPAISVAPARAQPPKNAAWDPTTGAQPPAPIPSMDAQAGQRRHVCTDCGRRFTYPSLLVSHRRMHSGERPFPCPECGMRFKRKFAVEAHQWIHRSCSGGRRGRRPGIRAVPRAPVRGDRDPPVLFRHYPDIFEECG>sp|P0C7X2-5|ZN688_HUMAN Isoform 2 of Zinc finger protein 688 OS=Homosapiens OX=9606 GN=ZNF688MPRSPLRSSLSTEASGPRGPFKCPASPRPITAQLLPGSSPIIGRCVLRVQRGFPGPKPALISWMEQESEAWSPAAQDPEKGERLGGARRGDVPNRKEEEPEEVPRAKGPRKAPVKESPEVLVERNPDPAISVAPARAQPPKNAAWDPTTGAQPPAPIPSMDAQAGQRRHVCTDCGRRFTYPSLLVSHRRMHSGERPFPCPECGMRFKRKFAVEAHQWIHRSCSGGRRGRRPGIRAVPRAPVRGDRDPPVLFRHYPDIFEECG>sp|A8MWA4|Z705E_HUMAN Putative zinc finger protein 705E OS=Homo sapiensOX=9606 GN=ZNF705E PE=3 SV=2MHSLKKVTFEDVAIDFTQEEWAMMDTSKRKLYRDVMLENISHLVSLGYQISKSYIILQLEQGKELWQEGREFLQDQNPDRESALKKTHMISMHPIIRKDAPTSMTMENSLILEDPFECNDSGEDCTHSSTIIQCLLTHSGKKPYVSKQCGKSLSNLLSPKPHKQIHTKGKSYQCNLCEKAYTNCFHLRRPKMTHTGERPYTCHLCRKAFTQCSHLRRHEKTHTGERPYKCHQCGKAFIQSFNLRRHERTHLGEKWYECDNSGKAFSQSSGFRGNKIIHTGEKPHACLLCGKAFSLSSDLR>sp|Q9H0D2|ZN541_HUMAN Zinc finger protein 541 OS=Homo sapiens OX=9606GN=ZNF541 PE=1 SV=3MDQYSLGDEGALPSEMHLPSFSESQGLNCSDTLNRDLGPNTRGFLYAGLSGLDPDPSLPTPDMSSEVLEDNLDTLSLYSGKDSDSVKLLEEYADSESQASLQDLGLGVLKAKEADEGGRATSGSARKGKRQHSSPQNPLLDCSLCGKVFSSASSLSKHYLTHSQERKHVCKICSKAFKRQDHLTGHMLTHQKTKPFVCIEQGCSKSYCDYRSLRRHYEVHHGLCILKEAPPEEEACGDSPHAHESAGQPPPSSLRSLVPPEARSPGSLLPHRDLLRRIVSSIVHQKTPSPGPAPAGASDSEGRNTACPCPASSGSSSCTPAGPHAAPAALDTELPEEPCLPQKEPATDVFTAPNSRAAENGAPDPPEPEPDTALLQARSTAECWPEGGSVPACLPLFRGQTVPASSQPSSHSFQWLRNLPGCPKSKGNNVFVVHKPSAVPSREGSESGPGPSSGSPSEESPPGPGGGLEDALPFPAALLRVPAEAPSDPRSASGEDDPCAPKKVKVDCDSFLCQNPGEPGLQEAQKAGGLPADASPLFRQLFLKSQEPLVSHEQMQVFQMITKSQRIFSHAQVAAVSSQLPAPEGKPAALRPLQGPWPQQPPPLAPAVDSLHAGPGNPEAEGSPARRRKTTPGVPREASPGSTRRDAKGGLKVAAVPTPLAAPSLDPSRNPDISSLAKQLRSSKGTLDLEDIFPSTGQRQTQLGGEEPPGASLPGKQAPAENGAASRITKGEKGPACSRGGGYRLLGNPRAPRFSGFRKEKAKMDMCCAASPSQVAMASFSSAGPPADPSKSKLTIFSRIQGGNIYRLPHPVKEENVAGRGNQQNGSPTDWTKPRSTFVCKNCSQMFYTEKGLSSHMCFHSDQWPSPRGKQEPQVFGTEFCKPLRQVLRPEGDRHSPPGTKKPLDPTAAAPLVVPQSIPVVPVTRHIGSMAMGQEKDGEERDSKESSQQRKRKKRPPPSTAGEPGPAGCHQSRLRSPMFLVDCLLKGLFQCSPYTPPPMLSPIREGSGVYFNTLCSTSTQASPDQLISSMLDQVDGSFGICVVKDDTKISIEPHINIGSRFQAEIPELQERSLAGTDEHVASLVWKPWGDMMISSETQDRVTELCNVACSSVMPGGGTNLELALHCLHEAQGNVQVALETLLLRGPHKPRTHLLADYRYTGSDVWTPIEKRLFKKAFYAHKKDFYLIHKMIQTKTVAQCVEYYYIWKKMIKFDCGRAPGLEKRVKREPEEVERTEEKVPCSPRERPSHHPTPKLKTKSYRRESILSSSPNAGSKRTPELLGSAESQGIFPCRECERVFDKIKSRNAHMKRHRLQDHVEPIIRVKWPVKPFQLKEEELGADIGPLQW>sp|Q9H0D2-2|ZN541_HUMAN Isoform 2 of Zinc finger protein 541 OS=Homosapiens OX=9606 GN=ZNF541MDQYSLGDEGALPSEMHLPSFSESQGLNCSDTLNRDLGPNTRGFLYAGLSGLDPDPSLPTPDMSSEVLEDNLDTLSLYSGKDSDSVKLLEEYADSESQASLQDLGLGVLKAKEADEGGRATSGSARKGKRQHSSPQNPLLDCSLCGKVFSSASSLSKHYLTHSQERKHVCKICSKAFKRQDHLTGHMLTHQKTKPFVCIEQGCSKSYCDYRSLRRHYEVHHGLCILKEAPPEEEACGDSPHAHESAGQPPPSSLRSLVPPEARSPGSLLPHRDLLRRIVSSIVHQKTPSPGPAPAGASDSEGRNTACPCPASSGSSSCTPAGPHAAPAALDTELPEEPCLPQKEPATDVFTAPNSRAAENGAPDPPEPEPDTALLQARSTAECWPEGGSVPACLPLFRGQTVPASSQPSSHSFQWLRNLPGCPKSKGNNVFVVHKPSAVPSREGSESGPGPSSGSPSEESPPGPGGGLEDALPFPAALLRVPAEAPSDPRSASGEDDPCAPKKVKVDCDSFLCQNPGEPGLQEAQKAGGLPADASPLFRQLFLKSQEPLVSHEQMQVFQMITKSQRIFSHAQVAAVSSQLPAPEGKPAALRPLQGPWPQQPPPLAPAVDSLHAGPGNPEAEGSPARRRKTTPGVPREASPGSTRRDAKGGLKVAAVPTPLAAPSLDPSRNPDISSLAKQLRSSKGTLDLEDIFPSTGQRQTQLGGEEPPGASLPGKQAPAENGAASRITKGEKGPACSRGGGYRLLGNPRAPRFSGFRKEKAKMDMCCAASPSQVAMASFSSAGPPADPSKSKLTIFSRIQGGNIYRLPHPVKEENVAGRGNQQNGSPTDWTKPRSTFVCKNCSQMFYTEKGLSSHMCFHSDQWPSPRGKQEPQVFGTEFCKPLRQVLRPEGDRHSPPGTKKPLDPTAAAPLVVPQSIPVVPVTRHIGSMAMIQTKTVAQCVEYYYIWKKMIKFDCGRAPGLEKRVKREPEEVERTEEKVPCSPRERPSHHPTPKLKTKSYRRESILSSSPNAGSKRTPELLGSAESQGIFPCRECERVFDKIKSRNAHMKRHRLQDHVEPIIRVKWPVKPFQLKEEELGADIGPLQW>sp|Q9UC07|ZNF69_HUMAN Zinc finger protein 69 OS=Homo sapiens OX=9606GN=ZNF69 PE=1 SV=2MPCCSHRRCREDPGTSESQEMDPVAFDDVAVNFTQEEWALLDISQRKLYKEVMLETFRNLTSVGKSWKDQNIEYEYQNPRRNFRSLIEKKVNEIKDDSHCGETFTQVPDDRLNFQEKKASPEIKSCDSFVCGEVGLGNSSFNMNIRGDIGHKAYEYQEYGPKPCKCQQPKKAFRYHPSFRTPQRDHTGEKPYACKECGKTFISHSSIQRHVVMHSGDGPYKCKFCGKAFHCLSLYLIHERIHTGEKPYECKQCGKSFSYSATLRIHERTHTGEKPYECQQCGKAFHSPRCYRRHERIHTGEKAYQCKECGKAFTCPQYVRIHERTHSRKKPYECTQCGKALSSLTSFQTHIRMHSGERPYECKICGKGFCSANSFQRHEKTHSGEKPYKCKQCGKAFIHSSSLRYHERIHTGEKPYECKQCGKAFRSSSHLQLHGRTHTGEKPYECQECGKAFRSMKNLQSHERTQTHVRIHSGERPYKCKLCGKGFYCPKSLQRHEKTHTGEKLYECKQCGEAFSSSSSFRYHERTHTGEKPYKCKQCGKAFRAASVLRMHGRTHPEDKPYECKQ>sp|Q9UC07-2|ZNF69_HUMAN Isoform 2 of Zinc finger protein 69 OS=Homosapiens OX=9606 GN=ZNF69MPCCSHRRCREDPGTSESQEMEEWALLDISQRKLYKEVMLETFRNLTSVGKSWKDQNIEYEYQNPRRNFRSLIEKKVNEIKDDSHCGETFTQVPDDRLNFQEKKASPEIKSCDSFVCGEVGLGNSSFNMNIRGDIGHKAYEYQEYGPKP>sp|Q5MCW4|ZN569_HUMAN Zinc finger protein 569 OS=Homo sapiens OX=9606GN=ZNF569 PE=1 SV=1MTESQGTVTFKDVAIDFTQEEWKRLDPAQRKLYRNVMLENYNNLITVGYPFTKPDVIFKLEQEEEPWVMEEEVLRRHWQGEIWGVDEHQKNQDRLLRQVEVKFQKTLTEEKGNECQKKFANVFPLNSDFFPSRHNLYEYDLFGKCLEHNFDCHNNVKCLMRKEHCEYNEPVKSYGNSSSHFVITPFKCNHCGKGFNQTLDLIRHLRIHTGEKPYECSNCRKAFSHKEKLIKHYKIHSREQSYKCNECGKAFIKMSNLIRHQRIHTGEKPYACKECEKSFSQKSNLIDHEKIHTGEKPYECNECGKAFSQKQSLIAHQKVHTGEKPYACNECGKAFPRIASLALHMRSHTGEKPYKCDKCGKAFSQFSMLIIHVRIHTGEKPYECNECGKAFSQSSALTVHMRSHTGEKPYECKECRKAFSHKKNFITHQKIHTREKPYECNECGKAFIQMSNLVRHQRIHTGEKPYICKECGKAFSQKSNLIAHEKIHSGEKPYECNECGKAFSQKQNFITHQKVHTGEKPYDCNECGKAFSQIASLTLHLRSHTGEKPYECDKCGKAFSQCSLLNLHMRSHTGEKPYVCNECGKAFSQRTSLIVHMRGHTGEKPYECNKCGKAFSQSSSLTIHIRGHTGEKPFDCSKCGKAFSQISSLTLHMRKHTGEKPYHCIECGKAFSQKSHLVRHQRIHTH>sp|Q5MCW4-2|ZN569_HUMAN Isoform 2 of Zinc finger protein 569 OS=Homosapiens OX=9606 GN=ZNF569MRKEHCEYNEPVKSYGNSSSHFVITPFKCNHCGKGFNQTLDLIRHLRIHTGEKPYECSNCRKAFSHKEKLIKHYKIHSREQSYKCNECGKAFIKMSNLIRHQRIHTGEKPYACKECEKSFSQKSNLIDHEKIHTGEKPYECNECGKAFSQKQSLIAHQKVHTGEKPYACNECGKAFPRIASLALHMRSHTGEKPYKCDKCGKAFSQFSMLIIHVRIHTGEKPYECNECGKAFSQSSALTVHMRSHTGEKPYECKECRKAFSHKKNFITHQKIHTREKPYECNECGKAFIQMSNLVRHQRIHTGEKPYICKECGKAFSQKSNLIAHEKIHSGEKPYECNECGKAFSQKQNFITHQKVHTGEKPYDCNECGKAFSQIASLTLHLRSHTGEKPYECDKCGKAFSQCSLLNLHMRSHTGEKPYVCNECGKAFSQRTSLIVHMRGHTGEKPYECNKCGKAFSQSSSLTIHIRGHTGEKPFDCSKCGKAFSQISSLTLHMRKHTGEKPYHCIECGKAFSQKSHLVRHQRIHTH>sp|Q9UPQ9|TNR6B_HUMAN Trinucleotide repeat-containing gene 6B proteinOS=Homo sapiens OX=9606 GN=TNRC6B PE=1 SV=4MREKEQEREEQLMEDKKRKKEDKKKKEATQKVTEQKTKVPEVTKPSLSQPTAASPIGSSPSPPVNGGNNAKRVAVPNGQPPSAARYMPREVPPRFRCQQDHKVLLKRGQPPPPSCMLLGGGAGPPPCTAPGANPNNAQVTGALLQSESGTAPDSTLGGAAASNYANSTWGSGASSNNGTSPNPIHIWDKVIVDGSDMEEWPCIASKDTESSSENTTDNNSASNPGSEKSTLPGSTTSNKGKGSQCQSASSGNECNLGVWKSDPKAKSVQSSNSTTENNNGLGNWRNVSGQDRIGPGSGFSNFNPNSNPSAWPALVQEGTSRKGALETDNSNSSAQVSTVGQTSREQQSKMENAGVNFVVSGREQAQIHNTDGPKNGNTNSLNLSSPNPMENKGMPFGMGLGNTSRSTDAPSQSTGDRKTGSVGSWGAARGPSGTDTVSGQSNSGNNGNNGKEREDSWKGASVQKSTGSKNDSWDNNNRSTGGSWNFGPQDSNDNKWGEGNKMTSGVSQGEWKQPTGSDELKIGEWSGPNQPNSSTGAWDNQKGHPLPENQGNAQAPCWGRSSSSTGSEVGGQSTGSNHKAGSSDSHNSGRRSYRPTHPDCQAVLQTLLSRTDLDPRVLSNTGWGQTQIKQDTVWDIEEVPRPEGKSDKGTEGWESAATQTKNSGGWGDAPSQSNQMKSGWGELSASTEWKDPKNTGGWNDYKNNNSSNWGGGRPDEKTPSSWNENPSKDQGWGGGRQPNQGWSSGKNGWGEEVDQTKNSNWESSASKPVSGWGEGGQNEIGTWGNGGNASLASKGGWEDCKRSPAWNETGRQPNSWNKQHQQQQPPQQPPPPQPEASGSWGGPPPPPPGNVRPSNSSWSSGPQPATPKDEEPSGWEEPSPQSISRKMDIDDGTSAWGDPNSYNYKNVNLWDKNSQGGPAPREPNLPTPMTSKSASVWSKSTPPAPDNGTSAWGEPNESSPGWGEMDDTGASTTGWGNTPANAPNAMKPNSKSMQDGWGESDGPVTGARHPSWEEEEDGGVWNTTGSQGSASSHNSASWGQGGKKQMKCSLKGGNNDSWMNPLAKQFSNMGLLSQTEDNPSSKMDLSVGSLSDKKFDVDKRAMNLGDFNDIMRKDRSGFRPPNSKDMGTTDSGPYFEKLTLPFSNQDGCLGDEAPCSPFSPSPSYKLSPSGSTLPNVSLGAIGTGLNPQNFAARQGGSHGLFGNSTAQSRGLHTPVQPLNSSPSLRAQVPPQFISPQVSASMLKQFPNSGLSPGLFNVGPQLSPQQIAMLSQLPQIPQFQLACQLLLQQQQQQQLLQNQRKISQAVRQQQEQQLARMVSALQQQQQQQQRQPGMKHSPSHPVGPKPHLDNMVPNALNVGLPDLQTKGPIPGYGSGFSSGGMDYGMVGGKEAGTESRFKQWTSMMEGLPSVATQEANMHKNGAIVAPGKTRGGSPYNQFDIIPGDTLGGHTGPAGDSWLPAKSPPTNKIGSKSSNASWPPEFQPGVPWKGIQNIDPESDPYVTPGSVLGGTATSPIVDTDHQLLRDNTTGSNSSLNTSLPSPGAWPYSASDNSFTNVHSTSAKFPDYKSTWSPDPIGHNPTHLSNKMWKNHISSRNTTPLPRPPPGLTNPKPSSPWSSTAPRSVRGWGTQDSRLASASTWSDGGSVRPSYWLVLHNLTPQIDGSTLRTICMQHGPLLTFHLNLTQGTALIRYSTKQEAAKAQTALHMCVLGNTTILAEFATDDEVSRFLAQAQPPTPAATPSAPAAGWQSLETGQNQSDPVGPALNLFGGSTGLGQWSSSAGGSSGADLAGASLWGPPNYSSSLWGVPTVEDPHRMGSPAPLLPGDLLGGGSDSI>sp|Q9UPQ9-1|TNR6B_HUMAN Isoform 2 of Trinucleotide repeat-containinggene 6B protein OS=Homo sapiens OX=9606 GN=TNRC6BMREKEQEREEQLMEDKKRKKEDKKKKEATQKVTEQKTKVPEVTKPSLSQPTAASPIGSSPSPPVNGGNNAKRVAVPNGQPPSAARYMPREVPPRFRCQQDHKVLLKRGQPPPPSCMLLGGGAGPPPCTAPGANPNNAQVTGALLQSESGTAPDSTLGGAAASNYANSTWGSGASSNNGTSPNPIHIWDKVIVDGSDMEEWPCIASKDTESSSENTTDNNSASNPGSEKSTLPGSTTSNKGKGSQCQSASSGNECNLGVWKSDPKAKSVQSSNSTTENNNGLGNWRNVSGQDRIGPGSGFSNFNPNSNPSAWPALVQEGTSRKGALETDNSNSSAQVSTVGQTSREQQSKMENAGVNFVVSGREQAQIHNTDGPKNGNTNSLNLSSPNPMENKGMPFGMGLGNTSRSTDAPSQSTGDRKTGSVGSWGAARGPSGTDTVSGQSNSGNNGNNGKEREDSWKGASVQKSTGSKNDSWDNNNRSTGGSWNFGPQDSNDNKWGEGNKMTSGVSQGEWKQPTGSDELKIGEWSGPNQPNSSTGAWDNQKGHPLPENQGNAQAPCWGRSSSSTGSEVGGQSTGSNHKAGSSDSHNSGRRSYRPTHPDCQAVLQTLLSRTDLDPRVLSNTGWGQTQIKQDTVWDIEEVPRPEGKSDKGTEGWESAATQTKNSGGWGDAPSQSNQMKSGWGELSASTEWKDPKNTGGWNDYKNNNSSNWGGGRPDEKTPSSWNENPSKDQGWGGGRQPNQGWSSGKNGWGEEVDQTKNSNWESSASKPVSGWGEGGQNEIGTWGNGGNASLASKGGWEDCKRSPAWNETGRQPNSWNKQHQQQQPPQQPPPPQPEASGSWGGPPPPPPGNVRPSNSSWSSGPQPATPKDEEPSGWEEPSPQSISRKMDIDDGTSAWGDPNSYNYKNVNLWDKNSQGGPAPREPNLPTPMTSKSASDSKSMQDGWGESDGPVTGARHPSWEEEEDGGVWNTTGSQGSASSHNSASWGQGGKKQMKCSLKGGNNDSWMNPLAKQFSNMGLLSQTEDNPSSKMDLSVGSLSDKKFDVDKRAMNLGDFNDIMRKDRSGFRPPNSKDMGTTDSGPYFEKGGSHGLFGNSTAQSRGLHTPVQPLNSSPSLRAQVPPQFISPQVSASMLKQFPNSGLSPGLFNVGPQLSPQQIAMLSQLPQIPQFQLACQLLLQQQQQQQLLQNQRKISQAVRQQQEQQLARMVSALQQQQQQQQRQPGMKHSPSHPVGPKPHLDNMVPNALNVGLPDLQTKGPIPGYGSGFSSGGMDYGMVGGKEAGTESRFKQWTSMMEGLPSVATQEANMHKNGAIVAPGKTRGGSPYNQFDIIPGDTLGGHTGPAGDSWLPAKSPPTNKIGSKSSNASWPPEFQPGVPWKGIQNIDPESDPYVTPGSVLGGTATSPIVDTDHQLLRDNTTGSNSSLNTSLPSPGAWPYSASDNSFTNVHSTSAKFPDYKSTWSPDPIGHNPTHLSNKMWKNHISSRNTTPLPRPPPGLTNPKPSSPWSSTAPRSVRGWGTQDSRLASASTWSDGGSVRPSYWLVLHNLTPQIDGSTLRTICMQHGPLLTFHLNLTQGTALIRYSTKQEAAKAQTALHMCVLGNTTILAEFATDDEVSRFLAQAQPPTPAATPSAPAAGWQSLETGQNQSDPVGPALNLFGGSTGLGQWSSSAGGSSGADLAGASLWGPPNYSSSLWGVPTVEDPHRMGSPAPLLPGDLLGGGSDSI>sp|Q9UPQ9-2|TNR6B_HUMAN Isoform 3 of Trinucleotide repeat-containinggene 6B protein OS=Homo sapiens OX=9606 GN=TNRC6BMQTNEGEVSEESSSKVEQEDFVMEGHGKTPPPGEESKQEKEQEREEQLMEDKKRKKEDKKKKEATQKVTEQKTKVPEVTKPSLSQPTAASPIGSSPSPPVNGGNNAKRVAVPNGQPPSAARYMPREVPPRFRCQQDHKVLLKRGQPPPPSCMLLGGGAGPPPCTAPGANPNNAQVTGALLQSESGTAPVWSKSTPPAPDNGTSAWGEPNESSPGWGEMDDTGASTTGWGNTPANAPNAMKPNSKSMQDGWGESDGPVTGARHPSWEEEEDGGVWNTTGSQGSASSHNSASWGQGGKKQMKCSLKGGNNDSWMNPLAKQFSNMGLLSQTEDNPSSKMDLSVGSLSDKKFDVDKRAMNLGDFNDIMRKDRSGFRPPNSKDMGTTDSGPYFEKGGSHGLFGNSTAQSRGLHTPVQPLNSSPSLRAQVPPQFISPQVSASMLKQFPNSGLSPGLFNVGPQLSPQQIAMLSQLPQIPQFQLACQLLLQQQQQQQLLQNQRKISQAVRQQQEQQLARMVSALQQQQQQQQRQPGMKHSPSHPVGPKPHLDNMVPNALNVGLPDLQTKGPIPGYGSGFSSGGMDYGMVGGKEAGTESRFKQWTSMMEGLPSVATQEANMHKNGAIVAPGKTRGGSPYNQFDIIPGDTLGGHTGPAGDSWLPAKSPPTNKIGSKSSNASWPPEFQPGVPWKGIQNIDPESDPYVTPGSVLGGTATSPIVDTDHQLLRDNTTGSNSSLNTSLPSPGAWPYSASDNSFTNVHSTSAKFPDYKSTWSPDPIGHNPTHLSNKMWKNHISSRNTTPLPRPPPGLTNPKPSSPWSSTAPRSVRGWGTQDSRLASASTWSDGGSVRPSYWLVLHNLTPQIDGSTLRTICMQHGPLLTFHLNLTQGTALIRYSTKQEAAKAQTALHMCVLGNTTILAEFATDDEVSRFLAQAQPPTPAATPSAPAAGWQSLETGQNQSDPVGPALNLFGGSTGLGQWSSSAGGSSGADLAGASLWGPPNYSSSLWGVPTVEDPHRMGSPAPLLPGDLLGGGSDSI>sp|Q5HYL7|TM196_HUMAN Transmembrane protein 196 OS=Homo sapiens OX=9606GN=TMEM196 PE=1 SV=2MCTSGQIIGSLLVLSVLEIGLGVSSVAVGAVSFSLALREHKPQLGDSSPVWSGVCFLLCGICGILCAKKKSGLVMILFSACCICGLIGGILNFQFLRAVTKKTSSLYPLHLASMSLACIGIGGCTLSSWLTCRLASYEQRRMFSEREHSLHHSHEMAEKEITDNMSNGGPQLIFNGRV>sp|Q5HYL7-2|TM196_HUMAN Isoform 2 of Transmembrane protein 196 OS=Homosapiens OX=9606 GN=TMEM196MILFSACCICGLIGGILNFQFLRAVTKKTSSLYPLHLASMSLACIGIGGCTLSSWLTCRLASYEQRRMFSEREHSLHHSHEMAEKEITDNMSNGGPQLIFNGRV>sp|Q5HYL7-3|TM196_HUMAN Isoform 3 of Transmembrane protein 196 OS=Homosapiens OX=9606 GN=TMEM196MILFSACCICGLIGGILNFQFLRAVTKKTSSLYPLHLASMSLACIGIGGCTLSSWLTCRLASYEQRRMFSEREHSLHHSHEMAEKIEGY>sp|Q5HYL7-4|TM196_HUMAN Isoform 4 of Transmembrane protein 196 OS=Homosapiens OX=9606 GN=TMEM196MCTSGQIIGSLLVLSVLEIGLGVSSVAVGAVSFSLALREHKPQLGDSSPFLLCGICGILCAKKKSGLVMILFSACCICGLIGGILNFQFLRAVTKKTSSLYPLHLASMSLACIGIGGCTLSSWLTCRLASYEQRRMFSEREHSLHHSHEMAEKEITDNMSNGGPQLIFNGRV>sp|Q9Y5L0|TNPO3_HUMAN Transportin-3 OS=Homo sapiens OX=9606 GN=TNPO3PE=1 SV=3MEGAKPTLQLVYQAVQALYHDPDPSGKERASFWLGELQRSVHAWEISDQLLQIRQDVESCYFAAQTMKMKIQTSFYELPTDSHASLRDSLLTHIQNLKDLSPVIVTQLALAIADLALQMPSWKGCVQTLVEKYSNDVTSLPFLLEILTVLPEEVHSRSLRIGANRRTEIIEDLAFYSSTVVSLLMTCVEKAGTDEKMLMKVFRCLGSWFNLGVLDSNFMANNKLLALLFEVLQQDKTSSNLHEAASDCVCSALYAIENVETNLPLAMQLFQGVLTLETAYHMAVAREDLDKVLNYCRIFTELCETFLEKIVCTPGQGLGDLRTLELLLICAGHPQYEVVEISFNFWYRLGEHLYKTNDEVIHGIFKAYIQRLLHALARHCQLEPDHEGVPEETDDFGEFRMRVSDLVKDLIFLIGSMECFAQLYSTLKEGNPPWEVTEAVLFIMAAIAKSVDPENNPTLVEVLEGVVRLPETVHTAVRYTSIELVGEMSEVVDRNPQFLDPVLGYLMKGLCEKPLASAAAKAIHNICSVCRDHMAQHFNGLLEIARSLDSFLLSPEAAVGLLKGTALVLARLPLDKITECLSELCSVQVMALKKLLSQEPSNGISSDPTVFLDRLAVIFRHTNPIVENGQTHPCQKVIQEIWPVLSETLNKHRADNRIVERCCRCLRFAVRCVGKGSAALLQPLVTQMVNVYHVHQHSCFLYLGSILVDEYGMEEGCRQGLLDMLQALCIPTFQLLEQQNGLQNHPDTVDDLFRLATRFIQRSPVTLLRSQVVIPILQWAIASTTLDHRDANCSVMRFLRDLIHTGVANDHEEDFELRKELIGQVMNQLGQQLVSQLLHTCCFCLPPYTLPDVAEVLWEIMQVDRPTFCRWLENSLKGLPKETTVGAVTVTHKQLTDFHKQVTSAEECKQVCWALRDFTRLFR>sp|Q9Y5L0-1|TNPO3_HUMAN Isoform 1 of Transportin-3 OS=Homo sapiensOX=9606 GN=TNPO3MEGAKPTLQLVYQAVQALYHDPDPSGKERASFWLGELQRSVHAWEISDQLLQIRQDVESCYFAAQTMKMKIQTSFYELPTDSHASLRDSLLTHIQNLKDLSPVIVTQLALAIADLALQMPSWKGCVQTLVEKYSNDVTSLPFLLEILTVLPEEVHSRSLRIGANRRTEIIEDLAFYSSTVVSLLMTCVEKAGTDEKMLMKVFRCLGSWFNLGVLDSNFMANNKLLALLFEVLQQDKTSSNLHEAASDCVCSALYAIENVETNLPLAMQLFQGVLTLETAYHMAVAREDLDKVLNYCRIFTELCETFLEKIVCTPGQGLGDLRTLELLLICAGHPQYEVVEISFNFWYRLGEHLYKTNDEVIHGIFKAYIQRLLHALARHCQLEPDHEGVPEETDDFGEFRMRVSDLVKDLIFLIGSMECFAQLYSTLKEGNPPWEVTEAVLFIMAAIAKSVDPKKPFSNAACHHSLLFGQNITSEISNCEYLPPVLRENNPTLVEVLEGVVRLPETVHTAVRYTSIELVGEMSEVVDRNPQFLDPVLGYLMKGLCEKPLASAAAKAIHNICSVCRDHMAQHFNGLLEIARSLDSFLLSPEAAVGLLKGTALVLARLPLDKITECLSELCSVQVMALKKLLSQEPSNGISSDPTVFLDRLAVIFRHTNPIVENGQTHPCQKVIQEIWPVLSETLNKHRADNRIVERCCRCLRFAVRCVGKGSAALLQPLVTQMVNVYHVHQHSCFLYLGSILVDEYGMEEGCRQGLLDMLQALCIPTFQLLEQQNGLQNHPDTVDDLFRLATRFIQRSPVTLLRSQVVIPILQWAIASTTLDHRDANCSVMRFLRDLIHTGVANDHEEDFELRKELIGQVMNQLGQQLVSQLLHTCCFCLPPYTLPDVAEVLWEIMQVDRPTFCRWLENSLKGLPKETTVGAVTVTHKQLTDFHKQVTSAEECKQVCWALRDFTRLFR>sp|Q9Y5L0-3|TNPO3_HUMAN Isoform 3 of Transportin-3 OS=Homo sapiensOX=9606 GN=TNPO3MEGAKPTLQLVYQAVQALYHDPDPSGKERASFWLGELQRSVHAWEISDQLLQIRQDVESCYFAAQTMKMKIQTSFYELPTDSHASLRDSLLTHIQNLKDLSPVIVTQLALAIADLALQMPSWKGCVQTLVEKYSNDVTSLPFLLEILTVLPEEVHSRSLRIGANRRTEIIEDLAFYSSTVVSLLMTCVEKAGTDEKMLMKVFRCLGSWFNLGVLDSNFMANNKLLALLFEVLQQDKTSSNLHEAASDCVCSALYAIENVETNLPLAMQLFQGVLTLETAYHMAVAREDLDKVLNYCRIFTELCETFLEKIVCTPGQGLGDLRTLELLLICAGHPQYEVVEISFNFWYRLGEHLYKTNDEVIHGIFKAYIQRLLHALARHCQLEPDHEGVPEETDDFGEFRMRVSDLVKDLIFLIGSMECFAQLYSTLKEGNPPWEVTEAVLFIMAAIAKSVDPENNPTLVEVLEGVVRLPETVHTAVRYTSIELVGEMSEVVDRNPQFLDPVLGYLMKGLCEKPLASAAAKAIHNICSVCRDHMAQHFNGLLEIARSLDSFLLSPEAAVGLLKGTALVLARLPLDKITECLSELCSVQVMALKKLLSQEPSNGISSDPTVFLDRLAVIFRHTNPIVENGQTHPCQKVIQEIWPVLSETLNKHRADNRIVERCCRCLRFAVRCVGKGSAALLQPLVTQMVNVYHVHQHSCFLYLGSILVDEYGMEEGCRQGLLDMLQALCIPTFQLLEQQNGLQNHPDTVDDLFRLATRFIQRSPVTLLRSQVVIPILQWAIASTTLDHRDANCSVMRFLRDLIHTGVANDHEEDFELRKELIGQVMNQLGQQLVSQLLHTCCFCLPPYTLPDVAEVLWEIMQVDRPTFCRWLENSLKGLPKETTVGAVTVTHKQLTDFHKQVTRNVFFN>sp|Q9Y5L0-5|TNPO3_HUMAN Isoform 4 of Transportin-3 OS=Homo sapiensOX=9606 GN=TNPO3MEGAKPTLQLVYQAVQALYHDPDPSGKERASFWLGELQRSVHAWEISDQLLQIRQDVESCYFAAQTMKMKIQTSFYELPTDSHASLRDSLLTHIQNLKDLSPVIVTQLALAIADLALQMPSWKGCVQTLVEKYSNDVTSLPFLLEILTVLPEEVHSRSLRIGANRRTEIIEDLAFYSSTVVSLLMTCVEKAGTDEKMLMKVFRCLGSWFNLGVLDSNFMANNKLLALLFEVLQQDKTSSNLHEAASDCVCSALYAIENVETNLPLAMQLFQGVLTLETAYHMAVAREDLDKVLNYCRIFTELCETFLEKIVCTPGQGLGDLRTLELLLICAGHPQYEVVEISFNFWYRLGEHLYKTNDEVIHGIFKAYIQRLLHALARHCQLEPDHEGVPEETDDFGEFRMRVSDLVKDLIFLIGSMECFAQLYSTLKEGNPPWEVTEAVLFIMAAIAKSVDPENNPTLVEVLEGVVRLPETVHTAVRYTSIELVGEMSEVVDRNPQFLGTALVLARLPLDKITECLSELCSVQVMALKKLLSQEPSNGISSDPTVFLDRLAVIFRHTNPIVENGQTHPCQKVIQEIWPVLSETLNKHRADNRIVERCCRCLRFAVRCVGKGSAALLQPLVTQMVNVYHVHQHSCFLYLGSILVDEYGMEEGCRQGLLDMLQALCIPTFQLLEQQNGLQNHPDTVDDLFRLATRFIQRSPVTLLRSQVVIPILQWAIASTTLDHRDANCSVMRFLRDLIHTGVANDHEEDFELRKELIGQVMNQLGQQLVSQLLHTCCFCLPPYTLPDVAEVLWEIMQVDRPTFCRWLENSLKGLPKETTVGAVTVTHKQLTDFHKQVTSAEECKQVCWALRDFTRLFR>sp|Q14669|TRIPC_HUMAN E3 ubiquitin-protein ligase TRIP12 OS=Homo sapiensOX=9606 GN=TRIP12 PE=1 SV=1MSNRPNNNPGGSLRRSQRNTAGAQPQDDSIGGRSCSSSSAVIVPQPEDPDRANTSERQKTGQVPKKDNSRGVKRSASPDYNRTNSPSSAKKPKALQHTESPSETNKPHSKSKKRHLDQEQQLKSAQSPSTSKAHTRKSGATGGSRSQKRKRTESSCVKSGSGSESTGAEERSAKPTKLASKSATSAKAGCSTITDSSSAASTSSSSSAVASASSTVPPGARVKQGKDQNKARRSRSASSPSPRRSSREKEQSKTGGSSKFDWAARFSPKVSLPKTKLSLPGSSKSETSKPGPSGLQAKLASLRKSTKKRSESPPAELPSLRRSTRQKTTGSCASTSRRGSGLGKRGAAEARRQEKMADPESNQEAVNSSAARTDEAPQGAAGAVGMTTSGESESDDSEMGRLQALLEARGLPPHLFGPLGPRMSQLFHRTIGSGASSKAQQLLQGLQASDESQQLQAVIEMCQLLVMGNEETLGGFPVKSVVPALITLLQMEHNFDIMNHACRALTYMMEALPRSSAVVVDAIPVFLEKLQVIQCIDVAEQALTALEMLSRRHSKAILQAGGLADCLLYLEFFSINAQRNALAIAANCCQSITPDEFHFVADSLPLLTQRLTHQDKKSVESTCLCFARLVDNFQHEENLLQQVASKDLLTNVQQLLVVTPPILSSGMFIMVVRMFSLMCSNCPTLAVQLMKQNIAETLHFLLCGASNGSCQEQIDLVPRSPQELYELTSLICELMPCLPKEGIFAVDTMLKKGNAQNTDGAIWQWRDDRGLWHPYNRIDSRIIEQINEDTGTARAIQRKPNPLANSNTSGYSESKKDDARAQLMKEDPELAKSFIKTLFGVLYEVYSSSAGPAVRHKCLRAILRIIYFADAELLKDVLKNHAVSSHIASMLSSQDLKIVVGALQMAEILMQKLPDIFSVYFRREGVMHQVKHLAESESLLTSPPKACTNGSGSMGSTTSVSSGTATAATHAAADLGSPSLQHSRDDSLDLSPQGRLSDVLKRKRLPKRGPRRPKYSPPRDDDKVDNQAKSPTTTQSPKSSFLASLNPKTWGRLSTQSNSNNIEPARTAGGSGLARAASKDTISNNREKIKGWIKEQAHKFVERYFSSENMDGSNPALNVLQRLCAATEQLNLQVDGGAECLVEIRSIVSESDVSSFEIQHSGFVKQLLLYLTSKSEKDAVSREIRLKRFLHVFFSSPLPGEEPIGRVEPVGNAPLLALVHKMNNCLSQMEQFPVKVHDFPSGNGTGGSFSLNRGSQALKFFNTHQLKCQLQRHPDCANVKQWKGGPVKIDPLALVQAIERYLVVRGYGRVREDDEDSDDDGSDEEIDESLAAQFLNSGNVRHRLQFYIGEHLLPYNMTVYQAVRQFSIQAEDERESTDDESNPLGRAGIWTKTHTIWYKPVREDEESNKDCVGGKRGRAQTAPTKTSPRNAKKHDELWHDGVCPSVSNPLEVYLIPTPPENITFEDPSLDVILLLRVLHAISRYWYYLYDNAMCKEIIPTSEFINSKLTAKANRQLQDPLVIMTGNIPTWLTELGKTCPFFFPFDTRQMLFYVTAFDRDRAMQRLLDTNPEINQSDSQDSRVAPRLDRKKRTVNREELLKQAESVMQDLGSSRAMLEIQYENEVGTGLGPTLEFYALVSQELQRADLGLWRGEEVTLSNPKGSQEGTKYIQNLQGLFALPFGRTAKPAHIAKVKMKFRFLGKLMAKAIMDFRLVDLPLGLPFYKWMLRQETSLTSHDLFDIDPVVARSVYHLEDIVRQKKRLEQDKSQTKESLQYALETLTMNGCSVEDLGLDFTLPGFPNIELKKGGKDIPVTIHNLEEYLRLVIFWALNEGVSRQFDSFRDGFESVFPLSHLQYFYPEELDQLLCGSKADTWDAKTLMECCRPDHGYTHDSRAVKFLFEILSSFDNEQQRLFLQFVTGSPRLPVGGFRSLNPPLTIVRKTFESTENPDDFLPSVMTCVNYLKLPDYSSIEIMREKLLIAAREGQQSFHLS>sp|Q14669-2|TRIPC_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIP12OS=Homo sapiens OX=9606 GN=TRIP12MSNRPNNNPGGSLRRSQRNTAGAQPQDDSIGGRSCSSSSAVIVPQPEDPDRANTSERQKTGQVPKKDNSRGVKRSASPDYNRTNSPSSAKKPKALQHTESPSETNKPHSKSKKRHLDQEQQLKSAQSPSTSKAHTRKSGATGGSRSQKRKRTESSCVKSGSGSESTGAEERSAKPTKLASKSATSAKAGCSTITDSSSAASTSSSSSAVASASSTVPPGARVKQGKDQNKARRSRSASSPSPRRSSREKEQSKTGGSSKFDWAARFSPKVSLPKTKLSLPGSSKSETSKPGPSGLQAKLASLRKSTKKRSESPPAELPSLRRSTRQKTTGSCASTSRRGSGLGKRGAAEARRQEKMADPESNQEAVNSSAARTDEAPQGAAASSSVAGAVGMTTSGESESDDSEMGRLQALLEARGLPPHLFGPLGPRMSQLFHRTIGSGASSKAQQLLQGLQASDESQQLQAVIEMCQLLVMGNEETLGGFPVKSVVPALITLLQMEHNFDIMNHACRALTYMMEALPRSSAVVVDAIPVFLEKLQVIQCIDVAEQALTALEMLSRRHSKAILQAGGLADCLLYLEFFSINAQRNALAIAANCCQSITPDEFHFVADSLPLLTQRLTHQDKKSVESTCLCFARLVDNFQHEENLLQQVASKDLLTNVQQLLVVTPPILSSGMFIMVVRMFSLMCSNCPTLAVQLMKQNIAETLHFLLCGASNGSCQEQIDLVPRSPQELYELTSLICELMPCLPKEGIFAVDTMLKKGNAQNTDGAIWQWRDDRGLWHPYNRIDSRIIEAAHQVGEDEISLSTLGRVYTIDFNSMQQINEDTGTARAIQRKPNPLANSNTSGYSESKKDDARAQLMKEDPELAKSFIKTLFGVLYEVYSSSAGPAVRHKCLRAILRIIYFADAELLKDVLKNHAVSSHIASMLSSQDLKIVVGALQMAEILMQKLPDIFSVYFRREGVMHQVKHLAESESLLTSPPKACTNGSGSMGSTTSVSSGTATAATHAAADLGSPSLQHSRDDSLDLSPQGRLSDVLKRKRLPKRGPRRPKYSPPRDDDKVDNQAKSPTTTQSPKSSFLASLNPKTWGRLSTQSNSNNIEPARTAGGSGLARAASKDTISNNREKIKGWIKEQAHKFVERYFSSENMDGSNPALNVLQRLCAATEQLNLQVDGGAECLVEIRSIVSESDVSSFEIQHSGFVKQLLLYLTSKSEKDAVSREIRLKRFLHVFFSSPLPGEEPIGRVEPVGNAPLLALVHKMNNCLSQMEQFPVKVHDFPSGNGTGGSFSLNRGSQALKFFNTHQLKCQLQRHPDCANVKQWKGGPVKIDPLALVQAIERYLVVRGYGRVREDDEDSDDDGSDEEIDESLAAQFLNSGNVRHRLQFYIGEHLLPYNMTVYQAVRQFSIQAEDERESTDDESNPLGRAGIWTKTHTIWYKPVREDEESNKDCVGGKRGRAQTAPTKTSPRNAKKHDELWHDGVCPSVSNPLEVYLIPTPPENITFEDPSLDVILLLRVLHAISRYWYYLYDNAMCKEIIPTSEFINSKLTAKANRQLQDPLVIMTGNIPTWLTELGKTCPFFFPFDTRQMLFYVTAFDRDRAMQRLLDTNPEINQSDSQDSRVAPRLDRKKRTVNREELLKQAESVMQDLGSSRAMLEIQYENEVGTGLGPTLEFYALVSQELQRADLGLWRGEEVTLSNPKGSQEGTKYIQNLQGLFALPFGRTAKPAHIAKVKMKFRFLGKLMAKAIMDFRLVDLPLGLPFYKWMLRQETSLTSHDLFDIDPVVARSVYHLEDIVRQKKRLEQDKSQTKESLQYALETLTMNGCSVEDLGLDFTLPGFPNIELKKGGKDIPVTIHNLEEYLRLVIFWALNEGVSRQFDSFRDGFESVFPLSHLQYFYPEELDQLLCGSKADTWDAKTLMECCRPDHGYTHDSRAVKFLFEILSSFDNEQQRLFLQFVTGSPRLPVGGFRSLNPPLTIVRKTFESTENPDDFLPSVMTCVNYLKLPDYSSIEIMREKLLIAAREGQQSFHLS>sp|Q14669-3|TRIPC_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIP12OS=Homo sapiens OX=9606 GN=TRIP12MSNRPNNNPGGSLRRSQRNTAGAQPQDDSIGGRSHLGQAKHKGYSPPESRKSNSKAPKVQSNTTSELSRGHLSKRSCSSSSAVIVPQPEDPDRANTSERQKTGQVPKKDNSRGVKRSASPDYNRTNSPSSAKKPKALQHTESPSETNKPHSKSKKRHLDQEQQLKSAQSPSTSKAHTRKSGATGGSRSQKRKRTESSCVKSGSGSESTGAEERSAKPTKLASKSATSAKAGCSTITDSSSAASTSSSSSAVASASSTVPPGARVKQGKDQNKARRSRSASSPSPRRSSREKEQSKTGGSSKFDWAARFSPKVSLPKTKLSLPGSSKSETSKPGPSGLQAKLASLRKSTKKRSESPPAELPSLRRSTRQKTTGSCASTSRRGSGLGKRGAAEARRQEKMADPESNQEAVNSSAARTDEAPQGAAASSSVAGAVGMTTSGESESDDSEMGRLQALLEARGLPPHLFGPLGPRMSQLFHRTIGSGASSKAQQLLQGLQASDESQQLQAVIEMCQLLVMGNEETLGGFPVKSVVPALITLLQMEHNFDIMNHACRALTYMMEALPRSSAVVVDAIPVFLEKLQVIQCIDVAEQALTALEMLSRRHSKAILQAGGLADCLLYLEFFSINAQRNALAIAANCCQSITPDEFHFVADSLPLLTQRLTHQDKKSVESTCLCFARLVDNFQHEENLLQQVASKDLLTNVQQLLVVTPPILSSGMFIMVVRMFSLMCSNCPTLAVQLMKQNIAETLHFLLCGASNGSCQEQIDLVPRSPQELYELTSLICELMPCLPKEGIFAVDTMLKKGNAQNTDGAIWQWRDDRGLWHPYNRIDSRIIEQINEDTGTARAIQRKPNPLANSNTSGYSESKKDDARAQLMKEDPELAKSFIKTLFGVLYEVYSSSAGPAVRHKCLRAILRIIYFADAELLKDVLKNHAVSSHIASMLSSQDLKIVVGALQMAEILMQKLPDIFSVYFRREGVMHQVKHLAESESLLTSPPKACTNGSGSMGSTTSVSSGTATAATHAAADLGSPSLQHSRDDSLDLSPQGRLSDVLKRKRLPKRGPRRPKYSPPRDDDKVDNQAKSPTTTQSPKSSFLASLNPKTWGRLSTQSNSNNIEPARTAGGSGLARAASKDTISNNREKIKGWIKEQAHKFVERYFSSENMDGSNPALNVLQRLCAATEQLNLQVDGGAECLVEIRSIVSESDVSSFEIQHSGFVKQLLLYLTSKSEKDAVSREIRLKRFLHVFFSSPLPGEEPIGRVEPVGNAPLLALVHKMNNCLSQMEQFPVKVHDFPSGNGTGGSFSLNRGSQALKFFNTHQLKCQLQRHPDCANVKQWKGGPVKIDPLALVQAIERYLVVRGYGRVREDDEDSDDDGSDEEIDESLAAQFLNSGNVRHRLQFYIGEHLLPYNMTVYQAVRQFSIQAEDERESTDDESNPLGRAGIWTKTHTIWYKPVREDEESNKDCVGGKRGRAQTAPTKTSPRNAKKHDELWHDGVCPSVSNPLEVYLIPTPPENITFEDPSLDVILLLRVLHAISRYWYYLYDNAMCKEIIPTSEFINSKLTAKANRQLQDPLVIMTGNIPTWLTELGKTCPFFFPFDTRQMLFYVTAFDRDRAMQRLLDTNPEINQSDSQDSRVAPRLDRKKRTVNREELLKQAESVMQDLGSSRAMLEIQYENEVGTGLGPTLEFYALVSQELQRADLGLWRGEEVTLSNPKGSQEGTKYIQNLQGLFALPFGRTAKPAHIAKVKMKFRFLGKLMAKAIMDFRLVDLPLGLPFYKWMLRQETSLTSHDLFDIDPVVARSVYHLEDIVRQKKRLEQDKSQTKESLQYALETLTMNGCSVEDLGLDFTLPGFPNIELKKGGKDIPVTIHNLEEYLRLVIFWALNEGVSRQFDSFRDGFESVFPLSHLQYFYPEELDQLLCGSKADTWDAKTLMECCRPDHGYTHDSRAVKFLFEILSSFDNEQQRLFLQFVTGSPRLPVGGFRSLNPPLTIVRKTFESTENPDDFLPSVMTCVNYLKLPDYSSIEIMREKLLIAAREGQQSFHLS>sp|Q14669-4|TRIPC_HUMAN Isoform 4 of E3 ubiquitin-protein ligase TRIP12OS=Homo sapiens OX=9606 GN=TRIP12MSNRPNNNPGGSLRRSQRNTAGAQPQDDSIGGSRRGSGLGKRGAAEARRQEKMADPESNQEAVNSSAARTDEAPQGAAASSSVAGAVGMTTSGESESDDSEMGRLQALLEARGLPPHLFGPLGPRMSQLFHRTIGSGASSKAQQLLQGLQASDESQQLQAVIEMCQLLVMGNEETLGGFPVKSVVPALITLLQMEHNFDIMNHACRALTYMMEALPRSSAVVVDAIPVFLEKLQVIQCIDVAEQALTALEMLSRRHSKAILQAGGLADCLLYLEFFSINAQRNALAIAANCCQSITPDEFHFVADSLPLLTQRLTHQDKKSVESTCLCFARLVDNFQHEENLLQQVASKDLLTNVQQLLVVTPPILSSGMFIMVVRMFSLMCSNCPTLAVQLMKQNIAETLHFLLCGASNGSCQEQIDLVPRSPQELYELTSLICELMPCLPKEGIFAVDTMLKKGNAQNTDGAIWQWRDDRGLWHPYNRIDSRIIEAAHQVGEDEISLSTLGRVYTIDFNSMQQINEDTGTARAIQRKPNPLANSNTSGYSESKKDDARAQLMKEDPELAKSFIKTLFGVLYEVYSSSAGPAVRHKCLRAILRIIYFADAELLKDVLKNHAVSSHIASMLSSQDLKIVVGALQMAEILMQKLPDIFSVYFRREGVMHQVKHLAESESLLTSPPKACTNGSGSMGSTTSVSSGTATAATHAAADLGSPSLQHSRDDSLDLSPQGRLSDVLKRKRLPKRGPRRPKYSPPRDDDKVDNQAKSPTTTQSPKSSFLASLNPKTWGRLSTQSNSNNIEPARTAGGSGLARAASKDTISNNREKIKGWIKEQAHKFVERYFSSENMDGSNPALNVLQRLCAATEQLNLQVDGGAECLVEIRSIVSESDVSSFEIQHSGFVKQLLLYLTSKSEKDAVSREIRLKRFLHVFFSSPLPGEEPIGRVEPVGNAPLLALVHKMNNCLSQMEQFPVKVHDFPSGNGTGGSFSLNRGSQALKFFNTHQLKCQLQRHPDCANVKQWKGGPVKIDPLALVQAIERYLVVRGYGRVREDDEDSDDDGSDEEIDESLAAQFLNSGNVRHRLQFYIGEHLLPYNMTVYQAVRQFSIQAEDERESTDDESNPLGRAGIWTKTHTIWYKPVREDEESNKDCVGGKRGRAQTAPTKTSPRNAKKHDELWHDGVCPSVSNPLEVYLIPTPPENITFEDPSLDVILLLRVLHAISRYWYYLYDNAMCKEIIPTSEFINSKLTAKANRQLQDPLVIMTGNIPTWLTELGKTCPFFFPFDTRQMLFYVTAFDRDRAMQRLLDTNPEINQSDSQDSRVAPRLDRKKRTVNREELLKQAESVMQDLGSSRAMLEIQYENEVGTGLGPTLEFYALVSQELQRADLGLWRGEEVTLSNPKGSQEGTKYIQNLQGLFALPFGRTAKPAHIAKVKMKFRFLGKLMAKAIMDFRLVDLPLGLPFYKWMLRQETSLTSHDLFDIDPVVARSVYHLEDIVRQKKRLEQDKSQTKESLQYALETLTMNGCSVEDLGLDFTLPGFPNIELKKGGKDIPVTIHNLEEYLRLVIFWALNEGVSRQFDSFRDGFESVFPLSHLQYFYPEELDQLLCGSKADTWDAKTLMECCRPDHGYTHDSRAVKFLFEILSSFDNEQQRLFLQFVTGSPRLPVGGFRSLNPPLTIVRKTFESTENPDDFLPSVMTCVNYLKLPDYSSIEIMREKLLIAAREGQQSFHLS>sp|Q15633|TRBP2_HUMAN RISC-loading complex subunit TARBP2 OS=Homosapiens OX=9606 GN=TARBP2 PE=1 SV=3MSEEEQGSGTTTGCGLPSIEQMLAANPGKTPISLLQEYGTRIGKTPVYDLLKAEGQAHQPNFTFRVTVGDTSCTGQGPSKKAAKHKAAEVALKHLKGGSMLEPALEDSSSFSPLDSSLPEDIPVFTAAAAATPVPSVVLTRSPPMELQPPVSPQQSECNPVGALQELVVQKGWRLPEYTVTQESGPAHRKEFTMTCRVERFIEIGSGTSKKLAKRNAAAKMLLRVHTVPLDARDGNEVEPDDDHFSIGVGSRLDGLRNRGPGCTWDSLRNSVGEKILSLRSCSLGSLGALGPACCRVLSELSEEQAFHVSYLDIEELSLSGLCQCLVELSTQPATVCHGSATTREAARGEAARRALQYLKIMAGSK>sp|Q15633-2|TRBP2_HUMAN Isoform 2 of RISC-loading complex subunit TARBP2OS=Homo sapiens OX=9606 GN=TARBP2MLAANPGKTPISLLQEYGTRIGKTPVYDLLKAEGQAHQPNFTFRVTVGDTSCTGQGPSKKAAKHKAAEVALKHLKGGSMLEPALEDSSSFSPLDSSLPEDIPVFTAAAAATPVPSVVLTRSPPMELQPPVSPQQSECNPVGALQELVVQKGWRLPEYTVTQESGPAHRKEFTMTCRVERFIEIGSGTSKKLAKRNAAAKMLLRVHTVPLDARDGNEVEPDDDHFSIGVGSRLDGLRNRGPGCTWDSLRNSVGEKILSLRSCSLGSLGALGPACCRVLSELSEEQAFHVSYLDIEELSLSGLCQCLVELSTQPATVCHGSATTREAARGEAARRALQYLKIMAGSK>sp|Q9NZ63|TLS1_HUMAN Telomere length and silencing protein 1 homologOS=Homo sapiens OX=9606 GN=C9orf78 PE=1 SV=1MPVVRKIFRRRRGDSESEEDEQDSEEVRLKLEETREVQNLRKRPNGVSAVALLVGEKVQEETTLVDDPFQMKTGGMVDMKKLKERGKDKISEEEDLHLGTSFSAETNRRDEDADMMKYIETELKKRKGIVEHEEQKVKPKNAEDCLYELPENIRVSSAKKTEEMLSNQMLSGIPEVDLGIDAKIKNIISTEDAKARLLAEQQNKKKDSETSFVPTNMAVNYVQHNRFYHEELNAPIRRNKEEPKARPLRVGDTEKPEPERSPPNRKRPANEKATDDYHYEKFKKMNRRY>sp|O60603|TLR2_HUMAN Toll-like receptor 2 OS=Homo sapiens OX=9606GN=TLR2 PE=1 SV=1MPHTLWMVWVLGVIISLSKEESSNQASLSCDRNGICKGSSGSLNSIPSGLTEAVKSLDLSNNRITYISNSDLQRCVNLQALVLTSNGINTIEEDSFSSLGSLEHLDLSYNYLSNLSSSWFKPLSSLTFLNLLGNPYKTLGETSLFSHLTKLQILRVGNMDTFTKIQRKDFAGLTFLEELEIDASDLQSYEPKSLKSIQNVSHLILHMKQHILLLEIFVDVTSSVECLELRDTDLDTFHFSELSTGETNSLIKKFTFRNVKITDESLFQVMKLLNQISGLLELEFDDCTLNGVGNFRASDNDRVIDPGKVETLTIRRLHIPRFYLFYDLSTLYSLTERVKRITVENSKVFLVPCLLSQHLKSLEYLDLSENLMVEEYLKNSACEDAWPSLQTLILRQNHLASLEKTGETLLTLKNLTNIDISKNSFHSMPETCQWPEKMKYLNLSSTRIHSVTGCIPKTLEILDVSNNNLNLFSLNLPQLKELYISRNKLMTLPDASLLPMLLVLKISRNAITTFSKEQLDSFHTLKTLEAGGNNFICSCEFLSFTQEQQALAKVLIDWPANYLCDSPSHVRGQQVQDVRLSVSECHRTALVSGMCCALFLLILLTGVLCHRFHGLWYMKMMWAWLQAKRKPRKAPSRNICYDAFVSYSERDAYWVENLMVQELENFNPPFKLCLHKRDFIPGKWIIDNIIDSIEKSHKTVFVLSENFVKSEWCKYELDFSHFRLFDENNDAAILILLEPIEKKAIPQRFCKLRKIMNTKTYLEWPMDEAQREGFWVNLRAAIKS>sp|Q9BZW4|TM6S2_HUMAN Transmembrane 6 superfamily member 2 OS=Homosapiens OX=9606 GN=TM6SF2 PE=1 SV=3MDIPPLAGKIAALSLSALPVSYALNHVSALSHPLWVALMSALILGLLFVAVYSLSHGEVSYDPLYAVFAVFAFTSVVDLIIALQEDSYVVGFMEFYTKEGEPYLRTAHGVFICYWDGTVHYLLYLAMAGAICRRKRYRNFGLYWLGSFAMSILVFLTGNILGKYSSEIRPAFFLTIPYLLVPCWAGMKVFSQPRALTRCTANMVQEEQRKGLLQRPADLALVIYLILAGFFTLFRGLVVLDCPTDACFVYIYQYEPYLRDPVAYPKVQMLMYMFYVLPFCGLAAYALTFPGCSWLPDWALVFAGGIGQAQFSHMGASMHLRTPFTYRVPEDTWGCFFVCNLLYALGPHLLAYRCLQWPAFFHQPPPSDPLALHKKQH>sp|Q9BZW4-2|TM6S2_HUMAN Isoform 2 of Transmembrane 6 superfamily member2 OS=Homo sapiens OX=9606 GN=TM6SF2MDIPPLAGKIAALSLSALPVSYALNHVSALSHPLWVALMSALILGLLFVAVYSLSHGEVSYDPLYAVFAVFAFTSVVDLIIALQEDSYVVGFMEFYTKEGEPYLRTAHGVFICYWDGTVHYLLYLAMAGAICRRKRYRNFGLYWLGSFAMSILVFLTGNILGKYSSEIRPAFFLTIPYLLVPCWAGMKVFSQPRALTRCTANMVQEEQRKGLLQRPADLALVIYLILAGFFTLFRGLVVLDCPTDACFVYIYQYEPYLRDPVAYPKVQMLMYMFYVLPFCGLAAYALTFPGCSWLPDWALVFAGGIGQAQFSHMGASMHLRTPFTYCLQWPAFFHQPPPSDPLALHKKQH>sp|Q9H0C3|TM117_HUMAN Transmembrane protein 117 OS=Homo sapiens OX=9606GN=TMEM117 PE=1 SV=1MGKDFRYYFQHPWSRMIVAYLVIFFNFLIFAEDPVSHSQTEANVIVVGNCFSFVTNKYPRGVGWRILKVLLWLLAILTGLIAGKFLFHQRLFGQLLRLKMFREDHGSWMTMFFSTILFLFIFSHIYNTILLMDGNMGAYIITDYMGIRNESFMKLAAVGTWMGDFVTAWMVTDMMLQDKPYPDWGKSARAFWKKGNVRITLFWTVLFTLTSVVVLVITTDWISWDKLNRGFLPSDEVSRAFLASFILVFDLLIVMQDWEFPHFMGDVDVNLPGLHTPHMQFKIPFFQKIFKEEYRIHITGKWFNYGIIFLVLILDLNMWKNQIFYKPHEYGQYIGPGQKIYTVKDSESLKDLNRTKLSWEWRSNHTNPRTNKTYVEGDMFLHSRFIGASLDVKCLAFVPSLIAFVWFGFFIWFFGRFLKNEPRMENQDKTYTRMKRKSPSEHSKDMGITRENTQASVEDPLNDPSLVCIRSDFNEIVYKSSHLTSENLSSQLNESTSATEADQDPTTSKSTPTN>sp|Q96GJ1|TRM2_HUMAN tRNA (uracil(54)-C(5))-methyltransferase homologOS=Homo sapiens OX=9606 GN=TRMT2B PE=1 SV=1MAGLKRRVPLHSLRYFISMVGLFSKPGLLPWYARNPPGWSQLFLGTVCKGDFTRVIATKCQKGQKSQKKPSHLGPLDGSWQERLADVVTPLWRLSYEEQLKVKFAAQKKILQRLESYIQMLNGVSVTTAVPKSERLSCLLHPIIPSPVINGYRNKSTFSVNRGPDGNPKTVGFYLGTWRDGNVVCVQSNHLKNIPEKHSQVAQYYEVFLRQSPLEPCLVFHEGGYWRELTVRTNSQGHTMAIITFHPQKLSQEELHVQKEIVKEFFIRGPGAACGLTSLYFQESTMTRCSHQQSPYQLLFGEPYIFEELLSLKIRISPDAFFQINTAGAEMLYRTVGELTGVNSDTILLDICCGTGVIGLSLAQHTSRVLGIELLEQAVEDARWTAAFNGITNSEFHTGQAEKILPGLLKSKEDGQSIVAVVNPARAGLHYKVIQAIRNFRAIHTLVFVSCKLHGESTRNVIELCCPPDPAKKLLGEPFVLQQAVPVDLFPHTPHCELVLLFTR>sp|Q96GJ1-2|TRM2_HUMAN Isoform 2 of tRNA (uracil(54)-C(5))-methyltransferase homolog OS=Homo sapiens OX=9606 GN=TRMT2BMAGLKRRVPLHSLRYFISMVGLFSKPGLLPWYARNPPGWSQLFLGTVCKGDFTRVIATKCQKGQKSQKKPSHLGPLDGSWQERLADVVTPLWRLSYEEQLKVKFAAQKKILQRLESYIQMLNGVSVTTAVPKSERLSCLLHPIIPSPVINGYRNKSTFSVNRGPDGNPKTVGFYLGTWRDGNVVCVQSNHLKNIPEKHSQVAQYYEVFLRQSPLEPCLVFHEGGYWRELTVRTNSQGHTMAIITFHPQKLSQEELHVQKEIVKEFFIRGPGAACGLTSLYFQESTMTRCSHQQSPYQLLFGEPYIFEELLSLKIRISPDAFFQINTAGAEMLYRTVGELTGVNSDTILLDICCGTGVIGLSLAQHTSRVLGIELLEQAVEDARWTAAFNGITNSEFHTGQAEKILPGLLKSKEDGQSIVAVVNPARAGLHYKVIQAIRNFRAIHTLVFVSCKLHGESTRNVIERSLILLECSGMVSAHCSLHLPGSSDSPASAS>sp|Q96GJ1-3|TRM2_HUMAN Isoform 3 of tRNA (uracil(54)-C(5))-methyltransferase homolog OS=Homo sapiens OX=9606 GN=TRMT2BMAGLKRRVPLHSLRYFISMVGLFSKPGLLPWYARNPPGWSQLFLGTVCKGDFTRVIATKCQKGQKSQKKPSHLGPLDGSWQERLADVVTPLWRLSYEEQLKPVINGYRNKSTFSVNRGPDGNPKTVGFYLGTWRDGNVVCVQSNHLKNIPEKHSQVAQYYEVFLRQSPLEPCLVFHEGGYWRELTVRTNSQGHTMAIITFHPQKLSQEELHVQKEIVKEFFIRGPGAACGLTSLYFQESTMTRCSHQQSPYQLLFGEPYIFEELLSLKIRISPDAFFQINTAGAEMLYRTVGELTGVNSDTILLDICCGTGVIGLSLAQHTSRVLGIELLEQAVEDARWTAAFNGITNSEFHTGQAEKILPGLLKSKEDGQSIVAVVNPARAGLHYKVIQAIRNFRAIHTLVFVSCKLHGESTRNVIELCCPPDPAKKLLGEPFVLQQAVPVDLFPHTPHCELVLLFTR>sp|P08138|TNR16_HUMAN Tumor necrosis factor receptor superfamily member16 OS=Homo sapiens OX=9606 GN=NGFR PE=1 SV=1MGAGATGRAMDGPRLLLLLLLGVSLGGAKEACPTGLYTHSGECCKACNLGEGVAQPCGANQTVCEPCLDSVTFSDVVSATEPCKPCTECVGLQSMSAPCVEADDAVCRCAYGYYQDETTGRCEACRVCEAGSGLVFSCQDKQNTVCEECPDGTYSDEANHVDPCLPCTVCEDTERQLRECTRWADAECEEIPGRWITRSTPPEGSDSTAPSTQEPEAPPEQDLIASTVAGVVTTVMGSSQPVVTRGTTDNLIPVYCSILAAVVVGLVAYIAFKRWNSCKQNKQGANSRPVNQTPPPEGEKLHSDSGISVDSQSLHDQQPHTQTASGQALKGDGGLYSSLPPAKREEVEKLLNGSAGDTWRHLAGELGYQPEHIDSFTHEACPVRALLASWATQDSATLDALLAALRRIQRADLVESLCSESTATSPV>sp|P08138-2|TNR16_HUMAN Isoform 2 of Tumor necrosis factor receptorsuperfamily member 16 OS=Homo sapiens OX=9606 GN=NGFRMSAPCVEADDAVCRCAYGYYQDETTGRCEACRVCEAGSGLVFSCQDKQNTVCEECPDGTYSDEANHVDPCLPCTVCEDTERQLRECTRWADAECEEIPGRWITRSTPPEGSDSTAPSTQEPEAPPEQDLIASTVAGVVTTVMGSSQPVVTRGTTDNLIPVYCSILAAVVVGLVAYIAFKRWNSCKQNKQGANSRPVNQTPPPEGEKLHSDSGISVDSQSLHDQQPHTQTASGQALKGDGGLYSSLPPAKREEVEKLLNGSAGDTWRHLAGELGYQPEHIDSFTHEACPVRALLASWATQDSATLDALLAALRRIQRADLVESLCSESTATSPV>sp|O60704|TPST2_HUMAN Protein-tyrosine sulfotransferase 2 OS=Homosapiens OX=9606 GN=TPST2 PE=1 SV=1MRLSVRRVLLAAGCALVLVLAVQLGQQVLECRAVLAGLRSPRGAMRPEQEELVMVGTNHVEYRYGKAMPLIFVGGVPRSGTTLMRAMLDAHPEVRCGEETRIIPRVLAMRQAWSKSGREKLRLDEAGVTDEVLDAAMQAFILEVIAKHGEPARVLCNKDPFTLKSSVYLSRLFPNSKFLLMVRDGRASVHSMITRKVTIAGFDLSSYRDCLTKWNKAIEVMYAQCMEVGKEKCLPVYYEQLVLHPRRSLKLILDFLGIAWSDAVLHHEDLIGKPGGVSLSKIERSTDQVIKPVNLEALSKWTGHIPGDVVRDMAQIAPMLAQLGYDPYANPPNYGNPDPFVINNTQRVLKGDYKTPANLKGYFQVNQNSTSSHLGSS>sp|Q8N9M5|TM102_HUMAN Transmembrane protein 102 OS=Homo sapiens OX=9606GN=TMEM102 PE=1 SV=1MASAVWGSAPWWGPPPPAPARPLTDIDFCSGAQLQELTQLIQELGVQESWSDGPKPGADLLRAKDFVFSLLGLVHRRDPRFPPQAELLLLRGGIREGSLDLGHAPLGPYARGPHYDAGFTLLVPMFSLDGTELQLDLESCYAQVCLPEMVCGTPIREMWQDCLGPPVPGARDSIHRTESEESSKDWQSSVDQPHSYVTEHEAPVSLEKSPSDVSASESPQHDVVDLGSTAPLKTMSSDVTKAAVESPVPKPSEAREAWPTLCSAQVAAWFFATLAAVAESLIPVPGAPRLVHAARHAGFTTVLLATPEPPRRLLLFDLIPVVSVAGWPEGARSHSWAGPLASESASFYLVPGGGTERPCASAWQLCFARQELALKARIPAPLLQAHAAAQALLRPLVAGTRAAAPYLLRTLLYWACERLPALYLARPENAGACCLGLLDELGRVLEAGTLPHYFLNGRQLRTGDDSAALLGELARLRGDPARALRAAVEEAKVARKGGGLAGVGGGAH>sp|Q6ZTA4|TRI67_HUMAN Tripartite motif-containing protein 67 OS=Homosapiens OX=9606 GN=TRIM67 PE=2 SV=3MEEELKCPVCGSLFREPIILPCSHNVCLPCARTIAVQTPDGEQHLPQPLLLSRGSGLQAGAAAAASLEHDAAAGPACGGAGGSAAGGLGGGAGGGGDHADKLSLYSETDSGYGSYTPSLKSPNGVRVLPMVPAPPGSSAAAARGAACSSLSSSSSSITCPQCHRSASLDHRGLRGFQRNRLLEAIVQRYQQGRGAVPGTSAAAAVAICQLCDRTPPEPAATLCEQCDVLYCSACQLKCHPSRGPFAKHRLVQPPPPPPPPAEAASGPTGTAQGAPSGGGGCKSPGGAGAGATGGSTARKFPTCPEHEMENYSMYCVSCRTPVCYLCLEEGRHAKHEVKPLGAMWKQHKAQLSQALNGVSDKAKEAKEFLVQLKNILQQIQENGLDYEACLVAQCDALVDALTRQKAKLLTKVTKEREHKLKMVWDQINHCTLKLRQSTGLMEYCLEVIKENDPSGFLQISDALIKRVQVSQEQWVKGALEPKVSAEFDLTLDSEPLLQAIHQLDFIQMKCRVPPVPLLQLEKCCTRNNSVTLAWRMPPFTHSPVDGYILELDDGAGGQFREVYVGKETLCTIDGLHFNSTYNARVKAFNSSGVGPYSKTVVLQTSDVAWFTFDPNSGHRDIILSNDNQTATCSSYDDRVVLGTAAFSKGVHYWELHVDRYDNHPDPAFGVARASVVKDMMLGKDDKAWAMYVDNNRSWFMHCNSHTNRTEGGVCKGATVGVLLDLNKHTLTFFINGQQQGPTAFSHVDGVFMPALSLNRNVQVTLHTGLEVPTNLGRPKLSGN>sp|Q6ZTA4-2|TRI67_HUMAN Isoform 2 of Tripartite motif-containing protein67 OS=Homo sapiens OX=9606 GN=TRIM67MEEELKCPVCGSLFREPIILPCSHNVCLPCARTIAVQTPDGGSAAGGLGGGAGGGGDHADKLSLYSETDSGYGSYTPSLKSPNGVRVLPMVPAPPGSSAAAARGAACSSLSSSSSSITCPQCHRSASLDHRGLRGFQRNRLLEAIVQRYQQGRGAVPGTSAAAAVAICQLCDRTPPEPAATLCEQCDVLYCSACQLKCHPSRGPFAKHRLGAPSGGGGCKSPGGAGAGATGGSTARKFPTCPEHEMENYSMYCVSCRTPVCYLCLEEGRHAKHEVKPLGAMWKQHKAQLSQALNGVSDKAKEAKEFLVQLKNILQQIQENGLDYEACLVAQCDALVDALTRQKAKLLTKVTKEREHKLKMVWDQINHCTLKLRQSTGLMEYCLEVIKENDPSGFLQISDALIKRVQVSQEQWVKGALEPKVSAEFDLTLDSEPLLQAIHQLDFIQMKCRVPPVPLLQLEKCCTRNNSVTLAWRMPPFTHSPVDGYILELDDGAGGQFREVYVGKETLCTIDGLHFNSTYNARVKAFNSSGVGPYSKTVVLQTSDVAWFTFDPNSGHRDIILSNDNQTATCSSYDDRVVLGTAAFSKGVHYWELHVDRYDNHPDPAFGVARASVVKDMMLGKDDKAWAMYVDNNRSWFMHCNSHTNRTEGGVCKGATVGVLLDLNKHTLTFFINGQQQGPTAFSHVDGVFMPALSLNRNVQVTLHTGLEVPTNLGRPKLSGN>sp|Q96GM8|TOE1_HUMAN Target of EGR1 protein 1 OS=Homo sapiens OX=9606GN=TOE1 PE=1 SV=1MAADSDDGAVSAPAASDGGVSKSTTSGEELVVQVPVVDVQSNNFKEMWPSLLLAIKTANFVAVDTELSGLGDRKSLLNQCIEERYKAVCHAARTRSILSLGLACFKRQPDKGEHSYLAQVFNLTLLCMEEYVIEPKSVQFLIQHGFNFNQQYAQGIPYHKGNDKGDESQSQSVRTLFLELIRARRPLVLHNGLIDLVFLYQNFYAHLPESLGTFTADLCEMFPAGIYDTKYAAEFHARFVASYLEYAFRKCERENGKQRAAGSPHLTLEFCNYPSSMRDHIDYRCCLPPATHRPHPTSICDNFSAYGWCPLGPQCPQSHDIDLIIDTDEAAAEDKRRRRRRREKRKRALLNLPGTQTSGEAKDGPPKKQVCGDSIKPEETEQEVAADETRNLPHSKQGNKNDLEMGIKAARPEIADRATSEVPGSQASPNPVPGDGLHRAGFDAFMTGYVMAYVEVSQGPQPCSSGPWLPECHNKVYLSGKAVPLTVAKSQFSRSSKAHNQKMKLTWGSS>sp|Q96GM8-2|TOE1_HUMAN Isoform 2 of Target of EGR1 protein 1 OS=Homosapiens OX=9606 GN=TOE1MAADSDDGAVSAPAASDGAEWAWGQEEFAEPGEHSYLAQVFNLTLLCMEEYVIEPKSVQFLIQHGFNFNQQYAQGIPYHKGNDKGDESQSQSVRTLFLELIRARRPLVLHNGLIDLVFLYQNFYAHLPESLGTFTADLCEMFPAGIYDTKYAAEFHARFVASYLEYAFRKCERENGKQRAAGSPHLTLEFCNYPSSMRDHIDYRCCLPPATHRPHPTSICDNFSAYGWCPLGPQCPQSHDIDLIIDTDEAAAEDKRRRRRRREKRKRALLNLPGTQTSGEAKDGPPKKQVCGDSIKPEETEQEVAADETRNLPHSKQGNKNDLEMGIKAARPEIADRATSEVPGSQASPNPVPGDGLHRAGFDAFMTGYVMAYVEVSQGPQPCSSGPWLPECHNKVYLSGKAVPLTVAKSQFSRSSKAHNQKMKLTWGSS>sp|Q8TDI7|TMC2_HUMAN Transmembrane channel-like protein 2 OS=Homosapiens OX=9606 GN=TMC2 PE=2 SV=3MSHQVKGLKEEARGGVKGRVKSGSPHTGDRLGRRSSSKRALKAEGTPGRRGAQRSQKERAGGSPSPGSPRRKQTGRRRHREELGEQERGEAERTCEGRRKRDERASFQERTAAPKREKEIPRREEKSKRQKKPRSSSLASSASGGESLSEEELAQILEQVEEKKKLIATMRSKPWPMAKKLTELREAQEFVEKYEGALGKGKGKQLYAYKMLMAKKWVKFKRDFDNFKTQCIPWEMKIKDIESHFGSSVASYFIFLRWMYGVNLVLFGLIFGLVIIPEVLMGMPYGSIPRKTVPRAEEEKAMDFSVLWDFEGYIKYSALFYGYYNNQRTIGWLRYRLPMAYFMVGVSVFGYSLIIVIRSMASNTQGSTGEGESDNFTFSFKMFTSWDYLIGNSETADNKYASITTSFKESIVDEQESNKEENIHLTRFLRVLANFLIICCLCGSGYLIYFVVKRSQQFSKMQNVSWYERNEVEIVMSLLGMFCPPLFETIAALENYHPRTGLKWQLGRIFALFLGNLYTFLLALMDDVHLKLANEETIKNITHWTLFNYYNSSGWNESVPRPPLHPADVPRGSCWETAVGIEFMRLTVSDMLVTYITILLGDFLRACFVRFMNYCWCWDLEAGFPSYAEFDISGNVLGLIFNQGMIWMGSFYAPGLVGINVLRLLTSMYFQCWAVMSSNVPHERVFKASRSNNFYMGLLLLVLFLSLLPVAYTIMSLPPSFDCGPFSGKNRMYDVLQETIENDFPTFLGKIFAFLANPGLIIPAILLMFLAIYYLNSVSKSLSRANAQLRKKIQVLREVEKSHKSVKGKATARDSEDTPKSSSKNATQLQLTKEETTPPSASQSQAMDKKAQGPGTSNSASRTTLPASGHLPISRPPGIGPDSGHAPSQTHPWRSASGKSAQRPPH>sp|Q8TDI7-3|TMC2_HUMAN Isoform 2 of Transmembrane channel-like protein 2OS=Homo sapiens OX=9606 GN=TMC2MSHQVKGLKEEARGGVKGRVKSGSPHTGDRLGRRSSSKRALKAEGTPGRRGAQRSQKERAGGSPSPGSPRRKQTGRRRHREELGEQERGEAERTCEGRRKRDERASFQERTAAPKREKEIPRREEKSKRQKKPRSSSLASSASGGESLSEEELAQILEQVEEKKKLIATMRSKPWPMAKKLTELREAQEFVEKYEGALGKGKGKQLYAYKMLMAKKWVKFKRDFDNFKTQCIPWEMKIKDIESHFGSSVASYFIFLRWMYGVNLVLFGLIFGLVIIPEVLMGMPYGSIPRKTVPRAEEEKAMDFSVLWDFEGYIKYSALFYGYYNNQRTIGWLRYRLPMAYFMVGVSVFGYSLIIVIRSMASNTQGSTGEGESDNFTFSFKMFTSWDYLIGNSETADNKYASITTSFKESIVDEQESNKEENIHLTRFLRVLANFLIICCLCGSGYLIYFVVKRSQQFSKMQNVSWYERNEVEIVMSLLGMFCPPLFETIAALENYHPRTGLKWQLGRIFALFLGNLYTFLLALMDDVHLKLANEETIKNITHWTLFNYYNSSGWNESVPRPPLHPADVPRGSCWETAVGIEFMRLTVSDMLVTYITILLGDFLRACFVRFMNYCWCWDLEAGFVGHHFMDIPHKGISTIFFDTYSQMHSWAFHFFGSLMTVSAL>sp|Q8TDI7-4|TMC2_HUMAN Isoform 3 of Transmembrane channel-like protein 2OS=Homo sapiens OX=9606 GN=TMC2MIWMGSFYAPGLVGINVLRLLTSMYFQCWAVMSSNVPHERVFKASRSNNFYMGLLLLVLFLSLLPVAYTIMSLPPSFDCGPFRCRVSVAREHLPSRGSLLRGPRPRIPVLVSCQPVKGHGTLGESPMPFKRVFCQDGNVRSFCVCAVHFSSHQPPVAVECLK>sp|Q6PI78|TMM65_HUMAN Transmembrane protein 65 OS=Homo sapiens OX=9606GN=TMEM65 PE=1 SV=2MSRLLPLLRSRTARSLRPGPAAAAAPRPPSWCCCGRGLLALAPPGGLPGGPRRLGTHPKKEPMEALNTAQGARDFIYSLHSTERSCLLKELHRFESIAIAQEKLEAPPPTPGQLRYVFIHNAIPFIGFGFLDNAIMIVAGTHIEMSIGIILGISTMAAAALGNLVSDLAGLGLAGYVEALASRLGLSIPDLTPKQVDMWQTRLSTHLGKAVGVTIGCILGMFPLIFFGGGEEDEKLETKS>sp|Q8IU68|TMC8_HUMAN Transmembrane channel-like protein 8 OS=Homosapiens OX=9606 GN=TMC8 PE=1 SV=1MLLPRSVSSERAPGVPEPEELWEAEMERLRGSGTPVRGLPYAMMDKRLIWQLREPAGVQTLRWQRWQRRRQTVERRLREAAQRLARGLGLWEGALYEIGGLFGTGIRSYFTFLRFLLLLNLLSLLLTASFVLLPLVWLRPPDPGPTLNLTLQCPGSRQSPPGVLRFHNQLWHVLTGRAFTNTYLFYGAYRVGPESSSVYSIRLAYLLSPLACLLLCFCGTLRRMVKGLPQKTLLGQGYQAPLSAKVFSSWDFCIRVQEAATIKKHEISNEFKVELEEGRRFQLMQQQTRAQTACRLLSYLRVNVLNGLLVVGAISAIFWATKYSQDNKEESLFLLLQYLPPGVIALVNFLGPLLFTFLVQLENYPPNTEVNLTLIWCVVLKLASLGMFSVSLGQTILCIGRDKSSCESYGYNVCDYQCWENSVGEELYKLSIFNFLLTVAFAFLVTLPRRLLVDRFSGRFWAWLEREEFLVPKNVLDIVAGQTVTWMGLFYCPLLPLLNSVFLFLTFYIKKYTLLKNSRASSRPFRASSSTFFFQLVLLLGLLLAAVPLGYVVSSIHSSWDCGLFTNYSAPWQVVPELVALGLPPIGQRALHYLGSHAFSFPLLIMLSLVLTVCVSQTQANARAIHRLRKQLVWQVQEKWHLVEDLSRLLPEPGPSDSPGPKYPASQASRPQSFCPGCPCPGSPGHQAPRPGPSVVDAAGLRSPCPGQHGAPASARRFRFPSGAEL>sp|Q8IU68-2|TMC8_HUMAN Isoform 2 of Transmembrane channel-like protein 8OS=Homo sapiens OX=9606 GN=TMC8MVKGLPQKTLLGQGYQAPLSAKVFSSWDFCIRVQEAATIKKHEISNEFKVELEEGRRFQLMQQQTRAQTACRLLSYLRVNVLNGLLVVGAISAIFWATKYSQDNKEESLFLLLQYLPPGVIALVNFLGPLLFTFLVQLENYPPNTEVNLTLIWCVVLKLASLGMFSVSLGQTILCIGRDKSSCESYGYNVCDYQCWENSVGEELYKLSIFNFLLTVAFAFLVTLPRRLLVDRFSGRFWAWLEREEFLVPKNVLDIVAGQTVTWMGLFYCPLLPLLNSVFLFLTFYIKKYTLLKNSRASSRPFRASSSTFFFQLVLLLGLLLAAVPLGYVVSSIHSSWDCGLFTNYSAPWQVVPELVALGLPPIGQRALHYLGSHAFSFPLLIMLSLVLTVCVSQTQANARAIHRLRKQLVWQVQEKWHLVEDLSRLLPEPGPSDSPGPKYPASQASRPQSFCPGCPCPGSPGHQAPRPGPSVVDAAGLRSPCPGQHGAPASARRFRFPSGAEL>sp|O15533|TPSN_HUMAN Tapasin OS=Homo sapiens OX=9606 GN=TAPBP PE=1 SV=1MKSLSLLLAVALGLATAVSAGPAVIECWFVEDASGKGLAKRPGALLLRQGPGEPPPRPDLDPELYLSVHDPAGALQAAFRRYPRGAPAPHCEMSRFVPLPASAKWASGLTPAQNCPRALDGAWLMVSISSPVLSLSSLLRPQPEPQQEPVLITMATVVLTVLTHTPAPRVRLGQDALLDLSFAYMPPTSEAASSLAPGPPPFGLEWRRQHLGKGHLLLAATPGLNGQMPAAQEGAVAFAAWDDDEPWGPWTGNGTFWLPRVQPFQEGTYLATIHLPYLQGQVTLELAVYKPPKVSLMPATLARAAPGEAPPELLCLVSHFYPSGGLEVEWELRGGPGGRSQKAEGQRWLSALRHHSDGSVSLSGHLQPPPVTTEQHGARYACRIHHPSLPASGRSAEVTLEVAGLSGPSLEDSVGLFLSAFLLLGLFKALGWAAVYLSTCKDSKKKAE>sp|O15533-2|TPSN_HUMAN Isoform 2 of Tapasin OS=Homo sapiens OX=9606GN=TAPBPMKSLSLLLAVALGLATAVSAGPAVIECWFVEDASGKGLAKRPGALLLRQGPGEPPPRPDLDPELYLSVHDPAGALQAAFRRYPRGAPAPHCEMSRFVPLPASAKWASGLTPAQNCPRALDGAWLMVSISSPVLSLSSLLRPQPEPQQEPVLITMATVVLTVLTHTPAPRVRLGQDALLDLSFAYMPPTSEAASSLAPGPPPFGLEWRRQHLGKGHLLLAATPGLNGQMPAAQEGAVAFAAWDDDEPWGPWTGNGTFWLPRVQPFQEGTYLATIHLPYLQGQVTLELAVYKPPKVSLMPATLARAAPGEAPPELLCLVSHFYPSGGLEVEWELRGGPGGRSQKAEGQRWLSALRHHSDGSVSLSGHLQPPPVTTEQHGARYACRIHHPSLPASGRSAEVTLEVAGKSWELCGI>sp|O15533-3|TPSN_HUMAN Isoform 3 of Tapasin OS=Homo sapiens OX=9606GN=TAPBPMKSLSLLLAVALGLATAVSAGPAVIECWFVEDASGKGLAKRPGALLLRQGPGEPPPRPDLDPELYLSVHDPAGALQAAFRRYPRGAPAPHCEMSRFVPLPASAKWASGLTPAQNCPRALDGAWLMVSISSPVLSLSSLLRPQPEPQQEPVLITMATVVLTVLTHTPAPRVRLGQDALLDLSFAYMPPTSEAASSLAPGPPPFGLEWRRQHLGKGHLLLAATPGLNGQMPAAQEGAVAFAAWDDDEPWGPWTGNGTFWLPRVQPFQEGTYLATIHLPYLQGQVTLELAVYKPPKVSLMPATLARAAPGEAPPELLCLVSHFYPSGGLEVEWELRGGPGGRSQKAEGQRWLSALRHHSDGSVSLSGHLQPPPVTTEQHGARYACRIHHPSLPASGRSAEVTLEVAGLSGPSLEDSVGLFLSAFLLLGLFKALGWAAVYLSTCKDSKKVQCSTSLYLSLVTLSPHPISKPMEGGCWCGRQNLGLEFTLIWVKTWHYILTVGLFEHAT>sp|O15533-4|TPSN_HUMAN Isoform 4 of Tapasin OS=Homo sapiens OX=9606GN=TAPBPMKSLSLLLAVALGLATAVSAGPAVIECWFVEDASGKGLAKRPGALLLRQGPGEPPPRPDLDPELYLSVHVVLTVLTHTPAPRVRLGQDALLDLSFAYMPPTSEAASSLAPGPPPFGLEWRRQHLGKGHLLLAATPGLNGQMPAAQEGAVAFAAWDDDEPWGPWTGNGTFWLPRVQPFQEGTYLATIHLPYLQGQVTLELAVYKPPKVSLMPATLARAAPGEAPPELLCLVSHFYPSGGLEVEWELRGGPGGRSQKAEGQRWLSALRHHSDGSVSLSGHLQPPPVTTEQHGARYACRIHHPSLPASGRSAEVTLEVAGLSGPSLEDSVGLFLSAFLLLGLFKALGWAAVYLSTCKDSKKKAE>sp|Q6P5X7|TMM71_HUMAN Transmembrane protein 71 OS=Homo sapiens OX=9606GN=TMEM71 PE=1 SV=2MYRISQLMSTPVASSSRLEREYAGELSPTCIFPSFTCDSLDGYHSFECGSIDPLTGSHYTCRRSPRLLTNGYYIWTEDSFLCDKDGNITLNPSQTSVMYKENLVRIFRKKKRICHSFSSLFNLSTSKSWLHGSIFGDINSSPSEDNWLKGTRRLDTDHCNGNADDLDCSSLTDDWESGKMNAESVITSSSSHIISQPPGGNSHSLSLQSQLTASERFQENSSDHSETRLLQEVFFQAILLAVCLIISACARWFMGEILASVFTCSLMITVAYVKSLFLSLASYFKTTACARFVKI>sp|Q6P5X7-2|TMM71_HUMAN Isoform 2 of Transmembrane protein 71 OS=Homosapiens OX=9606 GN=TMEM71MYRISQLMSTPVASSSRLEREYAGELSPTCIFPSFTCDSLDGYHSFECGSIDPLTGSHYTCRRSPRLLTNGYYIWTEDSFLCDKDGNITLNPSQTSVMYKENLVSTSKSWLHGSIFGDINSSPSEDNWLKGTRRLDTDHCNGNADDLDCSSLTDDWESGKMNAESVITSSSSHIISQPPGGNSHSLSLQSQLTASERFQENSSDHSETRLLQEVFFQAILLAVCLIISACARWFMGEILASVFTCSLMITVAYVKSLFLSLASYFKTTACARFVKI>sp|Q6P5X7-3|TMM71_HUMAN Isoform 3 of Transmembrane protein 71 OS=Homosapiens OX=9606 GN=TMEM71MYRISQLMSTPVASSSRLEREYAGELSPTCIFPSFTCDSLDGYHSFECGSIDPLTGSHYTCRRSPRLLTNGYYIWTEDSFLCDKDGNITLNPSQTSVMYKENLVRIFRKKKRICHSFSSLFNLSTSKSWLHGSIFGDINSSPSEDNWLKGTRRLDTDHCNGNETRLLQEVFFQAILLAVCLIISACARWFMGEILASVFTCSLMITVAYVKSLFLSLASYFKTTACARFVKI>sp|Q96DX7|TRI44_HUMAN Tripartite motif-containing protein 44 OS=Homosapiens OX=9606 GN=TRIM44 PE=1 SV=1MASGVGAAFEELPHDGTCDECEPDEAPGAEEVCRECGFCYCRRHAEAHRQKFLSHHLAEYVHGSQAWTPPADGEGAGKEEAEVKVEQEREIESEAGEESESEEESESEEESETEEESEDESDEESEEDSEEEMEDEQESEAEEDNQEEGESEAEGETEAESEFDPEIEMEAERVAKRKCPDHGLDLSTYCQEDRQLICVLCPVIGAHQGHQLSTLDEAFEELRSKDSGGLKAAMIELVERLKFKSSDPKVTRDQMKMFIQQEFKKVQKVIADEEQKALHLVDIQEAMATAHVTEILADIQSHMDRLMTQMAQAKEQLDTSNESAEPKAEGDEEGPSGASEEEDT>sp|Q96MH6|TMM68_HUMAN Transmembrane protein 68 OS=Homo sapiens OX=9606GN=TMEM68 PE=2 SV=2MIDKNQTCGVGQDSVPYMICLIHILEEWFGVEQLEDYLNFANYLLWVFTPLILLILPYFTIFLLYLTIIFLHIYKRKNVLKEAYSHNLWDGARKTVATLWDGHAAVWHGYEVHGMEKIPEDGPALIIFYHGAIPIDFYYFMAKIFIHKGRTCRVVADHFVFKIPGFSLLLDVFCALHGPREKCVEILRSGHLLAISPGGVREALISDETYNIVWGHRRGFAQVAIDAKVPIIPMFTQNIREGFRSLGGTRLFRWLYEKFRYPFAPMYGGFPVKLRTYLGDPIPYDPQITAEELAEKTKNAVQALIDKHQRIPGNIMSALLERFH>sp|Q96MH6-2|TMM68_HUMAN Isoform 2 of Transmembrane protein 68 OS=Homosapiens OX=9606 GN=TMEM68MIDKNQTCGVGQDSVPYMICLIHILEEWFGVEQLEDYLNFANYLLWVFTPLILLILPYFTIFLLYLTIIFLHIYKRKNVLKEAYSHNLWDGARKTVATLWDGHAAVWHGYEVHGMEKIPEDGPALIIFYHGAIPIDFYYFMAKIFIHKGRTCRVVADHFVFKIPGFSLLLDVFCALHGPREKCVEILRSGHLLAISPGGVREALISDETYNIVWGHRRGFAQVAIDAKVTKNAVQALIDKHQRIPGNIMSALLERFH>sp|Q96MH6-3|TMM68_HUMAN Isoform 3 of Transmembrane protein 68 OS=Homosapiens OX=9606 GN=TMEM68MIDKNQTCGVGQDSVPYMICLIHILEEWFGVEQLEDYLNFANYLLWVFTPLILLILPYFTIFLLYLTIIFLHIYKRKNVLKEAYSHNLWDGARKTVATLWDGHAAVWHGKQGYFHLCVAIHVCCIGTVLPFHFID>sp|A0PK05|TMM72_HUMAN Transmembrane protein 72 OS=Homo sapiens OX=9606GN=TMEM72 PE=1 SV=1MQLQVFWTGLEYTCRLLGITTAAVLIGVGTETFLQGQFKSLAFYLLFTGAAVSICEGAYFVAQLLAICFQCQPGSLADRVREKAHWLGCFQKFLAYLLLSVACFLHPVLVWHVTIPGSMLIITGLAYFLLSKRKKRKAAPEVLASPEQYTDPSSSAVSTTGSGDTEQTYTFHGALKEGPSSLFIHMKSILKGTKKPSALQPPNTLMELSLEPADSLAKKKQVHFEDNLVRIVPSLAEGLDDGDSEPEETTSDTTPIIPPPQAPLFLSSLTATGLF>sp|A0PK05-2|TMM72_HUMAN Isoform 2 of Transmembrane protein 72 OS=Homosapiens OX=9606 GN=TMEM72MLIITGLAYFLLSKRKKRKAAPEVLASPEQYTDPSSSAVSTTGSGDTEQTYTFHGALKEGPSSLFIHMKSILKGTKKPSALQPPNTLMELSLEPADSLAKKKQVHFEDNLVRIVPSLAEGLDDGDSEPEETTSDTTPIIPPPQAPLFLSSLTATGLF>sp|Q8WVR3|TPC14_HUMAN Trafficking protein particle complex subunit 14OS=Homo sapiens OX=9606 GN=TRAPPC14 PE=1 SV=2MESQCDYSMYFPAVPLPPRAELAGDPGRYRALPRRNHLYLGETVRFLLVLRCRGGAGSGTGGGPGLGSRGAWAELATALAALASVSAGGGMPGGGGAGDQDSEPPGGGDPGGGGLFRGCSPLLTHGPGPATSGGATTLPVEEPIVSTDEVIFPLTVSLDRLPPGTPKAKIVVTVWKREIEAPEVRDQGYLRLLQTRSPGETFRGEQSAFKAQVSTLLTLLPPPVLRCRQFTVAGKHLTVLKVLNSSSQEEISIWDIRILPNFNASYLPVMPDGSVLLVDNVCHQSGEVSMGSFCRLPGTSGCFPCPLNALEEHNFLFQLRGGEQPPPGAKEGLEVPLIAVVQWSTPKLPFTQSIYTHYRLPSVRLDRPCFVMTASCKSPVRTYERFTVTYTLLNNLQDFLAVRLVWTPEHAQAGKQLCEEERRAMQAALDSVVCHTPLNNLGFSRKGSALTFSVAFQALRTGLFELSQHMKLKLQFTASVSHPPPEARPLSRKSSPSSPAVRDLVERHQASLGRSQSFSHQQPSRSHLMRSGSVMERRAITPPVASPVGRPLYLPPDKAVLSLDKIAKRECKVLVVEPVK>sp|Q8WVR3-2|TPC14_HUMAN Isoform 2 of Trafficking protein particlecomplex subunit 14 OS=Homo sapiens OX=9606 GN=TRAPPC14MHRLSGFENQMRLCWRRPCGNEERCSVCWSLFLPPGKQLCEEERRAMQAALDSVVCHTPLNNLGFSRKGSALTFSVAFQALRTGLFEHMKLKLQFTASVSHPPPEARPLSRKSSPSSPAVRDLVERHQASLGRSQSFSHQQPSRSHLMRSGSVMERRAITPPVASPVGRPLYLPPDKAVLSLDKIAKRECKVLVVEPVK>sp|Q8WVR3-3|TPC14_HUMAN Isoform 3 of Trafficking protein particlecomplex subunit 14 OS=Homo sapiens OX=9606 GN=TRAPPC14MHRLFTPQSGFENQMRLCWRRPCGNEERCSVCWSLFLPPGKQLCEEERRAMQAALDSVVCHTPLNNLGFSRKGSALTFSVAFQALRTGLFELSQHMKLKLQFTASVSHPPPEARPLSRKSSPSSPAVRDLVERHQASLGRSQSFSHQQPSRSHLMRSGSVMERRAITPPVASPVGRPLYLPPDKAVLSLDKIAKRECKVLVVEPVK>sp|Q9NZR1|TMOD2_HUMAN Tropomodulin-2 OS=Homo sapiens OX=9606 GN=TMOD2PE=1 SV=1MALPFQKELEKYKNIDEDELLGKLSEEELKQLENVLDDLDPESAMLPAGFRQKDQTQKAATGPFDREHLLMYLEKEALEQKDREDFVPFTGEKKGRVFIPKEKPIETRKEEKVTLDPELEEALASASDTELYDLAAVLGVHNLLNNPKFDEETANNKGGKGPVRNVVKGEKVKPVFEEPPNPTNVEISLQQMKANDPSLQEVNLNNIKNIPIPTLREFAKALETNTHVKKFSLAATRSNDPVAIAFADMLKVNKTLTSLNIESNFITGTGILALVEALKENDTLTEIKIDNQRQQLGTAVEMEIAQMLEENSRILKFGYQFTKQGPRTRVAAAITKNNDLVRKKRVEADRR>sp|Q9NZR1-2|TMOD2_HUMAN Isoform 2 of Tropomodulin-2 OS=Homo sapiensOX=9606 GN=TMOD2MALPFQKELEKYKNIDEDELLGKLSEEELKQLENVLDDLDPESAMLPAGFRQKDQTQKAATGPFDREHLLMYLEKEALEQKDREDFVPFTGEKKGRVFIPKEKPIETRKEEKVTLDPELEEALASASDTELYDLAAVLGVHNLLNNPKFDEETANNKGGKGPVRNVVKGEKVKPVFEEPPNPTNVEISLQQMKANDPSLQEVNLNNIKAFADMLKVNKTLTSLNIESNFITGTGILALVEALKENDTLTEIKIDNQRQQLGTAVEMEIAQMLEENSRILKFGYQFTKQGPRTRVAAAITKNNDLVRKKRVEADRR>sp|O95985|TOP3B_HUMAN DNA topoisomerase 3-beta-1 OS=Homo sapiens OX=9606GN=TOP3B PE=1 SV=1MKTVLMVAEKPSLAQSIAKILSRGSLSSHKGLNGACSVHEYTGTFAGQPVRFKMTSVCGHVMTLDFLGKYNKWDKVDPAELFSQAPTEKKEANPKLNMVKFLQVEGRGCDYIVLWLDCDKEGENICFEVLDAVLPVMNKAHGGEKTVFRARFSSITDTDICNAMACLGEPDHNEALSVDARQELDLRIGCAFTRFQTKYFQGKYGDLDSSLISFGPCQTPTLGFCVERHDKIQSFKPETYWVLQAKVNTDKDRSLLLDWDRVRVFDREIAQMFLNMTKLEKEAQVEATSRKEKAKQRPLALNTVEMLRVASSSLGMGPQHAMQTAERLYTQGYISYPRTETTHYPENFDLKGSLRQQANHPYWADTVKRLLAEGINRPRKGHDAGDHPPITPMKSATEAELGGDAWRLYEYITRHFIATVSHDCKYLQSTISFRIGPELFTCSGKTVLSPGFTEVMPWQSVPLEESLPTCQRGDAFPVGEVKMLEKQTNPPDYLTEAELITLMEKHGIGTDASIPVHINNICQRNYVTVESGRRLKPTNLGIVLVHGYYKIDAELVLPTIRSAVEKQLNLIAQGKADYRQVLGHTLDVFKRKFHYFVDSIAGMDELMEVSFSPLAATGKPLSRCGKCHRFMKYIQAKPSRLHCSHCDETYTLPQNGTIKLYKELRCPLDDFELVLWSSGSRGKSYPLCPYCYNHPPFRDMKKGMGCNECTHPSCQHSLSMLGIGQCVECESGVLVLDPTSGPKWKVACNKCNVVAHCFENAHRVRVSADTCSVCEAALLDVDFNKAKSPLPGDETQHMGCVFCDPVFQELVELKHAASCHPMHRGGPGRRQGRGRGRARRPPGKPNPRRPKDKMSALAAYFV>sp|O95985-2|TOP3B_HUMAN Isoform 2 of DNA topoisomerase 3-beta-1 OS=Homosapiens OX=9606 GN=TOP3BMKTVLMVAEKPSLAQSIAKILSRGSLSSHKGLNGACSVHEYTGTFAGQPVRFKMTSVCGHVMTLDFLGKYNKWDKVDPAELFSQAPTEKKEANPKLNMVKFLQVEGRGCDYIVLWLDCDKEGENICFEVLDAVLPVMNKAHGGEKTVFRARFSSITDTDICNAMACLGEPDHNEALSVDARQELDLRIGCAFTRFQTKYFQGKYGDLDSSLISFGPCQTPTLGFCVERHDKIQSFKPETYWVLQAKVNTDKDRSLLLDWDRVRVFDREIAQMFLNMTKLEKEAQVEATSRKEKAKQRPLALNTVEMLRVASSSLGMGPQHAMQTAERLYTQGYISYPRTETTHYPENFDLKGSLRQQANHPYWADTVKRLLAEGINRPRKGHDAGDHPPITPMKSATEAELGGDAWRLYEYITRHFIATVSHDCKYLQSTISFRIGPELFTCSGKTVLSPGFTEVMPWQSVPLEESLPTCQRGDAFPVGEVKMLEKQTNPPDYLTEAELITLMEKHGIGTDASIPVHINNICQRNYVTVESGRRLKPTNLGIVLVHGYYKIDAELVLPTIRSAVEKQLNLIAQGKADYRQVLGHTLDVFKRKFHYFVDSIAGMDELMEVSFSPLAATGKPLSRCGKCHRFMKYIQAKPSRLHCSHCDETYTLPQNGTIKLYKELRCPLDDFELVLWSSGSRGKSYPLCPYCYNHPPFRDMKKGECSHSLLSTGSCSLFSVPTPALHQAGL>sp|O95985-3|TOP3B_HUMAN Isoform 3 of DNA topoisomerase 3-beta-1 OS=Homosapiens OX=9606 GN=TOP3BMKTVLMVAEKPSLAQSIAKILSRGSLSSHKGLNGACSVHEYTGTFAGQPVRFKMTSVCGHVMTLDFLGKYNKWDKVDPAELFSQAPTEKKEANPKLNMVKFLQVEGRGCDYIVLWLDCDKEGENICFEVLDAVLPVMNKAHGGEKTVFRARFSSITDTDICNAMACLGEPDHNEALSVDARQELDLRIGCAFTRFQTKYFQGKYGDLDSSLISFGPCQTPTLGFCVERHDKIQSFKPETYWVLQAKVNTDKDRSLLLDWDRVRVFDREIAQMFLNMTKLEKEAQVEATSRKEKAKQRPLALNTVEMLRVASSSLGMGPQHAMQTAERLYTQGYISYPRTETTHYPENFDLKGSLRQQANHPYWADTVKRLLAEGINRPRKGHDAGDHPPITPMKSATEAELGGDAWRLYEYITRHFIATVSHDCKYLQSTISFRIGPELFTCSGKTVLSPGFTEVMPWQSVPLEESLPTCQRGDAFPVGEVKMLEKQTNPPDYLTEAELITLMEKHGIGTDASIPVHINNICQRNYVTVESGRRLKPTNLGIVLVHGYYKIDAELVLPTIRSAVEKQLNLIAQGKADYRQVLGHTLDVFKRKFHYFVDSIAGMDELMEVSFSPLAATGKPLSRCGKCHRFMKYIQAKPSRLHCSHCDETYTLPQNGTIKLYKELRCPLDDFELVLWSSGSRGKSYPLCPYCYNHPPFRDMKKVVPCV>sp|Q96J77|TPD55_HUMAN Tumor protein D55 OS=Homo sapiens OX=9606GN=TPD52L3 PE=1 SV=2MPHARTETSVGTYESHSTSELEDLTEPEQRELKTKLTKLEAEIVTLRHVLAAKERRCGELKRKLGLTALVGLRQNLSKSWLDVQVSNTYVKQKTSAALSTMGTLICRKLGGVKKSATFRSFEGLMGTIKSKVSGGKRAWP>sp|Q96J77-2|TPD55_HUMAN Isoform 2 of Tumor protein D55 OS=Homo sapiensOX=9606 GN=TPD52L3MPHARTETSVGTYESHSTSELEDLTEPEQRELKTKLTKLEAEIVTLRHVLAAKERRCGELKRKLGLTALVGLRQNLSKSWLDVQVSNTYVKQKTSAALSTMGTLICRKLGGVKKSATFRSFEGLIFNKYTLNQGRN>sp|Q96J77-3|TPD55_HUMAN Isoform 3 of Tumor protein D55 OS=Homo sapiensOX=9606 GN=TPD52L3MPHARTETSVGTYESHSTSELEDLTEPEQRELKTKLTKLEAEIVTLRHVLAAKERRCGELKRKLGLTALVGLRQNLSKSWLDVQVSNTYVKQKTSAALSTMGTLICRKLGGVKKSATFRSFEGNPKGEGSRI>sp|Q15388|TOM20_HUMAN Mitochondrial import receptor subunit TOM20homolog OS=Homo sapiens OX=9606 GN=TOMM20 PE=1 SV=1MVGRNSAIAAGVCGALFIGYCIYFDRKRRSDPNFKNRLRERRKKQKLAKERAGLSKLPDLKDAEAVQKFFLEEIQLGEELLAQGEYEKGVDHLTNAIAVCGQPQQLLQVLQQTLPPPVFQMLLTKLPTISQRIVSAQSLAEDDVE>sp|A0A075B6Y9|TJA42_HUMAN T cell receptor alpha joining 42 OS=Homosapiens OX=9606 GN=TRAJ42 PE=4 SV=2YGGSQGNLIFGKGTKLSVKP>sp|Q9H6L2|TM231_HUMAN Transmembrane protein 231 OS=Homo sapiens OX=9606GN=TMEM231 PE=1 SV=1MALYELFSHPVERSYRAGLCSKAALFLLLAAALTYIPPLLVAFRSHGFWLKRSSYEEQPTVRFQHQVLLVALLGPESDGFLAWSTFPAFNRLQGDRLRVPLVSTREEDRNQDGKTDMLHFKLELPLQSTEHVLGVQLILTFSYRLHRMATLVMQSMAFLQSSFPVPGSQLYVNGDLRLQQKQPLSCGGLDARYNISVINGTSPFAYDYDLTHIVAAYQERNVTTVLNDPNPIWLVGRAADAPFVINAIIRYPVEVISYQPGFWEMVKFAWVQYVSILLIFLWVFERIKIFVFQNQVVTTIPVTVTPRGDLCKEHLS>sp|Q9H6L2-2|TM231_HUMAN Isoform 2 of Transmembrane protein 231 OS=Homosapiens OX=9606 GN=TMEM231MSSSLTRSSAVTARGSAPKPRCSCCWPLRSRTSRRCWWPSGATVSLPRPLCHEAPRARSARAGLPNRLPTALFNSGFWLKRSSYEEQPTVRFQHQVLLVALLGPESDGFLAWSTFPAFNRLQGDRLRVPLVSTREEDRNQDGKTDMLHFKLELPLQSTEHVLGVQLILTFSYRLHRMATLVMQSMAFLQSSFPVPGSQLYVNGDLRLQQKQPLSCGGLDARYNISVINGTSPFAYDYDLTHIVAAYQERNVTTVLNDPNPIWLVGRAADAPFVINAIIRYPVEVISYQPGFWEMVKFAWVQYVSILLIFLWVFERIKIFVFQNQVVTTIPVTVTPRGDLCKEHLS>sp|Q9H6L2-3|TM231_HUMAN Isoform 3 of Transmembrane protein 231 OS=Homosapiens OX=9606 GN=TMEM231MLHFKLELPLQSTEHVLGVQLILTFSYRLHRMATLVMQSMAFLQSSFPVPGSQLYVNGDLRLQQKQPLSCGGLDARYNISVINGTSPFAYDYDLTHIVAAYQERNVTTVLNDPNPIWLVGRAADAPFVINAIIRYPVEVISYQPGFWEMVKFAWVQYVSILLIFLWVFERIKIFVFQNQVVTTIPVTVTPRGDLCKEHLS>sp|P20366|TKN1_HUMAN Protachykinin-1 OS=Homo sapiens OX=9606 GN=TAC1PE=1 SV=1MKILVALAVFFLVSTQLFAEEIGANDDLNYWSDWYDSDQIKEELPEPFEHLLQRIARRPKPQQFFGLMGKRDADSSIEKQVALLKALYGHGQISHKRHKTDSFVGLMGKRALNSVAYERSAMQNYERRR>sp|P20366-2|TKN1_HUMAN Isoform Alpha of Protachykinin-1 OS=Homo sapiensOX=9606 GN=TAC1MKILVALAVFFLVSTQLFAEEIGANDDLNYWSDWYDSDQIKEELPEPFEHLLQRIARRPKPQQFFGLMGKRDADSSIEKQVALLKALYGHGQISHKMAYERSAMQNYERRR>sp|P20366-3|TKN1_HUMAN Isoform Gamma of Protachykinin-1 OS=Homo sapiensOX=9606 GN=TAC1MKILVALAVFFLVSTQLFAEEIGANDDLNYWSDWYDSDQIKEELPEPFEHLLQRIARRPKPQQFFGLMGKRDAGHGQISHKRHKTDSFVGLMGKRALNSVAYERSAMQNYERRR>sp|P20366-4|TKN1_HUMAN Isoform Delta of Protachykinin-1 OS=Homo sapiensOX=9606 GN=TAC1MKILVALAVFFLVSTQLFAEEIGANDDLNYWSDWYDSDQIKEELPEPFEHLLQRIARRPKPQQFFGLMGKRDAGHGQISHKMAYERSAMQNYERRR>sp|Q86WS5|TMPSC_HUMAN Transmembrane protease serine 12 OS=Homo sapiensOX=9606 GN=TMPRSS12 PE=1 SV=2MRLGLLSVALLFVGSSHLYSDHYSPSGRHRLGPSPEPAASSQQAEAVRKRLRRRREGGAHAEDCGTAPLKDVLQGSRIIGGTEAQAGAWPWVVSLQIKYGRVLVHVCGGTLVRERWVLTAAHCTKDASDPLMWTAVIGTNNIHGRYPHTKKIKIKAIIIHPNFILESYVNDIALFHLKKAVRYNDYIQPICLPFDVFQILDGNTKCFISGWGRTKEEGNATNILQDAEVHYISREMCNSERSYGGIIPNTSFCAGDEDGAFDTCRGDSGGPLMCYLPEYKRFFVMGITSYGHGCGRRGFPGVYIGPSFYQKWLTEHFFHASTQGILTINILRGQILIALCFVILLATT>sp|Q5VVB8|TM244_HUMAN Transmembrane protein 244 OS=Homo sapiens OX=9606GN=TMEM244 PE=4 SV=1MALQVRVAPSKVVLQKFLLCVILFYTVYYVSLSMGCVMFEVHELNVLAPFDFKTNPSWLNINYKVLLVSTEVTYFVCGLFFVPVVEEWVWDYAISVTILHVAITSTVMLEFPLTSHWWAALGISKLLV>sp|Q8IWU9|TPH2_HUMAN Tryptophan 5-hydroxylase 2 OS=Homo sapiens OX=9606GN=TPH2 PE=1 SV=1MQPAMMMFSSKYWARRGFSLDSAVPEEHQLLGSSTLNKPNSGKNDDKGNKGSSKREAATESGKTAVVFSLKNEVGGLVKALRLFQEKRVNMVHIESRKSRRRSSEVEIFVDCECGKTEFNELIQLLKFQTTIVTLNPPENIWTEEEELEDVPWFPRKISELDKCSHRVLMYGSELDADHPGFKDNVYRQRRKYFVDVAMGYKYGQPIPRVEYTEEETKTWGVVFRELSKLYPTHACREYLKNFPLLTKYCGYREDNVPQLEDVSMFLKERSGFTVRPVAGYLSPRDFLAGLAYRVFHCTQYIRHGSDPLYTPEPDTCHELLGHVPLLADPKFAQFSQEIGLASLGASDEDVQKLATCYFFTIEFGLCKQEGQLRAYGAGLLSSIGELKHALSDKACVKAFDPKTTCLQECLITTFQEAYFVSESFEEAKEKMRDFAKSITRPFSVYFNPYTQSIEILKDTRSIENVVQDLRSDLNTVCDALNKMNQYLGI>sp|Q8IWU9-2|TPH2_HUMAN Isoform b of Tryptophan 5-hydroxylase 2 OS=Homosapiens OX=9606 GN=TPH2MQPAMMMFSSKYWARRGFSLDSAVPEEHQLLGSSTLNKPNSGKNDDKGNKGSSKREAATESGKTAVVFSLKNEVGGLVKALRLFQEKRVNMVHIESRKSRRRSSEVEIFVDCECGKTEFNELIQLLKFQTTIVTLNPPENIWTEEEGKELEDVPWFPRKISELDKCSHRVLMYGSELDADHPGFKDNVYRQRRKYFVDVAMGYKYGQPIPRVEYTEEETKTWGVVFRELSKLYPTHACREYLKNFPLLTKYCGYREDNVPQLEDVSMFLKERSGFTVRPVAGYLSPRDFLAGLAYRVFHCTQYIRHGSDPLYTPEPDTCHELLGHVPLLADPKFAQFSQEIGLASLGASDEDVQKLATCYFFTIEFGLCKQEGQLRAYGAGLLSSIGELKHALSDKACVKAFDPKTTCLQECLITTFQEAYFVSESFEEAKEKMRDFAKSITRPFSVYFNPYTQSIEILKDTRSIENVVQDLRSDLNTVCDALNKMNQYLGI>sp|Q8TBM7|TM254_HUMAN Transmembrane protein 254 OS=Homo sapiens OX=9606GN=TMEM254 PE=1 SV=1MATAAGATYFQRGSLFWFTVITLSFGYYTWVVFWPQSIPYQNLGPLGPFTQYLVDHHHTLLCNGYWLAWLIHVGESLYAIVLCKHKGITSGRAQLLWFLQTFFFGIASLTILIAYKRKRQKQT>sp|Q8TBM7-2|TM254_HUMAN Isoform 2 of Transmembrane protein 254 OS=Homosapiens OX=9606 GN=TMEM254MATAAGATYFQRGSLFWFTVITLSFGYYTWVVFWPQSIPYQNLGPLGPFTQYLVDHHHTLLCNGYWLAWLIHVGESLYAIVLCK>sp|Q8TBM7-3|TM254_HUMAN Isoform 3 of Transmembrane protein 254 OS=Homosapiens OX=9606 GN=TMEM254MATAAGATYFQRGSLFWFTVITLSFGYYTWVVFWPQSIPYQNLGPLGPFTQYLVDHHHTLLCNGYWLAWLIHVGESLYAIVLCKQNELRIRIKMRKLILRDSE>sp|Q9NWH2|TM242_HUMAN Transmembrane protein 242 OS=Homo sapiens OX=9606GN=TMEM242 PE=1 SV=1METAGAATGQPASGLEAPGSTNDRLFLVKGGIFLGTVAAAGMLAGFITTLSLAKKKSPEWFNKGSMATAALPESGSSLALRALGWGSLYAWCGVGVISFAVWKALGVHSMNDFRSKMQSIFPTIPKNSESAVEWEETLKSK>sp|Q96B49|TOM6_HUMAN Mitochondrial import receptor subunit TOM6 homologOS=Homo sapiens OX=9606 GN=TOMM6 PE=1 SV=1MASSTVPVSAAGSANETPEIPDNVGDWLRGVYRFATDRNDFRRNLILNLGLFAAGVWLARNLSDIDLMAPQPGV>sp|Q24JQ0|TM241_HUMAN Transmembrane protein 241 OS=Homo sapiens OX=9606GN=TMEM241 PE=1 SV=1MCVRRSLVGLTFCTCYLASYLTNKYVLSVLKFTYPTLFQGWQTLIGGLLLHVSWKLGWVEINSSSRSHVLVWLPASVLFVGIIYAGSRALSRLAIPVFLTLHNVAEVIICGYQKCFQKEKTSPAKICSALLLLAAAGCLPFNDSQFNPDGYFWAIIHLLCVGAYKILQKSQKPSALSDIDQQYLNYIFSVVLLAFASHPTGDLFSVLDFPFLYFYRFHGSCCASGFLGFFLMFSTVKLKNLLAPGQCAAWIFFAKIITAGLSILLFDAILTSATTGCLLLGALGEALLVFSERKSS>sp|Q24JQ0-2|TM241_HUMAN Isoform 2 of Transmembrane protein 241 OS=Homosapiens OX=9606 GN=TMEM241MCVRRSLVGLTFCTCYLASYLTNKYVLSVLKFTYPTLFQGWQTLIGGLLLHVSWKLGWVEINSSSRSHVLVWLPASVLFVGIIYAGSRALSRLAIPVFLTLHNVAEVIICGYQKCFQKEKTSPAKICSALLLLAAAGCLPFNDSQGLIKFYRSPRNPVH>sp|Q24JQ0-3|TM241_HUMAN Isoform 3 of Transmembrane protein 241 OS=Homosapiens OX=9606 GN=TMEM241MCVRRSLVGLTFCTCYLASYLTNKYVLSVLKFTYPTLFQGSHVLVWLPASVLFVGIIYAGSRALSRLAIPVFLTLHNVAEVIICGYQKCFQKEKTSPAKICRLHLERTRQNQTSRLSSCLKGD>sp|Q9BYE2|TMPSD_HUMAN Transmembrane protease serine 13 OS=Homo sapiensOX=9606 GN=TMPRSS13 PE=2 SV=5MERDSHGNASPARTPSAGASPAQASPAGTPPGRASPAQASPAQASPAGTPPGRASPAQASPAGTPPGRASPGRASPAQASPAQASPARASPALASLSRSSSGRSSSARSASVTTSPTRVYLVRATPVGAVPIRSSPARSAPATRATRESPGTSLPKFTWREGQKQLPLIGCVLLLIALVVSLIILFQFWQGHTGIRYKEQRESCPKHAVRCDGVVDCKLKSDELGCVRFDWDKSLLKIYSGSSHQWLPICSSNWNDSYSEKTCQQLGFESAHRTTEVAHRDFANSFSILRYNSTIQESLHRSECPSQRYISLQCSHCGLRAMTGRIVGGALASDSKWPWQVSLHFGTTHICGGTLIDAQWVLTAAHCFFVTREKVLEGWKVYAGTSNLHQLPEAASIAEIIINSNYTDEEDDYDIALMRLSKPLTLSAHIHPACLPMHGQTFSLNETCWITGFGKTRETDDKTSPFLREVQVNLIDFKKCNDYLVYDSYLTPRMMCAGDLRGGRDSCQGDSGGPLVCEQNNRWYLAGVTSWGTGCGQRNKPGVYTKVTEVLPWIYSKMEVRSLQQDTAPSRLGTSSGGDPGGAPRL>sp|Q9BYE2-2|TMPSD_HUMAN Isoform 2 of Transmembrane protease serine 13OS=Homo sapiens OX=9606 GN=TMPRSS13MERDSHGNASPARTPSAGASPAQASPAGTPPGRASPAQASPAQASPAGTPPGRASPAQASPAGTPPGRASPGRASPAQASPAQASPARASPALASLSRSSSGRSSSARSASVTTSPTRVYLVRATPVGAVPIRSSPARSAPATRATRESPGTSLPKFTWREGQKQLPLIGCVLLLIALVVSLIILFQFWQGHTGIRYKEQRESCPKHAVRCDGVVDCKLKSDELGCVRFDWDKSLLKIYSGSSHQWLPICSSNWNDSYSEKTCQQLGFESAHRTTEVAHRDFANSFSILRYNSTIQESLHRSECPSQRYISLQCSHCGLRAMTGRIVGGALASDSKWPWQVSLHFGTTHICGGTLIDAQWVLTAAHCFFVTREKVLEGWKVYAGTSNLHQLPEAASIAEIIINSNYTDEEDDYDIALMRLSKPLTLSAHIHPACLPMHGQTFSLNETCWITGFGKTRETDDKTSPFLREVQVNLIDFKKCNDYLVYDSYLTPRMMCAGDLRGGRDSCQGDSGGPLVCEQNNRWYLAGVTSWGTGCGQRNKPGVYTKVTEVLPWIYSKMESSAG>sp|Q9BYE2-3|TMPSD_HUMAN Isoform 3 of Transmembrane protease serine 13OS=Homo sapiens OX=9606 GN=TMPRSS13MERDSHGNASPARTPSAGASPAQASPAGTPPGRASPAQASPAQASPAGTPPGRASPAQASPAGTPPGRASPGRASPAQASPAQASPARASPALASLSRSSSGRSSSARSASVTTSPTRVYLVRATPVGAVPIRSSPARSAPATRATRESPVQFWQGHTGIRYKEQRESCPKHAVRCDGVVDCKLKSDELGCVRFDWDKSLLKIYSGSSHQWLPICSSNWNDSYSEKTCQQLGFESAHRTTEVAHRDFANSFSILRYNSTIQESLHRSECPSQRYISLQCSHCGLRAMTGRIVGGALASDSKWPWQVSLHFGTTHICGGTLIDAQWVLTAAHCFFVTREKVLEGWKVYAGTSNLHQLPEAASIAEIIINSNYTDEEDDYDIALMRLSKPLTLSAHIHPACLPMHGQTFSLNETCWITGFGKTRETDDKTSPFLREVQVNLIDFKKCNDYLVYDSYLTPRMMCAGDLRGGRDSCQGDSGGPLVCEQNNRWYLAGVTSWGTGCGQRNKPGVYTKVTEVLPWIYSKMESEVRFRKS>sp|Q9BYE2-4|TMPSD_HUMAN Isoform 4 of Transmembrane protease serine 13OS=Homo sapiens OX=9606 GN=TMPRSS13MERDSHGNASPARTPSAGASPAQASPAGTPPGRASPAQASPAQASPAGTPPGRASPAQASPAGTPPGRASPGRASPAQASPAQASPARASPALASLSRSSSGRSSSARSASVTTSPTRVYLVRATPVGAVPIRSSPARSAPATRATRESPGTSLPKFTWREGQKQLPLIGCVLLLIALVVSLIILFQFWQGHTGIRYKEQRESCPKHAVRCDGVVDCKLKSDELGCVRFDWDKSLLKIYSGSSHQWLPICSSNWNDSYSEKTCQQLGFESAHRTTEVAHRDFANSFSILRYNSTIQESLHRSECPSQRYISLQCSHCGLRAMTGRIVGGALASDSKWPWQVSLHFGTTHICGGTLIDAQWVLTAAHCFFVTREKVLEGWKVYAGTSNLHQLPEAASIAEIIINSNYTDEEDDYDIALMRLSKPLTLSGEGICTPRSPAPQPQHPLQPSHLSASVNSYPGPKASAGQKSKTLKDPYMEHFCFIIRETEAQGL>sp|Q9BYE2-6|TMPSD_HUMAN Isoform 6 of Transmembrane protease serine 13OS=Homo sapiens OX=9606 GN=TMPRSS13MERDSHGNASPARTPSAGASPAQASPAGTPPGRASPAQASPAQASPAGTPPGRASPAQASPAGTPPGRASPGRASPAQASPAQASPARASPALASLSRSSSGRSSSARSASVTTSPTRVYLVRATPVGAVPIRSSPARSAPATRATRESPGTSLPKFTWREGQKQLPLIGCVLLLIALVVSLIILFQFWQGHTGIRYKEQRESCPKHAVRCDGVVDCKLKSDELGCVRFDWDKSLLKIYSGSSHQWLPICSSNWNDSYSEKTCQQLGFESAHRTTEVAHRDFANSFSILRYNSTIQESLHRSECPSQRYISLQCSHCGLRAMTGRIVGGALASDSKWPWQVSLHFGTTHICGGTLIDAQWVLTAAHCFFVTREKVLEGWKVYAGTSNLHQLPEAASIAEIIINSNYTDEEDDYDIALMRLSKPLTLSAHIHPACLPMHGQTFSLNETCWITGFGKTRETDDKTSPFLREVQVNLIDFKKCNDYLVYDSYLTPRMMCAGDLRGGRDSCQGDSGGPLVCEQNNRWYLAGVTSWGTGCGQRNKPGVYTKVTEVLPWIYSKMESEVRFRKS>sp|O94900|TOX_HUMAN Thymocyte selection-associated high mobility groupbox protein TOX OS=Homo sapiens OX=9606 GN=TOX PE=1 SV=3MDVRFYPPPAQPAAAPDAPCLGPSPCLDPYYCNKFDGENMYMSMTEPSQDYVPASQSYPGPSLESEDFNIPPITPPSLPDHSLVHLNEVESGYHSLCHPMNHNGLLPFHPQNMDLPEITVSNMLGQDGTLLSNSISVMPDIRNPEGTQYSSHPQMAAMRPRGQPADIRQQPGMMPHGQLTTINQSQLSAQLGLNMGGSNVPHNSPSPPGSKSATPSPSSSVHEDEGDDTSKINGGEKRPASDMGKKPKTPKKKKKKDPNEPQKPVSAYALFFRDTQAAIKGQNPNATFGEVSKIVASMWDGLGEEQKQVYKKKTEAAKKEYLKQLAAYRASLVSKSYSEPVDVKTSQPPQLINSKPSVFHGPSQAHSALYLSSHYHQQPGMNPHLTAMHPSLPRNIAPKPNNQMPVTVSIANMAVSPPPPLQISPPLHQHLNMQQHQPLTMQQPLGNQLPMQVQSALHSPTMQQGFTLQPDYQTIINPTSTAAQVVTQAMEYVRSGCRNPPPQPVDWNNDYCSSGGMQRDKALYLT>sp|Q2M3C6|TM266_HUMAN Transmembrane protein 266 OS=Homo sapiens OX=9606GN=TMEM266 PE=1 SV=2MAVAPSFNMTNPQPAIEGGISEVEIISQQVDEETKSIAPVQLVNFAYRDLPLAAVDLSTAGSQLLSNLDEDYQREGSNWLKPCCGKRAAVWQVFLLSASLNSFLVACVILVVILLTLELLIDIKLLQFSSAFQFAGVIHWISLVILSVFFSETVLRIVVLGIWDYIENKIEVFDGAVIILSLAPMVASTVANGPRSPWDAISLIIMLRIWRVKRVIDAYVLPVKLEMEMVIQQYEKAKVIQDEQLERLTQICQEQGFEIRQLRAHLAQQDLDLAAEREAALQAPHVLSQPRSRFKVLEAGTWDEETAAESVVEELQPSQEATMKDDMNSYISQYYNGPSSDSGVPEPAVCMVTTAAIDIHQPNISSDLFSLDMPLKLGGNGTSATSESASRSSVTRAQSDSSQTLGSSMDCSTAREEPSSEPGPSPPPLPSQQQVEEATVQDLLSSLSEDPCPSQKALDPAPLARPSPAGSAQTSPELEHRVSLFNQKNQEGFTVFQIRPVIHFQPTVPMLEDKFRSLESKEQKLHRVPEA>sp|Q2M3C6-2|TM266_HUMAN Isoform 2 of Transmembrane protein 266 OS=Homosapiens OX=9606 GN=TMEM266MAVAPSFNMTNPQPAIEGGISEVEIISQQVDEETKSIAPVQLVNFAYRDLPLAAVDLSTAGSQLLSNLDEDYQREGSNWLKPCCGKRAAVWQSSAFQFAGVIHWISLVILSVFFSETVLRIVVLGIWDYIENKIEVFDGAVIILSLAPMVASTVANGPRSPWDAISLIIMLRIWRVKRVIDAYVLPVKLEMEMVIQQYEKAKVIQDEQLERLTQICQEQGFEIRQLRAHLAQQDLDLAAEREAALQAPHVLSQPRSRFKVLEAGTWDEETAAESVVEELQPSQEATMKDDMNSYISQYYNGPSSDSGVPEPAVCMVTTAAIDIHQPNISSDLFSLDMPLKLGGNGTSATSESASRSSVTRAQSDSSQTLGSSMDCSTAREEPSSEPGPSPPPLPSQQQVEEATVQDLLSSLSEDPCPSQKALDPAPLARPSPAGSAQTSPELEHRVSLFNQKNQEGFTVFQIRPVIHFQPTVPMLEDKFRSLESKEQKLHRVPEA>sp|Q9BVV7|TIM21_HUMAN Mitochondrial import inner membrane translocasesubunit Tim21 OS=Homo sapiens OX=9606 GN=TIMM21 PE=1 SV=1MICTFLRAVQYTEKLHRSSAKRLLLPYIVLNKACLKTEPSLRCGLQYQKKTLRPRCILGVTQKTIWTQGPSPRKAKEDGSKQVSVHRSQRGGTAVPTSQKVKEAGRDFTYLIVVLFGISITGGLFYTIFKELFSSSSPSKIYGRALEKCRSHPEVIGVFGESVKGYGEVTRRGRRQHVRFTEYVKDGLKHTCVKFYIEGSEPGKQGTVYAQVKENPGSGEYDFRYIFVEIESYPRRTIIIEDNRSQDD>sp|Q16881|TRXR1_HUMAN Thioredoxin reductase 1, cytoplasmic OS=Homosapiens OX=9606 GN=TXNRD1 PE=1 SV=3MGCAEGKAVAAAAPTELQTKGKNGDGRRRSAKDHHPGKTLPENPAGFTSTATADSRALLQAYIDGHSVVIFSRSTCTRCTEVKKLFKSLCVPYFVLELDQTEDGRALEGTLSELAAETDLPVVFVKQRKIGGHGPTLKAYQEGRLQKLLKMNGPEDLPKSYDYDLIIIGGGSGGLAAAKEAAQYGKKVMVLDFVTPTPLGTRWGLGGTCVNVGCIPKKLMHQAALLGQALQDSRNYGWKVEETVKHDWDRMIEAVQNHIGSLNWGYRVALREKKVVYENAYGQFIGPHRIKATNNKGKEKIYSAERFLIATGERPRYLGIPGDKEYCISSDDLFSLPYCPGKTLVVGASYVALECAGFLAGIGLDVTVMVRSILLRGFDQDMANKIGEHMEEHGIKFIRQFVPIKVEQIEAGTPGRLRVVAQSTNSEEIIEGEYNTVMLAIGRDACTRKIGLETVGVKINEKTGKIPVTDEEQTNVPYIYAIGDILEDKVELTPVAIQAGRLLAQRLYAGSTVKCDYENVPTTVFTPLEYGACGLSEEKAVEKFGEENIEVYHSYFWPLEWTIPSRDNNKCYAKIICNTKDNERVVGFHVLGPNAGEVTQGFAAALKCGLTKKQLDSTIGIHPVCAEVFTTLSVTKRSGASILQAGCUG>sp|Q16881-2|TRXR1_HUMAN Isoform 2 of Thioredoxin reductase 1,cytoplasmic OS=Homo sapiens OX=9606 GN=TXNRD1MLSRLVLNSWAQAIIRPRPPKVLGLQVTTFSEAYQEGRLQKLLKMNGPEDLPKSYDYDLIIIGGGSGGLAAAKEAAQYGKKVMVLDFVTPTPLGTRWGLGGTCVNVGCIPKKLMHQAALLGQALQDSRNYGWKVEETVKHDWDRMIEAVQNHIGSLNWGYRVALREKKVVYENAYGQFIGPHRIKATNNKGKEKIYSAERFLIATGERPRYLGIPGDKEYCISSDDLFSLPYCPGKTLVVGASYVALECAGFLAGIGLDVTVMVRSILLRGFDQDMANKIGEHMEEHGIKFIRQFVPIKVEQIEAGTPGRLRVVAQSTNSEEIIEGEYNTVMLAIGRDACTRKIGLETVGVKINEKTGKIPVTDEEQTNVPYIYAIGDILEDKVELTPVAIQAGRLLAQRLYAGSTVKCDYENVPTTVFTPLEYGACGLSEEKAVEKFGEENIEVYHSYFWPLEWTIPSRDNNKCYAKIICNTKDNERVVGFHVLGPNAGEVTQGFAAALKCGLTKKQLDSTIGIHPVCAEVFTTLSVTKRSGASILQAGCUG>sp|Q16881-3|TRXR1_HUMAN Isoform 3 of Thioredoxin reductase 1,cytoplasmic OS=Homo sapiens OX=9606 GN=TXNRD1MQQVMLTCKGVNRGHAVPAGPGRKPRPRRSSRLLAGEKHLTRSALLLCHTEDGRALEGTLSELAAETDLPVVFVKQRKIGGHGPTLKAYQEGRLQKLLKMNGPEDLPKSYDYDLIIIGGGSGGLAAAKEAAQYGKKVMVLDFVTPTPLGTRWGLGGTCVNVGCIPKKLMHQAALLGQALQDSRNYGWKVEETVKHDWDRMIEAVQNHIGSLNWGYRVALREKKVVYENAYGQFIGPHRIKATNNKGKEKIYSAERFLIATGERPRYLGIPGDKEYCISSDDLFSLPYCPGKTLVVGASYVALECAGFLAGIGLDVTVMVRSILLRGFDQDMANKIGEHMEEHGIKFIRQFVPIKVEQIEAGTPGRLRVVAQSTNSEEIIEGEYNTVMLAIGRDACTRKIGLETVGVKINEKTGKIPVTDEEQTNVPYIYAIGDILEDKVELTPVAIQAGRLLAQRLYAGSTVKCDYENVPTTVFTPLEYGACGLSEEKAVEKFGEENIEVYHSYFWPLEWTIPSRDNNKCYAKIICNTKDNERVVGFHVLGPNAGEVTQGFAAALKCGLTKKQLDSTIGIHPVCAEVFTTLSVTKRSGASILQAGCUG>sp|Q16881-4|TRXR1_HUMAN Isoform 4 of Thioredoxin reductase 1,cytoplasmic OS=Homo sapiens OX=9606 GN=TXNRD1MSCEDGRALEGTLSELAAETDLPVVFVKQRKIGGHGPTLKAYQEGRLQKLLKMNGPEDLPKSYDYDLIIIGGGSGGLAAAKEAAQYGKKVMVLDFVTPTPLGTRWGLGGTCVNVGCIPKKLMHQAALLGQALQDSRNYGWKVEETVKHDWDRMIEAVQNHIGSLNWGYRVALREKKVVYENAYGQFIGPHRIKATNNKGKEKIYSAERFLIATGERPRYLGIPGDKEYCISSDDLFSLPYCPGKTLVVGASYVALECAGFLAGIGLDVTVMVRSILLRGFDQDMANKIGEHMEEHGIKFIRQFVPIKVEQIEAGTPGRLRVVAQSTNSEEIIEGEYNTVMLAIGRDACTRKIGLETVGVKINEKTGKIPVTDEEQTNVPYIYAIGDILEDKVELTPVAIQAGRLLAQRLYAGSTVKCDYENVPTTVFTPLEYGACGLSEEKAVEKFGEENIEVYHSYFWPLEWTIPSRDNNKCYAKIICNTKDNERVVGFHVLGPNAGEVTQGFAAALKCGLTKKQLDSTIGIHPVCAEVFTTLSVTKRSGASILQAGCUG>sp|Q16881-5|TRXR1_HUMAN Isoform 5 of Thioredoxin reductase 1,cytoplasmic OS=Homo sapiens OX=9606 GN=TXNRD1MNGPEDLPKSYDYDLIIIGGGSGGLAAAKEAAQYGKKVMVLDFVTPTPLGTRWGLGGTCVNVGCIPKKLMHQAALLGQALQDSRNYGWKVEETVKHDWDRMIEAVQNHIGSLNWGYRVALREKKVVYENAYGQFIGPHRIKATNNKGKEKIYSAERFLIATGERPRYLGIPGDKEYCISSDDLFSLPYCPGKTLVVGASYVALECAGFLAGIGLDVTVMVRSILLRGFDQDMANKIGEHMEEHGIKFIRQFVPIKVEQIEAGTPGRLRVVAQSTNSEEIIEGEYNTVMLAIGRDACTRKIGLETVGVKINEKTGKIPVTDEEQTNVPYIYAIGDILEDKVELTPVAIQAGRLLAQRLYAGSTVKCDYENVPTTVFTPLEYGACGLSEEKAVEKFGEENIEVYHSYFWPLEWTIPSRDNNKCYAKIICNTKDNERVVGFHVLGPNAGEVTQGFAAALKCGLTKKQLDSTIGIHPVCAEVFTTLSVTKRSGASILQAGCUG>sp|Q16881-6|TRXR1_HUMAN Isoform 6 of Thioredoxin reductase 1,cytoplasmic OS=Homo sapiens OX=9606 GN=TXNRD1MPVDDYWLCLPASCARPFVQTVRVVQSCPHCCWFPGVLPSVPEPLRMPAMLPTGSHSAVLPPSHCSTAPPSTSQEPSSSADPKLCLSPPTSDSRQERNVQFGLAYQEGRLQKLLKMNGPEDLPKSYDYDLIIIGGGSGGLAAAKEAAQYGKKVMVLDFVTPTPLGTRWGLGGTCVNVGCIPKKLMHQAALLGQALQDSRNYGWKVEETVKHDWDRMIEAVQNHIGSLNWGYRVALREKKVVYENAYGQFIGPHRIKATNNKGKEKIYSAERFLIATGERPRYLGIPGDKEYCISSDDLFSLPYCPGKTLVVGASYVALECAGFLAGIGLDVTVMVRSILLRGFDQDMANKIGEHMEEHGIKFIRQFVPIKVEQIEAGTPGRLRVVAQSTNSEEIIEGEYNTVMLAIGRDACTRKIGLETVGVKINEKTGKIPVTDEEQTNVPYIYAIGDILEDKVELTPVAIQAGRLLAQRLYAGSTVKCDYENVPTTVFTPLEYGACGLSEEKAVEKFGEENIEVYHSYFWPLEWTIPSRDNNKCYAKIICNTKDNERVVGFHVLGPNAGEVTQGFAAALKCGLTKKQLDSTIGIHPVCAEVFTTLSVTKRSGASILQAGCUG>sp|Q16881-7|TRXR1_HUMAN Isoform 7 of Thioredoxin reductase 1,cytoplasmic OS=Homo sapiens OX=9606 GN=TXNRD1MVLDFVTPTPLGTRWGLGGTCVNVGCIPKKLMHQAALLGQALQDSRNYGWKVEETVKHDWDRMIEAVQNHIGSLNWGYRVALREKKVVYENAYGQFIGPHRIKATNNKGKEKIYSAERFLIATGERPRYLGIPGDKEYCISSDDLFSLPYCPGKTLVVGASYVALECAGFLAGIGLDVTVMVRSILLRGFDQDMANKIGEHMEEHGIKFIRQFVPIKVEQIEAGTPGRLRVVAQSTNSEEIIEGEYNTVMLAIGRDACTRKIGLETVGVKINEKTGKIPVTDEEQTNVPYIYAIGDILEDKVELTPVAIQAGRLLAQRLYAGSTVKCDYENVPTTVFTPLEYGACGLSEEKAVEKFGEENIEVYHSYFWPLEWTIPSRDNNKCYAKIICNTKDNERVVGFHVLGPNAGEVTQGFAAALKCGLTKKQLDSTIGIHPVCAEVFTTLSVTKRSGASILQAGCUG>sp|Q6P2S7|TTC41_HUMAN Putative tetratricopeptide repeat protein 41OS=Homo sapiens OX=9606 GN=TTC41P PE=5 SV=3MSQKTNENVERYTQFLQKPQKPIQPYICSTLNDFQEERDFLANNIFPQLNELCNSWGTYFKAVDLSWSALKAPKSLPTHLFRQYSCLRSQRLKLCLDYVNSCFPFFICMLGQTYGDFLPDYSHFMTSKVTRLSSLSKVENLYVAAKNGYPWVLENPSCSLTEFEIIQAAFLNESQFQYFYFRTGTTLLKALDDEKKGERLPSSSSTNEEETLRIGKLKAKIISKGLPVRFYSDLHELGELVFKDWSVVIEKLHPATLMIENIDYKHSFERFYHEEFTEKCKQMCVISKESDRTFEILEKFALKDVELDFNNVAADSSLDSVPRFFRINPTPTYKSILLLSREHGCGKSTLIANWVNYFKKKHPSMLLIPHFVGSTCESSYIMSVIHYFITELQYRNYGTQLETDILNEDSDGLVFSFLVEVFIASISLKPCILVLDGIEELIGIYGISGQKVKDFSWLPHSLSPHCKFIMSTVSSSLSYKSLCARPDVRTVELISTGDEETKLNIFRKHLSIPMMDPFEQSTQALRKKPDLSPLKLTILANELKEYRINHNEFQCMKEYLEAVSVQELWELVLKRWIEDYSWTFQPKRANSDTVASGEGLDSWVADALCLLCLSHGGLAEDELLQLLDMLGYRNHYKVTALHWAAFRNATKQWVQEKPNGLLYFWHQSLSAVEHKLLGVITPVESSPCSFQTPMNHKKTHFHQVLIRYFQRQTSFWRVYQELPWHMKMSGCLRGLCGFLSSPTITDFISKIQSLGFWTRLHLIHFWNVLLEAGYDVSEAYLLSVAKIKADQCHTMRKSGTLSVLQCRLIELTVLDKCRLMFFIGSFLKFMGKTNEAEELFLSVEDMLVQSQSMTDMLLKVQNAIGELYLETGMTQEGFQYFQKAWSSMLRLSLSDLEDSRDLVKQKVRVLDNLAKSASEEYLKENHILEYATEISNLLDNNPRDQATMKYIEGVLMFVAGNTSLAKMKLRECLNIRKSLFGKKNMLVGEVMEFLADLLFFPQRDSKKSQRKQVLKYYKQVIKIKENAETLAKSSLLRKQLSISLSDTLCKLAGHLLASDSCHHVMIEAVGYLYRSVDLRVIHLGSSHSSIHGIHGILHLLREIEWIRSRRYWPQGMSQQHSEGSRNGFSLWEHLVKLNYHSAQSSNTVSSAMCMNADKLHRARRMDLAPQTISDKSKCAPGKGKKKPIICISAEEKIQRKTQNNAEIWNGSGKEASKKKTDYSSNILSLGKMNGLIKLSRQRILLAKSESGEGEITTIYHHPLPWPVSTKNPGESEFISEKWLFHSPDYISISQKSFLQRRLHIETKLLKTSNDINKE>sp|Q6P2S7-2|TTC41_HUMAN Isoform 2 of Putative tetratricopeptide repeatprotein 41 OS=Homo sapiens OX=9606 GN=TTC41PMSQKTNENVERYTQFLQKPQKPIQPYICSTLNDFQEERDFLANNIFPQLNELCNSWGTYFKAVDLSWSALKAPKSLPTHLFRQYSCLRSQRLKLCLDYVNSCFPFFICMLGQTYGDFLPDYSHFMTSKVTRLSSLSKVENLYVAAKNGYPWVLENPSCSLTEFEIIQAAFLNESQFQYFYFRTGTTLLKALDDEKKGERLPSSSSTNEEETLRIGKLKAKIISKGLPVRFYSDLHELGELVFKDWSVVIEKLHPATLMIENIDYKHSFERFYHEEFTEKCKQMCVISKESDRTFEILEKFALKDVELDFNNVAADSSLDSVPRFFRINPTPTYKSILLLSREHGCGKSTLIANWVNYFKKKHPSMLLIPHFVGSTCESSYIMSVIHYFITELQYRNYGTQLETDILNEDSDGLVFSFLVEVFIASISLKPCILVLDGIEELIGIYGISGQKVKDFSWLPHSLSPHCKFIMSTVSSSLSYKSLCARPDVRTVELISTGDEETKLNIFRKHLSIPMMDPFEQSTQALRKKPDLSPLKLTILANELKEYRINHNEFQCMKEYLEAVSVQELWELVLKRWIEDYSWTFQPKRANSDTVASGEGLDSWVADALCLLCLSHGGLAEDELLQLLDMLGYRNHYKVTALHWAAFRNATKQWVQEKPNGLLYFWHQSLSAVEHKLLGVITPVESSPCSFQTPMNHKKTHFHQVLIRYFQRQTSFWRVYQELPWHMKMSGCLRGLCGFLSSPTITDFISKIQSLGFWTRLHLIHFWNVLLEAGYDVSEAYLLSVAKIKADQCHTMRKSGTLSVLQCRLIELTVLDKCRLMFFIGSFLKFMGKTNEAEELFLSVEDMLVQSQSMTDMLLKVQNAIGELYLETGMTQEGFQYFQKAWSSMLRLSLSDLEDSRDLVKQKVRVLDNLAKSASEEYLKENHILEYATEISNLLDNNPRDQATMKYIEGVLMFVAGNTSLAKMKLRECLNIRKSLFGKKNMLVGEVMEFLADLLFFPQRDSKKSQRKQVLKYYKQVIKIKENAETLAKSSLLRKQLSISLSDTLCKLAF>sp|Q6P2S7-3|TTC41_HUMAN Isoform 3 of Putative tetratricopeptide repeatprotein 41 OS=Homo sapiens OX=9606 GN=TTC41PMSQKTNENVERYTQFLQKPQKPIQPYICSTLNDFQEERDFLANNIFPQLNELCNSWGTYFKAVDLSWSALKAPKSLPTHLFRQYSCLRSQRLKLCLDYVNSCFPFFICMLGQTYGDFLPDYSHFMTSKVTRLSSLSKVE>sp|Q96PN8|TSSK3_HUMAN Testis-specific serine/threonine-protein kinase 3OS=Homo sapiens OX=9606 GN=TSSK3 PE=1 SV=1MEDFLLSNGYQLGKTIGEGTYSKVKEAFSKKHQRKVAIKVIDKMGGPEEFIQRFLPRELQIVRTLDHKNIIQVYEMLESADGKICLVMELAEGGDVFDCVLNGGPLPESRAKALFRQMVEAIRYCHGCGVAHRDLKCENALLQGFNLKLTDFGFAKVLPKSHRELSQTFCGSTAYAAPEVLQGIPHDSKKGDVWSMGVVLYVMLCASLPFDDTDIPKMLWQQQKGVSFPTHLSISADCQDLLKRLLEPDMILRPSIEEVSWHPWLAST>sp|P36537|UDB10_HUMAN UDP-glucuronosyltransferase 2B10 OS=Homo sapiensOX=9606 GN=UGT2B10 PE=1 SV=1MALKWTTVLLIQLSFYFSSGSCGKVLVWAAEYSLWMNMKTILKELVQRGHEVTVLASSASILFDPNDSSTLKLEVYPTSLTKTEFENIIMQLVKRLSEIQKDTFWLPFSQEQEILWAINDIIRNFCKDVVSNKKLMKKLQESRFDIVFADAYLPCGELLAELFNIPFVYSHSFSPGYSFERHSGGFIFPPSYVPVVMSKLSDQMTFMERVKNMLYVLYFDFWFQIFNMKKWDQFYSEVLGRPTTLSETMRKADIWLMRNSWNFKFPHPFLPNVDFVGGLHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSMVSNMTEERANVIATALAKIPQKVLWRFDGNKPDALGLNTRLYKWIPQNDLLGHPKTRAFITHGGANGIYEAIYHGIPMVGIPLFFDQPDNIAHMKAKGAAVRVDFNTMSSTDLLNALKTVINDPSYKENIMKLSRIQHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHNLTWFQYHSLDVIGFLLACVATVLFIITKCCLFCFWKFARKGKKGKRD>sp|P36537-2|UDB10_HUMAN Isoform 2 of UDP-glucuronosyltransferase 2B10OS=Homo sapiens OX=9606 GN=UGT2B10MALKWTTVLLIQLSFYFSSGSCGKVLVWAAEYSLWMNMKTILKELVQRGHEVTVLASSASILFDPNDSSTLKLEVYPTSLTKTEFENIIMQLVKRLSEIQKDTFWLPFSQEQEILWAINDIIRNFCKDVVSNKKLMKKLQESRFDIVFADAYLPCGRPTTLSETMRKADIWLMRNSWNFKFPHPFLPNVDFVGGLHCKPAKPLPKEMEEFVQSSGENGVVVFSLGSMVSNMTEERANVIATALAKIPQKVLWRFDGNKPDALGLNTRLYKWIPQNDLLGHPKTRAFITHGGANGIYEAIYHGIPMVGIPLFFDQPDNIAHMKAKGAAVRVDFNTMSSTDLLNALKTVINDPSYKENIMKLSRIQHDQPVKPLDRAVFWIEFVMRHKGAKHLRVAAHNLTWFQYHSLDVIGFLLACVATVLFIITKCCLFCFWKFARKGKKGKRD>sp|Q86TZ1|TTC6_HUMAN Tetratricopeptide repeat protein 6 OS=Homo sapiensOX=9606 GN=TTC6 PE=2 SV=1MMKYYDLAKFTIYQIAEMDKGLSELSPMQQALIYSFCENHDKAIEVLDGISWNRAEMTMCALLAKVQMKAKRTKEAVEVLKKALDAISHSDKGPDATAISADCLYNLGLCYMEEGNLQMTYKLAITDLTTAISMDKNSYTAFYNRALCYTKIRELQMALTDYGIVLLLDATETVKLNTFLNRGLIYVELGQYGFALEDFKQAALISRTNGSLCHATAMCHHRINEFEEAVNFFTWALKINPCFLDAYVGRGNSYMEYGHDEATKQAQKDFLKALHINPAYIKARISFGYNLQAQGKFQKAWNHFTIAIDTDPKNYLAYEGRAVVCLQMGNNFAAMQDINAAMKISTTAEFLTNRGVIHEFMGHKQNAMKDYQDAITLNPKYSLAYFNAGNIYFHHRQFSQASDYFSKALKFDPENEYVLMNRAITNTILKKYEEAKEDFANVIESCPFWAAVYFNRAHFYYCLKQYELAEEDLNKALSLKPNDALVYNFRAKVRGKIGLIEEAMADYNQALDLEDYASVI>sp|Q86TZ1-2|TTC6_HUMAN Isoform 2 of Tetratricopeptide repeat protein 6OS=Homo sapiens OX=9606 GN=TTC6MDKGLSELSPMQQALIYSFCENHDKAIEVLDGISWNRAEMTMCALLAKVQMKAKRTKEAVEVLKKALDAISHSDKGPDATAISADCLYNLGLCYMEEGNLQMAFDSFTKAVKANPDFAESFYQRGLCKVKLHKDSSILDFNRAITLNPKHYQAYLSRVAFYGLKGRYSKAILNCNKAIKIYPESVRAYLYRGVLKYYNKTYKLAITDLTTAISMDKNSYTAFYNRALCYTKIRELQMALTDYGIVLLLDATETVKLNTFLNRGLIYVELGQYGFALEDFKQAALISRTNGSLCHATAMCHHRINEFEEAVNFFTWALKINPCFLDAYVGRGNSYMEYGHDEATKQAQKDFLKALHINPAYIKARISFGYNLQAQGKFQKAWNHFTIAIDTDPKNYLAYEGRAVVCLQMGNNFAAMQDINAAMKISTTAEFLTNRGVIHEFMGHKQNAMKDYQDAITLNPKYSLAYFNAGNIYFHHRQFSQEESLGLAWSLSLDSFLRTGGATFSSGVNPLQTLHRRMSILSPLPPTCPRDEMDFTS>sp|Q8NBP0|TTC13_HUMAN Tetratricopeptide repeat protein 13 OS=Homosapiens OX=9606 GN=TTC13 PE=2 SV=3MAPAGCCCCCCFWGGAVAAAGAARRVLLLLLLGVLSAGLRPGALATEHYSPLSLLKQELQHRQQQEAPAGGGGCSPQSGDWGDQYSAECGESSFLNFHDSDCEPKGSSPCDSLLSLNTEKILSQAKSIAEQKRFPFATDNDSTNEELAIAYVLIGSGLYDEAIRHFSTMLQEEPDLVSAIYGRGIAYGKKGLHDIKNAELALFELSRVITLEPDRPEVFEQRAEILSPLGRINEAVNDLTKAIQLQPSARLYRHRGTLYFISEDYATAHEDFQQSLELNKNQPIAMLYKGLTFFHRGLLKEAIESFKEALKQKVDFIDAYKSLGQAYRELGNFEAATESFQKALLLNQNHVQTLQLRGMMLYHHGSLQEALKNFKRCLQLEPYNEVCQYMKGLSHVAMGQFYEGIKAQTKVMLNDPLPGQKASPEYLKVKYLREYSRYLHAHLDTPLTEYNIDVDLPGSFKDHWAKNLPFLIEDYEEQPGLQPHIKDVLHQNFESYKPEVQELICVADRLGSLMQYETPGFLPNKRIHRAMGLAALEVMQAVQRTWTNSKVRMNGKTRLMQWRDMFDIAVKWRRIADPDQPVLWLDQMPARSLSRGFNNHINLIRGQVINMRYLEYFEKILHFIKDRILVYHGANNPKGLLEVREALEKVHKVEDLLPIMKQFNTKTKDGFTVNTKVPSLKDQGKEYDGFTITITGDKVGNILFSVETQTTEERTQLYHAEIDALYKDLTAKGKVLILSSEFGEADAVCNLILSLVYYFYNLMPLSRGSSVIAYSVIVGALMASGKEVAGKIPKGKLVDFEAMTAPGSEAFSKVAKSWMNLKSISPSYKTLPSVSETFPTLRSMIEVLNTDSSPRCLKKL>sp|Q8NBP0-2|TTC13_HUMAN Isoform 2 of Tetratricopeptide repeat protein 13OS=Homo sapiens OX=9606 GN=TTC13MAPAGCCCCCCFWGGAVAAAGAARRVLLLLLLGVLSAGLRPGALATEHYSPLSLLKQELQHRQQQEAPAGGGGCSPQSGDWGDQYSAECGESSFLNFHDSDCEPKGSSPCDSLLSLNTEKILSQAKSIAEQKRFPFATDNDSTNEELAIAYVLIGSGLYDEAIRHFSTMLQILSPLGRINEAVNDLTKAIQLQPSARLYRHRGTLYFISEDYATAHEDFQQSLELNKNQPIAMLYKGLTFFHRGLLKEAIESFKEALKQKVDFIDAYKSLGQAYRELGNFEAATESFQKALLLNQNHVQTLQLRGMMLYHHGSLQEALKNFKRCLQLEPYNEVCQYMKGLSHVAMGQFYEGIKAQTKVMLNDPLPGQKASPEYLKVKYLREYSRYLHAHLDTPLTEYNIDVDLPGSFKDHWAKNLPFLIEDYEEQPGLQPHIKDVLHQNFESYKPEVQELICVADRLGSLMQYETPGFLPNKRIHRAMGLAALEVMQAVQRTWTNSKVRMNGKTRLMQWRDMFDIAVKWRRIADPDQPVLWLDQMPARSLSRGFNNHINLIRGQVINMRYLEYFEKILHFIKDRILVYHGANNPKGLLEVREALEKVHKVEDLLPIMKFNTKTKDGFTVNTKVPSLKDQGKEYDGFTITITGDKVGNILFSVETQTTEERTQLYHAEIDALYKDLTAKGKVLILSSEFGEADAVCNLILSLVYYFYNLMPLSRGSSVIAYSVIVGALMASGKEVAGKIPKGKLVDFEAMTAPGSEAFSKVAKSWMNLKSISPSYKTLPSVSETFPTLRSMIEVLNTDSSPRCLKKL>sp|O60637|TSN3_HUMAN Tetraspanin-3 OS=Homo sapiens OX=9606 GN=TSPAN3PE=2 SV=1MGQCGITSSKTVLVFLNLIFWGAAGILCYVGAYVFITYDDYDHFFEDVYTLIPAVVIIAVGALLFIIGLIGCCATIRESRCGLATFVIILLLVFVTEVVVVVLGYVYRAKVENEVDRSIQKVYKTYNGTNPDAASRAIDYVQRQLHCCGIHNYSDWENTDWFKETKNQSVPLSCCRETASNCNGSLAHPSDLYAEGCEALVVKKLQEIMMHVIWAALAFAAIQLLGMLCACIVLCRRSRDPAYELLITGGTYA>sp|O60637-2|TSN3_HUMAN Isoform 2 of Tetraspanin-3 OS=Homo sapiensOX=9606 GN=TSPAN3MGQCGITSSKTVLVFLNLIFWGAAGILCYVGAYVFITYDDYDHFFEDVYTLIPAVVIIAVGALLFIIGLIGCCATIRESRCGLATVENEVDRSIQKVYKTYNGTNPDAASRAIDYVQRQLHCCGIHNYSDWENTDWFKETKNQSVPLSCCRETASNCNGSLAHPSDLYAEGCEALVVKKLQEIMMHVIWAALAFAAIQLLGMLCACIVLCRRSRDPAYELLITGGTYA>sp|O60637-3|TSN3_HUMAN Isoform 3 of Tetraspanin-3 OS=Homo sapiensOX=9606 GN=TSPAN3MGQCGITSSKTVLVFLNLIFWFVIILLLVFVTEVVVVVLGYVYRAKVENEVDRSIQKVYKTYNGTNPDAASRAIDYVQRQLHCCGIHNYSDWENTDWFKETKNQSVPLSCCRETASNCNGSLAHPSDLYAEGCEALVVKKLQEIMMHVIWAALAFAAIQLLGMLCACIVLCRRSRDPAYELLITGGTYA>sp|A6NN06|U633A_HUMAN Putative UPF0633 protein MGC21881 OS=Homo sapiensOX=9606 PE=5 SV=1MRKLRLRASNPGPSGAPGTRRHFSTSGGGHHCGRRWLRRVRRSRSQTPSCQNLDPNPPIARFPLPLERISEVPRRACLHGRDASSVWPPPERSD>sp|Q96K76|UBP47_HUMAN Ubiquitin carboxyl-terminal hydrolase 47 OS=Homosapiens OX=9606 GN=USP47 PE=1 SV=3MVPGEENQLVPKEDVFWRCRQNIFDEMKKKFLQIENAAEEPRVLCIIQDTTNSKTVNERITLNLPASTPVRKLFEDVANKVGYINGTFDLVWGNGINTADMAPLDHTSDKSLLDANFEPGKKNFLHLTDKDGEQPQILLEDSSAGEDSVHDRFIGPLPREGSGGSTSDYVSQSYSYSSILNKSETGYVGLVNQAMTCYLNSLLQTLFMTPEFRNALYKWEFEESEEDPVTSIPYQLQRLFVLLQTSKKRAIETTDVTRSFGWDSSEAWQQHDVQELCRVMFDALEQKWKQTEQADLINELYQGKLKDYVRCLECGYEGWRIDTYLDIPLVIRPYGSSQAFASVEEALHAFIQPEILDGPNQYFCERCKKKCDARKGLRFLHFPYLLTLQLKRFDFDYTTMHRIKLNDRMTFPEELDMSTFIDVEDEKSPQTESCTDSGAENEGSCHSDQMSNDFSNDDGVDEGICLETNSGTEKISKSGLEKNSLIYELFSVMVHSGSAAGGHYYACIKSFSDEQWYSFNDQHVSRITQEDIKKTHGGSSGSRGYYSSAFASSTNAYMLIYRLKDPARNAKFLEVDEYPEHIKNLVQKERELEEQEKRQREIERNTCKIKLFCLHPTKQVMMENKLEVHKDKTLKEAVEMAYKMMDLEEVIPLDCCRLVKYDEFHDYLERSYEGEEDTPMGLLLGGVKSTYMFDLLLETRKPDQVFQSYKPGEVMVKVHVVDLKAESVAAPITVRAYLNQTVTEFKQLISKAIHLPAETMRIVLERCYNDLRLLSVSSKTLKAEGFFRSNKVFVESSETLDYQMAFADSHLWKLLDRHANTIRLFVLLPEQSPVSYSKRTAYQKAGGDSGNVDDDCERVKGPVGSLKSVEAILEESTEKLKSLSLQQQQDGDNGDSSKSTETSDFENIESPLNERDSSASVDNRELEQHIQTSDPENFQSEERSDSDVNNDRSTSSVDSDILSSSHSSDTLCNADNAQIPLANGLDSHSITSSRRTKANEGKKETWDTAEEDSGTDSEYDESGKSRGEMQYMYFKAEPYAADEGSGEGHKWLMVHVDKRITLAAFKQHLEPFVGVLSSHFKVFRVYASNQEFESVRLNETLSSFSDDNKITIRLGRALKKGEYRVKVYQLLVNEQEPCKFLLDAVFAKGMTVRQSKEELIPQLREQCGLELSIDRFRLRKKTWKNPGTVFLDYHIYEEDINISSNWEVFLEVLDGVEKMKSMSQLAVLSRRWKPSEMKLDPFQEVVLESSSVDELREKLSEISGIPLDDIEFAKGRGTFPCDISVLDIHQDLDWNPKVSTLNVWPLYICDDGAVIFYRDKTEELMELTDEQRNELMKKESSRLQKTGHRVTYSPRKEKALKIYLDGAPNKDLTQD>sp|Q96K76-2|UBP47_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 47 OS=Homo sapiens OX=9606 GN=USP47MVPGEENQLVPKEAPLDHTSDKSLLDANFEPGKKNFLHLTDKDGEQPQILLEDSSAGEDSVHDRFIGPLPREGSGGSTSDYVSQSYSYSSILNKSETGYVGLVNQAMTCYLNSLLQTLFMTPEFRNALYKWEFEESEEDPVTSIPYQLQRLFVLLQTSKKRAIETTDVTRSFGWDSSEAWQQHDVQELCRVMFDALEQKWKQTEQADLINELYQGKLKDYVRCLECGYEGWRIDTYLDIPLVIRPYGSSQAFASVEEALHAFIQPEILDGPNQYFCERCKKKCDARKGLRFLHFPYLLTLQLKRFDFDYTTMHRIKLNDRMTFPEELDMSTFIDVEDEKSPQTESCTDSGAENEGSCHSDQMSNDFSNDDGVDEGICLETNSGTEKISKSGLEKNSLIYELFSVMVHSGSAAGGHYYACIKSFSDEQWYSFNDQHVSRITQEDIKKTHGGSSGSRGYYSSAFASSTNAYMLIYRLKDPARNAKFLEVDEYPEHIKNLVQKERELEEQEKRQREIERNTCKIKLFCLHPTKQVMMENKLEVHKDKTLKEAVEMAYKMMDLEEVIPLDCCRLVKYDEFHDYLERSYEGEEDTPMGLLLGGVKSTYMFDLLLETRKPDQVFQSYKPGEVMVKVHVVDLKAESVAAPITVRAYLNQTVTEFKQLISKAIHLPAETMRIVLERCYNDLRLLSVSSKTLKAEGFFRSNKVFVESSETLDYQMAFADSHLWKLLDRHANTIRLFVLLPEQSPVSYSKRTAYQKAGGDSGNVDDDCERVKGPVGSLKSVEAILEESTEKLKSLSLQQQQDGDNGDSSKSTETSDFENIESPLNERDSSASVDNRELEQHIQTSDPENFQSEERSDSDVNNDRSTSSVDSDILSSSHSSDTLCNADNAQIPLANGLDSHSITSSRRTKANEGKKETWDTAEEDSGTDSEYDESGKSRGEMQYMYFKAEPYAADEGSGEGHKWLMVHVDKRITLAAFKQHLEPFVGVLSSHFKVFRVYASNQEFESVRLNETLSSFSDDNKITIRLGRALKKGEYRVKVYQLLVNEQEPCKFLLDAVFAKGMTVRQSKEELIPQLREQCGLELSIDRFRLRKKTWKNPGTVFLDYHIYEEDINISSNWEVFLEVLDGVEKMKSMSQLAVLSRRWKPSEMKLDPFQEVVLESSSVDELREKLSEISGIPLDDIEFAKGRGTFPCDISVLDIHQDLDWNPKVSTLNVWPLYICDDGAVIFYRDKTEELMELTDEQRNELMKKESSRLQKTGHRVTYSPRKEKALKIYLDGAPNKDLTQD>sp|Q96K76-3|UBP47_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 47 OS=Homo sapiens OX=9606 GN=USP47MKSMSQLAVLSRRWKPSEMKLDPFQEVVLESSSVDELREKLSEISGIPLDDIEFAKGRGTFPCDISVLDIHQDLDWNPKVSTLNVWPLYICDDGAVIFYRDKTEELMELTDEQRNELMKKESSRLQKTGHRVTYSPRKEKALKIYLDGAPNKDLTQD>sp|Q96K76-4|UBP47_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase 47 OS=Homo sapiens OX=9606 GN=USP47MVPGEENQLVPKEIENAAEEPRVLCIIQDTTNSKTVNERITLNLPASTPVRKLFEDVANKVGYINGTFDLVWGNGINTADMAPLDHTSDKSLLDANFEPGKKNFLHLTDKDGEQPQILLEDSSAGEDSVHDRFIGPLPREGSGGSTSDYVSQSYSYSSILNKSETGYVGLVNQAMTCYLNSLLQTLFMTPEFRNALYKWEFEESEEDPVTSIPYQLQRLFVLLQTSKKRAIETTDVTRSFGWDSSEAWQQHDVQELCRVMFDALEQKWKQTEQADLINELYQGKLKDYVRCLECGYEGWRIDTYLDIPLVIRPYGSSQAFASVEEALHAFIQPEILDGPNQYFCERCKKKCDARKGLRFLHFPYLLTLQLKRFDFDYTTMHRIKLNDRMTFPEELDMSTFIDVEDEKSPQTESCTDSGAENEGSCHSDQMSNDFSNDDGVDEGICLETNSGTEKISKSGLEKNSLIYELFSVMVHSGSAAGGHYYACIKSFSDEQWYSFNDQHVSRITQEDIKKTHGGSSGSRGYYSSAFASSTNAYMLIYRLKDPARNAKFLEVDEYPEHIKNLVQKERELEEQEKRQREIERNTCKIKLFCLHPTKQVMMENKLEVHKDKTLKEAVEMAYKMMDLEEVIPLDCCRLVKYDEFHDYLERSYEGEEDTPMGLLLGGVKSTYMFDLLLETRKPDQVFQSYKPGEVMVKVHVVDLKAESVAAPITVRAYLNQTVTEFKQLISKAIHLPAETMRIVLERCYNDLRLLSVSSKTLKAEGFFRSNKVFVESSETLDYQMAFADSHLWKLLDRHANTIRLFVLLPEQSPVSYSKRTAYQKAGGDSGNVDDDCERVKGPVGSLKSVEAILEESTEKLKSLSLQQQQDGDNGDSSKSTETSDFENIESPLNERDSSASVDNRELEQHIQTSDPENFQSEERSDSDVNNDRSTSSVDSDILSSSHSSDTLCNADNAQIPLANGLDSHSITSSRRTKANEGKKETWDTAEEDSGTDSEYDESGKSRGEMQYMYFKAEPYAADEGSGEGHKWLMVHVDKRITLAAFKQHLEPFVGVLSSHFKVFRVYASNQEFESVRLNETLSSFSDDNKITIRLGRALKKGEYRVKVYQLLVNEQEPCKFLLDAVFAKGMTVRQSKEELIPQLREQCGLELSIDRFRLRKKTWKNPGTVFLDYHIYEEDINISSNWEVFLEVLDGVEKMKSMSQLAVLSRRWKPSEMKLDPFQEVVLESSSVDELREKLSEISGIPLDDIEFAKGRGTFPCDISVLDIHQDLDWNPKVSTLNVWPLYICDDGAVIFYRDKTEELMELTDEQRNELMKKESSRLQKTGHRVTYSPRKEKALKIYLDGAPNKDLTQD>sp|O75604|UBP2_HUMAN Ubiquitin carboxyl-terminal hydrolase 2 OS=Homosapiens OX=9606 GN=USP2 PE=1 SV=2MSQLSSTLKRYTESARYTDAHYAKSGYGAYTPSSYGANLAASLLEKEKLGFKPVPTSSFLTRPRTYGPSSLLDYDRGRPLLRPDITGGGKRAESQTRGTERPLGSGLSGGSGFPYGVTNNCLSYLPINAYDQGVTLTQKLDSQSDLARDFSSLRTSDSYRIDPRNLGRSPMLARTRKELCTLQGLYQTASCPEYLVDYLENYGRKGSASQVPSQAPPSRVPEIISPTYRPIGRYTLWETGKGQAPGPSRSSSPGRDGMNSKSAQGLAGLRNLGNTCFMNSILQCLSNTRELRDYCLQRLYMRDLHHGSNAHTALVEEFAKLIQTIWTSSPNDVVSPSEFKTQIQRYAPRFVGYNQQDAQEFLRFLLDGLHNEVNRVTLRPKSNPENLDHLPDDEKGRQMWRKYLEREDSRIGDLFVGQLKSSLTCTDCGYCSTVFDPFWDLSLPIAKRGYPEVTLMDCMRLFTKEDVLDGDEKPTCCRCRGRKRCIKKFSIQRFPKILVLHLKRFSESRIRTSKLTTFVNFPLRDLDLREFASENTNHAVYNLYAVSNHSGTTMGGHYTAYCRSPGTGEWHTFNDSSVTPMSSSQVRTSDAYLLFYELASPPSRM>sp|O75604-2|UBP2_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 2 OS=Homo sapiens OX=9606 GN=USP2MLNKAKNSKSAQGLAGLRNLGNTCFMNSILQCLSNTRELRDYCLQRLYMRDLHHGSNAHTALVEEFAKLIQTIWTSSPNDVVSPSEFKTQIQRYAPRFVGYNQQDAQEFLRFLLDGLHNEVNRVTLRPKSNPENLDHLPDDEKGRQMWRKYLEREDSRIGDLFVGQLKSSLTCTDCGYCSTVFDPFWDLSLPIAKRGYPEVTLMDCMRLFTKEDVLDGDEKPTCCRCRGRKRCIKKFSIQRFPKILVLHLKRFSESRIRTSKLTTFVNFPLRDLDLREFASENTNHAVYNLYAVSNHSGTTMGGHYTAYCRSPGTGEWHTFNDSSVTPMSSSQVRTSDAYLLFYELASPPSRM>sp|O75604-3|UBP2_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 2 OS=Homo sapiens OX=9606 GN=USP2MLVPGSTRPYSKKRQNSKSAQGLAGLRNLGNTCFMNSILQCLSNTRELRDYCLQRLYMRDLHHGSNAHTALVEEFAKLIQTIWTSSPNDVVSPSEFKTQIQRYAPRFVGYNQQDAQEFLRFLLDGLHNEVNRVTLRPKSNPENLDHLPDDEKGRQMWRKYLEREDSRIGDLFVGQLKSSLTCTDCGYCSTVFDPFWDLSLPIAKRGYPEVTLMDCMRLFTKEDVLDGDEKPTCCRCRGRKRCIKKFSIQRFPKILVLHLKRFSESRIRTSKLTTFVNFPLRDLDLREFASENTNHAVYNLYAVSNHSGTTMGGHYTAYCRSPGTGEWHTFNDSSVTPMSSSQVRTSDAYLLFYELASPPSRM>sp|O75604-4|UBP2_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase 2 OS=Homo sapiens OX=9606 GN=USP2MRTSYTVTLPEDPPAAPFPALAKELRPRSPLSPSLLLSTFVGLLLNKAKNSKSAQGLAGLRNLGNTCFMNSILQCLSNTRELRDYCLQRLYMRDLHHGSNAHTALVEEFAKLIQTIWTSSPNDVVSPSEFKTQIQRYAPRFVGYNQQDAQEFLRFLLDGLHNEVNRVTLRPKSNPENLDHLPDDEKGRQMWRKYLEREDSRIGDLFVGQLKSSLTCTDCGYCSTVFDPFWDLSLPIAKRGYPEVTLMDCMRLFTKEDVLDGDEKPTCCRCRGRKRCIKKFSIQRFPKILVLHLKRFSESRIRTSKLTTFVNFPLRDLDLREFASENTNHAVYNLYAVSNHSGTTMGGHYTAYCRSPGTGEWHTFNDSSVTPMSSSQVRTSDAYLLFYELASPPSRM>sp|A0AVT1|UBA6_HUMAN Ubiquitin-like modifier-activating enzyme 6 OS=Homosapiens OX=9606 GN=UBA6 PE=1 SV=1MEGSEPVAAHQGEEASCSSWGTGSTNKNLPIMSTASVEIDDALYSRQRYVLGDTAMQKMAKSHVFLSGMGGLGLEIAKNLVLAGIKAVTIHDTEKCQAWDLGTNFFLSEDDVVNKRNRAEAVLKHIAELNPYVHVTSSSVPFNETTDLSFLDKYQCVVLTEMKLPLQKKINDFCRSQCPPIKFISADVHGIWSRLFCDFGDEFEVLDTTGEEPKEIFISNITQANPGIVTCLENHPHKLETGQFLTFREINGMTGLNGSIQQITVISPFSFSIGDTTELEPYLHGGIAVQVKTPKTVFFESLERQLKHPKCLIVDFSNPEAPLEIHTAMLALDQFQEKYSRKPNVGCQQDSEELLKLATSISETLEEKPDVNADIVHWLSWTAQGFLSPLAAAVGGVASQEVLKAVTGKFSPLCQWLYLEAADIVESLGKPECEEFLPRGDRYDALRACIGDTLCQKLQNLNIFLVGCGAIGCEMLKNFALLGVGTSKEKGMITVTDPDLIEKSNLNRQFLFRPHHIQKPKSYTAADATLKINSQIKIDAHLNKVCPTTETIYNDEFYTKQDVIITALDNVEARRYVDSRCLANLRPLLDSGTMGTKGHTEVIVPHLTESYNSHRDPPEEEIPFCTLKSFPAAIEHTIQWARDKFESSFSHKPSLFNKFWQTYSSAEEVLQKIQSGHSLEGCFQVIKLLSRRPRNWSQCVELARLKFEKYFNHKALQLLHCFPLDIRLKDGSLFWQSPKRPPSPIKFDLNEPLHLSFLQNAAKLYATVYCIPFAEEDLSADALLNILSEVKIQEFKPSNKVVQTDETARKPDHVPISSEDERNAIFQLEKAILSNEATKSDLQMAVLSFEKDDDHNGHIDFITAASNLRAKMYSIEPADRFKTKRIAGKIIPAIATTTATVSGLVALEMIKVTGGYPFEAYKNCFLNLAIPIVVFTETTEVRKTKIRNGISFTIWDRWTVHGKEDFTLLDFINAVKEKYGIEPTMVVQGVKMLYVPVMPGHAKRLKLTMHKLVKPTTEKKYVDLTVSFAPDIDGDEDLPGPPVRYYFSHDTD>sp|A0AVT1-2|UBA6_HUMAN Isoform 2 of Ubiquitin-like modifier-activatingenzyme 6 OS=Homo sapiens OX=9606 GN=UBA6MLKNFALLGVGTSKEKGMITVTDPDLIEKSNLNRQFLFRPHHIQKPKSYTAADATLKINSQIKIDAHLNKVCPTTETIYNDEFYTKQDVIITALDNVEARRYVDSRCLANLRPLLDSGTMGTKGHTEVIVPHLTESYNSHRDPPEEEIPFCTLKSFPAAIEHTIQWARDKFESSFSHKPSLFNKFWQTYSSAEEVLQKIQSGHSLEGCFQVIKLLSRRPRNWSQCVELARLKFEKYFNHKALQLLHCFPLDIRLKDGSLFWQSPKRPPSPIKFDLNEPLHLSFLQNAAKLYATVYCIPFAEEDLSADALLNILSEVKIQEFKPSNKVVQTDETARKPDHVPISSEDERNAIFQLEKAILSNEATKSDLQMAVLSFEKDDDHNGHIDFITAASNLRAKMYSIEPADRFKTKRIAGKIIPAIATTTATVSGLVALEMIKVTGGYPFEAYKNCFLNLAIPIVVFTETTEVRKTKIRNGISFTIWDRWTVHGKEDFTLLDFINAVKEKYGIEPTMVVQGVKMLYVPVMPGHAKRLKLTMHKLVKPTTEKKYVDLTVSFAPDIDGDEDLPGPPVRYYFSHDTD>sp|A0AVT1-3|UBA6_HUMAN Isoform 3 of Ubiquitin-like modifier-activatingenzyme 6 OS=Homo sapiens OX=9606 GN=UBA6MEGSEPVAAHQGEEASCSSWGTGSTNKNLPIMSTASVEIDDALYSRQRYVLGDTAMQKMAKSHVFLSGMGGLGLEIAKNLVLAGIKAVTIHDTEKCQAWDLGTNFFLSEDDVVNKRNRAEAVLKHIAELNPYVHVTSSSVPFNETTDLSFLDKYQCVVLTEMKLPLQKKINDFCRSQCPPIKFISADVHGIWSRLFCDFGDEFEVLDTTGEEPKEIFISNITQANPGIVTCLENHPHKLETGQFLTFREINGMTGLNGSIQQITVISPFSFSIGDTTELEPYLHGGIAVQVKTPKTVFFESLERQLKHPKCLIVDFSNPEAPLEIHTAMLALDQFQEKYSRKPNVGCQQDSEELLKLATSISETLEEKVTIEIYGCPNICLLIHKCSVY>sp|A0AVT1-4|UBA6_HUMAN Isoform 4 of Ubiquitin-like modifier-activatingenzyme 6 OS=Homo sapiens OX=9606 GN=UBA6MEGSEPVAAHQGEEASCSSWGTGSTNKNLPIMSTASVEIDDALYSRQRYVLGDTAMQKMAKSHVFLSGMGGLGLEIAKNLVLAGIKAVTIHDTEKCQAWDLGTNFFLSEDDVVNKRNRAEAVLKHIAELNPYVHVTSSSVPFNETTDLSFLDKYQCVVLTEMKLPLQKKINDFCRSQCPPIKFISADVHGIWSRLFCDFGDEFEVLDTTGEEPKEIFISNITQANPGIVTCLENHPHKLETGQFLTFREINGMTGLNGSIQQITVISPFSFSIGDTTELEPYLHGGIAVQVKTPKTVFFESLERQLKHPKCLIVDFSNPEVNKHFAGLREAAESEMRISE>sp|Q8NB14|UBP38_HUMAN Ubiquitin carboxyl-terminal hydrolase 38 OS=Homosapiens OX=9606 GN=USP38 PE=1 SV=2MDKILEGLVSSSHPLPLKRVIVRKVVESAEHWLDEAQCEAMFDLTTRLILEGQDPFQRQVGHQVLEAYARYHRPEFESFFNKTFVLGLLHQGYHSLDRKDVAILDYIHNGLKLIMSCPSVLDLFSLLQVEVLRMVCERPEPQLCARLSDLLTDFVQCIPKGKLSITFCQQLVRTIGHFQCVSTQERELREYVSQVTKVSNLLQNIWKAEPATLLPSLQEVFASISSTDASFEPSVALASLVQHIPLQMITVLIRSLTTDPNVKDASMTQALCRMIDWLSWPLAQHVDTWVIALLKGLAAVQKFTILIDVTLLKIELVFNRLWFPLVRPGALAVLSHMLLSFQHSPEAFHLIVPHVVNLVHSFKNDGLPSSTAFLVQLTELIHCMMYHYSGFPDLYEPILEAIKDFPKPSEEKIKLILNQSAWTSQSNSLASCLSRLSGKSETGKTGLINLGNTCYMNSVIQALFMATDFRRQVLSLNLNGCNSLMKKLQHLFAFLAHTQREAYAPRIFFEASRPPWFTPRSQQDCSEYLRFLLDRLHEEEKILKVQASHKPSEILECSETSLQEVASKAAVLTETPRTSDGEKTLIEKMFGGKLRTHIRCLNCRSTSQKVEAFTDLSLAFCPSSSLENMSVQDPASSPSIQDGGLMQASVPGPSEEPVVYNPTTAAFICDSLVNEKTIGSPPNEFYCSENTSVPNESNKILVNKDVPQKPGGETTPSVTDLLNYFLAPEILTGDNQYYCENCASLQNAEKTMQITEEPEYLILTLLRFSYDQKYHVRRKILDNVSLPLVLELPVKRITSFSSLSESWSVDVDFTDLSENLAKKLKPSGTDEASCTKLVPYLLSSVVVHSGISSESGHYYSYARNITSTDSSYQMYHQSEALALASSQSHLLGRDSPSAVFEQDLENKEMSKEWFLFNDSRVTFTSFQSVQKITSRFPKDTAYVLLYKKQHSTNGLSGNNPTSGLWINGDPPLQKELMDAITKDNKLYLQEQELNARARALQAASASCSFRPNGFDDNDPPGSCGPTGGGGGGGFNTVGRLVF>sp|Q8NB14-2|UBP38_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 38 OS=Homo sapiens OX=9606 GN=USP38MDKILEGLVSSSHPLPLKRVIVRKVVESAEHWLDEAQCEAMFDLTTRLILEGQDPFQRQVGHQVLEAYARYHRPEFESFFNKTFVLGLLHQGYHSLDRKDVAILDYIHNGLKLIMSCPSVLDLFSLLQVEVLRMVCERPEPQLCARLSDLLTDFVQCIPKGKLSITFCQQLVRTIGHFQCVSTQERELREYVSQVTKVSNLLQNIWKAEPATLLPSLQEVFASISSTDASFEPSVALASLVQHIPLQMITVLIRSLTTDPNVKDASMTQALCRMIDWLSWPLAQHVDTWVIALLKGLAAVQKFTILIDVTLLKIELVFNRLWFPLVRPGALAVLSHMLLSFQHSPEAFHLIVPHVVNLVHSFKNDGLPSSTAFLVQLTELIHCMMYHYSGFPDLYEPILEAIKDFPKPSEEKIKLILNQSAWTSQSNSLASCLSRLSGKSETGKTGLINLGNTCYMNSVIQALFMATDFRRQVLSLNLNGCNSLMKKLQHLFAFLAHTQREAYAPRIFFEASRPPWFTPRSQQDCSEYLRFLLDRLHEEEKILKVQASHKPSEILECSETSLQEVASKAAVLTETPRTSDGEKTLIEKMFGGKLRTHIRCLNCRSTSQKVEAFTDLSLAFCPSSSLENMSVQDPASSPSIQDGGLMQASVPGPSEEPVVYNPTTAAFICDSLVNEKTIGSPPNEFYCSENTSVPNESNKILVNKDVPQKPGGETTPSVTDLLNYFLAPEILTGDNQYYCENCASLQNAEKTMQITEEPEYLILTLLRFSYDQKYHVRRKILDNVSLPLVLELPVKRITSFSSLSESWSVDVDFTDLSENLAKKLKPSGTDEASCTKLVPYLLSSVVVHSGISSESGHYYSYARNITSTDSSYQMYHQSEALALASSQSHLLGRDSPSAVFEQDLENKEMSKEWFLFNDSRVTFTSFQSVQKITSRFPKDTAYVLLYKKQHSTNGLSGNNPTSGLWINGDPPLQKELMDAITKDNKLYLQVSWKYKLYLLKILNN>sp|Q9BSL1|UBAC1_HUMAN Ubiquitin-associated domain-containing protein 1OS=Homo sapiens OX=9606 GN=UBAC1 PE=1 SV=1MFVQEEKIFAGKVLRLHICASDGAEWLEEATEDTSVEKLKERCLKHCAHGSLEDPKSITHHKLIHAASERVLSDARTILEENIQDQDVLLLIKKRAPSPLPKMADVSAEEKKKQDQKAPDKEAILRATANLPSYNMDRAAVQTNMRDFQTELRKILVSLIEVAQKLLALNPDAVELFKKANAMLDEDEDERVDEAALRQLTEMGFPENRATKALQLNHMSVPQAMEWLIEHAEDPTIDTPLPGQAPPEAEGATAAASEAAAGASATDEEARDELTEIFKKIRRKREFRADARAVISLMEMGFDEKEVIDALRVNNNQQNAACEWLLGDRKPSPEELDKGIDPDSPLFQAILDNPVVQLGLTNPKTLLAFEDMLENPLNSTQWMNDPETGPVMLQISRIFQTLNRT>sp|Q8TCY9|URGCP_HUMAN Up-regulator of cell proliferation OS=Homo sapiensOX=9606 GN=URGCP PE=1 SV=2MASPGIEVELLGKGHSDLGEVAPEIKASERRTAVAIADLEWREMEGDDCEFRYGDGTNEAQDNDFPTVERSRLQEMLSLLGLETYQVQKLSLQDSLQISFDSMKNWAPQVPKDLPWNFLRKLQALNADARNTTMVLDVLPDARPVEKESQMEEEIIYWDPADDLAADIYSFSELPTPDTPVNPLDLLCALLLSSDSFLQQEIALKMALCQFALPLVLPDSENHYHTFLLWAMRGIVRTWWSQPPRGMGSFREDSVVLSRAPAFAFVRMDVSSNSKSQLLNAVLSPGHRQWDCFWHRDLNLGTNAREISDGLVEISWFFPSGREDLDIFPEPVAFLNLRGDIGSHWLQFKLLTEISSAVFILTDNISKKEYKLLYSMKESTTKYYFILSPYRGKRNTNLRFLNKLIPVLKIDHSHVLVKVSSTDSDSFVKRIRAIVGNVLRAPCRRVSVEDMAHAARKLGLKVDEDCEECQKAKDRMERITRKIKDSDAYRRDELRLQGDPWRKAAQVEKEFCQLQWAVDPPEKHRAELRRRLLELRMQQNGHDPSSGVQEFISGISSPSLSEKQYFLRWMEWGLARVAQPRLRQPPETLLTLRPKHGGTTDVGEPLWPEPLGVEHFLREMGQFYEAESCLVEAGRLPAGQRRFAHFPGLASELLLTGLPLELIDGSTLSMPVRWVTGLLKELHVRLERRSRLVVLSTVGVPGTGKSTLLNTMFGLRFATGKSCGPRGAFMQLITVAEGFSQDLGCDHILVIDSGGLIGGALTSAGDRFELEASLATLLMGLSNVTVISLAETKDIPAAILHAFLRLEKTGHMPNYQFVYQNLHDVSVPGPRPRDKRQLLDPPGDLSRAAAQMEKQGDGFRALAGLAFCDPEKQHIWHIPGLWHGAPPMAAVSLAYSEAIFELKRCLLENIRNGLSNQNKNIQQLIELVRRL>sp|Q8TCY9-2|URGCP_HUMAN Isoform 2 of Up-regulator of cell proliferationOS=Homo sapiens OX=9606 GN=URGCPMASPGHSDLGEVAPEIKASERRTAVAIADLEWREMEGDDCEFRYGDGTNEAQDNDFPTVERSRLQEMLSLLGLETYQVQKLSLQDSLQISFDSMKNWAPQVPKDLPWNFLRKLQALNADARNTTMVLDVLPDARPVEKESQMEEEIIYWDPADDLAADIYSFSELPTPDTPVNPLDLLCALLLSSDSFLQQEIALKMALCQFALPLVLPDSENHYHTFLLWAMRGIVRTWWSQPPRGMGSFREDSVVLSRAPAFAFVRMDVSSNSKSQLLNAVLSPGHRQWDCFWHRDLNLGTNAREISDGLVEISWFFPSGREDLDIFPEPVAFLNLRGDIGSHWLQFKLLTEISSAVFILTDNISKKEYKLLYSMKESTTKYYFILSPYRGKRNTNLRFLNKLIPVLKIDHSHVLVKVSSTDSDSFVKRIRAIVGNVLRAPCRRVSVEDMAHAARKLGLKVDEDCEECQKAKDRMERITRKIKDSDAYRRDELRLQGDPWRKAAQVEKEFCQLQWAVDPPEKHRAELRRRLLELRMQQNGHDPSSGVQEFISGISSPSLSEKQYFLRWMEWGLARVAQPRLRQPPETLLTLRPKHGGTTDVGEPLWPEPLGVEHFLREMGQFYEAESCLVEAGRLPAGQRRFAHFPGLASELLLTGLPLELIDGSTLSMPVRWVTGLLKELHVRLERRSRLVVLSTVGVPGTGKSTLLNTMFGLRFATGKSCGPRGAFMQLITVAEGFSQDLGCDHILVIDSGGLIGGALTSAGDRFELEASLATLLMGLSNVTVISLAETKDIPAAILHAFLRLEKTGHMPNYQFVYQNLHDVSVPGPRPRDKRQLLDPPGDLSRAAAQMEKQGDGFRALAGLAFCDPEKQHIWHIPGLWHGAPPMAAVSLAYSEAIFELKRCLLENIRNGLSNQNKNIQQLIELVRRL>sp|Q8TCY9-3|URGCP_HUMAN Isoform 3 of Up-regulator of cell proliferationOS=Homo sapiens OX=9606 GN=URGCPMLSLLGLETYQVQKLSLQDSLQISFDSMKNWAPQVPKDLPWNFLRKLQALNADARNTTMVLDVLPDARPVEKESQMEEEIIYWDPADDLAADIYSFSELPTPDTPVNPLDLLCALLLSSDSFLQQEIALKMALCQFALPLVLPDSENHYHTFLLWAMRGIVRTWWSQPPRGMGSFREDSVVLSRAPAFAFVRMDVSSNSKSQLLNAVLSPGHRQWDCFWHRDLNLGTNAREISDGLVEISWFFPSGREDLDIFPEPVAFLNLRGDIGSHWLQFKLLTEISSAVFILTDNISKKEYKLLYSMKESTTKYYFILSPYRGKRNTNLRFLNKLIPVLKIDHSHVLVKVSSTDSDSFVKRIRAIVGNVLRAPCRRVSVEDMAHAARKLGLKVDEDCEECQKAKDRMERITRKIKDSDAYRRDELRLQGDPWRKAAQVEKEFCQLQWAVDPPEKHRAELRRRLLELRMQQNGHDPSSGVQEFISGISSPSLSEKQYFLRWMEWGLARVAQPRLRQPPETLLTLRPKHGGTTDVGEPLWPEPLGVEHFLREMGQFYEAESCLVEAGRLPAGQRRFAHFPGLASELLLTGLPLELIDGSTLSMPVRWVTGLLKELHVRLERRSRLVVLSTVGVPGTGKSTLLNTMFGLRFATGKSCGPRGAFMQLITVAEGFSQDLGCDHILVIDSGGLIGGALTSAGDRFELEASLATLLMGLSNVTVISLAETKDIPAAILHAFLRLEKTGHMPNYQFVYQNLHDVSVPGPRPRDKRQLLDPPGDLSRAAAQMEKQGDGFRALAGLAFCDPEKQHIWHIPGLWHGAPPMAAVSLAYSEAIFELKRCLLENIRNGLSNQNKNIQQLIELVRRL>sp|Q8TCY9-4|URGCP_HUMAN Isoform 4 of Up-regulator of cell proliferationOS=Homo sapiens OX=9606 GN=URGCPMEGDDCEFRYGDGTNEAQDNDFPTVERSRLQEMLSLLGLETYQVQKLSLQDSLQISFDSMKNWAPQVPKDLPWNFLRKLQALNADARNTTMVLDVLPDARPVEKESQMEEEIIYWDPADDLAADIYSFSELPTPDTPVNPLDLLCALLLSSDSFLQQEIALKMALCQFALPLVLPDSENHYHTFLLWAMRGIVRTWWSQPPRGMGSFREDSVVLSRAPAFAFVRMDVSSNSKSQLLNAVLSPGHRQWDCFWHRDLNLGTNAREISDGLVEISWFFPSGREDLDIFPEPVAFLNLRGDIGSHWLQFKLLTEISSAVFILTDNISKKEYKLLYSMKESTTKYYFILSPYRGKRNTNLRFLNKLIPVLKIDHSHVLVKVSSTDSDSFVKRIRAIVGNVLRAPCRRVSVEDMAHAARKLGLKVDEDCEECQKAKDRMERITRKIKDSDAYRRDELRLQGDPWRKAAQVEKEFCQLQWAVDPPEKHRAELRRRLLELRMQQNGHDPSSGVQEFISGISSPSLSEKQYFLRWMEWGLARVAQPRLRQPPETLLTLRPKHGGTTDVGEPLWPEPLGVEHFLREMGQFYEAESCLVEAGRLPAGQRRFAHFPGLASELLLTGLPLELIDGSTLSMPVRWVTGLLKELHVRLERRSRLVVLSTVGVPGTGKSTLLNTMFGLRFATGKSCGPRGAFMQLITVAEGFSQDLGCDHILVIDSGGLIGGALTSAGDRFELEASLATLLMGLSNVTVISLAETKDIPAAILHAFLRLEKTGHMPNYQFVYQNLHDVSVPGPRPRDKRQLLDPPGDLSRAAAQMEKQGDGFRALAGLAFCDPEKQHIWHIPGLWHGAPPMAAVSLAYSEAIFELKRCLLENIRNGLSNQNKNIQQLIELVRRL>sp|O95070|YIF1A_HUMAN Protein YIF1A OS=Homo sapiens OX=9606 GN=YIF1APE=1 SV=2MAYHSGYGAHGSKHRARAAPDPPPLFDDTSGGYSSQPGGYPATGADVAFSVNHLLGDPMANVAMAYGSSIASHGKDMVHKELHRFVSVSKLKYFFAVDTAYVAKKLGLLVFPYTHQNWEVQYSRDAPLPPRQDLNAPDLYIPTMAFITYVLLAGMALGIQKRFSPEVLGLCASTALVWVVMEVLALLLGLYLATVRSDLSTFHLLAYSGYKYVGMILSVLTGLLFGSDGYYVALAWTSSALMYFIVRSLRTAALGPDSMGGPVPRQRLQLYLTLGAAAFQPLIIYWLTFHLVR>sp|Q13426|XRCC4_HUMAN DNA repair protein XRCC4 OS=Homo sapiens OX=9606GN=XRCC4 PE=1 SV=2MERKISRIHLVSEPSITHFLQVSWEKTLESGFVITLTDGHSAWTGTVSESEISQEADDMAMEKGKYVGELRKALLSGAGPADVYTFNFSKESCYFFFEKNLKDVSFRLGSFNLEKVENPAEVIRELICYCLDTIAENQAKNEHLQKENERLLRDWNDVQGRFEKCVSAKEALETDLYKRFILVLNEKKTKIRSLHNKLLNAAQEREKDIKQEGETAICSEMTADRDPVYDESTDEESENQTDLSGLASAAVSKDDSIISSLDVTDIAPSRKRRQRMQRNLGTEPKMAPQENQLQEKENSRPDSSLPETSKKEHISAENMSLETLRNSSPEDLFDEI>sp|Q13426-2|XRCC4_HUMAN Isoform 2 of DNA repair protein XRCC4 OS=Homosapiens OX=9606 GN=XRCC4MERKISRIHLVSEPSITHFLQVSWEKTLESGFVITLTDGHSAWTGTVSESEISQEADDMAMEKGKYVGELRKALLSGAGPADVYTFNFSKESCYFFFEKNLKDVSFRLGSFNLEKVENPAEVIRELICYCLDTIAENQAKNEHLQKENERLLRDWNDVQGRFEKCVSAKEALETDLYKRFILVLNEKKTKIRSLHNKLLNAAQEREKDIKQEGETAICSEMTADRDPVYDESTDEESENQTDLSGLASAAVSKDDSIISSLDVTDIAPSRKRRQRMQRNLGTEPKMAPQENQLQEKEKPDSSLPETSKKEHISAENMSLETLRNSSPEDLFDEI>sp|Q13426-3|XRCC4_HUMAN Isoform 3 of DNA repair protein XRCC4 OS=Homosapiens OX=9606 GN=XRCC4MERKISRIHLVSEPSITHFLQVSWEKTLESGFVITLTDGHSAWTGTVSESEISQEADDMAMEKGKYVGELRKALLSGAGPADVYTFNFSKESCYFFFEKNLKDVSFRLGSFNLEKVENPAEVIRELICYCLDTIAENQAKNEHLQKENERLLRDWNDVQGRFEKCVSAKEALETDLYKRFILVLNEKKTKIRSLHNKLLNAAQEREKDIKQEGETAICSEMTADRDPVYDESTDEESENQTDLSGLASAAVSKDDSIISSLDVTDIAPSRKRRQRMQRNLGTEPKMAPQENQLQEKEKGRKKETSEKEAV>sp|P63127|VPK9_HUMAN Endogenous retrovirus group K member 9 Pro proteinOS=Homo sapiens OX=9606 GN=ERVK-9 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSMEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPLYSPTSQKIMTKRGYIPGKGLGKNEDGIKIPFEAKINQKREGIGYPF>sp|Q5GH73|XKR6_HUMAN XK-related protein 6 OS=Homo sapiens OX=9606GN=XKR6 PE=2 SV=1MAAKSDGGGVGVGFAQLHNLDEAVGSGGEEDGEPGGGGCGGGGDGSEPGESSSMHICHCCNTSSCYWGCRSACLRSLLGRKPRRSAAADGGDQPLQPPAAPGAGRQPPTPSAARPEPPPPQVERPWLDCLWIVLALLVFFGDVGTDLWLALDYYRKGDYVYFGLTLFFVLVPSLLVQSLSFRWFVQDYTGGGLGAVEGLTSRGPPMMGAGYVHGAARGGPGVRVSPTPGAQRLCRLSVWIWQSVIHLLQMGQVWRYIRTMYLGIQSQRRKEHQRRFYWAMMYEYADVNMLRLLETFLESAPQLVLQLYIMLQKNSAETLPCVSSVTSLMSLAWVLASYHKLLRDSRDDKKSMSYRGAIIQVFWRLFTISSRVISFALFASIFQLYFGIFVVVHWCAMAFWIIHGGTDFCMSKWEEILFNMVVGIVYIFCWFNVKEGRTRYRMFAYYTIVLTENAALTFLWYFYRDPETTDSYAVPALCCVFISFVAGIAMMLLYYGVLHPTGPRAKILASSCCAELLWGIPLPPDVEPMAPEIPGYRGTQVTPTRAVTEQQEDLTADTCLPVFQVRPMGPPTPLGRPYLPEGPLIKIDMPRKRYPAWDAHFVDRRLRRTINILQYVTPTAVGIRYRDGPLLYELLQYESSL>sp|Q5GH73-2|XKR6_HUMAN Isoform 2 of XK-related protein 6 OS=Homo sapiensOX=9606 GN=XKR6MMYEYADVNMLRLLETFLESAPQLVLQLYIMLQKNSAETLPCVSSVTSLMSLAWVLASYHKLLRDSRDDKKSMSYRGAIIQVFWRLFTISSRVISFALFASIFQLYFGIFVVVHWCAMAFWIIHGGTDFCMSKWEEILFNMVVGIVYIFCWFNVKEGRTRYRMFAYYTIVLTENAALTFLWYFYRDPETTDSYAVPALCCVFISFVAGIAMMLLYYGVLHPTGPRAKILASSCCAELLWGIPLPPDVEPMAPEIPGYRGTQVTPTRAVTEQQEDLTADTCLPVFQVRPMGPPTPLGRPYLPEGPLIKIDMPRKRYPAWDAHFVDRRLRRTINILQYVTPTAVGIRYRDGPLLYELLQYESSL>sp|Q9Y2I8|WDR37_HUMAN WD repeat-containing protein 37 OS=Homo sapiensOX=9606 GN=WDR37 PE=1 SV=2MPTESASCSTARQTKQKRKSHSLSIRRTNSSEQERTGLPRDMLEGQDSKLPSSVRSTLLELFGQIEREFENLYIENLELRREIDTLNERLAAEGQAIDGAELSKGQLKTKASHSTSQLSQKLKTTYKASTSKIVSSFKTTTSRAACQLVKEYIGHRDGIWDVSVAKTQPVVLGTASADHTALLWSIETGKCLVKYAGHVGSVNSIKFHPSEQLALTASGDQTAHIWRYAVQLPTPQPVADTSISGEDEVECSDKDEPDLDGDVSSDCPTIRVPLTSLKSHQGVVIASDWLVGGKQAVTASWDRTANLYDVETSELVHSLTGHDQELTHCCTHPTQRLVVTSSRDTTFRLWDFRDPSIHSVNVFQGHTDTVTSAVFTVGDNVVSGSDDRTVKVWDLKNMRSPIATIRTDSAINRINVCVGQKIIALPHDNRQVRLFDMSGVRLARLPRSSRQGHRRMVCCSAWSEDHPVCNLFTCGFDRQAIGWNINIPALLQEK>sp|Q9Y2I8-2|WDR37_HUMAN Isoform 2 of WD repeat-containing protein 37OS=Homo sapiens OX=9606 GN=WDR37MPTESASCSTARQTKQKRKSHSLSIRRTNSSEQERTGLPRDMLEGQDSKLPSSVRSTLLELFGQIEREFENLYIENLELRREIDTLNERLAAEGQAIDGAELSKGQLKTKASHSTSQLSQKLKTTYKASTSKIVSSFKTTTSRAACQLVKEYIGHRDGIWDVSVAKTQPVVLGTASADHTALLWSIETGKCLVKYAGHVGSVNSIKFHPSEQLALTASGDQTAHIWRYAVQLPTPQPVADTSQISGEDEVECSDKDEPDLDGDVSSDCPTIRVPLTSLKSHQGVVIASDWLVGGKQAVTASWDRTANLYDVETSELVHSLTGHDQELTHCCTHPTQRLVVTSSRDTTFRLWDFRDPSIHSVNVFQGHTDTVTSAVFTVGDNVVSGSDDRTVKVWDLKNMRSPIATIRTDSAINRINVCVGQKIIALPHDNRQVRLFDMSGVRLARLPRSSRQGHRRMVCCSAWSEDHPVCNLFTCGFDRQAIGWNINIPALLQEK>sp|Q9Y2I8-3|WDR37_HUMAN Isoform 3 of WD repeat-containing protein 37OS=Homo sapiens OX=9606 GN=WDR37MPTESASCSTARQTKQKRKSHSLSIRRTNSSEQERTGLPRDMLEGQDSKLPSSVRSTLLELFGQIEREFENLYIENLELRREIDTLNERLAAEGQAIDGAELSKGQLKTKASHSTSQLSQKLKTTYKASTSKIVSSFKTTTSRAACQLVKEYIGHRDGIWDVSVAKTQPVVLGTASADHTALLWSIETGKCLVKYAGHVGSVNSIKFHPSEQLALTASGDQTAHIWRYAVQLPTPQPVADTSVSTFPYLRMCRMLMSANLRIHL>sp|Q9NZC7|WWOX_HUMAN WW domain-containing oxidoreductase OS=Homo sapiensOX=9606 GN=WWOX PE=1 SV=1MAALRYAGLDDTDSEDELPPGWEERTTKDGWVYYANHTEEKTQWEHPKTGKRKRVAGDLPYGWEQETDENGQVFFVDHINKRTTYLDPRLAFTVDDNPTKPTTRQRYDGSTTAMEILQGRDFTGKVVVVTGANSGIGFETAKSFALHGAHVILACRNMARASEAVSRILEEWHKAKVEAMTLDLALLRSVQHFAEAFKAKNVPLHVLVCNAATFALPWSLTKDGLETTFQVNHLGHFYLVQLLQDVLCRSAPARVIVVSSESHRFTDINDSLGKLDFSRLSPTKNDYWAMLAYNRSKLCNILFSNELHRRLSPRGVTSNAVHPGNMMYSNIHRSWWVYTLLFTLARPFTKSMQQGAATTVYCAAVPELEGLGGMYFNNCCRCMPSPEAQSEETARTLWALSERLIQERLGSQSG>sp|Q9NZC7-2|WWOX_HUMAN Isoform 2 of WW domain-containing oxidoreductaseOS=Homo sapiens OX=9606 GN=WWOXMAALRYAGLDDTDSEDELPPGWEERTTKDGWVYYANHTEEKTQWEHPKTGKRKRVAGDLPYGWEQETDENGQVFFVDHINKRTTYLDPRLAFTVDDNPTKPTTRQRYDGSTTAMEILQGRDFTGKVVVVTGANSGIGFETAKSFALHGAHVILACRNMARASEAVSRILEEWHKAKVEAMTLDLALLRSVQHFAEAFKAKNVPLHVLVCNAATFALPWSLTKDGLETTFQVNHLGHFYLVQLLQDVLCRSAPARVIVVSSESHRFTDINDSLGKLDFSRLSPTKNDYWAMLAYNRSKLCNILFSNELHRRLSPRGVTSNAVHPGNMMYSNIHRSWWVYTLLFTLARPFTKSMVSDCLVEGGHF>sp|Q9NZC7-3|WWOX_HUMAN Isoform 3 of WW domain-containing oxidoreductaseOS=Homo sapiens OX=9606 GN=WWOXMAALRYAGLDDTDSEDELPPGWEERTTKDGWVYYANHTEEKTQWEHPKTGKRKRVAGDLPYGWEQETDENGQVFFVDHINKRTTYLDPRLAFTVDDNPTKPTTRQRYDGSTTAMEILQGRDFTGKVVVVTGANSGIGFETAKSFALHGAHVILACRNMARASEAVSRILEEWKTKYHPPPEKCRIKIFH>sp|Q9NZC7-4|WWOX_HUMAN Isoform 4 of WW domain-containing oxidoreductaseOS=Homo sapiens OX=9606 GN=WWOXMAALRYAGLDDTDSEDELPPGWEERTTKDGWVYYAK>sp|Q9NZC7-5|WWOX_HUMAN Isoform 5 of WW domain-containing oxidoreductaseOS=Homo sapiens OX=9606 GN=WWOXMAALRYAGLDDTDSEDELPPGWEERTTKDGWVYYANHTEEKTQWEHPKTGKRKRVAGDLPYGWEQETDENGQVFFVDHINKRTTYLDPRLAFTVDDNPTKPTTRQRYDGSTTAMEILQGRDFTGKVVVVTGANSGIGFETAKSFALHGAHVILACRNMARASEAVSRILEEWQQGAATTVYCAAVPELEGLGGMYFNNCCRCMPSPEAQSEETARTLWALSERLIQERLGSQSG>sp|Q9NZC7-6|WWOX_HUMAN Isoform 6 of WW domain-containing oxidoreductaseOS=Homo sapiens OX=9606 GN=WWOXMAALRYAGLDDTDSEDELPPGWEERTTKDGWVYYANHTEEKTQWEHPKTGKRKRVAGDLPYGWEQETDENGQVFFVDHINKRTTYLDPRLAFTVDDNPTKPTTRQRYDGSTTAMEILQGRDFTGKVVVVTGANSGIATGSCHHRVLCCCPRTGGSGRDVLQQLLPLHALTRSSERRDGPDPVGAQREADPRTAWQPVRLSGAQSGWAHTPALCVSPHASARAGPLPNVPPTQIRKSKGNKSSHNRVKNLKYQWEAGNSWGKVSLFWGWARHRSLCFLVVACLKVKTCLVCRFRISLEKHQQFSFFYCYRIA>sp|Q9NZC7-7|WWOX_HUMAN Isoform 7 of WW domain-containing oxidoreductaseOS=Homo sapiens OX=9606 GN=WWOXMAALRYAGLDDTDSEDELPPGWEERTTKDGWVYYANHTEEKTQWEHPKTGKRKRVAGDLPYGWEQETDENGQVFFVDHINKRTTYLDPRLAFTVDDNPTKPTTRQRYDGSTTAMEILQGRDFTGKVVVVTGANSGIGKASCHVGRTLKHTRVEELSLLPTAINRELPPPCTVLLSQNWRVWEGCTSTTAAAACPHQKLRAKRRPGPCGRSARG>sp|Q9UPT8|ZC3H4_HUMAN Zinc finger CCCH domain-containing protein 4OS=Homo sapiens OX=9606 GN=ZC3H4 PE=1 SV=3MEAAPGTPPPPPSESPPPPSPPPPSTPSPPPCSPDARPATPHLLHHRLPLPDDREDGELEEGELEDDGAEETQDTSGGPERSRKEKGEKHHSDSDEEKSHRRLKRKRKKEREKEKRRSKKRRKSKHKRHASSSDDFSDFSDDSDFSPSEKGHRKYREYSPPYAPSHQQYPPSHATPLPKKAYSKMDSKSYGMYEDYENEQYGEYEGDEEEDMGKEDYDDFTKELNQYRRAKEGSSRGRGSRGRGRGYRGRGSRGGSRGRGMGRGSRGRGRGSMGGDHPEDEEDFYEEEMDYGESEEPMGDDDYDEYSKELNQYRRSKDSRGRGLSRGRGRGSRGRGKGMGRGRGRGGSRGGMNKGGMNDDEDFYDEDMGDGGGGSYRSRDHDKPHQQSDKKGKVICKYFVEGRCTWGDHCNFSHDIELPKKRELCKFYITGFCARAENCPYMHGDFPCKLYHTTGNCINGDDCMFSHDPLTEETRELLDKMLADDAEAGAEDEKEVEELKKQGINPLPKPPPGVGLLPTPPRPPGPQAPTSPNGRPMQGGPPPPPPPPPPPPGPPQMPMPVHEPLSPQQLQQQDMYNKKIPSLFEIVVRPTGQLAEKLGVRFPGPGGPPGPMGPGPNMGPPGPMGGPMHPDMHPDMHPDMHPDMHADMHADMPMGPGMNPGPPMGPGGPPMMPYGPGDSPHSGMMPPIPPAQNFYENFYQQQEGMEMEPGLLGDAEDYGHYEELPGEPGEHLFPEHPLEPDSFSEGGPPGRPKPGAGVPDFLPSAQRALYLRIQQKQQEEEERARRLAESSKQDRENEEGDTGNWYSSDEDEGGSSVTSILKTLRQQTSSRPPASVGELSSSGLGDPRLQKGHPTGSRLADPRLSRDPRLTRHVEASGGSGPGDSGPSDPRLARALPTSKPEGSLHSSPVGPSSSKGSGPPPTEEEEGERALREKAVNIPLDPLPGHPLRDPRSQLQQFSHIKKDVTLSKPSFARTVLWNPEDLIPLPIPKQDAVPPVPAALQSMPTLDPRLHRAATAGPPNARQRPGASTDSSTQGANLPDFELLSRILKTVNATGSSAAPGSSDKPSDPRVRKAPTDPRLQKPTDSTASSRAAKPGPAEAPSPTASPSGDASPPATAPYDPRVLAAGGLGQGGGGGQSSVLSGISLYDPRTPNAGGKATEPAADTGAQPKGAEGNGKSSASKAKEPPFVRKSALEQPETGKAGADGGTPTDRYNSYNRPRPKAAAAPAATTATPPPEGAPPQPGVHNLPVPTLFGTVKQTPKTGSGSPFAGNSPAREGEQDAASLKDVFKGFDPTASPFCQ>sp|Q9UN37|VPS4A_HUMAN Vacuolar protein sorting-associated protein 4AOS=Homo sapiens OX=9606 GN=VPS4A PE=1 SV=1MTTSTLQKAIDLVTKATEEDKAKNYEEALRLYQHAVEYFLHAIKYEAHSDKAKESIRAKCVQYLDRAEKLKDYLRSKEKHGKKPVKENQSEGKGSDSDSEGDNPEKKKLQEQLMGAVVMEKPNIRWNDVAGLEGAKEALKEAVILPIKFPHLFTGKRTPWRGILLFGPPGTGKSYLAKAVATEANNSTFFSVSSSDLMSKWLGESEKLVKNLFELARQHKPSIIFIDEVDSLCGSRNENESEAARRIKTEFLVQMQGVGNNNDGTLVLGATNIPWVLDSAIRRRFEKRIYIPLPEEAARAQMFRLHLGSTPHNLTDANIHELARKTEGYSGADISIIVRDSLMQPVRKVQSATHFKKVCGPSRTNPSMMIDDLLTPCSPGDPGAMEMTWMDVPGDKLLEPVVCMSDMLRSLATTRPTVNADDLLKVKKFSEDFGQES>sp|P57081|WDR4_HUMAN tRNA (guanine-N(7)-)-methyltransferase non-catalytic subunit WDR4 OS=Homo sapiens OX=9606 GN=WDR4 PE=1 SV=2MAGSVGLALCGQTLVVRGGSRFLATSIASSDDDSLFIYDCSAAEKKSQENKGEDAPLDQGSGAILASTFSKSGSYFALTDDSKRLILFRTKPWQCLSVRTVARRCTALTFIASEEKVLVADKSGDVYSFSVLEPHGCGRLELGHLSMLLDVAVSPDDRFILTADRDEKIRVSWAAAPHSIESFCLGHTEFVSRISVVPTQPGLLLSSSGDGTLRLWEYRSGRQLHCCHLASLQELVDPQAPQKFAASRIAFWCQENCVALLCDGTPVVYIFQLDARRQQLVYRQQLAFQHQVWDVAFEETQGLWVLQDCQEAPLVLYRPVGDQWQSVPESTVLKKVSGVLRGNWAMLEGSAGADASFSSLYKATFDNVTSYLKKKEERLQQQLEKKQRRRSPPPGPDGHAKKMRPGEATLSC>sp|P57081-2|WDR4_HUMAN Isoform 2 of tRNA (guanine-N(7)-)-methyltransferase non-catalytic subunit WDR4 OS=Homo sapiens OX=9606GN=WDR4MAGSVGLALCGQTLVVRGGSRFLATSIASSDDDSLFIYDCSAAEKKSQENKGEDAPLDQGSGAILASTFSKSGSYFALTDDSKRLILFRTKPWQCLSVRTVARRCTALTFIASEEKVLVADKSGDVYSFSVLEPHGCGRLELGHLSMLLDVAVSPDDRFILTADRDEKIRVSWAAAPHSIESFCLGHTEFVSRISVVPTQPGLLLSSSGDGTLRLWEYRSGRQLHCCHLASLQELVDPQAPQFAASRIAFWCQENCVALLCDGTPVVYIFQLDARRQQLVYRQQLAFQHQVWDVAFEETQGLWVLQDCQEAPLVLYRPVGDQWQSVPESTVLKKVSGVLRGNWAMLEGSAGADASFSSLYKATFDNVTSYLKKKEERLQQQLEKKQRRRSPPPGPDGHAKKMRPGEATLSC>sp|P57081-3|WDR4_HUMAN Isoform 3 of tRNA (guanine-N(7)-)-methyltransferase non-catalytic subunit WDR4 OS=Homo sapiens OX=9606GN=WDR4MLLDVAVSPDDRFILTADRDEKIRVSWAAAPHSIESFCLGHTEFVSRISVVPTQPGLLLSSSGDGTLRLWEYRSGRQLHCCHLASLQELVDPQAPQKFAASRIAFWCQENCVALLCDGTPVVYIFQLDARRQQLVYRQQLAFQHQVWDVAFEETQGLWVLQDCQEAPLVLYRPVGDQWQSVPESTVLKKVSGVLRGNWAMLEGSAGADASFSSLYKATFDNVTSYLKKKEERLQQQLEKKQRRRSPPPGPDGHAKKMRPGEATLSC>sp|Q6AWC2|WWC2_HUMAN Protein WWC2 OS=Homo sapiens OX=9606 GN=WWC2 PE=1SV=2MPRRAGSGQLPLPRGWEEARDYDGKVFYIDHNTRRTSWIDPRDRLTKPLSFADCVGDELPWGWEAGFDPQIGVYYIDHINKTTQIEDPRKQWRGEQEKMLKDYLSVAQDALRTQKELYHVKEQRLALALDEYVRLNDAYKEKSSSHTSLFSGSSSSTKYDPDILKAEISTTRLRVKKLKRELSQMKQELLYKEQGFETLQQIDKKMSGGQSGYELSEAKAILTELKSIRKAISSGEKEKQDLMQSLAKLQERFHLDQNIGRSEPDLRCSPVNSHLCLSRQTLDAGSQTSISGDIGVRSRSNLAEKVRLSLQYEEAKRSMANLKIELSKLDSEAWPGALDIEKEKLMLINEKEELLKELQFVTPQKRTQDELERLEAERQRLEEELLSVRGTPSRALAERLRLEERRKELLQKLEETTKLTTYLHSQLKSLSASTLSMSSGSSLGSLASSRGSLNTSSRGSLNSLSSTELYYSSQSDQIDVDYQYKLDFLLQEKSGYIPSGPITTIHENEVVKSPSQPGQSGLCGVAAAATGHTPPLAEAPKSVASLSSRSSLSSLSPPGSPLVLEGTFPMSSSHDASLHQFTADFEDCELSSHFADISLIENQILLDSDSGGASQSLSEDKDLNECAREPLYEGTADVEKSLPKRRVIHLLGEKTTCVSAAVSDESVAGDSGVYEAFVKQPSEMEDVTYSEEDVAIVETAQVQIGLRYNAKSSSFMVIIAQLRNLHAFLIPHTSKVYFRVAVLPSSTDVSCLFRTKVHPPTESILFNDVFRVAISQTALQQKTLRVDLCSVSKHRREECLAGTQISLADLPFSSEVFTLWYNLLPSKQMPCKKNEENEDSVFQPNQPLVDSIDLDAVSALLARTSAELLAVEQELAQEEEEESGQEEPRGPDGDWLTMLREASDEIVAEKEAEVKLPEDSSCTEDLSSCTSVPEMNEDGNRKESNCAKDLRSQPPTRIPTLVDKETNTDEAANDNMAVRPKERSSLSSRQHPFVRSSVIVRSQTFSPGERNQYICRLNRSDSDSSTLAKKSLFVRNSTERRSLRVKRTVCQSVLRRTTQECPVRTSLDLELDLQASLTRQSRLNDELQALRDLRQKLEELKAQGETDLPPGVLEDERFQRLLKQAEKQAEQSKEEQKQGLNAEKLMRQVSKDVCRLREQSQKVPRQVQSFREKIAYFTRAKISIPSLPADDV>sp|Q6AWC2-2|WWC2_HUMAN Isoform 2 of Protein WWC2 OS=Homo sapiens OX=9606GN=WWC2MSGGQSGYELSEAKAILTELKSIRKAISSGEKEKQDLMQSLAKLQERFHLDQNIGRSEPDLRCSPVNSHLCLSRQTLDAGSQTSISGDIGVRSRSNLAEKVRLSLQYEEAKRSMANLKIELSKLDSEAWPGALDIEKEKLMLINEKEELLKELQFVTPQKRTQDELERLEAERQRLEEELLSVRGTPSRALAERLRLEERRKELLQKLEETTKLTTYLHSQLKSLSASTLSMSSGSSLGSLASSRGSLNTSSRGSLNSLSSTELYYSSQSDQIDVDYQYKLDFLLQEKSGYIPSGPITTIHENEVVKSPSQPGQSGLCGVAAAATGHTPPLAEAPKSVASLSSRSSLSSLSPPGSPLVLEGTFPMSSSHDASLHQFTADFEDCELSSHFADISLIENQILLDSDSGGASQSLSEDKDLNECAREPLYEGTADVEKSLPKRRVIHLLGEKTTCVSAAVSDESVAGDSGVYEAFVKQPSEMEDVTYSEEDVAIVETAQVQIGLRYNAKSSSFMVIIAQLRNLHAFLIPHTSKVYFRVAVLPSSTDVSCLFRTKVHPPTESILFNDVFRVAISQTALQQKTLRVDLCSVSKHRREECLAGTQISLADLPFSSEVFTLWYNLLPSKQMPCKKNEENEDSVFQPNQPLVDSIDLDAVSALLARTSAELLAVEQELAQEEEEESGQEEPRGPDGDWLTMLREASDEIVAEKEAEVKLPEDSSCTEDLSSCTSVPEMNEDGNRKESNCAKDLRSQPPTRIPTLVDKETNTDEAANDNMAVRPKERSSLSSRQHPFVRSSVIVRSQTFSPGERNQYICRLNRSDSDSSTLAKKSLFVRNSTERRSLRVKRTVCQSVLRRTTQECPVRTSLDLELDLQASLTRQSRLNDELQALRDLRQKLEELKAQGETDLPPGVLEDERFQRLLKQAEKQAEQSKEEQKQGLNAEKLMRQVSKDVCRLREQSQKVPRQVQSFREKIAYFTRAKISIPSLPADDV>sp|Q6AWC2-3|WWC2_HUMAN Isoform 3 of Protein WWC2 OS=Homo sapiens OX=9606GN=WWC2MANLKIELSKLDSEAWPGALDIEKEKLMLINEKEELLKELQFVTPQKRTQDELERLEAERQRLEEELLSVRGTPSRALAERLRLEERRKELLQKLEETTKLTTYLHSQLKSLSASTLSMSSGSSLGSLASSRGSLNTSSRGSLNSLSSTELYYSSQSDQIDVDYQYKLDFLLQEKSGYIPSGPITTIHENEVVKSPSQPGQSGLCGVAAAATGHTPPLAEAPKSVASLSSRSSLSSLSPPGSPLVLEGTFPMSSSHDASLHQFTADFEDCELSSHFADISLIENQILLDSDSGGASQSLSEDKDLNECAREPLYEGTADVEKSLPKRRVIHLLGEKTTCVSAAVSDESVAGDSGVYEAFVKQPSEMEDVTYSEEDVAIVETAQVQIGLRYNAKSSSFMVIIAQLRNLHAFLIPHTSKVYFRVAVLPSSTDVSCLFRTKVHPPTESILFNDVFRVAISQTALQQKTLRVDLCSVSKHRREECLAGTQISLADLPFSSEVFTLWYNLLPSKQMPCKKNEENEDSVFQPNQPLVDSIDLDAVSALLARTSAELLAVEQELAQEEEEESGQEEPRGPDGDWLTMLREASDEIVAEKEAEVKLPEDSSCTEDLSSCTSVPEMNEDGNRKESNCAKDLRSQPPTRIPTLVDKETNTDEAANDNMAVRPKERSSLSSRQHPFVRSSVIVRSQTFSPGERNQYICRLNRSDSDSSTLAKKSLFVRNSTERRSLRVKRTVCQSVLRRTTQECPVRTSLDLELDLQASLTRQSRLNDELQALRDLRQKLEELKAQGETDLPPGVLEDERFQRLLKQAEKQAEQSKEEQKQGLNAEKLMRQVSKDVCRLREQSQKVPRQVQSFREKIAYFTRAKISIPSLPADDV>sp|Q6AWC2-4|WWC2_HUMAN Isoform 4 of Protein WWC2 OS=Homo sapiens OX=9606GN=WWC2MPRRAGSGQLPLPRGWEEARDYDGKVFYIDHNTRRTSWIDPRDRLTKPLSFADCVGDELPWGWEAGFDPQIGVYYIDHINKTTQIEDPRKQWRGEQEKMLKDYLSVAQDALRTQKELYHVKEQRLALALDEYVRLNDAYKEKSSSHTSLFSGSSSSTKYDPDILKAEISTTRLRVKKLKRELSQMKQELLYKEQGFETLQQIDKKMSGGQSGYELSEAKAILTELKSIRKAISSGEKEKQDLMQSLAKLQERFHLDQNIGRSEPDLRCSPVNSHLCLSRQTLDAGSQTSISGDIGVRSRSNLAEKVRLSLQYEEAKRSMANLKIELSKLDSEAWPGALDIEKEKLMLINEKEELLKELQFVTPQKRTQDELERLEAERQRLEEELLSVRGTPSRALAERLRLEERRKELLQKLEETTKLTTYLHSQLKSLSASTLSMSSGSSLGSLASSRGSLNTSSRGSLNSLSSTELYYSSQSDQIDVDYQYKLDFLLQEKSGYIPSGPITTIHENEVVKSPSQPGQSGLCGVAAAATGHTPPLAEAPKSVASLSSRSSLSSLSPPGSPLVLEGTFPMSSSHDASLHQFTADFEDYVEKSLPKRRVIHLLGEKTTCVSAAVSDESVAGDSGVYEAFVKQPSEMEDVTYSEEDVAIVETAQVQIGLRYNAKSSSFMVIIAQLRNLHAFLIPHTSKVYFRVAVLPSSTDVSCLFRTKVHPPTESILFNDVFRVAISQTALQQKTLRVDLCSVSKHRREECLAGTQISLADLPFSSEVFTLWYNLLPSKQMPCKKNEENEDSVFQPNQPLVDSIDLDAVSALLARTSAELLAVEQELAQEEEEESGQEEPRGPDGDWLTMLREASDEIVAEKEAEVKLPEDSSCTEDLSSCTSVPEMNEDGNRKESNCAKDLRSQPPTRIPTLVDKETNTDEAANDNMAVRPKERSSLSSRQHPFVRSSVIVRSQTFSPGERNQYICRLNRSDSDSSTLAKKSLFVRNSTERRSLRVKRTVCQSVLRRTTQECPVRTSLDLELDLQASLTRQSRLNDELQALRDLRQKLEELKAQGETDLPPGVLEDERFQRLLKQAEKQAEQSKEEQKQGLNAEKLMRQVSKDVCRLREQSQKVPRQVQSFREKIAYFTRAKISIPSLPADDV>sp|Q6AWC2-5|WWC2_HUMAN Isoform 5 of Protein WWC2 OS=Homo sapiens OX=9606GN=WWC2MLKDYLSVAQDALRTQKELYHVKEQRLALALDEYVRLNDAYKEKSSSHTSLFSGSSSSTKYDPDILKAEISTTRLRVKKLKRELSQMKQELLYKEQGFETLQQIDKKMSGGQSGYELSEAKAILTELKSIRKAISSGEKEKQDLMQSLAKLQERFHLDQNIGRSEPDLRCSPVNSHLCLSRQTLDAGSQTSISGDIGVRSRSNLAEKVRLSLQYEEAKRSMANLKIELSKLDSEAWPGALDIEKEKLMLINEKEELLKELQFVTPQKRTQDELERLEAERQRLEEELLSVRGTPSRALAERLRLEERRKELLQKLEETTKLTTYLHSQLKSLSASTLSMSSGSSLGSLASSRGSLNTSSRGSLNSLSSTELYYSSQSDQIDVDYQYKLDFLLQEKSGYIPSGPITTIHENEVVKSPSQPGQSGLCGVAAAATGHTPPLAEAPKSVASLSSRSSLSSLSPPGSPLVLEGTFPMSSSHDASLHQFTADFEDCELSSHFADISLIENQILLDSDSGGASQSLSEDKDLNECAREPLYEGTADVEKSLPKRRVIHLLGEKTTCVSAAVSDESVAGDSGVYEAFVKQPSEMEDVTYSEEDVAIVETAQVQIGLRYNAKSSSFMVIIAQLRNLHAFLIPHTSKVYFRVAVLPSSTDVSCLFRTKVHPPTESILFNDVFRVAISQTALQQKTLRKNFTFVTAITHGVCLPLPVPMPSFA>sp|Q6AWC2-6|WWC2_HUMAN Isoform 6 of Protein WWC2 OS=Homo sapiens OX=9606GN=WWC2MPRRAGSGQLPLPRGWEEARDYDGKVFYIDHNTRRTSWIDPRDRLTKPLSFADCVGDELPWGWEAGFDPQIGVYYIDHINKTTQIEDPRKQWRGEQEKMLKDYLSVAQDALRTQKELYHVKEQRLALALDEYVRLNDAYKEKSSSHTSLFSGSSSSTKYDPDILKAEISTTRLRVKKLKRELSQMKQELLYKEQGFETLQQIDKKMSGGQSGYELSEAKAILTELKSIRKAISSGEKEKQDLMQSLAKLQERFHLDQNIGRSEPDLRCSPVNSHLCLSRQTLDAGSQTSISGDIGVRSRSNLAEKVRLSLQYEEAKRSMANLKIELSKLDSEAWPGALDIEKEKLMLINEKEELLKELQFVTPQKRTQDELERLEAERQRLEEELLSVRGTPSRALAERLRLEERRKELLQKLEETTKLTTYLHSQLKSLSASTLSMSSGSSLGSLASSRGSLNTSSRGSLNSLSSTELYYSSQSDQIDVDYQYKLDFLLQEKSGYIPSGPITTIHENEVVKSPSQPGQSGLCGVAAAATGHTPPLAEAPKSVASLSSRSSLSSLSPPGSPLVLEGTFPMSSSHDASLHQFTADFEDCELSSHFADISLIENQILLDSDSGGASQSLSEDKDLNECAREPLYEGTADVEKSLPKRRVIHLLGEKTTCVSAAVSDESVAGDSGVYEAFVKQPSEMEDVTYSEEDVAIVETAQVQIGLRYNAKSSSFMVIIAQLRNLHAFLIPHTSKVYFRVAVLPSSTDVSCLFRTKVHPPTESILFNDVFRVAISQTALQQKTLRVDLCSVSKHRREECLAGTQISLADLPFSSEVFTLWYNLLPSKQMPCKKNEENEDSVFQPNQPLVDSIDLDAVSALLARTSAELLAVEQELAQEEEEESGQEEPRGPDGDWLNTYFLCCWELKDDVFTRLTVKPLLTMLREASDEIVAEKEAEVKLPEDSSCTEDLSSCTSVPEMNEDGNRKESNCAKDLRSQPPTRIPTLVDKETNTDEAANDNMAVRPKERSSLSSRQHPFVRSSVIVRSQTFSPGERNQYICRLNRSDSDSSTLAKKSLFVRNSTERRSLRVKRTVCQSVLRRTTQECPVRTSLDLELDLQASLTRQSRLNDELQALRDLRQKLEELKAQGETDLPPGVLEDERFQRLLKQAEKQAEQSKEEQKQGLNAEKLMRQVSKDVCRLREQSQKVPRQVQSFREKIAYFTRAKISIPSLPADDV>sp|Q6AWC2-7|WWC2_HUMAN Isoform 7 of Protein WWC2 OS=Homo sapiens OX=9606GN=WWC2MPRLRVHGACLPTKSVLFLFYHRLTMLREASDEIVAEKEAEVKLPEDSSCTEDLSSCTSVPEMNEDGNRKESNCAKDLRSQPPTRIPTLVDKETNTDEAANDNMAVRPKERSSLSSRQHPFVRSSVIVRSQTFSPGERNQYICRLNRSDSDSSTLAKKSLFVRNSTERRSLRVKRTVCQSVLRRTTQECPVRTSLDLELDLQASLTRQSRLNDELQALRDLRQKLEELKAQGETDLPPGVLEDERFQRLLKQAEKQAEQSKEEQKQGLNAEKLMRQVSKDVCRLREQSQKVPRQVQSFREKIAYFTRAKISIPSLPADDV>sp|Q8N5P1|ZC3H8_HUMAN Zinc finger CCCH domain-containing protein 8OS=Homo sapiens OX=9606 GN=ZC3H8 PE=1 SV=2MDFENLFSKPPNPALGKTATDSDERIDDEIDTEVEETQEEKIKLECEQIPKKFRHSAISPKSSLHRKSRSKDYDVYSDNDICSQESEDNFAKELQQYIQAREMANAAQPEESTKKEGVKDTPQAAKQKNKNLKAGHKNGKQKKMKRKWPGPGNKGSNALLRNSGSQEEDGKPKEKQQHLSQAFINQHTVERKGKQICKYFLERKCIKGDQCKFDHDAEIEKKKEMCKFYVQGYCTRGENCLYLHNEYPCKFYHTGTKCYQGEYCKFSHAPLTPETQELLAKVLDTEKKSCK>sp|Q96EF9|ZHX1R_HUMAN Zinc fingers and homeoboxes protein 1, isoform 2OS=Homo sapiens OX=9606 GN=ZHX1-C8orf76 PE=1 SV=1MLRKLWQWFYEETESSDDVEVLTLKKFKGDLAYRRQEYQKALQEYSSISEKLSSTNFAMKRDVQEGQARCLAHLGRHMEALEIAANLENKATNTDHLTTVLYLQLAICSSLQNLEKTIFCLQKLISLHPFNPWNWGKLAEAYLNLGPALSAALASSQKQHSFTSSDKTIKSFFPHSGKDCLLCFPETLPESSLFSVEANSSNSQKNEKALTNIQNCMAEKRETVLIETQLKACASFIRTRLLLQFTQPQQTSFALERNLRTQQEIEDKMKGFSFKEDTLLLIAEVSVSLGFM>sp|O14972|VP26C_HUMAN Vacuolar protein sorting-associated protein 26COS=Homo sapiens OX=9606 GN=VPS26C PE=1 SV=1MGTALDIKIKRANKVYHAGEVLSGVVVISSKDSVQHQGVSLTMEGTVNLQLSAKSVGVFEAFYNSVKPIQIINSTIEMVKPGKFPSGKTEIPFEFPLHLKGNKVLYETYHGVFVNIQYTLRCDMKRSLLAKDLTKTCEFIVHSAPQKGKFTPSPVDFTITPETLQNVKERALLPKFLLRGHLNSTNCVITQPLTGELVVESSEAAIRSVELQLVRVETCGCAEGYARDATEIQNIQIADGDVCRGLSVPIYMVFPRLFTCPTLETTNFKVEFEVNIVVLLHPDHLITENFPLKLCRI>sp|O14972-2|VP26C_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 26C OS=Homo sapiens OX=9606 GN=VPS26CMGTALDIKIKRANKVYHAGEVLSGVVVISSKDSVQHQGVSLTMEGTVNLQLSAKSVGVFEAFYNSVKPIQIINSTIEMVKPGKFPSGKTEIPFEFPLHLKGNKVLYETYHGVFVNIQPQKGKFTPSPVDFTITPETLQNVKERALLPKFLLRGHLNSTNCVITQPLTGELVVESSEAAIRSVELQLVRVETCGCAEGYARDATEIQNIQIADGDVCRGLSVPIYMVFPRLFTCPTLETTNFKVEFEVNIVVLLHPDHLITENFPLKLCRI>sp|Q9UKY1|ZHX1_HUMAN Zinc fingers and homeoboxes protein 1 OS=Homosapiens OX=9606 GN=ZHX1 PE=1 SV=1MASRRKSTTPCMVLASEQDPDLELISDLDEGPPVLTPVENTRAESISSDEEVHESVDSDNQQNKKVEGGYECKYCTFQTPDLNMFTFHVDSEHPNVVLNSSYVCVECNFLTKRYDALSEHNLKYHPGEENFKLTMVKRNNQTIFEQTINDLTFDGSFVKEENAEQAESTEVSSSGISISKTPIMKMMKNKVENKRIAVHHNSVEDVPEEKENEIKPDREEIVENPSSSASESNTSTSIVNRIHPSTASTVVTPAAVLPGLAQVITAVSAQQNSNLIPKVLIPVNSIPTYNAALDNNPLLLNTYNKFPYPTMSEITVLSAQAKYTEEQIKIWFSAQRLKHGVSWTPEEVEEARRKQFNGTVHTVPQTITVIPTHISTGSNGLPSILQTCQIVGQPGLVLTQVAGTNTLPVTAPIALTVAGVPSQNNIQKSQVPAAQPTAETKPATAAVPTSQSVKHETALVNPDSFGIRAKKTKEQLAELKVSYLKNQFPHDSEIIRLMKITGLTKGEIKKWFSDTRYNQRNSKSNQCLHLNNDSSTTIIIDSSDETTESPTVGTAQPKQSWNPFPDFTPQKFKEKTAEQLRVLQASFLNSSVLTDEELNRLRAQTKLTRREIDAWFTEKKKSKALKEEKMEIDESNAGSSKEEAGETSPADESGAPKSGSTGKICKKTPEQLHMLKSAFVRTQWPSPEEYDKLAKESGLARTDIVSWFGDTRYAWKNGNLKWYYYYQSANSSSMNGLSSLRKRGRGRPKGRGRGRPRGRPRGSKRINNWDRGPSLIKFKTGTAILKDYYLKHKFLNEQDLDELVNKSHMGYEQVREWFAERQRRSELGIELFEENEEEDEVIDDQEEDEEETDDSDTWEPPRHVKRKLSKSDD>sp|Q9Y279|VSIG4_HUMAN V-set and immunoglobulin domain-containing protein4 OS=Homo sapiens OX=9606 GN=VSIG4 PE=1 SV=1MGILLGLLLLGHLTVDTYGRPILEVPESVTGPWKGDVNLPCTYDPLQGYTQVLVKWLVQRGSDPVTIFLRDSSGDHIQQAKYQGRLHVSHKVPGDVSLQLSTLEMDDRSHYTCEVTWQTPDGNQVVRDKITELRVQKLSVSKPTVTTGSGYGFTVPQGMRISLQCQARGSPPISYIWYKQQTNNQEPIKVATLSTLLFKPAVIADSGSYFCTAKGQVGSEQHSDIVKFVVKDSSKLLKTKTEAPTTMTYPLKATSTVKQSWDWTTDMDGYLGETSAGPGKSLPVFAIILIISLCCMVVFTMAYIMLCRKTSQQEHVYEAARAHAREANDSGETMRVAIFASGCSSDEPTSQNLGNNYSDEPCIGQEYQIIAQINGNYARLLDTVPLDYEFLATEGKSVC>sp|Q9Y279-2|VSIG4_HUMAN Isoform 2 of V-set and immunoglobulin domain-containing protein 4 OS=Homo sapiens OX=9606 GN=VSIG4MGILLGLLLLGHLTVDTYGRPILEVPESVTGPWKGDVNLPCTYDPLQGYTQVLVKWLVQRGSDPVTIFLRDSSGDHIQQAKYQGRLHVSHKVPGDVSLQLSTLEMDDRSHYTCEVTWQTPDGNQVVRDKITELRVQKLSVSKPTVTTGSGYGFTVPQGMRISLQCQARGSPPISYIWYKQQTNNQEPIKVATLSTLLFKPAVIADSGSYFCTAKGQVGSEQHSDIVKFVVKDSSKLLKTKTEAPTTMTYPLKATSTVKQSWDWTTDMDGYLGETSAGPGKSLPVFAIILIISLCCMVVFTMAYIMLCRKTSQQEHVYEAAR>sp|Q9Y279-3|VSIG4_HUMAN Isoform 3 of V-set and immunoglobulin domain-containing protein 4 OS=Homo sapiens OX=9606 GN=VSIG4MGILLGLLLLGHLTVDTYGRPILEVPESVTGPWKGDVNLPCTYDPLQGYTQVLVKWLVQRGSDPVTIFLRDSSGDHIQQAKYQGRLHVSHKVPGDVSLQLSTLEMDDRSHYTCEVTWQTPDGNQVVRDKITELRVQKHSSKLLKTKTEAPTTMTYPLKATSTVKQSWDWTTDMDGYLGETSAGPGKSLPVFAIILIISLCCMVVFTMAYIMLCRKTSQQEHVYEAARAHAREANDSGETMRVAIFASGCSSDEPTSQNLGNNYSDEPCIGQEYQIIAQINGNYARLLDTVPLDYEFLATEGKSVC>sp|Q6PJI9|WDR59_HUMAN GATOR complex protein WDR59 OS=Homo sapiensOX=9606 GN=WDR59 PE=1 SV=2MAARWSSENVVVEFRDSQATAMSVDCLGQHAVLSGRRFLYIVNLDAPFEGHRKISRQSKWDIGAVQWNPHDSFAHYFAASSNQRVDLYKWKDGSGEVGTTLQGHTRVISDLDWAVFEPDLLVTSSVDTYIYIWDIKDTRKPTVALSAVAGASQVKWNKKNANCLATSHDGDVRIWDKRKPSTAVEYLAAHLSKIHGLDWHPDSEHILATSSQDNSVKFWDYRQPRKYLNILPCQVPVWKARYTPFSNGLVTVMVPQLRRENSLLLWNVFDLNTPVHTFVGHDDVVLEFQWRKQKEGSKDYQLVTWSRDQTLRMWRVDSQMQRLCANDILDGVDEFIESISLLPEPEKTLHTEDTDHQHTASHGEEEALKEDPPRNLLEERKSDQLGLPQTLQQEFSLINVQIRNVNVEMDAADRSCTVSVHCSNHRVKMLVKFPAQYPNNAAPSFQFINPTTITSTMKAKLLKILKDTALQKVKRGQSCLEPCLRQLVSCLESFVNQEDSASSNPFALPNSVTPPLPTFARVTTAYGSYQDANIPFPRTSGARFCGAGYLVYFTRPMTMHRAVSPTEPTPRSLSALSAYHTGLIAPMKIRTEAPGNLRLYSGSPTRSEKEQVSISSFYYKERKSRRWKSKREGSDSGNRQIKAAGKVIIQDIACLLPVHKSLGELYILNVNDIQETCQKNAASALLVGRKDLVQVWSLATVATDLCLGPKSDPDLETPWARHPFGRQLLESLLAHYCRLRDVQTLAMLCSVFEAQSRPQGLPNPFGPFPNRSSNLVVSHSRYPSFTSSGSCSSMSDPGLNTGGWNIAGREAEHLSSPWGESSPEELRFGSLTYSDPRERERDQHDKNKRLLDPANTQQFDDFKKCYGEILYRWGLREKRAEVLKFVSCPPDPHKGIEFGVYCSHCRSEVRGTQCAICKGFTFQCAICHVAVRGSSNFCLTCGHGGHTSHMMEWFRTQEVCPTGCGCHCLLESTF>sp|Q6PJI9-2|WDR59_HUMAN Isoform 2 of GATOR complex protein WDR59 OS=Homosapiens OX=9606 GN=WDR59MAARWSSENVVVEFRDSQATAMSVDCLGQHAVLSGRRFLYIVNLDAPFEGHRKISRQSKWDIGAVQWNPHDSFAHYFAASSNQRVDLYKWKDGSGEVGTTLQGHTRVISDLDWAVFEPDLLVTSSVDTYIYIWDIKDTRKPTVALSAVAGASQVKWNKKNANCLATSHDGDVRIWDKRKPSTAVEYLAAHLSKIHGLDWHPDSEHILATSSQDNSVKFWDYRQPRKYLNILPCQVPVWKARYTPFSNGLVTVMVPQLRRENSLLLWNVFDLNTPVHTFVGHDDVVLEFQWRKQKEGSKDYQLVTWSRDQTLRMWRVDSQMQRLCANDILDGVDEFIESISLLPEPEKTLHTEDTDHQHTASHGEEEALKEDPPRNLLEERKSDQLGLPQTLQQEFSLINVQIRNVNVEMDAADRSCTVSVHCSNHRVKMLVKFPAQYPNNAAPSFQFINPTTITSTMKAKLLKILKDTALQKVKRGQSCLEPCLRQLVSCLESFVNQEDSASSNPFALPNSVTPPLPTFARVTTAYGSYQDANIPFPRTSGARFCGAGYLVYFTRPMTMHRAVSPTEPTPR>sp|Q6PJI9-3|WDR59_HUMAN Isoform 3 of GATOR complex protein WDR59 OS=Homosapiens OX=9606 GN=WDR59MDAADRSCTVSVHCSNHRVKMLVKFPAQYPNNAAPSFQFINPTTITSTMKAKLLKILKDTALQKVKRGQSCLEPCLRQLVSCLESFVNQEDSASSNPFALPNSVTPPLPTFARVTTAYGSYQDANIPFPRTSGARFCGAGYLVYFTRPMTMHRAVSPTEPTPRSLSALSAYHTGLIAPMKIRTEAPGNLRLYSGSPTRSEKEQVSISSFYYKERKSRRWKSKREGSDSGNRQIKAAGKVIIQDIACLLPVHKSLGELYILNVNDIQETCQKNAASALLVGRKDLVQVWSLATVATDLCLGPKSDPDLETPWARHPFGRQLLESLLAHYCRLRDVQTLAMLCSVFEAQSRPQGLPNPFGPFPNRSSNLVVSHSRYPSFTSSGSCSSMSDPGLNTGGWNIAGREAEHLSSPWGESSPEELRFGSLTYSDPRERERDQHDKNKRLLDPANTQQFDDFKKCYGEILYRWGLREKRAEVLKFVSCPPDPHKGIEFGVYCSHCRSEVRGTQCAICKGFTFQCAICHVAVRGSSNFCLTCGHGGHTSHMMEWFRTQEVCPTGCGCHCLLESTF>sp|Q6PJI9-4|WDR59_HUMAN Isoform 4 of GATOR complex protein WDR59 OS=Homosapiens OX=9606 GN=WDR59MTGLQPVWIIIIFNYRSLSALSAYHTGLIAPMKIRTEAPGNLRLYSGSPTRSEKEQVSISSFYYKERKSRRWKSKREGSDSGNRQIKAAGKVIIQDIACLLPVHKSLGELYILNVNDIQETCQKNAASALLVGRKDLVQVWSLATVATDLCLGPKSDPDLETPWARHPFGRQLLESLLAHYCRLRDVQTLAMLCSVFEAQSRPQGLPNPFGPFPNRSSNLVVSHSRYPSFTSSGSCSSMSDPGLNTGGWNIAGREAEHLSSPWGESSPEELRFGSLTYSDPRERERDQHDKNKRLLDPANTQQFDDFKKCYGEILYRWGLREKRAEVLKFVSCPPDPHKGIEFGVYCSHCRSEVRGTQCAICKGFTFQCAICHVAVRGSSNFCLTCGHGGHTSHMMEWFRTQEVCPTGCGCHCLLESTF>sp|P58557|YBEY_HUMAN Endoribonuclease YbeY OS=Homo sapiens OX=9606GN=YBEY PE=1 SV=2MSLVIRNLQRVIPIRRAPLRSKIEIVRRILGVQKFDLGIICVDNKNIQHINRIYRDRNVPTDVLSFPFHEHLKAGEFPQPDFPDDYNLGDIFLGVEYIFHQCKENEDYNDVLTVTATHGLCHLLGFTHGTEAEWQQMFQKEKAVLDELGRRTGTRLQPLTRGLFGGS>sp|P58557-2|YBEY_HUMAN Isoform B of Endoribonuclease YbeY OS=Homosapiens OX=9606 GN=YBEYMSLVIRNLQRVIPIRRAPLRSKIEIVRRILGVQKFDLGIICVDNKNIQHINRIYRDRNVPTDVLSFPFHEVTATHGLCHLLGFTHGTEAEWQQMFQKEKAVLDELGRRTGTRLQPLTRGLFGGS>sp|P58557-3|YBEY_HUMAN Isoform C of Endoribonuclease YbeY OS=Homosapiens OX=9606 GN=YBEYMSLVIRNLQRVIPIRRAPLRSKIEIHLKAGEFPQPDFPDDYNLGDIFLGVEYIFHQCKENEDYNDVLTVTATHGLCHLLGFTHGTEAEWQQMFQKEKAVLDELGRRTGTRLQPLTRGLFGGS>sp|P58557-4|YBEY_HUMAN Isoform D of Endoribonuclease YbeY OS=Homosapiens OX=9606 GN=YBEYMSLVIRNLQRVIPIRRAPLRSKIEIVTATHGLCHLLGFTHGTEAEWQQMFQKEKAVLDELGRRTGTRLQPLTRGLFGGS>sp|Q8N9X3|YA026_HUMAN Putative uncharacterized protein encoded byLINC01356 OS=Homo sapiens OX=9606 GN=LINC01356 PE=5 SV=1MSLRGRFYYCRHFRGRKQARRVGELPEVTELVSGPDWNPNTSQPMPGSPAPAPRRLPGCQRHPHPFKCCPVPAPQSLPSTTRPHLPPTPQGQASRWLFLFLFQKLRGETDVCVPDACRWRRRSRETRGENQSVRAAVRSPDQAFHALVSGSRGREGRLRPQCAGSAGGA>sp|Q86TA4|YB049_HUMAN Putative uncharacterized protein FLJ44553 OS=Homosapiens OX=9606 PE=5 SV=2MLEGVSNEFDHFGISLPLKICLHLGWDEGLVEGKVVRLGQGIGKSICSSCQLFEEAPTQMSTVPSGLPLPILMHLCLLPVCMAHLCPASPCYFGATPGSGKFCRLITYSHSSPQLAASLRHRGREVGKDLPYPGLCPLTFHPSFFPPVEGCVSSLPGKLLSPQTIFFQILWLYSKSSLVL>sp|Q6UY13|YB003_HUMAN Putative uncharacterized proteinUNQ5830/PRO19650/PRO19816 OS=Homo sapiens OX=9606GN=UNQ5830/PRO19650/PRO19816 PE=3 SV=1MAILMLSLQLILLLIPSISHEAHKTSLSSWKHDQDWANVSNMTFSNGKLRVKGIYYRNADICSRHRVTSAGLTLQDLQLWCNLRSVARGQIPSTL>sp|Q9NRH1|YAE1_HUMAN Protein YAE1 homolog OS=Homo sapiens OX=9606GN=YAE1 PE=1 SV=1MSWVQAASLIQGPGDKGDVFDEEADESLLAQREWQSNMQRRVKEGYRDGIDAGKAVTLQQGFNQGYKKGAEVILNYGRLRGTLSALLSWCHLHNNNSTLINKINNLLDAVGQCEEYVLKHLKSITPPSHVVDLLDSIEDMDLCHVVPAEKKIDEAKDERLCENNAEFNKNCSKSHSGIDCSYVECCRTQEHAHSENPSPTWILEQTASLVKQLGLSVDVLQHLKQL>sp|Q9NRH1-2|YAE1_HUMAN Isoform 2 of Protein YAE1 homolog OS=Homo sapiensOX=9606 GN=YAE1MSWVQAASLIQGPGDKGDVFDEEADESLLAQREWQSNMQRRVKEGYRDGIDAGKAVTLQQGFNQGYKKGAEVILNYGRLRGTLRNSTDWSLLGLRAPLRSPEVGTQLLPRPLPVPGHMASGATPKQPTELEATLLSLVPQSGRATPRFPARLRAPGPGTPSHRRRFRRKPHRDPAAACPAWPPEAPSNSETHFSTYNRIIIRGGHI>sp|Q3C1V9|YK041_HUMAN Putative uncharacterized protein ENSP00000334305OS=Homo sapiens OX=9606 PE=5 SV=2MTPPPPSPLLGTQVKEDRADYKEFQDFSSLPDTHNIAWDHSFYPFQEEEEHGVKGVESVLEKGVLDEGVLEAWGCCRRCRHAGWNRSQPSPELAGAVIHARAPAVGCRQRSGHLHVRLKQRLLERPCQEPLGKKYQLELPPLYERARKPEGSKNLPADGQGLRAVRADAALPVWPGGPGRPGPHAPEAGAEGQHQGQWPPADTRHLRTPKWPYKVATEEKPEAEEAEKKRQAKVQEKRLPPWKKRTLNQVHRVPWGQHRACQVMLLVSTKQLQRYLHFEKPAKPANMGQDPDCFGKSEGELATCLCGGESVVGETEAPGVRPDPRPEKDAKPAVSGCQEESWLQSEYDEMHPREEMNVPSLRSGSGCQVSGSPLAKGLHPLQPCHPHYMMWECCLFTLTLGTQACFEVCARRLKLAHFCPDTSLWSCGGQSPPVLCQLLDIISVSRDKVIGSHEKKPSSNPNQDDFHSSEYAYRCGIAEAVGLPSIPVHPIGYYDAEKLLEYESLLLQVSEPVNPELSAGPITGLLDRLSGFRDHGPPGSSCRSQRKGNGVETKDQAHRNRDPRGFQGGVLTARLFKMQVSLELFCGHQEHYLTRPVLAPGYPVHLGKAGTHWEQGPNMPTPEQHGTWGNRHLFAVLPLLFYTSLEIMSIGYSVVMAGRNVWQPTKGQMPHQPEQSCQTLALPMTIRHSWEGGAIRESSGWVSWKCHLKATEASQNPCVRATALRVGCSAVTYGVLGQAQGSAPWTSAFKTFSAGIAGLERHAWETM>sp|Q6ZQT7|YJ013_HUMAN Putative uncharacterized protein FLJ44672 OS=Homosapiens OX=9606 PE=2 SV=1MQPGGTAGPEEAPMREAEAGPPQVGLSRPTCSLPASSPGPALPPGCVSRPDSGLPTTSLDSAPAQLPAALVDPQLPEAKLPRPSSGLTVASPGSAPALRWHLQAPNGLRSVGSSRPSLGLPAASAGPKRPEVGLSRPSSGLPAAFAGPSRPQVGLELGLEEQQVSLSGPSSILSAASPGAKLPRVSLSRPSSSCLPLASFSPAQPSSWLSAAFPGPAFDFWRPLQAQNLPSSGPLQARPRPRPHSGLSTPS>sp|Q9Y2K1|ZBTB1_HUMAN Zinc finger and BTB domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZBTB1 PE=1 SV=3MAKPSHSSYVLQQLNNQREWGFLCDCCIAIDDIYFQAHKAVLAACSSYFRMFFMNHQHSTAQLNLSNMKISAECFDLILQFMYLGKIMTAPSSFEQFKVAMNYLQLYNVPDCLEDIQDADCSSSKCSSSASSKQNSKMIFGVRMYEDTVARNGNEANRWCAEPSSTVNTPHNREADEESLQLGNFPEPLFDVCKKSSVSKLSTPKERVSRRFGRSFTCDSCGFGFSCEKLLDEHVLTCTNRHLYQNTRSYHRIVDIRDGKDSNIKAEFGEKDSSKTFSAQTDKYRGDTSQAADDSASTTGSRKSSTVESEIASEEKSRAAERKRIIIKMEPEDIPTDELKDFNIIKVTDKDCNESTDNDELEDEPEEPFYRYYVEEDVSIKKSGRKTLKPRMSVSADERGGLENMRPPNNSSPVQEDAENASCELCGLTITEEDLSSHYLAKHIENICACGKCGQILVKGRQLQEHAQRCGEPQDLTMNGLGNTEEKMDLEENPDEQSEIRDMFVEMLDDFRDNHYQINSIQKKQLFKHSACPFRCPNCGQRFETENLVVEHMSSCLDQDMFKSAIMEENERDHRRKHFCNLCGKGFYQRCHLREHYTVHTKEKQFVCQTCGKQFLRERQLRLHNDMHKGMARYVCSICDQGNFRKHDHVRHMISHLSAGETICQVCFQIFPNNEQLEQHMDVHLYTCGICGAKFNLRKDMRSHYNAKHLKRT>sp|Q9Y2K1-2|ZBTB1_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 1 OS=Homo sapiens OX=9606 GN=ZBTB1MAKPSHSSYVLQQLNNQREWGFLCDCCIAIDDIYFQAHKAVLAACSSYFRMFFMNHQHSTAQLNLSNMKISAECFDLILQFMYLGKIMTAPSSFEQFKVAMNYLQLYNVPDCLEDIQDADCSSSKCSSSASSKQNSKMIFGVRMYEDTVARNGNEANRWCAEPSSTVNTPHNREADEESLQLGNFPEPLFDVCKKSSVSKLSTPKERVSRRFGRSFTCDSCGFGFSCEKLLDEHVLTCTNRHLYQNTRSYHRIVDIRDGKDSNIKAEFGEKDSSKTFSAQTDKYRGDTSQAADDSASTTGSRKSSTVESEIASEEKSRAAERKRIIIKMEPEDIPTDELKDFNIIKVTDKDCNESTDNDELEDEPEEPFYRYYVEEDVSIKKSGRKTLKPRMSVSADERGGLENMRPPNNSSPVQEDAENASCELCGLTITEEDLSSHYLAKHIENICACGKCGQILVKGRQLQEHAQRCGEPQDLTMNGLGNTEEKMDLEENPDEQSEIRDMFVEMLDDFRDNHYQINSIQKKQLFKHSACPFRCPNCGQRFETENLVVEHMSSCLDQDMFKSAIMEENERDHRRKHFCNLCGKGFYQRCHLREHYTVHTKEKQFVCQTCGKQFLRERQLRLHNDMHKGMASGEIGPSKPVEK>sp|Q9ULJ3|ZBT21_HUMAN Zinc finger and BTB domain-containing protein 21OS=Homo sapiens OX=9606 GN=ZBTB21 PE=1 SV=2MEGLLHYINPAHAISLLSALNEERLKGQLCDVLLIVGDQKFRAHKNVLAASSEYFQSLFTNKENESQTVFQLDFCEPDAFDNVLNYIYSSSLFVEKSSLAAVQELGYSLGISFLTNIVSKTPQAPFPTCPNRKKVFVEDDENSSQKRSVIVCQSRNEAQGKTVSQNQPDVSHTSRPSPSIAVKANTNKPHVPKPIEPLHNLSLTEKSWPKDSSVVYAKSLEHSGSLDDPNRISLVKRNAVLPSKPLQDREAMDDKPGVSGQLPKGKALELALKRPRPPVLSVCSSSETPYLLKETNKGNGQGEDRNLLYYSKLGLVIPSSGSGSGNQSIDRSGPLVKSLLRRSLSMDSQVPVYSPSIDLKSSQGSSSVSSDAPGNVLCALSQKSSLKDCSEKTALDDRPQVLQPHRLRSFSASQSTDREGASPVTEVRIKTEPSSPLSDPSDIIRVTVGDAATTAAASSSSVTRDLSLKTEDDQKDMSRLPAKRRFQADRRLPFKKLKVNEHGSPVSEDNFEEGSSPTLLDADFPDSDLNKDEFGELEGTRPNKKFKCKHCLKIFRSTAGLHRHVNMYHNPEKPYACDICHKRFHTNFKVWTHCQTQHGIVKNPSPASSSHAVLDEKFQRKLIDIVREREIKKALIIKLRRGKPGFQGQSSSQAQQVIKRNLRSRAKGAYICTYCGKAYRFLSQFKQHIKMHPGEKPLGVNKVAKPKEHAPLASPVENKEVYQCRLCNAKLSSLLEQGSHERLCRNAAVCPYCSLRFFSPELKQEHESKCEYKKLTCLECMRTFKSSFSIWRHQVEVHNQNNMAPTENFSLPVLDHNGDVTGSSRPQSQPEPNKVNHIVTTKDDNVFSDSSEQVNFDSEDSSCLPEDLSLSKQLKIQVKEEPVEEAEEEAPEASTAPKEAGPSKEASLWPCEKCGKMFTVHKQLERHQELLCSVKPFICHVCNKAFRTNFRLWSHFQSHMSQASEESAHKESEVCPVPTNSPSPPPLPPPPPLPKIQPLEPDSPTGLSENPTPATEKLFVPQESDTLFYHAPPLSAITFKRQFMCKLCHRTFKTAFSLWSHEQTHN>sp|Q9ULJ3-2|ZBT21_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 21 OS=Homo sapiens OX=9606 GN=ZBTB21MEGLLHYINPAHAISLLSALNEERLKGQLCDVLLIVGDQKFRAHKNVLAASSEYFQSLFTNKENESQTVFQLDFCEPDAFDNVLNYIYSSSLFVEKSSLAAVQELGYSLGISFLTNIVSKTPQAPFPTCPNRKKVFVEDDENSSQKRSVIVCQSRNEAQGKTVSQNQPDVSHTSRPSPSIAVKANTNKPHVPKPIEPLHNLSLTEKSWPKDSSVVYAKSLEHSGSLDDPNRISLVKRNAVLPSKPLQDREAMDDKPGVSGQLPKGKALELALKRPRPPVLSVCSSSETPYLLKETNKGNGQGEDRNLLYYSKLGLVIPSSGSGSGNQSIDRSGPLVKSLLRRSLSMDSQVPVYSPSIDLKSSQGSSSVSSDAPGNVLCALSQKSSLKDCSEKTALDDRPQVLQPHRLRSFSASQSTDREGASPVTEVRIKTEPSSPLSDPSDIIRVTVGDAATTAAASSSSVTRDLSLKTEDDQKDMSRLPAKRRFQADRRLPFKKLKVNEHGSPVSEDNFEEGSSPTLLDADFPDSDLNKDEFEQGSHERLCRNAAVCPYCSLRFFSPELKQEHESKCEYKKLTCLECMRTFKSSFSIWRHQVEVHNQNNMAPTENFSLPVLDHNGDVTGSSRPQSQPEPNKVNHIVTTKDDNVFSDSSEQVNFDSEDSSCLPEDLSLSKQLKIQVKEEPVEEAEEEAPEASTAPKEAGPSKEASLWPCEKCGKMFTVHKQLERHQELLCSVKPFICHVCNKAFRTNFRLWSHFQSHMSQASEESAHKESEVCPVPTNSPSPPPLPPPPPLPKIQPLEPDSPTGLSENPTPATEKLFVPQESDTLFYHAPPLSAITFKRQFMCKLCHRTFKTAFSLWSHEQTHN>sp|Q9UPR6|ZFR2_HUMAN Zinc finger RNA-binding protein 2 OS=Homo sapiensOX=9606 GN=ZFR2 PE=2 SV=3MATSQYFDFAQGGGPQYSAQPPTLPLPTVGASYTAQPTPGMDPAVNPAFPPAAPAGYGGYQPHSGQDFAYGSRPQEPVPTATTMATYQDSYSYGQSAAARSYEDRPYFQSAALQSGRMTAADSGQPGTQEACGQPSPHGSHSHAQPPQQAPIVESGQPASTLSSGYTYPTATGVQPESSASIVTSYPPPSYNPTCTAYTAPSYPNYDASVYSAASPFYPPAQPPPPPGPPQQLPPPPAPAGSGSSPRADSKPPLPSKLPRPKAGPRQLQLHYCDICKISCAGPQTYREHLGGQKHRKKEAAQKTGVQPNGSPRGVQAQLHCDLCAVSCTGADAYAAHIRGSKHQKVFKLHAKLGKPIPTLEPALATESPPGAEAKPTSPTGPSVCASSRPALAKRPVASKALCEGPPEPQAAGCRPQWGKPAQPKLEGPGAPTQGGSKEAPAGCSDAQPVGPEYVEEVFSDEGRVLRFHCKLCECSFNDLNAKDLHVRGRRHRLQYRKKVNPDLPIATEPSSRARKVLEERMRKQRHLAEERLEQLRRWHAERRRLEEEPPQDVPPHAPPDWAQPLLMGRPESPASAPLQPGRRPASSDDRHVMCKHATIYPTEQELLAVQRAVSHAERALKLVSDTLAEEDRGRREEEGDKRSSVAPQTRVLKGVMRVGILAKGLLLRGDRNVRLALLCSEKPTHSLLRRIAQQLPRQLQMVTEDEYEVSSDPEANIVISSCEEPRMQVTISVTSPLMREDPSTDPGVEEPQADAGDVLSPKKCLESLAALRHARWFQARASGLQPCVIVIRVLRDLCRRVPTWGALPAWAMELLVEKAVSSAAGPLGPGDAVRRVLECVATGTLLTDGPGLQDPCERDQTDALEPMTLQEREDVTASAQHALRMLAFRQTHKVLGMDLLPPRHRLGARFRKRQRGPGEGEEGAGEKKRGRRGGEGLV>sp|Q9UPR6-2|ZFR2_HUMAN Isoform 2 of Zinc finger RNA-binding protein 2OS=Homo sapiens OX=9606 GN=ZFR2MATSQYFDFAQGGGPQYSPEVETTPPALASGLPCALPWTVGCSGSDAVTALCPSLRGLACICSILWDPAW>sp|Q9UPR6-3|ZFR2_HUMAN Isoform 3 of Zinc finger RNA-binding protein 2OS=Homo sapiens OX=9606 GN=ZFR2MATSQYFDFAQGGGPQYSAQPPTLPLPTVGASYTAQPTPGMDPAVNPAFPPAAPAGYGGYQPHSGQDFAYGSRPQEPVPTATTMATYQDSYSYGQSAAARSYEDRPYFQSAALQSGRMTAADSGQPGTQEACGQPSPHGSHSHAQPPQQAPIVESGQPASTLSSGYTYPTATGVQPESSASIVTSYPPPSYNPTCTAYTAPSYPNYDASVYSAASPFYPPAQPPPPPGPPQQLPPPPAPAGSGSSPRADSKPPLPSKLPRPKAGPRQLQLHYCDICKISCAGPQTYREHLGGQKHRKKEAAQKTGVQPNGSPRGVQAQLHCDLCAVSCTGADAYAAHIRGSKHQKGLLSHRQQAADPSGGNQPNLN>sp|O43167|ZBT24_HUMAN Zinc finger and BTB domain-containing protein 24OS=Homo sapiens OX=9606 GN=ZBTB24 PE=1 SV=2MAETSPEPSGQLVVHSDAHSDTVLASFEDQRKKGFLCDITLIVENVHFRAHKALLAASSEYFSMMFAEEGEIGQSIYMLEGMVADTFGILLEFIYTGYLHASEKSTEQILATAQFLKVYDLVKAYTDFQNNHSSPKPTTLNTAGAPVVVISNKKNDPPKRKRGRPKKVNTLQEEKSELAAEEEIQLRVNNSVQNRQNFVVKGDSGVLNEQIAAKEKEESEPTCEPSREEEMPVEKDENYDPKTEDGQASQSRYSKRRIWRSVKLKDYKLVGDQEDHGSAKRICGRRKRPGGPEARCKDCGKVFKYNHFLAIHQRSHTGERPFKCNECGKGFAQKHSLQVHTRMHTGERPYTCTVCSKALTTKHSLLEHMSLHSGQKSFTCDQCGKYFSQNRQLKSHYRVHTGHSLPECKDCHRKFMDVSQLKKHLRTHTGEKPFTCEICGKSFTAKSSLQTHIRIHRGEKPYSCGICGKSFSDSSAKRRHCILHTGKKPFSCPECNLQFARLDNLKAHLKIHSKEKHASDASSISGSSNTEEVRNILQLQPYQLSTSGEQEIQLLVTDSVHNINFMPGPSQGISIVTAESSQNMTADQAANLTLLTQQPEQLQNLILSAQQEQTEHIQSLNMIESQMGPSQTEPVHVITLSKETLEHLHAHQEQTEELHLATSTSDPAQHLQLTQEPGPPPPTHHVPQPTPLGQEQS>sp|O43167-2|ZBT24_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 24 OS=Homo sapiens OX=9606 GN=ZBTB24MAETSPEPSGQLVVHSDAHSDTVLASFEDQRKKGFLCDITLIVENVHFRAHKALLAASSEYFSMMFAEEGEIGQSIYMLEGMVADTFGILLEFIYTGYLHASEKSTEQILATAQFLKVYDLVKAYTDFQNNHSSPKPTTLNTAGAPVVVISNKKNDPPKRKRGRPKKVNTLQEEKSELAAEEEIQLRVNNSVQNRQNFVVKGDSGVLNEQIAAKEKEESEPTCEPSREEEMPVEKDENYDPKTEDGQASQSRYSKRRIWRSVKLKDYKLVGDQEDHGSAKRICGRRKRPGGPEARCKDCGKVFKYNHFLAIHQRSHTGNDVFKADCSVLQNWE>sp|Q6ZRN7|YP029_HUMAN Putative uncharacterized protein FLJ46214 OS=Homosapiens OX=9606 PE=2 SV=1MSPTKDSHPSPHFPRDSGIHAPTPPDSGALTLSPPVSQGPGVGPRTGRGNRLCRPPGRSAARSFCLLPGPPLGTGALGSPRAAQGLGFRGSGQRARHNSFTSPSPPGAHHPLGTHTRALPPPLARCPCAALLAGRECHGGPSPAAPRPLPGTSLTWPSRAPLPRPPPRERQGPGDRSPSPSAPSCPGVGASSPRRRKPREAAGLTPDG>sp|A6NEH8|ZNAS2_HUMAN Putative uncharacterized protein encoded byZNF503-AS2 OS=Homo sapiens OX=9606 GN=ZNF503-AS2 PE=5 SV=1MGVWGKKHLRLTHAPSPTFSHLPPSPQAGEPGIDGISLAVVCAAFIRIHPARRHPARNGSRLACTPTPRPNAGLEVVSSARVAASLPSEGGWTSGAPRSSGLSLPGSAWQPPPLPVLRKPAWPGSPAVKNESKFPNRGSRNFPRRRLPPAPVSGEPPERCKLAREIRWRLWKAHEGWGGGAKRPLGDPAWSGVKR>sp|Q96F45|ZN503_HUMAN Zinc finger protein 503 OS=Homo sapiens OX=9606GN=ZNF503 PE=1 SV=1MSTAPSLSALRSSKHSGGGGGGGGGGGADPAWTSALSGNSSGPGPGSSPAGSTKPFVHAVPPSDPLRQANRLPIKVLKMLTARTGHILHPEYLQPLPSTPVSPIELDAKKSPLALLAQTCSQIGKPDPSPSSKLSSVASNGGGAGGAGGGAAGDKDTKSGPLKLSDIGVEDKSSFKPYSKPGSDKKEPGGGGGGGGGGGGGGGGVSSEKSGFRVPSATCQPFTPRTGSPSSSASACSPGGMLSSAGGAPEGKDDKKDTDVGGGGKGTGGASAEGGPTGLAHGRISCGGGINVDVNQHPDGGPGGKALGSDCGGSSGSSSGSGPSAPTSSSVLGSGLVAPVSPYKPGQTVFPLPPAGMTYPGSLAGAYAGYPPQFLPHGVALDPTKPGSLVGAQLAAAAAGSLGCSKPAGSSPLAGASPPSVMTASLCRDPYCLSYHCASHLAGAAAASASCAHDPAAAAAALKSGYPLVYPTHPLHGVHSSLTAAAAAGATPPSLAGHPLYPYGFMLPNDPLPHICNWVSANGPCDKRFATSEELLSHLRTHTAFPGTDKLLSGYPSSSSLASAAAAAMACHMHIPTSGAPGSPGTLALRSPHHALGLSSRYHPYSKSPLPTPGAPVPVPAATGPYYSPYALYGQRLTTASALGYQ>sp|Q96F45-2|ZN503_HUMAN Isoform 2 of Zinc finger protein 503 OS=Homosapiens OX=9606 GN=ZNF503MSTAPSLSALRSSKHSGGGGGGGGGGGADPAWTSALSGNSSGPGPGSSPAGSTKPFVHAVPPSDPLRQANRLPIKVLKMLTARTGHILHPEYLQPLPSTPVSPIELDAKKSPLALLAQTCSQIGKPDPSPSSKLSSVASNGGGAGGAGGGAAGDKDTKSGPLKLSDIGVEDKSSFKPYSKPGSDKKEPGGGGGGGGGGGGGGGGVSSEKSGFRVPSATCQPFTPRTGSPSSSASAEGGPTGLAHGRISCGGGINVDVNQHPDGGPGGKALGSDCGGSSGSSSGSGPSAPTSSSVLGSGLVAPVSPYKPGQTVFPLPPAGMTYPGSLAGAYAGYPPQFLPHGVALDPTKPGSLVGAQLAAAAAGSLGCSKPAGSSPLAGASPPSVMTASLCRDPYCLSYHCASHLAGAAAASASCAHDPAAAAAALKSGYPLVYPTHPLHGVHSSLTAAAAAGATPPSLAGHPLYPYGFMLPNDPLPHICNWVSANGPCDKRFATSEELLSHLRTHTAFPGTDKLLSGYPSSSSLASAAAAAMACHMHIPTSGAPGSPGTLALRSPHHALGLSSRYHPYSKSPLPTPGAPVPVPAATGPYYSPYALYGQRLTTASALGYQ>sp|Q96F45-3|ZN503_HUMAN Isoform 3 of Zinc finger protein 503 OS=Homosapiens OX=9606 GN=ZNF503MSTAPSLSALRSSKHSGGGGGGGGGGGADPAWTSALSGNSSGPGPGSSPAGSTKPFVHAVPPSDPLRQANRLPIKVLKMLTARTGHILHPEYLQPLPSTPVSPIELDAKKSPLALLAQTCSQIGKPDPSPSLAGHPLYPYGFMLPNDPLPHICNWVSANGPCDKRFATSEELLSHLRTHTAFPGTDKLLSGYPSSSSLASAAAAAMACHMHIPTSGAPGSPGTLALRSPHHALGLSSRYHPYSKSPLPTPGAPVPVPAATGPYYSPYALYGQRLTTASALGYQ>sp|O15090|ZN536_HUMAN Zinc finger protein 536 OS=Homo sapiens OX=9606GN=ZNF536 PE=1 SV=3MEEASLCLGVSSAEPEAEPHLSGPVLNGQYAMSQKLHQITSQLSHAFPELHPRPNPEEKPPASLEEKAHVPMSGQPMGSQMALLANQLGREVDTSLNGRVDLQQFLNGQNLGIMSQMSDIEDDARKNRKYPCPLCGKRFRFNSILSLHMRTHTGEKPFKCPYCDHRAAQKGNLKIHLRTHKLGNLGKGRGRVREENRLLHELEERAILRDKQLKGSLLQPRPDLKPPPHAQQAPLAACTLALQANHSVPDVAHPVPSPKPASVQEDAVAPAAGFRCTFCKGKFKKREELDRHIRILHKPYKCTLCDFAASQEEELISHVEKAHITAESAQGQGPNGGGEQSANEFRCEVCGQVFSQAWFLKGHMRKHKDSFEHCCQICGRRFKEPWFLKNHMKVHLNKLSVKNKSPSDPEVPVPMGGMSQEAHANLYSRYLSCLQSGFMTPDKAGLSEPSQLYGKGELPMKEKEALGKLLSPISSMAHGVPEGDKHSLLGCLNLVPPLKSSCIERLQAAAKAAEMDPVNSYQAWQLMARGMAMEHGFLSKEHPLQRNHEDTLANAGVLFDKEKREYVLVGADGSKQKMPADLVHSTKVGSQRDLPSKLDPLESSRDFLSHGLNQTLEYNLQGPGNMKEKPTECPDCGRVFRTYHQVVVHSRVHKRDRKGEEDGLHVGLDERRGSGSDQESQSVSRSTTPGSSNVTEESGVGGGLSQTGSAQEDSPHPSSPSSSDIGEEAGRSAGVQQPALLRDRSLGSAMKDCPYCGKTFRTSHHLKVHLRIHTGEKPYKCPHCDYAGTQSASLKYHLERHHRERQNGAGPLSGQPPNQDHKDEMSSKASLFIRPDILRGAFKGLPGIDFRGGPASQQWTSGVLSSGDHSGQATGMSSEVPSDALKGTDLPSKSTHFSEIGRAYQSIVSNGVNFQGSLQAFMDSFVLSSLKKEKDMKDKALADPPSMKVHGVDGGEEKPSGKSSQRKSEKSQYEPLDLSVRPDAASLPGSSVTVQDSIAWHGCLFCAFTTSSMELMALHLQANHLGKAKRKDNTIGVTVNCKDQAREASKMALLPSLQSNKDLGLSNMISSLDSASEKMAQGQLKETLGEQKSGAWTGHVDPAFCNFPSDFYKQFGVYPGMVGSGASSSCPNKEPDGKAHSEEDVPILIPETTSKNTTDDLSDIASSEDMDSSKGENNDEEDVETEPEMMTKPLSALSKDSSSDGGDSLQPTGTSQPVQGLVSPLSQAPEKQWHSQGLLQAQDPLAGLPKPERGPQSLDKPMNMLSVLRAYSSDGLAAFNGLASSTANSGCIKRPDLCGK>sp|Q8N9F8|ZN454_HUMAN Zinc finger protein 454 OS=Homo sapiens OX=9606GN=ZNF454 PE=2 SV=2MAVSHLPTMVQESVTFKDVAILFTQEEWGQLSPAQRALYRDVMLENYSNLVSLGLLGPKPDTFSQLEKREVWMPEDTPGGFCLDWMTMPASKKSTVKAEIPEEELDQWTIKERFSSSSHWKCASLLEWQCGGQEISLQRVVLTHPNTPSQECDESGSTMSSSLHSDQSQGFQPSKNAFECSECGKVFSKSSTLNKHQKIHNEKNANQKIHIKEKRYECRECGKAFHQSTHLIHHQRIHTGEKPYECKECGKAFSVSSSLTYHQKIHTGEKPFECNLCGKAFIRNIHLAHHHRIHTGEKPFKCNICEKAFVCRAHLTKHQNIHSGEKPYKCNECGKAFNQSTSFLQHQRIHTGEKPFECNECGKAFRVNSSLTEHQRIHTGEKPYKCNECGKAFRDNSSFARHRKIHTGEKPYRCGLCEKAFRDQSALAQHQRIHTGEKPYTCNICEKAFSDHSALTQHKRIHTREKPYKCKICEKAFIRSTHLTQHQRIHTGEKPYKCNKCGKAFNQTANLIQHQRHHIGEK>sp|Q8IUH5|ZDH17_HUMAN Palmitoyltransferase ZDHHC17 OS=Homo sapiensOX=9606 GN=ZDHHC17 PE=1 SV=2MQREEGFNTKMADGPDEYDTEAGCVPLLHPEEIKPQSHYNHGYGEPLGRKTHIDDYSTWDIVKATQYGIYERCRELVEAGYDVRQPDKENVTLLHWAAINNRIDLVKYYISKGAIVDQLGGDLNSTPLHWATRQGHLSMVVQLMKYGADPSLIDGEGCSCIHLAAQFGHTSIVAYLIAKGQDVDMMDQNGMTPLMWAAYRTHSVDPTRLLLTFNVSVNLGDKYHKNTALHWAVLAGNTTVISLLLEAGANVDAQNIKGESALDLAKQRKNVWMINHLQEARQAKGYDNPSFLRKLKADKEFRQKVMLGTPFLVIWLVGFIADLNIDSWLIKGLMYGGVWATVQFLSKSFFDHSMHSALPLGIYLATKFWMYVTWFFWFWNDLNFLFIHLPFLANSVALFYNFGKSWKSDPGIIKATEEQKKKTIVELAETGSLDLSIFCSTCLIRKPVRSKHCGVCNRCIAKFDHHCPWVGNCVGAGNHRYFMGYLFFLLFMICWMIYGCISYWGLHCETTYTKDGFWTYITQIATCSPWMFWMFLNSVFHFMWVAVLLMCQMYQISCLGITTNERMNARRYKHFKVTTTSIESPFNHGCVRNIIDFFEFRCCGLFRPVIVDWTRQYTIEYDQISGSGYQLV>sp|Q8IUH5-2|ZDH17_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC17OS=Homo sapiens OX=9606 GN=ZDHHC17MSTIPKRAVCPFSTQRYGIYERCRELVEAGYDVRQPDKENVTLLHWAAINNRIDLVKYYISKGAIVDQLGGDLNSTPLHWATRQGHLSMVVQLMKYGADPSLIDGEGCSCIHLAAQFGHTSIVAYLIAKGQDVDMMDQNGMTPLMWAAYRTHSVDPTRLLLTFNVSVNLGDKYHKNTALHWAVLAGNTTVISLLLEAGANVDAQNIKAILRCHMAL>sp|Q8IUH5-3|ZDH17_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC17OS=Homo sapiens OX=9606 GN=ZDHHC17MQREEGFNTKMADGPDEYDTEAGCVPLLHPEEIKPQSHYNHGYGEPLGRKTHIDDYSTWDIVKATQYGIYERCRELVEAGYDVRQPDKENVTLLHWAAINNRIDLVKYYISKGAIVDQLGGDLNSTPLHWATRQGHLSMVVQLMKYGADPSLIDGEGCSCIHLAAQFGHTSIVAYLIAKGQDVDMMDQNGMTPLMWAAYRTHS>sp|Q6ZS27|ZN662_HUMAN Zinc finger protein 662 OS=Homo sapiens OX=9606GN=ZNF662 PE=1 SV=1MLENYGAVASLAAFPFPKPALISQLERGETPWCSVPRGALDGEAPRGISSGYPFLKPAGISHPEQVEEPLNLKLQGEGPSLICPEGVLKRKKEDFILKEEIIEEAQDLMVLSSGPQWCGSQELWFGKTCEEKSRLGRWPGYLNGGRMESSTNDIIEVIVKDEMISVEESSGNTDVNNLLGIHHKILNEQIFYICEECGKCFDQNEDFDQHQKTHNGEKVYGCKECGKAFSFRSHCIAHQRIHSGVKPYECQECAKAFVWKSNLIRHQRIHTGEKPFECKECGKGFSQNTSLTQHQRIHTGEKPYTCKECGKSFTRNPALLRHQRMHTGEKPYECKDCGKGFMWNSDLSQHQRVHTGDKPHECTDCGKSFFCKAHLIRHQRIHTGERPYKCNDCGKAFSQNSVLIKHQRRHARDKPYNCQISHLLEH>sp|Q6ZS27-2|ZN662_HUMAN Isoform 2 of Zinc finger protein 662 OS=Homosapiens OX=9606 GN=ZNF662MVLSSGPQWCGSQELWFGKTCEEKSRLGRWPGYLNGGRMESSTNDIIEVIVKDEMISVEESSGNTDVNNLLGIHHKILNEQIFYICEECGKCFDQNEDFDQHQKTHNGEKVYGCKECGKAFSFRSHCIAHQRIHSGVKPYECQECAKAFVWKSNLIRHQRIHTGEKPFECKECGKGFSQNTSLTQHQRIHTGEKPYTCKECGKSFTRNPALLRHQRMHTGEKPYECKDCGKGFMWNSDLSQHQRVHTGDKPHECTDCGKSFFCKAHLIRHQRIHTGERPYKCNDCGKAFSQNSVLIKHQRRHARDKPYNCQISHLLEH>sp|Q6ZS27-3|ZN662_HUMAN Isoform 3 of Zinc finger protein 662 OS=Homosapiens OX=9606 GN=ZNF662MAAVALASGTRLGLVLELLPGQPALPRARRESVTFEDVAVYFSENEWIGLGPAQRALYRDVMLENYGAVASLAFPFPKPALISQLERGETPWCSVPRGALDGEAPRGISSEGVLKRKKEDFILKEEIIEEAQDLMVLSSGPQWCGSQELWFGKTCEEKSRLGRWPGYLNGGRMESSTNDIIEVIVKDEMISVEESSGNTDVNNLLGIHHKILNEQIFYICEECGKCFDQNEDFDQHQKTHNGEKVYGCKECGKAFSFRSHCIAHQRIHSGVKPYECQECAKAFVWKSNLIRHQRIHTGEKPFECKECGKGFSQNTSLTQHQRIHTGEKPYTCKECGKSFTRNPALLRHQRMHTGEKPYECKDCGKGFMWNSDLSQHQRVHTGDKPHECTDCGKSFFCKAHLIRHQRIHTGERPYKCNDCGKAFSQNSVLIKHQRRHARDKPYNCQISHLLEH>sp|Q08AN1|ZN616_HUMAN Zinc finger protein 616 OS=Homo sapiens OX=9606GN=ZNF616 PE=2 SV=2MATQGHLTFKDVAIEFSQEEWKCLEPVQKALYKDVMLENYRNLVFLGISPKCVIKELPPTENSNTGERFQTVALERHQSYDIENLYFREIQKHLHDLEFQWKDGETNDKEVPVPHENNLTGKRDQHSQGDVENNHIENQLTSNFESRLAELQKVQTEGRLYECNETEKTGNNGCLVSPHIREKTYVCNECGKAFKASSSLINHQRIHTTEKPYKCNECGKAFHRASLLTVHKVVHTRGKSYQCDVCGKIFRKNSYFVRHQRSHTGQKPYICNECGKSFSKSSHLAVHQRIHTGEKPYKCNLCGKSFSQRVHLRLHQTVHTGERPFKCNECGKTFKRSSNLTVHQVIHAGKKPYKCDVCGKAFRHRSNLVCHRRIHSGEKQYKCNECGKVFSKRSSLAVHRRIHTVEKPCKCNECGKVFSKRSSLAVHQRIHTGQKTYKCNKCGKVYSKHSHLAVHWRIHTGEKAYKCNECGKVFSIHSRLAAHQRIHTGEKPYKCNECGKVFSQHSRLAVHRRIHTGEKPYKCKECGKVFSDRSAFARHRRIHTGEKPYKCKECGKVFSQCSRLTVHRRIHSGEKPYKCNECGKVYSQYSHLVGHRRVHTGEKPYKCHECGKAFNQGSTLNRHQRIHTGEKPYKCNQCGNSFSQRVHLRLHQTVHTGDRPYKCNECGKTFKRSSNLTAHQIIHAGKKPYKCDECGKVFRHSSHLVSHQRIHTGEKRYKCIECGKAFGRLFSLSKHQRIHSGKKPYKCNECGKSFICRSGLTKHRIRHTGESLTTKLNVTRP>sp|P49750|YLPM1_HUMAN YLP motif-containing protein 1 OS=Homo sapiensOX=9606 GN=YLPM1 PE=1 SV=4MYPNWGRYGGSSHYPPPPVPPPPPVALPEASPGPGYSSSTTPAAPSSSGFMSFREQHLAQLQQLQQMHQKQMQCVLQPHHLPPPPLPPPPVMPGGGYGDWQPPPPPMPPPPGPALSYQKQQQYKHQMLHHQRDGPPGLVPMELESPPESPPVPPGSYMPPSQSYMPPPQPPPSYYPPTSSQPYLPPAQPSPSQSPPSQSYLAPTPSYSSSSSSSQSYLSHSQSYLPSSQASPSRPSQGHSKSQLLAPPPPSAPPGNKTTVQQEPLESGAKNKSTEQQQAAPEPDPSTMTPQEQQQYWYRQHLLSLQQRTKVHLPGHKKGPVVAKDTPEPVKEEVTVPATSQVPESPSSEEPPLPPPNEEVPPPLPPEEPQSEDPEEDARLKQLQAAAAHWQQHQQHRVGFQYQGIMQKHTQLQQILQQYQQIIQPPPHIQTMSVDMQLRHYEMQQQQFQHLYQEWEREFQLWEEQLHSYPHKDQLQEYEKQWKTWQGHMKATQSYLQEKVNSFQNMKNQYMGNMSMPPPFVPYSQMPPPLPTMPPPVLPPSLPPPVMPPALPATVPPPGMPPPVMPPSLPTSVPPPGMPPSLSSAGPPPVLPPPSLSSAGPPPVLPPPSLSSTAPPPVMPLPPLSSATPPPGIPPPGVPQGIPPQLTAAPVPPASSSQSSQVPEKPRPALLPTPVSFGSAPPTTYHPPLQSAGPSEQVNSKAPLSKSALPYSSFSSDQGLGESSAAPSQPITAVKDMPVRSGGLLPDPPRSSYLESPRGPRFDGPRRFEDLGSRCEGPRPKGPRFEGNRPDGPRPRYEGHPAEGTKSKWGMIPRGPASQFYITPSTSLSPRQSGPQWKGPKPAFGQQHQQQPKSQAEPLSGNKEPLADTSSNQQKNFKMQSAAFSIAADVKDVKAAQSNENLSDSQQEPPKSEVSEGPVEPSNWDQNVQSMETQIDKAQAVTQPVPLANKPVPAQSTFPSKTGGMEGGTAVATSSLTADNDFKPVGIGLPHSENNQDKGLPRPDNRDNRLEGNRGNSSSYRGPGQSRMEDTRDKGLVNRGRGQAISRGPGLVKQEDFRDKMMGRREDSREKMNRGEGSRDRGLVRPGSSREKVPGGLQGSQDRGAAGSRERGPPRRAGSQERGPLRRAGSRERIPPRRAGSRERGPPRGPGSRERGLGRSDFGRDRGPFRPEPGDGGEKMYPYHRDEPPRAPWNHGEERGHEEFPLDGRNAPMERERLDDWDRERYWRECERDYQDDTLELYNREDRFSAPPSRSHDGDRRGPWWDDWERDQDMDEDYNREMERDMDRDVDRISRPMDMYDRSLDNEWDRDYGRPLDEQESQFRERDIPSLPPLPPLPPLPPLDRYRDDRWREERNREHGYDRDFRDRGELRIREYPERGDTWREKRDYVPDRMDWERERLSDRWYPSDVDRHSPMAEHMPSSHHSSEMMGSDASLDSDQGLGGVMVLSQRQHEIILKAAQELKMLREQKEQLQKMKDFGSEPQMADHLPPQESRLQNTSSRPGMYPPPGSYRPPPPMGKPPGSIVRPSAPPARSSVPVTRPPVPIPPPPPPPPLPPPPPVIKPQTSAVEQERWDEDSFYGLWDTNDEQGLNSEFKSETAAIPSAPVLPPPPVHSSIPPPGPVPMGMPPMSKPPPVQQTVDYGHGRDISTNKVEQIPYGERITLRPDPLPERSTFETEHAGQRDRYDRERDREPYFDRQSNVIADHRDFKRDRETHRDRDRDRGVIDYDRDRFDRERRPRDDRAQSYRDKKDHSSSRRGGFDRPSYDRKSDRPVYEGPSMFGGERRTYPEERMPLPAPSLSHQPPPAPRVEKKPESKNVDDILKPPGRESRPERIVVIMRGLPGSGKTHVAKLIRDKEVEFGGPAPRVLSLDDYFITEVEKEEKDPDSGKKVKKKVMEYEYEAEMEETYRTSMFKTFKKTLDDGFFPFIILDAINDRVRHFDQFWSAAKTKGFEVYLAEMSADNQTCGKRNIHGRKLKEINKMADHWETAPRHMMRLDIRSLLQDAAIEEVEMEDFDANIEEQKEEKKDAEEEESELGYIPKSKWEMDTSEAKLDKLDGLRTGTKRKRDWEAIASRMEDYLQLPDDYDTRASEPGKKRVRWADLEEKKDADRKRAIGFVVGQTDWEKITDESGHLAEKALNRTKYI>sp|P49750-3|YLPM1_HUMAN Isoform 3 of YLP motif-containing protein 1OS=Homo sapiens OX=9606 GN=YLPM1MYPNWGRYGGSSHYPPPPVPPPPPVALPEASPGPGYSSSTTPAAPSSSGFMSFREQHLAQLQQLQQMHQKQMQCVLQPHHLPPPPLPPPPVMPGGGYGDWQPPPPPMPPPPGPALSYQKQQQYKHQMLHHQRDGPPGLVPMELESPPESPPVPPGSYMPPSQSYMPPPQPPPSYYPPTSSQPYLPPAQPSPSQSPPSQSYLAPTPSYSSSSSSSQSYLSHSQSYLPSSQASPSRPSQGHSKSQLLAPPPPSAPPGNKTTVQQEPLESGAKNKSTEQQQAAPEPDPSTMTPQEQQQYWYRQHLLSLQQRTKVHLPGHKKGPVVAKDTPEPVKEEVTVPATSQVPESPSSEEPPLPPPNEEVPPPLPPEEPQSEDPEEDARLKQLQAAAAHWQQHQQHRVGFQYQGIMQKHTQLQQILQQYQQIIQPPPHIQATTPPPGIPPPGVPQGIPPQLTAAPVPPASSSQSSQVPEKPRPALLPTPVSFGSAPPTTYHPPLQSAGPSEQVNSKAPLSKSALPYSSFSSDQGLGESSAAPSQPITAVKDMPVRSGGLLPDPPRSSYLESPRGPRFDGPRRFEDLGSRCEGPRPKGPRFEGNRPDGPRPRYEGHPAEGTKSKWGMIPRGPASQFYITPSTSLSPRQSGPQWKGPKPAFGQQHQQQPKSQAEPLSGNKEPLADTSSNQQKNFKMQSAAFSIAADVKDVKAAQSNENLSDSQQEPPKSEVSEGPVEPSNWDQNVQSMETQIDKAQAVTQPVPLANKPVPAQSTFPSKTGGMEGGTAVATSSLTADNDFKPVGIGLPHSENNQDKGLPRPDNRDNRLEGNRGNSSSYRGPGQSRMEDTRDKGLVNRGRGQAISRGPGLVKQEDFRDKMMGRREDSREKMNRGEGSRDRGLVRPGSSREKVPGGLQGSQDRGAAGSRERGPPRRAGSQERGPLRRAGSRERIPPRRAGSRERGPPRGPGSRERGLGRSDFGRDRGPFRPEPGDGGEKMYPYHRDEPPRAPWNHGEERGHEEFPLDGRNAPMERERLDDWDRERYWRECERDYQDDTLELYNREDRFSAPPSRSHDGDRRGPWWDDWERDQDMDEDYNREMERDMDRDVDRISRPMDMYDRSLDNEWDRDYGRPLDEQESQFRERDIPSLPPLPPLPPLPPLDRYRDDRWREERNREHGYDRDFRDRGELRIREYPERGDTWREKRDYVPDRMDWERERLSDRWYPSDVDRHSPMAEHMPSSHHSSEMMGSDASLDSDQGLGGVMVLSQRQHEIILKAAQELKMLREQKEQLQKMKDFGSEPQMADHLPPQESRLQNTSSRPGMYPPPGSYRPPPPMGKPPGSIVRPSAPPARSSVPVTRPPVPIPPPPPPPPLPPPPPVIKPQTSAVEQERWDEDSFYGLWDTNDEQGLNSEFKSETAAIPSAPVLPPPPVHSSIPPPGPVPMGMPPMSKPPPVQQTVDYGHGRDISTNKVEQIPYGERITLRPDPLPERSTFETEHAGQRDRYDRERDREPYFDRQSNVIADHRDFKRDRETHRDRDRDRGVIDYDRDRFDRERRPRDDRAQSYRDKKDHSSSRRGGFDRPSYDRKSDRPVYEGPSMFGGERRTYPEERMPLPAPSLSHQPPPAPRVEKKPESKNVDDILKPPGRESRPERIVVIMRGLPGSGKTHVAKLIRDKEVEFGGPAPRVLSLDDYFITEVEKEEKDPDSGKKVKKKVMEYEYEAEMEETYRTSMFKTFKKTLDDGFFPFIILDAINDRVRHFDQFWSAAKTKGFEVYLAEMSADNQTCGKRNIHGRKLKEINKMADHWETAPRHMMRLDIRSLLQDAAIEEVEMEDFDANIEEQKEEKKDAEEEESELVGDRPTTLNSVSLLKFLKKV>sp|P49750-1|YLPM1_HUMAN Isoform 1 of YLP motif-containing protein 1OS=Homo sapiens OX=9606 GN=YLPM1MYPNWGRYGGSSHYPPPPVPPPPPVALPEASPGPGYSSSTTPAAPSSSGFMSFREQHLAQLQQLQQMHQKQMQCVLQPHHLPPPPLPPPPVMPGGGYGDWQPPPPPMPPPPGPALSYQKQQQYKHQMLHHQRDGPPGLVPMELESPPESPPVPPGSYMPPSQSYMPPPQPPPSYYPPTSSQPYLPPAQPSPSQSPPSQSYLAPTPSYSSSSSSSQSYLSHSQSYLPSSQASPSRPSQGHSKSQLLAPPPPSAPPGNKTTVQQEPLESGAKNKSTEQQQAAPEPDPSTMTPQEQQQYWYRQHLLSLQQRTKVHLPGHKKGPVVAKDTPEPVKEEVTVPATSQVPESPSSEEPPLPPPNEEVPPPLPPEEPQSEDPEEDARLKQLQAAAAHWQQHQQHRVGFQYQGIMQKHTQLQQILQQYQQIIQPPPHIQATTPPPGIPPPGVPQGIPPQLTAAPVPPASSSQSSQVPEKPRPALLPTPVSFGSAPPTTYHPPLQSAGPSEQVNSKAPLSKSALPYSSFSSDQGLGESSAAPSQPITAVKDMPVRSGGLLPDPPRSSYLESPRGPRFDGPRRFEDLGSRCEGPRPKGPRFEGNRPDGPRPRYEGHPAEGTKSKWGMIPRGPASQFYITPSTSLSPRQSGPQWKGPKPAFGQQHQQQPKSQAEPLSGNKEPLADTSSNQQKNFKMQSAAFSIAADVKDVKAAQSNENLSDSQQEPPKSEVSEGPVEPSNWDQNVQSMETQIDKAQAVTQPVPLANKPVPAQSTFPSKTGGMEGGTAVATSSLTADNDFKPVGIGLPHSENNQDKGLPRPDNRDNRLEGNRGNSSSYRGPGQSRMEDTRDKGLVNRGRGQAISRGPGLVKQEDFRDKMMGRREDSREKMNRGEGSRDRGLVRPGSSREKVPGGLQGSQDRGAAGSRERGPPRRAGSQERGPLRRAGSRERIPPRRAGSRERGPPRGPGSRERGLGRSDFGRDRGPFRPEPGDGGEKMYPYHRDEPPRAPWNHGEERGHEEFPLDGRNAPMERERLDDWDRERYWRECERDYQDDTLELYNREDRFSAPPSRSHDGDRRGPWWDDWERDQDMDEDYNREMERDMDRDVDRISRPMDMYDRSLDNEWDRDYGRPLDEQESQFRERDIPSLPPLPPLPPLPPLDRYRDDRWREERNREHGYDRDFRDRGELRIREYPERGDTWREKRDYVPDRMDWERERLSDRWYPSDVDRHSPMAEHMPSSHHSSEMMGSDASLDSDQGLGGVMVLSQRQHEIILKAAQELKMLREQKEQLQKMKDFGSEPQMADHLPPQESRLQNTSSRPGMYPPPGSYRPPPPMGKPPGSIVRPSAPPARSSVPVTRPPVPIPPPPPPPPLPPPPPVIKPQTSAVEQERWDEDSFYGLWDTNDEQGLNSEFKSETAAIPSAPVLPPPPVHSSIPPPGPVPMGMPPMSKPPPVQQTVDYGHGRDISTNKVEQIPYGERITLRPDPLPERSTFETEHAGQRDRYDRERDREPYFDRQSNVIADHRDFKRDRETHRDRDRDRGVIDYDRDRFDRERRPRDDRAQSYRDKKDHSSSRRGGFDRPSYDRKSDRPVYEGPSMFGGERRTYPEERMPLPAPSLSHQPPPAPRVEKKPESKNVDDILKPPGRESRPERIVVIMRGLPGSGKTHVAKLIRDKEVEFGGPAPRVLSLDDYFITEVEKEEKDPDSGKKVKKKVMEYEYEAEMEETYRTSMFKTFKKTLDDGFFPFIILDAINDRVRHFDQFWSAAKTKGFEVYLAEMSADNQTCGKRNIHGRKLKEINKMADHWETAPRHMMRLDIRSLLQDAAIEEVEMEDFDANIEEQKEEKKDAEEEESELGYIPKSKWEMDTSEAKLDKLDGLRTGTKRKRDWEAIASRMEDYLQLPDDYDTRASEPGKKRVRWADLEEKKDADRKRAIGFVVGQTDWEKITDESGHLAEKALNRTKYI>sp|Q96AP4|ZUP1_HUMAN Zinc finger-containing ubiquitin peptidase 1OS=Homo sapiens OX=9606 GN=ZUP1 PE=1 SV=1MLSCNICGETVTSEPDMKAHLIVHMESEIICPFCKLSGVNYDEMCFHIETAHFEQNTLERNFERINTVQYGTSDNKKDNTLQCGMEVNSSILSGCASNHPKNSAQNLTKDSTLKHEGFYSENLTESRKFLKSREKQSSLTEIKGSVYETTYSPPECPFCGKIEEHSEDMETHVKTKHANLLDIPLEDCDQPLYDCPMCGLICTNYHILQEHVDLHLEENSFQQGMDRVQCSGDLQLAHQLQQEEDRKRRSEESRQEIEEFQKLQRQYGLDNSGGYKQQQLRNMEIEVNRGRMPPSEFHRRKADMMESLALGFDDGKTKTSGIIEALHRYYQNAATDVRRVWLSSVVDHFHSSLGDKGWGCGYRNFQMLLSSLLQNDAYNDCLKGMLIPCIPKIQSMIEDAWKEGFDPQGASQLNNRLQGTKAWIGACEVYILLTSLRVKCHIVDFHKSTGPLGTHPRLFEWILNYYSSEGEGSPKVVCTSKPPIYLQHQGHSRTVIGIEEKKNRTLCLLILDPGCPSREMQKLLKQDIEASSLKQLRKSMGNLKHKQYQILAVEGALSLEEKLARRQASQVFTAEKIP>sp|Q96AP4-2|ZUP1_HUMAN Isoform 2 of Zinc finger-containing ubiquitinpeptidase 1 OS=Homo sapiens OX=9606 GN=ZUP1MQKLLKQDIEASSLKQLRKSMGNLKHKQYQILAVEGALSLEEKLARRQASQVFTAEKIP>sp|Q9NV12|TM140_HUMAN Transmembrane protein 140 OS=Homo sapiens OX=9606GN=TMEM140 PE=1 SV=2MAGPRPRWRDQLLFMSIIVLVIVVICLMFYALLWEAGNLTDLPNLRIGFYNFCLWNEDTSTLQCHQFPELEALGVPRVGLGLARLGVYGSLVLTLFAPQPLLLAQCNSDERAWRLAVGFLAVSSVLLAGGLGLFLSYVWKWVRLSLPGPGFLALGSAQALLILLLIAMAVFPLRAERAESKLESC>sp|Q6UXP3|TM14E_HUMAN Transmembrane protein 14EP OS=Homo sapiens OX=9606GN=TMEM14EP PE=5 SV=1MQMDPGPQVPLYWLGFVYAALAALGGISGYAKVGSVQSPSAGFFFSELAGLDASQPSRNPKEHLSSPVYIWDLARYYANKILTLWNIYACGFSCRCLLIVSKLGSMYGEQILSVVAMSQLGLMKN>sp|Q53S58|TM177_HUMAN Transmembrane protein 177 OS=Homo sapiens OX=9606GN=TMEM177 PE=1 SV=1MAGPLWRTAAFVQRHRTGLLVGSCAGLFGVPISYHLFPDPVVQWLYQYWPQGQPAPLPPQLQSLFQEVLQDIGVPSGHCYKPFTTFTFQPVSAGFPRLPAGAVVGIPASFLGDLVINTNHPVVIHGHTVDWRSPAGARLRASLTLSREAQKFALAREVVYLESSTTAVHALLAPACLAGTWALGVGAKYTLGLHAGPMNLRAAFSLVAAVAGFVAYAFSQDSLTHAVESWLDRRTASLSAAYACGGVEFYEKLLSGNLALRSLLGKDGEKLYTPSGNIVPRHLFRIKHLPYTTRRDSVLQMWRGMLNPGRS>sp|O75888|TNF13_HUMAN Tumor necrosis factor ligand superfamily member 13OS=Homo sapiens OX=9606 GN=TNFSF13 PE=1 SV=1MPASSPFLLAPKGPPGNMGGPVREPALSVALWLSWGAALGAVACAMALLTQQTELQSLRREVSRLQGTGGPSQNGEGYPWQSLPEQSSDALEAWENGERSRKRRAVLTQKQKKQHSVLHLVPINATSKDDSDVTEVMWQPALRRGRGLQAQGYGVRIQDAGVYLLYSQVLFQDVTFTMGQVVSREGQGRQETLFRCIRSMPSHPDRAYNSCYSAGVFHLHQGDILSVIIPRARAKLNLSPHGTFLGFVKL>sp|O75888-2|TNF13_HUMAN Isoform Beta of Tumor necrosis factor ligandsuperfamily member 13 OS=Homo sapiens OX=9606 GN=TNFSF13MPASSPFLLAPKGPPGNMGGPVREPALSVALWLSWGAALGAVACAMALLTQQTELQSLRREVSRLQGTGGPSQNGEGYPWQSLPEQSSDALEAWENGERSRKRRAVLTQKQKNDSDVTEVMWQPALRRGRGLQAQGYGVRIQDAGVYLLYSQVLFQDVTFTMGQVVSREGQGRQETLFRCIRSMPSHPDRAYNSCYSAGVFHLHQGDILSVIIPRARAKLNLSPHGTFLGFVKL>sp|O75888-3|TNF13_HUMAN Isoform Gamma of Tumor necrosis factor ligandsuperfamily member 13 OS=Homo sapiens OX=9606 GN=TNFSF13MPASSPFLLAPKGPPGNMGGPVREPALSVALWLSWGAALGAVACAMALLTQQTELQSLRREVSRLQGTGGPSQNGEGYPWQSLPEQSSDALEAWENGERSRKRRAVLTQKQKKQHSVLHLVPINATSKDDSDVTEVMWQPALRRGRGLQAQGYGVRIQDAGVYLLYSQVLFQDVTFTMGQVVSREGQGRQETLFRCIRSMPSHPDRAYNSCYSAGVFHLHQGDILSVIIPRARAKLNLSPHGTFLGL>sp|O75888-4|TNF13_HUMAN Isoform 4 of Tumor necrosis factor ligandsuperfamily member 13 OS=Homo sapiens OX=9606 GN=TNFSF13MPASSPFLLAPKGPPGNMGGPVREPALSVALWLSWGAALGAVACAMALLTQQTELQSLRREVSRLQGTGGPSQNGEGYPWQSLPEQHSVLHLVPINATSKDDSDVTEVMWQPALRRGRGLQAQGYGVRIQDAGVYLLYSQVLFQDVTFTMGQVVSREGQGRQETLFRCIRSMPSHPDRAYNSCYSAGVFHLHQGDILSVIIPRARAKLNLSPHGTFLGFVKL>sp|O75888-5|TNF13_HUMAN Isoform 5 of Tumor necrosis factor ligandsuperfamily member 13 OS=Homo sapiens OX=9606 GN=TNFSF13MGGPVREPALSVALWLSWGAALGAVACAMALLTQQTELQSLRREVSRLQGTGGPSQNGEGYPWQSLPEQHSVLHLVPINATSKDDSDVTEVMWQPALRRGRGLQAQGYGVRIQDAGVYLLYSQVLFQDVTFTMGQVVSREGQGRQETLFRCIRSMPSHPDRAYNSCYSAGVFHLHQGDILSVIIPRARAKLNLSPHGTFLGFVKL>sp|Q96AN5|TM143_HUMAN Transmembrane protein 143 OS=Homo sapiens OX=9606GN=TMEM143 PE=1 SV=1MTVELWLRLRGKGLAMLHVTRGVWGSRVRVWPLLPALLGPPRALSSLAAKMGEYRKMWNPREPRDWAQQYRERFIPFSKEQLLRLLIQEFHSSPAEKAALEAFSAHVDFCTLFHYHQILARLQALYDPINPDRETLDQPSLTDPQRLSNEQEVLRALEPLLAQANFSPLSEDTLAYALVVHHPQDEVQVTVNLDQYVYIHFWALGQRVGQMPLKSSVGSRRGFFTKLPPAERRYFKRVVLAARTKRGHLVLKSFKDTPLEGLEQLLPELKVRTPTLQRALLNLMLVVSGVAIFVNVGMVVLTDLKVATSLLLLLFAIFMGLRASKMFGQRRSAQALELAHMLYYRSTSNNSELLSALALRAQDEHTKEALLAHSFLARRPGGTQGSPEETSRWLRSEVENWLLAKSGCEVTFNGTRALAHLQALTPSMGLYPPPGFPKLDPVAPITSEPPQATPSSNIS>sp|Q96AN5-2|TM143_HUMAN Isoform 2 of Transmembrane protein 143 OS=Homosapiens OX=9606 GN=TMEM143MTVELWLRLRGKGLAMLHVTRGVWGSRVRVWPLLPALLGPPRALSSLAAKMGEYRKMWNPREPRDWAQQYRERFIPFSKEQLLRLLIQVTVNLDQYVYIHFWALGQRVGQMPLKSSVGSRRGFFTKLPPAERRYFKRVVLAARTKRGHLVLKSFKDTPLEGLEQLLPELKVRTPTLQRALLNLMLVVSGVAIFVNVGMVVLTDLKVATSLLLLLFAIFMGLRASKMFGQRRSAQALELAHMLYYRSTSNNSELLSALALRAQDEHTKEALLAHSFLARRPGGTQGSPEETSRWLRSEVENWLLAKSGCEVTFNGTRALAHLQALTPSMGLYPPPGFPKLDPVAPITSEPPQATPSSNIS>sp|Q96AN5-3|TM143_HUMAN Isoform 3 of Transmembrane protein 143 OS=Homosapiens OX=9606 GN=TMEM143MTVELWLRLRGKGLAMLHVTRGVWGSRVRVWPLLPALLGPPRALSSLAAKMGEYRKMWNPREPRDWAQQYRERFIPFSKEQLLRLLIQVTGIPLESGREGGFGGVLSPRGLLHPVPLPPNPGPAAGLI>sp|Q9H6X4|TM134_HUMAN Transmembrane protein 134 OS=Homo sapiens OX=9606GN=TMEM134 PE=1 SV=1MSAARPQFSIDDAFELSLEDGGPGPESSGVARFGPLHFERRARFEVADEDKQSRLRYQNLENDEDGAQASPEPDGGVGTRDSSRTSIRSSQWSFSTISSSTQRSYNTCCSWTQHPLIQKNRRVVLASFLLLLLGLVLILVGVGLEATPSPGVSSAIFFVPGFLLLVPGVYHVIFIYCAVKGHRGFQFFYLPYFEK>sp|Q9H6X4-2|TM134_HUMAN Isoform 2 of Transmembrane protein 134 OS=Homosapiens OX=9606 GN=TMEM134MSAARPQFSIDDAFELSLEDGGPGPESSGVARFGPLHFERRARFEVADEDKQSRLRYQNLENDEDGAQASPEPDGGVGTRDSSRTSIRSSQWSFSTISSSTQRSYNTCCSWTQHPLIQKNRRVVLASFLLLLLGLGVSSAIFFVPGFLLLVPGVYHVIFIYCAVKGHRGFQFFYLPYFEK>sp|Q9H6X4-3|TM134_HUMAN Isoform 3 of Transmembrane protein 134 OS=Homosapiens OX=9606 GN=TMEM134MSAARPQFSIDDAFELSLEDGGPGPESSGVARFGPLHFERRARFEVADEDKQSRLRYQNLENDEDGAQASPEPDGGVGTRDSSRTSIRSSQWSFSTISSSTQRSYNTCCSWTQHPLIQKNRRVVLASFLLLLLGLGPAQCLALETELGELPGEGLCLGHLQLRWWVSRAGGGSPRPHHCSCPHPRGSVCVQC>sp|Q9BU70|TRMO_HUMAN tRNA (adenine(37)-N6)-methyltransferase OS=Homosapiens OX=9606 GN=TRMO PE=1 SV=2MRGLEESGPRPTATPCGCVKPALETGNLLTEPVGYLESCFSAKNGTPRQPSICSYSRACLRIRKRIFNNPEHSLMGLEQFSHVWILFVFHKNGHLSCKAKVQPPRLNGAKTGVFSTRSPHRPNAIGLTLAKLEKVEGGAIYLSGIDMIHGTPVLDIKPYIAEYDSPQNVMEPLADFNLQNNQHTPNTVSQSDSKTDSCDQRQLSGCDEPQPHHSTKRKPKCPEDRTSEENYLTHSDTARIQQAFPMHREIAVDFGLESRRDQSSSVAEEQIGPYCPEKSFSEKGTDKKLERVEGAAVLQGSRAETQPMAPHCPAGRADGAPRSVVPAWVTEAPVATLEVRFTPHAEMDLGQLSSQDVGQASFKYFQSAEEAKRAIEAVLSADPRSVYRRKLCQDRLFYFTVDIAHVTCWFGDGFAEVLRIKPASEPVHMTGPVGSLVSLGS>sp|P41732|TSN7_HUMAN Tetraspanin-7 OS=Homo sapiens OX=9606 GN=TSPAN7PE=1 SV=2MASRRMETKPVITCLKTLLIIYSFVFWITGVILLAVGVWGKLTLGTYISLIAENSTNAPYVLIGTGTTIVVFGLFGCFATCRGSPWMLKLYAMFLSLVFLAELVAGISGFVFRHEIKDTFLRTYTDAMQTYNGNDERSRAVDHVQRSLSCCGVQNYTNWSTSPYFLEHGIPPSCCMNETDCNPQDLHNLTVAATKVNQKGCYDLVTSFMETNMGIIAGVAFGIAFSQLIGMLLACCLSRFITANQYEMV>sp|Q5VV11|U633B_HUMAN Putative UPF0633 protein ENSP00000303136 OS=Homosapiens OX=9606 PE=5 SV=1MRKLRLRASNPGPSGAPGTRQHFSTSRGGHHCARRWLRRVRRSRSQTPSYQNLDPNPPIVRFPLPLERISEVPRRACLHGRDASSVWPPPERSD>sp|B0FP48|UPK3L_HUMAN Uroplakin-3b-like protein 1 OS=Homo sapiensOX=9606 GN=UPK3BL1 PE=2 SV=1MDNSWRLGPAIGLSAGQSQLLVSLLLLLTRVQPGTDVAAPEHISYVPQLSNDTLAGRLTLSTFTLEQPLGQFSSHNISDLDTIWLVVALSNATQSFTAPRTNQDIPAPANFSQRGYYLTLRANRVLYQTRGQLHVLRVGNDTHCQPTKIGCNHPLPGPGPYRVKFLVMNDEGPVAETKWSSDTRLQQAQALRAVPGPQSPGTVVIIAILSILLAVLLTVLLAVLIYTCFNSCRSTSLSGPEEAGSVRRYTTHLAFSTPAEGAS>sp|P83876|TXN4A_HUMAN Thioredoxin-like protein 4A OS=Homo sapiensOX=9606 GN=TXNL4A PE=1 SV=1MSYMLPHLHNGWQVDQAILSEEDRVVVIRFGHDWDPTCMKMDEVLYSIAEKVKNFAVIYLVDITEVPDFNKMYELYDPCTVMFFFRNKHIMIDLGTGNNNKINWAMEDKQEMVDIIETVYRGARKGRGLVVSPKDYSTKYRY>sp|Q9Y6I9|TX264_HUMAN Testis-expressed protein 264 OS=Homo sapiensOX=9606 GN=TEX264 PE=1 SV=1MSDLLLLGLIGGLTLLLLLTLLAFAGYSGLLAGVEVSAGSPPIRNVTVAYKFHMGLYGETGRLFTESCSISPKLRSIAVYYDNPHMVPPDKCRCAVGSILSEGEESPSPELIDLYQKFGFKVFSFPAPSHVVTATFPYTTILSIWLATRRVHPALDTYIKERKLCAYPRLEIYQEDQIHFMCPLARQGDFYVPEMKETEWKWRGLVEAIDTQVDGTGADTMSDTSSVSLEVSPGSRETSAATLSPGASSRGWDDGDTRSEHSYSESGASGSSFEELDLEGEGPLGESRLDPGTEPLGTTKWLWEPTAPEKGKE>sp|Q70EL4|UBP43_HUMAN Ubiquitin carboxyl-terminal hydrolase 43 OS=Homosapiens OX=9606 GN=USP43 PE=1 SV=2MDLGPGDAAGGGPLAPRPRRRRSLRRLFSRFLLALGSRSRPGDSPPRPQPGHCDGDGEGGFACAPGPVPAAPGSPGEERPPGPQPQLQLPAGDGARPPGAQGLKNHGNTCFMNAVVQCLSNTDLLAEFLALGRYRAAPGRAEVTEQLAALVRALWTREYTPQLSAEFKNAVSKYGSQFQGNSQHDALEFLLWLLDRVHEDLEGSSRGPVSEKLPPEATKTSENCLSPSAQLPLGQSFVQSHFQAQYRSSLTCPHCLKQSNTFDPFLCVSLPIPLRQTRFLSVTLVFPSKSQRFLRVGLAVPILSTVAALRKMVAEEGGVPADEVILVELYPSGFQRSFFDEEDLNTIAEGDNVYAFQVPPSPSQGTLSAHPLGLSASPRLAAREGQRFSLSLHSESKVLILFCNLVGSGQQASRFGPPFLIREDRAVSWAQLQQSILSKVRHLMKSEAPVQNLGSLFSIRVVGLSVACSYLSPKDSRPLCHWAVDRVLHLRRPGGPPHVKLAVEWDSSVKERLFGSLQEERAQDADSVWQQQQAHQQHSCTLDECFQFYTKEEQLAQDDAWKCPHCQVLQQGMVKLSLWTLPDILIIHLKRFCQVGERRNKLSTLVKFPLSGLNMAPHVAQRSTSPEAGLGPWPSWKQPDCLPTSYPLDFLYDLYAVCNHHGNLQGGHYTAYCRNSLDGQWYSYDDSTVEPLREDEVNTRGAYILFYQKRNSIPPWSASSSMRGSTSSSLSDHWLLRLGSHAGSTRGSLLSWSSAPCPSLPQVPDSPIFTNSLCNQEKGGLEPRRLVRGVKGRSISMKAPTTSRAKQGPFKTMPLRWSFGSKEKPPGASVELVEYLESRRRPRSTSQSIVSLLTGTAGEDEKSASPRSNVALPANSEDGGRAIERGPAGVPCPSAQPNHCLAPGNSDGPNTARKLKENAGQDIKLPRKFDLPLTVMPSVEHEKPARPEGQKAMNWKESFQMGSKSSPPSPYMGFSGNSKDSRRGTSELDRPLQGTLTLLRSVFRKKENRRNERAEVSPQVPPVSLVSGGLSPAMDGQAPGSPPALRIPEGLARGLGSRLERDVWSAPSSLRLPRKASRAPRGSALGMSQRTVPGEQASYGTFQRVKYHTLSLGRKKTLPESSF>sp|Q70EL4-2|UBP43_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 43 OS=Homo sapiens OX=9606 GN=USP43MPTVCGSSSRRISSTAVPWMNVFSSTPRRSRSRPGGPCPGREGGWLPLVGWPRAAGASQSGWFAFQLAQDDAWKCPHCQVLQQGMVKLSLWTLPDILIIHLKRFCQVGERRNKLSTLVKFPLSGLNMAPHVAQRSTSPEAGLGPWPSWKQPDCLPTSYPLDFLYDLYAVCNHHGNLQGGHYTAYCRNSLDGQWYSYDDSTVEPLREDEVNTRGAYILFYQKRNSIPPWSASSSMRGSTSSSLSDHWLLRLGSHAGSTRGSLLSWSSAPCPSLPQVPDSPIFTNSLCNQEKGGLEPRRLVRGVKGRSISMKAPTTSRAKQGPFKTMPLRWSFGSKEKPPGASVELVEYLESRRRPRSTSQSIVSLLTGTAGEDEKSASPRSNVALPANSEDGGRAIERGPAGVPCPSAQPNHCLAPGNSDGPNTARKLKENAGQDIKLPRKFDLPLTVMPSVEHEKPARPEGQKAMNWKESFQMGSKSSPPSPYMGFSGNSKDSRRGTSELDRPLQGTLTLLRSVFRKKENRRNERAEVSPQVPPVSLVSGGLSPAMDGQAPGSPPALRIPEGLARGLGSRLERDVWSAPSSLRLPRKASRAPRGSALGMSQRTVPGEQASYGTFQRVKYHTLSLGRKKTLPESSF>sp|Q70EL4-3|UBP43_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 43 OS=Homo sapiens OX=9606 GN=USP43MVAEEGGVPADEVILVELYPSGFQRSFFDEEDLNTIAEGDNVYAFQVPPSPSQGTLSAHPLGLSASPRLAAREGQRFSLSLHSESKVLILFCNLVGSGQQASRFGPPFLIREDRAVSWAQLQQSILSKVRHLMKSEAPVQNLGSLFSIRVVGLSVACSYLSPKDSRPLCHWAVDRVLHLRRPGGPPHVKLAVEWDSSVKERLFGSLQEERAQDADSVWQQQQAHQQHSCTLDECFQFYTKEEQLAQDDAWKCPHCQVLQQGMVKLSLWTLPDILIIHLKRFCQVGERRNKLSTLVKFPLSGLNMAPHVAQRSTSPEAGLGPWPSWKQPDCLPTSYPLDFLYDLYAVCNHHGNLQGGHYTAYCRNSLDGQWYSYDDSTVEPLREDEVNTRGAYILFYQKRNSIPPWSASSSMRGSTSSSLSDHWLLRLGSHAGSTRGSLLSWSSAPCPSLPQVPDSPIFTNSLCNQEKGGLEPRRLVRGVKGRSISMKAPTTSRAKQGPFKTMPLRWSFGSKEKPPGASVELVEYLESRRRPRSTSQSIVSLLTGTAGEDEKSASPRSNVALPANSEDGGRAIERGPAGVPCPSAQPNHCLAPGNSDGPNTARKLKENAGQDIKLPRKFDLPLTVMPSVEHEKPARPEGQKAMNWKESFQMGSKSSPPSPYMGFSGNSKDSRRGTSELDRPLQGTLTLLRSVFRKKENRRNERAEVSPQVPPVSLVSGGLSPAMDGQAPGSPPALRIPEGLARGLGSRLERDVWSAPSSLRLPRKASRAPRGSALGMSQRTVPGEQASYGTFQRVKYHTLSLGRKKTLPESSF>sp|Q70EL4-4|UBP43_HUMAN Isoform 4 of Ubiquitin carboxyl-terminalhydrolase 43 OS=Homo sapiens OX=9606 GN=USP43MDLGPGDAAGGGPLAPRPRRRRSLRRLFSRFLLALGSRSRPGDSPPRPQPGHCDGDGEGGFACAPGPVPAAPGSPGEERPPGPQPQLQLPAGDGARPPGAQGLKNHGNTCFMNAVVQCLSNTDLLAEFLALGRYRAAPGRAEVTEQLAALVRALWTREYTPQLSAEFKNAVSKYGSQFQGNSQHDALEFLLWLLDRVHEDLEGSSRGPVSEKLPPEATKTSENCLSPSAQLPLGQSFVQSHFQAQYRSSLTCPHCLKQSNTFDPFLCVSLPIPLRQTRFLSVTLVFPSKSQRFLRVGLAVPILSTVAALRKMVAEEGGVPADEVILVELYPSGFQRSFFDEEDLNTIAEGDNVYAFQVPPSPSQGTLSAHPLGLSASPRLAAREGQRFSLSLHSESKVLILFCNLVGSGQQASRFGPPFLIREDRAVSWAQLQQSILSKVRHLMKSEAPVQNLGSLFSIRVVGLSVACSYLSPKDSRPLCHWAVDRVLHLRRPGGPPHVKLAVEWDSSVKERLFGSLQEERAQDADSVWQQQQAHQQHSCTLDECFQFYTKEEQLAQDDAWKCPHCQVLQQGMVKLSLWTLPDILIIHLKRFCQVGERRNKLSTLVKFPLSGLNMAPHVAQRSTSPEAGLGPWPSWKQPDCLPTSYPLDFLYDLYAVCNHHGNLQAYCRNSLDGQWYSYDDSTVEPLREDEVNTRGAYILFYQKRNSIPPWSASSSMRGSTSSSLSDHWLLRLGSHAGSTRGSLLSWSSAPCPSLPQVPDSPIFTNSLCNQEKGGLEPRRLVRGVKGRSISMKAPTTSRAKQGPFKTMPLRWSFGSKEKPPGASVELVEYLESRRRPRSTSQSIVSLLTGTAGEDEKSASPRSNVALPANSEDGGRAIERGPAGVPCPSAQPNHCLAPGNSDGPNTARKLKENAGQDIKLPRKFDLPLTVMPSVEHEKPARPEGQKAMNWKESFQMGSKSSPPSPYMGFSGNSKDSRRGTSELDRPLQGTLTLLRSVFRKKENRRNERAEVSPQVPPVSLVSGGLSPAMDGQAPGSPPALRIPEGLARGLGSRLERDVWSAPSSLRLPRKASRAPRGSALGMSQRTVPGEQASYGTFQRVKYHTLSLGRKKTLPESSF>sp|Q70CQ1|UBP49_HUMAN Ubiquitin carboxyl-terminal hydrolase 49 OS=Homosapiens OX=9606 GN=USP49 PE=1 SV=1MDRCKHVGRLRLAQDHSILNPQKWCCLECATTESVWACLKCSHVACGRYIEDHALKHFEETGHPLAMEVRDLYVFCYLCKDYVLNDNPEGDLKLLRSSLLAVRGQKQDTPVRRGRTLRSMASGEDVVLPQRAPQGQPQMLTALWYRRQRLLARTLRLWFEKSSRGQAKLEQRRQEEALERKKEEARRRRREVKRRLLEELASTPPRKSARLLLHTPRDAGPAASRPAALPTSRRVPAATLKLRRQPAMAPGVTGLRNLGNTCYMNSILQVLSHLQKFRECFLNLDPSKTEHLFPKATNGKTQLSGKPTNSSATELSLRNDRAEACEREGFCWNGRASISRSLELIQNKEPSSKHISLCRELHTLFRVMWSGKWALVSPFAMLHSVWSLIPAFRGYDQQDAQEFLCELLHKVQQELESEGTTRRILIPFSQRKLTKQVLKVVNTIFHGQLLSQVTCISCNYKSNTIEPFWDLSLEFPERYHCIEKGFVPLNQTECLLTEMLAKFTETEALEGRIYACDQCNSKRRKSNPKPLVLSEARKQLMIYRLPQVLRLHLKRFRWSGRNHREKIGVHVVFDQVLTMEPYCCRDMLSSLDKETFAYDLSAVVMHHGKGFGSGHYTAYCYNTEGGFWVHCNDSKLNVCSVEEVCKTQAYILFYTQRTVQGNARISETHLQAQVQSSNNDEGRPQTFS>sp|Q70CQ1-2|UBP49_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 49 OS=Homo sapiens OX=9606 GN=USP49MDRCKHVGRLRLAQDHSILNPQKWCCLECATTESVWACLKCSHVACGRYIEDHALKHFEETGHPLAMEVRDLYVFCYLCKDYVLNDNPEGDLKLLRSSLLAVRGQKQDTPVRRGRTLRSMASGEDVVLPQRAPQGQPQMLTALWYRRQRLLARTLRLWFEKSSRGQAKLEQRRQEEALERKKEEARRRRREVKRRLLEELASTPPRKSARLLLHTPRDAGPAASRPAALPTSRRVPAATLKLRRQPAMAPGVTGLRNLGNTCYMNSILQVLSHLQKFRECFLNLDPSKTEHLFPKATNGKTQLSGKPTNSSATELSLRNDRAEACEREGFCWNGRASISRSLELIQNKEPSSKHISLCRELHTLFRVMWSGKWALVSPFAMLHSVWSLIPAFRGYDQQDAQEFLCELLHKVQQELESEGTTRRILIPFSQRKLTKQVLKVVNTIFHGQLLSQVTCISCNYKSNTIEPFWDLSLEFPERYHCIEKGFVPLNQTECLLTEMLAKFTETEALEGRIYACDQCNSKRRKSNPKPLVLSEARKQLMIYRLPQVLRLHLKRFRWSGRNHREKIGVHVVFDQVLTMEPYCCRDMLSSLDKETFAYDLSAVVMHHGKGFGSGHYTAYCYNTEGGACALLCGVGDTERG>sp|D6RCP7|U17LJ_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 19 OS=Homo sapiens OX=9606 GN=USP17L19 PE=3 SV=1MEEDSLYLGGEWQFNHFSKLTSSRPDAAFAEIQRTSLPEKSPLSCETRVDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHHSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQTNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASSITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDHWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLKLSSTTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|P22314|UBA1_HUMAN Ubiquitin-like modifier-activating enzyme 1 OS=Homosapiens OX=9606 GN=UBA1 PE=1 SV=3MSSSPLSKKRRVSGPDPKPGSNCSPAQSVLSEVPSVPTNGMAKNGSEADIDEGLYSRQLYVLGHEAMKRLQTSSVLVSGLRGLGVEIAKNIILGGVKAVTLHDQGTAQWADLSSQFYLREEDIGKNRAEVSQPRLAELNSYVPVTAYTGPLVEDFLSGFQVVVLTNTPLEDQLRVGEFCHNRGIKLVVADTRGLFGQLFCDFGEEMILTDSNGEQPLSAMVSMVTKDNPGVVTCLDEARHGFESGDFVSFSEVQGMVELNGNQPMEIKVLGPYTFSICDTSNFSDYIRGGIVSQVKVPKKISFKSLVASLAEPDFVVTDFAKFSRPAQLHIGFQALHQFCAQHGRPPRPRNEEDAAELVALAQAVNARALPAVQQNNLDEDLIRKLAYVAAGDLAPINAFIGGLAAQEVMKACSGKFMPIMQWLYFDALECLPEDKEVLTEDKCLQRQNRYDGQVAVFGSDLQEKLGKQKYFLVGAGAIGCELLKNFAMIGLGCGEGGEIIVTDMDTIEKSNLNRQFLFRPWDVTKLKSDTAAAAVRQMNPHIRVTSHQNRVGPDTERIYDDDFFQNLDGVANALDNVDARMYMDRRCVYYRKPLLESGTLGTKGNVQVVIPFLTESYSSSQDPPEKSIPICTLKNFPNAIEHTLQWARDEFEGLFKQPAENVNQYLTDPKFVERTLRLAGTQPLEVLEAVQRSLVLQRPQTWADCVTWACHHWHTQYSNNIRQLLHNFPPDQLTSSGAPFWSGPKRCPHPLTFDVNNPLHLDYVMAAANLFAQTYGLTGSQDRAAVATFLQSVQVPEFTPKSGVKIHVSDQELQSANASVDDSRLEELKATLPSPDKLPGFKMYPIDFEKDDDSNFHMDFIVAASNLRAENYDIPSADRHKSKLIAGKIIPAIATTTAAVVGLVCLELYKVVQGHRQLDSYKNGFLNLALPFFGFSEPLAAPRHQYYNQEWTLWDRFEVQGLQPNGEEMTLKQFLDYFKTEHKLEITMLSQGVSMLYSFFMPAAKLKERLDQPMTEIVSRVSKRKLGRHVRALVLELCCNDESGEDVEVPYVRYTIR>sp|P22314-2|UBA1_HUMAN Isoform 2 of Ubiquitin-like modifier-activatingenzyme 1 OS=Homo sapiens OX=9606 GN=UBA1MAKNGSEADIDEGLYSRQLYVLGHEAMKRLQTSSVLVSGLRGLGVEIAKNIILGGVKAVTLHDQGTAQWADLSSQFYLREEDIGKNRAEVSQPRLAELNSYVPVTAYTGPLVEDFLSGFQVVVLTNTPLEDQLRVGEFCHNRGIKLVVADTRGLFGQLFCDFGEEMILTDSNGEQPLSAMVSMVTKDNPGVVTCLDEARHGFESGDFVSFSEVQGMVELNGNQPMEIKVLGPYTFSICDTSNFSDYIRGGIVSQVKVPKKISFKSLVASLAEPDFVVTDFAKFSRPAQLHIGFQALHQFCAQHGRPPRPRNEEDAAELVALAQAVNARALPAVQQNNLDEDLIRKLAYVAAGDLAPINAFIGGLAAQEVMKACSGKFMPIMQWLYFDALECLPEDKEVLTEDKCLQRQNRYDGQVAVFGSDLQEKLGKQKYFLVGAGAIGCELLKNFAMIGLGCGEGGEIIVTDMDTIEKSNLNRQFLFRPWDVTKLKSDTAAAAVRQMNPHIRVTSHQNRVGPDTERIYDDDFFQNLDGVANALDNVDARMYMDRRCVYYRKPLLESGTLGTKGNVQVVIPFLTESYSSSQDPPEKSIPICTLKNFPNAIEHTLQWARDEFEGLFKQPAENVNQYLTDPKFVERTLRLAGTQPLEVLEAVQRSLVLQRPQTWADCVTWACHHWHTQYSNNIRQLLHNFPPDQLTSSGAPFWSGPKRCPHPLTFDVNNPLHLDYVMAAANLFAQTYGLTGSQDRAAVATFLQSVQVPEFTPKSGVKIHVSDQELQSANASVDDSRLEELKATLPSPDKLPGFKMYPIDFEKDDDSNFHMDFIVAASNLRAENYDIPSADRHKSKLIAGKIIPAIATTTAAVVGLVCLELYKVVQGHRQLDSYKNGFLNLALPFFGFSEPLAAPRHQYYNQEWTLWDRFEVQGLQPNGEEMTLKQFLDYFKTEHKLEITMLSQGVSMLYSFFMPAAKLKERLDQPMTEIVSRVSKRKLGRHVRALVLELCCNDESGEDVEVPYVRYTIR>sp|Q92738|US6NL_HUMAN USP6 N-terminal-like protein OS=Homo sapiensOX=9606 GN=USP6NL PE=1 SV=3MNSDQDVALKLAQERAEIVAKYDRGREGAEIEPWEDADYLVYKVTDRFGFLHEEELPDHNVAVERQKHLEIERTTKWLKMLKGWEKYKNTEKFHRRIYKGIPLQLRGEVWALLLEIPKMKEETRDLYSKLKHRARGCSPDIRQIDLDVNRTFRDHIMFRDRYGVKQQSLFHVLAAYSIYNTEVGYCQGMSQITALLLMYMNEEDAFWALVKLFSGPKHAMHGFFVQGFPKLLRFQEHHEKILNKFLSKLKQHLDSQEIYTSFYTMKWFFQCFLDRTPFTLNLRIWDIYIFEGERVLTAMSYTILKLHKKHLMKLSMEELVEFFQETLAKDFFFEDDFVIEQLQISMTELKRAKLDLPEPGKEDEYPKKPLGQLPPELQSWGVHHLSNGQRSVGRPSPLASGRRESGAPHRRHEHSPHPQSRTGTPERAQPPRRKSVEEESKKLKDEADFQRKLPSGPQDSSRQYNHAAANQNSNATSNIRKEFVPKWNKPSDVSATERTAKYTMEGKGRAAHPALAVTVPGPAEVRVSNVRPKMKALDAEDGKRGSTASQYDNVPGPELDSGASVEEALERAYSQSPRHALYPPSPRKHAEPSSSPSKVSNKFTFKVQPPSHARYPSQLDGEARGLAHPPSYSNPPVYHGNSPKHFPTANSSFASPQFSPGTQLNPSRRPHGSTLSVSASPEKSYSRPSPLVLPSSRIEVLPVDTGAGGYSGNSGSPKNGKLIIPPVDYLPDNRTWSEVSYTYRPETQGQSWTRDASRGNLPKYSAFQLAPFQDHGLPAVSVDSPVRYKASPAAEDASPSGYPYSGPPPPAYHYRNRDGLSIQESVLL>sp|Q92738-2|US6NL_HUMAN Isoform 2 of USP6 N-terminal-like proteinOS=Homo sapiens OX=9606 GN=USP6NLMRTEAVVNSQGQTDYLTKDSDQDVALKLAQERAEIVAKYDRGREGAEIEPWEDADYLVYKVTDRFGFLHEEELPDHNVAVERQKHLEIERTTKWLKMLKGWEKYKNTEKFHRRIYKGIPLQLRGEVWALLLEIPKMKEETRDLYSKLKHRARGCSPDIRQIDLDVNRTFRDHIMFRDRYGVKQQSLFHVLAAYSIYNTEVGYCQGMSQITALLLMYMNEEDAFWALVKLFSGPKHAMHGFFVQGFPKLLRFQEHHEKILNKFLSKLKQHLDSQEIYTSFYTMKWFFQCFLDRTPFTLNLRIWDIYIFEGERVLTAMSYTILKLHKKHLMKLSMEELVEFFQETLAKDFFFEDDFVIEQLQISMTELKRAKLDLPEPGKEDEYPKKPLGQLPPELQSWGVHHLSNGQRSVGRPSPLASGRRESGAPHRRHEHSPHPQSRTGTPERAQPPRRKSVEEESKKLKDEADFQRKLPSGPQDSSRQYNHAAANQNSNATSNIRKEFVPKWNKPSDVSATERTAKYTMEGKGRAAHPALAVTVPGPAEVRVSNVRPKMKALDAEDGKRGSTASQYDNVPGPELDSGASVEEALERAYSQSPRHALYPPSPRKHAEPSSSPSKVSNKFTFKVQPPSHARYPSQLDGEARGLAHPPSYSNPPVYHGNSPKHFPTANSSFASPQFSPGTQLNPSRRPHGSTLSVSASPEKSYSRPSPLVLPSSRIEVLPVDTGAGGYSGNSGSPKNGKLIIPPVDYLPDNRTWSEVSYTYRPETQGQSWTRDASRGNLPKYSAFQLAPFQDHGLPAVSVDSPVRYKASPAAEDASPSGYPYSGPPPPAYHYRNRDGLSIQESVLL>sp|P30518|V2R_HUMAN Vasopressin V2 receptor OS=Homo sapiens OX=9606GN=AVPR2 PE=1 SV=1MLMASTTSAVPGHPSLPSLPSNSSQERPLDTRDPLLARAELALLSIVFVAVALSNGLVLAALARRGRRGHWAPIHVFIGHLCLADLAVALFQVLPQLAWKATDRFRGPDALCRAVKYLQMVGMYASSYMILAMTLDRHRAICRPMLAYRHGSGAHWNRPVLVAWAFSLLLSLPQLFIFAQRNVEGGSGVTDCWACFAEPWGRRTYVTWIALMVFVAPTLGIAACQVLIFREIHASLVPGPSERPGGRRRGRRTGSPGEGAHVSAAVAKTVRMTLVIVVVYVLCWAPFFLVQLWAAWDPEAPLEGAPFVLLMLLASLNSCTNPWIYASFSSSVSSELRSLLCCARGRTPPSLGPQDESCTTASSSLAKDTSS>sp|P30518-2|V2R_HUMAN Isoform 2 of Vasopressin V2 receptor OS=Homosapiens OX=9606 GN=AVPR2MLMASTTSAVPGHPSLPSLPSNSSQERPLDTRDPLLARAELALLSIVFVAVALSNGLVLAALARRGRRGHWAPIHVFIGHLCLADLAVALFQVLPQLAWKATDRFRGPDALCRAVKYLQMVGMYASSYMILAMTLDRHRAICRPMLAYRHGSGAHWNRPVLVAWAFSLLLSLPQLFIFAQRNVEGGSGVTDCWACFAEPWGRRTYVTWIALMVFVAPTLGIAACQVLIFREIHASLVPGPSERPGGRRRGRRTGSPGEGAHVSAAVAKTVRMTLVIVVVYVLCWAPFFLVQLWAAWDPEAPLEGGCSRG>sp|P26368|U2AF2_HUMAN Splicing factor U2AF 65 kDa subunit OS=Homosapiens OX=9606 GN=U2AF2 PE=1 SV=4MSDFDEFERQLNENKQERDKENRHRKRSHSRSRSRDRKRRSRSRDRRNRDQRSASRDRRRRSKPLTRGAKEEHGGLIRSPRHEKKKKVRKYWDVPPPGFEHITPMQYKAMQAAGQIPATALLPTMTPDGLAVTPTPVPVVGSQMTRQARRLYVGNIPFGITEEAMMDFFNAQMRLGGLTQAPGNPVLAVQINQDKNFAFLEFRSVDETTQAMAFDGIIFQGQSLKIRRPHDYQPLPGMSENPSVYVPGVVSTVVPDSAHKLFIGGLPNYLNDDQVKELLTSFGPLKAFNLVKDSATGLSKGYAFCEYVDINVTDQAIAGLNGMQLGDKKLLVQRASVGAKNATLVSPPSTINQTPVTLQVPGLMSSQVQMGGHPTEVLCLMNMVLPEELLDDEEYEEIVEDVRDECSKYGLVKSIEIPRPVDGVEVPGCGKIFVEFTSVFDCQKAMQGLTGRKFANRVVVTKYCDPDSYHRRDFW>sp|P26368-2|U2AF2_HUMAN Isoform 2 of Splicing factor U2AF 65 kDa subunitOS=Homo sapiens OX=9606 GN=U2AF2MSDFDEFERQLNENKQERDKENRHRKRSHSRSRSRDRKRRSRSRDRRNRDQRSASRDRRRRSKPLTRGAKEEHGGLIRSPRHEKKKKVRKYWDVPPPGFEHITPMQYKAMQAAGQIPATALLPTMTPDGLAVTPTPVPVVGSQMTRQARRLYVGNIPFGITEEAMMDFFNAQMRLGGLTQAPGNPVLAVQINQDKNFAFLEFRSVDETTQAMAFDGIIFQGQSLKIRRPHDYQPLPGMSENPSVYVPGVVSTVVPDSAHKLFIGGLPNYLNDDQVKELLTSFGPLKAFNLVKDSATGLSKGYAFCEYVDINVTDQAIAGLNGMQLGDKKLLVQRASVGAKNATLSTINQTPVTLQVPGLMSSQVQMGGHPTEVLCLMNMVLPEELLDDEEYEEIVEDVRDECSKYGLVKSIEIPRPVDGVEVPGCGKIFVEFTSVFDCQKAMQGLTGRKFANRVVVTKYCDPDSYHRRDFW>sp|Q93008|USP9X_HUMAN Probable ubiquitin carboxyl-terminal hydrolaseFAF-X OS=Homo sapiens OX=9606 GN=USP9X PE=1 SV=4MTATTRGSPVGGNDNQGQAPDGQSQPPLQQNQTSSPDSSNENSPATPPDEQGQGDAPPQLEDEEPAFPHTDLAKLDDMINRPRWVVPVLPKGELEVLLEAAIDLSKKGLDVKSEACQRFFRDGLTISFTKILTDEAVSGWKFEIHRCIINNTHRLVELCVAKLSQDWFPLLELLAMALNPHCKFHIYNGTRPCESVSSSVQLPEDELFARSPDPRSPKGWLVDLLNKFGTLNGFQILHDRFINGSALNVQIIAALIKPFGQCYEFLTLHTVKKYFLPIIEMVPQFLENLTDEELKKEAKNEAKNDALSMIIKSLKNLASRVPGQEETVKNLEIFRLKMILRLLQISSFNGKMNALNEVNKVISSVSYYTHRHGNPEEEEWLTAERMAEWIQQNNILSIVLRDSLHQPQYVEKLEKILRFVIKEKALTLQDLDNIWAAQAGKHEAIVKNVHDLLAKLAWDFSPEQLDHLFDCFKASWTNASKKQREKLLELIRRLAEDDKDGVMAHKVLNLLWNLAHSDDVPVDIMDLALSAHIKILDYSCSQDRDTQKIQWIDRFIEELRTNDKWVIPALKQIREICSLFGEAPQNLSQTQRSPHVFYRHDLINQLQHNHALVTLVAENLATYMESMRLYARDHEDYDPQTVRLGSRYSHVQEVQERLNFLRFLLKDGQLWLCAPQAKQIWKCLAENAVYLCDREACFKWYSKLMGDEPDLDPDINKDFFESNVLQLDPSLLTENGMKCFERFFKAVNCREGKLVAKRRAYMMDDLELIGLDYLWRVVIQSNDDIASRAIDLLKEIYTNLGPRLQVNQVVIHEDFIQSCFDRLKASYDTLCVLDGDKDSVNCARQEAVRMVRVLTVLREYINECDSDYHEERTILPMSRAFRGKHLSFVVRFPNQGRQVDDLEVWSHTNDTIGSVRRCILNRIKANVAHTKIELFVGGELIDPADDRKLIGQLNLKDKSLITAKLTQISSNMPSSPDSSSDSSTGSPGNHGNHYSDGPNPEVESCLPGVIMSLHPRYISFLWQVADLGSSLNMPPLRDGARVLMKLMPPDSTTIEKLRAICLDHAKLGESSLSPSLDSLFFGPSASQVLYLTEVVYALLMPAGAPLADDSSDFQFHFLKSGGLPLVLSMLTRNNFLPNADMETRRGAYLNALKIAKLLLTAIGYGHVRAVAEACQPGVEGVNPMTQINQVTHDQAVVLQSALQSIPNPSSECMLRNVSVRLAQQISDEASRYMPDICVIRAIQKIIWASGCGSLQLVFSPNEEITKIYEKTNAGNEPDLEDEQVCCEALEVMTLCFALIPTALDALSKEKAWQTFIIDLLLHCHSKTVRQVAQEQFFLMCTRCCMGHRPLLFFITLLFTVLGSTARERAKHSGDYFTLLRHLLNYAYNSNINVPNAEVLLNNEIDWLKRIRDDVKRTGETGIEETILEGHLGVTKELLAFQTSEKKFHIGCEKGGANLIKELIDDFIFPASNVYLQYMRNGELPAEQAIPVCGSPPTINAGFELLVALAVGCVRNLKQIVDSLTEMYYIGTAITTCEALTEWEYLPPVGPRPPKGFVGLKNAGATCYMNSVIQQLYMIPSIRNGILAIEGTGSDVDDDMSGDEKQDNESNVDPRDDVFGYPQQFEDKPALSKTEDRKEYNIGVLRHLQVIFGHLAASRLQYYVPRGFWKQFRLWGEPVNLREQHDALEFFNSLVDSLDEALKALGHPAMLSKVLGGSFADQKICQGCPHRYECEESFTTLNVDIRNHQNLLDSLEQYVKGDLLEGANAYHCEKCNKKVDTVKRLLIKKLPPVLAIQLKRFDYDWERECAIKFNDYFEFPRELDMEPYTVAGVAKLEGDNVNPESQLIQQSEQSESETAGSTKYRLVGVLVHSGQASGGHYYSYIIQRNGGDGERNRWYKFDDGDVTECKMDDDEEMKNQCFGGEYMGEVFDHMMKRMSYRRQKRWWNAYILFYERMDTIDQDDELIRYISELAITTRPHQIIMPSAIERSVRKQNVQFMHNRMQYSMEYFQFMKKLLTCNGVYLNPPPGQDHLLPEAEEITMISIQLAARFLFTTGFHTKKVVRGSASDWYDALCILLRHSKNVRFWFAHNVLFNVSNRFSEYLLECPSAEVRGAFAKLIVFIAHFSLQDGPCPSPFASPGPSSQAYDNLSLSDHLLRAVLNLLRREVSEHGRHLQQYFNLFVMYANLGVAEKTQLLKLSVPATFMLVSLDEGPGPPIKYQYAELGKLYSVVSQLIRCCNVSSRMQSSINGNPPLPNPFGDPNLSQPIMPIQQNVADILFVRTSYVKKIIEDCSNSEETVKLLRFCCWENPQFSSTVLSELLWQVAYSYTYELRPYLDLLLQILLIEDSWQTHRIHNALKGIPDDRDGLFDTIQRSKNHYQKRAYQCIKCMVALFSNCPVAYQILQGNGDLKRKWTWAVEWLGDELERRPYTGNPQYTYNNWSPPVQSNETSNGYFLERSHSARMTLAKACELCPEEEPDDQDAPDEHESPPPEDAPLYPHSPGSQYQQNNHVHGQPYTGPAAHHMNNPQRTGQRAQENYEGSEEVSPPQTKDQ>sp|Q93008-3|USP9X_HUMAN Isoform 2 of Probable ubiquitin carboxyl-terminal hydrolase FAF-X OS=Homo sapiens OX=9606 GN=USP9XMTATTRGSPVGGNDNQGQAPDGQSQPPLQQNQTSSPDSSNENSPATPPDEQGQGDAPPQLEDEEPAFPHTDLAKLDDMINRPRWVVPVLPKGELEVLLEAAIDLSKKGLDVKSEACQRFFRDGLTISFTKILTDEAVSGWKFEIHRCIINNTHRLVELCVAKLSQDWFPLLELLAMALNPHCKFHIYNGTRPCESVSSSVQLPEDELFARSPDPRSPKGWLVDLLNKFGTLNGFQILHDRFINGSALNVQIIAALIKPFGQCYEFLTLHTVKKYFLPIIEMVPQFLENLTDEELKKEAKNEAKNDALSMIIKSLKNLASRVPGQEETVKNLEIFRLKMILRLLQISSFNGKMNALNEVNKVISSVSYYTHRHGNPEEEEWLTAERMAEWIQQNNILSIVLRDSLHQPQYVEKLEKILRFVIKEKALTLQDLDNIWAAQAGKHEAIVKNVHDLLAKLAWDFSPEQLDHLFDCFKASWTNASKKQREKLLELIRRLAEDDKDGVMAHKVLNLLWNLAHSDDVPVDIMDLALSAHIKILDYSCSQDRDTQKIQWIDRFIEELRTNDKWVIPALKQIREICSLFGEAPQNLSQTQRSPHVFYRHDLINQLQHNHALVTLVAENLATYMESMRLYARDHEDYDPQTVRLGSRYSHVQEVQERLNFLRFLLKDGQLWLCAPQAKQIWKCLAENAVYLCDREACFKWYSKLMGDEPDLDPDINKDFFESNVLQLDPSLLTENGMKCFERFFKAVNCREGKLVAKRRAYMMDDLELIGLDYLWRVVIQSNDDIASRAIDLLKEIYTNLGPRLQVNQVVIHEDFIQSCFDRLKASYDTLCVLDGDKDSVNCARQEAVRMVRVLTVLREYINECDSDYHEERTILPMSRAFRGKHLSFVVRFPNQGRQVDDLEVWSHTNDTIGSVRRCILNRIKANVAHTKIELFVGGELIDPADDRKLIGQLNLKDKSLITAKLTQISSNMPSSPDSSSDSSTGSPGNHGNHYSDGPNPEVESCLPGVIMSLHPRYISFLWQVADLGSSLNMPPLRDGARVLMKLMPPDSTTIEKLRAICLDHAKLGESSLSPSLDSLFFGPSASQVLYLTEVVYALLMPAGAPLADDSSDFQFHFLKSGGLPLVLSMLTRNNFLPNADMETRRGAYLNALKIAKLLLTAIGYGHVRAVAEACQPGVEGVNPMTQINQVTHDQAVVLQSALQSIPNPSSECMLRNVSVRLAQQISDEASRYMPDICVIRAIQKIIWASGCGSLQLVFSPNEEITKIYEKTNAGNEPDLEDEQVCCEALEVMTLCFALIPTALDALSKEKAWQTFIIDLLLHCHSKTVRQVAQEQFFLMCTRCCMGHRPLLFFITLLFTVLGSTARERAKHSGDYFTLLRHLLNYAYNSNINVPNAEVLLNNEIDWLKRIRDDVKRTGETGIEETILEGHLGVTKELLAFQTSEKKFHIGCEKGGANLIKELIDDFIFPASNVYLQYMRNGELPAEQAIPVCGSPPTINAGFELLVALAVGCVRNLKQIVDSLTEMYYIGTAITTCEALTEWEYLPPVGPRPPKGFVGLKNAGATCYMNSVIQQLYMIPSIRNGILAIEGTGSDVDDDMSGDEKQDNESNVDPRDDVFGYPQQFEDKPALSKTEDRKEYNIGVLRHLQVIFGHLAASRLQYYVPRGFWKQFRLWGEPVNLREQHDALEFFNSLVDSLDEALKALGHPAMLSKVLGGSFADQKICQGCPHRYECEESFTTLNVDIRNHQNLLDSLEQYVKGDLLEGANAYHCEKCNKKVDTVKRLLIKKLPPVLAIQLKRFDYDWERECAIKFNDYFEFPRELDMEPYTVAGVAKLEGDNVNPESQLIQQSEQSESETAGSTKYRLVGVLVHSGQASGGHYYSYIIQRNGGDGERNRWYKFDDGDVTECKMDDDEEMKNQCFGGEYMGEVFDHMMKRMSYRRQKRWWNAYILFYERMDTIDQDDELIRYISELAITTRPHQIIMPSAIERSVRKQNVQFMHNRMQYSMEYFQFMKKLLTCNGVYLNPPPGQDHLLPEAEEITMISIQLAARFLFTTGFHTKKVVRGSASDWYDALCILLRHSKNVRFWFAHNVLFNVSNRFSEYLLECPSAEVRGAFAKLIVFIAHFSLQDGPCPSPFASPGPSSQAYDNLSLSDHLLRAVLNLLRREVSEHGRHLQQYFNLFVMYANLGVAEKTQLLKLSVPATFMLVSLDEGPGPPIKYQYAELGKLYSVVSQLIRCCNVSSRMQSSINGNPPLPNPFGDPNLSQPIMPIQQNVADILFVRTSYVKKIIEDCSNSEETVKLLRFCCWENPQFSSTVLSELLWQVAYSYTYELRPYLDLLLQILLIEDSWQTHRIHNALKGIPDDRDGLFDTIQRSKNHYQKRAYQCIKCMVALFSNCPVAYQILQGNGDLKRKWTWAVEWLGDELERRPYTGNPQYTYNNWSPPVQSNETSNGYFLERSHSARMTLAKACELCPEEVKKATSVQQIEMEESKEPDDQDAPDEHESPPPEDAPLYPHSPGSQYQQNNHVHGQPYTGPAAHHMNNPQRTGQRAQENYEGSEEVSPPQTKDQ>sp|A0A0B4J248|TVA11_HUMAN T cell receptor alpha variable 1-1 OS=Homosapiens OX=9606 GN=TRAV1-1 PE=3 SV=1MWGAFLLYVSMKMGGTAGQSLEQPSEVTAVEGAIVQINCTYQTSGFYGLSWYQQHDGGAPTFLSYNALDGLEETGRFSSFLSRSDSYGYLLLQELQMKDSASYFCAVR>sp|Q9UI12|VATH_HUMAN V-type proton ATPase subunit H OS=Homo sapiensOX=9606 GN=ATP6V1H PE=1 SV=1MTKMDIRGAVDAAVPTNIIAAKAAEVRANKVNWQSYLQGQMISAEDCEFIQRFEMKRSPEEKQEMLQTEGSQCAKTFINLMTHICKEQTVQYILTMVDDMLQENHQRVSIFFDYARCSKNTAWPYFLPMLNRQDPFTVHMAARIIAKLAAWGKELMEGSDLNYYFNWIKTQLSSQKLRGSGVAVETGTVSSSDSSQYVQCVAGCLQLMLRVNEYRFAWVEADGVNCIMGVLSNKCGFQLQYQMIFSIWLLAFSPQMCEHLRRYNIIPVLSDILQESVKEKVTRIILAAFRNFLEKSTERETRQEYALAMIQCKVLKQLENLEQQKYDDEDISEDIKFLLEKLGESVQDLSSFDEYSSELKSGRLEWSPVHKSEKFWRENAVRLNEKNYELLKILTKLLEVSDDPQVLAVAAHDVGEYVRHYPRGKRVIEQLGGKQLVMNHMHHEDQQVRYNALLAVQKLMVHNWEYLGKQLQSEQPQTAAARS>sp|Q9UI12-2|VATH_HUMAN Isoform 2 of V-type proton ATPase subunit HOS=Homo sapiens OX=9606 GN=ATP6V1HMTKMDIRGAVDAAVPTNIIAAKAAEVRANKVNWQSYLQGQMISAEDCEFIQRFEMKRSPEEKQEMLQTEGSQCAKTFINLMTHICKEQTVQYILTMVDDMLQENHQRVSIFFDYARCSKNTAWPYFLPMLNRQDPFTVHMAARIIAKLAAWGKELMEGSDLNYYFNWIKTQLSSQSSQYVQCVAGCLQLMLRVNEYRFAWVEADGVNCIMGVLSNKCGFQLQYQMIFSIWLLAFSPQMCEHLRRYNIIPVLSDILQESVKEKVTRIILAAFRNFLEKSTERETRQEYALAMIQCKVLKQLENLEQQKYDDEDISEDIKFLLEKLGESVQDLSSFDEYSSELKSGRLEWSPVHKSEKFWRENAVRLNEKNYELLKILTKLLEVSDDPQVLAVAAHDVGEYVRHYPRGKRVIEQLGGKQLVMNHMHHEDQQVRYNALLAVQKLMVHNWEYLGKQLQSEQPQTAAARS>sp|Q9Y2Q1|ZN257_HUMAN Zinc finger protein 257 OS=Homo sapiens OX=9606GN=ZNF257 PE=2 SV=2MGPLTIRDVTVEFSLEEWHCLDTAQQNLYRDVMLENYRNLVFLGIAVSKPDLITCLEQGKEPCNMKRHEMVAKPPVMCSHIAEDLCPERDIKYFFQKVILRRYDKCEHENLQLRKGCKSVDECKVCKGGYNGLNQCLITTQSKMYQCDKYVKVFYKFSNSDRHKIRHTEKKTCKCKECGKSFCMLSQLTRHKRIHIRENSHKCEECGKAFNQSSALTRHKMTHTGEKPYKCEECGKAFNRSSHLTQHKVIHTREKPYKCEECGKAFNRSSHITQHKRIHNREKPFKYDECCKAFKWSSALTTLTQHKRIHTGEKPYKCEECGKAFNQSSALTRHKMIHTGEKPFQCEECGKAFNRSSHLTQHKIIHTKEKPYKCEECGKAFNRSSHLTKHKRIHTREKAYKCDEYCKAFNWSSALTTLTQHKIIHTGEKPYKCEECGKAFNRSSYLIRHKIIHTGEKPYKCEECGKAFNQSSHLTQHKIIHTGEKPYKCEECGKAFNRSSHLSQHKIIHTGEKPYKCEECGKPFNRFSYLTVHKRIHAGENPNKYEECGKACNHSSNLTKHNS>sp|Q9Y2Q1-2|ZN257_HUMAN Isoform 2 of Zinc finger protein 257 OS=Homosapiens OX=9606 GN=ZNF257MGPLTIRDVTVEFSLEEWHCLDTAQQNLYRDVMLENYRNLVFLGIAVSKPDLITCLEQGKEPCNMKRHEMVAKPPVMCSHIAEDLCPERDIKYFFQKVILRRYDKCEHENLQLRKGCKSVDECKVCKGGYNGLNQCLITTQSKMYQCDKYVKVFYKFSNSDRHKIRHTEKKTCKCKECGKAFNQSSALTRHKMTHTGEKPYKCEECGKAFNRSSHLTQHKVIHTREKPYKCEECGKAFNRSSHITQHKRIHNREKPFKYDECCKAFKWSSALTTLTQHKRIHTGEKPYKCEECGKAFNQSSALTRHKMIHTGEKPFQCEECGKAFNRSSHLTQHKIIHTKEKPYKCEECGKAFNRSSHLTKHKRIHTREKAYKCDEYCKAFNWSSALTTLTQHKIIHTGEKPYKCEECGKAFNRSSYLIRHKIIHTGEKPYKCEECGKAFNQSSHLTQHKIIHTGEKPYKCEECGKAFNRSSHLSQHKIIHTGEKPYKCEECGKPFNRFSYLTVHKRIHAGENPNKYEECGKACNHSSNLTKHNS>sp|Q9Y2Q1-3|ZN257_HUMAN Isoform 3 of Zinc finger protein 257 OS=Homosapiens OX=9606 GN=ZNF257MLENYRNLVFLGIAVSKPDLITCLEQGKEPCNMKRHEMVAKPPVMCSHIAEDLCPERDIKYFFQKVILRRYDKCEHENLQLRKGCKSVDECKVCKGGYNGLNQCLITTQSKMYQCDKYVKVFYKFSNSDRHKIRHTEKKTCKCKECGKSFCMLSQLTRHKRIHIRENSHKCEECGKAFNQSSALTRHKMTHTGEKPYKCEECGKAFNRSSHLTQHKVIHTREKPYKCEECGKAFNRSSHITQHKRIHNREKPFKYDECCKAFKWSSALTTLTQHKRIHTGEKPYKCEECGKAFNQSSALTRHKMIHTGEKPFQCEECGKAFNRSSHLTQHKIIHTKEKPYKCEECGKAFNRSSHLTKHKRIHTREKAYKCDEYCKAFNWSSALTTLTQHKIIHTGEKPYKCEECGKAFNRSSYLIRHKIIHTGEKPYKCEECGKAFNQSSHLTQHKIIHTGEKPYKCEECGKAFNRSSHLSQHKIIHTGEKPYKCEECGKPFNRFSYLTVHKRIHAGENPNKYEECGKACNHSSNLTKHNS>sp|Q9Y2Q1-4|ZN257_HUMAN Isoform 4 of Zinc finger protein 257 OS=Homosapiens OX=9606 GN=ZNF257MGPLTIRDVTVEFSLEEWHCLDTAQQNLYRDVMLENYRNLVFLGIAVSKPDLCPERDIKYFFQKVILRRYDKCEHENLQLRKGCKSVDECKVCKGGYNGLNQCLITTQSKMYQCDKYVKVFYKFSNSDRHKIRHTEKKTCKCKECGKSFCMLSQLTRHKRIHIRENSHKCEECGKAFNQSSALTRHKMTHTGEKPYKCEECGKAFNRSSHLTQHKVIHTREKPYKCEECGKAFNRSSHITQHKRIHNREKPFKYDECCKAFKWSSALTTLTQHKRIHTGEKPYKCEECGKAFNQSSALTRHKMIHTGEKPFQCEECGKAFNRSSHLTQHKIIHTKEKPYKCEECGKAFNRSSHLTKHKRIHTREKAYKCDEYCKAFNWSSALTTLTQHKIIHTGEKPYKCEECGKAFNRSSYLIRHKIIHTGEKPYKCEECGKAFNQSSHLTQHKIIHTGEKPYKCEECGKAFNRSSHLSQHKIIHTGEKPYKCEECGKPFNRFSYLTVHKRIHAGENPNKYEECGKACNHSSNLTKHNS>sp|P0C6A0|ZGLP1_HUMAN GATA-type zinc finger protein 1 OS=Homo sapiensOX=9606 GN=ZGLP1 PE=2 SV=1MTEPQVGCVACPRVHKEPAQVGTPWPAKPRSHPRKRDPTALLPRSLWPACQESVTALCFLQETVERLGQSPAQDTPVLGPCWDPMALGTQGRLLLDRDSKDTQTRISQKGRRLQPPGTPSAPPQRRPRKQLNPCRGTERVDPGFEGVTLKFQIKPDSSLQIIPTYSLPCSSRSQESPADAVGGPAAHPGGTEAHSAGSEALEPRRCASCRTQRTPLWRDAEDGTPLCNACGIRYKKYGTRCSSCWLVPRKNVQPKRLCGRCGVSLDPIQEG>sp|Q3ZCT1|ZN260_HUMAN Zinc finger protein 260 OS=Homo sapiens OX=9606GN=ZNF260 PE=1 SV=3MIGMLESLQHESDLLQHDQIHTGEKPYECNECRKTFSLKQNLVEHKKMHTGEKSHECTECGKVCSRVSSLTLHLRSHTGKKAYKCNKCGKAFSQKENFLSHQKHHTGEKPYECEKVSIQMPTIIRHQKNHTGTKPYACKECGKAFNGKAYLTEHEKIHTGEKPFECNQCGRAFSQKQYLIKHQNIHTGKKPFKCSECGKAFSQKENLIIHQRIHTGEKPYECKGCGKAFIQKSSLIRHQRSHTGEKPYTCKECGKAFSGKSNLTEHEKIHIGEKPYKCNECGTIFRQKQYLIKHHNIHTGEKPYECNKCGKAFSRITSLIVHVRIHTGDKPYECKVCGKAFCQSSSLTVHMRSHTGEKPYGCNECGKAFSQFSTLALHMRIHTGEKPYQCSECGKAFSQKSHHIRHQRIHTH>sp|Q14593|ZN273_HUMAN Zinc finger protein 273 OS=Homo sapiens OX=9606GN=ZNF273 PE=1 SV=3MSSAPRGPPSVAPLPAGIGRSTAKTPGLPGSLEMGPLTFRDVAIEFSLEEWQCLDTSQQNLYRNVMLDNYRNLVFLGIAVSKPDLITCLEQGKEPCNMKRHAMVAKPPVVCSHFAQDLWPKQGLKDSFQKVILRRYGKYGHENLQLRKGCKSADEHKVHKRGYNGLNQCLTTTQSKIFQCDKYVKVLHKFSNSNIHKKRQTGKKPFKCKECGKSCCILSQLTQHKKTATRVNFYKCKTCGKAFNQFSNLTKHKIIHPEVNPYKCEECGKAFNQSLTLTKHKKIHTEEKPYKCEDCGKVFSVFSVLTKHKIIHTGTKPYNCEECGKGFSIFSTLTKHKIIHTGEKPYKCNECGKAFNWSSTLTKHKRIHTGEKPYKCEECGKAFNQSSTLTRHKIVHTGEKPYKCEECGKAFKRSTTLTKHKRIYTKEKPYKCEECGKAFSVFSTLTKHKIIHTGAKPYKCEECGSAFRAFSTLTEHKRVHTGEKPYKCNECGKAFNWSSTLTKHKRIHTGEKPYKCEECGKAFNRSSNLTRHKKIHTGEKPYKPKRCDSAFDNTPNFSRHKRNHMGEKS>sp|Q14593-2|ZN273_HUMAN Isoform 2 of Zinc finger protein 273 OS=Homosapiens OX=9606 GN=ZNF273MLDNYRNLVFLGIAVSKPDLITCLEQGKEPCNMKRHAMVAKPPVVCSHFAQDLWPKQGLKDSFQKVILRRYGKYGHENLQLRKGCKSADEHKVHKRGYNGLNQCLTTTQSKIFQCDKYVKVLHKFSNSNIHKKRQTGKKPFKCKECGKSCCILSQLTQHKKTATRVNFYKCKTCGKAFNQFSNLTKHKIIHPEVNPYKCEECGKAFNQSLTLTKHKKIHTEEKPYKCEDCGKVFSVFSVLTKHKIIHTGTKPYNCEECGKGFSIFSTLTKHKIIHTGEKPYKCNECGKAFNWSSTLTKHKRIHTGEKPYKCEECGKAFNQSSTLTRHKIVHTGEKPYKCEECGKAFKRSTTLTKHKRIYTKEKPYKCEECGKAFSVFSTLTKHKIIHTGAKPYKCEECGSAFRAFSTLTEHKRVHTGEKPYKCNECGKAFNWSSTLTKHKRIHTGEKPYKCEECGKAFNRSSNLTRHKKIHTGEKPYKPKRCDSAFDNTPNFSRHKRNHMGEKS>sp|Q9BRT2|UQCC2_HUMAN Ubiquinol-cytochrome-c reductase complex assemblyfactor 2 OS=Homo sapiens OX=9606 GN=UQCC2 PE=1 SV=1MAASRYRRFLKLCEEWPVDETKRGRDLGAYLRQRVAQAFREGENTQVAEPEACDQMYESLARLHSNYYKHKYPRPRDTSFSGLSLEEYKLILSTDTLEELKEIDKGMWKKLQEKFAPKGPEEDHKA>sp|Q13488|VPP3_HUMAN V-type proton ATPase 116 kDa subunit a3 OS=Homosapiens OX=9606 GN=TCIRG1 PE=1 SV=3MGSMFRSEEVALVQLFLPTAAAYTCVSRLGELGLVEFRDLNASVSAFQRRFVVDVRRCEELEKTFTFLQEEVRRAGLVLPPPKGRLPAPPPRDLLRIQEETERLAQELRDVRGNQQALRAQLHQLQLHAAVLRQGHEPQLAAAHTDGASERTPLLQAPGGPHQDLRVNFVAGAVEPHKAPALERLLWRACRGFLIASFRELEQPLEHPVTGEPATWMTFLISYWGEQIGQKIRKITDCFHCHVFPFLQQEEARLGALQQLQQQSQELQEVLGETERFLSQVLGRVLQLLPPGQVQVHKMKAVYLALNQCSVSTTHKCLIAEAWCSVRDLPALQEALRDSSMEEGVSAVAHRIPCRDMPPTLIRTNRFTASFQGIVDAYGVGRYQEVNPAPYTIITFPFLFAVMFGDVGHGLLMFLFALAMVLAENRPAVKAAQNEIWQTFFRGRYLLLLMGLFSIYTGFIYNECFSRATSIFPSGWSVAAMANQSGWSDAFLAQHTMLTLDPNVTGVFLGPYPFGIDPIWSLAANHLSFLNSFKMKMSVILGVVHMAFGVVLGVFNHVHFGQRHRLLLETLPELTFLLGLFGYLVFLVIYKWLCVWAARAASAPSILIHFINMFLFSHSPSNRLLYPRQEVVQATLVVLALAMVPILLLGTPLHLLHRHRRRLRRRPADRQEENKAGLLDLPDASVNGWSSDEEKAGGLDDEEEAELVPSEVLMHQAIHTIEFCLGCVSNTASYLRLWALSLAHAQLSEVLWAMVMRIGLGLGREVGVAAVVLVPIFAAFAVMTVAILLVMEGLSAFLHALRLHWVEFQNKFYSGTGYKLSPFTFAATDD>sp|Q13488-2|VPP3_HUMAN Isoform Short of V-type proton ATPase 116 kDasubunit a3 OS=Homo sapiens OX=9606 GN=TCIRG1MTFLISYWGEQIGQKIRKITDCFHCHVFPFLQQEEARLGALQQLQQQSQELQEVLGETERFLSQVLGRVLQLLPPGQVQVHKMKAVYLALNQCSVSTTHKCLIAEAWCSVRDLPALQEALRDSSMEEGVSAVAHRIPCRDMPPTLIRTNRFTASFQGIVDAYGVGRYQEVNPAPYTIITFPFLFAVMFGDVGHGLLMFLFALAMVLAENRPAVKAAQNEIWQTFFRGRYLLLLMGLFSIYTGFIYNECFSRATSIFPSGWSVAAMANQSGWSDAFLAQHTMLTLDPNVTGVFLGPYPFGIDPIWSLAANHLSFLNSFKMKMSVILGVVHMAFGVVLGVFNHVHFGQRHRLLLETLPELTFLLGLFGYLVFLVIYKWLCVWAARAASAPSILIHFINMFLFSHSPSNRLLYPRQEVVQATLVVLALAMVPILLLGTPLHLLHRHRRRLRRRPADRQEENKAGLLDLPDASVNGWSSDEEKAGGLDDEEEAELVPSEVLMHQAIHTIEFCLGCVSNTASYLRLWALSLAHAQLSEVLWAMVMRIGLGLGREVGVAAVVLVPIFAAFAVMTVAILLVMEGLSAFLHALRLHWVEFQNKFYSGTGYKLSPFTFAATDD>sp|Q9Y487|VPP2_HUMAN V-type proton ATPase 116 kDa subunit a2 OS=Homosapiens OX=9606 GN=ATP6V0A2 PE=1 SV=2MGSLFRSETMCLAQLFLQSGTAYECLSALGEKGLVQFRDLNQNVSSFQRKFVGEVKRCEELERILVYLVQEINRADIPLPEGEASPPAPPLKQVLEMQEQLQKLEVELREVTKNKEKLRKNLLELIEYTHMLRVTKTFVKRNVEFEPTYEEFPSLESDSLLDYSCMQRLGAKLGFVSGLINQGKVEAFEKMLWRVCKGYTIVSYAELDESLEDPETGEVIKWYVFLISFWGEQIGHKVKKICDCYHCHVYPYPNTAEERREIQEGLNTRIQDLYTVLHKTEDYLRQVLCKAAESVYSRVIQVKKMKAIYHMLNMCSFDVTNKCLIAEVWCPEADLQDLRRALEEGSRESGATIPSFMNIIPTKETPPTRIRTNKFTEGFQNIVDAYGVGSYREVNPALFTIITFPFLFAVMFGDFGHGFVMFLFALLLVLNENHPRLNQSQEIMRMFFNGRYILLLMGLFSVYTGLIYNDCFSKSVNLFGSGWNVSAMYSSSHPPAEHKKMVLWNDSVVRHNSILQLDPSIPGVFRGPYPLGIDPIWNLATNRLTFLNSFKMKMSVILGIIHMTFGVILGIFNHLHFRKKFNIYLVSIPELLFMLCIFGYLIFMIFYKWLVFSAETSRVAPSILIEFINMFLFPASKTSGLYTGQEYVQRVLLVVTALSVPVLFLGKPLFLLWLHNGRSCFGVNRSGYTLIRKDSEEEVSLLGSQDIEEGNHQVEDGCREMACEEFNFGEILMTQVIHSIEYCLGCISNTASYLRLWALSLAHAQLSDVLWAMLMRVGLRVDTTYGVLLLLPVIALFAVLTIFILLIMEGLSAFLHAIRLHWVEFQNKFYVGAGTKFVPFSFSLLSSKFNNDDSVA>sp|Q53FD0|ZC21C_HUMAN Zinc finger C2HC domain-containing protein 1COS=Homo sapiens OX=9606 GN=ZC2HC1C PE=1 SV=3MAGLQRLASHLPVGVMLPHNTTEAPGPHSAKQDSYEQGDSSQQSLKGHLRNNFQKQLLSNKELILDKVYTHPKWNTQTKARSYSYPHCTGISQQDPESDSQGQGNGLFYSSGPQSWYPKANNQDFIPFTKKRVGVDRAFPLKPMVHRKSCSTGEAGTDGDHNVYPRPPEPREFSSRNFGVRNQGNFSVVGTVLAATQAEKAVANFDRTEWVQIRRLEAAGESLEEEIRRKQILLRGKLKKTEEELRRIQTQKEQAKENENGELQKIILPRSRVKGNKSNTMYKPIFSPEFEFEEEFSRDRREDETWGRSQQNSGPFQFSDYRIQRLKRERLVASNNKIRDPVSEPSVEKFSPPSETPVGALQGSARNSSLSMAPDSSGSSGSIEEPQLGECSHCGRKFLSFRLERHSNICSRMRGSKRKVFDSSRARAKGTELEQYLNWKGPASAKAEPPQKSNWR>sp|Q53FD0-2|ZC21C_HUMAN Isoform 2 of Zinc finger C2HC domain-containingprotein 1C OS=Homo sapiens OX=9606 GN=ZC2HC1CMAGLQRLASHLPVGVMLPHNTTEAPGPHSAKQDSYEQGDSSQQSLKGHLRNNFQKQLLSNKELILDKVYTHPKWNTQTKARSYSYPHCTGISQQDPESDSQGQGNGLFYSSGPQSWYPKANNQDFIPFTKKRVGVDRAFPLKPMVHRKSCSTGEAGTDGDHNVYPRPPEPREFSSRNFGVRNQGNFSVVGTVLAATQAEKAVANFDRTEWVQIRRLEAAGESLEEEIRRKQILLRGKLKKTEEELRRIQTQKEQAKENENGELQKIILPRSRVKG>sp|Q9H4A3|WNK1_HUMAN Serine/threonine-protein kinase WNK1 OS=Homosapiens OX=9606 GN=WNK1 PE=1 SV=2MSGGAAEKQSSTPGSLFLSPPAPAPKNGSSSDSSVGEKLGAAAADAVTGRTEEYRRRRHTMDKDSRGAAATTTTTEHRFFRRSVICDSNATALELPGLPLSLPQPSIPAAVPQSAPPEPHREETVTATATSQVAQQPPAAAAPGEQAVAGPAPSTVPSSTSKDRPVSQPSLVGSKEEPPPARSGSGGGSAKEPQEERSQQQDDIEELETKAVGMSNDGRFLKFDIEIGRGSFKTVYKGLDTETTVEVAWCELQDRKLTKSERQRFKEEAEMLKGLQHPNIVRFYDSWESTVKGKKCIVLVTELMTSGTLKTYLKRFKVMKIKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRRVTSGVKPASFDKVAIPEVKEIIEGCIRQNKDERYSIKDLLNHAFFQEETGVRVELAEEDDGEKIAIKLWLRIEDIKKLKGKYKDNEAIEFSFDLERDVPEDVAQEMVESGYVCEGDHKTMAKAIKDRVSLIKRKREQRQLVREEQEKKKQEESSLKQQVEQSSASQTGIKQLPSASTGIPTASTTSASVSTQVEPEEPEADQHQQLQYQQPSISVLSDGTVDSGQGSSVFTESRVSSQQTVSYGSQHEQAHSTGTVPGHIPSTVQAQSQPHGVYPPSSVAQGQSQGQPSSSSLTGVSSSQPIQHPQQQQGIQQTAPPQQTVQYSLSQTSTSSEATTAQPVSQPQAPQVLPQVSAGKQLPVSQPVPTIQGEPQIPVATQPSVVPVHSGAHFLPVGQPLPTPLLPQYPVSQIPISTPHVSTAQTGFSSLPITMAAGITQPLLTLASSATTAAIPGVSTVVPSQLPTLLQPVTQLPSQVHPQLLQPAVQSMGIPANLGQAAEVPLSSGDVLYQGFPPRLPPQYPGDSNIAPSSNVASVCIHSTVLSPPMPTEVLATPGYFPTVVQPYVESNLLVPMGGVGGQVQVSQPGGSLAQAPTTSSQQAVLESTQGVSQVAPAEPVAVAQTQATQPTTLASSVDSAHSDVASGMSDGNENVPSSSGRHEGRTTKRHYRKSVRSRSRHEKTSRPKLRILNVSNKGDRVVECQLETHNRKMVTFKFDLDGDNPEEIATIMVNNDFILAIERESFVDQVREIIEKADEMLSEDVSVEPEGDQGLESLQGKDDYGFSGSQKLEGEFKQPIPASSMPQQIGIPTSSLTQVVHSAGRRFIVSPVPESRLRESKVFPSEITDTVAASTAQSPGMNLSHSASSLSLQQAFSELRRAQMTEGPNTAPPNFSHTGPTFPVVPPFLSSIAGVPTTAAATAPVPATSSPPNDISTSVIQSEVTVPTEEGIAGVATSTGVVTSGGLPIPPVSESPVLSSVVSSITIPAVVSISTTSPSLQVPTSTSEIVVSSTALYPSVTVSATSASAGGSTATPGPKPPAVVSQQAAGSTTVGATLTSVSTTTSFPSTASQLCIQLSSSTSTPTLAETVVVSAHSLDKTSHSSTTGLAFSLSAPSSSSSPGAGVSSYISQPGGLHPLVIPSVIASTPILPQAAGPTSTPLLPQVPSIPPLVQPVANVPAVQQTLIHSQPQPALLPNQPHTHCPEVDSDTQPKAPGIDDIKTLEEKLRSLFSEHSSSGAQHASVSLETSLVIESTVTPGIPTTAVAPSKLLTSTTSTCLPPTNLPLGTVALPVTPVVTPGQVSTPVSTTTSGVKPGTAPSKPPLTKAPVLPVGTELPAGTLPSEQLPPFPGPSLTQSQQPLEDLDAQLRRTLSPEMITVTSAVGPVSMAAPTAITEAGTQPQKGVSQVKEGPVLATSSGAGVFKMGRFQVSVAADGAQKEGKNKSEDAKSVHFESSTSESSVLSSSSPESTLVKPEPNGITIPGISSDVPESAHKTTASEAKSDTGQPTKVGRFQVTTTANKVGRFSVSKTEDKITDTKKEGPVASPPFMDLEQAVLPAVIPKKEKPELSEPSHLNGPSSDPEAAFLSRDVDDGSGSPHSPHQLSSKSLPSQNLSQSLSNSFNSSYMSSDNESDIEDEDLKLELRRLRDKHLKEIQDLQSRQKHEIESLYTKLGKVPPAVIIPPAAPLSGRRRRPTKSKGSKSSRSSSLGNKSPQLSGNLSGQSAASVLHPQQTLHPPGNIPESGQNQLLQPLKPSPSSDNLYSAFTSDGAISVPSLSAPGQGTSSTNTVGATVNSQAAQAQPPAMTSSRKGTFTDDLHKLVDNWARDAMNLSGRRGSKGHMNYEGPGMARKFSAPGQLCISMTSNLGGSAPISAASATSLGHFTKSMCPPQQYGFPATPFGAQWSGTGGPAPQPLGQFQPVGTASLQNFNISNLQKSISNPPGSNLRTT>sp|Q9H4A3-2|WNK1_HUMAN Isoform 2 of Serine/threonine-protein kinase WNK1OS=Homo sapiens OX=9606 GN=WNK1MSGGAAEKQSSTPGSLFLSPPAPAPKNGSSSDSSVGEKLGAAAADAVTGRTEEYRRRRHTMDKDSRGAAATTTTTEHRFFRRSVICDSNATALELPGLPLSLPQPSIPAAVPQSAPPEPHREETVTATATSQVAQQPPAAAAPGEQAVAGPAPSTVPSSTSKDRPVSQPSLVGSKEEPPPARSGSGGGSAKEPQEERSQQQDDIEELETKAVGMSNDGRFLKFDIEIGRGSFKTVYKGLDTETTVEVAWCELQDRKLTKSERQRFKEEAEMLKGLQHPNIVRFYDSWESTVKGKKCIVLVTELMTSGTLKTYLKRFKVMKIKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRRVTSGVKPASFDKVAIPEVKEIIEGCIRQNKDERYSIKDLLNHAFFQEETGVRVELAEEDDGEKIAIKLWLRIEDIKKLKGKYKDNEAIEFSFDLERDVPEDVAQEMVESGYVCEGDHKTMAKAIKDRVSLIKRKREQRQLVREEQEKKKQEESSLKQQVEQSSASQTGIKQLPSASTGIPTASTTSASVSTQVEPEEPEADQHQQLQYQQPSISVLSDGTVDSGQGSSVFTESRVSSQQTVSYGSQHEQAHSTGTVPGHIPSTVQAQSQPHGVYPPSSVAQGQSQGQPSSSSLTGVSSSQPIQHPQQQGIQQTAPPQQTVQYSLSQTSTSSEATTAQPVSQPQAPQVLPQVSAGKQSTQGVSQVAPAEPVAVAQTQATQPTTLASSVDSAHSDVASGMSDGNENVPSSSGRHEGRTTKRHYRKSVRSRSRHEKTSRPKLRILNVSNKGDRVVECQLETHNRKMVTFKFDLDGDNPEEIATIMVNNDFILAIERESFVDQVREIIEKADEMLSEDVSVEPEGDQGLESLQGKDDYGFSGSQKLEGEFKQPIPASSMPQQIGIPTSSLTQVVHSAGRRFIVSPVPESRLRESKVFPSEITDTVAASTAQSPGMNLSHSASSLSLQQAFSELRRAQMTEGPNTAPPNFSHTGPTFPVVPPFLSSIAGVPTTAAATAPVPATSSPPNDISTSVIQSEVTVPTEEGIAGVATSTGVVTSGGLPIPPVSESPVLSSVVSSITIPAVVSISTTSPSLQVPTSTSEIVVSSTALYPSVTVSATSASAGGSTATPGPKPPAVVSQQAAGSTTVGATLTSVSTTTSFPSTASQLCIQLSSSTSTPTLAETVVVSAHSLDKTSHSSTTGLAFSLSAPSSSSSPGAGVSSYISQPGGLHPLVIPSVIASTPILPQAAGPTSTPLLPQVPSIPPLVQPVANVPAVQQTLIHSQPQPALLPNQPHTHCPEVDSDTQPKAPGIDDIKTLEEKLRSLFSEHSSSGAQHASVSLETSLVIESTVTPGIPTTAVAPSKLLTSTTSTCLPPTNLPLGTVALPVTPVVTPGQVSTPVSTTTSGVKPGTAPSKPPLTKAPVLPVGTELPAGTLPSEQLPPFPGPSLTQSQQPLEDLDAQLRRTLSPEMITVTSAVGPVSMAAPTAITEAGTQPQKGVSQVKEGPVLATSSGAGVFKMGRFQVSVAADGAQKEGKNKSEDAKSVHFESSTSESSVLSSSSPESTLVKPEPNGITIPGISSDVPESAHKTTASEAKSDTGQPTKVGRFQVTTTANKVGRFSVSKTEDKITDTKKEGPVASPPFMDLEQAVLPAVIPKKEKPELSEPSHLNGPSSDPEAAFLSRDVDDGSGSPHSPHQLSSKSLPSQNLSQSLSNSFNSSYMSSDNESDIEDEDLKLELRRLRDKHLKEIQDLQSRQKHEIESLYTKLGKVPPAVIIPPAAPLSGRRRRPTKSKGSKSSRSSSLGNKSPQLSGNLSGQSAASVLHPQQTLHPPGNIPESGQNQLLQPLKPSPSSDNLYSAFTSDGAISVPSLSAPGQGTSSTNTVGATVNSQAAQAQPPAMTSSRKGTFTDDLHKLVDNWARDAMNLSGRRGSKGHMNYEGPGMARKFSAPGQLCISMTSNLGGSAPISAASATSLGHFTKSMCPPQQYGFPATPFGAQWSGTGGPAPQPLGQFQPVGTASLQNFNISNLQKSISNPPGSNLRTT>sp|Q9H4A3-4|WNK1_HUMAN Isoform 3 of Serine/threonine-protein kinase WNK1OS=Homo sapiens OX=9606 GN=WNK1MDIKKKDFCSVFVIINSHCCCCPQKDCINEGVKPASFDKVAIPEVKEIIEGCIRQNKDERYSIKDLLNHAFFQEETGVRVELAEEDDGEKIAIKLWLRIEDIKKLKGKYKDNEAIEFSFDLERDVPEDVAQEMVESGYVCEGDHKTMAKAIKDRVSLIKRKREQRQLVREEQEKKKQEESSLKQQVEQSSASQTGIKQLPSASTGIPTASTTSASVSTQVEPEEPEADQHQQLQYQQPSISVLSDGTVDSGQGSSVFTESRVSSQQTVSYGSQHEQAHSTGTVPGHIPSTVQAQSQPHGVYPPSSVAQGQSQGQPSSSSLTGVSSSQPIQHPQQQQGIQQTAPPQQTVQYSLSQTSTSSEATTAQPVSQPQAPQVLPQVSAGKQLPVSQPVPTIQGEPQIPVATQPSVVPVHSGAHFLPVGQPLPTPLLPQYPVSQIPISTPHVSTAQTGFSSLPITMAAGITQPLLTLASSATTAAIPGVSTVVPSQLPTLLQPVTQLPSQVHPQLLQPAVQSMGIPANLGQAAEVPLSSGDVLYQGFPPRLPPQYPGDSNIAPSSNVASVCIHSTVLSPPMPTEVLATPGYFPTVVQPYVESNLLVPMGGVGGQVQVSQPGGSLAQAPTTSSQQAVLESTQGVSQVAPAEPVAVAQTQATQPTTLASSVDSAHSDVASGMSDGNENVPSSSGRHEGRTTKRHYRKSVRSRSRHEKTSRPKLRILNVSNKGDRVVECQLETHNRKMVTFKFDLDGDNPEEIATIMVNNDFILAIERESFVDQVREIIEKADEMLSEDVSVEPEGDQGLESLQGKDDYGFSGSQKLEGEFKQPIPASSMPQQIGIPTSSLTQVVHSAGRRFIVSPVPESRLRESKVFPSEITDTVAASTAQSPGMNLSHSASSLSLQQAFSELRRAQMTEGPNTAPPNFSHTGPTFPVVPPFLSSIAGVPTTAAATAPVPATSSPPNDISTSVIQSEVTVPTEEGIAGVATSTGVVTSGGLPIPPVSESPVLSSVVSSITIPAVVSISTTSPSLQVPTSTSEIVVSSTALYPSVTVSATSASAGGSTATPGPKPPAVVSQQAAGSTTVGATLTSVSTTTSFPSTASQLCIQLSSSTSTPTLAETVVVSAHSLDKTSHSSTTGLAFSLSAPSSSSSPGAGVSSYISQPGGLHPLVIPSVIASTPILPQAAGPTSTPLLPQVPSIPPLVQPVANVPAVQQTLIHSQPQPALLPNQPHTHCPEVDSDTQPKAPGIDDIKTLEEKLRSLFSEHSSSGAQHASVSLETSLVIESTVTPGIPTTAVAPSKLLTSTTSTCLPPTNLPLGTVALPVTPVVTPGQVSTPVSTTTSGVKPGTAPSKPPLTKAPVLPVGTELPAGTLPSEQLPPFPGPSLTQSQQPLEDLDAQLRRTLSPEMITVTSAVGPVSMAAPTAITEAGTQPQKGVSQVKEGPVLATSSGAGVFKMGRFQVSVAADGAQKEGKNKSEDAKSVHFESSTSESSVLSSSSPESTLVKPEPNGITIPGISSDVPESAHKTTASEAKSDTGQPTKVGRFQVTTTANKVGRFSVSKTEDKITDTKKEGPVASPPFMDLEQAVLPAVIPKKEKPELSEPSHLNGPSSDPEAAFLSRDVDDGSGSPHSPHQLSSKSLPSQNLSQSLSNSFNSSYMSSDNESDIEDEDLKLELRRLRDKHLKEIQDLQSRQKHEIESLYTKLGKVPPAVIIPPAAPLSGRRRRPTKSKGSKSSRSSSLGNKSPQLSGNLSGQSAASVLHPQQTLHPPGNIPESGQNQLLQPLKPSPSSDNLYSAFTSDGAISVPSLSAPGQGTSSTNTVGATVNSQAAQAQPPAMTSSRKGTFTDDLHKLVDNWARDAMNLSGRRGSKGHMNYEGPGMARKFSAPGQLCISMTSNLGGSAPISAASATSLGHFTKSMCPPQQYGFPATPFGAQWSGTGGPAPQPLGQFQPVGTASLQNFNISNLQKSISNPPGSNLRTT>sp|Q9H4A3-5|WNK1_HUMAN Isoform 4 of Serine/threonine-protein kinase WNK1OS=Homo sapiens OX=9606 GN=WNK1MSGGAAEKQSSTPGSLFLSPPAPAPKNGSSSDSSVGEKLGAAAADAVTGRTEEYRRRRHTMDKDSRGAAATTTTTEHRFFRRSVICDSNATALELPGLPLSLPQPSIPAAVPQSAPPEPHREETVTATATSQVAQQPPAAAAPGEQAVAGPAPSTVPSSTSKDRPVSQPSLVGSKEEPPPARSGSGGGSAKEPQEERSQQQDDIEELETKAVGMSNDGRFLKFDIEIGRGSFKTVYKGLDTETTVEVAWCELQDRKLTKSERQRFKEEAEMLKGLQHPNIVRFYDSWESTVKGKKCIVLVTELMTSGTLKTYLKRFKVMKIKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRRVTSGVKPASFDKVAIPEVKEIIEGCIRQNKDERYSIKDLLNHAFFQEETGVRVELAEEDDGEKIAIKLWLRIEDIKKLKGKYKDNEAIEFSFDLERDVPEDVAQEMVESGYVCEGDHKTMAKAIKDRVSLIKRKREQRQLVREEQEKKKQEESSLKQQVEQSSASQTGIKQLPSASTGIPTASTTSASVSTQVEPEEPEADQHQQLQYQQPSISVLSDGTVDSGQGSSVFTESRVSSQQTVSYGSQHEQAHSTGTVPGHIPSTVQAQSQPHGVYPPSSVPRRGRSMSVCVPIFLLLPLCPASLPVLFHPTASTVCTSFSFPPPDCPEETFAEKLSKALESVLPMHSASQRKHRRSSLPSLFVSTPQSMAHPCGGTPTYPESQIFFPTIHERPVSFSPPPTCPPKVAISQRRKSTSFLEAQTHHFQPLLRTVGQSLLPPGGSPTNWTPEAVVMLGTTASRVTGESCEIQVHPMFEPSQVYSDYRPGLVLPEEAHYFIPQEAVYVAGVHYQARVAEQYEGIPYNSSVLSSPMKQIPEQKPVQGGPTSSSVFEFPSGQAFLVGHLQNLRLDSGLGPGSPLSSISAPISTDATRLKFHPVFVPHSAPAVLTHNNESRSNCVFEFHVHTPSSSSGEGGGILPQRVYRNRQVAVDLNQEELPPQSVGLHGYLQPVTEEKHNYHAPELTVSVVEPIGQNWPIGSPEYSSDSSQITSSDPSDFQSPPPTGGAAAPFGSDVSMPFIHLPQTVLQESPLFFCFPQGTTSQQVLTASFSSGGSALHPQAQGQSQGQPSSSSLTGVSSSQPIQHPQQQQGIQQTAPPQQTVQYSLSQTSTSSEATTAQPVSQPQAPQVLPQVSAGKQSTQGVSQVAPAEPVAVAQTQATQPTTLASSVDSAHSDVASGMSDGNENVPSSSGRHEGRTTKRHYRKSVRSRSRHEKTSRPKLRILNVSNKGDRVVECQLETHNRKMVTFKFDLDGDNPEEIATIMVNNDFILAIERESFVDQVREIIEKADEMLSEDVSVEPEGDQGLESLQGKDDYGFSGSQKLEGEFKQPIPASSMPQQIGIPTSSLTQVVHSAGRRFIVSPVPESRLRESKVFPSEITDTVAASTAQSPGMNLSHSASSLSLQQAFSELRRAQMTEGPNTAPPNFSHTGPTFPVVPPFLSSIAGVPTTAAATAPVPATSSPPNDISTSVIQSEVTVPTEEGIAGVATSTGVVTSGGLPIPPVSESPVLSSVVSSITIPAVVSISTTSPSLQVPTSTSEIVVSSTALYPSVTVSATSASAGGSTATPGPKPPAVVSQQAAGSTTVGATLTSVSTTTSFPSTASQLCIQLSSSTSTPTLAETVVVSAHSLDKTSHSSTTGLAFSLSAPSSSSSPGAGVSSYISQPGGLHPLVIPSVIASTPILPQAAGPTSTPLLPQVPSIPPLVQPVANVPAVQQTLIHSQPQPALLPNQPHTHCPEVDSDTQPKAPGIDDIKTLEEKLRSLFSEHSSSGAQHASVSLETSLVIESTVTPGIPTTAVAPSKLLTSTTSTCLPPTNLPLGTVALPVTPVVTPGQVSTPVSTTTSGVKPGTAPSKPPLTKAPVLPVGTELPAGTLPSEQLPPFPGPSLTQSQQPLEDLDAQLRRTLSPEMITVTSAVGPVSMAAPTAITEAGTQPQKGVSQVKEGPVLATSSGAGVFKMGRFQVSVAADGAQKEGKNKSEDAKSVHFESSTSESSVLSSSSPESTLVKPEPNGITIPGISSDVPESAHKTTASEAKSDTGQPTKVGRFQVTTTANKVGRFSVSKTEDKITDTKKEGPVASPPFMDLEQAVLPAVIPKKEKPELSEPSHLNGPSSDPEAAFLSRDVDDGSGSPHSPHQLSSKSLPSQNLSQSLSNSFNSSYMSSDNESDIEDEDLKLELRRLRDKHLKEIQDLQSRQKHEIESLYTKLGKVPPAVIIPPAAPLSGRRRRPTKSKGSKSSRSSSLGNKSPQLSGNLSGQSAASVLHPQQTLHPPGNIPESGQNQLLQPLKPSPSSDNLYSAFTSDGAISVPSLSAPGQGTSSTNTVGATVNSQAAQAQPPAMTSSRKGTFTDDLHKLVDNWARDAMNLSGRRGSKGHMNYEGPGMARKFSAPGQLCISMTSNLGGSAPISAASATSLGHFTKSMCPPQQYGFPATPFGAQWSGTGGPAPQPLGQFQPVGTASLQNFNISNLQKSISNPPGSNLRTT>sp|Q9H4A3-6|WNK1_HUMAN Isoform 5 of Serine/threonine-protein kinase WNK1OS=Homo sapiens OX=9606 GN=WNK1MSGGAAEKQSSTPGSLFLSPPAPAPKNGSSSDSSVGEKLGAAAADAVTGRTEEYRRRRHTMDKDSRGAAATTTTTEHRFFRRSVICDSNATALELPGLPLSLPQPSIPAAVPQSAPPEPHREETVTATATSQVAQQPPAAAAPGEQAVAGPAPSTVPSSTSKDRPVSQPSLVGSKEEPPPARSGSGGGSAKEPQEERSQQQDDIEELETKAVGMSNDGRFLKFDIEIGRGSFKTVYKGLDTETTVEVAWCELQDRKLTKSERQRFKEEAEMLKGLQHPNIVRFYDSWESTVKGKKCIVLVTELMTSGTLKTYLKRFKVMKIKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRRVTSGVKPASFDKVAIPEVKEIIEGCIRQNKDERYSIKDLLNHAFFQEETGVRVELAEEDDGEKIAIKLWLRIEDIKKLKGKYKDNEAIEFSFDLERDVPEDVAQEMVESGYVCEGDHKTMAKAIKDRVSLIKRKREQRQLVREEQEKKKQEESSLKQQVEQSSASQTGIKQLPSASTGIPTASTTSASVSTQVEPEEPEADQHQQLQYQQPSISVLSDGTVDSGQGSSVFTESRVSSQQTVSYGSQHEQAHSTGTVPGHIPSTVQAQSQPHGVYPPSSVPQSMAHPCGGTPTYPESQIFFPTIHERPVSFSPPPTCPPKVAISQRRKSTSFLEAQTHHFQPLLRTVGQSLLPPGGSPTNWTPEAVVMLGTTASRVTGESCEIQVHPMFEPSQVYSDYRPGLVLPEEAHYFIPQEAVYVAGVHYQARVAEQYEGIPYNSSVLSSPMKQIPEQKPVQGGPTSSSVFEFPSGQAFLVGHLQNLRLDSGLGPGSPLSSISAPISTDATRLKFHPVFVPHSAPAVLTHNNESRSNCVFEFHVHTPSSSSGEGGGILPQRVYRNRQVAVDLNQEELPPQSVGLHGYLQPVTEEKHNYHAPELTVSVVEPIGQNWPIGSPEYSSDSSQITSSDPSDFQSPPPTGGAAAPFGSDVSMPFIHLPQTVLQESPLFFCFPQGTTSQQVLTASFSSGGSALHPQAQGQSQGQPSSSSLTGVSSSQPIQHPQQQQGIQQTAPPQQTVQYSLSQTSTSSEATTAQPVSQPQAPQVLPQVSAGKQGFPPRLPPQYPGDSNIAPSSNVASVCIHSTVLSPPMPTEVLATPGYFPTVVQPYVESNLLVPMGGVGGQVQVSQPGGSLAQAPTTSSQQAVLESTQGVSQVAPAEPVAVAQTQATQPTTLASSVDSAHSDVASGMSDGNENVPSSSGRHEGRTTKRHYRKSVRSRSRHEKTSRPKLRILNVSNKGDRVVECQLETHNRKMVTFKFDLDGDNPEEIATIMVNNDFILAIERESFVDQVREIIEKADEMLSEDVSVEPEGDQGLESLQGKDDYGFSGSQKLEGEFKQPIPASSMPQQIGIPTSSLTQVVHSAGRRFIVSPVPESRLRESKVFPSEITDTVAASTAQSPGMNLSHSASSLSLQQAFSELRRAQMTEGPNTAPPNFSHTGPTFPVVPPFLSSIAGVPTTAAATAPVPATSSPPNDISTSVIQSEVTVPTEEGIAGVATSTGVVTSGGLPIPPVSESPVLSSVVSSITIPAVVSISTTSPSLQVPTSTSEIVVSSTALYPSVTVSATSASAGGSTATPGPKPPAVVSQQAAGSTTVGATLTSVSTTTSFPSTASQLCIQLSSSTSTPTLAETVVVSAHSLDKTSHSSTTGLAFSLSAPSSSSSPGAGVSSYISQPGGLHPLVIPSVIASTPILPQAAGPTSTPLLPQVPSIPPLVQPVANVPAVQQTLIHSQPQPALLPNQPHTHCPEVDSDTQPKAPGIDDIKTLEEKLRSLFSEHSSSGAQHASVSLETSLVIESTVTPGIPTTAVAPSKLLTSTTSTCLPPTNLPLGTVALPVTPVVTPGQVSTPVSTTTSGVKPGTAPSKPPLTKAPVLPVGTELPAGTLPSEQLPPFPGPSLTQSQQPLEDLDAQLRRTLSPEMITVTSAVGPVSMAAPTAITEAGTQPQKGVSQVKEGPVLATSSGAGVFKMGRFQVSVAADGAQKEGKNKSEDAKSVHFESSTSESSVLSSSSPESTLVKPEPNGITIPGISSDVPESAHKTTASEAKSDTGQPTKVGRFQVTTTANKVGRFSVSKTEDKITDTKKEGPVASPPFMDLEQAVLPAVIPKKEKPELSEPSHLNGPSSDPEAAFLSRDVDDGSGSPHSPHQLSSKSLPSQNLSQSLSNSFNSSYMSSDNESDIEDEDLKLELRRLRDKHLKEIQDLQSRQKHEIESLYTKLGKVPPAVIIPPAAPLSGRRRRPTKSKGSKSSRSSSLGNKSPQLSGNLSGQSAASVLHPQQTLHPPGNIPESGQNQLLQPLKPSPSSDNLYSAFTSDGAISVPSLSAPGQGTSSTNTVGATVNSQAAQAQPPAMTSSRKGTFTDDLHKLVDNWARDAMNLSGRRGSKGHMNYEGPGMARKFSAPGQLCISMTSNLGGSAPISAASATSLGHFTKSMCPPQQYGFPATPFGAQWSGTGGPAPQPLGQFQPVGTASLQNFNISNLQKSISNPPGSNLRTT>sp|Q9H4A3-7|WNK1_HUMAN Isoform 6 of Serine/threonine-protein kinase WNK1OS=Homo sapiens OX=9606 GN=WNK1MSGGAAEKQSSTPGSLFLSPPAPAPKNGSSSDSSVGEKLGAAAADAVTGRTEEYRRRRHTMDKDSRGAAATTTTTEHRFFRRSVICDSNATALELPGLPLSLPQPSIPAAVPQSAPPEPHREETVTATATSQVAQQPPAAAAPGEQAVAGPAPSTVPSSTSKDRPVSQPSLVGSKEEPPPARSGSGGGSAKEPQEERSQQQDDIEELETKAVGMSNDGRFLKFDIEIGRGSFKTVYKGLDTETTVEVAWCELQDRKLTKSERQRFKEEAEMLKGLQHPNIVRFYDSWESTVKGKKCIVLVTELMTSGTLKTYLKRFKVMKIKVLRSWCRQILKGLQFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRRVTSGVKPASFDKVAIPEVKEIIEGCIRQNKDERYSIKDLLNHAFFQEETGVRVELAEEDDGEKIAIKLWLRIEDIKKLKGKYKDNEAIEFSFDLERDVPEDVAQEMVESGYVCEGDHKTMAKAIKDRVSLIKRKREQRQLVREEQEKKKQEESSLKQQVEQSSASQTGIKQLPSASTGIPTASTTSASVSTQVEPEEPEADQHQQLQYQQPSISVLSDGTVDSGQGSSVFTESRVSSQQTVSYGSQHEQAHSTGTVPGHIPSTVQAQSQPHGVYPPSSVPQSMAHPCGGTPTYPESQIFFPTIHERPVSFSPPPTCPPKVAISQRRKSTSFLEAQTHHFQPLLRTVGQSLLPPGGSPTNWTPEAVVMLGTTASRVTGESCEIQVHPMFEPSQVYSDYRPGLVLPEEAHYFIPQEAVYVAGVHYQARVAEQYEGIPYNSSVLSSPMKQIPEQKPVQGGPTSSSVFEFPSGQAFLVGHLQNLRLDSGLGPGSPLSSISAPISTDATRLKFHPVFVPHSAPAVLTHNNESRSNCVFEFHVHTPSSSSGEGGGILPQRVYRNRQVAVDLNQEELPPQSVGLHGYLQPVTEEKHNYHAPELTVSVVEPIGQNWPIGSPEYSSDSSQITSSDPSDFQSPPPTGGAAAPFGSDVSMPFIHLPQTVLQESPLFFCFPQGTTSQQVLTASFSSGGSALHPQAQGQSQGQPSSSSLTGVSSSQPIQHPQQQQGIQQTAPPQQTVQYSLSQTSTSSEATTAQPVSQPQAPQVLPQVSAGKQLPVSQPVPTIQGEPQIPVATQPSVVPVHSGAHFLPVGQPLPTPLLPQYPVSQIPISTPHVSTAQTGFSSLPITMAAGITQPLLTLASSATTAAIPGVSTVVPSQLPTLLQPVTQLPSQVHPQLLQPAVQSMGIPANLGQAAEVPLSSGDVLYQGFPPRLPPQYPGDSNIAPSSNVASVCIHSTVLSPPMPTEVLATPGYFPTVVQPYVESNLLVPMGGVGGQVQVSQPGGSLAQAPTTSSQQAVLESTQGVSQVAPAEPVAVAQTQATQPTTLASSVDSAHSDVASGMSDGNENVPSSSGRHEGRTTKRHYRKSVRSRSRHEKTSRPKLRILNVSNKGDRVVECQLETHNRKMVTFKFDLDGDNPEEIATIMVNNDFILAIERESFVDQVREIIEKADEMLSEDVSVEPEGDQGLESLQGKDDYGFSGSQKLEGEFKQPIPASSMPQQIGIPTSSLTQVVHSAGRRFIVSPVPESRLRESKVFPSEITDTVAASTAQSPGMNLSHSASSLSLQQAFSELRRAQMTEGPNTAPPNFSHTGPTFPVVPPFLSSIAGVPTTAAATAPVPATSSPPNDISTSVIQSEVTVPTEEGIAGVATSTGVVTSGGLPIPPVSESPVLSSVVSSITIPAVVSISTTSPSLQVPTSTSEIVVSSTALYPSVTVSATSASAGGSTATPGPKPPAVVSQQAAGSTTVGATLTSVSTTTSFPSTASQLCIQLSSSTSTPTLAETVVVSAHSLDKTSHSSTTGLAFSLSAPSSSSSPGAGVSSYISQPGGLHPLVIPSVIASTPILPQAAGPTSTPLLPQVPSIPPLVQPVANVPAVQQTLIHSQPQPALLPNQPHTHCPEVDSDTQPKAPGIDDIKTLEEKLRSLFSEHSSSGAQHASVSLETSLVIESTVTPGIPTTAVAPSKLLTSTTSTCLPPTNLPLGTVALPVTPVVTPGQVSTPVSTTTSGVKPGTAPSKPPLTKAPVLPVGTELPAGTLPSEQLPPFPGPSLTQSQQPLEDLDAQLRRTLSPEMITVTSAVGPVSMAAPTAITEAGTQPQKGVSQVKEGPVLATSSGAGVFKMGRFQVSVAADGAQKEGKNKSEDAKSVHFESSTSESSVLSSSSPESTLVKPEPNGITIPGISSDVPESAHKTTASEAKSDTGQPTKVGRFQVTTTANKVGRFSVSKTEDKITDTKKEGPVASPPFMDLEQAVLPAVIPKKEKPELSEPSHLNGPSSDPEAAFLSRDVDDGSGSPHSPHQLSSKSLPSQNLSQSLSNSFNSSYMSSDNESDIEDEDLKLELRRLRDKHLKEIQDLQSRQKHEIESLYTKLGKVPPAVIIPPAAPLSGRRRRPTKSKGSKSSRSSSLGNKSPQLSGNLSGQSAASVLHPQQTLHPPGNIPESGQNQLLQPLKPSPSSDNLYSAFTSDGAISVPSLSAPGQGCAKFNCASEQVTFKPGGRRTRFLRKMVKKVCPCNQLCRTSSTNTVGATVNSQAAQAQPPAMTSSRKGTFTDDLHKLVDNWARDAMNLSGRRGSKGHMNYEGPGMARKFSAPGQLCISMTSNLGGSAPISAASATSLGHFTKSMCPPQQYGFPATPFGAQWSGTGGPAPQPLGQFQPVGTASLQNFNISNLQKSISNPPGSNLRTT>sp|Q9NRW7|VPS45_HUMAN Vacuolar protein sorting-associated protein 45OS=Homo sapiens OX=9606 GN=VPS45 PE=1 SV=1MNVVFAVKQYISKMIEDSGPGMKVLLMDKETTGIVSMVYTQSEILQKEVYLFERIDSQNREIMKHLKAICFLRPTKENVDYIIQELRRPKYTIYFIYFSNVISKSDVKSLAEADEQEVVAEVQEFYGDYIAVNPHLFSLNILGCCQGRNWDPAQLSRTTQGLTALLLSLKKCPMIRYQLSSEAAKRLAECVKQVITKEYELFEFRRTEVPPLLLILDRCDDAITPLLNQWTYQAMVHELLGINNNRIDLSRVPGISKDLREVVLSAENDEFYANNMYLNFAEIGSNIKNLMEDFQKKKPKEQQKLESIADMKAFVENYPQFKKMSGTVSKHVTVVGELSRLVSERNLLEVSEVEQELACQNDHSSALQNIKRLLQNPKVTEFDAARLVMLYALHYERHSSNSLPGLMMDLRNKGVSEKYRKLVSAVVEYGGKRVRGSDLFSPKDAVAITKQFLKGLKGVENVYTQHQPFLHETLDHLIKGRLKENLYPYLGPSTLRDRPQDIIVFVIGGATYEEALTVYNLNRTTPGVRIVLGGTTVHNTKSFLEEVLASGLHSRSKESSQVTSRSASRR>sp|Q9NRW7-2|VPS45_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 45 OS=Homo sapiens OX=9606 GN=VPS45MVYTQSEILQKEVYLFERIDSQNREIMKHLKAICFLRPTKENVDYIIQELRRPKYTIYFIYFSNVISKSDVKSLAEADEQEVVAEVQQVITKEYELFEFRRTEVPPLLLILDRCDDAITPLLNQWTYQAMVHELLGINNNRIDLSRVPGISKDLREVVLSAENDEFYANNMYLNFAEIGSNIKNLMEDFQKKKPKEQQKLESIADMKAFVENYPQFKKMSGTVSKHVTVVGELSRLVSERNLLEVSEVEQELACQNDHSSALQNIKRLLQNPKVTEFDAARLVMLYALHYERHSSNSLPGLMMDLRNKGVSEKYRKLVSAVVEYGGKRVRGSDLFSPKDAVAITKQFLKGLKGVENVYTQHQPFLHETLDHLIKGRLKENLYPYLGPSTLRDRPQDIIVFVIGGATYEEALTVYNLNRTTPGVRIVLGGTTVHNTKRDGVSLCSPAWFRTPGLKRSTRLSLPKCWDYSFPRGSSGFWTAQPKQGELSSHIKVSEQKMKRWLGEGHSFLSCPHYRFSLLNKGVGEQLWVLCWLLELISR>sp|Q93050|VPP1_HUMAN V-type proton ATPase 116 kDa subunit a1 OS=Homosapiens OX=9606 GN=ATP6V0A1 PE=1 SV=3MGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCEEMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEIIQHDQLSTHSEDADEPSEDEVFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWVEFQNKFYSGTGFKFLPFSFEHIREGKFEE>sp|Q93050-1|VPP1_HUMAN Isoform 2 of V-type proton ATPase 116 kDa subunita1 OS=Homo sapiens OX=9606 GN=ATP6V0A1MGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCEEMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEIIQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWVEFQNKFYSGTGFKFLPFSFEHIREGKFEE>sp|Q93050-3|VPP1_HUMAN Isoform 3 of V-type proton ATPase 116 kDa subunita1 OS=Homo sapiens OX=9606 GN=ATP6V0A1MGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCEEMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEAELHHQQMADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEIIQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWVEFQNKFYSGTGFKFLPFSFEHIREGKFEE>sp|Q8IV35|WDR49_HUMAN WD repeat-containing protein 49 OS=Homo sapiensOX=9606 GN=WDR49 PE=2 SV=1MAWREKSKKRLNMTSFNIAQGIHAFDYHSRLNLIATAGINNKVCLWNPYVVSKPVGVLWGHSASVIAVQFFVERKQLFSFSKDKVLRLWDIQHQLSIQRIACSFPKSQDFRCLFHFDEAHGRLFISFNNQLALLAMKSEASKRVKSHEKAVTCVLYNSILKQVISSDTGSTVSFWMIDTGQKIKQFTGCHGNAEISTMALDANETRLLTGSTDGTVKIWDFNGYCHHTLNVGQDGAVDISQILILKKKILVTGWERAITVFRPQNFNQFFIQPEEWKGGIQHHDDILCAAFLPPQTLVTGSYDGEIVLWNNSTENAHHVLHPDYQRLLKSKLDTKPQKLLSAGRSQPSHPMADHSTTGVRNFEIDTEGKNAVMRLCFLKARKNTAVTGGANLVSCGGSGYVRFWDIYKKQLLAEFLAHSGVGSIIMSTDKMNRYLTTGDLDGWLKIWNIEEYCLNSSKNKITKAPTLIRSFQPHEDRISSLEMCEPGGQLLIISSSADCSICVTGVCNAPVWIFGQAKHWHIENCLFLPKRDTNLVESEIQKEISLFSKEESCLDPTEHSLLNKKNKDDSTYNVRPSEDINLDIKYKERSTCMKETQKPYYGEVIKKSFSTFRSLNIGALEELPEVNKPAFLLDPEKYFRKEPEEERPQILEAPSLFKTLKAVFDEKNLFPKEILHHERKAKQLCQEKSCEVKKNKK>sp|Q8IV35-2|WDR49_HUMAN Isoform 2 of WD repeat-containing protein 49OS=Homo sapiens OX=9606 GN=WDR49MIDTGQKIKQFTGCHGNAEISTMALDANETRLLTGSTDGTVKIWDFNGYCHHTLNVGQDGAVDISQILILKKKILVTGWERAITVFRPQNFNQFFIQPEEWKGGIQHHDDILCAAFLPPQTLVTGSYDGEIVLWNNSTENAHHVLHPDYQRLLKSKLDTKPQKLLSAGRSQPSHPMADHSTTGVRNFEIDTEGKNAVMRLCFLKARKNTAVTGGANLVSCGGSGYVRFWDIYKKQLLAEFLAHSGVGSIIMSTDKMNRYLTTGDLDGWLKIWNIEEYCLNSSKNKITKAPTLIRSFQPHEDRISSLEMCEPGGQLLIISSSADCSICVTGVCNAPVWIFGQAKHWHIENCLFLPKRDTNLVESEIQKEISLFSKEESCLDPTEHSLLNKKNKDDSTYNVRPSEDINLDIKYKERSTCMKETQKPYYGEVIKKSFSTFRSLNIGALEELPEVNKPAFLLDPEKYFRKEPEEERPQILEAPSLFKTLKAVFDEKNLFPKEILHHERKAKQLCQEKSCEVKKNKK>sp|Q9Y3C0|WASC3_HUMAN WASH complex subunit 3 OS=Homo sapiens OX=9606GN=WASHC3 PE=1 SV=1MDEDGLPLMGSGIDLTKVPAIQQKRTVAFLNQFVVHTVQFLNRFSTVCEEKLADLSLRIQQIETTLNILDAKLSSIPGLDDVTVEVSPLNVTSVTNGAHPEATSEQPQQNSTQDSGLQESEVSAENILTVAKDPRYARYLKMVQVGVPVMAIRNKMISEGLDPDLLERPDAPVPDGESEKTVEESSDSESSFSD>sp|Q9H1B5|XYLT2_HUMAN Xylosyltransferase 2 OS=Homo sapiens OX=9606GN=XYLT2 PE=1 SV=2MVASARVQKLVRRYKLAIATALAILLLQGLVVWSFSGLEEDEAGEKGRQRKPRPLDPGEGSKDTDSSAGRRGSTGRRHGRWRGRAESPGVPVAKVVRAVTSRQRASRRVPPAPPPEAPGRQNLSGAAAGEALVGAAGFPPHGDTGSVEGAPQPTDNGFTPKCEIVGKDALSALARASTKQCQQEIANVVCLHQAGSLMPKAVPRHCQLTGKMSPGIQWDESQAQQPMDGPPVRIAYMLVVHGRAIRQLKRLLKAVYHEQHFFYIHVDKRSDYLHREVVELAQGYDNVRVTPWRMVTIWGGASLLRMYLRSMRDLLEVPGWAWDFFINLSATDYPTRTNEELVAFLSKNRDKNFLKSHGRDNSRFIKKQGLDRLFHECDSHMWRLGERQIPAGIVVDGGSDWFVLTRSFVEYVVYTDDPLVAQLRQFYTYTLLPAESFFHTVLENSLACETLVDNNLRVTNWNRKLGCKCQYKHIVDWCGCSPNDFKPQDFLRLQQVSRPTFFARKFESTVNQEVLEILDFHLYGSYPPGTPALKAYWENTYDAADGPSGLSDVMLTAYTAFARLSLHHAATAAPPMGTPLCRFEPRGLPSSVHLYFYDDHFQGYLVTQAVQPSAQGPAETLEMWLMPQGSLKLLGRSDQASRLQSLEVGTDWDPKERLFRNFGGLLGPLDEPVAVQRWARGPNLTATVVWIDPTYVVATSYDITVDTETEVTQYKPPLSRPLRPGPWTVRLLQFWEPLGETRFLVLPLTFNRKLPLRKDDASWLHAGPPHNEYMEQSFQGLSSILNLPQPELAEEAAQRHTQLTGPALEAWTDRELSSFWSVAGLCAIGPSPCPSLEPCRLTSWSSLSPDPKSELGPVKADGRLR>sp|Q9H1B5-2|XYLT2_HUMAN Isoform 2 of Xylosyltransferase 2 OS=Homosapiens OX=9606 GN=XYLT2MVASARVQKLVRRYKLAIATALAILLLQGLVVWSFSGLEEDEAGEKGRQRKPRPLDPGEGSKDTDSSAGRRGSTGRRHGRWRGRAESPGVPVAKVVRAVTSRQRASRRVPPAPPPEAPGRQNLSGAAAGEALVGAAGFPPHGDTGSVEGAPQPTDNGFTPKCEIVGKDALSALARASTKQCQQEIANVVCLHQAGSLMPKAVPRHCQLTGKMSPGIQWDESQAQQPMDGPPVRIAYMLVVHGRAIRQLKRLLKAVYHEQHFFYIHVDKRSDYLHREVVELAQGYDNVRVTPWRMVTIWGGASLLRMYLRSMRDLLEVPGWAWDFFINLSATDYPTRTNEELVAFLSKNRDKNFLKSHGRDNSRFIKKQGLDRLFHECDSHMWRLGERQIPAGIVVDGGSDWFVLTRSFVEYVVYTDDPLVAQLRQFYTYTLLPAESFFHTVLENSLACETLVDNNLRVTNWNRKLGCKCQYKHIVDWCGCSPNDFKPQDFLRLQQVSRPTFFARKFESTVNQEVLEILDFHLYGSYPPGTPALKAYWENTYDAADGPSGLSDVMLTAYTAFARLSLHHAATAAPPMGTPLCRLALIGTPKSVFSGTLGGYWGRWTSLWPCSAGPGAPTSQPQWSGSTQPMWWPHLMTS>sp|Q86Y38|XYLT1_HUMAN Xylosyltransferase 1 OS=Homo sapiens OX=9606GN=XYLT1 PE=1 SV=1MVAAPCARRLARRSHSALLAALTVLLLQTLVVWNFSSLDSGAGERRGGAAVGGGEQPPPAPAPRRERRDLPAEPAAARGGGGGGGGGGGGRGPQARARGGGPGEPRGQQPASRGALPARALDPHPSPLITLETQDGYFSHRPKEKVRTDSNNENSVPKDFENVDNSNFAPRTQKQKHQPELAKKPPSRQKELLKRKLEQQEKGKGHTFPGKGPGEVLPPGDRAAANSSHGKDVSRPPHARKTGGSSPETKYDQPPKCDISGKEAISALSRAKSKHCRQEIGETYCRHKLGLLMPEKVTRFCPLEGKANKNVQWDEDSVEYMPANPVRIAFVLVVHGRASRQLQRMFKAIYHKDHFYYIHVDKRSNYLHRQVLQVSRQYSNVRVTPWRMATIWGGASLLSTYLQSMRDLLEMTDWPWDFFINLSAADYPIRTNDQLVAFLSRYRDMNFLKSHGRDNARFIRKQGLDRLFLECDAHMWRLGDRRIPEGIAVDGGSDWFLLNRRFVEYVTFSTDDLVTKMKQFYSYTLLPAESFFHTVLENSPHCDTMVDNNLRITNWNRKLGCKCQYKHIVDWCGCSPNDFKPQDFHRFQQTARPTFFARKFEAVVNQEIIGQLDYYLYGNYPAGTPGLRSYWENVYDEPDGIHSLSDVTLTLYHSFARLGLRRAETSLHTDGENSCRYYPMGHPASVHLYFLADRFQGFLIKHHATNLAVSKLETLETWVMPKKVFKIASPPSDFGRLQFSEVGTDWDAKERLFRNFGGLLGPMDEPVGMQKWGKGPNVTVTVIWVDPVNVIAATYDILIESTAEFTHYKPPLNLPLRPGVWTVKILHHWVPVAETKFLVAPLTFSNRQPIKPEEALKLHNGPLRNAYMEQSFQSLNPVLSLPINPAQVEQARRNAASTGTALEGWLDSLVGGMWTAMDICATGPTACPVMQTCSQTAWSSFSPDPKSELGAVKPDGRLR>sp|Q969M3|YIPF5_HUMAN Protein YIPF5 OS=Homo sapiens OX=9606 GN=YIPF5PE=1 SV=1MSGFENLNTDFYQTSYSIDDQSQQSYDYGGSGGPYSKQYAGYDYSQQGRFVPPDMMQPQQPYTGQIYQPTQAYTPASPQPFYGNNFEDEPPLLEELGINFDHIWQKTLTVLHPLKVADGSIMNETDLAGPMVFCLAFGATLLLAGKIQFGYVYGISAIGCLGMFCLLNLMSMTGVSFGCVASVLGYCLLPMILLSSFAVIFSLQGMVGIILTAGIIGWCSFSASKIFISALAMEGQQLLVAYPCALLYGVFALISVF>sp|Q969M3-2|YIPF5_HUMAN Isoform 2 of Protein YIPF5 OS=Homo sapiensOX=9606 GN=YIPF5MMQPQQPYTGQIYQPTQAYTPASPQPFYGNNFEDEPPLLEELGINFDHIWQKTLTVLHPLKVADGSIMNETDLAGPMVFCLAFGATLLLAGKIQFGYVYGISAIGCLGMFCLLNLMSMTGVSFGCVASVLGYCLLPMILLSSFAVIFSLQGMVGIILTAGIIGWCSFSASKIFISALAMEGQQLLVAYPCALLYGVFALISVF>sp|Q969M3-3|YIPF5_HUMAN Isoform 3 of Protein YIPF5 OS=Homo sapiensOX=9606 GN=YIPF5MSGFENLNTDFYQTSYSIDDQSQQSYDYGGSGGPYSKQYAGYDYSQQGRFVPPDMMQPQQPYTGQIYQPTQAYTPASPQPFYGNNFEDEPPLLEELGINFDHIWQKTLTVLHPLKVADGSIMNETDLAGPMVFCLAFGATLLLAGKIQFGYVYGISAIGCLGMFCLLNLMSMTGVSFGCVASVLGYCLLPMILLSSFAVIFSLQGMVGIILTAGIIGWCSFSASKIFISALAMEGQQLLVALQPNITYGSNYFLFCCLPYPQQHF>sp|Q6ZSN1|YI023_HUMAN Putative uncharacterized protein FLJ45355 OS=Homosapiens OX=9606 PE=2 SV=1MGVPRAREGRGAGSQSPPRGRCLHPFRWGSQDRGRGEGLALSPLLPGVPPPPAMGVPRDRGGRGAGSQSTPRGGCLLPPRLGSQQPAGEEGLVLSPRLAGDASPCCDGSPKSQGVKRGWLSVPTSRGVPPPPAIGVLIARGGRGAGSQSLPRGWSFTPLRWGS>sp|Q6ZRM9|YG024_HUMAN Putative uncharacterized protein FLJ46235 OS=Homosapiens OX=9606 PE=2 SV=1MASGRWASPGPAWASRRPLQAQVVLKSASPGPAPASQQASSFGSAPAQLPPAFVDPELSPAMLLSPTCLPVACTGPGLAGEQPLQAPLLPPRGISRPSSGLTAASRDQVPACLPAACVRPSSSVTVACSGPTHASGTLSRGVSPCLTLASLTLREFSVGPCLTLASLTLREVSMSPCLTLVSLTLRAILPHAGLLRPSSCLCWPFQAQPLPVGGL>sp|Q9ULC8|ZDHC8_HUMAN Palmitoyltransferase ZDHHC8 OS=Homo sapiensOX=9606 GN=ZDHHC8 PE=1 SV=3MPRSPGTRLKPAKYIPVATAAALLVGSSTLFFVFTCPWLTRAVSPAVPVYNGIIFLFVLANFSMATFMDPGVFPRADEDEDKEDDFRAPLYKNVDVRGIQVRMKWCATCHFYRPPRCSHCSVCDNCVEDFDHHCPWVNNCIGRRNYRYFFLFLLSLSAHMVGVVAFGLVYVLNHAEGLGAAHTTITMAVMCVAGLFFIPVIGLTGFHVVLVTRGRTTNEQVTGKFRGGVNPFTRGCCGNVEHVLCSPLAPRYVVEPPRLPLAVSLKPPFLRPELLDRAAPLKVKLSDNGLKAGLGRSKSKGSLDRLDEKPLDLGPPLPPKIEAGTFSSDLQTPRPGSAESALSVQRTSPPTPAMYKFRPAFPTGPKVPFCGPGEQVPGPDSLTLGDDSIRSLDFVSEPSLDLPDYGPGGLHAAYPPSPPLSASDAFSGALRSLSLKASSRRGGDHVALQPLRSEGGPPTPHRSIFAPHALPNRNGSLSYDSLLNPGSPGGHACPAHPAVGVAGYHSPYLHPGATGDPPRPLPRSFSPVLGPRPREPSPVRYDNLSRTIMASIQERKDREERERLLRSQADSLFGDSGVYDAPSSYSLQQASVLSEGPRGPALRYGSRDDLVAGPGFGGARNPALQTSLSSLSSSVSRAPRTSSSSLQADQASSNAPGPRPSSGSHRSPARQGLPSPPGTPHSPSYAGPKAVAFIHTDLPEPPPSLTVQRDHPQLKTPPSKLNGQSPGLARLGPATGPPGPSASPTRHTLVKKVSGVGGTTYEISV>sp|Q9ULC8-2|ZDHC8_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC8 OS=Homosapiens OX=9606 GN=ZDHHC8MPRSPGTRLKPAKYIPVATAAALLVGSSTLFFVFTCPWLTRAVSPAVPVYNGIIFLFVLANFSMATFMDPGVFPRADEDEDKEDDFRAPLYKNVDVRGIQVRMKWCATCHFYRPPRCSHCSVCDNCVEVTGKFRGGVNPFTRGCCGNVEHVLCSPLAPRYVVEPPRLPLAVSLKPPFLRPELLDRAAPLKVKLSDNGLKAGLGRSKSKGSLDRLDEKPLDLGPPLPPKIEAGTFSSDLQTPRPGSAESALSVQRTSPPTPAMYKFRPAFPTGPKVPFCGPGEQVPGPDSLTLGDDSIRSLDFVSEPSLDLPDYGPGGLHAAYPPSPPLSASDAFSGALRSLSLKASSRRGGDHVALQPLRSEGGPPTPHRSIFAPHALPNRNGSLSYDSLLNPGSPGGHACPAHPAVGVAGYHSPYLHPGATGDPPRPLPRSFSPVLGPRPREPSPVRYDNLSRTIMASIQERKDREERERLLRSQADSLFGDSGVYDAPSSYSLQQASVLSEGPRGPALRYGSRDDLVAGPGFGGARNPALQTSLSSLSSSVSRAPRTSSSSLQADQASSNAPGPRPSSGSHRSPARQGLPSPPGTPHSPSYAGPKAVAFIHTDLPEPPPSLTVQRDHPQLKTPPSKLNGQSPGLARLGPATGPPGPSASPTRHTLVKKVSGVGGTTYEISV>sp|Q9ULC8-3|ZDHC8_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC8 OS=Homosapiens OX=9606 GN=ZDHHC8MPRSPGTRLKPAKYIPVATAAALLVGSSTLFFVFTCPWLTRAVSPAVPVYNGIIFLFVLANFSMATFMDPGVFPRADEDEDKEDDFRAPLYKNVDVRGIQVRMKWCATCHFYRPPRCSHCSVCDNCVEDFDHHCPWVNNCIGRRNYRYFFLFLLSLSAHMVGVVAFGLVYVLNHAEGLGAAHTTITMAVMCVAGLFFIPVIGLTGFHVVLVTRGRTTNEQVTGKFRGGVNPFTRGCCGNVEHVLCSPLAPRYVVEPPRLPLAVSLKPPFLRPELLDRAAPLKVKLSDNGLKAGLGRSKSKGSLDRLDEKPLDLGPPLPPKIEAGTFSSDLQTPRPGSAESALSVQRTSPPTPAMYKFRPAFPTGPKVPFCGPGEQVPGPDSLTLGDDSIRSLDFVSEPSLDLPDYGPGGLHAAYPPSPPLSASDAFSGALRSLSLKASSRRGGDHVALQPLRSEGGPPTPHRSIFAPHALPNRNGSLSYDSLLNPGSPGGHACPAHPAVGVAGYHSPYLHPGATGDPPRPLPRSFSPVLGPRPREPSPVRYDNLSRTIMASIQERKDREERERLLRSQADSLFGDSGVYDAPSSYSLQQASVLSEGPRGPALRYGSRDDLVAGPGFGGARNPALQTSLSSLSSSVSRAPRTSSSSLQADQASSNAPGPRPSSGSHRSPARQGLPSPPGTPHSPSYAGPKAVAFIHTDLPEPPPSLTVQRGRIGTCTRGWGRRGQPWVPPGLHLCHLGRPEDRPPLRAPWSQAAGAPPRGAMCRLHLAASSLFPSLSGP>sp|O43296|ZN264_HUMAN Zinc finger protein 264 OS=Homo sapiens OX=9606GN=ZNF264 PE=1 SV=1MAAAVLTDRAQVSVTFDDVAVTFTKEEWGQLDLAQRTLYQEVMLENCGLLVSLGCPVPKAELICHLEHGQEPWTRKEDLSQDTCPGDKGKPKTTEPTTCEPALSEGISLQGQVTQGNSVDSQLGQAEDQDGLSEMQEGHFRPGIDPQEKSPGKMSPECDGLGTADGVCSRIGQEQVSPGDRVRSHNSCESGKDPMIQEEENNFKCSECGKVFNKKHLLAGHEKIHSGVKPYECTECGKTFIKSTHLLQHHMIHTGERPYECMECGKAFNRKSYLTQHQRIHSGEKPYKCNECGKAFTHRSNFVLHNRRHTGEKSFVCTECGQVFRHRPGFLRHYVVHSGENPYECLECGKVFKHRSYLMWHQQTHTGEKPYECSECGKVFLESAALIHHYVIHTGEKPFECLECGKAFNHRSYLKRHQRIHTGEKPFVCSECGKAFTHCSTFILHKRAHTGEKPFECKECGKAFSNRKDLIRHFSIHTGEKPYECVECGKAFTRMSGLTRHKRIHSGEKPYECVECGKSFCWSTNLIRHAIIHTGEKPYKCSECGKAFSRSSSLTQHQRMHTGKNPISVTDVGRPFTSGQTSVTLRELLLGKDFLNVTTEANILPEETSSSASDQPYQRETPQVSSL>sp|A6NDX4|YO011_HUMAN Putative transmembrane protein ENSP00000320207OS=Homo sapiens OX=9606 PE=5 SV=1MYVSISFLLGLSHLVLCCLLTFIVNFYLPPESIDFEFMAHNWSKGRSPSSTLGLSWFKAGFRFSDGWSMFYSSGLPGVALPGSPPRSHLLPGTQILIRSFQPCESAKHSARLSSLLTTTSYSVS>sp|Q8N8C0|ZN781_HUMAN Zinc finger protein 781 OS=Homo sapiens OX=9606GN=ZNF781 PE=2 SV=1MQRNAMYLKNVAETACNFQLTQYQISHANQKPYECQICGKPFRKRAHLTQHNRIHTGGKPYECKECGKVFICCSTLIQHKRTHTSEKPYECLECRKTFRRSAHLIRHQRIHTGEKPYKCKQCWKAFASVSDLIDIGKFTLMRDFTNVQNVGRHLTIAQLLFSIREFTLVRSPLNVRNVAKHSIIAQHLLNTRELILMRNLMNVRNVKRLLGKVHILLNIKEFILVRNHMSVSNVGRLSLVFLILIDIREFTLVKNPMNVKNVVELLTIVQLLFNTREFTLVRRLMNISSVGRFLSPVQHLFNIREHILMKNLMNVSNARRPSSIMHILFDIKEFILVRNLINVSNVGRPLLLFLI>sp|Q8N8C0-2|ZN781_HUMAN Isoform 2 of Zinc finger protein 781 OS=Homosapiens OX=9606 GN=ZNF781MQRNAMYLKNVAETACNFQLTQYQISHANQKPYECQICGKPFRKRAHLTQHNRIHTGGKPYECKECGKVFICCSTLIQHKRTHTSEKPYECLECRKTFRRSAHLIRHQRIHTGEKPYKCKQCWKAFASVSDLIDIGKFTLMRDFTNVQNVGRHLTIAQLLFSIREFTLVRSPLNVRNVAKHSIIAQHLLNTRELILMRNLMNVRNVKRLLGKVHILLNIKEFILVRNHMSVSNVGRLSLVFLILIDIREFTLVKNPMNVKNVVELLTIVQLLFNTREFTLVRRLMNISSVGRFLSPVQHLFNIREHILMKNLMNVSNARRPSSIMHI>sp|Q86XU0|ZN677_HUMAN Zinc finger protein 677 OS=Homo sapiens OX=9606GN=ZNF677 PE=2 SV=1MALSQGLFTFKDVAIEFSQEEWECLDPAQRALYRDVMLENYRNLLSLDEDNIPPEDDISVGFTSKGLSPKENNKEELYHLVILERKESHGINNFDLKEVWENMPKFDSLWDYDVKNYKGMPLTCNKNLTHRKDQQHNKSSIHFSLKQSVSIRDSAHQYFIHDKPFIRNLLKLKNNIRYAGNKYVKCFENKIGLSLQAQLAELQRFQTGEKMYECNPVEKSINSSSVSPLPPCVKNICNKYRKILKYPLLHTQYGRTHIREKSYKCNDCGKAFSKSSNLTNHQRIHSGQRPYKCNECGKAFNQCSNLTRHQRVHTGEKPYQCNICGKVCSQNSNLASHQRMHTGEKPYKCNECGKAFIQRSHLWGHERIHTGEKPYKCNECDKAFAERSSLTQHKRIHTGEKPYICNECGKAFKQCSHLTRHQNIHPGEKPHKCNVCGRAFIQSSSLVEHQRIHTGEKPYKCNKCDKAFIKRSHLWGHQRTHTGEKPYKCTECGKAFTERSNLTQHKKIHTGEKPYKCTECGKAFTQFANLTRHQKIHIEKKHCKHNIHGNALFQSSNLGDHQKSYNREKHIKYNETKIKYSSCT>sp|A6NNF4|ZN726_HUMAN Zinc finger protein 726 OS=Homo sapiens OX=9606GN=ZNF726 PE=1 SV=5MGLLTFRDVAIEFSLEEWQCLDTAQKNLYRNVMLENYRNLAFLGIAVSKPDLIICLEKEKEPWNMKRDEMVDEPPGICPHFAQDIWPEQGVEDSFQKVILRRFEKCGHENLQLRKGCKSVDECKVHKEGYNGLNQCFTTTQGKASQCGKYLKVFYKFINLNRYKIRHTRKKPFKCKNCVKSFCMFSHKTQHKSIYTTEKSYKCKECGKTFNWSSTLTNHKKTHTEEKPYKCEEYGKAFNQSSNYTTHKVTHTGEKPYKCEECGKAFSQSSTLTIHKRIHTGEKPCKCEECGKAFSQPSALTIHKRMHIGEKPYKCEECGKAFVWSSTLTRHKRLHSGEKPYKCEECAKAFSQFGHLTTHRIIHTGEKPYKCEECGKAFIWPSTLTKHKRIHTGEKPYKCEECGKAFHRSSNLTKHKIIHTGEKPYKCEECGKAFIWSSNLTEHKKIHTREKPYKCEECSKAFSRSSALTTHKRMHTGEKPYKCEECGKAFSQSSTLTAHKIIHTGEKPYKCEECGKAFILSSTLSKHKRIHTGEKPYKCEECGKTFNQSSNLSTHKIIHTGEKPYKCEECGKAFNRSSNLSTHKIIHTGEKPYKCDECGKSFIWSSTLFKHKRIHT>sp|A6NNF4-2|ZN726_HUMAN Isoform 2 of Zinc finger protein 726 OS=Homosapiens OX=9606 GN=ZNF726MGLLTFRDVAIEFSLEEWQCLDTAQKNLYRNVMLENYRNLAFLGIAVSKPDLIICLEKEKEPWNMKRDEMVDEPPGI>sp|Q5TYW1|ZN658_HUMAN Zinc finger protein 658 OS=Homo sapiens OX=9606GN=ZNF658 PE=1 SV=2MNMSQASVSFQDVTVEFTREEWQHLGPVERTLYRDVMLENYSHLISVGYCITKPKVISKLEKGEEPWSLEDEFLNQRYPGYFKVDHIKGIREKQEKPLWQEIFISDADKTLSKEGQKVLEKPFNLEIAPELSEKISCKCDSHRMNLPVASQLIISERKYSRKKTEYMNVCEKLQLDIKHEKAHAEEKSYEHGENAKAFSYKKDQHWKFQTLEESFECDGSGQGLYDKTICITPQSFLTGEKSCKDDEFRKNFDKITLFNHMRTDTRGKCSDLNEYGTSCDKTTAVEYNKVHMAMTHYECNERGINFSRKSPLTQSQRTITGWSAFESNKCEENFSQSSAHIVHQKTQAGDKFGEHNECTDALYQKLDFTAHQRIHTEDKFYLSDEHGKCRKSFYRKAHLIQHQRPHSGEKTYQYEECAKSFCSSSHPIQHPGTYVGFKLYECNECGKAFCQNSNLSKHLRIHTKEKPCDNNGCGRSYKSPLIGHQKTDAEMELCGGSEYGKTSHLKGHQRILMGEKPYECIECGKTFSKTSHLRAHQRIHTGEKPYECVECEKTFSHKTHLSVHQRVHTGEKPYECNDCGKSFTYNSALRAHQRIHTGEKPYECSDCEKTFAHNSALRAHHRIHTGEKPYECNECGRSFAHISVLKAHQRIHTGEKPYECNECGRSFTYNSALRAHQRIHTGRKPYECSDCEKTFAHNSALKIHQRIHTGEKPYECNECEKTFAHNSALRAHQNIHTGEKLYECSECGKTFFQKTRLSTHRRIHTGEKPYECSKCGKTFSQKSYLSGHERIHTGEKPYECNVCGKTFVYKAALIVHQRIHTGEKPYECNQCGKTFSQRTHLCAHQRIHTGEKPYECNECGKTFADNSALRAHHRIHTGEKPYECNDCGKTFSKTSHLRAHLRTRSGEKPYECSECGKTFSEKSYVSAHQRVHTGEKPYECNVCGKPFAHNSTLRVHQRIHTGEKSYECNDCGKTFSQKSHLSAHQRIHTGEKPYECNECGKAFAQNSTLRVHQRIHTGEKPYECDECGKTFVRKAALRVHHTRMHTREKTLACNGFGKS>sp|Q5TYW1-2|ZN658_HUMAN Isoform 2 of Zinc finger protein 658 OS=Homosapiens OX=9606 GN=ZNF658MNMSQASVSFQDVTVEFTREEWQHLGPVERTLYRDVMLENYSHLISVGYCITKPKVISKLEKGEEPWSLEDEFLNQRYPGYFKVDHIKGIREKQEKPLWQEIFISDADKTLSKEGQKVLEKPFNLEIAPELSEKISCKCDSHRMNLPVASQLIISERKYSRKKTEYMNVCEKLQLDIKHEKAHAEEKSYEHGENAKAFSYKKDQHWKFQTLEESFECDGSGQGLYDKTICITPQSFLTGEKSCKDDEFRKNFDKITLFNHMRTDTRGKCSDLNEYGTSCDKTTAVEYNKVHMAMTHYECNERGINFSRKSPLTQSQRTITGWSAFESNKCEENFSQSSAHIVHQKTQAGDKFGEHNECTDALYQKLDFTAHQRIHTEDKFYLSDEHGKCRKSFYRKAHLIQHQRPHSGEKTYQYEECAKSFCSSSHPIQHPGTYVGFKLYECNECGKAFCQNSNLSKHLRIHTKEKPCDNNGCGRSYKSPLIGHQKTDAEMELCGGSEYGKTSHLKGHQRILMGEKPYECIECGKTFSKTSHLRAHQRIHTGEKPYECVECEKTFSHKTHLSVHQRVHTGEKPYECNDCGKSFTYNSALRAHQRIHTGLAVCHVGILMATKSLFHQS>sp|Q8IVC4|ZN584_HUMAN Zinc finger protein 584 OS=Homo sapiens OX=9606GN=ZNF584 PE=2 SV=1MAGEAEAQLDPSLQGLVMFEDVTVYFSREEWGLLNVTQKGLYRDVMLENFALVSSLGLAPSRSPVFTQLEDDEQSWVPSWVDVTPVSRAEARRGFGLDGLCRVEDERAHPEHLKSYRVIQHQDTHSEGKPRRHTEHGAAFPPGSSCGQQQEVHVAEKLFKCSDCGKVFLKAFALLDHLITHSEERPFRCPTGRSAFKKSAHINPRKIHTGETAHVCNECGKAFSYPSKLRKHQKVHTGIKPFKCSDCGKTFNRKDALVLHQRIHTGERPYECSKCGKTFSVLSTLIRHRKVHIGERPYECTECGKFFKYNNSFILHQRVHTGERPFECKQCGKGYVTRSGLYQHWKVHTGERPYECSLCGKTFTTRSYRNRHQQFHTEERSYECTECGKAFKHSSTLLQHKKVHTPERRQEDRAHGKVVSC>sp|Q8NG76|O2T33_HUMAN Olfactory receptor 2T33 OS=Homo sapiens OX=9606GN=OR2T33 PE=2 SV=1MEMRNTTPDFILLGLFNHTRAHQVLFMMVLSIVLTSLFGNSLMILLIHWDHRLHTPMYFLLSQLSLMDMMLVSTTVPKMAADYLTGSKAISRAGCGVQIFFLPTLGGGECFLLAAMAYDRYAAVCHPLRYPTLMSWQLCLRMTMSCWLLGAADGLLQAVVTLSFPYCGAHEIDHFFCETPVLVRLACADTSVFENAMYICCVLMLLVPFSLILSSYGLILAAVLHMRSTEARKKAFATCSSHVAVVGLFYGAAIFTYMRPKSHRSTNHDKVVSAFYTMFTPLLNPLIYSVKNSEVKGALKRWLGTCVNIKHQQNEAHRSR>sp|Q8NGD0|OR4M1_HUMAN Olfactory receptor 4M1 OS=Homo sapiens OX=9606GN=OR4M1 PE=2 SV=1METANYTKVTEFVLTGLSQTREVQLVLFVIFLSFYLFILPGNILIICTIRLDPHLTSPMYFLLANLALLDIWYSSITAPKMLIDFFVERKIISFGGCIAQLFFLHFVGASEMFLLTVMAYDRYAAICRPLHYATIMNRRLCCILVALSWMGGFIHSIIQVALIVRLPFCGPNELDSYFCDITQVVRIACANTFPEELVMICSSGLISVVCFIALLMSYAFLLALLKKHSGSGENTNRAMSTCYSHITIVVLMFGPSIYIYARPFDSFSLDKVVSVFHTVIFPLLNPIIYTLRNKEVKAAMRKVVTKYILCEEK>sp|Q8NGR1|O13A1_HUMAN Olfactory receptor 13A1 OS=Homo sapiens OX=9606GN=OR13A1 PE=2 SV=2MKLWMESHLIVPETRPSPRMMSNQTLVTEFILQGFSEHPEYRVFLFSCFLFLYSGALTGNVLITLAITFNPGLHAPMYFFLLNLATMDIICTSSIMPKALASLVSEESSISYGGCMAQLYFLTWAASSELLLLTVMAYDRYAAICHPLHYSSMMSKVFCSGLATAVWLLCAVNTAIHTGLMLRLDFCGPNVIIHFFCEVPPLLLLSCSSTYVNGVMIVLADAFYGIVNFLMTIASYGFIVSSILKVKTAWGRQKAFSTCSSHLTVVCMYYTAVFYAYISPVSGYSAGKSKLAGLLYTVLSPTLNPLIYTLRNKEVKAALRKLFPFFRN>sp|Q8NGP8|OR5M1_HUMAN Olfactory receptor 5M1 OS=Homo sapiens OX=9606GN=OR5M1 PE=3 SV=1MFSPNHTIVTEFILLGLTDDPVLEKILFGVFLAIYLITLAGNLCMILLIRTNSHLQTPMYFFLGHLSFVDICYSSNVTPNMLHNFLSEQKTISYAGCFTQCLLFIALVITEFYILASMALDRYVAICSPLHYSSRMSKNICVCLVTIPYMYGFLSGFSQSLLTFHLSFCGSLEINHFYCADPPLIMLACSDTRVKKMAMFVVAGFNLSSSLFIILLSYLFIFAAIFRIRSAEGRHKAFSTCASHLTIVTLFYGTLFCMYVRPPSEKSVEESKITAVFYTFLSPMLNPLIYSLRNTDVILAMQQMIRGKSFHKIAV>sp|P51575|P2RX1_HUMAN P2X purinoceptor 1 OS=Homo sapiens OX=9606GN=P2RX1 PE=1 SV=1MARRFQEELAAFLFEYDTPRMVLVRNKKVGVIFRLIQLVVLVYVIGWVFLYEKGYQTSSGLISSVSVKLKGLAVTQLPGLGPQVWDVADYVFPAQGDNSFVVMTNFIVTPKQTQGYCAEHPEGGICKEDSGCTPGKAKRKAQGIRTGKCVAFNDTVKTCEIFGWCPVEVDDDIPRPALLREAENFTLFIKNSISFPRFKVNRRNLVEEVNAAHMKTCLFHKTLHPLCPVFQLGYVVQESGQNFSTLAEKGGVVGITIDWHCDLDWHVRHCRPIYEFHGLYEEKNLSPGFNFRFARHFVENGTNYRHLFKVFGIRFDILVDGKAGKFDIIPTMTTIGSGIGIFGVATVLCDLLLLHILPKRHYYKQKKFKYAEDMGPGAAERDLAATSSTLGLQENMRTS>sp|A6NFC9|OR2W5_HUMAN Putative olfactory receptor 2W5 pseudogene OS=Homosapiens OX=9606 GN=OR2W5P PE=5 SV=1MGKDNASYLQAFILVGSSDRPGLEKILFAVILIFCILTLVGNTAIILLLVMDVRLHTPMYFFLGNLSFLDLCFTASIAPQLLWNLGGPEKTITYHGCVAQLYIYMMLGSTECVLLVVMSHDRYVAVCRSLHYMAVMRPHLCLQLVTVAWCCGFLNSFIMCPQTMQLSRCGRRRVDHFLCEMPALIAMSCEETMLVEAIHLCPGGGSPPGAALPHPHLLWRDCSRGAEDEVSSRAKESLPHLLFSPHSGLSLLRNHHLRVPEAGQQLLPRSGEVPDSLLHHRHSQHQPPHLHFEEQGCEGDHEETSGVGERGWGASTRGTL>sp|O95997|PTTG1_HUMAN Securin OS=Homo sapiens OX=9606 GN=PTTG1 PE=1 SV=1MATLIYVDKENGEPGTRVVAKDGLKLGSGPSIKALDGRSQVSTPRFGKTFDAPPALPKATRKALGTVNRATEKSVKTKGPLKQKQPSFSAKKMTEKTVKAKSSVPASDDAYPEIEKFFPFNPLDFESFDLPEEHQIAHLPLSGVPLMILDEERELEKLFQLGPPSPVKMPSPPWESNLLQSPSSILSTLDVELPPVCCDIDI>sp|Q15113|PCOC1_HUMAN Procollagen C-endopeptidase enhancer 1 OS=Homosapiens OX=9606 GN=PCOLCE PE=1 SV=2MLPAATASLLGPLLTACALLPFAQGQTPNYTRPVFLCGGDVKGESGYVASEGFPNLYPPNKECIWTITVPEGQTVSLSFRVFDLELHPACRYDALEVFAGSGTSGQRLGRFCGTFRPAPLVAPGNQVTLRMTTDEGTGGRGFLLWYSGRATSGTEHQFCGGRLEKAQGTLTTPNWPESDYPPGISCSWHIIAPPDQVIALTFEKFDLEPDTYCRYDSVSVFNGAVSDDSRRLGKFCGDAVPGSISSEGNELLVQFVSDLSVTADGFSASYKTLPRGTAKEGQGPGPKRGTEPKVKLPPKSQPPEKTEESPSAPDAPTCPKQCRRTGTLQSNFCASSLVVTATVKSMVREPGEGLAVTVSLIGAYKTGGLDLPSPPTGASLKFYVPCKQCPPMKKGVSYLLMGQVEENRGPVLPPESFVVLHRPNQDQILTNLSKRKCPSQPVRAAASQD>sp|Q8NGB8|O4F15_HUMAN Olfactory receptor 4F15 OS=Homo sapiens OX=9606GN=OR4F15 PE=2 SV=1MNGMNHSVVSEFVFMGLTNSREIQLLLFVFSLLFYFASMMGNLVIVFTVTMDAHLHSPMYFLLANLSIIDMAFCSITAPKMICDIFKKHKAISFRGCITQIFFSHALGGTEMVLLIAMAFDRYMAICKPLHYLTIMSPRMCLYFLATSSIIGLIHSLVQLVFVVDLPFCGPNIFDSFYCDLPRLLRLACTNTQELEFMVTVNSGLISVGSFVLLVISYIFILFTVWKHSSGGLAKALSTLSAHVTVVILFFGPLMFFYTWPSPTSHLDKYLAIFDAFITPFLNPVIYTFRNKDMKVAMRRLCSRLAHFTKIL>sp|O60568|PLOD3_HUMAN Multifunctional procollagen lysine hydroxylase andglycosyltransferase LH3 OS=Homo sapiens OX=9606 GN=PLOD3 PE=1 SV=1MTSSGPGPRFLLLLPLLLPPAASASDRPRGRDPVNPEKLLVITVATAETEGYLRFLRSAEFFNYTVRTLGLGEEWRGGDVARTVGGGQKVRWLKKEMEKYADREDMIIMFVDSYDVILAGSPTELLKKFVQSGSRLLFSAESFCWPEWGLAEQYPEVGTGKRFLNSGGFIGFATTIHQIVRQWKYKDDDDDQLFYTRLYLDPGLREKLSLNLDHKSRIFQNLNGALDEVVLKFDRNRVRIRNVAYDTLPIVVHGNGPTKLQLNYLGNYVPNGWTPEGGCGFCNQDRRTLPGGQPPPRVFLAVFVEQPTPFLPRFLQRLLLLDYPPDRVTLFLHNNEVFHEPHIADSWPQLQDHFSAVKLVGPEEALSPGEARDMAMDLCRQDPECEFYFSLDADAVLTNLQTLRILIEENRKVIAPMLSRHGKLWSNFWGALSPDEYYARSEDYVELVQRKRVGVWNVPYISQAYVIRGDTLRMELPQRDVFSGSDTDPDMAFCKSFRDKGIFLHLSNQHEFGRLLATSRYDTEHLHPDLWQIFDNPVDWKEQYIHENYSRALEGEGIVEQPCPDVYWFPLLSEQMCDELVAEMEHYGQWSGGRHEDSRLAGGYENVPTVDIHMKQVGYEDQWLQLLRTYVGPMTESLFPGYHTKARAVMNFVVRYRPDEQPSLRPHHDSSTFTLNVALNHKGLDYEGGGCRFLRYDCVISSPRKGWALLHPGRLTHYHEGLPTTWGTRYIMVSFVDP>sp|Q9Y244|POMP_HUMAN Proteasome maturation protein OS=Homo sapiensOX=9606 GN=POMP PE=1 SV=1MNARGLGSELKDSIPVTELSASGPFESHDLLRKGFSCVKNELLPSHPLELSEKNFQLNQDKMNFSTLRNIQGLFAPLKLQMEFKAVQQVQRLPFLSSSNLSLDVLRGNDETIGFEDILNDPSQSEVMGEPHLMVEYKLGLL>sp|A2A3N6|PIPSL_HUMAN Putative PIP5K1A and PSMD4-like protein OS=Homosapiens OX=9606 GN=PIPSL PE=5 SV=1MASEVPYASGMPIKKIGHRSVDSSGGTTSSALKGAIQLGITHTVGSLSTKPESDVLMQDFHMVESIFFPSEGSNLTPAHHYNAFRFKTYAPVAFRYFWELFGIRPDDYLYSLCSEPLIELCSSGASGSLFYVSSDDEFIVKTVRHKEAEFLQKLLPGYYINLNQNPRTLLPKFYGLYCVQTGGKNIRIVVMNNLLPRSVKMHIKYDLKGSTYRRRASQKEREKPLPTFKDLDFLQDIPDGLFLDADVHNALCKTLQRDCLVLQSFKIMDYSLLMSIHNIDHAQREPLSSETQYSVDTRRPAPQKALYSTAMESIQGEARRGGTMETDDHMGGIPARNSKGERLLLYIGIIDILQSYRFVKKLEHSWKALIHDGDTVSVHRPGFYAEWFQRFMCNTVFKKIPLKPSPSKKLRSGSSFSQRAGSSGNSCITYQPLVSGEHKAQVTTKAEVEPGVHLGCPDVLPQTPPLEEISEGSPTPDPSFSPLVEETLQMLTTSVDNSEYMGNGDFLPTRLQAQQDAVNTVCHSKTRSNPENNVGLITLDNDCEVLTTLTPDTGRILSKLHTVQPKGKITFCMGIHVAHLALKHRQGNNHKIRIIAFVGNPVEDNEKNLVKLAKCLKKEKVNVDIINFGEEEVNTEKLTAFVNTLNGKDGTGSHLVTVPPGPSLADALISFPILAGEGGAMMGLGASDFEFGVDPSADPELALVLRVFMEEQRQRQEEEARQAAAASAAEAGIATTGTEDSDDALLKMTISQQEFGHTGLPDLSSMTEEEKIVCAMQMSLQGAEFGLAESADIDASSAMDTSEPAKEEDDYDVMQDPEFLQSVLENLPGVDPNNEAIRNAVGSLASQATKDSKKDKKEEDKK>sp|Q7Z2D5|PLPR4_HUMAN Phospholipid phosphatase-related protein type 4OS=Homo sapiens OX=9606 GN=PLPPR4 PE=1 SV=1MQRAGSSGGRGECDISGAGRLGLEEAARLSCAVHTSPGGGRRPGQAAGMSAKERPKGKVIKDSVTLLPCFYFVELPILASSVVSLYFLELTDVFKPVHSGFSCYDRSLSMPYIEPTQEAIPFLMLLSLAFAGPAITIMVGEGILYCCLSKRRNGVGLEPNINAGGCNFNSFLRRAVRFVGVHVFGLCSTALITDIIQLSTGYQAPYFLTVCKPNYTSLNVSCKENSYIVEDICSGSDLTVINSGRKSFPSQHATLAAFAAVYVSMYFNSTLTDSSKLLKPLLVFTFIICGIICGLTRITQYKNHPVDVYCGFLIGGGIALYLGLYAVGNFLPSDESMFQHRDALRSLTDLNQDPNRLLSAKNGSSSDGIAHTEGILNRNHRDASSLTNLKRANADVEIITPRSPMGKENMVTFSNTLPRANTPSVEDPVRRNASIHASMDSARSKQLLTQWKNKNESRKLSLQVIEPEPGQSPPRSIEMRSSSEPSRVGVNGDHHGPGNQYLKIQPGAVPGCNNSMPGGPRVSIQSRPGSSQLVHIPEETQENISTSPKSSSARAKWLKAAEKTVACNRSNSQPRIMQVIAMSKQQGVLQSSPKNTEGSTVSCTGSIRYKTLTDHEPSGIVRVEAHPENNRPIIQIPSTEGEGSGSWKWKAPEKGSLRQTYELNDLNRDSESCESLKDSFGSGDRKRSNIDSNEHHHHGITTIRVTPVEGSEIGSETLSISSSRDSTLRRKGNIILIPERSNSPENTRNIFYKGTSPTRAYKD>sp|Q7Z2D5-2|PLPR4_HUMAN Isoform 2 of Phospholipid phosphatase-relatedprotein type 4 OS=Homo sapiens OX=9606 GN=PLPPR4MQRAGSSGGRGECDISGAGRLGLEEAARLSCAVHTSPGGGRRPGQAAGMSAKERPKGKVIKDSVTLLPCFYFVELPILASSVVSLYFLELTDVFKPVHSGFSCYDRSLSMPYIEPTQEAIPFLMLLSLAFAGPAITIMVGEGILYCCLSKRRNGVGLEPNINAGGCNFNSFLRRAVRFVGVHVFGLCSTALITDIIQLSTGYQAPYFLTVCKPNYTSLNVSCKENSYIVEDICSGSDLTVINSGRKSFPSQHATLAAFAAVYVSMYFNSTLTDSSKLLKPLLVFTFIICGIICGLTRITQYKNHPVDVYCGFLIGGGIALYLGLYAVGNFLPSDESMFQHRDALRSLTDLNQDPNRLLSAKNGSSSDGIAHTEGILNRNHRDASSLTNLKRANADVEIITPRSPMGKENMVTFSNTLPRANTPSVEDPVRRNASIHASMDSARSKQLLTQWKNKNESRKLSLQVIEPEPGQSPPRSIEMRSSSEPSRVGVNGDHHGPGNQYLKIQPGAVPGCNNSMPGGPRVSIQSRPGSSQLVHIPEETQENISTSPKSSRVSSKAAPRTLKAARSPALAPSAIKP>sp|Q7Z2D5-3|PLPR4_HUMAN Isoform 3 of Phospholipid phosphatase-relatedprotein type 4 OS=Homo sapiens OX=9606 GN=PLPPR4MQRAGSSGGRGECDISGAGRLGLEEAARLSCAVHTSPGGGRRPGQAAGMSAKERPKGKVIKDSVTLLPCFYFVELPILASSVVSLYFLELTDVFKPVHSGFSCYDRSLSMPYIEPTQEAIPFLMLLSLAFAGPAITIMVGEGILYCCLSKRRNGVGLEPNINAGGCNFNSFLRRAVRFVGVHVFGLCSTALITDIIQLSTGYQAPYFLTVCKPNYTSLNVSCKENSYIVEDICSGSDLTVINSGRKSFPSQHATLAAFAAVYVSGLYAVGNFLPSDESMFQHRDALRSLTDLNQDPNRLLSAKNGSSSDGIAHTEGILNRNHRDASSLTNLKRANADVEIITPRSPMGKENMVTFSNTLPRANTPSVEDPVRRNASIHASMDSARSKQLLTQWKNKNESRKLSLQVIEPEPGQSPPRSIEMRSSSEPSRVGVNGDHHGPGNQYLKIQPGAVPGCNNSMPGGPRVSIQSRPGSSQLVHIPEETQENISTSPKSSSARAKWLKAAEKTVACNRSNSQPRIMQVIAMSKQQGVLQSSPKNTEGSTVSCTGSIRYKTLTDHEPSGIVRVEAHPENNRPIIQIPSTEGEGSGSWKWKAPEKGSLRQTYELNDLNRDSESCESLKDSFGSGDRKRSNIDSNEHHHHGITTIRVTPVEGSEIGSETLSISSSRDSTLRRKGNIILIPERSNSPENTRNIFYKGTSPTRAYKD>sp|Q9UL42|PNMA2_HUMAN Paraneoplastic antigen Ma2 OS=Homo sapiens OX=9606GN=PNMA2 PE=1 SV=2MALALLEDWCRIMSVDEQKSLMVTGIPADFEEAEIQEVLQETLKSLGRYRLLGKIFRKQENANAVLLELLEDTDVSAIPSEVQGKGGVWKVIFKTPNQDTEFLERLNLFLEKEGQTVSGMFRALGQEGVSPATVPCISPELLAHLLGQAMAHAPQPLLPMRYRKLRVFSGSAVPAPEEESFEVWLEQATEIVKEWPVTEAEKKRWLAESLRGPALDLMHIVQADNPSISVEECLEAFKQVFGSLESRRTAQVRYLKTYQEEGEKVSAYVLRLETLLRRAVEKRAIPRRIADQVRLEQVMAGATLNQMLWCRLRELKDQGPPPSFLELMKVIREEEEEEASFENESIEEPEERDGYGRWNHEGDD>sp|Q68D20|PMS2L_HUMAN Protein PMS2CL OS=Homo sapiens OX=9606 GN=PMS2CLPE=2 SV=1MHAADLEKPMVEKQDQSPSLRTGEEKRDVSISRLREAFSLRHTTENKPHSPKTPEPRRSPLGQKRGMSSSSTSDAISDRGVLRPQKEAVSSSQGPSDPTDRAEVEKDSGHGSTSVDSEGFSIPDTGSHCSSECVASTPGDRGSQEHVDSQEKAPETDDSFSDVDCHSNQEDTGCKFQVLPQPTNLTSPNTKVF>sp|Q9BX97|PLVAP_HUMAN Plasmalemma vesicle-associated protein OS=Homosapiens OX=9606 GN=PLVAP PE=1 SV=1MGLAMEHGGSYARAGGSSRGCWYYLRYFFLFVSLIQFLIILGLVLFMVYGNVHVSTESNLQATERRAEGLYSQLLGLTASQSNLTKELNFTTRAKDAIMQMWLNARRDLDRINASFRQCQGDRVIYTNNQRYMAAIILSEKQCRDQFKDMNKSCDALLFMLNQKVKTLEVEIAKEKTICTKDKESVLLNKRVAEEQLVECVKTRELQHQERQLAKEQLQKVQALCLPLDKDKFEMDLRNLWRDSIIPRSLDNLGYNLYHPLGSELASIRRACDHMPSLMSSKVEELARSLRADIERVARENSDLQRQKLEAQQGLRASQEAKQKVEKEAQAREAKLQAECSRQTQLALEEKAVLRKERDNLAKELEEKKREAEQLRMELAIRNSALDTCIKTKSQPMMPVSRPMGPVPNPQPIDPASLEEFKRKILESQRPPAGIPVAPSSG>sp|Q96PX9|PKH4B_HUMAN Pleckstrin homology domain-containing family Gmember 4B OS=Homo sapiens OX=9606 GN=PLEKHG4B PE=1 SV=4MEALRNPMPLGSSEEALGDLACSSLTGASRDLGTGAVASGTQEETSGPRGDPQQTPSLEKERHTPSRTGPGAAGRTLPRRSRSWERAPRSSRGAQAAACHTSHHSAGSRPGGHLGGQAVGTPNCVPVEGPGCTKEEDVLASSACVSTDGGSLHCHNPSGPSDVPARQPHPEQEGWPPGTGDFPSQVPKQVLDVSQELLQSGVVTLPGTRDRHGRAVVQVRTRSLLWTREHSSCAELTRLLLYFHSIPRKEVRDLGLVVLVDARRSPAAPAVSQALSGLQNNTSPIIHSILLLVDKESAFRPDKDAIIQCEVVSSLKAVHKFVDSCQLTADLDGSFPYSHGDWICFRQRLEHFAANCEEAIIFLQNSFCSLNTHRTPRTAQEVAELIDQHETMMKLVLEDPLLVSLRLEGGTVLARLRREELGTEDSRDTLEAATSLYDRVDEEVHRLVLTSNNRLQQLEHLRELASLLEGNDQQSCQKGLQLAKENPQRTEEMVQDFRRGLSAVVSQAECREGELARWTRSSELCETVSSWMGPLDPEACPSSPVAECLRSCHQEATSVAAEAFPGAGVAVLKPHALGKPWASQQDLWLQYPQTRLRLEEALSEAAPDPSLPPLAQSPPKHERAQEAMRRHQKPPSFPSTDSGGGAWEPAQPLSGLPGRALLCGQDGETLRPGLCALWDPLSLLRGLPGAGATTAHLEDSSACSSEPTQTLASRPRKHPQKKMIKKTQSFEIPQPDSGPRDSCQPDHTSVFSKGLEVTSTVATEKKLPLWQHARSPPVTQSRSLSSPSGLHPAEEDGRQQVGSSRLRHIMAEMIATEREYIRCLGYVIDNYFPEMERMDLPQGLRGKHHVIFGNLEKLHDFHQQHFLRELERCQHCPLAVGRSFLRHEEQFGMYVIYSKNKPQSDALLSSHGNAFFKDKQRELGDKMDLASYLLRPVQRVAKYALLLQDLLKEASCGLAQGQELGELRAAEVVVCFQLRHGNDLLAMDAIRGCDVNLKEQGQLRCRDEFIVCCGRKKYLRHVFLFEDLILFSKTQKVEGSHDVYLYKQSFKTAEIGMTENVGDSGLRFEIWFRRRRKSQDTYILQASSAEVKSAWTDVIGRILWRQALKSRELRIQEMASMGIGNQPFMDVKPRDRTPDCAVISDRAPKCAVMSDRVPDSIVKGTESQMRGSTAVSSSDHAAPFKRPHSTISDSSTSSSSSQSSSILGSLGLLVSSSPAHPGLWSPAHSPWSSDIRACVEEDEPEPELETGTQAAVCEGAPAVLLSRTRQA>sp|Q6S8J3|POTEE_HUMAN POTE ankyrin domain family member E OS=Homosapiens OX=9606 GN=POTEE PE=2 SV=3MVVEVDSMPAASSVKKPFGLRSKMGKWCCRCFPCYRESGKSNVGTSGDHDDSAMKTLRSKMGKWCHHCFPCCRGSGKSNVGASGDHDDSAMKTLRNKMGKWCCHCFPCCRGSGKSKVGAWGDYDDSAFMEPRYHVRGEDLDKLHRAAWWGKVPRKDLIVMLRDTDVNKKDKQKRTALHLASANGNSEVVKLLLDRRCQLNVLDNKKRTALIKAVQCQEDECALMLLEHGTDPNIPDEYGNTTLHYAIYNEDKLMAKALLLYGADIESKNKHGLTPLLLGVHEQKQQVVKFLIKKKANLNALDRYGRTALILAVCCGSASIVSLLLEQNIDVSSQDLSGQTAREYAVSSHHHVICQLLSDYKEKQMLKISSENSNPEQELKLTSEEESQRFKGSENSQPEKMSQELEINKDGDREVEEEMKKHESNNVGLLENLTNGVTAGNGDNGLIPQRKSRTPENQQFPDNESEEYHRICELLSDYKEKQMPKYSSENSNPEQDLKLTSEEESQRLKGSENGQPEKRSQEPEINKDGDRELENFMAIEEMKKHGSTHVGFPENLTNGATAGNGDDGLIPPRKSRTPESQQFPDTENEEYHSDEQNDTQKQFCEEQNTGILHDEILIHEEKQIEVVEKMNSELSLSCKKEKDVLHENSTLREEIAMLRLELDTMKHQSQLREKKYLEDIESVKKKNDNLLKALQLNELTMDDDTAVLVIDNGSGMCKAGFAGDDAPRAVFPSIVGRPRQQGMMGGMHQKESYVGKEAQSKRGILTLKYPMEHGIITNWDDMEKIWHHTFYNELRVAPEEHPILLTEAPLNPKANREKMTQIMFETFNTPAMYVAIQAVPSLYTSGRTTGIVMDSGDGVTHTVPIYEGNALPHATLRLDLAGRELPDYLMKILTERGYRFTTMAEREIVRDIKEKLCYVALDFEQEMATAASSSSLEKSYELPDGQVITIGNERFRCPEALFQPCFLGMESCGIHETTFNSIMKSDVDIRKDLYTNTVLSGGTTMYPGMAHRMQKEIAALAPSMMKIRIIAPPKRKYSVWVGGSILASLSTFQQMWISKQEYDESGPSIVHRKCF>sp|Q6S8J3-2|POTEE_HUMAN Isoform 2 of POTE ankyrin domain family member EOS=Homo sapiens OX=9606 GN=POTEEMVVEVDSMPAASSVKKPFGLRSKMGKWCCRCFPCYRESGKSNVGTSGDHDDSAMKTLRSKMGKWCHHCFPCCRGSGKSNVGASGDHDDSAMKTLRNKMGKWCCHCFPCCRGSGKSKVGAWGDYDDSAFMEPRYHVRGEDLDKLHRAAWWGKVPRKDLIVMLRDTDVNKKDKQKRTALHLASANGNSEVVKLLLDRRCQLNVLDNKKRTALIKVCSSQLYQHEAVQCQEDECALMLLEHGTDPNIPDEYGNTTLHYAIYNEDKLMAKALLLYGADIESKNKHGLTPLLLGVHEQKQQVVKFLIKKKANLNALDRYGRTALILAVCCGSASIVSLLLEQNIDVSSQDLSGQTAREYAVSSHHHVICQLLSDYKEKQMLKISSENSNPENVSRTRNK>sp|Q6S8J3-3|POTEE_HUMAN Isoform 3 of POTE ankyrin domain family member EOS=Homo sapiens OX=9606 GN=POTEEMVVEVDSMPAASSVKKPFGLRSKMGKWCCRCFPCYRESGKSNVGTSGDHDDSAMKTLRSKMGKWCHHCFPCCRGSGKSNVGASGDHDDSAMKTLRNKMGKWCCHCFPCCRGSGKSKVGAWGDYDDSAFMEPRYHVRGEDLDKLHRAAWWGKVPRKDLIVMLRDTDVNKKDKQKRTALHLASANGNSEVVKLLLDRRCQLNVLDNKKRTALIKAVQCQEDECALMLLEHGTDPNIPDEYGNTTLHYAIYNEDKLMAKALLLYGADIESKNKHGLTPLLLGVHEQKQQVVKFLIKKKANLNALDRYGRTALILAVCCGSASIVSLLLEQNIDVSSQDLSGQTAREYAVSSHHHVICQLLSDYKEKQMLKISSENSNPG>sp|Q9NS28|RGS18_HUMAN Regulator of G-protein signaling 18 OS=Homosapiens OX=9606 GN=RGS18 PE=1 SV=1METTLLFFSQINMCESKEKTFFKLIHGSGKEETSKEAKIRAKEKRNRLSLLVQKPEFHEDTRSSRSGHLAKETRVSPEEAVKWGESFDKLLSHRDGLEAFTRFLKTEFSEENIEFWIACEDFKKSKGPQQIHLKAKAIYEKFIQTDAPKEVNLDFHTKEVITNSITQPTLHSFDAAQSRVYQLMEQDSYTRFLKSDIYLDLMEGRPQRPTNLRRRSRSFTCNEFQDVQSDVAIWL>sp|Q3KR16|PKHG6_HUMAN Pleckstrin homology domain-containing family Gmember 6 OS=Homo sapiens OX=9606 GN=PLEKHG6 PE=1 SV=3MKAFGPPHEGPLQGLVASRIETYGGRHRASAQSTAGRLYPRGYPVLDPSRRRLQQYVPFARGSGQARGLSPMRLRDPEPEKRHGGHVGAGLLHSPKLKELTKAHELEVRLHTFSMFGMPRLPPEDRRHWEIGEGGDSGLTIEKSWRELVPGHKEMSQELCHQQEALWELLTTELIYVRKLKIMTDLLAAGLLNLQRVGLLMEVSAETLFGNVPSLIRTHRSFWDEVLGPTLEETRASGQPLDPIGLQSGFLTFGQRFHPYVQYCLRVKQTMAYAREQQETNPLFHAFVQWCEKHKRSGRQMLCDLLIKPHQRITKYPLLLHAVLKRSPEARAQEALNAMIEAVESFLRHINGQVRQGEEQESLAAAAQRIGPYEVLEPPSDEVEKNLRPFSTLDLTSPMLGVASEHTRQLLLEGPVRVKEGREGKLDVYLFLFSDVLLVTKPQRKADKAKVIRPPLMLEKLVCQPLRDPNSFLLIHLTEFQCVSSALLVHCPSPTDRAQWLEKTQQAQAALQKLKAEEYVQQKRELLTLYRDQDRESPSTRPSTPSLEGSQSSAEGRTPEFSTIIPHLVVTEDTDEDAPLVPDDTSDSGYGTLIPGTPTGSRSPLSRLRQRALRRDPRLTFSTLELRDIPLRPHPPDPQAPQRRSAPELPEGILKGGSLPQEDPPTWSEEEDGASERGNVVVETLHRARLRGQLPSSPTHADSAGESPWESSGEEEEEGPLFLKAGHTSLRPMRAEDMLREIREELASQRIEGAEEPRDSRPRKLTRAQLQRMRGPHIIQLDTPLSASEV>sp|Q3KR16-2|PKHG6_HUMAN Isoform 2 of Pleckstrin homology domain-containing family G member 6 OS=Homo sapiens OX=9606 GN=PLEKHG6MGCRLHAPGEKAAHDPSRRRLQQYVPFARGSGQARGLSPMRLRDPEPEKRHGGHVGAGLLHSPKLKELTKAHELEVRLHTFSMFGMPRLPPEDRRHWEIGEGGDSGLTIEKSWRELVPGHKEMSQELCHQQEALWELLTTELIYVRKLKIMTDLLAAGLLNLQRVGLLMEVSAETLFGNVPSLIRTHRSFWDEVLGPTLEETRASGQPLDPIGLQSGFLTFGQRFHPYVQYCLRVKQTMAYAREQQETNPLFHAFVQWCEKHKRSGRQMLCDLLIKPHQRITKYPLLLHAVLKRSPEARAQEALNAMIEAVESFLRHINGQVRQGEEQESLAAAAQRIGPYEVLEPPSDEVEKNLRPFSTLDLTSPMLGVASEHTRQLLLEGPVRVKEGREGKLDVYLFLFSDVLLVTKPQRKADKAKVIRPPLMLEKLVCQPLRDPNSFLLIHLTEFQCVSSALLVHCPSPTDRAQWLEKTQQAQAALQKLKAEEYVQQKRELLTLYRDQDRESPSTRPSTPSLEGSQSSAEGRTPEFSTIIPHLVVTEDTDEDAPLVPDDTSDSGYGTLIPGTPTGSRSPLSRLRQRALRRDPRLTFSTLELRDIPLRPHPPDPQAPQRRSAPELPEGILKGGSLPQEDPPTWSEEEDGASERGNVVVETLHRARLRGQLPSSPTHADSAGESPWESSGEEEEEGPLFLKAGHTSLRPMRAEDMLREIREELASQRIEGAEEPRDSRPRKLTRAQLQRMRGPHIIQLDTPLSASEV>sp|Q3KR16-3|PKHG6_HUMAN Isoform 3 of Pleckstrin homology domain-containing family G member 6 OS=Homo sapiens OX=9606 GN=PLEKHG6MCPREGGRASTIHQKTEKAFGQLLCQPLGEPKIQHPLKAALQKLKAEEYVQQKRELLTLYRDQDRESPSTRPSTPSLEGSQSSAEGRTPEFSTIIPHLVVTEDTDEDAPLVPDDTSDSGYGTLIPGTPTGSRSPLSRLRQRALRRDPRLTFSTLELRDIPLRPHPPDPQAPQRRSAPELPEGILKGGSLPQEDPPTWSEEEDGASERGNVVVETLHRARLRGQLPSSPTHADSAGESPWESSGEEEEEGPLFLKAGHTSLRPMRAEDMLREIREELASQRIEGAEEPRDSRPRKLTRAQLQRMRGPHIIQLDTPLSASEV>sp|P13727|PRG2_HUMAN Bone marrow proteoglycan OS=Homo sapiens OX=9606GN=PRG2 PE=1 SV=2MKLPLLLALLFGAVSALHLRSETSTFETPLGAKTLPEDEETPEQEMEETPCRELEEEEEWGSGSEDASKKDGAVESISVPDMVDKNLTCPEEEDTVKVVGIPGCQTCRYLLVRSLQTFSQAWFTCRRCYRGNLVSIHNFNINYRIQCSVSALNQGQVWIGGRITGSGRCRRFQWVDGSRWNFAYWAAHQPWSRGGHCVALCTRGGHWRRAHCLRRLPFICSY>sp|P13727-2|PRG2_HUMAN Isoform 2 of Bone marrow proteoglycan OS=Homosapiens OX=9606 GN=PRG2MKLPLLLALLFGAVSALHLRSETSTFETPLGAKTLPEDEETPEQEMEETPCRELEEEEEWGSGSEDASKKDGAVESISVPDMVDKNLTCPEEEDTVKVVGIPGCQTCRYLLFTCRRCYRGNLVSIHNFNINYRIQCSVSALNQGQVWIGGRITGSGRCRRFQWVDGSRWNFAYWAAHQPWSRGGHCVALCTRGGHWRRAHCLRRLPFICSY>sp|Q5VWM4|PRAM8_HUMAN PRAME family member 8 OS=Homo sapiens OX=9606GN=PRAMEF8 PE=2 SV=2MSIRAPPRLLELARQRLLRDQALAISTMEELPRELFPTLFMEAFSRRRCETLKTMVQAWPFTRLPLGSLMKSPHLESLKSVLEGVDVLLTQEVRPRQSKLQVLDLRNVDENFCDIFSGATASFPEALSQKQTADNCPGTGRQQPFMVFIDLCLKNRTLDECLTHLLEWGKQRKGLLHVCCKELQVFGMPIHSIIEVLNMVELDCIQEVEVCCPWELSTLVKFAPYLGQMRNLRKLVLFNIRASACIPPDNKGQFIARFTSQFLKLDYFQNLSMHSVSFLEGHLDQLLRCLQASLEMVVMTDCLLSESDLKHLSWCPSIRQLKELDLRGVTLTHFSPEPLTGLLEQVVATLQTLDLEDCGIMDSQLSAILPVLSRCSQLSTFSFCGNLISMAALENLLRHTVGLSKLSLELYPAPLESYDTQGALCWGRFAELGAELMNTLRDLRQPKIIVFCTVPCPRCGIRASYDLEPSHCLC>sp|P06401|PRGR_HUMAN Progesterone receptor OS=Homo sapiens OX=9606GN=PGR PE=1 SV=4MTELKAKGPRAPHVAGGPPSPEVGSPLLCRPAAGPFPGSQTSDTLPEVSAIPISLDGLLFPRPCQGQDPSDEKTQDQQSLSDVEGAYSRAEATRGAGGSSSSPPEKDSGLLDSVLDTLLAPSGPGQSQPSPPACEVTSSWCLFGPELPEDPPAAPATQRVLSPLMSRSGCKVGDSSGTAAAHKVLPRGLSPARQLLLPASESPHWSGAPVKPSPQAAAVEVEEEDGSESEESAGPLLKGKPRALGGAAAGGGAAAVPPGAAAGGVALVPKEDSRFSAPRVALVEQDAPMAPGRSPLATTVMDFIHVPILPLNHALLAARTRQLLEDESYDGGAGAASAFAPPRSSPCASSTPVAVGDFPDCAYPPDAEPKDDAYPLYSDFQPPALKIKEEEEGAEASARSPRSYLVAGANPAAFPDFPLGPPPPLPPRATPSRPGEAAVTAAPASASVSSASSSGSTLECILYKAEGAPPQQGPFAPPPCKAPGASGCLLPRDGLPSTSASAAAAGAAPALYPALGLNGLPQLGYQAAVLKEGLPQVYPPYLNYLRPDSEASQSPQYSFESLPQKICLICGDEASGCHYGVLTCGSCKVFFKRAMEGQHNYLCAGRNDCIVDKIRRKNCPACRLRKCCQAGMVLGGRKFKKFNKVRVVRALDAVALPQPVGVPNESQALSQRFTFSPGQDIQLIPPLINLLMSIEPDVIYAGHDNTKPDTSSSLLTSLNQLGERQLLSVVKWSKSLPGFRNLHIDDQITLIQYSWMSLMVFGLGWRSYKHVSGQMLYFAPDLILNEQRMKESSFYSLCLTMWQIPQEFVKLQVSQEEFLCMKVLLLLNTIPLEGLRSQTQFEEMRSSYIRELIKAIGLRQKGVVSSSQRFYQLTKLLDNLHDLVKQLHLYCLNTFIQSRALSVEFPEMMSEVIAAQLPKILAGMVKPLLFHKK>sp|P06401-2|PRGR_HUMAN Isoform A of Progesterone receptor OS=Homosapiens OX=9606 GN=PGRMSRSGCKVGDSSGTAAAHKVLPRGLSPARQLLLPASESPHWSGAPVKPSPQAAAVEVEEEDGSESEESAGPLLKGKPRALGGAAAGGGAAAVPPGAAAGGVALVPKEDSRFSAPRVALVEQDAPMAPGRSPLATTVMDFIHVPILPLNHALLAARTRQLLEDESYDGGAGAASAFAPPRSSPCASSTPVAVGDFPDCAYPPDAEPKDDAYPLYSDFQPPALKIKEEEEGAEASARSPRSYLVAGANPAAFPDFPLGPPPPLPPRATPSRPGEAAVTAAPASASVSSASSSGSTLECILYKAEGAPPQQGPFAPPPCKAPGASGCLLPRDGLPSTSASAAAAGAAPALYPALGLNGLPQLGYQAAVLKEGLPQVYPPYLNYLRPDSEASQSPQYSFESLPQKICLICGDEASGCHYGVLTCGSCKVFFKRAMEGQHNYLCAGRNDCIVDKIRRKNCPACRLRKCCQAGMVLGGRKFKKFNKVRVVRALDAVALPQPVGVPNESQALSQRFTFSPGQDIQLIPPLINLLMSIEPDVIYAGHDNTKPDTSSSLLTSLNQLGERQLLSVVKWSKSLPGFRNLHIDDQITLIQYSWMSLMVFGLGWRSYKHVSGQMLYFAPDLILNEQRMKESSFYSLCLTMWQIPQEFVKLQVSQEEFLCMKVLLLLNTIPLEGLRSQTQFEEMRSSYIRELIKAIGLRQKGVVSSSQRFYQLTKLLDNLHDLVKQLHLYCLNTFIQSRALSVEFPEMMSEVIAAQLPKILAGMVKPLLFHKK>sp|P06401-3|PRGR_HUMAN Isoform 3 of Progesterone receptor OS=Homosapiens OX=9606 GN=PGRMEGQHNYLCAGRNDCIVDKIRRKNCPACRLRKCCQAGMVLGGRKFKKFNKVRVVRALDAVALPQPVGVPNESQALSQRFTFSPGQDIQLIPPLINLLMSIEPDVIYAGHDNTKPDTSSSLLTSLNQLGERQLLSVVKWSKSLPGFRNLHIDDQITLIQYSWMSLMVFGLGWRSYKHVSGQMLYFAPDLILNEQRMKESSFYSLCLTMWQIPQEFVKLQVSQEEFLCMKVLLLLNTIPLEGLRSQTQFEEMRSSYIRELIKAIGLRQKGVVSSSQRFYQLTKLLDNLHDLVKQLHLYCLNTFIQSRALSVEFPEMMSEVIAAQLPKILAGMVKPLLFHKK>sp|P06401-4|PRGR_HUMAN Isoform 4 of Progesterone receptor OS=Homosapiens OX=9606 GN=PGRMEFIYIYMNFFFFFSVGRKFKKFNKVRVVRALDAVALPQPVGVPNESQALSQRFTFSPGQDIQLIPPLINLLMSIEPDVIYAGHDNTKPDTSSSLLTSLNQLGERQLLSVVKWSKSLPGFRNLHIDDQITLIQYSWMSLMVFGLGWRSYKHVSGQMLYFAPDLILNEQRMKESSFYSLCLTMWQIPQEFVKLQVSQEEFLCMKVLLLLNTIPLEGLRSQTQFEEMRSSYIRELIKAIGLRQKGVVSSSQRFYQLTKLLDNLHDLVKQLHLYCLNTFIQSRALSVEFPEMMSEVIAAQLPKILAGMVKPLLFHKK>sp|P06401-5|PRGR_HUMAN Isoform 5 of Progesterone receptor OS=Homosapiens OX=9606 GN=PGRMTELKAKGPRAPHVAGGPPSPEVGSPLLCRPAAGPFPGSQTSDTLPEVSAIPISLDGLLFPRPCQGQDPSDEKTQDQQSLSDVEGAYSRAEATRGAGGSSSSPPEKDSGLLDSVLDTLLAPSGPGQSQPSPPACEVTSSWCLFGPELPEDPPAAPATQRVLSPLMSRSGCKVGDSSGTAAAHKVLPRGLSPARQLLLPASESPHWSGAPVKPSPQAAAVEVEEEDGSESEESAGPLLKGKPRALGGAAAGGGAAAVPPGAAAGGVALVPKEDSRFSAPRVALVEQDAPMAPGRSPLATTVMDFIHVPILPLNHALLAARTRQLLEDESYDGGAGAASAFAPPRSSPCASSTPVAVGDFPDCAYPPDAEPKDDAYPLYSDFQPPALKIKEEEEGAEASARSPRSYLVAGANPAAFPDFPLGPPPPLPPRATPSRPGEAAVTAAPASASVSSASSSGSTLECILYKAEGAPPQQGPFAPPPCKAPGASGCLLPRDGLPSTSASAAAAGAAPALYPALGLNGLPQLGYQAAVLKEGLPQVYPPYLNYLRPDSEASQSPQYSFESLPQKICLICGDEASGCHYGVLTCGSCKVFFKRAMEGQHNYLCAGRNDCIVDKIRRKNCPACRLRKCCQAGMVLGGFRNLHIDDQITLIQYSWMSLMVFGLGWRSYKHVSGQMLYFAPDLILNEQRMKESSFYSLCLTMWQIPQEFVKLQVSQEEFLCMKVLLLLNTIPLEGLRSQTQFEEMRSSYIRELIKAIGLRQKGVVSSSQRFYQLTKLLDNLHDLVKQLHLYCLNTFIQSRALSVEFPEMMSEVIAAQLPKILAGMVKPLLFHKK>sp|P40306|PSB10_HUMAN Proteasome subunit beta type-10 OS=Homo sapiensOX=9606 GN=PSMB10 PE=1 SV=1MLKPALEPRGGFSFENCQRNASLERVLPGLKVPHARKTGTTIAGLVFQDGVILGADTRATNDSVVADKSCEKIHFIAPKIYCCGAGVAADAEMTTRMVASKMELHALSTGREPRVATVTRILRQTLFRYQGHVGASLIVGGVDLTGPQLYGVHPHGSYSRLPFTALGSGQDAALAVLEDRFQPNMTLEAAQGLLVEAVTAGILGDLGSGGNVDACVITKTGAKLLRTLSSPTEPVKRSGRYHFVPGTTAVLTQTVKPLTLELVEETVQAMEVE>sp|Q86XN7|PRSR1_HUMAN Proline and serine-rich protein 1 OS=Homo sapiensOX=9606 GN=PROSER1 PE=1 SV=2MDKKSFEMVLDEIRKAVLTEYKLKAIEYVHGYFSSEQVVDLLRYFSWAEPQLKAMKALQHKMVAVQPTEVVNILNCFTFSKDKLVALELLASNIIDAQNSRPIEDLFRVNMSEKKRCKRILEQAFKGGCKAPHAMISSCGTIPGNPYPKGRPSRINGIFPGTPLKKDGEECTNEGKGIAARILGPSKPPPSTYNPHKPVPYPIPPCRPHATIAPSAYNNAGLVPLANVIAPPPPPYTPNPVGTENEDLSNPSKPIQNQTFSTPASQLFSPHGSNPSTPAATPVPTASPVKAINHPSASAAATVSGMNLLNTVLPVFPGQVSSAVHTPQPSIPNPTVIRTPSLPTAPVTSIHSTTTTPVPSIFSGLVSLPGPSATPTAATPTPGPTPRSTLGSSEAFASTSAPFTSLPFSTSSSAASTSNPNSASLSSVFAGLPLPLPPTSQGLSNPTPVIAGGSTPSVAGPLGVNSPLLSALKGFLTSNDTNLINSSALSSAVTSGLASLSSLTLQNSDSSASAPNKCYAPSAIPTPQRTSTPGLALFPGLPSPVANSTSTPLTLPVQSPLATAASASTSVPVSCGSSASLLRGPHPGTSDLHISSTPAATTLPVMIKTEPTSPTPSAFKGPSHSGNPSHGTLGLSGTLGRAYTSTSVPISLSACLNPALSGLSSLSTPLNGSNPLSSISLPPHGSSTPIAPVFTALPSFTSLTNNFPLTGNPSLNPSVSLPGSLIATSSTAATSTSLPHPSSTAAVLSGLSASAPVSAAPFPLNLSTAVPSLFSVTQGPLSSSNPSYPGFSVSNTPSVTPALPSFPGLQAPSTVAAVTPLPVAATAPSPAPVLPGFASAFSSNFNSALVAQAGLSSGLQAAGSSVFPGLLSLPGIPGFPQNPSQSSLQELQHNAAAQSALLQQVHSASALESYPAQPDGFPSYPSAPGTPFSLQPSLSQSGWQ>sp|Q86XN7-2|PRSR1_HUMAN Isoform 2 of Proline and serine-rich protein 1OS=Homo sapiens OX=9606 GN=PROSER1MDKKSFEMVLDEIRKVVDLLRYFSWAEPQLKAMKALQHKMVAVQPTEVVNILNCFTFSKDKLVALELLASNIIDAQNSRPIEDLFRVNMSEKKRCKRILEQAFKGGCKAPHAMISSCGTIPGNPYPKGRPSRINGIFPGTPLKKDGEECTNEGKGIAARILGPSKPPPSTYNPHKPVPYPIPPCRPHATIAPSAYNNAGLVPLANVIAPPPPPYTPNPVGTENEDLSNPSKPIQNQTFSTPASQLFSPHGSNPSTPAATPVPTASPVKAINHPSASAAATVSGMNLLNTVLPVFPGQVSSAVHTPQPSIPNPTVIRTPSLPTAPVTSIHSTTTTPVPSIFSGLVSLPGPSATPTAATPTPGPTPRSTLGSSEAFASTSAPFTSLPFSTSSSAASTSNPNSASLSSVFAGLPLPLPPTSQGLSNPTPVIAGGSTPSVAGPLGVNSPLLSALKGFLTSNDTNLINSSALSSAVTSGLASLSSLTLQNSDSSASAPNKCYAPSAIPTPQRTSTPGLALFPGLPSPVANSTSTPLTLPVQSPLATAASASTSVPVSCGSSASLLRGPHPGTSDLHISSTPAATTLPVMIKTEPTSPTPSAFKGPSHSGNPSHGTLGLSGTLGRAYTSTSVPISLSACLNPALSGLSSLSTPLNGSNPLSSISLPPHGSSTPIAPVFTALPSFTSLTNNFPLTGNPSLNPSVSLPGSLIATSSTAATSTSLPHPSSTAAVLSGLSASAPVSAAPFPLNLSTAVPSLFSVTQGPLSSSNPSYPGFSVSNTPSVTPALPSFPGLQAPSTVAAVTPLPVAATAPSPAPVLPGFASAFSSNFNSALVAQAGLSSGLQAAGSSVFPGLLSLPGIPGFPQNPSQSSLQELQHNAAAQSALLQQVHSASALESYPAQPDGFPSYPSAPGTPFSLQPSLSQSGWQ>sp|O60508|PRP17_HUMAN Pre-mRNA-processing factor 17 OS=Homo sapiensOX=9606 GN=CDC40 PE=1 SV=1MSAAIAALAASYGSGSGSESDSDSESSRCPLPAADSLMHLTKSPSSKPSLAVAVDSAPEVAVKEDLETGVHLDPAVKEVQYNPTYETMFAPEFGPENPFRTQQMAAPRNMLSGYAEPAHINDFMFEQQRRTFATYGYALDPSLDNHQVSAKYIGSVEEAEKNQGLTVFETGQKKTEKRKKFKENDASNIDGFLGPWAKYVDEKDVAKPSEEEQKELDEITAKRQKKGKQEEEKPGEEKTILHVKEMYDYQGRSYLHIPQDVGVNLRSTMPPEKCYLPKKQIHVWSGHTKGVSAVRLFPLSGHLLLSCSMDCKIKLWEVYGERRCLRTFIGHSKAVRDICFNTAGTQFLSAAYDRYLKLWDTETGQCISRFTNRKVPYCVKFNPDEDKQNLFVAGMSDKKIVQWDIRSGEIVQEYDRHLGAVNTIVFVDENRRFVSTSDDKSLRVWEWDIPVDFKYIAEPSMHSMPAVTLSPNGKWLACQSMDNQILIFGAQNRFRLNKKKIFKGHMVAGYACQVDFSPDMSYVISGDGNGKLNIWDWKTTKLYSRFKAHDKVCIGAVWHPHETSKVITCGWDGLIKLWD>sp|Q9NRI7|PPY2_HUMAN Putative pancreatic polypeptide 2 OS=Homo sapiensOX=9606 GN=PPY2P PE=5 SV=1MAAACRCLSLLLLSTCVALLL>sp|Q5VTL8|PR38B_HUMAN Pre-mRNA-splicing factor 38B OS=Homo sapiensOX=9606 GN=PRPF38B PE=1 SV=1MANNSPALTGNSQPQHQAAAAAAQQQQQCGGGGATKPAVSGKQGNVLPLWGNEKTMNLNPMILTNILSSPYFKVQLYELKTYHEVVDEIYFKVTHVEPWEKGSRKTAGQTGMCGGVRGVGTGGIVSTAFCLLYKLFTLKLTRKQVMGLITHTDSPYIRALGFMYIRYTQPPTDLWDWFESFLDDEEDLDVKAGGGCVMTIGEMLRSFLTKLEWFSTLFPRIPVPVQKNIDQQIKTRPRKIKKDGKEGAEEIDRHVERRRSRSPRRSLSPRRSPRRSRSRSHHREGHGSSSFDRELEREKERQRLEREAKEREKERRRSRSIDRGLERRRSRSRERHRSRSRSRDRKGDRRDRDREREKENERGRRRDRDYDKERGNEREKERERSRERSKEQRSRGEVEEKKHKEDKDDRRHRDDKRDSKKEKKHSRSRSRERKHRSRSRSRNAGKRSRSRSKEKSSKHKNESKEKSNKRSRSGSQGRTDSVEKSKKREHSPSKEKSRKRSRSKERSHKRDHSDSKDQSDKHDRRRSQSIEQESQEKQHKNKDETV>sp|Q5VTL8-2|PR38B_HUMAN Isoform 2 of Pre-mRNA-splicing factor 38BOS=Homo sapiens OX=9606 GN=PRPF38BMANNSPALTGNSQPQHQAAAAAAQQQQQCGGGGATKPAVSGKQGNVLPLWGNEKTMNLNPMILTNILSSPYFKVQLYELKTYHEVVDEIYFKVTHVEPWEKGSRKTAGQTGMCGGVRGVGTGGIVSTAFCLLYKLFTLKLTRKQVMGLITHTDSPYIRALGFMYIRYTQPPTDLWDWFESFLDDEEFFTL>sp|P28074|PSB5_HUMAN Proteasome subunit beta type-5 OS=Homo sapiensOX=9606 GN=PSMB5 PE=1 SV=3MALASVLERPLPVNQRGFFGLGGRADLLDLGPGSLSDGLSLAAPGWGVPEEPGIEMLHGTTTLAFKFRHGVIVAADSRATAGAYIASQTVKKVIEINPYLLGTMAGGAADCSFWERLLARQCRIYELRNKERISVAAASKLLANMVYQYKGMGLSMGTMICGWDKRGPGLYYVDSEGNRISGATFSVGSGSVYAYGVMDRGYSYDLEVEQAYDLARRAIYQATYRDAYSGGAVNLYHVREDGWIRVSSDNVADLHEKYSGSTP>sp|P28074-2|PSB5_HUMAN Isoform 2 of Proteasome subunit beta type-5OS=Homo sapiens OX=9606 GN=PSMB5MALASVLERPLPVNQRGFFGLGGRADLLDLGPGSLSDGLSLAAPGWGVPEEPGIEMLHGTTTLAFKFRHGVIVAADSRATAGAYIASQTVKKVIEINPYLLGTMAGGAADCSFWERLLARQCRIYELRNKERISVAAASKLLANMVYQYKGMGLSMGTMICGWDKRGPVSEVLCLKPKSFGMYLFCGCAERIGNMARPLLRGQ>sp|P28074-3|PSB5_HUMAN Isoform 3 of Proteasome subunit beta type-5OS=Homo sapiens OX=9606 GN=PSMB5MAGGAADCSFWERLLARQCRIYELRNKERISVAAASKLLANMVYQYKGMGLSMGTMICGWDKRGPGLYYVDSEGNRISGATFSVGSGSVYAYGVMDRGYSYDLEVEQAYDLARRAIYQATYRDAYSGGAVNLYHVREDGWIRVSSDNVADLHEKYSGSTP>sp|P10696|PPBN_HUMAN Alkaline phosphatase, germ cell type OS=Homosapiens OX=9606 GN=ALPG PE=1 SV=4MQGPWVLLLLGLRLQLSLGIIPVEEENPDFWNRQAAEALGAAKKLQPAQTAAKNLIIFLGDGMGVSTVTAARILKGQKKDKLGPETFLAMDRFPYVALSKTYSVDKHVPDSGATATAYLCGVKGNFQTIGLSAAARFNQCNTTRGNEVISVMNRAKKAGKSVGVVTTTRVQHASPAGAYAHTVNRNWYSDADVPASARQEGCQDIATQLISNMDIDVILGGGRKYMFPMGTPDPEYPDDYSQGGTRLDGKNLVQEWLAKHQGARYVWNRTELLQASLDPSVTHLMGLFEPGDMKYEIHRDSTLDPSLMEMTEAALLLLSRNPRGFFLFVEGGRIDHGHHESRAYRALTETIMFDDAIERAGQLTSEEDTLSLVTADHSHVFSFGGYPLRGSSIFGLAPGKARDRKAYTVLLYGNGPGYVLKDGARPDVTESESGSPEYRQQSAVPLDGETHAGEDVAVFARGPQAHLVHGVQEQTFIAHVMAFAACLEPYTACDLAPRAGTTDAAHPGPSVVPALLPLLAGTLLLLGTATAP>sp|Q5VV67|PPRC1_HUMAN Peroxisome proliferator-activated receptor gammacoactivator-related protein 1 OS=Homo sapiens OX=9606 GN=PPRC1 PE=1 SV=1MAARRGRRDGVAPPPSGGPGPDPGGGARGSGWGSRSQAPYGTLGAVSGGEQVLLHEEAGDSGFVSLSRLGPSLRDKDLEMEELMLQDETLLGTMQSYMDASLISLIEDFGSLGESRLSLEDQNEVSLLTALTEILDNADSENLSPFDSIPDSELLVSPREGSSLHKLLTLSRTPPERDLITPVDPLGPSTGSSRGSGVEMSLPDPSWDFSPPSFLETSSPKLPSWRPPRSRPRWGQSPPPQQRSDGEEEEEVASFSGQILAGELDNCVSSIPDFPMHLACPEEEDKATAAEMAVPAAGDESISSLSELVRAMHPYCLPNLTHLASLEDELQEQPDDLTLPEGCVVLEIVGQAATAGDDLEIPVVVRQVSPGPRPVLLDDSLETSSALQLLMPTLESETEAAVPKVTLCSEKEGLSLNSEEKLDSACLLKPREVVEPVVPKEPQNPPANAAPGSQRARKGRKKKSKEQPAACVEGYARRLRSSSRGQSTVGTEVTSQVDNLQKQPQEELQKESGPLQGKGKPRAWARAWAAALENSSPKNLERSAGQSSPAKEGPLDLYPKLADTIQTNPIPTHLSLVDSAQASPMPVDSVEADPTAVGPVLAGPVPVDPGLVDLASTSSELVEPLPAEPVLINPVLADSAAVDPAVVPISDNLPPVDAVPSGPAPVDLALVDPVPNDLTPVDPVLVKSRPTDPRRGAVSSALGGSAPQLLVESESLDPPKTIIPEVKEVVDSLKIESGTSATTHEARPRPLSLSEYRRRRQQRQAETEERSPQPPTGKWPSLPETPTGLADIPCLVIPPAPAKKTALQRSPETPLEICLVPVGPSPASPSPEPPVSKPVASSPTEQVPSQEMPLLARPSPPVQSVSPAVPTPPSMSAALPFPAGGLGMPPSLPPPPLQPPSLPLSMGPVLPDPFTHYAPLPSWPCYPHVSPSGYPCLPPPPTVPLVSGTPGAYAVPPTCSVPWAPPPAPVSPYSSTCTYGPLGWGPGPQHAPFWSTVPPPPLPPASIGRAVPQPKMESRGTPAGPPENVLPLSMAPPLSLGLPGHGAPQTEPTKVEVKPVPASPHPKHKVSALVQSPQMKALACVSAEGVTVEEPASERLKPETQETRPREKPPLPATKAVPTPRQSTVPKLPAVHPARLRKLSFLPTPRTQGSEDVVQAFISEIGIEASDLSSLLEQFEKSEAKKECPPPAPADSLAVGNSGGVDIPQEKRPLDRLQAPELANVAGLTPPATPPHQLWKPLAAVSLLAKAKSPKSTAQEGTLKPEGVTEAKHPAAVRLQEGVHGPSRVHVGSGDHDYCVRSRTPPKKMPALVIPEVGSRWNVKRHQDITIKPVLSLGPAAPPPPCIAASREPLDHRTSSEQADPSAPCLAPSSLLSPEASPCRNDMNTRTPPEPSAKQRSMRCYRKACRSASPSSQGWQGRRGRNSRSVSSGSNRTSEASSSSSSSSSSSRSRSRSLSPPHKRWRRSSCSSSGRSRRCSSSSSSSSSSSSSSSSSSSSRSRSRSPSPRRRSDRRRRYSSYRSHDHYQRQRVLQKERAIEERRVVFIGKIPGRMTRSELKQRFSVFGEIEECTIHFRVQGDNYGFVTYRYAEEAFAAIESGHKLRQADEQPFDLCFGGRRQFCKRSYSDLDSNREDFDPAPVKSKFDSLDFDTLLKQAQKNLRR>sp|Q5VV67-2|PPRC1_HUMAN Isoform 2 of Peroxisome proliferator-activatedreceptor gamma coactivator-related protein 1 OS=Homo sapiens OX=9606GN=PPRC1MRHCWGPCRATWMPPLSPSLRILGALESIPDSELLVSPREGSSLHKLLTLSRTPPERDLITPVDPLGPSTGSSRGSGVEMSLPDPSWDFSPPSFLETSSPKLPSWRPPRSRPRWGQSPPPQQRSDGEEEEEVASFSGQILAGELDNCVSSIPDFPMHLACPEEEDKATAAEMAVPAAGDESISSLSELVRAMHPYCLPNLTHLASLEDELQEQPDDLTLPEGCVVLEIVGQAATAGDDLEIPVVVRQVSPGPRPVLLDDSLETSSALQLLMPTLESETEAAVPKVTLCSEKEGLSLNSEEKLDSACLLKPREVVEPVVPKEPQNPPANAAPGSQRARKGRKKKSKEQPAACVEGYARRLRSSSRGQSTVGTEVTSQVDNLQKQPQEELQKESGPLQGKGKPRAWARAWAAALENSSPKNLERSAGQSSPAKEGPLDLYPKLADTIQTNPIPTHLSLVDSAQASPMPVDSVEADPTAVGPVLAGPVPVDPGLVDLASTSSELVEPLPAEPVLINPVLADSAAVDPAVVPISDNLPPVDAVPSGPAPVDLALVDPVPNDLTPVDPVLVKSRPTDPRRGAVSSALGGSAPQLLVESESLDPPKTIIPEVKEVVDSLKIESGTSATTHEARPRPLSLSEYRRRRQQRQAETEERSPQPPTGKWPSLPETPTGLADIPCLVIPPAPAKKTALQRSPETPLEICLVPVGPSPASPSPEPPVSKPVASSPTEQVPSQEMPLLARPSPPVQSVSPAVPTPPSMSAALPFPAGGLGMPPSLPPPPLQPPSLPLSMGPVLPDPFTHYAPLPSWPCYPHVSPSGYPCLPPPPTVPLVSGTPGAYAVPPTCSVPWAPPPAPVSPYSSTCTYGPLGWGPGPQHAPFWSTVPPPPLPPASIGRAVPQPKMESRGTPAGPPENVLPLSMAPPLSLGLPGHGAPQTEPTKVEVKPVPASPHPKHKVSALVQSPQMKALACVSAEGVTVEEPASERLKPETQETRPREKPPLPATKAVPTPRQSTVPKLPAVHPARLRKLSFLPTPRTQGSEDVVQAFISEIGIEASDLSSLLEQFEKSEAKKECPPPAPADSLAVGNSGGVDIPQEKRPLDRLQAPELANVAGLTPPATPPHQLWKPLAAVSLLAKAKSPKSTAQEGTLKPEGVTEAKHPAAVRLQEGVHGPSRVHVGSGDHDYCVRSRTPPKKMPALVIPEVGSRWNVKRHQDITIKPVLSLGPAAPPPPCIAASREPLDHRTSSEQADPSAPCLAPSSLLSPEASPCRNDMNTRTPPEPSAKQRSMRCYRKACRSASPSSQGWQGRRGRNSRSVSSGSNRTSEASSSSSSSSSSSRSRSRSLSPPHKRWRRSSCSSSGRSRRCSSSSSSSSSSSSSSSSSSSSRSRSRSPSPRRRSDRRRRSYRSHDHYQRQRVLQKERAIEERRVVFIGKIPGRMTRSELKQRFSVFGEIEECTIHFRVQGDNYGFVTYRYAEEAFAAIESGHKLRQADEQPFDLCFGGRRQFCKRSYSDLDSNREDFDPAPVKSKFDSLDFDTLLKQAQKNLRR>sp|P25787|PSA2_HUMAN Proteasome subunit alpha type-2 OS=Homo sapiensOX=9606 GN=PSMA2 PE=1 SV=2MAERGYSFSLTTFSPSGKLVQIEYALAAVAGGAPSVGIKAANGVVLATEKKQKSILYDERSVHKVEPITKHIGLVYSGMGPDYRVLVHRARKLAQQYYLVYQEPIPTAQLVQRVASVMQEYTQSGGVRPFGVSLLICGWNEGRPYLFQSDPSGAYFAWKATAMGKNYVNGKTFLEKRYNEDLELEDAIHTAILTLKESFEGQMTEDNIEVGICNEAGFRRLTPTEVKDYLAAIA>sp|Q9H2H8|PPIL3_HUMAN Peptidyl-prolyl cis-trans isomerase-like 3 OS=Homosapiens OX=9606 GN=PPIL3 PE=1 SV=1MSVTLHTDVGDIKIEVFCERTPKTCENFLALCASNYYNGCIFHRNIKGFMVQTGDPTGTGRGGNSIWGKKFEDEYSEYLKHNVRGVVSMANNGPNTNGSQFFITYGKQPHLDMKYTVFGKVIDGLETLDELEKLPVNEKTYRPLNDVHIKDITIHANPFAQ>sp|Q9H2H8-2|PPIL3_HUMAN Isoform 2 of Peptidyl-prolyl cis-transisomerase-like 3 OS=Homo sapiens OX=9606 GN=PPIL3MSVTLHTDVGDIKIEVFCERTPKTCEMESRCVPQAGVQWRDLGSLQPPPPGFKQVFCLSLPRTGRGGNSIWGKKFEDEYSEYLKHNVRGVVSMANNGPNTNGSQFFITYGKQPHLDMKYTVFGKVIDGLETLDELEKLPVNEKTYRPLNDVHIKDITIHANPFAQ>sp|P57052|RBM11_HUMAN Splicing regulator RBM11 OS=Homo sapiens OX=9606GN=RBM11 PE=1 SV=1MFPAQEEADRTVFVGNLEARVREEILYELFLQAGPLTKVTICKDREGKPKSFGFVCFKHPESVSYAIALLNGIRLYGRPINVQYRFGSSRSSEPANQSFESCVKINSHNYRNEEMLVGRSSFPMQYFPINNTSLPQEYFLFQKMQWHVYNPVLQLPYYEMTAPLPNSASVSSSLNHVPDLEAGPSSYKWTHQQPSDSDLYQMTAPLPNSASVSSSLNHVPDLEAGPSSYKWTHQQPSDSDLYQMNKRKRQKQTSDSDSSTDNNRGNECSQKFRKSKKKKRY>sp|P57052-2|RBM11_HUMAN Isoform 2 of Splicing regulator RBM11 OS=Homosapiens OX=9606 GN=RBM11LRPRPEDVPCSGGGRQDRVCWEFRGPSSGRDSVRAVPSGSSRSSEPANQSFESCVKINSHNYRNEEMLVGRSSFPMQYFPINNTSLPQEYFLFQKMQWHVYNPVLQLPYYEMTAPLPNSASVSSSLNHVPDLEAGPSSYKWTHQQPSDSDLYQMTAPLPNSASVSSSLNHVPDLEAGPSSYKWTHQQPSDSDLYQMNKRKRQKQTSDSDSSTDNNRGNECSQKFRKSKKKKRY>sp|Q969Q0|RL36L_HUMAN 60S ribosomal protein L36a-like OS=Homo sapiensOX=9606 GN=RPL36AL PE=1 SV=3MVNVPKTRRTFCKKCGKHQPHKVTQYKKGKDSLYAQGRRRYDRKQSGYGGQTKPIFRKKAKTTKKIVLRLECVEPNCRSKRMLAIKRCKHFELGGDKKRKGQVIQF>sp|P09486|SPRC_HUMAN SPARC OS=Homo sapiens OX=9606 GN=SPARC PE=1 SV=1MRAWIFFLLCLAGRALAAPQQEALPDETEVVEETVAEVTEVSVGANPVQVEVGEFDDGAEETEEEVVAENPCQNHHCKHGKVCELDENNTPMCVCQDPTSCPAPIGEFEKVCSNDNKTFDSSCHFFATKCTLEGTKKGHKLHLDYIGPCKYIPPCLDSELTEFPLRMRDWLKNVLVTLYERDEDNNLLTEKQKLRVKKIHENEKRLEAGDHPVELLARDFEKNYNMYIFPVHWQFGQLDQHPIDGYLSHTELAPLRAPLIPMEHCTTRFFETCDLDNDKYIALDEWAGCFGIKQKDIDKDLVI>sp|Q96FX7|TRM61_HUMAN tRNA (adenine(58)-N(1))-methyltransferasecatalytic subunit TRMT61A OS=Homo sapiens OX=9606 GN=TRMT61A PE=1 SV=1MSFVAYEELIKEGDTAILSLGHGAMVAVRVQRGAQTQTRHGVLRHSVDLIGRPFGSKVTCGRGGWVYVLHPTPELWTLNLPHRTQILYSTDIALITMMLELRPGSVVCESGTGSGSVSHAIIRTIAPTGHLHTVEFHQQRAEKAREEFQEHRVGRWVTVRTQDVCRSGFGVSHVADAVFLDIPSPWEAVGHAWDALKVEGGRFCSFSPCIEQVQRTCQALAARGFSELSTLEVLPQVYNVRTVSLPPPDLGTGTDGPAGSDTSPFRSGTPMKEAVGHTGYLTFATKTPG>sp|Q9BX59|TPSNR_HUMAN Tapasin-related protein OS=Homo sapiens OX=9606GN=TAPBPL PE=1 SV=2MGTQEGWCLLLCLALSGAAETKPHPAEGQWRAVDVVLDCFLAKDGAHRGALASSEDRARASLVLKQVPVLDDGSLEDFTDFQGGTLAQDDPPIIFEASVDLVQIPQAEALLHADCSGKEVTCEISRYFLQMTETTVKTAAWFMANMQVSGGGPSISLVMKTPRVTKNEALWHPTLNLPLSPQGTVRTAVEFQVMTQTQSLSFLLGSSASLDCGFSMAPGLDLISVEWRLQHKGRGQLVYSWTAGQGQAVRKGATLEPAQLGMARDASLTLPGLTIQDEGTYICQITTSLYRAQQIIQLNIQASPKVRLSLANEALLPTLICDIAGYYPLDVVVTWTREELGGSPAQVSGASFSSLRQSVAGTYSISSSLTAEPGSAGATYTCQVTHISLEEPLGASTQVVPPERRTALGVIFASSLFLLALMFLGLQRRQAPTGLGLLQAERWETTSCADTQSSHLHEDRTARVSQPS>sp|Q9BX59-2|TPSNR_HUMAN Isoform beta of Tapasin-related protein OS=Homosapiens OX=9606 GN=TAPBPLMGTQEGWCLLLCLALSGAAETKPHPAEGQWRAVDVVLDCFLAKDGAHRGALASSEDRARASLVLKQVPVLDDGSLEDFTDFQGGTLAQDDPPIIFEASVDLVQIPQAEALLHADCSGKEVTCEISRYFLQMTETTVKTAAWFMANMQVSGGGPSISLVMKTPRVTKNEALWHPTLNLPLSPQGTVRTAVEFQVMTQTQSLSFLLGSSASLDCGFSMAPGLDLISVEWRLQHKGRGQLVYSWTAGQGQAVRKGATLEPAQLGMARDASLTLPGLTIQDEGTYICQITTSLYRAQQIIQLNIQASPKVRLSLANEALLPTLICDIAGYYPLDVVVTWTREELGGSPAQVSGASFSSLRQSVAGTYSISSSLTAEPGSAGATYTCQVTHISLEEPLGASTQVVPPERRTALGVIFASSLFLLALMFLGLQRRQEASAFLHCAPWAHAPRQRTGRSEGTRRRQNVQMEDKTKEPAPTGLGLLQAERWETTSCADTQSSHLHEDRTARVSQPS>sp|Q9BX59-3|TPSNR_HUMAN Isoform gamma of Tapasin-related protein OS=Homosapiens OX=9606 GN=TAPBPLMGTQEGWCLLLCLALSGAAETKPHPAEGQWRAVDVVLDCFLAKDGAHRGALASSEDRARASLVLKQVPVLDDGSLEDFTDFQGGTLAQDDPPIIFEASVDLVQIPQAEALLHADCSGKEVTCEISRYFLQMTETTVKTAAWFMANMQVSGGGPSISLVMKTPRVTKNEALWHPTLNLPLSPQGTVRTAVEFQVMTQTQSLSFLLGSSASLDCGFSMAPGLDLISVEWRLQHKGRGQLVYSWTAGQGQAVRKGATLEPAQLGMARDASLTLPGLTIQDEGTYICQITTSLYRAQQIIQLNIQERRTALGVIFASSLFLLALMFLGLQRRQAPTGLGLLQAERWETTSCADTQSSHLHEDRTARVSQPS>sp|Q9BX59-4|TPSNR_HUMAN Isoform delta of Tapasin-related protein OS=Homosapiens OX=9606 GN=TAPBPLMGTQEGWCLLLCLALSGAAETKPHPAEGQWRAVDVVLDCFLAKDGAHRGALASSEDRARASLVLKQVPVLDDGSLEDFTDFQGGTLAQDDPPIIFEASVDLVQIPQAEALLHADCSGKEVTCEISRYFLQMTETTVKTAAWFMANMQVSGGGPSISLVMKTPRVTKNEALWHPTLNLPLSPQGTVRTAVEFQVMTQTQSLSFLLGSSASLDCGFSMAPGLDLISVEWRLQHKGRGRGDLHLPDHHLSVPSSADHPAQHPSFP>sp|Q9BX59-5|TPSNR_HUMAN Isoform epsilon of Tapasin-related proteinOS=Homo sapiens OX=9606 GN=TAPBPLMGTQEGWCLLLCLALSGAAETKPHPAEGQWRAVDVVLDCFLAKDGAHRGALASSEDRARASLVLKQVPVLDDGSLEDFTDFQGGTLAQDDPPIIFEASVDLVQIPQAEALLHADCSGKEVTCEISRYFLQMTETTVKTAAWFMANMQVSGGGPSISLVMKTPRVTKNEALWHPTLNLPLSPQGTVRTAERRTALGVIFASSLFLLALMFLGLQRRQAPTGLGLLQAERWETTSCADTQSSHLHEDRTARVSQPS>sp|Q9BX59-6|TPSNR_HUMAN Isoform eta of Tapasin-related protein OS=Homosapiens OX=9606 GN=TAPBPLMGTQEGWCLLLCLALSGAAETKPHPAEGQWRAVDVVLDCFLAKDGAHRGALASSEDRARASLVLKQVPVLDDGSLEDFTDFQGGTLAQDDPPIIFEASVDLVQIPQAEALLHADCSGKEVTCEISRYFLQMTETTVKTAAWFMANMQVSGGGPSISLVMKTPRVTKNEALWHPTLNLPLSPQGTVRTAVEFQVMTQTQSLSFLLGSSASLDCGFSMAPGLDLISVEWRLQHKGRGRGDLHLPDHHLSVPSSADHPAQHPRAENSLGSHLCQQSLPSCTDVPGASETASTYRTWAASG>sp|Q9BX59-7|TPSNR_HUMAN Isoform zeta of Tapasin-related protein OS=Homosapiens OX=9606 GN=TAPBPLMGTQEGWCLLLCLALSGAAETKPHPAEGQWRAVDVVLDCFLAKDGAHRGALASSEDRARASLVLKQVPVLDDGSLEDFTDFQGGTLAQDDPPIIFEASVDLVQIPQAEALLHADCSGKEVTCEISRYFLQMTETTVKTAAWFMANMQVSGGGPSISLVMKTPRVTKNEALWHPTLNLPLSPQGTVRTAVEFQVMTQTQSLSFLLGSSASLDCGFSMAPGLDLISVEWRLQHKGRGQLVYSWTAGQGQAVRKGATLEPAQLGMARDASLTLPGLTIQDEGTYICQITTSLYRAQQIIQLNIQASPKVRLSLANEALLPTLICDIAGYYPLDVVVTWTREELGGSPAQVSGASFSSLRQSVAGTYSISSSLTAEPGSAGATYTCQVTHISLEEPLGASTQVVPPERRTALGVIFASSLFLLALMFLGLQRRQEASAFLHCAPWAHAPRQRTGRSEGTRRRQNVQMEDKTKEPGWWCDGRKTKLEEMEKEQVRDNEAWVGAGLPLPNSALSK>sp|Q8TC26|TM163_HUMAN Transmembrane protein 163 OS=Homo sapiens OX=9606GN=TMEM163 PE=2 SV=1MEPAAGIQRRSSQGPTVPPPPRGHAPPAAAPGPAPLSSPVREPPQLEEERQVRISESGQFSDGLEDRGLLESSTRLKPHEAQNYRKKALWVSWFSIIVTLALAVAAFTVSVMRYSASAFGFAFDAILDVLSSAIVLWRYSNAAAVHSAHREYIACVILGVIFLLSSICIVVKAIHDLSTRLLPEVDDFLFSVSILSGILCSILAVLKFMLGKVLTSRALITDGFNSLVGGVMGFSILLSAEVFKHDSAVWYLDGSIGVLIGLTIFAYGVKLLIDMVPRVRQTRHYEMFE>sp|Q8TC26-2|TM163_HUMAN Isoform 2 of Transmembrane protein 163 OS=Homosapiens OX=9606 GN=TMEM163MLPVSRTCLLESSTRLKPHEAQNYRKKALWVSWFSIIVTLALAVAAFTVSVMRYSASAFGFAFDAILDVLSSAIVLWRYSNAAAVHSAHREYMTISCSVSPF>sp|Q8TC26-3|TM163_HUMAN Isoform 3 of Transmembrane protein 163 OS=Homosapiens OX=9606 GN=TMEM163MLGKVLTSRALITDGFNSLVGGVMGFSILLSAEVFKHDSAVWYLDGSIGVLIGLTIFAYGVKLLIDMVPRVRQTRHYEMFE>sp|Q9BZW5|TM6S1_HUMAN Transmembrane 6 superfamily member 1 OS=Homosapiens OX=9606 GN=TM6SF1 PE=1 SV=2MSASAATGVFVLSLSAIPVTYVFNHLAAQHDSWTIVGVAALILFLVALLARVLVKRKPPRDPLFYVYAVFGFTSVVNLIIGLEQDGIIDGFMTHYLREGEPYLNTAYGHMICYWDGSAHYLMYLVMVAAIAWEETYRTIGLYWVGSIIMSVVVFVPGNIVGKYGTRICPAFFLSIPYTCLPVWAGFRIYNQPSENYNYPSKVIQEAQAKDLLRRPFDLMLVVCLLLATGFCLFRGLIALDCPSELCRLYTQFQEPYLKDPAAYPKIQMLAYMFYSVPYFVTALYGLVVPGCSWMPDITLIHAGGLAQAQFSHIGASLHARTAYVYRVPEEAKILFLALNIAYGVLPQLLAYRCIYKPEFFIKTKAEEKVE>sp|Q9BZW5-2|TM6S1_HUMAN Isoform 2 of Transmembrane 6 superfamily member1 OS=Homo sapiens OX=9606 GN=TM6SF1MSASAATGVFVLSLSAIPVTYVFNHLAAQHDSWTIVGVAALILFLVALLARVLVKRKPPRDPLFYVYAVFGFTSVVNLIIGLEQDGIIDGFMTHYLREGEPYLNTAYGHMICYWDGSAHYLMYLVMVAAIAWEETYRTIGLYWVGSIIMSVVVFVPGNIVGKYGTRICPAFFLSIPYTCLPVWAGFRIYNQPSENYNYPSKVIQEAQAKDLLRRPFDLMLVVCLLLATGFCLFRGLMLAYMFYSVPYFVTALYGLVVPGCSWMPDITLIHAGGLAQAQFSHIGASLHARTAYVYRVPEEAKILFLALNIAYGVLPQLLAYRCIYKPEFFIKTKAEEKVE>sp|P0DMS9|TMIG3_HUMAN Transmembrane domain-containing protein TMIGD3OS=Homo sapiens OX=9606 GN=TMIGD3 PE=1 SV=1MEGSPAGPIEQKEARWESSWEEQPDWTLGCLSPESQFRIPGLPGCILSFQLKVCFLPVMWLFILLSLALISDAMVMDEKVKRSFVLDTASAICNYNAHYKNHPKYWCRGYFRDYCNIIAFSPNSTNHVALRDTGNQLIVTMSCLTKEDTGWYWCGIQRDFARDDMDFTELIVTDDKGTLANDFWSGKDLSGNKTRSCKAPKVVRKADRSRTSILIICILITGLGIISVISHLTKRRRSQRNRRVGNTLKPFSRVLTPKEMAPTEQM>sp|P0DMS9-2|TMIG3_HUMAN Isoform 1 of Transmembrane domain-containingprotein TMIGD3 OS=Homo sapiens OX=9606 GN=TMIGD3MPNNSTALSLANVTYITMEIFIGLCAIVGNVLVICVVKLNPSLQTTTFYFIVSLALADIAVGVLVMPLAIVVSLGITIHFYSCLFMTCLLLIFTHASIMSLLAIAVDRYLRVKLTVRFRIPGLPGCILSFQLKVCFLPVMWLFILLSLALISDAMVMDEKVKRSFVLDTASAICNYNAHYKNHPKYWCRGYFRDYCNIIAFSPNSTNHVALRDTGNQLIVTMSCLTKEDTGWYWCGIQRDFARDDMDFTELIVTDDKGTLANDFWSGKDLSGNKTRSCKAPKVVRKADRSRTSILIICILITGLGIISVISHLTKRRRSQRNRRVGNTLKPFSRVLTPKEMAPTEQM>sp|Q9NRR2|TRYG1_HUMAN Tryptase gamma OS=Homo sapiens OX=9606 GN=TPSG1PE=1 SV=3MALGACGLLLLLAVPGVSLRTLQPGCGRPQVSDAGGRIVGGHAAPAGAWPWQASLRLRRMHVCGGSLLSPQWVLTAAHCFSGSLNSSDYQVHLGELEITLSPHFSTVRQIILHSSPSGQPGTSGDIALVELSVPVTLSSRILPVCLPEASDDFCPGIRCWVTGWGYTREGEPLPPPYSLREVKVSVVDTETCRRDYPGPGGSILQPDMLCARGPGDACQDDSGGPLVCQVNGAWVQAGTVSWGEGCGRPNRPGVYTRVPAYVNWIRRHITASGGSESGYPRLPLLAGLFLPGLFLLLVSCVLLAKCLLHPSADGTPFPAPD>sp|Q6ZSZ6|TSH1_HUMAN Teashirt homolog 1 OS=Homo sapiens OX=9606 GN=TSHZ1PE=1 SV=2MPRRKQQAPRRSAAYVPEEELKAAEIDEEHVEDDGLSLDIQESEYMCNEETEIKEAQSYQNSPVSSATNQDAGYGSPFSESSDQLAHFKGSSSREEKEDPQCPDSVSYPQDSLAQIKAVYANLFSESCWSSLALDLKKSGSTTSTNDASQKESSAPTPTPPTCPVSTTGPTTSTPSTSCSSSTSHSSTTSTSSSSGYDWHQAALAKTLQQTSSYGLLPEPSLFSTVQLYRQNNKLYGSVFTGASKFRCKDCSAAYDTLVELTVHMNETGHYRDDNRDKDSEKTKRWSKPRKRSLMEMEGKEDAQKVLKCMYCGHSFESLQDLSVHMIKTKHYQKVPLKEPVPAITKLVPSTKKRALQDLAPPCSPEPAGMAAEVALSESAKDQKAANPYVTPNNRYGYQNGASYTWQFEARKAQILKCMECGSSHDTLQQLTAHMMVTGHFLKVTTSASKKGKQLVLDPVVEEKIQSIPLPPTTHTRLPASSIKKQPDSPAGSTTSEEKKEPEKEKPPVAGDAEKIKEESEDSLEKFEPSTLYPYLREEDLDDSPKGGLDILKSLENTVSTAISKAQNGAPSWGGYPSIHAAYQLPGTVKPLPAAVQSVQVQPSYAGGVKSLSSAEHNALLHSPGSLTPPPHKSNVSAMEELVEKVTGKVNIKKEERPPEKEKSSLAKAASPIAKENKDFPKTEEVSGKPQKKGPEAETGKAKKEGPLDVHTPNGTEPLKAKVTNGCNNLGIIMDHSPEPSFINPLSALQSIMNTHLGKVSKPVSPSLDPLAMLYKISNSMLDKPVYPATPVKQADAIDRYYYENSDQPIDLTKSKNKPLVSSVADSVASPLRESALMDISDMVKNLTGRLTPKSSTPSTVSEKSDADGSSFEEALDELSPVHKRKGRQSNWNPQHLLILQAQFASSLRETTEGKYIMSDLGPQERVHISKFTGLSMTTISHWLANVKYQLRRTGGTKFLKNLDTGHPVFFCNDCASQFRTASTYISHLETHLGFSLKDLSKLPLNQIQEQQNVSKVLTNKTLGPLGATEEDLGSTFQCKLCNRTFASKHAVKLHLSKTHGKSPEDHLIYVTELEKQ>sp|Q6ZSZ6-2|TSH1_HUMAN Isoform 2 of Teashirt homolog 1 OS=Homo sapiensOX=9606 GN=TSHZ1MCNEETEIKEAQSYQNSPVSSATNQDAGYGSPFSESSDQLAHFKGSSSREEKEDPQCPDSVSYPQDSLAQIKAVYANLFSESCWSSLALDLKKSGSTTSTNDASQKESSAPTPTPPTCPVSTTGPTTSTPSTSCSSSTSHSSTTSTSSSSGYDWHQAALAKTLQQTSSYGLLPEPSLFSTVQLYRQNNKLYGSVFTGASKFRCKDCSAAYDTLVELTVHMNETGHYRDDNRDKDSEKTKRWSKPRKRSLMEMEGKEDAQKVLKCMYCGHSFESLQDLSVHMIKTKHYQKVPLKEPVPAITKLVPSTKKRALQDLAPPCSPEPAGMAAEVALSESAKDQKAANPYVTPNNRYGYQNGASYTWQFEARKAQILKCMECGSSHDTLQQLTAHMMVTGHFLKVTTSASKKGKQLVLDPVVEEKIQSIPLPPTTHTRLPASSIKKQPDSPAGSTTSEEKKEPEKEKPPVAGDAEKIKEESEDSLEKFEPSTLYPYLREEDLDDSPKGGLDILKSLENTVSTAISKAQNGAPSWGGYPSIHAAYQLPGTVKPLPAAVQSVQVQPSYAGGVKSLSSAEHNALLHSPGSLTPPPHKSNVSAMEELVEKVTGKVNIKKEERPPEKEKSSLAKAASPIAKENKDFPKTEEVSGKPQKKGPEAETGKAKKEGPLDVHTPNGTEPLKAKVTNGCNNLGIIMDHSPEPSFINPLSALQSIMNTHLGKVSKPVSPSLDPLAMLYKISNSMLDKPVYPATPVKQADAIDRYYYENSDQPIDLTKSKNKPLVSSVADSVASPLRESALMDISDMVKNLTGRLTPKSSTPSTVSEKSDADGSSFEEALDELSPVHKRKGRQSNWNPQHLLILQAQFASSLRETTEGKYIMSDLGPQERVHISKFTGLSMTTISHWLANVKYQLRRTGGTKFLKNLDTGHPVFFCNDCASQFRTASTYISHLETHLGFSLKDLSKLPLNQIQEQQNVSKVLTNKTLGPLGATEEDLGSTFQCKLCNRTFASKHAVKLHLSKTHGKSPEDHLIYVTELEKQ>sp|Q9NQA5|TRPV5_HUMAN Transient receptor potential cation channelsubfamily V member 5 OS=Homo sapiens OX=9606 GN=TRPV5 PE=1 SV=2MGGFLPKAEGPGSQLQKLLPSFLVREQDWDQHLDKLHMLQQKRILESPLLRASKENDLSVLRQLLLDCTCDVRQRGALGETALHIAALYDNLEAALVLMEAAPELVFEPTTCEAFAGQTALHIAVVNQNVNLVRALLTRRASVSARATGTAFRRSPRNLIYFGEHPLSFAACVNSEEIVRLLIEHGADIRAQDSLGNTVLHILILQPNKTFACQMYNLLLSYDGHGDHLQPLDLVPNHQGLTPFKLAGVEGNTVMFQHLMQKRRHIQWTYGPLTSILYDLTEIDSWGEELSFLELVVSSDKREARQILEQTPVKELVSFKWNKYGRPYFCILAALYLLYMICFTTCCVYRPLKFRGGNRTHSRDITILQQKLLQEAYETREDIIRLVGELVSIVGAVIILLLEIPDIFRVGASRYFGKTILGGPFHVIIITYASLVLVTMVMRLTNTNGEVVPMSFALVLGWCSVMYFTRGFQMLGPFTIMIQKMIFGDLMRFCWLMAVVILGFASAFYIIFQTEDPTSLGQFYDYPMALFTTFELFLTVIDAPANYDVDLPFMFSIVNFAFAIIATLLMLNLFIAMMGDTHWRVAQERDELWRAQVVATTVMLERKLPRCLWPRSGICGCEFGLGDRWFLRVENHNDQNPLRVLRYVEVFKNSDKEDDQEHPSEKQPSGAESGTLARASLALPTSSLSRTASQSSSHRGWEILRQNTLGHLNLGLNLSEGDGEEVYHF>sp|Q9NQA5-2|TRPV5_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily V member 5 OS=Homo sapiens OX=9606 GN=TRPV5MGGFLPKAEGPGSQLQKLLPSFLVREQDWDQHLDKLHMLQQKRILESPLLRASKENDLSVLRQLLLDCTCDVRQRGALGETALHIAALYDNLEAALVLMEAAPELVFEPTTCEAFAGQTALHIAVVNQNVNLVRALLTRRASVSARATGTAFRRSPRNLIYFGEHPLSFAACVNSEEIVRLLIEHGADIRAQDSLGNTVLHILILQPNKTFACQMYNLLLSYDGHGDHLQPLDLVPNHQGLTPFKLAGVEGNTVMFQHLMQKRRHIQWTYGPLTSILYDLTEIDSWGEELSFLELVVSSDKREARQILEQTPVKELVSFKWNKYGRPYFCILAALYLLYMICFTTCCVYRPLKFRGGNRTHSRDITILQQKLLQVILLRRG>sp|Q8TE23|TS1R2_HUMAN Taste receptor type 1 member 2 OS=Homo sapiensOX=9606 GN=TAS1R2 PE=3 SV=2MGPRAKTISSLFFLLWVLAEPAENSDFYLPGDYLLGGLFSLHANMKGIVHLNFLQVPMCKEYEVKVIGYNLMQAMRFAVEEINNDSSLLPGVLLGYEIVDVCYISNNVQPVLYFLAHEDNLLPIQEDYSNYISRVVAVIGPDNSESVMTVANFLSLFLLPQITYSAISDELRDKVRFPALLRTTPSADHHIEAMVQLMLHFRWNWIIVLVSSDTYGRDNGQLLGERVARRDICIAFQETLPTLQPNQNMTSEERQRLVTIVDKLQQSTARVVVVFSPDLTLYHFFNEVLRQNFTGAVWIASESWAIDPVLHNLTELRHLGTFLGITIQSVPIPGFSEFREWGPQAGPPPLSRTSQSYTCNQECDNCLNATLSFNTILRLSGERVVYSVYSAVYAVAHALHSLLGCDKSTCTKRVVYPWQLLEEIWKVNFTLLDHQIFFDPQGDVALHLEIVQWQWDRSQNPFQSVASYYPLQRQLKNIQDISWHTINNTIPMSMCSKRCQSGQKKKPVGIHVCCFECIDCLPGTFLNHTEDEYECQACPNNEWSYQSETSCFKRQLVFLEWHEAPTIAVALLAALGFLSTLAILVIFWRHFQTPIVRSAGGPMCFLMLTLLLVAYMVVPVYVGPPKVSTCLCRQALFPLCFTICISCIAVRSFQIVCAFKMASRFPRAYSYWVRYQGPYVSMAFITVLKMVIVVIGMLATGLSPTTRTDPDDPKITIVSCNPNYRNSLLFNTSLDLLLSVVGFSFAYMGKELPTNYNEAKFITLSMTFYFTSSVSLCTFMSAYSGVLVTIVDLLVTVLNLLAISLGYFGPKCYMILFYPERNTPAYFNSMIQGYTMRRD>sp|Q9NNW7|TRXR2_HUMAN Thioredoxin reductase 2, mitochondrial OS=Homosapiens OX=9606 GN=TXNRD2 PE=1 SV=3MAAMAVALRGLGGRFRWRTQAVAGGVRGAARGAAAGQRDYDLLVVGGGSGGLACAKEAAQLGRKVAVVDYVEPSPQGTRWGLGGTCVNVGCIPKKLMHQAALLGGLIQDAPNYGWEVAQPVPHDWRKMAEAVQNHVKSLNWGHRVQLQDRKVKYFNIKASFVDEHTVCGVAKGGKEILLSADHIIIATGGRPRYPTHIEGALEYGITSDDIFWLKESPGKTLVVGASYVALECAGFLTGIGLDTTIMMRSIPLRGFDQQMSSMVIEHMASHGTRFLRGCAPSRVRRLPDGQLQVTWEDSTTGKEDTGTFDTVLWAIGRVPDTRSLNLEKAGVDTSPDTQKILVDSREATSVPHIYAIGDVVEGRPELTPIAIMAGRLLVQRLFGGSSDLMDYDNVPTTVFTPLEYGCVGLSEEEAVARHGQEHVEVYHAHYKPLEFTVAGRDASQCYVKMVCLREPPQLVLGLHFLGPNAGEVTQGFALGIKCGASYAQVMRTVGIHPTCSEEVVKLRISKRSGLDPTVTGCUG>sp|Q9NNW7-2|TRXR2_HUMAN Isoform 2 of Thioredoxin reductase 2,mitochondrial OS=Homo sapiens OX=9606 GN=TXNRD2MEDQRGAAAGQRDYDLLVVGGGSGGLACAKEAAQLGRKVAVVDYVEPSPQGTRWGLGGTCVNVGCIPKKLMHQAALLGGLIQDAPNYGWEVAQPVPHDWRKMAEAVQNHVKSLNWGHRVQLQDRKVKYFNIKASFVDEHTVCGVAKGGKEILLSADHIIIATGGRPRYPTHIEGALEYGITSDDIFWLKESPGKTLVVGASYVALECAGFLTGIGLDTTIMMRSIPLRGFDQQMSSMVIEHMASHGTRFLRGCAPSRVRRLPDGQLQVTWEDSTTGKEDTGTFDTVLWAIGRVPDTRSLNLEKAGVDTSPDTQKILVDSREATSVPHIYAIGDVVEGRPELTPIAIMAGRLLVQRLFGGSSDLMDYDNVPTTVFTPLEYGCVGLSEEEAVARHGQEHVEVYHAHYKPLEFTVAGRDASQCYVKMVCLREPPQLVLGLHFLGPNAGEVTQGFALGIKCGASYAQVMRTVGIHPTCSEEVVKLRISKRSGLDPTVTGCUG>sp|Q9NNW7-3|TRXR2_HUMAN Isoform 3 of Thioredoxin reductase 2,mitochondrial OS=Homo sapiens OX=9606 GN=TXNRD2MHQAALLGGLIQDAPNYGWEVAQPVPHDWRKMAEAVQNHVKSLNWGHRVQLQDRKVKYFNIKASFVDEHTVCGVAKGGKEILLSADHIIIATGGRPRYPTHIEGALEYGITSDDIFWLKESPGKTLVVGASYVALECAGFLTGIGLDTTIMMRSIPLRGFDQQMSSMVIEHMASHGTRFLRGCAPSRVRRLPDGQLQVTWEDSTTGKEDTGTFDTVLWAIGRVPDTRSLNLEKAGVDTSPDTQKILVDSREATSVPHIYAIGDVVEGRPELTPIAIMAGRLLVQRLFGGSSDLMDYDNVPTTVFTPLEYGCVGLSEEEAVARHGQEHVEVYHAHYKPLEFTVAGRDASQCYVKMVCLREPPQLVLGLHFLGPNAGEVTQGFALGIKCGASYAQVMRTVGIHPTCSEEVVKLRISKRSGLDPTVTGCUG>sp|Q9NNW7-4|TRXR2_HUMAN Isoform 4 of Thioredoxin reductase 2,mitochondrial OS=Homo sapiens OX=9606 GN=TXNRD2MRSIPLRGFDQQMSSMVIEHMASHGTRFLRGCAPSRVRRLPDGQLQVTWEDSTTGKEDTGTFDTVLWAIGRVPDTRSLNLEKAGVDTSPDTQKILVDSREATSVPHIYAIGDVVEGRPELTPIAIMAGRLLVQRLFGGSSDLMDYDNVPTTVFTPLEYGCVGLSEEEAVARHGQEHVEVYHAHYKPLEFTVAGRDASQCYVKMVCLREPPQLVLGLHFLGPNAGEVTQGFALGIKCGASYAQVMRTVGIHPTCSEEVVKLRISKRSGLDPTVTGCUG>sp|Q9H1D0|TRPV6_HUMAN Transient receptor potential cation channelsubfamily V member 6 OS=Homo sapiens OX=9606 GN=TRPV6 PE=1 SV=3MGPLQGDGGPALGGADVAPRLSPVRVWPRPQAPKEPALHPMGLSLPKEKGLILCLWSKFCRWFQRRESWAQSRDEQNLLQQKRIWESPLLLAAKDNDVQALNKLLKYEDCKVHQRGAMGETALHIAALYDNLEAAMVLMEAAPELVFEPMTSELYEGQTALHIAVVNQNMNLVRALLARRASVSARATGTAFRRSPCNLIYFGEHPLSFAACVNSEEIVRLLIEHGADIRAQDSLGNTVLHILILQPNKTFACQMYNLLLSYDRHGDHLQPLDLVPNHQGLTPFKLAGVEGNTVMFQHLMQKRKHTQWTYGPLTSTLYDLTEIDSSGDEQSLLELIITTKKREARQILDQTPVKELVSLKWKRYGRPYFCMLGAIYLLYIICFTMCCIYRPLKPRTNNRTSPRDNTLLQQKLLQEAYMTPKDDIRLVGELVTVIGAIIILLVEVPDIFRMGVTRFFGQTILGGPFHVLIITYAFMVLVTMVMRLISASGEVVPMSFALVLGWCNVMYFARGFQMLGPFTIMIQKMIFGDLMRFCWLMAVVILGFASAFYIIFQTEDPEELGHFYDYPMALFSTFELFLTIIDGPANYNVDLPFMYSITYAAFAIIATLLMLNLLIAMMGDTHWRVAHERDELWRAQIVATTVMLERKLPRCLWPRSGICGREYGLGDRWFLRVEDRQDLNRQRIQRYAQAFHTRGSEDLDKDSVEKLELGCPFSPHLSLPMPSVSRSTSRSSANWERLRQGTLRRDLRGIINRGLEDGESWEYQI>sp|Q9H1D0-2|TRPV6_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily V member 6 OS=Homo sapiens OX=9606 GN=TRPV6MGPLQGDGGPALGGADVAPRLSPVRVWPRPQAPKEPALHPMGLSLPKEKGLILCLWSKFCRWFQDSLGNTVLHILILQPNKTFACQMYNLLLSYDRHGDHLQPLDLVPNHQGLTPFKLAGVEGNTVMFQHLMQKRKHTQWTYGPLTSTLYDLTEIDSSGDEQSLLELIITTKKREARQILDQTPVKELVSLKWKRYGRPYFCMLGAIYLLYIICFTMCCIYRPLKPRTNNRTSPRDNTLLQQKLLQEAYMTPKDDIRLVGELVTVIGAIIILLVEVPDIFRMGVTRFFGQTILGGPFHVLIITYAFMVLVTMVMRLISASGEVVPMSFALVLGWCNVMYFARGFQMLGPFTIMIQKMIFGDLMRFCWLMAVVILGFASAFYIIFQTEDPEELGHFYDYPMALFSTFELFLTIIDGPANYNVDLPFMYSITYAAFAIIATLLMLNLLIAMMGDTHWRVAHERDELWRAQIVATTVMLERKLPRCLWPRSGICGREYGLGDRWFLRVEDRQDLNRQRIQRYAQAFHTRGSEDLDKDSVEKLELGCPFSPHLSLPMPSVSRSTSRSSANWERLRQGTLRRDLRGIINRGLEDGESWEYQI>sp|Q9BZW7|TSG10_HUMAN Testis-specific gene 10 protein OS=Homo sapiensOX=9606 GN=TSGA10 PE=1 SV=1MMRSRSKSPRRPSPTARGANCDVELLKTTTRDREELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSCKSPKSTTAHAILRRVETERDVAFTDLRRMTTERDSLRERLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARKAMDTESELGRQKAENNSLRLLYENTEKDLSDTQRHLAKKKYELQLTQEKIMCLDEKIDNFTRQNIAQREEISILGGTLNDLAKEKECLQACLDKKSENIASLGESLAMKEKTISGMKNIIAEMEQASRQCTEALIVCEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEALLVANRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVAQFRNVVTQLEADLDITKRQLGTERFERERAVQELRRQNYSSNAYHMSSTMKPNTKCHSPERAHHRSPDRGLDRSLEENLCYRDF>sp|Q9BZW7-2|TSG10_HUMAN Isoform 2 of Testis-specific gene 10 proteinOS=Homo sapiens OX=9606 GN=TSGA10MMRSRSKSPRRPSPTARGANCDVELLKTTTRDREELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSCKSPKSTTAHAILRRVETERDVAFTDLRRMTTERDSLRERLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARKAMDTESELGRQKAENNSLRLLYENTEKDLSDTQRHLAKKKYELQLTQEKIMCLDEKIDNFTRQNIAQREEISILGGTLNDLAKEKECLQACLDKKSENIASLGESLAMKTVY>sp|A6NLP5|TTC36_HUMAN Tetratricopeptide repeat protein 36 OS=Homosapiens OX=9606 GN=TTC36 PE=1 SV=1MGTPNDQAVLQAIFNPDTPFGDIVGLDLGEEAEKEEREEDEVFPQAQLEQSKALELQGVMAAEAGDLSTALERFGQAICLLPERASAYNNRAQARRLQGDVAGALEDLERAVELSGGRGRAARQSFVQRGLLARLQGRDDDARRDFERAARLGSPFARRQLVLLNPYAALCNRMLADMMGQLRRPRDSR>sp|A6NLP5-2|TTC36_HUMAN Isoform 2 of Tetratricopeptide repeat protein 36OS=Homo sapiens OX=9606 GN=TTC36MAAEAGDLSTALERFGQAICLLPERASAYNNRAQARRLQGDVAGALEDLERAVELSGGRGRAARQSFVQRGLLARLQGRDDDARRDFERAARLGSPFARRQLVLLNPYAALCNRMLADMMGQLRRPRDSR>sp|O95801|TTC4_HUMAN Tetratricopeptide repeat protein 4 OS=Homo sapiensOX=9606 GN=TTC4 PE=1 SV=3MEQPGQDPTSDDVMDSFLEKFQSQPYRGGFHEDQWEKEFEKVPLFMSRAPSEIDPRENPDLACLQSIIFDEERSPEEQAKTYKDEGNDYFKEKDYKKAVISYTEGLKKKCADPDLNAVLYTNRAAAQYYLGNFRSALNDVTAARKLKPCHLKAIIRGALCHLELKHFAEAVNWCDEGLQIDAKEKKLLEMRAKADKLKRIEQRDVRKANLKEKKERNQNEALLQAIKARNIRLSEAACEDEDSASEGLGELFLDGLSTENPHGARLSLDGQGRLSWPVLFLYPEYAQSDFISAFHEDSRFIDHLMVMFGETPSWDLEQKYCPDNLEVYFEDEDRAELYRVPAKSTLLQVLQHQRYFVKALTPAFLVCVGSSPFCKNFLRGRKVYQIR>sp|A6NKD2|TSPY2_HUMAN Testis-specific Y-encoded protein 2 OS=Homosapiens OX=9606 GN=TSPY2 PE=1 SV=1MRPEGSLTYRVPERLRQGSCGVGRAAQALVCASAKEGTAFRMEAVQEGAAGVESEQAALGEEAVLLLDDIMAEVEVVAEEEGLVERREEAQRAQQAVPGPGPMTPESALEELLAVQVELEPVNAQARKAFSRQREKMERRRKPHLDRRGAVIQSVPGFWANVIANHPQMSALITDEDEDMLSYMVSLEVEEEKHRVHLCKIMLFFRSNPYFQNKVITKEYLVNITEYRASHSTPIEWYPDYEVEAYRRRHHNSSLNFFNWFSDHNFAGSNKIAEILCKDLWRNPLQYYKRMKPPEEGTETSGDSQLLS>sp|Q9UJ04|TSYL4_HUMAN Testis-specific Y-encoded-like protein 4 OS=Homosapiens OX=9606 GN=TSPYL4 PE=1 SV=2MSGLDGGNKLPLAQTGGLAAPDHASGDPDRDQCQGLREETEATQVMANTGGGSLETVAEGGASQDPVDCGPALRVPVAGSRGGAATKAGQEDAPPSTKGLEAASAAEAADSSQKNGCQLGEPRGPAGQKALEACGAGGLGSQMIPGKKAKEVTTKKRAISAAVEKEGEAGAAMEEKKVVQKEKKVAGGVKEETRPRAPKINNCMDSLEAIDQELSNVNAQADRAFLQLERKFGRMRRLHMQRRSFIIQNIPGFWVTAFRNHPQLSPMISGQDEDMLRYMINLEVEELKHPRAGCKFKFIFQGNPYFRNEGLVKEYERRSSGRVVSLSTPIRWHRGQDPQAHIHRNREGNTIPSFFNWFSDHSLLEFDRIAEIIKGELWPNPLQYYLMGEGPRRGIRGPPRQPVESARSFRFQSG>sp|Q6SA08|TSSK4_HUMAN Testis-specific serine/threonine-protein kinase 4OS=Homo sapiens OX=9606 GN=TSSK4 PE=1 SV=1MGKGDVLEAAPTTTAYHSLMDEYGYEVGKAIGHGSYGSVYEAFYTKQKVMVAVKIISKKKASDDYLNKFLPREIQVMKVLRHKYLINFYRAIESTSRVYIILELAQGGDVLEWIQRYGACSEPLAGKWFSQLTLGIAYLHSKSIVHRDLKLENLLLDKWENVKISDFGFAKMVPSNQPVGCSPSYRQVNCFSHLSQTYCGSFAYACPEILRGLPYNPFLSDTWSMGVILYTLVVAHLPFDDTNLKKLLRETQKEVTFPANHTISQECKNLILQMLRQATKRATILDIIKDSWVLKFQPEQPTHEIRLLEAMCQLHNTTKQHQSLQITT>sp|Q6SA08-2|TSSK4_HUMAN Isoform 2 of Testis-specific serine/threonine-protein kinase 4 OS=Homo sapiens OX=9606 GN=TSSK4MGKGDVLEAAPTTTAYHSLMDEYGYEVGKAIGHGSYGSVYEAFYTKQKVMVAVKIISKKKASDDYLNKFLPREIQVMKVLRHKYLINFYRAIESTSRVYIILELAQGGDVLEWIQRYGACSEPLAGKWFSQLTLGIAYLHSKSIVHRLMPSLSAAGRDLKLENLLLDKWENVKISDFGFAKMVPSNQPVGCSPSYRQVNCFSHLSQTYCGSFAYACPEILRGLPYNPFLSDTWSMGVILYTLVVAHLPFDDTNLKKLLRETQKEVTFPANHTISQECKNLILQMLRQATKRATILDIIKDSWVLKFQPEQPTHEIRLLEAMCQLHNTTKQHQSLQITT>sp|Q6SA08-3|TSSK4_HUMAN Isoform 3 of Testis-specific serine/threonine-protein kinase 4 OS=Homo sapiens OX=9606 GN=TSSK4MKVLRHKYLINFYRAIESTSRVYIILELAQGGDVLEWIQRYGACSEPLAGKWFSQLTLGIAYLHSKSIVHRDLKLENLLLDKWENVKISDFGFAKMVPSNQPVGCSPSYRQVNCFSHLSQTYCGSFAYACPEILRGLPYNPFLSDTWSMGVILYTLVVAHLPFDDTNLKKLLRETQKEVTFPANHTISQECKNLILQMLRQATKRATILDIIKDSWVLKFQPEQPTHEIRLLEAMCQLHNTTKQHQSLQITT>sp|C9JLJ4|U17LD_HUMAN Ubiquitin carboxyl-terminal hydrolase 17-likeprotein 13 OS=Homo sapiens OX=9606 GN=USP17L13 PE=3 SV=1MEEDSLYLGGEWQFNHFSKLTSSRLDAAFAEIQRTSLPEKSPLSCETRVDLCDDLVPEARQLAPREKLPLSSRRPAAVGAGLQNMGNTCYVNASLQCLTYTPPLANYMLSREHSQTCHRHKGCMLCTMQAHITRALHNPGHVIQPSQALAAGFHRGKQEDAHEFLMFTVDAMKKACLPGHKQVDHPSKDTTLIHQIFGGYWRSQIKCLHCHGISDTFDPYLDIALDIQAAQSVQQALEQLVKPEELNGENAYHCGVCLQRAPASKTLTLHTSAKVLILVLKRFSDVTGNKIAKNVQYPECLDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTAASITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRRATQGELKRDHPCLQAPELDEHLVERATQESTLDRWKFLQEQNKTKPEFNVRKVEGTLPPDVLVIHQSKYKCGMKNHHPEQQSSLLNLSSSTPTHQESMNTGTLASLRGRARRSKGKNKHSKRALLVCQ>sp|Q969E3|UCN3_HUMAN Urocortin-3 OS=Homo sapiens OX=9606 GN=UCN3 PE=1SV=2MLMPVHFLLLLLLLLGGPRTGLPHKFYKAKPIFSCLNTALSEAEKGQWEDASLLSKRSFHYLRSRDASSGEEEEGKEKKTFPISGARGGARGTRYRYVSQAQPRGKPRQDTAKSPHRTKFTLSLDVPTNIMNLLFNIAKAKNLRAQAAANAHLMAQIGRKK>sp|P55851|UCP2_HUMAN Mitochondrial uncoupling protein 2 OS=Homo sapiensOX=9606 GN=UCP2 PE=1 SV=1MVGFKATDVPPTATVKFLGAGTAACIADLITFPLDTAKVRLQIQGESQGPVRATASAQYRGVMGTILTMVRTEGPRSLYNGLVAGLQRQMSFASVRIGLYDSVKQFYTKGSEHASIGSRLLAGSTTGALAVAVAQPTDVVKVRFQAQARAGGGRRYQSTVNAYKTIAREEGFRGLWKGTSPNVARNAIVNCAELVTYDLIKDALLKANLMTDDLPCHFTSAFGAGFCTTVIASPVDVVKTRYMNSALGQYSSAGHCALTMLQKEGPRAFYKGFMPSFLRLGSWNVVMFVTYEQLKRALMAACTSREAPF>sp|Q6A555|TXND8_HUMAN Thioredoxin domain-containing protein 8 OS=Homosapiens OX=9606 GN=TXNDC8 PE=1 SV=2MVQIIKDTNEFKTFLTAAGHKLAVVQFSSKRCGPCKRMFPVFHAMSVKYQNVFFANVDVNNSPELAETCHIKTIPTFQMFKKSQKVTLFSRIKRIICCYRSGFMSNLIFEFCGADAKKLEAKTQELM>sp|Q6A555-2|TXND8_HUMAN Isoform 2 of Thioredoxin domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=TXNDC8MVQIIKDTNEFKTFLTAAGHKLAVVQFSSKRCGPCKRMFPVFHAMSVKYQNVFFANVDVNNSPELAETCHIKTIPTFQMFKKSQKVTLFSRIKRIICCYRSGFMSNLCLADDGNE>sp|P68036|UB2L3_HUMAN Ubiquitin-conjugating enzyme E2 L3 OS=Homo sapiensOX=9606 GN=UBE2L3 PE=1 SV=1MAASRRLMKELEEIRKCGMKNFRNIQVDEANLLTWQGLIVPDNPPYDKGAFRIEINFPAEYPFKPPKITFKTKIYHPNIDEKGQVCLPVISAENWKPATKTDQVIQSLIALVNDPQPEHPLRADLAEEYSKDRKKFCKNAEEFTKKYGEKRPVD>sp|P68036-2|UB2L3_HUMAN Isoform 2 of Ubiquitin-conjugating enzyme E2 L3OS=Homo sapiens OX=9606 GN=UBE2L3MAASRRLMKDNPPYDKGAFRIEINFPAEYPFKPPKITFKTKIYHPNIDEKGQVCLPVISAENWKPATKTDQVIQSLIALVNDPQPEHPLRADLAEEYSKDRKKFCKNAEEFTKKYGEKRPVD>sp|P68036-3|UB2L3_HUMAN Isoform 3 of Ubiquitin-conjugating enzyme E2 L3OS=Homo sapiens OX=9606 GN=UBE2L3MQVAAGTRGDTRLQEVALLPQLFDLLVLGQRRARLLRQVPSALAGKDLAQLQAGATLAGYRRAHGPEELEEIRKCGMKNFRNIQVDEANLLTWQGLIVPDNPPYDKGAFRIEINFPAEYPFKPPKITFKTKIYHPNIDEKGQVCLPVISAENWKPATKTDQVIQSLIALVNDPQPEHPLRADLAEEYSKDRKKFCKNAEEFTKKYGEKRPVD>sp|Q8TB05|UBAD1_HUMAN UBA-like domain-containing protein 1 OS=Homosapiens OX=9606 GN=UBALD1 PE=1 SV=1MSVNMDELKHQVMINQFVLTAGCAADQAKQLLQAAHWQFETALSAFFQETNIPYSHHHHQMMCTPANTPATPPNFPDALTMFSRLKASESFHSGGSGSPMAATATSPPPHFPHAATSSSAASSWPTAASPPGGPQHHQPQPPLWTPTPPSPASDWPPLAPQQATSEPRAHPAMEAER>sp|Q8TB05-2|UBAD1_HUMAN Isoform 2 of UBA-like domain-containing protein1 OS=Homo sapiens OX=9606 GN=UBALD1MKLLTLQPPGMLWLMERGGLGKPRGPRHRGLLRVRLGRFISRLLLWEPLGGGQAWGSGEGTQSLPRMGQPRISPWEAVGAPPGRGAHPISPLFPSQMCTPANTPATPPNFPDALTMFSRLKASESFHSGGSGSPMAATATSPPPHFPHAATSSSAASSWPTAASPPGGPQHHQPQPPLWTPTPPSPASDWPPLAPQQATSEPRAHPAMEAER>sp|P0C7H9|U17L7_HUMAN Inactive ubiquitin carboxyl-terminal hydrolase 17-like protein 7 OS=Homo sapiens OX=9606 GN=USP17L7 PE=3 SV=1MEDDSLYLGGDWQFNHFSKLTSSRLDAAFAEIQRTSLSEKSPLSSETRFDLCDDLAPVARQLAPREKLPLSSRRPAAVGAGLQKIGNTFYVNVSLQCLTYTLPLSNYMLSREDSQTCHLHKCCMFCTMQAHITWALHSPGHVIQPSQVLAAGFHRGEQEDAHEFLMFTVDAMKKACLPGHKQLDHHSKDTTLIHQIFGAYWRSQIKYLHCHGVSDTFDPYLDIALDIQAAQSVKQALEQLVKPKELNGENAYHCGLCLQKAPASKTLTLPTSAKVLILVLKRFSDVTGNKLAKNVQYPKCRDMQPYMSQQNTGPLVYVLYAVLVHAGWSCHNGHYFSYVKAQEGQWYKMDDAEVTASGITSVLSQQAYVLFYIQKSEWERHSESVSRGREPRALGAEDTDRPATQGELKRDHPCLQVPELDEHLVERATQESTLDHWKFPQEQNKTKPEFNVRKVEGTLPPNVLVIHQSKYKCGMKNHHPEQQSSLLNLSSTKPTDQESMNTGTLASLQGSTRRSKGNNKHSKRSLLVCQ>sp|Q9HAW9|UD18_HUMAN UDP-glucuronosyltransferase 1A8 OS=Homo sapiensOX=9606 GN=UGT1A8 PE=1 SV=1MARTGWTSPIPLCVSLLLTCGFAEAGKLLVVPMDGSHWFTMQSVVEKLILRGHEVVVVMPEVSWQLGKSLNCTVKTYSTSYTLEDLDREFMDFADAQWKAQVRSLFSLFLSSSNGFFNLFFSHCRSLFNDRKLVEYLKESSFDAVFLDPFDACGLIVAKYFSLPSVVFARGIACHYLEEGAQCPAPLSYVPRILLGFSDAMTFKERVRNHIMHLEEHLFCQYFSKNALEIASEILQTPVTAYDLYSHTSIWLLRTDFVLDYPKPVMPNMIFIGGINCHQGKPLPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|Q9HAW9-2|UD18_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A8OS=Homo sapiens OX=9606 GN=UGT1A8MARTGWTSPIPLCVSLLLTCGFAEAGKLLVVPMDGSHWFTMQSVVEKLILRGHEVVVVMPEVSWQLGKSLNCTVKTYSTSYTLEDLDREFMDFADAQWKAQVRSLFSLFLSSSNGFFNLFFSHCRSLFNDRKLVEYLKESSFDAVFLDPFDACGLIVAKYFSLPSVVFARGIACHYLEEGAQCPAPLSYVPRILLGFSDAMTFKERVRNHIMHLEEHLFCQYFSKNALEIASEILQTPVTAYDLYSHTSIWLLRTDFVLDYPKPVMPNMIFIGGINCHQGKPLPMEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|Q8TF42|UBS3B_HUMAN Ubiquitin-associated and SH3 domain-containingprotein B OS=Homo sapiens OX=9606 GN=UBASH3B PE=1 SV=2MAQYGHPSPLGMAAREELYSKVTPRRNRQQRPGTIKHGSALDVLLSMGFPRARAQKALASTGGRSVQAACDWLFSHVGDPFLDDPLPREYVLYLRPTGPLAQKLSDFWQQSKQICGKNKAHNIFPHITLCQFFMCEDSKVDALGEALQTTVSRWKCKFSAPLPLELYTSSNFIGLFVKEDSAEVLKKFAADFAAEAASKTEVHVEPHKKQLHVTLAYHFQASHLPTLEKLAQNIDVKLGCDWVATIFSRDIRFANHETLQVIYPYTPQNDDELELVPGDFIFMSPMEQTSTSEGWIYGTSLTTGCSGLLPENYITKADECSTWIFHGSYSILNTSSSNSLTFGDGVLERRPYEDQGLGETTPLTIICQPMQPLRVNSQPGPQKRCLFVCRHGERMDVVFGKYWLSQCFDAKGRYIRTNLNMPHSLPQRSGGFRDYEKDAPITVFGCMQARLVGEALLESNTIIDHVYCSPSLRCVQTAHNILKGLQQENHLKIRVEPGLFEWTKWVAGSTLPAWIPPSELAAANLSVDTTYRPHIPISKLVVSESYDTYISRSFQVTKEIISECKSKGNNILIVAHASSLEACTCQLQGLSPQNSKDFVQMVRKIPYLGFCSCEELGETGIWQLTDPPILPLTHGPTGGFNWRETLLQE>sp|Q8N6Y0|USBP1_HUMAN Usher syndrome type-1C protein-binding protein 1OS=Homo sapiens OX=9606 GN=USHBP1 PE=1 SV=1MSARATRPRSRRGRHAPPGELDPVAESSEEVEAASGSSKPSFAPPPVSSGLEQLGPMEEVSGQGLGSRTDKKMDGGSGRELASAPEVPHKPAVEAHQAPEAALQYKETVPPGNGAPDVFQTLQHTLSSLEAAAAAWRHQPPSHSGPMEFEGTSEGGAGSLGKQEGAGSCQREAARLAERNAWLRLALSSREDELVRTQASLEAIRAEKETLQKEVQELQDSLLRLEPCPHLSHNQAGGSGSGSSSSEADREPWETQDSFSLAHPLLRRLRSHSSTQILGSLPNQPLSPEMHIMEAQMEQLRGSIEKLKCFNRLLSAVLQGYKGRCEGLSMQLGQREAEATALHLALQYSEHCEEAYRVLLALREADSGAGDEAPMSDLQAAEKEAWRLLAQEEAAMDAGAQQNPQPSPEGSSVDKPTPQEVAFQLRSYVQRLQERRSLMKILSEPGPTLAPMPTVPRAEAMVQAILGTQAGPALPRLEKTQIQQDLVAAREALADLMLRLQLVRREKRGLELREAALRALGPAHVLLLEQLRWERAELQAGGANSSGGHSSGGGSSGDEEEWYQGLPAVPGGTSGIDGGQVGRAWDPEKLAQELAASLTRTLDLQEQLQSLRRELEQVAQKGRARRSQSAELNRDLCKAHSALVLAFRGAHRKQEEQRRKLEQQMALMEAQQAEEVAVLEATARALGKPRPPLPPPQLGDTFL>sp|Q8N6Y0-2|USBP1_HUMAN Isoform 2 of Usher syndrome type-1C protein-binding protein 1 OS=Homo sapiens OX=9606 GN=USHBP1MSARATRPRSRRGRHAPPGELDPVAESSEEVEAASGSSKPSFAPPPVSSGLEQLGPMEEVSGQGLGSR>sp|P36543|VATE1_HUMAN V-type proton ATPase subunit E 1 OS=Homo sapiensOX=9606 GN=ATP6V1E1 PE=1 SV=1MALSDADVQKQIKHMMAFIEQEANEKAEEIDAKAEEEFNIEKGRLVQTQRLKIMEYYEKKEKQIEQQKKIQMSNLMNQARLKVLRARDDLITDLLNEAKQRLSKVVKDTTRYQVLLDGLVLQGLYQLLEPRMIVRCRKQDFPLVKAAVQKAIPMYKIATKNDVDVQIDQESYLPEDIAGGVEIYNGDRKIKVSNTLESRLDLIAQQMMPEVRGALFGANANRKFLD>sp|P36543-2|VATE1_HUMAN Isoform 2 of V-type proton ATPase subunit E 1OS=Homo sapiens OX=9606 GN=ATP6V1E1MALSDADVQKQAEEEFNIEKGRLVQTQRLKIMEYYEKKEKQIEQQKKIQMSNLMNQARLKVLRARDDLITDLLNEAKQRLSKVVKDTTRYQVLLDGLVLQGLYQLLEPRMIVRCRKQDFPLVKAAVQKAIPMYKIATKNDVDVQIDQESYLPEDIAGGVEIYNGDRKIKVSNTLESRLDLIAQQMMPEVRGALFGANANRKFLD>sp|P36543-3|VATE1_HUMAN Isoform 3 of V-type proton ATPase subunit E 1OS=Homo sapiens OX=9606 GN=ATP6V1E1MALSDADVQKQIKHMMAFIEQEANEKAEEIDAKAEEEFNIEKGRLVQTQRLKIMEYYEKKEKQIEQQKKIQMSNLMNQARLKVLRARDDLITGLYQLLEPRMIVRCRKQDFPLVKAAVQKAIPMYKIATKNDVDVQIDQESYLPEDIAGGVEIYNGDRKIKVSNTLESRLDLIAQQMMPEVRGALFGANANRKFLD>sp|O15240|VGF_HUMAN Neurosecretory protein VGF OS=Homo sapiens OX=9606GN=VGF PE=1 SV=2MKALRLSASALFCLLLINGLGAAPPGRPEAQPPPLSSEHKEPVAGDAVPGPKDGSAPEVRGARNSEPQDEGELFQGVDPRALAAVLLQALDRPASPPAPSGSQQGPEEEAAEALLTETVRSQTHSLPAPESPEPAAPPRPQTPENGPEASDPSEELEALASLLQELRDFSPSSAKRQQETAAAETETRTHTLTRVNLESPGPERVWRASWGEFQARVPERAPLPPPAPSQFQARMPDSGPLPETHKFGEGVSSPKTHLGEALAPLSKAYQGVAAPFPKARRPESALLGGSEAGERLLQQGLAQVEAGRRQAEATRQAAAQEERLADLASDLLLQYLLQGGARQRGLGGRGLQEAAEERESAREEEEAEQERRGGEERVGEEDEEAAEAEAEAEEAERARQNALLFAEEEDGEAGAEDKRSQEETPGHRRKEAEGTEEGGEEEDDEEMDPQTIDSLIELSTKLHLPADDVVSIIEEVEEKRKRKKNAPPEPVPPPRAAPAPTHVRSPQPPPPAPAPARDELPDWNEVLPPWDREEDEVYPPGPYHPFPNYIRPRTLQPPSALRRRHYHHALPPSRHYPGREAQARRAQEEAEAEERRLQEQEELENYIEHVLLRRP>sp|Q9NNX9|VCX3_HUMAN Variable charge X-linked protein 3 OS=Homo sapiensOX=9606 GN=VCX3A PE=2 SV=1MSPKPRASGPPAKATEAGKRKSSSQPSPSDPKKKTTKVAKKGKAVRRGRRGKKGAATKMAAVTAPEAESGPAAPGPSDQPSQELPQHELPPEEPVSEGTQHDPLSQESELEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEVEEPLSQESQVEEPLSQESEMEELPSV>sp|Q96AJ9|VTI1A_HUMAN Vesicle transport through interaction with t-SNAREs homolog 1A OS=Homo sapiens OX=9606 GN=VTI1A PE=1 SV=2MSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQEMGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETEQIGQEMLENLSHDREKIQRARERLRETDANLGKSSRILTGMLRRIIQNRILLVILGIIVVITILMAITFSVRRH>sp|Q96AJ9-1|VTI1A_HUMAN Isoform 1 of Vesicle transport throughinteraction with t-SNAREs homolog 1A OS=Homo sapiens OX=9606 GN=VTI1AMSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQEMGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETEQIGQEMLENLSHDREKIQRARERLRETDANLGKSSRILTGMLRRGCSVKKQCNLSLAPKA>sp|Q9H1F0|WF10A_HUMAN WAP four-disulfide core domain protein 10A OS=Homosapiens OX=9606 GN=WFDC10A PE=3 SV=2MAPQTLLPVLVLCVLLLQAQGGYRDKKRMQKTQLSPEIKVCQQQPKLYLCKHLCESHRDCQANNICCSTYCGNVCMSIL>sp|P56704|WNT3A_HUMAN Protein Wnt-3a OS=Homo sapiens OX=9606 GN=WNT3APE=1 SV=2MAPLGYFLLLCSLKQALGSYPIWWSLAVGPQYSSLGSQPILCASIPGLVPKQLRFCRNYVEIMPSVAEGIKIGIQECQHQFRGRRWNCTTVHDSLAIFGPVLDKATRESAFVHAIASAGVAFAVTRSCAEGTAAICGCSSRHQGSPGKGWKWGGCSEDIEFGGMVSREFADARENRPDARSAMNRHNNEAGRQAIASHMHLKCKCHGLSGSCEVKTCWWSQPDFRAIGDFLKDKYDSASEMVVEKHRESRGWVETLRPRYTYFKVPTERDLVYYEASPNFCEPNPETGSFGTRDRTCNVSSHGIDGCDLLCCGRGHNARAERRREKCRCVFHWCCYVSCQECTRVYDVHTCK>sp|P56704-2|WNT3A_HUMAN Isoform 2 of Protein Wnt-3a OS=Homo sapiensOX=9606 GN=WNT3AMAPLGYFLLLCSLKQALGSYPIWWSLAVGPQYSSLGSQPILCASIPGLVPKQLRFCRNYVEIMPSVAEGIKIGIQECQHQFRGRRWNCTTVHDSLAIFGPVLDKATRESAFVHAIASAGVAFAVTRSCAEGTAAICGCSSRHQGSPGKGWKWGGCSEDIEFGGMVSREFADARENRPDARSAMNRHNNEAGRQAIASHMHLKCKCHGLSGSCEVKTCWWSQPDFRAIGDFLKDKYDSASEMVVEKHRESRGWVETLRPRYTYFKVPTERDLVYYEASPNFCEPNPETGSFGTRDRTCNVSSHGIDGCDLLCCGRGHNARAERRREKCRCVFHWCCYVSCQECTRVYDVHTCKNPGSRAGNSAHQPPHPQPPVRFHPPLRRAGKVP>sp|Q5GH77|XKR3_HUMAN XK-related protein 3 OS=Homo sapiens OX=9606GN=XKR3 PE=2 SV=1METVFEEMDEESTGGVSSSKEEIVLGQRLHLSFPFSIIFSTVLYCGEVAFGLYMFEIYRKANDTFWMSFTISFIIVGAILDQIILMFFNKDLRRNKAALLFWHILLLGPIVRCLHTIRNYHKWLKNLKQEKEETQVSITKRNTMLEREIAFSIRDNFMQQKAFKYMSVIQAFLGSVPQLILQMYISLTIREWPLNRALLMTFSLLSVTYGAIRCNILAIQISNDDTTIKLPPIEFFCVVMWRFLEVISRVVTLAFFIASLKLKSLPVLLIIYFVSLLAPWLEFWKSGAHLPGNKENNSNMVGTVLMLFLITLLYAAINFSCWSAVKLQLSDDKIIDGRQRWGHRILHYSFQFLENVIMILVFRFFGGKTLLNCCDSLIAVQLIISYLLATGFMLLFYQYLYPWQSGKVLPGRTENQPEAPYYYVNIEKTEKNKNKQLRNYCHSCNRVGYFSIRKSMTCS>sp|Q9Y4E1|WAC2C_HUMAN WASH complex subunit 2C OS=Homo sapiens OX=9606GN=WASHC2C PE=1 SV=4MMNRTTPDQELVPASEPVWERPWSVEEIRRSSQSWSLAADAGLLQFLQEFSQQTISRTHEIKKQVDGLIRETKATDCRLHNVFNDFLMLSNTQFIENRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNQHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAMGRVDEEPTTLPSGEAKPRKTLKEKKERRTPSDDEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEASQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSLKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTRKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSYSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASNLKGASLLPGKLPTSVSLFDDEDEEDNLFGGTAAKKQTLSLQAQREEKAKASELSKKKASALLFSSDEEDQWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDKEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKKKETVSEAPPLLFSDEEEKEAQLGVKSVDKKVESAKESLKFGRTDVAESEKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGCDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLVQEKKRVVKKDHSVNSFKNQKHPESIQGSKEKGIWKPETPQANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSEAEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDTSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSSSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSTGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|Q9Y4E1-1|WAC2C_HUMAN Isoform 4 of WASH complex subunit 2C OS=Homosapiens OX=9606 GN=WASHC2CMMNRTTPDQELVPASEPVWERPWSVEEIRRSSQSWSLAADAGLLQFLQEFSQQTISRTHEIKKQVDGLIRETKATDCRLHNVFNDFLMLSNTQFIENRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNQHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAMGRVDEEPTTLPSGEAKPRKTLKEKKERRTPSDDEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEASQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSLKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTRKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSYSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASNLKGASLLPGKLPTSVSLFDDEDEEDNLFGGTAAKKQTLSLQAQREEKAKASELSKKKASALLFSSDEEWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDKEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKKKETVSEAPPLLFSDEEEKEAQLGVKSVDKKVESAKESLKFGRTDVAESEKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGCDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLVQEKKRVVKKDHSVNSFKNQKHPESIQGSKEKGIWKPETPQANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSEAEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDTSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSSSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSTGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|Q9Y4E1-2|WAC2C_HUMAN Isoform 2 of WASH complex subunit 2C OS=Homosapiens OX=9606 GN=WASHC2CMMNRTTPDQELVPASEPVWERPWSVEEIRRSSQSWSLAADAGSQQTISRTHEIKKQVDGLIRETKATDCRLHNVFNDFLMLSNTQFIENRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNQHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAMGRVDEEPTTLPSGEAKPRKTLKEKKERRTPSDDEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEASQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSLKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTRKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSYSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASNLKGASLLPGKLPTSVSLFDDEDEEDNLFGGTAAKKQTLSLQAQREEKAKASELSKKKASALLFSSDEEWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDKEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKKKETVSEAPPLLFSDEEEKEAQLGVKSVDKKVESAKESLKFGRTDVAESEKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGCDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLVQEKKRVVKKDHSVNSFKNQKHPESIQGSKEKGIWKPETPQANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSEAEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDTSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSSSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSTGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|Q9Y4E1-3|WAC2C_HUMAN Isoform 3 of WASH complex subunit 2C OS=Homosapiens OX=9606 GN=WASHC2CMMNRTTPDQELVPASEPVWERPWSVEEIRRSSQSWSLAADAGRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNQHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAMGRVDEEPTTLPSGEAKPRKTLKEKKERRTPSDDEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEASQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSLKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTRKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSYSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASNLKGASLLPGKLPTSVSLFDDEDEEDNLFGGTAAKKQTLSLQAQREEKAKASELSKKKASALLFSSDEEWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDKEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKKKETVSEAPPLLFSDEEEKEAQLGVKSVDKKVESAKESLKFGRTDVAESEKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGCDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLVQEKKRVVKKDHSVNSFKNQKHPESIQGSKEKGIWKPETPQANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSEAEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDTSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSSSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSTGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|Q9Y4E1-5|WAC2C_HUMAN Isoform 5 of WASH complex subunit 2C OS=Homosapiens OX=9606 GN=WASHC2CMMNRTTPDQELVPASEPVWERPWSVEEIRRSSQSWSLAADAGLLQFLQEFSQQTISRTHEIKKQVDGLIRETKATDCRLHNVFNDFLMLSNTQFIENRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNQHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAMGRVDEEPTNEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEASQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSLKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTRKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSYSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASNLKGASLLPGKLPTSVSLFDDEDEEDNLFGGTAAKKQTLSLQAQREEKAKASELSKKKASALLFSSDEEDQWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDKEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGCDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLVQEKKRVVKKDHSVNSFKNQKHPESIQGSKEKGIWKPETPQANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSEAEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDTSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSSSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSTGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|Q9Y4E1-6|WAC2C_HUMAN Isoform 6 of WASH complex subunit 2C OS=Homosapiens OX=9606 GN=WASHC2CMMNRTTPDQELVPASEPVWERPWSVEEIRRSSQSWSLAADAGLLQFLQEFSQQTISRTHEIKKQVDGLIRETKATDCRLHNVFNDFLMLSNTQFIENRVYDEEVEEPVLKAEAEKTEQEKTREQKEVDLIPKVQEAVNYGLQVLDSAFEQLDIKAGNSDSEEDDANGRVELILEPKDLYIDRPLPYLIGSKLFMEQEDVGLGELSSEEGSVGSDRGSIVDTEEEKEEEESDEDFAHHSDNEQNQHTTQMSDEEEDDDGCDLFADSEKEEEDIEDIEENTRPKRSRPTSFADELAARIKGDAMGRVDEEPTTLPSGEAKPRKTLKEKKERRTPSDDEEDNLFAPPKLTDEDFSPFGSGGGLFSGGKGLFDDEDEESDLFTEASQDRQAGASVKEESSSSKPGKKIPAGAVSVFLGDTDVFGAASVPSLKEPQKPEQPTPRKSPYGPPPTGLFDDDDGDDDDDFFSAPHSKPSKTRKVQSTADIFGDEEGDLFKEKAVASPEATVSQTDENKARAEKKVTLSYSKNLKPSSETKTQKGLFSDEEDSEDLFSSQSASNLKGASLLPGKLPTSVSLFDDEDEEDNLFGGTAAKKQTLSLQAQREEKAKASELSKKKASALLFSSDEEDQWNIPASQTHLASDSRSKGEPRDSGTLQSQEAKAVKKTSLFEEDKEDDLFAIAKDSQKKTQRVSLLFEDDVDSGGSLFGSPPTSVPPATKKKETVSEAPPLLFSDEEEKEAQLGVKSVDKKVESAKESLKFGRTDVAESEKEGLLTRSAQETVKHSDLFSSSSPWDKGTKPRTKTVLSLFDEEEDKMEDQNIIQAPQKEVGKGCDPDAHPKSTGVFQDEELLFSHKLQKDNDPDVDLFAGTKKTKLLEPSVGSLFGDDEDDDLFSSAKSQPLANLAINPAALLPTAASQISEVKPVLPELAFPSSEHRRSHGLESVPVLPGSGEAGVSFDLPAQADTLHSANKSRVKMRGKRRPQTRAARRLAAQESSEAEDMSVPRGPIAQWADGAISPNGHRPQLRAASGEDSTEEALAAAAAPWEGGPVPGVDTSPFAKSLGHSRGEADLFDSGDIFSTGTGSQSVERTKPKAKIAENPANPPVGGKAKSPMFPALGEASSDDDLFQSAKPKPAKKTNPFPLLEDEDDLFTDQKVKKNETKSSSQQDVILTTQDIFEDDIFATEAIKPSQKTREKEKTLESNLFDDNIDIFADLTVKPKEKSKKKVEAKSIFDDDMDDIFSTGIQAKTTKPKSRSAQAAPEPRFEHKVSNIFDDPLNAFGGQ>sp|P17861|XBP1_HUMAN X-box-binding protein 1 OS=Homo sapiens OX=9606GN=XBP1 PE=1 SV=2MVVVAAAPNPADGTPKVLLLSGQPASAAGAPAGQALPLMVPAQRGASPEAASGGLPQARKRQRLTHLSPEEKALRRKLKNRVAAQTARDRKKARMSELEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSPLQNISPWILAVLTLQIQSLISCWAFWTTWTQSCSSNALPQSLPAWRSSQRSTQKDPVPYQPPFLCQWGRHQPSWKPLMN>sp|P17861-2|XBP1_HUMAN Isoform 2 of X-box-binding protein 1 OS=Homosapiens OX=9606 GN=XBP1MVVVAAAPNPADGTPKVLLLSGQPASAAGAPAGQALPLMVPAQRGASPEAASGGLPQARKRQRLTHLSPEEKALRRKLKNRVAAQTARDRKKARMSELEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAAGAGPVVTPPEHLPMDSGGIDSSDSESDILLGILDNLDPVMFFKCPSPEPASLEELPEVYPEGPSSLPASLSLSVGTSSAKLEAINELIRFDHIYTKPLVLEIPSETESQANVVVKIEEAPLSPSENDHPEFIVSVKEEPVEDDLVPELGISNLLSSSHCPKPSSCLLDAYSDCGYGGSLSPFSDMSSLLGVNHSWEDTFANELFPQLISV>sp|Q9BXE9|VN1R3_HUMAN Vomeronasal type-1 receptor 3 OS=Homo sapiensOX=9606 GN=VN1R3 PE=2 SV=1MASKDFAIGMILLSQIMVGFLGNFFLLYHYSFLCFTRGMLQSTDLILKHLTIANSLVILSKGIPQTMAAFGLKDSLSDIGCKFVFYVHRVGRAVCVGNACLLSVFQVITISPSEFRWAELKLHAHKYIRSFILVLCWILNTLVNITVLLHVTGKWNSINSTKTNDYGYCSGGSRSRIPHSLHIVLLSSLDVLCLGLMTLASGSMVFILHRHKQQVQHIHGTNLSARSSPESRVTQSILVLVSTLCYFTRSPPSLHMSLFPNPSWWLLNTSALITACFPMVSPFVLMSRHPRIPRLGSACCGRNPQFPKLVR>sp|C4AMC7|WASH3_HUMAN Putative WAS protein family homolog 3 OS=Homosapiens OX=9606 GN=WASH3P PE=1 SV=2MTPVRMQHSLAGQTYAVPLIQPDLRREEAVQQMADALQYLQKVSGDIFSRISQQVEQSRSQVQAIGEKVSLAQAKIEKIKGSKKAIKVFSSAKYPAPERLQEYGSIFTGAQDPGLQRRPRHRIQSKHRPLDERALQEKDFPVCVSTKPEPEDDAEEGLGGLPSNISSVSSLLLFNTTENLGKKYVFLDPLAGAVTKTHVMLGAETEEKLFDAPLSISKREQLEQQVPENYFYVPDLGQVPEIDVPSYLPDLPGITNDLMYIADLGPGIAPSAPGTIPELPTFHTEVAEPLKVDLQDGVLTPPPPPPPPPPAPEVLASAPPLPPSTAAPVGQGARQDDSSSSASPSVQGAPREVVDPSGGRATLLESIRQAGGIGKAKLRSMKERKLEKKQQKEQEQVRATSQGGHLMSDLFNKLVMRRKGISGKGPGAGEGPGGAFARVSDSIPPLPPPQQPQAEEDEDDWES>sp|Q9NW82|WDR70_HUMAN WD repeat-containing protein 70 OS=Homo sapiensOX=9606 GN=WDR70 PE=1 SV=1MERSGPSEVTGSDASGPDPQLAVTMGFTGFGKKARTFDLEAMFEQTRRTAVERSRKTLEAREKEEEMNREKELRRQNEDIEPTSSRSNVVRDCSKSSSRDTSSSESEQSSDSSDDELIGPPLPPKMVGKPVNFMEEDILGPLPPPLNEEEEEAEEEEEEEEEEENPVHKIPDSHEITLKHGTKTVSALGLDPSGARLVTGGYDYDVKFWDFAGMDASFKAFRSLQPCECHQIKSLQYSNTGDMILVVSGSSQAKVIDRDGFEVMECIKGDQYIVDMANTKGHTAMLHTGSWHPKIKGEFMTCSNDATVRTWEVENPKKQKSVFKPRTMQGKKVIPTTCTYSRDGNLIAAACQNGSIQIWDRNLTVHPKFHYKQAHDSGTDTSCVTFSYDGNVLASRGGDDSLKLWDIRQFNKPLFSASGLPTMFPMTDCCFSPDDKLIVTGTSIQRGCGSGKLVFFERRTFQRVYEIDITDASVVRCLWHPKLNQIMVGTGNGLAKVYYDPNKSQRGAKLCVVKTQRKAKQAETLTQDYIITPHALPMFREPRQRSTRKQLEKDRLDPLKSHKPEPPVAGPGRGGRVGTHGGTLSSYIVKNIALDKTDDSNPREAILRHAKAAEDSPYWVSPAYSKTQPKTMFAQVESDDEEAKNEPEWKKRKI>sp|Q6ZVL8|YP033_HUMAN Putative uncharacterized protein FLJ42384 OS=Homosapiens OX=9606 PE=2 SV=1MWPFRLRCPIYFKTRLLYSSSQDGFLSSSTNYYNHRTYPGLVNWLFVLTEPELTGELGDDDRKGMHTGGIIRWLGRPSSQLKPIFHAEERRVPPPPERLVGRASPREQATVFKRICAPLHAEVFCRAGLCACHPDCTAAG>sp|P43403|ZAP70_HUMAN Tyrosine-protein kinase ZAP-70 OS=Homo sapiensOX=9606 GN=ZAP70 PE=1 SV=1MPDPAAHLPFFYGSISRAEAEEHLKLAGMADGLFLLRQCLRSLGGYVLSLVHDVRFHHFPIERQLNGTYAIAGGKAHCGPAELCEFYSRDPDGLPCNLRKPCNRPSGLEPQPGVFDCLRDAMVRDYVRQTWKLEGEALEQAIISQAPQVEKLIATTAHERMPWYHSSLTREEAERKLYSGAQTDGKFLLRPRKEQGTYALSLIYGKTVYHYLISQDKAGKYCIPEGTKFDTLWQLVEYLKLKADGLIYCLKEACPNSSASNASGAAAPTLPAHPSTLTHPQRRIDTLNSDGYTPEPARITSPDKPRPMPMDTSVYESPYSDPEELKDKKLFLKRDNLLIADIELGCGNFGSVRQGVYRMRKKQIDVAIKVLKQGTEKADTEEMMREAQIMHQLDNPYIVRLIGVCQAEALMLVMEMAGGGPLHKFLVGKREEIPVSNVAELLHQVSMGMKYLEEKNFVHRDLAARNVLLVNRHYAKISDFGLSKALGADDSYYTARSAGKWPLKWYAPECINFRKFSSRSDVWSYGVTMWEALSYGQKPYKKMKGPEVMAFIEQGKRMECPPECPPELYALMSDCWIYKWEDRPDFLTVEQRMRACYYSLASKVEGPPGSTQKAEAACA>sp|P43403-2|ZAP70_HUMAN Isoform 2 of Tyrosine-protein kinase ZAP-70OS=Homo sapiens OX=9606 GN=ZAP70MPMDTSVYESPYSDPEELKDKKLFLKRDNLLIADIELGCGNFGSVRQGVYRMRKKQIDVAIKVLKQGTEKADTEEMMREAQIMHQLDNPYIVRLIGVCQAEALMLVMEMAGGGPLHKFLVGKREEIPVSNVAELLHQVSMGMKYLEEKNFVHRDLAARNVLLVNRHYAKISDFGLSKALGADDSYYTARSAGKWPLKWYAPECINFRKFSSRSDVWSYGVTMWEALSYGQKPYKKMKGPEVMAFIEQGKRMECPPECPPELYALMSDCWIYKWEDRPDFLTVEQRMRACYYSLASKVEGPPGSTQKAEAACA>sp|P43403-3|ZAP70_HUMAN Isoform 3 of Tyrosine-protein kinase ZAP-70OS=Homo sapiens OX=9606 GN=ZAP70MRLGPRWKGEALEQAIISQAPQVEKLIATTAHERMPWYHSSLTREEAERKLYSGAQTDGKFLLRPRKEQGTYALSLIYGKTVYHYLISQDKAGKYCIPEGTKFDTLWQLVEYLKLKADGLIYCLKEACPNSSASNASGAAAPTLPAHPSTLTHPQRRIDTLNSDGYTPEPARITSPDKPRPMPMDTSVYESPYSDPEELKDKKLFLKRDNLLIADIELGCGNFGSVRQGVYRMRKKQIDVAIKVLKQGTEKADTEEMMREAQIMHQLDNPYIVRLIGVCQAEALMLVMEMAGGGPLHKFLVGKREEIPVSNVAELLHQVSMGMKYLEEKNFVHRDLAARNVLLVNRHYAKISDFGLSKALGADDSYYTARSAGKWPLKWYAPECINFRKFSSRSDVWSYGVTMWEALSYGQKPYKKMKGPEVMAFIEQGKRMECPPECPPELYALMSDCWIYKWEDRPDFLTVEQRMRACYYSLASKVEGPPGSTQKAEAACA>sp|Q7Z3I7|ZN572_HUMAN Zinc finger protein 572 OS=Homo sapiens OX=9606GN=ZNF572 PE=1 SV=1MEQEKKLLVSDSNSFMERESLKSPFTGDTSMNNLETVHHNNSKADKLKEKPSEWSKRHRPQHYKHEDAKEMPLTWVQDEIWCHDSYESDGKSENWGNFIAKEEEKPNHQEWDSGEHTNACVQQNSSFVDRPYKCSECWKSFSNSSHLRTHQRTHSGEKPYKCSECAKCFCNSSHLIQHLRMHTGEKPYQCGECGKSFSNTSHLIIHERTHTGEKPYKCPECGKRFSSSSHLIQHHRSHTGEKPYECSVCGKGFSHSYVLIEHQRTHTGEKPYKCPDCGKSFSQSSSLIRHQRTHTGEKPYKCLECEKSFGCNSTLIKHQRIHTGEKPYQCPECGKNFSRSSNLITHQKMHTGEKSYESSEYEESLGQNCNVIEECRIQLGEKPYRCCECGKSFGLSSHLIRHQRTHTGEKPYRCSECWKTFSQSSTLVIHQRTHTGEKPYKCPDCGESFSQSFNLIRHRRTHIGEKPYKCTSCEKCFSRSAYLSQHRKIHVEKPFESPDVGDFPHEWTWKNCSGEMPFISSFSVSNSSS>sp|Q8N3J9|ZN664_HUMAN Zinc finger protein 664 OS=Homo sapiens OX=9606GN=ZNF664 PE=1 SV=1MIYKCPMCREFFSERADLFMHQKIHTAEKPHKCDKCDKGFFHISELHIHWRDHTGEKVYKCDDCGKDFSTTTKLNRHKKIHTVEKPYKCYECGKAFNWSSHLQIHMRVHTGEKPYVCSECGRGFSNSSNLCMHQRVHTGEKPFKCEECGKAFRHTSSLCMHQRVHTGEKPYKCYECGKAFSQSSSLCIHQRVHTGEKPYRCCGCGKAFSQSSSLCIHQRVHTGEKPFKCDECGKAFSQSTSLCIHQRVHTKERNHLKISVI>sp|Q5T7W0|ZN618_HUMAN Zinc finger protein 618 OS=Homo sapiens OX=9606GN=ZNF618 PE=1 SV=1MNQPGGAAAPQADGASAAGRKSTASRERLKRSQKSTKVEGPEPVPAEASLSAEQGTMTEVKVKTELPDDYIQEVIWQGEAKEEKKAVSKDGTSDVPAEICVVIGGVRNQQTLDGKAPEGSPHGGSVRSRYSGTWIFDQALRYASGSYECGICGKKYKYYNCFQTHVRAHRDTEATSGEGASQSNNFRYTCDICGKKYKYYSCFQEHRDLHAVDVFSVEGAPENRADPFDQGVVATDEVKEEPPEPFQKIGPKTGNYTCEFCGKQYKYYTPYQEHVALHAPISTAPGWEPPDDPDTGSECSHPEVSPSPRFVAAKTQTNQSGKKAPASVVRCATLLHRTPPATQTQTFRTPNSGSPASKATAAESAFSRRVEGKAQNHFEETNSSSQNSSEPYTCGACGIQFQFYNNLLEHMQSHAADNENNIASNQSRSPPAVVEEKWKPQAQRNSANNTTTSGLTPNSMIPEKERQNIAERLLRVMCADLGALSVVSGKEFLKLAQTLVDSGARYGAFSVTEILGNFNTLALKHLPRMYNQVKVKVTCALGSNACLGIGVTCHSQSVGPDSCYILTAYQAEGNHIKSYVLGVKGADIRDSGDLVHHWVQNVLSEFVMSEIRTVYVTDCRVSTSAFSKAGMCLRCSACALNSVVQSVLSKRTLQARSMHEVIELLNVCEDLAGSTGLAKETFGSLEETSPPPCWNSVTDSLLLVHERYEQICEFYSRAKKMNLIQSLNKHLLSNLAAILTPVKQAVIELSNESQPTLQLVLPTYVRLEKLFTAKANDAGTVSKLCHLFLEALKENFKVHPAHKVAMILDPQQKLRPVPPYQHEEIIGKVCELINEVKESWAEEADFEPAAKKPRSAAVENPAAQEDDRLGKNEVYDYLQEPLFQATPDLFQYWSCVTQKHTKLAKLAFWLLAVPAVGARSGCVNMCEQALLIKRRRLLSPEDMNKLMFLKSNML>sp|Q5T7W0-2|ZN618_HUMAN Isoform 2 of Zinc finger protein 618 OS=Homosapiens OX=9606 GN=ZNF618MNQPGGAAAPQADGASAAGRKSTASRERLKRSQKSTKVEGPEPVPAEASLSAEQGTMTEVKVKTELPDDYIQEVIWQGEAKEEKKAVSKDGTSDVPAEICVVIGGVRNQQTLGSYECGICGKKYKYYNCFQTHVRAHRDTEATSGEGASQSNNFRYTCDICGKKYKYYSCFQEHRDLHAVDVFSVEGAPENRADPFDQGVVATDEVKEEPPEPFQKIGPMNNITSDIFKKKEVRQCQKRETGNYTCEFCGKQYKYYTPYQEHVALHAPIKSAFSRRVEGKAQNHFEETNSSSQNSSEPYTCGACGIQFQFYNNLLEHMQSHAADNENNIASNQSRSPPAVVEEKWKPQAQRNSANNTTTSGLTPNSMIPEKERQNIAERLLRVMCADLGALSVVSGKEFLKLAQTLVDSGARYGAFSVTEILGNFNTLALKHLPRMYNQVKVKVTCALGSNACLGIGVTCHSQSVGPDSCYILTAYQAEGNHIKSYVLGVKGADIRDSGDLVHHWVQNVLSEFVMSEIRTVYVTDCRVSTSAFSKAGMCLRCSACALNSVVQSVLSKRTLQARSMHEVIELLNVCEDLAGSTGLAKETFGSLEETSPPPCWNSVTDSLLLVHERYEQICEFYSRAKKMNLIQSLNKHLLSNLAAILTPVKQAVIELSNESQPTLQLVLPTYVRLEKLFTAKANDAGTVSKLCHLFLEALKENFKVHPAHKVAMILDPQQKLRPVPPYQHEEIIGKVCELINEVKESWAEEADFEPAAKKPRSAAVENPAAQEDDRLGKNEVYDYLQEPLFQATPDLFQYWSCVTQKHTKLAKLAFWLLAVPAVGARSGCVNMCEQALLIKRRRLLSPEDMNKLMFLKSNML>sp|Q5T7W0-3|ZN618_HUMAN Isoform 3 of Zinc finger protein 618 OS=Homosapiens OX=9606 GN=ZNF618MNQPGGAAAPQADGASAAGRKSTASRERLKRSQKSTKVEGPEPVPAEASLSAEQGTMTEVKVKTELPDDYIQEVIWQGEAKEEKKAVSKDGTSDVPAEICVVIGGVRNQQTLGSYECGICGKKYKYYNCFQTHVRAHRDTEATSGEGASQSNNFRYTCDICGKKYKYYSCFQEHRDLHAVDVFSVEGAPENRADPFDQGVVATDEVKEEPPEPFQKIGPKTGNYTCEFCGKQYKYYTPYQEHVALHAPISEYLLPVGMGVGGPGTGWASRWPGLWNLARKW>sp|Q5T7W0-4|ZN618_HUMAN Isoform 4 of Zinc finger protein 618 OS=Homosapiens OX=9606 GN=ZNF618MNQPGGAAAPQADGASAAGRKSTASRERLKRSQKSTKVEGPEPVPAEASLSAEQGTMTEVKVKTELPDDYIQEVIWQGEAKEEKKAVSKDGTSDVPAEICVVIGGVRNQQTLGSYECGICGKKYKYYNCFQTHVRAHRDTEATSGEGASQSNNFRYTCDICGKKYKYYSCFQEHRDLHAVDVFSVEGAPENRADPFDQGVVATDEVKEEPPEPFQKIGPKTGNYTCEFCGKQYKYYTPYQEHVALHAPISTAPGWEPPDDPDTGSECSHPEVSPSPRFVAAKTQTNQSGKKAPASVVRCATLLHRTPPATQTQTFRTPNSGSPASKATAESAFSRRVEGKAQNHFEETNSSSQNSSEPYTCGACGIQFQFYNNLLEHMQSHAADNENNIASNQSRSPPAVVEEKWKPQAQRNSANNTTTSGLTPNSMIPEKERQNIAERLLRVMCADLGALSVVSGKEFLKLAQTLVDSGARYGAFSVTEILGNFNTLALKHLPRMYNQVKVKVTCALGSNACLGIGVTCHSQSVGPDSCYILTAYQAEGNHIKSYVLGVKGADIRDSGDLVHHWVQNVLSEFVMSEIRTVYVTDCRVSTSAFSKAGMCLRCSACALNSVVQSVLSKRTLQARSMHEVIELLNVCEDLAGSTGLAKETFGSLEETSPPPCWNSVTDSLLLVHERYEQICEFYSRAKKMNLIQSLNKHLLSNLAAILTPVKQAVIELSNESQPTLQLVLPTYVRLEKLFTAKANDAGTVSKLCHLFLEALKENFKVHPAHKVAMILDPQQKLRPVPPYQHEEIIGKVCELINEVKESWAEEADFEPAAKKPRSAAVENPAAQEDDRLGKNEVYDYLQEPLFQATPDLFQYWSCVTQKHTKLAKLAFWLLAVPAVGARSGCVNMCEQALLIKRRRLLSPEDMNKLMFLKSNML>sp|Q6IEE8|SN12L_HUMAN Schlafen family member 12-like OS=Homo sapiensOX=9606 GN=SLFN12L PE=2 SV=4MDLARKEFLRGNGLAAGKMNISIDLDTNYAELVLNVGRVTLGENNRKKMKDCQLRKQQNENVSRAVCALLNSGGGVIKAEVENKGYSYKKDGIGLDLENSFSNMLPFVPNFLDFMQNGNYFHIFVKSWSLETSGPQIATLSSSLYKRDVTSAKVMNASAALEFLKDMEKTGGRAYLRPEFPAKRACVDVQEESNMEALAADFFNRTELGYKEKLTFTESTHVEIKNFSTEKLLQRITEILPQYVSAFANTDGGYLFVGLNEDKEVIGFKAEKSYLTKLEEVTKNSIGKLPVHHFCVEKGTINYLCKFLGVYDKGRLCGYVYALRVERFCCAVFAKKPDSWHVKDNRVKQLTEKEWIQFMVDSEPVCEELPSPASTSSPVSQSYPLREYINFKIQPLRYHLPGLSEKITCAPKTFCRNLFSQHEGLKQLICEEMGSVNKGSLIFSRSWSLDLGLQENHKVLCDALLISQDKPPVLYTFHMVQDEEFKDYSTQTAQTLKQKLAKIGGYTKKVCVMTKIFYLSPEGKTSCQYDLNSQVIYPESYYWTTAQTMKDLEKALSNILPKENQIFLFVCLFRFCLFVCWFVCFFLR>sp|Q6IEE8-2|SN12L_HUMAN Isoform 2 of Schlafen family member 12-likeOS=Homo sapiens OX=9606 GN=SLFN12LMAMKIMEKIRNVFHCEAHRILYICESQFLRNFIRKEFLRGNGLAAGKMNISIDLDTNYAELVLNVGRVTLGENNRKKMKDCQLRKQQNENVSRAVCALLNSGGGVIKAEVENKGYSYKKDGIGLDLENSFSNMLPFVPNFLDFMQNGNYFHIFVKSWSLETSGPQIATLSSSLYKRDVTSAKVMNASAALEFLKDMEKTGGRAYLRPEFPAKRACVDVQEESNMEALAADFFNRTELGYKEKLTFTESTHVEIKNFSTEKLLQRITEILPQYVSAFANTDGGYLFVGLNEDKEVIGFKAEKSYLTKLEEVTKNSIGKLPVHHFCVEKGTINYLCKFLGVYDKGRLCGYVYALRVERFCCAVFAKKPDSWHVKDNRVKQLTEKEWIQFMVDSEPVCEELPSPASTSSPVSQSYPLREYINFKIQPLRYHLPGLSEKITCAPKTFCRNLFSQHEGLKQLICEEMGSVNKGSLIFSRSWSLDLGLQENHKVLCDALLISQDKPPVLYTFHMVQDEEFKDYSTQTAQTLKQKLAKIGGYTKKVCVMTKIFYLSPEGKTSCQYDLNSQVIYPESYYWTTAQTMKDLEKALSNILPKENQIFLFVCLFRFCLFVCWFVCFFLR>sp|Q9P0Z9|SOX_HUMAN Peroxisomal sarcosine oxidase OS=Homo sapiensOX=9606 GN=PIPOX PE=1 SV=2MAAQKDLWDAIVIGAGIQGCFTAYHLAKHRKRILLLEQFFLPHSRGSSHGQSRIIRKAYLEDFYTRMMHECYQIWAQLEHEAGTQLHRQTGLLLLGMKENQELKTIQANLSRQRVEHQCLSSEELKQRFPNIRLPRGEVGLLDNSGGVIYAYKALRALQDAIRQLGGIVRDGEKVVEINPGLLVTVKTTSRSYQAKSLVITAGPWTNQLLRPLGIEMPLQTLRINVCYWREMVPGSYGVSQAFPCFLWLGLCPHHIYGLPTGEYPGLMKVSYHHGNHADPEERDCPTARTDIGDVQILSSFVRDHLPDLKPEPAVIESCMYTNTPDEQFILDRHPKYDNIVIGAGFSGHGFKLAPVVGKILYELSMKLTPSYDLAPFRISRFPSLGKAHL>sp|Q9NRS6|SNX15_HUMAN Sorting nexin-15 OS=Homo sapiens OX=9606 GN=SNX15PE=1 SV=1MSRQAKDDFLRHYTVSDPRTHPKGYTEYKVTAQFISKKDPEDVKEVVVWKRYSDFRKLHGDLAYTHRNLFRRLEEFPAFPRAQVFGRFEASVIEERRKGAEDLLRFTVHIPALNNSPQLKEFFRGGEVTRPLEVSRDLHILPPPLIPTPPPDDPRLSQLLPAERRGLEELEVPVDPPPSSPAQEALDLLFNCESTEEASGSPARGPLTEAELALFDPFSKEEGAAPSPTHVAELATMEVESARLDQEPWEPGGQEEEEDGEGGPTPAYLSQATELITQALRDEKAGAYAAALQGYRDGVHVLLQGVPSDPLPARQEGVKKKAAEYLKRAEEILRLHLSQLPP>sp|Q9NRS6-2|SNX15_HUMAN Isoform 2 of Sorting nexin-15 OS=Homo sapiensOX=9606 GN=SNX15MSRQAKDDFLRHYTVSDPRTHPKGYTEYKVTAQFISKKDPEDVKEVVVWKRYSDFRKLHGDLAYTHRNLFRRLEEFPAFPRAQVFGRFEASVIEERRKGAEDLLRFTVHIPALNNSPQLKEFFRGGEVTRPLEVSRDLHILPPPLIPTPPPDDPRLSQLLPAERRGLEELEVPVDPPPSSPAQEALDLLFNCESTEEASGSPARGPLTEAELALFDPFSKEGDPLPARQEGVKKKAAEYLKRAEEILRLHLSQLPP>sp|Q6BEB4|SP5_HUMAN Transcription factor Sp5 OS=Homo sapiens OX=9606GN=SP5 PE=2 SV=1MAAVAVLRNDSLQAFLQDRTPSASPDLGKHSPLALLAATCSRIGQPGAAAPPDFLQVPYDPALGSPSRLFHPWTADMPAHSPGALPPPHPSLGLTPQKTHLQPSFGAAHELPLTPPADPSYPYEFSPVKMLPSSMAALPASCAPAYVPYAAQAALPPGYSNLLPPPPPPPPPPTCRQLSPNPAPDDLPWWSIPQAGAGPGASGVPGSGLSGACAGAPHAPRFPASAAAAAAAAAALQRGLVLGPSDFAQYQSQIAALLQTKAPLAATARRCRRCRCPNCQAAGGAPEAEPGKKKQHVCHVPGCGKVYGKTSHLKAHLRWHTGERPFVCNWLFCGKSFTRSDELQRHLRTHTGEKRFACPECGKRFMRSDHLAKHVKTHQNKKLKVAEAGVKREDARDL>sp|Q6UXR4|SPA13_HUMAN Putative serpin A13 OS=Homo sapiens OX=9606GN=SERPINA13P PE=5 SV=1MEASRWWLLVTVLMAGAHCVALVDQEASDLIHSGPQDSSPGPALPCHKISVSNIDFAFKLYRQLALNAPGENILFFPVSISLALAMLSWGAPVASRTQLLEGLGFTLTVVPEEEIQEGFWDLLIRLRGQGPRLLLTMDQRRFSGLGARANQSLEEAQKHIDEYTEQQTQGKLGAWEKDLGSETTAVLVNHMLLRAEWMKPFDSHATSPKEFFVDEHSAVWVPMMKEKASHRFLHDRELQCSVLRMDHAGNTTTFFIFPNRGKMRHLEDALLPETLIKWDSLLRTRELDFHFPKFSISRTCRLEMLLP>sp|Q9Y343|SNX24_HUMAN Sorting nexin-24 OS=Homo sapiens OX=9606 GN=SNX24PE=1 SV=1MEVYIPSFRYEESDLERGYTVFKIEVLMNGRKHFVEKRYSEFHALHKKLKKCIKTPEIPSKHVRNWVPKVLEQRRQGLETYLQAVILENEELPKLFLDFLNVRHLPSLPKAESCGSFDETESEESSKLSHQPVLLFLRDPYVLPAASDFPNVVIEGVLHGIFYPHLQPR>sp|Q9Y343-2|SNX24_HUMAN Isoform 2 of Sorting nexin-24 OS=Homo sapiensOX=9606 GN=SNX24MEVYIPSFRYEESDLERGYTVFKIEVLMNGRKHFVEKRYSEFHALHKKLKKCIKTPEIPSKHVRNWVPKVLEQRRQGLETYLQAVILENEELPKLFLDFLNVRHLPSLPKAESCGSFDETESEESSKLSHQPVLLFLRDPYVLPAASGNQTCHLLTALY>sp|P0DMR2|SG1C2_HUMAN Secretoglobin family 1C member 2 OS=Homo sapiensOX=9606 GN=SCGB1C2 PE=1 SV=1MKGSRALLLVALTLFCICRMATGEDNDEFFMDFLQTLLVGTPEELYEGTLGKYNVNEDAKAAMTELKSCRDGLQPMHKAELVKLLVQVLGSQDGA>sp|Q96PL1|SG3A2_HUMAN Secretoglobin family 3A member 2 OS=Homo sapiensOX=9606 GN=SCGB3A2 PE=1 SV=1MKLVTIFLLVTISLCSYSATAFLINKVPLPVDKLAPLPLDNILPFMDPLKLLLKTLGISVEHLVEGLRKCVNELGPEASEAVKKLLEALSHLV>sp|A0A1B0GVQ0|SPAR_HUMAN Small regulatory polypeptide of amino acidresponse OS=Homo sapiens OX=9606 GN=SPAAR PE=1 SV=2MGAKAPRGPKVAQWAMETAVIGVVVVLFVVTVAITCVLCCFSCDSRAQDPQGGPGRSFTVATFRQEASLFTGPVRHAQPVPSAQDFWTFM>sp|A0A1B0GVQ0-2|SPAR_HUMAN Isoform 2 of Small regulatory polypeptide ofamino acid response OS=Homo sapiens OX=9606 GN=SPAARMETAVIGVVVVLFVVTVAITCVLCCFSCDSRAQDPQGGPGRSFTVATFRQEASLFTGPVRHAQPVPSAQDFWTFM>sp|Q02086|SP2_HUMAN Transcription factor Sp2 OS=Homo sapiens OX=9606GN=SP2 PE=1 SV=3MSDPQTSMAATAAVSPSDYLQPAASTTQDSQPSPLALLAATCSKIGPPAVEAAVTPPAPPQPTPRKLVPIKPAPLPLSPGKNSFGILSSKGNILQIQGSQLSASYPGGQLVFAIQNPTMINKGTRSNANIQYQAVPQIQASNSQTIQVQPNLTNQIQIIPGTNQAIITPSPSSHKPVPIKPAPIQKSSTTTTPVQSGANVVKLTGGGGNVTLTLPVNNLVNASDTGAPTQLLTESPPTPLSKTNKKARKKSLPASQPPVAVAEQVETVLIETTADNIIQAGNNLLIVQSPGGGQPAVVQQVQVVPPKAEQQQVVQIPQQALRVVQAASATLPTVPQKPSQNFQIQAAEPTPTQVYIRTPSGEVQTVLVQDSPPATAAATSNTTCSSPASRAPHLSGTSKKHSAAILRKERPLPKIAPAGSIISLNAAQLAAAAQAMQTININGVQVQGVPVTITNTGGQQQLTVQNVSGNNLTISGLSPTQIQLQMEQALAGETQPGEKRRRMACTCPNCKDGEKRSGEQGKKKHVCHIPDCGKTFRKTSLLRAHVRLHTGERPFVCNWFFCGKRFTRSDELQRHARTHTGDKRFECAQCQKRFMRSDHLTKHYKTHLVTKNL>sp|Q02086-2|SP2_HUMAN Isoform 2 of Transcription factor Sp2 OS=Homosapiens OX=9606 GN=SP2MAATAAVSPSDYLQPAASTTQDSQPSPLALLAATCSKIGPPAVEAAVTPPAPPQPTPRKLVPIKPAPLPLSPGKNSFGILSSKGNILQIQGSQLSASYPGGQLVFAIQNPTMINKGTRSNANIQYQAVPQIQASNSQTIQVQPNLTNQIQIIPGTNQAIITPSPSSHKPVPIKPAPIQKSSTTTTPVQSGANVVKLTGGGGNVTLTLPVNNLVNASDTGAPTQLLTESPPTPLSKTNKKARKKSLPASQPPVAVAEQVETVLIETTADNIIQAGNNLLIVQSPGGGQPAVVQQVQVVPPKAEQQQVVQIPQQALRVVQAASATLPTVPQKPSQNFQIQAAEPTPTQVYIRTPSGEVQTVLVQDSPPATAAATSNTTCSSPASRAPHLSGTSKKHSAAILRKERPLPKIAPAGSIISLNAAQLAAAAQAMQTININGVQVQGVPVTITNTGGQQQLTVQNVSGNNLTISGLSPTQIQLQMEQALAGETQPGEKRRRMACTCPNCKDGEKRSGEQGKKKHVCHIPDCGKTFRKTSLLRAHVRLHTGERPFVCNWFFCGKRFTRSDELQRHARTHTGDKRFECAQCQKRFMRSDHLTKHYKTHLVTKNL>sp|Q8N196|SIX5_HUMAN Homeobox protein SIX5 OS=Homo sapiens OX=9606GN=SIX5 PE=1 SV=3MATLPAEPSAGPAAGGEAVAAAAATEEEEEEARQLLQTLQAAEGEAAAAAGAGAGAAAAGAEGPGSPGVPGSPPEAASEPPTGLRFSPEQVACVCEALLQAGHAGRLSRFLGALPPAERLRGSDPVLRARALVAFQRGEYAELYRLLESRPFPAAHHAFLQDLYLRARYHEAERARGRALGAVDKYRLRKKFPLPKTIWDGEETVYCFKERSRAALKACYRGNRYPTPDEKRRLATLTGLSLTQVSNWFKNRRQRDRTGAGGGAPCKSESDGNPTTEDESSRSPEDLERGAAPVSAEAAAQGSIFLAGTGPPAPCPASSSILVNGSFLAASGSPAVLLNGGPVIINGLALGEASSLGPLLLTGGGGAPPPQPSPQGASETKTSLVLDPQTGEVRLEEAQSEAPETKGAQVAAPGPALGEEVLGPLAQVVPGPPTAATFPLPPGPVPAVAAPQVVPLSPPPGYPTGLSPTSPLLNLPQVVPTSQVVTLPQAVGPLQLLAAGPGSPVKVAAAAGPANVHLINSGVGVTALQLPSATAPGNFLLANPVSGSPIVTGVALQQGKIILTATFPTSMLVSQVLPPAPGLALPLKPETAISVPEGGLPVAPSPALPEAHALGTLSAQQPPPAAATTSSTSLPFSPDSPGLLPNFPAPPPEGLMLSPAAVPVWSAGLELSAGTEGLLEAEKGLGTQAPHTVLRLPDPDPEGLLLGATAGGEVDEGLEAEAKVLTQLQSVPVEEPLEL>sp|Q13296|SG2A2_HUMAN Mammaglobin-A OS=Homo sapiens OX=9606 GN=SCGB2A2PE=1 SV=1MKLLMVLMLAALSQHCYAGSGCPLLENVISKTINPQVSKTEYKELLQEFIDDNATTNAIDELKECFLNQTDETLSNVEVFMQLIYDSSLCDLF>sp|Q13296-2|SG2A2_HUMAN Isoform 2 of Mammaglobin-A OS=Homo sapiensOX=9606 GN=SCGB2A2MKLLMVLMLAALSQHCYAGSGCPLLENVISKTINPQVSKTEYKELLQEFIDDNATTNAIDELKECFLNQTDETLSNVEQLIYDSSLCDLF>sp|Q9P0W8|SPAT7_HUMAN Spermatogenesis-associated protein 7 OS=Homosapiens OX=9606 GN=SPATA7 PE=1 SV=3MDGSRRVRATSVLPRYGPPCLFKGHLSTKSNAFCTDSSSLRLSTLQLVKNHMAVHYNKILSAKAAVDCSVPVSVSTSIKYADQQRREKLKKELAQCEKEFKLTKTAMRANYKNNSKSLFNTLQKPSGEPQIEDDMLKEEMNGFSSFARSLVPSSERLHLSLHKSSKVITNGPEKNSSSSPSSVDYAASGPRKLSSGALYGRRPRSTFPNSHRFQLVISKAPSGDLLDKHSELFSNKQLPFTPRTLKTEAKSFLSQYRYYTPAKRKKDFTDQRIEAETQTELSFKSELGTAETKNMTDSEMNIKQASNCVTYDAKEKIAPLPLEGHDSTWDEIKDDALQHSSPRAMCQYSLKPPSTRKIYSDEEELLYLSFIEDVTDEILKLGLFSNRFLERLFERHIKQNKHLEEEKMRHLLHVLKVDLGCTSEENSVKQNDVDMLNVFDFEKAGNSEPNELKNESEVTIQQERQQYQKALDMLLSAPKDENEIFPSPTEFFMPIYKSKHSEGVIIQQVNDETNLETSTLDENHPSISDSLTDRETSVNVIEGDSDPEKVEISNGLCGLNTSPSQSVQFSSVKGDNNHDMELSTLKIMEMSIEDCPLDV>sp|Q9P0W8-2|SPAT7_HUMAN Isoform 2 of Spermatogenesis-associated protein7 OS=Homo sapiens OX=9606 GN=SPATA7MDGSRRVRATSVLPRYGPPCLFKGHLSTKSNAAVDCSVPVSVSTSIKYADQQRREKLKKELAQCEKEFKLTKTAMRANYKNNSKSLFNTLQKPSGEPQIEDDMLKEEMNGFSSFARSLVPSSERLHLSLHKSSKVITNGPEKNSSSSPSSVDYAASGPRKLSSGALYGRRPRSTFPNSHRFQLVISKAPSGDLLDKHSELFSNKQLPFTPRTLKTEAKSFLSQYRYYTPAKRKKDFTDQRIEAETQTELSFKSELGTAETKNMTDSEMNIKQASNCVTYDAKEKIAPLPLEGHDSTWDEIKDDALQHSSPRAMCQYSLKPPSTRKIYSDEEELLYLSFIEDVTDEILKLGLFSNRFLERLFERHIKQNKHLEEEKMRHLLHVLKVDLGCTSEENSVKQNDVDMLNVFDFEKAGNSEPNELKNESEVTIQQERQQYQKALDMLLSAPKDENEIFPSPTEFFMPIYKSKHSEGVIIQQVNDETNLETSTLDENHPSISDSLTDRETSVNVIEGDSDPEKVEISNGLCGLNTSPSQSVQFSSVKGDNNHDMELSTLKIMEMSIEDCPLDV>sp|Q9P0W8-3|SPAT7_HUMAN Isoform 3 of Spermatogenesis-associated protein7 OS=Homo sapiens OX=9606 GN=SPATA7MDGSRRVRATSVLPRYGPPCLFKGHLSTKSNAFCTDSSSLRLSTLQLVKNHMAVHYNKILSAKAAVDCSVPVSVSTSIKYADQQRREKLKKELAQCEKEFKLTKTAMRANYKNNSKSLFNTLQKPSGEPQIEDDMLKEEMNGFSSFARSLVPSSERLHLSLHKSSKVITNGPEKNSSSSPSSVDYAASGPRKLSSGALYGRRPRSTFPNSHRFQLVISKAPSGDLLDKHSELFSNKQLPFTPRTLKTEAKSFLSQYRYYTPAKRKKDFTDQRIEAETQTELSFKSELGTAETKNMTDSEMNIKQASNCVTYDAKEKIAPLPLEGHDSTWDEIKDDALQHSSPRAMCQYSLKPPSTRKIYSDEEELLYLSFIEDVTDEILKLGLFSNRFLERLFERHIKQNKHLEEEKMRHLLHVLKVDLGCTSEENSFSSVKGDNNHDMELSTLKIMEMSIEDCPLDV>sp|A8MU46|SMTL1_HUMAN Smoothelin-like protein 1 OS=Homo sapiens OX=9606GN=SMTNL1 PE=1 SV=2MEQKEGKLSEDGTTVSPAADNPEMSGGGAPAEETKGTAGKAINEGPPTESGKQEKAPAEDGMSAELQGEANGLDEVKVESQREAGGKEDAEAELKKEDGEKEETTVGSQEMTGRKEETKSEPKEAEEKESTLASEKQKAEEKEAKPESGQKADANDRDKPEPKATVEEEDAKTASQEETGQRKECSTEPKEKATDEEAKAESQKAVVEDEAKAEPKEPDGKEEAKHGAKEEADAKEEAEDAEEAEPGSPSEEQEQDVEKEPEGGAGVIPSSPEEWPESPTGEGHNLSTDGLGPDCVASGQTSPSASESSPSDVPQSPPESPSSGEKKEKAPERRVSAPARPRGPRAQNRKAIVDKFGGAASGPTALFRNTKAAGAAIGGVKNMLLEWCRAMTKKYEHVDIQNFSSSWSSGMAFCALIHKFFPDAFDYAELDPAKRRHNFTLAFSTAEKLADCAQLLDVDDMVRLAVPDSKCVYTYIQELYRSLVQKGLVKTKKK>sp|Q96R06|SPAG5_HUMAN Sperm-associated antigen 5 OS=Homo sapiens OX=9606GN=SPAG5 PE=1 SV=2MWRVKKLSLSLSPSPQTGKPSMRTPLRELTLQPGALTNSGKRSPACSSLTPSLCKLGLQEGSNNSSPVDFVNNKRTDLSSEHFSHSSKWLETCQHESDEQPLDPIPQISSTPKTSEEAVDPLGNYMVKTIVLVPSPLGQQQDMIFEARLDTMAETNSISLNGPLRTDDLVREEVAPCMGDRFSEVAAVSEKPIFQESPSHLLEESPPNPCSEQLHCSKESLSSRTEAVREDLVPSESNAFLPSSVLWLSPSTALAADFRVNHVDPEEEIVEHGAMEEREMRFPTHPKESETEDQALVSSVEDILSTCLTPNLVEMESQEAPGPAVEDVGRILGSDTESWMSPLAWLEKGVNTSVMLENLRQSLSLPSMLRDAAIGTTPFSTCSVGTWFTPSAPQEKSTNTSQTGLVGTKHSTSETEQLLCGRPPDLTALSRHDLEDNLLSSLVILEVLSRQLRDWKSQLAVPHPETQDSSTQTDTSHSGITNKLQHLKESHEMGQALQQARNVMQSWVLISKELISLLHLSLLHLEEDKTTVSQESRRAETLVCCCFDLLKKLRAKLQSLKAEREEARHREEMALRGKDAAEIVLEAFCAHASQRISQLEQDLASMREFRGLLKDAQTQLVGLHAKQEELVQQTVSLTSTLQQDWRSMQLDYTTWTALLSRSRQLTEKLTVKSQQALQERDVAIEEKQEVSRVLEQVSAQLEECKGQTEQLELENSRLATDLRAQLQILANMDSQLKELQSQHTHCAQDLAMKDELLCQLTQSNEEQAAQWQKEEMALKHMQAELQQQQAVLAKEVRDLKETLEFADQENQVAHLELGQVECQLKTTLEVLRERSLQCENLKDTVENLTAKLASTIADNQEQDLEKTRQYSQKLGLLTEQLQSLTLFLQTKLKEKTEQETLLLSTACPPTQEHPLPNDRTFLGSILTAVADEEPESTPVPLLGSDKSAFTRVASMVSLQPAETPGMEESLAEMSIMTTELQSLCSLLQESKEEAIRTLQRKICELQARLQAQEEQHQEVQKAKEADIEKLNQALCLRYKNEKELQEVIQQQNEKILEQIDKSGELISLREEVTHLTRSLRRAETETKVLQEALAGQLDSNCQPMATNWIQEKVWLSQEVDKLRVMFLEMKNEKEKLMIKFQSHRNILEENLRRSDKELEKLDDIVQHIYKTLLSIPEVVRGCKELQGLLEFLS>sp|Q8TER0|SNED1_HUMAN Sushi, nidogen and EGF-like domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=SNED1 PE=2 SV=2MRHGVAWALLVAAALGLGARGVRGAVALADFYPFGAERGDAVTPKQDDGGSGLRPLSVPFPFFGAEHSGLYVNNNGIISFLKEVSQFTPVAFPIAKDRCVVAAFWADVDNRRAGDVYYREATDPAMLRRATEDVRHYFPELLDFNATWVFVATWYRVTFFGGSSSSPVNTFQTVLITDGKLSFTIFNYESIVWTTGTHASSGGNATGLGGIAAQAGFNAGDGQRYFSIPGSRTADMAEVETTTNVGVPGRWAFRIDDAQVRVGGCGHTTSVCLALRPCLNGGKCIDDCVTGNPSYTCSCLSGFTGRRCHLDVNECASQPCQNGGTCTHGINSFRCQCPAGFGGPTCETAQSPCDTKECQHGGQCQVENGSAVCVCQAGYTGAACEMDVDDCSPDPCLNGGSCVDLVGNYTCLCAEPFKGLRCETGDHPVPDACLSAPCHNGGTCVDADQGYVCECPEGFMGLDCRERVPDDCECRNGGRCLGANTTLCQCPLGFFGLLCEFEITAMPCNMNTQCPDGGYCMEHGGSYLCVCHTDHNASHSLPSPCDSDPCFNGGSCDAHDDSYTCECPRGFHGKHCEKARPHLCSSGPCRNGGTCKEAGGEYHCSCPYRFTGRHCEIGKPDSCASGPCHNGGTCFHYIGKYKCDCPPGFSGRHCEIAPSPCFRSPCVNGGTCEDRDTDFFCHCQAGYMGRRCQAEVDCGPPEEVKHATLRFNGTRLGAVALYACDRGYSLSAPSRIRVCQPHGVWSEPPQCLEIDECRSQPCLHGGSCQDRVAGYLCLCSTGYEGAHCELERDECRAHPCRNGGSCRNLPGAYVCRCPAGFVGVHCETEVDACDSSPCQHGGRCESGGGAYLCVCPESFFGYHCETVSDPCFSSPCGGRGYCLASNGSHSCTCKVGYTGEDCAKELFPPTALKMERVEESGVSISWNPPNGPAARQMLDGYAVTYVSSDGSYRRTDFVDRTRSSHQLQALAAGRAYNISVFSVKRNSNNKNDISRPAVLLARTRPRPVEGFEVTNVTASTISVQWALHRIRHATVSGVRVSIRHPEALRDQATDVDRSVDRFTFRALLPGKRYTIQLTTLSGLRGEEHPTESLATAPTHVWTRPLPPANLTAARVTATSAHVVWDAPTPGSLLEAYVINVTTSQSTKSRYVPNGKLASYTVRDLLPGRRYQLSVIAVQSTELGPQHSEPAHLYIITSPRDGADRRWHQGGHHPRVLKNRPPPARLPELRLLNDHSAPETPTQPPRFSELVDGRGRVSARFGGSPSKAATVRSQPTASAQLENMEEAPKRVSLALQLPEHGSKDIGNVPGNCSENPCQNGGTCVPGADAHSCDCGPGFKGRRCELACIKVSRPCTRLFSETKAFPVWEGGVCHHVYKRVYRVHQDICFKESCESTSLKKTPNRKQSKSQTLEKS>sp|Q8TER0-3|SNED1_HUMAN Isoform 2 of Sushi, nidogen and EGF-like domain-containing protein 1 OS=Homo sapiens OX=9606 GN=SNED1MRHGVAWALLVAAALGLGARGVRGAVALADFYPFGAERGDAVTPKQDDGGSGLRPLSVPFPFFGAEHSGLYVNNNGIISFLKEVSQFTPVAFPIAKDRCVVAAFWADVDNRRAGDVYYREATDPAMLRRATEDVRHYFPELLDFNATWVFVATWYRVTFFGGSSSSPVNTFQTVLITDGKLSFTIFNYESIVWTTGTHASSGGNATGLGGIAAQAGFNAGDGQRYFSIPGSRTADMAEVETTTNVGVPGRWAFRIDDAQVRVGGCGHTTSVCLALRPCLNGGKCIDDCVTGNPSYTCSCLSGFTGRRCHLDVNECASQPCQNGGTCTHGINSFRCQCPAGFGGPTCETAQSPCDTKECQHGGQCQVENGSAVCVCQAGYTGAACEMDVDDCSPDPCLNGGSCVDLVGNYTCLCAEPFKGLRCETGDHPVPDACLSAPCHNGGTCVDADQGYVCECPEGFMGLDCRERVPDDCECRNGGRCLGANTTLCQCPLGFFGLLCEFEITAMPCNMNTQCPDGGYCMEHGGSYLCVCHTDHNASHSLPSPCDSDPCFNGGSCDAHDDSYTCECPRGFHGKHCEKARPHLCSSGPCRNGGTCKEAGGEYHCSCPYRFTGRHCEIGKPDSCASGPCHNGGTCFHYIGKYKCDCPPGFSGRHCEIAPSPCFRSPCVNGGTCEDRDTDFFCHCQAGYMGRRCQAEVDCGPPEEVKHATLRFNGTRLGAVALYACDRGYSLSAPSRIRVCQPHGVWSEPPQCLEIDECRSQPCLHGGSCQDRVAGYLCLCSTGYEGAHCELERDECRAHPCRNGGSCRNLPGAYVCRCPAGFVGVHCETEVDACDSSPCQHGGRCESGGGAYLCVCPESFFGYHCETVSDPCFSSPCGGRGYCLASNGSHSCTCKVGYTGEDCAKELFPPTALKMERVEESGVSISWNPPNGPAARQMLDGYAVTYVSSDGSYRRTDFVDRTRSSHQLQALAAGRAYNISVFSVKRNSNNKNDISRPAVLLARTRPRPVEGFEVTNVTASTISVQWALHRIRHATVSGVRVSIRHPEALRDQATDVDRSVDRFTFRALLPGKRYTIQLTTLSGLRGEEHPTESLATAPTHVWTRPLPPANLTAARVTATSAHVVWDAPTPGSLLEAYVINVTTSQSTKSRYVPNGKLASYTVRDLLPGRRYQLSVIAVQSTELGPQHSEPAHLYIITSPRDGADRRWHQGGHHPRVLKNRPPPARLPELRLLNDHSAPETPTQPPRFSELVDGRGRVSARFGGSPSKAATVRSHVPGNCSENPCQNGGTCVPGADAHSCDCGPGFKGRRCELACIKVSRPCTRLFSETKAFPVWEGGVCHHVKQSKSQTLEKS>sp|Q8TER0-4|SNED1_HUMAN Isoform 3 of Sushi, nidogen and EGF-like domain-containing protein 1 OS=Homo sapiens OX=9606 GN=SNED1MRHGVAWALLVAAALGLGARGVRGAVALADFYPFGAERGDAVTPKQDDGGSGLRPLSVPFPFFGAEHSGLYVNNNGIISFLKEVSQFTPVAFPIAKDRCVVAAFWADVDNRRAGDVYYREATDPAMLRRATEDVRHYFPELLDFNATWVFVATWYRVTFFGGSSSSPVNTFQTVLITDGKLSFTIFNYESIVWTTGTHASSGGNATGLGGIAAQAGFNAGDGQRYFSIPGSRTADMAEVETTTNVGVPGRWAFRIDDAQVRVGGCGHTTSVCLALRPCLNGGKCIDDCVTGNPSYTCSCLSGFTGRRCHLDVNECASQPCQNGGTCTHGINSFRCQCPAGFGGPTCETAQSPCDTKECQHGGQCQVENGSAVCVCQAGYTGAACEMDVDDCSPDPCLNGGSCVDLVGNYTCLCAEPFKGLRCETGDHPVPDACLSAPCHNGGTCVDADQGYVCECPEGFMGLDCRERVPDDCECRNGGRCLGANTTLCQCPLGFFGLLCEFEITAMPCNMNTQCPDGGYCMEHGGSYLCVCHTDHNASHSLPSPCDSDPCFNGGSCDAHDDSYTCECPRGFHGKHCEKARPHLCSSGPCRNGGTCKEAGGEYHCSCPYRFTGRHCEIGKPDSCASGPCHNGGTCFHYIGKYKCDCPPGFSGRHCEIAPSPCFRSPCVNGGTCEDRDTDFFCHCQAGYMGRRCQAEVDCGPPEEVKHATLRFNGTRLGAVALYACDRGYSLSAPSRIRVCQPHGVWSEPPQCLEIDECRSQPCLHGGSCQDRVAGYLCLCSTGYEGAHCELERDECRAHPCRNGGSCRNLPGAYVCRCPAGFVGVHCETEVDACDSSPCQHGGRCESGGGAYLCVCPESFFGYHCETVSDPCFSSPCGGRGYCLASNGSHSCTCKVGYTGEDCAKELFPPTALKMERVEESGVSISWNPPNGPAARQMLDGYAVTYVSSDGSYRRTDFVDRTRSSHQLQALAAGRAYNISVFSVKRNSNNKNDISRPAVLLARTRPRPVEGFEVTNVTASTISVQWALHRIRHATVSGVRVSIRHPEALRDQATDVDRSVDRFTFRALLPGKRYTIQLTTLSGLRGEEHPTESLATAPTHVWTRPLPPANLTAARVTATSAHVVWDAPTPGSLLEAYVINVTTSQSTKSRYVPNGKLASYTVRDLLPGRRYQLSVIAVQSTELGPQHSEPAHLYIITSPRDGADRRWHQGGHHPRVLKNRPPPARLPELRLLNDHSAPETPTQPPRFSELVDGRGRVSARFGGSPSKAATVRSHVPGNCSENPCQNGGTCVPGADAHSCDCGPGFKGRRCELACIKVSRPCTRLFSETKAFPVWEGGVCHHVYKRVYRVHQDICFKESCESTSLKL>sp|Q8TER0-5|SNED1_HUMAN Isoform 4 of Sushi, nidogen and EGF-like domain-containing protein 1 OS=Homo sapiens OX=9606 GN=SNED1MRHGVAWALLVAAALGLGARGVRGAVALADFYPFGAERGDAVTPKQDDGGSGLRPLSVPFPFFGAEHSGLYVNNNGIISFLKEVSQFTPVAFPIAKDRCVVAAFWADVDNRRAGDVYYREATDPAMLRRATEDVRHYFPELLDFNATWVFVATWYRVTFFGGSSSSPVNTFQTVLITDGKLSFTIFNYESIVWTTGTHASSGGNATGLGGIAAQAGFNAGDGQRYFSIPGSRTADMAEVETTTNVGVPGRWAFRIDDAQVRVGGCGHTTSVCLALRPCLNGGKCIDDCVTGNPSYTCSCLSGFTGRRCHLDVNECASQPCQNGGTCTHGINSFRCQCPAGFGGPTCETAQSPCDTKECQHGGQCQVENGSAVCVCQAGYTGAACEMDVDDCSPDPCLNGGSCVDLVGNYTCLCAEPFKGLRCETGDHPVPDACLSAPCHNGGTCVDADQGYVCECPEGFMGLDCRERVPDDCECRNGGRCLGANTTLCQCPLGFFGLLCEFEITAMPCNMNTQCPDGGYCMEHGGSYLCVCHTDHNASHSLPSPCDSDPCFNGGSCDAHDDSYTCECPRGFHGKHCEKARPHLCSSGPCRNGGTCKEAGGEYHCSCPYRFTGRHCEIGKPDSCASGPCHNGGTCFHYIGKYKCDCPPGFSGRHCEIAPSPCFRSPCVNGGTCEDRDTDFFCHCQAGYMGRRCQAEVDCGPPEEVKHATLRFNGTRLGAVALYACDRGYSLSAPSRIRVCQPHGVWSEPPQCLEIDECRSQPCLHGGSCQDRVAGYLCLCSTGYEGAHCELERDECRAHPCRNGGSCRNLPGAYVCRCPAGFVGVHCETEVDACDSSPCQHGGRCESGGGAYLCVCPESFFGYHCETVSDPCFSSPCGGRGYCLASNGSHSCTCKVGYTGEDCAKELFPPTALKMERVEESGVSISWNPPNGPAARQMLDGYAVTYVSSDGSYRRTDFVDRTRSSHQLQALAAGRAYNISVFSVKRNSNNKNDISRPAVLLARTRPRPVEGFEVTNVTASTISVQWALHRIRHATVSGVRVSIRHPEALRDQATDVDRSVDRFTFRALLPGKRYTIQLTTLSGLRGEEHPTESLATAPTHVWTRPLPPANLTAARVTATSAHVVWDAPTPGSLLEAYVINVTTSQSTKSRYVPNGKLASYTVRDLLPGRRYQLSVIAVQSTELGPQHSEPAHLYIITSPRDGADRRWHQGGHHPRVLKNRPPPARLPELRLLNDHSAPETPTQPPRFSELVDGRGRVSARFGGSPSKAATVRSQPTASAQLENMEEAPKRVSLALQLPEHGSKDIGSESAALVGTLGLTDCSQGP>sp|P0CW21|SPGOS_HUMAN Putative uncharacterized protein SPART-AS1 OS=Homosapiens OX=9606 GN=SPART-AS1 PE=5 SV=1MKDIGHLQHLAQRLQWNRRAVNICGMHGWTKDLSPHSRMPSMLEHVKHYMSC>sp|Q5MJ10|SPXN2_HUMAN Sperm protein associated with the nucleus on the Xchromosome N2 OS=Homo sapiens OX=9606 GN=SPANXN2 PE=1 SV=1MEQPTSSTNGEKRKSPCESNNKKNDEMQEAPNRVLAPKQSLQKTKTIEYLTIIVYYYRKHTKINSNQLEKDQSRENSINPVQEEEDEGLDSAEGSSQEDEDLDSSEGSSQEDEDLDSSEGSSQEDEDLDSSEGSSQEDEDLDSSEGSSQEDEDLDPPEGSSQEDEDLDSSEGSSQEGGED>sp|P23327|SRCH_HUMAN Sarcoplasmic reticulum histidine-rich calcium-binding protein OS=Homo sapiens OX=9606 GN=HRC PE=1 SV=1MGHHRPWLHASVLWAGVASLLLPPAMTQQLRGDGLGFRNRNNSTGVAGLSEEASAELRHHLHSPRDHPDENKDVSTENGHHFWSHPDREKEDEDVSKEYGHLLPGHRSQDHKVGDEGVSGEEVFAEHGGQARGHRGHGSEDTEDSAEHRHHLPSHRSHSHQDEDEDEVVSSEHHHHILRHGHRGHDGEDDEGEEEEEEEEEEEEASTEYGHQAHRHRGHGSEEDEDVSDGHHHHGPSHRHQGHEEDDDDDDDDDDDDDDDDVSIEYRHQAHRHQGHGIEEDEDVSDGHHHRDPSHRHRSHEEDDNDDDDVSTEYGHQAHRHQDHRKEEVEAVSGEHHHHVPDHRHQGHRDEEEDEDVSTERWHQGPQHVHHGLVDEEEEEEEITVQFGHYVASHQPRGHKSDEEDFQDEYKTEVPHHHHHRVPREEDEEVSAELGHQAPSHRQSHQDEETGHGQRGSIKEMSHHPPGHTVVKDRSHLRKDDSEEEKEKEEDPGSHEEDDESSEQGEKGTHHGSRDQEDEEDEEEGHGLSLNQEEEEEEDKEEEEEEEDEERREERAEVGAPLSPDHSEEEEEEEEGLEEDEPRFTIIPNPLDRREEAGGASSEEESGEDTGPQDAQEYGNYQPGSLCGYCSFCNRCTECESCHCDEENMGEHCDQCQHCQFCYLCPLVCETVCAPGSYVDYFSSSLYQALADMLETPEP>sp|Q8WWF3|SSMM1_HUMAN Serine-rich single-pass membrane protein 1 OS=Homosapiens OX=9606 GN=SSMEM1 PE=1 SV=1MGDLFSLFWEVDPPPIPVNCAIPNQDYECWKDDSCGTIGSFLLWYFVIVFVLMFFSRASVWMSEDKKDEGSGTSTSVRKASKETSCKRQSKDSAWDPSQTMKKPKQNQLTPVTNSEVALVNAYPEQRRARRQSQFNEVNQNQHDSDTTEYGSEESNSEASSWKESESEHHPSPDSIKRRKMAQRQRNLGSYQMSERHCLHCKALRTNEWLAHHSRQKPSVTPPMKRDSQEESSISDINKKFSKF>sp|O75044|SRGP2_HUMAN SLIT-ROBO Rho GTPase-activating protein 2 OS=Homosapiens OX=9606 GN=SRGAP2 PE=1 SV=3MTSPAKFKKDKEIIAEYDTQVKEIRAQLTEQMKCLDQQCELRVQLLQDLQDFFRKKAEIEMDYSRNLEKLAERFLAKTRSTKDQQFKKDQNVLSPVNCWNLLLNQVKRESRDHTTLSDIYLNNIIPRFVQVSEDSGRLFKKSKEVGQQLQDDLMKVLNELYSVMKTYHMYNADSISAQSKLKEAEKQEEKQIGKSVKQEDRQTPRSPDSTANVRIEEKHVRRSSVKKIEKMKEKRQAKYTENKLKAIKARNEYLLALEATNASVFKYYIHDLSDLIDQCCDLGYHASLNRALRTFLSAELNLEQSKHEGLDAIENAVENLDATSDKQRLMEMYNNVFCPPMKFEFQPHMGDMASQLCAQQPVQSELVQRCQQLQSRLSTLKIENEEVKKTMEATLQTIQDIVTVEDFDVSDCFQYSNSMESVKSTVSETFMSKPSIAKRRANQQETEQFYFTKMKEYLEGRNLITKLQAKHDLLQKTLGESQRTDCSLARRSSTVRKQDSSQAIPLVVESCIRFISRHGLQHEGIFRVSGSQVEVNDIKNAFERGEDPLAGDQNDHDMDSIAGVLKLYFRGLEHPLFPKDIFHDLMACVTMDNLQERALHIRKVLLVLPKTTLIIMRYLFAFLNHLSQFSEENMMDPYNLAICFGPSLMSVPEGHDQVSCQAHVNELIKTIIIQHENIFPSPRELEGPVYSRGGSMEDYCDSPHGETTSVEDSTQDVTAEHHTSDDECEPIEAIAKFDYVGRTARELSFKKGASLLLYQRASDDWWEGRHNGIDGLIPHQYIVVQDTEDGVVERSSPKSEIEVISEPPEEKVTARAGASCPSGGHVADIYLANINKQRKRPESGSIRKTFRSDSHGLSSSLTDSSSPGVGASCRPSSQPIMSQSLPKEGPDKCSISGHGSLNSISRHSSLKNRLDSPQIRKTATAGRSKSFNNHRPMDPEVIAQDIEATMNSALNELRELERQSSVKHTPDVVLDTLEPLKTSPVVAPTSEPSSPLHTQLLKDPEPAFQRSASTAGDIACAFRPVKSVKMAAPVKPPATRPKPTVFPKTNATSPGVNSSTSPQSTDKSCTV>sp|Q96PU4|UHRF2_HUMAN E3 ubiquitin-protein ligase UHRF2 OS=Homo sapiensOX=9606 GN=UHRF2 PE=1 SV=1MWIQVRTIDGSKTCTIEDVSRKATIEELRERVWALFDVRPECQRLFYRGKQLENGYTLFDYDVGLNDIIQLLVRPDPDHLPGTSTQIEAKPCSNSPPKVKKAPRVGPSNQPSTSARARLIDPGFGIYKVNELVDARDVGLGAWFEAHIHSVTRASDGQSRGKTPLKNGSSCKRTNGNIKHKSKENTNKLDSVPSTSNSDCVAADEDVIYHIQYDEYPESGTLEMNVKDLRPRARTILKWNELNVGDVVMVNYNVESPGQRGFWFDAEITTLKTISRTKKELRVKIFLGGSEGTLNDCKIISVDEIFKIERPGAHPLSFADGKFLRRNDPECDLCGGDPEKKCHSCSCRVCGGKHEPNMQLLCDECNVAYHIYCLNPPLDKVPEEEYWYCPSCKTDSSEVVKAGERLKMSKKKAKMPSASTESRRDWGRGMACVGRTRECTIVPSNHYGPIPGIPVGSTWRFRVQVSEAGVHRPHVGGIHGRSNDGAYSLVLAGGFADEVDRGDEFTYTGSGGKNLAGNKRIGAPSADQTLTNMNRALALNCDAPLDDKIGAESRNWRAGKPVRVIRSFKGRKISKYAPEEGNRYDGIYKVVKYWPEISSSHGFLVWRYLLRRDDVEPAPWTSEGIERSRRLCLRLQYPAGYPSDKEGKKPKGQSKKQPSGTTKRPISDDDCPSASKVYKASDSAEAIEAFQLTPQQQHLIREDCQNQKLWDEVLSHLVEGPNFLKKLEQSFMCVCCQELVYQPVTTECFHNVCKDCLQRSFKAQVFSCPACRHDLGQNYIMIPNEILQTLLDLFFPGYSKGR>sp|Q96PU4-2|UHRF2_HUMAN Isoform 2 of E3 ubiquitin-protein ligase UHRF2OS=Homo sapiens OX=9606 GN=UHRF2MWIQVRTIDGSKTCTIEDVSRKATIEELRERVWALFDVRPECQRLFYRGKQLENGYTLFDYDVGLNDIIQLLVRPDPDHLPGTSTQIEAKPCSNSPPKVKKAPRVGPSNQPSTSARARLIDPGFGIYKVNELVDARDVGLGAWFEAHIHSVTRASDGQSRGKTPLKNGSSCKRTNGNIKHKSKENTNKLDSVPSTSNSDCVAADEDVIYHIQYDEYPESGTLEMNVKDLRPRARTILKWNELNVGDVVMVNYNVESPGQRGFWFDAEITTLKTISRTKKELRVKIFLGGSEGTLNDCKIISVDEIFKIERPGAHPLSFADGKFLRRNDPECDLCGGDPEKKCHSCSCRVCGGKHEPNMQLLCDECNVAYHIYCLNPPLDKVPEEEYWYCPSCKTDSSEVVKAGERLKMSKKKAKMPSASTESRRDWGRGMACVGRTRECTIVPSNHYGPIPGIPVGSTWRFRVQVSEAGVHRPHVGGIHGRSNDGAYSLVLAGGFADEVLTEL>sp|Q9NX95|SYBU_HUMAN Syntabulin OS=Homo sapiens OX=9606 GN=SYBU PE=1SV=2MGPLRESKKEHRVQHHDKEISRSRIPRLILRPHMPQQQHKVSPASESPFSEEESREFNPSSSGRSARTVSSNSFCSDDTGCPSSQSVSPVKTPSDAGNSPIGFCPGSDEGFTRKKCTIGMVGEGSIQSSRYKKESKSGLVKPGSEADFSSSSSTGSISAPEVHMSTAGSKRSSSSRNRGPHGRSNGASSHKPGSSPSSPREKDLLSMLCRNQLSPVNIHPSYAPSSPSSSNSGSYKGSDCSPIMRRSGRYMSCGENHGVRPPNPEQYLTPLQQKEVTVRHLKTKLKESERRLHERESEIVELKSQLARMREDWIEEECHRVEAQLALKEARKEIKQLKQVIETMRSSLADKDKGIQKYFVDINIQNKKLESLLQSMEMAHSGSLRDELCLDFPCDSPEKSLTLNPPLDTMADGLSLEEQVTGEGADRELLVGDSIANSTDLFDEIVTATTTESGDLELVHSTPGANVLELLPIVMGQEEGSVVVERAVQTDVVPYSPAISELIQSVLQKLQDPCPSSLASPDESEPDSMESFPESLSALVVDLTPRNPNSAILLSPVETPYANVDAEVHANRLMRELDFAACVEERLDGVIPLARGGVVRQYWSSSFLVDLLAVAAPVVPTVLWAFSTQRGGTDPVYNIGALLRGCCVVALHSLRRTAFRIKT>sp|Q9NX95-2|SYBU_HUMAN Isoform 2 of Syntabulin OS=Homo sapiens OX=9606GN=SYBUMGPFWARKDDTGCPSSQSVSPVKTPSDAGNSPIGFCPGSDEGFTRKKCTIGMVGEGSIQSSRYKKESKSGLVKPGSEADFSSSSSTGSISAPEVHMSTAGSKRSSSSRNRGPHGRSNGASSHKPGSSPSSPREKDLLSMLCRNQLSPVNIHPSYAPSSPSSSNSGSYKGSDCSPIMRRSGRYMSCGENHGVRPPNPEQYLTPLQQKEVTVRHLKTKLKESERRLHERESEIVELKSQLARMREDWIEEECHRVEAQLALKEARKEIKQLKQVIETMRSSLADKDKGIQKYFVDINIQNKKLESLLQSMEMAHSGSLRDELCLDFPCDSPEKSLTLNPPLDTMADGLSLEEQVTGEGADRELLVGDSIANSTDLFDEIVTATTTESGDLELVHSTPGANVLELLPIVMGQEEGSVVVERAVQTDVVPYSPAISELIQSVLQKLQDPCPSSLASPDESEPDSMESFPESLSALVVDLTPRNPNSAILLSPVETPYANVDAEVHANRLMRELDFAACVEERLDGVIPLARGGVVRQYWSSSFLVDLLAVAAPVVPTVLWAFSTQRGGTDPVYNIGALLRGCCVVALHSLRRTAFRIKT>sp|Q9NX95-3|SYBU_HUMAN Isoform 3 of Syntabulin OS=Homo sapiens OX=9606GN=SYBUMGPLRESKEHRVQHHDKEISRSRIPRLILRPHMPQQQHKVSPASESPFSEEESREFNPSSSGRSARTVSSNSFCSDDTGCPSSQSVSPVKTPSDAGNSPIGFCPGSDEGFTRKKCTIGMVGEGSIQSSRYKKESKSGLVKPGSEADFSSSSSTGSISAPEVHMSTAGSKRSSSSRNRGPHGRSNGASSHKPGSSPSSPREKDLLSMLCRNQLSPVNIHPSYAPSSPSSSNSGSYKGSDCSPIMRRSGRYMSCGENHGVRPPNPEQYLTPLQQKEVTVRHLKTKLKESERRLHERESEIVELKSQLARMREDWIEEECHRVEAQLALKEARKEIKQLKQVIETMRSSLADKDKGIQKYFVDINIQNKKLESLLQSMEMAHSGSLRDELCLDFPCDSPEKSLTLNPPLDTMADGLSLEEQVTGEGADRELLVGDSIANSTDLFDEIVTATTTESGDLELVHSTPGANVLELLPIVMGQEEGSVVVERAVQTDVVPYSPAISELIQSVLQKLQDPCPSSLASPDESEPDSMESFPESLSALVVDLTPRNPNSAILLSPVETPYANVDAEVHANRLMRELDFAACVEERLDGVIPLARGGVVRQYWSSSFLVDLLAVAAPVVPTVLWAFSTQRGGTDPVYNIGALLRGCCVVALHSLRRTAFRIKT>sp|Q9NX95-4|SYBU_HUMAN Isoform 4 of Syntabulin OS=Homo sapiens OX=9606GN=SYBUMSNFEKEHRVQHHDKEISRSRIPRLILRPHMPQQQHKVSPASESPFSEEESREFNPSSSGRSARTVSSNSFCSDDTGCPSSQSVSPVKTPSDAGNSPIGFCPGSDEGFTRKKCTIGMVGEGSIQSSRYKKESKSGLVKPGSEADFSSSSSTGSISAPEVHMSTAGSKRSSSSRNRGPHGRSNGASSHKPGSSPSSPREKDLLSMLCRNQLSPVNIHPSYAPSSPSSSNSGSYKGSDCSPIMRRSGRYMSCGENHGVRPPNPEQYLTPLQQKEVTVRHLKTKLKESERRLHERESEIVELKSQLARMREDWIEEECHRVEAQLALKEARKEIKQLKQVIETMRSSLADKDKGIQKYFVDINIQNKKLESLLQSMEMAHSGSLRDELCLDFPCDSPEKSLTLNPPLDTMADGLSLEEQVTGEGADRELLVGDSIANSTDLFDEIVTATTTESGDLELVHSTPGANVLELLPIVMGQEEGSVVVERAVQTDVVPYSPAISELIQSVLQKLQDPCPSSLASPDESEPDSMESFPESLSALVVDLTPRNPNSAILLSPVETPYANVDAEVHANRLMRELDFAACVEERLDGVIPLARGGVVRQYWSSSFLVDLLAVAAPVVPTVLWAFSTQRGGTDPVYNIGALLRGCCVVALHSLRRTAFRIKT>sp|Q9NX95-5|SYBU_HUMAN Isoform 5 of Syntabulin OS=Homo sapiens OX=9606GN=SYBUMVGEGSIQSSRYKKESKSGLVKPGSEADFSSSSSTGSISAPEVHMSTAGSKRSSSSRNRGPHGRSNGASSHKPGSSPSSPREKDLLSMLCRNQLSPVNIHPSYAPSSPSSSNSGSYKGSDCSPIMRRSGRYMSCGENHGVRPPNPEQYLTPLQQKEVTVRHLKTKLKESERRLHERESEIVELKSQLARMREDWIEEECHRVEAQLALKEARKEIKQLKQVIETMRSSLADKDKGIQKYFVDINIQNKKLESLLQSMEMAHSGSLRDELCLDFPCDSPEKSLTLNPPLDTMADGLSLEEQVTGEGADRELLVGDSIANSTDLFDEIVTATTTESGDLELVHSTPGANVLELLPIVMGQEEGSVVVERAVQTDVVPYSPAISELIQSVLQKLQDPCPSSLASPDESEPDSMESFPESLSALVVDLTPRNPNSAILLSPVETPYANVDAEVHANRLMRELDFAACVEERLDGVIPLARGGVVRQYWSSSFLVDLLAVAAPVVPTVLWAFSTQRGGTDPVYNIGALLRGCCVVALHSLRRTAFRIKT>sp|P09936|UCHL1_HUMAN Ubiquitin carboxyl-terminal hydrolase isozyme L1OS=Homo sapiens OX=9606 GN=UCHL1 PE=1 SV=2MQLKPMEINPEMLNKVLSRLGVAGQWRFVDVLGLEEESLGSVPAPACALLLLFPLTAQHENFRKKQIEELKGQEVSPKVYFMKQTIGNSCGTIGLIHAVANNQDKLGFEDGSVLKQFLSETEKMSPEDRAKCFEKNEAIQAAHDAVAQEGQCRVDDKVNFHFILFNNVDGHLYELDGRMPFPVNHGASSEDTLLKDAAKVCREFTEREQGEVRFSAVALCKAA>sp|Q6P1X5|TAF2_HUMAN Transcription initiation factor TFIID subunit 2OS=Homo sapiens OX=9606 GN=TAF2 PE=1 SV=3MPLTGVEPARMNRKKGDKGFESPRPYKLTHQVVCINNINFQRKSVVGFVELTIFPTVANLNRIKLNSKQCRIYRVRINDLEAAFIYNDPTLEVCHSESKQRNLNYFSNAYAAAVSAVDPDAGNGELCIKVPSELWKHVDELKVLKIHINFSLDQPKGGLHFVVPSVEGSMAERGAHVFSCGYQNSTRFWFPCVDSYSELCTWKLEFTVDAAMVAVSNGDLVETVYTHDMRKKTFHYMLTIPTAASNISLAIGPFEILVDPYMHEVTHFCLPQLLPLLKHTTSYLHEVFEFYEEILTCRYPYSCFKTVFIDEAYVEVAAYASMSIFSTNLLHSAMIIDETPLTRRCLAQSLAQQFFGCFISRMSWSDEWVLKGISGYIYGLWMKKTFGVNEYRHWIKEELDKIVAYELKTGGVLLHPIFGGGKEKDNPASHLHFSIKHPHTLSWEYYSMFQCKAHLVMRLIENRISMEFMLQVFNKLLSLASTASSQKFQSHMWSQMLVSTSGFLKSISNVSGKDIQPLIKQWVDQSGVVKFYGSFAFNRKRNVLELEIKQDYTSPGTQKYVGPLKVTVQELDGSFNHTLQIEENSLKHDIPCHSKSRRNKKKKIPLMNGEEVDMDLSAMDADSPLLWIRIDPDMSVLRKVEFEQADFMWQYQLRYERDVVAQQESILALEKFPTPASRLALTDILEQEQCFYRVRMSACFCLAKIANSMVSTWTGPPAMKSLFTRMFCCKSCPNIVKTNNFMSFQSYFLQKTMPVAMALLRDVHNLCPKEVLTFILDLIKYNDNRKNKFSDNYYRAEMIDALANSVTPAVSVNNEVRTLDNLNPDVRLILEEITRFLNMEKLLPSYRHTITVSCLRAIRVLQKNGHVPSDPALFKSYAEYGHFVDIRIAALEAVVDYTKVDRSYEELQWLLNMIQNDPVPYVRHKILNMLTKNPPFTKNMESPLCNEALVDQLWKLMNSGTSHDWRLRCGAVDLYFTLFGLSRPSCLPLPELGLVLNLKEKKAVLNPTIIPESVAGNQEAANNPSSHPQLVGFQNPFSSSQDEEEIDMDTVHDSQAFISHHLNMLERPSTPGLSKYRPASSRSALIPQHSAGCDSTPTTKPQWSLELARKGTGKEQAPLEMSMHPAASAPLSVFTKESTASKHSDHHHHHHHEHKKKKKKHKHKHKHKHKHDSKEKDKEPFTFSSPASGRSIRSPSLSD>sp|Q8N3T6|T132C_HUMAN Transmembrane protein 132C OS=Homo sapiens OX=9606GN=TMEM132C PE=2 SV=3MRSEGAAPGPAAPLCGALSLLLGALLGKVIEGHGVTDNIQRFSSLPPYLPVSYHILRAETSFFLKEANQDLLRNSSLQARVESFFTYKTRQPPVLNASYGPFSVEKVVPLDLMLTSNFLGPTNKFSFDWKLKAHILRDKVYLSRPKVQVLFHIMGRDWDDHGAGEKLPCLRVFAFRETREVRGSCRLKGDLGLCVAELELLSSWFSAPTVGAGRKKSMDQPEGTPVELYYTVHPGNERGDCAGGDFRKGNAIRPGKDGLEETTSHLQRIGTVGLYRAQDSAQLSELRLDGNVVIWLPSRPVKQGEVVTAYVTISSNSSVDLFILRAKVKKGVNILSAQTREPRQWGVKQEVGSGGKHVTATVACQRLGPSPRNRSSSLFNEVVQMNFEIASFSSLSGTQPITWQVEYPRKGTTDIAVSEIFVSQKDLVGIVPLAMDTEILNTAVLTGKTVAMPIKVVSVEENSAVMDISESVECKSTDEDVIKVSERCDYIFVNGKEIKGKMDAVVNFTYQYLSAPLCVTVWVPRLPLQIEVSDTELSQIKGWRVPIVTNKRPTRESEDEDEEERRGRGCALQYQHATVRVLTQFVSEGAGPWGQPNYLLSPNWQFDITHLVADFMKLEEPHVATLQDSRVLVGREVGMTTIQVLSPLSDSILAEKTITVLDDKVSVTDLAIQLVAGLSVALYPNAENSKAVTAVVTAEEVLRTPKQEAVFSTWLQFSDGSVTPLDIYDTKDFSLAATSQDEAVVSVPQPRSPRWPVVVAEGEGQGPLIRVDMTIAEACQKSKRKSILAVGVGNVRVKFGQNDADSSPGGDYEEDEIKNHASDRRQKGQHHERTGQDGHLYGSSPVEREEGALRRATTTARSLLDNKVVKNSRADGGRLAGEGQLQNIPIDFTNFPAHVDLPKAGSGLEENDLVQTPRGLSDLEIGMYALLGVFCLAILVFLINCATFALKYRHKQVPLEGQASMTHSHDWVWLGNEAELLESMGDAPPPQDEHTTIIDRGPGACEESNHLLLNGGSHKHVQSQIHRSADSGGRQGREQKQDPLHSPTSKRKKVKFTTFTTIPPDDSCPTVNSIVSSNDEDIKWVCQDVAVGAPKELRNYLEKLKDKA>sp|Q9P031|TAP26_HUMAN Thyroid transcription factor 1-associated protein26 OS=Homo sapiens OX=9606 GN=CCDC59 PE=1 SV=2MAPVRRSAKWRPGGIEARGEGVSTVGYRNKNVRQKTWRPNHPQAFVGSVREGQGFAFRRKLKIQQSYKKLLRKEKKAQTSLESQFTDRYPDNLKHLYLAEEERHRKQARKVDHPLSEQVHQPLLEEQCSIDEPLFEDQCSFDQPQPEEQCIKTVNSFTIPKKNKKKTSNQKAQEEYEQIQAKRAAKKQEFERRKQEREEAQRQYKKKKMEVFKILNKKTKKGQPNLNVQMEYLLQKIQEKC>sp|O43542|XRCC3_HUMAN DNA repair protein XRCC3 OS=Homo sapiens OX=9606GN=XRCC3 PE=1 SV=1MDLDLLDLNPRIIAAIKKAKLKSVKEVLHFSGPDLKRLTNLSSPEVWHLLRTASLHLRGSSILTALQLHQQKERFPTQHQRLSLGCPVLDALLRGGLPLDGITELAGRSSAGKTQLALQLCLAVQFPRQHGGLEAGAVYICTEDAFPHKRLQQLMAQQPRLRTDVPGELLQKLRFGSQIFIEHVADVDTLLECVNKKVPVLLSRGMARLVVIDSVAAPFRCEFDSQASAPRARHLQSLGATLRELSSAFQSPVLCINQVTEAMEEQGAAHGPLGFWDERVSPALGITWANQLLVRLLADRLREEEAALGCPARTLRVLSAPHLPPSSCSYTISAEGVRGTPGTQSH>sp|O60343|TBCD4_HUMAN TBC1 domain family member 4 OS=Homo sapiensOX=9606 GN=TBC1D4 PE=1 SV=2MEPPSCIQDEPFPHPLEPEPGVSAQPGPGKPSDKRFRLWYVGGSCLDHRTTLPMLPWLMAEIRRRSQKPEAGGCGAPAAREVILVLSAPFLRCVPAPGAGASGGTSPSATQPNPAVFIFEHKAQHISRFIHNSHDLTYFAYLIKAQPDDPESQMACHVFRATDPSQVPDVISSIRQLSKAAMKEDAKPSKDNEDAFYNSQKFEVLYCGKVTVTHKKAPSSLIDDCMEKFSLHEQQRLKIQGEQRGPDPGEDLADLEVVVPGSPGDCLPEEADGTDTHLGLPAGASQPALTSSRVCFPERILEDSGFDEQQEFRSRCSSVTGVQRRVHEGSQKSQPRRRHASAPSHVQPSDSEKNRTMLFQVGRFEINLISPDTKSVVLEKNFKDISSCSQGIKHVDHFGFICRESPEPGLSQYICYVFQCASESLVDEVMLTLKQAFSTAAALQSAKTQIKLCEACPMHSLHKLCERIEGLYPPRAKLVIQRHLSSLTDNEQADIFERVQKMKPVSDQEENELVILHLRQLCEAKQKTHVHIGEGPSTISNSTIPENATSSGRFKLDILKNKAKRSLTSSLENIFSRGANRMRGRLGSVDSFERSNSLASEKDYSPGDSPPGTPPASPPSSAWQTFPEEDSDSPQFRRRAHTFSHPPSSTKRKLNLQDGRAQGVRSPLLRQSSSEQCSNLSSVRRMYKESNSSSSLPSLHTSFSAPSFTAPSFLKSFYQNSGRLSPQYENEIRQDTASESSDGEGRKRTSSTCSNESLSVGGTSVTPRRISWRQRIFLRVASPMNKSPSAMQQQDGLDRNELLPLSPLSPTMEEEPLVVFLSGEDDPEKIEERKKSKELRSLWRKAIHQQILLLRMEKENQKLEASRDELQSRKVKLDYEEVGACQKEVLITWDKKLLNCRAKIRCDMEDIHTLLKEGVPKSRRGEIWQFLALQYRLRHRLPNKQQPPDISYKELLKQLTAQQHAILVDLGRTFPTHPYFSVQLGPGQLSLFNLLKAYSLLDKEVGYCQGISFVAGVLLLHMSEEQAFEMLKFLMYDLGFRKQYRPDMMSLQIQMYQLSRLLHDYHRDLYNHLEENEISPSLYAAPWFLTLFASQFSLGFVARVFDIIFLQGTEVIFKVALSLLSSQETLIMECESFENIVEFLKNTLPDMNTSEMEKIITQVFEMDISKQLHAYEVEYHVLQDELQESSYSCEDSETLEKLERANSQLKRQNMDLLEKLQVAHTKIQALESNLENLLTRETKMKSLIRTLEQEKMAYQKTVEQLRKLLPADALVNCDLLLRDLNCNPNNKAKIGNKP>sp|O60343-2|TBCD4_HUMAN Isoform 2 of TBC1 domain family member 4 OS=Homosapiens OX=9606 GN=TBC1D4MEPPSCIQDEPFPHPLEPEPGVSAQPGPGKPSDKRFRLWYVGGSCLDHRTTLPMLPWLMAEIRRRSQKPEAGGCGAPAAREVILVLSAPFLRCVPAPGAGASGGTSPSATQPNPAVFIFEHKAQHISRFIHNSHDLTYFAYLIKAQPDDPESQMACHVFRATDPSQVPDVISSIRQLSKAAMKEDAKPSKDNEDAFYNSQKFEVLYCGKVTVTHKKAPSSLIDDCMEKFSLHEQQRLKIQGEQRGPDPGEDLADLEVVVPGSPGDCLPEEADGTDTHLGLPAGASQPALTSSRVCFPERILEDSGFDEQQEFRSRCSSVTGVQRRVHEGSQKSQPRRRHASAPSHVQPSDSEKNRTMLFQVGRFEINLISPDTKSVVLEKNFKDISSCSQGIKHVDHFGFICRESPEPGLSQYICYVFQCASESLVDEVMLTLKQAFSTAAALQSAKTQIKLCEACPMHSLHKLCERIEGLYPPRAKLVIQRHLSSLTDNEQADIFERVQKMKPVSDQEENELVILHLRQLCEAKQKTHVHIGEGPSTISNSTIPENATSSGRFKLDILKNKAKRSLTSSLENIFSRGANRMRGRLGSVDSFERSNSLASEKDYSPGDSPPGTPPASPPSSAWQTFPEEDSDSPQFRRRAHTFSHPPSSTKRKLNLQDGRAQGVRSPLLRQSSSEQCSDGEGRKRTSSTCSNESLSVGGTSVTPRRISWRQRIFLRVASPMNKSPSAMQQQDGLDRNELLPLSPLSPTMEEEPLVVFLSGEDDPEKIEERKKSKELRSLWRKAIHQQILLLRMEKENQKLEASRDELQSRKVKLDYEEVGACQKEVLITWDKKLLNCRAKIRCDMEDIHTLLKEGVPKSRRGEIWQFLALQYRLRHRLPNKQQPPDISYKELLKQLTAQQHAILVDLGRTFPTHPYFSVQLGPGQLSLFNLLKAYSLLDKEVGYCQGISFVAGVLLLHMSEEQAFEMLKFLMYDLGFRKQYRPDMMSLQIQMYQLSRLLHDYHRDLYNHLEENEISPSLYAAPWFLTLFASQFSLGFVARVFDIIFLQGTEVIFKVALSLLSSQETLIMECESFENIVEFLKNTLPDMNTSEMEKIITQVFEMDISKQLHAYEVEYHVLQDELQESSYSCEDSETLEKLERANSQLKRQNMDLLEKLQVAHTKIQALESNLENLLTRETKMKSLIRTLEQEKMAYQKTVEQLRKLLPADALVNCDLLLRDLNCNPNNKAKIGNKP>sp|O60343-3|TBCD4_HUMAN Isoform 3 of TBC1 domain family member 4 OS=Homosapiens OX=9606 GN=TBC1D4MEPPSCIQDEPFPHPLEPEPGVSAQPGPGKPSDKRFRLWYVGGSCLDHRTTLPMLPWLMAEIRRRSQKPEAGGCGAPAAREVILVLSAPFLRCVPAPGAGASGGTSPSATQPNPAVFIFEHKAQHISRFIHNSHDLTYFAYLIKAQPDDPESQMACHVFRATDPSQVPDVISSIRQLSKAAMKEDAKPSKDNEDAFYNSQKFEVLYCGKVTVTHKKAPSSLIDDCMEKFSLHEQQRLKIQGEQRGPDPGEDLADLEVVVPGSPGDCLPEEADGTDTHLGLPAGASQPALTSSRVCFPERILEDSGFDEQQEFRSRCSSVTGVQRRVHEGSQKSQPRRRHASAPSHVQPSDSEKNRTMLFQVGRFEINLISPDTKSVVLEKNFKDISSCSQGIKHVDHFGFICRESPEPGLSQYICYVFQCASESLVDEVMLTLKQAFSTAAALQSAKTQIKLCEACPMHSLHKLCERIEGLYPPRAKLVIQRHLSSLTDNEQADIFERVQKMKPVSDQEENELVILHLRQLCEAKQKTHVHIGEGPSTISNSTIPENATSSGRFKLDILKNKAKRSLTSSLENIFSRGANRMRGRLGSVDSFERSNSLASEKDYSPGDSPPGTPPASPPSSAWQTFPEEDSDSPQFRRRAHTFSHPPSSTKRKLNLQDGRAQGVRSPLLRQSSSEQCSNLSSVRRMYKESNSSSSLPSLHTSFSAPSFTAPSFLKSFYQNSGRLSPQYENEISDGEGRKRTSSTCSNESLSVGGTSVTPRRISWRQRIFLRVASPMNKSPSAMQQQDGLDRNELLPLSPLSPTMEEEPLVVFLSGEDDPEKIEERKKSKELRSLWRKAIHQQILLLRMEKENQKLEASRDELQSRKVKLDYEEVGACQKEVLITWDKKLLNCRAKIRCDMEDIHTLLKEGVPKSRRGEIWQFLALQYRLRHRLPNKQQPPDISYKELLKQLTAQQHAILVDLGRTFPTHPYFSVQLGPGQLSLFNLLKAYSLLDKEVGYCQGISFVAGVLLLHMSEEQAFEMLKFLMYDLGFRKQYRPDMMSLQIQMYQLSRLLHDYHRDLYNHLEENEISPSLYAAPWFLTLFASQFSLGFVARVFDIIFLQGTEVIFKVALSLLSSQETLIMECESFENIVEFLKNTLPDMNTSEMEKIITQVFEMDISKQLHAYEVEYHVLQDELQESSYSCEDSETLEKLERANSQLKRQNMDLLEKLQVAHTKIQALESNLENLLTRETKMKSLIRTLEQEKMAYQKTVEQLRKLLPADALVNCDLLLRDLNCNPNNKAKIGNKP>sp|O60343-4|TBCD4_HUMAN Isoform 4 of TBC1 domain family member 4 OS=Homosapiens OX=9606 GN=TBC1D4MNKSPSAMQQQDGLDRNELLPLSPLSPTMEEEPLVVFLSGEDDPEKIEERKKSKELRSLWRKAIHQQILLLRMEKENQKLEGVPKSRRGEIWQFLALQYRLRHRLPNKQQPPDISYKELLKQLTAQQHAILVDLGRTFPTHPYFSVQLGPGQLSLFNLLKAYSLLDKEVGYCQGISFVAGVLLLHMSEEQAFEMLKFLMYDLGFRKQYRPDMMSLQIQMYQLSRLLHDYHRDLYNHLEENEISPSLYAAPWFLTLFASQFSLGFVARVFDIIFLQGTEVIFKVALSLLSSQETLIMECESFENIVEFLKNTLPDMNTSEMEKIITQVFEMDISKQLHAYEVEYHVLQDELQESSYSCEDSETLEKLERANSQLKRQNMDLLEKLQVAHTKIQALESNLENLLTRETKMKSLIRTLEQEKMAYQKTVEQLRKLLPADALVNCDLLLRDLNCNPNNKAKIGNKP>sp|O60343-5|TBCD4_HUMAN Isoform 5 of TBC1 domain family member 4 OS=Homosapiens OX=9606 GN=TBC1D4MNKSPSAMQQQDGLDRNELLPLSPLSPTMEEEPLVVFLSGEDDPEKIEERKKSKELRSLWRKAIHQQILLLRMEKENQKLEASRDELQSRKVKLDYEEVGACQKEVLITWDKKLLNCRAKIRCDMEDIHTLLKEGVPKSRRGEIWQFLALQYRLRHRLPNKQQPPDISYKELLKQLTAQQHAILVDLGRTFPTHPYFSVQLGPGQLSLFNLLKAYSLLDKEVGYCQGISFVAGVLLLHMSEEQAFEMLKFLMYDLGFRKQYRPDMMSLQIQMYQLSRLLHDYHRDLYNHLEENEISPSLYAAPWFLTLFASQFSLGFVARVFDIIFLQGTEVIFKVALSLLSSQETLIMECESFENIVEFLKNTLPDMNTSEMEKIITQVFEMDISKQLHAYEVEYHVLQDELQESSYSCEDSETLEKLERANSQLKRQNMDLLEKLQVAHTKIQALESNLENLLTRETKMKSLIRTLEQEKMAYQKTVEQLRKLLPADALVNCDLLLRDLNCNPNNKAKIGNKP>sp|Q8WZ71|TM158_HUMAN Transmembrane protein 158 OS=Homo sapiens OX=9606GN=TMEM158 PE=2 SV=2MLPLLAALLAAACPLPPVRGGAADAPGLLGVPSNASVNASSADEPIAPRLLASAAPGPPERPGPEEAAAAAAPCNISVQRQMLSSLLVRWGRPRGFQCDLLLFSTNAHGRAFFAAAFHRVGPPLLIEHLGLAAGGAQQDLRLCVGCGWVRGRRTGRLRPAAAPSAAAATAGAPTALPAYPAAEPPGPLWLQGEPLHFCCLDFSLEELQGEPGWRLNRKPIESTLVACFMTLVIVVWSVAALIWPVPIIAGFLPNGMEQRRTTASTTAATPAAVPAGTTAAAAAAAAAAAAAAVTSGVATK>sp|Q8WZ71-2|TM158_HUMAN Isoform 2 of Transmembrane protein 158 OS=Homosapiens OX=9606 GN=TMEM158MLPLLAALLAAACPLPPVRGGAADAPGLLGVPSNASVNASSADEPIAPRLLASAAPGPPERPGPEEAAAAAAPCNISVQRQMLSSLLVRWGRPRGFQCDLLLFSTNAHGRAFFAAAFHRVGPPLLIEHLGLAAGGAQQDLRLCVGCGWVRGRRTGRLRPAAAPSAAAATAGAPTALPAYPAAEPPGPLWLQGEPLHFCCLDFSLEELQGEPGWRLNRKPIESTLVACFMTLVIVVWSVAALIWPVPIIAGFLPNGMEQRRTTASTTAATPAAAAAAAAVTSGVATK>sp|Q6PIZ9|TRAT1_HUMAN T-cell receptor-associated transmembrane adapter 1OS=Homo sapiens OX=9606 GN=TRAT1 PE=1 SV=1MSGISGCPFFLWGLLALLGLALVISLIFNISHYVEKQRQDKMYSYSSDHTRVDEYYIEDTPIYGNLDDMISEPMDENCYEQMKARPEKSVNKMQEATPSAQATNETQMCYASLDHSVKGKRRKPRKQNTHFSDKDGDEQLHAIDASVSKTTLVDSFSPESQAVEENIHDDPIRLFGLIRAKREPIN>sp|Q9BQJ4|TMM47_HUMAN Transmembrane protein 47 OS=Homo sapiens OX=9606GN=TMEM47 PE=1 SV=1MASAGSGMEEVRVSVLTPLKLVGLVCIFLALCLDLGAVLSPAWVTADHQYYLSLWESCRKPASLDIWHCESTLSSDWQIATLALLLGGAAIILIAFLVGLISICVGSRRRFYRPVAVMLFAAVVLQVCSLVLYPIKFIETVSLKIYHEFNWGYGLAWGATIFSFGGAILYCLNPKNYEDYY>sp|Q14679|TTLL4_HUMAN Tubulin monoglutamylase TTLL4 OS=Homo sapiensOX=9606 GN=TTLL4 PE=1 SV=2MASAGTQHYSIGLRQKNSFKQSGPSGTVPATPPEKPSEGRVWPQAHQQVKPIWKLEKKQVETLSAGLGPGLLGVPPQPAYFFCPSTLCSSGTTAVIAGHSSSCYLHSLPDLFNSTLLYRRSSYRQKPYQQLESFCLRSSPSEKSPFSLPQKSLPVSLTANKATSSMVFSMAQPMASSSTEPYLCLAAAGENPSGKSLASAISGKIPSPLSSSYKPMLNNNSFMWPNSTPVPLLQTTQGLKPVSPPKIQPVSWHHSGGTGDCAPQPVDHKVPKSIGTVPADASAHIALSTASSHDTSTTSVASSWYNRNNLAMRAEPLSCALDDSSDSQDPTKEIRFTEAVRKLTARGFEKMPRQGCQLEQSSFLNPSFQWNVLNRSRRWKPPAVNQQFPQEDAGSVRRVLPGASDTLGLDNTVFCTKRISIHLLASHASGLNHNPACESVIDSSAFGEGKAPGPPFPQTLGIANVATRLSSIQLGQSEKERPEEARELDSSDRDISSATDLQPDQAETEDTEEELVDGLEDCCSRDENEEEEGDSECSSLSAVSPSESVAMISRSCMEILTKPLSNHEKVVRPALIYSLFPNVPPTIYFGTRDERVEKLPWEQRKLLRWKMSTVTPNIVKQTIGRSHFKISKRNDDWLGCWGHHMKSPSFRSIREHQKLNHFPGSFQIGRKDRLWRNLSRMQSRFGKKEFSFFPQSFILPQDAKLLRKAWESSSRQKWIVKPPASARGIGIQVIHKWSQLPKRRPLLVQRYLHKPYLISGSKFDLRIYVYVTSYDPLRIYLFSDGLVRFASCKYSPSMKSLGNKFMHLTNYSVNKKNAEYQANADEMACQGHKWALKALWNYLSQKGVNSDAIWEKIKDVVVKTIISSEPYVTSLLKMYVRRPYSCHELFGFDIMLDENLKPWVLEVNISPSLHSSSPLDISIKGQMIRDLLNLAGFVLPNAEDIISSPSSCSSSTTSLPTSPGDKCRMAPEHVTAQKMKKAYYLTQKIPDQDFYASVLDVLTPDDVRILVEMEDEFSRRGQFERIFPSHISSRYLRFFEQPRYFNILTTQWEQKYHGNKLKGVDLLRSWCYKGFHMGVVSDSAPVWSLPTSLLTISKDDVILNAFSKSETSKLGKQSSCEVSLLLSEDGTTPKSKKTQAGLSPYPQKPSSSKDSEDTSKEPSLSTQTLPVIKCSGQTSRLSASSTFQSISDSLLAVSP>sp|Q96Q11|TRNT1_HUMAN CCA tRNA nucleotidyltransferase 1, mitochondrialOS=Homo sapiens OX=9606 GN=TRNT1 PE=1 SV=2MLRCLYHWHRPVLNRRWSRLCLPKQYLFTMKLQSPEFQSLFTEGLKSLTELFVKENHELRIAGGAVRDLLNGVKPQDIDFATTATPTQMKEMFQSAGIRMINNRGEKHGTITARLHEENFEITTLRIDVTTDGRHAEVEFTTDWQKDAERRDLTINSMFLGFDGTLFDYFNGYEDLKNKKVRFVGHAKQRIQEDYLRILRYFRFYGRIVDKPGDHDPETLEAIAENAKGLAGISGERIWVELKKILVGNHVNHLIHLIYDLDVAPYIGLPANASLEEFDKVSKNVDGFSPKPVTLLASLFKVQDDVTKLDLRLKIAKEEKNLGLFIVKNRKDLIKATDSSDPLKPYQDFIIDSREPDATTRVCELLKYQGEHCLLKEMQQWSIPPFPVSGHDIRKVGISSGKEIGALLQQLREQWKKSGYQMEKDELLSYIKKT>sp|Q96Q11-2|TRNT1_HUMAN Isoform 2 of CCA tRNA nucleotidyltransferase 1,mitochondrial OS=Homo sapiens OX=9606 GN=TRNT1MLRCLYHWHRPVLNRRWSRLCLPKQYLFTMKLQSPEFQSLFTEGLKSLTELFVKENHELRIAGGAVRDLLNGVKPQDIDFATTATPTQMKEMFQSAGIRMINNRGEKHGTITARLHEENFEITTLRIDVTTDGRHAEVEFTTDWQKDAERRDLTINSMFLGFDGTLFDYFNGYEDLKNKKVRFVGHAKQRIQEDYLRILRYFRFYGRIVDKPGDHDPETLEAIAENAKGLAGISGERIWVELKKILVGLPANASLEEFDKVSKNVDGFSPKPVTLLASLFKVQDDVTKLDLRLKIAKEEKNLGLFIVKNRKDLIKATDSSDPLKPYQDFIIDSREPDATTRVCELLKYQGEHCLLKEMQQWSIPPFPVSGHDIRKVGISSGKEIGALLQQLREQWKKSGYQMEKDELLSYIKKT>sp|Q96Q11-3|TRNT1_HUMAN Isoform 3 of CCA tRNA nucleotidyltransferase 1,mitochondrial OS=Homo sapiens OX=9606 GN=TRNT1MLRCLYHWHRPVLNRRWSRLCLPKQYLFTMKLQSPEFQSLFTEGLKSLTGINAFHEN>sp|O00294|TULP1_HUMAN Tubby-related protein 1 OS=Homo sapiens OX=9606GN=TULP1 PE=1 SV=3MPLRDETLREVWASDSGHEEESLSPEAPRRPKQRPAPAQRLRKKRTEAPESPCPTGSKPRKPGAGRTGRPREEPSPDPAQARAPQTVYARFLRDPEAKKRDPRETFLVARAPDAEDEEEEEEEDEEDEEEEAEEKKEKILLPPKKPLREKSSADLKERRAKAQGPRGDLGSPDPPPKPLRVRNKEAPAGEGTKMRKTKKKGSGEADKDPSGSPASARKSPAAMFLVGEGSPDKKALKKKGTPKGARKEEEEEEEAATVIKKSNQKGKAKGKGKKKAKEERAPSPPVEVDEPREFVLRPAPQGRTVRCRLTRDKKGMDRGMYPSYFLHLDTEKKVFLLAGRKRKRSKTANYLISIDPTNLSRGGENFIGKLRSNLLGNRFTVFDNGQNPQRGYSTNVASLRQELAAVIYETNVLGFRGPRRMTVIIPGMSAENERVPIRPRNASDGLLVRWQNKTLESLIELHNKPPVWNDDSGSYTLNFQGRVTQASVKNFQIVHADDPDYIVLQFGRVAEDAFTLDYRYPLCALQAFAIALSSFDGKLACE>sp|O00294-2|TULP1_HUMAN Isoform 2 of Tubby-related protein 1 OS=Homosapiens OX=9606 GN=TULP1MPLRDETLREVWASDSGHEEESLSPEAPRRPKQRPAPAQRLRKKRTEAPESPCPTGSKPRKPGEEEEEEEDEEDEEEEAEEKKEKILLPPKKPLREKSSADLKERRAKAQGPRGDLGSPDPPPKPLRVRNKEAPAGEGTKMRKTKKKGSGEADKDPSGSPASARKSPAAMFLVGEGSPDKKALKKKGTPKGARKEEEEEEEAATVIKKSNQKGKAKGKGKKKAKEERAPSPPVEVDEPREFVLRPAPQGRTVRCRLTRDKKGMDRGMYPSYFLHLDTEKKVFLLAGRKRKRSKTANYLISIDPTNLSRGGENFIGKLRSNLLGNRFTVFDNGQNPQRGYSTNVASLRQELAAVIYETNVLGFRGPRRMTVIIPGMSAENERVPIRPRNASDGLLVRWQNKTLESLIELHNKPPVWNDDSGSYTLNFQGRVTQASVKNFQIVHADDPDYIVLQFGRVAEDAFTLDYRYPLCALQAFAIALSSFDGKLACE>sp|Q9BZM6|ULBP1_HUMAN UL16-binding protein 1 OS=Homo sapiens OX=9606GN=ULBP1 PE=1 SV=1MAAAASPAFLLCLPLLHLLSGWSRAGWVDTHCLCYDFIITPKSRPEPQWCEVQGLVDERPFLHYDCVNHKAKAFASLGKKVNVTKTWEEQTETLRDVVDFLKGQLLDIQVENLIPIEPLTLQARMSCEHEAHGHGRGSWQFLFNGQKFLLFDSNNRKWTALHPGAKKMTEKWEKNRDVTMFFQKISLGDCKMWLEEFLMYWEQMLDPTKPPSLAPGTTQPKAMATTLSPWSLLIIFLCFILAGR>sp|Q96QD9|UIF_HUMAN UAP56-interacting factor OS=Homo sapiens OX=9606GN=FYTTD1 PE=1 SV=3MNRFGTRLVGATATSSPPPKARSNENLDKIDMSLDDIIKLNRKEGKKQNFPRLNRRLLQQSGAQQFRMRVRWGIQQNSGFGKTSLNRRGRVMPGKRRPNGVITGLAARKTTGIRKGISPMNRPPLSDKNIEQYFPVLKRKANLLRQNEGQRKPVAVLKRPSQLSRKNNIPANFTRSGNKLNHQKDTRQATFLFRRGLKVQAQLNTEQLLDDVVAKRTRQWRTSTTNGGILTVSIDNPGAVQCPVTQKPRLTRTAVPSFLTKREQSDVKKVPKGVPLQFDINSVGKQTGMTLNERFGILKEQRATLTYNKGGSRFVTVG>sp|Q96QD9-2|UIF_HUMAN Isoform 2 of UAP56-interacting factor OS=Homosapiens OX=9606 GN=FYTTD1MEPSVIMGNDIIKLNRKEGKKQNFPRLNRRLLQQSGAQQFRMRVRWGIQQNSGFGKTSLNRRGRVMPGKRRPNGVITGLAARKTTGIRKGISPMNRPPLSDKNIEQYFPVLKRKANLLRQNEGQRKPVAVLKRPSQLSRKNNIPANFTRSGNKLNHQKDTRQATFLFRRGLKVQAQLNTEQLLDDVVAKRTRQWRTSTTNGGILTVSIDNPGAVQCPVTQKPRLTRTAVPSFLTKREQSDVKKVPKGVPLQFDINSVGKQTGMTLNERFGILKEQRATLTYNKGGSRFVTVG>sp|Q96QD9-3|UIF_HUMAN Isoform 3 of UAP56-interacting factor OS=Homosapiens OX=9606 GN=FYTTD1MRVRWGIQQNSGFGKTSLNRRGRVMPGKRRPNGVITGLAARKTTGIRKGISPMNRPPLSDKNIEQYFPVLKRKANLLRQNEGQRKPVAVLKRPSQLSRKNNIPANFTRSGNKLNHQKDTRQATFLFRRGLKVQAQLNTEQLLDDVVAKRTRQWRTSTTNGGILTVSIDNPGAVQCPVTQKPRLTRTAVPSFLTKREQSDVKKVPKGVPLQFDINSVGKQTGMTLNERFGILKEQRATLTYNKGGSRFVTVG>sp|Q96QD9-4|UIF_HUMAN Isoform 4 of UAP56-interacting factor OS=Homosapiens OX=9606 GN=FYTTD1MNRFGTRLVGATATSSPPPKARSNENLDKIDMSLDDIIKLNRKEGKKQNFPRLNRRLLQQSGAQQFRMRVRWGIQQNSGFGKTSLNRRGRVMPGKRRPNGVITGLAARKTTGIRKGISPMNRPPLSDKK>sp|Q8WVF2|UCMA_HUMAN Unique cartilage matrix-associated protein OS=Homosapiens OX=9606 GN=UCMA PE=2 SV=2MTWRQAVLLSCFSAVVLLSMLREGTSVSVGTMQMAGEEASEDAKQKIFMQESDASNFLKRRGKRSPKSRDEVNVENRQKLRVDELRREYYEEQRNEFENFVEEQNDEQEERSREAVEQWRQWHYDGLHPSYLYNRHHT>sp|Q9NUQ7|UFSP2_HUMAN Ufm1-specific protease 2 OS=Homo sapiens OX=9606GN=UFSP2 PE=1 SV=3MVISESMDILFRIRGGLDLAFQLATPNEIFLKKALKHVLSDLSTKLSSNALVFRICHSSVYIWPSSDINTIPGELTDASACKNILRFIQFEPEEDIKRKFMRKKDKKLSDMHQIVNIDLMLEMSTSLAAVTPIIERESGGHHYVNMTLPVDAVISVAPEETWGKVRKLLVDAIHNQLTDMEKCILKYMKGTSIVVPEPLHFLLPGKKNLVTISYPSGIPDGQLQAYRKELHDLFNLPHDRPYFKRSNAYHFPDEPYKDGYIRNPHTYLNPPNMETGMIYVVQGIYGYHHYMQDRIDDNGWGCAYRSLQTICSWFKHQGYTERSIPTHREIQQALVDAGDKPATFVGSRQWIGSIEVQLVLNQLIGITSKILFVSQGSEIASQGRELANHFQSEGTPVMIGGGVLAHTILGVAWNEITGQIKFLILDPHYTGAEDLQVILEKGWCGWKGPDFWNKDAYYNLCLPQRPNMI>sp|Q70CQ3|UBP30_HUMAN Ubiquitin carboxyl-terminal hydrolase 30 OS=Homosapiens OX=9606 GN=USP30 PE=1 SV=1MLSSRAEAAMTAADRAIQRFLRTGAAVRYKVMKNWGVIGGIAAALAAGIYVIWGPITERKKRRKGLVPGLVNLGNTCFMNSLLQGLSACPAFIRWLEEFTSQYSRDQKEPPSHQYLSLTLLHLLKALSCQEVTDDEVLDASCLLDVLRMYRWQISSFEEQDAHELFHVITSSLEDERDRQPRVTHLFDVHSLEQQSEITPKQITCRTRGSPHPTSNHWKSQHPFHGRLTSNMVCKHCEHQSPVRFDTFDSLSLSIPAATWGHPLTLDHCLHHFISSESVRDVVCDNCTKIEAKGTLNGEKVEHQRTTFVKQLKLGKLPQCLCIHLQRLSWSSHGTPLKRHEHVQFNEFLMMDIYKYHLLGHKPSQHNPKLNKNPGPTLELQDGPGAPTPVLNQPGAPKTQIFMNGACSPSLLPTLSAPMPFPLPVVPDYSSSTYLFRLMAVVVHHGDMHSGHFVTYRRSPPSARNPLSTSNQWLWVSDDTVRKASLQEVLSSSAYLLFYERVLSRMQHQSQECKSEE>sp|P42681|TXK_HUMAN Tyrosine-protein kinase TXK OS=Homo sapiens OX=9606GN=TXK PE=1 SV=3MILSSYNTIQSVFCCCCCCSVQKRQMRTQISLSTDEELPEKYTQRRRPWLSQLSNKKQSNTGRVQPSKRKPLPPLPPSEVAEEKIQVKALYDFLPREPCNLALRRAEEYLILEKYNPHWWKARDRLGNEGLIPSNYVTENKITNLEIYEWYHRNITRNQAEHLLRQESKEGAFIVRDSRHLGSYTISVFMGARRSTEAAIKHYQIKKNDSGQWYVAERHAFQSIPELIWYHQHNAAGLMTRLRYPVGLMGSCLPATAGFSYEKWEIDPSELAFIKEIGSGQFGVVHLGEWRSHIQVAIKAINEGSMSEEDFIEEAKVMMKLSHSKLVQLYGVCIQRKPLYIVTEFMENGCLLNYLRENKGKLRKEMLLSVCQDICEGMEYLERNGYIHRDLAARNCLVSSTCIVKISDFGMTRYVLDDEYVSSFGAKFPIKWSPPEVFLFNKYSSKSDVWSFGVLMWEVFTEGKMPFENKSNLQVVEAISEGFRLYRPHLAPMSIYEVMYSCWHEKPEGRPTFAELLRAVTEIAETW>sp|Q8TBC4|UBA3_HUMAN NEDD8-activating enzyme E1 catalytic subunitOS=Homo sapiens OX=9606 GN=UBA3 PE=1 SV=2MADGEEPEKKRRRIEELLAEKMAVDGGCGDTGDWEGRWNHVKKFLERSGPFTHPDFEPSTESLQFLLDTCKVLVIGAGGLGCELLKNLALSGFRQIHVIDMDTIDVSNLNRQFLFRPKDIGRPKAEVAAEFLNDRVPNCNVVPHFNKIQDFNDTFYRQFHIIVCGLDSIIARRWINGMLISLLNYEDGVLDPSSIVPLIDGGTEGFKGNARVILPGMTACIECTLELYPPQVNFPMCTIASMPRLPEHCIEYVRMLQWPKEQPFGEGVPLDGDDPEHIQWIFQKSLERASQYNIRGVTYRLTQGVVKRIIPAVASTNAVIAAVCATEVFKIATSAYIPLNNYLVFNDVDGLYTYTFEAERKENCPACSQLPQNIQFSPSAKLQEVLDYLTNSASLQMKSPAITATLEGKNRTLYLQSVTSIEERTRPNLSKTLKELGLVDGQELAVADVTTPQTVLFKLHFTS>sp|Q8TBC4-2|UBA3_HUMAN Isoform 2 of NEDD8-activating enzyme E1 catalyticsubunit OS=Homo sapiens OX=9606 GN=UBA3MADGEEPMAVDGGCGDTGDWEGRWNHVKKFLERSGPFTHPDFEPSTESLQFLLDTCKVLVIGAGGLGCELLKNLALSGFRQIHVIDMDTIDVSNLNRQFLFRPKDIGRPKAEVAAEFLNDRVPNCNVVPHFNKIQDFNDTFYRQFHIIVCGLDSIIARRWINGMLISLLNYEDGVLDPSSIVPLIDGGTEGFKGNARVILPGMTACIECTLELYPPQVNFPMCTIASMPRLPEHCIEYVRMLQWPKEQPFGEGVPLDGDDPEHIQWIFQKSLERASQYNIRGVTYRLTQGVVKRIIPAVASTNAVIAAVCATEVFKIATSAYIPLNNYLVFNDVDGLYTYTFEAERKENCPACSQLPQNIQFSPSAKLQEVLDYLTNSASLQMKSPAITATLEGKNRTLYLQSVTSIEERTRPNLSKTLKELGLVDGQELAVADVTTPQTVLFKLHFTS>sp|Q9H379|YI012_HUMAN Putative uncharacterized protein PRO3102 OS=Homosapiens OX=9606 GN=PRO3102 PE=5 SV=1MPLASPIQHHEVTRGVAPSMALRDGVCRIPLSAEFTAQCTDSQAPQMKRAPRCCCLAVVAQCPHHCPVLGCWSGCRCCCYCVFELHWLYCIQE>sp|O14771|ZN213_HUMAN Zinc finger protein 213 OS=Homo sapiens OX=9606GN=ZNF213 PE=1 SV=2MAAPLEAQDQAPGEGEGLLIVKVEDSSWEQESAQHEDGRDSEACRQRFRQFCYGDVHGPHEAFSQLWELCCRWLRPELRTKEQILELLVLEQFLTVLPGEIQGWVREQHPGSGEEAVALVEDLQKQPVKAWRQDVPSEEAEPEAAGRGSQATGPPPTVGARRRPSVPQEQHSHSAQPPALLKEGRPGETTDTCFVSGVHGPVALGDIPFYFSREEWGTLDPAQRDLFWDIKRENSRNTTLGFGLKGQSEKSLLQEMVPVVPGQTGSDVTVSWSPEEAEAWESENRPRAALGPVVGARRGRPPTRRRQFRDLAAEKPHSCGQCGKRFRWGSDLARHQRTHTGEKPHKCPECDKSFRSSSDLVRHQGVHTGEKPFSCSECGKSFSRSAYLADHQRIHTGEKPFGCSDCGKSFSLRSYLLDHRRVHTGERPFGCGECDKSFKQRAHLIAHQSLHAKMAQPVG>sp|O14771-2|ZN213_HUMAN Isoform 2 of Zinc finger protein 213 OS=Homosapiens OX=9606 GN=ZNF213MCPRRRRNPRLQAGDPRPRGLPRRWGHGGGRLFPRSSTAIAGPVALGDIPFYFSREEWGTLDPAQRDLFWDIKRENSRNTTLGFGLKGQSEKSLLQEMVPVVPGQTGSDVTVSWSPEEAEAWESENRPRAALGPVVGARRGRPPTRRRQFRDLAAEKPHSCGQCGKRFRWGSDLARHQRTHTGEKPHKCPECDKSFRSSSDLVRHQGVHTGEKPFSCSECGKSFSRSAYLADHQRIHTGEKPFGCSDCGKSFSLRSYLLDHRRVHTGERPFGCGECDKSFKQRAHLIAHQSLHAKMAQPVG>sp|P51786|ZN157_HUMAN Zinc finger protein 157 OS=Homo sapiens OX=9606GN=ZNF157 PE=2 SV=2MPANGTSPQRFPALIPGEPGRSFEGSVSFEDVAVDFTRQEWHRLDPAQRTMHKDVMLETYSNLASVGLCVAKPEMIFKLERGEELWILEEESSGHGYSGSLSLLCGNGSVGDNALRHDNDLLHHQKIQTLDQNVEYNGCRKAFHEKTGFVRRKRTPRGDKNFECHECGKAYCRKSNLVEHLRIHTGERPYECGECAKTFSARSYLIAHQKTHTGERPFECNECGKSFGRKSQLILHTRTHTGERPYECTECGKTFSEKATLTIHQRTHTGEKPYECSECGKTFRVKISLTQHHRTHTGEKPYECGECGKNFRAKKSLNQHQRIHTGEKPYECGECGKFFRMKMTLNNHQRTHTGEKPYQCNECGKSFRVHSSLGIHQRIHTGEKPYECNECGNAFYVKARLIEHQRMHSGEKPYECSECGKIFSMKKSLCQHRRTHTGEKPYECSECGNAFYVKVRLIEHQRIHTGERPFECQECGKAFCRKAHLTEHQRTHIGWSWRCTMKKASH>sp|Q9HC78|ZBT20_HUMAN Zinc finger and BTB domain-containing protein 20OS=Homo sapiens OX=9606 GN=ZBTB20 PE=1 SV=3MLERKKPKTAENQKASEENEITQPGGSSAKPGLPCLNFEAVLSPDPALIHSTHSLTNSHAHTGSSDCDISCKGMTERIHSINLHNFSNSVLETLNEQRNRGHFCDVTVRIHGSMLRAHRCVLAAGSPFFQDKLLLGYSDIEIPSVVSVQSVQKLIDFMYSGVLRVSQSEALQILTAASILQIKTVIDECTRIVSQNVGDVFPGIQDSGQDTPRGTPESGTSGQSSDTESGYLQSHPQHSVDRIYSALYACSMQNGSGERSFYSGAVVSHHETALGLPRDHHMEDPSWITRIHERSQQMERYLSTTPETTHCRKQPRPVRIQTLVGNIHIKQEMEDDYDYYGQQRVQILERNESEECTEDTDQAEGTESEPKGESFDSGVSSSIGTEPDSVEQQFGPGAARDSQAEPTQPEQAAEAPAEGGPQTNQLETGASSPERSNEVEMDSTVITVSNSSDKSVLQQPSVNTSIGQPLPSTQLYLRQTETLTSNLRMPLTLTSNTQVIGTAGNTYLPALFTTQPAGSGPKPFLFSLPQPLAGQQTQFVTVSQPGLSTFTAQLPAPQPLASSAGHSTASGQGEKKPYECTLCNKTFTAKQNYVKHMFVHTGEKPHQCSICWRSFSLKDYLIKHMVTHTGVRAYQCSICNKRFTQKSSLNVHMRLHRGEKSYECYICKKKFSHKTLLERHVALHSASNGTPPAGTPPGARAGPPGVVACTEGTTYVCSVCPAKFDQIEQFNDHMRMHVSDG>sp|Q9HC78-2|ZBT20_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 20 OS=Homo sapiens OX=9606 GN=ZBTB20MTERIHSINLHNFSNSVLETLNEQRNRGHFCDVTVRIHGSMLRAHRCVLAAGSPFFQDKLLLGYSDIEIPSVVSVQSVQKLIDFMYSGVLRVSQSEALQILTAASILQIKTVIDECTRIVSQNVGDVFPGIQDSGQDTPRGTPESGTSGQSSDTESGYLQSHPQHSVDRIYSALYACSMQNGSGERSFYSGAVVSHHETALGLPRDHHMEDPSWITRIHERSQQMERYLSTTPETTHCRKQPRPVRIQTLVGNIHIKQEMEDDYDYYGQQRVQILERNESEECTEDTDQAEGTESEPKGESFDSGVSSSIGTEPDSVEQQFGPGAARDSQAEPTQPEQAAEAPAEGGPQTNQLETGASSPERSNEVEMDSTVITVSNSSDKSVLQQPSVNTSIGQPLPSTQLYLRQTETLTSNLRMPLTLTSNTQVIGTAGNTYLPALFTTQPAGSGPKPFLFSLPQPLAGQQTQFVTVSQPGLSTFTAQLPAPQPLASSAGHSTASGQGEKKPYECTLCNKTFTAKQNYVKHMFVHTGEKPHQCSICWRSFSLKDYLIKHMVTHTGVRAYQCSICNKRFTQKSSLNVHMRLHRGEKSYECYICKKKFSHKTLLERHVALHSASNGTPPAGTPPGARAGPPGVVACTEGTTYVCSVCPAKFDQIEQFNDHMRMHVSDG>sp|Q14588|ZN234_HUMAN Zinc finger protein 234 OS=Homo sapiens OX=9606GN=ZNF234 PE=2 SV=3MTTFKEGLTFKDVAVVFTEEELGLLDPVQRNLYQDVMLENFRNLLSVGHHPFKHDVFLLEKEKKLDIMKTATQRKGKSADKIQSEVETVPEAGRHEELYWGQIWKQIASDLIKYEDSMISISRFPRQGDLSCQVRAGLYTTHTGQKFYQCDEYKKSFTDVFNFDLHQQLHSGEKSHTCDECGKSFCYISALHIHQRVHMGEKCYKCDVCGKEFSQSSHLQTHQRVHTVEKPFKCVECGKGFSRRSTLTVHCKLHSGEKPYNCEECGRAFIHASHLQEHQRIHTGEKPFKCDTCGKNFRRRSALNNHCMVHTGEKPYKCEDCGKCFTCSSNLRIHQRVHTGEKPYKCEECGKCFIQPSQFQAHRRIHTGEKPYVCKVCGKGFIYSSSFQAHQGVHTGEKPYKCNECGKSFRMKIHYQVHLVVHTGEKPYKCEVCGKAFRQSSYLKIHLKAHSVQKPFKCEECGQGFNQSSRLQIHQLIHTGEKPYKCEECGKGFSRRADLKIHCRIHTGEKPYNCEECGKVFSQASHLLTHQRVHSGEKPFKCEECGKSFSRSAHLQAHQKVHTGEKPYKCGECGKGFKWSLNLDMHQRVHTGEKPYTCGECGKHFSQASSLQLHQSVHTGEKPYKCDVCGKVFSRSSQLQYHRRVHTGEKPYKCEICGKRFSWRSNLVSHHKIHAAGTFYENDENSKNIRELSEGGSSTR>sp|P15622|ZN250_HUMAN Zinc finger protein 250 OS=Homo sapiens OX=9606GN=ZNF250 PE=1 SV=3MAAARLLPVPAGPQPLSFQAKLTFEDVAVLLSQDEWDRLCPAQRGLYRNVMMETYGNVVSLGLPGSKPDIISQLERGEDPWVLDRKGAKKSQGLWSDYSDNLKYDHTTACTQQDSLSCPWECETKGESQNTDLSPKPLISEQTVILGKTPLGRIDQENNETKQSFCLSPNSVDHREVQVLSQSMPLTPHQAVPSGERPYMCVECGKCFGRSSHLLQHQRIHTGEKPYVCSVCGKAFSQSSVLSKHRRIHTGEKPYECNECGKAFRVSSDLAQHHKIHTGEKPHECLECRKAFTQLSHLIQHQRIHTGERPYVCPLCGKAFNHSTVLRSHQRVHTGEKPHRCNECGKTFSVKRTLLQHQRIHTGEKPYTCSECGKAFSDRSVLIQHHNVHTGEKPYECSECGKTFSHRSTLMNHERIHTEEKPYACYECGKAFVQHSHLIQHQRVHTGEKPYVCGECGHAFSARRSLIQHERIHTGEKPFQCTECGKAFSLKATLIVHLRTHTGEKPYECNSCGKAFSQYSVLIQHQRIHTGEKPYECGECGRAFNQHGHLIQHQKVHRKL>sp|P15622-2|ZN250_HUMAN Isoform 2 of Zinc finger protein 250 OS=Homosapiens OX=9606 GN=ZNF250MAAARLLPVPAGPQAKLTFEDVAVLLSQDEWDRLCPAQRGLYRNVMMETYGNVVSLGLPGSKPDIISQLERGEDPWVLDRKGAKKSQGLWSDYSDNLKYDHTTACTQQDSLSCPWECETKGESQNTDLSPKPLISEQTVILGKTPLGRIDQENNETKQSFCLSPNSVDHREVQVLSQSMPLTPHQAVPSGERPYMCVECGKCFGRSSHLLQHQRIHTGEKPYVCSVCGKAFSQSSVLSKHRRIHTGEKPYECNECGKAFRVSSDLAQHHKIHTGEKPHECLECRKAFTQLSHLIQHQRIHTGERPYVCPLCGKAFNHSTVLRSHQRVHTGEKPHRCNECGKTFSVKRTLLQHQRIHTGEKPFQCTECGKAFSLKATLIVHLRTHTGEKPYECNSCGKAFSQYSVLIQHQRIHTGEKPYECGECGRAFNQHGHLIQHQKVHRKL>sp|P15622-3|ZN250_HUMAN Isoform 3 of Zinc finger protein 250 OS=Homosapiens OX=9606 GN=ZNF250MAAARLLPVPAGPQAKLTFEDVAVLLSQDEWDRLCPAQRGLYRNVMMETYGNVVSLGLPGSKPDIISQLERGEDPWVLDRKGAKKSQGLWSDYSDNLKYDHTTACTQQDSLSCPWECETKGESQNTDLSPKPLISEQTVILGKTPLGRIDQENNETKQSFCLSPNSVDHREVQVLSQSMPLTPHQAVPSGERPYMCVECGKCFGRSSHLLQHQRIHTGEKPYVCSVCGKAFSQSSVLSKHRRIHTGEKPYECNECGKAFRVSSDLAQHHKIHTGEKPHECLECRKAFTQLSHLIQHQRIHTGERPYVCPLCGKAFNHSTVLRSHQRVHTGEKPHRCNECGKTFSVKRTLLQHQRIHTGEKPYTCSECGKAFSDRSVLIQHHNVHTGEKPYECSECGKTFSHRSTLMNHERIHTEEKPYACYECGKAFVQHSHLIQHQRVHTGEKPYVCGECGHAFSARRSLIQHERIHTGEKPFQCTECGKAFSLKATLIVHLRTHTGEKPYECNSCGKAFSQYSVLIQHQRIHTGEKPYECGECGRAFNQHGHLIQHQKVHRKL>sp|Q8NCN2|ZBT34_HUMAN Zinc finger and BTB domain-containing protein 34OS=Homo sapiens OX=9606 GN=ZBTB34 PE=1 SV=4MDSSSFIQFDVPEYSSTVLSQLNELRLQGKLCDIIVHIQGQPFRAHKAVLAASSPYFRDHSALSTMSGLSISVIKNPNVFEQLLSFCYTGRMSLQLKDVVSFLTAASFLQMQCVIDKCTQILESIHSKISVGDVDSVTVGAEENPESRNGVKDSSFFANPVEISPPYCSQGRQPTASSDLRMETTPSKALRSRLQEEGHSDRGSSGSVSEYEIQIEGDHEQGDLLVRESQITEVKVKMEKSDRPSCSDSSSLGDDGYHTEMVDGEQVVAVNVGSYGSVLQHAYSYSQAASQPTNVSEAFGSLSNSSPSRSMLSCFRGGRARQKRALSVHLHSDLQGLVQGSDSEAMMNNPGYESSPRERSARGHWYPYNERLICIYCGKSFNQKGSLDRHMRLHMGITPFVCKFCGKKYTRKDQLEYHIRGHTDDKPFRCEICGKCFPFQGTLNQHLRKNHPGVAEVRSRIESPERTDVYVEQKLENDASASEMGLDSRMEIHTVSDAPD>sp|Q15916|ZBTB6_HUMAN Zinc finger and BTB domain-containing protein 6OS=Homo sapiens OX=9606 GN=ZBTB6 PE=1 SV=1MAAESDVLHFQFEQQGDVVLQKMNLLRQQNLFCDVSIYINDTEFQGHKVILAACSTFMRDQFLLTQSKHVRITILQSAEVGRKLLLSCYTGALEVKRKELLKYLTAASYLQMVHIVEKCTEALSKYLEIDLSMKNNNQHTDLCQSSDPDVKNEDENSDKDCEIIEISEDSPVNIDFHVKEEESNALQSTVESLTSERKEMKSPELSTVDIGFKDNEICILHVESISTAGVENGQFSQPCTSSKASMYFSETQHSLINSTVESRVAEVPGNQDQGLFCENTEGSYGTVSEIQNLEEGYSLRHQCPRCPRGFLHVENYLRHLKMHKLFLCLQCGKTFTQKKNLNRHIRGHMGIRPFQCTVCLKTFTAKSTLQDHLNIHSGDRPYKCHCCDMDFKHKSALKKHLTSVHGRSSGEKLSRPDLKRQSLL>sp|O95125|ZN202_HUMAN Zinc finger protein 202 OS=Homo sapiens OX=9606GN=ZNF202 PE=1 SV=4MATAVEPEDQDLWEEEGILMVKLEDDFTCRPESVLQRDDPVLETSHQNFRRFRYQEAASPREALIRLRELCHQWLRPERRTKEQILELLVLEQFLTVLPGELQSWVRGQRPESGEEAVTLVEGLQKQPRRPRRWVTVHVHGQEVLSEETVHLGVEPESPNELQDPVQSSTPEQSPEETTQSPDLGAPAEQRPHQEEELQTLQESEVPVPEDPDLPAERSSGDSEMVALLTALSQGLVTFKDVAVCFSQDQWSDLDPTQKEFYGEYVLEEDCGIVVSLSFPIPRPDEISQVREEEPWVPDIQEPQETQEPEILSFTYTGDRSKDEEECLEQEDLSLEDIHRPVLGEPEIHQTPDWEIVFEDNPGRLNERRFGTNISQVNSFVNLRETTPVHPLLGRHHDCSVCGKSFTCNSHLVRHLRTHTGEKPYKCMECGKSYTRSSHLARHQKVHKMNAPYKYPLNRKNLEETSPVTQAERTPSVEKPYRCDDCGKHFRWTSDLVRHQRTHTGEKPFFCTICGKSFSQKSVLTTHQRIHLGGKPYLCGECGEDFSEHRRYLAHRKTHAAEELYLCSECGRCFTHSAAFAKHLRGHASVRPCRCNECGKSFSRRDHLVRHQRTHTGEKPFTCPTCGKSFSRGYHLIRHQRTHSEKTS>sp|O95125-2|ZN202_HUMAN Isoform Alpha of Zinc finger protein 202 OS=Homosapiens OX=9606 GN=ZNF202MVALLTALSQGLVTFKDVAVCFSQDQWSDLDPTQKEFYGEYVLEEDCGIVVSLSFPIPRPDEISQVREEEPWVPDIQEPQETQEPEILSFTYTGDRSKDEEECLEQEDLSLEDIHRPVLGEPEIHQTPDWEIVFEDNPGRLNERRFGTNISQVNSFVNLRETTPVHPLLGRHHDCSVCGKSFTCNSHLVRHLRTHTGEKPYKCMECGKSYTRSSHLARHQKVHKMNAPYKYPLNRKNLEETSPVTQAERTPSVEKPYRCDDCGKHFRWTSDLVRHQRTHTGEKPFFCTICGKSFSQKSVLTTHQRIHLGGKPYLCGECGEDFSEHRRYLAHRKTHAAEELYLCSECGRCFTHSAAFAKHLRGHASVRPCRCNECGKSFSRRDHLVRHQRTHTGEKPFTCPTCGKSFSRGYHLIRHQRTHSEKTS>sp|O43298|ZBT43_HUMAN Zinc finger and BTB domain-containing protein 43OS=Homo sapiens OX=9606 GN=ZBTB43 PE=1 SV=1MEPGTNSFRVEFPDFSSTILQKLNQQRQQGQLCDVSIVVQGHIFRAHKAVLAASSPYFCDQVLLKNSRRIVLPDVMNPRVFENILLSSYTGRLVMPAPEIVSYLTAASFLQMWHVVDKCTEVLEGNPTVLCQKLNHGSDHQSPSSSSYNGLVESFELGSGGHTDFPKAQELRDGENEEESTKDELSSQLTEHEYLPSNSSTEHDRLSTEMASQDGEEGASDSAEFHYTRPMYSKPSIMAHKRWIHVKPERLEQACEGMDVHATYDEHQVTESINTVQTEHTVQPSGVEEDFHIGEKKVEAEFDEQADESNYDEQVDFYGSSMEEFSGERSDGNLIGHRQEAALAAGYSENIEMVTGIKEEASHLGFSATDKLYPCQCGKSFTHKSQRDRHMSMHLGLRPYGCGVCGKKFKMKHHLVGHMKIHTGIKPYECNICAKRFMWRDSFHRHVTSCTKSYEAAKAEQNTTEAN>sp|Q15911|ZFHX3_HUMAN Zinc finger homeobox protein 3 OS=Homo sapiensOX=9606 GN=ZFHX3 PE=1 SV=2MEGCDSPVVSGKDNGCGIPQHQQWTELNSTHLPDKPSSMEQSTGESHGPLDSLRAPFNERLAESTASAGPPSEPASKEVTCNECSASFASLQTYMEHHCPSARPPPPLREESASDTGEEGDEESDVENLAGEIVYQPDGSAYIVESLSQLTQGGGACGSGSGSGPLPSLFLNSLPGAGGKQGDPSCAAPVYPQIINTFHIASSFGKWFEGPDQAFPNTSALAGLSPVLHSFRVFDVRHKSNKDYLNSDGSAKSSCVSKDVPNNVDLSKFDGFVLYGKRKPILMCFLCKLSFGYVRSFVTHAVHDHRMTLSEDERKILSNKNISAIIQGIGKDKEPLVSFLEPKNKNFQHPLVSTANLIGPGHSFYGKFSGIRMEGEEALPAGSAAGPEQPQAGLLTPSTLLNLGGLTSSVLKTPITSVPLGPLASSPTKSSEGKDSGAAEGEKQEVGDGDCFSEKVEPAEEEAEEEEEEEEAEEEEEEEEEEEEEEEDEGCKGLFPSELDEELEDRPHEEPGAAAGSSSKKDLALSNQSISNSPLMPNVLQTLSRGTASTSSNSASSFVVFDGANRRNRLSFNSEGVRANVAEGGRRLDFADESANKDNATAPEPNESTEGDDGGFVPHHQHAGSLCELGVGECPSGSGVECPKCDTVLGSSRSLGGHMTMMHSRNSCKTLKCPKCNWHYKYQQTLEAHMKEKHPEPGGSCVYCKSGQPHPRLARGESYTCGYKPFRCEVCNYSTTTKGNLSIHMQSDKHLNNMQNLQNGGGEQVFSHTAGAAAAAVAAAAAAANISSSCGAPSPTKPKTKPTWRCEVCDYETNVARNLRIHMTSEKHMHNMMLLQQNMTQIQHNRHLGLGSLPSPAEAELYQYYLAQNMNLPNLKMDSAASDAQFMMSGFQLDPAGPMAAMTPALVGGEIPLDMRLGGGQLVSEELMNLGESFIQTNDPSLKLFQCAVCNKFTTDNLDMLGLHMNVERSLSEDEWKAVMGDSYQCKLCRYNTQLKANFQLHCKTDKHVQKYQLVAHIKEGGKANEWRLKCVAIGNPVHLKCNACDYYTNSLEKLRLHTVNSRHEASLKLYKHLQQHESGVEGESCYYHCVLCNYSTKAKLNLIQHVRSMKHQRSESLRKLQRLQKGLPEEDEDLGQIFTIRRCPSTDPEEAIEDVEGPSETAADPEELAKDQEGGASSSQAEKELTDSPATSKRISFPGSSESPLSSKRPKTAEEIKPEQMYQCPYCKYSNADVNRLRVHAMTQHSVQPMLRCPLCQDMLNNKIHLQLHLTHLHSVAPDCVEKLIMTVTTPEMVMPSSMFLPAAVPDRDGNSNLEEAGKQPETSEDLGKNILPSASTEQSGDLKPSPADPGSVREDSGFICWKKGCNQVFKTSAALQTHFNEVHAKRPQLPVSDRHVYKYRCNQCSLAFKTIEKLQLHSQYHVIRAATMCCLCQRSFRTFQALKKHLETSHLELSEADIQQLYGGLLANGDLLAMGDPTLAEDHTIIVEEDKEEESDLEDKQSPTGSDSGSVQEDSGSEPKRALPFRKGPNFTMEKFLDPSRPYKCTVCKESFTQKNILLVHYNSVSHLHKLKRALQESATGQPEPTSSPDNKPFKCNTCNVAYSQSSTLEIHMRSVLHQTKARAAKLEAASGSSNGTGNSSSISLSSSTPSPVSTSGSNTFTTSNPSSAGIAPSSNLLSQVPTESVGMPPLGNPIGANIASPSEPKEANRKKLADMIASRQQQQQQQQQQQQQQQQQQQAQTLAQAQAQVQAHLQQELQQQAALIQSQLFNPTLLPHFPMTTETLLQLQQQQHLLFPFYIPSAEFQLNPEVSLPVTSGALTLTGTGPGLLEDLKAQVQVPQQSHQQILPQQQQNQLSIAQSHSALLQPSQHPEKKNKLVIKEKEKESQRERDSAEGGEGNTGPKETLPDALKAKEKKELAPGGGSEPSMLPPRIASDARGNATKALLENFGFELVIQYNENKQKVQKKNGKTDQGENLEKLECDSCGKLFSNILILKSHQEHVHQNYFPFKQLERFAKQYRDHYDKLYPLRPQTPEPPPPPPPPPPPPLPAAPPQPASTPAIPASAPPITSPTIAPAQPSVPLTQLSMPMELPIFSPLMMQTMPLQTLPAQLPPQLGPVEPLPADLAQLYQHQLNPTLLQQQNKRPRTRITDDQLRVLRQYFDINNSPSEEQIKEMADKSGLPQKVIKHWFRNTLFKERQRNKDSPYNFSNPPITSLEELKIDSRPPSPEPPKQEYWGSKRSSRTRFTDYQLRVLQDFFDANAYPKDDEFEQLSNLLNLPTRVIVVWFQNARQKARKNYENQGEGKDGERRELTNDRYIRTSNLNYQCKKCSLVFQRIFDLIKHQKKLCYKDEDEEGQDDSQNEDSMDAMEILTPTSSSCSTPMPSQAYSAPAPSANNTASSAFLQLTAEAEELATFNSKTEAGDEKPKLAEAPSAQPNQTQEKQGQPKPELQQQEQPEQKTNTPQQKLPQLVSLPSLPQPPPQAPPPQCPLPQSSPSPSQLSHLPLKPLHTSTPQQLANLPPQLIPYQCDQCKLAFPSFEHWQEHQQLHFLSAQNQFIHPQFLDRSLDMPFMLFDPSNPLLASQLLSGAIPQIPASSATSPSTPTSTMNTLKRKLEEKASASPGENDSGTGGEEPQRDKRLRTTITPEQLEILYQKYLLDSNPTRKMLDHIAHEVGLKKRVVQVWFQNTRARERKGQFRAVGPAQAHRRCPFCRALFKAKTALEAHIRSRHWHEAKRAGYNLTLSAMLLDCDGGLQMKGDIFDGTSFSHLPPSSSDGQGVPLSPVSKTMELSPRTLLSPSSIKVEGIEDFESPSMSSVNLNFDQTKLDNDDCSSVNTAITDTTTGDEGNADNDSATGIATETKSSSAPNEGLTKAAMMAMSEYEDRLSSGLVSPAPSFYSKEYDNEGTVDYSETSSLADPCSPSPGASGSAGKSGDSGDRPGQKRFRTQMTNLQLKVLKSCFNDYRTPTMLECEVLGNDIGLPKRVVQVWFQNARAKEKKSKLSMAKHFGINQTSYEGPKTECTLCGIKYSARLSVRDHIFSQQHISKVKDTIGSQLDKEKEYFDPATVRQLMAQQELDRIKKANEVLGLAAQQQGMFDNTPLQALNLPTAYPALQGIPPVLLPGLNSPSLPGFTPSNTALTSPKPNLMGLPSTTVPSPGLPTSGLPNKPSSASLSSPTPAQATMAMGPQQPPQQQQQQQQPQVQQPPPPPAAQPPPTPQLPLQQQQQRKDKDSEKVKEKEKAHKGKGEPLPVPKKEKGEAPTATAATISAPLPTMEYAVDPAQLQALQAALTSDPTALLTSQFLPYFVPGFSPYYAPQIPGALQSGYLQPMYGMEGLFPYSPALSQALMGLSPGSLLQQYQQYQQSLQEAIQQQQQRQLQQQQQQKVQQQQPKASQTPVPPGAPSPDKDPAKESPKPEEQKNTPREVSPLLPKLPEEPEAESKSADSLYDPFIVPKVQYKLVCRKCQAGFSDEEAARSHLKSLCFFGQSVVNLQEMVLHVPTGGGGGGSGGGGGGGGGGGGGGSYHCLACESALCGEEALSQHLESALHKHRTITRAARNAKEHPSLLPHSACFPDPSTASTSQSAAHSNDSPPPPSAAAPSSASPHASRKSWPQVVSRASAAKPPSFPPLSSSSTVTSSSCSTSGVQPSMPTDDYSEESDTDLSQKSDGPASPVEGPKDPSCPKDSGLTSVGTDTFRL>sp|Q15911-2|ZFHX3_HUMAN Isoform B of Zinc finger homeobox protein 3OS=Homo sapiens OX=9606 GN=ZFHX3MRLGGGQLVSEELMNLGESFIQTNDPSLKLFQCAVCNKFTTDNLDMLGLHMNVERSLSEDEWKAVMGDSYQCKLCRYNTQLKANFQLHCKTDKHVQKYQLVAHIKEGGKANEWRLKCVAIGNPVHLKCNACDYYTNSLEKLRLHTVNSRHEASLKLYKHLQQHESGVEGESCYYHCVLCNYSTKAKLNLIQHVRSMKHQRSESLRKLQRLQKGLPEEDEDLGQIFTIRRCPSTDPEEAIEDVEGPSETAADPEELAKDQEGGASSSQAEKELTDSPATSKRISFPGSSESPLSSKRPKTAEEIKPEQMYQCPYCKYSNADVNRLRVHAMTQHSVQPMLRCPLCQDMLNNKIHLQLHLTHLHSVAPDCVEKLIMTVTTPEMVMPSSMFLPAAVPDRDGNSNLEEAGKQPETSEDLGKNILPSASTEQSGDLKPSPADPGSVREDSGFICWKKGCNQVFKTSAALQTHFNEVHAKRPQLPVSDRHVYKYRCNQCSLAFKTIEKLQLHSQYHVIRAATMCCLCQRSFRTFQALKKHLETSHLELSEADIQQLYGGLLANGDLLAMGDPTLAEDHTIIVEEDKEEESDLEDKQSPTGSDSGSVQEDSGSEPKRALPFRKGPNFTMEKFLDPSRPYKCTVCKESFTQKNILLVHYNSVSHLHKLKRALQESATGQPEPTSSPDNKPFKCNTCNVAYSQSSTLEIHMRSVLHQTKARAAKLEAASGSSNGTGNSSSISLSSSTPSPVSTSGSNTFTTSNPSSAGIAPSSNLLSQVPTESVGMPPLGNPIGANIASPSEPKEANRKKLADMIASRQQQQQQQQQQQQQQQQQQQAQTLAQAQAQVQAHLQQELQQQAALIQSQLFNPTLLPHFPMTTETLLQLQQQQHLLFPFYIPSAEFQLNPEVSLPVTSGALTLTGTGPGLLEDLKAQVQVPQQSHQQILPQQQQNQLSIAQSHSALLQPSQHPEKKNKLVIKEKEKESQRERDSAEGGEGNTGPKETLPDALKAKEKKELAPGGGSEPSMLPPRIASDARGNATKALLENFGFELVIQYNENKQKVQKKNGKTDQGENLEKLECDSCGKLFSNILILKSHQEHVHQNYFPFKQLERFAKQYRDHYDKLYPLRPQTPEPPPPPPPPPPPPLPAAPPQPASTPAIPASAPPITSPTIAPAQPSVPLTQLSMPMELPIFSPLMMQTMPLQTLPAQLPPQLGPVEPLPADLAQLYQHQLNPTLLQQQNKRPRTRITDDQLRVLRQYFDINNSPSEEQIKEMADKSGLPQKVIKHWFRNTLFKERQRNKDSPYNFSNPPITSLEELKIDSRPPSPEPPKQEYWGSKRSSRTRFTDYQLRVLQDFFDANAYPKDDEFEQLSNLLNLPTRVIVVWFQNARQKARKNYENQGEGKDGERRELTNDRYIRTSNLNYQCKKCSLVFQRIFDLIKHQKKLCYKDEDEEGQDDSQNEDSMDAMEILTPTSSSCSTPMPSQAYSAPAPSANNTASSAFLQLTAEAEELATFNSKTEAGDEKPKLAEAPSAQPNQTQEKQGQPKPELQQQEQPEQKTNTPQQKLPQLVSLPSLPQPPPQAPPPQCPLPQSSPSPSQLSHLPLKPLHTSTPQQLANLPPQLIPYQCDQCKLAFPSFEHWQEHQQLHFLSAQNQFIHPQFLDRSLDMPFMLFDPSNPLLASQLLSGAIPQIPASSATSPSTPTSTMNTLKRKLEEKASASPGENDSGTGGEEPQRDKRLRTTITPEQLEILYQKYLLDSNPTRKMLDHIAHEVGLKKRVVQVWFQNTRARERKGQFRAVGPAQAHRRCPFCRALFKAKTALEAHIRSRHWHEAKRAGYNLTLSAMLLDCDGGLQMKGDIFDGTSFSHLPPSSSDGQGVPLSPVSKTMELSPRTLLSPSSIKVEGIEDFESPSMSSVNLNFDQTKLDNDDCSSVNTAITDTTTGDEGNADNDSATGIATETKSSSAPNEGLTKAAMMAMSEYEDRLSSGLVSPAPSFYSKEYDNEGTVDYSETSSLADPCSPSPGASGSAGKSGDSGDRPGQKRFRTQMTNLQLKVLKSCFNDYRTPTMLECEVLGNDIGLPKRVVQVWFQNARAKEKKSKLSMAKHFGINQTSYEGPKTECTLCGIKYSARLSVRDHIFSQQHISKVKDTIGSQLDKEKEYFDPATVRQLMAQQELDRIKKANEVLGLAAQQQGMFDNTPLQALNLPTAYPALQGIPPVLLPGLNSPSLPGFTPSNTALTSPKPNLMGLPSTTVPSPGLPTSGLPNKPSSASLSSPTPAQATMAMGPQQPPQQQQQQQQPQVQQPPPPPAAQPPPTPQLPLQQQQQRKDKDSEKVKEKEKAHKGKGEPLPVPKKEKGEAPTATAATISAPLPTMEYAVDPAQLQALQAALTSDPTALLTSQFLPYFVPGFSPYYAPQIPGALQSGYLQPMYGMEGLFPYSPALSQALMGLSPGSLLQQYQQYQQSLQEAIQQQQQRQLQQQQQQKVQQQQPKASQTPVPPGAPSPDKDPAKESPKPEEQKNTPREVSPLLPKLPEEPEAESKSADSLYDPFIVPKVQYKLVCRKCQAGFSDEEAARSHLKSLCFFGQSVVNLQEMVLHVPTGGGGGGSGGGGGGGGGGGGGGSYHCLACESALCGEEALSQHLESALHKHRTITRAARNAKEHPSLLPHSACFPDPSTASTSQSAAHSNDSPPPPSAAAPSSASPHASRKSWPQVVSRASAAKPPSFPPLSSSSTVTSSSCSTSGVQPSMPTDDYSEESDTDLSQKSDGPASPVEGPKDPSCPKDSGLTSVGTDTFRL>sp|Q8TF50|ZN526_HUMAN Zinc finger protein 526 OS=Homo sapiens OX=9606GN=ZNF526 PE=1 SV=2MAEVVAEVAEMPTQMSPGAVEMSTPMSAEMMEMSTEVTEMTPGEALASSLFFQHHQFMCSECGSLYNTLEEVLSHQEQHMLAVSEEEALTTQNVGLEPELVPGAEGPFQCGECSQLILSPGELLAHQDAHLRESANQIQYQCWDCQELFPSPELWVAHRKAQHLSATVAEPPVPPPLPPPTPLPPPSPPSEVKMEPYECPECSTLCATPEEFLEHQGTHFDSLEKEERNGLEEEEEDDEEDEEDDEEMEDEEAMAEVGDDAVGGDESTAGWAQGCGDCPQHQPSAGARRQHRRTAHSPASATHPFHCSQCQRSFSSANRLQAHGRAHVGGTHECTTCSKVFKKAASLEQHLRLHRGEARYLCVDCGRGFGTELTLVAHRRAHTANPLHRCRCGKTFSNMTKFLYHRRTHAGKSGAPPTGATAPPAPAEPTPPPPPPAPPAQLPCPQCSKSFASASRLSRHRRAVHGPPERRHRCGVCGKGFKKLIHVRNHLRTHTGERPFQCHSCGKTFASLANLSRHQLTHTGARPYQCLDCGKRFTQSSNLQQHRRLHLRPVAFARAPRLPITGLYNKSPYYCGTCGRWFRAMAGLRLHQRVHARARTLTLQPPRSPSPAPPPPPEPQQTIMCTELGETIAIIETSQPLALEDTLQLCQAALGASEAGGLLQLDTAFV>sp|Q8NDQ6|ZN540_HUMAN Zinc finger protein 540 OS=Homo sapiens OX=9606GN=ZNF540 PE=1 SV=1MAHALVTFRDVAIDFSQKEWECLDTTQRKLYRDVMLENYNNLVSLGYSGSKPDVITLLEQGKEPCVVARDVTGRQCPGLLSRHKTKKLSSEKDIHEISLSKESIIEKSKTLRLKGSIFRNEWQNKSEFEGQQGLKERSISQKKIVSKKMSTDRKRPSFTLNQRIHNSEKSCDSHLVQHGKIDSDVKHDCKECGSTFNNVYQLTLHQKIHTGEKSCKCEKCGKVFSHSYQLTLHQRFHTGEKPYECQECGKTFTLYPQLNRHQKIHTGKKPYMCKKCDKGFFSRLELTQHKRIHTGKKSYECKECGKVFQLIFYFKEHERIHTGKKPYECKECGKAFSVCGQLTRHQKIHTGVKPYECKECGKTFRLSFYLTEHRRTHAGKKPYECKECGKSFNVRGQLNRHKTIHTGIKPFACKVCEKAFSYSGDLRVHSRIHTGEKPYECKECGKAFMLRSVLTEHQRLHTGVKPYECKECGKTFRVRSQISLHKKIHTDVKPYKCVRCGKTFRFGFYLTEHQRIHTGEKPYKCKECGKAFIRRGNLKEHLKIHSGLKPYDCKECGKSFSRRGQFTEHQKIHTGVKPYKCKECGKAFSRSVDLRIHQRIHTGEKPYECKQCGKAFRLNSHLTEHQRIHTGEKPYECKVCRKAFRQYSHLYQHQKTHNVI>sp|Q8NDQ6-2|ZN540_HUMAN Isoform 2 of Zinc finger protein 540 OS=Homosapiens OX=9606 GN=ZNF540MAHALVTFRDVAIDFSQKEWECLDTTQRKLYRDVMLENYNNLVSLGLLSRHKTKKLSSEKDIHEISLSKESIIEKSKTLRLKGSIFRNEWQNKSEFEGQQGLKERSISQKKIVSKKMSTDRKRPSFTLNQRIHNSEKSCDSHLVQHGKIDSDVKHDCKECGSTFNNVYQLTLHQKIHTGEKSCKCEKCGKVFSHSYQLTLHQRFHTGEKPYECQECGKTFTLYPQLNRHQKIHTGKKPYMCKKCDKGFFSRLELTQHKRIHTGKKSYECKECGKVFQLIFYFKEHERIHTGKKPYECKECGKAFSVCGQLTRHQKIHTGVKPYECKECGKTFRLSFYLTEHRRTHAGKKPYECKECGKSFNVRGQLNRHKTIHTGIKPFACKVCEKAFSYSGDLRVHSRIHTGEKPYECKECGKAFMLRSVLTEHQRLHTGVKPYECKECGKTFRVRSQISLHKKIHTDVKPYKCVRCGKTFRFGFYLTEHQRIHTGEKPYKCKECGKAFIRRGNLKEHLKIHSGLKPYDCKECGKSFSRRGQFTEHQKIHTGVKPYKCKECGKAFSRSVDLRIHQRIHTGEKPYECKQCGKAFRLNSHLTEHQRIHTGEKPYECKVCRKAFRQYSHLYQHQKTHNVI>sp|Q8NDQ6-4|ZN540_HUMAN Isoform 4 of Zinc finger protein 540 OS=Homosapiens OX=9606 GN=ZNF540MLPNFKLYNFIEIFFKPLTPSKNRFHFVSYFENVNFMLCWLQENNFCLLLCFLSGLLSRHKTKKLSSEKDIHEISLSKESIIEKSKTLRLKGSIFRNEWQNKSEFEGQQGLKERSISQKKIVSKKMSTDRKRPSFTLNQRIHNSEKSCDSHLVQHGKIDSDVKHDCKECGSTFNNVYQLTLHQKIHTGEKSCKCEKCGKVFSHSYQLTLHQRFHTGEKPYECQECGKTFTLYPQLNRHQKIHTGKKPYMCKKCDKGFFSRLELTQHKRIHTGKKSYECKECGKVFQLIFYFKEHERIHTGKKPYECKECGKAFSVCGQLTRHQKIHTGVKPYECKECGKTFRLSFYLTEHRRTHAGKKPYECKECGKSFNVRGQLNRHKTIHTGIKPFACKVCEKAFSYSGDLRVHSRIHTGEKPYECKECGKAFMLRSVLTEHQRLHTGVKPYECKECGKTFRVRSQISLHKKIHTDVKPYKCVRCGKTFRFGFYLTEHQRIHTGEKPYKCKECGKAFIRRGNLKEHLKIHSGLKPYDCKECGKSFSRRGQFTEHQKIHTGVKPYKCKECGKAFSRSVDLRIHQRIHTGEKPYECKQCGKAFRLNSHLTEHQRIHTGEKPYECKVCRKAFRQYSHLYQHQKTHNVI>sp|P17027|ZNF23_HUMAN Zinc finger protein 23 OS=Homo sapiens OX=9606GN=ZNF23 PE=1 SV=3MLENYGNVASLGFPLLKPAVISQLEGGSELGGSSPLAAGTGLQGLQTDIQTDNDLTKEMYEGKENVSFELQRDFSQETDFSEASLLEKQQEVHSAGNIKKEKSNTIDGTVKDETSPVEECFFSQSSNSYQCHTITGEQPSGCTGLGKSISFDTKLVKHEIINSEERPFKCEELVEPFRCDSQLIQHQENNTEEKPYQCSECGKAFSINEKLIWHQRLHSGEKPFKCVECGKSFSYSSHYITHQTIHSGEKPYQCKMCGKAFSVNGSLSRHQRIHTGEKPYQCKECGNGFSCSSAYITHQRVHTGEKPYECNDCGKAFNVNAKLIQHQRIHTGEKPYECNECGKGFRCSSQLRQHQSIHTGEKPYQCKECGKGFNNNTKLIQHQRIHTGEKPYECTECGKAFSVKGKLIQHQRIHTGEKPYECNECGKAFRCNSQFRQHLRIHTGEKPYECNECGKAFSVNGKLMRHQRIHTGEKPFECNECGRCFTSKRNLLDHHRIHTGEKPYQCKECGKAFSINAKLTRHQRIHTGEKPFKCMECEKAFSCSSNYIVHQRIHTGEKPFQCKECGKAFHVNAHLIRHQRSHTGEKPFRCVECGKGFSFSSDYIIHQTVHTWKKPYMCSVCGKAFRFSFQLSQHQSVHSEGKS>sp|P17027-2|ZNF23_HUMAN Isoform 2 of Zinc finger protein 23 OS=Homosapiens OX=9606 GN=ZNF23MYEGKENVSFELQRDFSQETDFSEASLLEKQQEVHSAGNIKKEKSNTIDGTVKDETSPVEECFFSQSSNSYQCHTITGEQPSGCTGLGKSISFDTKLVKHEIINSEERPFKCEELVEPFRCDSQLIQHQENNTEEKPYQCSECGKAFSINEKLIWHQRLHSGEKPFKCVECGKSFSYSSHYITHQTIHSGEKPYQCKMCGKAFSVNGSLSRHQRIHTGEKPYQCKECGNGFSCSSAYITHQRVHTGEKPYECNDCGKAFNVNAKLIQHQRIHTGEKPYECNECGKGFRCSSQLRQHQSIHTGEKPYQCKECGKGFNNNTKLIQHQRIHTGEKPYECTECGKAFSVKGKLIQHQRIHTGEKPYECNECGKAFRCNSQFRQHLRIHTGEKPYECNECGKAFSVNGKLMRHQRIHTGEKPFECNECGRCFTSKRNLLDHHRIHTGEKPYQCKECGKAFSINAKLTRHQRIHTGEKPFKCMECEKAFSCSSNYIVHQRIHTGEKPFQCKECGKAFHVNAHLIRHQRSHTGEKPFRCVECGKGFSFSSDYIIHQTVHTWKKPYMCSVCGKAFRFSFQLSQHQSVHSEGKS>sp|Q8WZ26|YS006_HUMAN Putative uncharacterized protein PP6455 OS=Homosapiens OX=9606 GN=PP6455 PE=2 SV=2MCEQLVCIFTYAYLKINLTKALGHHNPSYPVARAQPQTMFPSASECNAFPRVSKVPNRSGAAETALLVRVLPKPLKSQASLLSLPFIHITEQLSTHICVVLFKLFHVCLFTINNMNDCSMDAAERNAEGGLQLE>sp|Q86XF7|ZN575_HUMAN Zinc finger protein 575 OS=Homo sapiens OX=9606GN=ZNF575 PE=1 SV=1MLERGAESAAGATDPSPTGKEPVTKEAPHQGPPQKPSQSAPGPTASAGSPPRPRRRPPPQRPHRCPDCDKAFSYPSKLATHRLAHGGARPHPCPDCPKAFSYPSKLAAHRLTHSGARPHPCPHCPKSFGHRSKLAAHLWTHAPTRPYPCPDCPKSFCYPSKLAAHRHTHHATDARPYPCPHCPKAFSFPSKLAAHRLCHDPPTAPGSQATAWHRCSSCGQAFGQRRLLLLHQRSHHQVEHKGERD>sp|Q969S3|ZN622_HUMAN Zinc finger protein 622 OS=Homo sapiens OX=9606GN=ZNF622 PE=1 SV=1MATYTCITCRVAFRDADMQRAHYKTDWHRYNLRRKVASMAPVTAEGFQERVRAQRAVAEEESKGSATYCTVCSKKFASFNAYENHLKSRRHVELEKKAVQAVNRKVEMMNEKNLEKGLGVDSVDKDAMNAAIQQAIKAQPSMSPKKAPPAPAKEARNVVAVGTGGRGTHDRDPSEKPPRLQWFEQQAKKLAKQQEEDSEEEEEDLDGDDWEDIDSDEELECEDTEAMDDVVEQDAEEEEAEEGPPLGAIPITDCLFCSHHSSSLMKNVAHMTKDHSFFIPDIEYLSDIKGLIKYLGEKVGVGKICLWCNEKGKSFYSTEAVQAHMNDKSHCKLFTDGDAALEFADFYDFRSSYPDHKEGEDPNKAEELPSEKNLEYDDETMELILPSGARVGHRSLMRYYKQRFGLSRAVAVAKNRKAVGRVLQQYRALGWTGSTGAALMRERDMQYVQRMKSKWMLKTGMKNNATKQMHFRVQVRF>sp|Q8TAW3|ZN671_HUMAN Zinc finger protein 671 OS=Homo sapiens OX=9606GN=ZNF671 PE=2 SV=2MLSPVSRDASDALQGRKCLRPRSRRLPLPAAVRAHGPMAELTDSARGCVVFEDVFVYFSREEWELLDDAQRLLYHDVMLENFALLASLGIAFSRSRAVMKLERGEEPWVYDQVDMTSATEREAQRGLRPGCWHGVEDEEVSSEQSIFVAGVSEVRTLMAELESHPCDICGPILKDTLHLAKYHGGKARQKPYLCGACGKQFWFSTDFDQHQNQPNGGKLFPRKEGRDSVKSCRVHVPEKTLTCGKGRRDFSATSGLLQHQASLSSMKPHKSTKLVSGFLMGQRYHRCGECGKAFTRKDTLARHQRIHTGERPYECNECGKFFSQSYDLFKHQTVHTGERPYECSECGKFFRQISGLIEHRRVHTGERLYQCGKCGKFFSSKSNLIRHQEVHTGARPYVCSECGKEFSRKHTLVLHQRTHTGERPYECSECGKAFSQSSHLNVHWRIHSSDYECSRCGKAFSCISKLIQHQKVHSGEKPYECSKCGKAFTQRPNLIRHWKVHTGERPYVCSECGREFIRKQTLVLHQRVHAGEKL>sp|Q9UC06|ZNF70_HUMAN Zinc finger protein 70 OS=Homo sapiens OX=9606GN=ZNF70 PE=2 SV=2MEVPPATKFGETFAFENRLESQQGLFPGEDLGDPFLQERGLEQMAVIYKEIPLGEQDEENDDYEGNFSLCSSPVQHQSIPPGTRPQDDELFGQTFLQKSDLSMCQIIHSEEPSPCDCAETDRGDSGPNAPHRTPQPAKPYACRECGKAFSQSSHLLRHLVIHTGEKPYECCECGKAFSQSSHLLRHQIIHTGEKPYECRECGKAFRQSSALTQHQKIHTGKRPYECRECGKDFSRSSSLRKHERIHTGERPYQCKECGKSFNQSSGLSQHRKIHTLKKPHECDLCGKAFCHRSHLIRHQRIHTGKKPYKCDECGKAFSQSSNLIEHRKTHTGEKPYKCQKCGKAFSQSSSLIEHQRIHTGEKPYECCQCGKAFCHSSALIQHQRIHTGKKPYTCECGKAFRHRSALIEHYKTHTREKPYVCNLCGKSFRGSSHLIRHQKIHSGEKL>sp|Q8IYB9|ZN595_HUMAN Zinc finger protein 595 OS=Homo sapiens OX=9606GN=ZNF595 PE=1 SV=2MELVTFRDVAIEFSPEEWKCLDPAQQNLYRDVMLENYRNLVSLGFVISNPDLVTCLEQIKEPCNLKIHETAAKPPAICSPFSQDLSPVQGIEDSFHKLILKRYEKCGHENLQLRKGCKRVNECKVQKGVNNGVYQCLSTTQSKIFQCNTCVKVFSKFSNSNKHKIRHTGEKPFKCTECGRSFYMSHLTQHTGIHAGEKPYKCEKCGKAFNRSTSLSKHKRIHTGEKPYTCEECGKAFRRSTVLNEHKKIHTGEKPYKCEECGKAFTRSTTLNEHKKIHTGEKPYKCKECGKAFRWSTSLNEHKNIHTGEKPYKCKECGKAFRQSRSLNEHKNIHTGEKPYTCEKCGKAFNQSSSLIIHRSIHSEQKLYKCEECGKAFTWSSSLNKHKRIHTGEKPYTCEECGKAFYRSSHLAKHKRIHTGEKPYTCEECGKAFNQSSTLILHKRIHSGQKPYKCEECGKAFTRSTTLNEHKKIHTGEKPYKCEECGKAFIWSASLNEHKNIHTGEKPYKCKECGKAFNQSSGLIIHRSIHSEQKLYKCEECGKAFTRSTALNEHKKIHSGEKPYKCKECGKAYNLSSTLTKHKRIHTGEKPFTCEECGKAFNWSSSLTKHKIIHTGEKSYKCEECGKAFNRPSTLTVHKRIHTGKEHS>sp|Q9Y3Q8|T22D4_HUMAN TSC22 domain family protein 4 OS=Homo sapiensOX=9606 GN=TSC22D4 PE=1 SV=2MSGGKKKSSFQITSVTTDYEGPGSPGASDPPTPQPPTGPPPRLPNGEPSPDPGGKGTPRNGSPPPGAPSSRFRVVKLPHGLGEPYRRGRWTCVDVYERDLEPHSFGGLLEGIRGASGGAGGRSLDSRLELASLGLGAPTPPSGLSQGPTSWLRPPPTSPGPQARSFTGGLGQLVVPSKAKAEKPPLSASSPQQRPPEPETGESAGTSRAATPLPSLRVEAEAGGSGARTPPLSRRKAVDMRLRMELGAPEEMGQVPPLDSRPSSPALYFTHDASLVHKSPDPFGAVAAQKFSLAHSMLAISGHLDSDDDSGSGSLVGIDNKIEQAMDLVKSHLMFAVREEVEVLKEQIRELAERNAALEQENGLLRALASPEQLAQLPSSGVPRLGPPAPNGPSV>sp|Q9Y3Q8-2|T22D4_HUMAN Isoform 2 of TSC22 domain family protein 4OS=Homo sapiens OX=9606 GN=TSC22D4MRLRMELGAPEEMGQVPPLDSRPSSPALYFTHDASLVHKSPDPFGAVAAQKFSLAHSMLAISGHLDSDDDSGSGSLVGIDNKIEQAMDLVKSHLMFAVREEVEVLKEQIRELAERNAALEQENGLLRALASPEQLAQLPSSGVPRLGPPAPNGPSV>sp|P13693|TCTP_HUMAN Translationally-controlled tumor protein OS=Homosapiens OX=9606 GN=TPT1 PE=1 SV=1MIIYRDLISHDEMFSDIYKIREIADGLCLEVEGKMVSRTEGNIDDSLIGGNASAEGPEGEGTESTVITGVDIVMNHHLQETSFTKEAYKKYIKDYMKSIKGKLEEQRPERVKPFMTGAAEQIKHILANFKNYQFFIGENMNPDGMVALLDYREDGVTPYMIFFKDGLEMEKC>sp|P13693-2|TCTP_HUMAN Isoform 2 of Translationally-controlled tumorprotein OS=Homo sapiens OX=9606 GN=TPT1MVSRTEGNIDDSLIGGNASAEGPEGEGTESTVITGVDIVMNHHLQETSFTKEAYKKYIKDYMKSIKGKLEEQRPERVKPFMTGAAEQIKHILANFKNYQFFIGENMNPDGMVALLDYREDGVTPYMIFFKDGLEMEKC>sp|Q9UJT1|TBD_HUMAN Tubulin delta chain OS=Homo sapiens OX=9606 GN=TUBD1PE=2 SV=2MSIVTVQLGQCGNQIGFEVFDALLSDSHSSQGLCSMRENEAYQASCKERFFSEEENGVPIARAVLVDMEPKVINQMLSKAAQSGQWKYGQHACFCQKQGSGNNWAYGYSVHGPRHEESIMNIIRKEVEKCDSFSGFFIIMSMAGGTGSGLGAFVTQNLEDQYSNSLKMNQIIWPYGTGEVIVQNYNSILTLSHLYRSSDALLLHENDAIHKICAKLMNIKQISFSDINQVLAHQLGSVFQPTYSAESSFHYRRNPLGDLMEHLVPHPEFKMLSVRNIPHMSENSLAYTTFTWAGLLKHLRQMLISNAKMEEGIDRHVWPPLSGLPPLSKMSLNKDLHFNTSIANLVILRGKDVQSADVEGFKDPALYTSWLKPVNAFNVWKTQRAFSKYEKSAVLVSNSQFLVKPLDMIVGKAWNMFASKAYIHQYTKFGIEEEDFLDSFTSLEQVVASYCNL>sp|Q9UJT1-2|TBD_HUMAN Isoform 2 of Tubulin delta chain OS=Homo sapiensOX=9606 GN=TUBD1MSIVTVQLGQCGNQIGFEVFDALLSDSHSSQGLCSMRENEAYQASCKERFFSEEENGVPIARAVLVDMEPKVINQMLSKAAQSGQWKYGQHACFCQKQGSGNNWAYGYSVHGPRHEESIMNIIRKEVEKCDSFSGFFIIMSMAGGTGSGLGAFVTQNLEDQYSNSLKMNQIIWPYGTGEVIVQNYNSILTLSHLYRSSDALLLHENDAIHKICAKLMNIKQISFSDINQVLAHQLGSVFQPTYSAESSFHYRRNPLGIDRHVWPPLSGLPPLSKMSLNKDLHFNTSIANLVILRGKDVQSADVEGFKDPALYTSWLKPVNAFNVWKTQRAFSKYEKSAVLVSNSQFLVKPLDMIVGKAWNMFASKAYIHQYTKFGIEEEDFLDSFTSLEQVVASYCNL>sp|Q9UJT1-3|TBD_HUMAN Isoform 3 of Tubulin delta chain OS=Homo sapiensOX=9606 GN=TUBD1MSIVTVQLGQCGNQIGFEVFDALLSDSHSSQGLCSMRENEAYQASCKERFFSEEENGGIDRHVWPPLSGLPPLSKMSLNKDLHFNTSIANLVILRGKDVQSADVEGFKDPALYTSWLKPVNAFNVWKTQRAFSKYEKSAVLVSNSQFLVKPLDMIVGKAWNMFASKAYIHQYTKFGIEEEDFLDSFTSLEQVVASYCNL>sp|Q9UJT1-4|TBD_HUMAN Isoform 4 of Tubulin delta chain OS=Homo sapiensOX=9606 GN=TUBD1MNIKQISFSDINQVLAHQLGSVFQPTYSAESSFHYRRNPLGDLMEHLVPHPEFKMLSVRNIPHMSENSLAYTTFTWAGLLKHLRQMLISNAKMEEGIDRHVWPPLSGLPPLSKMSLNKDLHFNTSIANLVILRGKDVQSADVEGFKDPALYTSWLKPVNAFNVWKTQRAFSKYEKSAVLVSNSQFLVKPLDMIVGKAWNMFASKAYIHQYTKFGIEEEDFLDSFTSLEQVVASYCNL>sp|Q9UJT1-5|TBD_HUMAN Isoform 5 of Tubulin delta chain OS=Homo sapiensOX=9606 GN=TUBD1MSIVTVQLGQCGNQIGFEVFDALLSDSHSSQGLCSMRENEAYQASCKERFFSEEENGVPIARAVLVDMEPKVINQMLSKAAQSGQWKYGQHACFCQKQGSGNNWAYGYSVHGPRHEESIMNIIRKEVEKCDSFSGFFIIMSMAGGTGSGLGAFVTQNLEDQYSNSLKMNQIIWPYGTGEVIVQNYNSILTLSHLYRSSDALLLHENDAIHKICAKLMNIKQISFSDINQVLAHQLGSVFQPTYSAESSFHYRRNPLGDLMEHLVPHPEFKMLSVRNIPHMSENSLAYTTFTWAGLLKHLRQMLISNAKMEEGIDRHVWPPLSGLPPLSKMSLNKDLHFNTSIANLVILRGKDVQSADVGKKFRAYIHQYTKFGIEEEDFLDSFTSLEQVVASYCNL>sp|Q9UJT1-6|TBD_HUMAN Isoform 6 of Tubulin delta chain OS=Homo sapiensOX=9606 GN=TUBD1MSIVTVQLGQCGNQIGFEVFDALLSDSHSSQGLCSMRENEAYQASCKERFFSEEENGVPIARAVLVDMEPKVINQMLSKAAQSGQWKYGQHACFCQKQGSGNNWAYGYSVHGPRHEESIMNIIRKEVEKCDSFSGFFIIMSMAGGTGSGLGAFVTQNLEDQYSNSLKMNQIIWPYGTGEVIVQNYNSILTLSHLYRSSDALLLHENDAIHKICAKLMNIKQISFSDINQVLAHQLGSVFQPTYSAESSFHYRRNPLEGFKDPALYTSWLKPVNAFNVWKTQRAFSKYEKSAVLVSNSQFLVKPLDMIVGKAWNMFASKAYIHQYTKFGIEEEDFLDSFTSLEQVVASYCNL>sp|Q07283|TRHY_HUMAN Trichohyalin OS=Homo sapiens OX=9606 GN=TCHH PE=1SV=2MSPLLRSICDITEIFNQYVSHDCDGAALTKKDLKNLLEREFGAVLRRPHDPKTVDLILELLDLDSNGRVDFNEFLLFIFKVAQACYYALGQATGLDEEKRARCDGKESLLQDRRQEEDQRRFEPRDRQLEEEPGQRRRQKRQEQERELAEGEEQSEKQERLEQRDRQRRDEELWRQRQEWQEREERRAEEEQLQSCKGHETEEFPDEEQLRRRELLELRRKGREEKQQQRRERQDRVFQEEEEKEWRKRETVLRKEEEKLQEEEPQRQRELQEEEEQLRKLERQELRRERQEEEQQQQRLRREQQLRRKQEEERREQQEERREQQERREQQEERREQQLRREQEERREQQLRREQEEERREQQLRREQEEERREQQLRREQQLRREQQLRREQQLRREQQLRREQQLRREQQLRREQQLRREQQLRREQEEERHEQKHEQERREQRLKREQEERRDWLKREEETERHEQERRKQQLKRDQEEERRERWLKLEEEERREQQERREQQLRREQEERREQRLKRQEEEERLQQRLRSEQQLRREQEERREQLLKREEEKRLEQERREQRLKREQEERRDQLLKREEERRQQRLKREQEERLEQRLKREEVERLEQEERREQRLKREEPEEERRQQLLKSEEQEERRQQQLRREQQERREQRLKREEEEERLEQRLKREHEEERREQELAEEEQEQARERIKSRIPKWQWQLESEADARQSKVYSRPRKQEGQRRRQEQEEKRRRRESELQWQEEERAHRQQQEEEQRRDFTWQWQAEEKSERGRQRLSARPPLREQRERQLRAEERQQREQRFLPEEEEKEQRRRQRREREKELQFLEEEEQLQRRERAQQLQEEEDGLQEDQERRRSQEQRRDQKWRWQLEEERKRRRHTLYAKPALQEQLRKEQQLLQEEEEELQREEREKRRRQEQERQYREEEQLQQEEEQLLREEREKRRRQERERQYRKDKKLQQKEEQLLGEEPEKRRRQEREKKYREEEELQQEEEQLLREEREKRRRQEWERQYRKKDELQQEEEQLLREEREKRRLQERERQYREEEELQQEEEQLLGEERETRRRQELERQYRKEEELQQEEEQLLREEPEKRRRQERERQCREEEELQQEEEQLLREEREKRRRQELERQYREEEEVQQEEEQLLREEPEKRRRQELERQYREEEELQQEEEQLLREEQEKRRQERERQYREEEELQRQKRKQRYRDEDQRSDLKWQWEPEKENAVRDNKVYCKGRENEQFRQLEDSQLRDRQSQQDLQHLLGEQQERDREQERRRWQQRDRHFPEEEQLEREEQKEAKRRDRKSQEEKQLLREEREEKRRRQETDRKFREEEQLLQEREEQPLRRQERDRKFREEELRHQEQGRKFLEEEQRLRRQERERKFLKEEQQLRCQEREQQLRQDRDRKFREEEQQLSRQERDRKFREEEQQVRRQERERKFLEEEQQLRQERHRKFREEEQLLQEREEQQLHRQERDRKFLEEEQQLRRQERDRKFREQELRSQEPERKFLEEEQQLHRQQRQRKFLQEEQQLRRQERGQQRRQDRDRKFREEEQLRQEREEQQLSRQERDRKFRLEEQKVRRQEQERKFMEDEQQLRRQEGQQQLRQERDRKFREDEQLLQEREEQQLHRQERDRKFLEEEPQLRRQEREQQLRHDRDRKFREEEQLLQEGEEQQLRRQERDRKFREEEQQLRRQERERKFLQEEQQLRRQELERKFREEEQLRQETEQEQLRRQERYRKILEEEQLRPEREEQQLRRQERDRKFREEEQLRQEREEQQLRSQESDRKFREEEQLRQEREEQQLRPQQRDGKYRWEEEQLQLEEQEQRLRQERDRQYRAEEQFATQEKSRREEQELWQEEEQKRRQERERKLREEHIRRQQKEEQRHRQVGEIKSQEGKGHGRLLEPGTHQFASVPVRSSPLYEYIQEQRSQYRP>sp|Q9BSJ1|TRI51_HUMAN Tripartite motif-containing protein 51 OS=Homosapiens OX=9606 GN=TRIM51 PE=2 SV=2MNSGILQVFQRALTCPICMNYFLDPVTIDCGHSFCRPCLYLNWQDTAVLAQCSECKKTTRQRNLNTDICLKNMAFIARKASLRQFLSSEEQICGMHRETKKMFCEVDKSLLCLPCSNSQEHRNHIHCPIEWAAEERREELLKKMQSLWEKACENLRNLNMETTRTRCWKDYVSLRIEAIRAEYQKMPAFLHEEEQHHLERLRKEGEDIFQQLNESKARMEHSRELLRGMYEDLKQMCHKADVELLQAFGDILHRYESLLLQVSEPVNPELSAGPITGLLDSLSGFRVDFTLQPERANSHIFLCGDLRSMNVGCDPQDDPDITGKSECFLVWGAQAFTSGKYYWEVHMGDSWNWAFGVCNNYWKEKRQNDKIDGEEGLFLLGCVKEDTHCSLFTTSPLVVQYVPRPTSTVGLFLDCEGRTVSFVDVDQSSLIYTIPNCSFSPPLRPIFCCSHF>sp|Q9BSJ1-2|TRI51_HUMAN Isoform 2 of Tripartite motif-containing protein51 OS=Homo sapiens OX=9606 GN=TRIM51MQSLWEKACENLRNLNMETTRTRCWKDYVSLRIEAIRAEYQKMPAFLHEEEQHHLERLRKEGEDIFQQLNESKARMEHSRELLRGMYEDLKQMCHKADVELLQAFGDILHRYESLLLQVSEPVNPELSAGPITGLLDSLSGFRVDFTLQPERANSHIFLCGDLRSMNVGCDPQDDPDITGKSECFLVWGAQAFTSGKYYWEVHMGDSWNWAFGVCNNYWKEKRQNDKIDGEEGLFLLGCVKEDTHCSLFTTSPLVVQYVPRPTSTVGLFLDCEGRTVSFVDVDQSSLIYTIPNCSFSPPLRPIFCCSHF>sp|P48788|TNNI2_HUMAN Troponin I, fast skeletal muscle OS=Homo sapiensOX=9606 GN=TNNI2 PE=1 SV=2MGDEEKRNRAITARRQHLKSVMLQIAATELEKEESRREAEKQNYLAEHCPPLHIPGSMSEVQELCKQLHAKIDAAEEEKYDMEVRVQKTSKELEDMNQKLFDLRGKFKRPPLRRVRMSADAMLKALLGSKHKVCMDLRANLKQVKKEDTEKERDLRDVGDWRKNIEEKSGMEGRKKMFESES>sp|P48788-2|TNNI2_HUMAN Isoform 2 of Troponin I, fast skeletal muscleOS=Homo sapiens OX=9606 GN=TNNI2MSQCKKRNRAITARRQHLKSVMLQIAATELEKEESRREAEKQNYLAEHCPPLHIPGSMSEVQELCKQLHAKIDAAEEEKYDMEVRVQKTSKELEDMNQKLFDLRGKFKRPPLRRVRMSADAMLKALLGSKHKVCMDLRANLKQVKKEDTEKERDLRDVGDWRKNIEEKSGMEGRKKMFESES>sp|Q7Z2T5|TRM1L_HUMAN TRMT1-like protein OS=Homo sapiens OX=9606GN=TRMT1L PE=1 SV=2MENMAEEELLPLEKEEVEVAQVQVPTPARDSAGVPAPAPDSALDSAPTPASAPAPAPALAQAPALSPSLASAPEEAKSKRHISIQRQLADLENLAFVTDGNFDSASSLNSDNLDAGNRQACPLCPKEKFRACNSHKLRRHLQNLHWKVSVEFEGYRMCICHLPCRPVKPNIIGEQITSKMGAHYHCIICSATITRRTDMLGHVRRHMNKGETKSSYIAASTAKPPKEILKEADTDVQVCPNYSIPQKTDSYFNPKMKLNRQLIFCTLAALAEERKPLECLDAFGATGIMGLQWAKHLGNAVKVTINDLNENSVTLIQENCHLNKLKVVVDSKEKEKSDDILEEGEKNLGNIKVTKMDANVLMHLRSFDFIHLDPFGTSVNYLDSAFRNIRNLGIVSVTSTDISSLYAKAQHVARRHYGCNIVRTEYYKELAARIVVAAVARAAARCNKGIEVLFAVALEHFVLVVVRVLRGPTSADETAKKIQYLIHCQWCEERIFQKDGNMVEENPYRQLPCNCHGSMPGKTAIELGPLWSSSLFNTGFLKRMLFESLHHGLDDIQTLIKTLIFESECTPQSQFSIHASSNVNKQEENGVFIKTTDDTTTDNYIAQGKRKSNEMITNLGKKQKTDVSTEHPPFYYNIHRHSIKGMNMPKLKKFLCYLSQAGFRVSRTHFDPMGVRTDAPLMQFKSILLKYSTPTYTGGQSESHVQSASEDTVTERVEMSVNDKAEASGCRRW>sp|Q7Z2T5-2|TRM1L_HUMAN Isoform 2 of TRMT1-like protein OS=Homo sapiensOX=9606 GN=TRMT1LMCICHLPCRPVKPNIIGEQITSKMGAHYHCIICSATITRRTDMLGHVRRHMNKGETKSSYIAASTAKPPKEILKEADTDVQVCPNYSIPQKTDSYFNPKMKLNRQLIFCTLAALAEERKPLECLDAFGATGIMGLQWAKHLGNAVKVTINDLNENSVTLIQENCHLNKLKVVVDSKEKEKSDDILEEGEKNLGNIKVTKMDANVLMHLRSFDFIHLDPFGTSVNYLDSAFRNIRNLGIVSVTSTDISSLYAKAQHVARRHYGCNIVRTEYYKELAARIVVAAVARAAARCNKGIEVLFAVALEHFVLVVVRVLRGPTSADETAKKIQYLIHCQWCEERIFQKDGNMVEDYSANFVISYTGFPFVNRQDIRKTHIDSCLVTVMEACLERQQ>sp|P23510|TNFL4_HUMAN Tumor necrosis factor ligand superfamily member 4OS=Homo sapiens OX=9606 GN=TNFSF4 PE=1 SV=1MERVQPLEENVGNAARPRFERNKLLLVASVIQGLGLLLCFTYICLHFSALQVSHRYPRIQSIKVQFTEYKKEKGFILTSQKEDEIMKVQNNSVIINCDGFYLISLKGYFSQEVNISLHYQKDEEPLFQLKKVRSVNSLMVASLTYKDKVYLNVTTDNTSLDDFHVNGGELILIHQNPGEFCVL>sp|P23510-2|TNFL4_HUMAN Isoform 2 of Tumor necrosis factor ligandsuperfamily member 4 OS=Homo sapiens OX=9606 GN=TNFSF4MVSHRYPRIQSIKVQFTEYKKEKGFILTSQKEDEIMKVQNNSVIINCDGFYLISLKGYFSQEVNISLHYQKDEEPLFQLKKVRSVNSLMVASLTYKDKVYLNVTTDNTSLDDFHVNGGELILIHQNPGEFCVL>sp|Q5SNT2|TM201_HUMAN Transmembrane protein 201 OS=Homo sapiens OX=9606GN=TMEM201 PE=1 SV=1MEGVSALLARCPTAGLAGGLGVTACAAAGVLLYRIARRMKPTHTMVNCWFCNQDTLVPYGNRNCWDCPHCEQYNGFQENGDYNKPIPAQYLEHLNHVVSSAPSLRDPSQPQQWVSSQVLLCKRCNHHQTTKIKQLAAFAPREEGRYDEEVEVYRHHLEQMYKLCRPCQAAVEYYIKHQNRQLRALLLSHQFKRREADQTHAQNFSSAVKSPVQVILLRALAFLACAFLLTTALYGASGHFAPGTTVPLALPPGGNGSATPDNGTTPGAEGWRQLLGLLPEHMAEKLCEAWAFGQSHQTGVVALGLLTCLLAMLLAGRIRLRRIDAFCTCLWALLLGLHLAEQHLQAASPSWLDTLKFSTTSLCCLVGFTAAVATRKATGPRRFRPRRFFPGDSAGLFPTSPSLAIPHPSVGGSPASLFIPSPPSFLPLANQQLFRSPRRTSPSSLPGRLSRALSLGTIPSLTRADSGYLFSGSRPPSQVSRSGEFPVSDYFSLLSGSCPSSPLPSPAPSVAGSVASSSGSLRHRRPLISPARLNLKGQKLLLFPSPPGEAPTTPSSSDEHSPHNGSLFTMEPPHVPRKPPLQDVKHALDLRSKLERGSACSNRSIKKEDDSSQSSTCVVDTTTRGCSEEAATWRGRFGPSLVRGLLAVSLAANALFTSVFLYQSLR>sp|Q5SNT2-2|TM201_HUMAN Isoform 2 of Transmembrane protein 201 OS=Homosapiens OX=9606 GN=TMEM201MEGVSALLARCPTAGLAGGLGVTACAAAGVLLYRIARRMKPTHTMVNCWFCNQDTLVPYGNRNCWDCPHCEQYNGFQENGDYNKPIPAQYLEHLNHVVSSAPSLRDPSQPQQWVSSQVLLCKRCNHHQTTKIKQLAAFAPREEGRYDEEVEVYRHHLEQMYKLCRPCQAAVEYYIKHQNRQLRALLLSHQFKRREADQTHAQNFSSAVKSPVQVILLRALAFLACAFLLTTALYGASGHFAPGTTVPLALPPGGNGSATPDNGTTPGAEGWRQLLGLLPEHMAEKLCEAWAFGQSHQTGVVALGLLTCLLAMLLAGRIRLRRIDAFCTCLWALLLGLHLAEQHLQAASPSWLDTLKFSTTSLCCLVGFTAAVATRKATGPRRFRPRRSEKQP>sp|Q9H0V1|TM168_HUMAN Transmembrane protein 168 OS=Homo sapiens OX=9606GN=TMEM168 PE=2 SV=2MCKSLRYCFSHCLYLAMTRLEEVNREVNMHSSVRYLGYLARINLLVAICLGLYVRWEKTANSLILVIFILGLFVLGIASILYYYFSMEAASLSLSNLWFGFLLGLLCFLDNSSFKNDVKEESTKYLLLTSIVLRILCSLVERISGYVRHRPTLLTTVEFLELVGFAIASTTMLVEKSLSVILLVVALAMLIIDLRMKSFLAIPNLVIFAVLLFFSSLETPKNPIAFACFFICLITDPFLDIYFSGLSVTERWKPFLYRGRICRRLSVVFAGMIELTFFILSAFKLRDTHLWYFVIPGFSIFGIFWMICHIIFLLTLWGFHTKLNDCHKVYFTHRTDYNSLDRIMASKGMRHFCLISEQLVFFSLLATAILGAVSWQPTNGIFLSMFLIVLPLESMAHGLFHELGNCLGGTSVGYAIVIPTNFCSPDGQPTLLPPEHVQELNLRSTGMLNAIQRFFAYHMIETYGCDYSTSGLSFDTLHSKLKAFLELRTVDGPRHDTYILYYSGHTHGTGEWALAGGDTLRLDTLIEWWREKNGSFCSRLIIVLDSENSTPWVKEVRKINDQYIAVQGAELIKTVDIEEADPPQLGDFTKDWVEYNCNSSNNICWTEKGRTVKAVYGVSKRWSDYTLHLPTGSDVAKHWMLHFPRITYPLVHLANWLCGLNLFWICKTCFRCLKRLKMSWFLPTVLDTGQGFKLVKS>sp|Q9H0V1-2|TM168_HUMAN Isoform 2 of Transmembrane protein 168 OS=Homosapiens OX=9606 GN=TMEM168MFLIVLPLESMAHGLFHELGNCLGGTSVGYAIVIPTNFCSPDGQPTLLPPEHVQELNLRSTGMLNAIQRFFAYHMIETYGCDYSTSGLSFDTLHSKLKAFLELRTVDGPRHDTYILYYSGHTHGTGEWALAGGDTLRLDTLIEWWREKNGSFCSRLIIVLDSENSTPWVKEVRKINDQYIAVQGAELIKTVDIEEADPPQLGDFTKDWVEYNCNSSNNICWTEKGRTVKAVYGVSKRWSDYTLHLPTGSDVAKHWMLHFPRITYPLVHLANWLCGLNLFWICKTCFRCLKRLKMSWFLPTVLDTGQGFKLVKS>sp|Q56UQ5|TPT1L_HUMAN TPT1-like protein OS=Homo sapiens OX=9606 PE=2SV=2METVIMITYWDLISHSEMFSDSYMSQEIADGLRLEVEGKIVSRTEGNIFDSLIGGNASAEGPEGKGTESTVITGVDSVMNHHLQETSFTKEAYNKCIKDYMKSIKGKLEEQRPKRVKPFMTGAAEQIKHILANFKNYQKT>sp|Q6XPS3|TPTE2_HUMAN Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase TPTE2 OS=Homo sapiens OX=9606 GN=TPTE2 PE=1 SV=2MNESPQTNEFKGTTEEAPAKESPHTSEFKGAALVSPISKSMLERLSKFEVEDAENVASYDSKIKKIVHSIVSSFAFGIFGVFLVLLDVTLLLADLIFTDSKLYIPLEYRSISLAIGLFFLMDVLLRVFVEGRQQYFSDLFNILDTAIIVIPLLVDVIYIFFDIKLLRNIPRWTHLVRLLRLIILIRIFHLLHQKRQLEKLMRRLVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIEEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVSRIMIDDHNVPTLHEMVVFTKEVNEWMAQDLENIVAIHCKGGKGRTGTMVCALLIASEIFLTAEESLYYFGERRTNKTHSNKFQGVETPSQNRYVGYFAQVKHLYNWNLPPRRILFIKRFIIYSIRGDVCDLKVQVVMEKKVVFSSTSLGNCSILHDIETDKILINVYDGPPLYDDVKVQFFSSNLPKYYDNCPFFFWFNTSFIQNNRLCLPRNELDNPHKQKAWKIYPPEFAVEILFGEK>sp|Q6XPS3-2|TPTE2_HUMAN Isoform 2 of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase TPTE2 OS=Homo sapiens OX=9606 GN=TPTE2MNESPQTNEFKGTTEEAPAKESPHTSEFKGAALVSPISKSMLERLSKFEVEDAENVASYDSKIKKIVHSIVSSFAFGIFGVFLVLLDVTLLLADLIFTDSKLYIPLEYRSISLAIGLFFLMDVLLRVFVEGWTHLVRLLRLIILIRIFHLLHQKRQLEKLMRRLVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIEEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVSRIMIDDHNVPTLHEMVVFTKEVNEWMAQDLENIVAIHCKGGKGRTGTMVCALLIASEIFLTAEESLYYFGERRTNKTHSNKFQGVETPSQNRYVGYFAQVKHLYNWNLPPRRILFIKRFIIYSIRGDVCDLKVQVVMEKKVVFSSTSLGNCSILHDIETDKILINVYDGPPLYDDVKVQFFSSNLPKYYDNCPFFFWFNTSFIQNNRLCLPRNELDNPHKQKAWKIYPPEFAVEILFGEK>sp|Q6XPS3-3|TPTE2_HUMAN Isoform 3 of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase TPTE2 OS=Homo sapiens OX=9606 GN=TPTE2MNESPQTNEFKGTTEEAPAKESPHTSEFKGAALVSPISKRIFGVFLVLLDVTLLLADLIFTDSKLYIPLEYRSISLAIGLFFLMDVLLRVFVEGWTHLVRLLRLIILIRIFHLLHQKRQLEKLMRRLVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIEEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVSRIMIDDHNVPTLHEMVVFTKEVNEWMAQDLENIVAIHCKGGKGRTGTMVCALLIASEIFLTAEESLYYFGERRTNKTHSNKFQGVETPSQNRYVGYFAQVKHLYNWNLPPRRILFIKRFIIYSIRGDVCDLKVQVVMEKKVVFSSTSLGNCSILHDIETDKILINVYDGPPLYDDVKVQFFSSNLPKYYDNCPFFFWFNTSFIQNNRLCLPRNELDNPHKQKAWKIYPPEFAVEILFGEK>sp|Q6XPS3-4|TPTE2_HUMAN Isoform 4 of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase TPTE2 OS=Homo sapiens OX=9606 GN=TPTE2MNESPQTNEFKGTTEEAPAKESPHTSEFKGAALVSPISKRWTHLVRLLRLIILIRIFHLLHQKRQLEKLMRRLVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIEEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVSRIMIDDHNVPTLHEMVVFTKEVNEWMAQDLENIVAIHCKGGKGRTGTMVCALLIASEIFLTAEESLYYFGERRTNKTHSNKFQGVETPSQNRYVGYFAQVKHLYNWNLPPRRILFIKRFIIYSIRGDVCDLKVQVVMEKKVVFSSTSLGNCSREEGSTLRRANWKGEPSRRPVLD>sp|Q6XPS3-5|TPTE2_HUMAN Isoform 5 of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase TPTE2 OS=Homo sapiens OX=9606 GN=TPTE2MNESPQTNEFKGTTEEAPAKESPHTSEFKGAALVSPISKSMLERLSKFEVEDAENVASYEWTHLVRLLRLIILIRIFHLLHQKRQLEKLMRRLVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIEEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVSRIMIDDHNVPTLHEMVVFTKEVNEWMAQDLENIVAIHCKGGKGRTGTMVCALLIASEIFLTAEESLYYFGERRTNKTHSNKFQGVETPSQNRYVGYFAQVKHLYNWNLPPRRILFIKRFIIYSIRGDVCDLKVQVVMEKKVVFSSTSLGNCSILHDIETDKILINVYDGPPLYDDVKVQFFSSNLPKYYDNCPFFFWFNTSFIQNNRLCLPRNELDNPHKQKAWKIYPPEFAVEILFGEK>sp|Q6XPS3-6|TPTE2_HUMAN Isoform 6 of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase TPTE2 OS=Homo sapiens OX=9606 GN=TPTE2MVCALLIASEIFLTAEESLYYFGERRTNKTHSNKFQGVETPSQNRYVGYFAQVKHLYNWNLPPRRILFIKRFIIYSIRGDVCDLKVQVVMEKKVVFSSTSLGNCSILHDIETDKILINVYDGPPLYDDVKVQFFSSNLPKYYDNCPFFFWFNTSFIQNNRLCLPRNELDNPHKQKAWKIYPPEFAVEILFGEK>sp|Q6XPS3-7|TPTE2_HUMAN Isoform 7 of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase TPTE2 OS=Homo sapiens OX=9606 GN=TPTE2MNESPQTNEFKGTTEEAPAKESPHTSEFKGAALVSPISKSMLERLSKFEVEDAENVASYDSKIKKIVHSIVSSFAFGIFGVFLVLLDVTLLLADLIFTDSKLYIPLEYRSISLAIGLFFLMDVLLRVFVEGRQQYFSDLFNILDTAIIVIPLLVDVIYIFFDIKLLRNIPRWTHLVRLLRLIILIRIFHLLHQKRQLEKLMRRLVSENKRRYTRDGFDLDLTYVTERIIAMSFPSSGRQSFYRNPIEEVVRFLDKKHRNHYRVYNLCSERAYDPKHFHNRVSRIMIDDHNVPTLHEMVVFTKEVNEWMAQDLENIVAIHCKGGKGRTGTMVCALLIASEIFLTAEESLYYFGERRTNKTHSNKFQGVETPSQNRYVGYFAQVKHLYNWNLPPRRILFIKRFIIYSIRGDVCDLKVQVVMEKKVVFSSTSLGNCSILHDIETDKILINVYDGPPLYDDVKVQFFSSREEGSTLRRANWKGEPSRRPVLD>sp|P02766|TTHY_HUMAN Transthyretin OS=Homo sapiens OX=9606 GN=TTR PE=1SV=1MASHRLLLLCLAGLVFVSEAGPTGTGESKCPLMVKVLDAVRGSPAINVAVHVFRKAADDTWEPFASGKTSESGELHGLTTEEEFVEGIYKVEIDTKSYWKALGISPFHEHAEVVFTANDSGPRRYTIAALLSPYSYSTTAVVTNPKE>sp|Q6EMB2|TTLL5_HUMAN Tubulin polyglutamylase TTLL5 OS=Homo sapiensOX=9606 GN=TTLL5 PE=1 SV=3MPIVMARDLEETASSSEDEEVISQEDHPCIMWTGGCRRIPVLVFHADAILTKDNNIRVIGERYHLSYKIVRTDSRLVRSILTAHGFHEVHPSSTDYNLMWTGSHLKPFLLRTLSEAQKVNHFPRSYELTRKDRLYKNIIRMQHTHGFKAFHILPQTFLLPAEYAEFCNSYSKDRGPWIVKPVASSRGRGVYLINNPNQISLEENILVSRYINNPLLIDDFKFDVRLYVLVTSYDPLVIYLYEEGLARFATVRYDQGAKNIRNQFMHLTNYSVNKKSGDYVSCDDPEVEDYGNKWSMSAMLRYLKQEGRDTTALMAHVEDLIIKTIISAELAIATACKTFVPHRSSCFELYGFDVLIDSTLKPWLLEVNLSPSLACDAPLDLKIKASMISDMFTVVGFVCQDPAQRASTRPIYPTFESSRRNPFQKPQRCRPLSASDAEMKNLVGSAREKGPGKLGGSVLGLSMEEIKVLRRVKEENDRRGGFIRIFPTSETWEIYGSYLEHKTSMNYMLATRLFQDRMTADGAPELKIESLNSKAKLHAALYERKLLSLEVRKRRRRSSRLRAMRPKYPVITQPAEMNVKTETESEEEEEVALDNEDEEQEASQEESAGFLRENQAKYTPSLTALVENTPKENSMKVREWNNKGGHCCKLETQELEPKFNLMQILQDNGNLSKMQARIAFSAYLQHVQIRLMKDSGGQTFSASWAAKEDEQMELVVRFLKRASNNLQHSLRMVLPSRRLALLERRRILAHQLGDFIIVYNKETEQMAEKKSKKKVEEEEEDGVNMENFQEFIRQASEAELEEVLTFYTQKNKSASVFLGTHSKISKNNNNYSDSGAKGDHPETIMEEVKIKPPKQQQTTEIHSDKLSRFTTSAEKEAKLVYSNSSSGPTATLQKIPNTHLSSVTTSDLSPGPCHHSSLSQIPSAIPSMPHQPTILLNTVSASASPCLHPGAQNIPSPTGLPRCRSGSHTIGPFSSFQSAAHIYSQKLSRPSSAKAGSCYLNKHHSGIAKTQKEGEDASLYSKRYNQSMVTAELQRLAEKQAARQYSPSSHINLLTQQVTNLNLATGIINRSSASAPPTLRPIISPSGPTWSTQSDPQAPENHSSSPGSRSLQTGGFAWEGEVENNVYSQATGVVPQHKYHPTAGSYQLQFALQQLEQQKLQSRQLLDQSRARHQAIFGSQTLPNSNLWTMNNGAGCRISSATASGQKPTTLPQKVVPPPSSCASLVPKPPPNHEQVLRRATSQKASKGSSAEGQLNGLQSSLNPAAFVPITSSTDPAHTKI>sp|Q6EMB2-2|TTLL5_HUMAN Isoform 2 of Tubulin polyglutamylase TTLL5OS=Homo sapiens OX=9606 GN=TTLL5MEEIKVLRRVKEENDRRGGFIRIFPTSETWEIYGSYLEHKTSMNYMLATRLFQDRGNPRRSLLTGRTRMTADGAPELKIESLNSKAKLHAALYERKLLSLEVRKRRRRSSRLRAMRPKYPVITQPAEMNVKTETESEEEEEVALDNEDEEQEASQEESAGFLRENQAKYTPSLTALVENTPKENSMKVREWNNKGGHCCKLETQELEPKFNLMQILQDNGNLSKMQARIAFSAYLQHVQIRLMKDSGGQTFSASWAAKEDEQMELVVRFLKRASNNLQHSLRMVLPSRRLALLERRRILAHQLGDFIIVYNKETEQMAEKKSKKKVEEEEEDGVNMENFQEFIRQASEAELEEVLTFYTQKNKSASVFLGTHSKISKNNNNYSDSGAKGDHPETIMEEVKIKPPKQQQTTEIHSDKLSRFTTSAEKEAKLVYSNSSSGPTATLQKIPNTHLSSVTTSDLSPGPCHHSSLSQIPSAIPSMPHQPTILLNTVSASASPCLHPGAQNIPSPTGLPRCRSGSHTIGPFSSFQSAAHIYSQKLSRPSSAKAGSCYLNKHHSGIAKTQKEGEDASLYSKRYNQSMVTAELQRLAEKQAARQYSPSSHINLLTQQVTNLNLATGIINRSSASAPPTLRPIISPSGPTWSTQSDPQAPENHSSSPGSRSLQTGGFAWEGEVENNVYSQATGVVPQHKYHPTAGSYQLQFALQQLEQQKLQSRQLLDQSRARHQAIFGSQTLPNSNLWTMNNGAGCRISSATASGQKPTTLPQKVVPPPSSCASLVPKPPPNHEQVLRRATSQKASNTRFRSSFQNYLWYFFQAVS>sp|Q6EMB2-3|TTLL5_HUMAN Isoform 3 of Tubulin polyglutamylase TTLL5OS=Homo sapiens OX=9606 GN=TTLL5MPIVMARDLEETASSSEDEEVISQEDHPCIMWTGGCRRIPVLVFHADAILTKDNNIRVIGERYHLSYKIVRTDSRLVRSILTAHGFHEVHPSSTDYNLMWTGSHLKPFLLRTLSEAQKVNHFPRSYELTRKDRLYKNIIRMQHTHGFKAFHILPQTFLLPAEYAEFCNSYSKDRGPWIVKPVASSRGRGVYLINNPNQISLEENILVSRYINNPLLIDDFKFDVRLYVLVTSYDPLVIYLYEEGLARKCNWKMGNTMDKRRLPIYVQVL>sp|Q9Y210|TRPC6_HUMAN Short transient receptor potential channel 6OS=Homo sapiens OX=9606 GN=TRPC6 PE=1 SV=1MSQSPAFGPRRGSSPRGAAGAAARRNESQDYLLMDSELGEDGCPQAPLPCYGYYPCFRGSDNRLAHRRQTVLREKGRRLANRGPAYMFSDRSTSLSIEEERFLDAAEYGNIPVVRKMLEECHSLNVNCVDYMGQNALQLAVANEHLEITELLLKKENLSRVGDALLLAISKGYVRIVEAILSHPAFAEGKRLATSPSQSELQQDDFYAYDEDGTRFSHDVTPIILAAHCQEYEIVHTLLRKGARIERPHDYFCKCNDCNQKQKHDSFSHSRSRINAYKGLASPAYLSLSSEDPVMTALELSNELAVLANIEKEFKNDYKKLSMQCKDFVVGLLDLCRNTEEVEAILNGDVETLQSGDHGRPNLSRLKLAIKYEVKKFVAHPNCQQQLLSIWYENLSGLRQQTMAVKFLVVLAVAIGLPFLALIYWFAPCSKMGKIMRGPFMKFVAHAASFTIFLGLLVMNAADRFEGTKLLPNETSTDNAKQLFRMKTSCFSWMEMLIISWVIGMIWAECKEIWTQGPKEYLFELWNMLDFGMLAIFAASFIARFMAFWHASKAQSIIDANDTLKDLTKVTLGDNVKYYNLARIKWDPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVIFIMVFVAFMIGMFNLYSYYIGAKQNEAFTTVEESFKTLFWAIFGLSEVKSVVINYNHKFIENIGYVLYGVYNVTMVIVLLNMLIAMINSSFQEIEDDADVEWKFARAKLWFSYFEEGRTLPVPFNLVPSPKSLFYLLLKLKKWISELFQGHKKGFQEDAEMNKINEEKKLGILGSHEDLSKLSLDKKQVGHNKQPSIRSSEDFHLNSFNNPPRQYQKIMKRLIKRYVLQAQIDKESDEVNEGELKEIKQDISSLRYELLEEKSQNTEDLAELIRELGEKLSMEPNQEETNR>sp|Q9Y210-2|TRPC6_HUMAN Isoform 2 of Short transient receptor potentialchannel 6 OS=Homo sapiens OX=9606 GN=TRPC6MSQSPAFGPRRGSSPRGAAGAAARRNESQDYLLMDSELGEDGCPQAPLPCYGYYPCFRGSDNRLAHRRQTVLREKGRRLANRGPAYMFSDRSTSLSIEEERFLDAAEYGNIPVVRKMLEECHSLNVNCVDYMGQNALQLAVANEHLEITELLLKKENLSRVGDALLLAISKGYVRIVEAILSHPAFAEGKRLATSPSQSELQQDDFYAYDEDGTRFSHDVTPIILAAHCQEYEIVHTLLRKGARIERPHDYFCKCNDCNQKQKHDSFSHSRSRINAYKGLASPAYLSLSSEDPVMTALELSNELAVLANIEKEFKMGKIMRGPFMKFVAHAASFTIFLGLLVMNAADRFEGTKLLPNETSTDNAKQLFRMKTSCFSWMEMLIISWVIGMIWAECKEIWTQGPKEYLFELWNMLDFGMLAIFAASFIARFMAFWHASKAQSIIDANDTLKDLTKVTLGDNVKYYNLARIKWDPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVIFIMVFVAFMIGMFNLYSYYIGAKQNEAFTTVEESFKTLFWAIFGLSEVKSVVINYNHKFIENIGYVLYGVYNVTMVIVLLNMLIAMINSSFQEIEDDADVEWKFARAKLWFSYFEEGRTLPVPFNLVPSPKSLFYLLLKLKKWISELFQGHKKGFQEDAEMNKINEEKKLGILGSHEDLSKLSLDKKQVGHNKQPSIRSSEDFHLNSFNNPPRQYQKIMKRLIKRYVLQAQIDKESDEVNEGELKEIKQDISSLRYELLEEKSQNTEDLAELIRELGEKLSMEPNQEETNR>sp|Q9Y210-3|TRPC6_HUMAN Isoform 3 of Short transient receptor potentialchannel 6 OS=Homo sapiens OX=9606 GN=TRPC6MSQSPAFGPRRGSSPRGAAGAAARRNESQDYLLMDSELGEDGCPQAPLPCYGYYPCFRGSDNRLAHRRQTVLREKGRRLANRGPAYMFSDRSTSLSIEEERFLDAAEYGNIPVVRKMLEECHSLNVNCVDYMGQNALQLAVANEHLEITELLLKKENLSRVGDALLLAISKGYVRIVEAILSHPAFAEGKRLATSPSQSELQQDDFYAYDEDGTRFSHDVTPIILAAHCQEYEIVHTLLRKGARIERPHDYFCKCNDCNQKQKHDSFSHSRSRINAYKGLASPAYLSLSSEDPVMTALELSNELAVLANIEKEFKNDYKKLSMQCKDFVVGLLDLCRNTEEVEAILNGDVETLQSGDHGRPNLSRLKLAIKYEVKKMGKIMRGPFMKFVAHAASFTIFLGLLVMNAADRFEGTKLLPNETSTDNAKQLFRMKTSCFSWMEMLIISWVIGMIWAECKEIWTQGPKEYLFELWNMLDFGMLAIFAASFIARFMAFWHASKAQSIIDANDTLKDLTKVTLGDNVKYYNLARIKWDPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVIFIMVFVAFMIGMFNLYSYYIGAKQNEAFTTVEESFKTLFWAIFGLSEVKSVVINYNHKFIENIGYVLYGVYNVTMVIVLLNMLIAMINSSFQEIEDDADVEWKFARAKLWFSYFEEGRTLPVPFNLVPSPKSLFYLLLKLKKWISELFQGHKKGFQEDAEMNKINEEKKLGILGSHEDLSKLSLDKKQVGHNKQPSIRSSEDFHLNSFNNPPRQYQKIMKRLIKRYVLQAQIDKESDEVNEGELKEIKQDISSLRYELLEEKSQNTEDLAELIRELGEKLSMEPNQEETNR>sp|Q9BTX7|TTPAL_HUMAN Alpha-tocopherol transfer protein-like OS=Homosapiens OX=9606 GN=TTPAL PE=1 SV=2MSEESDSLRTSPSVASLSENELPPPPEPPGYVCSLTEDLVTKAREELQEKPEWRLRDVQALRDMVRKEYPNLSTSLDDAFLLRFLRARKFDYDRALQLLVNYHSCRRSWPEVFNNLKPSALKDVLASGFLTVLPHTDPRGCHVVCIRPDRWIPSNYPITENIRAIYLTLEKLIQSEETQVNGIVILADYKGVSLSKASHFGPFIAKKVIGILQDGFPIRIKAVHVVNEPRIFKGIFAIIKPFLKEKIANRFFLHGSDLNSLHTNLPRSILPKEYGGTAGELDTATWNAVLLASEDDFVKEFCQPVPACDSILGQTLLPEGLTSDAQCDDSLRAVKSQLYSCY>sp|Q86TV6|TTC7B_HUMAN Tetratricopeptide repeat protein 7B OS=Homosapiens OX=9606 GN=TTC7B PE=1 SV=3MATKKAGSRLETEIERCRSECQWERIPELVKQLSAKLIANDDMAELLLGESKLEQYLKEHPLRQGASPRGPKPQLTEVRKHLTAALDRGNLKSEFLQESNLIMAKLNYVEGDYKEALNIYARVGLDDLPLTAVPPYRLRVIAEAYATKGLCLEKLPISSSTSNLHVDREQDVITCYEKAGDIALLYLQEIERVILSNIQNRSPKPGPAPHDQELGFFLETGLQRAHVLYFKNGNLTRGVGRFRELLRAVETRTTQNLRMTIARQLAEILLRGMCEQSYWNPLEDPPCQSPLDDPLRKGANTKTYTLTRRARVYSGENIFCPQENTEEALLLLLISESMANRDAVLSRIPEHKSDRLISLQSASVVYDLLTIALGRRGQYEMLSECLERAMKFAFEEFHLWYQFALSLMAAGKSARAVKVLKECIRLKPDDATIPLLAAKLCMGSLHWLEEAEKFAKTVVDVGEKTSEFKAKGYLALGLTYSLQATDASLRGMQEVLQRKALLAFQRAHSLSPTDHQAAFYLALQLAISRQIPEALGYVRQALQLQGDDANSLHLLALLLSAQKHYHDALNIIDMALSEYPENFILLFSKVKLQSLCRGPDEALLTCKHMLQIWKSCYNLTNPSDSGRGSSLLDRTIADRRQLNTITLPDFSDPETGSVHATSVAASRVEQALSEVASSLQSSAPKQGPLHPWMTLAQIWLHAAEVYIGIGKPAEATACTQEAANLFPMSHNVLYMRGQIAELRGSMDEARRWYEEALAISPTHVKSMQRLALILHQLGRYSLAEKILRDAVQVNSTAHEVWNGLGEVLQAQGNDAAATECFLTALELEASSPAVPFTIIPRVL>sp|Q86TV6-2|TTC7B_HUMAN Isoform 2 of Tetratricopeptide repeat protein 7BOS=Homo sapiens OX=9606 GN=TTC7BMATKKAGSRLETEIERCRSECQWERIPELVKQLSAKLIANDDMAELLLGESKLEQYLKEHPLRQGASPRGPKPQLTEVRKHLTAALDRGNLKSEFLQESNLIMAKLNYVEGDYKEALNIYARVGLDDLPLTAVPPYRLRVIAEAYATKGLCLEKLPISSSTSNLHVDREQDVITCYEKAGDIALLYLQEIERVILSNIQNRSPKPGPAPHDQELGFFLETGLQRAHVLYFKNGNLTRGVGRFRELLRAVETRTTQNLRMTIARQLAEILLRGMCEQSYWNPLEDPPCQSPLDDPLRKGANTKTYTLTRRARVYSGENIFCPQENTEEALLLLLISESMANRDAVLSRIPEHKSDRLISLQSASVVYDLLTIALGRRGQYEMLSECLERAMKFAFEEFHLWYQFALSLMAAGKSARAVKVLKECIRLKPDDATIPLLAAKLCMGSLHWLEEAEKFAKTVVDVGEKTSEFKAKGYLALGLTYSLQATDASLRGMQEVLQRKALLAFQRAHSLSPTDHQAAFYLALQLAISRQIPEALGYVRQALQLQGDDANSLHLLALLLSAQKHYHDALNIIDMALSEYPENFILLFSKVKLQSLCRGPDEALLTCKHMLQIWKSCYNLTNPSDSGRGSSLLDRTIADRRQLNTITLPDFSDPETGNSPEAYFHGFPSLFSVSSVHATSVAASRVEQALSEVASSLQSSAPKQGPLHPWMTLAQIWLHAAEVYIGIGKPAEATACTQEAANLFPMSHNVLYMRGQIAELRGSMDEARRWYEEALAISPTHVKSMQRLALILHQLGRYSLAEKILRDAVQVNSTAHEVWNGLGEVLQAQGNDAAATECFLTALELEASSPAVPFTIIPRVL>sp|Q969E8|TSR2_HUMAN Pre-rRNA-processing protein TSR2 homolog OS=Homosapiens OX=9606 GN=TSR2 PE=1 SV=1MAGAAEDARALFRAGVCAALEAWPALQIAVENGFGGVHSQEKAKWLGGAVEDYFMRNADLELDEVEDFLGELLTNEFDTVVEDGSLPQVSQQLQTMFHHFQRGDGAALREMASCITQRKCKVTATALKTARETDEDEDDVDSVEEMEVTATNDGAATDGVCPQPEPSDPDAQTIKEEDIVEDGWTIVRRKK>sp|P49815|TSC2_HUMAN Tuberin OS=Homo sapiens OX=9606 GN=TSC2 PE=1 SV=2MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQAMACPNEVVSYEIVLSITRLIKKYRKELQVVAWDILLNIIERLLQQLQTLDSPELRTIVHDLLTTVEELCDQNEFHGSQERYFELVERCADQRPESSLLNLISYRAQSIHPAKDGWIQNLQALMERFFRSESRGAVRIKVLDVLSFVLLINRQFYEEELINSVVISQLSHIPEDKDHQVRKLATQLLVDLAEGCHTHHFNSLLDIIEKVMARSLSPPPELEERDVAAYSASLEDVKTAVLGLLVILQTKLYTLPASHATRVYEMLVSHIQLHYKHSYTLPIASSIRLQAFDFLLLLRADSLHRLGLPNKDGVVRFSPYCVCDYMEPERGSEKKTSGPLSPPTGPPGPAPAGPAVRLGSVPYSLLFRVLLQCLKQESDWKVLKLVLGRLPESLRYKVLIFTSPCSVDQLCSALCSMLSGPKTLERLRGAPEGFSRTDLHLAVVPVLTALISYHNYLDKTKQREMVYCLEQGLIHRCASQCVVALSICSVEMPDIIIKALPVLVVKLTHISATASMAVPLLEFLSTLARLPHLYRNFAAEQYASVFAISLPYTNPSKFNQYIVCLAHHVIAMWFIRCRLPFRKDFVPFITKGLRSNVLLSFDDTPEKDSFRARSTSLNERPKSLRIARPPKQGLNNSPPVKEFKESSAAEAFRCRSISVSEHVVRSRIQTSLTSASLGSADENSVAQADDSLKNLHLELTETCLDMMARYVFSNFTAVPKRSPVGEFLLAGGRTKTWLVGNKLVTVTTSVGTGTRSLLGLDSGELQSGPESSSSPGVHVRQTKEAPAKLESQAGQQVSRGARDRVRSMSGGHGLRVGALDVPASQFLGSATSPGPRTAPAAKPEKASAGTRVPVQEKTNLAAYVPLLTQGWAEILVRRPTGNTSWLMSLENPLSPFSSDINNMPLQELSNALMAAERFKEHRDTALYKSLSVPAASTAKPPPLPRSNTVASFSSLYQSSCQGQLHRSVSWADSAVVMEEGSPGEVPVLVEPPGLEDVEAALGMDRRTDAYSRSSSVSSQEEKSLHAEELVGRGIPIERVVSSEGGRPSVDLSFQPSQPLSKSSSSPELQTLQDILGDPGDKADVGRLSPEVKARSQSGTLDGESAAWSASGEDSRGQPEGPLPSSSPRSPSGLRPRGYTISDSAPSRRGKRVERDALKSRATASNAEKVPGINPSFVFLQLYHSPFFGDESNKPILLPNESQSFERSVQLLDQIPSYDTHKIAVLYVGEGQSNSELAILSNEHGSYRYTEFLTGLGRLIELKDCQPDKVYLGGLDVCGEDGQFTYCWHDDIMQAVFHIATLMPTKDVDKHRCDKKRHLGNDFVSIVYNDSGEDFKLGTIKGQFNFVHVIVTPLDYECNLVSLQCRKDMEGLVDTSVAKIVSDRNLPFVARQMALHANMASQVHHSRSNPTDIYPSKWIARLRHIKRLRQRICEEAAYSNPSLPLVHPPSHSKAPAQTPAEPTPGYEVGQRKRLISSVEDFTEFV>sp|P49815-2|TSC2_HUMAN Isoform 2 of Tuberin OS=Homo sapiens OX=9606GN=TSC2MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQAMACPNEVVSYEIVLSITRLIKKYRKELQVVAWDILLNIIERLLQQLQTLDSPELRTIVHDLLTTVEELCDQNEFHGSQERYFELVERCADQRPESSLLNLISYRAQSIHPAKDGWIQNLQALMERFFRSESRGAVRIKVLDVLSFVLLINRQFYEEELINSVVISQLSHIPEDKDHQVRKLATQLLVDLAEGCHTHHFNSLLDIIEKVMARSLSPPPELEERDVAAYSASLEDVKTAVLGLLVILQTKLYTLPASHATRVYEMLVSHIQLHYKHSYTLPIASSIRLQAFDFLLLLRADSLHRLGLPNKDGVVRFSPYCVCDYMEPERGSEKKTSGPLSPPTGPPGPAPAGPAVRLGSVPYSLLFRVLLQCLKQESDWKVLKLVLGRLPESLRYKVLIFTSPCSVDQLCSALCSMLSGPKTLERLRGAPEGFSRTDLHLAVVPVLTALISYHNYLDKTKQREMVYCLEQGLIHRCASQCVVALSICSVEMPDIIIKALPVLVVKLTHISATASMAVPLLEFLSTLARLPHLYRNFAAEQYASVFAISLPYTNPSKFNQYIVCLAHHVIAMWFIRCRLPFRKDFVPFITKGLRSNVLLSFDDTPEKDSFRARSTSLNERPKSRIQTSLTSASLGSADENSVAQADDSLKNLHLELTETCLDMMARYVFSNFTAVPKRSPVGEFLLAGGRTKTWLVGNKLVTVTTSVGTGTRSLLGLDSGELQSGPESSSSPGVHVRQTKEAPAKLESQAGQQVSRGARDRVRSMSGGHGLRVGALDVPASQFLGSATSPGPRTAPAAKPEKASAGTRVPVQEKTNLAAYVPLLTQGWAEILVRRPTGNTSWLMSLENPLSPFSSDINNMPLQELSNALMAAERFKEHRDTALYKSLSVPAASTAKPPPLPRSNTVASFSSLYQSSCQGQLHRSVSWADSAVVMEEGSPGEVPVLVEPPGLEDVEAALGMDRRTDAYSRSSSVSSQEEKSLHAEELVGRGIPIERVVSSEGGRPSVDLSFQPSQPLSKSSSSPELQTLQDILGDPGDKADVGRLSPEVKARSQSGTLDGESAAWSASGEDSRGQPEGPLPSSSPRSPSGLRPRGYTISDSAPSRRGKRVERDALKSRATASNAEKVPGINPSFVFLQLYHSPFFGDESNKPILLPNESQSFERSVQLLDQIPSYDTHKIAVLYVGEGQSNSELAILSNEHGSYRYTEFLTGLGRLIELKDCQPDKVYLGGLDVCGEDGQFTYCWHDDIMQAVFHIATLMPTKDVDKHRCDKKRHLGNDFVSIVYNDSGEDFKLGTIKGQFNFVHVIVTPLDYECNLVSLQCRKDMEGLVDTSVAKIVSDRNLPFVARQMALHANMASQVHHSRSNPTDIYPSKWIARLRHIKRLRQRICEEAAYSNPSLPLVHPPSHSKAPAQTPAEPTPGYEVGQRKRLISSVEDFTEFV>sp|P49815-3|TSC2_HUMAN Isoform 3 of Tuberin OS=Homo sapiens OX=9606GN=TSC2MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQAMACPNEVVSYEIVLSITRLIKKYRKELQVVAWDILLNIIERLLQQLQTLDSPELRTIVHDLLTTVEELCDQNEFHGSQERYFELVERCADQRPESSLLNLISYRAQSIHPAKDGWIQNLQALMERFFRSESRGAVRIKVLDVLSFVLLINRQFYEEELINSVVISQLSHIPEDKDHQVRKLATQLLVDLAEGCHTHHFNSLLDIIEKVMARSLSPPPELEERDVAAYSASLEDVKTAVLGLLVILQTKLYTLPASHATRVYEMLVSHIQLHYKHSYTLPIASSIRLQAFDFLLLLRADSLHRLGLPNKDGVVRFSPYCVCDYMEPERGSEKKTSGPLSPPTGPPGPAPAGPAVRLGSVPYSLLFRVLLQCLKQESDWKVLKLVLGRLPESLRYKVLIFTSPCSVDQLCSALCSMLSGPKTLERLRGAPEGFSRTDLHLAVVPVLTALISYHNYLDKTKQREMVYCLEQGLIHRCASQCVVALSICSVEMPDIIIKALPVLVVKLTHISATASMAVPLLEFLSTLARLPHLYRNFAAEQYASVFAISLPYTNPSKFNQYIVCLAHHVIAMWFIRCRLPFRKDFVPFITKGLRSNVLLSFDDTPEKDSFRARSTSLNERPKRIQTSLTSASLGSADENSVAQADDSLKNLHLELTETCLDMMARYVFSNFTAVPKRSPVGEFLLAGGRTKTWLVGNKLVTVTTSVGTGTRSLLGLDSGELQSGPESSSSPGVHVRQTKEAPAKLESQAGQQVSRGARDRVRSMSGGHGLRVGALDVPASQFLGSATSPGPRTAPAAKPEKASAGTRVPVQEKTNLAAYVPLLTQGWAEILVRRPTGNTSWLMSLENPLSPFSSDINNMPLQELSNALMAAERFKEHRDTALYKSLSVPAASTAKPPPLPRSNTVASFSSLYQSSCQGQLHRSVSWADSAVVMEEGSPGEVPVLVEPPGLEDVEAALGMDRRTDAYSRSSSVSSQEEKSLHAEELVGRGIPIERVVSSEGGRPSVDLSFQPSQPLSKSSSSPELQTLQDILGDPGDKADVGRLSPEVKARSQSGTLDGESAAWSASGEDSRGQPEGPLPSSSPRSPSGLRPRGYTISDSAPSRRGKRVERDALKSRATASNAEKVPGINPSFVFLQLYHSPFFGDESNKPILLPNESQSFERSVQLLDQIPSYDTHKIAVLYVGEGQSNSELAILSNEHGSYRYTEFLTGLGRLIELKDCQPDKVYLGGLDVCGEDGQFTYCWHDDIMQAVFHIATLMPTKDVDKHRCDKKRHLGNDFVSIVYNDSGEDFKLGTIKGQFNFVHVIVTPLDYECNLVSLQCRKDMEGLVDTSVAKIVSDRNLPFVARQMALHANMASQVHHSRSNPTDIYPSKWIARLRHIKRLRQRICEEAAYSNPSLPLVHPPSHSKAPAQTPAEPTPGYEVGQRKRLISSVEDFTEFV>sp|P49815-4|TSC2_HUMAN Isoform 4 of Tuberin OS=Homo sapiens OX=9606GN=TSC2MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQAMACPNEVVSYEIVLSITRLIKKYRKELQVVAWDILLNIIERLLQQLQTLDSPELRTIVHDLLTTVEELCDQNEFHGSQERYFELVERCADQRPESSLLNLISYRAQSIHPAKDGWIQNLQALMERFFRSESRGAVRIKVLDVLSFVLLINRQFYEEELINSVVISQLSHIPEDKDHQVRKLATQLLVDLAEGCHTHHFNSLLDIIEKVMARSLSPPPELEERDVAAYSASLEDVKTAVLGLLVILQTKLYTLPASHATRVYEMLVSHIQLHYKHSYTLPIASSIRLQAFDFLLLLRADSLHRLGLPNKDGVVRFSPYCVCDYMEPERGSEKKTSGPLSPPTGPPGPAPAGPAVRLGSVPYSLLFRVLLQCLKQESDWKVLKLVLGRLPESLRYKVLIFTSPCSVDQLCSALCSMLSGPKTLERLRGAPEGFSRTDLHLAVVPVLTALISYHNYLDKTKQREMVYCLEQGLIHRCASQCVVALSICSVEMPDIIIKALPVLVVKLTHISATASMAVPLLEFLSTLARLPHLYRNFAAEQYASVFAISLPYTNPSKFNQYIVCLAHHVIAMWFIRCRLPFRKDFVPFITKGLRSNVLLSFDDTPEKDSFRARSTSLNERPKSLRIARPPKQGLNNSPPVKEFKESSAAEAFRCRSISVSEHVVRSRIQTSLTSASLGSADENSVAQADDSLKNLHLELTETCLDMMARYVFSNFTAVPKRSPVGEFLLAGGRTKTWLVGNKLVTVTTSVGTGTRSLLGLDSGELQSGPESSSSPGVHVRQTKEAPAKLESQAGQQVSRGARDRVRSMSGGHGLRVGALDVPASQFLGSATSPGPRTAPAAKPEKASAGTRVPVQEKTNLAAYVPLLTQGWAEILVRRPTGNTSWLMSLENPLSPFSSDINNMPLQELSNALMAAERFKEHRDTALYKSLSVPAASTAKPPPLPRSNTDSAVVMEEGSPGEVPVLVEPPGLEDVEAALGMDRRTDAYSRSSSVSSQEEKSLHAEELVGRGIPIERVVSSEGGRPSVDLSFQPSQPLSKSSSSPELQTLQDILGDPGDKADVGRLSPEVKARSQSGTLDGESAAWSASGEDSRGQPEGPLPSSSPRSPSGLRPRGYTISDSAPSRRGKRVERDALKSRATASNAEKVPGINPSFVFLQLYHSPFFGDESNKPILLPNESQSFERSVQLLDQIPSYDTHKIAVLYVGEGQSNSELAILSNEHGSYRYTEFLTGLGRLIELKDCQPDKVYLGGLDVCGEDGQFTYCWHDDIMQAVFHIATLMPTKDVDKHRCDKKRHLGNDFVSIVYNDSGEDFKLGTIKGQFNFVHVIVTPLDYECNLVSLQCRKDMEGLVDTSVAKIVSDRNLPFVARQMALHANMASQVHHSRSNPTDIYPSKWIARLRHIKRLRQRICEEAAYSNPSLPLVHPPSHSKAPAQTPAEPTPGYEVGQRKRLISSVEDFTEFV>sp|P49815-5|TSC2_HUMAN Isoform 5 of Tuberin OS=Homo sapiens OX=9606GN=TSC2MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQAMACPNEVVSYEIVLSITRLIKKYRKELQVVAWDILLNIIERLLQQLQTLDSPELRTIVHDLLTTVEELCDQNEFHGSQERYFELVERCADQRPESSLLNLISYRAQSIHPAKDGWIQNLQALMERFFRSESRGAVRIKVLDVLSFVLLINRQFYEEELINSVVISQLSHIPEDKDHQVRKLATQLLVDLAEGCHTHHFNSLLDIIEKVMARSLSPPPELEERDVAAYSASLEDVKTAVLGLLVILQTKLYTLPASHATRVYEMLVSHIQLHYKHSYTLPIASSIRLQAFDFLLLLRADSLHRLGLPNKDGVVRFSPYCVCDYMEPERGSEKKTSGPLSPPTGPPGPAPAGPAVRLGSVPYSLLFRVLLQCLKQESDWKVLKLVLGRLPESLRYKVLIFTSPCSVDQLCSALCSMLSGPKTLERLRGAPEGFSRTDLHLAVVPVLTALISYHNYLDKTKQREMVYCLEQGLIHRCASQCVVALSICSVEMPDIIIKALPVLVVKLTHISATASMAVPLLEFLSTLARLPHLYRNFAAEQYASVFAISLPYTNPSKFNQYIVCLAHHVIAMWFIRCRLPFRKDFVPFITKGLRSNVLLSFDDTPEKDSFRARSTSLNERPKRIQTSLTSASLGSADENSVAQADDSLKNLHLELTETCLDMMARYVFSNFTAVPKRSPVGEFLLAGGRTKTWLVGNKLVTVTTSVGTGTRSLLGLDSGELQSGPESSSSPGVHVRQTKEAPAKLESQAGQQVSRGARDRVRSMSGGHGLRVGALDVPASQFLGSATSPGPRTAPAAKPEKASAGTRVPVQEKTNLAAYVPLLTQGWAEILVRRPTGNTSWLMSLENPLSPFSSDINNMPLQELSNALMAAERFKEHRDTALYKSLSVPAASTAKPPPLPRSNTDSAVVMEEGSPGEVPVLVEPPGLEDVEAALGMDRRTDAYSRSSSVSSQEEKSLHAEELVGRGIPIERVVSSEGGRPSVDLSFQPSQPLSKSSSSPELQTLQDILGDPGDKADVGRLSPEVKARSQSGTLDGESAAWSASGEDSRGQPEGPLPSSSPRSPSGLRPRGYTISDSAPSRRGKRVERDALKSRATASNAEKVPGINPSFVFLQLYHSPFFGDESNKPILLPNESQSFERSVQLLDQIPSYDTHKIAVLYVGEGQSNSELAILSNEHGSYRYTEFLTGLGRLIELKDCQPDKVYLGGLDVCGEDGQFTYCWHDDIMQAVFHIATLMPTKDVDKHRCDKKRHLGNDFVSIVYNDSGEDFKLGTIKGQFNFVHVIVTPLDYECNLVSLQCRKDMEGLVDTSVAKIVSDRNLPFVARQMALHANMASQVHHSRSNPTDIYPSKWIARLRHIKRLRQRICEEAAYSNPSLPLVHPPSHSKAPAQTPAEPTPGYEVGQRKRLISSVEDFTEFV>sp|P49815-6|TSC2_HUMAN Isoform 6 of Tuberin OS=Homo sapiens OX=9606GN=TSC2MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQAMACPNEVVSYEIVLSITRLIKKYRKELQVVAWDILLNIIERLLQQLQTLDSPELRTIVHDLLTTVEELCDQNEFHGSQERYFELVERCADQRPESSLLNLISYRAQSIHPAKDGWIQNLQALMERFFRSESRGAVRIKVLDVLSFVLLINRQFYEEELINSVVISQLSHIPEDKDHQVRKLATQLLVDLAEGCHTHHFNSLLDIIEKVMARSLSPPPELEERDVAAYSASLEDVKTAVLGLLVILQTKLYTLPASHATRVYEMLVSHIQLHYKHSYTLPIASSIRLQAFDFLLLLRADSLHRLGLPNKDGVVRFSPYCVCDYMEPERGSEKKTSGPLSPPTGPPGPAPAGPAVRLGSVPYSLLFRVLLQCLKQESDWKVLKLVLGRLPESLRYKVLIFTSPCSVDQLCSALCSMLSGPKTLERLRGAPEGFSRTDLHLAVVPVLTALISYHNYLDKTKQREMVYCLEQGLIHRCASQCVVALSICSVEMPDIIIKALPVLVVKLTHISATASMAVPLLEFLSTLARLPHLYRNFAAEQYASVFAISLPYTNPSKFNQYIVCLAHHVIAMWFIRCRLPFRKDFVPFITKGLRSNVLLSFDDTPEKDSFRARSTSLNERPKSRIQTSLTSASLGSADENSVAQADDSLKNLHLELTETCLDMMARYVFSNFTAVPKRSPVGEFLLAGGRTKTWLVGNKLVTVTTSVGTGTRSLLGLDSGELQSGPESSSSPGVHVRQTKEAPAKLESQAGQQVSRGARDRVRSMSGGHGLRVGALDVPASQFLGSATSPGPRTAPAAKPEKASAGTRVPVQEKTNLAAYVPLLTQGWAEILVRRPTGNTSWLMSLENPLSPFSSDINNMPLQELSNALMAAERFKEHRDTALYKSLSVPAASTAKPPPLPRSNTDSAVVMEEGSPGEVPVLVEPPGLEDVEAALGMDRRTDAYSRSSSVSSQEEKSLHAEELVGRGIPIERVVSSEGGRPSVDLSFQPSQPLSKSSSSPELQTLQDILGDPGDKADVGRLSPEVKARSQSGTLDGESAAWSASGEDSRGQPEGPLPSSSPRSPSGLRPRGYTISDSAPSRRGKRVERDALKSRATASNAEKVPGINPSFVFLQLYHSPFFGDESNKPILLPNESQSFERSVQLLDQIPSYDTHKIAVLYVGEGQSNSELAILSNEHGSYRYTEFLTGLGRLIELKDCQPDKVYLGGLDVCGEDGQFTYCWHDDIMQAVFHIATLMPTKDVDKHRCDKKRHLGNDFVSIVYNDSGEDFKLGTIKGQFNFVHVIVTPLDYECNLVSLQCRKDMEGLVDTSVAKIVSDRNLPFVARQMALHANMASQVHHSRSNPTDIYPSKWIARLRHIKRLRQRICEEAAYSNPSLPLVHPPSHSKAPAQTPAEPTPGYEVGQRKRLISSVEDFTEFV>sp|P49815-7|TSC2_HUMAN Isoform 7 of Tuberin OS=Homo sapiens OX=9606GN=TSC2MECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQAMACPNEVVSYEIVLSITRLIKKYRKELQVVAWDILLNIIERLLQQLQTLDSPELRTIVHDLLTTVEELCDQNEFHGSQERYFELVERCADQRPESSLLNLISYRAQSIHPAKDGWIQNLQALMERFFRSESRGAVRIKVLDVLSFVLLINRQFYEEELINSVVISQLSHIPEDKDHQVRKLATQLLVDLAEGCHTHHFNSLLDIIEKVMARSLSPPPELEERDVAAYSASLEDVKTAVLGLLVILQTKLYTLPASHATRVYEMLVSHIQLHYKHSYTLPIASSIRLQAFDFLLLLRADSLHRLGLPNKDGVVRFSPYCVCDYMEPERGSEKKTSGPLSPPTGPPGPAPAGPAVRLGSVPYSLLFRVLLQCLKQESDWKVLKLVLGRLPESLRYKVLIFTSPCSVDQLCSALCSMLSGPKTLERLRGAPEGFSRTDLHLAVVPVLTALISYHNYLDKTKQREMVYCLEQGLIHRCASQCVVALSICSVEMPDIIIKALPVLVVKLTHISATASMAVPLLEFLSTLARLPHLYRNFAAEQYASVFAISLPYTNPSKFNQYIVCLAHHVIAMWFIRCRLPFRKDFVPFITKGLRSNVLLSFDDTPEKDSFRARSTSLNERPKSRIQTSLTSASLGSADENSVAQADDSLKNLHLELTETCLDMMARYVFSNFTAVPKRSPVGEFLLAGGRTKTWLVGNKLVTVTTSVGTGTRSLLGLDSGELQSGPESSSSPGVHVRQTKEAPAKLESQAGQQVSRGARDRVRSMSGGHGLRVGALDVPASQFLGSATSPGPRTAPAAKPEKASAGTRVPVQEKTNLAAYVPLLTQGWAEILVRRPTGNTSWLMSLENPLSPFSSDINNMPLQELSNALMAAERFKEHRDTALYKSLSVPAASTAKPPPLPRSNTDSAVVMEEGSPGEVPVLVEPPGLEDVEAALGMDRRTDAYSRSSSVSSQEEKSLHAEELVGRGIPIERVVSSEGGRPSVDLSFQPSQPLSKSSSSPELQTLQDILGDPGDKADVGRLSPEVKARSQSGTLDGESAAWSASGEDSRGQPEGPLPSSSPRSPSGLRPRGYTISDSAPSRRGKRVERDALKSRATASNAEKVPGINPSFVFLQLYHSPFFGDESNKPILLPNESQSFERSVQLLDQIPSYDTHKIAVLYVGEGQSNSELAILSNEHGSYRYTEFLTGLGRLIELKDCQPDKVYLGGLDVCGEDGQFTYCWHDDIMQAVFHIATLMPTKDVDKHRCDKKRHLGNDFVSIVYNDSGEDFKLGTIKGQFNFVHVIVTPLDYECNLVSLQCRKDMEGLVDTSVAKIVSDRNLPFVARQMALHANMASQVHHSRSNPTDIYPSKWIARLRHIKRLRQRICEEAAYSNPSLPLVHPPSHSKAPAQTPAEPTPGYEVGQRKRLISSVEDFTEFV>sp|P49815-8|TSC2_HUMAN Isoform 8 of Tuberin OS=Homo sapiens OX=9606GN=TSC2MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQVRPRATLGWVTSGCPLTVLSLLGRVWTPASVSCWAQGLGADGLWSWMACGVSWCHEVCVTVGTASSPVNRWSLHLPLMGCSGDHMRQFSQSAEIVPGSWCGATVLFCPCTLSGPLPCSLHSICAGLG>sp|P11441|UBL4A_HUMAN Ubiquitin-like protein 4A OS=Homo sapiens OX=9606GN=UBL4A PE=1 SV=1MQLTVKALQGRECSLQVPEDELVSTLKQLVSEKLNVPVRQQRLLFKGKALADGKRLSDYSIGPNSKLNLVVKPLEKVLLEEGEAQRLADSPPPQVWQLISKVLARHFSAADASRVLEQLQRDYERSLSRLTLDDIERLASRFLHPEVTETMEKGFSK>sp|P0CV98|TSPY3_HUMAN Testis-specific Y-encoded protein 3 OS=Homosapiens OX=9606 GN=TSPY3 PE=3 SV=1MRPEGSLTYRVPERLRQGFCGVGRAAQALVCASAKEGTAFRMEAVQEGAAGVESEQAALGEEAVLLLDDIMAEVEVVAEEEGLVERREEAQRAQQAVPGPGPMTPESALEELLAVQVELEPVNAQARKAFSRQREKMERRRKPHLDRRGAVIQSVPGFWANVIANHPQMSALITDEDEDMLSYMVSLEVEEEKHPVHLCKIMLFFRSNPYFQNKVITKEYLVNITEYRASHSTPIEWYPDYEVEAYRRRHHNSSLNFFNWFSDHNFAGSNKIAEILCKDLWRNPLQYYKRMKPPEEGTETSGDSQLLS>sp|O95551|TYDP2_HUMAN Tyrosyl-DNA phosphodiesterase 2 OS=Homo sapiensOX=9606 GN=TDP2 PE=1 SV=1MELGSCLEGGREAAEEEGEPEVKKRRLLCVEFASVASCDAAVAQCFLAENDWEMERALNSYFEPPVEESALERRPETISEPKTYVDLTNEETTDSTTSKISPSEDTQQENGSMFSLITWNIDGLDLNNLSERARGVCSYLALYSPDVIFLQEVIPPYYSYLKKRSSNYEIITGHEEGYFTAIMLKKSRVKLKSQEIIPFPSTKMMRNLLCVHVNVSGNELCLMTSHLESTRGHAAERMNQLKMVLKKMQEAPESATVIFAGDTNLRDREVTRCGGLPNNIVDVWEFLGKPKHCQYTWDTQMNSNLGITAACKLRFDRIFFRAAAEEGHIIPRSLDLLGLEKLDCGRFPSDHWGLLCNLDIIL>sp|O95551-2|TYDP2_HUMAN Isoform 2 of Tyrosyl-DNA phosphodiesterase 2OS=Homo sapiens OX=9606 GN=TDP2MRERHDTGACAEPRVGLLFRLKGRCRGGRKMELGSCLEGGREAAEEEGEPEVKKRRLLCVEFASVASCDAAVAQCFLAENDWEMERALNSYFEPPVEESALERRPETISEPKTYVDLTNEETTDSTTSKISPSEDTQQENGSMFSLITWNIDGLDLNNLSERARGVCSYLALYSPDVIFLQEVIPPYYSYLKKRSSNYEIITGHEEGYFTAIMLKKSRVKLKSQEIIPFPSTKMMRNLLCVHVNVSGNELCLMTSHLESTRGHAAERMNQLKMVLKKMQEAPESATVIFAGDTNLRDREVTRCGGLPNNIVDVWEFLGKPKHCQYTWDTQMNSNLGITAACKLRFDRIFFRAAAEEGHIIPRSLDLLGLEKLDCGRFPSDHWGLLCNLDIIL>sp|O95551-3|TYDP2_HUMAN Isoform 3 of Tyrosyl-DNA phosphodiesterase 2OS=Homo sapiens OX=9606 GN=TDP2MELGSCLEGGREAAEEEGEPEVKKRRLLCVEFASVASCDAAVAQCFLAENDWEMERALNSYLALYSPDVIFLQEVIPPYYSYLKKRSSNYEIITGHEEGYFTAIMLKKSRVKLKSQEIIPFPSTKMMRNLLCVHVNVSGNELCLMTSHLESTRGHAAERMNQLKMVLKKMQEAPESATVIFAGDTNLRDREVTRCGGLPNNIVDVWEFLGKPKHCQYTWDTQMNSNLGITAACKLRFDRIFFRAAAEEGHIIPRSLDLLGLEKLDCGRFPSDHWGLLCNLDIIL>sp|P22310|UD14_HUMAN UDP-glucuronosyltransferase 1A4 OS=Homo sapiensOX=9606 GN=UGT1A4 PE=1 SV=1MARGLQVPLPRLATGLLLLLSVQPWAESGKVLVVPTDGSPWLSMREALRELHARGHQAVVLTPEVNMHIKEEKFFTLTAYAVPWTQKEFDRVTLGYTQGFFETEHLLKRYSRSMAIMNNVSLALHRCCVELLHNEALIRHLNATSFDVVLTDPVNLCGAVLAKYLSIPAVFFWRYIPCDLDFKGTQCPNPSSYIPKLLTTNSDHMTFLQRVKNMLYPLALSYICHTFSAPYASLASELFQREVSVVDLVSYASVWLFRGDFVMDYPRPIMPNMVFIGGINCANGKPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKSYKENIMRLSSLHKDRPVEPLDLAVFWVEFVMRHKGAPHLRPAAHDLTWYQYHSLDVIGFLLAVVLTVAFITFKCCAYGYRKCLGKKGRVKKAHKSKTH>sp|P22310-2|UD14_HUMAN Isoform 2 of UDP-glucuronosyltransferase 1A4OS=Homo sapiens OX=9606 GN=UGT1A4MARGLQVPLPRLATGLLLLLSVQPWAESGKVLVVPTDGSPWLSMREALRELHARGHQAVVLTPEVNMHIKEEKFFTLTAYAVPWTQKEFDRVTLGYTQGFFETEHLLKRYSRSMAIMNNVSLALHRCCVELLHNEALIRHLNATSFDVVLTDPVNLCGAVLAKYLSIPAVFFWRYIPCDLDFKGTQCPNPSSYIPKLLTTNSDHMTFLQRVKNMLYPLALSYICHTFSAPYASLASELFQREVSVVDLVSYASVWLFRGDFVMDYPRPIMPNMVFIGGINCANGKPLSQEFEAYINASGEHGIVVFSLGSMVSEIPEKKAMAIADALGKIPQTVLWRYTGTRPSNLANNTILVKWLPQNDLLGHPMTRAFITHAGSHGVYESICNGVPMVMMPLFGDQMDNAKRMETKGAGVTLNVLEMTSEDLENALKAVINDKRKKQQSGRQM>sp|Q8IYU4|UBQLN_HUMAN Ubiquilin-like protein OS=Homo sapiens OX=9606GN=UBQLNL PE=1 SV=3MWHAISRTSRMSQSGCPSGLLADKNISSSATRVIVKTAGNQKDFMVADDISVRQFKEMLLAHFQCQMDQLVLVFMGCLLKDHDTLSQRGIMDGHTIYLVIKSKQGSRSLAHSFRDLPTNDPCHRDRNTKGNSSRVHQPTGMNQAPVELAHFVGSDAPKVHTQNLEVSHPECKAQMLENPSIQRLLSNMEFMWQFISEHLDTQQLMQQNPEVSRLLLDNSEILLQTLELARNLAMIQEIMQIQQPSQNLEYPLNPQPYLGLETMPGGNNALGQNYADINDQMLNSMQDPFGGNPFTALLAGQVLEQVQSSPPPPPPSQEQQDQLTQHPATRVIYNSSGGFSSNTSANDTLNKVNHTSKANTAMISTKGQSHICATRQPAWIPALPSIELTQQLQEEYKDATVSLSSSRQTLKGDLQLSDEQSSSQITGGMMQLLMNNPYLAAQIMLFTSMPQLSEQWRQQLPTFLQQTQISDLLSA>sp|Q8IYU4-2|UBQLN_HUMAN Isoform 2 of Ubiquilin-like protein OS=Homosapiens OX=9606 GN=UBQLNLMWHAISRTSRMSQSGCPSGLLADKNISSSATRVIVKTAGNQKDFMVADDISVRQFKEMLLAHFQCQMDQLVLVFMGCLLKDHDTLSQRGIMDGHTIYLVIKSKQGSRSLAHSFRDLPTNDPCHRDRNTSANDTLNKVNHTSKANTAMISTKGQSHICATRQPAWIPALPSIELTQQLQEEYKDATVSLSSSRQTLKGDLQLSDEQSSSQITGGMMQLLMNNPYLAAQIMLFTSMPQLSEQWRQQLPTFLQQTQISDLLSA>sp|Q9Y6I4|UBP3_HUMAN Ubiquitin carboxyl-terminal hydrolase 3 OS=Homosapiens OX=9606 GN=USP3 PE=1 SV=2MECPHLSSSVCIAPDSAKFPNGSPSSWCCSVCRSNKSPWVCLTCSSVHCGRYVNGHAKKHYEDAQVPLTNHKKSEKQDKVQHTVCMDCSSYSTYCYRCDDFVVNDTKLGLVQKVREHLQNLENSAFTADRHKKRKLLENSTLNSKLLKVNGSTTAICATGLRNLGNTCFMNAILQSLSNIEQFCCYFKELPAVELRNGKTAGRRTYHTRSQGDNNVSLVEEFRKTLCALWQGSQTAFSPESLFYVVWKIMPNFRGYQQQDAHEFMRYLLDHLHLELQGGFNGVSRSAILQENSTLSASNKCCINGASTVVTAIFGGILQNEVNCLICGTESRKFDPFLDLSLDIPSQFRSKRSKNQENGPVCSLRDCLRSFTDLEELDETELYMCHKCKKKQKSTKKFWIQKLPKVLCLHLKRFHWTAYLRNKVDTYVEFPLRGLDMKCYLLEPENSGPESCLYDLAAVVVHHGSGVGSGHYTAYATHEGRWFHFNDSTVTLTDEETVVKAKAYILFYVEHQAKAGSDKL>sp|Q9Y6I4-2|UBP3_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 3 OS=Homo sapiens OX=9606 GN=USP3MECPHLSSSVCIAPDSAKFPNGSPSSWCCSVCRSNKSPWVCLTCSSVHCGSYRCDDFVVNDTKLGLVQKVREHLQNLENSAFTADRHKKRKLLENSTLNSKLLKVNGSTTAICATGLRNLGNTCFMNAILQSLSNIEQFCCYFKELPAVELRNGKTAGRRTYHTRSQGDNNVSLVEEFRKTLCALWQGSQTAFSPESLFYVVWKIMPNFRGYQQQDAHEFMRYLLDHLHLELQGGFNGVSRSAILQENSTLSASNKCCINGASTVVTAIFGGILQNEVNCLICGTESRKFDPFLDLSLDIPSQFRSKRSKNQENGPVCSLRDCLRSFTDLEELDETELYMCHKCKKKQKSTKKFWIQKLPKVLCLHLKRFHWTAYLRNKVDTYVEFPLRGLDMKCYLLEPENSGPESCLYDLAAVVVHHGSGVGSGHYTAYATHEGRWFHFNDSTVTLTDEETVVKAKAYILFYVEHQAKAGSDKL>sp|Q8IWV8|UBR2_HUMAN E3 ubiquitin-protein ligase UBR2 OS=Homo sapiensOX=9606 GN=UBR2 PE=1 SV=1MASELEPEVQAIDRSLLECSAEEIAGKWLQATDLTREVYQHLAHYVPKIYCRGPNPFPQKEDMLAQHVLLGPMEWYLCGEDPAFGFPKLEQANKPSHLCGRVFKVGEPTYSCRDCAVDPTCVLCMECFLGSIHRDHRYRMTTSGGGGFCDCGDTEAWKEGPYCQKHELNTSEIEEEEDPLVHLSEDVIARTYNIFAITFRYAVEILTWEKESELPADLEMVEKSDTYYCMLFNDEVHTYEQVIYTLQKAVNCTQKEAIGFATTVDRDGRRSVRYGDFQYCEQAKSVIVRNTSRQTKPLKVQVMHSSIVAHQNFGLKLLSWLGSIIGYSDGLRRILCQVGLQEGPDGENSSLVDRLMLSDSKLWKGARSVYHQLFMSSLLMDLKYKKLFAVRFAKNYQQLQRDFMEDDHERAVSVTALSVQFFTAPTLARMLITEENLMSIIIKTFMDHLRHRDAQGRFQFERYTALQAFKFRRVQSLILDLKYVLISKPTEWSDELRQKFLEGFDAFLELLKCMQGMDPITRQVGQHIEMEPEWEAAFTLQMKLTHVISMMQDWCASDEKVLIEAYKKCLAVLMQCHGGYTDGEQPITLSICGHSVETIRYCVSQEKVSIHLPVSRLLAGLHVLLSKSEVAYKFPELLPLSELSPPMLIEHPLRCLVLCAQVHAGMWRRNGFSLVNQIYYYHNVKCRREMFDKDVVMLQTGVSMMDPNHFLMIMLSRFELYQIFSTPDYGKRFSSEITHKDVVQQNNTLIEEMLYLIIMLVGERFSPGVGQVNATDEIKREIIHQLSIKPMAHSELVKSLPEDENKETGMESVIEAVAHFKKPGLTGRGMYELKPECAKEFNLYFYHFSRAEQSKAEEAQRKLKRQNREDTALPPPVLPPFCPLFASLVNILQSDVMLCIMGTILQWAVEHNGYAWSESMLQRVLHLIGMALQEEKQHLENVTEEHVVTFTFTQKISKPGEAPKNSPSILAMLETLQNAPYLEVHKDMIRWILKTFNAVKKMRESSPTSPVAETEGTIMEESSRDKDKAERKRKAEIARLRREKIMAQMSEMQRHFIDENKELFQQTLELDASTSAVLDHSPVASDMTLTALGPAQTQVPEQRQFVTCILCQEEQEVKVESRAMVLAAFVQRSTVLSKNRSKFIQDPEKYDPLFMHPDLSCGTHTSSCGHIMHAHCWQRYFDSVQAKEQRRQQRLRLHTSYDVENGEFLCPLCECLSNTVIPLLLPPRNIFNNRLNFSDQPNLTQWIRTISQQIKALQFLRKEESTPNNASTKNSENVDELQLPEGFRPDFRPKIPYSESIKEMLTTFGTATYKVGLKVHPNEEDPRVPIMCWGSCAYTIQSIERILSDEDKPLFGPLPCRLDDCLRSLTRFAAAHWTVASVSVVQGHFCKLFASLVPNDSHEELPCILDIDMFHLLVGLVLAFPALQCQDFSGISLGTGDLHIFHLVTMAHIIQILLTSCTEENGMDQENPPCEEESAVLALYKTLHQYTGSALKEIPSGWHLWRSVRAGIMPFLKCSALFFHYLNGVPSPPDIQVPGTSHFEHLCSYLSLPNNLICLFQENSEIMNSLIESWCRNSEVKRYLEGERDAIRYPRESNKLINLPEDYSSLINQASNFSCPKSGGDKSRAPTLCLVCGSLLCSQSYCCQTELEGEDVGACTAHTYSCGSGVGIFLRVRECQVLFLAGKTKGCFYSPPYLDDYGETDQGLRRGNPLHLCKERFKKIQKLWHQHSVTEEIGHAQEANQTLVGIDWQHL>sp|Q8IWV8-2|UBR2_HUMAN Isoform 2 of E3 ubiquitin-protein ligase UBR2OS=Homo sapiens OX=9606 GN=UBR2MASELEPEVQAIDRSLLECSAEEIAGKWLQATDLTREVYQHLAHYVPKIYCRGPNPFPQKEDMLAQHVLLGPMEWYLCGEDPAFGFPKLEQANKPSHLCGRVFKVGEPTYSCRDCAVDPTCVLCMECFLGSIHRDHRYRMTTSGGGGFCDCGDTEAWKEGPYCQKHELNTSEIEEEEDPLVHLSEDVIARTYNIFAITFRYAVEILTWEKESELPADLEMVEKSDTYYCMLFNDEVHTYEQVIYTLQKAVNCTQKEAIGFATTVDRDGRRSVRYGDFQYCEQAKSVIVRNTSRQTKPLKVQVMHSSIVAHQNFGLKLLSWLGSIIGYSDGLRRILCQVGLQEGPDGENSSLVDRLMLSDSKLWKGARSVYHQLFMSSLLMDLKYKKLFAVRFAKNYERLQSDYVTDDHDREFSVADLSVQIFTVPSLFSISAGRSGSPL>sp|Q8IWV8-3|UBR2_HUMAN Isoform 3 of E3 ubiquitin-protein ligase UBR2OS=Homo sapiens OX=9606 GN=UBR2MYAGNIPIYKTESRSRNEQGMDPITRQVGQHIEMEPEWEAAFTLQMKLTHVISMMQDWCASDEKVLIEAYKKCLAVLMQCHGGYTDGEQPITLSICGHSVETIRYCVSQEKVSIHLPVSRLLAGLHVLLSKSEVAYKFPELLPLSELSPPMLIEHPLRCLVLCAQVHAGMWRRNGFSLVNQIYYYHNVKCRREMFDKDVVMLQTGVSMMDPNHFLMIMLSRFELYQIFSTPDYGKRFSSEITHKDVVQQNNTLIEEMLYLIIMLVGERFSPGVGQVNATDEIKREIIHQLSIKPMAHSELVKSLPEDENKETGMESVIEAVAHFKKPGLTGRGMYELKPECAKEFNLYFYHFSRAEQSKAEEAQRKLKRQNREDTALPPPVLPPFCPLFASLVNILQSDVMLCIMGTILQWAVEHNGYAWSESMLQRVLHLIGMALQEEKQHLENVTEEHVVTFTFTQKISKPGEAPKNSPSILAMLETLQNAPYLEVHKDMIRWILKTFNAVKKMRESSPTSPVAETEGTIMEEHNFRVQGTKTKLRGREKQRLPDCAEKRSWLRCLKCSGILLMKTKNSFSRH>sp|Q8IWV8-4|UBR2_HUMAN Isoform 4 of E3 ubiquitin-protein ligase UBR2OS=Homo sapiens OX=9606 GN=UBR2MASELEPEVQAIDRSLLECSAEEIAGKWLQATDLTREVYQHLAHYVPKIYCRGPNPFPQKEDMLAQHVLLGPMEWYLCGEDPAFGFPKLEQANKPSHLCGRVFKVGEPTYSCRDCAVDPTCVLCMECFLGSIHRDHRYRMTTSGGGGFCDCGDTEAWKEGPYCQKHELNTSEIEEEEDPLVHLSEDVIARTYNIFAITFRYAVEILTWEKESELPADLEMVEKSDTYYCMLFNDEVHTYEQVIYTLQKAVNCTQKEAIGFATTVDRDGRRSVRYGDFQYCEQAKSVIVRNTSRQTKPLKVQVMHSSIVAHQNFGLKLLSWLGSIIGYSDGLRRILCQVGLQEGPDGENSSLVDRLMLSDSKLWKGARSVYHQLFMSSLLMDLKYKKLFAVRFAKNYERLQSDYVTDDHDREFSVADLSVQIFTVPSLARMLITEENLMSIIIKTFMDHLRHRDAQGRFQFERYTALQAFKFRRVQSLILDLKYVLISKPTEWSDELRQKFLEGFDAFLELLKCMQGMDPITRQVGQHIEMEPEWEAAFTLQMKLTHVISMMQDWCASDEKVLIEAYKKCLAVLMQCHGGYTDGEQPITLSICGHSVETIRYCVSQEKVSIHLPVSRLLAGLHVLLSKSEVAYKFPELLPLSELSPPMLIEHPLRCLVLCAQVHAGMWRRNGFSLVNQIYYYHNVKCRREMFDKDVVMLQTGVSMMDPNHFLMIMLSRFELYQIFSTPDYGKRFSSEITHKDVVQQNNTLIEEMLYLIIMLVGERFSPGVGQVNATDEIKREIIHQLSIKPMAHSELVKSLPEDENKETGMESVIEAVAHFKKPGLTGRGMYELKPECAKEFNLYFYHFSRAEQSKAEEAQRKLKRQNREDTALPPPVLPPFCPLFASLVNILQSDVMLCIMGTILQWAVEHNGYAWSESMLQRVLHLIGMALQEEKQHLENVTEEHVVTFTFTQKISKPGEAPKNSPSILAMLETLQNAPYLEVHKDMIRWILKTFNAVKKMRESSPTSPVAETEGTIMEESSRDKDKAERKRKAEIARLRREKIMAQMSEMQRHFIDENKELFQQTLELDASTSAVLDHSPVASDMTLTALGPAQTQVPEQRQFVTCILCQEEQEVKVESRAMVLAAFVQRSTVLSKNRSKFIQDPEKYDPLFMHPDLSCGTHTSSCGHIMHAHCWQRYFDSVQAKEQRRQQRLRLHTSYDVENGEFLCPLCECLSNTVIPLLLPPRNIFNNRLNFSDQPNLTQWIRTISQQIKALQFLRKEESTPNNASTKNSENVDELQLPEGFRPDFRPKIPYSESIKEMLTTFGTATYKVGLKVHPNEEDPRVPIMCWGSCAYTIQSIERILSDEDKPLFGPLPCRLDDCLRSLTRFAAAHWTVASVSVVQGHFCKLFASLVPNDSHEELPCILDIDMFHLLVGLVLAFPALQCQDFSGISLGTGDLHIFHLVTMAHIIQILLTSCTEENGMDQENPPCEEESAVLALYKTLHQYTGSALKEIPSGWHLWRSVRAGIMPFLKCSALFFHYLNGVPSPPDIQVPGTSHFEHLCSYLSLPNNLICLFQENSEIMNSLIESWCRNSEVKRYLEGERDAIRYPRESNKLINLPEDYSSLINQASNFSCPKSGGDKSRAPTLCLVCGSLLCSQSYCCQTELEGEDVGACTAHTYSCGSGVGIFLRVRECQVLFLAGKTKGCFYSPPYLDDYGETDQGLRRGNPLHLCKERFKKIQKLWHQHSVTEEIGHAQEANQTLVGIDWQHL>sp|O75379|VAMP4_HUMAN Vesicle-associated membrane protein 4 OS=Homosapiens OX=9606 GN=VAMP4 PE=1 SV=2MPPKFKRHLNDDDVTGSVKSERRNLLEDDSDEEEDFFLRGPSGPRFGPRNDKIKHVQNQVDEVIDVMQENITKVIERGERLDELQDKSESLSDNATAFSNRSKQLRRQMWWRGCKIKAIMALVAAILLLVIIILIVMKYRT>sp|O75379-2|VAMP4_HUMAN Isoform 2 of Vesicle-associated membrane protein4 OS=Homo sapiens OX=9606 GN=VAMP4MPPKFKRHLNDDDVTGSVKSERRNLLEDDSDEEEDFFLGPSGPRFGPRNDKIKHVQNQVDEVIDVMQENITKVIERGERLDELQDKSESLSDNATAFSNRSKQLRRQMWWRGCKIKAIMALVAAILLLVIIILIVMKYRT>sp|Q5W0Q7|USPL1_HUMAN SUMO-specific isopeptidase USPL1 OS=Homo sapiensOX=9606 GN=USPL1 PE=1 SV=1MMDSPKIGNGLPVIGPGTDIGISSLHMVGYLGKNFDSAKVPSDEYCPACREKGKLKALKTYRISFQESIFLCEDLQCIYPLGSKSLNNLISPDLEECHTPHKPQKRKSLESSYKDSLLLANSKKTRNYIAIDGGKVLNSKHNGEVYDETSSNLPDSSGQQNPIRTADSLERNEILEADTVDMATTKDPATVDVSGTGRPSPQNEGCTSKLEMPLESKCTSFPQALCVQWKNAYALCWLDCILSALVHSEELKNTVTGLCSKEESIFWRLLTKYNQANTLLYTSQLSGVKDGDCKKLTSEIFAEIETCLNEVRDEIFISLQPQLRCTLGDMESPVFAFPLLLKLETHIEKLFLYSFSWDFECSQCGHQYQNRHMKSLVTFTNVIPEWHPLNAAHFGPCNNCNSKSQIRKMVLEKVSPIFMLHFVEGLPQNDLQHYAFHFEGCLYQITSVIQYRANNHFITWILDADGSWLECDDLKGPCSERHKKFEVPASEIHIVIWERKISQVTDKEAACLPLKKTNDQHALSNEKPVSLTSCSVGDAASAETASVTHPKDISVAPRTLSQDTAVTHGDHLLSGPKGLVDNILPLTLEETIQKTASVSQLNSEAFLLENKPVAENTGILKTNTLLSQESLMASSVSAPCNEKLIQDQFVDISFPSQVVNTNMQSVQLNTEDTVNTKSVNNTDATGLIQGVKSVEIEKDAQLKQFLTPKTEQLKPERVTSQVSNLKKKETTADSQTTTSKSLQNQSLKENQKKPFVGSWVKGLISRGASFMPLCVSAHNRNTITDLQPSVKGVNNFGGFKTKGINQKASHVSKKARKSASKPPPISKPPAGPPSSNGTAAHPHAHAASEVLEKSGSTSCGAQLNHSSYGNGISSANHEDLVEGQIHKLRLKLRKKLKAEKKKLAALMSSPQSRTVRSENLEQVPQDGSPNDCESIEDLLNELPYPIDIASESACTTVPGVSLYSSQTHEEILAELLSPTPVSTELSENGEGDFRYLGMGDSHIPPPVPSEFNDVSQNTHLRQDHNYCSPTKKNPCEVQPDSLTNNACVRTLNLESPMKTDIFDEFFSSSALNALANDTLDLPHFDEYLFENY>sp|Q5W0Q7-2|USPL1_HUMAN Isoform 2 of SUMO-specific isopeptidase USPL1OS=Homo sapiens OX=9606 GN=USPL1MESPVFAFPLLLKLETHIEKLFLYSFSWDFECSQCGHQYQNRHMKSLVTFTNVIPEWHPLNAAHFGPCNNCNSKSQIRKMVLEKVSPIFMLHFVEGLPQNDLQHYAFHFEGCLYQITSVIQYRANNHFITWILDADGSWLECDDLKGPCSERHKKFEVPASEIHIVIWERKISQVTDKEAACLPLKKTNDQHALSNEKPVSLTSCSVGDAASAETASVTHPKDISVAPRTLSQDTAVTHGDHLLSGPKGLVDNILPLTLEETIQKTASVSQLNSEAFLLENKPVAENTGILKTNTLLSQESLMASSVSAPCNEKLIQDQFVDISFPSQVVNTNMQSVQLNTEDTVNTKSVNNTDATGLIQGVKSVEIEKDAQLKQFLTPKTEQLKPERVTSQVSNLKKKETTADSQTTTSKSLQNQSLKENQKKPFVGSWVKGLISRGASFMPLCVSAHNRNTITDLQPSVKGVNNFGGFKTKGINQKASHVSKKARKSASKPPPISKPPAGPPSSNGTAAHPHAHAASEVLEKSGSTSCGAQLNHSSYGNGISSANHEDLVEGQIHKLRLKLRKKLKAEKKKLAALMSSPQSRTVRSENLEQVPQDGSPNDCESIEDLLNELPYPIDIASESACTTVPGVSLYSSQTHEEILAELLSPTPVSTELSENGEGDFRYLGMGDSHIPPPVPSEFNDVSQNTHLRQDHNYCSPTKKNPCEVQPDSLTNNACVRTLNLESPMKTDIFDEFFSSSALNALANDTLDLPHFDEYLFENY>sp|Q8WVJ9|TWST2_HUMAN Twist-related protein 2 OS=Homo sapiens OX=9606GN=TWIST2 PE=1 SV=1MEEGSSSPVSPVDSLGTSEEELERQPKRFGRKRRYSKKSSEDGSPTPGKRGKKGSPSAQSFEELQSQRILANVRERQRTQSLNEAFAALRKIIPTLPSDKLSKIQTLKLAARYIDFLYQVLQSDEMDNKMTSCSYVAHERLSYAFSVWRMEGAWSMSASH>sp|Q5T230|UTF1_HUMAN Undifferentiated embryonic cell transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=UTF1 PE=1 SV=1MLLRPRRPPPLAPPAPPSPASPDPEPRTPGDAPGTPPRRPASPSALGELGLPVSPGSAQRTPWSARETELLLGTLLQPAVWRALLLDRRQALPTYRRVSAALAQQQVRRTPAQCRRRYKFLKDKFREAHGQPPGPFDEQIRKLMGLLGDNGRKRPRRRSPGSGRPQRARRPVPNAHAPAPSEPDATPLPTARDRDADPTWTLRFSPSPPKSADASPAPGSPPAPAPTALATCIPEDRAPVRGPGSPPPPPAREDPDSPPGRPEDCAPPPAAPPSLNTALLQTLGHLGDIANILGPLRDQLLTLNQHVEQLRGAFDQTVSLAVGFILGSAAAERGVLRDPCQ>sp|P47992|XCL1_HUMAN Lymphotactin OS=Homo sapiens OX=9606 GN=XCL1 PE=1SV=1MRLLILALLGICSLTAYIVEGVGSEVSDKRTCVSLTTQRLPVSRIKTYTITEGSLRAVIFITKRGLKVCADPQATWVRDVVRSMDRKSNTRNNMIQTKPTGTQQSTNTAVTLTG>sp|Q8TCV5|WFDC5_HUMAN WAP four-disulfide core domain protein 5 OS=Homosapiens OX=9606 GN=WFDC5 PE=1 SV=1MRTQSLLLLGALLAVGSQLPAVFGRKKGEKSGGCPPDDGPCLLSVPDQCVEDSQCPLTRKCCYRACFRQCVPRVSVKLGSCPEDQLRCLSPMNHLCHKDSDCSGKKRCCHSACGRDCRDPARGTAPGCPGQANSDLGSVALHLSWGPTERVHDGRPGALPAGQHYLYQRWFQPSDNHWPADTSLQPIHPWFLLLGVKVHSLSSEEGLCITPVLCTTAIRASHPS>sp|Q8TCV5-2|WFDC5_HUMAN Isoform 2 of WAP four-disulfide core domainprotein 5 OS=Homo sapiens OX=9606 GN=WFDC5MRTQSLLLLGALLAVGSQLPAVFGRKKGEKSGGCPPDDGPCLLSVPDQCVEDSQCPLTRKCCYRACFRQCVPRVSVKLGSCPEDQLRCLSPMNHLCHKDSDCSGKKRCCHSACGRDCRDPARG>sp|Q6UW78|UQCC3_HUMAN Ubiquinol-cytochrome-c reductase complex assemblyfactor 3 OS=Homo sapiens OX=9606 GN=UQCC3 PE=1 SV=2MDSLRKMLISVAMLGAGAGVGYALLVIVTPGERRKQEMLKEMPLQDPRSREEAARTQQLLLATLQEAATTQENVAWRKNWMVGGEGGAGGRSP>sp|Q96DN2|VWCE_HUMAN von Willebrand factor C and EGF domain-containingprotein OS=Homo sapiens OX=9606 GN=VWCE PE=1 SV=2MWAGLLLRAACVALLLPGAPARGYTGRKPPGHFAAERRRLGPHVCLSGFGSGCCPGWAPSMGGGHCTLPLCSFGCGSGICIAPNVCSCQDGEQGATCPETHGPCGEYGCDLTCNHGGCQEVARVCPVGFSMTETAVGIRCTDIDECVTSSCEGHCVNTEGGFVCECGPGMQLSADRHSCQDTDECLGTPCQQRCKNSIGSYKCSCRTGFHLHGNRHSCVDVNECRRPLERRVCHHSCHNTVGSFLCTCRPGFRLRADRVSCEAFPKAVLAPSAILQPRQHPSKMLLLLPEAGRPALSPGHSPPSGAPGPPAGVRTTRLPSPTPRLPTSSPSAPVWLLSTLLATPVPTASLLGNLRPPSLLQGEVMGTPSSPRGPESPRLAAGPSPCWHLGAMHESRSRWTEPGCSQCWCEDGKVTCEKVRCEAACSHPIPSRDGGCCPSCTGCFHSGVVRAEGDVFSPPNENCTVCVCLAGNVSCISPECPSGPCQTPPQTDCCTCVPVRCYFHGRWYADGAVFSGGGDECTTCVCQNGEVECSFMPCPELACPREEWRLGPGQCCFTCQEPTPSTGCSLDDNGVEFPIGQIWSPGDPCELCICQADGSVSCKRTDCVDSCPHPIRIPGQCCPDCSAGCTYTGRIFYNNETFPSVLDPCLSCICLLGSVACSPVDCPITCTYPFHPDGECCPVCRDCNYEGRKVANGQVFTLDDEPCTRCTCQLGEVSCEKVPCQRACADPALLPGDCCSSCPDSLSPLEEKQGLSPHGNVAFSKAGRSLHGDTEAPVNCSSCPGPPTASPSRPVLHLLQLLLRTNLMKTQTLPTSPAGAHGPHSLALGLTATFPGEPGASPRLSPGPSTPPGAPTLPLASPGAPQPPPVTPERSFSASGAQIVSRWPPLPGTLLTEASALSMMDPSPSKTPITLLGPRVLSPTTSRLSTALAATTHPGPQQPPVGASRGEESTM>sp|Q96DN2-2|VWCE_HUMAN Isoform 2 of von Willebrand factor C and EGFdomain-containing protein OS=Homo sapiens OX=9606 GN=VWCEMWAGLLLRAACVALLLPGAPARGYTGRKPPGHFAAERRRLGPHVCLSGFGSGCCPGWAPSMGGGHCTLPLCSFGCGSGICIAPNVCSCQDGEQGATCPETHGPCGEYGCDLTCNHGGCQEVARVCPVGFSMTETAVGIRCTDIDECVTSSCEGHCVNTEGGFVCECGPGMQLSADRHSCQDTDECLGTPCQQRCKNSIGSYKCSCRTGFHLHGNRHSCM>sp|Q2M389|WASC4_HUMAN WASH complex subunit 4 OS=Homo sapiens OX=9606GN=WASHC4 PE=1 SV=2MAVETLSPDWEFDRVDDGSQKIHAEVQLKNYGKFLEEYTSQLRRIEDALDDSIGDVWDFNLDPIALKLLPYEQSSLLELIKTENKVLNKVITVYAALCCEIKKLKYEAETKFYNGLLFYGEGATDASMVEGDCQIQMGRFISFLQELSCFVTRCYEVVMNVVHQLAALYISNKIAPKIIETTGVHFQTMYEHLGELLTVLLTLDEIIDNHITLKDHWTMYKRLLKSVHHNPSKFGIQEEKLKPFEKFLLKLEGQLLDGMIFQACIEQQFDSLNGGVSVSKNSTFAEEFAHSIRSIFANVEAKLGEPSEIDQRDKYVGICGLFVLHFQIFRTIDKKFYKSLLDICKKVPAITLTANIIWFPDNFLIQKIPAAAKLLDRKSLQAIKIHRDTFLQQKAQSLTKDVQSYYVFVSSWMMKMESILSKEQRMDKFAEDLTNRCNVFIQGFLYAYSISTIIKTTMNLYMSMQKPMTKTSVKALCRLVELLKAIEHMFYRRSMVVADSVSHITQHLQHQALHSISVAKKRVISDKKYSEQRLDVLSALVLAENTLNGPSTKQRRLIVSLALSVGTQMKTFKDEELFPLQVVMKKLDLISELRERVQTQCDCCFLYWHRAVFPIYLDDVYENAVDAARLHYMFSALRDCVPAMMHARHLESYEILLDCYDKEIMEILNEHLLDKLCKEIEKDLRLSVHTHLKLDDRNPFKVGMKDLALFFSLNPIRFFNRFIDIRAYVTHYLDKTFYNLTTVALHDWATYSEMRNLATQRYGLVMTEAHLPSQTLEQGLDVLEIMRNIHIFVSRYLYNLNNQIFIERTSNNKHLNTINIRHIANSIRTHGTGIMNTTVNFTYQFLKKKFYIFSQFMYDEHIKSRLIKDIRFFREIKDQNDHKYPFDRAEKFNRGIRKLGVTPEGQSYLDQFRQLISQIGNAMGYVRMIRSGGLHCSSNAIRFVPDLEDIVNFEELVKEEGLAEETLKAARHLDSVLSDHTRNSAEGTEYFKMLVDVFAPEFRRPKNIHLRNFYIIVPPLTLNFVEHSISCKEKLNKKNKIGAAFTDDGFAMGVAYILKLLDQYREFDSLHWFQSVREKYLKEIRAVAKQQNVQSASQDEKLLQTMNLTQKRLDVYLQEFELLYFSLSSARIFFRADKTAAEENQEKKEKEEETKTSNGDLSDSTVSADPVVK>sp|Q2M389-2|WASC4_HUMAN Isoform 2 of WASH complex subunit 4 OS=Homosapiens OX=9606 GN=WASHC4MAVETLSPDWEFDRVDDGSQKIHAEVQLKNYGKFLEEYTSQLRRIEDALDDSIGDVWDFNLDPIALKLLPYEQSSLLELIKTENKVLNKVITVYAALCCEIKKLKYEAETKFYNGLLFYGEGATDASMVEGDCQIQMGRFISFLQELSCFVTRCYEVVMNVVHQLAALYISNKIAPKIIETTGVHFQTMYEHLGELLTVLLTLDEIIDNHITLKDHWTMYKRLLKSVHHNPSKFGIQEEKLKPFEKFLLKLEGQLLDGMIFQACIEQQFDSLNGGVSVSKNSTFAEEFAHSIRSIFANVEAKLGEPSEIDQRDKYVGICGLFVLHFQIFRTIDKKFYKSLLDICKKVPAITLTANIIWFPDNFLIQKIPAAAKLLDRKSLQAIKIHRDTFLQQKAQSLTKDVQSYYVFVSSWMMKMESILSKEQRMDKFAEDLTNRCNVFIQGFLYAYSISTIIKTTMNLYMSMQKPMTKTSVKALCRLVELLKAIEHMFYRRSMVVADSVSHITQHLQHQALHSISVAKKRVISDKKYSEQRLDVLSALVLAENTLNGPSTKQRRLIVSLALSVGTQMKTFKDEELFPLQVVMKKLDLISELRERVQTQCDCCFLYWHRAVFPIYLDDVYENAVDAARLHYMFSALRDCVPAMMHARHLESYEILLDCYDKEIMEILNEHLLDKLCKEIEKDLRLSVHTHLKLDDRNPFKVGMKDLALFFSLNPIRFFNRFIDIRAYVTHYLDKTFYNLTTVALHDWATYSEMRNLATQRYGLVMTEAHLPSQTLEQGLDVLEIMRNIHIFVSRYLYNLNNQIFIERTSNNKHLNTINIRHIANSIRTHGTGIMNTTKWAFTAWRGGPRL>sp|Q9H1Z4|WDR13_HUMAN WD repeat-containing protein 13 OS=Homo sapiensOX=9606 GN=WDR13 PE=1 SV=2MAAVWQQVLAVDARYNAYRTPTFPQFRTQYIRRRSQLLRENAKAGHPPALRRQYLRLRGQLLGQRYGPLSEPGSARAYSNSIVRSSRTTLDRMEDFEDDPRALGARGHRRSVSRGSYQLQAQMNRAVYEDRPPGSVVPTSAAEASRAMAGDTSLSENYAFAGMYHVFDQHVDEAVPRVRFANDDRHRLACCSLDGSISLCQLVPAPPTVLRVLRGHTRGVSDFAWSLSNDILVSTSLDATMRIWASEDGRCIREIPDPDSAELLCCTFQPVNNNLTVVGNAKHNVHVMNISTGKKVKGGSSKLTGRVLALSFDAPGRLLWAGDDHGSVFSFLFDMATGKLTKAKRLVVHEGSPVTSISARSWVSREARDPSLLINACLNKLLLYRVVDNEGTLQLKRSFPIEQSSHPVRSIFCPLMSFRQGACVVTGSEDMCVHFFDVERAAKAAVNKLQGHSAPVLDVSFNCDESLLASSDASGMVIVWRREQK>sp|Q9H1Z4-2|WDR13_HUMAN Isoform 2 of WD repeat-containing protein 13OS=Homo sapiens OX=9606 GN=WDR13MEDFEDDPRALGARGHRRSVSRGSYQLQAQMNRAVYEDRPPGSVVPTSAAEASRAMAGDTSLSENYAFAGMYHVFDQHVDEAVPRVRFANDDRHRLACCSLDGSISLCQLVPAPPTVLRVLRGHTRGVSDFAWSLSNDILVSTSLDATMRIWASEDGRCIREIPDPDSAELLCCTFQPVNNNLTVVGNAKHNVHVMNISTGKKVKGGSSKLTGRVLALSFDAPGRLLWAGDDHGSVFSFLFDMATGKLTKAKRLVVHEGSPVTSISARSWVSREARDPSLLINACLNKLLLYRVVDNEGTLQLKRSFPIEQSSHPVRSIFCPLMSFRQGACVVTGSEDMCVHFFDVERAAKAAVNKLQGHSAPVLDVSFNCDESLLASSDASGMVIVWRREQK>sp|Q6ZQV5|ZN788_HUMAN Putative KRAB domain-containing protein ZNF788OS=Homo sapiens OX=9606 GN=ZNF788P PE=5 SV=3MRNMIPQDNENPPQQGEANQNDSVAFEDVAVNFTPDEWALLDPSQKNLYREVMQETLRNLASIEVLWKRDSLKVKVISMEKF>sp|Q6ZQV5-2|ZN788_HUMAN Isoform 2 of Putative KRAB domain-containingprotein ZNF788 OS=Homo sapiens OX=9606 GN=ZNF788PMDSVAFEDVAVNFTPDEWALLDPSQKNLYREVMQETLRNLASIEVLWKRDSLKVKVISMEKF>sp|P0CI00|Z705B_HUMAN Putative zinc finger protein 705B OS=Homo sapiensOX=9606 GN=ZNF705B PE=5 SV=1MHSLEKVTFEDVAIDFTQEEWDMMDTSKRKLYRDVMLENISHLVSLGYQISKSYIILQLEQGKELWWEGRVFLQDQNPDRESALKKKHMISMHPIIRKDTSTSMTMENSLILEDPFEYNDSGEDCTHSSTITQCLLTHSGKKPCVSKQCGKSLRNLLSPKPRKQIHTKGKSYQCNLCEKAYTNCFYLRRHKMTHTGERPYACHLCGKAFTQCSHLRRHEKTHTGERPYKCHQCGKAFIQSFNLRRHERTHLGQKCYECDKSGKAFSQSSGFRGNKIIHIGEKPPACLLCGKAFSLSSDLR>sp|Q9P255|ZN492_HUMAN Zinc finger protein 492 OS=Homo sapiens OX=9606GN=ZNF492 PE=2 SV=2MLENYRNLVFVGIAASKPDLITCLEQGKEPWNVKRHEMVAEPPVVCSYFARDLWPKQGKKNYFQKVILRRYKKCGCENLQLRKYCKSMDECKVHKECYNGLNQCLTTTQNKIFQCDKYVKVFHKFSNSNRHTIRHTGKKSFKCKECEKSFCMLSHLAQHKRIHSGEKPYKCKECGKAYNETSNLSTHKRIHTGKKPYKCEECGKAFNRLSHLTTHKIIHTGKKPYKCEECGKAFNQSANLTTHKRIHTGEKPYKCEECGRAFSQSSTLTAHKIIHAGEKPYKCEECGKAFSQSSTLTTHKIIHTGEKFYKCEECGKAFSQLSHLTTHKRIHSGEKPYKCEECGKAFKQSSTLTTHKRIHAGEKFYKCEVCSKAFSRFSHLTTHKRIHTGEKPYKCEECGKAFNLSSQLTTHKIIHTGEKPYKCEECGKAFNQSSTLSKHKVIHTGEKPYKYEECGKAFNQSSHLTTHKMIHTGEKPYKCEECGKAFNNSSILNRHKMIHTGEKLYKPESCNNACDNIAKISKYKRNCAGEK>sp|Q9NV72|ZN701_HUMAN Zinc finger protein 701 OS=Homo sapiens OX=9606GN=ZNF701 PE=1 SV=3MGFLHVGQDGLELPTSGDPPASASQSAGITGVSHRTQPPCFEGLTSKDLVREEKTRKRKRKAKESGMALLQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDTSSKCMMKMFSSTGQGNTEVVHTGTLQIHASHHIGDTCFQEIEKDIHDFVFQWQENETNGHEALMTKTKKLMSSTERHDQRHAGNKPIKNELGSSFHSHLPEVHIFHPEGKIGNQVEKAINDAFSVSASQRISCRPKTRISNKYRNNFLQSSLLTQKREVHTREKSFQRNESGKAFNGSSLLKKHQIIHLGDKQYKCDVCGKDFHQKRYLACHRCHTGENPYTCNECGKTFSHNSALLVHKAIHTGEKPYKCNECGKVFNQQSNLARHHRVHTGEKPYKCEECDKVFSRKSHLERHRRIHTGEKPYKCKVCDKAFRRDSHLAQHTVIHTGEKPYKCNECGKTFVQNSSLVMHKVIHTGEKRYKCNECGKVFNHKSNLACHRRLHTGEKPYKCNECGKVFNRKSNLERHHRLHTGKKS>sp|Q9NV72-2|ZN701_HUMAN Isoform 2 of Zinc finger protein 701 OS=Homosapiens OX=9606 GN=ZNF701MALLQGLLTFRDVAIEFSQEEWKCLDPAQRTLYRDVMLENYRNLVSLDTSSKCMMKMFSSTGQGNTEVVHTGTLQIHASHHIGDTCFQEIEKDIHDFVFQWQENETNGHEALMTKTKKLMSSTERHDQRHAGNKPIKNELGSSFHSHLPEVHIFHPEGKIGNQVEKAINDAFSVSASQRISCRPKTRISNKYRNNFLQSSLLTQKREVHTREKSFQRNESGKAFNGSSLLKKHQIIHLGDKQYKCDVCGKDFHQKRYLACHRCHTGENPYTCNECGKTFSHNSALLVHKAIHTGEKPYKCNECGKVFNQQSNLARHHRVHTGEKPYKCEECDKVFSRKSHLERHRRIHTGEKPYKCKVCDKAFRRDSHLAQHTVIHTGEKPYKCNECGKTFVQNSSLVMHKVIHTGEKRYKCNECGKVFNHKSNLACHRRLHTGEKPYKCNECGKVFNRKSNLERHHRLHTGKKS>sp|Q9Y6X8|ZHX2_HUMAN Zinc fingers and homeoboxes protein 2 OS=Homosapiens OX=9606 GN=ZHX2 PE=1 SV=1MASKRKSTTPCMVRTSQVVEQDVPEEVDRAKEKGIGTPQPDVAKDSWAAELENSSKENEVIEVKSMGESQSKKLQGGYECKYCPYSTQNLNEFTEHVDMQHPNVILNPLYVCAECNFTTKKYDSLSDHNSKFHPGEANFKLKLIKRNNQTVLEQSIETTNHVVSITTSGPGTGDSDSGISVSKTPIMKPGKPKADAKKVPKKPEEITPENHVEGTARLVTDTAEILSRLGGVELLQDTLGHVMPSVQLPPNINLVPKVPVPLNTTKYNSALDTNATMINSFNKFPYPTQAELSWLTAASKHPEEHIRIWFATQRLKHGISWSPEEVEEARKKMFNGTIQSVPPTITVLPAQLAPTKVTQPILQTALPCQILGQTSLVLTQVTSGSTTVSCSPITLAVAGVTNHGQKRPLVTPQAAPEPKRPHIAQVPEPPPKVANPPLTPASDRKKTKEQIAHLKASFLQSQFPDDAEVYRLIEVTGLARSEIKKWFSDHRYRCQRGIVHITSESLAKDQLAIAASRHGRTYHAYPDFAPQKFKEKTQGQVKILEDSFLKSSFPTQAELDRLRVETKLSRREIDSWFSERRKLRDSMEQAVLDSMGSGKKGQDVGAPNGALSRLDQLSGAQLTSSLPSPSPAIAKSQEQVHLLRSTFARTQWPTPQEYDQLAAKTGLVRTEIVRWFKENRCLLKTGTVKWMEQYQHQPMADDHGYDAVARKATKPMAESPKNGGDVVPQYYKDPKKLCEEDLEKLVTRVKVGSEPAKDCLPAKPSEATSDRSEGSSRDGQGSDENEESSVVDYVEVTVGEEDAISDRSDSWSQAAAEGVSELAESDSDCVPAEAGQA>sp|Q9H8G1|ZN430_HUMAN Zinc finger protein 430 OS=Homo sapiens OX=9606GN=ZNF430 PE=1 SV=3MENLKSGVYPLKEASGCPGADRNLLVYSFYEKGPLTFRDVAIEFSLEEWQCLDTAQQDLYRKVMLENYRNLVFLAGIAVSKPDLITCLEQGKEPWNMKRHAMVDQPPVTYSHFAQDLWPEQGIKDSFQEVILRRYGKCGHEDLQLRTGCKSVDECNLHKECYDELNQCLTTTQSEIFQYDKYVNVFYKFSNPNIQKIRHTGKKPFKCKKCDKSFCMLLHLTQHKRIHIRENSYQCEECGKVFNWFSTLTRHRRIHTGEKPYKCEQCGKAFKQSSTLTTHKIIHTGEKPYRCEECGKTFNRSSHLTTHKRIHTGEKPYRCEECGRAFNRSSHLTTHKIIHTGEKPYKCEECGKAFNQSSTLTTHKIIHAGEKPYKCEECGKAFYRFSYLTKHKIIHTGEKFYKCEECGKGFNWSSTLTKHKRIHTGEKPYKCEQCGKAFNESSNLTAHKIIHTGEKPYKCEECGKAFNRSPKLTAHKVIHSGEKPYKCEECGKAFNQFSNLTKHKITHIGDTSYKYLECDKAFSQSSTLTKHKVIHTGEKPYNCEEYGKAFNQSSNLIEQSNSYWRETLQM>sp|Q96CX3|ZN501_HUMAN Zinc finger protein 501 OS=Homo sapiens OX=9606GN=ZNF501 PE=2 SV=2MNSSQISLRMKHGRVNMQKKPSKCSECGKFFTQRSSLTQHQRIHRGEKPYVCSECGSCFRKQSNLTQHLRIHTGEKPYKCNECEKAFQTKAILVQHLRIHTGEKPYKCNECGKAFCQSPSLIKHQRIHTGEKPYKCTECGKAFSQSICLTRHQRSHSGDKPFKCNECGKAFNQSACLMQHQRIHSGEKPYTCTECGKAFTQNSSLVEHERTHTGEKLYKCSECEKTFRKQAHLSEHYRIHTGEKPYECVGCGKSFRHSSALLRHQRLHAGE>sp|Q96CX3-2|ZN501_HUMAN Isoform 2 of Zinc finger protein 501 OS=Homosapiens OX=9606 GN=ZNF501MNSSQISLRMKHGRVNMQKKPSKCSECGKFFTQRSSLTQHQRIHRGEKPYVCSECGSCFRKQSNLTQHLRIHTGEKPYKCNECEKAFQTKAILVQHLRIHTGEKPYKCNECGKAFCQSPSLIKHQRIHTGEKPYKCTECGKAFTQNSSLVEHERTHTGEKLYKCSECEKTFRKQAHLSEHYRIHTGEKPYECVGCGKSFRHSSALLRHQRLHAGE>sp|Q9BWM5|ZN416_HUMAN Zinc finger protein 416 OS=Homo sapiens OX=9606GN=ZNF416 PE=2 SV=1MAAAVLRDSTSVPVTAEAKLMGFTQGCVTFEDVAIYFSQEEWGLLDEAQRLLYRDVMLENFALITALVCWHGMEDEETPEQSVSVEGVPQVRTPEASPSTQKIQSCDMCVPFLTDILHLTDLPGQELYLTGACAVFHQDQKHHSAEKPLESDMDKASFVQCCLFHESGMPFTSSEVGKDFLAPLGILQPQAIANYEKPNKISKCEEAFHVGISHYKWSQCRRESSHKHTFFHPRVCTGKRLYESSKCGKACCCECSLVQLQRVHPGERPYECSECGKSFSQTSHLNDHRRIHTGERPYVCGQCGKSFSQRATLIKHHRVHTGERPYECGECGKSFSQSSNLIEHCRIHTGERPYECDECGKAFGSKSTLVRHQRTHTGEKPYECGECGKLFRQSFSLVVHQRIHTTARPYECGQCGKSFSLKCGLIQHQLIHSGARPFECDECGKSFSQRTTLNKHHKVHTAERPYVCGECGKAFMFKSKLVRHQRTHTGERPFECSECGKFFRQSYTLVEHQKIHTGLRPYDCGQCGKSFIQKSSLIQHQVVHTGERPYECGKCGKSFTQHSGLILHRKSHTVERPRDSSKCGKPYSPRSNIV>sp|P51508|ZNF81_HUMAN Zinc finger protein 81 OS=Homo sapiens OX=9606GN=ZNF81 PE=1 SV=3MPANEDAPQPGEHGSACEVSVSFEDVTVDFSREEWQQLDSTQRRLYQDVMLENYSHLLSVGFEVPKPEVIFKLEQGEGPWTLEGEAPHQSCSDGKFGIKPSQRRISGKSTFHSEMEGEDTRDDSLYSILEELWQDAEQIKRCQEKHNKLLSRTTFLNKKILNTEWDYEYKDFGKFVHPSPNLILSQKRPHKRDSFGKSFKHNLDLHIHNKSNAAKNLDKTIGHGQVFTQNSSYSHHENTHTGVKFCERNQCGKVLSLKHSLSQNVKFPIGEKANTCTEFGKIFTQRSHFFAPQKIHTVEKPHELSKCVNVFTQKPLLSIYLRVHRDEKLYICTKCGKAFIQNSELIMHEKTHTREKPYKCNECGKSFFQVSSLLRHQTTHTGEKLFECSECGKGFSLNSALNIHQKIHTGERHHKCSECGKAFTQKSTLRMHQRIHTGERSYICTQCGQAFIQKAHLIAHQRIHTGEKPYECSDCGKSFPSKSQLQMHKRIHTGEKPYICTECGKAFTNRSNLNTHQKSHTGEKSYICAECGKAFTDRSNFNKHQTIHTGEKPYVCADCGRAFIQKSELITHQRIHTTEKPYKCPDCEKSFSKKPHLKVHQRIHTGEKPYICAECGKAFTDRSNFNKHQTIHTGDKPYKCSDCGKGFTQKSVLSMHRNIHT>sp|Q16670|ZSC26_HUMAN Zinc finger and SCAN domain-containing protein 26OS=Homo sapiens OX=9606 GN=ZSCAN26 PE=1 SV=2MATALVSAHSLAPLNLKKEGLRVVREDHYSTWEQGFKLQGNSKGLGQEPLCKQFRQLRYEETTGPREALSRLRELCQQWLQPETHTKEQILELLVLEQFLIILPKELQARVQEHHPESREDVVVVLEDLQLDLGETGQQDPDQPKKQKILVEEMAPLKGVQEQQVRHECEVTKPEKEKGEETRIENGKLIVVTDSCGRVESSGKISEPMEAHNEGSNLERHQAKPKEKIEYKCSEREQRFIQHLDLIEHASTHTGKKLCESDVCQSSSLTGHKKVLSREKGHQCHECGKAFQRSSHLVRHQKIHLGEKPYQCNECGKVFSQNAGLLEHLRIHTGEKPYLCIHCGKNFRRSSHLNRHQRIHSQEEPCECKECGKTFSQALLLTHHQRIHSHSKSHQCNECGKAFSLTSDLIRHHRIHTGEKPFKCNICQKAFRLNSHLAQHVRIHNEEKPYQCSECGEAFRQRSGLFQHQRYHHKDKLA>sp|Q16670-2|ZSC26_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 26 OS=Homo sapiens OX=9606 GN=ZSCAN26MAPLKGVQEQQVRHECEVTKPEKEKGEETRIENGKLIVVTDSCGRVESSGKISEPMEAHNEGSNLERHQAKPKEKIEYKCSEREQRFIQHLDLIEHASTHTGKKLCESDVCQSSSLTGHKKVLSREKGHQCHECGKAFQRSSHLVRHQKIHLGEKPYQCNECGKVFSQNAGLLEHLRIHTGEKPYLCIHCGKNFRRSSHLNRHQRIHSQEEPCECKECGKTFSQALLLTHHQRIHSHSKSHQCNECGKAFSLTSDLIRHHRIHTGEKPFKCNICQKAFRLNSHLAQHVRIHNEEKPYQCSECGEAFRQRSGLFQHQRYHHKDKLA>sp|Q8NHG8|ZNRF2_HUMAN E3 ubiquitin-protein ligase ZNRF2 OS=Homo sapiensOX=9606 GN=ZNRF2 PE=1 SV=1MGAKQSGPAAANGRTRAYSGSDLPSSSSGGANGTAGGGGGARAAAAGRFPAQVPSAHQPSASGGAAAAAAAPAAPAAPRSRSLGGAVGSVASGARAAQSPFSIPNSSSGPYGSQDSVHSSPEDGGGGRDRPVGGSPGGPRLVIGSLPAHLSPHMFGGFKCPVCSKFVSSDEMDLHLVMCLTKPRITYNEDVLSKDAGECAICLEELQQGDTIARLPCLCIYHKGCIDEWFEVNRSCPEHPSD>sp|O95229|ZWINT_HUMAN ZW10 interactor OS=Homo sapiens OX=9606 GN=ZWINTPE=1 SV=2MEAAETEAEAAALEVLAEVAGILEPVGLQEEAELPAKILVEFVVDSQKKDKLLCSQLQVADFLQNILAQEDTAKGLDPLASEDTSRQKAIAAKEQWKELKATYREHVEAIKIGLTKALTQMEEAQRKRTQLREAFEQLQAKKQMAMEKRRAVQNQWQLQQEKHLQHLAEVSAEVRERKTGTQQELDRVFQKLGNLKQQAEQERDKLQRYQTFLQLLYTLQGKLLFPEAEAEAENLPDDKPQQPTRPQEQSTGDTMGRDPGVSFKAVGLQPAGDVNLP>sp|O95229-2|ZWINT_HUMAN Isoform 2 of ZW10 interactor OS=Homo sapiensOX=9606 GN=ZWINTMEAAETEAEAAALEVLAEVAGILEPVGLQEEAELPAKILVEFVVDSQKKDKLLCSQLQVADFLQNILAQEDTAKGLDPLASEDTSRQKAIAAKEQWKELKATYREHVEAIKIGLTKALTQMEEAQRKRTQLREAFEQLQAKKQMAMEKRRAVQNQWQLQQEKHLQHLAEVSAEGKLLFPEAEAEAENLPDDKPQQPTRPQEQSTGDTMGRDPGVSFKAVGLQPAGDVNLP>sp|Q05481|ZNF91_HUMAN Zinc finger protein 91 OS=Homo sapiens OX=9606GN=ZNF91 PE=2 SV=2MPGTPGSLEMGLLTFRDVAIEFSPEEWQCLDTAQQNLYRNVMLENYRNLAFLGIALSKPDLITYLEQGKEPWNMKQHEMVDEPTGICPHFPQDFWPEQSMEDSFQKVLLRKYEKCGHENLQLRKGCKSVDECKVHKEGYNKLNQCLTTAQSKVFQCGKYLKVFYKFLNSNRHTIRHTGKKCFKCKKCVKSFCIRLHKTQHKCVYITEKSCKCKECEKTFHWSSTLTNHKEIHTEDKPYKCEECGKAFKQLSTLTTHKIICAKEKIYKCEECGKAFLWSSTLTRHKRIHTGEKPYKCEECGKAFSHSSTLAKHKRIHTGEKPYKCEECGKAFSRSSTLAKHKRIHTGEKPYKCKECGKAFSNSSTLANHKITHTEEKPYKCKECDKAFKRLSTLTKHKIIHAGEKLYKCEECGKAFNRSSNLTIHKFIHTGEKPYKCEECGKAFNWSSSLTKHKRFHTREKPFKCKECGKAFIWSSTLTRHKRIHTGEKPYKCEECGKAFRQSSTLTKHKIIHTGEKPYKFEECGKAFRQSLTLNKHKIIHSREKPYKCKECGKAFKQFSTLTTHKIIHAGKKLYKCEECGKAFNHSSSLSTHKIIHTGEKSYKCEECGKAFLWSSTLRRHKRIHTGEKPYKCEECGKAFSHSSALAKHKRIHTGEKPYKCKECGKAFSNSSTLANHKITHTEEKPYKCKECDKTFKRLSTLTKHKIIHAGEKLYKCEECGKAFNRSSNLTIHKFIHTGEKPYKCEECGKAFNWSSSLTKHKRIHTREKPFKCKECGKAFIWSSTLTRHKRIHTGEKPYKCEECGKAFSRSSTLTKHKTIHTGEKPYKCKECGKAFKHSSALAKHKIIHAGEKLYKCEECGKAFNQSSNLTTHKIIHTKEKPSKSEECDKAFIWSSTLTEHKRIHTREKTYKCEECGKAFSQPSHLTTHKRMHTGEKPYKCEECGKAFSQSSTLTTHKIIHTGEKPYKCEECGKAFRKSSTLTEHKIIHTGEKPYKCEECGKAFSQSSTLTRHTRMHTGEKPYKCEECGKAFNRSSKLTTHKIIHTGEKPYKCEECGKAFISSSTLNGHKRIHTREKPYKCEECGKAFSQSSTLTRHKRLHTGEKPYKCGECGKAFKESSALTKHKIIHTGEKPYKCEKCGKAFNQSSILTNHKKIHTITPVIPLLWEAEAGGSRGQEMETILANTVKPLLY>sp|Q05481-2|ZNF91_HUMAN Isoform 2 of Zinc finger protein 91 OS=Homosapiens OX=9606 GN=ZNF91MPGTPGSLEMGLLTFRDVAIEFSPEEWQCLDTAQQNLYRNVMLENYRNLAFLGICPHFPQDFWPEQSMEDSFQKVLLRKYEKCGHENLQLRKGCKSVDECKVHKEGYNKLNQCLTTAQSKVFQCGKYLKVFYKFLNSNRHTIRHTGKKCFKCKKCVKSFCIRLHKTQHKCVYITEKSCKCKECEKTFHWSSTLTNHKEIHTEDKPYKCEECGKAFKQLSTLTTHKIICAKEKIYKCEECGKAFLWSSTLTRHKRIHTGEKPYKCEECGKAFSHSSTLAKHKRIHTGEKPYKCEECGKAFSRSSTLAKHKRIHTGEKPYKCKECGKAFSNSSTLANHKITHTEEKPYKCKECDKAFKRLSTLTKHKIIHAGEKLYKCEECGKAFNRSSNLTIHKFIHTGEKPYKCEECGKAFNWSSSLTKHKRFHTREKPFKCKECGKAFIWSSTLTRHKRIHTGEKPYKCEECGKAFRQSSTLTKHKIIHTGEKPYKFEECGKAFRQSLTLNKHKIIHSREKPYKCKECGKAFKQFSTLTTHKIIHAGKKLYKCEECGKAFNHSSSLSTHKIIHTGEKSYKCEECGKAFLWSSTLRRHKRIHTGEKPYKCEECGKAFSHSSALAKHKRIHTGEKPYKCKECGKAFSNSSTLANHKITHTEEKPYKCKECDKTFKRLSTLTKHKIIHAGEKLYKCEECGKAFNRSSNLTIHKFIHTGEKPYKCEECGKAFNWSSSLTKHKRIHTREKPFKCKECGKAFIWSSTLTRHKRIHTGEKPYKCEECGKAFSRSSTLTKHKTIHTGEKPYKCKECGKAFKHSSALAKHKIIHAGEKLYKCEECGKAFNQSSNLTTHKIIHTKEKPSKSEECDKAFIWSSTLTEHKRIHTREKTYKCEECGKAFSQPSHLTTHKRMHTGEKPYKCEECGKAFSQSSTLTTHKIIHTGEKPYKCEECGKAFRKSSTLTEHKIIHTGEKPYKCEECGKAFSQSSTLTRHTRMHTGEKPYKCEECGKAFNRSSKLTTHKIIHTGEKPYKCEECGKAFISSSTLNGHKRIHTREKPYKCEECGKAFSQSSTLTRHKRLHTGEKPYKCGECGKAFKESSALTKHKIIHTGEKPYKCEKCGKAFNQSSILTNHKKIHTITPVIPLLWEAEAGGSRGQEMETILANTVKPLLY>sp|Q6XR72|ZNT10_HUMAN Zinc transporter 10 OS=Homo sapiens OX=9606GN=SLC30A10 PE=1 SV=2MGRYSGKTCRLLFMLVLTVAFFVAELVSGYLGNSIALLSDSFNMLSDLISLCVGLSAGYIARRPTRGFSATYGYARAEVVGALSNAVFLTALCFTIFVEAVLRLARPERIDDPELVLIVGVLGLLVNVVGLLIFQDCAAWFACCLRGRSRRLQQRQQLAEGCVPGAFGGPQGAEDPRRAADPTAPGSDSAVTLRGTSVERKREKGATVFANVAGDSFNTQNEPEDMMKKEKKSEALNIRGVLLHVMGDALGSVVVVITAIIFYVLPLKSEDPCNWQCYIDPSLTVLMVIIILSSAFPLIKETAAILLQMVPKGVNMEELMSKLSAVPGISSVHEVHIWELVSGKIIATLHIKYPKDRGYQDASTKIREIFHHAGIHNVTIQFENVDLKEPLEQKDLLLLCNSPCISKGCAKQLCCPPGALPLAHVNGCAEHNGGPSLDTYGSDGLSRRDAREVAIEVSLDSCLSDHGQSLNKTQEDQCYVNRTHF>sp|Q6XR72-2|ZNT10_HUMAN Isoform 2 of Zinc transporter 10 OS=Homo sapiensOX=9606 GN=SLC30A10MGDALGSVVVVITAIIFYVLPLKSEDPCNWQCYIDPSLTVLMVIIILSSAFPLIKETAAILLQMVPKGVNMEELMSKLSAVPGISSVHEVHIWELVSGKIIATLHIKYPKDRGYQDASTKIREIFHHAGIHNVTIQFENVDLKEPLEQKDLLLLCNSPCISKGCAKQLCCPPGALPLAHVNGCAEHNGGPSLDTYGSDGLSRRDAREVAIEVSLDSCLSDHGQSLNKTQEDQCYVNRTHF>sp|Q6XR72-3|ZNT10_HUMAN Isoform 3 of Zinc transporter 10 OS=Homo sapiensOX=9606 GN=SLC30A10MGRYSGKTCRLLFMLVLTVAFFVAELVSGYLGNSIALLSDSFNMLSDLISLCVGLSAGYIARRPTRGFSATYGYARAEVVGALSNAVFLTALCFTIFVEAVLRLARPERIDDPELVLIVGVLGLLVNVVGLLIFQDCAAWFACCLRGRSRRLQQRQQLAEGCVPGAFGGPQGAEDPRRAADPTAPGSDSAVTLRGTSVERKREKGATVFANVAELIHNTRFLL>sp|P21754|ZP3_HUMAN Zona pellucida sperm-binding protein 3 OS=Homosapiens OX=9606 GN=ZP3 PE=1 SV=2MELSYRLFICLLLWGSTELCYPQPLWLLQGGASHPETSVQPVLVECQEATLMVMVSKDLFGTGKLIRAADLTLGPEACEPLVSMDTEDVVRFEVGLHECGNSMQVTDDALVYSTFLLHDPRPVGNLSIVRTNRAEIPIECRYPRQGNVSSQAILPTWLPFRTTVFSEEKLTFSLRLMEENWNAEKRSPTFHLGDAAHLQAEIHTGSHVPLRLFVDHCVATPTPDQNASPYHTIVDFHGCLVDGLTDASSAFKVPRPGPDTLQFTVDVFHFANDSRNMIYITCHLKVTLAEQDPDELNKACSFSKPSNSWFPVEGSADICQCCNKGDCGTPSHSRRQPHVMSQWSRSASRNRRHVTEEADVTVGPLIFLDRRGDHEVEQWALPSDTSVVLLGVGLAVVVSLTLTAVILVLTRRCRTASHPVSASE>sp|P21754-2|ZP3_HUMAN Isoform ZP3B of Zona pellucida sperm-bindingprotein 3 OS=Homo sapiens OX=9606 GN=ZP3MELSYRLFICLLLWGSTELCYPQPLWLLQGGASHPETSVQPVLVECQEATLMVMVSKDLFGTGKLIRAADLTLGPEACEPLVSMDTEDVVRFEVGLHECGNSMQVTDDALVYSTFLLHDPRPVGNLSIVRTNRAEIPIECRYPRQGNVSSQAILPTWLPFRTTVFSEEKLTFSLRLMEENWNAEKRSPTFHLGDAAHLQAEIHTGSHVPLRLFVDHCVATPTPDQNASPYHTIVDFHGCLVDGLTDASSAFKVPRPGPDTLQFTVDVFHFANDSRNMIYITCHLKVTLAEQDPDELNKACSFSKPSNSWFPVEGSADICQCCNKGDCGTPSHSRRQPHVMSQWSRSASRNRRHVTEEADVTVGATDLPGQEW>sp|P21754-3|ZP3_HUMAN Isoform 3 of Zona pellucida sperm-binding protein3 OS=Homo sapiens OX=9606 GN=ZP3MVMVSKDLFGTGKLIRAADLTLGPEACEPLVSMDTEDVVRFEVGLHECGNSMQVTDDALVYSTFLLHDPRPVGNLSIVRTNRAEIPIECRYPRQGNVSSQAILPTWLPFRTTVFSEEKLTFSLRLMEENWNAEKRSPTFHLGDAAHLQAEIHTGSHVPLRLFVDHCVATPTPDQNASPYHTIVDFHGCLVDGLTDASSAFKVPRPGPDTLQFTVDVFHFANDSRNMIYITCHLKVTLAEQDPDELNKACSFSKPSNSWFPVEGSADICQCCNKGDCGTPSHSRRQPHVMSQWSRSASRNRRHVTEEADVTVGPLIFLDRRGDHEVEQWALPSDTSVVLLGVGLAVVVSLTLTAVILVLTRRCRTASHPVSASE>sp|Q03936|ZNF92_HUMAN Zinc finger protein 92 OS=Homo sapiens OX=9606GN=ZNF92 PE=1 SV=2MGPLTFRDVKIEFSLEEWQCLDTAQRNLYRDVMLENYRNLVFLGIAVSKPDLITWLEQGKEPWNLKRHEMVDKTPVMCSHFAQDVWPEHSIKDSFQKVILRTYGKYGHENLQLRKDHKSVDACKVYKGGYNGLNQCLTTTDSKIFQCDKYVKVFHKFPNVNRNKIRHTGKKPFKCKNRGKSFCMLSQLTQHKKIHTREYSYKCEECGKAFNWSSTLTKHKIIHTGEKPYKCEECGKAFNRSSNLTKHKIIHTGEKPYKCEECGKAFNRSSTLTKHKRIHTEEKPYKCEECGKAFNQFSILNKHKRIHMEDKPYKCEECGKAFRVFSILKKHKIIHTGEKPYKCEECGKAFNQFSNLTKHKIIHTGEKPYKCDECGKAFNQSSTLTKHKRIHTGEKPYKCEECGKAFKQSSTLTEHKIIHTGEKPYKCEKCGKAFSWSSAFTKHKRNHMEDKPYKCEECGKAFSVFSTLTKHKIIHTREKPYKCEECGKAFNQSSIFTKHKIIHTEGKSYKCEKCGNAFNQSSNLTARKIIYTGEKPYKYEECDKAFNKFSTLITHQIIYTGEKPCKHECGRAFNKSSNYTKEKLQT>sp|Q03936-2|ZNF92_HUMAN Isoform 2 of Zinc finger protein 92 OS=Homosapiens OX=9606 GN=ZNF92MVDKTPVMCSHFAQDVWPEHSIKDSFQKVILRTYGKYGHENLQLRKDHKSVDACKVYKGGYNGLNQCLTTTDSKIFQCDKYVKVFHKFPNVNRNKIRHTGKKPFKCKNRGKSFCMLSQLTQHKKIHTREYSYKCEECGKAFNWSSTLTKHKIIHTGEKPYKCEECGKAFNRSSNLTKHKIIHTGEKPYKCEECGKAFNRSSTLTKHKRIHTEEKPYKCEECGKAFNQFSILNKHKRIHMEDKPYKCEECGKAFRVFSILKKHKIIHTGEKPYKCEECGKAFNQFSNLTKHKIIHTGEKPYKCDECGKAFNQSSTLTKHKRIHTGEKPYKCEECGKAFKQSSTLTEHKIIHTGEKPYKCEKCGKAFSWSSAFTKHKRNHMEDKPYKCEECGKAFSVFSTLTKHKIIHTREKPYKCEECGKAFNQSSIFTKHKIIHTEGKSYKCEKCGNAFNQSSNLTARKIIYTGEKPYKYEECDKAFNKFSTLITHQIIYTGEKPCKHECGRAFNKSSNYTKEKLQT>sp|Q03936-3|ZNF92_HUMAN Isoform 3 of Zinc finger protein 92 OS=Homosapiens OX=9606 GN=ZNF92MGPLTFRDVKIEFSLEEWQCLDTAQRNLYRDVMLENYRNLVFLVMCSHFAQDVWPEHSIKDSFQKVILRTYGKYGHENLQLRKDHKSVDACKVYKGGYNGLNQCLTTTDSKIFQCDKYVKVFHKFPNVNRNKIRHTGKKPFKCKNRGKSFCMLSQLTQHKKIHTREYSYKCEECGKAFNWSSTLTKHKIIHTGEKPYKCEECGKAFNRSSNLTKHKIIHTGEKPYKCEECGKAFNRSSTLTKHKRIHTEEKPYKCEECGKAFNQFSILNKHKRIHMEDKPYKCEECGKAFRVFSILKKHKIIHTGEKPYKCEECGKAFNQFSNLTKHKIIHTGEKPYKCDECGKAFNQSSTLTKHKRIHTGEKPYKCEECGKAFKQSSTLTEHKIIHTGEKPYKCEKCGKAFSWSSAFTKHKRNHMEDKPYKCEECGKAFSVFSTLTKHKIIHTREKPYKCEECGKAFNQSSIFTKHKIIHTEGKSYKCEKCGNAFNQSSNLTARKIIYTGEKPYKYEECDKAFNKFSTLITHQIIYTGEKPCKHECGRAFNKSSNYTKEKLQT>sp|Q9UK55|ZPI_HUMAN Protein Z-dependent protease inhibitor OS=Homosapiens OX=9606 GN=SERPINA10 PE=1 SV=1MKVVPSLLLSVLLAQVWLVPGLAPSPQSPETPAPQNQTSRVVQAPKEEEEDEQEASEEKASEEEKAWLMASRQQLAKETSNFGFSLLRKISMRHDGNMVFSPFGMSLAMTGLMLGATGPTETQIKRGLHLQALKPTKPGLLPSLFKGLRETLSRNLELGLTQGSFAFIHKDFDVKETFFNLSKRYFDTECVPMNFRNASQAKRLMNHYINKETRGKIPKLFDEINPETKLILVDYILFKGKWLTPFDPVFTEVDTFHLDKYKTIKVPMMYGAGKFASTFDKNFRCHVLKLPYQGNATMLVVLMEKMGDHLALEDYLTTDLVETWLRNMKTRNMEVFFPKFKLDQKYEMHELLRQMGIRRIFSPFADLSELSATGRNLQVSRVLQRTVIEVDERGTEAVAGILSEITAYSMPPVIKVDRPFHFMIYEETSGMLLFLGRVVNPTLL>sp|Q3MJ62|ZSC23_HUMAN Zinc finger and SCAN domain-containing protein 23OS=Homo sapiens OX=9606 GN=ZSCAN23 PE=1 SV=1MAITLTLQTAEMQEGLLAVKVKEEEEEHSCGPESGLSRNNPHTREIFRRRFRQFCYQESPGPREALQRLQELCHQWLRPEMHTKEQILELLVLEQFLTILPEELQAWVRQHRPVSGEEAVTVLEDLERELDDPGEQVLSHAHEQEEFVKEKATPGAAQESSNDQFQTLEEQLGYNLREVCPVQEIDGKAGTWNVELAPKREISQEVKSLIQVLGKQNGNITQIPEYGDTCDREGRLEKQRVSSSVERPYICSECGKSFTQNSILIEHQRTHTGEKPYECDECGRAFSQRSGLFQHQRLHTGEKRYQCSVCGKAFSQNAGLFHHLRIHTGEKPYQCNQCNKSFSRRSVLIKHQRIHTGERPYECEECGKNFIYHCNLIQHRKVHPVAESS>sp|A6NK75|ZNF98_HUMAN Zinc finger protein 98 OS=Homo sapiens OX=9606GN=ZNF98 PE=2 SV=4MPGPLGSLEMGVLTFRDVALEFSLEEWQCLDTAQQNLYRNVMLENYRNLVFVGIAASKPDLITCLEQGKEPWNVKRHEMVTEPPVVYSYFAQDLWPKQGKKNYFQKVILRTYKKCGRENLQLRKYCKSMDECKVHKECYNGLNQCLTTTQNKIFQYDKYVKVFHKFSNSNRHKIGHTGKKSFKCKECEKSFCMLSHLAQHKRIHSGEKPYKCKECGKAYNEASNLSTHKRIHTGKKPYKCEECGKAFNRLSHLTTHKIIHTGKKPYKCEECGKAFNQSANLTTHKRIHTGEKPYKCEECGRAFSQSSTLTAHKIIHAGEKPYKCEECGKAFSQSSTLTTHKIIHTGEKFYKCEECGKAFSRLSHLTTHKRIHSGEKPYKCEECGKAFKQSSTLTTHKRIHAGEKFYKCEVCSKAFSRFSHLTTHKRIHTGEKPYKCEECGKAFNLSSQLTTHKIIHTGEKPYKCEECGKAFNQSSTLSKHKVIHTGEKPYKCEECGKAFNQSSHLTTHKMIHTGEKPYKCEECGKAFNNSSILNRHKMIHTGEKLYKPESCNNACDNIAKISKYKRNCAGEK>sp|Q8NAM6|ZSCA4_HUMAN Zinc finger and SCAN domain-containing protein 4OS=Homo sapiens OX=9606 GN=ZSCAN4 PE=1 SV=1MALDLRTIFQCEPSENNLGSENSAFQQSQGPAVQREEGISEFSRMVLNSFQDSNNSYARQELQRLYRIFHSWLQPEKHSKDEIISLLVLEQFMIGGHCNDKASVKEKWKSSGKNLERFIEDLTDDSINPPALVHVHMQGQEALFSEDMPLRDVIVHLTKQVNAQTTREANMGTPSQTSQDTSLETGQGYEDEQDGWNSSSKTTRVNENITNQGNQIVSLIIIQEENGPRPEEGGVSSDNPYNSKRAELVTARSQEGSINGITFQGVPMVMGAGCISQPEQSSPESALTHQSNEGNSTCEVHQKGSHGVQKSYKCEECPKVFKYLCHLLAHQRRHRNERPFVCPECQKGFFQISDLRVHQIIHTGKKPFTCSMCKKSFSHKTNLRSHERIHTGEKPYTCPFCKTSYRQSSTYHRHMRTHEKITLPSVPSTPEAS>sp|Q8NEG5|ZSWM2_HUMAN E3 ubiquitin-protein ligase ZSWIM2 OS=Homo sapiensOX=9606 GN=ZSWIM2 PE=1 SV=2MLRRGYKASERRRHLSERLSWHQDQALSSSIYLLREMGPTGFLLREEEPEYMDFRVFLGNPHVCNCSTFPKGGELCKHICWVLLKKFKLPRNHESALQLGLGEREISDLLRGIHRVQTPQPGTNDENEHVEEDGYIKQKEIDSEDICSICQELLLEKKLPVTFCRFGCGNSIHIKCMKILANYQSTSNTSMLKCPLCRKEFAPLKLILEEFKNSSKLVAAAEKERLDKHLGIPCNNCKQFPIEGKCYKCTECIEYHLCQECFDSCCHLSHTFTFREKRNQKWRSLEKRADEVVKYIDTKNEIEEKMSHFQEKQGQVYTPKHIVRSLPLQLITKNSKLLAPGYQCLLCLKAFHLGQHTRLLPCTHKFHRKCIDNWLFHKCNSCPIDGQVIYNPLTWKNSAVNGQAHQSVSNRDIIHLSKQKEPDLFIPGTGLVLKQNRLGILPSIPQCNFDELNTPQSPKDAYENTTIDNLCSIKLDNSNSKKLTYDYKISQHFPRYLQDLPTVSFGKIPSQTLLPPIVHKNIVCPTAMESPCISGKFHTSLSRMTKGCKCNNHNLKKTPATKIREDNKRSTLLPEDFNLIVNWSTAKLSLSKRYSNCMGEITRKCSHLSRQPVSHSVNTKSTELSLIIEGVQL>sp|Q8TAD4|ZNT5_HUMAN Zinc transporter 5 OS=Homo sapiens OX=9606GN=SLC30A5 PE=1 SV=1MEEKYGGDVLAGPGGGGGLGPVDVPSARLTKYIVLLCFTKFLKAVGLFESYDLLKAVHIVQFIFILKLGTAFFMVLFQKPFSSGKTITKHQWIKIFKHAVAGCIISLLWFFGLTLCGPLRTLLLFEHSDIVVISLLSVLFTSSGGGPAKTRGAAFFIIAVICLLLFDNDDLMAKMAEHPEGHHDSALTHMLYTAIAFLGVADHKGGVLLLVLALCCKVGFHTASRKLSVDVGGAKRLQALSHLVSVLLLCPWVIVLSVTTESKVESWFSLIMPFATVIFFVMILDFYVDSICSVKMEVSKCARYGSFPIFISALLFGNFWTHPITDQLRAMNKAAHQESTEHVLSGGVVVSAIFFILSANILSSPSKRGQKGTLIGYSPEGTPLYNFMGDAFQHSSQSIPRFIKESLKQILEESDSRQIFYFLCLNLLFTFVELFYGVLTNSLGLISDGFHMLFDCSALVMGLFAALMSRWKATRIFSYGYGRIEILSGFINGLFLIVIAFFVFMESVARLIDPPELDTHMLTPVSVGGLIVNLIGICAFSHAHSHAHGASQGSCHSSDHSHSHHMHGHSDHGHGHSHGSAGGGMNANMRGVFLHVLADTLGSIGVIVSTVLIEQFGWFIADPLCSLFIAILIFLSVVPLIKDACQVLLLRLPPEYEKELHIALEKIQKIEGLISYRDPHFWRHSASIVAGTIHIQVTSDVLEQRIVQQVTGILKDAGVNNLTIQVEKEAYFQHMSGLSTGFHDVLAMTKQMESMKYCKDGTYIM>sp|Q8TAD4-2|ZNT5_HUMAN Isoform 2 of Zinc transporter 5 OS=Homo sapiensOX=9606 GN=SLC30A5MAKMAEHPEGHHDSALTHMLYTAIAFLGVADHKGGVLLLVLALCCKVGFHTASRKLSVDVGGAKRLQALSHLVSVLLLCPWVIVLSVTTESKVESWFSLIMPFATVIFFVMILDFYVDSICSVKMEVSKCARYGSFPIFISALLFGNFWTHPITDQLRAMNKAAHQESTEHVLSGGVVVSAIFFILSANILSSPSKRGQKGTLIGYSPEGTPLYNFMGDAFQHSSQSIPRFIKESLKQILEESDSRQIFYFLCLNLLFTFVELFYGVLTNSLGLISDGFHMLFDCSALVMGLFAALMSRWKATRIFSYGYGRIEILSGFINGLFLIVIAFFVFMESVARLIDPPELDTHMLTPVSVGGLIVNLIGICAFSHAHSHAHGASQGSCHSSDHSHSHHMHGHSDHGHGHSHGSAGGGMNANMRGVFLHVLADTLGSIGVIVSTVLIEQFGWFIADPLCSLFIAILIFLSVVPLIKDACQVLLLRLPPEYEKELHIALEKVLYVISSLLSSLKITFLKSLLEVKQTTK>sp|Q8TAD4-3|ZNT5_HUMAN Isoform 3 of Zinc transporter 5 OS=Homo sapiensOX=9606 GN=SLC30A5MEEKYGGDVLAGPGGGGGLGPVDVPSARLTKYIVLLCFTKFLKAVGLFESYDLLKAVHIVQFIFILKLGTAFFMVLFQKPFSSGKTITKHQIIGSLKIPGRKEFKDKKLNDPRKLVGN>sp|Q8TAD4-4|ZNT5_HUMAN Isoform 4 of Zinc transporter 5 OS=Homo sapiensOX=9606 GN=SLC30A5MEEKYGGDVLAGPGGGGGLGPVDVPSARTAFFMVLFQKPFSSGKTITKHQIIGSLKIPGRKEFKDKKLNDPRKLVGN>sp|Q96MP5|ZSWM3_HUMAN Zinc finger SWIM domain-containing protein 3OS=Homo sapiens OX=9606 GN=ZSWIM3 PE=1 SV=2MELGSCFKTYEDFKECFSAYKRENRCSFILRDCVSVRFHNLNHGTSIREDILYVQVKFVCIRTQSNRKRTREADMCPAYLLLRYNERLDRLFISELNTQHIHGDSKVASPGGDTTGKSQKTMCLQRLQPVQPTTKKDLDTAEKSLVEPSFCLDKVQVSSKPEQEGITPSDLAKIAKVMKNFLKVDEGSMASFSVGDSQHLDRLSFQSSKMTDLFIRFPENLLLHRVENTQGHILYAFLVENKERESRVVHFAVLKAETVTSVAKMLSIFTEFNSDWPKVKVVFVDPSFHYRAILQEIFPAARILLSIYHTTRLLEKKLHRSSANPSFKRLMKEALREAVFVTSEASLKNLCQMSQAVLDEDLFNFLQAHWFTCELLWYMHVRKGLLACNTYMDSLDIVTSKVSSLFREQQSLLDCILCFVDYIDFFNTKGLKNLPTPPPKLKRARPASMPLKSKKAFGICGESLTSLPAEETKPDAQQVQVQQQSQVPPSQVGMLDTLHQSGSELAYKLCHNEWEVVQNSTHLVDMAGSSVDVQLLEDSHQVSKDGCSCSCSFQQWYHLPCRHILALLHTSQQPVGEAMVCRRWQKKYQYLLGPNGELQDRGMVPNTGQPEKQGRNDMIQDLSRELANLLMQTEGPELEERYSTLRKIVDIWAGPSQPSELFQQPGDFKDVGRLPFLWGKQEEGEGFPPATAVMHY>sp|O15535|ZSC9_HUMAN Zinc finger and SCAN domain-containing protein 9OS=Homo sapiens OX=9606 GN=ZSCAN9 PE=1 SV=1MNTNSKEVLSLGVQVPEAWEELLTMKVEAKSHLQWQESRLKRSNPLAREIFRRHFRQLCYQETPGPREALTRLQELCYQWLRPHVSTKEQILDLLVLEQFLSILPKELQGWVREHCPESGEEAVILLEDLERELDEPQHEMVAHRHRQEVLCKEMVPLAEQTPLTLQSQPKEPQLTCDSAQKCHSIGETDEVTKTEDRELVLRKDCPKIVEPHGKMFNEQTWEVSQQDPSHGEVGEHKDRIERQWGNLLGEGQHKCDECGKSFTQSSGLIRHQRIHTGERPYECNECGKAFSRSSGLFNHRGIHNIQKRYHCKECGKVFSQSAGLIQHQRIHKGEKPYQCSQCSKSYSRRSFLIEHQRSHTGERPHQCIECGKSFNRHCNLIRHQKIHTVAELV>sp|O15535-2|ZSC9_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 9 OS=Homo sapiens OX=9606 GN=ZSCAN9MNTNSKEVLSLGVQVPEAWEELLTMKVEAKSHLQWQESRLKRSNPLAREIFRRHFRQLCYQETPGPREALTRLQELCYQWLRPHVSTKEQILDLLVLEQFLSILPKELQGWVREHCPESGEEAVILLEDLERELDEPQHEMVAHRHRQEVLCKEMVPLAEQTPLTLQSQPKEPQLTCDSAQKCHSIGETDLIRSLRRRAVLIPLGAHLFSTDTFLFSKPVVIPQLKGGGETWPNNRGVLRDEVTKTEDRELVLRKDCPKIVEPHGKMFNEQTWEVSQQDPSHGEVGEHKDRIERQWGNLLGEGQHKCDECGKSFTQSSGLIRHQRIHTGERPYECNECGKAFSRSSGLFNHRGIHNIQKRYHCKECGKVFSQSAGLIQHQRIHKGEKPYQCSQCSKSYSRRSFLIEHQRSHTGERPHQCIECGKSFNRHCNLIRHQKIHTVAELV>sp|C9JN71|ZN878_HUMAN Zinc finger protein 878 OS=Homo sapiens OX=9606GN=ZNF878 PE=3 SV=2MDSVAFEDVAVNFTQEEWALLDPSQKNLYREVMQETLRNLTSIGKKWNNQYIEDEHQNPRRNLRRLIGERLSESKESHQHGEVLTQVPDDTLKKKTPGVQSYESSVCGEIGIGLSSLNRHLRAFSYSSSLAIHGRTHTGEKPYECKECGKAFRFPSSVRRHERIHSAKKPYECKQCGKAFSFPSSVRRHERIHSAKKPYECKQCGKALSYLVSFQTHMRMHTGERPHKCNICGKAFFSPSSLKRHEKSHTGEKRYKCKQCDKAFNCPSSFQYHERTHSGEKPYECTQCRKAFRSVKYLRVHERKHTGEKPYECKLCGKGFISSTSFRYHEKTHTGEKPYECKKCVKAFSFVKDLRIHERTHTGEKPFECKQCGKTFTSSNSFHYHERTHTGEKPYECKQCGKAFRSASVLQKHIRTHTGEKPYGCKQCGKVFRVASQLKMHERTHTGEKPYECKQCGKAFISSNSIRYHKRTHTGEKPYKCKQCGKAFISSNSFLYHERIHTGEKPYECKQCGKAFRSASILQKHVRTHAG>sp|O75800|ZMY10_HUMAN Zinc finger MYND domain-containing protein 10OS=Homo sapiens OX=9606 GN=ZMYND10 PE=1 SV=2MGDLELLLPGEAEVLVRGLRSFPLREMGSEGWNQQHENLEKLNMQAILDATVSQGEPIQELLVTHGKVPTLVEELIAVEMWKQKVFPVFCRVEDFKPQNTFPIYMVVHHEASIINLLETVFFHKEVCESAEDTVLDLVDYCHRKLTLLVAQSGCGGPPEGEGSQDSNPMQELQKQAELMEFEIALKALSVLRYITDCVDSLSLSTLSRMLSTHNLPCLLVELLEHSPWSRREGGKLQQFEGSRWHTVAPSEQQKLSKLDGQVWIALYNLLLSPEAQARYCLTSFAKGRLLKLRAFLTDTLLDQLPNLAHLQSFLAHLTLTETQPPKKDLVLEQIPEIWERLERENRGKWQAIAKHQLQHVFSPSEQDLRLQARRWAETYRLDVLEAVAPERPRCAYCSAEASKRCSRCQNEWYCCRECQVKHWEKHGKTCVLAAQGDRAK>sp|O75800-2|ZMY10_HUMAN Isoform 2 of Zinc finger MYND domain-containingprotein 10 OS=Homo sapiens OX=9606 GN=ZMYND10MGDLELLLPGEAEVLVRGLRSFPLREMGSEGWNQQHENLEKLNMQAILDATVSQGEPIQELLVTHGKVPTLVEELIAVEMWKQKVFPVFCRVEDFKPQNTFPIYMVVHHEASIINLLETVFFHKEVCESAEDTVLDLVDYCHRKLTLLVAQSGCGGPPEGEGSQDSNPMQELQKQAELMEFEIALKALSVLRYITDCVDRQWSVSQPPQLAHLKRIQRLHPVCWFLSPGKLQQFEGSRWHTVAPSEQQKLSKLDGQVWIALYNLLLSPEAQARYCLTSFAKGRLLKLRAFLTDTLLDQLPNLAHLQSFLAHLTLTETQPPKKDLVLEQIPEIWERLERENRGKWQAIAKHQLQHVFSPSEQDLRLQARRWAETYRLDVLEAVAPERPRCAYCSAEASKRCSRCQNEWYCCRECQVKHWEKHGKTCVLAAQGDRAK>sp|Q96H40|ZN486_HUMAN Zinc finger protein 486 OS=Homo sapiens OX=9606GN=ZNF486 PE=2 SV=4MPGPLRSLEMESLQFRDVAVEFSLEEWHCLDTAQQNLYRDVMLENYRHLVFLGIIVSKPDLITCLEQGIKPLTMKRHEMIAKPPVVCSHFAQDLWPEQSIKDSYQKVILRKFEKCGHGNLHFKKGCESVDECKLHKRGYNGLNQCLTTTQSKIFQCGKYVKVFHQFSNSKRHKRRHTEKKPLKYIEGDKAFNQSSTHTTHKKIDTGEKPYKCEECGKAFNRSSHLTTHKITHTREKPYKCEECGKVFKYFSSFTTHKKIHSGEKPYICEECGKAFMYPYTLTTHKIIHTGEQPYKCKECDKAFNHPATLSSHKKIHTGEKPYTCDKCGKAFISSSILSKHEKIHTGEKPYKCEECGKAFTRSSHLTMHKIIHTGEKPYKCEECGKAFTWSAGLHKHRRTHTGEKPYKCEECGKAYTTSSNLTEHKTTHTGEKPYKCKECGKAFNWSSDLNKHKRIHIGQKPRT>sp|O00124|UBXN8_HUMAN UBX domain-containing protein 8 OS=Homo sapiensOX=9606 GN=UBXN8 PE=1 SV=2MASRGVVGIFFLSAVPLVCLELRRGIPDIGIKDFLLLCGRILLLLALLTLIISVTTSWLNSFKSPQVYLKEEEEKNEKRQKLVRKKQQEAQGEKASRYIENVLKPHQEMKLRKLEERFYQMTGEAWKLSSGHKLGGDEGTSQTSFETSNREAAKSQNLPKPLTEFPSPAEQPTCKEIPDLPEEPSQTAEEVVTVALRCPSGNVLRRRFLKSYSSQVLFDWMTRIGYHISLYSLSTSFPRRPLAVEGGQSLEDIGITVDTVLILEEKEQTN>sp|O00124-2|UBXN8_HUMAN Isoform 2 of UBX domain-containing protein 8OS=Homo sapiens OX=9606 GN=UBXN8MASRGVVGIFFLSAVPLVCLELRRGIPDIGIKDFLLLCGRILLLLALLTLIISVTTSWLNSFKSPQVYLKEEEEKNEKRQKLVRKKQQEAQGEKGDEGTSQTSFETSNREAAKSQNLPKPLTEFPSPAEQPTCKEIPDLPEEPSQTAEEVVTVALRCPSGNVLRRRFLKSYSSQVLFDWMTRIGYHISLYSLSTSFPRRPLAVEGGQSLEDIGITVDTVLILEEKEQTN>sp|O00124-3|UBXN8_HUMAN Isoform 3 of UBX domain-containing protein 8OS=Homo sapiens OX=9606 GN=UBXN8MASRGVVGIFFLSAVPLVCLELRRGIPDIVYLKEEEEKNEKRQKLVRKKQQEAQGEKASRYIENVLKPHQEMKLRKLEERFYQMTGEAWKLSSGHKLGGDEGTSQTSFETSNREAAKSQNLPKPLTEFPSPAEQPTCKEIPDLPEEPSQTAEEVVTVALRCPSGNVLRRRFLKSYSSQVLFDWMTRIGYHISLYSLSTSFPRRPLAVEGGQSLEDIGITVDTVLILEEKEQTN>sp|Q9BTM9|URM1_HUMAN Ubiquitin-related modifier 1 OS=Homo sapiensOX=9606 GN=URM1 PE=1 SV=1MAAPLSVEVEFGGGAELLFDGIKKHRVTLPGQEEPWDIRNLLIWIKKNLLKERPELFIQGDSVRPGILVLINDADWELLGELDYQLQDQDSVLFISTLHGG>sp|Q9BTM9-2|URM1_HUMAN Isoform 2 of Ubiquitin-related modifier 1 OS=Homosapiens OX=9606 GN=URM1MAAPLSVEVEFGGGAELLFDGIKKHRVTLPGQEEPWDIRNLLIWIKKNLLKERPELFIQGDSVRPGILVLINDADWELLVSTLGDIPPPAPALAASVGKRWASPQAHIEWLGNPPPHSSPTLRLLESPTPGEEGMGSWGHGSTPPS>sp|Q9BTM9-3|URM1_HUMAN Isoform 3 of Ubiquitin-related modifier 1 OS=Homosapiens OX=9606 GN=URM1MAAPLSVEVEFGGGAELLFDGIKKHRVTLPGQEEPWDIRNLLIWIKKNLLKERPELFIQGDSV>sp|Q8TEU8|WFKN2_HUMAN WAP, Kazal, immunoglobulin, Kunitz and NTR domain-containing protein 2 OS=Homo sapiens OX=9606 GN=WFIKKN2 PE=1 SV=1MWAPRCRRFWSRWEQVAALLLLLLLLGVPPRSLALPPIRYSHAGICPNDMNPNLWVDAQSTCRRECETDQECETYEKCCPNVCGTKSCVAARYMDVKGKKGPVGMPKEATCDHFMCLQQGSECDIWDGQPVCKCKDRCEKEPSFTCASDGLTYYNRCYMDAEACSKGITLAVVTCRYHFTWPNTSPPPPETTMHPTTASPETPELDMAAPALLNNPVHQSVTMGETVSFLCDVVGRPRPEITWEKQLEDRENVVMRPNHVRGNVVVTNIAQLVIYNAQLQDAGIYTCTARNVAGVLRADFPLSVVRGHQAAATSESSPNGTAFPAAECLKPPDSEDCGEEQTRWHFDAQANNCLTFTFGHCHRNLNHFETYEACMLACMSGPLAACSLPALQGPCKAYAPRWAYNSQTGQCQSFVYGGCEGNGNNFESREACEESCPFPRGNQRCRACKPRQKLVTSFCRSDFVILGRVSELTEEPDSGRALVTVDEVLKDEKMGLKFLGQEPLEVTLLHVDWACPCPNVTVSEMPLIIMGEVDGGMAMLRPDSFVGASSARRVRKLREVMHKKTCDVLKEFLGLH>sp|Q9UBD3|XCL2_HUMAN Cytokine SCM-1 beta OS=Homo sapiens OX=9606 GN=XCL2PE=1 SV=1MRLLILALLGICSLTAYIVEGVGSEVSHRRTCVSLTTQRLPVSRIKTYTITEGSLRAVIFITKRGLKVCADPQATWVRDVVRSMDRKSNTRNNMIQTKPTGTQQSTNTAVTLTG>sp|A6NLU5|VTM2B_HUMAN V-set and transmembrane domain-containing protein2B OS=Homo sapiens OX=9606 GN=VSTM2B PE=3 SV=2MEQRNRLGALGYLPPLLLHALLLFVADAAFTEVPKDVTVREGDDIEMPCAFRASGATSYSLEIQWWYLKEPPRELLHELALSVPGARSKVTNKDATKISTVRVQGNDISHRLRLSAVRLQDEGVYECRVSDYSDDDTQEHKAQAMLRVLSRFAPPNMQAAEAVSHIQSSGPRRHGPASAANANNAGAASRTTSEPGRGDKSPPPGSPPAAIDPAVPEAAAASAAHTPTTTVAAAAAASSASPPSGQAVLLRQRHGSGTGRSYTTDPLLSLLLLALHKFLRLLLGH>sp|Q14191|WRN_HUMAN Werner syndrome ATP-dependent helicase OS=Homosapiens OX=9606 GN=WRN PE=1 SV=2MSEKKLETTAQQRKCPEWMNVQNKRCAVEERKACVRKSVFEDDLPFLEFTGSIVYSYDASDCSFLSEDISMSLSDGDVVGFDMEWPPLYNRGKLGKVALIQLCVSESKCYLFHVSSMSVFPQGLKMLLENKAVKKAGVGIEGDQWKLLRDFDIKLKNFVELTDVANKKLKCTETWSLNSLVKHLLGKQLLKDKSIRCSNWSKFPLTEDQKLYAATDAYAGFIIYRNLEILDDTVQRFAINKEEEILLSDMNKQLTSISEEVMDLAKHLPHAFSKLENPRRVSILLKDISENLYSLRRMIIGSTNIETELRPSNNLNLLSFEDSTTGGVQQKQIREHEVLIHVEDETWDPTLDHLAKHDGEDVLGNKVERKEDGFEDGVEDNKLKENMERACLMSLDITEHELQILEQQSQEEYLSDIAYKSTEHLSPNDNENDTSYVIESDEDLEMEMLKHLSPNDNENDTSYVIESDEDLEMEMLKSLENLNSGTVEPTHSKCLKMERNLGLPTKEEEEDDENEANEGEEDDDKDFLWPAPNEEQVTCLKMYFGHSSFKPVQWKVIHSVLEERRDNVAVMATGYGKSLCFQYPPVYVGKIGLVISPLISLMEDQVLQLKMSNIPACFLGSAQSENVLTDIKLGKYRIVYVTPEYCSGNMGLLQQLEADIGITLIAVDEAHCISEWGHDFRDSFRKLGSLKTALPMVPIVALTATASSSIREDIVRCLNLRNPQITCTGFDRPNLYLEVRRKTGNILQDLQPFLVKTSSHWEFEGPTIIYCPSRKMTQQVTGELRKLNLSCGTYHAGMSFSTRKDIHHRFVRDEIQCVIATIAFGMGINKADIRQVIHYGAPKDMESYYQEIGRAGRDGLQSSCHVLWAPADINLNRHLLTEIRNEKFRLYKLKMMAKMEKYLHSSRCRRQIILSHFEDKQVQKASLGIMGTEKCCDNCRSRLDHCYSMDDSEDTSWDFGPQAFKLLSAVDILGEKFGIGLPILFLRGSNSQRLADQYRRHSLFGTGKDQTESWWKAFSRQLITEGFLVEVSRYNKFMKICALTKKGRNWLHKANTESQSLILQANEELCPKKLLLPSSKTVSSGTKEHCYNQVPVELSTEKKSNLEKLYSYKPCDKISSGSNISKKSIMVQSPEKAYSSSQPVISAQEQETQIVLYGKLVEARQKHANKMDVPPAILATNKILVDMAKMRPTTVENVKRIDGVSEGKAAMLAPLLEVIKHFCQTNSVQTDLFSSTKPQEEQKTSLVAKNKICTLSQSMAITYSLFQEKKMPLKSIAESRILPLMTIGMHLSQAVKAGCPLDLERAGLTPEVQKIIADVIRNPPVNSDMSKISLIRMLVPENIDTYLIHMAIEILKHGPDSGLQPSCDVNKRRCFPGSEEICSSSKRSKEEVGINTETSSAERKRRLPVWFAKGSDTSKKLMDKTKRGGLFS>sp|Q9HAD4|WDR41_HUMAN WD repeat-containing protein 41 OS=Homo sapiensOX=9606 GN=WDR41 PE=1 SV=3MLRWLIGGGREPQGLAEKSPLQTIGEEQTQNPYTELLVLKAHHDIVRFLVQLDDYRFASAGDDGIVVVWNAQTGEKLLELNGHTQKITAIITFPSLESCEEKNQLILTASADRTVIVWDGDTTRQVQRISCFQSTVKCLTVLQRLDVWLSGGNDLCVWNRKLDLLCKTSHLSDTGISALVEIPKNCVVAAVGKELIIFRLVAPTEGSLEWDILEVKRLLDHQDNILSLINVNDLSFVTGSHVGELIIWDALDWTMQAYERNFWDPSPQLDTQQEIKLCQKSNDISIHHFTCDEENVFAAVGRGLYVYSLQMKRVIACQKTAHDSNVLHVARLPNRQLISCSEDGSVRIWELREKQQLAAEPVPTGFFNMWGFGRVSKQASQPVKKQQENATSCSLELIGDLIGHSSSVEMFLYFEDHGLVTCSADHLIILWKNGERESGLRSLRLFQKLEENGDLYLAV>sp|Q9HAD4-2|WDR41_HUMAN Isoform 2 of WD repeat-containing protein 41OS=Homo sapiens OX=9606 GN=WDR41MLRWLIGGGREPQGLAETGEKLLELNGHTQKITAIITFPSLESCEEKNQLILTASADRTVIVWDGDTTRQVQRISCFQSTVKCLTVLQRLDVWLSGGNDLCVWNRKLDLLCKTSHLSDTGISALVEIPKNCVVAAVGKELIIFRLVAPTEGSLEWDILEVKRLLDHQDNILSLINVNDLSFVTGSHVGELIIWDALDWTMQAYERNFWDPSPQLDTQQEIKLCQKSNDISIHHFTCDEENVFAAVGRGLYVYSLQMKRVIACQKTAHDSNVLHVARLPNRQLISCSEDGSVRIWELREKQQLAAEPVPTGFFNMWGFGRVSKQASQPVKKQQENATSCSLELIGDLIGHSSSVEMFLYFEDHGLVTCSADHLIILWKNGERESGLRSLRLFQKLEENGDLYLAV>sp|Q9H7D7|WDR26_HUMAN WD repeat-containing protein 26 OS=Homo sapiensOX=9606 GN=WDR26 PE=1 SV=3MQANGAGGGGGGGGGGGGGGGGGGGQGQTPELACLSAQNGESSPSSSSSAGDLAHANGLLPSAPSAASNNSNSLNVNNGVPGGAAAASSATVAAASATTAASSSLATPELGSSLKKKKRLSQSDEDVIRLIGQHLNGLGLNQTVDLLMQESGCRLEHPSATKFRNHVMEGDWDKAENDLNELKPLVHSPHAIVVRGALEISQTLLGIIVRMKFLLLQQKYLEYLEDGKVLEALQVLRCELTPLKYNTERIHVLSGYLMCSHAEDLRAKAEWEGKGTASRSKLLDKLQTYLPPSVMLPPRRLQTLLRQAVELQRDRCLYHNTKLDNNLDSVSLLIDHVCSRRQFPCYTQQILTEHCNEVWFCKFSNDGTKLATGSKDTTVIIWQVDPDTHLLKLLKTLEGHAYGVSYIAWSPDDNYLVACGPDDCSELWLWNVQTGELRTKMSQSHEDSLTSVAWNPDGKRFVTGGQRGQFYQCDLDGNLLDSWEGVRVQCLWCLSDGKTVLASDTHQRIRGYNFEDLTDRNIVQEDHPIMSFTISKNGRLALLNVATQGVHLWDLQDRVLVRKYQGVTQGFYTIHSCFGGHNEDFIASGSEDHKVYIWHKRSELPIAELTGHTRTVNCVSWNPQIPSMMASASDDGTVRIWGPAPFIDHQNIEEECSSMDS>sp|Q9H7D7-2|WDR26_HUMAN Isoform 2 of WD repeat-containing protein 26OS=Homo sapiens OX=9606 GN=WDR26MQANGAGGGGGGGGGGGGGGGGGGGQGQTPELACLSAQNGESSPSSSSSAGDLAHANGLLPSAPSAASNNSNSLNVNNGVPGGAAAASSATVAAASATTAASSSLATPELGSSLKKKKRLSQSDEDVIRLIGQHLNGLGLNQTVDLLMQESGCRLEHPSATKFRNHVMEGDWDKAENDLNELKPLVHSPHAIVRMKFLLLQQKYLEYLEDGKVLEALQVLRCELTPLKYNTERIHVLSGYLMCSHAEDLRAKAEWEGKGTASRSKLLDKLQTYLPPSVMLPPRRLQTLLRQAVELQRDRCLYHNTKLDNNLDSVSLLIDHVCSRRQFPCYTQQILTEHCNEVWFCKFSNDGTKLATGSKDTTVIIWQVDPDTHLLKLLKTLEGHAYGVSYIAWSPDDNYLVACGPDDCSELWLWNVQTGELRTKMSQSHEDSLTSVAWNPDGKRFVTGGQRGQFYQCDLDGNLLDSWEGVRVQCLWCLSDGKTVLASDTHQRIRGYNFEDLTDRNIVQEDHPIMSFTISKNGRLALLNVATQGVHLWDLQDRVLVRKYQGVTQGFYTIHSCFGGHNEDFIASGSEDHKVYIWHKRSELPIAELTGHTRTVNCVSWNPQIPSMMASASDDGTVRIWGPAPFIDHQNIEEECSSMDS>sp|Q9H7D7-3|WDR26_HUMAN Isoform 3 of WD repeat-containing protein 26OS=Homo sapiens OX=9606 GN=WDR26MQANGAGGGGGGGGGGGGGGGGGGGQGQTPELACLSAQNGESSPSSSSSAGDLAHANGLLPSAPSAASNNSNSLNVNNGVPGGAAAASSATVAAASATTAASSSLATPELGSSLKKKKRLSQSDEDVIRLIGQHLNGLGLNQTVDLLMQESGCRLEHPSATKFRNHVMEGDWDKAENDLNELKPLVHSPHAIVAQTFSETSINFFPLTAAFCHVRG>sp|Q9H7D7-4|WDR26_HUMAN Isoform 4 of WD repeat-containing protein 26OS=Homo sapiens OX=9606 GN=WDR26MQANGAGGGGGGGGGGGGGGGGGGGQGQTPELACLSAQNGESSPSSSSSAGDLAHANGLLPSAPSAASNNSNSLNVNNGVPGGAAAASSATVAAASATTAASSSLATPELGSSLKKKKRLSQSDEDVIRLIGQHLNGLGLNQTVDLLMQESGCRLEHPSATKFRNHVMEGDWDKAENDLNELKPLVHSPHAIVVRGALEISQTLLGIIVVNTLLFLVSHLCLF>sp|Q2VY69|ZN284_HUMAN Zinc finger protein 284 OS=Homo sapiens OX=9606GN=ZNF284 PE=2 SV=1MTMFKEAVTFKDVAVVFTEEELGLLDVSQRKLYRDVMLENFRNLLSVGHQLSHRDTFHFQREEKFWIMETATQREGNSGGKIQTELESVPETGPHEEWSCQQIWEQTASELTRPQDSISSSQFSTQGDVPSQVDAGLSIIHIGETPSEHGKCKKFFSDVSILDLHQQLHSGKISHTCNEYRKRFCYSSALCLHQKVHMGEKRYKCDVCSKAFSQNSQLQTHQRIHTGEKPFKCEQCGKSFSRRSGMYVHCKLHTGEKPHICEECGKAFIHNSQLREHQRIHTGEKPFKCYICGKSFHSRSNLNRHSMVHMQEKSFRCDTCSNSFGQRSALNSHCMDHTKEKLYKCEECGRSFTCRQDLCKHQMDHTGDKPYNCNVCGKGFRWSSCLSRHQRVHNGETTFKCDGCGKRFYMNSQGHSHQRAYREEELYKCQKCGKGYISKFNLDLHQRVHTGERPYNCKECGKSFRWASGILRHKRLHTGEKPFKCEECGKRFTENSKLRFHQRIHTGEKPYKCEECGKGFRWASTHLTHQRLHSREKLFQCEDCGKSSEHSSCLQDQQSDHSGEKTSKCEDCGKRYERRLNLDMILSLFLNDI>sp|Q64LD2|WDR25_HUMAN WD repeat-containing protein 25 OS=Homo sapiensOX=9606 GN=WDR25 PE=1 SV=3MTARTLSLMASLVAYDDSDSEAETEHAGSFNATGQQKDTSGVARPPGQDFASGTLDVPKAGAQPTKHGSCEDPGGYRLPLAQLGRSDWGSCPSQRLQWPGKEPQVTFPIKEPSCSSLWTSHVPASHMPLAAARFKQVKLSRNFPKSSFHAQSESETVGKNGSSFQKKKCEDCVVPYTPRRLRQRQALSTETGKGKDVEPQGPPAGRAPAPLYVGPGVSEFIQPYLNSHYKETTVPRKVLFHLRGHRGPVNTIQWCPVLSKSHMLLSTSMDKTFKVWNAVDSGHCLQTYSLHTEAVRAARWAPCGRRILSGGFDFALHLTDLETGTQLFSGRSDFRITTLKFHPKDHNIFLCGGFSSEMKAWDIRTGKVMRSYKATIQQTLDILFLREGSEFLSSTDASTRDSADRTIIAWDFRTSAKISNQIFHERFTCPSLALHPREPVFLAQTNGNYLALFSTVWPYRMSRRRRYEGHKVEGYSVGCECSPGGDLLVTGSADGRVLMYSFRTASRACTLQGHTQACVGTTYHPVLPSVLATCSWGGDMKIWH>sp|Q64LD2-2|WDR25_HUMAN Isoform 2 of WD repeat-containing protein 25OS=Homo sapiens OX=9606 GN=WDR25MPALCLVLCWFQGLLGEVWNAVDSGHCLQTYSLHTEAVRAARWAPCGRRILSGGFDFALHLTDLETGTQLFSGRSDFRITTLKFHPKDHNIFLCGGFSSEMKAWDIRTGKVMRSYKATIQQTLDILFLREGSEFLSSTDASTRDSADRTIIAWDFRTSAKISNQIFHERFTCPSLALHPREPVFLAQTNGNYLALFSTVWPYRMSRRRRYEGHKVEGYSVGCECSPGGDLLVTGSADGRVLMYSFRTASRACTLQGHTQACVGTTYHPVLPSVLATCSWGGDMKIWH>sp|A8MUI8|YA034_HUMAN Putative UPF0607 protein ENSP00000383783 OS=Homosapiens OX=9606 PE=3 SV=2MRLCLIPQNTGTPQRVLPPVVWSPPSRKKPMLSACNSMMFGHLSPVRIPHLRGKFNLQLPSLDEQVIPARLPKMEVRAEEPKEATEVKDQVETQGQEDNKRGPCSNGEAASTSSLLETQGNLTSSWYNPRPLEGNVHLKSLIEKNQTDKAQVHAVSFYSKDHEVASSHSPAGGILSFGKPDPLPTVLPAPVPGCSLWPEKAALKVLGKDHLPSSPGLLMVGEDMQPKDPAALGSSRSSPSRAASHSSHKRKLSEPPLQLQPTPPLQLKWDRDEGPPPAKFPCLSPEALLVSQASQREGRLQQGNMCKNMRVLSRTSKFRRLRELLRRRKKRRQGRCGSSHL>sp|Q6ZSB9|ZBT49_HUMAN Zinc finger and BTB domain-containing protein 49OS=Homo sapiens OX=9606 GN=ZBTB49 PE=1 SV=3MDPVATHSCHLLQQLHEQRIQGLLCDCMLVVKGVCFKAHKNVLAAFSQYFRSLFQNSSSQKNDVFHLDVKNVSGIGQILDFMYTSHLDLNQDNIQVMLDTAQCLQVQNVLSLCHTFLKSATVVQPPGMPCNSTLSLQSTLTPDATCVISENYPPHLLQECSADAQQNKTLDESHPHASPSVNRHHSAGEISKQAPDTSDGSCTELPFKQPNYYYKLRNFYSKQYHKHAAGPSQERVVEQPFAFSTSTDLTTVESQPCAVSHSECILESPEHLPSNFLAQPVNDSAPHPESDATCQQPVKQMRLKKAIHLKKLNFLKSQKYAEQVSEPKSDDGLTKRLESASKNTLEKASSQSAEEKESEEVVSCENFNCISETERPEDPAALEDQSQTLQSQRQYACELCGKPFKHPSNLELHKRSHTGEKPFECNICGKHFSQAGNLQTHLRRHSGEKPYICEICGKRFAASGDVQRHIIIHSGEKPHLCDICGRGFSNFSNLKEHKKTHTADKVFTCDECGKSFNMQRKLVKHRIRHTGERPYSCSACGKCFGGSGDLRRHVRTHTGEKPYTCEICNKCFTRSAVLRRHKKMHCKAGDESPDVLEELSQAIETSDLEKSQSSDSFSQDTSVTLMPVSVKLPVHPVENSVAEFDSHSGGSYCKLRSMIQPHGVSDQEKLSLDPGKLAKPQMQQTQPQAYAYSDVDTPAGGEPLQADGMAMIRSSLAALDNHGGDPLGSRASSTTYRNSEGQFFSSMTLWGLAMKTLQNENELDQ>sp|Q6ZSB9-2|ZBT49_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 49 OS=Homo sapiens OX=9606 GN=ZBTB49MDPVATHSCHLLQQLHEQRIQGLLCDCMLVVKGVCFKAHKNVLAAFSQYFRSLFQNSSSQKNDVFHLDVKNVSGIGQILDFMYTSHLDLNQDNIQVMLDTAQCLQVQNVLSLCHTFLKSATVVQPPGMPCNSTLSLQSTLTPDATCVISENYPPHLLQECSADAQQNKTLDESHPHASPSVNRHHSAGEISKQAPDTSDGSCTELPFKQPNYYYKLRNFYSKQYHKHAAGPSQERVVEQPFAFSTSTDLTTVESQPCAVSHSECILESPEHLPSNFLAQPVNDSAPHPESDATCQQPVKQMRLKKAIHLKKLNFLKSQKYAEQVSEPKSDDGLTKRLESASKNTLEKASSQSAEEKESEEVVSCENFNCISETERPEDPAALEDQSQTLQSQRQYACELCGKPFKHPSNLELHKRSHTGKCFGGSGDLRRHVRTHTGEKPYTCEICNKCFTRSAVLRRHKKMHCKAGDESPDVLEELSQAIETSDLEKSQSSDSFSQDTSVTLMPVSVKLPVHPVENSVAEFDSHSGGSYCKLRSMIQPHGVSDQEKLSLDPGKLAKPQMQQTQPQAYAYSDVDTPAGGEPLQADGMAMIRSSLAALDNHGGDPLGSRASSTTYRNSEGQFFSSMTLWGLAMKTLQNENELDQ>sp|Q6ZSB9-3|ZBT49_HUMAN Isoform 3 of Zinc finger and BTB domain-containing protein 49 OS=Homo sapiens OX=9606 GN=ZBTB49MDPVATHSCHLLQQLHEQRIQGLLCDCMLVVKGVCFKAHKNVLAAFSQYFRSLFQNSSSQKNDVFHLDVKNVSGIGQILDFMYTSHLDLNQDNIQVMLDTAQCLQVQNVLSLCHTFLKSATVVQPPGMPCNSTLSLQSTLTPDATCVISENYPPHLLQECSADAQQNKTLDESHPHASPSVNRHHSAGEISKQAPDTSDGSCTELPFKQPNYYYKLRNFYSKQYHKHAAGPSQERVVEQPFAFSTSTDLTTVESQPCAVSHSECILESPEHLPSNFLAQPVNDSAPHPESDATCQQPVKQMRLKKAIHLKKLNFLKSQKYAEQVSEPKSDDGLTKRLESASKNTLEKASSQSAEEKESEEVVSCENFNCISETERPEDPAALEDQSQTLQSQRQYACELCGKPFKHPSNLELHKRSHTGN>sp|Q6ZSB9-4|ZBT49_HUMAN Isoform 4 of Zinc finger and BTB domain-containing protein 49 OS=Homo sapiens OX=9606 GN=ZBTB49MDPVATHSCHLLQQLHEQRIQGLLCDCMLVVKGVCFKAHKNVLAAFSQYFRSLFQNSSSQKNDVFHLDVKNVSGIGQILDFMYTSHLDLNQDNIQVMLDTAQCLQVQNVLSLCHTFLKSATVVQPPGMPCNSTLSLQSTLTPDATCVISENYPPHLLQECSADAQQNKTLDESHPHASPSVNRHHSAGEISKQAPDTSDGSCTELPFKQPNYYYKLRNFYSKQYHKHAAGPSQERVVEQPFAFSTSTDLTTVESQPCAVSHSECILESPEHLPSNFLAQPVNDSAPHPESDATCQQPVKQMRLKKAIHLKKLNFLKSQKYAEQVSEPKSDDGLTKRLESASKNTLEKASSQSAEEKESEEVVSCENFNCISETERPEDPAALEDQSQTLQSQRQYACELCGKPFKHPSNLELHKRSHTGR>sp|Q6ZSB9-5|ZBT49_HUMAN Isoform 5 of Zinc finger and BTB domain-containing protein 49 OS=Homo sapiens OX=9606 GN=ZBTB49MDPVATHSCHLLQQLHEQRIQGLLCDCMLVVKGVCFKAHKNVLAAFSQYFRSLFQNSSSQKNDVFHLDVKNVSGIGQILDFMYTSHLDLNQDNIQVMLDTAQCLQVQNVLSLCHTFLKSATVVQPPGMPCNSTLSLQSTLTPDATCVISENYPPHLLQECSADAQQNKTLDESHPHASPSVNRHHSAGEISKQAPDTSDGSCTELPFKQPNYYYKLRNFYSKQYHKHAAGPSQERVVEQPFAFSTSTDLTTVESQPCAVSHSECILESPEHLPSNFLAQPVNDSAPHPESDATCQQPVKQMRLKKAIHLKKLNFLKSQKYAEQVSEPKSDDGLTKRLESASKNTLEKASSQSAEEKESEEVVSCENFNCISETERPEDPAALEDQSQTLQSQRQYACELCGKPFKHPSNLELHKRSHTGEKPFECNICGKHFSQAGNLQTHLRRHSGEKPYICEICGKREMFWGIR>sp|Q9H5J0|ZBTB3_HUMAN Zinc finger and BTB domain-containing protein 3OS=Homo sapiens OX=9606 GN=ZBTB3 PE=1 SV=1MLREFSKWGVEASPGKAWERKRSLLRGAVGRYRGATGGDLFWAPFPSWGTMEFPEHSQQLLQSLREQRSQGFLCDCTVMVGSTQFLAHRAVLASCSPFFQLFYKERELDKRDLVCIHNEIVTAPAFGLLLDFMYAGQLTLRGDTPVEDVLAAASYLHMNDIVKVCKRRLQARALAEADSTKKEEETNSQLPSLEFLSSTSRGTQPSLASAETSGHWGKGEWKGSAAPSPTVRPPDEPPMSSGADTTQPGMEVDAPHLRAPHPPVADVSLASPSSSTETIPTNYFSSGISAVSLEPLPSLDVGPESLRVVEPKDPGGPLQGFYPPASAPTSAPAPVSAPVPSQAPAPAEAELVQVKVEAIVISDEETDVSDEQPQGPERAFPSGGAVYGAQPSQPEAFEDPGAAGLEEVGPSDHFLPTDPHLPYHLLPGAGQYHRGLVTSPLPAPASLHEPLYLSSEYEAAPGSFGVFTEDVPTCKTCGKTFSCSYTLRRHATVHTRERPYECRYCLRSYTQSGDLYRHIRKAHNEDLAKRSKPDPEVGPLLGVQPLPGSPTADRQSSSGGGPPKDFVLAPKTNI>sp|Q14586|ZN267_HUMAN Zinc finger protein 267 OS=Homo sapiens OX=9606GN=ZNF267 PE=1 SV=3MGLLTFRDVAVEFSLEEWEHLEPAQKNLYQDVMLENYRNLVSLGLVVSKPDLITFLEQRKEPWNVKSEETVAIQPDVFSHYNKDLLTEHCTEASFQKVISRRHGSCDLENLHLRKRWKREECEGHNGCYDEKTFKYDQFDESSVESLFHQQILSSCAKSYNFDQYRKVFTHSSLLNQQEEIDIWGKHHIYDKTSVLFRQVSTLNSYRNVFIGEKNYHCNNSEKTLNQSSSPKNHQENYFLEKQYKCKEFEEVFLQSMHGQEKQEQSYKCNKCVEVCTQSLKHIQHQTIHIRENSYSYNKYDKDLSQSSNLRKQIIHNEEKPYKCEKCGDSLNHSLHLTQHQIIPTEEKPCKWKECGKVFNLNCSLYLTKQQQIDTGENLYKCKACSKSFTRSSNLIVHQRIHTGEKPYKCKECGKAFRCSSYLTKHKRIHTGEKPYKCKECGKAFNRSSCLTQHQTTHTGEKLYKCKVCSKSYARSSNLIMHQRVHTGEKPYKCKECGKVFSRSSCLTQHRKIHTGENLYKCKVCAKPFTCFSNLIVHERIHTGEKPYKCKECGKAFPYSSHLIRHHRIHTGEKPYKCKACSKSFSDSSGLTVHRRTHTGEKPYTCKECGKAFSYSSDVIQHRRIHTGQRPYKCEECGKAFNYRSYLTTHQRSHTGERPYKCEECGKAFNSRSYLTTHRRRHTGERPYKCDECGKAFSYRSYLTTHRRSHSGERPYKCEECGKAFNSRSYLIAHQRSHTREKL>sp|Q9HCG1|ZN160_HUMAN Zinc finger protein 160 OS=Homo sapiens OX=9606GN=ZNF160 PE=2 SV=3MALTQVRLTFRDVAIEFSQEEWKCLDPAQRILYRDVMLENYWNLVSLGLCHFDMNIISMLEEGKEPWTVKSCVKIARKPRTPECVKGVVTDIPPKCTIKDLLPKEKSSTEAVFHTVVLERHESPDIEDFSFKEPQKNVHDFECQWRDDTGNYKGVLMAQKEGKRDQRDRRDIENKLMNNQLGVSFHSHLPELQLFQGEGKMYECNQVEKSTNNGSSVSPLQQIPSSVQTHRSKKYHELNHFSLLTQRRKANSCGKPYKCNECGKAFTQNSNLTSHRRIHSGEKPYKCSECGKTFTVRSNLTIHQVIHTGEKPYKCHECGKVFRHNSYLATHRRIHTGEKPYKCNECGKAFRGHSNLTTHQLIHTGEKPFKCNECGKLFTQNSHLISHWRIHTGEKPYKCNECGKAFSVRSSLAIHQTIHTGEKPYKCNECGKVFRYNSYLGRHRRVHTGEKPYKCNECGKAFSMHSNLATHQVIHTGTKPFKCNECSKVFTQNSQLANHRRIHTGEKPYKCNECGKAFSVRSSLTTHQAIHSGEKPYKCIECGKSFTQKSHLRSHRGIHSGEKPYKCNECGKVFAQTSQLARHWRVHTGEKPYKCNDCGRAFSDRSSLTFHQAIHTGEKPYKCHECGKVFRHNSYLATHRRIHTGEKPYKCNECGKAFSMHSNLTTHKVIHTGEKPYKCNQCGKVFTQNSHLANHQRTHTGEKPYRCNECGKAFSVRSSLTTHQAIHTGKKPYKCNECGKVFTQNAHLANHRRIHTGEKPYRCTECGKAFRVRSSLTTHMAIHTGEKRYKCNECGKVFRQSSNLASHHRMHTGEKPYK>sp|Q9HCG1-2|ZN160_HUMAN Isoform 2 of Zinc finger protein 160 OS=Homosapiens OX=9606 GN=ZNF160MALTQVRLTFRDVAIEFSQEEWKCLDPAQRILYRDVMLENYWNLVSLGLCHFDMNIISMLEEGKEPWTVKSCVKIARKPRTPECVKGVVTDLLRRWKHWLLLLGICCPKPHGRVSSRLRLSRSLGHFFHSAFATFMGVCDKRVGSIF>sp|Q9Y6Q3|ZFP37_HUMAN Zinc finger protein 37 homolog OS=Homo sapiensOX=9606 GN=ZFP37 PE=2 SV=3MSVSSGVQILTKPETVDRRRSAETTKEAGRPLEMAVSEPEASAAEWKQLDPAQSNLYNDVMLENYCNQASMGCQAPKPDMISKLEKGEAPWLGKGKRPSQGCPSKIARPKQKETDGKVQKDDDQLENIQKSQNKLLREVAVKKKTQAKKNGSDCGSLGKKNNLHKKHVPSKKRLLKFESCGKILKQNLDLPDHSRNCVKRKSDAAKEHKKSFNHSLSDTRKGKKQTGKKHEKLSSHSSSDKCNKTGKKHDKLCCHSSSHIKQDKIQTGEKHEKSPSLSSSTKHEKPQACVKPYECNQCGKVLSHKQGLIDHQRVHTGEKPYECNECGIAFSQKSHLVVHQRTHTGEKPYECIQCGKAHGHKHALTDHLRIHTGEKPYECAECGKTFRHSSNLIQHVRSHTGEKPYECKECGKSFRYNSSLTEHVRTHTGEIPYECNECGKAFKYSSSLTKHMRIHTGEKPFECNECGKAFSKKSHLIIHQRTHTKEKPYKCNECGKAFGHSSSLTYHMRTHTGESPFECNQCGKGFKQIEGLTQHQRVHTGEKPYECNECGKAFSQKSHLIVHQRTHTGEKPYECNECEKAFNAKSQLVIHQRSHTGEKPYECNECGKTFKQNASLTKHVKTHSEDKSHE>sp|Q9Y6Q3-2|ZFP37_HUMAN Isoform 2 of Zinc finger protein 37 homologOS=Homo sapiens OX=9606 GN=ZFP37MSVSSGVQILTKPETVDRRRSAETTKEAGRPLEMAVSEPEASAAVSVTFKHVTMAFTQKEWKQLDPAQSNLYNDVMLENYCNQASMGCQAPKPDMISKLEKGEAPWLGKGKRPSQGCPSKIARPKQKETDGKVQKDDDQLENIQKSQNKLLREVAVKKKTQAKKNGSDCGSLGKKNNLHKKHVPSKKRLLKFESCGKILKQNLDLPDHSRNCVKRKSDAAKEHKKSFNHSLSDTRKGKKQTGKKHEKLSSHSSSDKCNKTGKKHDKLCCHSSSHIKQDKIQTGEKHEKSPSLSSSTKHEKPQACVKPYECNQCGKVLSHKQGLIDHQRVHTGEKPYECNECGIAFSQKSHLVVHQRTHTGEKPYECIQCGKAHGHKHALTDHLRIHTGEKPYECAECGKTFRHSSNLIQHVRSHTGEKPYECKECGKSFRYNSSLTEHVRTHTGEIPYECNECGKAFKYSSSLTKHMRIHTGEKPFECNECGKAFSKKSHLIIHQRTHTKEKPYKCNECGKAFGHSSSLTYHMRTHTGESPFECNQCGKGFKQIEGLTQHQRVHTGEKPYECNECGKAFSQKSHLIVHQRTHTGEKPYECNECEKAFNAKSQLVIHQRSHTGEKPYECNECGKTFKQNASLTKHVKTHSEDKSHE>sp|Q9Y6Q3-3|ZFP37_HUMAN Isoform 3 of Zinc finger protein 37 homologOS=Homo sapiens OX=9606 GN=ZFP37MSVSSGVQILTKPETVDRRRSAETTKEAGRPLEMAVSEPEASAAKEWKQLDPAQSNLYNDVMLENYCNQASMGCQAPKPDMISKLEKGEAPWLGKGKRPSQGCPSKIARPKQKETDGKVQKDDDQLENIQKSQNKLLREVAVKKKTQAKKNGSDCGSLGKKNNLHKKHVPSKKRLLKFESCGKILKQNLDLPDHSRNCVKRKSDAAKEHKKSFNHSLSDTRKGKKQTGKKHEKLSSHSSSDKCNKTGKKHDKLCCHSSSHIKQDKIQTGEKHEKSPSLSSSTKHEKPQACVKPYECNQCGKVLSHKQGLIDHQRVHTGEKPYECNECGIAFSQKSHLVVHQRTHTGEKPYECIQCGKAHGHKHALTDHLRIHTGEKPYECAECGKTFRHSSNLIQHVRSHTGEKPYECKECGKSFRYNSSLTEHVRTHTGEIPYECNECGKAFKYSSSLTKHMRIHTGEKPFECNECGKAFSKKSHLIIHQRTHTKEKPYKCNECGKAFGHSSSLTYHMRTHTGESPFECNQCGKGFKQIEGLTQHQRVHTGEKPYECNECGKAFSQKSHLIVHQRTHTGEKPYECNECEKAFNAKSQLVIHQRSHTGEKPYECNECGKTFKQNASLTKHVKTHSEDKSHE>sp|Q15915|ZIC1_HUMAN Zinc finger protein ZIC 1 OS=Homo sapiens OX=9606GN=ZIC1 PE=1 SV=2MLLDAGPQYPAIGVTTFGASRHHSAGDVAERDVGLGINPFADGMGAFKLNPSSHELASAGQTAFTSQAPGYAAAAALGHHHHPGHVGSYSSAAFNSTRDFLFRNRGFGDAAAAASAQHSLFAASAGGFGGPHGHTDAAGHLLFPGLHEQAAGHASPNVVNGQMRLGFSGDMYPRPEQYGQVTSPRSEHYAAPQLHGYGPMNVNMAAHHGAGAFFRYMRQPIKQELICKWIEPEQLANPKKSCNKTFSTMHELVTHVTVEHVGGPEQSNHICFWEECPREGKPFKAKYKLVNHIRVHTGEKPFPCPFPGCGKVFARSENLKIHKRTHTGEKPFKCEFEGCDRRFANSSDRKKHMHVHTSDKPYLCKMCDKSYTHPSSLRKHMKVHESSSQGSQPSPAASSGYESSTPPTIVSPSTDNPTTSSLSPSSSAVHHTAGHSALSSNFNEWYV>sp|Q8N859|ZN713_HUMAN Zinc finger protein 713 OS=Homo sapiens OX=9606GN=ZNF713 PE=2 SV=2MPSQNAVFSQEGNMEEEEMNDGSQMVRSQESLTFQDVAVDFTREEWDQLYPAQKNLYRDVMLENYRNLVALGYQLCKPEVIAQLELEEEWVIERDSLLDTHPDGENRPEIKKSTTSQNISDENQTHEMIMERLAGDSFWYSILGGLWDFDYHPEFNQENHKRYLGQVTLTHKKITQERSLECNKFAENCNLNSNLMQQRIPSIKIPLNSDTQGNSIKHNSDLIYYQGNYVRETPYEYSECGKIFNQHILLTDHIHTAEKPSECGKAFSHTSSLSQPQMLLTGEKPYKCDECGKRFSQRIHLIQHQRIHTGEKPFICNGCGKAFRQHSSFTQHLRIHTGEKPYKCNQCGKAFSRITSLTEHHRLHTGEKPYECGFCGKAFSQRTHLNQHERTHTGEKPYKCNECGKAFSQSAHLNQHRKIHTREKLCEYKCEQTVRHSPSFSST>sp|Q969W1|ZDH16_HUMAN Palmitoyltransferase ZDHHC16 OS=Homo sapiensOX=9606 GN=ZDHHC16 PE=1 SV=1MRGQRSLLLGPARLCLRLLLLLGYRRRCPPLLRGLVQRWRYGKVCLRSLLYNSFGGSDTAVDAAFEPVYWLVDNVIRWFGVVFVVLVIVLTGSIVAIAYLCVLPLILRTYSVPRLCWHFFYSHWNLILIVFHYYQAITTPPGYPPQGRNDIATVSICKKCIYPKPARTHHCSICNRCVLKMDHHCPWLNNCVGHYNHRYFFSFCFFMTLGCVYCSYGSWDLFREAYAAIEKMKQLDKNKLQAVANQTYHQTPPPTFSFRERMTHKSLVYLWFLCSSVALALGALTVWHAVLISRGETSIERHINKKERRRLQAKGRVFRNPYNYGCLDNWKVFLGVDTGRHWLTRVLLPSSHLPHGNGMSWEPPPWVTAHSASVMAV>sp|Q969W1-2|ZDH16_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC16OS=Homo sapiens OX=9606 GN=ZDHHC16MRGQRSLLLGPARLCLRLLLLLGYRRRCPPLLRGLVQRWRYGKVCLRSLLYNSFGGSDTAVDAAFEPVYWLVDNVIRWFGVVFVVLVIVLTGSIVAIAYLCVLPLILRTYSVPRLCWHFFYSHWNLILIVFHYYQAITTPPGYPPQGRNDIATVSICKKCIYPKPARTHHCSICNRCVLKMDHHCPWLNNCVGHYNHRYFFSFCFFMTLGCVYCSYGSWDLFREAYAAIETYHQTPPPTFSFRERMTHKSLVYLWFLCSSVALALGALTVWHAVLISRGETSIERHINKKERRRLQAKGRVFRNPYNYGCLDNWKVFLGVDTGRHWLTRVLLPSSHLPHGNGMSWEPPPWVTAHSASVMAV>sp|Q969W1-3|ZDH16_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC16OS=Homo sapiens OX=9606 GN=ZDHHC16MRGQRSLLLGPARLCLRLLLLLGYRRRCPPLLRGLVQRWRYGKVCLRSLLYNSFGGSDTAVDAAFEPVYWLVDNVIRWFGVVFVVLVIVLTGSIVAIAYLCVLPLILRTYSVPRLCWHFFYSHWNLILIVFHYYQAITTPPGYPPQGRNDIATVSICKKCIYPKPARTHHCSICNSYGSWDLFREAYAAIEKMKQLDKNKLQAVANQTYHQTPPPTFSFRERMTHKSLVYLWFLCSSVALALGALTVWHAVLISRGETSIERHINKKERRRLQAKGRVFRNPYNYGCLDNWKVFLGVDTGRHWLTRVLLPSSHLPHGNGMSWEPPPWVTAHSASVMAV>sp|Q969W1-4|ZDH16_HUMAN Isoform 4 of Palmitoyltransferase ZDHHC16OS=Homo sapiens OX=9606 GN=ZDHHC16MRGQRSLLLGPARLCLRLLLLLGYRRRCPPLLRGLVQRWRYGKVCLRSLLYNSFGGSDTAVDAAFEPVYWLVDNVIRWFGVGRNDIATVSICKKCIYPKPARTHHCSICNRCVLKMDHHCPWLNNCVGHYNHRYFFSFCFFMTLGCVYCSYGSWDLFREAYAAIETYHQTPPPTFSFRERMTHKSLVYLWFLCSSVALALGALTVWHAVLISRGETSIERHINKKERRRLQAKGRVFRNPYNYGCLDNWKVFLGVDTGRHWLTRVLLPSSHLPHGNGMSWEPPPWVTAHSASVMAV>sp|Q96N20|ZN75A_HUMAN Zinc finger protein 75A OS=Homo sapiens OX=9606GN=ZNF75A PE=1 SV=1MYFSQEEWELLDPTQKALYNDVMQENYETVISLALFVLPKPKVISCLEQGEEPWVQVSPEFKDSAGKSPTGLKLKNDTENHQPVSLSDLEIQASAGVISKKAKVKVPQKTAGKENHFDMHRVGKWHQDFPVKKRKKLSTWKQELLKLMDRHKKDCAREKPFKCQECGKTFRVSSDLIKHQRIHTEEKPYKCQQCDKRFRWSSDLNKHLTTHQGIKPYKCSWCGKSFSQNTNLHTHQRTHTGEKPFTCHECGKKFSQNSHLIKHRRTHTGEQPYTCSICRRNFSRRSSLLRHQKLHL>sp|Q96CS4|ZN689_HUMAN Zinc finger protein 689 OS=Homo sapiens OX=9606GN=ZNF689 PE=1 SV=1MAPPSAPLPAQGPGKARPSRKRGRRPRALKFVDVAVYFSPEEWGCLRPAQRALYRDVMRETYGHLGALGCAGPKPALISWLERNTDDWEPAALDPQEYPRGLTVQRKSRTRKKNGEKEVFPPKEAPRKGKRGRRPSKPRLIPRQTSGGPICPDCGCTFPDHQALESHKCAQNLKKPYPCPDCGRRFSYPSLLVSHRRAHSGECPYVCDQCGKRFSQRKNLSQHQVIHTGEKPYHCPDCGRCFRRSRSLANHRTTHTGEKPHQCPSCGRRFAYPSLLAIHQRTHTGEKPYTCLECNRRFRQRTALVIHQRIHTGEKPYPCPDCERRFSSSSRLVSHRRVHSGERPYACEHCEARFSQRSTLLQHQLLHTGEKPYPCPDCGRAFRRSGSLAIHRSTHTEEKLHACDDCGRRFAYPSLLASHRRVHSGERPYACDLCSKRFAQWSHLAQHQLLHTGEKPFPCLECGRCFRQRWSLAVHKCSPKAPNCSPRSAIGGSSQRGNAH>sp|Q68DY1|ZN626_HUMAN Zinc finger protein 626 OS=Homo sapiens OX=9606GN=ZNF626 PE=2 SV=2MGPLQFRDVAIEFSLEEWHCLDTAQRNLYRNVMLENYSNLVFLGITVSKPDLITCLEQGRKPLTMKRNEMIAKPSVMCSHFAQDLWPEQSMKDSFQKVVLRRYEKCEHDNLQLKKGCISVDECKVHKEGYNELNQCLTTTPRKICQCDKYVKVLHQFPNSNGQKRGHTGKKPFKYIECGKAFKQFSTLTTHKKIHTGGKPYKCEECGKAFNHSCSLTRHKKIHTGEKPYKCEECGKAFKHSSTLTTHKRNHTGEKPYKCDKCGKAFMSSSTLSKHEIIHTEKKPYKCEECGKAFNRSSTLTTHKIIHTGEKPYKCEECDKAFKYSYTLTTHKRIHTEDKPYKCEECGKAFKYSSTLTTHKRIHTGEKPYKCEECGKAFKRSSDLTTHKIIHTGEKPYKCEECGKAFKYSSNLTTHKKIHTGERPYKCEECGKAFNQSSILTTHRRIHTGEKFYKCEECGKAFKCSSNLTTHKKIHTGERPYKCEECGKAFNQSSILTTHERIILERNSTNVKNVAKPSSGPHTLLHIR>sp|Q68DY1-2|ZN626_HUMAN Isoform 2 of Zinc finger protein 626 OS=Homosapiens OX=9606 GN=ZNF626MCSHFAQDLWPEQSMKDSFQKVVLRRYEKCEHDNLQLKKGCISVDECKVHKEGYNELNQCLTTTPRKICQCDKYVKVLHQFPNSNGQKRGHTGKKPFKYIECGKAFKQFSTLTTHKKIHTGGKPYKCEECGKAFNHSCSLTRHKKIHTGEKPYKCEECGKAFKHSSTLTTHKRNHTGEKPYKCDKCGKAFMSSSTLSKHEIIHTEKKPYKCEECGKAFNRSSTLTTHKIIHTGEKPYKCEECDKAFKYSYTLTTHKRIHTEDKPYKCEECGKAFKYSSTLTTHKRIHTGEKPYKCEECGKAFKRSSDLTTHKIIHTGEKPYKCEECGKAFKYSSNLTTHKKIHTGERPYKCEECGKAFNQSSILTTHRRIHTGEKFYKCEECGKAFKCSSNLTTHKKIHTGERPYKCEECGKAFNQSSILTTHERIILERNSTNVKNVAKPSSGPHTLLHIR>sp|Q68DY1-3|ZN626_HUMAN Isoform 3 of Zinc finger protein 626 OS=Homosapiens OX=9606 GN=ZNF626MGPLQFRDVAIEFSLEEWHCLDTAQRNLYRNVMLENYSNLVFLGITVSKPDLITCLEQGRKPLTMKRNEMIAKPSVSFLQVHSESQSPLHDI>sp|Q5HYK9|ZN667_HUMAN Zinc finger protein 667 OS=Homo sapiens OX=9606GN=ZNF667 PE=1 SV=2MPSARGKSKSKAPITFGDLAIYFSQEEWEWLSPIQKDLYEDVMLENYRNLVSLGLSFRRPNVITLLEKGKAPWMVEPVRRRRAPDSGSKCETKKLPPNQCNKSGQSICQKLVSAQQKAPTRKSGCNKNSVLVKPKKGHSGKKPLKCNDCGKTFSRSFSLKLHQNIHTGEKPFECSNCRKAFRQISSILLHQRIHSGKKSHECNKCGESFNQRTTLILHMRIHDGKEILDCGKALSQCQSFNIHQKIHVVGNVCQCRKCGKAFNQMSSLLLHKKIHNGKKTHKYNKCGRGFKKKSVFVVHKRIHAGEKIPENAKALSQSLQQRSHHLENPFKCRKCGKLFNRISPLMLHQRIHTSEKPYKCDKCDKFFRRLSTLILHLRIHNGEKLYRCNKCEKVCNRHSSLIQHQKVHTKKKKLFECKECGKMFSGTANLKIHQNIHSEEKPFKCNKCSKVFGRQSFLIEHQRIHTGEKPYQCEECGKAFSHRISLTRHKRIHTEDRPYECDQCGKAFSQSAHLAQHERIHTGEKPYTCKTCGKAFSQRTSLILHERSHTGEKPYECNECGKAFSSGSDLIRHQRSHSSEKPYECSKCGKAYSRSSSLIRHQNTHSEEKA>sp|Q6NUM6|TYW1B_HUMAN S-adenosyl-L-methionine-dependent tRNA 4-demethylwyosine synthase TYW1B OS=Homo sapiens OX=9606 GN=TYW1B PE=1 SV=4MDPSADTWDLSSPLISLWINRFYIYLGFAVSISLWICVQIVIEMQGFATVLAEAVTSLDLPVAIINLKEYDPDDHLIEEVTSKNVCVFLVATYTDGLPTESAEWFCKWLEEASIDFRFGKTYLKGMRDAVFGLGNSAYASHFNKVGKNVDKWLWMLGVHRVMSRGEGDCDVVKSKHGSIEANFRAWKTKFISQLQALQKGERKKSCGGHCKKGKCESHQHGSEEREEGSQEQDELHHRDTKEEEPFESSSEEEFGGEDHQSLNSIVDVEDLGKIMDHVKKEKREKEQQEEKSGLFRNMGRNEDGERRAMITPALREALTKQVDAPRERSLLQTHILWNESHRCMETTPSLACANKCVFCWWHHNNPVGTEWLWKMDQPEMILKEAIENHQNMIKQFKGVPGVKAERFEEGMTVKHCALSLVGEPIMYPEINRFLKLLHQCKISSFLVTNAQFPAEIRNLEPVTQLYVSVDASTKDSLKKIDRPLFKDFWQQFLDSLKALAVKQQRTVYRLMLVKAWNVDELQAYAQLVSLGNPDFIEVKGVTYCRESSASSLTMAHVPWHEEVVQFVRELVDLIPEYEIACEHEHSNCLLIAHRKFKIGGEWWTWIDYNRFQELIQEYEDSGGSKTFSAKDYMARTPHWALFGANERSFDPKDTRHQRKNKSKAISGC>sp|Q6NUM6-2|TYW1B_HUMAN Isoform 2 of S-adenosyl-L-methionine-dependenttRNA 4-demethylwyosine synthase TYW1B OS=Homo sapiens OX=9606 GN=TYW1BMDQPEMILKEAIENHQNMIKQFKGVPGVKAERFEEGMTVKHCALSLVGEPIMYPEINRFLKLLHQCKISSFLVTNAQFPAEIRNLEPVTQLYVSVDASTKDSLKKIDRPLFKDFWQQFLDSLKALAVKQQRTVYRLMLVKAWNVDELQAYAQLVSLGNPDFIEVKGVTYCRESSASSLTMAHVPWHEEVVQFVRELVDLIPEYEIACEHEHSNCLLIAHRKFKIGGEWWTWIDYNRFQELIQEYEDSGGSKTFSAKDYMARTPHWALFGANERSFDPKDTRHQRKNKSKAISGC>sp|P17948|VGFR1_HUMAN Vascular endothelial growth factor receptor 1OS=Homo sapiens OX=9606 GN=FLT1 PE=1 SV=2MVSYWDTGVLLCALLSCLLLTGSSSGSKLKDPELSLKGTQHIMQAGQTLHLQCRGEAAHKWSLPEMVSKESERLSITKSACGRNGKQFCSTLTLNTAQANHTGFYSCKYLAVPTSKKKETESAIYIFISDTGRPFVEMYSEIPEIIHMTEGRELVIPCRVTSPNITVTLKKFPLDTLIPDGKRIIWDSRKGFIISNATYKEIGLLTCEATVNGHLYKTNYLTHRQTNTIIDVQISTPRPVKLLRGHTLVLNCTATTPLNTRVQMTWSYPDEKNKRASVRRRIDQSNSHANIFYSVLTIDKMQNKDKGLYTCRVRSGPSFKSVNTSVHIYDKAFITVKHRKQQVLETVAGKRSYRLSMKVKAFPSPEVVWLKDGLPATEKSARYLTRGYSLIIKDVTEEDAGNYTILLSIKQSNVFKNLTATLIVNVKPQIYEKAVSSFPDPALYPLGSRQILTCTAYGIPQPTIKWFWHPCNHNHSEARCDFCSNNEESFILDADSNMGNRIESITQRMAIIEGKNKMASTLVVADSRISGIYICIASNKVGTVGRNISFYITDVPNGFHVNLEKMPTEGEDLKLSCTVNKFLYRDVTWILLRTVNNRTMHYSISKQKMAITKEHSITLNLTIMNVSLQDSGTYACRARNVYTGEEILQKKEITIRDQEAPYLLRNLSDHTVAISSSTTLDCHANGVPEPQITWFKNNHKIQQEPGIILGPGSSTLFIERVTEEDEGVYHCKATNQKGSVESSAYLTVQGTSDKSNLELITLTCTCVAATLFWLLLTLFIRKMKRSSSEIKTDYLSIIMDPDEVPLDEQCERLPYDASKWEFARERLKLGKSLGRGAFGKVVQASAFGIKKSPTCRTVAVKMLKEGATASEYKALMTELKILTHIGHHLNVVNLLGACTKQGGPLMVIVEYCKYGNLSNYLKSKRDLFFLNKDAALHMEPKKEKMEPGLEQGKKPRLDSVTSSESFASSGFQEDKSLSDVEEEEDSDGFYKEPITMEDLISYSFQVARGMEFLSSRKCIHRDLAARNILLSENNVVKICDFGLARDIYKNPDYVRKGDTRLPLKWMAPESIFDKIYSTKSDVWSYGVLLWEIFSLGGSPYPGVQMDEDFCSRLREGMRMRAPEYSTPEIYQIMLDCWHRDPKERPRFAELVEKLGDLLQANVQQDGKDYIPINAILTGNSGFTYSTPAFSEDFFKESISAPKFNSGSSDDVRYVNAFKFMSLERIKTFEELLPNATSMFDDYQGDSSTLLASPMLKRFTWTDSKPKASLKIDLRVTSKSKESGLSDVSRPSFCHSSCGHVSEGKRRFTYDHAELERKIACCSPPPDYNSVVLYSTPPI>sp|P17948-2|VGFR1_HUMAN Isoform 2 of Vascular endothelial growth factorreceptor 1 OS=Homo sapiens OX=9606 GN=FLT1MVSYWDTGVLLCALLSCLLLTGSSSGSKLKDPELSLKGTQHIMQAGQTLHLQCRGEAAHKWSLPEMVSKESERLSITKSACGRNGKQFCSTLTLNTAQANHTGFYSCKYLAVPTSKKKETESAIYIFISDTGRPFVEMYSEIPEIIHMTEGRELVIPCRVTSPNITVTLKKFPLDTLIPDGKRIIWDSRKGFIISNATYKEIGLLTCEATVNGHLYKTNYLTHRQTNTIIDVQISTPRPVKLLRGHTLVLNCTATTPLNTRVQMTWSYPDEKNKRASVRRRIDQSNSHANIFYSVLTIDKMQNKDKGLYTCRVRSGPSFKSVNTSVHIYDKAFITVKHRKQQVLETVAGKRSYRLSMKVKAFPSPEVVWLKDGLPATEKSARYLTRGYSLIIKDVTEEDAGNYTILLSIKQSNVFKNLTATLIVNVKPQIYEKAVSSFPDPALYPLGSRQILTCTAYGIPQPTIKWFWHPCNHNHSEARCDFCSNNEESFILDADSNMGNRIESITQRMAIIEGKNKMASTLVVADSRISGIYICIASNKVGTVGRNISFYITDVPNGFHVNLEKMPTEGEDLKLSCTVNKFLYRDVTWILLRTVNNRTMHYSISKQKMAITKEHSITLNLTIMNVSLQDSGTYACRARNVYTGEEILQKKEITIRGEHCNKKAVFSRISKFKSTRNDCTTQSNVKH>sp|P17948-3|VGFR1_HUMAN Isoform 3 of Vascular endothelial growth factorreceptor 1 OS=Homo sapiens OX=9606 GN=FLT1MVSYWDTGVLLCALLSCLLLTGSSSGSKLKDPELSLKGTQHIMQAGQTLHLQCRGEAAHKWSLPEMVSKESERLSITKSACGRNGKQFCSTLTLNTAQANHTGFYSCKYLAVPTSKKKETESAIYIFISDTGRPFVEMYSEIPEIIHMTEGRELVIPCRVTSPNITVTLKKFPLDTLIPDGKRIIWDSRKGFIISNATYKEIGLLTCEATVNGHLYKTNYLTHRQTNTIIDVQISTPRPVKLLRGHTLVLNCTATTPLNTRVQMTWSYPDEKNKRASVRRRIDQSNSHANIFYSVLTIDKMQNKDKGLYTCRVRSGPSFKSVNTSVHIYDKAFITVKHRKQQVLETVAGKRSYRLSMKVKAFPSPEVVWLKDGLPATEKSARYLTRGYSLIIKDVTEEDAGNYTILLSIKQSNVFKNLTATLIVNVKPQIYEKAVSSFPDPALYPLGSRQILTCTAYGIPQPTIKWFWHPCNHNHSEARCDFCSNNEESFILDADSNMGNRIESITQRMAIIEGKNKMASTLVVADSRISGIYICIASNKVGTVGRNISFYITDVPNGFHVNLEKMPTEGEDLKLSCTVNKFLYRDVTWILLRTVNNRTMHYSISKQKMAITKEHSITLNLTIMNVSLQDSGTYACRARNVYTGEEILQKKEITIRDQEAPYLLRNLSDHTVAISSSTTLDCHANGVPEPQITWFKNNHKIQQEPELYTSTSPSSSSSSPLSSSSSSSSSSSS>sp|P17948-4|VGFR1_HUMAN Isoform 4 of Vascular endothelial growth factorreceptor 1 OS=Homo sapiens OX=9606 GN=FLT1MVSYWDTGVLLCALLSCLLLTGSSSGSKLKDPELSLKGTQHIMQAGQTLHLQCRGEAAHKWSLPEMVSKESERLSITKSACGRNGKQFCSTLTLNTAQANHTGFYSCKYLAVPTSKKKETESAIYIFISDTGRPFVEMYSEIPEIIHMTEGRELVIPCRVTSPNITVTLKKFPLDTLIPDGKRIIWDSRKGFIISNATYKEIGLLTCEATVNGHLYKTNYLTHRQTNTIIDVQISTPRPVKLLRGHTLVLNCTATTPLNTRVQMTWSYPDEKNKRASVRRRIDQSNSHANIFYSVLTIDKMQNKDKGLYTCRVRSGPSFKSVNTSVHIYDKAFITVKHRKQQVLETVAGKRSYRLSMKVKAFPSPEVVWLKDGLPATEKSARYLTRGYSLIIKDVTEEDAGNYTILLSIKQSNVFKNLTATLIVNVKPQIYEKAVSSFPDPALYPLGSRQILTCTAYGIPQPTIKWFWHPCNHNHSEARCDFCSNNEESFILDADSNMGNRIESITQRMAIIEGKNKLPPANSSFMLPPTSFSSNYFHFLP>sp|P17948-5|VGFR1_HUMAN Isoform 5 of Vascular endothelial growth factorreceptor 1 OS=Homo sapiens OX=9606 GN=FLT1MKRSSSEIKTDYLSIIMDPDEVPLDEQCERLPYDASKWEFARERLKLGKSLGRGAFGKVVQASAFGIKKSPTCRTVAVKMLKEGATASEYKALMTELKILTHIGHHLNVVNLLGACTKQGGPLMVIVEYCKYGNLSNYLKSKRDLFFLNKDAALHMEPKKEKMEPGLEQGKKPRLDSVTSSESFASSGFQEDKSLSDVEEEEDSDGFYKEPITMEDLISYSFQVARGMEFLSSRKCIHRDLAARNILLSENNVVKICDFGLARDIYKNPDYVRKGDTRLPLKWMAPESIFDKIYSTKSDVWSYGVLLWEIFSLGGSPYPGVQMDEDFCSRLREGMRMRAPEYSTPEIYQIMLDCWHRDPKERPRFAELVEKLGDLLQANVQQDGKDYIPINAILTGNSGFTYSTPAFSEDFFKESISAPKFNSGSSDDVRYVNAFKFMSLERIKTFEELLPNATSMFDDYQGDSSTLLASPMLKRFTWTDSKPKASLKIDLRVTSKSKESGLSDVSRPSFCHSSCGHVSEGKRRFTYDHAELERKIACCSPPPDYNSVVLYSTPPI>sp|P17948-6|VGFR1_HUMAN Isoform 6 of Vascular endothelial growth factorreceptor 1 OS=Homo sapiens OX=9606 GN=FLT1MTELKILTHIGHHLNVVNLLGACTKQGGPLMVIVEYCKYGNLSNYLKSKRDLFFLNKDAALHMEPKKEKMEPGLEQGKKPRLDSVTSSESFASSGFQEDKSLSDVEEEEDSDGFYKEPITMEDLISYSFQVARGMEFLSSRKCIHRDLAARNILLSENNVVKICDFGLARDIYKNPDYVRKGDTRLPLKWMAPESIFDKIYSTKSDVWSYGVLLWEIFSLGGSPYPGVQMDEDFCSRLREGMRMRAPEYSTPEIYQIMLDCWHRDPKERPRFAELVEKLGDLLQANVQQDGKDYIPINAILTGNSGFTYSTPAFSEDFFKESISAPKFNSGSSDDVRYVNAFKFMSLERIKTFEELLPNATSMFDDYQGDSSTLLASPMLKRFTWTDSKPKASLKIDLRVTSKSKESGLSDVSRPSFCHSSCGHVSEGKRRFTYDHAELERKIACCSPPPDYNSVVLYSTPPI>sp|P17948-7|VGFR1_HUMAN Isoform 7 of Vascular endothelial growth factorreceptor 1 OS=Homo sapiens OX=9606 GN=FLT1MEDLISYSFQVARGMEFLSSRKCIHRDLAARNILLSENNVVKICDFGLARDIYKNPDYVRKGDTRLPLKWMAPESIFDKIYSTKSDVWSYGVLLWEIFSLGGSPYPGVQMDEDFCSRLREGMRMRAPEYSTPEIYQIMLDCWHRDPKERPRFAELVEKLGDLLQANVQQDGKDYIPINAILTGNSGFTYSTPAFSEDFFKESISAPKFNSGSSDDVRYVNAFKFMSLERIKTFEELLPNATSMFDDYQGDSSTLLASPMLKRFTWTDSKPKASLKIDLRVTSKSKESGLSDVSRPSFCHSSCGHVSEGKRRFTYDHAELERKIACCSPPPDYNSVVLYSTPPI>sp|P17948-8|VGFR1_HUMAN Isoform 8 of Vascular endothelial growth factorreceptor 1 OS=Homo sapiens OX=9606 GN=FLT1MNSDLLVDSDGFYKEPITMEDLISYSFQVARGMEFLSSRKCIHRDLAARNILLSENNVVKICDFGLARDIYKNPDYVRKGDTRLPLKWMAPESIFDKIYSTKSDVWSYGVLLWEIFSLGGSPYPGVQMDEDFCSRLREGMRMRAPEYSTPEIYQIMLDCWHRDPKERPRFAELVEKLGDLLQANVQQDGKDYIPINAILTGNSGFTYSTPAFSEDFFKESISAPKFNSGSSDDVRYVNAFKFMSLERIKTFEELLPNATSMFDDYQGDSSTLLASPMLKRFTWTDSKPKASLKIDLRVTSKSKESGLSDVSRPSFCHSSCGHVSEGKRRFTYDHAELERKIACCSPPPDYNSVVLYSTPPI>sp|Q9Y2C2|UST_HUMAN Uronyl 2-sulfotransferase OS=Homo sapiens OX=9606GN=UST PE=2 SV=1MKKKQQHPGGGADPWPHGAPMGGAPPGLGSWKRRVPLLPFLRFSLRDYGFCMATLLVFCLGSLLYQLSGGPPRFLLDLRQYLGNSTYLDDHGPPPSKVLPFPSQVVYNRVGKCGSRTVVLLLRILSEKHGFNLVTSDIHNKTRLTKNEQMELIKNISTAEQPYLFTRHVHFLNFSRFGGDQPVYINIIRDPVNRFLSNYFFRRFGDWRGEQNHMIRTPSMRQEERYLDINECILENYPECSNPRLFYIIPYFCGQHPRCREPGEWALERAKLNVNENFLLVGILEELEDVLLLLERFLPHYFKGVLSIYKDPEHRKLGNMTVTVKKTVPSPEAVQILYQRMRYEYEFYHYVKEQFHLLKRKFGLKSHVSKPPLRPHFFIPTPLETEEPIDDEEQDDEKWLEDIYKR>sp|Q9Y5J1|UTP18_HUMAN U3 small nucleolar RNA-associated protein 18homolog OS=Homo sapiens OX=9606 GN=UTP18 PE=1 SV=3MPPERRRRMKLDRRTGAKPKRKPGMRPDWKAGAGPGGPPQKPAPSSQRKPPARPSAAAAAIAVAAAEEERRLRQRNRLRLEEDKPAVERCLEELVFGDVENDEDALLRRLRGPRVQEHEDSGDSEVENEAKGNFPPQKKPVWVDEEDEDEEMVDMMNNRFRKDMMKNASESKLSKDNLKKRLKEEFQHAMGGVPAWAETTKRKTSSDDESEEDEDDLLQRTGNFISTSTSLPRGILKMKNCQHANAERPTVARISSVQFHPGAQIVMVAGLDNAVSLFQVDGKTNPKIQSIYLERFPIFKACFSANGEEVLATSTHSKVLYVYDMLAGKLIPVHQVRGLKEKIVRSFEVSPDGSFLLINGIAGYLHLLAMKTKELIGSMKINGRVAASTFSSDSKKVYASSGDGEVYVWDVNSRKCLNRFVDEGSLYGLSIATSRNGQYVACGSNCGVVNIYNQDSCLQETNPKPIKAIMNLVTGVTSLTFNPTTEILAIASEKMKEAVRLVHLPSCTVFSNFPVIKNKNISHVHTMDFSPRSGYFALGNEKGKALMYRLHHYSDF>sp|Q9UBV4|WNT16_HUMAN Protein Wnt-16 OS=Homo sapiens OX=9606 GN=WNT16PE=2 SV=1MDRAALLGLARLCALWAALLVLFPYGAQGNWMWLGIASFGVPEKLGCANLPLNSRQKELCKRKPYLLPSIREGARLGIQECGSQFRHERWNCMITAAATTAPMGASPLFGYELSSGTKETAFIYAVMAAGLVHSVTRSCSAGNMTECSCDTTLQNGGSASEGWHWGGCSDDVQYGMWFSRKFLDFPIGNTTGKENKVLLAMNLHNNEAGRQAVAKLMSVDCRCHGVSGSCAVKTCWKTMSSFEKIGHLLKDKYENSIQISDKTKRKMRRREKDQRKIPIHKDDLLYVNKSPNYCVEDKKLGIPGTQGRECNRTSEGADGCNLLCCGRGYNTHVVRHVERCECKFIWCCYVRCRRCESMTDVHTCK>sp|Q9UBV4-2|WNT16_HUMAN Isoform Wnt-16a of Protein Wnt-16 OS=Homosapiens OX=9606 GN=WNT16MERHPPMQLTTCLRETLFTGASQKTSLWWLGIASFGVPEKLGCANLPLNSRQKELCKRKPYLLPSIREGARLGIQECGSQFRHERWNCMITAAATTAPMGASPLFGYELSSGTKETAFIYAVMAAGLVHSVTRSCSAGNMTECSCDTTLQNGGSASEGWHWGGCSDDVQYGMWFSRKFLDFPIGNTTGKENKVLLAMNLHNNEAGRQAVAKLMSVDCRCHGVSGSCAVKTCWKTMSSFEKIGHLLKDKYENSIQISDKTKRKMRRREKDQRKIPIHKDDLLYVNKSPNYCVEDKKLGIPGTQGRECNRTSEGADGCNLLCCGRGYNTHVVRHVERCECKFIWCCYVRCRRCESMTDVHTCK>sp|Q9GZT5|WN10A_HUMAN Protein Wnt-10a OS=Homo sapiens OX=9606 GN=WNT10APE=1 SV=1MGSAHPRPWLRLRPQPQPRPALWVLLFFLLLLAAAMPRSAPNDILDLRLPPEPVLNANTVCLTLPGLSRRQMEVCVRHPDVAASAIQGIQIAIHECQHQFRDQRWNCSSLETRNKIPYESPIFSRGFRESAFAYAIAAAGVVHAVSNACALGKLKACGCDASRRGDEEAFRRKLHRLQLDALQRGKGLSHGVPEHPALPTASPGLQDSWEWGGCSPDMGFGERFSKDFLDSREPHRDIHARMRLHNNRVGRQAVMENMRRKCKCHGTSGSCQLKTCWQVTPEFRTVGALLRSRFHRATLIRPHNRNGGQLEPGPAGAPSPAPGAPGPRRRASPADLVYFEKSPDFCEREPRLDSAGTVGRLCNKSSAGSDGCGSMCCGRGHNILRQTRSERCHCRFHWCCFVVCEECRITEWVSVCK>sp|Q7Z7D3|VTCN1_HUMAN V-set domain-containing T-cell activationinhibitor 1 OS=Homo sapiens OX=9606 GN=VTCN1 PE=1 SV=1MASLGQILFWSIISIIIILAGAIALIIGFGISGRHSITVTTVASAGNIGEDGILSCTFEPDIKLSDIVIQWLKEGVLGLVHEFKEGKDELSEQDEMFRGRTAVFADQVIVGNASLRLKNVQLTDAGTYKCYIITSKGKGNANLEYKTGAFSMPEVNVDYNASSETLRCEAPRWFPQPTVVWASQVDQGANFSEVSNTSFELNSENVTMKVVSVLYNVTINNTYSCMIENDIAKATGDIKVTESEIKRRSHLQLLNSKASLCVSSFFAISWALLPLSPYLMLK>sp|Q7Z7D3-2|VTCN1_HUMAN Isoform 2 of V-set domain-containing T-cellactivation inhibitor 1 OS=Homo sapiens OX=9606 GN=VTCN1MASLGQILFWSIISIIIILAGAIALIIGFGISAFSMPEVNVDYNASSETLRCEAPRWFPQPTVVWASQVDQGANFSEVSNTSFELNSENVTMKVVSVLYNVTINNTYSCMIENDIAKATGDIKVTESEIKRRSHLQLLNSKASLCVSSFFAISWALLPLSPYLMLK>sp|Q7Z7D3-3|VTCN1_HUMAN Isoform 3 of V-set domain-containing T-cellactivation inhibitor 1 OS=Homo sapiens OX=9606 GN=VTCN1MASLGQILFWSIISIIIILAGAIALIIGFGISEVSVWLSAMKGWCRSSKASLSIDLCFLNFRETLHHSHYCRLSWEHWGGWNPELHF>sp|Q7Z7D3-4|VTCN1_HUMAN Isoform 4 of V-set domain-containing T-cellactivation inhibitor 1 OS=Homo sapiens OX=9606 GN=VTCN1MFRGRTAVFADQVIVGNASLRLKNVQLTDAGTYKCYIITSKGKGNANLEYKTGAFSMPEVNVDYNASSETLRCEAPRWFPQPTVVWASQVDQGANFSEVSNTSFELNSENVTMKVVSVLYNVTINNTYSCMIENDIAKATGDIKVTESEIKRRSHLQLLNSKASLCVSSFFAISWALLPLSPYLMLK>sp|P18887|XRCC1_HUMAN DNA repair protein XRCC1 OS=Homo sapiens OX=9606GN=XRCC1 PE=1 SV=2MPEIRLRHVVSCSSQDSTHCAENLLKADTYRKWRAAKAGEKTISVVLQLEKEEQIHSVDIGNDGSAFVEVLVGSSAGGAGEQDYEVLLVTSSFMSPSESRSGSNPNRVRMFGPDKLVRAAAEKRWDRVKIVCSQPYSKDSPFGLSFVRFHSPPDKDEAEAPSQKVTVTKLGQFRVKEEDESANSLRPGALFFSRINKTSPVTASDPAGPSYAAATLQASSAASSASPVSRAIGSTSKPQESPKGKRKLDLNQEEKKTPSKPPAQLSPSVPKRPKLPAPTRTPATAPVPARAQGAVTGKPRGEGTEPRRPRAGPEELGKILQGVVVVLSGFQNPFRSELRDKALELGAKYRPDWTRDSTHLICAFANTPKYSQVLGLGGRIVRKEWVLDCHRMRRRLPSRRYLMAGPGSSSEEDEASHSGGSGDEAPKLPQKQPQTKTKPTQAAGPSSPQKPPTPEETKAASPVLQEDIDIEGVQSEGQDNGAEDSGDTEDELRRVAEQKEHRLPPGQEENGEDPYAGSTDENTDSEEHQEPPDLPVPELPDFFQGKHFFLYGEFPGDERRKLIRYVTAFNGELEDNMSDRVQFVITAQEWDPSFEEALMDNPSLAFVRPRWIYSCNEKQKLLPHQLYGVVPQA>sp|Q9Y6I0|VPK6_HUMAN Endogenous retrovirus group K member 6 Pro proteinOS=Homo sapiens OX=9606 GN=ERVK-6 PE=3 SV=2WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPSYSPTSQKIMTKMGYIPGKGLGKNEDGIKIPVEAKINQEREGIGNPC>sp|Q2TAL6|VWC2_HUMAN Brorin OS=Homo sapiens OX=9606 GN=VWC2 PE=1 SV=1MPSSTAMAVGALSSSLLVTCCLMVALCSPSIPLEKLAQAPEQPGQEKREHASRDGPGRVNELGRPARDEGGSGRDWKSKSGRGLAGREPWSKLKQAWVSQGGGAKAGDLQVRPRGDTPQAEALAAAAQDAIGPELAPTPEPPEEYVYPDYRGKGCVDESGFVYAIGEKFAPGPSACPCLCTEEGPLCAQPECPRLHPRCIHVDTSQCCPQCKERKNYCEFRGKTYQTLEEFVVSPCERCRCEANGEVLCTVSACPQTECVDPVYEPDQCCPICKNGPNCFAETAVIPAGREVKTDECTICHCTYEEGTWRIERQAMCTRHECRQM>sp|Q5GH70|XKR9_HUMAN XK-related protein 9 OS=Homo sapiens OX=9606GN=XKR9 PE=1 SV=1MKYTKQNFMMSVLGIIIYVTDLIVDIWVSVRFFHEGQYVFSALALSFMLFGTLVAQCFSYSWFKADLKKAGQESQHCFLLLHCLQGGVFTRYWFALKRGYHAAFKYDSNTSNFVEEQIDLHKEVIDRVTDLSMLRLFETYLEGCPQLILQLYILLEHGQANFSQYAAIMVSCCAISWSTVDYQVALRKSLPDKKLLNGLCPKITYLFYKLFTLLSWMLSVVLLLFLNVKIALFLLLFLWLLGIIWAFKNNTQFCTCISMEFLYRIVVGFILIFTFFNIKGQNTKCPMSCYYIVRVLGTLGILTVFWVCPLTIFNPDYFIPISITIVLTLLLGILFLIVYYGSFHPNRSAETKCDEIDGKPVLRECRMRYFLME>sp|Q9UBQ0|VPS29_HUMAN Vacuolar protein sorting-associated protein 29OS=Homo sapiens OX=9606 GN=VPS29 PE=1 SV=1MLVLVLGDLHIPHRCNSLPAKFKKLLVPGKIQHILCTGNLCTKESYDYLKTLAGDVHIVRGDFDENLNYPEQKVVTVGQFKIGLIHGHQVIPWGDMASLALLQRQFDVDILISGHTHKFEAFEHENKFYINPGSATGAYNALETNIIPSFVLMDIQASTVVTYVYQLIGDDVKVERIEYKKP>sp|Q9UBQ0-2|VPS29_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 29 OS=Homo sapiens OX=9606 GN=VPS29MAGHRLVLVLGDLHIPHRCNSLPAKFKKLLVPGKIQHILCTGNLCTKESYDYLKTLAGDVHIVRGDFDENLNYPEQKVVTVGQFKIGLIHGHQVIPWGDMASLALLQRQFDVDILISGHTHKFEAFEHENKFYINPGSATGAYNALETNIIPSFVLMDIQASTVVTYVYQLIGDDVKVERIEYKKP>sp|Q9NYS7|WSB2_HUMAN WD repeat and SOCS box-containing protein 2 OS=Homosapiens OX=9606 GN=WSB2 PE=2 SV=1MEAGEEPLLLAELKPGRPHQFDWKSSCETWSVAFSPDGSWFAWSQGHCIVKLIPWPLEEQFIPKGFEAKSRSSKNETKGRGSPKEKTLDCGQIVWGLAFSPWPSPPSRKLWARHHPQVPDVSCLVLATGLNDGQIKIWEVQTGLLLLNLSGHQDVVRDLSFTPSGSLILVSASRDKTLRIWDLNKHGKQIQVLSGHLQWVYCCSISPDCSMLCSAAGEKSVFLWSMRSYTLIRKLEGHQSSVVSCDFSPDSALLVTASYDTNVIMWDPYTGERLRSLHHTQVDPAMDDSDVHISSLRSVCFSPEGLYLATVADDRLLRIWALELKTPIAFAPMTNGLCCTFFPHGGVIATGTRDGHVQFWTAPRVLSSLKHLCRKALRSFLTTYQVLALPIPKKMKEFLTYRTF>sp|Q9NYS7-2|WSB2_HUMAN Isoform 2 of WD repeat and SOCS box-containingprotein 2 OS=Homo sapiens OX=9606 GN=WSB2MRVDRESRFLRGTGTGEAVAVEEPLLLAELKPGRPHQFDWKSSCETWSVAFSPDGSWFAWSQGHCIVKLIPWPLEEQFIPKGFEAKSRSSKNETKGRGSPKEKTLDCGQIVWGLAFSPWPSPPSRKLWARHHPQVPDVSCLVLATGLNDGQIKIWEVQTGLLLLNLSGHQDVVRDLSFTPSGSLILVSASRDKTLRIWDLNKHGKQIQVLSGHLQWVYCCSISPDCSMLCSAAGEKSVFLWSMRSYTLIRKLEGHQSSVVSCDFSPDSALLVTASYDTNVIMWDPYTGERLRSLHHTQVDPAMDDSDVHISSLRSVCFSPEGLYLATVADDRLLRIWALELKTPIAFAPMTNGLCCTFFPHGGVIATGTRDGHVQFWTAPRVLSSLKHLCRKALRSFLTTYQVLALPIPKKMKEFLTYRTF>sp|Q9NYS7-3|WSB2_HUMAN Isoform 3 of WD repeat and SOCS box-containingprotein 2 OS=Homo sapiens OX=9606 GN=WSB2MLCSAAGEKSVFLWSMRSYTLIRKLEGHQSSVVSCDFSPDSALLVTASYDTNVIMWDPYTGERLRSLHHTQVDPAMDDSDVHISSLRSVCFSPEGLYLATVADDRLLRIWALELKTPIAFAPMTNGLCCTFFPHGGVIATGTRDGHVQFWTAPRVLSSLKHLCRKALRSFLTTYQVLALPIPKKMKEFLTYRTF>sp|O00744|WN10B_HUMAN Protein Wnt-10b OS=Homo sapiens OX=9606 GN=WNT10BPE=1 SV=2MLEEPRPRPPPSGLAGLLFLALCSRALSNEILGLKLPGEPPLTANTVCLTLSGLSKRQLGLCLRNPDVTASALQGLHIAVHECQHQLRDQRWNCSALEGGGRLPHHSAILKRGFRESAFSFSMLAAGVMHAVATACSLGKLVSCGCGWKGSGEQDRLRAKLLQLQALSRGKSFPHSLPSPGPGSSPSPGPQDTWEWGGCNHDMDFGEKFSRDFLDSREAPRDIQARMRIHNNRVGRQVVTENLKRKCKCHGTSGSCQFKTCWRAAPEFRAVGAALRERLGRAIFIDTHNRNSGAFQPRLRPRRLSGELVYFEKSPDFCERDPTMGSPGTRGRACNKTSRLLDGCGSLCCGRGHNVLRQTRVERCHCRFHWCCYVLCDECKVTEWVNVCK>sp|O00744-2|WN10B_HUMAN Isoform 2 of Protein Wnt-10b OS=Homo sapiensOX=9606 GN=WNT10BMLEEPRPRPPPSGLAGLLFLALCSRALSNEILGLKLPGEPPLTANTVCLTLSGLSKRQLGLCLRNPDVTASALQGLHIAVHECQHQLRDQRWNCSALEGGGRLPHHSAILKRGFRESAFSFSMLAAGVMHAVATACSLGKLVSCGCGWKGSGEQDRLRAKLLQLQALSRGKLPGTSRHECESTTTGWGARW>sp|Q5VIR6|VPS53_HUMAN Vacuolar protein sorting-associated protein 53homolog OS=Homo sapiens OX=9606 GN=VPS53 PE=1 SV=2MMEEEELEFVEELEAVLQLTPEVQLAIEQVFPSQDPLDRADFNAVEYINTLFPTEQSLANIDEVVNKIRLKIRRLDDNIRTVVRGQTNVGQDGRQALEEAQKAIQQLFGKIKDIKDKAEKSEQMVKEITRDIKQLDHAKRHLTTSITTLNHLHMLAGGVDSLEAMTRRRQYGEVANLLQGVMNVLEHFHKYMGIPQIRQLSERVKAAQTELGQQILADFEEAFPSQGTKRPGGPSNVLRDACLVANILDPRIKQEIIKKFIKQHLSEYLVLFQENQDVAWLDKIDRRYAWIKRQLVDYEEKYGRMFPREWCMAERIAVEFCHVTRAELAKIMRTRAKEIEVKLLLFAIQRTTNFEGFLAKRFSGCTLTDGTLKKLESPPPSTNPFLEDEPTPEMEELATEKGDLDQPKKPKAPDNPFHGIVSKCFEPHLYVYIESQDKNLGELIDRFVADFKAQGPPKPNTDEGGAVLPSCADLFVYYKKCMVQCSQLSTGEPMIALTTIFQKYLREYAWKILSGNLPKTTTSSGGLTISSLLKEKEGSEVAKFTLEELCLICNILSTAEYCLATTQQLEEKLKEKVDVSLIERINLTGEMDTFSTVISSSIQLLVQDLDAACDPALTAMSKMQWQNVEHVGDQSPYVTSVILHIKQNVPIIRDNLASTRKYFTQFCVKFANSFIPKFITHLFKCKPISMVGAEQLLLDTHSLKMVLLDLPSISSQVVRKAPASYTKIVVKGMTRAEMILKVVMAPHEPLVVFVDNYIKLLTDCNTETFQKILDMKGLKRSEQSSMLELLRQRLPAPPSGAESSGSLSLTAPTPEQESSRIRKLEKLIKKRL>sp|Q5VIR6-1|VPS53_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 53 homolog OS=Homo sapiens OX=9606 GN=VPS53MMEEEELEFVEELEAVLQLTPEVQLAIEQVFPSQDPLDRADFNAVEYINTLFPTEQSLANIDEVVNKIRLKIRRLDDNIRTVVRGQTNVGQDGRQALEEAQKAIQQLFGKIKDIKDKAEKSEQMVKEITRDIKQLDHAKRHLTTSITTLNHLHMLAGGVDSLEAMTRRRQYGEVANLLQGVMNVLEHFHKYMGIPQIRQLSERVKAAQTELGQQILADFEEAFPSQGTKRPGGPSNVLRDACLVANILDPRIKQEIIKKFIKQHLSEYLVLFQENQDVAWLDKIDRRYAWIKRQLVDYEEKYGRMFPREWCMAERIAVEFCHVTRAELAKIMRTRAKEIEVKLLLFAIQRTTNFEGFLAKRFSGCTLTDGTLKKLESPPPSTNPFLEDEPTPEMEELATEKGDLDQPKKPKAPDNPFHGIVSKCFEPHLYVYIESQDKNLGELIDRFVADFKAQGPPKPNTDEGGAVLPSCADLFVYYKKCMVQCSQLSTGEPMIALTTIFQKYLREYAWKILSGNLPKTTTSSGGLTISSLLKEKEGSEVAKFTLEELCLICNILSTAEYCLATTQQLEEKLKEKVDVSLIERINLTGEMDTFSTVISSSIQLLVQDLDAACDPALTAMSKMQWQNVEHVGDQSPYVTSVILHIKQNVPIIRDNLASTRKYFTQFCVKFANSFIPKFITHLFKCKPISMVGAEQVRWT>sp|Q5VIR6-2|VPS53_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 53 homolog OS=Homo sapiens OX=9606 GN=VPS53MMEEEELEFVEELEAVLQLTPEVQLAIEQVFPSQDPLDRADFNAVEYINTLFPTEQSLANIDEVVNKIRLKIRRLDDNIRTVVRGQTNVGQDGRQVKEITRDIKQLDHAKRHLTTSITTLNHLHMLAGGVDSLEAMTRRRQYGEVANLLQGVMNVLEHFHKYMGIPQIRQLSERVKAAQTELGQQILADFEEAFPSQGTKRPGGPSNVLRDACLVANILDPRIKQEIIKKFIKQHLSEYLVLFQENQDVAWLDKIDRRYAWIKRQLVDYEEKYGRMFPREWCMAERIAVEFCHVTRAELAKIMRTRAKEIEVKLLLFAIQRTTNFEGFLAKRFSGCTLTDGTLKKLESPPPSTNPFLEDEPTPEMEELATEKGDLDQPKKPKAPDNPFHGIVSKCFEPHLYVYIESQDKNLGELIDRFVADFKAQGPPKPNTDEGGAVLPSCADLFVYYKKCMVQCSQLSTGEPMIALTTIFQKYLREYAWKILSGNLPKTTTSSGGLTISSLLKEKEGSEVAKFTLEELCLICNILSTAEYCLATTQQLEEKLKEKVDVSLIERINLTGEMDTFSTVISSSIQLLVQDLDAACDPALTAMSKMQWQNVEHVGDQSPYVTSVILHIKQNVPIIRDNLASTRKYFTQFCVKFANSFIPKFITHLFKCKPISMVGAEQVRWT>sp|Q5VIR6-3|VPS53_HUMAN Isoform 4 of Vacuolar protein sorting-associatedprotein 53 homolog OS=Homo sapiens OX=9606 GN=VPS53MMEEEELEFVEELEAVLQLTPEVQLAIEQVFPSQDPLDRADFNAVEYINTLFPTEQSLANIDEVVNKIRLKIRRLDDNIRTVVRGQTNVGQDGRQALEEAQKAIQQLFGKIKDIKDKAEKSEQMVKEITRDIKQLDHAKRHLTTSITTLNHLHMLAGGVDSLEAMTRRRQYGEVANLLQGVMNVLEHFHKYMGIPQIRQLSERVKAAQTELGQQILADFEEAFPSQGTKRPGGPSNVLRDACLVANILDPRIKQEIIKKFIKQHLSEYLVLFQENQDVAWLDKIDRRYAWIKRQLVDYEEKYGRMFPREWCMAERIAVEFCHVTRAELAKIMRTRAKEIEVKLLLFAIQRTTNFEGFLAKRFSGCTLTDGTLKKLESPPPSTNPFLEDEPTPEMEELATEKGDLDQPKKPKAPDNPFHGIVSKCFEPHLYVYIESQDKNLGELIDRFVADFKAQGPPKPNTDEGGAVLPSCADLFVYYKKCMVQCSQLSTGEPMIALTTIFQKYLREYAWKILSGNLPKTTTSSGGLTISSLLKEKEGSEVAKFTLEELCLICNILSTAEYCLATTQQLEEKLKEKVDVSLIERINLTGEMDTFSTVISSSIQLLVQDLDAACDPALTAMSKMQWQNVEHVGDQSPYVTSVILHIKQNVPIIRDNLASTRKYFTQFCVKFAK>sp|Q00341|VIGLN_HUMAN Vigilin OS=Homo sapiens OX=9606 GN=HDLBP PE=1 SV=2MSSVAVLTQESFAEHRSGLVPQQIKVATLNSEEESDPPTYKDAFPPLPEKAACLESAQEPSGAWGNKIRPIKASVITQVFHVPLEERKYKDMNQFGEGEQAKICLEIMQRTGAHLELSLAKDQGLSIMVSGKLDAVMKARKDIVARLQTQASATVAIPKEHHRFVIGKNGEKLQDLELKTATKIQIPRPDDPSNQIKITGTKEGIEKARHEVLLISAEQDKRAVERLEVEKAFHPFIAGPYNRLVGEIMQETGTRINIPPPSVNRTEIVFTGEKEQLAQAVARIKKIYEEKKKKTTTIAVEVKKSQHKYVIGPKGNSLQEILERTGVSVEIPPSDSISETVILRGEPEKLGQALTEVYAKANSFTVSSVAAPSWLHRFIIGKKGQNLAKITQQMPKVHIEFTEGEDKITLEGPTEDVNVAQEQIEGMVKDLINRMDYVEINIDHKFHRHLIGKSGANINRIKDQYKVSVRIPPDSEKSNLIRIEGDPQGVQQAKRELLELASRMENERTKDLIIEQRFHRTIIGQKGERIREIRDKFPEVIINFPDPAQKSDIVQLRGPKNEVEKCTKYMQKMVADLVENSYSISVPIFKQFHKNIIGKGGANIKKIREESNTKIDLPAENSNSETIIITGKRANCEAARSRILSIQKDLANIAEVEVSIPAKLHNSLIGTKGRLIRSIMEECGGVHIHFPVEGSGSDTVVIRGPSSDVEKAKKQLLHLAEEKQTKSFTVDIRAKPEYHKFLIGKGGGKIRKVRDSTGARVIFPAAEDKDQDLITIIGKEDAVREAQKELEALIQNLDNVVEDSMLVDPKHHRHFVIRRGQVLREIAEEYGGVMVSFPRSGTQSDKVTLKGAKDCVEAAKKRIQEIIEDLEAQVTLECAIPQKFHRSVMGPKGSRIQQITRDFSVQIKFPDREENAVHSTEPVVQENGDEAGEGREAKDCDPGSPRRCDIIIISGRKEKCEAAKEALEALVPVTIEVEVPFDLHRYVIGQKGSGIRKMMDEFEVNIHVPAPELQSDIIAITGLAANLDRAKAGLLERVKELQAEQEDRALRSFKLSVTVDPKYHPKIIGRKGAVITQIRLEHDVNIQFPDKDDGNQPQDQITITGYEKNTEAARDAILRIVGELEQMVSEDVPLDHRVHARIIGARGKAIRKIMDEFKVDIRFPQSGAPDPNCVTVTGLPENVEEAIDHILNLEEEYLADVVDSEALQVYMKPPAHEEAKAPSRGFVVRDAPWTASSSEKAPDMSSSEEFPSFGAQVAPKTLPWGPKR>sp|Q00341-2|VIGLN_HUMAN Isoform 2 of Vigilin OS=Homo sapiens OX=9606GN=HDLBPMHLAERDRWLFVATVMMHFVSIKSGFPGLCVGVRSTMSSVAVLTQESFAEHRSGLVPQQIKVATLNSEEESDPPTYKDAFPPLPEKAACLESAQEPSGAWGNKIRPIKASVITQVFHVPLEERKYKDMNQFGEGEQAKICLEIMQRTGAHLELSLAKDQGLSIMVSGKLDAVMKARKDIVARLQTQASATVAIPKEHHRFVIGKNGEKLQDLELKTATKIQIPRPDDPSNQIKITGTKEGIEKARHEVLLISAEQDKRAVERLEVEKAFHPFIAGPYNRLVGEIMQETGTRINIPPPSVNRTEIVFTGEKEQLAQAVARIKKIYEEKANSFTVSSVAAPSWLHRFIIGKKGQNLAKITQQMPKVHIEFTEGEDKITLEGPTEDVNVAQEQIEGMVKDLINRMDYVEINIDHKFHRHLIGKSGANINRIKDQYKVSVRIPPDSEKSNLIRIEGDPQGVQQAKRELLELASRMENERTKDLIIEQRFHRTIIGQKGERIREIRDKFPEVIINFPDPAQKSDIVQLRGPKNEVEKCTKYMQKMVADLVENSYSISVPIFKQFHKNIIGKGGANIKKIREESNTKIDLPAENSNSETIIITGKRANCEAARSRILSIQKDLANIAEVEVSIPAKLHNSLIGTKGRLIRSIMEECGGVHIHFPVEGSGSDTVVIRGPSSDVEKAKKQLLHLAEEKQTKSFTVDIRAKPEYHKFLIGKGGGKIRKVRDSTGARVIFPAAEDKDQDLITIIGKEDAVREAQKELEALIQNLDNVVEDSMLVDPKHHRHFVIRRGQVLREIAEEYGGVMVSFPRSGTQSDKVTLKGAKDCVEAAKKRIQEIIEDLEAQVTLECAIPQKFHRSVMGPKGSRIQQITRDFSVQIKFPDREENAVHSTEPVVQENGDEAGEGREAKDCDPGSPRRCDIIIISGRKEKCEAAKEALEALVPVTIEVEVPFDLHRYVIGQKGSGIRKMMDEFEVNIHVPAPELQSDIIAITGLAANLDRAKAGLLERVKELQAEQEDRALRSFKLSVTVDPKYHPKIIGRKGAVITQIRLEHDVNIQFPDKDDGNQPQDQITITGYEKNTEAARDAILRIVGELEQMVSEDVPLDHRVHARIIGARGKAIRKIMDEFKVDIRFPQSGAPDPNCVTVTGLPENVEEAIDHILNLEEEYLADVVDSEALQVYMKPPAHEEAKAPSRGFVVRDAPWTASSSEKAPDMSSSEEFPSFGAQVAPKTLPWGPKR>sp|Q6ZQQ6|WDR87_HUMAN WD repeat-containing protein 87 OS=Homo sapiensOX=9606 GN=WDR87 PE=1 SV=3MSSPRLIPLWKDLKLLLNDTINKSKQPSEDPKNCLIVLSDRSQAVAWMKSKTEDMVEKRTFSMTERLPPIQSMVHAGSFHILVVYCGDLILRLFGDHFRAFKPLGKVPCRFNISCLCYDPEMKMLLSGILGAVVTWVIELGGTGLQIAHMVSMPGDELVQDIVLNGPSGSLLALCETVVRVLMHQGKGQLGEVKRFTSTSSGSSITCCFTCFDQGFLYAGNQAGEIQVWSLQQGHPLHSFQAHQSGVICIRSRPEAHTLLTAGSDSLIKEWNLTSGSLLRRLELGEELYRLQFIDSITFFCQTAHSFSLHRLPCFYSLFNVCGSAPQQLRRVCCGNNWFRILCTTEDGLLRFVSPVTGDLLVITWPFSILDQAVDWAYDPGKEELFVATGSSEVLVFDTTRCPCPAKYLLGTSPNSQDFVQCLAYGHFNLGRGLEGLIFSGHQSGVIRVLSQHSCARLEKFMHFGAVLALSTLSGGIFGGQGNSLLCSYGMDDYVHLSEAVLDGVKVQLRPLASILSSCHLTHLILLPKSVGAITETNCLRLWKFHDFLSSGSQNGLKFIETLPLHLCAITSFDVCLSLSLFVTGSADGSVRIWDFHGRLIGILDSSLHFGPVCFANDRGDLLVTFNQSLYLVSCLKLLPPALLTRLSFMSISDEVLEVPKPFIPSFFFSFETMFVPKYIYPGQAQQKLVGLEKLVNNRAIAFDHSVPHVIEEDEEGSPVLLRSSMHYSLQDMEDWMQVSKRYQCHYVLPPQLQLTSWDGLNPYQILRYYFGHGREWLFAPDCYIPNSVIRARLWPEGTPIYLQCNLHAPQRELEWDRSQEFFFWHSRVRAISNTEYPKNKEEDEHFLEMRLSKDVTYSVLTDGANRSWLGRKMSEITINSMIETMLNIMVHASLLKYQCCVGALGQIFASYQVSPALRSETARRLLNDTTNSNPLIRELAWEGLKRLGMITHLFAMPLAQGLMDKDERVRIKTLSLMAEIGIHSRTSLLQLTQKQETFREMQQQMIGEEPLDHLLGMRATDLQILSTQVEQRLNENLTLSHRDEKPAFSLDVSMPSELKSSLKPPTVSEESEVAIKPSKGQRRGQAGVKKHSQKWLRGLKKTKERDSKQMSTEPGLLEDESGTEAAPIEMEEASVYSQWSSSTSVIKLSKDVDSQEKDISKDHIALTLKRLQKIRDKRDKKATAQKLKKKHKKKGKEAKVINEETTPPVMEQPVTKKVKIQGRGASGISGRRSTAGDGSSWRDDLCRLMALRISGSQTKMSENLNAELVTFAQEMLVDRHPSWELFQEICPLLKKESKVLLEDLDWDVVPPEKKPIFIQEGAIREDMIQGVTQEVIRHKEVMPREEEQAQKKARDMLGLEETQVILKKGKKVIFLEPGNVTMGKEISKKEEKKTFQKSPKQGRKAVQKERKVGKIKREMTKEERDMSEEVEEMATLEEKVVKQEGKLVMIERTPSWQDWKKAWDEWKQVHGETRKSWKAWKEEWEKRLLQEEEKLHQAGEKLSPEEEMLQEDKKLKWEEWKQVWENMLSSKSKEQQYKDEEEVTLEEEVSREGEEKEQQVTEEQRHIQEEHKWARIHRKRARAEKKRAQEERKLAQEEEKLAQEERQLAQEERKLAQAYVKITQDDREMAQAEGKFAQKEETLAQRGEKLSQEAEKLAQKRKKLAKKWEKVAREEEKLAKKGGKLAEVKNILAQKVEELPQREQNLDWQEKELAQELEELEWDMEELSWKEEELNQEEGKLVEEKKKLAEEEEALAWQREKLSEEETKLAQEEELLIQEKEKLAQHKEKMPEEEERLGRKREQLIEKKMKLAQKRERWINSMEELTKNKMILYQKKNLAQEKKNLAQEKEKLAQRKENLLYNKERLTHSKKQLVQVKNKLGMFNKILAQVEEKLTQEKETVIKKKEKLAETEKKLVQVEDSLAKKQEKLAQEKMKLALEKAMVQGKKRLRGELDIAKEEKALNLEMKRLAEEKMRLVEGKETLSKGETPETSRQRKMTQVEQELFERKLSLEEKILLHEDRILAMEESEIAKGKLEFTRGQRIFVQGQRKLAKASRKLIKKRESLSKEPAKLNKILKALQKLTRDERKLTQEEIKMTKMKRALFVKERRLSIEQSKLDIKEWDFSEKRSELTKDEKKLARKQRKLANKMRRMINKEEKMTEEESKLARKHSEVILDDEEEGGIEEEEVIPFLKRRWRKRKEAKRGDKPKEKFSSQVDEVESEEHFSEEMESLLDELEKQESLSSEEEEEREEEEEREEEEVREEEEERKEEEEGEEKQVEKEEEEKKKKKKEKKKEEVQEKEEVFEEKEEIMSEEETESLSDEEEEEESCSLEEEVDREKEILKKEKQFKLQEQRRKSLRGRERVLSILRGVPHGKGRAIRLGVLKSPLKKLMSTALEMKEKTPVPVPEKQISWEDKKATVVEIPRKFLGTMDKEREVMGKYEPIPPHVLGTVLESQAQDLKTPFMSHILRRTVEAEELQHKPLGAWWKWFLQHPPLMGQTEVQLPLSQIPAKEQHADVSLSDVEWIRHVLERMEAGEQLSRDGFHRLCQLLKDLASKGNLEWLHLAKHEAIVYRHRQALESQDTRISSRQSMSPKYLKVIPPIKAKEKESWPKPLAVPTQKSPLATKRIPDPRAKNWHLLGEPYRSERAQQISIAHKEMEMQYFYPATRDIFPSAHASVEKQTLALMFQKDFWDFKDKRRFPKLPKLEKKTQPISKKKEELPLWETFVALYHVLRMLQQRYPKDSTAWMEQFYQLMDLYQLKSPRIQKLLQELLMREEPQPQEIIYEEALKATELVPGERLFCCLFCGSSHTPRSPQEFQGAVPLPWQNCVRTILPVGIARYGILELAWKSLPEADLHLTKALTHTVAPTL>sp|Q6ZQQ6-2|WDR87_HUMAN Isoform 2 of WD repeat-containing protein 87OS=Homo sapiens OX=9606 GN=WDR87MSSPRLIPLWKDLKLLLNDTINKSKQPSEDPKNCLIVLSDRSQALFKESRYPQNMPCVCYYFSDAHFFASLSWVTSNTKEIQAVAWMKSKTEDMVEKRTFSMTERLPPIQSMVHAGSFHILVVYCGDLILRLFGDHFRAFKPLGKVPCRFNISCLCYDPEMKMLLSGILGAVVTWVIELGGTGLQIAHMVSMPGDELVQDIVLNGPSGSLLALCETVVRVLMHQGKGQLGEVKRFTSTSSGSSITCCFTCFDQGFLYAGNQAGEIQVWSLQQGHPLHSFQAHQSGVICIRSRPEAHTLLTAGSDSLIKEWNLTSGSLLRRLELGEELYRLQFIDSITFFCQTAHSFSLHRLPCFYSLFNVCGSAPQQLRRVCCGNNWFRILCTTEDGLLRFVSPVTGDLLVITWPFSILDQAVDWAYDPGKEELFVATGSSEVLVFDTTRCPCPAKYLLGTSPNSQDFVQCLAYGHFNLGRGLEGLIFSGHQSGVIRVLSQHSCARLEKFMHFGAVLALSTLSGGIFGGQGNSLLCSYGMDDYVHLSEAVLDGVKVQLRPLASILSSCHLTHLILLPKSVGAITETNCLRLWKFHDFLSSGSQNGLKFIETLPLHLCAITSFDVCLSLSLFVTGSADGSVRIWDFHGRLIGILDSSLHFGPVCFANDRGDLLVTFNQSLYLVSCLKLLPPALLTRLSFMSISDEVLEVPKPFIPSFFFSFETMFVPKYIYPGQAQQKLVGLEKLVNNRAIAFDHSVPHVIEEDEEGSPVLLRSSMHYSLQDMEDWMQVSKRYQCHYVLPPQLQLTSWDGLNPYQILRYYFGHGREWLFAPDCYIPNSVIRARLWPEGTPIYLQCNLHAPQRELEWDRSQEFFFWHSRVRAISNTEYPKNKEEDEHFLEMRLSKDVTYSVLTDGANRSWLGRKMSEITINSMIETMLNIMVHASLLKYQCCVGALGQIFASYQVSPALRSETARRLLNDTTNSNPLIRELAWEGLKRLGMITHLFAMPLAQGLMDKDERVRIKTLSLMAEIGIHSRTSLLQLTQKQETFREMQQQMIGEEPLDHLLGMRATDLQILSTQVEQRLNENLTLSHRDEKPAFSLDVSMPSELKSSLKPPTVSEESEVAIKPSKGQRRGQAGVKKHSQKWLRGLKKTKERDSKQMSTEPGLLEDESGTEAAPIEMEEASVYSQWSSSTSVIKLSKDVDSQEKDISKDHIALTLKRLQKIRDKRDKKATAQKLKKKHKKKGKEAKVINEETTPPVMEQPVTKKVKIQGRGASGISGRRSTAGDGSSWRDDLCRLMALRISGSQTKMSENLNAELVTFAQEMLVDRHPSWELFQEICPLLKKESKVLLEDLDWDVVPPEKKPIFIQEGAIREDMIQGVTQEVIRHKEVMPREEEQAQKKARDMLGLEETQVILKKGKKVIFLEPGNVTMGKEISKKEEKKTFQKSPKQGRKAVQKERKVGKIKREMTKEERDMSEEVEEMATLEEKVVKQEGKLVMIERTPSWQDWKKAWDEWKQVHGETRKSWKAWKEEWEKRLLQEEEKLHQAGEKLSPEEEMLQEDKKLKWEEWKQVWENMLSSKSKEQQYKDEEEVTLEEEVSREGEEKEQQVTEEQRHIQEEHKWARIHRKRARAEKKRAQEERKLAQEEEKLAQEERQLAQEERKLAQAYVKITQDDREMAQAEGKFAQKEETLAQRGEKLSQEAEKLAQKRKKLAKKWEKVAREEEKLAKKGGKLAEVKNILAQKVEELPQREQNLDWQEKELAQELEELEWDMEELSWKEEELNQEEGKLVEEKKKLAEEEEALAWQREKLSEEETKLAQEEELLIQEKEKLAQHKEKMPEEEERLGRKREQLIEKKMKLAQKRERWINSMEELTKNKMILYQKKNLAQEKKNLAQEKEKLAQRKENLLYNKERLTHSKKQLVQVKNKLGMFNKILAQVEEKLTQEKETVIKKKEKLAETEKKLVQVEDSLAKKQEKLAQEKMKLALEKAMVQGKKRLRGELDIAKEEKALNLEMKRLAEEKMRLVEGKETLSKGETPETSRQRKMTQVEQELFERKLSLEEKILLHEDRILAMEESEIAKGKLEFTRGQRIFVQGQRKLAKASRKLIKKRESLSKEPAKLNKILKALQKLTRDERKLTQEEIKMTKMKRALFVKERRLSIEQSKLDIKEWDFSEKRSELTKDEKKLARKQRKLANKMRRMINKEEKMTEEESKLARKHSEVILDDEEEGGIEEEEVIPFLKRRWRKRKEAKRGDKPKEKFSSQVDEVESEEHFSEEMESLLDELEKQESLSSEEEEEREEEEEREEEEVREEEEERKEEEEGEEKQVEKEEEEKKKKKKEKKKEEVQEKEEVFEEKEEIMSEEETESLSDEEEEEESCSLEEEVDREKEILKKEKQFKLQEQRRKSLRGRERVLSILRGVPHGKGRAIRLGVLKSPLKKLMSTALEMKEKTPVPVPEKQISWEDKKATVVEIPRKFLGTMDKEREVMGKYEPIPPHVLGTVLESQAQDLKTPFMSHILRRTVEAEELQHKPLGAWWKWFLQHPPLMGQTEVQLPLSQIPAKEQHADVSLSDVEWIRHVLERMEAGEQLSRDGFHRLCQLLKDLASKGNLEWLHLAKHEAIVYRHRQALESQDTRISSRQSMSPKYLKVIPPIKAKEKESWPKPLAVPTQKSPLATKRIPDPRAKNWHLLGEPYRSERAQQISIAHKEMEMQYFYPATRDIFPSAHASVEKQTLALMFQKDFWDFKDKRRFPKLPKLEKKTQPISKKKEELPLWETFVALYHVLRMLQQRYPKDSTAWMEQFYQLMDLYQLKSPRIQKLLQELLMREEPQPQEIIYEEALKATELVPGERLFCCLFCGSSHTPRSPQEFQGAVPLPWQNCVRTILPVGIARYGILELAWKSLPEADLHLTKALTHTVAPTL>sp|Q9H354|YJ001_HUMAN Putative uncharacterized protein PRO1933 OS=Homosapiens OX=9606 GN=PRO1933 PE=5 SV=1MNKHNLRLVQLASELILIEIIPKLFLSQVTTISHIKREKIPPNHRKGILCMFPWQCVVYVFSNFVWLVIHRFSNGFIQFLGEPYRLMTASGTHGRIKFMVDIPIIKNTQVLRIPVLKDPKMLSKKH>sp|Q8NCA9|ZN784_HUMAN Zinc finger protein 784 OS=Homo sapiens OX=9606GN=ZNF784 PE=1 SV=1MAAARPEAQSRSSPTPESRSQEPLDLVLVPDDCRPGTPPSDLIEIQVVKVTDTTLVPEPPEPGSFHCALCPAAFRLVSELLFHEHGHLAGAEGGGQGGDPSRCHVCGHSCPGPASLRAHYSLHTGERPYRCALCPRAFKALAPLLRHQHRHGVEPGTSRRPPDTAAVAEQRPGVAPERAEVVMAAAAAGAAVGKPFACRFCAKPFRRSSDMRDHERVHTGERPYHCGICGKGFTQSSVLSGHARIHTGERPFRCTLCDRTFNNSSNFRKHQRTHFHGPGPGLGDSGGQLGSSAAEGSGSGCGVGDPAEEGRGETAKVKVEADQ>sp|Q9Y4E5|ZN451_HUMAN E3 SUMO-protein ligase ZNF451 OS=Homo sapiensOX=9606 GN=ZNF451 PE=1 SV=2MGDPGSEIIESVPPAGPEASESTTDENEDDIQFVSEGPLRPVLEYIDLVSSDDEEPSTSYTDENIKRKDHIDYQKDKVALTLARLARHVEVEKQQKEEKNRAFREKIDFQHAHGLQELEFIRGHSDTEAARLCVDQWLKMPGLKTGTINCGTKSSFRRGGHTWVSGKPILCPIMHCNKEFDNGHLLLGHLKRFDHSPCDPTITLHGPFFSSFACVVCYKKFVTQQQYRDHLFDKEATDDGHNNNLLPQIIQCFACPNCFLLFSRKEECSKHMSGKNHFHQSFKLGDNKGIAHPISFPSFAKKLLISLCKDVPFQVKCVACHKTLRSHMELTAHFRVHCRNAGPVAVAEKSITQVAEKFILRGYCPDCNQVFVDETSTQNHKQNSGHKVRVINSVEESVLLYCHSSEGNKDPSSDLHLLLDQSKFSSLKRTMSIKESSSLECIAIPKKKMNLKDKSHEGVACVQKEKSVVKTWFCECNQRFPSEDAVEKHVFSANTMGYKCVVCGKVCDDSGVIRLHMSRIHGGAHLNNFLFWCRTCKKELTRKDTIMAHVTEFHNGHRYFYEMDEVEGETLPSSSTTLDNLTANKPSSAITVIDHSPANSSPRGKWQCRICEDMFDSQEYVKQHCMSLASHKFHRYSCAHCRKPFHKIETLYRHCQDEHDNEIKIKYFCGLCDLIFNVEEAFLSHYEEHHSIDYVFVSEKTETSIKTEDDFPVIETSNQLTCGCRESYICKVNRKEDYSRCLQIMLDKGKLWFRCSLCSATAQNLTDMNTHIHQVHKEKSDEEEQQYVIKCGTCTKAFHDPESAQQHFHRKHCFLQKPSVAHFGSEKSNLYKFTASASHTERKLKQAINYSKSLDMEKGVENDLSYQNIEEEIVELPDLDYLRTMTHIVFVDFDNWSNFFGHLPGHLNQGTFIWGFQGGNTNWKPPLNCKIYNYLNRIGCFFLHPRCSKRKDAADFAICMHAGRLDEQLPKQIPFTILSGDQGFLELENQFKKTQRPAHILNPHHLEGDMMCALLNSISDTTKECDSDDNMGAKNTSIGEEFISTEDVELEEAIRRSLEEM>sp|Q9Y4E5-2|ZN451_HUMAN Isoform 2 of E3 SUMO-protein ligase ZNF451OS=Homo sapiens OX=9606 GN=ZNF451MGDPGSEIIESVPPAGPEASESTTDENEDDIQFVSEGPLRPVLEYIDLVSSDDEEPSTSYTDENIKRKDHIDYQKDKVALTLARLARHVEVEKQQKEEKNRAFREKIDFQHAHGLQELEFIRGHSDTEAARLCVDQWLKMPGLKTGTINCGTKSSFRRGGHTWVSGKPILCPIMHCNKEFDNGHLLLGHLKRFDHSPCDPTITLHGPFFSSFACVVCYKKFVTQQQYRDHLFDKEATDDGHNNNLLPQIIQCFACPNCFLLFSRKEECSKHMSGKNHFHQSFKLGDNKGIAHPISFPSFAKKLLISLCKDVPFQVKCVACHKTLRSHMELTAHFRVHCRNAGPVAVAEKSITQVAEKFILRGYCPDCNQVFVDETSTQNHKQNSGHKVRVINSVEESVLLYCHSSEGNKDPSSDLHLLLDQSKFSSLKRTMSIKESSSLECIAIPKKKMNLKDKSHEGVACVQKEKSVVKTWFCECNQRFPSEDAVEKHVFSANTMGYKCVVCGKVCDDSGVIRLHMSRIHGGAHLNNFLFWCRTCKKELTRKDTIMAHVTEFHNGHRYFYEMDEVEGETLPSSSTTLDNLTANKPSSAITVIDHSPANSSPRGKWQCRICEDMFDSQEYVKQHCMSLASHKFHRYSCAHCRKPFHKIETLYRHCQDEHDNEIKIKYFCGLCDLIFNVEEAFLSHYEEHHSIDYVFVSEKTETSIKTEDDFPVIETSNQLTCGCRESYICKVNRKEDYSRCLQIMLDKGKLWFRCSLCSATAQNLTDMNTHIHQVHKEKSDEEEQQYVIKCGTCTKAFHDPESAQQHFHRKHCFLQKPSVAHFGSEKSNLYKFTASASHTERKLKQAINYSKSLDMEKGVENDLSYQNIGGNTNWKPPLNCKIYNYLNRIGCFFLHPRCSKRKDAADFAICMHAGRLDEQLPKQIPFTILSGDQGFLELENQFKKTQRPAHILNPHHLEGDMMCALLNSISDTTKECDSDDNMGAKNTSIGEEFISTEDVELEEAIRRSLEEM>sp|Q9Y4E5-4|ZN451_HUMAN Isoform 3 of E3 SUMO-protein ligase ZNF451OS=Homo sapiens OX=9606 GN=ZNF451MGDPGSEIIESVPPAGPEASESTTDENEDDIQFVSEGPLRPVLEYIDLVSSDDEEPSTSYTDRMPESKVPSSENHRPEMCSSCNVPLPIGDSSSFSGSCSSSPERIVSQTSSVENPLENQKNDQNNSDTKISETETLKSSQNFQTLPSSPLLVPQESLASSEVKENLRIDSSSASQHGRDAILYLQTQVAEMSRVIRDLQSRSCFRFHHSRPSENSSVPWDISTSKEENLSTVEEETDYKSPSADDKGQPSDPSQSSFTGLLKRMEQRGVIKRVTLQSEAESCEGKPDCVTSKKRLVPPLHPLLRIATTEVFKDPADCHPSSFMGHRVYPVAKDTSPFQPNPPAEGPIVEALEHSKRGNTTSPLDSTSKEMEVMGCRFYHAASIAARAASYMAYMTQYQRKLWEDMEDLVHDPEFDRGKARCIISDGMDAGLWQLCTTRDIMDSVVRVMAMAIDYRRQAWLRLTSLTKKTQEKISHLPFDGTSLFGQDVKAVVAEDNNIKENDYKDHKYYNQHRYFYSHDQKAHYHNRGYSKGDWYKPRNHPYRYRKKGDSPERHGYKN>sp|P0CG32|ZCC18_HUMAN Zinc finger CCHC domain-containing protein 18OS=Homo sapiens OX=9606 GN=ZCCHC18 PE=3 SV=1MASITACVGNSRQQNAPLPPWAHSMLRSLGRSLCPLVVKMAERNMKLFSGRVVPAQGKETFENWLIQVNEVLPDWSMSEEEKLKRLMKTLRGPAREVMRLLQAANPNLSVADFLRAMKLVFGESESSVTAHGKFFNTLQAQGEKASLYVIRLEVQLQNAIQAGILAEKDANQTRLQQLLLGAELNRDLRFRLKHLLRMYANKQERLPNFLELIKMIREEEDWDDAFIKRKRPKRSEPIMERAASPVAFQGAQPIAISSADCNCNVIEIDDTLDDSDEDVILVVSLYPSLTPTGAPPFRGRARPLDQVLVIDSPNNSGAQSLSTSGGSGYKNDGPGNIRRARKRKYTTRCSYCGEEGHSKETCDNESNKAQVFENLIITLQELTHTEERSKEVPGEHSDASEPQ>sp|O60290|ZN862_HUMAN Zinc finger protein 862 OS=Homo sapiens OX=9606GN=ZNF862 PE=2 SV=2MEPRESGKAPVTFDDITVYLLQEEWVLLSQQQKELCGSNKLVAPLGPTVANPELFRKFGRGPEPWLGSVQGQRSLLEHHPGKKQMGYMGEMEVQGPTRESGQSLPPQKKAYLSHLSTGSGHIEGDWAGRNRKLLKPRSIQKSWFVQFPWLIMNEEQTALFCSACREYPSIRDKRSRLIEGYTGPFKVETLKYHAKSKAHMFCVNALAARDPIWAARFRSIRDPPGDVLASPEPLFTADCPIFYPPGPLGGFDSMAELLPSSRAELEDPGGDGAIPAMYLDCISDLRQKEITDGIHSSSDINILYNDAVESCIQDPSAEGLSEEVPVVFEELPVVFEDVAVYFTREEWGMLDKRQKELYRDVMRMNYELLASLGPAAAKPDLISKLERRAAPWIKDPNGPKWGKGRPPGNKKMVAVREADTQASAADSALLPGSPVEARASCCSSSICEEGDGPRRIKRTYRPRSIQRSWFGQFPWLVIDPKETKLFCSACIERPNLHDKSSRLVRGYTGPFKVETLKYHEVSKAHRLCVNTVEIKEDTPHTALVPEISSDLMANMEHFFNAAYSIAYHSRPLNDFEKILQLLQSTGTVILGKYRNRTACTQFIKYISETLKREILEDVRNSPCVSVLLDSSTDASEQACVGIYIRYFKQMEVKESYITLAPLYSETADGYFETIVSALDELDIPFRKPGWVVGLGTDGSAMLSCRGGLVEKFQEVIPQLLPVHCVAHRLHLAVVDACGSIDLVKKCDRHIRTVFKFYQSSNKRLNELQEGAAPLEQEIIRLKDLNAVRWVASRRRTLHALLVSWPALARHLQRVAEAGGQIGHRAKGMLKLMRGFHFVKFCHFLLDFLSIYRPLSEVCQKEIVLITEVNATLGRAYVALESLRHQAGPKEEEFNASFKDGRLHGICLDKLEVAEQRFQADRERTVLTGIEYLQQRFDADRPPQLKNMEVFDTMAWPSGIELASFGNDDILNLARYFECSLPTGYSEEALLEEWLGLKTIAQHLPFSMLCKNALAQHCRFPLLSKLMAVVVCVPISTSCCERGFKAMNRIRTDERTKLSNEVLNMLMMTAVNGVAVTEYDPQPAIQHWYLTSSGRRFSHVYTCAQVPARSPASARLRKEEMGALYVEEPRTQKPPILPSREAAEVLKDCIMEPPERLLYPHTSQEAPGMS>sp|O60290-2|ZN862_HUMAN Isoform 2 of Zinc finger protein 862 OS=Homosapiens OX=9606 GN=ZNF862MGRRWCEWTVLTGIEYLQQRFDADRPPQLKNMEVFDTMAWPSGIELASFGNDDILNLARYFECSLPTGYSEEALLEEWLGLKTIAQHLPFSMLCKNALAQHCRFPLLSKLMAVVVCVPISTSCCERGFKAMNRIRTDERTKLSNEVLNMLMMTAVNGVAVTEYDPQPAIQHWYLTSSGRRFSHVYTCAQVPARSPASARLRKEEMGALYVEEPRTQKPPILPSREAAEVLKDCIMEPPERLLYPHTSQEAPGMS>sp|Q9ULM2|ZN490_HUMAN Zinc finger protein 490 OS=Homo sapiens OX=9606GN=ZNF490 PE=1 SV=2MRRNSSLSFQMERPLEEQVQSKWSSSQGRTGTGGSDVLQMQNSEHHGQSIKTQTDSISLEDVAVNFTLEEWALLDPGQRNIYRDVMRATFKNLACIGEKWKDQDIEDEHKNQGRNLRSPMVEALCENKEDCPCGKSTSQIPDLNTNLETPTGLKPCDCSVCGEVFMHQVSLNRHMRSHTEQKPNECHEYGEKPHKCKECGKTFTRSSSIRTHERIHTGEKPYECKECGKAFAFLFSFRNHIRIHTGETPYECKECGKAFRYLTALRRHEKNHTGEKPYKCKQCGKAFIYYQPFLTHERTHTGEKPYECKQCGKAFSCPTYLRSHEKTHTGEKPFVCRECGRAFFSHSSLRKHVKTHTGVQPYTCKKCGEAFKSSSSCEVHERTHFGEKPYECKQCGKAFNSSSYLQLHERVHTGEKTYECKECGKAFLYSTHFRIHERTHTREKPYECKQCGRVFIYFSHLRRHERSHTGVKPCECKQCGKAFTCLNSLKVHKRIHTGERPFQCRQCGKAFSYSKSLHVHERTHSRQKP>sp|Q8N0V1|ZNAS1_HUMAN Putative uncharacterized protein ZNF295-AS1OS=Homo sapiens OX=9606 GN=ZNF295-AS1 PE=5 SV=2MKDKMWCEDTAQPHRRLPAPPSSSSPTVVFQSHRRLLAPPSSSWTLWVAPRCGCCSPLCPKRVCASLCRVLAVTWSLTKLPFPLSPILLSRPGWLPQPSSPGPACAEPSSQEGGDTDLRSYGCFVCGWAWPTLSPRP>sp|P15621|ZNF44_HUMAN Zinc finger protein 44 OS=Homo sapiens OX=9606GN=ZNF44 PE=2 SV=3MALCYGTFWGYPKMLEAANLMEGLVDIGPWVTLPRGQPEVLEWGLPKDQDSVAFEDVAVNFTHEEWALLGPSQKNLYRDVMRETIRNLNCIGMKWENQNIDDQHQNLRRNPRCDVVERFGKSKDGSQCGETLSQIRNSIVNKNTPARVDACGSSVNGEVIMGHSSLNCYIRVDTGHKHRECHEYAEKSYTHKQCGKGLSYRHSFQTCERPHTGKKPYDCKECGKTFSSPGNLRRHMVVKGGDGPYKCELCGKAFFWPSLLRMHERTHTGEKPYECKQCSKAFPVYSSYLRHEKIHTGEKPYECKQCSKAFPDYSSYLRHERTHTGEKPYKCKQCGKAFSVSGSLRVHERIHTGEKPYTCKQCGKAFCHLGSFQRHMIMHSGDGPHKCKICGKGFDFPGSARIHEGTHTLEKPYECKQCGKLLSHRSSFRRHMMAHTGDGPHKCTVCGKAFDSPSVFQRHERTHTGEKPYECKQCGKAFRTSSSLRKHETTHTGEQPYKCKCGKAFSDLFSFQSHETTHSEEEPYECKECGKAFSSFKYFCRHERTHSEEKSYECQICGKAFSRFSYLKTHERTHTAEKPYECKQCRKAFFWPSFLLRHERTHTGERPYECKHCGKAFSRSSFCREHERTHTGEKPYECKECGKAFSSLSSFNRHKRTHWKDIL>sp|P15621-2|ZNF44_HUMAN Isoform 2 of Zinc finger protein 44 OS=Homosapiens OX=9606 GN=ZNF44MDSVAFEDVAVNFTHEEWALLGPSQKNLYRDVMRETIRNLNCIGMKWENQNIDDQHQNLRRNPRCDVVERFGKSKDGSQCGETLSQIRNSIVNKNTPARVDACGSSVNGEVIMGHSSLNCYIRVDTGHKHRECHEYAEKSYTHKQCGKGLSYRHSFQTCERPHTGKKPYDCKECGKTFSSPGNLRRHMVVKGGDGPYKCELCGKAFFWPSLLRMHERTHTGEKPYECKQCSKAFPVYSSYLRHEKIHTGEKPYECKQCSKAFPDYSSYLRHERTHTGEKPYKCKQCGKAFSVSGSLRVHERIHTGEKPYTCKQCGKAFCHLGSFQRHMIMHSGDGPHKCKICGKGFDFPGSARIHEGTHTLEKPYECKQCGKLLSHRSSFRRHMMAHTGDGPHKCTVCGKAFDSPSVFQRHERTHTGEKPYECKQCGKAFRTSSSLRKHETTHTGEQPYKCKCGKAFSDLFSFQSHETTHSEEEPYECKECGKAFSSFKYFCRHERTHSEEKSYECQICGKAFSRFSYLKTHERTHTAEKPYECKQCRKAFFWPSFLLRHERTHTGERPYECKHCGKAFSRSSFCREHERTHTGEKPYE>sp|P15621-3|ZNF44_HUMAN Isoform 3 of Zinc finger protein 44 OS=Homosapiens OX=9606 GN=ZNF44MALCYGTFWGYPKMLEAANLMEGLVDIGPWVTLPRGQPEVLEWGLPKDQDSVAFEDVAVNFTHEEWALLGPSQKNLYRDVMRETIRNLNCIGMKWENQNIDDQHQNLRRNPRCDVVERFGKSKDGSQCGETLSQIRNSIVNKNTPARVDACGSSVNGEVIMGHSSLNCYIRVDTGHKHRECHEYAEKSYTHKQCGKGLSYRHSFQTCERPHTGKKPYDCKECGKTFSSPGNLRRHMVVKGGDGPYKCELCGKAFFWPSLLRMHERTHTGEKPYECKQCSKAFPVYSSYLRHEKIHTGEKPYECKQCSKAFPDYSSYLRHERTHTGEKPYKCKQCGKAFSVSGSLRVHERIHTGEKPYTCKQCGKAFCHLGSFQRHMIMHSGDGPHKCKICGKGFDFPGSARIHEGTHTLEKPYECKQCGKLLSHRSSFRRHMMAHTGDGPHKCTVCGKAFDSPSVFQRHERTHTGEKPYECKQCGKAFRTSSSLRKHETTHTGEQPYKCKCGKAFSDLFSFQSHETTHSEEEPYECKECGKAFSSFKYFCRHERTHSEEKSYECQICGKAFSRFSYLKTHERTHTAEKPYECKQCRKAFFWPSFLLRHERTHTGERPYECKHCGKAFSRSSFCREHERTHTGEKPYE>sp|A8K554|ZN815_HUMAN Putative protein ZNF815 OS=Homo sapiens OX=9606GN=ZNF815P PE=5 SV=1MEEEEIRTWSFPEEVWQVATQPDSQQQHEDQHLSHTFLDKKDWTGNELHECNELGKKLHQNPNLLPSKQQVRTRDLCRKSLMCNLDFTPNAYLARRRFQCDGHGNFFSVRNLKLHLQERIHAEVTSVEVL>sp|Q9HAH1|ZN556_HUMAN Zinc finger protein 556 OS=Homo sapiens OX=9606GN=ZNF556 PE=2 SV=1MDTVVFEDVVVDFTLEEWALLNPAQRKLYRDVMLETFKHLASVDNEAQLKASGSISQQDTSGEKLSLKQKIEKFTRKNIWASLLGKNWEEHSVKDKHNTKERHLSRNPRVERPCKSSKGNKRGRTFRKTRNCNRHLRKNCCTSVRRYECSQCGKLFTHSSSLIRHKRAHSGQKLYKCKECGKAFSRPSYLQTHEKTHSGEKPYACQSCGKTFLRSHSLTEHVRTHTGEKPYECGQCGKGFSCPKSFRAHVMMHAGGRPYECKHCGKAFRCQKSFRVHMIMHAGGRPYECKQCGKAYCWATSFQRHVRIHNGEKPYKCGKCGKAFGWPSSLHKHARTHAKKKPVSGGSVGKSSARPRPSTDVKSQTREKVYKCETCGKTYGWSSSLHKHERKHTGEKPVNAASVGKPSGGLCSSKNVRTQIGQKPSKCEKCGKAFSCPKAFQGHVRSHTGKKSCTSK>sp|Q9P0L1|ZKSC7_HUMAN Zinc finger protein with KRAB and SCAN domains 7OS=Homo sapiens OX=9606 GN=ZKSCAN7 PE=1 SV=2MTTAGRGNLGLIPRSTAFQKQEGRLTVKQEPANQTWGQGSSLQKNYPPVCEIFRLHFRQLCYHEMSGPQEALSRLRELCRWWLMPEVHTKEQILELLVLEQFLSILPGELRTWVQLHHPESGEEAVAVVEDFQRHLSGSEEVSAPAQKQEMHFEETTALGTTKESPPTSPLSGGSAPGAHLEPPYDPGTHHLPSGDFAQCTSPVPTLPQVGNSGDQAGATVLRMVRPQDTVAYEDLSVDYTQKKWKSLTLSQRALQWNMMPENHHSMASLAGENMMKGSELTPKQEFFKGSESSNRTSGGLFGVVPGAAETGDVCEDTFKELEGQTSDEEGSRLENDFLEITDEDKKKSTKDRYDKYKEVGEHPPLSSSPVEHEGVLKGQKSYRCDECGKAFNRSSHLIGHQRIHTGEKPYECNECGKTFRQTSQLIVHLRTHTGEKPYECSECGKAYRHSSHLIQHQRLHNGEKPYKCNECAKAFTQSSRLTDHQRTHTGEKPYECNECGEAFIRSKSLARHQVLHTGKKPYKCNECGRAFCSNRNLIDHQRIHTGEKPYECSECGKAFSRSKCLIRHQSLHTGEKPYKCSECGKAFNQNSQLIEHERIHTGEKPFECSECGKAFGLSKCLIRHQRLHTGEKPYKCNECGKSFNQNSHLIIHQRIHTGEKPYECNECGKVFSYSSSLMVHQRTHTGEKPYKCNDCGKAFSDSSQLIVHQRVHTGEKPYECSECGKAFSQRSTFNHHQRTHTGEKSSGLAWSVS>sp|Q9P0L1-2|ZKSC7_HUMAN Isoform 2 of Zinc finger protein with KRAB andSCAN domains 7 OS=Homo sapiens OX=9606 GN=ZKSCAN7MTTAGRGNLGLIPRSTAFQKQEGRLTVKQEPANQTWGQGSSLQKNYPPVCEIFRLHFRQLCYHEMSGPQEALSRLRELCRWWLMPEVHTKEQILELLVLEQFLSILPGELRTWVQLHHPESGEEAVAVVEDFQRHLSGSEEVSAPAQKQEMHFEETTALGTTKESPPTSPLSGGSAPGAHLEPPYDPGTHHLPSGDFAQCTSPVPTLPQVGNSGDQAGATVLRMVRPQDTVAYEDLSVDYTQKKWKSLTLSQRALQWNMMPENHHSMASLGWSTMA>sp|Q9UBW7|ZMYM2_HUMAN Zinc finger MYM-type protein 2 OS=Homo sapiensOX=9606 GN=ZMYM2 PE=1 SV=1MDTSSVGGLELTDQTPVLLGSTAMATSLTNVGNSFSGPANPLVSRSNKFQNSSVEDDDDVVFIEPVQPPPPSVPVVADQRTITFTSSKNEELQGNDSKITPSSKELASQKGSVSETIVIDDEEDMETNQGQEKNSSNFIERRPPETKNRTNDVDFSTSSFSRSKVNAGMGNSGITTEPDSEIQIANVTTLETGVSSVNDGQLENTDGRDMNLMITHVTSLQNTNLGDVSNGLQSSNFGVNIQTYTPSLTSQTKTGVGPFNPGRMNVAGDVFQNGESATHHNPDSWISQSASFPRNQKQPGVDSLSPVASLPKQIFQPSVQQQPTKPVKVTCANCKKPLQKGQTAYQRKGSAHLFCSTTCLSSFSHKPAPKKLCVMCKKDITTMKGTIVAQVDSSESFQEFCSTSCLSLYEDKQNPTKGALNKSRCTICGKLTEIRHEVSFKNMTHKLCSDHCFNRYRMANGLIMNCCEQCGEYLPSKGAGNNVLVIDGQQKRFCCQSCVSEYKQVGSHPSFLKEVRDHMQDSFLMQPEKYGKLTTCTGCRTQCRFFDMTQCIGPNGYMEPYCSTACMNSHKTKYAKSQSLGIICHFCKRNSLPQYQATMPDGKLYNFCNSSCVAKFQALSMQSSPNGQFVAPSDIQLKCNYCKNSFCSKPEILEWENKVHQFCSKTCSDDYKKLHCIVTYCEYCQEEKTLHETVNFSGVKRPFCSEGCKLLYKQDFARRLGLRCVTCNYCSQLCKKGATKELDGVVRDFCSEDCCKKFQDWYYKAARCDCCKSQGTLKERVQWRGEMKHFCDQHCLLRFYCQQNEPNMTTQKGPENLHYDQGCQTSRTKMTGSAPPPSPTPNKEMKNKAVLCKPLTMTKATYCKPHMQTKSCQTDDTWRTEYVPVPIPVPVYIPVPMHMYSQNIPVPTTVPVPVPVPVFLPAPLDSSEKIPAAIEELKSKVSSDALDTELLTMTDMMSEDEGKTETTNINSVIIETDIIGSDLLKNSDPETQSSMPDVPYEPDLDIEIDFPRAAEELDMENEFLLPPVFGEEYEEQPRPRSKKKGAKRKAVSGYQSHDDSSDNSECSFPFKYTYGVNAWKHWVKTRQLDEDLLVLDELKSSKSVKLKEDLLSHTTAELNYGLAHFVNEIRRPNGENYAPDSIYYLCLGIQEYLCGSNRKDNIFIDPGYQTFEQELNKILRSWQPSILPDGSIFSRVEEDYLWRIKQLGSHSPVALLNTLFYFNTKYFGLKTVEQHLRLSFGTVFRHWKKNPLTMENKACLRYQVSSLCGTDNEDKITTGKRKHEDDEPVFEQIENTANPSRCPVKMFECYLSKSPQNLNQRMDVFYLQPECSSSTDSPVWYTSTSLDRNTLENMLVRVLLVKDIYDKDNYELDEDTD>sp|Q9UBW7-2|ZMYM2_HUMAN Isoform 2 of Zinc finger MYM-type protein 2OS=Homo sapiens OX=9606 GN=ZMYM2MDTSSVGGLELTDQTPVLLGSTAMATSLTNVGNSFSGPANPLVSRSNKFQNSSVEDDDDVVFIEPVQPPPPSVPVVADQRTITFTSSKNEELQGNDSKITPSSKELASQKGSVSETIVIDDEEDMETNQGQEKNSSNFIERRPPETKNRTNDVDFSTSSFSRSKTKTGVGPFNPGRMNVAGDVFQNGESATHHNPDSWISQSASFPRNQKQPGVDSLSPVASLPKQIFQPSVQQQPTKPVKVTCANCKKPLQKGQTAYQRKGSAHLFCSTTCLSSFSHKPAPKKLCVMCKKDITTMKGTIVAQVDSSESFQEFCSTSCLSLYEDKQNPTKGALNKSRCTICGKLTEIRHEVSFKNMTHKLCSDHCFNRYRMANGLIMNCCEQCGEYLPSKGAGNNVLVIDGQQKRFCCQSCVSEYKQVGSHPSFLKEVRDHMQDSFLMQPEVSRNVNGVQGLNIFEHCYYCH>sp|P17097|ZNF7_HUMAN Zinc finger protein 7 OS=Homo sapiens OX=9606GN=ZNF7 PE=1 SV=1MEVVTFGDVAVHFSREEWQCLDPGQRALYREVMLENHSSVAGLAGFLVFKPELISRLEQGEEPWVLDLQGAEGTEAPRTSKTDSTIRTENEQACEDMDILKSESYGTVVRISPQDFPQNPGFGDVSDSEVWLDSHLGSPGLKVTGFTFQNNCLNEETVVPKTFTKDAPQGCKELGSSGLDCQPLESQGESAEGMSQRCEECGKGIRATSDIALHWEINTQKISRCQECQKKLSDCLQGKHTNNCHGEKPYECAECGKVFRLCSQLNQHQRIHTGEKPFKCTECGKAFRLSSKLIQHQRIHTGEKPYRCEECGKAFGQSSSLIHHQRIHTGERPYGCRECGKAFSQQSQLVRHQRTHTGERPYPCKECGKAFSQSSTLAQHQRMHTGEKAQILKASDSPSLVAHQRIHAVEKPFKCDECGKAFRWISRLSQHQLIHTGEKPYKCNKCTKAFGCSSRLIRHQRTHTGEKPFKCDECGKGFVQGSHLIQHQRIHTGEKPYVCNDCGKAFSQSSSLIYHQRIHKGEKPYECLQCGKAFSMSTQLTIHQRVHTGERPYKCNECGKAFSQNSTLFQHQIIHAGVKPYECSECGKAFSRSSYLIEHQRIHTRAQWFYEYGNALEGSTFVSRKKVNTIKKLHQCEDCEKIFRWRSHLIIHQRIHTGEKPYKCNDCGKAFNRSSRLTQHQKIHMG>sp|P17097-2|ZNF7_HUMAN Isoform 2 of Zinc finger protein 7 OS=Homosapiens OX=9606 GN=ZNF7MGFLGCWCVSFQEVVTFGDVAVHFSREEWQCLDPGQRALYREVMLENHSSVAGLAGFLVFKPELISRLEQGEEPWVLDLQGAEGTEAPRTSKTDSTIRTENEQACEDMDILKSESYGTVVRISPQDFPQNPGFGDVSDSEVWLDSHLGSPGLKVTGFTFQNNCLNEETVVPKTFTKDAPQGCKELGSSGLDCQPLESQGESAEGMSQRCEECGKGIRATSDIALHWEINTQKISRCQECQKKLSDCLQGKHTNNCHGEKPYECAECGKVFRLCSQLNQHQRIHTGEKPFKCTECGKAFRLSSKLIQHQRIHTGEKPYRCEECGKAFGQSSSLIHHQRIHTGERPYGCRECGKAFSQQSQLVRHQRTHTGERPYPCKECGKAFSQSSTLAQHQRMHTGEKAQILKASDSPSLVAHQRIHAVEKPFKCDECGKAFRWISRLSQHQLIHTGEKPYKCNKCTKAFGCSSRLIRHQRTHTGEKPFKCDECGKGFVQGSHLIQHQRIHTGEKPYVCNDCGKAFSQSSSLIYHQRIHKGEKPYECLQCGKAFSMSTQLTIHQRVHTGERPYKCNECGKAFSQNSTLFQHQIIHAGVKPYECSECGKAFSRSSYLIEHQRIHTRAQWFYEYGNALEGSTFVSRKKVNTIKKLHQCEDCEKIFRWRSHLIIHQRIHTGEKPYKCNDCGKAFNRSSRLTQHQKIHMG>sp|P17097-3|ZNF7_HUMAN Isoform 3 of Zinc finger protein 7 OS=Homosapiens OX=9606 GN=ZNF7MEVVTFGDVAVHFSREEWQCLDPGQRALYREVMLENHSSVAGLAGFLVFKPELISRLEQGEEPWVLDLQGAEGTEAPRTSKTGFLGRPTMGQEPRHPHAPPATPVPGLPKHCSQRLTLPPPGLSSSPLGHFLVHDQDRRRGTSAIWMV>sp|Q9BS86|ZPBP1_HUMAN Zona pellucida-binding protein 1 OS=Homo sapiensOX=9606 GN=ZPBP PE=2 SV=1MEAFALGPARRGRRRTRAAGSLLSRAAILLFISAFLVRVPSSVGHLVRLPRAFRLTKDSVKIVGSTSFPVKAYVMLHQKSPHVLCVTQQLRNAELIDPSFQWYGPKGKVVSVENRTAQITSTGSLVFQNFEESMSGIYTCFLEYKPTVEEIVKRLQLKYAIYAYREPHYYYQFTARYHAAPCNSIYNISFEKKLLQILSKLLLDLSCEISLLKSECHRVKMQRAGLQNELFFAFSVSSLDTEKGPKRCTDHNCEPYKRLFKAKNLIERFFNQQVEILGRRAEQLPQIYYIEGTLQMVWINRCFPGYGMNVQQHPKCPECCVICSPGSYNPRDGIHCLQCNSSLVYGAKTCL>sp|Q9BS86-2|ZPBP1_HUMAN Isoform 2 of Zona pellucida-binding protein 1OS=Homo sapiens OX=9606 GN=ZPBPMEAFALGPARRGRRRTRAAGSLLSRAAILLFISAFLVRVPSSVGHLVRLPRAFRLTKDSVKIVGSTSFPVKAYVMLHQKSPHVLCVTQQLRNAELIDPSFQWYGPKGKVVSENRTAQITSTGSLVFQNFEESMSGIYTCFLEYKPTVEEIVKRLQLKYAIYAYREPHYYYQFTARYHAAPCNSIYNISFEKKLLQILSKLLLDLSCEISLLKSECHRVKMQRAGLQNELFFAFSVSSLDTEKGPKRCTDHNCEPYKRLFKAKNLIERFFNQQVEILGRRAEQLPQIYYIEGTLQMVWINRCFPGYGMNVQQHPKCPECCVICSPGSYNPRDGIHCLQCNSSLVYGAKTCL>sp|P35789|ZNF93_HUMAN Zinc finger protein 93 OS=Homo sapiens OX=9606GN=ZNF93 PE=2 SV=4MGPLQFRDVAIEFSLEEWHCLDTAQRNLYRNVMLENYSNLVFLGIVVSKPDLIAHLEQGKKPLTMKRHEMVANPSVICSHFAQDLWPEQNIKDSFQKVILRRYEKRGHGNLQLIKRCESVDECKVHTGGYNGLNQCSTTTQSKVFQCDKYGKVFHKFSNSNRHNIRHTEKKPFKCIECGKAFNQFSTLITHKKIHTGEKPYICEECGKAFKYSSALNTHKRIHTGEKPYKCDKCDKAFIASSTLSKHEIIHTGKKPYKCEECGKAFNQSSTLTKHKKIHTGEKPYKCEECGKAFNQSSTLTKHKKIHTGEKPYVCEECGKAFKYSRILTTHKRIHTGEKPYKCNKCGKAFIASSTLSRHEFIHMGKKHYKCEECGKAFIWSSVLTRHKRVHTGEKPYKCEECGKAFKYSSTLSSHKRSHTGEKPYKCEECGKAFVASSTLSKHEIIHTGKKPYKCEECGKAFNQSSSLTKHKKIHTGEKPYKCEECGKAFNQSSSLTKHKKIHTGEKPYKCEECGKAFNQSSTLIKHKKIHTREKPYKCEECGKAFHLSTHLTTHKILHTGEKPYRCRECGKAFNHSATLSSHKKIHSGEKPYECDKCGKAFISPSSLSRHEIIHTGEKP>sp|P35789-2|ZNF93_HUMAN Isoform 2 of Zinc finger protein 93 OS=Homosapiens OX=9606 GN=ZNF93MGPLQFRDVAIEFSLEEWHCLDTAQRNLYRNVMLENYSNLVFLGIVVSKPDLIAHLEQGKKPLTMKRHEMVANPSVICSHFAQDLWPEQNIKDSFQKVILRRYEKRGHGNLQLIKRCESVDECKVHTGGYNGLNQCSTTTQSKVFQCDKYGKVFHKFSNSNRHNIRHTEKKPFKCIECGKAFNQFSTLITHKKIHTGEKPYICEECGKAFKYSSALNTHKRIHTGEKPYKCDKCDKAFIASSTLSKHEIIHTGKKPYKCEECGKAFNQSSTLTKHKKIHTGEKPYKCEECGKAFNQSSTLTKHKKIHTGEKPYVCEECGKAFKYSRILTTHKRIHTGEKPYKCNKCGKAFIASSTLSRHEFIHMGKKHYKCEECGKAFIWSSVLTRHKRVHTGEKPYKCEECGKAFVASSTLSKHEIIHTGKKPYKCEECGKAFNQSSSLTKHKKIHTGEKPYKCEECGKAFNQSSSLTKHKKIHTGEKPYKCEECGKAFNQSSTLIKHKKIHTREKPYKCEECGKAFHLSTHLTTHKILHTGEKPYRCRECGKAFNHSATLSSHKKIHSGEKPYECDKCGKAFISPSSLSRHEIIHTGEKP>sp|P35789-3|ZNF93_HUMAN Isoform 3 of Zinc finger protein 93 OS=Homosapiens OX=9606 GN=ZNF93MGPLQFRDVAIEFSLEEWHCLDTAQRNLYRNVMLENYSNLVFLGIVVSKPDLIAHLEQGKKPLTMKRHEMVANPSVICSHFAQDLWPEQNIKDSFQKVILRRYEKRGHGNLQLIKRCESVDECKVHTGGYNGLNQCSTTTQSKVFQCDKYGKVFHKFSNSNRHNIRHTEKKPFKCIECGKAFNQFSTLITHKKIHTGEKPYICEECGKAFKYSSALNTHKRIHTGEKPYKCDKCDKAFIASSTLSKHEIIHTGKKPYKCEECGKAFNQSSTLTKHKKIHTGEKPYKCEECGKAFNQSSTLTKHKKIHTGEKPYVCEECGKAFKYSRILTTHKRIHTGEKPYKCNKCGKAFIASSTLSRHEFIHMGKKHYKCEECGKAFIWSSVLTRHKRVHTGEKPYKCEECGKAFKYSSTLSSHKRSHTGEKPYKCEECGKAFVASSTLSKHEIIHTGKKPYKCEECGKAFNQSSSLTKHKKIHTGEKPYKCEECGKAFNQSSSLTKHKKIHSGEKPYECDKCGKAFISPSSLSRHEIIHTGEKP>sp|Q9BY14|TX101_HUMAN Testis-expressed protein 101 OS=Homo sapiensOX=9606 GN=TEX101 PE=1 SV=2MGTPRIQHLLILLVLGASLLTSGLELYCQKGLSMTVEADPANMFNWTTEEVETCDKGALCQETILIIKAGTETAILATKGCIPEGEEAITIVQHSSPPGLIVTSYSNYCEDSFCNDKDSLSQFWEFSETTASTVSTTLHCPTCVALGTCFSAPSLPCPNGTTRCYQGKLEITGGGIESSVEVKGCTAMIGCRLMSGILAVGPMFVREACPHQLLTQPRKTENGATCLPIPVWGLQLLLPLLLPSFIHFS>sp|Q9BY14-2|TX101_HUMAN Isoform 2 of Testis-expressed protein 101OS=Homo sapiens OX=9606 GN=TEX101MGARQIQTSSSQTSPEEAMGTPRIQHLLILLVLGASLLTSGLELYCQKGLSMTVEADPANMFNWTTEEVETCDKGALCQETILIIKAGTETAILATKGCIPEGEEAITIVQHSSPPGLIVTSYSNYCEDSFCNDKDSLSQFWEFSETTASTVSTTLHCPTCVALGTCFSAPSLPCPNGTTRCYQGKLEITGGGIESSVEVKGCTAMIGCRLMSGILAVGPMFVREACPHQLLTQPRKTENGATCLPIPVWGLQLLLPLLLPSFIHFS>sp|O96014|WNT11_HUMAN Protein Wnt-11 OS=Homo sapiens OX=9606 GN=WNT11PE=1 SV=2MRARPQVCEALLFALALQTGVCYGIKWLALSKTPSALALNQTQHCKQLEGLVSAQVQLCRSNLELMHTVVHAAREVMKACRRAFADMRWNCSSIELAPNYLLDLERGTRESAFVYALSAAAISHAIARACTSGDLPGCSCGPVPGEPPGPGNRWGGCADNLSYGLLMGAKFSDAPMKVKKTGSQANKLMRLHNSEVGRQALRASLEMKCKCHGVSGSCSIRTCWKGLQELQDVAADLKTRYLSATKVVHRPMGTRKHLVPKDLDIRPVKDSELVYLQSSPDFCMKNEKVGSHGTQDRQCNKTSNGSDSCDLMCCGRGYNPYTDRVVERCHCKYHWCCYVTCRRCERTVERYVCK>sp|Q8WWM1|XAGE5_HUMAN X antigen family member 5 OS=Homo sapiens OX=9606GN=XAGE5 PE=3 SV=1MSWRGRRYRPRRCLRLAQLVGPMLEPSVPEPQQEEPPTESQDHTPGQKREDDQGAAEIQVPNLEADLQELSQSKTGDECGDSPDVQGKILPKSEQFKMPEGGEGKPQL>sp|Q8NEX5|WFDC9_HUMAN Protein WFDC9 OS=Homo sapiens OX=9606 GN=WFDC9PE=1 SV=1MKPWILLLVMFISGVVMLLPVLGSFWNKDPFLDMIRETEQCWVQPPYKYCEKRCTKIMTCVRPNHTCCWTYCGNICLDNEEPLKSMLNP>sp|P63131|VPK7_HUMAN Endogenous retrovirus group K member 7 Pro proteinOS=Homo sapiens OX=9606 GN=ERVK-7 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPLYSPTSQKIMTKMGYIPGKGLGKNEDGIKVPVEAKINQEREGIGYPF>sp|O75063|XYLK_HUMAN Glycosaminoglycan xylosylkinase OS=Homo sapiensOX=9606 GN=FAM20B PE=1 SV=1MKLKQRVVLLAILLVIFIFTKVFLIDNLDTSAANREDQRAFHRMMTGLRVELAPKLDHTLQSPWEIAAQWVVPREVYPEETPELGAVMHAMATKKIIKADVGYKGTQLKALLILEGGQKVVFKPKRYSRDHVVEGEPYAGYDRHNAEVAAFHLDRILGFHRAPLVVGRFVNLRTEIKPVATEQLLSTFLTVGNNTCFYGKCYYCRETEPACADGDIMEGSVTLWLPDVWPLQKHRHPWGRTYREGKLARWEYDESYCDAVKKTSPYDSGPRLLDIIDTAVFDYLIGNADRHHYESFQDDEGASMLILLDNAKSFGNPSLDERSILAPLYQCCIIRVSTWNRLNYLKNGVLKSALKSAMAHDPISPVLSDPHLDAVDQRLLSVLATVKQCTDQFGMDTVLVEDRMPLSHL>sp|P63124|VPK04_HUMAN Endogenous retrovirus group K member 104 Proprotein OS=Homo sapiens OX=9606 GN=HERV-K104 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTEADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGQDLLQQWGAEITMPAPLYSPTSQKIMTKMGYIPGKGLGKNEDGIKVPVEAKINQKREGIGYPF>sp|A2RUG3|XKRY2_HUMAN Testis-specific XK-related protein, Y-linked 2OS=Homo sapiens OX=9606 GN=XKRY2 PE=2 SV=2MFIFNSIADDIFPLISCVGAIHCNILAIRTGNDFAAIKLQVIKLIYLMIWHSLVIISPVVTLAFFPASLKQGSLHFLLIIYFVLLLTPWLEFSKSGTHLPSNTKNNSSMVGKYGCLS>sp|Q96NJ3|ZN285_HUMAN Zinc finger protein 285 OS=Homo sapiens OX=9606GN=ZNF285 PE=1 SV=2MIKFQERVTFKDVAVVFTKEELALLDKAQINLYQDVMLENFRNLMLVRDGIKNNILNLQAKGLSYLSQEVLHCWQIWKQRIRDLTVSQDYIVNLQEECSPHLEDVSLSEEWAGISLQISENENYVVNAIIKNQDITAWQSLTQVLTPESWRKANIMTEPQNSQGRYKGIYMEEKLYRRAQHDDSLSWTSCDHHESQECKGEDPGRHPNCGKNLGMKSTVEKRNAAHVLPQPFPCNNCGVAFADDTDPHVHHSTHLGEKSYKCDQYGKNFSQSQDLIVHCKTHSGKTPYEFHEWPMGCKQSSDLPRYQKVSSGDKPYKCKECGKGFRRSSSLHNHHRVHTGEMPYKCDECGKGFGFRSLLCIHQGVHTGKKPYKCEECGKGFDQSSNLLVHQRVHTGEKPYKCSECGKCFSSSSVLQVHWRFHTGEKPYRCGECGKGFSQCTHLHIHQRVHTGEKPYKCNVCGKDFAYSSVLHTHQRVHTGEKPYKCEVCGKCFSYSSYFHLHQRDHIREKPYKCDECGKGFSRNSDLNVHLRVHTRERPYKCKACGKGFSRNSYLLAHQRVHIDETQYTHCERGKDLLTHQRLHEQRETL>sp|Q96NJ3-2|ZN285_HUMAN Isoform 2 of Zinc finger protein 285 OS=Homosapiens OX=9606 GN=ZNF285MTEPQNSQGRYKGIYMEEKLYRRAQHDDSLSWTSCDHHESQECKGEDPGRHPNCGKNLGMKSTVEKRNAAHVLPQPFPCNNCGVAFADDTDPHVHHSTHLGEKSYKCDQYGKNFSQSQDLIVHCKTHSGKTPYEFHEWPMGCKQSSDLPRYQKVSSGDKPYKCKECGKGFRRSSSLHNHHRVHTGEMPYKCDECGKGFGFRSLLCIHQGVHTGKKPYKCEECGKGFDQSSNLLVHQRVHTGEKPYKCSECGKCFSSSSVLQVHWRFHTGEKPYRCGECGKGFSQCTHLHIHQRVHTGEKPYKCNVCGKDFAYSSVLHTHQRVHTGEKPYKCEVCGKCFSYSSYFHLHQRDHIREKPYKCDECGKGFSRNSDLNVHLRVHTRERPYKCKACGKGFSRNSYLLAHQRVHIDETQYTHCERGKDLLTHQRLHEQRETL>sp|Q8TAF3|WDR48_HUMAN WD repeat-containing protein 48 OS=Homo sapiensOX=9606 GN=WDR48 PE=1 SV=1MAAHHRQNTAGRRKVQVSYVIRDEVEKYNRNGVNALQLDPALNRLFTAGRDSIIRIWSVNQHKQDPYIASMEHHTDWVNDIVLCCNGKTLISASSDTTVKVWNAHKGFCMSTLRTHKDYVKALAYAKDKELVASAGLDRQIFLWDVNTLTALTASNNTVTTSSLSGNKDSIYSLAMNQLGTIIVSGSTEKVLRVWDPRTCAKLMKLKGHTDNVKALLLNRDGTQCLSGSSDGTIRLWSLGQQRCIATYRVHDEGVWALQVNDAFTHVYSGGRDRKIYCTDLRNPDIRVLICEEKAPVLKMELDRSADPPPAIWVATTKSTVNKWTLKGIHNFRASGDYDNDCTNPITPLCTQPDQVIKGGASIIQCHILNDKRHILTKDTNNNVAYWDVLKACKVEDLGKVDFEDEIKKRFKMVYVPNWFSVDLKTGMLTITLDESDCFAAWVSAKDAGFSSPDGSDPKLNLGGLLLQALLEYWPRTHVNPMDEEENEVNHVNGEQENRVQKGNGYFQVPPHTPVIFGEAGGRTLFRLLCRDSGGETESMLLNETVPQWVIDITVDKNMPKFNKIPFYLQPHASSGAKTLKKDRLSASDMLQVRKVMEHVYEKIINLDNESQTTSSSNNEKPGEQEKEEDIAVLAEEKIELLCQDQVLDPNMDLRTVKHFIWKSGGDLTLHYRQKST>sp|Q8TAF3-2|WDR48_HUMAN Isoform 2 of WD repeat-containing protein 48OS=Homo sapiens OX=9606 GN=WDR48MPKFNKIPFYLQPHASSGAKTLKKDRLSASDMLQVRKVMEHVYEKIINLDNESQTTSSSNNEKPGEQEKEEDIAVLAEEKIELLCQDQVQVLDPNMDLRTVKHFIWKSGGDLTLHYRQKST>sp|Q8TAF3-3|WDR48_HUMAN Isoform 3 of WD repeat-containing protein 48OS=Homo sapiens OX=9606 GN=WDR48MAAHHRQNTAGRRKVQVSYVIRDEVEKYNRNGVNALQLDPALNRLFTAGRDSIIRIWSVNQHKQDPYIASMEHHTDWVNDIVLCCNGKTLKVWNAHKGFCMSTLRTHKDYVKALAYAKDKELVASAGLDRQIFLWDVNTLTALTASNNTVTTSSLSGNKDSIYSLAMNQLGTIIVSGSTEKVLRVWDPRTCAKLMKLKGHTDNVKALLLNRDGTQCLSGSSDGTIRLWSLGQQRCIATYRVHDEGVWALQVNDAFTHVYSGGRDRKIYCTDLRNPDIRVLICEEKAPVLKMELDRSADPPPAIWVATTKSTVNKWTLKGIHNFRASGDYDNDCTNPITPLCTQPDQVIKGGASIIQCHILNDKRHILTKDTNNNVAYWDVLKACKVEDLGKVDFEDEIKKRFKMVYVPNWFSVDLKTGMLTITLDESDCFAAWVSAKDAGFSSPDGSDPKLNLGGLLLQALLEYWPRTHVNPMDEEENEVNHVNGEQENRVQKGNGYFQVPPHTPVIFGEAGGRTLFRLLCRDSGGETESMLLNETVPQWVIDITVDKNMPKFNKIPFYLQPHASSGAKTLKKDRLSASDMLQVRKVMEHVYEKIINLDNESQTTSSSNNEKPGEQEKEEDIAVLAEEKIELLCQDQVLDPNMDLRTVKHFIWKSGGDLTLHYRQKST>sp|Q8TAF3-4|WDR48_HUMAN Isoform 4 of WD repeat-containing protein 48OS=Homo sapiens OX=9606 GN=WDR48MECQSAQVISASSDTTVKVWNAHKGFCMSTLRTHKDYVKALAYAKDKELVASAGLDRQIFLWDVNTLTALTASNNTVTTSSLSGNKDSIYSLAMNQLGTIIVSGSTEKVLRVWDPRTCAKLMKLKGHTDNVKALLLNRDGTQCLSGSSDGTIRLWSLGQQRCIATYRVHDEGVWALQVNDAFTHVYSGGRDRKIYCTDLRNPDIRVLICEEKAPVLKMELDRSADPPPAIWVATTKSTVNKWTLKGIHNFRASGDYDNDCTNPITPLCTQPDQVIKGGASIIQCHILNDKRHILTKDTNNNVAYWDVLKACKVEDLGKVDFEDEIKKRFKMVYVPNWFSVDLKTGMLTITLDESDCFAAWVSAKDAGFSSPDGSDPKLNLGGLLLQALLEYWPRTHVNPMDEEENEVNHVNGEQENRVQKGNGYFQVPPHTPVIFGEAGGRTLFRLLCRDSGGETESMLLNETVPQWVIDITVDKNMPKFNKIPFYLQPHASSGAKTLKKDRLSASDMLQVRKVMEHVYEKIINLDNESQTTSSSNNEKPGEQEKEEDIAVLAEEKIELLCQDQVLDPNMDLRTVKHFIWKSGGDLTLHYRQKST>sp|Q8TAF3-5|WDR48_HUMAN Isoform 5 of WD repeat-containing protein 48OS=Homo sapiens OX=9606 GN=WDR48MAAHHRQNTAGRRKVQCLSGSSDGTIRLWSLGQQRCIATYRVHDEGVWALQVNDAFTHVYSGGRDRKIYCTDLRNPDIRVLICEEKAPVLKMELDRSADPPPAIWVATTKSTVNKWACKVEDLGKVDFEDEIKKRFKMVYVPNWFSVDLKTGMLTITLDESDCFAAWVSAKDAGFSSPDGSDPKLNLGGLLLQALLEYWPRTHVNPMDEEENEVNHVNGEQENRVQKGNGYFQVPPHTPVIFGEAGGRTLFRLLCRDSGGETESMLLNETVPQWVIDITVDKNMPKFNKIPFYLQPHASSGAKTLKKDRLSASDMLQVRKVMEHVYEKIINLDNESQTTSSSNNEKPGEQEKEEDIAVLAEEKIELLCQDQVLDPNMDLRTVKHFIWKSGGDLTLHYRQKST>sp|O75351|VPS4B_HUMAN Vacuolar protein sorting-associated protein 4BOS=Homo sapiens OX=9606 GN=VPS4B PE=1 SV=2MSSTSPNLQKAIDLASKAAQEDKAGNYEEALQLYQHAVQYFLHVVKYEAQGDKAKQSIRAKCTEYLDRAEKLKEYLKNKEKKAQKPVKEGQPSPADEKGNDSDGEGESDDPEKKKLQNQLQGAIVIERPNVKWSDVAGLEGAKEALKEAVILPIKFPHLFTGKRTPWRGILLFGPPGTGKSYLAKAVATEANNSTFFSISSSDLVSKWLGESEKLVKNLFQLARENKPSIIFIDEIDSLCGSRSENESEAARRIKTEFLVQMQGVGVDNDGILVLGATNIPWVLDSAIRRRFEKRIYIPLPEPHARAAMFKLHLGTTQNSLTEADFRELGRKTDGYSGADISIIVRDALMQPVRKVQSATHFKKVRGPSRADPNHLVDDLLTPCSPGDPGAIEMTWMDVPGDKLLEPVVSMSDMLRSLSNTKPTVNEHDLLKLKKFTEDFGQEG>sp|P15822|ZEP1_HUMAN Zinc finger protein 40 OS=Homo sapiens OX=9606GN=HIVEP1 PE=1 SV=3MPRTKQIHPRNLRDKIEEAQKELNGAEVSKKEILQAGVKGTSESLKGVKRKKIVAENHLKKIPKSPLRNPLQAKHKQNTEESSFAVLHSASESHKKQNYIPVKNGKQFTKQNGETPGIIAEASKSEESVSPKKPLFLQQPSELRRWRSEGADPAKFSDLDEQCDSSSLSSKTRTDNSECISSHCGTTSPSYTNTAFDVLLKAMEPELSTLSQKGSPCAIKTEKLRPNKTARSPPKLKNSSMDAPNQTSQELVAESQSSCTSYTVHMSAAQKNEQGAMQSASHLYHQHEHFVPKSNQHNQQLPGCSGFTGSLTNLQNQENAKLEQVYNIAVTSSVGLTSPSSRSQVTPQNQQMDSASPLSISPANSTQSPPMPIYNSTHVASVVNQSVEQMCNLLLKDQKPKKQGKYICEYCNRACAKPSVLLKHIRSHTGERPYPCVTCGFSFKTKSNLYKHKKSHAHTIKLGLVLQPDAGGLFLSHESPKALSIHSDVEDSGESEEEGATDERQHDLGAMELQPVHIIKRMSNAETLLKSSFTPSSPENVIGDFLLQDRSAESQAVTELPKVVVHHVTVSPLRTDSPKAMDPKPELSSAQKQKDLQVTNVQPLSANMSQGGVSRLETNENSHQKGDMNPLEGKQDSHVGTVHAQLQRQQATDYSQEQQGKLLSPRSLGSTDSGYFSRSESADQTVSPPTPFARRLPSTEQDSGRSNGPSAALVTTSTPSALPTGEKALLLPGQMRPPLATKTLEERISKLISDNEALVDDKQLDSVKPRRTSLSRRGSIDSPKSYIFKDSFQFDLKPVGRRTSSSSDIPKSPFTPTEKSKQVFLLSVPSLDCLPITRSNSMPTTGYSAVPANIIPPPHPLRGSQSFDDKIGTFYDDVFVSGPNAPVPQSGHPRTLVRQAAIEDSSANESHVLGTGQSLDESHQGCHAAGEAMSVRSKALAQGPHIEKKKSHQGRGTMFECETCRNRYRKLENFENHKKFYCSELHGPKTKVAMREPEHSPVPGGLQPQILHYRVAGSSGIWEQTPQIRKRRKMKSVGDDEELQQNESGTSPKSSEGLQFQNALGCNPSLPKHNVTIRSDQQHKNIQLQNSHIHLVARGPEQTMDPKLSTIMEQQISSAAQDKIELQRHGTGISVIQHTNSLSRPNSFDKPEPFERASPVSFQELNRTGKSGSLKVIGISQEESHPSRDGSHPHQLALSDALRGELQESSRKSPSERHVLGQPSRLVRQHNIQVPEILVTEEPDRDLEAQCHDQEKSEKFSWPQRSETLSKLPTEKLPPKKKRLRLAEIEHSSTESSFDSTLSRSLSRESSLSHTSSFSASLDIEDVSKTEASPKIDFLNKAEFLMIPAGLNTLNVPGCHREMRRTASEQINCTQTSMEVSDLRSKSFDCGSITPPQTTPLTELQPPSSPSRVGVTGHVPLLERRRGPLVRQISLNIAPDSHLSPVHPTSFQNTALPSVNAVPYQGPQLTSTSLAEFSANTLHSQTQVKDLQAETSNSSSTNVFPVQQLCDINLLNQIHAPPSHQSTQLSLQVSTQGSKPDKNSVLSGSSKSEDCFAPKYQLHCQVFTSGPSCSSNPVHSLPNQVISDPVGTDHCVTSATLPTKLIDSMSNSHPLLPPELRPLGSQVQKVPSSFMLPIRLQSSVPAYCFATLTSLPQILVTQDLPNQPICQTNHSVVPISEEQNSVPTLQKGHQNALPNPEKEFLCENVFSEMSQNSSLSESLPITQKISVGRLSPQQESSASSKRMLSPANSLDIAMEKHQKRAKDENGAVCATDVRPLEALSSRVNEASKQKKPILVRQVCTTEPLDGVMLEKDVFSQPEISNEAVNLTNVLPADNSSTGCSKFVVIEPISELQEFENIKSSTSLTLTVRSSPAPSENTHISPLKCTDNNQERKSPGVKNQGDKVNIQEQSQQPVTSLSLFNIKDTQQLAFPSLKTTTNFTWCYLLRQKSLHLPQKDQKTSAYTDWTVSASNPNPLGLPTKVALALLNSKQNTGKSLYCQAITTHSKSDLLVYSSKWKSSLSKRALGNQKSTVVEFSNKDASEINSEQDKENSLIKSEPRRIKIFDGGYKSNEEYVYVRGRGRGKYICEECGIRCKKPSMLKKHIRTHTDVRPYHCTYCNFSFKTKGNLTKHMKSKAHSKKCVDLGVSVGLIDEQDTEESDEKQRFSYERSGYDLEESDGPDEDDNENEDDDEDSQAESVLSATPSVTASPQHLPSRSSLQDPVSTDEDVRITDCFSGVHTDPMDVLPRALLTRMTVLSTAQSDYNRKTLSPGKARQRAARDENDTIPSVDTSRSPCHQMSVDYPESEEILRSSMAGKAVAITQSPSSVRLPPAAAEHSPQTAAGMPSVASPHPDPQEQKQQITLQPTPGLPSPHTHLFSHLPLHSQQQSRTPYNMVPVGGIHVVPAGLTYSTFVPLQAGPVQLTIPAVSVVHRTLGTHRNTVTEVSGTTNPAGVAELSSVVPCIPIGQIRVPGLQNLSTPGLQSLPSLSMETVNIVGLANTNMAPQVHPPGLALNAVGLQVLTANPSSQSSPAPQAHIPGLQILNIALPTLIPSVSQVAVDAQGAPEMPASQSKACETQPKQTSVASANQVSRTESPQGLPTVQRENAKKVLNPPAPAGDHARLDGLSKMDTEKAASANHVKPKPELTSIQGQPASTSQPLLKAHSEVFTKPSGQQTLSPDRQVPRPTALPRRQPTVHFSDVSSDDDEDRLVIAT>sp|P15822-2|ZEP1_HUMAN Isoform 2 of Zinc finger protein 40 OS=Homosapiens OX=9606 GN=HIVEP1MGQKFQKKRALGNQKSTVVEFSNKDASEINSEQDKENSLIKSEPRRIKIFDGGYKSNEEYVYVRGRGRGKYICEECGIRCKKPSMLKKHIRTHTDVRPYHCTYCNFSFKTKGNLTKHMKSKAHSKKCVDLGVSVGLIDEQDTEESDEKQRFSYERSGYDLEESDGPDEDDNENEDDDEDSQAESVLSATPSVTASPQHLPSRSSLQDPVSTDEDVRITDCFSGVHTDPMDVLPRALLTRMTVLSTAQSDYNRKTLSPGKARQRAARDENDTIPSVDTSRSPCHQMSVDYPESEEILRSSMAGKAVAITQSPSSVRLPPAAAEHSPQTAAGMPSVASPHPDPQEQKQQITLQPTPGLPSPHTHLFSHLPLHSQQQSRTPYNMVPVGGIHVVPAGLTYSTFVPLQAGPVQLTIPAVSVVHRTLGTHRNTVTEVSGTTNPAGVAELSSVVPCIPIGQIRVPGLQNLSTPGLQSLPSLSMETVNIVGLANTNMAPQVHPPGLALNAVGLQVLTANPSSQSSPAPQAHIPGLQILNIALPTLIPSVSQVAVDAQGAPEMPASQSKACETQPKQTSVASANQVSRTESPQGLPTVQRENAKKVLNPPAPAGDHARLDGLSKMDTEKAASANHVKPKPELTSIQGQPASTSQPLLKAHSEVFTKPSGQQTLSPDRQVPRPTALPRRQPTVHFSDVSSDDDEDRLVIAT>sp|P15822-3|ZEP1_HUMAN Isoform 3 of Zinc finger protein 40 OS=Homosapiens OX=9606 GN=HIVEP1MGQKFQKKSYRLVLKELRNPLLKRALGNQKSTVVEFSNKDASEINSEQDKENSLIKSEPRRIKIFDGGYKSNEEYVYVRGRGRGKYICEECGIRCKKPSMLKKHIRTHTDVRPYHCTYCNFSFKTKGNLTKHMKSKAHSKKCVDLGVSVGLIDEQDTEESDEKQRFSYERSGYDLEESDGPDEDDNENEDDDEDSQAESVLSATPSVTASPQHLPSRSSLQDPVSTDEDVRITDCFSGVHTDPMDVLPRALLTRMTVLSTAQSDYNRKTLSPGKARQRAARDENDTIPSVDTSRSPCHQMSVDYPESEEILRSSMAGKAVAITQSPSSVRLPPAAAEHSPQTAAGMPSVASPHPDPQEQKQQITLQPTPGLPSPHTHLFSHLPLHSQQQSRTPYNMVPVGGIHVVPAGLTYSTFVPLQAGPVQLTIPAVSVVHRTLGTHRNTVTEVSGTTNPAGVAELSSVVPCIPIGQIRVPGLQNLSTPGLQSLPSLSMETVNIVGLANTNMAPQVHPPGLALNAVGLQVLTANPSSQSSPAPQAHIPGLQILNIALPTLIPSVSQVAVDAQGAPEMPASQSKACETQPKQTSVASANQVSRTESPQGLPTVQRENAKKVLNPPAPAGDHARLDGLSKMDTEKAASANHVKPKPELTSIQGQPASTSQPLLKAHSEVFTKPSGQQTLSPDRQVPRPTALPRRQPTVHFSDVSSDDDEDRLVIAT>sp|Q8WUU4|ZN296_HUMAN Zinc finger protein 296 OS=Homo sapiens OX=9606GN=ZNF296 PE=1 SV=1MSRRKAGSAPRRVEPAPAANPDDEMEMQDLVIELKPEPDAQPQQAPRLGPFSPKEVSSAGRFGGEPHHSPGPMPAGAALLALGPRNPWTLWTPLTPNYPDRQPWTDKHPDLLTCGRCLQTFPLEAITAFMDHKKLGCQLFRGPSRGQGSEREELKALSCLRCGKQFTVAWKLLRHAQWDHGLSIYQTESEAPEAPLLGLAEVAAAVSAVVGPAAEAKSPRASGSGLTRRSPTCPVCKKTLSSFSNLKVHMRSHTGERPYACDQCPYACAQSSKLNRHKKTHRQVPPQSPLMADTSQEQASAAPPEPAVHAAAPTSTLPCSGGEGAGAAATAGVQEPGAPGSGAQAGPGGDTWGAITTEQRTDPANSQKASPKKMPKSGGKSRGPGGSCEFCGKHFTNSSNLTVHRRSHTGERPYTCEFCNYACAQSSKLNRHRRMHGMTPGSTRFECPHCHVPFGLRATLDKHLRQKHPEAAGEA>sp|Q96K80|ZC3HA_HUMAN Zinc finger CCCH domain-containing protein 10OS=Homo sapiens OX=9606 GN=ZC3H10 PE=1 SV=1MPDRDSYANGTGSSGGGPGGGGSEEASGAGVGSGGASSDAICRDFLRNVCKRGKRCRYRHPDMSEVSNLGVSKNEFIFCHDFQNKECSRPNCRFIHGSKEDEDGYKKTGELPPRLRQKVAAGLGLSPADLPNGKEEVPICRDFLKGDCQRGAKCKFRHLQRDFEFDARGGGGTGGGSTGSVLPGRRHDLYDIYDLPDRGFEDHEPGPKRRRGGCCPPDGPHFESYEYSLAPPRGVECRLLEEENAMLRKRVEELKKQVSNLLATNEVLLEQNAQFRNQAKVITLSSTAPATEQTLAPTVGTVATFNHGIAQTHTTLSSQALQPRPVSQQELVAPAGAPAAPPTNAAPPAAPPPPPPHLTPEITPLSAALAQTIAQGMAPPPVSMAPVAVSVAPVAPVAVSMAQPLAGITMSHTTTPMVTYPIASQSMRITAMPH>sp|P31629|ZEP2_HUMAN Transcription factor HIVEP2 OS=Homo sapiens OX=9606GN=HIVEP2 PE=1 SV=2MDTGDTALGQKATSRSGETDKASGRWRQEQSAVIKMSTFGSHEGQRQPQIEPEQIGNTASAQLFGSGKLASPSEVVQQVAEKQYPPHRPSPYSCQHSLSFPQHSLPQGVMHSTKPHQSLEGPPWLFPGPLPSVASEDLFPFPIHGHSGGYPRKKISSLNPAYSQYSQKSIEQAEEAHKKEHKPKKPGKYICPYCSRACAKPSVLKKHIRSHTGERPYPCIPCGFSFKTKSNLYKHRKSHAHAIKAGLVPFTESAVSKLDLEAGFIDVEAEIHSDGEQSTDTDEESSLFAEASDKMSPGPPIPLDIASRGGYHGSLEESLGGPMKVPILIIPKSGIPLPNESSQYIGPDMLPNPSLNTKADDSHTVKQKLALRLSEKKGQDSEPSLNLLSPHSKGSTDSGYFSRSESAEQQISPPNTNAKSYEEIIFGKYCRLSPRNALSVTTTSQERAAMGRKGIMEPLPHVNTRLDVKMFEDPVSQLIPSKGDVDPSQTSMLKSTKFNSESRQPQIIPSSIRNEGKLYPANFQGSNPVLLEAPVDSSPLIRSNSVPTSSATNLTIPPSLRGSHSFDERMTGSDDVFYPGTVGIPPQRMLRRQAAFELPSVQEGHVEVEHHGRMLKGISSSSLKEKKLSPGDRVGYDYDVCRKPYKKWEDSETPKQNYRDISCLSSLKHGGEYFMDPVVPLQGVPSMFGTTCENRKRRKEKSVGDEEDTPMICSSIVSTPVGIMASDYDPKLQMQEGVRSGFAMAGHENLSHGHTERFDPCRPQLQPGSPSLVSEESPSAIDSDKMSDLGGRKPPGNVISVIQHTNSLSRPNSFERSESAELVACTQDKAPSPSETCDSEISEAPVSPEWAPPGDGAESGGKPSPSQQVQQQSYHTQPRLVRQHNIQVPEIRVTEEPDKPEKEKEAQSKEPEKPVEEFQWPQRSETLSQLPAEKLPPKKKRLRLADMEHSSGESSFESTGTGLSRSPSQESNLSHSSSFSMSFEREETSKLSALPKQDEFGKHSEFLTVPAGSYSLSVPGHHHQKEMRRCSSEQMPCPHPAEVPEVRSKSFDYGNLSHAPVSGAAASTVSPSRERKKCFLVRQASFSGSPEISQGEVGMDQSVKQEQLEHLHAGLRSGWHHGPPAVLPPLQQEDPGKQVAGPCPPLSSGPLHLAQPQIMHMDSQESLRNPLIQPTSYMTSKHLPEQPHLFPHQETIPFSPIQNALFQFQYPTVCMVHLPAQQPPWWQAHFPHPFAQHPQKSYGKPSFQTEIHSSYPLEHVAEHTGKKPAEYAHTKEQTYPCYSGASGLHPKNLLPKFPSDQSSKSTETPSEQVLQEDFASANAGSLQSLPGTVVPVRIQTHVPSYGSVMYTSISQILGQNSPAIVICKVDENMTQRTLVTNAAMQGIGFNIAQVLGQHAGLEKYPIWKAPQTLPLGLESSIPLCLPSTSDSVATLGGSKRMLSPASSLELFMETKQQKRVKEEKMYGQIVEELSAVELTNSDIKKDLSRPQKPQLVRQGCASEPKDGLQSGSSSFSSLSPSSSQDYPSVSPSSREPFLPSKEMLSGSRAPLPGQKSSGPSESKESSDELDIDETASDMSMSPQSSSLPAGDGQLEEEGKGHKRPVGMLVRMASAPSGNVADSTLLLTDMADFQQILQFPSLRTTTTVSWCFLNYTKPNYVQQATFKSSVYASWCISSCNPNPSGLNTKTTLALLRSKQKITAEIYTLAAMHRPGTGKLTSSSAWKQFTQMKPDASFLFGSKLERKLVGNILKERGKGDIHGDKDIGSKQTEPIRIKIFEGGYKSNEDYVYVRGRGRGKYICEECGIRCKKPSMLKKHIRTHTDVRPYVCKLCNFAFKTKGNLTKHMKSKAHMKKCLELGVSMTSVDDTETEEAENLEDLHKAAEKHSMSSISTDHQFSDAEESDGEDGDDNDDDDEDEDDFDDQGDLTPKTRSRSTSPQPPRFSSLPVNVGAVPHGVPSDSSLGHSSLISYLVTLPSIRVTQLMTPSDSCEDTQMTEYQRLFQSKSTDSEPDKDRLDIPSCMDEECMLPSEPSSSPRDFSPSSHHSSPGYDSSPCRDNSPKRYLIPKGDLSPRRHLSPRRDLSPMRHLSPRKEAALRREMSQRDVSPRRHLSPRRPVSPGKDITARRDLSPRRERRYMTTIRAPSPRRALYHNPPLSMGQYLQAEPIVLGPPNLRRGLPQVPYFSLYGDQEGAYEHPGSSLFPEGPNDYVFSHLPLHSQQQVRAPIPMVPVGGIQMVHSMPPALSSLHPSPTLPLPMEGFEEKKGASGESFSKDPYVLSKQHEKRGPHALQSSGPPSTPSSPRLLMKQSTSEDSLNATEREQEENIQTCTKAIASLRIATEEAALLGPDQPARVQEPHQNPLGSAHVSIRHFSRPEPGQPCTSATHPDLHDGEKDNFGTSQTPLAHSTFYSKSCVDDKQLDFHSSKELSSSTEESKDPSSEKSQLH>sp|Q96RE9|ZN300_HUMAN Zinc finger protein 300 OS=Homo sapiens OX=9606GN=ZNF300 PE=1 SV=1MMKSQGLVSFKDVAVDFTQEEWQQLDPSQRTLYRDVMLENYSHLVSMGYPVSKPDVISKLEQGEEPWIIKGDISNWIYPDEYQADGRQDRKSNLHNSQSCILGTVSFHHKILKGVTRDGSLCSILKVCQGDGQLQRFLENQDKLFRQVTFVNSKTVTEASGHKYNPLGKIFQECIETDISIQRFHKYDAFKKNLKPNIDLPSCYKSNSRKKPDQSFGGGKSSSQSEPNSNLEKIHNGVIPFDDNQCGNVFRNTQSLIQYQNVETKEKSCVCVTCGKAFAKKSQLIVHQRIHTGKKPYDCGACGKAFSEKFHLVVHQRTHTGEKPYDCSECGKAFSQKSSLIIHQRVHTGEKPYECSECGKAFSQKSPLIIHQRIHTGEKPYECRECGKAFSQKSQLIIHHRAHTGEKPYECTECGKAFCEKSHLIIHKRIHTGEKPYKCAQCEEAFSRKTELITHQLVHTGEKPYECTECGKTFSRKSQLIIHQRTHTGEKPYKCSECGKAFCQKSHLIGHQRIHTGEKPYICTECGKAFSQKSHLPGHQRIHTGEKPYICAECGKAFSQKSDLVLHQRIHTGERPYQCAICGKAFIQKSQLTVHQRIHTVVKS>sp|Q96RE9-2|ZN300_HUMAN Isoform 2 of Zinc finger protein 300 OS=Homosapiens OX=9606 GN=ZNF300MVPAETSSSGLLEEQKMKSQGLVSFKDVAVDFTQEEWQQLDPSQRTLYRDVMLENYSHLVSMGYPVSKPDVISKLEQGEEPWIIKGDISNWIYPDEYQADGRQDRKSNLHNSQSCILGTVSFHHKILKGVTRDGSLCSILKVCQGDGQLQRFLENQDKLFRQVTFVNSKTVTEASGHKYNPLGKIFQECIETDISIQRFHKYDAFKKNLKPNIDLPSCYKSNSRKKPDQSFGGGKSSSQSEPNSNLEKIHNGVIPFDDNQCGNVFRNTQSLIQYQNVETKEKSCVCVTCGKAFAKKSQLIVHQRIHTGKKPYDCGACGKAFSEKFHLVVHQRTHTGEKPYDCSECGKAFSQKSSLIIHQRVHTGEKPYECSECGKAFSQKSPLIIHQRIHTGEKPYECRECGKAFSQKSQLIIHHRAHTGEKPYECTECGKAFCEKSHLIIHKRIHTGEKPYKCAQCEEAFSRKTELITHQLVHTGEKPYECTECGKTFSRKSQLIIHQRTHTGEKPYKCSECGKAFCQKSHLIGHQRIHTGEKPYICTECGKAFSQKSHLPGHQRIHTGEKPYICAECGKAFSQKSDLVLHQRIHTGERPYQCAICGKAFIQKSQLTVHQRIHTVVKS>sp|Q96RE9-3|ZN300_HUMAN Isoform 3 of Zinc finger protein 300 OS=Homosapiens OX=9606 GN=ZNF300MVPAETSSSGLLEEQKMMKSQGLVSFKDVAVDFTQEEWQQLDPSQRTLYRDVMLENYSHLVSMGYPVSKPDVISKLEQGEEPWIIKGDISNWIYPDEYQADGRQDRKSNLHNSQSCILGTVSFHHKILKGVTRDGSLCSILKVCQGDGQLQRFLENQDKLFRQVTFVNSKTVTEASGHKYNPLGKIFQECIETDISIQRFHKYDAFKKNLKPNIDLPSCYKSNSRKKPDQSFGGGKSSSQSEPNSNLEKIHNGVIPFDDNQCGNVFRNTQSLIQYQNVETKEKSCVCVTCGKAFAKKSQLIVHQRIHTGKKPYDCGACGKAFSEKFHLVVHQRTHTGEKPYDCSECGKAFSQKSSLIIHQRVHTGEKPYECSECGKAFSQKSPLIIHQRIHTGEKPYECRECGKAFSQKSQLIIHHRAHTGEKPYECTECGKAFCEKSHLIIHKRIHTGEKPYKCAQCEEAFSRKTELITHQLVHTGEKPYECTECGKTFSRKSQLIIHQRTHTGEKPYKCSECGKAFCQKSHLIGHQRIHTGEKPYICTECGKAFSQKSHLPGHQRIHTGEKPYICAECGKAFSQKSDLVLHQRIHTGERPYQCAICGKAFIQKSQLTVHQRIHTVVKS>sp|Q96RE9-4|ZN300_HUMAN Isoform 4 of Zinc finger protein 300 OS=Homosapiens OX=9606 GN=ZNF300MLENYSHLVSMGYPVSKPDVISKLEQGEEPWIIKGDISNWIYPDEYQADGRQDRKSNLHNSQSCILGTVSFHHKILKGVTRDGSLCSILKVCQGDGQLQRFLENQDKLFRQVTFVNSKTVTEASGHKYNPLGKIFQECIETDISIQRFHKYDAFKKNLKPNIDLPSCYKSNSRKKPDQSFGGGKSSSQSEPNSNLEKIHNGVIPFDDNQCGNVFRNTQSLIQYQNVETKEKSCVCVTCGKAFAKKSQLIVHQRIHTGKKPYDCGACGKAFSEKFHLVVHQRTHTGEKPYDCSECGKAFSQKSSLIIHQRVHTGEKPYECSECGKAFSQKSPLIIHQRIHTGEKPYECRECGKAFSQKSQLIIHHRAHTGEKPYECTECGKAFCEKSHLIIHKRIHTGEKPYKCAQCEEAFSRKTELITHQLVHTGEKPYECTECGKTFSRKSQLIIHQRTHTGEKPYKCSECGKAFCQKSHLIGHQRIHTGEKPYICTECGKAFSQKSHLPGHQRIHTGEKPYICAECGKAFSQKSDLVLHQRIHTGERPYQCAICGKAFIQKSQLTVHQRIHTVVKS>sp|A6NFI3|ZN316_HUMAN Zinc finger protein 316 OS=Homo sapiens OX=9606GN=ZNF316 PE=1 SV=1MAALHTTPDSPAAQLERAEDGSECDPDQEEEEEEEEKGEEVQEVEEEEEEIVVEEEEEGVAEVVQDAQVEAVAEVEVEADVEEEDVKEVLAEEECPALGTQERLSRGGDAKSPVLQEKGLQASRAPATPRDEDLEEEEEEEEDEDEDDLLTAGCQELVTFEDVAVYFSLEEWERLEADQRGLYQEVMQENYGILVSLGYPIPKPDLIFRLEQGEEPWVPDSPRPEEGDIVTGVYTGAWFWTDDIEDHEEEDDEDFLAEVAEEENEPPGLWSAAYGVGDVPGTWGPDDSDSAQTPEGWGPDPGGLGVLADGSEAKPFLPGREPGANLLSPWAFPAAVAPPAGRPETTCDVCGKVFPHRSRLAKHQRYHAAVKPFGCEECGKGFVYRSHLAIHQRTHTGEKPFPCPDCGKRFVYKSHLVTHRRIHTGERPYRCAFCGAGFGRRSYLVTHQRTHTGERPYPCSHCGRSFSQSSALARHQAVHTADRPHCCPDCGQAFRLRADFQRHRRGGGCAEAGGDGPRREPGETAAAAGPEDTDPGPEGSEVGEADGEAEAAAEEREEAAVAAPTPSGKVDPAPERRFLELGNGLGEGEGPSSHPLGFHFPVHPKSWLHPDSFPILGLPDFRERLPVDGRPLPAPLGGPLSLVEGTGLACDPFGGGGAAGGGGGLRAFGPAIGGLLAEPAPAALAEEESPWICSDCGKTFGRRAALAKHQRYHAGERPHRCADCGKSFVYGSHLARHRRTHTGERPFPCPECGARFARGSHLAAHVRGHTGEKPFVCGVCGAGFSRRAHLTAHGRAHTGERPYACGECGRRFGQSAALTRHQWAHAEEKPHRCPDCGKGFGHSSDFKRHRRTHTGEKPFRCADCGRGFAQRSNLAKHRRGHTGERPFPCPECGKRFSQRSVLVTHQRTHTGERPYACANCGRRFSQSSHLLTHMKTHRGATAAPGSGSAPAPAPKPEAAAKGPSSAGPGERGSALLEFAGGTSFGSEHQAAFAGPSGAYREGVL>sp|Q8N9P0|YF006_HUMAN Putative uncharacterized protein FLJ36797 OS=Homosapiens OX=9606 PE=5 SV=1MTSVASLPEQSPGYRCRSLTGAGARTSAAGPLARLLPRRRLPPPHLPARPPGGWSRNQSHQRRGPGRCWGWGRGMTRICPLCPGAPEYINSAVSSQTLSQSCTPPQSPQPDPRPLSLRVGLALPGGRLGCGEAGSANRHWFSFLFPFIHFCWSPRAAAPGVAMNGWMPARWDHQVRRDVAGARGAPPAWGQAPSPRRSVGGPQKTLKRPKACSPRSPQHTPGVFSAPEKLGRKT>sp|A6NL46|YF016_HUMAN Putative UPF0607 protein ENSP00000332738 OS=Homosapiens OX=9606 PE=3 SV=3MRLCLIPWNTTPHRVLPPVVWSAPSRKKPVLSARNSMMFGHLSPVRNPRLRGKFNLQLPSLDEQVIPTRLPKMEVRAEEPKEATEVKDQVETQGQEDNKTGPCSNGKAASTSRPLETQGNLTSSWYNPRPLEGNVHLKSLTEKNQTDKAQVHAVSFYSKGHGVTSSHSPAGGILPFGKPDPLPAVLPAPVPDCSLWPEKAALKVLGKDHLPSSPGLLMVGEDMQPKDPAALRSSRSSPPRAAGHRPRKRKLSGPPLQLQQTPPLQLRWDRDEGPPPAKLPCLSPEALLVGKASQREGRLQQGNMRKNVRVLSRTSKFRRLRQLLRRRKKRWQGRRGGSRL>sp|Q6PG37|ZN790_HUMAN Zinc finger protein 790 OS=Homo sapiens OX=9606GN=ZNF790 PE=2 SV=2MAHLMMFRDVAVDFSQEEWECLDLEQRDLYRDVMLENYSNMVSLGFCIYQPEAFSLLEKGKEPWKILRDETRGPCPDMQSRCQTKKLLPKNGIFEREIAQLEIMRICKNHSLDCLCFRGDWEGNTQFQTLQDNQEECFKQVIRTCEKRPTFNQHTVFNLHQRLNTGDKLNEFKELGKAFISGSDHTQHQLIHTSEKFCGDKECGNTFLPDSEVIQYQTVHTVKKTYECKECGKSFSLRSSLTGHKRIHTGEKPFKCKDCGKAFRFHSQLSVHKRIHTGEKSYECKECGKAFSCGSDLTRHQRIHTGEKPYECNECRKAFSQRSHLIKHQRIHTGEKPYECKECGKAFTRGSHLTQHQRIHTGEKSHECKECGKAFIRGSNLAQHQNVHVGRKPYKCEKCGKAYIWSSHLARHQRIHTGRKPYECKQCGKTFTWASYLAQHEKIHNERKSYECKECGKTFLHGSEFNRHQKIHTGERNYECKECGKTFFRGSELNRHQKIHTGKRPYECEECGKAFLWGSQLTRHQRMHTGEEPYVCKECGKSFIWGSQLTRHKKIHTDAEPYGCKKSSHIFSHHSYFTEQKIHNSANLCEWTDYGNTFSHESNFAQHQNIYTFEKSYEFKDFEKAFSSSSHFISLL>sp|Q9BRR0|ZKSC3_HUMAN Zinc finger protein with KRAB and SCAN domains 3OS=Homo sapiens OX=9606 GN=ZKSCAN3 PE=1 SV=2MARELSESTALDAQSTEDQMELLVIKVEEEEAGFPSSPDLGSEGSRERFRGFRYPEAAGPREALSRLRELCRQWLQPEMHSKEQILELLVLEQFLTILPGNLQSWVREQHPESGEEVVVLLEYLERQLDEPAPQVSGVDQGQELLCCKMALLTPAPGSQSSQFQLMKALLKHESVGSQPLQDRVLQVPVLAHGGCCREDKVVASRLTPESQGLLKVEDVALTLTPEWTQQDSSQGNLCRDEKQENHGSLVSLGDEKQTKSRDLPPAEELPEKEHGKISCHLREDIAQIPTCAEAGEQEGRLQRKQKNATGGRRHICHECGKSFAQSSGLSKHRRIHTGEKPYECEECGKAFIGSSALVIHQRVHTGEKPYECEECGKAFSHSSDLIKHQRTHTGEKPYECDDCGKTFSQSCSLLEHHRIHTGEKPYQCSMCGKAFRRSSHLLRHQRIHTGDKNVQEPEQGEAWKSRMESQLENVETPMSYKCNECERSFTQNTGLIEHQKIHTGEKPYQCNACGKGFTRISYLVQHQRSHVGKNILSQ>sp|Q9BRR0-2|ZKSC3_HUMAN Isoform 2 of Zinc finger protein with KRAB andSCAN domains 3 OS=Homo sapiens OX=9606 GN=ZKSCAN3MALLTPAPGSQSSQFQLMKALLKHESVGSQPLQDRVLQVPVLAHGGCCREDKVVASRLTPESQGLLKVEDVALTLTPEWTQQDSSQGNLCRDEKQENHGSLVSLGDEKQTKSRDLPPAEELPEKEHGKISCHLREDIAQIPTCAEAGEQEGRLQRKQKNATGGRRHICHECGKSFAQSSGLSKHRRIHTGEKPYECEECGKAFIGSSALVIHQRVHTGEKPYECEECGKAFSHSSDLIKHQRTHTGEKPYECDDCGKTFSQSCSLLEHHRIHTGEKPYQCSMCGKAFRRSSHLLRHQRIHTGDKNVQEPEQGEAWKSRMESQLENVETPMSYKCNECERSFTQNTGLIEHQKIHTGEKPYQCNACGKGFTRISYLVQHQRSHVGKNILSQ>sp|P10072|ZN875_HUMAN Zinc finger protein 875 OS=Homo sapiens OX=9606GN=ZNF875 PE=2 SV=4MRVNHTVSTMLPTCMVHRQTMSCSGAGGITAFVAFRDVAVYFTQEEWRLLSPAQRTLHREVMLETYNHLVSLEIPSSKPKLIAQLERGEAPWREERKCPLDLCPESKPEIQLSPSCPLIFSSQQALSQHVWLSHLSQLFSSLWAGNPLHLGKHYPEDQKQQQDPFCFSGKAEWIQEGEDSRLLFGRVSKNGTSKALSSPPEEQQPAQSKEDNTVVDIGSSPERRADLEETDKVLHGLEVSGFGEIKYEEFGPGFIKESNLLSLQKTQTGETPYMYTEWGDSFGSMSVLIKNPRTHSGGKPYVCRECGRGFTWKSNLITHQRTHSGEKPYVCKDCGRGFTWKSNLFTHQRTHSGLKPYVCKECGQSFSLKSNLITHQRAHTGEKPYVCRECGRGFRQHSHLVRHKRTHSGEKPYICRECEQGFSQKSHLIRHLRTHTGEKPYVCTECGRHFSWKSNLKTHQRTHSGVKPYVCLECGQCFSLKSNLNKHQRSHTGEKPFVCTECGRGFTRKSTLSTHQRTHSGEKPFVCAECGRGFNDKSTLISHQRTHSGEKPFMCRECGRRFRQKPNLFRHKRAHSGAFVCRECGQGFCAKLTLIKHQRAHAGGKPHVCRECGQGFSRQSHLIRHQRTHSGEKPYICRKCGRGFSRKSNLIRHQRTHSG>sp|P10072-2|ZN875_HUMAN Isoform 2 of Zinc finger protein 875 OS=Homosapiens OX=9606 GN=ZNF875MATGLLRAKKEAFVAFRDVAVYFTQEEWRLLSPAQRTLHREVMLETYNHLVSLEIPSSKPKLIAQLERGEAPWREERKCPLDLCPESKPEIQLSPSCPLIFSSQQALSQHVWLSHLSQLFSSLWAGNPLHLGKHYPEDQKQQQDPFCFSGKAEWIQEGEDSRLLFGRVSKNGTSKALSSPPEEQQPAQSKEDNTVVDIGSSPERRADLEETDKVLHGLEVSGFGEIKYEEFGPGFIKESNLLSLQKTQTGETPYMYTEWGDSFGSMSVLIKNPRTHSGGKPYVCRECGRGFTWKSNLITHQRTHSGEKPYVCKDCGRGFTWKSNLFTHQRTHSGLKPYVCKECGQSFSLKSNLITHQRAHTGEKPYVCRECGRGFRQHSHLVRHKRTHSGEKPYICRECEQGFSQKSHLIRHLRTHTGEKPYVCTECGRHFSWKSNLKTHQRTHSGVKPYVCLECGQCFSLKSNLNKHQRSHTGEKPFVCTECGRGFTRKSTLSTHQRTHSGEKPFVCAECGRGFNDKSTLISHQRTHSGEKPFMCRECGRRFRQKPNLFRHKRAHSGAFVCRECGQGFCAKLTLIKHQRAHAGGKPHVCRECGQGFSRQSHLIRHQRTHSGEKPYICRKCGRGFSRKSNLIRHQRTHSG>sp|Q96H86|ZN764_HUMAN Zinc finger protein 764 OS=Homo sapiens OX=9606GN=ZNF764 PE=1 SV=2MAPPLAPLPPRDPNGAGPEWREPGAVSFADVAVYFCREEWGCLRPAQRALYRDVMRETYGHLSALGIGGNKPALISWVEEEAELWGPAAQDPEVAKCQTQTDPADSRNKKKERQREGTGALEKPDPVAAGSPGLKSPQAPSAGPPYGWEQLSKAPHRGRPSLCAHPPVPRADQRHGCYVCGKSFAWRSTLVEHVYSHTGEKPFHCTDCGKGFGHASSLSKHRAIHRGERPHRCLECGRAFTQRSALTSHLRVHTGEKPYGCADCGRRFSQSSALYQHRRVHSGETPFPCPDCGRAFAYPSDLRRHVRTHTGEKPYPCPDCGRCFRQSSEMAAHRRTHSGEKPYPCPQCGRRFGQKSAVAKHQWVHRPGAGGHRGRVAGRLSVTLTPGHGDLDPPVGFQLYPEIFQECG>sp|Q96H86-2|ZN764_HUMAN Isoform 2 of Zinc finger protein 764 OS=Homosapiens OX=9606 GN=ZNF764MAPPLAPLPPRDPNGAGPEWREPGAVSFADVAVYFCREEWGCLRPAQRALYRDVMRETYGHLSALGIGGNKPALISWVEEEAELWGPAAQDPEVAKCQTQTDPDSRNKKKERQREGTGALEKPDPVAAGSPGLKSPQAPSAGPPYGWEQLSKAPHRGRPSLCAHPPVPRADQRHGCYVCGKSFAWRSTLVEHVYSHTGEKPFHCTDCGKGFGHASSLSKHRAIHRGERPHRCLECGRAFTQRSALTSHLRVHTGEKPYGCADCGRRFSQSSALYQHRRVHSGETPFPCPDCGRAFAYPSDLRRHVRTHTGEKPYPCPDCGRCFRQSSEMAAHRRTHSGEKPYPCPQCGRRFGQKSAVAKHQWVHRPGAGGHRGRVAGRLSVTLTPGHGDLDPPVGFQLYPEIFQECG>sp|Q9UF83|YM012_HUMAN Uncharacterized protein DKFZp434B061 OS=Homosapiens OX=9606 PE=2 SV=2MRRPSTASLTRTPSRASPTRMPSRASLKMTPFRASLTKMESTALLRTLPRASLMRTPTRASLMRTPPRASPTRKPPRASPRTPSRASPTRRLPRASPMGSPHRASPMRTPPRASPTGTPSTASPTGTPSSASPTGTPPRASPTGTPPRAWATRSPSTASLTRTPSRASLTRWPPRASPTRTPPRESPRMSHRASPTRTPPRASPTRRPPRASPTRTPPRESLRTSHRASPTRMPPRASPTRRPPRASPTGSPPRASPMTPPRASPRTPPRASPTTTPSRASLTRTPSWASPTTTPSRASLMKMESTVSITRTPPRASPTGTPSRASPTGTPSRASLTGSPSRASLTGTPSRASLIGTPSRASLIGTPSRASLTGTPPRASLTGTSSTASLTRTPSRASLTRTQSSSSLTRTPSMASLTRTPPRASLTRTPPRASLTRTPPRASLTRTPPRASLTRTPSMVSLKRSPSRASLTRTPSRASLTMTPSRASLTRTPSTASLTGTPPTASLTRTPPTASLTRSPPTASLTRTPSTASLTRMPSTASLTRKSNVNQQCPASTPSSEVIS>sp|Q6AHZ1|Z518A_HUMAN Zinc finger protein 518A OS=Homo sapiens OX=9606GN=ZNF518A PE=1 SV=2MPSEQKQLFCDEKQTTLKKDYDVKNEIVDRSAPKPKISGSIHYALKNVKIDLPKINIPNEVLLKHEVDKYRKLFQSKQQTARKSISIKTVSCVEECTLLHKSERAEEEGVKMSAKILNFSCLKCRDNTRYSPNDLQKHFQMWHHGELPSYPCEMCNFSANDFQVFKQHRRTHRSTLVKCDICNNESVYTLLNLTKHFTSTHCVNGNFQCEKCKFSTQDVGTFVQHIHRHNEIHYKCGKCHHVCFTKGELQKHLHIHSGTFPFTCQYCSYGATRREHLVRHVITLHKEHLYAKEKLEKDKYEKRMAKTSAGLKLILKRYKIGASRKTFWKRKKINSGSDRSIEKNTQVLKKMNKTQTKSEDQSHVVQEHLSEEKDERLHCENNDKAPESESEKPTPLSTGQGNRAEEGPNASSGFMKTAVLGPTLKNVMMKNNKLAVSPNYNATFMGFKMMDGKQHIVLKLVPIKQNVCSPGSQSGAAKDGTANLQPQTLDTNGFLTGVTTELNDTVYMKAATPFSCSSSILSGKASSEKEMTLISQRNNMLQTMDYEKSVSSLSATSELVTASVNLTTKFETRDNVDFWGNHLTQSHPEVLGTTIKSPDKVNCVAKPNAYNSGDMHNYCINYGNCELPVESSNQGSLPFHNYSKVNNSNKRRRFSGTAVYENPQRESSSSKTVVQQPISESFLSLVRQESSKPDSLLASISLLNDKDGTLKAKSEIEEQYVLEKGQNIDGQNLYSNENQNLECATEKSKWEDFSNVDSPMMPRITSVFSLQSQQASEFLPPEVNQLLQDVLKIKPDVKQDSSNTPNKGLPLHCDQSFQKHEREGKIVESSKDFKVQGIFPVPPGSVGINVPTNDLNLKFGKEKQVSSIPQDVRDSEKMPRISGFGTLLKTQSDAIITQQLVKDKLRATTQNLGSFYMQSPLLNSEQKKTIIVQTSKGFLIPLNITNKPGLPVIPGNALPLVNSQGIPASLFVNKKPGMVLTLNNGKLEGVSAVKTEGAPARGTVTKEPCKTPILKVEPNNNCLTPGLCSSIGSCLSMKSSSENTLPLKGPYILKPTSSVKAVLIPNMLSEQQSTKLNISDSVKQQNEIFPKPPLYTFLPDGKQAVFLKCVMPNKTELLKPKLVQNSTYQNIQPKKPEGTPQRILLKIFNPVLNVTAANNLSVSNSASSLQKDNVPSNQIIGGEQKEPESRDALPFLLDDLMPANEIVITSTATCPESSEEPICVSDCSESRVLRCKTNCRIERNFNRKKTSKKIFSKTKTHGSKDSETAFVSRNRNCKRKCRDSYQEPPRRKATLHRKCKEKAKPEDVRETFGFSRPRLSKDSIRTLRLFPFSSKQLVKCPRRNQPVVVLNHPDADAPEVVSVMKTIAKFNGHVLKVSLSKRTINALLKPVCYNPPKTTYDDFSKRHKTFKPVSSVKERFVLKLTLKKTSKNNYQIVKTTSENILKAKFNCWFCGRVFDNQDTWAGHGQRHLMEATRDWNMLE>sp|Q6AHZ1-2|Z518A_HUMAN Isoform 2 of Zinc finger protein 518A OS=Homosapiens OX=9606 GN=ZNF518AMTLISQRNNMLQTMDYEKSVSSLSATSELVTASVNLTTKFETRDNVDFWGNHLTQSHPEVLGTTIKSPDKVNCVAKPNAYNSGDMHNYCINYGNCELPVESSNQGSLPFHNYSKVNNSNKRRRFSGTAVYENPQRESSSSKTVVQQPISESFLSLVRQESSKPDSLLASISLLNDKDGTLKAKSEIEEQYVLEKGQNIDGQNLYSNENQNLECATEKSKWEDFSNVDSPMMPRITSVFSLQSQQASEFLPPEVNQLLQDVLKIKPDVKQDSSNTPNKGLPLHCDQSFQKHEREGKIVESSKDFKVQGIFPVPPGSVGINVPTNDLNLKFGKEKQVSSIPQDVRDSEKMPRISGFGTLLKTQSDAIITQQLVKDKLRATTQNLGSFYMQSPLLNSEQKKTIIVQTSKGFLIPLNITNKPGLPVIPGNALPLVNSQGIPASLFVNKKPGMVLTLNNGKLEGVSAVKTEGAPARGTVTKEPCKTPILKVEPNNNCLTPGLCSSIGSCLSMKSSSENTLPLKGPYILKPTSSVKAVLIPNMLSEQQSTKLNISDSVKQQNEIFPKPPLYTFLPDGKQAVFLKCVMPNKTELLKPKLVQNSTYQNIQPKKPEGTPQRILLKIFNPVLNVTAANNLSVSNSASSLQKDNVPSNQIIGGEQKEPESRDALPFLLDDLMPANEIVITSTATCPESSEEPICVSDCSESRVLRCKTNCRIERNFNRKKTSKKIFSKTKTHGSKDSETAFVSRNRNCKRKCRDSYQEPPRRKATLHRKCKEKAKPEDVRETFGFSRPRLSKDSIRTLRLFPFSSKQLVKCPRRNQPVVVLNHPDADAPEVVSVMKTIAKFNGHVLKVSLSKRTINALLKPVCYNPPKTTYDDFSKRHKTFKPVSSVKERFVLKLTLKKTSKNNYQIVKTTSENILKAKFNCWFCGRVFDNQDTWAGHGQRHLMEATRDWNMLE>sp|O00233|PSMD9_HUMAN 26S proteasome non-ATPase regulatory subunit 9OS=Homo sapiens OX=9606 GN=PSMD9 PE=1 SV=3MSDEEARQSGGSSQAGVVTVSDVQELMRRKEEIEAQIKANYDVLESQKGIGMNEPLVDCEGYPRSDVDLYQVRTARHNIICLQNDHKAVMKQVEEALHQLHARDKEKQARDMAEAHKEAMSRKLGQSESQGPPRAFAKVNSISPGSPASIAGLQVDDEIVEFGSVNTQNFQSLHNIGSVVQHSEGKPLNVTVIRRGEKHQLRLVPTRWAGKGLLGCNIIPLQR>sp|O00233-2|PSMD9_HUMAN Isoform p27-S of 26S proteasome non-ATPaseregulatory subunit 9 OS=Homo sapiens OX=9606 GN=PSMD9MSDEEARQSGGSSQAGVVTVSDVQELMRRKEEIEAQIKANYDVLESQKGIGMNEPLVDCEGYPRSDVDLYQVRTARHNIICLQNDHKAVMKQVEEALHQLHARDKEKQARDMAEAHKEAMSRKLGQSESQGPPRAFAKVNSISPGSPASIAGLQVDDEIVEFGSVNTQNFQSLHNIGSVVQHSEGALAPTILLSVSMNLTTPGTSSRSP>sp|O00233-3|PSMD9_HUMAN Isoform 3 of 26S proteasome non-ATPaseregulatory subunit 9 OS=Homo sapiens OX=9606 GN=PSMD9MSDEEARQSGGSSQAGVVTVSDVQELMRRKEEIEAQIKANYDVLESGLQVDDEIVEFGSVNTQNFQSLHNIGSVVQHSEGKPLNVTVIRRGEKHQLRLVPTRWAGKGLLGCNIIPLQR>sp|Q02127|PYRD_HUMAN Dihydroorotate dehydrogenase (quinone),mitochondrial OS=Homo sapiens OX=9606 GN=DHODH PE=1 SV=3MAWRHLKKRAQDAVIILGGGGLLFASYLMATGDERFYAEHLMPTLQGLLDPESAHRLAVRFTSLGLLPRARFQDSDMLEVRVLGHKFRNPVGIAAGFDKHGEAVDGLYKMGFGFVEIGSVTPKPQEGNPRPRVFRLPEDQAVINRYGFNSHGLSVVEHRLRARQQKQAKLTEDGLPLGVNLGKNKTSVDAAEDYAEGVRVLGPLADYLVVNVSSPNTAGLRSLQGKAELRRLLTKVLQERDGLRRVHRPAVLVKIAPDLTSQDKEDIASVVKELGIDGLIVTNTTVSRPAGLQGALRSETGGLSGKPLRDLSTQTIREMYALTQGRVPIIGVGGVSSGQDALEKIRAGASLVQLYTALTFWGPPVVGKVKRELEALLKEQGFGGVTDAIGADHRR>sp|Q9NTZ6|RBM12_HUMAN RNA-binding protein 12 OS=Homo sapiens OX=9606GN=RBM12 PE=1 SV=1MAVVIRLQGLPIVAGTMDIRHFFSGLTIPDGGVHIVGGELGEAFIVFATDEDARLGMMRTGGTIKGSKVTLLLSSKTEMQNMIELSRRRFETANLDIPPANASRSGPPPSSGMSSRVNLPTTVSNFNNPSPSVVTATTSVHESNKNIQTFSTASVGTAPPNMGASFGSPTFSSTVPSTASPMNTVPPPPIPPIPAMPSLPPMPSIPPIPVPPPVPTLPPVPPVPPIPPVPSVPPMTPLPPMSGMPPLNPPPVAPLPAGMNGSGAPMNLNNNLNPMFLGPLNPVNPIQMNSQSSVKPLPINPDDLYVSVHGMPFSAMENDVRDFFHGLRVDAVHLLKDHVGRNNGNGLVKFLSPQDTFEALKRNRMLMIQRYVEVSPATERQWVAAGGHITFKQNMGPSGQTHPPPQTLPRSKSPSGQKRSRSRSPHEAGFCVYLKGLPFEAENKHVIDFFKKLDIVEDSIYIAYGPNGKATGEGFVEFRNEADYKAALCRHKQYMGNRFIQVHPITKKGMLEKIDMIRKRLQNFSYDQREMILNPEGDVNSAKVCAHITNIPFSITKMDVLQFLEGIPVDENAVHVLVDNNGQGLGQALVQFKNEDDARKSERLHRKKLNGREAFVHVVTLEDMREIEKNPPAQGKKGLKMPVPGNPAVPGMPNAGLPGVGLPSAGLPGAGLPSTGLPGSAITSAGLPGAGMPSAGIPSAGGEEHAFLTVGSKEANNGPPFNFPGNFGGSNAFGPPIPPPGLGGGAFGDARPGMPSVGNSGLPGLGLDVPGFGGGPNNLSGPSGFGGGPQNFGNGPGSLGGPPGFGSGPPGLGSAPGHLGGPPAFGPGPGPGPGPGPIHIGGPPGFASSSGKPGPTVIKVQNMPFTVSIDEILDFFYGYQVIPGSVCLKYNEKGMPTGEAMVAFESRDEATAAVIDLNDRPIGSRKVKLVLG>sp|P50749|RASF2_HUMAN Ras association domain-containing protein 2OS=Homo sapiens OX=9606 GN=RASSF2 PE=1 SV=1MDYSHQTSLVPCGQDKYISKNELLLHLKTYNLYYEGQNLQLRHREEEDEFIVEGLLNISWGLRRPIRLQMQDDNERIRPPPSSSSWHSGCNLGAQGTTLKPLTVPKVQISEVDAPPEGDQMPSSTDSRGLKPLQEDTPQLMRTRSDVGVRRRGNVRTPSDQRRIRRHRFSINGHFYNHKTSVFTPAYGSVTNVRINSTMTTPQVLKLLLNKFKIENSAEEFALYVVHTSGEKQKLKATDYPLIARILQGPCEQISKVFLMEKDQVEEVTYDVAQYIKFEMPVLKSFIQKLQEEEDREVKKLMRKYTVLRLMIRQRLEEIAETPATI>sp|P50749-2|RASF2_HUMAN Isoform 2 of Ras association domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=RASSF2MSLNWNLTLQNEWPLLEFSKTTLKPLTVPKVQISEVDAPPEGDQMPSSTDSRGLKPLQEDTPQLMRTRSDVGVRRRGNVRTPSDQRRIRRHRFSINGHFYNHKTSVFTPAYGSVTNVRINSTMTTPQVLKLLLNKFKIENSAEEFALYVVHTSGGPM>sp|P49756|RBM25_HUMAN RNA-binding protein 25 OS=Homo sapiens OX=9606GN=RBM25 PE=1 SV=3MSFPPHLNRPPMGIPALPPGIPPPQFPGFPPPVPPGTPMIPVPMSIMAPAPTVLVPTVSMVGKHLGARKDHPGLKAKENDENCGPTTTVFVGNISEKASDMLIRQLLAKCGLVLSWKRVQGASGKLQAFGFCEYKEPESTLRALRLLHDLQIGEKKLLVKVDAKTKAQLDEWKAKKKASNGNARPETVTNDDEEALDEETKRRDQMIKGAIEVLIREYSSELNAPSQESDSHPRKKKKEKKEDIFRRFPVAPLIPYPLITKEDINAIEMEEDKRDLISREISKFRDTHKKLEEEKGKKEKERQEIEKERRERERERERERERREREREREREREREKEKERERERERDRDRDRTKERDRDRDRERDRDRDRERSSDRNKDRSRSREKSRDREREREREREREREREREREREREREREREREREREKDKKRDREEDEEDAYERRKLERKLREKEAAYQERLKNWEIRERKKTREYEKEAEREEERRREMAKEAKRLKEFLEDYDDDRDDPKYYRGSALQKRLRDREKEMEADERDRKREKEELEEIRQRLLAEGHPDPDAELQRMEQEAERRRQPQIKQEPESEEEEEEKQEKEEKREEPMEEEEEPEQKPCLKPTLRPISSAPSVSSASGNATPNTPGDESPCGIIIPHENSPDQQQPEEHRPKIGLSLKLGASNSPGQPNSVKRKKLPVDSVFNKFEDEDSDDVPRKRKLVPLDYGEDDKNATKGTVNTEEKRKHIKSLIEKIPTAKPELFAYPLDWSIVDSILMERRIRPWINKKIIEYIGEEEATLVDFVCSKVMAHSSPQSILDDVAMVLDEEAEVFIVKMWRLLIYETEAKKIGLVK>sp|P49756-2|RBM25_HUMAN Isoform 2 of RNA-binding protein 25 OS=Homosapiens OX=9606 GN=RBM25MSFPPHLNRPPMGIPALPPGIPPPQFPGFPPPVPPGTPMIPVPMSIMAPAPTVLVPTVSMVGKHLGARKDHPGLKAKENDENCGPTTTVFVGNISEKASDMLIRQLLAKCGLVLSWKRVQGASGKLQAFGFCEYKEPESTLRALRLLHDLQIGEKKLLVKVDAKTKAQLDEWKAKKKASNGNARPETVTNDDEEALDEETKRRDQMIKGAIEVLIREYSSELNAPSQESDSHPRKKKKEKKEDIFRRFPVAPLIPYPLITKEDINAIEMEEDKRDLISREISKFRDTHKRSYGD>sp|P49756-3|RBM25_HUMAN Isoform 3 of RNA-binding protein 25 OS=Homosapiens OX=9606 GN=RBM25MSFPPHLNRPPMGIPALPPGIPPPQFPGFPPPVPPGTPMIPVPMSIMAPAPTVLVPTVSMVGKHLGARKDHPGLKAKENDENCGPTTTVFVGNISEKASDMLIRQLLAKCGLVLSWKRVQGASGKLQAFGFCEYKEPESTLRALRLLHDLQIGEKKLLVKVDAKTKAQLDEWKAKKKASNGNARPETVTNDDEEALDEETKRRDQMIKGAIEVLIREYSSELNAPSQESDSHPRKKKKEKKEDIFRRFPVAPLIPYPLITKEDINAIEMEEDKRDLISREISKFRDTHKVVFLSFHLIPI>sp|P49756-4|RBM25_HUMAN Isoform 4 of RNA-binding protein 25 OS=Homosapiens OX=9606 GN=RBM25MSFPPHLNRPPMGIPALPPGIPPPQFPGFPPPVPPGTPMIPVPMSIMAPAPTVLVPTVSMVGKHLGARKDHPGLKAKENDENCGPTTTVFVGNISEKASDMLIRQLLAPSDSVSTRSQNLPSVHSDYYMTCKLERKSYSLKLMQRQRHSWMNGKQRRKLLMGLG>sp|Q8N697|S15A4_HUMAN Solute carrier family 15 member 4 OS=Homo sapiensOX=9606 GN=SLC15A4 PE=1 SV=1MEGSGGGAGERAPLLGARRAAAAAAAAGAFAGRRAACGAVLLTELLERAAFYGITSNLVLFLNGAPFCWEGAQASEALLLFMGLTYLGSPFGGWLADARLGRARAILLSLALYLLGMLAFPLLAAPATRAALCGSARLLNCTAPGPDAAARCCSPATFAGLVLVGLGVATVKANITPFGADQVKDRGPEATRRFFNWFYWSINLGAILSLGGIAYIQQNVSFVTGYAIPTVCVGLAFVVFLCGQSVFITKPPDGSAFTDMFKILTYSCCSQKRSGERQSNGEGIGVFQQSSKQSLFDSCKMSHGGPFTEEKVEDVKALVKIVPVFLALIPYWTVYFQMQTTYVLQSLHLRIPEISNITTTPHTLPAAWLTMFDAVLILLLIPLKDKLVDPILRRHGLLPSSLKRIAVGMFFVMCSAFAAGILESKRLNLVKEKTINQTIGNVVYHAADLSLWWQVPQYLLIGISEIFASIAGLEFAYSAAPKSMQSAIMGLFFFFSGVGSFVGSGLLALVSIKAIGWMSSHTDFGNINGCYLNYYFFLLAAIQGATLLLFLIISVKYDHHRDHQRSRANGVPTSRRA>sp|Q8N697-2|S15A4_HUMAN Isoform 2 of Solute carrier family 15 member 4OS=Homo sapiens OX=9606 GN=SLC15A4MQTTYVLQSLHLRIPEISNITTTPHTLPAAWLTMFDAVLILLLIPLKDKLVDPILRRHGLLPSSLKRIAVGMFFVMCSAFAAGILESKRLNLVKEKTINQTIGNVVYHAADLSLWWQVPQYLLIGISEIFASIAGLEFAYSAAPKSMQSAIMGLFFFFSGVGSFVGSGLLALVSIKAIGWMSSHTDFGNINGCYLNYYFFLLAAIQGATLLLFLIISVKYDHHRDHQRSRANGVPTSRRA>sp|Q5T160|SYRM_HUMAN Probable arginine--tRNA ligase, mitochondrialOS=Homo sapiens OX=9606 GN=RARS2 PE=1 SV=1MACGFRRAIACQLSRVLNLPPENLITSISAVPISQKEEVADFQLSVDSLLEKDNDHSRPDIQVQAKRLAEKLRCDTVVSEISTGQRTVNFKINRELLTKTVLQQVIEDGSKYGLKSELFSGLPQKKIVVEFSSPNVAKKFHVGHLRSTIIGNFIANLKEALGHQVIRINYLGDWGMQFGLLGTGFQLFGYEEKLQSNPLQHLFEVYVQVNKEAADDKSVAKAAQEFFQRLELGDVQALSLWQKFRDLSIEEYIRVYKRLGVYFDEYSGESFYREKSQEVLKLLESKGLLLKTIKGTAVVDLSGNGDPSSICTVMRSDGTSLYATRDLAAAIDRMDKYNFDTMIYVTDKGQKKHFQQVFQMLKIMGYDWAERCQHVPFGVVQGMKTRRGDVTFLEDVLNEIQLRMLQNMASIKTTKELKNPQETAERVGLAALIIQDFKGLLLSDYKFSWDRVFQSRGDTGVFLQYTHARLHSLEETFGCGYLNDFNTACLQEPQSVSILQHLLRFDEVLYKSSQDFQPRHIVSYLLTLSHLAAVAHKTLQIKDSPPEVAGARLHLFKAVRSVLANGMKLLGITPVCRM>sp|P21675|TAF1_HUMAN Transcription initiation factor TFIID subunit 1OS=Homo sapiens OX=9606 GN=TAF1 PE=1 SV=2MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNISYGSYEEPDPKSNTQDTSFSSIGGYEVSEEEEDEEEEEQRSGPSVLSQVHLSEDEEDSEDFHSIAGDSDLDSDE>sp|P21675-2|TAF1_HUMAN Isoform 2 of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGVSENGEGIILPSIIAPSSLASEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNISYGSYEEPDPKSNTQDTSFSSIGGYEVSEEEEDEEEEEQRSGPSVLSQVHLSEDEEDSEDFHSIAGDSDLDSDE>sp|P21675-3|TAF1_HUMAN Isoform 3 of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQMRQGRGRLGEEDSDVDIEGYDDEEEDGKPKTPAPEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNIRYQ>sp|P21675-4|TAF1_HUMAN Isoform 4 of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQMRQGRGRLGEEDSDVDIEGYDDEEEDGKPKTPAPEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNISYGSYEEPDPKSNTQDTSFSSIGGYEVSEEEEDEEEEEQRSGPSVLSQVHLSEDEEDSEDFHSIAGDSDLDSDE>sp|P21675-5|TAF1_HUMAN Isoform 2a of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQMRQGRGRLGEEDSDVDIEGYDDEEEDGKPKTPAPEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNIRYQ>sp|P21675-6|TAF1_HUMAN Isoform 2c of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNIRYQ>sp|P21675-7|TAF1_HUMAN Isoform 2d of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQAKPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNIRYQ>sp|P21675-8|TAF1_HUMAN Isoform 2e of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGYMCTTCRT>sp|P21675-9|TAF1_HUMAN Isoform 2g of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQAKPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQMRQGRGRLGEEDSDVDIEGYDDEEEDGKPKTPAPEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNIRYQ>sp|P21675-10|TAF1_HUMAN Isoform 2h of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDIITK>sp|P21675-11|TAF1_HUMAN Isoform 2i of Transcription initiation factorTFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDVSCLCAKYFLAISSPS>sp|P21675-12|TAF1_HUMAN Isoform N-TAF1 of Transcription initiationfactor TFIID subunit 1 OS=Homo sapiens OX=9606 GN=TAF1MGPGCDLLLRTAATITAAAIMSDTDSDEDSAGGGPFSLAGFLFGNINGAGQLEGESVLDDECKKHLAGLGALGLGSLITELTANEELTGTDGALVNDEGWVRSTEDAVDYSDINEVAEDESRRYQQTMGSLQPLCHSDYDEDDYDADCEDIDCKLMPPPPPPPGPMKKDKDQDSITGVSENGEGIILPSIIAPSSLASEKVDFSSSSDSESEMGPQEATQAESEDGKLTLPLAGIMQHDATKLLPSVTELFPEFRPGKVLRFLRLFGPGKNVPSVWRSARRKRKKKHRELIQEEQIQEVECSVESEVSQKSLWNYDYAPPPPPEQCLSDDEITMMAPVESKFSQSTGDIDKVTDTKPRVAEWRYGPARLWYDMLGVPEDGSGFDYGFKLRKTEHEPVIKSRMIEEFRKLEENNGTDLLADENFLMVTQLHWEDDIIWDGEDVKHKGTKPQRASLAGWLPSSMTRNAMAYNVQQGFAATLDDDKPWYSIFPIDNEDLVYGRWEDNIIWDAQAMPRLLEPPVLTLDPNDENLILEIPDEKEEATSNSPSKESKKESSLKKSRILLGKTGVIKEEPQQNMSQPEVKDPWNLSNDEYYYPKQQGLRGTFGGNIIQHSIPAVELRQPFFPTHMGPIKLRQFHRPPLKKYSFGALSQPGPHSVQPLLKHIKKKAKMREQERQASGGGEMFFMRTPQDLTGKDGDLILAEYSEENGPLMMQVGMATKIKNYYKRKPGKDPGAPDCKYGETVYCHTSPFLGSLHPGQLLQAFENNLFRAPIYLHKMPETDFLIIRTRQGYYIRELVDIFVVGQQCPLFEVPGPNSKRANTHIRDFLQVFIYRLFWKSKDRPRRIRMEDIKKAFPSHSESSIRKRLKLCADFKRTGMDSNWWVLKSDFRLPTEEEIRAMVSPEQCCAYYSMIAAEQRLKDAGYGEKSFFAPEEENEEDFQMKIDDEVRTAPWNTTRAFIAAMKGKCLLEVTGVADPTGCGEGFSYVKIPNKPTQQKDDKEPQPVKKTVTGTDADLRRLSLKNAKQLLRKFGVPEEEIKKLSRWEVIDVVRTMSTEQARSGEGPMSKFARGSRFSVAEHQERYKEECQRIFDLQNKVLSSTEVLSTDTDSSSAEDSDFEEMGKNIENMLQNKKTSSQLSREREEQERKELQRMLLAAGSAASGNNHRDDDTASVTSLNSSATGRCLKIYRTFRDEEGKEYVRCETVRKPAVIDAYVRIRTTKDEEFIRKFALFDEQHREEMRKERRRIQEQLRRLKRNQEKEKLKGPPEKKPKKMKERPDLKLKCGACGAIGHMRTNKFCPLYYQTNAPPSNPVAMTEEQEEELEKTVIHNDNEELIKVEGTKIVLGKQLIESADEVRRKSLVLKFPKQQLPPKKKRRVGTTVHCDYLNRPHKSIHRRRTDPMVTLSSILESIINDMRDLPNTYPFHTPVNAKVVKDYYKIITRPMDLQTLRENVRKRLYPSREEFREHLELIVKNSATYNGPKHSLTQISQSMLDLCDEKLKEKEDKLARLEKAINPLLDDDDQVAFSFILDNIVTQKMMAVPDSWPFHHPVNKKFVPDYYKVIVNPMDLETIRKNISKHKYQSRESFLDDVNLILANSVKYNGPESQYTKTAQEIVNVCYQTLTEYDEHLTQLEKDICTAKEAALEEAELESLDPMTPGPYTPQAKPPDLYDTNTSLSMSRDASVFQDESNMSVLDIPSATPEKQVTQEGEDGDGDLADEEEGTVQQPQASVLYEDLLMSEGEDDEEDAGSDEEGDNPFSAIQLSESGSDSDVGSGGIRPKQPRMLQENTRMDMENEESMMSYEGDGGEASHGLEDSNISYGSYEEPDPKSNTQDTSFSSIGGYEVSEEEEDEEEEEQRSGPSVLSQVHLSEDEEDSEDFHSIAGDSDLDSDE>sp|Q9BRU9|UTP23_HUMAN rRNA-processing protein UTP23 homolog OS=Homosapiens OX=9606 GN=UTP23 PE=1 SV=2MKITRQKHAKKHLGFFRNNFGVREPYQILLDGTFCQAALRGRIQLREQLPRYLMGETQLCTTRCVLKELETLGKDLYGAKLIAQKCQVRNCPHFKNAVSGSECLLSMVEEGNPHHYFVATQDQNLSVKVKKKPGVPLMFIIQNTMVLDKPSPKTIAFVKAVESGQLVSVHEKESIKHLKEEQGLVKNTEQSRRKKRKKISGPNPLSCLKKKKKAPDTQSSASEKKRKRKRIRNRSNPKVLSEKQNAEGE>sp|Q9BRU9-2|UTP23_HUMAN Isoform 2 of rRNA-processing protein UTP23homolog OS=Homo sapiens OX=9606 GN=UTP23MKITRQKHAKKHLGFFRNNFGVREPYQILLDGTFCQAALRGRIQLREQLPRYLMGETQLCTTRCVLKELETLGKDLYGAKLIAQKCQVRNCPHFKNAVSGSECLLSMVEEGNPHHYFVATQYIPRMYTFCTNYGGQQYVIDALIG>sp|Q96C24|SYTL4_HUMAN Synaptotagmin-like protein 4 OS=Homo sapiensOX=9606 GN=SYTL4 PE=1 SV=2MSELLDLSFLSEEEKDLILSVLQRDEEVRKADEKRIRRLKNELLEIKRKGAKRGSQHYSDRTCARCQESLGRLSPKTNTCRGCNHLVCRDCRIQESNGTWRCKVCAKEIELKKATGDWFYDQKVNRFAYRTGSEIIRMSLRHKPAVSKRETVGQSLLHQTQMGDIWPGRKIIQERQKEPSVLFEVPKLKSGKSALEAESESLDSFTADSDSTSRRDSLDKSGLFPEWKKMSAPKSQVEKETQPGGQNVVFVDEGEMIFKKNTRKILRPSEYTKSVIDLRPEDVVHESGSLGDRSKSVPGLNVDMEEEEEEEDIDHLVKLHRQKLARSSMQSGSSMSTIGSMMSIYSEAGDFGNIFVTGRIAFSLKYEQQTQSLVVHVKECHQLAYADEAKKRSNPYVKTYLLPDKSRQGKRKTSIKRDTINPLYDETLRYEIPESLLAQRTLQFSVWHHGRFGRNTFLGEAEIQMDSWKLDKKLDHCLPLHGKISAESPTGLPSHKGELVVSLKYIPASKTPVGGDRKKSKGGEGGELQVWIKEAKNLTAAKAGGTSDSFVKGYLLPMRNKASKRKTPVMKKTLNPHYNHTFVYNGVRLEDLQHMCLELTVWDREPLASNDFLGGVRLGVGTGISNGEVVDWMDSTGEEVSLWQKMRQYPGSWAEGTLQLRSSMAKQKLGL>sp|Q96C24-2|SYTL4_HUMAN Isoform 2 of Synaptotagmin-like protein 4OS=Homo sapiens OX=9606 GN=SYTL4MSELLDLSFLSEEEKDLILSVLQRDEEVRKADEKRIRRLKNELLEIKRKGAKRGSQHYSDRTCARCQESLGRLSPKTNTCRGCNHLVCRDCRIQESNGTWRCKVCAKEIELKKATGDWFYDQKVNRFAYRTGSEIIRMSLRHKPAVSKRETVGQSLLHQTQMGDIWPGRKIIQERQKEPSVLFEVPKLKSGKSALEAESESLDSFTADSDSTSRRDSLDKSGLFPEWKKMSAPKSQVEKETQPGGQNVVFVDEGEMIFKKNTRKILRPSEYTKSVIDLRPEDVVHESGSLGDRSKSVPGLNVDMEEEEEEEDIDHLVKLHRQKLARSSMQSGSSMVSSIRSVVTGMLGY>sp|Q9NYW1|TA2R9_HUMAN Taste receptor type 2 member 9 OS=Homo sapiensOX=9606 GN=TAS2R9 PE=1 SV=1MPSAIEAIYIILIAGELTIGIWGNGFIVLVNCIDWLKRRDISLIDIILISLAISRICLLCVISLDGFFMLLFPGTYGNSVLVSIVNVVWTFANNSSLWFTSCLSIFYLLKIANISHPFFFWLKLKINKVMLAILLGSFLISLIISVPKNDDMWYHLFKVSHEENITWKFKVSKIPGTFKQLTLNLGVMVPFILCLISFFLLLFSLVRHTKQIRLHATGFRDPSTEAHMRAIKAVIIFLLLLIVYYPVFLVMTSSALIPQGKLVLMIGDIVTVIFPSSHSFILIMGNSKLREAFLKMLRFVKCFLRRRKPFVP>sp|Q96RJ0|TAAR1_HUMAN Trace amine-associated receptor 1 OS=Homo sapiensOX=9606 GN=TAAR1 PE=2 SV=1MMPFCHNIINISCVKNNWSNDVRASLYSLMVLIILTTLVGNLIVIVSISHFKQLHTPTNWLIHSMATVDFLLGCLVMPYSMVRSAEHCWYFGEVFCKIHTSTDIMLSSASIFHLSFISIDRYYAVCDPLRYKAKMNILVICVMIFISWSVPAVFAFGMIFLELNFKGAEEIYYKHVHCRGGCSVFFSKISGVLTFMTSFYIPGSIMLCVYYRIYLIAKEQARLISDANQKLQIGLEMKNGISQSKERKAVKTLGIVMGVFLICWCPFFICTVMDPFLHYIIPPTLNDVLIWFGYLNSTFNPMVYAFFYPWFRKALKMMLFGKIFQKDSSRCKLFLELSS>sp|Q8TDW5|SYTL5_HUMAN Synaptotagmin-like protein 5 OS=Homo sapiensOX=9606 GN=SYTL5 PE=1 SV=1MSKNSEFINLSFLLDHEKEMILGVLKRDEYLKKVEDKRIRKLKNELLEAKRRSGKTQQEASRVCVHCHRNLGLIFDRGDPCQACSLRVCRECRVAGPNGSWKCTVCDKIAQLRIITGEWFFEEKAKRFKQVNVLGTDVVRQSILRRSPGAEEVQSQEQTRQDAEKSDTSPVAGKKASHDGPKRKGFLLSKFRSATRGEIITPKTDTGRSYSLDLDGQHFRSLKSPPGSDRGSTGSSDLNDQEPGPRTPKSSRSNGVTPGTQSSPAPSTRTVTSVISREYGFENSMDLAAIEGTSQELTKSHRRNTSGTPSIAVSGTSLSSDQSRSELDLSESFTEDSEDTVSIRSKSVPGALDKDSLEETEESIDALVSSQLSTNTHRLASGLSTTSLNSMMSVYSETGDYGNVKVSGEILLHISYCYKTGGLYIFVKNCRNLAIGDEKKQRTDAYVKSYLLPDKSRNNKRKTKIRTGTNPEFNETLKYTISHTQLETRTLQLSVWHYDRFGRNSFLGEVEIPFDSWNFENPTDEWFVLQPKVEFAPDIGLQYKGELTVVLRYIPPEENLMLPPEQLQGNKTFKKGKKKESPVISGGILEVFIKEAKNLTAVKSGGTSDSFVKGYLLPDDSKATKHKTLVIKKSVNPQWNHTFMFSGIHPQDIKNVCLELTIWDKEAFSSNIFLGGVRLNSGSGVSHGKNVDWMDSQGEEQRLWQKMANNPGTPFEGVLMLRSSMGKCRL>sp|Q8TDW5-2|SYTL5_HUMAN Isoform 2 of Synaptotagmin-like protein 5OS=Homo sapiens OX=9606 GN=SYTL5MSKNSEFINLSFLLDHEKEMILGVLKRDEYLKKVEDKRIRKLKNELLEAKRRSGKTQQEASRVCVHCHRNLGLIFDRGDPCQACSLRVCRECRVAGPNGSWKCTVCDKIAQLRIITGEWFFEEKAKRFKQVNVLGTDVVRQSILRRSPGAEEVQSQEQTRQDAEKSDTSPVAGKKASHDGPKRKGFLLSKFRSATRGEIITPKTDTGRSYSLDLDGQHFRSLKSPPGSDRGSTGSSDLNDQEPGPRTPKSSRSNGVTPGTQSSPAPSTRTVTSVISREYGFENSMDLAAIEGTSQELTKSHRRNTSGTPSIAVSGTSLSSDQSRSELDLSESFTEDSEDTVSIRSKSVPGALDKDSLEETEESIDALVSSQLSTNTHRLASGLSTSSQAGSDRKWTYLNVPDADSDTTSLNSMMSVYSETGDYGNVKVSGEILLHISYCYKTGGLYIFVKNCRNLAIGDEKKQRTDAYVKSYLLPDKSRNNKRKTKIRTGTNPEFNETLKYTISHTQLETRTLQLSVWHYDRFGRNSFLGEVEIPFDSWNFENPTDEWFVLQPKVEFAPDIGLQYKGELTVVLRYIPPEENLMLPPEQLQGNKTFKKGKKKESPVISGGILEVFIKEAKNLTAVKSGGTSDSFVKGYLLPDDSKATKHKTLVIKKSVNPQWNHTFMFSGIHPQDIKNVCLELTIWDKEAFSSNIFLGGVRLNSGSGVSHGKNVDWMDSQGEEQRLWQKMANNPGTPFEGVLMLRSSMGKCRL>sp|Q96BN2|TADA1_HUMAN Transcriptional adapter 1 OS=Homo sapiens OX=9606GN=TADA1 PE=1 SV=1MATFVSELEAAKKNLSEALGDNVKQYWANLKLWFKQKISKEEFDLEAHRLLTQDNVHSHNDFLLAILTRCQILVSTPDGAGSLPWPGGSAAKPGKPKGKKKLSSVRQKFDHRFQPQNPLSGAQQFVAKDPQDDDDLKLCSHTMMLPTRGQLEGRMIVTAYEHGLDNVTEEAVSAVVYAVENHLKDILTSVVSRRKAYRLRDGHFKYAFGSNVTPQPYLKNSVVAYNNLIESPPAFTAPCAGQNPASHPPPDDAEQQAALLLACSGDTLPASLPPVNMYDLFEALQVHREVIPTHTVYALNIERIITKLWHPNHEELQQDKVHRQRLAAKEGLLLC>sp|Q9BQ16|TICN3_HUMAN Testican-3 OS=Homo sapiens OX=9606 GN=SPOCK3 PE=1SV=2MLKVSAVLCVCAAAWCSQSLAAAAAVAAAGGRSDGGNFLDDKQWLTTISQYDKEVGQWNKFRDEVEDDYFRTWSPGKPFDQALDPAKDPCLKMKCSRHKVCIAQDSQTAVCISHRRLTHRMKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQDPPCQTELSNIQKRQGVKKLLGQYIPLCDEDGYYKPTQCHGSVGQCWCVDRYGNEVMGSRINGVADCAIDFEISGDFASGDFHEWTDDEDDEDDIMNDEDEIEDDDEDEGDDDDGGDDHDVYI>sp|Q9BQ16-1|TICN3_HUMAN Isoform 1 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MLKVSAVLCVCAAAWCSQSLAAAAAVAAAGGRSDGGNFLDDKQWLTTISQYDKEVGQWNKFRDDDYFRTWSPGKPFDQALDPAKDPCLKMKCSRHKVCIAQDSQTAVCISHRRLTHRMKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQDPPCQTELSNIQKRQGVKKLLGQYIPLCDEDGYYKPTQCHGSVGQCWCVDRYGNEVMGSRINGVADCAIDFEISGDFASGDFHEWTDDEDDEDDIMNDEDEIEDDDEDEGDDDDGGDDHDVYI>sp|Q9BQ16-2|TICN3_HUMAN Isoform 2 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MLKVSAVLCVCAAAWCSQSLAAAAAVAAAGGRSDGGNFLDDKQWLTTISQYDKEVGQWNKFRDEVEDDYFRTWSPGKPFDQALDPAKDPCLKMKCSRHKVCIAQDSQTAVCISHRRLTHRMKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQGKR>sp|Q9BQ16-4|TICN3_HUMAN Isoform 4 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MITQDHIHMSSGLSQDDYFRTWSPGKPFDQALDPAKDPCLKMKCSRHKVCIAQDSQTAVCISHRRLTHRMKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQDPPCQTELSNIQKRQGVKKLLGQYIPLCDEDGYYKPTQCHGSVGQCWCVDRYGNEVMGSRINGVADCAIDFEISGDFASGDFHEWTDDEDDEDDIMNDEDEIEDDDEDEGDDDDGGDDHDVYI>sp|Q9BQ16-5|TICN3_HUMAN Isoform 5 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MLKVSAVLCVCAAAWCSQSLAAAAAVAAAGGRSDGGNFLDDKQWLTTISQYDKEVGQWNKFRDCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQDPPCQTELSNIQKRQGVKKLLGQYIPLCDEDGYYKPTQCHGSVGQCWCVDRYGNEVMGSRINGVADCAIDFEISGDFASGDFHEWTDDEDDEDDIMNDEDEIEDDDEDEGDDDDGGDDHDVYI>sp|Q9BQ16-6|TICN3_HUMAN Isoform 6 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MINNGSPQSLSMTRKSDSGTNSETMKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQDPPCQTELSNIQKRQGVKKLLGQYIPLCDEDGYYKPTQCHGSVGQCWCVDRYGNEVMGSRINGVADCAIDFEISGDFASGDFHEWTDDEDDEDDIMNDEDEIEDDDEDEGDDDDGGDDHDVYI>sp|Q9BQ16-7|TICN3_HUMAN Isoform 7 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQDPPCQTELSNIQKRQGVKKLLGQYIPLCDEDGYYKPTQCHGSVGQCWCVDRYGNEVMGSRINGVADCAIDFEISGDFASGDFHEWTDDEDDEDDIMNDEDEIEDDDEDEGDDDDGGDDHDVYI>sp|Q9BQ16-8|TICN3_HUMAN Isoform 8 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MLKVSAVLCVCAAAWCSQSLAAAAAVAAAGGRSDGGNFLDDKQWLTTISQYDKEVGQWNKFRDDDYFRTWSPGKPFDQALDPAKDPCLKMKCSRHKVCIAQDSQTAVCISHRRLTHRMKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRGFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQDPPCQTELSNIQKRQGVKKLLGQYIPLCDEDGYYKPTQCHGSVGQCWCVDRYGNEVMGSRINGVADCAIDFEISGDFASGDFHEWTDDEDDEDDIMNDEDEIEDDDEDEGDDDDGGDDHDVYI>sp|Q9BQ16-9|TICN3_HUMAN Isoform 9 of Testican-3 OS=Homo sapiens OX=9606GN=SPOCK3MLKVSAVLCVCAAAWCSQSLAAAAAVAAAGGRSDGGNFLDDKQWLTTISQYDKEVGQWNKFRDDDYFRTWSPGKPFDQALDPAKDPCLKMKCSRHKVCIAQDSQTAVCISHRRLTHRMKEAGVDHRQWRGPILSTCKQCPVVYPSPVCGSDGHTYSFQCKLEYQACVLGKQISVKCEGHCPCPSDKPTSTSRNVKRACSDLEFREVANRLRDWFKALHESGSQNKKTKTLLRPERSRFDTSILPICKDSLGWMFNRLDTNYDLLLDQSELRSIYLDKNEQCTKAFFNSCDTYKDSLISNNEWCYCFQRQQGKR>sp|Q9UGI8|TES_HUMAN Testin OS=Homo sapiens OX=9606 GN=TES PE=1 SV=1MDLENKVKKMGLGHEQGFGAPCLKCKEKCEGFELHFWRKICRNCKCGQEEHDVLLSNEEDRKVGKLFEDTKYTTLIAKLKSDGIPMYKRNVMILTNPVAAKKNVSINTVTYEWAPPVQNQALARQYMQMLPKEKQPVAGSEGAQYRKKQLAKQLPAHDQDPSKCHELSPREVKEMEQFVKKYKSEALGVGDVKLPCEMDAQGPKQMNIPGGDRSTPAAVGAMEDKSAEHKRTQYSCYCCKLSMKEGDPAIYAERAGYDKLWHPACFVCSTCHELLVDMIYFWKNEKLYCGRHYCDSEKPRCAGCDELIFSNEYTQAENQNWHLKHFCCFDCDSILAGEIYVMVNDKPVCKPCYVKNHAVVCQGCHNAIDPEVQRVTYNNFSWHASTECFLCSCCSKCLIGQKFMPVEGMVFCSVECKKRMS>sp|Q9UGI8-2|TES_HUMAN Isoform 2 of Testin OS=Homo sapiens OX=9606 GN=TESMGLGHEQGFGAPCLKCKEKCEGFELHFWRKICRNCKCGQEEHDVLLSNEEDRKVGKLFEDTKYTTLIAKLKSDGIPMYKRNVMILTNPVAAKKNVSINTVTYEWAPPVQNQALARQYMQMLPKEKQPVAGSEGAQYRKKQLAKQLPAHDQDPSKCHELSPREVKEMEQFVKKYKSEALGVGDVKLPCEMDAQGPKQMNIPGGDRSTPAAVGAMEDKSAEHKRTQYSCYCCKLSMKEGDPAIYAERAGYDKLWHPACFVCSTCHELLVDMIYFWKNEKLYCGRHYCDSEKPRCAGCDELIFSNEYTQAENQNWHLKHFCCFDCDSILAGEIYVMVNDKPVCKPCYVKNHAVVCQGCHNAIDPEVQRVTYNNFSWHASTECFLCSCCSKCLIGQKFMPVEGMVFCSVECKKRMS>sp|Q9BU02|THTPA_HUMAN Thiamine-triphosphatase OS=Homo sapiens OX=9606GN=THTPA PE=1 SV=3MAQGLIEVERKFLPGPGTEERLQELGGTLEYRVTFRDTYYDTPELSLMQADHWLRRREDSGWELKCPGAAGVLGPHTEYKELTAEPTIVAQLCKVLRADGLGAGDVAAVLGPLGLQEVASFVTKRSAWKLVLLGADEEEPQLRVDLDTADFGYAVGEVEALVHEEAEVPTALEKIHRLSSMLGVPAQETAPAKLIVYLQRFRPQDYQRLLEVNSSRERPQETEDPDHCLG>sp|Q9BU02-2|THTPA_HUMAN Isoform 2 of Thiamine-triphosphatase OS=Homosapiens OX=9606 GN=THTPAMAQGLIEVERKFLPGPGTEERLQELGGTLEYRVTFRDTYYDTPELSLMQADHWLRRREDSGWELKCPGAAGVLGPHTEYKELTAEPTIVAQLCKVCLHRRQHQPS>sp|Q02763|TIE2_HUMAN Angiopoietin-1 receptor OS=Homo sapiens OX=9606GN=TEK PE=1 SV=2MDSLASLVLCGVSLLLSGTVEGAMDLILINSLPLVSDAETSLTCIASGWRPHEPITIGRDFEALMNQHQDPLEVTQDVTREWAKKVVWKREKASKINGAYFCEGRVRGEAIRIRTMKMRQQASFLPATLTMTVDKGDNVNISFKKVLIKEEDAVIYKNGSFIHSVPRHEVPDILEVHLPHAQPQDAGVYSARYIGGNLFTSAFTRLIVRRCEAQKWGPECNHLCTACMNNGVCHEDTGECICPPGFMGRTCEKACELHTFGRTCKERCSGQEGCKSYVFCLPDPYGCSCATGWKGLQCNEACHPGFYGPDCKLRCSCNNGEMCDRFQGCLCSPGWQGLQCEREGIQRMTPKIVDLPDHIEVNSGKFNPICKASGWPLPTNEEMTLVKPDGTVLHPKDFNHTDHFSVAIFTIHRILPPDSGVWVCSVNTVAGMVEKPFNISVKVLPKPLNAPNVIDTGHNFAVINISSEPYFGDGPIKSKKLLYKPVNHYEAWQHIQVTNEIVTLNYLEPRTEYELCVQLVRRGEGGEGHPGPVRRFTTASIGLPPPRGLNLLPKSQTTLNLTWQPIFPSSEDDFYVEVERRSVQKSDQQNIKVPGNLTSVLLNNLHPREQYVVRARVNTKAQGEWSEDLTAWTLSDILPPQPENIKISNITHSSAVISWTILDGYSISSITIRYKVQGKNEDQHVDVKIKNATITQYQLKGLEPETAYQVDIFAENNIGSSNPAFSHELVTLPESQAPADLGGGKMLLIAILGSAGMTCLTVLLAFLIILQLKRANVQRRMAQAFQNVREEPAVQFNSGTLALNRKVKNNPDPTIYPVLDWNDIKFQDVIGEGNFGQVLKARIKKDGLRMDAAIKRMKEYASKDDHRDFAGELEVLCKLGHHPNIINLLGACEHRGYLYLAIEYAPHGNLLDFLRKSRVLETDPAFAIANSTASTLSSQQLLHFAADVARGMDYLSQKQFIHRDLAARNILVGENYVAKIADFGLSRGQEVYVKKTMGRLPVRWMAIESLNYSVYTTNSDVWSYGVLLWEIVSLGGTPYCGMTCAELYEKLPQGYRLEKPLNCDDEVYDLMRQCWREKPYERPSFAQILVSLNRMLEERKTYVNTTLYEKFTYAGIDCSAEEAA>sp|Q02763-2|TIE2_HUMAN Isoform 2 of Angiopoietin-1 receptor OS=Homosapiens OX=9606 GN=TEKMDSLASLVLCGVSLLLSGTVEGAMDLILINSLPLVSDAETSLTCIASGWRPHEPITIGRDFEALMNQHQDPLEVTQDVTREWAKKVVWKREKASKINGAYFCEGRVRGEAIRIRTMKMRQQASFLPATLTMTVDKGDNVNISFKKVLIKEEDAVIYKNGSFIHSVPRHEVPDILEVHLPHAQPQDAGVYSARYIGGNLFTSAFTRLIVRRCEAQKWGPECNHLCTACMNNGVCHEDTGECICPPGFMGRTCEKACELHTFGRTCKERCSGQEGCKSYVFCLPDPYGCSCATGWKGLQCNEGIQRMTPKIVDLPDHIEVNSGKFNPICKASGWPLPTNEEMTLVKPDGTVLHPKDFNHTDHFSVAIFTIHRILPPDSGVWVCSVNTVAGMVEKPFNISVKVLPKPLNAPNVIDTGHNFAVINISSEPYFGDGPIKSKKLLYKPVNHYEAWQHIQVTNEIVTLNYLEPRTEYELCVQLVRRGEGGEGHPGPVRRFTTASIGLPPPRGLNLLPKSQTTLNLTWQPIFPSSEDDFYVEVERRSVQKSDQQNIKVPGNLTSVLLNNLHPREQYVVRARVNTKAQGEWSEDLTAWTLSDILPPQPENIKISNITHSSAVISWTILDGYSISSITIRYKVQGKNEDQHVDVKIKNATITQYQLKGLEPETAYQVDIFAENNIGSSNPAFSHELVTLPESQAPADLGGGKMLLIAILGSAGMTCLTVLLAFLIILQLKRANVQRRMAQAFQNVREEPAVQFNSGTLALNRKVKNNPDPTIYPVLDWNDIKFQDVIGEGNFGQVLKARIKKDGLRMDAAIKRMKEYASKDDHRDFAGELEVLCKLGHHPNIINLLGACEHRGYLYLAIEYAPHGNLLDFLRKSRVLETDPAFAIANSTASTLSSQQLLHFAADVARGMDYLSQKQFIHRDLAARNILVGENYVAKIADFGLSRGQEVYVKKTMGRLPVRWMAIESLNYSVYTTNSDVWSYGVLLWEIVSLGGTPYCGMTCAELYEKLPQGYRLEKPLNCDDEVYDLMRQCWREKPYERPSFAQILVSLNRMLEERKTYVNTTLYEKFTYAGIDCSAEEAA>sp|Q02763-3|TIE2_HUMAN Isoform 3 of Angiopoietin-1 receptor OS=Homosapiens OX=9606 GN=TEKMDSLASLVLCGVSLLLSASFLPATLTMTVDKGDNVNISFKKVLIKEEDAVIYKNGSFIHSVPRHEVPDILEVHLPHAQPQDAGVYSARYIGGNLFTSAFTRLIVRRCEAQKWGPECNHLCTACMNNGVCHEDTGECICPPGFMGRTCEKACELHTFGRTCKERCSGQEGCKSYVFCLPDPYGCSCATGWKGLQCNEGIQRMTPKIVDLPDHIEVNSGKFNPICKASGWPLPTNEEMTLVKPDGTVLHPKDFNHTDHFSVAIFTIHRILPPDSGVWVCSVNTVAGMVEKPFNISVKVLPKPLNAPNVIDTGHNFAVINISSEPYFGDGPIKSKKLLYKPVNHYEAWQHIQVTNEIVTLNYLEPRTEYELCVQLVRRGEGGEGHPGPVRRFTTASIGLPPPRGLNLLPKSQTTLNLTWQPIFPSSEDDFYVEVERRSVQKSDQQNIKVPGNLTSVLLNNLHPREQYVVRARVNTKAQGEWSEDLTAWTLSDILPPQPENIKISNITHSSAVISWTILDGYSISSITIRYKVQGKNEDQHVDVKIKNATITQYQLKGLEPETAYQVDIFAENNIGSSNPAFSHELVTLPESQAPADLGGGKMLLIAILGSAGMTCLTVLLAFLIILQLKRANVQRRMAQAFQNREEPAVQFNSGTLALNRKVKNNPDPTIYPVLDWNDIKFQDVIGEGNFGQVLKARIKKDGLRMDAAIKRMKEYASKDDHRDFAGELEVLCKLGHHPNIINLLGACEHRGYLYLAIEYAPHGNLLDFLRKSRVLETDPAFAIANSTASTLSSQQLLHFAADVARGMDYLSQKQFIHRDLAARNILVGENYVAKIADFGLSRGQEVYVKKTMGRLPVRWMAIESLNYSVYTTNSDVWSYGVLLWEIVSLGGTPYCGMTCAELYEKLPQGYRLEKPLNCDDEVYDLMRQCWREKPYERPSFAQILVSLNRMLEERKTYVNTTLYEKFTYAGIDCSAEEAA>sp|Q9P016|THYN1_HUMAN Thymocyte nuclear protein 1 OS=Homo sapiensOX=9606 GN=THYN1 PE=1 SV=1MSRPRKRLAGTSGSDKGLSGKRTKTENSGEALAKVEDSNPQKTSATKNCLKNLSSHWLMKSEPESRLEKGVDVKFSIEDLKAQPKQTTCWDGVRNYQARNFLRAMKLGEEAFFYHSNCKEPGIAGLMKIVKEAYPDHTQFEKNNPHYDPSSKEDNPKWSMVDVQFVRMMKRFIPLAELKSYHQAHKATGGPLKNMVLFTRQRLSIQPLTQEEFDFVLSLEEKEPS>sp|Q9P016-2|THYN1_HUMAN Isoform 2 of Thymocyte nuclear protein 1 OS=Homosapiens OX=9606 GN=THYN1MSRPRKRLAGTSGSDKGLSGKRTKTENSGEALAKVEDSNPQKTSATKNCLKNLSSHWLMKSEPESRLEKGVDVKFSIEDLKAQPKQTTCWDGVRNYQARNFLRAMKLGEEAFFYHSNCKEPGIAGLMKIVKEAYPDHTQFEKNNPHYDPSSKEDNPKWSMKSLILF>sp|C9J3V5|TEX22_HUMAN Testis-expressed protein 22 OS=Homo sapiensOX=9606 GN=TEX22 PE=2 SV=1MDSRKLSPRGKKLESHLSQEHRRPPLGLIAAWGQPSIQSSVQQGLQTQDWVCEPPERRRPGRRWSVSIDERRRLATLGGRERPGAAGTQLHCRDVVQMVAQLVSEDVDKDVLLPHPLRSTESTNAFQAFLARSAPFWHNATFEASRSPPS>sp|Q96J92|WNK4_HUMAN Serine/threonine-protein kinase WNK4 OS=Homosapiens OX=9606 GN=WNK4 PE=1 SV=1MLASPATETTVLMSQTEADLALRPPPPLGTAGQPRLGPPPRRARRFSGKAEPRPRSSRLSRRSSVDLGLLSSWSLPASPAPDPPDPPDSAGPGPARSPPPSSKEPPEGTWTEGAPVKAAEDSARPELPDSAVGPGSREPLRVPEAVALERRREQEEKEDMETQAVATSPDGRYLKFDIEIGRGSFKTVYRGLDTDTTVEVAWCELQTRKLSRAERQRFSEEVEMLKGLQHPNIVRFYDSWKSVLRGQVCIVLVTELMTSGTLKTYLRRFREMKPRVLQRWSRQILRGLHFLHSRVPPILHRDLKCDNVFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDEAVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTSGRKPNSFHKVKIPEVKEIIEGCIRTDKNERFTIQDLLAHAFFREERGVHVELAEEDDGEKPGLKLWLRMEDARRGGRPRDNQAIEFLFQLGRDAAEEVAQEMVALGLVCEADYQPVARAVRERVAAIQRKREKLRKARELEALPPEPGPPPATVPMAPGPPSVFPPEPEEPEADQHQPFLFRHASYSSTTSDCETDGYLSSSGFLDASDPALQPPGGVPSSLAESHLCLPSAFALSIPRSGPGSDFSPGDSYASDAASGLSDVGEGMGQMRRPPGRNLRRRPRSRLRVTSVSDQNDRVVECQLQTHNSKMVTFRFDLDGDSPEEIAAAMVYNEFILPSERDGFLRRIREIIQRVETLLKRDTGPMEAAEDTLSPQEEPAPLPALPVPLPDPSNEELQSSTSLEHRSWTAFSTSSSSPGTPLSPGNPFSPGTPISPGPIFPITSPPCHPSPSPFSPISSQVSSNPSPHPTSSPLPFSSSTPEFPVPLSQCPWSSLPTTSPPTFSPTCSQVTLSSPFFPPCPSTSSFPSTTAAPLLSLASAFSLAVMTVAQSLLSPSPGLLSQSPPAPPSPLPSLPLPPPVAPGGQESPSPHTAEVESEASPPPARPLPGEARLAPISEEGKPQLVGRFQVTSSKEPAEPLPLQPTSPTLSGSPKPSTPQLTSESSDTEDSAGGGPETREALAESDRAAEGLGAGVEEEGDDGKEPQVGGSPQPLSHPSPVWMNYSYSSLCLSSEESESSGEDEEFWAELQSLRQKHLSEVETLQTLQKKEIEDLYSRLGKQPPPGIVAPAAMLSSRQRRLSKGSFPTSRRNSLQRSEPPGPGIMRRNSLSGSSTGSQEQRASKGVTFAGDVGRM>sp|Q96J92-2|WNK4_HUMAN Isoform 2 of Serine/threonine-protein kinase WNK4OS=Homo sapiens OX=9606 GN=WNK4MRRRQQGAAGGNFPVGGSFPEDVSPHQDSGYAPSPRYLRRFREMKPRVLQRWSRQILRGLHFLHSRVPPILHRDLKCDNVFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDEAVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTSGRKPNSFHKVKIPEVKEIIEGCIRTDKNERFTIQDLLAHAFFREERGVHVELAEEDDGEKPGLKLWLRMEDARRGGRPRDNQAIEFLFQLGRDAAEEVAQEMVALGLVCEADYQPVARAVRERVAAIQRKREKLRKARELEALPPEPGPPPATVPMAPGPPSVFPPEPEEPEADQHQPFLFRHASYSSTTSDCETDGYLSSSGFLDASDPALQPPGGVPSSLAESHLCLPSAFALSIPRSGPGSDFSPGDSYASDAASGLSDVGEGMGQMRRPPGRNLRRRPRSRLRVTSVSDQNDRVVECQLQTHNSKMVTFRFDLDGDSPEEIAAAMVYNEFILPSERDGFLRRIREIIQRVETLLKRDTGPMEAAEDTLSPQEEPAPLPALPVPLPDPSNEELQSSTSLEHRSWTAFSTSSSSPGTPLSPGNPFSPGTPISPGPGIMRRNSLSGSSTGSQEQRASKEAGQRPGKLWLRATVQLRVWGLELRRKEMMGRNPKLGAAPNP>sp|Q96J92-3|WNK4_HUMAN Isoform 3 of Serine/threonine-protein kinase WNK4OS=Homo sapiens OX=9606 GN=WNK4MLASPATETTVLMSQTEADLALRPPPPLGTAGQPRLGPPPRRARRFSGKAEPRPRSSRLSRRSSVDLGLLSSWSLPASPAPDPPDPPDSAGPGPARSPPPSSKEPPEGTWTEGAPVKAAEDSARPELPDSAVGPGSREPLRVPEAVALERRREQEEKEDMETQAVATSPDGRYLKFDIEIGRGSFKTVYRGLDTDTTVEVAWCELQTRKLSRAERQRFSEEVEMLKGLQHPNIVRFYDSWKSVLRGQVCIVLVTELMTSGTLKTYLRRFREMKPRVLQRWSRQILRGLHFLHSRVPPILHRDLKCDNVFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEKYDEAVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTSGRKPNSFHKVKIPEVKEIIEGCIRTDKNERFTIQDLLAHAFFREERGVHVELAEEDDGEKPGLKLWLRMEDARRGGRPRDNQAIEFLFQLGRDAAEEVAQEMVALGLVCEADYQPVARAVRERVAAIQRKREKLRKARELEALPPEPGPPPATVPMAPGPPSVFPPEPEEPEADQHQPFLFRHASYSSTTSDCETDGYLSSSGFLDASDPALQPPGGVPSSLAESHLCLPSAFALSIPRSGPGSDFSPGDSYASDAASGLSDVGEGMGQMRRPPGRNLRRRPRSRLRVTSVSDQNDRVVECQLQTHNSKMVTFRFDLDGDSPEEIAAAMVYNEFILPSERDGFLRRIREIIQRVETLLKRDTGPMEAAEDTLSPQEEPAPLPALPVPLPDPSNEELQSSTSLEHRSWTAFSTSSSSPGTPLSPGNPFSPGTPISPGPIFPITSPPCHPSPSPFSPISSQVSSNPSPHPTSSPLPFSSSTPEFPVPLSQCPWSSLPTTSPPTFSPTCSQVTLSSPFFPPCPSTSSFPSTTAAPLLSLASAFSLAVMTVAQSLLSPSPGLLSQSPPAPPSPLPSLPLPPPVAPGGQESPSPHTAEVESEASPPPARPLPGEARLAPISEEGKPQLVGRFQVTSSKEPAEPLPLQPTSPTLSGSPKPSTPQLTSESSDTEDSAGGGPETREALAESDRAAEGLGAGVEEEGDDGKEPQVGGSPQPLSHPSPVWMNYSYSSLCLSSEESESSGEDEEFWAELQSLRQKPFHALRASSGTCQRWKHYRHY>sp|Q9HC57|WFDC1_HUMAN WAP four-disulfide core domain protein 1 OS=Homosapiens OX=9606 GN=WFDC1 PE=2 SV=2MPLTGVGPGSCRRQIIRALCLLLLLLHAGSAKNIWKRALPARLAEKSRAEEAGAPGGPRQPRADRCPPPPRTLPPGACQAARCQADSECPRHRRCCYNGCAYACLEAVPPPPVLDWLVQPKPRWLGGNGWLLDGPEEVLQAEACSTTEDGAEPLLCPSGYECHILSPGDVAEGIPNRGQCVKQRRQADGRILRHKLYKEYPEGDSKNVAEPGRGQQKHFQ>sp|Q9BXT5|TEX15_HUMAN Testis-expressed protein 15 OS=Homo sapiensOX=9606 GN=TEX15 PE=1 SV=2MPSDAKDSVNGDLLLNWTSLKNILSGLNASFPLHNNTGSSTVTTSKSIKDPRLMRREESMGEQSSTAGLNEVLQFEKSSDNVNSEIKSTPSNSASSSEVVPGDCAVLTNGLDTPCFKTSVNDSQSWAHNMGSEDYDCIPPNKVTMAGQCKDQGNFSFPISVSNVVSEVENQNHSEEKAQRAQQESGNAYTKEYSSHIFQDSQSSDLKTIYQTGCQTSTVFPLKKKVSIDEYLQNTGKMKNFADLEDSSKHEEKQTSWKEIDNDFTNETKISPIDNYIVLHQEYKESESHNSFGKSCDKILITQELEITKSSTSTIKDKDELDHLALEWQITPSFESLSQKHPQHSVEYEGNIHTSLAIAQKLMELKLGKINQNYASIITEAFPKPKDIPQAKEMFIDTVISSYNIETAHDSSNCSITREHICVHRKNENEPVSLENIQRDYKETAYVEDRGQDHNLFCNSQLSNDIWLNVNFKKQTDRENQNEAKENSASCVENNIENIYGDKKQDSHTNENFSNIDEKEDKNYHNIEILSSEEFSTKFNLICREDNAVSAATALLESEEDTISAVKQKDTENTGRSVEHLASTTFPKTASSSVCVASNAAIQIASATMPALSLNNDDHQIYQFKETCSSESPDFGLLVKHRVSDCEIDTDKNKSQESFHQSINENLVLQSIELESEIEIELEDCDDAFIFQQDTHSHENMLCEEFVTSYKALKSRISWEGLLALDNGEMEVLESTTGRENSDQHYSKESNYFYSSTQNNETELTSPILLPDLQIKITNIFRPGFSPTADSLALKDSFCTHVTEATKPEINKEDGEILGFDIYSQPFGENADYPCEDKVDNIRQESGPVSNSEISLSFDLSRNTDVNHTSENQNSESLFTEPSNVTTIDDGSRCFFTKSKTDYNDTKNKKEVESRISKRKLHISSRDQNIPHKDLRRHKIYGRKRRLTSQDSSECFSSLSQGRIKTFSQSEKHIKSVLNILSDEASLCKSKCLSRKLDKAVVHLKKAHRRVHTSLQLITKVGEERKGPLPKSYAIICNNFWESCDLQGYSSVSQRKYYSTKHFSSKRKYDKRRKKRAPKADISKSLTHVSKHKSYKTSGEKKCLSRKSMASSVSKSHPTTSHMGEFCNQEHPESQLPVSSTSQSTSQSVYYNSSVSNPSLSEEHQPFSGKTAYLFSPDHSDEKLIEKENQIDTAFLSSTSKYEKLEKHSANHNVKDATKENSCDANEVINESNSVSLSCIKENINSSTGNDCDATCIGHTKAKTDVLISVLDSNVKHFLNDLYQQGNLILSDCKRNLEVKWTDPIERPKQNIITGNFLMGPLNLTLIASKKYSIPQLSAAAVTDSEGESSKSYLDKQRILTVDSFAASSTVPHCEQSCREKELLKTEQCSSGNCLHTDGNETNVTENYELDVASGTEEDKSYGENIVELSSSDSSLLLKDNVKGSSSETCIVKKDTEDRITWKVKQAEKAKDSVYKRSMTEGSTVNTEYKNQKNQISEESCLNEKIITTNLIDSHLSTKNTTTESVPLKNTVSNPLNKREKKGEIKVSKDSQSDLTLHSEIAYISKPGILGVNHTPILPAHSETCKVPTLLKKPASYVSDFKEKHCSANHTALIANLSQILQRADEASSLQILQEETKVCLNILPLFVEAFERKQECSVEQILISRELLVDQNLWNNCKHTLKPCAVDTLVELQMMMETIQFIENKKRHLEGEPTLRSLLWYDETLYAELLGKPRGFQQQSNFYPGFQGRLKYNAFCELQTYHDQLVELLEETKREKNSYYVFLKYKRQVNECEAIMEHCSDCFDFSLSVPFTCGVNFGDSLEDLEILRKSTLKLINVCGDSPKVHSYPGKQDHLWIIIEMISSKVNFIKNNEAVRVKISLYGLEHIFFDAAKNLVWKERTQSFSKKYSQKKDEERLLRVNKCAFSKLQKIYDTLSKDLNNEPISPIGLEEDTIIASRKSDHPINEATISIENSKFNSNLLAHPDICCISEILDQAEFADLKKLQDLTLRCTDHLEILKKYFQMLQDNNMDNIFITEENVLDVVINHSHEAIILKPEAIEMYIEIVMVSETIHFLKNSIAKKLDKQRFRGMLWFDLSLLPELVQCQEKMASFSFLKDNSTDVCLWKVIETAVSELKKDLDIICKYNEAVNCSYAIHLLSRELQELSEIKKLLKKSKYFISTYIDFVPYIASINYGSTVTELEYNYNQFSTLLKNVMSAPRKDLGKMAHIRKVMKTIEHMKMICTKNAELTISFFLCQMLYNRRKILQLKRKEKMNIHIVKPGENNNKFSISTMLPPVSECINKNISNSSKKRPSTVDKCEDSQEQQQDTTVSSCKKLKVDMKDVTKINREKATFKHPRTTGSHPKSENKIVPSSCDSLKRNHLTPKKVEMQRSLPGSLLPLENPKDTCASKSESKIDLTVSSDHFSGQQENLNSMKKRNVNFSAAETKSDKKDCAAFAICDQKSVHGTFSPDHGTLLQKFLKNSPDPTQKSCLSDINPETDVSLVPDASVLSKPIFCFVKDVHPDLEMNDTVFELQDNDIVNSSIKNSSCMTSPEPICIQNKIPTLQINKLQPTETESEDKYMKDTLNPNTVHTFGASGHITLNVNQGAEYSLSEQQNDKNSKVLMQNAATYWNELPQSACNPTYNSSEHLFGTSYPYSAWCVYQYSNSNGNAITQTYQGITSYEVQPSPSGLLTTVASTAQGTHSNLLYSQYFTYFAGEPQANGFVPVNGYFQSQIPASNFRQPIFSQYASHQPLPQATYPYLPNRFVPPEVPWVYAPWHQESFHPGH>sp|A0A1B0GTD5|TEX49_HUMAN Testis-expressed protein 49 OS=Homo sapiensOX=9606 GN=TEX49 PE=4 SV=1MAFFNLYLLGYQNSFQNKKRNTTEETNQKEPEPTRLPPIISKDGNYSVHQNSHTRYHEAVRKVLLKTFPNQVFRIPLTDAQNFSFWWSHDPGVRPEETMPWIRSPRHCLIKSAMTRFMDHSILNDRTFSLY>sp|A0A1B0GVG6|TEX54_HUMAN Testis-expressed protein 54 OS=Homo sapiensOX=9606 GN=TEX54 PE=2 SV=1MGCCQDKDFEMSDEQSKEEESEDGREDETTDTQRGPRECERGLPEGRGELRGLVVPSGAEDIDLNSPDHPNHKSNESLLITVLWRRLSTFGRRGSSRPSKRQPDQIRKQESPIREGNQEEPEKG>sp|Q9H3H9|TCAL2_HUMAN Transcription elongation factor A protein-like 2OS=Homo sapiens OX=9606 GN=TCEAL2 PE=2 SV=1MEKLFNENEGMPSNQGKIDNEEQPPHEGKPEVACILEDKKLENEGNTENTGKRVEEPLKDKEKPESAGKAKGEGKSERKGKSEMQGGSKTEGKPERGGRAEGEGEPDSEREPESEGEPESETRAAGKRPAEDDIPRKAKRKTNKGLAQYLKQYKEAIHDMNFSNEDMIREFDNMARVEDKRRKSKQKLGAFLWMQRNLQDPFYPRGPREFRGGCRAPRRDTEDIPYV>sp|A6NCI4|VWA3A_HUMAN von Willebrand factor A domain-containing protein3A OS=Homo sapiens OX=9606 GN=VWA3A PE=2 SV=3MKKYRKISIGCFAMATQTSHVFHGQENMFLENHCIRRNTGRDSKKPLKQKNMNGLGQNSDNGLLVTHVNQTQDLLRLQGSETQSSDWEDSEDWLSAHSLKCQKLTLADLISQGTEVLEEGTNVVQKICFSTQIIRHFESKLSDTIEVYQERIQWLTENSKKAFGLIKGARVSILIDVSAISSGPQKEEFQKDLMSLIDEQLSHKEKLFVLSFGTNAGSLWPDPMEVSASTLQELKLWVKTLQPDGGSNLLQALKKIFTLKGLDSLVAIMRSCPDQPSEILSDYIQQSTMGRDLIIHFITYRCDDQMPPAVLKNLAEAVRGYYHCYSPKMEHYTSRDMDELLAEIQKAQSLLSHVQALQHSSPCEALTCTMEEISTEITNGPLISLLPKPPKHDAPLTIEFPNLDKTSAEWLKVNGLKAKKLSLYQVLAPNAFSPVEEFVPILQKTVSSTIHEKAMIQFEWHDGTVKNIHVDPPFLYKYQQQLSRAMRMYERRIEWLSLASRRIWGTVCEKRVVVLLDISATNSMYIIHIQHSLRLLLEEQLSNKDCFNLIAFGSTIESWRPEMVPVSHNNLQSAWRWALNLRCRGSRNVLSALRKAVEVDFKDKDKHQSQGIYLFTGGIPDQDMPTLSAYMAEACGGCDLQLNVCLFYVGEPKMDTTPPARYASHTDTAAAYKEVTRAAGGRFHWFGDTGIYESDDINSIMSEMEKALNYSQKCAFLMASLKNHSGKVLGSSALPKEKPKTLQLRSQPKKLCPPRPTVPLGARMSIKDDPDREKSPPLKSLKWRPLSSRVGISPAAAQPTKEGMMELRRKTKSREAETSLLLFYTEKGNDVGSVYKKYPQGRGLRRTSSSIDLPRKDTVCSSQEWVAKYGLKKLKLEISRCMGPNCTHQKSGQRSASAKHCSIFPSVEIHGVVRHIQWTPREMEVYIRHLEKVLRRYVQRLQWLLSGSRRLFGTVLESKVCILLDTSGSMGPYLQQVKTELVLLIWEQLRKCCDSFNLLSFAESFQSWQDTLVETTDAACHEAMQWVTHLQAQGSTSILQALLKAFSFHDLEGLYLLTDGKPDTSCSLVLNEVQKLREKRDVKVHTISLNCSDRAAVEFLRKLASFTGGRYHCPVGEDTLSKIHSLLTKGFINEKDPTLPPFEGDDLRILAQEITKARSFLWQAQSFRSQLQKKNDAEPKVTLS>sp|A6NCI4-2|VWA3A_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 3A OS=Homo sapiens OX=9606 GN=VWA3AMKKYRKISLLPKPPKHDAPLTIEFPNLDKTSAEWLKVNGLKAKKLSLYQVLAPNAFSPVEEFVPILQKTVSSTIHEKAMIQFEWHDGTVKNIHVDPPFLYKYQQQLSRAMRMYERRIEWLSLASRRIWGTVCEKRVVVLLDISATNSMYIIHIQHSLRLLLEEQLSNKDCFNLIAFGSTIESWRPEMVPVSHNNLQSAWRWALNLRCRGSRNVLSALRKAVEVDFKDKDKHQSQGIYLFTGGIPDQDMPTLSAYMAEACGGCDLQLNVCLFYVGEPKMDTTPPARYASHTDTAAAYKEVTRAAGGRFHWFGDTGIYESDDINSIMSEMEKALNYSQKCAFLMASLKNHSGKVLGSSALPKEKPKTLQLRSQPKKLCPPRPTVPLGARMSIKDDPDREKSPPLKSLKWRPLSSRVGISPAAAQPTKEGMMELRRKTKSREAETSLLLFYTEKGNDVGSVYKKYPQGRGLRRTSSSIDLPRKDTVCSSQEWVAKYGLKKLKLEISRCMGPNCTHQKSGQRSASAKHCSIFPSVEIHGVVRHIQWTPREMEVYIRHLEKVLRRYVQRLQWLLSGSRRLFGTVLESKVCILLDTSGSMGPYLQQVKTELVLLIWEQLRKCCDSFNLLSFAESFQSWQDTLVETTDAACHEAMQWVTHLQAQGSTSILQALLKAFSFHDLEGLYLLTDGKPDTSCSLVLNEVQKLREKRDVKVHTISLNCSDRAAVEFLRKLASFTGGRYHCPVGEDTLSKIHSLLTKGFINEKDPTLPPFEGDDLRILAQEITKARSFLWQAQSFRSQLQKKNDAEPKVTLS>sp|A6NCI4-3|VWA3A_HUMAN Isoform 3 of von Willebrand factor A domain-containing protein 3A OS=Homo sapiens OX=9606 GN=VWA3AMEVYIRHLEKVLRRYVQRLQWLLSGSRRLFGTVLESKVCILLDTSGSMGPYLQQVKTELVLLIWEQLRKCCDSFNLLSFAESFQSWQDTLVETTDAACHEAMQWVTHLQAQGSTSILQALLKAFSFHDLEGLYLLTDGKPDTSCSLVLNEVQKLREKRDVKVHTISLNCSDRAAVEFLRKLASFTGGRYHCPVGEDTLSKIHSLLTKGFINEKDPTLPPFEGDDLRILAQEITKARSFLWQAQSFRSQLQKKNDAEPKVTLS>sp|A6NCI4-4|VWA3A_HUMAN Isoform 4 of von Willebrand factor A domain-containing protein 3A OS=Homo sapiens OX=9606 GN=VWA3AMEVYIRHLEKVLRRYVQRLQWLLSGPVLCSRTWYRQSMDRGVMMTAASGSRRLFGTVLESKVCILLDTSGSMGPYLQQVKTELVLLIWEQLRKCCDSFNLLSFAESFQSWQDTLVETTDAACHEAMQWVTHLQAQGSTSILQALLKAFSFHDLEGLYLLTDGKPDTSCSLVLNEVQKLREKRDVKVHTISLNCSDRAAVEFLRKLASFTGGRYHCPVGEDTLSKIHSLLTKGFINEKDPTLPPFEGDDLRILAQEITKARSFLWQAQSFRSQLQKKNDAEPKVTLS>sp|Q9NUY8|TBC23_HUMAN TBC1 domain family member 23 OS=Homo sapiensOX=9606 GN=TBC1D23 PE=1 SV=3MAEGEDVPPLPTSSGDGWEKDLEEALEAGGCDLETLRNIIQGRPLPADLRAKVWKIALNVAGKGDSLASWDGILDLPEQNTIHKDCLQFIDQLSVPEEKAAELLLDIESVITFYCKSRNIKYSTSLSWIHLLKPLVHLQLPRSDLYNCFYAIMNKYIPRDCSQKGRPFHLFRLLIQYHEPELCSYLDTKKITPDSYALNWLGSLFACYCSTEVTQAIWDGYLQQADPFFIYFLMLIILVNAKEVILTQESDSKEEVIKFLENTPSSLNIEDIEDLFSLAQYYCSKTPASFRKDNHHLFGSTLLGIKDDDADLSQALCLAISVSEILQANQLQGEGVRFFVVDCRPAEQYNAGHLSTAFHLDSDLMLQNPSEFAQSVKSLLEAQKQSIESGSIAGGEHLCFMGSGREEEDMYMNMVLAHFLQKNKEYVSIASGGFMALQQHLADINVDGPENGYGHWIASTSGSRSSINSVDGESPNGSSDRGMKSLVNKMTVALKTKSVNVREKVISFIENTSTPVDRMSFNLPWPDRSCTERHVSSSDRVGKPYRGVKPVFSIGDEEEYDTDEIDSSSMSDDDRKEVVNIQTWINKPDVKHHFPCKEVKESGHMFPSHLLVTATHMYCLREIVSRKGLAYIQSRQALNSVVKITSKKKHPELITFKYGNSSASGIEILAIERYLIPNAGDATKAIKQQIMKVLDALES>sp|Q9NUY8-2|TBC23_HUMAN Isoform 2 of TBC1 domain family member 23OS=Homo sapiens OX=9606 GN=TBC1D23MAEGEDVPPLPTSSGDGWEKDLEEALEAGGCDLETLRNIIQGRPLPADLRAKVWKIALNVAGKGDSLASWDGILDLPEQNTIHKDCLQFIDQLSVPEEKAAELLLDIESVITFYCKSRNIKYSTSLSWIHLLKPLVHLQLPRSDLYNCFYAIMNKYIPRDCSQKGRPFHLFRLLIQYHEPELCSYLDTKKITPDSYALNWLGSLFACYCSTEVTQAIWDGYLQQADPFFIYFLMLIILVNAKEVILTQESDSKEEVIKFLENTPSSLNIEDIEDLFSLAQYYCSKTPASFRKDNHHLFGSTLLGIKDDDADLSQALCLAISVSEILQANQLQGEGVRFFVVDCRPAEQYNAGHLSTAFHLDSDLMLQNPSEFAQSVKSLLEAQKQSIESGSIAGGEHLCFMGSGREEEDMYMNMVLAHFLQKNKEYVSIASGGFMALQQHLADINVDGPENGYGHWIASTSGSRSSINSVDGESPNGSSDRGMKSLVNKMTVALKTKSVNVREKVISFIENTSTPVDRHVSSSDRVGKPYRGVKPVFSIGDEEEYDTDEIDSSSMSDDDRKEVVNIQTWINKPDVKHHFPCKEVKESGHMFPSHLLVTATHMYCLREIVSRKGLAYIQSRQALNSVVKITSKKKHPELITFKYGNSSASGIEILAIERYLIPNAGDATKAIKQQIMKVLDALES>sp|Q9BUF5|TBB6_HUMAN Tubulin beta-6 chain OS=Homo sapiens OX=9606GN=TUBB6 PE=1 SV=1MREIVHIQAGQCGNQIGTKFWEVISDEHGIDPAGGYVGDSALQLERINVYYNESSSQKYVPRAALVDLEPGTMDSVRSGPFGQLFRPDNFIFGQTGAGNNWAKGHYTEGAELVDAVLDVVRKECEHCDCLQGFQLTHSLGGGTGSGMGTLLISKIREEFPDRIMNTFSVMPSPKVSDTVVEPYNATLSVHQLVENTDETYCIDNEALYDICFRTLKLTTPTYGDLNHLVSATMSGVTTSLRFPGQLNADLRKLAVNMVPFPRLHFFMPGFAPLTSRGSQQYRALTVPELTQQMFDARNMMAACDPRHGRYLTVATVFRGPMSMKEVDEQMLAIQSKNSSYFVEWIPNNVKVAVCDIPPRGLKMASTFIGNSTAIQELFKRISEQFSAMFRRKAFLHWFTGEGMDEMEFTEAESNMNDLVSEYQQYQDATANDGEEAFEDEEEEIDG>sp|Q8IZW8|TENS4_HUMAN Tensin-4 OS=Homo sapiens OX=9606 GN=TNS4 PE=1 SV=3MSQVMSSPLLAGGHAVSLAPCDEPRRTLHPAPSPSLPPQCSYYTTEGWGAQALMAPVPCMGPPGRLQQAPQVEAKATCFLPSPGEKALGTPEDLDSYIDFSLESLNQMILELDPTFQLLPPGTGGSQAELAQSTMSMRKKEESEALDIKYIEVTSARSRCHDGPQHCSSPSVTPPFGSLRSGGLLLSRDVPRETRSSSESLIFSGNQGRGHQRPLPPSEGLSPRPPNSPSISIPCMGSKASSPHGLGSPLVASPRLEKRLGGLAPQRGSRISVLSASPVSDVSYMFGSSQSLLHSSNSSHQSSSRSLESPANSSSSLHSLGSVSLCTRPSDFQAPRNPTLTMGQPRTPHSPPLAKEHASSCPPSITNSMVDIPIVLINGCPEPGSSPPQRTPGHQNSVQPGAASPSNPCPATRSNSQTLSDAPFTTCPEGPARDMQPTMKFVMDTSKYWFKPNITREQAIELLRKEEPGAFVIRDSSSYRGSFGLALKVQEVPASAQSRPGEDSNDLIRHFLIESSAKGVHLKGADEEPYFGSLSAFVCQHSIMALALPCKLTIPQRELGGADGASDSTDSPASCQKKSAGCHTLYLSSVSVETLTGALAVQKAISTTFERDILPTPTVVHFKVTEQGITLTDVQRKVFFRRHYPLTTLRFCGMDPEQRKWQKYCKPSWIFGFVAKSQTEPQENVCHLFAEYDMVQPASQVIGLVTALLQDAERM>sp|Q6P9G4|TM154_HUMAN Transmembrane protein 154 OS=Homo sapiens OX=9606GN=TMEM154 PE=1 SV=2MQAPRAALVFALVIALVPVGRGNYEELENSGDTTVESERPNKVTIPSTFAAVTIKETLNANINSTNFAPDENQLEFILMVLIPLILLVLLLLSVVFLATYYKRKRTKQEPSSQGSQSALQTYELGSENVKVPIFEEDTPSVMEIEMEELDKWMNSMNRNADFECLPTLKEEKESNHNPSDSES>sp|Q13470|TNK1_HUMAN Non-receptor tyrosine-protein kinase TNK1 OS=Homosapiens OX=9606 GN=TNK1 PE=1 SV=3MLPEAGSLWLLKLLRDIQLAQFYWPILEELNVTRPEHFDFVKPEDLDGIGMGRPAQRRLSEALKRLRSGPKSKNWVYKILGGFAPEHKEPTLPSDSPRHLPEPEGGLKCLIPEGAVCRGELLGSGCFGVVHRGLWTLPSGKSVPVAVKSLRVGPEGPMGTELGDFLREVSVMMNLEHPHVLRLHGLVLGQPLQMVMELAPLGSLHARLTAPAPTPPLLVALLCLFLRQLAGAMAYLGARGLVHRDLATRNLLLASPRTIKVADFGLVRPLGGARGRYVMGGPRPIPYAWCAPESLRHGAFSSASDVWMFGVTLWEMFSGGEEPWAGVPPYLILQRLEDRARLPRPPLCSRALYSLALRCWAPHPADRPSFSHLEGLLQEAGPSEACCVRDVTEPGALRMETGDPITVIEGSSSFHSPDSTIWKGQNGRTFKVGSFPASAVTLADAGGLPATRPVHRGTPARGDQHPGSIDGDRKKANLWDAPPARGQRRNMPLERMKGISRSLESVLSLGPRPTGGGSSPPEIRQARAVPQGPPGLPPRPPLSSSSPQPSQPSRERLPWPKRKPPHNHPMGMPGARKAAALSGGLLSDPELQRKIMEVELSVHGVTHQECQTALGATGGDVVSAIRNLKVDQLFHLSSRSRADCWRILEHYQWDLSAASRYVLARP>sp|Q13470-2|TNK1_HUMAN Isoform 2 of Non-receptor tyrosine-protein kinaseTNK1 OS=Homo sapiens OX=9606 GN=TNK1MLPEAGSLWLLKLLRDIQLAQFYWPILEELNVTRPEHFDFVKPEDLDGIGMGRPAQRRLSEALKRLRSGPKSKNWVYKILGGFAPEHKEPTLPSDSPRHLPEPEGGLKCLIPEGAVCRGELLGSGCFGVVHRGLWTLPSGKSVPVAVKSLRVGPEGPMGTELGDFLREVSVMMNLEHPHVLRLHGLVLGQPLQMVMELAPLGSLHARLTAPAPTPPLLVALLCLFLRQLAGAMAYLGARGLVHRDLATRNLLLASPRTIKVADFGLVRPLGGARGRYVMGGPRPIPYAWCAPESLRHGAFSSASDVWMFGVTLWEMFSGGEEPWAGVPPYLILQRLEDRARLPRPPLCSRALYSLALRCWAPHPADRPSFSHLEGLLQEAGPSEACCVRDVTEPGALRMETGDPITVIEGSPDSTIWKGQNGRTFKVGSFPASAVTLADAGGLPATRPVHRGTPARGDQHPGSIDGDRKKANLWDAPPARGQRRNMPLERMKGISRSLESVLSLGPRPTGGGSSPPEIRQARAVPQGPPGLPPRPPLSSSSPQPSQPSRERLPWPKRKPPHNHPMGMPGARKAAALSGGLLSDPELQRKIMEVELSVHGVTHQECQTALGATGGDVVSAIRNLKVDQLFHLSSRSRADCWRILEHYQWDLSAASRYVLARP>sp|Q8N3G9|TM130_HUMAN Transmembrane protein 130 OS=Homo sapiens OX=9606GN=TMEM130 PE=1 SV=1MAQAVWSRLGRILWLACLLPWAPAGVAAGLYELNLTTDSPATTGAVVTISASLVAKDNGSLALPADAHLYRFHWIHTPLVLTGKMEKGLSSTIRVVGHVPGEFPVSVWVTAADCWMCQPVARGFVVLPITEFLVGDLVVTQNTSLPWPSSYLTKTVLKVSFLLHDPSNFLKTALFLYSWDFGDGTQMVTEDSVVYYNYSIIGTFTVKLKVVAEWEEVEPDATRAVKQKTGDFSASLKLQETLRGIQVLGPTLIQTFQKMTVTLNFLGSPPLTVCWRLKPECLPLEEGECHPVSVASTAYNLTHTFRDPGDYCFSIRAENIISKTHQYHKIQVWPSRIQPAVFAFPCATLITVMLAFIMYMTLRNATQQKDMVEVADFDFSPMSDKNPEPPSGVRCCCQMCCGPFLLETPSEYLEIVRENHGLLPPLYKSVKTYTV>sp|Q8N3G9-2|TM130_HUMAN Isoform 2 of Transmembrane protein 130 OS=Homosapiens OX=9606 GN=TMEM130MAQAVWSRLGRILWLACLLPWAPAGVAAGLYELNLTTDSPATTGAVVTISASLVAKDNGSLALPADAHLYRFHWIHTPLVLTGKMEKGLSSTIRVVGHVPGEFPVSVWVTAADCWMCQPVARGFVVLPITEFLVGDLVVTQNTSLPWPSSYLTKTVLKVSFLLHDPSNFLKTALFLYSWDFGDGTQMVTEDSVVYYNYSIIGTFTVKLKVVAEWEEVEPDATRAVKQKTGDFSASLKLQETLRGIQVLGPTLIQTFQKMTVTLNFLGSPPLTVCWRLKPECLPLEEGECHPVSVASTAYNLTHTFRDPGDYCFSIRAENIISKTHQYHKIQVWPSRIQPAVFAFPCATLITVMLAFIMYMTLRNATQQKDMVENPEPPSGVRCCCQMCCGPFLLETPSEYLEIVRENHGLLPPLYKSVKTYTV>sp|Q8N3G9-3|TM130_HUMAN Isoform 3 of Transmembrane protein 130 OS=Homosapiens OX=9606 GN=TMEM130MAQAVWSRLGRILWLACLLPWAPAGVAAEFLVGDLVVTQNTSLPWPSSYLTKTVLKVSFLLHDPSNFLKTALFLYSWDFGDGTQMVTEDSVVYYNYSIIGTFTVKLKVVAEWEEVEPDATRAVKQKTGDFSASLKLQETLRGIQVLGPTLIQTFQKMTVTLNFLGSPPLTVCWRLKPECLPLEEGECHPVSVASTAYNLTHTFRDPGDYCFSIRAENIISKTHQYHKIQVWPSRIQPAVFAFPCATLITVMLAFIMYMTLRNATQQKDMVENPEPPSGVRCCCQMCCGPFLLETPSEYLEIVRENHGLLPPLYKSVKTYTV>sp|Q9C0B7|TNG6_HUMAN Transport and Golgi organization protein 6 homologOS=Homo sapiens OX=9606 GN=TANGO6 PE=1 SV=2MAARQAVGSGAQETCGLDRILEALKLLLSPGGSGSSSLQVTKHDVLLATLKSNLSALEDKFLKDPQWKNLKLLRDEIADKAEWPQNSVDVTWSFTSQTLLLLLCLKETMIRLAANFNPGKPNPRTPEVAPALSPDALSISQQKTVQFVLQFVVTLGICPYLMPGVGVPLRYRTEFGAVVQDVVCFDAAPDATRRLYTSCKALLNVAQHTSLGSLIFCHHFGDIAAGLCQLGFCPTKRKLLTPAEEVLTEEERTLSRGALRDMLDQVYQPLAVRELLILQGGPPQSCTDVKTQMRCRAPAWLRRLCGQLLSERLMRPNGVQAVVRGILEGAGAGAAGGSDAEVTAADWKKCDLIAKILASCPQQSLSPENYYRDICPQVLDLFHFQDKLTARQFQRVATTTFITLSRERPHLAAKYLLQPVLAPLHRCLNTAELSESDMVPGTILVTEEELSRCIEDVFKVYVVGNEPLTVLMDSLLPVLGVLFLLYCFTKQSVSHIRSLCQEILLWILGKLERKKAIASLKGFAGLDKAVPSLHSLCQFRVATQGGIMITIKEAISDEDEDEALYQKVSSEQGRVEHLGDLLSHCQECGLAGDFFIFCLKELTHVASENETELKTEPFSSKSLLELEQHQTLLVEGQERKLLVLQLMAVLCERMSEQIFTNVTQVVDFVAATLQRACASLAHQAESTVESQTLSMSMGLVAVMLGGAVQLKSSDFAVLKQLLPLLEKVSNTYPDPVIQELAVDLRITISTHGAFATEAVSMAAQSTLNRKDLEGKIEEQQQTSHERPTDVAHSHLEQQQSHETAPQTGLQSNAPIIPQGVNEPSTTTSQKSGSVTTEQLQEVLLSAYDPQIPTRAAALRTLSHWIEQREAKALEMQEKLLKIFLENLEHEDTFVYLSAIQGVALLSDVYPEKILPDLLAQYDSSKDKHTPETRMKVGEVLMRIVRALGDMVSKYREPLIHTFLRGVRDPDGAHRASSLANLGELCQRLDFLLGSVVHEVTACLIAVAKTDGEVQVRRAAIHVVVLLLRGLSQKATEVLSAVLKDLYHLLKHVVCLEPDDVAKLHAQLALEELDDIMKNFLFPPQKLEKKIMVLP>sp|O43508|TNF12_HUMAN Tumor necrosis factor ligand superfamily member 12OS=Homo sapiens OX=9606 GN=TNFSF12 PE=1 SV=1MAARRSQRRRGRRGEPGTALLVPLALGLGLALACLGLLLAVVSLGSRASLSAQEPAQEELVAEEDQDPSELNPQTEESQDPAPFLNRLVRPRRSAPKGRKTRARRAIAAHYEVHPRPGQDGAQAGVDGTVSGWEEARINSSSPLRYNRQIGEFIVTRAGLYYLYCQVHFDEGKAVYLKLDLLVDGVLALRCLEEFSATAASSLGPQLRLCQVSGLLALRPGSSLRIRTLPWAHLKAAPFLTYFGLFQVH>sp|O43508-2|TNF12_HUMAN Isoform TWE-PRIL of Tumor necrosis factor ligandsuperfamily member 12 OS=Homo sapiens OX=9606 GN=TNFSF12MAARRSQRRRGRRGEPGTALLVPLALGLGLALACLGLLLAVVSLGSRASLSAQEPAQEELVAEEDQDPSELNPQTEESQDPAPFLNRLVRPRRSAPKGRKTRARRAIAAHYEVHPRPGQDGAQAGVDGTVSGWEEARINSSSPLRYNRQIGEFIVTRAGLYYLYCQSSDALEAWENGERSRKRRAVLTQKQKKQHSVLHLVPINATSKDDSDVTEVMWQPALRRGRGLQAQGYGVRIQDAGVYLLYSQVLFQDVTFTMGQVVSREGQGRQETLFRCIRSMPSHPDRAYNSCYSAGVFHLHQGDILSVIIPRARAKLNLSPHGTFLGFVKL>sp|O15417|TNC18_HUMAN Trinucleotide repeat-containing gene 18 proteinOS=Homo sapiens OX=9606 GN=TNRC18 PE=1 SV=3MDGRDFGPQRSVHGPPPPLLSGLAMDSHRVGAATAGRLPASGLPGPLPPGKYMAGLNLHPHPGEAFLGSFVASGMGPSASSHGSPVPLPSDLSFRSPTPSNLPMVQLWAAHAHEGFSHLPSGLYPSYLHLNHLEPPSSGSPLLSQLGQPSIFDTQKGQGPGGDGFYLPTAGAPGSLHSHAPSARTPGGGHSSGAPAKGSSSRDGPAKERAGRGGEPPPLFGKKDPRARGEEASGPRGVVDLTQEARAEGRQDRGPPRLAERLSPFLAESKTKNAALQPSVLTMCNGGAGDVGLPALVAEAGRGGAKEAARQDEGARLLRRTETLLPGPRPCPSPLPPPPAPPKGPPAPPAATPAGVYTVFREQGREHRVVAPTFVPSVEAFDERPGPIQIASQARDARAREREAGRPGVLQAPPGSPRPLDRPEGLREKNSVIRSLKRPPPADAPTVRATRASPDPRAYVPAKELLKPEADPRPCERAPRGPAGPAAQQAAKLFGLEPGRPPPTGPEHKWKPFELGNFAATQMAVLAAQHHHSRAEEEAAVVAASSSKKAYLDPGAVLPRSAATCGRPVADMHSAAHGSGEASAMQSLIKYSGSFARDAVAVRPGGCGKKSPFGGLGTMKPEPAPTSAGASRAQARLPHSGGPAAGGGRQLKRDPERPESAKAFGREGSGAQGEAEVRHPPVGIAVAVARQKDSGGSGRLGPGLVDQERSLSLSNVKGHGRADEDCVDDRARHREERLLGARLDRDQEKLLRESKELADLARLHPTSCAPNGLNPNLMVTGGPALAGSGRWSADPAAHLATHPWLPRSGNASMWLAGHPYGLGPPSLHQGMAPAFPPGLGGSLPSAYQFVRDPQSGQLVVIPSDHLPHFAELMERATVPPLWPALYPPGRSPLHHAQQLQLFSQQHFLRQQEFLYLQQQAAQALELQRSAQLVQERLKAQEHRAEMEEKGSKRGLEAAGKAGLATAGPGLLPRKPPGLAAGPAGTYGKAVSPPPSPRASPVAALKAKVIQKLEDVSKPPAYAYPATPSSHPTSPPPASPPPTPGITRKEEAPENVVEKKDLELEKEAPSPFQALFSDIPPRYPFQALPPHYGRPYPFLLQPTAAADADGLAPDVPLPADGPERLALSPEDKPIRLSPSKITEPLREGPEEEPLAEREVKAEVEDMDEGPTELPPLESPLPLPAAEAMATPSPAGGCGGGLLEAQALSATGQSCAEPSECPDFVEGPEPRVDSPGRTEPCTAALDLGVQLTPETLVEAKEEPVEVPVAVPVVEAVPEEGLAQVAPSESQPTLEMSDCDVPAGEGQCPSLEPQEAVPVLGSTCFLEEASSDQFLPSLEDPLAGMNALAAAAELPQARPLPSPGAAGAQALEKLEAAESLVLEQSFLHGITLLSEIAELELERRSQEMGGAERALVARPSLESLLAAGSHMLREVLDGPVVDPLKNLRLPRELKPNKKYSWMRKKEERMYAMKSSLEDMDALELDFRMRLAEVQRQYKEKQRELVKLQRRRDSEDRREEPHRSLARRGPGRPRKRTHAPSALSPPRKRGKSGHSSGKLSSKSLLTSDDYELGAGIRKRHKGSEEEHDALIGMGKARGRNQTWDEHEASSDFISQLKIKKKKMASDQEQLASKLDKALSLTKQDKLKSPFKFSDSAGGKSKTSGGCGRYLTPYDSLLGKNRKALAKGLGLSLKSSREGKHKRAAKTRKMEVGFKARGQPKSAHSPFASEVSSYSYNTDSEEDEEFLKDEWPAQGPSSSKLTPSLLCSMVAKNSKAAGGPKLTKRGLAAPRTLKPKPATSRKQPFCLLLREAEARSSFSDSSEESFDQDESSEEEDEEEELEEEDEASGGGYRLGARERALSPGLEESGLGLLARFAASALPSPTVGPSLSVVQLEAKQKARKKEERQSLLGTEFEYTDSESEVKVRKRSPAGLLRPKKGLGEPGPSLAAPTPGARGPDPSSPDKAKLAVEKGRKARKLRGPKEPGFEAGPEASDDDLWTRRRSERIFLHDASAAAPAPVSTAPATKTSRCAKGGPLSPRKDAGRAKDRKDPRKKKKGKEAGPGAGLPPPRAPALPSEARAPHASSLTAAKRSKAKAKGKEVKKENRGKGGAVSKLMESMAAEEDFEPNQDSSFSEDEHLPRGGAVERPLTPAPRSCIIDKDELKDGLRVLIPMDDKLLYAGHVQTVHSPDIYRVVVEGERGNRPHIYCLEQLLQEAIIDVRPASTRFLPQGTRIAAYWSQQYRCLYPGTVVRGLLDLEDDGDLITVEFDDGDTGRIPLSHIRLLPPDYKIQCAEPSPALLVPSAKRRSRKTSKDTGEGKDGGTAGSEEPGAKARGRGRKPSAKAKGDRAATLEEGNPTDEVPSTPLALEPSSTPGSKKSPPEPVDKRAKAPKARPAPPQPSPAPPAFTSCPAPEPFAELPAPATSLAPAPLITMPATRPKPKKARAAEESGAKGPRRPGEEAELLVKLDHEGVTSPKSKKAKEALLLREDPGAGGWQEPKSLLSLGSYPPAAGSSEPKAPWPKATDGDLAQEPGPGLTFEDSGNPKSPDKAQAEQDGAEESESSSSSSSGSSSSSSSSSSSGSETEGEEEGDKNGDGGCGTGGRNCSAASSRAASPASSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSTTDEDSSCSSDDEAAPAPTAGPSAQAALPTKATKQAGKARPSAHSPGKKTPAPQPQAPPPQPTQPLQPKAQAGAKSRPKKREGVHLPTTKELAKRQRLPSVENRPKIAAFLPARQLWKWFGKPTQRRGMKGKARKLFYKAIVRGKEMIRIGDCAVFLSAGRPNLPYIGRIQSMWESWGNNMVVRVKWFYHPEETSPGKQFHQGQHWDQKSSRSLPAALRVSSQRKDFMERALYQSSHVDENDVQTVSHKCLVVGLEQYEQMLKTKKYQDSEGLYYLAGTYEPTTGMIFSTDGVPVLC>sp|O15417-2|TNC18_HUMAN Isoform 2 of Trinucleotide repeat-containinggene 18 protein OS=Homo sapiens OX=9606 GN=TNRC18MDGRDFGPQRSVHGPPPPLLSGLAMDSHRVGAATAGRLPASGLPGPLPPGKYMAGLNLHPHPGEAFLGSFVASGMGPSASSHGSPVPLPSDLSFRSPTPSNLPMVQLWAAHAHEGFSHLPSGLYPSYLHLNHLEPPSSGSPLLSQLGQPSIFDTQKGQGPGGDGFYLPTAGAPGSLHSHAPSARTPGGGHSSGAPAKGSSSRDGPAKERAGRGGEPPPLFGKKDPRARGEEASGPRGVVDLTQEARAEGRQDRGPPRLAERLSPFLAESKTKNAALQPSVLTMCNGGAGDVGLPALVAEAGRGGAKEAARQDEGARLLRRTETLLPGPRPCPSPLPPPPAPPKGPPAPPAATPAGVYTVFREQGREHRVVAPTFVPSVEAFDERPGPIQIASQARDARAREREAGRPGVLQAPPGSPRPLDRPEGLREKNSVIRSLKRPPPADAPTVRATRASPDPRAYVPAKELLKPEADPRPCERAPRGPAGPAAQQAAKLFGLEPGRPPPTGPEHKWKPFELGNFAATQMAVLAAQHHHSRAEEEAAVVAASSSKKAYLDPGAVLPRSAATCGRPVADMHSAAHGSGEASAMQSLIKYSGSFARDAVAVRPGGCGKKSPFGGLGTMKPEPAPTSAGASRAQARLPHSGGPAAGGGRQLKRDPERPESAKAFGREGSGAQGEAEVRHPPVGIAVAVARQKDSGGSGRLGPGLVDQERSLSLSNVKGHGRADEDCVDDRARHREERLLGARLDRDQEKLLRESKELADLARLHPTSCAPNGLNPNLMVTGGPALAGSGRWSADPAAHLATHPWLPRSGNASMWLAGHPYGLGPPSLHQGMAPAFPPGLGGSLPSAYQFVRDPQSGQLVVIPSDHLPHFAELMERATVPPLWPALYPPGRSPLHHAQQLQLFSQQHFLRQQEFLYLQQQAAQALELQRSAQLVQERLKAQEHRAEMEEKGSKRGLEAAGKAGLATAGPGLLPRKPPGLAAGPAGTYGKAVSPPPSPRASPVAALKAKVIQKLEDVSKPPAYAYPATPSSHPTSPPPASPPPTPGITRKEEAPENVVEKKDLELEKEAPSPFQALFSDIPPRYPFQALPPHYGRPYPFLLQPTAAADADGLAPDVPLPADGPERLALSPEDKPIRLSPSKITEPLREGPEEEPLAEREVKAEVEDMDEGPTELPPLESPLPLPAAEAMATPSPAGGCGGGLLEAQALSATGQSCAEPSECPDFVEGPEPRVDSPGRTEPCTAALDLGVQLTPETLVEAKEEPVEVPVAVPVVEAVPEEGLAQVAPSESQPTLEMSDCDVPAGEGQCPSLEPQEAVPVLGSTCFLEEASSDQFLPSLEDPLAGMNALAAAAELPQARPLPSPGAAGAQALEKLEAAESLVLEQSFLHGITLLSEIAELELERRSQEMGGAERALVARPSLESLLAAGSHMLREVLDGPVVDPLKNLRLPRELKPNKKYSWMRKKEERMYAMKSSLEDMDALELDFRMRLAEVQRQYKEKQRELVKLQRRRDSEDRREEPHRSLARRGPGRPRKRTHAPSALSPPRKRGKSGHSSGKLSSKSLLTSDDYELGAGIRKRHKGSEEEHDALIGMGKARGRNQTWDEHEASSDFISQLKIKKKKMASDQEQLASKLDKALSLTKQDKLKSPFKFSDSAGGKSKTSGGCGRYLTPYDSLLGKNRKALAKGLGLSLKSSREGKHKRAAKTRKMEVGFKARGQPKSAHSPFASEVSSYSYNTDSEEDEEFLKDEWPAQGPSSSKLTPSLLCSMVAKNSKAAGGPKLTKRGLAAPRTLKPKPATSRKQPFCLLLREAEARSSFSDSSEESFDQDESSEEEDEEEELEEEDEASGGGYRLGARERALSPGLEESGLGLLARFAASALPSPTVGPSLSVVQLEAKQKARKKEERQSLLGTEFEYTDSESEVKVRKRSPAGLLRPKKGLGEPGPSLAAPTPGARGPDPSSPDKAKLAVEKGRKARKLRGPKEPGFEAGPEASDDDLWTRRRSERIFLHDASAAAPAPVSTAPATKTSRCAKGGPLSPRKDAGRAKDRKDPRKKKKGKEAGPGAGLPPPRAPALPSEARAPPPPPPPPPHPPLPPPPLPPPPLPLRLPPLPPPPLPRPHPPPPPPLPPLLPPPQTRTLPAARTMRQPPPPRLALPRRRRSPPRPPSRPARRGPRPTPQARRRPRPSPRRLLRSPHSLCSPRLRPGPRADPRRERASTSPPPRSWPSGSACRPWRTGPRSPPSCQPGSSGSGSASPPSGVA>sp|O15417-3|TNC18_HUMAN Isoform 3 of Trinucleotide repeat-containinggene 18 protein OS=Homo sapiens OX=9606 GN=TNRC18KEAPSPFQALFSDIPPRYPFQALPPHYGRPYPFLLQPTAAADADGLAPDVPLPADGPERLALSPEDKPIRLSPSKITEPLREGPEEEPLAEREVKAEVEDMDEGPTELPPLESPLPLPAAEAMATPSPAGGCGGGLLEAQALSATGQSCAEPSECPDFVEGPEPRVDSPGRTEPCTAALDLGVQLTPETLVEAKEEPVEVPVAVPVVEAVPEEGLAQVAPSESQPTLEMSDCDVPAGEGQCPSLEPQEAVPVLGSTCFLEEASSDQFLPSLEDPLAGMNALAAAAELPQARPLPSPGAAGAQALEKLEAAESLVLEQSFLHGITLLSEIAELELERRSPPQGLPPCMGQGSPMPAGLPDCARGPAPTLSGWPRLGEQSRVGLQPGVSVKGTRWRGPGTGPPWSKPSHYRKPQWC>sp|P19237|TNNI1_HUMAN Troponin I, slow skeletal muscle OS=Homo sapiensOX=9606 GN=TNNI1 PE=1 SV=3MPEVERKPKITASRKLLLKSLMLAKAKECWEQEHEEREAEKVRYLAERIPTLQTRGLSLSALQDLCRELHAKVEVVDEERYDIEAKCLHNTREIKDLKLKVMDLRGKFKRPPLRRVRVSADAMLRALLGSKHKVSMDLRANLKSVKKEDTEKERPVEVGDWRKNVEAMSGMEGRKKMFDAAKSPTSQ>sp|Q15654|TRIP6_HUMAN Thyroid receptor-interacting protein 6 OS=Homosapiens OX=9606 GN=TRIP6 PE=1 SV=3MSGPTWLPPKQPEPARAPQGRAIPRGTPGPPPAHGAALQPHPRVNFCPLPSEQCYQAPGGPEDRGPAWVGSHGVLQHTQGLPADRGGLRPGSLDAEIDLLSSTLAELNGGRGHASRRPDRQAYEPPPPPAYRTGSLKPNPASPLPASPYGGPTPASYTTASTPAGPAFPVQVKVAQPVRGCGPPRRGASQASGPLPGPHFPLPGRGEVWGPGYRSQREPGPGAKEEAAGVSGPAGRGRGGEHGPQVPLSQPPEDELDRLTKKLVHDMNHPPSGEYFGQCGGCGEDVVGDGAGVVALDRVFHVGCFVCSTCRAQLRGQHFYAVERRAYCEGCYVATLEKCATCSQPILDRILRAMGKAYHPGCFTCVVCHRGLDGIPFTVDATSQIHCIEDFHRKFAPRCSVCGGAIMPEPGQEETVRIVALDRSFHIGCYKCEECGLLLSSEGECQGCYPLDGHILCKACSAWRIQELSATVTTDC>sp|Q15654-2|TRIP6_HUMAN Isoform 2 of Thyroid receptor-interactingprotein 6 OS=Homo sapiens OX=9606 GN=TRIP6MSGPTWLPPKQPEPARAPQGRAIPRGTPGPPPAHGAVLPGPRGTGGSGAGVGGVPWSTPAHAGAPCRQGGPSPWKPGRRDRLAEQHAGRAEWGSGSCVTATRPTGI>sp|Q15654-3|TRIP6_HUMAN Isoform 3 of Thyroid receptor-interactingprotein 6 OS=Homo sapiens OX=9606 GN=TRIP6MSGPTWLPPKQPEPARAPQGRAIPRGTPGPPPAHGAGAPCRQGGPSPWKPGRRDRLAEQHAGRAEWGSGSCVTATRPTGI>sp|O60858|TRI13_HUMAN E3 ubiquitin-protein ligase TRIM13 OS=Homo sapiensOX=9606 GN=TRIM13 PE=1 SV=2MELLEEDLTCPICCSLFDDPRVLPCSHNFCKKCLEGILEGSVRNSLWRPAPFKCPTCRKETSATGINSLQVNYSLKGIVEKYNKIKISPKMPVCKGHLGQPLNIFCLTDMQLICGICATRGEHTKHVFCSIEDAYAQERDAFESLFQSFETWRRGDALSRLDTLETSKRKSLQLLTKDSDKVKEFFEKLQHTLDQKKNEILSDFETMKLAVMQAYDPEINKLNTILQEQRMAFNIAEAFKDVSEPIVFLQQMQEFREKIKVIKETPLPPSNLPASPLMKNFDTSQWEDIKLVDVDKLSLPQDTGTFISKIPWSFYKLFLLILLLGLVIVFGPTMFLEWSLFDDLATWKGCLSNFSSYLTKTADFIEQSVFYWEQVTDGFFIFNERFKNFTLVVLNNVAEFVCKYKLL>sp|O60858-2|TRI13_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TRIM13OS=Homo sapiens OX=9606 GN=TRIM13MELLEEDLTCPICCSLFDDPRVLPCSHNFCKKCLEGILEGSVRNSLWRPAPFKCPTCRKETSATGINSLQVNYSLKGIVEKYNKIKISPKMPVCKGHLGQPLNIFCLTDMQLICGICATRGEHTKHVFCSIEDAYAQERDAFESLFQSFETWRRGDALSRLDTLETSKRKSLQLD>sp|O60858-3|TRI13_HUMAN Isoform 3 of E3 ubiquitin-protein ligase TRIM13OS=Homo sapiens OX=9606 GN=TRIM13MDVMELLEEDLTCPICCSLFDDPRVLPCSHNFCKKCLEGILEGSVRNSLWRPAPFKCPTCRKETSATGINSLQVNYSLKGIVEKYNKIKISPKMPVCKGHLGQPLNIFCLTDMQLICGICATRGEHTKHVFCSIEDAYAQERDAFESLFQSFETWRRGDALSRLDTLETSKRKSLQLLTKDSDKVKEFFEKLQHTLDQKKNEILSDFETMKLAVMQAYDPEINKLNTILQEQRMAFNIAEAFKDVSEPIVFLQQMQEFREKIKVIKETPLPPSNLPASPLMKNFDTSQWEDIKLVDVDKLSLPQDTGTFISKIPWSFYKLFLLILLLGLVIVFGPTMFLEWSLFDDLATWKGCLSNFSSYLTKTADFIEQSVFYWEQVTDGFFIFNERFKNFTLVVLNNVAEFVCKYKLL>sp|Q9UNS1|TIM_HUMAN Protein timeless homolog OS=Homo sapiens OX=9606GN=TIMELESS PE=1 SV=2MDLHMMNCELLATCSALGYLEGDTYHKEPDCLESVKDLIRYLRHEDETRDVRQQLGAAQILQSDLLPILTQHHQDKPLFDAVIRLMVNLTQPALLCFGNLPKEPSFRHHFLQVLTYLQAYKEAFASEKAFGVLSETLYELLQLGWEERQEEDNLLIERILLLVRNILHVPADLDQEKKIDDDASAHDQLLWAIHLSGLDDLLLFLASSSAEEQWSLHVLEIVSLMFRDQNPEQLAGVGQGRLAQERSADFAELEVLRQREMAEKKTRALQRGNRHSRFGGSYIVQGLKSIGERDLIFHKGLHNLRNYSSDLGKQPKKVPKRRQAARELSIQRRSALNVRLFLRDFCSEFLENCYNRLMGSVKDHLLREKAQQHDETYYMWALAFFMAFNRAASFRPGLVSETLSVRTFHFIEQNLTNYYEMMLTDRKEAASWARRMHLALKAYQELLATVNEMDISPDEAVRESSRIIKNNIFYVMEYRELFLALFRKFDERCQPRSFLRDLVETTHLFLKMLERFCRSRGNLVVQNKQKKRRKKKKKVLDQAIVSGNVPSSPEEVEAVWPALAEQLQCCAQNSELSMDSVVPFDAASEVPVEEQRAEAMVRIQDCLLAGQAPQALTLLRSAREVWPEGDVFGSQDISPEEEIQLLKQILSAPLPRQQGPEERGAEEEEEEEEEEEEELQVVQVSEKEFNFLDYLKRFACSTVVRAYVLLLRSYQQNSAHTNHCIVKMLHRLAHDLKMEALLFQLSVFCLFNRLLSDPAAGAYKELVTFAKYILGKFFALAAVNQKAFVELLFWKNTAVVREMTEGYGSLDDRSSSRRAPTWSPEEEAHLRELYLANKDVEGQDVVEAILAHLNTVPRTRKQIIHHLVQMGLADSVKDFQRKGTHIVLWTGDQELELQRLFEEFRDSDDVLGHIMKNITAKRSRARIVDKLLALGLVAERRELYKKRQKKLASSILPNGAESLKDFCQEDLEEEENLPEEDSEEEEEGGSEAEQVQGSLVLSNENLGQSLHQEGFSIPLLWLQNCLIRAADDREEDGCSQAVPLVPLTEENEEAMENEQFQQLLRKLGVRPPASGQETFWRIPAKLSPTQLRRAAASLSQPEEEQKLQPELQPKVPGEQGSDEEHCKEHRAQALRALLLAHKKKAGLASPEEEDAVGKEPLKAAPKKRQLLDSDEEQEEDEGRNRAPELGAPGIQKKKRYQIEDDEDD>sp|Q9UNS1-2|TIM_HUMAN Isoform 2 of Protein timeless homolog OS=Homosapiens OX=9606 GN=TIMELESSMDLHMMNCELLATCSALGYLEGDTYHKEPDCLESVKDLIRYLRHEDETRDVRQQLGAAQILQSDLLPILTQHHQDKPLFDAVIRLMVNLTQPALLCFGNLPKEPSFRHHFLQVLTYLQAYKEAFASEKAFGVLSETLYELLQLGWEERQEEDNLLIERILLLVRNILHVPADLDQEKIDDDASAHDQLLWAIHLSGLDDLLLFLASSSAEEQWSLHVLEIVSLMFRDQNPEQLAGVGQGRLAQERSADFAELEVLRQREMAEKKTRALQRGNRHSRFGGSYIVQGLKSIGERDLIFHKGLHNLRNYSSDLGKQPKKVPKRRQAARELSIQRRSALNVRLFLRDFCSEFLENCYNRLMGSVKDHLLREKAQQHDETYYMWALAFFMAFNRAASFRPGLVSETLSVRTFHFIEQNLTNYYEMMLTDRKEAASWARRMHLALKAYQELLATVNEMDISPDEAVRESSRIIKNNIFYVMEYRELFLALFRKFDERCQPRSFLRDLVETTHLFLKMLERFCRSRGNLVVQNKQKKRRKKKKKVLDQAIVSGNVPSSPEEVEAVWPALAEQLQCCAQNSELSMDSVVPFDAASEVPVEEQRAEAMVRIQDCLLAGQAPQALTLLRSAREVWPEGDVFGSQDISPEEEIQLLKQILSAPLPRQQGPEERGAEEEEEEEEEEEEELQVVQVSEKEFNFLDYLKRFACSTVVRAYVLLLRSYQQNSAHTNHCIVKMLHRLAHDLKMEALLFQLSVFCLFNRLLSDPAAGAYKELVTFAKYILGKFFALAAVNQKAFVELLFWKNTAVVREMTEGYGSLDDRSSSRRAPTWSPEEEAHLRELYLANKDVEGQDVVEAILAHLNTVPRTRKQIIHHLVQMGLADSVKDFQRKGTHIVLWTGDQELELQRLFEEFRDSDDVLGHIMKNITAKRSRARIVDKLLALGLVAERRELYKKRQKKLASSILPNGAESLKDFCQEDLEEEENLPEEDSEEEEEGGSEAEQVQGSLVLSNENLGQSLHQEGFSIPLLWLQNCLIRAADDREEDGCSQAVPLVPLTEENEEAMENEQFQQLLRKLGVRPPASGQETFWRIPAKLSPTQLRRAAASLSQPEEEQKLQPELQPKVPGEQGSDEEHCKEHRAQALRALLLAHKKKAGLASPEEEDAVGKEPLKAAPKKRQLLDSDEEQEEDEGRNRAPELGAPGIQKKKRYQIEDDEDD>sp|Q86X19|TMM17_HUMAN Transmembrane protein 17 OS=Homo sapiens OX=9606GN=TMEM17 PE=1 SV=2MELPDPVRQRLGNFSRAVFSDSNRTGPESNEGPENEMVSSLALQMSLYFNTYYFPLWWVSSIMMLHMKYSILPDYYKFIVITVIILITLIEAIRLYLGYVGNLQEKVPELAGFWLLSLLLQLPLILFLLFNEGLTNLPLEKAIHIIFTLFLAFQVVAAFLTLRKMVNQLAVRFHLQDFDRLSANRGDMRRMRSCIEEI>sp|Q6UXN2|TRML4_HUMAN Trem-like transcript 4 protein OS=Homo sapiensOX=9606 GN=TREML4 PE=2 SV=1MAWGGVHTCCFHLCCCCSWPQGAVPEELHKHPGQTLLLQCQYSPKRGPYQPKSWCQQTSPSRCTLLVTSSKPWTAVQKSHYTIWDKPNAGFFNITMIQLTQNDSGFYWCGIYNASENIITVLRNISLVVSPAPTTSPMWTLPWLPTSTVLITSPEGTSGHPSINGSETRKSRAPACLGSGGPRFLVLVLCGLLLAKGLML>sp|O43897|TLL1_HUMAN Tolloid-like protein 1 OS=Homo sapiens OX=9606GN=TLL1 PE=1 SV=1MGLGTLSPRMLVWLVASGIVFYGELWVCAGLDYDYTFDGNEEDKTETIDYKDPCKAAVFWGDIALDDEDLNIFQIDRTIDLTQNPFGNLGHTTGGLGDHAMSKKRGALYQLIDRIRRIGFGLEQNNTVKGKVPLQFSGQNEKNRVPRAATSRTERIWPGGVIPYVIGGNFTGSQRAMFKQAMRHWEKHTCVTFIERSDEESYIVFTYRPCGCCSYVGRRGNGPQAISIGKNCDKFGIVVHELGHVIGFWHEHTRPDRDNHVTIIRENIQPGQEYNFLKMEPGEVNSLGERYDFDSIMHYARNTFSRGMFLDTILPSRDDNGIRPAIGQRTRLSKGDIAQARKLYRCPACGETLQESNGNLSSPGFPNGYPSYTHCIWRVSVTPGEKIVLNFTTMDLYKSSLCWYDYIEVRDGYWRKSPLLGRFCGDKLPEVLTSTDSRMWIEFRSSSNWVGKGFAAVYEAICGGEIRKNEGQIQSPNYPDDYRPMKECVWKITVSESYHVGLTFQSFEIERHDNCAYDYLEVRDGTSENSPLIGRFCGYDKPEDIRSTSNTLWMKFVSDGTVNKAGFAANFFKEEDECAKPDRGGCEQRCLNTLGSYQCACEPGYELGPDRRSCEAACGGLLTKLNGTITTPGWPKEYPPNKNCVWQVVAPTQYRISVKFEFFELEGNEVCKYDYVEIWSGLSSESKLHGKFCGAEVPEVITSQFNNMRIEFKSDNTVSKKGFKAHFFSDKDECSKDNGGCQHECVNTMGSYMCQCRNGFVLHDNKHDCKEAECEQKIHSPSGLITSPNWPDKYPSRKECTWEISATPGHRIKLAFSEFEIEQHQECAYDHLEVFDGETEKSPILGRLCGNKIPDPLVATGNKMFVRFVSDASVQRKGFQATHSTECGGRLKAESKPRDLYSHAQFGDNNYPGQVDCEWLLVSERGSRLELSFQTFEVEEEADCGYDYVELFDGLDSTAVGLGRFCGSGPPEEIYSIGDSVLIHFHTDDTINKKGFHIRYKSIRYPDTTHTKK>sp|O43897-2|TLL1_HUMAN Isoform 2 of Tolloid-like protein 1 OS=Homosapiens OX=9606 GN=TLL1MGLGTLSPRMLVWLVASGIVFYGELWVCAGLDYDYTFDGNEEDKTETIDYKDPCKAAVFWGDIALDDEDLNIFQIDRTIDLTQNPFGNLGHTTGGLGDHAMSKKRGALYQLIDRIRRIGFGLEQNNTVKGKVPLQFSGQNEKNRVPRAATSRTERIWPGGVIPYVIGGNFTGSQRAMFKQAMRHWEKHTCVTFIERSDEESYIVFTYRPCGCCSYVGRRGNGPQAISIGKNCDKFGIVVHELGHVIGFWHEHTRPDRDNHVTIIRENIQPGQEYNFLKMEPGEVNSLGERYDFDSIMHYARNTFSRGMFLDTILPSRDDNGIRPAIGQRTRLSKGDIAQARKLYRCPACGETLQESNGNLSSPGFPNGYPSYTHCIWRVSVTPGEKVVFSLC>sp|Q9NZQ8|TRPM5_HUMAN Transient receptor potential cation channelsubfamily M member 5 OS=Homo sapiens OX=9606 GN=TRPM5 PE=1 SV=1MQDVQGPRPGSPGDAEDRRELGLHRGEVNFGGSGKKRGKFVRVPSGVAPSVLFDLLLAEWHLPAPNLVVSLVGEEQPFAMKSWLRDVLRKGLVKAAQSTGAWILTSALRVGLARHVGQAVRDHSLASTSTKVRVVAVGMASLGRVLHRRILEEAQEDFPVHYPEDDGGSQGPLCSLDSNLSHFILVEPGPPGKGDGLTELRLRLEKHISEQRAGYGGTGSIEIPVLCLLVNGDPNTLERISRAVEQAAPWLILVGSGGIADVLAALVNQPHLLVPKVAEKQFKEKFPSKHFSWEDIVRWTKLLQNITSHQHLLTVYDFEQEGSEELDTVILKALVKACKSHSQEPQDYLDELKLAVAWDRVDIAKSEIFNGDVEWKSCDLEEVMVDALVSNKPEFVRLFVDNGADVADFLTYGRLQELYRSVSRKSLLFDLLQRKQEEARLTLAGLGTQQAREPPAGPPAFSLHEVSRVLKDFLQDACRGFYQDGRPGDRRRAEKGPAKRPTGQKWLLDLNQKSENPWRDLFLWAVLQNRHEMATYFWAMGQEGVAAALAACKILKEMSHLETEAEAARATREAKYERLALDLFSECYSNSEARAFALLVRRNRCWSKTTCLHLATEADAKAFFAHDGVQAFLTRIWWGDMAAGTPILRLLGAFLCPALVYTNLITFSEEAPLRTGLEDLQDLDSLDTEKSPLYGLQSRVEELVEAPRAQGDRGPRAVFLLTRWRKFWGAPVTVFLGNVVMYFAFLFLFTYVLLVDFRPPPQGPSGPEVTLYFWVFTLVLEEIRQGFFTDEDTHLVKKFTLYVGDNWNKCDMVAIFLFIVGVTCRMLPSAFEAGRTVLAMDFMVFTLRLIHIFAIHKQLGPKIIVVERMMKDVFFFLFFLSVWLVAYGVTTQALLHPHDGRLEWIFRRVLYRPYLQIFGQIPLDEIDEARVNCSTHPLLLEDSPSCPSLYANWLVILLLVTFLLVTNVLLMNLLIAMFSYTFQVVQGNADMFWKFQRYNLIVEYHERPALAPPFILLSHLSLTLRRVFKKEAEHKREHLERDLPDPLDQKVVTWETVQKENFLSKMEKRRRDSEGEVLRKTAHRVDFIAKYLGGLREQEKRIKCLESQINYCSVLVSSVADVLAQGGGPRSSQHCGEGSQLVAADHRGGLDGWEQPGAGQPPSDT>sp|Q9NZQ8-2|TRPM5_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily M member 5 OS=Homo sapiens OX=9606 GN=TRPM5MQDVQGPRPGSPGDAEDRRELGLHRGEVNFGGSGKKRGKFVRVPSGVAPSVLFDLLLAEWHLPAPNLVVSLVGEEQPFAMKSWLRDVLRKGLVKAAQSTGAWILTSALRVGLARHVGQAVRDHSLASTSTKVRVVAVGMASLGRVLHRRILEEAQVHEDFPVHYPEDDGGSQGPLCSLDSNLSHFILVEPGPPGKGDGLTELRLRLEKHISEQRAGYGGTGSIEIPVLCLLVNGDPNTLERISRAVEQAAPWLILVGSGGIADVLAALVNQPHLLVPKVAEKQFKEKFPSKHFSWEDIVRWTKLLQNITSHQHLLTVYDFEQEGSEELDTVILKALVKACKSHSQEPQDYLDELKLAVAWDRVDIAKSEIFNGDVEWKSCDLEEVMVDALVSNKPEFVRLFVDNGADVADFLTYGRLQELYRSVSRKSLLFDLLQRKQEEARLTLAGLGTQQAREPPAGPPAFSLHEVSRVLKDFLQDACRGFYQDGRPGDRRRAEKGPAKRPTGQKWLLDLNQKSENPWRDLFLWAVLQNRHEMATYFWAMGQEGVAAALAACKILKEMSHLETEAEAARATREAKYERLALDLFSECYSNSEARAFALLVRRNRCWSKTTCLHLATEADAKAFFAHDGVQAFLTRIWWGDMAAGTPILRLLGAFLCPALVYTNLITFSEEAPLRTGLEDLQDLDSLDTEKSPLYGLQSRVEELVEAPRAQGDRGPRAVFLLTRWRKFWGAPVTVFLGNVVMYFAFLFLFTYVLLVDFRPPPQGPSGPEVTLYFWVFTLVLEEIRQGFFTDEDTHLVKKFTLYVGDNWNKCDMVAIFLFIVGVTCRMLPSAFEAGRTVLAMDFMVFTLRLIHIFAIHKQLGPKIIVVERMMKDVFFFLFFLSVWLVAYGVTTQALLHPHDGRLEWIFRRVLYRPYLQIFGQIPLDEIDEARVNCSTHPLLLEDSPSCPSLYANWLVILLLVTFLLVTNVLLMNLLIAMFSYTFQVVQGNADMFWKFQRYNLIVEYHERPALAPPFILLSHLSLTLRRVFKKEAEHKREHLERDLPDPLDQKVVTWETVQKENFLSKMEKRRRDSEGEVLRKTAHRVDFIAKYLGGLREQEKRIKCLESQINYCSVLVSSVADVLAQGGGPRSSQHCGEGSQLVAADHRGGLDGWEQPGAGQPPSDT>sp|Q9NZQ8-3|TRPM5_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily M member 5 OS=Homo sapiens OX=9606 GN=TRPM5MQDVQGPRPGSPGDAEDRRELGLHRGEVNFGGSGKKRGKFVRVPSGVAPSVLFDLLLAEWHLPAPNLVVSLVGEEQPFAMKSWLRDVLRKGLVKAAQSTGAWILTSALRVGLARHVGQAVRDHSLASTSTKVRVVAVGMASLGRVLHRRILEEAQEDFPVHYPEDDGGSQGPLCSLDSNLSHFILVEPGPPGKGDGLTELRLRLEKHISEQRAGYGGTGSIEIPVLCLLVNGDPNTLERISRAVEQAAPWLILVGSGGIADVLAALVNQPHLLVPKVAEKQFKEKFPSKHFSWEDIVRWTKLLQNITSHQHLLTVYDFEQEGSEELDTVILKALVKACKSHSQEPQDYLDELKLAVAWDRVDIAKSEIFNGDVEWKSCDLEEVMVDALVSNKPEFVRLFVDNGADVADFLTYGRLQELYRSVSRKSLLFDLLQRKQEEARLTLAGLGTQQAREPPAGPPAFSLHEVSRVLKDFLQDACRGFYQDGRPGDRRRAEKGPAKRPTGQKWLLDLNQKSENPWRDLFLWAVLQNRHEMATYFWAMGQEGVAAALAACKILKEMSHLETEAEAARATREAKYERLALDLFSECYSNSEARAFALLVRRNRCWSKTTCLHLATEADAKAFFAHDGVQAFLTRIWWGDMAAGTPILRLLGAFLCPALVYTNLITFSEEAPLRTGLEDLQDLDSLDTEKSPLYGLQSRVEELVEAPRAQGDRGPRAVFLLTRWRKFWGAPVTVFLGNVVMYFAFLFLFTYVLLVDFRPPPQGPSGPEVTLYFWVFTLVLEEIRQGFFTDEDTHLVKKFTLYVGDNWNKCDMVAIFLFIVGVTCRMLPSAFEAGRTVLAMDFMVFTLRLIHIFAIHKQLGPKIIVVERMKPV>sp|Q6PGP7|TTC37_HUMAN Tetratricopeptide repeat protein 37 OS=Homosapiens OX=9606 GN=TTC37 PE=1 SV=1MSSKEVKTALKSARDAIRNKEYKEALKHCKTVLKQEKNNYNAWVFIGVAAAELEQPDQAQSAYKKAAELEPDQLLAWQGLANLYEKYNHINAKDDLPGVYQKLLDLYESVDKQKWCDVCKKLVDLYYQEKKHLEVARTWHKLIKTRQEQGAENEELHQLWRKLTQFLAESTEDQNNETQQLLFTAFENALGLSDKIPSEDHQVLYRHFIQSLSKFPHESARLKKACEGMINIYPTVQYPLEVLCLHLIESGNLTDEGQQYCCRLVEMDSKSGPGLIGLGIKALQDKKYEDAVRNLTEGLKESPVCTSGWYHLAEAQVKMHRPKEAVLSCSQALKIVDNLGASGNSLYQRNLCLHLKAEALIKLSDYDSSEEAIRTLDQISDADNIPGLLVLKSLAYRNKGSFDEAAKIMEDLLSSYPDLAEVHALEALIHFTKKDYLQAEKCFQRALEKDTEVAEYHYQLGLTYWFMGEETRKDKTKALTHFLKAARLDTYMGKVFCYLGHYYRDVVGDKNRARGCYRKAFELDDTDAESGAAAVDLSVELEDMEMALAILTTVTQKASAGTAKWAWLRRGLYYLKAGQHSQAVADLQAALRADPKDFNCWESLGEAYLSRGGYTTALKSFTKASELNPESIYSVFKVAAIQQILGKYKEAVAQYQMIIKKKEDYVPALKGLGECHLMMAKAALVDYLDGKAVDYIEKALEYFTCALQHRADVSCLWKLAGDACTCLYAVAPSKVNVHVLGVLLGQKEGKQVLKKNELLHLGGRCYGRALKLMSTSNTWCDLGINYYRQAQHLAETGSNMNDLKELLEKSLHCLKKAVRLDSNNHLYWNALGVVACYSGIGNYALAQHCFIKSIQSEQINAVAWTNLGVLYLTNENIEQAHEAFKMAQSLDPSYLMCWIGQALIAEAVGSYDTMDLFRHTTELNMHTEGALGYAYWVCTTLQDKSNRETELYQYNILQMNAIPAAQVILNKYVERIQNYAPAFTMLGYLNEHLQLKKEAANAYQRAILLLQTAEDQDTYNVAIRNYGRLLCSTGEYDKAIQAFKSTPLEVLEDIIGFALALFMKGLYKESSKAYERALSIVESEQDKAHILTALAITEYKQGKTDVAKTLLFKCSILKEPTTESLQALCALGLAMQDATLSKAALNELLKHIKHKDSNYQRCLLTSAIYALQGRSVAVQKQISKAVHSNPGDPALWSLLSRVVAQYAQRNAKGGVVAGNVAHILDSNHGKKALLYTAVNQLAMGSSSAEDEKNTALKTIQKAALLSPGDPAIWAGLMAACHADDKLALVNNTQPKRIDLYLALLSAVSASIKDEKFFENYNQSLEKWSLSQAVTGLIDTGRISEAETLCTKNLKSNPDQPAVILLLRQVQCKPLLESQKPLPDAVLEELQKTVMSNSTSVPAWQWLAHVYQSQGMMRAAEMCYRKSLQLASQRGSWSGKLSSLLRLALLALKVCMANISNDHWPSLVQEATTEALKLCFCPLAVLLQALLQFKRKMGARETRRLLERVVYQPGYPKSIASTARWYLLRHLYAKDDYELIDVLVNNAKTHGDTRALELNQRLSSQ>sp|Q9NPG3|UBN1_HUMAN Ubinuclein-1 OS=Homo sapiens OX=9606 GN=UBN1 PE=1SV=2MSEPHRVQFTSLPGSLNPAFLKKSRKEEAGAGEQHQDCEPAAAAVRITLTLFEPDHKRCPEFFYPELVKNIRGKVKGLQPGDKKKDLSDPFNDEEKERHKVEALARKFEEKYGGKKRRKDRIQDLIDMGYGYDESDSFIDNSEAYDELVPASLTTKYGGFYINSGTLQFRQASESEDDFIKEKKKKSPKKRKLKEGGEKIKKKKKDDTYDKEKKSKKSKFSKAGFTALNASKEKKKKKYSGALSVKEMLKKFQKEKEAQKKREEEHKPVAVPSAEAQGLRELEGASDPLLSLFGSTSDNDLLQAATAMDSLTDLDLEHLLSESPEGSPFRDMDDGSDSLGVGLDQEFRQPSSLPEGLPAPLEKRVKELAQAARAAEGESRQKFFTQDINGILLDIEAQTRELSSQVRSGVYAYLASFLPCSKDALLKRARKLHLYEQGGRLKEPLQKLKEAIGRAMPEQMAKYQDECQAHTQAKVAKMLEEEKDKEQRDRICSDEEEDEEKGGRRIMGPRKKFQWNDEIRELLCQVVKIKLESQDLERNNKAQAWEDCVKGFLDAEVKPLWPKGWMQARTLFKESRRGHGHLTSILAKKKVMAPSKIKVKESSTKPDKKVSVPSGQIGGPIALPSDHQTGGLSIGASSRELPSQASGGLANPPPVNLEDSLDEDLIRNPASSVEAVSKELAALNSRAAGNSEFTLPAPSKAPAEKVGGVLCTEEKRNFAKPSPSAPPPASSLQSPLNFLAEQALALGQSSQEKKPESSGYKELSCQAPLNKGLPEVHQSKAKHHSLPRTSHGPQVAVPVPGPQVKVFHAGTQQQKNFTPPSPFANKLQGPKASPTQCHRSLLQLVKTAAKGQGFHPSAPATSGGLSASSSSSHKTPASSSSALSHPAKPHSVSSAGSSYKNNPFASSISKHGVSSGSSSSGGTPVQSSVSGSLVPGIQPPSVGQATSRPVPSSAGKKMPVSQKLTLVAPPGGPNGDSSGGTQGVAKLLTSPSLKPSAVSSVTSSTSLSKGASGTVLLAGSSLMASPYKSSSPKLSGAMSSNSLGIITPVPIPVHVLSFSADSSAKAGVSKDAIVTGPAPGSFHHGLGHSLLAGLHSSPPHAAPLPHAAVPTHIPQSLPGASQLHGKGPAVPRKL>sp|Q9NPG3-2|UBN1_HUMAN Isoform 2 of Ubinuclein-1 OS=Homo sapiens OX=9606GN=UBN1MSEPHRVQFTSLPGSLNPAFLKKSRKEEAGAGEQHQDCEPAAAAVRITLTLFEPDHKRCPEFFYPELVKNIRGKVKGLQPGDKKKDLSDPFNDEEKERHKVEALARKFEEKYGGKKRRKDRIQDLIDMGYGYDESDSFIDNSEAYDELVPASLTTKYGGFYINSGTLQFRQASESEDDFIKEKKKKSPKKRKLKEGGEKIKKKKKDDTYDKEKKSKKSKFSKAGFTALNASKEKKKKKYSGALSVKEMLKKFQKEKEAQKKREEEHKPVAVPSAEAQGLRELEGASDPLLSLFGSTSDNDLLQAATAMDSLTDLDLEHLLSESPEGSPFRDMDDGSDSLGVGLDQEFRQPSSLPEGLPAPLEKRVKELAQAARAAEGESRQKFFTQDINGILLDIEAQTRELSSQVRSGVYAYLASFLPCSKDALLKRARKLHLYEQGGRLKEPLQKLKEAIGRAMPEQMAKYQDECQAHTQAKVAKMLEEEKDKEQRDRICSDEEEDEEKGGRRIMGPRKKFQWNDEIRELLCQVVKIKLESQDLERNNKAQAWEDCVKGFLDAEVKPLWPKGWMQARTLFKESRRGHGHLTSILAKKKVMAPSKIKVKESSTKPDKKVSVPSGQIGGPIALPSDHQTGGLSIGASSRELPSQASGGLANPPPVNLEDSLDEDLIRNPASSVEAVSKELAALNSRAAGNSEFTLPAPSKAPAEKVGGVLCTEEKRNFAKPSPSAPPPASSLQSPLNFLAEQALALGQSSQEKKPESSGYKELSCQAPLNKGLPEVHQSKAKHHSLPRTSHGPQVAVPVPGPQVKVFHAGTQQQKNFTPPSPFANKLQGPKASPTQCHRSLLQLVKTAAKGQGFHPSAPATSGGLSASSSSSHKTPASSSSALSHPAKPHSVSSAGSSYKNNPFASSISKHGVSSGSSSSGGTPVQSSVSGSLVPGIQPPSVGQATSRPVPSSAGKKMPVSQKLTLVAPPGGPNGDSSGGTQGVAKLLTSPSLKPSAVSSVTSSTSLSKGASGTVLLAGSSLMASPYKSSSPKLSGAMSSNSLGIITPVPIPVHVLSFSADSSAKAGVSKDAIVTGPAPGSFHHGLGHSASQLHGKGPAVPRKL>sp|Q9BY10|TSCOT_HUMAN Thymic stromal cotransporter homolog OS=Homosapiens OX=9606 GN=SLC46A2 PE=2 SV=1MSPEVTCPRRGHLPRFHPRTWVEPVVASSQVAASLYDAGLLLVVKASYGTGGSSNHSASPSPRGALEDQQQRAISNFYIIYNLVVGLSPLLSAYGLGWLSDRYHRKISICMSLLGFLLSRLGLLLKVLLDWPVEVLYGAAALNGLFGGFSAFWSGVMALGSLGSSEGRRSVRLILIDLMLGLAGFCGSMASGHLFKQMAGHSGQGLILTACSVSCASFALLYSLLVLKVPESVAKPSQELPAVDTVSGTVGTYRTLDPDQLDQQYAVGHPPSPGKAKPHKTTIALLFVGAIIYDLAVVGTVDVIPLFVLREPLGWNQVQVGYGMAAGYTIFITSFLGVLVFSRCFRDTTMIMIGMVSFGSGALLLAFVKETYMFYIARAVMLFALIPVTTIRSAMSKLIKGSSYGKVFVILQLSLALTGVVTSTLYNKIYQLTMDMFVGSCFALSSFLSFLAIIPISIVAYKQVPLSPYGDIIEK>sp|Q6NVU6|UFSP1_HUMAN Inactive Ufm1-specific protease 1 OS=Homo sapiensOX=9606 GN=UFSP1 PE=1 SV=2MGDKPPGFRGSRDWIGCVEASLCLAHFGGPQGRLCHVPRGVGLHGELERLYSHFAGGGGPVMVGGDADARSKALLGVCVGSGTEAYVLVLDPHYWGTPKSPSELQAAGWVGWQEVSAAFDPNSFYNLCLTSLSSQQQQRTLD>sp|Q9UK80|UBP21_HUMAN Ubiquitin carboxyl-terminal hydrolase 21 OS=Homosapiens OX=9606 GN=USP21 PE=1 SV=1MPQASEHRLGRTREPPVNIQPRVGSKLPFAPRARSKERRNPASGPNPMLRPLPPRPGLPDERLKKLELGRGRTSGPRPRGPLRADHGVPLPGSPPPTVALPLPSRTNLARSKSVSSGDLRPMGIALGGHRGTGELGAALSRLALRPEPPTLRRSTSLRRLGGFPGPPTLFSIRTEPPASHGSFHMISARSSEPFYSDDKMAHHTLLLGSGHVGLRNLGNTCFLNAVLQCLSSTRPLRDFCLRRDFRQEVPGGGRAQELTEAFADVIGALWHPDSCEAVNPTRFRAVFQKYVPSFSGYSQQDAQEFLKLLMERLHLEINRRGRRAPPILANGPVPSPPRRGGALLEEPELSDDDRANLMWKRYLEREDSKIVDLFVGQLKSCLKCQACGYRSTTFEVFCDLSLPIPKKGFAGGKVSLRDCFNLFTKEEELESENAPVCDRCRQKTRSTKKLTVQRFPRILVLHLNRFSASRGSIKKSSVGVDFPLQRLSLGDFASDKAGSPVYQLYALCNHSGSVHYGHYTALCRCQTGWHVYNDSRVSPVSENQVASSEGYVLFYQLMQEPPRCL>sp|Q9UK80-2|UBP21_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 21 OS=Homo sapiens OX=9606 GN=USP21MPQASEHRLGRTREPPVNIQPRVGSKLPFAPRARSKERRNPASGPNPMLRPLPPRPGLPDERLKKLELGRGRTSGPRPRGPLRADHGVPLPGSPPPTVALPLPSRTNLARSKSVSSGDLRPMGIALGGHRGTGELGAALSRLALRPEPPTLRRSTSLRRLGGFPGPPTLFSIRTEPPASHGSFHMISARSSEPFYSDDKMAHHTLLLGSGHVGLRNLGNTCFLNAVLQCLSSTRPLRDFCLRRDFRQEVPGGGRAQELTEAFADVIGALWHPDSCEAVNPTRFRAVFQKYVPSFSGYSQQDAQEFLKLLMERLHLEINRRGRRAPPILANGPVPSPPRRGGALLEEPELSDDDRANLMWKRYLEREDSKIVGMEWGKAMREN>sp|Q9UK80-3|UBP21_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 21 OS=Homo sapiens OX=9606 GN=USP21MPQASEHRLGRTREPPVNIQPRVGSKLPFAPRARSKERRNPASGPNPMLRPLPPRPGLPDERLKKLELGRGRTSGPRPRGPLRADHGVPLPGSPPPTVALPLPSRTNLARSKSVSSGDLRPMGIALGGHRGTGELGAALSRLALRPEPPTLRRSTSLRRLGGFPGPPTLFSIRTEPPASHGSFHMISARSSEPFYSDDKMAHHTLLLGSGHVGLRNLGNTCFLNAVLQCLSSTRPLRDFCLRRDFRQEVPGGGRAQELTEAFADVIGALWHPDSCEAVNPTRFRAVFQKYVPSFSGYSQQDAQEFLKLLMERLHLEINRRGRRAPPILANGPVPSPPRRGGALLEEPELSDDDRANLMWKRYLEREDSKIVDLFVGQLKSCLKCQACGYRSTTFEVFCDLSLPIPKKGFAGGKVSLRDCFNLFTKEEELESENAPVCDRCRQKTRSTKKLTVQRFPRILVLHLNRFSASRGSIKKSSVGVDFPLQRLSLGDFASDKAGSVHYGHYTALCRCQTGWHVYNDSRVSPVSENQVASSEGYVLFYQLMQEPPRCL>sp|O95185|UNC5C_HUMAN Netrin receptor UNC5C OS=Homo sapiens OX=9606GN=UNC5C PE=1 SV=2MRKGLRATAARCGLGLGYLLQMLVLPALALLSASGTGSAAQDDDFFHELPETFPSDPPEPLPHFLIEPEEAYIVKNKPVNLYCKASPATQIYFKCNSEWVHQKDHIVDERVDETSGLIVREVSIEISRQQVEELFGPEDYWCQCVAWSSAGTTKSRKAYVRIAYLRKTFEQEPLGKEVSLEQEVLLQCRPPEGIPVAEVEWLKNEDIIDPVEDRNFYITIDHNLIIKQARLSDTANYTCVAKNIVAKRKSTTATVIVYVNGGWSTWTEWSVCNSRCGRGYQKRTRTCTNPAPLNGGAFCEGQSVQKIACTTLCPVDGRWTPWSKWSTCGTECTHWRRRECTAPAPKNGGKDCDGLVLQSKNCTDGLCMQTAPDSDDVALYVGIVIAVIVCLAISVVVALFVYRKNHRDFESDIIDSSALNGGFQPVNIKAARQDLLAVPPDLTSAAAMYRGPVYALHDVSDKIPMTNSPILDPLPNLKIKVYNTSGAVTPQDDLSEFTSKLSPQMTQSLLENEALSLKNQSLARQTDPSCTAFGSFNSLGGHLIVPNSGVSLLIPAGAIPQGRVYEMYVTVHRKETMRPPMDDSQTLLTPVVSCGPPGALLTRPVVLTMHHCADPNTEDWKILLKNQAAQGQWEDVVVVGEENFTTPCYIQLDAEACHILTENLSTYALVGHSTTKAAAKRLKLAIFGPLCCSSLEYSIRVYCLDDTQDALKEILHLERQMGGQLLEEPKALHFKGSTHNLRLSIHDIAHSLWKSKLLAKYQEIPFYHVWSGSQRNLHCTFTLERFSLNTVELVCKLCVRQVEGEGQIFQLNCTVSEEPTGIDLPLLDPANTITTVTGPSAFSIPLPIRQKLCSSLDAPQTRGHDWRMLAHKLNLDRYLNYFATKSSPTGVILDLWEAQNFPDGNLSMLAAVLEEMGRHETVVSLAAEGQY>sp|O95185-2|UNC5C_HUMAN Isoform 2 of Netrin receptor UNC5C OS=Homosapiens OX=9606 GN=UNC5CMRKGLRATAARCGLGLGYLLQMLVLPALALLSASGTGSAAQDDDFFHELPETFPSDPPEPLPHFLIEPEEAYIVKNKPVNLYCKASPATQIYFKCNSEWVHQKDHIVDERVDETSGLIVREVSIEISRQQVEELFGPEDYWCQCVAWSSAGTTKSRKAYVRIAYLRKTFEQEPLGKEVSLEQEVLLQCRPPEGIPVAEVEWLKNEDIIDPVEDRNFYITIDHNLIIKQARLSDTANYTCVAKNIVAKRKSTTATVIVYVNGGWSTWTEWSVCNSRCGRGYQKRTRTCTNPAPLNGGAFCEGQSVQKIACTTLCPVDGRWTPWSKWSTCGTECTHWRRRECTAPAPKNGGKDCDGLVLQSKNCTDGLCMQSFIYPISTEQRTQNEYGFSSAPDSDDVALYVGIVIAVIVCLAISVVVALFVYRKNHRDFESDIIDSSALNGGFQPVNIKAARQDLLAVPPDLTSAAAMYRGPVYALHDVSDKIPMTNSPILDPLPNLKIKVYNTSGAVTPQDDLSEFTSKLSPQMTQSLLENEALSLKNQSLARQTDPSCTAFGSFNSLGGHLIVPNSGVSLLIPAGAIPQGRVYEMYVTVHRKETMR>sp|Q969T4|UB2E3_HUMAN Ubiquitin-conjugating enzyme E2 E3 OS=Homo sapiensOX=9606 GN=UBE2E3 PE=1 SV=1MSSDRQRSDDESPSTSSGSSDADQRDPAAPEPEEQEERKPSATQQKKNTKLSSKTTAKLSTSAKRIQKELAEITLDPPPNCSAGPKGDNIYEWRSTILGPPGSVYEGGVFFLDITFSSDYPFKPPKVTFRTRIYHCNINSQGVICLDILKDNWSPALTISKVLLSICSLLTDCNPADPLVGSIATQYLTNRAEHDRIARQWTKRYAT>sp|Q93009|UBP7_HUMAN Ubiquitin carboxyl-terminal hydrolase 7 OS=Homosapiens OX=9606 GN=USP7 PE=1 SV=2MNHQQQQQQQKAGEQQLSEPEDMEMEAGDTDDPPRITQNPVINGNVALSDGHNTAEEDMEDDTSWRSEATFQFTVERFSRLSESVLSPPCFVRNLPWKIMVMPRFYPDRPHQKSVGFFLQCNAESDSTSWSCHAQAVLKIINYRDDEKSFSRRISHLFFHKENDWGFSNFMAWSEVTDPEKGFIDDDKVTFEVFVQADAPHGVAWDSKKHTGYVGLKNQGATCYMNSLLQTLFFTNQLRKAVYMMPTEGDDSSKSVPLALQRVFYELQHSDKPVGTKKLTKSFGWETLDSFMQHDVQELCRVLLDNVENKMKGTCVEGTIPKLFRGKMVSYIQCKEVDYRSDRREDYYDIQLSIKGKKNIFESFVDYVAVEQLDGDNKYDAGEHGLQEAEKGVKFLTLPPVLHLQLMRFMYDPQTDQNIKINDRFEFPEQLPLDEFLQKTDPKDPANYILHAVLVHSGDNHGGHYVVYLNPKGDGKWCKFDDDVVSRCTKEEAIEHNYGGHDDDLSVRHCTNAYMLVYIRESKLSEVLQAVTDHDIPQQLVERLQEEKRIEAQKRKERQEAHLYMQVQIVAEDQFCGHQGNDMYDEEKVKYTVFKVLKNSSLAEFVQSLSQTMGFPQDQIRLWPMQARSNGTKRPAMLDNEADGNKTMIELSDNENPWTIFLETVDPELAASGATLPKFDKDHDVMLFLKMYDPKTRSLNYCGHIYTPISCKIRDLLPVMCDRAGFIQDTSLILYEEVKPNLTERIQDYDVSLDKALDELMDGDIIVFQKDDPENDNSELPTAKEYFRDLYHRVDVIFCDKTIPNDPGFVVTLSNRMNYFQVAKTVAQRLNTDPMLLQFFKSQGYRDGPGNPLRHNYEGTLRDLLQFFKPRQPKKLYYQQLKMKITDFENRRSFKCIWLNSQFREEEITLYPDKHGCVRDLLEECKKAVELGEKASGKLRLLEIVSYKIIGVHQEDELLECLSPATSRTFRIEEIPLDQVDIDKENEMLVTVAHFHKEVFGTFGIPFLLRIHQGEHFREVMKRIQSLLDIQEKEFEKFKFAIVMMGRHQYINEDEYEVNLKDFEPQPGNMSHPRPWLGLDHFNKAPKRSRYTYLEKAIKIHN>sp|Q93009-3|UBP7_HUMAN Isoform 3 of Ubiquitin carboxyl-terminalhydrolase 7 OS=Homo sapiens OX=9606 GN=USP7MAGNHRLGLEAGDTDDPPRITQNPVINGNVALSDGHNTAEEDMEDDTSWRSEATFQFTVERFSRLSESVLSPPCFVRNLPWKIMVMPRFYPDRPHQKSVGFFLQCNAESDSTSWSCHAQAVLKIINYRDDEKSFSRRISHLFFHKENDWGFSNFMAWSEVTDPEKGFIDDDKVTFEVFVQADAPHGVAWDSKKHTGYVGLKNQGATCYMNSLLQTLFFTNQLRKAVYMMPTEGDDSSKSVPLALQRVFYELQHSDKPVGTKKLTKSFGWETLDSFMQHDVQELCRVLLDNVENKMKGTCVEGTIPKLFRGKMVSYIQCKEVDYRSDRREDYYDIQLSIKGKKNIFESFVDYVAVEQLDGDNKYDAGEHGLQEAEKGVKFLTLPPVLHLQLMRFMYDPQTDQNIKINDRFEFPEQLPLDEFLQKTDPKDPANYILHAVLVHSGDNHGGHYVVYLNPKGDGKWCKFDDDVVSRCTKEEAIEHNYGGHDDDLSVRHCTNAYMLVYIRESKLSEVLQAVTDHDIPQQLVERLQEEKRIEAQKRKERQEAHLYMQVQIVAEDQFCGHQGNDMYDEEKVKYTVFKVLKNSSLAEFVQSLSQTMGFPQDQIRLWPMQARSNGTKRPAMLDNEADGNKTMIELSDNENPWTIFLETVDPELAASGATLPKFDKDHDVMLFLKMYDPKTRSLNYCGHIYTPISCKIRDLLPVMCDRAGFIQDTSLILYEEVKPNLTERIQDYDVSLDKALDELMDGDIIVFQKDDPENDNSELPTAKEYFRDLYHRVDVIFCDKTIPNDPGFVVTLSNRMNYFQVAKTVAQRLNTDPMLLQFFKSQGYRDGPGNPLRHNYEGTLRDLLQFFKPRQPKKLYYQQLKMKITDFENRRSFKCIWLNSQFREEEITLYPDKHGCVRDLLEECKKAVELGEKASGKLRLLEIVSYKIIGVHQEDELLECLSPATSRTFRIEEIPLDQVDIDKENEMLVTVAHFHKEVFGTFGIPFLLRIHQGEHFREVMKRIQSLLDIQEKEFEKFKFAIVMMGRHQYINEDEYEVNLKDFEPQPGNMSHPRPWLGLDHFNKAPKRSRYTYLEKAIKIHN>sp|Q9ULK5|VANG2_HUMAN Vang-like protein 2 OS=Homo sapiens OX=9606GN=VANGL2 PE=1 SV=2MDTESQYSGYSYKSGHSRSSRKHRDRRDRHRSKSRDGGRGDKSVTIQAPGEPLLDNESTRGDERDDNWGETTTVVTGTSEHSISHDDLTRIAKDMEDSVPLDCSRHLGVAAGATLALLSFLTPLAFLLLPPLLWREELEPCGTACEGLFISVAFKLLILLLGSWALFFRRPKASLPRVFVLRALLMVLVFLLVVSYWLFYGVRILDARERSYQGVVQFAVSLVDALLFVHYLAVVLLELRQLQPQFTLKVVRSTDGASRFYNVGHLSIQRVAVWILEKYYHDFPVYNPALLNLPKSVLAKKVSGFKVYSLGEENSTNNSTGQSRAVIAAAARRRDNSHNEYYYEEAEHERRVRKRRARLVVAVEEAFTHIKRLQEEEQKNPREVMDPREAAQAIFASMARAMQKYLRTTKQQPYHTMESILQHLEFCITHDMTPKAFLERYLAAGPTIQYHKERWLAKQWTLVSEEPVTNGLKDGIVFLLKRQDFSLVVSTKKVPFFKLSEEFVDPKSHKFVMRLQSETSV>sp|Q9P0L0|VAPA_HUMAN Vesicle-associated membrane protein-associatedprotein A OS=Homo sapiens OX=9606 GN=VAPA PE=1 SV=3MASASGAMAKHEQILVLDPPTDLKFKGPFTDVVTTNLKLRNPSDRKVCFKVKTTAPRRYCVRPNSGIIDPGSTVTVSVMLQPFDYDPNEKSKHKFMVQTIFAPPNTSDMEAVWKEAKPDELMDSKLRCVFEMPNENDKLNDMEPSKAVPLNASKQDGPMPKPHSVSLNDTETRKLMEECKRLQGEMMKLSEENRHLRDEGLRLRKVAHSDKPGSTSTASFRDNVTSPLPSLLVVIAAIFIGFFLGKFIL>sp|Q9P0L0-2|VAPA_HUMAN Isoform 2 of Vesicle-associated membrane protein-associated protein A OS=Homo sapiens OX=9606 GN=VAPAMASASGAMAKHEQILVLDPPTDLKFKGPFTDVVTTNLKLRNPSDRKVCFKVKTTAPRRYCVRPNSGIIDPGSTVTVSVMLQPFDYDPNEKSKHKFMVQTIFAPPNTSDMEAVWKEAKPDELMDSKLRCVFEMPNENDKLGITPPGNAPTVTSMSSINNTVATPASYHTKDDPRGLSVLKQEKQKNDMEPSKAVPLNASKQDGPMPKPHSVSLNDTETRKLMEECKRLQGEMMKLSEENRHLRDEGLRLRKVAHSDKPGSTSTASFRDNVTSPLPSLLVVIAAIFIGFFLGKFIL>sp|P15692|VEGFA_HUMAN Vascular endothelial growth factor A OS=Homosapiens OX=9606 GN=VEGFA PE=1 SV=2MNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKKSVRGKGKGQKRKRKKSRYKSWSVYVGARCCLMPWSLPGPHPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-2|VEGFA_HUMAN Isoform VEGF189 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKKSVRGKGKGQKRKRKKSRYKSWSVPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-3|VEGFA_HUMAN Isoform VEGF183 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKKSVRGKGKGQKRKRKKSRPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-4|VEGFA_HUMAN Isoform VEGF165 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQENPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-5|VEGFA_HUMAN Isoform VEGF148 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQENPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKM>sp|P15692-6|VEGFA_HUMAN Isoform VEGF145 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKKSVRGKGKGQKRKRKKSRYKSWSVCDKPRR>sp|P15692-8|VEGFA_HUMAN Isoform VEGF165B of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQENPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRSLTRKD>sp|P15692-9|VEGFA_HUMAN Isoform VEGF121 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKCDKPRR>sp|P15692-10|VEGFA_HUMAN Isoform VEGF111 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRCDKPRR>sp|P15692-11|VEGFA_HUMAN Isoform L-VEGF165 of Vascular endothelialgrowth factor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQENPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-12|VEGFA_HUMAN Isoform L-VEGF121 of Vascular endothelialgrowth factor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKCDKPRR>sp|P15692-13|VEGFA_HUMAN Isoform L-VEGF189 of Vascular endothelialgrowth factor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKKSVRGKGKGQKRKRKKSRYKSWSVPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-14|VEGFA_HUMAN Isoform L-VEGF206 of Vascular endothelialgrowth factor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKKSVRGKGKGQKRKRKKSRYKSWSVYVGARCCLMPWSLPGPHPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-15|VEGFA_HUMAN Isoform 15 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQENPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRSLTRKD>sp|P15692-16|VEGFA_HUMAN Isoform 16 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQEKKSVRGKGKGQKRKRKKSRPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKARQLELNERTCRCDKPRR>sp|P15692-17|VEGFA_HUMAN Isoform 17 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRPKKDRARQENPCGPCSERRKHLFVQDPQTCKCSCKNTDSRCKM>sp|P15692-18|VEGFA_HUMAN Isoform 18 of Vascular endothelial growthfactor A OS=Homo sapiens OX=9606 GN=VEGFAMTDRQTDTAPSPSYHLLPGRRRTVDAAASRGQGPEPAPGGGVEGVGARGVALKLFVQLLGCSRFGGAVVRAGEAEPSGAARSASSGREEPQPEEGEEEEEKEEERGPQWRLGARKPGSWTGEAAVCADSAPAARAPQALARASGRGGRVARRGAEESGPPHSPSRRGSASRAGPGRASETMNFLLSWVHWSLALLLYLHHAKWSQAAPMAEGGGQNHHEVVKFMDVYQRSYCHPIETLVDIFQEYPDEIEYIFKPSCVPLMRCGGCCNDEGLECVPTEESNITMQIMRIKPHQGQHIGEMSFLQHNKCECRCDKPRR>sp|P45880|VDAC2_HUMAN Voltage-dependent anion-selective channel protein2 OS=Homo sapiens OX=9606 GN=VDAC2 PE=1 SV=2MATHGQTCARPMCIPPSYADLGKAARDIFNKGFGFGLVKLDVKTKSCSGVEFSTSGSSNTDTGKVTGTLETKYKWCEYGLTFTEKWNTDNTLGTEIAIEDQICQGLKLTFDTTFSPNTGKKSGKIKSSYKRECINLGCDVDFDFAGPAIHGSAVFGYEGWLAGYQMTFDSAKSKLTRNNFAVGYRTGDFQLHTNVNDGTEFGGSIYQKVCEDLDTSVNLAWTSGTNCTRFGIAAKYQLDPTASISAKVNNSSLIGVGYTQTLRPGVKLTLSALVDGKSINAGGHKVGLALELEA>sp|P45880-1|VDAC2_HUMAN Isoform 1 of Voltage-dependent anion-selectivechannel protein 2 OS=Homo sapiens OX=9606 GN=VDAC2MSWCNELRLPALKQHSIGRGLESHITMCIPPSYADLGKAARDIFNKGFGFGLVKLDVKTKSCSGVEFSTSGSSNTDTGKVTGTLETKYKWCEYGLTFTEKWNTDNTLGTEIAIEDQICQGLKLTFDTTFSPNTGKKSGKIKSSYKRECINLGCDVDFDFAGPAIHGSAVFGYEGWLAGYQMTFDSAKSKLTRNNFAVGYRTGDFQLHTNVNDGTEFGGSIYQKVCEDLDTSVNLAWTSGTNCTRFGIAAKYQLDPTASISAKVNNSSLIGVGYTQTLRPGVKLTLSALVDGKSINAGGHKVGLALELEA>sp|P45880-2|VDAC2_HUMAN Isoform 2 of Voltage-dependent anion-selectivechannel protein 2 OS=Homo sapiens OX=9606 GN=VDAC2MCIPPSYADLGKAARDIFNKGFGFGLVKLDVKTKSCSGVEFSTSGSSNTDTGKVTGTLETKYKWCEYGLTFTEKWNTDNTLGTEIAIEDQICQGLKLTFDTTFSPNTGKKSGKIKSSYKRECINLGCDVDFDFAGPAIHGSAVFGYEGWLAGYQMTFDSAKSKLTRNNFAVGYRTGDFQLHTNVNDGTEFGGSIYQKVCEDLDTSVNLAWTSGTNCTRFGIAAKYQLDPTASISAKVNNSSLIGVGYTQTLRPGVKLTLSALVDGKSINAGGHKVGLALELEA>sp|O76024|WFS1_HUMAN Wolframin OS=Homo sapiens OX=9606 GN=WFS1 PE=1 SV=2MDSNTAPLGPSCPQPPPAPQPQARSRLNATASLEQERSERPRAPGPQAGPGPGVRDAAAPAEPQAQHTRSRERADGTGPTKGDMEIPFEEVLERAKAGDPKAQTEVGKHYLQLAGDTDEELNSCTAVDWLVLAAKQGRREAVKLLRRCLADRRGITSENEREVRQLSSETDLERAVRKAALVMYWKLNPKKKKQVAVAELLENVGQVNEHDGGAQPGPVPKSLQKQRRMLERLVSSESKNYIALDDFVEITKKYAKGVIPSSLFLQDDEDDDELAGKSPEDLPLRLKVVKYPLHAIMEIKEYLIDMASRAGMHWLSTIIPTHHINALIFFFIVSNLTIDFFAFFIPLVIFYLSFISMVICTLKVFQDSKAWENFRTLTDLLLRFEPNLDVEQAEVNFGWNHLEPYAHFLLSVFFVIFSFPIASKDCIPCSELAVITGFFTVTSYLSLSTHAEPYTRRALATEVTAGLLSLLPSMPLNWPYLKVLGQTFITVPVGHLVVLNVSVPCLLYVYLLYLFFRMAQLRNFKGTYCYLVPYLVCFMWCELSVVILLESTGLGLLRASIGYFLFLFALPILVAGLALVGVLQFARWFTSLELTKIAVTVAVCSVPLLLRWWTKASFSVVGMVKSLTRSSMVKLILVWLTAIVLFCWFYVYRSEGMKVYNSTLTWQQYGALCGPRAWKETNMARTQILCSHLEGHRVTWTGRFKYVRVTDIDNSAESAINMLPFFIGDWMRCLYGEAYPACSPGNTSTAEEELCRLKLLAKHPCHIKKFDRYKFEITVGMPFSSGADGSRSREEDDVTKDIVLRASSEFKSVLLSLRQGSLIEFSTILEGRLGSKWPVFELKAISCLNCMAQLSPTRRHVKIEHDWRSTVHGAVKFAFDFFFFPFLSAA>sp|Q5TIE3|VW5B1_HUMAN von Willebrand factor A domain-containing protein5B1 OS=Homo sapiens OX=9606 GN=VWA5B1 PE=1 SV=2MPGLLNWITGAALPLTASDVTSCVSGYALGLTASLTYGNLEAQPFQGLFVYPLDECTTVIGFEAVIADRVVTVQIKDKAKLESGHFDASHVRSPTVTGNILQDGVSIAPHSCTPGKVTLDEDLERILFVANLGTIAPMENVTIFISTSSELPTLPSGAVRVLLPAVCAPTVPQFCTKSTGTSNQQAQGKDRHCFGAWAPGSWNKLCLATLLNTEVSNPMEYEFNFQLEIRGPCLLAGVESPTHEIRADAAPSARSAKSIIITLANKHTFDRPVEILIHPSEPHMPHVLIEKGDMTLGEFDQHLKGRTDFIKGMKKKSRAERKTEIIRKRLHKDIPHHSVIMLNFCPDLQSVQPCLRKAHGEFIFLIDRSSSMSGISMHRVKDAMLVALKSLMPACLFNIIGFGSTFKSLFPSSQTYSEDSLAMACDDIQRMKADMGGTNILSPLKWVIRQPVHRGHPRLLFVITDGAVNNTGKVLELVRNHAFSTRCYSFGIGPNVCHRLVKGLASVSEGSAELLMEGERLQPKMVKSLKKAMAPVLSDVTVEWIFPETTEVLVSPVSASSLFPGERLVGYGIVCDASLHISNPRSDKRRRYSMLHSQESGSSVFYHSQDDGPGLEGGDCAKNSGAPFILGQAKNARLASGDSTTKHDLNLSQRRRAYSTNQITNHKPLPRATMASDPMPAAKRYPLRKARLQDLTNQTSLDVQRWQIDLQPLLNSGQDLNQGPKLRGPGARRPSLLPQGCQPFLPWGQETQAWSPVRERTSDSRSPGDLEPSHHPSAFETETSSDWDPPAESQERASPSRPATPAPVLGKALVKGLHDSQRLQWEVSFELGTPGPERGGAQDADLWSETFHHLAARAIIRDFEQLAEREGEIEQGSNRRYQVSALHTSKACNIISKYTAFVPVDVSKSRYLPTVVEYPNSAALRMLGSRALAQQWRGTSSGFGRPQTMLGEDSAPGNGKFQALNMEASPTALFSEARSPGREKHGASEGPQRSLATNTLSSMKASENLFGSWLNLNKSRLLTRAAKGFLSKPLIKAVESTSGNQSFDYIPLVSLQLASGAFLLNEAFCEATHIPMEKLKWTSPFTCHRVSLTTRPSESKTPSPQLCTSSPPRHPSCDSFSLEPLAKGKLGLEPRAVVEHTGKLWATVVGLAWLEHSSASYFTEWELVAAKANSWLEQQEVPEGRTQGTLKAAARQLFVLLRHWDENLEFNMLCYNPNYV>sp|Q5TIE3-2|VW5B1_HUMAN Isoform 2 of von Willebrand factor A domain-containing protein 5B1 OS=Homo sapiens OX=9606 GN=VWA5B1MPGLLNWITGAALPLTASDVTSCVSGYALGLTASLTYGNLEAQPFQGLFVYPLDECTTVIGFEAVIADRVVTVQIKDKAKLESGHFDASHVRSPTVTGNILQDGVSIAPHSCTPGKVTLDEDLERILFVANLGTIAPMENVTIFISTSSELPTLPSGAVRVLLPAVCAPTVPQFCTKSTGTSNQQAQGKDRHCFGAWAPGSWNKLCLATLLNTEVSNPMEYEFNFQLEIRGPCLLAGVESPTHEIRADAAPSARSAKSIIITLANKHTFDRPVEILIHPSEPHMPHVLIEKGDMTLGEFDQHLKGRTDFIKGMKKKSRAERKTEIIRKRLHKDIPHHSVIMLNFCPDLQSVQPCLRKAHGEFIFLIDRSSSMSGISMHRVKDAMLVALKSLMPACLFNIIGFGSTFKSLFPSSQTYSEDSLAMACDDIQRMKADMGGTNILSPLKWVIRQPVHRGHPRLLFVITDGAVNNTGKVLELVRNHAFSTRCYSFGIGPNVCHRLVKGLASVSEGSAELLMEGERLQPKMVKSLKKAMAPVLSDVTVEWIFPETTEVLVSPVSASSLFPGERLVGYGIVCDASLHISNPRSDKRRRYSMLHSQESGSSVFYHSQDDGPGLEGGDCAKNSGAPFILGQAKNARLASGDSTTKHDLNLSQRRRAYSTNQITNHKPLPRATMASDPMPAAKRYPLRKARLQDLTNQTSLDVQRWQIDLQPLLNSGQDLNQGPKLRGPGARRPSLLPQGCQPFLPWGQETQAWSPVRERTSDSRSPGDLEPSHHPSAFETETSSDWDPPAESQERASPSRPATPAPVLGKALVKGLHDSQRLQWEVSFELGTPGPERGGAQDADLWSETFHHLAARAIIRDFEQLAEREGEIEQGSNRRYQVSALHTSKACNIISKYTAFVPVDVSKSRYLPTVVEYPNSGAALRMLGSRALAQQWRGTSSGFGRPQTMLGEDSAPGNDMEASPTALFSEARSPGREKHGASEGPQRSLATNTLSSMKASENLFGSWLNLNKSRLLTRAAKGFLSKPLIKAVESTSGNQSFDYIPLVSLQLASGAFLLNEAFCEATHIPMEKLKWTSPFTCHRVSLTTRPSESKTPSPQLCTSSPPRHPSCDSFSLEPLAKGKLGLEPRAVVEHTGKLWATVVGLAWLEHSSASYFTEWELVAAKANSWLEQQEVPEGRTQGTLKAAARQLFVLLRHWDENLEFNMLCYNPNYV>sp|Q5TIE3-3|VW5B1_HUMAN Isoform 3 of von Willebrand factor A domain-containing protein 5B1 OS=Homo sapiens OX=9606 GN=VWA5B1MPHVLIEKGDMTLGEFDQHLKGRTDFIKGMKKKSRAERKTEIIRKRLHKDIPHHSVIMLNFCPDLQSVQPCLRKAHGEFIFLIDRSSSMSGISMHRVKDAMLVALKSLMPACLFNIIGFGSTFKSLFPSSQTYSEDSLAMACDDIQRMKADMGGTNILSPLKWVIRQPVHRGHPRLLFVITDGAVNNTGKVLELVRNHAFSTRCYSFGIGPNVCHRLVKGLASVSEGSAELLMEGERLQPKMVKSLKKAMAPVLSDVTVEWIFPETTEVLVSPVSASSLFPGERLVGYGIVCDASLHISNPRSDKRRRYSMLHSQESGSSVFYHSQDDGPGLEGGDCAKNSGAPFILGQAKNARLASGDSTTKHDLNLSQRRRAYSTNQITNHKPLPRATMASDPMPAAKRYPLRKARLQDLTNQTSLDVQRWQIDLQAFICLTSEDTFQIRTPTGQ>sp|Q5TIE3-4|VW5B1_HUMAN Isoform 4 of von Willebrand factor A domain-containing protein 5B1 OS=Homo sapiens OX=9606 GN=VWA5B1MPGLLNWITGAALPLTASDVTSCVSGYALGLTASLTYGNLEAQPFQGLFVYPLDECTTVIGFEAVIADRVVTVQIKDKAKLESGHFDASHVRSPTVTGNILQDGVSIAPHSCTPGKVTLDEDLERILFVANLGTIAPMENVTIFISTSSELPTLPSGAVRVLLPAVCAPTVPQFCTKSTGTSNQQAQGKDRHCFGAWAPGSWNKLCLATLLNTEVSNPMEYEFNFQLEIRGPCLLAGVESPTHEIRADAAPSARSAKSIIITLANKHTFDRPVEILIHPSEPHMPHVLIEKGDMTLGEFDQHLKGRTDFIKGMKKKSRAERKTEIIRKRLHKDIPHHSVIMLNFCPDLQSVQPCLRKAHGEFIFLIDRSSSMSGISMHRVKDAMLVALKSLMPACLFNIIGFGSTFKSLFPSSQTYSEDSLAMACDDIQRMKADMGGTNILSPLKWVIRQPVHRGHPRLLFVITDGAVNNTGKVLELVRNHAFSTRCYSFGIGPNVCHRLVKGLASVSEGSAELLMEGERLQPKMVKSLKKAMAPVLSDVTVEWIFPETTEVLVSPVSASSLFPGERLVGYGIVCDASLHISNPRSDKRRRYSMLHSQESGSSVFYHSQDDGPGLEGGDCAKNSGAPFILGQAKNARLASGDSTTKHDLNLSQRRRAYSTNQITNHKPLPRATMASDPMPAAKRYPLRKARLQDLTNQTSLDVQRWQIDLQPLLNSGQDLNQGPKLRGPGARRPSLLPQGCQPFLPWGQETQAWSPVRERTSDSRSPGDLEPSHHPSAFETETSSDWDPPAESQERASPSRPATPAPVLGKALVKGLHDSQRLQWEVSFELGTPGPERGGAQDADLWSETFHHLAARAIIRDFEQLAEREGEIEQGSNRRYQVSALHTSKACNIISKYTAFVPVDVSKSRYLPTVVEYPNSGAALRMLGSRALAQQWRGTSSGFGRPQTMLGEDSAPGNGPRKCSQTLMGFKTKTETEHSVRGWKPRGALQNQSVLSTSWSHWPPKPRRTSSTPEPS>sp|Q5TIE3-5|VW5B1_HUMAN Isoform 5 of von Willebrand factor A domain-containing protein 5B1 OS=Homo sapiens OX=9606 GN=VWA5B1MPGLLNWITGAALPLTASDVTSCVSGYALGLTASLTYGNLEAQPFQGLFVYPLDECTTVIGFEAVIADRVVTVQIKDKAKLESGHFDASHVRSPTVTGNILQDGVSIAPHSCTPGKVTLDEDLERILFVANLGTIAPMENVTIFISTSSELPTLPSGAVRVLLPAVCAPTVPQFCTKSTGTSNQQAQGKDRHCFGAWAPGSWNKLCLATLLNTEVSNPMEYEFNFQLEIRGPCLLAGVESPTHEIRADAAPSARSAKSIIITLANKHTFDRPVEILIHPSEPHMPHVLIEKGDMTLGEFDQHLKGRTDFIKGMKKKSRAERKTEIIRKRLHKDIPHHSVIMLNFCPDLQSVQPCLRKAHGEFIFLIDRSSSMSGISMHRVKDAMLVALKSLMPACLFNIIGFGSTFKSLFPSSQTYSEDSLAMACDDIQRMKADMGGTNILSPLKWVIRQPVHRGHPRLLFVITDGAVNNTGKVLELVRNHAFSTRCYSFGIGPNVCHRLVKGLASVSEGSAELLMEGERLQPKMVKSLKKAMAPVLSDVTVEWIFPETTEVLVSPVSASSLFPGERLVGYGIVCDASLHISNPRSDKRRRYSMLHSQESGSSVFYHSQDDGPGLEGGDCAKNSGAPFILGQAKNARLASGDSTTKHDLNLSQRRRAYSTNQITNHKPLPRATMASDPMPAAKRYPLRKARLQDLTNQTSLDVQRWQIDLQPLLNSGQDLNQGPKLRGPGARRPSLLPQGCQPFLPWGQETQAWSPVRERTSDSRSPGDLEPSHHPSAFETETSSDWDPPAESQERASPSRPATPAPVLGKALVKGLHDSQRLQWEVSFELGTPGPERGGAQDADLWSETFHHLAARAIIRDFEQLAEREGEIEQGSNRRYQVSALHTSKACNIISKYTAFVPVDVSKSRYLPTVVEYPNSGAALRMLGSRALAQQWRGTSSGFGRPQTMLGEDSAPGNGPQRSLATNTLSSMKASENLFGSWLNLNKSRLLTRAAKGFLSKPLIKAVESTSGNQSFDYIPLVSLQLASGAFLLNEAFCEATHIPMEKLKWTSPFTCHRVSLTTRPSESKTPSPQLCTSSPPRHPSCDSFSLEPLAKGKLGLEPRAVVEHTGKLWATVVGLAWLEHSSASYFTEWELVAAKANSWLEQQEVPEGRTQGTLKAAARQLFVLLRHWDENLEFNMLCYNPNYV>sp|P15498|VAV_HUMAN Proto-oncogene vav OS=Homo sapiens OX=9606 GN=VAV1PE=1 SV=4MELWRQCTHWLIQCRVLPPSHRVTWDGAQVCELAQALRDGVLLCQLLNNLLPHAINLREVNLRPQMSQFLCLKNIRTFLSTCCEKFGLKRSELFEAFDLFDVQDFGKVIYTLSALSWTPIAQNRGIMPFPTEEESVGDEDIYSGLSDQIDDTVEEDEDLYDCVENEEAEGDEIYEDLMRSEPVSMPPKMTEYDKRCCCLREIQQTEEKYTDTLGSIQQHFLKPLQRFLKPQDIEIIFINIEDLLRVHTHFLKEMKEALGTPGAANLYQVFIKYKERFLVYGRYCSQVESASKHLDRVAAAREDVQMKLEECSQRANNGRFTLRDLLMVPMQRVLKYHLLLQELVKHTQEAMEKENLRLALDAMRDLAQCVNEVKRDNETLRQITNFQLSIENLDQSLAHYGRPKIDGELKITSVERRSKMDRYAFLLDKALLICKRRGDSYDLKDFVNLHSFQVRDDSSGDRDNKKWSHMFLLIEDQGAQGYELFFKTRELKKKWMEQFEMAISNIYPENATANGHDFQMFSFEETTSCKACQMLLRGTFYQGYRCHRCRASAHKECLGRVPPCGRHGQDFPGTMKKDKLHRRAQDKKRNELGLPKMEVFQEYYGLPPPPGAIGPFLRLNPGDIVELTKAEAEQNWWEGRNTSTNEIGWFPCNRVKPYVHGPPQDLSVHLWYAGPMERAGAESILANRSDGTFLVRQRVKDAAEFAISIKYNVEVKHIKIMTAEGLYRITEKKAFRGLTELVEFYQQNSLKDCFKSLDTTLQFPFKEPEKRTISRPAVGSTKYFGTAKARYDFCARDRSELSLKEGDIIKILNKKGQQGWWRGEIYGRVGWFPANYVEEDYSEYC>sp|P15498-2|VAV_HUMAN Isoform 2 of Proto-oncogene vav OS=Homo sapiensOX=9606 GN=VAV1MELWRQCTHWLIQCRVLPPSHRVTWDGAQVCELAQALRDGVLLCQLLNNLLPHAINLREVNLRPQMSQFLCLKNIRTFLSTCCEKFGLKRSELFEAFDLFDVQDFGKVIYTLSALSWTPIAQNRGIMPFPTEEESVGDEDIYSGLSDQIDDTVEEDEDLYDCVENEEAEGDEIYEDLMRSEPVSMPHFLKPLQRFLKPQDIEIIFINIEDLLRVHTHFLKEMKEALGTPGAANLYQVFIKYKERFLVYGRYCSQVESASKHLDRVAAAREDVQMKLEECSQRANNGRFTLRDLLMVPMQRVLKYHLLLQELVKHTQEAMEKENLRLALDAMRDLAQCVNEVKRDNETLRQITNFQLSIENLDQSLAHYGRPKIDGELKITSVERRSKMDRYAFLLDKALLICKRRGDSYDLKDFVNLHSFQVRDDSSGDRDNKKWSHMFLLIEDQGAQGYELFFKTRELKKKWMEQFEMAISNIYPENATANGHDFQMFSFEETTSCKACQMLLRGTFYQGYRCHRCRASAHKECLGRVPPCGRHGQDFPGTMKKDKLHRRAQDKKRNELGLPKMEVFQEYYGLPPPPGAIGPFLRLNPGDIVELTKAEAEQNWWEGRNTSTNEIGWFPCNRVKPYVHGPPQDLSVHLWYAGPMERAGAESILANRSDGTFLVRQRVKDAAEFAISIKYNVEVKHIKIMTAEGLYRITEKKAFRGLTELVEFYQQNSLKDCFKSLDTTLQFPFKEPEKRTISRPAVGSTKYFGTAKARYDFCARDRSELSLKEGDIIKILNKKGQQGWWRGEIYGRVGWFPANYVEEDYSEYC>sp|Q9UEU0|VTI1B_HUMAN Vesicle transport through interaction with t-SNAREs homolog 1B OS=Homo sapiens OX=9606 GN=VTI1B PE=1 SV=3MASSAASSEHFEKLHEIFRGLHEDLQGVPERLLGTAGTEEKKKLIRDFDEKQQEANETLAEMEEELRYAPLSFRNPMMSKLRNYRKDLAKLHREVRSTPLTATPGGRGDMKYGIYAVENEHMNRLQSQRAMLLQGTESLNRATQSIERSHRIATETDQIGSEIIEELGEQRDQLERTKSRLVNTSENLSKSRKILRSMSRKVTTNKLLLSIIILLELAILGGLVYYKFFRSH>sp|Q9UEU0-2|VTI1B_HUMAN Isoform Short of Vesicle transport throughinteraction with t-SNAREs homolog 1B OS=Homo sapiens OX=9606 GN=VTI1BMEEELRYAPLSFRNPMMSKLRNYRKDLAKLHREVRSTPLTATPGGRGDMKYGIYAVENEHMNRLQSQRAMLLQGTESLNRATQSIERSHRIATETDQIGSEIIEELGEQRDQLERTKSRLVNTSENLSKSRKILRSMSRKVTTNKLLLSIIILLELAILGGLVYYKFFRSH>sp|A8MXK1|VSTM5_HUMAN V-set and transmembrane domain-containing protein5 OS=Homo sapiens OX=9606 GN=VSTM5 PE=3 SV=1MRPLPSGRRKTRGISLGLFALCLAAARCLQSQGVSLYIPQATINATVKEDILLSVEYSCHGVPTIEWTYSSNWGTQKIVEWKPGTQANISQSHKDRVCTFDNGSIQLFSVGVRDSGYYVITVTERLGSSQFGTIVLHVSEILYEDLHFVAVILAFLAAVAAVLISLMWVCNKCAYKFQRKRRHKLKESTTEEIELEDVEC>sp|Q9HBG4|VPP4_HUMAN V-type proton ATPase 116 kDa subunit a isoform 4OS=Homo sapiens OX=9606 GN=ATP6V0A4 PE=1 SV=2MVSVFRSEEMCLSQLFLQVEAAYCCVAELGELGLVQFKDLNMNVNSFQRKFVNEVRRCESLERILRFLEDEMQNEIVVQLLEKSPLTPLPREMITLETVLEKLEGELQEANQNQQALKQSFLELTELKYLLKKTQDFFETETNLADDFFTEDTSGLLELKAVPAYMTGKLGFIAGVINRERMASFERLLWRICRGNVYLKFSEMDAPLEDPVTKEEIQKNIFIIFYQGEQLRQKIKKICDGFRATVYPCPEPAVERREMLESVNVRLEDLITVITQTESHRQRLLQEAAANWHSWLIKVQKMKAVYHILNMCNIDVTQQCVIAEIWFPVADATRIKRALEQGMELSGSSMAPIMTTVQSKTAPPTFNRTNKFTAGFQNIVDAYGVGSYREINPAPYTIITFPFLFAVMFGDCGHGTVMLLAALWMILNERRLLSQKTDNEIWNTFFHGRYLILLMGIFSIYTGLIYNDCFSKSLNIFGSSWSVQPMFRNGTWNTHVMEESLYLQLDPAIPGVYFGNPYPFGIDPIWNLASNKLTFLNSYKMKMSVILGIVQMVFGVILSLFNHIYFRRTLNIILQFIPEMIFILCLFGYLVFMIIFKWCCFDVHVSQHAPSILIHFINMFLFNYSDSSNAPLYKHQQEVQSFFVVMALISVPWMLLIKPFILRASHRKSQLQASRIQEDATENIEGDSSSPSSRSGQRTSADTHGALDDHGEEFNFGDVFVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVMNSGLQTRGWGGIVGVFIIFAVFAVLTVAILLIMEGLSAFLHALRLHWVEFQNKFYVGDGYKFSPFSFKHILDGTAEE>sp|Q9Y3S1|WNK2_HUMAN Serine/threonine-protein kinase WNK2 OS=Homosapiens OX=9606 GN=WNK2 PE=1 SV=4MDGDGGRRDVPGTLMEPGRGAGPAGMAEPRAKAARPGPQRFLRRSVVESDQEEPPGLEAAEAPGPQPPQPLQRRVLLLCKTRRLIAERARGRPAAPAPAALVAQPGAPGAPADAGPEPVGTQEPGPDPIAAAVETAPAPDGGPREEAAATVRKEDEGAAEAKPEPGRTRRDEPEEEEDDEDDLKAVATSLDGRFLKFDIELGRGSFKTVYKGLDTETWVEVAWCELQDRKLTKLERQRFKEEAEMLKGLQHPNIVRFYDFWESSAKGKRCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLLFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTCGIKPASFEKVHDPEIKEIIGECICKNKEERYEIKDLLSHAFFAEDTGVRVELAEEDHGRKSTIALRLWVEDPKKLKGKPKDNGAIEFTFDLEKETPDEVAQEMIESGFFHESDVKIVAKSIRDRVALIQWRRERIWPALQPKEQQDVGSPDKARGPPVPLQVQVTYHAQAGQPGPPEPEEPEADQHLLPPTLPTSATSLASDSTFDSGQGSTVYSDSQSSQQSVMLGSLADAAPSPAQCVCSPPVSEGPVLPQSLPSLGAYQQPTAAPGLPVGSVPAPACPPSLQQHFPDPAMSFAPVLPPPSTPMPTGPGQPAPPGQQPPPLAQPTPLPQVLAPQPVVPLQPVPPHLPPYLAPASQVGAPAQLKPLQMPQAPLQPLAQVPPQMPPIPVVPPITPLAGIDGLPPALPDLPTATVPPVPPPQYFSPAVILPSLAAPLPPASPALPLQAVKLPHPPGAPLAMPCRTIVPNAPATIPLLAVAPPGVAALSIHSAVAQLPGQPVYPAAFPQMAPTDVPPSPHHTVQNMRATPPQPALPPQPTLPPQPVLPPQPTLPPQPVLPPQPTRPPQPVLPPQPMLPPQPVLPPQPALPVRPEPLQPHLPEQAAPAATPGSQILLGHPAPYAVDVAAQVPTVPVPPAAVLSPPLPEVLLPAAPELLPQFPSSLATVSASVQSVPTQTATLLPPANPPLPGGPGIASPCPTVQLTVEPVQEEQASQDKPPGLPQSCESYGGSDVTSGKELSDSCEGAFGGGRLEGRAARKHHRRSTRARSRQERASRPRLTILNVCNTGDKMVECQLETHNHKMVTFKFDLDGDAPDEIATYMVEHDFILQAERETFIEQMKDVMDKAEDMLSEDTDADRGSDPGTSPPHLSTCGLGTGEESRQSQANAPVYQQNVLHTGKRWFIICPVAEHPAPEAPESSPPLPLSSLPPEASQGPCRGLTLPCLPWRRAACGAVFLSLFSAESAQSKQPPDSAPYKDQLSSKEQPSFLASQQLLSQAGPSNPPGAPPAPLAPSSPPVTALPQDGAAPATSTMPEPASGTASQAGGPGTPQGLTSELETSQPLAETHEAPLAVQPLVVGLAPCTPAPEAASTRDASAPREPLPPPAPEPSPHSGTPQPALGQPAPLLPAAVGAVSLATSQLPSPPLGPTVPPQPPSALESDGEGPPPRVGFVDSTIKSLDEKLRTLLYQEHVPTSSASAGTPVEVGDRDFTLEPLRGDQPRSEVCGGDLALPPVPKEAVSGRVQLPQPLVEKSELAPTRGAVMEQGTSSSMTAESSPRSMLGYDRDGRQVASDSHVVPSVPQDVPAFVRPARVEPTDRDGGEAGESSAEPPPSDMGTVGGQASHPQTLGARALGSPRKRPEQQDVSSPAKTVGRFSVVSTQDEWTLASPHSLRYSAPPDVYLDEAPSSPDVKLAVRRAQTASSIEVGVGEPVSSDSGDEGPRARPPVQKQASLPVSGSVAGDFVKKATAFLQRPSRAGSLGPETPSRVGMKVPTISVTSFHSQSSYISSDNDSELEDADIKKELQSLREKHLKEISELQSQQKQEIEALYRRLGKPLPPNVGFFHTAPPTGRRRKTSKSKLKAGKLLNPLVRQLKVVASSTGHLADSSRGPPAKDPAQASVGLTADSTGLSGKAVQTQQPCSVRASLSSDICSGLASDGGGARGQGWTVYHPTSERVTYKSSSKPRARFLSGPVSVSIWSALKRLCLGKEHSSRSSTSSLAPGPEPGPQPALHVQAQVNNSNNKKGTFTDDLHKLVDEWTSKTVGAAQLKPTLNQLKQTQKLQDMEAQAGWAAPGEARAMTAPRAGVGMPRLPPAPGPLSTTVIPGAAPTLSVPTPDGALGTARRNQVWFGLRVPPTACCGHSTQPRGGQRVGSKTASFAASDPVRS>sp|Q9Y3S1-2|WNK2_HUMAN Isoform 2 of Serine/threonine-protein kinase WNK2OS=Homo sapiens OX=9606 GN=WNK2MDGDGGRRDVPGTLMEPGRGAGPAGMAEPRAKAARPGPQRFLRRSVVESDQEEPPGLEAAEAPGPQPPQPLQRRVLLLCKTRRLIAERARGRPAAPAPAALVAQPGAPGAPADAGPEPVGTQEPGPDPIAAAVETAPAPDGGPREEAAATVRKEDEGAAEAKPEPGRTRRDEPEEEEDDEDDLKAVATSLDGRFLKFDIELGRGSFKTVYKGLDTETWVEVAWCELQDRKLTKLERQRFKEEAEMLKGLQHPNIVRFYDFWESSAKGKRCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLLFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTCGIKPASFEKVHDPEIKEIIGECICKNKEERYEIKDLLSHAFFAEDTGVRVELAEEDHGRKSTIALRLWVEDPKKLKGKPKDNGAIEFTFDLEKETPDEVAQEMIESGFFHESDVKIVAKSIRDRVALIQWRRERIWPALQPKEQQDVGSPDKARGPPVPLQVQVTYHAQAGQPGPPEPEEPEADQHLLPPTLPTSATSLASDSTFDSGQGSTVYSDSQSSQQSVMLGSLADAAPSPAQCVCSPPVSEGPVLPQSLPSLGAYQQPTAAPGLPVGSVPAPACPPSLQQHFPDPAMSFAPVLPPPSTPMPTGPGQPAPPGQQPPPLAQPTPLPQVLAPQPVVPLQPVPPHLPPYLAPASQVGAPAQLKPLQMPQAPLQPLAQVPPQMPPIPVVPPITPLAGIDGLPPALPDLPTATVPPVPPPQYFSPAVILPSLAAPLPPASPALPLQAVKLPHPPGAPLAMPCRTIVPNAPATIPLLAVAPPGVAALSIHSAVAQLPGQPVYPAAFPQMAPTDVPPSPHHTVQNMRATPPQPALPPQPTLPPQPVLPPQPTLPPQPVLPPQPTRPPQPVLPPQPMLPPQPVLPPQPALPVRPEPLQPHLPEQAAPAATPGSQILLGHPAPYAVDVAAQVPTVPVPPAAVLSPPLPEVLLPAAPELLPQFPSSLATVSASVQSVPTQTATLLPPANPPLPGGPGIASPCPTVQLTVEPVQEEQASQDKPPGLPQSCESYGGSDVTSGKELSDSCEGAFGGGRLEGRAARKHHRRSTRARSRQERASRPRLTILNVCNTGDKMVECQLETHNHKMVTFKFDLDGDAPDEIATYMVEHDFILQAERETFIEQMKDVMDKAEDMLSEDTDADRGSDPGTSPPHLSTCGLGTGEESRQSQANAPVYQQNVLHTGKRWFIICPVAEHPAPEAPESSPPLPLSSLPPEASQDSAPYKDQLSSKEQPSFLASQQLLSQAGPSNPPGAPPAPLAPSSPPVTALPQDGAAPATSTMPEPASGTASQAGGPGTPQGLTSELETSQPLAETHEAPLAVQPLVVGLAPCTPAPEAASTRDASAPREPLPPPAPEPSPHSGTPQPALGQPAPLLPAAVGAVSLATSQLPSPPLGPTVPPQPPSALESDGEGPPPRVGFVDSTIKSLDEKLRTLLYQEHVPTSSASAGTPVEVGDRDFTLEPLRGDQPRSEVCGGDLALPPVPKEAVSGRVQLPQPLVEKSELAPTRGAVMEQGTSSSMTAESSPRSMLGYDRDGRQVASDSHVVPSVPQDVPAFVRPARVEPTDRDGGEAGESSAEPPPSDMGTVGGQASHPQTLGARALGSPRKRPEQQDVSSPAKTVGRFSVVSTQDEWTLASPHSLRYSAPPDVYLDEAPSSPDVKLAVRRAQTASSIEVGVGEPVSSDSGDEGPRARPPVQKQASLPVSGSVAGDFVKKATAFLQRPSRAGSLGPETPSRVGMKVPTISVTSFHSQSSYISSDNDSELEDADIKKELQSLREKHLKEISELQSQQKQEIEALYRRLGKPLPPNVGFFHTAPPTGRRRKTSKSKLKAGKLLNPLVRQLKVVASSTGHLADSSRGPPAKDPAQASVGLTADSTGLSGKAVQTQQPCSVRASLSSDICSGLASDGGGARGQGWTVYHPTSERVTYKSSSKPRARFLSGPVSVSIWSALKRLCLGKEHSSRSSTSSLAPGPEPGPQPALHVQAQVNNSNNKKGTFTDDLHKLVDEWTSKTVGAAQLKPTLNQLKQTQKLQDMEAQAGWAAPGEARAMTAPRAGVGMPRLPPAPGPLSTTVIPGAAPTLSVPTPGSCGPRAVSTPTSYT>sp|Q9Y3S1-3|WNK2_HUMAN Isoform 3 of Serine/threonine-protein kinase WNK2OS=Homo sapiens OX=9606 GN=WNK2MEPGRGAGPAGMAEPRAKAARPGPQRFLRRSVVESDQEEPPGLEAAEAPGPQPPQPLQRRVLLLCKTRRLIAERARGRPAAPAPAALVAQPGAPGAPADAGPEPVGTQEPGPDPIAAAVETAPAPDGGPREEAAATVRKEDEGAAEAKPEPGRTRRDEPEEEEDDEDDLKAVATSLDGRFLKFDIELGRGSFKTVYKGLDTETWVEVAWCELQDRKLTKLERQRFKEEAEMLKGLQHPNIVRFYDFWESSAKGKRCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLLFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTCGIKPASFEKVHDPEIKEIIGECICKNKEERYEIKDLLSHAFFAEDTGVRVELAEEDHGRKSTIALRLWVEDPKKLKGKPKDNGAIEFTFDLEKETPDEVAQEMIESGFFHESDVKIVAKSIRDRVALIQWRRERIWPALQPKEQQDVGSPDKARGPPVPLQVQVTYHAQAGQPGPPEPEEPEADQHLLPPTLPTSATSLASDSTFDSGQGSTVYSDSQSSQQSVMLGSLADAAPSPAQCVCSPPVSEGPVLPQSLPSLGAYQQPTAAPPPLAQPTPLPQVLAPQPVVPLQPVPPHLPPYLAPASQVGAPAQLKPLQMPQAPLQPLAQVPPQMPPIPVVPPITPLAGIDGLPPALPDLPTATVPPVPPPQYFSPAVILPSRTR>sp|Q9Y3S1-4|WNK2_HUMAN Isoform 4 of Serine/threonine-protein kinase WNK2OS=Homo sapiens OX=9606 GN=WNK2MDGDGGRRDVPGTLMEPGRGAGPAGMAEPRAKAARPGPQRFLRRSVVESDQEEPPGLEAAEAPGPQPPQPLQRRVLLLCKTRRLIAERARGRPAAPAPAALVAQPGAPGAPADAGPEPVGTQEPGPDPIAAAVETAPAPDGGPREEAAATVRKEDEGAAEAKPEPGRTRRDEPEEEEDDEDDLKAVATSLDGRFLKFDIELGRGSFKTVYKGLDTETWVEVAWCELQDRKLTKLERQRFKEEAEMLKGLQHPNIVRFYDFWESSAKGKRCIVLVTELMTSGTLKTYLKRFKVMKPKVLRSWCRQILKGLLFLHTRTPPIIHRDLKCDNIFITGPTGSVKIGDLGLATLKRASFAKSVIGTPEFMAPEMYEEHYDESVDVYAFGMCMLEMATSEYPYSECQNAAQIYRKVTCGIKPASFEKVHDPEIKEIIGECICKNKEERYEIKDLLSHAFFAEDTGVRVELAEEDHGRKSTIALRLWVEDPKKLKGKPKDNGAIEFTFDLEKETPDEVAQEMIESGFFHESDVKIVAKSIRDRVALIQWRRERIWPALQPKEQQDVGSPDKARGPPVPLQVQVTYHAQAGQPGPPEPEEPEADQHLLPPTLPTSATSLASDSTFDSGQGSTVYSDSQSSQQSVMLGSLADAAPSPAQCVCSPPVSEGPVLPQSLPSLGAYQQPTAAPGLPVGSVPAPACPPSLQQHFPDPAMSFAPVLPPPSTPMPTGPGQPAPPGQQPPPLAQPTPLPQVLAPQPVVPLQPVPPHLPPYLAPASQVGAPAQLKPLQMPQAPLQPLAQVPPQMPPIPVVPPITPLAGIDGLPPALPDLPTATVPPVPPPQYFSPAVILPSLAAPLPPASPALPLQAVKLPHPPGAPLAMPCRTIVPNAPATIPLLAVAPPGVAALSIHSAVAQLPGQPVYPAAFPQMAPTDVPPSPHHTVQNMRATPPQPALPPQPTLPPQPVLPPQPTLPPQPVLPPQPTRPPQPVLPPQPMLPPQPVLPPQPALPVRPEPLQPHLPEQAAPAATPGSQILLGHPAPYAVDVAAQVPTVPVPPAAVLSPPLPEVLLPAAPELLPQFPSSLATVSASVQSVPTQTATLLPPANPPLPGGPGIASPCPTVQLTVEPVQEEQASQDKPPGLPQSCESYGGSDVTSGKELSDSCEGAFGGGRLEGRAARKHHRRSTRARSRQERASRPRLTILNVCNTGDKMVECQLETHNHKMVTFKFDLDGDAPDEIATYMVEHDFILQAERETFIEQMKDVMDKAEDMLSEDTDADRGSDPGTSPPHLSTCGLGTGEESRQSQANAPVYQQNVLHTGKRWFIICPVAEHPAPEAPESSPPLPLSSLPPEASQGPCRGLTLPCLPWRRAACGAVFLSLFSAESAQSKQPPDSAPYKDQLSSKEQPSFLASQQLLSQAGPSNPPGAPPAPLAPSSPPVTALPQDGAAPATSTMPEPASGTASQAGGPGTPQGLTSELETSQPLAETHEAPLAVQPLVVGLAPCTPAPEAASTRDASAPREPLPPPAPEPSPHSGTPQPALGQPAPLLPAAVGAVSLATSQLPSPPLGPTVPPQPPSALESDGEGPPPRVGFVDSTIKSLDEKLRTLLYQEHVPTSSASAGTPVEVGDRDFTLEPLRGDQPRSEVCGGDLALPPVPKEAVSGRVQLPQPLVEKSELAPTRGAVMEQGTSSSMTAESSPRSMLGYDRDGRQVASDSHVVPSVPQDVPAFVRPARVEPTDRDGGEAGESSAEPPPSDMGTVGGQASHPQTLGARALGSPRKRPEQQDVSSPAKTVGRFSVVSTQDEWTLASPHSLRYSAPPDVYLDEAPSSPDVKLAVRRAQTASSIEVGVGEPVSSDSGDEGPRARPPVQKQASLPVSGSVAGDFVKKATAFLQRPSRAGSLGPETPSRVGMKVPTISVTSFHSQSSYISSDNDSELEDADIKKELQSLREKHLKEISELQSQQKQEIEALYRRLGKPLPPNVGFFHTAPPTGRRRKTSKSKLKAGKLLNPLVRQLKVVASSTGHLADSSRGPPAKDPAQASVGLTADSTGLSGKAVQTQQPCSVRASLSSDICSGLASDGGGARGQGWTVYHPTSERVTYKSSSKPRARFLSGPVSVSIWSALKRLCLGKEHSSRSSTSSLAPGPEPGPQPALHVQAQVNNSNNKKGTFTDDLHKLVDEWTSKTVGAAQLKPTLNQLKQTQKLQDMEAQAGWAAPGEARAMTAPRAGVGMPRLPPAPGPLSTTVIPGAAPTLSVPTPDPESEKPD>sp|Q8IZH2|XRN1_HUMAN 5'-3' exoribonuclease 1 OS=Homo sapiens OX=9606GN=XRN1 PE=1 SV=1MGVPKFYRWISERYPCLSEVVKEHQIPEFDNLYLDMNGIIHQCSHPNDDDVHFRISDDKIFTDIFHYLEVLFRIIKPRKVFFMAVDGVAPRAKMNQQRGRRFRSAKEAEDKIKKAIEKGETLPTEARFDSNCITPGTEFMARLHEHLKYFVNMKISTDKSWQGVTIYFSGHETPGEGEHKIMEFIRSEKAKPDHDPNTRHCLYGLDADLIMLGLTSHEAHFSLLREEVRFGGKKTQRVCAPEETTFHLLHLSLMREYIDYEFSVLKEKITFKYDIERIIDDWILMGFLVGNDFIPHLPHLHINHDALPLLYGTYVTILPELGGYINESGHLNLPRFEKYLVKLSDFDREHFSEVFVDLKWFESKVGNKYLNEAAGVAAEEARNYKEKKKLKGQENSLCWTALDKNEGEMITSKDNLEDETEDDDLFETEFRQYKRTYYMTKMGVDVVSDDFLADQAACYVQAIQWILHYYYHGVQSWSWYYPYHYAPFLSDIHNISTLKIHFELGKPFKPFEQLLAVLPAASKNLLPACYQHLMTNEDSPIIEYYPPDFKTDLNGKQQEWEAVVLIPFIDEKRLLEAMETCNHSLKKEERKRNQHSECLMCWYDRDTEFIYPSPWPEKFPAIERCCTRYKIISLDAWRVDINKNKITRIDQKALYFCGFPTLKHIRHKFFLKKSGVQVFQQSSRGENMMLEILVDAESDELTVENVASSVLGKSVFVNWPHLEEARVVAVSDGETKFYLEEPPGTQKLYSGRTAPPSKVVHLGDKEQSNWAKEVQGISEHYLRRKGIIINETSAVVYAQLLTGRKYQINQNGEVRLEKQWSKQVVPFVYQTIVKDIRAFDSRFSNIKTLDDLFPLRSMVFMLGTPYYGCTGEVQDSGDVITEGRIRVIFSIPCEPNLDALIQNQHKYSIKYNPGYVLASRLGVSGYLVSRFTGSIFIGRGSRRNPHGDHKANVGLNLKFNKKNEEVPGYTKKVGSEWMYSSAAEQLLAEYLERAPELFSYIAKNSQEDVFYEDDIWPGENENGAEKVQEIITWLKGHPVSTLSRSSCDLQILDAAIVEKIEEEVEKCKQRKNNKKVRVTVKPHLLYRPLEQQHGVIPDRDAEFCLFDRVVNVRENFSVPVGLRGTIIGIKGANREADVLFEVLFDEEFPGGLTIRCSPGRGYRLPTSALVNLSHGSRSETGNQKLTAIVKPQPAVHQHSSSSSVSSGHLGALNHSPQSLFVPTQVPTKDDDEFCNIWQSLQGSGKMQYFQPTIQEKGAVLPQEISQVNQHHKSGFNDNSVKYQQRKHDPHRKFKEECKSPKAECWSQKMSNKQPNSGIENFLASLNISKENEVQSSHHGEPPSEEHLSPQSFAMGTRMLKEILKIDGSNTVDHKNEIKQIANEIPVSSNRRDEYGLPSQPKQNKKLASYMNKPHSANEYHNVQSMDNMCWPAPSQIPPVSTPVTELSRICSLVGMPQPDFSFLRMPQTMTVCQVKLSNGLLVHGPQCHSENEAKEKAALFALQQLGSLGMNFPLPSQVFANYPSAVPPGTIPPAFPPPTGWDHYGSNYALGAANIMPSSSHLFGSMPWGPSVPVPGKPFHHTLYSGTMPMAGGIPGGVHNQFIPLQVTKKRVANKKNFENKEAQSSQATPVQTSQPDSSNIVKVSPRESSSASLKSSPIAQPASSFQVETASQGHSISHHKSTPISSSRRKSRKLAVNFGVSKPSE>sp|Q8IZH2-2|XRN1_HUMAN Isoform 2 of 5'-3' exoribonuclease 1 OS=Homosapiens OX=9606 GN=XRN1MGVPKFYRWISERYPCLSEVVKEHQIPEFDNLYLDMNGIIHQCSHPNDDDVHFRISDDKIFTDIFHYLEVLFRIIKPRKVFFMAVDGVAPRAKMNQQRGRRFRSAKEAEDKIKKAIEKGETLPTEARFDSNCITPGTEFMARLHEHLKYFVNMKISTDKSWQGVTIYFSGHETPGEGEHKIMEFIRSEKAKPDHDPNTRHCLYGLDADLIMLGLTSHEAHFSLLREEVRFGGKKTQRVCAPEETTFHLLHLSLMREYIDYEFSVLKEKITFKYDIERIIDDWILMGFLVGNDFIPHLPHLHINHDALPLLYGTYVTILPELGGYINESGHLNLPRFEKYLVKLSDFDREHFSEVFVDLKWFESKVGNKYLNEAAGVAAEEARNYKEKKKLKGQENSLCWTALDKNEGEMITSKDNLEDETEDDDLFETEFRQYKRTYYMTKMGVDVVSDDFLADQAACYVQAIQWILHYYYHGVQSWSWYYPYHYAPFLSDIHNISTLKIHFELGKPFKPFEQLLAVLPAASKNLLPACYQHLMTNEDSPIIEYYPPDFKTDLNGKQQEWEAVVLIPFIDEKRLLEAMETCNHSLKKEERKRNQHSECLMCWYDRDTEFIYPSPWPEKFPAIERCCTRYKIISLDAWRVDINKNKITRIDQKALYFCGFPTLKHIRHKFFLKKSGVQVFQQSSRGENMMLEILVDAESDELTVENVASSVLGKSVFVNWPHLEEARVVAVSDGETKFYLEEPPGTQKLYSGRTAPPSKVVHLGDKEQSNWAKEVQGISEHYLRRKGIIINETSAVVYAQLLTGRKYQINQNGEVRLEKQWSKQVVPFVYQTIVKDIRAFDSRFSNIKTLDDLFPLRSMVFMLGTPYYGCTGEVQDSGDVITEGRIRVIFSIPCEPNLDALIQNQHKYSIKYNPGYVLASRLGVSGYLVSRFTGSIFIGRGSRRNPHGDHKANVGLNLKFNKKNEEVPGYTKKVGSEWMYSSAAEQLLAEYLERAPELFSYIAKNSQEDVFYEDDIWPGENENGAEKVQEIITWLKGHPVSTLSRSSCDLQILDAAIVEKIEEEVEKCKQRKNNKKVRVTVKPHLLYRPLEQQHGVIPDRDAEFCLFDRVVNVRENFSVPVGLRGTIIGIKGANREADVLFEVLFDEEFPGGLTIRCSPGRGYRLPTSALVNLSHGSRSETGNQKLTAIVKPQPAVHQHSSSSSVSSGHLGALNHSPQSLFVPTQVPTKDDDEFCNIWQSLQGSGKMQYFQPTIQEKGAVLPQEISQVNQHHKSGFNDNSVKYQQRKHDPHRKFKEECKSPKAECWSQKMSNKQPNSGIENFLASLNISKENEVQSSHHGEPPSEEHLSPQSFAMKGTRMLKEILKIDGSNTVDHKNEIKQIANEIPVSSNRRDEYGLPSQPKQNKKLASYMNKPHSANEYHNVQSMDNMCWPAPSQIPPVSTPVTELSRICSLVGMPQPDFSFLRMPQTMTVCQVKLSNGLLVHGPQCHSENEAKEKAALFALQQLGSLGMNFPLPSQVFANYPSAVPPGTIPPAFPPPTANIMPSSSHLFGSMPWGPSVPVPGKPFHHTLYSGTMPMAGGIPGGVHNQFIPLQVTKKRVANKKNFENKEAQSSQATPVQTSQPDSSNIVKVSPRESSSASLKSSPIAQPASSFQVETASQGHSISHHKSTPISSSRRKSRKLAVNFGVSKPSE>sp|Q8IZH2-3|XRN1_HUMAN Isoform 3 of 5'-3' exoribonuclease 1 OS=Homosapiens OX=9606 GN=XRN1MGVPKFYRWISERYPCLSEVVKEHQIPEFDNLYLDMNGIIHQCSHPNDDDVHFRISDDKIFTDIFHYLEVLFRIIKPRKVFFMAVDGVAPRAKMNQQRGRRFRSAKEAEDKIKKAIEKGETLPTEARFDSNCITPGTEFMARLHEHLKYFVNMKISTDKSWQGVTIYFSGHETPGEGEHKIMEFIRSEKAKPDHDPNTRHCLYGLDADLIMLGLTSHEAHFSLLREEVRFGGKKTQRVCAPEETTFHLLHLSLMREYIDYEFSVLKEKITFKYDIERIIDDWILMGFLVGNDFIPHLPHLHINHDALPLLYGTYVTILPELGGYINESGHLNLPRFEKYLVKLSDFDREHFSEVFVDLKWFESKVGNKYLNEAAGVAAEEARNYKEKKKLKGQENSLCWTALDKNEGEMITSKDNLEDETEDDDLFETEFRQYKRTYYMTKMGVDVVSEYVFANAFILK>sp|Q8IUB2|WFDC3_HUMAN WAP four-disulfide core domain protein 3 OS=Homosapiens OX=9606 GN=WFDC3 PE=1 SV=1MMLSCLFLLKALLALGSLESWITAGEHAKEGECPPHKNPCKELCQGDELCPAEQKCCTTGCGRICRDIPKGRKRDCPRVIRKQSCLKRCITDETCPGVKKCCTLGCNKSCVVPISKQKLAEFGGECPADPLPCEELCDGDASCPQGHKCCSTGCGRTCLGDIEGGRGGDCPKVLVGLCIVGCVMDENCQAGEKCCKSGCGRFCVPPVLPPKLTMNPNWTVRSDSELEIPVP>sp|P19544|WT1_HUMAN Wilms tumor protein OS=Homo sapiens OX=9606 GN=WT1PE=1 SV=2MGSDVRDLNALLPAVPSLGGGGGCALPVSGAAQWAPVLDFAPPGASAYGSLGGPAPPPAPPPPPPPPPHSFIKQEPSWGGAEPHEEQCLSAFTVHFSGQFTGTAGACRYGPFGPPPPSQASSGQARMFPNAPYLPSCLESQPAIRNQGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGVAAGSSSSVKWTEGQSNHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGKTSEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|P19544-2|WT1_HUMAN Isoform 2 of Wilms tumor protein OS=Homo sapiensOX=9606 GN=WT1MGSDVRDLNALLPAVPSLGGGGGCALPVSGAAQWAPVLDFAPPGASAYGSLGGPAPPPAPPPPPPPPPHSFIKQEPSWGGAEPHEEQCLSAFTVHFSGQFTGTAGACRYGPFGPPPPSQASSGQARMFPNAPYLPSCLESQPAIRNQGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|P19544-3|WT1_HUMAN Isoform 3 of Wilms tumor protein OS=Homo sapiensOX=9606 GN=WT1MGSDVRDLNALLPAVPSLGGGGGCALPVSGAAQWAPVLDFAPPGASAYGSLGGPAPPPAPPPPPPPPPHSFIKQEPSWGGAEPHEEQCLSAFTVHFSGQFTGTAGACRYGPFGPPPPSQASSGQARMFPNAPYLPSCLESQPAIRNQGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGKTSEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|P19544-4|WT1_HUMAN Isoform 4 of Wilms tumor protein OS=Homo sapiensOX=9606 GN=WT1MGSDVRDLNALLPAVPSLGGGGGCALPVSGAAQWAPVLDFAPPGASAYGSLGGPAPPPAPPPPPPPPPHSFIKQEPSWGGAEPHEEQCLSAFTVHFSGQFTGTAGACRYGPFGPPPPSQASSGQARMFPNAPYLPSCLESQPAIRNQGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGVAAGSSSSVKWTEGQSNHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|P19544-6|WT1_HUMAN Isoform 6 of Wilms tumor protein OS=Homo sapiensOX=9606 GN=WT1MEKGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGVAAGSSSSVKWTEGQSNHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|P19544-7|WT1_HUMAN Isoform 7 of Wilms tumor protein OS=Homo sapiensOX=9606 GN=WT1MDFLLLQDPASTCVPEPASQHTLRSGPGCLQQPEQQGVRDPGGIWAKLGAAEASAERLQGRRSRGASGSEPQQMGSDVRDLNALLPAVPSLGGGGGCALPVSGAAQWAPVLDFAPPGASAYGSLGGPAPPPAPPPPPPPPPHSFIKQEPSWGGAEPHEEQCLSAFTVHFSGQFTGTAGACRYGPFGPPPPSQASSGQARMFPNAPYLPSCLESQPAIRNQGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGVAAGSSSSVKWTEGQSNHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGKTSEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|P19544-8|WT1_HUMAN Isoform 8 of Wilms tumor protein OS=Homo sapiensOX=9606 GN=WT1MDFLLLQDPASTCVPEPASQHTLRSGPGCLQQPEQQGVRDPGGIWAKLGAAEASAERLQGRRSRGASGSEPQQMGSDVRDLNALLPAVPSLGGGGGCALPVSGAAQWAPVLDFAPPGASAYGSLGGPAPPPAPPPPPPPPPHSFIKQEPSWGGAEPHEEQCLSAFTVHFSGQFTGTAGACRYGPFGPPPPSQASSGQARMFPNAPYLPSCLESQPAIRNQGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGKTSEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|P19544-9|WT1_HUMAN Isoform 9 of Wilms tumor protein OS=Homo sapiensOX=9606 GN=WT1MEKGYSTVTFDGTPSYGHTPSHHAAQFPNHSFKHEDPMGQQGSLGEQQYSVPPPVYGCHTPTDSCTGSQALLLRTPYSSDNLYQMTSQLECMTWNQMNLGATLKGHSTGYESDNHTTPILCGAQYRIHTHGVFRGIQDVRRVPGVAPTLVRSASETSEKRPFMCAYPGCNKRYFKLSHLQMHSRKHTGEKPYQCDFKDCERRFSRSDQLKRHQRRHTGVKPFQCKTCQRKFSRSDHLKTHTRTHTGKTSEKPFSCRWPSCQKKFARSDELVRHHNMHQRNMTKLQLAL>sp|Q6ZSV7|YF010_HUMAN Putative uncharacterized protein FLJ45177 OS=Homosapiens OX=9606 PE=2 SV=1MAFGEPPSGHSTRHRTLHGLSFHTAMGMAWSLHYQGQGGTLCLVGVSTPSHDKAVLQGLPHFSVNLGVQPSALAGRRGDASCPSSWRSADPTVSPNLGAPGGPNAIDALHGEQLGLFLRTKMGRDPKDVHGLTPALCGPCLAGLPSSHSPQFSCNTAPLKMLS>sp|Q9Y473|ZN175_HUMAN Zinc finger protein 175 OS=Homo sapiens OX=9606GN=ZNF175 PE=1 SV=1MPADVNLSQKPQVLGPEKQDGSCEASVSFEDVTVDFSREEWQQLDPAQRCLYRDVMLELYSHLFAVGYHIPNPEVIFRMLKEKEPRVEEAEVSHQRCQEREFGLEIPQKEISKKASFQKDMVGEFTRDGSWCSILEELRLDADRTKKDEQNQIQPMSHSAFFNKKTLNTESNCEYKDPGKMIRTRPHLASSQKQPQKCCLFTESLKLNLEVNGQNESNDTEQLDDVVGSGQLFSHSSSDACSKNIHTGETFCKGNQCRKVCGHKQSLKQHQIHTQKKPDGCSECGGSFTQKSHLFAQQRIHSVGNLHECGKCGKAFMPQLKLSVYLTDHTGDIPCICKECGKVFIQRSELLTHQKTHTRKKPYKCHDCGKAFFQMLSLFRHQRTHSREKLYECSECGKGFSQNSTLIIHQKIHTGERQYACSECGKAFTQKSTLSLHQRIHSGQKSYVCIECGQAFIQKAHLIVHQRSHTGEKPYQCHNCGKSFISKSQLDIHHRIHTGEKPYECSDCGKTFTQKSHLNIHQKIHTGERHHVCSECGKAFNQKSILSMHQRIHTGEKPYKCSECGKAFTSKSQFKEHQRIHTGEKPYVCTECGKAFNGRSNFHKHQITHTRERPFVCYKCGKAFVQKSELITHQRTHMGEKPYECLDCGKSFSKKPQLKVHQRIHTGERPYVCSECGKAFNNRSNFNKHQTTHTRDKSYKCSYSVKGFTKQ>sp|O75346|ZN253_HUMAN Zinc finger protein 253 OS=Homo sapiens OX=9606GN=ZNF253 PE=2 SV=2MGPLQFRDVAIEFSLEEWHCLDTAQRNLYRDVMLENYRNLVFLGIVVSKPDLVTCLEQGKKPLTMERHEMIAKPPVMSSHFAQDLWPENIQNSFQIGMLRRYEECRHDNLQLKKGCKSVGEHKVHKGGYNGLNQCLTTTQKEIFQCDKYGKVFHKFSNSNTYKTRHTGINLFKCIICGKAFKRSSTLTTHKKIHTGEKPYRCEECGKAFNQSANLTTHKRIHTGEKPYRCEECGKAFKQSSNLTTHKKIHTGEKPYKCEECGKAFNRSTDLTTHKIVHTGEKPYKCEECGKAFKHPSHVTTHKKIHTRGKPYNCEECGKSFKHCSNLTIHKRIHTGEKPYKCEECGKAFHLSSHLTTHKILHTGEKPYRCRECGKAFNHSTTLFSHEKIHTGEKPYKCDECGKTFTWPSILSKHKRTHTGEKPYKCEECGKSFTASSTLTTHKRIHTGEKPYKCEECGKAFNWSSDLNKHKKIHIERKPYIVKNVTDLLNVPPLLISIR>sp|O75346-2|ZN253_HUMAN Isoform 2 of Zinc finger protein 253 OS=Homosapiens OX=9606 GN=ZNF253MSSHFAQDLWPENIQNSFQIGMLRRYEECRHDNLQLKKGCKSVGEHKVHKGGYNGLNQCLTTTQKEIFQCDKYGKVFHKFSNSNTYKTRHTGINLFKCIICGKAFKRSSTLTTHKKIHTGEKPYRCEECGKAFNQSANLTTHKRIHTGEKPYRCEECGKAFKQSSNLTTHKKIHTGEKPYKCEECGKAFNRSTDLTTHKIVHTGEKPYKCEECGKAFKHPSHVTTHKKIHTRGKPYNCEECGKSFKHCSNLTIHKRIHTGEKPYKCEECGKAFHLSSHLTTHKILHTGEKPYRCRECGKAFNHSTTLFSHEKIHTGEKPYKCDECGKTFTWPSILSKHKRTHTGEKPYKCEECGKSFTASSTLTTHKRIHTGEKPYKCEECGKAFNWSSDLNKHKKIHIERKPYIVKNVTDLLNVPPLLISIR>sp|O60293|ZC3H1_HUMAN Zinc finger C3H1 domain-containing protein OS=Homosapiens OX=9606 GN=ZFC3H1 PE=1 SV=3MATADTPAPASSGLSPKEEGELEDGEISDDDNNSQIRSRSSSSSSGGGLLPYPRRRPPHSARGGGSGGGGGSSSSSSSSQQQLRNFSRSRHASERGHLRGPSSYRPKEPFRSHPPSVRMPSSSLSESSPRPSFWERSHLALDRFRFRGRPYRGGSRWSRGRGVGERGGKPGCRPPLGGGAGSGFSSSQSWREPSPPRKSSKSFGRSPSRKQNYSSKNENCVEETFEDLLLKYKQIQLELECINKDEKLALSSKEENVQEDPKTLNFEDQTSTDNVSITKDSSKEVAPEEKTQVKTFQAFELKPLRQKLTLPGDKNRLKKVKDGAKPLSLKSDTTDSSQGLQDKEQNLTRRISTSDILSEKKLGEDEEELSELQLRLLALQSASKKWQQKEQQVMKESKEKLTKTKTVQQKVKTSTKTHSAKKVSTTAKQALRKQQTKAWKKLQQQKEQERQKEEDQRKQAEEEERRKREEEIRKIRDLSNQEEQYNRFMKLVGGKRRSRSKSSDPDLRRSLDKQPTDSGGGIYQYDNYEEVAMDTDSETSSPAPSPVQPPFFSECSLGYFSPAPSLSLPPPPQVSSLPPLSQPYVEGLCVSLEPLPPLPPLPPLPPEDPEQPPKPPFADEEEEEEMLLREELLKSLANKRAFKPEETSSNSDPPSPPVLNNSHPVPRSNLSIVSINTVSQPRIQNPKFHRGPRLPRTVISLPKHKSVVVTLNDSDDSESDGEASKSTNSVFGGLESMIKEARRTAEQASKPKVPPKSEKENDPLRTPEALPEEKKIEYRLLKEEIANREKQRLIKSDQLKTSSSSPANSDVEIDGIGRIAMVTKQVTDAESKLKKHRILLMKDESVLKNLVQQEAKKKESVRNAEAKITKLTEQLQATEKILNVNRMFLKKLQEQIHRVQQRVTIKKALTLKYGEELARAKAVASKEIGKRKLEQDRFGPNKMMRLDSSPVSSPRKHSAELIAMEKRRLQKLEYEYALKIQKLKEARALKAKEQQNISPVVEEEPEFSLPQPSLHDLTQDKLTLDTEENDVDDEILSGSSRERRRSFLESNYFTKPNLKHTDTANKECINKLNKNTVEKPELFLGLKIGELQKLYSKADSLKQLILKTTTGITEKVLHGQEISVDVDFVTAQSKTMEVKPCPFRPYHSPLLVFKSYRFSPYYRTKEKLPLSSVSYSNMIEPDQCFCRFDLTGTCNDDDCQWQHIQDYTLSRKQLFQDILSYNLSLIGCAETSTNEEITASAEKYVEKLFGVNKDRMSMDQMAVLLVSNINESKGHTPPFTTYKDKRKWKPKFWRKPISDNSFSSDEEQSTGPIKYAFQPENQINVPALDTVVTPDDVRYFTNETDDIANLEASVLENPSHVQLWLKLAYKYLNQNEGECSESLDSALNVLARALENNKDNPEIWCHYLRLFSKRGTKDEVQEMCETAVEYAPDYQSFWTFLHLESTFEEKDYVCERMLEFLMGAAKQETSNILSFQLLEALLFRVQLHIFTGRCQSALAILQNALKSANDGIVAEYLKTSDRCLAWLAYIHLIEFNILPSKFYDPSNDNPSRIVNTESFVMPWQAVQDVKTNPDMLLAVFEDAVKACTDESLAVEERIEACLPLYTNMIALHQLLERYEAAMELCKSLLESCPINCQLLEALVALYLQTNQHDKARAVWLTAFEKNPQNAEVFYHMCKFFILQNRGDNLLPFLRKFIASFFKPGFEKYNNLDLFRYLLNIPGPIDIPSRLCKGNFDDDMFNHQVPYLWLIYCLCHPLQSSIKETVEAYEAALGVAMRCDIVQKIWMDYLVFANNRAAGSRNKVQEFKFFTDLVNRCLVTVPARYPIPFSSADYWSNYEFHNRVIFFYLSCVPKTQHSKTLERFCSVMPANSGLALRLLQHEWEESNVQILKLQAKMFTYNIPTCLATWKIAIAAEIVLKGQREVHRLYQRALQKLPLCASLWKDQLLFEASEGGKTDNLRKLVSKCQEIGVSLNELLNLNSNKTESKNH>sp|O60293-2|ZC3H1_HUMAN Isoform 2 of Zinc finger C3H1 domain-containingprotein OS=Homo sapiens OX=9606 GN=ZFC3H1MATADTPAPASSGLSPKEEGELEDGEISDDDNNSQIRSRSSSSSSGGGLLPYPRRRPPHSARGGGSGGGGGSSSSSSSSQQQLRNFSRSRHASERGHLRGPSSYRPKEPFRSHPPSVRMPSSSLSESSPRPSFWERSHLALDRFRFRGRPYRGGSRWSRGRGVGERGGKPGCRPPLGGGAGSGFSSSQSWREPSPPRKSSKSFGRSPSRKQNYSSKNENCVEETFEDLLLKYKQIQLELECINKDEKLALSSKEENVQEDPKTLNFEDQTSTDNVSITKDSSKEVAPEEKTQVKTFQAFELKPLRQKLTLPGDKNRLKKVKDGAKPLSLKSDTTDSSQGLQDKEQNLTRRISTSDILSEKKLGEDEEELSELQLRLLALQSASKKWQQKEQQVMKESKEKLTKTKTVQQKVKTSTKTHSAKKVSTTAKQALRKQQTKAWKKLQQQKEQERQKEEDQRKQAEEEERRKREEEIRKIRDLSNQEEQYNRFMKLVGGKRRSRSKSSDPDLRRSLDKQPTDSGGGIYQYDNYEEVAMDTDSETSSPAPSPVQPPFFSECSLGYFSPAPSLSLPPPPQVSSLPPLSQPYVEGLCVSLEPLPPLPPLPPLPPEDPEQPPKPPFADEEEEEEMLLREELLKSLANKRAFKPEETSSNSDPPSPPVLNNSHPVPRSNLSIVSINTVSQPRIQNPKFHRGPRLPRTVISLPKHKSVVVTLNDSDDSESDGEASKSTNSVFGGLESMIKEARRTAEQASKPKVPPKSEKENDPLRTPEALPEEKKIEYRLLKEEIANREKQRLIKSDQLKTSSSSPANSDVEIDGIGRIAMVTKQVTDAESKLKKHRILLMKDESVLKNLVQQEAKKKESVRNAEAKITKLTEQLQATEKILNVNRMFLKKLQEQIHRVQQRVTIKKALTLKYGEELARAKAVASKEIGKRKLEQDRFGPNKMMRLDSSPVSSPRKHSAELIAMEKRRLQKLEYEYALKIQKLKEARALKAKEQQNISPVVEEEPEFSLPQPSLHDLTQDKLTLDTEENDVDDEILSGSSRERRRSFLESNYFTKPNLKHTDTANKECINKLNKNTVEKPELFLGLKIGELQKLYSKADSLKQLILKTTTGITEKVLHGQEISVDVDFVTAQSKTMEVKPCPFRPYHSPLLVFKSYRFSPYYRTKEKLPLSSVSYSNMIEPDQCFCRFDLTGTCNDDDCQWQHIQDYTLSRKQLFQDILSYNLSLIGCAETSTNEEITASAEKYVEKLFGVNKDRMSMDQMAVLLVSNINESKGHTPPFTTYKDKRKWKPKFWRKPISDNSFSSDEEQSTGPIKYAFQPENQINVPALDTVVTPDDVRYFTNETDDIANLEASVLENPSHVQLWLKLAYKYLNQNEGECSESLDSALNVLARALENNKDNPEIWCHYLRLFSKRGTKDEVQEMCETAVEYAPDYQSFWTFLHLESTFEEKDYVCERMLEFLMGAAKQETSNILSFQLLEALLFRVQLHIFTGRCQSALAILQNALKSANDGIVAEYLKTSDRCLAWLAYIHLIEFNILPSKFYDPSNDNPSRIVNTESFVMPWQAVQDVKTNPDMLLAVFEDAVKACTDESLAVEERIEACLPLYTNMIALHQLLERYEAAMELCKSLLESCPINCQLLEALVALYLQTNQHDKARAVWLTAFEKNPQNAEVFYHMCKFFILQNRGDNLLPFLRKFIASFFKPGFEKYNNLDLFRYLLNIPGPIDIPSRLCKGNFDDDMFNHQVPYLWLIYCLCHPLQSSIKETVEAYEAALGVAMRCDIVQKIWMDYLVFANNRAAGSRNKVQEFKFFTDLVNRCLVTVPARYPIPFSSADYWSNYEFHNRVIFFYLSCVPKTQHSKTLERFCSVMPANSGLALRLLQHEWEESNVQILKLQAKMFTYNIPTCLATWKM>sp|O60293-4|ZC3H1_HUMAN Isoform 4 of Zinc finger C3H1 domain-containingprotein OS=Homo sapiens OX=9606 GN=ZFC3H1MATADTPAPASSGLSPKEEGELEDGEISDDDNNSQIRSRSSSSSSGGGLLPYPRRRPPHSARGGGSGGGGGSSSSSSSSQQQLRNFSRSRHASERGHLRGPSSYRPKEPFRSHPPSVRMPSSSLSESSPRPSFWERSHLALDRFRFRGRPYRGGSRWSRGRGVGERGGKPGCRPPLGGGAGSGFSSSQSWREPSPPRKSSKSFGRSPSRKQNYSSKNENCVEETFEDLLLKYKQIQLELECINKDEKLALSSKEENVQEDPKTLNFEDQTSTDNVSITKDSSKEVAPEEKTQVKTFQAFELKPLRQKLTLPGDKNRLKKVKDGAKPLSLKSDTTDSSQGNGIKYFS>sp|Q9Y2P0|ZN835_HUMAN Zinc finger protein 835 OS=Homo sapiens OX=9606GN=ZNF835 PE=1 SV=2MEGLLSVALQGAELEGNWKHEGQVEDLQENQESCPEPEAVACKGDPAGDSMQERDEFSRIPRTISSPAATQASVPDDSSSRRCSAPGESPKERHPDSRQRERGGGPKKPWKCGDCGKAFSYCSAFILHQRIHTGEKPFACPECGKAFSQSVHLTLHQRTHTGEKPYACHECGKAFSQGSYLASHWRTHTGEKPHRCADCGKAFTRVTHLTQHRRVHTGERPYACAQCAKAFRNRSSLIEHQRIHTGEKPYECSACAKAFRFSSALIRHQRIHTEEKPYRCGQCAKAFAQIAHLTQHRRVHTGEKPYTCQDCGALFSQSASLAEHRRIHTGEKPYACGQCAKAFTQVSHLTQHQRTHTGERPYPCHDCGKRFSNRSHLLQHRLVHTGERPYRCLQCGAAFSHVSSLIEHQKIHTGERPYKCGECGKAFSQGSSLALHQRTHTGERPYTCPECGKAFSNRSYLIQHHIVHTGEKPYECSGCGKAFSFSSALIRHQRTHADSSGRLCPAPTPDSTPGLSQGGETCQQGCPGRNPRGPAED>sp|A6NHJ4|ZN860_HUMAN Zinc finger protein 860 OS=Homo sapiens OX=9606GN=ZNF860 PE=1 SV=3MLREEAAQKRKEKEPGMALPQGHLTFRDVAIEFSLEEWKCLDPTQRALYRAMMLENYRNLHSVDISSKCMMKKFSSTAQGNTEVDTGTLERHESHHIGDFCFQKIGKDIHDFEFQWQEDKRNSHEATMTQIKKLTGSTDRYDRRHPGNKPIKDQLGLSFHSHLPELHIFQTKGKVGNQVEKSINDASSVLTSQRISSRPKIHISNNYENNFFHSSLLTLKQEVHIREKSFQCNESGKAFNCSSLLRKHQIIYLGGKQYKCDVCGKVFNQKRYLACHHRCHTGEKPYKCNECGKVFNQQSNLASHHRLHTGEKPYKCEECDKVFSRKSNLERHRRIHTGEKPYKCKVCEKAFRRDSHLTQHTRIHTGEKPYKCNECGKAFSGQSTLIHHQAIHGIGKLYKCNDCHKVFSNATTIANHWRIHNEERSYKCNKCGKFFRRRSYLVVHWRTHTGEKPYKCNECGKTFHHNSALVIHKAIHTGEKPYKCNECGKTFRHNSALVIHKAIHTGEKPYKCNECGKVFNQQATLARHHRLHTGEKPYKCEECDTVFSRKSHHETHKRIHTGEKPYKCDDFDEAFSQASSYAKQRRIHMGEKHHKCDDCGKAFTSHSHRIRHQRIHTGQKSYKCHKRGKVFS>sp|Q6ZMY9|ZN517_HUMAN Zinc finger protein 517 OS=Homo sapiens OX=9606GN=ZNF517 PE=2 SV=2MAMALPMPGPQEAVVFEDVAVYFTRIEWSCLAPDQQALYRDVMLENYGNLASLGFLVAKPALISLLEQGEEPGALILQVAEQSVAKASLCTDSRMEAGIMESPLQRKLSRQAGLPGTVWGCLPWGHPVGGHPAPPHPHGGPEDGSDKPTHPRAREHSASPRVLQEDLGRPVGSSAPRYRCVCGKAFRYNSLLLRHQIIHTGAKPFQCTECGKAFKQSSILLRHQLIHTEEKPFQCGECGKAFRQSTQLAAHHRVHTRERPYACGECGKAFSRSSRLLQHQKFHTGEKPFACTECGKAFCRRFTLNEHGRIHSGERPYRCLRCGQRFIRGSSLLKHHRLHAQEGAQDGGVGQGALLGAAQRPQAGDPPHECPVCGRPFRHNSLLLLHLRLHTGEKPFECAECGKAFGRKSNLTLHQKIHTKEKPFACTECGKAFRRSYTLNEHYRLHSGERPYRCRACGRACSRLSTLIQHQKVHGREPGEDTEGRRAPCWAS>sp|O75132|ZBED4_HUMAN Zinc finger BED domain-containing protein 4OS=Homo sapiens OX=9606 GN=ZBED4 PE=1 SV=2MENNLKTCPKEDGDFVSDKIKFKIEEEDDDGIPPDSLERMDFKSEQEDMKQTDSGGERAGLGGTGCSCKPPGKYLSAESEDDYGALFSQYSSTLYDVAMEAVTQSLLSSRNMSSRKKSPAWKHFFISPRDSTKAICMYCVKEFSRGKNEKDLSTSCLMRHVRRAHPTVLIQENGSVSAVSSFPSPSLLLPPQPADAGDLSTILSPIKLVQKVASKIPSPDRITEESVSVVSSEEISSDMSVSEKCGREEALVGSSPHLPALHYDEPAENLAEKSLPLPKSTSGSRRRSAVWKHFYLSPLDNSKAVCIHCMNEFSRGKNGKDLGTSCLIRHMWRAHRAIVLQENGGTGIPPLYSTPPTLLPSLLPPEGELSSVSSSPVKPVRESPSASSSPDRLTEDLQSHLNPGDGLMEDVAAFSSSDDIGEASASSPEKQQADGLSPRLFESGAIFQQNKKVMKRLKSEVWHHFSLAPMDSLKAECRYCGCAISRGKKGDVGTSCLMRHLYRRHPEVVGSQKGFLGASLANSPYATLASAESSSSKLTDLPTVVTKNNQVMFPVNSKKTSKLWNHFSICSADSTKVVCLHCGRTISRGKKPTNLGTSCLLRHLQRFHSNVLKTEVSETARPSSPDTRVPRGTELSGASSFDDTNEKFYDSHPVAKKITSLIAEMIALDLQPYSFVDNVGFNRLLEYLKPQYSLPAPSYFSRTAIPGMYDNVKQIIMSHLKEAESGVIHFTSGIWMSNQTREYLTLTAHWVSFESPARPRCDDHHCSALLDVSQVDCDYSGNSIQKQLECWWEAWVTSTGLQVGITVTDNASIGKTLNEGEHSSVQCFSHTVNLIVSEAIKSQRMVQNLLSLARKICERVHRSPKAKEKLAELQREYALPQHHLIQDVPSKWSTSFHMLERLIEQKRAINEMSVECNFRELISCDQWEVMQSVCRALKPFEAASREMSTQMSTLSQVIPMVHILNRKVEMLFEETMGIDTMLRSLKEAMVSRLSATLHDPRYVFATLLDPRYKASLFTEEEAEQYKQDLIRELELMNSTSEDVAASHRCDAGSPSKDSAAEENLWSLVAKVKKKDPREKLPEAMVLAYLEEEVLEHSCDPLTYWNLKKASWPGLSALAVRFLGCPPSIVPSEKLFNTPTENGSLGQSRLMMEHFEKLIFLKVNLPLIYFQY>sp|Q96N58|ZN578_HUMAN Zinc finger protein 578 OS=Homo sapiens OX=9606GN=ZNF578 PE=1 SV=2MLHEEAAQKRKGKEPGMALPQGRLTFRDVAIEFSLAEWKFLNPAQRALYREVMLENYRNLEAVDISSKRMMKEVLSTGQGNTEVIHTGMLQRHESYHTGDFCFQEIEKDIHDFEFQSQKDERNGHEASMPKIKELMGSTDRHDQRHAGNKPIKDQLGLSFHLHLPELHIFQPEEKIANQVEKSVNDASSISTSQRISCRPETHTPNNYGNNFFHSSLLTQKQEVHMREKSFQCNETGEAFNCSSFVRKHQIIHLGEKQYKFDICGKVFNEKRYLARHRRCHTSEKPYKCNECGKSFSYKSSLTCHRRCHTGEKPYKCNECGKSFSYKSSLTCHHRCHTGEKPYKCNECGKSFSYKSSLRCHRRLHTGIKPYKCNECGKMFGQNSTLVIHKAIHTGEKPYKCNECGKAFNQQSHLSRHHRLHTGEKPYKCNDCGKAFIHQSSLARHHRLHTGEKSYKCEECDRVFSQKSNLERHKIIHTGEKPYKCNECHKTFSHRSSLPCHRRLHSGEKPYKCNECGKTFNVQSHLSRHHRLHTGEKPYKCKVCDKAFMCHSYLANHTRIHSGEKPYKCNECGKAHNHLIDSSIKPCMSS>sp|Q8N587|ZN561_HUMAN Zinc finger protein 561 OS=Homo sapiens OX=9606GN=ZNF561 PE=1 SV=2MAAIYLSRGFFSREPICPFEEKTKVERMVEDYLASGYQDSVTFDDVAVDFTPEEWALLDTTEKYLYRDVMLENYMNLASVEWEIQPRTKRSSLQQGFLKNQIFSGIQMTRGYSGWKLCDCKNCGEVFREQFCLKTHMRVQNGGNTSEGNCYGKDTLSVHKEASTGQELSKFNPCGKVFTLTPGLAVHLEVLNARQPYKCKECGKGFKYFASLDNHMGIHTDEKLCEFQEYGRAVTASSHLKQCVAVHTGKKSKKTKKCGKSFTNFSQLYAPVKTHKGEKSFECKECGRSFRNSSCLNDHIQIHTGIKPHKCTYCGKAFTRSTQLTEHVRTHTGIKPYECKECGQAFAQYSGLSIHIRSHSGKKPYQCKECGKAFTTSTSLIQHTRIHTGEKPYECVECGKTFITSSRRSKHLKTHSGEKPFVCKICGKAFLYSSRLNVHLRTHTGEKPFVCKECGKAFAVSSRLSRHERIHTGEKPYECKDMSVTI>sp|Q8N587-2|ZN561_HUMAN Isoform 2 of Zinc finger protein 561 OS=Homosapiens OX=9606 GN=ZNF561MRVQNGGNTSEGNCYGKDTLSVHKEASTGQELSKFNPCGKVFTLTPGLAVHLEVLNARQPYKCKECGKGFKYFASLDNHMGIHTDEKLCEFQEYGRAVTASSHLKQCVAVHTGKKSKKTKKCGKSFTNFSQLYAPVKTHKGEKSFECKECGRSFRNSSCLNDHIQIHTGIKPHKCTYCGKAFTRSTQLTEHVRTHTGIKPYECKECGQAFAQYSGLSIHIRSHSGKKPYQCKECGKAFTTSTSLIQHTRIHTGEKPYECVECGKTFITSSRRSKHLKTHSGEKPFVCKICGKAFLYSSRLNVHLRTHTGEKPFVCKECGKAFAVSSRLSRHERIHTGEKPYECKDMSVTI>sp|Q15940|ZNF67_HUMAN Putative zinc finger protein 726P1 OS=Homo sapiensOX=9606 GN=ZNF726P1 PE=5 SV=2MLSHKTQHKSIYTREKSYKCKKCGKTFNWSSILTNNKKIHTEQKPYKCEECGKAFKQHSTLTTHKIICAEEKLYRCEECGKAFCQPSTLTRYKRMHRRKKLYKCEECGKAFTQFSTLTKHKRIHTRGKHYKCEESGKAFIWSSGLTEHRRVHTRQKPYKCEECGKALIQFSTLTRHKRIHTGEKPNKSMWQTF>sp|O60688|YPEL1_HUMAN Protein yippee-like 1 OS=Homo sapiens OX=9606GN=YPEL1 PE=3 SV=1MVKMTKSKTFQAYLPNCHRTYSCIHCRAHLANHDELISKSFQGSQGRAYLFNSVVNVGCGPAEERVLLTGLHAVADIYCENCKTTLGWKYEHAFESSQKYKEGKFIIELAHMIKDNGWE>sp|P0C7X5|ZN806_HUMAN Zinc finger protein 806 OS=Homo sapiens OX=9606GN=ZNF806 PE=3 SV=1MIKFQERVTFKDIAVIFTKEELAVLDKAQINLYQDVMLENFRNFISVDGIKNNILNLQGKGLIYLSQEELHCWKIWKQRIRDLSVSQDYIMNLQEQCSPHLEDVSLCEEWAGMSLQISENENYVVNAIIKNQDITAWQSLTQVLTPESWRKANIMTEPQKSQGRYKGIYVEEKLYRHARHDESLNWTSRDHHESQECKGEDPGRHPNCGKNLGMKSTVEQHHAVHVLPQPFTCNNCGVAFADDTDPRVHHSTHLGEKSYKCDQYGKNLSQSQYLIVHCKTHSGETPYEFHEWPTGCKQSSDLPRCQKVPSGDNPYKCKECGKGFRCNSSLHNHHRVHTGEMPYKCHVCGKAFGFRSLPCIHQGVHTGKKPYKCEDCGKGFEQSSNLLIHQRVHTGEKPYKSSECGKCFSSSSVLQVHWRFHTGEKPYRCGECGKGFSQSTHLHIHQRVHTGEKQYNAMCVERILGIVLFFTLIREFTLQKNHINAKCVESALVTVHIFTSIKAITQERNHINVMSVVKASVGIQIFNVHLRVHRGQRPCKCKACGKGFSRNSHLLAQQRVRIDKTQYTHCEHGKDLLTHQRLHEQRETL>sp|Q9NNW5|WDR6_HUMAN WD repeat-containing protein 6 OS=Homo sapiensOX=9606 GN=WDR6 PE=1 SV=1MDALEDYVWPRATSELILLPVTGLECVGDRLLAGEGPDVLVYSLDFGGHLRMIKRVQNLLGHYLIHGFRVRPEPNGDLDLEAMVAVFGSKGLRVVKISWGQGHFWELWRSGLWNMSDWIWDARWLEGNIALALGHNSVVLYDPVVGCILQEVPCTDRCTLSSACLIGDAWKELTIVAGAVSNQLLVWYPATALADNKPVAPDRRISGHVGIIFSMSYLESKGLLATASEDRSVRIWKVGDLRVPGGRVQNIGHCFGHSARVWQVKLLENYLISAGEDCVCLVWSHEGEILQAFRGHQGRGIRAIAAHERQAWVITGGDDSGIRLWHLVGRGYRGLGVSALCFKSRSRPGTLKAVTLAGSWRLLAVTDTGALYLYDVEVKCWEQLLEDKHFQSYCLLEAAPGPEGFGLCAMANGEGRVKVVPINTPTAAVDQTLFPGKVHSLSWALRGYEELLLLASGPGGVVACLEISAAPSGKAIFVKERCRYLLPPSKQRWHTCSAFLPPGDFLVCGDRRGSVLLFPSRPGLLKDPGVGGKARAGAGAPVVGSGSSGGGNAFTGLGPVSTLPSLHGKQGVTSVTCHGGYVYTTGRDGAYYQLFVRDGQLQPVLRQKSCRGMNWLAGLRIVPDGSMVILGFHANEFVVWNPRSHEKLHIVNCGGGHRSWAFSDTEAAMAFAYLKDGDVMLYRALGGCTRPHVILREGLHGREITCVKRVGTITLGPEYGVPSFMQPDDLEPGSEGPDLTDIVITCSEDTTVCVLALPTTTGSAHALTAVCNHISSVRAVAVWGIGTPGGPQDPQPGLTAHVVSAGGRAEMHCFSIMVTPDPSTPSRLACHVMHLSSHRLDEYWDRQRNRHRMVKVDPETRYMSLAVCELDQPGLGPLVAAACSDGAVRLFLLQDSGRILQLLAETFHHKRCVLKVHSFTHEAPNQRRRLLLCSAATDGSLAFWDLTTMLDHDSTVLEPPVDPGLPYRLGTPSLTLQAHSCGINSLHTLPTREGHHLVASGSEDGSLHVFVLAVEMLQLEEAVGEAGLVPQLRVLEEYSVPCAHAAHVTGLKILSPSIMVSASIDQRLTFWRLGHGEPTFMNSTVFHVPDVADMDCWPVSPEFGHRCALGGQGLEVYNWYD>sp|Q96FK6|WDR89_HUMAN WD repeat-containing protein 89 OS=Homo sapiensOX=9606 GN=WDR89 PE=2 SV=1MEKIEEQFANLHIVKCSLGTKEPTYLLGIDTSKTVQAGKENLVAVLCSNGSIRIYDKERLNVLREFSGYPGLLNGVRFANSCDSVYSACTDGTVKCWDARVAREKPVQLFKGYPSNIFISFDINCNDHIICAGTEKVDDDALLVFWDARMNSQNLSTTKDSLGAYSETHSDDVTQVRFHPSNPNMVVSGSSDGLVNVFDINIDNEEDALVTTCNSISSVSCIGWSGKGYKQIYCMTHDEGFYWWDLNHLDTDEPVTRLNIQDVREVVNMKEDALDYLIGGLYHEKTDTLHVIGGTNKGRIHLMNCSMSGLTHVTSLQGGHAATVRSFCWNVQDDSLLTGGEDAQLLLWKPGAIEKTFTKKESMKIASSVHQRVRVHSNDSYKRRKKQ>sp|Q86Y07|VRK2_HUMAN Serine/threonine-protein kinase VRK2 OS=Homosapiens OX=9606 GN=VRK2 PE=1 SV=3MPPKRNEKYKLPIPFPEGKVLDDMEGNQWVLGKKIGSGGFGLIYLAFPTNKPEKDARHVVKVEYQENGPLFSELKFYQRVAKKDCIKKWIERKQLDYLGIPLFYGSGLTEFKGRSYRFMVMERLGIDLQKISGQNGTFKKSTVLQLGIRMLDVLEYIHENEYVHGDIKAANLLLGYKNPDQVYLADYGLSYRYCPNGNHKQYQENPRKGHNGTIEFTSLDAHKGVALSRRSDVEILGYCMLRWLCGKLPWEQNLKDPVAVQTAKTNLLDELPQSVLKWAPSGSSCCEIAQFLVCAHSLAYDEKPNYQALKKILNPHGIPLGPLDFSTKGQSINVHTPNSQKVDSQKAATKQVNKAHNRLIEKKVHSERSAESCATWKVQKEEKLIGLMNNEAAQESTRRRQKYQESQEPLNEVNSFPQKISYTQFPNSFYEPHQDFTSPDIFKKSRSPSWYKYTSTVSTGITDLESSTGLWPTISQFTLSEETNADVYYYRIIIPVLLMLVFLALFFL>sp|Q86Y07-2|VRK2_HUMAN Isoform 2 of Serine/threonine-protein kinase VRK2OS=Homo sapiens OX=9606 GN=VRK2MPPKRNEKYKLPIPFPEGKVLDDMEGNQWVLGKKIGSGGFGLIYLAFPTNKPEKDARHVVKVEYQENGPLFSELKFYQRVAKKDCIKKWIERKQLDYLGIPLFYGSGLTEFKGRSYRFMVMERLGIDLQKISGQNGTFKKSTVLQLGIRMLDVLEYIHENEYVHGDIKAANLLLGYKNPDQVYLADYGLSYRYCPNGNHKQYQENPRKGHNGTIEFTSLDAHKGVALSRRSDVEILGYCMLRWLCGKLPWEQNLKDPVAVQTAKTNLLDELPQSVLKWAPSGSSCCEIAQFLVCAHSLAYDEKPNYQALKKILNPHGIPLGPLDFSTKGQSINVHTPNSQKVDSQKAATKQVNKAHNRLIEKKVHSERSAESCATWKVQKEEKLIGLMNNEAAQVEA>sp|Q86Y07-3|VRK2_HUMAN Isoform 3 of Serine/threonine-protein kinase VRK2OS=Homo sapiens OX=9606 GN=VRK2MEGNQWVLGKKIGSGGFGLIYLAFPTNKPEKDARHVVKVEYQENGPLFSELKFYQRVAKKDCIKKWIERKQLDYLGIPLFYGSGLTEFKGRSYRFMVMERLGIDLQKISGQNGTFKKSTVLQLGIRMLDVLEYIHENEYVHGDIKAANLLLGYKNPDQVYLADYGLSYRYCPNGNHKQYQENPRKGHNGTIEFTSLDAHKGVALSRRSDVEILGYCMLRWLCGKLPWEQNLKDPVAVQTAKTNLLDELPQSVLKWAPSGSSCCEIAQFLVCAHSLAYDEKPNYQALKKILNPHGIPLGPLDFSTKGQSINVHTPNSQKVDSQKAATKQVNKAHNRLIEKKVHSERSAESCATWKVQKEEKLIGLMNNEAAQESTRRRQKYQESQEPLNEVNSFPQKISYTQFPNSFYEPHQDFTSPDIFKKSRSPSWYKYTSTVSTGITDLESSTGLWPTISQFTLSEETNADVYYYRIIIPVLLMLVFLALFFL>sp|Q86Y07-4|VRK2_HUMAN Isoform 4 of Serine/threonine-protein kinase VRK2OS=Homo sapiens OX=9606 GN=VRK2MVMERLGIDLQKISGQNGTFKKSTVLQLGIRMLDVLEYIHENEYVHGDIKAANLLLGYKNPDQVYLADYGLSYRYCPNGNHKQYQENPRKGHNGTIEFTSLDAHKGVALSRRSDVEILGYCMLRWLCGKLPWEQNLKDPVAVQTAKTNLLDELPQSVLKWAPSGSSCCEIAQFLVCAHSLAYDEKPNYQALKKILNPHGIPLGPLDFSTKGQSINVHTPNSQKVDSQKAATKQVNKAHNRLIEKKVHSERSAESCATWKVQKEEKLIGLMNNEAAQESTRRRQKYQESQEPLNEVNSFPQKISYTQFPNSFYEPHQDFTSPDIFKKSRSPSWYKYTSTVSTGITDLESSTGLWPTISQFTLSEETNADVYYYRIIIPVLLMLVFLALFFL>sp|Q86Y07-5|VRK2_HUMAN Isoform 5 of Serine/threonine-protein kinase VRK2OS=Homo sapiens OX=9606 GN=VRK2MPPKRNEKYKLPIPFPEGKVLDDMEGNQWVLGKKIGSGGFGLIYLAFPTNKPEKDARHVVKVEYQENGPLFSELKFYQRVAKKDCIKKWIERKQLDYLGIPLFYGSGLTEFKGRSYRFMVMERLGIDLQKISGQNGTFKKSTVLQLGIRMLDVLEYIHENEYVHGDIKAANLLLGYKNPDQVYLADYGLSYRYCPNGNHKQYQENPRKGHNGTIEFTSLDAHKGVALSRRSDVEILGYCMLRWLCGKLPWEQNLKDPVAVQTAKTNLLDELPQSVLKWAPSGSSCCEIAQFLVCAHSLAYDEKPNYQALKKILNPHGIPLGPLDFSTKGQSINVHTPNSQKVDSQKAATKQVNKAHNRLIEKKVHSERSAESCATWKVQKEEKLIGLMNNEAAQFR>sp|Q7Z3J2|VP35L_HUMAN VPS35 endosomal protein-sorting factor-likeOS=Homo sapiens OX=9606 GN=VPS35L PE=1 SV=2MAVFPWHSRNRNYKAEFASCRLEAVPLEFGDYHPLKPITVTESKTKKVNRKGSTSSTSSSSSSSVVDPLSSVLDGTDPLSMFAATADPAALAAAMDSSRRKRDRDDNSVVGSDFEPWTNKRGEILARYTTTEKLSINLFMGSEKGKAGTATLAMSEKVRTRLEELDDFEEGSQKELLNLTQQDYVNRIEELNQSLKDAWASDQKVKALKIVIQCSKLLSDTSVIQFYPSKFVLITDILDTFGKLVYERIFSMCVDSRSVLPDHFSPENANDTAKETCLNWFFKIASIRELIPRFYVEASILKCNKFLSKTGISECLPRLTCMIRGIGDPLVSVYARAYLCRVGMEVAPHLKETLNKNFFDFLLTFKQIHGDTVQNQLVVQGVELPSYLPLYPPAMDWIFQCISYHAPEALLTEMMERCKKLGNNALLLNSVMSAFRAEFIATRSMDFIGMIKECDESGFPKHLLFRSLGLNLALADPPESDRLQILNEAWKVITKLKNPQDYINCAEVWVEYTCKHFTKREVNTVLADVIKHMTPDRAFEDSYPQLQLIIKKVIAHFHDFSVLFSVEKFLPFLDMFQKESVRVEVCKCIMDAFIKHQQEPTKDPVILNALLHVCKTMHDSVNALTLEDEKRMLSYLINGFIKMVSFGRDFEQQLSFYVESRSMFCNLEPVLVQLIHSVNRLAMETRKVMKGNHSRKTAAFVRACVAYCFITIPSLAGIFTRLNLYLHSGQVALANQCLSQADAFFKAAISLVPEVPKMINIDGKMRPSESFLLEFLCNFFSTLLIVPDHPEHGVLFLVRELLNVIQDYTWEDNSDEKIRIYTCVLHLLSAMSQETYLYHIDKVDSNDSLYGGDSKFLAENNKLCETVMAQILEHLKTLAKDEALKRQSSLGLSFFNSILAHGDLRNNKLNQLSVNLWHLAQRHGCADTRTMVKTLEYIKKQSKQPDMTHLTELALRLPLQTRT>sp|Q7Z3J2-2|VP35L_HUMAN Isoform 2 of VPS35 endosomal protein-sortingfactor-like OS=Homo sapiens OX=9606 GN=VPS35LMPPLGVLVHEKSHLCDVNSFCLGKAGTATLAMSEKVRTRLEELDDFEEGSQKELLNLTQQDYVNRIEELNQSLKDAWASDQKVKALKIVIQEELVYERIFSMCVDSRSVLPDHFSPENANDTAKETCLNWFFKIASIRELIPRFYVEASILKCNKFLSKTGISECLPRLTCMIRGIGDPLVSVYARAYLCRVGMEVAPHLKETLNKNFFDFLLTFKQIHGDTVQNQLVVQGVELPSYLPLYPPAMDWIFQCISYHAPEALLTEMMERCKKLGNNALLLNSVMSAFRAEFIATRSMDFIGMIKECDESGFPKHLLFRSLGLNLALADPPESDRLQILNEAWKVITKLKNPQDYINCAEVWVEYTCKHFTKREVNTVLADVIKHMTPDRAFEDSYPQLQLIIKKVIAHFHDFSVLFSVEKFLPFLDMFQKESVRVEVCKCIMDAFIKHQQEPTKDPVILNALLHVCKTMHDSVNALTLEDEKRMLSYLINGFIKMVSFGRDFEQQLSFYVESRSMFCNLEPVLVQLIHSVNRLAMETRKVMKGNHSRKTAAFVRACVAYCFITIPSLAGIFTRLNLYLHSGQVALANQCLSQADAFFKAAISLVPEVPKMINIDGKMRPSESFLLEFLCNFFSTLLIVPDHPEHGVLFLVRELLNVIQDYTWEDNSDEKIRIYTCVLHLLSAMSQETYLYHIDKVDSNDSLYGGDSKFLAENNKLCETVMAQILEHLKTLAKDEALKRQSSLGLSFFNSILAHGDLRNNKLNQLSVNLWHLAQRHGCADTRTMVKTLEYIKKQSKQPDMTHLTELALRLPLQTRT>sp|O15498|YKT6_HUMAN Synaptobrevin homolog YKT6 OS=Homo sapiens OX=9606GN=YKT6 PE=1 SV=1MKLYSLSVLYKGEAKVVLLKAAYDVSSFSFFQRSSVQEFMTFTSQLIVERSSKGTRASVKEQDYLCHVYVRNDSLAGVVIADNEYPSRVAFTLLEKVLDEFSKQVDRIDWPVGSPATIHYPALDGHLSRYQNPREADPMTKVQAELDETKIILHNTMESLLERGEKLDDLVSKSEVLGTQSKAFYKTARKQNSCCAIM>sp|O15498-2|YKT6_HUMAN Isoform 2 of Synaptobrevin homolog YKT6 OS=Homosapiens OX=9606 GN=YKT6MKLYSLSVLYKGEAKVVLLKAAYDVSSFSFFQRSSVQEFMTFTSQLIVERSSKGTRASVKEQDYLCHVYVRNDSLAGVVIADNEYPSRVAFTLLEKVLDEFSKQVDRIDWPVGSPATIHYPALDGHLSRYQNPREADPMTKVQAELDETKIILARKQNSCCAIM>sp|Q9UI72|YE014_HUMAN Putative uncharacterized protein PRO0255 OS=Homosapiens OX=9606 GN=PRO0255 PE=5 SV=1MGMALELYWLCGFRSYWPLGTNAENEGNRKENRRQMQSRNERGCNVRQTKTYRDREADRHIHGIACLLF>sp|Q8NBF4|YG006_HUMAN Putative uncharacterized protein FLJ33307 OS=Homosapiens OX=9606 PE=5 SV=1MQLLQVRTTNTLRRLPGTPLMPSAGAVRVVASVQSGHSWWRMWDGPTGAAEAGSCAEMLRTSAPGTSRPNLSFLLGQVIPLAHTGSVETLPSEESWGCRQRASPLPPSTAPMAVSASHRGGTGTRTWLVDPTLSRDTSPLGGQSWGSPQPSRGA>sp|O95405|ZFYV9_HUMAN Zinc finger FYVE domain-containing protein 9OS=Homo sapiens OX=9606 GN=ZFYVE9 PE=1 SV=2MENYFQAEAYNLDKVLDEFEQNEDETVSSTLLDTKWNKILDPPSHRLSFNPTLASVNESAVSNESQPQLKVFSLAHSAPLTTEEEDHCANGQDCNLNPEIATMWIDENAVAEDQLIKRNYSWDDQCSAVEVGEKKCGNLACLPDEKNVLVVAVMHNCDKRTLQNDLQDCNNYNSQSLMDAFSCSLDNENRQTDQFSFSINESTEKDMNSEKQMDPLNRPKTEGRSVNHLCPTSSDSLASVCSPSQLKDDGSIGRDPSMSAITSLTVDSVISSQGTDGCPAVKKQENYIPDEDLTGKISSPRTDLGSPNSFSHMSEGILMKKEPAEESTTEESLRSGLPLLLKPDMPNGSGRNNDCERCSDCLVPNEVRADENEGYEHEETLGTTEFLNMTEHFSESQDMTNWKLTKLNEMNDSQVNEEKEKFLQISQPEDTNGDSGGQCVGLADAGLDLKGTCISESEECDFSTVIDTPAANYLSNGCDSYGMQDPGVSFVPKTLPSKEDSVTEEKEIEESKSECYSNIYEQRGNEATEGSGLLLNSTGDLMKKNYLHNFCSQVPSVLGQSSPKVVASLPSISVPFGGARPKQPSNLKLQIPKPLSDHLQNDFPANSGNNTKNKNDILGKAKLGENSATNVCSPSLGNISNVDTNGEHLESYEAEISTRPCLALAPDSPDNDLRAGQFGISARKPFTTLGEVAPVWVPDSQAPNCMKCEARFTFTKRRHHCRACGKVFCASCCSLKCKLLYMDRKEARVCVICHSVLMNAQAWENMMSASSQSPNPNNPAEYCSTIPPLQQAQASGALSSPPPTVMVPVGVLKHPGAEVAQPREQRRVWFADGILPNGEVADAAKLTMNGTSSAGTLAVSHDPVKPVTTSPLPAETDICLFSGSITQVGSPVGSAMNLIPEDGLPPILISTGVKGDYAVEEKPSQISVMQQLEDGGPDPLVFVLNANLLSMVKIVNYVNRKCWCFTTKGMHAVGQSEIVILLQCLPDEKCLPKDIFNHFVQLYRDALAGNVVSNLGHSFFSQSFLGSKEHGGFLYVTSTYQSLQDLVLPTPPYLFGILIQKWETPWAKVFPIRLMLRLGAEYRLYPCPLFSVRFRKPLFGETGHTIMNLLADFRNYQYTLPVVQGLVVDMEVRKTSIKIPSNRYNEMMKAMNKSNEHVLAGGACFNEKADSHLVCVQNDDGNYQTQAISIHNQPRKVTGASFFVFSGALKSSSGYLAKSSIVEDGVMVQITAENMDSLRQALREMKDFTITCGKADAEEPQEHIHIQWVDDDKNVSKGVVSPIDGKSMETITNVKIFHGSEYKANGKVIRWTEVFFLENDDQHNCLSDPADHSRLTEHVAKAFCLALCPHLKLLKEDGMTKLGLRVTLDSDQVGYQAGSNGQPLPSQYMNDLDSALVPVIHGGACQLSEGPVVMELIFYILENIV>sp|O95405-2|ZFYV9_HUMAN Isoform 2 of Zinc finger FYVE domain-containingprotein 9 OS=Homo sapiens OX=9606 GN=ZFYVE9MENYFQAEAYNLDKVLDEFEQNEDETVSSTLLDTKWNKILDPPSHRLSFNPTLASVNESAVSNESQPQLKVFSLAHSAPLTTEEEDHCANGQDCNLNPEIATMWIDENAVAEDQLIKRNYSWDDQCSAVEVGEKKCGNLACLPDEKNVLVVAVMHNCDKRTLQNDLQDCNNYNSQSLMDAFSCSLDNENRQTDQFSFSINESTEKDMNSEKQMDPLNRPKTEGRSVNHLCPTSSDSLASVCSPSQLKDDGSIGRDPSMSAITSLTVDSVISSQGTDGCPAVKKQENYIPDEDLTGKISSPRTDLGSPNSFSHMSEGILMKKEPAEESTTEESLRSGLPLLLKPDMPNGSGRNNDCERCSDCLVPNEVRADENEGYEHEETLGTTEFLNMTEHFSESQDMTNWKLTKLNEMNDSQVNEEKEKFLQISQPEDTNGDSGGQCVGLADAGLDLKGTCISESEECDFSTVIDTPAANYLSNGCDSYGMQDPGVSFVPKTLPSKEDSVTEEKEIEESKSECYSNIYEQRGNEATEGSGLLLNSTGDLMKKNYLHNFCSQVPSVLGQSSPKVVASLPSISVPFGGARPKQPSNLKLQIPKPLSDHLQNDFPANSGNNTKNKNDILGKAKLGENSATNVCSPSLGNISNVDTNGEHLESYEAEISTRPCLALAPDSPDNDLRAGQFGISARKPFTTLGEVAPVWVPDSQAPNCMKCEARFTFTKRRHHCRACGKVFCASCCSLKCKLLYMDRKEARVCVICHSVLMNVAQPREQRRVWFADGILPNGEVADAAKLTMNGTSSAGTLAVSHDPVKPVTTSPLPAETDICLFSGSITQVGSPVGSAMNLIPEDGLPPILISTGVKGDYAVEEKPSQISVMQQLEDGGPDPLVFVLNANLLSMVKIVNYVNRKCWCFTTKGMHAVGQSEIVILLQCLPDEKCLPKDIFNHFVQLYRDALAGNVVSNLGHSFFSQSFLGSKEHGGFLYVTSTYQSLQDLVLPTPPYLFGILIQKWETPWAKVFPIRLMLRLGAEYRLYPCPLFSVRFRKPLFGETGHTIMNLLADFRNYQYTLPVVQGLVVDMEVRKTSIKIPSNRYNEMMKAMNKSNEHVLAGGACFNEKADSHLVCVQNDDGNYQTQAISIHNQPRKVTGASFFVFSGALKSSSGYLAKSSIVEDGVMVQITAENMDSLRQALREMKDFTITCGKADAEEPQEHIHIQWVDDDKNVSKGVVSPIDGKSMETITNVKIFHGSEYKANGKVIRWTEVFFLENDDQHNCLSDPADHSRLTEHVAKAFCLALCPHLKLLKEDGMTKLGLRVTLDSDQVGYQAGSNGQPLPSQYMNDLDSALVPVIHGGACQLSEGPVVMELIFYILENIV>sp|O95405-3|ZFYV9_HUMAN Isoform 3 of Zinc finger FYVE domain-containingprotein 9 OS=Homo sapiens OX=9606 GN=ZFYVE9MENYFQAEAYNLDKVLDEFEQNEDETVSSTLLDTKWNKILDPPSHRLSFNPTLASVNESAVSNESQPQLKVFSLAHSAPLTTEEEDHCANGQDCNLNPEIATMWIDENAVAEDQLIKRNYSWDDQCSAVEVGEKKCGNLACLPDEKNVLVVAVMHNCDKRTLQNDLQDCNNYNSQSLMDAFSCSLDNENRQTDQFSFSINESTEKDMNSEKQMDPLNRPKTEGRSVNHLCPTSSDSLASVCSPSQLKDDGSIGRDPSMSAITSLTVDSVISSQGTDGCPAVKKQENYIPDEDLTGKISSPRTDLGSPNSFSHMSEGILMKKEPAEESTTEESLRSGLPLLLKPDMPNGSGRNNDCERCSDCLVPNEVRADENEGYEHEETLGTTEFLNMTEHFSESQDMTNWKLTKLNEMNDSQVNEEKEKFLQISQPEDTNGDSGGQCVGLADAGLDLKGTCISESEECDFSTVIDTPAANYLSNGCDSYGMQDPGVSFVPKTLPSKEDSVTEEKEIEESKSECYSNIYEQRGNEATEGSGLLLNSTGDLMKKNYLHNFCSQVPSVLGQSSPKVVASLPSISVPFGGARPKQPSNLKLQIPKPLSDHLQNDFPANSGNNTKNKNDILGKAKLGENSATNVCSPSLGNISNVDTNGEHLESYEAEISTRPCLALAPDSPDNDLRAGQFGISARKPFTTLGEVAPVWVPDSQAPNCMKCEARFTFTKRRHHCRACGKVFCASCCSLKCKLLYMDRKEARVCVICHSVLMNGKY>sp|Q9H8V8|YD018_HUMAN Putative uncharacterized protein FLJ13197 OS=Homosapiens OX=9606 PE=5 SV=1MKPDWPRRGAAGTRVRSRGEGDGTYFARRGAGRRRREIKAPIRAAWSPPSAAMSGLQSGRRWRPQGTGTGARAAGALAALRLGPRLRAAPLLAPLWLLAPTPDSHMTPAPLALRASRGWRENNLSDYQYSWMQKC>sp|Q9NUA8|ZBT40_HUMAN Zinc finger and BTB domain-containing protein 40OS=Homo sapiens OX=9606 GN=ZBTB40 PE=1 SV=4MELPNYSRQLLQQLYTLCKEQQFCDCTISIGTIYFRAHKLVLAAASLLFKTLLDNTDTISIDASVVSPEEFALLLEMMYTGKLPVGKHNFSKIISLADSLQMFDVAVSCKNLLTSLVNCSVQGQVVRDVSAPSSETFRKEPEKPQVEILSSEGAGEPHSSPELAATPGGPVKAETEEAAHSVSQEMSVNSPTAQESQRNAETPAETPTTAEACSPSPAVQTFSEAKKTSTEPGCERKHYQLNFLLENEGVFSDALMVTQDVLKKLEMCSEIKGPQKEMIVKCFEGEGGHSAFQRILGKVREESLDVQTVVSLLRLYQYSNPAVKTALLDRKPEDVDTVQPKGSTEEGKTLSVLLLEHKEDLIQCVTQLRPIMESLETAKEEFLTGTEKRVILNCCEGRTPKETIENLLHRMTEEKTLTAEGLVKLLQAVKTTFPNLGLLLEKLQKSATLPSTTVQPSPDDYGTELLRRYHENLSEIFTDNQILLKMISHMTSLAPGEREVMEKLVKRDSGSGGFNSLISAVLEKQTLSATAIWQLLLVVQETKTCPLDLLMEEIRREPGADAFFRAVTTPEHATLETILRHNQLILEAIQQKIEYKLFTSEEEHLAETVKEILSIPSETASPEASLRAVLSRAMEKSVPAIEICHLLCSVHKSFPGLQPVMQELAYIGVLTKEDGEKETWKVSNKFHLEANNKEDEKAAKEDSQPGEQNDQGETGSLPGQQEKEASASPDPAKKSFICKACDKSFHFYCRLKVHMKRCRVAKSKQVQCKECSETKDSKKELDKHQLEAHGAGGEPDAPKKKKKRLPVTCDLCGREFAHASGMQYHKLTEHFDEKPFSCEECGAKFAANSTLKNHLRLHTGDRPFMCKHCLMTFTQASALAYHTKKKHSEGKMYACQYCDAVFAQSIELSRHVRTHTGDKPYVCRDCGKGFRQANGLSIHLHTFHNIEDPYDCKKCRMSFPTLQDHRKHIHEVHSKEYHPCPTCGKIFSAPSMLERHVVTHVGGKPFSCGICNKAYQQLSGLWYHNRTHHPDVFAAQNHRSSKFSSLQCSSCDKTFPNTIEHKKHIKAEHADMKFHECDQCKELFPTPALLQVHVKCQHSGSQPFRCLYCAATFRFPGALQHHVTTEHFKQSETTFPCELCGELFTSQAQLDSHLESEHPKVMSTETQAAASQMAQVIQTPEPVAPTEQVITLEETQLAGSQVFVTLPDSQASQASSELVAVTVEDLLDGTVTLICGEAK>sp|Q9NUA8-2|ZBT40_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 40 OS=Homo sapiens OX=9606 GN=ZBTB40MELPNYSRQLLQQLYTLCKEQQFCDCTISIGTIYFRAHKLVLAAASLLFKTLLDNTDTISIDASVVSPEEFALLLEMMYTGKLPVGKHNFSKIISLADSLQMFDVAVSCKNLLTSLAATPGGPVKAETEEAAHSVSQEMSVNSPTAQESQRNAETPAETPTTAEACSPSPAVQTFSEAKKTSTEPGCERKHYQLNFLLENEGVFSDALMVTQDVLKKLEMCSNCCVPVEAVPIF>sp|Q9UK11|ZN223_HUMAN Zinc finger protein 223 OS=Homo sapiens OX=9606GN=ZNF223 PE=1 SV=2MTMSKEAVTFKDVAVVFTEEELGLLDLAQRKLYRDVMLENFRNLLSVGHQPFHRDTFHFLREEKFWMMDIATQREGNSGGKIQPEMKTFPEAGPHEGWSCQQIWEEIASDLTRPQDSTIKSSQFFEQGDAHSQVEEGLSIMHTGQKPSNCGKCKQSFSDMSIFDLPQQIRSAEKSHSCDECGKSFCYISALHIHQRVHLGEKLFKCDVCGKEFSQSLHLQTHQRVHTGEKPFKCEQCGRGFRCRSALTVHCKLHMGEKHYNCEACGRAFIHDFQLQKHQRIHTGEKPFKCEICSVSFRLRSSLNRHCVVHTGKKPNSTGEYGKGFIRRLDLCKHQTIHTGEKPYNCKECGKSFRRSSYLLIHQRVHTGEKPYKCDKCGKSYITKSGLDLHHRAHTGERPYNCDDCGKSFRQASSILNHKRLHCRKKPFKCEDCGKKLVYRSYRKDQQKNHSGENPSKCEDCGKRYKRRLNLDIILSLFLNDT>sp|Q9C0D7|ZC12C_HUMAN Probable ribonuclease ZC3H12C OS=Homo sapiensOX=9606 GN=ZC3H12C PE=1 SV=2MPGGGSQEYGVLCIQEYRKNSKVESSTRNNFMGLKDHLGHDLGHLYVESTDPQLSPAVPWSTVENPSMDTVNVGKDEKEASEENASSGDSEENTNSDHESEQLGSISVEPGLITKTHRQLCRSPCLEPHILKRNEILQDFKPEESQTTSKEAKKPPDVVREYQTKLEFALKLGYSEEQVQLVLNKLGTDALINDILGELVKLGNKSEADQTVSTINTITRETSSLESQRSESPMQEIVTDDGENLRPIVIDGSNVAMSHGNKEVFSCRGIKLAVDWFLERGHKDITVFVPAWRKEQSRPDALITDQEILRKLEKEKILVFTPSRRVQGRRVVCYDDRFIVKLAFESDGIIVSNDNYRDLANEKPEWKKFIDERLLMYSFVNDKFMPPDDPLGRHGPSLDNFLRKKPIVPEHKKQPCPYGKKCTYGHKCKYYHPERGSQPQRSVADELRAMSRNTAAKTANEGGLVKSNSVPCSTKADSTSDVKRGAPKRQSDPSIRTQVYQDLEEKLPTKNKLETRSVPSLVSIPATSTAKPQSTTSLSNGLPSGVHFPPQDQRPQGQYPSMMMATKNHGTPMPYEQYPKCDSPVDIGYYSMLNAYSNLSLSGPRSPERRFSLDTDYRISSVASDCSSEGSMSCGSSDSYVGYNDRSYVSSPDPQLEENLKCQHMHPHSRLNPQPFLQNFHDPLTRGQSYSHEEPKFHHKPPLPHLALHLPHSAVGARSSCPGDYPSPPSSAHSKAPHLGRSLVATRIDSISDSRLYDSSPSRQRKPYSRQEGLGSWERPGYGIDAYGYRQTYSLPDNSTQPCYEQFTFQSLPEQQEPAWRIPYCGMPQDPPRYQDNREKIYINLCNIFPPDLVRIVMKRNPHMTDAQQLAAAILVEKSQLGY>sp|Q9C0D7-2|ZC12C_HUMAN Isoform 2 of Probable ribonuclease ZC3H12COS=Homo sapiens OX=9606 GN=ZC3H12CMSLYFPANEYGVLCIQEYRKNSKVESSTRNNFMGLKDHLGHDLGHLYVESTDPQLSPAVPWSTVENPSMDTVNVGKDEKEASEENASSGDSEENTNSDHESEQLGSISVEPGLITKTHRQLCRSPCLEPHILKRNEILQDFKPEESQTTSKEAKKPPDVVREYQTKLEFALKLGYSEEQVQLVLNKLGTDALINDILGELVKLGNKSEADQTVSTINTITRETSSLESQRSESPMQEIVTDDGENLRPIVIDGSNVAMSHGNKEVFSCRGIKLAVDWFLERGHKDITVFVPAWRKEQSRPDALITDQEILRKLEKEKILVFTPSRRVQGRRVVCYDDRFIVKLAFESDGIIVSNDNYRDLANEKPEWKKFIDERLLMYSFVNDKFMPPDDPLGRHGPSLDNFLRKKPIVPEHKKQPCPYGKKCTYGHKCKYYHPERGSQPQRSVADELRAMSRNTAAKTANEGGLVKSNSVPCSTKADSTSDVKRGAPKRQSDPSIRTQVYQDLEEKLPTKNKLETRSVPSLVSIPATSTAKPQSTTSLSNGLPSGVHFPPQDQRPQGQYPSMMMATKNHGTPMPYEQYPKCDSPVDIGYYSMLNAYSNLSLSGPRSPERRFSLDTDYRISSVASDCSSEGSMSCGSSDSYVGYNDRSYVSSPDPQLEENLKCQHMHPHSRLNPQPFLQNFHDPLTRGQSYSHEEPKFHHKPPLPHLALHLPHSAVGARSSCPGDYPSPPSSAHSKAPHLGRSLVATRIDSISDSRLYDSSPSRQRKPYSRQEGLGSWERPGYGIDAYGYRQTYSLPDNSTQPCYEQFTFQSLPEQQEPAWRIPYCGMPQDPPRYQDNREKIYINLCNIFPPDLVRIVMKRNPHMTDAQQLAAAILVEKSQLGY>sp|Q9UQR1|ZN148_HUMAN Zinc finger protein 148 OS=Homo sapiens OX=9606GN=ZNF148 PE=1 SV=2MNIDDKLEGLFLKCGGIDEMQSSRTMVVMGGVSGQSTVSGELQDSVLQDRSMPHQEILAADEVLQESEMRQQDMISHDELMVHEETVKNDEEQMETHERLPQGLQYALNVPISVKQEITFTDVSEQLMRDKKQIREPVDLQKKKKRKQRSPAKILTINEDGSLGLKTPKSHVCEHCNAAFRTNYHLQRHVFIHTGEKPFQCSQCDMRFIQKYLLQRHEKIHTGEKPFRCDECGMRFIQKYHMERHKRTHSGEKPYQCEYCLQYFSRTDRVLKHKRMCHENHDKKLNRCAIKGGLLTSEEDSGFSTSPKDNSLPKKKRQKTEKKSSGMDKESALDKSDLKKDKNDYLPLYSSSTKVKDEYMVAEYAVEMPHSSVGGSHLEDASGEIHPPKLVLKKINSKRSLKQPLEQNQTISPLSTYEESKVSKYAFELVDKQALLDSEGNADIDQVDNLQEGPSKPVHSSTNYDDAMQFLKKKRYLQAASNNSREYALNVGTIASQPSVTQAAVASVIDESTTASILESQALNVEIKSNHDKNVIPDEVLQTLLDHYSHKANGQHEISFSVADTEVTSSISINSSEVPEVTPSENVGSSSQASSSDKANMLQEYSKFLQQALDRTSQNDAYLNSPSLNFVTDNQTLPNQPAFSSIDKQVYATMPINSFRSGMNSPLRTTPDKSHFGLIVGDSQHSFPFSGDETNHASATSTQDFLDQVTSQKKAEAQPVHQAYQMSSFEQPFRAPYHGSRAGIATQFSTANGQVNLRGPGTSAEFSEFPLVNVNDNRAGMTSSPDATTGQTFG>sp|Q9UQR1-2|ZN148_HUMAN Isoform 2 of Zinc finger protein 148 OS=Homosapiens OX=9606 GN=ZNF148MRFIQKYLLQRHEKIHTGEKPFRCDECGDETNHASATSTQDFLDQVTSQKKAEAQPVHQAYQMSSFEQPFRAPYHGSRAGIATQFSTANGQVNLRGPGTSAEFSEFPLVNVNDNRAGMTSSPDATTGQTFG>sp|Q9UDV6|ZN212_HUMAN Zinc finger protein 212 OS=Homo sapiens OX=9606GN=ZNF212 PE=1 SV=3MAESAPARHRRKRRSTPLTSSTLPSQATEKSSYFQTTEISLWTVVAAIQAVEKKMESQAARLQSLEGRTGTAEKKLADCEKMAVEFGNQLEGKWAVLGTLLQEYGLLQRRLENVENLLRNRNFWILRLPPGSKGEAPKVSRSLENDGVCFTEQEWENLEDWQKELYRNVMESNYETLVSLKVLGQTEGEAELGTEMLGDLEEEGPGGAHPAGGVMIKQELQYTQEGPADLPGEFSCIAEEQAFLSPEQTELWGGQGSSVLLETGPGDSTLEEPVGSRVPSSSRTVGCPKQKSHRQVQLDQECGQGLKLKKDTSRPYECSECEITFRYKQQLATHLRSHSGWGSCTPEEPEESLRPRPRLKPQTKKAKLHQCDVCLRSFSCKVSLVTHQRCHLQEGPSAGQHVQERFSPNSLVALPGHIPWRKSRSSLICGYCGKSFSHPSDLVRHQRIHTGERPYSCTECEKSFVQKQHLLQHQKIHQRERGGLALEPGRPNGLL>sp|Q5JNZ3|ZN311_HUMAN Zinc finger protein 311 OS=Homo sapiens OX=9606GN=ZNF311 PE=2 SV=2MQEVVLLDESSGPPSQLLWTRQDTQLPQESALLPAPYPAFTKDGSQGNLPQADITLMSQAQESVTFEDVAVNFTNREWQCLTYAQRHLYKDVMLENYGNMVSLGFPFPKPPLISHLEREVDPCVQDPQDRESLSCSYPVSADKMWPENEKASSQQEIFENGEAYWMKFNSLLKVDSRDPKVREVCVQDVKLENQWETSIREKLREEKEGSEEVTCKKGKNQKVLSKNLNPNSKHSQCNKVLIAQKLHECARCGKNFSWHSDLILHEQIHSGEKPHVCNECGKAFKTRNQLSMHRIIHTGEKPFNCTQCGKAFNSRSALCRHKKTHSGEKPHECRDCGKAFKTRNRLCMHQLIHTGEKPYKCNCCGKAFQFKHSLTIHGRIHTGEKPYECEECGKAFSGSSDLTKHIRIHTGERPYECSKCGRAFSRSSDLSKHKRIHTREKHYGCPQCGKDFSIKAELTKHRRIHTEEKRYRCEECGKAFRHNCKRRAHEREHTGEKPYQCRDCGKTFQDKHCLTIHQRIHTGEKPYKCLECGKAFSGKSNLTNHRRIHTGEKPHKCEVCGMAFHHSSVLRQHKRIHTGEKPYTCSECGTSFRQGSALIGHKRVHTGEKPYECEECGKAFRVSSNLTGHKKRKHQVWSTHELDGSRKSLSPVTVSQTSVVSILTSA>sp|Q8N8L2|ZN491_HUMAN Zinc finger protein 491 OS=Homo sapiens OX=9606GN=ZNF491 PE=1 SV=1MGERLFESAEGSQCGETFTQVPEDMLNKKTLPGVKSCESGTCGEIFMGYSSFNRNIRTDTGHQPHKCQKFLEKPYKHKQRRKALSHSHCFRTHERPHTREKPFDCKECEKSFISPASIRRYMVTHSGDGPYKCKFCGKALDCLSLYLTHERTHTGEKRYECKQCGKAFSWHSSVRIHERTHTGEKPYECKECGKSFNFSSSFRRHERTHTGEKPYKCKECGKAFNCPSSFHRHERTHTGEKPYECKLYGKALSRLISFRRHMRMHTGERPHKCKICGKAFYSPSSFQRHERSHTGEKPYKCKQCGKAFTCSTSFQYHERTHTGEKPDGCKQCGKAFRSAKYIRIHGRTHTGEKPYECKQCGKAFHCVSSFHRHERTHAGEKPYECKHCGKAFTCSIYIRIHERIHTGEKPYQCKECGKAFIRSSYCRKHERTHTINI>sp|Q8TD17|ZN398_HUMAN Zinc finger protein 398 OS=Homo sapiens OX=9606GN=ZNF398 PE=1 SV=1MAEAAPAPTSEWDSECLTSLQPLPLPTPPAANEAHLQTAAISLWTVVAAVQAIERKVEIHSRRLLHLEGRTGTAEKKLASCEKTVTELGNQLEGKWAVLGTLLQEYGLLQRRLENLENLLRNRNFWILRLPPGIKGDIPKVPVAFDDVSIYFSTPEWEKLEEWQKELYKNIMKGNYESLISMDYAINQPDVLSQIQPEGEHNTEDQAGPEESEIPTDPSEEPGISTSDILSWIKQEEEPQVGAPPESKESDVYKSTYADEELVIKAEGLARSSLCPEVPVPFSSPPAAAKDAFSDVAFKSQQSTSMTPFGRPATDLPEASEGQVTFTQLGSYPLPPPVGEQVFSCHHCGKNLSQDMLLTHQCSHATEHPLPCAQCPKHFTPQADLSSTSQDHASETPPTCPHCARTFTHPSRLTYHLRVHNSTERPFPCPDCPKRFADQARLTSHRRAHASERPFRCAQCGRSFSLKISLLLHQRGHAQERPFSCPQCGIDFNGHSALIRHQMIHTGERPYPCTDCSKSFMRKEHLLNHRRLHTGERPFSCPHCGKSFIRKHHLMKHQRIHTGERPYPCSYCGRSFRYKQTLKDHLRSGHNGGCGGDSDPSGQPPNPPGPLITGLETSGLGVNTEGLETNQWYGEGSGGGVL>sp|Q8TD17-2|ZN398_HUMAN Isoform 2 of Zinc finger protein 398 OS=Homosapiens OX=9606 GN=ZNF398MKGNYESLISMDYAINQPDVLSQIQPEGEHNTEDQAGPEESEIPTDPSEEPGISTSDILSWIKQEEEPQVGAPPESKESDVYKSTYADEELVIKAEGLARSSLCPEVPVPFSSPPAAAKDAFSDVAFKSQQSTSMTPFGRPATDLPEASEGQVTFTQLGSYPLPPPVGEQVFSCHHCGKNLSQDMLLTHQCSHATEHPLPCAQCPKHFTPQADLSSTSQDHASETPPTCPHCARTFTHPSRLTYHLRVHNSTERPFPCPDCPKRFADQARLTSHRRAHASERPFRCAQCGRSFSLKISLLLHQRGHAQERPFSCPQCGIDFNGHSALIRHQMIHTGERPYPCTDCSKSFMRKEHLLNHRRLHTGERPFSCPHCGKSFIRKHHLMKHQRIHTGERPYPCSYCGRSFRYKQTLKDHLRSGHNGGCGGDSDPSGQPPNPPGPLITGLETSGLGVNTEGLETNQWYGEGSGGGVL>sp|Q6ZN57|ZFP2_HUMAN Zinc finger protein 2 homolog OS=Homo sapiensOX=9606 GN=ZFP2 PE=1 SV=1MEREGIWHSTLGETWEPNNWLEGQQDSHLSQVGVTHKETFTEMRVCGGNEFERCSSQDSILDTQQSIPMVKRPHNCNSHGEDATQNSELIKTQRMFVGKKIYECNQCSKTFSQSSSLLKHQRIHTGEKPYKCNVCGKHFIERSSLTVHQRIHTGEKPYKCNECGKAFSQSMNLTVHQRTHTGEKPYQCKECGKAFHKNSSLIQHERIHTGEKPYKCNECGKAFTQSMNLTVHQRTHTGEKPYECNECGKAFSQSMHLIVHQRSHTGEKPYECSQCGKAFSKSSTLTLHQRNHTGEKPYKCNKCGKSFSQSTYLIEHQRLHSGVKPFECNECGKAFSKNSSLTQHRRIHTGEKPYECMVCGKHFTGRSSLTVHQVIHTGEKPYECNECGKAFSQSAYLIEHQRIHTGEKPYECDQCGKAFIKNSSLTVHQRTHTGEKPYQCNECGKAFSRSTNLTRHQRTHT>sp|Q9BSK1|ZN577_HUMAN Zinc finger protein 577 OS=Homo sapiens OX=9606GN=ZNF577 PE=2 SV=3MKNATIVMSVRREQGSSSGEGSLSFEDVAVGFTREEWQFLDQSQKVLYKEVMLENYINLVSIGYRGTKPDSLFKLEQGEPPGIAEGAAHSQICPGFVIQSRRYAGKDSDAFGGYGRSCLHIKRDKTLTGVKYHRCVKPSSPKSQLNDLQKICAGGKPHECSVCGRAFSRKAQLIQHQRTERGEKPHGCGECGKTFMRKIQLTEHQRTHTGEKPHECSECGKAFSRKSQLMVHQRTHTGEKPYRCSKCGKAFSRKCRLNRHQRSHTGEKLYGCSVCGKAFSQKAYLTAHQRLHTGDKPYKCSDCGRTFYFKSDLTRHQRIHTGEKPYECSECEKAFRSKSKLIQHQRTHTGERPYSCRECGKAFAHMSVLIKHEKTHIRETAINSLTVEKPSSRSHTSLYMSELIQEQKTVNTVPIEMPSSGTPPLLNKSERLVGRNVVIVEQPFPRNQAFVVNQEFEQRISLTNEVNVAPSVINYILYLTDIVSE>sp|Q9BSK1-2|ZN577_HUMAN Isoform 2 of Zinc finger protein 577 OS=Homosapiens OX=9606 GN=ZNF577MKNATIVMSVRREQGSSSGEGSLSFEDVAVGFTREEWQFLDQSQKVLYKEVMLENYINLVSIGYRGTKPDSLFKLEQGEPPGIAEGAAHSQICPGGKPHECSVCGRAFSRKAQLIQHQRTERGEKPHGCGECGKTFMRKIQLTEHQRTHTGEKPHECSECGKAFSRKSQLMVHQRTHTGEKPYRCSKCGKAFSRKCRLNRHQRSHTGEKLYGCSVCGKAFSQKAYLTAHQRLHTGDKPYKCSDCGRTFYFKSDLTRHQRIHTGEKPYECSECEKAFRSKSKLIQHQRTHTGERPYSCRECGKAFAHMSVLIKHEKTHIRETAINSLTVEKPSSRSHTSLYMSELIQEQKTVNTVPIEMPSSGTPPLLNKSERLVGRNVVIVEQPFPRNQAFVVNQEFEQRISLTNEVNVAPSVINYILYLTDIVSE>sp|Q96MV8|ZDH15_HUMAN Palmitoyltransferase ZDHHC15 OS=Homo sapiensOX=9606 GN=ZDHHC15 PE=1 SV=1MRRGWKMALSGGLRCCRRVLSWVPVLVIVLVVLWSYYAYVFELCLVTVLSPAEKVIYLILYHAIFVFFTWTYWKSIFTLPQQPNQKFHLSYTDKERYENEERPEVQKQMLVDMAKKLPVYTRTGSGAVRFCDRCHLIKPDRCHHCSVCAMCVLKMDHHCPWVNNCIGFSNYKFFLQFLAYSVLYCLYIATTVFSYFIKYWRGELPSVRSKFHVLFLLFVACMFFVSLVILFGYHCWLVSRNKTTLEAFCTPVFTSGPEKNGFNLGFIKNIQQVFGDKKKFWLIPIGSSPGDGHSFPMRSMNESQNPLLANEETWEDNEDDNQDYPEGSSSLAVETET>sp|Q96MV8-2|ZDH15_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC15OS=Homo sapiens OX=9606 GN=ZDHHC15MRRGWKMALSGGLRCCRRVLSWVPVLVIVLVVLWSYYAYVFELCLVIYLILYHAIFVFFTWTYWKSIFTLPQQPNQKFHLSYTDKERYENEERPEVQKQMLVDMAKKLPVYTRTGSGGQFIQRQLERQLSKYLRKAKSYMFSN>sp|Q96MV8-3|ZDH15_HUMAN Isoform 3 of Palmitoyltransferase ZDHHC15OS=Homo sapiens OX=9606 GN=ZDHHC15MRRGWKMALSGGLRCCRRVLSWVPVLVIVLVVLWSYYAYVFELCLVIYLILYHAIFVFFTWTYWKSIFTLPQQPNQKFHLSYTDKERYENEERPEVQKQMLVDMAKKLPVYTRTGSGAVRFCDRCHLIKPDRCHHCSVCAMCVLKMDHHCPWVNNCIGFSNYKFFLQFLAYSVLYCLYIATTVFSYFIKYWRGELPSVRSKFHVLFLLFVACMFFVSLVILFGYHCWLVSRNKTTLEAFCTPVFTSGPEKNGFNLGFIKNIQQVFGDKKKFWLIPIGSSPGDGHSFPMRSMNESQNPLLANEETWEDNEDDNQDYPEGSSSLAVETET>sp|O75691|UTP20_HUMAN Small subunit processome component 20 homologOS=Homo sapiens OX=9606 GN=UTP20 PE=1 SV=3MKTKPVSHKTENTYRFLTFAERLGNVNIDIIHRIDRTASYEEEVETYFFEGLLKWRELNLTEHFGKFYKEVIDKCQSFNQLVYHQNEIVQSLKTHLQVKNSFAYQPLLDLVVQLARDLQMDFYPHFPEFFLTITSILETQDTELLEWAFTSLSYLYKYLWRLMVKDMSSIYSMYSTLLAHKKLHIRNFAAESFTFLMRKVSDKNALFNLMFLDLDKHPEKVEGVGQLLFEMCKGVRNMFHSCTGQAVKLILRKLGPVTETETQLPWMLIGETLKNMVKSTVSYISKEHFGTFFECLQESLLDLHTKVTKTNCCESSEQIKRLLETYLILVKHGSGTKIPTPADVCKVLSQTLQVASLSTSCWETLLDVISALILGENVSLPETLIKETIEKIFESRFEKRLIFSFSEVMFAMKQFEQLFLPSFLSYIVNCFLIDDAVVKDEALAILAKLILNKAAPPTAGSMAIEKYPLVFSPQMVGFYIKQKKTRSKGRNEQFPVLDHLLSIIKLPPNKDTTYLSQSWAALVVLPHIRPLEKEKVIPLVTGFIEALFMTVDKGSFGKGNLFVLCQAVNTLLSLEESSELLHLVPVERVKNLVLTFPLEPSVLLLTDLYYQRLALCGCKGPLSQEALMELFPKLQANISTGVSKIRLLTIRILNHFDVQLPESMEDDGLSERQSVFAILRQAELVPATVNDYREKLLHLRKLRHDVVQTAVPDGPLQEVPLRYLLGMLYINFSALWDPVIELISSHAHEMENKQFWKVYYEHLEKAATHAEKELQNDMTDEKSVGDESWEQTQEGDVGALYHEQLALKTDCQERLDHTNFRFLLWRALTKFPERVEPRSRELSPLFLRFINNEYYPADLQVAPTQDLRRKGKGMVAEEIEEEPAAGDDEELEEEAVPQDESSQKKKTRRAAAKQLIAHLQVFSKFSNPRALYLESKLYELYLQLLLHQDQMVQKITLDCIMTYKHPHVLPYRENLQRLLEDRSFKEEIVHFSISEDNAVVKTAHRADLFPILMRILYGRMKNKTGSKTQGKSASGTRMAIVLRFLAGTQPEEIQIFLDLLFEPVRHFKNGECHSAVIQAVEDLDLSKVLPLGRQHGILNSLEIVLKNISHLISAYLPKILQILLCMTATVSHILDQREKIQLRFINPLKNLRRLGIKMVTDIFLDWESYQFRTEEIDAVFHGAVWPQISRLGSESQYSPTPLLKLISIWSRNARYFPLLAKQKPGHPECDILTNVFAILSAKNLSDATASIVMDIVDDLLNLPDFEPTETVLNLLVTGCVYPGIAENIGESITIGGRLILPHVPAILQYLSKTTISAEKVKKKKNRAQVSKELGILSKISKFMKDKEQSSVLITLLLPFLHRGNIAEDTEVDILVTVQNLLKHCVDPTSFLKPIAKLFSVIKNKLSRKLLCTVFETLSDFESGLKYITDVVKLNAFDQRHLDDINFDVRFETFQTITSYIKEMQIVDVNYLIPVMHNCFYNLELGDMSLSDNASMCLMSIIKKLAALNVTEKDYREIIHRSLLEKLRKGLKSQTESIQQDYTTILSCLIQTFPNQLEFKDLVQLTHYHDPEMDFFENMKHIQIHRRARALKKLAKQLMEGKVVLSSKSLQNYIMPYAMTPIFDEKMLKHENITTAATEIIGAICKHLSWSAYMYYLKHFIHVLQTGQINQKLGVSLLVIVLEAFHFDHKTLEEQMGKIENEENAIEAIELPEPEAMELERVDEEEKEYTCKSLSDNGQPGTPDPADSGGTSAKESECITKPVSFLPQNKEEIERTIKNIQGTITGDILPRLHKCLASTTKREEEHKLVKSKVVNDEEVVRVPLAFAMVKLMQSLPQEVMEANLPSILLKVCALLKNRAQEIRDIARSTLAKIIEDLGVHFLLYVLKELQTTLVRGYQVHVLTFTVHMLLQGLTNKLQVGDLDSCLDIMIEIFNHELFGAVAEEKEVKQILSKVMEARRSKSYDSYEILGKFVGKDQVTKLILPLKEILQNTTSLKLARKVHETLRRITVGLIVNQEMTAESILLLSYGLISENLPLLTEKEKNPVAPAPDPRLPPQSCLLLPPTPVRGGQKAVVSRKTNMHIFIESGLRLLHLSLKTSKIKSSGECVLEMLDPFVSLLIDCLGSMDVKVITGALQCLIWVLRFPLPSIETKAEQLTKHLFLLLKDYAKLGAARGQNFHLVVNCFKCVTILVKKVKSYQITEKQLQVLLAYAEEDIYDTSRQATAFGLLKAILSRKLLVPEIDEVMRKVSKLAVSAQSEPARVQCRQVFLKYILDYPLGDKLRPNLEFMLAQLNYEHETGRESTLEMIAYLFDTFPQGLLHENCGMFFIPLCLMTINDDSATCKKMASMTIKSLLGKISLEKKDWLFDMVTTWFGAKKRLNRQLAALICGLFVESEGVDFEKRLGTVLPVIEKEIDPENFKDIMEETEEKAADRLLFSFLTLITKLIKECNIIQFTKPAETLSKIWSHVHSHLRHPHNWVWLTAAQIFGLLFASCQPEELIQKWNTKKTKKHLPEPVAIKFLASDLDQKMKSISLASCHQLHSKFLDQSLGEQVVKNLLFAAKVLYLLELYCEDKQSKIKEDLEEQEALEDGVACADEKAESDGEEKEEVKEELGRPATLLWLIQKLSRIAKLEAAYSPRNPLKRTCIFKFLGAVAMDLGIDKVKPYLPMIIAPLFRELNSTYSEQDPLLKNLSQEIIELLKKLVGLESFSLAFASVQKQANEKRALRKKRKALEFVTNPDIAAKKKMKKHKNKSEAKKRKIEFLRPGYKAKRQKSHSLKDLAMVE>sp|Q8N554|ZN276_HUMAN Zinc finger protein 276 OS=Homo sapiens OX=9606GN=ZNF276 PE=1 SV=4MKRDRLGRFLSPGSSRQCGASDGGGGVSRTRGRPSLSGGPRVDGATARRAWGPVGSCGDAGEDGADEAGAGRALAMGHCRLCHGKFSSRSLRSISERAPGASMERPSAEERVLVRDFQRLLGVAVRQDPTLSPFVCKSCHAQFYQCHSLLKSFLQRVNASPAGRRKPCAKVGAQPPTGAEEGACLVDLITSSPQCLHGLVGWVHGHAASCGALPHLQRTLSSEYCGVIQVVWGCDQGHDYTMDTSSSCKAFLLDSALAVKWPWDKETAPRLPQHRGWNPGDAPQTSQGRGTGTPVGAETKTLPSTDVAQPPSDSDAVGPRSGFPPQPSLPLCRAPGQLGEKQLPSSTSDDRVKDEFSDLSEGDVLSEDENDKKQNAQSSDESFEPYPERKVSGKKSESKEAKKSEEPRIRKKPGPKPGWKKKLRCEREELPTIYKCPYQGCTAVYRGADGMKKHIKEHHEEVRERPCPHPGCNKVFMIDRYLQRHVKLIHTEVRNYICDECGQTFKQRKHLLVHQMRHSGAKPLQCEVCGFQCRQRASLKYHMTKHKAETELDFACDQCGRRFEKAHNLNVHMSMVHPLTQTQDKALPLEAEPPPGPPSPSVTTEGQAVKPEPT>sp|Q8N554-2|ZN276_HUMAN Isoform 2 of Zinc finger protein 276 OS=Homosapiens OX=9606 GN=ZNF276MGHCRLCHGKFSSRSLRSISERAPGASMERPSAEERVLVRDFQRLLGVAVRQDPTLSPFVCKSCHAQFYQCHSLLKSFLQRVNASPAGRRKPCAKVGAQPPTGAEEGACLVDLITSSPQCLHGLVGWVHGHAASCGALPHLQRTLSSEYCGVIQVVWGCDQGHDYTMDTSSSCKAFLLDSALAVKWPWDKETAPRLPQHRGWNPGDAPQTSQGRGTGTPVGAETKTLPSTDVAQPPSDSDAVGPRSGFPPQPSLPLCRAPGQLGEKQLPSSTSDDRVKDEFSDLSEGDVLSEDENDKKQNAQSSDESFEPYPERKVSGKKSESKEAKKSEEPRIRKKPGPKPGWKKKLRCEREELPTIYKCPYQGCTAVYRGADGMKKHIKEHHEEVRERPCPHPGCNKVFMIDRYLQRHVKLIHTEVRNYICDECGQTFKQRKHLLVHQMRHSGAKPLQCEVCGFQCRQRASLKYHMTKHKAETELDFACDQCGRRFEKAHNLNVHMSMVHPLTQTQDKALPLEAEPPPGPPSPSVTTEGQAVKPEPT>sp|P63129|VPK24_HUMAN Endogenous retrovirus group K member 24 Proprotein OS=Homo sapiens OX=9606 GN=ERVK-24 PE=3 SV=1WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSTEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPLYSPTSQKIMTKMGYIPGKGLGKNEDGIKIPFEAKINQKREGIGYPF>sp|Q8WWY7|WFD12_HUMAN WAP four-disulfide core domain protein 12 OS=Homosapiens OX=9606 GN=WFDC12 PE=1 SV=1MGSSSFLVLMVSLVLVTLVAVEGVKEGIEKAGVCPADNVRCFKSDPPQCHTDQDCLGERKCCYLHCGFKCVIPVKELEEGGNKDEDVSRPYPEPGWEAKCPGSSSTRCPQK>sp|Q9P2S5|WRP73_HUMAN WD repeat-containing protein WRAP73 OS=Homosapiens OX=9606 GN=WRAP73 PE=1 SV=1MNFSEVFKLSSLLCKFSPDGKYLASCVQYRLVVRDVNTLQILQLYTCLDQIQHIEWSADSLFILCAMYKRGLVQVWSLEQPEWHCKIDEGSAGLVASCWSPDGRHILNTTEFHLRITVWSLCTKSVSYIKYPKACLQGITFTRDGRYMALAERRDCKDYVSIFVCSDWQLLRHFDTDTQDLTGIEWAPNGCVLAVWDTCLEYKILLYSLDGRLLSTYSAYEWSLGIKSVAWSPSSQFLAVGSYDGKVRILNHVTWKMITEFGHPAAINDPKIVVYKEAEKSPQLGLGCLSFPPPRAGAGPLPSSESKYEIASVPVSLQTLKPVTDRANPKIGIGMLAFSPDSYFLATRNDNIPNAVWVWDIQKLRLFAVLEQLSPVRAFQWDPQQPRLAICTGGSRLYLWSPAGCMSVQVPGEGDFAVLSLCWHLSGDSMALLSKDHFCLCFLETEAVVGTACRQLGGHT>sp|O15537|XLRS1_HUMAN Retinoschisin OS=Homo sapiens OX=9606 GN=RS1 PE=1SV=2MSRKIEGFLLLLLFGYEATLGLSSTEDEGEDPWYQKACKCDCQGGPNALWSAGATSLDCIPECPYHKPLGFESGEVTPDQITCSNPEQYVGWYSSWTANKARLNSQGFGCAWLSKFQDSSQWLQIDLKEIKVISGILTQGRCDIDEWMTKYSVQYRTDERLNWIYYKDQTGNNRVFYGNSDRTSTVQNLLRPPIISRFIRLIPLGWHVRIAIRMELLECVSKCA>sp|Q86VR7|VS10L_HUMAN V-set and immunoglobulin domain-containing protein10-like OS=Homo sapiens OX=9606 GN=VSIG10L PE=2 SV=2MDNPQALPLFLLLASLVGILTLRASSGLQQTNFSSAFSSDSKSSSQGLGVEVPSIKPPSWKVPDQFLDSKASAGISDSSWFPEALSSNMSGSFWSNVSAEGQDLSPVSPFSETPGSEVFPDISDPQVPAKDPKPSFTVKTPASNISTQVSHTKLSVEAPDSKFSPDDMDLKLSAQSPESKFSAETHSAASFPQQVGGPLAVLVGTTIRLPLVPIPNPGPPTSLVVWRRGSKVLAAGGLGPGAPLISLDPAHRDHLRFDQARGVLELASAQLDDAGVYTAEVIRAGVSQQTHEFTVGVYEPLPQLSVQPKAPETEEGAAELRLRCLGWGPGRGELSWSRDGRALEAAESEGAETPRMRSEGDQLLIVRPVRSDHARYTCRVRSPFGHREAAADVSVFYGPDPPTITVSSDRDAAPARFVTAGSNVTLRCAAASRPPADITWSLADPAEAAVPAGSRLLLPAVGPGHAGTYACLAANPRTGRRRRSLLNLTVADLPPGAPQCSVEGGPGDRSLRFRCSWPGGAPAASLQFQGLPEGIRAGPVSSVLLAAVPAHPRLSGVPITCLARHLVATRTCTVTPEAPREVLLHPLVAETRLGEAEVALEASGCPPPSRASWAREGRPLAPGGGSRLRLSQDGRKLHIGNFSLDWDLGNYSVLCSGALGAGGDQITLIGPSISSWRLQRARDAAVLTWDVERGALISSFEIQAWPDGPALGRTSTYRDWVSLLILGPQERSAVVPLPPRNPGTWTFRILPILGGQPGTPSQSRVYRAGPTLSHGAIAGIVLGSLLGLALLAVLLLLCICCLCRFRGKTPEKKKHPSTLVPVVTPSEKKMHSVTPVEISWPLDLKVPLEDHSSTRAYQAQTPVQLSL>sp|Q86VR7-2|VS10L_HUMAN Isoform 2 of V-set and immunoglobulin domain-containing protein 10-like OS=Homo sapiens OX=9606 GN=VSIG10LMDNPQALPLFLLLASLVGILTLRASSGLQQTNFSSAFSSDSKSSSQGLGVEVPSIKPPSWKVPDQFLDSKASAGISDSSWFPEALSSNMSGSFWSNVSAEGQDLSPVSPFSETPGSEVFPDISDPQVPAKDPKPSFTVKTPASNISTQVSHTKLSVEAPDSKFSPDDMDLKLSAQSPESKFSAETHSAASFPQQVGGPLAVLVGTTIRLPLVPIPNPGPPTSLVVWRRGSKVLAAGGLGPGAPLISLDPAHRDHLRFDQARGVLELASAQLDDAGVYTAEVIRAGVSQQTHEFTVGVYEPLPQLSVQPKAPETEEGAAELRLRCLGWGPGRGELSWSRDGRALEAAESEGAETPRMRSEGDQLLIVRPVRSDHARYTCRVRSPFGHREAAADVSVFYGPDPPTITVSSDRDAAPARFVTAGSNVTLRCAAASRPPADITWSLADPAEAAVPAGSRLLLPAVGPGHAGTYACLAANPRTGRRRRSLLNLTVADLPPGAPQCSVEGGPGDRSLRFRCSWPGGAPAASLQFQGLPEGIRAGPVSSVLLAAVPAHPRLSGVPITCLARHLVATRTCTVTPEAPREVLLHPLVAETRLGEAEVALEASGCPPPSRASWAREGRPLAPGGGSRLRLSQDGRKLHIGNFSLDWDLGNYSVLCSGALGAGGDQITLIGPSISSWRLQRARDAAVLTWDVERGALISSFEIQAWPDGPALGRTSTYRDWVSLLILGPQERSAVVPLPPRNPGTWTFRILPILGGQPGTPSQSRVYRAGPTLSHGAIAGIVLGSLLGLALLAVLLLLCICCLCRFRGKTPEKKKHPSTLVPVVTPSEKKMHSVTPVEISWPLDLKVPLEDHSSTRAYQATDPSSVVSVGGGSKTVRAATQV>sp|Q7Z7G8|VP13B_HUMAN Vacuolar protein sorting-associated protein 13BOS=Homo sapiens OX=9606 GN=VPS13B PE=1 SV=2MLESYVTPILMSYVNRYIKNLKPSDLQLSLWGGDVVLSKLELKLDVLEQELKLPFTFLSGHIHELRIHVPWTKLGSEPVVITINTMECILKLKDGIQDDHESCGSNSTNRSTAESTKSSIKPRRMQQAAPTDPDLPPGYVQSLIRRVVNNVNIVINNLILKYVEDDIVLSVNITSAECYTVGELWDRAFMDISATDLVLRKVINFSDCTVCLDKRNASGKIEFYQDPLLYKCSFRTRLHFTYENLNSKMPSVIKIHTLVESLKLSITDQQLPMFIRIMQLGIALYYGEIGNFKEGEIEDLTCHNKDMLGNITGSEDETRIDMQYPAQHKGQELYSQQDEEQPQGWVSWAWSFVPAIVSYDDGEEDFVGNDPASTMHQQKAQTLKDPIVSIGFYCTKATVTFKLTEMQVESSYYSPQKVKSKEVLCWEQEGTTVEALMMGEPFFDCQIGFVGCRAMCLKGIMGVKDFEENMNRSETEACFFICGDNLSTKGFTYLTNSLFDYRSPENNGTRAEFILDSTHHKETYTEIAGMQRFGAFYMDYLYTMENTSGKGSTNQQDFSSGKSEDLGTVQEKSTKSLVIGPLDFRLDSSAVHRILKMIVCALEHEYEPYSRLKSDIKDENETILNPEEVALLEEYIPTRHTSVTLLKCTCTISMAEFNLLDHLLPVIMGEKNSSNFMNTTNFQSLRPLPSIRILVDKINLEHSVPMYAEQLVHVVSSLTQPSDNLLHYCYVHCYLKIFGFQAGLTSLDCSGSYCLPVPVIPSFSTALYGKLLKLPTCWTKRSQIAITEGIFELPNLTIQATRAQTLLLQAIYQSWSHLGNVSSSAVIEALINEIFLSIGVKSKNPLPTLEGSIQNVELKYCSTSLVKCASGTMGSIKICAKAPVDSGKEKLIPLLQGPSDTKDLHSTKWLNESRKPESLLAPDLMAFTIQVPQYIDYCHNSGAVLLCSIQGLAVNIDPILYTWLIYQPQKRTSRHMQQQPVVAVPLVMPVCRRKEDEVSIGSAPLAKQQSYQASEYASSPVKTKTVTESRPLSVPVKAMLNISESCRSPEERMKEFIGIVWNAVKHLTLQLEVQSCCVFIPNDSLPSPSTIVSGDIPGTVRSWYHGQTSMPGTLVLCLPQIKIISAGHKYMEPLQEIPFVIPRPILEEGDAFPWTISLHNFSIYTLLGKQVTLCLVEPMGCTSTLAVTSQKLLATGPDTRHSFVVCLHVDLESLEIKCSNPQVQLFYELTDIMNKVWNKIQKRGNLNLSPTSPETMAGPVPTSPVRSSIGTAPPDTSTCSPSADIGTTTEGDSIQAGEESPFSDSVTLEQTTSNIGGTSGRVSLWMQWVLPKITIKLFAPDPENKGTEVCMVSELEDLSASIDVQDVYTKVKCKIESFNIDHYRSSLGEECWSLGQCGGVFLSCTDKLNRRTLLVRPISKQDPFSNCSGFFPSTTTKLLDGTHQQHGFLSLTYTKAVTKNVRHKLTSRNERRSFHKLSEGLMDGSPHFLHEILLSAQAFDIVLYFPLLNAIASIFQAKLPKTQKEKRKSPGQPMRTHTLTSRNLPLIYVNTSVIRIFIPKTEEMQPTVEANQAAKEDTVVLKIGSVAMAPQADNPLGRSVLRKDIYQRALNLGILRDPGSEIEDRQYQIDLQSINIGTAQWHQLKPEKESVSGGVVTETERNSQNPALEWNMASSIRRHQERRAILTPVLTDFSVRITGAPAVIFTKVVSPENLHTEEILVCGHSLEVNITTNLDFFLSVAQVQLLHQLIVANMTGLEPSNKAAEISKQEQKKVDIFDGGMAETSSRYSGAQDSGIGSDSVKIRIVQIEQHSGASQHRIARPSRQSSIVKNLNFIPFDIFITASRISLMTYSCMALSKSKSQEQKNNEKTDKSSLNLPEVDSDVAKPNQACISTVTAEDLLRSSISFPSGKKIGVLSLESLHASTRSSARQALGITIVRQPGRRGTGDLQLEPFLYFIVSQPSLLLSCHHRKQRVEVSIFDAVLKGVASDYKCIDPGKTLPEALDYCTVWLQTVPGEIDSKSGIPPSFITLQIKDFLNGPADVNLDISKPLKANLSFTKLDQINLFLKKIKNAHSLAHSEETSAMSNTMVNKDDLPVSKYYRGKLSKPKIHGDGVQKISAQENMWRAVSCFQKISVQTTQIVISMETVPHTSKPCLLASLSNLNGSLSVKATQKVPGIILGSSFLLSINDFLLKTSLKERSRILIGPCCATANLEAKWCKHSGNPGPEQSIPKISIDLRGGLLQVFWGQEHLNCLVLLHELLNGYLNEEGNFEVQVSEPVPQMSSPVEKNQTFKSEQSSDDLRTGLFQYVQDAESLKLPGVYEVLFYNETEDCPGMMLWRYPEPRVLTLVRITPVPFNTTEDPDISTADLGDVLQVPCSLEYWDELQKVFVAFREFNLSESKVCELQLPDINLVNDQKKLVSSDLWRIVLNSSQNGADDQSSASESGSQSTCDPLVTPTALAACTRVDSCFTPWFVPSLCVSFQFAHLEFHLCHHLDQLGTAAPQYLQPFVSDRNMPSELEYMIVSFREPHMYLRQWNNGSVCQEIQFLAQADCKLLECRNVTMQSVVKPFSIFGQMAVSSDVVEKLLDCTVIVDSVFVNLGQHVVHSLNTAIQAWQQNKCPEVEELVFSHFVICNDTQETLRFGQVDTDENILLASLHSHQYSWRSHKSPQLLHICIEGWGNWRWSEPFSVDHAGTFIRTIQYRGRTASLIIKVQQLNGVQKQIIICGRQIICSYLSQSIELKVVQHYIGQDGQAVVREHFDCLTAKQKLPSYILENNELTELCVKAKGDEDWSRDVCLESKAPEYSIVIQVPSSNSSIIYVWCTVLTLEPNSQVQQRMIVFSPLFIMRSHLPDPIIIHLEKRSLGLSETQIIPGKGQEKPLQNIEPDLVHHLTFQAREEYDPSDCAVPISTSLIKQIATKVHPGGTVNQILDEFYGPEKSLQPIWPYNKKDSDRNEQLSQWDSPMRVKLSIWKPYVRTLLIELLPWALLINESKWDLWLFEGEKIVLQVPAGKIIIPPNFQEAFQIGIYWANTNTVHKSVAIKLVHNLTSPKWKDGGNGEVVTLDEEAFVDTEIRLGAFPGHQKLCQFCISSMVQQGIQIIQIEDKTTIINNTPYQIFYKPQLSVCNPHSGKEYFRVPDSATFSICPGGEQPAMKSSSLPCWDLMPDISQSVLDASLLQKQIMLGFSPAPGADSSQCWSLPAIVRPEFPRQSVAVPLGNFRENGFCTRAIVLTYQEHLGVTYLTLSEDPSPRVIIHNRCPVKMLIKENIKDIPKFEVYCKKIPSECSIHHELYHQISSYPDCKTKDLLPSLLLRVEPLDEVTTEWSDAIDINSQGTQVVFLTGFGYVYVDVVHQCGTVFITVAPEGKAGPILTNTNRAPEKIVTFKMFITQLSLAVFDDLTHHKASAELLRLTLDNIFLCVAPGAGPLPGEEPVAALFELYCVEICCGDLQLDNQLYNKSNFHFAVLVCQGEKAEPIQCSKMQSLLISNKELEEYKEKCFIKLCITLNEGKSILCDINEFSFELKPARLYVEDTFVYYIKTLFDTYLPNSRLAGHSTHLSGGKQVLPMQVTQHARALVNPVKLRKLVIQPVNLLVSIHASLKLYIASDHTPLSFSVFERGPIFTTARQLVHALAMHYAAGALFRAGWVVGSLDILGSPASLVRSIGNGVADFFRLPYEGLTRGPGAFVSGVSRGTTSFVKHISKGTLTSITNLATSLARNMDRLSLDEEHYNRQEEWRRQLPESLGEGLRQGLSRLGISLLGAIAGIVDQPMQNFQKTSEAQASAGHKAKGVISGVGKGIMGVFTKPIGGAAELVSQTGYGILHGAGLSQLPKQRHQPSDLHADQAPNSHVKYVWKMLQSLGRPEVHMALDVVLVRGSGQEHEGCLLLTSEVLFVVSVSEDTQQQAFPVTEIDCAQDSKQNNLLTVQLKQPRVACDVEVDGVRERLSEQQYNRLVDYITKTSCHLAPSCSSMQIPCPVVAAEPPPSTVKTYHYLVDPHFAQVFLSKFTMVKNKALRKGFP>sp|Q7Z7G8-2|VP13B_HUMAN Isoform 2 of Vacuolar protein sorting-associatedprotein 13B OS=Homo sapiens OX=9606 GN=VPS13BMLESYVTPILMSYVNRYIKNLKPSDLQLSLWGGDVVLSKLELKLDVLEQELKLPFTFLSGHIHELRIHVPWTKLGSEPVVITINTMECILKLKDGIQDDHESCGSNSTNRSTAESTKSSIKPRRMQQAAPTDPDLPPGYVQSLIRRVVNNVNIVINNLILKYVEDDIVLSVNITSAECYTVGELWDRAFMDISATDLVLRKVINFSDCTVCLDKRNASGKIEFYQDPLLYKCSFRTRLHFTYENLNSKMPSVIKIHTLVESLKLSITDQQLPMFIRIMQLGIALYYGEIGNFKEGEIEDLTCHNKDMLGNITGSEDETRIDMQYPAQHKGQELYSQQDEEQPQGWVSWAWSFVPAIVSYDDGEEDFVGNDPASTMHQQKAQTLKDPIVSIGFYCTKATVTFKLTEMQVESSYYSPQKVKSKEVLCWEQEGTTVEALMMGEPFFDCQIGFVGCRAMCLKGIMGVKDFEENMNRSETEACFFICGDNLSTKGFTYLTNSLFDYRSPENNGTRAEFILDSTHHKETYTEIAGMQRFGAFYMDYLYTMENTSGKGSTNQQDFSSGKSEDLGTVQEKSTKSLVIGPLDFRLDSSAVHRILKMIVCALEHEYEPYSRLKSDIKDENETILNPEEVALLEEYIPTRHTSVTLLKCTCTISMAEFNLLDHLLPVIMGEKNSSNFMNTTNFQSLRPLPSIRILVDKINLEHSVPMYAEQLVHVVSSLTQPSDNLLHYCYVHCYLKIFGFQAGLTSLDCSGSYCLPVPVIPSFSTALYGKLLKLPTCWTKRSQIAITEGIFELPNLTIQATRAQTLLLQAIYQSWSHLGNVSSSAVIEALINEIFLSIGVKSKNPLPTLEGSIQNVELKYCSTSLVKCASGTMGSIKICAKAPVDSGKEKLIPLLQGPSDTKDLHSTKWLNESRKPESLLAPDLMAFTIQVPQYIDYCHNSGAVLLCSIQGLAVNIDPILYTWLIYQPQKRTSRHMQQQPVVAVPLVMPVCRRKEDEVSIGSAPLAKQQSYQASEYASSPVKTKTVTESRPLSVPVKAMLNISESCRSPEERMKEFIGIVWNAVKHLTLQLEVQSCCVFIPNDSLPSPSTIVSGDIPGTVRSWYHGQTSMPGTLVLCLPQIKIISAGHKYMEPLQEIPFVIPRPILEEGDAFPWTISLHNFSIYTLLGKQVTLCLVEPMGCTSTLAVTSQKLLATGPDTRHSFVVCLHVDLESLEIKCSNPQVQLFYELTDIMNKVWNKIQKRGNLNLSPTSPETMAGPVPTSPVRSSIGTAPPDTSTCSPSADIGTTTEGDSIQAGEESPFSDSVTLEQTTSNIGGTSGRVSLWMQWVLPKITIKLFAPDPENKGTEVCMVSELEDLSASIDVQDVYTKVKCKIESFNIDHYRSRPGEGWQSGHFEGVFLQCKEKSVTTTKLLDGTHQQHGFLSLTYTKAVTKNVRHKLTSRNERRSFHKLSEGLMDGSPHFLHEILLSAQAFDIVLYFPLLNAIASIFQAKLPKTQKEKRKSPGQPMRTHTLTSRNLPLIYVNTSVIRIFIPKTEEMQPTVEANQAAKEDTVVLKIGSVAMAPQADNPLGRSVLRKDIYQRALNLGILRDPGSEIEDRQYQIDLQSINIGTAQWHQLKPEKESVSGGVVTETERNSQNPALEWNMASSIRRHQERRAILTPVLTDFSVRITGAPAVIFTKVVSPENLHTEEILVCGHSLEVNITTNLDFFLSVAQVQLLHQLIVANMTGLEPSNKAAEISKQEQKKVDIFDGGMAETSSRYSGAQDSGIGSDSVKIRIVQIEQHSGASQHRIARPSRQSSIVKNLNFIPFDIFITASRISLMTYSCMALSKSKSQEQKNNEKTDKSSLNLPEVDSDVAKPNQACISTVTAEDLLRSSISFPSGKKIGVLSLESLHASTRSSARQALGITIVRQPGRRGTGDLQLEPFLYFIVSQPSLLLSCHHRKQRVEVSIFDAVLKGVASDYKCIDPGKTLPEALDYCTVWLQTVPGEIDSKSGIPPSFITLQIKDFLNGPADVNLDISKPLKANLSFTKLDQINLFLKKIKNAHSLAHSEETSAMSNTMVNKDDLPVSKYYRGKLSKPKIHGDGVQKISAQENMWRAVSCFQKISVQTTQIVISMETVPHTSKPCLLASLSNLNGSLSVKATQKVPGIILGSSFLLSINDFLLKTSLKERSRILIGPCCATANLEAKWCKHSGNPGPEQSIPKISIDLRGGLLQVFWGQEHLNCLVLLHELLNGYLNEEGNFEVQVSEPVPQMSSPVEKNQTFKSEQSSDDLRTGLFQYVQDAESLKLPGVYEVLFYNETEDCPGMMLWRYPEPRVLTLVRITPVPFNTTEDPDISTADLGDVLQVPCSLEYWDELQKVFVAFREFNLSESKVCELQLPDINLVNDQKKLVSSDLWRIVLNSSQNGADDQSSASESGSQSTCDPLVTPTALAACTRVDSCFTPWFVPSLCVSFQFAHLEFHLCHHLDQLGTAAPQYLQPFVSDRNMPSELEYMIVSFREPHMYLRQWNNGSVCQEIQFLAQADCKLLECRNVTMQSVVKPFSIFGQMAVSSDVVEKLLDCTVIVDSVFVNLGQHVVHSLNTAIQAWQQNKCPEVEELVFSHFVICNDTQETLRFGQVDTDENILLASLHSHQYSWRSHKSPQLLHICIEGWGNWRWSEPFSVDHAGTFIRTIQYRGRTASLIIKVQQLNGVQKQIIICGRQIICSYLSQSIELKVVQHYIGQDGQAVVREHFDCLTAKQKLPSYILENNELTELCVKAKGDEDWSRDVCLESKAPEYSIVIQVPSSNSSIIYVWCTVLTLEPNSQVQQRMIVFSPLFIMRSHLPDPIIIHLEKRSLGLSETQIIPGKGQEKPLQNIEPDLVHHLTFQAREEYDPSDCAVPISTSLIKQIATKVHPGGTVNQILDEFYGPEKSLQPIWPYNKKDSDRNEQLSQWDSPMRVKLSIWKPYVRTLLIELLPWALLINESKWDLWLFEGEKIVLQVPAGKIIIPPNFQEAFQIGIYWANTNTVHKSVAIKLVHNLTSPKWKDGGNGEVVTLDEEAFVDTEIRLGAFPGHQKLCQFCISSMVQQGIQIIQIEDKTTIINNTPYQIFYKPQLSVCNPHSGKEYFRVPDSATFSICPGGEQPAMKSSSLPCWDLMPDISQSVLDASLLQKQIMLGFSPAPGADSSQCWSLPAIVRPEFPRQSVAVPLGNFRENGFCTRAIVLTYQEHLGVTYLTLSEDPSPRVIIHNRCPVKMLIKENIKDIPKFEVYCKKIPSECSIHHELYHQISSYPDCKTKDLLPSLLLRVEPLDEVTTEWSDAIDINSQGTQVVFLTGFGYVYVDVVHQCGTVFITVAPEGKAGPILTNTNRAPEKIVTFKMFITQLSLAVFDDLTHHKASAELLRLTLDNIFLCVAPGAGPLPGEEPVAALFELYCVEICCGDLQLDNQLYNKSNFHFAVLVCQGEKAEPIQCSKMQSLLISNKELEEYKEKCFIKLCITLNEGKSILCDINEFSFELKPARLYVEDTFVYYIKTLFDTYLPNSRLAGHSTHLSGGKQVLPMQVTQHARALVNPVKLRKLVIQPVNLLVSIHASLKLYIASDHTPLSFSVFERGPIFTTARQLVHALAMHYAAGALFRAGWVVGSLDILGSPASLVRSIGNGVADFFRLPYEGLTRGPGAFVSGVSRGTTSFVKHISKGTLTSITNLATSLARNMDRLSLDEEHYNRQEEWRRQLPESLGEGLRQGLSRLGISLLGAIAGIVDQPMQNFQKTSEAQASAGHKAKGVISGVGKGIMGVFTKPIGGAAELVSQTGYGILHGAGLSQLPKQRHQPSDLHADQAPNSHVKYVWKMLQSLGRPEVHMALDVVLVRGSGQEHEGCLLLTSEVLFVVSVSEDTQQQAFPVTEIDCAQDSKQNNLLTVQLKQPRVACDVEVDGVRERLSEQQYNRLVDYITKTSCHLAPSCSSMQIPCPVVAAEPPPSTVKTYHYLVDPHFAQVFLSKFTMVKNKALRKGFP>sp|Q7Z7G8-3|VP13B_HUMAN Isoform 3 of Vacuolar protein sorting-associatedprotein 13B OS=Homo sapiens OX=9606 GN=VPS13BMLESYVTPILMSYVNRYIKNLKPSDLQLSLWGGDVVLSKLELKLDVLEQELKLPFTFLSGHIHELRIHVPWTKLGSEPVVITINTMECILKLKDGIQDDHESCGSNSTNRSTAESTKSSIKPRRMQQAAPTDPDLPPGYVQSLIRRVVNNVNIVINNLILKYVEDDIVLSVNITSAECYTVGELWDRAFMDISATDLVLRKVINFSDCTVCLDKRNASGKIEFYQDPLLYKCSFRTRLHFTYENLNSKMPSVIKIHTLVESLKLSITDQQLPMFIRIMQLGIALYYGEIGNFKEGEIEDLTCHNKDMLGNITGSEDETRIDMQYPAQHKGQELYSQQDEEQPQGWVSWAWSFVPAIVSYDDGEEDFVGNDPASTMHQQKAQTLKDPIVSIGFYCTKATVTFKLTEMQVESSYYSPQKVKSKEVLCWEQEGTTVEALMMGEPFFDCQIGFVGCRAMCLKGIMGVKDFEENMNRSETEACFFICGDNLSTKGFTYLTNSLFDYRSPENNGTRAEFILDSTHHKETYTEIAGMQRFGAFYMDYLYTMENTSGKGSTNQQDFSSGKSEDLGTVQEKSTKSLVIGPLDFRLDSSAVHRILKMIVCALEHEYEPYSRLKSDIKDENETILNPEEVALLEEYIPTRHTSVTLLKCTCTISMAEFNLLDHLLPVIMGEKNSSNFMNTTNFQSLRPLPSIRILVDKINLEHSVPMYAEQLVHVVSSLTQPSDNLLHYCYVHCYLKIFGFQAGLTSLDCSGSYCLPVPVIPSFSTALYGKLLKLPTCWTKRSQIAITEGIFELPNLTIQATRAQTLLLQAIYQSWSHLGNVSSSAVIEALINEIFLSIGVKSKNPLPTLEGSIQNVELKYCSTSLVKCASGTMGSIKICAKAPVDSGKEKLIPLLQGPSDTKDLHSTKWLNESRKPESLLAPDLMAFTIQVPQYIDYCHNSGAVLLCSIQGLAVNIDPILYTWLIYQPQKRTSRHMQQQPVVAVPLVMPVCRRKEDEVSIGSAPLAKQQSYQASEYASSPVKTKTVTESRPLSVPVKAMLNISESCRSPEERMKEFIGIVWNAVKHLTLQLEVQSCCVFIPNDSLPSPSTIVSGDIPGTVRSWYHGQTSMPGTLVLCLPQIKIISAGHKYMEPLQEIPFVIPRPILEEGDAFPWTISLHNFSIYTLLGKQVTLCLVEPMGCTSTLAVTSQKLLATGPDTRHSFVVCLHVDLESLEIKCSNPQVQLFYELTDIMNKVWNKIQKRGNLNLSPTSPETMAGPVPTSPVRSSIGTAPPDTSTCSPSADIGTTTEGDSIQAGEESPFSDSVTLEQTTSNIGGTSGRVSLWMQWVLPKITIKLFAPDPENKGTEVCMVSELEDLSASIDVQDVYTKVKCKIESFNIDHYRSRPGEGWQSGHFEGVFLQCKEKSVPWGRVLVFGAMWRCLPFLY>sp|Q7Z7G8-4|VP13B_HUMAN Isoform 4 of Vacuolar protein sorting-associatedprotein 13B OS=Homo sapiens OX=9606 GN=VPS13BMLESYVTPILMSYVNRYIKNLKPSDLQLSLWGGDVVLSKLELKLDVLEQELKLPFTFLSGHIHELRIHVPWTKLGSEPVVITINTMECILKLKDGIQDDHESCGSNSTNRSTAESTKSSIKPRRMQQAAPTDPDLPPGYVQSLIRRVVNNVNIVINNLILKYVEDDIVLSVNITSAECYTVGELWDRAFMDISATDLVLRKVINFSDCTVCLDKRNASGKIEFYQDPLLYKCSFRTRLHFTYENLNSKMPSVIKIHTLVESLKLSITDQQLPMFIRIMQLGIALYYGEIGNFKEGEIEDLTCHNKDMLGNITGSEDETRIDMQYPAQHKGQELYSQQDEEQPQGWVSWAWSFVPAIVSYDDGEEDFVGNDPASTMHQQKAQTLKDPIVSIGFYCTKATVTFKLTEMQVESSYYSPQKVKSKEVLCWEQEGTTVEALMMGEPFFDCQIGFVGCRAMCLKGIMGVKDFEENMNRSETEACFFICGDNLSTKGFTYLTNSLFDYRSPENNGTRAEFILDSTHHKETYTEIAGMQRFGAFYMDYLYTMENTSGKGSTNQQDFSSGKSEDLGTVQEKSTKSLVIGPLDFRLDSSAVHRILKMIVCALEHEYEPYSRLKSDIKDENETILNPEEVALLEEYIPTRHTSVTLLKCTCTISMAEFNLLDHLLPVIMGEKNSSNFMNTTNFQSLRPLPSIRILVDKINLEHSVPMYAEQLVHVVSSLTQPSDNLLHYCYVHCYLKIFGFQAGLTSLDCSGSYCLPVPVIPSFSTALYGKLLKLPTCWTKRSQIAITEGIFELPNLTIQATRAQTLLLQAIYQSWSHLGNVSSSAVIEALINEIFLSIEIGSCYVAQVDLELLASNDPPTSTS>sp|Q7Z7G8-5|VP13B_HUMAN Isoform 5 of Vacuolar protein sorting-associatedprotein 13B OS=Homo sapiens OX=9606 GN=VPS13BMLESYVTPILMSYVNRYIKNLKPSDLQLSLWGGDVVLSKLELKLDVLEQELKLPFTFLSGHIHELRIHVPWTKLGSEPVVITINTMECILKLKDGIQDDHESCGSNSTNRSTAESTKSSIKPRRMQQAAPTDPDLPPGYVQSLIRRVVNNVNIVINNLILKYVEDDIVLSVNITSAECYTVGELWDRAFMDISATDLVLRKVINFSDCTVCLDKRNASGKIEFYQDPLLYKCSFRTRLHFTYENLNSKMPSVIKIHTLVESLKLSITDQQLPMFIRIMQLGIALYYGEIGNFKEGEIEDLTCHNKDMLGNITGSEDETRIDMQYPAQHKGQELYSQQDEEQPQGWVSWAWSFVPAIVSYDDGEEDFVGNDPASTMHQQKAQTLKDPIVSIGFYCTKATVTFKVGLFSCCLYLYQL>sp|Q7Z7G8-6|VP13B_HUMAN Isoform 6 of Vacuolar protein sorting-associatedprotein 13B OS=Homo sapiens OX=9606 GN=VPS13BMLESYVTPILMSYVNRYIKNLKPSDLQLSLWGGDVVLSKLELKLDVLEQELKLPFTFLSGHIHELRIHVPWTKLGSEPVVITINTMECILKLKDGIQDDHESCGSNSTNRSTAESTKSSIKPRRMQQAAPTDPDLPPGYVQSLIRRVVNNVNIVINNLILKYVEDDIVLSVNITSAECYTVGELWDRAFMDISATDLVLRKVINFSDCTVCLDKRNASGKIEFYQDPLLYKCSFRTRLHFTYENLNSKMPSVIKIHTLVESLKLSITDQQLPMFIRIMQLGIALYYGEIGNFKEGEIEDLTCHNKDMLGNITGSEDETRIDMQYPAQHKGQELYSQQDEEQPQGWVSWAWSFVPAIVSYDDGEEDFVGNDPASTMHQQKAQTLKDPIVSIGFYCTKATVTFKLTEMQVESSYYSPQKVKSKEVLCWEQEGTTVEALMMGEPFFDCQIGFVGCRAMCLKGIMGVKDFEENMNRSETEACFFICGDNLSTKGFTYLTNSLFDYRSPENNGTRAEFILDSTHHKETYTEIAGMQRFGAFYMDYLYTMENTSGKGSTNQQDFSSGKSEDLGTVQEKSTKSLVIGPLDFRLDSSAVHRILKMIVCALEHEYEPYSRLKSDIKDENETILNPEEVALLEEYIPTRHTSVTLLKCTCTISMAEFNLLDHLLPVIMGEKNSSNFMNTTNFQSLRPLPSIRILVDKINLEHSVPMYAEQLVHVVSSLTQPSDNLLHYCYVHCYLKIFGFQAGLTSLDCSGSYCLPVPVIPSFSTALYGKLLKLPTCWTKRSQIAITEGIFELPNLTIQATRAQTLLLQAIYQSWSHLGNVSSSAVIEALINEIFLSIGVKSKNPLPTLEGSIQNVELKYCSTSLVKCASGTMGSIKICAKAPVDSGKEKLIPLLQGPSDTKDLHSTKWLNESRKPESLLAPDLMAFTIQVPQYIDYCHNSGAVLLCSIQGLAVNIDPILYTWLIYQPQKRTSRHMQQPVVAVPLVMPVCRRKEDEVSIGSAPLAKQQSYQASEYASSPVKTKTVTESRPLSVPVKAMLNISESCRSPEERMKEFIGIVWNAVKHLTLQLEVQSCCVFIPNDSLPSPSTIVSGDIPGTVRSWYHGQTSMPGTLVLCLPQIKIISAGHKYMEPLQEIPFVIPRPILEEGDAFPWTISLHNFSIYTLLGKQVTLCLVEPMGCTSTLAVTSQKLLATGPDTRHSFVVCLHVDLESLEIKCSNPQVQLFYELTDIMNKVWNKIQKRGNLNLSPTSPETMAGPVPTSPVRSSIGTAPPDTSTCSPSADIGTTTEGDSIQAGEESPFSDSVTLEQTTSNIGGTSGRVSLWMQWVLPKITIKLFAPDPENKGTEVCMVSELEDLSASIDVQDVYTKVKCKIESFNIDHYRSSLGEECWSLGQCGGVFLSCTDKLNRRTLLVRPISKQDPFSNCSGFFPSTTTKLLDGTHQQHGFLSLTYTKAVTKNVRHKLTSRNERRSFHKLSEGLMDGSPHFLHEILLSAQAFDIVLYFPLLNAIASIFQAKLPKTQKEKRKSPGQPMRTHTLTSRNLPLIYVNTSVIRIFIPKTEEMQPTVEANQAAKEDTVVLKIGSVAMAPQADNPLGRSVLRKDIYQRALNLGILRDPGSEIEDRQYQIDLQSINIGTAQWHQLKPEKESVSGGVVTETERNSQNPALEWNMASSIRRHQERRAILTPVLTDFSVRITGAPAVIFTKVVSPENLHTEEILVCGHSLEVNITTNLDFFLSVAQVQLLHQLIVANMTGLEPSNKAAEISKQEQKKVDIFDGGMAETSSRYSGAQDSGIGSDSVKIRIVQIEQHSGASQHRIARPSRQSSIVKNLNFIPFDIFITASRISLMTYSCMALSKSKSQEQKNNEKTDKSSLNLPEVDSDVAKPNQACISTVTAEDLLRSSISFPSGKKIGVLSLESLHASTRSSARQALGITIVRQPGRRGTGDLQLEPFLYFIVSQPSLLLSCHHRKQRVEVSIFDAVLKGVASDYKCIDPGKTLPEALDYCTVWLQTVPGEIDSKSGIPPSFITLQIKDFLNGPADVNLDISKPLKANLSFTKLDQINLFLKKIKNAHSLAHSEETSAMSNTMVNKDDLPVSKYYRGKLSKPKIHGDGVQKISAQENMWRAVSCFQKISVQTTQIVISMETVPHTSKPCLLASLSNLNGSLSVKATQKVPGIILGSSFLLSINDFLLKTSLKERSRILIGPCCATANLEAKWCKHSGNPGPEQSIPKISIDLRGGLLQVFWGQEHLNCLVLLHELLNGYLNEEGNFEVQVSEPVPQMSSPVEKNQTFKSEQSSDDLRTGLFQYVQDAESLKLPGVYEVLFYNETEDCPGMMLWRYPEPRVLTLVRITPVPFNTTEDPDISTADLGDVLQVPCSLEYWDELQKVFVAFREFNLSESKVCELQLPDINLVNDQKKLVSSDLWRIVLNSSQNGADDQSSASESGSQSTCDPLVTPTALAACTRVDSCFTPWFVPSLCVSFQFAHLEFHLCHHLDQLGTAAPQYLQPFVSDRNMPSELEYMIVSFREPHMYLRQWNNGSVCQEIQFLAQADCKLLECRNVTMQSVVKPFSIFGQMAVSSDVVEKLLDCTVIVDSVFVNLGQHVVHSLNTAIQAWQQNKCPEVEELVFSHFVICNDTQETLRFGQVDTDENILLASLHSHQYSWRSHKSPQLLHICIEGWGNWRWSEPFSVDHAGTFIRTIQYRGRTASLIIKVQQLNGVQKQIIICGRQIICSYLSQSIELKVVQHYIGQDGQAVVREHFDCLTAKQKLPSYILENNELTELCVKAKGDEDWSRDVCLESKAPEYSIVIQVPSSNSSIIYVWCTVLTLEPNSQVQQRMIVFSPLFIMRSHLPDPIIIHLEKRSLGLSETQIIPGKGQEKPLQNIEPDLVHHLTFQAREEYDPSDCAVPISTSLIKQIATKVHPGGTVNQILDEFYGPEKSLQPIWPYNKKDSDRNEQLSQWDSPMRVKLSIWKPYVRTLLIELLPWALLINESKWDLWLFEGEKIVLQVPAGKIIIPPNFQEAFQIGIYWANTNTVHKSVAIKLVHNLTSPKWKDGGNGEVVTLDEEAFVDTEIRLGAFPGHQKLCQFCISSMVQQGIQIIQIEDKTTIINNTPYQIFYKPQLSVCNPHSGKEYFRVPDSATFSICPGGEQPAMKSSSLPCWDLMPDISQSVLDASLLQKQIMLGFSPAPGADSSQCWSLPAIVRPEFPRQSVAVPLGNFRENGFCTRAIVLTYQEHLGVTYLTLSEDPSPRVIIHNRCPVKMLIKENIKDIPKFEVYCKKIPSECSIHHELYHQISSYPDCKTKDLLPSLLLRVEPLDEVTTEWSDAIDINSQGTQVVFLTGFGYVYVDVVHQCGTVFITVAPEGKAGPILTNTNRAPEKIVTFKMFITQLSLAVFDDLTHHKASAELLRLTLDNIFLCVAPGAGPLPGEEPVAALFELYCVEICCGDLQLDNQLYNKSNFHFAVLVCQGEKAEPIQCSKMQSLLISNKELEEYKEKCFIKLCITLNEGKSILCDINEFSFELKPARLYVEDTFVYYIKTLFDTYLPNSRLAGHSTHLSGGKQVLPMQVTQHARALVNPVKLRKLVIQPVNLLVSIHASLKLYIASDHTPLSFSVFERGPIFTTARQLVHALAMHYAAGALFRAGWVVGSLDILGSPASLVRSIGNGVADFFRLPYEGLTRGPGAFVSGVSRGTTSFVKHISKGTLTSITNLATSLARNMDRLSLDEEHYNRQEEWRRQLPESLGEGLRQGLSRLGISLLGAIAGIVDQPMQNFQKTSEAQASAGHKAKGVISGVGKGIMGVFTKPIGGAAELVSQTGYGILHGAGLSQLPKQRHQPSDLHADQAPNSHVKYVWKMLQSLGRPEVHMALDVVLVRGSGQEHEGCLLLTSEVLFVVSVSEDTQQQAFPVTEIDCAQDSKQNNLLTVQLKQPRVACDVEVDGVRERLSEQQYNRLVDYITKTSCHLAPSCSSMQIPCPVVAAEPPPSTVKTYHYLVDPHFAQVFLSKFTMVKNKALRKGFP>sp|Q53GI3|ZN394_HUMAN Zinc finger protein 394 OS=Homo sapiens OX=9606GN=ZNF394 PE=1 SV=2MNSSLTAQRRGSDAELGPWVMAARSKDAAPSQRDGLLPVKVEEDSPGSWEPNYPAASPDPETSRLHFRQLRYQEVAGPEEALSRLRELCRRWLRPELLSKEQILELLVLEQFLTILPEELQAWVREHCPESGEEAVAVVRALQRALDGTSSQGMVTFEDTAVSLTWEEWERLDPARRDFCRESAQKDSGSTVPPSLESRVENKELIPMQQILEEAEPQGQLQEAFQGKRPLFSKCGSTHEDRVEKQSGDPLPLKLENSPEAEGLNSISDVNKNGSIEGEDSKNNELQNSARCSNLVLCQHIPKAERPTDSEEHGNKCKQSFHMVTWHVLKPHKSDSGDSFHHSSLFETQRQLHEERPYKCGNCGKSFKQRSDLFRHQRIHTGEKPYGCQECGKSFSQSAALTKHQRTHTGEKPYTCLKCGERFRQNSHLNRHQSTHSRDKHFKCEECGETCHISNLFRHQRLHKGERPYKCEECEKSFKQRSDLFKHHRIHTGEKPYGCSVCGKRFNQSATLIKHQRIHTGEKPYKCLECGERFRQSTHLIRHQRIHQNKVLSAGRGGSRL>sp|Q53GI3-3|ZN394_HUMAN Isoform 2 of Zinc finger protein 394 OS=Homosapiens OX=9606 GN=ZNF394MNSSLTAQRRGSDAELGPWVMAARSKDAAPSQRDGLLPVKVEEDSPGSWEPNYPAASPDPETSRLHFRQLRYQEVAGPEEALSRLRELCRRWLRPELLSKEQILELLVLEQFLTILPEELQAWVREHCPESGEEAVAVVRALQRALDGTSSQVWKAEWRTKS>sp|Q5BKY6|YV018_HUMAN Putative uncharacterized protein DKFZp434K191OS=Homo sapiens OX=9606 PE=1 SV=1MKKRHREGCDMPGPWSTLRSHRGHHCPHLHPVLRRPTLTDVEGCLQCLDVCGHPRHAVDAHLLHASALDLLHALAHDVGHLGPLSPAGGGNVLSVLTALLGP>sp|Q8WV99|ZFN2B_HUMAN AN1-type zinc finger protein 2B OS=Homo sapiensOX=9606 GN=ZFAND2B PE=1 SV=1MEFPDLGAHCSEPSCQRLDFLPLKCDACSGIFCADHVAYAQHHCGSAYQKDIQVPVCPLCNVPVPVARGEPPDRAVGEHIDRDCRSDPAQQKRKIFTNKCERAGCRQREMMKLTCERCSRNFCIKHRHPLDHDCSGEGHPTSRAGLAAISRAQAVASTSTVPSPSQTMPSCTSPSRATTRSPSWTAPPVIALQNGLSEDEALQRALEMSLAETKPQVPSCQEEEDLALAQALSASEAEYQRQQAQSRSSKPSNCSLC>sp|Q8WV99-2|ZFN2B_HUMAN Isoform 2 of AN1-type zinc finger protein 2BOS=Homo sapiens OX=9606 GN=ZFAND2BMEFPDLGAHCSEPSCQRLDFLPLKCDACSGIFCADHVAYAQHHCGSAYQKDIQVPVCPLCNVPVPVARGEPPDRAVGEHIDRDCRSDPAQQKRKIFTNKCERAGCRQREMMKLTCERCSRNFCIKHRHPLDHDCSGEGHPTSRAGLAAISRAQAVASTSTVPSPSQTMPSCTSPSR>sp|Q6ZN11|ZN793_HUMAN Zinc finger protein 793 OS=Homo sapiens OX=9606GN=ZNF793 PE=2 SV=2MIEYQIPVSFKDVVVGFTQEEWHRLSPAQRALYRDVMLETYSNLVSVGYEGTKPDVILRLEQEEAPWIGEAACPGCHCWEDIWRVNIQRKRRQDMLLRPGAAISKKTLPKEKSCEYNKFGKISLLSTDLFSSIQSPSNWNPCGKNLNHNLDLIGFKRNCAKKQDECYAYGKLLQRINHGRRPNGEKPRGCSHCEKAFTQNPALMYKPAVSDSLLYKRKRVPPTEKPHVCSECGKAFCYKSEFIRHQRSHTGEKPYGCTDCGKAFSHKSTLIKHQRIHTGVRPFECFFCGKAFTQKSHRTEHQRTHTGERPFVCSECGKSFGEKSYLNVHRKMHTGERPYRCRECGKSFSQKSCLNKHWRTHTGEKPYGCNECGKAFYQKPNLSRHQKIHARKNAYRNENLIIVGNT>sp|Q6ZN11-2|ZN793_HUMAN Isoform 2 of Zinc finger protein 793 OS=Homosapiens OX=9606 GN=ZNF793MIEYQIPVSFKDVVVGFTQEEWHRLSPAQRALYRDVMLETYSNLVSVGYEGTKPDVILRLEQEEAPWIGEAACPGCHCWEDIWRVNIQRKRRQDMLLRPGAAISKKTLPKEKSCEYNKFGKISLLSTDLFSSIQSPSNWNPCGKNLNHNLDLIGFKRNCAKKQDECYAYGKLLQRINHGRRPNGEKPRGCSHCEKAFTQNPALMYKPAVSDSLLYKRKRVPPTEKPHVCSECGKAFCYKSEFIRHQRSHTGEKPYGCTDCGKAFSHKSTLIKHQRIHTGVRPFECFFCGKAFTQKSHRTEHQRTHTGERPFVCSECGKSFGEKSYLNVHRKMHTGERPYRCRECGKSFSQKSCLNKHWRTHFGESSLRSKSSNT>sp|Q6ZN11-3|ZN793_HUMAN Isoform 3 of Zinc finger protein 793 OS=Homosapiens OX=9606 GN=ZNF793MLLRPGAAISKKTLPKEKSCEYNKFGKISLLSTDLFSSIQSPSNWNPCGKNLNHNLDLIGFKRNCAKKQDECYAYGKLLQRINHGRRPNGEKPRGCSHCEKAFTQNPALMYKPAVSDSLLYKRKRVPPTEKPHVCSECGKAFCYKSEFIRHQRSHTGEKPYGCTDCGKAFSHKSTLIKHQRIHTGVRPFECFFCGKAFTQKSHRTEHQRTHTGERPFVCSECGKSFGEKSYLNVHRKMHTGERPYRCRECGKSFSQKSCLNKHWRTHTGEKPYGCNECGKAFYQKPNLSRHQKIHARKNAYRNENLIIVGNT>sp|Q5H9K5|ZMAT1_HUMAN Zinc finger matrin-type protein 1 OS=Homo sapiensOX=9606 GN=ZMAT1 PE=2 SV=1MESCSVTRLECSGAISAHCSLHLPGSSDSPASASQIAGTTDAIWNEQEKAELFTDKFCQVCGVMLQFESQRISHYEGEKHAQNVSFYFQMHGEQNEVPGKKMKMHVENFQVHRYEGVDKNKFCDLCNMMFSSPLIAQSHYVGKVHAKKLKQLMEEHDQASPSGFQPEMAFSMRTYVCHICSIAFTSLDMFRSHMQGSEHQIKESIVINLVKNSRKTQDSYQNECADYINVQKARGLEAKTCFRKMEESSLETRRYREVVDSRPRHRMFEQRLPFETFRTYAAPYNISQAMEKQLPHSKKTYDSFQDELEDYIKVQKARGLDPKTCFRKMRENSVDTHGYREMVDSGPRSRMCEQRFSHEASQTYQRPYHISPVESQLPQWLPTHSKRTYDSFQDELEDYIKVQKARGLEPKTCFRKIGDSSVETHRNREMVDVRPRHRMLEQKLPCETFQTYSGPYSISQVVENQLPHCLPAHDSKQRLDSISYCQLTRDCFPEKPVPLSLNQQENNSGSYSVESEVYKHLSSENNTADHQAGHKQKHQKRKRHLEEGKERPEKEQSKHKRKKSYEDTDLDKDKSIRQRKREEDRVKVSSGKLKHRKKKKSHDVPSEKEERKHRKEKKKSVEERTEEEMLWDESILGF>sp|Q5H9K5-2|ZMAT1_HUMAN Isoform 2 of Zinc finger matrin-type protein 1OS=Homo sapiens OX=9606 GN=ZMAT1MRTYVCHICSIAFTSLDMFRSHMQGSEHQIKESIVINLVKNSRKTQDSYQNECADYINVQKARGLEAKTCFRKMEESSLETRRYREVVDSRPRHRMFEQRLPFETFRTYAAPYNISQAMEKQLPHSKKTYDSFQDELEDYIKVQKARGLDPKTCFRKMRENSVDTHGYREMVDSGPRSRMCEQRFSHEASQTYQRPYHISPVESQLPQWLPTHSKRTYDSFQDELEDYIKVQKARGLEPKTCFRKIGDSSVETHRNREMVDVRPRHRMLEQKLPCETFQTYSGPYSISQVVENQLPHCLPAHDSKQRLDSISYCQLTRDCFPEKPVPLSLNQQENNSGSYSVESEVYKHLSSENNTADHQAGHKQKHQKRKRHLEEGKERPEKEQSKHKRKKSYEDTDLDKDKSIRQRKREEDRVKVSSGKLKHRKKKKSHDVPSEKEERKHRKEKKKSVEERTEEEMLWDESILGF>sp|Q0VGE8|ZN816_HUMAN Zinc finger protein 816 OS=Homo sapiens OX=9606GN=ZNF816 PE=2 SV=2MLREEATKKSKEKEPGMALPQGRLTFRDVAIEFSLEEWKCLNPAQRALYRAVMLENYRNLEFVDSSLKSMMEFSSTRHSITGEVIHTGTLQRHKSHHIGDFCFPEMKKDIHHFEFQWQEVERNGHEAPMTKIKKLTGSTDRSDHRHAGNKPIKDQLGLSFHSHLPELHMFQTKGKISNQLDKSIGASSASESQRISCRLKTHISNKYGKNFLHSSFTQIQEICMREKPCQSNECGKAFNYSSLLRRHHITHSREREYKCDVCGKIFNQKQYIVYHHRCHTGEKTYKCNECGKTFTQMSSLVCHRRLHTGEKPYKCNECGKTFSEKSSLRCHRRLHTGEKPYKCNECGKTFGRNSALVIHKAIHTGEKPYKCNECGKTFSQKSSLQCHHILHTGEKPYKCEECDNVYIRRSHLERHRKIHTGEGSYKCKVCDKVFRSDSYLAEHQRVHTGEKPYKCNKCGRSFSRKSSLQYHHTLHTGEKPYTCNECGKVFSRRENLARHHRLHAGEKPYKCEECDKVFSRRSHLERHRRIHTGEKPYKCKVCDKAFRSDSCLANHTRVHTGEKPYKCNKCAKVFNQKGILAQHQRVHTGEKPYKCNECGKVFNQKASLAKHQRVHTAEKPYKCNECGKAFTGQSTLIHHQAIHGCRETLQM>sp|Q8IW36|ZN695_HUMAN Zinc finger protein 695 OS=Homo sapiens OX=9606GN=ZNF695 PE=1 SV=4MGLLAFRDVALEFSPEEWECLDPAQRSLYRDVMLENYRNLISLGEDSFNMQFLFHSLAMSKPELIICLEARKEPWNVNTEKTARHSVLSSYLTEDILPEQGLQVSFQKVMLRRYERCCLEKLRLRNDWEIVGEWKGQKASYNGLDLCSATTHSKNFQCNKCVKGFSKFANLNKCKISHTGEKPFKCKECGNVSCMSLIMTQQQRIHIGENPYQCKKCGKAFNECSCFTDCKRIHVGEKHCKCEECNNIFKSCSSLAVVEKNHTEKKTYRCEECGKAFNLCSVLTKHKKIHTGEKPYKCEECGKSFKLFPYLTQHKRIHSREKPYKCEECGKVFKLLSYLTQHRRIHTGEKTFRCEECGKAFNQSSHLTEHRRIHTGEKPYKCEECGKAFTWFSYLIQHKRIHTGQKPYKCEECGKAFTWFSYLTQHKRIHTGEKPYKCDECGKAFNWFSYLTNHKRIHTGEKPYKCEECGKAFGQSSHLSKHKTIHTREKPYKCEECGKAFNHSAQLAVHEKTHT>sp|Q8IW36-1|ZN695_HUMAN Isoform 1 of Zinc finger protein 695 OS=Homosapiens OX=9606 GN=ZNF695MGLLAFRDVALEFSPEEWECLDPAQRSLYRDVMLENYRNLISLGEDSFNMQFLFHSLAMSKPELIICLEARKEPWNVNTEKTARHSVLSSYLTEDILPEQGLQVSFQKVMLRRYERCCLEKLRLRNDWEIPCEDVLASPLPSAMILSFLRPPQKQKHVKPTEPVQSSTIELL>sp|Q8IW36-2|ZN695_HUMAN Isoform 2 of Zinc finger protein 695 OS=Homosapiens OX=9606 GN=ZNF695MGLLAFRDVALEFSPEEWECLDPAQRSLYRDVMLENYRNLISLGEDSFNMQFLFHSLAMSKPELIICLEARKEPWNVNTEKTARHSVLSSYLTEDILPEQGLQVSFQKVMLRRYERCCLEKLRLRNDWEIVAM>sp|Q8IW36-3|ZN695_HUMAN Isoform 3 of Zinc finger protein 695 OS=Homosapiens OX=9606 GN=ZNF695MGLLAFRDVALEFSPEEWECLDPAQRSLYRDVMLENYRNLISLGEDSFNMQFLFHSLAMSKPELIICLEARKEPWNVNTEKTARHSVM>sp|Q8TB69|ZN519_HUMAN Zinc finger protein 519 OS=Homo sapiens OX=9606GN=ZNF519 PE=2 SV=2MELLTFRDVAIEFSPEEWKCLDPAQQNLYRDVMLENYRNLVSLAVYSYYNQGILPEQGIQDSFKKATLGRYGSCGLENICLWKNWESIGEGEGQKECYNLCSQYLTTSHNKHLTVKGDKEYRIFQKKPQFLSAAPTEPCIPMNKYQHKFLKSVFCNKNQINFNHDSNISKHHSTHFLENYYNCNECEKVFYQSSKLIFPENIHIQKKPYNSNECGETSDPFSKLTQHQRIYIGESSQRCNKKCIIVFSQSHLKGHKIINTGEKSVKYKERGKAFTRGLHLGHQKIHTGEKPYKCKKCDKAFNKSSHLAQHQRIHTGEKPFKCKECGKAFNRGSYLTQHQRIHTGERAFKCEECGKAFNRGSYLTQHQRIHTGEKPFRCKECGKAFNRSSYVTQHQRMHTGEKPFKCKECGKAFNRASHLTQHQRIHTGEKHFKCKECGKAFNRGSHLTRHQRIHTGEKSFKCEECGKAFIWGSHLTQHQRVHTGEKFFKCKECGKAFTRSSHLTQHQRIHTGEKPFKCKECGKAFNRRSTLTQHQIIHTR>sp|Q86UE3|ZN546_HUMAN Zinc finger protein 546 OS=Homo sapiens OX=9606GN=ZNF546 PE=1 SV=2MQVDPPLHGPPNDFLIFQIIPLHSLSIMPRFLWILCFSMEETQGELTSSCGSKTMANVSLAFRDVSIDLSQEEWECLDAVQRDLYKDVMLENYSNLVSLGYTIPKPDVITLLEQEKEPWIVMREGTRNWFTDLEYKYITKNLLSEKNVCKIYLSQLQTGEKSKNTIHEDTIFRNGLQCKHEFERQERHQMGCVSQMLIQKQISHPLHPKIHAREKSYECKECRKAFRQQSYLIQHLRIHTGERPYKCMECGKAFCRVGDLRVHHTIHAGERPYECKECGKAFRLHYHLTEHQRIHSGVKPYECKECGKAFSRVRDLRVHQTIHAGERPYECKECGKAFRLHYQLTEHQRIHTGERPYECKVCGKTFRVQRHISQHQKIHTGVKPYKCNECGKAFSHGSYLVQHQKIHTGEKPYECKECGKSFSFHAELARHRRIHTGEKPYECRECGKAFRLQTELTRHHRTHTGEKPYECKECGKAFICGYQLTLHLRTHTGEIPYECKECGKTFSSRYHLTQHYRIHTGEKPYICNECGKAFRLQGELTRHHRIHTCEKPYECKECGKAFIHSNQFISHQRIHTSESTYICKECGKIFSRRYNLTQHFKIHTGEKPYICNECGKAFRFQTELTQHHRIHTGEKPYKCTECGKAFIRSTHLTQHHRIHTGEKPYECTECGKTFSRHYHLTQHHRGHTGEKPYICNECGNAFICSYRLTLHQRIHTGELPYECKECGKTFSRRYHLTQHFRLHTGEKPYSCKECGNAFRLQAELTRHHIVHTGEKPYKCKECGKAFSVNSELTRHHRIHTGEKPYQCKECGKAFIRSDQLTLHQRNHISEEVLCIM>sp|P52742|ZN135_HUMAN Zinc finger protein 135 OS=Homo sapiens OX=9606GN=ZNF135 PE=1 SV=3MTPGVRVSTDPEQVTFEDVVVGFSQEEWGQLKPAQRTLYRDVMLDTFRLLVSVGHWLPKPNVISLLEQEAELWAVESRLPQGVYPDLETRPKVKLSVLKQGISEEISNSVILVERFLWDGLWYCRGEDTEGHWEWSCESLESLAVPVAFTPVKTPVLEQWQRNGFGENISLNPDLPHQPMTPERQSPHTWGTRGKREKPDLNVLQKTCVKEKPYKCQECGKAFSHSSALIEHHRTHTGERPYECHECLKGFRNSSALTKHQRIHTGEKPYKCTQCGRTFNQIAPLIQHQRTHTGEKPYECSECGKSFSFRSSFSQHERTHTGEKPYECSECGKAFRQSIHLTQHLRIHTGEKPYQCGECGKAFSHSSSLTKHQRIHTGEKPYECHECGKAFTQITPLIQHQRTHTGEKPYECGECGKAFSQSTLLTEHRRIHTGEKPYGCNECGKTFSHSSSLSQHERTHTGEKPYECSQCGKAFRQSTHLTQHQRIHTGEKPYECNDCGKAFSHSSSLTKHQRIHTGEKPYECNQCGRAFSQLAPLIQHQRIHTGEKPYECNQCGRAFSQSSLLIEHQRIHTKEKPYGCNECGKSFSHSSSLSQHERTHTGEKPYECHDCGKSFRQSTHLTQHRRIHTGEKPYACRDCGKAFTHSSSLTKHQRTHTG>sp|P52742-2|ZN135_HUMAN Isoform 2 of Zinc finger protein 135 OS=Homosapiens OX=9606 GN=ZNF135MELGSRRRSVGCRCRGLCLAVRREQVTFEDVVVGFSQEEWGQLKPAQRTLYRDVMLDTFRLLVSVGHWLPKPNVISLLEQEAELWAVESRLPQGVYPDLETRPKVKLSVLKQGISEEISNSVILVERFLWDGLWYCRGEDTEGHWEWSCESLESLAVPVAFTPVKTPVLEQWQRNGFGENISLNPDLPHQPMTPERQSPHTWGTRGKREKPDLNVLQKTCVKEKPYKCQECGKAFSHSSALIEHHRTHTGERPYECHECLKGFRNSSALTKHQRIHTGEKPYKCTQCGRTFNQIAPLIQHQRTHTGEKPYECSECGKSFSFRSSFSQHERTHTGEKPYECSECGKAFRQSIHLTQHLRIHTGEKPYQCGECGKAFTHSSSLTKHQRTHTG>sp|P52742-3|ZN135_HUMAN Isoform 3 of Zinc finger protein 135 OS=Homosapiens OX=9606 GN=ZNF135MTPGVRVSTDPEQVTFEDVVVGFSQEEWGQLKPAQRTLYRDVMLDTFRLLVSVGHWLPKPNVISLLEQEAELWAVESRLPQGVYPEIKGHFQFLLLSDLETRPKVKLSVLKQGISEEISNSVILVERFLWDGLWYCRGEDTEGHWEWSCESLESLAVPVAFTPVKTPVLEQWQRNGFGENISLNPDLPHQPMTPERQSPHTWGTRGKREKPDLNVLQKTCVKEKPYKCQECGKAFSHSSALIEHHRTHTGERPYECHECLKGFRNSSALTKHQRIHTGEKPYKCTQCGRTFNQIAPLIQHQRTHTGEKPYECSECGKSFSFRSSFSQHERTHTGEKPYECSECGKAFRQSIHLTQHLRIHTGEKPYQCGECGKAFSHSSSLTKHQRIHTGEKPYECHECGKAFTQITPLIQHQRTHTGEKPYECGECGKAFSQSTLLTEHRRIHTGEKPYGCNECGKTFSHSSSLSQHERTHTGEKPYECSQCGKAFRQSTHLTQHQRIHTGEKPYECNDCGKAFSHSSSLTKHQRIHTGEKPYECNQCGRAFSQLAPLIQHQRIHTGEKPYECNQCGRAFSQSSLLIEHQRIHTKEKPYGCNECGKSFSHSSSLSQHERTHTGEKPYECHDCGKSFRQSTHLTQHRRIHTGEKPYACRDCGKAFTHSSSLTKHQRTHTG>sp|P52742-4|ZN135_HUMAN Isoform 4 of Zinc finger protein 135 OS=Homosapiens OX=9606 GN=ZNF135MELGSRRRSVGCRCRGLCLAVRREQVTFEDVVVGFSQEEWGQLKPAQRTLYRDVMLDTFRLLVSVGHWLPKPNVISLLEQEAELWAVESRLPQGVYPEIKGHFQFLLLSDLETRPKVKLSVLKQGISEEISNSVILVERFLWDGLWYCRGEDTEGHWEWSCESLESLAVPVAFTPVKTPVLEQWQRNGFGENISLNPDLPHQPMTPERQSPHTWGTRGKREKPDLNVLQKTCVKEKPYKCQECGKAFSHSSALIEHHRTHTGERPYECHECLKGFRNSSALTKHQRIHTGEKPYKCTQCGRTFNQIAPLIQHQRTHTGEKPYECSECGKSFSFRSSFSQHERTHTGEKPYECSECGKAFRQSIHLTQHLRIHTGEKPYQCGECGKAFSHSSSLTKHQRIHTGEKPYECHECGKAFTQITPLIQHQRTHTGEKPYECGECGKAFSQSTLLTEHRRIHTGEKPYGCNECGKTFSHSSSLSQHERTHTGEKPYECSQCGKAFRQSTHLTQHQRIHTGEKPYECNDCGKAFSHSSSLTKHQRIHTGEKPYECNQCGRAFSQLAPLIQHQRIHTGEKPYECNQCGRAFSQSSLLIEHQRIHTKEKPYGCNECGKSFSHSSSLSQHERTHTGEKPYECHDCGKSFRQSTHLTQHRRIHTGEKPYACRDCGKAFTHSSSLTKHQRTHTG>sp|Q96NI8|ZN570_HUMAN Zinc finger protein 570 OS=Homo sapiens OX=9606GN=ZNF570 PE=2 SV=1MAVGLLKAMYQELVTFRDVAVDFSQEEWDCLDSSQRHLYSNVMLENYRILVSLGLCFSKPSVILLLEQGKAPWMVKRELTKGLCSGWEPICETEELTPKQDFYEEHQSQKIIETLTSYNLEYSSLREEWKCEGYFERQPGNQKACFKEEIITHEEPLFDEREQEYKSWGSFHQNPLLCTQKIIPKEEKVHKHDTQKRSFKKNLMAIKPKSVCAEKKLLKCNDCEKVFSQSSSLTLHQRIHTGEKPYKCIECGKAFSQRSNLVQHQRIHTGEKPYECKECRKAFSQNAHLVQHLRVHTGEKPYECKVCRKAFSQFAYLAQHQRVHTGEKPYECIECGKAFSNRSSIAQHQRVHTGEKPYECNVCGKAFSLRAYLTVHQRIHTGERPYECKECGKAFSQNSHLAQHQRIHTGEKPYKCQECRKAFSQIAYLAQHQRVHTGEKPYECIECGKAFSNDSSLTQHQRVHTGEKPYECTVCGKAFSYCGSLAQHQRIHTGERPYECKECKKTFRQHAHLAHHQRIHIGESLSPPNPVNHQVL>sp|Q96NI8-2|ZN570_HUMAN Isoform 2 of Zinc finger protein 570 OS=Homosapiens OX=9606 GN=ZNF570MAIKPKSVCAEKKLLKCNDCEKVFSQSSSLTLHQRIHTGEKPYKCIECGKAFSQRSNLVQHQRIHTGEKPYECKECRKAFSQNAHLVQHLRVHTGEKPYECKVCRKAFSQFAYLAQHQRVHTGEKPYECIECGKAFSNRSSIAQHQRVHTGEKPYECNVCGKAFSLRAYLTVHQRIHTGERPYECKECGKAFSQNSHLAQHQRIHTGEKPYKCQECRKAFSQIAYLAQHQRVHTGEKPYECIECGKAFSNDSSLTQHQRVHTGEKPYECTVCGKAFSYCGSLAQHQRIHTGERPYECKECKKTFRQHAHLAHHQRIHIGESLSPPNPVNHQVL>sp|Q6ZSS3|ZN621_HUMAN Zinc finger protein 621 OS=Homo sapiens OX=9606GN=ZNF621 PE=2 SV=1MLQTTWPQESVTFEDVAVYFTQNQWASLDPAQRALYGEVMLENYANVASLVAFPFPKPALISHLERGEAPWGPDPWDTEILRGISQGGESWIKNEGLVIKQEASEETELHRMPVGGLLRNVSQHFDFKRKALKQTFNLNPNLILRGGMKFYECKECGKIFRYNSKLIRHQMSHTGEKPFKCKECGKAFKSSYDCIVHEKNHIGEGPYECKECGKGLSSNTALTQHQRIHTGEKPYECKECGKAFRRSAAYLQHQRLHTGEKLYKCKECWKAFGCRSLFIVHQRIHTGEKPYQCKECGKAFTQKIASIQHQRVHTGEKPYECKVCGKAFKWYGSFVQHQKLHPVEKKPVKVLGPSLVSPQCSSPAIPPVLLQGSCSASAVAVPSLTFPHAVLIPTSGNFFMLLPTSGIPSSSAQIVRVFQGLTPTVKPSPVILTPSSHSS>sp|Q6ZSS3-2|ZN621_HUMAN Isoform 2 of Zinc finger protein 621 OS=Homosapiens OX=9606 GN=ZNF621MLQTTWPQESVTFEDVAVYFTQNQWASLDPAQRALYGEVMLENYANVASLVAFPFPKPALISHLERGEAPWGPDPWDTEILRGISQGGESWIKNEGLVIKQEASEETELHRMPVGGLLRNVSQHFDFKRKALKQTFNLNPNLILRGGSVEVRSLRPA>sp|Q6ZNG1|ZN600_HUMAN Zinc finger protein 600 OS=Homo sapiens OX=9606GN=ZNF600 PE=1 SV=2MMKEVLSTGQGNTEVIHTGTLQRYQSYHIGDFCFQEIEKEIHDIEFQCQEDERNGHEAPMTKIKKLTGSTDQHDHRHAGNKPIKDQLGSSFYSHLPELHIIQIKGKIGNQFEKSTSDAPSVSTSQRISPRPQIHISNNYGNNSPNSSLLPQKQEVYMREKSFQCNESGKAFNCSSLLRKHQIPHLGDKQYKCDVCGKLFNHKQYLTCHCRCHTGEKPYKCNECGKSFSQVSSLTCHRRLHTAVKSHKCNECGKIFGQNSALVIHKAIHTGEKPYKCNECDKAFNQQSNLARHRRIHTGEKPYKCEECDKVFSRKSTLESHKRIHTGEKPYKCKVCDTAFTWNSQLARHKRIHTGEKTYKCNECGKTFSHKSSLVCHHRLHGGEKSYKCKVCDKAFAWNSHLVRHTRIHSGGKPYKCNECGKTFGQNSDLLIHKSIHTGEQPYKYEECEKVFSCGSTLETHKIIHTGEKPYKCKVCDKAFACHSYLAKHTRIHSGEKPYKCNECSKTFRLRSYLASHRRVHSGEKPYKCNECSKTFSQRSYLHCHRRLHSGEKPYKCNECGKTFSHKPSLVHHRRLHTGEKSYKCTVCDKAFVRNSYLARHTRIHTAEKPYKCNECGKAFNQQSQLSLHHRIHAGEKLYKCETCDKVFSRKSHLKRHRRIHPGKKPYKCKVCDKTFGSDSHLKQHTGLHTGEKPYKCNECGKAFSKQSTLIHHQAVHGVGKLD>sp|Q03923|ZNF85_HUMAN Zinc finger protein 85 OS=Homo sapiens OX=9606GN=ZNF85 PE=1 SV=3MGPLTFRDVAIEFSLKEWQCLDTAQRNLYRNVMLENYRNLVFLGITVSKPDLITCLEQGKEAWSMKRHEIMVAKPTVMCSHFAQDLWPEQNIKDSFQKVTLKRYGKCRHENLPLRKGCESMDECKMHKGGCNGLNQCLTATQSKIFQCDKYVKVAHKFSNSNRHEIRHTKKKPFKCTKCGKSFGMISCLTEHSRIHTRVNFYKCEECGKAFNWSSTLTKHKRIHTGEKPYKCEECGKAFNQSSNLIKHKKIHTGEKPYKCEECGKTFNRFSTLTTHKIIHTGEKPYKCKECGKAFNRSSTLTTHRKIHTGEKPYKCEECGKAFKQSSNLTTHKIIHTGEKPYKCKKCGKAFNQSAHLTTHEVIHTGEKPYKCEKCGKAFNHFSHLTTHKIIHTGEKPYKCKECGKAFKHSSTLTKHKIIHTGEKPYKCKECEKAFNQSSKLTEHKKIHTGEKPYECEKCGKAFNQSSNLTRHKKSHTEEKPYKCEECGKGFKWPSTLTIHKIIHTGEKPYKCEECGKAFNQSSKLTKHKKIHTGEKPYTCEECGKAFNQSSNLTKHKRIHTGEKPYKCEECDKAFKWSSVLTKHKIIHTGEKLQI>sp|Q03923-2|ZNF85_HUMAN Isoform 2 of Zinc finger protein 85 OS=Homosapiens OX=9606 GN=ZNF85MGPLTFRDVAIEFSLKEWQCLDTAQRNLYRNVMLENYRNLVFLVMCSHFAQDLWPEQNIKDSFQKVTLKRYGKCRHENLPLRKGCESMDECKMHKGGCNGLNQCLTATQSKIFQCDKYVKVAHKFSNSNRHEIRHTKKKPFKCTKCGKSFGMISCLTEHSRIHTRVNFYKCEECGKAFNWSSTLTKHKRIHTGEKPYKCEECGKAFNQSSNLIKHKKIHTGEKPYKCEECGKTFNRFSTLTTHKIIHTGEKPYKCKECGKAFNRSSTLTTHRKIHTGEKPYKCEECGKAFKQSSNLTTHKIIHTGEKPYKCKKCGKAFNQSAHLTTHEVIHTGEKPYKCEKCGKAFNHFSHLTTHKIIHTGEKPYKCKECGKAFKHSSTLTKHKIIHTGEKPYKCKECEKAFNQSSKLTEHKKIHTGEKPYECEKCGKAFNQSSNLTRHKKSHTEEKPYKCEECGKGFKWPSTLTIHKIIHTGEKPYKCEECGKAFNQSSKLTKHKKIHTGEKPYTCEECGKAFNQSSNLTKHKRIHTGEKPYKCEECDKAFKWSSVLTKHKIIHTGEKLQI>sp|Q03923-3|ZNF85_HUMAN Isoform 3 of Zinc finger protein 85 OS=Homosapiens OX=9606 GN=ZNF85MGPLTFRDVAIEFSLKEWQCLDTAQRNLYRNVMLENYRNLVFLGITVSKPDLITCLEQGKEAWSMKRHEIMVAKPTESYSVTQSGMQ>sp|O43257|ZNHI1_HUMAN Zinc finger HIT domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZNHIT1 PE=1 SV=1MVEKKTSVRSQDPGQRRVLDRAARQRRINRQLEALENDNFQDDPHAGLPQLGKRLPQFDDDADTGKKKKKTRGDHFKLRFRKNFQALLEEQNLSVAEGPNYLTACAGPPSRPQRPFCAVCGFPSPYTCVSCGARYCTVRCLGTHQETRCLKWTV>sp|Q8IYH5|ZZZ3_HUMAN ZZ-type zinc finger-containing protein 3 OS=Homosapiens OX=9606 GN=ZZZ3 PE=1 SV=1MAASRSTRVTRSTVGLNGLDESFCGRTLRNRSIAHPEEISSNSQVRSRSPKKRPEPVPIQKGNNNGRTTDLKQQSTRESWVSPRKRGLSSSEKDNIERQAIENCERRQTEPVSPVLKRIKRCLRSEAPNSSEEDSPIKSDKESVEQRSTVVDNDADFQGTKRACRCLILDDCEKREIKKVNVSEEGPLNSAVVEEITGYLAVNGVDDSDSAVINCDDCQPDGNTKQNSIGSYVLQEKSVAENGDTDTQTSMFLDSRKEDSYIDHKVPCTDSQVQVKLEDHKIVTACLPVEHVNQLTTEPATGPFSETQSSLRDSEEEVDVVGDSSASKEQCKENTNNELDTSLESMPASGEPEPSPVLDCVSAQMMSLSEPQEHRYTLRTSPRRAAPTRGSPTKNSSPYRENGQFEENNLSPNETNATVSDNVSQSPTNPGEISQNEKGICCDSQNNGSEGVSKPPSEARLNIGHLPSAKESASQHITEEEDDDPDVYYFESDHVALKHNKDYQRLLQTIAVLEAQRSQAVQDLESLGRHQREALKNPIGFVEKLQKKADIGLPYPQRVVQLPEIVWDQYTHSLGNFEREFKNRKRHTRRVKLVFDKVGLPARPKSPLDPKKDGESLSYSMLPLSDGPEGSSSRPQMIRGRLCDDTKPETFNQLWTVEEQKKLEQLLIKYPPEEVESRRWQKIADELGNRTAKQVASRVQKYFIKLTKAGIPVPGRTPNLYIYSKKSSTSRRQHPLNKHLFKPSTFMTSHEPPVYMDEDDDRSCFHSHMNTAVEDASDDESIPIMYRNLPEYKELLQFKKLKKQKLQQMQAESGFVQHVGFKCDNCGIEPIQGVRWHCQDCPPEMSLDFCDSCSDCLHETDIHKEDHQLEPIYRSETFLDRDYCVSQGTSYNYLDPNYFPANR>sp|Q8IYH5-2|ZZZ3_HUMAN Isoform 2 of ZZ-type zinc finger-containingprotein 3 OS=Homo sapiens OX=9606 GN=ZZZ3MAASRSTRVTRSTVGLNGLDESFCGRTLRNRSIAHPEEISSNSQVRSRSPKKRPEPVPIQKGNNNGRTTDLKQQSTRESWVSPRKRGLSSSEKDNIERQAIENCERRQTEPVSPVLKRIKRCLRSEAPNSSEEDSPIKSDKESVEQRSTVVDNDADFQGTKRACRCLILDDCEKREIKKVNVSEEGPLNSAVVEEITGYLAVNGVDDSDSAVINCDDCQPDGNTKQNSIGSYVLQEKSVAENGDTDTQTSMFLDSRKEDSYIDHKVPCTDSQVQVKLEDHKIVTACLPVEHVNQLTTEPATGPFSETQSSLRDSEEEVDVVGDSSASKEQCKENTNNELDTSLESMPASGEPEPSPVLDCVSAQMMSLSEPQEHRYTLRTSPRRAAPTRGSPTKNSSPYRENGQFEENNLSPNETNATVSDNVSQSPTNPGEISQNEKGICCDSQNNGSEGVSKPPSEARLNIGHLPSAKESASQHITEEEDDDPDVYYFESDHVALKHNKDYQRLLQTIAVLEAQRSQAVQDLESLGRHQREALKNPIGFVEKLQKKADIGLPYPQRVVQLPEIVWDQYTHSLGNFEREFKNRKRHTRRVKLVFDKGLPARPKSPLDPKKDGESLSYSMLPLSDGPEGSSSRPQMIRGRLCDDTKPETFNQLWTVEEQKKLEQLLIKYPPEEVESRRWQKIADELGNRTAKQVASRVQKYFIKLTKAGIPVPGRTPNLYIYSKKSSTSRRQHPLNKHLFKPSTFMTSHEPPVYMDEDDDRSCFHSHMNTAVEDASDDESIPIMYRNLPEYKELLQFKKLKKQKLQQMQAESGFVQHVGFKCDNCGIEPIQGVRWHCQDCPPEMSLDFCDSCSDCLHETDIHKEDHQLEPIYRSETFLDRDYCVSQGTSYNYLDPNYFPANR>sp|Q8IYH5-3|ZZZ3_HUMAN Isoform 3 of ZZ-type zinc finger-containingprotein 3 OS=Homo sapiens OX=9606 GN=ZZZ3MIDLWLYSYQRLLQTIAVLEAQRSQAVQDLESLGRHQREALKNPIGFVEKLQKKADIGLPYPQRVVQLPEIVWDQYTHSLGNFEREFKNRKRHTRRVKLVFDKVGLPARPKSPLDPKKDGESLSYSMLPLSDGPEGSSSRPQMIRGRLCDDTKPETFNQLWTVEEQKKLEQLLIKYPPEEVESRRWQKIADELGNRTAKQVASRVQKYFIKLTKAGIPVPGRTPNLYIYSKKSSTSRRQHPLNKHLFKPSTFMTSHEPPVYMDEDDDRSCFHSHMNTAVEDASDDESIPIMYRNLPEYKELLQFKKLKKQKLQQMQAESGFVQHVGFKCDNCGIEPIQGVRWHCQDCPPEMSLDFCDSCSDCLHETDIHKEDHQLEPIYRSETFLDRDYCVSQGTSYNYLDPNYFPANR>sp|Q8IYH5-4|ZZZ3_HUMAN Isoform 4 of ZZ-type zinc finger-containingprotein 3 OS=Homo sapiens OX=9606 GN=ZZZ3MAASRSTRVTRSTVGLNGLDESFCGRTLRNRSIAHPEEISSNSQVRSRSPKKRPEPVPIQKGNNNGRTTDLKQQSTRESWVSPRKRGLSSSEKDNIERQAIENCERRQTEPVSPVLKRIKRCLRSEAPNSSEEDSPIKSDKESVEQRSTVVDNDADFQGTKRACRCLILDDCEKREIKKVNVSEEGPLNSAVVEEITGYLAVNGVDDSDSAVINCDDCQPDGNTKQNSIGSYVLQEKSVAENGDTDTQTSMFLDSRKEDSYIDHKVPCTDSQVQVKLEDHKIVTACLPVEHVNQLTTEPATGPFSETQSSLRDSEEEVDVVGDSSASKEQCKENTNNELDTSLESMPASGEPEPSPVLDCVSAQMMSLSEPQEHRYTLRTSPRRAAPTRGSPTKNSSPYRENGQFEENNLSPNETNATVSDNVSQSPTNPGEISQNEKGICCDSQNNGSEGVSKPPSEARLNIGHLPSAKESASQHITEEEDDDPDVYYFESDHVALKHNKDYQRLLQTIAVLEAQRSQAVQDLESLGRHQREALKNPIGFVEKLQKKADIGLPYPQRVVQLPEIVWDQYTHSLGNFEREFKNRKRHTRRVKLVFDKVGLPARPKSPLDPKKDGESLSYSMLPLSDGPEGSSSRPQMIRGRLCDDTKPETFNQLWTVEEQVINISKSCRLKKTSKQLTSESVL>sp|Q8WWF5|ZNRF4_HUMAN E3 ubiquitin-protein ligase ZNRF4 OS=Homo sapiensOX=9606 GN=ZNRF4 PE=1 SV=3MPLCRPEHLMPRASRVPVAASLPLSHAVIPTQLPSRPGHRPPGRPRRCPKASCLPPPVGPSSTQTAKRVTMGWPRPGRALVAVKALLVLSLLQVPAQAVVRAVLEDNSSSVDFADLPALFGVPLAPEGIRGYLMEVKPANACHPIEAPRLGNRSLGAIVLIRRYDCTFDLKVLNAQRAGFEAAIVHNVHSDDLVSMTHVYEDLRGQIAIPSVFVSEAASQDLRVILGCNKSAHALLLPDDPPCHDLGCHPVLTVSWVLGCTLALVVSAFFVLNHLWLWAQACCSHRRPVKTSTCQKAQVRTFTWHNDLCAICLDEYEEGDQLKILPCSHTYHCKCIDPWFSQAPRRSCPVCKQSVAATEDSFDSTTYSFRDEDPSLPGHRPPIWAIQVQLRSRRLELLGRASPHCHCSTTSLEAEYTTVSSAPPEAPGQ>sp|O75312|ZPR1_HUMAN Zinc finger protein ZPR1 OS=Homo sapiens OX=9606GN=ZPR1 PE=1 SV=1MAASGAVEPGPPGAAVAPSPAPAPPPAPDHLFRPISAEDEEQQPTEIESLCMNCYCNGMTRLLLTKIPFFREIIVSSFSCEHCGWNNTEIQSAGRIQDQGVRYTLSVRALEDMNREVVKTDSAATRIPELDFEIPAFSQKGALTTVEGLITRAISGLEQDQPARRANKDATAERIDEFIVKLKELKQVASPFTLIIDDPSGNSFVENPHAPQKDDALVITHYNRTRQQEEMLGLQEEAPAEKPEEEDLRNEVLQFSTNCPECNAPAQTNMKLVQIPHFKEVIIMATNCENCGHRTNEVKSGGAVEPLGTRITLHITDASDMTRDLLKSETCSVEIPELEFELGMAVLGGKFTTLEGLLKDIRELVTKNPFTLGDSSNPGQTERLQEFSQKMDQIIEGNMKAHFIMDDPAGNSYLQNVYAPEDDPEMKVERYKRTFDQNEELGLNDMKTEGYEAGLAPQR>sp|P98169|ZXDB_HUMAN Zinc finger X-linked protein ZXDB OS=Homo sapiensOX=9606 GN=ZXDB PE=1 SV=2MEIPKLLPARGTLQGGGGGGIPAGGGRVHRGPDSPAGQVPTRRLLLLRGPQDGGPGRRREEASTASRGPGPSLLAPRTDQPSGGGGGGGDDFFLVLLDPVGGDVETAGSGQAAGPVLREEAEEGPGLQGGESGANPAGPTALGPRCLSAVPTPAPISAPGPAAAFAGTVTIHNQDLLLRFENGVLTLATPPPHAWEPGAAPAQQPGCLIAPQAGFPHAAHPGDCPELPPDLLLAEPAEPAPAPAPEEEAEGPAAALGPRGPLGSGPGVVLYLCPEAQCGQTFAKKHQLKVHLLTHSSSQGQRPFKCPLGGCGWTFTTSYKLKRHLQSHDKLRPFGCPAEGCGKSFTTVYNLKAHMKGHEQENSFKCEVCEESFPTQAKLSAHQRSHFEPERPYQCAFSGCKKTFITVSALFSHNRAHFREQELFSCSFPGCSKQYDKACRLKIHLRSHTGERPFLCDFDGCGWNFTSMSKLLRHKRKHDDDRRFMCPVEGCGKSFTRAEHLKGHSITHLGTKPFVCPVAGCCARFSARSSLYIHSKKHLQDVDTWKSRCPISSCNKLFTSKHSMKTHMVKRHKVGQDLLAQLEAANSLTPSSELTSQRQNDLSDAEIVSLFSDVPDSTSAALLDTALVNSGILTIDVASVSSTLAGHLPANNNNSVGQAVDPPSLMATSDPPQSLDTSLFFGTAATGFQQSSLNMDEVSSVSVGPLGSLDSLAMKNSSPEPQALTPSSKLTVDTDALTPSSTLCENSVSELLTPTKAEWNVHPDSDFFGQEGETQFGFPNAAGNHGSQKETDLITVTGSSFLV>sp|Q12836|ZP4_HUMAN Zona pellucida sperm-binding protein 4 OS=Homosapiens OX=9606 GN=ZP4 PE=1 SV=1MWLLRCVLLCVSLSLAVSGQHKPEAPDYSSVLHCGPWSFQFAVNLNQEATSPPVLIAWDNQGLLHELQNDSDCGTWIRKGPGSSVVLEATYSSCYVTEWDSHYIMPVGVEGAGAAEHKVVTERKLLKCPMDLLARDAPDTDWCDSIPARDRLPCAPSPISRGDCEGLGCCYSSEEVNSCYYGNTVTLHCTREGHFSIAVSRNVTSPPLLLDSVRLALRNDSACNPVMATQAFVLFQFPFTSCGTTRQITGDRAVYENELVATRDVKNGSRGSVTRDSIFRLHVSCSYSVSSNSLPINVQVFTLPPPFPETQPGPLTLELQIAKDKNYGSYYGVGDYPVVKLLRDPIYVEVSILHRTDPYLGLLLQQCWATPSTDPLSQPQWPILVKGCPYIGDNYQTQLIPVQKALDLPFPSHHQRFSIFTFSFVNPTVEKQALRGPVHLHCSVSVCQPAETPSCVVTCPDLSRRRNFDNSSQNTTASVSSKGPMILLQATKDPPEKLRVPVDSKVLWVAGLSGTLILGALLVSYLAVKKQKSCPDQMCQ>sp|Q5FWF4|ZRAB3_HUMAN DNA annealing helicase and endonuclease ZRANB3OS=Homo sapiens OX=9606 GN=ZRANB3 PE=1 SV=2MPRVHNIKKSLTPHISCVTNESDNLLDFLPDRLRAKLLPFQKDGIIFALKRNGRCMVADEMGLGKTIQAIGITYFYKEEWPLLIVVPSSLRYPWTEEIEKWIPELSPEEINVIQNKTDVRRMSTSKVTVLGYGLLTADAKTLIDALNNQNFKVVIVDESHYMKSRNATRSRILLPIVQKARRAILLTGTPALGRPEELFMQIEALFPQKFGRWTDYAKRYCNAHIRYFGKRPQWDCRGASNLNELHQLLSDIMIRRLKTEVLTQLPPKVRQRIPFDLPSAAAKELNTSFEEWEKIMRTPNSGAMETVMGLITRMFKQTAIAKAGAVKDYIKMMLQNDSLKFLVFAHHLSMLQACTEAVIENKTRYIRIDGSVSSSERIHLVNQFQKDPDTRVAILSIQAAGQGLTFTAASHVVFAELYWDPGHIKQAEDRAHRIGQCSSVNIHYLIANGTLDTLMWGMLNRKAQVTGSTLNGRKEKIQAEEGDKEKWDFLQFAEAWTPNDSSEELRKEALFTHFEKEKQHDIRSFFVPQPKKRQLMTSCDESKRFREENTVVSSDPTKTAARDIIDYESDVEPETKRLKLAASEDHCSPSEETPSQSKQIRTPLVESVQEAKAQLTTPAFPVEGWQCSLCTYINNSELPYCEMCETPQGSAVMQIDSLNHIQDKNEKDDSQKDTSKKVQTISDCEKQALAQSEPGQLADSKEETPKIEKEDGLTSQPGNEQWKSSDTLPVYDTLMFCASRNTDRIHIYTKDGKQMSCNFIPLDIKLDLWEDLPASFQLKQYRSLILRFVREWSSLTAMKQRIIRKSGQLFCSPILALEEITKQQTKQNCTKRYITKEDVAVASMDKVKNVGGHVRLITKESRPRDPFTKKLLEDGACVPFLNPYTVQADLTVKPSTSKGYLQAVDNEGNPLCLRCQQPTCQTKQACKANSWDSRFCSLKCQEEFWIRSNNSYLRAKVFETEHGVCQLCNVNAQELFLRLRDAPKSQRKNLLYATWTSKLPLEQLNEMIRNPGEGHFWQVDHIKPVYGGGGQCSLDNLQTLCTVCHKERTARQAKERSQVRRQSLASKHGSDITRFLVKK>sp|Q5FWF4-2|ZRAB3_HUMAN Isoform 2 of DNA annealing helicase andendonuclease ZRANB3 OS=Homo sapiens OX=9606 GN=ZRANB3MTSCDESKRFREENTVVSSDPTKTAARDIIDYESDVEPETKRLKLAASEDHCSPSEETPSQSKQIRTPLVESVQEAKAQLTTPAFPVEGWQCSLCTYINNSELPYCEMCETPQGSAVMQIDSLNHIQDKNEKDDSQKDTSKKVQTISDCEKQALAQSEPGQLADSKEETPKIEKEDGLTSQPEQWKSSDTLPVYDTLMFCASRNTDRIHIYTKDGKQMSCNFIPLDIKLDLWEDLPASFQLKQYRSLILRFVREWSSLTAMKQRIIRKSGQLFCSPILALEEITKQQTKQNCTKRYITKEDVAVASMDKVKNVGGHVRLITKESRPRDPFTKKLLEDGACVPFLNPYTVQADLTVKPSTSKGYLQAVDNEGNPLCLRCQQPTCQTKQACKANSWDSRFCSLKCQEEFWIRSNNSYLRAKVFETEHGVCQLCNVNAQELFLRLRDAPKSQRKNLLYATWTSKLPLEQLNEMIRNPGEGHFWQVDHIKPVYGGGGQCSLDNLQTLCTVCHKERTARQAKERSQVRRQSLASKHGSDITRFLETSKLHESHKVTGAEQGLQVSGLPDSAAPEGGAAHTNDQRRCQRMKQPLTEVQILSHSS>sp|Q5FWF4-3|ZRAB3_HUMAN Isoform 3 of DNA annealing helicase andendonuclease ZRANB3 OS=Homo sapiens OX=9606 GN=ZRANB3MPRVHNIKKSLTPHISCVTNESDNLLDFLPDRLRAKLLPFQKDGIIFALKRNGRCMVADEMGLGKTIQAIGITYFYKEEWPLLIVVPSSLRYPWTEEIEKWIPELSPEEINVIQNKTDVRRMSTSKVTVLGYGLLTADAKTLIDALNNQNFKVVIVDESHYMKSRNATRSRILLPIVQKARRAILLTGTPALGRPEELFMQIEALFPQKFGRWTDYAKRYCNAHIRYFGKRPQWDCRGASNLNELHQLLSDIMIRRLKTEVLTQLPPKVRQRIPFDLPSAAAKELNTSFEEWEKIMRTPNSGAMETVMGLITRMFKQTAIAKAGAVKDYIKMMLQNDSLKFLVFAHHLSMLQACTEAVIENKTRYIRIDGSVSSSERIHLVNQFQKDPDTRVAILSIQAAGQGLTFTAASHVVFAELYWDPGHIKQAEDRAHRIGQCSSVNIHYLIANGTLDTLMWGMLNRKAQVTGSTLNGRKEKIQAEEGDKEKWDFLQFAEAWTPNDSSEELRKEALFTHFEKEKQHDIRSFFVPQPKKRQLMTSCDESKRFREENTVVSSDPTKTAARDIIDYESDVEPETKRLKLAASEDHCSPSEETPSQSKQIRTPLVESVQEAKAQLTTPAFPVEGWQCSLCTYINNSELPYCEMCETPQGSAVMQIDSLNHIQDKNEKDDSQKDTSKKVQTISDCEKQALAQSEPGQLADSKEETPKIEKEDGLTSQPEQWKSSDTLPVYDTLMFCASRNTDRIHIYTKDGKQMSCNFIPLDIKLDLWEDLPASFQLKQYRSLILRFVREWSSLTAMKQRIIRKSGQLFCSPILALEEITKQQTKQNCTKRYITKEDVAVASMDKVKNVGGHVRLITKESRPRDPFTKKLLEDGACVPFLNPYTVQADLTVKPSTSKGYLQAVDNEGNPLCLRCQQPTCQTKQACKANSWDSRFCSLKCQEEFWIRSNNSYLRAKVFETEHGVCQLCNVNAQELFLRLRDAPKSQRKNLLYATWTSKLPLEQLNEMIRNPGEGHFWQVDHIKPVYGGGGQCSLDNLQTLCTVCHKERTARQAKERSQVRRQSLASKHGSDITRFLVKK>sp|Q5FWF4-4|ZRAB3_HUMAN Isoform 4 of DNA annealing helicase andendonuclease ZRANB3 OS=Homo sapiens OX=9606 GN=ZRANB3MCETPQGSAVMQIDSLNHIQDKNEKDDSQKDTSKKVQTISDCEKQALAQSEPGQLADSKEETPKIEKEDGLTSQPEQWKSSDTLPVYDTLMFCASRNTDRIHIYTKDGKQMSCNFIPLDIKLDLWEDLPASFQLKQYRSLILRFVREWSSLTAMKQRIIRKSGQLFCSPILALEEITKQQTKQNCTKRYITKEDVAVASMDKVKNVGGHVRLITKESRPRDPFTKKLLEDGACVPFLNPYTVQADLTVKPSTSKGYLQAVDNEGNPLCLRCQQPTCQTKQACKANSWDSRFCSLKCQEEFWIRSNNSYLRAKVFETEHGVCQLCNVNAQELFLRLRDAPKSQRKNLLYATWTSKLPLEQLNEMIRNPGEGHFWQVDHIKPVYGGGGQCSLDNLQTLCTVCHKERTARQAKERSQVRRQSLASKHGSDITRFLVKK>sp|Q5FWF4-5|ZRAB3_HUMAN Isoform 5 of DNA annealing helicase andendonuclease ZRANB3 OS=Homo sapiens OX=9606 GN=ZRANB3MGLGKTIQAIGITYFYKEEWPLLIVVPSSLRYPWTEEIEKWIPELSPEEINVIQNKTDVRRMSTSKVTVLGYGLLTADAKTLIDALNNQNFKVVIVDESHYMKSRNATRSRILLPIVQKARRAILLTGTPALGRPEELFMQIEALFPQKFGRWTDYAKRYCNAHIRYFGKRPQWDCRGASNLNELHQLLSDIMIRRLKTEVLTQLPPKVRQRIPFDLPSAAAKELNTSFEEWEKIMRTPNSGAMETVMGLITRMFKQTAIAKAGAVKDYIKMMLQNDSLKFLVFAHHLSMLQACTEAVIENKTRYIRIDGSVSSSERIHLVNQFQKDPDTRVAILSIQAAGQDLYDKVAWGKRTLVSGLFMECFCFVP>sp|Q2QGD7|ZXDC_HUMAN Zinc finger protein ZXDC OS=Homo sapiens OX=9606GN=ZXDC PE=1 SV=2MDLPALLPAPTARGGQHGGGPGPLRRAPAPLGASPARRRLLLVRGPEDGGPGARPGEASGPSPPPAEDDSDGDSFLVLLEVPHGGAAAEAAGSQEAEPGSRVNLASRPEQGPSGPAAPPGPGVAPAGAVTISSQDLLVRLDRGVLALSAPPGPATAGAAAPRRAPQASGPSTPGYRCPEPQCALAFAKKHQLKVHLLTHGGGQGRRPFKCPLEGCGWAFTTSYKLKRHLQSHDKLRPFGCPVGGCGKKFTTVYNLKAHMKGHEQESLFKCEVCAERFPTHAKLSSHQRSHFEPERPYKCDFPGCEKTFITVSALFSHNRAHFREQELFSCSFPGCSKQYDKACRLKIHLRSHTGERPFICDSDSCGWTFTSMSKLLRHRRKHDDDRRFTCPVEGCGKSFTRAEHLKGHSITHLGTKPFECPVEGCCARFSARSSLYIHSKKHVQDVGAPKSRCPVSTCNRLFTSKHSMKAHMVRQHSRRQDLLPQLEAPSSLTPSSELSSPGQSELTNMDLAALFSDTPANASGSAGGSDEALNSGILTIDVTSVSSSLGGNLPANNSSLGPMEPLVLVAHSDIPPSLDSPLVLGTAATVLQQGSFSVDDVQTVSAGALGCLVALPMKNLSDDPLALTSNSNLAAHITTPTSSSTPRENASVPELLAPIKVEPDSPSRPGAVGQQEGSHGLPQSTLPSPAEQHGAQDTELSAGTGNFYLESGGSARTDYRAIQLAKEKKQRGAGSNAGASQSTQRKIKEGKMSPPHFHASQNSWLCGSLVVPSGGRPGPAPAAGVQCGAQGVQVQLVQDDPSGEGVLPSARGPATFLPFLTVDLPVYVLQEVLPSSGGPAGPEATQFPGSTINLQDLQ>sp|Q2QGD7-2|ZXDC_HUMAN Isoform 2 of Zinc finger protein ZXDC OS=Homosapiens OX=9606 GN=ZXDCMDLPALLPAPTARGGQHGGGPGPLRRAPAPLGASPARRRLLLVRGPEDGGPGARPGEASGPSPPPAEDDSDGDSFLVLLEVPHGGAAAEAAGSQEAEPGSRVNLASRPEQGPSGPAAPPGPGVAPAGAVTISSQDLLVRLDRGVLALSAPPGPATAGAAAPRRAPQASGPSTPGYRCPEPQCALAFAKKHQLKVHLLTHGGGQGRRPFKCPLEGCGWAFTTSYKLKRHLQSHDKLRPFGCPVGGCGKKFTTVYNLKAHMKGHEQESLFKCEVCAERFPTHAKLSSHQRSHFEPERPYKCDFPGCEKTFITVSALFSHNRAHFREQELFSCSFPGCSKQYDKACRLKIHLRSHTGERPFICDSDSCGWTFTSMSKLLRHRRKHDDDRRFTCPVEGCGKSFTRAEHLKGHSITHLGTKPFECPVEGCCARFSARSSLYIHSKKHVQDVGAPKSRCPVSTCNRLFTSKHSMKAHMVRQHSRRQDLLPQLEAPSSLTPSSELSSPGQSELTNMDLAALFSDTPANASGSAGGSDEALNSGILTIDVTSVSSSLGGNLPANNSSLGPMEPLVLVAHSDIPPSLDSPLVLGTAATVLQQGSFSVDDVQTVSAGALGCLVALPMKNLSDDPLALTSNSNLAAHITTPTSSSTPRENASVPELLAPIKVEPDSPSRPGAVGQQEGSHGLPQSTLPSPAEQHGAQDTELSAGTGNFYLV>sp|Q2QGD7-3|ZXDC_HUMAN Isoform 3 of Zinc finger protein ZXDC OS=Homosapiens OX=9606 GN=ZXDCMKGHEQESLFKCEVCAERFPTHAKLSSHQRSHFEPERPYKCDFPGCEKTFITVSALFSHNRAHFREQELFSCSFPGCSKQYDKACRLKIHLRSHTGERPFICDSDSCGWTFTSMSKLLRHRRKHDDDRRFTCPVEGCGKSFTRAEHLKGHSITHLGTKPFECPVEGCCARFSARSSLYIHSKKHVQDVGAPKSRCPVSTCNRLFTSKHSMKAHMVRQHSRRQDLLPQLEAPSSLTPSSELSSPGQSELTNMDLAALFSDTPANASGSAGGSDEALNSGILTIDVTSVSSSLGGNLPANNSSLGPMEPLVLVAHSDIPPSLDSPLVLGTAATVLQQGSFSVDDVQTVSAGALGCLVALPMKNLSDDPLALTSNSNLAAHITTPTSSSTPRENASVPELLAPIKVEPDSPSRPGAVGQQEGSHGLPQSTLPSPAEQHGAQDTELSAGTGNFYLV>sp|Q9BUG6|ZSA5A_HUMAN Zinc finger and SCAN domain-containing protein 5AOS=Homo sapiens OX=9606 GN=ZSCAN5A PE=1 SV=1MAANCTSSWSLGESCNRPGLELPRSMASSETQLGNHDVDPEISHVNFRMFSCPKESDPIQALRKLTELCHLWLRPDLHTKEQILDMLVMEQFMISMPQELQVLVMMNGVQSCKDLEDLLRNNRRPKKWSVVTFHGKEYIVQDSDIEMAEAPSSVRDDLKDVSSQRASSVNQMRPGEGQAHRELQILPRVPALSRRQGEDFLLHKSIDVTGDPKSLRPKQTLEKDLKENREENPGLTSPEPQLPKSPTDLVRAKEGKDPPKIASVENVDADTPSACVVEREASTHSGNRGDALNLSSPKRSKPDASSISQEEPQGEATPVGNRESPGQAGMNSIHSPGPASPVSHPDGQEAKALPPFACDVCEKRFTCNSKLVIHKRSHTGERLFQCNLCGKRFMQLISLQFHQRTHTGERPYTCDVCQKQFTQKSYLKCHKRSHTGEKPFECKDCKKVFTYRGSLKEHQRIHSGEKPYKCSKCPRAFSRLKLLRRHQKTHPEATSQ>sp|Q9BUG6-2|ZSA5A_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 5A OS=Homo sapiens OX=9606 GN=ZSCAN5AMIVRPPQPRETSVVTFHGKEYIVQDSDIEMAEAPSSVRDDLKDVSSQRASSVNQMRPGEGQAHRELQILPRVPALSRRQGEDFLLHKSIDVTGDPKSLRPKQTLEKDLKENREENPGLTSPEPQLPKSPTDLVRAKEGKDPPKIASVENVDADTPSACVVEREASTHSGNRGDALNLSSPKRSKPDASSISQEEPQGEATPVGNRESPGQAGMNSIHSPGPASPVSHPDGQEAKALPPFACDVCEKRFTCNSKLVIHKRSHTGERLFQCNLCGKRFMQLISLQFHQRTHTGERPYTCDVCQKQFTQKSYLKCHKRSHTGEKPFECKDCKKVFTYRGSLKEHQRIHSGEKPYKCSKCPRAFSRLKLLRRHQKTHPEATSQ>sp|A6NGD5|ZSA5C_HUMAN Zinc finger and SCAN domain-containing protein 5COS=Homo sapiens OX=9606 GN=ZSCAN5C PE=3 SV=1MAANCTSSWSLGESCNSPGSEPPQSMPSPATQLGNHDSDPETCHVNFRMFSCPKESDPIQALRKLTELCHLWLRPDLHTKEQILDMLVMEQFMISMPQELQVLVMMNGVQSCKDLEDLLRNNRRPKKWSVVSFLGKEYLMQESDVEMAEAPASVRDDPRHVSSQRTSSVNQMCPEEGQASQELQTLPRVPALFRRQEEDFLLPETTVMKGDPKALRPKPTLEKDLEEDREENPGLTSPEPQLPNSPTGVVGAKEGKEPQKRASVENVDADTPSACVVEREASTHSGSRGDALNLRGLKRSKPDATSISQEEPQGEATPVGNRESPGQAEINPVHSPGPAGPVSHPSGQEVKELLPFACEVCGKRFKYRGKLAVHTRSHTGERLFQCNLCGKRFMQRIGLQFHQRTHTGERPYTCDICQKQFTQKSYLKCHKRSHTGEKPFECKDCKKVFTYKANLKEHQRIHSGEKPHKCSKCPRAFGRPATLRRHQKTHREATSQ>sp|Q9P217|ZSWM5_HUMAN Zinc finger SWIM domain-containing protein 5OS=Homo sapiens OX=9606 GN=ZSWIM5 PE=2 SV=2MADGGEREELLSPSPVSPAKRQCSWPSPQAHHPRGSPGAAGGGAGGVGSSCLVLGARPHLQPDSLLDCAAKTVAEKWAYERVEERFERIPEPVQRRIVYWSFPRNEREICMYSSFQYRGGPGAGAAGGAAGASPAEEGPQPPPGAAAPAGSAPGGVAAGASPGLGAGAGAAGCGGEGLPFRRGIRLLDSGSVENVLQVGFHLSGTVTELATASEPAVTYKVAISFDRCKITSVTCGCGNKDIFYCAHVVALSLYRIRKPDQVKLRLPISETLFQMNRDQLQKFIQYLITAHHTEVLPTAQKLADEILSSNSEINQVNGAPDPTAGASIDDENCWHLDEEQVKEQVKLFLSQGGYCGSGKQLNSMFAKVREMLRMRDSNGARMLTLITEQFVADPRLTLWRQQGTNMTDKCRQLWDELGALWVCIILNPHCKLEEKSCWLQQLQKWSDLDVCPLEDGNYGHELPNITNALPQSAIHSPDSLSRPRRTVFTRAIEGRELHWQDSHLQRIISSDVYTAPACQRESERLLFNSQGQPLWLEHVPTACARVDALRSHGYPKEALRLTVAIINTLRLQQQRQLEIYKHQKKELLQRGTTTITNLEGWVGHPLDPIDCLFLTLTEACRLNDDGYLEMSDMNESRPPVYQHVPVAAGSPNSSESYLSLALEVALMGLGQQRLMPEGLYAQDKVCRNEEQLLSQLQELQLDDELVQTLQKQCILLLEGGPFSGLGEVIHRESVPMHTFAKYLFSALLPHDPDLSYKLALRAMRLPVLENSASAGDTSHPHHMVSVVPSRYPRWFTLGHLESQQCELASTMLTAAKGDTLRLRTILEAIQKHIHSSSLIFKLAQDAFKIATPTDSSTDSTLLNVALELGLQVMRMTLSTLNWRRREMVRWLVTCATEVGVRALVSILQSWYTLFTPTEATSIVAATAVSHTTILRLSLDYPQREELASCARTLALQCAMKDPQSCALSALTLCEKDHIAFEAAYQIAIDAAAGGMTHSQLFTIARYMELRGYPLRAFKLASLAMSHLNLAYNQDTHPAINDVLWACALSHSLGKNELAALIPLVVKSVHCATVLSDILRRCTVTAPGLAGIPGRRSSGKLMSTDKAPLRQLLDATINAYINTTHSRLTHISPRHYGEFIEFLSKARETFLLPQDGHLQFAQFIDNLKQIYKGKKKLMLLVRERFG>sp|Q8NBB4|ZSCA1_HUMAN Zinc finger and SCAN domain-containing protein 1OS=Homo sapiens OX=9606 GN=ZSCAN1 PE=1 SV=2MLPRPKAPASPRRPQTPTPSEQDADPGPASPRDTEAQRLRFRQFQYHVASGPHLALGQLWTLCRQWLRPEARSKEQMLELLVLEQFLGALPSKMRTWVQSQGPRSCREAASLVEDLTQMCQQEVLVSLDSVEPQDWSFGEEEDGKSPRSQKEPSQASELILDAVAAAPALPEESEWLETTQLQQSLHTRAEAEAPRAPGLLGSRARLPLKPSIWDEPEDLLAGPSSDLRAEGTVISSPKGPSAQRISPRRRNRNTDQSGRHQPSLKHTKGGTQEAVAGISVVPRGPRGGRPFQCADCGMVFTWVTHFIEHQKTHREEGPFPCPECGKVFLHNSVLTEHGKIHLLEPPRKKAPRSKGPRESVPPRDGAQGPVAPRSPKRPFQCSVCGKAFPWMVHLIDHQKLHTAHGHM>sp|Q8NBB4-2|ZSCA1_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 1 OS=Homo sapiens OX=9606 GN=ZSCAN1MLPRPKAPASPRRPQTPTPSEQDADPGPASPRDTEAQRLRFRQFQYHVASGPHLALGQLWTLCRQWLRPEARSKEQMLELLVLEQFLGALPSKMRTWVQSQGPRSCREAASLVEDLTQMCQQEGERRRLRAPGRARGPDVSEDRTALLPAHIAPTPARPLPTSKPLLPRGCVFNYFYI>sp|Q7Z7L9|ZSCA2_HUMAN Zinc finger and SCAN domain-containing protein 2OS=Homo sapiens OX=9606 GN=ZSCAN2 PE=2 SV=2MMAADIPRVTTPLSSLVQVPQEEDRQEEEVTTMILEDDSWVQEAVLQEDGPESEPFPQSAGKGGPQEEVTRGPQGALGRLRELCRRWLRPEVHTKEQMLTMLPKEIQAWLQEHRPESSEEAAALVEDLTQTLQDSDFEIQSENGENCNQDMFENESRKIFSEMPEGESAQHSDGESDFERDAGIQRLQGHSPGEDHGEVVSQDREVGQLIGLQGTYLGEKPYECPQCGKTFSRKSHLITHERTHTGEKYYKCDECGKSFSDGSNFSRHQTTHTGEKPYKCRDCGKSFSRSANLITHQRIHTGEKPFQCAECGKSFSRSPNLIAHQRTHTGEKPYSCPECGKSFGNRSSLNTHQGIHTGEKPYECKECGESFSYNSNLIRHQRIHTGEKPYKCTDCGQRFSQSSALITHRRTHTGEKPYQCSECGKSFSRSSNLATHRRTHMVEKPYKCGVCGKSFSQSSSLIAHQGMHTGEKPYECLTCGESFSWSSNLLKHQRIHTGEKPYKCSECGKCFSQRSQLVVHQRTHTGEKPYKCLMCGKSFSRGSILVMHQRAHLGDKPYRCPECGKGFSWNSVLIIHQRIHTGEKPYKCPECGKGFSNSSNFITHQRTHMKEKLY>sp|Q7Z7L9-3|ZSCA2_HUMAN Isoform 3 of Zinc finger and SCAN domain-containing protein 2 OS=Homo sapiens OX=9606 GN=ZSCAN2MMAADIPRVTTPLSSLVQVPQEEDRQEEEVTTMILEDDSWVQEAVLQEDGPESEPFPQSAGKGGPQEEVTRGPQGALGRLRELCRRWLRPEVHTKEQMLTMLPKEIQAWLQEHRPESSEEAAALVEDLTQTLQDSAVAVVASLPVEVTSL>sp|Q7Z7L9-4|ZSCA2_HUMAN Isoform 4 of Zinc finger and SCAN domain-containing protein 2 OS=Homo sapiens OX=9606 GN=ZSCAN2MMAADIPRVTTPLSSLVQVPQEEDRQEEEVTTMILEDDSWVQEAVLQEDGPESEPFPQSAGKGGPQEEVTRGPQGALGRLRELCRRWLRPEVHTKEQMLTMLPKEIQAWLQEHRPESSEEAAALVEDLTQTLQDSETASCVHGCPV>sp|Q9H171|ZBP1_HUMAN Z-DNA-binding protein 1 OS=Homo sapiens OX=9606GN=ZBP1 PE=1 SV=2MAQAPADPGREGHLEQRILQVLTEAGSPVKLAQLVKECQAPKRELNQVLYRMKKELKVSLTSPATWCLGGTDPEGEGPAELALSSPAERPQQHAATIPETPGPQFSQQREEDIYRFLKDNGPQRALVIAQALGMRTAKDVNRDLYRMKSRHLLDMDEQSKAWTIYRPEDSGRRAKSASIIYQHNPINMICQNGPNSWISIANSEAIQIGHGNIITRQTVSREDGSAGPRHLPSMAPGDSSTWGTLVDPWGPQDIHMEQSILRRVQLGHSNEMRLHGVPSEGPAHIPPGSPPVSATAAGPEASFEARIPSPGTHPEGEAAQRIHMKSCFLEDATIGNSNKMSISPGVAGPGGVAGSGEGEPGEDAGRRPADTQSRSHFPRDIGQPITPSHSKLTPKLETMTLGNRSHKAAEGSHYVDEASHEGSWWGGGI>sp|Q9H171-2|ZBP1_HUMAN Isoform 2 of Z-DNA-binding protein 1 OS=Homosapiens OX=9606 GN=ZBP1MAQAPADPGREGHLEQRILQVLTEAGSPVKLAQLVKECQAPKRELNQVLYRMKKELKVSLTSPATWCLGGTDPEGEGPAELALSSPAERPQQHAATIPETPGPQFSQQREEDIYRFLKDNGPQRALVIAQALGMRTAKDVNRDLYRMKSRHLLDMDEQSKAWTIYRPEDSGRRAKSASIIYQHNPINMICQNGPNSWISIANSEAIQIGHGNIITRQTVSREDGSAGPRHLPSMAPGDSSTWGTLVDPWGPQDIHMEQSILRRVQLGHSNEMRLHGVPSEGPAHIPPGSPPVSATAAGPEASFEARIPSPGTHPEGEAAQRIHMKSCFLEDATIGNSNKMSISPGVAGPGGVAGSGEGEPGEDAVAAFTEVLNPSKSFMKFGINFFQTPVNVDSLTSSHESQMFLTACRLVIFSRRFSTYFAQIHLRNHSVLHLCPHKIYLLKNKK>sp|Q9H171-3|ZBP1_HUMAN Isoform 3 of Z-DNA-binding protein 1 OS=Homosapiens OX=9606 GN=ZBP1MAQAPADPGREGHLEQRILQVLTEAGSPVKLAQLVKECQAPKRELNQVLYRMKKELKVSLTSPATWCLGGTDPEGEGPAELALSSPAERPQQHAATIPETPGPQFSQQREEDIYRFLKDNGPQRALVIAQALGMRTAKDVNRDLYRMKSRHLLDMDEQSKAWTIYRPEDSGRRAKSASIIYQHNPINMICQNGPNSWISIANSEAIQIGHGNIITRQTVSREDGSAGPRHLPSMAPGDSSTWGTLVDPWGPQDIHMEQSILRRVQLGHSNEMRLHGVPSEGPAHIPPGSPPVSATAAGPEASFEARIPSPGTHPEGEAAQRIHMKSCFLEDATIGNSNKMSISPGVAGPGGVAGSGEGEPGEDAGRRPADTQSRSFDGQE>sp|Q9H171-4|ZBP1_HUMAN Isoform 4 of Z-DNA-binding protein 1 OS=Homosapiens OX=9606 GN=ZBP1MAQAPADPGREGHLEQRILQVLTEAGSPVKLAQLVKECQAPKRELNQVLYRMKKELKVSLTSPATWCLGGTDPEGEGPAELALSSPEEDIYRFLKDNGPQRALVIAQALGMRTAKDVNRDLYRMKSRHLLDMDEQSKAWTIYRPEDSGRRAKSASIIYQHNPINMICQNGPNSWISIANSEAIQIGHGNIITRQTVSREDGSAGPRHLPSMAPGDSSTWGTLVDPWGPQDIHMEQSILRRVQLGHSNEMRLHGVPSEGPAHIPPGSPPVSATAAGPEASFEARIPSPGTHPEGEAAQRIHMKSCFLEDATIGNSNKMSISPGVAGPGGVAGSGEGEPGEDAGRRPADTQSRSHFPRDIGQPITPSHSKLTPKLETMTLGNRSHKAAEGSHYVDEASHEGSWWGGGI>sp|Q9H171-5|ZBP1_HUMAN Isoform 5 of Z-DNA-binding protein 1 OS=Homosapiens OX=9606 GN=ZBP1MAQAPADPGREGHLEQRILQVLTEAGSPVKLAQLVKECQAPKRELNQVLYRMKKELKVSLTSPATWCLGGTDPEGEGPAELALSSPGNCHPGEAGLTLQGASWQWTSTDLSLGSNLNSATWELTGFLSLCLGFFFWLMELTAGLLGRGC>sp|Q9H171-6|ZBP1_HUMAN Isoform 6 of Z-DNA-binding protein 1 OS=Homosapiens OX=9606 GN=ZBP1MAQAPADPGREGHLEQRILQVLTEAGSPVKLAQLVKECQAPKRELNQVLYRMKKELKVSLTSPATWCLGGTDPEGEGPAELALSSPAERPQQHAATIPETPGPQFSQQREEDIYRFLKDNGPQRALVIAQALGMRTAKDVNRDLYRMKSRHLLDMDEQSKAWTIYRPEDSGRRAKSASIIYQHNPINMICQNGPNSWISIANSEAIQIGHGNIITRQTVSREDGKSPKRAQGGDLGGEPPDPLGGGKG>sp|Q9H171-7|ZBP1_HUMAN Isoform 7 of Z-DNA-binding protein 1 OS=Homosapiens OX=9606 GN=ZBP1MAQAPADPGREAERPQQHAATIPETPGPQFSQQREEDIYRFLKDNGPQRALVIAQALGMRTAKDVNRDLYRMKSRHLLDMDEQSKAWTIYRPEDSGRRAKSASIIYQHNPINMICQNGPNSWISIANSEAIQIGHGNIITRQTVSREDGSAGPRHLPSMAPGDSSTWGTLVDPWGPQDIHMEQSILRRVQLGHSNEMRLHGVPSEGPAHIPPGSPPVSATAAGPEASFEARIPSPGTHPEGEAAQRIHMKSCFLEDATIGNSNKMSISPGVAGPGGVAGSGEGEPGEDAGRRPADTQSRSHFPRDIGQPITPSHSKLTPKLETMTLGNRSHKAAEGSHYVDEASHEGSWWGGGI>sp|A0AVI4|TM129_HUMAN E3 ubiquitin-protein ligase TM129 OS=Homo sapiensOX=9606 GN=TMEM129 PE=1 SV=1MDSPEVTFTLAYLVFAVCFVFTPNEFHAAGLTVQNLLSGWLGSEDAAFVPFHLRRTAATLLCHSLLPLGYYVGMCLAASEKRLHALSQAPEAWRLFLLLAVTLPSIACILIYYWSRDRWACHPLARTLALYALPQSGWQAVASSVNTEFRRIDKFATGAPGARVIVTDTWVMKVTTYRVHVAQQQDVHLTVTESRQHELSPDSNLPVQLLTIRVASTNPAVQAFDIWLNSTEYGELCEKLRAPIRRAAHVVIHQSLGDLFLETFASLVEVNPAYSVPSSQELEACIGCMQTRASVKLVKTCQEAATGECQQCYCRPMWCLTCMGKWFASRQDPLRPDTWLASRVPCPTCRARFCILDVCTVR>sp|A0AVI4-2|TM129_HUMAN Isoform 2 of E3 ubiquitin-protein ligase TM129OS=Homo sapiens OX=9606 GN=TMEM129MDSPEVTFTLAYLVFAVCFVFTPNEFHAAGLTVQNLLSGWLGSEDAAFVPFHLRRTAATLLCHSLLPLGYYVGMCLAASEKRLHALSQAPEAWRLFLLLAVTLPSIACILIYYWSRDRWACHPLARTLALYALPQSGWQAVASSVNTEFRRIDKFATGAPGARVIVTDTWVMKVTTYRVHVAQQQDVHLTVTESRQHELSPDSNLPVQLLTIRVASTNPAVQAFDIWSWRPA>sp|Q8N9V2|TRIML_HUMAN Probable E3 ubiquitin-protein ligase TRIML1OS=Homo sapiens OX=9606 GN=TRIML1 PE=2 SV=1MSTADLMENLREELTCFICLDYFSSPVTTECGHSFCLVCLLRSWEEHNTPLSCPECWRTLEGPHFQSNERLGRLASIARQLRSQVLQSEDEQGSYGRMPTTAKALSDDEQGGSAFVAQSHGANRVHLSSEAEEHHREKLQEILNLLRVRRKEAQAVLTHEKERVKLCQEETKTCKQVVVSEYMKMHQFLKEEEQLQLQLLEQEEKENMRKLRNNEIKLTQQIRSLSKMIAQIESSSQSSAFESLEEVRGALERSEPLLLQCPEATTTELSLCRITGMKEMLRKFSTEITLDPATANAYLVLSEDLKSVKYGGSRQQLPDNPERFDQSATVLGTQIFTSGRHYWEVEVGNKTEWEVGICKDSVSRKGNLPKPPGDLFSLIGLKIGDDYSLWVSSPLKGQHVREPVCKVGVFLDYESGHIAFYNGTDESLIYSFPQASFQEALRPIFSPCLPNEGTNTDPLTICSLNSHV>sp|P07951|TPM2_HUMAN Tropomyosin beta chain OS=Homo sapiens OX=9606GN=TPM2 PE=1 SV=1MDAIKKKMQMLKLDKENAIDRAEQAEADKKQAEDRCKQLEEEQQALQKKLKGTEDEVEKYSESVKEAQEKLEQAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRAMKDEEKMELQEMQLKEAKHIAEDSDRKYEEVARKLVILEGELERSEERAEVAESKCGDLEEELKIVTNNLKSLEAQADKYSTKEDKYEEEIKLLEEKLKEAETRAEFAERSVAKLEKTIDDLEDEVYAQKMKYKAISEELDNALNDITSL>sp|P07951-2|TPM2_HUMAN Isoform 2 of Tropomyosin beta chain OS=Homosapiens OX=9606 GN=TPM2MDAIKKKMQMLKLDKENAIDRAEQAEADKKQAEDRCKQLEEEQQALQKKLKGTEDEVEKYSESVKEAQEKLEQAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRAMKDEEKMELQEMQLKEAKHIAEDSDRKYEEVARKLVILEGELERSEERAEVAESRARQLEEELRTMDQALKSLMASEEEYSTKEDKYEEEIKLLEEKLKEAETRAEFAERSVAKLEKTIDDLEETLASAKEENVEIHQTLDQTLLELNNL>sp|P07951-3|TPM2_HUMAN Isoform 3 of Tropomyosin beta chain OS=Homosapiens OX=9606 GN=TPM2MAGISSIDAVKKKIQSLQQVADEAEERAEHLQREADAERQARERAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERGMKVIENRAMKDEEKMELQEMQLKEAKHIAEDSDRKYEEVARKLVILEGELERSEERAEVAESRARQLEEELRTMDQALKSLMASEEEYSTKEDKYEEEIKLLEEKLKEAETRAEFAERSVAKLEKTIDDLEETLASAKEENVEIHQTLDQTLLELNNL>sp|P0DPR3|TRDD1_HUMAN T cell receptor delta diversity 1 OS=Homo sapiensOX=9606 GN=TRDD1 PE=1 SV=1EI>sp|Q9NR97|TLR8_HUMAN Toll-like receptor 8 OS=Homo sapiens OX=9606GN=TLR8 PE=1 SV=1MENMFLQSSMLTCIFLLISGSCELCAEENFSRSYPCDEKKQNDSVIAECSNRRLQEVPQTVGKYVTELDLSDNFITHITNESFQGLQNLTKINLNHNPNVQHQNGNPGIQSNGLNITDGAFLNLKNLRELLLEDNQLPQIPSGLPESLTELSLIQNNIYNITKEGISRLINLKNLYLAWNCYFNKVCEKTNIEDGVFETLTNLELLSLSFNSLSHVPPKLPSSLRKLFLSNTQIKYISEEDFKGLINLTLLDLSGNCPRCFNAPFPCVPCDGGASINIDRFAFQNLTQLRYLNLSSTSLRKINAAWFKNMPHLKVLDLEFNYLVGEIASGAFLTMLPRLEILDLSFNYIKGSYPQHINISRNFSKLLSLRALHLRGYVFQELREDDFQPLMQLPNLSTINLGINFIKQIDFKLFQNFSNLEIIYLSENRISPLVKDTRQSYANSSSFQRHIRKRRSTDFEFDPHSNFYHFTRPLIKPQCAAYGKALDLSLNSIFFIGPNQFENLPDIACLNLSANSNAQVLSGTEFSAIPHVKYLDLTNNRLDFDNASALTELSDLEVLDLSYNSHYFRIAGVTHHLEFIQNFTNLKVLNLSHNNIYTLTDKYNLESKSLVELVFSGNRLDILWNDDDNRYISIFKGLKNLTRLDLSLNRLKHIPNEAFLNLPASLTELHINDNMLKFFNWTLLQQFPRLELLDLRGNKLLFLTDSLSDFTSSLRTLLLSHNRISHLPSGFLSEVSSLKHLDLSSNLLKTINKSALETKTTTKLSMLELHGNPFECTCDIGDFRRWMDEHLNVKIPRLVDVICASPGDQRGKSIVSLELTTCVSDVTAVILFFFTFFITTMVMLAALAHHLFYWDVWFIYNVCLAKVKGYRSLSTSQTFYDAYISYDTKDASVTDWVINELRYHLEESRDKNVLLCLEERDWDPGLAIIDNLMQSINQSKKTVFVLTKKYAKSWNFKTAFYLALQRLMDENMDVIIFILLEPVLQHSQYLRLRQRICKSSILQWPDNPKAEGLFWQTLRNVVLTENDSRYNNMYVDSIKQY>sp|Q9NR97-2|TLR8_HUMAN Isoform 2 of Toll-like receptor 8 OS=Homo sapiensOX=9606 GN=TLR8MKESSLQNSSCSLGKETKKENMFLQSSMLTCIFLLISGSCELCAEENFSRSYPCDEKKQNDSVIAECSNRRLQEVPQTVGKYVTELDLSDNFITHITNESFQGLQNLTKINLNHNPNVQHQNGNPGIQSNGLNITDGAFLNLKNLRELLLEDNQLPQIPSGLPESLTELSLIQNNIYNITKEGISRLINLKNLYLAWNCYFNKVCEKTNIEDGVFETLTNLELLSLSFNSLSHVPPKLPSSLRKLFLSNTQIKYISEEDFKGLINLTLLDLSGNCPRCFNAPFPCVPCDGGASINIDRFAFQNLTQLRYLNLSSTSLRKINAAWFKNMPHLKVLDLEFNYLVGEIASGAFLTMLPRLEILDLSFNYIKGSYPQHINISRNFSKLLSLRALHLRGYVFQELREDDFQPLMQLPNLSTINLGINFIKQIDFKLFQNFSNLEIIYLSENRISPLVKDTRQSYANSSSFQRHIRKRRSTDFEFDPHSNFYHFTRPLIKPQCAAYGKALDLSLNSIFFIGPNQFENLPDIACLNLSANSNAQVLSGTEFSAIPHVKYLDLTNNRLDFDNASALTELSDLEVLDLSYNSHYFRIAGVTHHLEFIQNFTNLKVLNLSHNNIYTLTDKYNLESKSLVELVFSGNRLDILWNDDDNRYISIFKGLKNLTRLDLSLNRLKHIPNEAFLNLPASLTELHINDNMLKFFNWTLLQQFPRLELLDLRGNKLLFLTDSLSDFTSSLRTLLLSHNRISHLPSGFLSEVSSLKHLDLSSNLLKTINKSALETKTTTKLSMLELHGNPFECTCDIGDFRRWMDEHLNVKIPRLVDVICASPGDQRGKSIVSLELTTCVSDVTAVILFFFTFFITTMVMLAALAHHLFYWDVWFIYNVCLAKVKGYRSLSTSQTFYDAYISYDTKDASVTDWVINELRYHLEESRDKNVLLCLEERDWDPGLAIIDNLMQSINQSKKTVFVLTKKYAKSWNFKTAFYLALQRLMDENMDVIIFILLEPVLQHSQYLRLRQRICKSSILQWPDNPKAEGLFWQTLRNVVLTENDSRYNNMYVDSIKQY>sp|Q9BWF2|TRAIP_HUMAN E3 ubiquitin-protein ligase TRAIP OS=Homo sapiensOX=9606 GN=TRAIP PE=1 SV=1MPIRALCTICSDFFDHSRDVAAIHCGHTFHLQCLIQWFETAPSRTCPQCRIQVGKRTIINKLFFDLAQEEENVLDAEFLKNELDNVRAQLSQKDKEKRDSQVIIDTLRDTLEERNATVVSLQQALGKAEMLCSTLKKQMKYLEQQQDETKQAQEEARRLRSKMKTMEQIELLLQSQRPEVEEMIRDMGVGQSAVEQLAVYCVSLKKEYENLKEARKASGEVADKLRKDLFSSRSKLQTVYSELDQAKLELKSAQKDLQSADKEIMSLKKKLTMLQETLNLPPVASETVDRLVLESPAPVEVNLKLRRPSFRDDIDLNATFDVDTPPARPSSSQHGYYEKLCLEKSHSPIQDVPKKICKGPRKESQLSLGGQSCAGEPDEELVGAFPIFVRNAILGQKQPKRPRSESSCSKDVVRTGFDGLGGRTKFIQPTDTVMIRPLPVKPKTKVKQRVRVKTVPSLFQAKLDTFLWS>sp|P02585|TNNC2_HUMAN Troponin C, skeletal muscle OS=Homo sapiensOX=9606 GN=TNNC2 PE=1 SV=2MTDQQAEARSYLSEEMIAEFKAAFDMFDADGGGDISVKELGTVMRMLGQTPTKEELDAIIEEVDEDGSGTIDFEEFLVMMVRQMKEDAKGKSEEELAECFRIFDRNADGYIDPEELAEIFRASGEHVTDEEIESLMKDGDKNNDGRIDFDEFLKMMEGVQ>sp|Q9BVC6|TM109_HUMAN Transmembrane protein 109 OS=Homo sapiens OX=9606GN=TMEM109 PE=1 SV=1MAASSISSPWGKHVFKAILMVLVALILLHSALAQSRRDFAPPGQQKREAPVDVLTQIGRSVRGTLDAWIGPETMHLVSESSSQVLWAISSAISVAFFALSGIAAQLLNALGLAGDYLAQGLKLSPGQVQTFLLWGAGALVVYWLLSLLLGLVLALLGRILWGLKLVIFLAGFVALMRSVPDPSTRALLLLALLILYALLSRLTGSRASGAQLEAKVRGLERQVEELRWRQRRAAKGARSVEEE>sp|O00220|TR10A_HUMAN Tumor necrosis factor receptor superfamily member10A OS=Homo sapiens OX=9606 GN=TNFRSF10A PE=1 SV=3MAPPPARVHLGAFLAVTPNPGSAASGTEAAAATPSKVWGSSAGRIEPRGGGRGALPTSMGQHGPSARARAGRAPGPRPAREASPRLRVHKTFKFVVVGVLLQVVPSSAATIKLHDQSIGTQQWEHSPLGELCPPGSHRSEHPGACNRCTEGVGYTNASNNLFACLPCTACKSDEEERSPCTTTRNTACQCKPGTFRNDNSAEMCRKCSRGCPRGMVKVKDCTPWSDIECVHKESGNGHNIWVILVVTLVVPLLLVAVLIVCCCIGSGCGGDPKCMDRVCFWRLGLLRGPGAEDNAHNEILSNADSLSTFVSEQQMESQEPADLTGVTVQSPGEAQCLLGPAEAEGSQRRRLLVPANGADPTETLMLFFDKFANIVPFDSWDQLMRQLDLTKNEIDVVRAGTAGPGDALYAMLMKWVNKTGRNASIHTLLDALERMEERHAREKIQDLLVDSGKFIYLEDGTGSAVSLE>sp|A0A2R8Y7D0|TINCR_HUMAN Ubiquitin domain-containing protein TINCROS=Homo sapiens OX=9606 GN=TINCR PE=1 SV=1MEGLRRGLSRWKRYHIKVHLADEALLLPLTVRPRDTLSDLRAQLVGQGVSSWKRAFYYNARRLDDHQTVRDARLQDGSVLLLVSDPSEAQRLTPAIPALWEAEASRSLESRSSRPAWPTW>sp|O94759|TRPM2_HUMAN Transient receptor potential cation channelsubfamily M member 2 OS=Homo sapiens OX=9606 GN=TRPM2 PE=1 SV=2MEPSALRKAGSEQEEGFEGLPRRVTDLGMVSNLRRSNSSLFKSWRLQCPFGNNDKQESLSSWIPENIKKKECVYFVESSKLSDAGKVVCQCGYTHEQHLEEATKPHTFQGTQWDPKKHVQEMPTDAFGDIVFTGLSQKVKKYVRVSQDTPSSVIYHLMTQHWGLDVPNLLISVTGGAKNFNMKPRLKSIFRRGLVKVAQTTGAWIITGGSHTGVMKQVGEAVRDFSLSSSYKEGELITIGVATWGTVHRREGLIHPTGSFPAEYILDEDGQGNLTCLDSNHSHFILVDDGTHGQYGVEIPLRTRLEKFISEQTKERGGVAIKIPIVCVVLEGGPGTLHTIDNATTNGTPCVVVEGSGRVADVIAQVANLPVSDITISLIQQKLSVFFQEMFETFTESRIVEWTKKIQDIVRRRQLLTVFREGKDGQQDVDVAILQALLKASRSQDHFGHENWDHQLKLAVAWNRVDIARSEIFMDEWQWKPSDLHPTMTAALISNKPEFVKLFLENGVQLKEFVTWDTLLYLYENLDPSCLFHSKLQKVLVEDPERPACAPAAPRLQMHHVAQVLRELLGDFTQPLYPRPRHNDRLRLLLPVPHVKLNVQGVSLRSLYKRSSGHVTFTMDPIRDLLIWAIVQNRRELAGIIWAQSQDCIAAALACSKILKELSKEEEDTDSSEEMLALAEEYEHRAIGVFTECYRKDEERAQKLLTRVSEAWGKTTCLQLALEAKDMKFVSHGGIQAFLTKVWWGQLSVDNGLWRVTLCMLAFPLLLTGLISFREKRLQDVGTPAARARAFFTAPVVVFHLNILSYFAFLCLFAYVLMVDFQPVPSWCECAIYLWLFSLVCEEMRQLFYDPDECGLMKKAALYFSDFWNKLDVGAILLFVAGLTCRLIPATLYPGRVILSLDFILFCLRLMHIFTISKTLGPKIIIVKRMMKDVFFFLFLLAVWVVSFGVAKQAILIHNERRVDWLFRGAVYHSYLTIFGQIPGYIDGVNFNPEHCSPNGTDPYKPKCPESDATQQRPAFPEWLTVLLLCLYLLFTNILLLNLLIAMFNYTFQQVQEHTDQIWKFQRHDLIEEYHGRPAAPPPFILLSHLQLFIKRVVLKTPAKRHKQLKNKLEKNEEAALLSWEIYLKENYLQNRQFQQKQRPEQKIEDISNKVDAMVDLLDLDPLKRSGSMEQRLASLEEQVAQTAQALHWIVRTLRASGFSSEADVPTLASQKAAEEPDAEPGGRKKTEEPGDSYHVNARHLLYPNCPVTRFPVPNEKVPWETEFLIYDPPFYTAERKDAAAMDPMGDTLEPLSTIQYNVVDGLRDRRSFHGPYTVQAGLPLNPMGRTGLRGRGSLSCFGPNHTLYPMVTRWRRNEDGAICRKSIKKMLEVLVVKLPLSEHWALPGGSREPGEMLPRKLKRILRQEHWPSFENLLKCGMEVYKGYMDDPRNTDNAWIETVAVSVHFQDQNDVELNRLNSNLHACDSGASIRWQVVDRRIPLYANHKTLLQKAAAEFGAHY>sp|O94759-2|TRPM2_HUMAN Isoform 2 of Transient receptor potential cationchannel subfamily M member 2 OS=Homo sapiens OX=9606 GN=TRPM2MEPSALRKAGSEQEEGFEGLPRRVTDLGMVSNLRRSNSSLFKSWRLQCPFGNNDKQESLSSWIPENIKKKECVYFVESSKLSDAGKVVCQCGYTHEQHLEEATKPHTFQGTQWDPKKHVQEMPTDAFGDIVFTGLSQKVKKYVRVSQDTPSSVIYHLMTQHWGLDVPNLLISVTGGAKNFNMKPRLKSIFRRGLVKVAQTTGAWIITGGSHTGVMKQVGEAVRDFSLSSSYKEGELITIGVATWGTVHRREGLIHPTGSFPAEYILDEDGQGNLTCLDSNHSHFILVDDGTHGQYGVEIPLRTRLEKFISEQTKERGGVAIKIPIVCVVLEGGPGTLHTIDNATTNGTPCVVVEGSGRVADVIAQVANLPVSDITISLIQQKLSVFFQEMFETFTESRIVEWTKKIQDIVRRRQLLTVFREGKDGQQDVDVAILQALLKASRSQDHFGHENWDHQLKLAVAWNRVDIARSEIFMDEWQWKPSDLHPTMTAALISNKPEFVKLFLENGVQLKEFVTWDTLLYLYENLDPSCLFHSKLQMHHVAQVLRELLGDFTQPLYPRPRHNDRLRLLLPVPHVKLNVQGVSLRSLYKRSSGHVTFTMDPIRDLLIWAIVQNRRELAGIIWAQSQDCIAAALACSKILKELSKEEEDTDSSEEMLALAEEYEHRAIGVFTECYRKDEERAQKLLTRVSEAWGKTTCLQLALEAKDMKFVSHGGIQAFLTKVWWGQLSVDNGLWRVTLCMLAFPLLLTGLISFREKRLQDVGTPAARARAFFTAPVVVFHLNILSYFAFLCLFAYVLMVDFQPVPSWCECAIYLWLFSLVCEEMRQLFYDPDECGLMKKAALYFSDFWNKLDVGAILLFVAGLTCRLIPATLYPGRVILSLDFILFCLRLMHIFTISKTLGPKIIIVKRMMKDVFFFLFLLAVWVVSFGVAKQAILIHNERRVDWLFRGAVYHSYLTIFGQIPGYIDGVNFNPEHCSPNGTDPYKPKCPESDATQQRPAFPEWLTVLLLCLYLLFTNILLLNLLIAMFNYTFQQVQEHTDQIWKFQRHDLIEEYHGRPAAPPPFILLSHLQLFIKRVVLKTPAKRHKQLKNKLEKNEEAALLSWEIYLKENYLQNRQFQQKQRPEQKIEDISNKVDAMVDLLDLDPLKRSGSMEQRLASLEEQVAQTAQALHWIVRTLRASGFSSEADVPTLASQKAAEEPDAEPGGRKKTEEPGDSYHVNARHLLYPNCPVTRFPVPNEKVPWETEFLIYDPPFYTAERKDAAAMDPMGENPMGRTGLRGRGSLSCFGPNHTLYPMVTRWRRNEDGAICRKSIKKMLEVLVVKLPLSEHWALPGGSREPGEMLPRKLKRILRQEHWPSFENLLKCGMEVYKGYMDDPRNTDNAWIETVAVSVHFQDQNDVELNRLNSNLHACDSGASIRWQVVDRRIPLYANHKTLLQKAAAEFGAHY>sp|O94759-3|TRPM2_HUMAN Isoform 3 of Transient receptor potential cationchannel subfamily M member 2 OS=Homo sapiens OX=9606 GN=TRPM2MEPSALRKAGSEQEEGFEGLPRRVTDLGMVSNLRRSNSSLFKSWRLQCPFGNNDKQESLSSWIPENIKKKECVYFVESSKLSDAGKVVCQCGYTHEQHLEEATKPHTFQGTQWDPKKHVQEMPTDAFGDIVFTGLSQKVKKYVRVSQDTPSSVIYHLMTQHWGLDVPNLLISVTGGAKNFNMKPRLKSIFRRGLVKVAQTTGAWIITGGSHTGVMKQVGEAVRDFSLSSSYKEGELITIGVATWGTVHRREGLIHPTGSFPAEYILDEDGQGNLTCLDSNHSHFILVDDGTHGQYGVEIPLRTRLEKFISEQTKERGGVAIKIPIVCVVLEGGPGTLHTIDNATTNGTPCVVVEGSGRVADVIAQVANLPVSDITISLIQQKLSVFFQEMFETFTESRIVEWTKKIQDIVRRRQLLTVFREGKDGQQDVDVAILQALLKASRSQDHFGHENWDHQLKLAVAWNRVDIARSEIFMDEWQWKPSDLHPTMTAALISNKPEFVKLFLENGVQLKEFVTWDTLLYLYENLDPSCLFHSKLQKVLVEDPERPACAPAAPRLQMHHVAQVLRELLGDFTQPLYPRPRHNDRLRLLLPVPHVKLNVQGVSLRSLYKRSSGHVTFTMDPIRDLLIWAIVQNRRELAGIIWAQSQDCIAAALACSKILKELSKEEEDTDSSEEMLALAEEYEHRAIGVFTECYRKDEERAQKLLTRVSEAWGKTTCLQLALEAKDMKFVSHGGIQAFLTKVWWGQLSVDNGLWRVTLCMLAFPLLLTGLISFREKRLQDVGTPAARARAFFTAPVVVFHLNILSYFAFLCLFAYVLMVDFQPVPSWCECAIYLWLFSLVCEEMRQ>sp|P07477|TRY1_HUMAN Trypsin-1 OS=Homo sapiens OX=9606 GN=PRSS1 PE=1SV=1MNPLLILTFVAAALAAPFDDDDKIVGGYNCEENSVPYQVSLNSGYHFCGGSLINEQWVVSAGHCYKSRIQVRLGEHNIEVLEGNEQFINAAKIIRHPQYDRKTLNNDIMLIKLSSRAVINARVSTISLPTAPPATGTKCLISGWGNTASSGADYPDELQCLDAPVLSQAKCEASYPGKITSNMFCVGFLEGGKDSCQGDSGGPVVCNGQLQGVVSWGDGCAQKNKPGVYTKVYNYVKWIKNTIAANS>sp|Q12815|TROAP_HUMAN Tastin OS=Homo sapiens OX=9606 GN=TROAP PE=1 SV=3MTTRQATKDPLLRGVSPTPSKIPVRSQKRTPFPTVTSCAVDQENQDPRRWVQKPPLNIQRPLVDSAGPRPKARHQAETSQRLVGISQPRNPLEELRPSPRGQNVGPGPPAQTEAPGTIEFVADPAALATILSGEGVKSCHLGRQPSLAKRVLVRGSQGGTTQRVQGVRASAYLAPRTPTHRLDPARASCFSRLEGPGPRGRTLCPQRLQALISPSGPSFHPSTRPSFQELRRETAGSSRTSVSQASGLLLETPVQPAFSLPKGEREVVTHSDEGGVASLGLAQRVPLRENREMSHTRDSHDSHLMPSPAPVAQPLPGHVVPCPSPFGRAQRVPSPGPPTLTSYSVLRRLTVQPKTRFTPMPSTPRVQQAQWLRGVSPQSCSEDPALPWEQVAVRLFDQESCIRSLEGSGKPPVATPSGPHSNRTPSLQEVKIQRIGILQQLLRQEVEGLVGGQCVPLNGGSSLDMVELQPLLTEISRTLNATEHNSGTSHLPGLLKHSGLPKPCLPEECGEPQPCPPAEPGPPEAFCRSEPEIPEPSLQEQLEVPEPYPPAEPRPLESCCRSEPEIPESSRQEQLEVPEPCPPAEPRPLESYCRIEPEIPESSRQEQLEVPEPCPPAEPGPLQPSTQGQSGPPGPCPRVELGASEPCTLEHRSLESSLPPCCSQWAPATTSLIFSSQHPLCASPPICSLQSLRPPAGQAGLSNLAPRTLALRERLKSCLTAIHCFHEARLDDECAFYTSRAPPSGPTRVCTNPVATLLEWQDALCFIPVGSAAPQGSP>sp|Q12815-2|TROAP_HUMAN Isoform 2 of Tastin OS=Homo sapiens OX=9606GN=TROAPMTTRQATKDPLLRGVSPTPSKIPVRSQKRTPFPTVTSCAVDQENQDPRRWVQKPPLNIQRPLVDSAGPRPKARHQAETSQRLVGISQPRNPLEELRPSPRGQNVGPGPPAQTVLVPAPGKLFALRRSPFPPAKCHLARCHGLYL>sp|Q12815-3|TROAP_HUMAN Isoform 3 of Tastin OS=Homo sapiens OX=9606GN=TROAPMTTRQATKDPLLRGVSPTPSKIPVRSQKRTPFPTVTSCAVDQENQDPRRWVQKPPLNIQRPLVDSAGPRPKARHQAETSQRLVGISQPRNPLEELRPSPRGQNVGPGPPAQTGAMACTCNHSYSGG>sp|Q9NRE2|TSH2_HUMAN Teashirt homolog 2 OS=Homo sapiens OX=9606 GN=TSHZ2PE=1 SV=3MPRRKQQAPKRAAGYAQEEQLKEEEEIKEEEEEEDSGSVAQLQGGNDTGTDEELETGPEQKGCFSYQNSPGSHLSNQDAENESLLSDASDQVSDIKSVCGRDASDKKAHTHVRLPNEAHNCMDKMTAVYANILSDSYWSGLGLGFKLSNSERRNCDTRNGSNKSDFDWHQDALSKSLQQNLPSRSVSKPSLFSSVQLYRQSSKMCGTVFTGASRFRCRQCSAAYDTLVELTVHMNETGHYQDDNRKKDKLRPTSYSKPRKRAFQDMDKEDAQKVLKCMFCGDSFDSLQDLSVHMIKTKHYQKVPLKEPVPTISSKMVTPAKKRVFDVNRPCSPDSTTGSFADSFSSQKNANLQLSSNNRYGYQNGASYTWQFEACKSQILKCMECGSSHDTLQQLTTHMMVTGHFLKVTSSASKKGKQLVLDPLAVEKMQSLSEAPNSDSLAPKPSSNSASDCTASTTELKKESKKERPEETSKDEKVVKSEDYEDPLQKPLDPTIKYQYLREEDLEDGSKGGGDILKSLENTVTTAINKAQNGAPSWSAYPSIHAAYQLSEGTKPPLPMGSQVLQIRPNLTNKLRPIAPKWKVMPLVSMPTHLAPYTQVKKESEDKDEAVKECGKESPHEEASSFSHSEGDSFRKSETPPEAKKTELGPLKEEEKLMKEGSEKEKPQPLEPTSALSNGCALANHAPALPCINPLSALQSVLNNHLGKATEPLRSPSCSSPSSSTISMFHKSNLNVMDKPVLSPASTRSASVSRRYLFENSDQPIDLTKSKSKKAESSQAQSCMSPPQKHALSDIADMVKVLPKATTPKPASSSRVPPMKLEMDVRRFEDVSSEVSTLHKRKGRQSNWNPQHLLILQAQFASSLFQTSEGKYLLSDLGPQERMQISKFTGLSMTTISHWLANVKYQLRKTGGTKFLKNMDKGHPIFYCSDCASQFRTPSTYISHLESHLGFQMKDMTRLSVDQQSKVEQEISRVSSAQRSPETIAAEEDTDSKFKCKLCCRTFVSKHAVKLHLSKTHSKSPEHHSQFVTDVDEE>sp|Q9NRE2-2|TSH2_HUMAN Isoform 2 of Teashirt homolog 2 OS=Homo sapiensOX=9606 GN=TSHZ2MMAAALLHYTGYAQEEQLKEEEEIKEEEEEEDSGSVAQLQGGNDTGTDEELETGPEQKGCFSYQNSPGSHLSNQDAENESLLSDASDQVSDIKSVCGRDASDKKAHTHVRLPNEAHNCMDKMTAVYANILSDSYWSGLGLGFKLSNSERRNCDTRNGSNKSDFDWHQDALSKSLQQNLPSRSVSKPSLFSSVQLYRQSSKMCGTVFTGASRFRCRQCSAAYDTLVELTVHMNETGHYQDDNRKKDKLRPTSYSKPRKRAFQDMDKEDAQKVLKCMFCGDSFDSLQDLSVHMIKTKHYQKVPLKEPVPTISSKMVTPAKKRVFDVNRPCSPDSTTGSFADSFSSQKNANLQLSSNNRYGYQNGASYTWQFEACKSQILKCMECGSSHDTLQQLTTHMMVTGHFLKVTSSASKKGKQLVLDPLAVEKMQSLSEAPNSDSLAPKPSSNSASDCTASTTELKKESKKERPEETSKDEKVVKSEDYEDPLQKPLDPTIKYQYLREEDLEDGSKGGGDILKSLENTVTTAINKAQNGAPSWSAYPSIHAAYQLSEGTKPPLPMGSQVLQIRPNLTNKLRPIAPKWKVMPLVSMPTHLAPYTQVKKESEDKDEAVKECGKESPHEEASSFSHSEGDSFRKSETPPEAKKTELGPLKEEEKLMKEGSEKEKPQPLEPTSALSNGCALANHAPALPCINPLSALQSVLNNHLGKATEPLRSPSCSSPSSSTISMFHKSNLNVMDKPVLSPASTRSASVSRRYLFENSDQPIDLTKSKSKKAESSQAQSCMSPPQKHALSDIADMVKVLPKATTPKPASSSRVPPMKLEMDVRRFEDVSSEVSTLHKRKGRQSNWNPQHLLILQAQFASSLFQTSEGKYLLSDLGPQERMQISKFTGLSMTTISHWLANVKYQLRKTGGTKFLKNMDKGHPIFYCSDCASQFRTPSTYISHLESHLGFQMKDMTRLSVDQQSKVEQEISRVSSAQRSPETIAAEEDTDSKFKCKLCCRTFVSKHAVKLHLSKTHSKSPEHHSQFVTDVDEE>sp|Q96PP4|TSG13_HUMAN Testis-specific gene 13 protein OS=Homo sapiensOX=9606 GN=TSGA13 PE=1 SV=1MSQKRQTKFQNGKSKTSENSSAKREKGMVVNSKEISDAVGQSKFVLENLRHYTVHPNLAQYYKPLKATALQKFLAQNRKNTSFMLKVTQYDQDKTLLIMTNNPPPCSITQQDKESASKYFSKELLLKVMESHHQHKPTENLWLPRMPQKKKLRSKLKPIFPLILSDDPTSKREQWFRFSTDNDFKSEGKYSKVYALRTQKKMYPQLTFAPVHERDMRKDASKKSASERPISKVIREPLTLASLLEDMPTRTAPGESAFRNGRAPQWIIKKATVIG>sp|A1L157|TSN11_HUMAN Tetraspanin-11 OS=Homo sapiens OX=9606 GN=TSPAN11PE=2 SV=2MAHYKTEQDDWLIIYLKYLLFVFNFFFWVGGAAVLAVGIWTLVEKSGYLSVLASSTFAASAYILIFAGVLVMVTGFLGFGAILWERKGCLSTYFCLLLVIFLVELVAGVLAHVYYQRLSDELKQHLNRTLAENYGQPGATQITASVDRLQQDFKCCGSNSSADWQHSTYILLREAEGRQVPDSCCKTVVVRCGQRAHPSNIYKVEGGCLTKLEQFLADHLLLMGAVGIGVACLQICGMVLTCCLHQRLQRHFY>sp|Q8NB66|UN13C_HUMAN Protein unc-13 homolog C OS=Homo sapiens OX=9606GN=UNC13C PE=2 SV=3MVANFFKSLILPYIHKLCKGMFTKKLGNTNKNKEYRQQKKDQDFPTAGQTKSPKFSYTFKSTVKKIAKCSSTHNLSTEEDEASKEFSLSPTFSYRVAIANGLQKNAKVTNSDNEDLLQELSSIESSYSESLNELRSSTENQAQSTHTMPVRRNRKSSSSLAPSEGSSDGERTLHGLKLGALRKLRKWKKSQECVSSDSELSTMKKSWGIRSKSLDRTVRNPKTNALEPGFSSSGCISQTHDVMEMIFKELQGISQIETELSELRGHVNALKHSIDEISSSVEVVQSEIEQLRTGFVQSRRETRDIHDYIKHLGHMGSKASLRFLNVTEERFEYVESVVYQILIDKMGFSDAPNAIKIEFAQRIGHQRDCPNAKPRPILVYFETPQQRDSVLKKSYKLKGTGIGISTDILTHDIRERKEKGIPSSQTYESMAIKLSTPEPKIKKNNWQSPDDSDEDLESDLNRNSYAVLSKSELLTKGSTSKPSSKSHSARSKNKTANSSRISNKSDYDKISSQLPESDILEKQTTTHYADATPLWHSQSDFFTAKLSRSESDFSKLCQSYSEDFSENQFFTRTNGSSLLSSSDRELWQRKQEGTATLYDSPKDQHLNGGVQGIQGQTETENTETVDSGMSNGMVCASGDRSHYSDSQLSLHEDLSPWKEWNQGADLGLDSSTQEGFDYETNSLFDQQLDVYNKDLEYLGKCHSDLQDDSESYDLTQDDNSSPCPGLDNEPQGQWVGQYDSYQGANSNELYQNQNQLSMMYRSQSELQSDDSEDAPPKSWHSRLSIDLSDKTFSFPKFGSTLQRAKSALEVVWNKSTQSLSGYEDSGSSLMGRFRTLSQSTANESSTTLDSDVYTEPYYYKAEDEEDYTEPVADNETDYVEVMEQVLAKLENRTSITETDEQMQAYDHLSYETPYETPQDEGYDGPADDMVSEEGLEPLNETSAEMEIREDENQNIPEQPVEITKPKRIRPSFKEAALRAYKKQMAELEEKILAGDSSSVDEKARIVSGNDLDASKFSALQVCGGAGGGLYGIDSMPDLRRKKTLPIVRDVAMTLAARKSGLSLAMVIRTSLNNEELKMHVFKKTLQALIYPMSSTIPHNFEVWTATTPTYCYECEGLLWGIARQGMKCLECGVKCHEKCQDLLNADCLQRAAEKSSKHGAEDKTQTIITAMKERMKIREKNRPEVFEVIQEMFQISKEDFVQFTKAAKQSVLDGTSKWSAKITITVVSAQGLQAKDKTGSSDPYVTVQVGKNKRRTKTIFGNLNPVWDEKFYFECHNSTDRIKVRVWDEDDDIKSRVKQHFKKESDDFLGQTIVEVRTLSGEMDVWYNLEKRTDKSAVSGAIRLKINVEIKGEEKVAPYHIQYTCLHENLFHYLTEVKSNGGVKIPEVKGDEAWKVFFDDASQEIVDEFAMRYGIESIYQAMTHFSCLSSKYMCPGVPAVMSTLLANINAFYAHTTVSTNIQVSASDRFAATNFGREKFIKLLDQLHNSLRIDLSKYRENFPASNTERLQDLKSTVDLLTSITFFRMKVLELQSPPKASMVVKDCVRACLDSTYKYIFDNCHELYSQLTDPSKKQDIPREDQGPTTKNLDFWPQLITLMVTIIDEDKTAYTPVLNQFPQELNMGKISAEIMWTLFALDMKYALEEHENQRLCKSTDYMNLHFKVKWFYNEYVRELPAFKDAVPEYSLWFEPFVMQWLDENEDVSMEFLHGALGRDKKDGFQQTSEHALFSCSVVDVFAQLNQSFEIIKKLECPNPEALSHLMRRFAKTINKVLLQYAAIVSSDFSSHCDKENVPCILMNNIQQLRVQLEKMFESMGGKELDSEASTILKELQVKLSGVLDELSVTYGESFQVIIEECIKQMSFELNQMRANGNTTSNKNSAAMDAEIVLRSLMDFLDKTLSLSAKICEKTVLKRVLKELWKLVLNKIEKQIVLPPLTDQTGPQMIFIAAKDLGQLSKLKEHMIREDARGLTPRQCAIMEVVLATIKQYFHAGGNGLKKNFLEKSPDLQSLRYALSLYTQTTDALIKKFIDTQTSQSRSSKDAVGQISVHVDITATPGTGDHKVTVKVIAINDLNWQTTAMFRPFVEVCILGPNLGDKKRKQGTKTKSNTWSPKYNETFQFILGKENRPGAYELHLSVKDYCFAREDRIIGMTVIQLQNIAEKGSYGAWYPLLKNISMDETGLTILRILSQRTSDDVAKEFVRLKSETRSTEESA>sp|Q9BZL1|UBL5_HUMAN Ubiquitin-like protein 5 OS=Homo sapiens OX=9606GN=UBL5 PE=1 SV=1MIEVVCNDRLGKKVRVKCNTDDTIGDLKKLIAAQTGTRWNKIVLKKWYTIFKDHVSLGDYEIHDGMNLELYYQ>sp|O95858|TSN15_HUMAN Tetraspanin-15 OS=Homo sapiens OX=9606 GN=TSPAN15PE=1 SV=1MPRGDSEQVRYCARFSYLWLKFSLIIYSTVFWLIGALVLSVGIYAEVERQKYKTLESAFLAPAIILILLGVVMFMVSFIGVLASLRDNLYLLQAFMYILGICLIMELIGGVVALTFRNQTIDFLNDNIRRGIENYYDDLDFKNIMDFVQKKFKCCGGEDYRDWSKNQYHDCSAPGPLACGVPYTCCIRNTTEVVNTMCGYKTIDKERFSVQDVIYVRGCTNAVIIWFMDNYTIMAGILLGILLPQFLGVLLTLLYITRVEDIIMEHSVTDGLLGPGAKPSVEAAGTGCCLCYPN>sp|O75386|TULP3_HUMAN Tubby-related protein 3 OS=Homo sapiens OX=9606GN=TULP3 PE=1 SV=2MEASRCRLSPSGDSVFHEEMMKMRQAKLDYQRLLLEKRQRKKRLEPFMVQPNPEARLRRAKPRASDEQTPLVNCHTPHSNVILHGIDGPAAVLKPDEVHAPSVSSSVVEEDAENTVDTASKPGLQERLQKHDISESVNFDEETDGISQSACLERPNSASSQNSTDTGTSGSATAAQPADNLLGDIDDLEDFVYSPAPQGVTVRCRIIRDKRGMDRGLFPTYYMYLEKEENQKIFLLAARKRKKSKTANYLISIDPVDLSREGESYVGKLRSNLMGTKFTVYDRGICPMKGRGLVGAAHTRQELAAISYETNVLGFKGPRKMSVIIPGMTLNHKQIPYQPQNNHDSLLSRWQNRTMENLVELHNKAPVWNSDTQSYVLNFRGRVTQASVKNFQIVHKNDPDYIVMQFGRVADDVFTLDYNYPLCAVQAFGIGLSSFDSKLACE>sp|O75386-2|TULP3_HUMAN Isoform 2 of Tubby-related protein 3 OS=Homosapiens OX=9606 GN=TULP3MEASRCRLSPSGDSVFHEEMMKMRQAKLDYQRLLLEKRQRKKRLEPFMVQPNPEARLRRAKPRASDEQTPLVNCHTPHSNVILHGIDGPAAVLKPDEVHAPSVSSSVVEEDAENTVDTASKPGLQERLQKHDISESVNFDEETDGISQSACLERPNSASSQNSTDTGTSGSATAAQPADNLLGDIDDLEDFVYSPAPQGVTVRCRIIRDKRGMDRGLFPTYYMYLEKEENQKIFLLAARKRKKSKTANYLISIDPVDLSREGESYVGKLRSNLMGTKFTVYDRGICPMKGRGLVGAAHTRQELAAISYETNVLGFKGPRKMSVIIPGMTLNHKQIPYQPQNNHDSLLSRWQNRTMENLVELHNKAPVWNSDTQSYVLNFRGRVTQASVKNFQIVHKNDPDYIVMQFGRVADDVFTLDYNYPLCAVQAFGIGLSSFDKCIQTLRMQELCELHRQHHSAASLVHRTVCQRWVGHPWRLLPQTSLLWTDLSPPPVVPAPHQISM>sp|O75386-3|TULP3_HUMAN Isoform 3 of Tubby-related protein 3 OS=Homosapiens OX=9606 GN=TULP3MMKMRQAKLDYQRLLLEKRQRKKRLEPFMVQPNPEARLRRAKPRASDEQTPLVNCHTPHSNVILHGIDGPAAVLKPDEVHAPSVSSSVVEEDAENTVDTASKPGLQERLQKHDISESVNFDEETDGISQSACLERPNSASSQNSTFSSFCQKTEDTGYRHFRFCYCRPTS>sp|Q6ZN44|UNC5A_HUMAN Netrin receptor UNC5A OS=Homo sapiens OX=9606GN=UNC5A PE=1 SV=3MAVRPGLWPALLGIVLAAWLRGSGAQQSATVANPVPGANPDLLPHFLVEPEDVYIVKNKPVLLVCKAVPATQIFFKCNGEWVRQVDHVIERSTDGSSGLPTMEVRINVSRQQVEKVFGLEEYWCQCVAWSSSGTTKSQKAYIRIAYLRKNFEQEPLAKEVSLEQGIVLPCRPPEGIPPAEVEWLRNEDLVDPSLDPNVYITREHSLVVRQARLADTANYTCVAKNIVARRRSASAAVIVYVDGSWSPWSKWSACGLDCTHWRSRECSDPAPRNGGEECQGTDLDTRNCTSDLCVHTASGPEDVALYVGLIAVAVCLVLLLLVLILVYCRKKEGLDSDVADSSILTSGFQPVSIKPSKADNPHLLTIQPDLSTTTTTYQGSLCPRQDGPSPKFQLTNGHLLSPLGGGRHTLHHSSPTSEAEEFVSRLSTQNYFRSLPRGTSNMTYGTFNFLGGRLMIPNTGISLLIPPDAIPRGKIYEIYLTLHKPEDVRLPLAGCQTLLSPIVSCGPPGVLLTRPVILAMDHCGEPSPDSWSLRLKKQSCEGSWEDVLHLGEEAPSHLYYCQLEASACYVFTEQLGRFALVGEALSVAAAKRLKLLLFAPVACTSLEYNIRVYCLHDTHDALKEVVQLEKQLGGQLIQEPRVLHFKDSYHNLRLSIHDVPSSLWKSKLLVSYQEIPFYHIWNGTQRYLHCTFTLERVSPSTSDLACKLWVWQVEGDGQSFSINFNITKDTRFAELLALESEAGVPALVGPSAFKIPFLIRQKIISSLDPPCRRGADWRTLAQKLHLDSHLSFFASKPSPTAMILNLWEARHFPNGNLSQLAAAVAGLGQPDAGLFTVSEAEC>sp|Q6ZN44-2|UNC5A_HUMAN Isoform 2 of Netrin receptor UNC5A OS=Homosapiens OX=9606 GN=UNC5AMAVRPGLWPALLGIVLAAWLRGSGAQQSATVANPVPGANPDLLPHFLVEPEDVYIVKNKPVLLVCKAVPATQIFFKCNGEWVRQVDHVIERSTDGSSGLPTMEVRINVSRQQVEKVFGLEEYWCQCVAWSSSGTTKSQKAYIRIAYLRKNFEQEPLAKEVSLEQGIVLPCRPPEGIPPAEVEWLRNEDLVDPSLDPNVYITREHSLVVRQARLADTANYTCVAKNIVARRRSASAAVIVYVDGSWSPWSKWSACGLDCTHWRSRECSDPAPRNGGEECQGTDLDTRNCTSDLCVHSESSLP>sp|Q6ZN44-3|UNC5A_HUMAN Isoform 3 of Netrin receptor UNC5A OS=Homosapiens OX=9606 GN=UNC5AMAGTSERSLISSISQPKAIECFEVKKKAFLTHGRYHGSGATPPKTKDPKPETFCGQTGLPTMEVRINVSRQQVEKVFGLEEYWCQCVAWSSSGTTKSQKAYIRIAYLRKNFEQEPLAKEVSLEQGIVLPCRPPEGIPPAEVEWLRNEDLVDPSLDPNVYITREHSLVVRQARLADTANYTCVAKNIVARRRSASAAVIVYVDGSWSPWSKWSACGLDCTHWRSRECSDPAPRNGGEECQGTDLDTRNCTSDLCVHTASGPEDVALYVGLIAVAVCLVLLLLVLILVYCRKKEGLDSDVADSSILTSGFQPVSIKPSKADNPHLLTIQPDLSTTTTTYQGSLCPRQDGPSPKFQLTNGHLLSPLGGGRHTLHHSSPTSEAEEFVSRLSTQNYFRSLPRGTSNMTYGTFNFLGGRLMIPNTGISLLIPPDAIPRGKIYEIYLTLHKPEDVRLPLAGCQTLLSPIVSCGPPGVLLTRPVILAMDHCGEPSPDSWSLRLKKQSCEGSWEDVLHLGEEAPSHLYYCQLEASACYVFTEQLGRFALVGEALSVAAAKRLKLLLFAPVACTSLEYNIRVYCLHDTHDALKEVVQLEKQLGGQLIQEPRVLHFKDSYHNLRLSIHDVPSSLWKSKLLVSYQEIPFYHIWNGTQRYLHCTFTLERVSPSTSDLACKLWVWQVEGDGQSFSINFNITKDTRFAELLALESEAGVPALVGPSAFKIPFLIRQKIISSLDPPCRRGADWRTLAQKLHLDSHLSFFASKPSPTAMILNLWEARHFPNGNLSQLAAAVAGLGQPDAGLFTVSEAEC>sp|Q8IZQ1|WDFY3_HUMAN WD repeat and FYVE domain-containing protein 3OS=Homo sapiens OX=9606 GN=WDFY3 PE=1 SV=2MNMVKRIMGRPRQEECSPQDNALGLMHLRRLFTELCHPPRHMTQKEQEEKLYMMLPVFNRVFGNAPPNTMTEKFSDLLQFTTQVSRLMVTEIRRRASNKSTEAASRAIVQFLEINQSEEASRGWMLLTTINLLASSGQKTVDCMTTMSVPSTLVKCLYLFFDLPHVPEAVGGAQNELPLAERRGLLQKVFVQILVKLCSFVSPAEELAQKDDLQLLFSAITSWCPPYNLPWRKSAGEVLMTISRHGLSVNVVKYIHEKECLSTCVQNMQQSDDLSPLEIVEMFAGLSCFLKDSSDVSQTLLDDFRIWQGYNFLCDLLLRLEQAKEAESKDALKDLVNLITSLTTYGVSELKPAGITTGAPFLLPGFAVPQPAGKGHSVRNVQAFAVLQNAFLKAKTSFLAQIILDAITNIYMADNANYFILESQHTLSQFAEKISKLPEVQNKYFEMLEFVVFSLNYIPCKELISVSILLKSSSSYHCSIIAMKTLLKFTRHDYIFKDVFREVGLLEVMVNLLHKYAALLKDPTQALNEQGDSRNNSSVEDQKHLALLVMETLTVLLQGSNTNAGIFREFGGARCAHNIVKYPQCRQHALMTIQQLVLSPNGDDDMGTLLGLMHSAPPTELQLKTDILRALLSVLRESHRSRTVFRKVGGFVYITSLLVAMERSLSCPPKNGWEKVNQNQVFELLHTVFCTLTAAMRYEPANSHFFKTEIQYEKLADAVRFLGCFSDLRKISAMNVFPSNTQPFQRLLEEDVISIESVSPTLRHCSKLFIYLYKVATDSFDSRAEQIPPCLTSESSLPSPWGTPALSRKRHAYHSVSTPPVYPPKNVADLKLHVTTSSLQSSDAVIIHPGAMLAMLDLLASVGSVTQPEHALDLQLAVANILQSLVHTERNQQVMCEAGLHARLLQRCSAALADEDHSLHPPLQRMFERLASQALEPMVLREFLRLASPLNCGAWDKKLLKQYRVHKPSSLSYEPEMRSSMITSLEGLGTDNVFSLHEDNHYRISKSLVKSAEGSTVPLTRVKCLVSMTTPHDIRLHGSSVTPAFVEFDTSLEGFGCLFLPSLAPHNAPTNNTVTTGLIDGAVVSGIGSGERFFPPPSGLSYSSWFCIEHFSSPPNNHPVRLLTVVRRANSSEQHYVCLAIVLSAKDRSLIVSTKEELLQNYVDDFSEESSFYEILPCCARFRCGELIIEGQWHHLVLVMSKGMLKNSTAALYIDGQLVNTVKLHYVHSTPGGSGSANPPVVSTVYAYIGTPPAQRQIASLVWRLGPTHFLEEVLPSSNVTTIYELGPNYVGSFQAVCMPCKDAKSEGVVPSPVSLVPEEKVSFGLYALSVSSLTVARIRKVYNKLDSKAIAKQLGISSHENATPVKLIHNSAGHLNGSARTIGAALIGYLGVRTFVPKPVATTLQYVGGAAAILGLVAMASDVEGLYAAVKALVCVVKSNPLASKEMERIKGYQLLAMLLKKKRSLLNSHILHLTFSLVGTVDSGHETSIIPNSTAFQDLLCDFEVWLHAPYELHLSLFEHFIELLTESSEASKNAKLMREFQLIPKLLLTLRDMSLSQPTIAAISNVLSFLLQGFPSSNDLLRFGQFISSTLPTFAVCEKFVVMEINNEEKLDTGTEEEFGGLVSANLILLRNRLLDILLKLIYTSKEKTSINLQACEELVKTLGFDWIMMFMEEHLHSTTVTAAMRILVVLLSNQSILIKFKEGLSGGGWLEQTDSVLTNKIGTVLGFNVGRSAGGRSTVREINRDACHFPGFPVLQSFLPKHTNVPALYFLLMALFLQQPVSELPENLQVSVPVISCRSKQGCQFDLDSIWTFIFGVPASSGTVVSSIHNVCTEAVFLLLGMLRSMLTSPWQSEEEGSWLREYPVTLMQFFRYLYHNVPDLASMWMSPDFLCALAATVFPFNIRPYSEMVTDLDDEVGSPAEEFKAFAADTGMNRSQSEYCNVGTKTYLTNHPAKKFVFDFMRVLIIDNLCLTPASKQTPLIDLLLEASPERSTRTQQKEFQTYILDSVMDHLLAADVLLGEDASLPITSGGSYQVLVNNVFYFTQRVVDKLWQGMFNKESKLLIDFIIQLIAQSKRRSQGLSLDAVYHCLNRTILYQFSRAHKTVPQQVALLDSLRVLTVNRNLILGPGNHDQEFISCLAHCLINLHVGSNVDGFGLEAEARMTTWHIMIPSDIEPDGSYSQDISEGRQLLIKAVNRVWTELIHSKKQVLEELFKVTLPVNERGHVDIATARPLIEEAALKCWQNHLAHEKKCISRGEALAPTTQSKLSRVSSGFGLSKLTGSRRNRKESGLNKHSLSTQEISQWMFTHIAVVRDLVDTQYKEYQERQQNALKYVTEEWCQIECELLRERGLWGPPIGSHLDKWMLEMTEGPCRMRKKMVRNDMFYNHYPYVPETEQETNVASEIPSKQPETPDDIPQKKPARYRRAVSYDSKEYYMRLASGNPAIVQDAIVESSEGEAAQQEPEHGEDTIAKVKGLVKPPLKRSRSAPDGGDEENQEQLQDQIAEGSSIEEEEKTDNATLLRLLEEGEKIQHMYRCARVQGLDTSEGLLLFGKEHFYVIDGFTMTATREIRDIETLPPNMHEPIIPRGARQGPSQLKRTCSIFAYEDIKEVHKRRYLLQPIAVEVFSGDGRNYLLAFQKGIRNKVYQRFLAVVPSLTDSSESVSGQRPNTSVEQGSGLLSTLVGEKSVTQRWERGEISNFQYLMHLNTLAGRSYNDLMQYPVFPWILADYDSEEVDLTNPKTFRNLAKPMGAQTDERLAQYKKRYKDWEDPNGETPAYHYGTHYSSAMIVASYLVRMEPFTQIFLRLQGGHFDLADRMFHSVREAWYSASKHNMADVKELIPEFFYLPEFLFNSNNFDLGCKQNGTKLGDVILPPWAKGDPREFIRVHREALECDYVSAHLHEWIDLIFGYKQQGPAAVEAVNVFHHLFYEGQVDIYNINDPLKETATIGFINNFGQIPKQLFKKPHPPKRVRSRLNGDNAGISVLPGSTSDKIFFHHLDNLRPSLTPVKELKEPVGQIVCTDKGILAVEQNKVLIPPTWNKTFAWGYADLSCRLGTYESDKAMTVYECLSEWGQILCAICPNPKLVITGGTSTVVCVWEMGTSKEKAKTVTLKQALLGHTDTVTCATASLAYHIIVSGSRDRTCIIWDLNKLSFLTQLRGHRAPVSALCINELTGDIVSCAGTYIHVWSINGNPIVSVNTFTGRSQQIICCCMSEMNEWDTQNVIVTGHSDGVVRFWRMEFLQVPETPAPEPAEVLEMQEDCPEAQIGQEAQDEDSSDSEADEQSISQDPKDTPSQPSSTSHRPRAASCRATAAWCTDSGSDDSRRWSDQLSLDEKDGFIFVNYSEGQTRAHLQGPLSHPHPNPIEVRNYSRLKPGYRWERQLVFRSKLTMHTAFDRKDNAHPAEVTALGISKDHSRILVGDSRGRVFSWSVSDQPGRSAADHWVKDEGGDSCSGCSVRFSLTERRHHCRNCGQLFCQKCSRFQSEIKRLKISSPVRVCQNCYYNLQHERGSEDGPRNC>sp|Q8IZQ1-2|WDFY3_HUMAN Isoform 2 of WD repeat and FYVE domain-containing protein 3 OS=Homo sapiens OX=9606 GN=WDFY3MNMVKRIMGRPRQEECSPQDNALGLMHLRRLFTELCHPPRHMTQKEQEEKLYMMLPVFNRVFGNAPPNTMTEKFSDLLQFTTQVSRLMVTEIRRRASNKSTEAASRAIVQFLEINQSEEASRGWMLLTTINLLASSGQKTVDCMTTMSVPSTLVKCLYLFFDLPHVPEAVGGAQNELPLAERRGLLQKVFVQILVKLCSFVSPAEELAQKDDLQLLFSAITSWCPPYNLPWRKSAGEVLMTISRHGLSVNVVKYIHEKECLSTCVQNMQQSDDLSPLEIVEMFAGLSCFLKDSSDVSQTLLDDFRIWQGYNFLCDLLLRLEQAKEAESKDALKDLVNLITSLTTYGVSELKPAGITTGAPFLLPGFAVPQPAGKGHSVRNVQAFAVLQNAFLKAKTSFLAQIILDAITNIYMADNANYFILESQHTLSQFAEKISKLPEVQNKYFEMLEFVVFSLNYIPCKELISVSILLKSSSSYHCSIIAMKTLLKFTRHDYIFKDVFREVGLLEVMVNLLHKYAALLKDPTQALNEQGDSRNNSSVEDQKHLALLVMETLTVLLQGSNTNAGIFREFGGARCAHNIVKYPQCRQHALMTIQQLVLSPNGDDDMGTLLGLMHSAPPTELQLKTDILRALLSVLRESHRSRTVFRKVGGFVYITSLLVAMERSLSCPPKNGWEKVNQNQVFELLHTVFCTLTAAMRYEPANSHFFKTEIQYEKLADAVRFLGCFSDLRKISAMNVFPSNTQPFQRLLEEDVISIESVSPTLRHCSKLFIYLYKVATDSFDSRAEQIPPCLTSESSLPSPWGTPALSRKRHAYHSVSTPPVYPPKNVADLKLHVTTSSLQSSDAVIIHPGAMLAMLDLLASVGSVTQPEHALDLQLAVANILQSLVHTERNQQVMCEAGLHARLLQRCSAALADEDHSLHPPLQRMFERLASQALEPMVLREFLRLASPLNCGAWDKKLLKQYRVHKPSSLSYEPEMRSSMITSLEGLGTDNVFSLHEDNHYRISKSLVKSAEGSTVPLTRVKCLVSMTTPHDIRLHGSSVTPAFVEFDTSLEGFGCLFLPSLAPHNAPTNNTVTTGLIDGAVVSGIGSGERFFPPPSGLSYSSWFCIEHFSSPPNNHPVRLLTVVRRANSSEQHYVCLAIVLSAKDRSLIVSTKEELLQNYVDDFSEESSFYEILPCCARFRCGELIIEGQWHHLVLVMSKGMLKNSTAALYIDGQLVNTVKLHYVHSTPGGSGSANPPVVSTVYAYIGTPPAQRQIASLVWRLGPTHFLEEVLPSSNVTTIYELGPNYVGSFQAVCMPCKDAKSEGVVPSPVSLVPEEKVSFGLYALSVSSLTVARIRKVYNKLDSKAIAKQLGISSHENATPVKLIHNSAGHLNGSARTIGAALIGYLGVRTFVPKPVATTLQYVGGAAAILGLVAMASDVEGLYAAVKALVCVVKSNPLASKEMERIKGYQLLAMLLKKKRSLLNSHILHLTFSLVGTVDSGHETSIIPNSTAFQDLLCDFEVWLHAPYELHLSLFEHFIELLTESSEASKNAKLMREFQLIPKLLLTLRDMSLSQPTIAAISNVLSFLLQGFPSSNDLLRFGQFISSTLPTFAVCEKFVVMEINNEEKLDTGTEEEFGGLVSANLILLRNRLLDILLKLIYTSKEKTSINLQACEELVKTLGFDWIMMFMEEHLHSTTVTAAMRILVVLLSNQSILIKFKEGLSGGGWLEQTDSVLTNKIGTVLGFNVGRSAGGRSTVREINRDACHFPGFPVLQSFLPKHTNVPALYFLLMALFLQQPVSELPENLQVSVPVISCRSKQGCQFDLDSIWTFIFGVPASSGTVVSSIHNVCTEAVFLLLGMLRSMLTSPWQSEEEGSWLREYPVTLMQFFRYLYHNVPDLASMWMSPDFLCALAATVFPFNIRPYSEMVTDLDDEVGSPAEEFKAFAADTGMNRSQSEYCNVGTKTYLTNHPAKKFVFDFMRVLIIDNLCLTPASKQTPLIDLLLEASPERSTRTQQKEFQTYILDSVMDHLLAADVLLGEDASLPITSGGSYQVLVNNVFYFTQRVVDKLWQGMFNKESKLLIDFIIQLIAQSKRRSQGLSLDAVYHCLNRTILYQFSRAHKTVPQQVALLDSLRVLTVNRNLILGPGNHDQEFISCLAHCLINLHVGSNVDGFGLEAEARMTTWHIMIPSDIEPDGSYSQDISEGRQLLIKAVNRVWTELIHSKKQVLEELFKVTLPVNERGHVDIATARPLIEEAALKCWQNHLAHEKKCISRGEALAPTTQSKLSRVSSGFGLSKLTGSRRNRKESGLNKHSLSTQEISQWMFTHIAVVRDLVDTQYKEYQERQQNALKYVTEEWCQIECELLRERGLWGPPIGSHLDKWMLEMTEGPCRMRKKMVRNDMFYNHYPYVPETEQETNVAKPARYRRAVSYDSKEYYMRLASGNPAIVQDAIVESSEGEAAQQEPEHGEDTIAKVKGLVKPPLKRSRSAPDGGDEENQEQLQDQIAEGSSIEEEEKTDNATLLRLLEEGEKIQHMYRCARVQGLDTSEGLLLFGKEHFYVIDGFTMTATREIRDIETLPPNMHEPIIPRGARQGPSQLKRTCSIFAYEDIKEVHKRRYLLQPIAVEVFSGDGRNYLLAFQKGIRNKVYQRFLAVVPSLTDSSESVSGQRPNTSVEQGSGLLSTLVGEKSVTQRWERGEISNFQYLMHLNTLAGRSYNDLMQYPVFPWILADYDSEEVDLTNPKTFRNLAKPMGAQTDERLAQYKKRYKDWEDPNGETPAYHYGTHYSSAMIVASYLVRMEPFTQIFLRLQGGHFDLADRMFHSVREAWYSASKHNMADVKELIPEFFYLPEFLFNSNNFDLGCKQNGTKLGDVILPPWAKGDPREFIRVHREALECDYVSAHLHEWIDLIFGYKQQGPAAVEAVNVFHHLFYEGQVDIYNINDPLKETATIGFINNFGQIPKQLFKKPHPPKRVRSRLNGDNAGISVLPGSTSDKIFFHHLDNLRPSLTPVKELKEPVGQIVCTDKGILAVEQNKVLIPPTWNKTFAWGYADLSCRLGTYESDKAMTVYECLSEWGQILCAICPNPKLVITGGTSTVVCVWEMGTSKEKAKTVTLKQALLGHTDTVTCATASLAYHIIVSGSRDRTCIIWDLNKLSFLTQLRGHRAPVSALCINELTGDIVSCAGTYIHVWSINGNPIVSVNTFTGRSQQIICCCMSEMNEWDTQNVIVTGHSDGVVRFWRMEFLQVPETPAPEPAEVLEMQEDCPEAQIGQEAQDEDSSDSEADEQSISQDPKDTPSQPSSTSHRPRAASCRATAAWCTDSGSDDSRRWSDQLSLDEKDGFIFVNYSEGQTRAHLQGPLSHPHPNPIEVRNYSRLKPGYRWERQLVFRSKLTMHTAFDRKDNAHPAEVTALGISKDHSRILVGDSRGRVFSWSVSDQPGRSAADHWVKDEGGDSCSGCSVRFSLTERRHHCRNCGQLFCQKCSRFQSEIKRLKISSPVRVCQNCYYNLQHERGSEDGPRNC>sp|O43314|VIP2_HUMAN Inositol hexakisphosphate and diphosphoinositol-pentakisphosphate kinase 2 OS=Homo sapiens OX=9606 GN=PPIP5K2 PE=1 SV=3MSEAPRFFVGPEDTEINPGNYRHFFHHADEDDEEEDDSPPERQIVVGICSMAKKSKSKPMKEILERISLFKYITVVVFEEEVILNEPVENWPLCDCLISFHSKGFPLDKAVAYAKLRNPFVINDLNMQYLIQDRREVYSILQAEGILLPRYAILNRDPNNPKECNLIEGEDHVEVNGEVFQKPFVEKPVSAEDHNVYIYYPTSAGGGSQRLFRKIGSRSSVYSPESNVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEVRYPVILNAREKLIAWKVCLAFKQTVCGFDLLRANGQSYVCDVNGFSFVKNSMKYYDDCAKILGNIVMRELAPQFHIPWSIPLEAEDIPIVPTTSGTMMELRCVIAVIRHGDRTPKQKMKMEVRHQKFFDLFEKCDGYKSGKLKLKKPKQLQEVLDIARQLLMELGQNNDSEIEENKPKLEQLKTVLEMYGHFSGINRKVQLTYLPHGCPKTSSEEEDSRREEPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTYRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDSDSLSSCQQRVKARLHEILQKDRDFTAEDYEKLTPSGSISLIKSMHLIKNPVKTCDKVYSLIQSLTSQIRHRMEDPKSSDIQLYHSETLELMLRRWSKLEKDFKTKNGRYDISKIPDIYDCIKYDVQHNGSLKLENTMELYRLSKALADIVIPQEYGITKAEKLEIAKGYCTPLVRKIRSDLQRTQDDDTVNKLHPVYSRGVLSPERHVRTRLYFTSESHVHSLLSILRYGALCNESKDEQWKRAMDYLNVVNELNYMTQIVIMLYEDPNKDLSSEERFHVELHFSPGAKGCEEDKNLPSGYGYRPASRENEGRRPFKIDNDDEPHTSKRDEVDRAVILFKPMVSEPIHIHRKSPLPRSRKTATNDEESPLSVSSPEGTGTWLHYTSGVGTGRRRRRSGEQITSSPVSPKSLAFTSSIFGSWQQVVSENANYLRTPRTLVEQKQNPTVGSHCAGLFSTSVLGGSSSAPNLQDYARTHRKKLTSSGCIDDATRGSAVKRFSISFARHPTNGFELYSMVPSICPLETLHNALSLKQVDEFLASIASPSSDVPRKTAEISSTALRSSPIMRKKVSLNTYTPAKILPTPPATLKSTKASSKPATSGPSSAVVPNTSSRKKNITSKTETHEHKKNTGKKK>sp|O43314-2|VIP2_HUMAN Isoform 2 of Inositol hexakisphosphate anddiphosphoinositol-pentakisphosphate kinase 2 OS=Homo sapiens OX=9606GN=PPIP5K2MSEAPRFFVGPEDTEINPGNYRHFFHHADEDDEEEDDSPPERQIVVGICSMAKKSKSKPMKEILERISLFKYITVVVFEEEVILNEPVENWPLCDCLISFHSKGFPLDKAVAYAKLRNPFVINDLNMQYLIQDRREVYSILQAEGILLPRYAILNRDPNNPKECNLIEGEDHVEVNGEVFQKPFVEKPVSAEDHNVYIYYPTSAGGGSQRLFRKIGSRSSVYSPESNVRKTGSYIYEEFMPTDGTDVKVYTVGPDYAHAEARKSPALDGKVERDSEGKEVRYPVILNAREKLIAWKVCLAFKQTVCGFDLLRANGQSYVCDVNGFSFVKNSMKYYDDCAKILGNIVMRELAPQFHIPWSIPLEAEDIPIVPTTSGTMMELRCVIAVIRHGDRTPKQKMKMEVRHQKFFDLFEKCDGYKSGKLKLKKPKQLQEVLDIARQLLMELGQNNDSEIEENKPKLEQLKTVLEMYGHFSGINRKVQLTYLPHGCPKTSSEEEDSRREEPSLLLVLKWGGELTPAGRVQAEELGRAFRCMYPGGQGDYAGFPGCGLLRLHSTYRHDLKIYASDEGRVQMTAAAFAKGLLALEGELTPILVQMVKSANMNGLLDSDSDSLSSCQQRVKARLHEILQKDRDFTAEDYEKLTPSGSISLIKSMHLIKNPVKTCDKVYSLIQSLTSQIRHRMEDPKSSDIQLYHSETLELMLRRWSKLEKDFKTKNGRYDISKIPDIYDCIKYDVQHNGSLKLENTMELYRLSKALADIVIPQEYGITKAEKLEIAKGYCTPLVRKIRSDLQRTQDDDTVNKLHPVYSRGVLSPERHVRTRLYFTSESHVHSLLSILRYGALCNESKDEQWKRAMDYLNVVNELNYMTQIVIMLYEDPNKDLSSEERFHVELHFSPGAKGCEEDKNLPSGYGYRPASRENEGRRPFKIDNDDEPHTSKRDEVDRAVILFKPMVSEPIHIHRKSPLPRSRKTATNDEESPLSVSSPEGTGTWLHYTSGVGTGRRRRRSGEQITSSPVSPKSLAFTSSIFGSWQQVVSENANYLRTPRTLVEQKQNPTVGSHCAGLFSTSVLGGSSSAPNLQDYARTHRKKLTSSGCIDGFELYSMVPSICPLETLHNALSLKQVDEFLASIASPSSDVPRKTAEISSTALRSSPIMRKKVSLNTYTPAKILPTPPATLKSTKASSKPATSGPSSAVVPNTSSRKKNITSKTETHEHKKNTGKKK>sp|Q9BQB6|VKOR1_HUMAN Vitamin K epoxide reductase complex subunit 1OS=Homo sapiens OX=9606 GN=VKORC1 PE=1 SV=1MGSTWGSPGWVRLALCLTGLVLSLYALHVKAARARDRDYRALCDVGTAISCSRVFSSRWGRGFGLVEHVLGQDSILNQSNSIFGCIFYTLQLLLGCLRTRWASVLMLLSSLVSLAGSVYLAWILFFVLYDFCIVCITTYAINVSLMWLSFRKVQEPQGKAKRH>sp|Q9BQB6-2|VKOR1_HUMAN Isoform 2 of Vitamin K epoxide reductase complexsubunit 1 OS=Homo sapiens OX=9606 GN=VKORC1MGSTWGSPGWVRLALCLTGLVLSLYALHVKAARARDRDYRALCDVGTAISCSRVFSSRWGRGFGLVEHVLGQDSILNQSNSIFGCIFYTLQLLLDGVSPCCPGWSQAICLPQPPKVLGGLQALPADTLGLCPDAAELPGVSRWFCLPGLDPVLRAL>sp|Q9BQB6-3|VKOR1_HUMAN Isoform 3 of Vitamin K epoxide reductase complexsubunit 1 OS=Homo sapiens OX=9606 GN=VKORC1MGSTWGSPGWVRLALCLTGLVLSLYALHVKAARARDRDYRALCDVGTAISCSRVFSSRLPADTLGLCPDAAELPGVSRWFCLPGLDPVLRAL>sp|Q8N7Q3|ZN676_HUMAN Zinc finger protein 676 OS=Homo sapiens OX=9606GN=ZNF676 PE=2 SV=2MLENYRNLVFLGIAAFKPDLIIFLEQGKEPWNMKRHEMVEEPPVICSHFSQEFWPEQGIEDSFQKMILRRYDKCGHENLHLKISCTNVDECNVHKEGYNKLNQSLTTTQSKVFQCGKYANVFHKCSNSNRHKIRHTGEKGLKCKEYVRSFCMLSHLSQHERIYTRENSYKCEENGKAFNWSSTLTYYKSIHTGEKPYKCEECGKAFSKFSILTKHKVIHTGEKPYKCEECGKAFNRSSILTKHKIIHTGEKPYKCEECGKGFSSVSTLNTHKAIHAEEKPYKCEECGKASNSSSKLMEHKRIHTGEKPYKCEECGKAFSWSSSLTEHKRIHAGEKPYKCEECGKAFNRSSILTKHKIIHTGEKPYKCEGCGKAFSKVSTLNTHKAIHAEEKPYKCEECGKASNSSSKLMEHKRIHTGEKPYKCEECGKAFSWSSSLTEHKRIHAGEKPYKCEECGKAFTWSSSFTKHKRIHAAEKPYKCEECGKGFSTFSILTKHKIIHTGEKRYKCEECGKAFSWSSILTEHKIIHTGEKPYKCEECGKAFSRSSSLTRHKRIHTGEKPYKCEECGKAFKSSSTVSYHKKIHTGENP>sp|Q96NC0|ZMAT2_HUMAN Zinc finger matrin-type protein 2 OS=Homo sapiensOX=9606 GN=ZMAT2 PE=1 SV=1MASGSGTKNLDFRRKWDKDEYEKLAEKRLTEEREKKDGKPVQPVKRELLRHRDYKVDLESKLGKTIVITKTTPQSEMGGYYCNVCDCVVKDSINFLDHINGKKHQRNLGMSMRVERSTLDQVKKRFEVNKKKMEEKQKDYDFEERMKELREEEEKAKAYKKEKQKEKKRRAEEDLTFEEDDEMAAVMGFSGFGSTKKSY>sp|Q6ECI4|ZN470_HUMAN Zinc finger protein 470 OS=Homo sapiens OX=9606GN=ZNF470 PE=2 SV=3MKSQEEVEVAGIKLCKAMSLGSVTFTDVAIDFSQDEWEWLNLAQRSLYKKVMLENYRNLVSVGLCISKPDVISLLEQEKDPWVIKGGMNRGLCPDLECVWVTKSLSLNQDIYEEKLPPAIIMERLKSYDLECSTLGKNWKCEDLFERELVNQKTHFRQETITHIDTLIEKRDHSNKSGTVFHLNTLSYIKQIFPMEERIFNFHTDKKSLKTHSVVKKHKQDRGEKKLLKCNDCEKIFSKISTLTLHQRIHTGEKPYECIECGKAFSQSAHLAQHQRIHTGEKPFECTECGKAFSQNAHLVQHQRVHTGEKPYQCKQCNKAFSQLAHLAQHQRVHTGEKPYECIECGKAFSDCSSLAHHRRIHTGKRPYECIDCGKAFRQNASLIRHRRYYHTGEKPFDCIDCGKAFTDHIGLIQHKRTHTGERPYKCNVCGKAFSHGSSLTVHQRIHTGEKPYECNICEKAFSHRGSLTLHQRVHTGEKPYECKECGKAFRQSTHLAHHQRIHTGEKPYECKECSKTFSQNAHLAQHQKIHTGEKPYECKECGKAFSQIAHLVQHQRVHTGEKPYECIECGKAFSDGSYLVQHQRLHSGKRPYECLECGKAFRQRASLICHQRCHTGEKPYECNVCGKAFSHRKSLTLHQRIHTGEKPYECKECSKAFSQVAHLTLHKRIHTGERPYECKECGKAFRQSVHLAHHQRIHTGESSVILSSALPYHQVL>sp|Q6ECI4-2|ZN470_HUMAN Isoform 2 of Zinc finger protein 470 OS=Homosapiens OX=9606 GN=ZNF470MKSQEEVEVAGIKLCKAMSLGSVTFTDVAIDFSQDEWEWLNLAQRSLYKKVMLENYRNLVSVGKSIFLLLPPHDSVVFYAIIRISHSFPQHRQFLYVFLHAGLCISKPDVISLLEQEKDPWVIKGGMNRGLCPGEKPYECIECGKAFSQSAHLAQHQRIHTGEKPFECTECGKAFSQNAHLVQHQRVHTGEKPYQCKQCNKAFSQLAHLAQHQRVHTGEKPYECIECGKAFSDCSSLAHHRRIHTGKRPYECIDCGKAFRQNASLIRHRRYYHTGEKPFDCIDCGKAFTDHIGLIQHKRTHTGERPYKCNVCGKAFSHGSSLTVHQRIHTGEKPYECNICEKAFSHRGSLTLHQRVHTGEKPYECKECGKAFRQSTHLAHHQRIHTGEKPYECKECSKTFSQNAHLAQHQKIHTGEKPYECKECGKAFSQIAHLVQHQRVHTGEKPYECIECGKAFSDGSYLVQHQRLHSGKRPYECLECGKAFRQRASLICHQRCHTGEKPYECNVCGKAFSHRKSLTLHQRIHTGEKPYECKECSKAFSQVAHLTLHKRIHTGERPYECKECGKAFRQSVHLAHHQRIHTGESSVILSSALPYHQVL>sp|P17022|ZNF18_HUMAN Zinc finger protein 18 OS=Homo sapiens OX=9606GN=ZNF18 PE=1 SV=2MPVDLGQALGLLPSLAKAEDSQFSESDAALQEELSSPETARQLFRQFRYQVMSGPHETLKQLRKLCFQWLQPEVHTKEQILEILMLEQFLTILPGEIQMWVRKQCPGSGEEAVTLVESLKGDPQRLWQWISIQVLGQDILSEKMESPSCQVGEVEPHLEVVPQELGLENSSSGPGELLSHIVKEESDTEAELALAASQPARLEERLIRDQDLGASLLPAAPQEQWRQLDSTQKEQYWDLMLETYGKMVSGAGISHPKSDLTNSIEFGEELAGIYLHVNEKIPRPTCIGDRQENDKENLNLENHRDQELLHASCQASGEVPSQASLRGFFTEDEPGCFGEGENLPEALQNIQDEGTGEQLSPQERISEKQLGQHLPNPHSGEMSTMWLEEKRETSQKGQPRAPMAQKLPTCRECGKTFYRNSQLIFHQRTHTGETYFQCTICKKAFLRSSDFVKHQRTHTGEKPCKCDYCGKGFSDFSGLRHHEKIHTGEKPYKCPICEKSFIQRSNFNRHQRVHTGEKPYKCSHCGKSFSWSSSLDKHQRSHLGKKPFQ>sp|P17022-2|ZNF18_HUMAN Isoform 2 of Zinc finger protein 18 OS=Homosapiens OX=9606 GN=ZNF18MPVDLGQALGLLPSLAKAEDSQFSESDAALQEELSSPETARQLFRQFRYQVMSGPHETLKQLRKLCFQWLQPEVHTKEQILEILMLEQFLTILPGEIQMWVRKQCPGSGEEAVTLVESLKGDPQRLWQWISIQVLGQDILSEKMESPSCQVGEVEPHLEVVPQELGLENSSSGPGELLSHIVKEESDTEAELALAASQPARLEERLIRDQDLGASLLPAAPQEQWRQLDSTQKEQYWDLMLETYGKMVSGGISHPKSDLTNSIEFGEELAGIYLHVNEKIPRPTCIGDRQENDKENLNLENHRDQELLHASCQASGEVPSQASLRGFFTEDEPGCFGEGENLPEALQNIQDEGTGEQLSPQERISEKQLGQHLPNPHSGEMSTMWLEEKRETSQKGQPRAPMAQKLPTCRECGKTFYRNSQLIFHQRTHTGETYFQCTICKKAFLRSSDFVKHQRTHTGEKPCKCDYCGKGFSDFSGLRHHEKIHTGEKPYKCPICEKSFIQRSNFNRHQRVHTGEKPYKCSHCGKSFSWSSSLDKHQRSHLGKKPFQ>sp|Q499Z4|ZN672_HUMAN Zinc finger protein 672 OS=Homo sapiens OX=9606GN=ZNF672 PE=1 SV=2MFATSGAVAAGKPYSCSECGKSFCYSSVLLRHERAHGGDGRFRCLECGERCARAADLRAHRRTHAGQTLYICSECGQSFRHSGRLDLHLGAHRQRCRTCPCRTCGRRFPHLPALLLHRRRQHLPERPRRCPLCARTFRQSALLFHQARAHPLGTTSDPAAPPHRCAQCPRAFRSGAGLRSHARIHVSRSPTRPRVSDAHQCGVCGKCFGKSSTLTRHLQTHSGEKPFKCPECGKGFLESATLVRHQRTHTGEKPYACGDCGRCFSESSTLLRHRRSHQGERPHACATCGKGFGQRSDLVVHQRIHTGEKPFACPECGRRFSDRSDLTKHRRTHTGEKPYRCELCGKRFTCVSNLNVHRRNHAGHKPHKCPECSKAFSVASKLALHRKTHLGERPAECAECGKCFSHSRSLSQHQRAHTRARTAAAVAIQSAVGTALVFEGPAEQEKPGFSVS>sp|Q9P2J8|ZN624_HUMAN Zinc finger protein 624 OS=Homo sapiens OX=9606GN=ZNF624 PE=1 SV=3MSLQDSTLSREGKPEGEIMAAVFFSVGRLSPEVTQPDEDLHLQAEETQLVKESVTFKDVAIDFTLEEWRLMDPTQRNLHKDVMLENYRNLVSLGLAVSKPDMISHLENGKGPWVTVREISRIPYPDMEPKPATKKATRTKAISEDLSQEAILEKLTENGLWDSRMEGLWKWNDRILRLQNNQENHLSQRIIPLKKTPTSQRGFRFESILIPEPGIATEELHSRCQTQEENFTENLNLITDTHLGKIICKEMKGSKAIRQTSELTLGKKSNNKEKPYKCSTCEKAFHYRSLLIQHQRTHTKEKPYECNECGKTFSQPSYLSQHKKIHTGEKPYKCNECGKAFIASSSLMVHQRIHTKEKPYQCNVCGKSFSQCARLNQHQRIQTGEKPYKCSECGKAFSDKSKLARHQETHNGEKPYKCDDCGKAFRNKSYLSVHQKTHTEEKPYQCNECGKSFKNTTIFNVHQRIHTGEKPFRCNECGKAYRSNSSLIVHIRTHTGEKPYECNECGKAFNRIANFTEHQRIHTGEKPYKCNECGKAFINYSCLTVHHRMHTGEKPYKCTECGKAFMRSSSLIIHQRIHTEEKPYLCNECGESFRIKSHLTVHQRIHTGEKPYKCTDCERAFTKMVNLKEHQKIHTGVKPYKCYDCGKSFRTKSYLIVHQRTHTGEKPYKCNECEKAFTNTSQLTVHQRRHTGEKPYKCNECGKVFTSNSGFNTHQRTHTGEKPFKCNDCGKAFSQMVHVTEHQKIHSGEKPYKCDVCGKAFRRGSYLTVHWRTHTGEKPYTCKECGKGCITLSQLTLHQRIHTGERPYKCEECGKAFRTNSDFTVHLRMHTGEKPYKCNECGKAFRSSSSLTVHQRIHQRETQLI>sp|Q9P2J8-2|ZN624_HUMAN Isoform 2 of Zinc finger protein 624 OS=Homosapiens OX=9606 GN=ZNF624MEPKPATKKATRTKAISEDLSQEAILEKLTENGLWDSRMEGLWKWNDRILRLQNNQENHLSQRIIPLKKTPTSQRGFRFESILIPEPGIATEELHSRCQTQEENFTENLNLITDTHLGKIICKEMKGSKAIRQTSELTLGKKSNNKEKPYKCSTCEKAFHYRSLLIQHQRTHTKEKPYECNECGKTFSQPSYLSQHKKIHTGEKPYKCNECGKAFIASSSLMVHQRIHTKEKPYQCNVCGKSFSQCARLNQHQRIQTGEKPYKCSECGKAFSDKSKLARHQETHNGEKPYKCDDCGKAFRNKSYLSVHQKTHTEEKPYQCNECGKSFKNTTIFNVHQRIHTGEKPFRCNECGKAYRSNSSLIVHIRTHTGEKPYECNECGKAFNRIANFTEHQRIHTGEKPYKCNECGKAFINYSCLTVHHRMHTGEKPYKCTECGKAFMRSSSLIIHQRIHTEEKPYLCNECGESFRIKSHLTVHQRIHTGEKPYKCTDCERAFTKMVNLKEHQKIHTGVKPYKCYDCGKSFRTKSYLIVHQRTHTGEKPYKCNECEKAFTNTSQLTVHQRRHTGEKPYKCNECGKVFTSNSGFNTHQRTHTGEKPFKCNDCGKAFSQMVHVTEHQKIHSGEKPYKCDVCGKAFRRGSYLTVHWRTHTGEKPYTCKECGKGCITLSQLTLHQRIHTGERPYKCEECGKAFRTNSDFTVHLRMHTGEKPYKCNECGKAFRSSSSLTVHQRIHQRETQLI>sp|Q6WRX3|ZY11A_HUMAN Protein zyg-11 homolog A OS=Homo sapiens OX=9606GN=ZYG11A PE=2 SV=3MVHFLHPGHTPRNIVPPDAQKDALGCCVVQEEASPYTLVNICLNVLIANLEKLCSERPDGTLCLPEHWSFPQEVAERFLRVMTWQGKLTDRTASIFRGNQMKLKLVNIQKAKISTAAFIKAFCRHKLIELNATAVHADLPVPDIISGLCSNRWIQQNLQCLLLDSTSIPQNSRLLFFSQLTGLRILSVFNVCFHTEDLANVSQLPRLESLDISNTLVTDISALLTCKDRLKSLTMHYLKCLAMTKSQILAVIRELKCLLHLDISDHRQLKSDLAFHLLQQKDILPNVVSLDISGGNCITDEAVELFIRLRPAMQFVGLLATDAGSSDFFTTKQGLRVAGGASMSQISEALSRYRNRSCFVKEALHRLFTETFSMEVTMPAILKLVAIGMRNHPLDLRVQFTASACALNLTRQGLAKGMPVRLLSEVTCLLFKALKNFPHYQQLQKNCLLSLTNSRILVDVPFDRFDAAKFVMRWLCKHENPKMQTMAVSVTSILALQLSPEQTAQLEELFMAVKELLAIVKQKTTENLDDVTFLFTLKALWNLTDGSPAACKHFIENQGLQIFIQVLETFSESAIQSKVLGLLNNIAEVRELSSKLVTEDVLKHINSLLCSREMEVSYFAAGIIAHLTSDRQLWISRDFQRRTLLQDLHATIQNWPSSSCKMTALVTYRSFKTFFPLLGNFSQPEVQLWALWAMYHVCSKNPSKYCKMLVEEEGLQLLCDIQEHSEATPKAQQIAASILDDFRMHFMNYQRPTLCQMPF>sp|Q6WRX3-2|ZY11A_HUMAN Isoform 2 of Protein zyg-11 homolog A OS=Homosapiens OX=9606 GN=ZYG11AMSQISEALSRYRNRSCFVKEALHRLFTETFSMEVTMPAILKLVAIGMRNHPLDLRVQFTASACALNLTRQGLAKGMPVRLLSEVTCLLFKALKNFPHYQQLQKNCLLSLTNSRILVDVPFDRFDAAKFVMRWLCKHENPKMQTMAVSVTSILALQLSPEQTAQLEELFMAVKELLAIVKQKTTENLDDVTFLFTLKALWNLTDGSPAACKHFIENQGLQIFIQVLETFSESAIQSKVLGLLNNIAEVRELSSKLVTEDVLKHINSLLCSREMEVSYFAAGIIAHLTSDRQLWISRDFQRRTLLQDLHATIQNWPSSSCKMTALVTYRSFKTFFPLLGNFSQPEVQLWALWAMYHVCSKNPSKYCKMLVEEEGLQLLCDIQEHSEATPKAQQIAASILDDFRMHFMNYQRPTLCQMPF>sp|O43264|ZW10_HUMAN Centromere/kinetochore protein zw10 homolog OS=Homosapiens OX=9606 GN=ZW10 PE=1 SV=3MASFVTEVLAHSGRLEKEDLGTRISRLTRRVEEIKGEVCNMISKKYSEFLPSMQSAQGLITQVDKLSEDIDLLKSRIESEVRRDLHVSTGEFTDLKQQLERDSVVLSLLKQLQEFSTAIEEYNCALTEKKYVTGAQRLEEAQKCLKLLKSRKCFDLKILKSLSMELTIQKQNILYHLGEEWQKLIVWKFPPSKDTSSLESYLQTELHLYTEQSHKEEKTPMPPISSVLLAFSVLGELHSKLKSFGQMLLKYILRPLASCPSLHAVIESQPNIVIIRFESIMTNLEYPSPSEVFTKIRLVLEVLQKQLLDLPLDTDLENEKTSTVPLAEMLGDMIWEDLSECLIKNCLVYSIPTNSSKLQQYEEIIQSTEEFENALKEMRFLKGDTTDLLKYARNINSHFANKKCQDVIVAARNLMTSEIHNTVKIIPDSKINVPELPTPDEDNKLEVQKVSNTQYHEVMNLEPENTLDQHSFSLPTCRISESVKKLMELAYQTLLEATTSSDQCAVQLFYSVRNIFHLFHDVVPTYHKENLQKLPQLAAIHHNNCMYIAHHLLTLGHQFRLRLAPILCDGTATFVDLVPGFRRLGTECFLAQMRAQKGELLERLSSARNFSNMDDEENYSAASKAVRQVLHQLKRLGIVWQDVLPVNIYCKAMGTLLNTAISEVIGKITALEDISTEDGDRLYSLCKTVMDEGPQVFAPLSEESKNKKYQEEVPVYVPKWMPFKELMMMLQASLQEIGDRWADGKGPLAAAFSSSEVKALIRALFQNTERRAAALAKIK>sp|O43264-2|ZW10_HUMAN Isoform 2 of Centromere/kinetochore protein zw10homolog OS=Homo sapiens OX=9606 GN=ZW10MASFVTEVLAHSGRLEKEDLGTRISRLTRRVEEIKGEVCNMISKKYSEFLPSMQSAQGLITQVDKLSEDIDLLKSRIESEVRRDLHVSTGEFTDLKQQLERDSVVLSLLKQLQEFSTAIEEYNCALTEKKYVTGAQRLEEAQKCLKLLKSRKCFDLKILKSLSMELTIQKQNILYHLGEEWQKLIVWKFPPSKDTSSLESYLQTELHLYTEQSHKEEKTPMPPISSVLLAFSVLGELHSKLKSFGQMLLKYILRPLASCPSLHAVIESQPNIVIIRFESIMTNLEYPSPSEVFTKIRLVLEVLQKQLLDLPLDTDLENEKTSTVPLAEMLGDMIWEDLSECLIKNCLVYSIPTNSSKLQQYEEIIQSTEEFENALKEMRFLKGDTTDLLKYARNINSHFANKKCQDVIVAARNLMTSEIHNTVKIIPDSKINVPELPTPDEDNKLEVQKVSNTQYHEVMNLEPENTLDQHSFSLPTCRISESVKKLMELAYQTLLEATTSSDQCAVQLFYSVRNIFHLFHDVVPTYHKENLQKLPQLAAIHHNNCMYIAHHLLTLGHQFRLRLAPILCDGTATFVDLVPGFRRLGTECFLAQMRAQKGELLERLSSARNFSNMDDEENYSAASKAVRQVLHQLKRLGIVWQDVLPVNIYCKAMGTLLNTAISEVIGKITALE>sp|A7E2V4|ZSWM8_HUMAN Zinc finger SWIM domain-containing protein 8OS=Homo sapiens OX=9606 GN=ZSWIM8 PE=1 SV=1MELMFAEWEDGERFSFEDSDRFEEDSLCSFISEAESLCQNWRGWRKQSAGPNSPTGGGGGGGSGGTRMRDGLVIPLVELSAKQVAFHIPFEVVEKVYPPVPEQLQLRIAFWSFPENEEDIRLYSCLANGSADEFQRGDQLFRMRAVKDPLQIGFHLSATVVPPQMVPPKGAYNVAVMFDRCRVTSCSCTCGAGAKWCTHVVALCLFRIHNASAVCLRAPVSESLSRLQRDQLQKFAQYLISELPQQILPTAQRLLDELLSSQSTAINTVCGAPDPTAGPSASDQSTWYLDESTLTDNIKKTLHKFCGPSPVVFSDVNSMYLSSTEPPAAAEWACLLRPLRGREPEGVWNLLSIVREMFKRRDSNAAPLLEILTDQCLTYEQITGWWYSVRTSASHSSASGHTGRSNGQSEVAAHACASMCDEMVTLWRLAVLDPALSPQRRRELCTQLRQWQLKVIENVKRGQHKKTLERLFPGFRPAVEACYFNWEEAYPLPGVTYSGTDRKLALCWARALPSRPGASRSGGLEESRDRPRPLPTEPAVRPKEPGTKRKGLGEGVPSSQRGPRRLSAEGGDKALHKMGPGGGKAKALGGAGSGSKGSAGGGSKRRLSSEDSSLEPDLAEMSLDDSSLALGAEASTFGGFPESPPPCPLHGGSRGPSTFLPEPPDTYEEDGGVYFSEGPEPPTASVGPPGLLPGDVCTQDDLPSTDESGNGLPKTKEAAPAVGEEDDDYQAYYLNAQDGAGGEEEKAEGGAGEEHDLFAGLKPLEQESRMEVLFACAEALHAHGYSSEASRLTVELAQDLLANPPDLKVEPPPAKGKKNKVSTSRQTWVATNTLSKAAFLLTVLSERPEHHNLAFRVGMFALELQRPPASTKALEVKLAYQESEVAALLKKIPLGPSEMSTMRCRAEELREGTLCDYRPVLPLMLASFIFDVLCAPGSRPPSRNWNSETPGDEELGFEAAVAALGMKTTVSEAEHPLLCEGTRREKGDLALALMITYKDDQAKLKKILDKLLDRESQTHKPQTLSSFYSSSRPTTASQRSPSKHGGPSAPGALQPLTSGSAGPAQPGSVAGAGPGPTEGFTEKNVPESSPHSPCEGLPSEAALTPRPEGKVPSRLALGSRGGYNGRGWGSPGRPKKKHTGMASIDSSAPETTSDSSPTLSRRPLRGGWAPTSWGRGQDSDSISSSSSDSLGSSSSSGSRRASASGGARAKTVEVGRYKGRRPESHAPHVPNQPSEAAAHFYFELAKTVLIKAGGNSSTSIFTHPSSSGGHQGPHRNLHLCAFEIGLYALGLHNFVSPNWLSRTYSSHVSWITGQAMEIGSAALTILVECWDGHLTPPEVASLADRASRARDSNMVRAAAELALSCLPHAHALNPNEIQRALVQCKEQDNLMLEKACMAVEEAAKGGGVYPEVLFEVAHQWFWLYEQTAGGSSTAREGATSCSASGIRAGGEAGRGMPEGRGGPGTEPVTVAAAAVTAAATVVPVISVGSSLYPGPGLGHGHSPGLHPYTALQPHLPCSPQYLTHPAHPAHPMPHMPRPAVFPVPSSAYPQGVHPAFLGAQYPYSVTPPSLAATAVSFPVPSMAPITVHPYHTEPGLPLPTSVACELWGQGTVSSVHPASTFPAIQGASLPALTTQPSPLVSGGFPPPEEETHSQPVNPHSLHHLHAAYRVGMLALEMLGRRAHNDHPNNFSRSPPYTDDVKWLLGLAAKLGVNYVHQFCVGAAKGVLSPFVLQEIVMETLQRLSPAHAHNHLRAPAFHQLVQRCQQAYMQYIHHRLIHLTPADYDDFVNAIRSARSAFCLTPMGMMQFNDILQNLKRSKQTKELWQRVSLEMATFSP>sp|A7E2V4-2|ZSWM8_HUMAN Isoform 2 of Zinc finger SWIM domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=ZSWIM8MELMFAEWEDGERFSFEDSDRFEEDSLCSFISEAESLCQNWRGWRKQSAGPNSPTGGGGGGGSGGTRMRDGLVIPLVELSAKQVAFHIPFEVVEKVYPPVPEQLQLRIAFWSFPENEEDIRLYSCLANGSADEFQRGDQLFRMRAVKDPLQIGFHLSATVVPPQMVPPKGAYNVAVMFDRCRVTSCSCTCGAGAKWCTHVVALCLFRIHNASAVCLRAPVSESLSRLQRDQLQKFAQYLISELPQQILPTAQRLLDELLSSQSTAINTVCGAPDPTAGPSASDQSTWYLDESTLTDNIKKTLHKFCGPSPVVFSDVNSMYLSSTEPPAAAEWACLLRPLRGREPEGVWNLLSIVREMFKRRDSNAAPLLEILTDQCLTYEQITGWWYSVRTSASHSSASGHTGRSNGQSEVAAHACASMCDEMVTLWRLAVLDPALSPQRRRELCTQLRQWQLKVIENVKRGQHKKTLERLFPGFRPAVEACYFNWEEAYPLPGVTYSGTDRKLALCWARALPSRPGASRSGGLEESRDRPRPLPTEPAVRPKEPGTKRKGLGEGVPSSQRGPRRLSAEGGDKALHKMGPGGGKAKALGGAGSGSKGSAGGGSKRRLSSEDSSLEPDLAEMSLDDSSLALGAEASTFGGFPESPPPCPLHGGSRGPSTFLPEPPDTYEEDGGVYFSEGPEPPTASVGPPGLLPGDVCTQDDLPSTDESGNGLPKTKEAAPAVGEEDDDYQAYYLNAQDGAGGEEEKAEGGAGEEHDLFAGLKPLEQESRMEVLFACAEALHAHGYSSEASRLTVELAQDLLANPPDLKVEPPPAKGKKNKVSTSRQTWVATNTLSKAAFLLTVLSERPEHHNLAFRVGMFALELQRPPASTKALEVKLAYQESEVAALLKKIPLGPSEMSTMRCRAEELREGTLCDYRPVLPLMLASFIFDVLCAPGSRPPSRNWNSETPGDEELGFEAAVAALGMKTTVSEAEHPLLCEGTRREKGDLALALMITYKDDQAKLKKILDKLLDRESQTHKPQTLSSFYSSSRPTTASQRSPSKHGGPSAPGALQPLTSGSAGPAQPGSVAGAGPGPTEGFTEKNVPESSPHSPCEGLPSEAALTPRPEGKVPSRLALGSRGGYNGRGWGSPGRPKKKHTGMASIDSSAPETTSDSSPTLSRRPLRGGWAPTSWGRGQDSDSISSSSSDSLGSSSSSGSRRASASGGARAKTVEVGRYKGRRPESHAPHVPNQPSEAAAHFYFELAKTVLIKAGGNSSTSIFTHPSSSGGHQGPHRNLHLCAFEIGLYALGLHNFVSPNWLSRTYSSHVSWITGQAMEIGSAALTILVECWDGHLTPPEVASLADRASRARDSNMVRAAAELALSCLPHAHALNPNEIQRALVQCKEQDNLMLEKACMAVEEAAKGGGVYPEVLFEVAHQWFWLYEQTAGGSSTAREGATSCSASGIRAGGEAGRGMPEGRGGPGTEPVTVAAAAVTAAATVVPVISVGSSLYPGPGLGHGHSPGLHPYTALQPHLPCSPQYLTHPAHPAHPMPHMPRPAVFPVPSSAYPQGVHPAFLGAQYPYSVTPPSLAATAVSFPVPSMAPITVHPYHTEPGLPLPTSVALSSVHPASTFPAIQGASLPALTTQPSPLVSGGFPPPEEETHSQPVNPHSLHHLHAAYRVGMLALEMLGRRAHNDHPNNFSRSPPYTDDVKWLLGLAAKLGDRHGDAAAAESRSCPQPPACPGLPPTGAALPAGIHAVHPPPLDSPDSCGLRRLCECDPECPQRLLPDAHGHDAVQRHPTEPQAQQTDQGAVAAGLTRDGHLLPLSLSPLGSYTGTQACGYGGPSHRGSETWLDRSSSLSSLVAQTDSCSWAIAWGQDVSHPRSLGLGETALSGRGRWVASGIYLAFINI>sp|A7E2V4-3|ZSWM8_HUMAN Isoform 3 of Zinc finger SWIM domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=ZSWIM8MELMFAEWEDGERFSFEDSDRFEEDSLCSFISEAESLCQNWRGWRKQSAGPNSPTGGGGGGGSGGTRMRDGLVIPLVELSAKQVAFHIPFEVVEKVYPPVPEQLQLRIAFWSFPENEEDIRLYSCLANGSADEFQRGDQLFRMRAVKDPLQIGFHLSATVVPPQMVPPKGAYNVAVMFDRCRVTSCSCTCGAGAKWCTHVVALCLFRIHNASAVCLRAPVSESLSRLQRDQLQKFAQYLISELPQQILPTAQRLLDELLSSQSTAINTVCGAPDPTAGPSASDQSTWYLDESTLTDNIKKTLHKFCGPSPVVFSDVNSMYLSSTEPPAAAEWACLLRPLRGREPEGVWNLLSIVREMFKRRDSNAAPLLEILTDQCLTYEQITGWWYSVRTSASHSSASGHTGRSNGQSEVAAHACASMCDEMVTLWRLAVLDPALSPQRRRELCTQLRQWQLKVIENVKRGQHKKTLERLFPGFRPAVEACYFNWEEAYPLPGVTYSGTDRKLALCWARALPSRPGASRSGGLEESRDRPRPLPTEPAVRPKEPGTKRKGLGEGVPSSQRGPRRLSAEGGDKALHKMGPGGGKAKALGGAGSGSKGSAGGGSKRRLSSEDSSLEPDLAEMSLDDSSLALGAEASTFGGFPESPPPCPLHGGSRGPSTFLPEPPDTYEEDGGVYFSEGPEPPTASVGPPGLLPGDVCTQDDLPSTDESGNGLPKTKEAAPAVGEEDDDYQAYYLNAQDGAGGEEEKAEGGAGEEHDLFAGLKPLEQESRMEVLFACAEALHAHGYSSEASRLTVELAQDLLANPPDLKVEPPPAKGKKNKVSTSRQTWVATNTLSKAAFLLTVLSERPEHHNLAFRVGMFALELQRPPASTKALEVKLAYQESEVAALLKKIPLGPSEMSTMRCRAEELREGTLCDYRPVLPLMLASFIFDVLCAPVVSPTGSRPPSRNWNSETPGDEELGFEAAVAALGMKTTVSEAEHPLLCEGTRREKGDLALALMITYKDDQAKLKKVTASVFQILDKLLDRESQTHKPQTLSSFYSSSRPTTASQRSPSKHGGPSAPGALQPLTSGSAGPAQPGSVAGAGPGPTEGFTEKNVPESSPHSPCEGLPSEAALTPRPEGKVPSRLALGSRGGYNGRGWGSPGRPKKKHTGMASIDSSAPETTSDSSPTLSRRPLRGGWAPTSWGRGQDSDSISSSSSDSLGSSSSSGSRRASASGGARAKTVEVGRYKGRRPESHAPHVPNQPSEAAAHFYFELAKTVLIKAGGNSSTSIFTHPSSSGGHQGPHRNLHLCAFEIGLYALGLHNFVSPNWLSRTYSSHVSWITGQAMEIGSAALTILVECWDGHLTPPEVASLADRASRARDSNMVRAAAELALSCLPHAHALNPNEIQRALVQCKEQDNLMLEKACMAVEEAAKGGGVYPEVLFEVAHQWFWLYEQTAGGSSTAREGATSCSASGIRAGGEAGRGMPEGRGGPGTEPVTVAAAAVTAAATVVPVISVGSSLYPGPGLGHGHSPGLHPYTALQPHLPCSPQYLTHPAHPAHPMPHMPRPAVFPVPSSAYPQGVHPAFLGAQYPYSVTPPSLAATAVSFPVPSMAPITVHPYHTEPGLPLPTSVALSSVHPASTFPAIQGASLPALTTQPSPLVSGGFPPPEEETHSQPVNPHSLHHLHAAYRVGMLALEMLGRRAHNDHPNNFSRSPPYTDDVKWLLGLAAKLGVNYVHQFCVGAAKGVLSPFVLQEIVMETLQRLSPAHAHNHLRAPAFHQLVQRCQQAYMQYIHHRLIHLTPADYDDFVNAIRSARSAFCLTPMGMMQFNDILQNLKRSKQTKELWQRVSLEMATFSP>sp|A7E2V4-4|ZSWM8_HUMAN Isoform 4 of Zinc finger SWIM domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=ZSWIM8MELMFAEWEDGERFSFEDSDRFEEDSLCSFISEAESLCQNWRGWRKQSAGPNSPTGGGGGGGSGGTRMRDGLVIPLVELSAKQVAFHIPFEVVEKVYPPVPEQLQLRIAFWSFPENEEDIRLYSCLANGSADEFQRGDQLFRMRAVKDPLQIGFHLSATVVPPQMVPPKGAYNVAVMFDRCRVTSCSCTCGAGAKWCTHVVALCLFRIHNASAVCLRAPVSESLSRLQRDQLQKFAQYLISELPQQILPTAQRLLDELLSSQSTAINTVCGAPDPTAGPSASDQSTWYLDESTLTDNIKKTLHKFCGPSPVVFSDVNSMYLSSTEPPAAAEWACLLRPLRGREPEGVWNLLSIVREMFKRRDSNAAPLLEILTDQCLTYEQITGWWYSVRTSASHSSASGHTGRSNGQSEVAAHACASMCDEMVTLWRLAVLDPALSPQRRRELCTQLRQWQLKVIENVKRGQHKKTLERLFPGFRPAVEACYFNWEEAYPLPGVTYSGTDRKLALCWARALPSRPGASRSGGLEESRDRPRPLPTEPAVRPKEPGTKRKGLGEGVPSSQRGPRRLSAEGGDKALHKMGPGGGKAKALGGAGSGSKGSAGGGSKRRLSSEDSSLEPDLAEMSLDDSSLALGAEASTFGGFPESPPPCPLHGGSRGPSTFLPEPPDTYEEDGGVYFSEGPEPPTASVGPPGLLPGDVCTQDDLPSTDESGNGLPKTKEAAPAVGEEDDDYQAYYLNAQDGAGGEEEKAEGGAGEEHDLFAGLKPLEQESRMEVLFACAEALHAHGYSSEASRLTVELAQDLLANPPDLKVEPPPAKGKKNKVSTSRQTWVATNTLSKAAFLLTVLSERPEHHNLAFRVGMFALELQRPPASTKALEVKLAYQESEVAALLKKIPLGPSEMSTMRCRAEELREGTLCDYRPVLPLMLASFIFDVLCAPVVSPTGSRPPSRNWNSETPGDEELGFEAAVAALGMKTTVSEAEHPLLCEGTRREKGDLALALMITYKDDQAKLKKILDKLLDRESQTHKPQTLSSFYSSSRPTTASQRSPSKHGGPSAPGALQPLTSGSAGPAQPGSVAGAGPGPTEGFTEKNVPESSPHSPCEGLPSEAALTPRPEGKVPSRLALGSRGGYNGRGWGSPGRPKKKHTGMASIDSSAPETTSDSSPTLSRRPLRGGWAPTSWGRGQDSDSISSSSSDSLGSSSSSGSRRASASGGARAKTVEVGRYKGRRPESHAPHVPNQPSEAAAHFYFELAKTVLIKAGGNSSTSIFTHPSSSGGHQGPHRNLHLCAFEIGLYALGLHNFVSPNWLSRTYSSHVSWITGQAMEIGSAALTILVECWDGHLTPPEVASLADRASRARDSNMVRAAAELALSCLPHAHALNPNEIQRALVQCKEQDNLMLEKACMAVEEAAKGGGVYPEVLFEVAHQWFWLYEQTAGGSSTAREGATSCSASGIRAGGEAGRGMPEGRGGPGTEPVTVAAAAVTAAATVVPVISVGSSLYPGPGLGHGHSPGLHPYTALQPHLPCSPQYLTHPAHPAHPMPHMPRPAVFPVPSSAYPQGVHPAFLGAQYPYSVTPPSLAATAVSFPVPSMAPITVHPYHTEPGLPLPTSVACELWGQGTVSSVHPASTFPAIQGASLPALTTQPSPLVSGGFPPPEEETHSQPVNPHSLHHLHAAYRVGMLALEMLGRRAHNDHPNNFSRSPPYTDDVKWLLGLAAKLGVNYVHQFCVGAAKGVLSPFVLQEIVMETLQRLSPAHAHNHLRAPAFHQLVQRCQQAYMQYIHHRLIHLTPADYDDFVNAIRSARSAFCLTPMGMMQFNDILQNLKRSKQTKELWQRVSLEMATFSP>sp|A7E2V4-5|ZSWM8_HUMAN Isoform 5 of Zinc finger SWIM domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=ZSWIM8MELMFAEWEDGERFSFEDSDRFEEDSLCSFISEAESLCQNWRGWRKQSAGPNSPTGGGGGGGSGGTRMRDGLVIPLVELSAKQVAFHIPFEVVEKVYPPVPEQLQLRIAFWSFPENEEDIRLYSCLANGSADEFQRGDQLFRMRAVKDPLQIGFHLSATVVPPQMVPPKGAYNVAVMFDRCRVTSCSCTCGAGAKWCTHVVALCLFRIHNASAVCLRAPVSESLSRLQRDQLQKFAQYLISELPQQILPTAQRLLDELLSSQSTAINTVCGAPDPTAGPSASDQSTWYLDESTLTDNIKKTLHKFCGPSPVVFSDVNSMYLSSTEPPAAAEWACLLRPLRGREPEGVWNLLSIVREMFKRRDSNAAPLLEILTDQCLTYEQITGWWYSVRTSASHSSASGHTGRSNGQSEVAAHACASMCDEMVTLWRLAVLDPALSPQRRRELCTQLRQWQLKVIENVKRGQHKKTLERLFPGFRPAVEACYFNWEEAYPLPGVTYSGTDRKLALCWARALPSRPGASRSGGLEESRDRPRPLPTEPAVRPKEPGTKRKGLGEGVPSSQRGPRRLSAEGGDKALHKMGPGGGKAKALGGAGSGSKGSAGGGSKRRLSSEDSSLEPDLAEMSLDDSSLALGAEASTFGGFPESPPPCPLHGGSRGPSTFLPEPPDTYEEDGGVYFSEGPEPPTASVGPPGLLPGDVCTQDDLPSTDESGNGLPKTKEAAPAVGEEDDDYQAYYLNAQDGAGGEEEKAEGGAGEEHDLFAGLKPLEQESRMEVLFACAEALHAHGYSSEASRLTVELAQDLLANPPDLKVEPPPAKGKKNKVSTSRQTWVATNTLSKAAFLLTVLSERPEHHNLAFRVGMFALELQRPPASTKALEVKLAYQESEVAALLKKIPLGPSEMSTMRCRAEELREGTLCDYRPVLPLMLASFIFDVLCAPGSRPPSRNWNSETPGDEELGFEAAVAALGMKTTVSEAEHPLLCEGTRREKGDLALALMITYKDDQAKLKKILDKLLDRESQTHKPQTLSSFYSSSRPTTASQRSPSKHGGPSAPGALQPLTSGSAGPAQPGSVAGAGPGPTEGFTEKNVPESSPHSPCEGLPSEAALTPRPEGKVPSRLALGSRGGYNGRGWGSPGRPKKKHTGMASIDSSAPETTSDSSPTLSRRPLRGGWAPTSWGRGQDSDSISSSSSDSLGSSSSSGSRRASASGGARAKTVEVGRYKGRRPESHAPHVPNQPSEAAAHFYFELAKTVLIKAGGNSSTSIFTHPSSSGGHQGPHRNLHLCAFEIGLYALGLHNFVSPNWLSRTYSSHVSWITGQAMEIGSAALTILVECWDGHLTPPEVASLADRASRARDSNMVRAAAELALSCLPHAHALNPNEIQRALVQCKEQDNLMLEKACMAVEEAAKGGGVYPEVLFEVAHQWFWLYEQTAGGSSTAREGATSCSASGIRAGGEAGRGMPEGRGGPGTEPVTVAAAAVTAAATVVPVISVGSSLYPGPGLGHGHSPGLHPYTALQPHLPCSPQYLTHPAHPAHPMPHMPRPAVFPVPSSAYPQGVHPAFLGAQYPYSVTPPSLAATAVSFPVPSMAPITVHPYHTEPGLPLPTSVALSSVHPASTFPAIQGASLPALTTQPSPLVSGGFPPPEEETHSQPVNPHSLHHLHAAYRVGMLALEMLGRRAHNDHPNNFSRSPPYTDDVKWLLGLAAKLGVNYVHQFCVGAAKGVLSPFVLQEIVMETLQRLSPAHAHNHLRAPAFHQLVQRCQQAYMQYIHHRLIHLTPADYDDFVNAIRSARSAFCLTPMGMMQFNDILQNLKRSKQTKELWQRVSLEMATFSP>sp|Q8NEW0|ZNT7_HUMAN Zinc transporter 7 OS=Homo sapiens OX=9606GN=SLC30A7 PE=2 SV=1MLPLSIKDDEYKPPKFNLFGKISGWFRSILSDKTSRNLFFFLCLNLSFAFVELLYGIWSNCLGLISDSFHMFFDSTAILAGLAASVISKWRDNDAFSYGYVRAEVLAGFVNGLFLIFTAFFIFSEGVERALAPPDVHHERLLLVSILGFVVNLIGIFVFKHGGHGHSHGSGHGHSHSLFNGALDQAHGHVDHCHSHEVKHGAAHSHDHAHGHGHFHSHDGPSLKETTGPSRQILQGVFLHILADTLGSIGVIASAIMMQNFGLMIADPICSILIAILIVVSVIPLLRESVGILMQRTPPLLENSLPQCYQRVQQLQGVYSLQEQHFWTLCSDVYVGTLKLIVAPDADARWILSQTHNIFTQAGVRQLYVQIDFAAM>sp|P98168|ZXDA_HUMAN Zinc finger X-linked protein ZXDA OS=Homo sapiensOX=9606 GN=ZXDA PE=1 SV=2MEIPKLLPARGTLQGGGGGGIPAGGGRVHRGPDSPAGQVPTRRLLLPRGPQDGGPGRRREEASTASRGPGPSLFAPRPHQPSGGGDDFFLVLLDPVGGDVETAGSGQAAGPVLREEAKAGPGLQGDESGANPAGCSAQGPHCLSAVPTPAPISAPGPAAAFAGTVTIHNQDLLLRFENGVLTLATPPPHAWEPGAAPAQQPRCLIAPQAGFPQAAHPGDCPELRSDLLLAEPAEPAPAPAPQEEAEGLAAALGPRGLLGSGPGVVLYLCPEALCGQTFAKKHQLKMHLLTHSSSQGQRPFKCPLGGCGWTFTTSYKLKRHLQSHDKLRPFGCPAEGCGKSFTTVYNLKAHMKGHEQENSFKCEVCEESFPTQAKLGAHQRSHFEPERPYQCAFSGCKKTFITVSALFSHNRAHFREQELFSCSFPGCSKQYDKACRLKIHLRSHTGERPFLCDFDGCGWNFTSMSKLLRHKRKHDDDRRFMCPVEGCGKSFTRAEHLKGHSITHLGTKPFVCPVAGCCARFSARSSLYIHSKKHLQDVDTWKSRCPISSCNKLFTSKHSMKTHMVKRHKVGQDLLAQLEAANSLTPSSELTSQRQNDLSDAEIVSLFSDVPDSTSAALLDTALVNSGILTIDVASVSSTLAGHLPANNNNSVGQAVDPPSLMATSDPPQSLDTSLFFGTAATGFQQSSLNMDEVSSVSVGPLGSLDSLAMKNSSPEPQALTPSSKLTVDTDTLTPSSTLCENSVSELLTPAKAEWSVHPNSDFFGQEGETQFGFPNAAGNHGSQKERNLITVTGSSFLV>sp|O43149|ZZEF1_HUMAN Zinc finger ZZ-type and EF-hand domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=ZZEF1 PE=1 SV=6MGNAPSHSSEDEAAAAGGEGWGPHQDWAAVSGTTPGPGVAAPALPPAAALLEPARLREAAAALLPTPPCESLVSRHRGALFRWLEERLGRGEESVTLEQFRELLEARGAGCSSEQFEEAFAQFDAEGDGTVDAENMLEALKNSSGANLQGELSHIIRQLQACSLVPGFTDIFSESKEGLDIHSSMILRFLHRNRLSSAVMPYPMLEHCNNMCTMRSSVLKESLDQLVQKEKESPGDLTRSPEMDKLKSVAKCYAYIETSSNSADIDKMTNGETSSYWQSDGSACSHWIRLKMKPDVVLRHLSIAVAATDQSYMPQQVTVAVGRNASDLQEVRDVHIPSNVTGYVTLLENANVSQLYVQINIKRCLSDGCDTRIHGLRAVGFQRVKKSGVSVSDASAIWYWSLLTSLVTASMETNPAFVQTVLHNTQKALRHMPPLSLSPGSTDFSTFLSPNVLEEVDSFLIRITSCCSTPEVELTLLAFALARGSVAKVMSSLCTITDHLDTQYDASSLILSMASVRQNLLLKYGKPLQLTLQACDVKGKEDKSGPENLLVEPWTRDGFLTETGKTRASTIFSTGTESAFQVTQIRIMVRRGGIGAQCGLVFAYNSSSDKFCAEEHFKRFEKYDKWKLQELRQFVKSRIGCSSDDLGEDDPIGWFELEEEWDEADVKLQQCRVAKYLMVKFLCTRQESAERLGVQGLTISGYLRPARAEAEQSVTCAHCRKDTEESVCGATLLLRTLQFIQQLAHDLVQQKESGLKYKSFLDFAGLDLQIFWNFYSKLKQNPREECVSAQTLLLQLLQSCFSVLQGDVLAASEEEKAPIQSPKGVEAAKELYTHLCDVVDKVDGDSVPMEILKQEVRNTLLNGAAIFFPNRQTRRNHLFTMMNVTEQEHKQSLQLTFRSLCTYFSDKDPGGLLLLPEKNDLAKMNISEVLAVMDTLVSVAARECELLMLSGAPGEVGSVLFSLFWSVQGSLLSWCYLQLKSTDSGAKDLAVDLIEKYVGQFLASMRAILESLFSQYSGKTIVERLCNSVFSMAARQLVIFLLDFCTLDIPHCVLLREFSVLTELLKKLCSGPEGGLRKLDVETWQQEQPVVLHTWTKESAHNYENNCHEVSVFVSPGATYFEVEFDDRCETEKRYDYLEFTDARGRKTRYDTKVGTDKWPKKVTFKAGPRLQFLFHSDSSHNEWGYKFTVTACGLPDVAVSWGLDLQLLVSRLMGRLASQCMALKSVRQLGSNMVVPQAKMALVLSSPLWKPVFRHQVCPELELEASWPTHPHRNSKEVKNIPDDPCRHFLLDFAQSEPAQNFCGPYSELFKGFIQACRKQAPKTDIVAGSTIDQAVNATFAALVYRTPDLYEKLQKYVNSGGKIALSEEFAQVYSLADGIRIWMLEMKQKSLMSLGNEAEEKHSSEATEVNPESLAKECIEKSLLLLKFLPTGISSKESCEKLETADETSHLQPLNKRQRTSSVVEEHFQASVSPTEAAPPATGDQSPGLGTQPKLPSSSGLPAADVSPATAEEPLSPSTPTRRPPFTRGRLRLLSFRSMEEARLVPTVKEKYPVLKDVMDFIKDQSLSHRSVVKVLSLRKAQAQSILEVLKITQHCAESLGQPHCFHPPFILFLLELLTCQKDFTNYFGHLEGCGADLHKEIRDTYYQLVLFLVKAVKGFSSLNDRSLLPALSCVQTALLHLLDMGWEPNDLAFFVDIQLPDLLMKMSQENISVHDSVISQWSEEDELADAKQNSEWMDECQDGMFEAWYEKIAQEDPEKQRKMHMFIARYCDLLNVDISCDGCDEIAPWHRYRCLQCSDMDLCKTCFLGGVKPEGHGDDHEMVNMEFTCDHCQGLIIGRRMNCNVCDDFDLCYGCYAAKKYSYGHLPTHSITAHPMVTIRISDRQRLIQPYIHNYSWLLFAALALYSAHLASAEDVDGEKLDPQTRSSATTLRSQCMQLVGDCLMKAHQGKGLKALALLGVLPDGDSSLEDQALPVTVPTGASEEQLEKKAVQGAELSEAGNGKRAVHEEIRPVDFKQRNKADKGVSLSKDPSCQTQISDSPADASPPTGLPDAEDSEVSSQKPIEEKAVTPSPEQVFAECSQKRILGLLAAMLPPLKSGPTVPLIDLEHVLPLMFQVVISNAGHLNETYHLTLGLLGQLIIRLLPAEVDAAVIKVLSAKHNLFAAGDSSIVPDGWKTTHLLFSLGAVCLDSRVGLDWACSMAEILRSLNSAPLWRDVIATFTDHCIKQLPFQLKHTNIFTLLVLVGFPQVLCVGTRCVYMDNANEPHNVIILKHFTEKNRAVIVDVKTRKRKTVKDYQLVQKGGGQECGDSRAQLSQYSQHFAFIASHLLQSSMDSHCPEAVEATWVLSLALKGLYKTLKAHGFEEIRATFLQTDLLKLLVKKCSKGTGFSKTWLLRDLEILSIMLYSSKKEINALAEHGDLELDERGDREEEVERPVSSPGDPEQKKLDPLEGLDEPTRICFLMAHDALNAPLHILRAIYELQMKKTDYFFLEVQKRFDGDELTTDERIRSLAQRWQPSKSLRLEEQSAKAVDTDMIILPCLSRPARCDQATAESNPVTQKLISSTESELQQSYAKQRRSKSAALLHKELNCKSKRAVRDYLFRVNEATAVLYARHVLASLLAEWPSHVPVSEDILELSGPAHMTYILDMFMQLEEKHEWEKILQKVLQGCREDMLGTMALAACQFMEEPGMEVQVRESKHPYNNNTNFEDKVHIPGAIYLSIKFDSQCNTEEGCDELAMSSSSDFQQDRHSFSGSQQKWKDFELPGDTLYYRFTSDMSNTEWGYRFTVTAGHLGRFQTGFEILKQMLSEERVVPHLPLAKIWEWLVGVACRQTGHQRLKAIHLLLRIVRCCGHSDLCDLALLKPLWQLFTHMEYGLFEDVTQPGILLPLHRALTELFFVTENRAQELGVLQDYLLALTTDDHLLRCAAQALQNIAAISLAINYPNKATRLWNVEC>sp|O43149-2|ZZEF1_HUMAN Isoform 2 of Zinc finger ZZ-type and EF-handdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=ZZEF1LFLLELLTCQKDFTNYFGHLEGCGADLHKEIRDTYYQLVLFLVKAVKGFSSLNDRSLLPALSCVQTALLHLLDMGWEPNDLAFFVDIQLPDLLMKMSQENISVHDSVISQWSEEDELADAKQNSEWMDECQDGMFEAWYEKIAQEDPEKQRKMHMFIARYCDLLNVDISCDGCDEIAPWHRYRCLQCSDMDLCKTCFLGGVKPEGHGDDHEMVNMEFTCDHCQGLIIGRRMNCNVCDDFDLCYGCYAAKKYSYGHLPTHSITAHPMVTIRISDRQRLIQPYIHNYSWLLFAALALYSAHLASAEDVDGEKLDPQTRSSATTLRSQCMQLVGDCLMKAHQGKGLKALALLGVLPDGDSSLEDQALPVTVPTGASEEQLEKKAVQGAELSEAGNGKRAVHEEIRPVDFKQRNKADKGVSLSKDPSCQTQISDSPADASPPTGLPDAEDSEVSSQKPIEEKAVTPSPEQVFAECSQKRILGLLAAMLPPLKSGPTVPLIDLEHVLPLMFQVVISNAGHLNETYHLTLGLLGQLIIRLLPAEVDAAVIKVLSAKHNLFAAGDSSIVPDGWKTTHLLFSLGAVCLDSRVGLDWACSMAEILRSLNSAPLWRDVIATFTDHCIKQLPFQLKHTNIFTLLVLVGFPQVLCVGTRCVYMDNANEPHNVIILKHFTEKNRAVIVDVKTRKRKTVKDYQLVQKGGGQECGDSRAQLSQYSQHFAFIASHLLQSSMDSHCPEAVEATWVLSLALKGLYKTLKAHGFEEIRATFLQTDLLKLLVKKCSKGTGFSKTWLLRDLEVRDERDSCSSFLVQMCWPRS>sp|O43149-3|ZZEF1_HUMAN Isoform 3 of Zinc finger ZZ-type and EF-handdomain-containing protein 1 OS=Homo sapiens OX=9606 GN=ZZEF1MGNAPSHSSEDEAAAAGGEGWGPHQDWAAVSGTTPGPGVAAPALPPAAALLEPARLREAAAALLPTPPCESLVSRHRGALFRWLEERLGRGEESVTLEQFRELLEARGAGCSSEQFEEAFAQFDAEGDGTVDAENMLEALKNSSGANLQGELSHIIRQLQACSLVPGFTDIFSESKEGLDIHSSMILRFLHRNRLSSAVMPYPMLEHCNNMCTMRSSVLKESLDQLVQKEKESPGDLTRSPEMDKLKSVAKCYAYIETSSNSADIDKMTNGETSSYWQSDGSACSHWIRLKMKPDVVLRHLSIAVAATDQSYMPQQVTVAVGRNASDLQEVRDVHIPSNVTGYVTLLENANVSQLYVQINIKRCLSDGCDTRIHGLRAVGFQRVKKSGVSVSDASAIWYWSLLTSLVTASMETNPAFVQTVLHNTQKALRHMPPLSLSPGSTDFSTFLSPNVLEEVDSFLIRITSCCSTPEVELTLLAFALARGSVAKVMSSLCTITDHLDTQYDASSLILSMASVRQNLLLKYGKPLQLTLQACDVKGKEDKSGPENLLVEPWTRDGFLTETGKTRASTIFSTGTESAFQVTQIRIMVRRGGIGAQCGLVFAYNSSSDKFCAEEHFKRFEKYDKWKLQELRQFVKSRIGCSSDDLGEDDPIGWFELEEEWDEADVKLQQCRVAKYLMVKFLCTRQESAERLGVQGLTISGYLRPARAEAEQSVTCAHCRKDTEESVCGATLLLRTLQFIQQLAHDLVQQKESGLKYKSFLDFAGLDLQIFWNFYSKLKQNPREECVSAQTLLLQLLQSCFSVLQGDVLAASEEEKAPIQSPKGVEAAKELYTHLCDVVDKVDGDSVPMEILKQEVRNTLLNGAAIFFPNRQTRRNHLFTMMKNVTEQEHKQSLQLTFRSLCTYFSDKDPGGLLLLPEKNDLAKMNISEVLAVMDTLVSVAARECELLMLSGAPGEVGSVLFSLFWSVQGSLLSWCYLQLKSTDSGAKDLAVDLIEKYVGQFLASMRAILESLFSQYSGKTIVERLCNSVFSMAARQLVIFLLDFCTLDIPHCVLLREFSVLTELLKKLCSGPEGGLRKVTRVST>sp|Q6VEQ5|WASH2_HUMAN WAS protein family homolog 2 OS=Homo sapiensOX=9606 GN=WASH2P PE=2 SV=2MTPVRMQHSLAGQTYAVPLIQPDLRREEAVQQMADALQYLQKVSGDIFSRISQQVEQSRSQVQAIGEKVSLAQAKIEKIKGSKKAIKVFSSAKYPAPERLQEYGSIFTGAQDPGLQRRPRHRIQSKHRPLDERALQEKLKDFPVCVSTKPEPEDDAEEGLGGLPSNISSVSSLLLFNTTENLYKKYVFLDPLAGAVTKTHVMLGAETEEKLFDAPLSISKREQLEQQVPENYFYVPDLGQVPEIDVPSYLPDLPGIANDLMYIADLGPGIAPSAPGTIPELPTFHTEVAEPLKVDLQDGVLTPPPPPPPPPPAPEVLASAPPLPPSTAAPVGQGARQDDSSSSASPSVQGAPREVVDPSGGRATLLESIRQAGGIGKAKLRSMKERKLEKKKQKEQEQVRATSQGGHLMSDLFNKLVMRRKGISGKGPGAGEGPGGAFARVSDSIPPLPPPQQPQAEEDEDDWES>sp|Q9H8N7|ZN395_HUMAN Zinc finger protein 395 OS=Homo sapiens OX=9606GN=ZNF395 PE=1 SV=2MASVLSRRLGKRSLLGARVLGPSASEGPSAAPPSEPLLEGAAPQPFTTSDDTPCQEQPKEVLKAPSTSGLQQVAFQPGQKVYVWYGGQECTGLVEQHSWMEGQVTVWLLEQKLQVCCRVEEVWLAELQGPCPQAPPLEPGAQALAYRPVSRNIDVPKRKSDAVEMDEMMAAMVLTSLSCSPVVQSPPGTEANFSASRAACDPWKESGDISDSGSSTTSGHWSGSSGVSTPSPPHPQASPKYLGDAFGSPQTDHGFETDPDPFLLDEPAPRKRKNSVKVMYKCLWPNCGKVLRSIVGIKRHVKALHLGDTVDSDQFKREEDFYYTEVQLKEESAAAAAAAAAGTPVPGTPTSEPAPTPSMTGLPLSALPPPLHKAQSSGPEHPGPESSLPSGALSKSAPGSFWHIQADHAYQALPSFQIPVSPHIYTSVSWAAAPSAACSLSPVRSRSLSFSEPQQPAPAMKSHLIVTSPPRAQSGARKARGEAKKCRKVYGIEHRDQWCTACRWKKACQRFLD>sp|Q86V71|ZN429_HUMAN Zinc finger protein 429 OS=Homo sapiens OX=9606GN=ZNF429 PE=2 SV=2MGPLTFTDVAIEFSLEEWQCLDTAQQNLYRNVMLENYRNLVFLGIAVSKPDLITCLEKEKEPCKMKRHEMVDEPPVVCSHFAEDFWPEQDIKDSFQKVTLRRYDKRGHENLQLRKGYKTVGDCKLYKGGYNGLNQCLTLTQSKMYHCDIYVKVFYAFSNADRYKTRHTGKKPFQCKKCGKSFCMLSQLTQHKKIHIRENTYRCKEFGNAFNQSSALTNHKRIYVGEKHYRCEECGKAFNHYSTLTNHKRIHTGEKPYKCKECGKAFSRYSTLTTHKRIHSGEKPYKCDECGKTFSISSTFTKHKIIHTEEKPYKCKECGKAFNRSSTLTSHKRIHTGEKPYKCEECGKAFNWSSTLTKHKVIHTGEKPYKCEECGKAFNQSSRLTRHKKIHTGEEPYKFEKCGRVFTCSSTLTQDKKIHTGEKPYNCEECGKVFTYSSTLTRHKRIHTEEKPYKCNECGKAFNRSSHLTSHRRIHTGEKPYKCEECGKAFKQSSNLNSHKKIHSGEKPYKCEECGKAFILSSRLTQHKKIHTGEKPYKCEECGKAFNRSSRLTQHKKIHTGEKPYKCKQCDKAFTHSSNLSSHKKIHSGEKPYKCEECGKAFNRSSRLTQHKKIHTREKPYKCEECAKAFTRSSRLTQHKKIHRMGVVAHACNPSTLGGRGGRITRSGDRDRPG>sp|Q9UJU3|ZN112_HUMAN Zinc finger protein 112 OS=Homo sapiens OX=9606GN=ZNF112 PE=1 SV=2MTKFQEMVTFKDVAVVFTEEELGLLDSVQRKLYRDVMLENFRNLLLVAHQPFKPDLISQLEREEKLLMVETETPRDGCSGRKNQQKMESIQEVTVSYFSPKELSSRQTWQQSAGGLIRCQDFLKVFQGKNSQLQEQGNSLGQVWAGIPVQISEDKNYIFTHIGNGSNYIKSQGYPSWRAHHSWRKMYLKESHNYQCRCQQISMKNHFCKCDSVSWLSHHNDKLEVHRKENYSCHDCGEDIMKVSLLNQESIQTEEKPYPCTGYRKAFSNDSSSEVHQQFHLEGKPYTYSSCGKGCNYSSLLHIHQNIEREDDIENSHLKSYQRVHTEEKPCKCGEYGENFNHCSPLNTYELIHTGEMSYRHNIYEKAFSHSLDLNSIFRVHTRDEPHEYEENENVFNQSSCLQVHQKIHTEEKLYTDIEYGKSFICSSNLDIQHRVHMEENSYNSEECGNGFSLASHFQDLQIVHTKEQPYKRYVCSNSFSHNLYLQGHPKIHIGEKPRKEHGNGFNWSSKLKDHQRVHTGQKPYKCNICGKGFNHRSVLNVHQRVHTGEKPYKCEECDKGFSRSSYLQAHQRVHTGEKPYKCEECGKGFSRNSYLQGHQRVHTGEKPYKCEECGKGFSRSSHLQGHQRVHTGEKPFKCEECGKGFSWSFNLQIHQRVHTGEKPYKCEECGKGFSKASTLLAHQRVHTGEKPYQCDECGKSFSQRSYLQSHQSVHSGERPYICEVCGKGFSQRAYLQGHQRVHTRVKPYKCEMCGKGFSQSSRLEAHRRVHTGGKPYKCEVCTKGFSESSRLQAHQRVHVEGRPYKCEQCGKGFSGYSSLQAHHRVHTGEKPYKCEVCGKGFSQRSNLQAHQRVHTGEKPYKCDACGKGFRWSSGLLIHQRVHSSDKFYKSEDYGKDYPSSENLHRNEDSVLF>sp|Q9UJU3-2|ZN112_HUMAN Isoform 2 of Zinc finger protein 112 OS=Homosapiens OX=9606 GN=ZNF112MVTFKDVAVVFTEEELGLLDSVQRKLYRDVMLENFRNLLLVAHQPFKPDLISQLEREEKLLMVETETPRDGCSGRKNQQKMESIQEVTVSYFSPKELSSRQTWQQSAGGLIRCQDFLKVFQGKNSQLQEQGNSLGQVWAGIPVQISEDKNYIFTHIGNGSNYIKSQGYPSWRAHHSWRKMYLKESHNYQCRCQQISMKNHFCKCDSVSWLSHHNDKLEVHRKENYSCHDCGEDIMKVSLLNQESIQTEEKPYPCTGYRKAFSNDSSSEVHQQFHLEGKPYTYSSCGKGCNYSSLLHIHQNIEREDDIENSHLKSYQRVHTEEKPCKCGEYGENFNHCSPLNTYELIHTGEMSYRHNIYEKAFSHSLDLNSIFRVHTRDEPHEYEENENVFNQSSCLQVHQKIHTEEKLYTDIEYGKSFICSSNLDIQHRVHMEENSYNSEECGNGFSLASHFQDLQIVHTKEQPYKRYVCSNSFSHNLYLQGHPKIHIGEKPRKEHGNGFNWSSKLKDHQRVHTGQKPYKCNICGKGFNHRSVLNVHQRVHTGEKPYKCEECDKGFSRSSYLQAHQRVHTGEKPYKCEECGKGFSRNSYLQGHQRVHTGEKPYKCEECGKGFSRSSHLQGHQRVHTGEKPFKCEECGKGFSWSFNLQIHQRVHTGEKPYKCEECGKGFSKASTLLAHQRVHTGEKPYQCDECGKSFSQRSYLQSHQSVHSGERPYICEVCGKGFSQRAYLQGHQRVHTRVKPYKCEMCGKGFSQSSRLEAHRRVHTGGKPYKCEVCTKGFSESSRLQAHQRVHVEGRPYKCEQCGKGFSGYSSLQAHHRVHTGEKPYKCEVCGKGFSQRSNLQAHQRVHTGEKPYKCDACGKGFRWSSGLLIHQRVHSSDKFYKSEDYGKDYPSSENLHRNEDSVLF>sp|Q6ZMS4|ZN852_HUMAN Zinc finger protein 852 OS=Homo sapiens OX=9606GN=ZNF852 PE=1 SV=4MVRPQDTVAYEDLSEDYTQKKWKGLALSQRALHWNMMLENDRSMASLGRNMMESSELTPKQEIFKGSESSNSTSGGLFGVVPGGTETGDVCEDTFKELEGQPSNEEGSRLESDFLEIIDEDKKKSTKDRYEEYKEVEEHPPLSSSPVEHEGVLKGQKSYRCDECGKAFYWSSHLIGHRRIHTGEKPYECNECGKTFRQTSQLIVHLRTHTGEKPYECSECGKAYRHSSHLIQHQRLHNGEKPYKCNECAKAFNQSSKLFDHQRTHTGEKPYECKECGAAFSRSKNLVRHQFLHTGKKPYKCNECGRAFCSNRNLIDHQRTHTGEKPYKCNECGKAFSRSKCLIRHQSLHTGEKPYKCSECGKAFNQISQLVEHERIHTGEKPFKCSECGKAFGLSKCLIRHQRLHTSEKPYKCNECGKSFNQNSYLIIHQRIHTGEKPYECNECGKVFSYNSSLMVHQRTHTGEKPYKCNSCGKAFSDSSQLTVHQRVHTGEKNLMNVLSVGKPLVSVPLLITTSELMLERSPQVWLGHLLKAWFSETDSKDL>sp|Q6S9Z5|ZN474_HUMAN Zinc finger protein 474 OS=Homo sapiens OX=9606GN=ZNF474 PE=1 SV=1MERGKKKRISNKLQQTFHHSKEPTFLINQAGLLSSDSYSSLSPETESVNPGENIKTDTQKKRPGTVILSKLSSRRIISESQLSPPVIPARRPGFRVCYICGREFGSQSIAIHEPQCLQKWHIENSKLPKHLRRPEPSKPQSLSSSGSYSLQATNEAAFQSAQAQLLPCESCGRTFLPDHLLVHHRSCKPKGEGPRAPHSNSSDHLTGLKKACSGTPARPRTVICYICGKEFGTLSLPIHEPKCLEKWKMENDRLPVELHQPLPQKPQPLPNAQSSQAGPNQAQLVFCPHCSRIFTSDRLLVHQRSCKTHPYGPKYQNLNLGSKGGLKEYTNSKQQRNRAAPSVTDKVIHATQDALGEPGGALCL>sp|A6NP11|ZN716_HUMAN Zinc finger protein 716 OS=Homo sapiens OX=9606GN=ZNF716 PE=2 SV=4MAKRPGPPGSREMGLLTFRDIAIEFSLAEWQCLDHAQQNLYRDVMLENYRNLVSLGIAVSKPDLITCLEQNKEPQNIKRNEMVAKHPVTCSHFTQDLQSEQGIKDSLQKVILRRYGKCGQEDLQVKKCCKSVGECEVHKGGYNYVNQCLSATQNKTFQTHKCVKVFGKFSNSNRHKTRHTGKKHFKCKNDGKSFCMLSRLNQHQIIHTREKSYKCEECGKSFNCSSTLTRHKRIHTGEKPYRCEECGKAFSWSASLTKHKRIHTGEKPYTCEERGKVFSRSTLTNYKRIHTGEKPYTCEECGKAFSRSSTLTNHKRIHTGERPYKCEECGKAFSLSSTLKKHKIVHTGEKLYTCEECGKAFTFSSTLNTHKRIHTGEKPYTCEECGKAFSLPSTFTYHKRTHTGEKPYKCEECGKAFNCSSTLKKHKIIHTGEKLYKCKECGKAFTFSSTLNTHKRIHTGEKPYKCEECDQTFKWHSSLANHKNMHTGEKPYKYE>sp|Q8TF32|ZN431_HUMAN Zinc finger protein 431 OS=Homo sapiens OX=9606GN=ZNF431 PE=2 SV=2MDDLKYGVYPLKEASGCPGAERNLLVYSYFEKETLTFRDVAIEFSLEEWECLNPAQQNLYMNVMLENYKNLVFLGVAVSKQDPVTCLEQEKEPWNMKRHEMVDEPPAMCSYFTKDLWPEQDIKDSFQQVILRRYGKCEHENLQLRKGSASVDEYKVHKEGYNELNQCLTTTQSKIFPCDKYVKVFHKFLNANRHKTRHTGKKPFKCKKCGKSFCMLLHLSQHKRIHIRENSYQCEECGKAFKWFSTLTRHKRIHTGEKPFKCEECGKAFKQSSTLTTHKIIHTGEKPYRCEECGKAFNRSSHLTTHKIIHTGEKPYKCEECGKAFNQSSTLSTHKFIHAGEKPYKCEECDKAFNRFSYLTKHKIIHTGEKSYKCEECGKGFNWSSTLTKHKRIHTGEKPYKCEVCGKAFNESSNLTTHKMIHTGEKPYKCEECGKAFNRSPQLTAHKIIHTGEKPYKCEECGKAFSQSSILTTHKRIHTGEKPYKCEECGKAFNRSSNLTKHKIIHTGEKSYKCEECGKAFNQSSTLTKHRKIHTRQKPYNCEECDNTFNQSSNLIKQNNSYWRETLQMSRMWESL>sp|Q8NB42|ZN527_HUMAN Zinc finger protein 527 OS=Homo sapiens OX=9606GN=ZNF527 PE=2 SV=2MAVGLCKAMSQGLVTFRDVALDFSQEEWEWLKPSQKDLYRDVMLENYRNLVWLGLSISKPNMISLLEQGKEPWMVERKMSQGHCADWESWCEIEELSPKWFIDEDEISQEMVMERLASHGLECSSFREAWKYKGEFELHQGNAERHFMQVTAVKEISTGKRDNEFSNSGRSIPLKSVFLTQQKVPTIQQVHKFDIYDKLFPQNSVIIEYKRLHAEKESLIGNECEEFNQSTYLSKDIGIPPGEKPYESHDFSKLLSFHSLFTQHQTTHFGKLPHGYDECGDAFSCYSFFTQPQRIHSGEKPYACNDCGKAFSHDFFLSEHQRTHIGEKPYECKECNKAFRQSAHLAQHQRIHTGEKPFACNECGKAFSRYAFLVEHQRIHTGEKPYECKECNKAFRQSAHLNQHQRIHTGEKPYECNQCGKAFSRRIALTLHQRIHTGEKPFKCSECGKTFGYRSHLNQHQRIHTGEKPYECIKCGKFFRTDSQLNRHHRIHTGERPFECSKCGKAFSDALVLIHHKRSHAGEKPYECNKCGKAFSCGSYLNQHQRIHTGEKPYECSECGKAFHQILSLRLHQRIHAGEKPYKCNECGNNFSCVSALRRHQRIHNRETL>sp|Q8NB42-2|ZN527_HUMAN Isoform 2 of Zinc finger protein 527 OS=Homosapiens OX=9606 GN=ZNF527MAVGLCKAMSQGLVTFRDVALDFSQEEWEWLKPSQKDLYRDVMLENYRNLVWLDWESWCEIEELSPKWFIDEDEISQEMVMERLASHGLECSSFREAWKYKGEFELHQGNAERHFMQVTAVKEISTGKRDNEFSNSGRSIPLKSVFLTQQKVPTIQQVHKFDIYDKLFPQNSVIIEYKRLHAEKESLIGNECEEFNQSTYLSKDIGIPPGEKPYESHDFSKLLSFHSLFTQHQTTHFGKLPHGYDECGDAFSCYSFFTQPQRIHSGEKPYACNDCGKAFSHDFFLSEHQRTHIGEKPYECKECNKAFRQSAHLAQHQRIHTGEKPFACNECGKAFSRYAFLVEHQRIHTGEKPYECKECNKAFRQSAHLNQHQRIHTGEKPYECNQCGKAFSRRIALTLHQRIHTGEKPFKCSECGKTFGYRSHLNQHQRIHTGEKPYECIKCGKFFRTDSQLNRHHRIHTGERPFECSKCGKAFSDALVLIHHKRSHAGEKPYECNKCGKAFSCGSYLNQHQRIHTGEKPYECSECGKAFHQILSLRLHQRIHAGEKPYKCNECGNNFSCVSALRRHQRIHNRETL>sp|Q9H582|ZN644_HUMAN Zinc finger protein 644 OS=Homo sapiens OX=9606GN=ZNF644 PE=1 SV=2MRSFLQQDVNKTKSRLNVLNGLANNMDDLKINTDITGAKEELLDDNNFISDKESGVHKPKDCQTSFQKNNTLTLPEELSKDKSENALSGGQSSLFIHAGAPTVSSENFILPKGAAVNGPVSHSSLTKTSNMNKGSVSLTTGQPVDQPTTESCSTLKVAADLQLSTPQKASQHQVLFLLSDVAHAKNPTHSNKKLPTSASVGCDIQNSVGSNIKSDGTLINQVEVGEDGEDLLVKDDCVNTVTGISSGTDGFRSENDTNWDPQKEFIQFLMTNEETVDKAPPHSKIGLEKKRKRKMDVSKITRYTEDCFSDSNCVPNKSKMQEVDFLEQNEELQAVDSQKYALSKVKPESTDEDLESVDAFQHLIYNPDKCGEESSPVHTSTFLSNTLKKKCEESDSESPATFSTEEPSFYPCTKCNVNFREKKHLHRHMMYHLDGNSHFRHLNVPRPYACRECGRTFRDRNSLLKHMIIHQERRQKLMEEIRELKELQDEGRSARLQCPQCVFGTNCPKTFVQHAKTHEKDKRYYCCEECNFMAVTENELECHRGIAHGAVVKCPMVTSDIAQRKTQKKTFMKDSVVGSSKKSATYICKMCPFTTSAKSVLKKHTEYLHSSSCVDSFGSPLGLDKRKNDILEEPVDSDSTKTLTKQQSTTFPKNSALKQDVKRTFGSTSQSSSFSKIHKRPHRIQKARKSIAQSGVNMCNQNSSPHKNVTIKSSVDQKPKYFHQAAKEKSNAKANSHYLYRHKYENYRMIKKSGESYPVHFKKEEASSLNSLHLFSSSSNSHNNFISDPHKPDAKRPESFKDHRRVAVKRVIKESKKESSVGGEDLDSYPDFLHKMTVVVLQKLNSAEKKDSYETEDESSWDNVELGDYTTQAIEDETYSDINQEHVNLFPLFKSKVEGQEPGENATLSYDQNDGFYFEYYEDTGSNNFLHEIHDPQHLETADASLSKHSSVFHWTDLSLEKKSCPYCPATFETGVGLSNHVRGHLHRAGLSYEARHVVSPEQIATSDKMQHFKRTGTGTPVKRVRKAIEKSETTSEHTCQLCGGWFDTKIGLSNHVRGHLKRLGKTKWDAHKSPICVLNEMMQNEEKYEKILKALNSRRIIPRPFVAQKLASSDDFISQNVIPLEAYRNGLKTEALSVSASEEEGLNFLNEYDETKPELPSGKKNQSLTLIELLKNKRMGEERNSAISPQKIHNQTARKRFVQKCVLPLNEDSPLMYQPQKMDLTMHSALDCKQKKSRSRSGSKKKMLTLPHGADEVYILRCRFCGLVFRGPLSVQEDWIKHLQRHIVNANLPRTGAGMVEVTSLLKKPASITETSFSLLMAEAAS>sp|Q9H582-2|ZN644_HUMAN Isoform 2 of Zinc finger protein 644 OS=Homosapiens OX=9606 GN=ZNF644MRSFLQQDVNKTKSRLNVLNGLANNMDDLKINTDITGAKEELLDDNNFISDKESGVHKPKDCQTSFQKNNTLTLPEELSKDKSENALSGGQSSLFIHAGAPTVSSENFILPKGAAVNGPVSHSSLTKTSNMNKGSVSLTTGQPVDQPTTESCSTLKVAADLQLSTPQKASQHQVLFLLSDVAHAKNPTHSNKKLPTSASVGCDIQNSVGSNIKSDGTLINQVEVGEDGEDLLVKDDCVNTVTGISSGTDGFRSENDTNWDPQKEFIQFLMTNEETVDKAPPHSKIGLEKKRKRKMDVSKITRYTEDCFSDSNCVPNKSKMQEVDFLEQNEELQAVDSQKYALSKVKPESTDEDLESVDAFQHLIYNPDKCGEESSPVHTSTFLSNTLKKKCEESDSESPATFSTEEPSFYPCTKCNVNFREKKHLHRHMMYHLDGNSHFRHLNVPRPYACRECGRTFRDRNSLLKHMIIHQERRQKLMEEIRELKELQDEGRSARLQCPQCVFGTNCPKTFVQHAKTHEKDKRYYCCEECNFMAVTENELECHRGIAHGAVVKCPMVTSDIAQRKTQKKTFMKDSVVGSSKKSATYICKMCPFTTSAKSVLKKHTEYLHSSSCVDSFGSPLGLDKRKNDILEEPVDSDSTKTLTKQQSTTFPKNSALKQDVKRTFGSTSQSSSFSKIHKRPHRIQKARKSIAQSGVNMCNQNSSPHKNVTIKSSVDQKPKYFHQAAKEKSNAKANSHYLYRHKYENYRMIKKSGESYPVHFKKEEASSLNSLHLFSSSSNSHNNFISDPHKPDAKRPESFKDHRRVAVKRVIKESKKESSVGGEDLDSYPDFLHKMTVVVLQKLNSAEKKDSYETEDESSWDNVELGDYTTQAIEDETYSDINQEHVNLFPLFKSKVEGQEPGENATLSYDQNDGFYFEYYEDTGSNNFLHEIHDPQHLETADASLSKHSSVFHWTDLSLEKKSCPYCPATFETGVGLSNHVRGHLHRAGLSYEARHVVSPEQIATSDKMQHFKRTGTGTPVKRVRKAIEKSETTSEHTCQLCGGWFDTKIGLSNHVRGHLKRLGKTKWDAHKSPICVLNEMMQNEEKYEKILKALNSRRIIPRPFVAQKLASSDDFISQNVIPLEAYRNGLKTEALSVSASEEEGLNFLNEYDETKPELPSGKKNQSLTLIELLKNKRMGEERNSAISPQKIHNQTARKRFVQKCVLPLNEDSPLMYQPQKMDLTMHSGLI>sp|Q9H582-3|ZN644_HUMAN Isoform 3 of Zinc finger protein 644 OS=Homosapiens OX=9606 GN=ZNF644MLIRQNLALDCKQKKSRSRSGSKKKMLTLPHGADEVYILRCRFCGLVFRGPLSVQEDWIKHLQRHIVNANLPRTGAGMVEVTSLLKKPASITETSFSLLMAEAAS>sp|Q96RU7|TRIB3_HUMAN Tribbles homolog 3 OS=Homo sapiens OX=9606GN=TRIB3 PE=1 SV=2MRATPLAAPAGSLSRKKRLELDDNLDTERPVQKRARSGPQPRLPPCLLPLSPPTAPDRATAVATASRLGPYVLLEPEEGGRAYQALHCPTGTEYTCKVYPVQEALAVLEPYARLPPHKHVARPTEVLAGTQLLYAFFTRTHGDMHSLVRSRHRIPEPEAAVLFRQMATALAHCHQHGLVLRDLKLCRFVFADRERKKLVLENLEDSCVLTGPDDSLWDKHACPAYVGPEILSSRASYSGKAADVWSLGVALFTMLAGHYPFQDSEPVLLFGKIRRGAYALPAGLSAPARCLVRCLLRREPAERLTATGILLHPWLRQDPMPLAPTRSHLWEAAQVVPDGLGLDEAREEEGDREVVLYG>sp|P20396|TRH_HUMAN Pro-thyrotropin-releasing hormone OS=Homo sapiensOX=9606 GN=TRH PE=1 SV=1MPGPWLLLALALTLNLTGVPGGRAQPEAAQQEAVTAAEHPGLDDFLRQVERLLFLRENIQRLQGDQGEHSASQIFQSDWLSKRQHPGKREEEEEEGVEEEEEEEGGAVGPHKRQHPGRREDEASWSVDVTQHKRQHPGRRSPWLAYAVPKRQHPGRRLADPKAQRSWEEEEEEEEREEDLMPEKRQHPGKRALGGPCGPQGAYGQAGLLLGLLDDLSRSQGAEEKRQHPGRRAAWVREPLEE>sp|Q6UWW9|TM207_HUMAN Transmembrane protein 207 OS=Homo sapiens OX=9606GN=TMEM207 PE=1 SV=1MSRSRLFSVTSAISTIGILCLPLFQLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHRRTMAVFAVGDLDSIYGTEAAVSPTVGIHLQTQTPDLYPVPAPCFGPLGSPPPYEEIVKTT>sp|Q8TB96|TIP_HUMAN T-cell immunomodulatory protein OS=Homo sapiensOX=9606 GN=ITFG1 PE=1 SV=1MAAAGRLPSSWALFSPLLAGLALLGVGPVPARALHNVTAELFGAEAWGTLAAFGDLNSDKQTDLFVLRERNDLIVFLADQNAPYFKPKVKVSFKNHSALITSVVPGDYDGDSQMDVLLTYLPKNYAKSELGAVIFWGQNQTLDPNNMTILNRTFQDEPLIMDFNGDLIPDIFGITNESNQPQILLGGNLSWHPALTTTSKMRIPHSHAFIDLTEDFTADLFLTTLNATTSTFQFEIWENLDGNFSVSTILEKPQNMMVVGQSAFADFDGDGHMDHLLPGCEDKNCQKSTIYLVRSGMKQWVPVLQDFSNKGTLWGFVPFVDEQQPTEIPIPITLHIGDYNMDGYPDALVILKNTSGSNQQAFLLENVPCNNASCEEARRMFKVYWELTDLNQIKDAMVATFFDIYEDGILDIVVLSKGYTKNDFAIHTLKNNFEADAYFVKVIVLSGLCSNDCPRKITPFGVNQPGPYIMYTTVDANGYLKNGSAGQLSQSAHLALQLPYNVLGLGRSANFLDHLYVGIPRPSGEKSIRKQEWTAIIPNSQLIVIPYPHNVPRSWSAKLYLTPSNIVLLTAIALIGVCVFILAIIGILHWQEKKADDREKRQEAHRFHFDAM>sp|Q4KMQ1|TPRN_HUMAN Taperin OS=Homo sapiens OX=9606 GN=TPRN PE=1 SV=2MAALGRPGSGPRAAVPAWKREILERKRAKLAALGGGAGPGAAEPEQRVLAESLGPLRENPFMLLEAERRRGGGAAGARLLERYRRVPGVRALRADSVLIIETVPGFPPAPPAPGAAQIRAAEVLVYGAPPGRVSRLLERFDPPAAPRRRGSPERARPPPPPPPPAPPRPPPAAPSPPAAPGPRGGGASPGARRSDFLQKTGSNSFTVHPRGLHRGAGARLLSNGHSAPEPRAGPANRLAGSPPGSGQWKPKVESGDPSLHPPPSPGTPSATPASPPASATPSQRQCVSAATSTNDSFEIRPAPKPVMETIPLGDLQARALASLRANSRNSFMVIPKSKASGAPPPEGRQSVELPKGDLGPASPSQELGSQPVPGGDGAPALGKSPLEVEAQWAVEEGACPRTATALADRAIRWQRPSSPPPFLPAASEEAEPAEGLRVPGLAKNSREYVRPGLPVTFIDEVDSEEAPQAAKLPYLPHPARPLHPARPGCVAELQPRGSNTFTVVPKRKPGTLQDQHFSQANREPRPREAEEEEASCLLGPTLKKRYPTVHEIEVIGGYLALQKSCLTKAGSSRKKMKISFNDKSLQTTFEYPSESSLEQEEEVDQQEEEEEEEEEEEEEEEGSGSEEKPFALFLPRATFVSSVRPESSRLPEGSSGLSSYTPKHSVAFSKWQEQALEQAPREAEPPPVEAMLTPASQNDLSDFRSEPALYF>sp|Q4KMQ1-2|TPRN_HUMAN Isoform 2 of Taperin OS=Homo sapiens OX=9606GN=TPRNMETIPLGDLQARALASLRANSRNSFMVIPKSKASGAPPPEGRQSVELPKGDLGPASPSQELGSQPVPGGDGAPALGKSPLEVEAQWAVEEGACPRTATALADRAIRWQRPSSPPPFLPAASEEAEPAEGLRVPGLAKNSREYVRPGLPVTFIDEVDSEEAPQAAKLPYLPHPARPLHPARPGCVAELQPRGSNTFTVVPKRKPGTLQDQHFSQANREPRPREAEEEEASCLLGPTLKKRYPTVHEIEVIGGYLALQKSCLTKAGSSRKKMKISFNDKSLQTTFEYPSESSLEQEEEVDQQEEEEEEEEEEEEEEEGSGSEEKPFALFLPRATFVSSVRPESSRLPEGSSGLSSYTPKHSVAFSKWQEQALEQAPREAEPPPVEAMLTPASQNDLSDFRSEPALYF>sp|Q4KMQ1-3|TPRN_HUMAN Isoform 3 of Taperin OS=Homo sapiens OX=9606GN=TPRNMETIPLGDLQARALASLRANSRNSFMVIPKSKASGAPPPEGRQSVELPKGDLGPASPSQELGSQPVPGGDGAPALGKSPLEVEAQWAVEEGACPRTATALADRAIRWQRPSSPPPFLPAASEEAEPAEGLRVPGLAKNSREYVRPGLPVTFIDEVDSEEAPQAAKLPYLPHPARPLHPARPGCVAELQPRGSNTFTVVPKRKPGTLQDQHFSQANREPRPREAEEEEASCLLGPTLKKRYPTVHEIEVIGGYLALQKSCLTKAGSSRKKMKISFNDKSLQTTFEYPSESSLEQEEEVDQQEEEEEEEEEEEEEEEGSGSEEKPFALFLPRATFVSSVRPESSRLPEGSSGLSSYTPKHSVAFSKWQEQALEQAPREAEPPPVEAMVRCGGVERWGESDTRASPCVHILSSHFQLTPASQNDLSDFRSEPALYF>sp|Q4KMQ1-4|TPRN_HUMAN Isoform 4 of Taperin OS=Homo sapiens OX=9606GN=TPRNMVSITGLGDLQARALASLRANSRNSFMVIPKSKASGAPPPEGRQSVELPKGDLGPASPSQELGSQPVPGGDGAPALGKSPLEVEAQWAVEEGACPRTATALADRAIRWQRPSSPPPFLPAASEEAEPAEGLRVPGLAKNSREYVRPGLPVTFIDEVDSEEAPQAAKLPYLPHPARPLHPARPGCVAELQPRGSNTFTVVPKRKPGTLQDQHFSQANREPRPREAEEEEASCLLGPTLKKRYPTVHEIEVIGGYLALQKSCLTKAGSSRKKMKISFNDKSLQTTFEYPSESSLEQEEEVDQQEEEEEEEEEEEEEEEGSGSEEKPFALFLPRATFVSSVRPESSRLPEGSSGLSSYTPKHSVAFSKWQEQALEQAPREAEPPPVEAMLTPASQNDLSDFRSEPALYF>sp|A0A0C4DH28|TRGV4_HUMAN T cell receptor gamma variable 4 OS=Homosapiens OX=9606 GN=TRGV4 PE=1 SV=1MQWALAVLLAFLSPASQKSSNLEGRTKSVIRQTGSSAEITCDLAEGSTGYIHWYLHQEGKAPQRLLYYDSYTSSVVLESGISPGKYDTYGSTRKNLRMILRNLIENDSGVYYCATWDG>sp|Q96B42|TMM18_HUMAN Transmembrane protein 18 OS=Homo sapiens OX=9606GN=TMEM18 PE=1 SV=2MPSAFSVSSFPVSIPAVLTQTDWTEPWLMGLATFHALCVLLTCLSSRSYRLQIGHFLCLVILVYCAEYINEAAAMNWRLFSKYQYFDSRGMFISIVFSAPLLVNAMIIVVMWVWKTLNVMTDLKNAQERRKEKKRRRKED>sp|Q96B42-2|TMM18_HUMAN Isoform 2 of Transmembrane protein 18 OS=Homosapiens OX=9606 GN=TMEM18MLSGYLQTDWTEPWLMGLATFHALCVLLTCLSSRSYRLQIGHFLCLVILVYCAEYINEAAAMNWRLFSKYQYFDSRGMFISIVFSAPLLVNAMIIVVMWVWKTLNVMTDLKNAQERRKEKKRRRKED>sp|Q15029|U5S1_HUMAN 116 kDa U5 small nuclear ribonucleoproteincomponent OS=Homo sapiens OX=9606 GN=EFTUD2 PE=1 SV=1MDTDLYDEFGNYIGPELDSDEDDDELGRETKDLDEMDDDDDDDDVGDHDDDHPGMEVVLHEDKKYYPTAEEVYGPEVETIVQEEDTQPLTEPIIKPVKTKKFTLMEQTLPVTVYEMDFLADLMDNSELIRNVTLCGHLHHGKTCFVDCLIEQTHPEIRKRYDQDLCYTDILFTEQERGVGIKSTPVTVVLPDTKGKSYLFNIMDTPGHVNFSDEVTAGLRISDGVVLFIDAAEGVMLNTERLIKHAVQERLAVTVCINKIDRLILELKLPPTDAYYKLRHIVDEVNGLISMYSTDENLILSPLLGNVCFSSSQYSICFTLGSFAKIYADTFGDINYQEFAKRLWGDIYFNPKTRKFTKKAPTSSSQRSFVEFILEPLYKILAQVVGDVDTSLPRTLDELGIHLTKEELKLNIRPLLRLVCKKFFGEFTGFVDMCVQHIPSPKVGAKPKIEHTYTGGVDSDLGEAMSDCDPDGPLMCHTTKMYSTDDGVQFHAFGRVLSGTIHAGQPVKVLGENYTLEDEEDSQICTVGRLWISVARYHIEVNRVPAGNWVLIEGVDQPIVKTATITEPRGNEEAQIFRPLKFNTTSVIKIAVEPVNPSELPKMLDGLRKVNKSYPSLTTKVEESGEHVILGTGELYLDCVMHDLRKMYSEIDIKVADPVVTFCETVVETSSLKCFAETPNKKNKITMIAEPLEKGLAEDIENEVVQITWNRKKLGEFFQTKYDWDLLAARSIWAFGPDATGPNILVDDTLPSEVDKALLGSVKDSIVQGFQWGTREGPLCDELIRNVKFKILDAVVAQEPLHRGGGQIIPTARRVVYSAFLMATPRLMEPYYFVEVQAPADCVSAVYTVLARRRGHVTQDAPIPGSPLYTIKAFIPAIDSFGFETDLRTHTQGQAFSLSVFHHWQIVPGDPLDKSIVIRPLEPQPAPHLAREFMIKTRRRKGLSEDVSISKFFDDPMLLELAKQDVVLNYPM>sp|Q15029-2|U5S1_HUMAN Isoform 2 of 116 kDa U5 small nuclearribonucleoprotein component OS=Homo sapiens OX=9606 GN=EFTUD2MDDDDDDDDVGDHDDDHPGMEVVLHEDKKYYPTAEEVYGPEVETIVQEEDTQPLTEPIIKPVKTKKFTLMEQTLPVTVYEMDFLADLMDNSELIRNVTLCGHLHHGKTCFVDCLIEQTHPEIRKRYDQDLCYTDILFTEQERGVGIKSTPVTVVLPDTKGKSYLFNIMDTPGHVNFSDEVTAGLRISDGVVLFIDAAEGVMLNTERLIKHAVQERLAVTVCINKIDRLILELKLPPTDAYYKLRHIVDEVNGLISMYSTDENLILSPLLGNVCFSSSQYSICFTLGSFAKIYADTFGDINYQEFAKRLWGDIYFNPKTRKFTKKAPTSSSQRSFVEFILEPLYKILAQVVGDVDTSLPRTLDELGIHLTKEELKLNIRPLLRLVCKKFFGEFTGFVDMCVQHIPSPKVGAKPKIEHTYTGGVDSDLGEAMSDCDPDGPLMCHTTKMYSTDDGVQFHAFGRVLSGTIHAGQPVKVLGENYTLEDEEDSQICTVGRLWISVARYHIEVNRVPAGNWVLIEGVDQPIVKTATITEPRGNEEAQIFRPLKFNTTSVIKIAVEPVNPSELPKMLDGLRKVNKSYPSLTTKVEESGEHVILGTGELYLDCVMHDLRKMYSEIDIKVADPVVTFCETVVETSSLKCFAETPNKKNKITMIAEPLEKGLAEDIENEVVQITWNRKKLGEFFQTKYDWDLLAARSIWAFGPDATGPNILVDDTLPSEVDKALLGSVKDSIVQGFQWGTREGPLCDELIRNVKFKILDAVVAQEPLHRGGGQIIPTARRVVYSAFLMATPRLMEPYYFVEVQAPADCVSAVYTVLARRRGHVTQDAPIPGSPLYTIKAFIPAIDSFGFETDLRTHTQGQAFSLSVFHHWQIVPGDPLDKSIVIRPLEPQPAPHLAREFMIKTRRRKGLSEDVSISKFFDDPMLLELAKQDVVLNYPM>sp|Q15029-3|U5S1_HUMAN Isoform 3 of 116 kDa U5 small nuclearribonucleoprotein component OS=Homo sapiens OX=9606 GN=EFTUD2MDTDLYDEFGNYIGPELDSDEDDDELGRETKDLDEMDDDDDDDDVGDHDDDHPGMEVVLHEDKKYYPTAEEVYGPEVETIVQEEDTQPLTEPIIKPVKTKKFTLMEQTLPVTVYEMDFLADLMDNSELIRNVTLCGHLHHGKTHPEIRKRYDQDLCYTDILFTEQERGVGIKSTPVTVVLPDTKGKSYLFNIMDTPGHVNFSDEVTAGLRISDGVVLFIDAAEGVMLNTERLIKHAVQERLAVTVCINKIDRLILELKLPPTDAYYKLRHIVDEVNGLISMYSTDENLILSPLLGNVCFSSSQYSICFTLGSFAKIYADTFGDINYQEFAKRLWGDIYFNPKTRKFTKKAPTSSSQRSFVEFILEPLYKILAQVVGDVDTSLPRTLDELGIHLTKEELKLNIRPLLRLVCKKFFGEFTGFVDMCVQHIPSPKVGAKPKIEHTYTGGVDSDLGEAMSDCDPDGPLMCHTTKMYSTDDGVQFHAFGRVLSGTIHAGQPVKVLGENYTLEDEEDSQICTVGRLWISVARYHIEVNRVPAGNWVLIEGVDQPIVKTATITEPRGNEEAQIFRPLKFNTTSVIKIAVEPVNPSELPKMLDGLRKVNKSYPSLTTKVEESGEHVILGTGELYLDCVMHDLRKMYSEIDIKVADPVVTFCETVVETSSLKCFAETPNKKNKITMIAEPLEKGLAEDIENEVVQITWNRKKLGEFFQTKYDWDLLAARSIWAFGPDATGPNILVDDTLPSEVDKALLGSVKDSIVQGFQWGTREGPLCDELIRNVKFKILDAVVAQEPLHRGGGQIIPTARRVVYSAFLMATPRLMEPYYFVEVQAPADCVSAVYTVLARRRGHVTQDAPIPGSPLYTIKAFIPAIDSFGFETDLRTHTQGQAFSLSVFHHWQIVPGDPLDKSIVIRPLEPQPAPHLAREFMIKTRRRKGLSEDVSISKFFDDPMLLELAKQDVVLNYPM>sp|Q2TAM9|TUSC1_HUMAN Tumor suppressor candidate gene 1 protein OS=Homosapiens OX=9606 GN=TUSC1 PE=1 SV=3MGPMWRMRGGATRRGSCCGGDGAADGRGPGRSGRARGGGSPSGGGGGVGWRGRADGARQQLEERFADLAASHLEAIRARDEWDRQNARLRQENARLRLENRRLKRENRSLFRQALRLPGEGGNGTPAEARRVPEEASTNRRARDSGREDEPGSPRALRARLEKLEAMYRRALLQLHLEQRGPRPSGDKEEQPLQEPDSGLRSRDSEPSGPWL>sp|Q9H0U9|TSYL1_HUMAN Testis-specific Y-encoded-like protein 1 OS=Homosapiens OX=9606 GN=TSPYL1 PE=1 SV=3MSGLDGVKRTTPLQTHSIIISDQVPSDQDAHQYLRLRDQSEATQVMAEPGEGGSETVALPPPPPSEEGGVPQDAAGRGGTPQIRVVGGRGHVAIKAGQEEGQPPAEGLAAASVVMAADRSLKKGVQGGEKALEICGAQRSASELTAGAEAEAEEVKTGKCATVSAAVAERESAEVVKEGLAEKEVMEEQMEVEEQPPEGEEIEVAEEDRLEEEAREEEGPWPLHEALRMDPLEAIQLELDTVNAQADRAFQQLEHKFGRMRRHYLERRNYIIQNIPGFWMTAFRNHPQLSAMIRGQDAEMLRYITNLEVKELRHPRTGCKFKFFFRRNPYFRNKLIVKEYEVRSSGRVVSLSTPIIWRRGHEPQSFIRRNQDLICSFFTWFSDHSLPESDKIAEIIKEDLWPNPLQYYLLREGVRRARRRPLREPVEIPRPFGFQSG>sp|Q9NX07|TSAP1_HUMAN tRNA selenocysteine 1-associated protein 1 OS=Homosapiens OX=9606 GN=TRNAU1AP PE=1 SV=1MAASLWMGDLEPYMDENFISRAFATMGETVMSVKIIRNRLTGIPAGYCFVEFADLATAEKCLHKINGKPLPGATPAKRFKLNYATYGKQPDNSPEYSLFVGDLTPDVDDGMLYEFFVKVYPSCRGGKVVLDQTGVSKGYGFVKFTDELEQKRALTECQGAVGLGSKPVRLSVAIPKASRVKPVEYSQMYSYSYNQYYQQYQNYYAQWGYDQNTGSYSYSYPQYGYTQSTMQTYEEVGDDALEDPMPQLDVTEANKEFMEQSEELYDALMDCHWQPLDTVSSEIPAMM>sp|Q9NX07-2|TSAP1_HUMAN Isoform 2 of tRNA selenocysteine 1-associatedprotein 1 OS=Homo sapiens OX=9606 GN=TRNAU1APMLYEFFVKVYPSCRGGKVVLDQTGVSKGYGFVKFTDELEQKRALTECQGAVGLGSKPVRLSVAIPKASRVKPVEYSQMYSYSYNQYYQQYQNYYAQWGYDQNTGSYSYSYPQYGYTQSTMQTYEEVGDDALEDPMPQLDVTEANKEFMEQSEELYDALMDCHWQPLDTVSSEIPAMM>sp|Q9NX01|TXN4B_HUMAN Thioredoxin-like protein 4B OS=Homo sapiensOX=9606 GN=TXNL4B PE=1 SV=1MSFLLPKLTSKKEVDQAIKSTAEKVLVLRFGRDEDPVCLQLDDILSKTSSDLSKMAAIYLVDVDQTAVYTQYFDISYIPSTVFFFNGQHMKVDYGSPDHTKFVGSFKTKQDFIDLIEVIYRGAMRGKLIVQSPIDPKNIPKYDLLYQDI>sp|Q5VY80|ULBP6_HUMAN UL16-binding protein 6 OS=Homo sapiens OX=9606GN=RAET1L PE=1 SV=1MAAAAIPALLLCLPLLFLLFGWSRARRDDPHSLCYDITVIPKFRPGPRWCAVQGQVDEKTFLHYDCGNKTVTPVSPLGKKLNVTMAWKAQNPVLREVVDILTEQLLDIQLENYTPKEPLTLQARMSCEQKAEGHSSGSWQFSIDGQTFLLFDSEKRMWTTVHPGARKMKEKWENDKDVAMSFHYISMGDCIGWLEDFLMGMDSTLEPSAGAPLAMSSGTTQLRATATTLILCCLLIILPCFILPGI>sp|Q15819|UB2V2_HUMAN Ubiquitin-conjugating enzyme E2 variant 2 OS=Homosapiens OX=9606 GN=UBE2V2 PE=1 SV=4MAVSTGVKVPRNFRLLEELEEGQKGVGDGTVSWGLEDDEDMTLTRWTGMIIGPPRTNYENRIYSLKVECGPKYPEAPPSVRFVTKINMNGINNSSGMVDARSIPVLAKWQNSYSIKVVLQELRRLMMSKENMKLPQPPEGQTYNN>sp|Q9BT76|UPK3B_HUMAN Uroplakin-3b OS=Homo sapiens OX=9606 GN=UPK3B PE=1SV=2MGLPWGQPHLGLQMLLLALNCLRPSLSLGEWGSWMDASSQTQGAGGPAGVIGPWAPAPLRLGEAAPGTPTPVSVAHLLSPVATELVPYTPQITAWDLEGKVTATTFSLEQPRCVFDGLASASDTVWLVVAFSNASRGFQNPETLADIPASPQLLTDGHYMTLPLSPDQLPCGDPMAGSGGAPVLRVGHDHGCHQQPFCNAPLPGPGPYREDPRIHRHLARAAKWQHDRHYLHPLFSGRPPTLGLLGSLYHALLQPVVAGGGPGAAADRLLHGQALHDPPHPTQRGRHTAGGLQAWPGPPPQPQPLAWPLCMGLGEMGRWE>sp|Q9BT76-2|UPK3B_HUMAN Isoform 2 of Uroplakin-3b OS=Homo sapiensOX=9606 GN=UPK3BMGLPWGQPHLGLQMLLLALNCLRPSLSLELVPYTPQITAWDLEGKVTATTFSLEQPRCVFDGLASASDTVWLVVAFSNASRGFQNPETLADIPASPQLLTDGHYMTLPLSPDQLPCGDPMAGSGGAPVLRVGHDHGCHQQPFCNAPLPGPGPYREDPRIHRHLARAAKWQHDRHYLHPLFSGRPPTLGLLGSLYHALLQPVVAGGGPGAAADRLLHGQALHDPPHPTQRGRHTAGGLQAWPGPPPQPQPLAWPLCMGLGEMGRWE>sp|Q9BT76-3|UPK3B_HUMAN Isoform 3 of Uroplakin-3b OS=Homo sapiensOX=9606 GN=UPK3BMGLPWGQPHLGLQMLLLALNCLRPSLSLELVPYTPQITAWDLEGKVTATTFSLEQPRCVFDGLASASDTVWLVVAFSNASRGFQNPETLADIPASPQLLTDGHYMTLPLSPDQLPCGDPMAGSGGAPVLRVGHDHGCHQQPFCNAPLPGPGPYRVKFLLMDTRGSPRAETKWSDPITLHQGKTPGSIDTWPGRRSGSMIVITSILSSLAGLLLLAFLAASTMRFSSLWWPEEAPEQLRIGSFMGKRYMTHHIPPREAATLPVGCKPGLDPLPSLSP>sp|Q8NFA0|UBP32_HUMAN Ubiquitin carboxyl-terminal hydrolase 32 OS=Homosapiens OX=9606 GN=USP32 PE=1 SV=1MGAKESRIGFLSYEEALRRVTDVELKRLKDAFKRTCGLSYYMGQHCFIREVLGDGVPPKVAEVIYCSFGGTSKGLHFNNLIVGLVLLTRGKDEEKAKYIFSLFSSESGNYVIREEMERMLHVVDGKVPDTLRKCFSEGEKVNYEKFRNWLFLNKDAFTFSRWLLSGGVYVTLTDDSDTPTFYQTLAGVTHLEESDIIDLEKRYWLLKAQSRTGRFDLETFGPLVSPPIRPSLSEGLFNAFDENRDNHIDFKEISCGLSACCRGPLAERQKFCFKVFDVDRDGVLSRVELRDMVVALLEVWKDNRTDDIPELHMDLSDIVEGILNAHDTTKMGHLTLEDYQIWSVKNVLANEFLNLLFQVCHIVLGLRPATPEEEGQIIRGWLERESRYGLQAGHNWFIISMQWWQQWKEYVKYDANPVVIEPSSVLNGGKYSFGTAAHPMEQVEDRIGSSLSYVNTTEEKFSDNISTASEASETAGSGFLYSATPGADVCFARQHNTSDNNNQCLLGANGNILLHLNPQKPGAIDNQPLVTQEPVKATSLTLEGGRLKRTPQLIHGRDYEMVPEPVWRALYHWYGANLALPRPVIKNSKTDIPELELFPRYLLFLRQQPATRTQQSNIWVNMGNVPSPNAPLKRVLAYTGCFSRMQTIKEIHEYLSQRLRIKEEDMRLWLYNSENYLTLLDDEDHKLEYLKIQDEQHLVIEVRNKDMSWPEEMSFIANSSKIDRHKVPTEKGATGLSNLGNTCFMNSSIQCVSNTQPLTQYFISGRHLYELNRTNPIGMKGHMAKCYGDLVQELWSGTQKNVAPLKLRWTIAKYAPRFNGFQQQDSQELLAFLLDGLHEDLNRVHEKPYVELKDSDGRPDWEVAAEAWDNHLRRNRSIVVDLFHGQLRSQVKCKTCGHISVRFDPFNFLSLPLPMDSYMHLEITVIKLDGTTPVRYGLRLNMDEKYTGLKKQLSDLCGLNSEQILLAEVHGSNIKNFPQDNQKVRLSVSGFLCAFEIPVPVSPISASSPTQTDFSSSPSTNEMFTLTTNGDLPRPIFIPNGMPNTVVPCGTEKNFTNGMVNGHMPSLPDSPFTGYIIAVHRKMMRTELYFLSSQKNRPSLFGMPLIVPCTVHTRKKDLYDAVWIQVSRLASPLPPQEASNHAQDCDDSMGYQYPFTLRVVQKDGNSCAWCPWYRFCRGCKIDCGEDRAFIGNAYIAVDWDPTALHLRYQTSQERVVDEHESVEQSRRAQAEPINLDSCLRAFTSEEELGENEMYYCSKCKTHCLATKKLDLWRLPPILIIHLKRFQFVNGRWIKSQKIVKFPRESFDPSAFLVPRDPALCQHKPLTPQGDELSEPRILAREVKKVDAQSSAGEEDVLLSKSPSSLSANIISSPKGSPSSSRKSGTSCPSSKNSSPNSSPRTLGRSKGRLRLPQIGSKNKLSSSKENLDASKENGAGQICELADALSRGHVLGGSQPELVTPQDHEVALANGFLYEHEACGNGYSNGQLGNHSEEDSTDDQREDTRIKPIYNLYAISCHSGILGGGHYVTYAKNPNCKWYCYNDSSCKELHPDEIDTDSAYILFYEQQGIDYAQFLPKTDGKKMADTSSMDEDFESDYKKYCVLQ>sp|Q8NFA0-2|UBP32_HUMAN Isoform 2 of Ubiquitin carboxyl-terminalhydrolase 32 OS=Homo sapiens OX=9606 GN=USP32MGAKESRIGFLSYEEALRRVTDVELKRLKDAFKRTCGLSYYMGQHCFIREVLGDGVPPKVAEVIYCSFGGTSKGLHFNNLIVGLVLLTRGKDEEKAKYIFSLFSSESGNYVIREEMERMLHVVDGKVPDTLRKCFSEGEKVNYEKFRNWLFLNKDAFTFSRWLLSGGVYVTLTDDSDTPTFYQTLAGVTHLEESDIIDLEKRYWLLKAQSRTGRFDLETFGPLVSPPIRPSLSEGLFNAFDENRDNHIDFKEISCGLSACCRGPLAERQKFCFKVFDVDRDGVLSRVELRDMVVALLEVWKDNRTDDIPELHMDLSDIVEGILNAHDTTKMGHLTLEDYQIWSVKNVLANEFLNLLFQVCHIVLGLRPATPEEEGQIIRTLETDQIYTRN>sp|Q9NZ43|USE1_HUMAN Vesicle transport protein USE1 OS=Homo sapiensOX=9606 GN=USE1 PE=1 SV=2MAASRLELNLVRLLSRCEAMAAEKRDPDEWRLEKYVGALEDMLQALKVHASKPASEVINEYSWKVDFLKGMLQAEKLTSSSEKALANQFLAPGRVPTTARERVPATKTVHLQSRARYTSEMRSELLGTDSAEPEMDVRKRTGVAGSQPVSEKQLAAELDLVLQRHQNLQEKLAEEMLGLARSLKTNTLAAQSVIKKDNQTLSHSLKMADQNLEKLKTESERLEQHTQKSVNWLLWAMLIIVCFIFISMILFIRIMPKLK>sp|Q9NZ43-2|USE1_HUMAN Isoform 2 of Vesicle transport protein USE1OS=Homo sapiens OX=9606 GN=USE1MAASRLELNLVRLLSRCEAMAAEKRDPDEWRLEKYVGALEDMLQALKVHASKPASEVINEYSWKVDFLKGMLQAEKLTSSSEKALANQFLAPGRVPTTARERVPATKTVHLQSRARYTSEMRSELLGTDSAEPEMDVRKRTPCHTH>sp|Q9NZ43-3|USE1_HUMAN Isoform 3 of Vesicle transport protein USE1OS=Homo sapiens OX=9606 GN=USE1MAASRLELNLVRLLSRCEAMAAEKRDPDEWRLEKYVGALEDMLQALKVHASKPASEVINEYSWKVDFLKGMLQAEKLTSSSEKALANQFLAPGRVPTTARERVPATKTVHLQSRARYTSEMRSELLGTDSAGESP>sp|A0A0B4J240|TVA10_HUMAN T cell receptor alpha variable 10 OS=Homosapiens OX=9606 GN=TRAV10 PE=3 SV=1MKKHLTTFLVILWLYFYRGNGKNQVEQSPQSLIILEGKNCTLQCNYTVSPFSNLRWYKQDTGRGPVSLTIMTFSENTKSNGRYTATLDADTKQSSLHITASQLSDSASYICVVS>sp|Q14508|WFDC2_HUMAN WAP four-disulfide core domain protein 2 OS=Homosapiens OX=9606 GN=WFDC2 PE=1 SV=2MPACRLGPLAAALLLSLLLFGFTLVSGTGAEKTGVCPELQADQNCTQECVSDSECADNLKCCSAGCATFCSLPNDKEGSCPQVNINFPQLGLCRDQCQVDSQCPGQMKCCRNGCGKVSCVTPNF>sp|Q14508-2|WFDC2_HUMAN Isoform 2 of WAP four-disulfide core domainprotein 2 OS=Homo sapiens OX=9606 GN=WFDC2MLQVQVNLPVSPLPTYPYSFFYPDKEGSCPQVNINFPQLGLCRDQCQVDSQCPGQMKCCRNGCGKVSCVTPNF>sp|Q14508-3|WFDC2_HUMAN Isoform 3 of WAP four-disulfide core domainprotein 2 OS=Homo sapiens OX=9606 GN=WFDC2MPACRLGPLAAALLLSLLLFGFTLVSDKEGSCPQVNINFPQLGLCRDQCQVDSQCPGQMKCCRNGCGKVSCVTPNF>sp|Q14508-4|WFDC2_HUMAN Isoform 4 of WAP four-disulfide core domainprotein 2 OS=Homo sapiens OX=9606 GN=WFDC2MPACRLGPLAAALLLSLLLFGFTLVSGTGAEKTGVCPELQADQNCTQECVSDSECADNLKCCSAGCATFCLLCPNGQLAE>sp|Q14508-5|WFDC2_HUMAN Isoform 5 of WAP four-disulfide core domainprotein 2 OS=Homo sapiens OX=9606 GN=WFDC2MPACRLGPLAAALLLSLLLFGFTLVSGTGAEKTGVCPELQADQNCTQECVSDSECADNLKCCSAGCATFCSLPNALFHWHLKTRRLWEISGPRPRRPTWDSS>sp|Q9BRG1|VPS25_HUMAN Vacuolar protein-sorting-associated protein 25OS=Homo sapiens OX=9606 GN=VPS25 PE=1 SV=1MAMSFEWPWQYRFPPFFTLQPNVDTRQKQLAAWCSLVLSFCRLHKQSSMTVMEAQESPLFNNVKLQRKLPVESIQIVLEELRKKGNLEWLDKSKSSFLIMWRRPEEWGKLIYQWVSRSGQNNSVFTLYELTNGEDTEDEEFHGLDEATLLRALQALQQEHKAEIITVSDGRGVKFF>sp|Q9H270|VPS11_HUMAN Vacuolar protein sorting-associated protein 11homolog OS=Homo sapiens OX=9606 GN=VPS11 PE=1 SV=1MAAYLQWRRFVFFDKELVKEPLSNDGAAPGATPASGSAASKFLCLPPGITVCDSGRGSLVFGDMEGQIWFLPRSLQLTGFQAYKLRVTHLYQLKQHNILASVGEDEEGINPLVKIWNLEKRDGGNPLCTRIFPAIPGTEPTVVSCLTVHENLNFMAIGFTDGSVTLNKGDITRDRHSKTQILHKGNYPVTGLAFRQAGKTTHLFVVTTENVQSYIVSGKDYPRVELDTHGCGLRCSALSDPSQDLQFIVAGDECVYLYQPDERGPCFAFEGHKLIAHWFRGYLIIVSRDRKVSPKSEFTSRDSQSSDKQILNIYDLCNKFIAYSTVFEDVVDVLAEWGSLYVLTRDGRVHALQEKDTQTKLEMLFKKNLFEMAINLAKSQHLDSDGLAQIFMQYGDHLYSKGNHDGAVQQYIRTIGKLEPSYVIRKFLDAQRIHNLTAYLQTLHRQSLANADHTTLLLNCYTKLKDSSKLEEFIKKKSESEVHFDVETAIKVLRQAGYYSHALYLAENHAHHEWYLKIQLEDIKNYQEALRYIGKLPFEQAESNMKRYGKILMHHIPEQTTQLLKGLCTDYRPSLEGRSDREAPGCRANSEEFIPIFANNPRELKAFLEHMSEVQPDSPQGIYDTLLELRLQNWAHEKDPQVKEKLHAEAISLLKSGRFCDVFDKALVLCQMHDFQDGVLYLYEQGKLFQQIMHYHMQHEQYRQVISVCERHGEQDPSLWEQALSYFARKEEDCKEYVAAVLKHIENKNLMPPLLVVQTLAHNSTATLSVIRDYLVQKLQKQSQQIAQDELRVRRYREETTRIRQEIQELKASPKIFQKTKCSICNSALELPSVHFLCGHSFHQHCFESYSESDADCPTCLPENRKVMDMIRAQEQKRDLHDQFQHQLRCSNDSFSVIADYFGRGVFNKLTLLTDPPTARLTSSLEAGLQRDLLMHSRRGT>sp|Q9BTA9|WAC_HUMAN WW domain-containing adapter protein with coiled-coil OS=Homo sapiens OX=9606 GN=WAC PE=1 SV=3MVMYARKQQRLSDGCHDRRGDSQPYQALKYSSKSHPSSGDHRHEKMRDAGDPSPPNKMLRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGGTSYSPQENSHNHSALHSSNSHSSNPSNNPSKTSDAPYDSADDWSEHISSSGKKYYYNCRTEVSQWEKPKEWLEREQRQKEANKMAVNSFPKDRDYRREVMQATATSGFASGMEDKHSSDASSLLPQNILSQTSRHNDRDYRLPRAETHSSSTPVQHPIKPVVHPTATPSTVPSSPFTLQSDHQPKKSFDANGASTLSKLPTPTSSVPAQKTERKESTSGDKPVSHSCTTPSTSSASGLNPTSAPPTSASAVPVSPVPQSPIPPLLQDPNLLRQLLPALQATLQLNNSNVDISKINEVLTAAVTQASLQSIIHKFLTAGPSAFNITSLISQAAQLSTQAQPSNQSPMSLTSDASSPRSYVSPRISTPQTNTVPIKPLISTPPVSSQPKVSTPVVKQGPVSQSATQQPVTADKQQGHEPVSPRSLQRSSSQRSPSPGPNHTSNSSNASNATVVPQNSSARSTCSLTPALAAHFSENLIKHVQGWPADHAEKQASRLREEAHNMGTIHMSEICTELKNLRSLVRVCEIQATLREQRILFLRQQIKELEKLKNQNSFMV>sp|Q9BTA9-2|WAC_HUMAN Isoform 2 of WW domain-containing adapter proteinwith coiled-coil OS=Homo sapiens OX=9606 GN=WACMRDAGDPSPPNKMLRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGGTSYSPQENSHNHSALHSSNSHSSNPSNNPSKTSDAPYDSADDWSEHISSSGKKYYYNCRTEVSQWEKPKEWLEREQRQKEANKMAVNSFPKDRDYRREVMQATATSGFASGMEDKHSSDASSLLPQNILSQTSRHNDRDYRLPRAETHSSSTPVQHPIKPVVHPTATPSTVPSSPFTLQSDHQPKKSFDANGASTLSKLPTPTSSVPAQKTERKESTSGDKPVSHSCTTPSTSSASGLNPTSAPPTSASAVPVSPVPQSPIPPLLQDPNLLRQLLPALQATLQLNNSNVDISKINEVLTAAVTQASLQSIIHKFLTAGPSAFNITSLISQAAQLSTQAQPSNQSPMSLTSDASSPRSYVSPRISTPQTNTVPIKPLISTPPVSSQPKVSTPVVKQGPVSQSATQQPVTADKQQGHEPVSPRSLQRSSSQRSPSPGPNHTSNSSNASNATVVPQNSSARSTCSLTPALAAHFSENLIKHVQGWPADHAEKQASRLREEAHNMGTIHMSEICTELKNLRSLVRVCEIQATLREQRILFLRQQIKELEKLKNQNSFMV>sp|Q9BTA9-3|WAC_HUMAN Isoform 3 of WW domain-containing adapter proteinwith coiled-coil OS=Homo sapiens OX=9606 GN=WACMRDAGDPSPPNKMLRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGGTSYSPQENSHNHSALHSSNSHSSNPSNNPSKTSDAPYDSADDWSEHISSSGKKYYYNCRTEVSQWEKPKEWLEREQRQKEANKMAVNSFPKDRDYRREVMQATATSGFASGMEDKHSSDASSLLPQNILSQTSRHNDRDYRLPRAETHSSSTPVQHPIKPVVHPTATPSTVPSSPFTLQSDHQPKKSFDANGASTLSKLPTPTSSVPAQKTERKESTSGDKPVSHSCTTPSTSSASGLNPTSAPPTSASAVPVSPVPQSPIPPLLQDPNLLRQLLPALQATLQLNNSNVDISKINEVLTAAVTQASLQSIIHKFLTAGPSAFNITSLISQAAQLSTQDIPLHEGIQMERDTHRSKWEVKGSLCQKADKQQECLVWNGSIMVQRLLQPSG>sp|Q9BTA9-5|WAC_HUMAN Isoform 4 of WW domain-containing adapter proteinwith coiled-coil OS=Homo sapiens OX=9606 GN=WACMVMYARKQQRLSDGCHDRRGDSQPYQALKYSSKSHPSSGDHRHEKMRDAGDPSPPNKMLRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGGTSYSPQENSHNHSALHSSNSHSSNPSNNPSKTSDAPYDSADDWSEHISSSGKKYYYNCRTEVSQWEKPKEWLEREQRQKEANKMAVNSFPKDRDYRREVMQATATSGFASGKSTSGDKPVSHSCTTPSTSSASGLNPTSAPPTSASAVPVSPVPQSPIPPLLQDPNLLRQLLPALQATLQLNNSNVDISKINEVLTAAVTQASLQSIIHKFLTAGPSAFNITSLISQAAQLSTQAQPSNQSPMSLTSDASSPRSYVSPRISTPQTNTVPIKPLISTPPVSSQPKVSTPVVKQGPVSQSATQQPVTADKQQGHEPVSPRSLQRSSSQRSPSPGPNHTSNSSNASNATVVPQNSSARSTCSLTPALAAHFSENLIKHVQGWPADHAEKQASRLREEAHNMGTIHMSEICTELKNLRSLVRVCEIQATLREQRILFLRQQIKELEKLKNQNSFMV>sp|P10265|VPK10_HUMAN Endogenous retrovirus group K member 10 Proprotein OS=Homo sapiens OX=9606 GN=ERVK-10 PE=1 SV=2WASQVSENRPVCKAIIQGKQFEGLVDTGADVSIIALNQWPKNWPKQKAVTGLVGIGTASEVYQSMEILHCLGPDNQESTVQPMITSIPLNLWGRDLLQQWGAEITMPAPLYSPTSQKIMTKMGYIPGKGLGKNEDGIKVPVEAKINQEREGIGYPF>sp|Q6ZNH5|ZN497_HUMAN Zinc finger protein 497 OS=Homo sapiens OX=9606GN=ZNF497 PE=1 SV=2MESPRGWTLQVAPEEGQVLCNVKTATRGLSEGAVSGGWGAWENSTEVPREAGDGQRQQATLGAADEQGGPGRELGPADGGRDGAGPRSEPADRALRPSPLPEEPGCRCGECGKAFSQGSYLLQHRRVHTGEKPYTCPECGKAFAWSSNLSQHQRIHSGEKPYACRECGKAFRAHSQLIHHQETHSGLKPFRCPDCGKSFGRSTTLVQHRRTHTGEKPYECPECGKAFSWNSNFLEHRRVHTGARPHACRDCGKAFSQSSNLAEHLKIHAGARPHACPDCGKAFVRVAGLRQHRRTHSSEKPFPCAECGKAFRESSQLLQHQRTHTGERPFECAECGQAFVMGSYLAEHRRVHTGEKPHACAQCGKAFSQRSNLLSHRRTHSGAKPFACADCGKAFRGSSGLAHHRLSHTGERPFACAECGKAFRGSSELRQHQRLHSGERPFVCAHCSKAFVRKSELLSHRRTHTGERPYACGECGKPFSHRCNLNEHQKRHGGRAAP>sp|Q9BTP6|ZBED2_HUMAN Zinc finger BED domain-containing protein 2OS=Homo sapiens OX=9606 GN=ZBED2 PE=1 SV=2MMRREDEEEEGTMMKAKGDLEMKEEEEISETGELVGPFVSAMPTPMPHNKGTRFSEAWEYFHLAPARAGHHPNQYATCRLCGRQVSRGPGVNVGTTALWKHLKSMHREELEKSGHGQAGQRQDPRPHGPQLPTGIEGNWGRLLEQVGTMALWASQREKEVLRRERAVEWRERAVEKRERALEEVERAILEMKWKVRAEKEACQREKELPAAVHPFHFV>sp|P52739|ZN131_HUMAN Zinc finger protein 131 OS=Homo sapiens OX=9606GN=ZNF131 PE=1 SV=2MEAEETMECLQEFPEHHKMILDRLNEQREQDRFTDITLIVDGHHFKAHKAVLAACSKFFYKFFQEFTQEPLVEIEGVSKMAFRHLIEFTYTAKLMIQGEEEANDVWKAAEFLQMLEAIKALEVRNKENSAPLEENTTGKNEAKKRKIAETSNVITESLPSAESEPVEIEVEIAEGTIEVEDEGIETLEEVASAKQSVKYIQSTGSSDDSALALLADITSKYRQGDRKGQIKEDGCPSDPTSKQVEGIEIVELQLSHVKDLFHCEKCNRSFKLFYHFKEHMKSHSTESFKCEICNKRYLRESAWKQHLNCYHLEEGGVSKKQRTGKKIHVCQYCEKQFDHFGHFKEHLRKHTGEKPFECPNCHERFARNSTLKCHLTACQTGVGAKKGRKKLYECQVCNSVFNSWDQFKDHLVIHTGDKPNHCTLCDLWFMQGNELRRHLSDAHNISERLVTEEVLSVETRVQTEPVTSMTIIEQVGKVHVLPLLQVQVDSAQVTVEQVHPDLLQDSQVHDSHMSELPEQVQVSYLEVGRIQTEEGTEVHVEELHVERVNQMPVEVQTELLEADLDHVTPEIMNQEERESSQADAAEAAREDHEDAEDLETKPTVDSEAEKAENEDRTALPVLE>sp|P52739-2|ZN131_HUMAN Isoform 2 of Zinc finger protein 131 OS=Homosapiens OX=9606 GN=ZNF131MEAEETMECLQEFPEHHKMILDRLNEQREQDRFTDITLIVDGHHFKAHKAVLAACSKFFYKFFQEFTQEPLVEIEGVSKMAFRHLIEFTYTAKLMIQGEEEANDVWKAAEFLQMLEAIKALEVRNKENSAPLEENTTGKNEAKKRKIAETSNVITESLPSAESEPVEIEVEIAEGTIEVEDEGIETLEEVASAKQSVKYIQSTGSSDDSALALLADITSKYRQGDRKGQIKEDGCPSDPTSKQEHMKSHSTESFKCEICNKRYLRESAWKQHLNCYHLEEGGVSKKQRTGKKIHVCQYCEKQFDHFGHFKEHLRKHTGEKPFECPNCHERFARNSTLKCHLTACQTGVGAKKGRKKLYECQVCNSVFNSWDQFKDHLVIHTGDKPNHCTLCDLWFMQGNELRRHLSDAHNISERLVTEEVLSVETRVQTEPVTSMTIIEQVGKVHVLPLLQVQVDSAQVTVEQVHPDLLQDSQVHDSHMSELPEQVQVSYLEVGRIQTEEGTEVHVEELHVERVNQMPVEVQTELLEADLDHVTPEIMNQEERESSQADAAEAAREDHEDAEDLETKPTVDSEAEKAENEDRTALPVLE>sp|Q969J2|ZKSC4_HUMAN Zinc finger protein with KRAB and SCAN domains 4OS=Homo sapiens OX=9606 GN=ZKSCAN4 PE=1 SV=1MAREPRKNAALDAQSAEDQTGLLTVKVEKEEASALTAEVRAPCSPARGPERSRQRFRGFRYPEAAGPREALSRLRELCGQWLQPEMHSKEQILELLVLEQFLTILPGNLQSWVREQHPESGEEVVVLLEYLERQLDEPAPQVPVGDQGQELLCCKMALLTQTQGSQSSQCQPMKALFKHESLGSQPLHDRVLQVPGLAQGGCCREDAMVASRLTPGSQGLLKMEDVALTLTPGWTQLDSSQVNLYRDEKQENHSSLVSLGGEIQTKSRDLPPVKKLPEKEHGKICHLREDIAQIPTHAEAGEQEGRLQRKQKNAIGSRRHYCHECGKSFAQSSGLTKHRRIHTGEKPYECEDCGKTFIGSSALVIHQRVHTGEKPYECEECGKVFSHSSNLIKHQRTHTGEKPYECDDCGKTFSQSCSLLEHHKIHTGEKPYQCNMCGKAFRRNSHLLRHQRIHGDKNVQNPEHGESWESQGRTESQWENTEAPVSYKCNECERSFTRNRSLIEHQKIHTGEKPYQCDTCGKGFTRTSYLVQHQRSHVGKKTLSQ>sp|Q8NA42|ZN383_HUMAN Zinc finger protein 383 OS=Homo sapiens OX=9606GN=ZNF383 PE=1 SV=1MAEGSVMFSDVSIDFSQEEWDCLDPVQRDLYRDVMLENYGNLVSMGLYTPKPQVISLLEQGKEPWMVGRELTRGLCSDLESMCETKLLSLKKEVYEIELCQREIMGLTKHGLEYSSFGDVLEYRSHLAKQLGYPNGHFSQEIFTPEYMPTFIQQTFLTLHQIINNEDRPYECKKCGKAFSQNSQFIQHQRIHIGEKSYECKECGKFFSCGSHVTRHLKIHTGEKPFECKECGKAFSCSSYLSQHQRIHTGKKPYECKECGKAFSYCSNLIDHQRIHTGEKPYECKVCGKAFTKSSQLFQHARIHTGEKPYECKECGKAFTQSSKLVQHQRIHTGEKPYECKECGKAFSSGSALTNHQRIHTGEKPYDCKECGKAFTQSSQLRQHQRIHAGEKPFECLECGKAFTQNSQLFQHQRIHTDEKPYECNECGKAFNKCSNLTRHLRIHTGEKPYNCKECGKAFSSGSDLIRHQGIHTNK>sp|Q66K41|Z385C_HUMAN Zinc finger protein 385C OS=Homo sapiens OX=9606GN=ZNF385C PE=1 SV=4MLLGPASGAPSPLLASLPLPTRPLQPPLDFKHLLAFHFNGAAPLSLFPNFSTMDPVQKAVISHTFGVPSPLKKKLFISCNICHLRFNSANQAEAHYKGHKHARKLKAVEAAKSKQRPHTQAQDGAVVSPIPTLASGAPGEPQSKVPAAPPLGPPLQPPPTPDPTCREPAHSELLDAASSSSSSSCPPCSPEPGREAPGPEPAAAAVGSSMSGEGRSEKGHLYCPTCKVTVNSASQLQAHNTGAKHRWMMEGQRGAPRRSRGRPVSRGGAGHKAKRVTGGRGGRQGPSPAFHCALCQLQVNSETQLKQHMSSRRHKDRLAGKTPKPSSQHSKLQKHAALAVSILKSKLALQKQLTKTLAARFLPSPLPTAATAICALPGPLALRPAPTAATTLFPAPILGPALFRTPAGAVRPATGPIVLAPY>sp|Q66K41-2|Z385C_HUMAN Isoform 2 of Zinc finger protein 385C OS=Homosapiens OX=9606 GN=ZNF385CMEGQRGAPRRSRGRPVSRGGAGHKAKRVTGGRGGRQGPSPAFHCALCQLQVNSETQLKQHMSSRRHKDRLAGKTPKPSSQHSKLQKHAALAVSILKSKLALQKQLTKTLAARFLPSPLPTAATAICALPGPLALRPAPTAATTLFPAPILGPALFRTPAGAVRPATGPIVLAPY>sp|Q8N8J6|ZN615_HUMAN Zinc finger protein 615 OS=Homo sapiens OX=9606GN=ZNF615 PE=2 SV=2MMQAQESLTLEDVAVDFTWEEWQFLSPAQKDLYRDVMLENYSNLVAVGYQASKPDALSKLERGEETCTTEDEIYSRICSEIRKIDDPLQHHLQNQSIQKSVKQCHEQNMFGNIVNQNKGHFLLKQDCDTFDLHEKPLKSNLSFENQKRSSGLKNSAEFNRDGKSLFHANHKQFYTEMKFPAIAKPINKSQFIKQQRTHNIENAHVCSECGKAFLKLSQFIDHQRVHTGEKPHVCSMCGKAFSRKSRLMDHQRTHTELKHYECTECDKTFLKKSQLNIHQKTHMGGKPYTCSQCGKAFIKKCRLIYHQRTHTGEKPHGCSVCGKAFSTKFSLTTHQKTHTGEKPYICSECGKGFIEKRRLTAHHRTHTGEKPFICNKCGKGFTLKNSLITHQQTHTGEKLYTCSECGKGFSMKHCLMVHQRTHTGEKPYKCNECGKGFALKSPLIRHQRTHTGEKPYVCTECRKGFTMKSDLIVHQRTHTAEKPYICNDCGKGFTVKSRLIVHQRTHTGEKPYVCGECGKGFPAKIRLMGHQRTHTGEKPYICNECGKGFTEKSHLNVHRRTHTGEKPYVCSECGKGLTGKSMLIAHQRTHTGEKPYICNECGKGFTMKSTLSIHQQTHTGEKPYKCNECDKTFRKKTCLIQHQRFHTGKTSFACTECGKFSLRKNDLITHQRIHTGEKPYKCSDCGKAFTTKSGLNVHQRKHTGERPYGCSDCGKAFAHLSILVKHRRIHR>sp|Q8N8J6-2|ZN615_HUMAN Isoform 2 of Zinc finger protein 615 OS=Homosapiens OX=9606 GN=ZNF615MMQAQESLTLEDVAVDFTWEEWQFLSPAQKDLYRDVMLENYSNLVAVGYQASKPDALSKLERGEETCTTEDEIYSRICSDSGGASGGAYAEIRKIDDPLQHHLQNQSIQKSVKQCHEQNMFGNIVNQNKGHFLLKQDCDTFDLHEKPLKSNLSFENQKRSSGLKNSAEFNRDGKSLFHANHKQFYTEMKFPAIAKPINKSQFIKQQRTHNIENAHVCSECGKAFLKLSQFIDHQRVHTGEKPHVCSMCGKAFSRKSRLMDHQRTHTELKHYECTECDKTFLKKSQLNIHQKTHMGGKPYTCSQCGKAFIKKCRLIYHQRTHTGEKPHGCSVCGKAFSTKFSLTTHQKTHTGEKPYICSECGKGFIEKRRLTAHHRTHTGEKPFICNKCGKGFTLKNSLITHQQTHTGEKLYTCSECGKGFSMKHCLMVHQRTHTGEKPYKCNECGKGFALKSPLIRHQRTHTGEKPYVCTECRKGFTMKSDLIVHQRTHTAEKPYICNDCGKGFTVKSRLIVHQRTHTGEKPYVCGECGKGFPAKIRLMGHQRTHTGEKPYICNECGKGFTEKSHLNVHRRTHTGEKPYVCSECGKGLTGKSMLIAHQRTHTGEKPYICNECGKGFTMKSTLSIHQQTHTGEKPYKCNECDKTFRKKTCLIQHQRFHTGKTSFACTECGKFSLRKNDLITHQRIHTGEKPYKCSDCGKAFTTKSGLNVHQRKHTGERPYGCSDCGKAFAHLSILVKHRRIHR>sp|Q8N8J6-3|ZN615_HUMAN Isoform 3 of Zinc finger protein 615 OS=Homosapiens OX=9606 GN=ZNF615MESLTLEDVAVDFTWEEWQFLSPAQKDLYRDVMLENYSNLVAVGYQASKPDALSKLERGEETCTTEDEIYSRICSDSGGASGGAYAEIRKIDDPLQHHLQNQSIQKSVKQCHEQNMFGNIVNQNKGHFLLKQDCDTFDLHEKPLKSNLSFENQKRSSGLKNSAEFNRDGKSLFHANHKQFYTEMKFPAIAKPINKSQFIKQQRTHNIENAHVCSECGKAFLKLSQFIDHQRVHTGEKPHVCSMCGKAFSRKSRLMDHQRTHTELKHYECTECDKTFLKKSQLNIHQKTHMGGKPYTCSQCGKAFIKKCRLIYHQRTHTGEKPHGCSVCGKAFSTKFSLTTHQKTHTGEKPYICSECGKGFIEKRRLTAHHRTHTGEKPFICNKCGKGFTLKNSLITHQQTHTGEKLYTCSECGKGFSMKHCLMVHQRTHTGEKPYKCNECGKGFALKSPLIRHQRTHTGEKPYVCTECRKGFTMKSDLIVHQRTHTAEKPYICNDCGKGFTVKSRLIVHQRTHTGEKPYVCGECGKGFPAKIRLMGHQRTHTGEKPYICNECGKGFTEKSHLNVHRRTHTGEKPYVCSECGKGLTGKSMLIAHQRTHTGEKPYICNECGKGFTMKSTLSIHQQTHTGEKPYKCNECDKTFRKKTCLIQHQRFHTGKTSFACTECGKFSLRKNDLITHQRIHTGEKPYKCSDCGKAFTTKSGLNVHQRKHTGERPYGCSDCGKAFAHLSILVKHRRIHR>sp|P60852|ZP1_HUMAN Zona pellucida sperm-binding protein 1 OS=Homosapiens OX=9606 GN=ZP1 PE=1 SV=1MAGGSATTWGYPVALLLLVATLGLGRWLQPDPGLPGLRHSYDCGIKGMQLLVFPRPGQTLRFKVVDEFGNRFDVNNCSICYHWVTSRPQEPAVFSADYRGCHVLEKDGRFHLRVFMEAVLPNGRVDVAQDATLICPKPDPSRTLDSQLAPPAMFSVSTPQTLSFLPTSGHTSQGSGHAFPSPLDPGHSSVHPTPALPSPGPGPTLATLAQPHWGTLEHWDVNKRDYIGTHLSQEQCQVASGHLPCIVRRTSKEACQQAGCCYDNTREVPCYYGNTATVQCFRDGYFVLVVSQEMALTHRITLANIHLAYAPTSCSPTQHTEAFVVFYFPLTHCGTTMQVAGDQLIYENWLVSGIHIQKGPQGSITRDSTFQLHVRCVFNASDFLPIQASIFPPPSPAPMTQPGPLRLELRIAKDETFSSYYGEDDYPIVRLLREPVHVEVRLLQRTDPNLVLLLHQCWGAPSANPFQQPQWPILSDGCPFKGDSYRTQMVALDGATPFQSHYQRFTVATFALLDSGSQRALRGLVYLFCSTSACHTSGLETCSTACSTGTTRQRRSSGHRNDTARPQDIVSSPGPVGFEDSYGQEPTLGPTDSNGNSSLRPLLWAVLLLPAVALVLGFGVFVGLSQTWAQKLWESNRQ>sp|Q8TBC5|ZSC18_HUMAN Zinc finger and SCAN domain-containing protein 18OS=Homo sapiens OX=9606 GN=ZSCAN18 PE=1 SV=2MLPLEKAFASPRSSPAPPDLPTPGSAAGVQQEEPETIPERTPADLEFSRLRFREFVYQEAAGPHQTLARLHELCRQWLMPEARSKEQMLELLVLEQFLGILPDKVRPWVVAQYPESCKKAASLVEGLADVLEEPGMLLGSPAGSSSILSDGVYERHMDPLLLPGELASPSQALGAGEIPAPSETPWLSPDPLFLEQRRVREAKTEEDGPANTEQKLKSFPEDPQHLGEWGHLDPAEENLKSYRKLLLWGYQLSQPDAASRLDTEELRLVERDPQGSSLPEGGRRQESAGCACEEAAPAGVLPELPTEAPPGDALADPPSGTTEEEEEQPGKAPDPQDPQDAESDSATGSQRQSVIQQPAPDRGTAKLGTKRPHPEDGDGQSLEGVSSSGDSAGLEAGQGPGADEPGLSRGKPYACGECGEAFAWLSHLMEHHSSHGGRKRYACQGCWKTFHFSLALAEHQKTHEKEKSYALGGARGPQPSTREAQAGARAGGPPESVEGEAPPAPPEAQR>sp|Q8TBC5-2|ZSC18_HUMAN Isoform 2 of Zinc finger and SCAN domain-containing protein 18 OS=Homo sapiens OX=9606 GN=ZSCAN18MLPLEKAFASPRSSPAPPDLPTPGSAAGVQQEEPETIPERTPADLEFSRLRFREFVYQEAAGPHQTLARLHELCRQWLMPEARSKEQMLELLVLEQFLGILPDKVRPWVVAQYPESCKKAASLVEGLADVLEEPGMLLGSPAGSSSILSDGVYERHMDPLLLPGELASPSQALGAGEIPAPSETPWLSPDPLFLEQRRVREAKTEEDGPANTEQKLKSFPEDPQHLGEWGHLDPAEENLKSYRKLLLWGYQLSQPDAASRLDTEELRLVERDPQGSSLPGGRRQESAGCACEEAAPAGVLPELPTEAPPGDALADPPSGTTEEEEEQPGKAPDPQDPQDAESDSATGSQRQSVIQQPAPDRGTAKLGTKRPHPEDGDGQSLEGVSSSGDSAGLEAGQGPGADEPGLSRGKPYACGECGEAFAWLSHLMEHHSSHGGRKRYACQGCWKTFHFSLALAEHQKTHEKEKSYALGGARGPQPSTREAQAGARAGGPPESVEGEAPPAPPEAQR>sp|Q8TBC5-3|ZSC18_HUMAN Isoform 3 of Zinc finger and SCAN domain-containing protein 18 OS=Homo sapiens OX=9606 GN=ZSCAN18MRRVGGRADEDATAAGSLWVLAPPEPTGHLVIPGTSPLEPPCPWLDSHIFQCRFGKMLPLEKAFASPRSSPAPPDLPTPGSAAGVQQEEPETIPERTPADLEFSRLRFREFVYQEAAGPHQTLARLHELCRQWLMPEARSKEQMLELLVLEQFLGILPDKVRPWVVAQYPESCKKAASLVEGLADVLEEPGMLLGSPAGSSSILSDGVYERHMDPLLLPGELASPSQALGAGEIPAPSETPWLSPDPLFLEQRRVREAKTEEDGPANTEQKLKSFPEDPQHLGEWGHLDPAEENLKSYRKLLLWGYQLSQPDAASRLDTEELRLVERDPQGSSLPEGGRRQESAGCACEEAAPAGVLPELPTEAPPGDALADPPSGTTEEEEEQPGKAPDPQDPQDAESDSATGSQRQSVIQQPAPDRGTAKLGTKRPHPEDGDGQSLEGVSSSGDSAGLEAGQGPGADEPGLSRGKPYACGECGEAFAWLSHLMEHHSSHGGRKRYACQGCWKTFHFSLALAEHQKTHEKEKSYALGGARGPQPSTREAQAGARAGGPPESVEGEAPPAPPEAQR>sp|Q8TBC5-4|ZSC18_HUMAN Isoform 4 of Zinc finger and SCAN domain-containing protein 18 OS=Homo sapiens OX=9606 GN=ZSCAN18MLLGSPAGSSSILSDGVYERHMDPLLLPGELASPSQALGAGEIPAPSETPWLSPDPLFLEQRRVREAKTEEDGPANTEQKLKSFPEDPQHLGEWGHLDPAEENLKSYRKLLLWGYQLSQPDAASRLDTEELRLVERDPQGSSLPGGRRQESAGCACEEAAPAGVLPELPTEAPPGDALADPPSGTTEEEEEQPGKAPDPQDPQDAESDSATGSQRQSVIQQPAPDRGTAKLGTKRPHPEDGDGQSLEGVSSSGDSAGLEAGQGPGADEPGLSRGKPYACGECGEAFAWLSHLMEHHSSHGGRKRYACQGCWKTFHFSLALAEHQKTHEKEKSYALGGARGPQPSTREAQAGARAGGPPESVEGEAPPAPPEAQR>sp|Q15649|ZNHI3_HUMAN Zinc finger HIT domain-containing protein 3OS=Homo sapiens OX=9606 GN=ZNHIT3 PE=1 SV=2MASLKCSTVVCVICLEKPKYRCPACRVPYCSVVCFRKHKEQCNPETRPVEKKIRSALPTKTVKPVENKDDDDSIADFLNSDEEEDRVSLQNLKNLGESATLRSLLLNPHLRQLMVNLDQGEDKAKLMRAYMQEPLFVEFADCCLGIVEPSQNEES>sp|Q15649-2|ZNHI3_HUMAN Isoform 2 of Zinc finger HIT domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=ZNHIT3MASLKCSTVVCVICLEKPKYRCPACRVPYCSVVCFRKHKEQCNPETRPVEKKIRSALPTKTVKPVENKDDDDSIADFLNSDEEEDRVSLQNLKNLDGLSSCHPGWSAAAQSRLTATSPSQIQAILMPQPPEQLGLQAPATTPNQFLYF>sp|O60232|ZNRD2_HUMAN Protein ZNRD2 OS=Homo sapiens OX=9606 GN=ZNRD2PE=1 SV=1MALNGAEVDDFSWEPPTEAETKVLQARRERQDRISRLMGDYLLRGYRMLGETCADCGTILLQDKQRKIYCVACQELDSDVDKDNPALNAQAALSQAREHQLASASELPLGSRPAPQPPVPRPEHCEGAAAGLKAAQGPPAPAVPPNTDVMACTQTALLQKLTWASAELGSSTSLETSIQLCGLIRACAEALRSLQQLQH>sp|Q9UPX0|TUTLB_HUMAN Protein turtle homolog B OS=Homo sapiens OX=9606GN=IGSF9B PE=2 SV=2MIWYVATFIASVIGTRGLAAEGAHGLREEPEFVTARAGESVVLRCDVIHPVTGQPPPYVVEWFKFGVPIPIFIKFGYYPPHVDPEYAGRASLHDKASLRLEQVRSEDQGWYECKVLMLDQQYDTFHNGSWVHLTINAPPTFTETPPQYIEAKEGGSITMTCTAFGNPKPIVTWLKEGTLLGASGKYQVSDGSLTVTSVSREDRGAYTCRAYSIQGEAVHTTHLLVQGPPFIVSPPENITVNISQDALLTCRAEAYPGNLTYTWYWQDENVYFQNDLKLRVRILIDGTLIIFRVKPEDSGKYTCVPSNSLGRSPSASAYLTVQYPARVLNMPPVIYVPVGIHGYIRCPVDAEPPATVVKWNKDGRPLQVEKNLGWTLMEDGSIRIEEATEEALGTYTCVPYNTLGTMGQSAPARLVLKDPPYFTVLPGWEYRQEAGRELLIPCAAAGDPFPVITWRKVGKPSRSKHSALPSGSLQFRALSKEDHGEWECVATNVVTSITASTHLTVIGTSPHAPGSVRVQVSMTTANVSWEPGYDGGYEQTFSVWMKRAQFGPHDWLSLPVPPGPSWLLVDTLEPETAYQFSVLAQNKLGTSAFSEVVTVNTLAFPITTPEPLVLVTPPRCLIANRTQQGVLLSWLPPANHSFPIDRYIMEFRVAERWELLDDGIPGTEGEFFAKDLSQDTWYEFRVLAVMQDLISEPSNIAGVSSTDIFPQPDLTEDGLARPVLAGIVATICFLAAAILFSTLAACFVNKQRKRKLKRKKDPPLSITHCRKSLESPLSSGKVSPESIRTLRAPSESSDDQGQPAAKRMLSPTREKELSLYKKTKRAISSKKYSVAKAEAEAEATTPIELISRGPDGRFVMDPAEMEPSLKSRRIEGFPFAEETDMYPEFRQSDEENEDPLVPTSVAALKSQLTPLSSSQESYLPPPAYSPRFQPRGLEGPGGLEGRLQATGQARPPAPRPFHHGQYYGYLSSSSPGEVEPPPFYVPEVGSPLSSVMSSPPLPTEGPFGHPTIPEENGENASNSTLPLTQTPTGGRSPEPWGRPEFPFGGLETPAMMFPHQLPPCDVPESLQPKAGLPRGLPPTSLQVPAAYPGILSLEAPKGWAGKSPGRGPVPAPPAAKWQDRPMQPLVSQGQLRHTSQGMGIPVLPYPEPAEPGAHGGPSTFGLDTRWYEPQPRPRPSPRQARRAEPSLHQVVLQPSRLSPLTQSPLSSRTGSPELAARARPRPGLLQQAEMSEITLQPPAAVSFSRKSTPSTGSPSQSSRSGSPSYRPAMGFTTLATGYPSPPPGPAPAGPGDSLDVFGQTPSPRRTGEELLRPETPPPTLPTSGKLQRDRPAPATSPPERALSKL>sp|Q9UPX0-2|TUTLB_HUMAN Isoform 2 of Protein turtle homolog B OS=Homosapiens OX=9606 GN=IGSF9BMIWYVATFIASVIGTRGLAAEGAHGLREEPEFVTARAGESVVLRCDVIHPVTGQPPPYVVEWFKFGVPIPIFIKFGYYPPHVDPEYAGRASLHDKASLRLEQVRSEDQGWYECKVLMLDQQYDTFHNGSWVHLTINAPPTFTETPPQYIEAKEGGSITMTCTAFGNPKPIVTWLKEGTLLGASGKYQVSDGSLTVTSVSREDRGAYTCRAYSIQGEAVHTTHLLVQGPPFIVSPPENITVNISQDALLTCRAEAYPGNLTYTWYWQDENVYFQNDLKLRVRILIDGTLIIFRVKPEDSGKYTCVPSNSLGRSPSASAYLTVQYPARVLNMPPVIYVPVGIHGYIRCPVDAEPPATVVKWNKDGRPLQVEKNLGWTLMEDGSIRIEEATEEALGTYTCVPYNTLGTMGQSAPARLVLKDPPYFTVLPGWEYRQEAGRELLIPCAAAGDPFPVITWRKVGKPSRSKHSALPSGSLQFRALSKEDHGEWECVATNVVTSITASTHLTVIGTSPHAPGSVRVQVSMTTANVSWEPGYDGGYEQTFSVWMKRAQFGPHDWLSLPVPPGPSWLLVDTLEPETAYQFSVLAQNKLGTSAFSEVVTVNTLAFPITTPEPLVLVTPPRCLIANRTQQGVLLSWLPPANHSFPIDRYIMEFRVAERWELLDDGIPGTEGEFFAKDLSQDTWYEFRVLAVMQDLISEPSNIAGVSSTDIFPQPDLTEDGLARPVLAGIVATICFLAAAILFSTLAACFVNKQRKRKLKRKKDPPLSITHCRKSLESPLSSGKVSPESIRTLRAPSESSDDQGQPAAKRMLSPTREKELSLYKKTKRAISSKKYSVAKAEAEAEATTPIELISRGPDGRFVMDPAEMEPSLKSRRIEGFPFAEETDMYPEFRQSDEENEDPLVPTSVAALKSQLTPLSSSQESYLPPPAYSPRFQPRGLEGPGGLEGRLQATGQARPPAPRPFHHGQYYGYLSSSSPGEVEPPPFYVPEVGSPLSSVMSSPPLPTEGPFGHPTIPEENGENASNSTLPLTQTPTGGRSPEPWGRPEFPFGGLETPAMMFPHQLPPCDVPESLQPKAGLPRGLPPTSLQVPAAYPGILSLEAPKGWAGKSPGRGPVPAPPAAKWQDRPMQPLVSQGQLRHTSQGMGIPVLPYPEPAEPGAHGGPSTFGLDTRWYEPQPRPRPSPRQARRAEPSLHQVVLQPSRLSPLTQSPLSSRTGSPELAARARPRPGLLQQAEMSEITLQPPAAVSFSRKSTPSTGSPSQSSRSGSPSYRPAMGFTTLATGYPSPPPGPAPAGPGDSLDVFGQTPSPRRTGEELLRPETPPPTLPTSGTLPPAPGNAAAPERLEALKYQRIKKPKKSSKGSSKSKKRSDDSASQTQQLPNSQVLWPDEAVCLRKKKRHSRPDPFARLSDLCHRQLPEDQTAILNSVDHDDPGHATLL>sp|Q86UX7|URP2_HUMAN Fermitin family homolog 3 OS=Homo sapiens OX=9606GN=FERMT3 PE=1 SV=1MAGMKTASGDYIDSSWELRVFVGEEDPEAESVTLRVTGESHIGGVLLKIVEQINRKQDWSDHAIWWEQKRQWLLQTHWTLDKYGILADARLFFGPQHRPVILRLPNRRALRLRASFSQPLFQAVAAICRLLSIRHPEELSLLRAPEKKEKKKKEKEPEEELYDLSKVVLAGGVAPALFRGMPAHFSDSAQTEACYHMLSRPQPPPDPLLLQRLPRPSSLSDKTQLHSRWLDSSRCLMQQGIKAGDALWLRFKYYSFFDLDPKTDPVRLTQLYEQARWDLLLEEIDCTEEEMMVFAALQYHINKLSQSGEVGEPAGTDPGLDDLDVALSNLEVKLEGSAPTDVLDSLTTIPELKDHLRIFRIPRRPRKLTLKGYRQHWVVFKETTLSYYKSQDEAPGDPIQQLNLKGCEVVPDVNVSGQKFCIKLLVPSPEGMSEIYLRCQDEQQYARWMAGCRLASKGRTMADSSYTSEVQAILAFLSLQRTGSGGPGNHPHGPDASAEGLNPYGLVAPRFQRKFKAKQLTPRILEAHQNVAQLSLAEAQLRFIQAWQSLPDFGISYVMVRFKGSRKDEILGIANNRLIRIDLAVGDVVKTWRFSNMRQWNVNWDIRQVAIEFDEHINVAFSCVSASCRIVHEYIGGYIFLSTRERARGEELDEDLFLQLTGGHEAF>sp|Q86UX7-2|URP2_HUMAN Isoform 2 of Fermitin family homolog 3 OS=Homosapiens OX=9606 GN=FERMT3MAGMKTASGDYIDSSWELRVFVGEEDPEAESVTLRVTGESHIGGVLLKIVEQINRKQDWSDHAIWWEQKRQWLLQTHWTLDKYGILADARLFFGPQHRPVILRLPNRRALRLRASFSQPLFQAVAAICRLLSIRHPEELSLLRAPEKKEKKKKEKEPEEELYDLSKVVLAGGVAPALFRGMPAHFSDSAQTEACYHMLSRPQPPPDPLLLQRLPRPSSLSDKTQLHSRWLDSSRCLMQQGIKAGDALWLRFKYYSFFDLDPKTDPVRLTQLYEQARWDLLLEEIDCTEEEMMVFAALQYHINKLSQSGEVGEPAGTDPGLDDLDVALSNLEVKLEGSAPTDVLDSLTTIPELKDHLRIFRPRKLTLKGYRQHWVVFKETTLSYYKSQDEAPGDPIQQLNLKGCEVVPDVNVSGQKFCIKLLVPSPEGMSEIYLRCQDEQQYARWMAGCRLASKGRTMADSSYTSEVQAILAFLSLQRTGSGGPGNHPHGPDASAEGLNPYGLVAPRFQRKFKAKQLTPRILEAHQNVAQLSLAEAQLRFIQAWQSLPDFGISYVMVRFKGSRKDEILGIANNRLIRIDLAVGDVVKTWRFSNMRQWNVNWDIRQVAIEFDEHINVAFSCVSASCRIVHEYIGGYIFLSTRERARGEELDEDLFLQLTGGHEAF>sp|A0A087WT01|TVA27_HUMAN T cell receptor alpha variable 27 OS=Homosapiens OX=9606 GN=TRAV27 PE=1 SV=1MVLKFSVSILWIQLAWVSTQLLEQSPQFLSIQEGENLTVYCNSSSVFSSLQWYRQEPGEGPVLLVTVVTGGEVKKLKRLTFQFGDARKDSSLHITAAQTGDTGLYLCAG>sp|Q96AW1|VOPP1_HUMAN Vesicular, overexpressed in cancer, prosurvivalprotein 1 OS=Homo sapiens OX=9606 GN=VOPP1 PE=2 SV=1MRRQPAKVAALLLGLLLECTEAKKHCWYFEGLYPTYYICRSYEDCCGSRCCVRALSIQRLWYFWFLLMMGVLFCCGAGFFIRRRMYPPPLIEEPAFNVSYTRQPPNPGPGAQQPGPPYYTDPGGPGMNPVGNSMAMAFQVPPNSPQGSVACPPPPAYCNTPPPPYEQVVKAK>sp|Q96AW1-2|VOPP1_HUMAN Isoform 2 of Vesicular, overexpressed in cancer,prosurvival protein 1 OS=Homo sapiens OX=9606 GN=VOPP1MRRTGSHAQCTEAKKHCWYFEGLYPTYYICRSYEDCCGSRCCVRALSIQRLWYFWFLLMMGVLFCCGAGFFIRRRMYPPPLIEEPAFNVSYTRQPPNPGPGAQQPGPPYYTDPGGPGMNPVGNSMAMAFQVPPNSPQGSVACPPPPAYCNTPPPPYEQVVKAK>sp|Q96AW1-3|VOPP1_HUMAN Isoform 3 of Vesicular, overexpressed in cancer,prosurvival protein 1 OS=Homo sapiens OX=9606 GN=VOPP1MLSETLGYLSSVLLQCTEAKKHCWYFEGLYPTYYICRSYEDCCGSRCCVRALSIQRLWYFWFLLMMGVLFCCGAGFFIRRRMYPPPLIEEPAFNVSYTRQPPNPGPGAQQPGPPYYTDPGGPGMNPVGNSMAMAFQVPPNSPQGSVACPPPPAYCNTPPPPYEQVVKAK>sp|Q96AW1-4|VOPP1_HUMAN Isoform 4 of Vesicular, overexpressed in cancer,prosurvival protein 1 OS=Homo sapiens OX=9606 GN=VOPP1MCTEAKKHCWYFEGLYPTYYICRSYEDCCGSRCCVRALSIQRLWYFWFLLMMGVLFCCGAGFFIRRRMYPPPLIEEPAFNVSYTRQPPNPGPGAQQPGPPYYTDPGGPGMNPVGNSMAMAFQVPPNSPQGSVACPPPPAYCNTPPPPYEQVVKAK>sp|P46937|YAP1_HUMAN Transcriptional coactivator YAP1 OS=Homo sapiensOX=9606 GN=YAP1 PE=1 SV=2MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASGPLPDGWEQAMTQDGEIYYINHKNKTTSWLDPRLDPRFAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQAMRNINPSTANSPKCQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-2|YAP1_HUMAN Isoform 2 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASGPLPDGWEQAMTQDGEIYYINHKNKTTSWLDPRLDPRFAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-3|YAP1_HUMAN Isoform 3 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQVRPQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-4|YAP1_HUMAN Isoform 4 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASGPLPDGWEQAMTQDGEIYYINHKNKTTSWLDPRLDPRFAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQAMRNINPSTANSPKCQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-5|YAP1_HUMAN Isoform 5 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-6|YAP1_HUMAN Isoform 6 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQAMRNINPSTANSPKCQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-7|YAP1_HUMAN Isoform 7 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQVRPQAMRNINPSTANSPKCQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-8|YAP1_HUMAN Isoform 8 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASGPLPDGWEQAMTQDGEIYYINHKNKTTSWLDPRLDPRFAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQVRPQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|P46937-9|YAP1_HUMAN Isoform 9 of Transcriptional coactivator YAP1OS=Homo sapiens OX=9606 GN=YAP1MDPGQQPPPQPAPQGQGQPPSQPPQGQGPPSGPGQPAPAATQAAPQAPPAGHQIVHVRGDSETDLEALFNAVMNPKTANVPQTVPMRLRKLPDSFFKPPEPKSHSRQASTDAGTAGALTPQHVRAHSSPASLQLGAVSPGTLTPTGVVSGPAATPTAQHLRQSSFEIPDDVPLPAGWEMAKTSSGQRYFLNHIDQTTTWQDPRKAMLSQMNVTAPTSPPVQQNMMNSASGPLPDGWEQAMTQDGEIYYINHKNKTTSWLDPRLDPRFAMNQRISQSAPVKQPPPLAPQSPQGGVMGGSNSNQQQQMRLQQLQMEKERLRLKQQELLRQVRPQAMRNINPSTANSPKCQELALRSQLPTLEQDGGTQNPVSSPGMSQELRTMTTNSSDPFLNSGTYHSRDESTDSGLSMSSYSVPRTPDDFLNSVDEMDTGDTINQSTLPSQQNRFPDYLEAIPGTNVDLGTLEGDGMNIEGEELMPSLQEALSSDILNDMESVLAATKLDKESFLTWL>sp|Q8IYB0|YK038_HUMAN Putative uncharacterized protein MGC39545 OS=Homosapiens OX=9606 PE=5 SV=2MPSGEERRDRQKGRRAGCDTSSTPSNTAPRIPEPGAHPTAARPATAQPPRSLLPPVCSKTIALPASAAAASGSDTAGMRGLGKAPHSGEGHERGRGNSKMKACNNYQYGYLAKPDTSFWIKCRRWLLADAGRHTQRPFWTFRVSHSPLLEAEAGRPSDVSQLQLGSDLKPKMRRPAGELFSPKDAGWELDPAEKSE>sp|Q9BW85|YJU2_HUMAN Splicing factor YJU2 OS=Homo sapiens OX=9606GN=YJU2 PE=1 SV=1MSERKVLNKYYPPDFDPSKIPKLKLPKDRQYVVRLMAPFNMRCKTCGEYIYKGKKFNARKETVQNEVYLGLPIFRFYIKCTRCLAEITFKTDPENTDYTMEHGATRNFQAEKLLEEEEKRVQKEREDEELNNPMKVLENRTKDSKLEMEVLENLQELKDLNQRQAHVDFEAMLRQHRLSEEERRRQQQEEDEQETAALLEEARKRRLLEDSDSEDEAAPSPLQPALRPNPTAILDEAPKPKRKVEVWEQSVGSLGSRPPLSRLVVVKKAKADPDCSNGQPQAAPTPGAPQNRKEANPTPLTPGASSLSQLGAYLDSDDSNGSN>sp|Q8NF64|ZMIZ2_HUMAN Zinc finger MIZ domain-containing protein 2OS=Homo sapiens OX=9606 GN=ZMIZ2 PE=1 SV=2MNSMNPMKPALPPAPHGDGSFAYESVPWQQSATQPAGSLSVVTTVWGVGNATQSQVLGNPMGPAGSPSGSSMMPGVAGGSSALTSPQCLGQQAFAEGGANKGYVQQGVYSRGGYPGAPGFTTGYAGGPGGLGLPSHAARPSTDFTQAAAAAAVAAAAATATATATATVAALQEKQSQELSQYGAMGAGQSFNSQFLQHGGPRGPSVPAGMNPTGIGGVMGPSGLSPLAMNPTRAAGMTPLYAGQRLPQHGYPGPPQAQPLPRQGVKRTYSEVYPGQQYLQGGQYAPSTAQFAPSPGQPPAPSPSYPGHRLPLQQGMTQSLSVPGPTGLHYKPTEQFNGQGASFNGGSVSYSQPGLSGPTRSIPGYPSSPLPGNPTPPMTPSSSVPYMSPNQEVKSPFLPDLKPNLNSLHSSPSGSGPCDELRLTFPVRDGVVLEPFRLQHNLAVSNHVFQLRDSVYKTLIMRPDLELQFKCYHHEDRQMNTNWPASVQVSVNATPLTIERGDNKTSHKPLYLKHVCQPGRNTIQITVTACCCSHLFVLQLVHRPSVRSVLQGLLKKRLLPAEHCITKIKRNFSSGTIPGTPGPNGEDGVEQTAIKVSLKCPITFRRIQLPARGHDCRHIQCFDLESYLQLNCERGTWRCPVCNKTALLEGLEVDQYMLGILIYIQNSDYEEITIDPTCSWKPVPVKPDMHIKEEPDGPALKRCRTVSPAHVLMPSVMEMIAALGPGAAPFAPLQPPSVPAPSDYPGQGSSFLGPGTFPESFPPTTPSTPTLAEFTPGPPPISYQSDIPSSLLTSEKSTACLPSQMAPAGHLDPTHNPGTPGLHTSNLGAPPGPQLHHSNPPPASRQSLGQASLGPTGELAFSPATGVMGPPSMSGAGEAPEPALDLLPELTNPDELLSYLGPPDLPTNNNDDLLSLFENN>sp|Q8NF64-2|ZMIZ2_HUMAN Isoform 2 of Zinc finger MIZ domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=ZMIZ2MNSMNPMKPALPPAPHGDGSFAYESVPWQQSATQPAGSLSVVTTVWGVGNATQSQVLGNPMGPAGSPSGSSMMPGVAGGSSALTSPQCLGQQAFAEGGANKGYVQQGVYSRGGYPGAPGFTTGYAGGPGGLGLPSHAARPSTDFTQAAAAAAVAAAAATATATATATVAALQEKQSQELSQYGAMGAGQSFNSQFLQHGGPRGPSVPAGMNPTGIGGVMGPSGLSPLAMNPTRAAGMTPLYAGQRLPQHGYPGPPQAQPLPRQGVKRTYSEVYPGQQYLQGGQYAPSTAQFAPSPGQPPAPSPSYPGHRLPLQQGMTQSLSVPGPTGLHYKPTRSIPGYPSSPLPGNPTPPMTPSSSVPYMSPNQEVKSPFLPDLKPNLNSLHSSPSGSGPCDELRLTFPVRDGVVLEPFRLQHNLAVSNHVFQLRDSVYKTLIMRPDLELQFKCYHHEDRQMNTNWPASVQVSVNATPLTIERGDNKTSHKPLYLKHVCQPGRNTIQITVTACCCSHLFVLQLVHRPSVRSVLQGLLKKRLLPAEHCITKIKRNFSSGTIPGTPGPNGEDGVEQTAIKVSLKCPITFRRIQLPARGHDCRHIQCFDLESYLQLNCERGTWRCPVCNKTALLEGLEVDQYMLGILIYIQNSDYEEITIDPTCSWKPVPVKPDMHIKEEPDGPALKRCRTVSPAHVLMPSVMEMIAALGPGAAPFAPLQPPSVPAPSDYPGQGSSFLGPGTFPESFPPTTPSTPTLAEFTPGPPPISYQSDIPSSLLTSEKSTACLPSQMAPAGHLDPTHNPGTPGLHTSNLGAPPGPQLHHSNPPPASRQSLGQASLGPTGELAFSPATGVMGPPSMSGAGEAPEPALDLLPELTNPDELLSYLGPPDLPTNNNDDLLSLFENN>sp|Q8NF64-3|ZMIZ2_HUMAN Isoform 3 of Zinc finger MIZ domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=ZMIZ2MNSMNPMKPALPPAPHGDGSFAYESVPWQQSATQPAGSLSVVTTVWGVGNATQSQCLGQQAFAEGGANKGYVQQGVYSRGGYPGAPGFTTGYAGGPGGLGLPSHAARPSTDFTQAAAAAAVAAAAATATATATATVAALQEKQSQELSQYGAMGAGQSFNSQFLQHGGPRGPSVPAGMNPTGIGGVMGPSGLSPLAMNPTRAAGMTPLYAGQRLPQHGYPGPPQAQPLPRQGVKRTYSEVYPGQQYLQGGQYAPSTAQFAPSPGQPPAPSPSYPGHRLPLQQGMTQSLSVPGPTGLHYKPTRSIPGYPSSPLPGNPTPPMTPSSSVPYMSPNQEVKSPFLPDLKPNLNSLHSSPSGSGPCDELRLTFPVRDGVVLEPFRLQHNLAVSNHVFQLRDSVYKTLIMRPDLELQFKCYHHEDRQMNTNWPASVQVSVNATPLTIERGDNKTSHKPLYLKHVCQPGRNTIQITVTACCCSHLFVLQLVHRPSVRSVLQGLLKKRLLPAEHCITKIKRNFSSGTIPGTPGPNGEDGVEQTAIKVSLKCPITFRRIQLPARGHDCRHIQCFDLESYLQLNCERGTWRCPVCNKTALLEGLEVDQYMLGILIYIQNSDYEEITIDPTCSWKPVPVKPDMHIKEEPDGPALKRCRTVSPAHVLMPSVMEMIAALGPGAAPFAPLQPPSVPAPSDYPGQGSSFLGPGTFPESFPPTTPSTPTLAEFTPGPPPISYQSDIPSSLLTSEKSTACLPSQMAPAGHLDPTHNPGTPGLHTSNLGAPPGPQLHHSNPPPASRQSLGQASLGPTGELAFSPATGVMGPPSMSGAGEAPEPALDLLPELTNPDELLSYLGPPDLPTNNNDDLLSLFENN>sp|Q9H5H4|ZN768_HUMAN Zinc finger protein 768 OS=Homo sapiens OX=9606GN=ZNF768 PE=1 SV=2MEREALPWGLEPQDVQSSDEMRSPEGYLRGNMSENEEEEISQQEGSGDYEVEEIPFGLEPQSPGFEPQSPEFEPQSPRFEPESPGFESRSPGLVPPSPEFAPRSPESDSQSPEFESQSPRYEPQSPGYEPRSPGYEPRSPGYESESSRYESQNTELKTQSPEFEAQSSKFQEGAEMLLNPEEKSPLNISVGVHPLDSFTQGFGEQPTGDLPIGPPFEMPTGALLSTPQFEMLQNPLGLTGALRGPGRRGGRARGGQGPRPNICGICGKSFGRGSTLIQHQRIHTGEKPYKCEVCSKAFSQSSDLIKHQRTHTGERPYKCPRCGKAFADSSYLLRHQRTHSGQKPYKCPHCGKAFGDSSYLLRHQRTHSHERPYSCTECGKCYSQNSSLRSHQRVHTGQRPFSCGICGKSFSQRSALIPHARSHAREKPFKCPECGKRFGQSSVLAIHARTHLPGRTYSCPDCGKTFNRSSTLIQHQRSHTGERPYRCAVCGKGFCRSSTLLQHHRVHSGERPYKCDDCGKAFSQSSDLIRHQRTHAAGRR>sp|Q96NB3|ZN830_HUMAN Zinc finger protein 830 OS=Homo sapiens OX=9606GN=ZNF830 PE=1 SV=2MASSASARTPAGKRVINQEELRRLMKEKQRLSTSRKRIESPFAKYNRLGQLSCALCNTPVKSELLWQTHVLGKQHREKVAELKGAKEASQGSSASSAPHSVKRKAPDADDQDVKRAKATLVPQVQPSTSAWTTNFDKIGKEFIRATPSKPSGLSLLPDYEDEEEEEEEEEGDGERKRGDASKPLSDAQGKEHSVSSSREVTSSVLPNDFFSTNPPKAPIIPHSGSIEKAEIHEKVVERRENTAEALPEGFFDDPEVDARVRKVDAPKDQMDKEWDEFQKAMRQVNTISEAIVAEEDEEGRLDRQIGEIDEQIECYRRVEKLRNRQDEIKNKLKEILTIKELQKKEEENADSDDEGELQDLLSQDWRVKGALL>sp|Q6ZVQ6|YS045_HUMAN Putative uncharacterized protein FLJ42213 OS=Homosapiens OX=9606 PE=2 SV=1MHAGKRSPLTQSISCVCLPELGALWEIESARVNLRVSGREASREMESSPRPHRIAGVKRFLKHAGKWSLRWFLSPRWILQFRRWARKWSRFTRSSFQVRWAAVPAGKCSQHQGLSAVATASPGVFWEMEFDVSSPLTEGAGSPMSSKHAGE>sp|O75541|ZN821_HUMAN Zinc finger protein 821 OS=Homo sapiens OX=9606GN=ZNF821 PE=1 SV=3MSRRKQTNPNKVHWDQVFAGLEEQARQAMMKTDFPGDLGSQRQAIQQLRDQDSSSSDSEGDEEETTQDEVSSHTSEEDGGVVKVEKELENTEQPVGGNEVVEHEVTGNLNSDPLLELCQCPLCQLDCGSREQLIAHVYQHTAAVVSAKSYMCPVCGRALSSPGSLGRHLLIHSEDQRSNCAVCGARFTSHATFNSEKLPEVLNMESLPTVHNEGPSSAEGKDIAFSPPVYPAGILLVCNNCAAYRKLLEAQTPSVRKWALRRQNEPLEVRLQRLERERTAKKSRRDNETPEEREVRRMRDREAKRLQRMQETDEQRARRLQRDREAMRLKRANETPEKRQARLIREREAKRLKRRLEKMDMMLRAQFGQDPSAMAALAAEMNFFQLPVSGVELDSQLLGKMAFEEQNSSSLH>sp|O75541-2|ZN821_HUMAN Isoform 2 of Zinc finger protein 821 OS=Homosapiens OX=9606 GN=ZNF821MSRRKQTNPNKVHWDSEGDEEETTQDEVSSHTSEEDGGVVKVEKELENTEQPVGGNEVVEHEVTGNLNSDPLLELCQCPLCQLDCGSREQLIAHVYQHTAAVVSAKSYMCPVCGRALSSPGSLGRHLLIHSEDQRSNCAVCGARFTSHATFNSEKLPEVLNMESLPTVHNEGPSSAEGKDIAFSPPVYPAGILLVCNNCAAYRKLLEAQTPSVRKWALRRQNEPLEVRLQRLERERTAKKSRRDNETPEEREVRRMRDREAKRLQRMQETDEQRARRLQRDREAMRLKRANETPEKRQARLIREREAKRLKRRLEKMDMMLRAQFGQDPSAMAALAAEMNFFQLPVSGVELDSQLLGKMAFEEQNSSSLH>sp|P61236|YPEL3_HUMAN Protein yippee-like 3 OS=Homo sapiens OX=9606GN=YPEL3 PE=2 SV=1MVRISKPKTFQAYLDDCHRRYSCAHCRAHLANHDDLISKSFQGSQGRAYLFNSVVNVGCGPAEERVLLTGLHAVADIHCENCKTTLGWKYEQAFESSQKYKEGKYIIELNHMIKDNGWD>sp|P61236-2|YPEL3_HUMAN Isoform 2 of Protein yippee-like 3 OS=Homosapiens OX=9606 GN=YPEL3MCVAQVLTAHLLPPRQALGSLCSPWAAPRVGPLPPAPAMVRISKPKTFQAYLDDCHRRYSCAHCRAHLANHDDLISKSFQGSQGRAYLFNSVVNVGCGPAEERVLLTGLHAVADIHCENCKTTLGWKYEQAFESSQKYKEGKYIIELNHMIKDNGWD>sp|Q96LW1|Z354B_HUMAN Zinc finger protein 354B OS=Homo sapiens OX=9606GN=ZNF354B PE=1 SV=1MAAGQREARPQVSLTFEDVAVLFTWDEWRKLAPSQRNLYRDVMLENYRNLVSLGLSFTKPKVISLLQQGEDPWEVEKDSSGVSSLGCKSTPKMTKSTQTQDSFQEQIRKRLKRDEPWNFISERSCIYEEKLKKQQDKNENLQIISVAHTKILTVDRSHKNVEFGQNFYLKSVFIKQQRFAKEKTPSKCEIQRNSFKQNSNLLNQSKIKTAEKRYKCSTCEKAFIHNSSLRKHQKNHTGEKLFKCKECLKAFSQSSALIQHQRTHTGEKPYICKECGKAFSHSASLCKHLRTHTVEKCYRCKECGKSFSRRSGLFIHQKIHAQENPHKYNPGRKASSYSTSLSGSQKIHLRKKSYLCNECGNTFKSSSSLRYHQRIHTGEKPFKCSECGRAFSQSASLIQHERIHTGEKPYRCNECGKGFTSISRLNRHRIIHTGEKLYNCNECGKALSSHSTLIIHERIHTGEKPCKCKVCGKAFRQSSALIQHQRMHTGERPYKCNECDKTFRCNSSLSNHQRIHTGEKPYRCLECGMSFGQSAALIQHQRIHTGEKPFKCNTCGKTFRQSSSLIAHQRIHTGEKPYECNACGKLFSQRSSLTNHYKIHIEEDSLKADLHV>sp|P51523|ZNF84_HUMAN Zinc finger protein 84 OS=Homo sapiens OX=9606GN=ZNF84 PE=1 SV=2MTMLQESFSFDDLSVDFTQKEWQLLDPSQKNLYKDVMLENYSSLVSLGYEVMKPDVIFKLEQGEEPWVGDGEIPSSDSPEVWKVDGNMMWHQDNQDKLKIIKRGHECDAFGKNFNLNMNFVPLRKSNSEGDLDGLILKHHLDLLIPKGDYGKAESDDFNVFDNFFLHSKPEDTDTWLKYYDCDKYKESYKKSQIIIYHRNRLGEKLYECSECRKRFSKKPSLIKHQSRHIRDIAFGCGNCGKTFPQKSQFITHHRTHTGEKPYNCSQCGKAFSQKSQLTSHQRTHTGEKPYECGECGKAFSRKSHLISHWRTHTGEKPYGCNECGRAFSEKSNLINHQRIHTGEKPFECRECGKAFSRKSQLVTHHRTHTGTKPFGCSDCRKAFFEKSELIRHQTIHTGEKPYECSECRKAFRERSSLINHQRTHTGEKPHGCIQCGKAFSQKSHLISHQMTHTGEKPFICSKCGKAFSRKSQLVRHQRTHTGEKPYECSECGKAFSEKLSLTNHQRIHTGEKPYVCSECGKAFCQKSHLISHQRTHTGEKPYECSECGKAFGEKSSLATHQRTHTGEKPYECRDCEKAFSQKSQLNTHQRIHTGEKPYECSLCRKAFFEKSELIRHLRTHTGEKPYECNECRKAFREKSSLINHQRIHTGEKPFECSECGKAFSRKSHLIPHQRTHTGEKPYGCSECRKAFSQKSQLVNHQRIHTGEKPYRCIECGKAFSQKSQLINHQRTHTVKKS>sp|Q9H900|ZWILC_HUMAN Protein zwilch homolog OS=Homo sapiens OX=9606GN=ZWILCH PE=1 SV=2MWERLNCAAEDFYSRLLQKFNEEKKGIRKDPFLYEADVQVQLISKGQPNPLKNILNENDIVFIVEKVPLEKEETSHIEELQSEETAISDFSTGENVGPLALPVGKARQLIGLYTMAHNPNMTHLKINLPVTALPPLWVRCDSSDPEGTCWLGAELITTNNSITGIVLYVVSCKADKNYSVNLENLKNLHKKRHHLSTVTSKGFAQYELFKSSALDDTITASQTAIALDISWSPVDEILQIPPLSSTATLNIKVESGEPRGPLNHLYRELKFLLVLADGLRTGVTEWLEPLEAKSAVELVQEFLNDLNKLDGFGDSTKKDTEVETLKHDTAAVDRSVKRLFKVRSDLDFAEQLWCKMSSSVISYQDLVKCFTLIIQSLQRGDIQPWLHSGSNSLLSKLIHQSYHGTMDTVSLSGTIPVQMLLEIGLDKLKKDYISFFIGQELASLNHLEYFIAPSVDIQEQVYRVQKLHHILEILVSCMPFIKSQHELLFSLTQICIKYYKQNPLDEQHIFQLPVRPTAVKNLYQSEKPQKWRVEIYSGQKKIKTVWQLSDSSPIDHLNFHKPDFSELTLNGSLEERIFFTNMVTCSQVHFK>sp|Q9H900-2|ZWILC_HUMAN Isoform 2 of Protein zwilch homolog OS=Homosapiens OX=9606 GN=ZWILCHMAHNPNMTHLKINLPVTALPPLWVRCDSSDPEGTCWLGAELITTNNSITGIVLYVVSCKADKNYSVNLENLKNLHKKRHHLSTVTSKGFAQYELFKSSALDDTITASQTAIALDISWSPVDEILQIPPLSSTATLNIKVESGEPRGPLNHLYRELKFLLVLADGLRTGVTEWLEPLEAKSAVELVQEFLNDLNKLDGFGDSTKKDTEVETLKHDTAAVDRSVKRLFKVRSDLDFAEQLWCKMSSSVISYQDLVKCFTLIIQSLQRGDIQPWLHSGSNSLLSKLIHQSYHGTMDTVSLSGTIPVQMLLEIGLDKLKKDYISFFIGQELASLNHLEYFIAPSVDIQEQVYRVQKLHHILEILVSCMPFIKSQHELLFSLTQICIKYYKQNPLDEQHIFQLPVRPTAVKNLYQSEKPQKWRVEIYSGQKKIKTVWQLSDSSPIDHLNFHKPDFSELTLNGSLEERIFFTNMVTCSQVHFK>sp|Q9Y2W2|WBP11_HUMAN WW domain-binding protein 11 OS=Homo sapiensOX=9606 GN=WBP11 PE=1 SV=1MGRRSTSSTKSGKFMNPTDQARKEARKRELKKNKKQRMMVRAAVLKMKDPKQIIRDMEKLDEMEFNPVQQPQLNEKVLKDKRKKLRETFERILRLYEKENPDIYKELRKLEVEYEQKRAQLSQYFDAVKNAQHVEVESIPLPDMPHAPSNILIQDIPLPGAQPPSILKKTSAYGPPTRAVSILPLLGHGVPRLPPGRKPPGPPPGPPPPQVVQMYGRKVGFALDLPPRRRDEDMLYSPELAQRGHDDDVSSTSEDDGYPEDMDQDKHDDSTDDSDTDKSDGESDGDEFVHRDNGERDNNEEKKSGLSVRFADMPGKSRKKKKNMKELTPLQAMMLRMAGQEIPEEGREVEEFSEDDDEDDSDDSEAEKQSQKQHKEESHSDGTSTASSQQQAPPQSVPPSQIQAPPMPGPPPLGPPPAPPLRPPGPPTGLPPGPPPGAPPFLRPPGMPGLRGPLPRLLPPGPPPGRPPGPPPGPPPGLPPGPPPRGPPPRLPPPAPPGIPPPRPGMMRPPLVPPLGPAPPGLFPPAPLPNPGVLSAPPNLIQRPKADDTSAATIEKKATATISAKPQITNPKAEITRFVPTALRVRRENKGATAAPQRKSEDDSAVPLAKAAPKSGPSVPVSVQTKDDVYEAFMKEMEGLL>sp|P62760|VISL1_HUMAN Visinin-like protein 1 OS=Homo sapiens OX=9606GN=VSNL1 PE=1 SV=2MGKQNSKLAPEVMEDLVKSTEFNEHELKQWYKGFLKDCPSGRLNLEEFQQLYVKFFPYGDASKFAQHAFRTFDKNGDGTIDFREFICALSITSRGSFEQKLNWAFNMYDLDGDGKITRVEMLEIIEAIYKMVGTVIMMKMNEDGLTPEQRVDKIFSKMDKNKDDQITLDEFKEAAKSDPSIVLLLQCDIQK>sp|Q8N9G6|YJ012_HUMAN Putative UPF0607 protein FLJ37424 OS=Homo sapiensOX=9606 PE=2 SV=1MRLCLIPRNTGTPQRVLRPVVWSPPSRKKPVLSPHNSIMFGHLSPVRIPCLRGKFNLQLPSLDDQVIPARLPKTEVSAEEPKEATEVKDQVETQGQEDNKRGPCSNGEAASTSRPLETQGNLTSSWYNPRPLEGNVHLKSLTEKNQTDKAQVHAVSFYSKGHGVASSHSPAGGILPFGKPDPLPTVLPAPVPGCSLWPEKAALKVLGEDHLPSSPGLLMVGEDMQPKDPAALGSSRSSPPRAAGHRSHKRKLSGPPLQLQPTPPLQLRCDRDERPPPAKLPCLSPEALLVGQASQREGRLQHGNMRKNMRVLSRISKFRRLRQLLRRRKKTRQGRRGGSCL>sp|Q6ZUT4|YL014_HUMAN Putative uncharacterized protein FLJ43343 OS=Homosapiens OX=9606 PE=5 SV=1MARVHIWPQHTAVNPRLLENQARAMIHHHLMAATPAVFLVSSGPDGSQAKAAAASYLAEPPGSPTPGPFSYTKASVVLFLPNPRPNIFKLHSKEQLAECHQYLQSNMRWDFSFAIKTRMLFLPCSDNV>sp|Q71RG6|YH006_HUMAN Putative chemokine-related protein FP248 OS=Homosapiens OX=9606 GN=FP248 PE=5 SV=1MGTGGSLLCGCSLVLSCLCPSASLPDPGNSTWPPGAQAGLPAALALPLPRLPRILFPMAGRPARPSSDFVGCAQGMCCHGRQGTVHIHTSSVSCWTPCPVTGTGGTAVSRKDRVLPHRRQVSLACVCAVGERAGQLWSQKPVQMARPSARHLLPRGSSPNSQAVLLPSVCPVPWPPVGPSPGQGEGLSPAFPGVGTDRGDSWALVLQV>sp|Q8NCP5|ZBT44_HUMAN Zinc finger and BTB domain-containing protein 44OS=Homo sapiens OX=9606 GN=ZBTB44 PE=1 SV=1MGVKTFTHSSSSHSQEMLGKLNMLRNDGHFCDITIRVQDKIFRAHKVVLAACSDFFRTKLVGQAEDENKNVLDLHHVTVTGFIPLLEYAYTATLSINTENIIDVLAAASYMQMFSVASTCSEFMKSSILWNTPNSQPEKGLDAGQENNSNCNFTSRDGSISPVSSECSVVERTIPVCRESRRKRKSYIVMSPESPVKCGTQTSSPQVLNSSASYSENRNQPVDSSLAFPWTFPFGIDRRIQPEKVKQAENTRTLELPGPSETGRRMADYVTCESTKTTLPLGTEEDVRVKVERLSDEEVHEEVSQPVSASQSSLSDQQTVPGSEQVQEDLLISPQSSSIGSVDEGVSEGLPTLQSTSSTNAPPDDDDRLENVQYPYQLYIAPSTSSTERPSPNGPDRPFQCPTCGVRFTRIQNLKQHMLIHSGIKPFQCDRCGKKFTRAYSLKMHRLKHEGKRCFRCQICSATFTSFGEYKHHMRVSRHIIRKPRIYECKTCGAMLTNSGNLIVHLRSLNHEASELANYFQSSDFLVPDYLNQEQEETLVQYDLGEHGFESNSSVQMPVISQYHSKGKEP>sp|Q8NCP5-2|ZBT44_HUMAN Isoform 2 of Zinc finger and BTB domain-containing protein 44 OS=Homo sapiens OX=9606 GN=ZBTB44MGVKTFTHSSSSHSQEMLGKLNMLRNDGHFCDITIRVQDKIFRAHKVVLAACSDFFRTKLVGQAEDENKNVLDLHHVTVTGFIPLLEYAYTATLSINTENIIDVLAAASYMQMFSVASTCSEFMKSSILWNTPNSQPEKGLDAGQENNSNCNFTSRDGSISPVSSECSVVERTIPVCRESRRKRKSYIVMSPESPVKCGTQTSSPQVLNSSASYSENRNQPVDSSLAFPWTFPFGIDRRIQPEKVKQAENTRTLELPGPSETGRRMADYVTCESTKTTLPLGTEEDVRVKVERLSDEEVHEEVSQPVSASQSSLSDQQTVPGSEQVQEDLLISPQSSSIGSVDEGVSEGLPTLQSTSSTNAPPDDDDRLENVQYPYQLYIAPSTSSTERPSPNGPDRPFQCPTCGVRFTRIQNLKQHMLIHSGIKPFQCDRCGKKFTRAYSLKMHRLKHEVPLQRQGTMIDNSQAVDEMTRNGE>sp|Q8NCP5-3|ZBT44_HUMAN Isoform 3 of Zinc finger and BTB domain-containing protein 44 OS=Homo sapiens OX=9606 GN=ZBTB44MGVKTFTHSSSSHSQEMLGKLNMLRNDGHFCDITIRVQDKIFRAHKVVLAACSDFFRTKLVGQAEDENKNVLDLHHVTVTGFIPLLEYAYTATLSINTENIIDVLAAASYMQMFSVASTCSEFMKSSILWNTPNSQPEKGLDAGQENNSNCNFTSRDGSISPVSSECSVVERTIPVCRESRRKRKSYIVMSPESPVKCGTQTSSPQVLNSSASYSENRNQPVDSSLAFPWTFPFGIDRRIQPEKVKQAENTRTLELPGPSETGRRMADYVTCESTKTTLPLGTEEDVRVKVERLSDEEVHEEVSQPVSASQSSLSDQQTVPGSEQVQEDLLISPQSSSIGSVDEGVSEGLPTLQSTSSTNAPPDDDDRLENVQYPYQLYIAPSTSSTERPSPNGPDRPFQCPTCGVRFTRIQNLKQHMLIHSGIKPFQCDRCGKKFTRAYSLKMHRLKHEVIS>sp|Q8NCP5-4|ZBT44_HUMAN Isoform 4 of Zinc finger and BTB domain-containing protein 44 OS=Homo sapiens OX=9606 GN=ZBTB44MGVKTFTHSSSSHSQEMLGKLNMLRNDGHFCDITIRVQDKIFRAHKVVLAACSDFFRTKLVGQAEDENKNVLDLHHVTVTGFIPLLEYAYTATLSINTENIIDVLAAASYMQMFSVASTCSEFMKSSILWNTPNSQPEKGLDAGQENNSNCNFTSRDGSISPVSSECSVVERTIPVCRESRRKRKSYIVMSPESPVKCGTQTSSPQVLNSSASYSENRNQPVDSSLAFPWTFPFGIDRRIQPEKVKQAENTRTLELPGPSETGRRMADYVTCESTKTTLPLGTEEDVRVKVERLSDEEVHEEVSQPVSASQSSLSDQQTVPGSEQVQEDLLISPQSSSIGSVDEGVSEGLPTLQSTSSTNAPPDDDDRLENVQYPYQLYIAPSTSSTERPSPNGPDRPFQCPTCGVRFTRIQNLKQHMLIHSGIKPFQCDRCGKKFTRAYSLKMHRLKHEGHPRKSASRSSSATNCC>sp|P52747|ZN143_HUMAN Zinc finger protein 143 OS=Homo sapiens OX=9606GN=ZNF143 PE=1 SV=2MLLAQINRDSQGMTEFPGGGMEAQHVTLCLTEAVTVADGDNLENMEGVSLQAVTLADGSTAYIQHNSKDAKLIDGQVIQLEDGSAAYVQHVPIPKSTGDSLRLEDGQAVQLEDGTTAFIHHTSKDSYDQSALQAVQLEDGTTAYIHHAVQVPQSDTILAIQADGTVAGLHTGDATIDPDTISALEQYAAKVSIDGSESVAGTGMIGENEQEKKMQIVLQGHATRVTAKSQQSGEKAFRCEYDGCGKLYTTAHHLKVHERSHTGDRPYQCEHAGCGKAFATGYGLKSHVRTHTGEKPYRCSEDNCTKSFKTSGDLQKHIRTHTGERPFKCPFEGCGRSFTTSNIRKVHVRTHTGERPYYCTEPGCGRAFASATNYKNHVRIHTGEKPYVCTVPGCDKRFTEYSSLYKHHVVHTHSKPYNCNHCGKTYKQISTLAMHKRTAHNDTEPIEEEQEAFFEPPPGQGEDVLKGSQITYVTGVEGDDVVSTQVATVTQSGLSQQVTLISQDGTQHVNISQADMQAIGNTITMVTQDGTPITVPAHDAVISSAGTHSVAMVTAEGTEGEQVAIVAQDLAAFHTASSEMGHQQHSHHLVTTETRPLTLVATSNGTQIAVQLGEQPSLEEAIRIASRIQQGETPGLDD>sp|P52747-2|ZN143_HUMAN Isoform 2 of Zinc finger protein 143 OS=Homosapiens OX=9606 GN=ZNF143MLLAQINRDSQGMTEFPGGGMEAQHVTLCLTEAVTVADAKLIDGQVIQLEDGSAAYVQHVPIPKSTGDSLRLEDGQAVQLEDGTTAFIHHTSKDSYDQSALQAVQLEDGTTAYIHHAVQVPQSDTILAIQADGTVAGLHTGDATIDPDTISALEQYAAKVSIDGSESVAGTGMIGENEQEKKMQIVLQGHATRVTAKSQQSGEKAFRCEYDGCGKLYTTAHHLKVHERSHTGDRPYQCEHAGCGKAFATGYGLKSHVRTHTGEKPYRCSEDNCTKSFKTSGDLQKHIRTHTGERPFKCPFEGCGRSFTTSNIRKVHVRTHTGERPYYCTEPGCGRAFASATNYKNHVRIHTGEKPYVCTVPGCDKRFTEYSSLYKHHVVHTHSKPYNCNHCGKTYKQISTLAMHKRTAHNDTEPIEEEQEAFFEPPPGQGEDVLKGSQITYVTGVEGDDVVSTQVATVTQSGLSQQVTLISQDGTQHVNISQADMQAIGNTITMVTQDGTPITVPAHDAVISSAGTHSVAMVTAEGTEGEQVAIVAQDLAAFHTASSEMGHQQHSHHLVTTETRPLTLVATSNGTQIAVQLGEQPSLEEAIRIASRIQQGETPGLDD>sp|P52747-3|ZN143_HUMAN Isoform 3 of Zinc finger protein 143 OS=Homosapiens OX=9606 GN=ZNF143MLLAQINRDSQGMTEFPGGGMEAQHVTLCLTEAVTVADGDNLENMEGVSLQAVTLADGSTAYIQHNSKDAKLIDGQVIQLEDGSAAYVQHVPIPKSRDSLRLEDGQAVQLEDGTTAFIHHTSKDSYDQSALQAVQLEDGTTAYIHHAVQVPQSDTILAIQADGTVAGLHTGDATIDPDTISALEQYAAKVSIDGSESVAGTGMIGENEQEKKMQIVLQGHATRVTAKSQQSGEKAFRCEYDGCGKLYTTAHHLKVHERSHTGDRPYQCEHAGCGKAFATGYGLKSHVRTHTGEKPYRCSEDNCTKSFKTSGDLQKHIRTHTGERPFKCPFEGCGRSFTTSNIRKVHVRTHTGERPYYCTEPGCGRAFASATNYKNHVRIHTGEKPYVCTVPGCDKRFTEYSSLYKHHVVHTHSKPYNCNHCGKTYKQISTLAMHKRTAHNDTEPIEEEQEAFFEPPPGQGEDVLKGSQITYVTGVEGDDVVSTQVATVTQSGLSQQVTLISQDGTQHVNISQADMQAIGNTITMVTQDGTPITVPAHDAVISSAGTHSVAMVTAEGTEGEQVAIVAQDLAAFHTASSEMGHQQHSHHLVTTETRPLTLVATSNGTQIAVQLGEQPSLEEAIRIASRIQQGETPGLDD>sp|Q9Y397|ZDHC9_HUMAN Palmitoyltransferase ZDHHC9 OS=Homo sapiensOX=9606 GN=ZDHHC9 PE=1 SV=2MSVMVVRKKVTRKWEKLPGRNTFCCDGRVMMARQKGIFYLTLFLILGTCTLFFAFECRYLAVQLSPAIPVFAAMLFLFSMATLLRTSFSDPGVIPRALPDEAAFIEMEIEATNGAVPQGQRPPPRIKNFQINNQIVKLKYCYTCKIFRPPRASHCSICDNCVERFDHHCPWVGNCVGKRNYRYFYLFILSLSLLTIYVFAFNIVYVALKSLKIGFLETLKETPGTVLEVLICFFTLWSVVGLTGFHTFLVALNQTTNEDIKGSWTGKNRVQNPYSHGNIVKNCCEVLCGPLPPSVLDRRGILPLEESGSRPPSTQETSSSLLPQSPAPTEHLNSNEMPEDSSTPEEMPPPEPPEPPQEAAEAEK>sp|A2A288|ZC12D_HUMAN Probable ribonuclease ZC3H12D OS=Homo sapiensOX=9606 GN=ZC3H12D PE=1 SV=3MEHPSKMEFFQKLGYDREDVLRVLGKLGEGALVNDVLQELIRTGSRPGALEHPAAPRLVPRGSCGVPDSAQRGPGTALEEDFRTLASSLRPIVIDGSNVAMSHGNKETFSCRGIKLAVDWFRDRGHTYIKVFVPSWRKDPPRADTPIREQHVLAELERQAVLVYTPSRKVHGKRLVCYDDRYIVKVAYEQDGVIVSNDNYRDLQSENPEWKWFIEQRLLMFSFVNDRFMPPDDPLGRHGPSLSNFLSRKPKPPEPSWQHCPYGKKCTYGIKCKFYHPERPHHAQLAVADELRAKTGARPGAGAEEQRPPRAPGGSAGARAAPREPFAHSLPPARGSPDLAALRGSFSRLAFSDDLGPLGPPLPVPACSLTPRLGGPDWVSAGGRVPGPLSLPSPESQFSPGDLPPPPGLQLQPRGEHRPRDLHGDLLSPRRPPDDPWARPPRSDRFPGRSVWAEPAWGDGATGGLSVYATEDDEGDARARARIALYSVFPRDQVDRVMAAFPELSDLARLILLVQRCQSAGAPLGKP>sp|A2A288-3|ZC12D_HUMAN Isoform 2 of Probable ribonuclease ZC3H12DOS=Homo sapiens OX=9606 GN=ZC3H12DMEHPSKMEFFQKLGYDREDVLRVLGKLGEGALVNDVLQELIRTGSRPGALEHPAAPRLVPRGSCGVPDSAQRGPGTALEEDFRTLASSLRPIVIDGSNVAMSHGNKETFSCRGIKLAVDWFRDRGHTYIKVFVPSWRKDPPRADTPIREQHVLAELERQAVLVYTPSRKVHGKRLVCYDDRYIVKVAYEQDGVIVSNDNYRDLQSENPEWKWFIEQRLLMFSFVNDR>sp|A2A288-4|ZC12D_HUMAN Isoform 3 of Probable ribonuclease ZC3H12DOS=Homo sapiens OX=9606 GN=ZC3H12DMEHPSKMEFFQKLGYDREDVLRVLGKLGEGALVNDVLQELIRTGSRPGALEHPAAPRLVPRGSCGVPDSAQRGPGTALEEDFRTLASSLRPIVIDGSNVAMSHGNKETFSCRGIKLAVDWFRDRGHTYIKVFVPSWRKDPPRADTPIREQHVLAELERQAVLVYTPSRKVHGKRLVCYDDRYIVKVAYEQDGVIVSNDNYRDLQSENPEWKWFIEQRLLMFSFVNDRFMPPDDPLGRHGPSLSNFLSRKPKPPEPSWQHCPYGKKCTYGIKCKFYHPERPHHAQLAVADELRAKTGARPVLPGRPPASARPAAPAAGRTPP>sp|Q96JP5|ZFP91_HUMAN E3 ubiquitin-protein ligase ZFP91 OS=Homo sapiensOX=9606 GN=ZFP91 PE=1 SV=1MPGETEEPRPPEQQDQEGGEAAKAAPEEPQQRPPEAVAAAPAGTTSSRVLRGGRDRGRAAAAAAAAAVSRRRKAEYPRRRRSSPSARPPDVPGQQPQAAKSPSPVQGKKSPRLLCIEKVTTDKDPKEEKEEEDDSALPQEVSIAASRPSRGWRSSRTSVSRHRDTENTRSSRSKTGSLQLICKSEPNTDQLDYDVGEEHQSPGGISSEEEEEEEEEMLISEEEIPFKDDPRDETYKPHLERETPKPRRKSGKVKEEKEKKEIKVEVEVEVKEEENEIREDEEPPRKRGRRRKDDKSPRLPKRRKKPPIQYVRCEMEGCGTVLAHPRYLQHHIKYQHLLKKKYVCPHPSCGRLFRLQKQLLRHAKHHTDQRDYICEYCARAFKSSHNLAVHRMIHTGEKPLQCEICGFTCRQKASLNWHMKKHDADSFYQFSCNICGKKFEKKDSVVAHKAKSHPEVLIAEALAANAGALITSTDILGTNPESLTQPSDGQGLPLLPEPLGNSTSGECLLLEAEGMSKSYCSGTERVSLMADGKIFVGSGSSGGTEGLVMNSDILGATTEVLIEDSDSAGP>sp|Q96JP5-2|ZFP91_HUMAN Isoform 2 of E3 ubiquitin-protein ligase ZFP91OS=Homo sapiens OX=9606 GN=ZFP91MPGETEEPRPPEQQDQEGGEAAKAAPEEPQQRPPEAVAAAPAGTTSSRVLRGGRDRGRAAAAAAAAAVSRRRKAEYPRRRRSSPSARPPDVPGQQPQAAKSPSPVQGKKSPRLLCIEKVTTDKDPKEEKEEEDDSALPQEVSIAASRPSRGWRSSRTSVSRHRDTENTRSSRSKTGSLQLICKSEPNTDQLDYDVGEEHQSPGGISSEEEEEEEEEMLISEEEIPFKDDPRDETYKPHLERETPKPRRKSGKVKEEKEKKEIKVEVEVEVKEEENEIREDEEPPRKRGRRRKDDKSPRLPKRRKKPPIQYVRCEMEGCGTVLAHPRYLQHHIKYQHLLKKKYVCPHPSCGRLFRLQKQLLRHAKHHTDQRDYICEYCARAFKSSHNLAVHRMIHTGEKPLQCEICGFTCRQKASLNWHMKKHDADSFYQFSCNICGKKFEKKDSVVAHKAKSHPEVLIAEALAANAGALITSTDILGTNPESLTQPSDGQGLPLLPEPLGNSTSGECLLLEAEGMSKSYCSGTERSIHR>sp|Q5T200|ZC3HD_HUMAN Zinc finger CCCH domain-containing protein 13OS=Homo sapiens OX=9606 GN=ZC3H13 PE=1 SV=1MSKIRRKVTVENTKTISDSTSRRPSVFERLGPSTGSTAETQCRNWLKTGNCLYGNTCRFVHGPSPRGKGYSSNYRRSPERPTGDLRERMKNKRQDVDTEPQKRNTEESSSPVRKESSRGRHREKEDIKITKERTPESEEENVEWETNRDDSDNGDINYDYVHELSLEMKRQKIQRELMKLEQENMEKREEIIIKKEVSPEVVRSKLSPSPSLRKSSKSPKRKSSPKSSSASKKDRKTSAVSSPLLDQQRNSKTNQSKKKGPRTPSPPPPIPEDIALGKKYKEKYKVKDRIEEKTRDGKDRGRDFERQREKRDKPRSTSPAGQHHSPISSRHHSSSSQSGSSIQRHSPSPRRKRTPSPSYQRTLTPPLRRSASPYPSHSLSSPQRKQSPPRHRSPMREKGRHDHERTSQSHDRRHERREDTRGKRDREKDSREEREYEQDQSSSRDHRDDREPRDGRDRRDARDTRDRRELRDSRDMRDSREMRDYSRDTKESRDPRDSRSTRDAHDYRDREGRDTHRKEDTYPEESRSYGRNHLREESSRTEIRNESRNESRSEIRNDRMGRSRGRVPELPEKGSRGSRGSQIDSHSSNSNYHDSWETRSSYPERDRYPERDNRDQARDSSFERRHGERDRRDNRERDQRPSSPIRHQGRNDELERDERREERRVDRVDDRRDERARERDRERERDRERERERERERDREREKERELERERAREREREREKERDRERDRDRDHDRERERERERDREKEREREREERERERERERERERERERERERARERDKERERQRDWEDKDKGRDDRREKREEIREDRNPRDGHDERKSKKRYRNEGSPSPRQSPKRRREHSPDSDAYNSGDDKNEKHRLLSQVVRPQESRSLSPSHLTEDRQGRWKEEDRKPERKESSRRYEEQELKEKVSSVDKQREQTEILESSRMRAQDIIGHHQSEDRETSDRAHDENKKKAKIQKKPIKKKKEDDVGIERGNIETTSEDGQVFSPKKGQKKKSIEKKRKKSKGDSDISDEEAAQQSKKKRGPRTPPITTKEELVEMCNGKNGILEDSQKKEDTAFSDWSDEDVPDRTEVTEAEHTATATTPGSTPSPLSSLLPPPPPVATATATTVPATLAATTAAAATSFSTSAITISTSATPTNTTNNTFANEDSHRKCHRTRVEKVETPHVTIEDAQHRKPMDQKRSSSLGSNRSNRSHTSGRLRSPSNDSAHRSGDDQSGRKRVLHSGSRDREKTKSLEITGERKSRIDQLKRGEPSRSTSSDRQDSRSHSSRRSSPESDRQVHSRSGSFDSRDRLQERDRYEHDRERERERRDTRQREWDRDADKDWPRNRDRDRLRERERERERDKRRDLDRERERLISDSVERDRDRDRDRTFESSQIESVKRCEAKLEGEHERDLESTSRDSLALDKERMDKDLGSVQGFEETNKSERTESLEGDDESKLDDAHSLGSGAGEGYEPISDDELDEILAGDAEKREDQQDEEKMPDPLDVIDVDWSGLMPKHPKEPREPGAALLKFTPGAVMLRVGISKKLAGSELFAKVKETCQRLLEKPKDADNLFEHELGALNMAALLRKEERASLLSNLGPCCKALCFRRDSAIRKQLVKNEKGTIKQAYTSAPMVDNELLRLSLRLFKRKTTCHAPGHEKTEDNKLSQSSIQQELCVS>sp|Q5T200-2|ZC3HD_HUMAN Isoform 2 of Zinc finger CCCH domain-containingprotein 13 OS=Homo sapiens OX=9606 GN=ZC3H13MSKIRRKVTVENTKTISDSTSRRPSVFERLGPSTGSTAETQCRNWLKTGNCLYGNTCRFVHGPSPRGKGYSSNYRRSPERPTGDLRERMKNKRQDVDTEPQKRNTEESSSPVRKESSRGRHREKEDIKITKERTPESEEENVEWETNRDDSDNGDINYDYVHELSLEMKRQKIQRELMKLEQENMEKREEIIIKKEVSPEVVRSKLSPSPSLRKSSKSPKRKSSPKSSSASKKDRKTSAVSSPLLDQQRNSKTNQSKKKGPRTPSPPPPIPEDIALGKKYKEKYKVKDRIEEKTRDGKDRGRDFERQREKRDKPRSTSPAGQHHSPISSRHHSSSSQSGSSIQRHSPSPRRKRTPSPSYQRTLTPPLRRSASPYPSHSLSSPQRKQSPPRHRSPMREKGRHDHERTSQSHDRRHERREDTRGKRDREKDSREEREYEQDQSSSRDHRDDREPRDGRDRRDARDTRDRRELRDSRDMRDSREMRDYSRDTKESRDPRDSRSTRDAHDYRDREGRDTHRKEDTYPEESRSYGRNHLREESSRTEIRNESRNESRSEIRNDRMGRSRGRVPELPEKGSRGSRGSQIDSHSSNSNYHDSWETRSSYPERDRYPERDNRDQARDSSFERRHGERDRRDNRERDQRPSSPIRHQGRNDELERDERREERRVDRVDDRRDERARERDRERERDRERERERERERDREREKERELERERAREREREREKERDRERDRDRDHDRERERERERDREKEREREREERERERERERERERERERERERARERDKERERQRDWEDKDKGRDDRREKREEIREDRNPRDGHDERKSKKRYRNEGSPSPRQSPKRRREHSPDSDAYNSGDDKNEKHRLLSQVVRPQESRSLSPSHLTEDRQGRWKEEDRKPERKESSRRYEEQELKEKVSSVDKQREQTEILESSRMRAQDIIGHHQSEDRETSDRAHDENKKKAKIQKKPIKKKKEDDVGIERGNIETTSEDGQVFSPKKGQKKKSIEKKRKKSKGDSDISDEEAAQQSKKKRGPRTPPITTKEELVEMCNGKNGILEDSQKKEDTAFSDWSDEDVPDRTEVTEAEHTATATTPGSTPSPLSSLLPPPPPVATATATTVPATLAATTAAAATSFSTSAITISTSATPTNTTNNTFANEDSHRKCHRTRVEKVETPHVTIEDAQHRKPMDQKRSSSLGSNRSNRSHTSGRLRSPSNDSAHRSGDDQSGRKRVLHSGSRDREKTKSLEITGERKSRIDQLKRGEPSRSTSSDRQDSRSHSSRRSSPESDRQVHSRSGSFDSRDRLQERDRYEHDRERERERRDTRQREWDRDADKDWPRNRDRDRLRERERERERDKRRDLDRERERLISDSVERDRDRDRDRTFESSQIESVKRCEAKLEGEHERDLESTSRDSLALDKERMDKDLGSVQGFEETNKSERTESLEAGDDESKLDDAHSLGSGAGEGYEPISDDELDEILAGDAEKREDQQDEEKMPDPLDVIDVDWSGLMPKHPKEPREPGAALLKFTPGAVMLRVGISKKLAGSELFAKVKETCQRLLEKPKGSFILL>sp|A8MUN3|YQ048_HUMAN Putative uncharacterized protein ENSP00000381830OS=Homo sapiens OX=9606 PE=5 SV=1MSFEYRHYKREAKICTCRGGWAHVLLCIGVSQGACAEHLPHRPAVEKDVPGAGEVLFMCSWRIFPVASASPSSSISGLAGHSVFLVPGLAAHPGSHSDQPPGVPSRRKSRLERWSPSVSRSTSPPTEAPFCL>sp|Q96N95|ZN396_HUMAN Zinc finger protein 396 OS=Homo sapiens OX=9606GN=ZNF396 PE=1 SV=2MSAKLGKSSSLLTQTSEECNGILTEKMEEEEQTCDPDSSLHWSSSYSPETFRQQFRQFGYQDSPGPHEALSRLWELCHLWLRPEVHTKEQILELLVLEQFLAILPKELQAWVQKHHPENGEETVTMLEDVERELDGPKQIFFGRRKDMIAEKLAPSEITEELPSSQLMPVKKQLQGASWELQSLRPHDEDIKTTNVKSASRQKTSLGIELHCNVSNILHMNGSQSSTYRGTYEQDGRFEKRQGNPSWKKQQKCDECGKIFSQSSALILHQRIHSGKKPYACDECAKAFSRSAILIQHRRTHTGEKPYKCHDCGKAFSQSSNLFRHRKRHIRKKVP>sp|Q96N95-2|ZN396_HUMAN Isoform 2 of Zinc finger protein 396 OS=Homosapiens OX=9606 GN=ZNF396MSAKLGKSSSLLTQTSEECNGILTEKMEEEEQTCDPDSSLHWSSSYSPETFRQQFRQFGYQDSPGPHEALSRLWELCHLWLRPEVHTKEQILELLVLEQFLAILPKELQAWVQKHHPENGEETVTMLEDVERELDGPKQIFFGRRKDMIAEKLAPSEITEELPSSQLMPVKKQLQGASWELQSLRPHGEGAGFSSCWKVWGPSAHHTHLS>sp|Q96N95-3|ZN396_HUMAN Isoform 3 of Zinc finger protein 396 OS=Homosapiens OX=9606 GN=ZNF396MSAKLGKSSSLLTQTSEECNGILTEKMEEEEQTCDPDSSLHWSSSYSPETFRQQFRQFGYQDSPGPHEALSRLWELCHLWLRPEVHTKEQILELLVLEQFLAILPKELQAWVQKHHPENGEETVTMLEDVERELDGPKQIFFGRRKDMIAEKLAPSEITEELPSSQLMPVKKQLQGASWELQSLRPHDEDIKTTNVKSASRQKTSLGIELHCNVSNILHMNGSQSSTYRGTYEQDGRFEKRQGNPSWKKQQKCDECGKIFSQSSALILHQRIHSGKKPYACDECAKAFSRSAILIQHRRTHTDSKYEHAIAEAQKNMYFKTRLKCPRSLSGGR>sp|Q9UL40|ZN346_HUMAN Zinc finger protein 346 OS=Homo sapiens OX=9606GN=ZNF346 PE=1 SV=1MEYPAPATVQAADGGAAGPYSSSELLEGQEPDGVRFDRERARRLWEAVSGAQPVGREEVEHMIQKNQCLFTNTQCKVCCALLISESQKLAHYQSKKHANKVKRYLAIHGMETLKGETKKLDSDQKSSRSKDKNQCCPICNMTFSSPVVAQSHYLGKTHAKNLKLKQQSTKVEALHQNREMIDPDKFCSLCHATFNDPVMAQQHYVGKKHRKQETKLKLMARYGRLADPAVTDFPAGKGYPCKTCKIVLNSIEQYQAHVSGFKHKNQSPKTVASSLGQIPMQRQPIQKDSTTLED>sp|Q9UL40-2|ZN346_HUMAN Isoform 2 of Zinc finger protein 346 OS=Homosapiens OX=9606 GN=ZNF346MEYPAPATVQAADGGAAGPYSSSELLEGQEPDGVRFDRERARRLWEAVSGAQPVGREEAQFFPHSRTVIPILVLSETYSLCHPVEHMIQKNQCLFTNTQCKVCCALLISESQKLAHYQSKKHANKVKRYLAIHGMETLKGETKKLDSDQKSSRSKDKNQCCPICNMTFSSPVVAQSHYLGKTHAKNLKLKQQSTKVEALHQNREMIDPDKFCSLCHATFNDPVMAQQHYVGKKHRKQETKLKLMARYGRLADPAVTDFPAGKGYPCKTCKIVLNSIEQYQAHVSGFKHKNQSPKTVASSLGQIPMQRQPIQKDSTTLED>sp|Q9UL40-3|ZN346_HUMAN Isoform 3 of Zinc finger protein 346 OS=Homosapiens OX=9606 GN=ZNF346MEYPAPATVQAADGGAAGPYSSSELLEGQEPDGVRFDRERARRLWEAVSGAQPVGREEVEHMIQKNQCLFTNTQCKVCCALLISESQKLAHYQSSRSKDKNQCCPICNMTFSSPVVAQSHYLGKTHAKNLKLKQQSTKVEALHQNREMIDPDKFCSLCHATFNDPVMAQQHYVGKKHRKQETKLKLMARYGRLADPAVTDFPAGKGYPCKTCKIVLNSIEQYQAHVSGFKHKNQSPKTVASSLGQIPMQRQPIQKDSTTLED>sp|Q86VM9|ZCH18_HUMAN Zinc finger CCCH domain-containing protein 18OS=Homo sapiens OX=9606 GN=ZC3H18 PE=1 SV=2MDVAESPERDPHSPEDEEQPQGLSDDDILRDSGSDQDLDGAGVRASDLEDEESAARGPSQEEEDNHSDEEDRASEPKSQDQDSEVNELSRGPTSSPCEEEGDEGEEDRTSDLRDEASSVTRELDEHELDYDEEVPEEPAPAVQEDEAEKAGAEDDEEKGEGTPREEGKAGVQSVGEKESLEAAKEKKKEDDDGEIDDGEIDDDDLEEGEVKDPSDRKVRPRPTCRFFMKGNCTWGMNCRFIHPGVNDKGNYSLITKADPFPPNGAPPLGPHPLMPANPWGGPVVDEILPPPPPEPPTESAWERGLRHAKEVLKKATIRKEQEPDFEEKRFTVTIGEDEREFDKENEVFRDWNSRIPRDVRDTVLEPYADPYYDYEIERFWRGGQYENFRVQYTETEPYHNYRERERERERENRQRERERERERDRERERRQRERERERERERDKERQRRKEEWERERAKRDEKDRQHRDRDREKEREKEKGKPKPRSPQPPSRQAEPPKKEAATTGPQVKRADEWKDPWRRSKSPKKKLGVSVSPSRARRRRKTSASSASASNSSRSSSRSSSYSGSGSSRSRSRSSSYSSYSSRSSRHSSFSGSRSRSRSFSSSPSPSPTPSPHRPSIRTKGEPAPPPGKAGEKSVKKPAPPPAPPQATKTTAPVPEPTKPGDPREARRKERPARTPPRRRTLSGSGSGSGSSYSGSSSRSRSLSVSSVSSVSSATSSSSSAHSVDSEDMYADLASPVSSASSRSPAPAQTRKEKGKSKKEDGVKEEKRKRDSSTQPPKSAKPPAGGKSSQQPSTPQQAPPGQPQQGTFVAHKEIKLTLLNKAADKGSRKRYEPSDKDRQSPPPAKRPNTSPDRGSRDRKSGGRLGSPKPERQRGQNSKAPAAPADRKRQLSPQSKSSSKVTSVPGKASDPGAASTKSGKASTLSRREELLKQLKAVEDAIARKRAKIPGKA>sp|Q5HY98|ZN766_HUMAN Zinc finger protein 766 OS=Homo sapiens OX=9606GN=ZNF766 PE=1 SV=1MAQLRRGHLTFRDVAIEFSQEEWKCLDPVQKALYRDVMLENYRNLVSLGICLPDLSIISMMKQRTEPWTVENEMKVAKNPDRWEGIKDINTGRSCAVRSKAGNKPITNQLGLTFQLPLPELEIFQGEGKIYECNQVQKFISHSSSVSPLQRIYSGVKTHIFNKHRNDFVDFPLLSQEQKAHIRRKPYECNEQGKVFRVSSSLPNHQVIHTADKPNRCHECGKTVRDKSGLAEHWRIRTGEKPYKCKECGKLFNRIAYLARHEKVHTGESPYKCNECGKVFSRITYLVRHQKIHTREKPHKCNKCGKVYSSSSYLAQHWRIHTGEKLYKCNKCGKEFSGHSSLTTHLLIHTGEKPYKCKECDKAFRHKFSLTVHQRNHNGEKPYKCHECGKVFTQVSHLARHQKIHTGEKPYKCNECGKVFTQNSHLANHQRIHTGEKPYKCHVCGKVFRHSSWFVQHQRSVHERVLTN>sp|Q86XD8|ZFAN4_HUMAN AN1-type zinc finger protein 4 OS=Homo sapiensOX=9606 GN=ZFAND4 PE=2 SV=2MDNRKEPPFFNDDNMGPFYYRLHFCDTMELFIETLTGTCFELRVSPFETVISVKAKIRRLEGIPICRQHLIWNNMELENDYCLNDYNISEGCTLKLVLAMRGGPINTRRVPTDDPLRKMAEYLDSSRVEVWEKTSCSKQVTFLVYQEGDQLNFFPAVDRGDGTLTPLSDSSKKIDFHLHVLRRKGEHRMSGGSMYNSDTDEDEETEPSSSGQQIIENSITMNKMKLLKAKMKNMNLSKKPKKAVKIKPHPPVAPRPSSGSTAPSRHRLLRVLPNIGQSCSPAFGNAYPPEISRNGISSLATQLSAERYISSITGEFLKEDNSWENNTLSHFSSNVKLPPQIPHLELGNDQELADSVLHLGSSLPRQTKHFLGNLPSSNGNIVLPSEECVTEQSLLPKVGSLASFAEGNADEQSSGLEGACKVNLELLLTNADKGLKAPEQHLKHVAGVLNGESVETSVLNYRELSPHKNRLLSPLRCSAPMSLHNSLVKPERQSKCFEFGKLQPSSSQSLDVQNITDSSFSRTTCFQGVKVDSLGKRSDVISKVEARDITEMTNKASKEPVGCVNNISFLASLAGSTSRNRLQSTRGAGRLQNSGTGLSTNLQHFQEENFRKSSPQLEHTGVFLSTHGVGMNGNNAAAGKSVGECTTHHLPPVKAPLQTKKKTTNHCFLCGKKTGLASSYECRCGNNFCASHRYAETHGCTYDYKSAGRRYLHEANPVVNAPKLPKI>sp|Q9H521|YM006_HUMAN Putative uncharacterized protein LOC645739 OS=Homosapiens OX=9606 PE=5 SV=1MVWQENEDLRKQLVEASELLKSQAKELKDAHQQQKLALQDFLELCELVAELCSQKQKVWDKEGEMEVAMQKVNTMWQES>sp|A8MTY0|ZN724_HUMAN Zinc finger protein 724 OS=Homo sapiens OX=9606GN=ZNF724 PE=2 SV=3MGPLTFMDVAIEFSVEEWQCLDTAQQNLYRNVMLENYRNLVFLGIAVSKPDLITCLEQGKEPWNMERHEMVAKPPGMCCYFAQDLRPEQSIKASLQRIILRKYEKCGHHNLQLKKGYKSVDEYKVHKGSYNGFNQCLTTTQSKIFQCDKYVKDFHKFSNSNRHKTEKNPFKCKECGKSFCVLSHLTQHKRIHTTVNSYKLEECGKAFNVSSTLSQHKRIHTGQKHYKCEECGIAFNKSSHLNTHKIIHTGEKSYKREECGKAFNISSHLTTHKIIHTGENAYKCKECGKAFNQSSTLTRHKIIHAGEKPYICEHCGRAFNQSSNLTKHKRIHTGDKPYKCEECGKAFNVSSTLTQHKRIHTGEKPYKCEECGKAFNVSSTLTQHKRIHTGEKPYKCEECGKAFNTSSHLTTHKRIHTGEKPYKCEECGKAFNQFSQLTTHKIIHTGEKPYKCKECGKAFKRSSNLTEHRIIHTGEKPYKCEECGKAFNLSSHLTTHKKIHTGEKPYKCKECGKAFNQSSTLARHKIIHAGEKPYKCEECGKAFYQYSNLTQHKIIHTGEKPYKCEECGKAFNWSSTLTKHKVIHTGEKPYKCKECGKAFNQCSNLTTHKKIHAVEKSDK>sp|Q96IR3|YV007_HUMAN Putative uncharacterized protein MGC15705 OS=Homosapiens OX=9606 PE=5 SV=1MTRNVVRQEFEAPGKPQDSSQQDACLILVKGNWTTNEMEVK>sp|Q569K4|Z385B_HUMAN Zinc finger protein 385B OS=Homo sapiens OX=9606GN=ZNF385B PE=1 SV=1MNMANFLRGFEEKGIKNDRPEDQLSKEKKKILFSFCEVCNIQLNSAAQAQVHSNGKSHRKRVKQLSDGQPPPPAQASPSSNSSTGSTCHTTTLPALVRTPTLMMQPSLDIKPFMSFPVDSSSAVGLFPNFNTMDPVQKAVINHTFGVSIPPKKKQVISCNVCQLRFNSDSQAEAHYKGSKHAKKVKALDATKNKPKMVPSKDSAKANPSCSITPITGNNSDKSEDKGKLKASSSSQPSSSESGSFLLKSGTTPLPPGAATSPSKSTNGAPGTVVESEEEKAKKLLYCSLCKVAVNSLSQLEAHNTGSKHKTMVEARNGAGPIKSYPRPGSRLKMQNGSKGSGLQNKTFHCEICDVHVNSEIQLKQHISSRRHKDRVAGKPLKPKYSPYNKLQRSPSILAAKLAFQKDMMKPLAPAFLSSPLAAAAAVSSALSLPPRPSASLFQAPAIPPALLRPGHGPIRATPASILFAPY>sp|Q569K4-2|Z385B_HUMAN Isoform 2 of Zinc finger protein 385B OS=Homosapiens OX=9606 GN=ZNF385BMWSGLPSRGSTCHTTTLPALVRTPTLMMQPSLDIKPFMSFPVDSSSAVGLFPNFNTMDPVQKAVINHTFGVSIPPKKKQVISCNVCQLRFNSDSQAEAHYKGSKHAKKVKALDATKNKPKMVPSKDSAKANPSCSITPITGNNSDKSEDKGKLKASSSSQPSSSESGSFLLKSGTTPLPPGAATSPSKSTNGAPGTVVESEEEKAKKLLYCSLCKVAVNSLSQLEAHNTGSKHKTMVEARNGAGPIKSYPRPGSRLKMQNGSKGSGLQNKTFHCEICDVHVNSEIQLKQHISSRRHKDRVAGKPLKPKYSPYNKLQRSPSILAAKLAFQKDMMKPLAPAFLSSPLAAAAAVSSALSLPPRPSASLFQAPAIPPALLRPGHGPIRATPASILFAPY>sp|Q569K4-3|Z385B_HUMAN Isoform 3 of Zinc finger protein 385B OS=Homosapiens OX=9606 GN=ZNF385BMMQPSLDIKPFMSFPVDSSSAVGLFPNFNTMDPVQKAVINHTFGVSIPPKKKQVISCNVCQLRFNSDSQAEAHYKGSKHAKKVKALDATKNKPKMVPSKDSAKANPSCSITPITGNNSDKSEDKGKLKASSSSQPSSSESGSFLLKSGTTPLPPGAATSPSKSTNGAPGTVVESEEEKAKKLLYCSLCKVAVNSLSQLEAHNTGSKHKTMVEARNGAGPIKSYPRPGSRLKMQNGSKGSGLQNKTFHCEICDVHVNSEIQLKQHISSRRHKDRVAGKPLKPKYSPYNKLQRSPSILAAKLAFQKDMMKPLAPAFLSSPLAAAAAVSSALSLPPRPSASLFQAPAIPPALLRPGHGPIRATPASILFAPY>sp|Q569K4-4|Z385B_HUMAN Isoform 4 of Zinc finger protein 385B OS=Homosapiens OX=9606 GN=ZNF385BMVPSKDSAKANPSCSITPITGNNSDKSEDKGKLKASSSSQPSSSESGSFLLKSGTTPLPPGAATSPSKSTNGAPGTVVESEEEKAKKLLYCSLCKVAVNSLSQLEAHNTGSKHKTMVEARNGAGPIKSYPRPGSRLKMQNGSKGSGLQNKTFHCEICDVHVNSEIQLKQPKA>sp|Q569K4-5|Z385B_HUMAN Isoform 5 of Zinc finger protein 385B OS=Homosapiens OX=9606 GN=ZNF385BMRYSLSPDNHLEDGIMNMANFLRGFEEKGIKNDRPEDQLSKEKKKILFSFCEVCNIQLNSAAQAQVHSNGKSHRKRVKQLSDGQPPPPAQASPSSNSSTGSTCHTTTLPALVRTPTLMMQPSLDIKPFMSFPVDSSSAVGLFPNFNTMDPVQKAVINHTFGVSIPPKKKQVISCNVCQLRFNSDSQAEAHYKGSKHAKKVKALDATKNKPKMVPSKDSAKANPSCSITPITGNNSDKSEDKGKLKASSSSQPSSSESGSFLLKSGTTPLPPGAATSPSKSTNGAPGTVVESEEEKAKKLLYCSLCKVAVNSLSQLEAHNTGSKHKTMVEARNGAGPIKSYPRPGSRLKMQNGSKGSGLQNKTFHCEICDVHVNSEIQLKQHISSRRHKDRVAGKPLKPKYTPCKVIGLLPKPLPPANRQLS>sp|Q08AG5|ZN844_HUMAN Zinc finger protein 844 OS=Homo sapiens OX=9606GN=ZNF844 PE=1 SV=1MDLVAFEDVAVNFTQEEWSLLDPSQKNLYREVMQETLRNLASIGEKWKDQNIEDQYKNPRNNLRSLLGERVDENTEENHCGETSSQIPDDTLNKKTSPGVKSCESSVCGEVFVGHSSLNRHIRADTAHKPSEYQEYGQEPYKCQQRKKAFRCHPSFQMQEKAHTGEKLYDCKECGKTFISHSSIQRHMIMHNGDGTYKCKFCGKACPCLSIYLIHERVHTGEKPYKCKQCGKAFSYSTSLQIHERTHTGEKPYECKECGKAFGSPNSLYEHRRTHTGEKPYECKQCGKAFRWFHSFQIHERTHSEEKAYECTKCGKAFKCPSYLCRHEVTHSGKKPCECKQCGKALSYLNFQRHMKMHTRMRPYKCKTVEKPLILPVRFEDMKELTLERNLMNASTVVKPSIVPVPFTIMKGLTLERNPMNVSSVVKPSFLPLPFDIMKGLTLERNRMSVSNVGKPSDLPHTFKCMEGLTLKRNPMNVSSVVKPSFFPLPFDIMKGLTLERNPMSVSNVGKPSHLPHTFKCMKGLTLESNCMNLNNVKKPLDLSETFKFMKRHTLERNPIRNMEKHSTISLPFKYMQQCTEDRMPMNVKSVTKHSYLPRSFEYMQEHTLERNPMNVRNAEKRSIIFLLCVYTKGCTLERNHINVRIVGKHSVCLVPFVDIKGLTLE>sp|Q5TEC3|ZN697_HUMAN Zinc finger protein 697 OS=Homo sapiens OX=9606GN=ZNF697 PE=1 SV=2MKQEDNQGVCAHQDSEDKGMGSDFEDSEDREGDPEEREMGSNPHDTNKREGHPEPEMGSNPQDSRHREAVPDICTEGQLSEEEGVSVRGEEDDQSGVADMAMFPGLSESDSISRSLREDDDESAGENRLEEEEEQPAPPVLPWRRHLSLGSRHRGDKPAHRRFHRLHHPMAVDLGELDSLVASIMDAPTICPDCGESFSPGAAFLQHQRIHRLAEAAAAASLEPFGLAGECDAMVGMMGVGVAGGFGAGPPLARPPREKPFRCGECGKGFSRNTYLTNHLRLHTGERPNLCADCGKSFSWRADLLKHRRLHTGEKPYPCPECGEAFSLSSHLLSHRRAHAAASGAGAAALRPFACGECGKGFVRRSHLANHQRIHTGEKPHGCGECGKRFSWRSDLVKHQRVHTGEKPYMCSECGETFSVSSHLFTHKRTHSGERPYVCRECGKGFGRNSHLVNHLRVHTGEKPFRCGQCEKRFSDFSTLTQHQRTHTGEKPYTCIECGKSFIQSSHLIRHRRIHTGNKPHKCAGCGKGFRYKTHLAQHQKLHLC>sp|P52744|ZN138_HUMAN Zinc finger protein 138 OS=Homo sapiens OX=9606GN=ZNF138 PE=1 SV=2MKRHEMVVAKHSALCSRFAQDLWLEQNIKDSFQKVTLSRYGKYGHKNLQLRKGCKSVDECKGHQGGFNGLNQCLKITTSKIFQCNKYVKVMHKFSNSNRHKIRHTENKHFRCKECDKSLCMLSRLTQHKKIHTRENFYKCEECGKTFNWSTNLSKPKKIHTGEKPYKCEVCGKAFHQSSILTKHKIIRTGEKPYKCAHCGKAFKQSSHLTRHKIIHTEEKPYKCEQCGKVFKQSPTLTKHQIIYTGEEPYKCEECGKAFNLS>sp|P52744-2|ZN138_HUMAN Isoform 2 of Zinc finger protein 138 OS=Homosapiens OX=9606 GN=ZNF138MGPLTFMDVAIEFSLEEWQCLDTAQRNVYRHVMLENYRNLVFLALCSRFAQDLWLEQNIKDSFQKVTLSRYGKYGHKNLQLRKGCKSVDECKGHQGGFNGLNQCLKITTSKIFQCNKYVKVMHKFSNSNRHKIRHTENKHFRCKECDKSLCMLSRLTQHKKIHTRENFYKCEECGKTFNWSTNLSKPKKIHTGEKPYKCEVCGKAFHQSSILTKHKIIRTGEKPYKCAHCGKAFKQSSHLTRHKIIHTEEKPYKCEQCGKVFKQSPTLTKHQIIYTGEEPYKCEECGKAFNLS>sp|P52744-3|ZN138_HUMAN Isoform 3 of Zinc finger protein 138 OS=Homosapiens OX=9606 GN=ZNF138MGPLTFMDVAIEFSLEEWQCLDTAQRNVYRHVMLENYRNLVFLDLITCLEQGKEPWNMKRHEMVVAKHSAVAFTYDLSGLNILSFQSILPFVSALYVMGNRNQCLQKHLEARNKDLCVLVLPKTFG>sp|Q96BV0|ZN775_HUMAN Zinc finger protein 775 OS=Homo sapiens OX=9606GN=ZNF775 PE=1 SV=2MESGLAGNGTGAGLVMKVKQEKPERLLQTLAPQAMLVEKDKENIFQQHRGLPPRQTMGRPRALGGQEESGSPRWAPPTEQDAGLAGRAPGSASGPLSPSLSSGEGHFVCLDCGKRFSWWSSLKIHQRTHTGEKPYLCGKCGKSFSQKPNLARHQRHHTGERPFCCPECARRFSQKQHLLKHQKTHSRPATHSCPECERCFRHQVGLRIHQRAHARDRQGSRAGLHELIQDAAARRACRLQPGPPRGRPEWAWLGLCQGWWGQPGARAAVSGPEGPGEPRQFICNECGKSFTWWSSLNIHQRIHTGERPYACPECGRRFSQKPNLTRHLRNHTGERPHPCPHCGRGFRQKQHLLKHLRTHLPGAQAAPCPSCGKSCRSRAALRAHQRAHAVAEPAVPAGEPGDQPQAEAIPGLAARPRSSQRSPGARDTLWGRGQAGLAGPGEPRQFICNECGKSFSWWSALTIHQRIHTGERPYPCPECGRRFSQKPNLTRHRRNHTGERPYLCPACGRGFSQKQHLLKHQRVHRAAPACSPKEEAR>sp|Q8TC21|ZN596_HUMAN Zinc finger protein 596 OS=Homo sapiens OX=9606GN=ZNF596 PE=1 SV=2MPSPDSMTFEDIIVDFTQEEWALLDTSQRKLFQDVMLENISHLVSIGKQLCKSVVLSQLEQVEKLSTQRISLLQGREVGIKHQEIPFIQHIYQKGTSTISTMRSHTQEDPFLCNDLGEDFTQHIALTQNVITYMRTKHFVSKKFGKIFSDWLSFNQHKEIHTKCKSYGSHLFDYAFIQNSALRPHSVTHTREITLECRVCGKTFSKNSNLRRHEMIHTGEKPHGCHLCGKAFTHCSDLRKHERTHTGEKPYGCHLCGKAFSKSSNLRRHEMIHTREKAQICHLCGKAFTHCSDLRKHERTHLGDKPYGCLLCGKAFSKCSYLRQHERTHNGEKPYECHLCGKAFSHCSHLRQHERSHNGEKPHGCHLCGKAFTESSVLKRHERIHTGEKPYECHVCGKAFTESSDLRRHERTHTGEKPYECHLCGKAFNHSSVLRRHERTHTGEKPYECNICGKAFNRSYNFRLHRRVHTGEKPYVCPLCGKAFSKFFNLRQHERTHTKKAMNM>sp|Q8TC21-2|ZN596_HUMAN Isoform 2 of Zinc finger protein 596 OS=Homosapiens OX=9606 GN=ZNF596MPSPDSMTFEDIIVDFTQEEWALLDTSQRKLFQDVMLENISHLVSIGEDFTQHIALTQNVITYMRTKHFVSKKFGKIFSDWLSFNQHKEIHTKCKSYGSHLFDYAFIQNSALRPHSVTHTREITLECRVCGKTFSKNSNLRRHEMIHTGEKPHGCHLCGKAFTHCSDLRKHERTHTGEKPYGCHLCGKAFSKSSNLRRHEMIHTREKAQICHLCGKAFTHCSDLRKHERTHLGDKPYGCLLCGKAFSKCSYLRQHERTHNGEKPYECHLCGKAFSHCSHLRQHERSHNGEKPHGCHLCGKAFTESSVLKRHERIHTGEKPYECHVCGKAFTESSDLRRHERTHTGEKPYECHLCGKAFNHSSVLRRHERTHTGEKPYECNICGKAFNRSYNFRLHRRVHTGEKPYVCPLCGKAFSKFFNLRQHERTHTKKAMNM>sp|Q8TC21-3|ZN596_HUMAN Isoform 3 of Zinc finger protein 596 OS=Homosapiens OX=9606 GN=ZNF596MRSHTQEDPFLCNDLGEDFTQHIALTQNVITYMRTKHFVSKKFGKIFSDWLSFNQHKEIHTKCKSYGSHLFDYAFIQNSALRPHSVTHTREITLECRVCGKTFSKNSNLRRHEMIHTGEKPHGCHLCGKAFTHLIIVNT>sp|Q96BR6|ZN669_HUMAN Zinc finger protein 669 OS=Homo sapiens OX=9606GN=ZNF669 PE=1 SV=2MVSGLRLASRSGEEGWLKPAVARLGPPRHRLRNLRTESPWRSRGSVLFCSGPGRAGRAAEPLHPVCTCGRHFRRPEPCREPLASPIQDSVAFEDVAVNFTQEEWALLDSSQKNLYREVMQETCRNLASVGSQWKDQNIEDHFEKPGKDIRNHIVQRLCESKEDGQYGEVVSQIPNLDLNENISTGLKPCECSICGKVFVRHSLLNRHILAHSGYKPYGEKQYKCEQCGKFFVSVPGVRRHMIMHSGNPAYKCTICGKAFYFLNSVERHQRTHTGEKPYKCKQCGKAFTVSGSCLIHERTHTGEKPYECKECGKTFRFSCSFKTHERTHTGERPYKCTKCDKAFSCSTSLRYHGSIHTGERPYECKQCGKAFSRLSSLCNHRSTHTGEKPYECKQCDQAFSRLSSLHLHERIHTGEKPYECKKCGKAYTRSSHLTRHERSHDIEAGCSDSAYNPSTLGGQGVWIA>sp|Q96BR6-2|ZN669_HUMAN Isoform 2 of Zinc finger protein 669 OS=Homosapiens OX=9606 GN=ZNF669MDSVAFEDVAVNFTQEEWALLDSSQKNLYREVMQETCRNLASVGSQWKDQNIEDHFEKPGKDIRNHIVQRLCESKEDGQYGEVVSQIPNLDLNENISTGLKPCECSICGKVFVRHSLLNRHILAHSGYKPYGEKQYKCEQCGKFFVSVPGVRRHMIMHSGNPAYKCTICGKAFYFLNSVERHQRTHTGEKPYKCKQCGKAFTVSGSCLIHERTHTGEKPYECKECGKTFRFSCSFKTHERTHTGERPYKCTKCDKAFSCSTSLRYHGSIHTGERPYECKQCGKAFSRLSSLCNHRSTHTGEKPYECKQCDQAFSRLSSLHLHERIHTGEKPYECKKCGKAYTRSSHLTRHERSHDIEAGCSDSAYNPSTLGGQGVWIA>sp|Q96B54|ZN428_HUMAN Zinc finger protein 428 OS=Homo sapiens OX=9606GN=ZNF428 PE=1 SV=2MTETREPAETGGYASLEEDDEDLSPGPEHSSDSEYTLSEPDSEEEEDEEEEEEETTDDPEYDPGYKVKQRLGGGRGGPSRRAPRAAQPPAQPCQLCGRSPLGEAPPGTPPCRLCCPATAPQEAPAPEGRALGEEEEEPPRAGEGRPAGREEEEEEEEEGTYHCTECEDSFDNLGELHGHFMLHARGEV>sp|Q0P140|YA037_HUMAN Putative uncharacterized protein HSD52 OS=Homosapiens OX=9606 GN=HSD52 PE=5 SV=1MQDVHTKSIACDGDLLPVLQENSISFQMLSLEMSGSFHSSPALENATITILHVSLLSFFRGIQAPCRGSPLLVTDSPGG>sp|Q8NFD4|YI018_HUMAN Uncharacterized protein FLJ76381 OS=Homo sapiensOX=9606 PE=2 SV=1MGGFGSRFWQEGVWDRDLEKSTRLEEDAMESEPLAGTKTRGRGRRRWEARHGWTLPAHASQPSPRTVVATATGAEVSACAGRSAGTRVARPESQLSHLYGWDKYSNPRPSRRARAVARVHALEQAPILCRALRWGLTQFLRGTSPVTQSVPFS>sp|Q6ZS46|YF009_HUMAN Putative uncharacterized protein FLJ45840 OS=Homosapiens OX=9606 PE=5 SV=2MQTCSGKGIKMAFLDVQSSSTPQSLPLLLFSHREGGGRGAGDPGAPAVVPAPVSAPRPASSPARSESRSPPLTLISRHITCCSCESPGDVLLSGRGGGGGGGGGARTGGGEGEDRRPRPDFSRVTAVAIPGWMEVESPPHPPPQPQVCPTPSQGAPGHGRAGLPEGKGPGGRDWLRSQSSRCSRATLFGHRAPSPAAPRRGRLPAPGFPSLHSAVSLF>sp|Q9P1Z0|ZBTB4_HUMAN Zinc finger and BTB domain-containing protein 4OS=Homo sapiens OX=9606 GN=ZBTB4 PE=1 SV=3MPPPAEVTDPSHAPAVLRQLNEQRLRGLFCDVTLIAGDTKFPAHRSVLAASSPFFREALLTSAPLPLPPATGGAAPNPATTTAASSSSSSSSSSSSSSSSASSSSSSSSSSPPPASPPASSPPRVLELPGVPAAAFSDVLNFIYSARLALPGGGGDGAAVAEIGALGRRLGISRLQGLGEGGDAWVPPTPAPMATSQPEEDSFGPGPRPAGEWEGDRAEAQAPDLQCSLPRRPLPCPQCGKSFIHPKRLQTHEAQCRRGASTRGSTGLGAGGAGPGGPAGVDASALPPPVGFRGGPEHVVKVVGGHVLYVCAACERSYVTLSSLKRHSNVHSWRRKYPCRYCEKVFALAEYRTKHEVWHTGERRYQCIFCWETFVTYYNLKTHQRAFHGISPGLLASEKTPNGGYKPKLNTLKLYRLLPMRAAKRPYKTYSQGAPEAPLSPTLNTPAPVAMPASPPPGPPPAPEPGPPPSVITFAHPAPSVIVHGGSSSGGGGSGTASTGGSQAASVITYTAPPRPPKKREYPPPPPEPAATPTSPATAVSPATAAGPAMATTTEEAKGRNPRAGRTLTYTAKPVGGIGGGGGPPTGAGRGPSQLQAPPPLCQITVRIGEEAIVKRRISETDLRPGELSGEEMEESEEDEEEEDEEEEEEDEEESKAGGEDQLWRPYYSYKPKRKAGAAGGASVGGSGLPRGRRPPRWRQKLERRSWEETPAAESPAGRARTERRHRCGDCAQTFTTLRKLRKHQEAHGGGSHSSRAGRRPSTRFTCPHCAKVCKTAAALSRHGQRHAAERPGGTPTPVIAYSKGSAGTRPGDVKEEAPQEMQVSSSSGEAGGGSTAAEEASETASLQDPIISGGEEPPVVASGGSYVYPPVQEFPLALIGGGREPGGGRGKSGSEGPVGAGEGDRMEGIGAAKVTFYPEPYPLVYGPQLLAAYPYNFSNLAALPVALNMVLPDEKGAGALPFLPGVFGYAVNPQAAPPAPPTPPPPTLPPPIPPKGEGERAGVERTQKGDVG>sp|P24278|ZBT25_HUMAN Zinc finger and BTB domain-containing protein 25OS=Homo sapiens OX=9606 GN=ZBTB25 PE=1 SV=2MDTASHSLVLLQQLNMQREFGFLCDCTVAIGDVYFKAHRAVLAAFSNYFKMIFIHQTSECIKIQPTDIQPDIFSYLLHIMYTGKGPKQIVDHSRLEEGIRFLHADYLSHIATEMNQVFSPETVQSSNLYGIQISTTQKTVVKQGLEVKEAPSSNSGNRAAVQGDHPQLQLSLAIGLDDGTADQQRACPATQALEEHQKPPVSIKQERCDPESVISQSHPSPSSEVTGPTFTENSVKIHLCHYCGERFDSRSNLRQHLHTHVSGSLPFGVPASILESNDLGEVHPLNENSEALECRRLSSFIVKENEQQPDHTNRGTTEPLQISQVSLISKDTEPVELNCNFSFSRKRKMSCTICGHKFPRKSQLLEHMYTHKGKSYRYNRCQRFGNALAQRFQPYCDSWSDVSLKSSRLSQEHLDLPCALESELTQENVDTILVE>sp|Q9P2Y4|ZN219_HUMAN Zinc finger protein 219 OS=Homo sapiens OX=9606GN=ZNF219 PE=1 SV=2MEGSRPRAPSGHLAPSPPAFDGELDLQRYSNGPAVSAGSLGMGAVSWSESRAGERRFPCPVCGKRFRFNSILALHLRAHPGAQAFQCPHCGHRAAQRALLRSHLRTHQPERPRSPAARLLLELEERALLREARLGRARSSGGMQATPATEGLARPQAPSSSAFRCPYCKGKFRTSAERERHLHILHRPWKCGLCSFGSSQEEELLHHSLTAHGAPERPLAATSAAPPPQPQPQPPPQPEPRSVPQPEPEPEPEREATPTPAPAAPEEPPAPPEFRCQVCGQSFTQSWFLKGHMRKHKASFDHACPVCGRCFKEPWFLKNHMKVHASKLGPLRAPGPASGPARAPQPPDLGLLAYEPLGPALLLAPAPTPAERREPPSLLGYLSLRAGEGRPNGEGAEPGPGRSFGGFRPLSSALPARARRHRAEEPEEEEEVVEAEEETWARGRSLGSLASLHPRPGEGPGHSASAAGAQARSTATQEENGLLVGGTRPEGGRGATGKDCPFCGKSFRSAHHLKVHLRVHTGERPYKCPHCDYAGTQSGSLKYHLQRHHREQRSGAGPGPPPEPPPPSQRGSAPQSGAKPSPQPATWVEGASSPRPPSSGAGPGSRRKPASPGRTLRNGRGGEAEPLDLSLRAGPGGEAGPGGALHRCLFCPFATGAPELMALHLQVHHSRRARGRRPPQADASPPYARVPSGETPPSPSQEGEEGSGLSRPGEAGLGGQER>sp|Q9H6R6|ZDHC6_HUMAN Palmitoyltransferase ZDHHC6 OS=Homo sapiensOX=9606 GN=ZDHHC6 PE=1 SV=1MGTFCSVIKFENLQELKRLCHWGPIIALGVIAICSTMAMIDSVLWYWPLHTTGGSVNFIMLINWTVMILYNYFNAMFVGPGFVPLGWKPEISQDTMYLQYCKVCQAYKAPRSHHCRKCNRCVMKMDHHCPWINNCCGYQNHASFTLFLLLAPLGCIHAAFIFVMTMYTQLYHRLSFGWNTVKIDMSAARRDPLPIVPFGLAAFATTLFALGLALGTTIAVGMLFFIQMKIILRNKTSIESWIEEKAKDRIQYYQLDEVFVFPYDMGSRWRNFKQVFTWSGVPEGDGLEWPVREGCHQYSLTIEQLKQKADKRVRSVRYKVIEDYSGACCPLNKGIKTFFTSPCTEEPRIQLQKGEFILATRGLRYWLYGDKILDDSFIEGVSRIRGWFPRKCVEKCPCDAETDQAPEGEKKNR>sp|Q9H6R6-2|ZDHC6_HUMAN Isoform 2 of Palmitoyltransferase ZDHHC6 OS=Homosapiens OX=9606 GN=ZDHHC6MGTFCSVIKFENLQELKRLCHWGPIIALGVIAICSTMAMIDSVLWYWPLHTTGGSVNFIMLINWTVMILYNYFNAMFVGPGFVPLGWKPDTMYLQYCKVCQAYKAPRSHHCRKCNRCVMKMDHHCPWINNCCGYQNHASFTLFLLLAPLGCIHAAFIFVMTMYTQLYHRLSFGWNTVKIDMSAARRDPLPIVPFGLAAFATTLFALGLALGTTIAVGMLFFIQMKIILRNKTSIESWIEEKAKDRIQYYQLDEVFVFPYDMGSRWRNFKQVFTWSGVPEGDGLEWPVREGCHQYSLTIEQLKQKADKRVRSVRYKVIEDYSGACCPLNKGIKTFFTSPCTEEPRIQLQKGEFILATRGLRYWLYGDKILDDSFIEGVSRIRGWFPRKCVEKCPCDAETDQAPEGEKKNR>sp|Q5T4F4|ZFY27_HUMAN Protrudin OS=Homo sapiens OX=9606 GN=ZFYVE27 PE=1SV=1MQTSEREGSGPELSPSVMPEAPLESPPFPTKSPAFDLFNLVLSYKRLEIYLEPLKDAGDGVRYLLRWQMPLCSLLTCLGLNVLFLTLNEGAWYSVGALMISVPALLGYLQEVCRARLPDSELMRRKYHSVRQEDLQRGRLSRPEAVAEVKSFLIQLEAFLSRLCCTCEAAYRVLHWENPVVSSQFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTEDLTPGSVEEAEEAEPDEEFKDAIEETHLVVLEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGNCTGCSATFSVLKKRRSCSNCGNSFCSRCCSFKVPKSSMGATAPEAQRETVFVCASCNQTLSK>sp|Q5T4F4-2|ZFY27_HUMAN Isoform 2 of Protrudin OS=Homo sapiens OX=9606GN=ZFYVE27MQTSEREGSGPELSPSVMPEAPLESPPFPTKSPAFDLFNLVLSYKRLEIYLEPLKDAGDGVRYLLRWQMPLCSLLTCLGLNVLFLTLNEGAWYSVGALMISVPALLGYLQEVCRARLPDSELMRRKYHSVRQEDLQRGRLSRPEAVAEVKSFLIQLEAFLSRLCCTCEAAYRVLHWENPVVSSQFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTEDLTPGSVEEAEEAEPDEEFKDAIEEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGNCTGCSATFSVLKKRRSCSNCGNSFCSRCCSFKVPKSSMGATAPEAQRETVFVCASCNQTLSK>sp|Q5T4F4-3|ZFY27_HUMAN Isoform 3 of Protrudin OS=Homo sapiens OX=9606GN=ZFYVE27MQTSEREGSGPELSPSVMPEAPLESPPFPTKSPAFDLFNLVLSYKRLEIYLEPLKDAGDGVRYLLRWQMPLCSLLTCLGLNVLFLTLNEGAWYSVGALMISVPALLGYLQEVCRARLPDSELMRRKYHSVRQEDLQRGRLSRPEAVAEVKSFLIQLEAFLSRLCCTCEAAYRVLHWENPVVSSQFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTESLSSQDLTPGSVEEAEEAEPDEEFKDAIEETHLVVLEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGNCTGCSATFSVLKKRRSCSNCGNSFCSRCCSFKVPKSSMGATAPEAQRETVFVCASCNQTLSK>sp|Q5T4F4-4|ZFY27_HUMAN Isoform 4 of Protrudin OS=Homo sapiens OX=9606GN=ZFYVE27MPLCSLLTCLGLNVLFLTLNEGAWYSVGALMISVPALLGYLQEVCRARLPDSELMRRKYHSVRQEDLQRGRLSRPEAVAEVKSFLIQLEAFLSRLCCTCEAAYRVLHWENPVVSSQFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTESLSSQDLTPGSVEEAEEAEPDEEFKDAIEEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGVTGAGSS>sp|Q5T4F4-5|ZFY27_HUMAN Isoform 5 of Protrudin OS=Homo sapiens OX=9606GN=ZFYVE27MQTSEREGSGPELSPSVMPEAPLESPPFPTKSPAFDLFNLVLSYKRLEIYLEPLKDAGDGVRYLLSLIQLEAFLSRLCCTCEAAYRVLHWENPVVSSQFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTEDLTPGSVEEAEEAEPDEEFKDAIEEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGNCTGCSATFSVLKKRRSCSNCGNSFCSRCCSFKVPKSSMGATAPEAQRETVFVCASCNQTLSK>sp|Q5T4F4-6|ZFY27_HUMAN Isoform 6 of Protrudin OS=Homo sapiens OX=9606GN=ZFYVE27MQTSEREGSGPELSPSVMPEAPLESPPFPTKSPAFDLFNLVLSYKRLEIYLEPLKDAGDGVRYLLRFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTEDLTPGSVEEAEEAEPDEEFKDAIEEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGNCTGCSATFSVLKKRRSCSNCGNSFCSRCCSFKVPKSSMGATAPEAQRETVFVCASCNQTLSK>sp|Q5T4F4-7|ZFY27_HUMAN Isoform 7 of Protrudin OS=Homo sapiens OX=9606GN=ZFYVE27MISVPALLGYLQEVCRARLPDSELMRRKYHSVRQEDLQRGRLSRPEAVAEVKSFLIQLEAFLSRLCCTCEAAYRVLHWENPVVSSQFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTESLSSQDLTPGSVEEAEEAEPDEEFKDAIEEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGNCTGCSATFSVLKKRRSCSNCGNSFCSRCCSFKVPKSSMGATAPEAQRETVFVCASCNQTLSK>sp|Q5T4F4-8|ZFY27_HUMAN Isoform 8 of Protrudin OS=Homo sapiens OX=9606GN=ZFYVE27MQTSEREGSGPELSPSVMPEAPLESPPFPTKSPAFDLFNLVLSYKRLEIYLEPLKDAGAWYSVGALMISVPALLGYLQEVCRARLPDSELMRRKYHSVRQEDLQRGRLSRPEAVAEVKSFLIQLEAFLSRLCCTCEAAYRVLHWENPVVSSQFYGALLGTVCMLYLLPLCWVLTLLNSTLFLGNVEFFRVVSEYRASLQQRMNPKQEEHAFESPPPPDVGGKDGLMDSTPALTPTEDLTPGSVEEAEEAEPDEEFKDAIEEDDEGAPCPAEDELALQDNGFLSKNEVLRSKVSRLTERLRKRYPTNNFGNCTGCSATFSVLKKRRSCSNCGNSFCSRCCSFKVPKSSMGATAPEAQRETVFVCASCNQTLSK>sp|Q8TD23|ZN675_HUMAN Zinc finger protein 675 OS=Homo sapiens OX=9606GN=ZNF675 PE=1 SV=3MGLLTFRDVAIEFSLEEWQCLDTAQRNLYKNVILENYRNLVFLGIAVSKQDLITCLEQEKEPLTVKRHEMVNEPPVMCSHFAQEFWPEQNIKDSFEKVTLRRYEKCGNDNFQLKGCKSVDECKLHKGGYNGLNQCLPTMQSKMFQCDKYVKVFNKFSHSDRHKIKHMENKPFKCKECGRSFCMLSHLTRHERNYTKVNFCKCEECEKAVNQSSKLTKHKRIYTCEKLYKCQECDRTFNQFSNLTEYKKDYAREKPYKCEECGKAFNQSSHLTTHKIIHTGEKPYKCEECGKAFNQFSNLTTHKKIHTGEQPYICEECGKAFTQSSTLTTHKRIHTGEKPYKCEECGKAFNRSSKLTEHKNIHTGEQPYKCEECGKAFNRSSNLTEHRKIHTEEKPYKCKECGKAFKHSSALTTHKRIHTGEKPYKCEECGKAFNRSSKLTEHKKLHTGKKPYKCEECGKAFIQSSKLTEHKKIHSGEIPYKCEECGKAFKHSSSLTTHKRIHTGEKPYKCEECGKAFSRSSKLTEHKIIHTGEKPYKCERCDKAFNQSANLTKHKKIHTGEKLQNWNV>sp|Q96QA6|YPEL2_HUMAN Protein yippee-like 2 OS=Homo sapiens OX=9606GN=YPEL2 PE=1 SV=1MVKMTRSKTFQAYLPSCHRTYSCIHCRAHLANHDELISKSFQGSQGRAYLFNSVVNVGCGPAEERVLLTGLHAVADIYCENCKTTLGWKYEHAFESSQKYKEGKYIIELAHMIKDNGWD>sp|Q8N567|ZCHC9_HUMAN Zinc finger CCHC domain-containing protein 9OS=Homo sapiens OX=9606 GN=ZCCHC9 PE=1 SV=2MTRWARVSTTYNKRPLPATSWEDMKKGSFEGTSQNLPKRKQLEANRLSLKNDAPQAKHKKNKKKKEYLNEDVNGFMEYLRQNSQMVHNGQIIATDSEEVREEIAVALKKDSRREGRRLKRQAAKKNAMVCFHCRKPGHGIADCPAALENQDMGTGICYRCGSTEHEITKCKAKVDPALGEFPFAKCFVCGEMGHLSRSCPDNPKGLYADGGGCKLCGSVEHLKKDCPESQNSERMVTVGRWAKGMSADYEEILDVPKPQKPKTKIPKVVNF>sp|Q6PK81|ZN773_HUMAN Zinc finger protein 773 OS=Homo sapiens OX=9606GN=ZNF773 PE=1 SV=1MAAATLRDPAQQGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGLASSKTHEITQLESWEEPFMPAWEVVTSAILRGSWQGAKAEAAAEQSASVEVPSSNVQQHQKQHCGEKPLKRQEGRVPVLRSCRVHLSEKSLQSREVGKDLLTSSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHTGEKPYECSECGKLFSHKSNLFIHQIVHTGERPYGCSDCGKSFSRNADLIQHQRVHTGEKPFTCSECGKAFRHNSTLVQHHRIHTGVRPYECSECGKLFSFNSSLMKHQRVHTGERPYKCSECGKFYSHKSSLINHWRVHTGERPYECSECGKFFSQSSSLMQHRKVHTGEKPFKCNECGRFFSENSSLVKHQRVHTGAKPYECRECGKFFRHSSSLVKHRRIHTGEIQ>sp|Q6PK81-2|ZN773_HUMAN Isoform 2 of Zinc finger protein 773 OS=Homosapiens OX=9606 GN=ZNF773MAAATLRDPAQGYVTFEDVAVYFSQEEWRLLDDAQRLLYRNVMLENFTLLASLGLASSKTHEITQLESWEEPFMPAWEVVTSAILRGSWQGAKAEAAAEQSASVEVPSSNVQQHQKQHCGEKPLKRQEGRVPVLRSCRVHLSEKSLQSREVGKDLLTSSGVLKHQVTHTGEKSHRSSKSREAFHAGKRHYKCSECGKAFGQKYLLVQHQRLHTGEKPYECSECGKLFSHKSNLFIHQIVHTGERPYGCSDCGKSFSRNADLIQHQRVHTGEKPFTCSECGKAFRHNSTLVQHHRIHTGVRPYECSECGKLFSFNSSLMKHQRVHTGERPYKCSECGKFYSHKSSLINHWRVHTGERPYECSECGKFFSQSSSLMQHRKVHTGEKPFKCNECGRFFSENSSLVKHQRVHTGAKPYECRECGKFFRHSSSLVKHRRIHTGEIQ>sp|Q9BV97|ZN747_HUMAN KRAB domain-containing protein ZNF747 OS=Homosapiens OX=9606 GN=ZNF747 PE=1 SV=1MTDPSLGLTVPMAPPLAPLPPRDPNGAGSEWRKPGAVSFADVAVYFSREEWGCLRPAQRALYRDVMRETYGHLGALGESPTCLPGPCASTGPAAPLGAACGVGGPGAGQAASSQRGVCVLLPQESEAASRRSSPGWRRRPNCGIRLPRIRRWRSVRQKRTQQIPETRKRKDKGKGREPWRSPTLWPPGLLG>sp|Q9BV97-2|ZN747_HUMAN Isoform 2 of KRAB domain-containing proteinZNF747 OS=Homo sapiens OX=9606 GN=ZNF747MTDPSLGLTVPMAPPLAPLPPRDPNGAGSEWRKPGAVSFADVAVYFSREEWGCLRPAQRALYRDVMRETYGHLGALGESPTCLPGPCASTGPAAPLGAACGVGGPGAGQAASSQRGVCVLLPQESEAASRRSSPGWRRRPNCGIRLPRIRRWRSVRQKRTQIPETRKRKDKGKGREPWRSPTLWPPGLLG>sp|Q8N9L7|YV006_HUMAN Putative uncharacterized protein FLJ36925 OS=Homosapiens OX=9606 PE=5 SV=1MTMTMSYKAIEKIPRCSWNREEPGEQWNKIYSVETGLLGTYSFEWQSQVANKTMRKRNTNSICGRQHEPHCPVSITRAIAQPQLLTFPDSLASRGGHMTQSGQCHVSGSLLGRGHKSRGR>sp|Q8IZ13|ZBED8_HUMAN Protein ZBED8 OS=Homo sapiens OX=9606 GN=ZBED8PE=1 SV=1MSKKRKWDDDYVRYWFTCTTEVDGTQRPQCVLCNSVFSNADLRPSKLSDHFNRQHGGVAGHDLNSLKHMPAPSDQSETLKAFGVASHEDTLLQASYQFAYLCAKEKNPHTVAEKLVKPCALEIAQIVLGPDAQKKLQQVPLSDDVIHSRIDEMSQDILQQVLEDIKASPLKVGIQLAETTDMDDCSQLMAFVRYIKEREIVEEFLFCEPLQLSMKGIDVFNLFRDFFLKHKIALDVCGSVCTDGASSMLGENSEFVAYVKKEIPHIVVTHCLLNPHALVIKTLPTKLRDALFTVVRVINFIKGRAPNHRLFQAFFEEIGIEYSVLLFHTEMRWLSRGQILTHIFEMYEEINQFLHHKSSNLVDGFENKEFKIHLAYLADLFKHLNELSASMQRTGMNTVSAREKLSAFVRKFPFWQKRIEKRNFTNFPFLEEIIVSDNEGIFIAAEITLHLQQLSNFFHGYFSIGDLNEASKWILDPFLFNIDFVDDSYLMKNDLAELRASGQILMEFETMKLEDFWCAQFTAFPNLAKTALEILMPFATTYLCELGFSSLLHFKTKSRSCFNLSDDIRVAISKKVPRFSDIIEQKLQLQQKSL>sp|Q9BU19|ZN692_HUMAN Zinc finger protein 692 OS=Homo sapiens OX=9606GN=ZNF692 PE=1 SV=1MASSPAVDVSCRRREKRRQLDARRSKCRIRLGGHMEQWCLLKERLGFSLHSQLAKFLLDRYTSSGCVLCAGPEPLPPKGLQYLVLLSHAHSRECSLVPGLRGPGGQDGGLVWECSAGHTFSWGPSLSPTPSEAPKPASLPHTTRRSWCSEATSGQELADLESEHDERTQEARLPRRVGPPPETFPPPGEEEGEEEEDNDEDEEEMLSDASLWTYSSSPDDSEPDAPRLLPSPVTCTPKEGETPPAPAALSSPLAVPALSASSLSSRAPPPAEVRVQPQLSRTPQAAQQTEALASTGSQAQSAPTPAWDEDTAQIGPKRIRKAAKRELMPCDFPGCGRIFSNRQYLNHHKKYQHIHQKSFSCPEPACGKSFNFKKHLKEHMKLHSDTRDYICEFCARSFRTSSNLVIHRRIHTGEKPLQCEICGFTCRQKASLNWHQRKHAETVAALRFPCEFCGKRFEKPDSVAAHRSKSHPALLLAPQESPSGPLEPCPSISAPGPLGSSEGSRPSASPQAPTLLPQQ>sp|Q9BU19-2|ZN692_HUMAN Isoform 2 of Zinc finger protein 692 OS=Homosapiens OX=9606 GN=ZNF692MASSPAVDVSCRRREKRRQLDARRSKCRIRLGGHMEQWCLLKERLGFSLHSQLAKFLLDRYTSSGCVLCAGPEPLPPKGLQYLVLLSHAHSRECSLVPGLRGPGGQDGGLVWECSAGHTFSWGPSLSPTPSEAPKPASLPHTTRRSWCSEATSGQELADLESEHDERTQEARLPSSEPDAPRLLPSPVTCTPKEGETPPAPAALSSPLAVPALSASSLSSRAPPPAEVRVQPQLSRTPQAAQQTEALASTGSQAQSAPTPAWDEDTAQIGPKRIRKAAKRELMPCDFPGCGRIFSNRQYLNHHKKYQHIHQKSFSCPEPACGKSFNFKKHLKEHMKLHSDTRDYICEFCARSFRTSSNLVIHRRIHTGEKPLQCEICGFTCRQKASLNWHQRKHAETVAALRFPCEFCGKRFEKPDSVAAHRSKSHPALLLAPQESPSGPLEPCPSISAPGPLGSSEGSRPSASPQAPTLLPQQ>sp|Q9BU19-3|ZN692_HUMAN Isoform 3 of Zinc finger protein 692 OS=Homosapiens OX=9606 GN=ZNF692MASSPAVDVSCRRREKRRQLDARRSKCRIRLGGHMEQWCLLKERLGFSLHSQLAKFLLDRYTSSGCVLCAGPEPLPPKGLQYLVLLSASSLSSRAPPPAEVRVQPQLSRTPQAAQQTEALASTGSQAQSAPTPAWDEDTAQIGPKRIRKAAKRELMPCDFPGCGRIFSNRQYLNHHKKYQHIHQKSFSCPEPACGKSFNFKKHLKEHMKLHSDTRDYICEFCARSFRTSSNLVIHRRIHTGEKPLQCEICGFTCRQKASLNWHQRKHAETVAALRFPCEFCGKRFEKPDSVAAHRSKSHPALLLAPQESPSGPLEPCPSISAPGPLGSSEGSRPSASPQAPTLLPQQ>sp|Q9BU19-4|ZN692_HUMAN Isoform 4 of Zinc finger protein 692 OS=Homosapiens OX=9606 GN=ZNF692MASSPAVDVSCRRREKRRQLDARRSKCRIRLGGHMEQWCLLKERLGFSLHSQLAKFLLDRACPAALFHPQVSHFTRTACVTCGLRGSCSPPHGLSE>sp|Q9BU19-5|ZN692_HUMAN Isoform 5 of Zinc finger protein 692 OS=Homosapiens OX=9606 GN=ZNF692MPLVHMASSPAVDVSCRRREKRRQLDARRSKCRIRLGGHMEQWCLLKERLGFSLHSQLAKFLLDRYTSSGCVLCAGPEPLPPKGLQYLVLLSHAHSRECSLVPGLRGPGGQDGGLVWECSAGHTFSWGPSLSPTPSEAPKPASLPHTTRRSWCSEATSGQELADLESEHDERTQEARLPRRVGPPPETFPPPGEEEGEEEEDNDEDEEEMLSDASLWTYSSSPDDSEPDAPRLLPSPVTCTPKEGETPPAPAALSSPLAVPALSASSLSSRAPPPAEVRVQPQLSRTPQAAQQTEALASTGSQAQSAPTPAWDEDTAQIGPKRIRKAAKRELMPCDFPGCGRIFSNRQYLNHHKKYQHIHQKSFSCPEPACGKSFNFKKHLKEHMKLHSDTRDYICEFCARSFRTSSNLVIHRRIHTGEKPLQCEICGFTCRQKASLNWHQRKHAETVAALRFPCEFCGKRFEKPDSVAAHRSKSHPALLLAPQESPSGPLEPCPSISAPGPLGSSEGSRPSASPQAPTLLPQQ>sp|Q6UWF5|YF002_HUMAN Putative uncharacterized protein UNQ5815/PRO19632OS=Homo sapiens OX=9606 GN=UNQ5815/PRO19632 PE=4 SV=1MQIQNNLFFCCYTVMSAIFKWLLLYSLPALCFLLGTQESESFHSKAEILVTLSQVIISPAGPHALTWTTHFSPSVIIILVPCWWHAVIVTQHPVANCYVTNHLNIQWLELKAGS>sp|Q9UK10|ZN225_HUMAN Zinc finger protein 225 OS=Homo sapiens OX=9606GN=ZNF225 PE=1 SV=2MTTLKEAVTFKDVAVVFTEEELRLLDLAQRKLYREVMLENFRNLLSVGHQSLHRDTFHFLKEEKFWMMETATQREGNLGGKIQMEMETVSESGTHEGLFSHQTWEQISSDLTRFQDSMVNSFQFSKQDDMPCQVDAGLSIIHVRQKPSEGRTCKKSFSDVSVLDLHQQLQSREKSHTCDECGKSFCYSSALRIHQRVHMGEKLYNCDVCGKEFNQSSHLQIHQRIHTGEKPFKCEQCGKGFSRRSGLYVHRKLHTGVKPHICEKCGKAFIHDSQLQEHQRIHTGEKPFKCDICCKSFRSRANLNRHSMVHMREKPFRCDTCGKSFGLKSALNSHRMVHTGEKRYKCEECGKRFIYRQDLYKHQIDHTGEKPYNCKECGKSFRWASGLSRHVRVHSGETTFKCEECGKGFYTNSQRYSHQRAHSGEKPYRCEECGKGYKRRLDLDFHQRVHRGEKPYNCKECGKSFGWASCLLNHQRIHSGEKPFKCEECGKRFTQNSQLYTHRRVHSGEKPFKCEECGKRFTQNSQLYSHRRVHTGVKPYKCEECGKGFNSKFNLDMHQRVHTGERPYNCKECGKSFSRASSILNHKRLHGDEKPFKCEECGKRFTENSQLHSHQRVHTGEKPYKCEKCGKSFRWASTHLTHQRLHSREKLLQCEDCGKSIVHSSCLKDQQRDQSGEKTSKCEDCGKRYKRRLNLDTLLSLFLNDT>sp|O14978|ZN263_HUMAN Zinc finger protein 263 OS=Homo sapiens OX=9606GN=ZNF263 PE=1 SV=2MASGPGSQEREGLLIVKLEEDCAWSQELPPPDPGPSPEASHLRFRRFRFQEAAGPREALSRLQELCHGWLRPEMRTKEQILELLVLEQFLTILPQEIQSRVQELHPESGEEAVTLVEDMQRELGRLRQQVTNHGRGTEVLLEEPLPLETARESPSFKLEPMETERSPGPRLQELLGPSPQRDPQAVKERALSAPWLSLFPPEGNMEDKEMTGPQLPESLEDVAMYISQEEWGHQDPSKRALSRDTVQESYENVDSLESHIPSQEVPGTQVGQGGKLWDPSVQSCKEGLSPRGPAPGEEKFENLEGVPSVCSENIHPQVLLPDQARGEVPWSPELGRPHDRSQGDWAPPPEGGMEQALAGASSGRELGRPKELQPKKLHLCPLCGKNFSNNSNLIRHQRIHAAERLCMGVDCTEIFGGNPRFLSLHRAHLGEEAHKCLECGKCFSQNTHLTRHQRTHTGEKPYQCNICGKCFSCNSNLHRHQRTHTGEKPYKCPECGEIFAHSSNLLRHQRIHTGERPYKCPECGKSFSRSSHLVIHERTHERERLYPFSECGEAVSDSTPFLTNHGAHKAEKKLFECLTCGKSFRQGMHLTRHQRTHTGEKPYKCTLCGENFSHRSNLIRHQRIHTGEKPYTCHECGDSFSHSSNRIRHLRTHTGERPYKCSECGESFSRSSRLMSHQRTHTG>sp|Q32MQ0|ZN750_HUMAN Zinc finger protein 750 OS=Homo sapiens OX=9606GN=ZNF750 PE=1 SV=1MSLLKERKPKKPHYIPRPPGKPFKYKCFQCPFTCNEKSHLFNHMKYGLCKNSITLVSEQDRVPKCPKSNSLDPKQTNQPDATAKPASSKSVANGLSAFDSKLQHSSAREDIKENLELQARGTHRCLGQKPALHRASPCKSPAPEAALGAQPALEGAARPSAFVPVGEHRLKGPDNAEAPETLALHNPTAKAVSFHTKSAFHTPGYPWKAGSPFLPPEFPHKISSTKGLGAISPYMHPTIPEYPPHFYTEHGLATIYSPYLLAGSSPECDAPLLSVYGTQDPRHFLPHPGPIPKHLAPSPATYDHYRFFQQYPSNLPIPYGFYRPESAFSSYGLRLPPVTGLTRDQSSHLLEEATLVYPASSPSRLNPSDPNRKHVEFESPIPEAKDSSKAGQRDTEGSKMSPRAGSAATGSPGRPSPTDFMQTSQTCEGLYDLSNKAASSALGRLYPPEQSLTAFRPVKKSTECLPAQAAETTAESPVSLNVVNGDPPAPTGSASLVSEAAPSSPDDSSGMGPLNLSKKSEINLAATHEPTYQGSPQAETASFSELQDLPLNLSVKDPCNTQAPRPAFPGRPRAAEPAAAVPQKTGTEGSEDGPSHPETKPGSLDGDGAPPTGPGEEAPDACAVDSSEEQKQTAAVALCQLAAYSPRNIRVGDGDAAAPEPACRQDTPTLSSMESQEAQCDLRPKGQKRTSLRDAGKSQQGAKKAKLQDTARVFTLRRRARVS>sp|Q3SY52|ZIK1_HUMAN Zinc finger protein interacting withribonucleoprotein K OS=Homo sapiens OX=9606 GN=ZIK1 PE=1 SV=1MAAAALRAPTQVTVSPETHMDLTKGCVTFEDIAIYFSQDEWGLLDEAQRLLYLEVMLENFALVASLGCGHGTEDEETPSDQNVSVGVSQSKAGSSTQKTQSCEMCVPVLKDILHLADLPGQKPYLVGECTNHHQHQKHHSAKKSLKRDMDRASYVKCCLFCMSLKPFRKWEVGKDLPAMLRLLRSLVFPGGKKPGTITECGEDIRSQKSHYKSGECGKASRHKHTPVYHPRVYTGKKLYECSKCGKAFRGKYSLVQHQRVHTGERPWECNECGKFFSQTSHLNDHRRIHTGERPYECSECGKLFRQNSSLVDHQKIHTGARPYECSQCGKSFSQKATLVKHQRVHTGERPYKCGECGNSFSQSAILNQHRRIHTGAKPYECGQCGKSFSQKATLIKHQRVHTGERPYKCGDCGKSFSQSSILIQHRRIHTGARPYECGQCGKSFSQKSGLIQHQVVHTGERPYECNKCGNSFSQCSSLIHHQKCHNT>sp|Q3SY52-2|ZIK1_HUMAN Isoform 2 of Zinc finger protein interacting withribonucleoprotein K OS=Homo sapiens OX=9606 GN=ZIK1MLENFALVASLGCGHGTEDEETPSDQNVSVGVSQSKAGSSTQKTQSCEMCVPVLKDILHLADLPGQKPYLVGECTNHHQHQKHHSAKKSLKRDMDRASYVKCCLFCMSLKPFRKWEVGKDLPAMLRLLRSLVFPGGKKPGTITECGEDIRSQKSHYKSGECGKASRHKHTPVYHPRVYTGKKLYECSKCGKAFRGKYSLVQHQRVHTGERPWECNECGKFFSQTSHLNDHRRIHTGERPYECSECGKLFRQNSSLVDHQKIHTGARPYECSQCGKSFSQKATLVKHQRVHTGERPYKCGECGNSFSQSAILNQHRRIHTGAKPYECGQCGKSFSQKATLIKHQRVHTGERPYKCGDCGKSFSQSSILIQHRRIHTGARPYECGQCGKSFSQKSGLIQHQVVHTGERPYECNKCGNSFSQCSSLIHHQKCHNT>sp|Q3SY52-3|ZIK1_HUMAN Isoform 3 of Zinc finger protein interacting withribonucleoprotein K OS=Homo sapiens OX=9606 GN=ZIK1MCVPVLKDILHLADLPGQKPYLVGECTNHHQHQKHHSAKKSLKRDMDRASYVKCCLFCMSLKPFRKWEVGKDLPAMLRLLRSLVFPGGKKPGTITECGEDIRSQKSHYKSGECGKASRHKHTPVYHPRVYTGKKLYECSKCGKAFRGKYSLVQHQRVHTGERPWECNECGKFFSQTSHLNDHRRIHTGERPYECSECGKLFRQNSSLVDHQKIHTGARPYECSQCGKSFSQKATLVKHQRVHTGERPYKCGECGNSFSQSAILNQHRRIHTGAKPYECGQCGKSFSQKATLIKHQRVHTGERPYKCGDCGKSFSQSSILIQHRRIHTGARPYECGQCGKSFSQKSGLIQHQVVHTGERPYECNKCGNSFSQCSSLIHHQKCHNT>sp|Q8N446|ZN843_HUMAN Zinc finger protein 843 OS=Homo sapiens OX=9606GN=ZNF843 PE=1 SV=1MRSLPFALTVESVSARAPTCCSTGRFTQGRQPCKCKACGRGFTQSASLLQHWRVHSDWRETLSLSPVRQDLLWPLQPHQAPASPLGRSHSSAGVRQGFSGQLCCWLTKEHTLAEALRLSPVPAGFWGPVEADRPPANSHRRVCPFCCCSCGDSVNEKTSLSQRVLPHPGEKTCRGGSVESVSLAPSSVAPDSTSGLRPCGSPGSFLQHLPPSTLLPRPPFLYPGPPLSLQPLVPSGLPAVPAVPLGGLEVAQVPPATQPAAQQEGAMGPRSCASAGRDSREAVQAPGYPEPARKASQHRAAGPLGEARARLQRQCRAPPPPSNPHWRGALPVFPVWKASSRRSNLARH>sp|Q6ZT77|ZN826_HUMAN Putative zinc finger protein 826 OS=Homo sapiensOX=9606 GN=ZNF826P PE=5 SV=2MRRFILERNPTNVKNMAKLSPIPHTLLGIRKFMLERNHTSVINVAQPLFYPQPLVNMRRFILERNSTNVKNVAKPSTIFHTLLYIRQFILERNAINGIKTFTWSSSPHKHRRTHTGEKPYKCEECGKAFTASSTLSEYKTIHTGEKPCKCEECGKAFNWSSDFNKHKRIHSGQKPIL>sp|Q09FC8|ZN415_HUMAN Zinc finger protein 415 OS=Homo sapiens OX=9606GN=ZNF415 PE=1 SV=2MPELYTEDFIQGCDVGELQEPGLPGVLSYVGAQERALDHRKPSTSSKKTKRVEIDQRCENRLECNGAISAHCNLRLPDSNDSPASASRVAGITDLSRNCVIKELAPQQEGNPGEVFHTVTLEQHEKHDIEEFCFREIKKKIHDFDCQWRDDERNCNKVTTAPKENLTCRRDQRDRRGIGNKSIKHQLGLSFLPHPHELQQFQAEGKIYECNHVEKSVNHGSSVSPPQIISSTIKTHVSNKYGTDFICSSLLTQEQKSCIREKPYRYIECDKALNHGSHMTVRQVSHSGEKGYKCDLCGKVFSQKSNLARHWRVHTGEKPYKCNECDRSFSRNSCLALHRRVHTGEKPYKCYECDKVFSRNSCLALHQKTHIGEKPYTCKECGKAFSVRSTLTNHQVIHSGKKPYKCNECGKVFSQTSSLATHQRIHTGEKPYKCNECGKVFSQTSSLARHWRIHTGEKPYKCNECGKVFSYNSHLASHRRVHTGEKPYKCNECGKAFSVHSNLTTHQVIHTGEKPYKCNQCGKGFSVHSSLTTHQVIHTGEKPYKCNECGKSFSVRPNLTRHQIIHTGKKPYKCSDCGKSFSVRPNLFRHQIIHTKEKPYKRN>sp|Q09FC8-2|ZN415_HUMAN Isoform 2 of Zinc finger protein 415 OS=Homosapiens OX=9606 GN=ZNF415MPELYTEDFIQGCDVGELQEPGLPGLECNGAISAHCNLRLPDSNDSPASASRVAGITDLSRNCVIKELAPQQEGNPGEVFHTVTLEQHEKHDIEEFCFREIKKKIHDFDCQWRDDERNCNKVTTAPKENLTCRRDQRDRRGIGNKSIKHQLGLSFLPHPHELQQFQAEGKIYECNHVEKSVNHGSSVSPPQIISSTIKTHVSNKYGTDFICSSLLTQEQKSCIREKPYRYIECDKALNHGSHMTVRQVSHSGEKGYKCDLCGKVFSQKSNLARHWRVHTGEKPYKCNECDRSFSRNSCLALHRRVHTGEKPYKCYECDKVFSRNSCLALHQKTHIGEKPYTCKECGKAFSVRSTLTNHQVIHSGKKPYKCNECGKVFSQTSSLATHQRIHTGEKPYKCNECGKVFSQTSSLARHWRIHTGEKPYKCNECGKVFSYNSHLASHRRVHTGEKPYKCNECGKAFSVHSNLTTHQVIHTGEKPYKCNQCGKGFSVHSSLTTHQVIHTGEKPYKCNECGKSFSVRPNLTRHQIIHTGKKPYKCSDCGKSFSVRPNLFRHQIIHTKEKPYKRN>sp|Q09FC8-3|ZN415_HUMAN Isoform 3 of Zinc finger protein 415 OS=Homosapiens OX=9606 GN=ZNF415MTVRQVSHSGEKGYKCDLCGKVFSQKSNLARHWRVHTGEKPYKCNECDRSFSRNSCLALHRRVHTGEKPYKCYECDKVFSRNSCLALHQKTHIGEKPYTCKECGKAFSVRSTLTNHQVIHSGKKPYKCNECGKVFSQTSSLATHQRIHTGEKPYKCNECGKVFSQTSSLARHWRIHTGEKPYKCNECGKVFSYNSHLASHRRVHTGEKPYKCNECGKAFSVHSNLTTHQVIHTGEKPYKCNQCGKGFSVHSSLTTHQVIHTGEKPYKCNECGKSFSVRPNLTRHQIIHTGKKPYKCSDCGKSFSVRPNLFRHQIIHTKEKPYKRN>sp|Q09FC8-4|ZN415_HUMAN Isoform 4 of Zinc finger protein 415 OS=Homosapiens OX=9606 GN=ZNF415MWEHRKEPWTIESQVRVARKPKGWEWIKGVKTDLSRNCVIKELAPQQEGNPGEVFHTVTLEQHEKHDIEEFCFREIKKKIHDFDCQWRDDERNCNKVTTAPKENLTCRRDQRDRRGIGNKSIKHQLGLSFLPHPHELQQFQAEGKIYECNHVEKSVNHGSSVSPPQIISSTIKTHVSNKYGTDFICSSLLTQEQKSCIREKPYRYIECDKALNHGSHMTVRQVSHSGEKGYKCDLCGKVFSQKSNLARHWRVHTGEKPYKCNECDRSFSRNSCLALHRRVHTGEKPYKCYECDKVFSRNSCLALHQKTHIGEKPYTCKECGKAFSVRSTLTNHQVIHSGKKPYKCNECGKVFSQTSSLATHQRIHTGEKPYKCNECGKVFSQTSSLARHWRIHTGEKPYKCNECGKVFSYNSHLASHRRVHTGEKPYKCNECGKAFSVHSNLTTHQVIHTGEKPYKCNQCGKGFSVHSSLTTHQVIHTGEKPYKCNECGKSFSVRPNLTRHQIIHTGKKPYKCSDCGKSFSVRPNLFRHQIIHTKEKPYKRN>sp|Q09FC8-5|ZN415_HUMAN Isoform 5 of Zinc finger protein 415 OS=Homosapiens OX=9606 GN=ZNF415MAFTQLTFRDVAIEFSQDEWKCLNSTQRTLYRDVMLENYRNLVSLDLSRNCVIKELAPQQEGNPGEVFHTVTLEQHEKHDIEEFCFREIKKKIHDFDCQWRDDERNCNKVTTAPKENLTCRRDQRDRRGIGNKSIKHQLGLSFLPHPHELQQFQAEGKIYECNHVEKSVNHGSSVSPPQIISSTIKTHVSNKYGTDFICSSLLTQEQKSCIREKPYRYIECDKALNHGSHMTVRQVSHSGEKGYKCDLCGKVFSQKSNLARHWRVHTGEKPYKCNECDRSFSRNSCLALHRRVHTGEKPYKCYECDKVFSRNSCLALHQKTHIGEKPYTCKECGKAFSVRSTLTNHQVIHSGKKPYKCNECGKVFSQTSSLATHQRIHTGEKPYKCNECGKVFSQTSSLARHWRIHTGEKPYKCNECGKVFSYNSHLASHRRVHTGEKPYKCNECGKAFSVHSNLTTHQVIHTGEKPYKCNQCGKGFSVHSSLTTHQVIHTGEKPYKCNECGKSFSVRPNLTRHQIIHTGKKPYKCSDCGKSFSVRPNLFRHQIIHTKEKPYKRN>sp|Q09FC8-6|ZN415_HUMAN Isoform 6 of Zinc finger protein 415 OS=Homosapiens OX=9606 GN=ZNF415MDGDGLTFRDVAIEFSQDEWKCLNSTQRTLYRDVMLENYRNLVSLDLSRNCVIKELAPQQEGNPGEVFHTVTLEQHEKHDIEEFCFREIKKKIHDFDCQWRDDERNCNKVTTAPKENLTCRRDQRDRRGIGNKSIKHQLGLSFLPHPHELQQFQAEGKIYECNHVEKSVNHGSSVSPPQIISSTIKTHVSNKYGTDFICSSLLTQEQKSCIREKPYRYIECDKALNHGSHMTVRQVSHSGEKGYKCDLCGKVFSQKSNLARHWRVHTGEKPYKCNECDRSFSRNSCLALHRRVHTGEKPYKCYECDKVFSRNSCLALHQKTHIGEKPYTCKECGKAFSVRSTLTNHQVIHSGKKPYKCNECGKVFSQTSSLATHQRIHTGEKPYKCNECGKVFSQTSSLARHWRIHTGEKPYKCNECGKVFSYNSHLASHRRVHTGEKPYKCNECGKAFSVHSNLTTHQVIHTGEKPYKCNQCGKGFSVHSSLTTHQVIHTGEKPYKCNECGKSFSVRPNLTRHQIIHTGKKPYKCSDCGKSFSVRPNLFRHQIIHTKEKPYKRN>sp|Q8IUX4|ABC3F_HUMAN DNA dC->dU-editing enzyme APOBEC-3F OS=Homosapiens OX=9606 GN=APOBEC3F PE=1 SV=3MKPHFRNTVERMYRDTFSYNFYNRPILSRRNTVWLCYEVKTKGPSRPRLDAKIFRGQVYSQPEHHAEMCFLSWFCGNQLPAYKCFQITWFVSWTPCPDCVAKLAEFLAEHPNVTLTISAARLYYYWERDYRRALCRLSQAGARVKIMDDEEFAYCWENFVYSEGQPFMPWYKFDDNYAFLHRTLKEILRNPMEAMYPHIFYFHFKNLRKAYGRNESWLCFTMEVVKHHSPVSWKRGVFRNQVDPETHCHAERCFLSWFCDDILSPNTNYEVTWYTSWSPCPECAGEVAEFLARHSNVNLTIFTARLYYFWDTDYQEGLRSLSQEGASVEIMGYKDFKYCWENFVYNDDEPFKPWKGLKYNFLFLDSKLQEILE>sp|Q8IUX4-2|ABC3F_HUMAN Isoform 2 of DNA dC->dU-editing enzyme APOBEC-3FOS=Homo sapiens OX=9606 GN=APOBEC3FMKPHFRNTVERMYRDTFSYNFYNRPILSRRNTVWLCYEVKTKGPSRPRLDAKIFRGQVPPGLQSLCRQELSQLGKQTTH>sp|Q8IUX4-3|ABC3F_HUMAN Isoform 3 of DNA dC->dU-editing enzyme APOBEC-3FOS=Homo sapiens OX=9606 GN=APOBEC3FMKPHFRNTVERMYRDTFSYNFYNRPILSRRNTVWLCYEVKTKGPSRPRLDAKIFRGQVPRSFIRAPFQVLSSPFGQCAPPHGTAQVQWPPQLTAGREQGRP>sp|O14561|ACPM_HUMAN Acyl carrier protein, mitochondrial OS=Homo sapiensOX=9606 GN=NDUFAB1 PE=1 SV=3MASRVLSAYVSRLPAAFAPLPRVRMLAVARPLSTALCSAGTQTRLGTLQPALVLAQVPGRVTQLCRQYSDMPPLTLEGIQDRVLYVLKLYDKIDPEKLSVNSHFMKDLGLDSLDQVEIIMAMEDEFGFEIPDIDAEKLMCPQEIVDYIADKKDVYE>sp|Q8WW27|ABEC4_HUMAN Putative C->U-editing enzyme APOBEC-4 OS=Homosapiens OX=9606 GN=APOBEC4 PE=1 SV=1MEPIYEEYLANHGTIVKPYYWLSFSLDCSNCPYHIRTGEEARVSLTEFCQIFGFPYGTTFPQTKHLTFYELKTSSGSLVQKGHASSCTGNYIHPESMLFEMNGYLDSAIYNNDSIRHIILYSNNSPCNEANHCCISKMYNFLITYPGITLSIYFSQLYHTEMDFPASAWNREALRSLASLWPRVVLSPISGGIWHSVLHSFISGVSGSHVFQPILTGRALADRHNAYEINAITGVKPYFTDVLLQTKRNPNTKAQEALESYPLNNAFPGQFFQMPSGQLQPNLPPDLRAPVVFVLVPLRDLPPMHMGQNPNKPRNIVRHLNMPQMSFQETKDLGRLPTGRSVEIVEITEQFASSKEADEKKKKKGKK>sp|Q6UWZ7|ABRX1_HUMAN BRCA1-A complex subunit Abraxas 1 OS=Homo sapiensOX=9606 GN=ABRAXAS1 PE=1 SV=2MEGESTSAVLSGFVLGALAFQHLNTDSDTEGFLLGEVKGEAKNSITDSQMDDVEVVYTIDIQKYIPCYQLFSFYNSSGEVNEQALKKILSNVKKNVVGWYKFRRHSDQIMTFRERLLHKNLQEHFSNQDLVFLLLTPSIITESCSTHRLEHSLYKPQKGLFHRVPLVVANLGMSEQLGYKTVSGSCMSTGFSRAVQTHSSKFFEEDGSLKEVHKINEMYASLQEELKSICKKVEDSEQAVDKLVKDVNRLKREIEKRRGAQIQAAREKNIQKDPQENIFLCQALRTFFPNSEFLHSCVMSLKNRHVSKSSCNYNHHLDVVDNLTLMVEHTDIPEASPASTPQIIKHKALDLDDRWQFKRSRLLDTQDKRSKADTGSSNQDKASKMSSPETDEEIEKMKGFGEYSRSPTF>sp|Q6UWZ7-2|ABRX1_HUMAN Isoform 2 of BRCA1-A complex subunit Abraxas 1OS=Homo sapiens OX=9606 GN=ABRAXAS1MTFRERLLHKNLQEHFSNQDLVFLLLTPSIITESCSTHRLEHSLYKPQKGLFHRVPLVVANLGMSEQLGYKTVSGSCMSTGFSRAVQTHSSKFFEEDGSLKEVHKINEMYASLQEELKSICKKVEDSEQAVDKLVKDVNRLKREIEKRRGAQIQAAREKNIQKDPQENIFLCQALRTFFPNSEFLHSCVMSLKNRHVSKSSCNYNHHLDVVDNLTLMVEHTDIPEASPASTPQIIKHKALDLDDRWQFKRSRLLDTQDKRSKADTGSSNQDKASKMSSPETDEEIEKMKGFGEYSRSPTF>sp|Q9ULW3|ABT1_HUMAN Activator of basal transcription 1 OS=Homo sapiensOX=9606 GN=ABT1 PE=1 SV=1MEAEESEKAATEQEPLEGTEQTLDAEEEQEESEEAACGSKKRVVPGIVYLGHIPPRFRPLHVRNLLSAYGEVGRVFFQAEDRFVRRKKKAAAAAGGKKRSYTKDYTEGWVEFRDKRIAKRVAASLHNTPMGARRRSPFRYDLWNLKYLHRFTWSHLSEHLAFERQVRRQRLRAEVAQAKRETDFYLQSVERGQRFLAADGDPARPDGSWTFAQRPTEQELRARKAARPGGRERARLATAQDKARSNKGLLARIFGAPPPSESMEGPSLVRDS>sp|Q9Y6H3|ATP23_HUMAN Mitochondrial inner membrane protease ATP23homolog OS=Homo sapiens OX=9606 GN=ATP23 PE=1 SV=3MAGAPDERRRGPAAGEQLQQQHVSCQVFPERLAQGNPQQGFFSSFFTSNQKCQLRLLKTLETNPYVKLLLDAMKHSGCAVNKDRHFSCEDCNGNVSGGFDASTSQIVLCQNNIHNQAHMNRVVTHELIHAFDHCRAHVDWFTNIRHLACSEVRAANLSGDCSLVNEIFRLHFGLKQHHQTCVRDRATLSILAVRNISKEVAKKAVDEVFESCFNDHEPFGRIPHNKTYARYAHRDFENRDRYYSNI>sp|Q99758|ABCA3_HUMAN Phospholipid-transporting ATPase ABCA3 OS=Homosapiens OX=9606 GN=ABCA3 PE=1 SV=2MAVLRQLALLLWKNYTLQKRKVLVTVLELFLPLLFSGILIWLRLKIQSENVPNATIYPGQSIQELPLFFTFPPPGDTWELAYIPSHSDAAKTVTETVRRALVINMRVRGFPSEKDFEDYIRYDNCSSSVLAAVVFEHPFNHSKEPLPLAVKYHLRFSYTRRNYMWTQTGSFFLKETEGWHTTSLFPLFPNPGPREPTSPDGGEPGYIREGFLAVQHAVDRAIMEYHADAATRQLFQRLTVTIKRFPYPPFIADPFLVAIQYQLPLLLLLSFTYTALTIARAVVQEKERRLKEYMRMMGLSSWLHWSAWFLLFFLFLLIAASFMTLLFCVKVKPNVAVLSRSDPSLVLAFLLCFAISTISFSFMVSTFFSKANMAAAFGGFLYFFTYIPYFFVAPRYNWMTLSQKLCSCLLSNVAMAMGAQLIGKFEAKGMGIQWRDLLSPVNVDDDFCFGQVLGMLLLDSVLYGLVTWYMEAVFPGQFGVPQPWYFFIMPSYWCGKPRAVAGKEEEDSDPEKALRNEYFEAEPEDLVAGIKIKHLSKVFRVGNKDRAAVRDLNLNLYEGQITVLLGHNGAGKTTTLSMLTGLFPPTSGRAYISGYEISQDMVQIRKSLGLCPQHDILFDNLTVAEHLYFYAQLKGLSRQKCPEEVKQMLHIIGLEDKWNSRSRFLSGGMRRKLSIGIALIAGSKVLILDEPTSGMDAISRRAIWDLLQRQKSDRTIVLTTHFMDEADLLGDRIAIMAKGELQCCGSSLFLKQKYGAGYHMTLVKEPHCNPEDISQLVHHHVPNATLESSAGAELSFILPRESTHRFEGLFAKLEKKQKELGIASFGASITTMEEVFLRVGKLVDSSMDIQAIQLPALQYQHERRASDWAVDSNLCGAMDPSDGIGALIEEERTAVKLNTGLALHCQQFWAMFLKKAAYSWREWKMVAAQVLVPLTCVTLALLAINYSSELFDDPMLRLTLGEYGRTVVPFSVPGTSQLGQQLSEHLKDALQAEGQEPREVLGDLEEFLIFRASVEGGGFNERCLVAASFRDVGERTVVNALFNNQAYHSPATALAVVDNLLFKLLCGPHASIVVSNFPQPRSALQAAKDQFNEGRKGFDIALNLLFAMAFLASTFSILAVSERAVQAKHVQFVSGVHVASFWLSALLWDLISFLIPSLLLLVVFKAFDVRAFTRDGHMADTLLLLLLYGWAIIPLMYLMNFFFLGAATAYTRLTIFNILSGIATFLMVTIMRIPAVKLEELSKTLDHVFLVLPNHCLGMAVSSFYENYETRRYCTSSEVAAHYCKKYNIQYQENFYAWSAPGVGRFVASMAASGCAYLILLFLIETNLLQRLRGILCALRRRRTLTELYTRMPVLPEDQDVADERTRILAPSPDSLLHTPLIIKELSKVYEQRVPLLAVDRLSLAVQKGECFGLLGFNGAGKTTTFKMLTGEESLTSGDAFVGGHRISSDVGKVRQRIGYCPQFDALLDHMTGREMLVMYARLRGIPERHIGACVENTLRGLLLEPHANKLVRTYSGGNKRKLSTGIALIGEPAVIFLDEPSTGMDPVARRLLWDTVARARESGKAIIITSHSMEECEALCTRLAIMVQGQFKCLGSPQHLKSKFGSGYSLRAKVQSEGQQEALEEFKAFVDLTFPGSVLEDEHQGMVHYHLPGRDLSWAKVFGILEKAKEKYGVDDYSVSQISLEQVFLSFAHLQPPTAEEGR>sp|Q99758-2|ABCA3_HUMAN Isoform 2 of Phospholipid-transporting ATPaseABCA3 OS=Homo sapiens OX=9606 GN=ABCA3MAVLRQLALLLWKNYTLQKRKVLVTVLELFLPLLFSGILIWLRLKIQSENVPNATIYPGQSIQELPLFFTFPPPGDTWELAYIPSHSDAAKTVTETVRRALVINMRVRGFPSEKDFEDYIRYDNCSSSVLAAVVFEHPFNHSKEPLPLAVKYHLRFSYTRRNYMWTQTGSFFLKETEGWHTTSLFPLFPNPGPREPTSPDGGEPGEKLG>sp|Q8N6G6|ATL1_HUMAN ADAMTS-like protein 1 OS=Homo sapiens OX=9606GN=ADAMTSL1 PE=1 SV=4MECCRRATPGTLLLFLAFLLLSSRTARSEEDRDGLWDAWGPWSECSRTCGGGASYSLRRCLSSKSCEGRNIRYRTCSNVDCPPEAGDFRAQQCSAHNDVKHHGQFYEWLPVSNDPDNPCSLKCQAKGTTLVVELAPKVLDGTRCYTESLDMCISGLCQIVGCDHQLGSTVKEDNCGVCNGDGSTCRLVRGQYKSQLSATKSDDTVVAIPYGSRHIRLVLKGPDHLYLETKTLQGTKGENSLSSTGTFLVDNSSVDFQKFPDKEILRMAGPLTADFIVKIRNSGSADSTVQFIFYQPIIHRWRETDFFPCSATCGGGYQLTSAECYDLRSNRVVADQYCHYYPENIKPKPKLQECNLDPCPASDGYKQIMPYDLYHPLPRWEATPWTACSSSCGGGIQSRAVSCVEEDIQGHVTSVEEWKCMYTPKMPIAQPCNIFDCPKWLAQEWSPCTVTCGQGLRYRVVLCIDHRGMHTGGCSPKTKPHIKEECIVPTPCYKPKEKLPVEAKLPWFKQAQELEEGAAVSEEPSFIPEAWSACTVTCGVGTQVRIVRCQVLLSFSQSVADLPIDECEGPKPASQRACYAGPCSGEIPEFNPDETDGLFGGLQDFDELYDWEYEGFTKCSESCGGGVQEAVVSCLNKQTREPAEENLCVTSRRPPQLLKSCNLDPCPARWEIGKWSPCSLTCGVGLQTRDVFCSHLLSREMNETVILADELCRQPKPSTVQACNRFNCPPAWYPAQWQPCSRTCGGGVQKREVLCKQRMADGSFLELPETFCSASKPACQQACKKDDCPSEWLLSDWTECSTSCGEGTQTRSAICRKMLKTGLSTVVNSTLCPPLPFSSSIRPCMLATCARPGRPSTKHSPHIAAARKVYIQTRRQRKLHFVVGGFAYLLPKTAVVLRCPARRVRKPLITWEKDGQHLISSTHVTVAPFGYLKIHRLKPSDAGVYTCSAGPAREHFVIKLIGGNRKLVARPLSPRSEEEVLAGRKGGPKEALQTHKHQNGIFSNGSKAEKRGLAANPGSRYDDLVSRLLEQGGWPGELLASWEAQDSAERNTTSEEDPGAEQVLLHLPFTMVTEQRRLDDILGNLSQQPEELRDLYSKHLVAQLAQEIFRSHLEHQDTLLKPSERRTSPVTLSPHKHVSGFSSSLRTSSTGDAGGGSRRPHRKPTILRKISAAQQLSASEVVTHLGQTVALASGTLSVLLHCEAIGHPRPTISWARNGEEVQFSDRILLQPDDSLQILAPVEADVGFYTCNATNALGYDSVSIAVTLAGKPLVKTSRMTVINTEKPAVTVDIGSTIKTVQGVNVTINCQVAGVPEAEVTWFRNKSKLGSPHHLHEGSLLLTNVSSSDQGLYSCRAANLHGELTESTQLLILDPPQVPTQLEDIRALLAATGPNLPSVLTSPLGTQLVLDPGNSALLGCPIKGHPVPNITWFHGGQPIVTATGLTHHILAAGQILQVANLSGGSQGEFSCLAQNEAGVLMQKASLVIQDYWWSVDRLATCSASCGNRGVQQPRLRCLLNSTEVNPAHCAGKVRPAVQPIACNRRDCPSRWMVTSWSACTRSCGGGVQTRRVTCQKLKASGISTPVSNDMCTQVAKRPVDTQACNQQLCVEWAFSSWGQCNGPCIGPHLAVQHRQVFCQTRDGITLPSEQCSALPRPVSTQNCWSEACSVHWRVSLWTLCTATCGNYGFQSRRVECVHARTNKAVPEHLCSWGPRPANWQRCNITPCENMECRDTTRYCEKVKQLKLCQLSQFKSRCCGTCGKA>sp|Q8N6G6-1|ATL1_HUMAN Isoform 1 of ADAMTS-like protein 1 OS=Homosapiens OX=9606 GN=ADAMTSL1MECCRRATPGTLLLFLAFLLLSSRTARSEEDRDGLWDAWGPWSECSRTCGGGASYSLRRCLSSKSCEGRNIRYRTCSNVDCPPEAGDFRAQQCSAHNDVKHHGQFYEWLPVSNDPDNPCSLKCQAKGTTLVVELAPKVLDGTRCYTESLDMCISGLCQIVGCDHQLGSTVKEDNCGVCNGDGSTCRLVRGQYKSQLSATKSDDTVVAIPYGSRHIRLVLKGPDHLYLETKTLQGTKGENSLSSTGTFLVDNSSVDFQKFPDKEILRMAGPLTADFIVKIRNSGSADSTVQFIFYQPIIHRWRETDFFPCSATCGGGYQLTSAECYDLRSNRVVADQYCHYYPENIKPKPKLQECNLDPCPASDGYKQIMPYDLYHPLPRWEATPWTACSSSCGGGIQSRAVSCVEEDIQGHVTSVEEWKCMYTPKMPIAQPCNIFDCPKWLAQEWSPCTVTCGQGLRYRVVLCIDHRGMHTGGCSPKTKPHIKEECIVPTPCYKPKEKLPVEAKLPWFKQAQELEEGAAVSEEPS>sp|Q8N6G6-2|ATL1_HUMAN Isoform 2 of ADAMTS-like protein 1 OS=Homosapiens OX=9606 GN=ADAMTSL1MECCRRATPGTLLLFLAFLLLSSRTARSEEDRDGLWDAWGPWSECSRTCGGGASYSLRRCLSSKSCEGRNIRYRTCSNVDCPPEAGDFRAQQCSAHNDVKHHGQFYEWLPVSNDPDNPCSLKCQAKGTTLVVELAPKVLDGTRCYTESLDMCISGLCQIVGCDHQLGSTVKEDNCGVCNGDGSTCRLVRGQYKSQLSATKSDDTVVAIPYGSRHIRLVLKGPDHLYLETKTLQGTKGENSLSSTGTFLVDNSSVDFQKFPDKEILRMAGPLTADFIVKIRNSGSADSTVQFIFYQPIIHRWRETDFFPCSATCGGGYQLTSAECYDLRSNRVVADQYCHYYPENIKPKPKLQECNLDPCPARWEATPWTACSSSCGGGIQSRAVSCVEEDIQGHVTSVEEWKCMYTPKMPIAQPCNIFDCPKWLAQEWSPVTVPSFFVH>sp|Q8N6G6-4|ATL1_HUMAN Isoform 4 of ADAMTS-like protein 1 OS=Homosapiens OX=9606 GN=ADAMTSL1MECCRRATPGTLLLFLAFLLLSSRTARSEEDRDGLWDAWGPWSECSRTCGGGASYSLRRCLSSKSCEGRNIRYRTCSNVDCPPEAGDFRAQQCSAHNDVKHHGQFYEWLPVSNDPDNPCSLKCQAKGTTLVVELAPKVLDGTRCYTESLDMCISGLCQIVGCDHQLGSTVKEDNCGVCNGDGSTCRLVRGQYKSQLSATKSDDTVVAIPYGSRHIRLVLKGPDHLYLETKTLQGTKGENSLSSTGTFLVDNSSVDFQKFPDKEILRMAGPLTADFIVKIRNSGSADSTVQFIFYQPIIHRWRETDFFPCSATCGGGYQLTSAECYDLRSNRVVADQYCHYYPENIKPKPKLQECNLDPCPASDGYKQIMPYDLYHPLPRWEATPWTACSSSCGGGIQSRAVSCVEEDIQGHVTSVEEWKCMYTPKMPIAQPCNIFDCPKWLAQEWSPCTVTCGQGLRYRVVLCIDHRGMHTGGCSPKTKPHIKEECIVPTPCYKPKEKLPVEAKLPWFKQAQELEEGAAVSEEPSFIPEAWSACTVTCGVGTQVRIVRCQVLLSFSQSVADLPIDECEGPKPASQRACYAGPCSGEIPEFNPDETDGLFGGLQDFDELYDWEYEGFTKCSESCGGGVQEAVVSCLNKQTREPAEENLCVTSRRPPQLLKSCNLDPCPARSSIDSAWNACNVLC>sp|Q8N6G6-5|ATL1_HUMAN Isoform 5 of ADAMTS-like protein 1 OS=Homosapiens OX=9606 GN=ADAMTSL1MSGVFCFFFFFLGVPEAEVTWFRNKSKLGSPHHLHEGSLLLTNVSSSDQGLYSCRAANLHGELTESTQLLILDPPQVPTQLEDIRALLAATGPNLPSVLTSPLGTQLVLDPGNSALLGCPIKGHPVPNITWFHGGQPIVTATGLTHHILAAGQILQVANLSGGSQGEFSCLAQNEAGVLMQKASLVIQDYWWSVDRLATCSASCGNRGVQQPRLRCLLNSTEVNPAHCAGKVRPAVQPIACNRRDCPSRAMGLASGLT>sp|Q8N6G6-6|ATL1_HUMAN Isoform 6 of ADAMTS-like protein 1 OS=Homosapiens OX=9606 GN=ADAMTSL1MSGVFCFFFFFLGVPEAEVTWFRNKSKLGSPHHLHEGSLLLTNVSSSDQGLYSCRAANLHGELTESTQLLILDPPQVPTQLEDIRALLAATGPNLPSVLTSPLGTQLVLDPGNSALLGCPIKGHPVPNITWFHGGQPIVTATGLTHHILAAGQILQVANLSGGSQGEFSCLAQNEAGVLMQKASLVIQDYWWSVDRLATCSASCGNRGVQQPRLRCLLNSTEVNPAHCAGKVRPAVQPIACNRRDCPSRWMVTSWSACTRSCGGGVQTRRVTCQKLKASGISTPVSNDMCTQVAKRPVDTQACNQQLCVEWAFSSWGQCNGPCIGPHLAVQHRQVFCQTRDGITLPSEQCSALPRPVSTQNCWSEACSVHWRVSLWTLCTATCGNYGFQSRRVECVHARTNKAVPEHLCSWGPRPANWQRCNITPCENMECRDTTRYCEKVKQLKLCQLSQFKSRCCGTCGKA>sp|Q6UY14|ATL4_HUMAN ADAMTS-like protein 4 OS=Homo sapiens OX=9606GN=ADAMTSL4 PE=1 SV=2MENWTGRPWLYLLLLLSLPQLCLDQEVLSGHSLQTPTEEGQGPEGVWGPWVQWASCSQPCGVGVQRRSRTCQLPTVQLHPSLPLPPRPPRHPEALLPRGQGPRPQTSPETLPLYRTQSRGRGGPLRGPASHLGREETQEIRAARRSRLRDPIKPGMFGYGRVPFALPLHRNRRHPRSPPRSELSLISSRGEEAIPSPTPRAEPFSANGSPQTELPPTELSVHTPSPQAEPLSPETAQTEVAPRTRPAPLRHHPRAQASGTEPPSPTHSLGEGGFFRASPQPRRPSSQGWASPQVAGRRPDPFPSVPRGRGQQGQGPWGTGGTPHGPRLEPDPQHPGAWLPLLSNGPHASSLWSLFAPSSPIPRCSGESEQLRACSQAPCPPEQPDPRALQCAAFNSQEFMGQLYQWEPFTEVQGSQRCELNCRPRGFRFYVRHTEKVQDGTLCQPGAPDICVAGRCLSPGCDGILGSGRRPDGCGVCGGDDSTCRLVSGNLTDRGGPLGYQKILWIPAGALRLQIAQLRPSSNYLALRGPGGRSIINGNWAVDPPGSYRAGGTVFRYNRPPREEGKGESLSAEGPTTQPVDVYMIFQEENPGVFYQYVISSPPPILENPTPEPPVPQLQPEILRVEPPLAPAPRPARTPGTLQRQVRIPQMPAPPHPRTPLGSPAAYWKRVGHSACSASCGKGVWRPIFLCISRESGEELDERSCAAGARPPASPEPCHGTPCPPYWEAGEWTSCSRSCGPGTQHRQLQCRQEFGGGGSSVPPERCGHLPRPNITQSCQLRLCGHWEVGSPWSQCSVRCGRGQRSRQVRCVGNNGDEVSEQECASGPPQPPSREACDMGPCTTAWFHSDWSSKCSAECGTGIQRRSVVCLGSGAALGPGQGEAGAGTGQSCPTGSRPPDMRACSLGPCERTWRWYTGPWGECSSECGSGTQRRDIICVSKLGTEFNVTSPSNCSHLPRPPALQPCQGQACQDRWFSTPWSPCSRSCQGGTQTREVQCLSTNQTLSTRCPPQLRPSRKRPCNSQPCSQRPDDQCKDSSPHCPLVVQARLCVYPYYTATCCRSCAHVLERSPQDPS>sp|Q6UY14-2|ATL4_HUMAN Isoform 2 of ADAMTS-like protein 4 OS=Homosapiens OX=9606 GN=ADAMTSL4MENWTGRPWLYLLLLLSLPQLCLDQEVLSGHSLQTPTEEGQGPEGVWGPWVQWASCSQPCGVGVQRRSRTCQLPTVQLHPSLPLPPRPPRHPEALLPRGQGPRPQTSPETLPLYRTQSRGRGGPLRGPASHLGREETQEIRAARRSRLRDPIKPGMFGYGRVPFALPLHRNRRHPRSPPRSELSLISSRGEEAIPSPTPRAEPFSANGSPQTELPPTELSVHTPSPQAEPLSPETAQTEVAPRTRPAPLRHHPRAQASGTEPPSPTHSLGEGGFFRASPQPRRPSSQGWASPQVAGRRPDPFPSVPRGRGQQGQGPWGTGGTPHGPRLEPDPQHPGAWLPLLSNGPHASSLWSLFAPSSPIPRCSGESEQLRACSQAPCPPEQPDPRALQCAAFNSQEFMGQLYQWEPFTEVQGSQRCELNCRPRGFRFYVRHTEKVQDGTLCQPGAPDICVAGRCLSPGCDGILGSGRRPDGCGVCGGDDSTCRLVSGNLTDRGGPLGYQKILWIPAGALRLQIAQLRPSSNYLALRGPGGRSIINGNWAVDPPGSYRAGGTVFRYNRPPREEGKGESLSAEGPTTQPVDVYMIFQEENPGVFYQYVISSPPPILENPTPEPPVPQLQPEILRVEPPLAPAPRPARTPGTLQRQVRIPQMPAPPHPRTPLGSPAAYWKRVGHSACSASCGKGVWRPIFLCISRESGEELDERSCAAGARPPASPEPCHGTPCPPYWEAGEWTSCSRSCGPGTQHRQLQCRQEFGGGGSSVPPERCGHLPRPNITQSCQLRLCGHWEVGSPWSQCSVRCGRGQRSRQVRCVGNNGDEVSEQECASGPPQPPSREACDMGPCTTAWFHSDWSSKVSPEPPAISCILGNHAQDTSAFPA>sp|Q6UY14-3|ATL4_HUMAN Isoform 3 of ADAMTS-like protein 4 OS=Homosapiens OX=9606 GN=ADAMTSL4MENWTGRPWLYLLLLLSLPQLCLDQEVLSGHSLQTPTEEGQGPEGVWGPWVQWASCSQPCGVGVQRRSRTCQLPTVQLHPSLPLPPRPPRHPEALLPRGQGPRPQTSPETLPLYRTQSRGRGGPLRGPASHLGREETQEIRAARRSRLRDPIKPGMFGYGRVPFALPLHRNRRHPRSPPRSELSLISSRGEEAIPSPTPRAEPFSANGSPQTELPPTELSVHTPSPQAEPLSPETAQTEVAPRTRPAPLRHHPRAQASGTEPPSPTHSLGEGGFFRASPQPRRPSSQGWASPQVAGRRPDPFPSVPRGRGQQGQGPWGTGGTPHGPRLEPDPQHPGAWLPLLSNGPHASSLWSLFAPSSPIPRCSGESEQLRACSQAPCPPEQPDPRALQCAAFNSQEFMGQLYQWEPFTEAPLLPLRHAFFLLPGAGSGDSTGVQGSQRCELNCRPRGFRFYVRHTEKVQDGTLCQPGAPDICVAGRCLSPGCDGILGSGRRPDGCGVCGGDDSTCRLVSGNLTDRGGPLGYQKILWIPAGALRLQIAQLRPSSNYLALRGPGGRSIINGNWAVDPPGSYRAGGTVFRYNRPPREEGKGESLSAEGPTTQPVDVYMIFQEENPGVFYQYVISSPPPILENPTPEPPVPQLQPEILRVEPPLAPAPRPARTPGTLQRQVRIPQMPAPPHPRTPLGSPAAYWKRVGHSACSASCGKGVWRPIFLCISRESGEELDERSCAAGARPPASPEPCHGTPCPPYWEAGEWTSCSRSCGPGTQHRQLQCRQEFGGGGSSVPPERCGHLPRPNITQSCQLRLCGHWEVGSPWSQCSVRCGRGQRSRQVRCVGNNGDEVSEQECASGPPQPPSREACDMGPCTTAWFHSDWSSKCSAECGTGIQRRSVVCLGSGAALGPGQGEAGAGTGQSCPTGSRPPDMRACSLGPCERTWRWYTGPWGECSSECGSGTQRRDIICVSKLGTEFNVTSPSNCSHLPRPPALQPCQGQACQDRWFSTPWSPCSRSCQGGTQTREVQCLSTNQTLSTRCPPQLRPSRKRPCNSQPCSQRPDDQCKDSSPHCPLVVQARLCVYPYYTATCCRSCAHVLERSPQDPS>sp|P02763|A1AG1_HUMAN Alpha-1-acid glycoprotein 1 OS=Homo sapiensOX=9606 GN=ORM1 PE=1 SV=1MALSWVLTVLSLLPLLEAQIPLCANLVPVPITNATLDQITGKWFYIASAFRNEEYNKSVQEIQATFFYFTPNKTEDTIFLREYQTRQDQCIYNTTYLNVQRENGTISRYVGGQEHFAHLLILRDTKTYMLAFDVNDEKNWGLSVYADKPETTKEQLGEFYEALDCLRIPKSDVVYTDWKKDKCEPLEKQHEKERKQEEGES>sp|P20848|A1ATR_HUMAN Putative alpha-1-antitrypsin-related proteinOS=Homo sapiens OX=9606 GN=SERPINA2 PE=1 SV=1MPFSVSWGVLLLAGLCCLVPSSLVEDPQGDAAQKTDTSHHDQGDWEDLACQKISYNVTDLAFDLYKSWLIYHNQHVLVTPTSVAMAFRMLSLGTKADTRTEILEGLNVNLTETPEAKIHECFQQVLQALSRPDTRLQLTTGSSLFVNKSMKLVDTFLEDTKKLYHSEASSINFRDTEEAKEQINNYVEKRTGRKVVDLVKHLKKDTSLALVDYISFHGKWKDKFKAERIMVEGFHVDDKTIIRVPMINHLGRFDIHRDRELSSWVLAQHYVGNATAFFILPDPKKMWQLEEKLTYSHLENIQRAFDIRSINLHFPKLSISGTYKLKRVPRNLGITKIFSNEADLSGVSQEAPLKLSKAVHVAVLTIDEKGTEATGAPHLEEKAWSKYQTVMFNRPFLVIIKEYITNFPLFIGKVVNPTQK>sp|Q8IZY2|ABCA7_HUMAN Phospholipid-transporting ATPase ABCA7 OS=Homosapiens OX=9606 GN=ABCA7 PE=1 SV=3MAFWTQLMLLLWKNFMYRRRQPVQLLVELLWPLFLFFILVAVRHSHPPLEHHECHFPNKPLPSAGTVPWLQGLICNVNNTCFPQLTPGEEPGRLSNFNDSLVSRLLADARTVLGGASAHRTLAGLGKLIATLRAARSTAQPQPTKQSPLEPPMLDVAELLTSLLRTESLGLALGQAQEPLHSLLEAAEDLAQELLALRSLVELRALLQRPRGTSGPLELLSEALCSVRGPSSTVGPSLNWYEASDLMELVGQEPESALPDSSLSPACSELIGALDSHPLSRLLWRRLKPLILGKLLFAPDTPFTRKLMAQVNRTFEELTLLRDVREVWEMLGPRIFTFMNDSSNVAMLQRLLQMQDEGRRQPRPGGRDHMEALRSFLDPGSGGYSWQDAHADVGHLVGTLGRVTECLSLDKLEAAPSEAALVSRALQLLAEHRFWAGVVFLGPEDSSDPTEHPTPDLGPGHVRIKIRMDIDVVTRTNKIRDRFWDPGPAADPLTDLRYVWGGFVYLQDLVERAAVRVLSGANPRAGLYLQQMPYPCYVDDVFLRVLSRSLPLFLTLAWIYSVTLTVKAVVREKETRLRDTMRAMGLSRAVLWLGWFLSCLGPFLLSAALLVLVLKLGDILPYSHPGVVFLFLAAFAVATVTQSFLLSAFFSRANLAAACGGLAYFSLYLPYVLCVAWRDRLPAGGRVAASLLSPVAFGFGCESLALLEEQGEGAQWHNVGTRPTADVFSLAQVSGLLLLDAALYGLATWYLEAVCPGQYGIPEPWNFPFRRSYWCGPRPPKSPAPCPTPLDPKVLVEEAPPGLSPGVSVRSLEKRFPGSPQPALRGLSLDFYQGHITAFLGHNGAGKTTTLSILSGLFPPSGGSAFILGHDVRSSMAAIRPHLGVCPQYNVLFDMLTVDEHVWFYGRLKGLSAAVVGPEQDRLLQDVGLVSKQSVQTRHLSGGMQRKLSVAIAFVGGSQVVILDEPTAGVDPASRRGIWELLLKYREGRTLILSTHHLDEAELLGDRVAVVAGGRLCCCGSPLFLRRHLGSGYYLTLVKARLPLTTNEKADTDMEGSVDTRQEKKNGSQGSRVGTPQLLALVQHWVPGARLVEELPHELVLVLPYTGAHDGSFATLFRELDTRLAELRLTGYGISDTSLEEIFLKVVEECAADTDMEDGSCGQHLCTGIAGLDVTLRLKMPPQETALENGEPAGSAPETDQGSGPDAVGRVQGWALTRQQLQALLLKRFLLARRSRRGLFAQIVLPALFVGLALVFSLIVPPFGHYPALRLSPTMYGAQVSFFSEDAPGDPGRARLLEALLQEAGLEEPPVQHSSHRFSAPEVPAEVAKVLASGNWTPESPSPACQCSRPGARRLLPDCPAAAGGPPPPQAVTGSGEVVQNLTGRNLSDFLVKTYPRLVRQGLKTKKWVNEVRYGGFSLGGRDPGLPSGQELGRSVEELWALLSPLPGGALDRVLKNLTAWAHSLDAQDSLKIWFNNKGWHSMVAFVNRASNAILRAHLPPGPARHAHSITTLNHPLNLTKEQLSEGALMASSVDVLVSICVVFAMSFVPASFTLVLIEERVTRAKHLQLMGGLSPTLYWLGNFLWDMCNYLVPACIVVLIFLAFQQRAYVAPANLPALLLLLLLYGWSITPLMYPASFFFSVPSTAYVVLTCINLFIGINGSMATFVLELFSDQKLQEVSRILKQVFLIFPHFCLGRGLIDMVRNQAMADAFERLGDRQFQSPLRWEVVGKNLLAMVIQGPLFLLFTLLLQHRSQLLPQPRVRSLPLLGEEDEDVARERERVVQGATQGDVLVLRNLTKVYRGQRMPAVDRLCLGIPPGECFGLLGVNGAGKTSTFRMVTGDTLASRGEAVLAGHSVAREPSAAHLSMGYCPQSDAIFELLTGREHLELLARLRGVPEAQVAQTAGSGLARLGLSWYADRPAGTYSGGNKRKLATALALVGDPAVVFLDEPTTGMDPSARRFLWNSLLAVVREGRSVMLTSHSMEECEALCSRLAIMVNGRFRCLGSPQHLKGRFAAGHTLTLRVPAARSQPAAAFVAAEFPGAELREAHGGRLRFQLPPGGRCALARVFGELAVHGAEHGVEDFSVSQTMLEEVFLYFSKDQGKDEDTEEQKEAGVGVDPAPGLQHPKRVSQFLDDPSTAETVL>sp|Q8IZY2-2|ABCA7_HUMAN Isoform 2 of Phospholipid-transporting ATPaseABCA7 OS=Homo sapiens OX=9606 GN=ABCA7MVCLGTGQSAGPLVSVQNHCPPCGLSPQESLGLALGQAQEPLHSLLEAAEDLAQELLALRSLVELRALLQRPRGTSGPLELLSEALCSVRGPSSTVGPSLNWYEASDLMELVGQEPESALPDSSLSPACSELIGALDSHPLSRLLWRRLKPLILGKLLFAPDTPFTRKLMAQVNRTFEELTLLRDVREVWEMLGPRIFTFMNDSSNVAMLQRLLQMQDEGRRQPRPGGRDHMEALRSFLDPGSGGYSWQDAHADVGHLVGTLGRVTECLSLDKLEAAPSEAALVSRALQLLAEHRFWAGVVFLGPEDSSDPTEHPTPDLGPGHVRIKIRMDIDVVTRTNKIRDRFWDPGPAADPLTDLRYVWGGFVYLQDLVERAAVRVLSGANPRAGLYLQQMPYPCYVDDVFLRVLSRSLPLFLTLAWIYSVTLTVKAVVREKETRLRDTMRAMGLSRAVLWLGWFLSCLGPFLLSAALLVLVLKLGDILPYSHPGVVFLFLAAFAVATVTQSFLLSAFFSRANLAAACGGLAYFSLYLPYVLCVAWRDRLPAGGRVAASLLSPVAFGFGCESLALLEEQGEGAQWHNVGTRPTADVFSLAQVSGLLLLDAALYGLATWYLEAVCPGQYGIPEPWNFPFRRSYWCGPRPPKSPAPCPTPLDPKVLVEEAPPGLSPGVSVRSLEKRFPGSPQPALRGLSLDFYQGHITAFLGHNGAGKTTTLSILSGLFPPSGGSAFILGHDVRSSMAAIRPHLGVCPQYNVLFDMLTVDEHVWFYGRLKGLSAAVVGPEQDRLLQDVGLVSKQSVQTRHLSGGMQRKLSVAIAFVGGSQVVILDEPTAGVDPASRRGIWELLLKYREGRTLILSTHHLDEAELLGDRVAVVAGGRLCCCGSPLFLRRHLGSGYYLTLVKARLPLTTNEKADTDMEGSVDTRQEKKNGSQGSRVGTPQLLALVQHWVPGARLVEELPHELVLVLPYTGAHDGSFATLFRELDTRLAELRLTGYGISDTSLEEIFLKVVEECAADTDMEDGSCGQHLCTGIAGLDVTLRLKMPPQETALENGEPAGSAPETDQGSGPDAVGRVQGWALTRQQLQALLLKRFLLARRSRRGLFAQIVLPALFVGLALVFSLIVPPFGHYPALRLSPTMYGAQVSFFSEDAPGDPGRARLLEALLQEAGLEEPPVQHSSHRFSAPEVPAEVAKVLASGNWTPESPSPACQCSRPGARRLLPDCPAAAGGPPPPQAVTGSGEVVQNLTGRNLSDFLVKTYPRLVRQGLKTKKWVNEVRYGGFSLGGRDPGLPSGQELGRSVEELWALLSPLPGGALDRVLKNLTAWAHSLDAQDSLKIWFNNKGWHSMVAFVNRASNAILRAHLPPGPARHAHSITTLNHPLNLTKEQLSEGALMASSVDVLVSICVVFAMSFVPASFTLVLIEERVTRAKHLQLMGGLSPTLYWLGNFLWDMCNYLVPACIVVLIFLAFQQRAYVAPANLPALLLLLLLYGWSITPLMYPASFFFSVPSTAYVVLTCINLFIGINGSMATFVLELFSDQKLQEVSRILKQVFLIFPHFCLGRGLIDMVRNQAMADAFERLGDRQFQSPLRWEVVGKNLLAMVIQGPLFLLFTLLLQHRSQLLPQPRVRSLPLLGEEDEDVARERERVVQGATQGDVLVLRNLTKVYRGQRMPAVDRLCLGIPPGECFGLLGVNGAGKTSTFRMVTGDTLASRGEAVLAGHSVAREPSAAHLSMGYCPQSDAIFELLTGREHLELLARLRGVPEAQVAQTAGSGLARLGLSWYADRPAGTYSGGNKRKLATALALVGDPAVVFLDEPTTGMDPSARRFLWNSLLAVVREGRSVMLTSHSMEECEALCSRLAIMVNGRFRCLGSPQHLKGRFAAGHTLTLRVPAARSQPAAAFVAAEFPGAELREAHGGRLRFQLPPGGRCALARVFGELAVHGAEHGVEDFSVSQTMLEEVFLYFSKDQGKDEDTEEQKEAGVGVDPAPGLQHPKRVSQFLDDPSTAETVL>sp|P01009|A1AT_HUMAN Alpha-1-antitrypsin OS=Homo sapiens OX=9606GN=SERPINA1 PE=1 SV=3MPSSVSWGILLLAGLCCLVPVSLAEDPQGDAAQKTDTSHHDQDHPTFNKITPNLAEFAFSLYRQLAHQSNSTNIFFSPVSIATAFAMLSLGTKADTHDEILEGLNFNLTEIPEAQIHEGFQELLRTLNQPDSQLQLTTGNGLFLSEGLKLVDKFLEDVKKLYHSEAFTVNFGDTEEAKKQINDYVEKGTQGKIVDLVKELDRDTVFALVNYIFFKGKWERPFEVKDTEEEDFHVDQVTTVKVPMMKRLGMFNIQHCKKLSSWVLLMKYLGNATAIFFLPDEGKLQHLENELTHDIITKFLENEDRRSASLHLPKLSITGTYDLKSVLGQLGITKVFSNGADLSGVTEEAPLKLSKAVHKAVLTIDEKGTEAAGAMFLEAIPMSIPPEVKFNKPFVFLMIEQNTKSPLFMGKVVNPTQK>sp|P01009-2|A1AT_HUMAN Isoform 2 of Alpha-1-antitrypsin OS=Homo sapiensOX=9606 GN=SERPINA1MPSSVSWGILLLAGLCCLVPVSLAEDPQGDAAQKTDTSHHDQDHPTFNKITPNLAEFAFSLYRQLAHQSNSTNIFFSPVSIATAFAMLSLGTKADTHDEILEGLNFNLTEIPEAQIHEGFQELLRTLNQPDSQLQLTTGNGLFLSEGLKLVDKFLEDVKKLYHSEAFTVNFGDTEEAKKQINDYVEKGTQGKIVDLVKELDRDTVFALVNYIFFKGKWERPFEVKDTEEEDFHVDQVTTVKVPMMKRLGMFNIQHCKKLSSWVLLMKYLGNATAIFFLPDEGKLQHLENELTHDIITKFLENEDRRSASLHLPKLSITGTYDLKSVLGQLGITKVFSNGADLSGVTEEAPLKLSKVRSP>sp|P01009-3|A1AT_HUMAN Isoform 3 of Alpha-1-antitrypsin OS=Homo sapiensOX=9606 GN=SERPINA1MPSSVSWGILLLAGLCCLVPVSLAEDPQGDAAQKTDTSHHDQDHPTFNKITPNLAEFAFSLYRQLAHQSNSTNIFFSPVSIATAFAMLSLGTKADTHDEILEGLNFNLTEIPEAQIHEGFQELLRTLNQPDSQLQLTTGNGLFLSEGLKLVDKFLEDVKKLYHSEAFTVNFGDTEEAKKQINDYVEKGTQGKIVDLVKELDRDTVFALVNYIFFKGKWERPFEVKDTEEEDFHVDQVTTVKVPMMKRLGMFNIQHCKKLSSWVLLMKYLGNATAIFFLPDEGKLQHLENELTHDIITKFLENEDRR>sp|Q8TDN7|ACER1_HUMAN Alkaline ceramidase 1 OS=Homo sapiens OX=9606GN=ACER1 PE=1 SV=1MPSIFAYQSSEVDWCESNFQYSELVAEFYNTFSNIPFFIFGPLMMLLMHPYAQKRSRYIYVVWVLFMIIGLFSMYFHMTLSFLGQLLDEIAILWLLGSGYSIWMPRCYFPSFLGGNRSQFIRLVFITTVVSTLLSFLRPTVNAYALNSIALHILYIVCQEYRKTSNKELRHLIEVSVVLWAVALTSWISDRLLCSFWQRIHFFYLHSIWHVLISITFPYGMVTMALVDANYEMPGETLKVRYWPRDSWPVGLPYVEIRGDDKDC>sp|Q8TB40|ABHD4_HUMAN (Lyso)-N-acylphosphatidylethanolamine lipaseOS=Homo sapiens OX=9606 GN=ABHD4 PE=1 SV=1MADDLEQQSQGWLSSWLPTWRPTSMSQLKNVEARILQCLQNKFLARYVSLPNQNKIWTVTVSPEQNDRTPLVMVHGFGGGVGLWILNMDSLSARRTLHTFDLLGFGRSSRPAFPRDPEGAEDEFVTSIETWRETMGIPSMILLGHSLGGFLATSYSIKYPDRVKHLILVDPWGFPLRPTNPSEIRAPPAWVKAVASVLGRSNPLAVLRVAGPWGPGLVQRFRPDFKRKFADFFEDDTISEYIYHCNAQNPSGETAFKAMMESFGWARRPMLERIHLIRKDVPITMIYGSDTWIDTSTGKKVKMQRPDSYVRDMEIKGASHHVYADQPHIFNAVVEEICDSVD>sp|Q8TB40-2|ABHD4_HUMAN Isoform 2 of (Lyso)-N-acylphosphatidylethanolamine lipase OS=Homo sapiens OX=9606 GN=ABHD4MADDLEQQSQGWLSSWLPTWRPTSMSQLKNVEARILQCLQNKFLARYVSLPNQNKIWTVTVSPEQNDRTPLVMVHGFGGGVGLWILNMDSLSARRTLHTFDLLGFGRSSRPAFPRDPEGAEDEFVTSIETWRETMGIPSMILLGHSLGGFLATSYSIKYPDRAWSGAAIPAGLQTQVCRLL>sp|Q9NUJ1|ABHDA_HUMAN Palmitoyl-protein thioesterase ABHD10,mitochondrial OS=Homo sapiens OX=9606 GN=ABHD10 PE=1 SV=1MAVARLAAVAAWVPCRSWGWAAVPFGPHRGLSVLLARIPQRAPRWLPACRQKTSLSFLNRPDLPNLAYKKLKGKSPGIIFIPGYLSYMNGTKALAIEEFCKSLGHACIRFDYSGVGSSDGNSEESTLGKWRKDVLSIIDDLADGPQILVGSSLGGWLMLHAAIARPEKVVALIGVATAADTLVTKFNQLPVELKKEVEMKGVWSMPSKYSEEGVYNVQYSFIKEAEHHCLLHSPIPVNCPIRLLHGMKDDIVPWHTSMQVADRVLSTDVDVILRKHSDHRMREKADIQLLVYTIDDLIDKLSTIVN>sp|Q9NUJ1-2|ABHDA_HUMAN Isoform 2 of Palmitoyl-protein thioesteraseABHD10, mitochondrial OS=Homo sapiens OX=9606 GN=ABHD10MLHAAIARPEKVVALIGVATAADTLVTKFNQLPVELKKEVEMKGVWSMPSKYSEEGVYNVQYSFIKEAEHHCLLHSPIPVNCPIRLLHGMKDDIVPWHTSMQVADRVLSTDVDVILRKHSDHRMREKADIQLLVYTIDDLIDKLSTIVN>sp|Q9NUJ1-3|ABHDA_HUMAN Isoform 3 of Palmitoyl-protein thioesteraseABHD10, mitochondrial OS=Homo sapiens OX=9606 GN=ABHD10MAVARLAAVAAWVPCRSWGWAAVPFGPHRGLSVLLARIPQRAPRWLPACRQKTSLSFLNRPDLPNLAYKKLKGKSPGIIFIPGYLSYMNGTKALAIEEFCKSLGHACIRFDYSGVGSSDGNSEESTLGKWRKDVLSIIDDLADGPQILVGSSLGGWLMLHAAIARPEKVVALIGVATAADTLVTKFNQLPVEDSGRKNYISLHSA>sp|Q8IZP0|ABI1_HUMAN Abl interactor 1 OS=Homo sapiens OX=9606 GN=ABI1PE=1 SV=4MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPENISVPPPSGAPPAPPLAPLLPVSTVIAAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSISIAPPPPPMPQLTPQIPLTGFVARVQENIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-2|ABI1_HUMAN Isoform 2 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-3|ABI1_HUMAN Isoform 3 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPAAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-4|ABI1_HUMAN Isoform 4 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-5|ABI1_HUMAN Isoform 5 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPAAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSISIAPPPPPMPQLTPQIPLTGFVARVQENIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-6|ABI1_HUMAN Isoform 6 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSISIAPPPPPMPQLTPQIPLTGFVARVQENIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-7|ABI1_HUMAN Isoform 7 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPVSIAPPPPPMPQLTPQIPLTGFVARVQENIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-8|ABI1_HUMAN Isoform 8 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-9|ABI1_HUMAN Isoform 9 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPAAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSISIAPPPPPMPQLTPQIPLTGFVARVQENIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-10|ABI1_HUMAN Isoform 10 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPVADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-11|ABI1_HUMAN Isoform 11 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPVADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q8IZP0-12|ABI1_HUMAN Isoform 12 of Abl interactor 1 OS=Homo sapiensOX=9606 GN=ABI1MAELQMLLEEEIPSGKRALIESYQNLTRVADYCENNYIQRHGFAVLLCLLSNSWPQATDKRKALEETKAYTTQSLASVAYQINALANNVLQLLDIQASQLRRMESSINHISQTVDIHKEKVARREIGILTTNKNTSRTHKIIAPANMERPVRYIRKPIDYTVLDDVGHGVKWLKAKHGNNQPARTGTLSRTNPPTQKPPSPPMSGRGTLGRNTPYKTLEPVKPPTVPNDYMTSPARLGSQHSPGRTASLNQRPRTHSGSSGGSGSRENSGSSSIGIPIAVPTPSPPTIGPENISVPPPSGAPPAPPLAPLLPVSTVIAAPGSAPGSQYGTMTRQISRHNSTTSSTSSGGYRRTPSVTAQFSAQPHVNGGPLYSQNSIADSPTPPPPPPPDDIPMFDDSPPPPPPPPVDYEDEEAAVVQYNDPYADGDPAWAPKNYIEKVVAIYDYTKDKDDELSFMEGAIIYVIKKNDDGWYEGVCNRVTGLFPGNYVESIMHYTD>sp|Q4AC99|1A1L2_HUMAN Probable inactive 1-aminocyclopropane-1-carboxylate synthase-like protein 2 OS=Homo sapiens OX=9606 GN=ACCSL PE=2SV=3MSHRSDTLPVPSGQRRGRVPRDHSIYTQLLEITLHLQQAMTEHFVQLTSRQGLSLEERRHTEAICEHEALLSRLICRMINLLQSGAASGLELQVPLPSEDSRGDVRYGQRAQLSGQPDPVPQLSDCEAAFVNRDLSIRGIDISVFYQSSFQDYNAYQKDKYHKDKNTLGFINLGTSENKLCMDLMTERLQESDMNCIEDTLLQYPDWRGQPFLREEVARFLTYYCRAPTRLDPENVVVLNGCCSVFCALAMVLCDPGEAFLVPAPFYGGFAFSSRLYAKVELIPVHLESEVTVTNTHPFQLTVDKLEEALLEARLEGKKVRGLVLINPQNPLGDIYSPDSLMKYLEFAKRYNLHVIIDEIYMLSVFDESITFHSILSMKSLPDSNRTHVIWGTSKDFGISGFRFGALYTHNKEVASAVSAFGYLHSISGITQHKLCQLLQNTEWIDKVYLPTNCYRLREAHKYITAELKALEIPFHNRSSGLYVWINLKKYLDPCTFEEERLLYCRFLDNKLLLSRGKTYMCKEPGWFCLIFADELPRLKLAMRRFCDVLQEQKEALIVKQLEDAMRE>sp|Q9P203|BTBD7_HUMAN BTB/POZ domain-containing protein 7 OS=Homosapiens OX=9606 GN=BTBD7 PE=1 SV=3MGANASNYPHSCSPRVGGNSQAQQTFIGTSSYSQQGYGCESKLYSLDHGHEKPQDKKKRTSGLATLKKKFIKRRKSNRSADHAKQMRELLSGWDVRDVNALVEEYEGTSALKELSLQASLARPEARTLQKDMADLYEYKYCTDVDLIFQETCFPVHRAILAARCPFFKTLLSSSPEYGAEIIMDINTAGIDMPMFSALLHYLYTGEFGMEDSRFQNVDILVQLSEEFGTPNSLDVDMRGLFDYMCYYDVVLSFSSDSELVEAFGGNQNCLDEELKAHKAVISARSPFFRNLLQRRIRTGEEITDRTLRTPTRIILDESIIPKKYATVILHCMYTDVVDLSVLHCSPSVGSLSEVQALVAGKPNMTRAEEAMELYHIALFLEFNMLAQGCEDIIAESISLDTLIAILKWSSHPYGSKWVHRQALHFLCEEFSQVMTSDVFYELSKDHLLTAIQSDYLQASEQDILKYLIKWGEHQLMKRIADREPNLLSGTAHSVNKRGVKRRDLDMEELREILSSLLPFVRIEHILPINSEVLSDAMKRGLISTPPSDMLPTTEGGKSNAWLRQKNAGIYVRPRLFSPYVEEAKSVLDEMMVEQTDLVRLRMVRMSNVPDTLYMVNNAVPQCCHMISHQQISSNQSSPPSVVANEIPVPRLLIMKDMVRRLQELRHTEQVQRAYALNCGEGATVSYEIQIRVLREFGLADAAAELLQNPHKFFPDERFGDESPLLTMRQPGRCRVNSTPPAETMFTDLDSFVAFHPPLPPPPPPYHPPATPIHNQLKAGWKQRPPSQHPSRSFSYPCNHSLFHSRTAPKAGPPPVYLPSVKAAPPDCTSTAGLGRQTVAAAAATTTSTATAAAAAASEKQVRTQPVLNDLMPDIAVGVSTLSLKDRRLPELAVDTELSQSVSEAGPGPPQHLSCIPQRHTHTSRKKHTLEQKTDTRENPQEYPDFYDFSNAACRPSTPALSRRTPSPSQGGYFGPDLYSHNKASPSGLKSAYLPGQTSPKKQEEARREYPLSPDGHLHRQKNEPIHLDVVEQPPQRSDFPLAAPENASTGPAHVRGRTAVETDLTFGLTPNRPSLSACSSEAPEERSGRRLADSESLGHGAQRNTDLEREDSISRGRRSPSKPDFLYKKSAL>sp|Q9P203-3|BTBD7_HUMAN Isoform 3 of BTB/POZ domain-containing protein 7OS=Homo sapiens OX=9606 GN=BTBD7MGANASNYPHSCSPRVGGNSQAQQTFIGTSSYSQQGYGCESKLYSLDHGHEKPQDKKKRTSGLATLKKKFIKRRKSNRSADHAKQMRELLSGWDVRDVNALVEEYEGTSALKELSLQASLARPEARTLQKDMADLYEYKYCTDVDLIFQETCFPVHRAILAARCPFFKTLLSSSPEYGAEIIMDINTAGIDMPMFSALLHYLYTGEFGMEDSRFQNVDILVQLSEEFGTPNSLDVDMRGLFDYMCYYDVVLSFSSDSELVEAFGGNQNCLDEELKAHKAVISARSPFFRNLLQRRIRTGEEITDRTLRTPTRIILDESIIPKKYATVILHCMYTDVVDLSVLHCSPSVGSLSEVQALVAGKPNMTRAEEAMELYHIALFLEFNMLAQEETTVIRPACAAELSNSCLLPQS>sp|Q9P203-5|BTBD7_HUMAN Isoform 5 of BTB/POZ domain-containing protein 7OS=Homo sapiens OX=9606 GN=BTBD7MAGGAGAGADGGAGGGGGGGDGSGPSGSSSGGRSLRGCEDIIAESISLDTLIAILKWSSHPYGSKWVHRQALHFLCEEFSQVMTSDVFYELSKDHLLTAIQSDYLQASEQDILKYLIKWGEHQLMKRIADREPNLLSGTAHSVNKRGVKRRDLDMEELREILSSLLPFVRIEHILPINSEVLSDAMKRGLISTPPSDMLPTTEGGKSNAWLRQKNAGIYVRPRLFSPYVEEAKSVLDEMMVEQTDLVRLRMVRMSNVPDTLYMVNNAVPQCCHMISHQQISSNQSSPPSVVANEIPVPRLLIMKDMVRRLQELRHTEQVQRAYALNCGEGATVSYEIQIRVLREFGLADAAAELLQNPHKFFPDERFGDESPLLTMRQPGRCRVNSTPPAETMFTDLDSFVAFHPPLPPPPPPYHPPATPIHNQLKAGWKQRPPSQHPSRSFSYPCNHSLFHSRTAPKAGPPPVYLPSVKAAPPDCTSTAGLGRQTVAAAAATTTSTATAAAAAASEKQVRTQPVLNDLMPDIAVGVSTLSLKDRRLPELAVDTELSQSVSEAGPGPPQHLSCIPQRHTHTSRKKHTLEQKTDTRENPQEYPDFYDFSNAACRPSTPALSRRTPSPSQGGYFGPDLYSHNKASPSGLKSAYLPGQTSPKKQEEARREYPLSPDGHLHRQKNEPIHLDVVEQPPQRSDFPLAAPENASTGPAHVRGRTAVETDLTFGLTPNRPSLSACSSEAPEERSGRRLADSESLGHGAQRNTDLEREDSISRGRRSPSKPDFLYKKSAL>sp|A6QL63|BTBDB_HUMAN Ankyrin repeat and BTB/POZ domain-containingprotein BTBD11 OS=Homo sapiens OX=9606 GN=BTBD11 PE=2 SV=3MARRGKKPVVRTLEDLTLDSGYGGAADSVRSSNLSLCCSDSHPASPYGGSCWPPLADSMHSRHNSFDTVNTALVEDSEGLDCAGQHCSRLLPDLDEVPWTLQELEALLLRSRDPRAGPAVPGGLPKDALAKLSTLVSRALVRIAKEAQRLSLRFAKCTKYEIQSAMEIVLSWGLAAHCTAAALAALSLYNMSSAGGDRLGRGKSARCGLTFSVGRVYRWMVDSRVALRIHEHAAIYLTACMESLFRDIYSRVVASGVPRSCSGPGSGSGSGPGPSSGPGAAPAADKEREAPGGGAASGGACSAASSASGGSSCCAPPAAAAAAVPPAAAANHHHHHHHALHEAPKFTVETLEHTVNNDSEIWGLLQPYQHLICGKNASGVLCLPDSLNLHRDPQRSNKPGELPMFSQSELRTIEQSLLATRVGSIAELSDLVSRAMHHLQPLNAKHHGNGTPLHHKQGALYWEPEALYTLCYFMHCPQMEWENPNVEPSKVNLQVERPFLVLPPLMEWIRVAVAHAGHRRSFSMDSDDVRQAARLLLPGVDCEPRQLRADDCFCASRKLDAVAIEAKFKQDLGFRMLNCGRTDLVKQAVSLLGPDGINTMSEQGMTPLMYACVRGDEAMVQMLLDAGADLNVEVVSTPHKYPSVHPETRHWTALTFAVLHGHIPVVQLLLDAGAKVEGSVEHGEENYSETPLQLAAAVGNFELVSLLLERGADPLIGTMYRNGISTTPQGDMNSFSQAAAHGHRNVFRKLLAQPEKEKSDILSLEEILAEGTDLAETAPPPLCASRNSKAKLRALREAMYHSAEHGYVDVTIDIRSIGVPWTLHTWLESLRIAFQQHRRPLIQCLLKEFKTIQEEEYTEELVTQGLPLMFEILKASKNEVISQQLCVIFTHCYGPYPIPKLTEIKRKQTSRLDPHFLNNKEMSDVTFLVEGRPFYAHKVLLFTASPRFKALLSSKPTNDGTCIEIGYVKYSIFQLVMQYLYYGGPESLLIKNNEIMELLSAAKFFQLEALQRHCEIICAKSINTDNCVDIYNHAKFLGVTELSAYCEGYFLKNMMVLIENEAFKQLLYDKNGEGTGQDVLQDLQRTLAIRIQSIHLSSSKGSVV>sp|A6QL63-2|BTBDB_HUMAN Isoform 2 of Ankyrin repeat and BTB/POZ domain-containing protein BTBD11 OS=Homo sapiens OX=9606 GN=BTBD11MARRGKKPVVRTLEDLTLDSGYGGAADSVRSSNLSLCCSDSHPASPYGGSCWPPLADSMHSRHNSFDTVNTALVEDSEGLDCAGQHCSRLLPDLDEVPWTLQELEALLLRSRDPRAGPAVPGGLPKDALAKLSTLVSRALVRIAKEAQRLSLRFAKCTKYEIQSAMEIVLSWGLAAHCTAAALAALSLYNMSSAGGDRLGRGKSARCGLTFSVGRVYRWMVDSRVALRIHEHAAIYLTACMESLFRDIYSRVVASGVPRSCSGPGSGSGSGPGPSSGPGAAPAADKEREAPGGGAASGGACSAASSASGGSSCCAPPAAAAAAVPPAAAANHHHHHHHALHEAPKFTVETLEHTVNNDSEIWGLLQPYQHLICGKNASGVLCLPDSLNLHRDPQRSNKPGELPMFSQSELRTIEQSLLATRVGSIAELSDLVSRAMHHLQPLNAKHHGNGTPLHHKQGALYWEPEALYTLCYFMHCPQMEWENPNVEPSKVNLQVERPFLVLPPLMEWIRVAVAHAGHRRSFSMDSDDVRQAARLLLPGVDCEPRQLRADDCFCASRKLDAVAIEAKFKQDLGFRMLNCGRTDLVKQAVSLLGPDGINTMSEQGMTPLMYACVRGDEAMVQMLLDAGADLNVEVVSTPHKYPSVHPETRHWTALTFAVLHGHIPVVQLLLDAGAKVEGSVEHGEENYSETPLQLAAAVGVPWTLHTWLESLRIAFQQHRRPLIQCLLKEFKTIQEEEYTEELVTQGLPLMFEILKASKNEVISQQLCVIFTHCYGPYPIPKLTEIKRKQTSRLDPHFLNNKEMSDVTFLVEGRPFYAHKVLLFTASPRFKALLSSKPTNDGTCIEIGYVKYSIFQLVMQYLYYGGPESLLIKNNEIMELLSAAKFFQLEALQRHCEIICAKSINTDNCVDIYNHAKFLGVTELSAYCEGYFLKNMMVLIENEAFKQLLYDKNGEGTGQDVLQDLQRTLAIRIQSIHLSSSKGSVV>sp|A6QL63-3|BTBDB_HUMAN Isoform 3 of Ankyrin repeat and BTB/POZ domain-containing protein BTBD11 OS=Homo sapiens OX=9606 GN=BTBD11MARRGKKPVVRTLEDLTLDSGYGGAADSVRSSNLSLCCSDSHPASPYGGSCWPPLADSMHSRHNSFDTVNTALVEDSEGLDCAGQHCSRLLPDLDEVPWTLQELEALLLRSRDPRAGPAVPGGLPKDALAKLSTLVSRALVRIAKEAQRLSLRFAKCTKYEIQSAMEIVLSWGLAAHCTAAALAALSLYNMSSAGGDRLGRGKSARCGLTFSVGRVYRWMVDSRVALRIHEHAAIYLTACMESLFRDIYSRVVASGVPRSCSGPGSGSGSGPGPSSGPGAAPAADKEREAPGGGAASGGACSAASSASGGSSCCAPPAAAAAAVPPAAAANHHHHHHHALHEAPKFTVETLEHTVNNDSEIWGLLQPYQHLICGKNASGVLCLPDSLNLHRDPQRSNKPGELPMFSQSELRTIEQSLLATRVGSIAELSDLVSRAMHHLQPLNAKHHGNGTPLHHKQGALYWEPEALYTLCYFMHCPQMEWENPNVEPSKVNLQVERPFLVLPPLMEWIRVAVAHAGHRRSFSMDSDDVRQAARLLLPGVDCEPRQLRADDCFCASRKLDAVAIEAKFKQDLGFRMLNCGRTDLVKQAVSLLGPDGINTMSEQGMTPLMYACVRGDEAMVQMLLDAGADLNVEVVSTPHKYPSVHPETRHWTALTFAVLHGHIPVVQLLLDAGAKVEGSVEHGEENYSETPLQLAAAVGNFELVSLLLERGADPLIGTMYRNGISTTPQGDMNSFSQAAAHGHRNVFRKLLAQPEKEKSDILSLEEILAEGTDLAETAPPPLCASRNSKAKLRALREAMYHSAEHGYVDVTIDIRSIGVPWTLHTWLESLRIAFQQHRRPLIQCLLKEFKTIQEEEYTEELVTQGLPLMFEILKASKNEVISQQLCVIFTHCYGPYPIPKLTEIKRKQTSRLDPHFLNNKEMSDVTFLVEGRPFYAHKVLLFTASPRFKALLSSKPTNDGTCIEIGYVKYSIFQLVMQYLYYGGPESLLIKNNEIMEVRDPLWCWLS>sp|A6QL63-4|BTBDB_HUMAN Isoform 4 of Ankyrin repeat and BTB/POZ domain-containing protein BTBD11 OS=Homo sapiens OX=9606 GN=BTBD11MSDVTFLVEGRPFYAHKVLLFTASPRFKALLSSKPTNDGTCIEIGYVKYSIFQLVMQYLYYGGPESLLIKNNEIMELLSAAKFFQLEALQRHCEIICAKSINTDNCVDIYNHAKFLGVTELSAYCEGYFLKNMMVLIENEAFKQLLYDKNGEGTGQDVLQDLQRTLAIRIQSIHLSSSKGSVV>sp|A6QL63-5|BTBDB_HUMAN Isoform 5 of Ankyrin repeat and BTB/POZ domain-containing protein BTBD11 OS=Homo sapiens OX=9606 GN=BTBD11MRKLRPKDSREPAPGSPVRSGCLQRLSHYSGIQRPFLVLPPLMEWIRVAVAHAGHRRSFSMDSDDVRQAARLLLPGVDCEPRQLRADDCFCASRKLDAVAIEAKFKQDLGFRMLNCGRTDLVKQAVSLLGPDGINTMSEQGMTPLMYACVRGDEAMVQMLLDAGADLNVEVVSTPHKYPSVHPETRHWTALTFAVLHGHIPVVQLLLDAGAKVEGSVEHGEENYSETPLQLAAAVGNFELVSLLLERGADPLIGTMYRNGISTTPQGDMNSFSQAAAHGHRNVFRKLLAQPEKEKSDILSLEEILAEGTDLAETAPPPLCASRNSKAKLRALREAMYHSAEHGYVDVTIDIRSIGVPWTLHTWLESLRIAFQQHRRPLIQCLLKEFKTIQEEEYTEELVTQGLPLMFEILKASKNEVISQQLCVIFTHCYGPYPIPKLTEIKRKQTSRLDPHFLNNKEMSDVTFLVEGRPFYAHKVLLFTASPRFKALLSSKPTNDGTCIEIGYVKYSIFQLVMQYLYYGGPESLLIKNNEIMELLSAAKFFQLEALQRHCEIICAKSINTDNCVDIYNHAKFLGVTELSAYCEGYFLKNMMVLIENEAFKQLLYDKNGEGTGQDVLQDLQRTLAIRIQSIHLSSSKGSVV>sp|Q8NFL0|B3GN7_HUMAN UDP-GlcNAc:betaGal beta-1,3-N-acetylglucosaminyltransferase 7 OS=Homo sapiens OX=9606 GN=B3GNT7 PE=1SV=1MSLWKKTVYRSLCLALALLVAVTVFQRSLTPGQFLQEPPPPTLEPQKAQKPNGQLVNPNNFWKNPKDVAAPTPMASQGPQAWDVTTTNCSANINLTHQPWFQVLEPQFRQFLFYRHCRYFPMLLNHPEKCRGDVYLLVVVKSVITQHDRREAIRQTWGRERQSAGGGRGAVRTLFLLGTASKQEERTHYQQLLAYEDRLYGDILQWGFLDTFFNLTLKEIHFLKWLDIYCPHVPFIFKGDDDVFVNPTNLLEFLADRQPQENLFVGDVLQHARPIRRKDNKYYIPGALYGKASYPPYAGGGGFLMAGSLARRLHHACDTLELYPIDDVFLGMCLEVLGVQPTAHEGFKTFGISRNRNSRMNKEPCFFRAMLVVHKLLPPELLAMWGLVHSNLTCSRKLQVL>sp|Q7Z7M8|B3GN8_HUMAN UDP-GlcNAc:betaGal beta-1,3-N-acetylglucosaminyltransferase 8 OS=Homo sapiens OX=9606 GN=B3GNT8 PE=1SV=1MRCPKCLLCLSALLTLLGLKVYIEWTSESRLSKAYPSPRGTPPSPTPANPEPTLPANLSTRLGQTIPLPFAYWNQQQWRLGSLPSGDSTETGGCQAWGAAAATEIPDFASYPKDLRRFLLSAACRSFPQWLPGGGGSQVSSCSDTDVPYLLLAVKSEPGRFAERQAVRETWGSPAPGIRLLFLLGSPVGEAGPDLDSLVAWESRRYSDLLLWDFLDVPFNQTLKDLLLLAWLGRHCPTVSFVLRAQDDAFVHTPALLAHLRALPPASARSLYLGEVFTQAMPLRKPGGPFYVPESFFEGGYPAYASGGGYVIAGRLAPWLLRAAARVAPFPFEDVYTGLCIRALGLVPQAHPGFLTAWPADRTADHCAFRNLLLVRPLGPQASIRLWKQLQDPRLQC>sp|C9JJ37|BTBDJ_HUMAN BTB/POZ domain-containing protein 19 OS=Homosapiens OX=9606 GN=BTBD19 PE=2 SV=1MEPLGLVVHGKAEPFSAALRSLVNNPRYSDVCFVVGQERQEVFAHRCLLACRCNFFQRLLGTEPGPGVPSPVVLSTVPTEAFLAVLEFLYTNSVKLYRHSVLEVLTAAVEYGLEELRELCLQFVVKVLDVDLVCEALQVAVTFGLGQLQERCVAFIEAHSQEALRTRGFLELSAAALLPLLRSDKLCVDEAELVRAARSWARVGAAVLERPVAEVAAPVVKELRLALLAPAELSALEEQNRQEPLIPVEQIVEAWKCHALRRGDEARGAPCRRRRGTLPREHHRFLDLSFK>sp|C9JJ37-2|BTBDJ_HUMAN Isoform 2 of BTB/POZ domain-containing protein19 OS=Homo sapiens OX=9606 GN=BTBD19MEPLGLVVHGKAEPFSAALRSLVNNPRYSDVCFVVGQERQEVFAHRCLLACRCNFFQRLLGTEPGPGVPSPVVLSTVPTEAFLAVLEFLYTNSVKLYRHSVLEVLTAAVEYGLEELRELCLQFVVKVLDVDLVCEALQHFWRPRRADQEVRRSRPSWLTRWP>sp|P82251|BAT1_HUMAN b(0,+)-type amino acid transporter 1 OS=Homosapiens OX=9606 GN=SLC7A9 PE=1 SV=1MGDTGLRKRREDEKSIQSQEPKTTSLQKELGLISGISIIVGTIIGSGIFVSPKSVLSNTEAVGPCLIIWAACGVLATLGALCFAELGTMITKSGGEYPYLMEAYGPIPAYLFSWASLIVIKPTSFAIICLSFSEYVCAPFYVGCKPPQIVVKCLAAAAILFISTVNSLSVRLGSYVQNIFTAAKLVIVAIIIISGLVLLAQGNTKNFDNSFEGAQLSVGAISLAFYNGLWAYDGWNQLNYITEELRNPYRNLPLAIIIGIPLVTACYILMNVSYFTVMTATELLQSQAVAVTFGDRVLYPASWIVPLFVAFSTIGAANGTCFTAGRLIYVAGREGHMLKVLSYISVRRLTPAPAIIFYGIIATIYIIPGDINSLVNYFSFAAWLFYGLTILGLIVMRFTRKELERPIKVPVVIPVLMTLISVFLVLAPIISKPTWEYLYCVLFILSGLLFYFLFVHYKFGWAQKISKPITMHLQMLMEVVPPEEDPE>sp|Q9HBH7|BEX1_HUMAN Protein BEX1 OS=Homo sapiens OX=9606 GN=BEX1 PE=1SV=2MESKEKRAVNSLSMENANQENEEKEQVANKGEPLALPLDAGEYCVPRGNRRRFRVRQPILQYRWDMMHRLGEPQARMREENMERIGEEVRQLMEKLREKQLSHSLRAVSTDPPHHDHHDEFCLMP>sp|Q8WXI4|ACO11_HUMAN Acyl-coenzyme A thioesterase 11 OS=Homo sapiensOX=9606 GN=ACOT11 PE=1 SV=1MIQNVGNHLRRGLASVFSNRTSRKSALRAGNDSAMADGEGYRNPTEVQMSQLVLPCHTNQRGELSVGQLLKWIDTTACLSAERHAGCPCVTASMDDIYFEHTISVGQVVNIKAKVNRAFNSSMEVGIQVASEDLCSEKQWNVCKALATFVARREITKVKLKQITPRTEEEKMEHSVAAERRRMRLVYADTIKDLLANCAIQGDLESRDCSRMVPAEKTRVESVELVLPPHANHQGNTFGGQIMAWMENVATIAASRLCRAHPTLKAIEMFHFRGPSQVGDRLVLKAIVNNAFKHSMEVGVCVEAYRQEAETHRRHINSAFMTFVVLDADDQPQLLPWIRPQPGDGERRYREASARKKIRLDRKYIVSCKQTEVPLSVPWDPSNQVYLSYNNVSSLKMLVAKDNWVLSSEISQVRLYTLEDDKFLSFHMEMVVHVDAAQAFLLLSDLRQRPEWDKHYRSVELVQQVDEDDAIYHVTSPALGGHTKPQDFVILASRRKPCDNGDPYVIALRSVTLPTHRETPEYRRGETLCSGFCLWREGDQLTKCCWVRVSLTELVSASGFYSWGLESRSKGRRSDGWNGKLAGGHLSTLKAIPVAKINSRFGYLQDT>sp|Q8WXI4-2|ACO11_HUMAN Isoform 2 of Acyl-coenzyme A thioesterase 11OS=Homo sapiens OX=9606 GN=ACOT11MIQNVGNHLRRGLASVFSNRTSRKSALRAGNDSAMADGEGYRNPTEVQMSQLVLPCHTNQRGELSVGQLLKWIDTTACLSAERHAGCPCVTASMDDIYFEHTISVGQVVNIKAKVNRAFNSSMEVGIQVASEDLCSEKQWNVCKALATFVARREITKVKLKQITPRTEEEKMEHSVAAERRRMRLVYADTIKDLLANCAIQGDLESRDCSRMVPAEKTRVESVELVLPPHANHQGNTFGGQIMAWMENVATIAASRLCRAHPTLKAIEMFHFRGPSQVGDRLVLKAIVNNAFKHSMEVGVCVEAYRQEAETHRRHINSAFMTFVVLDADDQPQLLPWIRPQPGDGERRYREASARKKIRLDRKYIVSCKQTEVPLSVPWDPSNQVYLSYNNVSSLKMLVAKDNWVLSSEISQVRLYTLEDDKFLSFHMEMVVHVDAAQAFLLLSDLRQRPEWDKHYRSVELVQQVDEDDAIYHVTSPALGGHTKPQDFVILASRRKPCDNGDPYVIALRSVTLPTHRETPEYRRGETLCSGFCLWREGDQLTKVSYYNQATPGVLNYVTTNVAGLSSEFYTTFKACEQFLLDNRNDLAPSLQTL>sp|Q8WYK0|ACO12_HUMAN Acetyl-coenzyme A thioesterase OS=Homo sapiensOX=9606 GN=ACOT12 PE=1 SV=1MERPAPGEVVMSQAIQPAHATARGELSAGQLLKWIDTTACLAAEKHAGVSCVTASVDDIQFEETARVGQVITIKAKVTRAFSTSMEISIKVMVQDMLTGIEKLVSVAFSTFVAKPVGKEKIHLKPVTLLTEQDHVEHNLAAERRKVRLQHEDTFNNLMKESSKFDDLIFDEEEGAVSTRGTSVQSIELVLPPHANHHGNTFGGQIMAWMETVATISASRLCWAHPFLKSVDMFKFRGPSTVGDRLVFTAIVNNTFQTCVEVGVRVEAFDCQEWAEGRGRHINSAFLIYNAADDKENLITFPRIQPISKDDFRRYRGAIARKRIRLGRKYVISHKEEVPLCIHWDISKQASLSDSNVEALKKLAAKRGWEVTSTVEKIKIYTLEEHDVLSVWVEKHVGSPAHLAYRLLSDFTKRPLWDPHFVSCEVIDWVSEDDQLYHITCPILNDDKPKDLVVLVSRRKPLKDGNTYTVAVKSVILPSVPPSPQYIRSEIICAGFLIHAIDSNSCIVSYFNHMSASILPYFAGNLGGWSKSIEETAASCIQFLENPPDDGFVSTF>sp|Q8WYK0-2|ACO12_HUMAN Isoform 2 of Acetyl-coenzyme A thioesteraseOS=Homo sapiens OX=9606 GN=ACOT12MERPAPGEVVMSQAIQPAHATARGELSAGQLLKWIDTTACLAAEKHAGVSCVTASVDDIQFEETARVGQVITIKAKVTRAFSTSMEISIKVMVQDMLTGIEKLVSVAFSTFVAKPVGKEKIHLKPVTLLTEQDHVEHNLAAERRKVRLQHEDTFNNLMKESSKFDGQ>sp|O14678|ABCD4_HUMAN Lysosomal cobalamin transporter ABCD4 OS=Homosapiens OX=9606 GN=ABCD4 PE=1 SV=1MAVAGPAPGAGARPRLDLQFLQRFLQILKVLFPSWSSQNALMFLTLLCLTLLEQFVIYQVGLIPSQYYGVLGNKDLEGFKTLTFLAVMLIVLNSTLKSFDQFTCNLLYVSWRKDLTEHLHRLYFRGRAYYTLNVLRDDIDNPDQRISQDVERFCRQLSSMASKLIISPFTLVYYTYQCFQSTGWLGPVSIFGYFILGTVVNKTLMGPIVMKLVHQEKLEGDFRFKHMQIRVNAEPAAFYRAGHVEHMRTDRRLQRLLQTQRELMSKELWLYIGINTFDYLGSILSYVVIAIPIFSGVYGDLSPAELSTLVSKNAFVCIYLISCFTQLIDLSTTLSDVAGYTHRIGQLRETLLDMSLKSQDCEILGESEWGLDTPPGWPAAEPADTAFLLERVSISAPSSDKPLIKDLSLKISEGQSLLITGNTGTGKTSLLRVLGGLWTSTRGSVQMLTDFGPHGVLFLPQKPFFTDGTLREQVIYPLKEVYPDSGSADDERILRFLELAGLSNLVARTEGLDQQVDWNWYDVLSPGEMQRLSFARLFYLQPKYAVLDEATSALTEEVESELYRIGQQLGMTFISVGHRQSLEKFHSLVLKLCGGGRWELMRIKVE>sp|Q13362|2A5G_HUMAN Serine/threonine-protein phosphatase 2A 56 kDaregulatory subunit gamma isoform OS=Homo sapiens OX=9606 GN=PPP2R5C PE=1SV=3MLTCNKAGSRMVVDAANSNGPFQPVVLLHIRDVPPADQEKLFIQKLRQCCVLFDFVSDPLSDLKWKEVKRAALSEMVEYITHNRNVITEPIYPEVVHMFAVNMFRTLPPSSNPTGAEFDPEEDEPTLEAAWPHLQLVYEFFLRFLESPDFQPNIAKKYIDQKFVLQLLELFDSEDPRERDFLKTTLHRIYGKFLGLRAYIRKQINNIFYRFIYETEHHNGIAELLEILGSIINGFALPLKEEHKIFLLKVLLPLHKVKSLSVYHPQLAYCVVQFLEKDSTLTEPVVMALLKYWPKTHSPKEVMFLNELEEILDVIEPSEFVKIMEPLFRQLAKCVSSPHFQVAERALYYWNNEYIMSLISDNAAKILPIMFPSLYRNSKTHWNKTIHGLIYNALKLFMEMNQKLFDDCTQQFKAEKLKEKLKMKEREEAWVKIENLAKANPQYTVYSQASTMSIPVAMETDGPLFEDVQMLRKTVKDEAHQAQKDPKKDRPLARRKSELPQDPHTKKALEAHCRADELASQDGR>sp|Q13362-2|2A5G_HUMAN Isoform Gamma-1 of Serine/threonine-proteinphosphatase 2A 56 kDa regulatory subunit gamma isoform OS=Homo sapiensOX=9606 GN=PPP2R5CMLTCNKAGSRMVVDAANSNGPFQPVVLLHIRDVPPADQEKLFIQKLRQCCVLFDFVSDPLSDLKWKEVKRAALSEMVEYITHNRNVITEPIYPEVVHMFAVNMFRTLPPSSNPTGAEFDPEEDEPTLEAAWPHLQLVYEFFLRFLESPDFQPNIAKKYIDQKFVLQLLELFDSEDPRERDFLKTTLHRIYGKFLGLRAYIRKQINNIFYRFIYETEHHNGIAELLEILGSIINGFALPLKEEHKIFLLKVLLPLHKVKSLSVYHPQLAYCVVQFLEKDSTLTEPVVMALLKYWPKTHSPKEVMFLNELEEILDVIEPSEFVKIMEPLFRQLAKCVSSPHFQVAERALYYWNNEYIMSLISDNAAKILPIMFPSLYRNSKTHWNKTIHGLIYNALKLFMEMNQKLFDDCTQQFKAEKLKEKLKMKEREEAWVKIENLAKANPQVLKKRIT>sp|Q13362-3|2A5G_HUMAN Isoform Gamma-2 of Serine/threonine-proteinphosphatase 2A 56 kDa regulatory subunit gamma isoform OS=Homo sapiensOX=9606 GN=PPP2R5CMLTCNKAGSRMVVDAANSNGPFQPVVLLHIRDVPPADQEKLFIQKLRQCCVLFDFVSDPLSDLKWKEVKRAALSEMVEYITHNRNVITEPIYPEVVHMFAVNMFRTLPPSSNPTGAEFDPEEDEPTLEAAWPHLQLVYEFFLRFLESPDFQPNIAKKYIDQKFVLQLLELFDSEDPRERDFLKTTLHRIYGKFLGLRAYIRKQINNIFYRFIYETEHHNGIAELLEILGSIINGFALPLKEEHKIFLLKVLLPLHKVKSLSVYHPQLAYCVVQFLEKDSTLTEPVVMALLKYWPKTHSPKEVMFLNELEEILDVIEPSEFVKIMEPLFRQLAKCVSSPHFQVAERALYYWNNEYIMSLISDNAAKILPIMFPSLYRNSKTHWNKTIHGLIYNALKLFMEMNQKLFDDCTQQFKAEKLKEKLKMKEREEAWVKIENLAKANPQAQKDPKKDRPLARRKSELPQDPHTKKALEAHCRADELASQDGR>sp|Q13362-4|2A5G_HUMAN Isoform 4 of Serine/threonine-protein phosphatase2A 56 kDa regulatory subunit gamma isoform OS=Homo sapiens OX=9606GN=PPP2R5CMPNKNKKEKESPKAGKSGKSSKEGQDTVESEQISVRKNSLVAVPSTVSAKIKVPVSQPIVKKDKRQNSSRFSASNNRELQKLPSLKDVPPADQEKLFIQKLRQCCVLFDFVSDPLSDLKWKEVKRAALSEMVEYITHNRNVITEPIYPEVVHMFAVNMFRTLPPSSNPTGAEFDPEEDEPTLEAAWPHLQLVYEFFLRFLESPDFQPNIAKKYIDQKFVLQLLELFDSEDPRERDFLKTTLHRIYGKFLGLRAYIRKQINNIFYRFIYETEHHNGIAELLEILGSIINGFALPLKEEHKIFLLKVLLPLHKVKSLSVYHPQLAYCVVQFLEKDSTLTEPVVMALLKYWPKTHSPKEVMFLNELEEILDVIEPSEFVKIMEPLFRQLAKCVSSPHFQVAERALYYWNNEYIMSLISDNAAKILPIMFPSLYRNSKTHWNKTIHGLIYNALKLFMEMNQKLFDDCTQQFKAEKLKEKLKMKEREEAWVKIENLAKANPQAQKDPKKDRPLARRKSELPQDPHTKKALEAHCRADELASQDGR>sp|Q13362-5|2A5G_HUMAN Isoform 5 of Serine/threonine-protein phosphatase2A 56 kDa regulatory subunit gamma isoform OS=Homo sapiens OX=9606GN=PPP2R5CMPNKNKKEKESPKAGKSGKSSKEGQDTVESEGTSPEEPSSPKVPPPLLPELLVLIFGGLQGRDVPPADQEKLFIQKLRQCCVLFDFVSDPLSDLKWKEVKRAALSEMVEYITHNRNVITEPIYPEVVHMFAVNMFRTLPPSSNPTGAEFDPEEDEPTLEAAWPHLQLVYEFFLRFLESPDFQPNIAKKYIDQKFVLQLLELFDSEDPRERDFLKTTLHRIYGKFLGLRAYIRKQINNIFYRFIYETEHHNGIAELLEILGSIINGFALPLKEEHKIFLLKVLLPLHKVKSLSVYHPQLAYCVVQFLEKDSTLTEPVVMALLKYWPKTHSPKEVMFLNELEEILDVIEPSEFVKIMEPLFRQLAKCVSSPHFQVAERALYYWNNEYIMSLISDNAAKILPIMFPSLYRNSKTHWNKTIHGLIYNALKLFMEMNQKLFDDCTQQFKAEKLKEKLKMKEREEAWVKIENLAKANPQYTVYSQASTMSIPVAMETDGPLFEDVQMLRKTVKDEAHQAQKDPKKDRPLARRKSELPQDPHTKKALEAHCRADELASQDGR>sp|O43825|B3GT2_HUMAN Beta-1,3-galactosyltransferase 2 OS=Homo sapiensOX=9606 GN=B3GALT2 PE=1 SV=1MLQWRRRHCCFAKMTWNAKRSLFRTHLIGVLSLVFLFAMFLFFNHHDWLPGRAGFKENPVTYTFRGFRSTKSETNHSSLRNIWKETVPQTLRPQTATNSNNTDLSPQGVTGLENTLSANGSIYNEKGTGHPNSYHFKYIINEPEKCQEKSPFLILLIAAEPGQIEARRAIRQTWGNESLAPGIQITRIFLLGLSIKLNGYLQRAILEESRQYHDIIQQEYLDTYYNLTIKTLMGMNWVATYCPHIPYVMKTDSDMFVNTEYLINKLLKPDLPPRHNYFTGYLMRGYAPNRNKDSKWYMPPDLYPSERYPVFCSGTGYVFSGDLAEKIFKVSLGIRRLHLEDVYVGICLAKLRIDPVPPPNEFVFNHWRVSYSSCKYSHLITSHQFQPSELIKYWNHLQQNKHNACANAAKEKAGRYRHRKLH>sp|Q8N1L9|BATF2_HUMAN Basic leucine zipper transcriptional factor ATF-like 2 OS=Homo sapiens OX=9606 GN=BATF2 PE=1 SV=1MHLCGGNGLLTQTDPKEQQRQLKKQKNRAAAQRSRQKHTDKADALHQQHESLEKDNLALRKEIQSLQAELAWWSRTLHVHERLCPMDCASCSAPGLLGCWDQAEGLLGPGPQGQHGCREQLELFQTPGSCYPAQPLSPGPQPHDSPSLLQCPLPSLSLGPAVVAEPPVQLSPSPLLFASHTGSSLQGSSSKLSALQPSLTAQTAPPQPLELEHPTRGKLGSSPDNPSSALGLARLQSREHKPALSAATWQGLVVDPSPHPLLAFPLLSSAQVHF>sp|Q8N1L9-2|BATF2_HUMAN Isoform 2 of Basic leucine zippertranscriptional factor ATF-like 2 OS=Homo sapiens OX=9606 GN=BATF2MDCASCSAPGLLGCWDQAEGLLGPGPQGQHGCREQLELFQTPGSCYPAQPLSPGPQPHDSPSLLQCPLPSLSLGPAVVAEPPVQLSPSPLLFASHTGSSLQGSSSKLSALQPSLTAQTAPPQPLELEHPTRGKLGSSPDNPSSALGLARLQSREHKPALSAATWQGLVVDPSPHPLLAFPLLSSAQVHF>sp|Q00994|BEX3_HUMAN Protein BEX3 OS=Homo sapiens OX=9606 GN=BEX3 PE=1SV=1MANIHQENEEMEQPMQNGEEDRPLGGGEGHQPAGNRRGQARRLAPNFRWAIPNRQINDGMGGDGDDMEIFMEEMREIRRKLRELQLRNCLRILMGELSNHHDHHDEFCLMP>sp|Q00994-2|BEX3_HUMAN Isoform 2 of Protein BEX3 OS=Homo sapiens OX=9606GN=BEX3MEQPMQNGEEDRPLGGGEGHQPAGNRRGQARRLAPNFRWAIPNRQINDGMGGDGDDMEIFMEEMREIRRKLRELQLRNCLRILMGELSNHHDHHDEFCLMP>sp|A8K2U0|A2ML1_HUMAN Alpha-2-macroglobulin-like protein 1 OS=Homosapiens OX=9606 GN=A2ML1 PE=1 SV=3MWAQLLLGMLALSPAIAEELPNYLVTLPARLNFPSVQKVCLDLSPGYSDVKFTVTLETKDKTQKLLEYSGLKKRHLHCISFLVPPPAGGTEEVATIRVSGVGNNISFEEKKKVLIQRQGNGTFVQTDKPLYTPGQQVYFRIVTMDSNFVPVNDKYSMVELQDPNSNRIAQWLEVVPEQGIVDLSFQLAPEAMLGTYTVAVAEGKTFGTFSVEEYVLPKFKVEVVEPKELSTVQESFLVKICCRYTYGKPMLGAVQVSVCQKANTYWYREVEREQLPDKCRNLSGQTDKTGCFSAPVDMATFDLIGYAYSHQINIVATVVEEGTGVEANATQNIYISPQMGSMTFEDTSNFYHPNFPFSGKIRVRGHDDSFLKNHLVFLVIYGTNGTFNQTLVTDNNGLAPFTLETSGWNGTDVSLEGKFQMEDLVYNPEQVPRYYQNAYLHLRPFYSTTRSFLGIHRLNGPLKCGQPQEVLVDYYIDPADASPDQEISFSYYLIGKGSLVMEGQKHLNSKKKGLKASFSLSLTFTSRLAPDPSLVIYAIFPSGGVVADKIQFSVEMCFDNQVSLGFSPSQQLPGAEVELQLQAAPGSLCALRAVDESVLLLRPDRELSNRSVYGMFPFWYGHYPYQVAEYDQCPVSGPWDFPQPLIDPMPQGHSSQRSIIWRPSFSEGTDLFSFFRDVGLKILSNAKIKKPVDCSHRSPEYSTAMGAGGGHPEAFESSTPLHQAEDSQVRQYFPETWLWDLFPIGNSGKEAVHVTVPDAITEWKAMSFCTSQSRGFGLSPTVGLTAFKPFFVDLTLPYSVVRGESFRLTATIFNYLKDCIRVQTDLAKSHEYQLESWADSQTSSCLCADDAKTHHWNITAVKLGHINFTISTKILDSNEPCGGQKGFVPQKGRSDTLIKPVLVKPEGVLVEKTHSSLLCPKGKVASESVSLELPVDIVPDSTKAYVTVLGDIMGTALQNLDGLVQMPSGCGEQNMVLFAPIIYVLQYLEKAGLLTEEIRSRAVGFLEIGYQKELMYKHSNGSYSAFGERDGNGNTWLTAFVTKCFGQAQKFIFIDPKNIQDALKWMAGNQLPSGCYANVGNLLHTAMKGGVDDEVSLTAYVTAALLEMGKDVDDPMVSQGLRCLKNSATSTTNLYTQALLAYIFSLAGEMDIRNILLKQLDQQAIISGESIYWSQKPTPSSNASPWSEPAAVDVELTAYALLAQLTKPSLTQKEIAKATSIVAWLAKQHNAYGGFSSTQDTVVALQALAKYATTAYMPSEEINLVVKSTENFQRTFNIQSVNRLVFQQDTLPNVPGMYTLEASGQGCVYVQTVLRYNILPPTNMKTFSLSVEIGKARCEQPTSPRSLTLTIHTSYVGSRSSSNMAIVEVKMLSGFSPMEGTNQLLLQQPLVKKVEFGTDTLNIYLDELIKNTQTYTFTISQSVLVTNLKPATIKVYDYYLPDEQATIQYSDPCE>sp|A8K2U0-2|A2ML1_HUMAN Isoform 2 of Alpha-2-macroglobulin-like protein1 OS=Homo sapiens OX=9606 GN=A2ML1MLIGKGSLVMEGQKHLNSKKKGLKASFSLSLTFTSRLAPDPSLVIYAIFPSGGVVADKIQFSVEMCFDNQVSLGFSPSQQLPGAEVELQLQAAPGSLCALRAVDESVLLLRPDRELSNRSVYGMFPFWYGHYPYQVAEYDQCPVSGPWDFPQPLIDPMPQGHSSQRSIIWRPSFSEGTDLFSFFRDVGLKILSNAKIKKPVDCSHRSPEYSTAMGAGGGHPEAFESSTPLHQAEDSQVRQYFPETWLWDLFPIGNSGKEAVHVTVPDAITEWKAMSFCTSQSRGFGLSPTVGLTAFKPFFVDLTLPYSVVRGESFRLTATIFNYLKDCIRVQTDLAKSHEYQLESWADSQTSSCLCADDAKTHHWNITAVKLGHINFTISTKILDSNEPCGGQKGFVPQKGRSDTLIKPVLVKPEGVLVEKTHSSLLCPKGKVASESVSLELPVDIVPDSTKAYVTVLGDIMGTALQNLDGLVQMPSGCGEQNMVLFAPIIYVLQYLEKAGLLTEEIRSRAVGFLEIGYQKELMYKHSNGSYSAFGERDGNGNTWLTAFVTKCFGQAQKFIFIDPKNIQDALKWMAGNQLPSGCYANVGNLLHTAMKGGVDDEVSLTAYVTAALLEMGKDVDDPMVSQGLRCLKNSATSTTNLYTQALLAYIFSLAGEMDIRNILLKQLDQQAIISGESIYWSQKPTPSSNASPWSEPAAVDVELTAYALLAQLTKPSLTQKEIAKATSIVAWLAKQHNAYGGFSSTQDTVVALQALAKYATTAYMPSEEINLVVKSTENFQRTFNIQSVNRLVFQQDTLPNVPGMYTLEASGQGCVYVQTVLRYNILPPTNMKTFSLSVEIGKARCEQPTSPRSLTLTIHTSYVGSRSSSNMAIVEVKMLSGFSPMEGTNQLLLQQPLVKKVEFGTDTLNIYLDELIKNTQTYTFTISQSVLVTNLKPATIKVYDYYLPDEQATIQYSDPCE>sp|P43251|BTD_HUMAN Biotinidase OS=Homo sapiens OX=9606 GN=BTD PE=1 SV=2MAHAHIQGGRRAKSRFVVCIMSGARSKLALFLCGCYVVALGAHTGEESVADHHEAEYYVAAVYEHPSILSLNPLALISRQEALELMNQNLDIYEQQVMTAAQKDVQIIVFPEDGIHGFNFTRTSIYPFLDFMPSPQVVRWNPCLEPHRFNDTEVLQRLSCMAIRGDMFLVANLGTKEPCHSSDPRCPKDGRYQFNTNVVFSNNGTLVDRYRKHNLYFEAAFDVPLKVDLITFDTPFAGRFGIFTCFDILFFDPAIRVLRDYKVKHVVYPTAWMNQLPLLAAIEIQKAFAVAFGINVLAANVHHPVLGMTGSGIHTPLESFWYHDMENPKSHLIIAQVAKNPVGLIGAENATGETDPSHSKFLKILSGDPYCEKDAQEVHCDEATKWNVNAPPTFHSEMMYDNFTLVPVWGKEGYLHVCSNGLCCYLLYERPTLSKELYALGVFDGLHTVHGTYYIQVCALVRCGGLGFDTCGQEITEATGIFEFHLWGNFSTSYIFPLFLTSGMTLEVPDQLGWENDHYFLRKSRLSSGLVTAALYGRLYERD>sp|P43251-2|BTD_HUMAN Isoform 2 of Biotinidase OS=Homo sapiens OX=9606GN=BTDMARKETQLIIKMNHLARFVVCIMSGARSKLALFLCGCYVVALGAHTGEESVADHHEAEYYVAAVYEHPSILSLNPLALISRQEALELMNQNLDIYEQQVMTAAQKDVQIIVFPEDGIHGFNFTRTSIYPFLDFMPSPQVVRWNPCLEPHRFNDTEVLQRLSCMAIRGDMFLVANLGTKEPCHSSDPRCPKDGRYQFNTNVVFSNNGTLVDRYRKHNLYFEAAFDVPLKVDLITFDTPFAGRFGIFTCFDILFFDPAIRVLRDYKVKHVVYPTAWMNQLPLLAAIEIQKAFAVAFGINVLAANVHHPVLGMTGSGIHTPLESFWYHDMENPKSHLIIAQVAKNPVGLIGAENATGETDPSHSKFLKILSGDPYCEKDAQEVHCDEATKWNVNAPPTFHSEMMYDNFTLVPVWGKEGYLHVCSNGLCCYLLYERPTLSKELYALGVFDGLHTVHGTYYIQVCALVRCGGLGFDTCGQEITEATGIFEFHLWGNFSTSYIFPLFLTSGMTLEVPDQLGWENDHYFLRKSRLSSGLVTAALYGRLYERD>sp|P43251-3|BTD_HUMAN Isoform 3 of Biotinidase OS=Homo sapiens OX=9606GN=BTDMPEGGGTSRRLLPMQSRFVVCIMSGARSKLALFLCGCYVVALGAHTGEESVADHHEAEYYVAAVYEHPSILSLNPLALISRQEALELMNQNLDIYEQQVMTAAQKDVQIIVFPEDGIHGFNFTRTSIYPFLDFMPSPQVVRWNPCLEPHRFNDTEVLQRLSCMAIRGDMFLVANLGTKEPCHSSDPRCPKDGRYQFNTNVVFSNNGTLVDRYRKHNLYFEAAFDVPLKVDLITFDTPFAGRFGIFTCFDILFFDPAIRVLRDYKVKHVVYPTAWMNQLPLLAAIEIQKAFAVAFGINVLAANVHHPVLGMTGSGIHTPLESFWYHDMENPKSHLIIAQVAKNPVGLIGAENATGETDPSHSKFLKILSGDPYCEKDAQEVHCDEATKWNVNAPPTFHSEMMYDNFTLVPVWGKEGYLHVCSNGLCCYLLYERPTLSKELYALGVFDGLHTVHGTYYIQVCALVRCGGLGFDTCGQEITEATGIFEFHLWGNFSTSYIFPLFLTSGMTLEVPDQLGWENDHYFLRKSRLSSGLVTAALYGRLYERD>sp|P43251-4|BTD_HUMAN Isoform 4 of Biotinidase OS=Homo sapiens OX=9606GN=BTDMSGARSKLALFLCGCYVVALGAHTGEESVADHHEAEYYVAAVYEHPSILSLNPLALISRQEALELMNQNLDIYEQQVMTAAQKDVQIIVFPEDGIHGFNFTRTSIYPFLDFMPSPQVVRWNPCLEPHRFNDTEVLQRLSCMAIRGDMFLVANLGTKEPCHSSDPRCPKDGRYQFNTNVVFSNNGTLVDRYRKHNLYFEAAFDVPLKVDLITFDTPFAGRFGIFTCFDILFFDPAIRVLRDYKVKHVVYPTAWMNQLPLLAAIEIQKAFAVAFGINVLAANVHHPVLGMTGSGIHTPLESFWYHDMENPKSHLIIAQVAKNPVGLIGAENATGETDPSHSKFLKILSGDPYCEKDAQEVHCDEATKWNVNAPPTFHSEMMYDNFTLVPVWGKEGYLHVCSNGLCCYLLYERPTLSKELYALGVFDGLHTVHGTYYIQVCALVRCGGLGFDTCGQEITEATGIFEFHLWGNFSTSYIFPLFLTSGMTLEVPDQLGWENDHYFLRKSRLSSGLVTAALYGRLYERD>sp|P30153|2AAA_HUMAN Serine/threonine-protein phosphatase 2A 65 kDaregulatory subunit A alpha isoform OS=Homo sapiens OX=9606 GN=PPP2R1APE=1 SV=4MAAADGDDSLYPIAVLIDELRNEDVQLRLNSIKKLSTIALALGVERTRSELLPFLTDTIYDEDEVLLALAEQLGTFTTLVGGPEYVHCLLPPLESLATVEETVVRDKAVESLRAISHEHSPSDLEAHFVPLVKRLAGGDWFTSRTSACGLFSVCYPRVSSAVKAELRQYFRNLCSDDTPMVRRAAASKLGEFAKVLELDNVKSEIIPMFSNLASDEQDSVRLLAVEACVNIAQLLPQEDLEALVMPTLRQAAEDKSWRVRYMVADKFTELQKAVGPEITKTDLVPAFQNLMKDCEAEVRAAASHKVKEFCENLSADCRENVIMSQILPCIKELVSDANQHVKSALASVIMGLSPILGKDNTIEHLLPLFLAQLKDECPEVRLNIISNLDCVNEVIGIRQLSQSLLPAIVELAEDAKWRVRLAIIEYMPLLAGQLGVEFFDEKLNSLCMAWLVDHVYAIREAATSNLKKLVEKFGKEWAHATIIPKVLAMSGDPNYLHRMTTLFCINVLSEVCGQDITTKHMLPTVLRMAGDPVANVRFNVAKSLQKIGPILDNSTLQSEVKPILEKLTQDQDVDVKYFAQEALTVLSLA>sp|P61221|ABCE1_HUMAN ATP-binding cassette sub-family E member 1 OS=Homosapiens OX=9606 GN=ABCE1 PE=1 SV=1MADKLTRIAIVNHDKCKPKKCRQECKKSCPVVRMGKLCIEVTPQSKIAWISETLCIGCGICIKKCPFGALSIVNLPSNLEKETTHRYCANAFKLHRLPIPRPGEVLGLVGTNGIGKSTALKILAGKQKPNLGKYDDPPDWQEILTYFRGSELQNYFTKILEDDLKAIIKPQYVDQIPKAAKGTVGSILDRKDETKTQAIVCQQLDLTHLKERNVEDLSGGELQRFACAVVCIQKADIFMFDEPSSYLDVKQRLKAAITIRSLINPDRYIIVVEHDLSVLDYLSDFICCLYGVPSAYGVVTMPFSVREGINIFLDGYVPTENLRFRDASLVFKVAETANEEEVKKMCMYKYPGMKKKMGEFELAIVAGEFTDSEIMVMLGENGTGKTTFIRMLAGRLKPDEGGEVPVLNVSYKPQKISPKSTGSVRQLLHEKIRDAYTHPQFVTDVMKPLQIENIIDQEVQTLSGGELQRVALALCLGKPADVYLIDEPSAYLDSEQRLMAARVVKRFILHAKKTAFVVEHDFIMATYLADRVIVFDGVPSKNTVANSPQTLLAGMNKFLSQLEITFRRDPNNYRPRINKLNSIKDVEQKKSGNYFFLDD>sp|Q5T8D3|ACBD5_HUMAN Acyl-CoA-binding domain-containing protein 5OS=Homo sapiens OX=9606 GN=ACBD5 PE=1 SV=1MFQFHAGSWESWCCCCLIPADRPWDRGQHWQLEMADTRSVHETRFEAAVKVIQSLPKNGSFQPTNEMMLKFYSFYKQATEGPCKLSRPGFWDPIGRYKWDAWSSLGDMTKEEAMIAYVEEMKKIIETMPMTEKVEELLRVIGPFYEIVEDKKSGRSSDITSVRLEKISKCLEDLGNVLTSTPNAKTVNGKAESSDSGAESEEEEAQEEVKGAEQSDNDKKMMKKSADHKNLEVIVTNGYDKDGFVQDIQNDIHASSSLNGRSTEEVKPIDENLGQTGKSAVCIHQDINDDHVEDVTGIQHLTSDSDSEVYCDSMEQFGQEESLDSFTSNNGPFQYYLGGHSSQPMENSGFREDIQVPPGNGNIGNMQVVAVEGKGEVKHGGEDGRNNSGAPHREKRGGETDEFSNVRRGRGHRMQHLSEGTKGRQVGSGGDGERWGSDRGSRGSLNEQIALVLMRLQEDMQNVLQRLQKLETLTALQAKSSTSTLQTAPQPTSQRPSWWPFEMSPGVLTFAIIWPFIAQWLVYLYYQRRRRKLN>sp|Q5T8D3-2|ACBD5_HUMAN Isoform 2 of Acyl-CoA-binding domain-containingprotein 5 OS=Homo sapiens OX=9606 GN=ACBD5MADTRSVHETRFEAAVKVIQSLPKNGSFQPTNEMMLKFYSFYKQATEGPCKLSRPGFWDPIGRYKWDAWSSLGDMTKEEAMIAYVEEMKKIIETMPMTEKVEELLRVIGPFYEIVEDKKSGRSSDITSDLGNVLTSTPNAKTVNGKAESSDSGAESEEEEAQEEVKGAEQSDNDKKMMKKSADHKNLEVIVTNGYDKDGFVQDIQNDIHASSSLNGRSTEEVKPIDENLGQTGKSAVCIHQDINDDHVEDVTGIQHLTSDSDSEVYCDSMEQFGQEESLDSFTSNNGPFQYYLGGHSSQPMENSGFREDIQVPPGNGNIGNMQVVAVEGKGEVKHGGEDGRNNSGAPHREKRGGETDEFSNVRRGRGHRMQHLSEGTKGRQVGSGGDGERWGSDRGSRGSLNEQIALVLMRLQEDMQNVLQRLQKLETLTALQAKSSTSTLQTAPQPTSQRPSWWPFEMSPGVLTFAIIWPFIAQWLVYLYYQRRRRKLN>sp|Q5T8D3-3|ACBD5_HUMAN Isoform 3 of Acyl-CoA-binding domain-containingprotein 5 OS=Homo sapiens OX=9606 GN=ACBD5MLFLSFHAGSWESWCCCCLIPADRPWDRGQHWQLEMADTRSVHETRFEAAVKVIQSLPKNGSFQPTNEMMLKFYSFYKQATEGPCKLSRPGFWDPIGRYKWDAWSSLGDMTKEEAMIAYVEEMKKIIETMPMTEKVEELLRVIGPFYEIVEDKKSGRSSDITSDLGNVLTSTPNAKTVNGKAESSDSGAESEEEEAQEEVKGAEQSDNDKKMMKKSADHKNLEVIVTNGYDKDGFVQDIQNDIHASSSLNGRSTEEVKPIDENLGQTGKSAVCIHQDINDDHVEDVTGIQHLTSDSDSEVYCDSMEQFGQEESLDSFTSNNGPFQYYLGGHSSQPMENSGFREDIQVPPGNGNIGNMQVVAVEGKGEVKHGGEDGRNNSGAPHREKRGGETDEFSNVRRGRGHRMQHLSEGTKGRQVGSGGDGERWGSDRGSRGSLNEQIALVLMRLQEDMQNVLQRLQKLETLTALQAKSSTSTLQTAPQPTSQRPSWWPFEMSPGVLTFAIIWPFIAQWLVYLYYQRRRRKLN>sp|Q5T8D3-4|ACBD5_HUMAN Isoform 4 of Acyl-CoA-binding domain-containingprotein 5 OS=Homo sapiens OX=9606 GN=ACBD5MTKEEAMIAYVEEMKKIIETMPMTEKVEELLRVIGPFYEIVEDKKSGRSSDITSDLGNVLTSTPNAKTVNGKAESSDSGAESEEEEAQEEVKGAEQSDNDKKMMKKSADHKNLEVIVTNGYDKDGFVQDIQNDIHASSSLNGRSTEEVKPIDENLGQTGKSAVCIHQDINDDHVEDVTGIQHLTSDSDSEVYCDSMEQFGQEESLDSFTSNNGPFQYYLGGHSSQPMENSGFREDIQVPPGNGNIGNMQVVAVEGKGEVKHGGEDGRNNSGAPHREKRGGETDEFSNVRRGRGHRMQHLSEGTKGRQVGSGGDGERWGSDRGSRGSLNEQIALVLMRLQEDMQNVLQRLQKLETLTALQAKSSTSTLQTAPQPTSQRPSWWPFEMSPGVLTFAIIWPFIAQWLVYLYYQRRRRKLN>sp|Q8N6N7|ACBD7_HUMAN Acyl-CoA-binding domain-containing protein 7OS=Homo sapiens OX=9606 GN=ACBD7 PE=1 SV=1MALQADFDRAAEDVRKLKARPDDGELKELYGLYKQAIVGDINIACPGMLDLKGKAKWEAWNLKKGLSTEDATSAYISKAKELIEKYGI>sp|P46952|3HAO_HUMAN 3-hydroxyanthranilate 3,4-dioxygenase OS=Homosapiens OX=9606 GN=HAAO PE=1 SV=2MERRLGVRAWVKENRGSFQPPVCNKLMHQEQLKVMFIGGPNTRKDYHIEEGEEVFYQLEGDMVLRVLEQGKHRDVVIRQGEIFLLPARVPHSPQRFANTVGLVVERRRLETELDGLRYYVGDTMDVLFEKWFYCKDLGTQLAPIIQEFFSSEQYRTGKPIPDQLLKEPPFPLSTRSIMEPMSLDAWLDSHHRELQAGTPLSLFGDTYETQVIAYGQGSSEGLRQNVDVWLWQLEGSSVVTMGGRRLSLAPDDSLLVLAGTSYAWERTQGSVALSVTQDPACKKPLG>sp|P46952-2|3HAO_HUMAN Isoform 2 of 3-hydroxyanthranilate 3,4-dioxygenase OS=Homo sapiens OX=9606 GN=HAAOMERRLGVRAWVKENRGSFQPPVCNKLMHQEQLKVMFIGGPNTRKDYHIEEGEEVFYQLEGDMVLRVLEQGKHRDVVIRQGEIFLLPARVPHSPQRFANTVGLVVERRRLETELDGLRYYVGDTMDVLFEKWFYCKDLGTQLAPIIQE>sp|Q9NRL2|BAZ1A_HUMAN Bromodomain adjacent to zinc finger domain protein1A OS=Homo sapiens OX=9606 GN=BAZ1A PE=1 SV=2MPLLHRKPFVRQKPPADLRPDEEVFYCKVTNEIFRHYDDFFERTILCNSLVWSCAVTGRPGLTYQEALESEKKARQNLQSFPEPLIIPVLYLTSLTHRSRLHEICDDIFAYVKDRYFVEETVEVIRNNGARLQCRILEVLPPSHQNGFANGHVNSVDGETIIISDSDDSETQSCSFQNGKKKDAIDPLLFKYKVQPTKKELHESAIVKATQISRRKHLFSRDKLKLFLKQHCEPQDGVIKIKASSLSTYKIAEQDFSYFFPDDPPTFIFSPANRRRGRPPKRIHISQEDNVANKQTLASYRSKATKERDKLLKQEEMKSLAFEKAKLKREKADALEAKKKEKEDKEKKREELKKIVEEERLKKKEEKERLKVEREKEREKLREEKRKYVEYLKQWSKPREDMECDDLKELPEPTPVKTRLPPEIFGDALMVLEFLNAFGELFDLQDEFPDGVTLEVLEEALVGNDSEGPLCELLFFFLTAIFQAIAEEEEEVAKEQLTDADTKDLTEALDEDADPTKSALSAVASLAAAWPQLHQGCSLKSLDLDSCTLSEILRLHILASGADVTSANAKYRYQKRGGFDATDDACMELRLSNPSLVKKLSSTSVYDLTPGEKMKILHALCGKLLTLVSTRDFIEDYVDILRQAKQEFRELKAEQHRKEREEAAARIRKRKEEKLKEQEQKMKEKQEKLKEDEQRNSTADISIGEEEREDFDTSIESKDTEQKELDQDMVTEDEDDPGSHKRGRRGKRGQNGFKEFTRQEQINCVTREPLTADEEEALKQEHQRKEKELLEKIQSAIACTNIFPLGRDRMYRRYWIFPSIPGLFIEEDYSGLTEDMLLPRPSSFQNNVQSQDPQVSTKTGEPLMSESTSNIDQGPRDHSVQLPKPVHKPNRWCFYSSCEQLDQLIEALNSRGHRESALKETLLQEKSRICAQLARFSEEKFHFSDKPQPDSKPTYSRGRSSNAYDPSQMCAEKQLELRLRDFLLDIEDRIYQGTLGAIKVTDRHIWRSALESGRYELLSEENKENGIIKTVNEDVEEMEIDEQTKVIVKDRLLGIKTETPSTVSTNASTPQSVSSVVHYLAMALFQIEQGIERRFLKAPLDASDSGRSYKTVLDRWRESLLSSASLSQVFLHLSTLDRSVIWSKSILNARCKICRKKGDAENMVLCDGCDRGHHTYCVRPKLKTVPEGDWFCPECRPKQRSRRLSSRQRPSLESDEDVEDSMGGEDDEVDGDEEEGQSEEEEYEVEQDEDDSQEEEEVSLPKRGRPQVRLPVKTRGKLSSSFSSRGQQQEPGRYPSRSQQSTPKTTVSSKTGRSLRKINSAPPTETKSLRIASRSTRHSHGPLQADVFVELLSPRRKRRGRKSANNTPENSPNFPNFRVIATKSSEQSRSVNIASKLSLQESESKRRCRKRQSPEPSPVTLGRRSSGRQGGVHELSAFEQLVVELVRHDDSWPFLKLVSKIQVPDYYDIIKKPIALNIIREKVNKCEYKLASEFIDDIELMFSNCFEYNPRNTSEAKAGTRLQAFFHIQAQKLGLHVTPSNVDQVSTPPAAKKSRI>sp|Q9NRL2-2|BAZ1A_HUMAN Isoform 2 of Bromodomain adjacent to zinc fingerdomain protein 1A OS=Homo sapiens OX=9606 GN=BAZ1AMPLLHRKPFVRQKPPADLRPDEEVFYCKVTNEIFRHYDDFFERTILCNSLVWSCAVTGRPGLTYQEALESEKKARQNLQSFPEPLIIPVLYLTSLTHRSRLHEICDDIFAYVKDRYFVEETVEVIRNNGARLQCRILEVLPPSHQNGFANGHVNSVDGETIIISDSDDSETQSCSFQNGKKKDAIDPLLFKYKVQPTKKELHESAIVKATQISRRKHLFSRDKLKLFLKQHCEPQDGVIKIKASSLSTYKIAEQDFSYFFPDDPPTFIFSPANRRRGRPPKRIHISQEDNVANKQTLASYRSKATKERDKLLKQEEMKSLAFEKAKLKREKADALEAKKKEKEDKEKKREELKKIVEEERLKKKEEKERLKVEREKEREKLREEKRKYVEYLKQWSKPREDMECDDLKELPEPTPVKTRLPPEIFGDALMVLEFLNAFGELFDLQDEFPDGVTLEVLEEALVGNDSEGPLCELLFFFLTAIFQAIAEEEEEVAKEQLTDADTKGCSLKSLDLDSCTLSEILRLHILASGADVTSANAKYRYQKRGGFDATDDACMELRLSNPSLVKKLSSTSVYDLTPGEKMKILHALCGKLLTLVSTRDFIEDYVDILRQAKQEFRELKAEQHRKEREEAAARIRKRKEEKLKEQEQKMKEKQEKLKEDEQRNSTADISIGEEEREDFDTSIESKDTEQKELDQDMVTEDEDDPGSHKRGRRGKRGQNGFKEFTRQEQINCVTREPLTADEEEALKQEHQRKEKELLEKIQSAIACTNIFPLGRDRMYRRYWIFPSIPGLFIEEDYSGLTEDMLLPRPSSFQNNVQSQDPQVSTKTGEPLMSESTSNIDQGPRDHSVQLPKPVHKPNRWCFYSSCEQLDQLIEALNSRGHRESALKETLLQEKSRICAQLARFSEEKFHFSDKPQPDSKPTYSRGRSSNAYDPSQMCAEKQLELRLRDFLLDIEDRIYQGTLGAIKVTDRHIWRSALESGRYELLSEENKENGIIKTVNEDVEEMEIDEQTKVIVKDRLLGIKTETPSTVSTNASTPQSVSSVVHYLAMALFQIEQGIERRFLKAPLDASDSGRSYKTVLDRWRESLLSSASLSQVFLHLSTLDRSVIWSKSILNARCKICRKKGDAENMVLCDGCDRGHHTYCVRPKLKTVPEGDWFCPECRPKQRSRRLSSRQRPSLESDEDVEDSMGGEDDEVDGDEEEGQSEEEEYEVEQDEDDSQEEEEVSLPKRGRPQVRLPVKTRGKLSSSFSSRGQQQEPGRYPSRSQQSTPKTTVSSKTGRSLRKINSAPPTETKSLRIASRSTRHSHGPLQADVFVELLSPRRKRRGRKSANNTPENSPNFPNFRVIATKSSEQSRSVNIASKLSLQESESKRRCRKRQSPEPSPVTLGRRSSGRQGGVHELSAFEQLVVELVRHDDSWPFLKLVSKIQVPDYYDIIKKPIALNIIREKVNKCEYKLASEFIDDIELMFSNCFEYNPRNTSEAKAGTRLQAFFHIQAQKLGLHVTPSNVDQVSTPPAAKKSRI>sp|P31937|3HIDH_HUMAN 3-hydroxyisobutyrate dehydrogenase, mitochondrialOS=Homo sapiens OX=9606 GN=HIBADH PE=1 SV=2MAASLRLLGAASGLRYWSRRLRPAAGSFAAVCSRSVASKTPVGFIGLGNMGNPMAKNLMKHGYPLIIYDVFPDACKEFQDAGEQVVSSPADVAEKADRIITMLPTSINAIEAYSGANGILKKVKKGSLLIDSSTIDPAVSKELAKEVEKMGAVFMDAPVSGGVGAARSGNLTFMVGGVEDEFAAAQELLGCMGSNVVYCGAVGTGQAAKICNNMLLAISMIGTAEAMNLGIRLGLDPKLLAKILNMSSGRCWSSDTYNPVPGVMDGVPSANNYQGGFGTTLMAKDLGLAQDSATSTKSPILLGSLAHQIYRMMCAKGYSKKDFSSVFQFLREEETF>sp|Q5FVE4|ACBG2_HUMAN Long-chain-fatty-acid--CoA ligase ACSBG2 OS=Homosapiens OX=9606 GN=ACSBG2 PE=1 SV=2MTGTPKTQEGAKDLEVDMNKTEVTPRLWTTCRDGEVLLRLSKHGPGHETPMTIPEFFRESVNRFGTYPALASKNGKKWEILNFNQYYEACRKAAKSLIKLGLERFHGVGILGFNSAEWFITAVGAILAGGLCVGIYATNSAEVCQYVITHAKVNILLVENDQQLQKILSIPQSSLEPLKAIIQYRLPMKKNNNLYSWDDFMELGRSIPDTQLEQVIESQKANQCAVLIYTSGTTGIPKGVMLSHDNITWIAGAVTKDFKLTDKHETVVSYLPLSHIAAQMMDIWVPIKIGALTYFAQADALKGTLVSTLKEVKPTVFIGVPQIWEKIHEMVKKNSAKSMGLKKKAFVWARNIGFKVNSKKMLGKYNTPVSYRMAKTLVFSKVKTSLGLDHCHSFISGTAPLNQETAEFFLSLDIPIGELYGLSESSGPHTISNQNNYRLLSCGKILTGCKNMLFQQNKDGIGEICLWGRHIFMGYLESETETTEAIDDEGWLHSGDLGQLDGLGFLYVTGHIKEILITAGGENVPPIPVETLVKKKIPIISNAMLVGDKLKFLSMLLTLKCEMNQMSGEPLDKLNFEAINFCRGLGSQASTVTEIVKQQDPLVYKAIQQGINAVNQEAMNNAQRIEKWVILEKDFSIYGGELGPMMKLKRHFVAQKYKKQIDHMYH>sp|Q5FVE4-2|ACBG2_HUMAN Isoform 2 of Long-chain-fatty-acid--CoA ligaseACSBG2 OS=Homo sapiens OX=9606 GN=ACSBG2MTIPEFFRESVNRFGTYPALASKNGKKWEILNFNQYYEACRKAAKSLIKLGLERFHGVGILGFNSAEWFITAVGAILAGGLCVGIYATNSAEVCQYVITHAKVNILLVENDQQLQKILSIPQSSLEPLKAIIQYRLPMKKNNNLYSWDDFMELGRSIPDTQLEQVIESQKANQCAVLIYTSGTTGIPKGVMLSHDNITWIAGAVTKDFKLTDKHETVVSYLPLSHIAAQMMDIWVPIKIGALTYFAQADALKGTLVSTLKEVKPTVFIGVPQIWEKIHEMVKKNSAKSMGLKKKAFVWARNIGFKVNSKKMLGKYNTPVSYRMAKTLVFSKVKTSLGLDHCHSFISGTAPLNQETAEFFLSLDIPIGELYGLSESSGPHTISNQNNYRLLSCGKILTGCKNMLFQQNKDGIGEICLWGRHIFMGYLESETETTEAIDDEGWLHSGDLGQLDGLGFLYVTGHIKEILITAGGENVPPIPVETLVKKKIPIISNAMLVGDKLKFLSMLLTLKCEMNQMSGEPLDKLNFEAINFCRGLGSQASTVTEIVKQQDPLVYKAIQQGINAVNQEAMNNAQRIEKWVILEKDFSIYGGELGPMMKLKRHFVAQKYKKQIDHMYH>sp|Q5FVE4-3|ACBG2_HUMAN Isoform 3 of Long-chain-fatty-acid--CoA ligaseACSBG2 OS=Homo sapiens OX=9606 GN=ACSBG2MKKNNNLYSWDDFMELGRSIPDTQLEQVIESQKANQCAVLIYTSGTTGIPKGVMLSHDNITWIAGAVTKDFKLTDKHETVVSYLPLSHIAAQMMDIWVPIKIGALTYFAQADALKGTLVSTLKEVKPTVFIGVPQIWEKIHEMVKKNSAKSMGLKKKAFVWARNIGFKVNSKKMLGKYNTPVSYRMAKTLVFSKVKTSLGLDHCHSFISGTAPLNQETAEFFLSLDIPIGELYGLSESSGPHTISNQNNYRLLSCGKILTGCKNMLFQQNKDGIGEICLWGRHIFMGYLESETETTEAIDDEGWLHSGDLGQLDGLGFLYVTGHIKEILITAGGENVPPIPVETLVKKKIPIISNAMLVGDKLKFLSMLLTLKCEMNQMSGEPLDKLNFEAINFCRGLGSQASTVTEIVKQQDPLVYKAIQQGINAVNQEAMNNAQRIEKWVILEKDFSIYGGELGPMMKLKRHFVAQKYKKQIDHMYH>sp|Q5FVE4-4|ACBG2_HUMAN Isoform 4 of Long-chain-fatty-acid--CoA ligaseACSBG2 OS=Homo sapiens OX=9606 GN=ACSBG2MELGRSIPDTQLEQVIESQKANQCAVLIYTSGTTGIPKGVMLSHDNITWIAGAVTKDFKLTDKHETVVSYLPLSHIAAQMMDIWVPIKIGALTYFAQADALKGTLVSTLKEVKPTVFIGVPQIWEKIHEMVKKNSAKSMGLKKKAFVWARNIGFKVNSKKMLGKYNTPVSYRMAKTLVFSKVKTSLGLDHCHSFISGTAPLNQETAEFFLSLDIPIGELYGLSESSGPHTISNQNNYRLLSCGKILTGCKNMLFQQNKDGIGEICLWGRHIFMGYLESETETTEAIDDEGWLHSGDLGQLDGLGFLYVTGHIKEILITAGGENVPPIPVETLVKKKIPIISNAMLVGDKLKFLSMLLTLKCEMNQMSGEPLDKLNFEAINFCRGLGSQASTVTEIVKQQDPLVYKAIQQGINAVNQEAMNNAQRIEKWVILEKDFSIYGGELGPMMKLKRHFVAQKYKKQIDHMYH>sp|Q00973|B4GN1_HUMAN Beta-1,4 N-acetylgalactosaminyltransferase 1OS=Homo sapiens OX=9606 GN=B4GALNT1 PE=1 SV=2MWLGRRALCALVLLLACASLGLLYASTRDAPGLRLPLAPWAPPQSPRRPELPDLAPEPRYAHIPVRIKEQVVGLLAWNNCSCESSGGGLPLPFQKQVRAIDLTKAFDPAELRAASATREQEFQAFLSRSQSPADQLLIAPANSPLQYPLQGVEVQPLRSILVPGLSLQAASGQEVYQVNLTASLGTWDVAGEVTGVTLTGEGQADLTLVSPGLDQLNRQLQLVTYSSRSYQTNTADTVRFSTEGHEAAFTIRIRHPPNPRLYPPGSLPQGAQYNISALVTIATKTFLRYDRLRALITSIRRFYPTVTVVIADDSDKPERVSGPYVEHYLMPFGKGWFAGRNLAVSQVTTKYVLWVDDDFVFTARTRLERLVDVLERTPLDLVGGAVREISGFATTYRQLLSVEPGAPGLGNCLRQRRGFHHELVGFPGCVVTDGVVNFFLARTDKVREVGFDPRLSRVAHLEFFLDGLGSLRVGSCSDVVVDHASKLKLPWTSRDAGAETYARYRYPGSLDESQMAKHRLLFFKHRLQCMTSQ>sp|Q00973-2|B4GN1_HUMAN Isoform 2 of Beta-1,4 N-acetylgalactosaminyltransferase 1 OS=Homo sapiens OX=9606 GN=B4GALNT1MWLGRRALCALVLLLACASLGLLYASTRDAPGLRLPLAPWAPPQSPRRPELPDLAPEPRYAHIPVRIKEQVVGSQSPADQLLIAPANSPLQYPLQGVEVQPLRSILVPGLSLQAASGQEVYQVNLTASLGTWDVAGEVTGVTLTGEGQADLTLVSPGLDQLNRQLQLVTYSSRSYQTNTADTVRFSTEGHEAAFTIRIRHPPNPRLYPPGSLPQGAQYNISALVTIATKTFLRYDRLRALITSIRRFYPTVTVVIADDSDKPERVSGPYVEHYLMPFGKGWFAGRNLAVSQVTTKYVLWVDDDFVFTARTRLERLVDVLERTPLDLVGGAVREISGFATTYRQLLSVEPGAPGLGNCLRQRRGFHHELVGFPGCVVTDGVVNFFLARTDKVREVGFDPRLSRVAHLEFFLDGLGSLRVGSCSDVVVDHASKLKLPWTSRDAGAETYARYRYPGSLDESQMAKHRLLFFKHRLQCMTSQ>sp|Q00973-3|B4GN1_HUMAN Isoform 3 of Beta-1,4 N-acetylgalactosaminyltransferase 1 OS=Homo sapiens OX=9606 GN=B4GALNT1MWLGRRALCALVLLLACASLGLLYASTRDAPGLRLPLAPWAPPQSPRRPELPDLAPEPRYAHIPVRIKEQVVGLLAWNNCSCESSGGGLPLPFQKQVRAIDLTKAFDPAELRAASATREQEFQAFLSRSQSPADQLLIAPANSPLQYPLQGVEVQPLRSILVPGLSLQAASGQEVYQVNLTASLGTWDVAGEVTGVTLTGEGQADLTLVSPGLDQLNRQLQLVTYSSRSYQTNTADTGARPGWRDGQAGQTEKNQKGWSGQMAEGMGGIWAMARAVQPHNGCFNWTSRARGRKGAFVHLGLEQARGKPEPWVCLPFRPTVGGPRKRLV>sp|Q9NPC4|A4GAT_HUMAN Lactosylceramide 4-alpha-galactosyltransferaseOS=Homo sapiens OX=9606 GN=A4GALT PE=1 SV=1MSKPPDLLLRLLRGAPRQRVCTLFIIGFKFTFFVSIMIYWHVVGEPKEKGQLYNLPAEIPCPTLTPPTPPSHGPTPGNIFFLETSDRTNPNFLFMCSVESAARTHPESHVLVLMKGLPGGNASLPRHLGISLLSCFPNVQMLPLDLRELFRDTPLADWYAAVQGRWEPYLLPVLSDASRIALMWKFGGIYLDTDFIVLKNLRNLTNVLGTQSRYVLNGAFLAFERRHEFMALCMRDFVDHYNGWIWGHQGPQLLTRVFKKWCSIRSLAESRACRGVTTLPPEAFYPIPWQDWKKYFEDINPEELPRLLSATYAVHVWNKKSQGTRFEATSRALLAQLHARYCPTTHEAMKMYL>sp|Q9H221|ABCG8_HUMAN ATP-binding cassette sub-family G member 8 OS=Homosapiens OX=9606 GN=ABCG8 PE=1 SV=1MAGKAAEERGLPKGATPQDTSGLQDRLFSSESDNSLYFTYSGQPNTLEVRDLNYQVDLASQVPWFEQLAQFKMPWTSPSCQNSCELGIQNLSFKVRSGQMLAIIGSSGCGRASLLDVITGRGHGGKIKSGQIWINGQPSSPQLVRKCVAHVRQHNQLLPNLTVRETLAFIAQMRLPRTFSQAQRDKRVEDVIAELRLRQCADTRVGNMYVRGLSGGERRRVSIGVQLLWNPGILILDEPTSGLDSFTAHNLVKTLSRLAKGNRLVLISLHQPRSDIFRLFDLVLLMTSGTPIYLGAAQHMVQYFTAIGYPCPRYSNPADFYVDLTSIDRRSREQELATREKAQSLAALFLEKVRDLDDFLWKAETKDLDEDTCVESSVTPLDTNCLPSPTKMPGAVQQFTTLIRRQISNDFRDLPTLLIHGAEACLMSMTIGFLYFGHGSIQLSFMDTAALLFMIGALIPFNVILDVISKCYSERAMLYYELEDGLYTTGPYFFAKILGELPEHCAYIIIYGMPTYWLANLRPGLQPFLLHFLLVWLVVFCCRIMALAAAALLPTFHMASFFSNALYNSFYLAGGFMINLSSLWTVPAWISKVSFLRWCFEGLMKIQFSRRTYKMPLGNLTIAVSGDKILSVMELDSYPLYAIYLIVIGLSGGFMVLYYVSLRFIKQKPSQDW>sp|Q9H221-2|ABCG8_HUMAN Isoform 2 of ATP-binding cassette sub-family Gmember 8 OS=Homo sapiens OX=9606 GN=ABCG8MAGKAAEERGLPKGATPQDTSGLQDRLFSSESDNSLYFTYSGQPNTLEVRDLNYQVDLASQVPWFEQLAQFKMPWTSPSCQNSCELGIQNLSFKVRSGQMLAIIGSSGCGRASLLDVITGRGHGGKIKSGQIWINGQPSSPQLVRKCVAHVRQHNQLLPNLTVRETLAFIAQMRLPRTFSQAQRDKRVEDVIAELRLRQCADTRVGNMYVRGLSGGERRRVSIGVQLLWNPGILILDEPTSGLDSFTAHNLVKTLSRLAKGNRLVLISLHQPRSDIFRLFDLVLLMTSGTPIYLGAAQHMVQYFTAIGYPCPRYSNPADFYVDLTSIDRRSREQELATREKAQSLAALFLEKVRDLDDFLWKAETKDLDEDTCVESVTPLDTNCLPSPTKMPGAVQQFTTLIRRQISNDFRDLPTLLIHGAEACLMSMTIGFLYFGHGSIQLSFMDTAALLFMIGALIPFNVILDVISKCYSERAMLYYELEDGLYTTGPYFFAKILGELPEHCAYIIIYGMPTYWLANLRPGLQPFLLHFLLVWLVVFCCRIMALAAAALLPTFHMASFFSNALYNSFYLAGGFMINLSSLWTVPAWISKVSFLRWCFEGLMKIQFSRRTYKMPLGNLTIAVSGDKILSVMELDSYPLYAIYLIVIGLSGGFMVLYYVSLRFIKQKPSQDW>sp|Q05901|ACHB3_HUMAN Neuronal acetylcholine receptor subunit beta-3OS=Homo sapiens OX=9606 GN=CHRNB3 PE=2 SV=2MLPDFMLVLIVLGIPSSATTGFNSIAENEDALLRHLFQGYQKWVRPVLHSNDTIKVYFGLKISQLVDVDEKNQLMTTNVWLKQEWTDHKLRWNPDDYGGIHSIKVPSESLWLPDIVLFENADGRFEGSLMTKVIVKSNGTVVWTPPASYKSSCTMDVTFFPFDRQNCSMKFGSWTYDGTMVDLILINENVDRKDFFDNGEWEILNAKGMKGNRRDGVYSYPFITYSFVLRRLPLFYTLFLIIPCLGLSFLTVLVFYLPSDEGEKLSLSTSVLVSLTVFLLVIEEIIPSSSKVIPLIGEYLLFIMIFVTLSIIVTVFVINVHHRSSSTYHPMAPWVKRLFLQKLPKLLCMKDHVDRYSSPEKEESQPVVKGKVLEKKKQKQLSDGEKVLVAFLEKAADSIRYISRHVKKEHFISQVVQDWKFVAQVLDRIFLWLFLIVSVTGSVLIFTPALKMWLHSYH>sp|P30926|ACHB4_HUMAN Neuronal acetylcholine receptor subunit beta-4OS=Homo sapiens OX=9606 GN=CHRNB4 PE=1 SV=2MRRAPSLVLFFLVALCGRGNCRVANAEEKLMDDLLNKTRYNNLIRPATSSSQLISIKLQLSLAQLISVNEREQIMTTNVWLKQEWTDYRLTWNSSRYEGVNILRIPAKRIWLPDIVLYNNADGTYEVSVYTNLIVRSNGSVLWLPPAIYKSACKIEVKYFPFDQQNCTLKFRSWTYDHTEIDMVLMTPTASMDDFTPSGEWDIVALPGRRTVNPQDPSYVDVTYDFIIKRKPLFYTINLIIPCVLTTLLAILVFYLPSDCGEKMTLCISVLLALTFFLLLISKIVPPTSLDVPLIGKYLMFTMVLVTFSIVTSVCVLNVHHRSPSTHTMAPWVKRCFLHKLPTFLFMKRPGPDSSPARAFPPSKSCVTKPEATATSTSPSNFYGNSMYFVNPASAASKSPAGSTPVAIPRDFWLRSSGRFRQDVQEALEGVSFIAQHMKNDDEDQSVVEDWKYVAMVVDRLFLWVFMFVCVLGTVGLFLPPLFQTHAASEGPYAAQRD>sp|P30926-2|ACHB4_HUMAN Isoform 2 of Neuronal acetylcholine receptorsubunit beta-4 OS=Homo sapiens OX=9606 GN=CHRNB4MRRAPSLVLFFLVALCGRGNCRVANAEEKLMDDLLNKTRYNNLIRPATSSSQLISIKLQLSLAQLISVNEREQIMTTNVWLKQEWTDYRLTWNSSRYEGVNILRIPAKRIWLPDIVLYNKSLRTGSTWLWWWTGCSCGCSCLCASWALWGSSYRPSSRPMQLLRGPTLPSVTEGPLGCGVRGCEWPGGHFAASFWVVADEALSKYVSIGHQPHQTSHSRGTGKDGGLGCPL>sp|Q13515|BFSP2_HUMAN Phakinin OS=Homo sapiens OX=9606 GN=BFSP2 PE=1SV=1MSERRVVVDLPTSASSSMPLQRRRASFRGPRSSSSLESPPASRTNAMSGLVRAPGVYVGTAPSGCIGGLGARVTRRALGISSVFLQGLRSSGLATVPAPGLERDHGAVEDLGGCLVEYMAKVHALEQVSQELETQLRMHLESKATRSGNWGALRASWASSCQQVGEAVLENARLMLQTETIQAGADDFKERYENEQPFRKAAEEEINSLYKVIDEANLTKMDLESQIESLKEELGSLSRNYEEDVKLLHKQLAGCELEQMDAPIGTGLDDILETIRIQWERDVEKNRVEAGALLQAKQQAEVAHMSQTQEEKLAAALRVELHNTSCQVQSLQAETESLRALKRGLENTLHDAKHWHDMELQNLGAVVGRLEAELREIRAEAEQQQQERAHLLARKCQLQKDVASYHALLDREESG>sp|Q9BYD9|ACTT3_HUMAN Actin-related protein T3 OS=Homo sapiens OX=9606GN=ACTRT3 PE=2 SV=1MNHCQLPVVIDNGSGMIKAGVAGCREPQFIYPNIIGRAKGQSRAAQGGLELCVGDQAQDWRSSLFISYPVERGLITSWEDMEIMWKHIYDYNLKLKPCDGPVLITEPALNPLANRQQITEMFFEHLGVPAFYMSIQAVLALFAAGFTTGLVLNSGAGVTQSVPIFEGYCLPHGVQQLDLAGLDLTNYLMVLMKNHGIMLLSASDRKIVEDIKESFCYVAMNYEEEMAKKPDCLEKVYQLPDGKVIQLHDQLFSCPEALFSPCHMNLEAPGIDKICFSSIMKCDTGLRNSFFSNIILAGGSTSFPGLDKRLVKDIAKVAPANTAVQVIAPPERKISVWMGGSILASLSAFQDMWITAAEFKEVGPNIVHQRCF>sp|P30556|AGTR1_HUMAN Type-1 angiotensin II receptor OS=Homo sapiensOX=9606 GN=AGTR1 PE=1 SV=1MILNSSTEDGIKRIQDDCPKAGRHNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFFIENTNITVCAFHYESQNSTLPIGLGLTKNILGFLFPFLIILTSYTLIWKALKKAYEIQKNKPRNDDIFKIIMAIVLFFFFSWIPHQIFTFLDVLIQLGIIRDCRIADIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLLKYIPPKAKSHSNLSTKMSTLSYRPSDNVSSSTKKPAPCFEVE>sp|P49419|AL7A1_HUMAN Alpha-aminoadipic semialdehyde dehydrogenaseOS=Homo sapiens OX=9606 GN=ALDH7A1 PE=1 SV=5MWRLPRALCVHAAKTSKLSGPWSRPAAFMSTLLINQPQYAWLKELGLREENEGVYNGSWGGRGEVITTYCPANNEPIARVRQASVADYEETVKKAREAWKIWADIPAPKRGEIVRQIGDALREKIQVLGSLVSLEMGKILVEGVGEVQEYVDICDYAVGLSRMIGGPILPSERSGHALIEQWNPVGLVGIITAFNFPVAVYGWNNAIAMICGNVCLWKGAPTTSLISVAVTKIIAKVLEDNKLPGAICSLTCGGADIGTAMAKDERVNLLSFTGSTQVGKQVGLMVQERFGRSLLELGGNNAIIAFEDADLSLVVPSALFAAVGTAGQRCTTARRLFIHESIHDEVVNRLKKAYAQIRVGNPWDPNVLYGPLHTKQAVSMFLGAVEEAKKEGGTVVYGGKVMDRPGNYVEPTIVTGLGHDASIAHTETFAPILYVFKFKNEEEVFAWNNEVKQGLSSSIFTKDLGRIFRWLGPKGSDCGIVNVNIPTSGAEIGGAFGGEKHTGGGRESGSDAWKQYMRRSTCTINYSKDLPLAQGIKFQ>sp|P49419-2|AL7A1_HUMAN Isoform 2 of Alpha-aminoadipic semialdehydedehydrogenase OS=Homo sapiens OX=9606 GN=ALDH7A1MSTLLINQPQYAWLKELGLREENEGVYNGSWGGRGEVITTYCPANNEPIARVRQASVADYEETVKKAREAWKIWADIPAPKRGEIVRQIGDALREKIQVLGSLVSLEMGKILVEGVGEVQEYVDICDYAVGLSRMIGGPILPSERSGHALIEQWNPVGLVGIITAFNFPVAVYGWNNAIAMICGNVCLWKGAPTTSLISVAVTKIIAKVLEDNKLPGAICSLTCGGADIGTAMAKDERVNLLSFTGSTQVGKQVGLMVQERFGRSLLELGGNNAIIAFEDADLSLVVPSALFAAVGTAGQRCTTARRLFIHESIHDEVVNRLKKAYAQIRVGNPWDPNVLYGPLHTKQAVSMFLGAVEEAKKEGGTVVYGGKVMDRPGNYVEPTIVTGLGHDASIAHTETFAPILYVFKFKNEEEVFAWNNEVKQGLSSSIFTKDLGRIFRWLGPKGSDCGIVNVNIPTSGAEIGGAFGGEKHTGGGRESGSDAWKQYMRRSTCTINYSKDLPLAQGIKFQ>sp|P49419-4|AL7A1_HUMAN Isoform 4 of Alpha-aminoadipic semialdehydedehydrogenase OS=Homo sapiens OX=9606 GN=ALDH7A1MWRLPRALCVHAAKTSKLSGPWSRPAAFMSTLLINQPQYAWLKELGLREENEGVYNGSWGGRGEVITTYCPANNEPIARVRQASVADYEETVKKAREAWKIWADIPAPKRGEIVRQIGDALREKIQVLGSLVSLEMGKILVEGVGEVQEYVDICDYAVGLSRMIGGPILPSERSGHALIEQWNPVGLVGIITAFNFPVAVYGWNNAIAMICGNVCLWKGAPTTSLISVAVTKIIAKVLEDNKLPGAICSLTCGGADIGTAMAKDERVNLLSFTGSTQVGKQVGLMVQERFGRSLLELGGNNAIIAFEDADLSLVVPSALFAAVGTAGQRCTTARRLVMDRPGNYVEPTIVTGLGHDASIAHTETFAPILYVFKFKNEEEVFAWNNEVKQGLSSSIFTKDLGRIFRWLGPKGSDCGIVNVNIPTSGAEIGGAFGGEKHTGGGRESGSDAWKQYMRRSTCTINYSKDLPLAQGIKFQ>sp|P0C853|BAAS2_HUMAN Putative uncharacterized protein BAALC-AS2 OS=Homosapiens OX=9606 GN=BAALC-AS2 PE=5 SV=1MSLKSWHPQSKTKRVGASEGNPQWGSGSMEAPLLSSFLPPLASEAELTGNTWFLHRCSCILNLEESMDSDWGAWWGVSLPRRAPFLIYGSDGPWCTQAGFPGWGH>sp|Q9P281|BAHC1_HUMAN BAH and coiled-coil domain-containing protein 1OS=Homo sapiens OX=9606 GN=BAHCC1 PE=1 SV=4MDGRDFAPPPHLLSERGSLGHRSAAAAARLAPAGPAAQPPAHFQPGKYFPSPLPMASHTASSRLMGSSPASSFMGSFLTSSLGSAASTHPSGPSSSPPEQAYRGSHPTTSQIWFSHSHEAPGYPRFSGSLASTFLPVSHLDHHGNSNVLYGQHRFYGTQKDNFYLRNLPPQPTLLPANHNFPSVARAAPAHPMGSCSRDRDRGEAGSLQKGPKDFDRFLVGKELGREKAGKAAEGKERPAAEEDGGKERHKLVLPVPADGHCREGGPAPRGACEGRPKHLTSCLLNTKVLNGEMGRAALASCAGGMLGRPGTGVVTSGRCAKEAAGPPEPGPAFSECLERRQMLHHTASYAGPPPPLSTAAGSFPCLQLHGGPDGLCPLQDKAPRDLKASGPTFVPSVGHLADKGRPFQAAEACAVAGEGKDRHLEGTMAPDHAAPYGVSYAHLKAEGKGERRPGGFEAALNPRLKGLDYLSSAGPEASFPGLPKSGLDKSGYFELPTSSQDCARPGHQDPLGGKAPQACCTLDKTVGKEAPAGPPGAQKVARIRHQQHLMAAEVEQGGIGAEAKRKSLELASLGYSGPHLPPWGVQAGQGTAMAISEERKAGAYLDPFGSGLQQAALLPQELPAPPDEVSAMKNLLKYSSQALVVGQKAPLVGLGGLKASCIQQEAKFLSSKGPGQSERPDCARSREHDTTHGDGEVRQPPVGIAVALARQKDTVSRSEAAYGTNTARQGRAAPAFKGGGGPRSTHALDLEAEEERTRLCDDRLGLASRELLLQDSKDRVEFARIHPPSSCPGDLAPHLMMQSGQLGGDPAPHTHPHPPWLPRTRSPSLWMGGHSYGLGHPALHQNLPPGFPASVAGPVPSVFPLPQDAPTQLVILPSEPTPHSAPHALADVMDQASLWPPMYGGRGPASHMQHPGQLPVYSRPQLLRQQELYALQQQRAAQFQRKPEDQHLDLEEPAQEKAPKSTHKPVALTPTAPGAPSPAAGPTKLPPCCHPPDPKPPASSPTPPPRPSAPCTLNVCPASSPGPGSRVRSAEEKNGEGQQSTADIITSEPVARAHSVAHAGLEFLASNDPSTSASQSFGITDLPPGYLRPMAGLGFSLPSDVHSSNLEDPETMQTTAPGAQPEPTRTFLPGEPPPCSPRSLEEPGLLSGAREATQDLAATPYPTERGPQGKAADPSPLEGLQELQCAALLEAGGPEATGQAHSTQGGAREERSREEGEQGPSSGASSQVLEQRAGSPGALEDEGEQPAPEEDELEEDELGQQSMEDSEEDCGGAPDNSHPPRALPGLDALVAATINLGDLPSDSPPDPQPPAASGPPSTVPLPHSSGIHGIALLSELADLAIQRQRSERTVPEEEEDVLAFNLQHLATLATAWSLVEAAGLDSSTAPAQPPTANPCSGPRLTPRMQILQRKDTWTPKTKPVCPLKAAIDRLDTQEVGMRVRLAELQRRYKEKQRELARLQRKHDHERDESSRSPARRGPGRPRKRKHSSSLPAPRPTGPLPRSDGKKVKAVRTSLGLLCAELRGGSGGEPAKKRSKLERSVYAGLQTASVEKAQCKKSSCQGGLAPSVAHRVAQLKPKVKSKGLPTGLSSFQQKEATPGGRIREKLSRAKSAKVSGATRHPQPKGHGSRETPRCPAQPSVAASQEAGSGYDSEDCEGLLGTEAPPREAGLLLHTGASVAVLGPSPSSVVKMEANQKAKKKKERQGLLGACRLSSPESEVKIKRRSVKAKVGTTLERAPGQRPPGALGKKKAKGKAKGSLRAEPGATPSRDALFNPSRAFACREEGSQLASERLKRATRKGTVLQPVLRRKNGALSITLATRNAKAILGKGRKLSKVKHKAGKQGKGRAVSRLLESFAVEEDFEFDDNSSFSEEEEDEEEEEEDSGPLSAEQSAALARSCAIHKEDLRDGLPVLIPKEDSLLYAGSVRTLQPPDIYSIVIEGERGNRQRIYSLEQLLQEAVLDVRPQSSRYLPPGTRVCAYWSQKSRCLYPGNVVRGASGDEDEDLDSVVVEFDDGDTGHIAVSNVRLLPPDFKIQCTEPSPALLVSSSCRRTKKVSSEAPPPSEAATPSLSPKAQDGPEALKTPGKKSISKDKAGKAELLTSGAKSPTGASDHFLGRRGSPLLSWSAVAQTKRKAVAAASKGPGVLQNLFQLNGSSKKLRAREALFPVHSVATPIFGNGFRADSFSSLASSYAPFVGGTGPGLPRGAHKLLRAKKAERVEAEKGGRRRAGGEFLVKLDHEGVTSPKNKTCKALLMGDKDFSPKLGRPLPSPSYVHPALVGKDKKGRAPIPPLPMGLALRKYAGQAEFPLPYDSDCHSSFSDEDEDGPGLAAGVPSRFLARLSVSSSSSGSSTSSSSGSVSTSSLCSSDNEDSSYSSDDEDPALLLQTCLTHPVPTLLAQPEALRSKGSGPHAHAQRCFLSRATVAGTGAGSGPSSSSKSKLKRKEALSFSKAKELSRRQRPPSVENRPKISAFLPARQLWKWSGNPTQRRGMKGKARKLFYKAIVRGEETLRVGDCAVFLSAGRPNLPYIGRIESMWESWGSNMVVKVKWFYHPEETKLGKRQCDGKNALYQSCHEDENDVQTISHKCQVVAREQYEQMARSRKCQDRQDLYYLAGTYDPTTGRLVTADGVPILC>sp|Q9UKV3|ACINU_HUMAN Apoptotic chromatin condensation inducer in thenucleus OS=Homo sapiens OX=9606 GN=ACIN1 PE=1 SV=2MWRRKHPRTSGGTRGVLSGNRGVEYGSGRGHLGTFEGRWRKLPKMPEAVGTDPSTSRKMAELEEVTLDGKPLQALRVTDLKAALEQRGLAKSGQKSALVKRLKGALMLENLQKHSTPHAAFQPNSQIGEEMSQNSFIKQYLEKQQELLRQRLEREAREAAELEEASAESEDEMIHPEGVASLLPPDFQSSLERPELELSRHSPRKSSSISEEKGDSDDEKPRKGERRSSRVRQARAAKLSEGSQPAEEEEDQETPSRNLRVRADRNLKTEEEEEEEEEEEEDDEEEEGDDEGQKSREAPILKEFKEEGEEIPRVKPEEMMDERPKTRSQEQEVLERGGRFTRSQEEARKSHLARQQQEKEMKTTSPLEEEEREIKSSQGLKEKSKSPSPPRLTEDRKKASLVALPEQTASEEETPPPLLTKEASSPPPHPQLHSEEEIEPMEGPAPAVLIQLSPPNTDADTRELLVSQHTVQLVGGLSPLSSPSDTKAESPAEKVPEESVLPLVQKSTLADYSAQKDLEPESDRSAQPLPLKIEELALAKGITEECLKQPSLEQKEGRRASHTLLPSHRLKQSADSSSSRSSSSSSSSSRSRSRSPDSSGSRSHSPLRSKQRDVAQARTHANPRGRPKMGSRSTSESRSRSRSRSRSASSNSRKSLSPGVSRDSSTSYTETKDPSSGQEVATPPVPQLQVCEPKERTSTSSSSVQARRLSQPESAEKHVTQRLQPERGSPKKCEAEEAEPPAATQPQTSETQTSHLPESERIHHTVEEKEEVTMDTSENRPENDVPEPPMPIADQVSNDDRPEGSVEDEEKKESSLPKSFKRKISVVSATKGVPAGNSDTEGGQPGRKRRWGASTATTQKKPSISITTESLKSLIPDIKPLAGQEAVVDLHADDSRISEDETERNGDDGTHDKGLKICRTVTQVVPAEGQENGQREEEEEEKEPEAEPPVPPQVSVEVALPPPAEHEVKKVTLGDTLTRRSISQQKSGVSITIDDPVRTAQVPSPPRGKISNIVHISNLVRPFTLGQLKELLGRTGTLVEEAFWIDKIKSHCFVTYSTVEEAVATRTALHGVKWPQSNPKFLCADYAEQDELDYHRGLLVDRPSETKTEEQGIPRPLHPPPPPPVQPPQHPRAEQREQERAVREQWAEREREMERRERTRSEREWDRDKVREGPRSRSRSRDRRRKERAKSKEKKSEKKEKAQEEPPAKLLDDLFRKTKAAPCIYWLPLTDSQIVQKEAERAERAKEREKRRKEQEEEEQKEREKEAERERNRQLEREKRREHSRERDRERERERERDRGDRDRDRERDRERGRERDRRDTKRHSRSRSRSTPVRDRGGRR>sp|Q9UKV3-2|ACINU_HUMAN Isoform 2 of Apoptotic chromatin condensationinducer in the nucleus OS=Homo sapiens OX=9606 GN=ACIN1MSPADRCRSANTIEPATTSSLALFLLLQRDQSSRTRGLPEEKEEVTMDTSENRPENDVPEPPMPIADQVSNDDRPEGSVEDEEKKESSLPKSFKRKISVVSATKGVPAGNSDTEGGQPGRKRRWGASTATTQKKPSISITTESLKSLIPDIKPLAGQEAVVDLHADDSRISEDETERNGDDGTHDKGLKICRTVTQVVPAEGQENGQREEEEEEKEPEAEPPVPPQVSVEVALPPPAEHEVKKVTLGDTLTRRSISQQKSGVSITIDDPVRTAQVPSPPRGKISNIVHISNLVRPFTLGQLKELLGRTGTLVEEAFWIDKIKSHCFVTYSTVEEAVATRTALHGVKWPQSNPKFLCADYAEQDELDYHRGLLVDRPSETKTEEQGIPRPLHPPPPPPVQPPQHPRAEQREQERAVREQWAEREREMERRERTRSEREWDRDKVREGPRSRSRSRDRRRKERAKSKEKKSEKKEKAQEEPPAKLLDDLFRKTKAAPCIYWLPLTDSQIVQKEAERAERAKEREKRRKEQEEEEQKEREKEAERERNRQLEREKRREHSRERDRERERERERDRGDRDRDRERDRERGRERDRRDTKRHSRSRSRSTPVRDRGGRR>sp|Q9UKV3-3|ACINU_HUMAN Isoform 3 of Apoptotic chromatin condensationinducer in the nucleus OS=Homo sapiens OX=9606 GN=ACIN1MLSESKEGEEKEEVTMDTSENRPENDVPEPPMPIADQVSNDDRPEGSVEDEEKKESSLPKSFKRKISVVSATKGVPAGNSDTEGGQPGRKRRWGASTATTQKKPSISITTESLKSLIPDIKPLAGQEAVVDLHADDSRISEDETERNGDDGTHDKGLKICRTVTQVVPAEGQENGQREEEEEEKEPEAEPPVPPQVSVEVALPPPAEHEVKKVTLGDTLTRRSISQQKSGVSITIDDPVRTAQVPSPPRGKISNIVHISNLVRPFTLGQLKELLGRTGTLVEEAFWIDKIKSHCFVTYSTVEEAVATRTALHGVKWPQSNPKFLCADYAEQDELDYHRGLLVDRPSETKTEEQGIPRPLHPPPPPPVQPPQHPRAEQREQERAVREQWAEREREMERRERTRSEREWDRDKVREGPRSRSRSRDRRRKERAKSKEKKSEKKEKAQEEPPAKLLDDLFRKTKAAPCIYWLPLTDSQIVQKEAERAERAKEREKRRKEQEEEEQKEREKEAERERNRQLEREKRREHSRERDRERERERERDRGDRDRDRERDRERGRERDRRDTKRHSRSRSRSTPVRDRGGRR>sp|Q9UKV3-5|ACINU_HUMAN Isoform 4 of Apoptotic chromatin condensationinducer in the nucleus OS=Homo sapiens OX=9606 GN=ACIN1MWRRKHPRTSGGTRGVLSGNRGVEYGSGRGHLGTFEGRWRKLPKMPEAVGTDPSTSRKMAELEEVTLDGKPLQALRVTDLKAALEQRGLAKSGQKSALVKRLKGALMLENLQKHSTPHAAFQPNSQIGEEMSQNSFIKQYLEKQQELLRQRLEREAREAAELEEASAESEDEMIHPEGVASLLPPDFQSSLERPELELSRHSPRKSSSISEEKGDSDDEKPRKGERRSSRVRQARAAKLSEGSQPAEEEEDQETPSRNLRVRADRNLKTEEEEEEEEEEEEDDEEEEGDDEGQKSREAPILKEFKEEGEEIPRVKPEEMMDERPKTRSQEQEVLERGGRFTRSQEEARKSHLARQQQEKEMKTTSPLEEEEREIKSSQGLKEKSKSPSPPRLTEDRKKASLVALPEQTASEEETPPPLLTKEASSPPPHPQLHSEEEIEPMEGPAPAVLIQLSPPNTDADTRELLVSQHTVQLVGGLSPLSSPSDTKAESPAEKVPEESVLPLVQKSTLADYSAQKDLEPESDRSAQPLPLKIEELALAKGITEECLKQPSLEQKEGRRASHTLLPSHRLKQSADSSSSRSSSSSSSSSRSRSRSPDSSGSRSHSPLRSKQRDVAQARTHANPRGRPKMGSRSTSESRSRSRSRSRSASSNSRKSLSPGVSRDSSTSYTETKDPSSGQEVATPPVPQLQVCEPKERTSTSSSSVQARRLSQPESAEKHVTQRLQPERGSPKKCEAEEAEPPAATQPQTSETQTSHLPESERIHHTVEEKEEVTMDTSENRPENDVPEPPMPIADQVSNDDRPEGSVEDEEKKESSLPKSFKRKISVVSTKGVPAGNSDTEGGQPGRKRRWGASTATTQKKPSISITTESLKEAVVDLHADDSRISEDETERNGDDGTHDKGLKICRTVTQVVPAEGQENGQREEEEEEKEPEAEPPVPPQVSVEVALPPPAEHEVKKVTLGDTLTRRSISQQKSGVSITIDDPVRTAQVPSPPRGKISNIVHISNLVRPFTLGQLKELLGRTGTLVEEAFWIDKIKSHCFVTYSTVEEAVATRTALHGVKWPQSNPKFLCADYAEQDELDYHRGLLVDRPSETKTEEQGIPRPLHPPPPPPVQPPQHPRAEQREQERAVREQWAEREREMERRERTRSEREWDRDKVREGPRSRSRSRDRRRKERAKSKEKKSEKKEKAQEEPPAKLLDDLFRKTKAAPCIYWLPLTDSQIVQKEAERAERAKEREKRRKEQEEEEQKEREKEAERERNRQLEREKRREHSRERDRERERERERDRGDRDRDRERDRERGRERDRRDTKRHSRSRSRSTPVRDRGGRR>sp|Q12983|BNIP3_HUMAN BCL2/adenovirus E1B 19 kDa protein-interactingprotein 3 OS=Homo sapiens OX=9606 GN=BNIP3 PE=1 SV=3MGDAAADPPGPALPCEFLRPGCGAPLSPGAQLGRGAPTSAFPPPAAEAHPAARRGLRSPQLPSGAMSQNGAPGMQEESLQGSWVELHFSNNGNGGSVPASVSIYNGDMEKILLDAQHESGRSSSKSSHCDSPPRSQTPQDTNRASETDTHSIGEKNSSQSEEDDIERRKEVESILKKNSDWIWDWSSRPENIPPKEFLFKHPKRTATLSMRNTSVMKKGGIFSAEFLKVFLPSLLLSHLLAIGLGIYIGRRLTTSTSTF>sp|P26439|3BHS2_HUMAN 3 beta-hydroxysteroid dehydrogenase/Delta 5-->4-isomerase type 2 OS=Homo sapiens OX=9606 GN=HSD3B2 PE=1 SV=2MGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSKLQNRTKLTVLEGDILDEPFLKRACQDVSVVIHTACIIDVFGVTHRESIMNVNVKGTQLLLEACVQASVPVFIYTSSIEVAGPNSYKEIIQNGHEEEPLENTWPTPYPYSKKLAEKAVLAANGWNLKNGDTLYTCALRPTYIYGEGGPFLSASINEALNNNGILSSVGKFSTVNPVYVGNVAWAHILALRALRDPKKAPSVRGQFYYISDDTPHQSYDNLNYILSKEFGLRLDSRWSLPLTLMYWIGFLLEVVSFLLSPIYSYQPPFNRHTVTLSNSVFTFSYKKAQRDLAYKPLYSWEEAKQKTVEWVGSLVDRHKETLKSKTQ>sp|P26439-2|3BHS2_HUMAN Isoform 2 of 3 beta-hydroxysteroiddehydrogenase/Delta 5-->4-isomerase type 2 OS=Homo sapiens OX=9606GN=HSD3B2MGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSKLQNRTKLTVLEGDILDEPFLKRACQDVSVVIHTACIIDVFGVTHRESIMNVNVKELQNKIKLTVLEGDILDEPFLKRACQDVSVVIHTACIIDVFGVTHRQSIMNVNVKGRVAWGGDKARWGNEDQKEGQEGKRSLSIEHLLCSGPSDFADHYQLGELKAAIFSFIDEKTRTEQ>sp|P31946|1433B_HUMAN 14-3-3 protein beta/alpha OS=Homo sapiens OX=9606GN=YWHAB PE=1 SV=3MTMDKSELVQKAKLAEQAERYDDMAAAMKAVTEQGHELSNEERNLLSVAYKNVVGARRSSWRVISSIEQKTERNEKKQQMGKEYREKIEAELQDICNDVLELLDKYLIPNATQPESKVFYLKMKGDYFRYLSEVASGDNKQTTVSNSQQAYQEAFEISKKEMQPTHPIRLGLALNFSVFYYEILNSPEKACSLAKTAFDEAIAELDTLNEESYKDSTLIMQLLRDNLTLWTSENQGDEGDAGEGEN>sp|P31946-2|1433B_HUMAN Isoform Short of 14-3-3 protein beta/alphaOS=Homo sapiens OX=9606 GN=YWHABMDKSELVQKAKLAEQAERYDDMAAAMKAVTEQGHELSNEERNLLSVAYKNVVGARRSSWRVISSIEQKTERNEKKQQMGKEYREKIEAELQDICNDVLELLDKYLIPNATQPESKVFYLKMKGDYFRYLSEVASGDNKQTTVSNSQQAYQEAFEISKKEMQPTHPIRLGLALNFSVFYYEILNSPEKACSLAKTAFDEAIAELDTLNEESYKDSTLIMQLLRDNLTLWTSENQGDEGDAGEGEN>sp|P62258|1433E_HUMAN 14-3-3 protein epsilon OS=Homo sapiens OX=9606GN=YWHAE PE=1 SV=1MDDREDLVYQAKLAEQAERYDEMVESMKKVAGMDVELTVEERNLLSVAYKNVIGARRASWRIISSIEQKEENKGGEDKLKMIREYRQMVETELKLICCDILDVLDKHLIPAANTGESKVFYYKMKGDYHRYLAEFATGNDRKEAAENSLVAYKAASDIAMTELPPTHPIRLGLALNFSVFYYEILNSPDRACRLAKAAFDDAIAELDTLSEESYKDSTLIMQLLRDNLTLWTSDMQGDGEEQNKEALQDVEDENQ>sp|P62258-2|1433E_HUMAN Isoform SV of 14-3-3 protein epsilon OS=Homosapiens OX=9606 GN=YWHAEMVESMKKVAGMDVELTVEERNLLSVAYKNVIGARRASWRIISSIEQKEENKGGEDKLKMIREYRQMVETELKLICCDILDVLDKHLIPAANTGESKVFYYKMKGDYHRYLAEFATGNDRKEAAENSLVAYKAASDIAMTELPPTHPIRLGLALNFSVFYYEILNSPDRACRLAKAAFDDAIAELDTLSEESYKDSTLIMQLLRDNLTLWTSDMQGDGEEQNKEALQDVEDENQ>sp|Q9H2F3|3BHS7_HUMAN 3 beta-hydroxysteroid dehydrogenase type 7 OS=Homosapiens OX=9606 GN=HSD3B7 PE=1 SV=2MADSAQAQKLVYLVTGGCGFLGEHVVRMLLQREPRLGELRVFDQHLGPWLEELKTGPVRVTAIQGDVTQAHEVAAAVAGAHVVIHTAGLVDVFGRASPKTIHEVNVQGTRNVIEACVQTGTRFLVYTSSMEVVGPNTKGHPFYRGNEDTPYEAVHRHPYPCSKALAEWLVLEANGRKVRGGLPLVTCALRPTGIYGEGHQIMRDFYRQGLRLGGWLFRAIPASVEHGRVYVGNVAWMHVLAARELEQRATLMGGQVYFCYDGSPYRSYEDFNMEFLGPCGLRLVGARPLLPYWLLVFLAALNALLQWLLRPLVLYAPLLNPYTLAVANTTFTVSTDKAQRHFGYEPLFSWEDSRTRTILWVQAATGSAQ>sp|Q9H2F3-2|3BHS7_HUMAN Isoform 2 of 3 beta-hydroxysteroid dehydrogenasetype 7 OS=Homo sapiens OX=9606 GN=HSD3B7MADSAQAQKLVYLVTGGCGFLGEHVVRMLLQREPRLGELRVFDQHLGPWLEELKTGPVRVTAIQGDVTQAHEVAAAVAGAHVVIHTAGLVDVFGRASPKTIHEVNVQGTRNVIEACVQTGTRFLVYTSSMEVVGPNTKGHPFYRGNEDTPYEAVHRHPYPCSKALAEWLVLEANGRKAMLPGCTCWQPGSWSSGQP>sp|P27348|1433T_HUMAN 14-3-3 protein theta OS=Homo sapiens OX=9606GN=YWHAQ PE=1 SV=1MEKTELIQKAKLAEQAERYDDMATCMKAVTEQGAELSNEERNLLSVAYKNVVGGRRSAWRVISSIEQKTDTSDKKLQLIKDYREKVESELRSICTTVLELLDKYLIANATNPESKVFYLKMKGDYFRYLAEVACGDDRKQTIDNSQGAYQEAFDISKKEMQPTHPIRLGLALNFSVFYYEILNNPELACTLAKTAFDEAIAELDTLNEDSYKDSTLIMQLLRDNLTLWTSDSAGEECDAAEGAEN>sp|Q5QJU3|ACER2_HUMAN Alkaline ceramidase 2 OS=Homo sapiens OX=9606GN=ACER2 PE=1 SV=2MGAPHWWDQLQAGSSEVDWCEDNYTIVPAIAEFYNTISNVLFFILPPICMCLFRQYATCFNSGIYLIWTLLVVVGIGSVYFHATLSFLGQMLDELAVLWVLMCALAMWFPRRYLPKIFRNDRGRFKVVVSVLSAVTTCLAFVKPAINNISLMTLGVPCTALLIAELKRCDNMRVFKLGLFSGLWWTLALFCWISDRAFCELLSSFNFPYLHCMWHILICLAAYLGCVCFAYFDAASEIPEQGPVIKFWPNEKWAFIGVPYVSLLCANKKSSVKIT>sp|Q5QJU3-2|ACER2_HUMAN Isoform 2 of Alkaline ceramidase 2 OS=Homosapiens OX=9606 GN=ACER2MCLFRQYATCFNSGIYLIWTLLVVVGIGSVYFHATLSFLGQMLDELAVLWVLMCALAMWFPRRYLPKIFRNDRGRFKVVVSVLSAVTTCLAFVKPAINNISLMTLGVPCTALLIAELKRCDNMRVFKLGLFSGLWWTLALFCWISDRAFCELLSSFNFPYLHCMWHILICLAAYLGCVCFAYFDAASEIPEQGPVIKFWPNEKWAFIGVPYVSLLCANKKSSVKIT>sp|Q5QJU3-3|ACER2_HUMAN Isoform 3 of Alkaline ceramidase 2 OS=Homosapiens OX=9606 GN=ACER2MCLFRQYATCFNSGIYLIWTLLVVVGIGSVYFHATLSFLGQMLDELAVLWVLMCALAMWFPRRYLPKIFRNDRGRFKVVVSVLSAVTTCLAFVKPAINNISLMTLGVPCTALLIAELKRHERNQRRRHRKGGQQGGGDKV>sp|Q6PD74|AAGAB_HUMAN Alpha- and gamma-adaptin-binding protein p34OS=Homo sapiens OX=9606 GN=AAGAB PE=1 SV=1MAAGVPCALVTSCSSVFSGDQLVQHILGTEDLIVEVTSNDAVRFYPWTIDNKYYSADINLCVVPNKFLVTAEIAESVQAFVVYFDSTQKSGLDSVSSWLPLAKAWLPEVMILVCDRVSEDGINRQKAQEWCIKHGFELVELSPEELPEEDDDFPESTGVKRIVQALNANVWSNVVMKNDRNQGFSLLNSLTGTNHSIGSADPCHPEQPHLPAADSTESLSDHRGGASNTTDAQVDSIVDPMLDLDIQELASLTTGGGDVENFERLFSKLKEMKDKAATLPHEQRKVHAEKVAKAFWMAIGGDRDEIEGLSSDEEH>sp|Q6PD74-2|AAGAB_HUMAN Isoform 2 of Alpha- and gamma-adaptin-bindingprotein p34 OS=Homo sapiens OX=9606 GN=AAGABMILVCDRVSEDGINRQKAQEWCIKHGFELVELSPEELPEEDDDFPESTGVKRIVQALNANVWSNVVMKNDRNQGFSLLNSLTGTNHSIGSADPCHPEQPHLPAADSTESLSDHRGGASNTTDAQVDSIVDPMLDLDIQELASLTTGGGDVENFERLFSKLKEMKDKAATLPHEQRKVHAEKVAKAFWMAIGGDRDEIEGLSSDEEH>sp|Q9NUN7|ACER3_HUMAN Alkaline ceramidase 3 OS=Homo sapiens OX=9606GN=ACER3 PE=1 SV=3MAPAADREGYWGPTTSTLDWCEENYSVTWYIAEFWNTVSNLIMIIPPMFGAVQSVRDGLEKRYIASYLALTVVGMGSWCFHMTLKYEMQLLDELPMIYSCCIFVYCMFECFKIKNSVNYHLLFTLVLFSLIVTTVYLKVKEPIFHQVMYGMLVFTLVLRSIYIVTWVYPWLRGLGYTSLGIFLLGFLFWNIDNIFCESLRNFRKKVPPIIGITTQFHAWWHILTGLGSYLHILFSLYTRTLYLRYRPKVKFLFGIWPVILFEPLRKH>sp|Q9NUN7-2|ACER3_HUMAN Isoform 2 of Alkaline ceramidase 3 OS=Homosapiens OX=9606 GN=ACER3MAQSRLIGTSTSQVMYGMLVFTLVLRSIYIVTWVYPWLRGLGYTSLGIFLLGFLFWNIDNIFCESLRNFRKKVPPIIGITTQFHAWWHILTGLGSYLHILFSLYTRTLYLRYRPKVKFLFGIWPVILFEPLRKH>sp|O95972|BMP15_HUMAN Bone morphogenetic protein 15 OS=Homo sapiensOX=9606 GN=BMP15 PE=1 SV=2MVLLSILRILFLCELVLFMEHRAQMAEGGQSSIALLAEAPTLPLIEELLEESPGEQPRKPRLLGHSLRYMLELYRRSADSHGHPRENRTIGATMVRLVKPLTNVARPHRGTWHIQILGFPLRPNRGLYQLVRATVVYRHHLQLTRFNLSCHVEPWVQKNPTNHFPSSEGDSSKPSLMSNAWKEMDITQLVQQRFWNNKGHRILRLRFMCQQQKDSGGLELWHGTSSLDIAFLLLYFNDTHKSIRKAKFLPRGMEEFMERESLLRRTRQADGISAEVTASSSKHSGPENNQCSLHPFQISFRQLGWDHWIIAPPFYTPNYCKGTCLRVLRDGLNSPNHAIIQNLINQLVDQSVPRPSCVPYKYVPISVLMIEANGSILYKEYEGMIAESCTCR>sp|Q9NSY1|BMP2K_HUMAN BMP-2-inducible protein kinase OS=Homo sapiensOX=9606 GN=BMP2K PE=1 SV=2MKKFSRMPKSEGGSGGGAAGGGAGGAGAGAGCGSGGSSVGVRVFAVGRHQVTLEESLAEGGFSTVFLVRTHGGIRCALKRMYVNNMPDLNVCKREITIMKELSGHKNIVGYLDCAVNSISDNVWEVLILMEYCRAGQVVNQMNKKLQTGFTEPEVLQIFCDTCEAVARLHQCKTPIIHRDLKVENILLNDGGNYVLCDFGSATNKFLNPQKDGVNVVEEEIKKYTTLSYRAPEMINLYGGKPITTKADIWALGCLLYKLCFFTLPFGESQVAICDGNFTIPDNSRYSRNIHCLIRFMLEPDPEHRPDIFQVSYFAFKFAKKDCPVSNINNSSIPSALPEPMTASEAAARKSQIKARITDTIGPTETSIAPRQRPKANSATTATPSVLTIQSSATPVKVLAPGEFGNHRPKGALRPGNGPEILLGQGPPQQPPQQHRVLQQLQQGDWRLQQLHLQHRHPHQQQQQQQQQQQQQQQQQQQQQQQQQQQHHHHHHHHLLQDAYMQQYQHATQQQQMLQQQFLMHSVYQPQPSASQYPTMMPQYQQAFFQQQMLAQHQPSQQQASPEYLTSPQEFSPALVSYTSSLPAQVGTIMDSSYSANRSVADKEAIANFTNQKNISNPPDMSGWNPFGEDNFSKLTEEELLDREFDLLRSNRLEERASSDKNVDSLSAPHNHPPEDPFGSVPFISHSGSPEKKAEHSSINQENGTANPIKNGKTSPASKDQRTGKKTSVQGQVQKGNDESESDFESDPPSPKSSEEEEQDDEEVLQGEQGDFNDDDTEPENLGHRPLLMDSEDEEEEEKHSSDSDYEQAKAKYSDMSSVYRDRSGSGPTQDLNTILLTSAQLSSDVAVETPKQEFDVFGAVPFFAVRAQQPQQEKNEKNLPQHRFPAAGLEQEEFDVFTKAPFSKKVNVQECHAVGPEAHTIPGYPKSVDVFGSTPFQPFLTSTSKSESNEDLFGLVPFDEITGSQQQKVKQRSLQKLSSRQRRTKQDMSKSNGKRHHGTPTSTKKTLKPTYRTPERARRHKKVGRRDSQSSNEFLTISDSKENISVALTDGKDRGNVLQPEESLLDPFGAKPFHSPDLSWHPPHQGLSDIRADHNTVLPGRPRQNSLHGSFHSADVLKMDDFGAVPFTELVVQSITPHQSQQSQPVELDPFGAAPFPSKQ>sp|Q9NSY1-2|BMP2K_HUMAN Isoform 2 of BMP-2-inducible protein kinaseOS=Homo sapiens OX=9606 GN=BMP2KMKKFSRMPKSEGGSGGGAAGGGAGGAGAGAGCGSGGSSVGVRVFAVGRHQVTLEESLAEGGFSTVFLVRTHGGIRCALKRMYVNNMPDLNVCKREITIMKELSGHKNIVGYLDCAVNSISDNVWEVLILMEYCRAGQVVNQMNKKLQTGFTEPEVLQIFCDTCEAVARLHQCKTPIIHRDLKVENILLNDGGNYVLCDFGSATNKFLNPQKDGVNVVEEEIKKYTTLSYRAPEMINLYGGKPITTKADIWALGCLLYKLCFFTLPFGESQVAICDGNFTIPDNSRYSRNIHCLIRFMLEPDPEHRPDIFQVSYFAFKFAKKDCPVSNINNSSIPSALPEPMTASEAAARKSQIKARITDTIGPTETSIAPRQRPKANSATTATPSVLTIQSSATPVKVLAPGEFGNHRPKGALRPGNGPEILLGQGPPQQPPQQHRVLQQLQQGDWRLQQLHLQHRHPHQQQQQQQQQQQQQQQQQQQQQQQQQQQHHHHHHHHLLQDAYMQQYQHATQQQQMLQQQFLMHSVYQPQPSASQYPTMMPQYQQAFFQQQMLAQHQPSQQQASPEYLTSPQEFSPALVSYTSSLPAQVGTIMDSSYSANRSVADKEAIANFTNQKNISNPPDMSGWNPFGEDNFSKLTEEELLDREFDLLRSSKGHLKAYFASQ>sp|Q9NSY1-3|BMP2K_HUMAN Isoform 3 of BMP-2-inducible protein kinaseOS=Homo sapiens OX=9606 GN=BMP2KMKKFSRMPKSEGGSGGGAAGGGAGGAGAGAGCGSGGSSVGVRVFAVGRHQVTLEESLAEGGFSTVFLVRTHGGIRCALKRMYVNNMPDLNVCKREITIMKELSGHKNIVGYLDCAVNSISDNVWEVLILMEYCRAGQVVNQMNKKLQTGFTEPEVLQIFCDTCEAVARLHQCKTPIIHRDLKVENILLNDGGNYVLCDFGSATNKFLNPQKDGVNVVEEEIKKYTTLSYRAPEMINLYGGKPITTKADIWALGCLLYKLCFFTLPFGESQVAICDGNFTIPDNSRYSRNIHCLIRFMLEPDPEHRPDIFQVSYFAFKFAKKDCPVSNINKCCKQLLRHGALLTEILLFLQLFLNRMTASEAAARKSQIKARITDTIGPTETSIAPRQRPKANSATTATPSVLTIQSSATPVKVLAPGEFGNHRPKGALRPGNGPEILLGQGPPQQPPQQHRVLQQLQQGDWRLQQLHLQHRHPHQQQQQQQQQQQQQQQQQQQQQQQQQQQHHHHHHHHLLQDAYMQQYQHATQQQQMLQQQFLMHSVYQPQPSASQYPTMMPQYQQAFFQQQMLAQHQPSQQQASPEYLTSPQEFSPALVSYTSSLPAQVGTIMDSSYSANRSVADKEAIANFTNQKNISNPPDMSGWNPFGEDNFSKLTEEELLDREFDLLRSSKGHLKAYFASQ>sp|Q9GZZ6|ACH10_HUMAN Neuronal acetylcholine receptor subunit alpha-10OS=Homo sapiens OX=9606 GN=CHRNA10 PE=1 SV=1MGLRSHHLSLGLLLLFLLPAECLGAEGRLALKLFRDLFANYTSALRPVADTDQTLNVTLEVTLSQIIDMDERNQVLTLYLWIRQEWTDAYLRWDPNAYGGLDAIRIPSSLVWRPDIVLYNKADAQPPGSASTNVVLRHDGAVRWDAPAITRSSCRVDVAAFPFDAQHCGLTFGSWTHGGHQLDVRPRGAAASLADFVENVEWRVLGMPARRRVLTYGCCSEPYPDVTFTLLLRRRAAAYVCNLLLPCVLISLLAPLAFHLPADSGEKVSLGVTVLLALTVFQLLLAESMPPAESVPLIGKYYMATMTMVTFSTALTILIMNLHYCGPSVRPVPAWARALLLGHLARGLCVRERGEPCGQSRPPELSPSPQSPEGGAGPPAGPCHEPRCLCRQEALLHHVATIANTFRSHRAAQRCHEDWKRLARVMDRFFLAIFFSMALVMSLLVLVQAL>sp|Q5TH69|BIG3_HUMAN Brefeldin A-inhibited guanine nucleotide-exchangeprotein 3 OS=Homo sapiens OX=9606 GN=ARFGEF3 PE=1 SV=3MEEILRKLQKEASGSKYKAIKESCTWALETLGGLDTIVKIPPHVLREKCLLPLQLALESKNVKLAQHALAGMQKLLSEERFVSMETDSDEKQLLNQILNAVKVTPSLNEDLQVEVMKVLLCITYTPTFDLNGSAVLKIAEVCIETYISSCHQRSINTAVRATLSQMLSDLTLQLRQRQENTIIENPDVPQDFGNQGSTVESLCDDVVSVLTVLCEKLQAAINDSQQLQLLYLECILSVLSSSSSSMHLHRRFTDLIWKNLCPALIVILGNPIHDKTITSAHTSSTSTSLESDSASPGVSDHGRGSGCSCTAPALSGPVARTIYYIAAELVRLVGSVDSMKPVLQSLYHRVLLYPPPQHRVEAIKIMKEILGSPQRLCDLAGPSSTESESRKRSISKRKSHLDLLKLIMDGMTEACIKGGIEACYAAVSCVCTLLGALDELSQGKGLSEGQVQLLLLRLEELKDGAEWSRDSMEINEADFRWQRRVLSSEHTPWESGNERSLDISISVTTDTGQTTLEGELGQTTPEDHSGNHKNSLKSPAIPEGKETLSKVLETEAVDQPDVVQRSHTVPYPDITNFLSVDCRTRSYGSRYSESNFSVDDQDLSRTEFDSCDQYSMAAEKDSGRSDVSDIGSDNCSLADEEQTPRDCLGHRSLRTAALSLKLLKNQEADQHSARLFIQSLEGLLPRLLSLSNVEEVDTALQNFASTFCSGMMHSPGFDGNSSLSFQMLMNADSLYTAAHCALLLNLKLSHGDYYRKRPTLAPGVMKDFMKQVQTSGVLMVFSQAWIEELYHQVLDRNMLGEAGYWGSPEDNSLPLITMLTDIDGLESSAIGGQLMASAATESPFAQSRRIDDSTVAGVAFARYILVGCWKNLIDTLSTPLTGRMAGSSKGLAFILGAEGIKEQNQKERDAICMSLDGLRKAARLSCALGVAANCASALAQMAAASCVQEEKEEREAQEPSDAITQVKLKVEQKLEQIGKVQGVWLHTAHVLCMEAILSVGLEMGSHNPDCWPHVFRVCEYVGTLEHNHFSDGASQPPLTISQPQKATGSAGLLGDPECEGSPPEHSPEQGRSLSTAPVVQPLSIQDLVREGSRGRASDFRGGSLMSGSSAAKVVLTLSTQADRLFEDATDKLNLMALGGFLYQLKKASQSQLFHSVTDTVDYSLAMPGEVKSTQDRKSALHLFRLGNAMLRIVRSKARPLLHVMRCWSLVAPHLVEAACHKERHVSQKAVSFIHDILTEVLTDWNEPPHFHFNEALFRPFERIMQLELCDEDVQDQVVTSIGELVEVCSTQIQSGWRPLFSALETVHGGNKSEMKEYLVGDYSMGKGQAPVFDVFEAFLNTDNIQVFANAATSYIMCLMKFVKGLGEVDCKEIGDCAPAPGAPSTDLCLPALDYLRRCSQLLAKIYKMPLKPIFLSGRLAGLPRRLQEQSASSEDGIESVLSDFDDDTGLIEVWIILLEQLTAAVSNCPRQHQPPTLDLLFELLRDVTKTPGPGFGIYAVVHLLLPVMSVWLRRSHKDHSYWDMASANFKHAIGLSCELVVEHIQSFLHSDIRYESMINTMLKDLFELLVACVAKPTETISRVGCSCIRYVLVTAGPVFTEEMWRLACCALQDAFSATLKPVKDLLGCFHSGTESFSGEGCQVRVAAPSSSPSAEAEYWRIRAMAQQVFMLDTQCSPKTPNNFDHAQSCQLIIELPPDEKPNGHTKKSVSFREIVVSLLSHQVLLQNLYDILLEEFVKGPSPGEEKTIQVPEAKLAGFLRYISMQNLAVIFDLLLDSYRTAREFDTSPGLKCLLKKVSGIGGAANLYRQSAMSFNIYFHALVCAVLTNQETITAEQVKKVLFEDDERSTDSSQQCSSEDEDIFEETAQVSPPRGKEKRQWRARMPLLSVQPVSNADWVWLVKRLHKLCMELCNNYIQMHLDLENCMEEPPIFKGDPFFILPSFQSESSTPSTGGFSGKETPSEDDRSQSREHMGESLSLKAGGGDLLLPPSPKVEKKDPSRKKEWWENAGNKIYTMAADKTISKLMTEYKKRKQQHNLSAFPKEVKVEKKGEPLGPRGQDSPLLQRPQHLMDQGQMRHSFSAGPELLRQDKRPRSGSTGSSLSVSVRDAEAQIQAWTNMVLTVLNQIQILPDQTFTALQPAVFPCISQLTCHVTDIRVRQAVREWLGRVGRVYDIIV>sp|Q13131|AAPK1_HUMAN 5'-AMP-activated protein kinase catalytic subunitalpha-1 OS=Homo sapiens OX=9606 GN=PRKAA1 PE=1 SV=4MRRLSSWRKMATAEKQKHDGRVKIGHYILGDTLGVGTFGKVKVGKHELTGHKVAVKILNRQKIRSLDVVGKIRREIQNLKLFRHPHIIKLYQVISTPSDIFMVMEYVSGGELFDYICKNGRLDEKESRRLFQQILSGVDYCHRHMVVHRDLKPENVLLDAHMNAKIADFGLSNMMSDGEFLRTSCGSPNYAAPEVISGRLYAGPEVDIWSSGVILYALLCGTLPFDDDHVPTLFKKICDGIFYTPQYLNPSVISLLKHMLQVDPMKRATIKDIREHEWFKQDLPKYLFPEDPSYSSTMIDDEALKEVCEKFECSEEEVLSCLYNRNHQDPLAVAYHLIIDNRRIMNEAKDFYLATSPPDSFLDDHHLTRPHPERVPFLVAETPRARHTLDELNPQKSKHQGVRKAKWHLGIRSQSRPNDIMAEVCRAIKQLDYEWKVVNPYYLRVRRKNPVTSTYSKMSLQLYQVDSRTYLLDFRSIDDEITEAKSGTATPQRSGSVSNYRSCQRSDSDAEAQGKSSEVSLTSSVTSLDSSPVDLTPRPGSHTIEFFEMCANLIKILAQ>sp|Q13131-2|AAPK1_HUMAN Isoform 2 of 5'-AMP-activated protein kinasecatalytic subunit alpha-1 OS=Homo sapiens OX=9606 GN=PRKAA1MRRLSSWRKMATAEKQKHDGRVKIGHYILGDTLGVGTFGKVKVGKHELTGHKVAVKILNRQKIRSLDVVGKIRREIQNLKLFRHPHIIKLYQVISTPSDIFMVMEYVSGGELFDYICKNGRKSDVPGVVKTGSTKELDEKESRRLFQQILSGVDYCHRHMVVHRDLKPENVLLDAHMNAKIADFGLSNMMSDGEFLRTSCGSPNYAAPEVISGRLYAGPEVDIWSSGVILYALLCGTLPFDDDHVPTLFKKICDGIFYTPQYLNPSVISLLKHMLQVDPMKRATIKDIREHEWFKQDLPKYLFPEDPSYSSTMIDDEALKEVCEKFECSEEEVLSCLYNRNHQDPLAVAYHLIIDNRRIMNEAKDFYLATSPPDSFLDDHHLTRPHPERVPFLVAETPRARHTLDELNPQKSKHQGVRKAKWHLGIRSQSRPNDIMAEVCRAIKQLDYEWKVVNPYYLRVRRKNPVTSTYSKMSLQLYQVDSRTYLLDFRSIDDEITEAKSGTATPQRSGSVSNYRSCQRSDSDAEAQGKSSEVSLTSSVTSLDSSPVDLTPRPGSHTIEFFEMCANLIKILAQ>sp|Q5VST6|AB17B_HUMAN Alpha/beta hydrolase domain-containing protein 17BOS=Homo sapiens OX=9606 GN=ABHD17B PE=1 SV=1MNNLSFSELCCLFCCPPCPGKIASKLAFLPPDPTYTLMCDESGSRWTLHLSERADWQYSSREKDAIECFMTRTSKGNRIACMFVRCSPNAKYTLLFSHGNAVDLGQMSSFYIGLGSRINCNIFSYDYSGYGASSGKPTEKNLYADIEAAWLALRTRYGIRPENVIIYGQSIGTVPSVDLAARYESAAVILHSPLTSGMRVAFPDTKKTYCFDAFPNIDKISKITSPVLIIHGTEDEVIDFSHGLALFERCQRPVEPLWVEGAGHNDVELYGQYLERLKQFVSQELVNL>sp|Q5VST6-2|AB17B_HUMAN Isoform 2 of Alpha/beta hydrolase domain-containing protein 17B OS=Homo sapiens OX=9606 GN=ABHD17BMNNLSFSELCCLFCCPPCPGKIASKLAFLPPDPTYTLMCDESGSRWTLHLSERADWQYSSREKDAIECFMTRTSKGNRIACMFVRCSPNAKYTLLFSHGNAVDLGQMSSFYIGLGSRINCNIFSYDYSGYGASSGKPTEKNLYADIEAAWLALRTRYGIRPENVIIYGQSIGTVPSVDLAARYESAAVILHSPLTSGMRVAFPDTKKTYCFDAFPNIDKISKITSPVLIIHGTEDEVIDFSHGLALFERCQRPVEPLWVEGAGHNDVELYGQYLERLKQFVSQELVQKHKEGK>sp|P28221|5HT1D_HUMAN 5-hydroxytryptamine receptor 1D OS=Homo sapiensOX=9606 GN=HTR1D PE=1 SV=1MSPLNQSAEGLPQEASNRSLNATETSEAWDPRTLQALKISLAVVLSVITLATVLSNAFVLTTILLTRKLHTPANYLIGSLATTDLLVSILVMPISIAYTITHTWNFGQILCDIWLSSDITCCTASILHLCVIALDRYWAITDALEYSKRRTAGHAATMIAIVWAISICISIPPLFWRQAKAQEEMSDCLVNTSQISYTIYSTCGAFYIPSVLLIILYGRIYRAARNRILNPPSLYGKRFTTAHLITGSAGSSLCSLNSSLHEGHSHSAGSPLFFNHVKIKLADSALERKRISAARERKATKILGIILGAFIICWLPFFVVSLVLPICRDSCWIHPALFDFFTWLGYLNSLINPIIYTVFNEEFRQAFQKIVPFRKAS>sp|P28222|5HT1B_HUMAN 5-hydroxytryptamine receptor 1B OS=Homo sapiensOX=9606 GN=HTR1B PE=1 SV=1MEEPGAQCAPPPPAGSETWVPQANLSSAPSQNCSAKDYIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASILHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRQAKAEEEVSECVVNTDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRILKQTPNRTGKRLTRAQLITDSPGSTSSVTSINSRVPDVPSESGSPVYVNQVKVRVSDALLEKKKLMAARERKATKTLGIILGAFIVCWLPFFIISLVMPICKDACWFHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFKCTS>sp|Q70Z44|5HT3D_HUMAN 5-hydroxytryptamine receptor 3D OS=Homo sapiensOX=9606 GN=HTR3D PE=1 SV=3MQKHSPGPPALALLSQSLLTTGNGDTLIINCPGFGQHRVDPAAFQAVFDRKAIGPVTNYSVATHVNISFTLSAIWNCYSRIHTFNCHHARPWHNQFVQWNPDECGGIKKSGMATENLWLSDVFIEESVDQTPAGLMASMSIVKATSNTISQCGWSASANWTPSISPSMDRARAWRRMSRSFQIHHRTSFRTRREWVLLGIQKRTIKVTVATNQYEQAIFHVAIRRRCRPSPYVVNFLVPSGILIAIDALSFYLPLESGNCAPFKMTVLLGYSVFLLMMNDLLPATSTSSHASLVAPLALMQTPLPAGVYFALCLSLMVGSLLETIFITHLLHVATTQPLPLPRWLHSLLLHCTGQGRCCPTAPQKGNKGPGLTPTHLPGVKEPEVSAGQMPGPGEAELTGGSEWTRAQREHEAQKQHSVELWVQFSHAMDALLFRLYLLFMASSIITVICLWNT>sp|Q70Z44-2|5HT3D_HUMAN Isoform 2 of 5-hydroxytryptamine receptor 3DOS=Homo sapiens OX=9606 GN=HTR3DMASMSIVKATSNTISQCGWSASANWTPSISPSMDRAERSPSALSPTQVAIRRRCRPSPYVVNFLVPSGILIAIDALSFYLPLESGNCAPFKMTVLLGYSVFLLMMNDLLPATSTSSHASLVRPHPSRDQKRGVYFALCLSLMVGSLLETIFITHLLHVATTQPLPLPRWLHSLLLHCTGQGRCCPTAPQKGNKGPGLTPTHLPGVKEPEVSAGQMPGPGEAELTGGSEWTRAQREHEAQKQHSVELWVQFSHAMDALLFRLYLLFMASSIITVICLWNT>sp|Q70Z44-3|5HT3D_HUMAN Isoform 3 of 5-hydroxytryptamine receptor 3DOS=Homo sapiens OX=9606 GN=HTR3DMVAIRRRCRPSPYVVNFLVPSGILIAIDALSFYLPLESGNCAPFKMTVLLGYSVFLLMMNDLLPATSTSSHASLVRPHPSRDQKRGVYFALCLSLMVGSLLETIFITHLLHVATTQPLPLPRWLHSLLLHCTGQGRCCPTAPQKGNKGPGLTPTHLPGVKEPEVSAGQMPGPGEAELTGGSEWTRAQREHEAQKQHSVELWVQFSHAMDALLFRLYLLFMASSIITVICLWNT>sp|Q70Z44-4|5HT3D_HUMAN Isoform 4 of 5-hydroxytryptamine receptor 3DOS=Homo sapiens OX=9606 GN=HTR3DMERGWFHGKGFLLGFILHLLLQDSHLQLVTSFLWLNMWNPDECGGIKKSGMATENLWLSDVFIEESVDQTPAGLMASMSIVKATSNTISQCGWSASANWTPSISPSMDRGERSPSALSPTQVTRAWRRMSRSFQIHHRTSFRTRREWVLLGIQKRTIKVTVATNQYEQAIFHVAIRRRCRPSPYVVNFLVPSGILIAIDALSFYLPLESGNCAPFKMTVLLGYSVFLLMMNDLLPATSTSSHASLVRPHPSRDQKRGVYFALCLSLMVGSLLETIFITHLLHVATTQPLPLPRWLHSLLLHCTGQGRCCPTAPQKGNKGPGLTPTHLPGVKEPEVSAGQMPGPGEAELTGGSEWTRAQREHEAQKQHSVELWVQFSHAMDALLFRLYLLFMASSIITVICLWNT>sp|P01011|AACT_HUMAN Alpha-1-antichymotrypsin OS=Homo sapiens OX=9606GN=SERPINA3 PE=1 SV=2MERMLPLLALGLLAAGFCPAVLCHPNSPLDEENLTQENQDRGTHVDLGLASANVDFAFSLYKQLVLKAPDKNVIFSPLSISTALAFLSLGAHNTTLTEILKGLKFNLTETSEAEIHQSFQHLLRTLNQSSDELQLSMGNAMFVKEQLSLLDRFTEDAKRLYGSEAFATDFQDSAAAKKLINDYVKNGTRGKITDLIKDLDSQTMMVLVNYIFFKAKWEMPFDPQDTHQSRFYLSKKKWVMVPMMSLHHLTIPYFRDEELSCTVVELKYTGNASALFILPDQDKMEEVEAMLLPETLKRWRDSLEFREIGELYLPKFSISRDYNLNDILLQLGIEEAFTSKADLSGITGARNLAVSQVVHKAVLDVFEEGTEASAATAVKITLLSALVETRTIVRFNRPFLMIIVPTDTQNIFFMSKVTNPKQA>sp|P01011-2|AACT_HUMAN Isoform 2 of Alpha-1-antichymotrypsin OS=Homosapiens OX=9606 GN=SERPINA3MERMLPLLALGLLAAGFCPAVLCHPNSPLDEENLTQENQDRGTHVDLGLASANVDFAFSLYKQLVLKAPDKNVIFSPLSISTALAFLSLGAHNTTLTEILKGLKFNLTETSEAEIHQSFQHLLRTLNQSSDELQLSMGNAMFVKEQLSLLDRFTEDAKRLYGSEAFATDFQDSAAAKKLINDYVKNGTRGKITDLIKDLDSQTMMVLVNYIFFKER>sp|P01011-3|AACT_HUMAN Isoform 3 of Alpha-1-antichymotrypsin OS=Homosapiens OX=9606 GN=SERPINA3MERMLPLLALGLLAAGFCPAVLCHPNSPLDEENLTQENQDRGTHVDLGLASANVDFAFSLYKQSPRWSIRLCLMYLRRAQKHLLPQQSKSPSFLH>sp|P0DMS8|AA3R_HUMAN Adenosine receptor A3 OS=Homo sapiens OX=9606GN=ADORA3 PE=1 SV=1MPNNSTALSLANVTYITMEIFIGLCAIVGNVLVICVVKLNPSLQTTTFYFIVSLALADIAVGVLVMPLAIVVSLGITIHFYSCLFMTCLLLIFTHASIMSLLAIAVDRYLRVKLTVRYKRVTTHRRIWLALGLCWLVSFLVGLTPMFGWNMKLTSEYHRNVTFLSCQFVSVMRMDYMVYFSFLTWIFIPLVVMCAIYLDIFYIIRNKLSLNLSNSKETGAFYGREFKTAKSLFLVLFLFALSWLPLSIINCIIYFNGEVPQLVLYMGILLSHANSMMNPIVYAYKIKKFKETYLLILKACVVCHPSDSLDTSIEKNSE>sp|P49902|5NTC_HUMAN Cytosolic purine 5'-nucleotidase OS=Homo sapiensOX=9606 GN=NT5C2 PE=1 SV=1MSTSWSDRLQNAADMPANMDKHALKKYRREAYHRVFVNRSLAMEKIKCFGFDMDYTLAVYKSPEYESLGFELTVERLVSIGYPQELLSFAYDSTFPTRGLVFDTLYGNLLKVDAYGNLLVCAHGFNFIRGPETREQYPNKFIQRDDTERFYILNTLFNLPETYLLACLVDFFTNCPRYTSCETGFKDGDLFMSYRSMFQDVRDAVDWVHYKGSLKEKTVENLEKYVVKDGKLPLLLSRMKEVGKVFLATNSDYKYTDKIMTYLFDFPHGPKPGSSHRPWQSYFDLILVDARKPLFFGEGTVLRQVDTKTGKLKIGTYTGPLQHGIVYSGGSSDTICDLLGAKGKDILYIGDHIFGDILKSKKRQGWRTFLVIPELAQELHVWTDKSSLFEELQSLDIFLAELYKHLDSSSNERPDISSIQRRIKKVTHDMDMCYGMMGSLFRSGSRQTLFASQVMRYADLYAASFINLLYYPFSYLFRAAHVLMPHESTVEHTHVDINEMESPLATRNRTSVDFKDTDYKRHQLTRSISEIKPPNLFPLAPQEITHCHDEDDDEEEEEEEE>sp|P49902-2|5NTC_HUMAN Isoform 2 of Cytosolic purine 5'-nucleotidaseOS=Homo sapiens OX=9606 GN=NT5C2MSKEGVFVNRSLAMEKIKCFGFDMDYTLAVYKSPEYESLGFELTVERLVSIGYPQELLSFAYDSTFPTRGLVFDTLYGNLLKVDAYGNLLVCAHGFNFIRGPETREQYPNKFIQRDDTERFYILNTLFNLPETYLLACLVDFFTNCPRYTSCETGFKDGDLFMSYRSMFQDVRDAVDWVHYKGSLKEKTVENLEKYVVKDGKLPLLLSRMKEVGKVFLATNSDYKYTDKIMTYLFDFPHGPKPGSSHRPWQSYFDLILVDARKPLFFGEGTVLRQVDTKTGKLKIGTYTGPLQHGIVYSGGSSDTICDLLGAKGKDILYIGDHIFGDILKSKKRQGWRTFLVIPELAQELHVWTDKSSLFEELQSLDIFLAELYKHLDSSSNERPDISSIQRRIKKVTHDMDMCYGMMGSLFRSGSRQTLFASQVMRYADLYAASFINLLYYPFSYLFRAAHVLMPHESTVEHTHVDINEMESPLATRNRTSVDFKDTDYKRHQLTRSISEIKPPNLFPLAPQEITHCHDEDDDEEEEEEEE>sp|Q9H9L7|AKIR1_HUMAN Akirin-1 OS=Homo sapiens OX=9606 GN=AKIRIN1 PE=1SV=1MACGATLKRPMEFEAALLSPGSPKRRRCAPLPGPTPGLRPPDAEPPPPFQTQTPPQSLQQPAPPGSERRLPTPEQIFQNIKQEYSRYQRWRHLEVVLNQSEACASESQPHSSALTAPSSPGSSWMKKDQPTFTLRQVGIICERLLKDYEDKIREEYEQILNTKLAEQYESFVKFTHDQIMRRYGTRPTSYVS>sp|Q9H9L7-2|AKIR1_HUMAN Isoform 2 of Akirin-1 OS=Homo sapiens OX=9606GN=AKIRIN1MACGATLKRPMEFEAALLSPGSPKRRRCAPLPGPTPGLRPPDAEPPPPFQTQTPPQSLQQPAPPGSERRLPTPEQIFQNIKQEYSRYQRWRHLEVVLNQSEACASESQPHSSALTAPSSPEQYESFVKFTHDQIMRRYGTRPTSYVS>sp|Q719I0|AHSA2_HUMAN Putative activator of 90 kDa heat shock proteinATPase homolog 2 OS=Homo sapiens OX=9606 GN=AHSA2P PE=5 SV=2MAKWGQGNPHWIVEEREDGTNVNNWRWTERDATSLSKGKFQELLVGIVVENDAGRGEINELKQVEGEASCSSRKGKLIFFYEWNIKLGWKGIVKESGVKHKGLIEIPNLSEENEVDDTEVSLSKKKGDGVILKDLMKTAGTAKVREALGDYLKALKTEFTTGMILPTKAMATQELTVKRKLSGNTLQVQASSPVALGVRIPTVALHMMELFDTTVEQLYSIFTVKELTNKKIIMKWRCGNWPEEHYAMVALNFVPTLGQTELQLKEFLSICKEENMKFCWQKQHFEEIKGSLQLTPLNG>sp|Q719I0-2|AHSA2_HUMAN Isoform 2 of Putative activator of 90 kDa heatshock protein ATPase homolog 2 OS=Homo sapiens OX=9606 GN=AHSA2PMTLPEFTTGMILPTKAMATQELTVKRKLSGNTLQVQASSPVALGVRIPTVALHMMELFDTTVEQLYSIFTVKELTNKKIIMKWRCGNWPEEHYAMVALNFVPTLGQTELQLKEFLSICKEENMKFCWQKQHFEEIKGSLQLTPLNG>sp|Q719I0-3|AHSA2_HUMAN Isoform 3 of Putative activator of 90 kDa heatshock protein ATPase homolog 2 OS=Homo sapiens OX=9606 GN=AHSA2PMILPTKAMATQELTVKRKLSGNTLQVQASSPVALGVRIPTVALHMMELFDTTVEQLYSIFTVKELTNKKIIMKWRCGNWPEEHYAMVALNFVPTLGQTELQLKEFLSICKEENMKFCWQKQHFEEIKGSLQLTPLNG>sp|P19021|AMD_HUMAN Peptidyl-glycine alpha-amidating monooxygenaseOS=Homo sapiens OX=9606 GN=PAM PE=1 SV=2MAGRVPSLLVLLVFPSSCLAFRSPLSVFKRFKETTRPFSNECLGTTRPVVPIDSSDFALDIRMPGVTPKQSDTYFCMSMRIPVDEEAFVIDFKPRASMDTVHHMLLFGCNMPSSTGSYWFCDEGTCTDKANILYAWARNAPPTRLPKGVGFRVGGETGSKYFVLQVHYGDISAFRDNNKDCSGVSLHLTRLPQPLIAGMYLMMSVDTVIPAGEKVVNSDISCHYKNYPMHVFAYRVHTHHLGKVVSGYRVRNGQWTLIGRQSPQLPQAFYPVGHPVDVSFGDLLAARCVFTGEGRTEATHIGGTSSDEMCNLYIMYYMEAKHAVSFMTCTQNVAPDMFRTIPPEANIPIPVKSDMVMMHEHHKETEYKDKIPLLQQPKREEEEVLDQGDFYSLLSKLLGEREDVVHVHKYNPTEKAESESDLVAEIANVVQKKDLGRSDAREGAEHERGNAILVRDRIHKFHRLVSTLRPPESRVFSLQQPPPGEGTWEPEHTGDFHMEEALDWPGVYLLPGQVSGVALDPKNNLVIFHRGDHVWDGNSFDSKFVYQQIGLGPIEEDTILVIDPNNAAVLQSSGKNLFYLPHGLSIDKDGNYWVTDVALHQVFKLDPNNKEGPVLILGRSMQPGSDQNHFCQPTDVAVDPGTGAIYVSDGYCNSRIVQFSPSGKFITQWGEESSGSSPLPGQFTVPHSLALVPLLGQLCVADRENGRIQCFKTDTKEFVREIKHSSFGRNVFAISYIPGLLFAVNGKPHFGDQEPVQGFVMNFSNGEIIDIFKPVRKHFDMPHDIVASEDGTVYIGDAHTNTVWKFTLTEKLEHRSVKKAGIEVQEIKEAEAVVETKMENKPTSSELQKMQEKQKLIKEPGSGVPVVLITTLLVIPVVVLLAIAIFIRWKKSRAFGDSEHKLETSSGRVLGRFRGKGSGGLNLGNFFASRKGYSRKGFDRLSTEGSDQEKEDDGSESEEEYSAPLPALAPSSS>sp|P19021-2|AMD_HUMAN Isoform 2 of Peptidyl-glycine alpha-amidatingmonooxygenase OS=Homo sapiens OX=9606 GN=PAMMAGRVPSLLVLLVFPSSCLAFRSPLSVFKRFKETTRPFSNECLGTTRPVVPIDSSDFALDIRMPGVTPKQSDTYFCMSMRIPVDEEAFVIDFKPRASMDTVHHMLLFGCNMPSSTGSYWFCDEGTCTDKANILYAWARNAPPTRLPKGVGFRVGGETGSKYFVLQVHYGDISAFRDNNKDCSGVSLHLTRLPQPLIAGMYLMMSVDTVIPAGEKVVNSDISCHYKNYPMHVFAYRVHTHHLGKVVSGYRVRNGQWTLIGRQSPQLPQAFYPVGHPVDVSFGDLLAARCVFTGEGRTEATHIGGTSSDEMCNLYIMYYMEAKHAVSFMTCTQNVAPDMFRTIPPEANIPIPVKSDMVMMHEHHKETEYKDKIPLLQQPKREEEEVLDQDFHMEEALDWPGVYLLPGQVSGVALDPKNNLVIFHRGDHVWDGNSFDSKFVYQQIGLGPIEEDTILVIDPNNAAVLQSSGKNLFYLPHGLSIDKDGNYWVTDVALHQVFKLDPNNKEGPVLILGRSMQPGSDQNHFCQPTDVAVDPGTGAIYVSDGYCNSRIVQFSPSGKFITQWGEESSGSSPLPGQFTVPHSLALVPLLGQLCVADRENGRIQCFKTDTKEFVREIKHSSFGRNVFAISYIPGLLFAVNGKPHFGDQEPVQGFVMNFSNGEIIDIFKPVRKHFDMPHDIVASEDGTVYIGDAHTNTVWKFTLTEKLEHRSVKKAGIEVQEIKEAEAVVETKMENKPTSSELQKMQEKQKLIKEPGSGVPVVLITTLLVIPVVVLLAIAIFIRWKKSRAFGDSEHKLETSSGRVLGRFRGKGSGGLNLGNFFASRKGYSRKGFDRLSTEGSDQEKEDDGSESEEEYSAPLPALAPSSS>sp|P19021-3|AMD_HUMAN Isoform 3 of Peptidyl-glycine alpha-amidatingmonooxygenase OS=Homo sapiens OX=9606 GN=PAMMAGRVPSLLVLLVFPSSCLAFRSPLSVFKRFKETTRPFSNECLGTTRPVVPIDSSDFALDIRMPGVTPKQSDTYFCMSMRIPVDEEAFVIDFKPRASMDTVHHMLLFGCNMPSSTGSYWFCDEGTCTDKANILYAWARNAPPTRLPKGVGFRVGGETGSKYFVLQVHYGDISAFRDNNKDCSGVSLHLTRLPQPLIAGMYLMMSVDTVIPAGEKVVNSDISCHYKNYPMHVFAYRVHTHHLGKVVSGYRVRNGQWTLIGRQSPQLPQAFYPVGHPVDVSFGDLLAARCVFTGEGRTEATHIGGTSSDEMCNLYIMYYMEAKHAVSFMTCTQNVAPDMFRTIPPEANIPIPVKSDMVMMHEHHKETEYKDKIPLLQQPKREEEEVLDQGDFYSLLSKLLGEREDVVHVHKYNPTEKAESESDLVAEIANVVQKKDLGRSDAREGAEHERGNAILVRDRIHKFHRLVSTLRPPESRVFSLQQPPPGEGTWEPEHTGDFHMEEALDWPGVYLLPGQVSGVALDPKNNLVIFHRGDHVWDGNSFDSKFVYQQIGLGPIEEDTILVIDPNNAAVLQSSGKNLFYLPHGLSIDKDGNYWVTDVALHQVFKLDPNNKEGPVLILGRSMQPGSDQNHFCQPTDVAVDPGTGAIYVSDGYCNSRIVQFSPSGKFITQWGEESSGSSPLPGQFTVPHSLALVPLLGQLCVADRENGRIQCFKTDTKEFVREIKHSSFGRNVFAISYIPGLLFAVNGKPHFGDQEPVQGFVMNFSNGEIIDIFKPVRKHFDMPHDIVASEDGTVYIGDAHTNTVWKFTLTEKLEHRSVKKAGIEVQEIKDSEHKLETSSGRVLGRFRGKGSGGLNLGNFFASRKGYSRKGFDRLSTEGSDQEKEDDGSESEEEYSAPLPALAPSSS>sp|P19021-4|AMD_HUMAN Isoform 4 of Peptidyl-glycine alpha-amidatingmonooxygenase OS=Homo sapiens OX=9606 GN=PAMMAGRVPSLLVLLVFPSSCLAFRSPLSVFKRFKETTRPFSNECLGTTRPVVPIDSSDFALDIRMPGVTPKQSDTYFCMSMRIPVDEEAFVIDFKPRASMDTVHHMLLFGCNMPSSTGSYWFCDEGTCTDKANILYAWARNAPPTRLPKGVGFRVGGETGSKYFVLQVHYGDISAFRDNNKDCSGVSLHLTRLPQPLIAGMYLMMSVDTVIPAGEKVVNSDISCHYKNYPMHVFAYRVHTHHLGKVVSGYRVRNGQWTLIGRQSPQLPQAFYPVGHPVDVSFGDLLAARCVFTGEGRTEATHIGGTSSDEMCNLYIMYYMEAKHAVSFMTCTQNVAPDMFRTIPPEANIPIPVKSDMVMMHEHHKETEYKDKIPLLQQPKREEEEVLDQGDFYSLLSKLLGEREDVVHVHKYNPTEKAESESDLVAEIANVVQKKDLGRSDAREGAEHERGNAILVRDRIHKFHRLVSTLRPPESRVFSLQQPPPGEGTWEPEHTGDFHMEEALDWPGVYLLPGQVSGVALDPKNNLVIFHRGDHVWDGNSFDSKFVYQQIGLGPIEEDTILVIDPNNAAVLQSSGKNLFYLPHGLSIDKDGNYWVTDVALHQVFKLDPNNKEGPVLILGRSMQPGSDQNHFCQPTDVAVDPGTGAIYVSDGYCNSRIVQFSPSGKFITQWGEESSGSSPLPGQFTVPHSLALVPLLGQLCVADRENGRIQCFKTDTKEFVREIKHSSFGRNVFAISYIPGLLFAVNGKPHFGDQEPVQGFVMNFSNGEIIDIFKPVRKHFDMPHDIVASEDGTVYIGDAHTNTVWKFTLTEKLEHRSVKKAGIEVQEIKGKGSGGLNLGNFFASRKGYSRKGFDRLSTEGSDQEKEDDGSESEEEYSAPLPALAPSSS>sp|P19021-5|AMD_HUMAN Isoform 5 of Peptidyl-glycine alpha-amidatingmonooxygenase OS=Homo sapiens OX=9606 GN=PAMMAGRVPSLLVLLVFPSSCLAFRSPLSVFKRFKETTRPFSNECLGTTRPVVPIDSSDFALDIRMPGVTPKQSDTYFCMSMRIPVDEEAFVIDFKPRASMDTVHHMLLFGCNMPSSTGSYWFCDEGTCTDKANILYAWARNAPPTRLPKGVGFRVGGETGSKYFVLQVHYGDISAFRDNNKDCSGVSLHLTRLPQPLIAGMYLMMSVDTVIPAGEKVVNSDISCHYKNYPMHVFAYRVHTHHLGKVVSGYRVRNGQWTLIGRQSPQLPQAFYPVGHPVDVSFGDLLAARCVFTGEGRTEATHIGGTSSDEMCNLYIMYYMEAKHAVSFMTCTQNVAPDMFRTIPPEANIPIPVKSDMVMMHEHHKETEYKDKIPLLQQPKREEEEVLDQGDFYSLLSKLLGEREDVVHVHKYNPTEKAESESDLVAEIANVVQKKDLGRSDAREGAEHERGNAILVRDRIHKFHRLVSTLRPPESRVFSLQQPPPGEGTWEPEHTGDFHMEEALDWPGVYLLPGQVSGVALDPKNNLVIFHRGDHVWDGNSFDSKFVYQQIGLGPIEEDTILVIDPNNAAVLQSSGKNLFYLPHGLSIDKDGNYWVTDVALHQVFKLDPNNKEGPVLILGRSMQPGSDQNHFCQPTDVAVDPGTGAIYVSDGYCNSRIVQFSPSGKFITQWGEESSGSSPLPGQFTVPHSLALVPLLGQLCVADRENGRIQCFKTDTKEFVREIKHSSFGRNVFAISYIPGLLFAVNGKPHFGDQEPVQGFVMNFSNGEIIDIFKPVRKHFDMPHDIVASEDGTVYIGDAHTNTVWKFTLTEKLEHRSVKKAGIEVQEIKEAEAVVETKMENKPTSSELQKMQEKQKLIKEPGSGVPVVLITTLLVIPVVVLLAIAIFIRWKKSRAFGADSEHKLETSSGRVLGRFRGKGSGGLNLGNFFASRKGYSRKGFDRLSTEGSDQEKEDDGSESEEEYSAPLPALAPSSS>sp|P19021-6|AMD_HUMAN Isoform 6 of Peptidyl-glycine alpha-amidatingmonooxygenase OS=Homo sapiens OX=9606 GN=PAMMAGRVPSLLVLLVFPSSCLAFRSPLSVFKRFKETTRPFSNECLGTTRPVVPIDSSDFALDIRMPGVTPKQSDTYFCMSMRIPVDEEAFVIDFKPRASMDTVHHMLLFGCNMPSSTGSYWFCDEGTCTDKANILYAWARNAPPTRLPKGVGFRVGGETGSKYFVLQVHYGDISAFRDNNKDCSGVSLHLTRLPQPLIAGMYLMMSVDTVIPAGEKVVNSDISCHYKNYPMHVFAYRVHTHHLGKVVSGYRVRNGQWTLIGRQSPQLPQAFYPVGHPVDVSFGDLLAARCVFTGEGRTEATHIGGTSSDEMCNLYIMYYMEAKHAVSFMTCTQNVAPDMFRTIPPEANIPIPVKSDMVMMHEHHKETEYKDKIPLLQQPKREEEEVLDQGDFYSLLSKLLGEREDVVHVHKYNPTEKAESESDLVAEIANVVQKKDLGRSDAREGAEHERGNAILVRDRIHKFHRLVSTLRPPESRVFSLQQPPPGEGTWEPEHTGDFHMEEALDWPGVYLLPGQVSGVALDPKNNLVIFHRGDHVWDGNSFDSKFVYQQIGLGPIEEDTILVIDPNNAAVLQSSGKNLFYLPHGLSIDKDGNYWVTDVALHQVFKLDPNNKEGPVLILGRSMQPGSDQNHFCQPTDVAVDPGTGAIYVSDGYCNSRIVQFSPSGKFITQWGEESSGSSPLPGQFTVPHSLALVPLLGQLCVADRENGRIQCFKTDTKEFVREIKHSSFGRNVFAISYIPGLLFAVNGKPHFGDQEPVQGFVMNFSNGEIIDIFKPVRKHFDMPHDIVASEDGTVYIGDAHTNTVWKFTLTEKLEHRSVKKAGIEVQEIKEAEAVVETKMENKPTSSELQKMQEKQKLIKEPGSGVPVVLITTLLVIPVVVLLAIAIFIRWKKSRAFGGKGSGGLNLGNFFASRKGYSRKGFDRLSTEGSDQEKEDDGSESEEEYSAPLPALAPSSS>sp|P35858|ALS_HUMAN Insulin-like growth factor-binding protein complexacid labile subunit OS=Homo sapiens OX=9606 GN=IGFALS PE=1 SV=1MALRKGGLALALLLLSWVALGPRSLEGADPGTPGEAEGPACPAACVCSYDDDADELSVFCSSRNLTRLPDGVPGGTQALWLDGNNLSSVPPAAFQNLSSLGFLNLQGGQLGSLEPQALLGLENLCHLHLERNQLRSLALGTFAHTPALASLGLSNNRLSRLEDGLFEGLGSLWDLNLGWNSLAVLPDAAFRGLGSLRELVLAGNRLAYLQPALFSGLAELRELDLSRNALRAIKANVFVQLPRLQKLYLDRNLIAAVAPGAFLGLKALRWLDLSHNRVAGLLEDTFPGLLGLRVLRLSHNAIASLRPRTFKDLHFLEELQLGHNRIRQLAERSFEGLGQLEVLTLDHNQLQEVKAGAFLGLTNVAVMNLSGNCLRNLPEQVFRGLGKLHSLHLEGSCLGRIRPHTFTGLSGLRRLFLKDNGLVGIEEQSLWGLAELLELDLTSNQLTHLPHRLFQGLGKLEYLLLSRNRLAELPADALGPLQRAFWLDVSHNRLEALPNSLLAPLGRLRYLSLRNNSLRTFTPQPPGLERLWLEGNPWDCGCPLKALRDFALQNPSAVPRFVQAICEGDDCQPPAYTYNNITCASPPEVVGLDLRDLSEAHFAPC>sp|P35858-2|ALS_HUMAN Isoform 2 of Insulin-like growth factor-bindingprotein complex acid labile subunit OS=Homo sapiens OX=9606 GN=IGFALSMALRKAGDLEPQFTPERRFRLCWYQAHSGRALLGPPPQASPPAGGLALALLLLSWVALGPRSLEGADPGTPGEAEGPACPAACVCSYDDDADELSVFCSSRNLTRLPDGVPGGTQALWLDGNNLSSVPPAAFQNLSSLGFLNLQGGQLGSLEPQALLGLENLCHLHLERNQLRSLALGTFAHTPALASLGLSNNRLSRLEDGLFEGLGSLWDLNLGWNSLAVLPDAAFRGLGSLRELVLAGNRLAYLQPALFSGLAELRELDLSRNALRAIKANVFVQLPRLQKLYLDRNLIAAVAPGAFLGLKALRWLDLSHNRVAGLLEDTFPGLLGLRVLRLSHNAIASLRPRTFKDLHFLEELQLGHNRIRQLAERSFEGLGQLEVLTLDHNQLQEVKAGAFLGLTNVAVMNLSGNCLRNLPEQVFRGLGKLHSLHLEGSCLGRIRPHTFTGLSGLRRLFLKDNGLVGIEEQSLWGLAELLELDLTSNQLTHLPHRLFQGLGKLEYLLLSRNRLAELPADALGPLQRAFWLDVSHNRLEALPNSLLAPLGRLRYLSLRNNSLRTFTPQPPGLERLWLEGNPWDCGCPLKALRDFALQNPSAVPRFVQAICEGDDCQPPAYTYNNITCASPPEVVGLDLRDLSEAHFAPC>sp|Q9UKV5|AMFR_HUMAN E3 ubiquitin-protein ligase AMFR OS=Homo sapiensOX=9606 GN=AMFR PE=1 SV=2MPLLFLERFPWPSLRTYTGLSGLALLGTIISAYRALSQPEAGPGEPDQLTASLQPEPPAPARPSAGGPRARDVAQYLLSDSLFVWVLVNTACCVLMLVAKLIQCIVFGPLRVSERQHLKDKFWNFIFYKFIFIFGVLNVQTVEEVVMWCLWFAGLVFLHLMVQLCKDRFEYLSFSPTTPMSSHGRVLSLLVAMLLSCCGLAAVCSITGYTHGMHTLAFMAAESLLVTVRTAHVILRYVIHLWDLNHEGTWEGKGTYVYYTDFVMELTLLSLDLMHHIHMLLFGNIWLSMASLVIFMQLRYLFHEVQRRIRRHKNYLRVVGNMEARFAVATPEELAVNNDDCAICWDSMQAARKLPCGHLFHNSCLRSWLEQDTSCPTCRMSLNIADNNRVREEHQGENLDENLVPVAAAEGRPRLNQHNHFFHFDGSRIASWLPSFSVEVMHTTNILGITQASNSQLNAMAHQIQEMFPQVPYHLVLQDLQLTRSVEITTDNILEGRIQVPFPTQRSDSIRPALNSPVERPSSDQEEGETSAQTERVPLDLSPRLEETLDFGEVEVEPSEVEDFEARGSRFSKSADERQRMLVQRKDELLQQARKRFLNKSSEDDAASESFLPSEGASSDPVTLRRRMLAAAAERRLQKQQTS>sp|Q99217|AMELX_HUMAN Amelogenin, X isoform OS=Homo sapiens OX=9606GN=AMELX PE=1 SV=1MGTWILFACLLGAAFAMPLPPHPGHPGYINFSYEVLTPLKWYQSIRPPYPSYGYEPMGGWLHHQIIPVLSQQHPPTHTLQPHHHIPVVPAQQPVIPQQPMMPVPGQHSMTPIQHHQPNLPPPAQQPYQPQPVQPQPHQPMQPQPPVHPMQPLPPQPPLPPMFPMQPLPPMLPDLTLEAWPSTDKTKREEVD>sp|Q99217-2|AMELX_HUMAN Isoform 2 of Amelogenin, X isoform OS=Homosapiens OX=9606 GN=AMELXMGTWILFACLLGAAFAMPVLTPLKWYQSIRPPYPSYGYEPMGGWLHHQIIPVLSQQHPPTHTLQPHHHIPVVPAQQPVIPQQPMMPVPGQHSMTPIQHHQPNLPPPAQQPYQPQPVQPQPHQPMQPQPPVHPMQPLPPQPPLPPMFPMQPLPPMLPDLTLEAWPSTDKTKREEVD>sp|Q99217-3|AMELX_HUMAN Isoform 3 of Amelogenin, X isoform OS=Homosapiens OX=9606 GN=AMELXMGTWILFACLLGAAFAMPLPPHPGHPGYINFSYENSHSQAINVDRTALVLTPLKWYQSIRPPYPSYGYEPMGGWLHHQIIPVLSQQHPPTHTLQPHHHIPVVPAQQPVIPQQPMMPVPGQHSMTPIQHHQPNLPPPAQQPYQPQPVQPQPHQPMQPQPPVHPMQPLPPQPPLPPMFPMQPLPPMLPDLTLEAWPSTDKTKREEVD>sp|Q86WK7|AMGO3_HUMAN Amphoterin-induced protein 3 OS=Homo sapiensOX=9606 GN=AMIGO3 PE=2 SV=1MTWLVLLGTLLCMLRVGLGTPDSEGFPPRALHNCPYKCICAADLLSCTGLGLQDVPAELPAATADLDLSHNALQRLRPGWLAPLFQLRALHLDHNELDALGRGVFVNASGLRLLDLSSNTLRALGRHDLDGLGALEKLLLFNNRLVHLDEHAFHGLRALSHLYLGCNELASFSFDHLHGLSATHLLTLDLSSNRLGHISVPELAALPAFLKNGLYLHNNPLPCDCRLYHLLQRWHQRGLSAVRDFAREYVCLAFKVPASRVRFFQHSRVFENCSSAPALGLERPEEHLYALVGRSLRLYCNTSVPAMRIAWVSPQQELLRAPGSRDGSIAVLADGSLAIGNVQEQHAGLFVCLATGPRLHHNQTHEYNVSVHFPRPEPEAFNTGFTTLLGCAVGLVLVLLYLFAPPCRCCRRACRCRRWPQTPSPLQELSAQSSVLSTTPPDAPSRKASVHKHVVFLEPGRRGLNGRVQLAVAEEFDLYNPGGLQLKAGSESASSIGSEGPMTT>sp|P84996|ALEX_HUMAN Protein ALEX OS=Homo sapiens OX=9606 GN=GNAS PE=1SV=1MMARPVDPQRSPDPTFRSSTRHSGKLEPMEATAHLLRKQCPSRLNSPAWEASGLHWSSLDSPVGSMQALRPSAQHSWSPEPSVVPDQAWEDTALHQKKLCPLSLTSLPREAAVNFSYRSQTLLQEAQVLQGSPELLPRSPKPSGLQRLAPEEATALPLRRLCHLSLMEKDLGTTAHPRGFPELSHKSTAAASSRQSRPRVRSASLPPRTRLPSGSQAPSAAHPKRLSDLLLTSRAAAPGWRSPDPRSRLAAPPLGSTTLPSTWTAPQSRLTARPSRSPEPQIRESEQRDPQLRRKQQRWKEPLMPRREEKYPLRGTDPLPPGQPQRIPLPGQPLQPQPILTPGQPQKIPTPGQHQPILTPGHSQPIPTPGQPLPPQPIPTPGRPLTPQPIPTPGRPLTPQPIQMPGRPLRLPPPLRLLRPGQPMSPQLRQTQGLPLPQPLLPPGQPKSAGRPLQPLPPGPDARSISDPPAPRSRLPIRLLRGLLARLPGGASPRAAAAAACTTMKGWPAATMTPAETSPTMGPPDASAGFSIGEIAAAESPSATYSATFSCKPSGAASVDLRVPSPKPRALSRSRRYPWRRSADRCAKKPWRSGPRSAQRRNAVSSSTNNSRTKRWATCVRTACCF>sp|Q96QP1|ALPK1_HUMAN Alpha-protein kinase 1 OS=Homo sapiens OX=9606GN=ALPK1 PE=1 SV=3MNNQKVVAVLLQECKQVLDQLLLEAPDVSEEDKSEDQRCRALLPSELRTLIQEAKEMKWPFVPEKWQYKQAVGPEDKTNLKDVIGAGLQQLLASLRASILARDCAAAAAIVFLVDRFLYGLDVSGKLLQVAKGLHKLQPATPIAPQVVIRQARISVNSGKLLKAEYILSSLISNNGATGTWLYRNESDKVLVQSVCIQIRGQILQKLGMWYEAAELIWASIVGYLALPQPDKKGLSTSLGILADIFVSMSKNDYEKFKNNPQINLSLLKEFDHHLLSAAEACKLAAAFSAYTPLFVLTAVNIRGTCLLSYSSSNDCPPELKNLHLCEAKEAFEIGLLTKRDDEPVTGKQELHSFVKAAFGLTTVHRRLHGETGTVHAASQLCKEAMGKLYNFSTSSRSQDREALSQEVMSVIAQVKEHLQVQSFSNVDDRSYVPESFECRLDKLILHGQGDFQKILDTYSQHHTSVCEVFESDCGNNKNEQKDAKTGVCITALKTEIKNIDTVSTTQEKPHCQRDTGISSSLMGKNVQRELRRGGRRNWTHSDAFRVSLDQDVETETEPSDYSNGEGAVFNKSLSGSQTSSAWSNLSGFSSSASWEEVNYHVDDRSARKEPGKEHLVDTQCSTALSEELENDREGRAMHSLHSQLHDLSLQEPNNDNLEPSQNQPQQQMPLTPFSPHNTPGIFLAPGAGLLEGAPEGIQEVRNMGPRNTSAHSRPSYRSASWSSDSGRPKNMGTHPSVQKEEAFEIIVEFPETNCDVKDRQGKEQGEEISERGAGPTFKASPSWVDPEGETAESTEDAPLDFHRVLHNSLGNISMLPCSSFTPNWPVQNPDSRKSGGPVAEQGIDPDASTVDEEGQLLDSMDVPCTNGHGSHRLCILRQPPGQRAETPNSSVSGNILFPVLSEDCTTTEEGNQPGNMLNCSQNSSSSSVWWLKSPAFSSGSSEGDSPWSYLNSSGSSWVSLPGKMRKEILEARTLQPDDFEKLLAGVRHDWLFQRLENTGVFKPSQLHRAHSALLLKYSKKSELWTAQETIVYLGDYLTVKKKGRQRNAFWVHHLHQEEILGRYVGKDYKEQKGLWHHFTDVERQMTAQHYVTEFNKRLYEQNIPTQIFYIPSTILLILEDKTIKGCISVEPYILGEFVKLSNNTKVVKTEYKATEYGLAYGHFSYEFSNHRDVVVDLQGWVTGNGKGLIYLTDPQIHSVDQKVFTTNFGKRGIFYFFNNQHVECNEICHRLSLTRPSMEKPCT>sp|Q96QP1-2|ALPK1_HUMAN Isoform 2 of Alpha-protein kinase 1 OS=Homosapiens OX=9606 GN=ALPK1MCRKRTRARTSAAEASLRASILARDCAAAAAIVFLVDRFLYGLDVSGKLLQVAKGLHKLQPATPIAPQVVIRQARISVNSGKLLKAEYILSSLISNNGATGTWLYRNESDKVLVQSVCIQIRGQILQKLGMWYEAAELIWASIVGYLALPQPDKKGLSTSLGILADIFVSMSKNDYEKFKNNPQINLSLLKEFDHHLLSAAEACKLAAAFSAYTPLFVLTAVNIRGTCLLSYSSSNDCPPELKNLHLCEAKEAFEIGLLTKRDDEPVTGKQELHSFVKAAFGLTTVHRRLHGETGTVHAASQLCKEAMGKLYNFSTSSRSQDREALSQEVMSVIAQVKEHLQVQSFSNVDDRSYVPESFECRLDKLILHGQGDFQKILDTYSQHHTSVCEVFESDCGNNKNEQKDAKTGVCITALKTEIKNIDTVSTTQEKPHCQRDTGISSSLMGKNVQRELRRGGRRNWTHSDAFRVSLDQDVETETEPSDYSNGEGAVFNKSLSGSQTSSAWSNLSGFSSSASWEEVNYHVDDRSARKEPGKEHLVDTQCSTALSEELENDREGRAMHSLHSQLHDLSLQEPNNDNLEPSQNQPQQQMPLTPFSPHNTPGIFLAPGAGLLEGAPEGIQEVRNMGPRNTSAHSRPSYRSASWSSDSGRPKNMGTHPSVQKEEAFEIIVEFPETNCDVKDRQGKEQGEEISERGAGPTFKASPSWVDPEGETAESTEDAPLDFHRVLHNSLGNISMLPCSSFTPNWPVQNPDSRKSGGPVAEQGIDPDASTVDEEGQLLDSMDVPCTNGHGSHRLCILRQPPGQRAETPNSSVSGNILFPVLSEDCTTTEEGNQPGNMLNCSQNSSSSSVWWLKSPAFSSGSSEGDSPWSYLNSSGSSWVSLPGKMRKEILEARTLQPDDFEKLLAGVRHDWLFQRLENTGVFKPSQLHRAHSALLLKYSKKSELWTAQETIVYLGDYLTVKKKGRQRNAFWVHHLHQEEILGRYVGKDYKEQKGLWHHFTDVERQMTAQHYVTEFNKRLYEQNIPTQIFYIPSTILLILEDKTIKGCISVEPYILGEFVKLSNNTKVVKTEYKATEYGLAYGHFSYEFSNHRDVVVDLQGWVTGNGKGLIYLTDPQIHSVDQKVFTTNFGKRGIFYFFNNQHVECNEICHRLSLTRPSMEKPCT>sp|P24298|ALAT1_HUMAN Alanine aminotransferase 1 OS=Homo sapiens OX=9606GN=GPT PE=1 SV=3MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVLMEMGPPYAGQQELASFHSTSKGYMGECGFRGGYVEVVNMDAAVQQQMLKLMSVRLCPPVPGQALLDLVVSPPAPTDPSFAQFQAEKQAVLAELAAKAKLTEQVFNEAPGISCNPVQGAMYSFPRVQLPPRAVERAQELGLAPDMFFCLRLLEETGICVVPGSGFGQREGTYHFRMTILPPLEKLRLLLEKLSRFHAKFTLEYS>sp|Q9UEY8|ADDG_HUMAN Gamma-adducin OS=Homo sapiens OX=9606 GN=ADD3 PE=1SV=1MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLALQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLSFSEATASNLVKVNIIGEVVDQGSTNLKIDHTGFSPHAAIYSTRPDVKCVIHIHTLATAAVSSMKCGILPISQESLLLGDVAYYDYQGSLEEQEERIQLQKVLGPSCKVLVLRNHGVVALGETLEEAFHYIFNVQLACEIQVQALAGAGGVDNLHVLDFQKYKAFTYTVAASGGGGVNMGSHQKWKVGEIEFEGLMRTLDNLGYRTGYAYRHPLIREKPRHKSDVEIPATVTAFSFEDDTVPLSPLKYMAQRQQREKTRWLNSPNTYMKVNVPEESRNGETSPRTKITWMKAEDSSKVSGGTPIKIEDPNQFVPLNTNPNEVLEKRNKIREQNRYDLKTAGPQSQLLAGIVVDKPPSTMQFEDDDHGPPAPPNPFSHLTEGELEEYKRTIERKQQGLEDAEQELLSDDASSVSQIQSQTQSPQNVPEKLEENHELFSKSFISMEVPVMVVNGKDDMHDVEDELAKRVSRLSTSTTIENIEITIKSPEKIEEVLSPEGSPSKSPSKKKKKFRTPSFLKKNKKKEKVEA>sp|Q9UEY8-2|ADDG_HUMAN Isoform 1 of Gamma-adducin OS=Homo sapiensOX=9606 GN=ADD3MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLALQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLSFSEATASNLVKVNIIGEVVDQGSTNLKIDHTGFSPHAAIYSTRPDVKCVIHIHTLATAAVSSMKCGILPISQESLLLGDVAYYDYQGSLEEQEERIQLQKVLGPSCKVLVLRNHGVVALGETLEEAFHYIFNVQLACEIQVQALAGAGGVDNLHVLDFQKYKAFTYTVAASGGGGVNMGSHQKWKVGEIEFEGLMRTLDNLGYRTGYAYRHPLIREKPRHKSDVEIPATVTAFSFEDDTVPLSPLKYMAQRQQREKTRWLNSPNTYMKVNVPEESRNGETSPRTKITWMKAEDSSKVSGGTPIKIEDPNQFVPLNTNPNEVLEKRNKIREQNRYDLKTAGPQSQLLAGIVVDKPPSTMQFEDDDHGPPAPPNPFSHLTEGELEEYKRTIERKQQGLEENHELFSKSFISMEVPVMVVNGKDDMHDVEDELAKRVSRLSTSTTIENIEITIKSPEKIEEVLSPEGSPSKSPSKKKKKFRTPSFLKKNKKKEKVEA>sp|Q9UKJ8|ADA21_HUMAN Disintegrin and metalloproteinase domain-containing protein 21 OS=Homo sapiens OX=9606 GN=ADAM21 PE=1 SV=2MAVDGTLVYIRVTLLLLWLGVFLSISGYCQAGPSQHFTSPEVVIPLKVISRGRSAKAPGWLSYSLRFGGQKHVVHMRVKKLLVSRHLPVFTYTDDRALLEDQLFIPDDCYYHGYVEAAPESLVVFSACFGGFRGVLKISGLTYEIEPIRHSATFEHLVYKINSNETQFPAMRCGLTEKEVARQQLEFEEAENSALEPKSAGDWWTHAWFLELVVVVNHDFFIYSQSNISKVQEDVFLVVNIVDSMYKQLGTYIILIGIEIWNQGNVFPMTSIEQVLNDFSQWKQISLSQLQHDAAHMFIKNSLISILGLAYVAGICRPPIDCGVDNFQGDTWSLFANTVAHELGHTLGMQHDEEFCFCGERGCIMNTFRVPAEKFTNCSYADFMKTTLNQGSCLHNPPRLGEIFMLKRCGNGVVEREEQCDCGSVQQCEQDACCLLNCTLRPGAACAFGLCCKDCKFMPSGELCRQEVNECDLPEWCNGTSHQCPEDRYVQDGIPCSDSAYCYQKRCNNHDQHCREIFGKDAKSASQNCYKEINSQGNRFGHCGINGTTYLKCHISDVFCGRVQCENVRDIPLLQDHFTLQHTHINGVTCWGIDYHLRMNISDIGEVKDGTVCGPGKICIHKKCVSLSVLSHVCLPETCNMKGICNNKHHCHCGYGWSPPYCQHRGYGGSIDSGPASAKRGVFLPLIVIPSLSVLTFLFTVGLLMYLRQCSGPKETKAHSSG>sp|Q96M93|ADAD1_HUMAN Adenosine deaminase domain-containing protein 1OS=Homo sapiens OX=9606 GN=ADAD1 PE=2 SV=1MASNNHWFQSSQVPSFAQMLKKNLPVQPATKTITTPTGWSSESYGLSKMASKVTQVTGNFPEPLLSKNLSSISNPVLPPKKIPKEFIMKYKRGEINPVSALHQFAQMQRVQLDLKETVTTGNVMGPYFAFCAVVDGIQYKTGLGQNKKESRSNAAKLALDELLQLDEPEPRILETSGPPPFPAEPVVLSELAYVSKVHYEGRHIQYAKISQIVKERFNQLISNRSEYLKYSSSLAAFIIERAGQHEVVAIGTGEYNYSQDIKPDGRVLHDTHAVVTARRSLLRYFYRQLLLFYSKNPAMMEKSIFCTEPTSNLLTLKQNINICLYMNQLPKGSAQIKSQLRLNPHSISAFEANEELCLHVAVEGKIYLTVYCPKDGVNRISSMSSSDKLTRWEVLGVQGALLSHFIQPVYISSILIGDGNCSDTRGLEIAIKQRVDDALTSKLPMFYLVNRPHISLVPSAYPLQMNLEYKFLSLNWAQGDVSLEIVDGLSGKITESSPFKSGMSMASRLCKAAMLSRFNLLAKEAKKELLEAGTYHAAKCMSASYQEAKCKLKSYLQQHGYGSWIVKSPCIEQFNM>sp|Q96M93-2|ADAD1_HUMAN Isoform 2 of Adenosine deaminase domain-containing protein 1 OS=Homo sapiens OX=9606 GN=ADAD1MASNNHWFQSSQVPSFAQMLKKNLPVQPATKTITTPTGWSSESYGLSKMASKVTQVTGNFPEPLLSKNLSSISNPVLPPKKIPKEFIMKYKRGEINPVSALHQFAQMQRVQLDLKETVTTGNVMGPYFAFCAVVDGIQYKTGLGQNKKESRSNAAKLALDELLQLDEPEPRILETSGPPPFPAEPVVLSELAYVSKVHYEGRHIQYAKISQIVKERFNQLISNRSEYLKYSSSLAAFIIERAGQHEVVAIGTGEYNYSQDIKPDGRVLHDTHAVVTARRSLLSKNPAMMEKSIFCTEPTSNLLTLKQNINICLYMNQLPKGSAQIKSQLRLNPHSISAFEANEELCLHVAVEGKIYLTVYCPKDGVNRISSMSSSDKLTRWEVLGVQGALLSHFIQPVYISSILIGDGNCSDTRGLEIAIKQRVDDALTSKLPMFYLVNRPHISLVPSAYPLQMNLEYKFLSLNWAQGDVSLEIVDGLSGKITESSPFKSGMSMASRLCKAAMLSRFNLLAKEAKKELLEAGTYHAAKCMSASYQEAKCKLKSYLQQHGYGSWIVKSPCIEQFNM>sp|Q96M93-3|ADAD1_HUMAN Isoform 3 of Adenosine deaminase domain-containing protein 1 OS=Homo sapiens OX=9606 GN=ADAD1MLKKNLPVQPATKTITTPTGWSSESYGLSKMASKVTQVTGNFPEPLLSKNLSSISNPVLPPKKIPKEFIMKYKRGEINPVSALHQFAQMQRVQLDLKETVTTGNVMGPYFAFCAVVDGIQYKTGLGQNKKESRSNAAKLALDELLQLDEPEPRILETSGPPPFPAEPVVLSELAYVSKVHYEGRHIQYAKISQIVKERFNQLISNRSEYLKYSSSLAAFIIERAGQHEVVAIGTGEYNYSQDIKPDGRVLHDTHAVVTARRSLLRYFYRQLLLFYSKNPAMMEKSIFCTEPTSNLLTLKQNINICLYMNQLPKGSAQIKSQLRLNPHSISAFEANEELCLHVAVEGKIYLTVYCPKDGVNRISSMSSSDKLTRWEVLGVQGALLSHFIQPVYISSILIGDGNCSDTRGLEIAIKQRVDDALTSKLPMFYLVNRPHISLVPSAYPLQMNLEYKFLSLNWAQGDVSLEIVDGLSGKITESSPFKSGMSMASRLCKAAMLSRFNLLAKEAKKELLEAGTYHAAKCMSASYQEAKCKLKSYLQQHGYGSWIVKSPCIEQFNM>sp|Q8NCV1|ADAD2_HUMAN Adenosine deaminase domain-containing protein 2OS=Homo sapiens OX=9606 GN=ADAD2 PE=2 SV=1MASASQGADDDGSRRKPRLAASLQISPQPRPWRPLPAQAQSAWGPAPAPATYRAEGGWPQVSVLRDSGPGAGAGVGELGAARAWENLGEQMGKAPRVPVPPAGLSLPLKDPPASQAVSLLTEYAASLGIFLLFREDQPPGPCFPFSVSAELDGVVCPAGTANSKTEAKQQAALSALCYIRSQLENPESPQTSSRPPLAPLSVENILTHEQRCAALVSAGFDLLLDERSPYWACKGTVAGVILEREIPRARGHVKEIYKLVALGTGSSCCAGWLEFSGQQLHDCHGLVIARRALLRFLFRQLLLATQGGPKGKEQSVLAPQPGPGPPFTLKPRVFLHLYISNTPKGAARDIYLPPTSEGGLPHSPPMRLQAHVLGQLKPVCYVAPSLCDTHVGCLSASDKLARWAVLGLGGALLAHLVSPLYSTSLILADSCHDPPTLSRAIHTRPCLDSVLGPCLPPPYVRTALHLFAGPPVAPSEPTPDTCRGLSLNWSLGDPGIEVVDVATGRVKANAALGPPSRLCKASFLRAFHQAARAVGKPYLLALKTYEAAKAGPYQEARRQLSLLLDQQGLGAWPSKPLVGKFRN>sp|Q8NCV1-2|ADAD2_HUMAN Isoform 2 of Adenosine deaminase domain-containing protein 2 OS=Homo sapiens OX=9606 GN=ADAD2MASASQGADDDGSRRKPRLAASLQISPQPRPWRPLPAQAQSAWGPAPAPATYRAEGGWPQVSVLRDSGPGAGAGVGELGAARAWENLGEQMGKAPRVPVPPAGLSLPLKDPPASQAVSLLTEYAASLGIFLLFREDQPPGKVFKYRAPGGEELKAMCLWQVEVLRAFLLRTGWRGLWRGDLDLGPDSSWANRLPFLLICEMESRIPAVEELGPCFPFSVSAELDGVVCPAGTANSKTEAKQQAALSALCYIRSQLENPESPQTSSRPPLAPLSVENILTHEQRCAALVSAGFDLLLDERSPYWACKGTVAGVILERGWAVSAPSCTEIPRARGHVKEIYKLVALGTGSSCCAGWLEFSGQQLHDCHGLVIARRALLRFLFRQLLLATQGGPKGKEQSVLAPQPGPGPPFTLKPRVFLHLYISNTPKGAARDIYLPPTSEGGLPHSPPMRLQAHVLGQLKPVCYVAPSLCDTHVGCLSASDKLARWAVLGLGGALLAHLVSPLYSTSLILADSCHDPPTLSRAIHTRPCLDSVLGPCLPPPYVRTALHLFAGPPVAPSEPTPDTCRGLSLNWSLGDPGIEVVDVATGRVKANAALGPPSRLCKASFLRAFHQAARAVGKPYLLALKTYEAAKAGPYQEARRQLSLLLDQQGLGAWPSKPLVGKFRN>sp|P07311|ACYP1_HUMAN Acylphosphatase-1 OS=Homo sapiens OX=9606 GN=ACYP1PE=1 SV=2MAEGNTLISVDYEIFGKVQGVFFRKHTQAEGKKLGLVGWVQNTDRGTVQGQLQGPISKVRHMQEWLETRGSPKSHIDKANFNNEKVILKLDYSDFQIVK>sp|P07311-2|ACYP1_HUMAN Isoform 2 of Acylphosphatase-1 OS=Homo sapiensOX=9606 GN=ACYP1MAEGNTLISVDYEIFGKVQGVFFRKHTQEMTVENRIAETHSKSCVPVSFATSYAG>sp|O43687|AKA7A_HUMAN A-kinase anchor protein 7 isoforms alpha and betaOS=Homo sapiens OX=9606 GN=AKAP7 PE=1 SV=4MGQLCCFPFSRDEGKISELESSSSAVLQRYSKDIPSWSSGEKNGGEPDDAELVRLSKRLVENAVLKAVQQYLEETQNKNKPGEGSSVKTEAADQNGNDNENNRK>sp|O43687-2|AKA7A_HUMAN Isoform Alpha of A-kinase anchor protein 7isoforms alpha and beta OS=Homo sapiens OX=9606 GN=AKAP7MGQLCCFPFSRDEGKISEKNGGEPDDAELVRLSKRLVENAVLKAVQQYLEETQNKNKPGEGSSVKTEAADQNGNDNENNRK>sp|Q53H64|AK40L_HUMAN Putative ANKRD40 C-terminal-like protein OS=Homosapiens OX=9606 GN=ANKRD40CL PE=4 SV=2MAEPEQDIGEKPAVRIQNPKENDFIEIELKRQELSYQNLLNVSCCELGIKPERVEKIRKLPNTLLRKDKDIRRLRDFQEVELILMKNGSSRLTEYVPSLTERPCYDSKAAKMTY>sp|Q9BT30|ALKB7_HUMAN Alpha-ketoglutarate-dependent dioxygenase alkBhomolog 7, mitochondrial OS=Homo sapiens OX=9606 GN=ALKBH7 PE=1 SV=1MAGTGLLALRTLPGPSWVRGSGPSVLSRLQDAAVVRPGFLSTAEEETLSRELEPELRRRRYEYDHWDAAIHGFRETEKSRWSEASRAILQRVQAAAFGPGQTLLSSVHVLDLEARGYIKPHVDSIKFCGATIAGLSLLSPSVMRLVHTQEPGEWLELLLEPGSLYILRGSARYDFSHEILRDEESFFGERRIPRGRRISVICRSLPEGMGPGESGQPPPAC>sp|Q9Y6Z5|AFDDT_HUMAN Putative uncharacterized protein AFDN-DT OS=Homosapiens OX=9606 GN=AFDN-DT PE=5 SV=1MGAAGSDGRCCVRSGRAGTGGAGSKWVVMDLWTGGAGSRRAVLGPDGRWVRWAVLGSVRMGGARSKWAAPDPMGGAGFGPDWRVRVWTGGAGSKWGCSAGSGRAVLGPNGRWVPWAVLGSVRTGGAGSKWAALGPMGGTGSGRAVLGLDGRCSIQMGAAGSGRAVLGSVRTGGAGSKWAVLGSAGDRWAWRHRYGAQGRWSALSEGPCAPRARCSSCPRIAPGLLRVSSRVIPFRWVTSKPTFSSCFLPRRTRC>sp|Q9Y6Z5-2|AFDDT_HUMAN Isoform 2 of Putative uncharacterized proteinAFDN-DT OS=Homo sapiens OX=9606 GN=AFDN-DTMGAAGSDGRCCVRSGRAGTGGAGSRRAVLGPDGRWVRWAVLGSVRMGGARSKWAAPDPMGGAGFGPDWRVRVWTGGAGSKWGCSAGSGRAVLGPNGRWVPWAVLGSVRTGGAGSKWAALGPMGGTGSGRAVLGLDGRCSIQMGAAGSGRAVLGSVRTGGAGSKWAVLGSAGDRWAWRHRYGAQGRWSALSEGPCAPRARCSSCPRIAPGLLRVSSRVIPFRWVTSKPTFSSCFLPRRTRC>sp|Q8N556|AFAP1_HUMAN Actin filament-associated protein 1 OS=Homosapiens OX=9606 GN=AFAP1 PE=1 SV=2MEELIVELRLFLELLDHEYLTSTVREKKAVITNILLRIQSSKGFDVKDHAQKQETANSLPAPPQMPLPEIPQPWLPPDSGPPPLPTSSLPEGYYEEAVPLSPGKAPEYITSNYDSDAMSSSYESYDEEEEDGKGKKTRHQWPSEEASMDLVKDAKICAFLLRKKRFGQWTKLLCVIKDTKLLCYKSSKDQQPQMELPLQGCNITYIPKDSKKKKHELKITQQGTDPLVLAVQSKEQAEQWLKVIKEAYSGCSGPVDSECPPPPSSPVHKAELEKKLSSERPSSDGEGVVENGITTCNGKEQVKRKKSSKSEAKGTVSKVTGKKITKIISLGKKKPSTDEQTSSAEEDVPTCGYLNVLSNSRWRERWCRVKDNKLIFHKDRTDLKTHIVSIPLRGCEVIPGLDSKHPLTFRLLRNGQEVAVLEASSSEDMGRWIGILLAETGSSTDPEALHYDYIDVEMSASVIQTAKQTFCFMNRRVISANPYLGGTSNGYAHPSGTALHYDDVPCINGSLKGKKPPVASNGVTGKGKTLSSQPKKADPAAVVKRTGSNAAQYKYGKNRVEADAKRLQTKEEELLKRKEALRNRLAQLRKERKDLRAAIEVNAGRKPQAILEEKLKQLEEECRQKEAERVSLELELTEVKESLKKALAGGVTLGLAIEPKSGTSSPQSPVFRHRTLENSPISSCDTSDTEGPVPVNSAAVLKKSQAAPGSSPCRGHVLRKAKEWELKNGT>sp|Q8N556-2|AFAP1_HUMAN Isoform 2 of Actin filament-associated protein 1OS=Homo sapiens OX=9606 GN=AFAP1MEELIVELRLFLELLDHEYLTSTVREKKAVITNILLRIQSSKGFDVKDHAQKQETANSLPAPPQMPLPEIPQPWLPPDSGPPPLPTSSLPEGYYEEAVPLSPGKAPEYITSNYDSDAMSSSYESYDEEEEDGKGKKTRHQWPSEEASMDLVKDAKICAFLLRKKRFGQWTKLLCVIKDTKLLCYKSSKDQQPQMELPLQGCNITYIPKDSKKKKHELKITQQGTDPLVLAVQSKEQAEQWLKVIKEAYSGCSGPVDSECPPPPSSPVHKAELEKKLSSERPSSDGEGVVENGITTCNGKEQVKRKKSSKSEAKGTVSKVTGKKITKIISLGKKKPSTDEQTSSAEEDVPTCGYLNVLSNSRWRERWCRVKDNKLIFHKDRTDLKTHIVSIPLRGCEVIPGLDSKHPLTFRLLRNGQEVAVLEASSSEDMGRWIGILLAETGSSTDPEALHYDYIDVEMSASVIQTAKQTFCFMNRRVISANPYLGGTSNGYAHPSGTALHYDDVPCINGSWEPEDGFPASCSRGLGEEVLYDNAGLYDNLPPPHIFARYSPADRKASRLSADKLSSNHYKYPASAQSVTNTSSVGRASLGLNSQLKGKKPPVASNGVTGKGKTLSSQPKKADPAAVVKRTGSNAAQYKYGKNRVEADAKRLQTKEEELLKRKEALRNRLAQLRKERKDLRAAIEVNAGRKPQAILEEKLKQLEEECRQKEAERVSLELELTEVKESLKKALAGGVTLGLAIEPKSGTSSPQSPVFRHRTLENSPISSCDTSDTEGPVPVNSAAVLKKSQAAPGSSPCRGHVLRKAKEWELKNGT>sp|P78325|ADAM8_HUMAN Disintegrin and metalloproteinase domain-containing protein 8 OS=Homo sapiens OX=9606 GN=ADAM8 PE=1 SV=2MRGLGLWLLGAMMLPAIAPSRPWALMEQYEVVLPWRLPGPRVRRALPSHLGLHPERVSYVLGATGHNFTLHLRKNRDLLGSGYTETYTAANGSEVTEQPRGQDHCFYQGHVEGYPDSAASLSTCAGLRGFFQVGSDLHLIEPLDEGGEGGRHAVYQAEHLLQTAGTCGVSDDSLGSLLGPRTAAVFRPRPGDSLPSRETRYVELYVVVDNAEFQMLGSEAAVRHRVLEVVNHVDKLYQKLNFRVVLVGLEIWNSQDRFHVSPDPSVTLENLLTWQARQRTRRHLHDNVQLITGVDFTGTTVGFARVSAMCSHSSGAVNQDHSKNPVGVACTMAHEMGHNLGMDHDENVQGCRCQERFEAGRCIMAGSIGSSFPRMFSDCSQAYLESFLERPQSVCLANAPDLSHLVGGPVCGNLFVERGEQCDCGPPEDCRNRCCNSTTCQLAEGAQCAHGTCCQECKVKPAGELCRPKKDMCDLEEFCDGRHPECPEDAFQENGTPCSGGYCYNGACPTLAQQCQAFWGPGGQAAEESCFSYDILPGCKASRYRADMCGVLQCKGGQQPLGRAICIVDVCHALTTEDGTAYEPVPEGTRCGPEKVCWKGRCQDLHVYRSSNCSAQCHNHGVCNHKQECHCHAGWAPPHCAKLLTEVHAASGSLPVFVVVVLVLLAVVLVTLAGIIVYRKARSRILSRNVAPKTTMGRSNPLFHQAASRVPAKGGAPAPSRGPQELVPTTHPGQPARHPASSVALKRPPPAPPVTVSSPPFPVPVYTRQAPKQVIKPTFAPPVPPVKPGAGAANPGPAEGAVGPKVALKPPIQRKQGAGAPTAP>sp|P78325-2|ADAM8_HUMAN Isoform 2 of Disintegrin and metalloproteinasedomain-containing protein 8 OS=Homo sapiens OX=9606 GN=ADAM8MRGLGLWLLGAMMLPGPAPREGELRPWGHRAQLHPPPAEEQGPAGLRLHRDLYGCQWLRGDGAASRAGPLLLPGPRRGVPGLSRQPQHLCRPQVGSDLHLIEPLDEGGEGGRHAVYQAEHLLQTAGTCGVSDDSLGSLLGPRTAAVFRPRPGDSLPSRETRYVELYVVVDNAEFQMLGSEAAVRHRVLEVVNHVDKLYQKLNFRVVLVGLEIWNSQDRFHVSPDPSVTLENLLTWQARQRTRRHLHDNVQLITGVDFTGTTVGFARVSAMCSHSSGAVNQDHSKNPVGVACTMAHEMGHNLGMDHDENVQGCRCQERFEAGRCIMAGSIGSSFPRMFSDCSQAYLESFLERPQSVCLANAPDLSHLVGGPVCGNLFVERGEQCDCGPPEDCRNRCCNSTTCQLAEGAQCAHGTCCQECKVKPAGELCRPKKDMCDLEEFCDGRHPECPEDAFQENGTPCSGGYCYNGACPTLAQQCQAFWGPGGQAAEESCFSYDILPGCKASRYRADMCGVLQCKGGQQPLGRAICIVDVCHALTTEDGTAYEPVPEGTRCGPEKVCNHKQECHCHAGWAPPHCAKLLTEVHAASGSLPVFVVVVLVLLAVVLVTLAGIIVYRKARSRILSRNVAPKTTMGRSNPLFHQAASRVPAKGGAPAPSRGPQELVPTTHPGQPARHPASSVALKRPPPAPPVTVSSPPFPVPVYTRQAPKQGAVGPKVALKPPIQRKQGAGAPTAP>sp|P78325-3|ADAM8_HUMAN Isoform 3 of Disintegrin and metalloproteinasedomain-containing protein 8 OS=Homo sapiens OX=9606 GN=ADAM8MRGLGLWLLGAMMLPAIAPSRPWALMEQYEVVLPWRLPGPRVRRALPSHLGLHPERVSYVLGATGHNFTLHLRKNRDLLGSGYTETYTAANGSEVTEQPRGQDHCFYQGHVEGYPDSAASLSTCAGLRGFFQVGSDLHLIEPLDEGGEGGRHAVYQAEHLLQTAGTCGVSDDSLGSLLGPRTAAVFRPRPGDSLPSRETRYVELYVVVDNAEFQMLGSEAAVRHRVLEVVNHVDKLYQKLNFRVVLVGLEIWNSQDRFHVSPDPSVTLENLLTWQARQRTRRHLHDNVQLITGVDFTGTTVGFARVSAMCSHSSGAVNQDHSKNPVGVACTMAHEMGHNLGMDHDENVQGCRCQERFEAGRCIMAGSIGSSFPRMFSDCSQAYLESFLERPQSVCLANAPDLSHLVGGPVCGNLFVERGEQCDCGPPEDCRNRCCNSTTCQLAEGAQCAHGTCCQECKVKPAGELCRPKKDMCDLEEFCDGRHPECPEDAFQENGTPCSGGYCYNGACPTLAQQCQAFWGPGGQAAEESCFSYDILPGCKASRYRADMCGVLQCKGGQQPLGRAICIVDVCHALTTEDGTAYEPVPEGTRCGPEKVCWKGRCQDLHVYRSSNCSAQCHNHGVCNHKQECHCHAGWAPPHCAKLLTEVHAGCQPRAGQGRGSSPIQGPPRAGPHHPPGPARPTPGLLGGSEEAAPCSSGHCVQPTLPSSCLHPAGTKAGHQANVRTPSAPSQTRGWCGQPWSS>sp|P63261|ACTG_HUMAN Actin, cytoplasmic 2 OS=Homo sapiens OX=9606GN=ACTG1 PE=1 SV=1MEEEIAALVIDNGSGMCKAGFAGDDAPRAVFPSIVGRPRHQGVMVGMGQKDSYVGDEAQSKRGILTLKYPIEHGIVTNWDDMEKIWHHTFYNELRVAPEEHPVLLTEAPLNPKANREKMTQIMFETFNTPAMYVAIQAVLSLYASGRTTGIVMDSGDGVTHTVPIYEGYALPHAILRLDLAGRDLTDYLMKILTERGYSFTTTAEREIVRDIKEKLCYVALDFEQEMATAASSSSLEKSYELPDGQVITIGNERFRCPEALFQPSFLGMESCGIHETTFNSIMKCDVDIRKDLYANTVLSGGTTMYPGIADRMQKEITALAPSTMKIKIIAPPERKYSVWIGGSILASLSTFQQMWISKQEYDESGPSIVHRKCF>sp|Q8NB90|AFG2H_HUMAN ATPase family protein 2 homolog OS=Homo sapiensOX=9606 GN=SPATA5 PE=1 SV=3MSSKKNRKRLNQSAENGSSLPSAASSCAEARAPSAGSDFAATSGTLTVTNLLEKVDDKIPKTFQNSLIHLGLNTMKSANICIGRPVLLTSLNGKQEVYTAWPMAGFPGGKVGLSEMAQKNVGVRPGDAIQVQPLVGAVLQAEEMDVALSDKDMEINEEELTGCILRKLDGKIVLPGNFLYCTFYGRPYKLQVLRVKGADGMILGGPQSDSDTDAQRMAFEQSSMETSSLELSLQLSQLDLEDTQIPTSRSTPYKPIDDRITNKASDVLLDVTQSPGDGSGLMLEEVTGLKCNFESAREGNEQLTEEERLLKFSIGAKCNTDTFYFISSTTRVNFTEIDKNSKEQDNQFKVTYDMIGGLSSQLKAIREIIELPLKQPELFKSYGIPAPRGVLLYGPPGTGKTMIARAVANEVGAYVSVINGPEIISKFYGETEAKLRQIFAEATLRHPSIIFIDELDALCPKREGAQNEVEKRVVASLLTLMDGIGSEVSEGQVLVLGATNRPHALDAALRRPGRFDKEIEIGVPNAQDRLDILQKLLRRVPHLLTEAELLQLANSAHGYVGADLKVLCNEAGLCALRRILKKQPNLPDVKVAGLVKITLKDFLQAMNDIRPSAMREIAIDVPNVSWSDIGGLESIKLKLEQAVEWPLKHPESFIRMGIQPPKGVLLYGPPGCSKTMIAKALANESGLNFLAIKGPELMNKYVGESERAVRETFRKARAVAPSIIFFDELDALAVERGSSLGAGNVADRVLAQLLTEMDGIEQLKDVTILAATNRPDRIDKALMRPGRIDRIIYVPLPDAATRREIFKLQFHSMPVSNEVDLDELILQTDAYSGAEIVAVCREAALLALEEDIQANLIMKRHFTQALSTVTPRIPESLRRFYEDYQEKSGLHTL>sp|Q8NB90-2|AFG2H_HUMAN Isoform 2 of ATPase family protein 2 homologOS=Homo sapiens OX=9606 GN=SPATA5MSSKKNRKRLNQSAENGSSLPSAASSCAEARAPSAGSDFAATSGTLTVTNLLEKVDDKIPKTFQNSLIHLGLNTMKSANICIGRPVLLTSLNGKQEVYTAWPMAGFPGGKVGLSEMAQKNVGVRPGDAIQVQPLVGAVLQAEEMDVALSDKDMEINEEELTGCILRKLDGKIVLPGNFLYCTFYGRPYKLQVLRVKGADGMILGGPQSDSDTDAQRMAFEQSSMETSSLELSLQLSQLDLEDTQIPTSRSTPYKPIDDRITNKASDVLLDVTQSPGDGSGLMLEEVTGLKCNFESAREGNEQLTEEERLLKFSIGAKCNTDTFYFISSTTRVNFTEIDKNSKEQDNQFKVTYDMIGGLSSQLKAIREIIELPLKQPELFKSYGIPAPRGVLLYGPPGTGKTMIARAVANEVGAYVSVINGPEIISKFYGETEAKLRQIFAEATLRHPSIIFIDELDALCPKREGAQNEVEKRVVASLLTLMDGIGSEVSEGQVLVLGATNRPHALDAALRRPGRFDKEIEIGVPNAQDRLDILQKLLRRVPHLLTEAELLQLANSAHGYVGADLKVLCNEAGLCALRRILKKQPNLPDVKVAGLVKITLKDFLQAMNDIRPSAMREIAIDVPNVSWSDIGGLESIKLKLEQAVEWPLKHPESFIRMGIQPPKGVLLYGPPGCSKTMIAKALANESGLNFLAIKGPELMNKYVGESERAVRETFRKARAVAPSIIFFDELDALAVERGSSLGAGNVADRVLAQLLTEMDGIEQLKDVTILAATNRPDRIDKVPPSQTFLLL>sp|Q8NB90-3|AFG2H_HUMAN Isoform 3 of ATPase family protein 2 homologOS=Homo sapiens OX=9606 GN=SPATA5MSSKKNRKRLNQSAENGSSLPSAASSCAEARAPSAGSDFAATSGTLTVTNLLEKVDDKIPKTFQNSLIHLGLNTMKSANICIGRPVLLTSLNGKQEVYTAWPMAGFPGGKVGLSEMAQKNVGVRPGDAIQVQPLVGAVLQAEEMDVALSDKDMEINEEELTGCILRKLDGKIVLPGNFLYCTFYGRPYKLQVLRVKGADGMILGGPQSDSDTDAQRMAFEQSSMETSSLELSLQLSQLDLEDTQIPTSRSTPYKPIDDRITNKASDVLLDVTQSPGDGSGLMLEEVTGLKCNFESAREGNEQLTEEERLLKFSIGAKCNTDTFYFISSTTRVNFTEIDKNSKEQDNQFKVTYDMIGGLSSQLKAIREIIELPLKQPELFKSYGIPAPRGVLLYGPPGTGKTMIARAVANEVGAYVSVINGPEIISKFYGETEAKLRQIFAEATLRHPSIIFIDELDALCPKREGAQNEVEKRVVASLLTLMDGIGSEVSEGQVLVLGATNRPHALDAALRRPGRFDKEIEIGVPNAQDRLDILQKLLRRVPHLLTEAELLQLANSAHGYVGADLKVLCNEAGLCALRRILKKQPNLPDVKVAGLVKITLKDFLQAMNDIRPSAMREIAIDVPNVSWSDIGGLESIKLKLEQAVEWPLKHPESFIRMGIQPPKGVLLYGPPGCSKTMIAKALANESGLNFLAIKVGC>sp|Q01718|ACTHR_HUMAN Adrenocorticotropic hormone receptor OS=Homosapiens OX=9606 GN=MC2R PE=1 SV=1MKHIINSYENINNTARNNSDCPRVVLPEEIFFTISIVGVLENLIVLLAVFKNKNLQAPMYFFICSLAISDMLGSLYKILENILIILRNMGYLKPRGSFETTADDIIDSLFVLSLLGSIFSLSVIAADRYITIFHALRYHSIVTMRRTVVVLTVIWTFCTGTGITMVIFSHHVPTVITFTSLFPLMLVFILCLYVHMFLLARSHTRKISTLPRANMKGAITLTILLGVFIFCWAPFVLHVLLMTFCPSNPYCACYMSLFQVNGMLIMCNAVIDPFIYAFRSPELRDAFKKMIFCSRYW>sp|Q9Y4W6|AFG32_HUMAN AFG3-like protein 2 OS=Homo sapiens OX=9606GN=AFG3L2 PE=1 SV=2MAHRCLRLWGRGGCWPRGLQQLLVPGGVGPGEQPCLRTLYRFVTTQARASRNSLLTDIIAAYQRFCSRPPKGFEKYFPNGKNGKKASEPKEVMGEKKESKPAATTRSSGGGGGGGGKRGGKKDDSHWWSRFQKGDIPWDDKDFRMFFLWTALFWGGVMFYLLLKRSGREITWKDFVNNYLSKGVVDRLEVVNKRFVRVTFTPGKTPVDGQYVWFNIGSVDTFERNLETLQQELGIEGENRVPVVYIAESDGSFLLSMLPTVLIIAFLLYTIRRGPAGIGRTGRGMGGLFSVGETTAKVLKDEIDVKFKDVAGCEEAKLEIMEFVNFLKNPKQYQDLGAKIPKGAILTGPPGTGKTLLAKATAGEANVPFITVSGSEFLEMFVGVGPARVRDLFALARKNAPCILFIDEIDAVGRKRGRGNFGGQSEQENTLNQLLVEMDGFNTTTNVVILAGTNRPDILDPALLRPGRFDRQIFIGPPDIKGRASIFKVHLRPLKLDSTLEKDKLARKLASLTPGFSGADVANVCNEAALIAARHLSDSINQKHFEQAIERVIGGLEKKTQVLQPEEKKTVAYHEAGHAVAGWYLEHADPLLKVSIIPRGKGLGYAQYLPKEQYLYTKEQLLDRMCMTLGGRVSEEIFFGRITTGAQDDLRKVTQSAYAQIVQFGMNEKVGQISFDLPRQGDMVLEKPYSEATARLIDDEVRILINDAYKRTVALLTEKKADVEKVALLLLEKEVLDKNDMVELLGPRPFAEKSTYEEFVEGTGSLDEDTSLPEGLKDWNKEREKEKEEPPGEKVAN>sp|Q9UKU0|ACSL6_HUMAN Long-chain-fatty-acid--CoA ligase 6 OS=Homosapiens OX=9606 GN=ACSL6 PE=1 SV=4MQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTEKVIFPRQDDVLISFLPLAHMFERVIQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q9UKU0-1|ACSL6_HUMAN Isoform 1 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MLTFFLVSGGSLWLFVEFVLSLLEKMQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTEKVIFPRQDDVLISFLPLAHMFERVIQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q9UKU0-2|ACSL6_HUMAN Isoform 2 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTESQWAPTCADVHISYLPLAHMFERMVQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQDLPQCLIQIKVFSKY>sp|Q9UKU0-3|ACSL6_HUMAN Isoform 3 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTESQWAPTCADVHISYLPLAHMFERMVQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q9UKU0-5|ACSL6_HUMAN Isoform 5 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTEDDVLISFLPLAHMFERVIQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q9UKU0-6|ACSL6_HUMAN Isoform 6 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTGLSCQEGASATASTQADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTEKVIFPRQDDVLISFLPLAHMFERVIQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q9UKU0-7|ACSL6_HUMAN Isoform 7 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MQTQEILRILRLPELGDLGQFFRSLSATTLDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTEGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q9UKU0-8|ACSL6_HUMAN Isoform 8 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MLTFFLVSGGSLWLFVEFVLSLLEKMQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTESQWAPTCADVHISYLPLAHMFERMVQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q9UKU0-9|ACSL6_HUMAN Isoform 9 of Long-chain-fatty-acid--CoA ligase 6OS=Homo sapiens OX=9606 GN=ACSL6MPEFVLSLLEKMQTQEILRILRLPELGDLGQFFRSLSATTLVSMGALAAILAYWFTHRPKALQPPCNLLMQSEEVEDSGGARRSVIGSGPQLLTHYYDDARTMYQVFRRGLSISGNGPCLGFRKPKQPYQWLSYQEVADRAEFLGSGLLQHNCKACTDQFIGVFAQNRPEWIIVELACYTYSMVVVPLYDTLGPGAIRYIINTADISTVIVDKPQKAVLLLEHVERKETPGLKLIILMDPFEEALKERGQKCGVVIKSMQAVEDCGQENHQAPVPPQPDDLSIVCFTSGTTGNPKGAMLTHGNVVADFSGFLKVTEKVIFPRQDDVLISFLPLAHMFERVIQSVVYCHGGRVGFFQGDIRLLSDDMKALCPTIFPVVPRLLNRMYDKIFSQANTPLKRWLLEFAAKRKQAEVRSGIIRNDSIWDELFFNKIQASLGGCVRMIVTGAAPASPTVLGFLRAALGCQVYEGYGQTECTAGCTFTTPGDWTSGHVGAPLPCNHIKLVDVEELNYWACKGEGEICVRGPNVFKGYLKDPDRTKEALDSDGWLHTGDIGKWLPAGTLKIIDRKKHIFKLAQGEYVAPEKIENIYIRSQPVAQIYVHGDSLKAFLVGIVVPDPEVMPSWAQKRGIEGTYADLCTNKDLKKAILEDMVRLGKESGLHSFEQVKAIHIHSDMFSVQNGLLTPTLKAKRPELREYFKKQIEELYSISM>sp|Q4L235|ACSF4_HUMAN Beta-alanine-activating enzyme OS=Homo sapiensOX=9606 GN=AASDH PE=1 SV=3MTLQELVHKAASCYMDRVAVCFDECNNQLPVYYTYKTVVNAASELSNFLLLHCDFQGIREIGLYCQPGIDLPSWILGILQVPAAYVPIEPDSPPSLSTHFMKKCNLKYILVEKKQINKFKSFHETLLNYDTFTVEHNDLVLFRLHWKNTEVNLMLNDGKEKYEKEKIKSISSEHVNEEKAEEHMDLRLKHCLAYVLHTSGTTGIPKIVRVPHKCIVPNIQHFRVLFDITQEDVLFLASPLTFDPSVVEIFLALSSGASLLIVPTSVKLLPSKLASVLFSHHRVTVLQATPTLLRRFGSQLIKSTVLSATTSLRVLALGGEAFPSLTVLRSWRGEGNKTQIFNVYGITEVSSWATIYRIPEKTLNSTLKCELPVQLGFPLLGTVVEVRDTNGFTIQEGSGQVFLGGRNRVCFLDDEVTVPLGTMRATGDFVTVKDGEIFFLGRKDSQIKRHGKRLNIELVQQVAEELQQVESCAVTWYNQEKLILFMVSKDASVKEYIFKELQKYLPSHAVPDELVLIDSLPFTSHGKIDVSELNKIYLNYINLKSENKLSGKEDLWEKLQYLWKSTLNLPEDLLRVPDESLFLNSGGDSLKSIRLLSEIEKLVGTSVPGLLEIILSSSILEIYNHILQTVVPDEDVTFRKSCATKRKLSDINQEEASGTSLHQKAIMTFTCHNEINAFVVLSRGSQILSLNSTRFLTKLGHCSSACPSDSVSQTNIQNLKGLNSPVLIGKSKDPSCVAKVSEEGKPAIGTQKMELHVRWRSDTGKCVDASPLVVIPTFDKSSTTVYIGSHSHRMKAVDFYSGKVKWEQILGDRIESSACVSKCGNFIVVGCYNGLVYVLKSNSGEKYWMFTTEDAVKSSATMDPTTGLIYIGSHDQHAYALDIYRKKCVWKSKCGGTVFSSPCLNLIPHHLYFATLGGLLLAVNPATGNVIWKHSCGKPLFSSPQCCSQYICIGCVDGNLLCFTHFGEQVWQFSTSGPIFSSPCTSPSEQKIFFGSHDCFIYCCNMKGHLQWKFETTSRVYATPFAFHNYNGSNEMLLAAASTDGKVWILESQSGQLQSVYELPGEVFSSPVVLESMLIIGCRDNYVYCLDLLGGNQK>sp|Q4L235-2|ACSF4_HUMAN Isoform 2 of Beta-alanine-activating enzymeOS=Homo sapiens OX=9606 GN=AASDHMKKCNLKYILVEKKQINKFKSFHETLLNYDTFTVEHNDLVLFRLHWKNTEVNLMLNDGKEKYEKEKIKSISSEHVNEEKAEEHMDLRLKHCLAYVLHTSGTTGIPKIVRVPHKCIVPNIQHFRVLFDITQEDVLFLASPLTFDPSVVEIFLALSSGASLLIVPTSVKLLPSKLASVLFSHHRVTVLQATPTLLRRFGSQLIKSTVLSATTSLRVLALGGEAFPSLTVLRSWRGEGNKTQIFNVYGITEVSSWATIYRIPEKTLNSTLKCELPVQLGFPLLGTVVEVRDTNGFTIQEGSGQVFLGGRNRVCFLDDEVTVPLGTMRATGDFVTVKDGEIFFLGRKDSQIKRHGKRLNIELVQQVAEELQQVESCAVTWYNQEKLILFMVSKDASVKEYIFKELQKYLPSHAVPDELVLIDSLPFTSHGKIDVSELNKIYLNYINLKSENKLSGKEDLWEKLQYLWKSTLNLPEDLLRVPDESLFLNSGGDSLKSIRLLSEIEKLVGTSVPGLLEIILSSSILEIYNHILQTVVPDEDVTFRKSCATKRKLSDINQEEASGTSLHQKAIMTFTCHNEINAFVVLSRGSQILSLNSTRFLTKLGHCSSACPSDSVSQTNIQNLKGLNSPVLIGKSKDPSCVAKVSEEGKPAIGTQKMELHVRWRSDTGKCVDASPLVVIPTFDKSSTTVYIGSHSHRMKAVDFYSGKVKWEQILGDRIESSACVSKCGNFIVVGCYNGLVYVLKSNSGEKYWMFTTEDAVKSSATMDPTTGLIYIGSHDQHAYALDIYRKKCVWKSKCGGTVFSSPCLNLIPHHLYFATLGGLLLAVNPATGNVIWKHSCGKPLFSSPQCCSQYICIGCVDGNLLCFTHFGEQVWQFSTSGPIFSSPCTSPSEQKIFFGSHDCFIYCCNMKGHLQWKFETTSRVYATPFAFHNYNGSNEMLLAAASTDGKVWILESQSGQLQSVYELPGEVFSSPVVLESMLIIGCRDNYVYCLDLLGGNQK>sp|Q4L235-3|ACSF4_HUMAN Isoform 3 of Beta-alanine-activating enzymeOS=Homo sapiens OX=9606 GN=AASDHMTLQELVHKAASCYMDRVAVCFDECNNQLPVYYTYKTVVNAASELSNFLLLHCDFQGIREIGLYCQPGIDLPSWILGILQVPAAYVPIEPDSPPSLSTHFMKKCNLKYILVEKKQINKFKSFHETLLNYDTFTVEHNDLVLFRLHWKNTEVNLMLNDGKEKYEKEKIKSISSEHVNEEKAEEHMDLRLKHCLAYVLHTSGTTGIPKIVRVPHKCIVPNIQHFRVLFDITQEDVLFLASPLTFDPSVVEIFLALSSGASLLIVPTSVKLLPSKLASVLFSHHRVTVLQATPTLLRRFGSQLIKSTVLSATTSLRVLALGGEAFPSLTVLRSWRGEGNKTQIFNVYGITEVSSWATIYRIPEKTLNSTLKCELPVQLGFPLLGTVVEVRDTNGFTIQEGSGQVFLGGRNRVCFLDDEVTVPLGTMRATGDFVTVKDGEIFFLGRKDSQIKRHGKRLNIELVQQVAEELQQVESCAVTWYNQEKLILFMVSKDASVKEYIFKELQKYLPSHAVPDELVLIDSLPFTSHGKIDVSELNKIYLNYINLKSENKLSGKEDLWEKLQYLWKSTLNLPEDLLRVPDESLFLNSGGDSLKSIRLLSEIEKLVGTSVPGLLEIILSSSILEIYNHILQTVVPDEDVTFRKSCATKRKLSDINQEEASGTSLHQKAIMTFTCHNEINAFVVLSRGSQILSLNSTRFLTKLGHCSSACPSDSVSQTNIQNLKGLNSPVLIGKSKDPSCVAKVSEEGKPAIGTQKMELHVRWRSDTGKCVDASPLVVIPTFDKSSTTVYIGSHSHRMKAVDFYSGKVKWEQILGDRIESSACVSKCGNFIVVGKFLNLRFVELN>sp|Q4L235-4|ACSF4_HUMAN Isoform 4 of Beta-alanine-activating enzymeOS=Homo sapiens OX=9606 GN=AASDHMTLQELVHKAASCYMDRVAVCFDECNNQLPVYYTYKTVVNAASELSNFLLLHCDFQGIREIGLYCQPGIDLPSWILGILQVPAAYVPIEPDSPPSLSTHFMKKCNLKYILVEKKQINKFKSFHETLLNYDTFTVEHNDLVLFRLHWKNTEVNLMLNDGKEKYEKEKIKSISSEHVNEEKAEEHMDLRLKHCLAYVLHTSGTTGIPKIVRVPHKCIVPNIQHFRVLFDITQEDVLFLASPLTFDPSVVEIFLALSSGASLLIVPTSVKLLPSKLASVLFSHHRVTVLQATPTLLRRFGSQLIKSTVLSATTSLRVLALGGEAFPSLTVLRSWRGEGNKTQIFNVYGITEVSSWATIYRIPEKTLNSTLKCELPVQLGFPLLGTVVEVRDTNGFTIQEGSGQVFLGGRNRVCFLDDEVTVPLGTMRATGDFVTVKDGEIFFLGRKDSQIKRHGKRLNIELVQQVAEELQQVESCAVTWYNQEKLILFMVSKDASVKEYIFKELQKYLPSHAVPDELVLIDSLPFTSHGKIDVSELNKIYLNYINLKSENKLSGKEDLWEKLQYLWKSTLNLPEDLLRVPDESLFLNSGGDSLKSIRLLSEIEKLVGTSVPGLLEIILSSSILEIYNHILQTVVPDEDVTFRKSCATKRKLSDINQEEASGTSLHQKAIMTFTCHNEINAFVVLSRGSQILSLNSTRFLTKLGHCSSACPSDSVSQTNIQNLKGLNSPVLIGKSKDPSCVAKVSEEGKPAIGTQKMELHVRWRSDTGKCVDASPLVVIPTFDKSSTTVYIGSHSHRMKAVDFYSGKVKWEQILGDRIESSACVSKCGNFIVVGLAVLYQWTNLFIPVYLTIRAKNIFWFP>sp|P10109|ADX_HUMAN Adrenodoxin, mitochondrial OS=Homo sapiens OX=9606GN=FDX1 PE=1 SV=1MAAAGGARLLRAASAVLGGPAGRWLHHAGSRAGSSGLLRNRGPGGSAEASRSLSVSARARSSSEDKITVHFINRDGETLTTKGKVGDSLLDVVVENNLDIDGFGACEGTLACSTCHLIFEDHIYEKLDAITDEENDMLDLAYGLTDRSRLGCQICLTKSMDNMTVRVPETVADARQSIDVGKTS>sp|P35611|ADDA_HUMAN Alpha-adducin OS=Homo sapiens OX=9606 GN=ADD1 PE=1SV=2MNGDSRAAVVTSPPPTTAPHKERYFDRVDENNPEYLRERNMAPDLRQDFNMMEQKKRVSMILQSPAFCEELESMIQEQFKKGKNPTGLLALQQIADFMTTNVPNVYPAAPQGGMAALNMSLGMVTPVNDLRGSDSIAYDKGEKLLRCKLAAFYRLADLFGWSQLIYNHITTRVNSEQEHFLIVPFGLLYSEVTASSLVKINLQGDIVDRGSTNLGVNQAGFTLHSAIYAARPDVKCVVHIHTPAGAAVSAMKCGLLPISPEALSLGEVAYHDYHGILVDEEEKVLIQKNLGPKSKVLILRNHGLVSVGESVEEAFYYIHNLVVACEIQVRTLASAGGPDNLVLLNPEKYKAKSRSPGSPVGEGTGSPPKWQIGEQEFEALMRMLDNLGYRTGYPYRYPALREKSKKYSDVEVPASVTGYSFASDGDSGTCSPLRHSFQKQQREKTRWLNSGRGDEASEEGQNGSSPKSKTKWTKEDGHRTSTSAVPNLFVPLNTNPKEVQEMRNKIREQNLQDIKTAGPQSQVLCGVVMDRSLVQGELVTASKAIIEKEYQPHVIVSTTGPNPFTTLTDRELEEYRREVERKQKGSEENLDEAREQKEKSPPDQPAVPHPPPSTPIKLEEDLVPEPTTGDDSDAATFKPTLPDLSPDEPSEALGFPMLEKEEEAHRPPSPTEAPTEASPEPAPDPAPVAEEAAPSAVEEGAAADPGSDGSPGKSPSKKKKKFRTPSFLKKSKKKSDS>sp|P35611-2|ADDA_HUMAN Isoform 2 of Alpha-adducin OS=Homo sapiensOX=9606 GN=ADD1MNGDSRAAVVTSPPPTTAPHKERYFDRVDENNPEYLRERNMAPDLRQDFNMMEQKKRVSMILQSPAFCEELESMIQEQFKKGKNPTGLLALQQIADFMTTNVPNVYPAAPQGGMAALNMSLGMVTPVNDLRGSDSIAYDKGEKLLRCKLAAFYRLADLFGWSQLIYNHITTRVNSEQEHFLIVPFGLLYSEVTASSLVKINLQGDIVDRGSTNLGVNQAGFTLHSAIYAARPDVKCVVHIHTPAGAAVSAMKCGLLPISPEALSLGEVAYHDYHGILVDEEEKVLIQKNLGPKSKVLILRNHGLVSVGESVEEAFYYIHNLVVACEIQVRTLASAGGPDNLVLLNPEKYKAKSRSPGSPVGEGTGSPPKWQIGEQEFEALMRMLDNLGYRTGYPYRYPALREKSKKYSDVEVPASVTGYSFASDGDSGTCSPLRHSFQKQQREKTRWLNSGRGDEASEEGQNGSSPKSKTKWTKEDGHRTSTSAVPNLFVPLNTNPKEVQEMRNKIREQNLQDIKTAGPQSQVLCGVVMDRSLVQGELVTASKAIIEKEYQPHVIVSTTGPNPFTTLTDRELEEYRREVERKQKGSEENLDEAREQKEKSPPDQPAVPHPPPSTPIKLEEGDGCAREYLLP>sp|P35611-3|ADDA_HUMAN Isoform 3 of Alpha-adducin OS=Homo sapiensOX=9606 GN=ADD1MNGDSRAAVVTSPPPTTAPHKERYFDRVDENNPEYLRERNMAPDLRQDFNMMEQKKRVSMILQSPAFCEELESMIQEQFKKGKNPTGLLALQQIADFMTTNVPNVYPAAPQGGMAALNMSLGMVTPVNDLRGSDSIAYDKGEKLLRCKLAAFYRLADLFGWSQLIYNHITTRVNSEQEHFLIVPFGLLYSEVTASSLVKINLQGDIVDRGSTNLGVNQAGFTLHSAIYAARPDVKCVVHIHTPAGAAVSAMKCGLLPISPEALSLGEVAYHDYHGILVDEEEKVLIQKNLGPKSKVLILRNHGLVSVGESVEEAFYYIHNLVVACEIQVRTLASAGGPDNLVLLNPEKYKAKSRSPGSPVGEGTGSPPKWQIGEQEFEALMRMLDNLGYRTGYPYRYPALREKSKKYSDVEVPASVTGYSFASDGDSGTCSPLRHSFQKQQREKTRWLNSGRGDEASEEGQNGSSPKSKTKVWTNITHDHVKPLLQSLSSGVCVPSCITNCLWTKEDGHRTSTSAVPNLFVPLNTNPKEVQEMRNKIREQNLQDIKTAGPQSQVLCGVVMDRSLVQGELVTASKAIIEKEYQPHVIVSTTGPNPFTTLTDRELEEYRREVERKQKGSEENLDEAREQKEKSPPDQPAVPHPPPSTPIKLEEDLVPEPTTGDDSDAATFKPTLPDLSPDEPSEALGFPMLEKEEEAHRPPSPTEAPTEASPEPAPDPAPVAEEAAPSAVEEGAAADPGSDGSPGKSPSKKKKKFRTPSFLKKSKKKSDS>sp|P35611-4|ADDA_HUMAN Isoform 4 of Alpha-adducin OS=Homo sapiensOX=9606 GN=ADD1MNGDSRAAVVTSPPPTTAPHKERYFDRVDENNPEYLRERNMAPDLRQDFNMMEQKKRVSMILQSPAFCEELESMIQEQFKKGKNPTGLLALQQIADFMTTNVPNVYPAAPQGGMAALNMSLGMVTPVNDLRGSDSIAYDKGEKLLRCKLAAFYRLADLFGWSQLIYNHITTRVNSEQEHFLIVPFGLLYSEVTASSLVKINLQGDIVDRGSTNLGVNQAGFTLHSAIYAARPDVKCVVHIHTPAGAAVSAMKCGLLPISPEALSLGEVAYHDYHGILVDEEEKVLIQKNLGPKSKVLILRNHGLVSVGESVEEAFYYIHNLVVACEIQVRTLASAGGPDNLVLLNPEKYKAKSRSPGSPVGEGTGSPPKWQIGEQEFEALMRMLDNLGYRTGYPYRYPALREKSKKYSDVEVPASVTGYSFASDGDSGTCSPLRHSFQKQQREKTRWLNSGRGDEASEEGQNGSSPKSKTKWTKEDGHRTSTSAVPNLFVPLNTNPKEVQEMRNKIREQNLQDIKTAGPQSQVLCGVVMDRSLVQDAPLSDCTETIEGLELTEQTFSPAKSLSFRKGELVTASKAIIEKEYQPHVIVSTTGPNPFTTLTDRELEEYRREVERKQKGSEENLDEAREQKEKSPPDQPAVPHPPPSTPIKLEEGDGCAREYLLP>sp|P35611-5|ADDA_HUMAN Isoform 5 of Alpha-adducin OS=Homo sapiensOX=9606 GN=ADD1MNGDSRAAVVTSPPPTTAPHKERYFDRVDENNPEYLRERNMAPDLRQDFNMMEQKKRVSMILQSPAFCEELESMIQEQFKKGKNPTGLLALQQIADFMTTNVPNVYPAAPQGGMAALNMSLGMVTPVNDLRGSDSIAYDKGEKLLRCKLAAFYRLADLFGWSQLIYNHITTRVNSEQEHFLIVPFGLLYSEVTASSLVKINLQGDIVDRGSTNLGVNQAGFTLHSAIYAARPDVKCVVHIHTPAGAAVSAMKCGLLPISPEALSLGEVAYHDYHGILVDEEEKVLIQKNLGPKSKVLILRNHGLVSVGESVEEAFYYIHNLVVACEIQVRTLASAGGPDNLVLLNPEKYKAKSRSPGSPVGEGTGSPPKWQIGEQEFEALMRMLDNLGYRTGYPYRYPALREKSKKYSDVEVPASVTGYSFASDGDSGTCSPLRHSFQKQQREKTRWLNSGRGDEASEEGQNGSSPKSKTKVWTNITHDHVKPLLQSLSSGVCVPSCITNCLVCAYLTVHS>sp|P35611-6|ADDA_HUMAN Isoform 6 of Alpha-adducin OS=Homo sapiensOX=9606 GN=ADD1MNGDSRAAVVTSPPPTTAPHKERYFDRVDENNPEYLRERNMAPDLRQDFNMMEQKKRVSMILQSPAFCEELESMIQEQFKKGKNPTGLLALQQIADFMTTNVPNVYPAAPQGGMAALNMSLGMVTPVNDLRGSDSIAYDKGEKLLRCKLAAFYRLADLFGWSQLIYNHITTRVNSEQEHFLIVPFGLLYSEVTASSLVKINLQGDIVDRGSTNLGVNQAGFTLHSAIYAARPDVKCVVHIHTPAGAAVSAMKCGLLPISPEALSLGEVAYHDYHGILVDEEEKVLIQKNLGPKSKVLILRNHGLVSVGESVEEAFYYIHNLVVACEIQVRTLASAGGPDNLVLLNPEKYKAKSRSPGSPVGEGTGSPPKWQIGEQEFEALMRMLDNLGYRTGYPYRYPALREKSKKYSDVEVPASVTGYSFASDGDSGTCSPLRHSFQKQQREKTRWLNSGRGDEASEEGQNGSSPKSKTKVWTNITHDHVKPLLQSLSSGVCVPSCITNCLWTKEDGHRTSTSAVPNLFVPLNTNPKEVQEMRNKIREQNLQDIKTAGPQSQVLCGVVMDRSLVQGELVTASKAIIEKEYQPHVIVSTTGPNPFTTLTDRELEEYRREVERKQKGSEENLDEAREQKEKSPPDQPAVPHPPPSTPIKLEEGDGCAREYLLP>sp|Q9ULC5|ACSL5_HUMAN Long-chain-fatty-acid--CoA ligase 5 OS=Homosapiens OX=9606 GN=ACSL5 PE=1 SV=1MLFIFNFLFSPLPTPALICILTFGAAIFLWLITRPQPVLPLLDLNNQSVGIEGGARKGVSQKNNDLTSCCFSDAKTMYEVFQRGLAVSDNGPCLGYRKPNQPYRWLSYKQVSDRAEYLGSCLLHKGYKSSPDQFVGIFAQNRPEWIISELACYTYSMVAVPLYDTLGPEAIVHIVNKADIAMVICDTPQKALVLIGNVEKGFTPSLKVIILMDPFDDDLKQRGEKSGIEILSLYDAENLGKEHFRKPVPPSPEDLSVICFTSGTTGDPKGAMITHQNIVSNAAAFLKCVEHAYEPTPDDVAISYLPLAHMFERIVQAVVYSCGARVGFFQGDIRLLADDMKTLKPTLFPAVPRLLNRIYDKVQNEAKTPLKKFLLKLAVSSKFKELQKGIIRHDSFWDKLIFAKIQDSLGGRVRVIVTGAAPMSTSVMTFFRAAMGCQVYEAYGQTECTGGCTFTLPGDWTSGHVGVPLACNYVKLEDVADMNYFTVNNEGEVCIKGTNVFKGYLKDPEKTQEALDSDGWLHTGDIGRWLPNGTLKIIDRKKNIFKLAQGEYIAPEKIENIYNRSQPVLQIFVHGESLRSSLVGVVVPDTDVLPSFAAKLGVKGSFEELCQNQVVREAILEDLQKIGKESGLKTFEQVKAIFLHPEPFSIENGLLTPTLKAKRGELSKYFRTQIDSLYEHIQD>sp|Q9ULC5-3|ACSL5_HUMAN Isoform 2 of Long-chain-fatty-acid--CoA ligase 5OS=Homo sapiens OX=9606 GN=ACSL5MDALKPPCLWRNHERGKKDRDSCGRKNSEPGSPHSLEALRDAAPSQGLNFLLLFTKMLFIFNFLFSPLPTPALICILTFGAAIFLWLITRPQPVLPLLDLNNQSVGIEGGARKGVSQKNNDLTSCCFSDAKTMYEVFQRGLAVSDNGPCLGYRKPNQPYRWLSYKQVSDRAEYLGSCLLHKGYKSSPDQFVGIFAQNRPEWIISELACYTYSMVAVPLYDTLGPEAIVHIVNKADIAMVICDTPQKALVLIGNVEKGFTPSLKVIILMDPFDDDLKQRGEKSGIEILSLYDAENLGKEHFRKPVPPSPEDLSVICFTSGTTGDPKGAMITHQNIVSNAAAFLKCVEHAYEPTPDDVAISYLPLAHMFERIVQAVVYSCGARVGFFQGDIRLLADDMKTLKPTLFPAVPRLLNRIYDKVQNEAKTPLKKFLLKLAVSSKFKELQKGIIRHDSFWDKLIFAKIQDSLGGRVRVIVTGAAPMSTSVMTFFRAAMGCQVYEAYGQTECTGGCTFTLPGDWTSGHVGVPLACNYVKLEDVADMNYFTVNNEGEVCIKGTNVFKGYLKDPEKTQEALDSDGWLHTGDIGRWLPNGTLKIIDRKKNIFKLAQGEYIAPEKIENIYNRSQPVLQIFVHGESLRSSLVGVVVPDTDVLPSFAAKLGVKGSFEELCQNQVVREAILEDLQKIGKESGLKTFEQVKAIFLHPEPFSIENGLLTPTLKAKRGELSKYFRTQIDSLYEHIQD>sp|Q9ULC5-4|ACSL5_HUMAN Isoform 3 of Long-chain-fatty-acid--CoA ligase 5OS=Homo sapiens OX=9606 GN=ACSL5MLFIFNFLFSPLPTPALICILTFGAAIFLWLITRPQPVLPLLDLNNQSVGIEGGARKGVSQKNNDLTSCCFSDAKTMYEVFQRGLAVSDNGPCLGYRKPNQPYRWLSYKQVSDRAEYLGSCLLHKGYKSSPDQFVGIFAQNRPEWIISELACYTYSMVAVPLYDTLGPEAIVHIVNKADIAMVICDTPQKALVLIGNVEKGFTPSLKVIILMDPFDDDLKQRGEKSGIEILSLYDAENLGKEHFRKPVPPSPEDLSVICFTSGTTGDPKGAMITHQNIVSNAAAFLKCVEHAYEPTPDDVAISYLPLAHMFERIVQAVVYSCGARVGFFQGDIRLLADDMKTLKPTLFPAVPRLLNRIYDKVQNEAKTPLKKFLLKLAVSSKFKELQKGIIRHDSFWDKLIFAKIQDSLGGRVRVIVTGAAPMSTSVMTFFRAAMGCQVYEAYGQTECTGGCTFTLPGDWTSGHVGVPLACNYVKLEDVADMNYFTVNNEGEVCIKGTNVFKGYLKDPEKTQEALDSDGWLHTGDIGRWLPNGTLKIIDRKKNIFKLAQGEYIAPEKIENIYNRSQPVLQIFVHGESLRSSLVGVVVPDTDVLPSFAAKLGVKGSFEELCQNQVKAIFLHPEPFSIENGLLTPTLKAKRGELSKYFRTQIDSLYEHIQD>sp|Q9BV10|ALG12_HUMAN Dol-P-Man:Man(7)GlcNAc(2)-PP-Dol alpha-1,6-mannosyltransferase OS=Homo sapiens OX=9606 GN=ALG12 PE=1 SV=1MAGKGSSGRRPLLLGLLVAVATVHLVICPYTKVEESFNLQATHDLLYHWQDLEQYDHLEFPGVVPRTFLGPVVIAVFSSPAVYVLSLLEMSKFYSQLIVRGVLGLGVIFGLWTLQKEVRRHFGAMVATMFCWVTAMQFHLMFYCTRTLPNVLALPVVLLALAAWLRHEWARFIWLSAFAIIVFRVELCLFLGLLLLLALGNRKVSVVRALRHAVPAGILCLGLTVAVDSYFWRQLTWPEGKVLWYNTVLNKSSNWGTSPLLWYFYSALPRGLGCSLLFIPLGLVDRRTHAPTVLALGFMALYSLLPHKELRFIIYAFPMLNITAARGCSYLLNNYKKSWLYKAGSLLVIGHLVVNAAYSATALYVSHFNYPGGVAMQRLHQLVPPQTDVLLHIDVAAAQTGVSRFLQVNSAWRYDKREDVQPGTGMLAYTHILMEAAPGLLALYRDTHRVLASVVGTTGVSLNLTQLPPFNVHLQTKLVLLERLPRPS>sp|Q8IWK6|AGRA3_HUMAN Adhesion G protein-coupled receptor A3 OS=Homosapiens OX=9606 GN=ADGRA3 PE=1 SV=2MEPPGRRRGRAQPPLLLPLSLLALLALLGGGGGGGAAALPAGCKHDGRPRGAGRAAGAAEGKVVCSSLELAQVLPPDTLPNRTVTLILSNNKISELKNGSFSGLSLLERLDLRNNLISSIDPGAFWGLSSLKRLDLTNNRIGCLNADIFRGLTNLVRLNLSGNLFSSLSQGTFDYLASLRSLEFQTEYLLCDCNILWMHRWVKEKNITVRDTRCVYPKSLQAQPVTGVKQELLTCDPPLELPSFYMTPSHRQVVFEGDSLPFQCMASYIDQDMQVLWYQDGRIVETDESQGIFVEKNMIHNCSLIASALTISNIQAGSTGNWGCHVQTKRGNNTRTVDIVVLESSAQYCPPERVVNNKGDFRWPRTLAGITAYLQCTRNTHGSGIYPGNPQDERKAWRRCDRGGFWADDDYSRCQYANDVTRVLYMFNQMPLNLTNAVATARQLLAYTVEAANFSDKMDVIFVAEMIEKFGRFTKEEKSKELGDVMVDIASNIMLADERVLWLAQREAKACSRIVQCLQRIATYRLAGGAHVYSTYSPNIALEAYVIKSTGFTGMTCTVFQKVAASDRTGLSDYGRRDPEGNLDKQLSFKCNVSNTFSSLALKNTIVEASIQLPPSLFSPKQKRELRPTDDSLYKLQLIAFRNGKLFPATGNSTNLADDGKRRTVVTPVILTKIDGVNVDTHHIPVNVTLRRIAHGADAVAARWDFDLLNGQGGWKSDGCHILYSDENITTIQCYSLSNYAVLMDLTGSELYTQAASLLHPVVYTTAIILLLCLLAVIVSYIYHHSLIRISLKSWHMLVNLCFHIFLTCVVFVGGITQTRNASICQAVGIILHYSTLATVLWVGVTARNIYKQVTKKAKRCQDPDEPPPPPRPMLRFYLIGGGIPIIVCGITAAANIKNYGSRPNAPYCWMAWEPSLGAFYGPASFITFVNCMYFLSIFIQLKRHPERKYELKEPTEEQQRLAANENGEINHQDSMSLSLISTSALENEHTFHSQLLGASLTLLLYVALWMFGALAVSLYYPLDLVFSFVFGATSLSFSAFFVVHHCVNREDVRLAWIMTCCPGRSSYSVQVNVQPPNSNGTNGEAPKCPNSSAESSCTNKSASSFKNSSQGCKLTNLQAAAAQCHANSLPLNSTPQLDNSLTEHSMDNDIKMHVAPLEVQFRTNVHSSRHHKNRSKGHRASRLTVLREYAYDVPTSVEGSVQNGLPKSRLGNNEGHSRSRRAYLAYRERQYNPPQQDSSDACSTLPKSSRNFEKPVSTTSKKDALRKPAVVELENQQKSYGLNLAIQNGPIKSNGQEGPLLGTDSTGNVRTGLWKHETTV>sp|Q8IWK6-2|AGRA3_HUMAN Isoform 2 of Adhesion G protein-coupled receptorA3 OS=Homo sapiens OX=9606 GN=ADGRA3MEPPGRRRGRAQPPLLLPLSLLALLALLGGGGGGGAAALPAGCKHDGRPRGAGRAAGAAEGKVVCSSLELAQVLPPDTLPNRTVTLILSNNKISELKNGSFSGLSLLERLDLRNNLISSIDPGAFWGLSSLKRLDLTNNRIGCLNADIFRGLTNLVRLNLSGNLFSSLSQGTFDYLASLRSLEFQTEYLLCDCNILWMHRWVKEKNITVRDTRCVYPKSLQAQPVTGVKQELLTCDPPLELPSFYMTPSHRQVVFEGDSLPFQCMASYIDQDMQVLWYQDGRIVETDESQGIFVEKNMIHNCSLIASALTISNIQAGSTGNWGCHVQTKRGNNTRTVDIVVLESSAQYCPPERVVNNKGDFRWPRTLAGITAYLQCTRNTHGSGIYPGNPQDERKAWRRCDRGGFWADDDYSRCQYANDVTRVLYMFNQMPLNLTNAVATARQLLAYTVEAANFSDKMDVIFVAEMIEKFGRFTKEEKSKELGDVMVDIASNIMLADERVLWLAQREAKACSRIVQCLQRIATYRLAGGAHVYSTYSPNIALEAYVIKSTGFTGMTCTVFQKVAASDRTGLSDYGRRDPEGNLDKQLSFKCNVSNTFSSLALKVCYILQSFKTIYS>sp|Q8IWK6-3|AGRA3_HUMAN Isoform 3 of Adhesion G protein-coupled receptorA3 OS=Homo sapiens OX=9606 GN=ADGRA3MMRVMPCQVDLTNNRIGCLNADIFRGLTNLVRLNLSGNLFSSLSQGTFDYLASLRSLEFQTEYLLCDCNILWMHRWVKEKNITVRDTRCVYPKSLQAQPVTGVKQELLTCDPPLELPSFYMTPSHRQVVFEGDSLPFQCMASYIDQDMQVLWYQDGRIVETDESQGIFVEKNMIHNCSLIASALTISNIQAGSTGNWGCHVQTKRGNNTRTVDIVVLESSAQYCPPERVVNNKGDFRWPRTLAGITAYLQCTRNTHGSGIYPGNPQDERKAWRRCDRGGFWADDDYSRCQYANDVTRVLYMFNQMPLNLTNAVATARQLLAYTVEAANFSDKMDVIFVAEMIEKFGRFTKEEKSKELGDVMVDIASNIMLADERVLWLAQREAKACSRIVQCLQRIATYRLAGGAHVYSTYSPNIALEAYVIKSTGFTGMTCTVFQKVAASDRTGLSDYGRRDPEGNLDKQLSFKCNVSNTFSSLALKQKRELRPTDDSLYKLQLIAFRNGKLFPATGNSTNLADDGKRRTVVTPVILTKIDGVNVDTHHIPVNVTLRRIAHGADAVAARWDFDLLNGQGGWKSDGCHILYSDENITTIQCYSLSNYAVLMDLTGSELYTQAASLLHPVVYTTAIILLLCLLAVIVSYIYHHSLIRISLKSWHMLVNLCFHIFLTCVVFVGGITQTRNASICQAVGIILHYSTLATVLWVGVTARNIYKQVTKKAKRCQDPDEPPPPPRPMLRFYLIGGGIPIIVCGITAAANIKNYGSRPNAPYCWMAWEPSLGAFYGPASFITFVNCMYFLSIFIQLKRHPERKYELKEPTEEQQRLAANENGEINHQDSMSLSLISTSALENEHTFHSQLLGASLTLLLYVALWMFGALAVSLYYPLDLVFSFVFGATSLSFSAFFVVHHCVNREDVRLAWIMTCCPGRSSYSVQVNVQPPNSNGTNGEAPKCPNSSAESSCTNKSASSFKNSSQGCKLTNLQAAAAQCHANSLPLNSTPQLDNSLTEHSMDNDIKMHVAPLEVQFRTNVHSSRHHKNRSKGHRASRLTVLREYAYDVPTSVEGSVQNGLPKSRLGNNEGHSRSRRAYLAYRERQYNPPQQDSSDACSTLPKSSRNFEKPVSTTSKKDALRKPAVVELENQQKSYGLNLAIQNGPIKSNGQEGPLLGTDSTGNVRTGLWKHETTV>sp|Q8IWK6-4|AGRA3_HUMAN Isoform 4 of Adhesion G protein-coupled receptorA3 OS=Homo sapiens OX=9606 GN=ADGRA3MPLKRNNSKYPPLELPSFYMTPSHRQVVFEGDSLPFQCMASYIDQDMQVLWYQDGRIVETDESQGIFVEKNMIHNCSLIASALTISNIQAGSTGNWGCHVQTKRGNNTRTVDIVVLESSAQYCPPERVVNNKGDFRWPRTLAGITAYLQCTRNTHGSGIYPGNPQDERKAWRRCDRGGFWADDDYSRCQYANDVTRVLYMFNQMPLNLTNAVATARQLLAYTVEAANFSDKMDVIFVAEMIEKFGRFTKEEKSKELGDVMVDIASNIMLADERVLWLAQREAKACSRIVQCLQRIATYRLAGGAHVYSTYSPNIALEAYVIKSTGFTGMTCTVFQKVAASDRTGLSDYGRRDPEGNLDKQLSFKCNVSNTFSSLALKGKFR>sp|O95622|ADCY5_HUMAN Adenylate cyclase type 5 OS=Homo sapiens OX=9606GN=ADCY5 PE=1 SV=3MSGSKSVSPPGYAAQKTAAPAPRGGPEHRSAWGEADSRANGYPHAPGGSARGSTKKPGGAVTPQQQQRLASRWRSDDDDDPPLSGDDPLAGGFGFSFRSKSAWQERGGDDCGRGSRRQRRGAASGGSTRAPPAGGGGGSAAAAASAGGTEVRPRSVEVGLEERRGKGRAADELEAGAVEGGEGSGDGGSSADSGSGAGPGAVLSLGACCLALLQIFRSKKFPSDKLERLYQRYFFRLNQSSLTMLMAVLVLVCLVMLAFHAARPPLQLPYLAVLAAAVGVILIMAVLCNRAAFHQDHMGLACYALIAVVLAVQVVGLLLPQPRSASEGIWWTVFFIYTIYTLLPVRMRAAVLSGVLLSALHLAIALRTNAQDQFLLKQLVSNVLIFSCTNIVGVCTHYPAEVSQRQAFQETRECIQARLHSQRENQQQERLLLSVLPRHVAMEMKADINAKQEDMMFHKIYIQKHDNVSILFADIEGFTSLASQCTAQELVMTLNELFARFDKLAAENHCLRIKILGDCYYCVSGLPEARADHAHCCVEMGMDMIEAISLVREVTGVNVNMRVGIHSGRVHCGVLGLRKWQFDVWSNDVTLANHMEAGGKAGRIHITKATLNYLNGDYEVEPGCGGERNAYLKEHSIETFLILRCTQKRKEEKAMIAKMNRQRTNSIGHNPPHWGAERPFYNHLGGNQVSKEMKRMGFEDPKDKNAQESANPEDEVDEFLGRAIDARSIDRLRSEHVRKFLLTFREPDLEKKYSKQVDDRFGAYVACASLVFLFICFVQITIVPHSIFMLSFYLTCSLLLTLVVFVSVIYSCVKLFPSPLQTLSRKIVRSKMNSTLVGVFTITLVFLAAFVNMFTCNSRDLLGCLAQEHNISASQVNACHVAESAVNYSLGDEQGFCGSPWPNCNFPEYFTYSVLLSLLACSVFLQISCIGKLVLMLAIELIYVLIVEVPGVTLFDNADLLVTANAIDFFNNGTSQCPEHATKVALKVVTPIIISVFVLALYLHAQQVESTARLDFLWKLQATEEKEEMEELQAYNRRLLHNILPKDVAAHFLARERRNDELYYQSCECVAVMFASIANFSEFYVELEANNEGVECLRLLNEIIADFDEIISEDRFRQLEKIKTIGSTYMAASGLNDSTYDKVGKTHIKALADFAMKLMDQMKYINEHSFNNFQMKIGLNIGPVVAGVIGARKPQYDIWGNTVNVASRMDSTGVPDRIQVTTDMYQVLAANTYQLECRGVVKVKGKGEMMTYFLNGGPPLS>sp|O95622-2|ADCY5_HUMAN Isoform 2 of Adenylate cyclase type 5 OS=Homosapiens OX=9606 GN=ADCY5MKSQKEGCCSRGDLSIQTGPGGEWAPRRLVSNVLIFSCTNIVGVCTHYPAEVSQRQAFQETRECIQARLHSQRENQQQERLLLSVLPRHVAMEMKADINAKQEDMMFHKIYIQKHDNVSILFADIEGFTSLASQCTAQELVMTLNELFARFDKLAAENHCLRIKILGDCYYCVSGLPEARADHAHCCVEMGMDMIEAISLVREVTGVNVNMRVGIHSGRVHCGVLGLRKWQFDVWSNDVTLANHMEAGGKAGRIHITKATLNYLNGDYEVEPGCGGERNAYLKEHSIETFLILRCTQKRKEEKAMIAKMNRQRTNSIGHNPPHWGAERPFYNHLGGNQVSKEMKRMGFEDPKDKNAQESANPEDEVDEFLGRAIDARSIDRLRSEHVRKFLLTFREPDLEKKYSKQVDDRFGAYVACASLVFLFICFVQITIVPHSIFMLSFYLTCSLLLTLVVFVSVIYSCVKLFPSPLQTLSRKIVRSKMNSTLVGVFTITLVFLAAFVNMFTCNSRDLLGCLAQEHNISASQVNACHVAESAVNYSLGDEQGFCGSPWPNCNFPEYFTYSVLLSLLACSVFLQISCIGKLVLMLAIELIYVLIVEVPGVTLFDNADLLVTANAIDFFNNGTSQCPEHATKVALKVVTPIIISVFVLALYLHAQQVESTARLDFLWKLQATEEKEEMEELQAYNRRLLHNILPKDVAAHFLARERRNDELYYQSCECVAVMFASIANFSEFYVELEANNEGVECLRLLNEIIADFDEIISEDRFRQLEKIKTIGSTYMAASGLNDSTYDKVGKTHIKALADFAMKLMDQMKYINEHSFNNFQMKIGLNIGPVVAGVIGARKPQYDIWGNTVNVASRMDSTGVPDRIQVTTDMYQVLAANTYQLECRGVVKVKGKGEMMTYFLNGGPPLS>sp|Q53FZ2|ACSM3_HUMAN Acyl-coenzyme A synthetase ACSM3, mitochondrialOS=Homo sapiens OX=9606 GN=ACSM3 PE=1 SV=2MLARVTRKMLRHAKCFQRLAIFGSVRALHKDNRTATPQNFSNYESMKQDFKLGIPEYFNFAKDVLDQWTDKEKAGKKPSNPAFWWINRNGEEMRWSFEELGSLSRKFANILSEACSLQRGDRVILILPRVPEWWLANVACLRTGTVLIPGTTQLTQKDILYRLQSSKANCIITNDVLAPAVDAVASKCENLHSKLIVSENSREGWGNLKELMKHASDSHTCVKTKHNEIMAIFFTSGTSGYPKMTAHTHSSFGLGLSVNGRFWLDLTPSDVMWNTSDTGWAKSAWSSVFSPWIQGACVFTHHLPRFEPTSILQTLSKYPITVFCSAPTVYRMLVQNDITSYKFKSLKHCVSAGEPITPDVTEKWRNKTGLDIYEGYGQTETVLICGNFKGMKIKPGSMGKPSPAFDVKIVDVNGNVLPPGQEGDIGIQVLPNRPFGLFTHYVDNPSKTASTLRGNFYITGDRGYMDKDGYFWFVARADDVILSSGYRIGPFEVENALNEHPSVAESAVVSSPDPIRGEVVKAFVVLNPDYKSHDQEQLIKEIQEHVKKTTAPYKYPRKVEFIQELPKTISGKTKRNELRKKEWKTI>sp|Q53FZ2-2|ACSM3_HUMAN Isoform 2 of Acyl-coenzyme A synthetase ACSM3,mitochondrial OS=Homo sapiens OX=9606 GN=ACSM3MLARVTRKMLRHAKCFQRLAIFGSVRALHKDNRTATPQNFSNYESMKQDFKLGIPEYFNFAKDVLDQWTDKEKAGKKPSNPAFWWINRNGEEMRWSFEELGSLSRKFANILSEACSLQRGDRVILILPRVPEWWLANVACLRTGTVLIPGTTQLTQKDILYRLQSSKANCIITNDVLAPAVDAVASKCENLHSKLIVSENSREGWGNLKELMKHASDSHTCVKTKHNEIMAIFFTSGTSGYPKMTAHTHSSFGLGLSVNGRFWLDLTPSDVMWNTSDTGWAKSAWSSVFSPWIQGACVFTHHLPRFEPTSILQTLSKYPITVFCSAPTVYRMLVQNDITSYKFKSLKHCVSAGEPITPDVTEKWRNKTGLDIYEGYGQTETVLICGNFKGMKIKPGSMGKPSPAFDVKVCTSPSRRMFNNPICTLPTYRLPPYKLSLL>sp|P50747|BPL1_HUMAN Biotin--protein ligase OS=Homo sapiens OX=9606GN=HLCS PE=1 SV=1MEDRLHMDNGLVPQKIVSVHLQDSTLKEVKDQVSNKQAQILEPKPEPSLEIKPEQDGMEHVGRDDPKALGEEPKQRRGSASGSEPAGDSDRGGGPVEHYHLHLSSCHECLELENSTIESVKFASAENIPDLPYDYSSSLESVADETSPEREGRRVNLTGKAPNILLYVGSDSQEALGRFHEVRSVLADCVDIDSYILYHLLEDSALRDPWTDNCLLLVIATRESIPEDLYQKFMAYLSQGGKVLGLSSSFTFGGFQVTSKGALHKTVQNLVFSKADQSEVKLSVLSSGCRYQEGPVRLSPGRLQGHLENEDKDRMIVHVPFGTRGGEAVLCQVHLELPPSSNIVQTPEDFNLLKSSNFRRYEVLREILTTLGLSCDMKQVPALTPLYLLSAAEEIRDPLMQWLGKHVDSEGEIKSGQLSLRFVSSYVSEVEITPSCIPVVTNMEAFSSEHFNLEIYRQNLQTKQLGKVILFAEVTPTTMRLLDGLMFQTPQEMGLIVIAARQTEGKGRGGNVWLSPVGCALSTLLISIPLRSQLGQRIPFVQHLMSVAVVEAVRSIPEYQDINLRVKWPNDIYYSDLMKIGGVLVNSTLMGETFYILIGCGFNVTNSNPTICINDLITEYNKQHKAELKPLRADYLIARVVTVLEKLIKEFQDKGPNSVLPLYYRYWVHSGQQVHLGSAEGPKVSIVGLDDSGFLQVHQEGGEVVTVHPDGNSFDMLRNLILPKRR>sp|Q96F25|ALG14_HUMAN UDP-N-acetylglucosamine transferase subunit ALG14homolog OS=Homo sapiens OX=9606 GN=ALG14 PE=1 SV=1MVCVLVLAAAAGAVAVFLILRIWVVLRSMDVTPRESLSILVVAGSGGHTTEILRLLGSLSNAYSPRHYVIADTDEMSANKINSFELDRADRDPSNMYTKYYIHRIPRSREVQQSWPSTVFTTLHSMWLSFPLIHRVKPDLVLCNGPGTCVPICVSALLLGILGIKKVIIVYVESICRVETLSMSGKILFHLSDYFIVQWPALKEKYPKSVYLGRIV>sp|P35612|ADDB_HUMAN Beta-adducin OS=Homo sapiens OX=9606 GN=ADD2 PE=1SV=3MSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKVNILGEVVEKGSSCFPVDTTGFCLHSAIYAARPDVRCIIHLHTPATAAVSAMKWGLLPVSHNALLVGDMAYYDFNGEMEQEADRINLQKCLGPTCKILVLRNHGVVALGDTVEEAFYKIFHLQAACEIQVSALSSAGGVENLILLEQEKHRPHEVGSVQWAGSTFGPMQKSRLGEHEFEALMRMLDNLGYRTGYTYRHPFVQEKTKHKSEVEIPATVTAFVFEEDGAPVPALRQHAQKQQKEKTRWLNTPNTYLRVNVADEVQRSMGSPRPKTTWMKADEVEKSSSGMPIRIENPNQFVPLYTDPQEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPSTESQLMSKGDEDTKDDSEETVPNPFSQLTDQELEEYKKEVERKKLELDGEKETAPEEPGSPAKSAPASPVQSPAKEAETKSPLVSPSKSLEEGTKKTETSKAATTEPETTQPEGVVVNGREEEQTAEEILSKGLSQMTTSADTDVDTSKDKTESVTSGPMSPEGSPSKSPSKKKKKFRTPSFLKKSKKKEKVES>sp|P35612-2|ADDB_HUMAN Isoform 2 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKVNILGEVVEKGSSCFPVDTTGFCLHSAIYAARPDVRCIIHLHTPATAAVSAMKWGLLPVSHNALLVGDMAYYDFNGEMEQEADRINLQKCLGPTCKILVLRNHGVVALGDTVEEAFYKIFHLQAACEIQVSALSSAGGVENLILLEQEKHRPHEVGSVQWAGSTFGPMQKSRLGEHEFEALMRMLDNLGYRTGYTYRHPFVQEKTKHKSEVEIPATVTAFVFEEDGAPVPALRQHAQKQQKEKTRWLNTPNTYLRVNVADEVQRSMGSPRPKTTWMKADEVEKSSSGMPIRIENPNQFVPLYTDPQEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPVEQRLPLTGGETCLPSGSSVPGAGLQDP>sp|P35612-3|ADDB_HUMAN Isoform 3 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKVNILGEVVEKGSSCFPVDTTGFCLHSAIYAARPDVRCIIHLHTPATAAVSAMKWGLLPVSHNALLVGDMAYYDFNGEMEQEADRINLQKCLGPTCKILVLRNHGVVALGDTVEEAFYKIFHLQAACEIQVSALSSAGGVENLILLEQEKHRPHEVGSVQWAGSTFGPMQKSRLGEHEFEALMRMLDNLGYRTGYTYRHPFVQEKTKHKSEVEIPATVTAFVFEEDGAPVPALRQHAQKQQKEKTRWLNTPNTYLRVNVADEVQRSMGSPRPKTTWMKADEVEKSSSGMPIRIENPNQFVPLYTDPQEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPSTESQLMSKGDEDTKDDSEETVPNPFSQLTDQELEEYKKEVERKKLELDETGQEREPGSGPAVCEFFSVALHIWSNILERKKLPQKSLAHLQSLHLLLQCRAQRRRQRQRAL>sp|P35612-4|ADDB_HUMAN Isoform 4 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKVNILGEVVEKGSSCFPVDTTGFCLHSAIYAARPDVRCIIHLHTPATAAVSAMKWGLLPVSHNALLVGDMAYYDFNGEMEQEADRINLQKCLGPTCKILVLRNHGVVALGDTVEEAFYKIFHLQAACEIQVSALSSAGGVENLILLEQEKHRPHEVGSVQWAGSTFGPMQKSRLGEHEFEALMRMLDNLGYRTGYTYRHPFVQEKTKHKSEVEIPATVTAFVFEEDGAPVPALRQHAQKQQKEKTRWLNTPNTYLRVNVADEVQRSMGSPRPKTTWMKADEVEKSSSGMPIRIENPNQFVPLYTDPQEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPSTESQLMSKGDEDTKDDSEETVPNPFSQLTDQELEEYKKEVERKKLELDAPGWFSS>sp|P35612-5|ADDB_HUMAN Isoform 5 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPSTESQLMSKGDEDTKDDSEETVPNPFSQLTDQELEEYKKEVERKKLELDETGQER>sp|P35612-6|ADDB_HUMAN Isoform 6 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPSTESQLMSKGDEDTKDDSEETVPNPFSQLTDQELEEYKKEVERKKLELDAPGWFSS>sp|P35612-7|ADDB_HUMAN Isoform 7 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKEYKKEVERKKLELDAPGWFSS>sp|P35612-8|ADDB_HUMAN Isoform 8 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MPRRRVPGANCKPTGKSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKVNILGEVVEKGSSCFPVDTTGFCLHSAIYAARPDVRCIIHLHTPATAAVSAMKWGLLPVSHNALLVGDMAYYDFNGEMEQEADRINLQKCLGPTCKILVLRNHGVVALGDTVEEAFYKIFHLQAACEIQVSALSSAGGVENLILLEQEKHRPHEVGSVQWAGSTFGPMQKSRLGEHEFEALMRMLDNLGYRTGYTYRHPFVQEKTKHKSEVEIPATVTAFVFEEDGAPVPALRQHAQKQQKEKTRWLNTPNTYLRVNVADEVQRSMGSPRPKTTWMKADEVEKSSSGMPIRIENPNQFVPLYTDPQEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPVEQRLPLTGGETCLPSGSSVPGAGLQDP>sp|P35612-9|ADDB_HUMAN Isoform 9 of Beta-adducin OS=Homo sapiens OX=9606GN=ADD2MPRRRVPGANCKPTGKMSEETVPEAASPPPPQGQPYFDRFSEDDPEYMRLRNRAADLRQDFNLMEQKKRVTMILQSPSFREELEGLIQEQMKKGNNSSNIWALRQIADFMASTSHAVFPTSSMNVSMMTPINDLHTADSLNLAKGERLMRCKISSVYRLLDLYGWAQLSDTYVTLRVSKEQDHFLISPKGVSCSEVTASSLIKVNILGEVVEKGSSCFPVDTTGFCLHSAIYAARPDVRCIIHLHTPATAAVSAMKWGLLPVSHNALLVGDMAYYDFNGEMEQEADRINLQKCLGPTCKILVLRNHGVVALGDTVEEAFYKIFHLQAACEIQVSALSSAGGVENLILLEQEKHRPHEVGSVQWAGSTFGPMQKSRLGEHEFEALMRMLDNLGYRTGYTYRHPFVQEKTKHKSEVEIPATVTAFVFEEDGAPVPALRQHAQKQQKEKTRWLNTPNTYLRVNVADEVQRSMGSPRPKTTWMKADEVEKSSSGMPIRIENPNQFVPLYTDPQEVLEMRNKIREQNRQDVKSAGPQSQLLASVIAEKSRSPVEQRLPLTGGETCLPSGSSVPGAGLQDP>sp|Q8IZF5|AGRF3_HUMAN Adhesion G-protein coupled receptor F3 OS=Homosapiens OX=9606 GN=ADGRF3 PE=2 SV=1MVCSAAPLLLLATTLPLLGSPVAQASQPVSETGVRPREGLQRRQWGPLIGRDKAWNERIDRPFPACPIPLSSSFGRWPKGQTMWAQTSTLTLTEEELGQSQAGGESGSGQLLDQENGAGESALVSVYVHLDFPDKTWPPELSRTLTLPAASASSSPRPLLTGLRLTTECNVNHKGNFYCACLSGYQWNTSICLHYPPCQSLHNHQPCGCLVFSHPEPGYCQLLPPGSPVTCLPAVPGILNLNSQLQMPGDTLSLTLHLSQEATNLSWFLRHPGSPSPILLQPGTQVSVTSSHGQAALSVSNMSHHWAGEYMSCFEAQGFKWNLYEVVRVPLKATDVARLPYQLSISCATSPGFQLSCCIPSTNLAYTAAWSPGEGSKASSFNESGSQCFVLAVQRCPMADTTYACDLQSLGLAPLRVPISITIIQDGDITCPEDASVLTWNVTKAGHVAQAPCPESKRGIVRRLCGADGVWGPVHSSCTDARLLALFTRTKLLQAGQGSPAEEVPQILAQLPGQAAEASSPSDLLTLLSTMKYVAKVVAEARIQLDRRALKNLLIATDKVLDMDTRSLWTLAQARKPWAGSTLLLAVETLACSLCPQDHPFAFSLPNVLLQSQLFGPTFPADYSISFPTRPPLQAQIPRHSLAPLVRNGTEISITSLVLRKLDHLLPSNYGQGLGDSLYATPGLVLVISIMAGDRAFSQGEVIMDFGNTDGSPHCVFWDHSLFQGRGGWSKEGCQAQVASASPTAQCLCQHLTAFSVLMSPHTVPEEPALALLTQVGLGASILALLVCLGVYWLVWRVVVRNKISYFRHAALLNMVFCLLAADTCFLGAPFLSPGPRSPLCLAAAFLCHFLYLATFFWMLAQALVLAHQLLFVFHQLAKHRVLPLMVLLGYLCPLGLAGVTLGLYLPQGQYLREGECWLDGKGGALYTFVGPVLAIIGVNGLVLAMAMLKLLRPSLSEGPPAEKRQALLGVIKALLILTPIFGLTWGLGLATLLEEVSTVPHYIFTILNTLQGVFILLFGCLMDRKIQEALRKRFCRAQAPSSTISLVSCCLQILSCASKSMSEGIPWPSSEDMGTARS>sp|Q8IZF5-2|AGRF3_HUMAN Isoform 2 of Adhesion G-protein coupled receptorF3 OS=Homo sapiens OX=9606 GN=ADGRF3MTTRKLSAHSAATPGYKAVTHKHHTGWARMAKTGLPEKGQSQAGGESGSGQLLDQENGAGESALVSVYVHLDFPDKTWPPELSRTLTLPAASASSSPRPLLTGLRLTTGEYMSCFEAQGFKWNLYEVVRVPLKATDVARLPYQLSISCATSPGFQLSCCIPSTNLAYTAAWSPGEGSKASSFNESGSQCFVLAVQRCPMADTTYACDLQSLGLAPLRVPISITIIQDGDITCPEDASVLTWNVTKAGHVAQAPCPESKRGIVRRLCGADGVWGPVHSSCTDARLLALFTRTKLLQAGQGSPAEEVPQILAQLPGQAAEASSPSDLLTLLSTMKYVAKVVAEARIQLDRRALKNLLIATDKVLDMDTRSLWTLAQARKPWAGSTLLLAVETLACSLCPQDHPFAFSLPNVLLQSQLFGPTFPADYSISFPTRPPLQAQIPRHSLAPLVRNGTEISITSLVLRKLDHLLPSNYGQGLGDSLYATPGLVLVISIMAGDRAFSQGEVIMDFGNTDGSPHCVFWDHSLFQGRGGWSKEGCQAQVASASPTAQCLCQHLTAFSVLMSPHTVPEEPALALLTQVGLGASILALLVCLGVYWLVWRVVVRNKISYFRHAALLNMVFCLLAADTCFLGAPFLSPGPRSPLCLAAAFLCHFLYLATFFWMLAQALVLAHQLLFVFHQLAKHRVLPLMVLLGYLCPLGLAGVTLGLYLPQGQYLREGECWLDGKGGALYTFVGPVLAIIGVNGLVLAMAMLKLLRPSLSEGPPAEKRQALLGVIKALLILTPIFGLTWGLGLATLLEEVSTVPHYIFTILNTLQGVFILLFGCLMDRKIQEALRKRFCRAQAPSSTISLATNEGCILEHSKGGSDTARKTDASE>sp|Q8IZF5-3|AGRF3_HUMAN Isoform 3 of Adhesion G-protein coupled receptorF3 OS=Homo sapiens OX=9606 GN=ADGRF3MVCSAAPLLLLATTLPLLGSPVAQASQPGQSQAGGESGSGQLLDQENGAGESALVSVYVHLDFPDKTWPPELSRTLTLPAASASSSPRPLLTGLRLTTECNVNHKGNFYCACLSGYQWNTSICLHYPPCQSLHNHQPCGCLVFSHPEPGYCQLLPPGSPVTCLPAVPGILNLNSQLQMPGDTLSLTLHLSQEATNLSWFLRHPGSPSPILLQPGTQVSVTSSHGQAALSVSNMSHHWAGEYMSCFEAQGFKWNLYEVVRVPLKATDVARLPYQLSISCATSPGFQLSCCIPSTNLAYTAAWSPGEGSKASSFNESGSQCFVLAVQRCPMADTTYACDLQSLGLAPLRVPISITIIQDGDITCPEDASVLTWNVTKAGHVAQAPCPESKRGIVRRLCGADGVWGPVHSSCTDARLLALFTRTKLLQAGQGSPAEEVPQILAQLPGQAAEASSPSDLLTLLSTMKYVAKVVAEARIQLDRRALKNLLIATDKVLDMDTRSLWTLAQARKPWAGSTLLLAVETLACSLCPQDHPFAFSLPNVLLQSQLFGPTFPADYSISFPTRPPLQAQIPRHSLAPLVRNGTEISITSLVLRKLDHLLPSNYGQGLGDSLYATPGLVLVISIMAGDRAFSQGEVIMDFGNTDGSPHCVFWDHSLFQGRGGWSKEGCQAQVASASPTAQCLCQHLTAFSVLMSPHTVPEEPALALLTQVGLGASILALLVCLGVYWLVWRVVVRNKISYFRHAALLNMVFCLLAADTCFLGAPFLSPGPRSPLCLAAAFLCHFLYLATFFWMLAQALVLAHQLLFVFHQLAKHRVLPLMVLLGYLCPLGLAGVTLGLYLPQGQYLREGECWLDGKGGALYTFVGPVLAIIGVNGLVLAMAMLKLLRPSLSEGPPAEKRQALLGVIKALLILTPIFGLTWGLGLATLLEEVSTVPHYIFTILNTLQGVFILLFGCLMDRKIQEALRKRFCRAQAPSSTISLATNEGCILEHSKGGSDTAR>sp|Q8IZF7|AGRF2_HUMAN Adhesion G-protein coupled receptor F2 OS=Homosapiens OX=9606 GN=ADGRF2 PE=2 SV=1MGLTAYGNRRVQPGELPFGANLTLIHTRAQPVICSKLLLTKRVSPISFFLSKFQNSWGEDGWVQLDQLPSPNAVSSDQVHCSAGCTHRKCGWAASKSKEKVPARPHGVCDGVCTDYSQCTQPCPPDTQGNMGFSCRQKTWHKITDTCQTLNALNIFEEDSRLVQPFEDNIKISVYTGKSETITDMLLQKCPTDLSCVIRNIQQSPWIPGNIAVIVQLLHNISTAIWTGVDEAKMQSYSTIANHILNSKSISNWTFIPDRNSSYILLHSVNSFARRLFIDKHPVDISDVFIHTMGTTISGDNIGKNFTFSMRINDTSNEVTGRVLISRDELRKVPSPSQVISIAFPTIGAILEASLLENVTVNGLVLSAILPKELKRISLIFEKISKSEERRTQCVGWHSVENRWDQQACKMIQENSQQAVCKCRPSKLFTSFSILMSPHILESLILTYITYVGLGISICSLILCLSIEVLVWSQVTKTEITYLRHVCIVNIAATLLMADVWFIVASFLSGPITHHKGCVAATFFVHFFYLSVFFWMLAKALLILYGIMIVFHTLPKSVLVASLFSVGYGCPLAIAAITVAATEPGKGYLRPEICWLNWDMTKALLAFVIPALAIVVVNLITVTLVIVKTQRAAIGNSMFQEVRAIVRISKNIAILTPLLGLTWGFGVATVIDDRSLAFHIIFSLLNAFQVSPDASDQVQSERIHEDVL>sp|Q8IZF7-2|AGRF2_HUMAN Isoform 2 of Adhesion G-protein coupled receptorF2 OS=Homo sapiens OX=9606 GN=ADGRF2MTHILLLYYLVFLLPTESCRTLYQAASKSKEKVPARPHGVCDGVCTDYSQCTQPCPPDTQGNMGFSCRQKTWHKITDTCQTLNALNIFEEDSRLVQPFEDNIKISVYTGKSETITDMLLQKCPTDLSCVIRNIQQSPWIPGNIAVIVQLLHNISTAIWTGVDEAKMQSYSTIANHILNSKSISNWTFIPDRNSSYILLHSVNSFARRLFIDKHPVDISDVFIHTMGTTISGDNIGKNFTFSMRINDTSNEVTGRVLISRDELRKVPSPSQVISIAFPTIGAILEASLLENVTVNGLVLSAILPKELKRISLIFEKISKSEERRTQCVGWHSVENRWDQQACKMIQENSQQAVCKCRPSKLFTSFSILMSPHILESLILTYITYVGLGISICSLILCLSIEVLVWSQVTKTEITYLRHVCIVNIAATLLMADVWFIVASFLSGPITHHKGCVAATFFVHFFYLSVFFWMLAKALLILYGIMIVFHTLPKSVLVASLFSVGYGCPLAIAAITVAATEPGKGYLRPEICWLNWDMTKALLAFVIPALAIVVVNLITVTLVIVKTQRAAIGNSMFQEVRAIVRISKNIAILTPLLGLTWGFGVATVIDDRSLAFHIIFSLLNAFQGFFILVFGTILDPKIREALKG>sp|Q5VUJ5|AGAP7_HUMAN Putative Arf-GAP with GTPase, ANK repeat and PHdomain-containing protein 7 OS=Homo sapiens OX=9606 GN=AGAP7P PE=5 SV=1MGNILTCRVHPSVSLEFDQQQGSVCPSESEIYEAGAEDRMAGAPMAAAVQPAEVTVEVGEDLHMHHVRDREMPEALEFNPSANPEASTIFQRNSQTDVVEIRRSNCTNHVSTVHFSQQYSLCSTIFLDDSTAIQHYLTMTIISVTLEIPHHITQRDADRSLSIPDEQLHSFAVSTVHITKNRNGGGSLNNYSSSIPSTPSTSQEDPQFSVPPTANTPTPVCKRSMRWSNLFTSEKGSDPDKERKAPENHADTIGSGRAIPIKQGMLLKRSGKWLKTWKKKYVTLCSNGVLTYYSSLGDYMKYIHKKEIDLQTSTIKVPGKWPSLATLACTPISSSKSDGLSKDMDTGLGDSICFSPSISSTTIPKLNPPPSPHANKKKHLKKKSTNNFMIVSATGQTWHFEATTYEERDAWVQAIQSQILASLQSCESSKSKSQLTSQSEAMALQSIQNMRGNAHCVDCETQNPKWASLNLGVLMCIECSGIHRSLGTRLSRVRSLELDDWPVELRKVMSSIGNDLANSIWEGSSQGRTKPTEKSTREEKERWIRSKYEEKLFLAPLPCTELSLGQQLLRATADEDLQTAILLLAHGSREEVNETCGEGDGCTALHLACRKGNVVLAQLLIWYGVDVMARDAHGNTALTYARQASSQECINVLLQYGCPDECV>sp|Q9Y672|ALG6_HUMAN Dolichyl pyrophosphate Man9GlcNAc2 alpha-1,3-glucosyltransferase OS=Homo sapiens OX=9606 GN=ALG6 PE=1 SV=2MEKWYLMTVVVLIGLTVRWTVSLNSYSGAGKPPMFGDYEAQRHWQEITFNLPVKQWYFNSSDNNLQYWGLDYPPLTAYHSLLCAYVAKFINPDWIALHTSRGYESQAHKLFMRTTVLIADLLIYIPAVVLYCCCLKEISTKKKIANALCILLYPGLILIDYGHFQYNSVSLGFALWGVLGISCDCDLLGSLAFCLAINYKQMELYHALPFFCFLLGKCFKKGLKGKGFVLLVKLACIVVASFVLCWLPFFTEREQTLQVLRRLFPVDRGLFEDKVANIWCSFNVFLKIKDILPRHIQLIMSFCSTFLSLLPACIKLILQPSSKGFKFTLVSCALSFFLFSFQVHEKSILLVSLPVCLVLSEIPFMSTWFLLVSTFSMLPLLLKDELLMPSVVTTMAFFIACVTSFSIFEKTSEEELQLKSFSISVRKYLPCFTFLSRIIQYLFLISVITMVLLTLMTVTLDPPQKLPDLFSVLVCFVSCLNFLFFLVYFNIIIMWDSKSGRNQKKIS>sp|P16152|CBR1_HUMAN Carbonyl reductase [NADPH] 1 OS=Homo sapiensOX=9606 GN=CBR1 PE=1 SV=3MSSGIHVALVTGGNKGIGLAIVRDLCRLFSGDVVLTARDVTRGQAAVQQLQAEGLSPRFHQLDIDDLQSIRALRDFLRKEYGGLDVLVNNAGIAFKVADPTPFHIQAEVTMKTNFFGTRDVCTELLPLIKPQGRVVNVSSIMSVRALKSCSPELQQKFRSETITEEELVGLMNKFVEDTKKGVHQKEGWPSSAYGVTKIGVTVLSRIHARKLSEQRKGDKILLNACCPGWVRTDMAGPKATKSPEEGAETPVYLALLPPDAEGPHGQFVSEKRVEQW>sp|P16152-2|CBR1_HUMAN Isoform 2 of Carbonyl reductase [NADPH] 1 OS=Homosapiens OX=9606 GN=CBR1MSSGIHVALVTGGNKGIGLAIVRDLCRLFSGDVVLTARDVTRGQAAVQQLQAEGLSPRFHQLDIDDLQSIRALRDFLRKEYGGLDVLVNNAGIAFKVADPTPFHIQAEVTMKTNFFGTRDVCTELLPLIKPQASCVLSAWSCLSQNPSGGKSKPLAWFTEMSIICRCLTLGPF>sp|Q49A88|CCD14_HUMAN Coiled-coil domain-containing protein 14 OS=Homosapiens OX=9606 GN=CCDC14 PE=1 SV=3MKRGIRRDPFRKRKLGGRAKKVREPTAVNSFYREASLPSVWASLRRREMVRSGARPGQVLSSGRHTGPAKLTNGKKATYLRKIPRFNADSGYSIHSDSESQAETVHGLDGCASLLRDILRNEDSGSETAYLENRSNSRPLESKRYGSKKKRHEKHTIPLVVQKETSSSDNKKQIPNEASARSERDTSDLEQNWSLQDHYRMYSPIIYQALCEHVQTQMSLMNDLTSKNIPNGIPAVPCHAPSHSESQATPHSSYGLCTSTPVWSLQRPPCPPKVHSEVQTDGNSQFASQGKTVSATCTDVLRNSFNTSPGVPCSLPKTDISAIPTLQQLGLVNGILPQQGIHKETDLLKCIQTYLSLFRSHGKETHLDSQTHRSPTQSQPAFLATNEEKCAREQIREATSERKDLNIHVRDTKTVKDVQKAKNVNKTAEKVRIIKYLLGELKALVAEQEDSEIQRLITEMEACISVLPTVSGNTDIQVEIALAMQPLRSENAQLRRQLRILNQQLREQQKTQKPSGAVDCNLELFSLQSLNMSLQNQLEESLKSQELLQSKNEELLKVIENQKDENKKFSSIFKDKDQTILENKQQYDIEITRIKIELEEALVNVKSSQFKLETAEKENQILGITLRQRDAEVTRLRELTRTLQTSMAKLLSDLSVDSARCKPGNNLTKSLLNIHDKQLQHDPAPAHTSIMSYLNKLETNYSFTHSEPLSTIKNEETIEPDKTYENVLSSRGPQNSNTRGMEEASAPGIISALSKQDSDEGSETMALIEDEHNLDNTIYIPFARSTPEKKSPLSKRLSPQPQIRAATTQLVSNSGLAVSGKENKLCTPVICSSSTKEAEDAPEKLSRASDMKDTQLLKKIKEAIGKIPAATKEPEEQTACHGPSGCLSNSLQVKGNTVCDGSVFTSDLMSDWSISSFSTFTSRDEQDFRNGLAALDANIARLQKSLRTGLLEK>sp|Q49A88-2|CCD14_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=CCDC14MYSPIIYQALCEHVQTQMSLMNDLTSKNIPNGIPAVPCHAPSHSESQATPHSSYGLCTSTPVWSLQRPPCPPKVHSEVQTDGNSQFASQGKTVSATCTDVLRNSFNTSPGVPCSLPKTDISAIPTLQQLGLVNGILPQQGIHKETDLLKCIQTYLSLFRSHGKETHLDSQTHRSPTQSQPAFLATNEEKCAREQIREATSERKDLNIHVRDTKTVKDVQKAKNVNKTAEKVRIIKYLLGELKALVAEQEDSEIQRLITEMEACISVLPTVSGNTDIQVEIALAMQPLRSENAQLRRQLRILNQQLREQQKTQKPSGAVDCNLELFSLQSLNMSLQNQLEESLKSQELLQSKNEELLKVIENQKDENKKFSSIFKDKDQTILENKQQYDIEITRIKIELEEALVNVKSSQFKLETAEKENQILGITLRQRDAEVTRLRELTRTLQTSMAKLLSDLSVDSARCKPGNNLTKSLLNIHDKQLQHDPAPAHTSIMSYLNKLETNYSFTHSEPLSTIKNEETIEPDKTYENVLSSRGPQNSNTRGMEEASAPGIISALSKQDSDEGSETMALIEDEHNLDNTIYIPFARSTPEKKSPLSKRLSPQPQIRAATTQLVSNSGLAVSGKENKLCTPVICSSSTKEAEDAPEKLSRASDMKDTQLLKKIKEAIGKIPAATKEPEEQTACHGPSGCLSNSLQVKGNTVCDGSVFTSDLMSDWSISSFSTFTSRDEQDFRNGLAALDANIARLQKSLRTGLLEK>sp|Q49A88-3|CCD14_HUMAN Isoform 3 of Coiled-coil domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=CCDC14MPMESASSDNKKQIPNEASARSERDTSDLEQNWSLQDHYRMYSPIIYQALCEHVQTQMSLMNDLTSKNIPNGIPAVPCHAPSHSESQATPHSSYGLCTSTPVWSLQRPPCPPKVHSEVQTDGNSQFASQGKTVSATCTDVLRNSFNTSPGVPCSLPKTDISAIPTLQQLGLVNGILPQQGIHKETDLLKCIQTYLSLFRSHGKETHLDSQTHRSPTQSQPAFLATNEEKCAREQIREATSERKDLNIHVRDTKTVKDVQKAKNVNKTAEKVRIIKYLLGELKALVAEQEDSEIQRLITEMEACISVLPTVSGNTDIQVEIALAMQPLRSENAQLRRQLRILNQQLREQQKTQKPSGAVDCNLELFSLQSLNMSLQNQLEESLKSQELLQSKNEELLKVIENQKDENKKFSSIFKDKDQTILENKQQYDIEITRIKIELEEALVNVKSSQFKLETAEKENQILGITLRQRDAEVTRLRELTRTLQTSMAKLLSDLSVDSARCKPGNNLTKSLLNIHDKQLQHDPAPAHTSIMSYLNKLETNYSFTHSEPLSTIKNEETIEPDKTYENVLSSRGPQNSNTRGMEEASAPGIISALSKQDSDEGSETMALIEDEHNLDNTIYIPFARSTPEKKSPLSKRLSPQPQIRAATTQLVSNSGLAVSGKENKLCTPVICSSSTKEAEDAPEKLSRASDMKDTQLLKKIKEAIGKIPAATKEPEEQTACHGPSGCLSNSLQVKGNTVCDGSVFTSDLMSDWSISSFSTFTSRDEQDFRNGLAALDANIARLQKSLRTGLLEK>sp|Q49A88-4|CCD14_HUMAN Isoform 4 of Coiled-coil domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=CCDC14MYSPIIYQALCEHVQTQMSLMNDLTSKNIPNGIPAVPCHAPSHSESQATPHSSYGLCTSTPVWSLQRPPCPPKVHSEVQTDGNSQFASQGKTVSATCTDVLRNSFNTSPGVPCSLPKTDISAIPTLQQLGLVNGILPQQGIHKETDLLKCIQTYLSLFRSHGKETHLDSQTHRSPTQSQPAFLATNEEKCAREQIREATSERKDLNIHVRDTKTVKDVQKAKNVNKTAEKVRIIKYLLGELKALVAEQEDSEIQRLITEMEACISVLPTVSGNTDIQVEIALAMQPLRSENAQLRRQLRILNQQLREQQKTQKPSGAVDCNLELFSLQSLNMSLQNQLEESLKSQELLQSKNEELLKVIENQKDENKKFSSIFKDKDQTILENKQQYDIEITRIKIELEEALVNVKSSQFKLETAEKENQILGITLRQRDAEVTRLRELTRKQKMHLKNFPEHLI>sp|Q49A88-5|CCD14_HUMAN Isoform 5 of Coiled-coil domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=CCDC14MKRGIRRDPFRKRKLGGRAKKVREPTAVNSFYREASLPSVWASLRRREMVRSGARPGQVLSSGRHTGPAKLTNGKKATYLRKIPRFNADSGYSIHSDSESQAETVHGLDGCASLLRDILRNEDSGSETAYLENRSNSRPLESKRYGSKKKRHEKHTIPLVVQKETSSSDNKKQIPNEASARSERDTSDLEQNWSLQDHYRMYSPIIYQALCEHVQTQMSLMNDLTSKNIPNGIPAVPCHAPSHSESQATPHSSYGLCTSTPVWSLQRPPCPPKVHSEVQTDGNSQFASQEDSEIQRLITEMEACISVLPTVSGNTDIQVEIALAMQPLRSENAQLRRQLRILNQQLREQQKTQKPSGAVDCNLELFSLQSLNMSLQNQLEESLKSQELLQSKNEELLKVIENQKDENKKFSSIFKDKDQTILENKQQYDIEITRIKIELEEALVNVKSSQFKLETAEKENQILGITLRQRDAEVTRLRELTRTLQTSMAKLLSDLSVDSARCKPGNNLTKSLLNIHDKQLQHDPAPAHTSIMSYLNKLETNYSFTHSEPLSTIKNEETIEPDKTYENVLSSRGPQNSNTRGMEEASAPGIISALSKQDSDEGSETMALIEDEHNLDNTIYIPFARSTPEKKSPLSKRLSPQPQIRAATTQLVSNSGLAVSGKENKLCTPVICSSSTKEAEDAPEKLSRASDMKDTQLLKKIKEAIGKIPAATKEPEEQTACHGPSGCLSNSLQVKGNTVCDGSVFTSDLMSDWSISSFSTFTSRDEQDFRNGLAALDANIARLQKSLRTGLLEK>sp|Q49A88-6|CCD14_HUMAN Isoform 6 of Coiled-coil domain-containingprotein 14 OS=Homo sapiens OX=9606 GN=CCDC14MKRGIRRDPFRKRKLGGRAKKVREPTAVNSFYREASLPSVWASLRRREMVRSGARPGQVLSSGRHTGPAKLTNGKKATYLRKIPRFNADSGYSIHSDSESQAETVHGLDGCASLLRDILRNEDSASSDNKKQIPNEASARSERDTSDLEQNWSLQDHYRMYSPIIYQALCEHVQTQMSLMNDLTSKNIPNGIPAVPCHAPSHSESQATPHSSYGLCTSTPVWSLQRPPCPPKVHSEVQTDGNSQFASQGKTVSATCTDVLRNSFNTSPGVPCSLPKTDISAIPTLQQLGLVNGILPQQGIHKETDLLKCIQTYLSLFRSHGKETHLDSQTHRSPTQSQPAFLATNEEKCAREQIREATSERKDLNIHVRDTKTVKDVQKAKNVNKTAEKVRIIKYLLGELKALVAEQEDSEIQRLITEMEACISVLPTVSGNTDIQVEIALAMQPLRSENAQLRRQLRILNQQLREQQKTQKPSGAVDCNLELFSLQSLNMSLQNQLEESLKSQELLQSKNEELLKVIENQKDENKKFSSIFKDKDQTILENKQQYDIEITRIKIELEEALVNVKSSQFKLETAEKENQILGITLRQRDAEVTRLRELTRTLQTSMAKLLSDLSVDSARCKPGNNLTKSLLNIHDKQLQHDPAPAHTSIMSYLNKLETNYSFTHSEPLSTIKNEETIEPDKTYENVLSSRGPQNSNTRGMEEASAPGIISALSKQDSDEGSETMALIEDEHNLDNTIYIPFARSTPEKKSPLSKRLSPQPQIRAATTQLVSNSGLAVSGKENKLCTPVICSSSTKEAEDAPEKLSRASDMKDTQLLKKIKEAIGKIPAATKEPEEQTACHGPSGCLSNSLQVKGNTVCDGSVFTSDLMSDWSISSFSTFTSRDEQDFRNGLAALDANIARLQKSLRTGLLEK>sp|P15085|CBPA1_HUMAN Carboxypeptidase A1 OS=Homo sapiens OX=9606GN=CPA1 PE=1 SV=2MRGLLVLSVLLGAVFGKEDFVGHQVLRISVADEAQVQKVKELEDLEHLQLDFWRGPAHPGSPIDVRVPFPSIQAVKIFLESHGISYETMIEDVQSLLDEEQEQMFAFRSRARSTDTFNYATYHTLEEIYDFLDLLVAENPHLVSKIQIGNTYEGRPIYVLKFSTGGSKRPAIWIDTGIHSREWVTQASGVWFAKKITQDYGQDAAFTAILDTLDIFLEIVTNPDGFAFTHSTNRMWRKTRSHTAGSLCIGVDPNRNWDAGFGLSGASSNPCSETYHGKFANSEVEVKSIVDFVKDHGNIKAFISIHSYSQLLMYPYGYKTEPVPDQDELDQLSKAAVTALASLYGTKFNYGSIIKAIYQASGSTIDWTYSQGIKYSFTFELRDTGRYGFLLPASQIIPTAKETWLALLTIMEHTLNHPY>sp|Q9Y2G4|ANKR6_HUMAN Ankyrin repeat domain-containing protein 6 OS=Homosapiens OX=9606 GN=ANKRD6 PE=2 SV=3MSQQDAVAALSERLLVAAYKGQTENVVQLINKGARVAVTKHGRTPLHLAANKGHLPVVQILLKAGCDLDVQDDGDQTALHRATVVGNTEIIAALIHEGCALDRQDKDGNTALHEASWHGFSQSAKLLIKAGANVLAKNKAGNTALHLACQNSHSQSTRVLLLAGSRADLKNNAGDTCLHVAARYNHLSIIRLLLTAFCSVHEKNQAGDTALHVAAALNHKKVAKILLEAGADTTIVNNAGQTPLETARYHNNPEVALLLTKAPQVLRFSRGRSLRKKRERLKEERRAQSVPRDEVAQSKGSVSAGDTPSSEQAVARKEEAREEFLSASPEPRAKDDRRRKSRPKVSAFSDPTPPADQQPGHQKNLHAHNHPKKRNRHRCSSPPPPHEFRAYQLYTLYRGKDGKVMQAPINGCRCEPLINKLENQLEATVEEIKAELGSVQDKMNTKLGQMENKTQHQMRVLDKLMVERLSAERTECLNRLQQHSDTEKHEGEKRQISLVDELKTWCMLKIQNLEQKLSGDSRACRAKSTPSTCESSTGVDQLVVTAGPAAASDSSPPVVRPKEKALNSTATQRLQQELSSSDCTGSRLRNVKVQTALLPMNEAARSDQQAGPCVNRGTQTKKSGKSGPTRHRAQQPAASSTCGQPPPATGSEQTGPHIRDTSQALELTQYFFEAVSTQMEKWYERKIEEARSQANQKAQQDKATLKEHIKSLEEELAKLRTRVQKEN>sp|Q9Y2G4-1|ANKR6_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 6 OS=Homo sapiens OX=9606 GN=ANKRD6MSQQDAVAALSERLLVAAYKGQTENVVQLINKGARVAVTKHGRTPLHLAANKGHLPVVQILLKAGCDLDVQDDGDQTALHRATVVGNTEIIAALIHEGCALDRQDKDGNTALHEASWHGFSQSAKLLIKAGANVLAKNKAGNTALHLACQNSHSQSTRVLLLAGSRADLKNNAGDTCLHVAARYNHLSIIRLLLTAFCSVHEKNQAGDTALHVAAALNHKKVAKILLEAGADTTIVNNAGQTPLETARYHNNPEVALLLTKAPQGSVSAGDTPSSEQAVARKEEAREEFLSASPEPRAKDDRRRKSRPKVSAFSDPTPPADQQPGHQKNLHAHNHPKKRNRHRCSSPPPPHEFRAYQLYTLYRGKDGKVMQAPINGCRCEPLINKLENQLEATVEEIKAELGSVQDKMNTKLGQMENKTQHQMRVLDKLMVERLSAERTECLNRLQQHSDTEKHEGEKRQISLVDELKTWCMLKIQNLEQKLSGDSRACRAKSTPSTCESSTGVDQLVVTAGPAAASDSSPPVVRPKEKALNSTATQRLQQELSSSDCTGSRLRNVKVQTALLPMNEAARSDQQAGPCVNRGTQTKKSGKSGPTRHRAQQPAASSTCGQPPPATGSEQTGPHIRDTSQALELTQYFFEAVSTQMEKWYERKIEEARSQANQKAQQDKATLKEHIKSLEEELAKLRTRVQKEN>sp|Q9Y2G4-3|ANKR6_HUMAN Isoform 3 of Ankyrin repeat domain-containingprotein 6 OS=Homo sapiens OX=9606 GN=ANKRD6MSQQDAVAALSERLLVAAYKGQTENVVQLINKGARVAVTKHGRTPLHLAANKGHLPVVQILLKAGCDLDVQDDGDQTALHRATVVGNTEIIAALIHEGCALDRQDKDGNTALHEASWHGFSQSAKLLIKAGANVLAKNKAGNTALHLACQNSHSQSTRVLLLAGSRADLKNNAGDTCLHVAARYNHLSIIRLLLTAFCSVHEKNQAGDTALHVAAALNHKKVAKILLEAGADTTIVNNAGQTPLETARYHNNPEVALLLTKAPQVLRFSRGRSLRKKRERLKEERRAQSVPRDEVAQSKGSVSAGDTPSSEQAVARKEEAREEFLSASPEPRAKDDRRRKSRPKVSAFSDPTPPADQQPGHQKNLHAHNHPKKRNRHRCSSPPPPHEFRAYQLYTLYRGKDGKVMQAPINGCRCEPLINKLENQLEATVEEIKAELGSVQDKMNTKLGQMENKTQHQMRVLDKLMVERLSAERTECLNRLQQHSDTEKHEGEKRQISLVDELKTWCMLKIQNLEQKLSGDSRACRAKSTPSTCVDQLVVTAGPAAASDSSPPVVRPKEKALNSTATQRLQQELSSSDCTGSRLRNVKVQTALLPMNEAARSDQQAGPCVNRGTQTKKSGKSGPTRHRAQQPAASSTCGQPPPATGSEQTGPHIRDTSQALELTQYFFEAVSTQMEKWYERKIEEARSQANQKAQQDKATLKEHIKSLEEELAKLRTRVQKEN>sp|Q9Y2G4-4|ANKR6_HUMAN Isoform 4 of Ankyrin repeat domain-containingprotein 6 OS=Homo sapiens OX=9606 GN=ANKRD6MSQQDAVAALSERLLVAAYKGQTENVVQLINKGARVAVTKHGRTPLHLAANKGHLPVVQILLKAGCDLDVQDDGDQTALHRATVVGNTEIIAALIHEGCALDRQDKAGNTALHLACQNSHSQSTRVLLLAGSRADLKNNAGDTCLHVAARYNHLSIIRLLLTAFCSVHEKNQAGDTALHVAAALNHKKVAKILLEAGADTTIVNNVLRFSRGRSLRKKRERLKEERRAQSVPRDEVAQSKGSVSAGDTPSSEQAVARKEEAREEFLSASPEPRAKDDRRRKSRPKVSAFSDPTPPADQQPGHQKNLHAHNHPKKRNRHRCSSPPPPHEFRAYQLYTLYRGKDGKVMQAPINGCRCEPLINKLENQLEATVEEIKAELGSVQDKMNTKLGQMENKTQHQMRVLDKLMVERLSAERTECLNRLQQHSDTEKHEGEKRQISLVDELKTWCMLKIQNLEQKLSGDSRACRAKSTPSTCVDQLVVTAGPAAASDSSPPVVRPKEKALNSTATQRLQQELSSSDCTGSRLRNVKVQTALLPMNEAARSDQQAGPCVNRGTQTKKSGKSGPTRHRAQQPAASSTCGQPPPATGSEQTGPHIRDTSQALELTQYFFEAVSTQMEKWYERKIEEARSQANQKAQQDKATLKEHIKSLEEELAKLRTRVQKEN>sp|Q8IV38|ANKY2_HUMAN Ankyrin repeat and MYND domain-containing protein2 OS=Homo sapiens OX=9606 GN=ANKMY2 PE=1 SV=1MVHIKKGELTQEEKELLEVIGKGTVQEAGTLLSSKNVRVNCLDENGMTPLMHAAYKGKLDMCKLLLRHGADVNCHQHEHGYTALMFAALSGNKDITWVMLEAGAETDVVNSVGRTAAQMAAFVGQHDCVTIINNFFPRERLDYYTKPQGLDKEPKLPPKLAGPLHKIITTTNLHPVKIVMLVNENPLLTEEAALNKCYRVMDLICEKCMKQRDMNEVLAMKMHYISCIFQKCINFLKDGENKLDTLIKSLLKGRASDGFPVYQEKIIRESIRKFPYCEATLLQQLVRSIAPVEIGSDPTAFSVLTQAITGQVGFVDVEFCTTCGEKGASKRCSVCKMVIYCDQTCQKTHWFTHKKICKNLKDIYEKQQLEAAKEKRQEENHGKLDVNSNCVNEEQPEAEVGISQKDSNPEDSGEGKKESLESEAELEGLQDAPAGPQVSEE>sp|Q9NQW6|ANLN_HUMAN Anillin OS=Homo sapiens OX=9606 GN=ANLN PE=1 SV=2MDPFTEKLLERTRARRENLQRKMAERPTAAPRSMTHAKRARQPLSEASNQQPLSGGEEKSCTKPSPSKKRCSDNTEVEVSNLENKQPVESTSAKSCSPSPVSPQVQPQAADTISDSVAVPASLLGMRRGLNSRLEATAASSVKTRMQKLAEQRRRWDNDDMTDDIPESSLFSPMPSEEKAASPPRPLLSNASATPVGRRGRLANLAATICSWEDDVNHSFAKQNSVQEQPGTACLSKFSSASGASARINSSSVKQEATFCSQRDGDASLNKALSSSADDASLVNASISSSVKATSPVKSTTSITDAKSCEGQNPELLPKTPISPLKTGVSKPIVKSTLSQTVPSKGELSREICLQSQSKDKSTTPGGTGIKPFLERFGERCQEHSKESPARSTPHRTPIITPNTKAIQERLFKQDTSSSTTHLAQQLKQERQKELACLRGRFDKGNIWSAEKGGNSKSKQLETKQETHCQSTPLKKHQGVSKTQSLPVTEKVTENQIPAKNSSTEPKGFTECEMTKSSPLKITLFLEEDKSLKVTSDPKVEQKIEVIREIEMSVDDDDINSSKVINDLFSDVLEEGELDMEKSQEEMDQALAESSEEQEDALNISSMSLLAPLAQTVGVVSPESLVSTPRLELKDTSRSDESPKPGKFQRTRVPRAESGDSLGSEDRDLLYSIDAYRSQRFKETERPSIKQVIVRKEDVTSKLDEKNNAFPCQVNIKQKMQELNNEINMQQTVIYQASQALNCCVDEEHGKGSLEEAEAERLLLIATGKRTLLIDELNKLKNEGPQRKNKASPQSEFMPSKGSVTLSEIRLPLKADFVCSTVQKPDAANYYYLIILKAGAENMVATPLASTSNSLNGDALTFTTTFTLQDVSNDFEINIEVYSLVQKKDPSGLDKKKKTSKSKAITPKRLLTSITTKSNIHSSVMASPGGLSAVRTSNFALVGSYTLSLSSVGNTKFVLDKVPFLSSLEGHIYLKIKCQVNSSVEERGFLTIFEDVSGFGAWHRRWCVLSGNCISYWTYPDDEKRKNPIGRINLANCTSRQIEPANREFCARRNTFELITVRPQREDDRETLVSQCRDTLCVTKNWLSADTKEERDLWMQKLNQVLVDIRLWQPDACYKPIGKP>sp|Q9NQW6-2|ANLN_HUMAN Isoform 2 of Anillin OS=Homo sapiens OX=9606GN=ANLNMDPFTEKLLERTRARRENLQRKMAERPTAAPRSMTHAKRARQPLSEASNQQPLSGGEEKSCTKPSPSKKRCSDNTEVEVSNLENKQPVESTSAKSCSPSPVSPQVQPQAADTISDSVAVPASLLGMRRGLNSRLEATAASSVKTRMQKLAEQRRRWDNDDMTDDIPESSLFSPMPSEEKAASPPRPLLSNASATPVGRRGRLANLAATICSWEDDVNHSFAKQNSVQEQPGTACLSKFSSASGASARINSSSVKQEATFCSQRDGDASLNKALSSSADDASLVNASISSSVKATSPVKSTTSITDAKSCEGQNPELLPKTPISPLKTGVSKPIVKSTLSQTVPSKGELSREICLQSQSKDKSTTPGGTGIKPFLERFGERCQEHSKESPARSTPHRTPIITPNTKAIQERLFKQDTSSSTTHLAQQLKQERQKELACLRGRFDKGNIWSAEKGGNSKSKQLETKQETHCQSTPLKKHQGVSKTQSLPVTEKVTENQIPAKNSSTEPKEVIREIEMSVDDDDINSSKVINDLFSDVLEEGELDMEKSQEEMDQALAESSEEQEDALNISSMSLLAPLAQTVGVVSPESLVSTPRLELKDTSRSDESPKPGKFQRTRVPRAESGDSLGSEDRDLLYSIDAYRSQRFKETERPSIKQVIVRKEDVTSKLDEKNNAFPCQVNIKQKMQELNNEINMQQTVIYQASQALNCCVDEEHGKGSLEEAEAERLLLIATGKRTLLIDELNKLKNEGPQRKNKASPQSEFMPSKGSVTLSEIRLPLKADFVCSTVQKPDAANYYYLIILKAGAENMVATPLASTSNSLNGDALTFTTTFTLQDVSNDFEINIEVYSLVQKKDPSGLDKKKKTSKSKAITPKRLLTSITTKSNIHSSVMASPGGLSAVRTSNFALVGSYTLSLSSVGNTKFVLDKVPFLSSLEGHIYLKIKCQVNSSVEERGFLTIFEDVSGFGAWHRRWCVLSGNCISYWTYPDDEKRKNPIGRINLANCTSRQIEPANREFCARRNTFELITVRPQREDDRETLVSQCRDTLCVTKNWLSADTKEERDLWMQKLNQVLVDIRLWQPDACYKPIGKP>sp|P36405|ARL3_HUMAN ADP-ribosylation factor-like protein 3 OS=Homosapiens OX=9606 GN=ARL3 PE=1 SV=2MGLLSILRKLKSAPDQEVRILLLGLDNAGKTTLLKQLASEDISHITPTQGFNIKSVQSQGFKLNVWDIGGQRKIRPYWKNYFENTDILIYVIDSADRKRFEETGQELAELLEEEKLSCVPVLIFANKQDLLTAAPASEIAEGLNLHTIRDRVWQIQSCSALTGEGVQDGMNWVCKNVNAKKK>sp|Q8IWT0|ARCH_HUMAN Protein archease OS=Homo sapiens OX=9606 GN=ZBTB8OSPE=1 SV=2MAQEEEDVRDYNLTEEQKAIKAKYPPVNRKYEYLDHTADVQLHAWGDTLEEAFEQCAMAMFGYMTDTGTVEPLQTVEVETQGDDLQSLLFHFLDEWLYKFSADEFFIPREVKVLSIDQRNFKLRSIGWGEEFSLSKHPQGTEVKAITYSAMQVYNEENPEVFVIIDI>sp|Q8IWT0-2|ARCH_HUMAN Isoform 2 of Protein archease OS=Homo sapiensOX=9606 GN=ZBTB8OSMAQEEEDVRDYNLTEEQKAIKAKYPPVNRKYEYLDHTADVQLHAWGDTLEEAFEQCAMAMFGYMTDTGTVEPLQTVEVETQGDDLQSLLFHFLDEWLYKFSADEFFIPRVGRRIFIVQAPSGNRSQSNNIFSNAGL>sp|O15033|AREL1_HUMAN Apoptosis-resistant E3 ubiquitin protein ligase 1OS=Homo sapiens OX=9606 GN=AREL1 PE=1 SV=3MFYVIGGITVSVVAFFFTIKFLFELAARVVSFLQNEDRERRGDRTIYDYVRGNYLDPRSCKVSWDWKDPYEVGHSMAFRVHLFYKNGQPFPAHRPVGLRVHISHVELAVEIPVTQEVLQEPNSNVVKVAFTVRKAGRYEITVKLGGLNVAYSPYYKIFQPGMVVPSKTKIVCHFSTLVLTCGQPHTLQIVPRDEYDNPTNNSMSLRDEHNYTLSIHELGPQEEESTGVSFEKSVTSNRQTFQVFLRLTLHSRGCFHACISYQNQPINNGEFDIIVLSEDEKNIVERNVSTSGVSIYFEAYLYNATNCSSTPWHLPPMHMTSSQRRPSTAVDEEDEDSPSECHTPEKVKKPKKVYCYVSPKQFSVKEFYLKIIPWRLYTFRVCPGTKFSYLGPDPVHKLLTLVVDDGIQPPVELSCKERNILAATFIRSLHKNIGGSETFQDKVNFFQRELRQVHMKRPHSKVTLKVSRHALLESSLKATRNFSISDWSKNFEVVFQDEEALDWGGPRREWFELICKALFDTTNQLFTRFSDNNQALVHPNPNRPAHLRLKMYEFAGRLVGKCLYESSLGGAYKQLVRARFTRSFLAQIIGLRMHYKYFETDDPEFYKSKVCFILNNDMSEMELVFAEEKYNKSGQLDKVVELMTGGAQTPVTNANKIFYLNLLAQYRLASQVKEEVEHFLKGLNELVPENLLAIFDENELELLMCGTGDISVSDFKAHAVVVGGSWHFREKVMRWFWTVVSSLTQEELARLLQFTTGSSQLPPGGFAALCPSFQIIAAPTHSTLPTAHTCFNQLCLPTYDSYEEVHRMLQLAISEGCEGFGML>sp|O15033-2|AREL1_HUMAN Isoform 2 of Apoptosis-resistant E3 ubiquitinprotein ligase 1 OS=Homo sapiens OX=9606 GN=AREL1MFYVIGGITVSVVAFFFTIKFLFELAARVVSFLQNEDRERRGDRTIYDYVRGNYLDPRSCKVSWDWKDPYEVGHSMAFRVHLFYKNGQPFPAHRPVGLRVHISHVELAVEIPVTQEVLQEPNSNVVKVAFTVRKAGRYEITVKLGGLNVAYSPYYKIFQPGMVVPSKTKIVCHFSTLVLTCGQPHTLQIVPRDEYDNPTNNSMSLRDEHNYTLSIHELGPQEEESTGVSFEKSVTSNRQTFQVFLRLTLHSRGCFHACISYQNQPINNGEFDIIVLSEDEKNIVERNVSTSGVSIYFEAYLYNATNCSSTPWHLPPMHMTSSQRRPSTAVDEEDEDSPSECHTPEKVKKPKKVYCYVSPKQFSVKEFYLKIIPWRLYTFRVCPGTKFSYLGPDPVHKLLTLVVDDGIQPPVELSCKERNILAATFIRSLHKNIGGSETFQDKVNFFQRELRQVHMKRPHSKVTLKVSRHALLESSLKATRNFSISDWSKNFEVVFQDEEALDWGGPRREWFELICKALFDTTNQLFTRFSDNNQALVHPNPNRPAHLRLKMYEFAGRLVGKCLYESSLGGAYKQLVRARFTRSFLAQIIGLRMHYKYFETDDPEFYKSKVCFILNNDMSEMELVFAEEKYNKSGQLDKVVELMTGGAQTPVTNANKIFYLNLLAQYRLASQVKEEVEHFLKGLNELVPENLLAIFDENELELLMCGTGDISVSDFKAHAVVVGGSWHFREKVMRWFWTVVSSLTQEELARLLQFTTGSSQLPPGGFAALCPSFQIIAAPTHSTLPTAHT>sp|P55087|AQP4_HUMAN Aquaporin-4 OS=Homo sapiens OX=9606 GN=AQP4 PE=1SV=2MSDRPTARRWGKCGPLCTRENIMVAFKGVWTQAFWKAVTAEFLAMLIFVLLSLGSTINWGGTEKPLPVDMVLISLCFGLSIATMVQCFGHISGGHINPAVTVAMVCTRKISIAKSVFYIAAQCLGAIIGAGILYLVTPPSVVGGLGVTMVHGNLTAGHGLLVELIITFQLVFTIFASCDSKRTDVTGSIALAIGFSVAIGHLFAINYTGASMNPARSFGPAVIMGNWENHWIYWVGPIIGAVLAGGLYEYVFCPDVEFKRRFKEAFSKAAQQTKGSYMEVEDNRSQVETDDLILKPGVVHVIDVDRGEEKKGKDQSGEVLSSV>sp|P55087-2|AQP4_HUMAN Isoform 1 of Aquaporin-4 OS=Homo sapiens OX=9606GN=AQP4MVAFKGVWTQAFWKAVTAEFLAMLIFVLLSLGSTINWGGTEKPLPVDMVLISLCFGLSIATMVQCFGHISGGHINPAVTVAMVCTRKISIAKSVFYIAAQCLGAIIGAGILYLVTPPSVVGGLGVTMVHGNLTAGHGLLVELIITFQLVFTIFASCDSKRTDVTGSIALAIGFSVAIGHLFAINYTGASMNPARSFGPAVIMGNWENHWIYWVGPIIGAVLAGGLYEYVFCPDVEFKRRFKEAFSKAAQQTKGSYMEVEDNRSQVETDDLILKPGVVHVIDVDRGEEKKGKDQSGEVLSSV>sp|O14744|ANM5_HUMAN Protein arginine N-methyltransferase 5 OS=Homosapiens OX=9606 GN=PRMT5 PE=1 SV=4MAAMAVGGAGGSRVSSGRDLNCVPEIADTLGAVAKQGFDFLCMPVFHPRFKREFIQEPAKNRPGPQTRSDLLLSGRDWNTLIVGKLSPWIRPDSKVEKIRRNSEAAMLQELNFGAYLGLPAFLLPLNQEDNTNLARVLTNHIHTGHHSSMFWMRVPLVAPEDLRDDIIENAPTTHTEEYSGEEKTWMWWHNFRTLCDYSKRIAVALEIGADLPSNHVIDRWLGEPIKAAILPTSIFLTNKKGFPVLSKMHQRLIFRLLKLEVQFIITGTNHHSEKEFCSYLQYLEYLSQNRPPPNAYELFAKGYEDYLQSPLQPLMDNLESQTYEVFEKDPIKYSQYQQAIYKCLLDRVPEEEKDTNVQVLMVLGAGRGPLVNASLRAAKQADRRIKLYAVEKNPNAVVTLENWQFEEWGSQVTVVSSDMREWVAPEKADIIVSELLGSFADNELSPECLDGAQHFLKDDGVSIPGEYTSFLAPISSSKLYNEVRACREKDRDPEAQFEMPYVVRLHNFHQLSAPQPCFTFSHPNRDPMIDNNRYCTLEFPVEVNTVLHGFAGYFETVLYQDITLSIRPETHSPGMFSWFPILFPIKQPITVREGQTICVRFWRCSNSKKVWYEWAVTAPVCSAIHNPTGRSYTIGL>sp|O14744-2|ANM5_HUMAN Isoform 2 of Protein arginine N-methyltransferase5 OS=Homo sapiens OX=9606 GN=PRMT5MRGPNSGTEKGRLVIPEKQGFDFLCMPVFHPRFKREFIQEPAKNRPGPQTRSDLLLSGRDWNTLIVGKLSPWIRPDSKVEKIRRNSEAAMLQELNFGAYLGLPAFLLPLNQEDNTNLARVLTNHIHTGHHSSMFWMRVPLVAPEDLRDDIIENAPTTHTEEYSGEEKTWMWWHNFRTLCDYSKRIAVALEIGADLPSNHVIDRWLGEPIKAAILPTSIFLTNKKGFPVLSKMHQRLIFRLLKLEVQFIITGTNHHSEKEFCSYLQYLEYLSQNRPPPNAYELFAKGYEDYLQSPLQPLMDNLESQTYEVFEKDPIKYSQYQQAIYKCLLDRVPEEEKDTNVQVLMVLGAGRGPLVNASLRAAKQADRRIKLYAVEKNPNAVVTLENWQFEEWGSQVTVVSSDMREWVAPEKADIIVSELLGSFADNELSPECLDGAQHFLKDDGVSIPGEYTSFLAPISSSKLYNEVRACREKDRDPEAQFEMPYVVRLHNFHQLSAPQPCFTFSHPNRDPMIDNNRYCTLEFPVEVNTVLHGFAGYFETVLYQDITLSIRPETHSPGMFSWFPILFPIKQPITVREGQTICVRFWRCSNSKKVWYEWAVTAPVCSAIHNPTGRSYTIGL>sp|O14744-4|ANM5_HUMAN Isoform 4 of Protein arginine N-methyltransferase5 OS=Homo sapiens OX=9606 GN=PRMT5MRGPNSGTEKGRLVIPEKQGFDFLCMPVFHPRFKREFIQEPAKNRPGPQTRSDLLLSGRDWNTLIVGKLSPWIRPDSKVEKIRRNSEALEVQFIITGTNHHSEKEFCSYLQYLEYLSQNRPPPNAYELFAKGYEDYLQSPLQPLMDNLESQTYEVFEKDPIKYSQYQQAIYKCLLDRVPEEEKDTNVQVLMVLGAGRGPLVNASLRAAKQADRRIKLYAVEKNPNAVVTLENWQFEEWGSQVTVVSSDMREWVAPEKADIIVSELLGSFADNELSPECLDGAQHFLKDDGVSIPGEYTSFLAPISSSKLYNEVRACREKDRDPEAQFEMPYVVRLHNFHQLSAPQPCFTFSHPNRDPMIDNNRYCTLEFPVEVNTVLHGFAGYFETVLYQDITLSIRPETHSPGMFSWFPILFPIKQPITVREGQTICVRFWRCSNSKKVWYEWAVTAPVCSAIHNPTGRSYTIGL>sp|O14744-5|ANM5_HUMAN Isoform 5 of Protein arginine N-methyltransferase5 OS=Homo sapiens OX=9606 GN=PRMT5MAAMAVGGAGGSRVSSGRDLNCVPEIADTLGAVAKQGFDFLCMPVFHPRFKREFIQEPAKNRPGPQTRSDLLLSGRAFLLPLNQEDNTNLARVLTNHIHTGHHSSMFWMRVPLVAPEDLRDDIIENAPTTHTEEYSGEEKTWMWWHNFRTLCDYSKRIAVALEIGADLPSNHVIDRWLGEPIKAAILPTSIFLTNKKGFPVLSKMHQRLIFRLLKLEVQFIITGTNHHSEKEFCSYLQYLEYLSQNRPPPNAYELFAKGYEDYLQSPLQPLMDNLESQTYEVFEKDPIKYSQYQQAIYKCLLDRVPEEEKDTNVQVLMVLGAGRGPLVNASLRAAKQADRRIKLYAVEKNPNAVVTLENWQFEEWGSQVTVVSSDMREWVAPEKADIIVSELLGSFADNELSPECLDGAQHFLKDDGVSIPGEYTSFLAPISSSKLYNEVRACREKDRDPEAQFEMPYVVRLHNFHQLSAPQPCFTFSHPNRDPMIDNNRYCTLEFPVEVNTVLHGFAGYFETVLYQDITLSIRPETHSPGMFSWFPILFPIKQPITVREGQTICVRFWRCSNSKKVWYEWAVTAPVCSAIHNPTGRSYTIGL>sp|O14744-3|ANM5_HUMAN Isoform 3 of Protein arginine N-methyltransferase5 OS=Homo sapiens OX=9606 GN=PRMT5MRGPNSGTEKGRLVIPEKQGFDFLCMPVFHPRFKREFIQEPAKNRPGPQTRSDLLLSGRAFLLPLNQEDNTNLARVLTNHIHTGHHSSMFWMRVPLVAPEDLRDDIIENAPTTHTEEYSGEEKTWMWWHNFRTLCDYSKRIAVALEIGADLPSNHVIDRWLGEPIKAAILPTSIFLTNKKGFPVLSKMHQRLIFRLLKLEVQFIITGTNHHSEKEFCSYLQYLEYLSQNRPPPNAYELFAKGYEDYLQSPLQPLMDNLESQTYEVFEKDPIKYSQYQQAIYKCLLDRVPEEEKDTNVQVLMVLGAGRGPLVNASLRAAKQADRRIKLYAVEKNPNAVVTLENWQFEEWGSQVTVVSSDMREWVAPEKADIIVSELLGSFADNELSPECLDGAQHFLKDDGVSIPGEYTSFLAPISSSKLYNEVRACREKDRDPEAQFEMPYVVRLHNFHQLSAPQPCFTFSHPNRDPMIDNNRYCTLEFPVEVNTVLHGFAGYFETVLYQDITLSIRPETHSPGMFSWFPILFPIKQPITVREGQTICVRFWRCSNSKKVWYEWAVTAPVCSAIHNPTGRSYTIGL>sp|O14520|AQP7_HUMAN Aquaporin-7 OS=Homo sapiens OX=9606 GN=AQP7 PE=1SV=1MVQASGHRRSTRGSKMVSWSVIAKIQEILQRKMVREFLAEFMSTYVMMVFGLGSVAHMVLNKKYGSYLGVNLGFGFGVTMGVHVAGRISGAHMNAAVTFANCALGRVPWRKFPVYVLGQFLGSFLAAATIYSLFYTAILHFSGGQLMVTGPVATAGIFATYLPDHMTLWRGFLNEAWLTGMLQLCLFAITDQENNPALPGTEALVIGILVVIIGVSLGMNTGYAINPSRDLPPRIFTFIAGWGKQVFSNGENWWWVPVVAPLLGAYLGGIIYLVFIGSTIPREPLKLEDSVAYEDHGITVLPKMGSHEPTISPLTPVSVSPANRSSVHPAPPLHESMALEHF>sp|O14520-2|AQP7_HUMAN Isoform 2 of Aquaporin-7 OS=Homo sapiens OX=9606GN=AQP7MNAAVTFANCALGRVPWRKFPVYVLGQFLGSFLAAATIYSLFYTAILHFSGGQLMVTGPVATAGIFATYLPDHMTLWRGFLNEAWLTGMLQLCLFAITDQENNPALPGTEALVIGILVVIIGVSLGMNTGYAINPSRDLPPRIFTFIAGWGKQVFRYCPCPGPFL>sp|P20851|C4BPB_HUMAN C4b-binding protein beta chain OS=Homo sapiensOX=9606 GN=C4BPB PE=1 SV=1MFFWCACCLMVAWRVSASDAEHCPELPPVDNSIFVAKEVEGQILGTYVCIKGYHLVGKKTLFCNASKEWDNTTTECRLGHCPDPVLVNGEFSSSGPVNVSDKITFMCNDHYILKGSNRSQCLEDHTWAPPFPICKSRDCDPPGNPVHGYFEGNNFTLGSTISYYCEDRYYLVGVQEQQCVDGEWSSALPVCKLIQEAPKPECEKALLAFQESKNLCEAMENFMQQLKESGMTMEELKYSLELKKAELKAKLL>sp|P20851-2|C4BPB_HUMAN Isoform 2 of C4b-binding protein beta chainOS=Homo sapiens OX=9606 GN=C4BPBMFFWCACCLMVAWRVSASDEHCPELPPVDNSIFVAKEVEGQILGTYVCIKGYHLVGKKTLFCNASKEWDNTTTECRLGHCPDPVLVNGEFSSSGPVNVSDKITFMCNDHYILKGSNRSQCLEDHTWAPPFPICKSRDCDPPGNPVHGYFEGNNFTLGSTISYYCEDRYYLVGVQEQQCVDGEWSSALPVCKLIQEAPKPECEKALLAFQESKNLCEAMENFMQQLKESGMTMEELKYSLELKKAELKAKLL>sp|Q8N283|ANR35_HUMAN Ankyrin repeat domain-containing protein 35OS=Homo sapiens OX=9606 GN=ANKRD35 PE=2 SV=2MKRIFSCSSTQVAVERWNRHDQKLLEAVHRGDVGRVAALASRKSARPTKLDSNGQSPFHLAASKGLTECLTILLANGADINSKNEDGSTALHLATISCQPQCVKVLLQHGANEDAVDAENRSPLHWAASSGCASSVLLLCDHEAFLDVLDNDGRTPLMIASLGGHAAICSQLLQRGARVNVTDKNDKSALILACEKGSAEVAELLLSHGADAGAVDSTGHDALHYALHTQDKALWRHLQQALSRRRRGGQRLVQHPDLASQASPSEPQAGSPPKSSWRAEPEEEQEEKEDEDPCSEEWRWKYEEERRKVVRLEQELVQKTEECKTQAAAYLDLENQIREQAQELGVLLSWEPRASGKQGSSLRPGGDGMEQGCPKDLLAESTQELKKQQQAAATVNPVLAPKKAEDSAPGKIQYEVHGRSQPEEQGPPQSPASETIRKATGQQLTTNGAQTFGPDHADQLPAGQKESSQVLGVEPGGTVAEPVGPAAMNQLLLQLREELAAVWREKDAARGALSRPVMEGALGTPRAEAAAAAWEKMEARLERVLARLEWAKAGLQVKPEVPSQESREGALKAAPGSIKQDEEKEKRVPGARGEPLGALGGEKALGGLAKGQLEKEMSVLRLSNSNLLEELGELGRERQRLQRELQSLSQRLQREFVPKPEAQVQLQQLRQSVGLLTNELAMEKEATEKLRKLLASQSSGLRGLWDCLPADLVGERSAQSKAAESLEELRACISTLVDRHREAQQVLARLQEENQQLRGSLSPCREPGTSLKAPASPQVAALEQDLGKLEEELRAVQATMSGKSQEIGKLKQLLYQATEEVAELRAREAASLRQHEKTRGSLVAQAQAWGQELKALLEKYNTACREVGRLREAVAEERRRSGDLAAQAAEQERQASEMRGRSEQFEKTAELLKEKMEHLIGACRDKEAKIKELLKKLEQLSEEVLAIRGENARLALQLQDSQKNHEEIISTYRNHLLNAARGYMEHEVYNILLQILSMEEE>sp|Q8N283-2|ANR35_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 35 OS=Homo sapiens OX=9606 GN=ANKRD35MKRIFSCSSTQVAVERWNRHDQKLLEAVHRGDVGRVAALASRKSARPTKLDSNGQSPFHLAASKGLTECLTILLANGADINSKNEDGSTALHLATISCQPQCVKVLLQPPLAVPQVCSCCVTTKPSWTCWIMMDVHP>sp|P02649|APOE_HUMAN Apolipoprotein E OS=Homo sapiens OX=9606 GN=APOEPE=1 SV=1MKVLWAALLVTFLAGCQAKVEQAVETEPEPELRQQTEWQSGQRWELALGRFWDYLRWVQTLSEQVQEELLSSQVTQELRALMDETMKELKAYKSELEEQLTPVAEETRARLSKELQAAQARLGADMEDVCGRLVQYRGEVQAMLGQSTEELRVRLASHLRKLRKRLLRDADDLQKRLAVYQAGAREGAERGLSAIRERLGPLVEQGRVRAATVGSLAGQPLQERAQAWGERLRARMEEMGSRTRDRLDEVKEQVAEVRAKLEEQAQQIRLQAEAFQARLKSWFEPLVEDMQRQWAGLVEKVQAAVGTSAAPVPSDNH>sp|Q8IYE0|CC146_HUMAN Coiled-coil domain-containing protein 146 OS=Homosapiens OX=9606 GN=CCDC146 PE=1 SV=2MEDSSTDTEKEEEEEKDEKDQEPIYAIVPTINIQDERFVDLSETPAFIFLHELHAMGKLPGTRMAALKAKYTLLHDAVMSTQESEVQLLQNAKRFTEQIQQQQFHLQQADNFPEAFSTEVSKMREQLLKYQNEYNAVKEREFHNQYRLNSLKEEKIIIVKEFEKITKPGEMEKKMKILRESTEELRKEIMQKKLEIKNLREDLASKQKQLLKEQKELEELLGHQVVLKDEVAHHQTIPVQIGKEIEKITRKKVEMEKKKIVLEQEVKTLNDSLKKVENKVSAIVDEKENVIKEVEGKRALLEIKEREHNQLVKLLELARENEATSLTERGILDLNLRNSLIDKQNYHDELSRKQREKERDFRNLRKMELLLKVSWDALRQTQALHQRLLLEMEAIPKDDSTLSERRRELHKEVEVAKRNLAQQKIISEMESKLVEQQLAEENKLLKEQENMKELVVNLLRMTQIKIDEKEQKSKDFLKAQQKYTNIVKEMKAKDLEIRIHKKKKCEIYRRLREFAKLYDTIRNERNKFVNLLHKAHQKVNEIKERHKMSLNELEILRNSAVSQERKLQNSMLKHANNVTIRESMQNDVRKIVSKLQEMKEKKEAQLNNIDRLANTITMIEEEMVQLRKRYEKAVQHRNESGVQLIEREEEICIFYEKINIQEKMKLNGEIEIHLLEEKIQFLKMKIAEKQRQICVTQKLLPAKRSLDADLAVLQIQFSQCTDRIKDLEKQFVKPDGENRARFLPGKDLTEKEMIQKLDKLELQLAKKEEKLLEKDFIYEQVSRLTDRLCSKTQGCKQDTLLLAKKMNGYQRRIKNATEKMMALVAELSMKQALTIELQKEVREKEDFIFTCNSRIEKGLPLNKEIEKEWLKVLRDEEMHALAIAEKSQEFLEADNRQLPNGVYTTAEQRPNAYIPEADATLPLPKPYGALAPFKPSEPGANMRHIRKPVIKPVEI>sp|Q8IYE0-2|CC146_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 146 OS=Homo sapiens OX=9606 GN=CCDC146MEKKKIVLEQEVKTLNDSLKKVENKVSAIVDEKENVIKEVEGKRALLEIKEREHNQLVKLLELARENEATSLTERGILDLNLRNSLIDKQNYHDELSRKQREKERDFRNLRKMELLLKVSWDALRQTQALHQRLLLEKIISEMESKLVEQQLAEENKLLKEQENMKELVVNLLRMTQIKIDEKEQKSKDFLKAQQKYTNIVKEMKAKDLEIRIHKKKKCEIYRRLREFAKLYDTIRNERNKFVNLLHKAHQKVNEIKERHKMSLNELEILRNSAVSQERKLQNSMLKHANNVTIRESMQNDVRKIVSKLQEMKEKKEAQLNNIDRLANTITMIEEEMVQLRKRYEKAVQHRNESGVQLIEREEEICIFYEKINIQEKMKLNGEIEIHLLEEKIQFLKMKIAEKQRQICVTQKLLPAKRSLDADLAVLQIQFSQCTDRIKDLEKQFVKPDGENRARFLPGKDLTEKEMIQKLDKLELQLAKKEEKLLEKDFIYEQVSRLTDRLCSKTQGCKQDTLLLAKKMNGYQRRIKNATEKMMALVAELSMKQALTIELQKEVREKEDFIFTCNSRIEKGLPLNKEIEKEWLKVLRDEEMHALAIAEKSQEFLEADNRQLPNGVYTTAEQRPNAYIPEADATLPLPKPYGALAPFKPSEPGANMRHIRKPVIKPVEI>sp|Q9UNH5|CC14A_HUMAN Dual specificity protein phosphatase CDC14AOS=Homo sapiens OX=9606 GN=CDC14A PE=1 SV=1MAAESGELIGACEFMKDRLYFATLRNRPKSTVNTHYFSIDEELVYENFYADFGPLNLAMVYRYCCKLNKKLKSYSLSRKKIVHYTCFDQRKRANAAFLIGAYAVIYLKKTPEEAYRALLSGSNPPYLPFRDASFGNCTYNLTILDCLQGIRKGLQHGFFDFETFDVDEYEHYERVENGDFNWIVPGKFLAFSGPHPKSKIENGYPLHAPEAYFPYFKKHNVTAVVRLNKKIYEAKRFTDAGFEHYDLFFIDGSTPSDNIVRRFLNICENTEGAIAVHCKAGLGRTGTLIACYVMKHYRFTHAEIIAWIRICRPGSIIGPQQHFLEEKQASLWVQGDIFRSKLKNRPSSEGSINKILSGLDDMSIGGNLSKTQNMERFGEDNLEDDDVEMKNGITQGDKLRALKSQRQPRTSPSCAFRSDDTKGHPRAVSQPFRLSSSLQGSAVTLKTSKMALSPSATAKRINRTSLSSGATVRSFSINSRLASSLGNLNAATDDPENKKTSSSSKAGFTASPFTNLLNGSSQPTTRNYPELNNNQYNRSSNSNGGNLNSPPGPHSAKTEEHTTILRPSYTGLSSSSARFLSRSIPSLQSEYVHY>sp|Q9UNH5-2|CC14A_HUMAN Isoform 2 of Dual specificity proteinphosphatase CDC14A OS=Homo sapiens OX=9606 GN=CDC14AMAAESGELIGACEFMKDRLYFATLRNRPKSTVNTHYFSIDEELVYENFYADFGPLNLAMVYRYCCKLNKKLKSYSLSRKKIVHYTCFDQRKRANAAFLIGAYAVIYLKKTPEEAYRALLSGSNPPYLPFRDASFGNCTYNLTILDCLQGIRKGLQHGFFDFETFDVDEYEHYERVENGDFNWIVPGKFLAFSGPHPKSKIENGYPLHAPEAYFPYFKKHNVTAVVRLNKKIYEAKRFTDAGFEHYDLFFIDGSTPSDNIVRRFLNICENTEGAIAVHCKAGLGRTGTLIACYVMKHYRFTHAEIIAWIRICRPGSIIGPQQHFLEEKQASLWVQGDIFRSKLKNRPSSEGSINKILSGLDDMSIGGNLSKTQNMERFGEDNLEDDDVEMKNGITQGDKLRALKSQRQPRTSPSCAFRSDDTKGHPRAVSQPFRLSSSLQGSAVTLKTSKMALSPSATAKRINRTSLSSGATVRSFSINSRLASSLGNLNAATDDPENKKTSSSSKAGFTASPFTNLLNGSSQPTTRNYPELNNNQYNRSSNSNGGNLNSPPGPHSAKTEEHTTILRPSYTGLSSSSARFLSRSIPVSAQTPPPGPQNPECNFCALPSQPRLPPKKFNSAKEAF>sp|Q9UNH5-3|CC14A_HUMAN Isoform 3 of Dual specificity proteinphosphatase CDC14A OS=Homo sapiens OX=9606 GN=CDC14AMAAESGELIGACEFMKDRLYFATLRNRPKSTVNTHYFSIDEELVYENFYADFGPLNLAMVYRYCCKLNKKLKSYSLSRKKIVHYTCFDQRKRANAAFLIGAYAVIYLKKTPEEAYRALLSGSNPPYLPFRDASFGNCTYNLTILDCLQGIRKGLQHGFFDFETFDVDEYEHYERVENGDFNWIVPGKFLAFSGPHPKSKIENGYPLHAPEAYFPYFKKHNVTAVVRLNKKIYEAKRFTDAGFEHYDLFFIDGSTPSDNIVRRFLNICENTEGAIAVHCKAGLGRTGTLIACYVMKHYRFTHAEIIAWIRICRPGSIIGPQQHFLEEKQASLWVQGDIFRSKLKNRPSSEGSINKILSGLDDMSIGGNLSKTQNMERFGEVSFP>sp|Q9UNH5-4|CC14A_HUMAN Isoform 4 of Dual specificity proteinphosphatase CDC14A OS=Homo sapiens OX=9606 GN=CDC14AMAAESGELIGACEFMKDRLYFATLRNRPKSTVNTHYFSIDEELVYENFYADFGPLNLAMVYRYCCKLNKKLKSYSLSRKKIVHYTCFDQRKRANAAFLIGAYAVIYLKKTPEEAYRALLSGSNPPYLPFRDASFGNCTYNLTILDCLQGIRKGLQHGFFDFETFDVDEYEHYEVILFTPLKPTFLISKSIM>sp|Q9UNH5-5|CC14A_HUMAN Isoform 5 of Dual specificity proteinphosphatase CDC14A OS=Homo sapiens OX=9606 GN=CDC14AMAAESGELIGACEFMKDRLYFATLRNRPKSTVNTHYFSIDEELVYENFYADFGPLNLAMVYRYCCKLNKKLKSYSLSRKKIVHYTCFDQRKRANAAFLIGAYAVIYLKKTPEEAYRALLSGSNPPYLPFRDASFGNCTYNLTILDCLQGIRKGLQHGFFDFETFDVDEYEHYERVENGDFNWIVPGKFLAFSGPHPKSKIENGYPLHAPEAYFPYFKKHNVTAVVRLNKKIYEAKRFTDAGFEHYDLFFIDGSTPSDNIVRRFLNICENTEGAIAVHCKAGLGRTGTLIACYVMKHYRFTHAEIIAWIRICRPGSIIGPQQHFLEEKQASLWVQGDIFRSKLKNRPSSEGSINKILSGLDDMSIGGNLSKTQNMERFGEDNLEDDDVEMKNGITQGDKLRALKSQRQPRTSPSCAFRSDDTKGHPRAVSQPFRLSSSLQGSAVTLKTSKMALSPSATAKRINRTSLSSGATVRSFSINSRLASSLGNLNAATDDPENKKTSSSSKAGFTASPFTNLLNGSSQPTTRNYPELNNNQYNRSSNSNGGNLNSPPGPHSAKTEEHTTILRPSYTGLSSSSARFLSRSIPCSCLLLVFRKPFLGSPLLSLPISHL>sp|P18085|ARF4_HUMAN ADP-ribosylation factor 4 OS=Homo sapiens OX=9606GN=ARF4 PE=1 SV=3MGLTISSLFSRLFGKKQMRILMVGLDAAGKTTILYKLKLGEIVTTIPTIGFNVETVEYKNICFTVWDVGGQDRIRPLWKHYFQNTQGLIFVVDSNDRERIQEVADELQKMLLVDELRDAVLLLFANKQDLPNAMAISEMTDKLGLQSLRNRTWYVQATCATQGTGLYEGLDWLSNELSKR>sp|Q76M96|CCD80_HUMAN Coiled-coil domain-containing protein 80 OS=Homosapiens OX=9606 GN=CCDC80 PE=1 SV=1MTWRMGPRFTMLLAMWLVCGSEPHPHATIRGSHGGRKVPLVSPDSSRPARFLRHTGRSRGIERSTLEEPNLQPLQRRRSVPVLRLARPTEPPARSDINGAAVRPEQRPAARGSPREMIRDEGSSARSRMLRFPSGSSSPNILASFAGKNRVWVISAPHASEGYYRLMMSLLKDDVYCELAERHIQQIVLFHQAGEEGGKVRRITSEGQILEQPLDPSLIPKLMSFLKLEKGKFGMVLLKKTLQVEERYPYPVRLEAMYEVIDQGPIRRIEKIRQKGFVQKCKASGVEGQVVAEGNDGGGGAGRPSLGSEKKKEDPRRAQVPPTRESRVKVLRKLAATAPALPQPPSTPRATTLPPAPATTVTRSTSRAVTVAARPMTTTAFPTTQRPWTPSPSHRPPTTTEVITARRPSVSENLYPPSRKDQHRERPQTTRRPSKATSLESFTNAPPTTISEPSTRAAGPGRFRDNRMDRREHGHRDPNVVPGPPKPAKEKPPKKKAQDKILSNEYEEKYDLSRPTASQLEDELQVGNVPLKKAKESKKHEKLEKPEKEKKKKMKNENADKLLKSEKQMKKSEKKSKQEKEKSKKKKGGKTEQDGYQKPTNKHFTQSPKKSVADLLGSFEGKRRLLLITAPKAENNMYVQQRDEYLESFCKMATRKISVITIFGPVNNSTMKIDHFQLDNEKPMRVVDDEDLVDQRLISELRKEYGMTYNDFFMVLTDVDLRVKQYYEVPITMKSVFDLIDTFQSRIKDMEKQKKEGIVCKEDKKQSLENFLSRFRWRRRLLVISAPNDEDWAYSQQLSALSGQACNFGLRHITILKLLGVGEEVGGVLELFPINGSSVVEREDVPAHLVKDIRNYFQVSPEYFSMLLVGKDGNVKSWYPSPMWSMVIVYDLIDSMQLRRQEMAIQQSLGMRCPEDEYAGYGYHSYHQGYQDGYQDDYRHHESYHHGYPY>sp|Q76M96-2|CCD80_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 80 OS=Homo sapiens OX=9606 GN=CCDC80MTSVHRKVDYTMTWRMGPRFTMLLAMWLVCGSEPHPHATIRGSHGGRKVPLVSPDSSRPARFLRHTGRSRGIERSTLEEPNLQPLQRRRSVPVLRLARPTEPPARSDINGAAVRPEQRPAARGSPREMIRDEGSSARSRMLRFPSGSSSPNILASFAGKNRVWVISAPHASEGYYRLMMSLLKDDVYCELAERHIQQIVLFHQAGEEGGKVRRITSEGQILEQPLDPSLIPKLMSFLKLEKGKFGMVLLKKTLQVEERYPYPVRLEAMYEVIDQGPIRRIEKIRQKGFVQKCKASGVEGQVVAEGNDGGGGAGRPSLGSEKKKEDPRRAQVPPTRESRVKVLRKLAATAPALPQPPSTPRATTLPPAPATTVTRSTSRAVTVAARPMTTTAFPTTQRPWTPSPSHRPPTTTEVITARRPSVSENLYPPSRKDQHRERPQTTRRPSKATSLESFTNAPPTTISEPSTRAAGPGRFRDNRMDRREHGHRDPNVVPGPPKPAKEKPPKKKAQDKILSNEYEEKYDLSRPTASQLEDELQVGNVPLKKAKESKKHEKLEKPEKEKKKKMKNENADKLLKSEKQMKKSEKKSKQEKEKSKKKKGGKTEQDGYQKPTNKHFTQSPKKSVADLLGSFEGKRRLLLITAPKAENNMYVQQRDEYLESFCKMATRKISVITIFGPVNNSTMKIDHFQLDNEKPMRVVDDEDLVDQRLISELRKEYGMTYNDFFMVLTDVDLRVKQYYEVPITMKSVFDLIDTFQSRIKDMEKQKKEGIVCKEDKKQSLENFLSRFRWRRRLLVISAPNDEDWAYSQQLSALSGQACNFGLRHITILKLLGVGEEVGGVLELFPINGSSVVEREDVPAHLVKDIRNYFQVSPEYFSMLLVGKDGNVKSWYPSPMWSMVIVYDLIDSMQLRRQEMAIQQSLGMRCPEDEYAGYGYHSYHQGYQDGYQDDYRHHESYHHGYPY>sp|Q76M96-3|CCD80_HUMAN Isoform 3 of Coiled-coil domain-containingprotein 80 OS=Homo sapiens OX=9606 GN=CCDC80MLLVGKDGNVKSWYPSPMWSMVIVYDLIDSMQLRRQEMAIQQSLGMRCPEDEYAGYGYHSYHQGYQDGYQDDYRHHESYHHGYPY>sp|O60729|CC14B_HUMAN Dual specificity protein phosphatase CDC14BOS=Homo sapiens OX=9606 GN=CDC14B PE=1 SV=1MKRKSERRSSWAAAPPCSRRCSSTSPGVKKIRSSTQQDPRRRDPQDDVYLDITDRLCFAILYSRPKSASNVHYFSIDNELEYENFYADFGPLNLAMVYRYCCKINKKLKSITMLRKKIVHFTGSDQRKQANAAFLVGCYMVIYLGRTPEEAYRILIFGETSYIPFRDAAYGSCNFYITLLDCFHAVKKAMQYGFLNFNSFNLDEYEHYEKAENGDLNWIIPDRFIAFCGPHSRARLESGYHQHSPETYIQYFKNHNVTTIIRLNKRMYDAKRFTDAGFDHHDLFFADGSTPTDAIVKEFLDICENAEGAIAVHCKAGLGRTGTLIACYIMKHYRMTAAETIAWVRICRPGSVIGPQQQFLVMKQTNLWLEGDYFRQKLKGQENGQHRAAFSKLLSGVDDISINGVENQDQQEPEPYSDDDEINGVTQGDRLRALKSRRQSKTNAIPLTVILQSSVQSCKTSEPNISGSAGITKRTTRSASRKSSVKSLSISRTKTVLR>sp|O60729-2|CC14B_HUMAN Isoform 1 of Dual specificity proteinphosphatase CDC14B OS=Homo sapiens OX=9606 GN=CDC14BMKRKSERRSSWAAAPPCSRRCSSTSPGVKKIRSSTQQDPRRRDPQDDVYLDITDRLCFAILYSRPKSASNVHYFSIDNELEYENFYADFGPLNLAMVYRYCCKINKKLKSITMLRKKIVHFTGSDQRKQANAAFLVGCYMVIYLGRTPEEAYRILIFGETSYIPFRDAAYGSCNFYITLLDCFHAVKKAMQYGFLNFNSFNLDEYEHYEKAENGDLNWIIPDRFIAFCGPHSRARLESGYHQHSPETYIQYFKNHNVTTIIRLNKRMYDAKRFTDAGFDHHDLFFADGSTPTDAIVKEFLDICENAEGAIAVHCKAGLGRTGTLIACYIMKHYRMTAAETIAWVRICRPGSVIGPQQQFLVMKQTNLWLEGDYFRQKLKGQENGQHRAAFSKLLSGVDDISINGVENQDQQEPEPYSDDDEINGVTQGDRLRALKSRRQSKTNAIPLTLSISRTKTVLR>sp|O60729-3|CC14B_HUMAN Isoform 3 of Dual specificity proteinphosphatase CDC14B OS=Homo sapiens OX=9606 GN=CDC14BMKRKSERRSSWAAAPPCSRRCSSTSPGVKKIRSSTQQDPRRRDPQDDVYLDITDRLCFAILYSRPKSASNVHYFSIDNELEYENFYADFGPLNLAMVYRYCCKINKKLKSITMLRKKIVHFTGSDQRKQANAAFLVGCYMVIYLGRTPEEAYRILIFGETSYIPFRDAAYGSCNFYITLLDCFHAVKKAMQYGFLNFNSFNLDEYEHYEKAENGDLNWIIPDRFIAFCGPHSRARLESGYHQHSPETYIQYFKNHNVTTIIRLNKRMYDAKRFTDAGFDHHDLFFADGSTPTDAIVKEFLDICENAEGAIAVHCKAGLGRTGTLIACYIMKHYRMTAAETIAWVRICRPGSVIGPQQQFLVMKQTNLWLEGDYFRQKLKGQENGQHRAAFSKLLSGVDDISINGVENQDQQEPEPYSDDDEINGVTQGDRLRALKSRRQSKTNAIPLTDGWLSQAVTFLDRLLIWLGIHKD>sp|O60729-4|CC14B_HUMAN Isoform 4 of Dual specificity proteinphosphatase CDC14B OS=Homo sapiens OX=9606 GN=CDC14BMKRKSERRSSWAAAPPCSRRCSSTSPGVKKIRSSTQQDPRRRDPQDDVYLDITDRLCFAILYSRPKSASNVHYFSIDNELEYENFYADFGPLNLAMVYRYCCKINKKLKSITMLRKKIVHFTGSDQRKQANAAFLVGCYMVIYLGRTPEEAYRILIFGETSYIPFRDAAYGSCNFYITLLDCFHAVKKAMQYGFLNFNSFNLDEYEHYEKAENGDLNWIIPDRFIAFCGPHSRARLESGYHQHSPETYIQYFKNHNVTTIIRLNKRMYDAKRFTDAGFDHHDLFFADGSTPTDAIVKEFLDICENAEGAIAVHCKAGLGRTGTLIACYIMKHYRMTAAETIAWVRICRPGSVIGPQQQFLVMKQTNLWLEGDYFRQKLKGQENGQHRAAFSKLLSGVDDISINGVENQDQQEPEPYSDDDEINGVTQGDRLRALKSRRQSKTNAIPLTCPLAVLTSALCSVVIWWIVCDYILPILLFCLDGFRTQ>sp|O60729-5|CC14B_HUMAN Isoform 5 of Dual specificity proteinphosphatase CDC14B OS=Homo sapiens OX=9606 GN=CDC14BMSREGAGAALVAEVIKDRLCFAILYSRPKSASNVHYFSIDNELEYENFYADFGPLNLAMVYRYCCKINKKLKSITMLRKKIVHFTGSDQRKQANAAFLVGCYMVIYLGRTPEEAYRILIFGETSYIPFRDAAYGSCNFYITLLDCFHAVKKAMQYGFLNFNSFNLDEYEHYEKAENGDLNWIIPDRFIAFCGPHSRARLESGYHQHSPETYIQYFKNHNVTTIIRLNKRMYDAKRFTDAGFDHHDLFFADGSTPTDAIVKEFLDICENAEGAIAVHCKAGLGRTGTLIACYIMKHYRMTAAETIAWVRICRPGSVIGPQQQFLVMKQTNLWLEGDYFRQKLKGQENGQHRAAFSKLLSGVDDISINGVENQDQQEPEPYSDDDEINGVTQGDRLRALKSRRQSKTNAIPLTVILQSSVQSCKTSEPNISGSAGITKRTTRSASRKSSVKSLSISRTKTVLR>sp|A4D256|CC14C_HUMAN Dual specificity protein phosphatase CDC14COS=Homo sapiens OX=9606 GN=CDC14C PE=2 SV=3MRSSTLQDPRRRDPQDDVYVDITDRLRFAILYSRPKSASNVHYFSIDNELEYENFSEDFGPLNLAMVYRYCCKINKKLKSITMLRKKIVHFTGSDQRKQANAAFLVGCYMVIYLGRTPEAAYRILIFGDTPYIPFRDAAYGSCNFYITLLDCFHAVKKAMQYGFLNFNSFNLDEYEHYEKAENGDLNWIIPDRFIAFCGPHSRARLESGYHQHSPETYIQYFKNHNVTTIIRLNKRMYDAKRFTDAGFDHHDLFFADGSTPTDAIVKRFLDICENAEGAIAVHCKAGLGRTGTLIACYIMKHYRMTAAETIAWVRICRPGLVIGPQQQFLVMKQTSLWLEGDYFRQRLKGQENGQHRAAFSKLLSGVDDISINGVENQDQQEPKPYSDDDEINGVTQGDRSRALKRRRQSKTNDILLPSPLAVLTFTLCSVVIWWIVCDYILPILLF>sp|Q7Z5L3|C1QL2_HUMAN Complement C1q-like protein 2 OS=Homo sapiensOX=9606 GN=C1QL2 PE=2 SV=2MALGLLIAVPLLLQAAPRGAAHYEMMGTCRMICDPYTAAPGGEPPGAKAQPPGPSTAALEVMQDLSANPPPPFIQGPKGDPGRPGKPGPRGPPGEPGPPGPRGPPGEKGDSGRPGLPGLQLTAGTASGVGVVGGGAGVGGDSEGEVTSALSATFSGPKIAFYVGLKSPHEGYEVLKFDDVVTNLGNHYDPTTGKFSCQVRGIYFFTYHILMRGGDGTSMWADLCKNGQVRASAIAQDADQNYDYASNSVVLHLDSGDEVYVKLDGGKAHGGNNNKYSTFSGFLLYPD>sp|Q494R4|CC153_HUMAN Coiled-coil domain-containing protein 153 OS=Homosapiens OX=9606 GN=CCDC153 PE=1 SV=2MPPKNKEKGKKSGAQKKKKNWGADVVAESRHRLVVLEKELLRDHLALRRDEARRAKASEDQLRQRLQGVEAELEGARSEGKAIYAEMSRQCHALQEDMQTRSKQLEEEVKGLRGQLEACQREAAAAREEAEQALGERDQALAQLRAHMADMEAKYEEILHDSLDRLLAKLRAIKQQWDGAALRLHARHKEQQRQFGLTPPGSLRPPAPSL>sp|Q494R4-2|CC153_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 153 OS=Homo sapiens OX=9606 GN=CCDC153MSRQCHALQEDMQTRSKQLEEEVKGLRGQLEACQREAAAAREEAEQALGERDQALAQLRAHMADMEAKYEEILHDSLDRLLAKLRAIKQQWDGAALRLHARHKEQQRQFGLTPPGSLRPPAPSL>sp|Q8IWF9|CCD83_HUMAN Coiled-coil domain-containing protein 83 OS=Homosapiens OX=9606 GN=CCDC83 PE=1 SV=2MENSGKANKKDTHDGPPKEIKLPTSEALLDYQCQIKEDAVEQFMFQIKTLRKKNQKYHERNSRLKEEQIWHIRHLLKELSEEKAEGLPVVTREDVEEAMKEKWKFERDQEKNLRDMRMQISNAEKLFLEKLSEKEYWEEYKNVGSERHAKLITSLQNDINTVKENAEKMSEHYKITLEDTRKKIIKETLLQLDQKKEWATQNAVKLIDKGSYLEIWENDWLKKEVAIHRKEVEELKNAIHELEAENLVLIDQLSNCRLVDLKIPRRLYLTQAAGLEVPPEEMSLELPETHIEEKSELQPTEVESRDLMSSSDESTILHLSHENSIEDLQYVKIDKEENSGTEFGDTDMKYLLYEDEKDFKDYVNLGPLGVKLMSVESKKMPIHFQEKEIPVKLYKDVRSPESHITYKMMKSFL>sp|Q8IWF9-2|CCD83_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 83 OS=Homo sapiens OX=9606 GN=CCDC83MENSGKANKKDTHDGPPKEIKLPTSEALLDYQCQIKEDAVEQFMFQIKTLRKKNQKYHERNSRLKEEQIWHIRHLLKELSEEKAEGLPVVTREDVEEAMKEKWKFERDQEKNLRDMRMQISNAEKLFLEKLSEKEYWEEYKNVGSERHAKLITSLQNDINTVKENAEKMSEHYKITLEDTRKKIIKETLLQLDQKKEWATQNAVKLIDKGSYLEIWENDWLKKEVAIHRKEVEELKNAIHELEAENLVLIDQLSNCRLVDLKIPRYPVLHSCPTSNPRHLLLLPLESCLISARRCWRLYLTQAAGLEVPPEEMSLELPETHIEEKSELQPTEVESRDLMSSSDESTILHLSHENSIEDLQYVKIDKEENSGTEFGDTDMKYLLYEDEKDFKDYVNLGPLGVKLMSVESKKMPIHFQEKEIPVKLYKDVRSPESHITYKMMKSFL>sp|Q8IWF9-3|CCD83_HUMAN Isoform 3 of Coiled-coil domain-containingprotein 83 OS=Homo sapiens OX=9606 GN=CCDC83MFQIKTLRKKNQKYHERNSRLKEEQIWHIRHLLKELSEEKAEGLPVVTREDVEEAMKEKWKFERDQEKNLREHYKITLEDTRKKIIKETLLQLDQKKEWATQNAVKLIDKGSYLEIWENDWLKKEVAIHRKEVEELKNAIHELEAENLVLIDQLSNCRLVDLKIPRRLYLTQAAGLEVPPEEMSLELPETHIEKSELQPTEVESRDLMSSSDESTILHLSHENSIEDLQYVKIDKEENSGTEFGDTDMKYLLYEDEKDFKDYVNLGPLGVKLMSVESKKMPIHFQEKEIPVKLYKDVRSPESHITYKMMKSFL>sp|A6NI56|CC154_HUMAN Coiled-coil domain-containing protein 154 OS=Homosapiens OX=9606 GN=CCDC154 PE=2 SV=5MSELADSGPSGASAPSQLRAVTLEDLGLLLAGGLASPEPLSLEELSERYESSHPTSTASVPEQDTAKHWNQLEQWVVELQAEVACLREHKQRCERATRSLLRELLQVRARVQLQGSELRQLQQEARPAAQAPEKEAPEFSGLQNQMQALDKRLVEVREALTRLRRRQVQQEAERRGAEQEAGLRLAKLTDLLQQEEQGREVACGALQKNQEDSSRRVDLEVARMQAQVTKLGEEVSLRFLKREAKLCGFLQKSFLALEKRMKASESSRLKLEGSLRGELESRWEKLRGLMEERLRALQGQHEESHLLEQCQGLDAAVAQLTKFVQQNQASLNRVLLAEEKAWDAKGRLEESRAGELAAYVQENLEAAQLAGELARQEMHGELVLLREKSRALEASVAQLAGQLKELSGHLPALSSRLDLQEQMLGLRLSEAKTEWEGAERKSLEDLARWRKEVTEHLRGVREKVDGLPQQIESVSDKCLLHKSDSDLRISAEGKAREFKVGALRQELATLLSSVQLLKEDNPGRKIAEMQGKLATFQNQIMKLENCVQANKTIQNLRFNTEARLRTQEMATLWESVLRLWSEEGPRTPLGSWKALPSLVRPRVFIKDMAPGKVVPMNCWGVYQAVRWLRWKASLIKLRALRRPGGVLEKPHSQEQVQQLTPSLFIQK>sp|Q5VWW1|C1QL3_HUMAN Complement C1q-like protein 3 OS=Homo sapiensOX=9606 GN=C1QL3 PE=2 SV=1MVLLLVILIPVLVSSAGTSAHYEMLGTCRMVCDPYGGTKAPSTAATPDRGLMQSLPTFIQGPKGEAGRPGKAGPRGPPGEPGPPGPMGPPGEKGEPGRQGLPGPPGAPGLNAAGAISAATYSTVPKIAFYAGLKRQHEGYEVLKFDDVVTNLGNHYDPTTGKFTCSIPGIYFFTYHVLMRGGDGTSMWADLCKNNQVRASAIAQDADQNYDYASNSVVLHLEPGDEVYIKLDGGKAHGGNNNKYSTFSGFIIYAD>sp|Q5VWW1-2|C1QL3_HUMAN Isoform 2 of Complement C1q-like protein 3OS=Homo sapiens OX=9606 GN=C1QL3MVLLLVILIPVLVSSAGTSAHYEMLGTCRMVCDPYGGTKAPSTAATPDRGLMQSLPTFIQGPMGPPGEKGEPGRQGLPGPPGAPGLNAAGAISAATYSTVPKIAFYAGLKRQHEGYEVLKFDDVVTNLGNHYDPTTGKFTCSIPGIYFFTYHVLMRGGDGTSMWADLCKNNQVRASAIAQDADQNYDYASNSVVLHLEPGDEVYIKLDGGKAHGGNNNKYSTFSGFIIYAD>sp|Q5VWW1-3|C1QL3_HUMAN Isoform 3 of Complement C1q-like protein 3OS=Homo sapiens OX=9606 GN=C1QL3MVLLLVILIPVLVSSAGTSAHYEMLGTCRMVCDPYGGTKAPSTAATPDRGLMQSLPTFIQGPPGAPGLNAAGAISAATYSTVPKIAFYAGLKRQHEGYEVLKFDDVVTNLGNHYDPTTGKFTCSIPGIYFFTYHVLMRGGDGTSMWADLCKNNQVRASAIAQDADQNYDYASNSVVLHLEPGDEVYIKLDGGKAHGGNNNKYSTFSGFIIYAD>sp|P62330|ARF6_HUMAN ADP-ribosylation factor 6 OS=Homo sapiens OX=9606GN=ARF6 PE=1 SV=2MGKVLSKIFGNKEMRILMLGLDAAGKTTILYKLKLGQSVTTIPTVGFNVETVTYKNVKFNVWDVGGQDKIRPLWRHYYTGTQGLIFVVDCADRDRIDEARQELHRIINDREMRDAIILIFANKQDLPDAMKPHEIQEKLGLTRIRDRNWYVQPSCATSGDGLYEGLTWLTSNYKS>sp|Q9H6F5|CCD86_HUMAN Coiled-coil domain-containing protein 86 OS=Homosapiens OX=9606 GN=CCDC86 PE=1 SV=1MDTPLRRSRRLGGLRPESPESLTSVSRTRRALVEFESNPEETREPGSPPSVQRAGLGSPERPPKTSPGSPRLQQGAGLESPQGQPEPGAASPQRQQDLHLESPQRQPEYSPESPRCQPKPSEEAPKCSQDQGVLASELAQNKEELTPGAPQHQLPPVPGSPEPYPGQQAPGPEPSQPLLELTPRAPGSPRGQHEPSKPPPAGETVTGGFGAKKRKGSSSQAPASKKLNKEELPVIPKGKPKSGRVWKDRSKKRFSQMLQDKPLRTSWQRKMKERQERKLAKDFARHLEEEKERRRQEKKQRRAENLKRRLENERKAEVVQVIRNPAKLKRAKKKQLRSIEKRDTLALLQKQPPQQPAAKI>sp|Q9H6F5-2|CCD86_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 86 OS=Homo sapiens OX=9606 GN=CCDC86MLQDKPLRTSWQRKMKERQERKLAKDFARHLEEEKERRRQEKKQRRAENLKRRLENERKAEVVQVIRNPAKLKRAKKKQLRSIEKRDTLALLQKQPPQQPAAKI>sp|Q86Y37|CACL1_HUMAN CDK2-associated and cullin domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=CACUL1 PE=1 SV=1MEESMEEEEGGSYEAMMDDQNHNNWEAAVDGFRQPLPPPPPPSSIPAPAREPPGGQLLAVPAVSVDRKGPKEGLPMGPQPPPEANGVIMMLKSCDAAAAVAKAAPAPTASSTININTSTSKFLMNVITIEDYKSTYWPKLDGAIDQLLTQSPGDYIPISYEQIYSCVYKCVCQQHSEQMYSDLIKKITNHLERVSKELQASPPDLYIERFNIALGQYMGALQSIVPLFIYMNKFYIETKLNRDLKDDLIKLFTEHVAEKHIYSLMPLLLEAQSTPFQVTPSTMANIVKGLYTLRPEWVQMAPTLFSKFIPNILPPAVESELSEYAAQDQKFQRELIQNGFTRGDQSRKRAGDELAYNSSSACASSRGYR>sp|Q86Y37-2|CACL1_HUMAN Isoform 2 of CDK2-associated and cullin domain-containing protein 1 OS=Homo sapiens OX=9606 GN=CACUL1MEESMEEEEGGSYEAMMDDQNHNNWEAAVDGFRQPLPPPPPPSSIPAPAREPPGGQLLAVPAVSVDRKGPKEGLPMGPQPPPEANGVIMMLKSCDAAAAVAKAAPAPTASSTININTSTSKFLMNVITIEDYKSTYWPKLDGAIDQLLTQSPGDYIPISYEQIYSCVYKCVCQQHSEQMYSDLIKKITNHLERVSKELQASPPDLYIERFNIALGQYMGALQSIVPLFIYMNKFYIETKLNRDLKDDLIKLFTEHVAEKHIYSLMPLLLEAQSTPFQVTPSTMANIVKGLYTLRPVSQNFTAV>sp|Q86Y37-4|CACL1_HUMAN Isoform 4 of CDK2-associated and cullin domain-containing protein 1 OS=Homo sapiens OX=9606 GN=CACUL1MNVITIEDYKSTYWPKLDGAIDQLLTQSPGDYIPISYEQIYSCVYKCVCQQHSEQMYSDLIKKITNHLERVSKELQASPPDLYIERFNIALGQYMGALQSIVPLFIYMNKFYIETKLNRDLKDDLIKLFTEHVAEKHIYSLMPLLLEAQSTPFQVTPSTMANIVKGLYTLRPEWVQMAPTLFSKFIPNILPPAVESELSEYAAQDQKFQRELIQNGFTRGDQSRKRAGDELAYNSSSACASSRGYR>sp|Q9NPY3|C1QR1_HUMAN Complement component C1q receptor OS=Homo sapiensOX=9606 GN=CD93 PE=1 SV=3MATSMGLLLLLLLLLTQPGAGTGADTEAVVCVGTACYTAHSGKLSAAEAQNHCNQNGGNLATVKSKEEAQHVQRVLAQLLRREAALTARMSKFWIGLQREKGKCLDPSLPLKGFSWVGGGEDTPYSNWHKELRNSCISKRCVSLLLDLSQPLLPSRLPKWSEGPCGSPGSPGSNIEGFVCKFSFKGMCRPLALGGPGQVTYTTPFQTTSSSLEAVPFASAANVACGEGDKDETQSHYFLCKEKAPDVFDWGSSGPLCVSPKYGCNFNNGGCHQDCFEGGDGSFLCGCRPGFRLLDDLVTCASRNPCSSSPCRGGATCVLGPHGKNYTCRCPQGYQLDSSQLDCVDVDECQDSPCAQECVNTPGGFRCECWVGYEPGGPGEGACQDVDECALGRSPCAQGCTNTDGSFHCSCEEGYVLAGEDGTQCQDVDECVGPGGPLCDSLCFNTQGSFHCGCLPGWVLAPNGVSCTMGPVSLGPPSGPPDEEDKGEKEGSTVPRAATASPTRGPEGTPKATPTTSRPSLSSDAPITSAPLKMLAPSGSPGVWREPSIHHATAASGPQEPAGGDSSVATQNNDGTDGQKLLLFYILGTVVAILLLLALALGLLVYRKRRAKREEKKEKKPQNAADSYSWVPERAESRAMENQYSPTPGTDC>sp|A6NGH7|CC160_HUMAN Coiled-coil domain-containing protein 160 OS=Homosapiens OX=9606 GN=CCDC160 PE=3 SV=3MDARRKHWKENMFTPFFSAQDVLEETSEPESSSEQTTADSSKGMEEIYNLSSRKFQEESKFKRKKYIFQLNEIEQEQNLRENKRNISKNETDTNSASYESSNVDVTTEESFNSTEDNSTCSTDNLPALLRQDIRKKFMERMSPKLCLNLLNEELEELNMKYRKIEEEFENAEKELLHYKKEIFTKPLNFQETETDASKSDYELQALRNDLSEKATNVKNLSEQLQQAKEVIHKLNLENRNLKEAVRKLKHQTEVGNVLLKEEMKSYYELEMAKIRGELSVIKNELRTEKTLQARNNRALELLRKYYASSMVTSSSILDHFTGDFF>sp|Q9NVE4|CCD87_HUMAN Coiled-coil domain-containing protein 87 OS=Homosapiens OX=9606 GN=CCDC87 PE=1 SV=2MMEPPKPEPELQRFYHRLLRPLSLFPTRTTSPEPQKRPPQEGRILQSFPLAKLTVASLCSQVAKLLAGSGIAAGVPPEARLRLIKVILDELKCSWREPPAELSLSHKNNQKLRKRLEAYVLLSSEQLFLRYLHLLVTMSTPRGVFTESATLTRLAASLARDCTLFLTSPNVYRGLLADFQALLRAEQASGDVDKLHPVCPAGTFKLCPIPWPHSTGFAQVQCSNLNLNYLIQLSRPPEFLNEPGRMDPVKELKSIPRLKRKKPFHWLPSIGKKREIDISSSQMVSLPSYPVAPTSRASPSPFCPELRRGQSMPSLREGWRLADELGLPPLPSRPLTPLVLATESKPELTGLIVAEDLKQLIKKMKLEGTRYPPLDSGLPPLLGVVTRHPAAGHRLEELEKMLRNLQEEEASGQWDPQPPKSFPLHPQPVTITLKLRNEVVVQAAAVRVSDRNFLDSFHIEGAGALYNHLAGELDPKAIEKMDIDNFVGSTTREVYKELMSHVSSDHLHFDQGPLVEPAADKDWSTFLSSAFLRQEKQPQIINPELVGLYSQRANTLQSNTKKMPSLPSLQATKSWEKWSNKASLMNSWKTTLSVDDYFKYLTNHETDFLHVIFQMHEEEVPVEIVAPARESLEIQHPPPLLEDEEPDFVPGEWDWNTVLEHRLGAGKTPHLGEPHKILSLQKHLEQLWSVLEVPDKDQVDMTIKYSSKARLRQLPSLVNAWERALKPIQLREALLARLEWFEGQASNPNRFFKKTNLSSSHFLEENQVRSHLHRKLNLMESSLVSLLEEIELIFGEPVIFKGRPYLDKMKSDKVEMLYWLQQQRRVRHLVSALKDPHQSTLFRSSAASL>sp|Q86YS7|C2CD5_HUMAN C2 domain-containing protein 5 OS=Homo sapiensOX=9606 GN=C2CD5 PE=1 SV=1MPGKLKVKIVAGRHLPVMDRASDLTDAFVEVKFGNTTFKTDVYLKSLNPQWNSEWFKFEVDDEDLQDEPLQITVLDHDTYSANDAIGKVYIDIDPLLYSEAATVISGWFPIYDTIHGIRGEINVVVKVDLFNDLNRFRQSSCGVKFFCTTSIPKCYRAVIIHGFVEELVVNEDPEYQWIDRIRTPRASNEARQRLISLMSGELQRKIGLKVLEMRGNAVVGYLQCFDLEGESGLVVRAIGTACTLDKLSSPAAFLPACNSPSKEMKEIPFNEDPNPNTHSSGPSTPLKNQTYSFSPSKSYSRQSSSSDTDLSLTPKTGMGSGSAGKEGGPFKALLRQQTQSALEQREFPFFTLTAFPPGFLVHVGGVVSARSVKLLDRIHNPDEPETRDAWWAEIRQEIKSHAKALGCHAVVGYSESTSICEEVCILSASGTAAVLNPRFLQDGTVEGCLEQRLEENLPTRCGFCHIPYDELNMPFPAHLTYCYNCRKQKVPDVLFTTIDLPTDATVIGKGCLIQARLCRLKKKAQAEANATAISNLLPFMEYEVHTQLMNKLKLKGMNALFGLRIQITVGENMLMGLASATGVYLAALPTPGGIQIAGKTPNDGSYEQHISHMQKKINDTIAKNKELYEINPPEISEEIIGSPIPEPRQRSRLLRSQSESSDEVTELDLSHGKKDAFVLEIDDTDAMEDVHSLLTDVPPPSGFYSCNTEIMPGINNWTSEIQMFTSVRVIRLSSLNLTNQALNKNFNDLCENLLKSLYFKLRSMIPCCLCHVNFTVSLPEDELIQVTVTAVAITFDKNQALQTTKTPVEKSLQRASTDNEELLQFPLELCSDSLPSHPFPPAKAMTVEKASPVGDGNFRNRSAPPCANSTVGVVKMTPLSFIPGAKITKYLGIINMFFIRETTSLREEGGVSGFLHAFIAEVFAMVRAHVAALGGNAVVSYIMKQCVFMENPNKNQAQCLINVSGDAVVFVRESDLEVVSSQQPTTNCQSSCTEGEVTT>sp|Q86YS7-2|C2CD5_HUMAN Isoform 2 of C2 domain-containing protein 5OS=Homo sapiens OX=9606 GN=C2CD5MPGKLKVKIVAGRHLPVMDRASDLTDAFVEVKFGNTTFKTDVYLKSLNPQWNSEWFKFEVDDEDLQDEPLQITVLDHDTYSANDAIGKVYIDIDPLLYSEAATVISGWFPIYDTIHGIRGEINVVVKVDLFNDLNRFRQSSCGVKFFCTTSIPKCYRAVIIHGFVEELVVNEDPEYQWIDRIRTPRASNEARQRLISLMSGELQRKIGLKVLEMRGNAVVGYLQCFDLEGESGLVVRAIGTACTLDKLSSPAAFLPACNSPSKEMKESPLVHPPSHGCRSTHNSPIHTATGSRLTQNFSVSVPTLIYTGMGSGSAGKEGGPFKALLRQQTQSALEQREFPFFTLTAFPPGFLVHVGGVVSARSVKLLDRIHNPDEPETRDAWWAEIRQEIKSHAKALGCHAVVGYSESTSICEEVCILSASGTAAVLNPRFLQDGTVEGCLEQRLEENLPTRCGFCHIPYDELNMPFPAHLTYCYNCRKQKVPDVLFTTIDLPTDATVIGKGCLIQARLCRLKKKAQAEANATAISNLLPFMEYEVHTQLMNKLKLKGMNALFGLRIQITVGENMLMGLASATGVYLAALPTPGGIQIAGKTPNDGSYEQHISHMQKKINDTIAKNKELYEINPPEISEEIIGSPIPEPRQRSRLLRSQSESSDEVTELDLSHGKKDAFVLEIDDTDAMEDVHSLLTDVPPPSGFYSCNTEIMPGINNWTSEIQMFTSVRVIRLSSLNLTNQALNKNFNDLCENLLKSLYFKLRSMIPCCLCHVNFTVSLPEDELIQVTVTAVAITFDKNQALQTTKTPVEKSLQRASTDNEELLQFPLELCSDSLPSHPFPPAKEHLESASSNSGIPAAQRATSVDYSSFADRCSSWIELIKLKAQTIRRGSIKTTMTVEKASPVGDGNFRNRSAPPCANSTVGVVKMTPLSFIPGAKITKYLGIINMFFIRETTSLREEGGVSGFLHAFIAEVFAMVRAHVAALGGNAVVSYIMKQCVFMENPNKNQAQCLINVSGDAVVFVRESDLEVVSSQQPTTNCQSSCTEGEVTT>sp|Q86YS7-3|C2CD5_HUMAN Isoform 3 of C2 domain-containing protein 5OS=Homo sapiens OX=9606 GN=C2CD5MPGKLKVKIVAGRHLPVMDRASDLTDAFVEVKFGNTTFKTDVYLKSLNPQWNSEWFKFEVDDEDLQDEPLQITVLDHDTYSANDAIGKVYIDIDPLLYSEAATVISGWFPIYDTIHGIRGEINVVVKVDLFNDLNRFRQSSCGVKFFCTTSIPKCYRAVIIHGFVEELVVNEDPEYQWIDRIRTPRASNEARQRLISLMSGELQRKIGLKVLEMRGNAVVGYLQCFDLEGESGLVVRAIGTACTLDKLSSPAAFLPACNSPSKEMKEIPFNEDPNPNTHSSGPSTPLKNQTYSFSPSKSYSRQSSSSDTDLSLTPKTGMGSGSAGKEGGPFKALLRQQTQSALEQREFPFFTLTAFPPGFLVHVGGVVSARSVKLLDRIHNPDEPETRDAWWAEIRQEIKSHAKALGCHAVVGYSESTSICEEVCILSASGTAAVLNPRFLQDGTVEGCLEQRLEENLPTRCGFCHIPYDELNMPFPAHLTYCYNCRKQKVPDVLFTTIDLPTDATVIGKGCLIQARLCRLKKKAQAEANATAISNLLPFMEYEVHTQLMNKLKLKGMNALFGLRIQITVGENMLMGLASATGVYLAALPTPGGIQIAGKTPNDGSYEQHISHMQKKINDTIAKNKELYEINPPEISEEIIGSPIPEPRQRSRLLRSQSESSDEVTELDLSHGKKDAFVLEIDDTDAMEDVHSLLTDVPPPSGFYSCNTEIMPGINNWTSEIQMFTSVRVIRLSSLNLTNQALNKNFNDLCENLLKSLYFKLRSMIPCCLCHVNFTVSLPEDELIQVTVTAVAITFDKNQALQTTKTPVEKSLQRASTDNEELLQFPLELCSDSLPSHPFPPAKEHLESASSNSGIPAAQRATSVDYSSFADRCSSWIELIKLKAQTIRRGSIKTTMTVEKASPVGDGNFRNRSAPPCANSTVGVVKMTPLSFIPGAKITKYLGIINMFFIRETTSLREEGGVSGFLHAFIAEVFAMVRAHVAALGGNAVVSYIMKQCVFMENPNKNQAQCLINVSGDAVVFVRESDLEVVSSQQPTTNCQSSCTEGEVTT>sp|Q86YS7-4|C2CD5_HUMAN Isoform 4 of C2 domain-containing protein 5OS=Homo sapiens OX=9606 GN=C2CD5MPGKLKVKIVAGRHLPVMDRASDLTDAFVEVKFGNTTFKTDVYLKSLNPQWNSEWFKFEVDDEDLQDEPLQITVLDHDTYSANDAIGKVYIDIDPLLYSEAATVISGWFPIYDTIHGIRGEINVVVKVDLFNDLNRFRQSSCGVKFFCTTSIPKCYRAVIIHGFVEELVVNEDPEYQWIDRIRTPRASNEARQRLISLMSGELQRKIGLKVLEMRGNAVVGYLQCFDLEGESGLVVRAIGTACTLDKLSSPAAFLPACNSPSKEMKESPLVHPPSHGCRSTHNSPIHTATGSRLTQNFSVSVPTLIYTGMGSGSAGKEGGPFKALLRQQTQSALEQRGGSPHRFCRRREFPFFTLTAFPPGFLVHVGGVVSARSVKLLDRIHNPDEPETRDAWWAEIRQEIKSHAKALGCHAVVGYSESTSICEEVCILSASGTAAVLNPRFLQDGTVEGCLEQRLEENLPTRCGFCHIPYDELNMPFPAHLTYCYNCRKQKVPDVLFTTIDLPTDATVIGKGCLIQARLCRLKKKAQAEANATAISNLLPFMEYEVHTQLMNKLKLKGMNALFGLRIQITVGENMLMGLASATGVYLAALPTPGGIQIAGKTPNDGSYEQHISHMQKKINDTIAKNKELYEINPPEISEEIIGSPIPEPRQRSRLLRSQSESSDEVTELDLSHGKKDAFVLEIDDTDAMEDVHSLLTDVPPPSGFYSCNTEIMPGINNWTSEIQMFTSVRVIRLSSLNLTNQALNKNFNDLCENLLKSLYFKLRSMIPCCLCHVNFTVSLPEDELIQVTVTAVAITFDKNQALQTTKTPVEKSLQRASTDNEELLQFPLELCSDSLPSHPFPPAKEHLESASSNSGIPAAQRATSVDYSSFADRCSSWIELIKLKAQTIRRGSIKTTMTVEKASPVGDGNFRNRSAPPCANSTVGVVKMTPLSFIPGAKITKYLGIINMFFIRETTSLREEGGVSGFLHAFIAEVFAMVRAHVAALGGNAVVSYIMKQCVFMENPNKNQAQCLINVSGDAVVFVRESDLEVVSSQQPTTNCQSSCTEGEVTT>sp|Q86YS7-5|C2CD5_HUMAN Isoform 5 of C2 domain-containing protein 5OS=Homo sapiens OX=9606 GN=C2CD5MPGKLKVKIVAGRHLPVMDRASDLTDAFVEVKFGNTTFKTDVYLKSLNPQWNSEWFKFEVDDEDLQDEPLQITVLDHDTYSANDAIGKVYIDIDPLLYSEAATVISGWFPIYDTIHGIRGEINVVVKVDLFNDLNRFRQSSCGVKFFCTTSIPKCYRAVIIHGFVEELVVNEDPEYQWIDRIRTPRASNEARQRLISLMSGELQRKIGLKVLEMRGNAVVGYLQCFDLEGESGLVVRAIGTACTLDKLSSPAAFLPACNSPSKEMKESPLVHPPSHGCRSTHNSPIHTATGSRLTQNFSVSVPTLIYTGMGSGSAGKEGGPFKALLRQQTQSALEQREFPFFTLTAFPPGFLVHVGGVVSARSVKLLDRIHNPAFVGIMGNTRSYKLLDWNSFNSDEPETRDAWWAEIRQEIKSHAKALGCHAVVGYSESTSICEEVCILSASGTAAVLNPRFLQDGTVEGCLEQRLEENLPTRCGFCHIPYDELNMPFPAHLTYCYNCRKQKVPDVLFTTIDLPTDATVIGKGCLIQARLCRLKKKAQAEANATAISNLLPFMEYEVHTQLMNKLKLKGMNALFGLRIQITVGENMLMGLASATGVYLAALPTPGGIQIAGKTPNDGSYEQHISHMQKKINDTIAKNKELYEINPPEISEEIIGSPIPEPRQRSRLLRSQSESSDEVTELDLSHGKKDAFVLEIDDTDAMEDVHSLLTDVPPPSGFYSCNTEIMPGINNWTSEIQMFTSVRVIRLSSLNLTNQALNKNFNDLCENLLKSLYFKLRSMIPCCLCHVNFTVSLPEDELIQVTVTAVAITFDKNQALQTTKTPVEKSLQRASTDNEELLQFPLELCSDSLPSHPFPPAKEHLESASSNSGIPAAQRDRCSSWIELIKLKAQTIRRGSIKTTMTVEKASPVGDGNFRNRSAPPCANSTVGVVKMTPLSFIPGAKITKYLGIINMFFIRETTSLREEGGVSGFLHAFIAEVFAMVRAHVAALGGNAVVSYIMKQCVFMENPNKNQAQCLINVSGDAVVFVRESDLEVVSSQQPTTNCQSSCTEGEVTT>sp|Q9BZZ5|API5_HUMAN Apoptosis inhibitor 5 OS=Homo sapiens OX=9606GN=API5 PE=1 SV=3MPTVEELYRNYGILADATEQVGQHKDAYQVILDGVKGGTKEKRLAAQFIPKFFKHFPELADSAINAQLDLCEDEDVSIRRQAIKELPQFATGENLPRVADILTQLLQTDDSAEFNLVNNALLSIFKMDAKGTLGGLFSQILQGEDIVRERAIKFLSTKLKTLPDEVLTKEVEELILTESKKVLEDVTGEEFVLFMKILSGLKSLQTVSGRQQLVELVAEQADLEQTFNPSDPDCVDRLLQCTRQAVPLFSKNVHSTRFVTYFCEQVLPNLGTLTTPVEGLDIQLEVLKLLAEMSSFCGDMEKLETNLRKLFDKLLEYMPLPPEEAENGENAGNEEPKLQFSYVECLLYSFHQLGRKLPDFLTAKLNAEKLKDFKIRLQYFARGLQVYIRQLRLALQGKTGEALKTEENKIKVVALKITNNINVLIKDLFHIPPSYKSTVTLSWKPVQKVEIGQKRASEDTTSGSPPKKSSAGPKRDARQIYNPPSGKYSSNLGNFNYEQRGAFRGSRGGRGWGTRGNRSRGRLY>sp|Q9BZZ5-1|API5_HUMAN Isoform 1 of Apoptosis inhibitor 5 OS=Homosapiens OX=9606 GN=API5DEDVSIRRQAIKELPQFATGENLPRVADILTQLLQTDDSAEFNLVNNALLSIFKMDAKGTLGGLFSQILQGEDIVRERAIKFLSTKLKTLPDEVLTKEVEELILTESKKVLEDVTGEEFVLFMKILSGLKSLQTVSGRQQLVELVAEQADLEQTFNPSDPDCVDRLLQCTRQAVPLFSKNVHSTRFVTYFCEQVLPNLGTLTTPVEGLDIQLEVLKLLAEMSSFCGDMEKLETNLRKLFDKLLEYMPLPPEEAENGENAGNEEPKLQFSYVECLLYSFHQLGRKLPDFLTAKLNAEKLKDFKIRLQYFARGLQVYIRQLRLALQGKTGEALKTEENKIKVVALKITNNINVLIKDLFHIPPSYKSTVTLSWKPVQKVEIGQKRASEDTTSGSPPKKSSAGPKRDARQIYNPPSGKYSSNLGNFNYGERFRLGTRNMRD>sp|Q9BZZ5-2|API5_HUMAN Isoform 2 of Apoptosis inhibitor 5 OS=Homosapiens OX=9606 GN=API5MPTVEELYRNYGILADATEQVGQHKDAYQVILDGVKGGTKEKRLAAQFIPKFFKHFPELADSAINAQLDLCEDEDVSIRRQAIKELPQFATGENLPRVADILTQLLQTDDSAEFNLVNNALLSIFKMDAKGTLGGLFSQILQGEDIVRERAIKFLSTKLKTLPDEVLTKEVEELILTESKKVLEDVTGEEFVLFMKILSGLKSLQTVSGRQQLVELVAEQADLEQTFNPSDPDCVDRLLQCTRQAVPLFSKNVHSTRFVTYFCEQVLPNLGTLTTPVEGLDIQLEVLKLLAEMSSFCGDMEKLETNLRKLFDKLLEYMPLPPEEAENGENAGNEEPKLQFSYVECLLYSFHQLGRKLPDFLTAKLNAEKLKDFKIRLQYFARGLQVYIRQLRLALQGKTGEALKTEENKIKVVALKITNNINVLIKDLFHIPPSYKSTVTLSWKPVQKVEIGQKRASEDTTSGSPPKKSSAGPKRDARQIYNPPSGKYSSNLGNFNYERSLQGK>sp|Q9BZZ5-3|API5_HUMAN Isoform 3 of Apoptosis inhibitor 5 OS=Homosapiens OX=9606 GN=API5MPTVEELYRNYGILADATEQVGQHKDAYQVILDGVKGGTKEKRLAAQFIPKFFKHFPELADSAINAQLDLCEDEDVSIRRQAIKELPQFATGENLPRVADILTQLLQTDDSAEFNLVNNALLSIFKMDAKGTLGGLFSQILQGEDIVRERAIKFLSTKLKTLPDEVLTKEVEELILTESKKVLEDVTGEEFVLFMKILSGLKSLQTVSGRQQLVELVAEQADLEQTFNPSDPDCVDRLLQCTRQAVPLFSKNVHSTRFVTYFCEQVLPNLGTLTTPVEGLDIQLEVLKLLAEMSSFCGDMEKLETNLRKLFDKLLEYMPLPPEEAENGENAGNEEPKLQFSYVECLLYSFHQLGRKLPDFLTAKLNAEKLKDFKIRLQYFARGLQVYIRQLRLALQGKTGEALKTEENKIKVVALKITNNINVLIKAKESQGWGTRGNRSRGRLY>sp|Q9BZZ5-5|API5_HUMAN Isoform 5 of Apoptosis inhibitor 5 OS=Homosapiens OX=9606 GN=API5MPTVEELYRNYGILADATEQVGQIRRQAIKELPQFATGENLPRVADILTQLLQTDDSAEFNLVNNALLSIFKMDAKGTLGGLFSQILQGEDIVRERAIKFLSTKLKTLPDEVLTKEVEELILTESKKVLEDVTGEEFVLFMKILSGLKSLQTVSGRQQLVELVAEQADLEQTFNPSDPDCVDRLLQCTRQAVPLFSKNVHSTRFVTYFCEQVLPNLGTLTTPVEGLDIQLEVLKLLAEMSSFCGDMEKLETNLRKLFDKLLEYMPLPPEEAENGENAGNEEPKLQFSYVECLLYSFHQLGRKLPDFLTAKLNAEKLKDFKIRLQYFARGLQVYIRQLRLALQGKTGEALKTEENKIKVVALKITNNINVLIKDLFHIPPSYKSTVTLSWKPVQKVEIGQKRASEDTTSGSPPKKSSAGPKRDARQIYNPPSGKYSSNLGNFNYERSLQGK>sp|Q9BZZ5-6|API5_HUMAN Isoform 6 of Apoptosis inhibitor 5 OS=Homosapiens OX=9606 GN=API5MKQRWRENGIGKHKDAYQVILDGVKGGTKEKRLAAQFIPKFFKHFPELADSAINAQLDLCEDEDVSIRRQAIKELPQFATGENLPRVADILTQLLQTDDSAEFNLVNNALLSIFKMDAKGTLGGLFSQILQGEDIVRERAIKFLSTKLKTLPDEVLTKEVEELILTESKKVLEDVTGEEFVLFMKILSGLKSLQTVSGRQQLVELVAEQADLEQTFNPSDPDCVDRLLQCTRQAVPLFSKNVHSTRFVTYFCEQVLPNLGTLTTPVEGLDIQLEVLKLLAEMSSFCGDMEKLETNLRKLFDKLLEYMPLPPEEAENGENAGNEEPKLQFSYVECLLYSFHQLGRKLPDFLTAKLNAEKLKDFKIRLQYFARGLQVYIRQLRLALQGKTGEALKTEENKIKVVALKITNNINVLIKDLFHIPPSYKSTVTLSWKPVQKVEIGQKRASEDTTSGSPPKKSSAGPKRDARQIYNPPSGKYSSNLGNFNYEQRGAFRGSRGGRGWGTRGNRSRGRLY>sp|Q9Y259|CHKB_HUMAN Choline/ethanolamine kinase OS=Homo sapiens OX=9606GN=CHKB PE=1 SV=3MAAEATAVAGSGAVGGCLAKDGLQQSKCPDTTPKRRRASSLSRDAERRAYQWCREYLGGAWRRVQPEELRVYPVSGGLSNLLFRCSLPDHLPSVGEEPREVLLRLYGAILQGVDSLVLESVMFAILAERSLGPQLYGVFPEGRLEQYIPSRPLKTQELREPVLSAAIATKMAQFHGMEMPFTKEPHWLFGTMERYLKQIQDLPPTGLPEMNLLEMYSLKDEMGNLRKLLESTPSPVVFCHNDIQEGNILLLSEPENADSLMLVDFEYSSYNYRGFDIGNHFCEWVYDYTHEEWPFYKARPTDYPTQEQQLHFIRHYLAEAKKGETLSQEEQRKLEEDLLVEVSRYALASHFFWGLWSILQASMSTIEFGYLDYAQSRFQFYFQQKGQLTSVHSSS>sp|Q9Y259-2|CHKB_HUMAN Isoform 2 of Choline/ethanolamine kinase OS=Homosapiens OX=9606 GN=CHKBMAAEATAVAGSGAVGGCLAKDGLQQSKCPDTTPKRRRASSLSRDAERRAYQWCREYLGGAWRRVQPEELRVYPVRWEVRGQPLRCADRGQGSAAGPSGCSMFSPPSCARAWGGAGPAWPGGGRGRGR>sp|Q92974|ARHG2_HUMAN Rho guanine nucleotide exchange factor 2 OS=Homosapiens OX=9606 GN=ARHGEF2 PE=1 SV=4MSRIESLTRARIDRSRELASKTREKEKMKEAKDARYTNGHLFTTISVSGMTMCYACNKSITAKEALICPTCNVTIHNRCKDTLANCTKVKQKQQKAALLKNNTALQSVSLRSKTTIRERPSSAIYPSDSFRQSLLGSRRGRSSLSLAKSVSTTNIAGHFNDESPLGLRRILSQSTDSLNMRNRTLSVESLIDEAEVIYSELMSDFEMDEKDFAADSWSLAVDSSFLQQHKKEVMKQQDVIYELIQTELHHVRTLKIMTRLFRTGMLEELHLEPGVVQGLFPCVDELSDIHTRFLSQLLERRRQALCPGSTRNFVIHRLGDLLISQFSGPSAEQMCKTYSEFCSRHSKALKLYKELYARDKRFQQFIRKVTRPAVLKRHGVQECILLVTQRITKYPLLISRILQHSHGIEEERQDLTTALGLVKELLSNVDEGIYQLEKGARLQEIYNRMDPRAQTPVPGKGPFGREELLRRKLIHDGCLLWKTATGRFKDVLVLLMTDVLVFLQEKDQKYIFPTLDKPSVVSLQNLIVRDIANQEKGMFLISAAPPEMYEVHTASRDDRSTWIRVIQQSVRTCPSREDFPLIETEDEAYLRRIKMELQQKDRALVELLREKVGLFAEMTHFQAEEDGGSGMALPTLPRGLFRSESLESPRGERLLQDAIREVEGLKDLLVGPGVELLLTPREPALPLEPDSGGNTSPGVTANGEARTFNGSIELCRADSDSSQRDRNGNQLRSPQEEALQRLVNLYGLLHGLQAAVAQQDTLMEARFPEGPERREKLCRANSRDGEAGRAGAAPVAPEKQATELALLQRQHALLQEELRRCRRLGEERATEAGSLEARLRESEQARALLEREAEEARRQLAALGQTEPLPAEAPWARRPVDPRRRSLPAGDALYLSFNPPQPSRGTDRLDLPVTTRSVHRNFEDRERQELGSPEERLQDSSDPDTGSEEEGSSRLSPPHSPRDFTRMQDIPEETESRDGEAVASES>sp|Q92974-2|ARHG2_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor 2 OS=Homo sapiens OX=9606 GN=ARHGEF2MSRIESLTRARIDRSRELASKTREKEKMKEAKDARYTNGHLFTTISVSGMTMCYACNKSITAKEALICPTCNVTIHNRCKDTLANCTKVKQKQQKAALLKNNTALQSVSLRSKTTIRERPSSAIYPSDSFRQSLLGSRRGRSSLSLAKSVSTTNIAGHFNDESPLGLRRILSQSTDSLNMRNRTLSVESLIDEEVIYSELMSDFEMDEKDFAADSWSLAVDSSFLQQHKKEVMKQQDVIYELIQTELHHVRTLKIMTRLFRTGMLEELHLEPGVVQGLFPCVDELSDIHTRFLSQLLERRRQALCPGSTRNFVIHRLGDLLISQFSGPSAEQMCKTYSEFCSRHSKALKLYKELYARDKRFQQFIRKVTRPAVLKRHGVQECILLVTQRITKYPLLISRILQHSHGIEEERQDLTTALGLVKELLSNVDEGIYQLEKGARLQEIYNRMDPRAQTPVPGKGPFGREELLRRKLIHDGCLLWKTATGRFKDVLVLLMTDVLVFLQEKDQKYIFPTLDKPSVVSLQNLIVRDIANQEKGMFLISAAPPEMYEVHTASRDDRSTWIRVIQQSVRTCPSREDFPLIETEDEAYLRRIKMELQQKDRALVELLREKVGLFAEMTHFQAEEDGGSGMALPTLPRGLFRSESLESPRGERLLQDAIREVEGLKDLLVGPGVELLLTPREPALPLEPDSGGNTSPGVTANGEARTFNGSIELCRADSDSSQRDRNGNQLRSPQEEALQRLVNLYGLLHGLQAAVAQQDTLMEARFPEGPERREKLCRANSRDGEAGRAGAAPVAPEKQATELALLQRQHALLQEELRRCRRLGEERATEAGSLEARLRESEQARALLEREAEEARRQLAALGQTEPLPAEAPWARRPVDPRRRSLPAGDALYLSFNPPQPSRGTDRLDLPVTTRSVHRNFEDRERQELGSPEERLQDSSDPDTGSEEEGSSRLSPPHSPRDFTRMQDIPEETESRDGEAVASES>sp|Q92974-3|ARHG2_HUMAN Isoform 3 of Rho guanine nucleotide exchangefactor 2 OS=Homo sapiens OX=9606 GN=ARHGEF2MKEAKDARYTNGHLFTTISVSGMTMCYACNKSITAKEALICPTCNVTIHNRCKDTLANCTKVKQKQQKAALLKNNTALQSVSLRSKTTIRERPSSAIYPSDSFRQSLLGSRRGRSSLSLAKSVSTTNIAGHFNDESPLGLRRILSQSTDSLNMRNRTLSVESLIDEEVIYSELMSDFEMDEKDFAADSWSLAVDSSFLQQHKKEVMKQQDVIYELIQTELHHVRTLKIMTRLFRTGMLEELHLEPGVVQGLFPCVDELSDIHTRFLSQLLERRRQALCPGSTRNFVIHRLGDLLISQFSGPSAEQMCKTYSEFCSRHSKALKLYKELYARDKRFQQFIRKVTRPAVLKRHGVQECILLVTQRITKYPLLISRILQHSHGIEEERQDLTTALGLVKELLSNVDEGIYQLEKGARLQEIYNRMDPRAQTPVPGKGPFGREELLRRKLIHDGCLLWKTATGRFKDVLVLLMTDVLVFLQEKDQKYIFPTLDKPSVVSLQNLIVRDIANQEKGMFLISAAPPEMYEVHTASRDDRSTWIRVIQQSVRTCPSREDFPLIETEDEAYLRRIKMELQQKDRALVELLREKVGLFAEMTHFQAEEDGGSGMALPTLPRGLFRSESLESPRGERLLQDAIREVEGLKDLLVGPGVELLLTPREPALPLEPDSGGNTSPGVTANGEARTFNGSIELCRADSDSSQRDRNGNQLRSPQEEALQRLVNLYGLLHGLQAAVAQQDTLMEARFPEGPERREKLCRANSRDGEAGRAGAAPVAPEKQATELALLQRQHALLQEELRRCRRLGEERATEAGSLEARLRESEQARALLEREAEEARRQLAALGQTEPLPAEAPWARRPVDPRRRSLPAGDALYLSFNPPQPSRGTDRLDLPVTTRSVHRNFEDRERQELGSPEERLQDSSDPDTGSEEEGSSRLSPPHSPRDFTRMQDIPEETESRDGEAVASES>sp|P63010|AP2B1_HUMAN AP-2 complex subunit beta OS=Homo sapiens OX=9606GN=AP2B1 PE=1 SV=1MTDSKYFTTNKKGEIFELKAELNNEKKEKRKEAVKKVIAAMTVGKDVSSLFPDVVNCMQTDNLELKKLVYLYLMNYAKSQPDMAIMAVNSFVKDCEDPNPLIRALAVRTMGCIRVDKITEYLCEPLRKCLKDEDPYVRKTAAVCVAKLHDINAQMVEDQGFLDSLRDLIADSNPMVVANAVAALSEISESHPNSNLLDLNPQNINKLLTALNECTEWGQIFILDCLSNYNPKDDREAQSICERVTPRLSHANSAVVLSAVKVLMKFLELLPKDSDYYNMLLKKLAPPLVTLLSGEPEVQYVALRNINLIVQKRPEILKQEIKVFFVKYNDPIYVKLEKLDIMIRLASQANIAQVLAELKEYATEVDVDFVRKAVRAIGRCAIKVEQSAERCVSTLLDLIQTKVNYVVQEAIVVIRDIFRKYPNKYESIIATLCENLDSLDEPDARAAMIWIVGEYAERIDNADELLESFLEGFHDESTQVQLTLLTAIVKLFLKKPSETQELVQQVLSLATQDSDNPDLRDRGYIYWRLLSTDPVTAKEVVLSEKPLISEETDLIEPTLLDELICHIGSLASVYHKPPNAFVEGSHGIHRKHLPIHHGSTDAGDSPVGTTTATNLEQPQVIPSQGDLLGDLLNLDLGPPVNVPQVSSMQMGAVDLLGGGLDSLVGQSFIPSSVPATFAPSPTPAVVSSGLNDLFELSTGIGMAPGGYVAPKAVWLPAVKAKGLEISGTFTHRQGHIYMEMNFTNKALQHMTDFAIQFNKNSFGVIPSTPLAIHTPLMPNQSIDVSLPLNTLGPVMKMEPLNNLQVAVKNNIDVFYFSCLIPLNVLFVEDGKMERQVFLATWKDIPNENELQFQIKECHLNADTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLTNGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN>sp|P63010-2|AP2B1_HUMAN Isoform 2 of AP-2 complex subunit beta OS=Homosapiens OX=9606 GN=AP2B1MTDSKYFTTNKKGEIFELKAELNNEKKEKRKEAVKKVIAAMTVGKDVSSLFPDVVNCMQTDNLELKKLVYLYLMNYAKSQPDMAIMAVNSFVKDCEDPNPLIRALAVRTMGCIRVDKITEYLCEPLRKCLKDEDPYVRKTAAVCVAKLHDINAQMVEDQGFLDSLRDLIADSNPMVVANAVAALSEISESHPNSNLLDLNPQNINKLLTALNECTEWGQIFILDCLSNYNPKDDREAQSICERVTPRLSHANSAVVLSAVKVLMKFLELLPKDSDYYNMLLKKLAPPLVTLLSGEPEVQYVALRNINLIVQKRPEILKQEIKVFFVKYNDPIYVKLEKLDIMIRLASQANIAQVLAELKEYATEVDVDFVRKAVRAIGRCAIKVEQSAERCVSTLLDLIQTKVNYVVQEAIVVIRDIFRKYPNKYESIIATLCENLDSLDEPDARAAMIWIVGEYAERIDNADELLESFLEGFHDESTQVQLTLLTAIVKLFLKKPSETQELVQQVLSLATQDSDNPDLRDRGYIYWRLLSTDPVTAKEVVLSEKPLISEETDLIEPTLLDELICHIGSLASVYHKPPNAFVEGSHGIHRKHLPIHHGSTDAGDSPVGTTTATNLEQPQVIPSQGDLLGDLLNLDLGPPVNVPQVSSMQMGAVDLLGGGLDSLLGSDLGGGIGGSPAVGQSFIPSSVPATFAPSPTPAVVSSGLNDLFELSTGIGMAPGGYVAPKAVWLPAVKAKGLEISGTFTHRQGHIYMEMNFTNKALQHMTDFAIQFNKNSFGVIPSTPLAIHTPLMPNQSIDVSLPLNTLGPVMKMEPLNNLQVAVKNNIDVFYFSCLIPLNVLFVEDGKMERQVFLATWKDIPNENELQFQIKECHLNADTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLTNGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN>sp|P63010-3|AP2B1_HUMAN Isoform 3 of AP-2 complex subunit beta OS=Homosapiens OX=9606 GN=AP2B1MQTDNLELKKLVYLYLMNYAKSQPDMAIMAVNSFVKDCEDPNPLIRALAVRTMGCIRVDKITEYLCEPLRKCLKDEDPYVRKTAAVCVAKLHDINAQMVEDQGFLDSLRDLIADSNPMVVANAVAALSEISESHPNSNLLDLNPQNINKLLTALNECTEWGQIFILDCLSNYNPKDDREAQSICERVTPRLSHANSAVVLSAVKVLMKFLELLPKDSDYYNMLLKKLAPPLVTLLSGEPEVQYVALRNINLIVQKRPEILKQEIKVFFVKYNDPIYVKLEKLDIMIRLASQANIAQVLAELKEYATEVDVDFVRKAVRAIGRCAIKVEQSAERCVSTLLDLIQTKVNYVVQEAIVVIRDIFRKYPNKYESIIATLCENLDSLDEPDARAAMIWIVGEYAERIDNADELLESFLEGFHDESTQVQLTLLTAIVKLFLKKPSETQELVQQVLSLATQDSDNPDLRDRGYIYWRLLSTDPVTAKEVVLSEKPLISEETDLIEPTLLDELICHIGSLASVYHKPPNAFVEGSHGIHRKHLPIHHGSTDAGDSPVGTTTATNLEQPQVIPSQGDLLGDLLNLDLGPPVNVPQVSSMQMGAVDLLGGGLDSLVGQSFIPSSVPATFAPSPTPAVVSSGLNDLFELSTGIGMAPGGYVAPKAVWLPAVKAKGLEISGTFTHRQGHIYMEMNFTNKALQHMTDFAIQFNKNSFGVIPSTPLAIHTPLMPNQSIDVSLPLNTLGPVMKMEPLNNLQVAVKNNIDVFYFSCLIPLNVLFVEDGKMERQVFLATWKDIPNENELQFQIKECHLNADTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLTNGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN>sp|P15391|CD19_HUMAN B-lymphocyte antigen CD19 OS=Homo sapiens OX=9606GN=CD19 PE=1 SV=6MPPPRLLFFLLFLTPMEVRPEEPLVVKVEEGDNAVLQCLKGTSDGPTQQLTWSRESPLKPFLKLSLGLPGLGIHMRPLAIWLFIFNVSQQMGGFYLCQPGPPSEKAWQPGWTVNVEGSGELFRWNVSDLGGLGCGLKNRSSEGPSSPSGKLMSPKLYVWAKDRPEIWEGEPPCLPPRDSLNQSLSQDLTMAPGSTLWLSCGVPPDSVSRGPLSWTHVHPKGPKSLLSLELKDDRPARDMWVMETGLLLPRATAQDAGKYYCHRGNLTMSFHLEITARPVLWHWLLRTGGWKVSAVTLAYLIFCLCSLVGILHLQRALVLRRKRKRMTDPTRRFFKVTPPPGSGPQNQYGNVLSLPTPTSGLGRAQRWAAGLGGTAPSYGNPSSDVQADGALGSRSPPGVGPEEEEGEGYEEPDSEEDSEFYENDSNLGQDQLSQDGSGYENPEDEPLGPEDEDSFSNAESYENEDEELTQPVARTMDFLSPHGSAWDPSREATSLGSQSYEDMRGILYAAPQLRSIRGQPGPNHEEDADSYENMDNPDGPDPAWGGGGRMGTWSTR>sp|P15391-2|CD19_HUMAN Isoform 2 of B-lymphocyte antigen CD19 OS=Homosapiens OX=9606 GN=CD19MPPPRLLFFLLFLTPMEVRPEEPLVVKVEEGDNAVLQCLKGTSDGPTQQLTWSRESPLKPFLKLSLGLPGLGIHMRPLAIWLFIFNVSQQMGGFYLCQPGPPSEKAWQPGWTVNVEGSGELFRWNVSDLGGLGCGLKNRSSEGPSSPSGKLMSPKLYVWAKDRPEIWEGEPPCLPPRDSLNQSLSQDLTMAPGSTLWLSCGVPPDSVSRGPLSWTHVHPKGPKSLLSLELKDDRPARDMWVMETGLLLPRATAQDAGKYYCHRGNLTMSFHLEITARPVLWHWLLRTGGWKVSAVTLAYLIFCLCSLVGILHLQRALVLRRKRKRMTDPTRRFFKVTPPPGSGPQNQYGNVLSLPTPTSGLGRAQRWAAGLGGTAPSYGNPSSDVQADGALGSRSPPGVGPEEEEGEGYEEPDSEEDSEFYENDSNLGQDQLSQDGSGYENPEDEPLGPEDEDSFSNAESYENEDEELTQPVARTMDFLSPHGSAWDPSREATSLAGSQSYEDMRGILYAAPQLRSIRGQPGPNHEEDADSYENMDNPDGPDPAWGGGGRMGTWSTR>sp|Q9Y6K0|CEPT1_HUMAN Choline/ethanolaminephosphotransferase 1 OS=Homosapiens OX=9606 GN=CEPT1 PE=1 SV=1MSGHRSTRKRCGDSHPESPVGFGHMSTTGCVLNKLFQLPTPPLSRHQLKRLEEHRYQSAGRSLLEPLMQGYWEWLVRRVPSWIAPNLITIIGLSINICTTILLVFYCPTATEQAPLWAYIACACGLFIYQSLDAIDGKQARRTNSSSPLGELFDHGCDSLSTVFVVLGTCIAVQLGTNPDWMFFCCFAGTFMFYCAHWQTYVSGTLRFGIIDVTEVQIFIIIMHLLAVIGGPPFWQSMIPVLNIQMKIFPALCTVAGTIFSCTNYFRVIFTGGVGKNGSTIAGTSVLSPFLHIGSVITLAAMIYKKSAVQLFEKHPCLYILTFGFVSAKITNKLVVAHMTKSEMHLHDTAFIGPALLFLDQYFNSFIDEYIVLWIALVFSFFDLIRYCVSVCNQIASHLHIHVFRIKVSTAHSNHH>sp|Q00532|CDKL1_HUMAN Cyclin-dependent kinase-like 1 OS=Homo sapiensOX=9606 GN=CDKL1 PE=1 SV=6MMEKYEKIGKIGEGSYGVVFKCRNRDTGQIVAIKKFLESEDDPVIKKIALREIRMLKQLKHPNLVNLLEVFRRKRRLHLVFEYCDHTVLHELDRYQRGVPEHLVKSITWQTLQAVNFCHKHNCIHRDVKPENILITKHSVIKLCDFGFARLLAGPSDYYTDYVATRWYRSPELLVGDTQYGPPVDVWAIGCVFAELLSGVPLWPGKSDVDQLYLIRKTLGDLIPRHQQVFSTNQYFSGVKIPDPEDMEPLELKFPNISYPALGLLKGCLHMDPTQRLTCEQLLHHPYFENIREIEDLAKEHNKPTRKTLRKSRKHHCFTETSKLQYLPQLTGSSILPALDNKKYYCDTKKLNYRFPNI>sp|Q00532-2|CDKL1_HUMAN Isoform 2 of Cyclin-dependent kinase-like 1OS=Homo sapiens OX=9606 GN=CDKL1MMELSTDTGWNQKSNFPPCDSRVSKEEAQLPFPTPSSYGADSSNQTYAHKSQSEREQHKEVRAVLNHCSGLDGGEESGLCGTSTRIDAGTGNGTDDKVTDQHRHRRCLQGTKGNNRGSEVWGLLLQGNVDRSGGAPSAGVLLRRRGYSCALHGLRKFANLAGLLSRQQDSARGVSHHSRLKIHFKKIYSSMMEKYEKIGKIGEGSYGVVFKCRNRDTGQIVAIKKFLESEDDPVIKKIALREIRMLKAPSPYAAEPSLCGMKMVRRGKKEFLPAVAEKVDAPSGVGGQGQDSVTVGSLGRRSTYGRKQEKQVRQREGIIYCYVAVLLRIYYFDQGCVAREEEQFQELVFGPFCHIGSYFTGHRTNVRPYILLLSRPSPFKTAAGTYEAGLVILECSYFLAEQEPYCPTQALQQPHPIIGPWALEGGGVESKEDRHPPPKEAPASCEGFLRSAVPKQAYTPFKTSPDKRLSDCVATPPWAPPTPLIISSGVLVAICSMIDPVPEFHSEGLLAKATSGSAGILVWIFLCNDAFIYGKYILRSGVLWVRGLPGFKSEAAALCHKCYSSADPKREQQQDLLQRVKEQSFHSVNGAQARHKGSPSPHQTQEPSWPHPVDPTPGHRWSCLPVPCRAPALLSPWVVDGTGCCGAGGGSDRGGSAAQEPTQLKHPNLVNLLEVFRRKRRLHLVFEYCDHTVLHELDRYQRGICNIFVCTGRRLGEHTEALSKKKKKGGGGPFLKLRAASCRITLFKNVGCGLETTGDLSLNSGGGAASRGVAAALRALVCGTELTSSDSPQRCIHRDVKPENILITKHSVIKLCDFGFARLLAGPSDYYTDYVATRWYRSPELLVGDTQYGPPVDVWAIGCVFAELLSGVPLWPGKSDVDQLYLIRKTLGDLIPRHQQVFSTNQYFSGVKIPDPEDMSLCLSVTLTEGGLLASGAVKRSQMGSSVSQATSWPHPDIVAETAELDDIAMARQTPVMLRFNRQKEQEKYLSYGA>sp|Q00532-3|CDKL1_HUMAN Isoform 3 of Cyclin-dependent kinase-like 1OS=Homo sapiens OX=9606 GN=CDKL1MMEKYEKIGKIGEGSYGVVFKCRNRDTGQIVAIKKFLESEDDPVIKKIALREIRMLKQLKHPNLVNLLEVFRRKRRLHLVFEYCDHTVLHELDRYQRGVPEHLVKSITWQTLQAVNFCHKHNCIHRDVKPENILITKHSVIKLCDFGFARLLAGPSDYYTDYVATRWYRSPELLVGDTQYGPPVDVWAIGCVFAELLSGVPLWPGKSDVDQLYLIRKTLGDLIPRHQQVFSTNQYFSGVKIPDPEDMEPLELKFPNISYPALGLLKGRVPIASRTE>sp|O14617|AP3D1_HUMAN AP-3 complex subunit delta-1 OS=Homo sapiensOX=9606 GN=AP3D1 PE=1 SV=1MALKMVKGSIDRMFDKNLQDLVRGIRNHKEDEAKYISQCIDEIKQELKQDNIAVKANAVCKLTYLQMLGYDISWAAFNIIEVMSASKFTFKRIGYLAASQSFHEGTDVIMLTTNQIRKDLSSPSQYDTGVALTGLSCFVTPDLARDLANDIMTLMSHTKPYIRKKAVLIMYKVFLKYPESLRPAFPRLKEKLEDPDPGVQSAAVNVICELARRNPKNYLSLAPLFFKLMTSSTNNWVLIKIIKLFGALTPLEPRLGKKLIEPLTNLIHSTSAMSLLYECVNTVIAVLISLSSGMPNHSASIQLCVQKLRILIEDSDQNLKYLGLLAMSKILKTHPKSVQSHKDLILQCLDDKDESIRLRALDLLYGMVSKKNLMEIVKKLMTHVDKAEGTTYRDELLTKIIDICSQSNYQYITNFEWYISILVELTRLEGTRHGHLIAAQMLDVAIRVKAIRKFAVSQMSALLDSAHLLASSTQRNGICEVLYAAAWICGEFSEHLQEPHHTLEAMLRPRVTTLPGHIQAVYVQNVVKLYASILQQKEQAGEAEGAQAVTQLMVDRLPQFVQSADLEVQERASCILQLVKHIQKLQAKDVPVAEEVSALFAGELNPVAPKAQKKVPVPEGLDLDAWINEPLSDSESEDERPRAVFHEEEQRRPKHRPSEADEEELARRREARKQEQANNPFYIKSSPSPQKRYQDTPGVEHIPVVQIDLSVPLKVPGLPMSDQYVKLEEERRHRQKLEKDKRRKKRKEKEKKGKRRHSSLPTESDEDIAPAQQVDIVTEEMPENALPSDEDDKDPNDPYRALDIDLDKPLADSEKLPIQKHRNTETSKSPEKDVPMVEKKSKKPKKKEKKHKEKERDKEKKKEKEKKKSPKPKKKKHRKEKEERTKGKKKSKKQPPGSEEAAGEPVQNGAPEEEQLPPESSYSLLAENSYVKMTCDIRGSLQEDSQVTVAIVLENRSSSILKGMELSVLDSLNARMARPQGSSVHDGVPVPFQLPPGVSNEAQYVFTIQSIVMAQKLKGTLSFIAKNDEGATHEKLDFRLHFSCSSYLITTPCYSDAFAKLLESGDLSMSSIKVDGIRMSFQNLLAKICFHHHFSVVERVDSCASMYSRSIQGHHVCLLVKKGENSVSVDGKCSDSTLLSNLLEEMKATLAKC>sp|O14617-2|AP3D1_HUMAN Isoform 2 of AP-3 complex subunit delta-1OS=Homo sapiens OX=9606 GN=AP3D1MALKMVKGSIDRMFDKNLQDLVRGIRNHKEDEAKYISQCIDEIKQELKQDNIAVKANAVCKLTYLQMLGYDISWAAFNIIEVMSASKFTFKRIGYLAASQSFHEGTDVIMLTTNQIRKDLSSPSQYDTGVALTGLSCFVTPDLARDLANDIMTLMSHTKPYIRKKAVLIEPLTNLIHSTSAMSLLYECVNTVIAVLISLSSGMPNHSASIQLCVQKLRILIEDSDQNLKYLGLLAMSKILKTHPKSVQSHKDLILQCLDDKDESIRLRALDLLYGMVSKKNLMEIVKKLMTHVDKAEGTTYRDELLTKIIDICSQSNYQYITNFEWYISILVELTRLEGTRHGHLIAAQMLDVAIRVKAIRKFAVSQMSALLDSAHLLASSTQRNGICEVLYAAAWICGEFSEHLQEPHHTLEAMLRPRVTTLPGHIQAVYVQNVVKLYASILQQKEQAGEAEGAQAVTQLMVDRLPQFVQSADLEVQERASCILQLVKHIQKLQAKDVPVAEEVSALFAGELNPVAPKAQKKVPVPEGLDLDAWINEPLSDSESEDERPRAVFHEEEQRRPKHRPSEADEEELARRREARKQEQANNPFYIKSSPSPQKRYQDTPGVEHIPVVQIDLSVPLKVPGLPMSDQYVKLEEERRHRQKLEKDKRRKKRKEKEKKGKRRHSSLPTESDEDIAPAQQVDIVTEEMPENALPSDEDDKDPNDPYRALDIDLDKPLADSEKLPIQKHRNTETSKSPEKDVPMVEKKSKKPKKKEKKHKEKERDKEKKKEKEKKAEDLDFWLSTTPPPAPAPAPAPVPSTDECEDAKTEAQGEEDDAEGQDQDKKSPKPKKKKHRKEKEERTKGKKKSKKQPPGSEEAAGEPVQNGAPEEEQLPPESSYSLLAENSYVKMTCDIRGSLQEDSQVTVAIVLENRSSSILKGMELSVLDSLNARMARPQGSSVHDGVPVPFQLPPGVSNEAQYVFTIQSIVMAQKLKGTLSFIAKNDEGATHEKLDFRLHFSCSSYLITTPCYSDAFAKLLESGDLSMSSIKVDGIRMSFQNLLAKICFHHHFSVVERVDSCASMYSRSIQGHHVCLLVKKGENSVSVDGKCSDSTLLSNLLEEMKATLAKC>sp|O14617-3|AP3D1_HUMAN Isoform 3 of AP-3 complex subunit delta-1OS=Homo sapiens OX=9606 GN=AP3D1MALKMVKGSIDRMFDKNLQDLVRGIRNHKEDEAKYISQCIDEIKQELKQDNIAVKANAVCKLTYLQMLGYDISWAAFNIIEVMSASKFTFKRIGYLAASQSFHEGTDVIMLTTNQIVLISLSSGMPNHSASIQLCVQKLRILIEDSDQNLKYLGLLAMSKILKTHPKSVQSHKDLILQCLDDKDESIRLRALDLLYGMVSKKNLMEIVKKLMTHVDKAEGTTYRDELLTKIIDICSQSNYQYITNFEWYISILVELTRLEGTRHGHLIAAQMLDVAIRVKAIRKFAVSQMSALLDSAHLLASSTQRNGICEVLYAAAWICGEFSEHLQEPHHTLEAMLRPRVTTLPGHIQAVYVQNVVKLYASILQQKEQAGEAEGAQAVTQLMVDRLPQFVQSADLEVQERASCILQLVKHIQKLQAKDVPVAEEVSALFAGELNPVAPKAQKKVPVPEGLDLDAWINEPLSDSESEDERPRAVFHEEEQRRPKHRPSEADEEELARRREARKQEQANNPFYIKSSPSPQKRYQDTPGVEHIPVVQIDLSVPLKVPGLPMSDQYVKLEEERRHRQKLEKDKRRKKRKEKEKKGKRRHSSLPTESDEDIAPAQQVDIVTEEMPENALPSDEDDKDPNDPYRALDIDLDKPLADSEKLPIQKHRNTETSKSPEKDVPMVEKKSKKPKKKEKKHKEKERDKEKKKEKEKKKSPKPKKKKHRKEKEERTKGKKKSKKQPPGSEEAAGEPVQNGAPEEEQLPPESSYSLLAENSYVKMTCDIRGSLQEDSQVTVAIVLENRSSSILKGMELSVLDSLNARMARPQGSSVHDGVPVPFQLPPGVSNEAQYVFTIQSIVMAQKLKGTLSFIAKNDEGATHEKLDFRLHFSCSSYLITTPCYSDAFAKLLESGDLSMSSIKVDGIRMSFQNLLAKICFHHHFSVVERVDSCASMYSRSIQGHHVCLLVKKGENSVSVDGKCSDSTLLSNLLEEMKATLAKC>sp|O14617-4|AP3D1_HUMAN Isoform 4 of AP-3 complex subunit delta-1OS=Homo sapiens OX=9606 GN=AP3D1MALKMVKGSIDRMFDKNLQDLVRGIRNHKEDEAKYISQCIDEIKQELKQDNIAVKANAVCKLTYLQMLGYDISWAAFNIIEVMSASKFTFKRIGYLAASQSFHEGTDVIMLTTNQIRKDLSSPSQYDTGVALTGLSCFVTPDLARDLANDIMTLMSHTKPYIRKKAVLIMYKVFLKYPESLRPAFPRLKEKLEDPDPGVQSAAVNVICELARRNPKNYLSLAPLFFKLMTSSTNNWVLIKIIKLFGALTPLEPRLGKKLIEPLTNLIHSTSAMSLLYECVNTVIAVLISLSSGMPNHSASIQLCVQKLRILIEDSDQNLKYLGLLAMSKILKTHPKSVQSHKDLILQCLDDKDESIRLRALDLLYGMVSKKNLMEIVKKLMTHVDKAEGTTYRDELLTKIIDICSQSNYQYITNFEWYISILVELTRLEGTRHGHLIAAQMLDVAIRVKAIRKFAVSQMSALLDSAHLLASSTQRNGICEVLYAAAWICGEFSEHLQEPHHTLEAMLRPRVTTLPGHIQAVYVQNVVKLYASILQQKEQAGEAEGAQAVTQLMVDRLPQFVQSADLEVQERASCILQLVKHIQKLQAKDVPVAEEVSALFAGELNPVAPKAQKKVPVPEGLDLDAWINEPLSDSESEDERPRAVFHEEEQRRPKHRPSEADEEELARRREARKQEQANNPFYIKSSPSPQKRYQDTPGVEHIPVVQIDLSVPLKVPGLPMSDQYVKLEEERRHRQKLEKDKRRKKRKEKEERTKGKKKSKKQPPGSEEAAGEPVQNGAPEEEQLPPESSYSLLAENSYVKMTCDIRGSLQEDSQVTVAIVLENRSSSILKGMELSVLDSLNARMARPQGSSVHDGVPVPFQLPPGVSNEAQYVFTIQSIVMAQKLKGTLSFIAKNDEGATHEKLDFRLHFSCSSYLITTPCYSDAFAKLLESGDLSMSSIKVDGIRMSFQNLLAKICFHHHFSVVERVDSCASMYSRSIQGHHVCLLVKKGENSVSVDGKCSDSTLLSNLLEEMKATLAKC>sp|O14617-5|AP3D1_HUMAN Isoform 5 of AP-3 complex subunit delta-1OS=Homo sapiens OX=9606 GN=AP3D1MALKMVKGSIDRMFDKNLQDLVRGIRNHKEDEAKYISQCIDEIKQELKQDNIAVKANAVCKLTYLQMLGYDISWAAFNIIEVMSASKFTFKRIGYLAASQSFHEGTDVIMLTTNQIRKDLSSPSQYDTGVALTGLSCFVTPDLARDLANDIMTLMSHTKPYIRKKAVLIMYKVFLKYPESLRPAFPRLKEKLEDPDPGVQSAAVNVICELARRNPKNYLSLAPLFFKLMTSSTNNWVLIKIIKLFGALTPLEPRLGKKLIEPLTNLIHSTSAMSLLYECVNTVIAVLISLSSGMPNHSASIQLCVQKLRILIEDSDQNLKYLGLLAMSKILKTHPKSVQSHKDLILQCLDDKDESIRLRALDLLYGMVSKKNLMEIVKKLMTHVDKAEGTTYRDELLTKIIDICSQSNYQYITNFEWYISILVELTRLEGTRHGHLIAAQMLDVAIRVKAIRKFAVSQMSALLDSAHLLASSTQRNGICEVLYAAAWICGEFSEHLQEPHHTLEAMLRPRVTTLPGHIQAVYVQNVVKLYASILQQKEQAGEAEGAQAVTQLMVDRLPQFVQSADLEVQERASCILQLVKHIQKLQAKDVPVAEEVSALFAGELNPVAPKAQKKVPVPEGLDLDAWINEPLSDSESEDERPRAVFHEEEQRRPKHRPSEADEEELARRREARKQEQANNPFYIKSSPSPQKRYQDTPGVEHIPVVQIDLSVPLKVPGLPMSDQYVKLEEERRHRQKLEKDKRRKKRKEKEKKGKRRHSSLPTESDEDIAPAQQVDIVTEEMPENALPSDEDDKDPNDPYRALDIDLDKPLADSEKLPIQKHRNTETSKSPEKDVPMVEKKSKKPKKKEKKHKEKERDKEKKKEKEKKAEDLDFWLSTTPPPAPAPAPAPVPSTGELSVNTVTTPKDECEDAKTEAQGEEDDAEGQDQDKKSPKPKKKKHRKEKEERTKGKKKSKKQPPGSEEAAGEPVQNGAPEEEQLPPESSYSLLAENSYVKMTCDIRGSLQEDSQVTVAIVLENRSSSILKGMELSVLDSLNARMARPQGSSVHDGVPVPFQLPPGVSNEAQYVFTIQSIVMAQKLKGTLSFIAKNDEGATHEKLDFRLHFSCSSYLITTPCYSDAFAKLLESGDLSMSSIKVDGIRMSFQNLLAKICFHHHFSVVERVDSCASMYSRSIQGHHVCLLVKKGENSVSVDGKCSDSTLLSNLLEEMKATLAKC>sp|P28906|CD34_HUMAN Hematopoietic progenitor cell antigen CD34 OS=Homosapiens OX=9606 GN=CD34 PE=1 SV=2MLVRRGARAGPRMPRGWTALCLLSLLPSGFMSLDNNGTATPELPTQGTFSNVSTNVSYQETTTPSTLGSTSLHPVSQHGNEATTNITETTVKFTSTSVITSVYGNTNSSVQSQTSVISTVFTTPANVSTPETTLKPSLSPGNVSDLSTTSTSLATSPTKPYTSSSPILSDIKAEIKCSGIREVKLTQGICLEQNKTSSCAEFKKDRGEGLARVLCGEEQADADAGAQVCSLLLAQSEVRPQCLLLVLANRTEISSKLQLMKKHQSDLKKLGILDFTEQDVASHQSYSQKTLIALVTSGALLAVLGITGYFLMNRRSWSPTGERLGEDPYYTENGGGQGYSSGPGTSPEAQGKASVNRGAQENGTGQATSRNGHSARQHVVADTEL>sp|P28906-2|CD34_HUMAN Isoform CD34-T of Hematopoietic progenitor cellantigen CD34 OS=Homo sapiens OX=9606 GN=CD34MLVRRGARAGPRMPRGWTALCLLSLLPSGFMSLDNNGTATPELPTQGTFSNVSTNVSYQETTTPSTLGSTSLHPVSQHGNEATTNITETTVKFTSTSVITSVYGNTNSSVQSQTSVISTVFTTPANVSTPETTLKPSLSPGNVSDLSTTSTSLATSPTKPYTSSSPILSDIKAEIKCSGIREVKLTQGICLEQNKTSSCAEFKKDRGEGLARVLCGEEQADADAGAQVCSLLLAQSEVRPQCLLLVLANRTEISSKLQLMKKHQSDLKKLGILDFTEQDVASHQSYSQKTLIALVTSGALLAVLGITGYFLMNRRSWSPTGERLELEP>sp|P16671|CD36_HUMAN Platelet glycoprotein 4 OS=Homo sapiens OX=9606GN=CD36 PE=1 SV=2MGCDRNCGLIAGAVIGAVLAVFGGILMPVGDLLIQKTIKKQVVLEEGTIAFKNWVKTGTEVYRQFWIFDVQNPQEVMMNSSNIQVKQRGPYTYRVRFLAKENVTQDAEDNTVSFLQPNGAIFEPSLSVGTEADNFTVLNLAVAAASHIYQNQFVQMILNSLINKSKSSMFQVRTLRELLWGYRDPFLSLVPYPVTTTVGLFYPYNNTADGVYKVFNGKDNISKVAIIDTYKGKRNLSYWESHCDMINGTDAASFPPFVEKSQVLQFFSSDICRSIYAVFESDVNLKGIPVYRFVLPSKAFASPVENPDNYCFCTEKIISKNCTSYGVLDISKCKEGRPVYISLPHFLYASPDVSEPIDGLNPNEEEHRTYLDIEPITGFTLQFAKRLQVNLLVKPSEKIQVLKNLKRNYIVPILWLNETGTIGDEKANMFRSQVTGKINLLGLIEMILLSVGVVMFVAFMISYCACRSKTIK>sp|P16671-2|CD36_HUMAN Isoform 2 of Platelet glycoprotein 4 OS=Homosapiens OX=9606 GN=CD36MGCDRNCGLIAGAVIGAVLAVFGGILMPVGDLLIQKTIKKQVVLEEGTIAFKNWVKTGTEVYRQFWIFDVQNPQEVMMNSSNIQVKQRGPYTYRVRFLAKENVTQDAEDNTVSFLQPNGAIFEPSLSVGTEADNFTVLNLAVAAASHIYQNQFVQMILNSLINKSKSSMFQVRTLRELLWGYRDPFLSLVPYPVTTTVGLFYPYNNTADGVYKVFNGKDNISKVAIIDTYKGKRNLSYWESHCDMINGTDAASFPPFVEKSQVLQFFSSDICRETCVHFTSSFSVCKS>sp|P16671-3|CD36_HUMAN Isoform 3 of Platelet glycoprotein 4 OS=Homosapiens OX=9606 GN=CD36MGCDRNCGLIAGAVIGAVLAVFGGILMPVGDLLIQKTIKKQVVLEEGTIAFKNWVKTGTEVYRQFWIFDVQNPQEVMMNSSNIQVKQRGPYTYRVRFLAKENVTQDAEDNTVSFLQPNGAIFEPSLSVGTEADNFTVLNLAVAAASHIYQNQFVQMILNSLINKSKSSMFQVRTLRELLWGYRDPFLSLVPYPVTTTVGLFYPYNNTADGVYKVFNGKDNISKVAIIDTYKGKRSIYAVFESDVNLKGIPVYRFVLPSKAFASPVENPDNYCFCTEKIISKNCTSYGVLDISKCKEGRPVYISLPHFLYASPDVSEPIDGLNPNEEEHRTYLDIEPITGFTLQFAKRLQVNLLVKPSEKIQVLKNLKRNYIVPILWLNETGTIGDEKANMFRSQVTGKINLLGLIEMILLSVGVVMFVAFMISYCACRSKTIK>sp|P16671-4|CD36_HUMAN Isoform 4 of Platelet glycoprotein 4 OS=Homosapiens OX=9606 GN=CD36MGCDRNCGLIAGAVIGAVLAVFGGILMPVGDLLIQKTIKKQVVLEEGTIAFKNWVKTGTEVYRQFWIFDVQNPQEVMMNSSNIQVKQRGPYTYRVRFLAKENVTQDAEDNTVSFLQPNGAIFEPSLSVGTEADNFTVLNLAVAYNNTADGVYKVFNGKDNISKVAIIDTYKGKRNLSYWESHCDMINGTDAASFPPFVEKSQVLQFFSSDICRSIYAVFESDVNLKGIPVYRFVLPSKAFASPVENPDNYCFCTEKIISKNCTSYGVLDISKCKEGRPVYISLPHFLYASPDVSEPIDGLNPNEEEHRTYLDIEPITGFTLQFAKRLQVNLLVKPSEKIQVLKNLKRNYIVPILWLNETGTIGDEKANMFRSQVTGKINLLGLIEMILLSVGVVMFVAFMISYCACRSKTIK>sp|Q8IZ07|AN13A_HUMAN Ankyrin repeat domain-containing protein 13AOS=Homo sapiens OX=9606 GN=ANKRD13A PE=1 SV=3MSSACDAGDHYPLHLLVWKNDYRQLEKELQGQNVEAVDPRGRTLLHLAVSLGHLESARVLLRHKADVTKENRQGWTVLHEAVSTGDPEMVYTVLQHRDYHNTSMALEGVPELLQKILEAPDFYVQMKWEFTSWVPLVSRICPNDVCRIWKSGAKLRVDITLLGFENMSWIRGRRSFIFKGEDNWAELMEVNHDDKVVTTERFDLSQEMERLTLDLMKPKSREVERRLTSPVINTSLDTKNIAFERTKSGFWGWRTDKAEVVNGYEAKVYTVNNVNVITKIRTEHLTEEEKKRYKADRNPLESLLGTVEHQFGAQGDLTTECATANNPTAITPDEYFNEEFDLKDRDIGRPKELTIRTQKFKAMLWMCEEFPLSLVEQVIPIIDLMARTSAHFARLRDFIKLEFPPGFPVKIEIPLFHVLNARITFGNVNGCSTAEESVSQNVEGTQADSASHITNFEVDQSVFEIPESYYVQDNGRNVHLQDEDYEIMQFAIQQSLLESSRSQELSGPASNGGISQTNTYDAQYERAIQESLLTSTEGLCPSALSETSRFDNDLQLAMELSAKELEEWELRLQEEEAELQQVLQLSLTDK>sp|Q16880|CGT_HUMAN 2-hydroxyacylsphingosine 1-beta-galactosyltransferase OS=Homo sapiens OX=9606 GN=UGT8 PE=1 SV=2MKSYTPYFILLWSAVGIAKAAKIIIVPPIMFESHMYIFKTLASALHERGHHTVFLLSEGRDIAPSNHYSLQRYPGIFNSTTSDAFLQSKMRNIFSGRLTAIELFDILDHYTKNCDLMVGNHALIQGLKKEKFDLLLVDPNDMCGFVIAHLLGVKYAVFSTGLWYPAEVGAPAPLAYVPEFNSLLTDRMNLLQRMKNTGVYLISRLGVSFLVLPKYERIMQKYNLLPEKSMYDLVHGSSLWMLCTDVALEFPRPTLPNVVYVGGILTKPASPLPEDLQRWVNGANEHGFVLVSFGAGVKYLSEDIANKLAGALGRLPQKVIWRFSGPKPKNLGNNTKLIEWLPQNDLLGHSKIKAFLSHGGLNSIFETIYHGVPVVGIPLFGDHYDTMTRVQAKGMGILLEWKTVTEKELYEALVKVINNPSYRQRAQKLSEIHKDQPGHPVNRTIYWIDYIIRHNGAHHLRAAVHQISFCQYFLLDIAFVLLLGAALLYFLLSWVTKFIYRKIKSLWSRNKHSTVNGHYHNGILNGKYKRNGHIKHEKKVK>sp|Q9Y6A4|CFA20_HUMAN Cilia- and flagella-associated protein 20 OS=Homosapiens OX=9606 GN=CFAP20 PE=1 SV=1MFKNTFQSGFLSILYSIGSKPLQIWDKKVRNGHIKRITDNDIQSLVLEIEGTNVSTTYITCPADPKKTLGIKLPFLVMIIKNLKKYFTFEVQVLDDKNVRRRFRASNYQSTTRVKPFICTMPMRLDDGWNQIQFNLLDFTRRAYGTNYIETLRVQIHANCRIRRVYFSDRLYSEDELPAEFKLYLPVQNKAKQ>sp|Q400G9|AMZ1_HUMAN Archaemetzincin-1 OS=Homo sapiens OX=9606 GN=AMZ1PE=2 SV=1MLQCRPAQEFSFGPRALKDALVSTDAALQQLYVSAFSPAERLFLAEAYNPQRTLFCTLLIRTGFDWLLSRPEAPEDFQTFHASLQHRKPRLARKHIYLQPIDLSEEPVGSSLLHQLCSCTEAFFLGLRVKCLPSVAAASIRCSSRPSRDSDRLQLHTDGILSFLKNNKPGDALCVLGLTLSDLYPHEAWSFTFSKFLPGHEVGVCSFARFSGEFPKSGPSAPDLALVEAAADGPEAPLQDRGWALCFSALGMVQCCKVTCHELCHLLGLGNCRWLRCLMQGALSLDEALRRPLDLCPICLRKLQHVLGFRLIERYQRLYTWTQAVVGTWPSQEAGEPSVWEDTPPASADSGMCCESDSEPGTSVSEPLTPDAGSHTFASGPEEGLSYLAASEAPLPPGGPAEAIKEHERWLAMCIQALQREVAEEDLVQVDRAVDALDRWEMFTGQLPATRQDPPSSRDSVGLRKVLGDKFSSLRRKLSARKLARAESAPRPWDGEES>sp|Q400G9-2|AMZ1_HUMAN Isoform 2 of Archaemetzincin-1 OS=Homo sapiensOX=9606 GN=AMZ1MLQCRPAQEFSFGPRALKDALVSTDAALQQLYVSAFSPAERLFLAEAYNPQRTLFCTLLIRTGFDWLLSRPEAPEDFQTFHASLQHRKPRLARKHIYLQPIDLSEEPVGSSLLHQLCSCTEAFFLGLRVKCLPSVAAASIRCSSRPSRDSDRLQLHTDGILSFLKNNKPGDALCVLGLTLSDLYPHEAWSFTFSKFLPGHGHVPRALPPSGPGELPLAPLPHAGCAQPGRGPAAAPGPLSHLPEEAAACPGFQAHREVPETLHLDSGGGGDVAQPGGGGAVSVGGHPACQRRLGHVL>sp|Q69YU3|AN34A_HUMAN Ankyrin repeat domain-containing protein 34AOS=Homo sapiens OX=9606 GN=ANKRD34A PE=1 SV=2MLHTEGHALLRAVGQGKLRLARLLLEGGAYVNEGDAQGETALMAACRARYDDPQNKARMVRYLLEQGADPNIADRLGRTALMHACAGGGGAAVASLLLAHGADPSVRDHAGASALVHALDRGDRETLATLLDACKAKGTEVIIITTDTSPSGTKKTRQYLNSPPSPGVEDPAPASPSPGFCTSPSEIQLQTAGGGGRGMLSPRAQEEEEKRDVFEFPLPKPPDDPSPSEPLPKPPRHPPKPLKRLNSEPWGLVAPPQPVPPTEGRPGIERLTAEFNGLTLTGRPRLSRRHSTEGPEDPPPWAEKVTSGGPLSRRNTAPEAQESGPPSGLRQKLSRMEPVELDTPGHLCPDSPESSRLSLERRRYSASPLTLPPAGSAPSPRQSQESLPGAVSPLSGRRRSPGLLERRGSGTLLLDHISQTRPGFLPPLNVSPHPPIPDIRPQPGGRAPSLPAPPYAGAPGSPRTKRKLVRRHSMQTEQIRLLGGFQSLGGPGEPGR>sp|A5PLL1|AN34B_HUMAN Ankyrin repeat domain-containing protein 34BOS=Homo sapiens OX=9606 GN=ANKRD34B PE=2 SV=3MDEGMEISSEGNSLIKAVHQSRLRLTRLLLEGGAYINESNDRGETPLMIACKTKHVDHQSVSKAKMVKYLLENNADPNIQDKSGKTALMHACLEKAGPEVVSLLLKSGADLSLQDHSSYSALVYAINSEDTETLKVLLSACKAKGKEVIIITTAKLPCGKHTTKQYLNMPPVDIDGCHSPATCTTPSEIDIKTASSPLSHSSETELTLFGFKDLELAGSNDDTWDPGSPVRKPALAPKGPKLPHAPPWVKSPPLLMHQNRVASLQEELQDITPEEELSYKTNGLALSKRFITRHQSIDVKDTAHLLRAFDQASSRKMSYDEINCQSYLSEGNQQCIEVPVDQDPDSNQTIFASTLRSIVQKRNLGANHYSSDSQLSAGLTPPTSEDGKALIGKKKILSPSPSQLSESKELLENIPPGPLSRRNHAVLERRGSGAFPLDHSVTQTRQGFLPPLNVNSHPPISDINVNNKICSLLSCGQKVLMPTVPIFPKEFKSKKMLLRRQSLQTEQIKQLVNF>sp|O14727|APAF_HUMAN Apoptotic protease-activating factor 1 OS=Homosapiens OX=9606 GN=APAF1 PE=1 SV=2MDAKARNCLLQHREALEKDIKTSYIMDHMISDGFLTISEEEKVRNEPTQQQRAAMLIKMILKKDNDSYVSFYNALLHEGYKDLAALLHDGIPVVSSSSGKDSVSGITSYVRTVLCEGGVPQRPVVFVTRKKLVNAIQQKLSKLKGEPGWVTIHGMAGCGKSVLAAEAVRDHSLLEGCFPGGVHWVSVGKQDKSGLLMKLQNLCTRLDQDESFSQRLPLNIEEAKDRLRILMLRKHPRSLLILDDVWDSWVLKAFDSQCQILLTTRDKSVTDSVMGPKYVVPVESSLGKEKGLEILSLFVNMKKADLPEQAHSIIKECKGSPLVVSLIGALLRDFPNRWEYYLKQLQNKQFKRIRKSSSYDYEALDEAMSISVEMLREDIKDYYTDLSILQKDVKVPTKVLCILWDMETEEVEDILQEFVNKSLLFCDRNGKSFRYYLHDLQVDFLTEKNCSQLQDLHKKIITQFQRYHQPHTLSPDQEDCMYWYNFLAYHMASAKMHKELCALMFSLDWIKAKTELVGPAHLIHEFVEYRHILDEKDCAVSENFQEFLSLNGHLLGRQPFPNIVQLGLCEPETSEVYQQAKLQAKQEVDNGMLYLEWINKKNITNLSRLVVRPHTDAVYHACFSEDGQRIASCGADKTLQVFKAETGEKLLEIKAHEDEVLCCAFSTDDRFIATCSVDKKVKIWNSMTGELVHTYDEHSEQVNCCHFTNSSHHLLLATGSSDCFLKLWDLNQKECRNTMFGHTNSVNHCRFSPDDKLLASCSADGTLKLWDATSANERKSINVKQFFLNLEDPQEDMEVIVKCCSWSADGARIMVAAKNKIFLFDIHTSGLLGEIHTGHHSTIQYCDFSPQNHLAVVALSQYCVELWNTDSRSKVADCRGHLSWVHGVMFSPDGSSFLTSSDDQTIRLWETKKVCKNSAVMLKQEVDVVFQENEVMVLAVDHIRRLQLINGRTGQIDYLTEAQVSCCCLSPHLQYIAFGDENGAIEILELVNNRIFQSRFQHKKTVWHIQFTADEKTLISSSDDAEIQVWNWQLDKCIFLRGHQETVKDFRLLKNSRLLSWSFDGTVKVWNIITGNKEKDFVCHQGTVLSCDISHDATKFSSTSADKTAKIWSFDLLLPLHELRGHNGCVRCSAFSVDSTLLATGDDNGEIRIWNVSNGELLHLCAPLSEEGAATHGGWVTDLCFSPDGKMLISAGGYIKWWNVVTGESSQTFYTNGTNLKKIHVSPDFKTYVTVDNLGILYILQTLE>sp|O14727-2|APAF_HUMAN Isoform 2 of Apoptotic protease-activating factor1 OS=Homo sapiens OX=9606 GN=APAF1MDAKARNCLLQHREALEKDIKTSYIMDHMISDGFLTISEEEKVRNEPTQQQRAAMLIKMILKKDNDSYVSFYNALLHEGYKDLAALLHDGIPVVSSSSVRTVLCEGGVPQRPVVFVTRKKLVNAIQQKLSKLKGEPGWVTIHGMAGCGKSVLAAEAVRDHSLLEGCFPGGVHWVSVGKQDKSGLLMKLQNLCTRLDQDESFSQRLPLNIEEAKDRLRILMLRKHPRSLLILDDVWDSWVLKAFDSQCQILLTTRDKSVTDSVMGPKYVVPVESSLGKEKGLEILSLFVNMKKADLPEQAHSIIKECKGSPLVVSLIGALLRDFPNRWEYYLKQLQNKQFKRIRKSSSYDYEALDEAMSISVEMLREDIKDYYTDLSILQKDVKVPTKVLCILWDMETEEVEDILQEFVNKSLLFCDRNGKSFRYYLHDLQVDFLTEKNCSQLQDLHKKIITQFQRYHQPHTLSPDQEDCMYWYNFLAYHMASAKMHKELCALMFSLDWIKAKTELVGPAHLIHEFVEYRHILDEKDCAVSENFQEFLSLNGHLLGRQPFPNIVQLGLCEPETSEVYQQAKLQAKQEVDNGMLYLEWINKKNITNLSRLVVRPHTDAVYHACFSEDGQRIASCGADKTLQVFKAETGEKLLEIKAHEDEVLCCAFSTDDRFIATCSVDKKVKIWNSMTGELVHTYDEHSEQVNCCHFTNSSHHLLLATGSSDCFLKLWDLNQKECRNTMFGHTNSVNHCRFSPDDKLLASCSADGTLKLWDATSANERKSINVKQFFLNLEDPQEDMEVIVKCCSWSADGARIMVAAKNKIFLFDIHTSGLLGEIHTGHHSTIQYCDFSPQNHLAVVALSQYCVELWNTDSRSKVADCRGHLSWVHGVMFSPDGSSFLTSSDDQTIRLWETKKVCKNSAVMLKQEVDVVFQENEVMVLAVDHIRRLQLINGRTGQIDYLTEAQVSCCCLSPHLQYIAFGDENGAIEILELVNNRIFQSRFQHKKTVWHIQFTADEKTLISSSDDAEIQVWNWQLDKCIFLRGHQETVKDFRLLKNSRLLSWSFDGTVKVWNIITGNKEKDFVCHQGTVLSCDISHDATKFSSTSADKTAKIWSFDLLLPLHELRGHNGCVRCSAFSVDSTLLATGDDNGEIRIWNVSNGELLHLCAPLSEEGAATHGGWVTDLCFSPDGKMLISAGGYIKWWNVVTGESSQTFYTNGTNLKKIHVSPDFKTYVTVDNLGILYILQTLE>sp|O14727-3|APAF_HUMAN Isoform 3 of Apoptotic protease-activating factor1 OS=Homo sapiens OX=9606 GN=APAF1MDAKARNCLLQHREALEKDIKTSYIMDHMISDGFLTISEEEKVRNEPTQQQRAAMLIKMILKKDNDSYVSFYNALLHEGYKDLAALLHDGIPVVSSSSVRTVLCEGGVPQRPVVFVTRKKLVNAIQQKLSKLKGEPGWVTIHGMAGCGKSVLAAEAVRDHSLLEGCFPGGVHWVSVGKQDKSGLLMKLQNLCTRLDQDESFSQRLPLNIEEAKDRLRILMLRKHPRSLLILDDVWDSWVLKAFDSQCQILLTTRDKSVTDSVMGPKYVVPVESSLGKEKGLEILSLFVNMKKADLPEQAHSIIKECKGSPLVVSLIGALLRDFPNRWEYYLKQLQNKQFKRIRKSSSYDYEALDEAMSISVEMLREDIKDYYTDLSILQKDVKVPTKVLCILWDMETEEVEDILQEFVNKSLLFCDRNGKSFRYYLHDLQVDFLTEKNCSQLQDLHKKIITQFQRYHQPHTLSPDQEDCMYWYNFLAYHMASAKMHKELCALMFSLDWIKAKTELVGPAHLIHEFVEYRHILDEKDCAVSENFQEFLSLNGHLLGRQPFPNIVQLGLCEPETSEVYQQAKLQAKQEVDNGMLYLEWINKKNITNLSRLVVRPHTDAVYHACFSEDGQRIASCGADKTLQVFKAETGEKLLEIKAHEDEVLCCAFSTDDRFIATCSVDKKVKIWNSMTGELVHTYDEHSEQVNCCHFTNSSHHLLLATGSSDCFLKLWDLNQKECRNTMFGHTNSVNHCRFSPDDKLLASCSADGTLKLWDATSANERKSINVKQFFLNLEDPQEDMEVIVKCCSWSADGARIMVAAKNKIFLWNTDSRSKVADCRGHLSWVHGVMFSPDGSSFLTSSDDQTIRLWETKKVCKNSAVMLKQEVDVVFQENEVMVLAVDHIRRLQLINGRTGQIDYLTEAQVSCCCLSPHLQYIAFGDENGAIEILELVNNRIFQSRFQHKKTVWHIQFTADEKTLISSSDDAEIQVWNWQLDKCIFLRGHQETVKDFRLLKNSRLLSWSFDGTVKVWNIITGNKEKDFVCHQGTVLSCDISHDATKFSSTSADKTAKIWSFDLLLPLHELRGHNGCVRCSAFSVDSTLLATGDDNGEIRIWNVSNGELLHLCAPLSEEGAATHGGWVTDLCFSPDGKMLISAGGYIKWWNVVTGESSQTFYTNGTNLKKIHVSPDFKTYVTVDNLGILYILQTLE>sp|O14727-4|APAF_HUMAN Isoform 4 of Apoptotic protease-activating factor1 OS=Homo sapiens OX=9606 GN=APAF1MDAKARNCLLQHREALEKDIKTSYIMDHMISDGFLTISEEEKVRNEPTQQQRAAMLIKMILKKDNDSYVSFYNALLHEGYKDLAALLHDGIPVVSSSSGKDSVSGITSYVRTVLCEGGVPQRPVVFVTRKKLVNAIQQKLSKLKGEPGWVTIHGMAGCGKSVLAAEAVRDHSLLEGCFPGGVHWVSVGKQDKSGLLMKLQNLCTRLDQDESFSQRLPLNIEEAKDRLRILMLRKHPRSLLILDDVWDSWVLKAFDSQCQILLTTRDKSVTDSVMGPKYVVPVESSLGKEKGLEILSLFVNMKKADLPEQAHSIIKECKGSPLVVSLIGALLRDFPNRWEYYLKQLQNKQFKRIRKSSSYDYEALDEAMSISVEMLREDIKDYYTDLSILQKDVKVPTKVLCILWDMETEEVEDILQEFVNKSLLFCDRNGKSFRYYLHDLQVDFLTEKNCSQLQDLHKKIITQFQRYHQPHTLSPDQEDCMYWYNFLAYHMASAKMHKELCALMFSLDWIKAKTELVGPAHLIHEFVEYRHILDEKDCAVSENFQEFLSLNGHLLGRQPFPNIVQLGLCEPETSEVYQQAKLQAKQEVDNGMLYLEWINKKNITNLSRLVVRPHTDAVYHACFSEDGQRIASCGADKTLQVFKAETGEKLLEIKAHEDEVLCCAFSTDDRFIATCSVDKKVKIWNSMTGELVHTYDEHSEQVNCCHFTNSSHHLLLATGSSDCFLKLWDLNQKECRNTMFGHTNSVNHCRFSPDDKLLASCSADGTLKLWDATSANERKSINVKQFFLNLEDPQEDMEVIVKCCSWSADGARIMVAAKNKIFLWNTDSRSKVADCRGHLSWVHGVMFSPDGSSFLTSSDDQTIRLWETKKVCKNSAVMLKQEVDVVFQENEVMVLAVDHIRRLQLINGRTGQIDYLTEAQVSCCCLSPHLQYIAFGDENGAIEILELVNNRIFQSRFQHKKTVWHIQFTADEKTLISSSDDAEIQVWNWQLDKCIFLRGHQETVKDFRLLKNSRLLSWSFDGTVKVWNIITGNKEKDFVCHQGTVLSCDISHDATKFSSTSADKTAKIWSFDLLLPLHELRGHNGCVRCSAFSVDSTLLATGDDNGEIRIWNVSNGELLHLCAPLSEEGAATHGGWVTDLCFSPDGKMLISAGGYIKWWNVVTGESSQTFYTNGTNLKKIHVSPDFKTYVTVDNLGILYILQTLE>sp|O14727-5|APAF_HUMAN Isoform 5 of Apoptotic protease-activating factor1 OS=Homo sapiens OX=9606 GN=APAF1MDAKARNCLLQHREALEKDIKTSYIMDHMISDGFLTISEEEKVRNEPTQQQRAAMLIKMILKKDNDSYVSFYNALLHEGYKDLAALLHDGIPVVSSSSGKDSVSGITSYVRTVLCEGGVPQRPVVFVTRKKLVNAIQQKLSKLKGEPGWVTIHGMAGCGKSVLAAEAVRDHSLLEGCFPGGVHWVSVGKQDKSGLLMKLQNLCTRLDQDESFSQRLPLNIEEAKDRLRILMLRKHPRSLLILDDVWDSWVLKAFDSQCQILLTTRDKSVTDSVMGPKYVVPVESSLGKEKGLEILSLFVNMKKADLPEQAHSIIKECKGSPLVVSLIGALLRDFPNRWEYYLKQLQNKQFKRIRKSSSYDYEALDEAMSISVEMLREDIKDYYTDLSILQKDVKVPTKVLCILWDMETEEVEDILQEFVNKSLLFCDRNGKSFRYYLHDLQVDFLTEKNCSQLQDLHKKIITQFQRYHQPHTLSPDQEDCMYWYNFLAYHMASAKMHKELCALMFSLDWIKAKTELVGPAHLIHEFVEYRHILDEKDCAVSENFQEFLSLNGHLLGRQPFPNIVQLGLCEPETSETLGFESKKVYQQAKLQAKQEVDNGMLYLEWINKKNITNLSRLVVRPHTDAVYHACFSEDGQRIASCGADKTLQVFKAETGEKLLEIKAHEDEVLCCAFSTDDRFIATCSVDKKVKIWNSMTGELVHTYDEHSEQVNCCHFTNSSHHLLLATGSSDCFLKLWDLNQKECRNTMFGHTNSVNHCRFSPDDKLLASCSADGTLKLWDATSANERKSINVKQFFLNLEDPQEDMEVIVKCCSWSADGARIMVAAKNKIFLWNTDSRSKVADCRGHLSWVHGVMFSPDGSSFLTSSDDQTIRLWETKKVCKNSAVMLKQEVDVVFQENEVMVLAVDHIRRLQLINGRTGQIDYLTEAQVSCCCLSPHLQYIAFGDENGAIEILELVNNRIFQSRFQHKKTVWHIQFTADEKTLISSSDDAEIQVWNWQLDKCIFLRGHQETVKDFRLLKNSRLLSWSFDGTVKVWNIITGNKEKDFVCHQGTVLSCDISHDATKFSSTSADKTAKIWNVSNGELLHLCAPLSEEGAATHGGWVTDLCFSPDGKMLISAGGYIKWWNVVTGESSQTFYTNGTNLKKIHVSPDFKTYVTVDNLGILYILQTLE>sp|O14727-6|APAF_HUMAN Isoform 6 of Apoptotic protease-activating factor1 OS=Homo sapiens OX=9606 GN=APAF1MDAKARNCLLQHREALEKDIKTSYIMDHMISDGFLTISEEEKVRNEPTQQQRAAMLIKMILKKDNDSYVSFYNALLHEGYKDLAALLHDGIPVVSSSSGKDSVSGITSYVRTVLCEGGVPQRPVVFVTRKKLVNAIQQKLSKLKGEPGWVTIHGMAGCGKSVLAAEAVRDHSLLEGCFPGGVHWVSVGKQDKSGLLMKLQNLCTRLDQDESFSQRLPLNIEEAKDRLRILMLRKHPRSLLILDDVWDSWVLKAFDSQCQILLTTRDKSVTDSVMGPKYVVPVESSLGKEKGLEILSLFVNMKKADLPEQAHSIIKECKVVERCHWGILTDLLHKWNQS>sp|P56377|AP1S2_HUMAN AP-1 complex subunit sigma-2 OS=Homo sapiensOX=9606 GN=AP1S2 PE=1 SV=1MQFMLLFSRQGKLRLQKWYVPLSDKEKKKITRELVQTVLARKPKMCSFLEWRDLKIVYKRYASLYFCCAIEDQDNELITLEIIHRYVELLDKYFGSVCELDIIFNFEKAYFILDEFLLGGEVQETSKKNVLKAIEQADLLQEEAETPRSVLEEIGLT>sp|P56377-2|AP1S2_HUMAN Isoform 2 of AP-1 complex subunit sigma-2OS=Homo sapiens OX=9606 GN=AP1S2MPAGCPPHSTTASLPQHGDRGFPFAAAAAAGQAPPRPRPAAAMQFMLLFSRQGKLRLQKWYVPLSDKEKKKITRELVQTVLARKPKMCSFLEWRDLKIVYKRYASLYFCCAIEDQDNELITLEIIHRYVELLDKYFGSVCELDIIFNFEKAYFILDEFLLGGEVQETSKKNVLKAIEQADLLQEKTETMYHSKSFIGFKKAY>sp|Q8N6M6|AMPO_HUMAN Aminopeptidase O OS=Homo sapiens OX=9606 GN=AOPEPPE=2 SV=2MDIQLDPARDDLPLMANTSHILVKHYVLDLDVDFESQVIEGTIVLFLEDGNRFKKQNSSIEEACQSESNKACKFGMPEPCHIPVTNARTFSSEMEYNDFAICSKGEKDTSDKDGNHDNQEHASGISSSKYCCDTGNHGSEDFLLVLDCCDLSVLKVEEVDVAAVPGLEKFTRSPELTVVSEEFRNQIVRELVTLPANRWREQLDYYARCSQAPGCGELLFDTDTWSLQIRKTGAQTATDFPHAIRIWYKTKPEGRSVTWTSDQSGRPCVYTVGSPINNRALFPCQEPPVAMSTWQATVRAAASFVVLMSGENSAKPTQLWEECSSWYYYVTMPMPASTFTIAVGCWTEMKMETWSSNDLATERPFSPSEANFRHVGVCSHMEYPCRFQNASATTQEIIPHRVFAPVCLTGACQETLLRLIPPCLSAAHSVLGAHPFSRLDVLIVPANFPSLGMASPHIMFLSQSILTGGNHLCGTRLCHEIAHAWFGLAIGARDWTEEWLSEGFATHLEDVFWATAQQLAPYEAREQQELRACLRWRRLQDEMQCSPEEMQVLRPSKDKTGHTSDSGASVIKHGLNPEKIFMQVHYLKGYFLLRFLAKRLGDETYFSFLRKFVHTFHGQLILSQDFLQMLLENIPEEKRLELSVENIYQDWLESSGIPKPLQRERRAGAECGLARQVRAEVTKWIGVNRRPRKRKRREKEEVFEKLLPDQLVLLLEHLLEQKTLSPRTLQSLQRTYHLQDQDAEVRHRWCELIVKHKFTKAYKSVERFLQEDQAMGVYLYGELMVSEDARQQQLARRCFERTKEQMDRSSAQVVAEMLF>sp|Q8N6M6-2|AMPO_HUMAN Isoform 2 of Aminopeptidase O OS=Homo sapiensOX=9606 GN=AOPEPMDIQLDPARDDLPLMANTSHILVKHYVLDLDVDFESQVIEGTIVLFLEDGNRFKKQNSSIEEACQSESNKACKFGMPEPCHIPVTNARTFSSEMEYNDFAICSKGEKDTSDKDGNHDNQEHASGISSSKYCCDTGNHGSEDFLLVLDCCDLSVLKVEEVDVAAVPGLEKFTRSPELTVVSEEFRNQIVRELVTLPANRWREQLDYYARCSQAPGCGELLFDTDTWSLQIRKTGAQTATDFPHAIRIWYKTKPEGRSVTWTSDQSGRPCVYTVGSPINNRALFPCQEPPVAMSTWQATVRAAASFVVLMSGENSAKPTQLWEECSSWYYYVTMPMPASTFTIAVGCWTEMKMETWSSNDLATERPFSPSEANFRHVGVCSHMEYPCRFQNASATTQEIIPHRVFAPVCLTGACQETLLRLIPPCLSAAHSVLGAHPFSRLDVLIVPANFPSLGMARPSKDKTGHTSDSGASVIKHGLNPEKIFMQVHYLKGYFLLRFLAKRLGDETYFSFLRKFVHTFHGQLILSQDFLQMLLENIPEEKRLELSVENIYQDWLESSGIPKPLQRERRAGAECGLARQVRAEVTKWIGVNRRPRKRKRREKEEVFEKLLPDQLVLLLEHLLEQKTLSPRTLQSLQRTYHLQDQDAEVRHRWCELIVKHKFTKAYKSVERFLQEDQAMGVYLYGELMVSEDARQQQLARRCFERTKEQMDRSSAQVVAEMLF>sp|Q8N6M6-3|AMPO_HUMAN Isoform 3 of Aminopeptidase O OS=Homo sapiensOX=9606 GN=AOPEPMDIQLDPARDDLPLMANTSHILVKHYVLDLDVDFESQVIEGTIVLFLEDGNRFKKQNSSIEEACQSESNKACKFGMPEPCHIPVTNARTFSSEMEYNDFAICSKGEKDTSDKDGNHDNQEHASGISSSKYCCDTGNHGSEDFLLVLDCCDLSVLKVEEVDVAAVPGLEKFTRSPELTVVSEEFRNQIVRELVTLPANRWREQLDYYARCSQAPGCGELLFDTDTWSLQIRKTGAQTATDFPHAIRIWYKTKPEGRSVTWTSDQSGRPCVYTVGSPINNRALFPCQEPPVAMSTWQATVRAAASFVVLMSGENSAKPTQLWEECSSWYYYVTMPMPASTFTIAVGCWTEMKMETWSSNDLATERPFSPSEANFRHVGVCSHMEYPCRFQNASATTQEIIPHRVFAPVCLTGACQETLLRLIPPCLSAAHSVLGAHPFSRLDVLIVPANFPSLGMASPHIMFLSQSILTGGNHLCGTRLCHEIAHAWFGLAIGARDWTEEWLSEGFATHLEDVFWATAQQLAPYEAREQQELRACLRWRRLQDEMQCSPEEMQVLRFPHVGGCSGSFS>sp|Q8N6M6-4|AMPO_HUMAN Isoform 4 of Aminopeptidase O OS=Homo sapiensOX=9606 GN=AOPEPMDIQLDPARDDLPLMANTSHILVKHYVLDLDVDFESQVIEGTIVLFLEDGNRFKKQNSSIEEACQSESNKACKFGMPEPCHIPVTNARTFSSEMEYNDFAICSKGEKDTSDKDGNHDNQEHASGISSSKYCCDTGNHGSEDFLLVLDCCDLSVLKVEEVDVAAVPGLEKFTRSPELTVVSEEFRNQIVRELVTLPANRWREQLDYYARCSQAPGCGELLFDTDTWSLQIRKTGAQTATDFPHAIRIWYKTKPEGRSVTWTSDQSGRPCVYTVGSPINNRALFPCQEPPVAMSTWQATVRAAASFVVLMSGENSAKPTQLWEECSSWYYYVTMPMPASTFTIAVGCWTEMKMETWSSNDLATERPFSPSEANFRHVGVCSHMEYPCRFQNASATTQEIIPHRVFAPVCLTGACQETLLRLIPPCLSAAHSVLGAHPFSRLDVLIVPANFPSLGMARPSKDKTGHTSDSGASVIKHGLNPEKIFMQVHYLKGYFLLRFLAKRLGDETYFSFLRKFVHTFHGQLILSQDFLQMLLENIPEEKRLELSVENIYQDWLESSGIPKPLQRERRAGAECGLARQVRAEVTKWIGVNRRPRKRKRREKEEVFEKLLPDQLVLLLEHLLEQKTLSPRTLQSLQRTYHLQDQDAEVRHRWCELIVKHKFTKAYKSVERFLQEDQVGVIFQQMGIL>sp|Q96K21|ANCHR_HUMAN Abscission/NoCut checkpoint regulator OS=Homosapiens OX=9606 GN=ZFYVE19 PE=1 SV=3MNYDSQQPPLPPLPYAGCRRASGFPALGRGGTVPVGVWGGAGQGREGRSWGEGPRGPGLGRRDLSSADPAVLGATMESRCYGCAVKFTLFKKEYGCKNCGRAFCSGCLSFSAAVPRTGNTQQKVCKQCHEVLTRGSSANASKWSPPQNYKKRVAALEAKQKPSTSQSQGLTRQDQMIAERLARLRQENKPKLVPSQAEIEARLAALKDERQGSIPSTQEMEARLAALQGRVLPSQTPQPAHHTPDTRTQAQQTQDLLTQLAAEVAIDESWKGGGPAASLQNDLNQGGPGSTNSKRQANWSLEEEKSRLLAEAALELREENTRQERILALAKRLAMLRGQDPERVTLQDYRLPDSDDDEDEETAIQRVLQQLTEEASLDEASGFNIPAEQASRPWTQPRGAEPEAQDVDPRPEAEEEELPWCCICNEDATLRCAGCDGDLFCARCFREGHDAFELKEHQTSAYSPPRAGQEH>sp|Q96K21-2|ANCHR_HUMAN Isoform 2 of Abscission/NoCut checkpointregulator OS=Homo sapiens OX=9606 GN=ZFYVE19MPAVAEALGQEGPPDLSRSAFLATVLTSLSAAFSSMPSSAYSLPFSRSLELDYHTSSCFRGTMVKADCPVPITDLPDSSGKLQYGCKNCGRAFCSGCLSFSAAVPRTGNTQQKVCKQCHEVLTRGSSANASKWSPPQNYKKRVAALEAKQKPSTSQSQGLTRQDQMIAERLARLRQENKPKLVPSQAEIEARLAALKDERQGSIPSTQEMEARLAALQGRVLPSQTPQPAHHTPDTRTQAQQTQDLLTQLAAEVAIDESWKGGGPAASLQNDLNQGGPGSTNSKRQANWSLEEEKSRLLAEAALELREENTRQERILALAKRLAMLRGQDPERVTLQDYRLPDSDDDEDEETAIQRVLQQLTEEASLDEASGFNIPAEQASRPWTQPRGAEPEAQDVDPRPEAEEEELPWCCICNEDATLRCAGCDGDLFCARCFREGHDAFELKEHQTSAYSPPRAGQEH>sp|Q96K21-3|ANCHR_HUMAN Isoform 3 of Abscission/NoCut checkpointregulator OS=Homo sapiens OX=9606 GN=ZFYVE19MNYDSQQPPLPPLPYAGCRRASGFPALGRGGTVPVGVWGGAGQGREGRSWGEGPRGPGLGRRDLSSADPAVLGATMESRCYGCAVKFTLFKKEYGCKNCGRAFCSGCLSFSAAVPRTGNTQQKVCKQCHEVLTRGSSANASKWSPPQNYKKRVAALEAKQKPSTSQSQGLTRQDQMIAERLARLRQENKPKLVPSQAEIEARLAALKDERQGSIPSTQEMEARLAALQGRVLPSQTPQPAHHTPDTRTQAQQTQDLLTQLAAEVAIDESWKGGGPVTLQDYRLPDSDDDEDEETAIQRVLQQLTEEASLDEASGFNIPAEQASRPWTQPRGAEPEAQDVDPRPEAEEEELPWCCICNEDATLRCAGCDGDLFCARCFREGHDAFELKEHQTSAYSPPRAGQEH>sp|Q96K21-4|ANCHR_HUMAN Isoform 4 of Abscission/NoCut checkpointregulator OS=Homo sapiens OX=9606 GN=ZFYVE19MIAERLARLRQENKPKLVPSQAEIEARLAALKDERQGSIPSTQEMEARLAALQGRVLPSQTPQPAHHTPDTRTQAQQTQDLLTQLAAEVAIDESWKGGGPAASLQNDLNQGGPGSTNSKRQANWSLEEEKSRLLAEAALELREENTRQERILALAKRLAMLRGQDPERVTLQDYRLPDSDDDEDEETAIQRVLQQLTEEASLDEASGFNIPAEQASRPWTQPRGAEPEAQDVDPRPEAEEEELPWCCICNEDATLRCAGCDGDLFCARCFREGHDAFELKEHQTSAYSPPRAGQEH>sp|Q8TF21|ANR24_HUMAN Ankyrin repeat domain-containing protein 24OS=Homo sapiens OX=9606 GN=ANKRD24 PE=2 SV=2MKTLRARFKKTELRLSPTDLGSCPPCGPCPIPKPAARGRRQSQDWGKSDERLLQAVENNDAPRVAALIARKGLVPTKLDPEGKSAFHLAAMRGAASCLEVMIAHGSNVMSADGAGYNALHLAAKYGHPQCLKQLLQASCVVDVVDSSGWTALHHAAAGGCLSCSEVLCSFKAHLNPQDRSGATPLIIAAQMCHTDLCRLLLQQGAAANDQDLQGRTALMLACEGASPETVEVLLQGGAQPGITDALGQDAAHYGALAGDKLILHLLQEAAQRPSPPSALTEDDSGEASSQNSMSSHGKQGAPKKRKAPPPPASIPMPDDRDAYEEIVRLRQERGRLLQKIRGLEQHKERRQQESPEASSLHILERQVQELQQLLVERQEEKESLGREVESLQSRLSLLENERENTSYDVTTLQDEEGELPDLPGAEVLLSRQLSPSAQEHLASLQEQVAVLTRQNQELMEKVQILENFEKDETQMEVEALAEVIPLALYDSLRAEFDQLRRQHAEALQALRQQETREVPREEGAACGESEVAGATATKNGPTHMELNGSVAPETKVNGAETIDEEAAGDETMEARTMEAEATGAEATGAEATGAKVTETKPTGAEVREMETTEEEANMETKPTGAQATDTETTGVEAMGVEATKTKAEEAEMQAYGVGAGQAEPPVTGTTNMEATGSRATGMESTGVSATGVENPGVEATVPGISAGPILHPGAAEASEKLQVELETRIRGLEEALRQREREAAAELEAALGKCEAAEAEAGRLRERVREAEGSGASGGGGGDTTQLRAALEQAREDLRDRDSRLRELEAASACLDEARASRLLAEEEARGLRAELAQREEARLEQSRELEVLREQLATARATGEQQRTAAAELGRARDAAEARVAELPAACEEARQGLAELREASEALRQSVVPASEHRRLQEEALELRGRAASLEQEVVATGKEAARLRAELERERVCSVALSEHERIVGTLQANVAQLEGQLEELGRRHEKTSAEVFQVQREALFMKSERHAAEAQLATAEQQLRGLRTEAERARQAQSRAQEALDKAKEKDKKITELSKEVFNLKEALKEQPAALATPEVEALRDQVKDLQQQLQEAARDHSSVVALYRSHLLYAIQGQMDEDVQRILSQILQMQRLQAQGR>sp|Q8TF21-2|ANR24_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 24 OS=Homo sapiens OX=9606 GN=ANKRD24MQPAACAGEGAGPPAPRPPHPPGDKVRRGRGGAPSLSPQPPAPYLGLPIPSRGGGGWRGGQGGGGGTREGGTGRAGGAGSSGSAQPRPPAAPRGPSRPSGRRLLLEPRAPPAPRAPDAMKQLCLCAAASFASQDWGKSDERLLQAVENNDAPRVAALIARKGLVPTKLDPEGKSAFHLAAMRGAASCLEVMIAHGSNVMSADGAGYNALHLAAKYGHPQCLKQLLQASCVVDVVDSSGWTALHHAAAGGCLSCSEVLCSFKAHLNPQDRSGATPLIIAAQMCHTDLCRLLLQQGAAANDQDLQGRTALMLACEGASPETVEVLLQGGAQPGITDALGQDAAHYGALAGDKLILHLLQEAAQRPSPPSALTEDDSGEASSQNSMSSHGKQGAPKKRKAPPPPASIPMPDDRDAYEEIVRLRQERGRLLQKIRGLEQHKERRQQESPEASSLHILERQVQELQQLLVERQEEKESLGREVESLQSRLSLLENERENTSYDVTTLQDEEGELPDLPGAEVLLSRQLSPSAQEHLASLQEQVAVLTRQNQELMEKVQILENFEKDETQMEVEALAEVIPLALYDSLRAEFDQLRRQHAEALQALRQQETREVPREEGAACGESEVAGATATKNGPTHMELNGSVAPETKVNGAETIDEEAAGDETMEARTMEAEATGAEATGAEATGAKVTETKPTGAEVREMETTEEEANMETKPTGAQATDTETTGVEAMGVEATKTKAEEAEMQAYGVGAGQAEPPVTGTTNMEATGSRATGMESTGVSATGVENPGVEATVPGISAGPILHPGAAEASEKLQVELETRIRGLEEALRQREREAAAELEAALGKCEAAEAEAGRLRERVREAEGSGASGGGGGDTTQLRAALEQAREDLRDRDSRLRELEAASACLDEARASRLLAEEEARGLRAELAQREEARLEQSRELEVLREQLATARATGEQQRTAAAELGRARDAAEARVAELPAACEEARQGLAELREASEALRQSVVPASEHRRLQEEALELRGRAASLEQEVVATGKEAARLRAELERERVCSVALSEHERIVGTLQANVAQLEGQLEELGRRHEKTSAEVFQVQREALFMKSERHAAEAQLATAEQQLRGLRTEAERARQAQSRAQEALDKAKEKDKKITELSKEVFNLKEALKEQPAALATPEVEALRDQVKDLQQQLQEAARDHSSVVALYRSHLLYAIQGQMDEDVQRILSQILQMQRLQAQGR>sp|Q6AI12|ANR40_HUMAN Ankyrin repeat domain-containing protein 40OS=Homo sapiens OX=9606 GN=ANKRD40 PE=1 SV=2MNALLEQKEQQERLREAAALGDIREVQKLVESGVDVNSQNEVNGWTCLHWACKRNHGQVVSYLLKSGADKEILTTKGEMPVQLTSRREIRKIMGVEEEDDDDDDDDNLPQLKKESELPFVPNYLANPAFPFIYTPTAEDSAQMQNGGPSTPPASPPADGSPPLLPPGEPPLLGTFPRDHTSLALVQNGDVSAPSAILRTPESTKPGPVCQPPVSQSRSLFSSVPSKPPMSLEPQNGTYAGPAPAFQPFFFTGAFPFNMQELVLKVRIQNPSLRENDFIEIELDRQELTYQELLRVCCCELGVNPDQVEKIRKLPNTLLRKDKDVARLQDFQELELVLMISENNFLFRNAASTLTERPCYNRRASKLTY>sp|Q96LR9|APLD1_HUMAN Apolipoprotein L domain-containing protein 1OS=Homo sapiens OX=9606 GN=APOLD1 PE=2 SV=2MFRAPCHRLRARGTRKARAGAWRGCTFPCLGKGMERPAAREPHGPDALRRFQGLLLDRRGRLHGQVLRLREVARRLERLRRRSLVANVAGSSLSATGALAAIVGLSLSPVTLGTSLLVSAVGLGVATAGGAVTITSDLSLIFCNSRELRRVQEIAATCQDQMREILSCLEFFCRWQGCGDRQLLQCGRNASIALYNSVYFIVFFGSRGFLIPRRAEGDTKVSQAVLKAKIQKLAESLESCTGALDELSEQLESRVQLCTKSSRGHDLKISADQRAGLFF>sp|Q96LR9-2|APLD1_HUMAN Isoform 2 of Apolipoprotein L domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=APOLD1MGMERPAAREPHGPDALRRFQGLLLDRRGRLHGQVLRLREVARRLERLRRRSLVANVAGSSLSATGALAAIVGLSLSPVTLGTSLLVSAVGLGVATAGGAVTITSDLSLIFCNSRELRRVQEIAATCQDQMREILSCLEFFCRWQGCGDRQLLQCGRNASIALYNSVYFIVFFGSRGFLIPRRAEGDTKVSQAVLKAKIQKLAESLESCTGALDELSEQLESRVQLCTKSSRGHDLKISADQRAGLFF>sp|P08133|ANXA6_HUMAN Annexin A6 OS=Homo sapiens OX=9606 GN=ANXA6 PE=1SV=3MAKPAQGAKYRGSIHDFPGFDPNQDAEALYTAMKGFGSDKEAILDIITSRSNRQRQEVCQSYKSLYGKDLIADLKYELTGKFERLIVGLMRPPAYCDAKEIKDAISGIGTDEKCLIEILASRTNEQMHQLVAAYKDAYERDLEADIIGDTSGHFQKMLVVLLQGTREEDDVVSEDLVQQDVQDLYEAGELKWGTDEAQFIYILGNRSKQHLRLVFDEYLKTTGKPIEASIRGELSGDFEKLMLAVVKCIRSTPEYFAERLFKAMKGLGTRDNTLIRIMVSRSELDMLDIREIFRTKYEKSLYSMIKNDTSGEYKKTLLKLSGGDDDAAGQFFPEAAQVAYQMWELSAVARVELKGTVRPANDFNPDADAKALRKAMKGLGTDEDTIIDIITHRSNVQRQQIRQTFKSHFGRDLMTDLKSEISGDLARLILGLMMPPAHYDAKQLKKAMEGAGTDEKALIEILATRTNAEIRAINEAYKEDYHKSLEDALSSDTSGHFRRILISLATGHREEGGENLDQAREDAQVAAEILEIADTPSGDKTSLETRFMTILCTRSYPHLRRVFQEFIKMTNYDVEHTIKKEMSGDVRDAFVAIVQSVKNKPLFFADKLYKSMKGAGTDEKTLTRIMVSRSEIDLLNIRREFIEKYDKSLHQAIEGDTSGDFLKALLALCGGED>sp|P08133-2|ANXA6_HUMAN Isoform 2 of Annexin A6 OS=Homo sapiens OX=9606GN=ANXA6MKGFGSDKEAILDIITSRSNRQRQEVCQSYKSLYGKDLIADLKYELTGKFERLIVGLMRPPAYCDAKEIKDAISGIGTDEKCLIEILASRTNEQMHQLVAAYKDAYERDLEADIIGDTSGHFQKMLVVLLQGTREEDDVVSEDLVQQDVQDLYEAGELKWGTDEAQFIYILGNRSKQHLRLVFDEYLKTTGKPIEASIRGELSGDFEKLMLAVVKCIRSTPEYFAERLFKAMKGLGTRDNTLIRIMVSRSELDMLDIREIFRTKYEKSLYSMIKNDTSGEYKKTLLKLSGGDDDAAGQFFPEAAQVAYQMWELSAVARVELKGTVRPANDFNPDADAKALRKAMKGLGTDEDTIIDIITHRSNVQRQQIRQTFKSHFGRDLMTDLKSEISGDLARLILGLMMPPAHYDAKQLKKAMEGAGTDEKALIEILATRTNAEIRAINEAYKEDYHKSLEDALSSDTSGHFRRILISLATGHREEGGENLDQAREDAQVAAEILEIADTPSGDKTSLETRFMTILCTRSYPHLRRVFQEFIKMTNYDVEHTIKKEMSGDVRDAFVAIVQSVKNKPLFFADKLYKSMKGAGTDEKTLTRIMVSRSEIDLLNIRREFIEKYDKSLHQAIEGDTSGDFLKALLALCGGED>sp|Q96NW4|ANR27_HUMAN Ankyrin repeat domain-containing protein 27OS=Homo sapiens OX=9606 GN=ANKRD27 PE=1 SV=2MALYDEDLLKNPFYLALQKCRPDLCSKVAQIHGIVLVPCKGSLSSSIQSTCQFESYILIPVEEHFQTLNGKDVFIQGNRIKLGAGFACLLSVPILFEETFYNEKEESFSILCIAHPLEKRESSEEPLAPSDPFSLKTIEDVREFLGRHSERFDRNIASFHRTFRECERKSLRHHIDSANALYTKCLQQLLRDSHLKMLAKQEAQMNLMKQAVEIYVHHEIYNLIFKYVGTMEASEDAAFNKITRSLQDLQQKDIGVKPEFSFNIPRAKRELAQLNKCTSPQQKLVCLRKVVQLITQSPSQRVNLETMCADDLLSVLLYLLVKTEIPNWMANLSYIKNFRFSSLAKDELGYCLTSFEAAIEYIRQGSLSAKPPESEGFGDRLFLKQRMSLLSQMTSSPTDCLFKHIASGNQKEVERLLSQEDHDKDTVQKMCHPLCFCDDCEKLVSGRLNDPSVVTPFSRDDRGHTPLHVAAVCGQASLIDLLVSKGAMVNATDYHGATPLHLACQKGYQSVTLLLLHYKASAEVQDNNGNTPLHLACTYGHEDCVKALVYYDVESCRLDIGNEKGDTPLHIAARWGYQGVIETLLQNGASTEIQNRLKETPLKCALNSKILSVMEAYHLSFERRQKSSEAPVQSPQRSVDSISQESSTSSFSSMSASSRQEETKKDYREVEKLLRAVADGDLEMVRYLLEWTEEDLEDAEDTVSAADPEFCHPLCQCPKCAPAQKRLAKVPASGLGVNVTSQDGSSPLHVAALHGRADLIPLLLKHGANAGARNADQAVPLHLACQQGHFQVVKCLLDSNAKPNKKDLSGNTPLIYACSGGHHELVALLLQHGASINASNNKGNTALHEAVIEKHVFVVELLLLHGASVQVLNKRQRTAVDCAEQNSKIMELLQVVPSCVASLDDVAETDRKEYVTVKIRKKWNSKLYDLPDEPFTRQFYFVHSAGQFKGKTSREIMARDRSVPNLTEGSLHEPGRQSVTLRQNNLPAQSGSHAAEKGNSDWPERPGLTQTGPGHRRMLRRHTVEDAVVSQGPEAAGPLSTPQEVSASRS>sp|O14791|APOL1_HUMAN Apolipoprotein L1 OS=Homo sapiens OX=9606 GN=APOL1PE=1 SV=5MEGAALLRVSVLCIWMSALFLGVGVRAEEAGARVQQNVPSGTDTGDPQSKPLGDWAAGTMDPESSIFIEDAIKYFKEKVSTQNLLLLLTDNEAWNGFVAAAELPRNEADELRKALDNLARQMIMKDKNWHDKGQQYRNWFLKEFPRLKSELEDNIRRLRALADGVQKVHKGTTIANVVSGSLSISSGILTLVGMGLAPFTEGGSLVLLEPGMELGITAALTGITSSTMDYGKKWWTQAQAHDLVIKSLDKLKEVREFLGENISNFLSLAGNTYQLTRGIGKDIRALRRARANLQSVPHASASRPRVTEPISAESGEQVERVNEPSILEMSRGVKLTDVAPVSFFLVLDVVYLVYESKHLHEGAKSETAEELKKVAQELEEKLNILNNNYKILQADQEL>sp|O14791-2|APOL1_HUMAN Isoform 2 of Apolipoprotein L1 OS=Homo sapiensOX=9606 GN=APOL1MRFKSHTVELRRPCSDMEGAALLRVSVLCIWMSALFLGVGVRAEEAGARVQQNVPSGTDTGDPQSKPLGDWAAGTMDPESSIFIEDAIKYFKEKVSTQNLLLLLTDNEAWNGFVAAAELPRNEADELRKALDNLARQMIMKDKNWHDKGQQYRNWFLKEFPRLKSELEDNIRRLRALADGVQKVHKGTTIANVVSGSLSISSGILTLVGMGLAPFTEGGSLVLLEPGMELGITAALTGITSSTMDYGKKWWTQAQAHDLVIKSLDKLKEVREFLGENISNFLSLAGNTYQLTRGIGKDIRALRRARANLQSVPHASASRPRVTEPISAESGEQVERVNEPSILEMSRGVKLTDVAPVSFFLVLDVVYLVYESKHLHEGAKSETAEELKKVAQELEEKLNILNNNYKILQADQEL>sp|O14791-3|APOL1_HUMAN Isoform 3 of Apolipoprotein L1 OS=Homo sapiensOX=9606 GN=APOL1MEGAALLRVSVLCIWVQQNVPSGTDTGDPQSKPLGDWAAGTMDPESSIFIEDAIKYFKEKVSTQNLLLLLTDNEAWNGFVAAAELPRNEADELRKALDNLARQMIMKDKNWHDKGQQYRNWFLKEFPRLKSELEDNIRRLRALADGVQKVHKGTTIANVVSGSLSISSGILTLVGMGLAPFTEGGSLVLLEPGMELGITAALTGITSSTMDYGKKWWTQAQAHDLVIKSLDKLKEVREFLGENISNFLSLAGNTYQLTRGIGKDIRALRRARANLQSVPHASASRPRVTEPISAESGEQVERVNEPSILEMSRGVKLTDVAPVSFFLVLDVVYLVYESKHLHEGAKSETAEELKKVAQELEEKLNILNNNYKILQADQEL>sp|P23582|ANFC_HUMAN C-type natriuretic peptide OS=Homo sapiens OX=9606GN=NPPC PE=1 SV=1MHLSQLLACALLLTLLSLRPSEAKPGAPPKVPRTPPAEELAEPQAAGGGQKKGDKAPGGGGANLKGDRSRLLRDLRVDTKSRAAWARLLQEHPNARKYKGANKKGLSKGCFGLKLDRIGSMSGLGC>sp|Q9UKU9|ANGL2_HUMAN Angiopoietin-related protein 2 OS=Homo sapiensOX=9606 GN=ANGPTL2 PE=1 SV=1MRPLCVTCWWLGLLAAMGAVAGQEDGFEGTEEGSPREFIYLNRYKRAGESQDKCTYTFIVPQQRVTGAICVNSKEPEVLLENRVHKQELELLNNELLKQKRQIETLQQLVEVDGGIVSEVKLLRKESRNMNSRVTQLYMQLLHEIIRKRDNALELSQLENRILNQTADMLQLASKYKDLEHKYQHLATLAHNQSEIIAQLEEHCQRVPSARPVPQPPPAAPPRVYQPPTYNRIINQISTNEIQSDQNLKVLPPPLPTMPTLTSLPSSTDKPSGPWRDCLQALEDGHDTSSIYLVKPENTNRLMQVWCDQRHDPGGWTVIQRRLDGSVNFFRNWETYKQGFGNIDGEYWLGLENIYWLTNQGNYKLLVTMEDWSGRKVFAEYASFRLEPESEYYKLRLGRYHGNAGDSFTWHNGKQFTTLDRDHDVYTGNCAHYQKGGWWYNACAHSNLNGVWYRGGHYRSRYQDGVYWAEFRGGSYSLKKVVMMIRPNPNTFH>sp|Q9UKU9-2|ANGL2_HUMAN Isoform 2 of Angiopoietin-related protein 2OS=Homo sapiens OX=9606 GN=ANGPTL2MQVWCDQRHDPGGWTVIQRRLDGSVNFFRNWETYKQGFGNIDGEYWLGLENIYWLTNQGNYKLLVTMEDWSGRKVFAEYASFRLEPESEYYKLRLGRYHGNAGDSFTWHNGKQFTTLDRDHDVYTGNCAHYQKGGWWYNACAHSNLNGVWYRGGHYRSRYQDGVYWAEFRGGSYSLKKVVMMIRPNPNTFH>sp|Q6IPU0|CENPP_HUMAN Centromere protein P OS=Homo sapiens OX=9606GN=CENPP PE=1 SV=1MDAELAEVRALQAEIAALRRACEDPPAPWEEKSRVQKSFQAIHQFNLEGWKSSKDLKNQLGHLESELSFLSTLTGINIRNHSKQTEDLTSTEMTEKSIRKVLQRHRLSGNCHMVTFQLEFQILEIQNKERLSSAVTDLNIIMEPTECSELSEFVSRAEERKDLFMFFRSLHFFVEWFEYRKRTFKHLKEKYPDAVYLSEGPSSCSMGIRSASRPGFELVIVWRIQIDEDGKVFPKLDLLTKVPQRALELDKNRAIETAPLSFRTLVGLLGIEAALESLIKSLCAEENN>sp|Q6IPU0-2|CENPP_HUMAN Isoform 2 of Centromere protein P OS=Homosapiens OX=9606 GN=CENPPMEAPSWSVLQRSGDEEKYPDAVYLSEGPSSCSMGIRSASRPGFELVIVWRIQIDEDGKVFPKLDLLTKVPQRALELDKNRAIETAPLSFRTLVGLLGIEAALESLIKSLCAEENN>sp|Q5K130|CLU1O_HUMAN Putative uncharacterized protein CLLU1-AS1 OS=Homosapiens OX=9606 GN=CLLU1-AS1 PE=5 SV=1MNKLGHNELKECLKTATDSLQTVQPSISQTCTSYGPALGAPLPGRNEVALLTSLPPNYEISEGKPRAISAYVRAGKGNVTRRRKKTHLGNDDGKKEAQEKM>sp|Q9H1Y0|ATG5_HUMAN Autophagy protein 5 OS=Homo sapiens OX=9606 GN=ATG5PE=1 SV=2MTDDKDVLRDVWFGRIPTCFTLYQDEITEREAEPYYLLLPRVSYLTLVTDKVKKHFQKVMRQEDISEIWFEYEGTPLKWHYPIGLLFDLLASSSALPWNITVHFKSFPEKDLLHCPSKDAIEAHFMSCMKEADALKHKSQVINEMQKKDHKQLWMGLQNDRFDQFWAINRKLMEYPAEENGFRYIPFRIYQTTTERPFIQKLFRPVAADGQLHTLGDLLKEVCPSAIDPEDGEKKNQVMIHGIEPMLETPLQWLSEHLSYPDNFLHISIIPQPTD>sp|Q9H1Y0-2|ATG5_HUMAN Isoform Short of Autophagy protein 5 OS=Homosapiens OX=9606 GN=ATG5MHYPIGLLFDLLASSSALPWNITVHFKSFPEKDLLHCPSKDAIEAHFMSCMKEADALKHKSQVINEMQKKDHKQLWMGLQNDRFDQFWAINRKLMEYPAEENGFRYIPFRIYQTTTERPFIQKLFRPVAADGQLHTLGDLLKEVCPSAIDPEDGEKKNQVMIHGIEPMLETPLQWLSEHLSYPDNFLHISIIPQPTD>sp|P11245|ARY2_HUMAN Arylamine N-acetyltransferase 2 OS=Homo sapiensOX=9606 GN=NAT2 PE=1 SV=1MDIEAYFERIGYKNSRNKLDLETLTDILEHQIRAVPFENLNMHCGQAMELGLEAIFDHIVRRNRGGWCLQVNQLLYWALTTIGFQTTMLGGYFYIPPVNKYSTGMVHLLLQVTIDGRNYIVDAGSGSSSQMWQPLELISGKDQPQVPCIFCLTEERGIWYLDQIRREQYITNKEFLNSHLLPKKKHQKIYLFTLEPRTIEDFESMNTYLQTSPTSSFITTSFCSLQTPEGVYCLVGFILTYRKFNYKDNTDLVEFKTLTEEEVEEVLKNIFKISLGRNLVPKPGDGSLTI>sp|P0C7U1|ASA2B_HUMAN Putative inactive neutral ceramidase B OS=Homosapiens OX=9606 GN=ASAH2B PE=2 SV=1MRQHRQFMDRTHYLLTFSSSETLLRLLLRIVDRAPKGRTFGDVLQPAKPEYRVGEVAEVIFVGANPKNSVQNQTHQTFLTVEKYEATSTSWQIVCNDASWETRFYWHKGLLGLSNATVEWHIPDTAQPGIYRIRYFGHNRKQDILKPAVILSFEGTSPAFEVVTI>sp|P0C7U1-2|ASA2B_HUMAN Isoform 2 of Putative inactive neutralceramidase B OS=Homo sapiens OX=9606 GN=ASAH2BMVANLSRGPEPPFFKQLIVPLIPSIVDRAPKGRTFGDVLQPAKPEYRVGEVAEVIFVGANPKNSVQNQTHQTFLTVEKYEATSTSWQIVCNDASWETRFYWHKGLLGLSNATVEWHIPDTAQPGIYRIRYFGHNRKQDILKPAVILSFEGTSPAFEVVTI>sp|Q9NR71|ASAH2_HUMAN Neutral ceramidase OS=Homo sapiens OX=9606GN=ASAH2 PE=1 SV=2MAKRTFSNLETFLIFLLVMMSAITVALLSLLFITSGTIENHKDLGGHFFSTTQSPPATQGSTAAQRSTATQHSTATQSSTATQTSPVPLTPESPLFQNFSGYHIGVGRADCTGQVADINLMGYGKSGQNAQGILTRLYSRAFIMAEPDGSNRTVFVSIDIGMVSQRLRLEVLNRLQSKYGSLYRRDNVILSGTHTHSGPAGYFQYTVFVIASEGFSNQTFQHMVTGILKSIDIAHTNMKPGKIFINKGNVDGVQINRSPYSYLQNPQSERARYSSNTDKEMIVLKMVDLNGDDLGLISWFAIHPVSMNNSNHLVNSDNVGYASYLLEQEKNKGYLPGQGPFVAAFASSNLGDVSPNILGPRCINTGESCDNANSTCPIGGPSMCIAKGPGQDMFDSTQIIGRAMYQRAKELYASASQEVTGPLASAHQWVDMTDVTVWLNSTHASKTCKPALGYSFAAGTIDGVGGLNFTQGKTEGDPFWDTIRDQILGKPSEEIKECHKPKPILLHTGELSKPHPWHPDIVDVQIITLGSLAITAIPGEFTTMSGRRLREAVQAEFASHGMQNMTVVISGLCNVYTHYITTYEEYQAQRYEAASTIYGPHTLSAYIQLFRNLAKAIATDTVANLSRGPEPPFFKQLIVPLIPSIVDRAPKGRTFGDVLQPAKPEYRVGEVAEVIFVGANPKNSVQNQTHQTFLTVEKYEATSTSWQIVCNDASWETRFYWHKGLLGLSNATVEWHIPDTAQPGIYRIRYFGHNRKQDILKPAVILSFEGTSPAFEVVTI>sp|Q9NR71-2|ASAH2_HUMAN Isoform 2 of Neutral ceramidase OS=Homo sapiensOX=9606 GN=ASAH2MAKRTFSNLETFLIFLLVMMSAITVALLSLLFITSGTIENHKDLGGHFFSTTQSPPATQGSTAAQRSTATQHSTATQSSTATQTSPVPLTPESPLFQNFSGYHIGVGRADCTGQVADINLMGYGKSGQNAQGILTRLYSRAFIMAEPDGSNRTVFVSIDIGMVSQRLRLEVLNRLQSKYGSLYRRDNVILSGTHTHSGPAGYFQYTVFVIASEGFSNQTFQHMVTGILKSIDIAHTNMKPGKIFINKGNVDGVQINRSPYSYLQNPQSERARYSSNTDKEMIVLKMVDLNGDDLGLISWFAIHPVSMNNSNHLVNSDNVGYASYLLEQEKNKGYLPGQGPFVAAFASSNLGDVSPNILGPRCINTGESCDNANSTCPIGGPSMCIAKGPGQDMFDSTQIIGRAMYQRAKSKTCKPALGYSFAAGTIDGVGGLNFTQGKTEGDPFWDTIRDQILGKPSEEIKECHKPKPILLHTGELSKPHPWHPDIVDVQIITLGSLAITAIPGEFTTMSGRRLREAVQAEFASHGMQNMTVVISGLCNVYTHYITTYEEYQAQRYEAASTIYGPHTLSAYIQLFRNLAKAIATDTVANLSRGPEPPFFKQLIVPLIPSIVDRAPKGRTFGDVLQPAKPEYRVGEVAEVIFVGANPKNSVQNQTHQTFLTVEKYEATSTSWQIVCNDASWETRFYWHKGLLGLSNATVEWHIPDTAQPGIYRIRYFGHNRKQDILKPAVILSFEGTSPAFEVVTI>sp|O94817|ATG12_HUMAN Ubiquitin-like protein ATG12 OS=Homo sapiensOX=9606 GN=ATG12 PE=1 SV=1MAEEPQSVLQLPTSIAAGGEGLTDVSPETTTPEPPSSAAVSPGTEEPAGDTKKKIDILLKAVGDTPIMKTKKWAVERTRTIQGLIDFIKKFLKLVASEQLFIYVNQSFAPSPDQEVGTLYECFGSDGKLVLHYCKSQAWG>sp|O94817-4|ATG12_HUMAN Isoform 2 of Ubiquitin-like protein ATG12OS=Homo sapiens OX=9606 GN=ATG12MAEEPQSVLQLPTSIAAGGEGLTDVSPETTTPEPPSSAAVSPGTEEPAGDTKKKIYLCESVLCSFPRPRSWNSL>sp|O43150|ASAP2_HUMAN Arf-GAP with SH3 domain, ANK repeat and PH domain-containing protein 2 OS=Homo sapiens OX=9606 GN=ASAP2 PE=1 SV=3MPDQISVSEFVAETHEDYKAPTASSFTTRTAQCRNTVAAIEEALDVDRMVLYKMKKSVKAINSSGLAHVENEEQYTQALEKFGGNCVCRDDPDLGSAFLKFSVFTKELTALFKNLIQNMNNIISFPLDSLLKGDLKGVKGDLKKPFDKAWKDYETKITKIEKEKKEHAKLHGMIRTEISGAEIAEEMEKERRFFQLQMCEYLLKVNEIKIKKGVDLLQNLIKYFHAQCNFFQDGLKAVESLKPSIETLSTDLHTIKQAQDEERRQLIQLRDILKSALQVEQKEDSQIRQSTAYSLHQPQGNKEHGTERNGSLYKKSDGIRKVWQKRKCSVKNGFLTISHGTANRPPAKLNLLTCQVKTNPEEKKCFDLISHDRTYHFQAEDEQECQIWMSVLQNSKEEALNNAFKGDDNTGENNIVQELTKEIISEVQRMTGNDVCCDCGAPDPTWLSTNLGILTCIECSGIHRELGVHYSRMQSLTLDVLGTSELLLAKNIGNAGFNEIMECCLPAEDSVKPNPGSDMNARKDYITAKYIERRYARKKHADNAAKLHSLCEAVKTRDIFGLLQAYADGVDLTEKIPLANGHEPDETALHLAVRSVDRTSLHIVDFLVQNSGNLDKQTGKGSTALHYCCLTDNAECLKLLLRGKASIEIANESGETPLDIAKRLKHEHCEELLTQALSGRFNSHVHVEYEWRLLHEDLDESDDDMDEKLQPSPNRREDRPISFYQLGSNQLQSNAVSLARDAANLAKEKQRAFMPSILQNETYGALLSGSPPPAQPAAPSTTSAPPLPPRNVGKVQTASSANTLWKTNSVSVDGGSRQRSSSDPPAVHPPLPPLRVTSTNPLTPTPPPPVAKTPSVMEALSQPSKPAPPGISQIRPPPLPPQPPSRLPQKKPAPGADKSTPLTNKGQPRGPVDLSATEALGPLSNAMVLQPPAPMPRKSQATKLKPKRVKALYNCVADNPDELTFSEGDVIIVDGEEDQEWWIGHIDGDPGRKGAFPVSFVHFIAD>sp|O43150-2|ASAP2_HUMAN Isoform 2 of Arf-GAP with SH3 domain, ANK repeatand PH domain-containing protein 2 OS=Homo sapiens OX=9606 GN=ASAP2MPDQISVSEFVAETHEDYKAPTASSFTTRTAQCRNTVAAIEEALDVDRMVLYKMKKSVKAINSSGLAHVENEEQYTQALEKFGGNCVCRDDPDLGSAFLKFSVFTKELTALFKNLIQNMNNIISFPLDSLLKGDLKGVKGDLKKPFDKAWKDYETKITKIEKEKKEHAKLHGMIRTEISGAEIAEEMEKERRFFQLQMCEYLLKVNEIKIKKGVDLLQNLIKYFHAQCNFFQDGLKAVESLKPSIETLSTDLHTIKQAQDEERRQLIQLRDILKSALQVEQKEDSQIRQSTAYSLHQPQGNKEHGTERNGSLYKKSDGIRKVWQKRKCSVKNGFLTISHGTANRPPAKLNLLTCQVKTNPEEKKCFDLISHDRTYHFQAEDEQECQIWMSVLQNSKEEALNNAFKGDDNTGENNIVQELTKEIISEVQRMTGNDVCCDCGAPDPTWLSTNLGILTCIECSGIHRELGVHYSRMQSLTLDVLGTSELLLAKNIGNAGFNEIMECCLPAEDSVKPNPGSDMNARKDYITAKYIERRYARKKHADNAAKLHSLCEAVKTRDIFGLLQAYADGVDLTEKIPLANGHEPDETALHLAVRSVDRTSLHIVDFLVQNSGNLDKQTGKGSTALHYCCLTDNAECLKLLLRGKASIEIANESGETPLDIAKRLKHEHCEELLTQALSGRFNSHVHVEYEWRLLHEDLDESDDDMDEKLQPSPNRREDRPISFYQLGSNQLQSNAVSLARDAANLAKEKQRAFMPSILQNETYGALLSGSPPPAQPAAPSTTSAPPLPPRNVGKDPLTPTPPPPVAKTPSVMEALSQPSKPAPPGISQIRPPPLPPQPPSRLPQKKPAPGADKSTPLTNKGQPRGPVDLSATEALGPLSNAMVLQPPAPMPRKSQATKLKPKRVKALYNCVADNPDELTFSEGDVIIVDGEEDQEWWIGHIDGDPGRKGAFPVSFVHFIAD>sp|Q96DT6|ATG4C_HUMAN Cysteine protease ATG4C OS=Homo sapiens OX=9606GN=ATG4C PE=1 SV=1MEATGTDEVDKLKTKFISAWNNMKYSWVLKTKTYFSRNSPVLLLGKCYHFKYEDEDKTLPAESGCTIEDHVIAGNVEEFRKDFISRIWLTYREEFPQIEGSALTTDCGWGCTLRTGQMLLAQGLILHFLGRAWTWPDALNIENSDSESWTSHTVKKFTASFEASLSGEREFKTPTISLKETIGKYSDDHEMRNEVYHRKIISWFGDSPLALFGLHQLIEYGKKSGKKAGDWYGPAVVAHILRKAVEEARHPDLQGITIYVAQDCTVYNSDVIDKQSASMTSDNADDKAVIILVPVRLGGERTNTDYLEFVKGILSLEYCVGIIGGKPKQSYYFAGFQDDSLIYMDPHYCQSFVDVSIKDFPLETFHCPSPKKMSFRKMDPSCTIGFYCRNVQDFKRASEEITKMLKFSSKEKYPLFTFVNGHSRDYDFTSTTTNEEDLFSEDEKKQLKRFSTEEFVLL>sp|Q3KR37|ASTRB_HUMAN Protein Aster-B OS=Homo sapiens OX=9606 GN=GRAMD1BPE=1 SV=1MKGFKLSCTASNSNRSTPACSPILRKRSRSPTPQNQDGDTMVEKGSDHSSDKSPSTPEQGVQRSCSSQSGRSGGKNSKKSQSWYNVLSPTYKQRNEDFRKLFKQLPDTERLIVDYSCALQRDILLQGRLYLSENWICFYSNIFRWETLLTVRLKDICSMTKEKTARLIPNAIQVCTDSEKHFFTSFGARDRTYMMMFRLWQNALLEKPLCPKELWHFVHQCYGNELGLTSDDEDYVPPDDDFNTMGYCEEIPVEENEVNDSSSKSSIETKPDASPQLPKKSITNSTLTSTGSSEAPVSFDGLPLEEEALEGDGSLEKELAIDNIMGEKIEMIAPVNSPSLDFNDNEDIPTELSDSSDTHDEGEVQAFYEDLSGRQYVNEVFNFSVDKLYDLLFTNSPFQRDFMEQRRFSDIIFHPWKKEENGNQSRVILYTITLTNPLAPKTATVRETQTMYKASQESECYVIDAEVLTHDVPYHDYFYTINRYTLTRVARNKSRLRVSTELRYRKQPWGLVKTFIEKNFWSGLEDYFRHLESELAKTESTYLAEMHRQSPKEKASKTTTVRRRKRPHAHLRVPHLEEVMSPVTTPTDEDVGHRIKHVAGSTQTRHIPEDTPNGFHLQSVSKLLLVISCVICFSLVLLVILNMMLFYKLWMLEYTTQTLTAWQGLRLQERLPQSQTEWAQLLESQQKYHDTELQKWREIIKSSVMLLDQMKDSLINLQNGIRSRDYTSESEEKRNRYH>sp|Q3KR37-2|ASTRB_HUMAN Isoform 2 of Protein Aster-B OS=Homo sapiensOX=9606 GN=GRAMD1BMVEKGSDHSSDKSPSTPEQGVQRSCSSQSGRSGGKNSKKSQSWYNVLSPTYKQRNEDFRKLFKQLPDTERLIVDYSCALQRDILLQGRLYLSENWICFYSNIFRWETLLTVRLKDICSMTKEKTARLIPNAIQVCTDSEKHFFTSFGARDRTYMMMFRLWQNALLEKPLCPKELWHFVHQCYGNELGLTSDDEDYVPPDDDFNTMGYCEEIPVEENEVNDSSSKSSIETKPDASPQLPKKSITNSTLTSTGSSEAPVSFDGLPLEEEALEGDGSLEKELAIDNIMGEKIEMIAPVNSPSLDFNDNEDIPTELSDSSDTHDEGEVQAFYEDLSGRQYVNEVFNFSVDKLYDLLFTNSPFQRDFMEQRRFSDIIFHPWKKEENGNQSRVILYTITLTNPLAPKTATVRETQTMYKASQESECYVIDAEVLTHDVPYHDYFYTINRYTLTRVARNKSRLRVSTELRYRKQPWGLVKTFIEKNFWSGLEDYFRHLESELAKTESTYLAEMHRQSPKEKASKTTTVRRRKRPHAHLRVPHLEEVMSPVTTPTDEDVGHRIKHVAGSTQTRHIPEDTPNGFHLQSVSKLLLVISCVICFSLVLLVILNMMLFYKLWMLEYTTQTLTAWQGLRLQERLPQSQTEWAQLLESQQKYHDTELQKWREIIKSSVMLLDQMKDSLINLQNGIRSRDYTSESEEKRNRYH>sp|Q3KR37-3|ASTRB_HUMAN Isoform 3 of Protein Aster-B OS=Homo sapiensOX=9606 GN=GRAMD1BMPTSSAVLLRVLSIPLLTVLILARDLSALGGCPWGPLPLRCHCLLPDPLFCAGEVQAFYEDLSGRQYVNEVFNFSVDKLYDLLFTNSPFQRDFMEQRRFSDIIFHPWKKEENGNQSRVILYTITLTNPLAPKTATVRETQTMYKASQESECYVIDAEVLTHDVPYHDYFYTINRYTLTRVARNKSRLRVSTELRYRKQPWGLVKTFIEKNFWSGLEDYFRHLESELAKTESTYLAEMHRQSPKEKASKTTTVRRRKRPHAHLRVPHLEEVMSPVTTPTDEDVGHRIKHVAGSTQTRHIPEDTPNGFHLQSVSKLLLVISCVLVLLVILNMMLFYKLWMLEYTTQTLTAWQGLRLQERLPQSQTEWAQLLESQQKYHDTELQKWREIIKSSVMLLDQMKDSLINLQNGIRSRDYTSESEEKRNRYH>sp|Q3KR37-4|ASTRB_HUMAN Isoform 4 of Protein Aster-B OS=Homo sapiensOX=9606 GN=GRAMD1BMKGFKLSCTASNSNRSTPACSPILRKRSRSPTPQNQDGDTMVEKGSDHSSDKSPSTPEQGVQRSCSSQSGRSGGKNSKSHKRLSKKSQSWYNVLSPTYKQRNEDFRKLFKQLPDTERLIVDYSCALQRDILLQGRLYLSENWICFYSNIFRWETLLTVRLKDICSMTKEKTARLIPNAIQVCTDSEKHFFTSFGARDRTYMMMFRLWQNALLEKPLCPKELWHFVHQCYGNELGLTSDDEDYVPPDDDFNTMGYCEEIPVEENEVNDSSSKSSIETKPDASPQLPKKSITNSTLTSTGSSEAPVSFDGLPLEEEALEGDGSLEKELAIDNIMGEKIEMIAPVNSPSLDFNDNEDIPTELSDSSDTHDEGEVQAFYEDLSGRQYVNEVFNFSVDKLYDLLFTNSPFQRDFMEQRRFSDIIFHPWKKEENGNQSRVILYTITLTNPLAPKTATVRETQTMYKASQESECYVIDAEVLTHDVPYHDYFYTINRYTLTRVARNKSRLRVSTELRYRKQPWGLVKTFIEKNFWSGLEDYFRHLESELAKTESTYLAEMHRQSPKEKASKTTTVRRRKRPHAHLRVPHLEEVMSPVTTPTDEDVGHRIKHVAGSTQTRHIPEDTPNGFHLQSVSKLLLVISCVICFSLVLLVILNMMLFYKLWMLEYTTQTLTAWQGLRLQERLPQSQTEWAQLLESQQKYHDTELQKWREIIKSSVMLLDQMKDSLINLQNGIRSRDYTSESEEKRNRYH>sp|Q76L83|ASXL2_HUMAN Putative Polycomb group protein ASXL2 OS=Homosapiens OX=9606 GN=ASXL2 PE=1 SV=1MREKGRRKKGRTWAEAAKTVLEKYPNTPMSHKEILQVIQREGLKEIRSGTSPLACLNAMLHTNSRGEEGIFYKVPGRMGVYTLKKDVPDGVKELSEGSEESSDGQSDSQSSENSSSSSDGGSNKEGKKSRWKRKVSSSSPQSGCPSPTIPAGKVISPSQKHSKKALKQALKQQQQKKQQQQCRPSISISSNQHLSLKTVKAASDSVPAKPATWEGKQSDGQTGSPQNSNSSFSSSVKVENTLLGLGKKSFQRSERLHTRQMKRTKCADIDVETPDSILVNTNLRALINKHTFSVLPGDCQQRLLLLLPEVDRQVGPDGLMKLNGSALNNEFFTSAAQGWKERLSEGEFTPEMQVRIRQEIEKEKKVEPWKEQFFESYYGQSSGLSLEDSKKLTASPSDPKVKKTPAEQPKSMPVSEASLIRIVPVVSQSECKEEALQMSSPGRKEECESQGEVQPNFSTSSEPLLSSALNTHELSSILPIKCPKDEDLLEQKPVTSAEQESEKNHLTTASNYNKSESQESLVTSPSKPKSPGVEKPIVKPTAGAGPQETNMKEPLATLVDQSPESLKRKSSLTQEEAPVSWEKRPRVTENRQHQQPFQVSPQPFLNRGDRIQVRKVPPLKIPVSRISPMPFHPSQVSPRARFPVSITSPNRTGARTLADIKAKAQLVKAQRAAAAAAAAAAAAASVGGTIPGPGPGGGQGPGEGGEGQTARGGSPGSDRVSETGKGPTLELAGTGSRGGTRELLPCGPETQPQSETKTTPSQAQPHSVSGAQLQQTPPVPPTPAVSGACTSVPSPAHIEKLDNEKLNPTRATATVASVSHPQGPSSCRQEKAPSPTGPALISGASPVHCAADGTVELKAGPSKNIPNPSASSKTDASVPVAVTPSPLTSLLTTATLEKLPVPQVSATTAPAGSAPPSSTLPAASSLKTPGTSLNMNGPTLRPTSSIPANNPLVTQLLQGKDVPMEQILPKPLTKVEMKTVPLTAKEERGMGALIATNTTENSTREEVNERQSHPATQQQLGKTLQSKQLPQVPRPLQLFSAKELRDSSIDTHQYHEGLSKATQDQILQTLIQRVRRQNLLSVVPPSQFNFAHSGFQLEDISTSQRFMLGFAGRRTSKPAMAGHYLLNISTYGRGSESFRRTHSVNPEDRFCLSSPTEALKMGYTDCKNATGESSSSKEDDTDEESTGDEQESVTVKEEPQVSQSAGKGDTSSGPHSRETLSTSDCLASKNVKAEIPLNEQTTLSKENYLFTRGQTFDEKTLARDLIQAAQKQMAHAVRGKAIRSSPELFSSTVLPLPADSPTHQPLLLPPLQTPKLYGSPTQIGPSYRGMINVSTSSDMDHNSAVPGSQVSSNVGDVMSFSVTVTTIPASQAMNPSSHGQTIPVQAFSEENSIEGTPSKCYCRLKAMIMCKGCGAFCHDDCIGPSKLCVSCLVVR>sp|Q76L83-2|ASXL2_HUMAN Isoform 2 of Putative Polycomb group proteinASXL2 OS=Homo sapiens OX=9606 GN=ASXL2MKRTKCADIDVETPDSILVNTNLRALINKHTFSVLPGDCQQRLLLLLPEVDRQVGPDGLMKLNGSALNNEFFTSAAQGWKERLSEGEFTPEMQVRIRQEIEKEKKVEPWKEQFFESYYGQSSGLSLEDSKKLTASPSDPKVKKTPAEQPKSMPVSEASLIRIVPVVSQSECKEEALQMSSPGRKEECESQGEVQPNFSTSSEPLLSSALNTHELSSILPIKCPKDEDLLEQKPVTSAEQESEKNHLTTASNYNKSESQESLVTSPSKPKSPGVEKPIVKPTAGAGPQETNMKEPLATLVDQSPESLKRKSSLTQEEAPVSWEKRPRVTENRQHQQPFQVSPQPFLNRGDRIQVRKVPPLKIPVSRISPMPFHPSQVSPRARFPVSITSPNRTGARTLADIKAKAQLVKAQRAAAAAAAAAAAAASVGGTIPGPGPGGGQGPGEGGEGQTARGGSPGSDRVSETGKGPTLELAGTGSRGGTRELLPCGPETQPQSETKTTPSQAQPHSVSGAQLQQTPPVPPTPAVSGACTSVPSPAHIEKLDNEKLNPTRATATVASVSHPQGPSSCRQEKAPSPTGFQLEDISTSQRFMLGFAGRRTSKPAMAGHYLLNISTYGRGSESFRRTHSVNPEDRFCLSSPTEALKMGYTDCKNATGESSSSKEDDTDEESTGDEQESVTVKEEPQVSQSAGKGDTSSGPHSRETLSTSDCLASKNVKAEIPLNEQTTLSKENYLFTRGQTFDEKTLARDLIQAAQKQMAHAVRGKAIRSSPELFSSTVLPLPADSPTHQPLLLPPLQTPKLYGSPTQIGPSYRGMINVSTSSDMDHNSAVPGSQVSSNVGDVMSFSVTVTTIPASQAMNPSSHGQTIPVQAFSEENSIEGTPSKCYCRLKAMIMCKGCGAFCHDDCIGPSKLCVSCLVVR>sp|Q8WXK4|ASB12_HUMAN Ankyrin repeat and SOCS box protein 12 OS=Homosapiens OX=9606 GN=ASB12 PE=1 SV=2MNLMDITKIFSLLQPDKEEEDTDTEEKQALNQAVYDNDSYTLDQLLRQERYKRFINSRSGWGVPGTPLRLAASYGHLSCLQVLLAHGADVDSLDVKAQTPLFTAVSHGHLDCVRVLLEAGASPGGSIYNNCSPVLTAARDGAVAILQELLDHGAEANVKAKLPVWASNIASCSGPLYLAAVYGHLDCFRLLLLHGADPDYNCTDQGLLARVPRPRTLLEICLHHNCEPEYIQLLIDFGANIYLPSLSLDLTSQDDKGIALLLQARATPRSLLSQVRLVVRRALCQAGQPQAINQLDIPPMLISYLKHQL>sp|Q8WXK4-2|ASB12_HUMAN Isoform 2 of Ankyrin repeat and SOCS box protein12 OS=Homo sapiens OX=9606 GN=ASB12MRIVLQLAKMNLMDITKIFSLLQPDKEEEDTDTEEKQALNQAVYDNDSYTLDQLLRQERYKRFINSRSGWGVPGTPLRLAASYGHLSCLQVLLAHGADVDSLDVKAQTPLFTAVSHGHLDCVRVLLEAGASPGGSIYNNCSPVLTAARDGAVAILQELLDHGAEANVKAKLPVWASNIASCSGPLYLAAVYGHLDCFRLLLLHGADPDYNCTDQGLLARVPRPRTLLEICLHHNCEPEYIQLLIDFGANIYLPSLSLDLTSQDDKGIALLLQARATPRSLLSQVRLVVRRALCQAGQPQAINQLDIPPMLISYLKHQL>sp|O60312|AT10A_HUMAN Phospholipid-transporting ATPase VA OS=Homosapiens OX=9606 GN=ATP10A PE=1 SV=2MEREPAGTEEPGPPGRRRRREGRTRTVRSNLLPPPGAEDPAAGAAKGERRRRRGCAQHLADNRLKTTKYTLLSFLPKNLFEQFHRPANVYFVFIALLNFVPAVNAFQPGLALAPVLFILAITAFRDLWEDYSRHRSDHKINHLGCLVFSREEKKYVNRFWKEIHVGDFVRLRCNEIFPADILLLSSSDPDGLCHIETANLDGETNLKRRQVVRGFSELVSEFNPLTFTSVIECEKPNNDLSRFRGCIIHDNGKKAGLYKENLLLRGCTLRNTDAVVGIVIYAGHETKALLNNSGPRYKRSKLERQMNCDVLWCVLLLVCMSLFSAVGHGLWIWRYQEKKSLFYVPKSDGSSLSPVTAAVYSFLTMIIVLQVLIPISLYVSIEIVKACQVYFINQDMQLYDEETDSQLQCRALNITEDLGQIQYIFSDKTGTLTENKMVFRRCTVSGVEYSHDANAQRLARYQEADSEEEEVVPRGGSVSQRGSIGSHQSVRVVHRTQSTKSHRRTGSRAEAKRASMLSKHTAFSSPMEKDITPDPKLLEKVSECDKSLAVARHQEHLLAHLSPELSDVFDFFIALTICNTVVVTSPDQPRTKVRVRFELKSPVKTIEDFLRRFTPSCLTSGCSSIGSLAANKSSHKLGSSFPSTPSSDGMLLRLEERLGQPTSAIASNGYSSQADNWASELAQEQESERELRYEAESPDEAALVYAARAYNCVLVERLHDQVSVELPHLGRLTFELLHTLGFDSVRKRMSVVIRHPLTDEINVYTKGADSVVMDLLQPCSSVDARGRHQKKIRSKTQNYLNVYAAEGLRTLCIAKRVLSKEEYACWLQSHLEAESSLENSEELLFQSAIRLETNLHLLGATGIEDRLQDGVPETISKLRQAGLQIWVLTGDKQETAVNIAYACKLLDHDEEVITLNATSQEACAALLDQCLCYVQSRGLQRAPEKTKGKVSMRFSSLCPPSTSTASGRRPSLVIDGRSLAYALEKNLEDKFLFLAKQCRSVLCCRSTPLQKSMVVKLVRSKLKAMTLAIGDGANDVSMIQVADVGVGISGQEGMQAVMASDFAVPKFRYLERLLILHGHWCYSRLANMVLYFFYKNTMFVGLLFWFQFFCGFSASTMIDQWYLIFFNLLFSSLPPLVTGVLDRDVPANVLLTNPQLYKSGQNMEEYRPRTFWFNMADAAFQSLVCFSIPYLAYYDSNVDLFTWGTPIVTIALLTFLLHLGIETKTWTWLNWITCGFSVLLFFTVALIYNASCATCYPPSNPYWTMQALLGDPVFYLTCLMTPVAALLPRLFFRSLQGRVFPTQLQLARQLTRKSPRRCSAPKETFAQGRLPKDSGTEHSSGRTVKTSVPLSQPSWHTQQPVCSLEASGEPSTVDMSMPVREHTLLEGLSAPAPMSSAPGEAVLRSPGGCPEESKVRAASTGRVTPLSSLFSLPTFSLLNWISSWSLVSRLGSVLQFSRTEQLADGQAGRGLPVQPHSGRSGLQGPDHRLLIGASSRRSQ>sp|O60312-2|AT10A_HUMAN Isoform 2 of Phospholipid-transporting ATPase VAOS=Homo sapiens OX=9606 GN=ATP10AMEREPAGTEEPGPPGRRRRREGRTRTVRSNLLPPPGAEDPAAGAAKGERRRRRGCAQHLADNRLKTTKYTLLSFLPKNLFEQFHRPANVYFVFIALLNFVPAVNAFQPGLALAPVLFILAITAFRDLWEDYSRHRSDHKINHLGCLVFSSRSHLK>sp|Q9NWX5|ASB6_HUMAN Ankyrin repeat and SOCS box protein 6 OS=Homosapiens OX=9606 GN=ASB6 PE=1 SV=1MPFLHGFRRIIFEYQPLVDAILGSLGIQDPERQESLDRPSYVASEESRILVLTELLERKAHSPFYQEGVSNALLKMAELGLTRAADVLLRHGANLNFEDPVTYYTALHIAVLRNQPDMVELLVHHGADVNRRDRIHESSPLDLASEEPERLPCLQRLLDLGADVNAADKHGKTALLHALASSDGVQIHNTENIRLLLEGGADVKATTKDGDTVFTCIIFLLGETVGGDKEEAQMINRFCFQVTRLLLAHGADPSECPAHESLTHICLKSFKLHFPLLRFLLESGAAYNCSLHGASCWSGFHIIFERLCSHPGCTEDESHADLLRKAETVLDLMVTNSQKLQLPENFDIHPVGSLAEKIQALHFSLRQLESYPPPLKHLCRVAIRLYLQPWPVDVKVKALPLPDRLKWYLLSEHSGSVEDDI>sp|Q9NWX5-2|ASB6_HUMAN Isoform 2 of Ankyrin repeat and SOCS box protein6 OS=Homo sapiens OX=9606 GN=ASB6MPFLHGFRRIIFEYQPLVDAILGSLGIQDPERQESLDRPSYVASEESRILVLTELLERKAHSPFYQEGVSNALLKMAELGLTRAADVLLRHGANLNFEDPVTYYTALHIAVLRNQPDMVELLVHHGADVNRRDREKLLCSMLWPAATGCRSTILRTFVSYWKEGQTSRPPPKMGTQCSPASSSCLVRPWEGTKRRPR>sp|Q9Y575|ASB3_HUMAN Ankyrin repeat and SOCS box protein 3 OS=Homosapiens OX=9606 GN=ASB3 PE=1 SV=1MDFTEAYADTCSTVGLAAREGNVKVLRKLLKKGRSVDVADNRGWMPIHEAAYHNSVECLQMLINADSSENYIKMKTFEGFCALHLAASQGHWKIVQILLEAGADPNATTLEETTPLFLAVENGQIDVLRLLLQHGANVNGSHSMCGWNSLHQASFQENAEIIKLLLRKGANKECQDDFGITPLFVAAQYGKLESLSILISSGANVNCQALDKATPLFIAAQEGHTKCVELLLSSGADPDLYCNEDSWQLPIHAAAQMGHTKILDLLIPLTNRACDTGLNKVSPVYSAVFGGHEDCLEILLRNGYSPDAQACLVFGFSSPVCMAFQKDCEFFGIVNILLKYGAQINELHLAYCLKYEKFSIFRYFLRKGCSLGPWNHIYEFVNHAIKAQAKYKEWLPHLLVAGFDPLILLCNSWIDSVSIDTLIFTLEFTNWKTLAPAVERMLSARASNAWILQQHIATVPSLTHLCRLEIRSSLKSERLRSDSYISQLPLPRSLHNYLLYEDVLRMYEVPELAAIQDG>sp|Q9Y575-2|ASB3_HUMAN Isoform 2 of Ankyrin repeat and SOCS box protein3 OS=Homo sapiens OX=9606 GN=ASB3MKTFEGFCALHLAASQGHWKIVQILLEAGADPNATTLEETTPLFLAVENGQIDVLRLLLQHGANVNGSHSMCGWNSLHQASFQENAEIIKLLLRKGANKECQDDFGITPLFVAAQYGKLESLSILISSGANVNCQALDKATPLFIAAQEGHTKCVELLLSSGADPDLYCNEDSWQLPIHAAAQMGHTKILDLLIPLTNRACDTGLNKVSPVYSAVFGGHEDCLEILLRNGYSPDAQACLVFGFSSPVCMAFQKDCEFFGIVNILLKYGAQINELHLAYCLKYEKFSIFRYFLRKGCSLGPWNHIYEFVNHAIKAQAKYKEWLPHLLVAGFDPLILLCNSWIDSVSIDTLIFTLEFTNWKTLAPAVERMLSARASNAWILQQHIATVPSLTHLCRLEIRSSLKSERLRSDSYISQLPLPRSLHNYLLYEDVLRMYEVPELAAIQDG>sp|Q9Y575-3|ASB3_HUMAN Isoform 3 of Ankyrin repeat and SOCS box protein3 OS=Homo sapiens OX=9606 GN=ASB3MAMMPLVLHHPERQAELGSGLRDGGGAALRPPGRLVKQMDFTEAYADTCSTVGLAAREGNVKVLRKLLKKGRSVDVADNRGWMPIHEAAYHNSVECLQMLINADSSENYIKMKTFEGFCALHLAASQGHWKIVQILLEAGADPNATTLEETTPLFLAVENGQIDVLRLLLQHGANVNGSHSMCGWNSLHQASFQENAEIIKLLLRKGANKECQDDFGITPLFVAAQYGKLESLSILISSGANVNCQALDKATPLFIAAQEGHTKCVELLLSSGADPDLYCNEDSWQLPIHAAAQMGHTKILDLLIPLTNRACDTGLNKVSPVYSAVFGGHEDCLEILLRNGYSPDAQACLVFGFSSPVCMAFQKDCEFFGIVNILLKYGAQINELHLAYCLKYEKFSIFRYFLRKGCSLGPWNHIYEFVNHAIKAQAKYKEWLPHLLVAGFDPLILLCNSWIDSVSIDTLIFTLEFTNWKTLAPAVERMLSARASNAWILQQHIATVPSLTHLCRLEIRSSLKSERLRSDSYISQLPLPRSLHNYLLYEDVLRMYEVPELAAIQDG>sp|Q86WG3|ATCAY_HUMAN Caytaxin OS=Homo sapiens OX=9606 GN=ATCAY PE=1SV=2MGTTEATLRMENVDVKEEWQDEDLPRPLPEETGVELLGSPVEDTSSPPNTLNFNGAHRKRKTLVAPEINISLDQSEGSLLSDDFLDTPDDLDINVDDIETPDETDSLEFLGNGNELEWEDDTPVATAKNMPGDSADLFGDGTTEDGSAANGRLWRTVIIGEQEHRIDLHMIRPYMKVVTHGGYYGEGLNAIIVFAACFLPDSSLPDYHYIMENLFLYVISSLELLVAEDYMIVYLNGATPRRRMPGIGWLKKCYQMIDRRLRKNLKSLIIVHPSWFIRTVLAISRPFISVKFINKIQYVHSLEDLEQLIPMEHVQIPDCVLQYEEERLKARRESARPQPEFVLPRSEEKPEVAPVENRSALVSEDQETSMS>sp|Q86WG3-3|ATCAY_HUMAN Isoform 2 of Caytaxin OS=Homo sapiens OX=9606GN=ATCAYMGTTEATLRMENVDVKEEWQDEDLPRPLPEETGVELLGSPVEDTSSPPNTLNFNGAHRKRKTLVAPEINISLDQSEGSLLSDDFLDTPDDLDINVDDIETPDETDSLEFLGNGNELEWEDDTPVATAKNMPGDSADLFGDGTTEDGSAANGRLWRTVIIGEQEHRIDLHMIRPYMKVVTHGGYYGEGLNAIIVFAACFLPDSSLPDYHYIMENLFLYVISSLELLVAEDYMIVYLNGATPRRRMPGIGWLKKCYQMIDRRLRKNLKSLIIVHPSWFIRTVLAISRPFISVKFINKIQYVHSLEDLEQLIPMEHVQIPDCVLQYEEERLKARRESARPQPEFVLPRSEEKPEVAPVENRSALVSEDQETSLQPLHRSS>sp|Q4VNC0|AT135_HUMAN Probable cation-transporting ATPase 13A5 OS=Homosapiens OX=9606 GN=ATP13A5 PE=2 SV=1MEENSKKDHRALLNQGEEDELEVFGYRDHNVRKAFCLVASVLTCGGLLLVFYWRPQWRVWANCIPCPLQEADTVLLRTTDEFQRYMRKKVFCLYLSTLKFPVSKKWEESLVADRHSVINQALIKPELKLRCMEVQKIRYVWNDLEKRFQKVGLLEDSNSCSDIHQTFGLGLTSEEQEVRRLVCGPNAIEVEIQPIWKLLVKQVLNPFYVFQAFTLTLWLSQGYIEYSVAIIILTVISIVLSVYDLRQQSVKLHNLVEDHNKVQVTIIVKDKGLEELESRLLVPGDILILPGKFSLPCDAVLIDGSCVVNEGMLTGESIPVTKTPLPQMENTMPWKCHSLEDYRKHVLFCGTEVIQVKPSGQGPVRAVVLQTGYNTAKGDLVRSILYPRPLNFKLYSDAFKFIVFLACLGVMGFFYALGVYMYHGVPPKDTVTMALILLTVTVPPVLPAALTIGNVYAQKRLKKKKIFCISPQRINMCGQINLVCFDKTGTLTEDGLDLWGTVPTADNCFQEAHSFASGQAVPWSPLCAAMASCHSLILLNGTIQGDPLDLKMFEGTAWKMEDCIVDSCKFGTSVSNIIKPGPKASKSPVEAIITLCQFPFSSSLQRMSVIAQLAGENHFHVYMKGAPEMVARFCRSETVPKNFPQELRSYTVQGFRVIALAHKTLKMGNLSEVEHLAREKVESELTFLGLLIMENRLKKETKLVLKELSEARIRTVMITGDNLQTAITVAKNSEMIPPGSQVIIVEADEPEEFVPASVTWQLVENQETGPGKKEIYMHTGNSSTPRGEGGSCYHFAMSGKSYQVIFQHFNSLLPKILVNGTVFARMSPGQKSSLIEEFQKLNYYVGMCGDGANDCGALKAAHAGISLSEQEASVASPFTSKTTNIQCVPHLIREGRAALVSSFGVFKYLTMYGIIQFISALLLYWQLQLFGNYQYLMQDVAITLMVCLTMSSTHAYPKLAPYRPAGQLLSPPLLLSIFLNSCFSCIVQISAFLYVKQQPWYCEVYQYSECFLANQSNFSTNVSLERNWTGNATLIPGSILSFETTTLWPITTINYITVAFIFSKGKPFRKPIYTNYIFSFLLLAALGLTIFILFSDFQVIYRGMELIPTITSWRVLILVVALTQFCVAFFVEDSILQNHELWLLIKREFGFYSKSQYRTWQKKLAEDSTWPPINRTDYSGDGKNGFYINGGYESHEQIPKRKLKLGGQPTEQHFWARL>sp|Q9H1I8|ASCC2_HUMAN Activating signal cointegrator 1 complex subunit 2OS=Homo sapiens OX=9606 GN=ASCC2 PE=1 SV=3MPALPLDQLQITHKDPKTGKLRTSPALHPEQKADRYFVLYKPPPKDNIPALVEEYLERATFVANDLDWLLALPHDKFWCQVIFDETLQKCLDSYLRYVPRKFDEGVASAPEVVDMQKRLHRSVFLTFLRMSTHKESKDHFISPSAFGEILYNNFLFDIPKILDLCVLFGKGNSPLLQKMIGNIFTQQPSYYSDLDETLPTILQVFSNILQHCGLQGDGANTTPQKLEERGRLTPSDMPLLELKDIVLYLCDTCTTLWAFLDIFPLACQTFQKHDFCYRLASFYEAAIPEMESAIKKRRLEDSKLLGDLWQRLSHSRKKLMEIFHIILNQICLLPILESSCDNIQGFIEEFLQIFSSLLQEKRFLRDYDALFPVAEDISLLQQASSVLDETRTAYILQAVESAWEGVDRRKATDAKDPSVIEEPNGEPNGVTVTAEAVSQASSHPENSEEEECMGAAAAVGPAMCGVELDSLISQVKDLLPDLGEGFILACLEYYHYDPEQVINNILEERLAPTLSQLDRNLDREMKPDPTPLLTSRHNVFQNDEFDVFSRDSVDLSRVHKGKSTRKEENTRSLLNDKRAVAAQRQRYEQYSVVVEEVPLQPGESLPYHSVYYEDEYDDTYDGNQVGANDADSDDELISRRPFTIPQVLRTKVPREGQEEDDDDEEDDADEEAPKPDHFVQDPAVLREKAEARRMAFLAKKGYRHDSSTAVAGSPRGHGQSRETTQERRKKEANKATRANHNRRTMADRKRSKGMIPS>sp|Q9H1I8-2|ASCC2_HUMAN Isoform 2 of Activating signal cointegrator 1complex subunit 2 OS=Homo sapiens OX=9606 GN=ASCC2MQKRLHRSVFLTFLRMSTHKESKDHFISPSAFGEILYNNFLFDIPKILDLCVLFGKGNSPLLQKMIGNIFTQQPSYYSDLDETLPTILQVFSNILQHCGLQGDGANTTPQKLEERGRLTPSDMPLLELKDIVLYLCDTCTTLWAFLDIFPLACQTFQKHDFCYRLASFYEAAIPEMESAIKKRRLEDSKLLGDLWQRLSHSRKKLMEIFHIILNQICLLPILESSCDNIQGFIEEFLQIFSSLLQEKRFLRDYDALFPVAEDISLLQQASSVLDETRTAYILQAVESAWEGVDRRKATDAKDPSVIEEPNGEPNGVTVTAEAVSQASSHPENSEEEECMGAAAAVGPAMCGVELDSLISQVKDLLPDLEK>sp|Q9H1I8-3|ASCC2_HUMAN Isoform 3 of Activating signal cointegrator 1complex subunit 2 OS=Homo sapiens OX=9606 GN=ASCC2MPALPLDQLQITHKDPKTGKLRTSPALVIFDETLQKCLDSYLRYVPRKFDEGVASAPEVVDMQKRLHRSVFLTFLRMSTHKESKILDLCVLFGKGNSPLLQKMIGNIFTQQPSYYSDLDETLPTILQVFSNILQHCGLQGDGANTTPQKLEERGRLTPSDMPLLELKDIVLYLCDTCTTLWAFLDIFPLACQTFQKHDFCYRLASFYEAAIPEMESAIKKRRLEDSKLLGDLWQRLSHSRKKLMEIFHIILNQICLLPILESSCDNIQGFIEEFLQIFSSLLQEKRFLRDYDALFPVAEDISLLQQASSVLDETRTAYILQAVESAWEGVDRRKATDAKDPSVIEEPNGEPNGVTVTAEAVSQASSHPENSEEEECMGAAAAVGPAMCGVELDSLISQVKDLLPDLGEGFILACLEYYHYDPEQVINNILEERLAPTLSQLDRNLDREMKPDPTPLLTSRHNVFQNDEFDVFSRDSVDLSRVHKGKSTRKEENTRSLLNDKRAVAAQRQRYEQYSVVVEEVPLQPGESLPYHSVYYEDEYDDTYDGNQVGANDADSDDELISRRPFTIPQVLRTKVPREGQEEDDDDEEDDADEEAPKPDHFVQDPAVLREKAEARRMAFLAKKGYRHDSSTAVAGSPRGHGQSRETTQERRKKEANKATRANHNRRTMADRKRSKGMIPS>sp|Q9H7F0|AT133_HUMAN Polyamine-transporting ATPase 13A3 OS=Homo sapiensOX=9606 GN=ATP13A3 PE=1 SV=4MDREERKTINQGQEDEMEIYGYNLSRWKLAIVSLGVICSGGFLLLLLYWMPEWRVKATCVRAAIKDCEVVLLRTTDEFKMWFCAKIRVLSLETYPVSSPKSMSNKLSNGHAVCLIENPTEENRHRISKYSQTESQQIRYFTHHSVKYFWNDTIHNFDFLKGLDEGVSCTSIYEKHSAGLTKGMHAYRKLLYGVNEIAVKVPSVFKLLIKEVLNPFYIFQLFSVILWSTDEYYYYALAIVVMSIVSIVSSLYSIRKQYVMLHDMVATHSTVRVSVCRVNEEIEEIFSTDLVPGDVMVIPLNGTIMPCDAVLINGTCIVNESMLTGESVPVTKTNLPNPSVDVKGIGDELYNPETHKRHTLFCGTTVIQTRFYTGELVKAIVVRTGFSTSKGQLVRSILYPKPTDFKLYRDAYLFLLCLVAVAGIGFIYTIINSILNEVQVGVIIIESLDIITITVPPALPAAMTAGIVYAQRRLKKIGIFCISPQRINICGQLNLVCFDKTGTLTEDGLDLWGIQRVENARFLSPEENVCNEMLVKSQFVACMATCHSLTKIEGVLSGDPLDLKMFEAIGWILEEATEEETALHNRIMPTVVRPPKQLLPESTPAGNQEMELFELPATYEIGIVRQFPFSSALQRMSVVARVLGDRKMDAYMKGAPEAIAGLCKPETVPVDFQNVLEDFTKQGFRVIALAHRKLESKLTWHKVQNISRDAIENNMDFMGLIIMQNKLKQETPAVLEDLHKANIRTVMVTGDSMLTAVSVARDCGMILPQDKVIIAEALPPKDGKVAKINWHYADSLTQCSHPSAIDPEAIPVKLVHDSLEDLQMTRYHFAMNGKSFSVILEHFQDLVPKLMLHGTVFARMAPDQKTQLIEALQNVDYFVGMCGDGANDCGALKRAHGGISLSELEASVASPFTSKTPSISCVPNLIREGRAALITSFCVFKFMALYSIIQYFSVTLLYSILSNLGDFQFLFIDLAIILVVVFTMSLNPAWKELVAQRPPSGLISGALLFSVLSQIIICIGFQSLGFFWVKQQPWYEVWHPKSDACNTTGSGFWNSSHVDNETELDEHNIQNYENTTVFFISSFQYLIVAIAFSKGKPFRQPCYKNYFFVFSVIFLYIFILFIMLYPVASVDQVLQIVCVPYQWRVTMLIIVLVNAFVSITVEESVDRWGKCCLPWALGCRKKTPKAKYMYLAQELLVDPEWPPKPQTTTEAKALVKENGSCQIITIT>sp|Q9H7F0-2|AT133_HUMAN Isoform 2 of Polyamine-transporting ATPase 13A3OS=Homo sapiens OX=9606 GN=ATP13A3MSEIEEIFSTDLVPGDVMVIPLNGTIMPCDAVLINGTCIVNESMLTGESVPVTKTNLPNPSVDVKGIGDELYNPETHKRHTLFCGTTVIQTRFYTGELVKAIVVRTGFSTSKGQLVRSILYPKPTDFKLYRDAYLFLLCLVAVAGIGFIYTIINSILNEVQVGVIIIESLDIITITVPPALPAAMTAGIVYAQRRLKKIGIFCISPQRINICGQLNLVCFDKTGTLTEDGLDLWGIQRVENARFLSPEENVCNEMLVKSQFVACMATCHSLTKIEGVLSGDPLDLKMFEAIGWILEEATEEETALHNRIMPTVVRPPKQLLPESTPAGNQEMELFELPATYEIGIVRQFPFSSALQRMSVVARVLGDRKMDAYMKGAPEAIAGLCKPETVPVDFQNVLEDFTKQGFRVIALAHRKLESKLTWHKVQNISRDAIENNMDFMGLIIMQNKLKQETPAVLEDLHKANIRTVMVTGDSMLTAVSVARDCGMILPQDKVIIAEALPPKDGKVAKINWHYADSLTQCSHPSAIDPEAIPVKLVHDSLEDLQMTRYHFAMNGKSFSVILEHFQDLVPKLMLHGTVFARMAPDQKTQLIEALQNVDYFVGMCGDGANDCGALKRAHGGISLSELEASVASPFTSKTPSISCVPNLIREGRAALITSSCELALFSIVTYSLDHFIISILISSMLVLFFSDFHNCAFYSLV>sp|Q8N1G2|CMTR1_HUMAN Cap-specific mRNA (nucleoside-2'-O-)-methyltransferase 1 OS=Homo sapiens OX=9606 GN=CMTR1 PE=1 SV=1MKRRTDPECTAPIKKQKKRVAELALSLSSTSDDEPPSSVSHGAKASTTSLSGSDSETEGKQHSSDSFDDAFKADSLVEGTSSRYSMYNSVSQKLMAKMGFREGEGLGKYSQGRKDIVEASSQKGRRGLGLTLRGFDQELNVDWRDEPEPSACEQVSWFPECTTEIPDTQEMSDWMVVGKRKMIIEDETEFCGEELLHSVLQCKSVFDVLDGEEMRRARTRANPYEMIRGVFFLNRAAMKMANMDFVFDRMFTNPRDSYGKPLVKDREAELLYFADVCAGPGGFSEYVLWRKKWHAKGFGMTLKGPNDFKLEDFYSASSELFEPYYGEGGIDGDGDITRPENISAFRNFVLDNTDRKGVHFLMADGGFSVEGQENLQEILSKQLLLCQFLMALSIVRTGGHFICKTFDLFTPFSVGLVYLLYCCFERVCLFKPITSRPANSERYVVCKGLKVGIDDVRDYLFAVNIKLNQLRNTDSDVNLVVPLEVIKGDHEFTDYMIRSNESHCSLQIKALAKIHAFVQDTTLSEPRQAEIRKECLRLWGIPDQARVAPSSSDPKSKFFELIQGTEIDIFSYKPTLLTSKTLEKIRPVFDYRCMVSGSEQKFLIGLGKSQIYTWDGRQSDRWIKLDLKTELPRDTLLSVEIVHELKGEGKAQRKISAIHILDVLVLNGTDVREQHFNQRIQLAEKFVKAVSKPSRPDMNPIRVKEVYRLEEMEKIFVRLEMKIIKGSSGTPKLSYTGRDDRHFVPMGLYIVRTVNEPWTMGFSKSFKKKFFYNKKTKDSTFDLPADSIAPFHICYYGRLFWEWGDGIRVHDSQKPQDQDKLSKEDVLSFIQMHRA>sp|P05026|AT1B1_HUMAN Sodium/potassium-transporting ATPase subunit beta-1 OS=Homo sapiens OX=9606 GN=ATP1B1 PE=1 SV=1MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKRDEDKDKVGNVEYFGLGNSPGFPLQYYPYYGKLLQPKYLQPLLAVQFTNLTMDTEIRIECKAYGENIGYSEKDRFQGRFDVKIEVKS>sp|P05026-2|AT1B1_HUMAN Isoform 2 of Sodium/potassium-transportingATPase subunit beta-1 OS=Homo sapiens OX=9606 GN=ATP1B1MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKRDEDKDKVGNVEYFGLGNSPGFPLQYYPYYGKLLQPKYLQPLLAVQFTNLTMDTEIRIECKAYGENIGYSEKDRFQGRFDVKIKF>sp|Q7L266|ASGL1_HUMAN Isoaspartyl peptidase/L-asparaginase OS=Homosapiens OX=9606 GN=ASRGL1 PE=1 SV=2MNPIVVVHGGGAGPISKDRKERVHQGMVRAATVGYGILREGGSAVDAVEGAVVALEDDPEFNAGCGSVLNTNGEVEMDASIMDGKDLSAGAVSAVQCIANPIKLARLVMEKTPHCFLTDQGAAQFAAAMGVPEIPGEKLVTERNKKRLEKEKHEKGAQKTDCQKNLGTVGAVALDCKGNVAYATSTGGIVNKMVGRVGDSPCLGAGGYADNDIGAVSTTGHGESILKVNLARLTLFHIEQGKTVEEAADLSLGYMKSRVKGLGGLIVVSKTGDWVAKWTSTSMPWAAAKDGKLHFGIDPDDTTITDLP>sp|Q7L266-2|ASGL1_HUMAN Isoform 2 of Isoaspartyl peptidase/L-asparaginase OS=Homo sapiens OX=9606 GN=ASRGL1MGVPEIPGEKLVTERNKKRLEKEKHEKGAQKTDCQKNLGTVGAVALDCKGNVAYATSTGGIVNKMVGRVGDSPCLGAGGYADNDIGAVSTTGHGESILKVNLARLTLFHIEQGKTVEEAADLSLGYMKSRVKGLGGLIVVSKTGDWVAKWTSTSMPWAAAKDGKLHFGIDPDDTTITDLP>sp|Q9UHC3|ASIC3_HUMAN Acid-sensing ion channel 3 OS=Homo sapiens OX=9606GN=ASIC3 PE=1 SV=2MKPTSGPEEARRPASDIRVFASNCSMHGLGHVFGPGSLSLRRGMWAAAVVLSVATFLYQVAERVRYYREFHHQTALDERESHRLIFPAVTLCNINPLRRSRLTPNDLHWAGSALLGLDPAEHAAFLRALGRPPAPPGFMPSPTFDMAQLYARAGHSLDDMLLDCRFRGQPCGPENFTTIFTRMGKCYTFNSGADGAELLTTTRGGMGNGLDIMLDVQQEEYLPVWRDNEETPFEVGIRVQIHSQEEPPIIDQLGLGVSPGYQTFVSCQQQQLSFLPPPWGDCSSASLNPNYEPEPSDPLGSPSPSPSPPYTLMGCRLACETRYVARKCGCRMVYMPGDVPVCSPQQYKNCAHPAIDAMLRKDSCACPNPCASTRYAKELSMVRIPSRAAARFLARKLNRSEAYIAENVLALDIFFEALNYETVEQKKAYEMSELLGDIGGQMGLFIGASLLTILEILDYLCEVFRDKVLGYFWNRQHSQRHSSTNLLQEGLGSHRTQVPHLSLGPRPPTPPCAVTKTLSASHRTCYLVTQL>sp|Q9UHC3-2|ASIC3_HUMAN Isoform 2 of Acid-sensing ion channel 3 OS=Homosapiens OX=9606 GN=ASIC3MKPTSGPEEARRPASDIRVFASNCSMHGLGHVFGPGSLSLRRGMWAAAVVLSVATFLYQVAERVRYYREFHHQTALDERESHRLIFPAVTLCNINPLRRSRLTPNDLHWAGSALLGLDPAEHAAFLRALGRPPAPPGFMPSPTFDMAQLYARAGHSLDDMLLDCRFRGQPCGPENFTTIFTRMGKCYTFNSGADGAELLTTTRGGMGNGLDIMLDVQQEEYLPVWRDNEETPFEVGIRVQIHSQEEPPIIDQLGLGVSPGYQTFVSCQQQQLSFLPPPWGDCSSASLNPNYEPEPSDPLGSPSPSPSPPYTLMGCRLACETRYVARKCGCRMVYMPGDVPVCSPQQYKNCAHPAIDAMLRKDSCACPNPCASTRYAKELSMVRIPSRAAARFLARKLNRSEAYIAENVLALDIFFEALNYETVEQKKAYEMSELLGDIGGQMGLFIGASLLTILEILDYLCEVFRDKVLGYFWNRQHSQRHSSTNLTSHPSLCRHQDSLRLPPHLLPCHTALDLLSVSSEPRPDILDMPSLHVAFPSSPQIKS>sp|Q9UHC3-3|ASIC3_HUMAN Isoform 3 of Acid-sensing ion channel 3 OS=Homosapiens OX=9606 GN=ASIC3MKPTSGPEEARRPASDIRVFASNCSMHGLGHVFGPGSLSLRRGMWAAAVVLSVATFLYQVAERVRYYREFHHQTALDERESHRLIFPAVTLCNINPLRRSRLTPNDLHWAGSALLGLDPAEHAAFLRALGRPPAPPGFMPSPTFDMAQLYARAGHSLDDMLLDCRFRGQPCGPENFTTIFTRMGKCYTFNSGADGAELLTTTRGGMGNGLDIMLDVQQEEYLPVWRDNEETPFEVGIRVQIHSQEEPPIIDQLGLGVSPGYQTFVSCQQQQLSFLPPPWGDCSSASLNPNYEPEPSDPLGSPSPSPSPPYTLMGCRLACETRYVARKCGCRMVYMPGDVPVCSPQQYKNCAHPAIDAMLRKDSCACPNPCASTRYAKELSMVRIPSRAAARFLARKLNRSEAYIAENVLALDIFFEALNYETVEQKKAYEMSELLGDIGGQMGLFIGASLLTILEILDYLCEVFRDKVLGYFWNRQHSQRHSSTNLLQEGLGSHRTQVPHLSLGPSTLLCSEDLPPLPVPSPRLSPPPTAPATLSHSSRPAVCVLGAPP>sp|Q9UHC3-4|ASIC3_HUMAN Isoform 4 of Acid-sensing ion channel 3 OS=Homosapiens OX=9606 GN=ASIC3MKPTSGPEEARRPASDIRVFASNCSMHGLGHVFGPGSLSLRRGMWAAAVVLSVATFLYQVAERVRYYREFHHQTALDERESHRLIFPAVTLCNINPLRRSRLTPNDLHWAGSALLGLDPAEHAAFLRALGRPPAPPGFMPSPTFDMAQLYARAGHSLDDMLLDCRFRGQPCGPENFTTIFTRMGKCYTFNSGADGAELLTTTRGGMGNGLDIMLDVQQEEYLPVWRDNEETPFEVGIRVQIHSQEEPPIIDQLGLGVSPGYQTFVSCQQQQLSFLPPPWGDCSSASLNPNYEPEPSDPLGSPSPSPSPPYTLMGCRLACETRYVARKCGCRMVYMPGDVPVCSPQQYKNCAHPAIGRTCWPWTSSLRPSTMRPWSRRRPMRCQSCLVTLGARWGCSSGPACSPSSRS>sp|Q96M20|CNBD2_HUMAN Cyclic nucleotide-binding domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=CNBD2 PE=2 SV=2MRRHMVTYAWQLLKKELGLYQLAMDIIIMIRVCKMFRQGLRGFREYQIIETAHWKHPIFSFWDKKMQSRVTFDTMDFIAEEGHFPPKAIQIMQKKPSWRTEDEIQAVCNILQVLDSYRNYAEPLQLLLAKVMRFERFGRRRVIIKKGQKGNSFYFIYLGTVAITKDEDGSSAFLDPHPKLLHKGSCFGEMDVLHASVRRSTIVCMEETEFLVVDREDFFANKLDQEVQKDAQYRFEFFRKMELFASWSDEKLWQLVAMAKIERFSYGQLISKDFGESPFIMFISKGSCEVLRLLDLGASPSYRRWIWQHLELIDGRPLKTHLSEYSPMERFKEFQIKSYPLQDFSSLKLPHLKKAWGLQGTSFSRKIRTSGDTLPKMLGPKIQSRPAQSIKCAMINIKPGELPKEAAVGAYVKVHTVEQGEILGLHQAFLPEGECDTRPLILMSLGNELIRIRKEIFYELIDNDDEMIKKLLKLNIAFPSDEDMCQKFLQQNSWNIFRKDLLQLLVEPCQSQLFTPNRPKKREIYNPKSVVLDLCSINKTTKPRYPIFMAPQKYLPPLRIVQAIKAPRYKIRELLA>sp|Q96M20-2|CNBD2_HUMAN Isoform 2 of Cyclic nucleotide-binding domain-containing protein 2 OS=Homo sapiens OX=9606 GN=CNBD2MRRHMVTYAWQLLKKELGLYQLAMDIIIMIRVCKMFRQGLRGFREYQIIETAHWKHPIFSFWDKKMQSRVTFDTMDFIAEEGHFPPKAIQIMQKKPSWRTEDEIQAVCNILQVLDSYRNYAEPLQLLLAKVMRFERFGRRRVIIKKGQKGNSFYFIYLGTVAITKDEDGSSAFLDPHPKLLHKGSCFGEMDVLHASVRRSTIVCMEETEFLVVDREDFFANKLDQEVQKDAQYRFEFFRKMELFASWSDEKLWQLVAMAKIERFSYGQLISKDFGESPFIMFISKGSCEVLRLLDLGASPSYRRWIWQHLELIDGRPLKTHLSEYSPMERFKEFQIKSYPLQDFSSLKLPHLKKAWGLQGTSFSRKIRTSGDTLPKMLGPKIQSRPAQSIKCAMINIKPGELPKEAAVGAYVKVHTVEQGEILAFLPEGECDTRPLILMSLGNELIRIRKEIFYELIDNDDEMIKKLLKLNIAFPSDEDMCQKFLQQNSWNIFRKDLLQLLVEPCQSQLFTPNRPKKREIYNPKSVVLDLCSINKTTKPRYPIFMAPQKYLPPLRIVQAIKAPRYKIRELLA>sp|Q96M20-3|CNBD2_HUMAN Isoform 3 of Cyclic nucleotide-binding domain-containing protein 2 OS=Homo sapiens OX=9606 GN=CNBD2MRRHMVTYAWQLLKKELGLYQLAMDIIIMIRVCKMFRQGLRGFREYQIIETAHWKHPIFSFWDKKMQSRVTFDTMDFIAEEGHFPPKAIQIMQKKPSWRTEDEIQAVCNILQVLDSYRNYAEPLQLLLAKVMRFERFGRRRVIIKKGQKGNSFYFIYLGTVAITKDEDGSSAFLDPHPKLLHKGSCFGEMDVLHASVRRSTIVCMEETEFLVVDREDFFANKLDQEVQKDAQYRFEFFRKMELFASWSDEKLWQLVAMAKIERFSYGQLISKDFGESPFIMFISKGSCEVLRLLDLGASPSYRRWIWQHLELIDGRPLKTHLSEYSPMERFKEFQIKSYPLQDFSSLKLPHLKKAWGLQGTSFSRKIRTSGDTLPKMLGPKIQSRPAQSIKCAMINIKPGELPKEAAVGAYVKVHTVEQGEIL>sp|P32121|ARRB2_HUMAN Beta-arrestin-2 OS=Homo sapiens OX=9606 GN=ARRB2PE=1 SV=2MGEKPGTRVFKKSSPNCKLTVYLGKRDFVDHLDKVDPVDGVVLVDPDYLKDRKVFVTLTCAFRYGREDLDVLGLSFRKDLFIATYQAFPPVPNPPRPPTRLQDRLLRKLGQHAHPFFFTIPQNLPCSVTLQPGPEDTGKACGVDFEIRAFCAKSLEEKSHKRNSVRLVIRKVQFAPEKPGPQPSAETTRHFLMSDRSLHLEASLDKELYYHGEPLNVNVHVTNNSTKTVKKIKVSVRQYADICLFSTAQYKCPVAQLEQDDQVSPSSTFCKVYTITPLLSDNREKRGLALDGKLKHEDTNLASSTIVKEGANKEVLGILVSYRVKVKLVVSRGGDVSVELPFVLMHPKPHDHIPLPRPQSAAPETDVPVDTNLIEFDTNYATDDDIVFEDFARLRLKGMKDDDYDDQLC>sp|P32121-3|ARRB2_HUMAN Isoform 2 of Beta-arrestin-2 OS=Homo sapiensOX=9606 GN=ARRB2MGEKPGTRVFKKSSPNCKLTVYLGKRDFVDHLDKVDPVDGVVLVDPDYLKDRKVFVTLTCAFRYGREDLDVLGLSFRKDLFIATYQAFPPVPNPPRPPTRLQDRLLRKLGQHAHPFFFTIPQNLPCSVTLQPGPEDTGKACGVDFEIRAFCAKSLEEKSHKRNSVRLVIRKVQFAPEKPGPQPSAETTRHFLMSDRSLHLEASLDKELYYHGEPLNVNVHVTNNSTKTVKKIKVSVRQYADICLFSTAQYKCPVAQLEQDDQVSPSSTFCKVYTITPLLSDNREKRGLALDGKLKHEDTNLASSTIVKEGANKEVLGILVSYRVKVKLVVSRGGDVSVELPFVLMHPKPHDHIPLPRPQSAPTPTPPLPVPPAAPETDVPVDTNLIEFDTNYATDDDIVFEDFARLRLKGMKDDDYDDQLC>sp|P32121-2|ARRB2_HUMAN Isoform 3 of Beta-arrestin-2 OS=Homo sapiensOX=9606 GN=ARRB2MGEKPGTRVFKKSSPNCKLTVYLGKRDFVDHLDKVDPVVFVTLTCAFRYGREDLDVLGLSFRKDLFIATYQAFPPVPNPPRPPTRLQDRLLRKLGQHAHPFFFTIPQNLPCSVTLQPGPEDTGKACGVDFEIRAFCAKSLEEKSHKRNSVRLVIRKVQFAPEKPGPQPSAETTRHFLMSDRSLHLEASLDKELYYHGEPLNVNVHVTNNSTKTVKKIKVSVRQYADICLFSTAQYKCPVAQLEQDDQVSPSSTFCKVYTITPLLSDNREKRGLALDGKLKHEDTNLASSTIVKEGANKEVLGILVSYRVKVKLVVSRGGDVSVELPFVLMHPKPHDHIPLPRPQSAPTPTPPLPVPPAAPETDVPVDTNLIEFDTNYATDDDIVFEDFARLRLKGMKDDDYDDQLC>sp|P32121-4|ARRB2_HUMAN Isoform 4 of Beta-arrestin-2 OS=Homo sapiensOX=9606 GN=ARRB2MGEKPGTRVFKKSSPNCKLTVYLGKRDFVDHLDKVDPVDGVVLVDPDYLKDRKVFVTLTCAFRYGREDLDVLGLSFRKDLFIATYQAFPPVPNPPRPPTRLQDRLLRKLGQHAHPFFFTVRMPLPSEGQGAGAGTVSGVGIPQNLPCSVTLQPGPEDTGKACGVDFEIRAFCAKSLEEKSHKRNSVRLVIRKVQFAPEKPGPQPSAETTRHFLMSDRSLHLEASLDKELYYHGEPLNVNVHVTNNSTKTVKKIKVSVRQYADICLFSTAQYKCPVAQLEQDDQVSPSSTFCKVYTITPLLSDNREKRGLALDGKLKHEDTNLASSTIVKEGANKEVLGILVSYRVKVKLVVSRGGDVSVELPFVLMHPKPHDHIPLPRPQSAAPETDVPVDTNLIEFDTNYATDDDIVFEDFARLRLKGMKDDDYDDQLC>sp|P32121-5|ARRB2_HUMAN Isoform 5 of Beta-arrestin-2 OS=Homo sapiensOX=9606 GN=ARRB2MGEKPGTRVFKKSSPNCKLTVYLGKRDFVDHLDKVDPVVFVTLTCAFRYGREDLDVLGLSFRKDLFIATYQAFPPVPNPPRPPTRLQDRLLRKLGQHAHPFFFTIPQNLPCSVTLQPGPEDTGKACGVDFEIRAFCAKSLEEKSHKRNSVRLVIRKVQFAPEKPGPQPSAETTRHFLMSDRSLHLEASLDKELYYHGEPLNVNVHVTNNSTKTVKKIKVSVRQYADICLFSTAQYKCPVAQLEQDDQVSPSSTFCKVYTITPLLSDNREKRGLALDGKLKHEDTNLASSTIVKEGANKEVLGILVSYRVKVKLVVSRGGDVSVELPFVLMHPKPHDHIPLPRPQSAAPETDVPVDTNLIEFDTNYATDDDIVFEDFARLRLKGMKDDDYDDQLC>sp|Q8N8G6|CO054_HUMAN Putative uncharacterized protein encoded byLINC02915 OS=Homo sapiens OX=9606 GN=LINC02915 PE=2 SV=1MEVKFITGKHGGRRPQRAEPQRICRALWLTPWPSLILKLLSWIILSNLFLHLRATHHMTELPLRFLYIALSEMTFREQTSHQIIQQMSLSNKLEQNQLYGEVINKETDNPVISSGLTLLFAQKPQSPGWKNMSSTKRVCTILADSCRAQAHAADRGERGHFGVQILHHFIEVFNVMAVRSNPF>sp|A6NEK1|ARRD5_HUMAN Arrestin domain-containing protein 5 OS=Homosapiens OX=9606 GN=ARRDC5 PE=3 SV=2MGDREECLSTPQPPMSVVKSIELVLPEDRIYLAGSSIKGQVILTLNSTLVDPIVKVELVGRGYVEWSEEAGASCDYSRNVICNNKADYVHKTKTFPVEDNWLSAGSHTFDFHFNLPPRLPSTFTSKFGHVFYFVQASCMGREHILAKKRMYLLVQGTSTFHKETPFQNPLFVEAEEKVSYNCCRQGTVCLQIQMERNTFTPGEKVVFTTEINNQTSKCIKTVVFALYAHIQYEGFTPSAERRSRLDSSELLRQEANTPVTRFNTTKVVSTFNLPLLLSVSSSTQDGEIMHTRYELVTTVHLPWSLTSLKAKVPIIITSASVDSAICQLSEDGVLPVNPDHQN>sp|Q9UKP4|ATS7_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 7 OS=Homo sapiens OX=9606 GN=ADAMTS7 PE=1 SV=2MPGGPSPRSPAPLLRPLLLLLCALAPGAPGPAPGRATEGRAALDIVHPVRVDAGGSFLSYELWPRALRKRDVSVRRDAPAFYELQYRGRELRFNLTANQHLLAPGFVSETRRRGGLGRAHIRAHTPACHLLGEVQDPELEGGLAAISACDGLKGVFQLSNEDYFIEPLDSAPARPGHAQPHVVYKRQAPERLAQRGDSSAPSTCGVQVYPELESRRERWEQRQQWRRPRLRRLHQRSVSKEKWVETLVVADAKMVEYHGQPQVESYVLTIMNMVAGLFHDPSIGNPIHITIVRLVLLEDEEEDLKITHHADNTLKSFCKWQKSINMKGDAHPLHHDTAILLTRKDLCAAMNRPCETLGLSHVAGMCQPHRSCSINEDTGLPLAFTVAHELGHSFGIQHDGSGNDCEPVGKRPFIMSPQLLYDAAPLTWSRCSRQYITRFLDRGWGLCLDDPPAKDIIDFPSVPPGVLYDVSHQCRLQYGAYSAFCEDMDNVCHTLWCSVGTTCHSKLDAAVDGTRCGENKWCLSGECVPVGFRPEAVDGGWSGWSAWSICSRSCGMGVQSAERQCTQPTPKYKGRYCVGERKRFRLCNLQACPAGRPSFRHVQCSHFDAMLYKGQLHTWVPVVNDVNPCELHCRPANEYFAEKLRDAVVDGTPCYQVRASRDLCINGICKNVGCDFEIDSGAMEDRCGVCHGNGSTCHTVSGTFEEAEGLGYVDVGLIPAGAREIRIQEVAEAANFLALRSEDPEKYFLNGGWTIQWNGDYQVAGTTFTYARRGNWENLTSPGPTKEPVWIQLLFQESNPGVHYEYTIHREAGGHDEVPPPVFSWHYGPWTKCTVTCGRGVQRQNVYCLERQAGPVDEEHCDPLGRPDDQQRKCSEQPCPARWWAGEWQLCSSSCGPGGLSRRAVLCIRSVGLDEQSALEPPACEHLPRPPTETPCNRHVPCPATWAVGNWSQCSVTCGEGTQRRNVLCTNDTGVPCDEAQQPASEVTCSLPLCRWPLGTLGPEGSGSGSSSHELFNEADFIPHHLAPRPSPASSPKPGTMGNAIEEEAPELDLPGPVFVDDFYYDYNFINFHEDLSYGPSEEPDLDLAGTGDRTPPPHSHPAAPSTGSPVPATEPPAAKEEGVLGPWSPSPWPSQAGRSPPPPSEQTPGNPLINFLPEEDTPIGAPDLGLPSLSWPRVSTDGLQTPATPESQNDFPVGKDSQSQLPPPWRDRTNEVFKDDEEPKGRGAPHLPPRPSSTLPPLSPVGSTHSSPSPDVAELWTGGTVAWEPALEGGLGPVDSELWPTVGVASLLPPPIAPLPEMKVRDSSLEPGTPSFPTPGPGSWDLQTVAVWGTFLPTTLTGLGHMPEPALNPGPKGQPESLSPEVPLSSRLLSTPAWDSPANSHRVPETQPLAPSLAEAGPPADPLVVRNAGWQAGNWSECSTTCGLGAVWRPVRCSSGRDEDCAPAGRPQPARRCHLRPCATWHSGNWSKCSRSCGGGSSVRDVQCVDTRDLRPLRPFHCQPGPAKPPAHRPCGAQPCLSWYTSSWRECSEACGGGEQQRLVTCPEPGLCEEALRPNTTRPCNTHPCTQWVVGPWGQCSGPCGGGVQRRLVKCVNTQTGLPEEDSDQCGHEAWPESSRPCGTEDCEPVEPPRCERDRLSFGFCETLRLLGRCQLPTIRTQCCRSCSPPSHGAPSRGHQRVARR>sp|Q9P1U1|ARP3B_HUMAN Actin-related protein 3B OS=Homo sapiens OX=9606GN=ACTR3B PE=2 SV=1MAGSLPPCVVDCGTGYTKLGYAGNTEPQFIIPSCIAIRESAKVVDQAQRRVLRGVDDLDFFIGDEAIDKPTYATKWPIRHGIIEDWDLMERFMEQVVFKYLRAEPEDHYFLMTEPPLNTPENREYLAEIMFESFNVPGLYIAVQAVLALAASWTSRQVGERTLTGIVIDSGDGVTHVIPVAEGYVIGSCIKHIPIAGRDITYFIQQLLREREVGIPPEQSLETAKAIKEKYCYICPDIVKEFAKYDVDPRKWIKQYTGINAINQKKFVIDVGYERFLGPEIFFHPEFANPDFMESISDVVDEVIQNCPIDVRRPLYKNVVLSGGSTMFRDFGRRLQRDLKRVVDARLRLSEELSGGRIKPKPVEVQVVTHHMQRYAVWFGGSMLASTPEFFQVCHTKKDYEEYGPSICRHNPVFGVMS>sp|Q9P1U1-2|ARP3B_HUMAN Isoform 2 of Actin-related protein 3B OS=Homosapiens OX=9606 GN=ACTR3BMERFMEQVVFKYLRAEPEDHYFLMTEPPLNTPENREYLAEIMFESFNVPGLYIAVQAVLALAASWTSRQVGERTLTGIVIDSGDGVTHVIPVAEGYVIGSCIKHIPIAGRDITYFIQQLLREREVGIPPEQSLETAKAIKEKYCYICPDIVKEFAKYDVDPRKWIKQYTGINAINQKKFVIDVGYERFLGPEIFFHPEFANPDFMESISDVVDEVIQNCPIDVRRPLYKNVVLSGGSTMFRDFGRRLQRDLKRVVDARLRLSEELSGGRIKPKPVEVQVVTHHMQRYAVWFGGSMLASTPEFFQVCHTKKDYEEYGPSICRHNPVFGVMS>sp|Q9P1U1-3|ARP3B_HUMAN Isoform 3 of Actin-related protein 3B OS=Homosapiens OX=9606 GN=ACTR3BMAGSLPPCVVDCGTGYTKLGYAGNTEPQFIIPSCIAIRESAKVVDQAQRRVLRGVDDLDFFIGDEAIDKPTYATKWPIRHGIIEDWDLMERFMEQVVFKYLRAEPEDHYFLMTEPPLNTPENREYLAEIMFESFNVPGLYIAVQAVLALAASWTSRQVGERTLTGIVIDSGDGVTHVIPVAEGYVIGSCIKHIPIAGRDITYFIQQLLREREVGIPPEQSLETAKAIKEKYCYICPDIVKEFAKYDVDPRKWIKQYTGINAINQKKFVIDVGYERFLGPEIFFHPEFANPDFMESISDVVDEVIQNCPIDVRRPLYKPEFFQVCHTKKDYEEYGPSICRHNPVFGVMS>sp|Q8N6F1|CLD19_HUMAN Claudin-19 OS=Homo sapiens OX=9606 GN=CLDN19 PE=1SV=2MANSGLQLLGYFLALGGWVGIIASTALPQWKQSSYAGDAIITAVGLYEGLWMSCASQSTGQVQCKLYDSLLALDGHIQSARALMVVAVLLGFVAMVLSVVGMKCTRVGDSNPIAKGRVAIAGGALFILAGLCTLTAVSWYATLVTQEFFNPSTPVNARYEFGPALFVGWASAGLAVLGGSFLCCTCPEPERPNSSPQPYRPGPSAAAREPVVKLPASAKGPLGV>sp|Q8N6F1-2|CLD19_HUMAN Isoform 2 of Claudin-19 OS=Homo sapiens OX=9606GN=CLDN19MANSGLQLLGYFLALGGWVGIIASTALPQWKQSSYAGDAIITAVGLYEGLWMSCASQSTGQVQCKLYDSLLALDGHIQSARALMVVAVLLGFVAMVLSVVGMKCTRVGDSNPIAKGRVAIAGGALFILAGLCTLTAVSWYATLVTQEFFNPSTPVNARYEFGPALFVGWASAGLAVLGGSFLCCTCPEPERPNSSPQPYRPGPSAAAREYV>sp|Q8N6F1-3|CLD19_HUMAN Isoform 3 of Claudin-19 OS=Homo sapiens OX=9606GN=CLDN19MANSGLQLLGYFLALGGWVGIIASTALPQWKQSSYAGDAIITAVGLYEGLWMSCASQSTGQVQCKLYDSLLALDGHIQSARALMVVAVLLGFVAMVLSVVGMKCTRVGDSNPIAKGRVAIAGGALFILAGMNLAQPCSWAGPQLAWPCWAAPSSAAHARSQRDPTAAHSPIGLDPLLLPESTSELRLPWPAPHPVAPLPSIQPASQHPGQGHWGIGWA>sp|Q8WXS8|ATS14_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 14 OS=Homo sapiens OX=9606 GN=ADAMTS14 PE=2 SV=2MAPLRALLSYLLPLHCALCAAAGSRTPELHLSGKLSDYGVTVPCSTDFRGRFLSHVVSGPAAASAGSMVVDTPPTLPRHSSHLRVARSPLHPGGTLWPGRVGRHSLYFNVTVFGKELHLRLRPNRRLVVPGSSVEWQEDFRELFRQPLRQECVYTGGVTGMPGAAVAISNCDGLAGLIRTDSTDFFIEPLERGQQEKEASGRTHVVYRREAVQQEWAEPDGDLHNEAFGLGDLPNLLGLVGDQLGDTERKRRHAKPGSYSIEVLLVVDDSVVRFHGKEHVQNYVLTLMNIVDEIYHDESLGVHINIALVRLIMVGYRQSLSLIERGNPSRSLEQVCRWAHSQQRQDPSHAEHHDHVVFLTRQDFGPSGYAPVTGMCHPLRSCALNHEDGFSSAFVIAHETGHVLGMEHDGQGNGCADETSLGSVMAPLVQAAFHRFHWSRCSKLELSRYLPSYDCLLDDPFDPAWPQPPELPGINYSMDEQCRFDFGSGYQTCLAFRTFEPCKQLWCSHPDNPYFCKTKKGPPLDGTECAPGKWCFKGHCIWKSPEQTYGQDGGWSSWTKFGSCSRSCGGGVRSRSRSCNNPSPAYGGRLCLGPMFEYQVCNSEECPGTYEDFRAQQCAKRNSYYVHQNAKHSWVPYEPDDDAQKCELICQSADTGDVVFMNQVVHDGTRCSYRDPYSVCARGECVPVGCDKEVGSMKADDKCGVCGGDNSHCRTVKGTLGKASKQAGALKLVQIPAGARHIQIEALEKSPHRIVVKNQVTGSFILNPKGKEATSRTFTAMGLEWEDAVEDAKESLKTSGPLPEAIAILALPPTEGGPRSSLAYKYVIHEDLLPLIGSNNVLLEEMDTYEWALKSWAPCSKACGGGIQFTKYGCRRRRDHHMVQRHLCDHKKRPKPIRRRCNQHPCSQPVWVTEEWGACSRSCGKLGVQTRGIQCLLPLSNGTHKVMPAKACAGDRPEARRPCLRVPCPAQWRLGAWSQCSATCGEGIQQRQVVCRTNANSLGHCEGDRPDTVQVCSLPACGGNHQNSTVRADVWELGTPEGQWVPQSEPLHPINKISSTEPCTGDRSVFCQMEVLDRYCSIPGYHRLCCVSCIKKASGPNPGPDPGPTSLPPFSTPGSPLPGPQDPADAAEPPGKPTGSEDHQHGRATQLPGALDTSSPGTQHPFAPETPIPGASWSISPTTPGGLPWGWTQTPTPVPEDKGQPGEDLRHPGTSLPAASPVT>sp|Q8WXS8-2|ATS14_HUMAN Isoform B of A disintegrin and metalloproteinasewith thrombospondin motifs 14 OS=Homo sapiens OX=9606 GN=ADAMTS14MVVDTPPTLPRHSSHLRVARSPLHPGGTLWPGRVGRHSLYFNVTVFGKELHLRLRPNRRLVVPGSSVEWQEDFRELFRQPLRQECVYTGGVTGMPGAAVAISNCDGLAGLIRTDSTDFFIEPLERGQQEKEASGRTHVVYRREAVQQEWAEPDGDLHNEAFGLGDLPNLLGLVGDQLGDTERKRRHAKPGSYSIEVLLVVDDSVVRFHGKEHVQNYVLTLMNIVDEIYHDESLGVHINIALVRLIMVGYRQSLSLIERGNPSRSLEQVCRWAHSQQRQDPSHAEHHDHVVFLTRQDFGPSGYAPVTGMCHPLRSCALNHEDGFSSAFVIAHETGHVLGMEHDGQGNGCADETSLGSVMAPLVQAAFHRFHWSRCSKLELSRYLPSYDCLLDDPFDPAWPQPPELPGINYSMDEQCRFDFGSGYQTCLAFRTFEPCKQLWCSHPDNPYFCKTKKGPPLDGTECAPGKWCFKGHCIWKSPEQTYGQDGGWSSWTKFGSCSRSCGGGVRSRSRSCNNPSPAYGGRLCLGPMFEYQVCNSEECPGTYEDFRAQQCAKRNSYYVHQNAKHSWVPYEPDDDAQKCELICQSADTGDVVFMNQVVHDGTRCSYRDPYSVCARGECVPVGCDKEVGSMKADDKCGVCGGDNSHCRTVKGTLGKASKQAGALKLVQIPAGARHIQIEALEKSPHRIVVKNQVTGSFILNPKGKEATSRTFTAMGLEWEDAVEDAKESLKTSGPLPEAIAILALPPTEGGPRSSLAYKYVIHEDLLPLIGSNNVLLEEMDTYEWALKSWAPCSKACGGGIQFTKYGCRRRRDHHMVQRHLCDHKKRPKPIRRRCNQHPCSQPVWVTEEWGACSRSCGKLGVQTRGIQCLLPLSNGTHKVMPAKACAGDRPEARRPCLRVPCPAQWRLGAWSQCSATCGEGIQQRQVVCRTNANSLGHCEGDRPDTVQVCSLPACGGNHQNSTVRADVWELGTPEGQWVPQSEPLHPINKISSTEPCTGDRSVFCQMEVLDRYCSIPGYHRLCCVSCIKKASGPNPGPDPGPTSLPPFSTPGSPLPGPQDPADAAEPPGKPTGSEDHQHGRATQLPGALDTSSPGTQHPFAPETPIPGASWSISPTTPGGLPWGWTQTPTPVPEDKGQPGEDLRHPGTSLPAASPVT>sp|Q8WXS8-3|ATS14_HUMAN Isoform C of A disintegrin and metalloproteinasewith thrombospondin motifs 14 OS=Homo sapiens OX=9606 GN=ADAMTS14MVVDTPPTLPRHSSHLRVARSPLHPGGTLWPGRVGRHSLYFNVTVFGKELHLRLRPNRRLVVPGSSVEWQEDFRELFRQPLRQECVYTGGVTGMPGAAVAISNCDGLAGLIRTDSTDFFIEPLERGQQEKEASGRTHVVYRREAVQQEWAEPDGDLHNEAFGLGDLPNLLGLVGDQLGDTERKRRHAKPGSYSIEVLLVVDDSVVRFHGKEHVQNYVLTLMNIVDEIYHDESLGVHINIALVRLIMVGYRQSLSLIERGNPSRSLEQVCRWAHSQQRQDPSHAEHHDHVVFLTRQDFGPSGMQGYAPVTGMCHPLRSCALNHEDGFSSAFVIAHETGHVLGMEHDGQGNGCADETSLGSVMAPLVQAAFHRFHWSRCSKLELSRYLPSYDCLLDDPFDPAWPQPPELPGINYSMDEQCRFDFGSGYQTCLAFRTFEPCKQLWCSHPDNPYFCKTKKGPPLDGTECAPGKWCFKGHCIWKSPEQTYGQDGGWSSWTKFGSCSRSCGGGVRSRSRSCNNPSPAYGGRLCLGPMFEYQVCNSEECPGTYEDFRAQQCAKRNSYYVHQNAKHSWVPYEPDDDAQKCELICQSADTGDVVFMNQVVHDGTRCSYRDPYSVCARGECVPVGCDKEVGSMKADDKCGVCGGDNSHCRTVKGTLGKASKQAGALKLVQIPAGARHIQIEALEKSPHRIVVKNQVTGSFILNPKGKEATSRTFTAMGLEWEDAVEDAKESLKTSGPLPEAIAILALPPTEGGPRSSLAYKYVIHEDLLPLIGSNNVLLEEMDTYEWALKSWAPCSKACGGGIQFTKYGCRRRRDHHMVQRHLCDHKKRPKPIRRRCNQHPCSQPVWVTEEWGACSRSCGKLGVQTRGIQCLLPLSNGTHKVMPAKACAGDRPEARRPCLRVPCPAQWRLGAWSQCSATCGEGIQQRQVVCRTNANSLGHCEGDRPDTVQVCSLPACGGNHQNSTVRADVWELGTPEGQWVPQSEPLHPINKISSTEPCTGDRSVFCQMEVLDRYCSIPGYHRLCCVSCIKKASGPNPGPDPGPTSLPPFSTPGSPLPGPQDPADAAEPPGKPTGSEDHQHGRATQLPGALDTSSPGTQHPFAPETPIPGASWSISPTTPGGLPWGWTQTPTPVPEDKGQPGEDLRHPGTSLPAASPVT>sp|Q8WXS8-4|ATS14_HUMAN Isoform D of A disintegrin and metalloproteinasewith thrombospondin motifs 14 OS=Homo sapiens OX=9606 GN=ADAMTS14MAPLRALLSYLLPLHCALCAAAGSRTPELHLSGKLSDYGVTVPCSTDFRGRFLSHVVSGPAAASAGSMVVDTPPTLPRHSSHLRVARSPLHPGGTLWPGRVGRHSLYFNVTVFGKELHLRLRPNRRLVVPGSSVEWQEDFRELFRQPLRQECVYTGGVTGMPGAAVAISNCDGLAGLIRTDSTDFFIEPLERGQQEKEASGRTHVVYRREAVQQEWAEPDGDLHNEAFGLGDLPNLLGLVGDQLGDTERKRRHAKPGSYSIEVLLVVDDSVVRFHGKEHVQNYVLTLMNIVDEIYHDESLGVHINIALVRLIMVGYRQSLSLIERGNPSRSLEQVCRWAHSQQRQDPSHAEHHDHVVFLTRQDFGPSGMQGYAPVTGMCHPLRSCALNHEDGFSSAFVIAHETGHVLGMEHDGQGNGCADETSLGSVMAPLVQAAFHRFHWSRCSKLELSRYLPSYDCLLDDPFDPAWPQPPELPGINYSMDEQCRFDFGSGYQTCLAFRTFEPCKQLWCSHPDNPYFCKTKKGPPLDGTECAPGKWCFKGHCIWKSPEQTYGQDGGWSSWTKFGSCSRSCGGGVRSRSRSCNNPSPAYGGRLCLGPMFEYQVCNSEECPGTYEDFRAQQCAKRNSYYVHQNAKHSWVPYEPDDDAQKCELICQSADTGDVVFMNQVVHDGTRCSYRDPYSVCARGECVPVGCDKEVGSMKADDKCGVCGGDNSHCRTVKGTLGKASKQAGALKLVQIPAGARHIQIEALEKSPHRIVVKNQVTGSFILNPKGKEATSRTFTAMGLEWEDAVEDAKESLKTSGPLPEAIAILALPPTEGGPRSSLAYKYVIHEDLLPLIGSNNVLLEEMDTYEWALKSWAPCSKACGGGIQFTKYGCRRRRDHHMVQRHLCDHKKRPKPIRRRCNQHPCSQPVWVTEEWGACSRSCGKLGVQTRGIQCLLPLSNGTHKVMPAKACAGDRPEARRPCLRVPCPAQWRLGAWSQCSATCGEGIQQRQVVCRTNANSLGHCEGDRPDTVQVCSLPACGGNHQNSTVRADVWELGTPEGQWVPQSEPLHPINKISSTEPCTGDRSVFCQMEVLDRYCSIPGYHRLCCVSCIKKASGPNPGPDPGPTSLPPFSTPGSPLPGPQDPADAAEPPGKPTGSEDHQHGRATQLPGALDTSSPGTQHPFAPETPIPGASWSISPTTPGGLPWGWTQTPTPVPEDKGQPGEDLRHPGTSLPAASPVT>sp|P51793|CLCN4_HUMAN H(+)/Cl(-) exchange transporter 4 OS=Homo sapiensOX=9606 GN=CLCN4 PE=1 SV=2MVNAGAMSGSGNLMDFLDEPFPDVGTYEDFHTIDWLREKSRDTDRHRKITSKSKESIWEFIKSLLDAWSGWVVMLLIGLLAGTLAGVIDLAVDWMTDLKEGVCLSAFWYSHEQCCWTSNETTFEDRDKCPLWQKWSELLVNQSEGASAYILNYLMYILWALLFAFLAVSLVRVFAPYACGSGIPEIKTILSGFIIRGYLGKWTLLIKTVTLVLVVSSGLSLGKEGPLVHVACCCGNFFSSLFSKYSKNEGKRREVLSAAAAAGVSVAFGAPIGGVLFSLEEVSYYFPLKTLWRSFFAALVAAFTLRSINPFGNSRLVLFYVEYHTPWYMAELFPFILLGVFGGLWGTLFIRCNIAWCRRRKTTRLGKYPVLEVIVVTAITAIIAYPNPYTRQSTSELISELFNDCGALESSQLCDYINDPNMTRPVDDIPDRPAGVGVYTAMWQLALALIFKIVVTIFTFGMKIPSGLFIPSMAVGAIAGRMVGIGVEQLAYHHHDWIIFRNWCRPGADCVTPGLYAMVGAAACLGGVTRMTVSLVVIMFELTGGLEYIVPLMAAAVTSKWVADAFGKEGIYEAHIHLNGYPFLDVKDEFTHRTLATDVMRPRRGEPPLSVLTQDSMTVEDVETLIKETDYNGFPVVVSRDSERLIGFAQRRELILAIKNARQRQEGIVSNSIMYFTEEPPELPANSPHPLKLRRILNLSPFTVTDHTPMETVVDIFRKLGLRQCLVTRSGRLLGIITKKDVLRHMAQMANQDPESIMFN>sp|P51793-2|CLCN4_HUMAN Isoform 2 of H(+)/Cl(-) exchange transporter 4OS=Homo sapiens OX=9606 GN=CLCN4MTDLKEGVCLSAFWYSHEQCCWTSNETTFEDRDKCPLWQKWSELLVNQSEGASAYILNYLMYILWALLFAFLAVSLVRVFAPYACGSGIPEIKTILSGFIIRGYLGKWTLLIKTVTLVLVVSSGLSLGKEGPLVHVACCCGNFFSSLFSKYSKNEGKRREVLSAAAAAGVSVAFGAPIGGVLFSLEEVSYYFPLKTLWRSFFAALVAAFTLRSINPFGNSRLVLFYVEYHTPWYMAELFPFILLGVFGGLWGTLFIRCNIAWCRRRKTTRLGKYPVLEVIVVTAITAIIAYPNPYTRQSTSELISELFNDCGALESSQLCDYINDPNMTRPVDDIPDRPAGVGVYTAMWQLALALIFKIVVTIFTFGMKIPSGLFIPSMAVGAIAGRMVGIGVEQLAYHHHDWIIFRNWCRPGADCVTPGLYAMVGAAACLGGVTRMTVSLVVIMFELTGGLEYIVPLMAAAVTSKWVADAFGKEGIYEAHIHLNGYPFLDVKDEFTHRTLATDVMRPRRGEPPLSVLTQDSMTVEDVETLIKETDYNGFPVVVSRDSERLIGFAQRRELILAIKNARQRQEGIVSNSIMYFTEEPPELPANSPHPLKLRRILNLSPFTVTDHTPMETVVDIFRKLGLRQCLVTRSGRLLGIITKKDVLRHMAQMANQDPESIMFN>sp|Q8IXQ3|CI040_HUMAN Uncharacterized protein C9orf40 OS=Homo sapiensOX=9606 GN=C9orf40 PE=1 SV=1MAKRRAAEPVTFHVPWKRLLLCDFAEQPPPPPLWIRPPGVAHAGQLLGVPEQHRKRKIDAGTMAEPSASPSKRRDSGDNSAPSGQEREDHGLETGDPPLPPPPVLPGPGEELPGARLPGGGGDDGAGRAGPPRGDWGVASRQHNEEFWQYNTFQYWRNPLPPIDLADIEDLSEDTLTEATLQGRNEGAEVDMES>sp|Q8IZ96|CKLF1_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=CMTM1 PE=2 SV=1MDPEHAKPESSEAPSGNLKQPETAAALSLILGALACFIITQANESFITITSLEICIVVFFILIYVLTLHHLLTYLHWPLLDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGSLCLTAVIVCCIDAFVVTTKMRTNLKRFLGVEVERKLSPAKDAYPETGPDAPQRPA>sp|Q8IZ96-2|CKLF1_HUMAN Isoform 1a of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MLKILRLSLILGALACFIITQANESFITITSLEICIVVFFILIYVLTLHHLLTYLHWPLLDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGSLCLTAVIVCCIDAFVVTTKMRTNLKRFLGVEVERKLSPAKDAYPETGPDAPQRPA>sp|Q8IZ96-3|CKLF1_HUMAN Isoform 1b of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MLKILRLSLILGALACFIITQANESFITITSLEICIVVFFILIYVLTLHHLLTYLHWPLLDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGS>sp|Q8IZ96-4|CKLF1_HUMAN Isoform 2 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALSLILGALACFIITQANESFITITSLEICIVVFFILIYVLTLHHLLTYLHWPLLDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGR>sp|Q8IZ96-5|CKLF1_HUMAN Isoform 3 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALASSGSVDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGSLCLTAVIVCCIDAFVVTTKMRTNLKRFLGVEVERKLSPAKDAYPETGPDAPQRPA>sp|Q8IZ96-6|CKLF1_HUMAN Isoform 4 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGSLCLTAVIVCCIDAFVVTTKMRTNLKRFLGVEVERKLSPAKDAYPETGPDAPQRPA>sp|Q8IZ96-7|CKLF1_HUMAN Isoform 5 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGR>sp|Q8IZ96-8|CKLF1_HUMAN Isoform 6 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALASSGSVVSSVPKAQRNISAKTAPRKHPAVSIRSAQSAAAARPQGSEGTAPSRILPTVSLQLCSFQ>sp|Q8IZ96-9|CKLF1_HUMAN Isoform 8 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALSLILGALACFIITQANESFITITSLEICIVVFFILIYVLTLHHLLTYLHWPLLNAEYRKQTKQI>sp|Q8IZ96-10|CKLF1_HUMAN Isoform 10 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALASSGSVVSSVPKAQRNISAKTAPRKHPETGPDAPQRPA>sp|Q8IZ96-11|CKLF1_HUMAN Isoform 11 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALEAYNSK>sp|Q8IZ96-12|CKLF1_HUMAN Isoform 12 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKLTLHHLLTYLHRPLLAAELSLSHRMPSTGSRQSKYEQL>sp|Q8IZ96-13|CKLF1_HUMAN Isoform 13 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALEADKANMSNFN>sp|Q8IZ96-14|CKLF1_HUMAN Isoform 14 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALLCSFQ>sp|Q8IZ96-15|CKLF1_HUMAN Isoform 16 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALR>sp|Q8IZ96-16|CKLF1_HUMAN Isoform 19 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MLKILRLSLILGALACFIITQANESFITITSLEICIVVFFILIYVLTLHHLLTYLHWPLLNAEYRKQTKQI>sp|Q8IZ96-17|CKLF1_HUMAN Isoform 24 of CKLF-like MARVEL transmembranedomain-containing protein 1 OS=Homo sapiens OX=9606 GN=CMTM1MDPEHAKPESSEAPSGNLKQPETAAALASSGSVVSSVPKAQRNISAKTAPRKHPAVSIRSAQSAAAARPQGSEGTAPSRKATTRPPPKPTLPPPTPSAHTESKLLNEMAIKERVEGRAKVPYKFRDSLKRFSFSPTGMLKILRLSLILGALACFIITQANESFITITSLEICIVVFFILIYVLTLHHLLTYLHWPLLDLTNSIITAVFLSVVAILAMQEKKRRHLLYVGGSLCLTAVIVCCIDAFVVTTKMRTNLKRFLGVEVERKLSPAKDAYPETGPDAPQRPA>sp|Q5TC12|ATPF1_HUMAN ATP synthase mitochondrial F1 complex assemblyfactor 1 OS=Homo sapiens OX=9606 GN=ATPAF1 PE=1 SV=1MAAVVVAAAGGAGPAVLQVAGLYRGLCAVRSRALGLGLVSPAQLRVFPVRPGSGRPEGGADSSGVGAEAELQANPFYDRYRDKIQLLRRSDPAAFESRLEKRSEFRKQPVGHSRQGDFIKCVEQKTDALGKQSVNRGFTKDKTLSSIFNIEMVKEKTAEEIKQIWQQYFAAKDTVYAVIPAEKFDLIWNRAQSCPTFLCALPRREGYEFFVGQWTGTELHFTALINIQTRGEAAASQLILYHYPELKEEKGIVLMTAEMDSTFLNVAEAQCIANQVQLFYATDRKETYGLVETFNLRPNEFKYMSVIAELEQSGLGAELKCAQNQNKT>sp|Q5TC12-2|ATPF1_HUMAN Isoform 2 of ATP synthase mitochondrial F1complex assembly factor 1 OS=Homo sapiens OX=9606 GN=ATPAF1MVKEKTAEEIKQIWQQYFAAKDTVYAVIPAEKFDLIWNRAQSCPTFLCALPRREGYEFFVGQWTGTELHFTALINIQTRGEAAASQLILYHYPELKEEKGIVLMTAEMDSTFLNVAEAQCIANQVQLFYATDRKETYGLVETFNLRPNEFKYMSVIAELEQSGLGAELKCAQNQNKT>sp|Q5TC12-3|ATPF1_HUMAN Isoform 3 of ATP synthase mitochondrial F1complex assembly factor 1 OS=Homo sapiens OX=9606 GN=ATPAF1MSDPAAFESRLEKRSEFRKQPVGHSRQGDFIKCVEQKTDALGKQSVNRGFTKDKTLSSIFNIEMVKEKTAEEIKQIWQQYFAAKDTVYAVIPAEKFDLIWNRAQSCPTFLCALPRREGYEFFVGQWTGTELHFTALINIQTRGEAAASQLILYHYPELKEEKGIVLMTAEMDSTFLNVAEAQCIANQVQLFYATDRKETYGLVETFNLRPNEFKYMSVIAELEQSGLGAELKCAQNQNKT>sp|Q96MX0|CKLF3_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=CMTM3 PE=1 SV=1MWPPDPDPDPDPEPAGGSRPGPAVPGLRALLPARAFLCSLKGRLLLAESGLSFITFICYVASSASAFLTAPLLEFLLALYFLFADAMQLNDKWQGLCWPMMDFLRCVTAALIYFAISITAIAKYSDGASKAAGVFGFFATIVFATDFYLIFNDVAKFLKQGDSADETTAHKTEEENSDSDSD>sp|Q96MX0-2|CKLF3_HUMAN Isoform 2 of CKLF-like MARVEL transmembranedomain-containing protein 3 OS=Homo sapiens OX=9606 GN=CMTM3MWPPDPDPDPDPEPAGGSRPGPAVPGLRALLPARAFLCSLKGPGGFVCTWCSCPHQPLW>sp|O15072|ATS3_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 3 OS=Homo sapiens OX=9606 GN=ADAMTS3 PE=1 SV=4MVLLSLWLIAAALVEVRTSADGQAGNEEMVQIDLPIKRYREYELVTPVSTNLEGRYLSHTLSASHKKRSARDVSSNPEQLFFNITAFGKDFHLRLKPNTQLVAPGAVVEWHETSLVPGNITDPINNHQPGSATYRIRRTEPLQTNCAYVGDIVDIPGTSVAISNCDGLAGMIKSDNEEYFIEPLERGKQMEEEKGRIHVVYKRSAVEQAPIDMSKDFHYRESDLEGLDDLGTVYGNIHQQLNETMRRRRHAGENDYNIEVLLGVDDSVVRFHGKEHVQNYLLTLMNIVNEIYHDESLGVHINVVLVRMIMLGYAKSISLIERGNPSRSLENVCRWASQQQRSDLNHSEHHDHAIFLTRQDFGPAGMQGYAPVTGMCHPVRSCTLNHEDGFSSAFVVAHETGHVLGMEHDGQGNRCGDETAMGSVMAPLVQAAFHRYHWSRCSGQELKRYIHSYDCLLDDPFDHDWPKLPELPGINYSMDEQCRFDFGVGYKMCTAFRTFDPCKQLWCSHPDNPYFCKTKKGPPLDGTECAAGKWCYKGHCMWKNANQQKQDGNWGSWTKFGSCSRTCGTGVRFRTRQCNNPMPINGGQDCPGVNFEYQLCNTEECQKHFEDFRAQQCQQRNSHFEYQNTKHHWLPYEHPDPKKRCHLYCQSKETGDVAYMKQLVHDGTHCSYKDPYSICVRGECVKVGCDKEIGSNKVEDKCGVCGGDNSHCRTVKGTFTRTPRKLGYLKMFDIPPGARHVLIQEDEASPHILAIKNQATGHYILNGKGEEAKSRTFIDLGVEWDYNIEDDIESLHTDGPLHDPVIVLIIPQENDTRSSLTYKYIIHEDSVPTINSNNVIQEELDTFEWALKSWSQCSKPCGGGFQYTKYGCRRKSDNKMVHRSFCEANKKPKPIRRMCNIQECTHPLWVAEEWEHCTKTCGSSGYQLRTVRCLQPLLDGTNRSVHSKYCMGDRPESRRPCNRVPCPAQWKTGPWSECSVTCGEGTEVRQVLCRAGDHCDGEKPESVRACQLPPCNDEPCLGDKSIFCQMEVLARYCSIPGYNKLCCESCSKRSSTLPPPYLLEAAETHDDVISNPSDLPRSLVMPTSLVPYHSETPAKKMSLSSISSVGGPNAYAAFRPNSKPDGANLRQRSAQQAGSKTVRLVTVPSSPPTKRVHLSSASQMAAASFFAASDSIGASSQARTSKKDGKIIDNRRPTRSSTLER>sp|Q8IZV2|CKLF8_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 8 OS=Homo sapiens OX=9606 GN=CMTM8 PE=1 SV=2MEEPQRARSHTVTTTASSFAENFSTSSSSFAYDREFLRTLPGFLIVAEIVLGLLVWTLIAGTEYFRVPAFGWVMFVAVFYWVLTVFFLIIYITMTYTRIPQVPWTTVGLCFNGSAFVLYLSAAVVDASSVSPERDSHNFNSWAASSFFAFLVTICYAGNTYFSFIAWRSRTIQ>sp|Q8IZV2-2|CKLF8_HUMAN Isoform 2 of CKLF-like MARVEL transmembranedomain-containing protein 8 OS=Homo sapiens OX=9606 GN=CMTM8MEEPQRARSHTVTTTASSFAENFSTSSSSFAYDREFLRTLPGFLIVAEIGLCFNGSAFVLYLSAAVVDASSVSPERDSHNFNSWAASSFFAFLVTICYAGNTYFSFIAWRSRTIQ>sp|Q5T035|CI129_HUMAN Putative uncharacterized protein C9orf129 OS=Homosapiens OX=9606 GN=C9orf129 PE=4 SV=1MPGMVPPHVPPQMLNIPQTSLQAKPVAPQVPSPGGAPGQGPYPYSLSEPAPLTLDTSGKNLTEQNSYSNIPHEGKHTPLYERSLPINPAQSGSPNHVDSAYFPGSSTSSSSDNDEGSGGATKYTIYWGFRATDHHVQGRDSQARGTAAHWHGGHVCSPNVFWRISHGPAQQLTFPTEQAAPPVCPAPASRRLSAPG>sp|O75173|ATS4_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 4 OS=Homo sapiens OX=9606 GN=ADAMTS4 PE=1 SV=3MSQTGSHPGRGLAGRWLWGAQPCLLLPIVPLSWLVWLLLLLLASLLPSARLASPLPREEEIVFPEKLNGSVLPGSGAPARLLCRLQAFGETLLLELEQDSGVQVEGLTVQYLGQAPELLGGAEPGTYLTGTINGDPESVASLHWDGGALLGVLQYRGAELHLQPLEGGTPNSAGGPGAHILRRKSPASGQGPMCNVKAPLGSPSPRPRRAKRFASLSRFVETLVVADDKMAAFHGAGLKRYLLTVMAAAAKAFKHPSIRNPVSLVVTRLVILGSGEEGPQVGPSAAQTLRSFCAWQRGLNTPEDSDPDHFDTAILFTRQDLCGVSTCDTLGMADVGTVCDPARSCAIVEDDGLQSAFTAAHELGHVFNMLHDNSKPCISLNGPLSTSRHVMAPVMAHVDPEEPWSPCSARFITDFLDNGYGHCLLDKPEAPLHLPVTFPGKDYDADRQCQLTFGPDSRHCPQLPPPCAALWCSGHLNGHAMCQTKHSPWADGTPCGPAQACMGGRCLHMDQLQDFNIPQAGGWGPWGPWGDCSRTCGGGVQFSSRDCTRPVPRNGGKYCEGRRTRFRSCNTEDCPTGSALTFREEQCAAYNHRTDLFKSFPGPMDWVPRYTGVAPQDQCKLTCQAQALGYYYVLEPRVVDGTPCSPDSSSVCVQGRCIHAGCDRIIGSKKKFDKCMVCGGDGSGCSKQSGSFRKFRYGYNNVVTIPAGATHILVRQQGNPGHRSIYLALKLPDGSYALNGEYTLMPSPTDVVLPGAVSLRYSGATAASETLSGHGPLAQPLTLQVLVAGNPQDTRLRYSFFVPRPTPSTPRPTPQDWLHRRAQILEILRRRPWAGRK>sp|O75173-2|ATS4_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 4 OS=Homo sapiens OX=9606 GN=ADAMTS4MSQTGSHPGRGLAGRWLWGAQPCLLLPIVPLSWLVWLLLLLLASLLPSARLASPLPREEEIVFPEKLNGSVLPGSGAPARLLCRLQAFGETLLLELEQDSGVQVEGLTVQYLGQAPELLGGAEPGTYLTGTINGDPESVASLHWDGGALLGVLQYRGAELHLQPLEGGTPNSAGGPGAHILRRKSPASGQGPMCNVKAPLGSPSPRPRRAKRFASLSRFVETLVVADDKMAAFHGAGLKRYLLTVMAAAAKAFKHPSIRNPVSLVVTRLVILGSGEEGPQVGPSAAQTLRSFCAWQRGLNTPEDSDPDHFDTAILFTRQDLCGVSTCDTLGMADVGTVCDPARSCAIVEDDGLQSAFTAAHELGHVFNMLHDNSKPCISLNGPLSTSRHVMAPVMAHVDPEEPWSPCSARFITDFLDNGYGHCLLDKPEAPLHLPVTFPGKDYDADRQCQLTFGPDSRHCPQLPPPCAALWCSGHLNGHAMCQTKHSPWADGTPCGPAQACMGGRCLHMDQLQDFNIPQAGGWGPWGPWGDCSRTCGGGVQFSSRDCTRPVPRNGGKYCEGRRTRFRSCNTEDCPTGSALTFREEQCAAYNHRTDLFKSFPGPMDWVPRYTGVAPQDQCKLTCQAQALGYYYVLEPRVVDGTPCSPDSSSVCVQGRCIHAGCDRIIGSKKKFDKCMVCGGDGSGCSKQSGSFRKFRCGTAWGSQLALQRGHCSLRDTVRPWATGPAFDTASPSGWQPPGHTPPIQLLRAPADPFNATPHSPGLAAPKSTDSGDPSAAPLGGQEITSLSRLPFLGTGASDLAGRKRELLLLPHAKTQWGGAVGVRPAPPLCPNAQAGPALVSCPGRQ>sp|Q9UBR5|CKLF_HUMAN Chemokine-like factor OS=Homo sapiens OX=9606GN=CKLF PE=1 SV=1MDNVQPKIKHRPFCFSVKGHVKMLRLALTVTSMTFFIIAQAPEPYIVITGFEVTVILFFILLYVLRLDRLMKWLFWPLLDIINSLVTTVFMLIVSVLALIPETTTLTVGGGVFALVTAVCCLADGALIYRKLLFNPSGPYQKKPVHEKKEVL>sp|Q9UBR5-2|CKLF_HUMAN Isoform 1 of Chemokine-like factor OS=Homosapiens OX=9606 GN=CKLFMDNVQPKIKHRPFCFSVKGHVKMLRLDIINSLVTTVFMLIVSVLALIPETTTLTVGGGVFALVTAVCCLADGALIYRKLLFNPSGPYQKKPVHEKKEVL>sp|Q9UBR5-3|CKLF_HUMAN Isoform 3 of Chemokine-like factor OS=Homosapiens OX=9606 GN=CKLFMDNVQPKIKHRPFCFSVKGHVKMLRLVFALVTAVCCLADGALIYRKLLFNPSGPYQKKPVHEKKEVL>sp|Q9UBR5-4|CKLF_HUMAN Isoform 4 of Chemokine-like factor OS=Homosapiens OX=9606 GN=CKLFMDNVQPKIKHRPFCFSVKGHVKMLRLALTVTSMTFFIIAQAPEPYIVITGFEVTVILFFILLYVLRLDRLMKWLFWPLLVFALVTAVCCLADGALIYRKLLFNPSGPYQKKPVHEKKEVL>sp|Q9UBR5-5|CKLF_HUMAN Isoform 5 of Chemokine-like factor OS=Homosapiens OX=9606 GN=CKLFMDNVQPKIKHRPFCFSVKGHVKMLRLALTVTSMTFFIIAQAPEPYIVITGFEVTVILFFILLYVLRLDRLMKWLFWPLLDIINSLVTTVFMLIVSVLALIPETTTLTVGGGLF>sp|P02458|CO2A1_HUMAN Collagen alpha-1(II) chain OS=Homo sapiens OX=9606GN=COL2A1 PE=1 SV=3MIRLGAPQTLVLLTLLVAAVLRCQGQDVQEAGSCVQDGQRYNDKDVWKPEPCRICVCDTGTVLCDDIICEDVKDCLSPEIPFGECCPICPTDLATASGQPGPKGQKGEPGDIKDIVGPKGPPGPQGPAGEQGPRGDRGDKGEKGAPGPRGRDGEPGTPGNPGPPGPPGPPGPPGLGGNFAAQMAGGFDEKAGGAQLGVMQGPMGPMGPRGPPGPAGAPGPQGFQGNPGEPGEPGVSGPMGPRGPPGPPGKPGDDGEAGKPGKAGERGPPGPQGARGFPGTPGLPGVKGHRGYPGLDGAKGEAGAPGVKGESGSPGENGSPGPMGPRGLPGERGRTGPAGAAGARGNDGQPGPAGPPGPVGPAGGPGFPGAPGAKGEAGPTGARGPEGAQGPRGEPGTPGSPGPAGASGNPGTDGIPGAKGSAGAPGIAGAPGFPGPRGPPGPQGATGPLGPKGQTGEPGIAGFKGEQGPKGEPGPAGPQGAPGPAGEEGKRGARGEPGGVGPIGPPGERGAPGNRGFPGQDGLAGPKGAPGERGPSGLAGPKGANGDPGRPGEPGLPGARGLTGRPGDAGPQGKVGPSGAPGEDGRPGPPGPQGARGQPGVMGFPGPKGANGEPGKAGEKGLPGAPGLRGLPGKDGETGAAGPPGPAGPAGERGEQGAPGPSGFQGLPGPPGPPGEGGKPGDQGVPGEAGAPGLVGPRGERGFPGERGSPGAQGLQGPRGLPGTPGTDGPKGASGPAGPPGAQGPPGLQGMPGERGAAGIAGPKGDRGDVGEKGPEGAPGKDGGRGLTGPIGPPGPAGANGEKGEVGPPGPAGSAGARGAPGERGETGPPGPAGFAGPPGADGQPGAKGEQGEAGQKGDAGAPGPQGPSGAPGPQGPTGVTGPKGARGAQGPPGATGFPGAAGRVGPPGSNGNPGPPGPPGPSGKDGPKGARGDSGPPGRAGEPGLQGPAGPPGEKGEPGDDGPSGAEGPPGPQGLAGQRGIVGLPGQRGERGFPGLPGPSGEPGKQGAPGASGDRGPPGPVGPPGLTGPAGEPGREGSPGADGPPGRDGAAGVKGDRGETGAVGAPGAPGPPGSPGPAGPTGKQGDRGEAGAQGPMGPSGPAGARGIQGPQGPRGDKGEAGEPGERGLKGHRGFTGLQGLPGPPGPSGDQGASGPAGPSGPRGPPGPVGPSGKDGANGIPGPIGPPGPRGRSGETGPAGPPGNPGPPGPPGPPGPGIDMSAFAGLGPREKGPDPLQYMRADQAAGGLRQHDAEVDATLKSLNNQIESIRSPEGSRKNPARTCRDLKLCHPEWKSGDYWIDPNQGCTLDAMKVFCNMETGETCVYPNPANVPKKNWWSSKSKEKKHIWFGETINGGFHFSYGDDNLAPNTANVQMTFLRLLSTEGSQNITYHCKNSIAYLDEAAGNLKKALLIQGSNDVEIRAEGNSRFTYTALKDGCTKHTGKWGKTVIEYRSQKTSRLPIIDIAPMDIGGPEQEFGVDIGPVCFL>sp|P02458-1|CO2A1_HUMAN Isoform 1 of Collagen alpha-1(II) chain OS=Homosapiens OX=9606 GN=COL2A1MIRLGAPQTLVLLTLLVAAVLRCQGQDVRQPGPKGQKGEPGDIKDIVGPKGPPGPQGPAGEQGPRGDRGDKGEKGAPGPRGRDGEPGTPGNPGPPGPPGPPGPPGLGGNFAAQMAGGFDEKAGGAQLGVMQGPMGPMGPRGPPGPAGAPGPQGFQGNPGEPGEPGVSGPMGPRGPPGPPGKPGDDGEAGKPGKAGERGPPGPQGARGFPGTPGLPGVKGHRGYPGLDGAKGEAGAPGVKGESGSPGENGSPGPMGPRGLPGERGRTGPAGAAGARGNDGQPGPAGPPGPVGPAGGPGFPGAPGAKGEAGPTGARGPEGAQGPRGEPGTPGSPGPAGASGNPGTDGIPGAKGSAGAPGIAGAPGFPGPRGPPGPQGATGPLGPKGQTGEPGIAGFKGEQGPKGEPGPAGPQGAPGPAGEEGKRGARGEPGGVGPIGPPGERGAPGNRGFPGQDGLAGPKGAPGERGPSGLAGPKGANGDPGRPGEPGLPGARGLTGRPGDAGPQGKVGPSGAPGEDGRPGPPGPQGARGQPGVMGFPGPKGANGEPGKAGEKGLPGAPGLRGLPGKDGETGAAGPPGPAGPAGERGEQGAPGPSGFQGLPGPPGPPGEGGKPGDQGVPGEAGAPGLVGPRGERGFPGERGSPGAQGLQGPRGLPGTPGTDGPKGASGPAGPPGAQGPPGLQGMPGERGAAGIAGPKGDRGDVGEKGPEGAPGKDGGRGLTGPIGPPGPAGANGEKGEVGPPGPAGSAGARGAPGERGETGPPGPAGFAGPPGADGQPGAKGEQGEAGQKGDAGAPGPQGPSGAPGPQGPTGVTGPKGARGAQGPPGATGFPGAAGRVGPPGSNGNPGPPGPPGPSGKDGPKGARGDSGPPGRAGEPGLQGPAGPPGEKGEPGDDGPSGAEGPPGPQGLAGQRGIVGLPGQRGERGFPGLPGPSGEPGKQGAPGASGDRGPPGPVGPPGLTGPAGEPGREGSPGADGPPGRDGAAGVKGDRGETGAVGAPGAPGPPGSPGPAGPTGKQGDRGEAGAQGPMGPSGPAGARGIQGPQGPRGDKGEAGEPGERGLKGHRGFTGLQGLPGPPGPSGDQGASGPAGPSGPRGPPGPVGPSGKDGANGIPGPIGPPGPRGRSGETGPAGPPGNPGPPGPPGPPGPGIDMSAFAGLGPREKGPDPLQYMRADQAAGGLRQHDAEVDATLKSLNNQIESIRSPEGSRKNPARTCRDLKLCHPEWKSGDYWIDPNQGCTLDAMKVFCNMETGETCVYPNPANVPKKNWWSSKSKEKKHIWFGETINGGFHFSYGDDNLAPNTANVQMTFLRLLSTEGSQNITYHCKNSIAYLDEAAGNLKKALLIQGSNDVEIRAEGNSRFTYTALKDGCTKHTGKWGKTVIEYRSQKTSRLPIIDIAPMDIGGPEQEFGVDIGPVCFL>sp|P02458-3|CO2A1_HUMAN Isoform 3 of Collagen alpha-1(II) chain OS=Homosapiens OX=9606 GN=COL2A1MSAFAGLGPREKGPDPLQYMRADQAAGGLRQHDAEVDATLKSLNNQIESIRSPEGSRKNPARTCRDLKLCHPEWKSGDYWIDPNQGCTLDAMKVFCNMETGETCVYPNPANVPKKNWWSSKSKEKKHIWFGETINGGFHFSYGDDNLAPNTANVQMTFLRLLSTEGSQNITYHCKNSIAYLDEAAGNLKKALLIQGSNDVEIRAEGNSRFTYTALKDGCTKHTGKWGKTVIEYRSQKTSRLPIIDIAPMDIGGPEQEFGVDIGPVCFL>sp|Q5VTT2|CI135_HUMAN Protein C9orf135 OS=Homo sapiens OX=9606GN=C9orf135 PE=1 SV=1MDSLDRSCQDWCDRKQHWLEIGPPDLVERKGSLTLRSHHKKYSKPVLVYSWHRDREAFPKGYDIEGPEKVKKLCNSTYRRLGTDESPIWTSETHEKLSQMCLNTEWVEMKSKALLNEETVSSGIIERVTGLPATGFGAVFPRHPPDWSKMCALTTYSEDYVPPYDYQPHAYPCQDDYSIVHRKCRSQFTDLNGSKRFGINTWHDESGIYANSDVKQKLYPLTSGPIVPI>sp|Q5VTT2-2|CI135_HUMAN Isoform 2 of Protein C9orf135 OS=Homo sapiensOX=9606 GN=C9orf135MDSLDRSCQDWCDRKQHWLEIGPPDLVERKGSLTLRSHHKKYSKPVLVYSWHRDREAFPKGYDIEGPEKVKKLCNSTYRRLGTDESPIWTSETHEKLSQMCLNTEWVEMKSKALLNEETVSSGIIERVTGLPATGFGAVFPRHPPDWSKMLIPVKMIIP>sp|Q86X95|CIR1_HUMAN Corepressor interacting with RBPJ 1 OS=Homo sapiensOX=9606 GN=CIR1 PE=1 SV=1MGKSFANFMCKKDFHPASKSNIKKVWMAEQKISYDKKKQEELMQQYLKEQESYDNRLLMGDERVKNGLNFMYEAPPGAKKENKEKEETEGETEYKFEWQKGAPREKYAKDDMNIRDQPFGIQVRNVRCIKCHKWGHVNTDRECPLFGLSGINASSVPTDGSGPSMHPSELIAEMRNSGFALKRNVLGRNLTANDPSQEYVASEGEEDPEVEFLKSLTTKQKQKLLRKLDRLEKKKKKKDRKKKKFQKSRSKHKKHKSSSSSSSSSSSSSSTETSESSSESESNNKEKKIQRKKRKKNKCSGHNNSDSEEKDKSKKRKLHEELSSSHHNREKAKEKPRFLKHESSREDSKWSHSDSDKKSRTHKHSPEKRGSERKEGSSRSHGREERSRRSRSRSPGSYKQRETRKRAQRNPGEEQSRRNDSRSHGTDLYRGEKMYREHPGGTHTKVTQRE>sp|Q86X95-2|CIR1_HUMAN Isoform 2 of Corepressor interacting with RBPJ 1OS=Homo sapiens OX=9606 GN=CIR1MGKSFANFMCKKDFHPASKSNIKKVWMAEQKISYDKKKQEELMQQYLKEQESYDNRLLMGDERVKNGLNFMYEAPPGAKKENKEKEETEGETEYKFEWQKGAPREKYAKDDMNIRDQPFGIQVRNVRCIKCHKWGHVNTDRECPLFGLSGINASSVPTDGSDAVLQIEGFWAIDAPLGANSGDEKQWVCTETKCTGEKLDRK>sp|P29400|CO4A5_HUMAN Collagen alpha-5(IV) chain OS=Homo sapiens OX=9606GN=COL4A5 PE=1 SV=2MKLRGVSLAAGLFLLALSLWGQPAEAAACYGCSPGSKCDCSGIKGEKGERGFPGLEGHPGLPGFPGPEGPPGPRGQKGDDGIPGPPGPKGIRGPPGLPGFPGTPGLPGMPGHDGAPGPQGIPGCNGTKGERGFPGSPGFPGLQGPPGPPGIPGMKGEPGSIIMSSLPGPKGNPGYPGPPGIQGLPGPTGIPGPIGPPGPPGLMGPPGPPGLPGPKGNMGLNFQGPKGEKGEQGLQGPPGPPGQISEQKRPIDVEFQKGDQGLPGDRGPPGPPGIRGPPGPPGGEKGEKGEQGEPGKRGKPGKDGENGQPGIPGLPGDPGYPGEPGRDGEKGQKGDTGPPGPPGLVIPRPGTGITIGEKGNIGLPGLPGEKGERGFPGIQGPPGLPGPPGAAVMGPPGPPGFPGERGQKGDEGPPGISIPGPPGLDGQPGAPGLPGPPGPAGPHIPPSDEICEPGPPGPPGSPGDKGLQGEQGVKGDKGDTCFNCIGTGISGPPGQPGLPGLPGPPGSLGFPGQKGEKGQAGATGPKGLPGIPGAPGAPGFPGSKGEPGDILTFPGMKGDKGELGSPGAPGLPGLPGTPGQDGLPGLPGPKGEPGGITFKGERGPPGNPGLPGLPGNIGPMGPPGFGPPGPVGEKGIQGVAGNPGQPGIPGPKGDPGQTITQPGKPGLPGNPGRDGDVGLPGDPGLPGQPGLPGIPGSKGEPGIPGIGLPGPPGPKGFPGIPGPPGAPGTPGRIGLEGPPGPPGFPGPKGEPGFALPGPPGPPGLPGFKGALGPKGDRGFPGPPGPPGRTGLDGLPGPKGDVGPNGQPGPMGPPGLPGIGVQGPPGPPGIPGPIGQPGLHGIPGEKGDPGPPGLDVPGPPGERGSPGIPGAPGPIGPPGSPGLPGKAGASGFPGTKGEMGMMGPPGPPGPLGIPGRSGVPGLKGDDGLQGQPGLPGPTGEKGSKGEPGLPGPPGPMDPNLLGSKGEKGEPGLPGIPGVSGPKGYQGLPGDPGQPGLSGQPGLPGPPGPKGNPGLPGQPGLIGPPGLKGTIGDMGFPGPQGVEGPPGPSGVPGQPGSPGLPGQKGDKGDPGISSIGLPGLPGPKGEPGLPGYPGNPGIKGSVGDPGLPGLPGTPGAKGQPGLPGFPGTPGPPGPKGISGPPGNPGLPGEPGPVGGGGHPGQPGPPGEKGKPGQDGIPGPAGQKGEPGQPGFGNPGPPGLPGLSGQKGDGGLPGIPGNPGLPGPKGEPGFHGFPGVQGPPGPPGSPGPALEGPKGNPGPQGPPGRPGLPGPEGPPGLPGNGGIKGEKGNPGQPGLPGLPGLKGDQGPPGLQGNPGRPGLNGMKGDPGLPGVPGFPGMKGPSGVPGSAGPEGEPGLIGPPGPPGLPGPSGQSIIIKGDAGPPGIPGQPGLKGLPGPQGPQGLPGPTGPPGDPGRNGLPGFDGAGGRKGDPGLPGQPGTRGLDGPPGPDGLQGPPGPPGTSSVAHGFLITRHSQTTDAPQCPQGTLQVYEGFSLLYVQGNKRAHGQDLGTAGSCLRRFSTMPFMFCNINNVCNFASRNDYSYWLSTPEPMPMSMQPLKGQSIQPFISRCAVCEAPAVVIAVHSQTIQIPHCPQGWDSLWIGYSFMMHTSAGAEGSGQALASPGSCLEEFRSAPFIECHGRGTCNYYANSYSFWLATVDVSDMFSKPQSETLKAGDLRTRISRCQVCMKRT>sp|P29400-2|CO4A5_HUMAN Isoform 2 of Collagen alpha-5(IV) chain OS=Homosapiens OX=9606 GN=COL4A5MKLRGVSLAAGLFLLALSLWGQPAEAAACYGCSPGSKCDCSGIKGEKGERGFPGLEGHPGLPGFPGPEGPPGPRGQKGDDGIPGPPGPKGIRGPPGLPGFPGTPGLPGMPGHDGAPGPQGIPGCNGTKGERGFPGSPGFPGLQGPPGPPGIPGMKGEPGSIIMSSLPGPKGNPGYPGPPGIQGLPGPTGIPGPIGPPGPPGLMGPPGPPGLPGPKGNMGLNFQGPKGEKGEQGLQGPPGPPGQISEQKRPIDVEFQKGDQGLPGDRGPPGPPGIRGPPGPPGGEKGEKGEQGEPGKRGKPGKDGENGQPGIPGLPGDPGYPGEPGRDGEKGQKGDTGPPGPPGLVIPRPGTGITIGEKGNIGLPGLPGEKGERGFPGIQGPPGLPGPPGAAVMGPPGPPGFPGERGQKGDEGPPGISIPGPPGLDGQPGAPGLPGPPGPAGPHIPPSDEICEPGPPGPPGSPGDKGLQGEQGVKGDKGDTCFNCIGTGISGPPGQPGLPGLPGPPGSLGFPGQKGEKGQAGATGPKGLPGIPGAPGAPGFPGSKGEPGDILTFPGMKGDKGELGSPGAPGLPGLPGTPGQDGLPGLPGPKGEPGGITFKGERGPPGNPGLPGLPGNIGPMGPPGFGPPGPVGEKGIQGVAGNPGQPGIPGPKGDPGQTITQPGKPGLPGNPGRDGDVGLPGDPGLPGQPGLPGIPGSKGEPGIPGIGLPGPPGPKGFPGIPGPPGAPGTPGRIGLEGPPGPPGFPGPKGEPGFALPGPPGPPGLPGFKGALGPKGDRGFPGPPGPPGRTGLDGLPGPKGDVGPNGQPGPMGPPGLPGIGVQGPPGPPGIPGPIGQPGLHGIPGEKGDPGPPGLDVPGPPGERGSPGIPGAPGPIGPPGSPGLPGKAGASGFPGTKGEMGMMGPPGPPGPLGIPGRSGVPGLKGDDGLQGQPGLPGPTGEKGSKGEPGLPGPPGPMDPNLLGSKGEKGEPGLPGIPGVSGPKGYQGLPGDPGQPGLSGQPGLPGPPGPKGNPGLPGQPGLIGPPGLKGTIGDMGFPGPQGVEGPPGPSGVPGQPGSPGLPGQKGDKGDPGISSIGLPGLPGPKGEPGLPGYPGNPGIKGSVGDPGLPGLPGTPGAKGQPGLPGFPGTPGPPGPKGISGPPGNPGLPGEPGPVGGGGHPGQPGPPGEKGKPGQDGIPGPAGQKGEPGQPGFGNPGPPGLPGLSGQKGDGGLPGIPGNPGLPGPKGEPGFHGFPGVQGPPGPPGSPGPALEGPKGNPGPQGPPGRPGPTGFQGLPGPEGPPGLPGNGGIKGEKGNPGQPGLPGLPGLKGDQGPPGLQGNPGRPGLNGMKGDPGLPGVPGFPGMKGPSGVPGSAGPEGEPGLIGPPGPPGLPGPSGQSIIIKGDAGPPGIPGQPGLKGLPGPQGPQGLPGPTGPPGDPGRNGLPGFDGAGGRKGDPGLPGQPGTRGLDGPPGPDGLQGPPGPPGTSSVAHGFLITRHSQTTDAPQCPQGTLQVYEGFSLLYVQGNKRAHGQDLGTAGSCLRRFSTMPFMFCNINNVCNFASRNDYSYWLSTPEPMPMSMQPLKGQSIQPFISRCAVCEAPAVVIAVHSQTIQIPHCPQGWDSLWIGYSFMMHTSAGAEGSGQALASPGSCLEEFRSAPFIECHGRGTCNYYANSYSFWLATVDVSDMFSKPQSETLKAGDLRTRISRCQVCMKRT>sp|Q9UNA0|ATS5_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 5 OS=Homo sapiens OX=9606 GN=ADAMTS5 PE=1 SV=2MLLGWASLLLCAFRLPLAAVGPAATPAQDKAGQPPTAAAAAQPRRRQGEEVQERAEPPGHPHPLAQRRRSKGLVQNIDQLYSGGGKVGYLVYAGGRRFLLDLERDGSVGIAGFVPAGGGTSAPWRHRSHCFYRGTVDGSPRSLAVFDLCGGLDGFFAVKHARYTLKPLLRGPWAEEEKGRVYGDGSARILHVYTREGFSFEALPPRASCETPASTPEAHEHAPAHSNPSGRAALASQLLDQSALSPAGGSGPQTWWRRRRRSISRARQVELLLVADASMARLYGRGLQHYLLTLASIANRLYSHASIENHIRLAVVKVVVLGDKDKSLEVSKNAATTLKNFCKWQHQHNQLGDDHEEHYDAAILFTREDLCGHHSCDTLGMADVGTICSPERSCAVIEDDGLHAAFTVAHEIGHLLGLSHDDSKFCEETFGSTEDKRLMSSILTSIDASKPWSKCTSATITEFLDDGHGNCLLDLPRKQILGPEELPGQTYDATQQCNLTFGPEYSVCPGMDVCARLWCAVVRQGQMVCLTKKLPAVEGTPCGKGRICLQGKCVDKTKKKYYSTSSHGNWGSWGSWGQCSRSCGGGVQFAYRHCNNPAPRNNGRYCTGKRAIYRSCSLMPCPPNGKSFRHEQCEAKNGYQSDAKGVKTFVEWVPKYAGVLPADVCKLTCRAKGTGYYVVFSPKVTDGTECRLYSNSVCVRGKCVRTGCDGIIGSKLQYDKCGVCGGDNSSCTKIVGTFNKKSKGYTDVVRIPEGATHIKVRQFKAKDQTRFTAYLALKKKNGEYLINGKYMISTSETIIDINGTVMNYSGWSHRDDFLHGMGYSATKEILIVQILATDPTKPLDVRYSFFVPKKSTPKVNSVTSHGSNKVGSHTSQPQWVTGPWLACSRTCDTGWHTRTVQCQDGNRKLAKGCPLSQRPSAFKQCLLKKC>sp|Q96Q77|CIB3_HUMAN Calcium and integrin-binding family member 3OS=Homo sapiens OX=9606 GN=CIB3 PE=1 SV=3MGNKQTVFTHEQLEAYQDCTFFTRKEIMRLFYRYQDLAPQLVPLDYTTCPDVKVPYELIGSMPELKDNPFRQRIAQVFSEDGDGHMTLDNFLDMFSVMSEMAPRDLKAYYAFKIYDFNNDDYICAWDLEQTVTKLTRGGLSAEEVSLVCEKVLDEADGDHDGRLSLEDFQNMILRAPDFLSTFHIRI>sp|Q96Q77-2|CIB3_HUMAN Isoform 2 of Calcium and integrin-binding familymember 3 OS=Homo sapiens OX=9606 GN=CIB3MGNKQTVFTHEQLEAYQDNPFRQRIAQVFSEDGDGHMTLDNFLDMFSVMSEMAPRDLKAYYAFKIYDFNNDDYICAWDLEQTVTKLTRGGLSAEEVSLVCEKVLDEADGDHDGRLSLEDFQNMILRAPDFLSTFHIRI>sp|Q14031|CO4A6_HUMAN Collagen alpha-6(IV) chain OS=Homo sapiens OX=9606GN=COL4A6 PE=1 SV=3MLINKLWLLLVTLCLTEELAAAGEKSYGKPCGGQDCSGSCQCFPEKGARGRPGPIGIQGPTGPQGFTGSTGLSGLKGERGFPGLLGPYGPKGDKGPMGVPGFLGINGIPGHPGQPGPRGPPGLDGCNGTQGAVGFPGPDGYPGLLGPPGLPGQKGSKGDPVLAPGSFKGMKGDPGLPGLDGITGPQGAPGFPGAVGPAGPPGLQGPPGPPGPLGPDGNMGLGFQGEKGVKGDVGLPGPAGPPPSTGELEFMGFPKGKKGSKGEPGPKGFPGISGPPGFPGLGTTGEKGEKGEKGIPGLPGPRGPMGSEGVQGPPGQQGKKGTLGFPGLNGFQGIEGQKGDIGLPGPDVFIDIDGAVISGNPGDPGVPGLPGLKGDEGIQGLRGPSGVPGLPALSGVPGALGPQGFPGLKGDQGNPGRTTIGAAGLPGRDGLPGPPGPPGPPSPEFETETLHNKESGFPGLRGEQGPKGNLGLKGIKGDSGFCACDGGVPNTGPPGEPGPPGPWGLIGLPGLKGARGDRGSGGAQGPAGAPGLVGPLGPSGPKGKKGEPILSTIQGMPGDRGDSGSQGFRGVIGEPGKDGVPGLPGLPGLPGDGGQGFPGEKGLPGLPGEKGHPGPPGLPGNGLPGLPGPRGLPGDKGKDGLPGQQGLPGSKGITLPCIIPGSYGPSGFPGTPGFPGPKGSRGLPGTPGQPGSSGSKGEPGSPGLVHLPELPGFPGPRGEKGLPGFPGLPGKDGLPGMIGSPGLPGSKGATGDIFGAENGAPGEQGLQGLTGHKGFLGDSGLPGLKGVHGKPGLLGPKGERGSPGTPGQVGQPGTPGSSGPYGIKGKSGLPGAPGFPGISGHPGKKGTRGKKGPPGSIVKKGLPGLKGLPGNPGLVGLKGSPGSPGVAGLPALSGPKGEKGSVGFVGFPGIPGLPGIPGTRGLKGIPGSTGKMGPSGRAGTPGEKGDRGNPGPVGIPSPRRPMSNLWLKGDKGSQGSAGSNGFPGPRGDKGEAGRPGPPGLPGAPGLPGIIKGVSGKPGPPGFMGIRGLPGLKGSSGITGFPGMPGESGSQGIRGSPGLPGASGLPGLKGDNGQTVEISGSPGPKGQPGESGFKGTKGRDGLIGNIGFPGNKGEDGKVGVSGDVGLPGAPGFPGVAGMRGEPGLPGSSGHQGAIGPLGSPGLIGPKGFPGFPGLHGLNGLPGTKGTHGTPGPSITGVPGPAGLPGPKGEKGYPGIGIGAPGKPGLRGQKGDRGFPGLQGPAGLPGAPGISLPSLIAGQPGDPGRPGLDGERGRPGPAGPPGPPGPSSNQGDTGDPGFPGIPGPKGPKGDQGIPGFSGLPGELGLKGMRGEPGFMGTPGKVGPPGDPGFPGMKGKAGPRGSSGLQGDPGQTPTAEAVQVPPGPLGLPGIDGIPGLTGDPGAQGPVGLQGSKGLPGIPGKDGPSGLPGPPGALGDPGLPGLQGPPGFEGAPGQQGPFGMPGMPGQSMRVGYTLVKHSQSEQVPPCPIGMSQLWVGYSLLFVEGQEKAHNQDLGFAGSCLPRFSTMPFIYCNINEVCHYARRNDKSYWLSTTAPIPMMPVSQTQIPQYISRCSVCEAPSQAIAVHSQDITIPQCPLGWRSLWIGYSFLMHTAAGAEGGGQSLVSPGSCLEDFRATPFIECSGARGTCHYFANKYSFWLTTVEERQQFGELPVSETLKAGQLHTRVSRCQVCMKSL>sp|Q14031-2|CO4A6_HUMAN Isoform B of Collagen alpha-6(IV) chain OS=Homosapiens OX=9606 GN=COL4A6MHPGLWLLLVTLCLTEELAAAGEKSYGKPCGGQDCSGSCQCFPEKGARGRPGPIGIQGPTGPQGFTGSTGLSGLKGERGFPGLLGPYGPKGDKGPMGVPGFLGINGIPGHPGQPGPRGPPGLDGCNGTQGAVGFPGPDGYPGLLGPPGLPGQKGSKGDPVLAPGSFKGMKGDPGLPGLDGITGPQGAPGFPGAVGPAGPPGLQGPPGPPGPLGPDGNMGLGFQGEKGVKGDVGLPGPAGPPPSTGELEFMGFPKGKKGSKGEPGPKGFPGISGPPGFPGLGTTGEKGEKGEKGIPGLPGPRGPMGSEGVQGPPGQQGKKGTLGFPGLNGFQGIEGQKGDIGLPGPDVFIDIDGAVISGNPGDPGVPGLPGLKGDEGIQGLRGPSGVPGLPALSGVPGALGPQGFPGLKGDQGNPGRTTIGAAGLPGRDGLPGPPGPPGPPSPEFETETLHNKESGFPGLRGEQGPKGNLGLKGIKGDSGFCACDGGVPNTGPPGEPGPPGPWGLIGLPGLKGARGDRGSGGAQGPAGAPGLVGPLGPSGPKGKKGEPILSTIQGMPGDRGDSGSQGFRGVIGEPGKDGVPGLPGLPGLPGDGGQGFPGEKGLPGLPGEKGHPGPPGLPGNGLPGLPGPRGLPGDKGKDGLPGQQGLPGSKGITLPCIIPGSYGPSGFPGTPGFPGPKGSRGLPGTPGQPGSSGSKGEPGSPGLVHLPELPGFPGPRGEKGLPGFPGLPGKDGLPGMIGSPGLPGSKGATGDIFGAENGAPGEQGLQGLTGHKGFLGDSGLPGLKGVHGKPGLLGPKGERGSPGTPGQVGQPGTPGSSGPYGIKGKSGLPGAPGFPGISGHPGKKGTRGKKGPPGSIVKKGLPGLKGLPGNPGLVGLKGSPGSPGVAGLPALSGPKGEKGSVGFVGFPGIPGLPGIPGTRGLKGIPGSTGKMGPSGRAGTPGEKGDRGNPGPVGIPSPRRPMSNLWLKGDKGSQGSAGSNGFPGPRGDKGEAGRPGPPGLPGAPGLPGIIKGVSGKPGPPGFMGIRGLPGLKGSSGITGFPGMPGESGSQGIRGSPGLPGASGLPGLKGDNGQTVEISGSPGPKGQPGESGFKGTKGRDGLIGNIGFPGNKGEDGKVGVSGDVGLPGAPGFPGVAGMRGEPGLPGSSGHQGAIGPLGSPGLIGPKGFPGFPGLHGLNGLPGTKGTHGTPGPSITGVPGPAGLPGPKGEKGYPGIGIGAPGKPGLRGQKGDRGFPGLQGPAGLPGAPGISLPSLIAGQPGDPGRPGLDGERGRPGPAGPPGPPGPSSNQGDTGDPGFPGIPGPKGPKGDQGIPGFSGLPGELGLKGMRGEPGFMGTPGKVGPPGDPGFPGMKGKAGPRGSSGLQGDPGQTPTAEAVQVPPGPLGLPGIDGIPGLTGDPGAQGPVGLQGSKGLPGIPGKDGPSGLPGPPGALGDPGLPGLQGPPGFEGAPGQQGPFGMPGMPGQSMRVGYTLVKHSQSEQVPPCPIGMSQLWVGYSLLFVEGQEKAHNQDLGFAGSCLPRFSTMPFIYCNINEVCHYARRNDKSYWLSTTAPIPMMPVSQTQIPQYISRCSVCEAPSQAIAVHSQDITIPQCPLGWRSLWIGYSFLMHTAAGAEGGGQSLVSPGSCLEDFRATPFIECSGARGTCHYFANKYSFWLTTVEERQQFGELPVSETLKAGQLHTRVSRCQVCMKSL>sp|A0PJX0|CIB4_HUMAN Calcium and integrin-binding family member 4OS=Homo sapiens OX=9606 GN=CIB4 PE=1 SV=1MGQCLRYQMHWEDLEEYQALTFLTRNEILCIHDTFLKLCPPGKYYKEATLTMDQVSSLPALRVNPFRDRICRVFSHKGMFSFEDVLGMASVFSEQACPSLKIEYAFRIYDFNENGFIDEEDLQRIILRLLNSDDMSEDLLMDLTNHVLSESDLDNDNMLSFSEFEHAMAKSPDFMNSFRIHFWGC>sp|Q9UP79|ATS8_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 8 OS=Homo sapiens OX=9606 GN=ADAMTS8 PE=2 SV=2MLPAPAAPRWPPLLLLLLLLLPLARGAPARPAAGGQASELVVPTRLPGSAGELALHLSAFGKGFVLRLAPDDSFLAPEFKIERLGGSGRATGGERGLRGCFFSGTVNGEPESLAAVSLCRGLSGSFLLDGEEFTIQPQGAGGSLAQPHRLQRWGPAGARPLPRGPEWEVETGEGQRQERGDHQEDSEEESQEEEAEGASEPPPPLGATSRTKRFVSEARFVETLLVADASMAAFYGADLQNHILTLMSVAARIYKHPSIKNSINLMVVKVLIVEDEKWGPEVSDNGGLTLRNFCNWQRRFNQPSDRHPEHYDTAILLTRQNFCGQEGLCDTLGVADIGTICDPNKSCSVIEDEGLQAAHTLAHELGHVLSMPHDDSKPCTRLFGPMGKHHVMAPLFVHLNQTLPWSPCSAMYLTELLDGGHGDCLLDAPAAALPLPTGLPGRMALYQLDQQCRQIFGPDFRHCPNTSAQDVCAQLWCHTDGAEPLCHTKNGSLPWADGTPCGPGHLCSEGSCLPEEEVERPKPVADGGWAPWGPWGECSRTCGGGVQFSHRECKDPEPQNGGRYCLGRRAKYQSCHTEECPPDGKSFREQQCEKYNAYNYTDMDGNLLQWVPKYAGVSPRDRCKLFCRARGRSEFKVFEAKVIDGTLCGPETLAICVRGQCVKAGCDHVVDSPRKLDKCGVCGGKGNSCRKVSGSLTPTNYGYNDIVTIPAGATNIDVKQRSHPGVQNDGNYLALKTADGQYLLNGNLAISAIEQDILVKGTILKYSGSIATLERLQSFRPLPEPLTVQLLTVPGEVFPPKVKYTFFVPNDVDFSMQSSKERATTNIIQPLLHAQWVLGDWSECSSTCGAGWQRRTVECRDPSGQASATCNKALKPEDAKPCESQLCPL>sp|Q6ZS10|CL17A_HUMAN C-type lectin domain family 17, member A OS=Homosapiens OX=9606 GN=CLEC17A PE=1 SV=2MHNLYSITGYPDPPGTMEEEEEDDDYENSTPPYKDLPPKPGTMEEEEEDDDYENSTPPYKDLPPKPGTMEEEEEDDDYENSTPPYKDLPPKPGSSAPPRPPRAAKETEKPPLPCKPRNMTGLDLAAVTCPPPQLAVNLEPSPLQPSLAATPVPWLNQRSGGPGCCQKRWMVYLCLLVVTSLFLGCLGLTVTLIKYQELMEELRMLSFQQMTWRTNMTGMAGLAGLKHDIARVRADTNQSLVELWGLLDCRRITCPEGWLPFEGKCYYFSPSTKSWDEARMFCQENYSHLVIINSFAEHNFVAKAHGSPRVYWLGLNDRAQEGDWRWLDGSPVTLSFWEPEEPNNIHDEDCATMNKGGTWNDLSCYKTTYWICERKCSC>sp|Q6ZS10-2|CL17A_HUMAN Isoform 2 of C-type lectin domain family 17,member A OS=Homo sapiens OX=9606 GN=CLEC17AMHNLYSITGYPDPPGTMEEEEEDDDYENSTPPYKDLPPKPGTMEEEEEDDDYENSTPPYKDLPPKPGTMEEEEEDDDYENSTPPYKDLPPKPGSSAPPRPPRAAKETEKPPLPCKPRNMTGLDLAAVTCPPPQLAVNLEPSPLQPSLAATPVPWLNQRSGGPGCCQKRWMVYLCLLVVTSLFLGCLGLTVTLIKYQELMEELRMLSFQQMTWRTNMTGMAGLAGLKHDIARVRADTNQSLVELWGLLEFCGQGPWLSTGVLAGAE>sp|Q6ZS10-3|CL17A_HUMAN Isoform 3 of C-type lectin domain family 17,member A OS=Homo sapiens OX=9606 GN=CLEC17AMHNLYSITGYPDPPGTMEEEEEDDDYENSTPPYKDLPPKPGTMEEEEEDDDYENSTPPYKDLPPKPGTMEEEEEDDDYENSTPPYKDLPPKPGSSAPPRPPRAAKETEKPPLPCKPRNMTGLDLAAVTCPPPQLAVNLEPSPLQPSLAATPVPWLNQRSGGPGCCQKRWMVYLCLLVVTSLFLGCLGLTVTLIKYQELMEELRMLSFQQMTWRTNMTGMAGLAGLKHDIARVRADTNQSLVELWGLLDCRRITCPEGWLPFEGKCYYFSPSTKSWDEARMFCQENYSHLVIINSFAEHLLGARGTQ>sp|Q9Y3Y2|CHTOP_HUMAN Chromatin target of PRMT1 protein OS=Homo sapiensOX=9606 GN=CHTOP PE=1 SV=2MAAQSAPKVVLKSTTKMSLNERFTNMLKNKQPTPVNIRASMQQQQQLASARNRRLAQQMENRPSVQAALKLKQSLKQRLGKSNIQARLGRPIGALARGAIGGRGLPIIQRGLPRGGLRGGRATRTLLRGGMSLRGQNLLRGGRAVAPRMGLRRGGVRGRGGPGRGGLGRGAMGRGGIGGRGRGMIGRGRGGFGGRGRGRGRGRGALARPVLTKEQLDNQLDAYMSKTKGHLDAELDAYMAQTDPETND>sp|Q9Y3Y2-3|CHTOP_HUMAN Isoform 2 of Chromatin target of PRMT1 proteinOS=Homo sapiens OX=9606 GN=CHTOPMAAQSAPKVVLKSTTKMSLNERFTNMLKNKQPTPVNIRASMQQQQQLASARNRRLAQQMENRPSVQAALKLKQKSLKQRLGKSNIQARLGRPIGALARGAIGGRGLPIIQRGLPRGGLRGGRATRTLLRGGMSLRGQNLLRGGRAVAPRMGLRRGGVRGRGGPGRGGLGRGAMGRGGIGGRGRGMIGRGRGGFGGRGRGRGRGRGALARPVLTKEQLDNQLDAYMSKTKGHLDAELDAYMAQTDPETND>sp|Q9Y3Y2-4|CHTOP_HUMAN Isoform 3 of Chromatin target of PRMT1 proteinOS=Homo sapiens OX=9606 GN=CHTOPMAAQSAPKVVLKSTTKMSLNERFTNMLKNKQPTPVNIRASMQQQQQLASARNRRLAQQMENRPSVQAALKLKQSLKQRLGKSNIQARLGRPIGALARGAIGGRGLPIIQRGLPRGGLRGGRATRTLLRGGMSLRGRGMIGRGRGGFGGRGRGRGRGRGALARPVLTKEQLDNQLDAYMSKTKGHLDAELDAYMAQTDPETND>sp|O00299|CLIC1_HUMAN Chloride intracellular channel protein 1 OS=Homosapiens OX=9606 GN=CLIC1 PE=1 SV=4MAEEQPQVELFVKAGSDGAKIGNCPFSQRLFMVLWLKGVTFNVTTVDTKRRTETVQKLCPGGQLPFLLYGTEVHTDTNKIEEFLEAVLCPPRYPKLAALNPESNTAGLDIFAKFSAYIKNSNPALNDNLEKGLLKALKVLDNYLTSPLPEEVDETSAEDEGVSQRKFLDGNELTLADCNLLPKLHIVQVVCKKYRGFTIPEAFRGVHRYLSNAYAREEFASTCPDDEEIELAYEQVAKALK>sp|A5D8T8|CL18A_HUMAN C-type lectin domain family 18 member A OS=Homosapiens OX=9606 GN=CLEC18A PE=1 SV=3MLHPETSPGRGHLLAVLLALLGTAWAEVWPPQLQEQAPMAGALNRKESFLLLSLHNRLRSWVQPPAADMRRLDWSDSLAQLAQARAALCGTPTPSLASGLWRTLQVGWNMQLLPAGLVSFVEVVSLWFAEGQRYSHAAGECARNATCTHYTQLVWATSSQLGCGRHLCSAGQAAIEAFVCAYSPRGNWEVNGKTIVPYKKGAWCSLCTASVSGCFKAWDHAGGLCEVPRNPCRMSCQNHGRLNISTCHCHCPPGYTGRYCQVRCSLQCVHGRFREEECSCVCDIGYGGAQCATKVHFPFHTCDLRIDGDCFMVSSEADTYYRARMKCQRKGGVLAQIKSQKVQDILAFYLGRLETTNEVIDSDFETRNFWIGLTYKTAKDSFRWATGEHQAFTSFAFGQPDNHGFGNCVELQASAAFNWNDQRCKTRNRYICQFAQEHISRWGPGS>sp|A5D8T8-2|CL18A_HUMAN Isoform 2 of C-type lectin domain family 18member A OS=Homo sapiens OX=9606 GN=CLEC18AMGAASAGKRGQKGSWQQTPGSEWANLDYPGPGLTYKTAKDSFRWATGEHQAFTSFAFGQPDNHGFGNCVELQASAAFNWNDQRCKTRNRYICQFAQEHISRWGPGS>sp|Q6UXF7|CL18B_HUMAN C-type lectin domain family 18 member B OS=Homosapiens OX=9606 GN=CLEC18B PE=2 SV=2MLHPETSPGRGHLLAVLLALLGTTWAEVWPPQLQEQAPMAGALNRKESFLLLSLHNRLRSWVQPPAADMRRLDWSDSLAQLAQARAALCGIPTPSLASGLWRTLQVGWNMQLLPAGLASFVEVVSLWFAEGQRYSHAAGECARNATCTHYTQLVWATSSQLGCGRHLCSAGQTAIEAFVCAYSPGGNWEVNGKTIIPYKKGAWCSLCTASVSGCFKAWDHAGGLCEVPRNPCRMSCQNHGRLNISTCHCHCPPGYTGRYCQVRCSLQCVHGRFREEECSCVCDIGYGGAQCATKVHFPFHTCDLRIDGDCFMVSSEADTYYRARMKCQRKGGVLAQIKSQKVQDILAFYLGRLETTNEVIDSDFETRNFWIGLTYKTAKDSFRWATGEHQAFTSFAFGQPDNHGLVWLSAAMGFGNCVELQASAAFNWNDQRCKTRNRYICQFAQEHISRWGPGS>sp|Q6UXF7-2|CL18B_HUMAN Isoform 2 of C-type lectin domain family 18member B OS=Homo sapiens OX=9606 GN=CLEC18BMLHPETSPGRGHLLAVLLALLGTTWAEVWPPQLQEQAPMAGALNRKESFLLLSLHNRLRSWVQPPAADMRRLLVWATSSQLGCGRHLCSAGQTAIEAFVCAYSPGGNWEVNGKTIIPYKKGAWCSLCTASVSGCFKAWDHAGGLCEVPRNPCRMSCQNHGRLNISTCHCHCPPGYTGRYCQGHLPNSNMPHSAMGTKPKTPGVPAIGSLVRCSLQCVHGRFREEECSCVCDIGYGGAQCASESCPRAPKEPAPLKTPLQWGISSQEPAVCLSFQLIQ>sp|Q9P2N4|ATS9_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 9 OS=Homo sapiens OX=9606 GN=ADAMTS9 PE=1 SV=4MQFVSWATLLTLLVRDLAEMGSPDAAAAVRKDRLHPRQVKLLETLSEYEIVSPIRVNALGEPFPTNVHFKRTRRSINSATDPWPAFASSSSSSTSSQAHYRLSAFGQQFLFNLTANAGFIAPLFTVTLLGTPGVNQTKFYSEEEAELKHCFYKGYVNTNSEHTAVISLCSGMLGTFRSHDGDYFIEPLQSMDEQEDEEEQNKPHIIYRRSAPQREPSTGRHACDTSEHKNRHSKDKKKTRARKWGERINLAGDVAALNSGLATEAFSAYGNKTDNTREKRTHRRTKRFLSYPRFVEVLVVADNRMVSYHGENLQHYILTLMSIVASIYKDPSIGNLINIVIVNLIVIHNEQDGPSISFNAQTTLKNFCQWQHSKNSPGGIHHDTAVLLTRQDICRAHDKCDTLGLAELGTICDPYRSCSISEDSGLSTAFTIAHELGHVFNMPHDDNNKCKEEGVKSPQHVMAPTLNFYTNPWMWSKCSRKYITEFLDTGYGECLLNEPESRPYPLPVQLPGILYNVNKQCELIFGPGSQVCPYMMQCRRLWCNNVNGVHKGCRTQHTPWADGTECEPGKHCKYGFCVPKEMDVPVTDGSWGSWSPFGTCSRTCGGGIKTAIRECNRPEPKNGGKYCVGRRMKFKSCNTEPCLKQKRDFRDEQCAHFDGKHFNINGLLPNVRWVPKYSGILMKDRCKLFCRVAGNTAYYQLRDRVIDGTPCGQDTNDICVQGLCRQAGCDHVLNSKARRDKCGVCGGDNSSCKTVAGTFNTVHYGYNTVVRIPAGATNIDVRQHSFSGETDDDNYLALSSSKGEFLLNGNFVVTMAKREIRIGNAVVEYSGSETAVERINSTDRIEQELLLQVLSVGKLYNPDVRYSFNIPIEDKPQQFYWNSHGPWQACSKPCQGERKRKLVCTRESDQLTVSDQRCDRLPQPGHITEPCGTDCDLRWHVASRSECSAQCGLGYRTLDIYCAKYSRLDGKTEKVDDGFCSSHPKPSNREKCSGECNTGGWRYSAWTECSKSCDGGTQRRRAICVNTRNDVLDDSKCTHQEKVTIQRCSEFPCPQWKSGDWSECLVTCGKGHKHRQVWCQFGEDRLNDRMCDPETKPTSMQTCQQPECASWQAGPWGQCSVTCGQGYQLRAVKCIIGTYMSVVDDNDCNAATRPTDTQDCELPSCHPPPAAPETRRSTYSAPRTQWRFGSWTPCSATCGKGTRMRYVSCRDENGSVADESACATLPRPVAKEECSVTPCGQWKALDWSSCSVTCGQGRATRQVMCVNYSDHVIDRSECDQDYIPETDQDCSMSPCPQRTPDSGLAQHPFQNEDYRPRSASPSRTHVLGGNQWRTGPWGACSSTCAGGSQRRVVVCQDENGYTANDCVERIKPDEQRACESGPCPQWAYGNWGECTKLCGGGIRTRLVVCQRSNGERFPDLSCEILDKPPDREQCNTHACPHDAAWSTGPWSSCSVSCGRGHKQRNVYCMAKDGSHLESDYCKHLAKPHGHRKCRGGRCPKWKAGAWSQCSVSCGRGVQQRHVGCQIGTHKIARETECNPYTRPESERDCQGPRCPLYTWRAEEWQECTKTCGEGSRYRKVVCVDDNKNEVHGARCDVSKRPVDRESCSLQPCEYVWITGEWSECSVTCGKGYKQRLVSCSEIYTGKENYEYSYQTTINCPGTQPPSVHPCYLRDCPVSATWRVGNWGSCSVSCGVGVMQRSVQCLTNEDQPSHLCHTDLKPEERKTCRNVYNCELPQNCKEVKRLKGASEDGEYFLMIRGKLLKIFCAGMHSDHPKEYVTLVHGDSENFSEVYGHRLHNPTECPYNGSRRDDCQCRKDYTAAGFSSFQKIRIDLTSMQIITTDLQFARTSEGHPVPFATAGDCYSAAKCPQGRFSINLYGTGLSLTESARWISQGNYAVSDIKKSPDGTRVVGKCGGYCGKCTPSSGTGLEVRVL>sp|Q9P2N4-1|ATS9_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 9 OS=Homo sapiens OX=9606 GN=ADAMTS9MQFVSWATLLTLLVRDLAEMGSPDAAAAVRKDRLHPRQVKLLETLSEYEIVSPIRVNALGEPFPTNVHFKRTRRSINSATDPWPAFASSSSSSTSSQAHYRLSAFGQQFLFNLTANAGFIAPLFTVTLLGTPGVNQTKFYSEEEAELKHCFYKGYVNTNSEHTAVISLCSGMLGTFRSHDGDYFIEPLQSMDEQEDEEEQNKPHIIYRRSAPQREPSTGRHACDTSEHKNRHSKDKKKTRARKWGERINLAGDVAALNSGLATEAFSAYGNKTDNTREKRTHRRTKRFLSYPRFVEVLVVADNRMVSYHGENLQHYILTLMSIVASIYKDPSIGNLINIVIVNLIVIHNEQDGPSISFNAQTTLKNFCQWQHSKNSPGGIHHDTAVLLTRQDICRAHDKCDTLGLAELGTICDPYRSCSISEDSGLSTAFTIAHELGHVFNMPHDDNNKCKEEGVKSPQHVMAPTLNFYTNPWMWSKCSRKYITEFLDTGYGECLLNEPESRPYPLPVQLPGILYNVNKQCELIFGPGSQVCPYMMQCRRLWCNNVNGVHKGCRTQHTPWADGTECEPGKHCKYGFCVPKEMDVPVTDGSWGSWSPFGTCSRTCGGGIKTAIRECNRPEPKNGGKYCVGRRMKFKSCNTEPCLKQKRDFRDEQCAHFDGKHFNINGLLPNVRWVPKYSGILMKDRCKLFCRVAGNTAYYQLRDRVIDGTPCGQDTNDICVQGLCRQAGCDHVLNSKARRDKCGVCGGDNSSCKTVAGTFNTVHYGYNTVVRIPAGATNIDVRQHSFSGETDDDNYLALSSSKGEFLLNGNFVVTMAKREIRIGNAVVEYSGSETAVERINSTDRIEQELLLQVLSVGKLYNPDVRYSFNIPIEDKPQQFYWNSHGPWQACSKPCQGERKRKLVCTRESDQLTVSDQRCDRLPQPGHITEPCGTDCDLRWHVASRSECSAQCGLGYRTLDIYCAKYSRLDGKTEKVDDGFCSSHPKPSNREKCSGECNTGGWRYSAWTECSKSCDGGTQRRRAICVNTRNDVLDDSKCTHQEKVTIQRCSEFPCPQWKSGDWSECLVTCGKGHKHRQVWCQFGEDRLNDRMCDPETKPTSMQTCQQPECASWQAGPWGQCSVTCGQGYQLRAVKCIIGTYMSVVDDNDCNAATRPTDTQDCELPSCHPPPAAPETRRSTYSAPRTQWRFGSWTPCSATCGKGTRMRYVSCRDENGSVADESACATLPRPVAKEECSVTPCGQWKALDWSSCSVTCGQGRATRQVMCVNYSDHVIDRSECDQDYIPETDQDCSMSPCPQRTPDSGLAQHPFQNEDYRPRSASPSRTHVLGGNQWRTGPWGACSSTCAGGSQRRVVVCQDENGYTANDCVERIKPDEQRACESGPCPQWAYGNWGECTKLCGGGIRTRLVVCQRSNGERFPDLSCEILDKPPDREQCNTHACPHDAAWSTGPWSSCSVSCGRGHKQRNVYCMAKDGSHLESDYCKHLAKPHGHRKCRGGRCPKWKAGAWSQCSVSCGRGVQQRHVGCQIGTHKIARETECNPYTRPESERDCQGPRCPLYTWRAEEWQECTKTCGEGSRYRKVVCVDDNKNEVHGARCDVSKRPVDRESCSLQPCEYVWITGEWSEVPSWEL>sp|Q9P2N4-2|ATS9_HUMAN Isoform 3 of A disintegrin and metalloproteinasewith thrombospondin motifs 9 OS=Homo sapiens OX=9606 GN=ADAMTS9MQFVSWATLLTLLVRDLAEMGSPDAAAAVRKDRLHPRQVKLLETLSEYEIVSPIRVNALGEPFPTNVHFKRTRRSINSATDPWPAFASSSSSSTSSQAHYRLSAFGQQFLFNLTANAGFIAPLFTVTLLGTPGVNQTKFYSEEEAELKHCFYKGYVNTNSEHTAVISLCSGMLGTFRSHDGDYFIEPLQSMDEQEDEEEQNKPHIIYRRSAPQREPSTGRHACDTSEHKNRHSKDKKKTRARKWGERINLAGDVAALNSGLATEAFSAYGNKTDNTREKRTHRRTKRFLSYPRFVEVLVVADNRMVSYHGENLQHYILTLMSIVASIYKDPSIGNLINIVIVNLIVIHNEQDGPSISFNAQTTLKNFCQWQHSKNSPGGIHHDTAVLLTRQDICRAHDKCDTLGLAELGTICDPYRSCSISEDSGLSTAFTIAHELGHVFNMPHDDNNKCKEEGVKSPQHVMAPTLNFYTNPWMWSKCSRKYITEFLDTGYGECLLNEPESRPYPLPVQLPGILYNVNKQCELIFGPGSQVCPYMMQCRRLWCNNVNGVHKGCRTQHTPWADGTECEPGKHCKYGFCVPKEMDVPVTDGSWGSWSPFGTCSRTCGGGIKTAIRECNRPEPKNGGKYCVGRRMKFKSCNTEPCLKQKRDFRDEQCAHFDGKHFNINGLLPNVRWVPKYSGILMKDRCKLFCRVAGNTAYYQLRDRVIDGTPCGQDTNDICVQGLCRQAGCDHVLNSKARRDKCGVCGGDNSSCKTVAGTFNTVHYGYNTVVRIPAGATNIDVRQHSFSGETDDDNYLALSSSKGEFLLNGNFVVTMAKREIRIGNAVVEYSGSETAVERINSTDRIEQELLLQVLSVGKLYNPDVRYSFNIPIEDKPQQFYWNSHGPWQACSKPCQGERKRKLVCTRESDQLTVSDQRCDRLPQPGHITEPCGTDCDLRWHVASRSECSAQCGLGYRTLDIYCAKYSRLDGKTEKVDDGFCSSHPKPSNREKCSGECNTGGWRYSAWTECSKSCDGGTQRRRAICVNTRNDVLDDSKCTHQEKVTIQRCSEFPCPQWKSGDWSEVRWEGCYFP>sp|Q9P2N4-4|ATS9_HUMAN Isoform 4 of A disintegrin and metalloproteinasewith thrombospondin motifs 9 OS=Homo sapiens OX=9606 GN=ADAMTS9MQFVSWATLLTLLVRDLAEMGSPDAAAAVRKDRLHPRQVKLLETLSEYEIVSPIRVNALGEPFPTNVHFKRTRRSINSATDPWPAFASSSSSSTSSQAHYRLSAFGQQFLFNLTANAGFIAPLFTVTLLGTPGVNQTKFYSEEEAELKHCFYKGYVNTNSEHTAVISLCSGMLGTFRSHDGDYFIEPLQSMDEQEDEEEQNKPHIIYRRSAPQREPSTGRHACDTSEHKNRHSKDKKKTRARKWGERINLAGDVAALNSGLATEAFSAYGNKTDNTREKRTHRRTKRFLSYPRFVEVLVVADNRMVSYHGENLQHYILTLMSIDGPSISFNAQTTLKNFCQWQHSKNSPGGIHHDTAVLLTRQDICRAHDKCDTLGLAELGTICDPYRSCSISEDSGLSTAFTIAHELGHVFNMPHDDNNKCKEEGVKSPQHVMAPTLNFYTNPWMWSKCSRKYITEFLDTGYGECLLNEPESRPYPLPVQLPGILYNVNKQCELIFGPGSQVCPYMMQCRRLWCNNVNGVHKGCRTQHTPWADGTECEPGKHCKYGFCVPKEMDVPVTDGSWGSWSPFGTCSRTCGGGIKTAIRECNRPEPKNGGKYCVGRRMKFKSCNTEPCLKQKRDFRDEQCAHFDGKHFNINGLLPNVRWVPKYSGILMKDRCKLFCRVAGNTAYYQLRDRVIDGTPCGQDTNDICVQGLCRQAGCDHVLNSKARRDKCGVCGGDNSSCKTVAGTFNTVHYGYNTVVRIPAGATNIDVRQHSFSGETDDDNYLALSSSKGEFLLNGNFVVTMAKREIRIGNAVVEYSGSETAVERINSTDRIEQELLLQVLSVGKLYNPDVRYSFNIPIEDKPQQFYWNSHGPWQACSKPCQGERKRKLVCTRESDQLTVSDQRCDRLPQPGHITEPCGTDCDLRWHVASRSECSAQCGLGYRTLDIYCAKYSRLDGKTEKVDDGFCSSHPKPSNREKCSGECNTGGWRYSAWTECSKSCDGGTQRRRAICVNTRNDVLDDSKCTHQEKVTIQRCSEFPCPQWKSGDWSECLVTCGKGHKHRQVWCQFGEDRLNDRMCDPETKPTSMQTCQQPECASWQAGPWGQCSVTCGQGYQLRAVKCIIGTYMSVVDDNDCNAATRPTDTQDCELPSCHPPPAAPETRRSTYSAPRTQWRFGSWTPCSATCGKGTRMRYVSCRDENGSVADESACATLPRPVAKEECSVTPCGQWKALDWSSCSVTCGQGRATRQVMCVNYSDHVIDRSECDQDYIPETDQDCSMSPCPQRTPDSGLAQHPFQNEDYRPRSASPSRTHVLGGNQWRTGPWGACSSTCAGGSQRRVVVCQDENGYTANDCVERIKPDEQRACESGPCPQWAYGNWGECTKLCGGGIRTRLVVCQRSNGERFPDLSCEILDKPPDREQCNTHACPHDAAWSTGPWSSCSVSCGRGHKQRNVYCMAKDGSHLESDYCKHLAKPHGHRKCRGGRCPKWKAGAWSQCSVSCGRGVQQRHVGCQIGTHKIARETECNPYTRPESERDCQGPRCPLYTWRAEEWQECTKTCGEGSRYRKVVCVDDNKNEVHGARCDVSKRPVDRESCSLQPCEYVWITGEWSECSVTCGKGYKQRLVSCSEIYTGKENYEYSYQTTINCPGTQPPSVHPCYLRDCPVSATWRVGNWGSCSVSCGVGVMQRSVQCLTNEDQPSHLCHTDLKPEERKTCRNVYNCELPQNCKEVKRLKGASEDGEYFLMIRGKLLKIFCAGMHSDHPKEYVTLVHGDSENFSEVYGHRLHNPTECPYNGSRRDDCQCRKDYTAAGFSSFQKIRIDLTSMQIITTDLQFARTSEGHPVPFATAGDCYSAAKCPQGRFSINLYGTGLSLTESARWISQGNYAVSDIKKSPDGTRVVGKCGGYCGKCTPSSGTGLEVRVL>sp|Q8NCF0|CL18C_HUMAN C-type lectin domain family 18 member C OS=Homosapiens OX=9606 GN=CLEC18C PE=2 SV=2MLHPETSPGRGHLLAVLLALLGTAWAEVWPPQLQEQAPMAGALNRKESFLLLSLHNRLRSWVQPPAADMRRLDWSDSLAQLAQARAALCGIPTPSLASGLWRTLQVGWNMQLLPAGLASFVEVVSLWFAEGQRYSHAAGECARNATCTHYTQLVWATSSQLGCGRHLCSAGQAAIEAFVCAYSPRGNWEVNGKTIVPYKKGAWCSLCTASVSGCFKAWDHAGGLCEVPRNPCRMSCQNHGRLNISTCHCHCPPGYTGRYCQVRCSLQCVHGRFREEECSCVCDIGYGGAQCATKVHFPFHTCDLRIDGDCFMVSSEADTYYRARMKCQRKGGVLAQIKSQKVQDILAFYLGRLETTNEVIDSDFETRNFWIGLTYKTAKDSFRWATGEHQAFTSFAFGQPDNHGFGNCVELQASAAFNWNNQRCKTRNRYICQFAQEHISRWGPGS>sp|Q8NCF0-2|CL18C_HUMAN Isoform 2 of C-type lectin domain family 18member C OS=Homo sapiens OX=9606 GN=CLEC18CMLHPETSPGRGHLLAVLLALLGTAWAEVWPPQLQEQAPMAGALNRKESFLLLSLHNRLRSWVQPPAADMRRLDWSDSLAQLAQARAALCGIPTPSLASGLWRTLQVGWNMQLLPAGLASFVEVVSLWFAEGQRYSHAAGECARNATCTHYTQLVWATSSQLGCGRHLCSAGQAAIEAFVCAYSPRGNWEVNGKTIVPYKKGAWCSLCTASVSGCFKAWDHAGGLCEVPRNPCRMSCQNHGRLNISTCHCHCPPGYTGRYCQVRCSLQCVHGRFREEECSCVCDIGYGGAQCATKVHFPFHTCDLRIDGDCFMVSSEADTYYRARMKCQVTVTPSFLGTP>sp|P20908|CO5A1_HUMAN Collagen alpha-1(V) chain OS=Homo sapiens OX=9606GN=COL5A1 PE=1 SV=3MDVHTRWKARSALRPGAPLLPPLLLLLLWAPPPSRAAQPADLLKVLDFHNLPDGITKTTGFCATRRSSKGPDVAYRVTKDAQLSAPTKQLYPASAFPEDFSILTTVKAKKGSQAFLVSIYNEQGIQQIGLELGRSPVFLYEDHTGKPGPEDYPLFRGINLSDGKWHRIALSVHKKNVTLILDCKKKTTKFLDRSDHPMIDINGIIVFGTRILDEEVFEGDIQQLLFVSDHRAAYDYCEHYSPDCDTAVPDTPQSQDPNPDEYYTEGDGEGETYYYEYPYYEDPEDLGKEPTPSKKPVEAAKETTEVPEELTPTPTEAAPMPETSEGAGKEEDVGIGDYDYVPSEDYYTPSPYDDLTYGEGEENPDQPTDPGAGAEIPTSTADTSNSSNPAPPPGEGADDLEGEFTEETIRNLDENYYDPYYDPTSSPSEIGPGMPANQDTIYEGIGGPRGEKGQKGEPAIIEPGMLIEGPPGPEGPAGLPGPPGTMGPTGQVGDPGERGPPGRPGLPGADGLPGPPGTMLMLPFRFGGGGDAGSKGPMVSAQESQAQAILQQARLALRGPAGPMGLTGRPGPVGPPGSGGLKGEPGDVGPQGPRGVQGPPGPAGKPGRRGRAGSDGARGMPGQTGPKGDRGFDGLAGLPGEKGHRGDPGPSGPPGPPGDDGERGDDGEVGPRGLPGEPGPRGLLGPKGPPGPPGPPGVTGMDGQPGPKGNVGPQGEPGPPGQQGNPGAQGLPGPQGAIGPPGEKGPLGKPGLPGMPGADGPPGHPGKEGPPGEKGGQGPPGPQGPIGYPGPRGVKGADGIRGLKGTKGEKGEDGFPGFKGDMGIKGDRGEIGPPGPRGEDGPEGPKGRGGPNGDPGPLGPPGEKGKLGVPGLPGYPGRQGPKGSIGFPGFPGANGEKGGRGTPGKPGPRGQRGPTGPRGERGPRGITGKPGPKGNSGGDGPAGPPGERGPNGPQGPTGFPGPKGPPGPPGKDGLPGHPGQRGETGFQGKTGPPGPPGVVGPQGPTGETGPMGERGHPGPPGPPGEQGLPGLAGKEGTKGDPGPAGLPGKDGPPGLRGFPGDRGLPGPVGALGLKGNEGPPGPPGPAGSPGERGPAGAAGPIGIPGRPGPQGPPGPAGEKGAPGEKGPQGPAGRDGLQGPVGLPGPAGPVGPPGEDGDKGEIGEPGQKGSKGDKGEQGPPGPTGPQGPIGQPGPSGADGEPGPRGQQGLFGQKGDEGPRGFPGPPGPVGLQGLPGPPGEKGETGDVGQMGPPGPPGPRGPSGAPGADGPQGPPGGIGNPGAVGEKGEPGEAGEPGLPGEGGPPGPKGERGEKGESGPSGAAGPPGPKGPPGDDGPKGSPGPVGFPGDPGPPGEPGPAGQDGPPGDKGDDGEPGQTGSPGPTGEPGPSGPPGKRGPPGPAGPEGRQGEKGAKGEAGLEGPPGKTGPIGPQGAPGKPGPDGLRGIPGPVGEQGLPGSPGPDGPPGPMGPPGLPGLKGDSGPKGEKGHPGLIGLIGPPGEQGEKGDRGLPGPQGSSGPKGEQGITGPSGPIGPPGPPGLPGPPGPKGAKGSSGPTGPKGEAGHPGPPGPPGPPGEVIQPLPIQASRTRRNIDASQLLDDGNGENYVDYADGMEEIFGSLNSLKLEIEQMKRPLGTQQNPARTCKDLQLCHPDFPDGEYWVDPNQGCSRDSFKVYCNFTAGGSTCVFPDKKSEGARITSWPKENPGSWFSEFKRGKLLSYVDAEGNPVGVVQMTFLRLLSASAHQNVTYHCYQSVAWQDAATGSYDKALRFLGSNDEEMSYDNNPYIRALVDGCATKKGYQKTVLEIDTPKVEQVPIVDIMFNDFGEASQKFGFEVGPACFMG>sp|P20908-2|CO5A1_HUMAN Isoform 2 of Collagen alpha-1(V) chain OS=Homosapiens OX=9606 GN=COL5A1MDVHTRWKARSALRPGAPLLPPLLLLLLWAPPPSRAAQPADLLKVLDFHNLPDGITKTTGFCATRRSSKGPDVAYRVTKDAQLSAPTKQLYPASAFPEDFSILTTVKAKKGSQAFLVSIYNEQGIQQIGLELGRSPVFLYEDHTGKPGPEDYPLFRGINLSDGKWHRIALSVHKKNVTLILDCKKKTTKFLDRSDHPMIDINGIIVFGTRILDEEVFEGDIQQLLFVSDHRAAYDYCEHYSPDCDTAVPDTPQSQDPNPDEYYTEGDGEGETYYYEYPYYEDPEDLGKEPTPSKKPVEAAKETTEVPEELTPTPTEAAPMPETSEGAGKEEDVGIGDYDYVPSEDYYTPSPYDDLTYGEGEENPDQPTDPGAGAEIPTSTADTSNSSNPAPPPGEGADDLEGEFTEETIRNLDENYYDPYYDPTSSPSEIGPGMPANQDTIYEGIGGPRGEKGQKGEPAIIEPGMLIEGPPGPEGPAGLPGPPGTMGPTGQVGDPGERGPPGRPGLPGADGLPGPPGTMLMLPFRFGGGGDAGSKGPMVSAQESQAQAILQQARLALRGPAGPMGLTGRPGPVGPPGSGGLKGEPGDVGPQGPRGVQGPPGPAGKPGRRGRAGSDGARGMPGQTGPKGDRGFDGLAGLPGEKGHRGDPGPSGPPGPPGDDGERGDDGEVGPRGLPGEPGPRGLLGPKGPPGPPGPPGVTGMDGQPGPKGNVGPQGEPGPPGQQGNPGAQGLPGPQGAIGPPGEKGPLGKPGLPGMPGADGPPGHPGKEGPPGEKGGQGPPGPQGPIGYPGPRGVKGADGIRGLKGTKGEKGEDGFPGFKGDMGIKGDRGEIGPPGPRGEDGPEGPKGRGGPNGDPGPLGPPGEKGKLGVPGLPGYPGRQGPKGSIGFPGFPGANGEKGGRGTPGKPGPRGQRGPTGPRGERGPRGITGKPGPKGNSGGDGPAGPPGERGPNGPQGPTGFPGPKGPPGPPGKDGLPGHPGQRGETGFQGKTGPPGPPGVVGPQGPTGETGPMGERGHPGPPGPPGEQGLPGLAGKEGTKGDPGPAGLPGKDGPPGLRGFPGDRGLPGPVGALGLKGNEGPPGPPGPAGSPGERGPAGAAGPIGIPGRPGPQGPPGPAGEKGAPGEKGPQGPAGRDGLQGPVGLPGPAGPVGPPGEDGDKGEIGEPGQKGSKGDKGEQGPPGPTGPQGPIGQPGPSGADGEPGPRGQQGLFGQKGDEGPRGFPGPPGPVGLQGLPGPPGEKGETGDVGQMGPPGPPGPRGPSGAPGADGPQGPPGGIGNPGAVGEKGEPGEAGEPGLPGEGGPPGPKGERGEKGESGPSGAAGPPGPKGPPGDDGPKGSPGPVGFPGDPGPPGEPGPAGQDGPPGDKGDDGEPGQTGSPGPTGEPGPSGPPGKRGPPGPAGPEGRQGEKGAKGEAGLEGPPGKTGPIGPQGAPGKPGPDGLRGIPGPVGEQGLPGSPGPDGPPGPMGPPGLPGLKGDSGPKGEKGHPGLIGLIGPPGEQGEKGDRGLPGPQGSSGPKGEQGITGPSGPIGPPGPPGLPGPPGPKGAKGSSGPTGPKGEAGHPGPPGPPGPPGEVIQPLPIQASRTRRNIDASQLLDDGNGENYVDYADGMEEIFGSLNSLKLEIEQMKRPLGTQQNPARTCKDLQLCHPDFPDGEYWVDPNQGCSRDSFKVYCNFTAGGSTCVFPDKKSEGSKMARWPKEQPSTWYSQYKRGSLLSYVDAEGNPVGVVQMTFLRLLSASAHQNVTYHCYQSVAWQDAATGSYDKALRFLGSNDEEMSYDNNPYIRALVDGCATKKGYQKTVLEIDTPKVEQVPIVDIMFNDFGEASQKFGFEVGPACFMG>sp|Q96RK0|CIC_HUMAN Protein capicua homolog OS=Homo sapiens OX=9606GN=CIC PE=1 SV=2MYSAHRPLMPASSAASRGLGMFVWTNVEPRSVAVFPWHSLVPFLAPSQPDPSVQPSEAQQPASHPVASNQSKEPAESAAVAHERPPGGTGSADPERPPGATCPESPGPGPPHPLGVVESGKGPPPTTEEEASGPPGEPRLDSETESDHDDAFLSIMSPEIQLPLPPGKRRTQSLSALPKERDSSSEKDGRSPNKREKDHIRRPMNAFMIFSKRHRALVHQRHPNQDNRTVSKILGEWWYALGPKEKQKYHDLAFQVKEAHFKAHPDWKWCNKDRKKSSSEAKPTSLGLAGGHKETRERSMSETGTAAAPGVSSELLSVAAQTLLSSDTKAPGSSSCGAERLHTVGGPGSARPRAFSHSGVHSLDGGEVDSQALQELTQMVSGPASYSGPKPSTQYGAPGPFAAPGEGGALAATGRPPLLPTRASRSQRAASEDMTSDEERMVICEEEGDDDVIADDGFGTTDIDLKCKERVTDSESGDSSGEDPEGNKGFGRKVFSPVIRSSFTHCRPPLDPEPPGPPDPPVAFGKGYGSAPSSSASSPASSSASAATSFSLGSGTFKAQESGQGSTAGPLRPPPPGAGGPATPSKATRFLPMDPATFRRKRPESVGGLEPPGPSVIAAPPSGGGNILQTLVLPPNKEEQEGGGARVPSAPAPSLAYGAPAAPLSRPAATMVTNVVRPVSSTPVPIASKPFPTSGRAEASPNDTAGARTEMGTGSRVPGGSPLGVSLVYSDKKSAAATSPAPHLVAGPLLGTVGKAPATVTNLLVGTPGYGAPAPPAVQFIAQGAPGGGTTAGSGAGAGSGPNGPVPLGILQPGALGKAGGITQVQYILPTLPQQLQVAPAPAPAPGTKAAAPSGPAPTTSIRFTLPPGTSTNGKVLAATAPTPGIPILQSVPSAPPPKAQSVSPVQAPPPGGSAQLLPGKVLVPLAAPSMSVRGGGAGQPLPLVSPPFSVPVQNGAQPPSKIIQLTPVPVSTPSGLVPPLSPATLPGPTSQPQKVLLPSSTRITYVQSAGGHALPLGTSPASSQAGTVTSYGPTSSVALGFTSLGPSGPAFVQPLLSAGQAPLLAPGQVGVSPVPSPQLPPACAAPGGPVITAFYSGSPAPTSSAPLAQPSQAPPSLVYTVATSTTPPAATILPKGPPAPATATPAPTSPFPSATAGSMTYSLVAPKAQRPSPKAPQKVKAAIASIPVGSFEAGASGRPGPAPRQPLEPGPVREPTAPESELEGQPTPPAPPPLPETWTPTARSSPPLPPPAEERTSAKGPETMASKFPSSSSDWRVPGQGLENRGEPPTPPSPAPAPAVAPGGSSESSSGRAAGDTPERKEAAGTGKKVKVRPPPLKKTFDSVDNRVLSEVDFEERFAELPEFRPEEVLPSPTLQSLATSPRAILGSYRKKRKNSTDLDSAPEDPTSPKRKMRRRSSCSSEPNTPKSAKCEGDIFTFDRTGTEAEDVLGELEYDKVPYSSLRRTLDQRRALVMQLFQDHGFFPSAQATAAFQARYADIFPSKVCLQLKIREVRQKIMQAATPTEQPPGAEAPLPVPPPTGTAAAPAPTPSPAGGPDPTSPSSDSGTAQAAPPLPPPPESGPGQPGWEGAPQPSPPPPGPSTAATGR>sp|Q6UXS0|CL19A_HUMAN C-type lectin domain family 19 member A OS=Homosapiens OX=9606 GN=CLEC19A PE=1 SV=1MQRWTLWAAAFLTLHSAQAFPQTDISISPALPELPLPSLCPLFWMEFKGHCYRFFPLNKTWAEADLYCSEFSVGRKSAKLASIHSWEENVFVYDLVNSCVPGIPADVWTGLHDHRQVRKQWPLGPLGSSSQDSILI>sp|P12111|CO6A3_HUMAN Collagen alpha-3(VI) chain OS=Homo sapiens OX=9606GN=COL6A3 PE=1 SV=5MRKHRHLPLVAVFCLFLSGFPTTHAQQQQADVKNGAAADIIFLVDSSWTIGEEHFQLVREFLYDVVKSLAVGENDFHFALVQFNGNPHTEFLLNTYRTKQEVLSHISNMSYIGGTNQTGKGLEYIMQSHLTKAAGSRAGDGVPQVIVVLTDGHSKDGLALPSAELKSADVNVFAIGVEDADEGALKEIASEPLNMHMFNLENFTSLHDIVGNLVSCVHSSVSPERAGDTETLKDITAQDSADIIFLIDGSNNTGSVNFAVILDFLVNLLEKLPIGTQQIRVGVVQFSDEPRTMFSLDTYSTKAQVLGAVKALGFAGGELANIGLALDFVVENHFTRAGGSRVEEGVPQVLVLISAGPSSDEIRYGVVALKQASVFSFGLGAQAASRAELQHIATDDNLVFTVPEFRSFGDLQEKLLPYIVGVAQRHIVLKPPTIVTQVIEVNKRDIVFLVDGSSALGLANFNAIRDFIAKVIQRLEIGQDLIQVAVAQYADTVRPEFYFNTHPTKREVITAVRKMKPLDGSALYTGSALDFVRNNLFTSSAGYRAAEGIPKLLVLITGGKSLDEISQPAQELKRSSIMAFAIGNKGADQAELEEIAFDSSLVFIPAEFRAAPLQGMLPGLLAPLRTLSGTPEVHSNKRDIIFLLDGSANVGKTNFPYVRDFVMNLVNSLDIGNDNIRVGLVQFSDTPVTEFSLNTYQTKSDILGHLRQLQLQGGSGLNTGSALSYVYANHFTEAGGSRIREHVPQLLLLLTAGQSEDSYLQAANALTRAGILTFCVGASQANKAELEQIAFNPSLVYLMDDFSSLPALPQQLIQPLTTYVSGGVEEVPLAQPESKRDILFLFDGSANLVGQFPVVRDFLYKIIDELNVKPEGTRIAVAQYSDDVKVESRFDEHQSKPEILNLVKRMKIKTGKALNLGYALDYAQRYIFVKSAGSRIEDGVLQFLVLLVAGRSSDRVDGPASNLKQSGVVPFIFQAKNADPAELEQIVLSPAFILAAESLPKIGDLHPQIVNLLKSVHNGAPAPVSGEKDVVFLLDGSEGVRSGFPLLKEFVQRVVESLDVGQDRVRVAVVQYSDRTRPEFYLNSYMNKQDVVNAVRQLTLLGGPTPNTGAALEFVLRNILVSSAGSRITEGVPQLLIVLTADRSGDDVRNPSVVVKRGGAVPIGIGIGNADITEMQTISFIPDFAVAIPTFRQLGTVQQVISERVTQLTREELSRLQPVLQPLPSPGVGGKRDVVFLIDGSQSAGPEFQYVRTLIERLVDYLDVGFDTTRVAVIQFSDDPKVEFLLNAHSSKDEVQNAVQRLRPKGGRQINVGNALEYVSRNIFKRPLGSRIEEGVPQFLVLISSGKSDDEVDDPAVELKQFGVAPFTIARNADQEELVKISLSPEYVFSVSTFRELPSLEQKLLTPITTLTSEQIQKLLASTRYPPPAVESDAADIVFLIDSSEGVRPDGFAHIRDFVSRIVRRLNIGPSKVRVGVVQFSNDVFPEFYLKTYRSQAPVLDAIRRLRLRGGSPLNTGKALEFVARNLFVKSAGSRIEDGVPQHLVLVLGGKSQDDVSRFAQVIRSSGIVSLGVGDRNIDRTELQTITNDPRLVFTVREFRELPNIEERIMNSFGPSAATPAPPGVDTPPPSRPEKKKADIVFLLDGSINFRRDSFQEVLRFVSEIVDTVYEDGDSIQVGLVQYNSDPTDEFFLKDFSTKRQIIDAINKVVYKGGRHANTKVGLEHLRVNHFVPEAGSRLDQRVPQIAFVITGGKSVEDAQDVSLALTQRGVKVFAVGVRNIDSEEVGKIASNSATAFRVGNVQELSELSEQVLETLHDAMHETLCPGVTDAAKACNLDVILGFDGSRDQNVFVAQKGFESKVDAILNRISQMHRVSCSGGRSPTVRVSVVANTPSGPVEAFDFDEYQPEMLEKFRNMRSQHPYVLTEDTLKVYLNKFRQSSPDSVKVVIHFTDGADGDLADLHRASENLRQEGVRALILVGLERVVNLERLMHLEFGRGFMYDRPLRLNLLDLDYELAEQLDNIAEKACCGVPCKCSGQRGDRGPIGSIGPKGIPGEDGYRGYPGDEGGPGERGPPGVNGTQGFQGCPGQRGVKGSRGFPGEKGEVGEIGLDGLDGEDGDKGLPGSSGEKGNPGRRGDKGPRGEKGERGDVGIRGDPGNPGQDSQERGPKGETGDLGPMGVPGRDGVPGGPGETGKNGGFGRRGPPGAKGNKGGPGQPGFEGEQGTRGAQGPAGPAGPPGLIGEQGISGPRGSGGAAGAPGERGRTGPLGRKGEPGEPGPKGGIGNRGPRGETGDDGRDGVGSEGRRGKKGERGFPGYPGPKGNPGEPGLNGTTGPKGIRGRRGNSGPPGIVGQKGDPGYPGPAGPKGNRGDSIDQCALIQSIKDKCPCCYGPLECPVFPTELAFALDTSEGVNQDTFGRMRDVVLSIVNDLTIAESNCPRGARVAVVTYNNEVTTEIRFADSKRKSVLLDKIKNLQVALTSKQQSLETAMSFVARNTFKRVRNGFLMRKVAVFFSNTPTRASPQLREAVLKLSDAGITPLFLTRQEDRQLINALQINNTAVGHALVLPAGRDLTDFLENVLTCHVCLDICNIDPSCGFGSWRPSFRDRRAAGSDVDIDMAFILDSAETTTLFQFNEMKKYIAYLVRQLDMSPDPKASQHFARVAVVQHAPSESVDNASMPPVKVEFSLTDYGSKEKLVDFLSRGMTQLQGTRALGSAIEYTIENVFESAPNPRDLKIVVLMLTGEVPEQQLEEAQRVILQAKCKGYFFVVLGIGRKVNIKEVYTFASEPNDVFFKLVDKSTELNEEPLMRFGRLLPSFVSSENAFYLSPDIRKQCDWFQGDQPTKNLVKFGHKQVNVPNNVTSSPTSNPVTTTKPVTTTKPVTTTTKPVTTTTKPVTIINQPSVKPAAAKPAPAKPVAAKPVATKMATVRPPVAVKPATAAKPVAAKPAAVRPPAAAAAKPVATKPEVPRPQAAKPAATKPATTKPMVKMSREVQVFEITENSAKLHWERAEPPGPYFYDLTVTSAHDQSLVLKQNLTVTDRVIGGLLAGQTYHVAVVCYLRSQVRATYHGSFSTKKSQPPPPQPARSASSSTINLMVSTEPLALTETDICKLPKDEGTCRDFILKWYYDPNTKSCARFWYGGCGGNENKFGSQKECEKVCAPVLAKPGVISVMGT>sp|P12111-2|CO6A3_HUMAN Isoform 2 of Collagen alpha-3(VI) chain OS=Homosapiens OX=9606 GN=COL6A3MRKHRHLPLVAVFCLFLSGFPTTHAQQQQAAQDSADIIFLIDGSNNTGSVNFAVILDFLVNLLEKLPIGTQQIRVGVVQFSDEPRTMFSLDTYSTKAQVLGAVKALGFAGGELANIGLALDFVVENHFTRAGGSRVEEGVPQVLVLISAGPSSDEIRYGVVALKQASVFSFGLGAQAASRAELQHIATDDNLVFTVPEFRSFGDLQEKLLPYIVGVAQRHIVLKPPTIVTQVIEVNKRDIVFLVDGSSALGLANFNAIRDFIAKVIQRLEIGQDLIQVAVAQYADTVRPEFYFNTHPTKREVITAVRKMKPLDGSALYTGSALDFVRNNLFTSSAGYRAAEGIPKLLVLITGGKSLDEISQPAQELKRSSIMAFAIGNKGADQAELEEIAFDSSLVFIPAEFRAAPLQGMLPGLLAPLRTLSGTPEVHSNKRDIIFLLDGSANVGKTNFPYVRDFVMNLVNSLDIGNDNIRVGLVQFSDTPVTEFSLNTYQTKSDILGHLRQLQLQGGSGLNTGSALSYVYANHFTEAGGSRIREHVPQLLLLLTAGQSEDSYLQAANALTRAGILTFCVGASQANKAELEQIAFNPSLVYLMDDFSSLPALPQQLIQPLTTYVSGGVEEVPLAQPESKRDILFLFDGSANLVGQFPVVRDFLYKIIDELNVKPEGTRIAVAQYSDDVKVESRFDEHQSKPEILNLVKRMKIKTGKALNLGYALDYAQRYIFVKSAGSRIEDGVLQFLVLLVAGRSSDRVDGPASNLKQSGVVPFIFQAKNADPAELEQIVLSPAFILAAESLPKIGDLHPQIVNLLKSVHNGAPAPVSGEKDVVFLLDGSEGVRSGFPLLKEFVQRVVESLDVGQDRVRVAVVQYSDRTRPEFYLNSYMNKQDVVNAVRQLTLLGGPTPNTGAALEFVLRNILVSSAGSRITEGVPQLLIVLTADRSGDDVRNPSVVVKRGGAVPIGIGIGNADITEMQTISFIPDFAVAIPTFRQLGTVQQVISERVTQLTREELSRLQPVLQPLPSPGVGGKRDVVFLIDGSQSAGPEFQYVRTLIERLVDYLDVGFDTTRVAVIQFSDDPKVEFLLNAHSSKDEVQNAVQRLRPKGGRQINVGNALEYVSRNIFKRPLGSRIEEGVPQFLVLISSGKSDDEVDDPAVELKQFGVAPFTIARNADQEELVKISLSPEYVFSVSTFRELPSLEQKLLTPITTLTSEQIQKLLASTRYPPPAVESDAADIVFLIDSSEGVRPDGFAHIRDFVSRIVRRLNIGPSKVRVGVVQFSNDVFPEFYLKTYRSQAPVLDAIRRLRLRGGSPLNTGKALEFVARNLFVKSAGSRIEDGVPQHLVLVLGGKSQDDVSRFAQVIRSSGIVSLGVGDRNIDRTELQTITNDPRLVFTVREFRELPNIEERIMNSFGPSAATPAPPGVDTPPPSRPEKKKADIVFLLDGSINFRRDSFQEVLRFVSEIVDTVYEDGDSIQVGLVQYNSDPTDEFFLKDFSTKRQIIDAINKVVYKGGRHANTKVGLEHLRVNHFVPEAGSRLDQRVPQIAFVITGGKSVEDAQDVSLALTQRGVKVFAVGVRNIDSEEVGKIASNSATAFRVGNVQELSELSEQVLETLHDAMHETLCPGVTDAAKACNLDVILGFDGSRDQNVFVAQKGFESKVDAILNRISQMHRVSCSGGRSPTVRVSVVANTPSGPVEAFDFDEYQPEMLEKFRNMRSQHPYVLTEDTLKVYLNKFRQSSPDSVKVVIHFTDGADGDLADLHRASENLRQEGVRALILVGLERVVNLERLMHLEFGRGFMYDRPLRLNLLDLDYELAEQLDNIAEKACCGVPCKCSGQRGDRGPIGSIGPKGIPGEDGYRGYPGDEGGPGERGPPGVNGTQGFQGCPGQRGVKGSRGFPGEKGEVGEIGLDGLDGEDGDKGLPGSSGEKGNPGRRGDKGPRGEKGERGDVGIRGDPGNPGQDSQERGPKGETGDLGPMGVPGRDGVPGGPGETGKNGGFGRRGPPGAKGNKGGPGQPGFEGEQGTRGAQGPAGPAGPPGLIGEQGISGPRGSGGAAGAPGERGRTGPLGRKGEPGEPGPKGGIGNRGPRGETGDDGRDGVGSEGRRGKKGERGFPGYPGPKGNPGEPGLNGTTGPKGIRGRRGNSGPPGIVGQKGDPGYPGPAGPKGNRGDSIDQCALIQSIKDKCPCCYGPLECPVFPTELAFALDTSEGVNQDTFGRMRDVVLSIVNDLTIAESNCPRGARVAVVTYNNEVTTEIRFADSKRKSVLLDKIKNLQVALTSKQQSLETAMSFVARNTFKRVRNGFLMRKVAVFFSNTPTRASPQLREAVLKLSDAGITPLFLTRQEDRQLINALQINNTAVGHALVLPAGRDLTDFLENVLTCHVCLDICNIDPSCGFGSWRPSFRDRRAAGSDVDIDMAFILDSAETTTLFQFNEMKKYIAYLVRQLDMSPDPKASQHFARVAVVQHAPSESVDNASMPPVKVEFSLTDYGSKEKLVDFLSRGMTQLQGTRALGSAIEYTIENVFESAPNPRDLKIVVLMLTGEVPEQQLEEAQRVILQAKCKGYFFVVLGIGRKVNIKEVYTFASEPNDVFFKLVDKSTELNEEPLMRFGRLLPSFVSSENAFYLSPDIRKQCDWFQGDQPTKNLVKFGHKQVNVPNNVTSSPTSNPVTTTKPVTTTKPVTTTTKPVTTTTKPVTIINQPSVKPAAAKPAPAKPVAAKPVATKMATVRPPVAVKPATAAKPVAAKPAAVRPPAAAAAKPVATKPEVPRPQAAKPAATKPATTKPMVKMSREVQVFEITENSAKLHWERAEPPGPYFYDLTVTSAHDQSLVLKQNLTVTDRVIGGLLAGQTYHVAVVCYLRSQVRATYHGSFSTKKSQPPPPQPARSASSSTINLMVSTEPLALTETDICKLPKDEGTCRDFILKWYYDPNTKSCARFWYGGCGGNENKFGSQKECEKVCAPVLAKPGVISVMGT>sp|P12111-3|CO6A3_HUMAN Isoform 3 of Collagen alpha-3(VI) chain OS=Homosapiens OX=9606 GN=COL6A3MRKHRHLPLVAVFCLFLSGFPTTHAQQQQAVIEVNKRDIVFLVDGSSALGLANFNAIRDFIAKVIQRLEIGQDLIQVAVAQYADTVRPEFYFNTHPTKREVITAVRKMKPLDGSALYTGSALDFVRNNLFTSSAGYRAAEGIPKLLVLITGGKSLDEISQPAQELKRSSIMAFAIGNKGADQAELEEIAFDSSLVFIPAEFRAAPLQGMLPGLLAPLRTLSGTPEVHSNKRDIIFLLDGSANVGKTNFPYVRDFVMNLVNSLDIGNDNIRVGLVQFSDTPVTEFSLNTYQTKSDILGHLRQLQLQGGSGLNTGSALSYVYANHFTEAGGSRIREHVPQLLLLLTAGQSEDSYLQAANALTRAGILTFCVGASQANKAELEQIAFNPSLVYLMDDFSSLPALPQQLIQPLTTYVSGGVEEVPLAQPESKRDILFLFDGSANLVGQFPVVRDFLYKIIDELNVKPEGTRIAVAQYSDDVKVESRFDEHQSKPEILNLVKRMKIKTGKALNLGYALDYAQRYIFVKSAGSRIEDGVLQFLVLLVAGRSSDRVDGPASNLKQSGVVPFIFQAKNADPAELEQIVLSPAFILAAESLPKIGDLHPQIVNLLKSVHNGAPAPVSGEKDVVFLLDGSEGVRSGFPLLKEFVQRVVESLDVGQDRVRVAVVQYSDRTRPEFYLNSYMNKQDVVNAVRQLTLLGGPTPNTGAALEFVLRNILVSSAGSRITEGVPQLLIVLTADRSGDDVRNPSVVVKRGGAVPIGIGIGNADITEMQTISFIPDFAVAIPTFRQLGTVQQVISERVTQLTREELSRLQPVLQPLPSPGVGGKRDVVFLIDGSQSAGPEFQYVRTLIERLVDYLDVGFDTTRVAVIQFSDDPKVEFLLNAHSSKDEVQNAVQRLRPKGGRQINVGNALEYVSRNIFKRPLGSRIEEGVPQFLVLISSGKSDDEVDDPAVELKQFGVAPFTIARNADQEELVKISLSPEYVFSVSTFRELPSLEQKLLTPITTLTSEQIQKLLASTRYPPPGEMGASEVLLGAFSI>sp|P12111-4|CO6A3_HUMAN Isoform 4 of Collagen alpha-3(VI) chain OS=Homosapiens OX=9606 GN=COL6A3MRKHRHLPLVAVFCLFLSGFPTTHAQQQQAVIEVNKRDIVFLVDGSSALGLANFNAIRDFIAKVIQRLEIGQDLIQVAVAQYADTVRPEFYFNTHPTKREVITAVRKMKPLDGSALYTGSALDFVRNNLFTSSAGYRAAEGIPKLLVLITGGKSLDEISQPAQELKRSSIMAFAIGNKGADQAELEEIAFDSSLVFIPAEFRAAPLQGMLPGLLAPLRTLSGTPEESKRDILFLFDGSANLVGQFPVVRDFLYKIIDELNVKPEGTRIAVAQYSDDVKVESRFDEHQSKPEILNLVKRMKIKTGKALNLGYALDYAQRYIFVKSAGSRIEDGVLQFLVLLVAGRSSDRVDGPASNLKQSGVVPFIFQAKNADPAELEQIVLSPAFILAAESLPKIGDLHPQIVNLLKSVHNGAPAPVSGEKDVVFLLDGSEGVRSGFPLLKEFVQRVVESLDVGQDRVRVAVVQYSDRTRPEFYLNSYMNKQDVVNAVRQLTLLGGPTPNTGAALEFVLRNILVSSAGSRITEGVPQLLIVLTADRSGDDVRNPSVVVKRGGAVPIGIGIGNADITEMQTISFIPDFAVAIPTFRQLGTVQQVISERVTQLTREELSRLQPVLQPLPSPGVGGKRDVVFLIDGSQSAGPEFQYVRTLIERLVDYLDVGFDTTRVAVIQFSDDPKVEFLLNAHSSKDEVQNAVQRLRPKGGRQINVGNALEYVSRNIFKRPLGSRIEEGVPQFLVLISSGKSDDEVDDPAVELKQFGVAPFTIARNADQEELVKISLSPEYVFSVSTFRELPSLEQKLLTPITTLTSEQIQKLLASTRYPPPAVESDAADIVFLIDSSEGVRPDGFAHIRDFVSRIVRRLNIGPSKVRVGVVQFSNDVFPEFYLKTYRSQAPVLDAIRRLRLRGGSPLNTGKALEFVARNLFVKSAGSRIEDGVPQHLVLVLGGKSQDDVSRFAQVIRSSGIVSLGVGDRNIDRTELQTITNDPRLVFTVREFRELPNIEERIMNSFGPSAATPAPPGVDTPPPSRPEKKKADIVFLLDGSINFRRDSFQEVLRFVSEIVDTVYEDGDSIQVGLVQYNSDPTDEFFLKDFSTKRQIIDAINKVVYKGGRHANTKVGLEHLRVNHFVPEAGSRLDQRVPQIAFVITGGKSVEDAQDVSLALTQRGVKVFAVGVRNIDSEEVGKIASNSATAFRVGNVQELSELSEQVLETLHDAMHETLCPGVTDAAKACNLDVILGFDGSRDQNVFVAQKGFESKVDAILNRISQMHRVSCSGGRSPTVRVSVVANTPSGPVEAFDFDEYQPEMLEKFRNMRSQHPYVLTEDTLKVYLNKFRQSSPDSVKVVIHFTDGADGDLADLHRASENLRQEGVRALILVGLERVVNLERLMHLEFGRGFMYDRPLRLNLLDLDYELAEQLDNIAEKACCGVPCKCSGQRGDRGPIGSIGPKGIPGEDGYRGYPGDEGGPGERGPPGVNGTQGFQGCPGQRGVKGSRGFPGEKGEVGEIGLDGLDGEDGDKGLPGSSGEKGNPGRRGDKGPRGEKGERGDVGIRGDPGNPGQDSQERGPKGETGDLGPMGVPGRDGVPGGPGETGKNGGFGRRGPPGAKGNKGGPGQPGFEGEQGTRGAQGPAGPAGPPGLIGEQGISGPRGSGGAAGAPGERGRTGPLGRKGEPGEPGPKGGIGNRGPRGETGDDGRDGVGSEGRRGKKGERGFPGYPGPKGNPGEPGLNGTTGPKGIRGRRGNSGPPGIVGQKGDPGYPGPAGPKGNRGDSIDQCALIQSIKDKCPCCYGPLECPVFPTELAFALDTSEGVNQDTFGRMRDVVLSIVNDLTIAESNCPRGARVAVVTYNNEVTTEIRFADSKRKSVLLDKIKNLQVALTSKQQSLETAMSFVARNTFKRVRNGFLMRKVAVFFSNTPTRASPQLREAVLKLSDAGITPLFLTRQEDRQLINALQINNTAVGHALVLPAGRDLTDFLENVLTCHVCLDICNIDPSCGFGSWRPSFRDRRAAGSDVDIDMAFILDSAETTTLFQFNEMKKYIAYLVRQLDMSPDPKASQHFARVAVVQHAPSESVDNASMPPVKVEFSLTDYGSKEKLVDFLSRGMTQLQGTRALGSAIEYTIENVFESAPNPRDLKIVVLMLTGEVPEQQLEEAQRVILQAKCKGYFFVVLGIGRKVNIKEVYTFASEPNDVFFKLVDKSTELNEEPLMRFGRLLPSFVSSENAFYLSPDIRKQCDWFQGDQPTKNLVKFGHKQVNVPNNVTSSPTSNPVTTTKPVTTTKPVTTTTKPVTTTTKPVTIINQPSVKPAAAKPAPAKPVAAKPVATKMATVRPPVAVKPATAAKPVAAKPAAVRPPAAAAAKPVATKPEVPRPQAAKPAATKPATTKPMVKMSREVQVFEITENSAKLHWERAEPPGPYFYDLTVTSAHDQSLVLKQNLTVTDRVIGGLLAGQTYHVAVVCYLRSQVRATYHGSFSTKKSQPPPPQPARSASSSTINLMVSTEPLALTETDICKLPKDEGTCRDFILKWYYDPNTKSCARFWYGGCGGNENKFGSQKECEKVCAPVLAKPGVISVMGT>sp|P12111-5|CO6A3_HUMAN Isoform 5 of Collagen alpha-3(VI) chain OS=Homosapiens OX=9606 GN=COL6A3MRKHRHLPLVAVFCLFLSGFPTTHAQQQQAAQDSADIIFLIDGSNNTGSVNFAVILDFLVNLLEKLPIGTQQIRVGVVQFSDEPRTMFSLDTYSTKAQVLGAVKALGFAGGELANIGLALDFVVENHFTRAGGSRVEEGVPQVLVLISAGPSSDEIRYGVVALKQASVFSFGLGAQAASRAELQHIATDDNLVFTVPEFRSFGDLQEKLLPYIVGVAQRHIVLKPPTIVTQVIEVNKRDIVFLVDGSSALGLANFNAIRDFIAKVIQRLEIGQDLIQVAVAQYADTVRPEFYFNTHPTKREVITAVRKMKPLDGSALYTGSALDFVRNNLFTSSAGYRAAEGIPKLLVLITGGKSLDEISQPAQELKRSSIMAFAIGNKGADQAELEEIAFDSSLVFIPAEFRAAPLQGMLPGLLAPLRTLSGTPEVHSNKRDIIFLLDGSANVGKTNFPYVRDFVMNLVNSLDIGNDNIRVGLVQFSDTPVTEFSLNTYQTKSDILGHLRQLQLQGGSGLNTGSALSYVYANHFTEAGGSRIREHVPQLLLLLTAGQSEDSYLQAANALTRAGILTFCVGASQANKAELEQIAFNPSLVYLMDDFSSLPALPQQLIQPLTTYVSGGVEEVPLAQPESKRDILFLFDGSANLVGQFPVVRDFLYKIIDELNVKPEGTRIAVAQYSDDVKVESRFDEHQSKPEILNLVKRMKIKTGKALNLGYALDYAQRYIFVKSAGSRIEDGVLQFLVLLVAGRSSDRVDGPASNLKQSGVVPFIFQAKNADPAELEQIVLSPAFILAAESLPKIGDLHPQIVNLLKSVHNGAPAPVSGEKDVVFLLDGSEGVRSGFPLLKEFVQRVVESLDVGQDRVRVAVVQYSDRTRPEFYLNSYMNKQDVVNAVRQLTLLGGPTPNTGAALEFVLRNILVSSAGSRITEGVPQLLIVLTADRSGDDVRNPSVVVKRGGAVPIGIGIGNADITEMQTISFIPDFAVAIPTFRQLGTVQQVISERVTQLTREELSRLQPVLQPLPSPGVGGKRDVVFLIDGSQSAGPEFQYVRTLIERLVDYLDVGFDTTRVAVIQFSDDPKVEFLLNAHSSKDEVQNAVQRLRPKGGRQINVGNALEYVSRNIFKRPLGSRIEEGVPQFLVLISSGKSDDEVDDPAVELKQFGVAPFTIARNADQEELVKISLSPEYVFSVSTFRELPSLEQKLLTPITTLTSEQIQKLLASTRYPPPGEMGASEVLLGAFSI>sp|Q86WW8|COA5_HUMAN Cytochrome c oxidase assembly factor 5 OS=Homosapiens OX=9606 GN=COA5 PE=1 SV=1MPKYYEDKPQGGACAGLKEDLGACLLQSDCVVQEGKSPRQCLKEGYCNSLKYAFFECKRSVLDNRARFRGRKGY>sp|Q6JBY9|CPZIP_HUMAN CapZ-interacting protein OS=Homo sapiens OX=9606GN=RCSD1 PE=1 SV=1MEERPAETNANVDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPPKVDLGQNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPAVPKPEDDTPVQDTKM>sp|Q6JBY9-2|CPZIP_HUMAN Isoform 2 of CapZ-interacting protein OS=Homosapiens OX=9606 GN=RCSD1MEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPAVPKPEDDTPVQDTKM>sp|Q8WWM7|ATX2L_HUMAN Ataxin-2-like protein OS=Homo sapiens OX=9606GN=ATXN2L PE=1 SV=2MLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQHQAGQAPHLGSGQPQQNLYHPGALTGTPPSLPPGPSAQSPQSSFPQPAAVYAIHHQQLPHGFTNMAHVTQAHVQTGITAAPPPHPGAPHPPQVMLLHPPQSHGGPPQGAVPQSGVPALSASTPSPYPYIGHPQGEQPGQAPGFPGGADDRIREFSLAGGIWHGRAEGLQVGQDARVLGGE>sp|Q8WWM7-2|ATX2L_HUMAN Isoform 2 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQHQAGQAPHLGSGQPQQNLYHPGALTGTPPSLPPGPSAQSPQSSFPQPAAVYAIHHQQLPHGFTNMAHVTQAHVQTGITAAPPPHPGAPHPPQVMLLHPPQSHGGPPQGAVPQSGVPALSASTPSPYPYIGHPQGEQPGQAPGFPGGADDRIPPLPPPGELKIVLAAT>sp|Q8WWM7-3|ATX2L_HUMAN Isoform 3 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQHQAGQAPHLGSGQPQQNLYHPGALTGTPPSLPPGPSAQSPQSSFPQPAAVYAIHHQQLPHGFTNMAHVTQAHVQTGITAAPPPHPGAPHPPQVMLLHPPQSHGGPPQGAVPQSGVPALSASTPSPYPYIGHPQGEQPGQAPGFPGGADDRILCRVGRSHSRRRQGLAPGSVLCFPPSSLSCDPAAPLPTASPALSDPDCLLT>sp|Q8WWM7-4|ATX2L_HUMAN Isoform 4 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQHQAGQAPHLGSGQPQQNLYHPGALTGTPPSLPPGPSAQSPQSSFPQPAAVYAIHHQQLPHGFTNMAHVTQAHVQTGITAAPPPHPGAPHPPQVMLLHPPQSHGGPPQGAVPQSGVPALSASTPSPYPYIGHPQVQSHPSQQLPFHPPGN>sp|Q8WWM7-5|ATX2L_HUMAN Isoform 5 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQHQAGQAPHLGSGQPQQNLYHPGALTGTPPSLPPGPSAQSPQSSFPQPAAVYAIHHQQLPHGFTNMAHVTQAHVQTGITAAPPPHPGAPHPPQVMLLHPPQSHGGPPQGAVPQSGVPALSASTPSPYPYIGHPQAPFPPPGELKIVLAAT>sp|Q8WWM7-6|ATX2L_HUMAN Isoform 6 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQVPAMGGAEWSWCRNGWPEEGIELGVISEWRGLGASELLACVALNLPLPSSIRRGRPHTWAVDSHSRICTTQGP>sp|Q8WWM7-7|ATX2L_HUMAN Isoform 7 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPHRGQGQGPAGVGGSCSAPARPHPVLPSHPLIYSPAGDGRSFIFYYL>sp|Q8WWM7-8|ATX2L_HUMAN Isoform 8 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQHQAGQAPHLGSGQPQQNLYHPGALTGTPPSLPPGPSAQSPQSSFPQPAAVYAIHHQQLPHGFTNMAHVTQAHVQTGITAAPPPHPGAPHPPQVMLLHPPQSHGGPPQGAVPQSGVPALSASTPSPYPYIGHPQAPLPPPGELKIVLAAT>sp|Q8WWM7-9|ATX2L_HUMAN Isoform 9 of Ataxin-2-like protein OS=Homosapiens OX=9606 GN=ATXN2LMLKPQPLQQPSQPQQPPPTQQAVARRPPGGTSPPNGGLPGPLATSAAPPGPPAAASPCLGPVAAAGSGLRRGAEGILAPQPPPPQQHQERPGAAAIGSARGQSTGKGPPQSPVFEGVYNNSRMLHFLTAVVGSTCDVKVKNGTTYEGIFKTLSSKFELAVDAVHRKASEPAGGPRREDIVDTMVFKPSDVMLVHFRNVDFNYATKDKFTDSAIAMNSKVNGEHKEKVLQRWEGGDSNSDDYDLESDMSNGWDPNEMFKFNEENYGVKTTYDSSLSSYTVPLEKDNSEEFRQRELRAAQLAREIESSPQYRLRIAMENDDGRTEEEKHSAVQRQGSGRESPSLASREGKYIPLPQRVREGPRGGVRCSSSRGGRPGLSSLPPRGPHHLDNSSPGPGSEARGINGGPSRMSPKAQRPLRGAKTLSSPSNRPSGETSVPPPPAVGRMYPPRSPKSAAPAPISASCPEPPIGSAVPTSSASIPVTSSVSDPGVGSISPASPKISLAPTDVKELSTKEPGRTLEPQELARIAGKVPGLQNEQKRFQLEELRKFGAQFKLQPSSSPENSLDPFPPRILKEEPKGKEKEVDGLLTSEPMGSPVSSKTESVSDKEDKPPLAPSGGTEGPEQPPPPCPSQTGSPPVGLIKGEDKDEGPVAEQVKKSTLNPNAKEFNPTKPLLSVNKSTSTPTSPGPRTHSTPSIPVLTAGQSGLYSPQYISYIPQIHMGPAVQAPQMYPYPVSNSVPGQQGKYRGAKGSLPPQRSDQHQPASAPPMMQAAAAAGPPLVAATPYSSYIPYNPQQFPGQPAMMQPMAHYPSQPVFAPMLQSNPRMLTSGSHPQAIVSSSTPQYPSAEQPTPQALYATVHQSYPHHATQLHAHQPQPATTPTGSQPQSQHAAPSPVQHQAGQAPHLGSGQPQQNLYHPGALTGTPPSLPPGPSAQSPQSSFPQPAAVYAIHHQQLPHGFTNMAHVTQAHVQTGITAAPPPHPGAPHPPQVMLLHPPQSHGGPPQGAVPQSGVPALSASTPSPYPYIGHPQGEQPGQAPGFPGGADDRILQSHPSQQLPFHPPGN>sp|Q6ZR85|CQ107_HUMAN Uncharacterized protein C17orf107 OS=Homo sapiensOX=9606 GN=C17orf107 PE=2 SV=1MKGTPSSLDTLMWIYHFHSSTEVALQPPLLSSLELSVAAAHEYLEQRFRELKSLEPPEPKMQGMLPAPKPTLGLVLREATASLVSFGTTLLEISALWLQQEARRLDGSAGPAPDGRDPGAALSRVAQAAGQGVRQAGAAVGASARLLVQGAWLCLCGRGLQGSASFLRQSQQQLGLGIPGEPVSSGHGVS>sp|Q96MF6|CQ10A_HUMAN Coenzyme Q-binding protein COQ10 homolog A,mitochondrial OS=Homo sapiens OX=9606 GN=COQ10A PE=2 SV=2MAWAGSRRVPAGTRAAAERCCRLSLSPGAQPAPPPGPLPPPRPMRFLTSCSLLLPRAAQILAAEAGLPSSRSFMGFAAPFTNKRKAYSERRIMGYSMQEMYEVVSNVQEYREFVPWCKKSLVVSSRKGHLKAQLEVGFPPVMERYTSAVSMVKPHMVKAVCTDGKLFNHLETIWRFSPGIPAYPRTCTVDFSISFEFRSLLHSQLATMFFDEVVKQNVAAFERRAATKFGPETAIPRELMFHEVHQT>sp|Q96MF6-2|CQ10A_HUMAN Isoform 2 of Coenzyme Q-binding protein COQ10homolog A, mitochondrial OS=Homo sapiens OX=9606 GN=COQ10AMHSSSPSPTNDRGLRRTIRLAPLSFGLRFLTSCSLLLPRAAQILAAEAGLPSSRSFMGFAAPFTNKRKAYSERRIMGYSMQEMYEVVSNVQEYREFVPWCKKSLVVSSRKGHLKAQLEVGFPPVMERYTSAVSMVKPHMVKAVCTDGKLFNHLETIWRFSPGIPAYPRTCTVDFSISFEFRSLLHSQLATMFFDEVVKQNVAAFERRAATKFGPETAIPRELMFHEVHQT>sp|Q96MF6-3|CQ10A_HUMAN Isoform 3 of Coenzyme Q-binding protein COQ10homolog A, mitochondrial OS=Homo sapiens OX=9606 GN=COQ10AMLLQVVREGKFSGFLTSCSLLLPRAAQILAAEAGLPSSRSFMGFAAPFTNKRKAYSERRIMGYSMQEMYEVVSNVQEYREFVPWCKKSLVVSSRKGHLKAQLEVGFPPVMERYTSAVSMVKPHMVKAVCTDGKLFNHLETIWRFSPGIPAYPRTCTVDFSISFEFRSLLHSQLATMFFDEVVKQNVAAFERRAATKFGPETAIPRELMFHEVHQT>sp|Q9Y6Z7|COL10_HUMAN Collectin-10 OS=Homo sapiens OX=9606 GN=COLEC10PE=1 SV=2MNGFASLLRRNQFILLVLFLLQIQSLGLDIDSRPTAEVCATHTISPGPKGDDGEKGDPGEEGKHGKVGRMGPKGIKGELGDMGDQGNIGKTGPIGKKGDKGEKGLLGIPGEKGKAGTVCDCGRYRKFVGQLDISIARLKTSMKFVKNVIAGIRETEEKFYYIVQEEKNYRESLTHCRIRGGMLAMPKDEAANTLIADYVAKSGFFRVFIGVNDLEREGQYMFTDNTPLQNYSNWNEGEPSDPYGHEDCVEMLSSGRWNDTECHLTMYFVCEFIKKKK>sp|P11712|CP2C9_HUMAN Cytochrome P450 2C9 OS=Homo sapiens OX=9606GN=CYP2C9 PE=1 SV=3MDSLVVLVLCLSCLLLLSLWRQSSGRGKLPPGPTPLPVIGNILQIGIKDISKSLTNLSKVYGPVFTLYFGLKPIVVLHGYEAVKEALIDLGEEFSGRGIFPLAERANRGFGIVFSNGKKWKEIRRFSLMTLRNFGMGKRSIEDRVQEEARCLVEELRKTKASPCDPTFILGCAPCNVICSIIFHKRFDYKDQQFLNLMEKLNENIKILSSPWIQICNNFSPIIDYFPGTHNKLLKNVAFMKSYILEKVKEHQESMDMNNPQDFIDCFLMKMEKEKHNQPSEFTIESLENTAVDLFGAGTETTSTTLRYALLLLLKHPEVTAKVQEEIERVIGRNRSPCMQDRSHMPYTDAVVHEVQRYIDLLPTSLPHAVTCDIKFRNYLIPKGTTILISLTSVLHDNKEFPNPEMFDPHHFLDEGGNFKKSKYFMPFSAGKRICVGEALAGMELFLFLTSILQNFNLKSLVDPKNLDTTPVVNGFASVPPFYQLCFIPV>sp|P11712-2|CP2C9_HUMAN Isoform 2 of Cytochrome P450 2C9 OS=Homo sapiensOX=9606 GN=CYP2C9MDSLVVLVLCLSCLLLLSLWRQSSGRGKLPPGPTPLPVIGNILQIGIKDISKSLTNLSKVYGPVFTLYFGLKPIVVLHGYEAVKEALIDLGEEFSGRGIFPLAERANRGFGIVFSNGKKWKEIRRFSLMTLRNFGMGKRSIEDRVQEEARCLVEELRKTKGG>sp|Q9BZP3|CR002_HUMAN Putative uncharacterized protein encoded byLINC00470 OS=Homo sapiens OX=9606 GN=LINC00470 PE=5 SV=1MVRHPYSVQTQLSTEAKAIWRSMQQQETNLLANLTTNDARDNSKDFQNSKVGAAATSRDEGCNCPIIGEIVISCYWLFEIPPLISE>sp|Q9BZP3-2|CR002_HUMAN Isoform 2 of Putative uncharacterized proteinencoded by LINC00470 OS=Homo sapiens OX=9606 GN=LINC00470MQQQETNLLANLTTNDARDNSKDFQNSKVGAAATSRDEGCNCPIIGEIVISCYWLFEIPPLISE>sp|Q9BZP3-3|CR002_HUMAN Isoform 3 of Putative uncharacterized proteinencoded by LINC00470 OS=Homo sapiens OX=9606 GN=LINC00470MQCLYFILILKGYFHQQHHTLLITIALCFLQQQQETNLLANLTTNDARDNSKDFQNSKVGAAATSRDEGETQKCIQKPLHEK>sp|Q96N68|CR015_HUMAN Putative uncharacterized protein C18orf15 OS=Homosapiens OX=9606 GN=C18orf15 PE=5 SV=1MQGQGALKESHIHLPTEQPEASLVLQGQLAESSALGPKGALRPQAQSPDVPVSWWQGSGKRLSHRLPHICSQPPLGPFLPLTWPSCGFFGLGGAASASLGLEVLQDSVSTWARGPCCPVHPQSLTVVCMCACMCVCVHVCACVYVCMCVLVCMCACACMRAHRYFLMDCAGICSPHGPGTQ>sp|Q9BWP8|COL11_HUMAN Collectin-11 OS=Homo sapiens OX=9606 GN=COLEC11PE=1 SV=1MRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGDAGEKGDKGAPGRPGRVGPTGEKGDMGDKGQKGSVGRHGKIGPIGSKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-2|COL11_HUMAN Isoform 2 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGDMGDKGQKGSVGRHGKIGPIGSKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-3|COL11_HUMAN Isoform 3 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGDAGEKGDKGAPGRPGRVGPTGEKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-4|COL11_HUMAN Isoform 4 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MWWVPPSPYGCLPCALPGDAGEKGDKGAPGRPGRVGPTGEKGDMGDKGQKGSVGRHGKIGPIGSKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-5|COL11_HUMAN Isoform 5 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-6|COL11_HUMAN Isoform 6 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MWWVPPSPYGCLPCALPGDMGDKGQKGSVGRHGKIGPIGSKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-7|COL11_HUMAN Isoform 7 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MWWVPPSPYGCLPCALPGDAGEKGDKGAPGRPGRVGPTGEKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-8|COL11_HUMAN Isoform 8 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MWWVPPSPYGCLPCALPGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-9|COL11_HUMAN Isoform 9 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MTPALCRSSSLASKGMRERRETKAPPDGLEESAPREKKQSQPVVTASDISKRKCTSSFVEMGSQGDMGDKGQKGSVGRHGKIGPIGSKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q9BWP8-10|COL11_HUMAN Isoform 10 of Collectin-11 OS=Homo sapiensOX=9606 GN=COLEC11MKKQRGVGVLPALRMRGNLALVGVLISLAFLSLLPSGHPQPAGDDACSVQILVPGLKGDAGEKGDKGAPGRPGRVGPTGEKGDMGDKGQKGSVGRHGKIGPIGSKGEKGDSGDIGPPGPNGEPGLPCECSQLRKAIGEMDNQVSQLTSELKFIKNAVAGVRETESKIYLLVKEEKRYADAQLSCQGRGGTLSMPKDEAANGLMAAYLAQAGLARVFIGINDLEKEGAFVYSDHSPMRTFNKWRSGEPNNAYDEEDCVEMVASGGWNDVACHTTMYFMCEFDKENM>sp|Q7KZN9|COX15_HUMAN Cytochrome c oxidase assembly protein COX15homolog OS=Homo sapiens OX=9606 GN=COX15 PE=1 SV=1MQRLLFPPLRALKGRQYLPLLAPRAAPRAQCDCIRRPLRPGQYSTISEVALQSGRGTVSLPSKAAERVVGRWLLVCSGTVAGAVILGGVTRLTESGLSMVDWHLIKEMKPPTSQEEWEAEFQRYQQFPEFKILNHDMTLTEFKFIWYMEYSHRMWGRLVGLVYILPAAYFWRKGWLSRGMKGRVLALCGLVCFQGLLGWYMVKSGLEEKSDSHDIPRVSQYRLAAHLGSALVLYCASLWTSLSLLLPPHKLPETHQLLQLRRFAHGTAGLVFLTALSGAFVAGLDAGLVYNSFPKMGESWIPEDLFTFSPILRNVFENPTMVQFDHRILGITSVTAITVLYFLSRRIPLPRRTKMAAVTLLALAYTQVGLGISTLLMYVPTPLAATHQSGSLALLTGALWLMNELRRVPK>sp|Q7KZN9-2|COX15_HUMAN Isoform 2 of Cytochrome c oxidase assemblyprotein COX15 homolog OS=Homo sapiens OX=9606 GN=COX15MQRLLFPPLRALKGRQYLPLLAPRAAPRAQCDCIRRPLRPGQYSTISEVALQSGRGTVSLPSKAAERVVGRWLLVCSGTVAGAVILGGVTRLTESGLSMVDWHLIKEMKPPTSQEEWEAEFQRYQQFPEFKILNHDMTLTEFKFIWYMEYSHRMWGRLVGLVYILPAAYFWRKGWLSRGMKGRVLALCGLVCFQGLLGWYMVKSGLEEKSDSHDIPRVSQYRLAAHLGSALVLYCASLWTSLSLLLPPHKLPETHQLLQLRRFAHGTAGLVFLTALSGAFVAGLDAGLVYNSFPKMGESWIPEDLFTFSPILRNVFENPTMVQFDHRILGITSVTAITVLYFLSRRIPLPRRTKMAAVTLLALAYTQGPVLFNFTFKISDLDEGIRNI>sp|O94886|CSCL1_HUMAN CSC1-like protein 1 OS=Homo sapiens OX=9606GN=TMEM63A PE=1 SV=3MMDSPFLELWQSKAVSIREQLGLGDRPNDSYCYNSAKNSTVLQGVTFGGIPTVLLIDVSCFLFLILVFSIIRRRFWDYGRIALVSEADSESRFQRLSSTSSSGQQDFENELGCCPWLTAIFRLHDDQILEWCGEDAIHYLSFQRHIIFLLVVVSFLSLCVILPVNLSGDLLDKDPYSFGRTTIANLQTDNDLLWLHTIFAVIYLFLTVGFMRHHTQSIKYKEENLVRRTLFITGLPRDARKETVESHFRDAYPTCEVVDVQLCYNVAKLIYLCKEKKKTEKSLTYYTNLQVKTGQRTLINPKPCGQFCCCEVLGCEWEDAISYYTRMKDRLLERITEEERHVQDQPLGMAFVTFQEKSMATYILKDFNACKCQSLQCKGEPQPSSHSRELYTSKWTVTFAADPEDICWKNLSIQGLRWWLQWLGINFTLFLGLFFLTTPSIILSTMDKFNVTKPIHALNNPIISQFFPTLLLWSFSALLPSIVYYSTLLESHWTKSGENQIMMTKVYIFLIFMVLILPSLGLTSLDFFFRWLFDKTSSEASIRLECVFLPDQGAFFVNYVIASAFIGNGMELLRLPGLILYTFRMIMAKTAADRRNVKQNQAFQYEFGAMYAWMLCVFTVIVAYSITCPIIAPFGLIYILLKHMVDRHNLYFVYLPAKLEKGIHFAAVNQALAAPILCLFWLYFFSFLRLGMKAPATLFTFLVLLLTILVCLAHTCFGCFKHLSPLNYKTEEPASDKGSEAEAHMPPPFTPYVPRILNGLASERTALSPQQQQQQTYGAIHNISGTIPGQCLAQSATGSVAAAPQEA>sp|Q6ZS62|COLC1_HUMAN Colorectal cancer-associated protein 1 OS=Homosapiens OX=9606 GN=COLCA1 PE=2 SV=1MESCSVAQAGVLTSPFMWRWTGMAGALSALDNTIEDDADDQLPCGEGRPGWVRGELLGSQGVCKDSKDLFVPTSSSLYGCFCVGLVSGMAISVLLLASDFRKLDFSRPEPCFEKEASLWFVAQH>sp|Q6ZST2|COLDT_HUMAN Putative uncharacterized protein COL25A1-DTOS=Homo sapiens OX=9606 GN=COL25A1-DT PE=5 SV=1MLLLNQTLATTEKQTALQAAEKFVDELCISYSAKKGRGYARKRQKNLLATLQAYKPQNPKDAPVNCDKCGKPGNVKNDCPGSMRKPARPCPICGGDHWRVDCPQRCRSLGPKPVSQVSNRIDGPQGSCPWL>sp|P24903|CP2F1_HUMAN Cytochrome P450 2F1 OS=Homo sapiens OX=9606GN=CYP2F1 PE=1 SV=2MDSISTAILLLLLALVCLLLTLSSRDKGKLPPGPRPLSILGNLLLLCSQDMLTSLTKLSKEYGSMYTVHLGPRRVVVLSGYQAVKEALVDQGEEFSGRGDYPAFFNFTKGNGIAFSSGDRWKVLRQFSIQILRNFGMGKRSIEERILEEGSFLLAELRKTEGEPFDPTFVLSRSVSNIICSVLFGSRFDYDDERLLTIIRLINDNFQIMSSPWGELYDIFPSLLDWVPGPHQRIFQNFKCLRDLIAHSVHDHQASLDPRSPRDFIQCFLTKMAEEKEDPLSHFHMDTLLMTTHNLLFGGTKTVSTTLHHAFLALMKYPKVQARVQEEIDLVVGRARLPALKDRAAMPYTDAVIHEVQRFADIIPMNLPHRVTRDTAFRGFLIPKGTDVITLLNTVHYDPSQFLTPQEFNPEHFLDANQSFKKSPAFMPFSAGRRLCLGESLARMELFLYLTAILQSFSLQPLGAPEDIDLTPLSSGLGNLPRPFQLCLRPR>sp|P24903-2|CP2F1_HUMAN Isoform 2 of Cytochrome P450 2F1 OS=Homo sapiensOX=9606 GN=CYP2F1MDSISTAILLLLLALVCLLLTLSSRDKGKLPPGPRPLSILGNLLLLCSQDMLTSLTKLSKEYGSMYTVHLGPRRVVVLSGYQAVKEALVDQGEEFSGRGDYPAFFNFTKGNGIAFSSGDRWKVLRQFSIQILRNFGMGKRSIEERILEEGSFLLAELRKTEGEPFDPTFVLSRSVSNIICSVLFGSRFDYDDERLLTIIRLINDNFQIMSSPWGELYDIFPSLLDWVPGPHQRIFQNFKCLRDLIAHSVHDHQASLDPRSPRDFIQCFLTKMAEEKEDPLSHFHMDTLLMTTHNLLFGGTKTPACRRRSTSWWDARGCRR>sp|P01189|COLI_HUMAN Pro-opiomelanocortin OS=Homo sapiens OX=9606GN=POMC PE=1 SV=2MPRSCCSRSGALLLALLLQASMEVRGWCLESSQCQDLTTESNLLECIRACKPDLSAETPMFPGNGDEQPLTENPRKYVMGHFRWDRFGRRNSSSSGSSGAGQKREDVSAGEDCGPLPEGGPEPRSDGAKPGPREGKRSYSMEHFRWGKPVGKKRRPVKVYPNGAEDESAEAFPLEFKRELTGQRLREGDGPDGPADDGAGAQADLEHSLLVAAEKKDEGPYRMEHFRWGSPPKDKRYGGFMTSEKSQTPLVTLFKNAIIKNAYKKGE>sp|Q7Z449|CP2U1_HUMAN Cytochrome P450 2U1 OS=Homo sapiens OX=9606GN=CYP2U1 PE=1 SV=1MSSPGPSQPPAEDPPWPARLLRAPLGLLRLDPSGGALLLCGLVALLGWSWLRRRRARGIPPGPTPWPLVGNFGHVLLPPFLRRRSWLSSRTRAAGIDPSVIGPQVLLAHLARVYGSIFSFFIGHYLVVVLSDFHSVREALVQQAEVFSDRPRVPLISIVTKEKGVVFAHYGPVWRQQRKFSHSTLRHFGLGKLSLEPKIIEEFKYVKAEMQKHGEDPFCPFSIISNAVSNIICSLCFGQRFDYTNSEFKKMLGFMSRGLEICLNSQVLLVNICPWLYYLPFGPFKELRQIEKDITSFLKKIIKDHQESLDRENPQDFIDMYLLHMEEERKNNSNSSFDEEYLFYIIGDLFIAGTDTTTNSLLWCLLYMSLNPDVQEKVHEEIERVIGANRAPSLTDKAQMPYTEATIMEVQRLTVVVPLAIPHMTSENTVLQGYTIPKGTLILPNLWSVHRDPAIWEKPEDFYPNRFLDDQGQLIKKETFIPFGIGKRVCMGEQLAKMELFLMFVSLMQSFAFALPEDSKKPLLTGRFGLTLAPHPFNITISRR>sp|Q7Z449-2|CP2U1_HUMAN Isoform 2 of Cytochrome P450 2U1 OS=Homo sapiensOX=9606 GN=CYP2U1MSSPGPSQPPAEDPPWPARLLRAPLGLLRLDPSGGALLLCGLVALLGWSWLRRRRARGIPPGPTPWPLVGNFGHVLLPPFLRRRSWLSSRTRAAGIDPSVIGPQVLLAHLARVYGSIFSFFIGHYLVVVLSDFHSVREALVQQAEVFSDRPRVPLISIVTKEKELFQE>sp|O43405|COCH_HUMAN Cochlin OS=Homo sapiens OX=9606 GN=COCH PE=1 SV=1MSAAWIPALGLGVCLLLLPGPAGSEGAAPIAITCFTRGLDIRKEKADVLCPGGCPLEEFSVYGNIVYASVSSICGAAVHRGVISNSGGPVRVYSLPGRENYSSVDANGIQSQMLSRWSASFTVTKGKSSTQEATGQAVSTAHPPTGKRLKKTPEKKTGNKDCKADIAFLIDGSFNIGQRRFNLQKNFVGKVALMLGIGTEGPHVGLVQASEHPKIEFYLKNFTSAKDVLFAIKEVGFRGGNSNTGKALKHTAQKFFTVDAGVRKGIPKVVVVFIDGWPSDDIEEAGIVAREFGVNVFIVSVAKPIPEELGMVQDVTFVDKAVCRNNGFFSYHMPNWFGTTKYVKPLVQKLCTHEQMMCSKTCYNSVNIAFLIDGSSSVGDSNFRLMLEFVSNIAKTFEISDIGAKIAAVQFTYDQRTEFSFTDYSTKENVLAVIRNIRYMSGGTATGDAISFTVRNVFGPIRESPNKNFLVIVTDGQSYDDVQGPAAAAHDAGITIFSVGVAWAPLDDLKDMASKPKESHAFFTREFTGLEPIVSDVIRGICRDFLESQQ>sp|O43405-2|COCH_HUMAN Isoform 2 of Cochlin OS=Homo sapiens OX=9606GN=COCHMSAAWIPALGLGVCLLLLPGPAGSEGAAPIAITCFTRGLDIRKEKADVLCPGGCPLEEFSVYGNIVYASVSSICGAAVHRGVISNSGGPVRVYSLPGRENYSSVDANGIQSQMLSRWSASFTVTKGKSSTQEATGQAVSTAHPPTGKRLKKTPEKKTGNKDCKADIAFLIDGSFNIGQRRFNLQKNFVGKVALMLGIGTEGPHVGLVQASEHPKIEFYLKNFTSAKDVLFAIKEVGFRGGNSNTGKALKHTAQKFFTVDAGVRKGIPKVVVVFIDGWPSDDIEEAGIVAREFGVNVFIVSVAKPIPEELGMVQDVTFVDKAVCRNNGFFSYHMPNWFGTTKYVKPLVQKLCTHEQMMCSKTCYNSVNIAFLIDGSSSVGDSNFRLMLEFVSNIAKTFEISDIGAKIAAVQFTYDQRTEFSFTDYSTKENVLAVIRNIRYMSGGTATGDAISFTVRNVFGPIRESPNKNFLVIVTDGQSYDDVQGPAAAAHDAAK>sp|Q96BA8|CR3L1_HUMAN Cyclic AMP-responsive element-binding protein 3-like protein 1 OS=Homo sapiens OX=9606 GN=CREB3L1 PE=1 SV=1MDAVLEPFPADRLFPGSSFLDLGDLNESDFLNNAHFPEHLDHFTENMEDFSNDLFSSFFDDPVLDEKSPLLDMELDSPTPGIQAEHSYSLSGDSAPQSPLVPIKMEDTTQDAEHGAWALGHKLCSIMVKQEQSPELPVDPLAAPSAMAAAAAMATTPLLGLSPLSRLPIPHQAPGEMTQLPVIKAEPLEVNQFLKVTPEDLVQMPPTPPSSHGSDSDGSQSPRSLPPSSPVRPMARSSTAISTSPLLTAPHKLQGTSGPLLLTEEEKRTLIAEGYPIPTKLPLTKAEEKALKRVRRKIKNKISAQESRRKKKEYVECLEKKVETFTSENNELWKKVETLENANRTLLQQLQKLQTLVTNKISRPYKMAATQTGTCLMVAALCFVLVLGSLVPCLPEFSSGSQTVKEDPLAADGVYTASQMPSRSLLFYDDGAGLWEDGRSTLLPMEPPDGWEINPGGPAEQRPRDHLQHDHLDSTHETTKYLSEAWPKDGGNGTSPDFSHSKEWFHDRDLGPNTTIKLS>sp|Q96BA8-2|CR3L1_HUMAN Isoform 2 of Cyclic AMP-responsive element-binding protein 3-like protein 1 OS=Homo sapiens OX=9606 GN=CREB3L1MDAVLEPFPADRLFPGSSFLDLGDLNESDFLNNAHFPEHLDHFTENMEDFSNDLFSSFFDDPVLDEKSPLLDMELDSPTPGIQAEHSYSLSGDSAPQSPLVPIKMEDTTQEDLVQMPPTPPSSHGSDSDGSQSPRSLPPSSPVRPMARSSTAISTSPLLTAPHKLQGTSGPLLLTEEEKRTLIAEGYPIPTKLPLTKAEEKALKRVRRKIKNKISAQESRRKKKEYVECLEKKVETFTSENNELWKKVETLENANRTLLQQLQKLQTLVTNKISRPYKMAATQTGTCLMVAALCFVLVLGSLVPCLPEFSSGSQTVKEDPLAADGVYTASQMPSRSLLFYDDGAGLWEDGRSTLLPMEPPDGWEINPGGPAEQRPRDHLQHDHLDSTHETTKYLSEAWPKDGGNGTSPDFSHSKEWFHDRDLGPNTTIKLS>sp|Q9BZB8|CPEB1_HUMAN Cytoplasmic polyadenylation element-bindingprotein 1 OS=Homo sapiens OX=9606 GN=CPEB1 PE=1 SV=1MALSLEEEAGRIKDCWDNQEAPALSTCSNANIFRRINAILDNSLDFSRVCTTPINRGIHDHLPDFQDSEETVTSRMLFPTSAQESSRGLPDANDLCLGLQSLSLTGWDRPWSTQDSDSSAQSSTHSVLSMLHNPLGNVLGKPPLSFLPLDPLGSDLVDKFPAPSVRGSRLDTRPILDSRSSSPSDSDTSGFSSGSDHLSDLISSLRISPPLPFLSLSGGGPRDPLKMGVGSRMDQEQAALAAVTPSPTSASKRWPGASVWPSWDLLEAPKDPFSIEREARLHRQAAAVNEATCTWSGQLPPRNYKNPIYSCKVFLGGVPWDITEAGLVNTFRVFGSLSVEWPGKDGKHPRCPPKGNMPKGYVYLVFELEKSVRSLLQACSHDPLSPDGLSEYYFKMSSRRMRCKEVQVIPWVLADSNFVRSPSQRLDPSRTVFVGALHGMLNAEALAAILNDLFGGVVYAGIDTDKHKYPIGSGRVTFNNQRSYLKAVSAAFVEIKTTKFTKKVQIDPYLEDSLCHICSSQPGPFFCRDQVCFKYFCRSCWHWRHSMEGLRHHSPLMRNQKNRDSS>sp|Q9BZB8-2|CPEB1_HUMAN Isoform 2 of Cytoplasmic polyadenylationelement-binding protein 1 OS=Homo sapiens OX=9606 GN=CPEB1MLFPTSAQESSRGLPDANDLCLGLQSLSLTGWDRPWSTQDSDSSAQSSTHSVLSMLHNPLGNVLGKPPLSFLPLDPLGSDLVDKFPAPSVRGSRLDTRPILDSRSSSPSDSDTSGFSSGSDHLSDLISSLRISPPLPFLSLSGGGPRDPLKMGVGSRMDQEQAALAAVTPSPTSASKRWPGASVWPSWDLLEAPKDPFSIEREARLHRQAAAVNEATCTWSGQLPPRNYKNPIYSCKVFLGGVPWDITEAGLVNTFRVFGSLSVEWPGKDGKHPRCPPKGNMPKGYVYLVFELEKSVRSLLQACSHDPLSPDGLSEYYFKMSSRRMRCKEVQVIPWVLADSNFVRSPSQRLDPSRTVFVGALHGMLNAEALAAILNDLFGGVVYAGIDTDKHKYPIGSGRVTFNNQRSYLKAVSAAFVEIKTTKFTKKVQIDPYLEDSLCHICSSQPGPFFCRDQVCFKYFCRSCWHWRHSMEGLRHHSPLMRNQKNRDSS>sp|Q9BZB8-3|CPEB1_HUMAN Isoform 3 of Cytoplasmic polyadenylationelement-binding protein 1 OS=Homo sapiens OX=9606 GN=CPEB1MAFPLEEEAGRIKDCWDNQEAPALSTCSNANIFRRINAILDNSLDFSRVCTTPINRGIHDHLPDFQDSEETVTSRMLFPTSAQESSRGLPDANDLCLGLQSLSLTGWDRPWSTQDSDSSAQSSTHSVLSMLHNPLGNVLGKPPLSFLPLDPLGSDLVDKFPAPSVRGSRLDTRPILDSRSSSPSDSDTSGFSSGSDHLSDLISSLRISPPLPFLSLSGGGPRDPLKMGVGSRMDQEQAALAAVTPSPTSASKRWPGASVWPSWDLLEAPKDPFSIEREARLHRQAAAVNEATCTWSGQLPPRNYKNPIYSCKVFLGGVPWDITEAGLVNTFRVFGSLSVEWPGKDGKHPRCPPKGYVYLVFELEKSVRSLLQACSHDPLSPDGLSEYYFKMSSRRMRCKEVQVIPWVLADSNFVRSPSQRLDPSRTVFVGALHGMLNAEALAAILNDLFGGVVYAGIDTDKHKYPIGSGRVTFNNQRSYLKAVSAAFVEIKTTKFTKKVQIDPYLEDSLCHICSSQPGPFFCRDQVCFKYFCRSCWHWRHSMEGLRHHSPLMRNQKNRDSS>sp|Q9BZB8-4|CPEB1_HUMAN Isoform 4 of Cytoplasmic polyadenylationelement-binding protein 1 OS=Homo sapiens OX=9606 GN=CPEB1MLFPTSAQESSRGLPDANDLCLGLQSLSLTGWDRPWSTQDSDSSAQSSTHSVLSMLHNPLGNVLGKPPLSFLPLDPLGSDLVDKFPAPSVRGSRLDTRPILDSRSSSPSDSDTSGFSSGSDHLSDLISSLRISPPLPFLSLSGGGPRDPLKMGVGSRMDQEQAALAAVTPSPTSASKRWPGASVWPSWDLLEAPKDPFSIEREARLHRQAAAVNEATCTWSGQLPPRNYKNPIYSCKVFLGGVPWDITEAGLVNTFRVFGSLSVEWPGKDGKHPRCPPKGYVYLVFELEKSVRSLLQACSHDPLSPDGLSEYYFKMSSRRMRCKEVQVIPWVLADSNFVRSPSQRLDPSRTVFVGALHGMLNAEALAAILNDLFGGVVYAGIDTDKHKYPIGSGRVTFNNQRSYLKAVSAAFVEIKTTKFTKKVQIDPYLEDSLCHICSSQPGPFFCRDQVCFKYFCRSCWHWRHSMEGLRHHSPLMRNQKNRDSS>sp|P53673|CRBA4_HUMAN Beta-crystallin A4 OS=Homo sapiens OX=9606GN=CRYBA4 PE=1 SV=3MTLQCTKSAGPWKMVVWDEDGFQGRRHEFTAECPSVLELGFETVRSLKVLSGAWVGFEHAGFQGQQYILERGEYPSWDAWGGNTAYPAERLTSFRPAACANHRDSRLTIFEQENFLGKKGELSDDYPSLQAMGWEGNEVGSFHVHSGAWVCSQFPGYRGFQYVLECDHHSGDYKHFREWGSHAPTFQVQSIRRIQQ>sp|Q9Y215|COLQ_HUMAN Acetylcholinesterase collagenic tail peptideOS=Homo sapiens OX=9606 GN=COLQ PE=1 SV=2MVVLNPMTLGIYLQLFFLSIVSQPTFINSVLPISAALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPLLSPDMKNLMLELETSQSPCMQGSLGSPGPPGPQGPPGLPGKTGPKGEKGELGRPGRKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQGQKGDSGVMGPPGKPGPSGQPGRPGPPGPPPAGQLIMGPKGERGFPGPPGRCLCGPTMNVNNPSYGESVYGPSSPRVPVIFVVNNQEELERLNTQNAIAFRRDQRSLYFKDSLGWLPIQLTPFYPVDYTADQHGTCGDGLLQPGEECDDGNSDVGDDCIRCHRAYCGDGHRHEGVEDCDGSDFGYLTCETYLPGSYGDLQCTQYCYIDSTPCRYFT>sp|Q9Y215-2|COLQ_HUMAN Isoform II of Acetylcholinesterase collagenictail peptide OS=Homo sapiens OX=9606 GN=COLQMTGSSFSLAHLLIISGLLCYSAGCLALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPLLSPDMKNLMLELETSQSPCMQGSLGSPGPPGPQGPPGLPGKTGPKGEKGELGRPGRKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQGQKGDSGVMGPPGKPGPSGQPGRPGPPGPPPAGQLIMGPKGERGFPGPPGRCLCGPTMNVNNPSYGESVYGPSSPRVPVIFVVNNQEELERLNTQNAIAFRRDQRSLYFKDSLGWLPIQLTPFYPVDYTADQHGTCGDGLLQPGEECDDGNSDVGDDCIRCHRAYCGDGHRHEGVEDCDGSDFGYLTCETYLPGSYGDLQCTQYCYIDSTPCRYFT>sp|Q9Y215-3|COLQ_HUMAN Isoform III of Acetylcholinesterase collagenictail peptide OS=Homo sapiens OX=9606 GN=COLQMVVLNPMTLGIYLQLFFLSIVSQPTFINSVLPISAALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPGPPGLPGKTGPKGEKGELGRPGRKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQGQKGDSGVMGPPGKPGPSGQPGRPGPPGPPPAGQLIMGPKGERGFPGPPGRCLCGPTMNVNNPSYGESVYGPSSPRVPVIFVVNNQEELERLNTQNAIAFRRDQRSLYFKDSLGWLPIQLTPFYPVDYTADQHGTCGDGLLQPGEECDDGNSDVGDDCIRCHRAYCGDGHRHEGVEDCDGSDFGYLTCETYLPGSYGDLQCTQYCYIDSTPCRYFT>sp|Q9Y215-4|COLQ_HUMAN Isoform IV of Acetylcholinesterase collagenictail peptide OS=Homo sapiens OX=9606 GN=COLQMVVLNPMTLGIYLQLFFLSIVSQPTFINSVLPISAALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPDMKNLMLELETSQSPCMQGSLGSPGPPGPQGPPGLPGKTGPKGEKGELGRPGRKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQGQKGDSGVMGPPGKPGPSGQPGRPGPPGPPPAGQLIMGPKGERGFPGPPGRCLCGPTMNVNNPSYGESVYGPSSPRVPVIFVVNNQEELERLNTQNAIAFRRDQRSLYFKDSLGWLPIQLTPFYPVDYTADQHGTCGDGLLQPGEECDDGNSDVGDDCIRCHRAYCGDGHRHEGVEDCDGSDFGYLTCETYLPGSYGDLQCTQYCYIDSTPCRYFT>sp|Q9Y215-5|COLQ_HUMAN Isoform V of Acetylcholinesterase collagenic tailpeptide OS=Homo sapiens OX=9606 GN=COLQMVVLNPMTLGIYLQLFFLSIVSQPTFINSVLPISAALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPLLSPDMKNLMLELETSQSPCMQGSLGSPGPPGPQGPPGLPGKTGPKGEKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQGQKGDSGVMGPPGKPGPSGQPGRPGPPGPPPAGQLIMGPKGERGFPGPPGRCLCGPTMNVNNPSYGESVYGPSSPRVPVIFVVNNQEELERLNTQNAIAFRRDQRSLYFKDSLGWLPIQLTPFYPVDYTADQHGTCGDGLLQPGEECDDGNSDVGDDCIRCHRAYCGDGHRHEGVEDCDGSDFGYLTCETYLPGSYGDLQCTQYCYIDSTPCRYFT>sp|Q9Y215-6|COLQ_HUMAN Isoform VI of Acetylcholinesterase collagenictail peptide OS=Homo sapiens OX=9606 GN=COLQMVVLNPMTLGIYLQLFFLSIVSQPTFINSVLPISAALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPLLSPDMKNLMLELETSQSPCMQGSLGSPGPPGPQGPPGLPGKTGPKGEKGELGRPGRKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQSSRTPCTLPRRPPVPCGQGSRSPVTVVAGNESQACLLPRFEEDYISSGTERG>sp|Q9Y215-7|COLQ_HUMAN Isoform VII of Acetylcholinesterase collagenictail peptide OS=Homo sapiens OX=9606 GN=COLQMVVLNPMTLGIYLQLFFLSIVSQPTFINSVLPISAALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPLLSPDMKNLMLELETSQSPCMQGSLGSPGPPGPQGPPGLPGKTGPKGEKGELGRPGRKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQGQKGDSGVMGPPGKPGPSGQPGRPGPPGPPPADFCGQQPGGA>sp|Q9Y215-8|COLQ_HUMAN Isoform VIII of Acetylcholinesterase collagenictail peptide OS=Homo sapiens OX=9606 GN=COLQMVVLNPMTLGIYLQLFFLSIVSQPTFINSVLPISAALPSLDQKKRGGHKACCLLTPPPPPLFPPPFFRGGRSPLLSPDMKNLMLELETSQSPCMQGSLGSPGPPGPQGPPGLPGKTGPKGEKGELGRPGRKGRPGPPGVPGMPGPIGWPGPEGPRGEKGDLGMMGLPGSRGPMGSKGYPGSRGEKGSRGEKGDLGPKGEKGFPGFPGMLGQKGEMGPKGEPGIAGHRGPTGRPGKRGKQGQKGDSGVMGPPGKPGPSGQPGRPGPPGPPPAGHMETCNAPSTATSTPRPAATSPEGREEKVGCAPQNWQQLLHCHQTGHVLAPSPPTFV>sp|Q5TAT6|CODA1_HUMAN Collagen alpha-1(XIII) chain OS=Homo sapiensOX=9606 GN=COL13A1 PE=1 SV=1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKLLPLLNSVRLAPPPVIKRRTFQGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPGEKGEAGEKGNPGAEVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGASGLDGRPGPPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-2|CODA1_HUMAN Isoform 2 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPGEKGEAGEKGNPGAEVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGASGLDGRPGPPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-3|CODA1_HUMAN Isoform 3 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPGEKGEAGEKGNPGAEVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-4|CODA1_HUMAN Isoform 4 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-5|CODA1_HUMAN Isoform 5 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKLLPLLNSVRLAPPPVIKRRTFQGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGASGLDGRPGPPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-6|CODA1_HUMAN Isoform 6 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKLLPLLNSVRLAPPPVIKRRTFQGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPGEKGEAGEKGNPGAEGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGASGLDGRPGPPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-7|CODA1_HUMAN Isoform 7 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKLLPLLNSVRLAPPPVIKRRTFQGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPGEKGEAGEKGNPGAEGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-8|CODA1_HUMAN Isoform 8 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRLLPLLNSVRLAPPPVIKRRTFQGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPGEKGEAGEKGNPGAEVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-9|CODA1_HUMAN Isoform 9 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGDKGAIGMPGRVGSPGDAGLSIIGPRGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNREDGLPVQGCWNK>sp|Q5TAT6-10|CODA1_HUMAN Isoform 10 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRLLPLLNSVRLAPPPVIKRRTFQGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGASGLDGRPGPPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGERGKKGSRGPKGDKGDQGAPGLDAPCPLGEDGLPVQGCWNK>sp|Q5TAT6-11|CODA1_HUMAN Isoform 11 of Collagen alpha-1(XIII) chainOS=Homo sapiens OX=9606 GN=COL13A1MVAERTHKAAATGARGPGELGAPGTVALVAARAERGARLPSPGSCGLLTLALCSLALSLLAHFRTAELQARVLRLEAERGEQQMETAILGRVNQLLDEKWKLHSRRRREAPKTSPGCNCPPGPPGPTGRPGLPGQPGTRGFPGFPGPIGLDGKPGHPGPKGDMGLTGPPGQPGPQGQKGEKGQCGEYPHRECLSSMPAALRSSQIIALKGEQSQASIQGPPGPPGPPGPSGPLGHPGLPGPMGPPGLPGPPGPKGDPGIQGYHGRKGERGMPGMPGKHGAKGAPGIAVAGMKGEPGIPGTKGEKGAEGSPGLPGLLGQKGEKGDAGNSIGGGRGEPGPPGLPGPPGPKGEAGVDGQVGPPGQPGDKGERGAAGEQGPDGPKGSKGEPGKGEMVDYNGNINEALQEIRTLALMGPPGLPGQIGPPGAPGIPGQKGEIGLPGPPGHDGEKGPRGKPGDMGPPGPQGPPGKDGPPGVKGENGHPGSPGEKGEKGETGQAGSPVPGLPGPEGPPGPPGLQGVPGPKGEAGLDGAKGEKGFQGEKGDRGPLGLPGTPGPIGVPGPAGPKGERGSKGDPGMTGPTGAAGLPGLHGPPGDKGNRGEDGLPVQGCWNK>sp|Q7Z5Q1|CPEB2_HUMAN Cytoplasmic polyadenylation element-bindingprotein 2 OS=Homo sapiens OX=9606 GN=CPEB2 PE=2 SV=3MPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPTSGGGGGGFGGPFSATAVPPPPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQVRSSLQLPAWGSDSLQDSWCTAAGTSRIDQDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|Q7Z5Q1-3|CPEB2_HUMAN Isoform 2 of Cytoplasmic polyadenylationelement-binding protein 2 OS=Homo sapiens OX=9606 GN=CPEB2MPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQVRSSLQLPAWGSDSLQDSWCTAAGTSRIDQDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNARSYGRRRGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|Q7Z5Q1-4|CPEB2_HUMAN Isoform 3 of Cytoplasmic polyadenylationelement-binding protein 2 OS=Homo sapiens OX=9606 GN=CPEB2MPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPTSGGGGGGFGGPFSATAVPPPPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQVRMDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|Q7Z5Q1-5|CPEB2_HUMAN Isoform 4 of Cytoplasmic polyadenylationelement-binding protein 2 OS=Homo sapiens OX=9606 GN=CPEB2MPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPTSGGGGGGFGGPFSATAVPPPPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|Q7Z5Q1-6|CPEB2_HUMAN Isoform 5 of Cytoplasmic polyadenylationelement-binding protein 2 OS=Homo sapiens OX=9606 GN=CPEB2MPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPTSGGGGGGFGGPFSATAVPPPPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNARSYGRRRGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|Q7Z5Q1-7|CPEB2_HUMAN Isoform 6 of Cytoplasmic polyadenylationelement-binding protein 2 OS=Homo sapiens OX=9606 GN=CPEB2MPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQVRMDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNARSYGRRRGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|Q7Z5Q1-8|CPEB2_HUMAN Isoform 7 of Cytoplasmic polyadenylationelement-binding protein 2 OS=Homo sapiens OX=9606 GN=CPEB2MRDFGFGVLQTAPLRSSSPGPLFCGEAYGPYAVGSVNPLPSATPFGPLSPPPLPVTGFLEAASPFSVPLGGGAGSPAAAASSSSPFLAHQQTMQDELLLGLTQQPARPLSGAAATEKLPDHHPGGGTIAGVTHLLPSQDFKPSLHHPSSSSASSCCCCRTSSPQDFSKRQQQQLSSQKRKEFSPPHLPHPPDSKPPPPPPPLHCPGRFSPPPPPAGPLLQPAQLAQRQQQQPPQQFSLLHQQHLSPQDFAPRQRPADLPPLPQLPPSPPAAPRRRHGGAGSPRKTPAAGEGSAAESPNAGLASSTPVNPAPGSMESPNHPLLNSPSNLLPGGALGAGAFSSLQSPDLPHPGGGGGGGGGGPPGGGGGGGSASPPPLPGFGTPWSVQTASPPPQPQQPPPTQPQQQPPPPQQPPQPQPQPPGSSATTPGGGSGGSLSAMPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPTSGGGGGGFGGPFSATAVPPPPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQVRMDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNARSYGRRRGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|Q7Z5Q1-9|CPEB2_HUMAN Isoform 8 of Cytoplasmic polyadenylationelement-binding protein 2 OS=Homo sapiens OX=9606 GN=CPEB2MRDFGFGVLQTAPLRSSSPGPLFCGEAYGPYAVGSVNPLPSATPFGPLSPPPLPVTGFLEAASPFSVPLGGGAGSPAAAASSSSPFLAHQQTMQDELLLGLTQQPARPLSGAAATEKLPDHHPGGGTIAGVTHLLPSQDFKPSLHHPSSSSASSCCCCRTSSPQDFSKRQQQQLSSQKRKEFSPPHLPHPPDSKPPPPPPPLHCPGRFSPPPPPAGPLLQPAQLAQRQQQQPPQQFSLLHQQHLSPQDFAPRQRPADLPPLPQLPPSPPAAPRRRHGGAGSPRKTPAAGEGSAAESPNAGLASSTPVNPAPGSMESPNHPLLNSPSNLLPGGALGAGAFSSLQSPDLPHPGGGGGGGGGGPPGGGGGGGSASPPPLPGFGTPWSVQTASPPPQPQQPPPTQPQQQPPPPQQPPQPQPQPPGSSATTPGGGSGGSLSAMPPPSPDSENGFYPGLPSSMNPAFFPSFSPVSPHGCTGLSVPTSGGGGGGFGGPFSATAVPPPPPPAMNIPQQQPPPPAAPQQPQSRRSPVSPQLQQQHQAAAAAFLQQRNSYNHHQPLLKQSPWSNHQSSGWGTGSMSWGAMHGRDHRRTGNMGIPGTMNQISPLKKPFSGNVIAPPKFTRSTPSLTPKSWIEDNVFRTDNNSNTLLPLQVRSSLQLPAWGSDSLQDSWCTAAGTSRIDQDRSRMYDSLNMHSLENSLIDIMRAEHDPLKGRLSYPHPGTDNLLMLNARSYGRRRGRSSLFPIDDGLLDDGHSDQVGVLNSPTCYSAHQNGERIERFSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGDIDKRVEVKPYVLDDQMCDECQGARCGGKFAPFFCANVTCLQYYCEFCWANIHSRAGREFHKPLVKEGADRPRQIHFRWN>sp|P53674|CRBB1_HUMAN Beta-crystallin B1 OS=Homo sapiens OX=9606GN=CRYBB1 PE=1 SV=2MSQAAKASASATVAVNPGPDTKGKGAPPAGTSPSPGTTLAPTTVPITSAKAAELPPGNYRLVVFELENFQGRRAEFSGECSNLADRGFDRVRSIIVSAGPWVAFEQSNFRGEMFILEKGEYPRWNTWSSSYRSDRLMSFRPIKMDAQEHKISLFEGANFKGNTIEIQGDDAPSLWVYGFSDRVGSVKVSSGTWVGYQYPGYRGYQYLLEPGDFRHWNEWGAFQPQMQSLRRLRDKQWHLEGSFPVLATEPPK>sp|Q70SY1|CR3L2_HUMAN Cyclic AMP-responsive element-binding protein 3-like protein 2 OS=Homo sapiens OX=9606 GN=CREB3L2 PE=1 SV=3MEVLESGEQGVLQWDRKLSELSEPGDGEALMYHTHFSELLDEFSQNVLGQLLNDPFLSEKSVSMEVEPSPTSPAPLIQAEHSYSLCEEPRAQSPFTHITTSDSFNDDEVESEKWYLSTDFPSTSIKTEPVTDEPPPGLVPSVTLTITAISTPLEKEEPPLEMNTGVDSSCQTIIPKIKLEPHEVDQFLNFSPKEAPVDHLHLPPTPPSSHGSDSEGSLSPNPRLHPFSLPQTHSPSRAAPRAPSALSSSPLLTAPHKLQGSGPLVLTEEEKRTLIAEGYPIPTKLPLSKSEEKALKKIRRKIKNKISAQESRRKKKEYMDSLEKKVESCSTENLELRKKVEVLENTNRTLLQQLQKLQTLVMGKVSRTCKLAGTQTGTCLMVVVLCFAVAFGSFFQGYGPYPSATKMALPSQHSLQEPYTASVVRSRNLLIYEEHSPPEESSSPGSAGELGGWDRGSSLLRVSGLESRPDVDLPHFIISNETSLEKSVLLELQQHLVSAKLEGNETLKVVELDRRVNTTF>sp|Q70SY1-2|CR3L2_HUMAN Isoform 2 of Cyclic AMP-responsive element-binding protein 3-like protein 2 OS=Homo sapiens OX=9606 GN=CREB3L2MEVLESGEQGVLQWDRKLSELSEPGDGEALMYHTHFSELLDEFSQNVLGQLLNDPFLSEKSVSMEVEPSPTSPAPLIQAEHSYSLCEEPRAQSPFTHITTSDSFNDDEVESEKWYLSTDFPSTSIKTEPVTDEPPPGLVPSVTLTITAISTPLEKEEPPLEMNTGVDSSCQTIIPKIKLEPHEVDQFLNFSPKEAPVDHLHLPPTPPSSHGSDSEGSLSPNPRLHPFSLPQTHSPSRAAPRAPSALSSSPLLTAPHKLQGSGPLVLTEEEKRTLIAEGYPIPTKLPLSKSEEKALKKIRRKIKNKISAQESRRKKKEYMDSLEKKVESCSTENLELRKKVEVLENTNRTLLQQLQKLQTLVMGKVSRTCKLAGTQTGTCLMVVVLCFAVAFGSFFQGYGPYPSATKMALPSQHSLQEPYTASVGKTACGKLGRVLFYFPRAGFLSLPKGIFCESPMFKKW>sp|Q70SY1-3|CR3L2_HUMAN Isoform 3 of Cyclic AMP-responsive element-binding protein 3-like protein 2 OS=Homo sapiens OX=9606 GN=CREB3L2MEVLESGEQGVLQWDRKLSELSEPGDGEALMYHTHFSELLDEFSQNVLGQLLNDPFLSEKSVSMEVEPSPTSPAPLIQAEHSYSLCEEPRAQSPFTHITTSDSFNDDEVESEKWYLSTDFPSTSIKTEPVTDEPPPGLVPSVTLTITAISTPLEKEEPPLEMNTGVDSSCQTIIPKIKLEPHEVDQFLNFSPKEGLSALPVSLWVMDMVSGSTEREYGERAGMSLYHRCCSWLYEIALFLKNKNFASK>sp|Q8NE35|CPEB3_HUMAN Cytoplasmic polyadenylation element-bindingprotein 3 OS=Homo sapiens OX=9606 GN=CPEB3 PE=1 SV=2MQDDLLMDKSKTQPQPQQQQRQQQQPQPESSVSEAPSTPLSSETPKPEENSAVPALSPAAAPPAPNGPDKMQMESPLLPGLSFHQPPQQPPPPQEPAAPGASLSPSFGSTWSTGTTNAVEDSFFQGITPVNGTMLFQNFPHHVNPVFGGTFSPQIGLAQTQHHQQPPPPAPAPQPAQPAQPPQAQPPQQRRSPASPSQAPYAQRSAAAAYGHQPIMTSKPSSSSAVAAAAAAAAASSASSSWNTHQSVNAAWSAPSNPWGGLQAGRDPRRAVGVGVGVGVGVPSPLNPISPLKKPFSSNVIAPPKFPRAAPLTSKSWMEDNAFRTDNGNNLLPFQDRSRPYDTFNLHSLENSLMDMIRTDHEPLKGKHYPPSGPPMSFADIMWRNHFAGRMGINFHHPGTDNIMALNNAFLDDSHGDQALSSGLSSPTRCQNGERVERYSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACLEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHNDIDKRVEVKPYVLDDQMCDECQGTRCGGKFAPFFCANVTCLQYYCEYCWASIHSRAGREFHKPLVKEGGDRPRHVPFRWS>sp|Q8NE35-2|CPEB3_HUMAN Isoform 2 of Cytoplasmic polyadenylationelement-binding protein 3 OS=Homo sapiens OX=9606 GN=CPEB3MQDDLLMDKSKTQPQPQQQQRQQQQPQPESSVSEAPSTPLSSETPKPEENSAVPALSPAAAPPAPNGPDKMQMESPLLPGLSFHQPPQQPPPPQEPAAPGASLSPSFGSTWSTGTTNAVEDSFFQGITPVNGTMLFQNFPHHVNPVFGGTFSPQIGLAQTQHHQQPPPPAPAPQPAQPAQPPQAQPPQQRRSPASPSQAPYAQRSAAAAYGHQPIMTSKPSSSSAVAAAAAAAAASSASSSWNTHQSVNAAWSAPSNPWGGLQAGRDPRRAVGVGVGVGVGVPSPLNPISPLKKPFSSNVIAPPKFPRAAPLTSKSWMEDNAFRTDNGNNLLPFQDRSRPYDTFNLHSLENSLMDMIRTDHEPLKGRMGINFHHPGTDNIMALNSRSSLFPFEDAFLDDSHGDQALSSGLSSPTRCQNGERVERYSRKVFVGGLPPDIDEDEITASFRRFGPLVVDWPHKAESKSYFPPKGYAFLLFQEESSVQALIDACLEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHNDIDKRVEVKPYVLDDQMCDECQGTRCGGKFAPFFCANVTCLQYYCEYCWASIHSRAGREFHKPLVKEGGDRPRHVPFRWS>sp|P43320|CRBB2_HUMAN Beta-crystallin B2 OS=Homo sapiens OX=9606GN=CRYBB2 PE=1 SV=2MASDHQTQAGKPQSLNPKIIIFEQENFQGHSHELNGPCPNLKETGVEKAGSVLVQAGPWVGYEQANCKGEQFVFEKGEYPRWDSWTSSRRTDSLSSLRPIKVDSQEHKIILYENPNFTGKKMEIIDDDVPSFHAHGYQEKVSSVRVQSGTWVGYQYPGYRGLQYLLEKGDYKDSSDFGAPHPQVQSVRRIRDMQWHQRGAFHPSN>sp|Q17RY0|CPEB4_HUMAN Cytoplasmic polyadenylation element-bindingprotein 4 OS=Homo sapiens OX=9606 GN=CPEB4 PE=1 SV=1MGDYGFGVLVQSNTGNKSAFPVRFHPHLQPPHHHQNATPSPAAFINNNTAANGSSAGSAWLFPAPATHNIQDEILGSEKAKSQQQEQQDPLEKQQLSPSPGQEAGILPETEKAKSEENQGDNSSENGNGKEKIRIESPVLTGFDYQEATGLGTSTQPLTSSASSLTGFSNWSAAIAPSSSTIINEDASFFHQGGVPAASANNGALLFQNFPHHVSPGFGGSFSPQIGPLSQHHPHHPHFQHHHSQHQQQRRSPASPHPPPFTHRNAAFNQLPHLANNLNKPPSPWSSYQSPSPTPSSSWSPGGGGYGGWGGSQGRDHRRGLNGGITPLNSISPLKKNFASNHIQLQKYARPSSAFAPKSWMEDSLNRADNIFPFPDRPRTFDMHSLESSLIDIMRAENDTIKGRLNYSYPGSDSSLLINARTYGRRRGQSSLFPMEDGFLDDGRGDQPLHSGLGSPHCFSHQNGERVERYSRKVFVGGLPPDIDEDEITASFRRFGPLIVDWPHKAESKSYFPPKGYAFLLFQDESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGEIDKRVEVKPYVLDDQLCDECQGARCGGKFAPFFCANVTCLQYYCEYCWAAIHSRAGREFHKPLVKEGGDRPRHISFRWN>sp|Q17RY0-2|CPEB4_HUMAN Isoform 2 of Cytoplasmic polyadenylationelement-binding protein 4 OS=Homo sapiens OX=9606 GN=CPEB4MGDYGFGVLVQSNTGNKSAFPVRFHPHLQPPHHHQNATPSPAAFINNNTAANGSSAGSAWLFPAPATHNIQDEILGSEKAKSQQQEQQDPLEKQQLSPSPGQEAGILPETEKAKSEENQGDNSSENGNGKEKIRIESPVLTGFDYQEATGLGTSTQPLTSSASSLTGFSNWSAAIAPSSSTIINEDASFFHQGGVPAASANNGALLFQNFPHHVSPGFGGSFSPQIGPLSQHHPHHPHFQHHHSQHQQQRRSPASPHPPPFTHRNAAFNQLPHLANNLNKPPSPWSSYQSPSPTPSSSWSPGGGGYGGWGGSQGRDHRRGLNGGITPLNSISPLKKNFASNHIQLQKYARPSSAFAPKSWMEDSLNRADNIFPFPDRPRTFDMHSLESSLIDIMRAENDTIKARTYGRRRGQSSLFPMEDGFLDDGRGDQPLHSGLGSPHCFSHQNGERVERYSRKVFVGGLPPDIDEDEITASFRRFGPLIVDWPHKAESKSYFPPKGYAFLLFQDESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGEIDKRVEVKPYVLDDQLCDECQGARCGGKFAPFFCANVTCLQYYCEYCWAAIHSRAGREFHKPLVKEGGDRPRHISFRWN>sp|Q17RY0-3|CPEB4_HUMAN Isoform 3 of Cytoplasmic polyadenylationelement-binding protein 4 OS=Homo sapiens OX=9606 GN=CPEB4MHSLESSLIDIMRAENDTIKGQSSLFPMEDGFLDDGRGDQPLHSGLGSPHCFSHQNGERVERYSRKVFVGGLPPDIDEDEITASFRRFGPLIVDWPHKAESKSYFPPKGYAFLLFQDESSVQALIDACIEEDGKLYLCVSSPTIKDKPVQIRPWNLSDSDFVMDGSQPLDPRKTIFVGGVPRPLRAVELAMIMDRLYGGVCYAGIDTDPELKYPKGAGRVAFSNQQSYIAAISARFVQLQHGEIDKRVEVKPYVLDDQLCDECQGARCGGKFAPFFCANVTCLQYYCEYCWAAIHSRAGREFHKPLVKEGGDRPRHISFRWN>sp|Q68CJ9|CR3L3_HUMAN Cyclic AMP-responsive element-binding protein 3-like protein 3 OS=Homo sapiens OX=9606 GN=CREB3L3 PE=1 SV=2MNTDLAAGKMASAACSMDPIDSFELLDLLFDRQDGILRHVELGEGWGHVKDQQVLPNPDSDDFLSSILGSGDSLPSSPLWSPEGSDSGISEDLPSDPQDTPPRSGPATSPAGCHPAQPGKGPCLSYHPGNSCSTTTPGPVIQVPEASVTIDLEMWSPGGRICAEKPADPVDLSPRCNLTVKDLLLSGSSGDLQQHHLGASYLLRPGAGHCQELVLTEDEKKLLAKEGITLPTQLPLTKYEERVLKKIRRKIRNKQSAQESRKKKKEYIDGLETRMSACTAQNQELQRKVLHLEKQNLSLLEQLKKLQAIVVQSTSKSAQTGTCVAVLLLSFALIILPSISPFGPNKTESPGDFAPVRVFSRTLHNDAASRVAADAVPGSEAPGPRPEADTTREESPGSPGADWGFQDTANLTNSTEELDNATLVLRNATEGLGQVALLDWVAPGPSTGSGRAGLEAAGDEL>sp|Q68CJ9-2|CR3L3_HUMAN Isoform 2 of Cyclic AMP-responsive element-binding protein 3-like protein 3 OS=Homo sapiens OX=9606 GN=CREB3L3MNTDLAAGKMASAACSMDPIDSFELLDLLFDRQDGILRHVELGEGWGHVKDQVLPNPDSDDFLSSILGSGDSLPSSPLWSPEGSDSGISEDLPSDPQDTPPRSGPATSPAGCHPAQPGKGPCLSYHPGNSCSTTTPGPVIQVPEASVTIDLEMWSPGGRICAEKPADPVDLSPRCNLTVKDLLLSGSSGDLQQHHLGASYLLRPGAGHCQELVLTEDEKKLLAKEGITLPTQLPLTKYEERVLKKIRRKIRNKQSAQESRKKKKEYIDGLETRMSACTAQNQELQRKVLHLEKQNLSLLEQLKKLQAIVVQSTSKSAQTGTCVAVLLLSFALIILPSISPFGPNKTESPGDFAPVRVFSRTLHNDAASRVAADAVPGSEAPGPRPEADTTREESPGSPGADWGFQDTANLTNSTEELDNATLVLRNATEGLGQVALLDWVAPGPSTGSGRAGLEAAGDEL>sp|Q68CJ9-4|CR3L3_HUMAN Isoform 3 of Cyclic AMP-responsive element-binding protein 3-like protein 3 OS=Homo sapiens OX=9606 GN=CREB3L3MNTDLAAGKMASAACSMDPIDSFELLDLLFDRQDGILRHVELGEGWGHVKDQQVLPNPDSDDFLSSILGSGDSLPSSPLWSPEGSDSGISEDLPSDPQDTPPRSGPATSPAGCHPAQPGKGPCLSYHPGNSCSTTTPGPVIQVPEASVTIDLEMWSPGGRICAEKPADPVDLSPRCNLTVKDLLLSGSSGDLHHLGASYLLRPGAGHCQELVLTEDEKKLLAKEGITLPTQLPLTKYEERVLKKIRRKIRNKQSAQESRKKKKEYIDGLETRMSACTAQNQELQRKVLHLEKQNLSLLEQLKKLQAIVVQSTSKSAQTGTCVAVLLLSFALIILPSISPFGPNKTESPGDFAPVRVFSRTLHNDAASRVAADAVPGSEAPGPRPEADTTREESPGSPGADWGFQDTANLTNSTEELDNATLVLRNATEGLGQVALLDWVAPGPSTGSGRAGLEAAGDEL>sp|Q68CJ9-5|CR3L3_HUMAN Isoform 4 of Cyclic AMP-responsive element-binding protein 3-like protein 3 OS=Homo sapiens OX=9606 GN=CREB3L3MNTDLAAGKMASAACSMDPIDSFELLDLLFDRQDGILRHVELGEGWGHVKDQQVLPNPDSDDFLSSILGSGDSLPSSPLWSPEGSDSGISEDLPSDPQDTPPRSGPATSPAGCHPAQPGKGPCLSYHPGNSCSTTTPGPVIQVPEASVTIDLEMWSPGGRICAEKPADPVDLSPRCNLTVKDLLLSGSSGDLQQHHLGASYLLRPGAGHCQELVLTEDEKKLLAKEGITLPTQLPLTKDVSLHCSESGVTEESLASREAKPVPLGATEETPGHCGAVHQQVSPDRHLCRSPVAVLCPHHPPLHQPFWPQQNREPWGLCACTSVLQNFAQRCCLPRGC>sp|Q9NYL5|CP39A_HUMAN 24-hydroxycholesterol 7-alpha-hydroxylase OS=Homosapiens OX=9606 GN=CYP39A1 PE=1 SV=2MELISPTVIIILGCLALFLLLQRKNLRRPPCIKGWIPWIGVGFEFGKAPLEFIEKARIKYGPIFTVFAMGNRMTFVTEEEGINVFLKSKKVDFELAVQNIVYRTASIPKNVFLALHEKLYIMLKGKMGTVNLHQFTGQLTEELHEQLENLGTHGTMDLNNLVRHLLYPVTVNMLFNKSLFSTNKKKIKEFHQYFQVYDEDFEYGSQLPECLLRNWSKSKKWFLELFEKNIPDIKACKSAKDNSMTLLQATLDIVETETSKENSPNYGLLLLWASLSNAVPVAFWTLAYVLSHPDIHKAIMEGISSVFGKAGKDKIKVSEDDLENLLLIKWCVLETIRLKAPGVITRKVVKPVEILNYIIPSGDLLMLSPFWLHRNPKYFPEPELFKPERWKKANLEKHSFLDCFMAFGSGKFQCPARWFALLEVQMCIILILYKYDCSLLDPLPKQSYLHLVGVPQPEGQCRIEYKQRI>sp|P00395|COX1_HUMAN Cytochrome c oxidase subunit 1 OS=Homo sapiensOX=9606 GN=MT-CO1 PE=1 SV=1MFADRWLFSTNHKDIGTLYLLFGAWAGVLGTALSLLIRAELGQPGNLLGNDHIYNVIVTAHAFVMIFFMVMPIMIGGFGNWLVPLMIGAPDMAFPRMNNMSFWLLPPSLLLLLASAMVEAGAGTGWTVYPPLAGNYSHPGASVDLTIFSLHLAGVSSILGAINFITTIINMKPPAMTQYQTPLFVWSVLITAVLLLLSLPVLAAGITMLLTDRNLNTTFFDPAGGGDPILYQHLFWFFGHPEVYILILPGFGMISHIVTYYSGKKEPFGYMGMVWAMMSIGFLGFIVWAHHMFTVGMDVDTRAYFTSATMIIAIPTGVKVFSWLATLHGSNMKWSAAVLWALGFIFLFTVGGLTGIVLANSSLDIVLHDTYYVVAHFHYVLSMGAVFAIMGGFIHWFPLFSGYTLDQTYAKIHFTIMFIGVNLTFFPQHFLGLSGMPRRYSDYPDAYTTWNILSSVGSFISLTAVMLMIFMIWEAFASKRKVLMVEEPSMNLEWLYGCPPPYHTFEEPVYMKS>sp|P07333|CSF1R_HUMAN Macrophage colony-stimulating factor 1 receptorOS=Homo sapiens OX=9606 GN=CSF1R PE=1 SV=2MGPGVLLLLLVATAWHGQGIPVIEPSVPELVVKPGATVTLRCVGNGSVEWDGPPSPHWTLYSDGSSSILSTNNATFQNTGTYRCTEPGDPLGGSAAIHLYVKDPARPWNVLAQEVVVFEDQDALLPCLLTDPVLEAGVSLVRVRGRPLMRHTNYSFSPWHGFTIHRAKFIQSQDYQCSALMGGRKVMSISIRLKVQKVIPGPPALTLVPAELVRIRGEAAQIVCSASSVDVNFDVFLQHNNTKLAIPQQSDFHNNRYQKVLTLNLDQVDFQHAGNYSCVASNVQGKHSTSMFFRVVESAYLNLSSEQNLIQEVTVGEGLNLKVMVEAYPGLQGFNWTYLGPFSDHQPEPKLANATTKDTYRHTFTLSLPRLKPSEAGRYSFLARNPGGWRALTFELTLRYPPEVSVIWTFINGSGTLLCAASGYPQPNVTWLQCSGHTDRCDEAQVLQVWDDPYPEVLSQEPFHKVTVQSLLTVETLEHNQTYECRAHNSVGSGSWAFIPISAGAHTHPPDEFLFTPVVVACMSIMALLLLLLLLLLYKYKQKPKYQVRWKIIESYEGNSYTFIDPTQLPYNEKWEFPRNNLQFGKTLGAGAFGKVVEATAFGLGKEDAVLKVAVKMLKSTAHADEKEALMSELKIMSHLGQHENIVNLLGACTHGGPVLVITEYCCYGDLLNFLRRKAEAMLGPSLSPGQDPEGGVDYKNIHLEKKYVRRDSGFSSQGVDTYVEMRPVSTSSNDSFSEQDLDKEDGRPLELRDLLHFSSQVAQGMAFLASKNCIHRDVAARNVLLTNGHVAKIGDFGLARDIMNDSNYIVKGNARLPVKWMAPESIFDCVYTVQSDVWSYGILLWEIFSLGLNPYPGILVNSKFYKLVKDGYQMAQPAFAPKNIYSIMQACWALEPTHRPTFQQICSFLQEQAQEDRRERDYTNLPSSSRSGGSGSSSSELEEESSSEHLTCCEQGDIAQPLLQPNNYQFC>sp|P07333-2|CSF1R_HUMAN Isoform 2 of Macrophage colony-stimulatingfactor 1 receptor OS=Homo sapiens OX=9606 GN=CSF1RMGPGVLLLLLVATAWHGQGIPVIEPSVPELVVKPGATVTLRCVGNGSVEWDGPPSPHWTLYSDGSSSILSTNNATFQNTGTYRCTEPGDPLGGSAAIHLYVKDPARPWNVLAQEVVVFEDQDALLPCLLTDPVLEAGVSLVRVRGRPLMRHTNYSFSPWHGFTIHRAKFIQSQDYQCSALMGGRKVMSISIRLKVQKVIPGPPALTLVPAELVRIRGEAAQIVCSASSVDVNFDVFLQHNNTKLAIPQQSDFHNNRYQKVLTLNLDQVDFQHAGNYSCVASNVQGKHSTSMFFRVVGTPSPSLCPA>sp|Q9NQ79|CRAC1_HUMAN Cartilage acidic protein 1 OS=Homo sapiens OX=9606GN=CRTAC1 PE=1 SV=2MAPSADPGMSRMLPFLLLLWFLPITEGSQRAEPMFTAVTNSVLPPDYDSNPTQLNYGVAVTDVDHDGDFEIVVAGYNGPNLVLKYDRAQKRLVNIAVDERSSPYYALRDRQGNAIGVTACDIDGDGREEIYFLNTNNAFSGVATYTDKLFKFRNNRWEDILSDEVNVARGVASLFAGRSVACVDRKGSGRYSIYIANYAYGNVGPDALIEMDPEASDLSRGILALRDVAAEAGVSKYTGGRGVSVGPILSSSASDIFCDNENGPNFLFHNRGDGTFVDAAASAGVDDPHQHGRGVALADFNRDGKVDIVYGNWNGPHRLYLQMSTHGKVRFRDIASPKFSMPSPVRTVITADFDNDQELEIFFNNIAYRSSSANRLFRVIRREHGDPLIEELNPGDALEPEGRGTGGVVTDFDGDGMLDLILSHGESMAQPLSVFRGNQGFNNNWLRVVPRTRFGAFARGAKVVLYTKKSGAHLRIIDGGSGYLCEMEPVAHFGLGKDEASSVEVTWPDGKMVSRNVASGEMNSVLEILYPRDEDTLQDPAPLECGQGFSQQENGHCMDTNECIQFPFVCPRDKPVCVNTYGSYRCRTNKKCSRGYEPNEDGTACVGTLGQSPGPRPTTPTAAAATAAAAAAAGAATAAPVLVDGDLNLGSVVKESCEPSC>sp|Q9NQ79-2|CRAC1_HUMAN Isoform 2 of Cartilage acidic protein 1 OS=Homosapiens OX=9606 GN=CRTAC1MAPSADPGMSRMLPFLLLLWFLPITEGSQRAEPMFTAVTNSVLPPDYDSNPTQLNYGVAVTDVDHDGDFEIVVAGYNGPNLVLKYDRAQKRLVNIAVDERSSPYYALRDRQGNAIGVTACDIDGDGREEIYFLNTNNAFSGVATYTDKLFKFRNNRWEDILSDEVNVARGVASLFAGRSVACVDRKGSGRYSIYIANYAYGNVGPDALIEMDPEASDLSRGILALRDVAAEAGVSKYTGGRGVSVGPILSSSASDIFCDNENGPNFLFHNRGDGTFVDAAASAGVDDPHQHGRGVALADFNRDGKVDIVYGNWNGPHRLYLQMSTHGKVRFRDIASPKFSMPSPVRTVITADFDNDQELEIFFNNIAYRSSSANRLFRVIRREHGDPLIEELNPGDALEPEGRGTGGVVTDFDGDGMLDLILSHGESMAQPLSVFRGNQGFNNNWLRVVPRTRFGAFARGAKVVLYTKKSGAHLRIIDGGSGYLCEMEPVAHFGLGKDEASSVEVTWPDGKMVSRNVASGEMNSVLEILYPRDEDTLQDPAPLECGQGFSQQENGHCMDTNECIQFPFVCPRDKPVCVNTYGSYRCRTNKKCSRGYEPNEDGTACVAQVAFLGGYSSAASRISEPLSRASYLSLGLGLCLQLYAL>sp|Q9NQ79-3|CRAC1_HUMAN Isoform 3 of Cartilage acidic protein 1 OS=Homosapiens OX=9606 GN=CRTAC1MAPSADPGMSRMLPFLLLLWFLPITEGSQRAEPMFTAVTNSVLPPDYDSNPTQLNYGVAVTDVDHDGDFEIVVAGYNGPNLVLKYDRAQKRLVNIAVDERSSPYYALRDRQGNAIGVTACDIDGDGREEIYFLNTNNAFSGVATYTDKLFKFRNNRWEDILSDEVNVARGVASLFAGRSVACVDRKGSGRYSIYIANYAYGNVGPDALIEMDPEASDLSRGILALRDVAAEAGVSKYTGGRGVSVGPILSSSASDIFCDNENGPNFLFHNRGDGTFVDAAASAGVDDPHQHGRGVALADFNRDGKVDIVYGNWNGPHRLYLQMSTHGKVRFRDIASPKFSMPSPVRTVITADFDNDQELEIFFNNIAYRSSSANRLFRVIRREHGDPLIEELNPGDALEPEGRGTGGVVTDFDGDGMLDLILSHGESMAQPLSVFRGNQGFNNNWLRVVPRTRFGAFARGAKVVLYTKKSGAHLRIIDGGSGYLCEMEPVAHFGLGKDEASSVEVTWPDGKMVSRNVASGEMNSVLEILYPRDEDTLQDPAPLETPMNASSSHSCALETSPYVSTPMEATGAGPTRSAVGATSPTRMAQPAWGLSASHRAPAPPPPPLLLPLPLLLPLLELPLLHRSS>sp|P04141|CSF2_HUMAN Granulocyte-macrophage colony-stimulating factorOS=Homo sapiens OX=9606 GN=CSF2 PE=1 SV=1MWLQSLLLLGTVACSISAPARSPSPSTQPWEHVNAIQEARRLLNLSRDTAAEMNETVEVISEMFDLQEPTCLQTRLELYKQGLRGSLTKLKGPLTMMASHYKQHCPPTPETSCATQIITFESFKENLKDFLLVIPFDCWEPVQE>sp|O75366|AVIL_HUMAN Advillin OS=Homo sapiens OX=9606 GN=AVIL PE=1 SV=3MPLTSAFRAVDNDPGIIVWRIEKMELALVPVSAHGNFYEGDCYVILSTRRVASLLSQDIHFWIGKDSSQDEQSCAAIYTTQLDDYLGGSPVQHREVQYHESDTFRGYFKQGIIYKQGGVASGMKHVETNTYDVKRLLHVKGKRNIRATEVEMSWDSFNRGDVFLLDLGKVIIQWNGPESNSGERLKAMLLAKDIRDRERGGRAKIGVIEGDKEAASPELMKVLQDTLGRRSIIKPTVPDEIIDQKQKSTIMLYHISDSAGQLAVTEVATRPLVQDLLNHDDCYILDQSGTKIYVWKGKGATKAEKQAAMSKALGFIKMKSYPSSTNVETVNDGAESAMFKQLFQKWSVKDQTMGLGKTFSIGKIAKVFQDKFDVTLLHTKPEVAAQERMVDDGNGKVEVWRIENLELVPVEYQWYGFFYGGDCYLVLYTYEVNGKPHHILYIWQGRHASQDELAASAYQAVEVDRQFDGAAVQVRVRMGTEPRHFMAIFKGKLVIFEGGTSRKGNAEPDPPVRLFQIHGNDKSNTKAVEVPAFASSLNSNDVFLLRTQAEHYLWYGKGSSGDERAMAKELASLLCDGSENTVAEGQEPAEFWDLLGGKTPYANDKRLQQEILDVQSRLFECSNKTGQFVVTEITDFTQDDLNPTDVMLLDTWDQVFLWIGAEANATEKESALATAQQYLHTHPSGRDPDTPILIIKQGFEPPIFTGWFLAWDPNIWSAGKTYEQLKEELGDAAAIMRITADMKNATLSLNSNDSEPKYYPIAVLLKNQNQELPEDVNPAKKENYLSEQDFVSVFGITRGQFAALPGWKQLQMKKEKGLF>sp|O75366-2|AVIL_HUMAN Isoform 2 of Advillin OS=Homo sapiens OX=9606GN=AVILMSSTGHPGSYKIWGEKMELALVPVSAHGNFYEGDCYVILSTRRVASLLSQDIHFWIGKDSSQDEQSCAAIYTTQLDDYLGGSPVQHREVQYHESDTFRGYFKQGIIYKQGGVASGMKHVETNTYDVKRLLHVKGKRNIRATEVEMSWDSFNRGDVFLLDLGKVIIQWNGPESNSGERLKAMLLAKDIRDRERGGRAKIGVIEGDKEAASPELMKVLQDTLGRRSIIKPTVPDEIIDQKQKSTIMLYHISDSAGQLAVTEVATRPLVQDLLNHDDCYILDQSGTKIYVWKGKGATKAEKQAAMSKALGFIKMKSYPSSTNVETVNDGAESAMFKQLFQKWSVKDQTMGLGKTFSIGKIAKVFQDKFDVTLLHTKPEVAAQERMVDDGNGKVEVWRIENLELVPVEYQWYGFFYGGDCYLVLYTYEVNGKPHHILYIWQGRHASQDELAASAYQAVEVDRQFDGAAVQVRVRMGTEPRHFMAIFKGKLVIFEGGTSRKGNAEPDPPVRLFQIHGNDKSNTKAVEVPAFASSLNSNDVFLLRTQAEHYLWYGKGSSGDERAMAKELASLLCDGSENTVAEGQEPAEFWDLLGGKTPYANDKRLQQEILDVQSRLFECSNKTGQFVVTEITDFTQDDLNPTDVMLLDTWDQVFLWIGAEANATEKESALATAQQYLHTHPSGRDPDTPILIIKQGFEPPIFTGWFLAWDPNIWSAGKTYEQLKEELGDAAAIMRITADMKNATLSLNSNDSEPKYYPIAVLLKNQNQELPEDVNPAKKENYLSEQDFVSVFGITRGQFAALPGWKQLQMKKEKGLF>sp|P48047|ATPO_HUMAN ATP synthase subunit O, mitochondrial OS=Homosapiens OX=9606 GN=ATP5PO PE=1 SV=1MAAPAVSGLSRQVRCFSTSVVRPFAKLVRPPVQVYGIEGRYATALYSAASKQNKLEQVEKELLRVAQILKEPKVAASVLNPYVKRSIKVKSLNDITAKERFSPLTTNLINLLAENGRLSNTQGVVSAFSTMMSVHRGEVPCTVTSASPLEEATLSELKTVLKSFLSQGQVLKLEAKTDPSILGGMIVRIGEKYVDMSVKTKIQKLGRAMREIV>sp|Q13705|AVR2B_HUMAN Activin receptor type-2B OS=Homo sapiens OX=9606GN=ACVR2B PE=1 SV=3MTAPWVALALLWGSLCAGSGRGEAETRECIYYNANWELERTNQSGLERCEGEQDKRLHCYASWRNSSGTIELVKKGCWLDDFNCYDRQECVATEENPQVYFCCCEGNFCNERFTHLPEAGGPEVTYEPPPTAPTLLTVLAYSLLPIGGLSLIVLLAFWMYRHRKPPYGHVDIHEDPGPPPPSPLVGLKPLQLLEIKARGRFGCVWKAQLMNDFVAVKIFPLQDKQSWQSEREIFSTPGMKHENLLQFIAAEKRGSNLEVELWLITAFHDKGSLTDYLKGNIITWNELCHVAETMSRGLSYLHEDVPWCRGEGHKPSIAHRDFKSKNVLLKSDLTAVLADFGLAVRFEPGKPPGDTHGQVGTRRYMAPEVLEGAINFQRDAFLRIDMYAMGLVLWELVSRCKAADGPVDEYMLPFEEEIGQHPSLEELQEVVVHKKMRPTIKDHWLKHPGLAQLCVTIEECWDHDAEARLSAGCVEERVSLIRRSVNGTTSDCLVSLVTSVTNVDLPPKESSI>sp|Q9Y679|AUP1_HUMAN Lipid droplet-regulating VLDL assembly factor AUP1OS=Homo sapiens OX=9606 GN=AUP1 PE=1 SV=2MELPSGPGPERLFDSHRLPGDCFLLLVLLLYAPVGFCLLVLRLFLGIHVFLVSCALPDSVLRRFVVRTMCAVLGLVARQEDSGLRDHSVRVLISNHVTPFDHNIVNLLTTCSTPLLNSPPSFVCWSRGFMEMNGRGELVESLKRFCASTRLPPTPLLLFPEEEATNGREGLLRFSSWPFSIQDVVQPLTLQVQRPLVSVTVSDASWVSELLWSLFVPFTVYQVRWLRPVHRQLGEANEEFALRVQQLVAKELGQTGTRLTPADKAEHMKRQRHPRLRPQSAQSSFPPSPGPSPDVQLATLAQRVKEVLPHVPLGVIQRDLAKTGCVDLTITNLLEGAVAFMPEDITKGTQSLPTASASKFPSSGPVTPQPTALTFAKSSWARQESLQERKQALYEYARRRFTERRAQEAD>sp|Q9Y679-3|AUP1_HUMAN Isoform 2 of Lipid droplet-regulating VLDLassembly factor AUP1 OS=Homo sapiens OX=9606 GN=AUP1MELPSGPGPERLFDSHRLPGDCFLLLVLLLYAPVGFCLLVLRLFLGIHVFLVSCALPDSVLRRFVVRTMCAVLGLVARQEDSGLRDHSVRVLISNHVTPFDHNIVNLLTTCSTPLLNSPPSFVCWSRGFMEMNGRGELVESLKRFCASTRLPPTPLLLFPEEEATNGREGLLRFSSWPFSIQDVVQPLTLQVQRPLVSVTVSDASWVSELLWSLFVPFTVYQVRWLRPVHRQLGEANEEFALRVQQLVAKELGQTGTRLTPADKAEHMKRQRHPRLRPQSAQSSFPPSPGPSPDVQLATLAQRVKEVLPHVPLGVIQRDLAKTGCVDLTITNLLEGAVAFMPEDITKGTQSLPTASASKAFDACLMMMTPQAL>sp|P56385|ATP5I_HUMAN ATP synthase subunit e, mitochondrial OS=Homosapiens OX=9606 GN=ATP5ME PE=1 SV=2MVPPVQVSPLIKLGRYSALFLGVAYGATRYNYLKPRAEEERRIAAEEKKKQDELKRIARELAEDDSILK>sp|Q99766|ATP5S_HUMAN ATP synthase subunit s, mitochondrial OS=Homosapiens OX=9606 GN=DMAC2L PE=1 SV=3MCCAVSEQRLTCADQMMPFGKISQQLCGVKKLPWSCDSRYFWGWLNAVFNKVDYDRIRDVGPDRAASEWLLRCGAMVRYHGQERWQKDYNHLPTGPLDKYKIQAIDATDSCIMSIGFDHMEGLEHVEKIRLCKCHYIEDDCLLRLSQLENLQKTILEMEIISCGNITDKGIIALRHLRNLKYLLLSDLPGVREKENLVQAFKTALPSLELKLQLK>sp|Q99766-2|ATP5S_HUMAN Isoform 2 of ATP synthase subunit s,mitochondrial OS=Homo sapiens OX=9606 GN=DMAC2LMCCAVSEQRLTCADQMMPFGKISQQLCGVKKLPWSCDSRYFWGWLNAVFNKVDYDRIRDVGPDRAASEWLLRCGAMVRYHGQERWQKDYNHLPTGPLDKYKIQAIDATDSCIMSIGFDHMGNYPIVLLIENADDLQ>sp|Q99766-3|ATP5S_HUMAN Isoform 3 of ATP synthase subunit s,mitochondrial OS=Homo sapiens OX=9606 GN=DMAC2LMCCAVSEQRLTCADQMMPFGKISQQLCGVKKLPWSCDSRYFWGWLNAVFNKVDYDRIRDVGPDRAASEWLLRCGAMVRYHGQERWQKDYNHLPTGPLDKYKIQAIDATDSCIMSIGFDHMETSNICC>sp|O43174|CP26A_HUMAN Cytochrome P450 26A1 OS=Homo sapiens OX=9606GN=CYP26A1 PE=1 SV=2MGLPALLASALCTFVLPLLLFLAAIKLWDLYCVSGRDRSCALPLPPGTMGFPFFGETLQMVLQRRKFLQMKRRKYGFIYKTHLFGRPTVRVMGADNVRRILLGEHRLVSVHWPASVRTILGSGCLSNLHDSSHKQRKKVIMRAFSREALECYVPVITEEVGSSLEQWLSCGERGLLVYPEVKRLMFRIAMRILLGCEPQLAGDGDSEQQLVEAFEEMTRNLFSLPIDVPFSGLYRGMKARNLIHARIEQNIRAKICGLRASEAGQGCKDALQLLIEHSWERGERLDMQALKQSSTELLFGGHETTASAATSLITYLGLYPHVLQKVREELKSKGLLCKSNQDNKLDMEILEQLKYIGCVIKETLRLNPPVPGGFRVALKTFELNGYQIPKGWNVIYSICDTHDVAEIFTNKEEFNPDRFMLPHPEDASRFSFIPFGGGLRSCVGKEFAKILLKIFTVELARHCDWQLLNGPPTMKTSPTVYPVDNLPARFTHFHGEI>sp|O43174-2|CP26A_HUMAN Isoform 2 of Cytochrome P450 26A1 OS=Homosapiens OX=9606 GN=CYP26A1MKRRKYGFIYKTHLFGRPTVRVMGADNVRRILLGEHRLVSVHWPASVRTILGSGCLSNLHDSSHKQRKKVIMRAFSREALECYVPVITEEVGSSLEQWLSCGERGLLVYPEVKRLMFRIAMRILLGCEPQLAGDGDSEQQLVEAFEEMTRNLFSLPIDVPFSGLYRGMKARNLIHARIEQNIRAKICGLRASEAGQGCKDALQLLIEHSWERGERLDMQALKQSSTELLFGGHETTASAATSLITYLGLYPHVLQKVREELKSKGLLCKSNQDNKLDMEILEQLKYIGCVIKETLRLNPPVPGGFRVALKTFELNGYQIPKGWNVIYSICDTHDVAEIFTNKEEFNPDRFMLPHPEDASRFSFIPFGGGLRSCVGKEFAKILLKIFTVELARHCDWQLLNGPPTMKTSPTVYPVDNLPARFTHFHGEI>sp|A6NCJ1|CS071_HUMAN Uncharacterized protein C19orf71 OS=Homo sapiensOX=9606 GN=C19orf71 PE=4 SV=2MQTLRQEAARPCIPSGTLEASFPAPLYSDDYLSLEGSRWPPAIRQATRWKYTPMGRDAAGQLWYTGLTNSDAWEAWYNLPRAPASPFREAYNRWHSCYQHRECSMPSAYTQHLRETAWHDPIVPAQYQAPSTRWGSALWKDRPIRGKEYVLNRNRYGVEPLWRASDYVPSLSAPQRPPGTTQNYREWVLEPYCPSTCQRSPPSLTPTPR>sp|Q96KJ9|COX42_HUMAN Cytochrome c oxidase subunit 4 isoform 2,mitochondrial OS=Homo sapiens OX=9606 GN=COX4I2 PE=1 SV=2MLPRAAWSLVLRKGGGGRRGMHSSEGTTRGGGKMSPYTNCYAQRYYPMPEEPFCTELNAEEQALKEKEKGSWTQLTHAEKVALYRLQFNETFAEMNRRSNEWKTVMGCVFFFIGFAALVIWWQRVYVFPPKPITLTDERKAQQLQRMLDMKVNPVQGLASRWDYEKKQWKK>sp|Q6QNY1|BL1S2_HUMAN Biogenesis of lysosome-related organelles complex1 subunit 2 OS=Homo sapiens OX=9606 GN=BLOC1S2 PE=1 SV=1MAAAAEGVLATRSDEPARDDAAVETAEEAKEPAEADITELCRDMFSKMATYLTGELTATSEDYKLLENMNKLTSLKYLEMKDIAINISRNLKDLNQKYAGLQPYLDQINVIEEQVAALEQAAYKLDAYSKKLEAKYKKLEKR>sp|Q6QNY1-2|BL1S2_HUMAN Isoform 2 of Biogenesis of lysosome-relatedorganelles complex 1 subunit 2 OS=Homo sapiens OX=9606 GN=BLOC1S2MFSKMATYLTGELTATSEDYKLLENMNKLTSLKYLEMKDIAINISRNLKDLNQKYAGLQPYLDQINVIEEQVAALEQAAYKLDAYSKKLEAKYKKLEKR>sp|Q8WXE0|CSKI2_HUMAN Caskin-2 OS=Homo sapiens OX=9606 GN=CASKIN2 PE=1SV=2MGREQDLILAVKNGDVTGVQKLVAKVKATKTKLLGSTKRLNVNYQDADGFSALHHAALGGSLELIALLLEAQATVDIKDSNGMRPLHYAAWQGRLEPVRLLLRASAAVNAASLDGQIPLHLAAQYGHYEVSEMLLQHQSNPCLVNKAKKTPLDLACEFGRLKVAQLLLNSHLCVALLEGEAKDPCDPNYTTPLHLAAKNGHREVIRQLLRAGIEINRQTKTGTALHEAALYGKTEVVRLLLEGGVDVNIRNTYNQTALDIVNQFTTSQASREIKQLLREASGILKVRALKDFWNLHDPTALNVRAGDVITVLEQHPDGRWKGHIHESQRGTDRIGYFPPGIVEVVSKRVGIPAARLPSAPTPLRPGFSRTPQPPAEEPPHPLTYSQLPRVGLSPDSPAGDRNSVGSEGSVGSIRSAGSGQSSEGTNGHGPGLLIENAQPLPSAGEDQVLPGLHPPSLADNLSHRPLANCRSGEQIFTQDVRPEQLLEGKDAQAIHNWLSEFQLEGYTAHFLQAGYDVPTISRMTPEDLTAIGVTKPGHRKKIASEIAQLSIAEWLPSYIPTDLLEWLCALGLPQYHKQLVSSGYDSMGLVADLTWEELQEIGVNKLGHQKKLMLGVKRLAELRRGLLQGEALSEGGRRLAKGPELMAIEGLENGEGPATAGPRLLTFQGSELSPELQAAMAGGGPEPLPLPPARSPSQESIGARSRGSGHSQEQPAPQPSGGDPSPPQERNLPEGTERPPKLCSSLPGQGPPPYVFMYPQGSPSSPAPGPPPGAPWAFSYLAGPPATPPDPPRPKRRSHSLSRPGPTEGDAEGEAEGPVGSTLGSYATLTRRPGRSALVRTSPSVTPTPARGTPRSQSFALRARRKGPPPPPPKRLSSVSGPSPEPPPLDESPGPKEGATGPRRRTLSEPAGPSEPPGPPAPAGPASDTEEEEPGPEGTPPSRGSSGEGLPFAEEGNLTIKQRPKPAGPPPRETPVPPGLDFNLTESDTVKRRPKCREREPLQTALLAFGVASATPGPAAPLPSPTPGESPPASSLPQPEPSSLPAQGVPTPLAPSPAMQPPVPPCPGPGLESSAASRWNGETEPPAAPAALLKVPGAGTAPKPVSVACTQLAFSGPKLAPRLGPRPVPPPRPESTGTVGPGQAQQRLEQTSSSLAAALRAAEKSIGTKEQEGTPSASTKHILDDISTMFDALADQLDAMLD>sp|Q8WXE0-2|CSKI2_HUMAN Isoform 2 of Caskin-2 OS=Homo sapiens OX=9606GN=CASKIN2MRPLHYAAWQGRLEPVRLLLRASAAVNAASLDGQIPLHLAAQYGHYEVSEMLLQHQSNPCLVNKAKKTPLDLACEFGRLKVAQLLLNSHLCVALLEGEAKDPCDPNYTTPLHLAAKNGHREVIRQLLRAGIEINRQTKTGTALHEAALYGKTEVVRLLLEGGVDVNIRNTYNQTALDIVNQFTTSQASREIKQLLREASGILKVRALKDFWNLHDPTALNVRAGDVITVLEQHPDGRWKGHIHESQRGTDRIGYFPPGIVEVVSKRVGIPAARLPSAPTPLRPGFSRTPQPPAEEPPHPLTYSQLPRVGLSPDSPAGDRNSVGSEGSVGSIRSAGSGQSSEGTNGHGPGLLIENAQPLPSAGEDQVLPGLHPPSLADNLSHRPLANCRSGEQIFTQDVRPEQLLEGKDAQAIHNWLSEFQLEGYTAHFLQAGYDVPTISRMTPEDLTAIGVTKPGHRKKIASEIAQLSIAEWLPSYIPTDLLEWLCALGLPQYHKQLVSSGYDSMGLVADLTWEELQEIGVNKLGHQKKLMLGVKRLAELRRGLLQGEALSEGGRRLAKGPELMAIEGLENGEGPATAGPRLLTFQGSELSPELQAAMAGGGPEPLPLPPARSPSQESIGARSRGSGHSQEQPAPQPSGGDPSPPQERNLPEGTERPPKLCSSLPGQGPPPYVFMYPQGSPSSPAPGPPPGAPWAFSYLAGPPATPPDPPRPKRRSHSLSRPGPTEGDAEGEAEGPVGSTLGSYATLTRRPGRSALVRTSPSVTPTPARGTPRSQSFALRARRKGPPPPPPKRLSSVSGPSPEPPPLDESPGPKEGATGPRRRTLSEPAGPSEPPGPPAPAGPASDTEEEEPGPEGTPPSRGSSGEGLPFAEEGNLTIKQRPKPAGPPPRETPVPPGLDFNLTESDTVKRRPKCREREPLQTALLAFGVASATPGPAAPLPSPTPGESPPASSLPQPEPSSLPAQGVPTPLAPSPAMQPPVPPCPGPGLESSAASRWNGETEPPAAPAALLKVPGAGTAPKPVSVACTQLAFSGPKLAPRLGPRPVPPPRPESTGTVGPGQAQQRLEQTSSSLAAALRAAEKSIGTKEQEGTPSASTKHILDDISTMFDALADQLDAMLD>sp|P61769|B2MG_HUMAN Beta-2-microglobulin OS=Homo sapiens OX=9606 GN=B2MPE=1 SV=1MSRSVALAVLALLSLSGLEAIQRTPKIQVYSRHPAENGKSNFLNCYVSGFHPSDIEVDLLKNGERIEKVEHSDLSFSKDWSFYLLYYTEFTPTEKDEYACRVNHVTLSQPKIVKWDRDM>sp|P31146|COR1A_HUMAN Coronin-1A OS=Homo sapiens OX=9606 GN=CORO1A PE=1SV=4MSRQVVRSSKFRHVFGQPAKADQCYEDVRVSQTTWDSGFCAVNPKFVALICEASGGGAFLVLPLGKTGRVDKNAPTVCGHTAPVLDIAWCPHNDNVIASGSEDCTVMVWEIPDGGLMLPLREPVVTLEGHTKRVGIVAWHTTAQNVLLSAGCDNVIMVWDVGTGAAMLTLGPEVHPDTIYSVDWSRDGGLICTSCRDKRVRIIEPRKGTVVAEKDRPHEGTRPVRAVFVSEGKILTTGFSRMSERQVALWDTKHLEEPLSLQELDTSSGVLLPFFDPDTNIVYLCGKGDSSIRYFEITSEAPFLHYLSMFSSKESQRGMGYMPKRGLEVNKCEIARFYKLHERRCEPIAMTVPRKSDLFQEDLYPPTAGPDPALTAEEWLGGRDAGPLLISLKDGYVPPKSRELRVNRGLDTGRRRAAPEASGTPSSDAVSRLEEEMRKLQATVQELQKRLDRLEETVQAK>sp|Q8WXF5|CRGN_HUMAN Gamma-crystallin N OS=Homo sapiens OX=9606 GN=CRYGNPE=2 SV=1MAQRSGKITLYEGKHFTGQKLEVFGDCDNFQDRGFMNRVNSIHVESGAWVCFNHPDFRGQQFILEHGDYPDFFRWNSHSDHMGSCRPVGMHGEHFRLEIFEGCNFTGQCLEFLEDSPFLQSRGWVKNCVNTIKVYGDGAAWSPRSFGAEDFQLSSSLQSDQGPEEATTKPATTQPPFLTANL>sp|Q8WXF5-2|CRGN_HUMAN Isoform 2 of Gamma-crystallin N OS=Homo sapiensOX=9606 GN=CRYGNMAQRSGKITLYEGKHFTGQKLEVFGDCDNFQDRGFMNRVNSIHVESGAWVCFNHPDFRGQQFILEHGDYPDFFRWNSHSDHMGSCRPVGMVSGPVHRRLSLPAGGTEGQPWQTVARNRGAWSSRL>sp|Q9ULV4|COR1C_HUMAN Coronin-1C OS=Homo sapiens OX=9606 GN=CORO1C PE=1SV=1MRRVVRQSKFRHVFGQAVKNDQCYDDIRVSRVTWDSSFCAVNPRFVAIIIEASGGGAFLVLPLHKTGRIDKSYPTVCGHTGPVLDIDWCPHNDQVIASGSEDCTVMVWQIPENGLTLSLTEPVVILEGHSKRVGIVAWHPTARNVLLSAGCDNAIIIWNVGTGEALINLDDMHSDMIYNVSWNRNGSLICTASKDKKVRVIDPRKQEIVAEKEKAHEGARPMRAIFLADGNVFTTGFSRMSERQLALWNPKNMQEPIALHEMDTSNGVLLPFYDPDTSIIYLCGKGDSSIRYFEITDESPYVHYLNTFSSKEPQRGMGYMPKRGLDVNKCEIARFFKLHERKCEPIIMTVPRKSDLFQDDLYPDTAGPEAALEAEEWFEGKNADPILISLKHGYIPGKNRDLKVVKKNILDSKPTANKKCDLISIPKKTTDTASVQNEAKLDEILKEIKSIKDTICNQDERISKLEQQMAKIAA>sp|Q9ULV4-2|COR1C_HUMAN Isoform 2 of Coronin-1C OS=Homo sapiens OX=9606GN=CORO1CMRWKDTMRRVVRQSKFRHVFGQAVKNDQCYDDIRVSRVTWDSSFCAVNPRFVAIIIEASGGGAFLVLPLHKTGRIDKSYPTVCGHTGPVLDIDWCPHNDQVIASGSEDCTVMVWQIPENGLTLSLTEPVVILEGHSKRVGIVAWHPTARNVLLSAGCDNAIIIWNVGTGEALINLDDMHSDMIYNVSWNRNGSLICTASKDKKVRVIDPRKQEIVAEKEKAHEGARPMRAIFLADGNVFTTGFSRMSERQLALWNPKNMQEPIALHEMDTSNGVLLPFYDPDTSIIYLCGKGDSSIRYFEITDESPYVHYLNTFSSKEPQRGMGYMPKRGLDVNKCEIARFFKLHERKCEPIIMTVPRKSDLFQDDLYPDTAGPEAALEAEEWFEGKNADPILISLKHGYIPGKNRDLKVVKKNILDSKPTANKKCDLISIPKKTTDTASVQNEAKLDEILKEIKSIKDTICNQDERISKLEQQMAKIAA>sp|Q9ULV4-3|COR1C_HUMAN Isoform 3 of Coronin-1C OS=Homo sapiens OX=9606GN=CORO1CMYGPGSQLGKSGNNSWAKERGCSIACQGSLTSARLHAPSIGERPLSHMRWKDTMRRVVRQSKFRHVFGQAVKNDQCYDDIRVSRVTWDSSFCAVNPRFVAIIIEASGGGAFLVLPLHKTGRIDKSYPTVCGHTGPVLDIDWCPHNDQVIASGSEDCTVMVWQIPENGLTLSLTEPVVILEGHSKRVGIVAWHPTARNVLLSAGCDNAIIIWNVGTGEALINLDDMHSDMIYNVSWNRNGSLICTASKDKKVRVIDPRKQEIVAEKEKAHEGARPMRAIFLADGNVFTTGFSRMSERQLALWNPKNMQEPIALHEMDTSNGVLLPFYDPDTSIIYLCGKGDSSIRYFEITDESPYVHYLNTFSSKEPQRGMGYMPKRGLDVNKCEIARFFKLHERKCEPIIMTVPRKSDLFQDDLYPDTAGPEAALEAEEWFEGKNADPILISLKHGYIPGKNRDLKVVKKNILDSKPTANKKCDLISIPKKTTDTASVQNEAKLDEILKEIKSIKDTICNQDERISKLEQQMAKIAA>sp|Q6NV74|CRCDL_HUMAN CRACD-like protein OS=Homo sapiens OX=9606GN=CRACDL PE=1 SV=3MISTRVMDIKLREAAEGLGEDSTGKKKSKFKTFKKFFGKKKRKESPSSTGSSTWKQSQTRNEVIAIESGPVGYDSEDELEESRGTLGSRALSHDSIFIPESGQDATRPVRVFSQENVCDRIKALQLKIQCNVKMGPPPPPGGLPAKRGEDAGMSSEDDGLPRSPPEMSLLHDVGPGTTIKVSVVSPDHVSDSTVSARISDNSLAPVADFSYPAESSSCLDNSAAKHKLQVKPRNQRSSKMRRLSSRAQSESLSDLTCTPEEEENEEKPLLEVSPEERPSSGQQDVAPDRGPEPGPPAPLPPPGGARARRARLQHSSALTASVEEGGVPGEDPSSRPATPELAEPESAPTLRVEPPSPPEGPPNPGPDGGKQDGEAPPAGPCAPATDKAEEVVCAPEDVASPFPTAIPEGDTTPPETDPAATSEAPSARDGPERSVPKEAEPTPPVLPDEEKGPPGPAPEPEREAETEPERGAGTEPERIGTEPSTAPAPSPPAPKSCLKHRPAAASEGPAASPPLAAAESPPVEPGPGSLDAEAAAPERPKAERAEAPPAGAERAAPERKAERGGAELRGAKKFSVSSCRARPRPGVSRPLERASGRLPLARSGPVWRSEAALDDLQGLPEPQHAKPGPRKLAERGPQDSGDRAASPAGPRKSPQEAAAAPGTREPCPAAQEPAPSEDRNPFPVKLRSTSLSLKYRDGASQEVKGVKRYSAEVRLERSLTVLPKEEKCPLGTAPALRGTRAPSDQGKGKARPPEPLSSKPPLPRKPLLQSFTLPHQPAPPDAGPGEREPRKEPRTAEKRPLRRGAEKSLPPAATGPGADGQPAPPWITVTRQKRRGTLDQPPNQEDKPGARTLKSEPGKQAKVPERGQEPVKQADFVRSKSFLITPVKPAVDRKQGAKLNFKEGLQRGISLSHQNLAQSAVMMEKELHQLKRASYASTDQPSWMELARKKSQAWSDMPQIIK>sp|P10176|COX8A_HUMAN Cytochrome c oxidase subunit 8A, mitochondrialOS=Homo sapiens OX=9606 GN=COX8A PE=1 SV=2MSVLTPLLLRGLTGSARRLPVPRAKIHSLPPEGKLGIMELAVGLTSCFVTFLLPAGWILSHLETYRRPE>sp|Q9C0J1|B3GN4_HUMAN N-acetyllactosaminide beta-1,3-N-acetylglucosaminyltransferase 4 OS=Homo sapiens OX=9606 GN=B3GNT4 PE=1SV=1MLPPQPSAAHQGRGGRSGLLPKGPAMLCRLCWLVSYSLAVLLLGCLLFLRKAAKPAGDPTAHQPFWAPPTPRHSRCPPNHTVSSASLSLPSRHRLFLTYRHCRNFSILLEPSGCSKDTFLLLAIKSQPGHVERRAAIRSTWGRVGGWARGRQLKLVFLLGVAGSAPPAQLLAYESREFDDILQWDFTEDFFNLTLKELHLQRWVVAACPQAHFMLKGDDDVFVHVPNVLEFLDGWDPAQDLLVGDVIRQALPNRNTKVKYFIPPSMYRATHYPPYAGGGGYVMSRATVRRLQAIMEDAELFPIDDVFVGMCLRRLGLSPMHHAGFKTFGIRRPLDPLDPCLYRGLLLVHRLSPLEMWTMWALVTDEGLKCAAGPIPQR>sp|Q9C0J1-2|B3GN4_HUMAN Isoform 2 of N-acetyllactosaminide beta-1,3-N-acetylglucosaminyltransferase 4 OS=Homo sapiens OX=9606 GN=B3GNT4MLCRLCWLVSYSLAVLLLGCLLFLRKAAKPAGDPTAHQPFWAPPTPRHSRCPPNHTVSSASLSLPSRHRLFLTYRHCRNFSILLEPSGCSKDTFLLLAIKSQPGHVERRAAIRSTWGRVGGWARGRQLKLVFLLGVAGSAPPAQLLAYESREFDDILQWDFTEDFFNLTLKELHLQRWVVAACPQAHFMLKGDDDVFVHVPNVLEFLDGWDPAQDLLVGDVIRQALPNRNTKVKYFIPPSMYRATHYPPYAGGGGYVMSRATVRRLQAIMEDAELFPIDDVFVGMCLRRLGLSPMHHAGFKTFGIRRPLDPLDPCLYRGLLLVHRLSPLEMWTMWALVTDEGLKCAAGPIPQR>sp|Q5XKL5|BTBD8_HUMAN BTB/POZ domain-containing protein 8 OS=Homosapiens OX=9606 GN=BTBD8 PE=2 SV=2MARCGEGSAAPMVLLGSAGVCSKGLQRKGPCERRRLKATVSEQLSQDLLRLLREEFHTDVTFSVGCTLFKAHKAVLLARVPDFYFHTIGQTSNSLTNQEPIAVENVEALEFRTFLQIIYSSNRNIKNYEEEILRKKIMEIGISQKQLDISFPKCENSSDCSLQKHEIPEDISDRDDDFISNDNYDLEPASELGEDLLKLYVKPCCPDIDIFVDGKRFKAHRAILSARSSYFAAMLSGCWAESSQEYVTLQGISHVELNVMMHFIYGGTLDIPDKTNVGQILNMADMYGLEGLKEVAIYILRRDYCNFFQKPVPRTLTSILECLIIAHSVGVESLFADCMKWIVKHFARFWSERSFANIPPEIQKSCLNMLIQSLVSIT>sp|Q5XKL5-2|BTBD8_HUMAN Isoform 2 of BTB/POZ domain-containing protein 8OS=Homo sapiens OX=9606 GN=BTBD8MARCGEGSAAPMVLLGSAGVCSKGLQRKGPCERRRLKATVSEQLSQDLLRLLREEFHTDVTFSVGCTLFKAHKAVLLARVPDFYFHTIGQTSNSLTNQEPIAVENVEALEFRTFLQIIYSSNRNIKNYEEEILRKKIMEIGISQKQLDISFPKCENSSDCSLQKHEIPEDISDRDDDFISNDNYDLEPASELGEDLLKLYVKPCCPDIDIFVDGKRFKAHRAILSARSSYFAAMLSGCWAESSQEYVTLQGISHVELNVMMHFIYGGTLDIPDKTNVGYVFLFNNLKYKRVRFCFVELCCKVLMK>sp|Q9Y2F9|BTBD3_HUMAN BTB/POZ domain-containing protein 3 OS=Homosapiens OX=9606 GN=BTBD3 PE=1 SV=1MVDDKEKNMKCLTFFLMLPETVKNRSKKSSKKANTSSSSSNSSKLPPVCYEIITLKTKKKKMAADIFPRKKPANSSSTSVQQYHQQNLSNNNLIPAPNWQGLYPTIRERNAMMFNNDLMADVHFVVGPPGGTQRLPGHKYVLAVGSSVFHAMFYGELAEDKDEIRIPDVEPAAFLAMLKYIYCDEIDLAADTVLATLYAAKKYIVPHLARACVNFLETSLSAKNACVLLSQSCLFEEPDLTQRCWEVIDAQAELALKSEGFCDIDFQTLESILRRETLNAKEIVVFEAALNWAEVECQRQDLALSIENKRKVLGKALYLIRIPTMALDDFANGAAQSGVLTLNETNDIFLWYTAAKKPELQFVSKARKGLVPQRCHRFQSCAYRSNQWRYRGRCDSIQFAVDKRVFIAGFGLYGSSCGSAEYSAKIELKRQGVVLGQNLSKYFSDGSSNTFPVWFEYPVQIEPDTFYTASVILDGNELSYFGQEGMTEVQCGKVTVQFQCSSDSTNGTGVQGGQIPELIFYA>sp|Q9Y2F9-2|BTBD3_HUMAN Isoform 2 of BTB/POZ domain-containing protein 3OS=Homo sapiens OX=9606 GN=BTBD3MAADIFPRKKPANSSSTSVQQYHQQNLSNNNLIPAPNWQGLYPTIRERNAMMFNNDLMADVHFVVGPPGGTQRLPGHKYVLAVGSSVFHAMFYGELAEDKDEIRIPDVEPAAFLAMLKYIYCDEIDLAADTVLATLYAAKKYIVPHLARACVNFLETSLSAKNACVLLSQSCLFEEPDLTQRCWEVIDAQAELALKSEGFCDIDFQTLESILRRETLNAKEIVVFEAALNWAEVECQRQDLALSIENKRKVLGKALYLIRIPTMALDDFANGAAQSGVLTLNETNDIFLWYTAAKKPELQFVSKARKGLVPQRCHRFQSCAYRSNQWRYRGRCDSIQFAVDKRVFIAGFGLYGSSCGSAEYSAKIELKRQGVVLGQNLSKYFSDGSSNTFPVWFEYPVQIEPDTFYTASVILDGNELSYFGQEGMTEVQCGKVTVQFQCSSDSTNGTGVQGGQIPELIFYA>sp|Q9Y2C3|B3GT5_HUMAN Beta-1,3-galactosyltransferase 5 OS=Homo sapiensOX=9606 GN=B3GALT5 PE=1 SV=1MAFPKMRLMYICLLVLGALCLYFSMYSLNPFKEQSFVYKKDGNFLKLPDTDCRQTPPFLVLLVTSSHKQLAERMAIRQTWGKERMVKGKQLKTFFLLGTTSSAAETKEVDQESQRHGDIIQKDFLDVYYNLTLKTMMGIEWVHRFCPQAAFVMKTDSDMFINVDYLTELLLKKNRTTRFFTGFLKLNEFPIRQPFSKWFVSKSEYPWDRYPPFCSGTGYVFSGDVASQVYNVSKSVPYIKLEDVFVGLCLERLNIRLEELHSQPTFFPGGLRFSVCLFRRIVACHFIKPRTLLDYWQALENSRGEDCPPV>sp|P20290|BTF3_HUMAN Transcription factor BTF3 OS=Homo sapiens OX=9606GN=BTF3 PE=1 SV=1MRRTGAPAQADSRGRGRARGGCPGGEATLSQPPPRGGTRGQEPQMKETIMNQEKLAKLQAQVRIGGKGTARRKKKVVHRTATADDKKLQFSLKKLGVNNISGIEEVNMFTNQGTVIHFNNPKVQASLAANTFTITGHAETKQLTEMLPSILNQLGADSLTSLRRLAEALPKQSVDGKAPLATGEDDDDEVPDLVENFDEASKNEAN>sp|P20290-2|BTF3_HUMAN Isoform 2 of Transcription factor BTF3 OS=Homosapiens OX=9606 GN=BTF3MKETIMNQEKLAKLQAQVRIGGKGTARRKKKVVHRTATADDKKLQFSLKKLGVNNISGIEEVNMFTNQGTVIHFNNPKVQASLAANTFTITGHAETKQLTEMLPSILNQLGADSLTSLRRLAEALPKQSVDGKAPLATGEDDDDEVPDLVENFDEASKNEAN>sp|Q16520|BATF_HUMAN Basic leucine zipper transcriptional factor ATF-like OS=Homo sapiens OX=9606 GN=BATF PE=1 SV=1MPHSSDSSDSSFSRSPPPGKQDSSDDVRRVQRREKNRIAAQKSRQRQTQKADTLHLESEDLEKQNAALRKEIKQLTEELKYFTSVLNSHEPLCSVLAASTPSPPEVVYSAHAFHQPHVSSPRFQP>sp|Q5H9J7|BEX5_HUMAN Protein BEX5 OS=Homo sapiens OX=9606 GN=BEX5 PE=1SV=1MENVPKENKVVEKAPVQNEAPALGGGEYQEPGGNVKGVWAPPAPGFGEDVPNRLVDNIDMIDGDGDDMERFMEEMRELRRKIRELQLRYSLRILIGDPPHHDHHDEFCLMP>sp|Q99708|CTIP_HUMAN DNA endonuclease RBBP8 OS=Homo sapiens OX=9606GN=RBBP8 PE=1 SV=2MNISGSSCGSPNSADTSSDFKDLWTKLKECHDREVQGLQVKVTKLKQERILDAQRLEEFFTKNQQLREQQKVLHETIKVLEDRLRAGLCDRCAVTEEHMRKKQQEFENIRQQNLKLITELMNERNTLQEENKKLSEQLQQKIENDQQHQAAELECEEDVIPDSPITAFSFSGVNRLRRKENPHVRYIEQTHTKLEHSVCANEMRKVSKSSTHPQHNPNENEILVADTYDQSQSPMAKAHGTSSYTPDKSSFNLATVVAETLGLGVQEESETQGPMSPLGDELYHCLEGNHKKQPFEESTRNTEDSLRFSDSTSKTPPQEELPTRVSSPVFGATSSIKSGLDLNTSLSPSLLQPGKKKHLKTLPFSNTCISRLEKTRSKSEDSALFTHHSLGSEVNKIIIQSSNKQILINKNISESLGEQNRTEYGKDSNTDKHLEPLKSLGGRTSKRKKTEEESEHEVSCPQASFDKENAFPFPMDNQFSMNGDCVMDKPLDLSDRFSAIQRQEKSQGSETSKNKFRQVTLYEALKTIPKGFSSSRKASDGNCTLPKDSPGEPCSQECIILQPLNKCSPDNKPSLQIKEENAVFKIPLRPRESLETENVLDDIKSAGSHEPIKIQTRSDHGGCELASVLQLNPCRTGKIKSLQNNQDVSFENIQWSIDPGADLSQYKMDVTVIDTKDGSQSKLGGETVDMDCTLVSETVLLKMKKQEQKGEKSSNEERKMNDSLEDMFDRTTHEEYESCLADSFSQAADEEEELSTATKKLHTHGDKQDKVKQKAFVEPYFKGDERETSLQNFPHIEVVRKKEERRKLLGHTCKECEIYYADMPAEEREKKLASCSRHRFRYIPPNTPENFWEVGFPSTQTCMERGYIKEDLDPCPRPKRRQPYNAIFSPKGKEQKT>sp|Q99708-2|CTIP_HUMAN Isoform 2 of DNA endonuclease RBBP8 OS=Homosapiens OX=9606 GN=RBBP8MNISGSSCGSPNSADTSSDFKDLWTKLKECHDREVQGLQVKVTKLKQERILDAQRLEEFFTKNQQLREQQKVLHETIKVLEDRLRAGLCDRCAVTEEHMRKKQQEFENIRQQNLKLITELMNERNTLQEENKKLSEQLQQKIENDQQHQAAELECEEDVIPDSPITAFSFSGVNRLRRKENPHVRYIEQTHTKLEHSVCANEMRKVSKSSTHPQHNPNENEILVADTYDQSQSPMAKAHGTSSYTPDKSSFNLATVVAETLGLGVQEESETQGPMSPLGDELYHCLEGNHKKQPFEESTRNTEDSLRFSDSTSKTPPQEELPTRVSSPVFGATSSIKSGLDLNTSLSPSLLQPGKKKHLKTLPFSNTCISRLEKTRSKSEDSALFTHHSLGSEVNKIIIQSSNKQILINKNISESLGEQNRTEYGKDSNTDKHLEPLKSLGGRTSKRKKTEEESEHEVSCPQASFDKENAFPFPMDNQFSMNGDCVMDKPLDLSDRFSAIQRQEKSQGSETSKNKFRQVTLYEALKTIPKGFSSSRKASDGNCTLPKDSPGEPCSQECIILQPLNKCSPDNKPSLQIKEENAVFKIPLRPRESLETENVLDDIKSAGSHEPIKIQTRSDHGGCELASVLQLNPCRTGKIKSLQNNQDVSFENIQWSIDPGADLSQYKMDVTVIDTKDGSQSKLGGETVDMDCTLVSETVLLKMKKQEQKGEKSSMLFYINEERKMNDSLEDMFDRTTHEEYESCLADSFSQAADEEEELSTATKKLHTHGDKQDKVKQKAFVEPYFKGDERETSLQNFPHIEVVRKKEERRKLLGHTCKECEIYYADMPAEEREKKLASCSRHRFRYIPPNTPENFWEVGFPSTQTCMERGYIKEDLDPCPRPKRRQPYNAIFSPKGKEQKT>sp|Q99708-3|CTIP_HUMAN Isoform 3 of DNA endonuclease RBBP8 OS=Homosapiens OX=9606 GN=RBBP8MNISGSSCGSPNSADTSSDFKDLWTKLKECHDREVQGLQVKVTKLKQERILDAQRLEEFFTKNQQLREQQKVLHETIKVLEDRLRAGLCDRCAVTEEHMRKKQQEFENIRQQNLKLITELMNERNTLQEENKKLSEQLQQKIENDQQHQAAELECEEDVIPDSPITAFSFSGVNRLRRKENPHVRYIEQTHTKLEHSVCANEMRKVSKSSTHPQHNPNENEILVADTYDQSQSPMAKAHGTSSYTPDKSSFNLATVVAETLGLGVQEESETQGPMSPLGDELYHCLEGNHKKQPFEESTRNTEDSLRFSDSTSKTPPQEELPTRVSSPVFGATSSIKSGLDLNTSLSPSLLQPGKKKHLKTLPFSNTCISRLEKTRSKSEDSALFTHHSLGSEVNKIIIQSSNKQILINKNISESLGEQNRTEYGKDSNTDKHLEPLKSLGGRTSKRKKTEEESEHEVSCPQASFDKENAFPFPMDNQFSMNGDCVMDKPLDLSDRFSAIQRQEKSQGSETSKNKFRQVTLYEALKTIPKGFSSSRKASDGNCTLPKDSPGEPCSQECIILQPLNKCSPDNKPSLQIKEENAVFKIPLRPRESLETENVLDDIKSAGSHEPIKIQTRSDHGGCELASVLQLNPCRTGKIKSLQNNQDVSFENIQWSIDPGADLSQYKMDVTVIDTKDGSQSKLGGETVDMDCTLVSETVLLKMKKQEQKGEKSSNEERKMNDSLEDMFDRTTHEEYESCLADSFSQAADEEEELSTATKKLHTHGDKQDKVKQKAFVEPYFKGDESIMQICQQKKEKRNWLPAQDTDSATFHPTHQRIFGKLVFLPLRLVWKEVILRKILILVLVQKDVSLTTQYFLQKARSRRHRR>sp|Q9UIG0|BAZ1B_HUMAN Tyrosine-protein kinase BAZ1B OS=Homo sapiensOX=9606 GN=BAZ1B PE=1 SV=2MAPLLGRKPFPLVKPLPGEEPLFTIPHTQEAFRTREEYEARLERYSERIWTCKSTGSSQLTHKEAWEEEQEVAELLKEEFPAWYEKLVLEMVHHNTASLEKLVDTAWLEIMTKYAVGEECDFEVGKEKMLKVKIVKIHPLEKVDEEATEKKSDGACDSPSSDKENSSQIAQDHQKKETVVKEDEGRRESINDRARRSPRKLPTSLKKGERKWAPPKFLPHKYDVKLQNEDKIISNVPADSLIRTERPPNKEIVRYFIRHNALRAGTGENAPWVVEDELVKKYSLPSKFSDFLLDPYKYMTLNPSTKRKNTGSPDRKPSKKSKTDNSSLSSPLNPKLWCHVHLKKSLSGSPLKVKNSKNSKSPEEHLEEMMKMMSPNKLHTNFHIPKKGPPAKKPGKHSDKPLKAKGRSKGILNGQKSTGNSKSPKKGLKTPKTKMKQMTLLDMAKGTQKMTRAPRNSGGTPRTSSKPHKHLPPAALHLIAYYKENKDREDKRSALSCVISKTARLLSSEDRARLPEELRSLVQKRYELLEHKKRWASMSEEQRKEYLKKKREELKKKLKEKAKERREKEMLERLEKQKRYEDQELTGKNLPAFRLVDTPEGLPNTLFGDVAMVVEFLSCYSGLLLPDAQYPITAVSLMEALSADKGGFLYLNRVLVILLQTLLQDEIAEDYGELGMKLSEIPLTLHSVSELVRLCLRRSDVQEESEGSDTDDNKDSAAFEDNEVQDEFLEKLETSEFFELTSEEKLQILTALCHRILMTYSVQDHMETRQQMSAELWKERLAVLKEENDKKRAEKQKRKEMEAKNKENGKVENGLGKTDRKKEIVKFEPQVDTEAEDMISAVKSRRLLAIQAKKEREIQEREMKVKLERQAEEERIRKHKAAAEKAFQEGIAKAKLVMRRTPIGTDRNHNRYWLFSDEVPGLFIEKGWVHDSIDYRFNHHCKDHTVSGDEDYCPRSKKANLGKNASMNTQHGTATEVAVETTTPKQGQNLWFLCDSQKELDELLNCLHPQGIRESQLKERLEKRYQDIIHSIHLARKPNLGLKSCDGNQELLNFLRSDLIEVATRLQKGGLGYVEETSEFEARVISLEKLKDFGECVIALQASVIKKFLQGFMAPKQKRRKLQSEDSAKTEEVDEEKKMVEEAKVASALEKWKTAIREAQTFSRMHVLLGMLDACIKWDMSAENARCKVCRKKGEDDKLILCDECNKAFHLFCLRPALYEVPDGEWQCPACQPATARRNSRGRNYTEESASEDSEDDESDEEEEEEEEEEEEEDYEVAGLRLRPRKTIRGKHSVIPPAARSGRRPGKKPHSTRRSQPKAPPVDDAEVDELVLQTKRSSRRQSLELQKCEEILHKIVKYRFSWPFREPVTRDEAEDYYDVITHPMDFQTVQNKCSCGSYRSVQEFLTDMKQVFTNAEVYNCRGSHVLSCMVKTEQCLVALLHKHLPGHPYVRRKRKKFPDRLAEDEGDSEPEAVGQSRGRRQKK>sp|Q9UIG0-2|BAZ1B_HUMAN Isoform 2 of Tyrosine-protein kinase BAZ1BOS=Homo sapiens OX=9606 GN=BAZ1BMAPLLGRKPFPLVKPLPGEEPLFTIPHTQEAFRTREEYEARLERYSERIWTCKSTGSSQLTHKEAWEEEQEVAELLKEEFPAWYEKLVLEMVHHNTASLEKLVDTAWLEIMTKYAVGEECDFEVGKEKMLKVKIVKIHPLEKVDEEATEKKSDGACDSPSSDKENSSQIAQDHQKKETVVKEDEGRRESINDRARRSPRKLPTSLKKGERKWAPPKFLPHKYDVKLQNEDKIISNVPADSLIRTERPPNKEIVRYFIRHNALRAGTGENAPWVVEDELVKKYSLPSKFSDFLLDPYKYMTLNPSTKRKNTGSPDRKPSKKSKTDNSSLSSPLNPKLWCHVHLKKSLSGSPLKVKNSKNSKSPEEHLEEMMKMMSPNKLHTNFHIPKKGPPAKKPGKHSDKPLKAKGRSKGILNGQKSTGNSKSPKKGLKTPKTKMKQMTLLDMAKGTQKMTRAPRNSGGTPRTSSKPHKHLPPAALHLIAYYKENKDREDKRSALSCVISKTARLLSSEDRARLPEELRSLVQKRYELLEHKKRWASMSEEQRKEYLKKKREELKKKLKEKAKERREKEMLERLEKQKRYEDQELTGKNLPAFRLVDTPEGLPNTLFGDVAMVVEFLSCYSGLLLPDAQYPITAVSLMEALSADKGGFLYLNRVLVILLQDEIAEDYGELGMKLSEIPLTLHSVSELVRLCLRRSDVQEESEGSDTDDNKDSAAFEDNEVQDEFLEKLETSEFFELTSEEKLQILTALCHRILMTYSVQDHMETRQQMSAELWKERLAVLKEENDKKRAEKQKRKEMEAKNKENGKVENGLGKTDRKKEIVKFEPQVDTEAEDMISAVKSRRLLAIQAKKEREIQEREMKVKLERQAEEERIRKHKAAAEKAFQEGIAKAKLVMRRTPIGTDRNHNRYWLFSDEVPGLFIEKGWVHDSIDYRFNHHCKDHTVSGDEDYCPRSKKANLGKNASMNTQHGTATEVAVETTTPKQGQNLWFLCDSQKELDELLNCLHPQGIRESQLKERLEKRYQDIIHSIHLARKPNLGLKSCDGNQELLNFLRSDLIEVATRLQKGGLGYVEETSEFEARVISLEKLKDFGECVIALQASVIKKFLQGFMAPKQKRRKLQSEDSAKTEEVDEEKKMVEEAKVASALEKWKTAIREAQTFSRMHVLLGMLDACIKWDMSAENARCKVCRKKGEDDKLILCDECNKAFHLFCLRPALYEVPDGEWQCPACQPATARRNSRGRNYTEESASEDSEDDESDEEEEEEEEEEEEEDYEVAGLRLRPRKTIRGKHSVIPPAARSGRRPGKKPHSTRRSQPKAPPVDDAEVDELVLQTKRSSRRQSLELQKCEEILHKIVKYRFSWPFREPVTRDEAEDYYDVITHPMDFQTVQNKCSCGSYRSVQEFLTDMKQVFTNAEVYNCRGSHVLSCMVKTEQCLVALLHKHLPGHPYVRRKRKKFPDRLAEDEGDSEPEAVGQSRGRRQKK>sp|Q99933|BAG1_HUMAN BAG family molecular chaperone regulator 1 OS=Homosapiens OX=9606 GN=BAG1 PE=1 SV=4MAQRGGARRPRGDRERLGSRLRALRPGREPRQSEPPAQRGPPPSGRPPARSTASGHDRPTRGAAAGARRPRMKKKTRRRSTRSEELTRSEELTLSEEATWSEEATQSEEATQGEEMNRSQEVTRDEESTRSEEVTREEMAAAGLTVTVTHSNEKHDLHVTSQQGSSEPVVQDLAQVVEEVIGVPQSFQKLIFKGKSLKEMETPLSALGIQDGCRVMLIGKKNSPQEEVELKKLKHLEKSVEKIADQLEELNKELTGIQQGFLPKDLQAEALCKLDRRVKATIEQFMKILEEIDTLILPENFKDSRLKRKGLVKKVQAFLAECDTVEQNICQETERLQSTNFALAE>sp|Q99933-2|BAG1_HUMAN Isoform 2 of BAG family molecular chaperoneregulator 1 OS=Homo sapiens OX=9606 GN=BAG1MAQRGGARRPRGDRERLGSRLRALRPGREPRQSEPPAQRGPPPSGRPPARSTASGHDRPTRGAAAGARRPRMKKKTRRRSTRSEELTRSEELTLSEEATWSEEATQSEEATQGEEMNRSQEVTRDEESTRSEEVTREEMAAAGLTVTVTHSNEKHDLHVTSQQGSSEPVVQDLAQVVEEVIGVPQSFQKLIFKGKSLKEMETPLSALGIQDGCRVMLIGKKNSPQEEVELKKLKHLEKSVEKIADQLEELNKELTGIQQGFLPKDLQAEALCKLDRRVKATIEQFMKILEEIDTLILPENFPTLTLVLNEK>sp|Q99933-3|BAG1_HUMAN Isoform 3 of BAG family molecular chaperoneregulator 1 OS=Homo sapiens OX=9606 GN=BAG1MKKKTRRRSTRSEELTRSEELTLSEEATWSEEATQSEEATQGEEMNRSQEVTRDEESTRSEEVTREEMAAAGLTVTVTHSNEKHDLHVTSQQGSSEPVVQDLAQVVEEVIGVPQSFQKLIFKGKSLKEMETPLSALGIQDGCRVMLIGKKNSPQEEVELKKLKHLEKSVEKIADQLEELNKELTGIQQGFLPKDLQAEALCKLDRRVKATIEQFMKILEEIDTLILPENFKDSRLKRKGLVKKVQAFLAECDTVEQNICQETERLQSTNFALAE>sp|Q99933-4|BAG1_HUMAN Isoform 4 of BAG family molecular chaperoneregulator 1 OS=Homo sapiens OX=9606 GN=BAG1MNRSQEVTRDEESTRSEEVTREEMAAAGLTVTVTHSNEKHDLHVTSQQGSSEPVVQDLAQVVEEVIGVPQSFQKLIFKGKSLKEMETPLSALGIQDGCRVMLIGKKNSPQEEVELKKLKHLEKSVEKIADQLEELNKELTGIQQGFLPKDLQAEALCKLDRRVKATIEQFMKILEEIDTLILPENFKDSRLKRKGLVKKVQAFLAECDTVEQNICQETERLQSTNFALAE>sp|Q8IWQ3|BRSK2_HUMAN Serine/threonine-protein kinase BRSK2 OS=Homosapiens OX=9606 GN=BRSK2 PE=1 SV=3MTSTGKDGGAQHAQYVGPYRLEKTLGKGQTGLVKLGVHCVTCQKVAIKIVNREKLSESVLMKVEREIAILKLIEHPHVLKLHDVYENKKYLYLVLEHVSGGELFDYLVKKGRLTPKEARKFFRQIISALDFCHSHSICHRDLKPENLLLDEKNNIRIADFGMASLQVGDSLLETSCGSPHYACPEVIRGEKYDGRKADVWSCGVILFALLVGALPFDDDNLRQLLEKVKRGVFHMPHFIPPDCQSLLRGMIEVDAARRLTLEHIQKHIWYIGGKNEPEPEQPIPRKVQIRSLPSLEDIDPDVLDSMHSLGCFRDRNKLLQDLLSEEENQEKMIYFLLLDRKERYPSQEDEDLPPRNEIDPPRKRVDSPMLNRHGKRRPERKSMEVLSVTDGGSPVPARRAIEMAQHGQRSRSISGASSGLSTSPLSSPRVTPHPSPRGSPLPTPKGTPVHTPKESPAGTPNPTPPSSPSVGGVPWRARLNSIKNSFLGSPRFHRRKLQVPTPEEMSNLTPESSPELAKKSWFGNFISLEKEEQIFVVIKDKPLSSIKADIVHAFLSIPSLSHSVISQTSFRAEYKATGGPAVFQKPVKFQVDITYTEGGEAQKENGIYSVTFTLLSGPSRRFKRVVETIQAQLLSTHDPPAAQHLSDTTNCMEMMTGRLSKCGSPLSNFFDVIKQLFSDEKNGQAAQAPSTPAKRSAHGPLGDSAAAGPGPGGDAEYPTGKDTAKMGPPTARREQP>sp|Q8IWQ3-2|BRSK2_HUMAN Isoform 2 of Serine/threonine-protein kinaseBRSK2 OS=Homo sapiens OX=9606 GN=BRSK2MTSTGKDGGAQHAQYVGPYRLEKTLGKGQTGLVKLGVHCVTCQKVAIKIVNREKLSESVLMKVEREIAILKLIEHPHVLKLHDVYENKKYLYLVLEHVSGGELFDYLVKKGRLTPKEARKFFRQIISALDFCHSHSICHRDLKPENLLLDEKNNIRIADFGMASLQVGDSLLETSCGSPHYACPEVIRGEKYDGRKADVWSCGVILFALLVGALPFDDDNLRQLLEKVKRGVFHMPHFIPPDCQSLLRGMIEVDAARRLTLEHIQKHIWYIGGKNEPEPEQPIPRKVQIRSLPSLEDIDPDVLDSMHSLGCFRDRNKLLQDLLSEEENQEKMIYFLLLDRKERYPSQEDEDLPPRNEIDPPRKRVDSPMLNRHGKRRPERKSMEVLSVTDGGSPVPARRAIEMAQHGQRSRSISGASSGLSTSPLSSPRVTPHPSPRGSPLPTPKGTPVHTPKESPAGTPNPTPPSSPSVGGVPWRARLNSIKNSFLGSPRFHRRKLQVPTPEEMSNLTPESSPELAKKSWFGNFISLEKEEQIFVVIKDKPLSSIKADIVHAFLSIPSLSHSVISQTSFRAEYKATGGPAVFQKPVKFQVDITYTEGGEAQKENGIYSVTFTLLSGPSRRFKRVVETIQAQLLSTHDPPAAQHLSEPPPPAPGLSWGAGLKGQKVATSYESSL>sp|Q8IWQ3-3|BRSK2_HUMAN Isoform 3 of Serine/threonine-protein kinaseBRSK2 OS=Homo sapiens OX=9606 GN=BRSK2MTSTGKDGGAQHAQYVGPYRLEKTLGKGQTGLVKLGVHCVTCQKVAIKIVNREKLSESVLMKVEREIAILKLIEHPHVLKLHDVYENKKYLYLVLEHVSGGELFDYLVKKGRLTPKEARKFFRQIISALDFCHSHSICHRDLKPENLLLDEKNNIRIADFGMASLQVGDSLLETSCGSPHYACPEVIRGEKYDGRKADVWSCGVILFALLVGALPFDDDNLRQLLEKVKRGVFHMPHFIPPDCQSLLRGMIEVDAARRLTLEHIQKHIWYIGGKNEPEPEQPIPRKVQIRSLPSLEDIDPDVLDSMHSLGCFRDRNKLLQDLLSEEENQEKMIYFLLLDRKERYPSQEDEDLPPRNEIDPPRKRVDSPMLNRHGKRRPERKSMEVLSVTDGGSPVPARRAIEMAQHGQRSRSISGASSGLSTSPLSSPRVTPHPSPRGSPLPTPKGTPVHTPKESPAGTPNPTPPSSPSVGGVPWRARLNSIKNSFLGSPRFHRRKLQVPTPEEMSNLTPESSPELAKKSWFGNFISLEKEEQIFVVIKDKPLSSIKADIVHAFLSIPSLSHSVISQTSFRAEYKATGGPAVFQKPVKFQVDITYTEGGEAQKENGIYSVTFTLLSGPSRRFKRVVETIQAQLLSTHDPPAAQHLSDTTNCMEMMTGRLSKCGIIPKS>sp|Q8IWQ3-4|BRSK2_HUMAN Isoform 4 of Serine/threonine-protein kinaseBRSK2 OS=Homo sapiens OX=9606 GN=BRSK2MTSTGKDGGAQHAQYVGPYRLEKTLGKGQTGLVKLGVHCVTCQKVAIKIVNREKLSESVLMKVEREIAILKLIEHPHVLKLHDVYENKKYLYLVLEHVSGGELFDYLVKKGRLTPKEARKFFRQIISALDFCHSHSICHRDLKPENLLLDEKNNIRIADFGMASLQVGDSLLETSCGSPHYACPEVIRGEKYDGRKADVWSCGVILFALLVGALPFDDDNLRQLLEKVKRGVFHMPHFIPPDCQSLLRGMIEVDAARRLTLEHIQKHIWYIGGKNEPEPEQPIPRKVQIRSLPSLEDIDPDVLDSMHSLGCFRDRNKLLQDLLSEEENQEKMIYFLLLDRKERYPSQEDEDLPPRNEIDPPRKRVDSPMLNRHGKRRPERKSMEVLSVTDGGSPVPARRAIEMAQHGQSKAMFSKSLDIAEAHPQFSKEDRSRSISGASSGLSTSPLSSPRVTPHPSPRGSPLPTPKGTPVHTPKESPAGTPNPTPPSSPSVGGVPWRARLNSIKNSFLGSPRFHRRKLQVPTPEEMSNLTPESSPELAKKSWFGNFISLEKEEQIFVVIKDKPLSSIKADIVHAFLSIPSLSHSVISQTSFRAEYKATGGPAVFQKPVKFQVDITYTEGGEAQKENGIYSVTFTLLSGPSRRFKRVVETIQAQLLSTHDPPAAQHLSEPPPPAPGLSWGAGLKGQKVATSYESSL>sp|Q8IWQ3-5|BRSK2_HUMAN Isoform 5 of Serine/threonine-protein kinaseBRSK2 OS=Homo sapiens OX=9606 GN=BRSK2MSPEGHPSRWARPRRPCICPSSLCSPREPRSGPAVGRGGAAHHRVPAGHTPGPQLLQPHLHLPQGQTWLCLQPSPAGLVKLGVHCVTCQKVAIKIVNREKLSESVLMKVEREIAILKLIEHPHVLKLHDVYENKKYLYLVLEHVSGGELFDYLVKKGRLTPKEARKFFRQIISALDFCHSHSICHRDLKPENLLLDEKNNIRIADFGMASLQVGDSLLETSCGSPHYACPEVIRGEKYDGRKADVWSCGVILFALLVGALPFDDDNLRQLLEKVKRGVFHMPHFIPPDCQSLLRGMIEVDAARRLTLEHIQKHIWYIGGKNEPEPEQPIPRKVQIRSLPSLEDIDPDVLDSMHSLGCFRDRNKLLQDLLSEEENQEKMIYFLLLDRKERYPSQEDEDLPPRNEIDPPRKRVDSPMLNRHGKRRPERKSMEVLSVTDGGSPVPARRAIEMAQHGQRSRSISGASSGLSTSPLSSPRVTPHPSPRGSPLPTPKGTPVHTPKESPAGTPNPTPPSSPSVGGVPWRARLNSIKNSFLGSPRFHRRKLQVPTPEEMSNLTPESSPELAKKSWFGNFISLEKEEQIFVVIKDKPLSSIKADIVHAFLSIPSLSHSVISQTSFRAEYKATGGPAVFQKPVKFQVDITYTEGGEAQKENGIYSVTFTLLSGPSRRFKRVVETIQAQLLSTHDPPAAQHLSDTTNCMEMMTGRLSKCDEKNGQAAQAPSTPAKRSAHGPLGDSAAAGPGPGGDAEYPTGKDTAKMGPPTARREQP>sp|Q8IWQ3-6|BRSK2_HUMAN Isoform 6 of Serine/threonine-protein kinaseBRSK2 OS=Homo sapiens OX=9606 GN=BRSK2MKVEREIAILKLIEHPHVLKLHDVYENKKYLYLVLEHVSGGELFDYLVKKGRLTPKEARKFFRQIISALDFCHSHSICHRDLKPENLLLDEKNNIRIADFGMASLQVGDSLLETSCGSPHYACPEVIRGEKYDGRKADVWSCGVILFALLVGALPFDDDNLRQLLEKVKRGVFHMPHFIPPDCQSLLRGMIEVDAARRLTLEHIQKHIWYIGGKNEPEPEQPIPRKVQIRSLPSLEDIDPDVLDSMHSLGCFRDRNKLLQDLLSEEENQEKMIYFLLLDRKERYPSQEDEDLPPRNEIDPPRKRVDSPMLNRHGKRRPERKSMEVLSVTDGGSPVPARRAIEMAQHGQRSRSISGASSGLSTSPLSSPRVTPHPSPRGSPLPTPKGTPVHTPKESPAGTPNPTPPSSPSVGGVPWRARLNSIKNSFLGSPRFHRRKLQVPTPEEMSNLTPESSPELAKKSWFGNFISLEKEEQIFVVIKDKPLSSIKADIVHAFLSIPSLSHSVISQTSFRAEYKATGGPAVFQKPVKFQVDITYTEGGEAQKENGIYSVTFTLLSGPSRRFKRVVETIQAQLLSTHDPPAAQHLSEPPPPAPGLSWGAGLKGQKVATSYESSL>sp|Q13075|BIRC1_HUMAN Baculoviral IAP repeat-containing protein 1OS=Homo sapiens OX=9606 GN=NAIP PE=1 SV=3MATQQKASDERISQFDHNLLPELSALLGLDAVQLAKELEEEEQKERAKMQKGYNSQMRSEAKRLKTFVTYEPYSSWIPQEMAAAGFYFTGVKSGIQCFCCSLILFGAGLTRLPIEDHKRFHPDCGFLLNKDVGNIAKYDIRVKNLKSRLRGGKMRYQEEEARLASFRNWPFYVQGISPCVLSEAGFVFTGKQDTVQCFSCGGCLGNWEEGDDPWKEHAKWFPKCEFLRSKKSSEEITQYIQSYKGFVDITGEHFVNSWVQRELPMASAYCNDSIFAYEELRLDSFKDWPRESAVGVAALAKAGLFYTGIKDIVQCFSCGGCLEKWQEGDDPLDDHTRCFPNCPFLQNMKSSAEVTPDLQSRGELCELLETTSESNLEDSIAVGPIVPEMAQGEAQWFQEAKNLNEQLRAAYTSASFRHMSLLDISSDLATDHLLGCDLSIASKHISKPVQEPLVLPEVFGNLNSVMCVEGEAGSGKTVLLKKIAFLWASGCCPLLNRFQLVFYLSLSSTRPDEGLASIICDQLLEKEGSVTEMCVRNIIQQLKNQVLFLLDDYKEICSIPQVIGKLIQKNHLSRTCLLIAVRTNRARDIRRYLETILEIKAFPFYNTVCILRKLFSHNMTRLRKFMVYFGKNQSLQKIQKTPLFVAAICAHWFQYPFDPSFDDVAVFKSYMERLSLRNKATAEILKATVSSCGELALKGFFSCCFEFNDDDLAEAGVDEDEDLTMCLMSKFTAQRLRPFYRFLSPAFQEFLAGMRLIELLDSDRQEHQDLGLYHLKQINSPMMTVSAYNNFLNYVSSLPSTKAGPKIVSHLLHLVDNKESLENISENDDYLKHQPEISLQMQLLRGLWQICPQAYFSMVSEHLLVLALKTAYQSNTVAACSPFVLQFLQGRTLTLGALNLQYFFDHPESLSLLRSIHFPIRGNKTSPRAHFSVLETCFDKSQVPTIDQDYASAFEPMNEWERNLAEKEDNVKSYMDMQRRASPDLSTGYWKLSPKQYKIPCLEVDVNDIDVVGQDMLEILMTVFSASQRIELHLNHSRGFIESIRPALELSKASVTKCSISKLELSAAEQELLLTLPSLESLEVSGTIQSQDQIFPNLDKFLCLKELSVDLEGNINVFSVIPEEFPNFHHMEKLLIQISAEYDPSKLVKLIQNSPNLHVFHLKCNFFSDFGSLMTMLVSCKKLTEIKFSDSFFQAVPFVASLPNFISLKILNLEGQQFPDEETSEKFAYILGSLSNLEELILPTGDGIYRVAKLIIQQCQQLHCLRVLSFFKTLNDDSVVEIAKVAISGGFQKLENLKLSINHKITEEGYRNFFQALDNMPNLQELDISRHFTECIKAQATTVKSLSQCVLRLPRLIRLNMLSWLLDADDIALLNVMKERHPQSKYLTILQKWILPFSPIIQK>sp|Q13075-2|BIRC1_HUMAN Isoform 2 of Baculoviral IAP repeat-containingprotein 1 OS=Homo sapiens OX=9606 GN=NAIPMPLHIGDFVWDSKVHSLQSSLNIFSLLPTKGRTEHLFFSHILSFHWPAFSSIRLELWINLRCEFLRSKKSSEEITQYIQSYKGFVDITGEHFVNSWVQRELPMASAYCNDSIFAYEELRLDSFKDWPRESAVGVAALAKAGLFYTGIKDIVQCFSCGGCLEKWQEGDDPLDDHTRCFPNCPFLQNMKSSAEVTPDLQSRGELCELLETTSESNLEDSIAVGPIVPEMAQGEAQWFQEAKNLNEQLRAAYTSASFRHMSLLDISSDLATDHLLGCDLSIASKHISKPVQEPLVLPEVFGNLNSVMCVEGEAGSGKTVLLKKIAFLWASGCCPLLNRFQLVFYLSLSSTRPDEGLASIICDQLLEKEGSVTEMCVRNIIQQLKNQVLFLLDDYKEICSIPQVIGKLIQKNHLSRTCLLIAVRTNRARDIRRYLETILEIKAFPFYNTVCILRKLFSHNMTRLRKFMVYFGKNQSLQKIQKTPLFVAAICAHWFQYPFDPSFDDVAVFKSYMERLSLRNKATAEILKATVSSCGELALKGFFSCCFEFNDDDLAEAGVDEDEDLTMCLMSKFTAQRLRPFYRFLSPAFQEFLAGMRLIELLDSDRQEHQDLGLYHLKQINSPMMTVSAYNNFLNYVSSLPSTKAGPKIVSHLLHLVDNKESLENISENDDYLKHQPEISLQMQLLRGLWQICPQAYFSMVSEHLLVLALKTAYQSNTVAACSPFVLQFLQGRTLTLGALNLQYFFDHPESLSLLRSIHFPIRGNKTSPRAHFSVLETCFDKSQVPTIDQDYASAFEPMNEWERNLAEKEDNVKSYMDMQRRASPDLSTGYWKLSPKQYKIPCLEVDVNDIDVVGQDMLEILMTVFSASQRIELHLNHSRGFIESIRPALELSKASVTKCSISKLELSAAEQELLLTLPSLESLEVSGTIQSQDQIFPNLDKFLCLKELSVDLEGNINVFSVIPEEFPNFHHMEKLLIQISAEYDPSKLVKLIQNSPNLHVFHLKCNFFSDFGSLMTMLVSCKKLTEIKFSDSFFQAVPFVASLPNFISLKILNLEGQQFPDEETSEKFAYILGSLSNLEELILPTGDGIYRVAKLIIQQCQQLHCLRVLSFFKTLNDDSVVEIAKVAISGGFQKLENLKLSINHKITEEGYRNFFQALDNMPNLQELDISRHFTECIKAQATTVKSLSQCVLRLPRLIRLNMLSWLLDADDIALLNVMKERHPQSKYLTILQKWILPFSPIIQK>sp|Q13072|BAGE1_HUMAN B melanoma antigen 1 OS=Homo sapiens OX=9606GN=BAGE PE=1 SV=1MAARAVFLALSAQLLQARLMKEESPVVSWRLEPEDGTALCFIF>sp|Q86Y30|BAGE2_HUMAN B melanoma antigen 2 OS=Homo sapiens OX=9606GN=BAGE2 PE=2 SV=1MAAGVVFLALSAQLLQARLMKEESPVVSWRLEPEDGTALDVHFVSTLEPLSNAVKRNVPRCIIILVLQEPTAFRISVTSSCFVQNTLTKLLKDRRKMQTVQCATARETS>sp|Q9BPU9|B9D2_HUMAN B9 domain-containing protein 2 OS=Homo sapiensOX=9606 GN=B9D2 PE=1 SV=2MAEVHVIGQIIGASGFSESSLFCKWGIHTGAAWKLLSGVREGQTQVDTPQIGDMAYWSHPIDLHFATKGLQGWPRLHFQVWSQDSFGRCQLAGYGFCHVPSSPGTHQLACPTWRPLGSWREQLARAFVGGGPQLLHGDTIYSGADRYRLHTAAGGTVHLEIGLLLRNFDRYGVEC>sp|P51813|BMX_HUMAN Cytoplasmic tyrosine-protein kinase BMX OS=Homosapiens OX=9606 GN=BMX PE=1 SV=1MDTKSILEELLLKRSQQKKKMSPNNYKERLFVLTKTNLSYYEYDKMKRGSRKGSIEIKKIRCVEKVNLEEQTPVERQYPFQIVYKDGLLYVYASNEESRSQWLKALQKEIRGNPHLLVKYHSGFFVDGKFLCCQQSCKAAPGCTLWEAYANLHTAVNEEKHRVPTFPDRVLKIPRAVPVLKMDAPSSSTTLAQYDNESKKNYGSQPPSSSTSLAQYDSNSKKIYGSQPNFNMQYIPREDFPDWWQVRKLKSSSSSEDVASSNQKERNVNHTTSKISWEFPESSSSEEEENLDDYDWFAGNISRSQSEQLLRQKGKEGAFMVRNSSQVGMYTVSLFSKAVNDKKGTVKHYHVHTNAENKLYLAENYCFDSIPKLIHYHQHNSAGMITRLRHPVSTKANKVPDSVSLGNGIWELKREEITLLKELGSGQFGVVQLGKWKGQYDVAVKMIKEGSMSEDEFFQEAQTMMKLSHPKLVKFYGVCSKEYPIYIVTEYISNGCLLNYLRSHGKGLEPSQLLEMCYDVCEGMAFLESHQFIHRDLAARNCLVDRDLCVKVSDFGMTRYVLDDQYVSSVGTKFPVKWSAPEVFHYFKYSSKSDVWAFGILMWEVFSLGKQPYDLYDNSQVVLKVSQGHRLYRPHLASDTIYQIMYSCWHELPEKRPTFQQLLSSIEPLREKDKH>sp|Q8WXS3|BAALC_HUMAN Brain and acute leukemia cytoplasmic proteinOS=Homo sapiens OX=9606 GN=BAALC PE=1 SV=4MGCGGSRADAIEPRYYESWTRETESTWLTYTDSDAPPSAAAPDSGPEAGGLHSGMLEDGLPSNGVPRSTAPGGIPNPEKKTNCETQCPNPQSLSSGPLTQKQNGLQTTEAKRDAKRMPAKEVTINVTDSIQQMDRSRRITKNCVN>sp|Q8WXS3-1|BAALC_HUMAN Isoform 2 of Brain and acute leukemiacytoplasmic protein OS=Homo sapiens OX=9606 GN=BAALCMGCGGSRADAIEPRYYESWTRETESTWLTYTDSDAPPSAAAPDSGPEAGGLHSVLEAEKSKIKAPTDSVSDEGLFSASKMAPLAVFSHGMLEDGLPSNGVPRSTAPGGIPNPEKKTNCETQCPNPQSLSSGPLTQKQNGLQTTEAKRDAKRMPAKEVTINVTDSIQQMDRSRRITKNCVN>sp|Q8WXS3-3|BAALC_HUMAN Isoform 3 of Brain and acute leukemiacytoplasmic protein OS=Homo sapiens OX=9606 GN=BAALCMGCGGSRADAIEPRYYESWTRETESTWLTYTDSDAPPSAAAPDSGPEAGGLHSVLEAEKSKIKAPTDSVSDEGLFSASKMAPLAVFSHGMLEDGLPSNGVPRSTAPGGIPNPEKKTNCETQCPNPQSLSSGPLTQKQNGLQTTEVLLPS>sp|Q8WXS3-4|BAALC_HUMAN Isoform 4 of Brain and acute leukemiacytoplasmic protein OS=Homo sapiens OX=9606 GN=BAALCMGCGGSRADAIEPRYYESWTRETESTWLTYTDSDAPPSAAAPDSGPEAGGLHSAHYPLAFALAWRDNSLGALLVQEGLCR>sp|Q8WXS3-5|BAALC_HUMAN Isoform 5 of Brain and acute leukemiacytoplasmic protein OS=Homo sapiens OX=9606 GN=BAALCMGCGGSRADAIEPRYYESWTRETESTWLTYTDSDAPPSAAAPDSGPEAGGLHSGCLEEHYHLTALQKVGHPNH>sp|Q8WXS3-6|BAALC_HUMAN Isoform 6 of Brain and acute leukemiacytoplasmic protein OS=Homo sapiens OX=9606 GN=BAALCMGCGGSRADAIEPRYYESWTRETESTWLTYTDSDAPPSAAAPDSGPEAGGLHSG>sp|Q01954|BNC1_HUMAN Zinc finger protein basonuclin-1 OS=Homo sapiensOX=9606 GN=BNC1 PE=1 SV=2MRRRPPSRGGRGAARARETRRQPRHRSGRRMAEAISCTLNCSCQSFKPGKINHRQCDQCKHGWVAHALSKLRIPPMYPTSQVEIVQSNVVFDISSLMLYGTQAIPVRLKILLDRLFSVLKQDEVLQILHALDWTLQDYIRGYVLQDASGKVLDHWSIMTSEEEVATLQQFLRFGETKSIVELMAIQEKEEQSIIIPPSTANVDIRAFIESCSHRSSSLPTPVDKGNPSSIHPFENLISNMTFMLPFQFFNPLPPALIGSLPEQYMLEQGHDQSQDPKQEVHGPFPDSSFLTSSSTPFQVEKDQCLNCPDAITKKEDSTHLSDSSSYNIVTKFERTQLSPEAKVKPERNSLGTKKGRVFCTACEKTFYDKGTLKIHYNAVHLKIKHKCTIEGCNMVFSSLRSRNRHSANPNPRLHMPMNRNNRDKDLRNSLNLASSENYKCPGFTVTSPDCRPPPSYPGSGEDSKGQPAFPNIGQNGVLFPNLKTVQPVLPFYRSPATPAEVANTPGILPSLPLLSSSIPEQLISNEMPFDALPKKKSRKSSMPIKIEKEAVEIANEKRHNLSSDEDMPLQVVSEDEQEACSPQSHRVSEEQHVQSGGLGKPFPEGERPCHRESVIESSGAISQTPEQATHNSERETEQTPALIMVPREVEDGGHEHYFTPGMEPQVPFSDYMELQQRLLAGGLFSALSNRGMAFPCLEDSKELEHVGQHALARQIEENRFQCDICKKTFKNACSVKIHHKNMHVKEMHTCTVEGCNATFPSRRSRDRHSSNLNLHQKALSQEALESSEDHFRAAYLLKDVAKEAYQDVAFTQQASQTSVIFKGTSRMGSLVYPITQVHSASLESYNSGPLSEGTILDLSTTSSMKSESSSHSSWDSDGVSEEGTVLMEDSDGNCEGSSLVPGEDEYPICVLMEKADQSLASLPSGLPITCHLCQKTYSNKGTFRAHYKTVHLRQLHKCKVPGCNTMFSSVRSRNRHSQNPNLHKSLASSPSHLQ>sp|Q6UX04|CWC27_HUMAN Spliceosome-associated protein CWC27 homologOS=Homo sapiens OX=9606 GN=CWC27 PE=1 SV=1MSNIYIQEPPTNGKVLLKTTAGDIDIELWSKEAPKACRNFIQLCLEAYYDNTIFHRVVPGFIVQGGDPTGTGSGGESIYGAPFKDEFHSRLRFNRRGLVAMANAGSHDNGSQFFFTLGRADELNNKHTIFGKVTGDTVYNMLRLSEVDIDDDERPHNPHKIKSCEVLFNPFDDIIPREIKRLKKEKPEEEVKKLKPKGTKNFSLLSFGEEAEEEEEEVNRVSQSMKGKSKSSHDLLKDDPHLSSVPVVESEKGDAPDLVDDGEDESAEHDEYIDGDEKNLMRERIAKKLKKDTSANVKSAGEGEVEKKSVSRSEELRKEARQLKRELLAAKQKKVENAAKQAEKRSEEEEAPPDGAVAEYRREKQKYEALRKQQSKKGTSREDQTLALLNQFKSKLTQAIAETPENDIPETEVEDDEGWMSHVLQFEDKSRKVKDASMQDSDTFEIYDPRNPVNKRRREESKKLMREKKERR>sp|Q6UX04-2|CWC27_HUMAN Isoform 2 of Spliceosome-associated proteinCWC27 homolog OS=Homo sapiens OX=9606 GN=CWC27MSNIYIQEPPTNGKVLLKTTAGDIDIELWSKEAPKACRNFIQLCLEAYYDNTIFHRVVPGFIVQGGDPTGTGSGGESIYGAPFKDEFHSRLRFNRRGLVAMANAGSHDNGSQFFFTLGRADELNNKHTIFGKVTGDTVYNMLRLSEVDIDDDERPHNPHKIKSCEVLFNPFDDIIPREIKRLKKEKPEEEVKKLKPKGTKNFSLLSFGEEAEEEEEEVNRVSQSMKGKSKSSHDLLKDDPHLSSVPVVESEKGDAPDLVDDGEDESAEHDEYIDGDEKNLMRERIAKKLKKDTSANVKSAGEGEVEKKSVSRSEELRKEARQLKRELLAAKQKKVENAAKQAEKRSEEEEAPPDGAVAEYRREKQKYEALRKQQSKKGTSREDQDVTCTS>sp|Q9BWK5|CYREN_HUMAN Cell cycle regulator of non-homologous end joiningOS=Homo sapiens OX=9606 GN=CYREN PE=1 SV=2METLQSETKTRVLPSWLTAQVATKNVAPMKAPKRMRMAAVPVAAARLPATRTVYCMNEAEIVDVALGILIESRKQEKACEQPALAGADNPEHSPPCSVSPHTSSGSSSEEEDSGKQALAPGLSPSQRPGGSSSACSRSPEEEEEEDVLKYVREIFFS>sp|Q9BWK5-2|CYREN_HUMAN Isoform 2 of Cell cycle regulator of non-homologous end joining OS=Homo sapiens OX=9606 GN=CYRENMRLESLCHLCLACLFFRLPATRTVYCMNEAEIVDVALGILIESRKQEKACEQPALAGADNPEHSPPCSVSPHTSSGSSSEEEDSGKQALAPGLSPSQRPGGSSSACSRSPEEEEEEDVLKYVREIFFS>sp|Q9BWK5-3|CYREN_HUMAN Isoform 3 of Cell cycle regulator of non-homologous end joining OS=Homo sapiens OX=9606 GN=CYRENMNEAEIVDVALGILIESRKQEKACEQPALAGADNPEHSPPCSVSPHTSSGSSSEEEDSGKQALAPGLSPSQRPGGSSSACSRSPEEEEEEDVLKYVREIFFS>sp|Q9BWK5-4|CYREN_HUMAN Isoform 4 of Cell cycle regulator of non-homologous end joining OS=Homo sapiens OX=9606 GN=CYRENMETLQSETKTRVLPSWLTAQVATKNVAPMKAPKRMRMAAVPVAAARCDSSGQKTPANLTPCDKDCVLHE>sp|Q9P0U4|CXXC1_HUMAN CXXC-type zinc finger protein 1 OS=Homo sapiensOX=9606 GN=CXXC1 PE=1 SV=2MEGDGSDPEPPDAGEDSKSENGENAPIYCICRKPDINCFMIGCDNCNEWFHGDCIRITEKMAKAIREWYCRECREKDPKLEIRYRHKKSRERDGNERDSSEPRDEGGGRKRPVPDPDLQRRAGSGTGVGAMLARGSASPHKSSPQPLVATPSQHHQQQQQQIKRSARMCGECEACRRTEDCGHCDFCRDMKKFGGPNKIRQKCRLRQCQLRARESYKYFPSSLSPVTPSESLPRPRRPLPTQQQPQPSQKLGRIREDEGAVASSTVKEPPEATATPEPLSDEDLPLDPDLYQDFCAGAFDDHGLPWMSDTEESPFLDPALRKRAVKVKHVKRREKKSEKKKEERYKRHRQKQKHKDKWKHPERADAKDPASLPQCLGPGCVRPAQPSSKYCSDDCGMKLAANRIYEILPQRIQQWQQSPCIAEEHGKKLLERIRREQQSARTRLQEMERRFHELEAIILRAKQQAVREDEESNEGDSDDTDLQIFCVSCGHPINPRVALRHMERCYAKYESQTSFGSMYPTRIEGATRLFCDVYNPQSKTYCKRLQVLCPEHSRDPKVPADEVCGCPLVRDVFELTGDFCRLPKRQCNRHYCWEKLRRAEVDLERVRVWYKLDELFEQERNVRTAMTNRAGLLALMLHQTIQHDPLTTDLRSSADR>sp|Q9P0U4-2|CXXC1_HUMAN Isoform 2 of CXXC-type zinc finger protein 1OS=Homo sapiens OX=9606 GN=CXXC1MEGDGSDPEPPDAGEDSKSENGENAPIYCICRKPDINCFMIGCDNCNEWFHGDCIRITEKMAKAIREWYCRECREKDPKLEIRYRHKKSRERDGNERDSSEPRDEGGGRKRPVPDPDLQRRAGSGTGVGAMLARGSASPHKSSPQPLVATPSQHHQQQQQQIKRSARMCGECEACRRTEDCGHCDFCRDMKKFGGPNKIRQKCRLRQCQLRARESYKYFPSSLSPVTPSESLPRPRRPLPTQQQPQPSQKLGRIREDEGAVASSTVKEPPEATATPEPLSDEDLPLDPDLYQDFCAGAFDDHGLPWMSDTEESPFLDPALRKRAVKVKHVKRREKKSEKKVMERKEERYKRHRQKQKHKDKWKHPERADAKDPASLPQCLGPGCVRPAQPSSKYCSDDCGMKLAANRIYEILPQRIQQWQQSPCIAEEHGKKLLERIRREQQSARTRLQEMERRFHELEAIILRAKQQAVREDEESNEGDSDDTDLQIFCVSCGHPINPRVALRHMERCYAKYESQTSFGSMYPTRIEGATRLFCDVYNPQSKTYCKRLQVLCPEHSRDPKVPADEVCGCPLVRDVFELTGDFCRLPKRQCNRHYCWEKLRRAEVDLERVRVWYKLDELFEQERNVRTAMTNRAGLLALMLHQTIQHDPLTTDLRSSADR>sp|Q13829|BACD2_HUMAN BTB/POZ domain-containing adapter for CUL3-mediated RhoA degradation protein 2 OS=Homo sapiens OX=9606 GN=TNFAIP1PE=1 SV=1MSGDTCLCPASGAKPKLSGFKGGGLGNKYVQLNVGGSLYYTTVRALTRHDTMLKAMFSGRMEVLTDKEGWILIDRCGKHFGTILNYLRDDTITLPQNRQEIKELMAEAKYYLIQGLVNMCQSALQDKKDSYQPVCNIPIITSLKEEERLIESSTKPVVKLLYNRSNNKYSYTSNSDDHLLKNIELFDKLSLRFNGRVLFIKDVIGDEICCWSFYGQGRKLAEVCCTSIVYATEKKQTKVEFPEARIYEETLNVLLYETPRVPDNSLLEATSRSRSQASPSEDEETFELRDRVRRIHVKRYSTYDDRQLGHQSTHRD>sp|Q13829-2|BACD2_HUMAN Isoform 2 of BTB/POZ domain-containing adapterfor CUL3-mediated RhoA degradation protein 2 OS=Homo sapiens OX=9606GN=TNFAIP1MAEAKYYLIQGLVNMCQSALQDKKDSYQPVCNIPIITSLKEEERLIESSTKPVVKLLYNRSNNKYSYTSNSDDHLLKNIELFDKLSLRFNGRVLFIKDVIGDEICCWSFYGQGRKLAEVCCTSIVYATEKKQTKVEFPEARIYEETLNVLLYETPRVPDNSLLEATSRSRSQASPSEDEETFELRDRVRRIHVKRYSTYDDRQLGHQSTHRD>sp|Q16611|BAK_HUMAN Bcl-2 homologous antagonist/killer OS=Homo sapiensOX=9606 GN=BAK1 PE=1 SV=1MASGQGPGPPRQECGEPALPSASEEQVAQDTEEVFRSYVFYRHQQEQEAEGVAAPADPEMVTLPLQPSSTMGQVGRQLAIIGDDINRRYDSEFQTMLQHLQPTAENAYEYFTKIATSLFESGINWGRVVALLGFGYRLALHVYQHGLTGFLGQVTRFVVDFMLHHCIARWIAQRGGWVAALNLGNGPILNVLVVLGVVLLGQFVVRRFFKS>sp|Q16611-2|BAK_HUMAN Isoform 2 of Bcl-2 homologous antagonist/killerOS=Homo sapiens OX=9606 GN=BAK1MASGQGPGPPRQECGEPALPSASEEQVAQDTEEVFRSYVFYRHQQEQEAEGVAAPADPEMVTLPLQPSSTMGQVGRQLAIIGDDINRRYDSEFQTMLQHLQPTAENAYEYFTKIATRPAATPTACLRVASIGAVWWLFWASATVWPYTSTSMA>sp|Q96G97|BSCL2_HUMAN Seipin OS=Homo sapiens OX=9606 GN=BSCL2 PE=1 SV=3MVNDPPVPALLWAQEVGQVLAGRARRLLLQFGVLFCTILLLLWVSVFLYGSFYYSYMPTVSHLSPVHFYYRTDCDSSTTSLCSFPVANVSLTKGGRDRVLMYGQPYRVTLELELPESPVNQDLGMFLVTISCYTRGGRIISTSSRSVMLHYRSDLLQMLDTLVFSSLLLFGFAEQKQLLEVELYADYRENSYVPTTGAIIEIHSKRIQLYGAYLRIHAHFTGLRYLLYNFPMTCAFIGVASNFTFLSVIVLFSYMQWVWGGIWPRHRFSLQVNIRKRDNSRKEVQRRISAHQPGPEGQEESTPQSDVTEDGESPEDPSGTEGQLSEEEKPDQQPLSGEEELEPEASDGSGSWEDAALLTEANLPAPAPASASAPVLETLGSSEPAGGALRQRPTCSSS>sp|Q96G97-3|BSCL2_HUMAN Isoform 2 of Seipin OS=Homo sapiens OX=9606GN=BSCL2MVNDPPVPALLWAQEVGQVLAGRARRLLLQFGVLFCTILLLLWVSVFLYGSFYYSYMPTVSHLSPVHFYYRTDCDSSTTSLCSFPVANVSLTKGGRDRVLMYGQPYRVTLELELPESPVNQDLGMFLVTISCYTRGGRIISTSSRSVMLHYRSDLLQMLDTLVFSSLLLFGFAEQKQLLEVELYADYRENSYVPTTGAIIEIHSKRIQLYGAYLRIHAHFTGLRLTSEKETIPGRKSNEGSLLISQGLKARRSQLRNQMLQRMVRALKIPQGQRVSCPRRRNQISSP>sp|Q96G97-4|BSCL2_HUMAN Isoform 3 of Seipin OS=Homo sapiens OX=9606GN=BSCL2MSTEKVDQKEEAGEKEVCGDQIKGPDKEEEPPAAASHGQGWRPGGRAARNARPEPGARHPALPAMVNDPPVPALLWAQEVGQVLAGRARRLLLQFGVLFCTILLLLWVSVFLYGSFYYSYMPTVSHLSPVHFYYRTDCDSSTTSLCSFPVANVSLTKGGRDRVLMYGQPYRVTLELELPESPVNQDLGMFLVTISCYTRGGRIISTSSRSVMLHYRSDLLQMLDTLVFSSLLLFGFAEQKQLLEVELYADYRENSYVPTTGAIIEIHSKRIQLYGAYLRIHAHFTGLRYLLYNFPMTCAFIGVASNFTFLSVIVLFSYMQWVWGGIWPRHRFSLQVNIRKRDNSRKEVQRRISAHQPGPEGQEESTPQSDVTEDGESPEDPSGTEGQLSEEEKPDQQPLSGEEELEPEASDGSGSWEDAALLTEANLPAPAPASASAPVLETLGSSEPAGGALRQRPTCSSS>sp|Q6UXY1|BI2L2_HUMAN Brain-specific angiogenesis inhibitor 1-associatedprotein 2-like protein 2 OS=Homo sapiens OX=9606 GN=BAIAP2L2 PE=1 SV=1MAPEMDQFYRSTMAIYKSIMEQFNPALENLVYLGNNYLRAFHALSEAAEVYFSAIQKIGERALQSPTSQILGEILVQMSDTQRHLNSDLEVVVQTFHGGLLQHMEKNTKLDMQFIKDSRQHYELEYRHRAANLEKCMSELWRMERKRDKNVREMKESVNRLHAQMQAFVSESQRAAELEEKRRYRFLAEKHLLLSNTFLQFFGRARGMLQNRVLLWKEQSEASRSPSRAHSPGLLGPALGPPYPSGRLTPTCLDMPPRPLGEFSSPRSRHGSGSYGTEPDARPASQLEPDRRSLPRTPSASSLYSGSAQSSRSNSFGERPGGGGGARRVRALVSHSEGANHTLLRFSAGDVVEVLVPEAQNGWLYGKLEGSSASGWFPEAYVKALEEGPVNPMTPVTPMTSMTSMSPMTPMNPGNELPSRSYPLRGSHSLDDLLDRPGNSIAPSEYWDGQSRSRTPSRVPSRAPSPAPPPLPSSRRSSMGSTAVATDVKKLMSSEQYPPQELFPRGTNPFATVKLRPTITNDRSAPLIR>sp|Q6UXY1-2|BI2L2_HUMAN Isoform 2 of Brain-specific angiogenesisinhibitor 1-associated protein 2-like protein 2 OS=Homo sapiens OX=9606GN=BAIAP2L2MAPEMDQFYRSTMAIYKSIMEQFNPALENLVYLGNNYLRAFHALSEAAEVYFSAIQKIGERALQSPTSQILGEILVQMSDTQRHLNSDLEVVVQTFHGGLLQHMEKNTKLDMQFIKDSRQHYELEYRHRAANLEKCMSELWRMERKRDKNVREMKESVNRLHAQMQAFVSESQRAAELEEKRRYRFLAEKHLLLSNTFLQFFGRARGMLQNRVLLWKEQSEASRSPSRAHSPGLLGPALGPPYPSGRLTPTCLDMPPRPLGEFSSPRSRHGSGSYGTEPDARPASQLEPDRRSLPRTPSASSLYSGSAQSSRSNSFGERPGGGGGARRVRALVSHSEGANHTLLRFSAGDVVEVLVPEAQNGWLYGKLEGSSASGWFPEAYVKALEEGPVNPMTPVTPMTSMTSMSPMTPMNPGNELPSRSYPLRGSHSLDDLLDRPGNSTPSRVPSRAPSPAPPPLPSSRRSSMGSTAVATDVKKLMSSEQYPPQELFPRGTNPFATVKLRPTITNDRSAPLIR>sp|O75936|BODG_HUMAN Gamma-butyrobetaine dioxygenase OS=Homo sapiensOX=9606 GN=BBOX1 PE=1 SV=1MACTIQKAEALDGAHLMQILWYDEEESLYPAVWLRDNCPCSDCYLDSAKARKLLVEALDVNIGIKGLIFDRKKVYITWPDEHYSEFQADWLKKRCFSKQARAKLQRELFFPECQYWGSELQLPTLDFEDVLRYDEHAYKWLSTLKKVGIVRLTGASDKPGEVSKLGKRMGFLYLTFYGHTWQVQDKIDANNVAYTTGKLSFHTDYPALHHPPGVQLLHCIKQTVTGGDSEIVDGFNVCQKLKKNNPQAFQILSSTFVDFTDIGVDYCDFSVQSKHKIIELDDKGQVVRINFNNATRDTIFDVPVERVQPFYAALKEFVDLMNSKESKFTFKMNPGDVITFDNWRLLHGRRSYEAGTEISRHLEGAYADWDVVMSRLRILRQRVENGN>sp|Q14457|BECN1_HUMAN Beclin-1 OS=Homo sapiens OX=9606 GN=BECN1 PE=1SV=2MEGSKTSNNSTMQVSFVCQRCSQPLKLDTSFKILDRVTIQELTAPLLTTAQAKPGETQEEETNSGEEPFIETPRQDGVSRRFIPPARMMSTESANSFTLIGEASDGGTMENLSRRLKVTGDLFDIMSGQTDVDHPLCEECTDTLLDQLDTQLNVTENECQNYKRCLEILEQMNEDDSEQLQMELKELALEEERLIQELEDVEKNRKIVAENLEKVQAEAERLDQEEAQYQREYSEFKRQQLELDDELKSVENQMRYAQTQLDKLKKTNVFNATFHIWHSGQFGTINNFRLGRLPSVPVEWNEINAAWGQTVLLLHALANKMGLKFQRYRLVPYGNHSYLESLTDKSKELPLYCSGGLRFFWDNKFDHAMVAFLDCVQQFKEEVEKGETRFCLPYRMDVEKGKIEDTGGSGGSYSIKTQFNSEEQWTKALKFMLTNLKWGLAWVSSQFYNK>sp|Q13145|BAMBI_HUMAN BMP and activin membrane-bound inhibitor homologOS=Homo sapiens OX=9606 GN=BAMBI PE=1 SV=1MDRHSSYIFIWLQLELCAMAVLLTKGEIRCYCDAAHCVATGYMCKSELSACFSRLLDPQNSNSPLTHGCLDSLASTTDICQAKQARNHSGTTIPTLECCHEDMCNYRGLHDVLSPPRGEASGQGNRYQHDGSRNLITKVQELTSSKELWFRAAVIAVPIAGGLILVLLIMLALRMLRSENKRLQDQRQQMLSRLHYSFHGHHSKKGQVAKLDLECMVPVSGHENCCLTCDKMRQADLSNDKILSLVHWGMYSGHGKLEFV>sp|Q8WYA1|BMAL2_HUMAN Aryl hydrocarbon receptor nuclear translocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2 PE=1 SV=2MAAEEEAAAGGKVLREENQCIAPVVSSRVSPGTRPTAMGSFSSHMTEFPRKRKGSDSDPSQSGIMTEKVVEKLSQNPLTYLLSTRIEISASSGSRVEDGEHQVKMKAFREAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-2|BMAL2_HUMAN Isoform 2 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MAAEEEAAAGGKVLREENQCIAPVVSSRVSPGTRPTAMGSFSSHMTEFPRKRKGSDSDPSQSGIMTEKVVEKLSQNPLTYLLSTRIEISASSGSREAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-3|BMAL2_HUMAN Isoform 3 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MAAEEEAAAGGEVAGGEATAPGKVLREENQCIAPVVSSRVSPGTRPTAMGSFSSHMTEFPRKRKGSDSDPSQEAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-4|BMAL2_HUMAN Isoform 4 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MAAEEEAAAGGKVLREENQCIAPVVSSRVSPGTRPTAMGSFSSHMTEFPRKRKGSDSDPSQEAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-5|BMAL2_HUMAN Isoform 5 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MAAEEEAAAGGKVLREENQCIAPVVSSRVSPGTRPTAMGSFSSHMTEFPRKRKGSDSDPSQVEDGEHQVKMKAFREAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-6|BMAL2_HUMAN Isoform 6 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MGSFSSHMTEFPRKRKGSDSDPSQEAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-7|BMAL2_HUMAN Isoform 7 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MGSFSSHMTEFPRKRKGSDSDPSQSGIMTEKVVEKLSQNPLTYLLSTRIEISASSGSREAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-8|BMAL2_HUMAN Isoform 8 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MGSFSSHMTEFPRKRKGSDSDPSHQNPLTYLLSTRIEISASSGSREAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSMSNKELFPPSPSEMGELEATRQNQSTVAVHSHEPLLSDGAQLDFDALCDNDDTAMAAFMNYLEAEGGLGDPGDFSDIQWTL>sp|Q8WYA1-9|BMAL2_HUMAN Isoform 9 of Aryl hydrocarbon receptor nucleartranslocator-like protein 2 OS=Homo sapiens OX=9606 GN=ARNTL2MAAEEEAAAGGEVAGGEATAPGKVLREENQCIAPVVSSRVSPGTRPTAMGSFSSHMTEFPRKRKGSDSDPSQEAHSQTEKRRRDKMNNLIEELSAMIPQCNPMARKLDKLTVLRMAVQHLRSLKGLTNSYVGSNYRPSFLQDNELRHLILKTAEGFLFVVGCERGKILFVSKSVSKILNYDQASLTGQSLFDFLHPKDVAKVKEQLSSFDISPREKLIDAKTGLQVHSNLHAGRTRVYSGSRRSFFCRIKSCKISVKEEHGCLPNSKKKEHRKFYTIHCTGYLRSWPPNIVGMEEERNSKKDNSNFTCLVAIGRLQPYIVPQNSGEINVKPTEFITRFAVNGKFVYVDQRATAILGYLPQELLGTSCYEYFHQDDHNNLTDKHKAVLQSKEKILTDSYKFRAKDGSFVTLKSQWFSFTNPWTKELEYIVSVNTLVLGHSEPGEASFLPCSSQSSEESSRQSCMSVPGMSTGTVLGAGSIGTDIANEILDLQRLQSSSYLDDSSPTGLMKDTHTVNCRSVMVHSWISMPYVTMMTQPWLHL>sp|Q8TD16|BICD2_HUMAN Protein bicaudal D homolog 2 OS=Homo sapiensOX=9606 GN=BICD2 PE=1 SV=1MSAPSEEEEYARLVMEAQPEWLRAEVKRLSHELAETTREKIQAAEYGLAVLEEKHQLKLQFEELEVDYEAIRSEMEQLKEAFGQAHTNHKKVAADGESREESLIQESASKEQYYVRKVLELQTELKQLRNVLTNTQSENERLASVAQELKEINQNVEIQRGRLRDDIKEYKFREARLLQDYSELEEENISLQKQVSVLRQNQVEFEGLKHEIKRLEEETEYLNSQLEDAIRLKEISERQLEEALETLKTEREQKNSLRKELSHYMSINDSFYTSHLHVSLDGLKFSDDAAEPNNDAEALVNGFEHGGLAKLPLDNKTSTPKKEGLAPPSPSLVSDLLSELNISEIQKLKQQLMQMEREKAGLLATLQDTQKQLEHTRGSLSEQQEKVTRLTENLSALRRLQASKERQTALDNEKDRDSHEDGDYYEVDINGPEILACKYHVAVAEAGELREQLKALRSTHEAREAQHAEEKGRYEAEGQALTEKVSLLEKASRQDRELLARLEKELKKVSDVAGETQGSLSVAQDELVTFSEELANLYHHVCMCNNETPNRVMLDYYREGQGGAGRTSPGGRTSPEARGRRSPILLPKGLLAPEAGRADGGTGDSSPSPGSSLPSPLSDPRREPMNIYNLIAIIRDQIKHLQAAVDRTTELSRQRIASQELGPAVDKDKEALMEEILKLKSLLSTKREQITTLRTVLKANKQTAEVALANLKSKYENEKAMVTETMMKLRNELKALKEDAATFSSLRAMFATRCDEYITQLDEMQRQLAAAEDEKKTLNSLLRMAIQQKLALTQRLELLELDHEQTRRGRAKAAPKTKPATPSL>sp|Q8TD16-2|BICD2_HUMAN Isoform 2 of Protein bicaudal D homolog 2OS=Homo sapiens OX=9606 GN=BICD2MSAPSEEEEYARLVMEAQPEWLRAEVKRLSHELAETTREKIQAAEYGLAVLEEKHQLKLQFEELEVDYEAIRSEMEQLKEAFGQAHTNHKKVAADGESREESLIQESASKEQYYVRKVLELQTELKQLRNVLTNTQSENERLASVAQELKEINQNVEIQRGRLRDDIKEYKFREARLLQDYSELEEENISLQKQVSVLRQNQVEFEGLKHEIKRLEEETEYLNSQLEDAIRLKEISERQLEEALETLKTEREQKNSLRKELSHYMSINDSFYTSHLHVSLDGLKFSDDAAEPNNDAEALVNGFEHGGLAKLPLDNKTSTPKKEGLAPPSPSLVSDLLSELNISEIQKLKQQLMQMEREKAGLLATLQDTQKQLEHTRGSLSEQQEKVTRLTENLSALRRLQASKERQTALDNEKDRDSHEDGDYYEVDINGPEILACKYHVAVAEAGELREQLKALRSTHEAREAQHAEEKGRYEAEGQALTEKVSLLEKASRQDRELLARLEKELKKVSDVAGETQGSLSVAQDELVTFSEELANLYHHVCMCNNETPNRVMLDYYREGQGGAGRTSPGGRTSPEARGRRSPILLPKGLLAPEAGRADGGTGDSSPSPGSSLPSPLSDPRREPMNIYNLIAIIRDQIKHLQAAVDRTTELSRQRIASQELGPAVDKDKEALMEEILKLKSLLSTKREQITTLRTVLKANKQTAEVALANLKSKYENEKAMVTETMMKLRNELKALKEDAATFSSLRAMFATRCDEYITQLDEMQRQLAAAEDEKKTLNSLLRMAIQQKLALTQRLELLELDHEQTRRGRAKAAPKTKPATPSVSHTCACASDRAEGTGLANQVFCSEKHSIYCD>sp|A6NGU7|CX028_HUMAN Putative uncharacterized protein encoded byLINC01546 OS=Homo sapiens OX=9606 GN=LINC01546 PE=5 SV=1MGELAASANHGHSPCYPERKGTPGDLSKRKMLVHFYPRRHSHPRATQQWILKNKTLCRRIKE>sp|A6NGU7-2|CX028_HUMAN Isoform 2 of Putative uncharacterized proteinencoded by LINC01546 OS=Homo sapiens OX=9606 GN=LINC01546MGELAASANHGHSPCYPERKGTPGDLSKRKMLVHFYPRRHSHPRATQQWILKNKTQEGSHLQTKRRVLSRPWICWHPDLGLPASRTMRN>sp|P00167|CYB5_HUMAN Cytochrome b5 OS=Homo sapiens OX=9606 GN=CYB5A PE=1SV=2MAEQSDEAVKYYTLEEIQKHNHSKSTWLILHHKVYDLTKFLEEHPGGEEVLREQAGGDATENFEDVGHSTDAREMSKTFIIGELHPDDRPKLNKPPETLITTIDSSSSWWTNWVIPAISAVAVALMYRLYMAED>sp|P00167-2|CYB5_HUMAN Isoform 2 of Cytochrome b5 OS=Homo sapiensOX=9606 GN=CYB5AMAEQSDEAVKYYTLEEIQKHNHSKSTWLILHHKVYDLTKFLEEHPGGEEVLREQAGGDATENFEDVGHSTDAREMSKTFIIGELHPDDRPKLNKPPEP>sp|P00167-3|CYB5_HUMAN Isoform 3 of Cytochrome b5 OS=Homo sapiensOX=9606 GN=CYB5AMAEQSDEAVKYYTLEEIQKHNHSKSTWLILHHKVYDLTKFLEEHPGGEEVLREQAGGDATENFEDVGHSTDAREMSKTFIIGELHPETLITTIDSSSSWWTNWVIPAISAVAVALMYRLYMAED>sp|Q53S33|BOLA3_HUMAN BolA-like protein 3 OS=Homo sapiens OX=9606GN=BOLA3 PE=1 SV=1MAAWSPAAAAPLLRGIRGLPLHHRMFATQTEGELRVTQILKEKFPRATAIKVTDISGGCGAMYEIKIESEEFKEKRTVQQHQMVNQALKEEIKEMHGLRIFTSVPKR>sp|Q53S33-2|BOLA3_HUMAN Isoform 2 of BolA-like protein 3 OS=Homo sapiensOX=9606 GN=BOLA3MAAWSPAAAAPLLRGIRGLPLHHRMFATQTEGELRVTQILKEKFPRATAIKVTDISGTKRRNQRDAWIADIYLCPQTLTTPWLHRCCCLRPWMNFTDIILP>sp|Q8N9T2|CX042_HUMAN Putative uncharacterized protein CXorf42 OS=Homosapiens OX=9606 GN=NKAPP1 PE=5 SV=3MSRFRGCSSSGVRFCSAEREASGSGRGNVLQFVQEPQAQQSRPFPAGAQLSLELLFSDWGMEWAQPRLPKPALPLPVVVAFSRAADCAVDHHFRFCLLLRLLRQLLTLLRDEEREVNPWQRKIVV>sp|Q7L3V2|BOP_HUMAN Protein Bop OS=Homo sapiens OX=9606 GN=RTL10 PE=1SV=1MPRGRCRQQGPRIPIWAAANYANAHPWQQMDKASPGVAYTPLVDPWIERPCCGDTVCVRTTMEQKSTASGTCGGKPAERGPLAGHMPSSRPHRVDFCWVPGSDPGTFDGSPWLLDRFLAQLGDYMSFHFEHYQDNISRVCEILRRLTGRAQAWAAPYLDGDLPLPDDYELFCQDLKEVVQDPNSFAEYHAVVTCPLPLASSQLPVAPQLPVVRQYLARFLEGLALDMGTAPRSLPAAMATPAVSGSNSVSRSALFEQQLTKESTPGPKEPPVLPSSTCSSKPGPVEPASSQPEEAAPTPVPRLSESANPPAQRPDPAHPGGPKPQKTEEEVLETEGDQEVSLGTPQEVVEAPETPGEPPLSPGF>sp|Q9H503|BAFL_HUMAN Barrier-to-autointegration factor-like proteinOS=Homo sapiens OX=9606 GN=BANF2 PE=1 SV=1MDNMSPRLRAFLSEPIGEKDVCWVDGISHELAINLVTKGINKAYILLGQFLLMHKNEAEFQRWLICCFGATECEAQQTSHCLKEWCACFL>sp|Q9H503-2|BAFL_HUMAN Isoform 2 of Barrier-to-autointegration factor-like protein OS=Homo sapiens OX=9606 GN=BANF2MLRGTKEMDNMSPRLRAFLSEPIGEKDVCWVDGISHELAINLVTKGINKAYILLGQFLLMHKNEAEFQRWLICCFGATECEAQQTSHCLKEWCACFL>sp|Q6ZU67|BEND4_HUMAN BEN domain-containing protein 4 OS=Homo sapiensOX=9606 GN=BEND4 PE=2 SV=3MEEEMQPAEEGPSVPKIYKQRSPYSVLKTFPSKRPALAKRYERPTLVELPHVRAPPPPPPPFAPHAAVSISSSEPPPQQFQAQSSYPPGPGRAAAAASSSSPSCTPATSQGHLRTPAQPPPASPAASSSSSFAAVVRYGPGAAAAAGTGGTGSDSASLELSAESRMILDAFAQQCSRVLSLLNCGGKLLDSNHSQSMISCVKQEGSSYNERQEHCHIGKGVHSQTSDNVDIEMQYMQRKQQTSAFLRVFTDSLQNYLLSGSFPTPNPSSASEYGHLADVDPLSTSPVHTLGGWTSPATSESHGHPSSSTLPEEEEEEDEEGYCPRCQELEQEVISLQQENEELRRKLESIPVPCQTVLDYLKMVLQHHNQLLIPQPADQPTEGSKQLLNNYPVYITSKQWDEAVNSSKKDGRRLLRYLIRFVFTTDELKYSCGLGKRKRSVQSGETGPERRPLDPVKVTCLREFIRMHCTSNPDWWMPSEEQINKVFSDAVGHARQGRAVGTFLHNGGSFYEGIDHQASQDEVFNKSSQDGSGD>sp|Q6ZU67-2|BEND4_HUMAN Isoform 2 of BEN domain-containing protein 4OS=Homo sapiens OX=9606 GN=BEND4MEEEMQPAEEGPSVPKIYKQRSPYSVLKTFPSKRPALAKRYERPTLVELPHVRAPPPPPPPFAPHAAVSISSSEPPPQQFQAQSSYPPGPGRAAAAASSSSPSCTPATSQGHLRTPAQPPPASPAASSSSSFAAVVRYGPGAAAAAGTGGTGSDSASLELSAESRMILDAFAQQCSRVLSLLNCGGKLLDSNHSQSMISCVKQEGSSYNERQEHCHIGKGVHSQTSDNVDIEMQYMQRKQQTSAFLRVFTDSLQNYLLSGSFPTPNPSSASEYGHLADVDPLSTSPVHTLGGWTSPATSESHGHPSSSTLPEEEEEEDEEGYCPRCQELEQEVISLQQENEELRRKLESIPVPCQTVLDYLKMVLQHHNQLLIPQPADQPTEGSKQLLNNYPVYITSKQWDEAVNSSKKDGRRLLRYLIRFVFTTDELKYSCGLGKRKRIH>sp|Q6ZU67-3|BEND4_HUMAN Isoform 3 of BEN domain-containing protein 4OS=Homo sapiens OX=9606 GN=BEND4MQGAPRARFGSRTPPAAAASSSSPSCTPATSQGHLRTPAQPPPASPAASSSSSFAAVVRYGPGAAAAAGTGGTGSDSASLELSAESRMILDAFAQQCSRVLSLLNCGGKLLDSNHSQSMISCVKQEGSSYNERQEHCHIGKGVHSQTSDNVDIEMQYMQRKQQTSAFLRVFTDSLQNYLLSGSFPTPNPSSASEYGHLADVDPLSTSPVHTLGGWTSPATSESHGHPSSSTLPEEEEEEDEEGYCPRCQELEQEVISLQQENEELRRKLESIPVPCQTVLDYLKMVLQHHNQLLIPQPADQPTEGSKQLLNNYPVYITSKQWDEAVNSSKKDGRRLLRYLIRFVFTTDELKYSCGLGKRKRSVQSGETGPERRPLDPVKVTCLRGTASFRSVSPSVISFHRIGCGSPRTSVQPSVF>sp|Q6ZU67-4|BEND4_HUMAN Isoform 4 of BEN domain-containing protein 4OS=Homo sapiens OX=9606 GN=BEND4MEEEMQPAEEGPSVPKIYKQRSPYSVLKTFPSLELSAESRMILDAFAQQCSRVLSLLNCGGKLLDSNHSQSMISCVKQEGSSYNERQEHCHIGKGVHSQTSDNVDIEMQYMQRKQQTSAFLRVFTDSLQNYLLSGSFPTPNPSSASEYGHLADVDPLSTSPVHTLGGWTSPATSESHGHPSSSTLPEEEEEEDEEGYCPRCQELEQEVISLQQENEELRRKLESIPVPCQTVLDYLKMVLQHHNQLLIPQPADQPTEGSKQLLNNYPVYITSKQWDEAVNSSKKDGRRLLRYLIRFVFTTDELKYSCGLGKRKRSVQSGETGPERRPLDPVKVTCLREFIRMHCTSNPDWWMPSEEQINKVFSDAVGHARQGRAVGTFLHNGGSFYEGIDHQASQDEVFNKSSQDGSGD>sp|Q6ZU67-5|BEND4_HUMAN Isoform 5 of BEN domain-containing protein 4OS=Homo sapiens OX=9606 GN=BEND4MEEEMQPAEEGPSVPKIYKQRSPYSVLKTFPSLELSAESRMILDAFAQQCSRVLSLLNCGGKLLDSNHSQSMISCVKQEGSSYNERQEHCHIGKGVHSQTSDNVDIEMQYMQRKQQTSAFLRVFTDSLQNYLLSGSFPTPNPSSASEYGHLADVDPLSTSPVHTLGGWTSPATSESHGHPSSSTLPEEEEEEDEEGYCPRCQELEQEVISLQQENEELRRKLESIPVPCQTVLDYLKMVLQHHNQLLIPQPADQPTEGSKQLLNNYPVYITSKQWDEAVNSSKKDGRRLLRYLIRFVFTTDELKYSCGLGKRKRIH>sp|Q96NH3|BROMI_HUMAN Protein broad-minded OS=Homo sapiens OX=9606GN=TBC1D32 PE=1 SV=4MAHFSSEDQAMLQAMLRRLFQSVKEKITGAPSLECAEEILLHLEETDENFHNYEFVKYLRQHIGNTLGSMIEEEMEKCTSDRNQGEECGYDTVVQQVTKRTQESKEYKEMMHYLKNIMIAVVESMINKFEEDETRNQERQKKIQKEKSHSYRTDNCSDSDSSLNQSYKFCQGKLQLILDQLDPGQPKEVRYEALQTLCSAPPSDVLNCENWTTLCEKLTVSLSDPDPVFSDRILKFCAQTFLLSPLHMTKEIYTSLAKYLESYFLSRENHIPTLSAGVDITNPNMTRLLKKVRLLNEYQKEAPSFWIRHPEKYMEEIVESTLSLLTVKHNQSHVVSQKILDPIYFFALVDTKAVWFKKWMHAHYSRTTVLRLLETKYKSLVTTAIQQCVQYFEMCKTRKADETLGHSKHCRNKQKTFYYLGQELQYIYFIHSLCLLGRLLIYKQGRKLFPIKLKNKKGLVSLIDLLVLFTQLIYYSPSCPKMTSAAHSENYSPASMVTEVLWILSDQKECAVECLYNNIVIETLLQPIHNLMKGNEASPNCSETALIHIAGILARIASVEEGLILLLYGANMNSSEESPTGAHIIAQFSKKLLDEDISIFSGSEMLPVVKGAFISVCRHIYSTCEGLQVLITYNLHESIAKAWKKTSLLSERIPTPVEGSDSVSSVSQESQNIMAWEDNLLDDLLHFAATPKGLLLLQRTGAINECVTFIFNRYAKKLQVSRHKKFGYGVLVTRVASTAAGGIALKKSGFINELITELWSNLEYGRDDVRVTHPRTTPVDPIDRSCQKSFLALVNLLSYPAIYELVRNQDLPNKTEYSLREVPTCVIDIIDRLIILNSEAKIRSLFNYEQSHIFGLRDFIIDGLSVERNHVLVRINLVGGPLERILPPRLLEKSDNPYPWPMFSSYPLPNCYLSDITRNAGIKQDNDLDKLLLCLKISDKQTEWIENCQRQFCKMMKAKPDIISGEALIELLEKFVLHLTESPSECYFPSVEYTATDANVKNESLSSVQQLGIKMTVRYGKFLSLLKDGAENDLTWVLKHCERFLKQQQTSIKSSLLCLQGNYAGHDWFVSSLFMIMLGDKEKTFQFLHQFSRLLTSAFLWLPRLHISSYLPNDTVESGIHPVYFCSTHYIEMLLKAELPLVFSAFHMSGFAPSQICLQWITQCFWNYLDWIEICHYIATCVFLGPDYQVYICIAVFKHLQQDILQHTQTQDLQVFLKEEALHGFRVSDYFEYMEILEQNYRTVLLRDMRNIRLQST>sp|Q96NH3-4|BROMI_HUMAN Isoform 2 of Protein broad-minded OS=Homosapiens OX=9606 GN=TBC1D32MAHFSSEDQAMLQAMLRRLFQSVKEKITGAPSLECAEEILLHLEETDENFHNYEFVKYLRQHIGNTLGSMIEEEMEKCTSDRNQGEECGYDTVVQQVTKRTQESKEYKEMMHYLKNIMIAVVESMINKFEEDETRNQERQKKIQKEKSHSYRTDNCSDSDSSLNQSYKFCQGKLQLILDQLDPGQPKEVRYEALQTLCSAPPSDVLNCENWTTLCEKLTVSLSDPDPVFSDRILKFCAQTFLLSPLHMTKEIYTSLAKYLESYFLSRENHIPTLSAGVDITNPNMTRLLKKVRLLNEYQKEAPSFWIRHPEKYMEEIVESTLSLLTVKHNQSHVVSQKILDPIYFFALVDTKAVWFKKWMHAHYSRTTVLRLLETKYKSLVTTAIQQCVQYFEMCKTRKADETLGHSKHCRNKQKTFYYLGQELQYIYFIHSLCLLGRLLIYKQGRKLFPIKLKNKKGLVSLIDLLVLFTQLIYYSPSCPKMTSAAHSENYSPASMVTEVLWILSDQKECAVECLYNNIVIETLLQPIHNLMKGNEASPNCSETALIHIAGILARIASVEEGLILLLYGANMNSSEESPTGAHIIAQFSKKLLDEDISIFSGSEMLPVVKGAFISVCRHIYSTCEGLQVLITYNLHESIAKAWKKTSLLSERIPTPVEGSDSVSSVSQESQNIMAWEDNLLDDLLHFAATPKGLLLLQRTGAINECVTFIFNRYAKKLQVSRHKKFGYGVLVTRVASTAAGGIALKKSGFINELITELWSNLEYGRDDVRVTHPRTTPVDPIDRSCQKSFLALVNLLSYPAIYELVRNQDLPNKTEYSLREVPTCVIDIIDRLIILNSEAKIRSLFNYEQSHIFGLRLLSVICCDLDTLLLLEAQYQVSEMLLNAQEENILEISESHRDFIIDGLSVERNHVLVRINLVGGPLERILPPRLLEKSDNPYPWPMFSSYPLPNCYLSDITRNAGIKQDNDLDKLLLCLKISDKQTEWIENCQRQFCKMMKAKPDIISGEALIELLEKFVLHLTESPSECYFPSVEYTATDANVKNESLSSVQQLGIKMTVRYGKFLSLLKDGAENDLTWVLKHCERFLKQQQTSIKSSLLCLQGNYAGHDWFVSSLFMIMLGDKEKTFQFLHQFSRLLTSAFLWLPRLHISSYLPNDTVESGIHPVYFCSTHYIEMLLKAELPLVFSAFHMSGFAPSQICLQWITQCFWNYLDWIEICHYIATCVFLGPDYQVYICIAVFKHLQQDILQHTQTQDLQVFLKEEALHGFRVSDYFEYMEILEQNYRTVLLRDMRNIRLQST>sp|Q96NH3-5|BROMI_HUMAN Isoform 3 of Protein broad-minded OS=Homosapiens OX=9606 GN=TBC1D32MAHFSSEDQAMLQAMLRRLFQSVKEKITGAPSLECAEEILLHLEETDENFHNYEFVKYLRQHIGNTLGSMIEEEMEKCTSDRNQGEECGYDTVVQQVTKRTQESKELP>sp|A8MVZ5|BTNLA_HUMAN Butyrophilin-like protein 10 OS=Homo sapiensOX=9606 GN=BTNL10 PE=5 SV=2MAVTCDPEAFLSICFVTLVFLQLPLASIWKADFDVTGPHAPILAMAGGHVELQCQLFPNISAEDMELRWYRCQPSLAVHMHERGMDMDGEQKWQYRGRTTFMSDHVARGKAMVRSHRVTTFDNRTYCCRFKDGVKFGEATVQVQVAGLGREPRIQVTDQQDGVRAECTSAGCFPKSWVERRDFRGQARPAVTNLSASATTRLWAVASSLTLWDRAVEGLSCSISSPLLPERRKVAESHLPATFSRSSQFTAWKAALPLILVAMGLVIAGGICIFWKRQREKNKASLEEERE>sp|Q8NFJ8|BHE22_HUMAN Class E basic helix-loop-helix protein 22 OS=Homosapiens OX=9606 GN=BHLHE22 PE=2 SV=1MERGMHLGAAAAGEDDLFLHKSLSASTSKRLEAAFRSTPPGMDLSLAPPPRERPASSSSSPLGCFEPADPEGAGLLLPPPGGGGGGSAGSGGGGGGGVGVPGLLVGSAGVGGDPSLSSLPAGAALCLKYGESASRGSVAESSGGEQSPDDDSDGRCELVLRAGVADPRASPGAGGGGAKAAEGCSNAHLHGGASVPPGGLGGGGGGGSSSGSSGGGGGSGSGSGGSSSSSSSSSKKSKEQKALRLNINARERRRMHDLNDALDELRAVIPYAHSPSVRKLSKIATLLLAKNYILMQAQALEEMRRLVAYLNQGQAISAASLPSSAAAAAAAAALHPALGAYEQAAGYPFSAGLPPAASCPEKCALFNSVSSSLCKQCTEKP>sp|Q7RTS1|BHA15_HUMAN Class A basic helix-loop-helix protein 15 OS=Homosapiens OX=9606 GN=BHLHA15 PE=1 SV=1MKTKNRPPRRRAPVQDTEATPGEGTPDGSLPNPGPEPAKGLRSRPARAAARAPGEGRRRRPGPSGPGGRRDSSIQRRLESNERERQRMHKLNNAFQALREVIPHVRADKKLSKIETLTLAKNYIKSLTATILTMSSSRLPGLEGPGPKLYQHYQQQQQVAGGALGATEAQPQGHLQRYSTQIHSFREGT>sp|Q6ZT62|BGIN_HUMAN Bargin OS=Homo sapiens OX=9606 GN=BARGIN PE=1 SV=2MDRGLPGPATPAVTPQPPARPQDDEEAAAPHAAAGPDGQLGTVEQRLEPAKRAAHNIHKRLQACLQGQSGADMDKRVKKLPLMALSTTMAESFKELDPDSSMGKALEMSCAIQNQLARILAEFEMTLERDVLQPLSRLSEEELPAILKHKKSLQKLVSDWNTLKSRLSQATKNSGSSQGLGGSPGSHSHTTMANKVETLKEEEEELKRKVEQCRDEYLADLYHFVTKEDSYANYFIRLLEIQADYHRRSLSSLDTALAELRENHGQADHSPSMTATHFPRVYGVSLATHLQELGREIALPIEACVMMLLSEGMKEEGLFRLAAGASVLKRLKQTMASDPHSLEEFCSDPHAVAGALKSYLRELPEPLMTFDLYDDWMRAASLKEPGARLQALQEVCSRLPPENLSNLRYLMKFLARLAEEQEVNKMTPSNIAIVLGPNLLWPPEKEGDQAQLDAASVSSIQVVGVVEALIQSADTLFPGDINFNVSGLFSAVTLQDTVSDRLASEELPSTAVPTPATTPAPAPAPAPAPAPALASAATKERTESEVPPRPASPKVTRSPPETAAPVEDMARRSTGSLAAAVETASGRQALVVGKPSPYMFECITENFSIDPARTLMVGDRLETDILFGHRCGMTTVLTLTGVSRLEEAQAYLAAGQHDLVPHYYVESIADLTEGLED>sp|Q6ZT62-2|BGIN_HUMAN Isoform Short BGIN of Bargin OS=Homo sapiensOX=9606 GN=BARGINMDKRVKKLPLMALSTTMAESFKELDPDSSMGKALEMSCAIQNQLARILAEFEMTLERDVLQPLSRLSEEELPAILKHKKSLQKLVSDWNTLKSRLSQATKNSGSSQGLGGSPGSHSHTTMANKVETLKEEEEELKRKVEQCRDEYLADLYHFVTKEDSYANYFIRLLEIQADYHRRSLSSLDTALAELRENHGQADHSPSMTATHFPRVYGVSLATHLQELGREIALPIEACVMMLLSEGMKEEGLFRLAAGASVLKRLKQTMASDPHSLEEFCSDPHAVAGALKSYLRELPEPLMTFDLYDDWMRAASLKEPGARLQALQEVCSRLPPENLSNLRYLMKFLARLAEEQEVNKMTPSNIAIVLGPNLLWPPEKEGDQAQLDAASVSSIQVVGVVEALIQSADTLFPGDINFNVSGLFSAVTLQDTVSDRLASEELPSTAVPTPATTPAPAPAPAPAPAPALASAATKERTESEVPPRPASPKVTRSPPETAAPVEDMARRSTGSLAAAVETASGRQALVVGKPSPYMFECITENFSIDPARTLMVGDRLETDILFGHRCGMTTVLTLTGVSRLEEAQAYLAAGQHDLVPHYYVESIADLTEGLED>sp|P14091|CATE_HUMAN Cathepsin E OS=Homo sapiens OX=9606 GN=CTSE PE=1SV=3MKTLLLLLLVLLELGEAQGSLHRVPLRRHPSLKKKLRARSQLSEFWKSHNLDMIQFTESCSMDQSAKEPLINYLDMEYFGTISIGSPPQNFTVIFDTGSSNLWVPSVYCTSPACKTHSRFQPSQSSTYSQPGQSFSIQYGTGSLSGIIGADQVSVEGLTVVGQQFGESVTEPGQTFVDAEFDGILGLGYPSLAVGGVTPVFDNMMAQNLVDLPMFSVYMSSNPEGGAGSELIFGGYDHSHFSGSLNWVPVTKQAYWQIALDNIQVGGTVMFCSEGCQAIVDTGTSLITGPSDKIKQLQNAIGAAPVDGEYAVECANLNVMPDVTFTINGVPYTLSPTAYTLLDFVDGMQFCSSGFQGLDIHPPAGPLWILGDVFIRQFYSVFDRGNNRVGLAPAVP>sp|P14091-2|CATE_HUMAN Isoform 2 of Cathepsin E OS=Homo sapiens OX=9606GN=CTSEMKTLLLLLLVLLELGEAQGSLHRVPLRRHPSLKKKLRARSQLSEFWKSHNLDMIQFTESCSMDQSAKEPLINYLDMEYFGTISIGSPPQNFTVIFDTGSSNLWVPSVYCTSPACKTHSRFQPSQSSTYSQPGQSFSIQYGTGSLSGIIGADQVSVEGLTVVGQQFGESVTEPGQTFVDAEFDGILGLGYPSLAVGGVTPVFDNMMAQNLVDLPMFSVYMSSNPEGGAGSELIFGGYDHSHFSGSLNWVPVTKQAYWQIALDNMLWSVPTLTSCRMSPSPLTESPIPSAQLPTPYWTSWMECSSAAVAFKDLTSTLQLGPSGSWGMSSFDSFTQSLTVGITVWDWPQQSPKEGPCVCACLSDRP>sp|P14091-3|CATE_HUMAN Isoform 3 of Cathepsin E OS=Homo sapiens OX=9606GN=CTSEMKTLLLLLLVLLELGEAQGSLHRVPLRRHPSLKKKLRARSQLSEFWKSHNLDMIQFTESCSMDQSAKEPLINYLDMEYFGTISIGSPPQNFTVIFDTGSSNLWVPSVYCTSPACKTHSRFQPSQSSTYSQPGQSFSIQYGTGSLSGIIGADQVSAFATQVEGLTVVGQQFGESVTEPGQTFVDAEFDGILGLGYPSLAVGGVTPVFDNMMAQNLVDLPMFSVYMSSNPEGGAGSELIFGGYDHSHFSGSLNWVPVTKQAYWQIALDNIQVGGTVMFCSEGCQAIVDTGTSLITGPSDKIKQLQNAIGAAPVDGEYAVECANLNVMPDVTFTINGVPYTLSPTAYTLLDFVDGMQFCSSGFQGLDIHPPAGPLWILGDVFIRQFYSVFDRGNNRVGLAPAVP>sp|Q5T5A4|CA194_HUMAN Protein C1orf194 OS=Homo sapiens OX=9606GN=C1orf194 PE=1 SV=1MPPTRDPFQQPTLDNDDSYLGELRASKKLPYKNPTHLAQQQEPWSRLNSTPTITSMRRDAYYFDPEIPKDDLDFRLAALYNHHTGTFKNKSEILLNQKTTQDTYRTKIQFPGEFLTPPTPPITFLANIRHWINPKKESIHSIQGSIVSPHTAATNGGYSRKKDGGFFST>sp|Q5T5A4-2|CA194_HUMAN Isoform 2 of Protein C1orf194 OS=Homo sapiensOX=9606 GN=C1orf194MERSPSRRRRLEEAPKLPYKNPTHLAQQQEPWSRLNSTPTITSMRRDAYYFDPEIPKDDLDFRLAALYNHHTGTFKNKSEILLNQKTTQDTYRTKIQFPGEFLTPPTPPITFLANIRHWINPKKESIHSIQGSIVSPHTAATNGGYSRKKDGGFFST>sp|A0A0U1RR37|CA232_HUMAN Uncharacterized protein C1orf232 OS=Homosapiens OX=9606 GN=C1orf232 PE=4 SV=1MNQAFWKTYKSKVLQTLSGESEEDLAEERENPALVGSETAEPTEETFNPMSQLARRVQGVGVKGWLTMSSLFNKEDEDKLLPSEPCADHPLAARPPSQAAAAAEARGPGFWDAFASRWQQQQAAAASMLRGTEPTPEPDPEPADEAAEEAAERPESQEAEPVAGFKWGFLTHKLAEMRVKAAPKGD>sp|Q8NFJ9|BBS1_HUMAN Bardet-Biedl syndrome 1 protein OS=Homo sapiensOX=9606 GN=BBS1 PE=1 SV=1MAAASSSDSDACGAESNEANSKWLDAHYDPMANIHTFSACLALADLHGDGEYKLVVGDLGPGGQQPRLKVLKGPLVMTESPLPALPAAAATFLMEQHEPRTPALALASGPCVYVYKNLRPYFKFSLPQLPPNPLEQDLWNQAKEDRIDPLTLKEMLESIRETAEEPLSIQSLRFLQLELSEMEAFVNQHKSNSIKRQTVITTMTTLKKNLADEDAVSCLVLGTENKELLVLDPEAFTILAKMSLPSVPVFLEVSGQFDVEFRLAAACRNGNIYILRRDSKHPKYCIELSAQPVGLIRVHKVLVVGSTQDSLHGFTHKGKKLWTVQMPAAILTMNLLEQHSRGLQAVMAGLANGEVRIYRDKALLNVIHTPDAVTSLCFGRYGREDNTLIMTTRGGGLIIKILKRTAVFVEGGSEVGPPPAQAMKLNVPRKTRLYVDQTLREREAGTAMHRAFQTDLYLLRLRAARAYLQALESSLSPLSTTAREPLKLHAVVQGLGPTFKLTLHLQNTSTTRPVLGLLVCFLYNEALYSLPRAFFKVPLLVPGLNYPLETFVESLSNKGISDIIKVLVLREGQSAPLLSAHVNMPGSEGLAAA>sp|Q8NFJ9-2|BBS1_HUMAN Isoform 3 of Bardet-Biedl syndrome 1 proteinOS=Homo sapiens OX=9606 GN=BBS1MDPSWRRSSHSWPQPMPDSGRAPVRPHLAKLEEDVWPCPQFHQTKAASGPPFVNEANSKWLDAHYDPMANIHTFSACLALADLHGDGEYKLVVGDLGPGGQQPRLKVLKGPLVMTESPLPALPAAAATFLMEQHEPRTPALALASGPCVYVYKNLRPYFKFSLPQLPPNPLEQDLWNQAKEDRIDPLTLKEMLESIRETAEEPLSIQSLRFLQLELSEMEAFVNQHKSNSIKRQTVITTMTTLKKNLADEDAVSCLVLGTENKELLVLDPEAFTILAKMSLPSVPVFLEVSGQFDVEFRLAAACRNGNIYILRRDSKHPKYCIELSAQPVGLIRVHKVLVVGSTQDSLHGFTHKGKKLWTVQMPAAILTMNLLEQHSRGLQAVMAGLANGEVRIYRDKALLNVIHTPDAVTSLCFGRYGREDNTLIMTTRGGGLIIKILKRTAVFVEGGSEVGPPPAQAMKLNVPRKTRLYVDQTLREREAGTAMHRAFQTDLYLLRLRAARAYLQALESSLSPLSTTAREPLKLHAVVQGLGPTFKLTLHLQNTSTTRPVLGLLVCFLYNEALYSLPRAFFKVPLLVPGLNYPLETFVESLSNKGISDIIKVLVLREGQSAPLLSAHVNMPGSEGLAAA>sp|Q8NFJ9-3|BBS1_HUMAN Isoform 2 of Bardet-Biedl syndrome 1 proteinOS=Homo sapiens OX=9606 GN=BBS1MAAASSSDSDACGAESNEANSKWLDAHYDPMANIHTFSACLALADLHGDGEYKLVVGDLGPGGQQPRLKVLKGPLVMTESPLPALPAAAATFLMEQHEPRTPALALASGPCVYVYKNLRPYFKFSLPQLPPNPLEQDLWNQAKEDRIDPLTLKEMLESIRETAEEPLSIQSLRFLQLELSEMEAFVNQHKSNSIKRQTVITTMTTLKKNLADEDAVSCLVLGTENKELLVLDPEAFTILAKDAVTSLCFGRYGREDNTLIMTTRGGGLIIKILKRTAVFVEGGSEVGPPPAQAMKLNVPRKTRLYVDQTLREREAGTAMHRAFQTDLYLLRLRAARAYLQALESSLSPLSTTAREPLKLHAVVQGLGPTFKLTLHLQNTSTTRPVLGLLVCFLYNEALYSLPRAFFKVPLLVPGLNYPLETFVESLSNKGISDIIKVGPALVPRGR>sp|Q13939|CALI_HUMAN Calicin OS=Homo sapiens OX=9606 GN=CCIN PE=1 SV=3MKLEFTEKNYNSFVLQNLNRQRKRKEYWDMALSVDNHVFFAHRNVLAAVSPLVRSLISSNDMKTADELFITIDTSYLSPVTVDQLLDYFYSGKVVISEQNVEELLRGAQYFNTPRLRVHCNDFLIKSICRANCLRYLFLAELFELKEVSDVAYSGIRDNFHYWASPEGSMHFMRCPPVIFGRLLRDENLHVLNEDQALSALINWVYFRKEDREKYFKKFFNYINLNAVSNKTLVFASNKLVGMENTSSHTTLIESVLMDRKQERPCSLLVYQRKGALLDSVVILGGQKAHGQFNDGVFAYIIQENLWMKLSDMPYRAAALSATSAGRYIYISGGTTEQISGLKTAWRYDMDDNSWTKLPDLPIGLVFHTMVTCGGTVYSVGGSIAPRRYVSNIYRYDERKEVWCLAGKMSIPMDGTAVITKGDRHLYIVTGRCLVKGYISRVGVVDCFDTSTGDVVQCITFPIEFNHRPLLSFQQDNILCVHSHRQSVEINLQKVKASKTTTSVPVLPNSCPLDVSHAICSIGDSKVFVCGGVTTASDVQTKDYTINPNAFLLDQKTGKWKTLAPPPEALDCPACCLAKLPCKILQRI>sp|Q5TID7|CC181_HUMAN Coiled-coil domain-containing protein 181 OS=Homosapiens OX=9606 GN=CCDC181 PE=2 SV=1MNENKDTDSKKSEEYEDDFEKDLEWLINENEKSDASIIEMACEKEENINQDLKENETVMEHTKRHSDPDKSLQDEVSPRRNDIISVPGIQPLDPISDSDSENSFQESKLESQKDLEEEEDEEVRRYIMEKIVQANKLLQNQEPVNDKRERKLKFKDQLVDLEVPPLEDTTTFKNYFENERNMFGKLSQLCISNDFGQEDVLLSLTNGSCEENKDRTILVERDGKFELLNLQDIASQGFLPPINNANSTENDPQQLLPRSSNSSVSGTKKEDSTAKIHAVTHSSTGEPLAYIAQPPLNRKTCPSSAVNSDRSKGNGKSNHRTQSAHISPVTSTYCLSPRQKELQKQLEEKREKLKREEERRKIEEEKEKKRENDIVFKAWLQKKREQVLEMRRIQRAKEIEDMNSRQENRDPQQAFRLWLKKKHEEQMKERQTEELRKQEECLFFLKGTEGRERAFKQWLRRKRMEKMAEQQAVRERTRQLRLEAKRSKQLQHHLYMSEAKPFRFTDHYN>sp|Q5TID7-2|CC181_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 181 OS=Homo sapiens OX=9606 GN=CCDC181MNENKDTDSKKSEEYEDDFEKDLEWLINENEKSDASIIEMACEKEENINQDLKENETVMEHTKRHSDPDKSLQDEVSPRRNDIISVPGIQPLDPISDSDSENSFQESKLESQKDLEEEEDEEVRRYIMEKIVQANKLLQNQEPVNDKRERKLKFKDQLVDLEVPPLEDTTTFKNYFENERNMFGKLSQLCISNDFGQEDVLLSLTNGSCEENKDRTILVERDGKFELLNLQDIASQGFLPPINNANSTENDPQQLLPRSSNSSVSGTKKEDSTAKIHAVTHSSTGEPLAYIAQPPLNRKTCPSSAVNSDRSKGNGKSNHRTQSAHISPVTSTYCLSPRQKELQKQLEEKREKLKREEERRKIEEEKEKKRENDIVFKAWLQKKREQVLEMRRIQRAKEIEDMNSRVSKTSLKNKFIQI>sp|Q5TID7-3|CC181_HUMAN Isoform 3 of Coiled-coil domain-containingprotein 181 OS=Homo sapiens OX=9606 GN=CCDC181MNENKDTDSKKSEEYEDDFEKDLEWLINENEKSDASIIEMACEKEENINQDLKENETVMEHTKRHSDPDKSLQDEVSPRRNDIISVPGIQPLDPISDSDSENSFQESKLESQKDLEEEEDEEVRRYIMEKIVQANKLLQNQEPVNDKRERKLKFKDQLVDLEVPPLEDTTTFKNYFENERNMFGKLSQLCISNDFGQEDVLLSLTNGSCEENKDRTILVERDGKFELLNLQDIASQGFLPPINNANSTENDPQQLLPRSSNSSVSGTKKEDSTAKIHAVTHSSTGEPLAYIAQPPLNRKTCPSSAVNSDRSKGNGKSNHRTQSAHISPVTSTYCLSPRQKELQKQLEEKREKLKREEERRKIEEEKEKKRENDIVFKAWLQKKREQVLEMRRIQRAKEIEDMNSRENRDPQQAFRLWLKKKHEEQMKERQTEELRKQEECLFFLKGTEGRERAFKQWLRRKRMEKMAEQQAVRERTRQLRLEAKRSKQLQHHLYMSEAKPFRFTDHYN>sp|O75493|CAH11_HUMAN Carbonic anhydrase-related protein 11 OS=Homosapiens OX=9606 GN=CA11 PE=1 SV=2MGAAARLSAPRALVLWAALGAAAHIGPAPDPEDWWSYKDNLQGNFVPGPPFWGLVNAAWSLCAVGKRQSPVDVELKRVLYDPFLPPLRLSTGGEKLRGTLYNTGRHVSFLPAPRPVVNVSGGPLLYSHRLSELRLLFGARDGAGSEHQINHQGFSAEVQLIHFNQELYGNFSAASRGPNGLAILSLFVNVASTSNPFLSRLLNRDTITRISYKNDAYFLQDLSLELLFPESFGFITYQGSLSTPPCSETVTWILIDRALNITSLQMHSLRLLSQNPPSQIFQSLSGNSRPLQPLAHRALRGNRDPRHPERRCRGPNYRLHVDGVPHGR>sp|P0C221|CC175_HUMAN Coiled-coil domain-containing protein 175 OS=Homosapiens OX=9606 GN=CCDC175 PE=4 SV=2MALSPWTPGLGAGEKLVQAAAVSTGPSLELCTLPSTLGSSVAVEALEQLFVVEQSLQSDYFKCNEEAKIFLKDIAVAVKKLEEMRKATIDLLEIESMELNKLYYLLETLPNSIKRELEECVRDARRLNLFEINTIKMRITRTENEIELLKKKITDLTKYNEALGEKQEELARKHARFVLSLNQTMEKKATTTVYINETYTKINLKREDIALQKKCIQEAEELMEKERAEYLIRKQELTAQINEFENTREVKRMETYQKKKELDKLQTKMSKIKETVTVSAAVLSDHNLEIARLHESIRYWEQEVSELKKDLAILEAKLCFFTDNKEKLDDISNDEKNEFLNKIKQLVETLHAARMEYKDLREKMKTLARQYKIVLSEEEKAFLQKQKIHDENQKQLTFISQKEYFLSQKRVDIKNMEEGLITLQELQQATKTVYQQQIKILSANLERESQRCVITQWKMACLRKKHARWTAKIKAEIQAITEKIQNAEVRRIELLNETSFRQQEISGFVAQIEKLTTELKEEEKAFVNKEKMLMKELSKYEEIFVKETQINKEKEEELVEYLPQLQVAEQEYKEKRRKLEELSNIITAQRQEEDLLNNHIFLFTRDFSRYISNMEDVKQELQQLRDQESKKNKDHFETLKNLENGFYINDQKADLLLLENKKLKEYILYLKNNIEKYREGQEALMHTSSDLSRQLIAQEAQYKDLWAEFQTTVKILVDNGEETLQDINNLTDKLRERDEKMQHVSTWLRGSLEGLRLLVEQESPMDLLKKKKHIRTRVHFPVVKCTEKNTLTK>sp|P54687|BCAT1_HUMAN Branched-chain-amino-acid aminotransferase,cytosolic OS=Homo sapiens OX=9606 GN=BCAT1 PE=1 SV=3MKDCSNGCSAECTGEGGSKEVVGTFKAKDLIVTPATILKEKPDPNNLVFGTVFTDHMLTVEWSSEFGWEKPHIKPLQNLSLHPGSSALHYAVELFEGLKAFRGVDNKIRLFQPNLNMDRMYRSAVRATLPVFDKEELLECIQQLVKLDQEWVPYSTSASLYIRPTFIGTEPSLGVKKPTKALLFVLLSPVGPYFSSGTFNPVSLWANPKYVRAWKGGTGDCKMGGNYGSSLFAQCEAVDNGCQQVLWLYGEDHQITEVGTMNLFLYWINEDGEEELATPPLDGIILPGVTRRCILDLAHQWGEFKVSERYLTMDDLTTALEGNRVREMFGSGTACVVCPVSDILYKGETIHIPTMENGPKLASRILSKLTDIQYGREESDWTIVLS>sp|P54687-2|BCAT1_HUMAN Isoform 2 of Branched-chain-amino-acidaminotransferase, cytosolic OS=Homo sapiens OX=9606 GN=BCAT1MKAKDLIVTPATILKEKPDPNNLVFGTVFTDHMLTVEWSSEFGWEKPHIKPLQNLSLHPGSSALHYAVEVFDKEELLECIQQLVKLDQEWVPYSTSASLYIRPTFIGTEPSLGVKKPTKALLFVLLSPVGPYFSSGTFNPVSLWANPKYVRAWKGGTGDCKMGGNYGSSLFAQCEAVDNGCQQVLWLYGEDHQITEVGTMNLFLYWINEDGEEELATPPLDGIILPGVTRRCILDLAHQWGEFKVSERYLTMDDLTTALEGNRVREMFGSGTACVVCPVSDILYKGETIHIPTMENGPKLASRILSKLTDIQYGREESDWTIVLS>sp|P54687-3|BCAT1_HUMAN Isoform 3 of Branched-chain-amino-acidaminotransferase, cytosolic OS=Homo sapiens OX=9606 GN=BCAT1MKDCSNGCSAECTGEGGSKEVVGTFKAKDLIVTPATILKEKPDPNNLVFGTVFTDHMLTVEWSSEFGWEKPHIKPLQNLSLHPGSSALHYAVEVFDKEELLECIQQLVKLDQEWVPYSTSASLYIRPTFIGTEPSLGVKKPTKALLFVLLSPVGPYFSSGTFNPVSLWANPKYVRAWKGGTGDCKMGGNYGSSLFAQCEAVDNGCQQVLWLYGEDHQITEVGTMNLFLYWINEDGEEELATPPLDGIILPGVTRRCILDLAHQWGEFKVSERYLTMDDLTTALEGNRVREMFGSGTACVVCPVSDILYKGETIHIPTMENGPKLASRILSKLTDIQYGREESDWTIVLS>sp|P54687-4|BCAT1_HUMAN Isoform 4 of Branched-chain-amino-acidaminotransferase, cytosolic OS=Homo sapiens OX=9606 GN=BCAT1MDCSNGCSAECTGEGGSKEVVGTFKAKDLIVTPATILKEKPDPNNLVFGTVFTDHMLTVEWSSEFGWEKPHIKPLQNLSLHPGSSALHYAVELFEGLKAFRGVDNKIRLFQPNLNMDRMYRSAVRATLPVFDKEELLECIQQLVKLDQEWVPYSTSASLYIRPTFIGTEPSLGVKKPTKALLFVLLSPVGPYFSSGTFNPVSLWANPKYVRAWKGGTGDCKMGGNYGSSLFAQCEAVDNGCQQVLWLYGEDHQITEVGTMNLFLYWINEDGEEELATPPLDGIILPGVTRRCILDLAHQWGEFKVSERYLTMDDLTTALEGNRVREMFGSGTACVVCPVSDILYKGETIHIPTMENGPKLASRILSKLTDIQYGREESDWTIVLS>sp|P54687-5|BCAT1_HUMAN Isoform 5 of Branched-chain-amino-acidaminotransferase, cytosolic OS=Homo sapiens OX=9606 GN=BCAT1MASPLRSAAALARQDCSNGCSAECTGEGGSKEVVGTFKAKDLIVTPATILKEKPDPNNLVFGTVFTDHMLTVEWSSEFGWEKPHIKPLQNLSLHPGSSALHYAVELFEGLKAFRGVDNKIRLFQPNLNMDRMYRSAVRATLPVFDKEELLECIQQLVKLDQEWVPYSTSASLYIRPTFIGTEPSLGVKKPTKALLFVLLSPVGPYFSSGTFNPVSLWANPKYVRAWKGGTGDCKMGGNYGSSLFAQCEAVDNGCQQVLWLYGEDHQITEVGTMNLFLYWINEDGEEELATPPLDGIILPGVTRRCILDLAHQWGEFKVSERYLTMDDLTTALEGNRVREMFGSGTACVVCPVSDILYKGETIHIPTMENGPKLASRILSKLTDIQYGREESDWTIVLS>sp|Q52MB2|CC184_HUMAN Coiled-coil domain-containing protein 184 OS=Homosapiens OX=9606 GN=CCDC184 PE=1 SV=2MEDGLLEIMTKDGGDMPAPLEVSTVPAVGDVISGEYNGGMKELMEHLKAQLQALFEDVRAMRGALDEQASHIQVLSDDVCANQRAIVSMCQIMTTAPRQGGLGVVGGKGSFQSDPQEPETPSPGIGDSGLLGRDPEDEEEEEEEKEMPSPATPSSHCERPESPCAGLLGGDGPLVEPLDMPDITLLQLEGEASL>sp|Q5VZK9|CARL1_HUMAN F-actin-uncapping protein LRRC16A OS=Homo sapiensOX=9606 GN=CARMIL1 PE=1 SV=1MTEESSDVPRELIESIKDVIGRKIKISVKKKVKLEVKGDKVENKVLVLTSCRAFLVTARIPTKLELTFSYLEIHGVVCSKSAQMIVETEKCSISMKMASPEDVSEVLAHIGTCLRKIFPGLSPVRIMKKVSMEPSERLASLQALWDSQTVAEQGPCGGFSQMYACVCDWLGFSYREEVQWDVDTIYLTQDTRELNLQDFSHLDHRDLIPIIAALEYNQWFTKLSSKDLKLSTDVCEQILRVVSRSNRLEELVLENAGLRTDFAQKLASALAHNPNSGLHTINLAGNPLEDRGVSSLSIQFAKLPKGLKHLNLSKTSLSPKGVNSLSQSLSANPLTASTLVHLDLSGNVLRGDDLSHMYNFLAQPNAIVHLDLSNTECSLDMVCGALLRGCLQYLAVLNLSRTVFSHRKGKEVPPSFKQFFSSSLALMHINLSGTKLSPEPLKALLLGLACNHNLKGVSLDLSNCELRSGGAQVLEGCIAEIHNITSLDISDNGLESDLSTLIVWLSKNRSIQHLALGKNFNNMKSKNLTPVLDNLVQMIQDEESPLQSLSLADSKLKTEVTIIINALGSNTSLTKVDISGNGMGDMGAKMLAKALQINTKLRTVIWDKNNITAQGFQDIAVAMEKNYTLRFMPIPMYDASQALKTNPEKTEDALQKIENYLLRNHETRKYLQEQAYRLQQGIVTSTTQQMIDRICVKVQDHLNSLRNCGGDAIQEDLKSAERLMRDAKNSKTLLPNLYHVGGASWAGASGLLSSPIQETLESMAGEVTRVVDEQLKALLESMVDAAENLCPNVMKKAHIRQDLIHASTEKISIPRTFVKNVLLEQSGIDILNKISEVKLTVASFLSDRIVDEILDALSHCHHKLADHFSRRGKTLPQQESLEIELAEEKPVKRSIITVEELTEIERLEDLDTCMMTPKSKRKSIHSRMLRPVSRAFEMEFDLDKALEEVPIHIEDPPFPSLRQEKRSSGFISELPSEEGKKLEHFTKLRPKRNKKQQPTQAAVCAANIVSQDGEQNGLMGRVDEGVDEFFTKKVTKMDSKKWSTRGSESHELNEGGDEKKKRDSRKSSGFLNLIKSRSKSERPPTILMTEEPSSPKGAVRSPPVDCPRKDTKAAEHNGNSERIEEIKTPDSFEESQGEEIGKVERSDSKSSPQAGRRYGVQVMGSGLLAEMKAKQEKRAACAQKKLGNDAVSQDSSSPALSGVERSDGGGAVPKLHPGLPENRFGLGTPEKNTKAEPKAEAGSRSRSSSSTPTSPKPLLQSPKPSLAARPVIPQKPRTASRPDDIPDSPSSPKVALLPPVLKKVPSDKERDGQSSPQPSPRTFSQEVSRRSWGQQAQEYQEQKQRSSSKDGHQGSKSNDSGEEAEKEFIFV>sp|Q5VZK9-2|CARL1_HUMAN Isoform 2 of F-actin-uncapping protein LRRC16AOS=Homo sapiens OX=9606 GN=CARMIL1MTEESSDVPRELIESIKDVIGRKIKISVKKKVKLEVKGDKVENKVLVLTSCRAFLVTARIPTKLELTFSYLEIHGVVCSKSAQMIVETEKCSISMKMASPEDVSEVLAHIGTCLRKIFPGLSPVRIMKKVSMEPSERLASLQALWDSQTVAEQGPCGGFSQMYACVCDWLGFSYREEVQWDVDTIYLTQDTRELNLQDFSHLDHRDLIPIIAALEYNQWFTKLSSKDLKLSTDVCEQILRVVSRSNRLEELVLENAGLRTDFAQKLASALAHNPNSGLHTINLAGNPLEDRGVSSLSIQFAKLPKGLKHLNLSKTSLSPKGVNSLSQSLSANPLTASTLVHLDLSGNVLRGDDLSHMYNFLAQPNAIVHLDLSNTECSLDMVCGALLRGCLQYLAVLNLSRTVFSHRKGKEVPPSFKQFFSSSLALMHINLSGTKLSPEPLKALLLGLACNHNLKGVSLDLSNCELRSGGAQVLEGCIAEIHNITSLDISDNGLESDLSTLIVWLSKNRSIQHLALGKNFNNMKSKNLTPVLDNLVQMIQDEESPLQSLSLADSKLKTEVTIIINALGSNTSLTKVDISGNGMGDMGAKMLAKALQINTKLRTVIWDKNNITAQGFQDIAVAMEKNYTLRFMPIPMYDASQALKTNPEKTEDALQKIENYLLRNHETRKYLQEQAYRLQQGIVTSTTQQMIDRICVKVQDHLNSLRNCGGDAIQEDLKSAERLMRDAKNSKTLLPNLYHVGGASWAGASGLLSSPIQETLESMAGEVTRVVDEQLKALLESMVDAAENLCPNVMKKAHIRQDLIHASTEKISIPRTFVKNVLLEQSGIDILNKISEVKLTVASFLSDRIVDEILDALSHCHHKLADHFSRRGKTLPQQESLEIELAEEKPVKRSIITVEELTEIERLEDLDTCMMTPKSKRKSIHSRMLRPVSRAFEMEFDLDKALEEVPIHIEDPPFPSLRQEKRSSGFISELPSEEGKKLEHFTKLRPKRNKKQQPTQAAVCAANIVSQDGEQNGLMGRVDEGVDEFFTKKVTKMDSKKWSTRGSESHELNEGGDEKKKRDSRKSSGFLNLIKSRSKSERPPTILMTEEPSSPKGAVRSPPVDCPRKDTKAAEHNGNSERIEEIKTPDSFEESQGEEIGKVERSDSKSSPQAGRRYGVQVMGSGLLAEMKAKQENRFGLGTPEKNTKAEPKAEAGSRSRSSSSTPTSPKPLLQSPKPSLAARPVIPQKPRTASRPDDIPDSPSSPKVALLPPVLKKVPSDKERDGQSSPQPSPRTFSQEVSRRSWGQQAQEYQEQKQRSSSKDGHQGSKSNDSGEEAEKEFIFV>sp|Q5VZK9-3|CARL1_HUMAN Isoform 3 of F-actin-uncapping protein LRRC16AOS=Homo sapiens OX=9606 GN=CARMIL1MTEESSDVPRELIESIKDVIGRKIKISVKKKVKLEVKGDKVENKVLVLTSCRAFLVTARIPTKLELTFSYLEIHGVVCSKSAQMIVETEKCSISMKMASPEDVSEVLAHIGTCLRKIFPGLSPVRIMKKVSMEPSERLASLQALWDSQTVAEQGPCGGFSQMYACVCDWLGFSYREEVQWDVDTIYLTQDTRELNLQDFSHLDHRDLIPIIAALEYNQWFTKLSSKDLKLSTDVCEQILRVVSRSNRLEELVLENAGLRTDFAQKLASALAHNPNSGLHTINLAGNPLEDRGVSSLSIQFAKLPKGLKHLNLSKTSLSPKGVNSLSQSLSANPLTASTLVHLDLSGNVLRGDDLSHMYNFLAQPNAIVHLDLSNTECSLDMVCGALLRGCLQYLAVLNLSRTVFSHRKGKEVPPSFKQFFSSSLALMHINLSGTKLSPEPLKALLLGLACNHNLKGVSLDLSNCELRSGGAQVLEGCIAEIHNITQLGTRYRNAVLRVY>sp|Q5VZK9-4|CARL1_HUMAN Isoform 4 of F-actin-uncapping protein LRRC16AOS=Homo sapiens OX=9606 GN=CARMIL1MYACVCDWLGFSYREEVQWDVDTIYLTQDTRELNLQDFSHLDHRDLIPIIAALEYNQWFTKLSSKDLKLSTDVCEQILRVVSRSNRLEELVLENAGLRTDFAQKLASALAHNPNSGLHTINLAGNPLEDRETTTKIKRQNVPTVLQTYLVVCPSDYQPCPLPLGKDNYYSDFSHDG>sp|H7C350|CC188_HUMAN Coiled-coil domain-containing protein 188 OS=Homosapiens OX=9606 GN=CCDC188 PE=3 SV=2MEGLKTLGPCGHPHPQCPPTPASSSHGGGLDQPCQGFVGWPCLGPISSAHSVQSQRPFPVPGAGGSGPTVEGEAPGLFLSSQEQRARDTEGPRQGDLEAGLGWGWPLHPGSNQGAPRQGGSIGSGTRPCPCPPLSREGGALASPRVALSQLQCGLLGSAEQSFLQLEQENHSLKRQNQELREQLGALLGPGQQFLPLCPEHSSCTALAWPPDPAGTQPLGNRAPLQLLRRELCQGQEAFVQQSQNELQQIRLCFERKKMVITEVWDNVAEMHMALNNQATGLLNLKKDIRGVLDQMEDIQLEILRERAQCRTRARKEKQMASMSKGRPKLGSSKGLAGQLWLLTLRLLLGALLVWTAAYVYVVNPTPFEGLVPPLLSRATVWKLRALLDPFLRLKVDGFLPF>sp|P60022|DEFB1_HUMAN Beta-defensin 1 OS=Homo sapiens OX=9606 GN=DEFB1PE=1 SV=1MRTSYLLLFTLCLLLSEMASGGNFLTGLGHRSDHYNCVSSGGQCLYSACPIFTKIQGTCYRGKAKCCK>sp|P56202|CATW_HUMAN Cathepsin W OS=Homo sapiens OX=9606 GN=CTSW PE=1SV=2MALTAHPSCLLALLVAGLAQGIRGPLRAQDLGPQPLELKEAFKLFQIQFNRSYLSPEEHAHRLDIFAHNLAQAQRLQEEDLGTAEFGVTPFSDLTEEEFGQLYGYRRAAGGVPSMGREIRSEEPEESVPFSCDWRKVASAISPIKDQKNCNCCWAMAAAGNIETLWRISFWDFVDVSVQELLDCGRCGDGCHGGFVWDAFITVLNNSGLASEKDYPFQGKVRAHRCHPKKYQKVAWIQDFIMLQNNEHRIAQYLATYGPITVTINMKPLQLYRKGVIKATPTTCDPQLVDHSVLLVGFGSVKSEEGIWAETVSSQSQPQPPHPTPYWILKNSWGAQWGEKGYFRLHRGSNTCGITKFPLTARVQKPDMKPRVSCPP>sp|A0A1B0GTZ2|CC196_HUMAN Putative coiled-coil domain-containing protein196 OS=Homo sapiens OX=9606 GN=CCDC196 PE=5 SV=1MTSGANSSGSYLPSEIRSSKIDDNYLKELNEDLKLRKQELLEMLKPLEDKNNLLFQKLMSNLEEKQRSLQIMRQIMAGKGCEESSVMELLKEAEEMKQNLERKNKMLRKEMEMLWNKTFEAEELSDQQKAPQTKNKADLQDGKAPKSPSSPRKTESELEKSFAEKVKEIRKEKQQRKMEWVKYQEQNNILQNDFHGKVIELRIEALKNYQKANDLKLSLYLQQNFEPMQAFLNLPGSQGTMGITTMDRVTTGRNEHHVRILGTKIYTEQQGTKGSQLDNTGGRLFFLRSLPDEALKN>sp|Q8NCU1|CC197_HUMAN Uncharacterized protein CCDC197 OS=Homo sapiensOX=9606 GN=CCDC197 PE=1 SV=2MAAMDTGQRADPSNPGDKEGDLQGLWQELYQLQAKQKKLKREVEKHKLFEDYLIKVLEKIPEGCTGWEEPEEVLVEATVKHYGKLFTASQDTQKRLEAFCQMIQAVHRSLESLEEDHRALIASRSGCVSCRRSATASRSSGGS>sp|Q8NCU1-2|CC197_HUMAN Isoform 2 of Uncharacterized protein CCDC197OS=Homo sapiens OX=9606 GN=CCDC197MAAMDTGQRADPSNPGDKEGDLQGLWQELYQLQAKQKKLKREVEKHKLFEDYLIKVLEKIPEGCTGWEEPEEVLVEATVKHYGKLFTASQDTQKRLEAFCQMIQAVHRSLESLEEDHRALMLLSHNK>sp|Q9NVL8|CC198_HUMAN Uncharacterized protein CCDC198 OS=Homo sapiensOX=9606 GN=CCDC198 PE=1 SV=2MGLSHSKTHLRVIKVAPLQNKEVETPSAGRVDFAFNQNLEEKTSYSLARLQDQNKALEGQLPPLQENWYGRYSTASRDMYFDIPLEHRETSIIKRHPPQRLQKLEPIDLPRVITSGRLLSQREARTMHKAKQVLEKKMQTPMYTSENRQYLHKMQVLEMIRKRQEAQMELKKSLHGEARINKQSPRDHKAKKTLQSTPRNDDHDLLTMLPDEILNRGPGNSKNTEFLKHQAVNNYCPWKIGKMETWLHEQEAQGQLLWDSSSSDSDEQGKDEKKPRALVRTRTERIPLFDEFFDQE>sp|A0A1B0GVQ3|CC200_HUMAN Coiled-coil domain-containing protein 200OS=Homo sapiens OX=9606 GN=CCDC200 PE=4 SV=1MGSAYHWEARRRQMALDRRRWLMAQQQQELQQKEQELKNHQEEEQQSEEKLQPHKKLNVPQPPVAKLWTSQEQPQPSQQQPSVQPPSQPPPQPSTLPQAQVWPGPQPPQPQPPPQPTQPSAQARCTQHTSKCNLQDSQRPGLMNPCQSSPIRNTGYSQLKSTNYIQQW>sp|A6NH13|DAS1_HUMAN Putative uncharacterized protein DNAJC9-AS1 OS=Homosapiens OX=9606 GN=DNAJC9-AS1 PE=2 SV=2MPGGDTTPEEAAAPSCAGYNPGLLLFRAQKAQGACVTSTEGAWPRRASALYGGRKMRCGESGAGPDPRSNSAEVSSSQPALASKSQSKWGPTSNNPRGALTTTEFEMAGNRSQNIKHKQTALIAIPMSSQTPRMLGRPRNQGQLYPQP>sp|Q13561|DCTN2_HUMAN Dynactin subunit 2 OS=Homo sapiens OX=9606GN=DCTN2 PE=1 SV=4MADPKYADLPGIARNEPDVYETSDLPEDDQAEFDAEELTSTSVEHIIVNPNAAYDKFKDKRVGTKGLDFSDRIGKTKRTGYESGEYEMLGEGLGVKETPQQKYQRLLHEVQELTTEVEKIKTTVKESATEEKLTPVLLAKQLAALKQQLVASHLEKLLGPDAAINLTDPDGALAKRLLLQLEATKNSKGGSGGKTTGTPPDSSLVTYELHSRPEQDKFSQAAKVAELEKRLTELETAVRCDQDAQNPLSAGLQGACLMETVELLQAKVSALDLAVLDQVEARLQSVLGKVNEIAKHKASVEDADTQSKVHQLYETIQRWSPIASTLPELVQRLVTIKQLHEQAMQFGQLLTHLDTTQQMIANSLKDNTTLLTQVQTTMRENLATVEGNFASIDERMKKLGK>sp|Q13561-2|DCTN2_HUMAN Isoform 2 of Dynactin subunit 2 OS=Homo sapiensOX=9606 GN=DCTN2MADPKYADLPGIARNEPDVYETSDLPEDDQAEFDAFAQELEELTSTSVEHIIVNPNAAYDKFKDKRVGTKGLDFSDRIGKTKRTGYESGEYEMLGEGLGVKETPQQKYQRLLHEVQELTTEVEKIKTTVKESATEEKLTPVLLAKQLAALKQQLVASHLEKLLGPDAAINLTDPDGALAKRLLLQLEATKNSKGGSGGKTTGTPPDSSLVTYELHSRPEQDKFSQAAKVAELEKRLTELETAVRCDQDAQNPLSAGLQGACLMETVELLQAKVSALDLAVLDQVEARLQSVLGKVNEIAKHKASVEDADTQSKVHQLYETIQRWSPIASTLPELVQRLVTIKQLHEQAMQFGQLLTHLDTTQQMIANSLKDNTTLLTQVQTTMRENLATVEGNFASIDERMKKLGK>sp|Q13561-3|DCTN2_HUMAN Isoform 3 of Dynactin subunit 2 OS=Homo sapiensOX=9606 GN=DCTN2MADPKYADLPGIARNEPDVYETSDLPEDDQAEFDAELEELTSTSVEHIIVNPNAAYDKFKDKRVGTKGLDFSDRIGKTKRTGYESGEYEMLGEGLGVKETPQQKYQRLLHEVQELTTEVEKIKTTVKESATEEKLTPVLLAKQLAALKQQLVASHLEKLLGPDAAINLTDPDGALAKRLLLQLEATKNSKGGSGGKTTGTPPDSSLVTYELHSRPEQDKFSQAAKVAELEKRLTELETAVRCDQDAQNPLSAGLQGACLMETVELLQAKVSALDLAVLDQVEARLQSVLGKVNEIAKHKASVEDADTQSKVHQLYETIQRWSPIASTLPELVQRLVTIKQLHEQAMQFGQLLTHLDTTQQMIANSLKDNTTLLTQVQTTMRENLATVEGNFASIDERMKKLGK>sp|P81605|DCD_HUMAN Dermcidin OS=Homo sapiens OX=9606 GN=DCD PE=1 SV=2MRFMTLLFLTALAGALVCAYDPEAASAPGSGNPCHEASAAQKENAGEDPGLARQAPKPRKQRSSLLEKGLDGAKKAVGGLGKLGKDAVEDLESVGKGAVHDVKDVLDSVL>sp|P81605-2|DCD_HUMAN Isoform 2 of Dermcidin OS=Homo sapiens OX=9606GN=DCDMRFMTLLFLTALAGALVCAYDPEAASAPGSGNPCHEASAAQKENAGEDPGLARQAPKPRKQRSSLLEKGLDGAKKAVGGLGKLGKDAVEDLESVGKGGEERLVFGAPVNLTSIPLTSVSRP>sp|P81605-3|DCD_HUMAN Isoform 3 of Dermcidin OS=Homo sapiens OX=9606GN=DCDMRFMTLLFLTALAGALVCAYDPEAASAPGSGNHKQMDCLQLQKPPSETAKFLSSSTNLPRREKLVPSAKPPHTRGLV>sp|O75935|DCTN3_HUMAN Dynactin subunit 3 OS=Homo sapiens OX=9606GN=DCTN3 PE=1 SV=1MAGLTDLQRLQARVEELERWVYGPGGARGSRKVADGLVKVQVALGNISSKRERVKILYKKIEDLIKYLDPEYIDRIAIPDASKLQFILAEEQFILSQVALLEQVNALVPMLDSAHIKAVPEHAARLQRLAQIHIQQQDQCVEITEESKALLEEYNKTTMLLSKQFVQWDELLCQLEAATQVKPAEE>sp|O75935-2|DCTN3_HUMAN Isoform 2 of Dynactin subunit 3 OS=Homo sapiensOX=9606 GN=DCTN3MAGLTDLQRLQARVEELERWVYGPGGARGSRKVADGLVKVQVALGNISSKRERVKILYKKIEDLIKYLDPEYIDRIAIPDASKLQFILAEEQFILSQVALLEQVNALVPMLDSAHIKAVPEHAARLQRLAQIHIQQQAPWGVGVRDEAGSLVEDVGFAQFLSVLHFGPTGPVCGNH>sp|O75935-3|DCTN3_HUMAN Isoform 3 of Dynactin subunit 3 OS=Homo sapiensOX=9606 GN=DCTN3MAGLTDLQRLQARVEELERWVYGPGGARGSRKVADGLVKVQVALGNISSKRERVKILYKKIEDLIKYLDPEYIDRIAIPDASKLQFILAAVPEHAARLQRLAQIHIQQQDQCVEITEESKALLEEYNKTTMLLSKQFVQWDELLCQLEAATQVKPAEE>sp|Q9UJW0|DCTN4_HUMAN Dynactin subunit 4 OS=Homo sapiens OX=9606GN=DCTN4 PE=1 SV=1MASLLQSDRVLYLVQGEKKVRAPLSQLYFCRYCSELRSLECVSHEVDSHYCPSCLENMPSAEAKLKKNRCANCFDCPGCMHTLSTRATSISTQLPDDPAKTTMKKAYYLACGFCRWTSRDVGMADKSVASGGWQEPENPHTQRMNKLIEYYQQLAQKEKVERDRKKLARRRNYMPLAFSDKYGLGTRLQRPRAGASISTLAGLSLKEGEDQKEIKIEPAQAVDEVEPLPEDYYTRPVNLTEVTTLQQRLLQPDFQPVCASQLYPRHKHLLIKRSLRCRKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSLGPLLP>sp|Q9UJW0-2|DCTN4_HUMAN Isoform 2 of Dynactin subunit 4 OS=Homo sapiensOX=9606 GN=DCTN4MPSAEAKLKKNRCANCFDCPGCMHTLSTRATSISTQLPDDPAKTTMKKAYYLACGFCRWTSRDVGMADKSVASGGWQEPENPHTQRMNKLIEYYQQLAQKEKVERDRKKLARRRNYMPLAFSDKYGLGTRLQRPRAGASISTLAGLSLKEGEDQKEIKIEPAQAVDEVEPLPEDYYTRPVNLTEVTTLQQRLLQPDFQPVCASQLYPRHKHLLIKRSLRCRKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSLGPLLP>sp|Q9UJW0-3|DCTN4_HUMAN Isoform 3 of Dynactin subunit 4 OS=Homo sapiensOX=9606 GN=DCTN4MASLLQSDRVLYLVQGEKKVRAPLSQLYFCRYCSELRSLECVSHEVDSHYCPSCLENMPSAEAKLKKNRCANCFDCPGCMHTLSTRATSISTQLPDDPAKTTMKKAYYLACGFCRWTSRDVGMADKSVASGGWQEPENPHTQRMNKLIEYYQQLAQKEKVERDRKKLARRRNYMPLAFSQHTIHVVDKYGLGTRLQRPRAGASISTLAGLSLKEGEDQKEIKIEPAQAVDEVEPLPEDYYTRPVNLTEVTTLQQRLLQPDFQPVCASQLYPRHKHLLIKRSLRCRKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSLGPLLP>sp|Q9BTE1|DCTN5_HUMAN Dynactin subunit 5 OS=Homo sapiens OX=9606GN=DCTN5 PE=1 SV=1MELGELLYNKSEYIETASGNKVSRQSVLCGSQNIVLNGKTIVMNDCIIRGDLANVRVGRHCVVKSRSVIRPPFKKFSKGVAFFPLHIGDHVFIEEDCVVNAAQIGSYVHVGKNCVIGRRCVLKDCCKILDNTVLPPETVVPPFTVFSGCPGLFSGELPECTQELMIDVTKSYYQKFLPLTQV>sp|Q9BTE1-2|DCTN5_HUMAN Isoform 2 of Dynactin subunit 5 OS=Homo sapiensOX=9606 GN=DCTN5MELGELLYNKSEYIETASGNKVSRQSVLCGSQNIVLNGKTIVMNDCIIRGDLANVRVGRHCVVKSRSVIRPPFKKFSKGVAFFPLHIGDHVFIEEDCVVNAAQIGSYVHVGKNCVIGRRCVLKDCCKILDNTVLPPETVVPPFTVFSGCPAP>sp|Q9BTE1-3|DCTN5_HUMAN Isoform 3 of Dynactin subunit 5 OS=Homo sapiensOX=9606 GN=DCTN5MELGELLYNKSEYIETASGNKVSRQSVLCGSQNIVLNGKNFVISVFLSPYIRCHSACRDRKRSDESVRLSVNNREWWGLVNWRM>sp|Q03135|CAV1_HUMAN Caveolin-1 OS=Homo sapiens OX=9606 GN=CAV1 PE=1SV=4MSGGKYVDSEGHLYTVPIREQGNIYKPNNKAMADELSEKQVYDAHTKEIDLVNRDPKHLNDDVVKIDFEDVIAEPEGTHSFDGIWKASFTTFTVTKYWFYRLLSALFGIPMALIWGIYFAILSFLHIWAVVPCIKSFLIEIQCISRVYSIYVHTVCDPLFEAVGKIFSNVRINLQKEI>sp|Q03135-2|CAV1_HUMAN Isoform 2 of Caveolin-1 OS=Homo sapiens OX=9606GN=CAV1MADELSEKQVYDAHTKEIDLVNRDPKHLNDDVVKIDFEDVIAEPEGTHSFDGIWKASFTTFTVTKYWFYRLLSALFGIPMALIWGIYFAILSFLHIWAVVPCIKSFLIEIQCISRVYSIYVHTVCDPLFEAVGKIFSNVRINLQKEI>sp|Q96PX6|CC85A_HUMAN Coiled-coil domain-containing protein 85A OS=Homosapiens OX=9606 GN=CCDC85A PE=1 SV=3MSKAAGGAAAAAAAAESCSPAPAGSSAAPPAPVEDLSKVSDEELLQWSKEELIRSLRRAEAEKVSAMLDHSNLIREVNRRLQLHLGEIRGLKDINQKLQEDNQELRDLCCFLDDDRQKGKRVSREWQRLGRYTAGVMHKEVALYLQKLKDLEVKQEEVVKENMELKELCVLLDEEKGAGCAGSRCSIDSQASLCQLTASTAPYVRDVGDGSSTSSTGSTDSPDHHKHHASSGSPEHLQKPRSEGSPEHSKHRSASPEHPQKPRACGTPDRPKALKGPSPEHHKPLCKGSPEQQRHPHPGSSPETLPKHVLSGSPEHFQKHRSGSSPEHARHSGGSPEHLQKHALGGSLEHLPRARGTSPEHLKQHYGGSPDHKHGGGSGGSGGSGGGSREGTLRRQAQEDGSPHHRNVYSGMNESTLSYVRQLEARVRQLEEENRMLPQASQNRRQPPTRNSSNMEKGWGSRARRVLQWWQGCRGIGRCLPTLPGSFRLSSGADGSNSSPNSAASFSGHATPSQQPEPVVHSLKVVWRKLGDAAGSCPGIRQHLSGNQYKGPM>sp|O00399|DCTN6_HUMAN Dynactin subunit 6 OS=Homo sapiens OX=9606GN=DCTN6 PE=1 SV=1MAEKTQKSVKIAPGAVVCVESEIRGDVTIGPRTVIHPKARIIAEAGPIVIGEGNLIEEQALIINAYPDNITPDTEDPEPKPMIIGTNNVFEVGCYSQAMKMGDNNVIESKAYVGRNVILTSGCIIGACCNLNTFEVIPENTVIYGADCLRRVQTERPQPQTLQLDFLMKILPNYHHLKKTMKGSSTPVKN>sp|Q9H773|DCTP1_HUMAN dCTP pyrophosphatase 1 OS=Homo sapiens OX=9606GN=DCTPP1 PE=1 SV=1MSVAGGEIRGDTGGEDTAAPGRFSFSPEPTLEDIRRLHAEFAAERDWEQFHQPRNLLLALVGEVGELAELFQWKTDGEPGPQGWSPRERAALQEELSDVLIYLVALAARCRVDLPLAVLSKMDINRRRYPAHLARSSSRKYTELPHGAISEDQAVGPADIPCDSTGQTST>sp|Q9H4E7|DEFI6_HUMAN Differentially expressed in FDCP 6 homolog OS=Homosapiens OX=9606 GN=DEF6 PE=1 SV=1MALRKELLKSIWYAFTALDVEKSGKVSKSQLKVLSHNLYTVLHIPHDPVALEEHFRDDDDGPVSSQGYMPYLNKYILDKVEEGAFVKEHFDELCWTLTAKKNYRADSNGNSMLSNQDAFRLWCLFNFLSEDKYPLIMVPDEVEYLLKKVLSSMSLEVSLGELEELLAQEAQVAQTTGGLSVWQFLELFNSGRCLRGVGRDTLSMAIHEVYQELIQDVLKQGYLWKRGHLRRNWAERWFQLQPSCLCYFGSEECKEKRGIIPLDAHCCVEVLPDRDGKRCMFCVKTANRTYEMSASDTRQRQEWTAAIQMAIRLQAEGKTSLHKDLKQKRREQREQRERRRAAKEEELLRLQQLQEEKERKLQELELLQEAQRQAERLLQEEEERRRSQHRELQQALEGQLREAEQARASMQAEMELKEEEAARQRQRIKELEEMQQRLQEALQLEVKARRDEESVRIAQTRLLEEEEEKLKQLMQLKEEQERYIERAQQEKEELQQEMAQQSRSLQQAQQQLEEVRQNRQRADEDVEAAQRKLRQASTNVKHWNVQMNRLMHPIEPGDKRPVTSSSFSGFQPPLLAHRDSSLKRLTRWGSQGNRTPSPNSNEQQKSLNGGDEAPAPASTPQEDKLDPAPEN>sp|Q08AD1|CAMP2_HUMAN Calmodulin-regulated spectrin-associated protein 2OS=Homo sapiens OX=9606 GN=CAMSAP2 PE=1 SV=3MGDAADPREMRKTFIVPAIKPFDHYDFSRAKIACNLAWLVAKAFGTENVPEELQEPFYTDQYDQEHIKPPVVNLLLSAELYCRAGSLILKSDAAKPLLGHDAVIQALAQKGLYVTDQEKLVTERDLHKKPIQMSAHLAMIDTLMMAYTVEMVSIEKVIACAQQYSAFFQATDLPYDIEDAVMYWINKVNEHLKDIMEQEQKLKEHHTVEAPGGQKSPSKWFWKLVPARYRKEQTLLKQLPCIPLVENLLKDGTDGCALAALIHFYCPDVVRLEDICLKETMSLADSLYNLQLIQEFCQEYLNQCCHFTLEDMLYAASSIKSNYLVFMAELFWWFEVVKPSFVQPRVVRPQGAEPVKDMPSIPVLNAAKRNVLDSSSDFPSSGEGATFTQSHHHLPSRYSRPQAHSSASGGIRRSSSMSYVDGFIGTWPKEKRSSVHGVSFDISFDKEDSVQRSTPNRGITRSISNEGLTLNNSHVSKHIRKNLSFKPINGEEEAESIEEELNIDSHSDLKSCVPLNTNELNSNENIHYKLPNGALQNRILLDEFGNQIETPSIEEALQIIHDTEKSPHTPQPDQIANGFFLHSQEMSILNSNIKLNQSSPDNVTDTKGALSPITDNTEVDTGIHVPSEDIPETMDEDSSLRDYTVSLDSDMDDASKFLQDYDIRTGNTREALSPCPSTVSTKSQPGSSASSSSGVKMTSFAEQKFRKLNHTDGKSSGSSSQKTTPEGSELNIPHVVAWAQIPEETGLPQGRDTTQLLASEMVHLRMKLEEKRRAIEAQKKKMEAAFTKQRQKMGRTAFLTVVKKKGDGISPLREEAAGAEDEKVYTDRAKEKESQKTDGQRSKSLADIKESMENPQAKWLKSPTTPIDPEKQWNLASPSEETLNEGEILEYTKSIEKLNSSLHFLQQEMQRLSLQQEMLMQMREQQSWVISPPQPSPQKQIRDFKPSKQAGLSSAIAPFSSDSPRPTHPSPQSSNRKSASFSVKSQRTPRPNELKITPLNRTLTPPRSVDSLPRLRRFSPSQVPIQTRSFVCFGDDGEPQLKESKPKEEVKKEELESKGTLEQRGHNPEEKEIKPFESTVSEVLSLPVTETVCLTPNEDQLNQPTEPPPKPVFPPTAPKNVNLIEVSLSDLKPPEKADVPVEKYDGESDKEQFDDDQKVCCGFFFKDDQKAENDMAMKRAALLEKRLRREKETQLRKQQLEAEMEHKKEETRRKTEEERQKKEDERARREFIRQEYMRRKQLKLMEDMDTVIKPRPQVVKQKKQRPKSIHRDHIESPKTPIKGPPVSSLSLASLNTGDNESVHSGKRTPRSESVEGFLSPSRCGSRNGEKDWENASTTSSVASGTEYTGPKLYKEPSAKSNKHIIQNALAHCCLAGKVNEGQKKKILEEMEKSDANNFLILFRDSGCQFRSLYTYCPETEEINKLTGIGPKSITKKMIEGLYKYNSDRKQFSHIPAKTLSASVDAITIHSHLWQTKRPVTPKKLLPTKA>sp|Q08AD1-2|CAMP2_HUMAN Isoform 2 of Calmodulin-regulated spectrin-associated protein 2 OS=Homo sapiens OX=9606 GN=CAMSAP2MGDAADPREMRKTFIVPAIKPFDHYDFSRAKIACNLAWLVAKAFGTENVPEELQEPFYTDQYDQEHIKPPVVNLLLSAELYCRAGSLILKSDAAKPLLGHDAVIQALAQKGLYVTDQEKLVTERDLHKKPIQMSAHLAMIDTLMMAYTVEMVSIEKVIACAQQYSAFFQATDLPYDIEDAVMYWINKVNEHLKDIMEQEQKLKEHHTVEAPGGQKARYRKEQTLLKQLPCIPLVENLLKDGTDGCALAALIHFYCPDVVRLEDICLKETMSLADSLYNLQLIQEFCQEYLNQCCHFTLEDMLYAASSIKSNYLVFMAELFWWFEVVKPSFVQPRVVRPQGAEPVKDMPSIPVLNAAKRNVLDSSSDFPSRYSRPQAHSSASGGIRRSSSMSYVDGFIGTWPKEKRSSVHGVSFDISFDKEDSVQRSTPNRGITRSISNEGLTLNNSHVSKHIRKNLSFKPINGEEEAESIEEELNIDSHSDLKSCVPLNTNELNSNENIHYKLPNGALQNRILLDEFGNQIETPSIEEALQIIHDTEKSPHTPQPDQIANGFFLHSQEMSILNSNIKLNQSSPDNVTDTKGALSPITDNTEVDTGIHVPSEDIPETMDEDSSLRDYTVSLDSDMDDASKFLQDYDIRTGNTREALSPCPSTVSTKSQPGSSASSSSGVKMTSFAEQKFRKLNHTDGKSSGSSSQKTTPEGSELNIPHVVAWAQIPEETGLPQGRDTTQLLASEMVHLRMKLEEKRRAIEAQKKKMEAAFTKQRQKMGRTAFLTVVKKKGDGISPLREEAAGAEDEKVYTDRAKEKESQKTDGQRSKSLADIKESMENPQAKWLKSPTTPIDPEKQWNLASPSEETLNEGEILEYTKSIEKLNSSLHFLQQEMQRLSLQQEMLMQMREQQSWVISPPQPSPQKQIRDFKPSKQAGLSSAIAPFSSDSPRPTHPSPQSSNRKSASFSVKSQRTPRPNELKITPLNRTLTPPRSVDSLPRLRRFSPSQVPIQTRSFVCFGDDGEPQLKESKPKEEVKKEELESKGTLEQRGHNPEEKEIKPFESTVSEVLSLPVTETVCLTPNEDQLNQPTEPPPKPVFPPTAPKNVNLIEVSLSDLKPPEKADVPVEKYDGESDKEQFDDDQKVCCGFFFKDDQKAENDMAMKRAALLEKRLRREKETQLRKQQLEAEMEHKKEETRRKTEEERQKKEDERARREFIRQEYMRRKQLKLMEDMDTVIKPRPQVVKQKKQRPKSIHRDHIESPKTPIKGPPVSSLSLASLNTGDNESVHSGKRTPRSESVEGFLSPSRCGSRNGEKDWENASTTSSVASGTEYTGPKLYKEPSAKSNKHIIQNALAHCCLAGKVNEGQKKKILEEMEKSDANNFLILFRDSGCQFRSLYTYCPETEEINKLTGIGPKSITKKMIEGLYKYNSDRKQFSHIPAKTLSASVDAITIHSHLWQTKRPVTPKKLLPTKA>sp|Q08AD1-3|CAMP2_HUMAN Isoform 3 of Calmodulin-regulated spectrin-associated protein 2 OS=Homo sapiens OX=9606 GN=CAMSAP2MGDAADPREMRKTFIVPAIKPFDHYDFSRAKIACNLAWLVAKAFGTENVPEELQEPFYTDQYDQEHIKPPVVNLLLSAELYCRAGSLILKSDAAKPLLGHDAVIQALAQKGLYVTDQEKLVTERDLHKKPIQMSAHLAMIDTLMMAYTVEMVSIEKVIACAQQYSAFFQATDLPYDIEDAVMYWINKVNEHLKDIMEQEQKLKEHHTVEAPGGQKARYRKEQTLLKQLPCIPLVENLLKDGTDGCALAALIHFYCPDVVRLEDICLKETMSLADSLYNLQLIQEFCQEYLNQCCHFTLEDMLYAASSIKSNYLVFMAELFWWFEVVKPSFVQPRVVRPQGAEPVKDMPSIPVLNAAKRNVLDSSSDFPSSGEGATFTQSHHHLPSRYSRPQAHSSASGGIRRSSSMSYVDGFIGTWPKEKRSSVHGVSFDISFDKEDSVQRSTPNRGITRSISNEGLTLNNSHVSKHIRKNLSFKPINGEEEAESIEEELNIDSHSDLKSCVPLNTNELNSNENIHYKLPNGALQNRILLDEFGNQIETPSIEEALQIIHDTEKSPHTPQPDQIANGFFLHSQEMSILNSNIKLNQSSPDNVTDTKGALSPITDNTEVDTGIHVPSEDIPETMDEDSSLRDYTVSLDSDMDDASKFLQDYDIRTGNTREALSPCPSTVSTKSQPGSSASSSSGVKMTSFAEQKFRKLNHTDGKSSGSSSQKTTPEGSELNIPHVVAWAQIPEETGLPQGRDTTQLLASEMVHLRMKLEEKRRAIEAQKKKMEAAFTKQRQKMGRTAFLTVVKKKGDGISPLREEAAGAEDEKVYTDRAKEKESQKTDGQRSKSLADIKESMENPQAKWLKSPTTPIDPEKQWNLASPSEETLNEGEILEYTKSIEKLNSSLHFLQQEMQRLSLQQEMLMQMREQQSWVISPPQPSPQKQIRDFKPSKQAGLSSAIAPFSSDSPRPTHPSPQSSNRKSASFSVKSQRTPRPNELKITPLNRTLTPPRSVDSLPRLRRFSPSQVPIQTRSFVCFGDDGEPQLKESKPKEEVKKEELESKGTLEQRGHNPEEKEIKPFESTVSEVLSLPVTETVCLTPNEDQLNQPTEPPPKPVFPPTAPKNVNLIEVSLSDLKPPEKADVPVEKYDGESDKEQFDDDQKVCCGFFFKDDQKAENDMAMKRAALLEKRLRREKETQLRKQQLEAEMEHKKEETRRKTEEERQKKEDERARREFIRQEYMRRKQLKLMEDMDTVIKPRPQVVKQKKQRPKSIHRDHIESPKTPIKGPPVSSLSLASLNTGDNESVHSGKRTPRSESVEGFLSPSRCGSRNGEKDWENASTTSSVASGTEYTGPKLYKEPSAKSNKHIIQNALAHCCLAGKVNEGQKKKILEEMEKSDANNFLILFRDSGCQFRSLYTYCPETEEINKLTGIGPKSITKKMIEGLYKYNSDRKQFSHIPAKTLSASVDAITIHSHLWQTKRPVTPKKLLPTKA>sp|P47756|CAPZB_HUMAN F-actin-capping protein subunit beta OS=Homosapiens OX=9606 GN=CAPZB PE=1 SV=4MSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDN>sp|P47756-2|CAPZB_HUMAN Isoform 2 of F-actin-capping protein subunitbeta OS=Homo sapiens OX=9606 GN=CAPZBMSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC>sp|Q6ZN54|DEFI8_HUMAN Differentially expressed in FDCP 8 homolog OS=Homosapiens OX=9606 GN=DEF8 PE=1 SV=2MAILSLRAPGPWQAMQVWADRTLLTPHTGVTSQVLGVAAAVMTPLPGGHAAGRTREARWDAMEYDEKLARFRQAHLNPFNKQSGPRQHEQGPGEEVPDVTPEEALPELPPGEPEFRCPERVMDLGLSEDHFSRPVGLFLASDVQQLRQAIEECKQVILELPEQSEKQKDAVVRLIHLRLKLQELKDPNEDEPNIRVLLEHRFYKEKSKSVKQTCDKCNTIIWGLIQTWYTCTGCYYRCHSKCLNLISKPCVSSKVSHQAEYELNICPETGLDSQDYRCAECRAPISLRGVPSEARQCDYTGQYYCSHCHWNDLAVIPARVVHNWDFEPRKVSRCSMRYLALMVSRPVLRLREINPLLFSYVEELVEIRKLRQDILLMKPYFITCREAMEARLLLQLQDRQHFVENDEMYSVQDLLDVHAGRLGCSLTEIHTLFAKHIKLDCERCQAKGFVCELCREGDVLFPFDSHTSVCADCSAVFHRDCYYDNSTTCPKCARLSLRKQSLFQEPGPDVEA>sp|Q6ZN54-2|DEFI8_HUMAN Isoform 2 of Differentially expressed in FDCP 8homolog OS=Homo sapiens OX=9606 GN=DEF8MEYDEKLARFRQAHLNPFNKQSGPRQHEQGPGEEVPDVTPEEALPELPPGEPEFRCPERVMDLGLSEDHFSRPVGLFLASDVQQLRQAIEECKQVILELPEQSEKQKDAVVRLIHLRLKLQELKDPNEDEPNIRVLLEHRFYKEKSKSVKQTCDKCNTIIWGLIQTWYTCTGGPRPRRGVRNERDQSSCLRWAHIQM>sp|Q6ZN54-3|DEFI8_HUMAN Isoform 3 of Differentially expressed in FDCP 8homolog OS=Homo sapiens OX=9606 GN=DEF8MEYDEKLARFRQAHLNPFNKQSGPRQHEQGPGEEVPDVTPEEALPELPPGEPEFRCPERVMDLGLSEDHFSRPVLRQAIEECKQVILELPEQSEKQKDAVVRLIHLRLKLQELKDPNEDEPNIRVLLEHRFYKEKSKSVKQTCDKCNTIIWGLIQTWYTCTGCYYRCHSKCLNLISKPCVSSKVSHQAEYELNICPETGLDSQDYRCAECRAPISLRGVPSEARQCDYTGQYYCSHCHWNDLAVIPARVVHNWDFEPRKVSRCSMRYLALMVSRPVLRLREINPLLFSYVEELVEIRKLRQDILLMKPYFITCREAMEARLLLQLQDRQHFVENDEMYSVQDLLDVHAGRLGCSLTEIHTLFAKHIKLDCERCQAKGFVCELCREGDVLFPFDSHTSVCADCSAVFHRDCYYDNSTTCPKCARLSLRKQSLFQEPGPDVEA>sp|Q6ZN54-4|DEFI8_HUMAN Isoform 4 of Differentially expressed in FDCP 8homolog OS=Homo sapiens OX=9606 GN=DEF8MDLGLSEDHFSRPVGLFLASDVQQLRQAIEECKQVILELPEQSEKQKDAVVRLIHLRLKLQELKDPNEDEPNIRVLLEHRFYKEKSKSVKQTCDKCNTIIWGLIQTWYTCTGCYYRCHSKCLNLISKPCVSSKVSHQAEYELNICPETGLDSQDYRCAECRAPISLRGVPSEARQCDYTGQYYCSHCHWNDLAVIPARVVHNWDFEPRKVSRCSMRYLALMVSRPVLRLREINPLLFSYVEELVEIRKLRQDILLMKPYFITCREAMEARLLLQLQDRQHFVENDEMYSVQDLLDVHAGRLGCSLTEIHTLFAKHIKLDCERCQAKGFVCELCREGDVLFPFDSHTSVCADCSAVFHRDCYYDNSTTCPKCARLSLRKQSLFQEPGPDVEA>sp|Q6ZN54-5|DEFI8_HUMAN Isoform 5 of Differentially expressed in FDCP 8homolog OS=Homo sapiens OX=9606 GN=DEF8MEYDEKLARFRQAHLNPFNKQSGPRQHEQGPGEEVPDVTPEEALPELPPGEPEFRCPERVMDLGLSEDHFSRPVGLFLASDVQQLRQAIEECKQVILELPEQSEKQKDAVVRLIHLRLKLQELKDPNEDEPNIRVLLEHRFYKEKSKSVKQTCDKCNTIIWGLIQTWYTCTGCYYRCHSKCLNLISKPCVSSKVSHQAEYELNICPETGLDSQDYRCAECRAPISLRGVPSEARQCDYTGQYYCSHCHWNDLAVIPARVVHNWDFEPRKVSRCSMRYLALMVSRPVLRLREINPLLFSYVEELVEIRKLRQDILLMKPYFITCREAMEARLLLQLQDRQHFVENDEMYSVQDLLDVHAGRLGCSLTEIHTLFAKHIKLDCERCQAKGFVCELCREGDVLFPFDSHTSVCADCSAVFHRDCYYDNSTTCPKCARLSLRKQSLFQEPGPDVEA>sp|Q6ZN54-6|DEFI8_HUMAN Isoform 6 of Differentially expressed in FDCP 8homolog OS=Homo sapiens OX=9606 GN=DEF8MEYDEKLARFRQAHLNPFNKQSGPRQHEQGPGEEVPDVTPEEALPELPPGEPEFRCPERVMDLGLSEDHFSRPVGLFLASDVQQLRQAIEECKQVILELPEQSEKQKDAVVRLIHLRLKLQELKDPNEDEPNIRVLLEHRFYKEKSKSVKQTCDKCNTIIWGLIQTWYTCTGCYYRCHSKCLNLISKPCVSSKVSHQAEYELNICPETGLDSQDYRCAECRAPISLRGVPSEARQCDYTGQYYCSHCHWNDLAVIPARVVHNWDFEPRKVSRCSMRYLALMVSRPVLRLREINPLLFSYVEELVEIRKLRQDILLMKPYFITCREAMEARLLLQDLLDVHAGRLGCSLTEIHTLFAKHIKLDCERCQAKGFVCELCREGDVLFPFDSHTSVCADCSAVFHRDCYYDNSTTCPKCARLSLRKQSLFQEPGPDVEA>sp|Q8N136|DAW1_HUMAN Dynein assembly factor with WDR repeat domains 1OS=Homo sapiens OX=9606 GN=DAW1 PE=1 SV=1MKLKSLLLRYYPPGIMLEYEKHGELKTKSIDLLDLGPSTDVSALVEEIQKAEPLLTASRTEQVKLLIQRLQEKLGQNSNHTFYLFKVLKAHILPLTNVALNKSGSCFITGSYDRTCKLWDTASGEELNTLEGHRNVVYAIAFNNPYGDKIATGSFDKTCKLWSVETGKCYHTFRGHTAEIVCLSFNPQSTLVATGSMDTTAKLWDIQNGEEVYTLRGHSAEIISLSFNTSGDRIITGSFDHTVVVWDADTGRKVNILIGHCAEISSASFNWDCSLILTGSMDKTCKLWDATNGKCVATLTGHDDEILDSCFDYTGKLIATASADGTARIFSAATRKCIAKLEGHEGEISKISFNPQGNHLLTGSSDKTARIWDAQTGQCLQVLEGHTDEIFSCAFNYKGNIVITGSKDNTCRIWR>sp|Q8N136-2|DAW1_HUMAN Isoform 2 of Dynein assembly factor with WDRrepeat domains 1 OS=Homo sapiens OX=9606 GN=DAW1MKLKSLLLRYYPPGIMLEYEKHGELKTKSIDLLDLGPSTDVSALVEEIQKAEPLLTASRTEQVKLLIQRLQEKLGQNSNHTFYLFKVLKAHILPLTNVALNKSGSCFITGSYDRTCKLWDTASGEELNTLEGHRNVVYAIAFNNPYGDKIATGSFDKTCKLWSVETGKCYHTFRGHTAEIVCLSFNPQSTLVATGSMDTTAKLWDIQNGEEVYTLRGHSAEIISLSFNTSGDRIITGSFDHTVVVWDADTGRKVNILIGHCAEISSASFNWDCSLILTGSMDKTCKLWDATNGKCVATLTGHDDEILDSCFDYTGKLIATASADDGVSLCRPGRSAVARSWLTATCASQVQAILLPQPPELCHVLGNHV>sp|Q14790|CASP8_HUMAN Caspase-8 OS=Homo sapiens OX=9606 GN=CASP8 PE=1SV=1MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKERSSSLEGSPDEFSNGEELCGVMTISDSPREQDSESQTLDKVYQMKSKPRGYCLIINNHNFAKAREKVPKLHSIRDRNGTHLDAGALTTTFEELHFEIKPHDDCTVEQIYEILKIYQLMDHSNMDCFICCILSHGDKGIIYGTDGQEAPIYELTSQFTGLKCPSLAGKPKVFFIQACQGDNYQKGIPVETDSEEQPYLEMDLSSPQTRYIPDEADFLLGMATVNNCVSYRNPAEGTWYIQSLCQSLRERCPRGDDILTILTEVNYEVSNKDDKKNMGKQMPQPTFTLRKKLVFPSD>sp|Q14790-2|CASP8_HUMAN Isoform 2 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKGEELCGVMTISDSPREQDSESQTLDKVYQMKSKPRGYCLIINNHNFAKAREKVPKLHSIRDRNGTHLDAGALTTTFEELHFEIKPHDDCTVEQIYEILKIYQLMDHSNMDCFICCILSHGDKGIIYGTDGQEAPIYELTSQFTGLKCPSLAGKPKVFFIQACQGDNYQKGIPVETDSEEQPYLEMDLSSPQTRYIPDEADFLLGMATVNNCVSYRNPAEGTWYIQSLCQSLRERCPRGDDILTILTEVNYEVSNKDDKKNMGKQMPQPTFTLRKKLVFPSD>sp|Q14790-3|CASP8_HUMAN Isoform 3 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKGALTTTFEELHFEIKPHDDCTVEQIYEILKIYQLMDHSNMDCFICCILSHGDKGIIYGTDGQEAPIYELTSQFTGLKCPSLAGKPKVFFIQACQGDNYQKGIPVETDSEEQPYLEMDLSSPQTRYIPDEADFLLGMATVNNCVSYRNPAEGTWYIQSLCQSLRERCPRGDDILTILTEVNYEVSNKDDKKNMGKQMPQPTFTLRKKLVFPSD>sp|Q14790-4|CASP8_HUMAN Isoform 4 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRFHFCRMSWAEANSQCQTQSVPFWRRVDHLLIRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKGEELCGVMTISDSPREQDSESQTLDKVYQMKSKPRGYCLIINNHNFAKAREKVPKLHSIRDRNGTHLDAGALTTTFEELHFEIKPHDDCTVEQIYEILKIYQLMDHSNMDCFICCILSHGDKGIIYGTDGQEAPIYELTSQFTGLKCPSLAGKPKVFFIQACQGDNYQKGIPVETDSEEQPYLEMDLSSPQTRYIPDEADFLLGMATVNNCVSYRNPAEGTWYIQSLCQSLRERCPRGDDILTILTEVNYEVSNKDDKKNMGKQMPQPTFTLRKKLVFPSD>sp|Q14790-5|CASP8_HUMAN Isoform 5 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKERSSSLEGSPDEFSNDFGQSLPNEKQTSGILSDHQQSQFCKSTGESAQTSQH>sp|Q14790-6|CASP8_HUMAN Isoform 6 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKDFGQSLPNEKQTSGILSDHQQSQFCKSTGESAQTSQH>sp|Q14790-7|CASP8_HUMAN Isoform 7 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKERSSSLEGSPDEFSNGEELCGVMTISDSPREQDSESQTLDKVYQMKSKPRGYCLIINNHNFAKAREKVPKLHSIRDRNGTHLDAGTVEPKREK>sp|Q14790-8|CASP8_HUMAN Isoform 8 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKGEELCGVMTISDSPREQDSESQTLDKVYQMKSKPRGYCLIINNHNFAKAREKVPKLHSIRDRNGTHLDAGTVEPKREK>sp|Q14790-9|CASP8_HUMAN Isoform 9 of Caspase-8 OS=Homo sapiens OX=9606GN=CASP8MEGGRRARVVIESKRNFFLGAFPTPFPAEHVELGRLGDSETAMVPGKGGADYILLPFKKMDFSRNLYDIGEQLDSEDLASLKFLSLDYIPQRKQEPIKDALMLFQRLQEKRMLEESNLSFLKELLFRINRLDLLITYLNTRKEEMERELQTPGRAQISAYRVMLYQISEEVSRSELRSFKFLLQEEISKCKLDDDMNLLDIFIEMEKRVILGEGKLDILKRVCAQINKSLLKIINDYEEFSKERSSSLEGSPDEFSNGEELCGVMTISDSPREQDSESQTLDKVYQMKSKPRGYCLIINNHNFAKAREKVPKLHSIRDRNGTHLDAGALTTTFEELHFEIKPHDDCTVEQIYEILKIYQLMDHSNMDCFICCILSHGDKGIIYGTDGQEAPIYELTSQFTGLKCPSLAGKPKVFFIQACQGDNYQKGIPVETDSEEQPYLEMDLSSPQTRYIPDEADFLLGMATVNNCVSYRNPAEGTWYIQSLCQSLRERCPRGDDILTILTEVNYEVSNKDDKKNMGKQMPQPTFTLRKKLVFPSD>sp|Q9UKL3|C8AP2_HUMAN CASP8-associated protein 2 OS=Homo sapiens OX=9606GN=CASP8AP2 PE=1 SV=1MAADDDNGDGTSLFDVFSASPLKNNDEGSLDIYAGLDSAVSDSASKSCVPSRNCLDLYEEILTEEGTAKEATYNDLQVEYGKCQLQMKELMKKFKEIQTQNFSLINENQSLKKNISALIKTARVEINRKDEEISNLHQRLSEFPHFRNNHKTARTFDTVKTKDLKSRSPHLDDCSKTDHRAKSDVSKDVHHSTSLPNLEKEGKPHSDKRSTSHLPTSVEKHCTNGVWSRSHYQVGEGSSNEDSRRGRKDIRHSQFNRGTERVRKDLSTGCGDGEPRILEASQRLQGHPEKYGKGEPKTESKSSKFKSNSDSDYKGERINSSWEKETPGERSHSRVDSQSDKKLERQSERSQNINRKEVKSQDKEERKVDQKPKSVVKDQDHWRRSERASLPHSKNEITFSHNSSKYHLEERRGWEDCKRDKSVNSHSFQDGRCPSSLSNSRTHKNIDSKEVDAMHQWENTPLKAERHRTEDKRKREQESKEENRHIRNEKRVPTEHLQKTNKETKKTTTDLKKQNEPKTDKGEVLDNGVSEGADNKELAMKAESGPNETKNKDLKLSFMKKLNLTLSPAKKQPVSQDNQHKITDIPKSSGVCDSESSMQVKTVAYVPSISEHILGEAAVSEHTMGETKSTLLEPKVALLAVTEPRIGISETNKEDENSLLVRSVDNTMHCEEPICGTETSFPSPMEIQQTESLFPSTGMKQTINNGRAAAPVVMDVLQTDVSQNFGLELDTKRNDNSDYCGISEGMEMKVALSTTVSETTESILQPSIEEADILPIMLSEDNNPKFEPSVIVTPLVESKSCHLEPCLPKETLDSSLQQTELMDHRMATGETNSVYHDDDNSVLSIDLNHLRPIPEAISPLNSPVRPVAKVLRNESPPQVPVYNNSHKDVFLPNSAHSTSKSQSDLNKENQKPIYKSDKCTEADTCKNSPLDELEEGEIRSDSETSKPQESFEKNSKRRVSADVRKSKTIPRRGKSTVCLDKDSRKTHVRIHQTNNKWNKRPDKSSRSSKTEKKDKVMSTSSLEKIVPIIAVPSSEQEIMHMLRMIRKHVRKNYMKFKAKFSLIQFHRIIESAILSFTSLIKHLNLHKISKSVTTLQKNLCDIIESKLKQVKKNGIVDRLFEQQLPDMKKKLWKFVDDQLDYLFAKLKKILVCDSKSFGRDSDEGKLEKTSKQNAQYSNSQKRSVDNSNRELLKEKLSKSEDPVHYKSLVGCKKSEENYQDQNNSSINTVKHDIKKNFNICFDNIKNSQSEERSLEVHCPSTPKSEKNEGSSIEDAQTSQHATLKPERSFEILTEQQASSLTFNLVSDAQMGEIFKSLLQGSDLLDSSVNCTEKSEWELKTPEKQLLETLKCESIPACTTEELVSGVASPCPKMISDDNWSLLSSEKGPSLSSGLSLPVHPDVLDESCMFEVSTNLPLSKDNVCSVEKSKPCVSSILLEDLAVSLTVPSPLKSDGHLSFLKPDMSSSSTPEEVISAHFSEDALLEEEDASEQDIHLALESDNSSSKSSCSSSWTSRSVAPGFQYHPNLPMHAVIMEKSNDHFIVKIRRATPSTSSGLKQSMMPDELLTSLPRHGKEADEGPEKEYISCQNTVFKSVEELENSNKNVDGSKSTHEEQSSMIQTQVPDIYEFLKDASDKMGHSDEVADECFKLHQVWETKVPESIEELPSMEEISHSVGEHLPNTYVDLTKDPVTETKNLGEFIEVTVLHIDQLGCSGGNLNQSAQILDNSLQADTVGAFIDLTQDASSEAKSEGNHPALAVEDLGCGVIQVDEDNCKEEKAQVANRPLKCIVEETYIDLTTESPSSCEVKKDELKSEPGSNCDNSELPGTLHNSHKKRRNISDLNHPHKKQRKETDLTNKEKTKKPTQDSCENTEAHQKKASKKKAPPVTKDPSSLKATPGIKDSSAALATSTSLSAKNVIKKKGEIIILWTRNDDREILLECQKRGPSFKTFAYLAAKLDKNPNQVSERFQQLMKLFEKSKCR>sp|O15234|CASC3_HUMAN Protein CASC3 OS=Homo sapiens OX=9606 GN=CASC3PE=1 SV=2MADRRRQRASQDTEDEESGASGSDSGGSPLRGGGSCSGSAGGGGSGSLPSQRGGRTGALHLRRVESGGAKSAEESECESEDGIEGDAVLSDYESAEDSEGEEGEYSEEENSKVELKSEANDAVNSSTKEEKGEEKPDTKSTVTGERQSGDGQESTEPVENKVGKKGPKHLDDDEDRKNPAYIPRKGLFFEHDLRGQTQEEEVRPKGRQRKLWKDEGRWEHDKFREDEQAPKSRQELIALYGYDIRSAHNPDDIKPRRIRKPRYGSPPQRDPNWNGERLNKSHRHQGLGGTLPPRTFINRNAAGTGRMSAPRNYSRSGGFKEGRAGFRPVEAGGQHGGRSGETVKHEISYRSRRLEQTSVRDPSPEADAPVLGSPEKEEAASEPPAAAPDAAPPPPDRPIEKKSYSRARRTRTKVGDAVKLAEEVPPPPEGLIPAPPVPETTPTPPTKTGTWEAPVDSSTSGLEQDVAQLNIAEQNWSPGQPSFLQPRELRGMPNHIHMGAGPPPQFNRMEEMGVQGGRAKRYSSQRQRPVPEPPAPPVHISIMEGHYYDPLQFQGPIYTHGDSPAPLPPQGMLVQPGMNLPHPGLHPHQTPAPLPNPGLYPPPVSMSPGQPPPQQLLAPTYFSAPGVMNFGNPSYPYAPGALPPPPPPHLYPNTQAPSQVYGGVTYYNPAQQQVQPKPSPPRRTPQPVTIKPPPPEVVSRGSS>sp|Q13948|CASP_HUMAN Protein CASP OS=Homo sapiens OX=9606 GN=CUX1 PE=1SV=2MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPDPVPALDLGQQLQLKVQRLHDIETENQKLRETLEEYNKEFAEVKNQEVTIKALKEKIREYEQTLKNQAETIALEKEQKLQNDFAEKERKLQETQMSTTSKLEEAEHKVQSLQTALEKTRTELFDLKTKYDEETTAKADEIEMIMTDLERANQRAEVAQREAETLREQLSSANHSLQLASQIQKAPDVEQAIEVLTRSSLEVELAAKEREIAQLVEDVQRLQASLTKLRENSASQISQLEQQLSAKNSTLKQLEEKLKGQADYEEVKKELNILKSMEFAPSEGAGTQDAAKPLEVLLLEKNRSLQSENAALRISNSDLSGRCAELQVRITEAVATATEQRELIARLEQDLSIIQSIQRPDAEGAAEHRLEKIPEPIKEATALFYGPAAPASGALPEGQVDSLLSIISSQRERFRARNQELEAENRLAQHTLQALQSELDSLRADNIKLFEKIKFLQSYPGRGSGSDDTELRYSSQYEERLDPFSSFSKRERQRKYLSLSPWDKATLSMGRLVLSNKMARTIGFFYTLFLHCLVFLVLYKLAWSESMERDCATFCAKKFADHLHKFHENDNGAAAGDLWQ>sp|Q13948-2|CASP_HUMAN Isoform 8 of Protein CASP OS=Homo sapiens OX=9606GN=CUX1MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPDPVPALDLGQQLQLKVQRLHDIETENQKLRETLEEYNKEFAEVKNQEVTIKALKEKIREYEQTLKNQAETIALEKEQKLQNDFAEKERKLQETQMSTTSKLEEAEHKVQSLQTALEKTRTELFDLKTKYDEETTAKADEIEMIMTDLERANQRAEVAQREAETLREQLSSANHSLQLASQIQKAPDVAIEVLTRSSLEVELAAKEREIAQLVEDVQRLQASLTKLRENSASQISQLEQQLSAKNSTLKQLEEKLKGQADYEEVKKELNILKSMEFAPSEGAGTQDAAKPLEVLLLEKNRSLQSENAALRISNSDLSGRCAELQVRITEAVATATEQRELIARLEQDLSIIQSIQRPDAEGAAEHRLEKIPEPIKEATALFYGPAAPASGALPEGQVDSLLSIISSQRERFRARNQELEAENRLAQHTLQALQSELDSLRADNIKLFEKIKFLQSYPGRGSGSDDTELRYSSQYEERLDPFSSFSKRERQRKYLSLSPWDKATLSMGRLVLSNKMARTIGFFYTLFLHCLVFLVLYKLAWSESMERDCATFCAKKFADHLHKFHENDNGAAAGDLWQ>sp|Q13948-9|CASP_HUMAN Isoform 9 of Protein CASP OS=Homo sapiens OX=9606GN=CUX1MAANVGSMFQYWKRFDLQQLQDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPDPVPALDLGQQLQLKVQRLHDIETENQKLRETLEEYNKEFAEVKNQEVTIKALKEKIREYEQTLKNQAETIALEKEQKLQNDFAEKERKLQETQMSTTSKLEEAEHKVQSLQTALEKTRTELFDLKTKYDEETTAKADEIEMIMTDLERANQRAEVAQREAETLREQLSSANHSLQLASQIQKAPDVAIEVLTRSSLEVELAAKEREIAQLVEDVQRLQASLTKLRENSASQISQLEQQLSAKNSTLKQLEEKLKGQADYEEVKKELNILKSMEFAPSEGAGTQDAAKPLEVLLLEKNRSLQSENAALRISNSDLSGRCAELQVRITEAVATATEQRELIARLEQDLSIIQSIQRPDAEGAAEHRLEKIPEPIKEATALFYGPAAPASGALPEGQVDSLLSIISSQRERFRARNQELEAENRLAQHTLQALQSELDSLRADNIKLFEKIKFLQSYPGRGSGSDDTELRYSSQYEERLDPFSSFSKRERQRKYLSLSPWDKATLSMGRLVLSNKMARTIGFFYTLFLHCLVFLVLYKLAWSESMERDCATFCAKKFADHLHKFHENDNGAAAGDLWQ>sp|Q13948-10|CASP_HUMAN Isoform 10 of Protein CASP OS=Homo sapiensOX=9606 GN=CUX1MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEIDALSKRSKEAEAAFLNVYKRLIDVPDPVPALDLGQQLQLKVQRLHDIETENQKLRETLEEYNKEFAEVKNQEVTIKALKEKIREYEQTLKNQAETIALEKEQKLQNDFAEKERKLQETQMSTTSKLEEAEHKVQSLQTALEKTRTELFDLKTKYDEETTAKADEIEMIMTDLERANQRAEVAQREAETLREQLSSANHSLQLASQIQKAPDVEQAIEVLTRSSLEVELAAKEREIAQLVEDVQRLQASLTKLRENSASQISQLEQQLSAKNSTLKQLEEKLKGQADYEEVKKELNILKSMEFAPSEGAGTQDAAKPLEVLLLEKNRSLQSENAALRISNSDLSGRCAELQVRITEAVATATEQRELIARLEQDLSIIQSIQRPDAEGAAEHRLEKIPEPIKEATALFYGPAAPASGALPEGQVDSLLSIISSQRERFRARNQELEAENRLAQHTLQALQSELDSLRADNIKLFEKIKFLQSYPGRGSGSDDTELRYSSQYEERLDPFSSFSKRERQRKYLSLSPWDKATLSMGRLVLSNKMARTIGFFYTLFLHCLVFLVLYKLAWSESMERDCATFCAKKFADHLHKFHENDNGAAAGDLWQ>sp|Q5BKX8|CAVN4_HUMAN Caveolae-associated protein 4 OS=Homo sapiensOX=9606 GN=CAVIN4 PE=1 SV=2MEHNGSASNADKIHQNRLSSVTEDEDQDAALTIVTVLDKVASIVDSVQASQKRIEERHREMENAIKSVQIDLLKLSQSHSNTGHIINKLFEKTRKVSAHIKDVKARVEKQQIHVKKVEVKQEEIMKKNKFRVVIFQEKFRCPTSLSVVKDRNLTENQEEDDDDIFDPPVDLSSDEEYYVEESRSARLRKSGKEHIDNIKKAFSKENMQKTRQNLDKKVNRIRTRIVTPERRERLRQSGERLRQSGERLRQSGERFKKSISNAAPSKEAFKMRSLRKGKDRTVAEGEECAREMGVDIIARSESLGPISELYSDELSEPEHEAARPVYPPHEGREIPTPEPLKVTFKSQVKVEDDESLLLDLKHSS>sp|Q9UER7|DAXX_HUMAN Death domain-associated protein 6 OS=Homo sapiensOX=9606 GN=DAXX PE=1 SV=2MATANSIIVLDDDDEDEAAAQPGPSHPLPNAASPGAEAPSSSEPHGARGSSSSGGKKCYKLENEKLFEEFLELCKMQTADHPEVVPFLYNRQQRAHSLFLASAEFCNILSRVLSRARSRPAKLYVYINELCTVLKAHSAKKKLNLAPAATTSNEPSGNNPPTHLSLDPTNAENTASQSPRTRGSRRQIQRLEQLLALYVAEIRRLQEKELDLSELDDPDSAYLQEARLKRKLIRLFGRLCELKDCSSLTGRVIEQRIPYRGTRYPEVNRRIERLINKPGPDTFPDYGDVLRAVEKAAARHSLGLPRQQLQLMAQDAFRDVGIRLQERRHLDLIYNFGCHLTDDYRPGVDPALSDPVLARRLRENRSLAMSRLDEVISKYAMLQDKSEEGERKKRRARLQGTSSHSADTPEASLDSGEGPSGMASQGCPSASRAETDDEDDEESDEEEEEEEEEEEEEATDSEEEEDLEQMQEGQEDDEEEDEEEEAAAGKDGDKSPMSSLQISNEKNLEPGKQISRSSGEQQNKGRIVSPSLLSEEPLAPSSIDAESNGEQPEELTLEEESPVSQLFELEIEALPLDTPSSVETDISSSRKQSEEPFTTVLENGAGMVSSTSFNGGVSPHNWGDSGPPCKKSRKEKKQTGSGPLGNSYVERQRSVHEKNGKKICTLPSPPSPLASLAPVADSSTRVDSPSHGLVTSSLCIPSPARLSQTPHSQPPRPGTCKTSVATQCDPEEIIVLSDSD>sp|Q9UER7-2|DAXX_HUMAN Isoform 2 of Death domain-associated protein 6OS=Homo sapiens OX=9606 GN=DAXXMATANSIIVLDDDDEDEAAAQPGPSHPLPNAASPGAEAPSSSEPHGARGSSSSGGKKCYKLENEKLFEEFLELCKMQTADHPEVVPFLYNRQQRAHSLFLASAEFCNILSRVLSRARSRPAKLYVYINELCTVLKAHSAKKKLNLAPAATTSNEPSGNNPPTHLSLDPTNAENTASQSPRTRGSRRQIQRLEQLLALYVAEIRRLQEKELDLSELDDPDSAYLQEARLKRKLIRLFGRLCELKDCSSLTGRVIEQRIPYRGTRYPEVNRRIERLINKPGPDTFPDYGDVLRAVEKAAARHSLGLPRQQLQLMAQDAFRDVGIRLQERRHLDLIYNFGCHLTDDYRPGVDPALSDPVLARRLRENRSLAMSRLDEVISKYAMLQDKSEEGERKKRRARLQGTSSHSADTPEASLDSGEGPSGMASQGCPSASRAETDDEDDEESDEEEEEEEEEEEEEATDSEEEEDLEQMQEGQEDDEEEDEEEEAAAGKDGDKSPMSSLQISNEKNLEPGKQISRSSGEQQNKGRIVSPSLLSEEPLAPSSIDAESNGEQPEELTLEEESPVSQLFELEIEALPLDTPSSVETDISSSRKQSEEPFTTVLENGAGMVSSTSFNGGVSPHNWGDSGPPCKKSRKEKKQTGSGPLGNSYVERQRSVHEKNGKKICTLPSPPSPLASLAPVADSSTRVDSPSHGLVTPAKNLGRRRSKQDQG>sp|Q9UER7-3|DAXX_HUMAN Isoform 3 of Death domain-associated protein 6OS=Homo sapiens OX=9606 GN=DAXXMQTADHPEVVPFLYNRQQRAHSLFLASAEFCNILSRVLSRARSRPAKLYVYINELCTVLKAHSAKKKLNLAPAATTSNEPSGNNPPTHLSLDPTNAENTASQSPRTRGSRRQIQRLEQLLALYVAEIRRLQEKELDLSELDDPDSAYLQEARLKRKLIRLFGRLCELKDCSSLTGRVIEQRIPYRGTRYPEVNRRIERLINKPGPDTFPDYGDVLRAVEKAAARHSLGLPRQQLQLMAQDAFRDVGIRLQERRHLDLIYNFGCHLTDDYRPGVDPALSDPVLARRLRENRSLAMSRLDEVISKYAMLQDKSEEGERKKRRARLQGTSSHSADTPEASLDSGEGPSGMASQGCPSASRAETDDEDDEESDEEEEEEEEEEEEEATDSEEEEDLEQMQEGQEDDEEEDEEEEAAAGKDGDKSPMSSLQISNEKNLEPGKQISRSSGEQQNKGRIVSPSLLSEEPLAPSSIDAESNGEQPEELTLEEESPVSQLFELEIEALPLDTPSSVETDISSSRKQSEEPFTTVLENGAGMVSSTSFNGGVSPHNWGDSGPPCKKSRKEKKQTGSGPLGNSYVERQRSVHEKNGKKICTLPSPPSPLASLAPVADSSTRVDSPSHGLVTSSLCIPSPARLSQTPHSQPPRPGTCKTSVATQCDPEEIIVLSDSD>sp|Q9UER7-4|DAXX_HUMAN Isoform beta of Death domain-associated protein 6OS=Homo sapiens OX=9606 GN=DAXXMATANSIIVLDDDDEDEAAAQPGPSHPLPNAASPGAEAPSSSEPHGARGSSSSGGKKCYKLENEKLFEEFLELCKMQTADHPEVVPFLYNRQQRAHSLFLASAEFCNILSRVLSRARSRPAKLYVYINELCTVLKAHSAKKKLNLAPAATTSNEPSGNNPPTHLSLDPTNAENTASQSPRTRGSRRQIQRLEQLLALYVAEIRRLQEKELDLSELDDPDSAYLQEARLKRKLIRLFGRLCELKDCSSLTGRVIEQRIPYRGTRYPEVNRRIERLINKPGPDTFPDYGDVLRAVEKAAARHSLGLPRQQLQLMAQDAFRDVGIRLQERRHLDLIYNFGCHLTDDYRPGVDPALSDPVLARRLRENRSLAMSRLDEVISKYAMLQDKSEEGERKKRRARLQGTSSHSADTPEASLDSGEGPSGMASQGCPSASRAETDDEDDEESDEEEEEEEEEEEEEATDSEEEEDLEQMQEGQEDDEEEDEEEEAAAGKDGDKSPMSSLQISNEKNLEPGKQISRSSGEQQNKGRIVSPSLLSEEPLAPSSIDAESNGEQPEELTLEEESPVSQLFELEIEALPLDTPSSVETDISSSRKQSEEPFTTVLENGAGMVSSTSFNGGVSPHNWGDSGPPCKKSRKEKKQTGSGPLGNSYVERQSPAVPNPPFTASSAWYLQDKCGHTMRSRRDHRALRL>sp|Q9UER7-5|DAXX_HUMAN Isoform gamma of Death domain-associated protein6 OS=Homo sapiens OX=9606 GN=DAXXMATANSIIVLDDDDEDEAAAQPGPSHPLPNAASPGAEAPSSSEPHGARGSSSSGGKKCYKLENEKLFEEFLELCKMQTADHPEVVPFLYNRQQRAHSLFLASAEFCNILSRVLSRARSRPAKLYVYINELCTVLKAHSAKKKLNLAPAATTSNEPSGNNPPTHLSLDPTNAENTASQSPRTRGSRRQIQRLEQLLALYVAEIRRLQEKELDLSELDDPDSAYLQEARLKRKLIRLFGRLCELKDCSSLTGRVIEQRIPYRGTRYPEVNRRIERLINKPGPDTFPDYGDVLRAVEKAAARHSLGLPRQQLQLMAQDAFRDVGIRLQERRHLDLIYNFGCHLTDDYRPGVDPALSDPVLARRLRENRSLAMSRLDEVISKYAMLQDKSEEGERKKRRARLQGTSSHSADTPEASLDSGEGPSGMASQGCPSASRAETDDEDDEESDEEEEEEEEEEEEEATDSEEEEDLEQMQEGQEDDEEEDEEEEAAAGKDGDKSPMSSLQISNEKNLEPGKQISRSSGEQQNKGRIVSPSLLSEEPLAPSSIDAESNGEQPEELTLEEESPVSQLFELEIEALPLDTPSSVETDISSSRKQSEEPFTTVLENGAGMVSSTSFNGGVSPHNWGDSGPPCKKSRKEKKQTGSGPLGNSPAVPNPPFTASSAWYLQDKCGHTMRSRRDHRALRL>sp|Q9NQZ3|DAZ1_HUMAN Deleted in azoospermia protein 1 OS=Homo sapiensOX=9606 GN=DAZ1 PE=1 SV=2MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQPFPAYPSSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q9NQZ3-2|DAZ1_HUMAN Isoform 2 of Deleted in azoospermia protein 1OS=Homo sapiens OX=9606 GN=DAZ1MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVCEICKILVLKNAAAFLCHSKVNRSI>sp|Q13117|DAZ2_HUMAN Deleted in azoospermia protein 2 OS=Homo sapiensOX=9606 GN=DAZ2 PE=1 SV=3MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQPFPAYPSSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q13117-2|DAZ2_HUMAN Isoform 2 of Deleted in azoospermia protein 2OS=Homo sapiens OX=9606 GN=DAZ2MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q13117-3|DAZ2_HUMAN Isoform 3 of Deleted in azoospermia protein 2OS=Homo sapiens OX=9606 GN=DAZ2MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQPFPAYPSSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q9HBH1|DEFM_HUMAN Peptide deformylase, mitochondrial OS=Homo sapiensOX=9606 GN=PDF PE=1 SV=1MARLWGALSLWPLWAAVPWGGAAAVGVRACSSTAAPDGVEGPALRRSYWRHLRRLVLGPPEPPFSHVCQVGDPVLRGVAAPVERAQLGGPELQRLTQRLVQVMRRRRCVGLSAPQLGVPRQVLALELPEALCRECPPRQRALRQMEPFPLRVFVNPSLRVLDSRLVTFPEGCESVAGFLACVPRFQAVQISGLDPNGEQVVWQASGWAARIIQHEMDHLQGCLFIDKMDSRTFTNVYWMKVND>sp|Q9NR90|DAZ3_HUMAN Deleted in azoospermia protein 3 OS=Homo sapiensOX=9606 GN=DAZ3 PE=1 SV=1MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQPFPAYPSSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q9NR90-2|DAZ3_HUMAN Isoform 2 of Deleted in azoospermia protein 3OS=Homo sapiens OX=9606 GN=DAZ3MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q86SG3|DAZ4_HUMAN Deleted in azoospermia protein 4 OS=Homo sapiensOX=9606 GN=DAZ4 PE=1 SV=2MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQPFPAYPSSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPSSPFQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q86SG3-2|DAZ4_HUMAN Isoform 2 of Deleted in azoospermia protein 4OS=Homo sapiens OX=9606 GN=DAZ4MSAANPETPNSTISREASTQSSSAAASQGWVLPEGKIVPNTVFVGGIDARMDETEIGSCFGRYGSVKEVKIITNRTGVSKGYGFVSFVNDVDVQKIVGSQIHFHGKKLKLGPAIRKQKLCARHVQPRPLVVNPPPPPQFQNVWRNPNTETYLQPQITPNPVTQHVQAYSAYPHSPGQVITGCQLLVYNYQEYPTYPDSAFQVTTGYQLPVYNYQPFPAYPRSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQPFPAYPSSPFQVTAGYQLPVYNYQAFPAYPNSPFQVATGYQFPVYNYQAFPAYPNSPVQVTTGYQLPVYNYQAFPAYPNSAVQVTTGYQFHVYNYQMPPQCPVGEQRRNLWTEAYKWWYLVCLIQRRD>sp|Q92904|DAZL_HUMAN Deleted in azoospermia-like OS=Homo sapiens OX=9606GN=DAZL PE=1 SV=1MSTANPETPNSTISREASTQSSSAATSQGYILPEGKIMPNTVFVGGIDVRMDETEIRSFFARYGSVKEVKIITDRTGVSKGYGFVSFFNDVDVQKIVESQINFHGKKLKLGPAIRKQNLCAYHVQPRPLVFNHPPPPQFQNVWTNPNTETYMQPTTTMNPITQYVQAYPTYPNSPVQVITGYQLPVYNYQMPPQWPVGEQRSYVVPPAYSAVNYHCNEVDPGAEVVPNECSVHEATPPSGNGPQKKSVDRSIQTVVSCLFNPENRLRNSVVTQDDYFKDKRVHHFRRSRAMLKSV>sp|Q92904-2|DAZL_HUMAN Isoform 2 of Deleted in azoospermia-like OS=Homosapiens OX=9606 GN=DAZLMAAPSCGGDRKARLTPSLPHESTANPETPNSTISREASTQSSSAATSQGYILPEGKIMPNTVFVGGIDVRMDETEIRSFFARYGSVKEVKIITDRTGVSKGYGFVSFFNDVDVQKIVESQINFHGKKLKLGPAIRKQNLCAYHVQPRPLVFNHPPPPQFQNVWTNPNTETYMQPTTTMNPITQYVQAYPTYPNSPVQVITGYQLPVYNYQMPPQWPVGEQRSYVVPPAYSAVNYHCNEVDPGAEVVPNECSVHEATPPSGNGPQKKSVDRSIQTVVSCLFNPENRLRNSVVTQDDYFKDKRVHHFRRSRAMLKSV>sp|Q96EP5|DAZP1_HUMAN DAZ-associated protein 1 OS=Homo sapiens OX=9606GN=DAZAP1 PE=1 SV=1MNNSGADEIGKLFVGGLDWSTTQETLRSYFSQYGEVVDCVIMKDKTTNQSRGFGFVKFKDPNCVGTVLASRPHTLDGRNIDPKPCTPRGMQPERTRPKEGWQKGPRSDNSKSNKIFVGGIPHNCGETELREYFKKFGVVTEVVMIYDAEKQRPRGFGFITFEDEQSVDQAVNMHFHDIMGKKVEVKRAEPRDSKSQAPGQPGASQWGSRVVPNAANGWAGQPPPTWQQGYGPQGMWVPAGQAIGGYGPPPAGRGAPPPPPPFTSYIVSTPPGGFPPPQGFPQGYGAPPQFSFGYGPPPPPPDQFAPPGVPPPPATPGAAPLAFPPPPSQAAPDMSKPPTAQPDFPYGQYAGYGQDLSGFGQGFSDPSQQPPSYGGPSVPGSGGPPAGGSGFGRGQNHNVQGFHPYRR>sp|Q96EP5-2|DAZP1_HUMAN Isoform 2 of DAZ-associated protein 1 OS=Homosapiens OX=9606 GN=DAZAP1MNNSGADEIGKLFVGGLDWSTTQETLRSYFSQYGEVVDCVIMKDKTTNQSRGFGFVKFKDPNCVGTVLASRPHTLDGRNIDPKPCTPRGMQPERTRPKEGWQKGPRSDNSKSNKIFVGGIPHNCGETELREYFKKFGVVTEVVMIYDAEKQRPRGFGFITFEDEQSVDQAVNMHFHDIMGKKVEVKRAEPRDSKSQAPGQPGASQWGSRVVPNAANGWAGQPPPTWQQGYGPQGMWVPAGQAIGGYGPPPAGRGAPPPPPPFTSYIVSTPPGGFPPPQGFPQGYGAPPQFSFGYGPPPPPPDQFAPPGVPPPPATPGAAPLAFPPPPSQAAPDMSKPPTAQPDFPYGQYGLGSYSPAPPGCGPHFVYSLMVRLSSDVA>sp|Q15038|DAZP2_HUMAN DAZ-associated protein 2 OS=Homo sapiens OX=9606GN=DAZAP2 PE=1 SV=1MNSKGQYPTQPTYPVQPPGNPVYPQTLHLPQAPPYTDAPPAYSELYRPSFVHPGAATVPTMSAAFPGASLYLPMAQSVAVGPLGSTIPMAYYPVGPIYPPGSTVLVEGGYDAGARFGAGATAGNIPPPPPGCPPNAAQLAVMQGANVLVTQRKGNFFMGGSDGGYTIW>sp|Q15038-2|DAZP2_HUMAN Isoform 2 of DAZ-associated protein 2 OS=Homosapiens OX=9606 GN=DAZAP2MNSKGQYPTQPTYPVQPPGNPVYPQTLHLPQAPPYTDAPPAYSELYRPSFVHPGAATVPTMSAAFPGASLYLPMAQSVAVGPLGSTIPMAYYPVGPIYPPGSTVLVEGGYDAGARFGAGATAGNIPVKEDQDHDREQGEEDNGDNNLERRGKM>sp|Q15038-6|DAZP2_HUMAN Isoform 6 of DAZ-associated protein 2 OS=Homosapiens OX=9606 GN=DAZAP2MNSKGQYPTQPTYPVQPPGNPVYPQTLHLPQAPPYTDAPPAYSELYRPSFVHPGAATVPTMSAAIPMAYYPVGPIYPPGSTVLVEGGYDAGARFGAGATAGNIPPPPPGCPPNAAQLAVMQGANVLVTQRKGNFFMGGSDGGYTIW>sp|Q15038-3|DAZP2_HUMAN Isoform 3 of DAZ-associated protein 2 OS=Homosapiens OX=9606 GN=DAZAP2MNSKGQYPTQPTYPVQPPGNPVYPQTLHLPQAPPYTDAPPAYSESVAVGPLGSTIPMAYYPVGPIYPPGSTVLVEGGYDAGARFGAGATAGNIPPPPPGCPPNAAQLAVMQGANVLVTQRKGNFFMGGSDGGYTIW>sp|Q15038-4|DAZP2_HUMAN Isoform 4 of DAZ-associated protein 2 OS=Homosapiens OX=9606 GN=DAZAP2MNSKGQYPTQPTYPVQPPGNPVYPQTLHLPQAPPYTDAPPAYSEPPPPGCPPNAAQLAVMQGANVLVTQRKGNFFMGGSDGGYTIW>sp|Q15038-5|DAZP2_HUMAN Isoform 5 of DAZ-associated protein 2 OS=Homosapiens OX=9606 GN=DAZAP2MNSKGQYPTQPTYPVQPPGNPVYPQTLHLPQAPPYTDAPPAYSELYRPSFVHPGAATVPTMSAAFPGASLYLPMAQSVAVGPLGSTIPMAYYPVGPIYPPASTSWMPSQCCSACSHAGSQRPRNSAEGELLHGWFRWWLHHLVRNQGHLCAGKDITYLQHFSQCNCFSHINLKLQFRHMLLGCLSGAQTFRHFSNLIRNHVMVAVPP>sp|Q9NUI1|DECR2_HUMAN Peroxisomal 2,4-dienoyl-CoA reductase [(3E)-enoyl-CoA-producing] OS=Homo sapiens OX=9606 GN=DECR2 PE=1 SV=1MAQPPPDVEGDDCLPAYRHLFCPDLLRDKVAFITGGGSGIGFRIAEIFMRHGCHTVIASRSLPRVLTAARKLAGATGRRCLPLSMDVRAPPAVMAAVDQALKEFGRIDILINCAAGNFLCPAGALSFNAFKTVMDIDTSGTFNVSRVLYEKFFRDHGGVIVNITATLGNRGQALQVHAGSAKAAVDAMTRHLAVEWGPQNIRVNSLAPGPISGTEGLRRLGGPQASLSTKVTASPLQRLGNKTEIAHSVLYLASPLASYVTGAVLVADGGAWLTFPNGVKGLPDFASFSAKL>sp|Q9NUI1-2|DECR2_HUMAN Isoform 2 of Peroxisomal 2,4-dienoyl-CoAreductase [(3E)-enoyl-CoA-producing] OS=Homo sapiens OX=9606 GN=DECR2MAQPPPDVEGDDCLPAYRHLFCPDLLRDKVAFITGGGSGIGFRIAEIFMRASEDQMGHCSSSGTCLAGVATFMVIVGKQPPNQKSRETKEQGRQIPFVCVRHGCHTVIASRSLPRVLTAARKLAGATGRRCLPLSMDVRAPPAVMAAVDQALKEFGRIDILINCSSSSCGLPFCRCGRELPVPRWRLVLQRLQDRDGHRYQRHLQCVSCAL>sp|Q9NUI1-3|DECR2_HUMAN Isoform 3 of Peroxisomal 2,4-dienoyl-CoAreductase [(3E)-enoyl-CoA-producing] OS=Homo sapiens OX=9606 GN=DECR2MRHGCHTVIASRSLPRVLTAARKLAGATGRRCLPLSMDVRAPPAVMAAVDQALKEFGRIDILINCAAGNFLCPAGALSFNAFKTVMDIDTSGTFNVSRVLYEKFFRDHGGVIVNITATLGNRGQALQVHAGSAKAAVDAMTRHLAVEWGPQNIRVNSLAPGPISGTEGLRRLGGPQASLSTKVTASPLQRLGNKTEIAHSVLYLASPLASYVTGAVLVADGGAWLTFPNGVKGLPDFASFSAKL>sp|A8MXU0|DB108_HUMAN Putative beta-defensin 108A OS=Homo sapiensOX=9606 GN=DEFB108A PE=5 SV=2MRIAVLFFTIFFFMSQVLPAKGKFKEICERPNGSCRDFCLETEIHVGRCLNSRPCCLPLGHQPRIESTTPKKD>sp|Q30KR1|DB109_HUMAN Putative beta-defensin 109B OS=Homo sapiensOX=9606 GN=DEFB109B PE=5 SV=1MRLHLLLLILLLFSILLSPVRGGLGPAEGHCLNLFGVCRTDVCNIVEDQIGACRRRMKCCRAWWILMPIPTPLIMSDYQEPLKPNLK>sp|Q30KQ9|DB110_HUMAN Beta-defensin 110 OS=Homo sapiens OX=9606GN=DEFB110 PE=3 SV=1MKIQLFFFILHFWVTILPAKKKYPEYGSLDLRRECRIGNGQCKNQCHENEIRIAYCIRPGTHCCLQQ>sp|Q30KQ9-2|DB110_HUMAN Isoform 2 of Beta-defensin 110 OS=Homo sapiensOX=9606 GN=DEFB110MKIQLFFFILHFWVTILPARSNFEPKYRFERCEKVRGICKTFCDDVEYDYGYCIKWRSQCCV>sp|Q30KQ8|DB112_HUMAN Beta-defensin 112 OS=Homo sapiens OX=9606GN=DEFB112 PE=1 SV=1MKLLTTICRLKLEKMYSKTNTSSTIFEKARHGTEKISTARSEGHHITFSRWKSCTAIGGRCKNQCDDSEFRISYCARPTTHCCVTECDPTDPNNWIPKDSVGTQEWYPKDSRH>sp|P35659|DEK_HUMAN Protein DEK OS=Homo sapiens OX=9606 GN=DEK PE=1 SV=1MSASAPAAEGEGTPTQPASEKEPEMPGPREESEEEEDEDDEEEEEEEKEKSLIVEGKREKKKVERLTMQVSSLQREPFTIAQGKGQKLCEIERIHFFLSKKKTDELRNLHKLLYNRPGTVSSLKKNVGQFSGFPFEKGSVQYKKKEEMLKKFRNAMLKSICEVLDLERSGVNSELVKRILNFLMHPKPSGKPLPKSKKTCSKGSKKERNSSGMARKAKRTKCPEILSDESSSDEDEKKNKEESSDDEDKESEEEPPKKTAKREKPKQKATSKSKKSVKSANVKKADSSTTKKNQNSSKKESESEDSSDDEPLIKKLKKPPTDEELKETIKKLLASANLEEVTMKQICKKVYENYPTYDLTERKDFIKTTVKELIS>sp|P35659-2|DEK_HUMAN Isoform 2 of Protein DEK OS=Homo sapiens OX=9606GN=DEKMSASAPAAEGEGTPTQPASEKEPEMPGPREESEEEEDEDDEEEEEEEKGKGQKLCEIERIHFFLSKKKTDELRNLHKLLYNRPGTVSSLKKNVGQFSGFPFEKGSVQYKKKEEMLKKFRNAMLKSICEVLDLERSGVNSELVKRILNFLMHPKPSGKPLPKSKKTCSKGSKKERNSSGMARKAKRTKCPEILSDESSSDEDEKKNKEESSDDEDKESEEEPPKKTAKREKPKQKATSKSKKSVKSANVKKADSSTTKKNQNSSKKESESEDSSDDEPLIKKLKKPPTDEELKETIKKLLASANLEEVTMKQICKKVYENYPTYDLTERKDFIKTTVKELIS>sp|Q30KQ7|DB113_HUMAN Beta-defensin 113 OS=Homo sapiens OX=9606GN=DEFB113 PE=3 SV=1MKILCIFLTFVFTVSCGPSVPQKKTREVAERKRECQLVRGACKPECNSWEYVYYYCNVNPCCAVWEYQKPIINKITSKLHQK>sp|Q30KQ6|DB114_HUMAN Beta-defensin 114 OS=Homo sapiens OX=9606GN=DEFB114 PE=1 SV=1MRIFYYLHFLCYVTFILPATCTLVNADRCTKRYGRCKRDCLESEKQIDICSLPRKICCTEKLYEEDDMF>sp|Q30KQ5|DB115_HUMAN Beta-defensin 115 OS=Homo sapiens OX=9606GN=DEFB115 PE=1 SV=1MLPDHFSPLSGDIKLSVLALVVLVVLAQTAPDGWIRRCYYGTGRCRKSCKEIERKKEKCGEKHICCVPKEKDKLSHIHDQKETSELYI>sp|Q08345|DDR1_HUMAN Epithelial discoidin domain-containing receptor 1OS=Homo sapiens OX=9606 GN=DDR1 PE=1 SV=1MGPEALSSLLLLLLVASGDADMKGHFDPAKCRYALGMQDRTIPDSDISASSSWSDSTAARHSRLESSDGDGAWCPAGSVFPKEEEYLQVDLQRLHLVALVGTQGRHAGGLGKEFSRSYRLRYSRDGRRWMGWKDRWGQEVISGNEDPEGVVLKDLGPPMVARLVRFYPRADRVMSVCLRVELYGCLWRDGLLSYTAPVGQTMYLSEAVYLNDSTYDGHTVGGLQYGGLGQLADGVVGLDDFRKSQELRVWPGYDYVGWSNHSFSSGYVEMEFEFDRLRAFQAMQVHCNNMHTLGARLPGGVECRFRRGPAMAWEGEPMRHNLGGNLGDPRARAVSVPLGGRVARFLQCRFLFAGPWLLFSEISFISDVVNNSSPALGGTFPPAPWWPPGPPPTNFSSLELEPRGQQPVAKAEGSPTAILIGCLVAIILLLLLIIALMLWRLHWRRLLSKAERRVLEEELTVHLSVPGDTILINNRPGPREPPPYQEPRPRGNPPHSAPCVPNGSALLLSNPAYRLLLATYARPPRGPGPPTPAWAKPTNTQAYSGDYMEPEKPGAPLLPPPPQNSVPHYAEADIVTLQGVTGGNTYAVPALPPGAVGDGPPRVDFPRSRLRFKEKLGEGQFGEVHLCEVDSPQDLVSLDFPLNVRKGHPLLVAVKILRPDATKNARNDFLKEVKIMSRLKDPNIIRLLGVCVQDDPLCMITDYMENGDLNQFLSAHQLEDKAAEGAPGDGQAAQGPTISYPMLLHVAAQIASGMRYLATLNFVHRDLATRNCLVGENFTIKIADFGMSRNLYAGDYYRVQGRAVLPIRWMAWECILMGKFTTASDVWAFGVTLWEVLMLCRAQPFGQLTDEQVIENAGEFFRDQGRQVYLSRPPACPQGLYELMLRCWSRESEQRPPFSQLHRFLAEDALNTV>sp|Q08345-2|DDR1_HUMAN Isoform 2 of Epithelial discoidin domain-containing receptor 1 OS=Homo sapiens OX=9606 GN=DDR1MGPEALSSLLLLLLVASGDADMKGHFDPAKCRYALGMQDRTIPDSDISASSSWSDSTAARHSRLESSDGDGAWCPAGSVFPKEEEYLQVDLQRLHLVALVGTQGRHAGGLGKEFSRSYRLRYSRDGRRWMGWKDRWGQEVISGNEDPEGVVLKDLGPPMVARLVRFYPRADRVMSVCLRVELYGCLWRDGLLSYTAPVGQTMYLSEAVYLNDSTYDGHTVGGLQYGGLGQLADGVVGLDDFRKSQELRVWPGYDYVGWSNHSFSSGYVEMEFEFDRLRAFQAMQVHCNNMHTLGARLPGGVECRFRRGPAMAWEGEPMRHNLGGNLGDPRARAVSVPLGGRVARFLQCRFLFAGPWLLFSEISFISDVVNNSSPALGGTFPPAPWWPPGPPPTNFSSLELEPRGQQPVAKAEGSPTAILIGCLVAIILLLLLIIALMLWRLHWRRLLSKAERRVLEEELTVHLSVPGDTILINNRPGPREPPPYQEPRPRGNPPHSAPCVPNGSAYSGDYMEPEKPGAPLLPPPPQNSVPHYAEADIVTLQGVTGGNTYAVPALPPGAVGDGPPRVDFPRSRLRFKEKLGEGQFGEVHLCEVDSPQDLVSLDFPLNVRKGHPLLVAVKILRPDATKNARNDFLKEVKIMSRLKDPNIIRLLGVCVQDDPLCMITDYMENGDLNQFLSAHQLEDKAAEGAPGDGQAAQGPTISYPMLLHVAAQIASGMRYLATLNFVHRDLATRNCLVGENFTIKIADFGMSRNLYAGDYYRVQGRAVLPIRWMAWECILMGKFTTASDVWAFGVTLWEVLMLCRAQPFGQLTDEQVIENAGEFFRDQGRQVYLSRPPACPQGLYELMLRCWSRESEQRPPFSQLHRFLAEDALNTV>sp|Q08345-4|DDR1_HUMAN Isoform 3 of Epithelial discoidin domain-containing receptor 1 OS=Homo sapiens OX=9606 GN=DDR1MGPEALSSLLLLLLVASGDADMKGHFDPAKCRYALGMQDRTIPDSDISASSSWSDSTAARHSRLESSDGDGAWCPAGSVFPKEEEYLQVDLQRLHLVALVGTQGRHAGGLGKEFSRSYRLRYSRDGRRWMGWKDRWGQEVISGNEDPEGVVLKDLGPPMVARLVRFYPRADRVMSVCLRVELYGCLWRDCSMGVWASWQMVWWGWMTLGRVRSCGSGQAMTMWDGATTASPVAMWRWSLSLTG>sp|Q08345-5|DDR1_HUMAN Isoform 4 of Epithelial discoidin domain-containing receptor 1 OS=Homo sapiens OX=9606 GN=DDR1MGPEALSSLLLLLLVASGDADMKGHFDPAKCRYALGMQDRTIPDSDISASSSWSDSTAARHSRLESSDGDGAWCPAGSVFPKEEEYLQVDLQRLHLVALVGTQGRHAGGLGKEFSRSYRLRYSRDGRRWMGWKDRWGQEVISGNEDPEGVVLKDLGPPMVARLVRFYPRADRVMSVCLRVELYGCLWRDGLLSYTAPVGQTMYLSEAVYLNDSTYDGHTVGGLQYGGLGQLADGVVGLDDFRKSQELRVWPGYDYVGWSNHSFSSGYVEMEFEFDRLRAFQAMQVHCNNMHTLGARLPGGVECRFRRGPAMAWEGEPMRHNLGGNLGDPRARAVSVPLGGRVARFLQCRFLFAGPWLLFSEISFISDVVNNSSPALGGTFPPAPWWPPGPPPTNFSSLELEPRGQQPVAKAEGSPTAILIGCLVAIILLLLLIIALMLWRLHWRRLLSKAERRVLEEELTVHLSVPGDTILINNRPGPREPPPYQEPRPRGNPPHSAPCVPNGSALLLSNPAYRLLLATYARPPRGPGPPTPAWAKPTNTQAYSGDYMEPEKPGAPLLPPPPQNSVPHYAEADIVTLQGVTGGNTYAVPALPPGAVGDGPPRVDFPRSRLRFKEKLGEGQFGEVHLCEVDSPQDLVSLDFPLNVRKGHPLLVAVKILRPDATKNASFSLFSRNDFLKEVKIMSRLKDPNIIRLLGVCVQDDPLCMITDYMENGDLNQFLSAHQLEDKAAEGAPGDGQAAQGPTISYPMLLHVAAQIASGMRYLATLNFVHRDLATRNCLVGENFTIKIADFGMSRNLYAGDYYRVQGRAVLPIRWMAWECILMGKFTTASDVWAFGVTLWEVLMLCRAQPFGQLTDEQVIENAGEFFRDQGRQVYLSRPPACPQGLYELMLRCWSRESEQRPPFSQLHRFLAEDALNTV>sp|Q08345-6|DDR1_HUMAN Isoform 5 of Epithelial discoidin domain-containing receptor 1 OS=Homo sapiens OX=9606 GN=DDR1MSLPRCCPHPLRPEGSGAMGPEALSSLLLLLLVASGDADMKGHFDPAKCRYALGMQDRTIPDSDISASSSWSDSTAARHSRLESSDGDGAWCPAGSVFPKEEEYLQVDLQRLHLVALVGTQGRHAGGLGKEFSRSYRLRYSRDGRRWMGWKDRWGQEVISGNEDPEGVVLKDLGPPMVARLVRFYPRADRVMSVCLRVELYGCLWRDGLLSYTAPVGQTMYLSEAVYLNDSTYDGHTVGGLQYGGLGQLADGVVGLDDFRKSQELRVWPGYDYVGWSNHSFSSGYVEMEFEFDRLRAFQAMQVHCNNMHTLGARLPGGVECRFRRGPAMAWEGEPMRHNLGGNLGDPRARAVSVPLGGRVARFLQCRFLFAGPWLLFSEISFISDVVNNSSPALGGTFPPAPWWPPGPPPTNFSSLELEPRGQQPVAKAEGSPTAILIGCLVAIILLLLLIIALMLWRLHWRRLLSKAERRVLEEELTVHLSVPGDTILINNRPGPREPPPYQEPRPRGNPPHSAPCVPNGSAYSGDYMEPEKPGAPLLPPPPQNSVPHYAEADIVTLQGVTGGNTYAVPALPPGAVGDGPPRVDFPRSRLRFKEKLGEGQFGEVHLCEVDSPQDLVSLDFPLNVRKGHPLLVAVKILRPDATKNARNDFLKEVKIMSRLKDPNIIRLLGVCVQDDPLCMITDYMENGDLNQFLSAHQLEDKAAEGAPGDGQAAQGPTISYPMLLHVAAQIASGMRYLATLNFVHRDLATRNCLVGENFTIKIADFGMSRNLYAGDYYRVQGRAVLPIRWMAWECILMGKFTTASDVWAFGVTLWEVLMLCRAQPFGQLTDEQVIENAGEFFRDQGRQVYLSRPPACPQGLYELMLRCWSRESEQRPPFSQLHRFLAEDALNTV>sp|Q30KQ4|DB116_HUMAN Beta-defensin 116 OS=Homo sapiens OX=9606GN=DEFB116 PE=3 SV=1MSVMKPCLMTIAILMILAQKTPGGLFRSHNGKSREPWNPCELYQGMCRNACREYEIQYLTCPNDQKCCLKLSVKITSSKNVKEDYDSNSNLSVTNSSSYSHI>sp|Q5D0E6|DALD3_HUMAN DALR anticodon-binding domain-containing protein 3OS=Homo sapiens OX=9606 GN=DALRD3 PE=1 SV=2MATRRLGVGETLGALNAALGPGGPVWIKETRTRHLRSRDFLAPHRALQARFDDGQVPEHLLHALACLQGPGVAPVLRCAPTPAGLSLQLQRSAVFERVLSAVAAYATPASPASLGQRVLLHCPALRSSPCALRLSQLRTVLVADHLARALRAHGVCVRLVPAVRDPHMLTFLQQLRVDWPAASERASSHTLRSHALEELTSANDGRTLSPGILGRLCLKELVEEQGRTAGYDPNLDNCLVTEDLLSVLAELQEALWHWPEDSHPGLAGASDTGTGGCLVVHVVSCEEEFQQQKLDLLWQKLVDKAPLRQKHLICGPVKVAGAPGTLMTAPEYYEFRHTQVCKASALKHGGDLAQDPAWTEIFGVLSVATIKFEMLSTAPQSQLFLALADSSISTKGTKSGTFVMYNCARLATLFESYKCSMEQGLYPTFPPVSSLDFSLLHDEGEWLLLFNSILPFPDLLSRTAVLDCTAPGLHIAVRTEMICKFLVQLSMDFSSYYNRVHILGEPRPHLFGQMFVRLQLLRAVREVLHTGLAMLGLPPLSHI>sp|Q5D0E6-2|DALD3_HUMAN Isoform 2 of DALR anticodon-binding domain-containing protein 3 OS=Homo sapiens OX=9606 GN=DALRD3MATRRLGVGETLGALNAALGPGGPVWIKETRTRHLRSRDFLAPHRALQARFDDGQVPEHLLHALACLQGPGVAPVLRCAPTPAGLSLQLQRSAVFERVLSAVAAYATPASPASLGQRVLLHCPALRSSPCALRLSQLRTVLVADHLARALRAHGVCVRLVPAVRDPHMLTFLQQLRVDWPAASERASSHTLRSHALEELTSANDGRTLSPGILGRLCLKELVEEQGRTAGYDPNLDNCLVTEDLLSVLAELQEALWHWPEDSHPGLAGASDTGTGGCLVVHVVSCEEEFQQQKLDLLWQKLVDKAPLRQKHLICGPVKVAGAPGTLMTAPEYYEFRHTQVCKASALKHGGDLAQDPAWTEIFGVLSVATIKFEMLSTAPQSQLFLALADSSISTKGTKSGTFVMYNCARLATLFESYKCSMEQGLYPTFPPVSSLDFSLLHDEYPPLSGSAEPDSSAGLHSPGAPHCCTHRDDMQVPGTAQHGFQLLLQPGTHPGGASTTPLWSDVRPPAASESCA>sp|Q5D0E6-3|DALD3_HUMAN Isoform 3 of DALR anticodon-binding domain-containing protein 3 OS=Homo sapiens OX=9606 GN=DALRD3MATRRLGVGETLGALNAALGPGGPVWIKETRTRHLRSRDFLAPHRALQARFDDGQVPEHLLHALACLQGPGVAPVLRCAPTPAGLSLQLQRSAVFERVLSAVAAYATPASPASLGQRVLLHCPALRSSPCALTGCACA>sp|Q5D0E6-4|DALD3_HUMAN Isoform 4 of DALR anticodon-binding domain-containing protein 3 OS=Homo sapiens OX=9606 GN=DALRD3MLTFLQQLRVDWPAASERASSHTLRSHALEELTSANDGRTLSPGILGRLCLKELVEEQGRTAGYDPNLDNCLVTEDLLSVLAELQEALWHWPEDSHPGLAGASDTGTGGCLVVHVVSCEEEFQQQKLDLLWQKLVDKAPLRQKHLICGPVKVAGAPGTLMTAPEYYEFRHTQVCKASALKHGGDLAQDPAWTEIFGVLSVATIKFEMLSTAPQSQLFLALADSSISTKGTKSGTFVMYNCARLATLFESYKCSMEQGLYPTFPPVSSLDFSLLHDEGEWLLLFNSILPFPDLLSRTAVLDCTAPGLHIAVRTEMICKFLVQLSMDFSSYYNRVHILGEPRPHLFGQMFVRLQLLRAVREVLHTGLAMLGLPPLSHI>sp|Q16698|DECR_HUMAN 2,4-dienoyl-CoA reductase [(3E)-enoyl-CoA-producing], mitochondrial OS=Homo sapiens OX=9606 GN=DECR1 PE=1 SV=1MKLPARVFFTLGSRLPCGLAPRRFFSYGTKILYQNTEALQSKFFSPLQKAMLPPNSFQGKVAFITGGGTGLGKGMTTLLSSLGAQCVIASRKMDVLKATAEQISSQTGNKVHAIQCDVRDPDMVQNTVSELIKVAGHPNIVINNAAGNFISPTERLSPNAWKTITDIVLNGTAFVTLEIGKQLIKAQKGAAFLSITTIYAETGSGFVVPSASAKAGVEAMSKSLAAEWGKYGMRFNVIQPGPIKTKGAFSRLDPTGTFEKEMIGRIPCGRLGTVEELANLAAFLCSDYASWINGAVIKFDGGEEVLISGEFNDLRKVTKEQWDTIEELIRKTKGS>sp|Q16698-2|DECR_HUMAN Isoform 2 of 2,4-dienoyl-CoA reductase [(3E)-enoyl-CoA-producing], mitochondrial OS=Homo sapiens OX=9606 GN=DECR1MSGLGKKHLLLMGEFFSYGTKILYQNTEALQSKFFSPLQKAMLPPNSFQGKVAFITGGGTGLGKGMTTLLSSLGAQCVIASRKMDVLKATAEQISSQTGNKVHAIQCDVRDPDMVQNTVSELIKVAGHPNIVINNAAGNFISPTERLSPNAWKTITDIVLNGTAFVTLEIGKQLIKAQKGAAFLSITTIYAETGSGFVVPSASAKAGVEAMSKSLAAEWGKYGMRFNVIQPGPIKTKGAFSRLDPTGTFEKEMIGRIPCGRLGTVEELANLAAFLCSDYASWINGAVIKFDGGEEVLISGEFNDLRKVTKEQWDTIEELIRKTKGS>sp|Q96PH6|DB118_HUMAN Beta-defensin 118 OS=Homo sapiens OX=9606GN=DEFB118 PE=1 SV=1MKLLLLALPMLVLLPQVIPAYSGEKKCWNRSGHCRKQCKDGEAVKDTCKNLRACCIPSNEDHRRVPATSPTPLSDSTPGIIDDILTVRFTTDYFEVSSKKDMVEESEAGRGTETSLPNVHHSS>sp|Q14154|DELE1_HUMAN DAP3-binding cell death enhancer 1 OS=Homo sapiensOX=9606 GN=DELE1 PE=1 SV=3MWRLPGLLGRALPRTLGPSLWRVTPKSTSPDGPQTTSSTLLVPVPNLDRSGPHGPGTSGGPRSHGWKDAFQWMSSRVSPNTLWDAISWGTLAVLALQLARQIHFQASLPAGPQRVEHCSWHSPLDRFFSSPLWHPCSSLRQHILPSPDGPAPRHTGLREPRLGQEEASAQPRNFSHNSLRGARPQDPSEEGPGDFGFLHASSSIESEAKPAQPQPTGEKEQDKSKTLSLEEAVTSIQQLFQLSVSIAFNFLGTENMKSGDHTAAFSYFQKAAARGYSKAQYNAGLCHEHGRGTPRDISKAVLYYQLAASQGHSLAQYRYARCLLRDPASSWNPERQRAVSLLKQAADSGLREAQAFLGVLFTKEPYLDEQRAVKYLWLAANNGDSQSRYHLGICYEKGLGVQRNLGEALRCYQQSAALGNEAAQERLRALFSMGAAAPGPSDLTVTGLKSFSSPSLCSLNTLLAGTSRLPHASSTGNLGLLCRSGHLGASLEASSRAIPPHPYPLERSVVRLGFG>sp|Q8N690|DB119_HUMAN Beta-defensin 119 OS=Homo sapiens OX=9606GN=DEFB119 PE=2 SV=2MKLLYLFLAILLAIEEPVISGKRHILRCMGNSGICRASCKKNEQPYLYCRNCQSCCLQSYMRISISGKEENTDWSYEKQWPRLP>sp|Q8N690-2|DB119_HUMAN Isoform 2 of Beta-defensin 119 OS=Homo sapiensOX=9606 GN=DEFB119MKLLYLFLAILLAIEEPVISVECWMDGHCRLLCKDGEDSIIRCRNRKRCCVPSRYLTIQPVTIHGILGWTTPQMSTTAPKMKTNITNR>sp|Q8N690-3|DB119_HUMAN Isoform 3 of Beta-defensin 119 OS=Homo sapiensOX=9606 GN=DEFB119MKLLYLFLAILLAIEEPVISALVRTVGCCLDTARQTPHPSMHG>sp|Q16832|DDR2_HUMAN Discoidin domain-containing receptor 2 OS=Homosapiens OX=9606 GN=DDR2 PE=1 SV=2MILIPRMLLVLFLLLPILSSAKAQVNPAICRYPLGMSGGQIPDEDITASSQWSESTAAKYGRLDSEEGDGAWCPEIPVEPDDLKEFLQIDLHTLHFITLVGTQGRHAGGHGIEFAPMYKINYSRDGTRWISWRNRHGKQVLDGNSNPYDIFLKDLEPPIVARFVRFIPVTDHSMNVCMRVELYGCVWLDGLVSYNAPAGQQFVLPGGSIIYLNDSVYDGAVGYSMTEGLGQLTDGVSGLDDFTQTHEYHVWPGYDYVGWRNESATNGYIEIMFEFDRIRNFTTMKVHCNNMFAKGVKIFKEVQCYFRSEASEWEPNAISFPLVLDDVNPSARFVTVPLHHRMASAIKCQYHFADTWMMFSEITFQSDAAMYNNSEALPTSPMAPTTYDPMLKVDDSNTRILIGCLVAIIFILLAIIVIILWRQFWQKMLEKASRRMLDDEMTVSLSLPSDSSMFNNNRSSSPSEQGSNSTYDRIFPLRPDYQEPSRLIRKLPEFAPGEEESGCSGVVKPVQPSGPEGVPHYAEADIVNLQGVTGGNTYSVPAVTMDLLSGKDVAVEEFPRKLLTFKEKLGEGQFGEVHLCEVEGMEKFKDKDFALDVSANQPVLVAVKMLRADANKNARNDFLKEIKIMSRLKDPNIIHLLAVCITDDPLCMITEYMENGDLNQFLSRHEPPNSSSSDVRTVSYTNLKFMATQIASGMKYLSSLNFVHRDLATRNCLVGKNYTIKIADFGMSRNLYSGDYYRIQGRAVLPIRWMSWESILLGKFTTASDVWAFGVTLWETFTFCQEQPYSQLSDEQVIENTGEFFRDQGRQTYLPQPAICPDSVYKLMLSCWRRDTKNRPSFQEIHLLLLQQGDE>sp|Q5J5C9|DB121_HUMAN Beta-defensin 121 OS=Homo sapiens OX=9606GN=DEFB121 PE=1 SV=1MKLLLLLLTVTLLLAQVTPVMKCWGKSGRCRTTCKESEVYYILCKTEAKCCVDPKYVPVKPKLTDTNTSLESTSAV>sp|Q99259|DCE1_HUMAN Glutamate decarboxylase 1 OS=Homo sapiens OX=9606GN=GAD1 PE=1 SV=1MASSTPSSSATSSNAGADPNTTNLRPTTYDTWCGVAHGCTRKLGLKICGFLQRTNSLEEKSRLVSAFKERQSSKNLLSCENSDRDARFRRTETDFSNLFARDLLPAKNGEEQTVQFLLEVVDILLNYVRKTFDRSTKVLDFHHPHQLLEGMEGFNLELSDHPESLEQILVDCRDTLKYGVRTGHPRFFNQLSTGLDIIGLAGEWLTSTANTNMFTYEIAPVFVLMEQITLKKMREIVGWSSKDGDGIFSPGGAISNMYSIMAARYKYFPEVKTKGMAAVPKLVLFTSEQSHYSIKKAGAALGFGTDNVILIKCNERGKIIPADFEAKILEAKQKGYVPFYVNATAGTTVYGAFDPIQEIADICEKYNLWLHVDAAWGGGLLMSRKHRHKLNGIERANSVTWNPHKMMGVLLQCSAILVKEKGILQGCNQMCAGYLFQPDKQYDVSYDTGDKAIQCGRHVDIFKFWLMWKAKGTVGFENQINKCLELAEYLYAKIKNREEFEMVFNGEPEHTNVCFWYIPQSLRGVPDSPQRREKLHKVAPKIKALMMESGTTMVGYQPQGDKANFFRMVISNPAATQSDIDFLIEEIERLGQDL>sp|Q99259-3|DCE1_HUMAN Isoform 3 of Glutamate decarboxylase 1 OS=Homosapiens OX=9606 GN=GAD1MASSTPSSSATSSNAGADPNTTNLRPTTYDTWCGVAHGCTRKLGLKICGFLQRTNSLEEKSRLVSAFKERQSSKNLLSCENSDRDARFRRTETDFSNLFARDLLPAKNGEEQTVQFLLEVVDILLNYVRKTFDRSTKVLDFHHPHQLLEGMEGFNLELSDHPESLEQILVDCRDTLKYGVRTGHPRFFNQLSTGLDIIGLAGEWLTSTANTNMPSDMRECWLLR>sp|Q99259-4|DCE1_HUMAN Isoform 4 of Glutamate decarboxylase 1 OS=Homosapiens OX=9606 GN=GAD1MASSTPSSSATSSNAGADPNTTNLRPTTYDTWCGVAHGCTRKLGLKICGFLQRTNSLEEKSRLVSAFKERQSSKNLLSCENSDRDARFRRTETDFSNLFARDLLPAKNGEEQTVQFLLEVVDILLNYVRKTFDRSTKVLDFHHPHQLLEGMEGFNLELSDHPESLEQILVDCRDTLKYGVRTGHPRFFNQLSTGLDIIGLAGEWLTSTANTNMFTYEIAPVFVLMEQITLKKMREIVGWSSKDGDGIFSPGGAISNMYSIMAARYKYFPEVKTKGMAAVPKLVLFTSEQSHYSIKKAGAALGFGTDNVILIKCNERGKIIPADFEAKILEAKQKGYVPFYVNATAGTTVYGAFDPIQEIADICEKYNLWLHVDGFNFSQLANRIICLATELMTNKGCVTWHPNYSVNMHHGCLGRWAAHVQEAPP>sp|Q8N688|DB123_HUMAN Beta-defensin 123 OS=Homo sapiens OX=9606GN=DEFB123 PE=2 SV=1MKLLLLTLTVLLLLSQLTPGGTQRCWNLYGKCRYRCSKKERVYVYCINNKMCCVKPKYQPKERWWPF>sp|Q8N688-2|DB123_HUMAN Isoform 2 of Beta-defensin 123 OS=Homo sapiensOX=9606 GN=DEFB123MKLLLLTLTVLLLLSQLTPDLSNPESTC>sp|O15484|CAN5_HUMAN Calpain-5 OS=Homo sapiens OX=9606 GN=CAPN5 PE=1SV=2MFSCVKPYEDQNYSALRRDCRRRKVLFEDPLFPATDDSLYYKGTPGPAVRWKRPKGICEDPRLFVDGISSHDLHQGQVGNCWFVAACSSLASRESLWQKVIPDWKEQEWDPEKPNAYAGIFHFHFWRFGEWVDVVIDDRLPTVNNQLIYCHSNSRNEFWCALVEKAYAKLAGCYQALDGGNTADALVDFTGGVSEPIDLTEGDFANDETKRNQLFERMLKVHSRGGLISASIKAVTAADMEARLACGLVKGHAYAVTDVRKVRLGHGLLAFFKSEKLDMIRLRNPWGEREWNGPWSDTSEEWQKVSKSEREKMGVTVQDDGEFWMTFEDVCRYFTDIIKCRVINTSHLSIHKTWEEARLHGAWTLHEDPRQNRGGGCINHKDTFFQNPQYIFEVKKPEDEVLICIQQRPKRSTRREGKGENLAIGFDIYKVEENRQYRMHSLQHKAASSIYINSRSVFLRTDQPEGRYVIIPTTFEPGHTGEFLLRVFTDVPSNCRELRLDEPPHTCWSSLCGYPQLVTQVHVLGAAGLKDSPTGANSYVIIKCEGDKVRSAVQKGTSTPEYNVKGIFYRKKLSQPITVQVWNHRVLKDEFLGQVHLKADPDNLQALHTLHLRDRNSRQPSNLPGTVAVHILSSTSLMAV>sp|Q96F63|CCD97_HUMAN Coiled-coil domain-containing protein 97 OS=Homosapiens OX=9606 GN=CCDC97 PE=1 SV=1MEAVATATAAKEPDKGCIEPGPGHWGELSRTPVPSKPQDKVEAAEATPVALDSDTSGAENAAVSAMLHAVAASRLPVCSQQQGEPDLTEHEKVAILAQLYHEKPLVFLERFRTGLREEHLACFGHVRGDHRADFYCAEVARQGTARPRTLRTRLRNRRYAALRELIQGGEYFSDEQMRFRAPLLYEQYIGQYLTQEELSARTPTHQPPKPGSPGRPACPLSNLLLQSYEERELQQRLLQQQEEEEACLEEEEEEEDSDEEDQRSGKDSEAWVPDSEERLILREEFTSRMHQRFLDGKDGDFDYSTVDDNPDFDNLDIVARDEEERYFDEEEPEDAPSPELDGD>sp|Q9Y6W3|CAN7_HUMAN Calpain-7 OS=Homo sapiens OX=9606 GN=CAPN7 PE=1SV=1MDATALERDAVQFARLAVQRDHEGRYSEAVFYYKEAAQALIYAEMAGSSLENIQEKITEYLERVQALHSAVQSKSADPLKSKHQLDLERAHFLVTQAFDEDEKENVEDAIELYTEAVDLCLKTSYETADKVLQNKLKQLARQALDRAEALSEPLTKPVGKISSTSVKPKPPPVRAHFPLGANPFLERPQSFISPQSCDAQGQRYTAEEIEVLRTTSKINGIEYVPFMNVDLRERFAYPMPFCDRWGKLPLSPKQKTTFSKWVRPEDLTNNPTMIYTVSSFSIKQTIVSDCSFVASLAISAAYERRFNKKLITGIIYPQNKDGEPEYNPCGKYMVKLHLNGVPRKVIIDDQLPVDHKGELLCSYSNNKSELWVSLIEKAYMKVMGGYDFPGSNSNIDLHALTGWIPERIAMHSDSQTFSKDNSFRMLYQRFHKGDVLITASTGMMTEAEGEKWGLVPTHAYAVLDIREFKGLRFIQLKNPWSHLRWKGRYSENDVKNWTPELQKYLNFDPRTAQKIDNGIFWISWDDLCQYYDVIYLSWNPGLFKESTCIHSTWDAKQGPVKDAYSLANNPQYKLEVQCPQGGAAVWVLLSRHITDKDDFANNREFITMVVYKTDGKKVYYPADPPPYIDGIRINSPHYLTKIKLTTPGTHTFTLVVSQYEKQNTIHYTVRVYSACSFTFSKIPSPYTLSKRINGKWSGQSAGGCGNFQETHKNNPIYQFHIEKTGPLLIELRGPRQYSVGFEVVTVSTLGDPGPHGFLRKSSGDYRCGFCYLELENIPSGIFNIIPSTFLPKQEGPFFLDFNSIIPIKITQLQ>sp|P42575|CASP2_HUMAN Caspase-2 OS=Homo sapiens OX=9606 GN=CASP2 PE=1SV=2MAAPSAGSWSTFQHKELMAADRGRRILGVCGMHPHHQETLKKNRVVLAKQLLLSELLEHLLEKDIITLEMRELIQAKVGSFSQNVELLNLLPKRGPQAFDAFCEALRETKQGHLEDMLLTTLSGLQHVLPPLSCDYDLSLPFPVCESCPLYKKLRLSTDTVEHSLDNKDGPVCLQVKPCTPEFYQTHFQLAYRLQSRPRGLALVLSNVHFTGEKELEFRSGGDVDHSTLVTLFKLLGYDVHVLCDQTAQEMQEKLQNFAQLPAHRVTDSCIVALLSHGVEGAIYGVDGKLLQLQEVFQLFDNANCPSLQNKPKMFFIQACRGDETDRGVDQQDGKNHAGSPGCEESDAGKEKLPKMRLPTRSDMICGYACLKGTAAMRNTKRGSWYIEALAQVFSERACDMHVADMLVKVNALIKDREGYAPGTEFHRCKEMSEYCSTLCRHLYLFPGHPPT>sp|P42575-2|CASP2_HUMAN Isoform 2 of Caspase-2 OS=Homo sapiens OX=9606GN=CASP2MHPHHQETLKKNRVVLAKQLLLSELLEHLLEKDIITLEMRELIQAKVGSFSQNVELLNLLPKRGPQAFDAFCEALRETKQGHLEDMLLTTLSGLQHVLPPLSCDYDLSLPFPVCESCPLYKKLRLSTDTVEHSLDNKDGPVCLQVKPCTPEFYQTHFQLAYRLQSRPRGLALVLSNVHFTGEKELEFRSGGDVDHSTLVTLFKLLGYDVHVLCDQTAQEMQEKLQNFAQLPAHRVTDSCIVALLSHGVEGAIYGVDGKLLQLQEVFQLFDNANCPSLQNKPKMFFIQACRGGGAIGSLGHLLLFTAATASLAL>sp|P42575-3|CASP2_HUMAN Isoform 3 of Caspase-2 OS=Homo sapiens OX=9606GN=CASP2MAADRGRRILGVCGMHPHHQETLKKNRVVLAKQLLLSELLEHLLEKDIITLEMRELIQAKVGSFSQNVELLNLLPKRGPQAFDAFCEALHS>sp|A6NHC0|CAN8_HUMAN Calpain-8 OS=Homo sapiens OX=9606 GN=CAPN8 PE=1SV=3MAAQAAGVSRQRAATQGLGSNQNALKYLGQDFKTLRQQCLDSGVLFKDPEFPACPSALGYKDLGPGSPQTQGIIWKRPTELCPSPQFIVGGATRTDICQGGLGDCWLLAAIASLTLNEELLYRVVPRDQDFQENYAGIFHFQFWQYGEWVEVVIDDRLPTKNGQLLFLHSEQGNEFWSALLEKAYAKLNGCYEALAGGSTVEGFEDFTGGISEFYDLKKPPANLYQIIRKALCAGSLLGCSIDVSSAAEAEAITSQKLVKSHAYSVTGVEEVNFQGHPEKLIRLRNPWGEVEWSGAWSDDAPEWNHIDPRRKEELDKKVEDGEFWMSLSDFVRQFSRLEICNLSPDSLSSEEVHKWNLVLFNGHWTRGSTAGGCQNYPATYWTNPQFKIRLDEVDEDQEESIGEPCCTVLLGLMQKNRRWRKRIGQGMLSIGYAVYQVPKELESHTDAHLGRDFFLAYQPSARTSTYVNLREVSGRARLPPGEYLVVPSTFEPFKDGEFCLRVFSEKKAQALEIGDVVAGNPYEPHPSEVDQEDDQFRRLFEKLAGKDSEITANALKILLNEAFSKRTDIKFDGFNINTCREMISLLDSNGTGTLGAVEFKTLWLKIQKYLEIYWETDYNHSGTIDAHEMRTALRKAGFTLNSQVQQTIALRYACSKLGINFDSFVACMIRLETLFKLFSLLDEDKDGMVQLSLAEWLCCVLV>sp|Q68DN1|CB016_HUMAN Uncharacterized protein C2orf16 OS=Homo sapiensOX=9606 GN=C2orf16 PE=2 SV=3MELTPGAQQQGINYQELTSGWQDVKSMMLVPEPTRKFPSGPLLTSVRFSNLSPESQQQDVKSLEFTVEPKLQSVKHVKLSSVSLQQTIKSVELAPGSLPQRVKYGEQTPRTNYQIMESSELIPRPGHQFAKYAEMIPQPKYQIPKSANLISIPIYHATESSEMAQGLAYKGIDTVEKSVGLTPKLTGRAKESLGMLLQPDLQVPKFVDLTPMVRDQGSKFLGLTPEKSYQILETMELLSQSRPRVKDVGELYMKPLQQTVEYEGITPELKHYFTEAMGLTAEARIQANEFFGMTPKPTSQATGFAERSPRLCPQNLECVEVISEKRLQGEESVVLIPKSLHHVPDSASGMTPGLGHRVPESVELTSKSGVQVEKTLQLTPKPQHHVGSPGIISGLGHQVPESVNLTCKQWLQMEESLEVPLKQTSQVIGHEESVELTSEARQHREVSMGLTKSKNQSMKSPGTTPGPLGRIVEFMRISPEPLDQVTESARTQLQVAQSEEVILIDVPKVVQSVKVTPGPPFQIVKSVTIPRPTPQMVEYIELTPKLQYVRPSEHHTGPCLQDVKSTKLITKPKHQILETVELTGFQIVKTMLIPGPSLQIVKSEELAPGPIPQVVEPIGVALESGIEAINCVDLLPRPHLQELIVPAELTPSPCTQVKSAELTSPQTSPFEEHTILTHKQGLQAVKSTVIKTEPPKVMETEDLNLGHVCQNRDCQKLTSEELQVGTDFSRFLQSSSTTLISSSVRTASELGGLWDSGIQEVSRALDIKNPGTDILQPEETYIDPTMIQSLTFPLALHNQSSDKTANIVENPCPEILGVDVISKETTKRKQMEELENSLQRHLPQSWRSRSRTFQAESGVQKGLIKSFPGRQHNVWESHAWRQRLPRKYLSTMLMLGNILGTTMERKLCSQTSLAERATADTCQSIQNLFGIPAELMEPSQSLPEKGPVTISQPSVVKNYIQRHTFYHGHKKRMALRIWTRGSTSSIIQQYSGTRVRIKKTNSTFNGISQEVIQHMPVSCAGGQLPVLVKSESSLSIFYDREDLVPMEESEDSQSDSQTRISESQHSLKPNYLSQAKTDFSEQFQLLEDLQLKIAAKLLRSQIPPDVPPPLASGLVLKYPICLQCGRCSGLNCHHKLQTTSGPYLLIYPQLHLVRTPEGHGEVRLHLGFRLRIGKRSQISKYRERDRPVIRRSPISPSQRKAKIYTQASKSPTSTIDLQSGPSQSPAPVQVYIRRGQRSRPDLVEKTKTRAPGHYEFTQVHNLPESDSESTQNEKRAKVRTKKTSDSKYPMKRITKRLRKHRKFYTNSRTTIESPSRELAAHLRRKRIGATQTSTASLKRQPKKPSQPKFMQLLFQSLKRAFQTAHRVIASVGRKPVDGTRPDNLWASKNYYPKQNARDYCLPSSIKRDKRSADKLTPAGSTIKQEDILWGGTVQCRSAQQPRRAYSFQPRPLRLPKPTDSQSGIAFQTASVGQPLRTVQKDSSSRSKKNFYRNETSSQESKNLSTPGTRVQARGRILPGSPVKRTWHRHLKDKLTHKEHNHPSFYRERTPRGPSERTRHNPSWRNHRSPSERSQRSSLERRHHSPSQRSHCSPSRKNHSSPSERSWRSPSQRNHCSPPERSCHSLSERGLHSPSQRSHRGPSQRRHHSPSERSHRSPSERSHRSSSERRHRSPSQRSHRGPSERSHCSPSERRHRSPSQRSHRGPSERRHHSPSKRSHRSPARRSHRSPSERSHHSPSERSHHSPSERRHHSPSERSHCSPSERSHCSPSERRHRSPSERRHHSPSEKSHHSPSERSHHSPSERRRHSPLERSRHSLLERSHRSPSERRSHRSFERSHRRISERSHSPSEKSHLSPLERSRCSPSERRGHSSSGKTCHSPSERSHRSPSGMRQGRTSERSHRSSCERTRHSPSEMRPGRPSGRNHCSPSERSRRSPLKEGLKYSFPGERPSHSLSRDFKNQTTLLGTTHKNPKAGQVWRPEATR>sp|Q9NR30|DDX21_HUMAN Nucleolar RNA helicase 2 OS=Homo sapiens OX=9606GN=DDX21 PE=1 SV=5MPGKLRSDAGLESDTAMKKGETLRKQTEEKEKKEKPKSDKTEEIAEEEETVFPKAKQVKKKAEPSEVDMNSPKSKKAKKKEEPSQNDISPKTKSLRKKKEPIEKKVVSSKTKKVTKNEEPSEEEIDAPKPKKMKKEKEMNGETREKSPKLKNGFPHPEPDCNPSEAASEESNSEIEQEIPVEQKEGAFSNFPISEETIKLLKGRGVTFLFPIQAKTFHHVYSGKDLIAQARTGTGKTFSFAIPLIEKLHGELQDRKRGRAPQVLVLAPTRELANQVSKDFSDITKKLSVACFYGGTPYGGQFERMRNGIDILVGTPGRIKDHIQNGKLDLTKLKHVVLDEVDQMLDMGFADQVEEILSVAYKKDSEDNPQTLLFSATCPHWVFNVAKKYMKSTYEQVDLIGKKTQKTAITVEHLAIKCHWTQRAAVIGDVIRVYSGHQGRTIIFCETKKEAQELSQNSAIKQDAQSLHGDIPQKQREITLKGFRNGSFGVLVATNVAARGLDIPEVDLVIQSSPPKDVESYIHRSGRTGRAGRTGVCICFYQHKEEYQLVQVEQKAGIKFKRIGVPSATEIIKASSKDAIRLLDSVPPTAISHFKQSAEKLIEEKGAVEALAAALAHISGATSVDQRSLINSNVGFVTMILQCSIEMPNISYAWKELKEQLGEEIDSKVKGMVFLKGKLGVCFDVPTASVTEIQEKWHDSRRWQLSVATEQPELEGPREGYGGFRGQREGSRGFRGQRDGNRRFRGQREGSRGPRGQRSGGGNKSNRSQNKGQKRSFSKAFGQ>sp|Q9NR30-2|DDX21_HUMAN Isoform 2 of Nucleolar RNA helicase 2 OS=Homosapiens OX=9606 GN=DDX21MNSPKSKKAKKKEEPSQNDISPKTKSLRKKKEPIEKKVVSSKTKKVTKNEEPSEEEIDAPKPKKMKKEKEMNGETREKSPKLKNGFPHPEPDCNPSEAASEESNSEIEQEIPVEQKEGAFSNFPISEETIKLLKGRGVTFLFPIQAKTFHHVYSGKDLIAQARTGTGKTFSFAIPLIEKLHGELQDRKRGRAPQVLVLAPTRELANQVSKDFSDITKKLSVACFYGGTPYGGQFERMRNGIDILVGTPGRIKDHIQNGKLDLTKLKHVVLDEVDQMLDMGFADQVEEILSVAYKKDSEDNPQTLLFSATCPHWVFNVAKKYMKSTYEQVDLIGKKTQKTAITVEHLAIKCHWTQRAAVIGDVIRVYSGHQGRTIIFCETKKEAQELSQNSAIKQDAQSLHGDIPQKQREITLKGFRNGSFGVLVATNVAARGLDIPEVDLVIQSSPPKDVESYIHRSGRTGRAGRTGVCICFYQHKEEYQLVQVEQKAGIKFKRIGVPSATEIIKASSKDAIRLLDSVPPTAISHFKQSAEKLIEEKGAVEALAAALAHISGATSVDQRSLINSNVGFVTMILQCSIEMPNISYAWKELKEQLGEEIDSKVKGMVFLKGKLGVCFDVPTASVTEIQEKWHDSRRWQLSVATEQPELEGPREGYGGFRGQREGSRGFRGQRDGNRRFRGQREGSRGPRGQRSGGGNKSNRSQNKGQKRSFSKAFGQ>sp|Q2NKX9|CB068_HUMAN UPF0561 protein C2orf68 OS=Homo sapiens OX=9606GN=C2orf68 PE=1 SV=1MEAGPHPRPGHCCKPGGRLDMNHGFVHHIRRNQIARDDYDKKVKQAAKEKVRRRHTPAPTRPRKPDLQVYLPRHRDVSAHPRNPDYEESGESSSSGGSELEPSGHQLFCLEYEADSGEVTSVIVYQGDDPGKVSEKVSAHTPLDPPMREALKLRIQEEIAKRQSQH>sp|Q2NKX9-3|CB068_HUMAN Isoform 2 of UPF0561 protein C2orf68 OS=Homosapiens OX=9606 GN=C2orf68MEAGPHPRPGHCCKPGGRLDMNHGFVHHIRRNQIARDDYDKKVKQAAKEKVRRRHTPAPTRPRKPDLQVYLPRHRGEAARPACLQPARSSCNALPFSIGKNHFLLLRFSSSRLFPEPPPQRSQISAE>sp|Q9BQI4|CCDC3_HUMAN Coiled-coil domain-containing protein 3 OS=Homosapiens OX=9606 GN=CCDC3 PE=2 SV=1MLRQLLLAALCLAGPPAPARACQLPSEWRPLSEGCRAELAETIVYARVLALHPEAPGLYNHLPWQYHAGQGGLFYSAEVEMLCDQAWGSMLEVPAGSRLNLTGLGYFSCHSHTVVQDYSYFFFLRMDENYNLLPHGVNFQDAIFPDTQENRRMFSSLFQFSNCSQGQQLATFSSDWEIQEDSRLMCSSVQKALFEEEDHVKKLQQKVATLEKRNRQLRERVKKVKRSLRQARKKGRHLELANQKLSEKLAAGALPHINARGPVRPPYLRG>sp|Q9BQI4-2|CCDC3_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 3 OS=Homo sapiens OX=9606 GN=CCDC3MDENYNLLPHGVNFQDAIFPDTQENRRMFSSLFQFSNCSQGQQLATFSSDWEIQEDSRLMCSSVQKALFEEEDHVKKLQQKVATLEKRNRQLRERVKKVKRSLRQARKKGRHLELANQKLSEKLAAGALPHINARGPVRPPYLRG>sp|P04040|CATA_HUMAN Catalase OS=Homo sapiens OX=9606 GN=CAT PE=1 SV=3MADSRDPASDQMQHWKEQRAAQKADVLTTGAGNPVGDKLNVITVGPRGPLLVQDVVFTDEMAHFDRERIPERVVHAKGAGAFGYFEVTHDITKYSKAKVFEHIGKKTPIAVRFSTVAGESGSADTVRDPRGFAVKFYTEDGNWDLVGNNTPIFFIRDPILFPSFIHSQKRNPQTHLKDPDMVWDFWSLRPESLHQVSFLFSDRGIPDGHRHMNGYGSHTFKLVNANGEAVYCKFHYKTDQGIKNLSVEDAARLSQEDPDYGIRDLFNAIATGKYPSWTFYIQVMTFNQAETFPFNPFDLTKVWPHKDYPLIPVGKLVLNRNPVNYFAEVEQIAFDPSNMPPGIEASPDKMLQGRLFAYPDTHRHRLGPNYLHIPVNCPYRARVANYQRDGPMCMQDNQGGAPNYYPNSFGAPEQQPSALEHSIQYSGEVRRFNTANDDNVTQVRAFYVNVLNEEQRKRLCENIAGHLKDAQIFIQKKAVKNFTEVHPDYGSHIQALLDKYNAEKPKNAIHTFVQSGSHLAAREKANL>sp|Q96LW7|CAR19_HUMAN Caspase recruitment domain-containing protein 19OS=Homo sapiens OX=9606 GN=CARD19 PE=1 SV=1MTDQTYCDRLVQDTPFLTGHGRLSEQQVDRIILQLNRYYPQILTNKEAEKFRNPKASLRVRLCDLLSHLQRSGERDCQEFYRALYIHAQPLHSRLPSRHALRKFHITNHACLVLARGGHPSLPLMAWMSSMTTQVCCSPGLASPLASAPPQRPPSGPEGRVWQAQAVQMLVSVSHFLPLPPSLSHGSFHTAWGILYVHSCPSFSNLIPRGSLHVCVDSNLVPTAAWRS>sp|Q96LW7-2|CAR19_HUMAN Isoform 2 of Caspase recruitment domain-containing protein 19 OS=Homo sapiens OX=9606 GN=CARD19MTDQTYCDRLVQDTPFLTGHGRLSEQQVDRIILQLNRYYPQILTNKEAEKFRNPKASLRVRLCDLLSHLQRSGERDCQEFYRALYIHAQPLHSRLPSRHALQNSDCTELDSGSQSGELSNRGPMSFLAGLGLAVGLALLLYCYPPDPKGLPGTRRVLGFSPVIIDRHVSRYLLAFLADDLGGL>sp|Q9UHL0|DDX25_HUMAN ATP-dependent RNA helicase DDX25 OS=Homo sapiensOX=9606 GN=DDX25 PE=1 SV=2MASLLWGGDAGAAESERLNSHFSNLSQPRKNLWGIKSTAVRNIDGSINNINEDDEEDVVDLAANSLLNKLIHQSLVESSHRVEVLQKDPSSPLYSVKTFEELRLKEELLKGIYAMGFNRPSKIQEMALPMMLAHPPQNLIAQSQSGTGKTAAFVLAMLSRVNALELFPQCLCLAPTYELALQTGRVVEQMGKFCVDVQVMYAIRGNRIPRGTDITKQIIIGTPGTVLDWCFKLKLIDLTKIRVFVLDEADVMIDTQGFSDHSIRIQRALPSECQMLLFSATFEDSVWHFAERIIPDPNVIKLRKEELTLNNIRQYYVLCEHRKDKYQALCNIYGSITIGQAIIFCQTRRNAKWLTVEMIQDGHQVSLLSGELTVEQRASIIQRFRDGKEKVLITTNVCARGIDVKQVTIVVNFDLPVKQGEEPDYETYLHRIGRTGRFGKKGLAFNMIEVDELPSLMKIQDHFNSSIKQLNAEDMDEIEKIDY>sp|Q9UHL0-2|DDX25_HUMAN Isoform 2 of ATP-dependent RNA helicase DDX25OS=Homo sapiens OX=9606 GN=DDX25MGFNRPSKIQEMALPMMLAHPPQNLIAQSQSGTGKTAAFVLAMLSRVNALELFPQCLCLAPTYELALQTGRVVEQMGKFCVDVQVMYAIRGNRIPRGTDITKQIIIGTPGTVLDWCFKLKLIDLTKIRVFVLDEADVMIDTQGFSDHSIRIQRALPSECQMLLFSATFEDSVWHFAERIIPDPNVIKLRKEELTLNNIRQYYVLCEHRKDKYQALCNIYGSITIGQAIIFCQTRRNAKWLTVEMIQDGHQVSLLSGELTVEQRASIIQRFRDGKEKVLITTNVCARGIDVKQVTIVVNFDLPVKQGEEPDYETYLHRIGRTGRFGKKGLAFNMIEVDELPSLMKIQDHFNSSIKQLNAEDMDEIEKIDY>sp|Q9ULB5|CADH7_HUMAN Cadherin-7 OS=Homo sapiens OX=9606 GN=CDH7 PE=2SV=2MKLGKVEFCHFLQLIALFLCFSGMSQAELSRSRSKPYFQSGRSRTKRSWVWNQFFVLEEYMGSDPLYVGKLHSDVDKGDGSIKYILSGEGASSIFIIDENTGDIHATKRLDREEQAYYTLRAQALDRLTNKPVEPESEFVIKIQDINDNEPKFLDGPYTAGVPEMSPVGTSVVQVTATDADDPTYGNSARVVYSILQGQPYFSVEPKTGVIKTALPNMDREAKDQYLLVIQAKDMVGQNGGLSGTTSVTVTLTDVNDNPPRFPRRSYQYNVPESLPVASVVARIKAADADIGANAEMEYKIVDGDGLGIFKISVDKETQEGIITIQKELDFEAKTSYTLRIEAANKDADPRFLSLGPFSDTTTVKIIVEDVDEPPVFSSPLYPMEVSEATQVGNIIGTVAAHDPDSSNSPVRYSIDRNTDLERYFNIDANSGVITTAKSLDRETNAIHNITVLAMESQNPSQVGRGYVAITILDINDNAPEFAMDYETTVCENAQPGQVIQKISAVDKDEPSNGHQFYFSLTTDATNNHNFSLKDNKDNTASILTRRNGFRRQEQSVYYLPIFIVDSGSPSLSSTNTLTIRVCDCDADGVAQTCNAEAYVLPAGLSTGALIAILACVLTLLVLILLIVTMRRRKKEPLIFDEERDIRENIVRYDDEGGGEEDTEAFDMAALRNLNVIRDTKTRRDVTPEIQFLSRPAFKSIPDNVIFREFIWERLKEADVDPGAPPYDSLQTYAFEGNGSVAESLSSLDSISSNSDQNYDYLSDWGPRFKRLADMYGTGQESLYS>sp|Q8N568|DCLK2_HUMAN Serine/threonine-protein kinase DCLK2 OS=Homosapiens OX=9606 GN=DCLK2 PE=1 SV=4MASTRSIELEHFEERDKRPRPGSRRGAPSSSGGSSSSGPKGNGLIPSPAHSAHCSFYRTRTLQALSSEKKAKKARFYRNGDRYFKGLVFAISSDRFRSFDALLIELTRSLSDNVNLPQGVRTIYTIDGSRKVTSLDELLEGESYVCASNEPFRKVDYTKNINPNWSVNIKGGTSRALAAASSVKSEVKESKDFIKPKLVTVIRSGVKPRKAVRILLNKKTAHSFEQVLTDITEAIKLDSGVVKRLCTLDGKQVTCLQDFFGDDDVFIACGPEKFRYAQDDFVLDHSECRVLKSSYSRSSAVKYSGSKSPGPSRRSKSPASVNGTPSSQLSTPKSTKSSSSSPTSPGSFRGLKQISAHGRSSSNVNGGPELDRCISPEGVNGNRCSESSTLLEKYKIGKVIGDGNFAVVKECIDRSTGKEFALKIIDKAKCCGKEHLIENEVSILRRVKHPNIIMLVEEMETATELFLVMELVKGGDLFDAITSSTKYTERDGSAMVYNLANALRYLHGLSIVHRDIKPENLLVCEYPDGTKSLKLGDFGLATVVEGPLYTVCGTPTYVAPEIIAETGYGLKVDIWAAGVITYILLCGFPPFRSENNLQEDLFDQILAGKLEFPAPYWDNITDSAKELISQMLQVNVEARCTAGQILSHPWVSDDASQENNMQAEVTGKLKQHFNNALPKQNSTTTGVSVIMNTALDKEGQIFCSKHCQDSGRPGMEPISPVPPSVEEIPVPGEAVPAPTPPESPTPHPPPAAPGGERAGTWRRHRD>sp|Q8N568-2|DCLK2_HUMAN Isoform 2 of Serine/threonine-protein kinaseDCLK2 OS=Homo sapiens OX=9606 GN=DCLK2MASTRSIELEHFEERDKRPRPGSRRGAPSSSGGSSSSGPKGNGLIPSPAHSAHCSFYRTRTLQALSSEKKAKKARFYRNGDRYFKGLVFAISSDRFRSFDALLIELTRSLSDNVNLPQGVRTIYTIDGSRKVTSLDELLEGESYVCASNEPFRKVDYTKNINPNWSVNIKGGTSRALAAASSVKSEVKESKDFIKPKLVTVIRSGVKPRKAVRILLNKKTAHSFEQVLTDITEAIKLDSGVVKRLCTLDGKQVTCLQDFFGDDDVFIACGPEKFRYAQDDFVLDHSECRVLKSSYSRSSAVKYSGSKSPGPSRRSKSPASVNGTPSSQLSTPKSTKSSSSSPTSPGSFRGLKISAHGRSSSNVNGGPELDRCISPEGVNGNRCSESSTLLEKYKIGKVIGDGNFAVVKECIDRSTGKEFALKIIDKAKCCGKEHLIENEVSILRRVKHPNIIMLVEEMETATELFLVMELVKGGDLFDAITSSTKYTERDGSAMVYNLANALRYLHGLSIVHRDIKPENLLVCEYPDGTKSLKLGDFGLATVVEGPLYTVCGTPTYVAPEIIAETGYGLKVDIWAAGVITYILLCGFPPFRSENNLQEDLFDQILAGKLEFPAPYWDNITDSAKELISQMLQVNVEARCTAGQILSHPWVSDDASQENNMQAEVTGKLKQHFNNALPKQNSTTTGVSVIMNTALDKEGQIFCSKHCQDSGRPGMEPISPVPPSVEEIPVPGEAVPAPTPPESPTPHPPPAAPGGERAGTWRRHRD>sp|Q8N568-3|DCLK2_HUMAN Isoform 3 of Serine/threonine-protein kinaseDCLK2 OS=Homo sapiens OX=9606 GN=DCLK2MASTRSIELEHFEERDKRPRPGSRRGAPSSSGGSSSSGPKGNGLIPSPAHSAHCSFYRTRTLQALSSEKKAKKARFYRNGDRYFKGLVFAISSDRFRSFDALLIELTRSLSDNVNLPQGVRTIYTIDGSRKVTSLDELLEGESYVCASNEPFRKVDYTKNINPNWSVNIKGGTSRALAAASSVKSEVKESKDFIKPKLVTVIRSGVKPRKAVRILLNKKTAHSFEQVLTDITEAIKLDSGVVKRLCTLDGKQVTCLQDFFGDDDVFIACGPEKFRYAQDDFVLDHSECRVLKSSYSRSSAVKYSGSKSPGPSRRSKSPASVKRGGHYSSAYSTAKSPVNGTPSSQLSTPKSTKSSSSSPTSPGSFRGLKQISAHGRSSSNVNGGPELDRCISPEGVNGNRCSESSTLLEKYKIGKVIGDGNFAVVKECIDRSTGKEFALKIIDKAKCCGKEHLIENEVSILRRVKHPNIIMLVEEMETATELFLVMELVKGGDLFDAITSSTKYTERDGSAMVYNLANALRYLHGLSIVHRDIKPENLLVCEYPDGTKSLKLGDFGLATVVEGPLYTVCGTPTYVAPEIIAETGYGLKVDIWAAGVITYILLCGFPPFRSENNLQEDLFDQILAGKLEFPAPYWDNITDSAKELISQMLQVNVEARCTAGQILSHPWVSDDASQENNMQAEVTGKLKQHFNNALPKQNSTTTGVSVIMNTALDKEGQIFCSKHCQDSGRPGMEPISPVPPSVEEIPVPGEAVPAPTPPESPTPHPPPAAPGGERAGTWRRHRD>sp|Q9H8H2|DDX31_HUMAN Probable ATP-dependent RNA helicase DDX31 OS=Homosapiens OX=9606 GN=DDX31 PE=1 SV=2MAPDLASQRHSESFPSVNSRPNVILPGREGRREGLPPGGGTRGSLVPTRPVPPSPAPLGTSPYSWSRSGPGRGGGAGSSRVPRGVPGPAVCAPGSLLHHASPTQTMAAADGSLFDNPRTFSRRPPAQASRQAKATKRKYQASSEAPPAKRRNETSFLPAKKTSVKETQRTFKGNAQKMFSPKKHSVSTSDRNQEERQCIKTSSLFKNNPDIPELHRPVVKQVQEKVFTSAAFHELGLHPHLISTINTVLKMSSMTSVQKQSIPVLLEGRDALVRSQTGSGKTLAYCIPVVQSLQAMESKIQRSDGPYALVLVPTRELALQSFDTVQKLLKPFTWIVPGVLMGGEKRKSEKARLRKGINILISTPGRLVDHIKSTKNIHFSRLRWLVFDEADRILDLGFEKDITVILNAVNAECQKRQNVLLSATLTEGVTRLADISLHDPVSISVLDKSHDQLNPKDKAVQEVCPPPAGDKLDSFAIPESLKQHVTVVPSKLRLVCLAAFILQKCKFEEDQKMVVFFSSCELVEFHYSLFLQTLLSSSGAPASGQLPSASMRLKFLRLHGGMEQEERTAVFQEFSHSRRGVLLCTDVAARGLDLPQVTWIVQYNAPSSPAEYIHRIGRTARIGCHGSSLLILAPSEAEYVNSLASHKINVSEIKMEDILCVLTRDDCFKGKRWGAQKSHAVGPQEIRERATVLQTVFEDYVHSSERRVSWAKKALQSFIQAYATYPRELKHIFHVRSLHLGHVAKSFGLRDAPRNLSALTRKKRKAHVKRPDLHKKTQSKHSLAEILRSEYSSGMEADIAKVKKQNAPGEPGGRPLQHSLQPTPCFGRGKTLKWRKTQKGVQRDSKTSQKV>sp|Q9H8H2-2|DDX31_HUMAN Isoform 2 of Probable ATP-dependent RNA helicaseDDX31 OS=Homo sapiens OX=9606 GN=DDX31MAPDLASQRHSESFPSVNSRPNVILPGREGRREGLPPGGGTRGSLVPTRPVPPSPAPLGTSPYSWSRSGPGRGGGAGSSRVPRGVPGPAVCAPGSLLHHASPTQTMAAADGSLFDNPRTFSRRPPAQASRQAKATKRKYQASSEAPPAKRRNETSFLPAKKTSVKETQRTFKGNAQKMFSPKKHSVSTSDRNQEERQCIKTSSLFKNNPDIPELHRPVVKQVQEKVFTSAAFHELGLHPHLISTINTVLKMSSMTSVQKQSIPVLLEGRDALVRSQTGSGKTLAYCIPVVQSLQAMESKIQRSDGPYALVLVPTRELALQSFDTVQKLLKPFTWIVPGVLMGGEKRKSEKARLRKGINILISTPGRLVDHIKSTKNIHFSRLRWLVFDEADRILDLGFEKDITVILNAVNAECQKRQNVLLSATLTEGVTRLADISLHDPVSISVLDKSHDQLNPKDKAVQEVCPPPAGDKLDSFAIPESLKQHVTVVPSKLRLVCLAAFILQKCKFEEDQKMVVFFSSCELVEFHYSLFLQTLLSSSGAPASGQLPSASMRLKFLRLHGGMEQEERTAVFQEFSHSRRGVLLCTDVAARGLDLPQVTWIVQNTSTGLEEPPGLAAMGAACSFWLLRRQNMSTRWLLTKSTLQSFIQAYATYPRELKHIFHVRSLHLGHVAKSFGLRDAPRNLSALTRKKRKAHVKRPDLHKKTQSKHSLAEILRSEYSSGMEADIAKVKKQNAPGEPGGRPLQHSLQPTPCFGRGKTLKWRKTQKGVQRDSKTSQKV>sp|Q9H8H2-3|DDX31_HUMAN Isoform 3 of Probable ATP-dependent RNA helicaseDDX31 OS=Homo sapiens OX=9606 GN=DDX31MAPDLASQRHSESFPSVNSRPNVILPGREGRREGLPPGGGTRGSLVPTRPVPPSPAPLGTSPYSWSRSGPGRGGGAGSSRVPRGVPGPAVCAPGSLLHHASPTQTMAAADGSLFDNPRTFSRRPPAQASRQAKATKRKYQASSEAPPAKRRNETSFLPAKKTSVKETQRTFKGNAQKMFSPKKHSVSTSDRNQEERQCIKTSSLFKNNPDIPELHRPVVKQVQEKVFTSAAFHELGLHPHLISTINTVLKMSSMTSVQKQSIPVLLEGRDALVRSQTGSGKTLAYCIPVVQSLQAMESKIQVLLLSTFYEEEQRLRKVK>sp|Q9H8H2-4|DDX31_HUMAN Isoform 4 of Probable ATP-dependent RNA helicaseDDX31 OS=Homo sapiens OX=9606 GN=DDX31MAPDLASQRHSESFPSVNSRPNVILPGREGRREGLPPGGGTRGSLVPTRPVPPSPAPLGTSPYSWSRSGPGRGGGAGSSRVPRGVPGPAVCAPGSLLHHASPTQTMAAADGSLFDNPRTFSRRPPAQASRQAKATKRKYQASSEAPPAKRRNETSFLPAKKTSVKETQRTFKGNAQKMFSPKKHSVSTSDRNQEERQCIKTSSLFKNNPDIPELHRPVVKQVQEKVFTSAAFHELGLHPHLISTINTVLKMSSMTSVQKQSIPVLLEGRDALVRSQTGSGKTLAYCIPVVQSLQAMESKIQRSDGPYALVLVPTRELALQSFDTVQKLLKPFTWIVPGVLMGGEKRKSEKARLRKGINILISTPGRLVDHIKSTKNIHFSRLRWLVFDEADRILDLGFEKDITVILNAVNAECQKRQNVLLSATLTEGVTRLADISLHDPVSISVLDKSHDQLNPKDKAVQEVCPPPAGDKLDSFAIPESLKQHVTVVPSKLRLVCLAAFILQKCKFEEDQKMVVFFSSCELVEFHYSLFLQTLLSSSGAPASGQLPSASMRLKFLRLHGGMEQEERTAVFQEFSHSRRGVLLCT>sp|P32238|CCKAR_HUMAN Cholecystokinin receptor type A OS=Homo sapiensOX=9606 GN=CCKAR PE=1 SV=1MDVVDSLLVNGSNITPPCELGLENETLFCLDQPRPSKEWQPAVQILLYSLIFLLSVLGNTLVITVLIRNKRMRTVTNIFLLSLAVSDLMLCLFCMPFNLIPNLLKDFIFGSAVCKTTTYFMGTSVSVSTFNLVAISLERYGAICKPLQSRVWQTKSHALKVIAATWCLSFTIMTPYPIYSNLVPFTKNNNQTANMCRFLLPNDVMQQSWHTFLLLILFLIPGIVMMVAYGLISLELYQGIKFEASQKKSAKERKPSTTSSGKYEDSDGCYLQKTRPPRKLELRQLSTGSSSRANRIRSNSSAANLMAKKRVIRMLIVIVVLFFLCWMPIFSANAWRAYDTASAERRLSGTPISFILLLSYTSSCVNPIIYCFMNKRFRLGFMATFPCCPNPGPPGARGEVGEEEEGGTTGASLSRFSYSHMSASVPPQ>sp|Q9UPW5|CBPC1_HUMAN Cytosolic carboxypeptidase 1 OS=Homo sapiensOX=9606 GN=AGTPBP1 PE=1 SV=3MSKLKVIPEKSLTNNSRIVGLLAQLEKINAEPSESDTARYVTSKILHLAQSQEKTRREMTAKGSTGMEILLSTLENTKDLQTTLNILSILVELVSAGGGRRVSFLVTKGGSQILLQLLMNASKESPPHEDLMVQIHSILAKIGPKDKKFGVKARINGALNITLNLVKQNLQNHRLVLPCLQLLRVYSANSVNSVSLGKNGVVELMFKIIGPFSKKNSSLIKVALDTLAALLKSKTNARRAVDRGYVQVLLTIYVDWHRHDNRHRNMLIRKGILQSLKSVTNIKLGRKAFIDANGMKILYNTSQECLAVRTLDPLVNTSSLIMRKCFPKNRLPLPTIKSSFHFQLPVIPVTGPVAQLYSLPPEVDDVVDESDDNDDIDVEAENETENEDDLDQNFKNDDIETDINKLKPQQEPGRTIEDLKMYEHLFPELVDDFQDYDLISKEPKPFVFEGKVRGPIVVPTAGEETSGNSGNLRKVVMKENISSKGDEGEKKSTFMDLAKEDIKDNDRTLQQQPGDQNRTISSVHGLNNDIVKALDRITLQNIPSQTAPGFTAEMKKDCSLPLTVLTCAKACPHMATCGNVLFEGRTVQLGKLCCTGVETEDDEDTESNSSVEQASVEVPDGPTLHDPDLYIEIVKNTKSVPEYSEVAYPDYFGHIPPPFKEPILERPYGVQRTKIAQDIERLIHQSDIIDRVVYDLDNPNYTIPEEGDILKFNSKFESGNLRKVIQIRKNEYDLILNSDINSNHYHQWFYFEVSGMRPGVAYRFNIINCEKSNSQFNYGMQPLMYSVQEALNARPWWIRMGTDICYYKNHFSRSSVAAGGQKGKSYYTITFTVNFPHKDDVCYFAYHYPYTYSTLQMHLQKLESAHNPQQIYFRKDVLCETLSGNSCPLVTITAMPESNYYEHICHFRNRPYVFLSARVHPGETNASWVMKGTLEYLMSNNPTAQSLRESYIFKIVPMLNPDGVINGNHRCSLSGEDLNRQWQSPSPDLHPTIYHAKGLLQYLAAVKRLPLVYCDYHGHSRKKNVFMYGCSIKETVWHTNDNATSCDVVEDTGYRTLPKILSHIAPAFCMSSCSFVVEKSKESTARVVVWREIGVQRSYTMESTLCGCDQGKYKGLQIGTRELEEMGAKFCVGLLRLKRLTSPLEYNLPSSLLDFENDLIESSCKVTSPTTYVLDEDEPRFLEEVDYSAESNDELDIELAENVGDYEPSAQEEVLSDSELSRTYLP>sp|Q9UPW5-2|CBPC1_HUMAN Isoform 2 of Cytosolic carboxypeptidase 1OS=Homo sapiens OX=9606 GN=AGTPBP1MSKLKVIPEKSLTNNSRIVGLLAQLEKINAEPSESDTARYVTSKILHLAQSQEKTRREMTAKGSTGMEILLSTLENTKDLQTTLNILSILVELVSAGGGRRVSFLVTKGGSQILLQLLMNASKESPPHEDLMVQIHSILAKIGPKDKKFGVKARINGALNITLNLVKQNLQNHRLVLPCLQLLRVYSANSVNSVSLGKNGVVELMFKIIGPFSKKNSSLIKVALDTLAALLKSKTNARRAVDRGYVQVLLTIYVDWHRHDNRHRNMLIRKGILQSLKSVTNIKLGRKAFIDANGMKILYNTSQLPVIPVTGPVAQLYSLPPEVDDVVDESDDNDDIDVEAENETENEDDLDQNFKNDDIETDINKLKPQQEPGRTIEDLKMYEHLFPELVDDFQDYDLISKEPKPFVFEGKVRGPIVVPTAGEETSGNSGNLRKVVMKENISSKGDEGEKKSTFMDLAKEDIKDNDRTLQQQPGDQNRTISSVHGLNNDIVKALDRITLQNIPSQTAPGFTAEMKKDCSLPLTVLTCAKACPHMATCGNVLFEGRTVQLGKLCCTGVETEDDEDTESNSSVEQASVEVPDGPTLHDPDLYIEIVKNTKSVPEYSEVAYPDYFGHIPPPFKEPILERPYGVQRTKIAQDIERLIHQSDIIDRVVYDLDNPNYTIPEEGDILKFNSKFESGNLRKVIQIRKNEYDLILNSDINSNHYHQWFYFEVSGMRPGVAYRFNIINCEKSNSQFNYGMQPLMYSVQEALNARPWWIRMGTDICYYKNHFSRSSVAAGGQKGKSYYTITFTVNFPHKDDVCYFAYHYPYTYSTLQMHLQKLESAHNPQQIYFRKDVLCETLSGNSCPLVTITAMPESNYYEHICHFRNRPYVFLSARVHPGETNASWVMKGTLEYLMSNNPTAQSLRESYIFKIVPMLNPDGVINGNHRCSLSGEDLNRQWQSPSPDLHPTIYHAKGLLQYLAAVKRLPLVYCDYHGHSRKKNVFMYGCSIKETVWHTNDNATSCDVVEDTGYRTLPKILSHIAPAFCMSSCSFVVEKSKESTARVVVWREIGVQRSYTMESTLCGCDQGKYKGLQIGTRELEEMGAKFCVGLLRLKRLTSPLEYNLPSSLLDFENDLIESSCKVTSPTTYVLDEDEPRFLEEVDYSAESNDELDIELAENVGDYEPSAQEEVLSDSELSRTYLP>sp|Q9UPW5-3|CBPC1_HUMAN Isoform 3 of Cytosolic carboxypeptidase 1OS=Homo sapiens OX=9606 GN=AGTPBP1MRTGSAASSAAAAAAAAAASASPATGVCMKTPGGGRRGIRRDPGAEPGAAALRGPRQRPILSRLTNNSRIVGLLAQLEKINAEPSESDTARYVTSKILHLAQSQEKTRREMTAKGSTGMEILLSTLENTKDLQTTLNILSILVELVSAGGGRRVSFLVTKGGSQILLQLLMNASKESPPHEDLMVQIHSILAKIGPKDKKFGVKARINGALNITLNLVKQNLQNHRLVLPCLQLLRVYSANSVNSVSLGKNGVVELMFKIIGPFSKKNSSLIKVALDTLAALLKSKTNARRAVDRGYVQVLLTIYVDWHRHDNRHRNMLIRKGILQSLKSVTNIKLGRKAFIDANGMKILYNTSQLPVIPVTGPVAQLYSLPPEVDDVVDESDDNDDIDVEAENETENEDDLDQNFKNDDIETDINKLKPQQEPGRTIEDLKMYEHLFPELVDDFQDYDLISKEPKPFVFEGKVRGPIVVPTAGEETSGNSGNLRKVVMKENISSKGDEGEKKSTFMDLAKEDIKDNDRTLQQQPGDQNRTISSVHGLNNDIVKALDRITLQNIPSQTAPGFTAEMKKDCSLPLTVLTCAKACPHMATCGNVLFEGRTVQLGKLCCTGVETEDDEDTESNSSVEQASVEVPDGPTLHDPDLYIEIVKNTKSVPEYSEVAYPDYFGHIPPPFKEPILERPYGVQRTKIAQDIERLIHQSDIIDRVVYDLDNPNYTIPEEGDILKFNSKFESGNLRKVIQIRKNEYDLILNSDINSNHYHQWFYFEVSGMRPGVAYRFNIINCEKSNSQFNYGMQPLMYSVQEALNARPWWIRMGTDICYYKNHFSRSSVAAGGQKGKSYYTITFTVNFPHKDDVCYFAYHYPYTYSTLQMHLQKLESAHNPQQIYFRKDVLCETLSGNSCPLVTITAMPESNYYEHICHFRNRPYVFLSARVHPGETNASWVMKGTLEYLMSNNPTAQSLRESYIFKIVPMLNPDGVINGNHRCSLSGEDLNRQWQSPSPDLHPTIYHAKGLLQYLAAVKRLPLVYCDYHGHSRKKNVFMYGCSIKETVWHTNDNATSCDVVEDTGYRTLPKILSHIAPAFCMSSCSFVVEKSKESTARVVVWREIGVQRSYTMESTLCGCDQGKYKGLQIGTRELEEMGAKFCVGLLRLKRLTSPLEYNLPSSLLDFENDLIESSCKVTSPTTYVLDEDEPRFLEEVDYSAESNDELDIELAENVGDYEPSAQEEVLSDSELSRTYLP>sp|Q5U5Z8|CBPC2_HUMAN Cytosolic carboxypeptidase 2 OS=Homo sapiensOX=9606 GN=AGBL2 PE=1 SV=2MFPALETHLKQTIPDPYEDFMYRHLQYYGYFKAQRGSLPNSATHQHVRKNNPQCLLNGSLGEKDDLIPDTLQKEKLLWPISLSSAVHRQIEAINRDFHSCLGWMQWRGLSSLQPPPPRFKDSPASAFRVAGITDSHMLSLPHLRSRQLLYDELDEVNPRLREPQELFSILSTKRPLQAPRWPIECEVIKENIHHIEWAPPQPEYFYQPKGNEKVPEIVGEKKGTVVYQLDSVPIEGSYFTSSRVGGKRGIVKELAVTLQGPEDNTLLFESRFESGNLQKAVRVDTYEYELTLRTDLYTNKHTQWFYFRVQNTRKDATYRFTIVNLLKPKSLYTVGMKPLLYSQLDANTRNIGWRREGNEIKYYKNNTDDGQQPFYCLTWTIQFPYDQDTCFFAHFYPYTYTDLQCYLLSVANNPIQSQFCKLQTLCRSLAGNTVYLLTITNPSQTPQEAAAKKAVVLSARVHPGESNGSWVMKGFLDFILSNSPDAQLLRDIFVFKVLPMLNPDGVIVGNYRCSLAGRDLNRHYKTILKESFPCIWYTRNMIKRLLEEREVLLYCDFHGHSRKNNIFLYGCNNNNRKYWLHERVFPLMLCKNAPDKFSFHSCNFKVQKCKEGTGRVVMWRMGILNSYTMESTFGGSTLGNKRDTHFTIEDLKSLGYHVCDTLLDFCDPDQMKFTQCLAELKELLRQEIHKKFHELGQDVDLEGSWSDISLSDIESSTSGSDSSLSDGLPVHLANIADELTQKKKMFKKKKKKSLQTRKQRNEQYQKKNLMQKLKLTEDTSEKAGFASTLQKQPTFFKNSENSSFLPMKNENPRLNETNLNRRDKDTPLDPSMATLILPKNKGRMQNKKPGFTVSCSPKRTINSSQEPAPGMKPNWPRSRYPATKRGCAAMAAYPSLHIYTYP>sp|Q5U5Z8-2|CBPC2_HUMAN Isoform 2 of Cytosolic carboxypeptidase 2OS=Homo sapiens OX=9606 GN=AGBL2MKGFLDFILSNSPDAQLLRDIFVFKVLPMLNPDGVIVGNYRCSLAGRDLNRHYKTILKESFPCIWYTRNMIKRLLEEREVLLYCDFHGHSRKNNIFLYGCNNNNRKYWLHERVFPLMLCKNAPDKFSFHSCNFKVQKCKEGTGRVVMWRMGILNSYTMESTFGGSTLGNKRDTHFTIEDLKSLGYHVCDTLLDFCDPDQMKFTQCLAELKELLRQEIHKKFHELGQDVDLEGSWSDISLSDIESSTSGSDSSLSDGLPVHLANIADELTQKKKMFKKKKKKSLQTRKQRNEQYQKKNLMQKLKLTEDTSEKAGFASTLQKQPTFFKNSENSSFLPMKNENPRLNETNLNRRDKDTPLDPSMATLILPKNKGRMQNKKPGFTVSCSPKRTINSSQEPAPGMKPNWPRSRYPATKRGCAAMAAYPSLHIYTYP>sp|Q5U5Z8-3|CBPC2_HUMAN Isoform 3 of Cytosolic carboxypeptidase 2OS=Homo sapiens OX=9606 GN=AGBL2MWRMGILNSYTMESTFGGSTLGNKRDTHFTIEDLKSLGYHVCDTLLDFCDPDQMKFTQCLAELKELLRQEIHKKFHELGQDVDLEGSWSDISLSDIESSTSGSDSSLSDGLPVHLANIADELTQKKKMFKKKKKKSLQTRKQRNEQYQKKNLMQKLKLTEDTSEKAGFASTLQKQPTFFKNSENSSFLPMKNENPRLNETNLNRRDKDTPLDPSMATLILPKNKGRMQNKKPGFTVSCSPKRTINSSQEPAPGMKPNWPRSRYPATKRGCAAMAAYPSLHIYTYP>sp|Q9H9R9|DBND1_HUMAN Dysbindin domain-containing protein 1 OS=Homosapiens OX=9606 GN=DBNDD1 PE=1 SV=2MEPPEGAGTGEIVKEAEVPQAALGVPAQGTGDNGHTPVEEEVGGIPVPAPGLLQVTERRQPLSSVSSLEVHFDLLDLTELTDMSDQELAEVFADSDDENLNTESPAGLHPLPRAGYLRSPSWTRTRAEQSHEKQPLGDPERQATVLDTFLTVERPQED>sp|Q9H9R9-2|DBND1_HUMAN Isoform 2 of Dysbindin domain-containing protein1 OS=Homo sapiens OX=9606 GN=DBNDD1MGETWKNICSTVRHGWWLRDHRMAGLPIPPEIVKEAEVPQAALGVPAQGTGDNGHTPVEEEVGGIPVPAPGLLQVTERRQPLSSVSSLEVHFDLLDLTELTDMSDQELAEVFADSDDENLNTESPAGLHPLPRAGYLRSPSWTRTRAEQSHEKQPLGDPERQATVLDTFLTVERPQED>sp|Q9H9R9-3|DBND1_HUMAN Isoform 3 of Dysbindin domain-containing protein1 OS=Homo sapiens OX=9606 GN=DBNDD1MTQQWREVNEDREAVAQARSWQSLNLGDRDMGVSFIETALALSAARARRPLLTSHPPSRPFQPPKHTPSPPPAPRVNSRHPGRSVSLSLPSASQAPPVPLASPEGRPHTVGAPHASTWKRTRGRQRARPPKIVKEAEVPQAALGVPAQGTGDNGHTPVEEEVGGIPVPAPGLLQVTERRQPLSSVSSLEVHFDLLDLTELTDMSDQELAEVFADSDDENLNTESPAGLHPLPRAGYLRSPSWTRTRAEQSHEKQPLGDPERQATVLDTFLTVERPQED>sp|O00571|DDX3X_HUMAN ATP-dependent RNA helicase DDX3X OS=Homo sapiensOX=9606 GN=DDX3X PE=1 SV=3MSHVAVENALGLDQQFAGLDLNSSDNQSGGSTASKGRYIPPHLRNREATKGFYDKDSSGWSSSKDKDAYSSFGSRSDSRGKSSFFSDRGSGSRGRFDDRGRSDYDGIGSRGDRSGFGKFERGGNSRWCDKSDEDDWSKPLPPSERLEQELFSGGNTGINFEKYDDIPVEATGNNCPPHIESFSDVEMGEIIMGNIELTRYTRPTPVQKHAIPIIKEKRDLMACAQTGSGKTAAFLLPILSQIYSDGPGEALRAMKENGRYGRRKQYPISLVLAPTRELAVQIYEEARKFSYRSRVRPCVVYGGADIGQQIRDLERGCHLLVATPGRLVDMMERGKIGLDFCKYLVLDEADRMLDMGFEPQIRRIVEQDTMPPKGVRHTMMFSATFPKEIQMLARDFLDEYIFLAVGRVGSTSENITQKVVWVEESDKRSFLLDLLNATGKDSLTLVFVETKKGADSLEDFLYHEGYACTSIHGDRSQRDREEALHQFRSGKSPILVATAVAARGLDISNVKHVINFDLPSDIEEYVHRIGRTGRVGNLGLATSFFNERNINITKDLLDLLVEAKQEVPSWLENMAYEHHYKGSSRGRSKSSRFSGGFGARDYRQSSGASSSSFSSSRASSSRSGGGGHGSSRGFGGGGYGGFYNSDGYGGNYNSQGVDWWGN>sp|O00571-2|DDX3X_HUMAN Isoform 2 of ATP-dependent RNA helicase DDX3XOS=Homo sapiens OX=9606 GN=DDX3XMSHVAVENALGLDQQFAGLDLNSSDNQSGGSTASSFYDKDSSGWSSSKDKDAYSSFGSRSDSRGKSSFFSDRGSGSRGRFDDRGRSDYDGIGSRGDRSGFGKFERGGNSRWCDKSDEDDWSKPLPPSERLEQELFSGGNTGINFEKYDDIPVEATGNNCPPHIESFSDVEMGEIIMGNIELTRYTRPTPVQKHAIPIIKEKRDLMACAQTGSGKTAAFLLPILSQIYSDGPGEALRAMKENGRYGRRKQYPISLVLAPTRELAVQIYEEARKFSYRSRVRPCVVYGGADIGQQIRDLERGCHLLVATPGRLVDMMERGKIGLDFCKYLVLDEADRMLDMGFEPQIRRIVEQDTMPPKGVRHTMMFSATFPKEIQMLARDFLDEYIFLAVGRVGSTSENITQKVVWVEESDKRSFLLDLLNATGKDSLTLVFVETKKGADSLEDFLYHEGYACTSIHGDRSQRDREEALHQFRSGKSPILVATAVAARGLDISNVKHVINFDLPSDIEEYVHRIGRTGRVGNLGLATSFFNERNINITKDLLDLLVEAKQEVPSWLENMAYEHHYKGSSRGRSKSSRFSGGFGARDYRQSSGASSSSFSSSRASSSRSGGGGHGSSRGFGGGGYGGFYNSDGYGGNYNSQGVDWWGN>sp|Q9BQY9|DBND2_HUMAN Dysbindin domain-containing protein 2 OS=Homosapiens OX=9606 GN=DBNDD2 PE=1 SV=3MGAGNFLTALEVPVAALAGAASDRRASCERVSPPPPLPHFRLPPLPRSRLPGPVSRPEPGAPLLGCWLQWGAPSPGPLCLLFRLCSCTCFAPLPAGADMDPNPRAALERQQLRLRERQKFFEDILQPETEFVFPLSHLHLESQRPPIGSISSMEVNVDTLEQVELIDLGDPDAADVFLPCEDPPPTPQSSGMDNHLEELSLPVPTSDRTTSRTSSSSSSDSSTNLHSPNPSDDGADTPLAQSDEEEERGDGGAEPGACS>sp|Q9BQY9-2|DBND2_HUMAN Isoform 2 of Dysbindin domain-containing protein2 OS=Homo sapiens OX=9606 GN=DBNDD2MDPNPRAALERQQLRLRERQKFFEDILQPETEFVFPLSHLHLESQRPPIGSISSMEVNVDTLEQVELIDLGDPDAADVFLPCEDPPPTPQSSGMDNHLEELSLPVPTSDRTTSRTSSSSSSDSSTNLHSPNPSDDGADTPLAQSDEEEERGDGGAEPGACS>sp|Q9BQY9-3|DBND2_HUMAN Isoform 3 of Dysbindin domain-containing protein2 OS=Homo sapiens OX=9606 GN=DBNDD2MDPNPRAALERQQLRLRERQKFFEDILQPETEFVFPLSHLHLESQRPPIGSISSMEVNVDTLEQVELIDLGDPDAADVFLPCEDPPPTPQSSGMPLCFGDFSASQPEPDVRL>sp|Q9BQY9-4|DBND2_HUMAN Isoform 4 of Dysbindin domain-containing protein2 OS=Homo sapiens OX=9606 GN=DBNDD2MESWALAVFPEYRVSLLWCLELASPLWSLGQAPPLHETWFVGHTWFQGRGKRSPRAEVSRPEPGAPLLGCWLQWGAPSPGPLCLLFRLCSCTCFAPLPAGADMDPNPRAALERQQLRLRERQKFFEDILQPETEFVFPLSHLHLESQRPPIGSISSMEVNVDTLEQVELIDLGDPDAADVFLPCEDPPPTPQSSGMDNHLEELSLPVPTSDRTTSRTSSSSSSDSSTNLHSPNPSDDGADTPLAQSDEEEERGDGGAEPGACS>sp|O15523|DDX3Y_HUMAN ATP-dependent RNA helicase DDX3Y OS=Homo sapiensOX=9606 GN=DDX3Y PE=1 SV=2MSHVVVKNDPELDQQLANLDLNSEKQSGGASTASKGRYIPPHLRNREASKGFHDKDSSGWSCSKDKDAYSSFGSRDSRGKPGYFSERGSGSRGRFDDRGRSDYDGIGNRERPGFGRFERSGHSRWCDKSVEDDWSKPLPPSERLEQELFSGGNTGINFEKYDDIPVEATGSNCPPHIENFSDIDMGEIIMGNIELTRYTRPTPVQKHAIPIIKGKRDLMACAQTGSGKTAAFLLPILSQIYTDGPGEALKAVKENGRYGRRKQYPISLVLAPTRELAVQIYEEARKFSYRSRVRPCVVYGGADIGQQIRDLERGCHLLVATPGRLVDMMERGKIGLDFCKYLVLDEADRMLDMGFEPQIRRIVEQDTMPPKGVRHTMMFSATFPKEIQMLARDFLDEYIFLAVGRVGSTSENITQKVVWVEDLDKRSFLLDILGATGSDSLTLVFVETKKGADSLEDFLYHEGYACTSIHGDRSQRDREEALHQFRSGKSPILVATAVAARGLDISNVRHVINFDLPSDIEEYVHRIGRTGRVGNLGLATSFFNEKNMNITKDLLDLLVEAKQEVPSWLENMAYEHHYKGGSRGRSKSNRFSGGFGARDYRQSSGSSSSGFGASRGSSSRSGGGGYGNSRGFGGGGYGGFYNSDGYGGNYNSQGVDWWGN>sp|O15523-2|DDX3Y_HUMAN Isoform 2 of ATP-dependent RNA helicase DDX3YOS=Homo sapiens OX=9606 GN=DDX3YMEIGRPRKDTWKLANLDLNSEKQSGGASTASKGRYIPPHLRNREASKGFHDKDSSGWSCSKDKDAYSSFGSRDSRGKPGYFSERGSGSRGRFDDRGRSDYDGIGNRERPGFGRFERSGHSRWCDKSVEDDWSKPLPPSERLEQELFSGGNTGINFEKYDDIPVEATGSNCPPHIENFSDIDMGEIIMGNIELTRYTRPTPVQKHAIPIIKGKRDLMACAQTGSGKTAAFLLPILSQIYTDGPGEALKAVKENGRYGRRKQYPISLVLAPTRELAVQIYEEARKFSYRSRVRPCVVYGGADIGQQIRDLERGCHLLVATPGRLVDMMERGKIGLDFCKYLVLDEADRMLDMGFEPQIRRIVEQDTMPPKGVRHTMMFSATFPKEIQMLARDFLDEYIFLAVGRVGSTSENITQKVVWVEDLDKRSFLLDILGATGSDSLTLVFVETKKGADSLEDFLYHEGYACTSIHGDRSQRDREEALHQFRSGKSPILVATAVAARGLDISNVRHVINFDLPSDIEEYVHRIGRTGRVGNLGLATSFFNEKNMNITKDLLDLLVEAKQEVPSWLENMAYEHHYKGGSRGRSKSNRFSGGFGARDYRQSSGSSSSGFGASRGSSSRSGGGGYGNSRGFGGGGYGGFYNSDGYGGNYNSQGVDWWGN>sp|O15523-3|DDX3Y_HUMAN Isoform 3 of ATP-dependent RNA helicase DDX3YOS=Homo sapiens OX=9606 GN=DDX3YMSHVVVKNDPELDQQLANLDLNSEKQSGGASTASKGRYIPPHLRNREASKGFHDKDSSGWSCSKDKDAYSSFGSRDSRGKPGYFSERGSGSRGRFDDRGRSDYDGIGNRERPGFGRFERSGHSRWCDKSVEDDWSKPLPPSERLEQELFSGGNTGINFEKYDDIPVEATGSNCPPHIENFSDIDMGEIIMGNIELTRYTRPTPVQKHAIPIIKGKRDLMACAQTGSGKTAAFLLPILSQIYTDGPGEALKAVKENGRYGRRKQYPISLVLAPTRELAVQIYEEARKVKYSF>sp|O95822|DCMC_HUMAN Malonyl-CoA decarboxylase, mitochondrial OS=Homosapiens OX=9606 GN=MLYCD PE=1 SV=3MRGFGPGLTARRLLPLRLPPRPPGPRLASGQAAGALERAMDELLRRAVPPTPAYELREKTPAPAEGQCADFVSFYGGLAETAQRAELLGRLARGFGVDHGQVAEQSAGVLHLRQQQREAAVLLQAEDRLRYALVPRYRGLFHHISKLDGGVRFLVQLRADLLEAQALKLVEGPDVREMNGVLKGMLSEWFSSGFLNLERVTWHSPCEVLQKISEAEAVHPVKNWMDMKRRVGPYRRCYFFSHCSTPGEPLVVLHVALTGDISSNIQAIVKEHPPSETEEKNKITAAIFYSISLTQQGLQGVELGTFLIKRVVKELQREFPHLGVFSSLSPIPGFTKWLLGLLNSQTKEHGRNELFTDSECKEISEITGGPINETLKLLLSSSEWVQSEKLVRALQTPLMRLCAWYLYGEKHRGYALNPVANFHLQNGAVLWRINWMADVSLRGITGSCGLMANYRYFLEETGPNSTSYLGSKIIKASEQVLSLVAQFQKNSKL>sp|O95822-2|DCMC_HUMAN Isoform Cytoplasmic+peroxisomal of Malonyl-CoAdecarboxylase, mitochondrial OS=Homo sapiens OX=9606 GN=MLYCDMDELLRRAVPPTPAYELREKTPAPAEGQCADFVSFYGGLAETAQRAELLGRLARGFGVDHGQVAEQSAGVLHLRQQQREAAVLLQAEDRLRYALVPRYRGLFHHISKLDGGVRFLVQLRADLLEAQALKLVEGPDVREMNGVLKGMLSEWFSSGFLNLERVTWHSPCEVLQKISEAEAVHPVKNWMDMKRRVGPYRRCYFFSHCSTPGEPLVVLHVALTGDISSNIQAIVKEHPPSETEEKNKITAAIFYSISLTQQGLQGVELGTFLIKRVVKELQREFPHLGVFSSLSPIPGFTKWLLGLLNSQTKEHGRNELFTDSECKEISEITGGPINETLKLLLSSSEWVQSEKLVRALQTPLMRLCAWYLYGEKHRGYALNPVANFHLQNGAVLWRINWMADVSLRGITGSCGLMANYRYFLEETGPNSTSYLGSKIIKASEQVLSLVAQFQKNSKL>sp|Q9UJU6|DBNL_HUMAN Drebrin-like protein OS=Homo sapiens OX=9606GN=DBNL PE=1 SV=1MAANLSRNGPALQEAYVRVVTEKSPTDWALFTYEGNSNDIRVAGTGEGGLEEMVEELNSGKVMYAFCRVKDPNSGLPKFVLINWTGEGVNDVRKGACASHVSTMASFLKGAHVTINARAEEDVEPECIMEKVAKASGANYSFHKESGRFQDVGPQAPVGSVYQKTNAVSEIKRVGKDSFWAKAEKEEENRRLEEKRRAEEAQRQLEQERRERELREAARREQRYQEQGGEASPQRTWEQQQEVVSRNRNEQESAVHPREIFKQKERAMSTTSISSPQPGKLRSPFLQKQLTQPETHFGREPAAAISRPRADLPAEEPAPSTPPCLVQAEEEAVYEEPPEQETFYEQPPLVQQQGAGSEHIDHHIQGQGLSGQGLCARALYDYQAADDTEISFDPENLITGIEVIDEGWWRGYGPDGHFGMFPANYVELIE>sp|Q9UJU6-2|DBNL_HUMAN Isoform 2 of Drebrin-like protein OS=Homo sapiensOX=9606 GN=DBNLMAANLSRNGPALQEAYVRVVTEKSPTDWALFTYEGNSNDIRVAGTGEGGLEEMVEELNSGKVMYAFCRVKDPNSGLPKFVLINWTGEGVNDVRKGACASHVSTMASFLKGAHVTINARAEEDVEPECIMEKVAKASGANYSFHKESGRFQDVGPQAPVGSVYQKTNAVSEIKRVGKDSFWAKAEKEEENRRLEEKRRAEEAQRQLEQERRERELREAARREQRYQEQGGEASPQSRTWEQQQEVVSRNRNEQESAVHPREIFKQKERAMSTTSISSPQPGKLRSPFLQKQLTQPETHFGREPAAAISRPRADLPAEEPAPSTPPCLVQAEEEAVYEEPPEQETFYEQPPLVQQQGAGSEHIDHHIQGQGLSGQGLCARALYDYQAADDTEISFDPENLITGIEVIDEGWWRGYGPDGHFGMFPANYVELIE>sp|Q9UJU6-3|DBNL_HUMAN Isoform 3 of Drebrin-like protein OS=Homo sapiensOX=9606 GN=DBNLMAANLSRNGPALQEAYVRVVTEKSPTDWALFTYEGNSNDIRVAGTGEGGLEEMVEELNSGKVMYAFCRVKDPNSGLPKFVLINWTGEGVNDVRKGACASHVSTMASFLKGAHVTINARAEEDVEPECIMEKVAKASGANYSFHKESGRFQDVGPQAPVGSVYQKTNAVSEIKRVGKDSFWAKAEKEEENRRLEEKRRAEEAQRQLEQERRERELREAARREQRYQEQGGEASPQSRTWEQQQEVVSRNRNEQGSTCASLQESAVHPREIFKQKERAMSTTSISSPQPGKLRSPFLQKQLTQPETHFGREPAAAISRPRADLPAEEPAPSTPPCLVQAEEEAVYEEPPEQETFYEQPPLVQQQGAGSEHIDHHIQGQGLSGQGLCARALYDYQAADDTEISFDPENLITGIEVIDEGWWRGYGPDGHFGMFPANYVELIE>sp|Q9UJU6-4|DBNL_HUMAN Isoform 4 of Drebrin-like protein OS=Homo sapiensOX=9606 GN=DBNLMKATAMTSAWLAQGGAHVTINARAEEDVEPECIMEKVAKASGANYSFHKESGRFQDVGPQAPVGSVYQKTNAVSEIKRVGKDSFWAKAEKEEENRRLEEKRRAEEAQRQLEQERRERELREAARREQRYQEQGGEASPQSRTWEQQQEVVSRNRNEQESAVHPREIFKQKERAMSTTSISSPQPGKLRSPFLQKQLTQPETHFGREPAAAISRPRADLPAEEPAPSTPPCLVQAEEEAVYEEPPEQETFYEQPPLVQQQGAGSEHIDHHIQGQGLSGQGLCARALYDYQAADDTEISFDPENLITGIEVIDEGWWRGYGPDGHFGMFPANYVELIE>sp|Q9UJU6-5|DBNL_HUMAN Isoform 5 of Drebrin-like protein OS=Homo sapiensOX=9606 GN=DBNLMASFLKGAHVTINARAEEDVEPECIMEKVAKASGANYSFHKESGRFQDVGPQAPVGSVYQKTNAVSEIKRVGKDSFWAKAEKEEENRRLEEKRRAEEAQRQLEQERRERELREAARREQRYQEQGGEASPQRTWEQQQEVVSRNRNEQESAVHPREIFKQKERAMSTTSISSPQPGKLRSPFLQKQLTQPETHFGREPAAAISRPRADLPAEEPAPSTPPCLVQAEEEAVYEEPPEQETFYEQPPLVQQQGAGSEHIDHHIQGQGLSGQGLCARALYDYQAADDTEISFDPENLITGIEVIDEGWWRGYGPDGHFGMFPANYVELIE>sp|Q9UJU6-6|DBNL_HUMAN Isoform 6 of Drebrin-like protein OS=Homo sapiensOX=9606 GN=DBNLMAANLSRNGPALQEAYVRVVTEKSPTDWALFTYEGNSNDIRVAGTGEGGLEEMVEELNSGKVMYAFCRVKDPNSGLPKFVLINWTGEGVNDVRKGACASHVSTMASFLKGSVYQKTNAVSEIKRVGKDSFWAKAEKEEENRRLEEKRRAEEAQRQLEQERRERELREAARREQRYQEQGGEASPQSRTWEQQQEVVSRNRNEQESAVHPREIFKQKERAMSTTSISSPQPGKLRSPFLQKQLTQPETHFGREPAAAISRPRADLPAEEPAPSTPPCLVQAEEEAVYEEPPEQETFYEQPPLVQQQGAGSEHIDHHIQGQGLSGQGLCARALYDYQAADDTEISFDPENLITGIEVIDEGWWRGYGPDGHFGMFPANYVELIE>sp|P59666|DEF3_HUMAN Neutrophil defensin 3 OS=Homo sapiens OX=9606GN=DEFA3 PE=1 SV=1MRTLAILAAILLVALQAQAEPLQARADEVAAAPEQIAADIPEVVVSLAWDESLAPKHPGSRKNMDCYCRIPACIAGERRYGTCIYQGRLWAFCC>sp|Q9UJV9|DDX41_HUMAN Probable ATP-dependent RNA helicase DDX41 OS=Homosapiens OX=9606 GN=DDX41 PE=1 SV=2MEESEPERKRARTDEVPAGGSRSEAEDEDDEDYVPYVPLRQRRQLLLQKLLQRRRKGAAEEEQQDSGSEPRGDEDDIPLGPQSNVSLLDQHQHLKEKAEARKESAKEKQLKEEEKILESVAEGRALMSVKEMAKGITYDDPIKTSWTPPRYVLSMSEERHERVRKKYHILVEGDGIPPPIKSFKEMKFPAAILRGLKKKGIHHPTPIQIQGIPTILSGRDMIGIAFTGSGKTLVFTLPVIMFCLEQEKRLPFSKREGPYGLIICPSRELARQTHGILEYYCRLLQEDSSPLLRCALCIGGMSVKEQMETIRHGVHMMVATPGRLMDLLQKKMVSLDICRYLALDEADRMIDMGFEGDIRTIFSYFKGQRQTLLFSATMPKKIQNFAKSALVKPVTINVGRAGAASLDVIQEVEYVKEEAKMVYLLECLQKTPPPVLIFAEKKADVDAIHEYLLLKGVEAVAIHGGKDQEERTKAIEAFREGKKDVLVATDVASKGLDFPAIQHVINYDMPEEIENYVHRIGRTGRSGNTGIATTFINKACDESVLMDLKALLLEAKQKVPPVLQVLHCGDESMLDIGGERGCAFCGGLGHRITDCPKLEAMQTKQVSNIGRKDYLAHSSMDF>sp|Q86XP3|DDX42_HUMAN ATP-dependent RNA helicase DDX42 OS=Homo sapiensOX=9606 GN=DDX42 PE=1 SV=1MNWNKGGPGTKRGFGFGGFAISAGKKEEPKLPQQSHSAFGATSSSSGFGKSAPPQLPSFYKIGSKRANFDEENAYFEDEEEDSSNVDLPYIPAENSPTRQQFHSKPVDSDSDDDPLEAFMAEVEDQAARDMKRLEEKDKERKNVKGIRDDIEEEDDQEAYFRYMAENPTAGVVQEEEEDNLEYDSDGNPIAPTKKIIDPLPPIDHSEIDYPPFEKNFYNEHEEITNLTPQQLIDLRHKLNLRVSGAAPPRPGSSFAHFGFDEQLMHQIRKSEYTQPTPIQCQGVPVALSGRDMIGIAKTGSGKTAAFIWPMLIHIMDQKELEPGDGPIAVIVCPTRELCQQIHAECKRFGKAYNLRSVAVYGGGSMWEQAKALQEGAEIVVCTPGRLIDHVKKKATNLQRVSYLVFDEADRMFDMGFEYQVRSIASHVRPDRQTLLFSATFRKKIEKLARDILIDPIRVVQGDIGEANEDVTQIVEILHSGPSKWNWLTRRLVEFTSSGSVLLFVTKKANAEELANNLKQEGHNLGLLHGDMDQSERNKVISDFKKKDIPVLVATDVAARGLDIPSIKTVINYDVARDIDTHTHRIGRTGRAGEKGVAYTLLTPKDSNFAGDLVRNLEGANQHVSKELLDLAMQNAWFRKSRFKGGKGKKLNIGGGGLGYRERPGLGSENMDRGNNNVMSNYEAYKPSTGAMGDRLTAMKAAFQSQYKSHFVAASLSNQKAGSSAAGASGWTSAGSLNSVPTNSAQQGHNSPDSPVTSAAKGIPGFGNTGNISGAPVTYPSAGAQGVNNTASGNNSREGTGGSNGKRERYTENRGSSRHSHGETGNRHSDSPRHGDGGRHGDGYRHPESSSRHTDGHRHGENRHGGSAGRHGENRGANDGRNGESRKEAFNRESKMEPKMEPKVDSSKMDKVDSKTDKTADGFAVPEPPKRKKSRWDS>sp|Q86XP3-2|DDX42_HUMAN Isoform 2 of ATP-dependent RNA helicase DDX42OS=Homo sapiens OX=9606 GN=DDX42MAEVEDQAARDMKRLEEKDKERKNVKGIRDDIEEEDDQEAYFRYMAENPTAGVVQEEEEDNLEYDSDGNPIAPTKKIIDPLPPIDHSEIDYPPFEKNFYNEHEEITNLTPQQLIDLRHKLNLRVSGAAPPRPGSSFAHFGFDEQLMHQIRKSEYTQPTPIQCQGVPVALSGRDMIGIAKTGSGKTAAFIWPMLIHIMDQKELEPGDGPIAVIVCPTRELCQQIHAECKRFGKAYNLRSVAVYGGGSMWEQAKALQEGAEIVVCTPGRLIDHVKKKATNLQRVSYLVFDEADRMFDMGFEYQVRSIASHVRPDRQTLLFSATFRKKIEKLARDILIDPIRVVQGDIGEANEDVTQIVEILHSGPSKWNWLTRRLVEFTSSGSVLLFVTKKANAEELANNLKQEGHNLGLLHGDMDQSERNKVISDFKKKDIPVLVATDVAARGLDIPSIKTVINYDVARDIDTHTHRIGRTGRAGEKGVAYTLLTPKDSNFAGDLVRNLEGANQHVSKELLDLAMQNAWFRKSRFKGGKGKKLNIGGGGLGYRERPGLGSENMDRGNNNVMSNYEAYKPSTGAMGDRLTAMKAAFQSQYKSHFVAASLSNQKAGSSAAGASGWTSAGSLNSVPTNSAQQGHNSPDSPVTSAAKGIPGFGNTGNISGAPVTYPSAGAQGVNNTASGNNSREGTGGSNGKRERYTENRGSSRHSHGETGNRHSDSPRHGDGGRHGDGYRHPESSSRHTDGHRHGENRHGGSAGRHGENRGANDGRNGESRKEAFNRESKMEPKMEPKVDSSKMDKVDSKTDKTADGFAVPEPPKRKKSRWDS>sp|Q9H295|DCSTP_HUMAN Dendritic cell-specific transmembrane proteinOS=Homo sapiens OX=9606 GN=DCSTAMP PE=1 SV=1MGIWTSGTDIFLSLWEIYVSPRSPGWMDFIQHLGVCCLVALISVGLLSVAACWFLPSIIAAAASWIITCVLLCCSKHARCFILLVFLSCGLREGRNALIAAGTGIVILGHVENIFHNFKGLLDGMTCNLRAKSFSIHFPLLKKYIEAIQWIYGLATPLSVFDDLVSWNQTLAVSLFSPSHVLEAQLNDSKGEVLSVLYQMATTTEVLSSLGQKLLAFAGLSLVLLGTGLFMKRFLGPCGWKYENIYITRQFVQFDERERHQQRPCVLPLNKEERRKYVIIPTFWPTPKERKNLGLFFLPILIHLCIWVLFAAVDYLLYRLIFSVSKQFQSLPGFEVHLKLHGEKQGTQDIIHDSSFNISVFEPNCIPKPKFLLSETWVPLSVILLILVMLGLLSSILMQLKILVSASFYPSVERKRIQYLHAKLLKKRSKQPLGEVKRRLSLYLTKIHFWLPVLKMIRKKQMDMASADKS>sp|Q9H295-2|DCSTP_HUMAN Isoform 2 of Dendritic cell-specifictransmembrane protein OS=Homo sapiens OX=9606 GN=DCSTAMPMGIWTSGTDIFLSLWEIYVSPRSPGWMDFIQHLGVCCLVALISVGLLSVAACWFLPSIIAAAASWIITCVLLCCSKHARCFILLVFLSCGLREGRNALIAAGTGIVILGHVENIFHNFKGLLDGMTCNLRAKSFSIHFPLLKKYIEAIQWIYGLATPLSVFDDLVSWNQTLAVSLFSPSHVLEAQLNDSKGEVLSVLYQMATTTEVLSSLGQKLLAFAGLSLVLLGTGLFMKRFLGPCGWKYENIYITRQFVQFDERERHQQRPCVLPLNKEERRKFISGFQS>sp|Q7L014|DDX46_HUMAN Probable ATP-dependent RNA helicase DDX46 OS=Homosapiens OX=9606 GN=DDX46 PE=1 SV=2MGRESRHYRKRSASRGRSGSRSRSRSPSDKRSKRGDDRRSRSRDRDRRRERSRSRDKRRSRSRDRKRLRRSRSRERDRSRERRRSRSRDRRRSRSRSRGRRSRSSSPGNKSKKTENRSRSKEKTDGGESSKEKKKDKDDKEDEKEKDAGNFDQNKLEEEMRKRKERVEKWREEQRKKAMENIGELKKEIEEMKQGKKWSLEDDDDDEDDPAEAEKEGNEMEGEELDPLDAYMEEVKEEVKKFNMRSVKGGGGNEKKSGPTVTKVVTVVTTKKAVVDSDKKKGELMENDQDAMEYSSEEEEVDLQTALTGYQTKQRKLLEPVDHGKIEYEPFRKNFYVEVPELAKMSQEEVNVFRLEMEGITVKGKGCPKPIKSWVQCGISMKILNSLKKHGYEKPTPIQTQAIPAIMSGRDLIGIAKTGSGKTIAFLLPMFRHIMDQRSLEEGEGPIAVIMTPTRELALQITKECKKFSKTLGLRVVCVYGGTGISEQIAELKRGAEIIVCTPGRMIDMLAANSGRVTNLRRVTYVVLDEADRMFDMGFEPQVMRIVDNVRPDRQTVMFSATFPRAMEALARRILSKPIEVQVGGRSVVCSDVEQQVIVIEEEKKFLKLLELLGHYQESGSVIIFVDKQEHADGLLKDLMRASYPCMSLHGGIDQYDRDSIINDFKNGTCKLLVATSVAARGLDVKHLILVVNYSCPNHYEDYVHRAGRTGRAGNKGYAYTFITEDQARYAGDIIKALELSGTAVPPDLEKLWSDFKDQQKAEGKIIKKSSGFSGKGFKFDETEQALANERKKLQKAALGLQDSDDEDAAVDIDEQIESMFNSKKRVKDMAAPGTSSVPAPTAGNAEKLEIAKRLALRINAQKNLGIESQDVMQQATNAILRGGTILAPTVSAKTIAEQLAEKINAKLNYVPLEKQEEERQDGGQNESFKRYEEELEINDFPQTARWKVTSKEALQRISEYSEAAITIRGTYFPPGKEPKEGERKIYLAIESANELAVQKAKAEITRLIKEELIRLQNSYQPTNKGRYKVL>sp|Q9NQI0|DDX4_HUMAN Probable ATP-dependent RNA helicase DDX4 OS=Homosapiens OX=9606 GN=DDX4 PE=1 SV=2MGDEDWEAEINPHMSSYVPIFEKDRYSGENGDNFNRTPASSSEMDDGPSRRDHFMKSGFASGRNFGNRDAGECNKRDNTSTMGGFGVGKSFGNRGFSNSRFEDGDSSGFWRESSNDCEDNPTRNRGFSKRGGYRDGNNSEASGPYRRGGRGSFRGCRGGFGLGSPNNDLDPDECMQRTGGLFGSRRPVLSGTGNGDTSQSRSGSGSERGGYKGLNEEVITGSGKNSWKSEAEGGESSDTQGPKVTYIPPPPPEDEDSIFAHYQTGINFDKYDTILVEVSGHDAPPAILTFEEANLCQTLNNNIAKAGYTKLTPVQKYSIPIILAGRDLMACAQTGSGKTAAFLLPILAHMMHDGITASRFKELQEPECIIVAPTRELVNQIYLEARKFSFGTCVRAVVIYGGTQLGHSIRQIVQGCNILCATPGRLMDIIGKEKIGLKQIKYLVLDEADRMLDMGFGPEMKKLISCPGMPSKEQRQTLMFSATFPEEIQRLAAEFLKSNYLFVAVGQVGGACRDVQQTVLQVGQFSKREKLVEILRNIGDERTMVFVETKKKADFIATFLCQEKISTTSIHGDREQREREQALGDFRFGKCPVLVATSVAARGLDIENVQHVINFDLPSTIDEYVHRIGRTGRCGNTGRAISFFDLESDNHLAQPLVKVLTDAQQDVPAWLEEIAFSTYIPGFSGSTRGNVFASVDTRKGKSTLNTAGFSSSQAPNPVDDESWD>sp|Q9NQI0-2|DDX4_HUMAN Isoform 2 of Probable ATP-dependent RNA helicaseDDX4 OS=Homo sapiens OX=9606 GN=DDX4MGDEDWEAEINPHMSSYVPIFEKDRYSGENGDNFNRTPASSSEMDDGPSRRDHFMKSGFASGRNFGNRDAGECNKRDNTSTMGGFGVGKSFGNRGFSNSRFEDGDSSGFWRESSNDCEDNPTRNRGFSKRGDNDLDPDECMQRTGGLFGSRRPVLSGTGNGDTSQSRSGSGSERGGYKGLNEEVITGSGKNSWKSEAEGGESSDTQGPKVTYIPPPPPEDEDSIFAHYQTGINFDKYDTILVEVSGHDAPPAILTFEEANLCQTLNNNIAKAGYTKLTPVQKYSIPIILAGRDLMACAQTGSGKTAAFLLPILAHMMHDGITASRFKELQEPECIIVAPTRELVNQIYLEARKFSFGTCVRAVVIYGGTQLGHSIRQIVQGCNILCATPGRLMDIIGKEKIGLKQIKYLVLDEADRMLDMGFGPEMKKLISCPGMPSKEQRQTLMFSATFPEEIQRLAAEFLKSNYLFVAVGQVGGACRDVQQTVLQVGQFSKREKLVEILRNIGDERTMVFVETKKKADFIATFLCQEKISTTSIHGDREQREREQALGDFRFGKCPVLVATSVAARGLDIENVQHVINFDLPSTIDEYVHRIGRTGRCGNTGRAISFFDLESDNHLAQPLVKVLTDAQQDVPAWLEEIAFSTYIPGFSGSTRGNVFASVDTRKGKSTLNTAGFSSSQAPNPVDDESWD>sp|Q9NQI0-3|DDX4_HUMAN Isoform 3 of Probable ATP-dependent RNA helicaseDDX4 OS=Homo sapiens OX=9606 GN=DDX4MGSRNLFLTNSPESSNDCEDNPTRNRGFSKRGDNDLDPDECMQRTGGLFGSRRPVLSGTGNGDTSQSRSGSGSERDSWKSEAEGGESSDTQGPKVTYIPPPPPEDEDSIFAHYQTGINFDKYDTILVEVSGHDAPPAILTFEEANLCQTLNNNIAKAGYTKLTPVQKYSIPIILAGRDLMACAQTGSGKTAAFLLPILAHMMHDGITASRFKELQEPECIIVAPTRELVNQIYLEARKFSFGTCVRAVVIYGGTQLGHSIRQIVQGCNILCATPGRLMDIIGKEKIGLKQIKYLVLDEADRMLDMGFGPEMKKLISCPGMPSKEQRQTLMFSATFPEEIQRLAAEFLKSNYLFVAVGQVGGACRDVQQTVLQVGQFSKREKLVEILRNIGDERTMVFVETKKKADFIATFLCQEKISTTSIHGDREQREREQALGDFRFGKCPVLVATSVAARGLDIENVQHVINFDLPSTIDEYVHRIGRTGRCGNTGRAISFFDLESDNHLAQPLVKVLTDAQQDVPAWLEEIAFSTYIPGFSGSTRGNVFASVDTRKGKSTLNTAGFSSSQAPNPVDDESWD>sp|Q9NQI0-4|DDX4_HUMAN Isoform 4 of Probable ATP-dependent RNA helicaseDDX4 OS=Homo sapiens OX=9606 GN=DDX4MGDEDWEAEINPHMSSYVPIFEKDRYSGENGDNFNRTPASSSEMDDGPSRRDHFMKSGFASGRNFGNRDAGECNKRDNTSTMGGFGVGKSFGNRGFSNSRFEDGDSSGFWRGYRDGNNSEASGPYRRGGRGSFRGCRGGFGLGSPNNDLDPDECMQRTGGLFGSRRPVLSGTGNGDTSQSRSGSGSERGGYKGLNEEVITGSGKNSWKSEAEGGESSDTQGPKVTYIPPPPPEDEDSIFAHYQTGINFDKYDTILVEVSGHDAPPAILTFEEANLCQTLNNNIAKAGYTKLTPVQKYSIPIILAGRDLMACAQTGSGKTAAFLLPILAHMMHDGITASRFKELQEPECIIVAPTRELVNQIYLEARKFSFGTCVRAVVIYGGTQLGHSIRQIVQGCNILCATPGRLMDIIGKEKIGLKQIKYLVLDEADRMLDMGFGPEMKKLISCPGMPSKEQRQTLMFSATFPEEIQRLAAEFLKSNYLFVAVGQVGGACRDVQQTVLQVGQFSKREKLVEILRNIGDERTMVFVETKKKADFIATFLCQEKISTTSIHGDREQREREQALGDFRFGKCPVLVATSVAARGLDIENVQHVINFDLPSTIDEYVHRIGRTGRCGNTGRAISFFDLESDNHLAQPLVKVLTDAQQDVPAWLEEIAFSTYIPGFSGSTRGNVFASVDTRKGKSTLNTAGFSSSQAPNPVDDESWD>sp|Q9Y4B6|DCAF1_HUMAN DDB1- and CUL4-associated factor 1 OS=Homo sapiensOX=9606 GN=DCAF1 PE=1 SV=3MTTVVVHVDSKAELTTLLEQWEKEHGSGQDMVPILTRMSQLIEKETEEYRKGDPDPFDDRHPGRADPECMLGHLLRILFKNDDFMNALVNAYVMTSREPPLNTAACRLLLDIMPGLETAVVFQEKEGIVENLFKWAREADQPLRTYSTGLLGGAMENQDIAANYRDENSQLVAIVLRRLRELQLQEVALRQENKRPSPRKLSSEPLLPLDEEAVDMDYGDMAVDVVDGDQEEASGDMEISFHLDSGHKTSSRVNSTTKPEDGGLKKNKSAKQGDRENFRKAKQKLGFSSSDPDRMFVELSNSSWSEMSPWVIGTNYTLYPMTPAIEQRLILQYLTPLGEYQELLPIFMQLGSRELMMFYIDLKQTNDVLLTFEALKHLASLLLHNKFATEFVAHGGVQKLLEIPRPSMAATGVSMCLYYLSYNQDAMERVCMHPHNVLSDVVNYTLWLMECSHASGCCHATMFFSICFSFRAVLELFDRYDGLRRLVNLISTLEILNLEDQGALLSDDEIFASRQTGKHTCMALRKYFEAHLAIKLEQVKQSLQRTEGGILVHPQPPYKACSYTHEQIVEMMEFLIEYGPAQLYWEPAEVFLKLSCVQLLLQLISIACNWKTYYARNDTVRFALDVLAILTVVPKIQLQLAESVDVLDEAGSTVSTVGISIILGVAEGEFFIHDAEIQKSALQIIINCVCGPDNRISSIGKFISGTPRRKLPQNPKSSEHTLAKMWNVVQSNNGIKVLLSLLSIKMPITDADQIRALACKALVGLSRSSTVRQIISKLPLFSSCQIQQLMKEPVLQDKRSDHVKFCKYAAELIERVSGKPLLIGTDVSLARLQKADVVAQSRISFPEKELLLLIRNHLISKGLGETATVLTKEADLPMTAASHSSAFTPVTAAASPVSLPRTPRIANGIATRLGSHAAVGASAPSAPTAHPQPRPPQGPLALPGPSYAGNSPLIGRISFIRERPSPCNGRKIRVLRQKSDHGAYSQSPAIKKQLDRHLPSPPTLDSIITEYLREQHARCKNPVATCPPFSLFTPHQCPEPKQRRQAPINFTSRLNRRASFPKYGGVDGGCFDRHLIFSRFRPISVFREANEDESGFTCCAFSARERFLMLGTCTGQLKLYNVFSGQEEASYNCHNSAITHLEPSRDGSLLLTSATWSQPLSALWGMKSVFDMKHSFTEDHYVEFSKHSQDRVIGTKGDIAHIYDIQTGNKLLTLFNPDLANNYKRNCATFNPTDDLVLNDGVLWDVRSAQAIHKFDKFNMNISGVFHPNGLEVIINTEIWDLRTFHLLHTVPALDQCRVVFNHTGTVMYGAMLQADDEDDLMEERMKSPFGSSFRTFNATDYKPIATIDVKRNIFDLCTDTKDCYLAVIENQGSMDALNMDTVCRLYEVGRQRLAEDEDEEEDQEEEEQEEEDDDEDDDDTDDLDELDTDQLLEAELEEDDNNENAGEDGDNDFSPSDEELANLLEEGEDGEDEDSDADEEVELILGDTDSSDNSDLEDDIILSLNE>sp|Q9Y4B6-2|DCAF1_HUMAN Isoform 2 of DDB1- and CUL4-associated factor 1OS=Homo sapiens OX=9606 GN=DCAF1MTTVVVHVDSKAELTTLLEQWEKEHGSGQDMVPILTRMSQLIEKETEEYRKGDPDPFDDRHPGRADPECMLGHLLRILFKNDDFMNLVNAYVMTSREPPLNTAACRLLLDIMPGLETAVVFQEKEGIVENLFKWAREADQPLRTYSTGLLGGAMENQDIAANYRDENSQLVAIVLRRLRELQLQEVALRQENKRPSPRKLSSEPLLPLDEEAVDMDYGDMAVDVVDGDQEEASGDMEISFHLDSGHKTSSRVNSTTKPEDGGLKKNKSAKQGDRENFRKAKQKLGFSSSDPDRMFVELSNSSWSEMSPWVIGTNYTLYPMTPAIEQRLILQYLTPLGEYQELLPIFMQLGSRELMMFYIDLKQTNDVLLTFEALKHLASLLLHNKFATEFVAHGGVQKLLEIPRPSMAATGVSMCLYYLSYNQDAMERVCMHPHNVLSDVVNYTLWLMECSHASGCCHATMFFSICFSFRAVLELFDRYDGLRRLVNLISTLEILNLEDQGALLSDDEIFASRQTGKHTCMALRKYFEAHLAIKLEQVKQSLQRTEGGILVHPQPPYKACSYTHEQIVEMMEFLIEYGPAQLYWEPAEVFLKLSCVQLLLQLISIACNWKTYYARNDTVRFALDVLAILTVVPKIQLQLAESVDVLDEAGSTVSTVGISIILGVAEGEFFIHDAEIQKSALQIIINCVCGPDNRISSIGKFISGTPRRKLPQNPKSSEHTLAKMWNVVQSNNGIKVLLSLLSIKMPITDADQIRALACKALVGLSRSSTVRQIISKLPLFSSCQIQQLMKEPVLQDKRSDHVKFCKYAAELIERVSGKPLLIGTDVSLARLQKADVVAQSRISFPEKELLLLIRNHLISKGLGETATVLTKEADLPMTAASHSSAFTPVTAAASPVSLPRTPRIANGIATRLGSHAAVGASAPSAPTAHPQPRPPQGPLALPGPSYAGNSPLIGRISFIRERPSPCNGRKIRVLRQKSDHGAYSQSPAIKKQLDRHLPSPPTLDSIITEYLREQHARCKNPVATCPPFSLFTPHQCPEPKQRRQAPINFTSRLNRRASFPKYGGVDGGCFDRHLIFSRFRPISVFREANEDESGFTCCAFSARERFLMLGTCTGQLKLYNVFSGQEEASYNCHNSAITHLEPSRDGSLLLTSATWSQPLSALWGMKSVFDMKHSFTEDHYVEFSKHSQDRVIGTKGDIAHIYDIQTGNKLLTLFNPDLANNYKRNCATFNPTDDLVLNDGVLWDVRSAQAIHKFDKFNMNISGVFHPNGLEVIINTEIWDLRTFHLLHTVPALDQCRVVFNHTGTVMYGAMLQADDEDDLMEERMKSPFGSSFRTFNATDYKPIATIDVKRNIFDLCTDTKDCYLAVIENQGSMDALNMDTVCRLYEVGRQRLAEDEDEEEDQEEEEQEEEDDDEDDDDTDDLDELDTDQLLEAELEEDDNNENAGEDGDNDFSPSDEELANLLEEGEDGEDEDSDADEEVELILGDTDSSDNSDLEDDIILSLNE>sp|Q9Y4B6-3|DCAF1_HUMAN Isoform 3 of DDB1- and CUL4-associated factor 1OS=Homo sapiens OX=9606 GN=DCAF1MTTVVVHVDSKAELTTLLEQWEKEHGSGQDMVPILTRMSQLIEKETEEYRKGDPDPFDDRHPGRADPECMLGHLLRILFKNDDFMNALVNAYVMTSREPPLNTAACRLLLDIMPGLETAVVFQEKEGIVENLFKWAREADQPLRTYSTGLLGGAMENQDIAANYRDENSQLVAIVLRRLRELQLQEVALRQENKRPSPRKLSSEPLLPLDEEAVDMDYGDMAVDDAEIQKSALQIIINCVCGPDNRISSIGKFISGTPRRKLPQNPKSSEHTLAKMWNVVQSNNGIKVLLSLLSIKMPITDADQIRALACKALVGLSRSSTVRQIISKLPLFSSCQIQQLMKEPVLQDKRSDHVKFCKYAAELIERVSGKPLLIGTDVSLARLQKADVVAQSRISFPEKELLLLIRNHLISKGLGETATVLTKEADLPMTAASHSSAFTPVTAAASPVSLPRTPRIANGIATRLGSHAAVGASAPSAPTAHPQPRPPQGPLALPGPSYAGNSPLIGRISFIRERPSPCNGRKIRVLRQKSDHGAYSQSPAIKKQLDRHLPSPPTLDSIITEYLREQHARCKNPVATCPPFSLFTPHQCPEPKQRRQAPINFTSRLNRRASFPKYGGVDGGCFDRHLIFSRFRPISVFREANEDESGFTCCAFSARERFLMLGTCTGQLKLYNVFSGQEEASYNCHNSAITHLEPSRDGSLLLTSATWSQPLSALWGMKSVFDMKHSFTEDHYVEFSKHSQDRVIGTKGDIAHIYDIQTGNKLLTLFNPDLANNYKRNCATFNPTDDLVLNDGVLWDVRSAQAIHKFDKFNMNISGVFHPNGLEVIINTEIWDLRTFHLLHTVPALDQCRVVFNHTGTVMYGAMLQADDEDDLMEERMKSPFGSSFRTFNATDYKPIATIDVKRNIFDLCTDTKDCYLAVIENQGSMDALNMDTVCRLYEVGRQRLAEDEDEEEDQEEEEQEEEDDDEDDDDTDDLDELDTDQLLEAELEEDDNNENAGEDGDNDFSPSDEELANLLEEGEDGEDEDSDADEEVELILGDTDSSDNSDLEDDIILSLNE>sp|Q9BQ39|DDX50_HUMAN ATP-dependent RNA helicase DDX50 OS=Homo sapiensOX=9606 GN=DDX50 PE=1 SV=1MPGKLLWGDIMELEAPLEESESQKKERQKSDRRKSRHHYDSDEKSETRENGVTDDLDAPKAKKSKMKEKLNGDTEEGFNRLSDEFSKSHKSRRKDLPNGDIDEYEKKSKRVSSLDTSTHKSSDNKLEETLTREQKEGAFSNFPISEETIKLLKGRGVTYLFPIQVKTFGPVYEGKDLIAQARTGTGKTFSFAIPLIERLQRNQETIKKSRSPKVLVLAPTRELANQVAKDFKDITRKLSVACFYGGTSYQSQINHIRNGIDILVGTPGRIKDHLQSGRLDLSKLRHVVLDEVDQMLDLGFAEQVEDIIHESYKTDSEDNPQTLLFSATCPQWVYKVAKKYMKSRYEQVDLVGKMTQKAATTVEHLAIQCHWSQRPAVIGDVLQVYSGSEGRAIIFCETKKNVTEMAMNPHIKQNAQCLHGDIAQSQREITLKGFREGSFKVLVATNVAARGLDIPEVDLVIQSSPPQDVESYIHRSGRTGRAGRTGICICFYQPRERGQLRYVEQKAGITFKRVGVPSTMDLVKSKSMDAIRSLASVSYAAVDFFRPSAQRLIEEKGAVDALAAALAHISGASSFEPRSLITSDKGFVTMTLESLEEIQDVSCAWKELNRKLSSNAVSQITRMCLLKGNMGVCFDVPTTESERLQAEWHDSDWILSVPAKLPEIEEYYDGNTSSNSRQRSGWSSGRSGRSGRSGGRSGGRSGRQSRQGSRSGSRQDGRRRSGNRNRSRSGGHKRSFD>sp|Q8N8A6|DDX51_HUMAN ATP-dependent RNA helicase DDX51 OS=Homo sapiensOX=9606 GN=DDX51 PE=1 SV=3MALFYVARYPGPDAAAAAGPEGAEAGAHGRARALLERLQSRARERQQQREPAQTEAAASTEPATRRRRRPRRRRRVNDAEPGSPEAPQGKRRKADGEDAGAESNEEAPGEPSAGSSEEAPGEPSAGSSEEAPGERSTSASAEAAPDGPALEEAAGPLVPGLVLGGFGKRKAPKVQPFLPRWLAEPNCVRRNVTEDLVPIEDIPDVHPDLQKQLRAHGISSYFPVQAAVIPALLESAACGFLVGRGGYRPSDLCVSAPTGSGKTLAFVIPVVQALLSRVVCHIRALVVLPTKELAQQVSKVFNIYTDATPLRVSLVTGQKSLAKEQESLVQKTADGYRCLADIVVATPGRLVDHIDQTPGFSLQQLRFLIIDEADRMIDSMHQSWLPRVVAAAFQSEDPADPCALLQRRQAQAVTAASTCCPQMPLQKLLFSATLTQNPEKLQQLGLHQPRLFSTGLAHRGLEDTDGDGDSGKYAFPVGLTHHYVPCSLSSKPLVVLHLVLEMGFSRVLCFTNSRENSHRLFLLVQAFGGVDVAEFSSRYGPGQRRMILKQFEQGKIQLLISTDATARGIDVQGVELVVNYDAPQYLRTYVHRVGRTARAGKTGQAFTLLLKVQERRFLRMLTEAGAPELQRHELSSKLLQPLVPRYEEALSQLEESVKEERKQRAA>sp|Q96JK2|DCAF5_HUMAN DDB1- and CUL4-associated factor 5 OS=Homo sapiensOX=9606 GN=DCAF5 PE=1 SV=2MKRRAGLGGSMRSVVGFLSQRGLHGDPLLTQDFQRRRLRGCRNLYKKDLLGHFGCVNAIEFSNNGGQWLVSGGDDRRVLLWHMEQAIHSRVKPIQLKGEHHSNIFCLAFNSGNTKVFSGGNDEQVILHDVESSETLDVFAHEDAVYGLSVSPVNDNIFASSSDDGRVLIWDIRESPHGEPFCLANYPSAFHSVMFNPVEPRLLATANSKEGVGLWDIRKPQSSLLRYGGNLSLQSAMSVRFNSNGTQLLALRRRLPPVLYDIHSRLPVFQFDNQGYFNSCTMKSCCFAGDRDQYILSGSDDFNLYMWRIPADPEAGGIGRVVNGAFMVLKGHRSIVNQVRFNPHTYMICSSGVEKIIKIWSPYKQPGCTGDLDGRIEDDSRCLYTHEEYISLVLNSGSGLSHDYANQSVQEDPRMMAFFDSLVRREIEGWSSDSDSDLSESTILQLHAGVSERSGYTDSESSASLPRSPPPTVDESADNAFHLGPLRVTTTNTVASTPPTPTCEDAASRQQRLSALRRYQDKRLLALSNESDSEENVCEVELDTDLFPRPRSPSPEDESSSSSSSSSSEDEEELNERRASTWQRNAMRRRQKTTREDKPSAPIKPTNTYIGEDNYDYPQIKVDDLSSSPTSSPERSTSTLEIQPSRASPTSDIESVERKIYKAYKWLRYSYISYSNNKDGETSLVTGEADEGRAGTSHKDNPAPSSSKEACLNIAMAQRNQDLPPEGCSKDTFKEETPRTPSNGPGHEHSSHAWAEVPEGTSQDTGNSGSVEHPFETKKLNGKALSSRAEEPPSPPVPKASGSTLNSGSGNCPRTQSDDSEERSLETICANHNNGRLHPRPPHPHNNGQNLGELEVVAYSSPGHSDTDRDNSSLTGTLLHKDCCGSEMACETPNAGTREDPTDTPATDSSRAVHGHSGLKRQRIELEDTDSENSSSEKKLKT>sp|Q96JK2-2|DCAF5_HUMAN Isoform 2 of DDB1- and CUL4-associated factor 5OS=Homo sapiens OX=9606 GN=DCAF5MEQAIHSRVKPIQLKGEHHSNIFCLAFNSGNTKVFSGGNDEQVILHDVESSETLDVFAHEDAVYGLSVSPVNDNIFASSSDDGRVLIWDIRESPHGEPFCLANYPSAFHSVMFNPVEPRLLATANSKEGVGLWDIRKPQSSLLRYGGNLSLQSAMSVRFNSNGTQLLALRRRLPPVLYDIHSRLPVFQFDNQGYFNSCTMKSCCFAGDRDQYILSGSDDFNLYMWRIPADPEAGGIGRVVNGAFMVLKGHRSIVNQVRFNPHTYMICSSGVEKIIKIWSPYKQPGCTGDLDGRIEDDSRCLYTHEEYISLVLNSGSGLSHDYANQSVQEDPRMMAFFDSLVRREIEGWSSDSDSDLSESTILQLHAGVSERSGYTDSESSASLPRSPPPTVDESADNAFHLGPLRVTTTNTVASTPPTPTCEDAASRQQRLSALRRYQDKRLLALSNESDSEENVCEVELDTDLFPRPRSPSPEDESSSSSSSSSSEDEEELNERRASTWQRNAMRRRQKTTREDKPSAPIKPTNTYIGEDNYDYPQIKVDDLSSSPTSSPERSTSTLEIQPSRASPTSDIESVERKIYKAYKWLRYSYISYSNNKDGETSLVTGEADEGRAGTSHKDNPAPSSSKEACLNIAMAQRNQDLPPEGCSKDTFKEETPRTPSNGPGHEHSSHAWAEVPEGTSQDTGNSGSVEHPFETKKLNGKALSSRAEEPPSPPVPKASGSTLNSGSGNCPRTQSDDSEERSLETICANHNNGRLHPRPPHPHNNGQNLGELEVVAYSSPGHSDTDRDNSSLTGTLLHKDCCGSEMACETPNAGTREDPTDTPATDSSRAVHGHSGLKRQRIELEDTDSENSSSEKKLKT>sp|Q96JK2-3|DCAF5_HUMAN Isoform 3 of DDB1- and CUL4-associated factor 5OS=Homo sapiens OX=9606 GN=DCAF5MKRRAGLGGSMRSVVGFLSQRGLHGDPLLTQDFQRRRLRGCRNLYKKDLLGHFGCVNAIEFSNNGGQWLVSGGDDRRVLLWHMEQAIHSRVKPIQLKGEHHSNIFCLAFNSGNTKVFSGGNDEQVILHDVESETLDVFAHEDAVYGLSVSPVNDNIFASSSDDGRVLIWDIRESPHGEPFCLANYPSAFHSVMFNPVEPRLLATANSKEGVGLWDIRKPQSSLLRYGGNLSLQSAMSVRFNSNGTQLLALRRRLPPVLYDIHSRLPVFQFDNQGYFNSCTMKSCCFAGDRDQYILSGSDDFNLYMWRIPADPEAGGIGRVVNGAFMVLKGHRSIVNQVRFNPHTYMICSSGVEKIIKIWSPYKQPGCTGDLDGRIEDDSRCLYTHEEYISLVLNSGSGLSHDYANQSVQEDPRMMAFFDSLVRREIEGWSSDSDSDLSESTILQLHAGVSERSGYTDSESSASLPRSPPPTVDESADNAFHLGPLRVTTTNTVASTPPTPTCEDAASRQQRLSALRRYQDKRLLALSNESDSEENVCEVELDTDLFPRPRSPSPEDESSSSSSSSSSEDEEELNERRASTWQRNAMRRRQKTTREDKPSAPIKPTNTYIGEDNYDYPQIKVDDLSSSPTSSPERSTSTLEIQPSRASPTSDIESVERKIYKAYKWLRYSYISYSNNKDGETSLVTGEADEGRAGTSHKDNPAPSSSKEACLNIAMAQRNQDLPPEGCSKDTFKEETPRTPSNGPGHEHSSHAWAEVPEGTSQDTGNSGSVEHPFETKKLNGKALSSRAEEPPSPPVPKASGSTLNSGSGNCPRTQSDDSEERSLETICANHNNGRLHPRPPHPHNNGQNLGELEVVAYSSPGHSDTDRDNSSLTGTLLHKDCCGSEMACETPNAGTREDPTDTPATDSSRAVHGHSGLKRQRIELEDTDSENSSSEKKLKT>sp|Q9Y2R4|DDX52_HUMAN Probable ATP-dependent RNA helicase DDX52 OS=Homosapiens OX=9606 GN=DDX52 PE=1 SV=3MDVHDLFRRLGAGAKFDTRRFSADAARFQIGKRKYDFDSSEVLQGLDFFGNKKSVPGVCGASQTHQKPQNGEKKEESLTERKREQSKKKRKTMTSEIASQEEGATIQWMSSVEAKIEDKKVQRESKLTSGKLENLRKEKINFLRNKHKIHVQGTDLPDPIATFQQLDQEYKINSRLLQNILDAGFQMPTPIQMQAIPVMLHGRELLASAPTGSGKTLAFSIPILMQLKQPANKGFRALIISPTRELASQIHRELIKISEGTGFRIHMIHKAAVAAKKFGPKSSKKFDILVTTPNRLIYLLKQDPPGIDLASVEWLVVDESDKLFEDGKTGFRDQLASIFLACTSHKVRRAMFSATFAYDVEQWCKLNLDNVISVSIGARNSAVETVEQELLFVGSETGKLLAMRELVKKGFNPPVLVFVQSIERAKELFHELIYEGINVDVIHAERTQQQRDNTVHSFRAGKIWVLICTALLARGIDFKGVNLVINYDFPTSSVEYIHRIGRTGRAGNKGKAITFFTEDDKPLLRSVANVIQQAGCPVPEYIKGFQKLLSKQKKKMIKKPLERESISTTPKCFLEKAKDKQKKVTGQNSKKKVALEDKS>sp|Q58WW2|DCAF6_HUMAN DDB1- and CUL4-associated factor 6 OS=Homo sapiensOX=9606 GN=DCAF6 PE=1 SV=1MSRGGSYPHLLWDVRKRSLGLEDPSRLRSRYLGRREFIQRLKLEATLNVHDGCVNTICWNDTGEYILSGSDDTKLVISNPYSRKVLTTIRSGHRANIFSAKFLPCTNDKQIVSCSGDGVIFYTNVEQDAETNRQCQFTCHYGTTYEIMTVPNDPYTFLSCGEDGTVRWFDTRIKTSCTKEDCKDDILINCRRAATSVAICPPIPYYLAVGCSDSSVRIYDRRMLGTRATGNYAGRGTTGMVARFIPSHLNNKSCRVTSLCYSEDGQEILVSYSSDYIYLFDPKDDTARELKTPSAEERREELRQPPVKRLRLRGDWSDTGPRARPESERERDGEQSPNVSLMQRMSDMLSRWFEEASEVAQSNRGRGRSRPRGGTSQSDISTLPTVPSSPDLEVSETAMEVDTPAEQFLQPSTSSTMSAQAHSTSSPTESPHSTPLLSSPDSEQRQSVEASGHHTHHQSDNNNEKLSPKPGTGEPVLSLHYSTEGTTTSTIKLNFTDEWSSIASSSRGIGSHCKSEGQEESFVPQSSVQPPEGDSETKAPEESSEDVTKYQEGVSAENPVENHINITQSDKFTAKPLDSNSGERNDLNLDRSCGVPEESASSEKAKEPETSDQTSTESATNENNTNPEPQFQTEATGPSAHEETSTRDSALQDTDDSDDDPVLIPGARYRAGPGDRRSAVARIQEFFRRRKERKEMEELDTLNIRRPLVKMVYKGHRNSRTMIKEANFWGANFVMSGSDCGHIFIWDRHTAEHLMLLEADNHVVNCLQPHPFDPILASSGIDYDIKIWSPLEESRIFNRKLADEVITRNELMLEETRNTITVPASFMLRMLASLNHIRADRLEGDRSEGSGQENENEDEE>sp|Q58WW2-2|DCAF6_HUMAN Isoform 2 of DDB1- and CUL4-associated factor 6OS=Homo sapiens OX=9606 GN=DCAF6MSRGGSYPHLLWDVRKRSLGLEDPSRLRSRYLGRREFIQRLKLEATLNVHDGCVNTICWNDTGEYILSGSDDTKLVISNPYSRKVLTTIRSGHRANIFSAKFLPCTNDKQIVSCSGDGVIFYTNVEQDAETNRQCQFTCHYGTTYEIMTVPNDPYTFLSCGEDGTVRWFDTRIKTSCTKEDCKDDILINCRRAATSVAICPPIPYYLAVGCSDSSVRIYDRRMLGTRATGNYAGRGTTGMVARFIPSHLNNKSCRVTSLCYSEDGQEILVSYSSDYIYLFDPKDDTARELKTPSAEERREELRQPPVKRLRLRGDWSDTGPRARPESERERDGEQSPNVSLMQRMSDMLSRWFEEASEVAQSNRGRGRSRPRGGTSQSDISTLPTVPSSPDLEVSETAMEVDTPAEQFLQPSTSSTMSAQAHSTSSPTESPHSTPLLSSPDSEQRQSVEASGHHTHHQSDSPSSVVNKQLGSMSLDEQQDNNNEKLSPKPGTGEPVLSLHYSTEGTTTSTIKLNFTDEWSSIASSSRGIGSHCKSEGQEESFVPQSSVQPPEGDSETKAPEESSEDVTKYQEGVSAENPVENHINITQSDKFTAKPLDSNSGERNDLNLDRSCGVPEESASSEKAKEPETSDQTSTESATNENNTNPEPQFQTEATGPSAHEETSTRDSALQDTDDSDDDPVLIPGARYRAGPGDRRSAVARIQEFFRRRKERKEMEELDTLNIRRPLVKMVYKGHRNSRTMIKEANFWGANFVMSGSDCGHIFIWDRHTAEHLMLLEADNHVVNCLQPHPFDPILASSGIDYDIKIWSPLEESRIFNRKLADEVITRNELMLEETRNTITVPASFMLRMLASLNHIRADRLEGDRSEGSGQENENEDEE>sp|Q58WW2-3|DCAF6_HUMAN Isoform 3 of DDB1- and CUL4-associated factor 6OS=Homo sapiens OX=9606 GN=DCAF6MSRGGSYPHLLWDVRKRSLGLEDPSRLRSRYLGRREFIQRLKLEATLNVHDGCVNTICWNDTGEYILSGSDDTKLVISNPYSRKVLTTIRSGHRANIFSAKFLPCTNDKQIVSCSGDGVIFYTNVEQDAETNRQCQFTCHYGTTYEIMTVPNDPYTFLSCGEDGTVRWFDTRIKTSCTKEDCKDDILINCRRAATSVAICPPIPYYLAVGCSDSSVRIYDRRMLGTRATGNYAGRGTTGMVARFIPSHLNNKSCRVTSLCYSEDGQEILVSYSSDYIYLFDPKDDTARELKTPSAEERREELRQPPVKRLRLRGDWSDTGPRARPESERERDGEQSPNVSLMQRMSDMLSRWFEEASEVAQSNRGRGRSRPRGGTSQSDISTLPTVPSSPDLEVSETAMEVDTPAEQFLQPSTSSTMSAQAHSTSSPTESPHSTPLLSSPDSEQRQSVEASGHHTHHQSEFLRGPEIALLRKRLQQLRLKKAEQQRQQELAAHTQQQPSTSDQSSHEGSSQDPHASDSPSSVVNKQLGSMSLDEQQDNNNEKLSPKPGTGEPVLSLHYSTEGTTTSTIKLNFTDEWSSIASSSRGIGSHCKSEGQEESFVPQSSVQPPEGDSETKAPEESSEDVTKYQEGVSAENPVENHINITQSDKFTAKPLDSNSGERNDLNLDRSCGVPEESASSEKAKEPETSDQTSTESATNENNTNPEPQFQTEATGPSAHEETSTRDSALQDTDDSDDDPVLIPGARYRAGPGDRFNIRGTTIGDRIMRRSAVARIQEFFRRRKERKEMEELDTLNIRRPLVKMVYKGHRNSRTMIKEANFWGANFVMSGSDCGHIFIWDRHTAEHLMLLEADNHVVNCLQPHPFDPILASSGIDYDIKIWSPLEESRIFNRKLADEVITRNELMLEETRNTITVPASFMLRMLASLNHIRADRLEGDRSEGSGQENENEDEE>sp|Q58WW2-4|DCAF6_HUMAN Isoform 4 of DDB1- and CUL4-associated factor 6OS=Homo sapiens OX=9606 GN=DCAF6MSRGGSYPHLLWDVRKRSLGLEDPSRLRSRYLGRREFIQRLKLEATLNVHDGCVLTTIRSGHRANIFSAKFLPCTNDKQIVSCSGDGVIFYTNVEQDAETNRQCQFTCHYGTTYEIMTVPNDPYTFLSCGEDGTVRWFDTRIKTSCTKEDCKDDILINCRRAATSVAICPPIPYYLAVGCSDSSVRIYDRRMLGTRATGNYAGRGTTGMVARFIPSHLNNKSCRVTSLCYSEDGQEILVSYSSDYIYLFDPKDDTARELKTPSAEERREELRQPPVKRLRLRGDWSDTGPRARPESERERDGEQSPNVSLMQRMSDMLSRWFEEASEVAQSNRGRGRSRPRGGTSQSDISTLPTVPSSPDLEVSETAMEVDTPAEQFLQPSTSSTMSAQAHSTSSPTESPHSTPLLSSPDSEQRQSVEASGHHTHHQSEFLRGPEIALLRKRLQQLRLKKAEQQRQQELAAHTQQQPSTSDQSSHEGSSQDPHASDSPSSVVNKQLGSMSLDEQQDNNNEKLSPKPGTGEPVLSLHYSTEGTTTSTIKLNFTDEWSSIASSSRGIGSHCKSEGQEESFVPQSSVQPPEGDSETKAPEESSEDVTKYQEGVSAENPVENHINITQSDKFTAKPLDSNSGERNDLNLDRSCGVPEESASSEKAKEPETSDQTSTESATNENNTNPEPQFQTEATGPSAHEETSTRDSALQDTDDSDDDPVLIPGARYRAGPGDRFNIRGTTIGDRIMRRSAVARIQEFFRRRKERKEMEELDTLNIRRPLVKMVYKGHRNSRTMIKEANFWGANFVMSGSDCGHIFIWDRHTAEHLMLLEADNHVVNCLQPHPFDPILASSGIDYDIKIWSPLEESRIFNRKLADEVITRNELMLEETRNTITVPASFMLRMLASLNHIRADRLEGDRSEGSGQENENEDEE>sp|Q86TM3|DDX53_HUMAN Probable ATP-dependent RNA helicase DDX53 OS=Homosapiens OX=9606 GN=DDX53 PE=1 SV=3MSHWAPEWKRAEANPRDLGASWDVRGSRGSGWSGPFGHQGPRAAGSREPPLCFKIKNNMVGVVIGYSGSKIKDLQHSTNTKIQIINGESEAKVRIFGNREMKAKAKAAIETLIRKQESYNSESSVDNAASQTPIGRNLGRNDIVGEAEPLSNWDRIRAAVVECEKRKWADLPPVKKNFYIESKATSCMSEMQVINWRKENFNITCDDLKSGEKRLIPKPTCRFKDAFQQYPDLLKSIIRVGIVKPTPIQSQAWPIILQGIDLIVVAQTGTGKTLSYLMPGFIHLDSQPISREQRNGPGMLVLTPTRELALHVEAECSKYSYKGLKSICIYGGRNRNGQIEDISKGVDIIIATPGRLNDLQMNNSVNLRSITYLVIDEADKMLDMEFEPQIRKILLDVRPDRQTVMTSATWPDTVRQLALSYLKDPMIVYVGNLNLVAVNTVKQNIIVTTEKEKRALTQEFVENMSPNDKVIMFVSQKHIADDLSSDFNIQGISAESLHGNSEQSDQERAVEDFKSGNIKILITTDIVSRGLDLNDVTHVYNYDFPRNIDVYVHRVGYIGRTGKTGTSVTLITQRDSKMAGELIKILDRANQSVPEDLVVMAEQYKLNQQKRHRETRSRKPGQRRKEFYFLS>sp|P61962|DCAF7_HUMAN DDB1- and CUL4-associated factor 7 OS=Homo sapiensOX=9606 GN=DCAF7 PE=1 SV=1MSLHGKRKEIYKYEAPWTVYAMNWSVRPDKRFRLALGSFVEEYNNKVQLVGLDEESSEFICRNTFDHPYPTTKLMWIPDTKGVYPDLLATSGDYLRVWRVGETETRLECLLNNNKNSDFCAPLTSFDWNEVDPYLLGTSSIDTTCTIWGLETGQVLGRVNLVSGHVKTQLIAHDKEVYDIAFSRAGGGRDMFASVGADGSVRMFDLRHLEHSTIIYEDPQHHPLLRLCWNKQDPNYLATMAMDGMEVVILDVRVPCTPVARLNNHRACVNGIAWAPHSSCHICTAADDHQALIWDIQQMPRAIEDPILAYTAEGEINNVQWASTQPDWIAICYNNCLEILRV>sp|P61962-2|DCAF7_HUMAN Isoform 2 of DDB1- and CUL4-associated factor 7OS=Homo sapiens OX=9606 GN=DCAF7MSLHGKRKEIYKYEAPWTVYAMNWSVRPDKRFRLALGSFVEEYNNKVVILDVRVPCTPVARLNNHRACVNGIAWAPHSSCHICTAADDHQALIWDIQQMPRAIEDPILAYTAEGEINNVQWASTQPDWIAICYNNCLEILRV>sp|Q8TDD1|DDX54_HUMAN ATP-dependent RNA helicase DDX54 OS=Homo sapiensOX=9606 GN=DDX54 PE=1 SV=2MAADKGPAAGPRSRAAMAQWRKKKGLRKRRGAASQARGSDSEDGEFEIQAEDDARARKLGPGRPLPTFPTSECTSDVEPDTREMVRAQNKKKKKSGGFQSMGLSYPVFKGIMKKGYKVPTPIQRKTIPVILDGKDVVAMARTGSGKTACFLLPMFERLKTHSAQTGARALILSPTRELALQTLKFTKELGKFTGLKTALILGGDRMEDQFAALHENPDIIIATPGRLVHVAVEMSLKLQSVEYVVFDEADRLFEMGFAEQLQEIIARLPGGHQTVLFSATLPKLLVEFARAGLTEPVLIRLDVDTKLNEQLKTSFFLVREDTKAAVLLHLLHNVVRPQDQTVVFVATKHHAEYLTELLTTQRVSCAHIYSALDPTARKINLAKFTLGKCSTLIVTDLAARGLDIPLLDNVINYSFPAKGKLFLHRVGRVARAGRSGTAYSLVAPDEIPYLLDLHLFLGRSLTLARPLKEPSGVAGVDGMLGRVPQSVVDEEDSGLQSTLEASLELRGLARVADNAQQQYVRSRPAPSPESIKRAKEMDLVGLGLHPLFSSRFEEEELQRLRLVDSIKNYRSRATIFEINASSRDLCSQVMRAKRQKDRKAIARFQQGQQGRQEQQEGPVGPAPSRPALQEKQPEKEEEEEAGESVEDIFSEVVGRKRQRSGPNRGAKRRREEARQRDQEFYIPYRPKDFDSERGLSISGEGGAFEQQAAGAVLDLMGDEAQNLTRGRQQLKWDRKKKRFVGQSGQEDKKKIKTESGRYISSSYKRDLYQKWKQKQKIDDRDSDEEGASDRRGPERRGGKRDRGQGASRPHAPGTPAGRVRPELKTKQQILKQRRRAQKLHFLQRGGLKQLSARNRRRVQELQQGAFGRGARSKKGKMRKRM>sp|Q8TDD1-2|DDX54_HUMAN Isoform 2 of ATP-dependent RNA helicase DDX54OS=Homo sapiens OX=9606 GN=DDX54MAADKGPAAGPRSRAAMAQWRKKKGLRKRRGAASQARGSDSEDGEFEIQAEDDARARKLGPGRPLPTFPTSECTSDVEPDTREMVRAQNKKKKKSGGFQSMGLSYPVFKGIMKKGYKVPTPIQRKTIPVILDGKDVVAMARTGSGKTACFLLPMFERLKTHSAQTGARALILSPTRELALQTLKFTKELGKFTGLKTALILGGDRMEDQFAALHENPDIIIATPGRLVHVAVEMSLKLQSVEYVVFDEADRLFEMGFAEQLQEIIARLPGGHQTVLFSATLPKLLVEFARAGLTEPVLIRLDVDTKLNEQLKTSFFLVREDTKAAVLLHLLHNVVRPQDQTVVFVATKHHAEYLTELLTTQRVSCAHIYSALDPTARKINLAKFTLGKCSTLIVTDLAARGLDIPLLDNVINYSFPAKGKLFLHRVGRVARAGRSGTAYSLVAPDEIPYLLDLHLFLGRSLTLARPLKEPSGVAGVDGMLGRVPQSVVDEEDSGLQSTLEASLELRGLARVADNAQQQYVRSRPAPSPESIKRAKEMDLVGLGLHPLFSSRFEEEELQRLRLVDSIKNYRSRATIFEINASSRDLCSQVMRAKRQKDRKAIARFQQGQQGRQEQQEGPVGPAPSRPALQEKQPEKEEEEEAGESVEDIFSEVVGRKRQRSGPNRGAKRRREEARQRDQEFYIPYRPKDFDSERGLSISGEGGAFEQQAAGAVLDLMGDEAQNLTRGRQQLKWDRKKKRFVGQSGQEDKKKIKTESGRYISSSYKRDLYQKWKQKQKIDDRDSDEEGASDRRGPERRGGKRDRGQAGASRPHAPGTPAGRVRPELKTKQQILKQRRRAQKLHFLQRGGLKQLSARNRRRVQELQQGAFGRGARSKKGKMRKRM>sp|Q5TAQ9|DCAF8_HUMAN DDB1- and CUL4-associated factor 8 OS=Homo sapiensOX=9606 GN=DCAF8 PE=1 SV=1MSSKGSSTDGRTDLANGSLSSSPEEMSGAEEGRETSSGIEVEASDLSLSLTGDDGGPNRTSTESRGTDTESSGEDKDSDSMEDTGHYSINDENRVHDRSEEEEEEEEEEEEEQPRRRVQRKRANRDQDSSDDERALEDWVSSETSALPRPRWQALPALRERELGSSARFVYEACGARVFVQRFRLQHGLEGHTGCVNTLHFNQRGTWLASGSDDLKVVVWDWVRRQPVLDFESGHKSNVFQAKFLPNSGDSTLAMCARDGQVRVAELSATQCCKNTKRVAQHKGASHKLALEPDSPCTFLSAGEDAVVFTIDLRQDRPASKLVVTKEKEKKVGLYTIYVNPANTHQFAVGGRDQFVRIYDQRKIDENENNGVLKKFCPHHLVNSESKANITCLVYSHDGTELLASYNDEDIYLFNSSHSDGAQYVKRYKGHRNNATVKGVNFYGPKSEFVVSGSDCGHIFLWEKSSCQIIQFMEGDKGGVVNCLEPHPHLPVLATSGLDHDVKIWAPTAEASTELTGLKDVIKKNKRERDEDSLHQTDLFDSHMLWFLMHHLRQRRHHRRWREPGVGATDADSDESPSSSDTSDEEEGPDRVQCMPS>sp|Q5TAQ9-2|DCAF8_HUMAN Isoform 2 of DDB1- and CUL4-associated factor 8OS=Homo sapiens OX=9606 GN=DCAF8MSSKGSSTDGRTDLANGSLSSSPEEMSGAEEGRETSSGIEVEASDLSLSLTGDDGGPNRTSTESRGTDTESSGEDKDSDSMEDTGHYSINDENRVHDRSEEEEEEEEEEEEEQPRRRVQRKRANRDQDSSDDERALEDWVSSETSALPRPRWQALPALRERELGSSARFVYEACGARVFVQRFRLQHGLEGHTGCVNTLHFNQRGTWLASGSDDLKVVVWDWVRRQPVLDFESGHKSNVFQVRQGSIIATERIRHELEKSELQHGLGADSELL>sp|Q8WVC6|DCAKD_HUMAN Dephospho-CoA kinase domain-containing proteinOS=Homo sapiens OX=9606 GN=DCAKD PE=1 SV=1MFLVGLTGGIASGKSSVIQVFQQLGCAVIDVDVMARHVVQPGYPAHRRIVEVFGTEVLLENGDINRKVLGDLIFNQPDRRQLLNAITHPEIRKEMMKETFKYFLRGYRYVILDIPLLFETKKLLKYMKHTVVVYCDRDTQLARLMRRNSLNRKDAEARINAQLPLTDKARMARHVLDNSGEWSVTKRQVILLHTELERSLEYLPLRFGVLTGLAAIASLLYLLTHYLLPYA>sp|Q8WVC6-2|DCAKD_HUMAN Isoform 2 of Dephospho-CoA kinase domain-containing protein OS=Homo sapiens OX=9606 GN=DCAKDMFLVGLTGGIASGKSSVIQVFQQLGCAVIDVDVMARHVVQPGYPAHRRIVEVFGTEVLLENGDINRKVLGDLIFNQPDRRQLLNAITHPEIRKEMMKETFKYFLREPRTSPRGKKHVPSALKEADSLMRRDT>sp|Q8NHQ9|DDX55_HUMAN ATP-dependent RNA helicase DDX55 OS=Homo sapiensOX=9606 GN=DDX55 PE=1 SV=3MEHVTEGSWESLPVPLHPQVLGALRELGFPYMTPVQSATIPLFMRNKDVAAEAVTGSGKTLAFVIPILEILLRREEKLKKSQVGAIIITPTRELAIQIDEVLSHFTKHFPEFSQILWIGGRNPGEDVERFKQQGGNIIVATPGRLEDMFRRKAEGLDLASCVRSLDVLVLDEADRLLDMGFEASINTILEFLPKQRRTGLFSATQTQEVENLVRAGLRNPVRVSVKEKGVAASSAQKTPSRLENYYMVCKADEKFNQLVHFLRNHKQEKHLVFFSTCACVEYYGKALEVLVKGVKIMCIHGKMKYKRNKIFMEFRKLQSGILVCTDVMARGIDIPEVNWVLQYDPPSNASAFVHRCGRTARIGHGGSALVFLLPMEESYINFLAINQKCPLQEMKPQRNTADLLPKLKSMALADRAVFEKGMKAFVSYVQAYAKHECNLIFRLKDLDFASLARGFALLRMPKMPELRGKQFPDFVPVDVNTDTIPFKDKIREKQRQKLLEQQRREKTENEGRRKFIKNKAWSKQKAKKEKKKKMNEKRKREEGSDIEDEDMEELLNDTRLLKKLKKGKITEEEFEKGLLTTGKRTIKTVDLGISDLEDDC>sp|Q8NHQ9-2|DDX55_HUMAN Isoform 2 of ATP-dependent RNA helicase DDX55OS=Homo sapiens OX=9606 GN=DDX55MKPQRNTADLLPKLKSMALADRAVFEKGMKAFVSYVQAYAKHECNLIFRLKDLDFASLARGFALLRMPKMPELRGKQFPDFVPVDVNTDTIPFKDKIREKQRQKLLEQQRREKTENEGRRKFIKNKAWSKQKAKKEKKKKMNEKRKREEGSDIEDEDMEELLNDTRLLKKLKKGKITEEEFEKGLLTTGKRTIKTVDLGISDLEDDC>sp|P13500|CCL2_HUMAN C-C motif chemokine 2 OS=Homo sapiens OX=9606GN=CCL2 PE=1 SV=1MKVSAALLCLLLIAATFIPQGLAQPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKT>sp|Q9BX69|CARD6_HUMAN Caspase recruitment domain-containing protein 6OS=Homo sapiens OX=9606 GN=CARD6 PE=1 SV=2MATESTPSEIIERERKKLLEILQHDPDSILDTLTSRRLISEEEYETLENVTDLLKKSRKLLILVQKKGEATCQHFLKCLFSTFPQSAAICGLRHEVLKHENTVPPQSMGASSNSEDAFSPGIKQPEAPEITVFFSEKEHLDLETSEFFRDKKTSYRETALSARKNEKEYDTPEVTLSYSVEKVGCEVPATITYIKDGQRYEELDDSLYLGKEEYLGSVDTPEDAEATVEEEVYDDPEHVGYDGEEDFENSETTEFSGEEPSYEGSETSLSLEEEQEKSIEERKKVFKDVLLCLNMDRSRKVLPDFVKQFSLDRGCKWTPESPGDLAWNFLMKVQARDVTARDSILSHKVLDEDSKEDLLAGVENLEIRDIQTINPLDVLCATMLCSDSSLQRQVMSNMYQCQFALPLLLPDAENNKSILMLGAMKDIVKKQSTQFSGGPTEDTEKFLTLMKMPVISFVRLGYCSFSKSRILNTLLSPAQLKLHKIFLHQDLPLLVLPRQISDGLVEITWCFPDSDDRKENPFFQKPVALANLRGNLESFWTQFGFLMEVSSAVFFFTDCLGEKEWDLLMFLGEAAIERCYFVLSSQARESEEAQIFQRILNLKPAQLLFWERGDAGDRRKNMEGLQAALQEVMFSSCLRCVSVEDMAALARELGIQVDEDFENTQRIQVSSGENMAGTAEGEGQQRHSQLKSSSKSQALMPIQEPGTQCELSQNLQNLYGTPVFRPVLENSWLFPTRIGGNFNHVSLKASWVMGRPFGSEQRPKWFHPLPFQNAGAQGRGKSFGIQSFHPQIFYSGERFMKFSRVARGCHSNGTFGRLPRPICQHVQACPERPQMMGTLERSRAVASKIGHSYSLDSQPARAVGKPWPQQACTRVTELTEATGKLIRTSHIGKPHPQSFQPAAATQKLRPASQQGVQMKTQGGASNPALQIGSHPMCKSSQFKSDQSNPSTVKHSQPKPFHSVPSQPKSSQTKSCQSQPSQTKPSPCKSTQPKPSQPWPPQSKPSQPRPPQPKSSSTNPSQAKAHHSKAGQKRGGKH>sp|P13501|CCL5_HUMAN C-C motif chemokine 5 OS=Homo sapiens OX=9606GN=CCL5 PE=1 SV=3MKVSAAALAVILIATALCAPASASPYSSDTTPCCFAYIARPLPRAHIKEYFYTSGKCSNPAVVFVTRKNRQVCANPEKKWVREYINSLEMS>sp|Q8WTZ4|CA5BL_HUMAN Putative inactive carbonic anhydrase 5B-likeprotein OS=Homo sapiens OX=9606 GN=CA5BP1 PE=5 SV=2MTQPPASTSGIMGTLSSWNLKILQINQLHLVHWNAVKFENFEDAALEENGLAVIGVFLKISETSGSPVSTGRPKPLARKLRPAQKHWVLQSRPFLSSQVQENCKVTYFHRKHWVRIRPLRTTPPSWDYTRICIQREMVPARIRVLREMVPEAWRCFPNRLPLLSNIRPDFSKAPLAYVKRWLWTARHPHSLSAAW>sp|Q1T7F1|CCB42_HUMAN Putative chemokine-related protein B42 OS=Homosapiens OX=9606 PE=5 SV=1MPLSDWCCGICEEAPLGRAYTQTWMETGCGPHGVTALGQQELKDCLRARSGGTASSVDWIMEAARGSLNVHNCLIKFGRRD>sp|Q8TDN4|CABL1_HUMAN CDK5 and ABL1 enzyme substrate 1 OS=Homo sapiensOX=9606 GN=CABLES1 PE=1 SV=2MAAAAAAATTAACSSGSAGTDAAGASGLQQPPPQPQPQPAAAAPAQPPPEPPRKPRMDPRRRQAALSFLTNISLDGRLPPQDAEWGGGEEGGAAKPGAGGACGARTRFSLLAAAERGGCIALAAPGTPAAGLAAGSGPCLPQPSSLPPLIPGGHATVSGPGVARGFASPLGAGRASGEQWQPPRPAPLAACAQLQLLDGSGAAGQEELEEDDAFISVQVPAAAFLGSGTPGSGSGSRGRLNSFTQGILPIAFSRPTSQNYCSLEQPGQGGSTSAFEQLQRSRRRLISQRSSLETLEDIEENAPLRRCRTLSGSPRPKNFKKIHFIKNMRQHDTRNGRIVLISGRRSFCSIFSVLPYRDSTQVGDLKLDGGRQSTGAVSLKEIIGLEGVELGADGKTVSYTQFLLPTNAFGARRNTIDSTSSFSQFRNLSHRSLSIGRASGTQGSLDTGSDLGDFMDYDPNLLDDPQWPCGKHKRVLIFPSYMTTVIDYVKPSDLKKDMNETFKEKFPHIKLTLSKIRSLKREMRKLAQEDCGLEEPTVAMAFVYFEKLALKGKLNKQNRKLCAGACVLLAAKIGSDLKKHEVKHLIDKLEEKFRLNRRELIAFEFPVLVALEFALHLPEHEVMPHYRRLVQSS>sp|Q8TDN4-2|CABL1_HUMAN Isoform 2 of CDK5 and ABL1 enzyme substrate 1OS=Homo sapiens OX=9606 GN=CABLES1MLSKRGCHARIYADFPIRRLISQRSSLETLEDIEENAPLRRCRTLSGSPRPKNFKKIHFIKNMRQHDTRNGRIVLISGRRSFCSIFSVLPYRDSTQVGDLKLDGGRQSTGAVSLKEIIGLEGVELGADGKTVSYTQFLLPTNAFGARRNTIDSTSSFSQFRNLSHRSLSIGRASGTQGSLDTGSDLGDFMDYDPNLLDDPQWPCGKHKRVLIFPSYMTTVIDYVKPSDLKKDMNETFKEKFPHIKLTLSKIRSLKREMRKLAQEDCGLEEPTVAMAFVYFEKLALKGKLNKQNRKLCAGACVLLAAKIGSDLKKHEVKHLIDKLEEKFRLNRRELIAFEFPVLVALEFALHLPEHEVMPHYRRLVQSS>sp|Q8TDN4-3|CABL1_HUMAN Isoform 3 of CDK5 and ABL1 enzyme substrate 1OS=Homo sapiens OX=9606 GN=CABLES1MNETFKEKFPHIKLTLSKIRSLKREMRKLAQEDCGLEEPTVAMAFVYFEKLALKGKLNKQNRKLCAGACVLLAAKIGSDLKKHEVKHLIDKLEEKFRLNRRELIAFEFPVLVALEFALHLPEHEVMPHYRRLVQSS>sp|Q8TDN4-4|CABL1_HUMAN Isoform 4 of CDK5 and ABL1 enzyme substrate 1OS=Homo sapiens OX=9606 GN=CABLES1MRQHDTRNGRIVLISGRRSFCSIFSVLPYRDSTQVGDLKLDGGRQSTGAVSLKEIIGLEGVELGADGKTVSYTQFLLPTNAFGARRNTIDSTSSFSQFRNLSHRSLSIGRASGTQGSLDTGSDLGDFMDYDPNLLDDPQWPCGKHKRVLIFPSYMTTVIDYVKPSDLKKDMNETFKEKFPHIKLTLSKIRSLKREMRKLAQEDCGLEEPTVAMAFVYFEKLALKGKLNKQNRKLCAGACVLLAAKIGSDLKKHEVKHLIDKLEEKFRLNRRELIAFEFPVLVALEFALHLPEHEVMPHYRRLVQSS>sp|Q92793|CBP_HUMAN CREB-binding protein OS=Homo sapiens OX=9606GN=CREBBP PE=1 SV=3MAENLLDGPPNPKRAKLSSPGFSANDSTDFGSLFDLENDLPDELIPNGGELGLLNSGNLVPDAASKHKQLSELLRGGSGSSINPGIGNVSASSPVQQGLGGQAQGQPNSANMASLSAMGKSPLSQGDSSAPSLPKQAASTSGPTPAASQALNPQAQKQVGLATSSPATSQTGPGICMNANFNQTHPGLLNSNSGHSLINQASQGQAQVMNGSLGAAGRGRGAGMPYPTPAMQGASSSVLAETLTQVSPQMTGHAGLNTAQAGGMAKMGITGNTSPFGQPFSQAGGQPMGATGVNPQLASKQSMVNSLPTFPTDIKNTSVTNVPNMSQMQTSVGIVPTQAIATGPTADPEKRKLIQQQLVLLLHAHKCQRREQANGEVRACSLPHCRTMKNVLNHMTHCQAGKACQVAHCASSRQIISHWKNCTRHDCPVCLPLKNASDKRNQQTILGSPASGIQNTIGSVGTGQQNATSLSNPNPIDPSSMQRAYAALGLPYMNQPQTQLQPQVPGQQPAQPQTHQQMRTLNPLGNNPMNIPAGGITTDQQPPNLISESALPTSLGATNPLMNDGSNSGNIGTLSTIPTAAPPSSTGVRKGWHEHVTQDLRSHLVHKLVQAIFPTPDPAALKDRRMENLVAYAKKVEGDMYESANSRDEYYHLLAEKIYKIQKELEEKRRSRLHKQGILGNQPALPAPGAQPPVIPQAQPVRPPNGPLSLPVNRMQVSQGMNSFNPMSLGNVQLPQAPMGPRAASPMNHSVQMNSMGSVPGMAISPSRMPQPPNMMGAHTNNMMAQAPAQSQFLPQNQFPSSSGAMSVGMGQPPAQTGVSQGQVPGAALPNPLNMLGPQASQLPCPPVTQSPLHPTPPPASTAAGMPSLQHTTPPGMTPPQPAAPTQPSTPVSSSGQTPTPTPGSVPSATQTQSTPTVQAAAQAQVTPQPQTPVQPPSVATPQSSQQQPTPVHAQPPGTPLSQAAASIDNRVPTPSSVASAETNSQQPGPDVPVLEMKTETQAEDTEPDPGESKGEPRSEMMEEDLQGASQVKEETDIAEQKSEPMEVDEKKPEVKVEVKEEEESSSNGTASQSTSPSQPRKKIFKPEELRQALMPTLEALYRQDPESLPFRQPVDPQLLGIPDYFDIVKNPMDLSTIKRKLDTGQYQEPWQYVDDVWLMFNNAWLYNRKTSRVYKFCSKLAEVFEQEIDPVMQSLGYCCGRKYEFSPQTLCCYGKQLCTIPRDAAYYSYQNRYHFCEKCFTEIQGENVTLGDDPSQPQTTISKDQFEKKKNDTLDPEPFVDCKECGRKMHQICVLHYDIIWPSGFVCDNCLKKTGRPRKENKFSAKRLQTTRLGNHLEDRVNKFLRRQNHPEAGEVFVRVVASSDKTVEVKPGMKSRFVDSGEMSESFPYRTKALFAFEEIDGVDVCFFGMHVQEYGSDCPPPNTRRVYISYLDSIHFFRPRCLRTAVYHEILIGYLEYVKKLGYVTGHIWACPPSEGDDYIFHCHPPDQKIPKPKRLQEWYKKMLDKAFAERIIHDYKDIFKQATEDRLTSAKELPYFEGDFWPNVLEESIKELEQEEEERKKEESTAASETTEGSQGDSKNAKKKNNKKTNKNKSSISRANKKKPSMPNVSNDLSQKLYATMEKHKEVFFVIHLHAGPVINTLPPIVDPDPLLSCDLMDGRDAFLTLARDKHWEFSSLRRSKWSTLCMLVELHTQGQDRFVYTCNECKHHVETRWHCTVCEDYDLCINCYNTKSHAHKMVKWGLGLDDEGSSQGEPQSKSPQESRRLSIQRCIQSLVHACQCRNANCSLPSCQKMKRVVQHTKGCKRKTNGGCPVCKQLIALCCYHAKHCQENKCPVPFCLNIKHKLRQQQIQHRLQQAQLMRRRMATMNTRNVPQQSLPSPTSAPPGTPTQQPSTPQTPQPPAQPQPSPVSMSPAGFPSVARTQPPTTVSTGKPTSQVPAPPPPAQPPPAAVEAARQIEREAQQQQHLYRVNINNSMPPGRTGMGTPGSQMAPVSLNVPRPNQVSGPVMPSMPPGQWQQAPLPQQQPMPGLPRPVISMQAQAAVAGPRMPSVQPPRSISPSALQDLLRTLKSPSSPQQQQQVLNILKSNPQLMAAFIKQRTAKYVANQPGMQPQPGLQSQPGMQPQPGMHQQPSLQNLNAMQAGVPRPGVPPQQQAMGGLNPQGQALNIMNPGHNPNMASMNPQYREMLRRQLLQQQQQQQQQQQQQQQQQQGSAGMAGGMAGHGQFQQPQGPGGYPPAMQQQQRMQQHLPLQGSSMGQMAAQMGQLGQMGQPGLGADSTPNIQQALQQRILQQQQMKQQIGSPGQPNPMSPQQHMLSGQPQASHLPGQQIATSLSNQVRSPAPVQSPRPQSQPPHSSPSPRIQPQPSPHHVSPQTGSPHPGLAVTMASSIDQGHLGNPEQSAMLPQLNTPSRSALSSELSLVGDTTGDTLEKFVEGL>sp|Q92793-2|CBP_HUMAN Isoform 2 of CREB-binding protein OS=Homo sapiensOX=9606 GN=CREBBPMAENLLDGPPNPKRAKLSSPGFSANDSTDFGSLFDLENDLPDELIPNGGELGLLNSGNLVPDAASKHKQLSELLRGGSGSSINPGIGNVSASSPVQQGLGGQAQGQPNSANMASLSAMGKSPLSQGDSSAPSLPKQAASTSGPTPAASQALNPQAQKQVGLATSSPATSQTGPGICMNANFNQTHPGLLNSNSGHSLINQASQGQAQVMNGSLGAAGRGRGAGMPYPTPAMQGASSSVLAETLTQVSPQMTGHAGLNTAQAGGMAKMGITGNTSPFGQPFSQAGGQPMGATGVNPQLASKQSMVNSLPTFPTDIKNTSVTNVPNMSQMQTSVGIVPTQAIATGPTADPEKRKLIQQQLVLLLHAHKCQRREQANGEVRACSLPHCRTMKNVLNHMTHCQAGKACQAILGSPASGIQNTIGSVGTGQQNATSLSNPNPIDPSSMQRAYAALGLPYMNQPQTQLQPQVPGQQPAQPQTHQQMRTLNPLGNNPMNIPAGGITTDQQPPNLISESALPTSLGATNPLMNDGSNSGNIGTLSTIPTAAPPSSTGVRKGWHEHVTQDLRSHLVHKLVQAIFPTPDPAALKDRRMENLVAYAKKVEGDMYESANSRDEYYHLLAEKIYKIQKELEEKRRSRLHKQGILGNQPALPAPGAQPPVIPQAQPVRPPNGPLSLPVNRMQVSQGMNSFNPMSLGNVQLPQAPMGPRAASPMNHSVQMNSMGSVPGMAISPSRMPQPPNMMGAHTNNMMAQAPAQSQFLPQNQFPSSSGAMSVGMGQPPAQTGVSQGQVPGAALPNPLNMLGPQASQLPCPPVTQSPLHPTPPPASTAAGMPSLQHTTPPGMTPPQPAAPTQPSTPVSSSGQTPTPTPGSVPSATQTQSTPTVQAAAQAQVTPQPQTPVQPPSVATPQSSQQQPTPVHAQPPGTPLSQAAASIDNRVPTPSSVASAETNSQQPGPDVPVLEMKTETQAEDTEPDPGESKGEPRSEMMEEDLQGASQVKEETDIAEQKSEPMEVDEKKPEVKVEVKEEEESSSNGTASQSTSPSQPRKKIFKPEELRQALMPTLEALYRQDPESLPFRQPVDPQLLGIPDYFDIVKNPMDLSTIKRKLDTGQYQEPWQYVDDVWLMFNNAWLYNRKTSRVYKFCSKLAEVFEQEIDPVMQSLGYCCGRKYEFSPQTLCCYGKQLCTIPRDAAYYSYQNRYHFCEKCFTEIQGENVTLGDDPSQPQTTISKDQFEKKKNDTLDPEPFVDCKECGRKMHQICVLHYDIIWPSGFVCDNCLKKTGRPRKENKFSAKRLQTTRLGNHLEDRVNKFLRRQNHPEAGEVFVRVVASSDKTVEVKPGMKSRFVDSGEMSESFPYRTKALFAFEEIDGVDVCFFGMHVQEYGSDCPPPNTRRVYISYLDSIHFFRPRCLRTAVYHEILIGYLEYVKKLGYVTGHIWACPPSEGDDYIFHCHPPDQKIPKPKRLQEWYKKMLDKAFAERIIHDYKDIFKQATEDRLTSAKELPYFEGDFWPNVLEESIKELEQEEEERKKEESTAASETTEGSQGDSKNAKKKNNKKTNKNKSSISRANKKKPSMPNVSNDLSQKLYATMEKHKEVFFVIHLHAGPVINTLPPIVDPDPLLSCDLMDGRDAFLTLARDKHWEFSSLRRSKWSTLCMLVELHTQGQDRFVYTCNECKHHVETRWHCTVCEDYDLCINCYNTKSHAHKMVKWGLGLDDEGSSQGEPQSKSPQESRRLSIQRCIQSLVHACQCRNANCSLPSCQKMKRVVQHTKGCKRKTNGGCPVCKQLIALCCYHAKHCQENKCPVPFCLNIKHKLRQQQIQHRLQQAQLMRRRMATMNTRNVPQQSLPSPTSAPPGTPTQQPSTPQTPQPPAQPQPSPVSMSPAGFPSVARTQPPTTVSTGKPTSQVPAPPPPAQPPPAAVEAARQIEREAQQQQHLYRVNINNSMPPGRTGMGTPGSQMAPVSLNVPRPNQVSGPVMPSMPPGQWQQAPLPQQQPMPGLPRPVISMQAQAAVAGPRMPSVQPPRSISPSALQDLLRTLKSPSSPQQQQQVLNILKSNPQLMAAFIKQRTAKYVANQPGMQPQPGLQSQPGMQPQPGMHQQPSLQNLNAMQAGVPRPGVPPQQQAMGGLNPQGQALNIMNPGHNPNMASMNPQYREMLRRQLLQQQQQQQQQQQQQQQQQQGSAGMAGGMAGHGQFQQPQGPGGYPPAMQQQQRMQQHLPLQGSSMGQMAAQMGQLGQMGQPGLGADSTPNIQQALQQRILQQQQMKQQIGSPGQPNPMSPQQHMLSGQPQASHLPGQQIATSLSNQVRSPAPVQSPRPQSQPPHSSPSPRIQPQPSPHHVSPQTGSPHPGLAVTMASSIDQGHLGNPEQSAMLPQLNTPSRSALSSELSLVGDTTGDTLEKFVEGL>sp|P45973|CBX5_HUMAN Chromobox protein homolog 5 OS=Homo sapiens OX=9606GN=CBX5 PE=1 SV=1MGKKTKRTADSSSSEDEEEYVVEKVLDRRVVKGQVEYLLKWKGFSEEHNTWEPEKNLDCPELISEFMKKYKKMKEGENNKPREKSESNKRKSNFSNSADDIKSKKKREQSNDIARGFERGLEPEKIIGATDSCGDLMFLMKWKDTDEADLVLAKEANVKCPQIVIAFYEERLTWHAYPEDAENKEKETAKS>sp|Q96KC9|CABS1_HUMAN Calcium-binding and spermatid-specific protein 1OS=Homo sapiens OX=9606 GN=CABS1 PE=2 SV=3MAEDGLPKIYSHPPTESSKTPTAATIFFGADNAIPKSETTITSEGDHVTSVNEYMLESDFSTTTDNKLTAKKEKLKSEDDMGTDFIKSTTHLQKEITSLTGTTNSITRDSITEHFMPVKIGNISSPVTTVSLIDFSTDIAKEDILLATIDTGDAEISITSEVSGTLKDSSAGVADAPAFPRKKDEADMSNYNSSIKSNVPADEAVQVTDSTIPEAEIPPAPEESFTTIPDITALEEEKITEIDLSVLEDDTSAVATLTDSDEKFITVFELTTSAEKDKDKREDTLLTDEETTEGASIWMERDTANEAETHSVLLTAVESRYDFVVPASIATNLVEESSTEEDLSETDNTETVPKITEPFSGTTSVLDTPDYKEDTSTTETDIFELLKEEPDEFMI>sp|O60826|CCD22_HUMAN Coiled-coil domain-containing protein 22 OS=Homosapiens OX=9606 GN=CCDC22 PE=1 SV=1MEEADRILIHSLRQAGTAVPPDVQTLRAFTTELVVEAVVRCLRVINPAVGSGLSPLLPLAMSARFRLAMSLAQACMDLGYPLELGYQNFLYPSEPDLRDLLLFLAERLPTDASEDADQPAGDSAILLRAIGSQIRDQLALPWVPPHLRTPKLQHLQGSALQKPFHASRLVVPELSSRGEPREFQASPLLLPVPTQVPQPVGRVASLLEHHALQLCQQTGRDRPGDEDWVHRTSRLPPQEDTRAQRQRLQKQLTEHLRQSWGLLGAPIQARDLGELLQAWGAGAKTGAPKGSRFTHSEKFTFHLEPQAQATQVSDVPATSRRPEQVTWAAQEQELESLREQLEGVNRSIEEVEADMKTLGVSFVQAESECRHSKLSTAEREQALRLKSRAVELLPDGTANLAKLQLVVENSAQRVIHLAGQWEKHRVPLLAEYRHLRKLQDCRELESSRRLAEIQELHQSVRAAAEEARRKEEVYKQLMSELETLPRDVSRLAYTQRILEIVGNIRKQKEEITKILSDTKELQKEINSLSGKLDRTFAVTDELVFKDAKKDDAVRKAYKYLAALHENCSQLIQTIEDTGTIMREVRDLEEQIETELGKKTLSNLEKIREDYRALRQENAGLLGRVREA>sp|Q9BXU9|CABP8_HUMAN Calcium-binding protein 8 OS=Homo sapiens OX=9606GN=CALN1 PE=1 SV=2MRLPEQPGEGKPENEKKGDGGALGGGEEPPRSQAPDFPTWEKMPFHHVTAGLLYKGNYLNRSLSAGSDSEQLANISVEELDEIREAFRVLDRDGNGFISKQELGMAMRSLGYMPSEVELAIIMQRLDMDGDGQVDFDEFMTILGPKLVSSEGRDGFLGNTIDSIFWQFDMQRITLEELKHILYHAFRDHLTMKDIENIIINEEESLNETSGNCQTEFEGVHSQKQNRQTCVRKSLICAFAMAFIISVMLIAANQILRSGME>sp|Q9BXU9-1|CABP8_HUMAN Isoform 2 of Calcium-binding protein 8 OS=Homosapiens OX=9606 GN=CALN1MPFHHVTAGLLYKGNYLNRSLSAGSDSEQLANISVEELDEIREAFRVLDRDGNGFISKQELGMAMRSLGYMPSEVELAIIMQRLDMDGDGQVDFDEFMTILGPKLVSSEGRDGFLGNTIDSIFWQFDMQRITLEELKHILYHAFRDHLTMKDIENIIINEEESLNETSGNCQTEFEGVHSQKQNRQTCVRKSLICAFAMAFIISVMLIAANQILRSGME>sp|Q8N4T0|CBPA6_HUMAN Carboxypeptidase A6 OS=Homo sapiens OX=9606GN=CPA6 PE=1 SV=2MKCLGKRRGQAAAFLPLCWLFLKILQPGHSHLYNNRYAGDKVIRFIPKTEEEAYALKKISYQLKVDLWQPSSISYVSEGTVTDVHIPQNGSRALLAFLQEANIQYKVLIEDLQKTLEKGSSLHTQRNRRSLSGYNYEVYHSLEEIQNWMHHLNKTHSGLIHMFSIGRSYEGRSLFILKLGRRSRLKRAVWIDCGIHAREWIGPAFCQWFVKEALLTYKSDPAMRKMLNHLYFYIMPVFNVDGYHFSWTNDRFWRKTRSRNSRFRCRGVDANRNWKVKWCDEGASMHPCDDTYCGPFPESEPEVKAVANFLRKHRKHIRAYLSFHAYAQMLLYPYSYKYATIPNFRCVESAAYKAVNALQSVYGVRYRYGPASTTLYVSSGSSMDWAYKNGIPYAFAFELRDTGYFGFLLPEMLIKPTCTETMLAVKNITMHLLKKCP>sp|Q8N4T0-2|CBPA6_HUMAN Isoform 2 of Carboxypeptidase A6 OS=Homo sapiensOX=9606 GN=CPA6MKCLGKRRGQAAAFLPLCWLFLKILQPGHSHLYNNRYAGDKVIRFIPKTEEEAYALKKISYQLKVDLWQPSSISYVSEGTVTDVHIPQNGSRALLAFLQEANIQYKVLIEDLQKTLEKGSSLHTQRNRRSLSGYNYEVYHSLEEIQNWMHHLNKTHSGLIHMFSIGRSYEGRSLFILKLGRRSRLKRAVWIDCGIHAREWIGPAFCQWFVKEALLTYKSDPAMRKMLNHLYFYIMPVFNVDGYHFSWTNDRFWRKTRSRNSRFRCRGVDANRNWKVKWCGKFGTNWDPDPKVSAGFTLQNMSPEDSHGRLMFFCM>sp|Q8N4T0-3|CBPA6_HUMAN Isoform 3 of Carboxypeptidase A6 OS=Homo sapiensOX=9606 GN=CPA6MKCLGKRRGQAAAFLPLCWLFLKILQPGHSHLYNNRYAGDKVIRFIPKTEEEAYALKKISYQLKGPHRRSSENTGEGKQLAHPEKPKIPLWI>sp|O75952|CABYR_HUMAN Calcium-binding tyrosine phosphorylation-regulatedprotein OS=Homo sapiens OX=9606 GN=CABYR PE=1 SV=2MISSKPRLVVPYGLKTLLEGISRAVLKTNPSNINQFAAAYFQELTMYRGNTTMDIKDLVKQFHQIKVEKWSEGTTPQKKLECLKEPGKTSVESKVPTQMEKSTDTDEDNVTRTEYSDKTTQFPSVYAVPGTEQTEAVGGLSSKPATPKTTTPPSSPPPTAVSPEFAYVPADPAQLAAQMLGKVSSIHSDQSDVLMVDVATSMPVVIKEVPSSEAAEDVMVAAPLVCSGKVLEVQVVNQTSVHVDLGSQPKENEAEPSTASSVPLQDEQEPPAYDQAPEVTLQADIEVMSTVHISSVYNDVPVTEGVVYIEQLPEQIVIPFTDQVACLKENEQSKENEQSPRVSPKSVVEKTTSGMSKKSVESVKLAQLEENAKYSSVYMEAEATALLSDTSLKGQPEVPAQLLDAEGAIKIGSEKSLHLEVEITSIVSDNTGQEESGENSVPQEMEGKPVLSGEAAEAVHSGTSVKSSSGPFPPAPEGLTAPEIEPEGESTAE>sp|O75952-2|CABYR_HUMAN Isoform 2 of Calcium-binding tyrosinephosphorylation-regulated protein OS=Homo sapiens OX=9606 GN=CABYRMISSKPRLVVPYGLKTLLEGISRAVLKTNPSNINQFAAAYFQELTMYRVEKWSEGTTPQKKLECLKEPGKTSVESKVPTQMEKSTDTDEDNVTRTEYSDKTTQFPSVYAVPGTEQTEAVGGLSSKPATPKTTTPPSSPPPTAVSPEFAYVPADPAQLAAQMLGKVSSIHSDQSDVLMVDVATSMPVVIKEVPSSEAAEDVMVAAPLVCSGKVLEVQVVNQTSVHVDLGSQPKENEAEPSTASSVPLQDEQEPPAYDQAPEVTLQADIEVMSTVHISSVYNDVPVTEGVVYIEQLPEQIVIPFTDQVACLKENEQSKENEQSPRVSPKSVVEKTTSGMSKKSVESVKLAQLEENAKYSSVYMEAEATALLSDTSLKGQPEVPAQLLDAEGAIKIGSEKSLHLEVEITSIVSDNTGQEESGENSVPQEMEGKPVLSGEAAEAVHSGTSVKSSSGPFPPAPEGLTAPEIEPEGESTAE>sp|O75952-3|CABYR_HUMAN Isoform 3 of Calcium-binding tyrosinephosphorylation-regulated protein OS=Homo sapiens OX=9606 GN=CABYRMISSKPRLVVPYGLKTLLEGISRAVLKTNPSNINQFAAAYFQELTMYRGNTTMDIKDLVKQFHQIKVEKWSEGTTPQKKLECLKEPGKTSVESKVPTQMEKSTDTDEDNVTRTEYSDKTTQFPSVYAVPGTEQTEAVGGLSSKPATPKTTTPPSSPPPTAVSPEFAYVPADPAQLAAQMLAMATSERGQPPPCSNMWTLYCLTDKNQQGHPSPPPAPGPFPQATLYLPNPKDPQFQQHPPKVTFPTYVMGDTKKTSAPPFILVGSNVQEAQGWKPLPGHAVVSQSDVLRYVAMQVPIAVPADEKYQKHTLSPQNANPPSGQDVPRPKSPVFLSVAFPVEDVAKKSSGSGDKCAPFGSYGIAGEVTVTTAHKRRKAETEN>sp|O75952-4|CABYR_HUMAN Isoform 4 of Calcium-binding tyrosinephosphorylation-regulated protein OS=Homo sapiens OX=9606 GN=CABYRMISSKPRLVVPYGLKTLLEGISRAVLKTNPSNINQFAAAYFQELTMYRGNTTMDIKDLVKQFHQIKVEKWSEGTTPQKKLECLKEPGKTSVESKVPTQMEKSTDTDEDNVTRTEYSDKTTQFPSVYAVPGTEQTEAVGGLSSKPATPKTTTPPSSPPPTAVSPEFAYVPADPAQLAAQMLEDVAKKSSGSGDKCAPFGSYGIAGEVTVTTAHKRRKAETEN>sp|O75952-5|CABYR_HUMAN Isoform 5 of Calcium-binding tyrosinephosphorylation-regulated protein OS=Homo sapiens OX=9606 GN=CABYRMEKSTDTDEDNVTRTEYSDKTTQFPSVYAVPGTEQTEAVGGLSSKPATPKTTTPPSSPPPTAVSPEFAYVPADPAQLAAQMLAMATSERGQPPPCSNMWTLYCLTDKNQQGHPSPPPAPGPFPQATLYLPNPKDPQFQQHPPKVTFPTYVMGDTKKTSAPPFILVGSNVQEAQGWKPLPGHAVVSQSDVLRYVAMQVPIAVPADEKYQKHTLSPQNANPPSGQDVPRPKSPVFLSVAFPVEDVAKKSSGSGDKCAPFGSYGIAGEVTVTTAHKRRKAETEN>sp|O75952-6|CABYR_HUMAN Isoform 6 of Calcium-binding tyrosinephosphorylation-regulated protein OS=Homo sapiens OX=9606 GN=CABYRMPVVIKEVPSSEAAEDVMVAAPLVCSGKVLEVQVVNQTSVHVDLGSQPKENEAEPSTASSVPLQDEQEPPAYDQAPEVTLQADIEVMSTVHISSVYNDVPVTEGVVYIEQLPEQIVIPFTDQVACLKENEQSKENEQSPRVSPKSVVEKTTSGMSKKSVESVKLAQLEENAKYSSVYMEAEATALLSDTSLKGQPEVPAQLLDAEGAIKIGSEKSLHLEVEITSIVSDNTGQEESGENSVPQEMEGKPVLSGEAAEAVHSGTSVKSSSGPFPPAPEGLTAPEIEPEGESTAE>sp|Q8NA61|CBY2_HUMAN Protein chibby homolog 2 OS=Homo sapiens OX=9606GN=CBY2 PE=1 SV=1MSPLECSECFGDQLLHRTYTWQLTLHSRPNYTRKRDTRSESLEIPISVVLPQRGTAEPFPRLHNLYSTPRCAQQAALPRLSRRMASQHSYPLNRFSSVPLDPMERPMSQADLELDYNPPRVQLSDEMFVFQDGRWVNENCRLQSPYFSPSASFHHKLHHKRLAKECMLQEENKSLREENKALREENRMLSKENKILQVFWEEHKASLGREESRAPSPLLHKDSASLEVVKKDHVALQVPRGKEDSTLQLLREENRALQQLLEQKQAYWAQAEDTAAPAEESKPAPSPHEEPCSPGLLQDQGSGLSSRFEEPKGPPARQEDSKELRALRKMVSNMSGPSGEEEAKVGPGLPDGCQPLQLLREMRQALQALLKENRLLQEENRTLQVLRAEHRGFQEENKALWENNKLKLQQKLVIDTVTEVTARMEMLIEELYAFMPARSQDPKKPSRV>sp|Q8NA61-2|CBY2_HUMAN Isoform 2 of Protein chibby homolog 2 OS=Homosapiens OX=9606 GN=CBY2MQPEGLKCRMEESNAERGTAEPFPRLHNLYSTPRCAQQAALPRLSRRMASQHSYPLNRFSSVPLDPMERPMSQADLELDYNPPRVQLSDEMFVFQDGRWVNENCRLQSPYFSPSASFHHKLHHKRLAKECMLQEENKSLREENKALREENRMLSKENKILQVFWEEHKASLGREESRAPSPLLHKDSASLEVVKKDHVALQVPRGKEDSTLQLLREENRALQQLLEQKQAYWAQAEDTAAPAEESKPAPSPHEEPCSPGLLQDQGSGLSSRFEEPKGPPARQEDSKELRALRKMVSNMSGPSGEEEAKVGPGLPDGCQPLQLLREMRQALQALLKENRLLQEENRTLQVLRAEHRGFQEENKALWENNKLKLQQKLVIDTVTEVTARMEMLIEELYAFMPARSQDPKKPSRV>sp|Q8IYK2|CC105_HUMAN Coiled-coil domain-containing protein 105 OS=Homosapiens OX=9606 GN=CCDC105 PE=1 SV=3MRVLVPPAERSQDTRVGAPAWREAAQAMARTAHILTDRCGQEAVTMWQPKDSVLDPNVAHHLGRAAYIQPWRFRVEMIKGGGTLEKPPPGEGVTLWKGKMKPPAWYARLPLPLHRKARALQTTEVVHAHARGARLTAARLGRAQHQINGRVRQLLRQREVTDHRLSEVRKGLLINQQSVKLRGYRPKSEKVPDKADSMLTWEKEELKSMKRKMERDMEKSEVLLKTLASCRDTLNFCFKERLQAVDLMNQPLDKVLEQARRHSWVNLSRAPTPRTQGQKTPPPDPVGTYNPACALALNEAKRLLVESKDTLVEMAKNEVDVREQQLQISDRVCASLAQKASETLELKERLNMTLGLMRGTILRCTKYNQELYTTHGLIKGPLSKVHLETAEKLDRPLVRMYQRHVGTQLPEAARLAQGTDKLQCHITYLEKNLDELLATHKNLSWGLNCKNIGHEVDGNVVRLRLRQRQPHVCYEQAQRLVKDWDPRTPPPRSKSSADP>sp|P08571|CD14_HUMAN Monocyte differentiation antigen CD14 OS=Homosapiens OX=9606 GN=CD14 PE=1 SV=2MERASCLLLLLLPLVHVSATTPEPCELDDEDFRCVCNFSEPQPDWSEAFQCVSAVEVEIHAGGLNLEPFLKRVDADADPRQYADTVKALRVRRLTVGAAQVPAQLLVGALRVLAYSRLKELTLEDLKITGTMPPLPLEATGLALSSLRLRNVSWATGRSWLAELQQWLKPGLKVLSIAQAHSPAFSCEQVRAFPALTSLDLSDNPGLGERGLMAALCPHKFPAIQNLALRNTGMETPTGVCAALAAAGVQPHSLDLSHNSLRATVNPSAPRCMWSSALNSLNLSFAGLEQVPKGLPAKLRVLDLSCNRLNRAPQPDELPEVDNLTLDGNPFLVPGTALPHEGSMNSGVVPACARSTLSVGVSGTLVLLQGARGFA>sp|Q13409|DC1I2_HUMAN Cytoplasmic dynein 1 intermediate chain 2 OS=Homosapiens OX=9606 GN=DYNC1I2 PE=1 SV=3MSDKSELKAELERKKQRLAQIREEKKRKEEERKKKETDQKKEAVAPVQEESDLEKKRREAEALLQSMGLTPESPIVFSEYWVPPPMSPSSKSVSTPSEAGSQDSGDGAVGSRTLHWDTDPSVLQLHSDSDLGRGPIKLGMAKITQVDFPPREIVTYTKETQTPVMAQPKEDEEEDDDVVAPKPPIEPEEEKTLKKDEENDSKAPPHELTEEEKQQILHSEEFLSFFDHSTRIVERALSEQINIFFDYSGRDLEDKEGEIQAGAKLSLNRQFFDERWSKHRVVSCLDWSSQYPELLVASYNNNEDAPHEPDGVALVWNMKYKKTTPEYVFHCQSAVMSATFAKFHPNLVVGGTYSGQIVLWDNRSNKRTPVQRTPLSAAAHTHPVYCVNVVGTQNAHNLISISTDGKICSWSLDMLSHPQDSMELVHKQSKAVAVTSMSFPVGDVNNFVVGSEEGSVYTACRHGSKAGISEMFEGHQGPITGIHCHAAVGAVDFSHLFVTSSFDWTVKLWTTKNNKPLYSFEDNADYVYDVMWSPTHPALFACVDGMGRLDLWNLNNDTEVPTASISVEGNPALNRVRWTHSGREIAVGDSEGQIVIYDVGEQIAVPRNDEWARFGRTLAEINANRADAEEEAATRIPA>sp|Q13409-2|DC1I2_HUMAN Isoform 2B of Cytoplasmic dynein 1 intermediatechain 2 OS=Homo sapiens OX=9606 GN=DYNC1I2MSDKSELKAELERKKQRLAQIREEKKRKEEERKKKETDQKKEAVAPVQEESDLEKKRREAEALLQSMGLTPESPIVPPPMSPSSKSVSTPSEAGSQDSGDGAVGSRTLHWDTDPSVLQLHSDSDLGRGPIKLGMAKITQVDFPPREIVTYTKETQTPVMAQPKEDEEEDDDVVAPKPPIEPEEEKTLKKDEENDSKAPPHELTEEEKQQILHSEEFLSFFDHSTRIVERALSEQINIFFDYSGRDLEDKEGEIQAGAKLSLNRQFFDERWSKHRVVSCLDWSSQYPELLVASYNNNEDAPHEPDGVALVWNMKYKKTTPEYVFHCQSAVMSATFAKFHPNLVVGGTYSGQIVLWDNRSNKRTPVQRTPLSAAAHTHPVYCVNVVGTQNAHNLISISTDGKICSWSLDMLSHPQDSMELVHKQSKAVAVTSMSFPVGDVNNFVVGSEEGSVYTACRHGSKAGISEMFEGHQGPITGIHCHAAVGAVDFSHLFVTSSFDWTVKLWTTKNNKPLYSFEDNADYVYDVMWSPTHPALFACVDGMGRLDLWNLNNDTEVPTASISVEGNPALNRVRWTHSGREIAVGDSEGQIVIYDVGEQIAVPRNDEWARFGRTLAEINANRADAEEEAATRIPA>sp|Q13409-3|DC1I2_HUMAN Isoform 2C of Cytoplasmic dynein 1 intermediatechain 2 OS=Homo sapiens OX=9606 GN=DYNC1I2MSDKSELKAELERKKQRLAQIREEKKRKEEERKKKETDQKKEAVAPVQEESDLEKKRREAEALLQSMGLTPESPIVPPPMSPSSKSVSTPSEAGSQDSGDGAVGSRRGPIKLGMAKITQVDFPPREIVTYTKETQTPVMAQPKEDEEEDDDVVAPKPPIEPEEEKTLKKDEENDSKAPPHELTEEEKQQILHSEEFLSFFDHSTRIVERALSEQINIFFDYSGRDLEDKEGEIQAGAKLSLNRQFFDERWSKHRVVSCLDWSSQYPELLVASYNNNEDAPHEPDGVALVWNMKYKKTTPEYVFHCQSAVMSATFAKFHPNLVVGGTYSGQIVLWDNRSNKRTPVQRTPLSAAAHTHPVYCVNVVGTQNAHNLISISTDGKICSWSLDMLSHPQDSMELVHKQSKAVAVTSMSFPVGDVNNFVVGSEEGSVYTACRHGSKAGISEMFEGHQGPITGIHCHAAVGAVDFSHLFVTSSFDWTVKLWTTKNNKPLYSFEDNADYVYDVMWSPTHPALFACVDGMGRLDLWNLNNDTEVPTASISVEGNPALNRVRWTHSGREIAVGDSEGQIVIYDVGEQIAVPRNDEWARFGRTLAEINANRADAEEEAATRIPA>sp|Q13409-5|DC1I2_HUMAN Isoform 2E of Cytoplasmic dynein 1 intermediatechain 2 OS=Homo sapiens OX=9606 GN=DYNC1I2MSDKSELKAELERKKQRLAQIREEKKRKEEERKKKETDQKKEAVAPVQEESDLEKKRREAEALLQSMGLTPESPIVFSEYWVPPPMSPSSKSVSTPSEAGSQDSGDGAVGSRTLHWDTDPSVLQLHSDSDLGRGPIKLGMAKITQVDFPPREIVTYTKETQTPVMAQPKEDEEEDDDVVAPKPPIEPEEEKTLKKDEENDSKAPPHELTEEEKQQILHSEEFLSFFDHSTRIVERALSEQINIFFDYSGRDLEDKEGEIQAGAKLSLNRQFFDERWSKHRVVSCLDWSSQYPELLVASYNNNEDAPHEPDGVALVWNMKYKKTTPEYVFHCQSAVMSATFAKFHPNLVVGGTYSGQIVLWDNRSNKRTPVQRTPLSAAAHTHPVYCVNVVGTQNAHNLISISTDGKICSWSLDMLSHPQDSMELVHKQSKAVAVTSMSFPVGDVNNFVVGSEEGSVYTACRHGSKAGISEMFEGHQGPITGIHCHAAVGAVDFSHLFVTSSFDWTVKLWTTKNNKPLYSFEDNADYVYDVMWSPTHPALFACVDGMGRLDLWNLNNDTEVPTASISVEGNPALNRVRWTHSGREIAVGDSEGQIVIYDVGEIAVPRNDEWARFGRTLAEINANRADAEEEAATRIPA>sp|Q13409-6|DC1I2_HUMAN Isoform 2F of Cytoplasmic dynein 1 intermediatechain 2 OS=Homo sapiens OX=9606 GN=DYNC1I2MSDKSELKAELERKKQRLAQIREEKKRKEEERKKKETDQKKEAVAPVQEESDLEKKRREAEALLQSMGLTPESPIVPPPMSPSSKSVSTPSEAGSQDSGDGAVGSRRGPIKLGMAKITQVDFPPREIVTYTKETQTPVMAQPKEDEEEDDDVVAPKPPIEPEEEKTLKKDEENDSKAPPHELTEEEKQQILHSEEFLSFFDHSTRIVERALSEQINIFFDYSGRDLEDKEGEIQAGAKLSLNRQFFDERWSKHRVVSCLDWSSQYPELLVASYNNNEDAPHEPDGVALVWNMKYKKTTPEYVFHCQSAVMSATFAKFHPNLVVGGTYSGQIVLWDNRSNKRTPVQRTPLSAAAHTHPVYCVNVVGTQNAHNLISISTDGKICSWSLDMLSHPQDSMELVHKQSKAVAVTSMSFPVGDVNNFVVGSEEGSVYTACRHGSKAGISEMFEGHQGPITGIHCHAAVGAVDFSHLFVTSSFDWTVKLWTTKNNKPLYSFEDNADYVYDVMWSPTHPALFACVDGMGRLDLWNLNNDTEVPTASISVEGNPALNRVRWTHSGREIAVGDSEGQIVIYDVGEIAVPRNDEWARFGRTLAEINANRADAEEEAATRIPA>sp|Q13409-7|DC1I2_HUMAN Isoform 3 of Cytoplasmic dynein 1 intermediatechain 2 OS=Homo sapiens OX=9606 GN=DYNC1I2MSDKSELKAELERKKQRLAQIREEKKRKEEERKKKETDQKKEAVAPVQEESDLEKKRREAEALLQSMGLTPESPIAEQPLRVVTADTCLFHYLVPPPMSPSSKSVSTPSEAGSQDSGDGAVGSRRGPIKLGMAKITQVDFPPREIVTYTKETQTPVMAQPKEDEEEDDDVVAPKPPIEPEEEKTLKKDEENDSKAPPHELTEEEKQQILHSEEFLSFFDHSTRIVERALSEQINIFFDYSGRDLEDKEGEIQAGAKLSLNRQFFDERWSKHRVVSCLDWSSQYPELLVASYNNNEDAPHEPDGVALVWNMKYKKTTPEYVFHCQSAVMSATFAKFHPNLVVGGTYSGQIVLWDNRSNKRTPVQRTPLSAAAHTHPVYCVNVVGTQNAHNLISISTDGKICSWSLDMLSHPQDSMELVHKQSKAVAVTSMSFPVGDVNNFVVGSEEGSVYTACRHGSKAGISEMFEGHQGPITGIHCHAAVGAVDFSHLFVTSSFDWTVKLWTTKNNKPLYSFEDNADYVYDVMWSPTHPALFACVDGMGRLDLWNLNNDTEVPTASISVEGNPALNRVRWTHSGREIAVGDSEGQIVIYDVGEQIAVPRNDEWARFGRTLAEINANRADAEEEAATRIPA>sp|Q5VUD6|DIK1B_HUMAN Divergent protein kinase domain 1B OS=Homo sapiensOX=9606 GN=DIPK1B PE=1 SV=3MRRLRRLAHLVLFCPFSKRLQGRLPGLRVRCIFLAWLGVFAGSWLVYVHYSSYSERCRGHVCQVVICDQYRKGIISGSVCQDLCELHMVEWRTCLSVAPGQQVYSGLWRDKDVTIKCGIEETLDSKARSDAAPRRELVLFDKPTRGTSIKEFREMTLSFLKANLGDLPSLPALVGQVLLMADFNKDNRVSLAEAKSVWALLQRNEFLLLLSLQEKEHASRLLGYCGDLYLTEGVPHGAWHAAALPPLLRPLLPPALQGALQQWLGPAWPWRAKIAIGLLEFVEELFHGSYGTFYMCETTLANVGYTATYDFKMADLQQVAPEATVRRFLQGRRCEHSTDCTYGRDCRAPCDRLMRQCKGDLIQPNLAKVCALLRGYLLPGAPADLREELGTQLRTCTTLSGLASQVEAHHSLVLSHLKTLLWKKISNTKYS>sp|Q5VUD6-2|DIK1B_HUMAN Isoform 2 of Divergent protein kinase domain 1BOS=Homo sapiens OX=9606 GN=DIPK1BMVEWRTCLSVAPGQQVYSGLWRDKDVTIKCGIEETLDSKARSDAAPRRELVLFDKPTRGTSIKEFREMTLSFLKANLGDLPSLPALVGQVLLMADFNKDNRVSLAEAKSVWALLQRNEFLLLLSLQEKEHASRLLGYCGDLYLTEGVPHGAWHAAALPPLLRPLLPPALQGALQQWLGPAWPWRAKIAIGLLEFVEELFHGSYGTFYMCETTLANVGYTATYDFKMADLQQVAPEATVRRFLQGRRCEHSTDCTYGRDCRAPCDRLMRQCKGDLIQPNLAKVCALLRGYLLPGAPADLREELGTQLRTCTTLSGLASQVEAHHSLVLSHLKTLLWKKISNTKYS>sp|Q8NHQ1|CEP70_HUMAN Centrosomal protein of 70 kDa OS=Homo sapiensOX=9606 GN=CEP70 PE=1 SV=2MFPVAPKPQDSSQPSDRLMTEKQQEEAEWESINVLLMMHGLKPLSLVKRTDLKDLIIFDKQSSQRMRQNLKLLVEETSCQQNMIQELIETNQQLRNELQLEQSRAANQEQRANDLEQIMESVKSKIGELEDESLSRACHQQNKIKDLQKEQKTLQVKCQHYKKKRTEQEETIASLQMEVCRLKKEEEDRIVTQNRVFAYLCKRVPHTVLDRQLLCLIDYYESKIRKIHTQRQYKEDESQSEEENDYRNLDASPTYKGLLMSLQNQLKESKSKIDALSSEKLNLQKDLETRPTQHELRLYKQQVKKLEKALKKNVKLQELINHKKAEDTEKKDEPSKYNQQQALIDQRYFQVLCSINSIIHNPRAPVIIYKQTKGGVQNFNKDLVQDCGFEHLVPVIEMWADQLTSLKDLYKSLKTLSAELVPWLNLKKQDENEGIKVEDLLFIVDTMLEEVENKEKDSNMPHFQTLQAIVSHFQKLFDVPSLNGVYPRMNEVYTRLGEMNNAVRNLQELLELDSSSSLCVLVSTVGKLCRLINEDVNEQVMQVLGPEDLQSIIYKLEEHEEFFPAFQAFTNDLLEILEIDDLDAIVPAVKKLKVLSY>sp|Q8NHQ1-2|CEP70_HUMAN Isoform 2 of Centrosomal protein of 70 kDaOS=Homo sapiens OX=9606 GN=CEP70MFPVAPKPQDSSQPSDRLMTEKQQEEAEWESINVLLMMHGLKPLSLVKRTDLKDLIIFDKQSSQRMRQNLKLLVEETSCQQNMIQELIETNQQLRNELQLEQSRAANQEQRANDLEQIMESVKSKIGELEDESLSRACHQQNKIKDLQKEQKTLQVKCQHYKKKRTEQEETIASLQMEVCRLKKEEEDRIVTQNRVFAYLCKRVPHTVLDRQLLCLIDYYESKIRKIHTQRQYKEDESQSEEENDYRNLDASPTYKGLLMSLQNQLKESKSKIDALSSEKLNLQKDLETRPTQHELRLYKQQVKKLEKALKKNVKLQELINHKKAEDTEKKDEPSKYNQQQALIDQRYFQVLCSINSIIHNPRAPVIIYKQTKGGVQNFNKDLVQDCGFEHLVPVIEMWADQLTSLKDLYKSLKTLSAELVPWLNLKKQDENEGIKVEDLLFIVDTMLEEVENKEKDSNMPHFQTLQAIVSHFQKLFDVPSLNGVYPRMNEVYTRLGEMNNAVRNLQELLELDSSSSLCVLVSTVGKLCRLINEDVNEQVMQVLGPEDLQRYLF>sp|Q8NHQ1-3|CEP70_HUMAN Isoform 3 of Centrosomal protein of 70 kDaOS=Homo sapiens OX=9606 GN=CEP70MFPVAPKPQDSSQPSDRLMTEKQQEEAEWESINVLLMMHGLKPLSLVKRTDLKDLIIFDKQSSQRMRQNLKLLVEETSCQQNMIQELIETNQQLRNELQLEQSRAANQEQRANDLEQIMESVKSKIGELEDESLSRACHQQNKIKDLQKEQKTLQVKCQHYKKKRTEQEETIASLQMEVCRLKKEEEDRIVTQNRVFAYLCKRVPHTVLDRQ>sp|Q8NHQ1-4|CEP70_HUMAN Isoform 4 of Centrosomal protein of 70 kDaOS=Homo sapiens OX=9606 GN=CEP70MTEKQQEEAEWESINVLLMMHGLKPLSLVKRTDLKDLIIFDKQSSQRMRQNLKLLVEETSCQQNMIQELIETNQQLRNELQLEQSRAANQEQRANDLEQIMESVKSKIGELEDESLSRACHQQNKIKDLQKEQKTLQVKCQHYKKKRTEQEETIASLQMEVCRLKKEEEDRIVTQNRVFAYLCKRVPHTVLDRQLLCLIDYYESKIRKIHTQRQYKEDESQSEEENDYRNLDASPTYKGLLMSLQNQLKESKSKIDALSSEKLNLQKDLETRPTQHELRLYKQQVKKLEKALKKNVKLQELINHKKAEDTEKKDEPSKYNQQQALIDQRYFQVLCSINSIIHNPRAPVIIYKQTKGGVQNFNKDLVQDCGFEHLVPVIEMWADQLTSLKDLYKSLKTLSAELVPWLNLKKQDENEGIKVEDLLFIVDTMLEEVENKEKDSNMPHFQTLQAIVSHFQKLFDVPSLNGVYPRMNEVYTRLGEMNNAVRNLQELLELDSSSSLCVLVSTVGKLCRLINEDVNEQVMQVLGPEDLQSIIYKLEEHEEFFPAFQAFTNDLLEILEIDDLDAIVPAVKKLKVLSY>sp|Q8NHQ1-5|CEP70_HUMAN Isoform 5 of Centrosomal protein of 70 kDaOS=Homo sapiens OX=9606 GN=CEP70MTEQEEAEWESINVLLMMHGLKPLSLVKRTDLKDLIIFDKQSSQRMRQNLKLLVEETSCQQNMIQELIETNQQLRNELQLEQSRAANQEQRANDLEQIMESVKSKIGELEDESLSRACHQQNKIKDLQKEQKTLQVKCQHYKKKRTEQEETIASLQMEVCRLKKEEEDRIVTQNRVFAYLCKRVPHTVLDRQLLCLIDYYESKIRKIHTQRQYKEDESQSEEENDYRNLDASPTYKGLLMSLQNQLKESKSKIDALSSEKLNLQKDLETRPTQHELRLYKQQVKKLEKALKKNVKLQELINHKKAEDTEKKDEPSKYNQQQALIDQRYFQVLCSINSIIHNPRAPVIIYKQTKGGVQNFNKDLVQDCGFEHLVPVIEMWADQLTSLKDLYKSLKTLSAELVPWLNLKKQDENEGIKVEDLLFIVDTMLEEVENKEKDSNMPHFQTLQAIVSHFQKLFDVPSLNGVYPRMNEVYTRLGEMNNAVRNLQELLELDSSSSLCVLVSTVGKLCRLINEDVNEQVMQVLGPEDLQSIIYKLEEHEEFFPAFQAFTNDLLEILEIDDLDAIVPAVKKLKVLSY>sp|Q96ST8|CEP89_HUMAN Centrosomal protein of 89 kDa OS=Homo sapiensOX=9606 GN=CEP89 PE=1 SV=3MLLGFRRGRRSHFKHIIHGLLPAASVAPKAAVPRTPPPRSPNPSPERPRSALAAAILATTLTGRTVAIPQPRQRSRSESDVSSVEQDSFIEPYATTSQLRPRPNWQSEMGRRSSLPSFETLDYGDEEDIETQLSSSGKELGDVSAREDRGGHSDDLYAVPHRNQVPLLHEVNSEDDENISHQDGFPGSPPAPQRTQQKDGKHPVLNLKDEKPPLCEKPPPSPDITGRARQRYTEITREKFEALKEENMDLNNMNQSLTLELNTMKQAMKELQLKLKGMEKEKRKLKEAEKASSQEVAAPELLYLRKQAQELVDENDGLKMTVHRLNVELSRYQTKFRHLSKEESLNIEGLPSKGPIPPWLLDIKYLSPLLLAYEDMMKEKDELNATLKEEMRMFRMRVQEVVKENEELHQELNKSSAVTSEEWRQLQTQAKLVLEENKLLLEQLEIQQRKAKDSHQERLQEVSKLTKQLMLLEAKTHGQEKELAENREQLEILRAKCQELKTHSDGKIAVEVHKSIVNELKSQLQKEEEKERAEMEELMEKLTVLQAQKKSLLLEKNSLTEQNKALEAELERAQKINRKSQKKIEVLKKQVEKAMGNEMSAHQYLANLVGLAENITQERDSLMCLAKCLESEKDGVLNKVIKSNIRLGKLEEKVKGYKKQAALKLGDISHRLLEQQEDFAGKTAQYRQEMRHLHQVLKDKQEVLDQALQQNREMEGELEVIWESTFRENRRIRELLQDTLTRTGVQDNPRALVAPSLNGVSQADLLDGCDVCSYDLKSHAPTC>sp|Q96ST8-2|CEP89_HUMAN Isoform 2 of Centrosomal protein of 89 kDaOS=Homo sapiens OX=9606 GN=CEP89MDLNNMNQSLTLELNTMKQAMKELQLKLKGMEKEKRKLKEAEKASSQEVAAPELLYLRKQAQELVDENDGLKMTVHRLNVELSRYQTKFRHLSKEESLNIEGLPSKGPIPPWLLDIKYLSPLLLAYEDMMKEKDELNATLKEEMRMFRMRVQEVVKENEELHQELNKSSAVTSEEWRQLQTQAKLVLEENKLLLEQLEIQQRKAKDSHQERLQEVSKLTKQLMLLEAKTHGQEKELAENREQLEILRAKCQELKTHSDGKIAVEVHKSIVNELKSQLQKEEEKERAEMEELMEKLTVLQAQKKSLLLEKNSLTEQNKALEAELERAQKINRKSQKKIEVLKKQVEKAMGNEMSAHQYLANLVGLAENITQERDSLMCLAKCLESEKDGVLNKVIKSNIRLGKLEEKVKGYKKQAALKLGDISHRLLEQQEDFAGKTAQYRQEMRHLHQVLKDKQEVLDQALQQNREMEGELEVIWESTFRENRRIRELLQDTLTRTGVQDNPRALVAPSLNGVSQADLLDGCDVCSYDLKSHAPTC>sp|Q96ST8-3|CEP89_HUMAN Isoform 3 of Centrosomal protein of 89 kDaOS=Homo sapiens OX=9606 GN=CEP89MLLGFRRGRRSHFKHIIHGLLPAASVAPKAAVPRTPPPRSPNPSPERPRSALAAAILATTLTGRTVAIPQPRQRSRSESDVSSVEQDSFIEPYATTSQLRPRPNWQSEMGRRSSLPSFETLDYGDEEDIETQLSSSGKELGDVSAREDRGGHSDDLYAVPHRNQVPLLHEVNSEDDENISHQDGFPGSPPAPQRTQQKDGKHPVLNLKDEKPPLCEKPPPSPDITGRARQRYTEITREKFEALKEENMDLNNMNQSLTLELNTMKQAMKELQLKLKGMEKEKRKLKEAEKASSQEVAAPELLYLRKQAQELVDENDGLKMTVHRLNVELSRYQTKFRHLSKEEVTFPIVKISFSDFC>sp|Q6P2H3|CEP85_HUMAN Centrosomal protein of 85 kDa OS=Homo sapiensOX=9606 GN=CEP85 PE=1 SV=1MAMQEKYPTEGISHVTSPSSDVIQKGSSLGTEWQTPVISEPFRSRFSRCSSVADSGDTAIGTSCSDIAEDFCSSSGSPPFQPIKSHVTIPTAHVMPSTLGTSPAKPNSTPVGPSSSKLPLSGLAESVGMTRNGDLGAMKHSPGLSRDLMYFSGATGENGIEQSWFPAVGHERQEEARKFDIPSMESTLNQSAMMETLYSDPHHRVRFHNPRTSTSKELYRVLPEAKKAPGSGAVFERNGPHSNSSGVLPLGLQPAPGLSKPLPSQVWQPSPDTWHPREQSCELSTCRQQLELIRLQMEQMQLQNGAICHHPAAFGPSLPILEPAQWISILNSNEHLLKEKELLIDKQRKHISQLEQKVRESELQVHSALLGRPAPFGDVCLLRLQELQRENTFLRAQFAQKTEALSREKIDLEKKLSASEVEVQLIRESLKVALQKHSEEVKKQEERVKGRDKHINNLKKKCQKESEQNREKQQRIETLERYLADLPTLEDHQKQSQQLKDSELKSTELQEKVTELESLLEETQAICREKEIQLESLRQREAEFSSAGHSLQDKQSVEETSGEGPEVEMESWQKRYDSLQKIVEKQQQKMDQLRSQVQSLEQEVAQEEGTSQALREEAQRRDSALQQLRTAVKELSVQNQDLIEKNLTLQEHLRQAQPGSPPSPDTAQLALELHQELASCLQDLQAVCSIVTQRAQGHDPNLSLLLGIHSAQHPETQLDLQKPDVIKRKLEEVQQLRRDIEDLRTTMSDRYAQDMGENCVTQ>sp|Q6P2H3-2|CEP85_HUMAN Isoform 2 of Centrosomal protein of 85 kDaOS=Homo sapiens OX=9606 GN=CEP85MAMQEKYPTEGISHVTSPSSDVIQKGSSLGTEWQTPVISEPFRSRFSRCSSVADSGDTAIGTSCSDIAEDFCSSSGSPPFQPIKSHVTIPTAHVMPSTLGTSPAKPNSTPVGPSSSKLPLSGLAESVGMTRNGDLGAMKHSPGLSRDLMYFSGATGENGIEQSWFPAVGHERQEEARKFDIPSMESTLNQSAMMETLYSDPHHRVRFHNPRTSTSKELYRVLPEAKKAPGSGAVFERNGPHSNSSGVLPLGLQPAPGLSKPLPSQVWQPSPDTWHPREQSCELSTCRQQLELIRLQMEQMQLQNGAICHHPAAFGPSLPILEPAQWISILNSNEHLLKEKELLIDKQRKHISQLEQKVRESELQVHSALLGRPAPFGDVCLLRLQELQRENTFLRAQFAQKTEALSREKIDLEKKLSASEVEVQLIRESLKVALQKHSEEVKKQEERVKGRDKHINNLKKKCQKESEQNREKQQRIETLERYLADLPTLEDHQKQSQQLKDSELKSTELQEKVTELESLLEETQAICREKEIQLESLRQREAEFSSAGHSLQDKQSVEETSGEGPEVEMESWQKRYDSLQKIVEKQQQKMDQLRSQVQSLEQEVAQEEGTSQALREEAQRRDSALQQLRTAVKELSVQNQDLIEKNLTLQEHLRQAQPGSPPSPDTAQLALELHQELASCLQDLQAVCSIVTQRAQGHDPNLSLLLGIHSQHPETQLDLQKPDVIKRKLEEVQQLRRDIEDLRTTMSDRYAQDMGENCVTQ>sp|Q6P2H3-3|CEP85_HUMAN Isoform 3 of Centrosomal protein of 85 kDaOS=Homo sapiens OX=9606 GN=CEP85MESWQKRYDSLQKIVEKQQQKMDQLRSQVQSLEQEVAQEEGTSQALREEAQRRDSALQQLRTAVKELSVQNQDLIEKNLTLQEHLRQAQPGSPPSPDTAQLALELHQELASCLQDLQAVCSIVTQRAQGHDPNLSLLLGIHSAQHPETQLDLQKPDVIKRKLEEVQQLRRDIEDLRTTMSDRYAQDMGENCVTQ>sp|Q6P2H3-4|CEP85_HUMAN Isoform 4 of Centrosomal protein of 85 kDaOS=Homo sapiens OX=9606 GN=CEP85MAMQEKYPTEGISHVTSPNFCSSSGSPPFQPIKSHVTIPTAHVMPSTLGTSPAKPNSTPVGPSSSKLPLSGLAESVGMTRNGDLGAMKHSPGLSRDLMYFSGATGENGIEQSWFPAVGHERQEEARKFDIPSMESTLNQSAMMETLYSDPHHRVRFHNPRTSTSKELYRVLPEAKKAPGSGAVFERNGPHSNSSGVLPLGLQPAPGLSKPLPSQVWQPSPDTWHPREQSCELSTCRQQLELIRLQMEQMQLQNGAICHHPAAFGPSLPILEPAQWISILNSNEHLLKEKELLIDKQRKHISQLEQKVRESELQVHSALLGRPAPFGDVCLLRLQELQRENTFLRAQFAQKTEALSREKIDLEKKLSASEVEVQLIRESLKVALQKHSEEVKKQEERVKGRDKHINNLKKKCQKESEQNREKQQRIETLERYLADLPTLEDHQKQSQQLKDSELKSTELQEKVTELESLLEETQAICREKEIQLESLRQREAEFSSAGHSLQDKQSVEETSGEGPEVEMESWQKRYDSLQKIVEKQQQKMDQLRSQVQSLEQEVAQEEGTSQALREEAQRRDSALQQLRTAVKELSVQNQDLIEKNLTLQEHLRQAQPGSPPSPDTAQLALELHQELASCLQDLQAVCSIVTQRAQGHDPNLSLLLGIHSAQHPETQLDLQKPDVIKRKLEEVQQLRRDIEDLRTTMSDRYAQDMGENCVTQ>sp|P11049|CD37_HUMAN Leukocyte antigen CD37 OS=Homo sapiens OX=9606GN=CD37 PE=1 SV=2MSAQESCLSLIKYFLFVFNLFFFVLGSLIFCFGIWILIDKTSFVSFVGLAFVPLQIWSKVLAISGIFTMGIALLGCVGALKELRCLLGLYFGMLLLLFATQITLGILISTQRAQLERSLRDVVEKTIQKYGTNPEETAAEESWDYVQFQLRCCGWHYPQDWFQVLILRGNGSEAHRVPCSCYNLSATNDSTILDKVILPQLSRLGHLARSRHSADICAVPAESHIYREGCAQGLQKWLHNNLISIVGICLGVGLLELGFMTLSIFLCRNLDHVYNRLARYR>sp|P11049-2|CD37_HUMAN Isoform 2 of Leukocyte antigen CD37 OS=Homosapiens OX=9606 GN=CD37MGIALLGCVGALKELRCLLGLYFGMLLLLFATQITLGILISTQRAQLERSLRDVVEKTIQKYGTNPEETAAEESWDYVQFQLRCCGWHYPQDWFQVLILRGNGSEAHRVPCSCYNLSATNDSTILDKVILPQLSRLGHLARSRHSADICAVPAESHIYREGCAQGLQKWLHNNLISIVGICLGVGLLELGFMTLSIFLCRNLDHVYNRLARYR>sp|P11049-3|CD37_HUMAN Isoform 3 of Leukocyte antigen CD37 OS=Homosapiens OX=9606 GN=CD37MGIALLGCVGALKELRCLLGLYFGMLLLLFATQITLGILISTQRAQLERSLRDVVEKTIQKYGTNPEETAAEESWDYVQFQLRCCGWHYPQDWFQVLILRGNGSEAHRVPCSCYNLSATNDSTILDKVILPQLSRLGHLARSRHSADICAVPAESHIYREGCAQGLQKWLHNNLISIVGICLGVGLLEVIWPRPHPRSALNP>sp|O76039|CDKL5_HUMAN Cyclin-dependent kinase-like 5 OS=Homo sapiensOX=9606 GN=CDKL5 PE=1 SV=2MKIPNIGNVMNKFEILGVVGEGAYGVVLKCRHKETHEIVAIKKFKDSEENEEVKETTLRELKMLRTLKQENIVELKEAFRRRGKLYLVFEYVEKNMLELLEEMPNGVPPEKVKSYIYQLIKAIHWCHKNDIVHRDIKPENLLISHNDVLKLCDFGFARNLSEGNNANYTEYVATRWYRSPELLLGAPYGKSVDMWSVGCILGELSDGQPLFPGESEIDQLFTIQKVLGPLPSEQMKLFYSNPRFHGLRFPAVNHPQSLERRYLGILNSVLLDLMKNLLKLDPADRYLTEQCLNHPTFQTQRLLDRSPSRSAKRKPYHVESSTLSNRNQAGKSTALQSHHRSNSKDIQNLSVGLPRADEGLPANESFLNGNLAGASLSPLHTKTYQASSQPGSTSKDLTNNNIPHLLSPKEAKSKTEFDFNIDPKPSEGPGTKYLKSNSRSQQNRHSFMESSQSKAGTLQPNEKQSRHSYIDTIPQSSRSPSYRTKAKSHGALSDSKSVSNLSEARAQIAEPSTSRYFPSSCLDLNSPTSPTPTRHSDTRTLLSPSGRNNRNEGTLDSRRTTTRHSKTMEELKLPEHMDSSHSHSLSAPHESFSYGLGYTSPFSSQQRPHRHSMYVTRDKVRAKGLDGSLSIGQGMAARANSLQLLSPQPGEQLPPEMTVARSSVKETSREGTSSFHTRQKSEGGVYHDPHSDDGTAPKENRHLYNDPVPRRVGSFYRVPSPRPDNSFHENNVSTRVSSLPSESSSGTNHSKRQPAFDPWKSPENISHSEQLKEKEKQGFFRSMKKKKKKSQTVPNSDSPDLLTLQKSIHSASTPSSRPKEWRPEKISDLQTQSQPLKSLRKLLHLSSASNHPASSDPRFQPLTAQQTKNSFSEIRIHPLSQASGGSSNIRQEPAPKGRPALQLPGQMDPGWHVSSVTRSATEGPSYSEQLGAKSGPNGHPYNRTNRSRMPNLNDLKETAL>sp|O76039-1|CDKL5_HUMAN Isoform 2 of Cyclin-dependent kinase-like 5OS=Homo sapiens OX=9606 GN=CDKL5MKIPNIGNVMNKFEILGVVGEGAYGVVLKCRHKETHEIVAIKKFKDSEENEEVKETTLRELKMLRTLKQENIVELKEAFRRRGKLYLVFEYVEKNMLELLEEMPNGVPPEKVKSYIYQLIKAIHWCHKNDIVHRDIKPENLLISHNDVLKLCDFGFARNLSEGNNANYTEYVATRWYRSPELLLGAPYGKSVDMWSVGCILGELSDGQPLFPGESEIDQLFTIQKVLGPLPSEQMKLFYSNPRFHGLRFPAVNHPQSLERRYLGILNSVLLDLMKNLLKLDPADRYLTEQCLNHPTFQTQRLLDRSPSRSAKRKPYHVESSTLSNRNQAGKSTALQSHHRSNSKDIQNLSVGLPRADEGLPANESFLNGNLAGASLSPLHTKTYQASSQPGSTSKDLTNNNIPHLLSPKEAKSKTEFDFNIDPKPSEGPGTKYLKSNSRSQQNRHSFMESSQSKAGTLQPNEKQSRHSYIDTIPQSSRSPSYRTKAKSHGALSDSKSVSNLSEARAQIAEPSTSRYFPSSCLDLNSPTSPTPTRHSDTRTLLSPSGRNNRNEGTLDSRRTTTRHSKTMEELKLPEHMDSSHSHSLSAPHESFSYGLGYTSPFSSQQRPHRHSMYVTRDKVRAKGLDGSLSIGQGMAARANSLQLLSPQPGEQLPPEMTVARSSVKETSREGTSSFHTRQKSEGGVYHDPHSDDGTAPKENRHLYNDPVPRRVGSFYRVPSPRPDNSFHENNVSTRVSSLPSESSSGTNHSKRQPAFDPWKSPENISHSEQLKEKEKQGFFRSMKKKKKKSQTVPNSDSPDLLTLQKSIHSASTPSSRPKEWRPEKISDLQTQSQPLKSLRKLLHLSSASNHPASSDPRFQPLTAQQTKNSFSEIRIHPLSQASGGSSNIRQEPAPKGRPALQLPDGGCDGRRQRHHSGPQDRRFMLRTTEQQGEYFCCGDPKKPHTPCVPNRALHRPISSPAPYPVLQVRGTSMCPTLQVRGTDAFSCPTQQSGFSFFVRHVMREALIHRAQVNQAALLTYHENAALTGK>sp|Q9BZP6|CHIA_HUMAN Acidic mammalian chitinase OS=Homo sapiens OX=9606GN=CHIA PE=1 SV=1MTKLILLTGLVLILNLQLGSAYQLTCYFTNWAQYRPGLGRFMPDNIDPCLCTHLIYAFAGRQNNEITTIEWNDVTLYQAFNGLKNKNSQLKTLLAIGGWNFGTAPFTAMVSTPENRQTFITSVIKFLRQYEFDGLDFDWEYPGSRGSPPQDKHLFTVLVQEMREAFEQEAKQINKPRLMVTAAVAAGISNIQSGYEIPQLSQYLDYIHVMTYDLHGSWEGYTGENSPLYKYPTDTGSNAYLNVDYVMNYWKDNGAPAEKLIVGFPTYGHNFILSNPSNTGIGAPTSGAGPAGPYAKESGIWAYYEICTFLKNGATQGWDAPQEVPYAYQGNVWVGYDNIKSFDIKAQWLKHNKFGGAMVWAIDLDDFTGTFCNQGKFPLISTLKKALGLQSASCTAPAQPIEPITAAPSGSGNGSGSSSSGGSSGGSGFCAVRANGLYPVANNRNAFWHCVNGVTYQQNCQAGLVFDTSCDCCNWA>sp|Q9BZP6-2|CHIA_HUMAN Isoform 2 of Acidic mammalian chitinase OS=Homosapiens OX=9606 GN=CHIAMVSTPENRQTFITSVIKFLRQYEFDGLDFDWEYPGSRGSPPQDKHLFTVLVQEMREAFEQEAKQINKPRLMVTAAVAAGISNIQSGYEIPQLSQYLDYIHVMTYDLHGSWEGYTGENSPLYKYPTDTGSNAYLNVDYVMNYWKDNGAPAEKLIVGFPTYGHNFILSNPSNTGIGAPTSGAGPAGPYAKESGIWAYYEICTFLKNGATQGWDAPQEVPYAYQGNVWVGYDNIKSFDIKAQWLKHNKFGGAMVWAIDLDDFTGTFCNQGKFPLISTLKKALGLQSASCTAPAQPIEPITAAPSGSGNGSGSSSSGGSSGGSGFCAVRANGLYPVANNRNAFWHCVNGVTYQQNCQAGLVFDTSCDCCNWA>sp|Q9BZP6-3|CHIA_HUMAN Isoform 3 of Acidic mammalian chitinase OS=Homosapiens OX=9606 GN=CHIAMREAFEQEAKQINKPRLMVTAAVAAGISNIQSGYEIPQLSQYLDYIHVMTYDLHGSWEGYTGENSPLYKYPTDTGSNAYLNVDYVMNYWKDNGAPAEKLIVGFPTYGHNFILSNPSNTGIGAPTSGAGPAGPYAKESGIWAYYEICTFLKNGATQGWDAPQEVPYAYQGNVWVGYDNIKSFDIKAQWLKHNKFGGAMVWAIDLDDFTGTFCNQGKFPLISTLKKALGLQSASCTAPAQPIEPITAAPSGSGNGSGSSSSGGSSGGSGFCAVRANGLYPVANNRNAFWHCVNGVTYQQNCQAGLVFDTSCDCCNWA>sp|Q5T5N4|CF118_HUMAN Uncharacterized protein C6orf118 OS=Homo sapiensOX=9606 GN=C6orf118 PE=2 SV=1MAEEREPELYLKWKHCETPGVKTLCNLKHCETPGVKTLCNLKKLLNRLQKDHREDVYLYISGHLNPNKLYQPPETILQHWPNAHRPKGERASEVGEPPAGKVARMKEALAHFTIHTALVPSEAQDTPLFRYLNPQASLSHTSEEDFLPVEAVREGKEEKKGGPPGRGPPGWRRREELRLPDLKVLCYQEAGSRGTRDRHHYVSSYLAGATSADRYRMFLRFQKEVLAKQDLLKNDFTGSKAAAGHERKLQQELQKICTCSPQQFNRLHVFGKVFEDICNSSLIFGDLLKKVKDEYELYMATLLESQPAAQYEALLAQLKALGQRPVKTADMDLAREELRMLVTATKAALEQNDRLRSELEMEVALLQSAKERSESSEKHIIDENRLTLTEKVEKKRCEILSKWDEIQALEKEIKTTLVHTGISDITENRIKSIEHEAIQLETENMILKKKIKGPLEIYQGICKIRGNRR>sp|Q5SZD1|CF141_HUMAN Uncharacterized protein C6orf141 OS=Homo sapiensOX=9606 GN=C6orf141 PE=1 SV=3MNDPFARMETRGPQGAANPMDSSRSLGDLGPFPREVGRGAPLAPGARNPATAGASRSQGGGHEDRTADRALGPRAGEELDRESWVREKVLFLLHPERWLGTRGDPAREEVAGAEDLPHAGGEDHGEEPNYPSVFQRQKRISGRRVAPPRDAADPPKYVLVRVEDYQVTQEVLQTSWAKGRMTTRTEEHFVTALTFRSSREGQPGERWGPAESRALQARTGASRVHAAGRRVSPSPGTWLEEIKL>sp|Q5T6M2|CF122_HUMAN Putative uncharacterized protein encoded byLINC00242 OS=Homo sapiens OX=9606 GN=LINC00242 PE=5 SV=1MMPRHLLPHSGITSLRRVPRRRLPSRRREDFRRCLFLSFVSTDKDGDPTGQASPAVPVPHFTTWGSLIPIDSQRNKERTRFTWMDGPPHGGLGTRFSGRGSASLTAPPGRCFTRERHPVPRQRKCRRQHSTGRKPHCGTRSAAPRNPKSIHKRSFSAKSLKNKTRNESPPVSALVSRTKTQPGQLHFCCQPSSSQAPASRRAKGR>sp|Q8WUX2|CHAC2_HUMAN Glutathione-specific gamma-glutamylcyclotransferase 2 OS=Homo sapiens OX=9606 GN=CHAC2 PE=1 SV=1MWVFGYGSLIWKVDFPYQDKLVGYITNYSRRFWQGSTDHRGVPGKPGRVVTLVEDPAGCVWGVAYRLPVGKEEEVKAYLDFREKGGYRTTTVIFYPKDPTTKPFSVLLYIGTCDNPDYLGPAPLEDIAEQIFNAAGPSGRNTEYLFELANSIRNLVPEEADEHLFALEKLVKERLEGKQNLNCI>sp|A8MTB9|CEA18_HUMAN Carcinoembryonic antigen-related cell adhesionmolecule 18 OS=Homo sapiens OX=9606 GN=CEACAM18 PE=3 SV=4MDLSRPRWSLWRRVFLMASLLACGICQASGQIFITQTLGIKGYRTVVALDKVPEDVQEYSWYWGANDSAGNMIISHKPPSAQQPGPMYTGRERVNREGSLLIRPTALNDTGNYTVRVVAGNETQRATGWLEVLELGSNLGISVNASSLVENMDSVAADCLTNVTNITWYVNDVPTSSSDRMTISPDGKTLVILRVSRYDRTIQCMIESFPEIFQRSERISLTVAYGPDYVLLRSNPDDFNGIVTAEIGSQVEMECICYSFLDLKYHWIHNGSLLNFSDAKMNLSSLAWEQMGRYRCTVENPVTQLIMYMDVRIQAPHEDLTCCPQRFLHLRIHGDVPHHADSAGWRLHLWSPDPCSDQPLLNQDKSGSMSVHPRPEDKTRRASR>sp|P15882|CHIN_HUMAN N-chimaerin OS=Homo sapiens OX=9606 GN=CHN1 PE=1SV=3MALTLFDTDEYRPPVWKSYLYQLQQEAPHPRRITCTCEVENRPKYYGREFHGMISREAADQLLIVAEGSYLIRESQRQPGTYTLALRFGSQTRNFRLYYDGKHFVGEKRFESIHDLVTDGLITLYIETKAAEYIAKMTINPIYEHVGYTTLNREPAYKKHMPVLKETHDERDSTGQDGVSEKRLTSLVRRATLKENEQIPKYEKIHNFKVHTFRGPHWCEYCANFMWGLIAQGVKCADCGLNVHKQCSKMVPNDCKPDLKHVKKVYSCDLTTLVKAHTTKRPMVVDMCIREIESRGLNSEGLYRVSGFSDLIEDVKMAFDRDGEKADISVNMYEDINIITGALKLYFRDLPIPLITYDAYPKFIESAKIMDPDEQLETLHEALKLLPPAHCETLRYLMAHLKRVTLHEKENLMNAENLGIVFGPTLMRSPELDAMAALNDIRYQRLVVELLIKNEDILF>sp|P15882-2|CHIN_HUMAN Isoform Alpha-1 of N-chimaerin OS=Homo sapiensOX=9606 GN=CHN1MPSKESWSGRKTNRAAVHKSKQEGRQQDLLIAALGMKLGSPKSSVTIWQPLKLFAYSQLTSLVRRATLKENEQIPKYEKIHNFKVHTFRGPHWCEYCANFMWGLIAQGVKCADCGLNVHKQCSKMVPNDCKPDLKHVKKVYSCDLTTLVKAHTTKRPMVVDMCIREIESRGLNSEGLYRVSGFSDLIEDVKMAFDRDGEKADISVNMYEDINIITGALKLYFRDLPIPLITYDAYPKFIESAKIMDPDEQLETLHEALKLLPPAHCETLRYLMAHLKRVTLHEKENLMNAENLGIVFGPTLMRSPELDAMAALNDIRYQRLVVELLIKNEDILF>sp|P15882-3|CHIN_HUMAN Isoform 3 of N-chimaerin OS=Homo sapiens OX=9606GN=CHN1MALTLFDTDEYRPPVWKSYLYQLQQEAPHPRRITCTCEVENRPKYYGREFHGMISREAADQLLIVAEGSYLIRESQRQPGTYTLALRFGSQTRNFRLYYDGKHFVGEKRFESIHDLVTDGLITLYIETKAAEYIAKMTINPIYEHVGYTTLNREPAYKKHMPVLKETHDERDSTGQDGVSEKRVHTFRGPHWCEYCANFMWGLIAQGVKCADCGLNVHKQCSKMVPNDCKPDLKHVKKVYSCDLTTLVKAHTTKRPMVVDMCIREIESRGLNSEGLYRVSGFSDLIEDVKMAFDRDGEKADISVNMYEDINIITGALKLYFRDLPIPLITYDAYPKFIESAKIMDPDEQLETLHEALKLLPPAHCETLRYLMAHLKRVTLHEKENLMNAENLGIVFGPTLMRSPELDAMAALNDIRYQRLVVELLIKNEDILF>sp|Q6ZTQ4|CDHR3_HUMAN Cadherin-related family member 3 OS=Homo sapiensOX=9606 GN=CDHR3 PE=1 SV=1MQEAIILLALLGAMSGGEALHLILLPATGNVAENSPPGTSVHKFSVKLSASLSPVIPGFPQIVNSNPLTEAFRVNWLSGTYFEVVTTGMEQLDFETGPNIFDLQIYVKDEVGVTDLQVLTVQVTDVNEPPQFQGNLAEGLHLYIVERANPGFIYQVEAFDPEDTSRNIPLSYFLISPPKSFRMSANGTLFSTTELDFEAGHRSFHLIVEVRDSGGLKASTELQVNIVNLNDEVPRFTSPTRVYTVLEELSPGTIVANITAEDPDDEGFPSHLLYSITTVSKYFMINQLTGTIQVAQRIDRDAGELRQNPTISLEVLVKDRPYGGQENRIQITFIVEDVNDNPATCQKFTFSIMVPERTAKGTLLLDLNKFCFDDDSEAPNNRFNFTMPSGVGSGSRFLQDPAGSGKIVLIGDLDYENPSNLAAGNKYTVIIQVQDVAPPYYKNNVYVYILTSPENEFPLIFDRPSYVFDVSERRPARTRVGQVRATDKDLPQSSLLYSISTGGASLQYPNVFWINPKTGELQLVTKVDCETTPIYILRIQATNNEDTSSVTVTVNILEENDEKPICTPNSYFLALPVDLKVGTNIQNFKLTCTDLDSSPRSFRYSIGPGNVNNHFTFSPNAGSNVTRLLLTSRFDYAGGFDKIWDYKLLVYVTDDNLMSDRKKAEALVETGTVTLSIKVIPHPTTIITTTPRPRVTYQVLRKNVYSPSAWYVPFVITLGSILLLGLLVYLVVLLAKAIHRHCPCKTGKNKEPLTKKGETKTAERDVVVETIQMNTIFDGEAIDPVTGETYEFNSKTGARKWKDPLTQMPKWKESSHQGAAPRRVTAGEGMGSLRSANWEEDELSGKAWAEDAGLGSRNEGGKLGNPKNRNPAFMNRAYPKPHPGK>sp|Q6ZTQ4-2|CDHR3_HUMAN Isoform 2 of Cadherin-related family member 3OS=Homo sapiens OX=9606 GN=CDHR3MINQLTGTIQVAQRIDRDAGELRQNPTISLEVLVKDRPYGGQENRIQITFIVEDVNDNPATCQKFTFSIMVPERTAKGTLLLDLNKFCFDDDSEAPNNRFNFTMPSGVGSGSRFLQDPAGSGKIVLIGDLDYENPSNLAAGNKYTVIIQVQDVAPPYYKNNVYVYILTSPENEFPLIFDRPSYVFDVSERRPAQGHLSGPEEKRLLSICMVRAVCHHFGLHIASGSPRVPGRPIGQSRPQTLPLQDWEEQGTSDKERRNEDCRERRRGGNYPDEHYL>sp|Q5TEZ5|CF163_HUMAN Uncharacterized protein C6orf163 OS=Homo sapiensOX=9606 GN=C6orf163 PE=4 SV=2MIRNSDYKNFVCCAVCNKIIPPAPFGKTFKRIHEYKPLKTRFYTHKDILDIGANILKKEEQFQEDILREHIAKAEAEVWAQANERQKQAVEKALEEANDRHKIEIQILKEEHQKDLQEVTAKTKTEMYQNMDDEMKREHLAAEQRMVHRIQRIMMECHREKVEAVEKARAEERHIAQEAIQAQKSKAVEEIVNTGVTVIKDEKTSVARLMREKEHEMSILYGIAQRQRQEEVQEVLQEAEKTHQATLGNMMDKLANTQGELLSIAKQLGIMTNWKDFLEEELQETRMAFQKYINYTFPKLSPGHADFILPERKKTPSNLVIKENKTTLD>sp|Q96NL8|CF418_HUMAN Cilia- and flagella-associated protein 418 OS=Homosapiens OX=9606 GN=CFAP418 PE=1 SV=1MAEDLDELLDEVESKFCTPDLLRRGMVEQPKGCGGGTHSSDRNQAKAKETLRSTETFKKEDDLDSLINEILEEPNLDKKPSKLKSKSSGNTSVRASIEGLGKSCSPVYLGGSSIPCGIGTNISWRACDHLRCIACDFLVVSYDDYMWDKSCDYLFFRNNMPEFHKLKAKLIKKKGTRAYACQCSWRTIEEVTDLQTDHQLRWVCGKH>sp|P0C7V0|CF217_HUMAN Putative uncharacterized protein encoded byLINC00271 OS=Homo sapiens OX=9606 GN=LINC00271 PE=5 SV=1MLNSPGTRRPVKEAQKYGEDSQKSHSPGTPGPRSSVTTLSASALSDSSSPDTPPRRGPGRPSTPARAPATSAPMMYSRRGVRRTARPAGADTRSSANQLPQPSGACANADSAPPADVSACLRRRSHGDRCVPRSRRRPRPRPRASTAFFQEEGPCGACPGALRPQAGASFRELRGLPPPRPREREQSPPLGAAPSSALSHQGWKNTRCATRGLVNTLVNTGHFLYLQPPAPLIMPYLDDAEVPGNRRSHPSLSFSWLSKALYHVTFLLRIL>sp|Q5T2Q4|CCYL2_HUMAN Cyclin-Y-like protein 2 OS=Homo sapiens OX=9606GN=CCNYL2 PE=3 SV=2MGNILTCCVCPRASPGLHQHQGLVCHCESEIYEAAAGDLIAGVPVAAAVEPGEVTFVAGEGLHMHHICEREMPEDIPLEPNPSDHPKASTIFLRKSQTDVQEKKKKQLCKVSTEHFTQQYSSCSTIFLDDSIASQPHLTMTLKSCDLGTILSYQAKRDAHRSLGIFDEQLHPLTVRKEVLEEYFKYDPEHKLIFRFVRTLFKAMRLTAEFAIVSLIYIERLVSYADIDICPTNWKRIVLGAILLASKVWSDMAVWNEDYCKLFKNITVEEMNELERQFLKLINYNNSITNSVYSRFYFDLRTLAHNNGLYSPVYLLDRERAWKLEAFSRMEQDKVFYSAAKNGSLSADDLIHLQRAKAILF>sp|Q14002|CEAM7_HUMAN Carcinoembryonic antigen-related cell adhesionmolecule 7 OS=Homo sapiens OX=9606 GN=CEACAM7 PE=1 SV=1MGSPSACPYRVCIPWQGLLLTASLLTFWNLPNSAQTNIDVVPFNVAEGKEVLLVVHNESQNLYGYNWYKGERVHANYRIIGYVKNISQENAPGPAHNGRETIYPNGTLLIQNVTHNDAGFYTLHVIKENLVNEEVTRQFYVFSEPPKPSITSNNFNPVENKDIVVLTCQPETQNTTYLWWVNNQSLLVSPRLLLSTDNRTLVLLSATKNDIGPYECEIQNPVGASRSDPVTLNVRYESVQASSPDLSAGTAVSIMIGVLAGMALI>sp|Q14002-2|CEAM7_HUMAN Isoform 2b of Carcinoembryonic antigen-relatedcell adhesion molecule 7 OS=Homo sapiens OX=9606 GN=CEACAM7MGSPSACPYRVCIPWQGLLLTASLLTFWNLPNSAQTNIDVVPFNVAEGKEVLLVVHNESQNLYGYNWYKGERVHANYRIIGYVKNISQENAPGPAHNGRETIYPNGTLLIQNVTHNDAGFYTLHVIKENLVNEEVTRQFYVFYESVQASSPDLSAGTAVSIMIGVLAGMALI>sp|Q7Z4U5|CF201_HUMAN Uncharacterized protein C6orf201 OS=Homo sapiensOX=9606 GN=C6orf201 PE=1 SV=3MLSNLHELLPNHLMETLYSRKSEEDKKKCENPELSGLERILARHQLPKEINLTPKPNRMPPWKRKIINNVTDGWKKCHLLKRNTKEPPMSTIVVRKLIQKNVPRRHSLRNTSRKLRNLPTTAKGTQTGKSQCLLGISEPT>sp|Q7Z4U5-3|CF201_HUMAN Isoform 2 of Uncharacterized protein C6orf201OS=Homo sapiens OX=9606 GN=C6orf201MASGPLGPGARPTRLHPPFPPPAHIKPGAPPGENPELSGLERILARHQLPKEINLTPKPNRMPPWKRKIINNVTDGWKKCHLLKRNTKEPPMSTIVVRKLIQKNVPRRHSLRNTSRKLRNLPTTAKGTQTE>sp|Q96M91|CFA53_HUMAN Cilia- and flagella-associated protein 53 OS=Homosapiens OX=9606 GN=CFAP53 PE=1 SV=2MYSQRFGTVQREVKGPTPKVVIVRSKPPKGQGAEHHLERIRRSHQKHNAILASIKSSERDRLKAEWDQHNDCKILDSLVRARIKDAVQGFIINIEERRNKLRELLALEENEYFTEMQLKKETIEEKKDRMREKTKLLKEKNEKERQDFVAEKLDQQFRERCEELRVELLSIHQKKVCEERKAQIAFNEELSRQKLVEEQMFSKLWEEDRLAKEKREAQEARRQKELMENTRLGLNAQITSIKAQRQATQLLKEEEARLVESNNAQIKHENEQDMLKKQKAKQETRTILQKALQERIEHIQQEYRDEQDLNMKLVQRALQDLQEEADKKKQKREDMIREQKIYHKYLAQRREEEKAQEKEFDRILEEDKAKKLAEKDKELRLEKEARRQLVDEVMCTRKLQVQEKLQREAKEQEERAMEQKHINESLKELNCEEKENFARRQRLAQEYRKQLQMQIAYQQQSQEAEKEEKRREFEAGVAANKMCLDKVQEVLSTHQVLPQNIHPMRKACPSKLPP>sp|Q9BY43|CHM4A_HUMAN Charged multivesicular body protein 4a OS=Homosapiens OX=9606 GN=CHMP4A PE=1 SV=3MSGLGRLFGKGKKEKGPTPEEAIQKLKETEKILIKKQEFLEQKIQQELQTAKKYGTKNKRAALQALRRKKRFEQQLAQTDGTLSTLEFQREAIENATTNAEVLRTMELAAQSMKKAYQDMDIDKVDELMTDITEQQEVAQQISDAISRPMGFGDDVDEDELLEELEELEQEELAQELLNVGDKEEEPSVKLPSVPSTHLPAGPAPKVDEDEEALKQLAEWVS>sp|Q9BY43-2|CHM4A_HUMAN Isoform 2 of Charged multivesicular body protein4a OS=Homo sapiens OX=9606 GN=CHMP4AMSRRRPEDGLGKAGPCVMRHHPPRSKAEVWRTLRGGGGRGELAMSGLGRLFGKGKKEKGPTPEEAIQKLKETEKILIKKQEFLEQKIQQELQTAKKYGTKNKRAALQALRRKKRFEQQLAQTDGTLSTLEFQREAIENATTNAEVLRTMELAAQSMKKAYQDMDIDKVDELMTDITEQQEVAQQISDAISRPMGFGDDVDEDELLEELEELEQEELAQELLNVGDKEEEPSVKLPSVPSTHLPAGPAPKVDEDEEALKQLAEWVS>sp|Q9UEE9|CFDP1_HUMAN Craniofacial development protein 1 OS=Homo sapiensOX=9606 GN=CFDP1 PE=1 SV=1MEEFDSEDFSTSEEDEDYVPSGGEYSEDDVNELVKEDEVDGEEQTQKTQGKKRKAQSIPARKRRQGGLSLEEEEEEDANSESEGSSSEEEDDAAEQEKGIGSEDARKKKEDELWASFLNDVGPKSKVPPSTQVKKGEETEETSSSKLLVKAEELEKPKETEKVKITKVFDFAGEEVRVTKEVDATSKEAKSFFKQNEKEKPQANVPSALPSLPAGSGLKRSSGMSSLLGKIGAKKQKMSTLEKSKLDWESFKEEEGIGEELAIHNRGKEGYIERKAFLDRVDHRQFEIERDLRLSKMKP>sp|Q9UEE9-2|CFDP1_HUMAN Isoform 2 of Craniofacial development protein 1OS=Homo sapiens OX=9606 GN=CFDP1MEEFDSEDFSTSEEDEDYVPSGGEYSEDDVNELVKEDEVDGEEQTQKTQGKKRKAQSIPARKRRQGGLSLEEEEEEDANSESEGSSSEEEDDAAEQEKGIGSEDARKKKEDELWASFLNDVGPKSKVPPSTQVKKGEETEETSSSKLLVKAEELEKPKETEKVKITKVFDFAGEEVRVTKEVDATSKEAKSFFKQNEKEKPQANVPSALPSLPAGSG>sp|Q9C0B2|CFA74_HUMAN Cilia- and flagella-associated protein 74 OS=Homosapiens OX=9606 GN=CFAP74 PE=2 SV=3MEDDGSLLPEDELLADALLLEDERDELEDPEFDIKCLLQEAEDDVDPGHSSSVKELDTDADKLKKKTAEDRTQAFHLRQNLSALDKMHEEQELFTEKMRGELRACRQRRDLIDKQQEAVAAEIATEEEAGNMAAVGRLQAVSRRLFAELENERDLQSRTEAVLKESENTMWHIEIQEGRLEAFRTADREEVEATGRRLQVRAAEQLCREQEALGKVERNRLLRIRKSLNTQKELGLRHQKLLEDARKNHKVAVRFLKASLGRIREQEKKEEMECHEYMRRRMDAVVALKGSISANRDTLRKFQAWDRAKAELAEQRVQAEKKAILAQGRDAFRHLVHQRRRQELEAQKRAFEEEQKLRKQEIISRILKEEAEEEKRKKQHPPTSARHRLTLRDKTWNYISDFCKKTTVPTNTYTLDYEAAAGPGPSRLLEVVSSELIQGDPGASSEEETLAEPEISGLWNEDYKPYQVPKEDVDRKPVGGTKMDKDILERTVERLRSRVVHKQVVWGREFQGRPFNSKPELLHFQDFDIGKVYKKKITLVNTTYTINYCKLVGVEEHLRDFIHVDFDPPGPLSAGMSCEVLVTFKPMINKDLEGNISFLAQTGEFSVPLKCSTKKCSLSLDKELIDFGSYVVGETTSRTITLTNVGGLGTTFKFLPASEPCEMDDSQSALKLSSLLTYEDKSLYDKAATSFSEQQLEGTESSQADMQSRKELEKLDKEQEEEQPAEPERLTTVIPPSEEQTEITLGEVTEGEIGPFSSIKVPIVFTPVVPGDVQARFKVTFKNPQCPTLHFRVVGVAIDVPVWVPKPSVDLKICMYDRLYQDSVLVHTRSKAALRLKFEVCKELRAHLELLPKTGYIQAQSSYSVQLKFLPRHSLPEDAGRYFDKETRVLEAPMTIWVADQNKPVGFTVHAIVTTSDLELSPSEVDFGYCTIYEAIRTEISLHNHSLLPQEFGFVRLPKFVDVQPNDGFGTILPLETLQFCVIFQPTKAEEHRFQLTCKSEINRCFKLSCRAVGVHPPLELSHYQIKFAATALYDTSVATVYVINSHLSMSSPTHSKPRIGSEDASPMGPTSFEFLLPPDSPITISPSVGTVWPGKRCLVQVAFRPVLPEKLIRQEALPLLNKEMETKSFRKNMAPQRKDLHGLSFSVLRAQNRDKLFKVSVPHVLEMRKRELRPSSDEYQAARATLLRAFQAKFDTFVVPCVVASGDIKDRKGSEPLSFSPHNTLYLELWCPTVAPSVVVTSHKGKTIFNFGDVAVGHRSIKKISIQNVSPEDLALDFSLLNPNGPFVLLNHSSLLRAGGTQVLVLSFSPHESILAQETLDIITKRGTLTLTLMGTGVASMITCSIEGSVLNMGYVIAGESVSSGFKLQNNSLLPIKFSMHLDSLSSTRGRGQQQLPQFLSSPSQRTEVVGTQNLNGQSVFSVAPVKGVMDPGKTQDFTVTFSPDHESLYFSDKLQVVLFEKKISHQILLKGAACQHMMFVEGGDPLDVPVESLTAIPVFDPRHREEAEELRPILVTLDYIQFDTDTPAPPATRELQVGCIRTTQPSPKKPDHPLMVSALLQLRGDVKETYKVIFVAQVLTGP>sp|Q9C0B2-2|CFA74_HUMAN Isoform 2 of Cilia- and flagella-associatedprotein 74 OS=Homo sapiens OX=9606 GN=CFAP74MEDDGSLLPEDELLADALLLEDERDELEDPEFDIKCLLQEAEDDVDPGHSSSVKELDTDADKLKKKTAEDRTQAFHLRQNLSALDKMHEEQELFTEKMRGELRACRQRRDLIDKQQEAVAAEIATEEEAGNMAAVGRLQAVSRRLFAELENERDLQSRTEAVLKESENTMWHIEIQEGRLEAFRTADREEVEATGRRLQVRAAEQLCREQEALGKVERNRLLRIRKSLNTQKELGLRHQKLLEDARKNHKVAVRFLKASLGRIREQEKKEEMECHEYMRRRMDAVVALKGSISANRDTLRKFQAWDRAKAELAEQRVQAEKKAILAQGRDAFRHLVHQRRRQELEAQKRAFEEEQKLRKQEIISRILKEEAEEEKRKKQHPPTSARHRLTLRDKTWNYISDFCKKTTVPTNTYTLDYEAAAGPGPSRLLEVVSSELIQGDPGASSEEETLAEPEISGLWNEDYKPYQVPKEDVDRKPVGGTKMDKDILERTVERLRSRVVHKQVVWGREFQGRPFNSKPELLHFQDFDIGKVYKKKITLVNTTYTINYCKLVGVEEHLRDFIHVDFDPPGPLSAGMSCEVLVTFKPMINKDLEGNISFLAQTGEFSVPLKCSTKKCSLSLDKELIDFGSYVVGETTSRTITLTNVGGLGTTFKFLPASEPCEMDDSQSALKLSSLLTYEDKSLYDKAATSFSEQQLEGTESSQADMQSRKELEKLDKEQEEEQPAVLFLEWTKMYIHVDANRRLEGTSSIGPAGPARAEPHRAGKRLCGAPWRGRAAGGFCLALQLWLLLDAHQRGEVPRNGRALPSPCLLPCSPPPSGIACVSSLLLLIVFPHTHRDPETSVLLLSVFAW>sp|Q9C0B2-3|CFA74_HUMAN Isoform 3 of Cilia- and flagella-associatedprotein 74 OS=Homo sapiens OX=9606 GN=CFAP74MEDDGSLLPEDELLADALLLEDERDELEDPEFDIKCLLQEAEDDVDPGHSSSVKELDTDADKLKKKTAEDRTQAFHLRQNLSALDKMHEEQELFTEKMRGELRACRQRRDLIDKQQEAVAAEIATEEEAGNMAAVGRLQAVSRRLFAELENERDLQSRTEAVLKESE>sp|Q9P2D1|CHD7_HUMAN Chromodomain-helicase-DNA-binding protein 7 OS=Homosapiens OX=9606 GN=CHD7 PE=1 SV=3MADPGMMSLFGEDGNIFSEGLEGLGECGYPENPVNPMGQQMPIDQGFASLQPSLHHPSTNQNQTKLTHFDHYNQYEQQKMHLMDQPNRMMSNTPGNGLASPHSQYHTPPVPQVPHGGSGGGQMGVYPGMQNERHGQSFVDSSSMWGPRAVQVPDQIRAPYQQQQPQPQPPQPAPSGPPAQGHPQHMQQMGSYMARGDFSMQQHGQPQQRMSQFSQGQEGLNQGNPFIATSGPGHLSHVPQQSPSMAPSLRHSVQQFHHHPSTALHGESVAHSPRFSPNPPQQGAVRPQTLNFSSRSQTVPSPTINNSGQYSRYPYSNLNQGLVNNTGMNQNLGLTNNTPMNQSVPRYPNAVGFPSNSGQGLMHQQPIHPSGSLNQMNTQTMHPSQPQGTYASPPPMSPMKAMSNPAGTPPPQVRPGSAGIPMEVGSYPNMPHPQPSHQPPGAMGIGQRNMGPRNMQQSRPFIGMSSAPRELTGHMRPNGCPGVGLGDPQAIQERLIPGQQHPGQQPSFQQLPTCPPLQPHPGLHHQSSPPHPHHQPWAQLHPSPQNTPQKVPVHQHSPSEPFLEKPVPDMTQVSGPNAQLVKSDDYLPSIEQQPQQKKKKKKNNHIVAEDPSKGFGKDDFPGGVDNQELNRNSLDGSQEEKKKKKRSKAKKDPKEPKEPKEKKEPKEPKTPKAPKIPKEPKEKKAKTATPKPKSSKKSSNKKPDSEASALKKKVNKGKTEGSENSDLDKTPPPSPPPEEDEDPGVQKRRSSRQVKRKRYTEDLEFKISDEEADDADAAGRDSPSNTSQSEQQESVDAEGPVVEKIMSSRSVKKQKESGEEVEIEEFYVKYKNFSYLHCQWASIEDLEKDKRIQQKIKRFKAKQGQNKFLSEIEDELFNPDYVEVDRIMDFARSTDDRGEPVTHYLVKWCSLPYEDSTWERRQDIDQAKIEEFEKLMSREPETERVERPPADDWKKSESSREYKNNNKLREYQLEGVNWLLFNWYNMRNCILADEMGLGKTIQSITFLYEIYLKGIHGPFLVIAPLSTIPNWEREFRTWTELNVVVYHGSQASRRTIQLYEMYFKDPQGRVIKGSYKFHAIITTFEMILTDCPELRNIPWRCVVIDEAHRLKNRNCKLLEGLKMMDLEHKVLLTGTPLQNTVEELFSLLHFLEPSRFPSETTFMQEFGDLKTEEQVQKLQAILKPMMLRRLKEDVEKNLAPKEETIIEVELTNIQKKYYRAILEKNFTFLSKGGGQANVPNLLNTMMELRKCCNHPYLINGAEEKILEEFKETHNAESPDFQLQAMIQAAGKLVLIDKLLPKLKAGGHRVLIFSQMVRCLDILEDYLIQRRYPYERIDGRVRGNLRQAAIDRFSKPDSDRFVFLLCTRAGGLGINLTAADTCIIFDSDWNPQNDLQAQARCHRIGQSKSVKIYRLITRNSYEREMFDKASLKLGLDKAVLQSMSGRENATNGVQQLSKKEIEDLLRKGAYGALMDEEDEGSKFCEEDIDQILLRRTHTITIESEGKGSTFAKASFVASGNRTDISLDDPNFWQKWAKKAELDIDALNGRNNLVIDTPRVRKQTRLYSAVKEDELMEFSDLESDSEEKPCAKPRRPQDKSQGYARSECFRVEKNLLVYGWGRWTDILSHGRYKRQLTEQDVETICRTILVYCLNHYKGDENIKSFIWDLITPTADGQTRALVNHSGLSAPVPRGRKGKKVKAQSTQPVVQDADWLASCNPDALFQEDSYKKHLKHHCNKVLLRVRMLYYLRQEVIGDQADKILEGADSSEADVWIPEPFHAEVPADWWDKEADKSLLIGVFKHGYEKYNSMRADPALCFLERVGMPDAKAIAAEQRGTDMLADGGDGGEFDREDEDPEYKPTRTPFKDEIDEFANSPSEDKEESMEIHATGKHSESNAELGQLYWPNTSTLTTRLRRLITAYQRSYKRQQMRQEALMKTDRRRRRPREEVRALEAEREAIISEKRQKWTRREEADFYRVVSTFGVIFDPVKQQFDWNQFRAFARLDKKSDESLEKYFSCFVAMCRRVCRMPVKPDDEPPDLSSIIEPITEERASRTLYRIELLRKIREQVLHHPQLGERLKLCQPSLDLPEWWECGRHDRDLLVGAAKHGVSRTDYHILNDPELSFLDAHKNFAQNRGAGNTSSLNPLAVGFVQTPPVISSAHIQDERVLEQAEGKVEEPENPAAKEKCEGKEEEEETDGSGKESKQECEAEASSVKNELKGVEVGADTGSKSISEKGSEEDEEEKLEDDDKSEESSQPEAGAVSRGKNFDEESNASMSTARDETRDGFYMEDGDPSVAQLLHERTFAFSFWPKDRVMINRLDNICEAVLKGKWPVNRRQMFDFQGLIPGYTPTTVDSPLQKRSFAELSMVGQASISGSEDITTSPQLSKEDALNLSVPRQRRRRRRKIEIEAERAAKRRNLMEMVAQLRESQVVSENGQEKVVDLSKASREATSSTSNFSSLSSKFILPNVSTPVSDAFKTQMELLQAGLSRTPTRHLLNGSLVDGEPPMKRRRGRRKNVEGLDLLFMSHKRTSLSAEDAEVTKAFEEDIETPPTRNIPSPGQLDPDTRIPVINLEDGTRLVGEDAPKNKDLVEWLKLHPTYTVDMPSYVPKNADVLFSSFQKPKQKRHRCRNPNKLDINTLTGEERVPVVNKRNGKKMGGAMAPPMKDLPRWLEENPEFAVAPDWTDIVKQSGFVPESMFDRLLTGPVVRGEGASRRGRRPKSEIARAAAAAAAVASTSGINPLLVNSLFAGMDLTSLQNLQNLQSLQLAGLMGFPPGLATAATAGGDAKNPAAVLPLMLPGMAGLPNVFGLGGLLNNPLSAATGNTTTASSQGEPEDSTSKGEEKGNENEDENKDSEKSTDAVSAADSANGSVGAATAPAGLPSNPLAFNPFLLSTMAPGLFYPSMFLPPGLGGLTLPGFPALAGLQNAVGSSEEKAADKAEGGPFKDGETLEGSDAEESLDKTAESSLLEDEIAQGEELDSLDGGDEIENNENDE>sp|Q9P2D1-2|CHD7_HUMAN Isoform 2 of Chromodomain-helicase-DNA-bindingprotein 7 OS=Homo sapiens OX=9606 GN=CHD7MADPGMMSLFGEDGNIFSEGLEGLGECGYPENPVNPMGQQMPIDQGFASLQPSLHHPSTNQNQTKLTHFDHYNQYEQQKMHLMDQPNRMMSNTPGNGLASPHSQYHTPPVPQVPHGGSGGGQMGVYPGMQNERHGQSFVDSSSMWGPRAVQVPDQIRAPYQQQQPQPQPPQPAPSGPPAQGHPQHMQQMGSYMARGDFSMQQHGQPQQRMSQFSQGQEGLNQGNPFIATSGPGHLSHVPQQSPSMAPSLRHSVQQFHHHPSTALHGESVAHSPRFSPNPPQQGAVRPQTLNFSSRSQTVPSPTINNSGQYSRYPYSNLNQGLVNNTGMNQNLGLTNNTPMNQSVPRYPNAVGFPSNSGQGLMHQQPIHPSGSLNQMNTQTMHPSQPQGTYASPPPMSPMKAMSNPAGTPPPQVRPGSAGIPMEVGSYPNMPHPQPSHQPPGAMGIGQRNMGPRNMQQSRPFIGMSSAPRELTGHMRPNGCPGVGLGDPQAIQERLIPGQQHPGQQPSFQQLPTCPPLQPHPGLHHQSSPPHPHHQPWAQLHPSPQNTPQKVPVHQHSPSEPFLEKPVPDMTQVSGPNAQLVKSDDYLPSIEQQPQQKKKKKKNNHIVAEDPSKGFGKDDFPGGVDNQELNRNSLDGSQEEKKKKKRSKAKKDPKEPKEPKEKKEPKEPKTPKAPKIPKEPKEKKAKTATPKPKSSKKSSNKKPDSEASALKKKVNKGKTEGSENSDLDKTPPPSPPPEEDEDPGVQKRRSSRQVKRKRYTEDLEFKISDEEADDADAAGRDSPSNTSQSEQQESVDAEGPVVEKIMSSRSVKKQKESGEEVEIEEFYVKYKNFSYLHCQWASIEDLEKDKRIQQKIKRFKAKQGQNKFLSEIEDELFNPDYVEVDRIMDFARSTDDRGEPVTHYLVKWCSLPYEDSTWERRQDIDQAKIEEFEKLMSREPETERVERPPADDWKKSESSREYKNNNKLREYQLEGVNWLLFNWYNMRNCILADEMGLGKTIQSITFLYEIYLKGIHGPFLVIAPLSTIPNWEREFRTWTELNVVVYHGSQASRRTIQLYEMYFKDPQGRVIKGSYKFHAIITTFEMILTDCPELRNIPWRCVVIDEAHRLKNRNCKLLEGLKMMDLVSDHIGDCTEPE>sp|Q9P2D1-3|CHD7_HUMAN Isoform 3 of Chromodomain-helicase-DNA-bindingprotein 7 OS=Homo sapiens OX=9606 GN=CHD7MADPGMMSLFGEDGNIFSEGLEGLGECGYPENPVNPMGQQMPIDQGFASLQPSLHHPSTNQNQTKLTHFDHYNQYEQQKMHLMDQPNRMMSNTPGNGLASPHSQYHTPPVPQVPHGGSGGGQMGVYPGMQNERHGQSFVDSSSMWGPRAVQVPDQIRAPYQQQQPQPQPPQPAPSGPPAQGHPQHMQQMGSYMARGDFSMQQHGQPQQRMSQFSQGQEGLNQGNPFIATSGPGHLSHVPQQSPSMAPSLRHSVQQFHHHPSTALHGESVAHSPRFSPNPPQQGAVRPQTLNFSSRSQTVPSPTINNSGQYSRYPYSNLNQGLVNNTGMNQNLGLTNNTPMNQSVPRYPNAVGFPSNSGQGLMHQQPIHPSGSLNQMNTQTMHPSQPQGTYASPPPMSPMKAMSNPAGTPPPQVRPGSAGIPMEVGSYPNMPHPQPSHQPPGAMGIGQRNMGPRNMQQSRPFIGMSSAPRELTGHMRPNGCPGVGLGDPQAIQERLIPGQQHPGQQPSFQQLPTCPPLQPHPGLHHQSSPPHPHHQPWAQLHPSPQNTPQKVPVHQHSPSEPFLEKPVPDMTQVSGPNAQLVKSDDYLPSIEQQPQQKKKKKKNNHIVAEDPSKGFGKDDFPGGVDNQELNRNSLDGSQEEKKKKKRSKAKKDPKEPKEPKEKKEPKEPKTPKAPKIPKEPKEKKAKTATPKPKSSKKSSNKKPDSEASALKKKVNKGKTEGSENSDLDKTPPPSPPPEEDEDPGVQKRRSSRQVKRKRYTEDLEFKISDEEADDADAAGRDSPSNTSQSEQQESVDAEGPVVEKIMSSRSVKKQKESGEEVEIEEFYVKYKNLQKPKQKRHRCRNPNKLDINTLTGEERVPVVNKRNGKKMGGAMAPPMKDLPRWLEENPEFAVAPDWTDIVKQSGFVPESMFDRLLTGPVVRGEGASRRGRRPKSEIARAAAAAAAVASTSGINPLLVNSLFAGMDLTSLQNLQNLQSLQLAGLMGFPPGLATAATAGGDAKNPAAVLPLMLPGMAGLPNVFGLGGLLNNPLSAATGNTTTASSQGEPEDSTSKGEEKGNENEDENKDSEKSTDAVSAADSANGSVGAATAPAGLPSNPLAFNPFLLSTMAPGLFYPSMFLPPGLGGLTLPGFPALAGLQNAVGSSEEKAADKAEGGPFKDGETLEGSDAEESLDKTAESSLLEDEIAQGEELDSLDGGDEIENNENDE>sp|Q9P2D1-4|CHD7_HUMAN Isoform 4 of Chromodomain-helicase-DNA-bindingprotein 7 OS=Homo sapiens OX=9606 GN=CHD7MADPGMMSLFGEDGNIFSEGLEGLGECGYPENPVNPMGQQMPIDQGFASLQPSLHHPSTNQNQTKLTHFDHYNQYEQQKMHLMDQPNRMMSNTPGNGLASPHSQYHTPPVPQVPHGGSGGGQMGVYPGMQNERHGQSFVDSSSMWGPRAVQVPDQIRAPYQQQQPQPQPPQPAPSGPPAQGHPQHMQQMGSYMARGDFSMQQHGQPQQRMSQFSQGQEGLNQGNPFIATSGPGHLSHVPQQSPSMAPSLRHSVQQFHHHPSTALHGESVAHSPRFSPNPPQQGAVRPQTLNFSSRSQTVPSPTINNSGQYSRYPYSNLNQGLVNNTGMNQNLGLTNNTPMNQSVPRYPNAVGFPSNSGQGLMHQQPIHPSGSLNQMNTQTMHPSQPQGTYASPPPMSPMKAMSNPAGTPPPQVRPGSAGIPMEVGSYPNMPHPQPSHQPPGAMGIGQRNMGPRNMQQSRPFIGMSSAPRELTGHMRPNGCPGVGLGDPQAIQERLIPGQQHPGQQPSFQQLPTCPPLQPHPGLHHQSSPPHPHHQPWAQLHPSPQNTPQKVPVHQHSPSEPFLEKPVPDMTQKPKQKRHRCRNPNKLDINTLTGEERVPVVNKRNGKKMGGAMAPPMKDLPRWLEENPEFAVAPDWTDIVKQSGFVPESMFDRLLTGPVVRGEGASRRGRRPKSEIARAAAAAAAVASTSGINPLLVNSLFAGMDLTSLQNLQNLQSLQLAGLMGFPPGLATAATAGGDAKNPAAVLPLMLPGMAGLPNVFGLGGLLNNPLSAATGNTTTASSQGEPEDSTSKGEEKGNENEDENKDSEKSTDAVSAADSANGSVGAATAPAGLPSNPLAFNPFLLSTMAPGLFYPSMFLPPGLGGLTLPGFPALAGLQNAVGSSEEKAADKAEGGPFKDGETLEGSDAEESLDKTAESSLLEDEIAQGEELDSLDGGDEIENNENDE>sp|P08603|CFAH_HUMAN Complement factor H OS=Homo sapiens OX=9606 GN=CFHPE=1 SV=4MRLLAKIICLMLWAICVAEDCNELPPRRNTEILTGSWSDQTYPEGTQAIYKCRPGYRSLGNVIMVCRKGEWVALNPLRKCQKRPCGHPGDTPFGTFTLTGGNVFEYGVKAVYTCNEGYQLLGEINYRECDTDGWTNDIPICEVVKCLPVTAPENGKIVSSAMEPDREYHFGQAVRFVCNSGYKIEGDEEMHCSDDGFWSKEKPKCVEISCKSPDVINGSPISQKIIYKENERFQYKCNMGYEYSERGDAVCTESGWRPLPSCEEKSCDNPYIPNGDYSPLRIKHRTGDEITYQCRNGFYPATRGNTAKCTSTGWIPAPRCTLKPCDYPDIKHGGLYHENMRRPYFPVAVGKYYSYYCDEHFETPSGSYWDHIHCTQDGWSPAVPCLRKCYFPYLENGYNQNYGRKFVQGKSIDVACHPGYALPKAQTTVTCMENGWSPTPRCIRVKTCSKSSIDIENGFISESQYTYALKEKAKYQCKLGYVTADGETSGSITCGKDGWSAQPTCIKSCDIPVFMNARTKNDFTWFKLNDTLDYECHDGYESNTGSTTGSIVCGYNGWSDLPICYERECELPKIDVHLVPDRKKDQYKVGEVLKFSCKPGFTIVGPNSVQCYHFGLSPDLPICKEQVQSCGPPPELLNGNVKEKTKEEYGHSEVVEYYCNPRFLMKGPNKIQCVDGEWTTLPVCIVEESTCGDIPELEHGWAQLSSPPYYYGDSVEFNCSESFTMIGHRSITCIHGVWTQLPQCVAIDKLKKCKSSNLIILEEHLKNKKEFDHNSNIRYRCRGKEGWIHTVCINGRWDPEVNCSMAQIQLCPPPPQIPNSHNMTTTLNYRDGEKVSVLCQENYLIQEGEEITCKDGRWQSIPLCVEKIPCSQPPQIEHGTINSSRSSQESYAHGTKLSYTCEGGFRISEENETTCYMGKWSSPPQCEGLPCKSPPEISHGVVAHMSDSYQYGEEVTYKCFEGFGIDGPAIAKCLGEKWSHPPSCIKTDCLSLPSFENAIPMGEKKDVYKAGEQVTYTCATYYKMDGASNVTCINSRWTGRPTCRDTSCVNPPTVQNAYIVSRQMSKYPSGERVRYQCRSPYEMFGDEEVMCLNGNWTEPPQCKDSTGKCGPPPPIDNGDITSFPLSVYAPASSVEYQCQNLYQLEGNKRITCRNGQWSEPPKCLHPCVISREIMENYNIALRWTAKQKLYSRTGESVEFVCKRGYRLSSRSHTLRTTCWDGKLEYPTCAKR>sp|P08603-2|CFAH_HUMAN Isoform 2 of Complement factor H OS=Homo sapiensOX=9606 GN=CFHMRLLAKIICLMLWAICVAEDCNELPPRRNTEILTGSWSDQTYPEGTQAIYKCRPGYRSLGNVIMVCRKGEWVALNPLRKCQKRPCGHPGDTPFGTFTLTGGNVFEYGVKAVYTCNEGYQLLGEINYRECDTDGWTNDIPICEVVKCLPVTAPENGKIVSSAMEPDREYHFGQAVRFVCNSGYKIEGDEEMHCSDDGFWSKEKPKCVEISCKSPDVINGSPISQKIIYKENERFQYKCNMGYEYSERGDAVCTESGWRPLPSCEEKSCDNPYIPNGDYSPLRIKHRTGDEITYQCRNGFYPATRGNTAKCTSTGWIPAPRCTLKPCDYPDIKHGGLYHENMRRPYFPVAVGKYYSYYCDEHFETPSGSYWDHIHCTQDGWSPAVPCLRKCYFPYLENGYNQNYGRKFVQGKSIDVACHPGYALPKAQTTVTCMENGWSPTPRCIRVSFTL>sp|B2RD01|CENP1_HUMAN Putative CENPB DNA-binding domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=CENPBD1P PE=5 SV=1MPGERPTDATVIPSAKRERKAITLDLKLEVLRRFEAGEKLSQIAKALDLAISTVATIRDSKEKIKASSQIATPLRASRLTRHRSAVMESMEQLLSLWLEDQSQPNATLSAAIVQEKAEFDDLQREHGEGSQTERFHASQGWLVRFKECHCLPHFKMNSAAPSNKDMYTEMLKSIIEEGEYTPQVSLT>sp|Q8N111|CEND_HUMAN Cell cycle exit and neuronal differentiationprotein 1 OS=Homo sapiens OX=9606 GN=CEND1 PE=1 SV=1MESRGKSASSPKPDTKVPQVTTEAKVPPAADGKAPLTKPSKKEAPAEKQQPPAAPTTAPAKKTSAKADPALLNNHSNLKPAPTVPSSPDATPEPKGPGDGAEEDEAASGGPGGRGPWSCENFNPLLVAGGVAVAAIALILGVAFLVRKK>sp|P0DPI3|CENL2_HUMAN Centromere protein V-like protein 2 OS=Homosapiens OX=9606 GN=CENPVL2 PE=3 SV=1MGRVRNRATAQRRRRKRPGDPPAACAAIAVTGASRAQCPRVQVGVGSHAAAKRWLGRWRRKRRWRRVRKAGPRDLLPSAPTPDPPGPAPSPKDLDLGAQRERWETFRKLRGLSCEGAAKVLLDTFEYPGLVHHTGGCHCGAVRFAVWAPADLRVVDCSCRLCRKKQHRHFLVPASRFTLLQGAESIVTYRSNTHPALHSFCSRCGVQSFHAAVSDPRVYGVAPHCLDEGTVRSVVIEEVGGGDPGEEAAEEHKAIHKTSSQSAPACPREQEQ>sp|Q5T0N1|CFA70_HUMAN Cilia- and flagella-associated protein 70 OS=Homosapiens OX=9606 GN=CFAP70 PE=1 SV=3MEQVPSAGRLVQITVTEGYDLKGFKGDTPVTFIRAEFNQVVLGDSAKITVSPEGSAKYNFTSSFEFNPEGGITSDDLAHKPVFLTVTEVLPKEKKQKEEKTLILGQAVVDLLPLLEGQSSFQTTVPLHPVQGSPLETPRSSAKQCSLEVKVLVAEPLLTTAQISGGNLLKVTLEAAYSVPESFIPTGPGQNYMVGLQVPSLGEKDYPILFKNGTLKLGGEREPVPRPKKWPIANILAPGANNIPDAFIVGGPYEEEEGELNHPEDSEFRNQAECIKKRIIWDLESRCYLDPSAVVSFQKRIADCRLWPVEITRVPLVTIPKGKAGKTEKTDEEAQLSFHGVAYVNMVPLLYPGVKRIRGAFHVYPYLDSVVHEKTKCLLSLFRDIGHHLIHNNKIGGINSLLSKQAVSKNLKEDKPVKEKDIDGRPRPGDVQAPSIKSQSSDTPLEGEPPLSHNPEGQQYVEAGTYIVLEIQLDKALVPKRMPEELARRVKEMIPPRPPLTRRTGGAQKAMSDYHIQIKNISRAILDEYYRMFGKQVAKLESDMDSETLEEQKCQLSYELNCSGKYFAFKEQLKHAVVKIVRDKYLKTTSFESQEELQTFISELYVFLVDQMHVALNQTMPDDVQGTVATIYTSSEQLQLFAFEAEVNENFEMAAAYYKERLVREPQNLDHWLDYGAFCLLTEDNIKAQECFQKALSLNQSHIHSLLLCGVLAVLLENYEQAEIFFEDATCLEPTNVVAWTLLGLYYEIQNNDIRMEMAFHEASKQLQARMLQAQVTKQKSTGVEDTEERGKRESSLGPWGITNGSATAIKVEAPAGPGAALSILDKFLEESSKLQSDSQEPILTTQTWDPSISQKPSNTFIKEIPTKKEASKCQDSSALLHPGLHYGVSQTTTIFMETIHFLMKVKAVQYVHRVLAHELLCPQGGPSCEYYLVLAQTHILKKNFAKAEEYLQQAAQMDYLNPNVWGLKGHLYFLSGNHSEAKACYERTISFVVDASEMHFIFLRLGLIYLEEKEYEKAKKTYMQACKRSPSCLTWLGLGIACYRLEELTEAEDALSEANALNNYNAEVWAYLALVCLKVGRQLEAEQAYKYMIKLKLKDEALLAEIHTLQETVGFGNPSF>sp|Q5T0N1-2|CFA70_HUMAN Isoform 2 of Cilia- and flagella-associatedprotein 70 OS=Homo sapiens OX=9606 GN=CFAP70MEQVPSAGRLVQITVTEGYDLKGFKGDTPVTFIRAEFNQVVLGDSAKITVSPEGSAKYNFTSSFEFNPEGGITSDDLAHKPVFLTVTEVLPKEKKQKEEKTLILGQAVVDLLPLLEGQSSFQTTVPLHPVQGSPLETPRSSAKQCSLEVKVLVAEPLLTTAQISGGNLLKVTLEAAYSVPESFIPTGPGQNYMVGLQVPSLGEKDYPILFKNGTLKLGGEREPVPRPKKWPIANILAPGANNIPDAFIVGGPYEEEEGELNHPEDSEFRNQAECIKKRIIWDLESRCYLDPSAVVSFQKRIADCRLWPVEITRVPLVTIPKGKAGKTEKTDEEAQLSFHGVAYVNMVPLLYPGVKRIRGAFHVYPYLDSVVHEKTKCLLSLFRDIGHHLIHNNKIGGINSLLSKQAVSKNLKEDKPVKEKDIDGRPRPGDVQAPSIKSQSSDTPLEGEPPLSHNPEGQQYVEAGTYIVLEIQLDKALVPKRMPEELARRVKEMIPPRPPLTRRTGGAQKAMSDYHIQIKNISRAILDEYYRMFGKQVAKLESDMDSETLEEQKCQLSYELNCSGKYFAFKEQLKHAVVKIVRDKYLKTTSFESQEELQTFISELYVFLVDQMHVALNQTMPDDVQGTVATIYTSSEQLQLFAFEAEVNENFEMAAAYYKERLVREPQNLDHWLDYGAFCLLTEDNIKAQECFQKALSLNQSHIHSLLLCGVLAVLLENYEQAEIFFEDATCLEPTNVVAWTLLGLYYEIQNNDIRMEMAFHEASKQLQARMLQAQVTKQKSTGVEDTEERGKRESSLGPWGITNGSATAIKVEAPAGPGAALSILDKFLEESSKLQSDSQEPILTTQTWDPSISQKPSNTFIKEIPTKKEASKCQDSSALLHPGLHYGVSQTTTIFMETIHFLMKVKAVQYVHRVLAHELLCPQGGPSCEYYLVLAQTHILKKNFAKAEEYLQQAAQMDYLNPNVWGLKGHLYFLSGNHSEAKACYERTISFVVDASEMHFIFLRLGLIYLEEKELEELTEAEDALSEANALNNYNAEVWAYLALVCLKVGRQLEAEQAYKYMIKLKLKDEALLAEIHTLQETVGFGNPSF>sp|Q5T0N1-3|CFA70_HUMAN Isoform 3 of Cilia- and flagella-associatedprotein 70 OS=Homo sapiens OX=9606 GN=CFAP70MEQVPSAGRLVQITVTEGYDLKGFKGDTPVTFIRAEFNQVVLGDSAKITVSPEGSAKYNFTSSFEFNPEGGITSDDLAHKPVFLTVTEVLPKEKKQKEEKTLILGQAVVDLLPLLEVQS>sp|Q5T0N1-6|CFA70_HUMAN Isoform 4 of Cilia- and flagella-associatedprotein 70 OS=Homo sapiens OX=9606 GN=CFAP70METIHFLMKVKAVQYVHRVLAHELLCPQGGPSCEYYLVLAQTHILKKNFAKAEEYLQQAAQMDYLNPNVWGLKGHLYFLSGNHSEAKACYERTISFVVDASEMHFIFLRLGLIYLEEKELEELTEAEDALSEANALNNYNAEVWAYLALVCLKVGRQLEAEQAYKYMIKLKLKDEALLAEIHTLQETVGFGNPSF>sp|Q5T0N1-7|CFA70_HUMAN Isoform 5 of Cilia- and flagella-associatedprotein 70 OS=Homo sapiens OX=9606 GN=CFAP70METIHFLMKVKAVQYVHRVLAHELLCPQGGPSCEYYLVLAQTHILKKNFAKAEEYLQQAAQMDYLNPNVWGLKGHLYFLSGNHSEAKACYERTISFVVDASEMHFIFLRLGLIYLEEKEYEKAKKTYMQACKRSPSCLTWLGLGIACYRLEELTEAEDALSEANALNNYNAEVWAYLALVCLKVGRQLEAEQAYKYMIKLKLKDEALLAEIHTLQETVGFGNPSF>sp|P49450|CENPA_HUMAN Histone H3-like centromeric protein A OS=Homosapiens OX=9606 GN=CENPA PE=1 SV=1MGPRRRSRKPEAPRRRSPSPTPTPGPSRRGPSLGASSHQHSRRRQGWLKEIRKLQKSTHLLIRKLPFSRLAREICVKFTRGVDFNWQAQALLALQEAAEAFLVHLFEDAYLLTLHAGRVTLFPKDVQLARRIRGLEEGLG>sp|P49450-2|CENPA_HUMAN Isoform 2 of Histone H3-like centromeric proteinA OS=Homo sapiens OX=9606 GN=CENPAMGPRRRSRKPEAPRRRSPSPTPTPGPSRRGPSLGASSHQHSRRRQGWLKEIRKLQKSTHLLIRKLPFSRLAAEAFLVHLFEDAYLLTLHAGRVTLFPKDVQLARRIRGLEEGLG>sp|Q02224|CENPE_HUMAN Centromere-associated protein E OS=Homo sapiensOX=9606 GN=CENPE PE=1 SV=2MAEEGAVAVCVRVRPLNSREESLGETAQVYWKTDNNVIYQVDGSKSFNFDRVFHGNETTKNVYEEIAAPIIDSAIQGYNGTIFAYGQTASGKTYTMMGSEDHLGVIPRAIHDIFQKIKKFPDREFLLRVSYMEIYNETITDLLCGTQKMKPLIIREDVNRNVYVADLTEEVVYTSEMALKWITKGEKSRHYGETKMNQRSSRSHTIFRMILESREKGEPSNCEGSVKVSHLNLVDLAGSERAAQTGAAGVRLKEGCNINRSLFILGQVIKKLSDGQVGGFINYRDSKLTRILQNSLGGNAKTRIICTITPVSFDETLTALQFASTAKYMKNTPYVNEVSTDEALLKRYRKEIMDLKKQLEEVSLETRAQAMEKDQLAQLLEEKDLLQKVQNEKIENLTRMLVTSSSLTLQQELKAKRKRRVTWCLGKINKMKNSNYADQFNIPTNITTKTHKLSINLLREIDESVCSESDVFSNTLDTLSEIEWNPATKLLNQENIESELNSLRADYDNLVLDYEQLRTEKEEMELKLKEKNDLDEFEALERKTKKDQEMQLIHEISNLKNLVKHAEVYNQDLENELSSKVELLREKEDQIKKLQEYIDSQKLENIKMDLSYSLESIEDPKQMKQTLFDAETVALDAKRESAFLRSENLELKEKMKELATTYKQMENDIQLYQSQLEAKKKMQVDLEKELQSAFNEITKLTSLIDGKVPKDLLCNLELEGKITDLQKELNKEVEENEALREEVILLSELKSLPSEVERLRKEIQDKSEELHIITSEKDKLFSEVVHKESRVQGLLEEIGKTKDDLATTQSNYKSTDQEFQNFKTLHMDFEQKYKMVLEENERMNQEIVNLSKEAQKFDSSLGALKTELSYKTQELQEKTREVQERLNEMEQLKEQLENRDSTLQTVEREKTLITEKLQQTLEEVKTLTQEKDDLKQLQESLQIERDQLKSDIHDTVNMNIDTQEQLRNALESLKQHQETINTLKSKISEEVSRNLHMEENTGETKDEFQQKMVGIDKKQDLEAKNTQTLTADVKDNEIIEQQRKIFSLIQEKNELQQMLESVIAEKEQLKTDLKENIEMTIENQEELRLLGDELKKQQEIVAQEKNHAIKKEGELSRTCDRLAEVEEKLKEKSQQLQEKQQQLLNVQEEMSEMQKKINEIENLKNELKNKELTLEHMETERLELAQKLNENYEEVKSITKERKVLKELQKSFETERDHLRGYIREIEATGLQTKEELKIAHIHLKEHQETIDELRRSVSEKTAQIINTQDLEKSHTKLQEEIPVLHEEQELLPNVKEVSETQETMNELELLTEQSTTKDSTTLARIEMERLRLNEKFQESQEEIKSLTKERDNLKTIKEALEVKHDQLKEHIRETLAKIQESQSKQEQSLNMKEKDNETTKIVSEMEQFKPKDSALLRIEIEMLGLSKRLQESHDEMKSVAKEKDDLQRLQEVLQSESDQLKENIKEIVAKHLETEEELKVAHCCLKEQEETINELRVNLSEKETEISTIQKQLEAINDKLQNKIQEIYEKEEQFNIKQISEVQEKVNELKQFKEHRKAKDSALQSIESKMLELTNRLQESQEEIQIMIKEKEEMKRVQEALQIERDQLKENTKEIVAKMKESQEKEYQFLKMTAVNETQEKMCEIEHLKEQFETQKLNLENIETENIRLTQILHENLEEMRSVTKERDDLRSVEETLKVERDQLKENLRETITRDLEKQEELKIVHMHLKEHQETIDKLRGIVSEKTNEISNMQKDLEHSNDALKAQDLKIQEELRIAHMHLKEQQETIDKLRGIVSEKTDKLSNMQKDLENSNAKLQEKIQELKANEHQLITLKKDVNETQKKVSEMEQLKKQIKDQSLTLSKLEIENLNLAQKLHENLEEMKSVMKERDNLRRVEETLKLERDQLKESLQETKARDLEIQQELKTARMLSKEHKETVDKLREKISEKTIQISDIQKDLDKSKDELQKKIQELQKKELQLLRVKEDVNMSHKKINEMEQLKKQFEAQNLSMQSVRMDNFQLTKKLHESLEEIRIVAKERDELRRIKESLKMERDQFIATLREMIARDRQNHQVKPEKRLLSDGQQHLTESLREKCSRIKELLKRYSEMDDHYECLNRLSLDLEKEIEFQKELSMRVKANLSLPYLQTKHIEKLFTANQRCSMEFHRIMKKLKYVLSYVTKIKEEQHESINKFEMDFIDEVEKQKELLIKIQHLQQDCDVPSRELRDLKLNQNMDLHIEEILKDFSESEFPSIKTEFQQVLSNRKEMTQFLEEWLNTRFDIEKLKNGIQKENDRICQVNNFFNNRIIAIMNESTEFEERSATISKEWEQDLKSLKEKNEKLFKNYQTLKTSLASGAQVNPTTQDNKNPHVTSRATQLTTEKIRELENSLHEAKESAMHKESKIIKMQKELEVTNDIIAKLQAKVHESNKCLEKTKETIQVLQDKVALGAKPYKEEIEDLKMKLVKIDLEKMKNAKEFEKEISATKATVEYQKEVIRLLRENLRRSQQAQDTSVISEHTDPQPSNKPLTCGGGSGIVQNTKALILKSEHIRLEKEISKLKQQNEQLIKQKNELLSNNQHLSNEVKTWKERTLKREAHKQVTCENSPKSPKVTGTASKKKQITPSQCKERNLQDPVPKESPKSCFFDSRSKSLPSPHPVRYFDNSSLGLCPEVQNAGAESVDSQPGPWHASSGKDVPECKTQ>sp|Q02224-3|CENPE_HUMAN Isoform 3 of Centromere-associated protein EOS=Homo sapiens OX=9606 GN=CENPEMAEEGAVAVCVRVRPLNSREESLGETAQVYWKTDNNVIYQVDGSKSFNFDRVFHGNETTKNVYEEIAAPIIDSAIQGYNGTIFAYGQTASGKTYTMMGSEDHLGVIPRAIHDIFQKIKKFPDREFLLRVSYMEIYNETITDLLCGTQKMKPLIIREDVNRNVYVADLTEEVVYTSEMALKWITKGEKSRHYGETKMNQRSSRSHTIFRMILESREKGEPSNCEGSVKVSHLNLVDLAGSERAAQTGAAGVRLKEGCNINRSLFILGQVIKKLSDGQVGGFINYRDSKLTRILQNSLGGNAKTRIICTITPVSFDETLTALQFASTAKYMKNTPYVNEVSTDEALLKRYRKEIMDLKKQLEEVSLETRAQAMEKDQLAQLLEEKDLLQKVQNEKIENLTRMLVTSSSLTLQQELKAKRKRRVTWCLGKINKMKNSNYADQFNIPTNITTKTHKLSINLLREIDESVCSESDVFSNTLDTLSEIEWNPATKLLNQENIESELNSLRADYDNLVLDYEQLRTEKEEMELKLKEKNDLDEFEALERKTKKDQENELSSKVELLREKEDQIKKLQEYIDSQKLENIKMDLSYSLESIEDPKQMKQTLFDAETVALDAKRESAFLRSENLELKEKMKELATTYKQMENDIQLYQSQLEAKKKMQVDLEKELQSAFNEITKLTSLIDGKVPKDLLCNLELEGKITDLQKELNKEVEENEALREEVILLSELKSLPSEVERLRKEIQDKSEELHIITSEKDKLFSEVVHKESRVQGLLEEIGKTKDDLATTQSNYKSTDQEFQNFKTLHMDFEQKYKMVLEENERMNQEIVNLSKEAQKFDSSLGALKTELSYKTQELQEKTREVQERLNEMEQLKEQLENRDSTLQTVEREKTLITEKLQQTLEEVKTLTQEKDDLKQLQESLQIERDQLKSDIHDTVNMNIDTQEQLRNALESLKQHQETINTLKSKISEEVSRNLHMEENTGETKDEFQQKMVGIDKKQDLEAKNTQTLTADVKDNEIIEQQRKIFSLIQEKNELQQMLESVIAEKEQLKTDLKENIEMTIENQEELRLLGDELKKQQEIVAQEKNHAIKKEGELSRTCDRLAEVEEKLKEKSQQLQEKQQQLLNVQEEMSEMQKKINEIENLKNELKNKELTLEHMETERLELAQKLNENYEEVKSITKERKVLKELQKSFETERDHLRGYIREIEATGLQTKEELKIAHIHLKEHQETIDELRRSVSEKTAQIINTQDLEKSHTKLQEEIPVLHEEQELLPNVKEVSETQETMNELELLTEQSTTKDSTTLARIEMERLRLNEKFQESQEEIKSLTKERDNLKTIKEALEVKHDQLKEHIRETLAKIQESQSKQEQSLNMKEKDNETTKIVSEMEQFKPKDSALLRIEIEMLGLSKRLQESHDEMKSVAKEKDDLQRLQEVLQSESDQLKENIKEIVAKHLETEEELKVAHCCLKEQEETINELRVNLSEKETEISTIQKQLEAINDKLQNKIQEIYEKEEQFNIKQISEVQEKVNELKQFKEHRKAKDSALQSIESKMLELTNRLQESQEEIQIMIKEKEEMKRVQEALQIERDQLKENTKEIVAKMKESQEKEYQFLKMTAVNETQEKMCEIEHLKEQFETQKLNLENIETENIRLTQILHENLEEMRSVTKERDDLRSVEETLKVERDQLKENLRETITRDLEKQEELKIVHMHLKEHQETIDKLRGIVSEKTNEISNMQKDLEHSNDALKAQDLKIQEELRIAHMHLKEQQETIDKLRGIVSEKTDKLSNMQKDLENSNAKLQEKIQELKANEHQLITLKKDVNETQKKVSEMEQLKKQIKDQSLTLSKLEIENLNLAQKLHENLEEMKSVMKERDNLRRVEETLKLERDQLKESLQETKARDLEIQQELKTARMLSKEHKETVDKLREKISEKTIQISDIQKDLDKSKDELQKKQDRQNHQVKPEKRLLSDGQQHLTESLREKCSRIKELLKRYSEMDDHYECLNRLSLDLEKEIEFQKELSMRVKANLSLPYLQTKHIEKLFTANQRCSMEFHRIMKKLKYVLSYVTKIKEEQHESINKFEMDFIDEVEKQKELLIKIQHLQQDCDVPSRELRDLKLNQNMDLHIEEILKDFSESEFPSIKTEFQQVLSNRKEMTQFLEEWLNTRFDIEKLKNGIQKENDRICQVNNFFNNRIIAIMNESTEFEERSATISKEWEQDLKSLKEKNEKLFKNYQTLKTSLASGAQVNPTTQDNKNPHVTSRATQLTTEKIRELENSLHEAKESAMHKESKIIKMQKELEVTNDIIAKLQAKVHESNKCLEKTKETIQVLQDKVALGAKPYKEEIEDLKMKLVKIDLEKMKNAKEFEKEISATKATVEYQKEVIRLLRENLRRSQQAQDTSVISEHTDPQPSNKPLTCGGGSGIVQNTKALILKSEHIRLEKEISKLKQQNEQLIKQKNELLSNNQHLSNEVKTWKERTLKREAHKQVTCENSPKSPKVTGTASKKKQITPSQCKERNLQDPVPKESPKSCFFDSRSKSLPSPHPVRYFDNSSLGLCPEVQNAGAESVDSQPGPWHASSGKDVPECKTQ>sp|P30279|CCND2_HUMAN G1/S-specific cyclin-D2 OS=Homo sapiens OX=9606GN=CCND2 PE=1 SV=1MELLCHEVDPVRRAVRDRNLLRDDRVLQNLLTIEERYLPQCSYFKCVQKDIQPYMRRMVATWMLEVCEEQKCEEEVFPLAMNYLDRFLAGVPTPKSHLQLLGAVCMFLASKLKETSPLTAEKLCIYTDNSIKPQELLEWELVVLGKLKWNLAAVTPHDFIEHILRKLPQQREKLSLIRKHAQTFIALCATDFKFAMYPPSMIATGSVGAAICGLQQDEEVSSLTCDALTELLAKITNTDVDCLKACQEQIEAVLLNSLQQYRQDQRDGSKSEDELDQASTPTDVRDIDL>sp|P30279-2|CCND2_HUMAN Isoform 2 of G1/S-specific cyclin-D2 OS=Homosapiens OX=9606 GN=CCND2MELLCHEVDPVRRAVRDRNLLRDDRVLQNLLTIEERYLPQCSYFKCVQKDIQPYMRRMVATWMLEVCEEQKCEEEVFPLAMNYLDRFLAGVPTPKSHLQLLGAVCMFLASKLKETSPLTAEKLCIYTDNSIKPQELLVMTGPFLPSFLRFPLSPGQQYAFYHHCQSKFLGSRMTPPIEFTHLWAIAHLIGNHCLFFVCSYYVPRLRAQH>sp|P08962|CD63_HUMAN CD63 antigen OS=Homo sapiens OX=9606 GN=CD63 PE=1SV=2MAVEGGMKCVKFLLYVLLLAFCACAVGLIAVGVGAQLVLSQTIIQGATPGSLLPVVIIAVGVFLFLVAFVGCCGACKENYCLMITFAIFLSLIMLVEVAAAIAGYVFRDKVMSEFNNNFRQQMENYPKNNHTASILDRMQADFKCCGAANYTDWEKIPSMSKNRVPDSCCINVTVGCGINFNEKAIHKEGCVEKIGGWLRKNVLVVAAAALGIAFVEVLGIVFACCLVKSIRSGYEVM>sp|P08962-2|CD63_HUMAN Isoform 2 of CD63 antigen OS=Homo sapiens OX=9606GN=CD63MAVEGGMKCVKFLLYVLLLAFCGATPGSLLPVVIIAVGVFLFLVAFVGCCGACKENYCLMITFAIFLSLIMLVEVAAAIAGYVFRDKVMSEFNNNFRQQMENYPKNNHTASILDRMQADFKCCGAANYTDWEKIPSMSKNRVPDSCCINVTVGCGINFNEKAIHKEGCVEKIGGWLRKNVLVVAAAALGIAFVEVLGIVFACCLVKSIRSGYEVM>sp|P08962-3|CD63_HUMAN Isoform 3 of CD63 antigen OS=Homo sapiens OX=9606GN=CD63MITFAIFLSLIMLVEVAAAIAGYVFRDKVMSEFNNNFRQQMENYPKNNHTASILDRMQADFKCCGAANYTDWEKIPSMSKNRVPDSCCINVTVGCGINFNEKAIHKEGCVEKIGGWLRKNVLVVAAAALGIAFVEVLGIVFACCLVKSIRSGYEVM>sp|Q9UJX2|CDC23_HUMAN Cell division cycle protein 23 homolog OS=Homosapiens OX=9606 GN=CDC23 PE=1 SV=3MAASTSMVPVAVTAAVAPVLSINSDFSDLREIKKQLLLIAGLTRERGLLHSSKWSAELAFSLPALPLAELQPPPPITEEDAQDMDAYTLAKAYFDVKEYDRAAHFLHGCNSKKAYFLYMYSRYLSGEKKKDDETVDSLGPLEKGQVKNEALRELRVELSKKHQARELDGFGLYLYGVVLRKLDLVKEAIDVFVEATHVLPLHWGAWLELCNLITDKEMLKFLSLPDTWMKEFFLAHIYTELQLIEEALQKYQNLIDVGFSKSSYIVSQIAVAYHNIRDIDKALSIFNELRKQDPYRIENMDTFSNLLYVRSMKSELSYLAHNLCEIDKYRVETCCVIGNYYSLRSQHEKAALYFQRALKLNPRYLGAWTLMGHEYMEMKNTSAAIQAYRHAIEVNKRDYRAWYGLGQTYEILKMPFYCLYYYRRAHQLRPNDSRMLVALGECYEKLNQLVEAKKCYWRAYAVGDVEKMALVKLAKLHEQLTESEQAAQCYIKYIQDIYSCGEIVEHLEESTAFRYLAQYYFKCKLWDEASTCAQKCCAFNDTREEGKALLRQILQLRNQGETPTTEVPAPFFLPASLSANNTPTRRVSPLNLSSVTP>sp|Q9UJX2-2|CDC23_HUMAN Isoform 2 of Cell division cycle protein 23homolog OS=Homo sapiens OX=9606 GN=CDC23MAASTSMVPVAVTAAVAPVLSINSDFSDLREIKKQLLLIAGLTRERGLLHSSKWSAELAFSLPALPLAELQPPPPITEEDAQDMDAYTLAKAYFDVKEYDRAAHFLHGCNSKKAYFLYMYSRYLVRAILKCHSAFSETSIFRTNGKVKSFK>sp|Q9UJX2-3|CDC23_HUMAN Isoform 3 of Cell division cycle protein 23homolog OS=Homo sapiens OX=9606 GN=CDC23MYSRYLSGEKKKDDETVDSLGPLEKGQVKNEALRELRVELSKKHQARELDGFGLYLYGVVLRKLDLVKEAIDVFVEATHVLPLHWGAWLELCNLITDKEMLKFLSLPDTWMKEFFLAHIYTELQLIEEALQKYQNLIDVGFSKSSYIVSQIAVAYHNIRDIDKALSIFNELRKQDPYRIENMDTFSNLLYVRSMKSELSYLAHNLCEIDKYRVETCCVIGNYYSLRSQHEKAALYFQRALKLNPRYLGAWTLMGHEYMEMKNTSAAIQAYRHAIEVNKRDYRAWYGLGQTYEILKMPFYCLYYYRRAHQLRPNDSRMLVALGECYEKLNQLVEAKKCYWRAYAVGDVEKMALVKLAKLHEQLTESEQAAQCYIKYIQDIYSCGEIVEHLEESTAFRYLAQYYFKCKLWDEASTCAQKCCAFNDTREEGKALLRQILQLRNQGETPTTEVPAPFFLPASLSANNTPTRRVSPLNLSSVTP>sp|P01730|CD4_HUMAN T-cell surface glycoprotein CD4 OS=Homo sapiensOX=9606 GN=CD4 PE=1 SV=1MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLTKGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLTLTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSIVYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI>sp|Q96S94|CCNL2_HUMAN Cyclin-L2 OS=Homo sapiens OX=9606 GN=CCNL2 PE=1SV=1MAAAAAAAGAAGSAAPAAAAGAPGSGGAPSGSQGVLIGDRLYSGVLITLENCLLPDDKLRFTPSMSSGLDTDTETDLRVVGCELIQAAGILLRLPQVAMATGQVLFQRFFYTKSFVKHSMEHVSMACVHLASKIEEAPRRIRDVINVFHRLRQLRDKKKPVPLLLDQDYVNLKNQIIKAERRVLKELGFCVHVKHPHKIIVMYLQVLECERNQHLVQTSWNYMNDSLRTDVFVRFQPESIACACIYLAARTLEIPLPNRPHWFLLFGATEEEIQEICLKILQLYARKKVDLTHLEGEVEKRKHAIEEAKAQARGLLPGGTQVLDGTSGFSPAPKLVESPKEGKGSKPSPLSVKNTKRRLEGAKKAKADSPVNGLPKGRESRSRSRSREQSYSRSPSRSASPKRRKSDSGSTSGGSKSQSRSRSRSDSPPRQAPRSAPYKGSEIRGSRKSKDCKYPQKPHKSRSRSSSRSRSRSRERADNPGKYKKKSHYYRDQRRERSRSYERTGRRYERDHPGHSRHRR>sp|Q96S94-2|CCNL2_HUMAN Isoform 2 of Cyclin-L2 OS=Homo sapiens OX=9606GN=CCNL2MAAAAAAAGAAGSAAPAAAAGAPGSGGAPSGSQGVLIGDRLYSGVLITLENCLLPDDKLRFTPSMSSGLDTDTETDLRVVGCELIQAAGILLRLPQVAMATGQVLFQRFFYTKSFVKHSMEHVSMACVHLASKIEEAPRRIRDVINVFHRLRQLRDKKKPVPLLLDQDYVNLKNQIIKAERRVLKELGFCVHVKHPHKIIVMYLQVLECERNQHLVQTSWVASEGIT>sp|Q96S94-3|CCNL2_HUMAN Isoform 3 of Cyclin-L2 OS=Homo sapiens OX=9606GN=CCNL2MNDSLRTDVFVRFQPESIACACIYLAARTLEIPLPNRPHWFLLFGATEEEIQEICLKILQLYARKKVDLTHLEGEVEKRKHAIEEAKAQARGLLPGGTQVLDGTSGFSPAPKLVESPKEGKGSKPSPLSVKNTKRRLEGAKKAKADSPVNGLPKGRESRSRSRSREQSYSRSPSRSASPKRRKSDSGSTSGGSKSQSRSRSRSDSPPRQAPRSAPYKGSEIRGSRKSKDCKYPQKPHKSRSRSSSRSRSRSRERADNPGKYKKKSHYYRDQRRERSRSYERTGRRYERDHPGHSRHRR>sp|Q96S94-4|CCNL2_HUMAN Isoform 4 of Cyclin-L2 OS=Homo sapiens OX=9606GN=CCNL2MAAAAAAAGAAGSAAPAAAAGAPGSGGAPSGSQGVLIGDRLYSGVLITLENCLLPDDKLRFTPSMSSGLDTDTETDLRVVGCELIQAAGILLRLPQVAMATGQVLFQRFFYTKSFVKHSMEHVSMACVHLASKIEEAPRRIRDVINVFHRLRQLRDKKKPVPLLLDQDYVNLKNQIIKAERRVLKELGFCVHVKHPHKIIVMYLQVLECERNQHLVQTSWVASEDPLLKWDSWQRL>sp|Q96S94-5|CCNL2_HUMAN Isoform 5 of Cyclin-L2 OS=Homo sapiens OX=9606GN=CCNL2MAAAAAAAGAAGSAAPAAAAGAPGSGGAPSGSQGVLIGDRLYSGVLITLENCLLPDDKLRFTPSMSSGLDTDTETDLRVVGCELIQAAGILLRLPQVAMATGQVLFQRFFYTKSFVKHSMEHVSMACVHLASKIEEAPRRIRDVINVFHRLRQLRDKKKPVPLLLDQDYVNLKNQIIKAERRVLKELGFCVHVKHPHKIIVMYLQVLECERNQHLVQTSWVASEGK>sp|Q3B7I2|CNPY1_HUMAN Protein canopy homolog 1 OS=Homo sapiens OX=9606GN=CNPY1 PE=3 SV=1MNDYKLEEDPVTKERTFKRFAPRKGDKIYQEFKKLYFYSDAYRPLKFACETIIEEYEDEISSLIAQETHYLADKLCSEKSDLCETSANHTEL>sp|P21554|CNR1_HUMAN Cannabinoid receptor 1 OS=Homo sapiens OX=9606GN=CNR1 PE=1 SV=1MKSILDGLADTTFRTITTDLLYVGSNDIQYEDIKGDMASKLGYFPQKFPLTSFRGSPFQEKMTAGDNPQLVPADQVNITEFYNKSLSSFKENEENIQCGENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLTAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLGWNCEKLQSVCSDIFPHIDETYLMFWIGVTSVLLLFIVYAYMYILWKAHSHAVRMIQRGTQKSIIIHTSEDGKVQVTRPDQARMDIRLAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMFPSCEGTAQPLDNSMGDSDCLHKHANNAASVHRAAESCIKSTVKIAKVTMSVSTDTSAEAL>sp|P21554-2|CNR1_HUMAN Isoform 2 of Cannabinoid receptor 1 OS=Homosapiens OX=9606 GN=CNR1MALQIPPSAPSPLTSCTWAQMTFSTKTSKENEENIQCGENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLTAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLGWNCEKLQSVCSDIFPHIDETYLMFWIGVTSVLLLFIVYAYMYILWKAHSHAVRMIQRGTQKSIIIHTSEDGKVQVTRPDQARMDIRLAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMFPSCEGTAQPLDNSMGDSDCLHKHANNAASVHRAAESCIKSTVKIAKVTMSVSTDTSAEAL>sp|P21554-3|CNR1_HUMAN Isoform 3 of Cannabinoid receptor 1 OS=Homosapiens OX=9606 GN=CNR1MKSILDGLADTTFRTITTDLLGSPFQEKMTAGDNPQLVPADQVNITEFYNKSLSSFKENEENIQCGENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLTAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLGWNCEKLQSVCSDIFPHIDETYLMFWIGVTSVLLLFIVYAYMYILWKAHSHAVRMIQRGTQKSIIIHTSEDGKVQVTRPDQARMDIRLAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMFPSCEGTAQPLDNSMGDSDCLHKHANNAASVHRAAESCIKSTVKIAKVTMSVSTDTSAEAL>sp|Q5SY13|COAS1_HUMAN Putative uncharacterized protein encoded byCOL5A1-AS1 OS=Homo sapiens OX=9606 GN=COL5A1-AS1 PE=5 SV=1MRRPWEKKEATRNPIAEVLARKKRTEELISLQEHGSRKQKIKEASISWAETSRQIG>sp|Q96A22|CK052_HUMAN Uncharacterized protein C11orf52 OS=Homo sapiensOX=9606 GN=C11orf52 PE=1 SV=2MGNRVCCGGSWSCPSTFQKKKKTGSQTRRTLKPQPQQLQQNLPKGHETTGHTYERVLQQQGSQERSPGLMSEDSNLHYADIQVCSRPHAREVKHVHLENATEYATLRFPQATPRYDSKNGTLV>sp|O95639|CPSF4_HUMAN Cleavage and polyadenylation specificity factorsubunit 4 OS=Homo sapiens OX=9606 GN=CPSF4 PE=1 SV=1MQEIIASVDHIKFDLEIAVEQQLGAQPLPFPGMDKSGAAVCEFFLKAACGKGGMCPFRHISGEKTVVCKHWLRGLCKKGDQCEFLHEYDMTKMPECYFYSKFGECSNKECPFLHIDPESKIKDCPWYDRGFCKHGPLCRHRHTRRVICVNYLVGFCPEGPSCKFMHPRFELPMGTTEQPPLPQQTQPPAKQSNNPPLQRSSSLIQLTSQNSSPNQQRTPQVIGVMQSQNSSAGNRGPRPLEQVTCYKCGEKGHYANRCTKGHLAFLSGQ>sp|O95639-2|CPSF4_HUMAN Isoform 2 of Cleavage and polyadenylationspecificity factor subunit 4 OS=Homo sapiens OX=9606 GN=CPSF4MQEIIASVDHIKFDLEIAVEQQLGAQPLPFPGMDKSGAAVCEFFLKAACGKGGMCPFRHISGEKTVVCKHWLRGLCKKGDQCEFLHEYDMTKMPECYFYSKFGECSNKECPFLHIDPESKIKDCPWYDRGFCKHGPLCRHRHTRRVICVNYLVGFCPEGPSCKFMHPRFELPMGTTEQPPLPQQTQPPAKQRTPQVIGVMQSQNSSAGNRGPRPLEQVTCYKCGEKGHYANRCTKGHLAFLSGQ>sp|O95639-3|CPSF4_HUMAN Isoform 3 of Cleavage and polyadenylationspecificity factor subunit 4 OS=Homo sapiens OX=9606 GN=CPSF4MQEIIASVDHIKFDLEIAVEQQLGAQPLPFPGMDKSGAAVCEFFLKAACGKGGMCPFRHISGEKTVVCKHWLRGLCKKGDQCEFLHEYDMTKMPECYFYSKFGECSNKECPFLHIDPESKIKDCPWYDRGFCKHGPLCRHRHTRRVICVNYLVGFCPEGPSCKFMHPRFELPMGTTEQPPLPQQTQPPAKRTPQVIGVMQSQNSSAGNRGPRPLEQVTCYKCGEKGHYANRCTKGHLAFLSGQ>sp|P98187|CP4F8_HUMAN Cytochrome P450 4F8 OS=Homo sapiens OX=9606GN=CYP4F8 PE=1 SV=1MSLLSLSWLGLRPVAASPWLLLLVVGASWLLARILAWTYAFYHNGRRLRCFPQPRKQNWFLGHLGLVTPTEEGLRVLTQLVATYPQGFVRWLGPITPIINLCHPDIVRSVINTSDAITDKDIVFYKTLKPWLGDGLLLSVGDKWRHHRRLLTPAFHFNILKPYIKIFSKSANIMHAKWQRLAMEGSTCLDVFEHISLMTLDSLQKCIFSFDSNCQEKPSEYITAIMELSALVVKRNNQFFRYKDFLYFLTPCGRRFHRACRLVHDFTDAVIQERRRTLTSQGVDDFLQAKAKSKTLDFIDVLLLSEDKNGKELSDEDIRAEADTFMFGGHDTTASGLSWVLYNLARHPEYQERCRQEVQELLKDREPKEIEWDDLAQLPFLTMCLKESLRLHPPIPTFARGCTQDVVLPDSRVIPKGNVCNINIFAIHHNPSVWPDPEVYDPFRFDPENAQKRSPMAFIPFSAGPRNCIGQKFAMAEMKVVLALTLLRFRILPDHREPRRTPEIVLRAEDGLWLRVEPLG>sp|O43186|CRX_HUMAN Cone-rod homeobox protein OS=Homo sapiens OX=9606GN=CRX PE=1 SV=1MMAYMNPGPHYSVNALALSGPSVDLMHQAVPYPSAPRKQRRERTTFTRSQLEELEALFAKTQYPDVYAREEVALKINLPESRVQVWFKNRRAKCRQQRQQQKQQQQPPGGQAKARPAKRKAGTSPRPSTDVCPDPLGISDSYSPPLPGPSGSPTTAVATVSIWSPASESPLPEAQRAGLVASGPSLTSAPYAMTYAPASAFCSSPSAYGSPSSYFSGLDPYLSPMVPQLGGPALSPLSGPSVGPSLAQSPTSLSGQSYGAYSPVDSLEFKDPTGTWKFTYNPMDPLDYKDQSAWKFQIL>sp|O14810|CPLX1_HUMAN Complexin-1 OS=Homo sapiens OX=9606 GN=CPLX1 PE=1SV=1MEFVMKQALGGATKDMGKMLGGDEEKDPDAAKKEEERQEALRQAEEERKAKYAKMEAEREAVRQGIRDKYGIKKKEEREAEAQAAMEANSEGSLTRPKKAIPPGCGDEVEEEDESILDTVIKYLPGPLQDMLKK>sp|Q6FI81|CPIN1_HUMAN Anamorsin OS=Homo sapiens OX=9606 GN=CIAPIN1 PE=1SV=2MADFGISAGQFVAVVWDKSSPVEALKGLVDKLQALTGNEGRVSVENIKQLLQSAHKESSFDIILSGLVPGSTTLHSAEILAEIARILRPGGCLFLKEPVETAVDNNSKVKTASKLCSALTLSGLVEVKELQREPLTPEEVQSVREHLGHESDNLLFVQITGKKPNFEVGSSRQLKLSITKKSSPSVKPAVDPAAAKLWTLSANDMEDDSMDLIDSDELLDPEDLKKPDPASLRAASCGEGKKRKACKNCTCGLAEELEKEKSREQMSSQPKSACGNCYLGDAFRCASCPYLGMPAFKPGEKVLLSDSNLHDA>sp|Q6FI81-2|CPIN1_HUMAN Isoform 2 of Anamorsin OS=Homo sapiens OX=9606GN=CIAPIN1MEDDSMDLIDSDELLDPEDLKKPDPASLRAASCGEGKKRKACKNCTCGLAEELEKEKSREQMSSQPKSACGNCYLGDAFRCASCPYLGMPAFKPGEKVLLSDSNLHDA>sp|Q6FI81-3|CPIN1_HUMAN Isoform 3 of Anamorsin OS=Homo sapiens OX=9606GN=CIAPIN1MADFGISAGQFVAVVWDKSSPVEALKGLVDKLQALTGNEGRVSVENIKQLLQCLVPGSTTLHSAEILAEIARILRPGGCLFLKEPVETAVDNNSKVKTASKLCSALTLSGLVEVKELQREPLTPEEVQSVREHLGHESDNLLFVQITGKKPNFEVGSSRQLKLSITKKSSPSVKPAVDPAAAKLWTLSANDMEDDSMDLIDSDELLDPEDLKKPDPASLRAASCGEGKKRKACKNCTCGLAEELEKEKSREQMSSQPKSACGNCYLGDAFRCASCPYLGMPAFKPGEKVLLSDSNLHDA>sp|Q96FN4|CPNE2_HUMAN Copine-2 OS=Homo sapiens OX=9606 GN=CPNE2 PE=1SV=3MAHIPSGGAPAAGAAPMGPQYCVCKVELSVSGQNLLDRDVTSKSDPFCVLFTENNGRWIEYDRTETAINNLNPAFSKKFVLDYHFEEVQKLKFALFDQDKSSMRLDEHDFLGQFSCSLGTIVSSKKITRPLLLLNDKPAGKGLITIAAQELSDNRVITLSLAGRRLDKKDLFGKSDPFLEFYKPGDDGKWMLVHRTEVIKYTLDPVWKPFTVPLVSLCDGDMEKPIQVMCYDYDNDGGHDFIGEFQTSVSQMCEARDSVPLEFECINPKKQRKKKNYKNSGIIILRSCKINRDYSFLDYILGGCQLMFTVGIDFTASNGNPLDPSSLHYINPMGTNEYLSAIWAVGQIIQDYDSDKMFPALGFGAQLPPDWKVSHEFAINFNPTNPFCSGVDGIAQAYSACLPHIRFYGPTNFSPIVNHVARFAAQATQQRTATQYFILLIITDGVISDMEETRHAVVQASKLPMSIIIVGVGNADFAAMEFLDGDSRMLRSHTGEEAARDIVQFVPFREFRNAAKETLAKAVLAELPQQVVQYFKHKNLPPTNSEPA>sp|Q96FN4-2|CPNE2_HUMAN Isoform 2 of Copine-2 OS=Homo sapiens OX=9606GN=CPNE2MRLDEHDFLGQFSCSLGTIVSSKKITRPLLLLNDKPAGKGLITIAAQELSDNRVITLSLAGRRLDKKDLFGKSDPFLEFYKPGDDGKWMLVHRTEVIKYTLDPVWKPFTVPLVSLCDGDMEKPIQVMCYDYDNDGGHDFIGEFQTSVSQMCEARDSVPLEFECINPKKQRKKKNYKNSGIIILRSCKINRDYSFLDYILGGCQLMFTVGIDFTASNGNPLDPSSLHYINPMGTNEYLSAIWAVGQIIQDYDSDKMFPALGFGAQLPPDWKVSHEFAINFNPTNPFCSGVDGIAQAYSACLPHIRFYGPTNFSPIVNHVARFAAQATQQRTATQYFILLIITDGVISDMEETRHAVVQASKLPMSIIIVGVGNADFAAMEFLDGDSRMLRSHTGEEAARDIVQFVPFREFRNAAKETLAKAVLAELPQQVVQYFKHKNLPPTNSEPA>sp|Q9NQ92|COPRS_HUMAN Coordinator of PRMT5 and differentiationstimulator OS=Homo sapiens OX=9606 GN=COPRS PE=1 SV=3MDLQAAGAQAQGAAEPSRGPPLPSARGAPPSPEAGFATADHSSQERETEKAMDRLARGTQSIPNDSPARGEGTHSEEEGFAMDEEDSDGELNTWELSEGTNCPPKEQPGDLFNEDWDSELKADQGNPYDADDIQESISQELKPWVCCAPQGDMIYDPSWHHPPPLIPYYSKMVFETGQFDDAED>sp|Q8NEA5|CS018_HUMAN Uncharacterized protein C19orf18 OS=Homo sapiensOX=9606 GN=C19orf18 PE=1 SV=1MDKVQSGFLILFLFLMECQLHLCLPYADGLHPTGNITGLPGSKRSQPPRNITKEPKVFFHKTQLPGIQGAASRSTAASPTNPMKFLRNKAIIRHRPALVKVILISSVAFSIALICGMAISYMIYRLAQAEERQQLESLYKNLRIPLLGDEEEGSEDEGESTHLLPENENELEKFIHSVIISKRSKNIKKKLKEEQNSVTENKTKNASHNGKMEDL>sp|Q9UNS2|CSN3_HUMAN COP9 signalosome complex subunit 3 OS=Homo sapiensOX=9606 GN=COPS3 PE=1 SV=3MASALEQFVNSVRQLSAQGQMTQLCELINKSGELLAKNLSHLDTVLGALDVQEHSLGVLAVLFVKFSMPSVPDFETLFSQVQLFISTCNGEHIRYATDTFAGLCHQLTNALVERKQPLRGIGILKQAIDKMQMNTNQLTSIHADLCQLCLLAKCFKPALPYLDVDMMDICKENGAYDAKHFLCYYYYGGMIYTGLKNFERALYFYEQAITTPAMAVSHIMLESYKKYILVSLILLGKVQQLPKYTSQIVGRFIKPLSNAYHELAQVYSTNNPSELRNLVNKHSETFTRDNNMGLVKQCLSSLYKKNIQRLTKTFLTLSLQDMASRVQLSGPQEAEKYVLHMIEDGEIFASINQKDGMVSFHDNPEKYNNPAMLHNIDQEMLKCIELDERLKAMDQEITVNPQFVQKSMGSQEDDSGNKPSSYS>sp|Q9UNS2-2|CSN3_HUMAN Isoform 2 of COP9 signalosome complex subunit 3OS=Homo sapiens OX=9606 GN=COPS3MTQLCELINKSGELLAKNLSHLDTVLGALDVQEHSLGVLAVLFVKFSMPSVPDFETLFSQVQLFISTCNGEHIRYATDTFAGLCHQLTNALVERKQPLRGIGILKQAIDKMQMNTNQLTSIHADLCQLCLLAKCFKPALPYLDVDMMDICKENGAYDAKHFLCYYYYGGMIYTGLKNFERALYFYEQAITTPAMAVSHIMLESYKKYILVSLILLGKVQQLPKYTSQIVGRFIKPLSNAYHELAQVYSTNNPSELRNLVNKHSETFTRDNNMGLVKQCLSSLYKKNIQRLTKTFLTLSLQDMASRVQLSGPQEAEKYVLHMIEDGEIFASINQKDGMVSFHDNPEKYNNPAMLHNIDQEMLKCIELDERLKAMDQEITVNPQFVQKSMGSQEDDSGNKPSSYS>sp|P20674|COX5A_HUMAN Cytochrome c oxidase subunit 5A, mitochondrialOS=Homo sapiens OX=9606 GN=COX5A PE=1 SV=2MLGAALRRCAVAATTRADPRGLLHSARTPGPAVAIQSVRCYSHGSQETDEEFDARWVTYFNKPDIDAWELRKGINTLVTYDMVPEPKIIDAALRACRRLNDFASTVRILEVVKDKAGPHKEIYPYVIQELRPTLNELGISTPEELGLDKV>sp|P06850|CRF_HUMAN Corticoliberin OS=Homo sapiens OX=9606 GN=CRH PE=1SV=1MRLPLLVSAGVLLVALLPCPPCRALLSRGPVPGARQAPQHPQPLDFFQPPPQSEQPQQPQARPVLLRMGEEYFLRLGNLNKSPAAPLSPASSLLAGGSGSRPSPEQATANFFRVLLQQLLLPRRSLDSPAALAERGARNALGGHQEAPERERRSEEPPISLDLTFHLLREVLEMARAEQLAQQAHSNRKLMEIIGK>sp|Q96GX8|CP074_HUMAN Uncharacterized protein C16orf74 OS=Homo sapiensOX=9606 GN=C16orf74 PE=1 SV=2MGLKMSCLKGFQMCVSSSSSSHDEAPVLNDKHLDVPDIIITPPTPTGMMLPRDLGSTVWLDETGSCPDDGEIDPEA>sp|P53621|COPA_HUMAN Coatomer subunit alpha OS=Homo sapiens OX=9606GN=COPA PE=1 SV=2MLTKFETKSARVKGLSFHPKRPWILTSLHNGVIQLWDYRMCTLIDKFDEHDGPVRGIDFHKQQPLFVSGGDDYKIKVWNYKLRRCLFTLLGHLDYIRTTFFHHEYPWILSASDDQTIRVWNWQSRTCVCVLTGHNHYVMCAQFHPTEDLVVSASLDQTVRVWDISGLRKKNLSPGAVESDVRGITGVDLFGTTDAVVKHVLEGHDRGVNWAAFHPTMPLIVSGADDRQVKIWRMNESKAWEVDTCRGHYNNVSCAVFHPRQELILSNSEDKSIRVWDMSKRTGVQTFRRDHDRFWVLAAHPNLNLFAAGHDGGMIVFKLERERPAYAVHGNMLHYVKDRFLRQLDFNSSKDVAVMQLRSGSKFPVFNMSYNPAENAVLLCTRASNLENSTYDLYTIPKDADSQNPDAPEGKRSSGLTAVWVARNRFAVLDRMHSLLIKNLKNEITKKVQVPNCDEIFYAGTGNLLLRDADSITLFDVQQKRTLASVKISKVKYVIWSADMSHVALLAKHAIVICNRKLDALCNIHENIRVKSGAWDESGVFIYTTSNHIKYAVTTGDHGIIRTLDLPIYVTRVKGNNVYCLDRECRPRVLTIDPTEFKFKLALINRKYDEVLHMVRNAKLVGQSIIAYLQKKGYPEVALHFVKDEKTRFSLALECGNIEIALEAAKALDDKNCWEKLGEVALLQGNHQIVEMCYQRTKNFDKLSFLYLITGNLEKLRKMMKIAEIRKDMSGHYQNALYLGDVSERVRILKNCGQKSLAYLTAATHGLDEEAESLKETFDPEKETIPDIDPNAKLLQPPAPIMPLDTNWPLLTVSKGFFEGTIASKGKGGALAADIDIDTVGTEGWGEDAELQLDEDGFVEATEGLGDDALGKGQEEGGGWDVEEDLELPPELDISPGAAGGAEDGFFVPPTKGTSPTQIWCNNSQLPVDHILAGSFETAMRLLHDQVGVIQFGPYKQLFLQTYARGRTTYQALPCLPSMYGYPNRNWKDAGLKNGVPAVGLKLNDLIQRLQLCYQLTTVGKFEEAVEKFRSILLSVPLLVVDNKQEIAEAQQLITICREYIVGLSVETERKKLPKETLEQQKRICEMAAYFTHSNLQPVHMILVLRTALNLFFKLKNFKTAATFARRLLELGPKPEVAQQTRKILSACEKNPTDAYQLNYDMHNPFDICAASYRPIYRGKPVEKCPLSGACYSPEFKGQICRVTTVTEIGKDVIGLRISPLQFR>sp|P53621-2|COPA_HUMAN Isoform 2 of Coatomer subunit alpha OS=Homosapiens OX=9606 GN=COPAMLTKFETKSARVKGLSFHPKRPWILTSLHNGVIQLWDYRMCTLIDKFDEHDGPVRGIDFHKQQPLFVSGGDDYKIKVWNYKLRRCLFTLLGHLDYIRTTFFHHEYPWILSASDDQTIRVWNWQSRTCVCVLTGHNHYVMCAQFHPTEDLVVSASLDQTVRVWDISGLRKKNLSPGAVESDVRGITGVDLFGTTDAVVKHVLEGHDRGVNWAAFHPTMPLIVSGADDRQVKIWRMNESKAWEVDTCRGHYNNVSCAVFHPRQELILSNSEDKSIRVWDMSKRTGVQTFRRDHDRFWVLAAHPNLNLFAAGHDGGMIVFKLERERPAYAVHGNMLHYVKDRFLRQLDFNSSKDVAVMQLRSGSKFPVFNMSYNPAENAVLLCTRASNLENSTYDLYTIPKDADSQNPDAPEGKRSSGLTAVWVARNRFAVLDRMHSLLIKNLKNEITKKVQVPNCDEIFYAGTGNLLLRDADSITLFDVQQKRTLASVKISKVKYVIWSADMSHVALLAKHEHSCPLPLTAIVICNRKLDALCNIHENIRVKSGAWDESGVFIYTTSNHIKYAVTTGDHGIIRTLDLPIYVTRVKGNNVYCLDRECRPRVLTIDPTEFKFKLALINRKYDEVLHMVRNAKLVGQSIIAYLQKKGYPEVALHFVKDEKTRFSLALECGNIEIALEAAKALDDKNCWEKLGEVALLQGNHQIVEMCYQRTKNFDKLSFLYLITGNLEKLRKMMKIAEIRKDMSGHYQNALYLGDVSERVRILKNCGQKSLAYLTAATHGLDEEAESLKETFDPEKETIPDIDPNAKLLQPPAPIMPLDTNWPLLTVSKGFFEGTIASKGKGGALAADIDIDTVGTEGWGEDAELQLDEDGFVEATEGLGDDALGKGQEEGGGWDVEEDLELPPELDISPGAAGGAEDGFFVPPTKGTSPTQIWCNNSQLPVDHILAGSFETAMRLLHDQVGVIQFGPYKQLFLQTYARGRTTYQALPCLPSMYGYPNRNWKDAGLKNGVPAVGLKLNDLIQRLQLCYQLTTVGKFEEAVEKFRSILLSVPLLVVDNKQEIAEAQQLITICREYIVGLSVETERKKLPKETLEQQKRICEMAAYFTHSNLQPVHMILVLRTALNLFFKLKNFKTAATFARRLLELGPKPEVAQQTRKILSACEKNPTDAYQLNYDMHNPFDICAASYRPIYRGKPVEKCPLSGACYSPEFKGQICRVTTVTEIGKDVIGLRISPLQFR>sp|Q8N9R0|CP081_HUMAN Putative uncharacterized protein encoded byLINC00304 OS=Homo sapiens OX=9606 GN=LINC00304 PE=5 SV=2MQYLHCCLQIAPNQEGMVQAGGQGHGLARVVLRAVLSPPCWAPHSPCGSPAATEAGRLMRRLPSVGGRMTAPKTPRFLTRRPPASSPEDPPLPHPKTPRFLTQRPPASLPRRPRFLTLGPVSSHSSGDLRLWTAHQLPQQGGCPG>sp|P00414|COX3_HUMAN Cytochrome c oxidase subunit 3 OS=Homo sapiensOX=9606 GN=MT-CO3 PE=1 SV=2MTHQSHAYHMVKPSPWPLTGALSALLMTSGLAMWFHFHSMTLLMLGLLTNTLTMYQWWRDVTRESTYQGHHTPPVQKGLRYGMILFITSEVFFFAGFFWAFYHSSLAPTPQLGGHWPPTGITPLNPLEVPLLNTSVLLASGVSITWAHHSLMENNRNQMIQALLITILLGLYFTLLQASEYFESPFTISDGIYGSTFFVATGFHGLHVIIGSTFLTICFIRQLMFHFTSKHHFGFEAAAWYWHFVDVVWLFLYVSIYWWGS>sp|P16562|CRIS2_HUMAN Cysteine-rich secretory protein 2 OS=Homo sapiensOX=9606 GN=CRISP2 PE=1 SV=1MALLPVLFLVTVLLPSLPAEGKDPAFTALLTTQLQVQREIVNKHNELRKAVSPPASNMLKMEWSREVTTNAQRWANKCTLQHSDPEDRKTSTRCGENLYMSSDPTSWSSAIQSWYDEILDFVYGVGPKSPNAVVGHYTQLVWYSTYQVGCGIAYCPNQDSLKYYYVCQYCPAGNNMNRKNTPYQQGTPCAGCPDDCDKGLCTNSCQYQDLLSNCDSLKNTAGCEHELLKEKCKATCLCENKIY>sp|P16562-2|CRIS2_HUMAN Isoform 2 of Cysteine-rich secretory protein 2OS=Homo sapiens OX=9606 GN=CRISP2MALLPVLFLVTVLLPSLPAEGKDPAFTALLTTQLQVQREIVNKHNELRKAVSPPASNMLKMEWSREVTTNAQRWANKCTLQHSDPEDRKTSTRCGENLYMSSDPTSWSSAIQSWYDEILDFVYGVGPKSPNAVVGHYTQLVWYSTYQVGCGIAYCPNQDSLKYYYVCQYCPAMKTYLNKREGINVWKCFLRLRHFQLLRGEQLLTFSGNNMNRKNTPYQQGTPCAGCPDDCDKGLCTNSCQYQDLLSNCDSLKNTAGCEHELLKEKCKATCLCENKIY>sp|P0DPD8|EFCE2_HUMAN EEF1AKMT4-ECE2 readthrough transcript proteinOS=Homo sapiens OX=9606 GN=EEF1AKMT4-ECE2 PE=1 SV=1MASPGAGRAPPELPERNCGYREVEYWDQRYQGAADSAPYDWFGDFSSFRALLEPELRPEDRILVLGCGNSALSYELFLGGFPNVTSVDYSSVVVAAMQARHAHVPQLRWETMDVRKLDFPSASFDVVLEKGTLDALLAGERDPWTVSSEGVHTVDQVLSEVGFQKGTRQLLGSRTQLELVLAGASLLLAALLLGCLVALGVQYHRDPSHSTCLTEACIRVAGKILESLDRGVSPCEDFYQFSCGGWIRRNPLPDGRSRWNTFNSLWDQNQAILKHLLENTTFNSSSEAEQKTQRFYLSCLQVERIEELGAQPLRDLIEKIGGWNITGPWDQDNFMEVLKAVAGTYRATPFFTVYISADSKSSNSNVIQVDQSGLFLPSRDYYLNRTANEKVLTAYLDYMEELGMLLGGRPTSTREQMQQVLELEIQLANITVPQDQRRDEEKIYHKMSISELQALAPSMDWLEFLSFLLSPLELSDSEPVVVYGMDYLQQVSELINRTEPSILNNYLIWNLVQKTTSSLDRRFESAQEKLLETLYGTKKSCVPRWQTCISNTDDALGFALGSLFVKATFDRQSKEIAEGMISEIRTAFEEALGQLVWMDEKTRQAAKEKADAIYDMIGFPDFILEPKELDDVYDGYEISEDSFFQNMLNLYNFSAKVMADQLRKPPSRDQWSMTPQTVNAYYLPTKNEIVFPAGILQAPFYARNHPKALNFGGIGVVMGHELTHAFDDQGREYDKEGNLRPWWQNESLAAFRNHTACMEEQYNQYQVNGERLNGRQTLGENIADNGGLKAAYNAYKAWLRKHGEEQQLPAVGLTNHQLFFVGFAQVWCSVRTPESSHEGLVTDPHSPARFRVLGTLSNSRDFLRHFGCPVGSPMNPGQLCEVW>sp|O75629|CREG1_HUMAN Protein CREG1 OS=Homo sapiens OX=9606 GN=CREG1PE=1 SV=1MAGLSRGSARALLAALLASTLLALLVSPARGRGGRDHGDWDEASRLPPLPPREDAARVARFVTHVSDWGALATISTLEAVRGRPFADVLSLSDGPPGAGSGVPYFYLSPLQLSVSNLQENPYATLTMTLAQTNFCKKHGFDPQSPLCVHIMLSGTVTKVNETEMDIAKHSLFIRHPEMKTWPSSHNWFFAKLNITNIWVLDYFGGPKIVTPEEYYNVTVQ>sp|P00533|EGFR_HUMAN Epidermal growth factor receptor OS=Homo sapiensOX=9606 GN=EGFR PE=1 SV=2MRPSGTAGAALLALLAALCPASRALEEKKVCQGTSNKLTQLGTFEDHFLSLQRMFNNCEVVLGNLEITYVQRNYDLSFLKTIQEVAGYVLIALNTVERIPLENLQIIRGNMYYENSYALAVLSNYDANKTGLKELPMRNLQEILHGAVRFSNNPALCNVESIQWRDIVSSDFLSNMSMDFQNHLGSCQKCDPSCPNGSCWGAGEENCQKLTKIICAQQCSGRCRGKSPSDCCHNQCAAGCTGPRESDCLVCRKFRDEATCKDTCPPLMLYNPTTYQMDVNPEGKYSFGATCVKKCPRNYVVTDHGSCVRACGADSYEMEEDGVRKCKKCEGPCRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGPKIPSIATGMVGALLLLLVVALGIGLFMRRRHIVRKRTLRRLLQERELVEPLTPSGEAPNQALLRILKETEFKKIKVLGSGAFGTVYKGLWIPEGEKVKIPVAIKELREATSPKANKEILDEAYVMASVDNPHVCRLLGICLTSTVQLITQLMPFGCLLDYVREHKDNIGSQYLLNWCVQIAKGMNYLEDRRLVHRDLAARNVLVKTPQHVKITDFGLAKLLGAEEKEYHAEGGKVPIKWMALESILHRIYTHQSDVWSYGVTVWELMTFGSKPYDGIPASEISSILEKGERLPQPPICTIDVYMIMVKCWMIDADSRPKFRELIIEFSKMARDPQRYLVIQGDERMHLPSPTDSNFYRALMDEEDMDDVVDADEYLIPQQGFFSSPSTSRTPLLSSLSATSNNSTVACIDRNGLQSCPIKEDSFLQRYSSDPTGALTEDSIDDTFLPVPEYINQSVPKRPAGSVQNPVYHNQPLNPAPSRDPHYQDPHSTAVGNPEYLNTVQPTCVNSTFDSPAHWAQKGSHQISLDNPDYQQDFFPKEAKPNGIFKGSTAENAEYLRVAPQSSEFIGA>sp|P00533-2|EGFR_HUMAN Isoform 2 of Epidermal growth factor receptorOS=Homo sapiens OX=9606 GN=EGFRMRPSGTAGAALLALLAALCPASRALEEKKVCQGTSNKLTQLGTFEDHFLSLQRMFNNCEVVLGNLEITYVQRNYDLSFLKTIQEVAGYVLIALNTVERIPLENLQIIRGNMYYENSYALAVLSNYDANKTGLKELPMRNLQEILHGAVRFSNNPALCNVESIQWRDIVSSDFLSNMSMDFQNHLGSCQKCDPSCPNGSCWGAGEENCQKLTKIICAQQCSGRCRGKSPSDCCHNQCAAGCTGPRESDCLVCRKFRDEATCKDTCPPLMLYNPTTYQMDVNPEGKYSFGATCVKKCPRNYVVTDHGSCVRACGADSYEMEEDGVRKCKKCEGPCRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGLS>sp|P00533-3|EGFR_HUMAN Isoform 3 of Epidermal growth factor receptorOS=Homo sapiens OX=9606 GN=EGFRMRPSGTAGAALLALLAALCPASRALEEKKVCQGTSNKLTQLGTFEDHFLSLQRMFNNCEVVLGNLEITYVQRNYDLSFLKTIQEVAGYVLIALNTVERIPLENLQIIRGNMYYENSYALAVLSNYDANKTGLKELPMRNLQEILHGAVRFSNNPALCNVESIQWRDIVSSDFLSNMSMDFQNHLGSCQKCDPSCPNGSCWGAGEENCQKLTKIICAQQCSGRCRGKSPSDCCHNQCAAGCTGPRESDCLVCRKFRDEATCKDTCPPLMLYNPTTYQMDVNPEGKYSFGATCVKKCPRNYVVTDHGSCVRACGADSYEMEEDGVRKCKKCEGPCRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGPGNESLKAMLFCLFKLSSCNQSNDGSVSHQSGSPAAQESCLGWIPSLLPSEFQLGWGGCSHLHAWPSASVIITASSCH>sp|P00533-4|EGFR_HUMAN Isoform 4 of Epidermal growth factor receptorOS=Homo sapiens OX=9606 GN=EGFRMRPSGTAGAALLALLAALCPASRALEEKKVCQGTSNKLTQLGTFEDHFLSLQRMFNNCEVVLGNLEITYVQRNYDLSFLKTIQEVAGYVLIALNTVERIPLENLQIIRGNMYYENSYALAVLSNYDANKTGLKELPMRNLQEILHGAVRFSNNPALCNVESIQWRDIVSSDFLSNMSMDFQNHLGSCQKCDPSCPNGSCWGAGEENCQKLTKIICAQQCSGRCRGKSPSDCCHNQCAAGCTGPRESDCLVCRKFRDEATCKDTCPPLMLYNPTTYQMDVNPEGKYSFGATCVKKCPRNYVVTDHGSCVRACGADSYEMEEDGVRKCKKCEGPCRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGS>sp|O95567|CV031_HUMAN Uncharacterized protein C22orf31 OS=Homo sapiensOX=9606 GN=C22orf31 PE=2 SV=1MHPINVRRDPSIPIYGLRQSILLNTRLQDCYVDSPALTNIWMARTCAKQNINAPAPATTSSWEVVRNPLIASSFSLVKLVLRRQLKNKCCPPPCKFGEGKLSKRLKHKDDSVMKATQQARKRNFISSKSKQPAGHRRPAGGIRESKESSKEKKLTVRQDLEDRYAEHVAATQALPQDSGTAAWKGRVLLPETQKRQQLSEDTLTIHGLPTEGYQALYHAVVEPMLWNPSGTPKRYSLELGKAIKQKLWEALCSQGAISEGAQRDRFPGRKQPGVHEEPVLKKWPKLKSKK>sp|Q9Y5B0|CTDP1_HUMAN RNA polymerase II subunit A C-terminal domainphosphatase OS=Homo sapiens OX=9606 GN=CTDP1 PE=1 SV=3MEVPAAGRVPAEGAPTAAVAEVRCPGPAPLRLLEWRVAAGAAVRIGSVLAVFEAAASAQSSGASQSRVASGGCVRPARPERRLRSERAGVVRELCAQPGQVVAPGAVLVRLEGCSHPVVMKGLCAECGQDLTQLQSKNGKQQVPLSTATVSMVHSVPELMVSSEQAEQLGREDQQRLHRNRKLVLMVDLDQTLIHTTEQHCQQMSNKGIFHFQLGRGEPMLHTRLRPHCKDFLEKIAKLYELHVFTFGSRLYAHTIAGFLDPEKKLFSHRILSRDECIDPFSKTGNLRNLFPCGDSMVCIIDDREDVWKFAPNLITVKKYVYFQGTGDMNAPPGSRESQTRKKVNHSRGTEVSEPSPPVRDPEGVTQAPGVEPSNGLEKPARELNGSEAATPRDSPRPGKPDERDIWPPAQAPTSSQELAGAPEPQGSCAQGGRVAPGQRPAQGATGTDLDFDLSSDSESSSESEGTKSSSSASDGESEGKRGRQKPKAAPEGAGALAQGSSLEPGRPAAPSLPGEAEPGAHAPDKEPELGGQEEGERDGLCGLGNGCADRKEAETESQNSELSGVTAGESLDQSMEEEEEEDTDEDDHLIYLEEILVRVHTDYYAKYDRYLNKEIEEAPDIRKIVPELKSKVLADVAIIFSGLHPTNFPIEKTREHYHATALGAKILTRLVLSPDAPDRATHLIAARAGTEKVLQAQECGHLHVVNPDWLWSCLERWDKVEEQLFPLRDDHTKAQRENSPAAFPDREGVPPTALFHPMPVLPKAQPGPEVRIYDSNTGKLIRTGARGPPAPSSSLPIRQEPSSFRAVPPPQPQMFGEELPDAQDGEQPGPSRRKRQPSMSETMPLYTLCKEDLESMDKEVDDILGEGSDDSDSEKRRPEEQEEEPQPRKPGTRRERTLGAPASSERSAAGGRGPRGHKRKLNEEDAASESSRESSNEDEGSSSEADEMAKALEAELNDLM>sp|Q9Y5B0-4|CTDP1_HUMAN Isoform 4 of RNA polymerase II subunit A C-terminal domain phosphatase OS=Homo sapiens OX=9606 GN=CTDP1MEVPAAGRVPAEGAPTAAVAEVRCPGPAPLRLLEWRVAAGAAVRIGSVLAVFEAAASAQSSGASQSRVASGGCVRPARPERRLRSERAGVVRELCAQPGQVVAPGAVLVRLEGCSHPVVMKGLCAECGQDLTQLQSKNGKQQVPLSTATVSMVHSVPELMVSSEQAEQLGREDQQRLHRNRKLVLMVDLDQTLIHTTEQHCQQMSNKGIFHFQLGRGEPMLHTRLRPHCKDFLEKIAKLYELHVFTFGSRLYAHTIAGFLDPEKKLFSHRILSRDECIDPFSKTGNLRNLFPCGDSMVCIIDDREDVWKFAPNLITVKKYVYFQGTGDMNAPPGSRESQTRKKVNHSRGTEVSEPSPPVRDPEGVTQAPGVEPSNGLEKPARELNGSEAATPRDSPRPGKPDERDIWPPAQAPTSSQELAGAPEPQGSCAQGGRVAPGQRPAQGATGTDLDFDLSSDSESSSESEGTKSSSSASDGESEGKRGRQKPKAAPEGAGALAQGSSLEPGRPAAPSLPGEAEPGAHAPDKEPELGGQEEGERDGLCGLGNGCADRKEAETESQNSELSGVTAGESLDQSMEEEEEEDTDEDDHLIYLEEILVRVHTDYYAKYDRYLNKEIEEAPDIRKIVPELKSKVLADVAIIFSGLHPTNFPIEKTREHYHATALGAKILTRLVLSPDAPDRATHLIAARAGTEKVLQAQECGHLHVVNPDWLWSCLERWDKVEEQLFPLRDDHTKAQRENSPAAFPDREGVPPTALFHPMPVLPKAQPGPEVRIYDSNTGKLIRTGARGPPAPSSSLPIRQEPSSFRWTTSLEKAATTATARRGGLRSRRRSPSPGSQGPAGSGRSGHLRPARGARQGAGGPEATRGS>sp|Q86X51|EZHIP_HUMAN EZH inhibitory protein OS=Homo sapiens OX=9606GN=EZHIP PE=1 SV=1MATQSDMEKEQKHQQDEGQGGLNNETALASGDACGTGNQDPAASVTTVSSQASPSGGAALSSSTAGSSAAAATSAAIFITDEASGLPIIAAVLTERHSDRQDCRSPHEVFGCVVPEGGSQAAVGPQKATGHADEHLAQTKSPGNSRRRKQPCRNQAAPAQKPPGRRLFPEPLPPSSPGFRPSSYPCSGASTSSQATQPGPALLSHASEARPATRSRITLVASALRRRASGPGPVIRGCTAQPGPAFPHRATHLDPARLSPESAPGPARRGRASVPGPARRGCDSAPGPARRGRDSAPVSAPRGRDSAPGSARRGRDSAPGPALRVRTARSDAGHRSTSTTPGTGLRSRSTQQRSALLSRRSLSGSADENPSCGTGSERLAFQSRSGSPDPEVPSRASPPVWHAVRMRASSPSPPGRFFLPIPQQWDESSSSSYASNSSSPSRSPGLSPSSPSPEFLGLRSISTPSPESLRYALMPEFYALSPVPPEEQAEIESTAHPATPPEP>sp|Q8IWA5|CTL2_HUMAN Choline transporter-like protein 2 OS=Homo sapiensOX=9606 GN=SLC44A2 PE=1 SV=3MGDERPHYYGKHGTPQKYDPTFKGPIYNRGCTDIICCVFLLLAIVGYVAVGIIAWTHGDPRKVIYPTDSRGEFCGQKGTKNENKPYLFYFNIVKCASPLVLLEFQCPTPQICVEKCPDRYLTYLNARSSRDFEYYKQFCVPGFKNNKGVAEVLQDGDCPAVLIPSKPLARRCFPAIHAYKGVLMVGNETTYEDGHGSRKNITDLVEGAKKANGVLEARQLAMRIFEDYTVSWYWIIIGLVIAMAMSLLFIILLRFLAGIMVWVMIIMVILVLGYGIFHCYMEYSRLRGEAGSDVSLVDLGFQTDFRVYLHLRQTWLAFMIILSILEVIIILLLIFLRKRILIAIALIKEASRAVGYVMCSLLYPLVTFFLLCLCIAYWASTAVFLSTSNEAVYKIFDDSPCPFTAKTCNPETFPSSNESRQCPNARCQFAFYGGESGYHRALLGLQIFNAFMFFWLANFVLALGQVTLAGAFASYYWALRKPDDLPAFPLFSAFGRALRYHTGSLAFGALILAIVQIIRVILEYLDQRLKAAENKFAKCLMTCLKCCFWCLEKFIKFLNRNAYIMIAIYGTNFCTSARNAFFLLMRNIIRVAVLDKVTDFLFLLGKLLIVGSVGILAFFFFTHRIRIVQDTAPPLNYYWVPILTVIVGSYLIAHGFFSVYGMCVDTLFLCFLEDLERNDGSAERPYFMSSTLKKLLNKTNKKAAES>sp|Q8IWA5-2|CTL2_HUMAN Isoform 2 of Choline transporter-like protein 2OS=Homo sapiens OX=9606 GN=SLC44A2MGDERPHYYGKHGTPQKYDPTFKGPIYNRGCTDIICCVFLLLAIVGYVAVGIIAWTHGDPRKVIYPTDSRGEFCGQKGTKNENKPYLFYFNIVKCASPLVLLEFQCPTPQICVEKCPDRYLTYLNARSSRDFEYYKQFCVPGFKNNKGVAEVLQDGDCPAVLIPSKPLARRCFPAIHAYKGVLMVGNETTYEDGHGSRKNITDLVEGAKKANGVLEARQLAMRIFEDYTVSWYWIIIGLVIAMAMSLLFIILLRFLAGIMVWVMIIMVILVLGYGIFHCYMEYSRLRGEAGSDVSLVDLGFQTDFRVYLHLRQTWLAFMIILSILEVIIILLLIFLRKRILIAIALIKEASRAVGYVMCSLLYPLVTFFLLCLCIAYWASTAVFLSTSNEAVYKIFDDSPCPFTAKTCNPETFPSSNESRQCPNARCQFAFYGGESGYHRALLGLQIFNAFMFFWLANFVLALGQVTLAGAFASYYWALRKPDDLPAFPLFSAFGRALRYHTGSLAFGALILAIVQIIRVILEYLDQRLKAAENKFAKCLMTCLKCCFWCLEKFIKFLNRNAYIMIAIYGTNFCTSARNAFFLLMRNIIRVAVLDKVTDFLFLLGKLLIVGSVGILAFFFFTHRIRIVQDTAPPLNYYWVPILTVIVGSYLIAHGFFSVYGMCVDTLFLCFCEDLERNDGSQERPYFMSPELRDILLKGSAEEGKRAEAEE>sp|Q8IWA5-3|CTL2_HUMAN Isoform 3 of Choline transporter-like protein 2OS=Homo sapiens OX=9606 GN=SLC44A2MEDERKNGAYGTPQKYDPTFKGPIYNRGCTDIICCVFLLLAIVGYVAVGIIAWTHGDPRKVIYPTDSRGEFCGQKGTKNENKPYLFYFNIVKCASPLVLLEFQCPTPQICVEKCPDRYLTYLNARSSRDFEYYKQFCVPGFKNNKGVAEVLQDGDCPAVLIPSKPLARRCFPAIHAYKGVLMVGNETTYEDGHGSRKNITDLVEGAKKANGVLEARQLAMRIFEDYTVSWYWIIIGLVIAMAMSLLFIILLRFLAGIMVWVMIIMVILVLGYGIFHCYMEYSRLRGEAGSDVSLVDLGFQTDFRVYLHLRQTWLAFMIILSILEVIIILLLIFLRKRILIAIALIKEASRAVGYVMCSLLYPLVTFFLLCLCIAYWASTAVFLSTSNEAVYKIFDDSPCPFTAKTCNPETFPSSNESRQCPNARCQFAFYGGESGYHRALLGLQIFNAFMFFWLANFVLALGQVTLAGAFASYYWALRKPDDLPAFPLFSAFGRALRYHTGSLAFGALILAIVQIIRVILEYLDQRLKAAENKFAKCLMTCLKCCFWCLEKFIKFLNRNAYIMIAIYGTNFCTSARNAFFLLMRNIIRVAVLDKVTDFLFLLGKLLIVGSVGILAFFFFTHRIRIVQDTAPPLNYYWVPILTVIVGSYLIAHGFFSVYGMCVDTLFLCFLEDLERNDGSAERPYFMSSTLKKLLNKTNKKAAES>sp|Q9NUQ9|CYRIB_HUMAN CYFIP-related Rac1 interactor B OS=Homo sapiensOX=9606 GN=CYRIB PE=1 SV=1MGNLLKVLTCTDLEQGPNFFLDFENAQPTESEKEIYNQVNVVLKDAEGILEDLQSYRGAGHEIREAIQHPADEKLQEKAWGAVVPLVGKLKKFYEFSQRLEAALRGLLGALTSTPYSPTQHLEREQALAKQFAEILHFTLRFDELKMTNPAIQNDFSYYRRTLSRMRINNVPAEGENEVNNELANRMSLFYAEATPMLKTLSDATTKFVSENKNLPIENTTDCLSTMASVCRVMLETPEYRSRFTNEETVSFCLRVMVGVIILYDHVHPVGAFAKTSKIDMKGCIKVLKDQPPNSVEGLLNALRYTTKHLNDETTSKQIKSMLQ>sp|Q9NUQ9-2|CYRIB_HUMAN Isoform 2 of CYFIP-related Rac1 interactor BOS=Homo sapiens OX=9606 GN=CYRIBMTNPAIQNDFSYYRRTLSRMRINNVPAEGENEVNNELANRMSLFYAEATPMLKTLSDATTKFVSENKNLPIENTTDCLSTMASVCRVMLETPEYRSRFTNEETVSFCLRVMVGVIILYDHVHPVGAFAKTSKIDMKGCIKVLKDQPPNSVEGLLNALRYTTKHLNDETTSKQIKSMLQ>sp|P19235|EPOR_HUMAN Erythropoietin receptor OS=Homo sapiens OX=9606GN=EPOR PE=1 SV=1MDHLGASLWPQVGSLCLLLAGAAWAPPPNLPDPKFESKAALLAARGPEELLCFTERLEDLVCFWEEAASAGVGPGNYSFSYQLEDEPWKLCRLHQAPTARGAVRFWCSLPTADTSSFVPLELRVTAASGAPRYHRVIHINEVVLLDAPVGLVARLADESGHVVLRWLPPPETPMTSHIRYEVDVSAGNGAGSVQRVEILEGRTECVLSNLRGRTRYTFAVRARMAEPSFGGFWSAWSEPVSLLTPSDLDPLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTEDPPASLEVLSERCWGTMQAVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASSCSSALASKPSPEGASAASFEYTILDPSSQLLRPWTLCPELPPTPPHLKYLYLVVSDSGISTDYSSGDSQGAQGGLSDGPYSNPYENSLIPAAEPLPPSYVACS>sp|P19235-2|EPOR_HUMAN Isoform EPOR-S of Erythropoietin receptor OS=Homosapiens OX=9606 GN=EPORMDHLGASLWPQVGSLCLLLAGAAWAPPPNLPDPKFESKAALLAARGPEELLCFTERLEDLVCFWEEAASAGVGPGNYSFSYQLEDEPWKLCRLHQAPTARGAVRFWCSLPTADTSSFVPLELRVTAASGAPRYHRVIHINEVVLLDAPVGLVARLADESGHVVLRWLPPPETPMTSHIRYEVDVSAGNGAGSVQRGTVFLSPDWLSSTRARPHVIYFCLLRVPRPDSAPRWRSWRAAPSVC>sp|P19235-3|EPOR_HUMAN Isoform EPOR-T of Erythropoietin receptor OS=Homosapiens OX=9606 GN=EPORMDHLGASLWPQVGSLCLLLAGAAWAPPPNLPDPKFESKAALLAARGPEELLCFTERLEDLVCFWEEAASAGVGPGNYSFSYQLEDEPWKLCRLHQAPTARGAVRFWCSLPTADTSSFVPLELRVTAASGAPRYHRVIHINEVVLLDAPVGLVARLADESGHVVLRWLPPPETPMTSHIRYEVDVSAGNGAGSVQRVEILEGRTECVLSNLRGRTRYTFAVRARMAEPSFGGFWSAWSEPVSLLTPSDLDPLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQVGGLVVPSVPGLPCFLQPNCRPL>sp|P13498|CY24A_HUMAN Cytochrome b-245 light chain OS=Homo sapiensOX=9606 GN=CYBA PE=1 SV=3MGQIEWAMWANEQALASGLILITGGIVATAGRFTQWYFGAYSIVAGVFVCLLEYPRGKRKKGSTMERWGQKYMTAVVKLFGPFTRNYYVRAVLHLLLSVPAGFLLATILGTACLAIASGIYLLAAVRGEQWTPIEPKPRERPQIGGTIKQPPSNPPPRPPAEARKKPSEEEAAVAAGGPPGGPQVNPIPVTDEVV>sp|Q8NCA5|FA98A_HUMAN Protein FAM98A OS=Homo sapiens OX=9606 GN=FAM98APE=1 SV=2MECDLMETDILESLEDLGYKGPLLEDGALSQAVSAGASSPEFTKLCAWLVSELRVLCKLEENVQATNSPSEAEEFQLEVSGLLGEMNCPYLSLTSGDVTKRLLIQKNCLLLLTYLISELEAARMLCVNAPPKKAQEGGGSEVFQELKGICIALGMSKPPANITMFQFFSGIEKKLKETLAKVPPNHVGKPLLKKPMGPAHWEKIEAINQAIANEYEVRRKLLIKRLDVTVQSFGWSDRAKSQTEKLAKVYQPKRSVLSPKTTISVAHLLAARQDLSKILRTSSGSIREKTACAINKVLMGRVPDRGGRPNEIEPPPPEMPPWQKRQDGPQQQTGGRGGGRGGYEHSSYGGRGGHEQGGGRGGRGGYDHGGRGGGRGNKHQGGWTDGGSGGGGGYQDGGYRDSGFQPGGYHGGHSSGGYQGGGYGGFQTSSSYTGSGYQGGGYQQDNRYQDGGHHGDRGGGRGGRGGRGGRGGRAGQGGGWGGRGSQNYHQGGQFEQHFQHGGYQYNHSGFGQGRHYTS>sp|O96002|CX001_HUMAN Putative transmembrane protein CXorf1 OS=Homosapiens OX=9606 GN=CXorf1 PE=5 SV=1MYSRLFYLKSSYIIYFEPLFSNAIINILSFINSLASPLTIFCFALSAQALSTIFYFRIFIFIFHSWILLFHFYFTCSFKTYEHQHSKMVPAYRMQSPRALPRTYLYVWPYK>sp|Q8TB33|CX024_HUMAN Putative uncharacterized protein encoded byLINC01560 OS=Homo sapiens OX=9606 GN=LINC01560 PE=4 SV=2MGALFRLLLQERGKAAEFYSRGRKQRRPSASCTFGGIWSSGVDMLPNGAVGSLTQLGPSRPVLGIDYSKKEFRGTAENVTGLNTILHFRKRTRS>sp|Q12929|EPS8_HUMAN Epidermal growth factor receptor kinase substrate 8OS=Homo sapiens OX=9606 GN=EPS8 PE=1 SV=1MNGHISNHPSSFGMYPSQMNGYGSSPTFSQTDREHGSKTSAKALYEQRKNYARDSVSSVSDISQYRVEHLTTFVLDRKDAMITVDDGIRKLKLLDAKGKVWTQDMILQVDDRAVSLIDLESKNELENFPLNTIQHCQAVMHSCSYDSVLALVCKEPTQNKPDLHLFQCDEVKANLISEDIESAISDSKGGKQKRRPDALRMISNADPSIPPPPRAPAPAPPGTVTQVDVRSRVAAWSAWAADQGDFEKPRQYHEQEETPEMMAARIDRDVQILNHILDDIEFFITKLQKAAEAFSELSKRKKNKKGKRKGPGEGVLTLRAKPPPPDEFLDCFQKFKHGFNLLAKLKSHIQNPSAADLVHFLFTPLNMVVQATGGPELASSVLSPLLNKDTIDFLNYTVNGDERQLWMSLGGTWMKARAEWPKEQFIPPYVPRFRNGWEPPMLNFMGATMEQDLYQLAESVANVAEHQRKQEIKRLSTEHSSVSEYHPADGYAFSSNIYTRGSHLDQGEAAVAFKPTSNRHIDRNYEPLKTQPKKYAKSKYDFVARNNSELSVLKDDILEILDDRKQWWKVRNASGDSGFVPNNILDIVRPPESGLGRADPPYTHTIQKQRMEYGPRPADTPPAPSPPPTPAPVPVPLPPSTPAPVPVSKVPANITRQNSSSSDSGGSIVRDSQRHKQLPVDRRKSQMEEVQDELIHRLTIGRSAAQKKFHVPRQNVPVINITYDSTPEDVKTWLQSKGFNPVTVNSLGVLNGAQLFSLNKDELRTVCPEGARVYSQITVQKAALEDSSGSSELQEIMRRRQEKISAAASDSGVESFDEGSSH>sp|Q12929-2|EPS8_HUMAN Isoform 2 of Epidermal growth factor receptorkinase substrate 8 OS=Homo sapiens OX=9606 GN=EPS8MMAARIDRDVQILNHILDDIEFFITKLQKAAEAFSELSKRKKNKKGKRKGPGEGVLTLRAKPPPPDEFLDCFQKFKHGFNLLAKLKSHIQNPSAADLVHFLFTPLNMVVQATGGPELASSVLSPLLNKDTIDFLNYTVNGDERQLWMSLGGTWMKARAEWPKEQFIPPYVPRFRNGWEPPMLNFMGATMEQDLYQLAESVANVAEHQRKQEIKRLSTEHSSVSEYHPADGYAFSSNIYTRGSHLDQGEAAVAFKPTSNRHIDRNYEPLKTQPKKYAKSKYDFVARNNSELSVLKDDILEILDDRKQWWKVRNASGDSGFVPNNILDIVRPPESGLGRADPPYTHTIQKQRMEYGPRPADTPPAPSPPPTPAPVPVPLPPSTPAPVPVSKVPANITRQNSSSSDSGGSIVRDSQRHKQLPVDRRKSQMEEVQDELIHRLTIGRSAAQKKFHVPRQNVPVINITYDSTPEDVKTWLQSKGFNPVTVNSLGVLNGAQLFSLNKDELRTVCPEGARVYSQITVQKAALEDSSGSSELQEIMRRRQEKISAAASDSGVESFDEGSSH>sp|Q9UQB3|CTND2_HUMAN Catenin delta-2 OS=Homo sapiens OX=9606 GN=CTNND2PE=1 SV=3MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQELQFERLTRELEAERQIVASQLERCKLGSETGSMSSMSSAEEQFQWQSQDGQKDIEDELTTGLELVDSCIRSLQESGILDPQDYSTGERPSLLSQSALQLNSKPEGSFQYPASYHSNQTLALGETTPSQLPARGTQARATGQSFSQGTTSRAGHLAGPEPAPPPPPPPREPFAPSLGSAFHLPDAPPAAAAAALYYSSSTLPAPPRGGSPLAAPQGGSPTKLQRGGSAPEGATYAAPRGSSPKQSPSRLAKSYSTSSPINIVVSSAGLSPIRVTSPPTVQSTISSSPIHQLSSTIGTYATLSPTKRLVHASEQYSKHSQELYATATLQRPGSLAAGSRASYSSQHGHLGPELRALQSPEHHIDPIYEDRVYQKPPMRSLSQSQGDPLPPAHTGTYRTSTAPSSPGVDSVPLQRTGSQHGPQNAAAATFQRASYAAGPASNYADPYRQLQYCPSVESPYSKSGPALPPEGTLARSPSIDSIQKDPREFGWRDPELPEVIQMLQHQFPSVQSNAAAYLQHLCFGDNKIKAEIRRQGGIQLLVDLLDHRMTEVHRSACGALRNLVYGKANDDNKIALKNCGGIPALVRLLRKTTDLEIRELVTGVLWNLSSCDALKMPIIQDALAVLTNAVIIPHSGWENSPLQDDRKIQLHSSQVLRNATGCLRNVSSAGEEARRRMRECDGLTDALLYVIQSALGSSEIDSKTVENCVCILRNLSYRLAAETSQGQHMGTDELDGLLCGEANGKDAESSGCWGKKKKKKKSQDQWDGVGPLPDCAEPPKGIQMLWHPSIVKPYLTLLSECSNPDTLEGAAGALQNLAAGSWKWSVYIRAAVRKEKGLPILVELLRIDNDRVVCAVATALRNMALDVRNKELIGKYAMRDLVHRLPGGNNSNNTASKAMSDDTVTAVCCTLHEVITKNMENAKALRDAGGIEKLVGISKSKGDKHSPKVVKAASQVLNSMWQYRDLRSLYKKDGWSQYHFVASSSTIERDRQRPYSSSRTPSISPVRVSPNNRSASAPASPREMISLKERKTDYECTGSNATYHGAKGEHTSRKDAMTAQNTGISTLYRNSYGAPAEDIKHNQVSAQPVPQEPSRKDYETYQPFQNSTRNYDESFFEDQVHHRPPASEYTMHLGLKSTGNYVDFYSAARPYSELNYETSHYPASPDSWV>sp|Q9UQB3-2|CTND2_HUMAN Isoform 2 of Catenin delta-2 OS=Homo sapiensOX=9606 GN=CTNND2MFARKPPGAAPLGAMPVPDQPSSASEKTSSLSPGLNTSNGDGSETETTSAILASVKEQELQFERLTRELEAERQIVASQLERCKLGSETGSMSSMSSAEEQFQWQSQDGQKDIEDELTTGLELVDSCIRSLQESGILDPQDYSTGERPSLLSQSALQLNSKPEGSFQYPASYHSNQTLALGETTPSQLPARGTQARATGQSFSQGTTSRAGHLAGPEPAPPPPPPPREPFAPSLGSAFHLPDAPPAAAAAALYYSSSTLPAPPRGGSPLAAPQGGSPTKLQRGGSAPEGATYAAPRGSSPKQSPSRLAKSYSTSSPINIVVSSAGLSPIRVTSPPTVQSTISSSPIHQLSSTIGTYATLSPTKRLVHASEQYSKHSQELYATATLQRPGSLAAGSRASYSSQHGHLGPELRALQSPEHHIDPIYEDRVYQKPPMRSLSQSQGDPLPPAHTGTYRTSTAPSSPGVDSVPLQRTGSQHGPQNAAAATFQRASYAAGPASNYADPYRQLQYCPSVESPYSKSGPALPPEGTLARSPSIDSIQKDPREFGWRDPELPEVIQMLQHQFPSVQSNAAAYLQHLCFGDNKIKAEIRRQGGIQLLVDLLDHRMTEVHRSACGALRNLVYGKANDDNKIALKNCGGIPALVRLLRKTTDLEIRELVTGVLWNLSSCDALKMPIIQDALAVLTNAVIIPHSGWENSPLQDDRKIQLHSSQVLRNATGCLRNVSSAGEEARRRMRECDGLTDALLYVIQSALGSSEIDSKTVENCVCILRNLSYRLAAETSQGQHMGTDELDGLLCGEANGKDAESSGCWGKKKKKKKSQDQWSVYIRAAVRKEKGLPILVELLRIDNDRVVCAVATALRNMALDVRNKELIGKYAMRDLVHRLPGGNNSNNTASKAMSDDTVTAVCCTLHEVITKNMENAKALRDAGGIEKLVGISKSKGDKHSPKVVKAASQVLNSMWQYRDLRSLYKKDGWSQYHFVASSSTIERDRQRPYSSSRTPSISPVRVSPNNRSASAPASPREMISLKERKTDYECTGSNATYHGAKGEHTSRKDAMTAQNTGISTLYRNSYGAPAEDIKHNQVSAQPVPQEPSRKDYETYQPFQNSTRNYDESFFEDQVHHRPPASEYTMHLGLKSTGNYVDFYSAARPYSELNYETSHYPASPDSWV>sp|Q8TCP9|F200A_HUMAN Protein FAM200A OS=Homo sapiens OX=9606 GN=FAM200APE=1 SV=1MTPESRDTTDLSPGGTQEMEGIVIVKVEEEDEEDHFQKERNKVESSPQVLSRSTTMNERALLSSYLVAYRVAKEKMAHTAAEKIILPACMDMVRTIFDDKSADKLRTIPLSDNTISRRICTIAKHLEAMLITRLQSGIDFAIQLDESTDIASCPTLLVYVRYVWQDDFVEDLLCCLNLNSHITGLDLFTELENCLLGQYKLNWKHCKGISSDGTANMTGKHSRLTEKLLEATHNNAVWNHCFIHREALVSKEISPSLMDVLKNAVKTVNFIKGSSLNSRLLEIFCSEIGVNHTHLLFHTEVRWLSQGKVLSRVYELRNEIYIFLVEKQSHLANIFEDDIWVTKLAYLSDIFGILNELSLKMQGKNNDIFQYLEHILGFQKTLLLWQARLKSNRPSYYMFPTLLQHIEENIINEDCLKEIKLEILLHLTSLSQTFNYYFPEEKFESLKENIWMKDPFAFQNPESIIELNLEPEEENELLQLSSSFTLKNYYKILSLSAFWIKIKDDFPLLSRKSILLLLPFTTTYLCELGFSILTRLKTKKRNRLNSAPDMRVALSSCVPDWKELMNRQAHPSH>sp|Q6XXX2|CU024_HUMAN Putative uncharacterized protein encoded byLINC00114 OS=Homo sapiens OX=9606 GN=LINC00114 PE=5 SV=1MQTTWQPGCSYPTSWLSSQESFSKMRTGWRGAIPLRWRNRARNREKPHSPRAVSSPATHSLPPSNPCRLTPTLSSARPREGSCPSKCSCPGGNWSNTALSAELMWAEGRFSGGCLPVYMRQNINPGCQEQWEGEERSRWL>sp|Q6ZN03|CU136_HUMAN Putative uncharacterized protein encoded byLINC00322 OS=Homo sapiens OX=9606 GN=LINC00322 PE=5 SV=1MALLITPAGVATVNRHSTIPSDTHTSREKPRFHKPCRNDLESLLSEGRLDTSVQTPCPQHPHTQLSCEPQPLEHSSCLSTCLAGCFLPVPSSPHTHPLLPGSRWLPPPLALLMGTLSPGLAVKPSWVPRFPLLARQSPATSVGMPLSAATQPGSVGRLHFPKLRSSSPFSGHSDENKATGQGRENRDQPQRPSHLCECPEAAKQSATNGVAETNRSVFPLGSEARSLSLRRQESQPHSGSSRRESVSCSPSFWCCWQPLAFLTCGCAAPISVPGVTRPSPRPCCVSPPLVRLQSLGLGPTQI>sp|P25025|CXCR2_HUMAN C-X-C chemokine receptor type 2 OS=Homo sapiensOX=9606 GN=CXCR2 PE=1 SV=2MEDFNMESDSFEDFWKGEDLSNYSYSSTLPPFLLDAAPCEPESLEINKYFVVIIYALVFLLSLLGNSLVMLVILYSRVGRSVTDVYLLNLALADLLFALTLPIWAASKVNGWIFGTFLCKVVSLLKEVNFYSGILLLACISVDRYLAIVHATRTLTQKRYLVKFICLSIWGLSLLLALPVLLFRRTVYSSNVSPACYEDMGNNTANWRMLLRILPQSFGFIVPLLIMLFCYGFTLRTLFKAHMGQKHRAMRVIFAVVLIFLLCWLPYNLVLLADTLMRTQVIQETCERRNHIDRALDATEILGILHSCLNPLIYAFIGQKFRHGLLKILAIHGLISKDSLPKDSRPSFVGSSSGHTSTTL>sp|A6H8Z2|F221B_HUMAN Protein FAM221B OS=Homo sapiens OX=9606 GN=FAM221BPE=1 SV=2MEAHEIIEEPHITMDAEKHPPSKDPSAEDLQENHISESFLKPSTSETPLEPHTSESPLVPSPSQIPLEAHSPETHQEPSISETPSETPTYEASLDSPISVVPEKHLTLPPQSRDYVCLSSSDTLKEDLSSESSSNEVPWTRRSTHLSESESLPEHCLSGPSSQVQVDTTEKQEEEAGEVEKGVDASDSTAHTAQPGHQLGNTARPVFPARQTELVEVAKAMHREEFGAQVNNLFQWEKDAALNAIQTGLYIGWRCPHYLWDCFRIGDESRCFCGHLLREHRIISDISVPCKVSQCRCFMFCFIPSRPEEVGEFWLKRRATFDPKAWRAQCRCKHSHEEHAATGPHPCRHHGCCCGCFESNFLCAACDRRWEEHETFFDTQKTRQRGGRPRGTDTVSNWHRPL>sp|A6H8Z2-2|F221B_HUMAN Isoform 2 of Protein FAM221B OS=Homo sapiensOX=9606 GN=FAM221BMGLYIGWRCPHYLWDCFRIGDESRCFCGHLLREHRIISDISVPCKVSQCRCFMFCFIPSRPEEVGEFWLKRRATFDPKAWRAQCRCKHSHEEHAATGPHPCRHHGCCCGCFESNFLCAACDRRWEEHETFFDTQKTRQRGGRPRGTDTVSNWHRPL>sp|A6H8Z2-3|F221B_HUMAN Isoform 3 of Protein FAM221B OS=Homo sapiensOX=9606 GN=FAM221BMEAHEIIEEPHITMDAEKHPPSKDPSAEDLQENHISESFLKPSTSETPLEPHTSESPLVPSPSQIPLEAHSPETHQEPSISETPSETPTYEASLDSPISVVPEKHLTLPPQSRDYVCLSSSDTLKEDLSSESSSNEVPWTRRSTHLSESESLPEHCLSGPSSQVQVDTTEKQEEEAGEVEKGVDASDSTAHTAQPGHQLGNTARPVFPARQTELVEVAKAMHREEFGAQVNNLFQWEKDAALNAIQTDRIRNSSSGILAPAHLHCDCLYLALSTKPPWCKGALALQAISIKTEEAKPKATSRQALDPDRLWVSTLAGAAPITYGTVSGLGMSPDAFVDTC>sp|Q9NRW3|ABC3C_HUMAN DNA dC->dU-editing enzyme APOBEC-3C OS=Homosapiens OX=9606 GN=APOBEC3C PE=1 SV=2MNPQIRNPMKAMYPGTFYFQFKNLWEANDRNETWLCFTVEGIKRRSVVSWKTGVFRNQVDSETHCHAERCFLSWFCDDILSPNTKYQVTWYTSWSPCPDCAGEVAEFLARHSNVNLTIFTARLYYFQYPCYQEGLRSLSQEGVAVEIMDYEDFKYCWENFVYNDNEPFKPWKGLKTNFRLLKRRLRESLQ>sp|Q9HC16|ABC3G_HUMAN DNA dC->dU-editing enzyme APOBEC-3G OS=Homosapiens OX=9606 GN=APOBEC3G PE=1 SV=1MKPHFRNTVERMYRDTFSYNFYNRPILSRRNTVWLCYEVKTKGPSRPPLDAKIFRGQVYSELKYHPEMRFFHWFSKWRKLHRDQEYEVTWYISWSPCTKCTRDMATFLAEDPKVTLTIFVARLYYFWDPDYQEALRSLCQKRDGPRATMKIMNYDEFQHCWSKFVYSQRELFEPWNNLPKYYILLHIMLGEILRHSMDPPTFTFNFNNEPWVRGRHETYLCYEVERMHNDTWVLLNQRRGFLCNQAPHKHGFLEGRHAELCFLDVIPFWKLDLDQDYRVTCFTSWSPCFSCAQEMAKFISKNKHVSLCIFTARIYDDQGRCQEGLRTLAEAGAKISIMTYSEFKHCWDTFVDHQGCPFQPWDGLDEHSQDLSGRLRAILQNQEN>sp|Q9HC16-3|ABC3G_HUMAN Isoform 3 of DNA dC->dU-editing enzyme APOBEC-3GOS=Homo sapiens OX=9606 GN=APOBEC3GMKPHFRNTVERMYRDTFSYNFYNRPILSRRNTVWLCYEVKTKGPSRPPLDAKIFRGQVPPGLQSLCRQELSQLGKQTTH>sp|Q8N0Z2|ABRA_HUMAN Actin-binding Rho-activating protein OS=Homosapiens OX=9606 GN=ABRA PE=1 SV=1MAPGEKESGEGPAKSALRKIRTATLVISLARGWQQWANENSIRQAQEPTGWLPGGTQDSPQAPKPITPPTSHQKAQSAPKSPPRLPEGHGDGQSSEKAPEVSHIKKKEVSKTVVSKTYERGGDVSHLSHRYERDAGVLEPGQPENDIDRILHSHGSPTRRRKCANLVSELTKGWRVMEQEEPTWRSDSVDTEDSGYGGEAEERPEQDGVQVAVVRIKRPLPSQVNRFTEKLNCKAQQKYSPVGNLKGRWQQWADEHIQSQKLNPFSEEFDYELAMSTRLHKGDEGYGRPKEGTKTAERAKRAEEHIYREMMDMCFIICTMARHRRDGKIQVTFGDLFDRYVRISDKVVGILMRARKHGLVDFEGEMLWQGRDDHVVITLLK>sp|P0DKL9|A14EL_HUMAN ARL14 effector protein-like OS=Homo sapiensOX=9606 GN=ARL14EPL PE=4 SV=1MNEQSEKNNSIQERHTDHSFPEKNCQIGQKQLQQIERQLKCLAFRNPGPQVADFNPETRQQKKKARMSKMNEYFSTKYKIMRKYDKSGRLICNDADLCDCLEKNCLGCFYPCPKCNSNKCGPECRCNRRWVYDAIVTESGEVISTLPFNVPD>sp|Q13873|BMPR2_HUMAN Bone morphogenetic protein receptor type-2 OS=Homosapiens OX=9606 GN=BMPR2 PE=1 SV=2MTSSLQRPWRVPWLPWTILLVSTAAASQNQERLCAFKDPYQQDLGIGESRISHENGTILCSKGSTCYGLWEKSKGDINLVKQGCWSHIGDPQECHYEECVVTTTPPSIQNGTYRFCCCSTDLCNVNFTENFPPPDTTPLSPPHSFNRDETIIIALASVSVLAVLIVALCFGYRMLTGDRKQGLHSMNMMEAAASEPSLDLDNLKLLELIGRGRYGAVYKGSLDERPVAVKVFSFANRQNFINEKNIYRVPLMEHDNIARFIVGDERVTADGRMEYLLVMEYYPNGSLCKYLSLHTSDWVSSCRLAHSVTRGLAYLHTELPRGDHYKPAISHRDLNSRNVLVKNDGTCVISDFGLSMRLTGNRLVRPGEEDNAAISEVGTIRYMAPEVLEGAVNLRDCESALKQVDMYALGLIYWEIFMRCTDLFPGESVPEYQMAFQTEVGNHPTFEDMQVLVSREKQRPKFPEAWKENSLAVRSLKETIEDCWDQDAEARLTAQCAEERMAELMMIWERNKSVSPTVNPMSTAMQNERNLSHNRRVPKIGPYPDYSSSSYIEDSIHHTDSIVKNISSEHSMSSTPLTIGEKNRNSINYERQQAQARIPSPETSVTSLSTNTTTTNTTGLTPSTGMTTISEMPYPDETNLHTTNVAQSIGPTPVCLQLTEEDLETNKLDPKEVDKNLKESSDENLMEHSLKQFSGPDPLSSTSSSLLYPLIKLAVEATGQQDFTQTANGQACLIPDVLPTQIYPLPKQQNLPKRPTSLPLNTKNSTKEPRLKFGSKHKSNLKQVETGVAKMNTINAAEPHVVTVTMNGVAGRNHSVNSHAATTQYANGTVLSGQTTNIVTHRAQEMLQNQFIGEDTRLNINSSPDEHEPLLRREQQAGHDEGVLDRLVDRRERPLEGGRTNSNNNNSNPCSEQDVLAQGVPSTAADPGPSKPRRAQRPNSLDLSATNVLDGSSIQIGESTQDGKSGSGEKIKKRVKTPYSLKRWRPSTWVISTESLDCEVNNNGSNRAVHSKSSTAVYLAEGGTATTMVSKDIGMNCL>sp|Q13873-2|BMPR2_HUMAN Isoform 2 of Bone morphogenetic protein receptortype-2 OS=Homo sapiens OX=9606 GN=BMPR2MTSSLQRPWRVPWLPWTILLVSTAAASQNQERLCAFKDPYQQDLGIGESRISHENGTILCSKGSTCYGLWEKSKGDINLVKQGCWSHIGDPQECHYEECVVTTTPPSIQNGTYRFCCCSTDLCNVNFTENFPPPDTTPLSPPHSFNRDETIIIALASVSVLAVLIVALCFGYRMLTGDRKQGLHSMNMMEAAASEPSLDLDNLKLLELIGRGRYGAVYKGSLDERPVAVKVFSFANRQNFINEKNIYRVPLMEHDNIARFIVGDERVTADGRMEYLLVMEYYPNGSLCKYLSLHTSDWVSSCRLAHSVTRGLAYLHTELPRGDHYKPAISHRDLNSRNVLVKNDGTCVISDFGLSMRLTGNRLVRPGEEDNAAISEVGTIRYMAPEVLEGAVNLRDCESALKQVDMYALGLIYWEIFMRCTDLFPGESVPEYQMAFQTEVGNHPTFEDMQVLVSREKQRPKFPEAWKENSLAVRSLKETIEDCWDQDAEARLTAQCAEERMAELMMIWERNKSVSPTVNPMSTAMQNERR>sp|Q9Y312|AAR2_HUMAN Protein AAR2 homolog OS=Homo sapiens OX=9606GN=AAR2 PE=1 SV=2MAAVQMDPELAKRLFFEGATVVILNMPKGTEFGIDYNSWEVGPKFRGVKMIPPGIHFLHYSSVDKANPKEVGPRMGFFLSLHQRGLTVLRWSTLREEVDLSPAPESEVEAMRANLQELDQFLGPYPYATLKKWISLTNFISEATVEKLQPENRQICAFSDVLPVLSMKHTKDRVGQNLPRCGIECKSYQEGLARLPEMKPRAGTEIRFSELPTQMFPEGATPAEITKHSMDLSYALETVLNKQFPSSPQDVLGELQFAFVCFLLGNVYEAFEHWKRLLNLLCRSEAAMMKHHTLYINLISILYHQLGEIPADFFVDIVSQDNFLTSTLQVFFSSACSIAVDATLRKKAEKFQAHLTKKFRWDFAAEPEDCAPVVVELPEGIEMG>sp|P86434|AAS1_HUMAN Putative uncharacterized protein ADORA2A-AS1OS=Homo sapiens OX=9606 GN=ADORA2A-AS1 PE=5 SV=1MEQDWQPGEEVTPGPEPCSKGQAPLYPIVHVTELKHTDPNFPSNSNAVGTSSGWNRIGTGCSHTWDWRFSCTQQALLPLLGAWEWSIDTEAGGGRREQSQKPCSNGGPAAAGEGRVLPSPCFPWSTCQAAIHKVCRWQGCTRPALLAPSLATLKEHSYP>sp|P08236|BGLR_HUMAN Beta-glucuronidase OS=Homo sapiens OX=9606 GN=GUSBPE=1 SV=2MARGSAVAWAALGPLLWGCALGLQGGMLYPQESPSRECKELDGLWSFRADFSDNRRRGFEEQWYRRPLWESGPTVDMPVPSSFNDISQDWRLRHFVGWVWYEREVILPERWTQDLRTRVVLRIGSAHSYAIVWVNGVDTLEHEGGYLPFEADISNLVQVGPLPSRLRITIAINNTLTPTTLPPGTIQYLTDTSKYPKGYFVQNTYFDFFNYAGLQRSVLLYTTPTTYIDDITVTTSVEQDSGLVNYQISVKGSNLFKLEVRLLDAENKVVANGTGTQGQLKVPGVSLWWPYLMHERPAYLYSLEVQLTAQTSLGPVSDFYTLPVGIRTVAVTKSQFLINGKPFYFHGVNKHEDADIRGKGFDWPLLVKDFNLLRWLGANAFRTSHYPYAEEVMQMCDRYGIVVIDECPGVGLALPQFFNNVSLHHHMQVMEEVVRRDKNHPAVVMWSVANEPASHLESAGYYLKMVIAHTKSLDPSRPVTFVSNSNYAADKGAPYVDVICLNSYYSWYHDYGHLELIQLQLATQFENWYKKYQKPIIQSEYGAETIAGFHQDPPLMFTEEYQKSLLEQYHLGLDQKRRKYVVGELIWNFADFMTEQSPTRVLGNKKGIFTRQRQPKSAAFLLRERYWKIANETRYPHSVAKSQCLENSLFT>sp|P08236-2|BGLR_HUMAN Isoform 2 of Beta-glucuronidase OS=Homo sapiensOX=9606 GN=GUSBMARGSAVAWAALGPLLWGCALGLQGGMLYPQESPSRECKELDGLWSFRADFSDNRRRGFEEQWYRRPLWESGPTVDMPVPSSFNDISQDWRLRHFVGWVWYEREVILPERWTQDLRTRVVLRIGSAHSYAIVWVNGVDTLEHEGGYLPFEADISNLVQVGPLPSRLRITIAINNTLTPTTLPPGTIQYLTDTSKYPKGYFVQNTYFDFFNYAGLQRSVLLYTTPTTYIDDITVTTSVEQDSGLVNYQISVKGSNLFKLEVRLLDAENKVVANGTGTQGQLKVPGVSLWWPYLMHERPAYLYSLEIRGKGFDWPLLVKDFNLLRWLGANAFRTSHYPYAEEVMQMCDRYGIVVIDECPGVGLALPQFFNNVSLHHHMQVMEEVVRRDKNHPAVVMWSVANEPASHLESAGYYLKMVIAHTKSLDPSRPVTFVSNSNYAADKGAPYVDVICLNSYYSWYHDYGHLELIQLQLATQFENWYKKYQKPIIQSEYGAETIAGFHQDPPLMFTEEYQKSLLEQYHLGLDQKRRKYVVGELIWNFADFMTEQSPTRVLGNKKGIFTRQRQPKSAAFLLRERYWKIANETRYPHSVAKSQCLENSLFT>sp|P08236-3|BGLR_HUMAN Isoform 3 of Beta-glucuronidase OS=Homo sapiensOX=9606 GN=GUSBMARGSAVAWAALGPLLWGCALGLQGGMLYPQESPSRECKELDGLWSFRADFSDNRRRGFEEQWYRRPLWESGPTVDMPVPSSFNDISQDWRLRHFVGWVWYEREVILPERWTQDLRTRVVLRIGSAHSYAIVWVNGVDTLEHEGGYLPFEADISNLVQVQLTAQTSLGPVSDFYTLPVGIRTVAVTKSQFLINGKPFYFHGVNKHEDADIRGKGFDWPLLVKDFNLLRWLGANAFRTSHYPYAEEVMQMCDRYGIVVIDECPGVGLALPQFFNNVSLHHHMQVMEEVVRRDKNHPAVVMWSVANEPASHLESAGYYLKMVIAHTKSLDPSRPVTFVSNSNYAADKGAPYVDVICLNSYYSWYHDYGHLELIQLQLATQFENWYKKYQKPIIQSEYGAETIAGFHQDPPLMFTEEYQKSLLEQYHLGLDQKRRKYVVGELIWNFADFMTEQSPTRVLGNKKGIFTRQRQPKSAAFLLRERYWKIANETRYPHSVAKSQCLENSLFT>sp|P34969|5HT7R_HUMAN 5-hydroxytryptamine receptor 7 OS=Homo sapiensOX=9606 GN=HTR7 PE=1 SV=2MMDVNSSGRPDLYGHLRSFLLPEVGRGLPDLSPDGGADPVAGSWAPHLLSEVTASPAPTWDAPPDNASGCGEQINYGRVEKVVIGSILTLITLLTIAGNCLVVISVCFVKKLRQPSNYLIVSLALADLSVAVAVMPFVSVTDLIGGKWIFGHFFCNVFIAMDVMCCTASIMTLCVISIDRYLGITRPLTYPVRQNGKCMAKMILSVWLLSASITLPPLFGWAQNVNDDKVCLISQDFGYTIYSTAVAFYIPMSVMLFMYYQIYKAARKSAAKHKFPGFPRVEPDSVIALNGIVKLQKEVEECANLSRLLKHERKNISIFKREQKAATTLGIIVGAFTVCWLPFFLLSTARPFICGTSCSCIPLWVERTFLWLGYANSLINPFIYAFFNRDLRTTYRSLLQCQYRNINRKLSAAGMHEALKLAERPERPEFVLRACTRRVLLRPEKRPPVSVWVLQSPDHHNWLADKMLTTVEKKVMIHD>sp|P34969-2|5HT7R_HUMAN Isoform A of 5-hydroxytryptamine receptor 7OS=Homo sapiens OX=9606 GN=HTR7MMDVNSSGRPDLYGHLRSFLLPEVGRGLPDLSPDGGADPVAGSWAPHLLSEVTASPAPTWDAPPDNASGCGEQINYGRVEKVVIGSILTLITLLTIAGNCLVVISVCFVKKLRQPSNYLIVSLALADLSVAVAVMPFVSVTDLIGGKWIFGHFFCNVFIAMDVMCCTASIMTLCVISIDRYLGITRPLTYPVRQNGKCMAKMILSVWLLSASITLPPLFGWAQNVNDDKVCLISQDFGYTIYSTAVAFYIPMSVMLFMYYQIYKAARKSAAKHKFPGFPRVEPDSVIALNGIVKLQKEVEECANLSRLLKHERKNISIFKREQKAATTLGIIVGAFTVCWLPFFLLSTARPFICGTSCSCIPLWVERTFLWLGYANSLINPFIYAFFNRDLRTTYRSLLQCQYRNINRKLSAAGMHEALKLAERPERPEFVLQNADYCRKKGHDS>sp|P34969-3|5HT7R_HUMAN Isoform B of 5-hydroxytryptamine receptor 7OS=Homo sapiens OX=9606 GN=HTR7MMDVNSSGRPDLYGHLRSFLLPEVGRGLPDLSPDGGADPVAGSWAPHLLSEVTASPAPTWDAPPDNASGCGEQINYGRVEKVVIGSILTLITLLTIAGNCLVVISVCFVKKLRQPSNYLIVSLALADLSVAVAVMPFVSVTDLIGGKWIFGHFFCNVFIAMDVMCCTASIMTLCVISIDRYLGITRPLTYPVRQNGKCMAKMILSVWLLSASITLPPLFGWAQNVNDDKVCLISQDFGYTIYSTAVAFYIPMSVMLFMYYQIYKAARKSAAKHKFPGFPRVEPDSVIALNGIVKLQKEVEECANLSRLLKHERKNISIFKREQKAATTLGIIVGAFTVCWLPFFLLSTARPFICGTSCSCIPLWVERTFLWLGYANSLINPFIYAFFNRDLRTTYRSLLQCQYRNINRKLSAAGMHEALKLAERPERPEFVL>sp|P05408|7B2_HUMAN Neuroendocrine protein 7B2 OS=Homo sapiens OX=9606GN=SCG5 PE=1 SV=2MVSRMVSTMLSGLLFWLASGWTPAFAYSPRTPDRVSEADIQRLLHGVMEQLGIARPRVEYPAHQAMNLVGPQSIEGGAHEGLQHLGPFGNIPNIVAELTGDNIPKDFSEDQGYPDPPNPCPVGKTADDGCLENTPDTAEFSREFQLHQHLFDPEHDYPGLGKWNKKLLYEKMKGGERRKRRSVNPYLQGQRLDNVVAKKSVPHFSDEDKDPE>sp|P05408-2|7B2_HUMAN Isoform 2 of Neuroendocrine protein 7B2 OS=Homosapiens OX=9606 GN=SCG5MVSRMVSTMLSGLLFWLASGWTPAFAYSPRTPDRVSEADIQRLLHGVMEQLGIARPRVEYPAHQAMNLVGPQSIEGGAHEGLQHLGPFGNIPNIVAELTGDNIPKDFSEDQGYPDPPNPCPVGKTDDGCLENTPDTAEFSREFQLHQHLFDPEHDYPGLGKWNKKLLYEKMKGGERRKRRSVNPYLQGQRLDNVVAKKSVPHFSDEDKDPE>sp|O00512|BCL9_HUMAN B-cell CLL/lymphoma 9 protein OS=Homo sapiensOX=9606 GN=BCL9 PE=1 SV=4MHSSNPKVRSSPSGNTQSSPKSKQEVMVRPPTVMSPSGNPQLDSKFSNQGKQGGSASQSQPSPCDSKSGGHTPKALPGPGGSMGLKNGAGNGAKGKGKRERSISADSFDQRDPGTPNDDSDIKECNSADHIKSQDSQHTPHSMTPSNATAPRSSTPSHGQTTATEPTPAQKTPAKVVYVFSTEMANKAAEAVLKGQVETIVSFHIQNISNNKTERSTAPLNTQISALRNDPKPLPQQPPAPANQDQNSSQNTRLQPTPPIPAPAPKPAAPPRPLDRESPGVENKLIPSVGSPASSTPLPPDGTGPNSTPNNRAVTPVSQGSNSSSADPKAPPPPPVSSGEPPTLGENPDGLSQEQLEHRERSLQTLRDIQRMLFPDEKEFTGAQSGGPQQNPGVLDGPQKKPEGPIQAMMAQSQSLGKGPGPRTDVGAPFGPQGHRDVPFSPDEMVPPSMNSQSGTIGPDHLDHMTPEQIAWLKLQQEFYEEKRRKQEQVVVQQCSLQDMMVHQHGPRGVVRGPPPPYQMTPSEGWAPGGTEPFSDGINMPHSLPPRGMAPHPNMPGSQMRLPGFAGMINSEMEGPNVPNPASRPGLSGVSWPDDVPKIPDGRNFPPGQGIFSGPGRGERFPNPQGLSEEMFQQQLAEKQLGLPPGMAMEGIRPSMEMNRMIPGSQRHMEPGNNPIFPRIPVEGPLSPSRGDFPKGIPPQMGPGRELEFGMVPSGMKGDVNLNVNMGSNSQMIPQKMREAGAGPEEMLKLRPGGSDMLPAQQKMVPLPFGEHPQQEYGMGPRPFLPMSQGPGSNSGLRNLREPIGPDQRTNSRLSHMPPLPLNPSSNPTSLNTAPPVQRGLGRKPLDISVAGSQVHSPGINPLKSPTMHQVQSPMLGSPSGNLKSPQTPSQLAGMLAGPAAAASIKSPPVLGSAAASPVHLKSPSLPAPSPGWTSSPKPPLQSPGIPPNHKAPLTMASPAMLGNVESGGPPPPTASQPASVNIPGSLPSSTPYTMPPEPTLSQNPLSIMMSRMSKFAMPSSTPLYHDAIKTVASSDDDSPPARSPNLPSMNNMPGMGINTQNPRISGPNPVVPMPTLSPMGMTQPLSHSNQMPSPNAVGPNIPPHGVPMGPGLMSHNPIMGHGSQEPPMVPQGRMGFPQGFPPVQSPPQQVPFPHNGPSGGQGSFPGGMGFPGEGPLGRPSNLPQSSADAALCKPGGPGGPDSFTVLGNSMPSVFTDPDLQEVIRPGATGIPEFDLSRIIPSEKPSQTLQYFPRGEVPGRKQPQGPGPGFSHMQGMMGEQAPRMGLALPGMGGPGPVGTPDIPLGTAPSMPGHNPMRPPAFLQQGMMGPHHRMMSPAQSTMPGQPTLMSNPAAAVGMIPGKDRGPAGLYTHPGPVGSPGMMMSMQGMMGPQQNIMIPPQMRPRGMAADVGMGGFSQGPGNPGNMMF>sp|Q13685|AAMP_HUMAN Angio-associated migratory cell protein OS=Homosapiens OX=9606 GN=AAMP PE=1 SV=2MESESESGAAADTPPLETLSFHGDEEIIEVVELDPGPPDPDDLAQEMEDVDFEEEEEEEGNEEGWVLEPQEGVVGSMEGPDDSEVTFALHSASVFCVSLDPKTNTLAVTGGEDDKAFVWRLSDGELLFECAGHKDSVTCAGFSHDSTLVATGDMSGLLKVWQVDTKEEVWSFEAGDLEWMEWHPRAPVLLAGTADGNTWMWKVPNGDCKTFQGPNCPATCGRVLPDGKRAVVGYEDGTIRIWDLKQGSPIHVLKGTEGHQGPLTCVAANQDGSLILTGSVDCQAKLVSATTGKVVGVFRPETVASQPSLGEGEESESNSVESLGFCSVMPLAAVGYLDGTLAIYDLATQTLRHQCQHQSGIVQLLWEAGTAVVYTCSLDGIVRLWDARTGRLLTDYRGHTAEILDFALSKDASLVVTTSGDHKAKVFCVQRPDR>sp|P22760|AAAD_HUMAN Arylacetamide deacetylase OS=Homo sapiens OX=9606GN=AADAC PE=1 SV=5MGRKSLYLLIVGILIAYYIYTPLPDNVEEPWRMMWINAHLKTIQNLATFVELLGLHHFMDSFKVVGSFDEVPPTSDENVTVTETKFNNILVRVYVPKRKSEALRRGLFYIHGGGWCVGSAALSGYDLLSRWTADRLDAVVVSTNYRLAPKYHFPIQFEDVYNALRWFLRKKVLAKYGVNPERIGISGDSAGGNLAAAVTQQLLDDPDVKIKLKIQSLIYPALQPLDVDLPSYQENSNFLFLSKSLMVRFWSEYFTTDRSLEKAMLSRQHVPVESSHLFKFVNWSSLLPERFIKGHVYNNPNYGSSELAKKYPGFLDVRAAPLLADDNKLRGLPLTYVITCQYDLLRDDGLMYVTRLRNTGVQVTHNHVEDGFHGAFSFLGLKISHRLINQYIEWLKENL>sp|O95264|5HT3B_HUMAN 5-hydroxytryptamine receptor 3B OS=Homo sapiensOX=9606 GN=HTR3B PE=1 SV=1MLSSVMAPLWACILVAAGILATDTHHPQDSALYHLSKQLLQKYHKEVRPVYNWTKATTVYLDLFVHAILDVDAENQILKTSVWYQEVWNDEFLSWNSSMFDEIREISLPLSAIWAPDIIINEFVDIERYPDLPYVYVNSSGTIENYKPIQVVSACSLETYAFPFDVQNCSLTFKSILHTVEDVDLAFLRSPEDIQHDKKAFLNDSEWELLSVSSTYSILQSSAGGFAQIQFNVVMRRHPLVYVVSLLIPSIFLMLVDLGSFYLPPNCRARIVFKTSVLVGYTVFRVNMSNQVPRSVGSTPLIGHFFTICMAFLVLSLAKSIVLVKFLHDEQRGGQEQPFLCLRGDTDADRPRVEPRAQRAVVTESSLYGEHLAQPGTLKEVWSQLQSISNYLQTQDQTDQQEAEWLVLLSRFDRLLFQSYLFMLGIYTITLCSLWALWGGV>sp|O95264-2|5HT3B_HUMAN Isoform 2 of 5-hydroxytryptamine receptor 3BOS=Homo sapiens OX=9606 GN=HTR3BMIVYFPGILATDTHHPQDSALYHLSKQLLQKYHKEVRPVYNWTKATTVYLDLFVHAILDVDAENQILKTSVWYQEVWNDEFLSWNSSMFDEIREISLPLSAIWAPDIIINEFVDIERYPDLPYVYVNSSGTIENYKPIQVVSACSLETYAFPFDVQNCSLTFKSILHTVEDVDLAFLRSPEDIQHDKKAFLNDSEWELLSVSSTYSILQSSAGGFAQIQFNVVMRRHPLVYVVSLLIPSIFLMLVDLGSFYLPPNCRARIVFKTSVLVGYTVFRVNMSNQVPRSVGSTPLIGHFFTICMAFLVLSLAKSIVLVKFLHDEQRGGQEQPFLCLRGDTDADRPRVEPRAQRAVVTESSLYGEHLAQPGTLKEVWSQLQSISNYLQTQDQTDQQEAEWLVLLSRFDRLLFQSYLFMLGIYTITLCSLWALWGGV>sp|P21589|5NTD_HUMAN 5'-nucleotidase OS=Homo sapiens OX=9606 GN=NT5EPE=1 SV=1MCPRAARAPATLLLALGAVLWPAAGAWELTILHTNDVHSRLEQTSEDSSKCVNASRCMGGVARLFTKVQQIRRAEPNVLLLDAGDQYQGTIWFTVYKGAEVAHFMNALRYDAMALGNHEFDNGVEGLIEPLLKEAKFPILSANIKAKGPLASQISGLYLPYKVLPVGDEVVGIVGYTSKETPFLSNPGTNLVFEDEITALQPEVDKLKTLNVNKIIALGHSGFEMDKLIAQKVRGVDVVVGGHSNTFLYTGNPPSKEVPAGKYPFIVTSDDGRKVPVVQAYAFGKYLGYLKIEFDERGNVISSHGNPILLNSSIPEDPSIKADINKWRIKLDNYSTQELGKTIVYLDGSSQSCRFRECNMGNLICDAMINNNLRHTDEMFWNHVSMCILNGGGIRSPIDERNNGTITWENLAAVLPFGGTFDLVQLKGSTLKKAFEHSVHRYGQSTGEFLQVGGIHVVYDLSRKPGDRVVKLDVLCTKCRVPSYDPLKMDEVYKVILPNFLANGGDGFQMIKDELLRHDSGDQDINVVSTYISKMKVIYPAVEGRIKFSTGSHCHGSFSLIFLSLWAVIFVLYQ>sp|P21589-2|5NTD_HUMAN Isoform 2 of 5'-nucleotidase OS=Homo sapiensOX=9606 GN=NT5EMCPRAARAPATLLLALGAVLWPAAGAWELTILHTNDVHSRLEQTSEDSSKCVNASRCMGGVARLFTKVQQIRRAEPNVLLLDAGDQYQGTIWFTVYKGAEVAHFMNALRYDAMALGNHEFDNGVEGLIEPLLKEAKFPILSANIKAKGPLASQISGLYLPYKVLPVGDEVVGIVGYTSKETPFLSNPGTNLVFEDEITALQPEVDKLKTLNVNKIIALGHSGFEMDKLIAQKVRGVDVVVGGHSNTFLYTGNPPSKEVPAGKYPFIVTSDDGRKVPVVQAYAFGKYLGYLKIEFDERGNVISSHGNPILLNSSIPEDPSIKADINKWRIKLDNYSTQELGKTIVYLDGSSQSCRFRECNMGNLICDAMINNNLRHTDEMFWNHVSMCILNGGGIRSPIDERNNGIHVVYDLSRKPGDRVVKLDVLCTKCRVPSYDPLKMDEVYKVILPNFLANGGDGFQMIKDELLRHDSGDQDINVVSTYISKMKVIYPAVEGRIKFSTGSHCHGSFSLIFLSLWAVIFVLYQ>sp|Q53H80|AKIR2_HUMAN Akirin-2 OS=Homo sapiens OX=9606 GN=AKIRIN2 PE=1SV=2MACGATLKRTLDFDPLLSPASPKRRRCAPLSAPTSAAASPLSAAAATAASFSAAAASPQKYLRMEPSPFGDVSSRLTTEQILYNIKQEYKRMQKRRHLETSFQQTDPCCTSDAQPHAFLLSGPASPGTSSAASSPLKKEQPLFTLRQVGMICERLLKEREEKVREEYEEILNTKLAEQYDAFVKFTHDQIMRRYGEQPASYVS>sp|Q9NYF8|BCLF1_HUMAN Bcl-2-associated transcription factor 1 OS=Homosapiens OX=9606 GN=BCLAF1 PE=1 SV=2MGRSNSRSHSSRSKSRSQSSSRSRSRSHSRKKRYSSRSRSRTYSRSRSRDRMYSRDYRRDYRNNRGMRRPYGYRGRGRGYYQGGGGRYHRGGYRPVWNRRHSRSPRRGRSRSRSPKRRSVSSQRSRSRSRRSYRSSRSPRSSSSRSSSPYSKSPVSKRRGSQEKQTKKAEGEPQEESPLKSKSQEEPKDTFEHDPSESIDEFNKSSATSGDIWPGLSAYDNSPRSPHSPSPIATPPSQSSSCSDAPMLSTVHSAKNTPSQHSHSIQHSPERSGSGSVGNGSSRYSPSQNSPIHHIPSRRSPAKTIAPQNAPRDESRGRSSFYPDGGDQETAKTGKFLKRFTDEESRVFLLDRGNTRDKEASKEKGSEKGRAEGEWEDQEALDYFSDKESGKQKFNDSEGDDTEETEDYRQFRKSVLADQGKSFATASHRNTEEEGLKYKSKVSLKGNRESDGFREEKNYKLKETGYVVERPSTTKDKHKEEDKNSERITVKKETQSPEQVKSEKLKDLFDYSPPLHKNLDAREKSTFREESPLRIKMIASDSHRPEVKLKMAPVPLDDSNRPASLTKDRLLASTLVHSVKKEQEFRSIFDHIKLPQASKSTSESFIQHIVSLVHHVKEQYFKSAAMTLNERFTSYQKATEEHSTRQKSPEIHRRIDISPSTLRKHTRLAGEERVFKEENQKGDKKLRCDSADLRHDIDRRRKERSKERGDSKGSRESSGSRKQEKTPKDYKEYKSYKDDSKHKREQDHSRSSSSSASPSSPSSREEKESKKEREEEFKTHHEMKEYSGFAGVSRPRGTFFRIRGRGRARGVFAGTNTGPNNSNTTFQKRPKEEEWDPEYTPKSKKYFLHDDRDDGVDYWAKRGRGRGTFQRGRGRFNFKKSGSSPKWTHDKYQGDGIVEDEEETMENNEEKKDRRKEEKE>sp|Q9NYF8-2|BCLF1_HUMAN Isoform 2 of Bcl-2-associated transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=BCLAF1MGRSNSRSHSSRSKSRSQSSSRSRSRSHSRKKRYRSRSRTYSRSRSRDRMYSRDYRRDYRNNRGMRRPYGYRGRGRGYYQGGGGRYHRGGYRPVWNRRHSRSPRRGRSRSRSPKRRSVSSQRSRSRSRRSYRSSRSPRSSSSRSSSPYSKSPVSKRRGSQEKQTKKAEGEPQEESPLKSKSQEEPKDTFEHDPSESIDEFNKSSATSGDIWPGLSAYDNSPRSPHSPSPIATPPSQSSSCSDAPMLSTVHSAKNTPSQHSHSIQHSPERSGSGSVGNGSSRYSPSQNSPIHHIPSRRSPAKTIAPQNAPRDESRGRSSFYPDGGDQETAKTGKFLKRFTDEESRVFLLDRGNTRDKEASKEKGSEKGRAEGEWEDQEALDYFSDKESGKQKFNDSEGDDTEETEDYRQFRKSVLADQGKSFATASHRNTEEEGLKYKSKVSLKGNRESDGFREEKNYKLKETGYVVERPSTTKDKHKEEDKNSERITVKKETQSPEQVKSEKLKDLFDYSPPLHKNLDAREKSTFREESPLRIKMIASDSHRPEVKLKMAPVPLDDSNRPASLTKDRLLASTLVHSVKKEQEFRSIFDHIKLPQASKSTSESFIQHIVSLVHHVKEQYFKSAAMTLNERFTSYQKATEEHSTRQKSPEIHRRIDISPSTLRKHTRLAGEERVFKEENQKGDKKLRCDSADLRHDIDRRRKERSKERGDSKGSRESSGSRKQEKTPKDYKEYKSYKDDSKHKREQDHSRSSSSSASPSSPSSREEKESKKEREEEFKTHHEMKEYSGFAGVSRPRGTFFRIRGRGRARGVFAGTNTGPNNSNTTFQKRPKEEEWDPEYTPKSKKYFLHDDRDDGVDYWAKRGRGRGTFQRGRGRFNFKKSGSSPKWTHDKYQGDGIVEDEEETMENNEEKKDRRKEEKE>sp|Q9NYF8-3|BCLF1_HUMAN Isoform 3 of Bcl-2-associated transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=BCLAF1MGRSNSRSHSSRSKSRSQSSSRSRSRSHSRKKRYRSRSRTYSRSRSRDRMYSRDYRRDYRNNRGMRRPYGYRGRGRGYYQGGGGRYHRGGYRPVWNRRHSRSPRRGRSRSRSPKRRSVSSQRSRSRSRRSYRSSRSPRSSSSRSSSPYSKSPVSKRRGSQEKQTKKAEGEPQEESPLKSKSQEEPKDTFEHDPSESIDEFNKSSATSGDIWPGLSAYDNSPRSPHSPSPIATPPSQSSSCSDAPMLSTVHSAKNTPSQHSHSIQHSPERSGSGSVGNGSSRYSPSQNSPIHHIPSRRSPAKTIAPQNAPRDESRGRSSFYPDGGDQETAKTGKFLKRFTDEESRVFLLDRGNTRDKEASKEKGSEKGRAEGEWEDQEALDYFSDKESGKQKFNDSEGDDTEETEDYRQFRKSVLADQGKSFATASHRNTEEEGLKYKSKVSLKGNRESDGFREEKNYKLKETGYVVERPSTTKDKHKEEDKNSERITVKKETQSPEQVKSEKLKDLFDYSPPLHKNLDAREKSTFREESPLRIKMIASDSHRPEVKLKMAPVPLDDSNRPASLTKDRLLASTLVHSVKKEQEFRSIFDHIKLPQASKSTSESFIQHIVSLVHHVKEQYFKSAAMTLNERFTSYQKATEEHSTRQKSPEIHRRIDISPSTLRKHTRLAGEERVFKEENQKGDKKLRCDSADLRHDIDRRRKERSKERGDSKGSRESSGSRKQEKTPKDYKEYKSYKDDSKHKREQDHSRSSSSSASPSSPSSREEKESKKEREEEFKTHHEMKEYSGFAGVSRPRGTFHDDRDDGVDYWAKRGRGRGTFQRGRGRFNFKKSGSSPKWTHDKYQGDGIVEDEEETMENNEEKKDRRKEEKE>sp|Q9NYF8-4|BCLF1_HUMAN Isoform 4 of Bcl-2-associated transcriptionfactor 1 OS=Homo sapiens OX=9606 GN=BCLAF1MGRSNSRSHSSRSKSRSQSSSRSRSRSHSRKKRYSSRSRSRTYSRSRSRDRMYSRDYRRDYRNNRGMRRPYGYRGRGRGYYQGGGGRYHRGGYRPVWNRRHSRSPRRGRSRSRSPKRRSVSSQRSRSRSRRSYRSSRSPRSSSSRSSSPYSKSPVSKRRGSQEKQTKKAEGEPQEESPLKSKSQEEPKDTFEHDPSESIDEFNKSSATSGDIWPGLSAYDNSPRSPHSPSPIATPPSQSSSCSDAPMLSTVHSAKNTPSQHSHSIQHSPERSGSGSVGNGSSRYSPSQNSPIHHIPSRRSPAKTIAPQNAPRDESRGRSSFYPDGGDQETAKTGKFLKSPPLHKNLDAREKSTFREESPLRIKMIASDSHRPEVKLKMAPVPLDDSNRPASLTKDRLLASTLVHSVKKEQEFRSIFDHIKLPQASKSTSESFIQHIVSLVHHVKEQYFKSAAMTLNERFTSYQKATEEHSTRQKSPEIHRRIDISPSTLRKHTRLAGEERVFKEENQKGDKKLRCDSADLRHDIDRRRKERSKERGDSKGSRESSGSRKQEKTPKDYKEYKSYKDDSKHKREQDHSRSSSSSASPSSPSSREEKESKKEREEEFKTHHEMKEYSGFAGVSRPRGTFFRIRGRGRARGVFAGTNTGPNNSNTTFQKRPKEEEWDPEYTPKSKKYFLHDDRDDGVDYWAKRGRGRGTFQRGRGRFNFKKSGSSPKWTHDKYQGDGIVEDEEETMENNEEKKDRRKEEKE>sp|Q6NZY7|BORG3_HUMAN Cdc42 effector protein 5 OS=Homo sapiens OX=9606GN=CDC42EP5 PE=2 SV=1MPVLKQLGPAQPKKRPDRGALSISAPLGDFRHTLHVGRGGDAFGDTSFLSRHGGGPPPEPRAPPAGAPRSPPPPAVPQSAAPSPADPLLSFHLDLGPSMLDAVLGVMDAARPEAAAAKPDAEPRPGTQPPQARCRPNADLELNDVIGL>sp|Q8N1D0|BWR1B_HUMAN Beckwith-Wiedemann syndrome chromosomal region 1candidate gene B protein OS=Homo sapiens OX=9606 GN=SLC22A18AS PE=1 SV=3MGELPGSEGMWENCPLGWVKKKASGTLAPLDFLLQRKRLWLWASEPVRPQPQGIHRFREARRQFCRMRGSRLTGGRKGFGSSGLRFGRGGFSEEVMPQPVLKAMRCAEGAWWFSPDGPAGSAASIWPAEGAEGLPGQLGRDRLEVVYSVPDNVPGQNGSRRPLVCKITGKCLSVCSEENAKAGGCSAFPLLLSQLGARMTGREHAHKGPELTTPDSGLPRPPNPALAGFRALAQHSPPLGTSTPSAVLLSAAT>sp|Q8N1D0-2|BWR1B_HUMAN Isoform 2 of Beckwith-Wiedemann syndromechromosomal region 1 candidate gene B protein OS=Homo sapiens OX=9606GN=SLC22A18ASMRCAEGAWWFSPDGPAGSAASIWPAEGAEGLPGQLGRDRLEVVYSVPDNVPGQNGSRRPLVCKITGKCLSVCSEENAKAGGCSAFPLLLSQLGARMTGREHAHKGPELTTPDSGLPRPPNPALAGFRALAQHSPPLGTSTPSAVLLSAAT>sp|Q7Z591|AKNA_HUMAN Microtubule organization protein AKNA OS=Homosapiens OX=9606 GN=AKNA PE=1 SV=2MASSETEIRWAEPGLGKGPQRRRWAWAEDKRDVDRSSSQSWEEERLFPNATSPELLEDFRLAQQHLPPLEWDPHPQPDGHQDSESGETSGEEAEAEDVDSPASSHEPLAWLPQQGRQLDMTEEEPDGTLGSLEVEEAGESSSRLGYEAGLSLEGHGNTSPMALGHGQARGWVASGEQASGDKLSEHSEVNPSVELSPARSWSSGTVSLDHPSDSLDSTWEGETDGPQPTALAETLPEGPSHHLLSPDGRTGGSVARATPMEFQDSSAPPAQSPQHATDRWRRETTRFFCPQPKEHIWKQTKTSPKPLPSRFIGSISPLNPQPRPTRQGRPLPRQGATLAGRSSSNAPKYGRGQLNYPLPDFSKVGPRVRFPKDESYRPPKSRSHNRKPQAPARPLIFKSPAEIVQEVLLSSGEAALAKDTPPAHPITRVPQEFQTPEQATELVHQLQEDYHRLLTKYAEAENTIDQLRLGAKVNLFSDPPQPNHSIHTGMVPQGTKVLSFTIPQPRSAEWWPGPAEDPQASAASGWPSARGDLSPSSLTSMPTLGWLPENRDISEDQSSAEQTQALASQASQFLAKVESFERLIQAGRLMPQDQVKGFQRLKAAHAALEEEYLKACREQHPAQPLAGSKGTPGRFDPRRELEAEIYRLGSCLEELKEHIDQTQQEPEPPGSDSALDSTPALPCLHQPTHLPAPSGQAPMPAIKTSCPEPATTTAAASTGPCPLHVNVEVSSGNSEVEDRPQDPLARLRHKELQMEQVYHGLMERYLSVKSLPEAMRMEEEEEGEEEEEEEGGGDSLEVDGVAATPGKAEATRVLPRQCPVQAEKSHGAPLEEATEKMVSMKPPGFQASLARDGHMSGLGKAEAAPPGPGVPPHPPGTKSAASHQSSMTSLEGSGISERLPQKPLHRGGGPHLEETWMASPETDSGFVGSETSRVSPLTQTPEHRLSHISTAGTLAQPFAASVPRDGASYPKARGSLIPRRATEPSTPRSQAQRYLSSPSGPLRQRAPNFSLERTLAAEMAVPGSEFEGHKRISEQPLPNKTISPPPAPAPAAAPLPCGPTETIPSFLLTRAGRDQAICELQEEVSRLRLRLEDSLHQPLQGSPTRPASAFDRPARTRGRPADSPATWGSHYGSKSTERLPGEPRGEEQIVPPGRQRARSSSVPREVLRLSLSSESELPSLPLFSEKSKTTKDSPQAARDGKRGVGSAGWPDRVTFRGQYTGHEYHVLSPKAVPKGNGTVSCPHCRPIRTQDAGGAVTGDPLGPPPADTLQCPLCGQVGSPPEADGPGSATSGAEKATTRRKASSTPSPKQRSKQAGSSPRPPPGLWYLATAPPAPAPPAFAYISSVPIMPYPPAAVYYAPAGPTSAQPAAKWPPTASPPPARRHRHSIQLDLGDLEELNKALSRAVQAAESVRSTTRQMRSSLSADLRQAHSLRGSCLF>sp|Q7Z591-2|AKNA_HUMAN Isoform 2 of Microtubule organization proteinAKNA OS=Homo sapiens OX=9606 GN=AKNAMLRSEWPVFPEAEAEDVDSPASSHEPLAWLPQQGRQLDMTEEEPDGTLGSLEVEEAGESSSRLGYEAGLSLEGHGNTSPMALGHGQARGWVASGEQASGDKLSEHSEVNPSVELSPARSWSSGTVSLDHPSDSLDSTWEGETDGPQPTALAETLPEGPSHHLLSPDGRTGGSVARATPMEFQDSSAPPAQSPQHATDRWRRETTRFFCPQPKEHIWKQTKTSPKPLPSRFIGSISPLNPQPRPTRQGRPLPRQGATLAGRSSSNAPKYGRGQLNYPLPDFSKVGPRVRFPKDESYRPPKSRSHNRKPQAPARPLIFKSPAEIVQEVLLSSGEAALAKDTPPAHPITRVPQEFQTPEQATELVHQLQEDYHRLLTKYAEAENTIDQLRLGAKVNLFSDPPQPNHSIHTGMVPQGTKVLSFTIPQPRSAEWWPGPAEDPQASAASGWPSARGDLSPSSLTSMPTLGWLPENRDISEDQSSAEQTQALASQASQFLAKVESFERLIQAGRLMPQDQVKGFQRLKAAHAALEEEYLKACREQHPAQPLAGSKGTPGRFDPRRELEAEIYRLGSCLEELKEHIDQTQQEPEPPGSDSALDSTPALPCLHQPTHLPAPSGQAPMPAIKTSCPEPATTTAAASTGPCPLHVNVEVSSGNSEVEDRPQDPLARLRHKELQMEQVYHGLMERYLSVKSLPEAMRMEEEEEGEEEEEEEGGGDSLEVDGVAATPGKAEATRVLPRQCPVQAEKSHGAPLEEATEKMVSMKPPGFQASLARDGHMSGLGKAEAAPPGPGVPPHPPGTKSAASHQSSMTSLEGSGISERLPQKPLHRGGGPHLEETWMASPETDSGFVGSETSRVSPLTQTPEHRLSHISTAGTLAQPFAASVPRDGASYPKARGSLIPRRATEPSTPRSQAQRYLSSPSGPLRQRAPNFSLERTLAAEMAVPGSEFEGHKRISEQPLPNKTISPPPAPAPAAAPLPCGPTETIPSFLLTRAGRDQAICELQEEVSRLRLRLEDSLHQPLQGSPTRPASAFDRPARTRGRPADSPATWGSHYGSKSTERLPGEPRGEEQIVPPGRQRARSSSVPREVLRLSLSSESELPSLPLFSEKSKTTKDSPQAARDGKRGVGSAGWPDRVTFRGQYTGHEYHVLSPKAVPKGNGTVSCPHCRPIRTQDAGGAVTGDPLGPPPADTLQCPLCGQVGSPPEADGPGSATSGAEKATTRRKASSTPSPKQRSKQAGSSPRPPPGLWYLATAPPAPAPPAFAYISSVPIMPYPPAAVYYAPAGPTSAQPAAKWPPTASPPPARRHRHSIQLDLGDLEELNKALSRAVQAAESVRSTTRQMRSSLSADLRQAHSLRGSCLF>sp|Q7Z591-3|AKNA_HUMAN Isoform 3 of Microtubule organization proteinAKNA OS=Homo sapiens OX=9606 GN=AKNAMASSETEIRWAEPGLGKGPQRRRWAWAEDKRDVDRSSSQSWEEERLFPNATSPELLEDFRLAQQHLPPLEWDPHPQPDGHQDSESGETSGEEAEAEDVDSPASSHEPLAWLPQQGRQLDMTEEEPDGTLGSLEVEEAGESSSRLGYEAGLSLEGHGNTSPMALGHGQARGWVASGEQASGDKLSEHSEVNPSVELSPARSWSSGTVSLDHPSDSLDSTWEGETDGPQPTALAETLPEGPSHHLLSPDGRTGGSVARATPMEFQDSSAPPAQSPQHATDRWRRETTRFFCPQPKEHIWKQTKTSPKPLPSRFIGSISPLNPQPRPTRQGRPLPRQGATLAGRSSSNAPKYGRGQLNYPLPDFSKVGPRVRFPKDESYRPPKSRSHNRKPQAPARPLIFKSPAEIVQEVLLSSGEAALAKDTPPAHPITRVPQEFQTPEQATELVHQLQEDYHRLLTKYAEAENTIDQLRLGAKVNLFSDPPQPNHSIHTGMVPQGTKVLSFTIPQPRSAEWWPGPAEDPQASAASGWPSARGDLSPSSLTSMPTLGWLPENRDISEDQSSAEQTQALASQASQFLAKVESFERLIQAGRLMPQDQVKGFQRLKAAHAALEEEYLKACREQHPAQPLAGSKGTPGRFDPRRELEAEIYRLGSCLEELKEHIDQTQQEPEPPGSDSALDSTPALPCLHQPTHLPAPSGQAPMPAIKTSCPEPATTTAAASTGPCPLHVNVEVSSGNSEVEDRPQDPLARLRHKELQMEQVYHGLMERYLSVKSLPEAMRMEEEEEGEEEEEEEGGGDSLEVDGVAATPGKAEATRVLPRQCPVQAEKSHGAPLE>sp|Q7Z591-4|AKNA_HUMAN Isoform 4 of Microtubule organization proteinAKNA OS=Homo sapiens OX=9606 GN=AKNAMSAGGGTRGYSPRSPGATSQAICELQEEVSRLRLRLEDSLHQPLQGSPTRPASAFDRPARTRGRPADSPATWGSHYGSKSTERLPGEPRGEEQIVPPGRQRARSSSVPREVLRLSLSSESELPSLPLFSEKSKTTKDSPQAARDGKRGVGSAGWPDRVTFRGQYTGHEYHVLSPKAVPKGNGTVSCPHCRPIRTQDAGGAVTGDPLGPPPADTLQCPLCGQVGSPPEADGPGSATSGAEKATTRRKASSTPSPKQRSKQAGSSPRPPPGLWYLATAPPAPAPPAFAYISSVPIMPYPPAAVYYAPAGPTSAQPAAKWPPTASPPPARRHRHSIQLDLGDLEELNKALSRAVQAAESVRSTTRQMRSSLSADLRQAHSLRGSCLF>sp|Q7Z591-5|AKNA_HUMAN Isoform 5 of Microtubule organization proteinAKNA OS=Homo sapiens OX=9606 GN=AKNAMEQVYHGLMERYLSVKSLPEAMRMEEEEEGEEEEEEEGGGDSLEVDGVAATPGKAEATRVLPRQCPVQAEKSHGAPLEEATEKMVSMKPPGFQASLARDGHMSGLGKAEAAPPGPGVPPHPPGTKSAASHQSSMTSLEGSGISERLPQKPLHRGGGPHLEETWMASPETDSGFVGSETSRVSPLTQTPEHRLSHISTAGTLAQPFAASVPRDGASYPKARGSLIPRRATEPSTPRSQAQRYLSSPSGPLRQRAPNFSLERTLAAEMAVPGSEFEGHKRISEQPLPNKTISPPPAPAPAAAPLPCGPTETIPSFLLTRAGRDQAICELQEEVSRLRLRLEDSLHQPLQGSPTRPASAFDRPARTRGRPADSPATWGSHYGSKSTERLPGEPRGEEQIVPPGRQRARSSSVPREVLRLSLSSESELPSLPLFSEKSKTTKDSPQAARDGKRGVGSAGWPDRVTFRGQYTGHEYHVLSPKAVPKGNGTVSCPHCRPIRTQDAGGAVTGDPLGPPPADTLQCPLCGQVGSPPEADGPGSATSGAEKATTRRKASSTPSPKQRSKQAGSSPRPPPGLWYLATAPPAPAPPAFAYISSVPIMPYPPAAVYYAPAGPTSAQPAAKWPPTASPPPARRHRHSIQLDLGDLEELNKALSRAVQAAESVRSTTRQMRSSLSADLRQAHSLRGSCLF>sp|Q7Z591-6|AKNA_HUMAN Isoform 6 of Microtubule organization proteinAKNA OS=Homo sapiens OX=9606 GN=AKNAMASSETEIRWAEPGLGKGPQRRRWAWAEDKRDVDRSSSQSWEEERLFPNATSPELLEDFRLAQQHLPPLEWDPHPQPDGHQDSESGETSGEEAEAEDVDSPASSHEPLAWLPQQGRQLDMTEEEPDGTLGSLEVEEAGESSSRLGYEAGLSLEGHGNTSPMALGHGQARGWVASGEQASGDKLSEHSEVNPSVELSPARSWSSGTVSLDHPSDSLDSTWEGETDGPQPTALAETLPEGPSHHLLSPDGRTGGSVARATPMEFQDSSAPPAQSPQHATDRWRRETTRFFCPQPKEHIWKQTKTSPKPLPSRFIGSISPLNPQPRPTRQGRPLPRQGATLAGRSSSNAPKYGRGQLNYPLPDFSKVGPRVRFPKDESYRPPKSRSHNRKPQAPARPLIFKSPAEIVQEVLLSSGEAALAKDTPPAHPITRVPQEFQTPEQATELVHQLQVSGTHGCGCVTKAPVGLGWRLIGVGRPGVEAGWGGEAWDRAWLGWEALGRRLVGWGGLGWRLARVGSPGMEASGVGRPGVGSPGVEPGGVGRPGVEAGWGRKPWDRGWWGGEAWGGGWLGQEALG>sp|Q7Z591-7|AKNA_HUMAN Isoform 7 of Microtubule organization proteinAKNA OS=Homo sapiens OX=9606 GN=AKNAMTEEEPDGTLGSLEVEEAGESSSRLGYEAGLSLEGHGNTSPMALGHGQARGWVASGEQASGDKLSEHSEVNPSVELSPARSWSSGTVSLDHPSDSLDSTWEGETDGPQPTALAETLPEGPSHHLLSPDGRTGGSVARATPMEFQDSSAPPAQSPQHATDRWRRETTRFFCPQPKEHIWKQTKTSPKPLPSRFIGSISPLNPQPRPTRQGRPLPRQGATLAGRSSSNAPKYGRGQLNYPLPDFSKVGPRVRFPKDESYRPPKSRSHNRKPQAPARPLIFKSPAEIVQEVLLSSGEAALAKDTPPAHPITRVPQEFQTPEQATELVHQLQEDYHRLLTKYAEAENTIDQLRLGAKVNLFSDPPQPNHSIHTGMVPQGTKVLSFTIPQPRSAEWWPGPAEDPQASAASGWPSARGDLSPSSLTSMPTLGWLPENRDISEDQSSAEQTQALASQASQFLAKVESFERLIQAGRLMPQDQVKGFQRLKAAHAALEEEYLKACREQHPAQPLAGSKGTPGRFDPRRELEAEIYRLGSCLEELKEHIDQTQQEPEPPGSDSALDSTPALPCLHQPTHLPAPSGQAPMPAIKTSCPEPATTTAAASTGPCPLHVNVEVSSGNSEVEDRPQDPLARLRHKELQMEQVYHGLMERYLSVKSLPEAMRMEEEEEGEEEEEEEGGGDSLEVDGVAATPGKAEATRVLPRQCPVQAEKSHGAPLEEATEKMVSMKPPGFQASLARDGHMSGLGKAEAAPPGPGVPPHPPGTKSAASHQSSMTSLEGSGISERLPQKPLHRGGGPHLEETWMASPETDSGFVGSETSRVSPLTQTPEHRLSHISTAGTLAQPFAASVPRDGASYPKARGSLIPRRATEPSTPRSQAQRYLSSPSGPLRQRAPNFSLERTLAAEMAVPGSEFEGHKRISEQPLPNKTISPPPAPAPAAAPLPCGPTETIPSFLLTRAGRDQAICELQEEVSRLRLRLEDSLHQPLQGSPTRPASAFDRPARTRGRPADSPATWGSHYGSKSTERLPGEPRGEEQIVPPGRQRARSSSVPREVLRLSLSSESELPSLPLFSEKSKTTKDSPQAARDGKRGVGSAGWPDRVTFRGQYTGHEYHVLSPKAVPKGNGTVSCPHCRPIRTQDAGGAVTGDPLGPPPADTLQCPLCGQVGSPPEADGPGSATSGAEKATTRRKASSTPSPKQRSKQAGSSPRPPPGLWYLATAPPAPAPPAFAYISSVPIMPYPPAAVYYAPAGPTSAQPAAKWPPTASPPPARRHRHSIQLDLGDLEELNKALSRAVQAAESVRSTTRQMRSSLSADLRQAHSLRGSCLF>sp|Q7Z591-8|AKNA_HUMAN Isoform 8 of Microtubule organization proteinAKNA OS=Homo sapiens OX=9606 GN=AKNAMPTLGWLPENRDISEDQSSAEQTQALASQASQFLAKVESFERLIQAGRLMPQDQVKGFQRLKAAHAALEEEYLKACREQHPAQPLAGSKGTPGRFDPRRELEAEIYRLGSCLEELKEHIDQTQQEPEPPGSDSALDSTPALPCLHQPTHLPAPSGQAPMPAIKTSCPEPATTTAAASTGPCPLHVNVEVSSGNSEVEDRPQDPLARLRHKELQMEQVYHGLMERYLSVKSLPEAMRMEEEEEGEEEEEEEGGGDSLEVDGVAATPGKAEATRVLPRQCPVQAEKSHGAPLEEATEKMVSMKPPGFQASLARDGHMSGLGKAEAAPPGPGVPPHPPGTKSAASHQSSMTSLEGSGISERLPQKPLHRGGGPHLEETWMASPETDSGFVGSETSRVSPLTQTPEHRLSHISTAGTLAQPFAASVPRDGASYPKARGSLIPRRATEPSTPRSQAQRYLSSPSGPLRQRAPNFSLERTLAAEMAVPGSEFEGHKRISEQPLPNKTISPPPAPAPAAAPLPCGPTETIPSFLLTRAGRDQAICELQEEVSRLRLRLEDSLHQPLQGSPTRPASAFDRPARTRGRPADSPATWGSHYGSKSTERLPGEPRGEEQIVPPGRQRARSSSVPREVLRLSLSSESELPSLPLFSEKSKTTKDSPQAARDGKRGVGSAGWPDRVTFRGQYTGHEYHVLSPKAVPKGNGTVSCPHCRPIRTQDAGGAVTGDPLGPPPADTLQCPLCGQVGSPPEADGPGSATSGAEKATTRRKASSTPSPKQRSKQAGSSPRPPPGLWYLATAPPAPAPPAFAYISSVPIMPYPPAAVYYAPAGPTSAQPAAKWPPTASPPPARRHRHSIQLDLGDLEELNKALSRAVQAAESVRSTTRQMRSSLSADLRQAHSLRGSCLF>sp|Q9UHK6|AMACR_HUMAN Alpha-methylacyl-CoA racemase OS=Homo sapiensOX=9606 GN=AMACR PE=1 SV=2MALQGISVVELSGLAPGPFCAMVLADFGARVVRVDRPGSRYDVSRLGRGKRSLVLDLKQPRGAAVLRRLCKRSDVLLEPFRRGVMEKLQLGPEILQRENPRLIYARLSGFGQSGSFCRLAGHDINYLALSGVLSKIGRSGENPYAPLNLLADFAGGGLMCALGIIMALFDRTRTGKGQVIDANMVEGTAYLSSFLWKTQKLSLWEAPRGQNMLDGGAPFYTTYRTADGEFMAVGAIEPQFYELLIKGLGLKSDELPNQMSMDDWPEMKKKFADVFAEKTKAEWCQIFDGTDACVTPVLTFEEVVHHDHNKERGSFITSEEQDVSPRPAPLLLNTPAIPSFKRDPFIGEHTEEILEEFGFSREEIYQLNSDKIIESNKVKASL>sp|Q9UHK6-2|AMACR_HUMAN Isoform 2 of Alpha-methylacyl-CoA racemaseOS=Homo sapiens OX=9606 GN=AMACRMALQGISVVELSGLAPGPFCAMVLADFGARVVRVDRPGSRYDVSRLGRGKRSLVLDLKQPRGAAVLRRLCKRSDVLLEPFRRGVMEKLQLGPEILQRENPRLIYARLSGFGQSGSFCRLAGHDINYLALSGGRNSIFKFFSVENSEIESVGSTSRTEHVGWWSTFLYDLQDSRWGIHGCWSNRTPVLRAADQRSLIPYFNLYLQFLNISMQNLFKVHTLLRPCYFLGQK>sp|Q9UHK6-4|AMACR_HUMAN Isoform 3 of Alpha-methylacyl-CoA racemaseOS=Homo sapiens OX=9606 GN=AMACRMALQGISVVELSGLAPGPFCAMVLADFGARVVRVDRPGSRYDVSRLGRGKRSLVLDLKQPRGAAVLRRLCKRSDVLLEPFRRGVMEKLQLGPEILQRENPRLIYARLSGFGQSGSFCRLAGHDINYLALSGGRNSIFKFFSVENSEIESVGSTSRTEHVGWWSTFLYDLQDSRWGIHGCWSNRTPVLRAADQRTWTKV>sp|Q9UHK6-5|AMACR_HUMAN Isoform 4 of Alpha-methylacyl-CoA racemaseOS=Homo sapiens OX=9606 GN=AMACRMALQGISVVELSGLAPGPFCAMVLADFGARVVRVDRPGSRYDVSRLGRGKRSLVLDLKQPRGAAVLRRLCKRSDVLLEPFRRGVMEKLQLGPEILQRENPRLIYARLSGFGQSGSFCRLAGHDINYLALSGVLSKIGRSGENPYAPLNLLADFAGGGLMCALGIIMALFDRTRTGKGQVIDANMVEGTAYLSSFLWKTQKLSLWEAPRGQNMLDGGAPFYTTYRTADGEFMAVGAIEPQFYELLIKGLGLKSDELPNQMSMDDWPEMKKKFADVFAEKTKAEWCQIFDGTDACVTPVLTFEEVVHHDHNKERGSFITSEEQDVSPRPAPLLLNTPAIPSFKRDPFIGEHTEEILEEFGFSREEIYQLNSDKIIESNKAGSKFWILYPTHSNIQK>sp|P05062|ALDOB_HUMAN Fructose-bisphosphate aldolase B OS=Homo sapiensOX=9606 GN=ALDOB PE=1 SV=2MAHRFPALTQEQKKELSEIAQSIVANGKGILAADESVGTMGNRLQRIKVENTEENRRQFREILFSVDSSINQSIGGVILFHETLYQKDSQGKLFRNILKEKGIVVGIKLDQGGAPLAGTNKETTIQGLDGLSERCAQYKKDGVDFGKWRAVLRIADQCPSSLAIQENANALARYASICQQNGLVPIVEPEVIPDGDHDLEHCQYVTEKVLAAVYKALNDHHVYLEGTLLKPNMVTAGHACTKKYTPEQVAMATVTALHRTVPAAVPGICFLSGGMSEEDATLNLNAINLCPLPKPWKLSFSYGRALQASALAAWGGKAANKEATQEAFMKRAMANCQAAKGQYVHTGSSGAASTQSLFTACYTY>sp|Q4VCS5|AMOT_HUMAN Angiomotin OS=Homo sapiens OX=9606 GN=AMOT PE=1SV=1MRNSEEQPSGGTTVLQRLLQEQLRYGNPSENRSLLAIHQQATGNGPPFPSGSGNPGPQSDVLSPQDHHQQLVAHAARQEPQGQEIQSENLIMEKQLSPRMQNNEELPTYEEAKVQSQYFRGQQHASVGAAFYVTGVTNQKMRTEGRPSVQRLNPGKMHQDEGLRDLKQGHVRSLSERLMQMSLATSGVKAHPPVTSAPLSPPQPNDLYKNPTSSSEFYKAQGPLPNQHSLKGMEHRGPPPEYPFKGMPPQSVVCKPQEPGHFYSEHRLNQPGRTEGQLMRYQHPPEYGAARPAQDISLPLSARNSQPHSPTSSLTSGGSLPLLQSPPSTRLSPARHPLVPNQGDHSAHLPRPQQHFLPNQAHQGDHYRLSQPGLSQQQQQQQQQHHHHHHHQQQQQQQPQQQPGEAYSAMPRAQPSSASYQPVPADPFAIVSRAQQMVEILSDENRNLRQELEGCYEKVARLQKVETEIQRVSEAYENLVKSSSKREALEKAMRNKLEGEIRRMHDFNRDLRERLETANKQLAEKEYEGSEDTRKTISQLFAKNKESQREKEKLEAELATARSTNEDQRRHIEIRDQALSNAQAKVVKLEEELKKKQVYVDKVEKMQQALVQLQAACEKREQLEHRLRTRLERELESLRIQQRQGNCQPTNVSEYNAAALMELLREKEERILALEADMTKWEQKYLEENVMRHFALDAAATVAAQRDTTVISHSPNTSYDTALEARIQKEEEEILMANKRCLDMEGRIKTLHAQIIEKDAMIKVLQQRSRKEPSKTEQLSCMRPAKSLMSISNAGSGLLSHSSTLTGSPIMEEKRDDKSWKGSLGILLGGDYRAEYVPSTPSPVPPSTPLLSAHSKTGSRDCSTQTERGTESNKTAAVAPISVPAPVAAAATAAAITATAATITTTMVAAAPVAVAAAAAPAAAAAPSPATAAATAAAVSPAAAGQIPAAASVASAAAVAPSAAAAAAVQVAPAAPAPVPAPALVPVPAPAAAQASAPAQTQAPTSAPAVAPTPAPTPTPAVAQAEVPASPATGPGPHRLSIPSLTCNPDKTDGPVFHSNTLERKTPIQILGQEPDAEMVEYLI>sp|Q4VCS5-2|AMOT_HUMAN Isoform 2 of Angiomotin OS=Homo sapiens OX=9606GN=AMOTMPRAQPSSASYQPVPADPFAIVSRAQQMVEILSDENRNLRQELEGCYEKVARLQKVETEIQRVSEAYENLVKSSSKREALEKAMRNKLEGEIRRMHDFNRDLRERLETANKQLAEKEYEGSEDTRKTISQLFAKNKESQREKEKLEAELATARSTNEDQRRHIEIRDQALSNAQAKVVKLEEELKKKQVYVDKVEKMQQALVQLQAACEKREQLEHRLRTRLERELESLRIQQRQGNCQPTNVSEYNAAALMELLREKEERILALEADMTKWEQKYLEENVMRHFALDAAATVAAQRDTTVISHSPNTSYDTALEARIQKEEEEILMANKRCLDMEGRIKTLHAQIIEKDAMIKVLQQRSRKEPSKTEQLSCMRPAKSLMSISNAGSGLLSHSSTLTGSPIMEEKRDDKSWKGSLGILLGGDYRAEYVPSTPSPVPPSTPLLSAHSKTGSRDCSTQTERGTESNKTAAVAPISVPAPVAAAATAAAITATAATITTTMVAAAPVAVAAAAAPAAAAAPSPATAAATAAAVSPAAAGQIPAAASVASAAAVAPSAAAAAAVQVAPAAPAPVPAPALVPVPAPAAAQASAPAQTQAPTSAPAVAPTPAPTPTPAVAQAEVPASPATGPGPHRLSIPSLTCNPDKTDGPVFHSNTLERKTPIQILGQEPDAEMVEYLI>sp|Q96PN6|ADCYA_HUMAN Adenylate cyclase type 10 OS=Homo sapiens OX=9606GN=ADCY10 PE=1 SV=3MNTPKEEFQDWPIVRIAAHLPDLIVYGHFSPERPFMDYFDGVLMFVDISGFTAMTEKFSSAMYMDRGAEQLVEILNYHISAIVEKVLIFGGDILKFAGDALLALWRVERKQLKNIITVVIKCSLEIHGLFETQEWEEGLDIRVKIGLAAGHISMLVFGDETHSHFLVIGQAVDDVRLAQNMAQMNDVILSPNCWQLCDRSMIEIESVPDQRAVKVNFLKPPPNFNFDEFFTKCTTFMHYYPSGEHKNLLRLACTLKPDPELEMSLQKYVMESILKQIDNKQLQGYLSELRPVTIVFVNLMFEDQDKAEEIGPAIQDAYMHITSVLKIFQGQINKVFMFDKGCSFLCVFGFPGEKVPDELTHALECAMDIFDFCSQVHKIQTVSIGVASGIVFCGIVGHTVRHEYTVIGQKVNLAARMMMYYPGIVTCDSVTYNGSNLPAYFFKELPKKVMKGVADSGPLYQYWGRTEKVMFGMACLICNRKEDYPLLGRNKEINYFMYTMKKFLISNSSQVLMYEGLPGYGKSQILMKIEYLAQGKNHRIIAISLNKISFHQTFYTIQMFMANVLGLDTCKHYKERQTNLRNKVMTLLDEKFYCLLNDIFHVQFPISREISRMSTLKKQKQLEILFMKILKLIVKEERIIFIIDEAQFVDSTSWRFMEKLIRTLPIFIIMSLCPFVNIPCAAARAVIKNRNTTYIVIGAVQPNDISNKICLDLNVSCISKELDSYLGEGSCGIPFYCEELLKNLEHHEVLVFQQTESEEKTNRTWNNLFKYSIKLTEKLNMVTLHSDKESEEVCHLTSGVRLKNLSPPTSLKEISLIQLDSMRLSHQMLVRCAAIIGLTFTTELLFEILPCWNMKMMIKTLATLVESNIFYCFRNGKELQKALKQNDPSFEVHYRSLSLKPSEGMDHGEEEQLRELENEVIECHRIRFCNPMMQKTAYELWLKDQRKAMHLKCARFLEEDAHRCDHCRGRDFIPYHHFTVNIRLNALDMDAIKKMAMSHGFKTEEKLILSNSEIPETSAFFPENRSPEEIREKILNFFDHVLTKMKTSDEDIIPLESCQCEEILEIVILPLAHHFLALGENDKALYYFLEIASAYLIFCDNYMAYMYLNEGQKLLKTLKKDKSWSQTFESATFYSLKGEVCFNMGQIVLAKKMLRKALKLLNRIFPYNLISLFLHIHVEKNRHFHYVNRQAQESPPPGKKRLAQLYRQTVCLSLLWRIYSYSYLFHCKYYAHLAVMMQMNTALETQNCFQIIKAYLDYSLYHHLAGYKGVWFKYEVMAMEHIFNLPLKGEGIEIVAYVAETLVFNKLIMGHLDLAIELGSRALQMWALLQNPNRHYQSLCRLSRCLLLNSRYPQLIQVLGRLWELSVTQEHIFSKAFFYFVCLDILLYSGFVYRTFEECLEFIHQYENNRILKFHSGLLLGLYSSVAIWYARLQEWDNFYKFSNRAKNLLPRRTMTLTYYDGISRYMEGQVLHLQKQIKEQSENAQASGEELLKNLENLVAQNTTGPVFCPRLYHLMAYVCILMGDGQKCGLFLNTALRLSETQGNILEKCWLNMNKESWYSTSELKEDQWLQTILSLPSWEKIVAGRVNIQDLQKNKFLMRANTVDNHF>sp|Q96PN6-2|ADCYA_HUMAN Isoform 2 of Adenylate cyclase type 10 OS=Homosapiens OX=9606 GN=ADCY10MSLSEGDALLALWRVERKQLKNIITVVIKCSLEIHGLFETQEWEEGLDIRVKIGLAAGHISMLVFGDETHSHFLVIGQAVDDVRLAQNMAQMNDVILSPNCWQLCDRSMIEIESVPDQRAVKVNFLKPPPNFNFDEFFTKCTTFMHYYPSGEHKNLLRLACTLKPDPELEMSLQKYVMESILKQIDNKQLQGYLSELRPVTIVFVNLMFEDQDKAEEIGPAIQDAYMHITSVLKIFQGQINKVFMFDKGCSFLCVFGFPGEKVPDELTHALECAMDIFDFCSQVHKIQTVSIGVASGIVFCGIVGHTVRHEYTVIGQKVNLAARMMMYYPGIVTCDSVTYNGSNLPAYFFKELPKKVMKGVADSGPLYQYWGRTEKVMFGMACLICNRKEDYPLLGRNKEINYFMYTMKKFLISNSSQVLMYEGLPGYGKSQILMKIEYLAQGKNHRIIAISLNKISFHQTFYTIQMFMANVLGLDTCKHYKERQTNLRNKVMTLLDEKFYCLLNDIFHVQFPISREISRMSTLKKQKQLEILFMKILKLIVKEERIIFIIDEAQFVDSTSWRFMEKLIRTLPIFIIMSLCPFVNIPCAAARAVIKNRNTTYIVIGAVQPNDISNKICLDLNVSCISKELDSYLGEGSCGIPFYCEELLKNLEHHEVLVFQQTESEEKTNRTWNNLFKYSIKLTEKLNMVTLHSDKESEEVCHLTSGVRLKNLSPPTSLKEISLIQLDSMRLSHQMLVRCAAIIGLTFTTELLFEILPCWNMKMMIKTLATLVESNIFYCFRNGKELQKALKQNDPSFEVHYRSLSLKPSEGMDHGEEEQLRELENEVIECHRIRFCNPMMQKTAYELWLKDQRKAMHLKCARFLEEDAHRCDHCRGRDFIPYHHFTVNIRLNALDMDAIKKMAMSHGFKTEEKLILSNSEIPETSAFFPENRSPEEIREKILNFFDHVLTKMKTSDEDIIPLESCQCEEILEIVILPLAHHFLALGENDKALYYFLEIASAYLIFCDNYMAYMYLNEGQKLLKTLKKDKSWSQTFESATFYSLKGEVCFNMGQIVLAKKMLRKALKLLNRIFPYNLISLFLHIHVEKNRHFHYVNRQAQESPPPGKKRLAQLYRQTVCLSLLWRIYSYSYLFHCKYYAHLAVMMQMNTALETQNCFQIIKAYLDYSLYHHLAGYKGVWFKYEVMAMEHIFNLPLKGEGIEIVAYVAETLVFNKLIMGHLDLAIELGSRALQMWALLQNPNRHYQSLCRLSRCLLLNSRYPQLIQVLGRLWELSVTQEHIFSKAFFYFVCLDILLYSGFVYRTFEECLEFIHQYENNRILKFHSGLLLGLYSSVAIWYARLQEWDNFYKFSNRAKNLLPRRTMTLTYYDGISRYMEGQVLHLQKQIKEQSENAQASGEELLKNLENLVAQNTTGPVFCPRLYHLMAYVCILMGDGQKCGLFLNTALRLSETQGNILEKCWLNMNKESWYSTSELKEDQWLQTILSLPSWEKIVAGRVNIQDLQKNKFLMRANTVDNHF>sp|Q96PN6-3|ADCYA_HUMAN Isoform 3 of Adenylate cyclase type 10 OS=Homosapiens OX=9606 GN=ADCY10MLFKAYMYLNEGQKLLKTLKKDKSWSQTFESATFYSLKGEVCFNMGQIVLAKKMLRKALKLLNRIFPYNLISLFLHIHVEKNRHFHYVNRQAQESPPPGKKRLAQLYRQTVCLSLLWRIYSYSYLFHCKYYAHLAVMMQMNTALETQNCFQIIKAYLDYSLYHHLAGYKGVWFKYEVMAMEHIFNLPLKGEGIEIVAYVAETLVFNKLIMGHLDLAIELGSRALQMWALLQNPNRHYQSLCRLSRCLLLNSRYPQLIQVLGRLWELSVTQEHIFSKAFFYFVCLDILLYSGFVYRTFEECLEFIHQYENNRILKFHSGLLLGLYSSVAIWECEAGVGRRLHTSRDPGMPDFRNGTTFTNFPIELKIFCQEEP>sp|Q96PN6-4|ADCYA_HUMAN Isoform 4 of Adenylate cyclase type 10 OS=Homosapiens OX=9606 GN=ADCY10MLVFGDETHSHFLVIGQAVDDVRLAQNMAQMNDVILSPNCWQLCDRSMIEIESVPDQRAVKVNFLKPPPNFNFDEFFTKCTTFMHYYPSGEHKNLLRLACTLKPDPELEMSLQKYVMESILKQIDNKQLQGYLSELRPVTIVFVNLMFEDQDKAEEIGPAIQDAYMHITSVLKIFQGQINKVFMFDKGCSFLCVFGFPGEKVPDELTHALECAMDIFDFCSQVHKIQTVSIGVASGIVFCGIVGHTVRHEYTVIGQKVNLAARMMMYYPGIVTCDSVTYNGSNLPAYFFKELPKKVMKGVADSGPLYQYWGRTEKVMFGMACLICNRKEDYPLLGRNKEINYFMYTMKKFLISNSSQVLMYEGLPGYGKSQILMKIEYLAQGKNHRIIAISLNKISFHQTFYTIQMFMANVLGLDTCKHYKERQTNLRNKVMTLLDEKFYCLLNDIFHVQFPISREISRMSTLKKQKQLEILFMKILKLIVKEERIIFIIDEAQFVDSTSWRFMEKLIRTLPIFIIMSLCPFVNIPCAAARAVIKNRNTTYIVIGAVQPNDISNKICLDLNVSCISKELDSYLGEGSCGIPFYCEELLKNLEHHEVLVFQQTESEEKTNRTWNNLFKYSIKLTEKLNMVTLHSDKESEEVCHLTSGVRLKNLSPPTSLKEISLIQLDSMRLSHQMLVRCAAIIGLTFTTELLFEILPCWNMKMMIKTLATLVESNIFYCFRNGKELQKALKQNDPSFEVHYRSLSLKPSEGMDHGEEEQLRELENEVIECHRIRFCNPMMQKTAYELWLKDQRKAMHLKCARFLEEDAHRCDHCRGRDFIPYHHFTVNIRLNALDMDAIKKMAMSHGFKTEEKLILSNSEIPETSAFFPENRSPEEIREKILNFFDHVLTKMKTSDEDIIPLESCQCEEILEIVILPLAHHFLALGENDKALYYFLEIASAYLIFCDNYMAYMYLNEGQKLLKTLKKDKSWSQTFESATFYSLKGEVCFNMGQIVLAKKMLRKALKLLNRIFPYNLISLFLHIHVEKNRHFHYVNRQAQESPPPGKKRLAQLYRQTVCLSLLWRIYSYSYLFHCKYYAHLAVMMQMNTALETQNCFQIIKAYLDYSLYHHLAGYKGVWFKYEVMAMEHIFNLPLKGEGIEIVAYVAETLVFNKLIMGHLDLAIELGSRALQMWALLQNPNRHYQSLCRLSRCLLLNSRYPQLIQVLGRLWELSVTQEHIFSKAFFYFVCLDILLYSGFVYRTFEECLEFIHQYENNRILKFHSGLLLGLYSSVAIWYARLQEWDNFYKFSNRAKNLLPRRTMTLTYYDGISRYMEGQVLHLQKQIKEQSENAQASGEELLKNLENLVAQNTTGPVFCPRLYHLMAYVCILMGDGQKCGLFLNTALRLSETQGNILEKCWLNMNKESWYSTSELKEDQWLQTILSLPSWEKIVAGRVNIQDLQKNKFLMRANTVDNHF>sp|P12235|ADT1_HUMAN ADP/ATP translocase 1 OS=Homo sapiens OX=9606GN=SLC25A4 PE=1 SV=4MGDHAWSFLKDFLAGGVAAAVSKTAVAPIERVKLLLQVQHASKQISAEKQYKGIIDCVVRIPKEQGFLSFWRGNLANVIRYFPTQALNFAFKDKYKQLFLGGVDRHKQFWRYFAGNLASGGAAGATSLCFVYPLDFARTRLAADVGKGAAQREFHGLGDCIIKIFKSDGLRGLYQGFNVSVQGIIIYRAAYFGVYDTAKGMLPDPKNVHIFVSWMIAQSVTAVAGLVSYPFDTVRRRMMMQSGRKGADIMYTGTVDCWRKIAKDEGAKAFFKGAWSNVLRGMGGAFVLVLYDEIKKYV>sp|Q8NFQ6|BPIFC_HUMAN BPI fold-containing family C protein OS=Homosapiens OX=9606 GN=BPIFC PE=2 SV=1MCTKTIPVLWGCFLLWNLYVSSSQTIYPGIKARITQRALDYGVQAGMKMIEQMLKEKKLPDLSGSESLEFLKVDYVNYNFSNIKISAFSFPNTSLAFVPGVGIKALTNHGTANISTDWGFESPLFQDTGGADLFLSGVYFTGIIILTRNDFGHPTLKLQDCYAQLSHAHVSFSGELSVLYNSFAEPMEKPILKNLNEMLCPIIASEVKALNANLSTLEVLTKIDNYTLLDYSLISSPEITENYLDLNLKGVFYPLENLTDPPFSPVPFVLPERSNSMLYIGIAEYFFKSASFAHFTAGVFNVTLSTEEISNHFVQNSQGLGNVLSRIAEIYILSQPFMVRIMATEPPIINLQPGNFTLDIPASIMMLTQPKNSTVETIVSMDFVASTSVGLVILGQRLVCSLSLNRFRLALPESNRSNIEVLRFENILSSILHFGVLPLANAKLQQGFPLSNPHKFLFVNSDIEVLEGFLLISTDLKYETSSKQQPSFHVWEGLNLISRQWRGKSAP>sp|Q8NFQ6-2|BPIFC_HUMAN Isoform 2 of BPI fold-containing family Cprotein OS=Homo sapiens OX=9606 GN=BPIFCMEKPILKNLNEMLCPIIASEVKALNANLSTLEVLTKIDNYTLLDYSLISSPEITENYLDLNLKGVFYPLENLTDPPFSPVPFVLPERSNSMLYIGIAEYFFKSASFAHFTAGVFNVTLSTEEISNHFVQNSQGLGNVLSRVASTSVGLVILGQRLVCSLSLNRFRLALPESNRSNIEVLRFENILSSILHFGVLPLANAKLQQGFPLSNPHKFLFVNSDIEVLEGFLLISTDLKYETSSKQQPSFHVWEGLNLISRQWRGKSAP>sp|Q4G176|ACSF3_HUMAN Malonate--CoA ligase ACSF3, mitochondrial OS=Homosapiens OX=9606 GN=ACSF3 PE=1 SV=3MLPHVVLTFRRLGCALASCRLAPARHRGSGLLHTAPVARSDRSAPVFTRALAFGDRIALVDQHGRHTYRELYSRSLRLSQEICRLCGCVGGDLREERVSFLCANDASYVVAQWASWMSGGVAVPLYRKHPAAQLEYVICDSQSSVVLASQEYLELLSPVVRKLGVPLLPLTPAIYTGAVEEPAEVPVPEQGWRNKGAMIIYTSGTTGRPKGVLSTHQNIRAVVTGLVHKWAWTKDDVILHVLPLHHVHGVVNALLCPLWVGATCVMMPEFSPQQVWEKFLSSETPRINVFMAVPTIYTKLMEYYDRHFTQPHAQDFLRAVCEEKIRLMVSGSAALPLPVLEKWKNITGHTLLERYGMTEIGMALSGPLTTAVRLPGSVGTPLPGVQVRIVSENPQREACSYTIHAEGDERGTKVTPGFEEKEGELLVRGPSVFREYWNKPEETKSAFTLDGWFKTGDTVVFKDGQYWIRGRTSVDIIKTGGYKVSALEVEWHLLAHPSITDVAVIGVPDMTWGQRVTAVVTLREGHSLSHRELKEWARNVLAPYAVPSELVLVEEIPRNQMGKIDKKALIRHFHPS>sp|Q8TC94|ACTL9_HUMAN Actin-like protein 9 OS=Homo sapiens OX=9606GN=ACTL9 PE=1 SV=3MDASRPKSSESQSSLEAPRPGPNPSPNVVNKPLQRDFPGMVADRLPPKTGVVVIDMGTGTCKVGFAGQASPTYTVATILGCQPKKPATSGQSGLQTFIGEAARVLPELTLVQPLRSGIVVDWDAAELIWRHLLEHDLRVATHDHPLLFSDPPFSPATNREKLVEVAFESLRSPAMYVASQSVLSVYAHGRVSGLVVDTGHGVTYTVPVFQGYNLLHATERLDLAGNHLTAFLAEMLLQAGLPLGQQDLDLVENIKHHYCYVASDFQKEQARPEQEYKRTLKLPDGRTVTLGKELFQCPELLFNPPEVPGLSPVGLSTMAKQSLRKLSLEMRADLAQNVLLCGGSSLFTGFEGRFRAELLRALPAETHVVVAAQPTRNFSVWIGGSILASLRAFQSCWVLREQYEEQGPYIVYRKCY>sp|Q9H0C2|ADT4_HUMAN ADP/ATP translocase 4 OS=Homo sapiens OX=9606GN=SLC25A31 PE=1 SV=1MHREPAKKKAEKRLFDASSFGKDLLAGGVAAAVSKTAVAPIERVKLLLQVQASSKQISPEARYKGMVDCLVRIPREQGFFSFWRGNLANVIRYFPTQALNFAFKDKYKQLFMSGVNKEKQFWRWFLANLASGGAAGATSLCVVYPLDFARTRLGVDIGKGPEERQFKGLGDCIMKIAKSDGIAGLYQGFGVSVQGIIVYRASYFGAYDTVKGLLPKPKKTPFLVSFFIAQVVTTCSGILSYPFDTVRRRMMMQSGEAKRQYKGTLDCFVKIYQHEGISSFFRGAFSNVLRGTGGALVLVLYDKIKEFFHIDIGGR>sp|O95994|AGR2_HUMAN Anterior gradient protein 2 homolog OS=Homo sapiensOX=9606 GN=AGR2 PE=1 SV=1MEKIPVSAFLLLVALSYTLARDTTVKPGAKKDTKDSRPKLPQTLSRGWGDQLIWTQTYEEALYKSKTSNKPLMIIHHLDECPHSQALKKVFAENKEIQKLAEQFVLLNLVYETTDKHLSPDGQYVPRIMFVDPSLTVRADITGRYSNRLYAYEPADTALLLDNMKKALKLLKTEL>sp|P51828|ADCY7_HUMAN Adenylate cyclase type 7 OS=Homo sapiens OX=9606GN=ADCY7 PE=1 SV=1MPAKGRYFLNEGEEGPDQDALYEKYQLTSQHGPLLLTLLLVAATACVALIIIAFSQGDPSRHQAILGMAFLVLAVFAALSVLMYVECLLRRWLRALALLTWACLVALGYVLVFDAWTKAACAWEQVPFFLFIVFVVYTLLPFSMRGAVAVGAVSTASHLLVLGSLMGGFTTPSVRVGLQLLANAVIFLCGNLTGAFHKHQMQDASRDLFTYTVKCIQIRRKLRIEKRQQENLLLSVLPAHISMGMKLAIIERLKEHGDRRCMPDNNFHSLYVKRHQNVSILYADIVGFTQLASDCSPKELVVVLNELFGKFDQIAKANECMRIKILGDCYYCVSGLPVSLPTHARNCVKMGLDMCQAIKQVREATGVDINMRVGIHSGNVLCGVIGLRKWQYDVWSHDVSLANRMEAAGVPGRVHITEATLKHLDKAYEVEDGHGQQRDPYLKEMNIRTYLVIDPRSQQPPPPSQHLPRPKGDAALKMRASVRMTRYLESWGAARPFAHLNHRESVSSGETHVPNGRRPKSVPQRHRRTPDRSMSPKGRSEDDSYDDEMLSAIEGLSSTRPCCSKSDDFYTFGSIFLEKGFEREYRLAPIPRARHDFACASLIFVCILLVHVLLMPRTAALGVSFGLVACVLGLVLGLCFATKFSRCCPARGTLCTISERVETQPLLRLTLAVLTIGSLLTVAIINLPLMPFQVPELPVGNETGLLAASSKTRALCEPLPYYTCSCVLGFIACSVFLRMSLEPKVVLLTVALVAYLVLFNLSPCWQWDCCGQGLGNLTKPNGTTSGTPSCSWKDLKTMTNFYLVLFYITLLTLSRQIDYYCRLDCLWKKKFKKEHEEFETMENVNRLLLENVLPAHVAAHFIGDKLNEDWYHQSYDCVCVMFASVPDFKVFYTECDVNKEGLECLRLLNEIIADFDELLLKPKFSGVEKIKTIGSTYMAAAGLSVASGHENQELERQHAHIGVMVEFSIALMSKLDGINRHSFNSFRLRVGINHGPVIAGVIGARKPQYDIWGNTVNVASRMESTGELGKIQVTEETCTILQGLGYSCECRGLINVKGKGELRTYFVCTDTAKFQGLGLN>sp|Q8NFM4|ADCY4_HUMAN Adenylate cyclase type 4 OS=Homo sapiens OX=9606GN=ADCY4 PE=1 SV=1MARLFSPRPPPSEDLFYETYYSLSQQYPLLLLLLGIVLCALAALLAVAWASGRELTSDPSFLTTVLCALGGFSLLLGLASREQRLQRWTRPLSGLVWVALLALGHAFLFTGGVVSAWDQVSYFLFVIFTAYAMLPLGMRDAAVAGLASSLSHLLVLGLYLGPQPDSRPALLPQLAANAVLFLCGNVAGVYHKALMERALRATFREALSSLHSRRRLDTEKKHQEHLLLSILPAYLAREMKAEIMARLQAGQGSRPESTNNFHSLYVKRHQGVSVLYADIVGFTRLASECSPKELVLMLNELFGKFDQIAKEHECMRIKILGDCYYCVSGLPLSLPDHAINCVRMGLDMCRAIRKLRAATGVDINMRVGVHSGSVLCGVIGLQKWQYDVWSHDVTLANHMEAGGVPGRVHITGATLALLAGAYAVEDAGMEHRDPYLRELGEPTYLVIDPRAEEEDEKGTAGGLLSSLEGLKMRPSLLMTRYLESWGAAKPFAHLSHGDSPVSTSTPLPEKTLASFSTQWSLDRSRTPRGLDDELDTGDAKFFQVIEQLNSQKQWKQSKDFNPLTLYFREKEMEKEYRLSAIPAFKYYEACTFLVFLSNFIIQMLVTNRPPALAITYSITFLLFLLILFVCFSEDLMRCVLKGPKMLHWLPALSGLVATRPGLRIALGTATILLVFAMAITSLFFFPTSSDCPFQAPNVSSMISNLSWELPGSLPLISVPYSMHCCTLGFLSCSLFLHMSFELKLLLLLLWLAASCSLFLHSHAWLSECLIVRLYLGPLDSRPGVLKEPKLMGAISFFIFFFTLLVLARQNEYYCRLDFLWKKKLRQEREETETMENLTRLLLENVLPAHVAPQFIGQNRRNEDLYHQSYECVCVLFASVPDFKEFYSESNINHEGLECLRLLNEIIADFDELLSKPKFSGVEKIKTIGSTYMAATGLNATSGQDAQQDAERSCSHLGTMVEFAVALGSKLDVINKHSFNNFRLRVGLNHGPVVAGVIGAQKPQYDIWGNTVNVASRMESTGVLGKIQVTEETAWALQSLGYTCYSRGVIKVKGKGQLCTYFLNTDLTRTGPPSATLG>sp|Q8NFM4-2|ADCY4_HUMAN Isoform 2 of Adenylate cyclase type 4 OS=Homosapiens OX=9606 GN=ADCY4MSRGTRESACCMLTSWASRGWPASVPLRSWCSCSMSSLASSTRLPRKLRAATGVDINMRVGVHSGSVLCGVIGLQKWQYDVWSHDVTLANHMEAGGVPGRVHITGATLALLAGAYAVEDAGMEHRDPYLRELGEPTYLVIDPRAEEEDEKGTAGGLLSSLEGLKMRPSLLMTRYLESWGAAKPFAHLSHGDSPVSTSTPLPEKTLASFSTQWSLDRSRTPRGLDDELDTGDAKFFQVIEQLNSQKQWKQSKDFNPLTLYFREKEMEKEYRLSAIPAFKYYEACTFLVFLSNFIIQMLVTNRPPALAITYSITFLLFLLILFVCFSEDLMRCVLKGPKMLHWLPALSGLVATRPGLRIALGTATILLVFAMAITSLFFFPTSSDCPFQAPNVSSMISNLSWELPGSLPLISVPVSVPTCP>sp|Q5VUY0|ADCL3_HUMAN Arylacetamide deacetylase-like 3 OS=Homo sapiensOX=9606 GN=AADACL3 PE=2 SV=5MWDLALIFLAAACVFSLGVTLWVICSHFFTVHIPAAVGHPVKLRVLHCIFQLLLTWGMIFEKLRICSMPQFFCFMQDLPPLKYDPDVVVTDFRFGTIPVKLYQPKASTCTLKPGIVYYHGGGGVMGSLKTHHGICSRLCKESDSVVLAVGYRKLPKHKFPVPVRDCLVATIHFLKSLDAYGVDPARVVVCGDSFGGAIAAVVCQQLVDRPDLPRIRAQILIYAILQALDLQTPSFQQRKNIPLLTWSFICYFFFQNLDFSSSWQEVIMKGAHLPAEVWEKYRKWLGPENIPERFKERGYQLKPHEPMNEAAYLEVSVVLDVMCSPLIAEDDIVSQLPETCIVSCEYDALRDNSLLYKKRLEDLGVPVTWHHMEDGFHGVLRTIDMSFLHFPCSMRILSALVQFVKGL>sp|O60242|AGRB3_HUMAN Adhesion G protein-coupled receptor B3 OS=Homosapiens OX=9606 GN=ADGRB3 PE=1 SV=2MKAVRNLLIYIFSTYLLVMFGFNAAQDFWCSTLVKGVIYGSYSVSEMFPKNFTNCTWTLENPDPTKYSIYLKFSKKDLSCSNFSLLAYQFDHFSHEKIKDLLRKNHSIMQLCNSKNAFVFLQYDKNFIQIRRVFPTNFPGLQKKGEEDQKSFFEFLVLNKVSPSQFGCHVLCTWLESCLKSENGRTESCGIMYTKCTCPQHLGEWGIDDQSLILLNNVVLPLNEQTEGCLTQELQTTQVCNLTREAKRPPKEEFGMMGDHTIKSQRPRSVHEKRVPQEQADAAKFMAQTGESGVEEWSQWSTCSVTCGQGSQVRTRTCVSPYGTHCSGPLRESRVCNNTALCPVHGVWEEWSPWSLCSFTCGRGQRTRTRSCTPPQYGGRPCEGPETHHKPCNIALCPVDGQWQEWSSWSQCSVTCSNGTQQRSRQCTAAAHGGSECRGPWAESRECYNPECTANGQWNQWGHWSGCSKSCDGGWERRIRTCQGAVITGQQCEGTGEEVRRCNEQRCPAPYEICPEDYLMSMVWKRTPAGDLAFNQCPLNATGTTSRRCSLSLHGVAFWEQPSFARCISNEYRHLQHSIKEHLAKGQRMLAGDGMSQVTKTLLDLTQRKNFYAGDLLMSVEILRNVTDTFKRASYIPASDGVQNFFQIVSNLLDEENKEKWEDAQQIYPGSIELMQVIEDFIHIVGMGMMDFQNSYLMTGNVVASIQKLPAASVLTDINFPMKGRKGMVDWARNSEDRVVIPKSIFTPVSSKELDESSVFVLGAVLYKNLDLILPTLRNYTVINSKIIVVTIRPEPKTTDSFLEIELAHLANGTLNPYCVLWDDSKTNESLGTWSTQGCKTVLTDASHTKCLCDRLSTFAILAQQPREIIMESSGTPSVTLIVGSGLSCLALITLAVVYAALWRYIRSERSIILINFCLSIISSNILILVGQTQTHNKSICTTTTAFLHFFFLASFCWVLTEAWQSYMAVTGKIRTRLIRKRFLCLGWGLPALVVATSVGFTRTKGYGTDHYCWLSLEGGLLYAFVGPAAAVVLVNMVIGILVFNKLVSRDGILDKKLKHRAGQMSEPHSGLTLKCAKCGVVSTTALSATTASNAMASLWSSCVVLPLLALTWMSAVLAMTDKRSILFQILFAVFDSLQGFVIVMVHCILRREVQDAFRCRLRNCQDPINADSSSSFPNGHAQIMTDFEKDVDIACRSVLHKDIGPCRAATITGTLSRISLNDDEEEKGTNPEGLSYSTLPGNVISKVIIQQPTGLHMPMSMNELSNPCLKKENSELRRTVYLCTDDNLRGADMDIVHPQERMMESDYIVMPRSSVNNQPSMKEESKMNIGMETLPHERLLHYKVNPEFNMNPPVMDQFNMNLEQHLAPQEHMQNLPFEPRTAVKNFMASELDDNAGLSRSETGSTISMSSLERRKSRYSDLDFEKVMHTRKRHMELFQELNQKFQTLDRFRDIPNTSSMENPAPNKNPWDTFKNPSEYPHYTTINVLDTEAKDALELRPAEWEKCLNLPLDVQEGDFQTEV>sp|O60242-2|AGRB3_HUMAN Isoform 2 of Adhesion G protein-coupled receptorB3 OS=Homo sapiens OX=9606 GN=ADGRB3MVIGILVFNKLVSRDGILDKKLKHRAGQMSEPHSGLTLKCAKCGVVSTTALSATTASNAMASLWSSCVVLPLLALTWMSAVLAMTDKRSILFQILFAVFDSLQGFVIVMVHCILRREVQDAFRCRLRNCQDPINADSSSSFPNGHAQIMTDFEKDVDIACRSVLHKDIGPCRAATITGTLSRISLNDDEEEKGTNPEGLSYSTLPGNVISKVIIQQPTGLHMPMSMNELSNPCLKKENSELRRTVYLCTDDNLRGADMDIVHPQERMMESDYIVMPRSSVNNQPSMKEESKMNIGMETLPHERLLHYKVNPEFNMNPPVMDQFNMNLEQHLAPQEHMQNLPFEPRTAVKNFMASELDDNAGLSRSETGSTISMSSLERRKSRYSDLDFEKVMHTRKRHMELFQELNQKFQTLDRFRDIPNTSSMENPAPNKNPWDTFKNPSEYPHYTTINVLDTEAKDALELRPAEWEKCLNLPLDVQEGDFQTEV>sp|O43306|ADCY6_HUMAN Adenylate cyclase type 6 OS=Homo sapiens OX=9606GN=ADCY6 PE=1 SV=2MSWFSGLLVPKVDERKTAWGERNGQKRSRRRGTRAGGFCTPRYMSCLRDAEPPSPTPAGPPRCPWQDDAFIRRGGPGKGKELGLRAVALGFEDTEVTTTAGGTAEVAPDAVPRSGRSCWRRLVQVFQSKQFRSAKLERLYQRYFFQMNQSSLTLLMAVLVLLTAVLLAFHAAPARPQPAYVALLACAAALFVGLMVVCNRHSFRQDSMWVVSYVVLGILAAVQVGGALAADPRSPSAGLWCPVFFVYIAYTLLPIRMRAAVLSGLGLSTLHLILAWQLNRGDAFLWKQLGANVLLFLCTNVIGICTHYPAEVSQRQAFQETRGYIQARLHLQHENRQQERLLLSVLPQHVAMEMKEDINTKKEDMMFHKIYIQKHDNVSILFADIEGFTSLASQCTAQELVMTLNELFARFDKLAAENHCLRIKILGDCYYCVSGLPEARADHAHCCVEMGVDMIEAISLVREVTGVNVNMRVGIHSGRVHCGVLGLRKWQFDVWSNDVTLANHMEAGGRAGRIHITRATLQYLNGDYEVEPGRGGERNAYLKEQHIETFLILGASQKRKEEKAMLAKLQRTRANSMEGLMPRWVPDRAFSRTKDSKAFRQMGIDDSSKDNRGTQDALNPEDEVDEFLSRAIDARSIDQLRKDHVRRFLLTFQREDLEKKYSRKVDPRFGAYVACALLVFCFICFIQLLIFPHSTLMLGIYASIFLLLLITVLICAVYSCGSLFPKALQRLSRSIVRSRAHSTAVGIFSVLLVFTSAIANMFTCNHTPIRSCAARMLNLTPADITACHLQQLNYSLGLDAPLCEGTMPTCSFPEYFIGNMLLSLLASSVFLHISSIGKLAMIFVLGLIYLVLLLLGPPATIFDNYDLLLGVHGLASSNETFDGLDCPAAGRVALKYMTPVILLVFALALYLHAQQVESTARLDFLWKLQATGEKEEMEELQAYNRRLLHNILPKDVAAHFLARERRNDELYYQSCECVAVMFASIANFSEFYVELEANNEGVECLRLLNEIIADFDEIISEERFRQLEKIKTIGSTYMAASGLNASTYDQVGRSHITALADYAMRLMEQMKHINEHSFNNFQMKIGLNMGPVVAGVIGARKPQYDIWGNTVNVSSRMDSTGVPDRIQVTTDLYQVLAAKGYQLECRGVVKVKGKGEMTTYFLNGGPSS>sp|O43306-2|ADCY6_HUMAN Isoform 2 of Adenylate cyclase type 6 OS=Homosapiens OX=9606 GN=ADCY6MSWFSGLLVPKVDERKTAWGERNGQKRSRRRGTRAGGFCTPRYMSCLRDAEPPSPTPAGPPRCPWQDDAFIRRGGPGKGKELGLRAVALGFEDTEVTTTAGGTAEVAPDAVPRSGRSCWRRLVQVFQSKQFRSAKLERLYQRYFFQMNQSSLTLLMAVLVLLTAVLLAFHAAPARPQPAYVALLACAAALFVGLMVVCNRHSFRQDSMWVVSYVVLGILAAVQVGGALAADPRSPSAGLWCPVFFVYIAYTLLPIRMRAAVLSGLGLSTLHLILAWQLNRGDAFLWKQLGANVLLFLCTNVIGICTHYPAEVSQRQAFQETRGYIQARLHLQHENRQQERLLLSVLPQHVAMEMKEDINTKKEDMMFHKIYIQKHDNVSILFADIEGFTSLASQCTAQELVMTLNELFARFDKLAAENHCLRIKILGDCYYCVSGLPEARADHAHCCVEMGVDMIEAISLVREVTGVNVNMRVGIHSGRVHCGVLGLRKWQFDVWSNDVTLANHMEAGGRAGRIHITRATLQYLNGDYEVEPGRGGERNAYLKEQHIETFLILGASQKRKEEKAMLAKLQRTRANSMEGLMPRWVPDRAFSRTKDSKAFRQMGIDDSSKDNRGTQDALNPEDEVDEFLSRAIDARSIDQLRKDHVRRFLLTFQREDLEKKYSRKVDPRFGAYVACALLVFCFICFIQLLIFPHSTLMLGIYASIFLLLLITVLICAVYSCGSLFPKALQRLSRSIVRSRAHSTAVGIFSVLLVFTSAIANMYFIGNMLLSLLASSVFLHISSIGKLAMIFVLGLIYLVLLLLGPPATIFDNYDLLLGVHGLASSNETFDGLDCPAAGRVALKYMTPVILLVFALALYLHAQQVESTARLDFLWKLQATGEKEEMEELQAYNRRLLHNILPKDVAAHFLARERRNDELYYQSCECVAVMFASIANFSEFYVELEANNEGVECLRLLNEIIADFDEIISEERFRQLEKIKTIGSTYMAASGLNASTYDQVGRSHITALADYAMRLMEQMKHINEHSFNNFQMKIGLNMGPVVAGVIGARKPQYDIWGNTVNVSSRMDSTGVPDRIQVTTDLYQVLAAKGYQLECRGVVKVKGKGEMTTYFLNGGPSS>sp|Q8TF27|AGA11_HUMAN Arf-GAP with GTPase, ANK repeat and PH domain-containing protein 11 OS=Homo sapiens OX=9606 GN=AGAP11 PE=2 SV=2MTIISVTLEIHHHITERDADRSLTILDEQLYSFAFSTVHITKKRNGGGSLNNYSSSIPLTPSTSQEDLYFSVPPTANTPTPICKQSMGWSNLFTSEKGSDPDKGRKALESHADTIGSGRAIPIKQGMLLKRSGKWLKTWKKKYVTLCSNGVLTYYSSLGDYMKNIHKKEIDLRTSTIKVPGKWPSLATSACAPISSSKSNGLSKDMEALHMSANSDIGLGDSICFSPSISSTTSPKLNLPPSPHANKKKHLKKKSTNNLKDDGLSSTAEEEEEKFMIVSVTGQTCHFKATTYEERDAWVQAIQSQILASLQSCESSKSKSQLTSQSEAMALQSIQNMRGNSHCVDCETQNPKWASLNLGVLMCIECSGIHRSLGTRLSRVRSLELDDWPVELRKVMSSIGNDLANSIWEGSSQGQTKPSIESTREEKERWIRSKYEHKLFLAPLPCTELSLGQHLLRATADEDLRTAILLLAHGSREEVNETCGEGDGCTALHLACRKGNVVLAQLLIWYGVDVMARDAHGNTALTYARQASSQECINVLLQYGCPDECV>sp|P68133|ACTS_HUMAN Actin, alpha skeletal muscle OS=Homo sapiensOX=9606 GN=ACTA1 PE=1 SV=1MCDEDETTALVCDNGSGLVKAGFAGDDAPRAVFPSIVGRPRHQGVMVGMGQKDSYVGDEAQSKRGILTLKYPIEHGIITNWDDMEKIWHHTFYNELRVAPEEHPTLLTEAPLNPKANREKMTQIMFETFNVPAMYVAIQAVLSLYASGRTTGIVLDSGDGVTHNVPIYEGYALPHAIMRLDLAGRDLTDYLMKILTERGYSFVTTAEREIVRDIKEKLCYVALDFENEMATAASSSSLEKSYELPDGQVITIGNERFRCPETLFQPSFIGMESAGIHETTYNSIMKCDIDIRKDLYANNVMSGGTTMYPGIADRMQKEITALAPSTMKIKIIAPPERKYSVWIGGSILASLSTFQQMWITKQEYDEAGPSIVHRKCF>sp|Q9H553|ALG2_HUMAN Alpha-1,3/1,6-mannosyltransferase ALG2 OS=Homosapiens OX=9606 GN=ALG2 PE=1 SV=1MAEEQGRERDSVPKPSVLFLHPDLGVGGAERLVLDAALALQARGCSVKIWTAHYDPGHCFAESRELPVRCAGDWLPRGLGWGGRGAAVCAYVRMVFLALYVLFLADEEFDVVVCDQVSACIPVFRLARRRKKILFYCHFPDLLLTKRDSFLKRLYRAPIDWIEEYTTGMADCILVNSQFTAAVFKETFKSLSHIDPDVLYPSLNVTSFDSVVPEKLDDLVPKGKKFLLLSINRYERKKNLTLALEALVQLRGRLTSQDWERVHLIVAGGYDERVLENVEHYQELKKMVQQSDLGQYVTFLRSFSDKQKISLLHSCTCVLYTPSNEHFGIVPLEAMYMQCPVIAVNSGGPLESIDHSVTGFLCEPDPVHFSEAIEKFIREPSLKATMGLAGRARVKEKFSPEAFTEQLYRYVTKLLV>sp|Q9H553-2|ALG2_HUMAN Isoform 2 of Alpha-1,3/1,6-mannosyltransferaseALG2 OS=Homo sapiens OX=9606 GN=ALG2MPLLKLVHGSPLVFGEKFKLFTLVSACIPVFRLARRRKKILFYCHFPDLLLTKRDSFLKRLYRAPIDWIEEYTTGMADCILVNSQFTAAVFKETFKSLSHIDPDVLYPSLNVTSFDSVVPEKLDDLVPKGKKFLLLSINRYERKKNLTLALEALVQLRGRLTSQDWERVHLIVAGGYDERVLENVEHYQELKKMVQQSDLGQYVTFLRSFSDKQKISLLHSCTCVLYTPSNEHFGIVPLEAMYMQCPVIAVNSGGPLESIDHSVTGFLCEPDPVHFSEAIEKFIREPSLKATMGLAGRARVKEKFSPEAFTEQLYRYVTKLLV>sp|Q3LIE5|ADPRM_HUMAN Manganese-dependent ADP-ribose/CDP-alcoholdiphosphatase OS=Homo sapiens OX=9606 GN=ADPRM PE=1 SV=1MDDKPNPEALSDSSERLFSFGVIADVQFADLEDGFNFQGTRRRYYRHSLLHLQGAIEDWNNESSMPCCVLQLGDIIDGYNAQYNASKKSLELVMDMFKRLKVPVHHTWGNHEFYNFSREYLTHSKLNTKFLEDQIVHHPETMPSEDYYAYHFVPFPKFRFILLDAYDLSVLGVDQSSPKYEQCMKILREHNPNTELNSPQGLSEPQFVQFNGGFSQEQLNWLNEVLTFSDTNQEKVVIVSHLPIYPDASDNVCLAWNYRDALAVIWSHECVVCFFAGHTHDGGYSEDPFGVYHVNLEGVIETAPDSQAFGTVHVYPDKMMLKGRGRVPDRIMNYKKERAFHC>sp|Q3LIE5-3|ADPRM_HUMAN Isoform 2 of Manganese-dependent ADP-ribose/CDP-alcohol diphosphatase OS=Homo sapiens OX=9606 GN=ADPRMMDDKPNPEALSDSSERLFSFGVIADVQFADLEDGFNFQGTRRRYYRHSLLHLQGAIEDWNNESSMPCCVLQLGDIIDGYNAQYNASKKSLELVMDMFKRLKVPVHHTWGNHEFYNFSREYLTHSKLNTKFLEDQIVHHPETMPSEDYYAYHFVPFPKFRFILLDAYDLSVLGVDQSSPKYEQCMKILREHNPNTELNSPQGELFL>sp|Q5VW22|AGAP6_HUMAN Arf-GAP with GTPase, ANK repeat and PH domain-containing protein 6 OS=Homo sapiens OX=9606 GN=AGAP6 PE=2 SV=1MGNILTCRVHPSVSLEFDQQQGSVCPSESETYEAGARDRMAGAPMAAAVQPAEVTVEVGEDLHMHHVRDREMPEALEFNPSANPEASTIFQRNSQTDVVEIRRSNCTNHVSAVRFSQQYSLCSTIFLDDSTAIQHYLTMTIISVTLEIPHHITQRDADRTLSIPDEQLHSFAVSTVHIMKKRNGGGSLNNYSSSIPSTPSTSQEDPQFSVPPTANTPTPVCKRSMRWSNLFTSEKGSDPDKERKAPENHADTIGSGRAIPIKQGMLLKRSGKWLKTWKKKYVTLCSNGMLTYYSSLGDYMKNIHKKEIDLQTSTIKVPGKWPSLATSACTPISSSKSNGLSKDMDTGLGDSICFSPSISSTTSPKLNPPPSPHANKKKHLKKKSTNNFMIVSATGQTWHFEATTYEERDAWVQAIQSQILASLQSCESSKSKSQLTSQSEAMALQSIQNMRGNAHCVDCETQNPKWASLNLGVLMCIECSGIHRSLGPHLSRVRSLELDDWPVELRKVMSSIVNDLANSIWEGSSQGQTKPSEKSTREEKERWIRSKYEEKLFLAPLPCTELSLGQQLLRATADEDLQTAILLLAHGSCEEVNETCGEGDGCTALHLACRKGNVVLAQLLIWYGVDVMARDAHGNTALTYARQASSQECINVLLQYGCPDECV>sp|Q5VW22-2|AGAP6_HUMAN Isoform 2 of Arf-GAP with GTPase, ANK repeat andPH domain-containing protein 6 OS=Homo sapiens OX=9606 GN=AGAP6MGNILTCRVHPSVSLEFDQQQGSVCPSESETYEAGARDRMAGAPMAAAVQPAEVTVEVGEDLHMHHVRDREMPEALEFNLSANPESSTIFQRNSQTEALEFNPSANPEASTIFQRNSQTDVVEIRRSNCTNHVSAVRFSQQYSLCSTIFLDDSTAIQHYLTMTIISVTLEIPHHITQRDADRTLSIPDEQLHSFAVSTVHIMKKRNGGGSLNNYSSSIPSTPSTSQEDPQFSVPPTANTPTPVCKRSMRWSNLFTSEKGSDPDKERKAPENHADTIGSGRAIPIKQGMLLKRSGKWLKTWKKKYVTLCSNGMLTYYSSLGDYMKNIHKKEIDLQTSTIKVPGKWPSLATSACTPISSSKSNGLSKDMDTGLGDSICFSPSISSTTSPKLNPPPSPHANKKKHLKKKSTNNFMIVSATGQTWHFEATTYEERDAWVQAIQSQILASLQSCESSKSKSQLTSQSEAMALQSIQNMRGNAHCVDCETQNPKWASLNLGVLMCIECSGIHRSLGPHLSRVRSLELDDWPVELRKVMSSIVNDLANSIWEGSSQGQTKPSEKSTREEKERWIRSKYEEKLFLAPLPCTELSLGQQLLRATADEDLQTAILLLAHGSCEEVNETCGEGDGCTALHLACRKGNVVLAQLLIWYGVDVMARDAHGNTALTYARQASSQECINVLLQYGCPDECV>sp|P62736|ACTA_HUMAN Actin, aortic smooth muscle OS=Homo sapiens OX=9606GN=ACTA2 PE=1 SV=1MCEEEDSTALVCDNGSGLCKAGFAGDDAPRAVFPSIVGRPRHQGVMVGMGQKDSYVGDEAQSKRGILTLKYPIEHGIITNWDDMEKIWHHSFYNELRVAPEEHPTLLTEAPLNPKANREKMTQIMFETFNVPAMYVAIQAVLSLYASGRTTGIVLDSGDGVTHNVPIYEGYALPHAIMRLDLAGRDLTDYLMKILTERGYSFVTTAEREIVRDIKEKLCYVALDFENEMATAASSSSLEKSYELPDGQVITIGNERFRCPETLFQPSFIGMESAGIHETTYNSIMKCDIDIRKDLYANNVLSGGTTMYPGIADRMQKEITALAPSTMKIKIIAPPERKYSVWIGGSILASLSTFQQMWISKQEYDEAGPSIVHRKCF>sp|Q15847|ADIRF_HUMAN Adipogenesis regulatory factor OS=Homo sapiensOX=9606 GN=ADIRF PE=1 SV=1MASKGLQDLKQQVEGTAQEAVSAAGAAAQQVVDQATEAGQKAMDQLAKTTQETIDKTANQASDTFSGIGKKFGLLK>sp|Q9Y2D8|ADIP_HUMAN Afadin- and alpha-actinin-binding protein OS=Homosapiens OX=9606 GN=SSX2IP PE=1 SV=3MGDWMTVTDPGLSSESKTISQYTSETKMSPSSLYSQQVLCSSIPLSKNVHSFFSAFCTEDNIEQSISYLDQELTTFGFPSLYEESKGKETKRELNIVAVLNCMNELLVLQRKNLLAQENVETQNLKLGSDMDHLQSCYSKLKEQLETSRREMIGLQERDRQLQCKNRNLHQLLKNEKDEVQKLQNIIASRATQYNHDMKRKEREYNKLKERLHQLVMNKKDKKIAMDILNYVGRADGKRGSWRTGKTEARNEDEMYKILLNDYEYRQKQILMENAELKKVLQQMKKEMISLLSPQKKKPRERVDDSTGTVISDVEEDAGELSRESMWDLSCETVREQLTNSIRKQWRILKSHVEKLDNQVSKVHLEGFNDEDVISRQDHEQETEKLELEIQQCKEMIKTQQQLLQQQLATAYDDDTTSLLRDCYLLEEKERLKEEWSLFKEQKKNFERERRSFTEAAIRLGLERKAFEEERASWLKQQFLNMTTFDHQNSENVKLFSAFSGSSDWDNLIVHSRQPQKKPHSVSNGSPVCMSKLTKSLPASPSTSDFCQTRSCISEHSSINVLNITAEEIKPNQVGGECTNQKWSVASRPGSQEGCYSGCSLSYTNSHVEKDDLP>sp|Q9Y2D8-2|ADIP_HUMAN Isoform 2 of Afadin- and alpha-actinin-bindingprotein OS=Homo sapiens OX=9606 GN=SSX2IPMGDWMTVTDPGLSSESKTISQYTSETKMSPSSLYSQQVLCSSIPLSKNVHSFFSAFCTEDNIEQSISYLDQELTTFGFPSLYEESKGKETKRELNIVAVLNCMNELLVLQRKNLLAQENVETQNLKLGSDMDHLQSCYSKLKEQLETSRREMIGLQERDRQLQCKNRNLHQLLKNEKDEVQKLQNIIASRATQYNHDMKRKEREYNKLKERLHQLVMNKKDKKIAMDILNYVGRADGKRGSWRTGKTEARNEDEMYKILLNDYEYRQKQILMENAELKKVLQQMKKEMISLLSPQKKKPRERVDDSTGTVISDVEEDAGELSRESMWDLSCETVREQLTNSIRKQWRILKSHVEKLDNQVSKVHLEGFNDEDVISRQDHEQETEKLELEIQQCKEMIKTQQQLLQQQLATAYDDDTTSLLRDCYLLEEKERLKEEWSLFKEQKKNFERERRSFTEAAIRLGLERKAFEEERASWLKQQFLNMTTFDHQNSENVKLFSAFSGSSDWDNLIVHSRQPQKKPHSVSNGSPVCMSKLTKSLPASPSTSDFCQTRSCISEHRAKN>sp|Q9Y2D8-3|ADIP_HUMAN Isoform 3 of Afadin- and alpha-actinin-bindingprotein OS=Homo sapiens OX=9606 GN=SSX2IPMSPSSLYSQQVLCSSIPLSKNVHSFFSAFCTEDNIEQSISYLDQELTTFGFPSLYEESKGKETKRELNIVAVLNCMNELLVLQRKNLLAQENVETQNLKLGSDMDHLQSCYSKLKEQLETSRREMIGLQERDRQLQCKNRNLHQLLKNEKDEVQKLQNIIASRATQYNHDMKRKEREYNKLKERLHQLVMNKKDKKIAMDILNYVGRADGKRGSWRTGKTEARNEDEMYKILLNDYEYRQKQILMENAELKKVLQQMKKEMISLLSPQKKKPRERVDDSTGTVISDVEEDAGELSRESMWDLSCETVREQLTNSIRKQWRILKSHVEKLDNQVSKVHLEGFNDEDVISRQDHEQETEKLELEIQQCKEMIKTQQQLLQQQLATAYDDDTTSLLRDCYLLEEKERLKEEWSLFKEQKKNFERERRSFTEAAIRLGLERKAFEEERASWLKQQFLNMTTFDHQNSENVKLFSAFSGSSDWDNLIVHSRQPQKKPHSVSNGSPVCMSKLTKSLPASPSTSDFCQTRSCISEHSSINVLNITAEEIKPNQVGGECTNQKWSVASRPGSQEGCYSGCSLSYTNSHVEKDDLP>sp|Q8IYE1|CCD13_HUMAN Coiled-coil domain-containing protein 13 OS=Homosapiens OX=9606 GN=CCDC13 PE=1 SV=2MAADESSQNTLRLQFKAMQEMQHKRLQKQMEKKREKELSLKSRADDQEEPLEVSDGLSLLHAGEPNSKNSFEKRVLEDEIEHLRNELRETVDENGRLYKLLKERDFEIKHLKKKIEEDRFAFTGTAGVAGDVVATKIVELSKKNRLLMAESEGAKTRVKQLTNRIQELERELQTALTRLSAKGATDAGAKPPRAQMGDRALLETPEVKALQDRLVATNLKMSDLRNQIQSVKQELRMAQKVLAREVGEDINVQQLLSSPGTWRGRAQQILVLQSKVQELEKQLGQARSQSAGTASDELSVYPDPRKLSAQEKNLLRIRSLEREKQEGLEKLASERDVLQRELEELKKKFEGMRSRNKLLSSEMKTLKSQMGTLVEKGRHDDELIDALMDQLKQLQEILGSLSLQEEKTRVSQHHLDQQLNSEAQRSNSLVAQLQAMVAEREAKVRQLEMEIGQLNVHYLRNKGVGEGSSGREVSPAYTQFLEDPGLTKSPASAGDHVGRLGSSRSVTSLGHTLVESALTRPSLPSPHRTSPRFSDSPEQKGWQAQVSEIKALWQAAEVERDRLTEFVTVLQKRVEESNSKLLESERKLQEERHRTVVLEQHLEKIRLEPGKASASQRAAPRTKTGLPTSNNRHNPTGSEKKDPSFAQLSDVPVESQMEELTTRLAIQVEENEMLKAALGSALRGKEEDFRMYHEILGQVKSVFLQALRQQKTGKQ>sp|Q8NCL9|APCDL_HUMAN Protein APCDD1-like OS=Homo sapiens OX=9606GN=APCDD1L PE=1 SV=1MPAAMLPYACVLVLLGAHTAPAAGEAGGSCLRWEPHCQQPLPDRVPSTAILPPRLNGPWISTGCEVRPGPEFLTRAYTFYPSRLFRAHQFYYEDPFCGEPAHSLLVKGKVRLRRASWVTRGATEADYHLHKVGIVFHSRRALVDVTGRLNQTRAGRDCARRLPPARAWLPGALYELRSARAQGDCLEALGLTMHELSLVRVQRRLQPQPRASPRLVEELYLGDIHTDPAERRHYRPTGYQRPLQSALHHVQPCPACGLIARSDVHHPPVLPPPLALPLHLGGWWVSSGCEVRPAVLFLTRLFTFHGHSRSWEGYYHHFSDPACRQPTFTVYAAGRYTRGTPSTRVRGGTELVFEVTRAHVTPMDQVTTAMLNFSEPSSCGGAGAWSMGTERDVTATNGCLPLGIRLPHVEYELFKMEQDPLGQSLLFIGQRPTDGSSPDTPEKRPTSYQAPLVLCHGEAPDFSRPPQHRPSLQKHPSTGGLHIAPFPLLPLVLGLAFLHWL>sp|P83916|CBX1_HUMAN Chromobox protein homolog 1 OS=Homo sapiens OX=9606GN=CBX1 PE=1 SV=1MGKKQNKKKVEEVLEEEEEEYVVEKVLDRRVVKGKVEYLLKWKGFSDEDNTWEPEENLDCPDLIAEFLQSQKTAHETDKSEGGKRKADSDSEDKGEESKPKKKKEESEKPRGFARGLEPERIIGATDSSGELMFLMKWKNSDEADLVPAKEANVKCPQVVISFYEERLTWHSYPSEDDDKKDDKN>sp|Q0P6D6|CCD15_HUMAN Coiled-coil domain-containing protein 15 OS=Homosapiens OX=9606 GN=CCDC15 PE=2 SV=2MLGSMARKKPRNTSRLPLALNPLKSKDVLAVLAERNEAIVPVGAWVEPASPGSSEIPAYTSAYLIEEELKEQLRKKQEALKHFQKQVKYRVNQQIRLRKKQQLQKSYERAQKEGSIAMQSSATHLTSKRTSVFPNNLNVAIGSSRLPPSLMPGDGIEDEENQNELFQQQAQALSETMKQARHRLASFKTVIKKKGSVFPDDGRKSFLTREEVLSRKPASTGINTGIRGELPIKVHQGLLAAVPYQNYMENQELDYEEPDYEESSSLVTDEKGKEDLFGRGQQDQQAIHSEDKNKPFSRVQKVKFKNPLFVLMEEEEQKQLHFEGLQDILPEAQDYFLEAQGDLLETQGDLTGIQSVKPDTQAVEMKVQVTEPEGQAIEPEGQPIKTETQGIMLKAQSIELEEGSIVLKTQDFLPTNQALLTKNQDVLLKDHCVLPKDQSILLKYQDQDFLPRDQHVLHKDQDILPKYQDQNFLPKDQNFLSRDQHVLPKDQDILPKYQDQNFLPKDQNFLSRDQHVLPKDQNILPKYQGQDFLPKDQDFLSRDQHVLPKDWNILPKCQDQDFLPRDQGVLPKDQNILPICQDQDFLPRDQGYLPKDQNILPICQDRDFLPRDLHVLSNDQNILPKCQDQDFLPKYQKVHFKEPYSDMTDEKGREDFSLADYQCLPPKSQDQDDIKNQQPASFMREERVREELPLDYHQYVVPKIQDQDSPREQNKHIKLPSSFEKWEIARGNTPGVPLAYDRYQSGLSTEFQAPLAFQSDVDKEEDKKERQKQYLRHRRLFMDIEREQVKEQQRQKEQKKKIEKIKKKREQECYAAEQRILRMNFHEDPYSGEKLSEILAQLQLQEIKGTREKQQREKEYLRYVEALRAQIQEKMQLYNITLPPLCCCGPDFWDAHPDTCANNCIFYKNHRAYTRALHSFINSCDVPGGNSTLRVAIHNFASAHRRTLKNL>sp|Q8NAG6|ANKL1_HUMAN Ankyrin repeat and LEM domain-containing protein 1OS=Homo sapiens OX=9606 GN=ANKLE1 PE=1 SV=2MCSEARLARRLRDALREEEPWAVEELLRCGADPNLVLEDGAAAVHLAAGARHPRGLRCLGALLRQGGDPNARSVEALTPLHVAAAWGCRRGLELLLSQGADPALRDQDGLRPLDLALQQGHLECARVLQDLDTRTRTRTRIGAETQEPEPAPGTPGLSGPTDETLDSIALQKQPCRGDNRDIGLEADPGPPSLPVPLETVDKHGSSASPPGHWDYSSDASFVTAVEVSGAEDPASDTPPWAGSLPPTRQGLLHVVHANQRVPRSQGTEAELNARLQALTLTPPNAAGFQSSPSSMPLLDRSPAHSPPRTPTPGASDCHCLWEHQTSIDSDMATLWLTEDEASSTGGREPVGPCRHLPVSTVSDLELLKGLRALGENPHPITPFTRQLYHQQLEEAQIAPGPEFSGHSLELAAALRTGCIPDVQADEDALAQQFEQPDPARRWREGVVKSSFTYLLLDPRETQDLPARAFSLTPAERLQTFIRAIFYVGKGTRARPYVHLWEALGHHGRSRKQPHQACPKVRQILDIWASGCGVVSLHCFQHVVAVEAYTREACIVEALGIQTLTNQKQGHCYGVVAGWPPARRRRLGVHLLHRALLVFLAEGERQLHPQDIQARG>sp|Q8NAG6-1|ANKL1_HUMAN Isoform 2 of Ankyrin repeat and LEM domain-containing protein 1 OS=Homo sapiens OX=9606 GN=ANKLE1MRCGRRSRVEELLRCGADPNLVLEDGAAAVHLAAGARHPRGLRCLGALLRQGGDPNARSVEALTPLHVAAAWGCRRGLELLLSQGADPALRDQDGLRPLDLALQQGHLECARVLQDLDTRTRTRTRIGAETQEPEPAPGTPGLSGPTDETLDSIALQKQPCRGDNRDIGLEADPGPPSLPVPLETVDKHGSSASPPGHWDYSSDASFVTAVEVSGAEDPASDTPPWAGSLPPTRQGLLHVVHANQRVPRSQGTEAELNARLQALTLTPPNAAGFQSSPSSMPLLDRSPAHSPPRTPTPGASDCHCLWEHQTSIDSDMATLWLTEDEASSTGGREPVGPCRHLPVSTVSDLELLKGLRALGPEFSGHSLELAAALRTGCIPDVQADEDALAQQFEQPDPARRWREGVVKSSFTYLLLDPRETQDLPARAFSLTPAERLQTFIRAIFYVGKGTRARPYVHLWEALGHHGRSRKQPHQACPKVRQILDIWASGCGVVSLHCFQHVVAVEAYTREACIVEALGIQTLTNQKQGHCYGVVAGWPPARRRRLGVHLLHRALLVFLAEGERQLHPQDIQARG>sp|Q8NHP1|ARK74_HUMAN Aflatoxin B1 aldehyde reductase member 4 OS=Homosapiens OX=9606 GN=AKR7L PE=2 SV=7MSRQLSRARPATVLGAMEMGRRMDAPTSAAVTRAFLERGHTEIDTAFLYSDGQSETILGGLGLRMGSSDCRVKIATKANPWIGNSLKPDSVRSQLETSLKRLQCPRVDLFYLHAPDHSAPVEETLRACHQLHQEGKFVELGLSNYAAWEVAEICTLCKSNGWILPTVYQGMYSATTRQVETELFPCLRHFGLRFYAYNPLAGGLLTGKYKYEDKDGKQPVGRFFGTQWAEIYRNHFWKEHHFEGIALVEKALQAAYGASAPSMTSAALRWMYHHSQLQGAHGDAVILGMSSLEQLEQNLAAAEEGPLEPAVVDAFNQAWHLFAHECPNYFI>sp|Q8NHP1-3|ARK74_HUMAN Isoform 2 of Aflatoxin B1 aldehyde reductasemember 4 OS=Homo sapiens OX=9606 GN=AKR7LMSRQLSRARPATVLGAMEMGRRMDAPTSAAVTRAFLERGHTEIDTAFLYSDGQSETILGGLGLRMGSSDCRVKIATKANPWIGNSLKPDSVRSQLETSLKRLQCPRVDLFYLHAPDHSAPVEETLRACHQLHQEGKFVELGLSNYAAWEVAEICTLCKSNGWILPTVYQLLEGAPLRGHCPGGEGPAGRVWRQRSQHDLGRPPVDVPPLTAAGCPRGRGHPGHVQPGAAGAELGSGRGRAPGAGCRGRL>sp|Q8N8L6|ARL10_HUMAN ADP-ribosylation factor-like protein 10 OS=Homosapiens OX=9606 GN=ARL10 PE=2 SV=1MAPRPLGPLVLALGGAAAVLGSVLFILWKTYFGRGRERRWDRGEAWWGAEAARLPEWDEWDPEDEEDEEPALEELEQREVLVLGLDGAGKSTFLRVLSGKPPLEGHIPTWGFNSVRLPTKDFEVDLLEIGGSQNLRFYWKEFVSEVDVLVFVVDSADRLRLPWARQELHKLLDKDPDLPVVVVANKQDLSEAMSMGELQRELGLQAIDNQREVFLLAASIAPAGPTFEEPGTVHIWKLLLELLS>sp|Q9NPB3|CABP2_HUMAN Calcium-binding protein 2 OS=Homo sapiens OX=9606GN=CABP2 PE=1 SV=4MGNCAKRPWRRGPKDPLQWLGSPPRGSCPSPSSSPKEQGDPAPGVQGYSVLNSLVGPACIFLRPSIAATQLDRELRPEEIEELQVAFQEFDRDRDGYIGCRELGACMRTLGYMPTEMELIEISQQISGGKVDFEDFVELMGPKLLAETADMIGVRELRDAFREFDTNGDGRISVGELRAALKALLGERLSQREVDEILQDVDLNGDGLVDFEEFVRMMSR>sp|Q9NPB3-2|CABP2_HUMAN Isoform S-CaBP2 of Calcium-binding protein 2OS=Homo sapiens OX=9606 GN=CABP2MGNCAKRPWRRGPKDRELRPEEIEELQVAFQEFDRDRDGYIGCRELGACMRTLGYMPTEMELIEISQQISGGKVDFEDFVELMGPKLLAETADMIGVRELRDAFREFDTNGDGRISVGELRAALKALLGERLSQREVDEILQDVDLNGDGLVDFEEFVRMMSR>sp|Q96BM1|ANKR9_HUMAN Ankyrin repeat domain-containing protein 9 OS=Homosapiens OX=9606 GN=ANKRD9 PE=1 SV=1MPWDARRPGGGADGGPEASGAARSRAQKQCRKSSFAFYQAVRDLLPVWLLEDMRASEAFHWDERGRAAAYSPSEALLYALVHDHQAYAHYLLATFPRRALAPPSAGFRCCAAPGPHVALAVRYNRVGILRRILRTLRDFPAEERARVLDRRGCSRVEGGGTSLHVACELARPECLFLLLGHGASPGLRDGGGLTPLELLLRQLGRDAGATPSAAGAPASAPGEPRQRRLLLLDLLALYTPVGAAGSARQELLGDRPRWQRLLGEDKFQWLAGLAPPSLFARAMQVLVTAISPGRFPEALDELPLPPFLQPLDLTGKG>sp|Q92527|ANKR7_HUMAN Ankyrin repeat domain-containing protein 7 OS=Homosapiens OX=9606 GN=ANKRD7 PE=2 SV=3MNKLFSFWKRKNETRSQGYNLREKDLKKLHRAASVGDLKKLKEYLQIKKYDVNMQDKKYRTPLHLACANGHTDVVLFLIEQQCKINVRDSENKSPLIKAVQCQNEDCATILLNFGADPDLRDIRYNTVLHYAVCGQSLSLVEKLLEYEADLEAKNKDGYTPLLVAVINNNPKMVKFLLEKGADVNASDNYQRTALILAVSGEPPCLVKLLLQQGVELCYEGIVDSQLRNMFISMVLLHRYPQFTASHGKKKHAK>sp|Q92527-2|ANKR7_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 7 OS=Homo sapiens OX=9606 GN=ANKRD7MNKLFSFWKRKNETRSQGYNLREKDLKKLHRAASVGDLKKLKEYLQIKKYDVNMQDKKYSVVQSSRWLLSYTTPLNDFIRTPLHLACANGHTDVVLFLIEQQCKINVRDSENKSPLIKAVQCQNEDCATILLNFGADPDLRDIRYNTVLHYAVCGQSLSLVEKLLEYEADLEAKNKDGYTPLLVAVINNNPKMVKFLLEKGADVNASDNYQRTALILAVSGEPPCLVKLLLQQGVELCYEGIVDSQLRNMFISMVLLHRYPQFTASHGKKKHAK>sp|Q13185|CBX3_HUMAN Chromobox protein homolog 3 OS=Homo sapiens OX=9606GN=CBX3 PE=1 SV=4MASNKTTLQKMGKKQNGKSKKVEEAEPEEFVVEKVLDRRVVNGKVEYFLKWKGFTDADNTWEPEENLDCPELIEAFLNSQKAGKEKDGTKRKSLSDSESDDSKSKKKRDAADKPRGFARGLDPERIIGATDSSGELMFLMKWKDSDEADLVLAKEANMKCPQIVIAFYEERLTWHSCPEDEAQ>sp|Q969Q4|ARL11_HUMAN ADP-ribosylation factor-like protein 11 OS=Homosapiens OX=9606 GN=ARL11 PE=1 SV=1MGSVNSRGHKAEAQVVMMGLDSAGKTTLLYKLKGHQLVETLPTVGFNVEPLKAPGHVSLTLWDVGGQAPLRASWKDYLEGTDILVYVLDSTDEARLPESAAELTEVLNDPNMAGVPFLVLANKQEAPDALPLLKIRNRLSLERFQDHCWELRGCSALTGEGLPEALQSLWSLLKSRSCMCLQARAHGAERGDSKRS>sp|Q9H8Y5|ANKZ1_HUMAN Ankyrin repeat and zinc finger domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=ANKZF1 PE=1 SV=1MSPAPDAAPAPASISLFDLSADAPVFQGLSLVSHAPGEALARAPRTSCSGSGERESPERKLLQGPMDISEKLFCSTCDQTFQNHQEQREHYKLDWHRFNLKQRLKDKPLLSALDFEKQSSTGDLSSISGSEDSDSASEEDLQTLDRERATFEKLSRPPGFYPHRVLFQNAQGQFLYAYRCVLGPHQDPPEEAELLLQNLQSRGPRDCVVLMAAAGHFAGAIFQGREVVTHKTFHRYTVRAKRGTAQGLRDARGGPSHSAGANLRRYNEATLYKDVRDLLAGPSWAKALEEAGTILLRAPRSGRSLFFGGKGAPLQRGDPRLWDIPLATRRPTFQELQRVLHKLTTLHVYEEDPREAVRLHSPQTHWKTVREERKKPTEEEIRKICRDEKEALGQNEESPKQGSGSEGEDGFQVELELVELTVGTLDLCESEVLPKRRRRKRNKKEKSRDQEAGAHRTLLQQTQEEEPSTQSSQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVLKLQLAPSPADPRVLSLLSAPLGSGGFTLLHAAAAAGRGSVVRLLLEAGADPTVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKAQVPGPLTPEMEARQATRKREQKAARRQREEQQQRQQEQEEREREEQRRFAALSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWSCGASLQGLTPFHYLDFSFCSTRCLQDHRRQAGRPSS>sp|H3BNL1|CC084_HUMAN Uncharacterized protein C3orf84 OS=Homo sapiensOX=9606 GN=C3orf84 PE=2 SV=1MQSALVGSWHNNGFYGHYRSQFKSESAREYHLAAKPQPPAVFLQRCQEPAQRHFFSKHDNRTSFDKGPYCLLQGIGRRKDLERLWQRHTFLRWAPCEIELRQQGPLESSYQADFRPGPGLSGLPQHLIHFVQVQPSHTRTTYQQNFCCPSQGGHYGSYKVGPQAPVTDVLPDLPGIPRPKLLQHYLHAGVSECLNWSRALNKDS>sp|Q01668|CAC1D_HUMAN Voltage-dependent L-type calcium channel subunitalpha-1D OS=Homo sapiens OX=9606 GN=CACNA1D PE=1 SV=2MMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAKSKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLEKVEYAFLIIFTVETFLKIIAYGLLLHPNAYVRNGWNLLDFVIVIVGLFSVILEQLTKETEGGNHSSGKSGGFDVKALRAFRVLRPLRLVSGVPSLQVVLNSIIKAMVPLLHIALLVLFVIIIYAIIGLELFIGKMHKTCFFADSDIVAEEDPAPCAFSGNGRQCTANGTECRSGWVGPNGGITNFDNFAFAMLTVFQCITMEGWTDVLYWMNDAMGFELPWVYFVSLVIFGSFFVLNLVLGVLSGEFSKEREKAKARGDFQKLREKQQLEEDLKGYLDWITQAEDIDPENEEEGGEEGKRNTSMPTSETESVNTENVSGEGENRGCCGSLCQAISKSKLSRRWRRWNRFNRRRCRAAVKSVTFYWLVIVLVFLNTLTISSEHYNQPDWLTQIQDIANKVLLALFTCEMLVKMYSLGLQAYFVSLFNRFDCFVVCGGITETILVELEIMSPLGISVFRCVRLLRIFKVTRHWTSLSNLVASLLNSMKSIASLLLLLFLFIIIFSLLGMQLFGGKFNFDETQTKRSTFDNFPQALLTVFQILTGEDWNAVMYDGIMAYGGPSSSGMIVCIYFIILFICGNYILLNVFLAIAVDNLADAESLNTAQKEEAEEKERKKIARKESLENKKNNKPEVNQIANSDNKVTIDDYREEDEDKDPYPPCDVPVGEEEEEEEEDEPEVPAGPRPRRISELNMKEKIAPIPEGSAFFILSKTNPIRVGCHKLINHHIFTNLILVFIMLSSAALAAEDPIRSHSFRNTILGYFDYAFTAIFTVEILLKMTTFGAFLHKGAFCRNYFNLLDMLVVGVSLVSFGIQSSAISVVKILRVLRVLRPLRAINRAKGLKHVVQCVFVAIRTIGNIMIVTTLLQFMFACIGVQLFKGKFYRCTDEAKSNPEECRGLFILYKDGDVDSPVVRERIWQNSDFNFDNVLSAMMALFTVSTFEGWPALLYKAIDSNGENIGPIYNHRVEISIFFIIYIIIVAFFMMNIFVGFVIVTFQEQGEKEYKNCELDKNQRQCVEYALKARPLRRYIPKNPYQYKFWYVVNSSPFEYMMFVLIMLNTLCLAMQHYEQSKMFNDAMDILNMVFTGVFTVEMVLKVIAFKPKGYFSDAWNTFDSLIVIGSIIDVALSEADPTESENVPVPTATPGNSEESNRISITFFRLFRVMRLVKLLSRGEGIRTLLWTFIKSFQALPYVALLIAMLFFIYAVIGMQMFGKVAMRDNNQINRNNNFQTFPQAVLLLFRCATGEAWQEIMLACLPGKLCDPESDYNPGEEYTCGSNFAIVYFISFYMLCAFLIINLFVAVIMDNFDYLTRDWSILGPHHLDEFKRIWSEYDPEAKGRIKHLDVVTLLRRIQPPLGFGKLCPHRVACKRLVAMNMPLNSDGTVMFNATLFALVRTALKIKTEGNLEQANEELRAVIKKIWKKTSMKLLDQVVPPAGDDEVTVGKFYATFLIQDYFRKFKKRKEQGLVGKYPAKNTTIALQAGLRTLHDIGPEIRRAISCDLQDDEPEETKREEEDDVFKRNGALLGNHVNHVNSDRRDSLQQTNTTHRPLHVQRPSIPPASDTEKPLFPPAGNSVCHNHHNHNSIGKQVPTSTNANLNNANMSKAAHGKRPSIGNLEHVSENGHHSSHKHDREPQRRSSVKRTRYYETYIRSDSGDEQLPTICREDPEIHGYFRDPHCLGEQEYFSSEECYEDDSSPTWSRQNYGYYSRYPGRNIDSERPRGYHHPQGFLEDDDSPVCYDSRRSPRRRLLPPTPASHRRSSFNFECLRRQSSQEEVPSSPIFPHRTALPLHLMQQQIMAVAGLDSSKAQKYSPSHSTRSWATPPATPPYRDWTPCYTPLIQVEQSEALDQVNGSLPSLHRSSWYTDEPDISYRTFTPASLTVPSSFRNKNSDKQRSADSLVEAVLISEGLGRYARDPKFVSATKHEIADACDLTIDEMESAASTLLNGNVRPRANGDVGPLSHRQDYELQDFGPGYSDEEPDPGRDEEDLADEMICITTL>sp|Q01668-2|CAC1D_HUMAN Isoform Beta-cell-type of Voltage-dependent L-type calcium channel subunit alpha-1D OS=Homo sapiens OX=9606 GN=CACNA1DMMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAKSKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLEKVEYAFLIIFTVETFLKIIAYGLLLHPNAYVRNGWNLLDFVIVIVGLFSVILEQLTKETEGGNHSSGKSGGFDVKALRAFRVLRPLRLVSGVPSLQVVLNSIIKAMVPLLHIALLVLFVIIIYAIIGLELFIGKMHKTCFFADSDIVAEEDPAPCAFSGNGRQCTANGTECRSGWVGPNGGITNFDNFAFAMLTVFQCITMEGWTDVLYWVNDAIGWEWPWVYFVSLIILGSFFVLNLVLGVLSGEFSKEREKAKARGDFQKLREKQQLEEDLKGYLDWITQAEDIDPENEEEGGEEGKRNTSMPTSETESVNTENVSGEGENRGCCGSLWCWWRRRGAAKAGPSGCRRWGQAISKSKLSRRWRRWNRFNRRRCRAAVKSVTFYWLVIVLVFLNTLTISSEHYNQPDWLTQIQDIANKVLLALFTCEMLVKMYSLGLQAYFVSLFNRFDCFVVCGGITETILVELEIMSPLGISVFRCVRLLRIFKVTRHWTSLSNLVASLLNSMKSIASLLLLLFLFIIIFSLLGMQLFGGKFNFDETQTKRSTFDNFPQALLTVFQILTGEDWNAVMYDGIMAYGGPSSSGMIVCIYFIILFICGNYILLNVFLAIAVDNLADAESLNTAQKEEAEEKERKKIARKESLENKKNNKPEVNQIANSDNKVTIDDYREEDEDKDPYPPCDVPVGEEEEEEEEDEPEVPAGPRPRRISELNMKEKIAPIPEGSAFFILSKTNPIRVGCHKLINHHIFTNLILVFIMLSSAALAAEDPIRSHSFRNTILGYFDYAFTAIFTVEILLKMTTFGAFLHKGAFCRNYFNLLDMLVVGVSLVSFGIQSSAISVVKILRVLRVLRPLRAINRAKGLKHVVQCVFVAIRTIGNIMIVTTLLQFMFACIGVQLFKGKFYRCTDEAKSNPEECRGLFILYKDGDVDSPVVRERIWQNSDFNFDNVLSAMMALFTVSTFEGWPALLYKAIDSNGENIGPIYNHRVEISIFFIIYIIIVAFFMMNIFVGFVIVTFQEQGEKEYKNCELDKNQRQCVEYALKARPLRRYIPKNPYQYKFWYVVNSSPFEYMMFVLIMLNTLCLAMQHYEQSKMFNDAMDILNMVFTGVFTVEMVLKVIAFKPKGYFSDAWNTFDSLIVIGSIIDVALSEADPTESENVPVPTATPGNSEESNRISITFFRLFRVMRLVKLLSRGEGIRTLLWTFIKSFQALPYVALLIAMLFFIYAVIGMQMFGKVAMRDNNQINRNNNFQTFPQAVLLLFRCATGEAWQEIMLACLPGKLCDPESDYNPGEEYTCGSNFAIVYFISFYMLCAFLIINLFVAVIMDNFDYLTRDWSILGPHHLDEFKRIWSEYDPEAKGRIKHLDVVTLLRRIQPPLGFGKLCPHRVACKRLVAMNMPLNSDGTVMFNATLFALVRTALKIKTEGNLEQANEELRAVIKKIWKKTSMKLLDQVVPPAGDDEVTVGKFYATFLIQDYFRKFKKRKEQGLVGKYPAKNTTIALQAGLRTLHDIGPEIRRAISCDLQDDEPEETKREEEDDVFKRNGALLGNHVNHVNSDRRDSLQQTNTTHRPLHVQRPSIPPASDTEKPLFPPAGNSVCHNHHNHNSIGKQVPTSTNANLNNANMSKAAHGKRPSIGNLEHVSENGHHSSHKHDREPQRRSSVKRTRYYETYIRSDSGDEQLPTICREDPEIHGYFRDPHCLGEQEYFSSEECYEDDSSPTWSRQNYGYYSRYPGRNIDSERPRGYHHPQGFLEDDDSPVCYDSRRSPRRRLLPPTPASHRRSSFNFECLRRQSSQEEVPSSPIFPHRTALPLHLMQQQIMAVAGLDSSKAQKYSPSHSTRSWATPPATPPYRDWTPCYTPLIQVEQSEALDQVNGSLPSLHRSSWYTDEPDISYRTFTPASLTVPSSFRNKNSDKQRSADSLVEAVLISEGLGRYARDPKFVSATKHEIADACDLTIDEMESAASTLLNGNVRPRANGDVGPLSHRQDYELQDFGPGYSDEEPDPGRDEEDLADEMICITTL>sp|Q01668-4|CAC1D_HUMAN Isoform 4 of Voltage-dependent L-type calciumchannel subunit alpha-1D OS=Homo sapiens OX=9606 GN=CACNA1DMMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAKSKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLEKVEYAFLIIFTVETFLKIIAYGLLLHPNAYVRNGWNLLDFVIVIVGLFSVILEQLTKETEGGNHSSGKSGGFDVKALRAFRVLRPLRLVSGVPSLQVVLNSIIKAMVPLLHIALLVLFVIIIYAIIGLELFIGKMHKTCFFADSDIVAEEDPAPCAFSGNGRQCTANGTECRSGWVGPNGGITNFDNFAFAMLTVFQCITMEGWTDVLYWMNDAMGFELPWVYFVSLVIFGSFFVLNLVLGVLSGEFSKEREKAKARGDFQKLREKQQLEEDLKGYLDWITQAEDIDPENEEEGGEEGKRNTSMPTSETESVNTENVSGEGENRGCCGSLCQAISKSKLSRRWRRWNRFNRRRCRAAVKSVTFYWLVIVLVFLNTLTISSEHYNQPDWLTQIQDIANKVLLALFTCEMLVKMYSLGLQAYFVSLFNRFDCFVVCGGITETILVELEIMSPLGISVFRCVRLLRIFKVTRHWTSLSNLVASLLNSMKSIASLLLLLFLFIIIFSLLGMQLFGGKFNFDETQTKRSTFDNFPQALLTVFQILTGEDWNAVMYDGIMAYGGPSSSGMIVCIYFIILFICGNYILLNVFLAIAVDNLADAESLNTAQKEEAEEKERKKIARKESLENKKNNKPEVNQIANSDNKVTIDDYREEDEDKDPYPPCDVPVGEEEEEEEEDEPEVPAGPRPRRISELNMKEKIAPIPEGSAFFILSKTNPIRVGCHKLINHHIFTNLILVFIMLSSAALAAEDPIRSHSFRNTILGYFDYAFTAIFTVEILLKMTTFGAFLHKGAFCRNYFNLLDMLVVGVSLVSFGIQSSAISVVKILRVLRVLRPLRAINRAKGLKHVVQCVFVAIRTIGNIMIVTTLLQFMFACIGVQLFKGKFYRCTDEAKSNPEECRGLFILYKDGDVDSPVVRERIWQNSDFNFDNVLSAMMALFTVSTFEGWPALLYKAIDSNGENIGPIYNHRVEISIFFIIYIIIVAFFMMNIFVGFVIVTFQEQGEKEYKNCELDKNQRQCVEYALKARPLRRYIPKNPYQYKFWYVVNSSPFEYMMFVLIMLNTLCLAMQHYEQSKMFNDAMDILNMVFTGVFTVEMVLKVIAFKPKGYFSDAWNTFDSLIVIGSIIDVALSEADPTESENVPVPTATPGNSEESNRISITFFRLFRVMRLVKLLSRGEGIRTLLWTFIKSFQALPYVALLIAMLFFIYAVIGMQMFGKVAMRDNNQINRNNNFQTFPQAVLLLFRCATGEAWQEIMLACLPGKLCDPESDYNPGEEYTCGSNFAIVYFISFYMLCAFLIINLFVAVIMDNFDYLTRDWSILGPHHLDEFKRIWSEYDPEAKGRIKHLDVVTLLRRIQPPLGFGKLCPHRVACKRLVAMNMPLNSDGTVMFNATLFALVRTALKIKTEGNLEQANEELRAVIKKIWKKTSMKLLDQVVPPAGDDEVTVGKFYATFLIQDYFRKFKKRKEQGLVGKYPAKNTTIALQMLERML>sp|Q01668-3|CAC1D_HUMAN Isoform 3 of Voltage-dependent L-type calciumchannel subunit alpha-1D OS=Homo sapiens OX=9606 GN=CACNA1DMMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAKSKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLEKVEYAFLIIFTVETFLKIIAYGLLLHPNAYVRNGWNLLDFVIVIVGLFSVILEQLTKETEGGNHSSGKSGGFDVKALRAFRVLRPLRLVSGVPSLQVVLNSIIKAMVPLLHIALLVLFVIIIYAIIGLELFIGKMHKTCFFADSDIVAEEDPAPCAFSGNGRQCTANGTECRSGWVGPNGGITNFDNFAFAMLTVFQCITMEGWTDVLYWMNDAMGFELPWVYFVSLVIFGSFFVLNLVLGVLSGEFSKEREKAKARGDFQKLREKQQLEEDLKGYLDWITQAEDIDPENEEEGGEEGKRNTSMPTSETESVNTENVSGEGENRGCCGSLCQAISKSKLSRRWRRWNRFNRRRCRAAVKSVTFYWLVIVLVFLNTLTISSEHYNQPDWLTQIQDIANKVLLALFTCEMLVKMYSLGLQAYFVSLFNRFDCFVVCGGITETILVELEIMSPLGISVFRCVRLLRIFKVTRHWTSLSNLVASLLNSMKSIASLLLLLFLFIIIFSLLGMQLFGGKFNFDETQTKRSTFDNFPQALLTVFQILTGEDWNAVMYDGIMAYGGPSSSGMIVCIYFIILFICGNYILLNVFLAIAVDNLADAESLNTAQKEEAEEKERKKIARKESLENKKNNKPEVNQIANSDNKVTIDDYREEDEDKDPYPPCDVPVGEEEEEEEEDEPEVPAGPRPRRISELNMKEKIAPIPEGSAFFILSKTNPIRVGCHKLINHHIFTNLILVFIMLSSAALAAEDPIRSHSFRNTILGYFDYAFTAIFTVEILLKMTTFGAFLHKGAFCRNYFNLLDMLVVGVSLVSFGIQSSAISVVKILRVLRVLRPLRAINRAKGLKHVVQCVFVAIRTIGNIMIVTTLLQFMFACIGVQLFKGKFYRCTDEAKSNPEECRGLFILYKDGDVDSPVVRERIWQNSDFNFDNVLSAMMALFTVSTFEGWPALLYKAIDSNGENIGPIYNHRVEISIFFIIYIIIVAFFMMNIFVGFVIVTFQEQGEKEYKNCELDKNQRQCVEYALKARPLRRYIPKNPYQYKFWYVVNSSPFEYMMFVLIMLNTLCLAMQHYEQSKMFNDAMDILNMVFTGVFTVEMVLKVIAFKPKGYFSDAWNTFDSLIVIGSIIDVALSEADNSEESNRISITFFRLFRVMRLVKLLSRGEGIRTLLWTFIKSFQALPYVALLIAMLFFIYAVIGMQMFGKVAMRDNNQINRNNNFQTFPQAVLLLFRCATGEAWQEIMLACLPGKLCDPESDYNPGEEYTCGSNFAIVYFISFYMLCAFLIINLFVAVIMDNFDYLTRDWSILGPHHLDEFKRIWSEYDPEAKGRIKHLDVVTLLRRIQPPLGFGKLCPHRVACKRLVAMNMPLNSDGTVMFNATLFALVRTALKIKTEGNLEQANEELRAVIKKIWKKTSMKLLDQVVPPAGDDEVTVGKFYATFLIQDYFRKFKKRKEQGLVGKYPAKNTTIALQAGLRTLHDIGPEIRRAISCDLQDDEPEETKREEEDDVFKRNGALLGNHVNHVNSDRRDSLQQTNTTHRPLHVQRPSIPPASDTEKPLFPPAGNSVCHNHHNHNSIGKQVPTSTNANLNNANMSKAAHGKRPSIGNLEHVSENGHHSSHKHDREPQRRSSVKRSDSGDEQLPTICREDPEIHGYFRDPHCLGEQEYFSSEECYEDDSSPTWSRQNYGYYSRYPGRNIDSERPRGYHHPQGFLEDDDSPVCYDSRRSPRRRLLPPTPASHRRSSFNFECLRRQSSQEEVPSSPIFPHRTALPLHLMQQQIMAVAGLDSSKAQKYSPSHSTRSWATPPATPPYRDWTPCYTPLIQVEQSEALDQVNGSLPSLHRSSWYTDEPDISYRTFTPASLTVPSSFRNKNSDKQRSADSLVEAVLISEGLGRYARDPKFVSATKHEIADACDLTIDEMESAASTLLNGNVRPRANGDVGPLSHRQDYELQDFGPGYSDEEPDPGRDEEDLADEMICITTL>sp|Q8TBZ0|CC110_HUMAN Coiled-coil domain-containing protein 110 OS=Homosapiens OX=9606 GN=CCDC110 PE=1 SV=1MSPEKQHREEDEVDSVLLSASKILNSSEGVKESGCSDTEYGCIAESENQIQPQSALKVLQQQLESFQALRMQTLQNVSMVQSEISEILNKSIIEVENPQFSSEKNLVFGTRIEKDLPTENQEENLSMEKSHHFEDSKTLHSVEEKLSGDSVNSLPQSVNVPSQIHSEDTLTLRTSTDNLSSNIIIHPSENSDILKNYNNFYRFLPTAPPNVMSQADTVILDKSKITVPFLKHGFCENLDDICHSIKQMKEELQKSHDGEVALTNELQTLQTDPDVHRNGKYDMSPIHQDKMNFIKEENLDGNLNEDIKSKRISELEALVKKLLPFRETVSKFHVHFCRKCKKLSKSEMHRGKKNEKNNKEIPITGKNITDLKFHSRVPRYTLSFLDQTKHEMKDKERQPFLVKQGSIISENEKTSKVNSVTEQCVAKIQYLQNYLKESVQIQKKVMELESENLNLKSKMKPLIFTTQSLIQKVETYEKQLKNLVEEKSTIQSKLSKTEEYSKECLKEFKKIISKYNVLQGQNKTLEEKNIQLSLEKQQMMEALDQLKSKEHKTQSDMAIVNNENNRMSIEMEAMKTNILLIQDEKEMLEKKTHQLLKEKSSLGNELKESQLEIIQLKEKERLAKTEQETLLQIIETVKDEKLNLETTLQESTAARQIMEREIENIQTYQSTAEENFLQEIKNAKSEASIYKNSLSEIGKECEMLSKMVMETKTDNQILKEELKKHSQENIKFENSISRLTEDKILLENYVRSIENERDTLEFEMRHLQREYLSLSDKICNQHNDPSKTTYISRREKFHFDNYTHEDTSSPQSRPLASDLKGYFKVKDRTLKHH>sp|Q8TBZ0-2|CC110_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 110 OS=Homo sapiens OX=9606 GN=CCDC110MSPEKQHREEDEVDSVLLSASKILNSSEGVKESGCSDTEYGCIAESENQIQPQSALKVLQQQLESFQALRMQTLQNVSMPTENQEENLSMEKSHHFEDSKTLHSVEEKLSGDSVNSLPQSVNVPSQIHSEDTLTLRTSTDNLSSNIIIHPSENSDILKNYNNFYRFLPTAPPNVMSQADTVILDKSKITVPFLKHGFCENLDDICHSIKQMKEELQKSHDGEVALTNELQTLQTDPDVHRNGKYDMSPIHQDKMNFIKEENLDGNLNEDIKSKRISELEALVKKLLPFRETVSKFHVHFCRKCKKLSKSEMHRGKKNEKNNKEIPITGKNITDLKFHSRVPRYTLSFLDQTKHEMKDKERQPFLVKQGSIISENEKTSKVNSVTEQCVAKIQYLQNYLKESVQIQKKVMELESENLNLKSKMKPLIFTTQSLIQKVETYEKQLKNLVEEKSTIQSKLSKTEEYSKECLKEFKKIISKYNVLQGQNKTLEEKNIQLSLEKQQMMEALDQLKSKEHKTQSDMAIVNNENNRMSIEMEAMKTNILLIQDEKEMLEKKTHQLLKEKSSLGNELKESQLEIIQLKEKERLAKTEQETLLQIIETVKDEKLNLETTLQESTAARQIMEREIENIQTYQSTAEENFLQEIKNAKSEASIYKNSLSEIGKECEMLSKMVMETKTDNQILKEELKKHSQENIKFENSISRLTEDKILLENYVRSIENERDTLEFEMRHLQREYLSLSDKICNQHNDPSKTTYISRREKFHFDNYTHEDTSSPQSRPLASDLKGYFKVKDRTLKHH>sp|P41181|AQP2_HUMAN Aquaporin-2 OS=Homo sapiens OX=9606 GN=AQP2 PE=1SV=1MWELRSIAFSRAVFAEFLATLLFVFFGLGSALNWPQALPSVLQIAMAFGLGIGTLVQALGHISGAHINPAVTVACLVGCHVSVLRAAFYVAAQLLGAVAGAALLHEITPADIRGDLAVNALSNSTTAGQAVTVELFLTLQLVLCIFASTDERRGENPGTPALSIGFSVALGHLLGIHYTGCSMNPARSLAPAVVTGKFDDHWVFWIGPLVGAILGSLLYNYVLFPPAKSLSERLAVLKGLEPDTDWEEREVRRRQSVELHSPQSLPRGTKA>sp|O95971|BY55_HUMAN CD160 antigen OS=Homo sapiens OX=9606 GN=CD160 PE=1SV=1MLLEPGRGCCALAILLAIVDIQSGGCINITSSASQEGTRLNLICTVWHKKEEAEGFVVFLCKDRSGDCSPETSLKQLRLKRDPGIDGVGEISSQLMFTISQVTPLHSGTYQCCARSQKSGIRLQGHFFSILFTETGNYTVTGLKQRQHLEFSHNEGTLSSGFLQEKVWVMLVTSLVALQAL>sp|O95971-2|BY55_HUMAN Isoform 2 of CD160 antigen OS=Homo sapiensOX=9606 GN=CD160MLLEPGRGCCALAILLAIVDIQSGETGNYTVTGLKQRQHLEFSHNEGTLSSGFLQEKVWVMLVTSLVALQAL>sp|O95971-3|BY55_HUMAN Isoform 3 of CD160 antigen OS=Homo sapiensOX=9606 GN=CD160MLLEPGRGCCALAILLAIVDIQSGGCINITSSASQEGTRLNLICTVWHKKEEAEGFVVFLCKDRSGDCSPETSLKQLRLKRDPGIDGVGEISSQLMFTISQVTPLHSGTYQCCARSQKSGIRLQGHFFSILFTETGNYTVTGLKQRQHLEFSHNEGTLSSGFLQEKVWVMLVTSLVALQGMSKRAVSTPSNEGAIIFLPPWLFSRRRRLERMSRGREKCYSSPGYPQESSNQFH>sp|O95971-4|BY55_HUMAN Isoform 4 of CD160 antigen OS=Homo sapiensOX=9606 GN=CD160MLLEPGRGCCALAILLAIVDIQSGETGNYTVTGLKQRQHLEFSHNEGTLSSGFLQEKVWVMLVTSLVALQGMSKRAVSTPSNEGAIIFLPPWLFSRRRRLERMSRGREKCYSSPGYPQESSNQFH>sp|O60678|ANM3_HUMAN Protein arginine N-methyltransferase 3 OS=Homosapiens OX=9606 GN=PRMT3 PE=1 SV=4MCSLASGATGGRGAVENEEDLPELSDSGDEAAWEDEDDADLPHGKQQTPCLFCNRLFTSAEETFSHCKSEHQFNIDSMVHKHGLEFYGYIKLINFIRLKNPTVEYMNSIYNPVPWEKEEYLKPVLEDDLLLQFDVEDLYEPVSVPFSYPNGLSENTSVVEKLKHMEARALSAEAALARAREDLQKMKQFAQDFVMHTDVRTCSSSTSVIADLQEDEDGVYFSSYGHYGIHEEMLKDKIRTESYRDFIYQNPHIFKDKVVLDVGCGTGILSMFAAKAGAKKVLGVDQSEILYQAMDIIRLNKLEDTITLIKGKIEEVHLPVEKVDVIISEWMGYFLLFESMLDSVLYAKNKYLAKGGSVYPDICTISLVAVSDVNKHADRIAFWDDVYGFKMSCMKKAVIPEAVVEVLDPKTLISEPCGIKHIDCHTTSISDLEFSSDFTLKITRTSMCTAIAGYFDIYFEKNCHNRVVFSTGPQSTKTHWKQTVFLLEKPFSVKAGEALKGKVTVHKNKKDPRSLTVTLTLNNSTQTYGLQ>sp|O60678-2|ANM3_HUMAN Isoform 2 of Protein arginine N-methyltransferase3 OS=Homo sapiens OX=9606 GN=PRMT3MCSLASGATGYSHLLKKHFHTVSLSISLILTAWFINMNPTVEYMNSIYNPVPWEKEEYLKPVLEDDLLLQFDVEDLYEPVSVPFSYPNGLSENTSVVEKLKHMEARALSAEAALARAREDLQKMKQFAQDFVMHTDVRTCSSSTSVIADLQEDEDGVYFSSYGHYGIHEEMLKDKIRTESYRDFIYQNPHIFKDKVVLDVGCGTGILSMFAAKAGAKKVLGVDQSEILYQAMDIIRLNKLEDTITLIKGKIEEVHLPVEKVDVIISEWMGYFLLFESMLDSVLYAKNKYLAKGGSVYPDICTISLVAVSDVNKHADRIAFWDDVYGFKMSCMKKAVIPEAVVEVLDPKTLISEPCGIKHIDCHTTSISDLEFSSDFTLKITRTSMCTAIAGYFDIYFEKNCHNRVVFSTGPQSTKTHWKQTVFLLEKPFSVKAGEALKGKVTVHKNKKDPRSLTVTLTLNNSTQTYGLQ>sp|O60306|AQR_HUMAN RNA helicase aquarius OS=Homo sapiens OX=9606 GN=AQRPE=1 SV=4MAAPAQPKKIVAPTVSQINAEFVTQLACKYWAPHIKKKSPFDIKVIEDIYEKEIVKSRFAIRKIMLLEFSQYLENYLWMNYSPEVSSKAYLMSICCMVNEKFRENVPAWEIFKKKPDHFPFFFKHILKAALAETDGEFSLHEQTVLLLFLDHCFNSLEVDLIRSQVQQLISLPMWMGLQLARLELELKKTPKLRKFWNLIKKNDEKMDPEAREQAYQERRFLSQLIQKFISVLKSVPLSEPVTMDKVHYCERFIELMIDLEALLPTRRWFNTILDDSHLLVHCYLSNLVRREEDGHLFSQLLDMLKFYTGFEINDQTGNALTENEMTTIHYDRITSLQRAAFAHFPELYDFALSNVAEVDTRESLVKFFGPLSSNTLHQVASYLCLLPTLPKNEDTTFDKEFLLELLVSRHERRISQIQQLNQMPLYPTEKIIWDENIVPTEYYSGEGCLALPKLNLQFLTLHDYLLRNFNLFRLESTYEIRQDIEDSVSRMKPWQSEYGGVVFGGWARMAQPIVAFTVVEVAKPNIGENWPTRVRADVTINLNVRDHIKDEWEGLRKHDVCFLITVRPTKPYGTKFDRRRPFIEQVGLVYVRGCEIQGMLDDKGRVIEDGPEPRPNLRGESRTFRVFLDPNQYQQDMTNTIQNGAEDVYETFNIIMRRKPKENNFKAVLETIRNLMNTDCVVPDWLHDIILGYGDPSSAHYSKMPNQIATLDFNDTFLSIEHLKASFPGHNVKVTVEDPALQIPPFRITFPVRSGKGKKRKDADVEDEDTEEAKTLIVEPHVIPNRGPYPYNQPKRNTIQFTHTQIEAIRAGMQPGLTMVVGPPGTGKTDVAVQIISNIYHNFPEQRTLIVTHSNQALNQLFEKIMALDIDERHLLRLGHGEEELETEKDFSRYGRVNYVLARRIELLEEVKRLQKSLGVPGDASYTCETAGYFFLYQVMSRWEEYISKVKNKGSTLPDVTEVSTFFPFHEYFANAPQPIFKGRSYEEDMEIAEGCFRHIKKIFTQLEEFRASELLRSGLDRSKYLLVKEAKIIAMTCTHAALKRHDLVKLGFKYDNILMEEAAQILEIETFIPLLLQNPQDGFSRLKRWIMIGDHHQLPPVIKNMAFQKYSNMEQSLFTRFVRVGVPTVDLDAQGRARASLCNLYNWRYKNLGNLPHVQLLPEFSTANAGLLYDFQLINVEDFQGVGESEPNPYFYQNLGEAEYVVALFMYMCLLGYPADKISILTTYNGQKHLIRDIINRRCGNNPLIGRPNKVTTVDRFQGQQNDYILLSLVRTRAVGHLRDVRRLVVAMSRARLGLYIFARVSLFQNCFELTPAFSQLTARPLHLHIIPTEPFPTTRKNGERPSHEVQIIKNMPQMANFVYNMYMHLIQTTHHYHQTLLQLPPAMVEEGEEVQNQETELETEEEAMTVQADIIPSPTDTSCRQETPAFQTDTTPSETGATSTPEAIPALSETTPTVVGAVSAPAEANTPQDATSAPEETK>sp|Q9NXL2|ARH38_HUMAN Rho guanine nucleotide exchange factor 38 OS=Homosapiens OX=9606 GN=ARHGEF38 PE=1 SV=2MEPKEATGKENMVTKKKNLAFLRSRLYMLERRKTDTVVESSVSGDHSGTLRRSQSDRTEYNQKLQEKMTPQGECSVAETLTPEEEHHMKRMMAKREKIIKELIQTEKDYLNDLELCVREVVQPLRNKKTDRLDVDSLFSNIESVHQISAKLLSLLEEATTDVEPAMQVIGEVFLQIKGPLEDIYKIYCYHHDEAHSILESYEKEEELKEHLSHCIQSLKKIYMQEGKPNLLDMGSLMIKPIQRVMKYPLLLCELRNSTPPSHPDYRALDDAFAAVKDINVNINELKRRKDLVLKYKKNDEDESLKDKLSKLNIHSISKKSKRVTNHLKILTRGESQVKDNTFNREEKLFRALEKTVRLCVKNISLCLQHIQDAMPLALQSVMDLQEISYNKDDEMDYSETLSNALNSCHDFASHLQRLILTPLSALLSLFPGPHKLIQKRYDKLLDCNSYLQRSTGEESDLAKKEYEALNAQLVEELQAFNQAARKILLNCLCSFITLLRDLMLVAQQAYSTLVPMPLLVSSISEIQNQVLEEIQNLNCVKENSATFIERKLSFEKKKPVQILPEMPHQTDIHRSKLLSTYSAEELYQAKRKCNATQEYDINLLEGDLVAVIEQKDPLGSTSRWLVDTGNVKGYVYSSFLKPYNPAKMQKVDAENRFCDDDFENISLFVSSRPASDSVTGTSESSIGDSSSSLSGTCGKFETNGTDVDSFQEVDEQIFYAVHAFQARSDHELSLQEYQRVHILRFCDLSGNKEWWLAEAQGQKGYVPANYLGKMTYA>sp|Q9NXL2-1|ARH38_HUMAN Isoform 1 of Rho guanine nucleotide exchangefactor 38 OS=Homo sapiens OX=9606 GN=ARHGEF38MEPKEATGKENMVTKKKNLAFLRSRLYMLERRKTDTVVESSVSGDHSGTLRRSQSDRTEYNQKLQEKMTPQGECSVAETLTPEEEHHMKRMMAKREKIIKELIQTEKDYLNDLELCVREVVQPLRNKKTDRLDVDSLFSNIESVHQISAKLLSLLEEATTDVEPAMQVIGEVFLQIKGPLEDIYKIYCYHHDEAHSILESYEKEEELKEHLSHCIQSLK>sp|Q92888|ARHG1_HUMAN Rho guanine nucleotide exchange factor 1 OS=Homosapiens OX=9606 GN=ARHGEF1 PE=1 SV=2MEDFARGAASPGPSRPGLVPVSIIGAEDEDFENELETNSEEQNSQFQSLEQVKRRPAHLMALLQHVALQFEPGPLLCCLHADMLGSLGPKEAKKAFLDFYHSFLEKTAVLRVPVPPNVAFELDRTRADLISEDVQRRFVQEVVQSQQVAVGRQLEDFRSKRLMGMTPWEQELAQLEAWVGRDRASYEARERHVAERLLMHLEEMQHTISTDEEKSAAVVNAIGLYMRHLGVRTKSGDKKSGRNFFRKKVMGNRRSDEPAKTKKGLSSILDAARWNRGEPQVPDFRHLKAEVDAEKPGATDRKGGVGMPSRDRNIGAPGQDTPGVSLHPLSLDSPDREPGADAPLELGDSSPQGPMSLESLAPPESTDEGAETESPEPGDEGEPGRSGLELEPEEPPGWRELVPPDTLHSLPKSQVKRQEVISELLVTEAAHVRMLRVLHDLFFQPMAECLFFPLEELQNIFPSLDELIEVHSLFLDRLMKRRQESGYLIEEIGDVLLARFDGAEGSWFQKISSRFCSRQSFALEQLKAKQRKDPRFCAFVQEAESRPRCRRLQLKDMIPTEMQRLTKYPLLLQSIGQNTEEPTEREKVELAAECCREILHHVNQAVRDMEDLLRLKDYQRRLDLSHLRQSSDPMLSEFKNLDITKKKLVHEGPLTWRVTKDKAVEVHVLLLDDLLLLLQRQDERLLLKSHSRTLTPTPDGKTMLRPVLRLTSAMTREVATDHKAFYVLFTWDQEAQIYELVAQTVSERKNWCALITETAGSLKVPAPASRPKPRPSPSSTREPLLSSSENGNGGRETSPADARTERILSDLLPFCRPGPEGQLAATALRKVLSLKQLLFPAEEDNGAGPPRDGDGVPGGGPLSPARTQEIQENLLSLEETMKQLEELEEEFCRLRPLLSQLGGNSVPQPGCT>sp|Q92888-2|ARHG1_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor 1 OS=Homo sapiens OX=9606 GN=ARHGEF1MEDFARGAASPGPSRPGLVPVSIIGAEDEDFENELETNSEEQNSQFQSLEQVKRRPAHLMALLQHVALQFEPGPLVLRVPVPPNVAFELDRTRADLISEDVQRRFVQEVVQSQQVAVGRQLEDFRSKRLMGMTPWEQELAQLEAWVGRDRASYEARERHVAERLLMHLEEMQHTISTDEEKSAAVVNAIGLYMRHLGVRTKSGDKKSGRNFFRKKVMGNRRSDEPAKTKKGLSSILDAARWNRGEPQVPDFRHLKAEVDAEKPGATDRKGGVGMPSRDRNIGAPGQDTPGVSLHPLSLDSPDREPGADAPLELGDSSPQGPMSLESLAPPESTDEGAETESPEPGDEGEPGRSGLELEPEEPPGWRELVPPDTLHSLPKSQVKRQEVISELLVTEAAHVRMLRVLHDLFFQPMAECLFFPLEELQNIFPSLDELIEVHSLFLDRLMKRRQESGYLIEEIGDVLLARFDGAEGSWFQKISSRFCSRQSFALEQLKAKQRKDPRFCAFVQEAESRPRCRRLQLKDMIPTEMQRLTKYPLLLQSIGQNTEEPTEREKVELAAECCREILHHVNQAVRDMEDLLRLKDYQRRLDLSHLRQSSDPMLSEFKNLDITKKKLVHEGPLTWRVTKDKAVEVHVLLLDDLLLLLQRQDERLLLKSHSRTLTPTPDGKTMLRPVLRLTSAMTREVATDHKAFYVLFTWDQEAQIYELVAQTVSERKNWCALITETAGSLKVPAPASRPKPRPSPSSTREPLLSSSENGNGGRETSPADARTERILSDLLPFCRPGPEGQLAATALRKVLSLKQLLFPAEEDNGAGPPRDGDGVPGGGPLSPARTQEIQENLLSLEETMKQLEELEEEFCRLRPLLSQLGGNSVPQPGCT>sp|Q92888-3|ARHG1_HUMAN Isoform 3 of Rho guanine nucleotide exchangefactor 1 OS=Homo sapiens OX=9606 GN=ARHGEF1MASLSTWSSPAEPREMEDFARGAASPGPSRPGLVPVSIIGAEDEDFENELETNSEEQNSQFQSLEQVKRRPAHLMALLQHVALQFEPGPLLCCLHADMLGSLGPKEAKKAFLDFYHSFLEKTAVLRVPVPPNVAFELDRTRADLISEDVQRRFVQEVVQSQQVAVGRQLEDFRSKRLMGMTPWEQELAQLEAWVGRDRASYEARERHVAERLLMHLEEMQHTISTDEEKSAAVVNAIGLYMRHLGVRTKSGDKKSGRNFFRKKVMGNRRSDEPAKTKKGLSSILDAARWNRGEPQVPDFRHLKAEVDAEKPGATDRKGGVGMPSRDRNIGAPGQDTPGVSLHPLSLDSPDREPGADAPLELGDSSPQGPMSLESLAPPESTDEGAETESPEPGDEGEPGRSGLELEPEEPPGWRELVPPDTLHSLPKSQVKRQEVISELLVTEAAHVRMLRVLHDLFFQPMAECLFFPLEELQNIFPSLDELIEVHSLFLDRLMKRRQESGYLIEEIGDVLLARFDGAEGSWFQKISSRFCSRQSFALEQLKAKQRKDPRFCAFVQEAESRPRCRRLQLKDMIPTEMQRLTKYPLLLQSIGQNTEEPTEREKVELAAECCREILHHVNQAVRDMEDLLRLKDYQRRLDLSHLRQSSDPMLSEFKNLDITKKKLVHEGPLTWRVTKDKAVEVHVLLLDDLLLLLQRQDERLLLKSHSRTLTPTPDGKTMLRPVLRLTSAMTREVATDHKAFYVLFTWDQEAQIYELVAQTVSERKNWCALITETAGSLKVPAPASRPKPRPSPSSTREPLLSSSENGNGGRETSPADARTERILSDLLPFCRPGPEGQLAATALRKVLSLKQLLFPAEEDNGAGPPRDGDGVPGGGPLSPARTQEIQENLLSLEETMKQLEELEEEFCRLRPLLSQLGGNSVPQPGCT>sp|Q92888-4|ARHG1_HUMAN Isoform 4 of Rho guanine nucleotide exchangefactor 1 OS=Homo sapiens OX=9606 GN=ARHGEF1MASLSTWSSPAEPREMEDFARGAASPGPSRPGLVPVSIIGAEDEDFENELETNSEEQNSQFQSLEQVKRRPAHLMALLQHVALQFEPGPLVLRVPVPPNVAFELDRTRADLISEDVQRRFVQEVVQSQQVAVGRQLEDFRSKRLMGMTPWEQELAQLEAWVGRDRASYEARERHVAERLLMHLEEMQHTISTDEEKSAAVVNAIGLYMRHLGVRTKSGDKKSGRNFFRKKVMGNRRSDEPAKTKKGLSSILDAARWNRGEPQVPDFRHLKAEVDAEKPGATDRKGGVGMPSRDRNIGAPGQDTPGVSLHPLSLDSPDREPGADAPLELGDSSPQGPMSLESLAPPESTDEGAETESPEPGDEGEPGRSGLELEPEEPPGWRELVPPDTLHSLPKSQVKRQEVISELLVTEAAHVRMLRVLHDLFFQPMAECLFFPLEELQNIFPSLDELIEVHSLFLDRLMKRRQESGYLIEEIGDVLLARFDGAEGSWFQKISSRFCSRQSFALEQLKAKQRKDPRFCAFVQEAESRPRCRRLQLKDMIPTEMQRLTKYPLLLQSIGQNTEEPTEREKVELAAECCREILHHVNQAVRDMEDLLRLKDYQRRLDLSHLRQSSDPMLSEFKNLDITKKKLVHEGPLTWRVTKDKAVEVHVLLLDDLLLLLQRQDERLLLKSHSRTLTPTPDGKTMLRPVLRLTSAMTREVATDHKAFYVLFTWDQEAQIYELVAQTVSERKNWCALITETAGSLKVPAPASRPKPRPSPSSTREPLLSSSENGNGGRETSPADARTERILSDLLPFCRPGPEGQLAATALRKGVGGGILPPETPPVSAWGELCPPAWLHLRFPPRKAFCKKERNGGEDVRDHPHPHSCRSISHPEGLRRGSCGPRLGGAQLGLLAPHEPRPSLPPALCLGDSGLHSGGHHGDPGHLSIACGGHPSTPTPKCLRSVFIP>sp|Q5H913|AR13A_HUMAN ADP-ribosylation factor-like protein 13A OS=Homosapiens OX=9606 GN=ARL13A PE=2 SV=2MFRLLSSCCSCLRTTEETRRNVTIPIIGLNNSGKTVLVEAFQKLLPSKTDHCMKSELTTLLLDEYELSIYDLNGDLKGREAWPNYYAQAHGLVFVLDSSDIRRMQEVKIILTHLLSDKRVAGKPILILANKQDKKKALMPCDIIDYLLLKKLVKENKCPCRVEPCSAIRNLERRNHQPIVEGLRWLLAVIDTCQLPPTSSISISKNNTGSGERCSSHSFSTRTGMSKEKRQHLEQCSIEAKPLKSILQKEGTRLWSKKNMSVTFALDEPMKEGECSRRMRAQNTTKLCYN>sp|Q5H913-2|AR13A_HUMAN Isoform 2 of ADP-ribosylation factor-likeprotein 13A OS=Homo sapiens OX=9606 GN=ARL13AMFRLLSSCCSCLRTTEETRRNVTIPIIGLNNSGKTVLVEAFQKLLPSKTDHCMKSELTTLLLDEYELSIYDLNGDLKGREAWPNYYAQAHGLVFVLDSSDIRRMQEVKIILTHLLSDKRVAGKPILILANKQDKKKALMPCDIIDYLLLKKLVKENKCPCRVEPCSAIRNLERRNHQPIVEGLRWLLAVIDTCQLPPTSSISISKNNTGSGERCSSHSFSTRTGMSKEKRQHLEQCSIEAKPLKSILQPSNQSYTH>sp|P50613|CDK7_HUMAN Cyclin-dependent kinase 7 OS=Homo sapiens OX=9606GN=CDK7 PE=1 SV=1MALDVKSRAKRYEKLDFLGEGQFATVYKARDKNTNQIVAIKKIKLGHRSEAKDGINRTALREIKLLQELSHPNIIGLLDAFGHKSNISLVFDFMETDLEVIIKDNSLVLTPSHIKAYMLMTLQGLEYLHQHWILHRDLKPNNLLLDENGVLKLADFGLAKSFGSPNRAYTHQVVTRWYRAPELLFGARMYGVGVDMWAVGCILAELLLRVPFLPGDSDLDQLTRIFETLGTPTEEQWPDMCSLPDYVTFKSFPGIPLHHIFSAAGDDLLDLIQGLFLFNPCARITATQALKMKYFSNRPGPTPGCQLPRPNCPVETLKEQSNPALAIKRKRTEALEQGGLPKKLIF>sp|P0DTE8|AMY1C_HUMAN Alpha-amylase 1C OS=Homo sapiens OX=9606 GN=AMY1CPE=1 SV=1MKLFWLLFTIGFCWAQYSSNTQQGRTSIVHLFEWRWVDIALECERYLAPKGFGGVQVSPPNENVAIHNPFRPWWERYQPVSYKLCTRSGNEDEFRNMVTRCNNVGVRIYVDAVINHMCGNAVSAGTSSTCGSYFNPGSRDFPAVPYSGWDFNDGKCKTGSGDIENYNDATQVRDCRLSGLLDLALGKDYVRSKIAEYMNHLIDIGVAGFRIDASKHMWPGDIKAILDKLHNLNSNWFPEGSKPFIYQEVIDLGGEPIKSSDYFGNGRVTEFKYGAKLGTVIRKWNGEKMSYLKNWGEGWGFMPSDRALVFVDNHDNQRGHGAGGASILTFWDARLYKMAVGFMLAHPYGFTRVMSSYRWPRYFENGKDVNDWVGPPNDNGVTKEVTINPDTTCGNDWVCEHRWRQIRNMVNFRNVVDGQPFTNWYDNGSNQVAFGRGNRGFIVFNNDDWTFSLTLQTGLPAGTYCDVISGDKINGNCTGIKIYVSDDGKAHFSISNSAEDPFIAIHAESKL>sp|P61604|CH10_HUMAN 10 kDa heat shock protein, mitochondrial OS=Homosapiens OX=9606 GN=HSPE1 PE=1 SV=2MAGQAFRKFLPLFDRVLVERSAAETVTKGGIMLPEKSQGKVLQATVVAVGSGSKGKGGEIQPVSVKVGDKVLLPEYGGTKVVLDDKDYFLFRDGDILGKYVD>sp|Q5ZPR3|CD276_HUMAN CD276 antigen OS=Homo sapiens OX=9606 GN=CD276PE=1 SV=1MLRRRGSPGMGVHVGAALGALWFCLTGALEVQVPEDPVVALVGTDATLCCSFSPEPGFSLAQLNLIWQLTDTKQLVHSFAEGQDQGSAYANRTALFPDLLAQGNASLRLQRVRVADEGSFTCFVSIRDFGSAAVSLQVAAPYSKPSMTLEPNKDLRPGDTVTITCSSYQGYPEAEVFWQDGQGVPLTGNVTTSQMANEQGLFDVHSILRVVLGANGTYSCLVRNPVLQQDAHSSVTITPQRSPTGAVEVQVPEDPVVALVGTDATLRCSFSPEPGFSLAQLNLIWQLTDTKQLVHSFTEGRDQGSAYANRTALFPDLLAQGNASLRLQRVRVADEGSFTCFVSIRDFGSAAVSLQVAAPYSKPSMTLEPNKDLRPGDTVTITCSSYRGYPEAEVFWQDGQGVPLTGNVTTSQMANEQGLFDVHSVLRVVLGANGTYSCLVRNPVLQQDAHGSVTITGQPMTFPPEALWVTVGLSVCLIALLVALAFVCWRKIKQSCEEENAGAEDQDGEGEGSKTALQPLKHSDSKEDDGQEIA>sp|Q5ZPR3-2|CD276_HUMAN Isoform 2 of CD276 antigen OS=Homo sapiensOX=9606 GN=CD276MLRRRGSPGMGVHVGAALGALWFCLTGALEVQVPEDPVVALVGTDATLCCSFSPEPGFSLAQLNLIWQLTDTKQLVHSFAEGQDQGSAYANRTALFPDLLAQGNASLRLQRVRVADEGSFTCFVSIRDFGSAAVSLQVAAPYSKPSMTLEPNKDLRPGDTVTITCSSYRGYPEAEVFWQDGQGVPLTGNVTTSQMANEQGLFDVHSVLRVVLGANGTYSCLVRNPVLQQDAHGSVTITGQPMTFPPEALWVTVGLSVCLIALLVALAFVCWRKIKQSCEEENAGAEDQDGEGEGSKTALQPLKHSDSKEDDGQEIA>sp|Q5ZPR3-3|CD276_HUMAN Isoform 3 of CD276 antigen OS=Homo sapiensOX=9606 GN=CD276MLRRRGSPGMGVHVGAALGALWFCLTGALEVQVPEDPVVALVGTDATLCCSFSPEPGFSLAQLNLIWQLTDTKQLVHSFAEGQDQGSAYANRTALFPDLLAQGNASLRLQRVRVADEGSFTCFVSIRDFGSAAVSLQVAAPYSKPSMTLEPNKDLRPGDTVTITCSSYQGYPEAEVFWQDGQGVPLTGNVTTSQMANEQGLFDVHSILRVVLGANGTYSCLVRNPVLQQDAHSSVTITPQRSPTGAVEVQVPEDPVVALVGTDATLRCSFSPEPGFSLAQLNLIWQLTDTKQLVHSFTEGRDQGSAYANRTALFPDLLAQGNASLRLQRVRVADEGSFTCFVSIRDFGSAAVSLQVAAPYSKPSMTLEPNKDLRPGDTVTITCSSYRGYPEAEVFWQDGQGVPLTGNVTTSQMANEQGLFDVHSVLRVVLGANGTYSCLVRNPVLQQDAHGSVTITGQPMTFPPGPASSAVPLSPAHPPHGSMCWSHWFSRGL>sp|Q5ZPR3-4|CD276_HUMAN Isoform 4 of CD276 antigen OS=Homo sapiensOX=9606 GN=CD276MLRRRGSPGMGVHVGAALGALWFCLTGALEVQVPEDPVVALVGTDATLCCSFSPEPGFSLAQLNLIWQLTDTKQLVHSFAEGQDQGSAYANRTALFPDLLAQGNASLRLQRVRVADEGSFTCFVSIRDFGSAAVSLQVAAPYSKPSMTLEPNKDLRPGDTVTITCSSYQGYPEAEVFWQDGQGVPLTGNVTTSQMANEQGLFDVHSILRVVLGANGTYSCLVRNPVLQQDAHSSVTITPQRSPTGAVEVQVPEDPVVALVGTDATLRCSFSPEPGFSLAQLNLIWQLTDTKQLVHSFTEGRDQGSAYANRTALFPDLLAQGNASLRLQRVRVADEGSFTCFVSIRDFGSAAVSLQVAAPYSKPSMTLEPNKDLRPGDTVTITCSSYRGYPEAEVFWQDGQGVPLTGNVTTSQMANEQGLFDVHSVLRVVLGANGTYSCLVRNPVLQQDAHGSVTITGQPMTFPPEALWVTVGLSVCLIALLVALAFVCWRKIKQSCEEENAGAEDQDGEGEGSKTALQPLKHSDSKEGKDTWA>sp|O75106|AOC2_HUMAN Retina-specific copper amine oxidase OS=Homosapiens OX=9606 GN=AOC2 PE=1 SV=2MHLKIVLAFLALSLITIFALAYVLLTSPGGSSQPPHCPSVSHRAQPWPHPGQSQLFADLSREELTAVMRFLTQRLGPGLVDAAQAQPSDNCIFSVELQLPPKAAALAHLDRGSPPPAREALAIVLFGGQPQPNVSELVVGPLPHPSYMRDVTVERHGGPLPYHRRPVLRAEFTQMWRHLKEVELPKAPIFLSSTFNYNGSTLAAVHATPRGLRSGDRATWMALYHNISGVGLFLHPVGLELLLDHRALDPAHWTVQQVFYLGHYYADLGQLEREFKSGRLEVVRVPLPPPNGASSLRSRNSPGPLPPLQFSPQGSQYSVQGNLVVSSLWSFTFGHGVFSGLRIFDVRFQGERIAYEVSVQECVSIYGADSPKTMLTRYLDSSFGLGRNSRGLVRGVDCPYQATMVDIHILVGKGAVQLLPGAVCVFEEAQGLPLRRHHNYLQNHFYGGLASSALVVRSVSSVGNYDYIWDFVLYPNGALEGRVHATGYINTAFLKGGEEGLLFGNRVGERVLGTVHTHAFHFKLDLDVAGLKNWVVAEDVVFKPVAAPWNPEHWLQRPQLTRQVLGKEDLTAFSLGSPLPRYLYLASNQTNAWGHQRGYRIQIHSPLGIHIPLESDMERALSWGRYQLVVTQRKEEESQSSSIYHQNDIWTPTVTFADFINNETLLGEDLVAWVTASFLHIPHAEDIPNTVTLGNRVGFLLRPYNFFDEDPSIFSPGSVYFEKGQDAGLCSINPVACLPDLAACVPDLPPFSYHGF>sp|O75106-2|AOC2_HUMAN Isoform 2 of Retina-specific copper amine oxidaseOS=Homo sapiens OX=9606 GN=AOC2MHLKIVLAFLALSLITIFALAYVLLTSPGGSSQPPHCPSVSHRAQPWPHPGQSQLFADLSREELTAVMRFLTQRLGPGLVDAAQAQPSDNCIFSVELQLPPKAAALAHLDRGSPPPAREALAIVLFGGQPQPNVSELVVGPLPHPSYMRDVTVERHGGPLPYHRRPVLRAEFTQMWRHLKEVELPKAPIFLSSTFNYNGSTLAAVHATPRGLRSGDRATWMALYHNISGVGLFLHPVGLELLLDHRALDPAHWTVQQVFYLGHYYADLGQLEREFKSGRLEVVRVPLPPPNGASSLRSRNSPGPLPPLQFSPQGSQYSVQGNLVVSSLWSFTFGHGVFSGLRIFDVRFQGERIAYEVSVQECVSIYGADSPKTMLTRYLDSSFGLGRNSRGLVRGVDCPYQATMVDIHILVGKGAVQLLPGAVCVFEEAQGLPLRRHHNYLQNHFYGGLASSALVVRSVSSVGNYDYIWDFVLYPNGALEGRVHATGYINTAFLKGGEEGLLFGNRVGERVLGTVHTHAFHFKLDLDVAGLKNWVVAEDVVFKPVAAPWNPEHWLQRPQLTRQVLGKEDLTAFSLGSPLPRYLYLASNQTNAWGHQRGYQLVVTQRKEEESQSSSIYHQNDIWTPTVTFADFINNETLLGEDLVAWVTASFLHIPHAEDIPNTVTLGNRVGFLLRPYNFFDEDPSIFSPGSVYFEKGQDAGLCSINPVACLPDLAACVPDLPPFSYHGF>sp|O95170|CDRT1_HUMAN CMT1A duplicated region transcript 1 proteinOS=Homo sapiens OX=9606 GN=CDRT1 PE=2 SV=3MENLESRLKNAPYFRCEKGTDSIPLCRKCETRVLAWKIFSTKEWFCRINDISQRRFLVGILKQLNSLYLLHYFQNILQTTQGKDFIYNRSRIDLSKKEGKVVKSSLNQMLDKTVEQKMKEILYWFANSTQWTKANYTLLLLQMCNPKLLLTAANVIRVLFLREENNISGLNQDITDVCFSPEKDHSSKSATSQVYWTAKTQHTSLPLSKAPENEHFLGAASNPEEPWRNSLRCISEMNRLFSGKADITKPGYDPCNLLVDLDDIRDLSSGFSKYRDFIRYLPIHLSKYILRMLDRHTLNKCASVSQHWAAMAQQVKMDLSAHGFIQNQITFLQGSYTRGIDPNYANKVSIPVPKMVDDGKSMRVKHPKWKLRTKNEYNLWTAYQNEETQQVLMEERNVFCGTYNVRILSDTWDQNRVIHYSGGDLIAVSSNRKIHLLDIIQVKAIPVEFRGHAGSVRALFLCEEENFLLSGSYDLSIRYWDLKSGVCTRIFGGHQGTITCMDLCKNRLVSGGRDCQVKVWDVDTGKCLKTFRHKDPILATRINDTYIVSSCERGLVKVWHIAMAQLVKTLSGHEGAVKCLFFDQWHLLSGSTDGLVMAWSMVGKYERCLMAFKHPKEVLDVSLLFLRVISACADGKIRIYNFFNGNCMKVIKANGRGDPVLSFFIQGNRISVCHISTFAKRINVGWNGIEPSATAQGGNASLTECAHVRLHIAGHLPASRLPVAAVQPMTGGMAPTTAPTHVLAMLILFSGV>sp|O95170-2|CDRT1_HUMAN Isoform 2 of CMT1A duplicated region transcript1 protein OS=Homo sapiens OX=9606 GN=CDRT1MDLCKNRLVSGGRDCQVKVWDVDTGKCLKTFRHKDPILATRINDTYIVSSCERGLVKVWHIAMAQLVKTLSGHEGAVKCLFFDQWHLLSGSTDGLVMAWSMVGKYERCLMAFKHPKEVLDVSLLFLRVISACADGKIRIYNFFNGNCMKVIKANGRGDPVLSFFIQGNRISVCHISTFAKRINVGWNGIEPSATAQGGNASLTECAHVRLHIAGHLPASRLPVAAVQPMTGGMAPTTAPTHVLAMLILFSGV>sp|P53680|AP2S1_HUMAN AP-2 complex subunit sigma OS=Homo sapiens OX=9606GN=AP2S1 PE=1 SV=2MIRFILIQNRAGKTRLAKWYMQFDDDEKQKLIEEVHAVVTVRDAKHTNFVEFRNFKIIYRRYAGLYFCICVDVNDNNLAYLEAIHNFVEVLNEYFHNVCELDLVFNFYKVYTVVDEMFLAGEIRETSQTKVLKQLLMLQSLE>sp|P53680-2|AP2S1_HUMAN Isoform 2 of AP-2 complex subunit sigma OS=Homosapiens OX=9606 GN=AP2S1MIRFILIQNRAGKTRLAKWYMQFDDDEKQKLIEEVHAVVTVRDAKHTNFVEVLNEYFHNVCELDLVFNFYKVYTVVDEMFLAGEIRETSQTKVLKQLLMLQSLE>sp|O95674|CDS2_HUMAN Phosphatidate cytidylyltransferase 2 OS=Homosapiens OX=9606 GN=CDS2 PE=1 SV=1MTELRQRVAHEPVAPPEDKESESEAKVDGETASDSESRAESAPLPVSADDTPEVLNRALSNLSSRWKNWWVRGILTLAMIAFFFIIIYLGPMVLMIIVMCVQIKCFHEIITIGYNVYHSYDLPWFRTLSWYFLLCVNYFFYGETVTDYFFTLVQREEPLRILSKYHRFISFTLYLIGFCMFVLSLVKKHYRLQFYMFGWTHVTLLIVVTQSHLVIHNLFEGMIWFIVPISCVICNDIMAYMFGFFFGRTPLIKLSPKKTWEGFIGGFFATVVFGLLLSYVMSGYRCFVCPVEYNNDTNSFTVDCEPSDLFRLQEYNIPGVIQSVIGWKTVRMYPFQIHSIALSTFASLIGPFGGFFASGFKRAFKIKDFANTIPGHGGIMDRFDCQYLMATFVNVYIASFIRGPNPSKLIQQFLTLRPDQQLHIFNTLRSHLIDKGMLTSTTEDE>sp|O95674-2|CDS2_HUMAN Isoform 2 of Phosphatidate cytidylyltransferase 2OS=Homo sapiens OX=9606 GN=CDS2MSRLRHPRTRWKNWWVRGILTLAMIAFFFIIIYLGPMVLMIIVMCVQIKCFHEIITIGYNVYHSYDLPWFRTLSWYFLLCVNYFFYGETVTDYFFTLVQREEPLRILSKYHRFISFTLYLIGFCMFVLSLVKKHYRLQFYMFGWTHVTLLIVVTQSHLVIHNLFEGMIWFIVPISCVICNDIMAYMFGFFFGRTPLIKLSPKKTWEGFIGGFFATVVFGLLLSYVMSGYRCFVCPVEYNNDTNSFTVDCE>sp|Q8IU89|CERS3_HUMAN Ceramide synthase 3 OS=Homo sapiens OX=9606GN=CERS3 PE=1 SV=2MFWTFKEWFWLERFWLPPTIKWSDLEDHDGLVFVKPSHLYVTIPYAFLLLIIRRVFEKFVASPLAKSFGIKETVRKVTPNTVLENFFKHSTRQPLQTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAFYLMITVAGIAFLYDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSGTLVMIVHDVADIWLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYYILKMLNRCIFMKSIQDVRSDDEDYEEEEEEEEEEATKGKEMDCLKNGLRAERHLIPNGQHGH>sp|P20138|CD33_HUMAN Myeloid cell surface antigen CD33 OS=Homo sapiensOX=9606 GN=CD33 PE=1 SV=2MPLLLLLPLLWAGALAMDPNFWLQVQESVTVQEGLCVLVPCTFFHPIPYYDKNSPVHGYWFREGAIISRDSPVATNKLDQEVQEETQGRFRLLGDPSRNNCSLSIVDARRRDNGSYFFRMERGSTKYSYKSPQLSVHVTDLTHRPKILIPGTLEPGHSKNLTCSVSWACEQGTPPIFSWLSAAPTSLGPRTTHSSVLIITPRPQDHGTNLTCQVKFAGAGVTTERTIQLNVTYVPQNPTTGIFPGDGSGKQETRAGVVHGAIGGAGVTALLALCLCLIFFIVKTHRRKAARTAVGRNDTHPTTGSASPKHQKKSKLHGPTETSSCSGAAPTVEMDEELHYASLNFHGMNPSKDTSTEYSEVRTQ>sp|P20138-2|CD33_HUMAN Isoform 3 of Myeloid cell surface antigen CD33OS=Homo sapiens OX=9606 GN=CD33MPLLLLLPLLWAGALAMDPNFWLQVQESVTVQEGLCVLVPCTFFHPIPYYDKNSPVHGYWFREGAIISRDSPVATNKLDQEVQEETQGRFRLLGDPSRNNCSLSIVDARRRDNGSYFFRMERGSTKYSYKSPQLSVHVTDLTHRPKILIPGTLEPGHSKNLTCSVSWACEQGTPPIFSWLSAAPTSLGPRTTHSSVLIITPRPQDHGTNLTCQVKFAGAGVTTERTIQLNVTYVPQNPTTGIFPGDGSGKQETRAGVVHGAIGGAGVTALLALCLCLIFFIVKTHRRKAARTAVGRNDTHPTTGSASPVR>sp|P20138-3|CD33_HUMAN Isoform CD33m of Myeloid cell surface antigenCD33 OS=Homo sapiens OX=9606 GN=CD33MPLLLLLPLLWADLTHRPKILIPGTLEPGHSKNLTCSVSWACEQGTPPIFSWLSAAPTSLGPRTTHSSVLIITPRPQDHGTNLTCQVKFAGAGVTTERTIQLNVTYVPQNPTTGIFPGDGSGKQETRAGVVHGAIGGAGVTALLALCLCLIFFIVKTHRRKAARTAVGRNDTHPTTGSASPKHQKKSKLHGPTETSSCSGAAPTVEMDEELHYASLNFHGMNPSKDTSTEYSEVRTQ>sp|Q86W34|AMZ2_HUMAN Archaemetzincin-2 OS=Homo sapiens OX=9606 GN=AMZ2PE=2 SV=2MQIIRHSEQTLKTALISKNPVLVSQYEKLNAGEQRLMNEAFQPASDLFGPITLHSPSDWITSHPEAPQDFEQFFSDPYRKTPSPNKRSIYIQSIGSLGNTRIISEEYIKWLTGYCKAYFYGLRVKLLEPVPVSVTRCSFRVNENTHNLQIHAGDILKFLKKKKPEDAFCVVGITMIDLYPRDSWNFVFGQASLTDGVGIFSFARYGSDFYSMHYKGKVKKLKKTSSSDYSIFDNYYIPEITSVLLLRSCKTLTHEIGHIFGLRHCQWLACLMQGSNHLEEADRRPLNLCPICLHKLQCAVGFSIVERYKALVRWIDDESSDTPGATPEHSHEDNGNLPKPVEAFKEWKEWIIKCLAVLQK>sp|Q86W34-5|AMZ2_HUMAN Isoform 2 of Archaemetzincin-2 OS=Homo sapiensOX=9606 GN=AMZ2MQIIRHSEQTLKTALISKNPVLVSQYEKLNAGEQRLMNEAFQPASDLFGPITLHSPSDWITSHPEAPQDFEQFFSDPYRKTPSPNKRSIYIQSIGDILKFLKKKKPEDAFCVVGITMIDLYPRDSWNFVFGQASLTDGVGIFSFARYGSDFYSMHYKGKVKKLKKTSSSDYSIFDNYYIPEITSVLLLRSCKTLTHEIGHIFGLRHCQWLACLMQGSNHLEEADRRPLNLCPICLHKLQCAVGFSIVERYKALVRWIDDESSDTPGATPEHSHEDNGNLPKPVEAFKEWKEWIIKCLAVLQK>sp|P30533|AMRP_HUMAN Alpha-2-macroglobulin receptor-associated proteinOS=Homo sapiens OX=9606 GN=LRPAP1 PE=1 SV=1MAPRRVRSFLRGLPALLLLLLFLGPWPAASHGGKYSREKNQPKPSPKRESGEEFRMEKLNQLWEKAQRLHLPPVRLAELHADLKIQERDELAWKKLKLDGLDEDGEKEARLIRNLNVILAKYGLDGKKDARQVTSNSLSGTQEDGLDDPRLEKLWHKAKTSGKFSGEELDKLWREFLHHKEKVHEYNVLLETLSRTEEIHENVISPSDLSDIKGSVLHSRHTELKEKLRSINQGLDRLRRVSHQGYSTEAEFEEPRVIDLWDLAQSANLTDKELEAFREELKHFEAKIEKHNHYQKQLEIAHEKLRHAESVGDGERVSRSREKHALLEGRTKELGYTVKKHLQDLSGRISRARHNEL>sp|Q8IVF6|AN18A_HUMAN Ankyrin repeat domain-containing protein 18AOS=Homo sapiens OX=9606 GN=ANKRD18A PE=2 SV=3MRKLFSFGRRLGQALLSSMDQEYAGPGYDIRDWELRKIHRAAIKGDAAEVERCLTRRFRDLDARDRKDRTVLHLACAHGRVQVVTLLLHRRCQIDICDRLNRTPLMKAVHSQEEACAIVLLECGANPNIEDIYGNTALHYAVYNKGTSLAERLLSHHANIEALNKEGNTPLLFAINSRRQHMVEFLLKNQANIHAVDNFKRTALILAVQHNLSSIVTLLLQQNIRISSQDMFGQTAEDYALCSDLRSIRQQILEHKNKMLKNHLRNDNQETAAMKPANLKKRKERAKAEHNLKVASEEKQERLQRSENKQPQDSQSYGKKKDAMYGNFMLKKDIAMLKEELYAIKNDSLRKEKKYIQEIKSITEINANFEKSVRLNEKMITKTVARYSQQLNDLKAENARLNSELEKEKHNKERLEAEVESLHSSLATAINEYNEIVERKDLELVLWRADDVSRHEKMGSNISQLTDKNELLTEQVHKARVKFNTLKGKLRETRDALREKTLALGSVQLDLRQAQHRIKEMKQMHPNGEAKESQSIGKQNSLEERIRQQELENLLLERQLEDARKEGDNKEIVINIHRDCLENGKEDLLEERNKELMKEYNYLKEKLLQCEKEKAEREVIVREFQEELVDHLKTFSISESPLEGTSHCHINLNETWTSKKKLFQVEIQPEEKHEEFRKLFELISLLNYTADQIRKKNRELEEEATGYKKCLEMTINMLNAFANEDFSCHGDLNTDQLKMDILFKKLKQKFNDLVAEKEAVSSECVNLAKDNEVLHQELLSMRNVQEKCEKLEKDKKMLEEEVLNLKTHMEKDMVELGKLQEYKSELDERAVQEIEKLEEIHLQKQAEYEKQLEQLNKDNTASLKKKELTLKDVECKFSKMKTAYEEVTTELEEFKEAFAGAVKANNSMSKKLMKSDKKIAVISTKLFTEKQRMKYFLSTLPTRPEPELPCVENLNSIELNRKYIPKTAIRIPTSNPQTSNNCKNFLTEVLLC>sp|Q8IVF6-2|AN18A_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 18A OS=Homo sapiens OX=9606 GN=ANKRD18AMKTAYEEVTTELEEFKEAFAGAVKANNSMSKKLMKSDKKIAVISTKLFTEKQRMKYFLSTLPTRPEPELPCVENLNSIELNRKYIPKTAIRIPTSNPQTSNNCKNFLTEMELDRVEQIITGTKKSFAMLSTCSRLLSFVESTAPRKHRRALPIMRSLVPNRRTTVASTESRTNRPGGVRSPGLQLEGTSTLQWEQGPIAHPRHRC>sp|P50583|AP4A_HUMAN Bis(5'-nucleosyl)-tetraphosphatase [asymmetrical]OS=Homo sapiens OX=9606 GN=NUDT2 PE=1 SV=3MALRACGLIIFRRCLIPKVDNNAIEFLLLQASDGIHHWTPPKGHVEPGEDDLETALRETQEEAGIEAGQLTIIEGFKRELNYVARNKPKTVIYWLAEVKDYDVEIRLSHEHQAYRWLGLEEACQLAQFKEMKAALQEGHQFLCSIEA>sp|A2A2Z9|AN18B_HUMAN Ankyrin repeat domain-containing protein 18BOS=Homo sapiens OX=9606 GN=ANKRD18B PE=1 SV=1MRKLLSFGRRLGQALLSSMDQEYAGRGYHIRDWELRKIHRAAIKGDAAEVEHCLTRRFRDLDVRDRKDRTVLHLACAHGRVQVVTLLLDRKCQINICDRLNRTPLMKAVHCQEEACAIILLKRGANPNIKDIYGNTALHYAVYNEGTSLAERLLSHHANIEALNKEGNTPLLFAINSRRQHMVEFLLKNQANIHAVDNFKRTALILAVQHNLSSIVTLLLQQNIHISSQDMFGQTAEDYAFCCDLRSIQQQILEHKNKMLKNHLRNDNQETAAMKPENLKKRKKRKKLKKRKEGAKAEHNLKVASEEKQERLERSENKQPQDSQSYGKKKDEMFGNFMLKRDIAMLKEELYAIKNDSLRKEKKYIQEIKSITEINANFEKSVRLNEEMITKKVAQYSQQLNDLKAENARLNSKLEKEKHNKERLEAEVESLHSNLATAINEYNEILERKDLELVLWRADDVSRHETMGSNISQLTDKNELLTEQVHKARVKFNTLKGKLRETRDALREKTLALESVQLDLKQAQHRIKEMKQMHPNGEAKESQSIGKQNSSEERIRQRELENLLLERQLEDARKEGDNKEIVINIHRDCLENGKEDLLEERNKELMNEYNYLKEKLLQYEKEKAEREVIVREFQEELVDHLKKFSMSESPLEGTSHCHINLDETWTSKKKLFQVEIQPEEKHEEFRKVFELISLLNYTADQIRKKNRELEEEATGYKKCLEMTINMLNAFANEDFSCHGDLNTDQLKMDILFKKLKQKFDDLMAEKEAVSSKCVNLAKDNEVLHQELLSMGKVQEKCEKLEKDKKMLEEKVLNLKTHMEKDMVELGKVQEYKSELDERAMQAIEKLEEIHLQKQAEYEKQLEQLNKDNTASLKKKELTLKDVECKFSKMKTAYEDVTTELEEYKEAFAVALKANSSMSEKITKSDKKIAVISTKLFMEKERMEYFLSTLPMRPDPELPCVENLNSIELNRKYIPKMAIRIPTSNPQTSNNCKNSLTELLLRWALAPIYFLL>sp|O43747|AP1G1_HUMAN AP-1 complex subunit gamma-1 OS=Homo sapiensOX=9606 GN=AP1G1 PE=1 SV=5MPAPIRLRELIRTIRTARTQAEEREMIQKECAAIRSSFREEDNTYRCRNVAKLLYMHMLGYPAHFGQLECLKLIASQKFTDKRIGYLGAMLLLDERQDVHLLMTNCIKNDLNHSTQFVQGLALCTLGCMGSSEMCRDLAGEVEKLLKTSNSYLRKKAALCAVHVIRKVPELMEMFLPATKNLLNEKNHGVLHTSVVLLTEMCERSPDMLAHFRKLVPQLVRILKNLIMSGYSPEHDVSGISDPFLQVRILRLLRILGRNDDDSSEAMNDILAQVATNTETSKNVGNAILYETVLTIMDIKSESGLRVLAINILGRFLLNNDKNIRYVALTSLLKTVQTDHNAVQRHRSTIVDCLKDLDVSIKRRAMELSFALVNGNNIRGMMKELLYFLDSCEPEFKADCASGIFLAAEKYAPSKRWHIDTIMRVLTTAGSYVRDDAVPNLIQLITNSVEMHAYTVQRLYKAILGDYSQQPLVQVAAWCIGEYGDLLVSGQCEEEEPIQVTEDEVLDILESVLISNMSTSVTRGYALTAIMKLSTRFTCTVNRIKKVVSIYGSSIDVELQQRAVEYNALFKKYDHMRSALLERMPVMEKVTTNGPTEIVQTNGETEPAPLETKPPPSGPQPTSQANDLLDLLGGNDITPVIPTAPTSKPSSAGGELLDLLGDINLTGAPAAAPAPASVPQISQPPFLLDGLSSQPLFNDIAAGIPSITAYSKNGLKIEFTFERSNTNPSVTVITIQASNSTELDMTDFVFQAAVPKTFQLQLLSPSSSIVPAFNTGTITQVIKVLNPQKQQLRMRIKLTYNHKGSAMQDLAEVNNFPPQSWQ>sp|O43747-2|AP1G1_HUMAN Isoform 2 of AP-1 complex subunit gamma-1OS=Homo sapiens OX=9606 GN=AP1G1MPAPIRLRELIRTIRTARTQAEEREMIQKECAAIRSSFREEDNTYRCRNVAKLLYMHMLGYPAHFGQLECLKLIASQKFTDKRIGYLGAMLLLDERQDVHLLMTNCIKNDLNHSTQFVQGLALCTLGCMGSSEMCRDLAGEVEKLLKTSNSYLRKKAALCAVHVIRKVPELMEMFLPATKNLLNEKNHGVLHTSVVLLTEMCERSPDMLAHFRKNEKLVPQLVRILKNLIMSGYSPEHDVSGISDPFLQVRILRLLRILGRNDDDSSEAMNDILAQVATNTETSKNVGNAILYETVLTIMDIKSESGLRVLAINILGRFLLNNDKNIRYVALTSLLKTVQTDHNAVQRHRSTIVDCLKDLDVSIKRRAMELSFALVNGNNIRGMMKELLYFLDSCEPEFKADCASGIFLAAEKYAPSKRWHIDTIMRVLTTAGSYVRDDAVPNLIQLITNSVEMHAYTVQRLYKAILGDYSQQPLVQVAAWCIGEYGDLLVSGQCEEEEPIQVTEDEVLDILESVLISNMSTSVTRGYALTAIMKLSTRFTCTVNRIKKVVSIYGSSIDVELQQRAVEYNALFKKYDHMRSALLERMPVMEKVTTNGPTEIVQTNGETEPAPLETKPPPSGPQPTSQANDLLDLLGGNDITPVIPTAPTSKPSSAGGELLDLLGDINLTGAPAAAPAPASVPQISQPPFLLDGLSSQPLFNDIAAGIPSITAYSKNGLKIEFTFERSNTNPSVTVITIQASNSTELDMTDFVFQAAVPKTFQLQLLSPSSSIVPAFNTGTITQVIKVLNPQKQQLRMRIKLTYNHKGSAMQDLAEVNNFPPQSWQ>sp|D6REC4|CFA99_HUMAN Cilia- and flagella-associated protein 99 OS=Homosapiens OX=9606 GN=CFAP99 PE=3 SV=1MPRSCRERVQGSKQQLRLQFPPRIRKTPKLTFYRPDNILVKLNTTAILREGALYQRQVEQELQRVDKLVDGAGDFSEFFEWQKKMQAKDREEQLAASECRRLQGKLSHEEAVLARQSLMQENKQRVEQQKEQMAKLMLQRAERRLREDRSRKELVEQVIEGQKNAKAAQTKLAKGRQQTVQEAIEESRGLLQRRAQAAQEEQRRRCELISQLRALETQPTRKGKLVDLTQIPGYGLEGEMSIVELRERLALLKENQRRKEEEKRDQIIQGKHTKSQELQNMVEQISLCRAAMGRSAALRWEEKKALAAAPAAPSQDERVQQLRRRISERAAERSRQAALLHVSAPRTARPKPRVSPDWWEEPGRLKAGAGWGWRARRAGTGVPGRGWRGDRVRSAAGRYAAAGAGGGGGVPARADAFPGLQAQLEAQHWLELERSRERRLQALQQGGSGPGPARRLEAA>sp|Q15744|CEBPE_HUMAN CCAAT/enhancer-binding protein epsilon OS=Homosapiens OX=9606 GN=CEBPE PE=1 SV=2MSHGTYYECEPRGGQQPLEFSGGRAGPGELGDMCEHEASIDLSAYIESGEEQLLSDLFAVKPAPEARGLKGPGTPAFPHYLPPDPRPFAYPPHTFGPDRKALGPGIYSSPGSYDPRAVAVKEEPRGPEGSRAASRGSYNPLQYQVAHCGQTAMHLPPTLAAPGQPLRVLKAPLATAAPPCSPLLKAPSPAGPLHKGKKAVNKDSLEYRLRRERNNIAVRKSRDKAKRRILETQQKVLEYMAENERLRSRVEQLTQELDTLRNLFRQIPEAANLIKGVGGCS>sp|Q9Y587|AP4S1_HUMAN AP-4 complex subunit sigma-1 OS=Homo sapiensOX=9606 GN=AP4S1 PE=1 SV=1MIKFFLMVNKQGQTRLSKYYEHVDINKRTLLETEVIKSCLSRSNEQCSFIEYKDFKLIYRQYAALFIVVGVNDTENEMAIYEFIHNFVEVLDEYFSRVSELDIMFNLDKVHIILDEMVLNGCIVETNRARILAPLLILDKMSES>sp|Q9Y587-2|AP4S1_HUMAN Isoform 2 of AP-4 complex subunit sigma-1OS=Homo sapiens OX=9606 GN=AP4S1MIKFFLMVNKQGQTRLSKYYEHVDINKRTLLETEVIKSCLSRSNEQCSFIEYKDFKLIYRQYAALFIVVGVNDTENEMAIYEFIHNFVEVLDEYFSRVSELDVSFFNTVFHSTWQMHSGPYQEPIDELPKICSALEPQQTCFSPDSSSFKGAASTTPIY>sp|Q9Y587-3|AP4S1_HUMAN Isoform 3 of AP-4 complex subunit sigma-1OS=Homo sapiens OX=9606 GN=AP4S1MIKFFLMVNKQGQTRLSKYYEHVDINKRTLLETEVIKSCLSRSNEQCSFIEYKDFKLIYRQYAALFIVVGVNDTENEMAIYEFIHNFVEVLDEYFSRVEPIDELPKICSALEPQQTCFSPDSSSFKGAASTTPIY>sp|Q9Y587-4|AP4S1_HUMAN Isoform 4 of AP-4 complex subunit sigma-1OS=Homo sapiens OX=9606 GN=AP4S1MIKFFLMVNKQGQTRLSKYYEHVDINKRTLLETEVIKSCLSRSNEQCSFIEYKDFKLIYRQYAALFIVVGVNDTENEMAIYEFIHNFVEVLDEYFSRVSELDVSFFNTVFHSTWQMHSGPYQTRSCSVTQAGVQRCDHGSLHPGSPGLK>sp|Q8IXF9|AQ12A_HUMAN Aquaporin-12A OS=Homo sapiens OX=9606 GN=AQP12APE=2 SV=1MAGLNVSLSFFFATFALCEAARRASKALLPVGAYEVFAREAMRTLVELGPWAGDFGPDLLLTLLFLLFLAHGVTLDGASANPTVSLQEFLMAEQSLPGTLLKLAAQGLGMQAACTLMRLCWAWELSDLHLLQSLMAQSCSSALRTSVPHGALVEAACAFCFHLTLLHLRHSPPAYSGPAVALLVTVTAYTAGPFTSAFFNPALAASVTFACSGHTLLEYVQVYWLGPLTGMVLAVLLHQGRLPHLFQRNLFYGQKNKYRAPRGKPAPASGDTQTPAKGSSVREPGRSGVEGPHSS>sp|O43423|AN32C_HUMAN Acidic leucine-rich nuclear phosphoprotein 32family member C OS=Homo sapiens OX=9606 GN=ANP32C PE=2 SV=1MEMGRRIHSELRNRAPSDVKELALDNSRSNEGKLEALTDEFEELEFLSKINGGLTSISDLPKLKLRKLELRVSGGLEVLAEKCPNLTHLYLSGNKIKDLSTIEPLKQLENLKSLDLFNCEVTNLNDYGENVFKLLLQLTYLDSCYWDHKEAPYSDIEDHVEGLDDEEEGEHEEEYDEDAQVVEDEEGEEEEEEGEEEDVSGGDEEDEEGYNDGEVDGEEDEEELGEEERGQKRK>sp|O95626|AN32D_HUMAN Acidic leucine-rich nuclear phosphoprotein 32family member D OS=Homo sapiens OX=9606 GN=ANP32D PE=2 SV=2MEMGKWIHLELRNRTPSDVKELFLDNSQSNEGKLEGLTDEFEELELLNTINIGLTSIANLPKLNKLKKLELSSNRASVGLEVLAEKCPNLIHLNLSGNKIKDLSTIEPLKKLENLESLDLFTCEVTNLNNY>sp|P00751|CFAB_HUMAN Complement factor B OS=Homo sapiens OX=9606 GN=CFBPE=1 SV=2MGSNLSPQLCLMPFILGLLSGGVTTTPWSLARPQGSCSLEGVEIKGGSFRLLQEGQALEYVCPSGFYPYPVQTRTCRSTGSWSTLKTQDQKTVRKAECRAIHCPRPHDFENGEYWPRSPYYNVSDEISFHCYDGYTLRGSANRTCQVNGRWSGQTAICDNGAGYCSNPGIPIGTRKVGSQYRLEDSVTYHCSRGLTLRGSQRRTCQEGGSWSGTEPSCQDSFMYDTPQEVAEAFLSSLTETIEGVDAEDGHGPGEQQKRKIVLDPSGSMNIYLVLDGSDSIGASNFTGAKKCLVNLIEKVASYGVKPRYGLVTYATYPKIWVKVSEADSSNADWVTKQLNEINYEDHKLKSGTNTKKALQAVYSMMSWPDDVPPEGWNRTRHVIILMTDGLHNMGGDPITVIDEIRDLLYIGKDRKNPREDYLDVYVFGVGPLVNQVNINALASKKDNEQHVFKVKDMENLEDVFYQMIDESQSLSLCGMVWEHRKGTDYHKQPWQAKISVIRPSKGHESCMGAVVSEYFVLTAAHCFTVDDKEHSIKVSVGGEKRDLEIEVVLFHPNYNINGKKEAGIPEFYDYDVALIKLKNKLKYGQTIRPICLPCTEGTTRALRLPPTTTCQQQKEELLPAQDIKALFVSEEEKKLTRKEVYIKNGDKKGSCERDAQYAPGYDKVKDISEVVTPRFLCTGGVSPYADPNTCRGDSGGPLIVHKRSRFIQVGVISWGVVDVCKNQKRQKQVPAHARDFHINLFQVLPWLKEKLQDEDLGFL>sp|P00751-2|CFAB_HUMAN Isoform 2 of Complement factor B OS=Homo sapiensOX=9606 GN=CFBMGSNLSPQLCLMPFILGLLSGGVTTTPWSLARPQGSCSLEGVEIKGGSFRLLQEGQALEYVCPSGFYPYPVQTRTCRSTGSWSTLKTQDQKTVRKAECRAIHCPRPHDFENGEYWPRSPYYNVSDEISFHCYDGYTLRGSANRTCQVNGRWSGQTAICDNGAGYCSNPGIPIGTRKVGSQYRLEDSVTYHCSRGLTLRGSQRRTCQEGGSWSGTEPSCQDSFMYDTPQEVAEAFLSSLTETIEGVDAEDGHGPGEQQKRKIVLDPSGSMNIYLVLDGSDSIGASNFTGAKKCLVNLIEKVASYGVKPRYGLVTYATYPKIWVKVSEADSSNADWVTKQLNEINYEDHKLKSGTNTKKALQAVYSMMSWPDDVPPEGWNRTRHVIILMTDGLHNMGGDPITVIDEIRDLLYIGKDRKNPREDYLDVYVFGVGPLVNQVNINALASKKDNEQHVFKVKDMENLEDVFYQMIDESQSLSLCGMVWEHRKGTDYHKQPWQAKISVIRPSKGHESCMGAVVSEYFVLTAAHCFTVDDKEHSIKVSVGKDATEGPGLHLCSPGNTSHFLQILHSTHPQCSPIPCTPDQSGMGEDVKLGMTRGQRQEAAHKEVVPTLLLQEGRSGTWR>sp|Q5CZ79|AN20B_HUMAN Ankyrin repeat domain-containing protein 20BOS=Homo sapiens OX=9606 GN=ANKRD20A8P PE=2 SV=2MKLFGFGSRRGQTAEGSIDHVYTGSGYRIRDSELQKIHRAAVKGDAAEVERCLARRSGDLDARDKQHRTALHLACASGHVQVVTLLVNRKCQIDICDKENRTPLIQAVHCQEEACAVILLKHGANPNLKDIYGNTALHYAVYSESTSLAEKLLSHGAHIEALDKDSNTPLLFAIICKKEKMVEFLLKKKASTHAVDRLRRSALMLAVYYDSPGIVSILLKQNIDVFAQDMCGRDAEDYAISHHLTKIQQQILEHKQKILKKEKSDVGSSDESAVSIFHELRVDSLPASDDKDLSVATKQCVPEKVSEPLPGPSHEKGNRIVNGQGEGPPAKHPSLKPTTGVEDPAVKGAVQRKNVQTLRAEQALPVASEEEQERHERSEKKQPQVKKGNNTNKSEKIQLSENICDSTSSAAAGRLTQQRKIGKTYPQQFPKKLKEEHDKCTLKQENEEKTNVNMLYKKNREELERKEKQYKKEVEAKQLEPTVQSLEMKSKTARNTPNRDFHNHEETKGLMDENCILKADIAILRQEICTMKNDNLEKENKYLKDIKIVKETNAALEKYIKLNEEMITETAFRYQQELNDLKAENTRLNAELLKEKESKKRLEADIESYQSRLAAAIGKHSESVKTERNVKLALERTQDVSVQVEMSSAISKVKDENEFLTEQLSETQIKFNALKDKFRKTRDSLRKKSLALETVQNDLRKTQQQTQEMKEMYQNAEAKVNNSTGKWNCVEERICHLQRENAWLVQQLDDVHQKEDHKEIVTNIQRGFIESGKKDLVLEEKSKKLMNECDHLKESLFQYEREKAEGVVSIKEDKYFQTSRKKI>sp|Q5CZ79-2|AN20B_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 20B OS=Homo sapiens OX=9606 GN=ANKRD20A8PMNFKINVFICRCTLKQENEEKTNVNMLYKKNREELERKEKQYKKEVEAKQLEPTVQSLEMKSKTARNTPNRDFHNHEETKGLMDENCILKADIAILRQEICTMKNDNLEKENKYLKDIKIVKETNAALEKYIKLNEEMITETAFRYQQELNDLKAENTRLNAELLKEKESKKRLEADIESYQSRLAAAIGKHSESVKTERNVKLALERTQDVSVQVEMSSAISKVKDENEFLTEQLSETQIKFNALKDKFRKTRDSLRKKSLALETVQNDLRKTQQQTQEMKEMYQNAEAKVNNSTGKWNCVEERICHLQRENAWLVQQLDDVHQKEDHKEIVTNIQRGFIESGKKDLVLEEKSKKLMNECDHLKESLFQYEREKAEGVVSIKEDKYFQTSRKKI>sp|Q03701|CEBPZ_HUMAN CCAAT/enhancer-binding protein zeta OS=Homosapiens OX=9606 GN=CEBPZ PE=1 SV=3MAAVKEPLEFHAKRPWRPEEAVEDPDEEDEDNTSEAENGFSLEEVLRLGGTKQDYLMLATLDENEEVIDGGKKGAIDDLQQGELEAFIQNLNLAKYTKASLVEEDEPAEKENSSKKEVKIPKINNKNTAESQRTSVNKVKNKNRPEPHSDENGSTTPKVKKDKQNIFEFFERQTLLLRPGGKWYDLEYSNEYSLKPQPQDVVSKYKTLAQKLYQHEINLFKSKTNSQKGASSTWMKAIVSSGTLGDRMAAMILLIQDDAVHTLQFVETLVNLVKKKGSKQQCLMALDTFKELLITDLLPDNRKLRIFSQRPFDKLEQLSSGNKDSRDRRLILWYFEHQLKHLVAEFVQVLETLSHDTLVTTKTRALTVAHELLCNKPEEEKALLVQVVNKLGDPQNRIATKASHLLETLLCKHPNMKGVVSGEVERLLFRSNISSKAQYYAICFLNQMALSHEESELANKLITVYFCFFRTCVKKKDVESKMLSALLTGVNRAYPYSQTGDDKVREQIDTLFKVLHIVNFNTSVQALMLLFQVMNSQQTISDRYYTALYRKMLDPGLMTCSKQAMFLNLVYKSLKADIVLRRVKAFVKRLLQVTCQQMPPFICGALYLVSEILKAKPGLRSQLDDHPESDDEENFIDANDDEDMEKFTDADKETEIVKKLETEETVPETDVETKKPEVASWVHFDNLKGGKQLNKYDPFSRNPLFCGAENTSLWELKKLSVHFHPSVALFAKTILQGNYIQYSGDPLQDFTLMRFLDRFVYRNPKPHKGKENTDSVVMQPKRKHFIKDIRHLPVNSKEFLAKEESQIPVDEVFFHRYYKKVAVKEKQKRDADEESIEDVDDEEFEELIDTFEDDNCFSSGKDDMDFAGNVKKRTKGAKDNTLDEDSEGSDDELGNLDDDEVSLGSMDDEEFAEVDEDGGTFMDVLDDESESVPELEVHSKVSTKKSKRKGTDDFDFAGSFQGPRKKKRNLNDSSLFVSAEEFGHLLDENMGSKFDNIGMNAMANKDNASLKQLRWEAERDDWLHNRDAKSIIKKKKHFKKKRIKTTQKTKKQRK>sp|P49418|AMPH_HUMAN Amphiphysin OS=Homo sapiens OX=9606 GN=AMPH PE=1SV=1MADIKTGIFAKNVQKRLNRAQEKVLQKLGKADETKDEQFEEYVQNFKRQEAEGTRLQRELRGYLAAIKGMQEASMKLTESLHEVYEPDWYGREDVKMVGEKCDVLWEDFHQKLVDGSLLTLDTYLGQFPDIKNRIAKRSRKLVDYDSARHHLEALQSSKRKDESRISKAEEEFQKAQKVFEEFNVDLQEELPSLWSRRVGFYVNTFKNVSSLEAKFHKEIAVLCHKLYEVMTKLGDQHADKAFTIQGAPSDSGPLRIAKTPSPPEEPSPLPSPTASPNHTLAPASPAPARPRSPSQTRKGPPVPPLPKVTPTKELQQENIISFFEDNFVPEISVTTPSQNEVPEVKKEETLLDLDFDPFKPEVTPAGSAGVTHSPMSQTLPWDLWTTSTDLVQPASGGSFNGFTQPQDTSLFTMQTDQSMICNLAESEQAPPTEPKAEEPLAAVTPAVGLDLGMDTRAEEPVEEAVIIPGADADAAVGTLVSAAEGAPGEEAEAEKATVPAGEGVSLEEAKIGTETTEGAESAQPEAEELEATVPQEKVIPSVVIEPASNHEEEGENEITIGAEPKETTEDAAPPGPTSETPELATEQKPIQDPQPTPSAPAMGAADQLASAREASQELPPGFLYKVETLHDFEAANSDELTLQRGDVVLVVPSDSEADQDAGWLVGVKESDWLQYRDLATYKGLFPENFTRRLD>sp|P49418-2|AMPH_HUMAN Isoform 2 of Amphiphysin OS=Homo sapiens OX=9606GN=AMPHMADIKTGIFAKNVQKRLNRAQEKVLQKLGKADETKDEQFEEYVQNFKRQEAEGTRLQRELRGYLAAIKGMQEASMKLTESLHEVYEPDWYGREDVKMVGEKCDVLWEDFHQKLVDGSLLTLDTYLGQFPDIKNRIAKRSRKLVDYDSARHHLEALQSSKRKDESRISKAEEEFQKAQKVFEEFNVDLQEELPSLWSRRVGFYVNTFKNVSSLEAKFHKEIAVLCHKLYEVMTKLGDQHADKAFTIQGAPSDSGPLRIAKTPSPPEEPSPLPSPTASPNHTLAPASPAPARPRSPSQTRKGPPVPPLPKVTPTKELQQENIISFFEDNFVPEISVTTPSQNEVPEVKKEETLLDLDFDPFKPEVTPAGSAGVTHSPMSQTLPWDLWTTSTDLVQPASGGSFNGFTQPQDTSLFTMQTDQSMICNLIIPGADADAAVGTLVSAAEGAPGEEAEAEKATVPAGEGVSLEEAKIGTETTEGAESAQPEAEELEATVPQEKVIPSVVIEPASNHEEEGENEITIGAEPKETTEDAAPPGPTSETPELATEQKPIQDPQPTPSAPAMGAADQLASAREASQELPPGFLYKVETLHDFEAANSDELTLQRGDVVLVVPSDSEADQDAGWLVGVKESDWLQYRDLATYKGLFPENFTRRLD>sp|P05023|AT1A1_HUMAN Sodium/potassium-transporting ATPase subunitalpha-1 OS=Homo sapiens OX=9606 GN=ATP1A1 PE=1 SV=1MGKGVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVVHGSDLKDMTSEQLDDILKYHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLIFIIANIPLPLGTVTILCIDLGTDMVPAISLAYEQAESDIMKRQPRNPKTDKLVNERLISMAYGQIGMIQALGGFFTYFVILAENGFLPIHLLGLRVDWDDRWINDVEDSYGQQWTYEQRKIVEFTCHTAFFVSIVVVQWADLVICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMGVALRMYPLKPTWWFCAFPYSLLIFVYDEVRKLIIRRRPGGWVEKETYY>sp|P05023-2|AT1A1_HUMAN Isoform 2 of Sodium/potassium-transportingATPase subunit alpha-1 OS=Homo sapiens OX=9606 GN=ATP1A1MGKGVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGSGPMSRGKSWSSPATQPSSSVSWWCSGPTWSSVRPGGIRSSSRG>sp|P05023-3|AT1A1_HUMAN Isoform 3 of Sodium/potassium-transportingATPase subunit alpha-1 OS=Homo sapiens OX=9606 GN=ATP1A1MDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVVHGSDLKDMTSEQLDDILKYHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLIFIIANIPLPLGTVTILCIDLGTDMVPAISLAYEQAESDIMKRQPRNPKTDKLVNERLISMAYGQIGMIQALGGFFTYFVILAENGFLPIHLLGLRVDWDDRWINDVEDSYGQQWTYEQRKIVEFTCHTAFFVSIVVVQWADLVICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMGVALRMYPLKPTWWFCAFPYSLLIFVYDEVRKLIIRRRPGGWVEKETYY>sp|P05023-4|AT1A1_HUMAN Isoform 4 of Sodium/potassium-transportingATPase subunit alpha-1 OS=Homo sapiens OX=9606 GN=ATP1A1MAFKVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVVHGSDLKDMTSEQLDDILKYHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLIFIIANIPLPLGTVTILCIDLGTDMVPAISLAYEQAESDIMKRQPRNPKTDKLVNERLISMAYGQIGMIQALGGFFTYFVILAENGFLPIHLLGLRVDWDDRWINDVEDSYGQQWTYEQRKIVEFTCHTAFFVSIVVVQWADLVICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMGVALRMYPLKPTWWFCAFPYSLLIFVYDEVRKLIIRRRPGGWVEKETYY>sp|Q9ULJ7|ANR50_HUMAN Ankyrin repeat domain-containing protein 50OS=Homo sapiens OX=9606 GN=ANKRD50 PE=1 SV=4MTNPWEEKVCKMAQTSLLQGKQFYCREWVFHKLQHCLQEKSNCCNSAVNAPSLVMNSGNNASGVSGKGAAWGVLLVGGPGSGKTALCTELLWPSSPASLQRGLHRQALAFHFCKAQDSDTLCVGGFIRGLVAQICRSGLLQGYEDKLRDPAVQSLLQPGECERNPAEAFKRCVLLPLLGMKPPQQSLYLLVDSVDEGCNITEGEQTSTSLSGTVAALLAGHHEFFPPWLLLLCSARKQSKAVTKMFTGFRKISLDDLRKAYIVKDVQQYILHRLDQEEALRQHLTKETAEMLNQLHIKSSGCFLYLERVLDGVVENFIMLREIRDIPGTLNGLYLWLCQRLFVRKQFAKVQPILNVILAACRPLTITELYHAVWTKNMSLTLEDFQRKLDILSKLLVDGLGNTKILFHYSFAEWLLDVKHCTQKYLCNAAEGHRMLAMSYTCQAKNLTPLEAQEFALHLINSNLQLETAELALWMIWNGTPVRDSLSTLIPKEQEVLQLLVKAGAHVNSEDDRTSCIVRQALEREDSIRTLLDNGASVNQCDSNGRTLLANAAYSGSLDVVNLLVSRGADLEIEDAHGHTPLTLAARQGHTKVVNCLIGCGANINHTDQDGWTALRSAAWGGHTEVVSALLYAGVKVDCADADSRTALRAAAWGGHEDIVLNLLQHGAEVNKADNEGRTALIAAAYMGHREIVEHLLDHGAEVNHEDVDGRTALSVAALCVPASKGHASVVSLLIDRGAEVDHCDKDGMTPLLVAAYEGHVDVVDLLLEGGADVDHTDNNGRTPLLAAASMGHASVVNTLLFWGAAVDSIDSEGRTVLSIASAQGNVEVVRTLLDRGLDENHRDDAGWTPLHMAAFEGHRLICEALIEQGARTNEIDNDGRIPFILASQEGHYDCVQILLENKSNIDQRGYDGRNALRVAALEGHRDIVELLFSHGADVNCKDADGRPTLYILALENQLTMAEYFLENGANVEASDAEGRTALHVSCWQGHMEMVQVLIAYHADVNAADNEKRSALQSAAWQGHVKVVQLLIEHGAVVDHTCNQGATALCIAAQEGHIDVVQVLLEHGADPNHADQFGRTAMRVAAKNGHSQIIKLLEKYGASSLNGCSPSPVHTMEQKPLQSLSSKVQSLTIKSNSSGSTGGGDMQPSLRGLPNGPTHAFSSPSESPDSTVDRQKSSLSNNSLKSSKNSSLRTTSSTATAQTVPIDSFHNLSFTEQIQQHSLPRSRSRQSIVSPSSTTQSLGQSHNSPSSEFEWSQVKPSLKSTKASKGGKSENSAKSGSAGKKAKQSNSSQPKVLEYEMTQFDRRGPIAKSGTAAPPKQMPAESQCKIMIPSAQQEIGRSQQQFLIHQQSGEQKKRNGIMTNPNYHLQSNQVFLGRVSVPRTMQDRGHQEVLEGYPSSETELSLKQALKLQIEGSDPSFNYKKETPL>sp|Q9ULJ7-2|ANR50_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 50 OS=Homo sapiens OX=9606 GN=ANKRD50MKPPQQSLYLLVDSVDEGCNITEGEQTSTSLSGTVAALLAGHHEFFPPWLLLLCSARKQSKAVTKMFTGFRKISLDDLRKAYIVKDVQQYILHRLDQEEALRQHLTKETAEMLNQLHIKSSGCFLYLERVLDGVVENFIMLREIRDIPGTLNGLYLWLCQRLFVRKQFAKVQPILNVILAACRPLTITELYHAVWTKNMSLTLEDFQRKLDILSKLLVDGLGNTKILFHYSFAEWLLDVKHCTQKYLCNAAEGHRMLAMSYTCQAKNLTPLEAQEFALHLINSNLQLETAELALWMIWNGTPVRDSLSTLIPKEQEVLQLLVKAGAHVNSEDDRTSCIVRQALEREDSIRTLLDNGASVNQCDSNGRTLLANAAYSGSLDVVNLLVSRGADLEIEDAHGHTPLTLAARQGHTKVVNCLIGCGANINHTDQDGWTALRSAAWGGHTEVVSALLYAGVKVDCADADSRTALRAAAWGGHEDIVLNLLQHGAEVNKADNEGRTALIAAAYMGHREIVEHLLDHGAEVNHEDVDGRTALSVAALCVPASKGHASVVSLLIDRGAEVDHCDKDGMTPLLVAAYEGHVDVVDLLLEGGADVDHTDNNGRTPLLAAASMGHASVVNTLLFWGAAVDSIDSEGRTVLSIASAQGNVEVVRTLLDRGLDENHRDDAGWTPLHMAAFEGHRLICEALIEQGARTNEIDNDGRIPFILASQEGHYDCVQILLENKSNIDQRGYDGRNALRVAALEGHRDIVELLFSHGADVNCKDADGRPTLYILALENQLTMAEYFLENGANVEASDAEGRTALHVSCWQGHMEMVQVLIAYHADVNAADNEKRSALQSAAWQGHVKVVQLLIEHGAVVDHTCNQGATALCIAAQEGHIDVVQVLLEHGADPNHADQFGRTAMRVAAKNGHSQIIKLLEKYGASSLNGCSPSPVHTMEQKPLQSLSSKVQSLTIKSNSSGSTGGGDMQPSLRGLPNGPTHAFSSPSESPDSTVDRQKSSLSNNSLKSSKNSSLRTTSSTATAQTVPIDSFHNLSFTEQIQQHSLPRSRSRQSIVSPSSTTQSLGQSHNSPSSEFEWSQVKPSLKSTKASKGGKSENSAKSGSAGKKAKQSNSSQPKVLEYEMTQFDRRGPIAKSGTAAPPKQMPAESQCKIMIPSAQQEIGRSQQQFLIHQQSGEQKKRNGIMTNPNYHLQSNQVFLGRVSVPRTMQDRGHQEVLEGYPSSETELSLKQALKLQIEGSDPSFNYKKETPL>sp|Q8IW19|APLF_HUMAN Aprataxin and PNK-like factor OS=Homo sapiensOX=9606 GN=APLF PE=1 SV=1MSGGFELQPRDGGPRVALAPGETVIGRGPLLGITDKRVSRRHAILEVAGGQLRIKPIHTNPCFYQSSEKSQLLPLKPNLWCYLNPGDSFSLLVDKYIFRILSIPSEVEMQCTLRNSQVLDEDNILNETPKSPVINLPHETTGASQLEGSTEIAKTQMTPTNSVSFLGENRDCNKQQPILAERKRILPTWMLAEHLSDQNLSVPAISGGNVIQGSGKEEICKDKSQLNTTQQGRRQLISSGSSENTSAEQDTGEECKNTDQEESTISSKEMPQSFSAITLSNTEMNNIKTNAQRNKLPIEELGKVSKHKIATKRTPHKEDEAMSCSENCSSAQGDSLQDESQGSHSESSSNPSNPETLHAKATDSVLQGSEGNKVKRTSCMYGANCYRKNPVHFQHFSHPGDSDYGGVQIVGQDETDDRPECPYGPSCYRKNPQHKIEYRHNTLPVRNVLDEDNDNVGQPNEYDLNDSFLDDEEEDYEPTDEDSDWEPGKEDEEKEDVEELLKEAKRFMKRK>sp|P07355|ANXA2_HUMAN Annexin A2 OS=Homo sapiens OX=9606 GN=ANXA2 PE=1SV=2MSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGTRDKVLIRIMVSRSEVDMLKIRSEFKRKYGKSLYYYIQQDTKGDYQKALLYLCGGDD>sp|P07355-2|ANXA2_HUMAN Isoform 2 of Annexin A2 OS=Homo sapiens OX=9606GN=ANXA2MGRQLAGCGDAGKKASFKMSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYFADRLYDSMKGKGTRDKVLIRIMVSRSEVDMLKIRSEFKRKYGKSLYYYIQQDTKGDYQKALLYLCGGDD>sp|Q9BQE5|APOL2_HUMAN Apolipoprotein L2 OS=Homo sapiens OX=9606 GN=APOL2PE=1 SV=1MNPESSIFIEDYLKYFQDQVSRENLLQLLTDDEAWNGFVAAAELPRDEADELRKALNKLASHMVMKDKNRHDKDQQHRQWFLKEFPRLKRELEDHIRKLRALAEEVEQVHRGTTIANVVSNSVGTTSGILTLLGLGLAPFTEGISFVLLDTGMGLGAAAAVAGITCSVVELVNKLRARAQARNLDQSGTNVAKVMKEFVGGNTPNVLTLVDNWYQVTQGIGRNIRAIRRARANPQLGAYAPPPHIIGRISAEGGEQVERVVEGPAQAMSRGTMIVGAATGGILLLLDVVSLAYESKHLLEGAKSESAEELKKRAQELEGKLNFLTKIHEMLQPGQDQ>sp|P01160|ANF_HUMAN Natriuretic peptides A OS=Homo sapiens OX=9606GN=NPPA PE=1 SV=2MSSFSTTTVSFLLLLAFQLLGQTRANPMYNAVSNADLMDFKNLLDHLEEKMPLEDEVVPPQVLSEPNEEAGAALSPLPEVPPWTGEVSPAQRDGGALGRGPWDSSDRSALLKSKLRALLTAPRSLRRSSCFGGRMDRIGAQSGLGCNSFRY>sp|Q711Q0|CEFIP_HUMAN Cardiac-enriched FHL2-interacting protein OS=Homosapiens OX=9606 GN=CEFIP PE=1 SV=2MMQGNKKCTDAFSDSSSIGSVLDDADREVSSLTDRAFRSLCISEDTSFHDSYLAVSPDITRQVFGTFHQRTVGHTQRKSGIWSQLPSQGTEHSGWAATFQQLPKYVQGEEKYPKTSPPPTPVQRRLEVPVSGLRSSNKPVSKVSTLIKSFDRTESQRCESRPTASKPPALKNPPKFAPLPENSVNFCFDSAFLTVRRVPAEVSNTHQNSYQPGRKHGEQESSKNPEMACHGSSSFLPAANDTATLCESKFPSPHHKPVTGEPGRGKGTFLHSENSAFESWNAHQPKLLERKDTAGTVPESKAPKHYGDTTLLREPCPPERTVSPCQVQASCSQEENRLAAGALSTSIPWGCRDPGAQVFAVEGKAPSSQPDSQEKPAQPPWRKPKTGKKGKESLQDTLEEKTQTNQRGPPLYTKHNPQEQFSENNALDLPVEPNEHYDPPFNISKLLTPIIPSKHALDSADSQPAERTPSPPGQLNGYQEKEPSECQSRDSYKSKAPSLLFNLKDVRKRVKSTYSSSPLLKVLDEKTRGKVDGKQEPVSNGVILPNGLEESPPNELSKERPADDPTASHINPQKDPTADPSEPSADSYLTLSTAPTIAKAPFYVNGEAAERSSYENKEVEGELEMGPAGSSWCPDSREHRPRKHLSLRLCNRDPEPGGATEKMKTHQLENGLSRSVSQETEPEREAGLQNTHLNQKFFPGPLSPEEEDVFYSDSQSDFMPSLKGKAKFSTSSSDQSFASFDDQQKMWFTENQREDRRKDVSAGDSQKDEKENVMRKDELQYCALSNGHACLENRSQGEALQRERESVSGGRTRKASAEEANFRGSWIGENKGTTFSQAKDLTPSPSSASNRHMLFTIKDNTLRATPVIKPIMLPLLRTMSLEDSLSSGHKEEELPRPEWGEDPGFCAPENQDILGTSTPTNTRGTRVKCMANEVMEDPGQGSSMARMEASQPAPKGNFPSMPLVGEGDRVKAPPDAAPGLVASNCKSGSADSGKLAAPWHIPTIALPEGDIEDQPPPWQPENCWEEQTPGFKSHFLSTPRAGPPGRRLVPSERANSPNPGSPGESSACSPAASNIWEESSQAPGGPELLPEEPNQASPWASSSPARVTRREDLTHALVWEGGSDPLLELSAEDLRTLSPRGSLLDVATSPAGTSGRLELPAQLERTASKPPAVPPKTEKALRRAKKLASKRRKTDQAQEKHGESQEGKPCPEDLEQTQQRPLCPRERPRHNFPVVRSLPPPVHRHSVSGFSEPVGRRPGGPQSLTPLPAYPATQKVLQDPQSGEYFVFDLPLQVKIKTFYDPETGKYVKVSIPSSEGASPEPPPPDALAAPYVLYPGFQPVPVTALMPLRCSSQLSAPTFLRQGPRASAARARTQSVHESGLQLDPGPHGDCTPHSAGQRPHGPPQSPGEEGVEAPGLGIISTDDLEDFATEGIS>sp|Q711Q0-3|CEFIP_HUMAN Isoform 3 of Cardiac-enriched FHL2-interactingprotein OS=Homo sapiens OX=9606 GN=CEFIPMMQGNKKCTDAFSDSSSIGSVLDDADREVSSLTDRAFRSLCISEDTSFHDSYLAVSPDITRQVFGTFHQRTVGHTQRKSGIWSQLPSQGTEHSGWAATFQQLPKYVQGEEKYPKTSPPPTPVQRRLEVPVSGLRSSNKPVSKVSTLIKSFDRTESQRCESRPTASKPPALKNPPKFAPLPENSVNFCFDSAFLTVRRVPAEVSNTHQNSYQPGRKHGEQESSKNPEMACHGSSSFLPAANDTATLCESKFPSPHHKPVTGEPGRGKGTFLHSENSAFESWNAHQPKLLERKDTAGTVPESKAPKHYGDTTLLREPCPPERTVSPCQVQASCSQEENRLAAGALSTSIPWGCRDPGAQVFAVEGKAPSSQPDSQEKPAQPPWRKPKTGKKGKESLQDTLEEKTQTNQRGPPLYTKHNPQEQFSENNALDLPVEPNEHYDPPFNISKLLTPIIPSKHALDSADSQPAERTPSPPGQLNGYQEKEPSECQSRDSYKSKAPSLLFNLKDVRKRVKSTYSSSPLLKVLDEKTRGKVDGKQEPVSNGVILPNGLEESPPNELSKERPADDPTASHINPQKDPTADPSEPSADSYLTLSTAPTIAKAPFYVNGEAAERSSYENKEVEGELEMGPAGSSWCPDSREHRPRKHLSLRLCNRDPEPGGATEKMKTHQLENGLSRSVSQETEPEREAGLQNTHTHTHTHTHTHDHQHILSLFRSIKSRRQ>sp|Q5T2N8|ATD3C_HUMAN ATPase family AAA domain-containing protein 3COS=Homo sapiens OX=9606 GN=ATAD3C PE=2 SV=2MSKDALNLAQMQEQTLQLEQQSKLKQLVNEDLRKQEESVQKHHQTFLESIRAAGTLFGEGFRAFVTDRDKVTATVAGLTLLAVGVYSAKNATAVTGRYIEARLGKPSLVRETSRITVLEALRHPIQQVSRRLLSRPQDVLEGVVLSPSLEARVRDIAIMTRNIKKNRGLYRHILLYGPPGTGKTLFAKKLALHSGMDYAIMTGGDVAPMGREGVTAMHKLFDWANTSRRGLLLFVDEADAFLRKRATEKISEDLRATLNAFLYRTGQHSNKFMLILASCHPEQFDWAINACIDVMVHFDLPGQEERARLVRMYLNEYVLKPATEGKRRLKLAQFDYGRKCLEIARLTEGMSCRKIAQLAVSWQATAYASKDGVLTEAMMDACVQDFVQQHQQMMRWLKGERPGPEDEQPSS>sp|P51690|ARSL_HUMAN Arylsulfatase L OS=Homo sapiens OX=9606 GN=ARSLPE=1 SV=2MLHLHHSCLCFRSWLPAMLAVLLSLAPSASSDISASRPNILLLMADDLGIGDIGCYGNNTMRTPNIDRLAEDGVKLTQHISAASLCTPSRAAFLTGRYPVRSGMVSSIGYRVLQWTGASGGLPTNETTFAKILKEKGYATGLIGKWHLGLNCESASDHCHHPLHHGFDHFYGMPFSLMGDCARWELSEKRVNLEQKLNFLFQVLALVALTLVAGKLTHLIPVSWMPVIWSALSAVLLLASSYFVGALIVHADCFLMRNHTITEQPMCFQRTTPLILQEVASFLKRNKHGPFLLFVSFLHVHIPLITMENFLGKSLHGLYGDNVEEMDWMVGRILDTLDVEGLSNSTLIYFTSDHGGSLENQLGNTQYGGWNGIYKGGKGMGGWEGGIRVPGIFRWPGVLPAGRVIGEPTSLMDVFPTVVRLAGGEVPQDRVIDGQDLLPLLLGTAQHSDHEFLMHYCERFLHAARWHQRDRGTMWKVHFVTPVFQPEGAGACYGRKVCPCFGEKVVHHDPPLLFDLSRDPSETHILTPASEPVFYQVMERVQQAVWEHQRTLSPVPLQLDRLGNIWRPWLQPCCGPFPLCWCLREDDPQ>sp|Q8TBG4|AT2L1_HUMAN Ethanolamine-phosphate phospho-lyase OS=Homosapiens OX=9606 GN=ETNPPL PE=1 SV=1MCELYSKRDTLGLRKKHIGPSCKVFFASDPIKIVRAQRQYMFDENGEQYLDCINNVAHVGHCHPGVVKAALKQMELLNTNSRFLHDNIVEYAKRLSATLPEKLSVCYFTNSGSEANDLALRLARQFRGHQDVITLDHAYHGHLSSLIEISPYKFQKGKDVKKEFVHVAPTPDTYRGKYREDHADSASAYADEVKKIIEDAHNSGRKIAAFIAESMQSCGGQIIPPAGYFQKVAEYVHGAGGVFIADEVQVGFGRVGKHFWSFQMYGEDFVPDIVTMGKPMGNGHPVACVVTTKEIAEAFSSSGMEYFNTYGGNPVSCAVGLAVLDIIENEDLQGNAKRVGNYLTELLKKQKAKHTLIGDIRGIGLFIGIDLVKDHLKRTPATAEAQHIIYKMKEKRVLLSADGPHRNVLKIKPPMCFTEEDAKFMVDQLDRILTVLEEAMGTKTESVTSENTPCKTKMLKEAHIELLRDSTTDSKENPSRKRNGMCTDTHSLLSKRLKT>sp|Q8TBG4-2|AT2L1_HUMAN Isoform 2 of Ethanolamine-phosphate phospho-lyase OS=Homo sapiens OX=9606 GN=ETNPPLMCELYSKRDTLGLRKKHIGPSCKVFFASDPIKIVRAQRQYMFDENGEQYLDCINNVAHGVVKAALKQMELLNTNSRFLHDNIVEYAKRLSATLPEKLSVCYFTNSGSEANDLALRLARQFRGHQDVITLDHAYHGHLSSLIEISPYKFQKGKDVKKEFVHVAPTPDTYRGKYREDHADSASAYADEVKKIIEDAHNSGRKIAAFIAESMQSCGGQIIPPAGYFQKVAEYVHGAGGVFIADEVQVGFGRVGKHFWSFQMYGEDFVPDIVTMGKPMGNGHPVACVVTTKEIAEAFSSSGMEYFNTYGGNPVSCAVGLAVLDIIENEDLQGNAKRVGNYLTELLKKQKAKHTLIGDIRGIGLFIGIDLVKDHLKRTPATAEAQHIIYKMKEKRVLLSADGPHRNVLKIKPPMCFTEEDAKFMVDQLDRILTVLEEAMGTKTESVTSENTPCKTKMLKEAHIELLRDSTTDSKENPSRKRNGMCTDTHSLLSKRLKT>sp|Q8TBG4-3|AT2L1_HUMAN Isoform 3 of Ethanolamine-phosphate phospho-lyase OS=Homo sapiens OX=9606 GN=ETNPPLMGHCHPGVVKAALKQMELLNTNSRFLHDNIVEYAKRLSATLPEKLSVCYFTNSGSEANDLALRLARQFRGHQDVITLDHAYHGHLSSLIEISPYKFQKGKDVKKEFVHVAPTPDTYRGKYREDHADSASAYADEVKKIIEDAHNSGRKIAAFIAESMQSCGGQIIPPAGYFQKVAEYVHGAGGVFIADEVQVGFGRVGKHFWSFQMYGEDFVPDIVTMGKPMGNGHPVACVVTTKEIAEAFSSSGMEYFNTYGGNPVSCAVGLAVLDIIENEDLQGNAKRVGNYLTELLKKQKAKHTLIGDIRGIGLFIGIDLVKDHLKRTPATAEAQHIIYKMKEKRVLLSADGPHRNVLKIKPPMCFTEEDAKFMVDQLDRILTVLEEAMGTKTESVTSENTPCKTKMLKEAHIELLRDSTTDSKENPSRKRNGMCTDTHSLLSKRLKT>sp|Q01814|AT2B2_HUMAN Plasma membrane calcium-transporting ATPase 2OS=Homo sapiens OX=9606 GN=ATP2B2 PE=1 SV=2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKGVKKGDGLQLPAADGAAASNAADSANASLVNGKMQDGNVDASQSKAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIRVVKAFRSSLYEGLEKPESRTSIHNFMAHPEFRIEDSQPHIPLIDDTDLEEDAALKQNSSPPSSLNKNNSAIDSGINLTTDTSKSATSSSPGSPIHSLETSL>sp|Q01814-2|AT2B2_HUMAN Isoform WA of Plasma membrane calcium-transporting ATPase 2 OS=Homo sapiens OX=9606 GN=ATP2B2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKGVKKGDGLQLPAADGAAASNAADSANASLVNGKMQDGNVDASQSKAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIEVVNTFKSGASFQGALRRQSSVTSQSQDVANLSSPSRVSLSNALSSPTSLPPAAAGQG>sp|Q01814-3|AT2B2_HUMAN Isoform YA of Plasma membrane calcium-transporting ATPase 2 OS=Homo sapiens OX=9606 GN=ATP2B2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKGVKKGDGLQLPAADGAAASNAADSANASLVNAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIEVVNTFKSGASFQGALRRQSSVTSQSQDVANLSSPSRVSLSNALSSPTSLPPAAAGQG>sp|Q01814-4|AT2B2_HUMAN Isoform ZA of Plasma membrane calcium-transporting ATPase 2 OS=Homo sapiens OX=9606 GN=ATP2B2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIEVVNTFKSGASFQGALRRQSSVTSQSQDVANLSSPSRVSLSNALSSPTSLPPAAAGQG>sp|Q01814-5|AT2B2_HUMAN Isoform YB of Plasma membrane calcium-transporting ATPase 2 OS=Homo sapiens OX=9606 GN=ATP2B2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKGVKKGDGLQLPAADGAAASNAADSANASLVNAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIRVVKAFRSSLYEGLEKPESRTSIHNFMAHPEFRIEDSQPHIPLIDDTDLEEDAALKQNSSPPSSLNKNNSAIDSGINLTTDTSKSATSSSPGSPIHSLETSL>sp|Q01814-6|AT2B2_HUMAN Isoform ZB of Plasma membrane calcium-transporting ATPase 2 OS=Homo sapiens OX=9606 GN=ATP2B2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIRVVKAFRSSLYEGLEKPESRTSIHNFMAHPEFRIEDSQPHIPLIDDTDLEEDAALKQNSSPPSSLNKNNSAIDSGINLTTDTSKSATSSSPGSPIHSLETSL>sp|Q01814-7|AT2B2_HUMAN Isoform XA of Plasma membrane calcium-transporting ATPase 2 OS=Homo sapiens OX=9606 GN=ATP2B2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKGKMQDGNVDASQSKAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIEVVNTFKSGASFQGALRRQSSVTSQSQDVANLSSPSRVSLSNALSSPTSLPPAAAGQG>sp|Q01814-8|AT2B2_HUMAN Isoform XB of Plasma membrane calcium-transporting ATPase 2 OS=Homo sapiens OX=9606 GN=ATP2B2MGDMTNSDFYSKNQRNESSHGGEFGCTMEELRSLMELRGTEAVVKIKETYGDTEAICRRLKTSPVEGLPGTAPDLEKRKQIFGQNFIPPKKPKTFLQLVWEALQDVTLIILEIAAIISLGLSFYHPPGEGNEGCATAQGGAEDEGEAEAGWIEGAAILLSVICVVLVTAFNDWSKEKQFRGLQSRIEQEQKFTVVRAGQVVQIPVAEIVVGDIAQVKYGDLLPADGLFIQGNDLKIDESSLTGESDQVRKSVDKDPMLLSGTHVMEGSGRMLVTAVGVNSQTGIIFTLLGAGGEEEEKKDKKGKMQDGNVDASQSKAKQQDGAAAMEMQPLKSAEGGDADDRKKASMHKKEKSVLQGKLTKLAVQIGKAGLVMSAITVIILVLYFTVDTFVVNKKPWLPECTPVYVQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTTNRMTVVQAYVGDVHYKEIPDPSSINTKTMELLINAIAINSAYTTKILPPEKEGALPRQVGNKTECGLLGFVLDLKQDYEPVRSQMPEEKLYKVYTFNSVRKSMSTVIKLPDESFRMYSKGASEIVLKKCCKILNGAGEPRVFRPRDRDEMVKKVIEPMACDGLRTICVAYRDFPSSPEPDWDNENDILNELTCICVVGIEDPVRPEVPEAIRKCQRAGITVRMVTGDNINTARAIAIKCGIIHPGEDFLCLEGKEFNRRIRNEKGEIEQERIDKIWPKLRVLARSSPTDKHTLVKGIIDSTHTEQRQVVAVTGDGTNDGPALKKADVGFAMGIAGTDVAKEASDIILTDDNFSSIVKAVMWGRNVYDSISKFLQFQLTVNVVAVIVAFTGACITQDSPLKAVQMLWVNLIMDTFASLALATEPPTETLLLRKPYGRNKPLISRTMMKNILGHAVYQLALIFTLLFVGEKMFQIDSGRNAPLHSPPSEHYTIIFNTFVMMQLFNEINARKIHGERNVFDGIFRNPIFCTIVLGTFAIQIVIVQFGGKPFSCSPLQLDQWMWCIFIGLGELVWGQVIATIPTSRLKFLKEAGRLTQKEEIPEEELNEDVEEIDHAERELRRGQILWFRGLNRIQTQIRVVKAFRSSLYEGLEKPESRTSIHNFMAHPEFRIEDSQPHIPLIDDTDLEEDAALKQNSSPPSSLNKNNSAIDSGINLTTDTSKSATSSSPGSPIHSLETSL>sp|Q5T9A4|ATD3B_HUMAN ATPase family AAA domain-containing protein 3BOS=Homo sapiens OX=9606 GN=ATAD3B PE=1 SV=1MSWLFGVNKGPKGEGAGPPPPLPPAQPGAEGGGDRGLGDRPAPKDKWSNFDPTGLERAAKAARELEHSRYAKEALNLAQMQEQTLQLEQQSKLKEYEAAVEQLKSEQIRAQAEERRKTLSEETRQHQARAQYQDKLARQRYEDQLKQQQLLNEENLRKQEESVQKQEAMRRATVEREMELRHKNEMLRVETEARARAKAERENADIIREQIRLKASEHRQTVLESIRTAGTLFGEGFRAFVTDRDKVTATVAGLTLLAVGVYSAKNATAVTGRFIEARLGKPSLVRETSRITVLEALRHPIQVSRRLLSRPQDVLEGVVLSPSLEARVRDIAIATRNTKKNRGLYRHILLYGPPGTGKTLFAKKLALHSGMDYAIMTGGDVAPMGREGVTAMHKLFDWANTSRRGLLLFMDEADAFLRKRATEEISKDLRATLNAFLYHMGQHSNKFMLVLASNLPEQFDCAINSRIDVMVHFDLPQQEERERLVRLHFDNCVLKPATEGKRRLKLAQFDYGRKCSEVARLTEGMSGREIAQLAVSWQATAYASKDGVLTEAMMDACVQDAVQQYRQKMRWLKAEGPGRGVEHPLSGVQGETLTSWSLATDPSYPCLAGPCTFRICSWMGTGLCPGPLSPRMSCGGGRPFCPPGHPLL>sp|Q5T9A4-2|ATD3B_HUMAN Isoform 2 of ATPase family AAA domain-containingprotein 3B OS=Homo sapiens OX=9606 GN=ATAD3BMCLCRPLLPQRAQYQDKLARQRYEDQLKQQQLLNEENLRKQEESVQKQEAMRRATVEREMELRHKNEMLRVETEARARAKAERENADIIREQIRLKASEHRQTVLESIRTAGTLFGEGFRAFVTDRDKVTATVNIFIKQGWQVAERQHVGASWSPRSCPCRLCTAL>sp|Q5T9A4-3|ATD3B_HUMAN Isoform 3 of ATPase family AAA domain-containingprotein 3B OS=Homo sapiens OX=9606 GN=ATAD3BMQLEALNLLHTLVWARSLCRAGAVQTQERLSGSASPEQVPAGECCALQEYEAAVEQLKSEQIRAQAEERRKTLSEETRQHQARAQYQDKLARQRYEDQLKQQQLLNEENLRKQEESVQKQEAMRRATVEREMELRHKNEMLRVETEARARAKAERENADIIREQIRLKASEHRQTVLESIRTAGTLFGEGFRAFVTDRDKVTATVAGLTLLAVGVYSAKNATAVTGRFIEARLGKPSLVRETSRITVLEALRHPIQVSRRLLSRPQDVLEGVVLSPSLEARVRDIAIATRNTKKNRGLYRHILLYGPPGTGKTLFAKKLALHSGMDYAIMTGGDVAPMGREGVTAMHKLFDWANTSRRGLLLFMDEADAFLRKRATEEISKDLRATLNAFLYHMGQHSNKFMLVLASNLPEQFDCAINSRIDVMVHFDLPQQEERERLVRLHFDNCVLKPATEGKRRLKLAQFDYGRKCSEVARLTEGMSGREIAQLAVSWQATAYASKDGVLTEAMMDACVQDAVQQYRQKMRWLKAEGPGRGVEHPLSGVQGETLTSWSLATDPSYPCLAGPCTFRICSWMGTGLCPGPLSPRMSCGGGRPFCPPGHPLL>sp|Q92600|CNOT9_HUMAN CCR4-NOT transcription complex subunit 9 OS=Homosapiens OX=9606 GN=CNOT9 PE=1 SV=1MHSLATAAPVPTTLAQVDREKIYQWINELSSPETRENALLELSKKRESVPDLAPMLWHSFGTIAALLQEIVNIYPSINPPTLTAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLHTVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILGKMVLQLSKEPSARLLKHVVRCYLRLSDNPRAREALRQCLPDQLKDTTFAQVLKDDTTTKRWLAQLVKNLQEGQVTDPRGIPLPPQ>sp|Q92600-2|CNOT9_HUMAN Isoform 2 of CCR4-NOT transcription complexsubunit 9 OS=Homo sapiens OX=9606 GN=CNOT9MHSLATAAPVPTTLAQVDREKIYQWINELSSPETRENALLELSKKRESVPDLAPMLWHSFGTIAALLQEIVNIYPSINPPTLTAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLHTVSKTRPFEYLRLTSLGVIVETGFHHVGQADLELPTSSDLPASASQSAGITGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILGKMVLQLSKEPSARLLKHVVRCYLRLSDNPRAREALRQCLPDQLKDTTFAQVLKDDTTTKRWLAQLVKNLQEGQVTDPRGIPLPPQ>sp|Q92600-3|CNOT9_HUMAN Isoform 3 of CCR4-NOT transcription complexsubunit 9 OS=Homo sapiens OX=9606 GN=CNOT9MHSLATAAPVPTTLAQVDREKIYQWINELSSPETRENALLELSKKRESVPDLAPMLWHSFGTIAALLQEIVNIYPSINPPTLTAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLHTVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILGKMVLQLSKEPSARLLKHVVRCYLRLSDNPRFSDLTFCWSSFQRK>sp|Q9ULK2|AT7L1_HUMAN Ataxin-7-like protein 1 OS=Homo sapiens OX=9606GN=ATXN7L1 PE=1 SV=3MTSERSRIPCLSAAAAEGTGKKQQEGRAMATLDRKVPSPEAFLGKPWSSWIDAAKLHCSDNVDLEEAGKEGGKSREVMRLNKEDMHLFGHYPAHDDFYLVVCSACNQVVKPQVFQSHCERRHGSMCRPSPSPVSPASNPRTSLVQVKTKACLSGHHSASSTSKPFKTPKDNLLTSSSKQHTVFPAKGSRDKPCVPVPVVSLEKIPNLVKADGANVKMNSTTTTAVSASSTSSSAVSTPPLIKPVLMSKSVPPSPEKILNGKGILPTTIDKKHQNGTKNSNKPYRRLSEREFDPNKHCGVLDPETKKPCTRSLTCKTHSLSHRRAVPGRKKQFDLLLAEHKAKSREKEVKDKEHLLTSTREILPSQSGPAQDSLLGSSGSSGPEPKVASPAKSRPPNSVLPRPSSANSISSSTSSNHSGHTPEPPLPPVGGDLASRLSSDEGEMDGADESEKLDCQFSTHHPRPLAFCSFGSRLMGRGYYVFDRRWDRFRFALNSMVEKHLNSQMWKKIPPAADSPLPSPAAHITTPVPASVLQPFSNPSAVYLPSAPISSRLTSSYIMTSAMLSNAAFVTSPDPSALMSHTTAFPHVAATLSIMDSTFKAPSAVSPIPAVIPSPSHKPSKTKTSKSSKVKDLSTRSDESPSNKKRKPQSSTSSSSSSSSSSLQTSLSSPLSGPHKKNCVLNASSALNSYQAAPPYNSLSVHNSNNGVSPLSAKLEPSGRTSLPGGPADIVRQVGAVGGSSDSCPLSVPSLALHAGDLSLASHNAVSSLPLSFDKSEGKKRKNSSSSSKACKITKMPGMNSVHKKNPPSLLAPVPDPVNSTSSRQVGKNSSLALSQSSPSSISSPGHSRQNTNRTGRIRTLP>sp|Q9ULK2-2|AT7L1_HUMAN Isoform 2 of Ataxin-7-like protein 1 OS=Homosapiens OX=9606 GN=ATXN7L1MTSERSRIPCLSAAAAEGTGKKQQEGRAMATLDRKVPSPEAFLGKPWSSWIDAAKLHCSDNVDLEEAGKEGGKSREVMRLNKEDMHLFGHYPAHDDFYLVVCSACNQVVKPQVFQSHCGRKQDNRRNEGISRSGPESSQAIEKHQV>sp|Q9ULK2-3|AT7L1_HUMAN Isoform 3 of Ataxin-7-like protein 1 OS=Homosapiens OX=9606 GN=ATXN7L1MCRPSPSPVSPASNPRTSLVQVKTKACLSGHHSASSTSKPFKTPKDNLLTSSSKQHTVFPAKGSRDKPCVPVPVVSLEKIPNLVKADGANVKMNSTTTTAVSASSTSSSAVSTPPLIKPVLMSKSVPPSPEKILNGKGILPTTIDKKHQNGTKNSNKPYRRLSEREFDPNKHCGVLDPETKKPCTRSLTCKTHSLSHRRAVPGRKKQFDLLLAEHKAKSREKEVKDKEHLLTSTREILPSQSGPAQDSLLGSSGSSGPEPKVASPAKSRPPNSVLPRPSSANSISSSTSSNHSGHTPEPPLPPVGGDLASRLSSDEGEMDGADESEKLDCQFSTHHPRPLAFCSFGSRLMGRGYYVFDRRWDRFRFALNSMVEKHLNSQMWKKIPPAADSPLPSPAAHITTPVPASVLQPFSNPSAVYLPSAPISSRLTSSYIMTSAMLSNAAFVTSPDPSALMSHTTAFPHVAATLSIMDSTFKAPSAVSPIPAVIPSPSHKPSKTKTSKSSKVKDLSTRSDESPSNKKRKPQSSTSSSSSSSSSSLQTSLSSPLSGPHKKNCVLNASSALNSYQAAPPYNSLSVHNSNNGVSPLSAKLEPSGRTSLPGGPADIVRQVGAVGGSSDSCPLSVPSLALHAGDLSLASHNAVSSLPLSFDKSEGKKRKNSSSSSKACKITKMPGMNSVHKKNPPSLLAPVPDPVNSTSSRQVGKNSSLALSQSSPSSISSPGHSRQKNTNRTGRIRTLP>sp|Q5TC04|ATAS1_HUMAN Putative uncharacterized protein ATP1A1-AS1OS=Homo sapiens OX=9606 GN=ATP1A1-AS1 PE=5 SV=1MAHFKDDLQTNVEIIPGESAPRKESPRPPAPPSSAAGVGGCSNHSPSVQESPLSPPALAQLGSAQQPSMRTELSFSEKKDTMIIWQITITVWCQR>sp|O94823|AT10B_HUMAN Phospholipid-transporting ATPase VB OS=Homosapiens OX=9606 GN=ATP10B PE=1 SV=2MALSVDSSWHRWQWRVRDGFPHCPSETTPLLSPEKGRQSYNLTQQRVVFPNNSIFHQDWEEVSRRYPGNRTCTTKYTLFTFLPRNLFEQFHRWANLYFLFLVILNWMPSMEVFHREITMLPLAIVLFVIMIKDGMEDFKRHRFDKAINCSNIRIYERKEQTYVQKCWKDVRVGDFIQMKCNEIVPADILLLFSSDPNGICHLETASLDGETNLKQRCVVKGFSQQEVQFEPELFHNTIVCEKPNNHLNKFKGYMEHPDQTRTGFGCESLLLRGCTIRNTEMAVGIVIYAGHETKAMLNNSGPRYKRSKIERRMNIDIFFCIGILILMCLIGAVGHSIWNGTFEEHPPFDVPDANGSFLPSALGGFYMFLTMIILLQVLIPISLYVSIELVKLGQVFFLSNDLDLYDEETDLSIQCRALNIAEDLGQIQYIFSDKTGTLTENKMVFRRCTIMGSEYSHQENAKRLETPKELDSDGEEWTQYQCLSFSARWAQDPATMRSQKGAQPLRRSQSARVPIQGHYRQRSMGHRESSQPPVAFSSSIEKDVTPDKNLLTKVRDAALWLETLSDSRPAKASLSTTSSIADFFLALTICNSVMVSTTTEPRQRVTIKPSSKALGTSLEKIQQLFQKLKLLSLSQSFSSTAPSDTDLGESLGANVATTDSDERDDASVCSGGDSTDDGGYRSSMWDQGDILESGSGTSLEEALEAPATDLARPEFCYEAESPDEAALVHAAHAYSFTLVSRTPEQVTVRLPQGTCLTFSLLCTLGFDSVRKRMSVVVRHPLTGEIVVYTKGADSVIMDLLEDPACVPDINMEKKLRKIRARTQKHLDLYARDGLRTLCIAKKVVSEEDFRRWASFRREAEASLDNRDELLMETAQHLENQLTLLGATGIEDRLQEGVPDTIATLREAGIQLWVLTGDKQETAVNIAHSCRLLNQTDTVYTINTENQETCESILNCALEELKQFRELQKPDRKLFGFRLPSKTPSITSEAVVPEAGLVIDGKTLNAIFQGKLEKKFLELTQYCRSVLCCRSTPLQKSMIVKLVRDKLRVMTLSIGDGANDVSMIQAADIGIGISGQEGMQAVMSSDFAITRFKHLKKLLLVHGHWCYSRLARMVVYYLYKNVCYVNLLFWYQFFCGFSSSTMIDYWQMIFFNLFFTSLPPLVFGVLDKDISAETLLALPELYKSGQNSECYNLSTFWISMVDAFYQSLICFFIPYLAYKGSDIDVFTFGTPINTISLTTILLHQAMEMKTWTIFHGVVLLGSFLMYFLVSLLYNATCVICNSPTNPYWVMEGQLSNPTFYLVCFLTPVVALLPRYFFLSLQGTCGKSLISKAQKIDKLPPDKRNLEIQSWRSRQRPAPVPEVARPTHHPVSSITGQDFSASTPKSSNPPKRKHVEESVLHEQRCGTECMRDDSCSGDSSAQLSSGEHLLGPNRIMAYSRGQTDMCRCSKRSSHRRSQSSLTI>sp|O94823-2|AT10B_HUMAN Isoform B of Phospholipid-transporting ATPase VBOS=Homo sapiens OX=9606 GN=ATP10BMALSVDSSWHRWQWRVRDGFPHCPSETTPLLSPEKGRQSYNLTQQRVVFPNNSIFHQDWEEVSRRYPGNRTCTTKYTLFTFLPRNLFEQFHRWANLYFLFLVILNWMPSMEVFHREITMLPLAIVLFVIMIKDGMEDFKRHRFDKAINCSNIRIYERKEQTYVQKCWKDVRVGDFIQMKCNEIVPADILLLFSSDPNGICHLETASLDGETNLKQRCVVKGFSQQEVQFEPELFHNTIVCEKPNNHLNKFKGYMEHPDQTRTGFGCESLLLRGCTIRNTEMAVGIVIYAGHETKAMLNNSGPRYKRSKIERRMNIDIFFCIGILILMCLIGAVGHSIWNGTFEEHPPFDVPDANGSFLPSALGGFYMFLTMIILLQVLIPISLYVSIELVKLGQVFFLSNDLDLYDEETDLSIQCRALNIAEDLGQIQYIFSDKTGTLTENKMVFRRCTIMGSEYSHQENGIEAPKGSIPLSKRKYPALLRNEEIKDILLALLEAVWHFHKLLPVSLWSSLSQIRAVPITCKLSFVYKG>sp|O94823-3|AT10B_HUMAN Isoform C of Phospholipid-transporting ATPase VBOS=Homo sapiens OX=9606 GN=ATP10BMKKEGRKRWKRKEDKKRVVVSNLLFEGWSHKENPNRHHRGNQIKTSKYTVLSFVPKNIFEQLHRFANLYFVGIAVLNFIPVVNAFQPEVSMIPICVILAVTAIKDAWEDLRRYKSDKVINNRECLIYSRKEQTYVQKCWKDVRVGDFIQMKCNEIVPADILLLFSSDPNGICHLETASLDGETNLKQRCVVKGFSQQEVQFEPELFHNTIVCEKPNNHLNKFKGYMEHPDQTRTGFGCESLLLRGCTIRNTEMAVGIVIYAGHETKAMLNNSGPRYKRSKIERRMNIDIFFCIGILILMCLIGAVGHSIWNGTFEEHPPFDVPDANGSFLPSALGGFYMFLTMIILLQVLIPISLYVSIELVKLGQVFFLSNDLDLYDEETDLSIQCRALNIAEDLGQIQYIFSDKTGTLTENKMVFRRCTIMGSEYSHQENGIEAPKGSIPLSKRKYPALLRNEEIKDILLALLEAVWHFHKLLPVSLWSSLSQIRAVPITCKLSFVYKG>sp|Q9H672|ASB7_HUMAN Ankyrin repeat and SOCS box protein 7 OS=Homosapiens OX=9606 GN=ASB7 PE=1 SV=2MLHHHCRRNPELQEELQIQAAVAAGDVHTVRKMLEQGYSPNGRDANGWTLLHFSAARGKERCVRVFLEHGADPTVKDLIGGFTALHYAAMHGRARIARLMLESEYRSDIINAKSNDGWTPLHVAAHYGRDSFVRLLLEFKAEVDPLSDKGTTPLQLAIIRERSSCVKILLDHNANIDIQNGFLLRYAVIKSNHSYCRMFLQRGADTNLGRLEDGQTPLHLSALRDDVLCARMLYNYGADTNTRNYEGQTPLAVSISISGSSRPCLDFLQEVTRQPRNLQDLCRIKIRQCIGLQNLKLLDELPIAKVMKDYLKHKFDDI>sp|Q9H672-2|ASB7_HUMAN Isoform 2 of Ankyrin repeat and SOCS box protein7 OS=Homo sapiens OX=9606 GN=ASB7MLHHHCRRNPELQEELQIQAAVAAGDVHTVRKMLEQGYSPNGRDANGWTLLHFSAARGKERCVRVFLEHGADPTVKDLIGGFTALHYAAMHGRARIARLMLESEYRSDIINAKSNDGWTPLHVAAHYGRDSFVRLLLEFKAEVDPLSDKGTTPLQLAIIRERSSCVKILLDHNANIDIQNGFLLRYAVIKSNHSYCRMFLQRGADTNLGRLEDGQTPLHLSALRDDVLCARMLYNYGADTNTRNYEGQTPLAVSISISGSSRPCLDFLQEVTSM>sp|Q6IPW1|CK071_HUMAN Uncharacterized protein C11orf71 OS=Homo sapiensOX=9606 GN=C11orf71 PE=2 SV=2MALNNVSLSSGDQRSRVAYRSSHGDLRPRASALAMVSGDGFLVSRPEAIHLGPRQAVRPSVRAESRRVDGGGRSPREPDGRGRSRQARFSPYPIPAVEPDLLRSVLQQRLIALGGVIAARISV>sp|Q6IPW1-2|CK071_HUMAN Isoform 2 of Uncharacterized protein C11orf71OS=Homo sapiens OX=9606 GN=C11orf71MALNNVSLSSGDQRSRVAYRSSHGDLRPRASALAMVSGDGFLVSRPEAIHLGPRQAVRPSVRAESRRVDGGGRSPREPDGRGRSRQARFSPYPIPAVEPDLLRSVLQQRLIALGVTTWTLKLSESATPDLRWCSTCSHSNIFEILVI>sp|Q8N9N2|ASCC1_HUMAN Activating signal cointegrator 1 complex subunit 1OS=Homo sapiens OX=9606 GN=ASCC1 PE=1 SV=1MEVLRPQLIRIDGRNYRKNPVQEQTYQHEEDEEDFYQGSMECADEPCDAYEVEQTPQGFRSTLRAPSLLYNLIHLNTSNDCGFQKITLDCQNIYTWKSRHIVGKRGDTRKKIEMETKTSISIPKPGQDGEIVITGQHRNGVISARTRIDVLLDTFRRKQPFTHFLAFFLNEVEVQEGFLRFQEEVLAKCSMDHGVDSSIFQNPKKLHLTIGMLVLLSEEEIQQTCEMLQQCKEEFINDISGGKPLEVEMAGIEYMNDDPGMVDVLYAKVHMKDGSNRLQELVDRVLERFQASGLIVKEWNSVKLHATVMNTLFRKDPNAEGRYNLYTAEGKYIFKERESFDGRNILKSFALLPRLEYNDAISAHCNLCLPGSSDSPASASQVAGITGVSDAYSQSLPGKS>sp|Q8N9N2-2|ASCC1_HUMAN Isoform 2 of Activating signal cointegrator 1complex subunit 1 OS=Homo sapiens OX=9606 GN=ASCC1MEVLRPQLIRIDGRNYRKNPVQEQTYQHEEDEEDFYQGSMECADEPCDAYEVEQTPQGFRSTLRAPSLLYKHIVGKRGDTRKKIEMETKTSISIPKPGQDGEIVITGQHRNGVISARTRIDVLLDTFRRKQPFTHFLAFFLNEVEVQEGFLRFQEEVLAKCSMDHGVDSSIFQNPKKLHLTIGMLVLLSEEEIQQTCEMLQQCKEEFINDISGGKPLEVEMAGIEYMNDDPGMVDVLYAKVHMKDGSNRLQELVDRVLERFQASGLIVKEWNSVKLHATVMNTLFRKDPNAEGRYNLYTAEGKYIFKERESFDGRNILKLFENFYFGSLKLNSIHISQRFTVDSFGNYASCGQIDFS>sp|O75110|ATP9A_HUMAN Probable phospholipid-transporting ATPase IIAOS=Homo sapiens OX=9606 GN=ATP9A PE=1 SV=3MTDNIPLQPVRQKKRMDSRPRAGCCEWLRCCGGGEARPRTVWLGHPEKRDQRYPRNVINNQKYNFFTFLPGVLFNQFKYFFNLYFLLLACSQFVPEMRLGALYTYWVPLGFVLAVTVIREAVEEIRCYVRDKEVNSQVYSRLTARGTVKVKSSNIQVGDLIIVEKNQRVPADMIFLRTSEKNGSCFLRTDQLDGETDWKLRLPVACTQRLPTAADLLQIRSYVYAEEPNIDIHNFVGTFTREDSDPPISESLSIENTLWAGTVVASGTVVGVVLYTGRELRSVMNTSNPRSKIGLFDLEVNCLTKILFGALVVVSLVMVALQHFAGRWYLQIIRFLLLFSNIIPISLRVNLDMGKIVYSWVIRRDSKIPGTVVRSSTIPEQLGRISYLLTDKTGTLTQNEMIFKRLHLGTVAYGLDSMDEVQSHIFSIYTQQSQDPPAQKGPTLTTKVRRTMSSRVHEAVKAIALCHNVTPVYESNGVTDQAEAEKQYEDSCRVYQASSPDEVALVQWTESVGLTLVGRDQSSMQLRTPGDQILNFTILQIFPFTYESKRMGIIVRDESTGEITFYMKGADVVMAGIVQYNDWLEEECGNMAREGLRVLVVAKKSLAEEQYQDFEARYVQAKLSVHDRSLKVATVIESLEMEMELLCLTGVEDQLQADVRPTLETLRNAGIKVWMLTGDKLETATCTAKNAHLVTRNQDIHVFRLVTNRGEAHLELNAFRRKHDCALVISGDSLEVCLKYYEYEFMELACQCPAVVCCRCAPTQKAQIVRLLQERTGKLTCAVGDGGNDVSMIQESDCGVGVEGKEGKQASLAADFSITQFKHLGRLLMVHGRNSYKRSAALSQFVIHRSLCISTMQAVFSSVFYFASVPLYQGFLIIGYSTIYTMFPVFSLVLDKDVKSEVAMLYPELYKDLLKGRPLSYKTFLIWVLISIYQGSTIMYGALLLFESEFVHIVAISFTSLILTELLMVALTIQTWHWLMTVAELLSLACYIASLVFLHEFIDVYFIATLSFLWKVSVITLVSCLPLYVLKYLRRRFSPPSYSKLTS>sp|O75110-2|ATP9A_HUMAN Isoform Short of Probable phospholipid-transporting ATPase IIA OS=Homo sapiens OX=9606 GN=ATP9AMTDNIPLQPVRQKKRMDSRPRAGCCEWLRCCGGGEARPRTVWLGHPEKRDQRYPRNVINNQKYNFFTFLPGVLFNQFKYFFNLYFLLLACSQFVPEMRLGALYTYWVPLGFVLAVTVIREAVEEIRCYVRDKEVNSQVYSRLTARGTVVGVVLYTGRELRSVMNTSNPRSKIGLFDLEVNCLTKILFGALVVVSLVMVALQHFAGRWYLQIIRFLLLFSNIIPISLRVNLDMGKIVYSWVIRRDSKIPGTVVRSSTIPEQLGRISYLLTDKTGTLTQNEMIFKRLHLGTVAYGLDSMDEVQSHIFSIYTQQSQDPPAQKGPTLTTKVRRTMSSRVHEAVKAIALCHNVTPVYESNGVTDQAEAEKQYEDSCRVYQASSPDEVALVQWTESVGLTLVGRDQSSMQLRTPGDQILNFTILQIFPFTYESKRMGIIVRDESTGEITFYMKGADVVMAGIVQYNDWLEEECGNMAREGLRVLVVAKKSLAEEQYQDFEARYVQAKLSVHDRSLKVATVIESLEMEMELLCLTGVEDQLQADVRPTLETLRNAGIKVWMLTGDKLETATCTAKNAHLVTRNQDIHVFRLVTNRGEAHLELNAFRRKHDCALVISGDSLEVCLKYYEYEFMELACQCPAVVCCRCAPTQKAQIVRLLQERTGKLTCAVGDGGNDVSMIQESDCGVGVEGKEGKQASLAADFSITQFKHLGRLLMVHGRNSYKRSAALSQFVIHRSLCISTMQAVFSSVFYFASVPLYQGFLIIGYSTIYTMFPVFSLVLDKDVKSEVAMLYPELYKDLLKGRPLSYKTFLIWVLISIYQGSTIMYGALLLFESEFVHIVAISFTSLILTELLMVALTIQTWHWLMTVAELLSLACYIASLVFLHEFIDVYFIATLSFLWKVSVITLVSCLPLYVLKYLRRRFSPPSYSKLTS>sp|Q2TAZ0|ATG2A_HUMAN Autophagy-related protein 2 homolog A OS=Homosapiens OX=9606 GN=ATG2A PE=1 SV=3MSRWLWPWSNCVKERVCRYLLHHYLGHFFQEHLSLDQLSLDLYKGSVALRDIHLEIWSVNEVLESMESPLELVEGFVGSIEVAVPWAALLTDHCTVRVSGLQLTLQPRRGPAPGAADSQSWASCMTTSLQLAQECLRDGLPEPSEPPQPLEGLEMFAQTIETVLRRIKVTFLDTVVRVEHSPGDGERGVAVEVRVQRLEYCDEAVRDPSQAPPVDVHQPPAFLHKLLQLAGVRLHYEELPAQEEPPEPPLQIGSCSGYMELMVKLKQNEAFPGPKLEVAGQLGSLHLLLTPRQLQQLQELLSAVSLTDHEGLADKLNKSRPLGAEDLWLIEQDLNQQLQAGAVAEPLSPDPLTNPLLNLDNTDLFFSMAGLTSSVASALSELSLSDVDLASSVRSDMASRRLSAQAHPAGKMAPNPLLDTMRPDSLLKMTLGGVTLTLLQTSAPSSGPPDLATHFFTEFDATKDGPFGSRDFHHLRPRFQRACPCSHVRLTGTAVQLSWELRTGSRGRRTTSMEVHFGQLEVLECLWPRGTSEPEYTEILTFPGTLGSQASARPCAHLRHTQILRRVPKSRPRRSVACHCHSELALDLANFQADVELGALDRLAALLRLATVPAEPPAGLLTEPLPAMEQQTVFRLSAPRATLRLRFPIADLRPEPDPWAGQAVRAEQLRLELSEPQFRSELSSGPGPPVPTHLELTCSDLHGIYEDGGKPPVPCLRVSKALDPKSTGRKYFLPQVVVTVNPQSSSTQWEVAPEKGEELELSVESPCELREPEPSPFSSKRTMYETEEMVIPGDPEEMRTFQSRTLALSRCSLEVILPSVHIFLPSKEVYESIYNRINNDLLMWEPADLLPTPDPAAQPSGFPGPSGFWHDSFKMCKSAFKLANCFDLTPDSDSDDEDAHFFSVGASGGPQAAAPEAPSLHLQSTFSTLVTVLKGRITALCETKDEGGKRLEAVHGELVLDMEHGTLFSVSQYCGQPGLGYFCLEAEKATLYHRAAVDDYPLPSHLDLPSFAPPAQLAPTIYPSEEGVTERGASGRKGQGRGPHMLSTAVRIHLDPHKNVKEFLVTLRLHKATLRHYMALPEQSWHSQLLEFLDVLDDPVLGYLPPTVITILHTHLFSCSVDYRPLYLPVRVLITAETFTLSSNIIMDTSTFLLRFILDDSALYLSDKCEVETLDLRRDYVCVLDVDLLELVIKTWKGSTEGKLSQPLFELRCSNNVVHVHSCADSCALLVNLLQYVMSTGDLHPPPRPPSPTEIAGQKLSESPASLPSCPPVETALINQRDLADALLDTERSLRELAQPSGGHLPQASPISVYLFPGERSGAPPPSPPVGGPAGSLGSCSEEKEDEREEEGDGDTLDSDEFCILDAPGLGIPPRDGEPVVTQLHPGPIVVRDGYFSRPIGSTDLLRAPAHFPVPSTRVVLREVSLVWHLYGGRDFGPHPGHRARTGLSGPRSSPSRCSGPNRPQNSWRTQGGSGRQHHVLMEIQLSKVSFQHEVYPAEPATGPAAPSQELEERPLSRQVFIVQELEVRDRLASSQINKFLYLHTSERMPRRAHSNMLTIKALHVAPTTNLGGPECCLRVSLMPLRLNVDQDALFFLKDFFTSLVAGINPVVPGETSAEARPETRAQPSSPLEGQAEGVETTGSQEAPGGGHSPSPPDQQPIYFREFRFTSEVPIWLDYHGKHVTMDQVGTFAGLLIGLAQLNCSELKLKRLCCRHGLLGVDKVLGYALNEWLQDIRKNQLPGLLGGVGPMHSVVQLFQGFRDLLWLPIEQYRKDGRLMRGLQRGAASFGSSTASAALELSNRLVQAIQATAETVYDILSPAAPVSRSLQDKRSARRLRRGQQPADLREGVAKAYDTVREGILDTAQTICDVASRGHEQKGLTGAVGGVIRQLPPTVVKPLILATEATSSLLGGMRNQIVPDAHKDHALKWRSDSAQD>sp|Q2TAZ0-3|ATG2A_HUMAN Isoform 2 of Autophagy-related protein 2 homologA OS=Homo sapiens OX=9606 GN=ATG2AMSRWLWPWSNCVKERVCRYLLHHYLGHFFQEHLSLDQLSLDLYKGSVALRDIHLEIWSVNEVLESMESPLELVEGFVGSIEVAVPWAALLTDHCTVRVSGLQLTLQPRRGPAPGAADSQSWASCMTTSLQLAQECLRDGLPEPSEPPQPLEGLEMFAQTIETVLRRIKVTFLDTVVRVEHSPGDGERGVAVEVRVQRLEYCDEAVRDPSQAPPVDVHQPPAFLHKLLQLAGVRLHYEELPAQEEPPEPPLQIGSCSGYMELMVKLKQNEAFPGPKLEVAGQLGSLHLLLTPRQLQQLQELLSAVSLTDHEGLADKLNKSRPLGAEDLWLIEQDLNQQLQAGAVAEPLSPDPLTNPLLNLDNTDLFFSMAGLTSSVASALSELSLSDVDLASSVRSDMASRRLSAQAHPAGKMAPNPLLDTMRPDSLLKMTLGGVTLTLLQTSAPSSGPPDLATHFFTEFDATKDGPFGSRDFHHLRPRFQRACPCSHVRLTGTAVQLSWELRTGSRGRRTTSMEVHFGQLEVLECLWPRGTSEPEYTEILTFPGTLGSQASARPCAHLRHTQILRRVPKSRPRRSVACHCHSELALDLANFQADVELGALDRLAALLRLATVPAEPPAGLLTEPLPAMEQQTVFRLSAPRATLRLRFPIADLRPEPDPWAGQAVRAEQLRLELSEPQFRSELSSGPGPPVPTHLELTCSDLHGIYEDGGKPPVPCLRVSKALDPKSTGRKYFLPQVVVTVNPQSSSTQWEVAPEKGEELELSVESPCELREPEPSPFSSKRTMYETEEMVIPGDPEEMRTFQSRTLALSRCSLEVILPSVHIFLPSKEVYESIYNRINNDLLMWEPADLLPTPDPAAQPSGFPGPSGFWHDSFKMCKSAFKLANCFDLTPDSDSDDEDAHFFSVGASGGPQAAAPEAPSLHLQSTFSTLVTVLKGRITALCETKDEGGKRLEAVHGELVLDMEHGTLFSVSQYCGQPGLGYFCLEAEKATLYHRAAVDDYPLPSHLDLPSFAPPAQLAPTIYPSEEGVTERGASGRKGQGRGPHMLSTAVRIHLDPHKNVKEFLVTLRLHKATLRHYMALPEQSWHSQLLEFLDVLDDPVLGYLPPTVITILHTHLFSCSVDYRPLYLPVRVLITAETFTLSSNIIMDTSTFLLRFILDDSALYLSDKCEVETLDLRRDYVCVLDVDLLELVIKTWKGSTEGKLSQPLFELRCSNNVVHVHSCADSCALLVNLLQYVMSTGDLHPPPRPPSPTEIAGQKVQLSESPASLPSCPPVETALINQRDLADALLDTERSLRELAQPSGGHLPQASPISVYLFPGERSGAPPPSPPVGGPAGSLGSCSEEKEDEREEEGDGDTLDSDEFCILDAPGLGIPPRDGEPVVTQLHPGPIVVRDGYFSRPIGSTDLLRAPAHFPVPSTRVVLREVSLVWHLYGGRDFGPHPGHRARTGLSGPRSSPSRCSGPNRPQNSWRTQGGSGRQHHVLMEIQLSKVSFQHEVYPAEPATGPAAPSQELEERPLSRQVFIVQELEVRDRLASSQINKFLYLHTSERMPRRAHSNMLTIKALHVAPTTNLGGPECCLRVSLMPLRLNVDQDALFFLKDFFTSLVAGINPVVPGETSAEARPETRAQPSSPLEGQAEGVETTGSQEAPGGGHSPSPPDQQPIYFREFRFTSEVPIWLDYHGKHVTMDQVGTFAGLLIGLAQLNCSELKLKRLCCRHGLLGVDKVLGYALNEWLQDIRKNQLPGLLGGVGPMHSVVQLFQGFRDLLWLPIEQYRKDGRLMRGLQRGAASFGSSTASAALELSNRLVQAIQATAETVYDILSPAAPVSRSLQDKRSARRLRRGQQPADLREGVAKAYDTVREGILDTAQTICDVASRGHEQKGLTGAVGGVIRQLPPTVVKPLILATEATSSLLGGMRNQIVPDAHKDHALKWRSDSAQD>sp|Q2TAZ0-4|ATG2A_HUMAN Isoform 3 of Autophagy-related protein 2 homologA OS=Homo sapiens OX=9606 GN=ATG2AMAVAMVKLCERAGLPLLAAPLLRSLLPRAPQPGPAQPRSVQGQRCPARHPPGNLVCERGAGVNGVTAGAGGRLRGLHRGGRALGCSAHRPLHSARVRPPAHLAAPPGSSARGCRLTELGYALNEWLQDIRKNQLPGLLGGVGPMHSVVQLFQGFRDLLWLPIEQYRKDGRLMRGLQRGAASFGSSTASAALELSNRLVQAIQATAETVYDILSPAAPVSRSLQDKRSARRLRRGQQPADLREGVAKAYDTVREGILDTAQTICDVASRGHEQKGLTGAVGGVIRQLPPTVVKPLILATEATSSLLGGMRNQIVPDAHKDHALKWRSDSAQD>sp|Q2TAZ0-5|ATG2A_HUMAN Isoform 4 of Autophagy-related protein 2 homologA OS=Homo sapiens OX=9606 GN=ATG2AMSRWLWPWSNCVKERVCRYLLHHYLGHFFQEHLSLDQLSLDLYKGSVALRDIHLEIWVRSQARVQEVCERGAGVNGVTAGAGGRLRGLHRGGRALGCSAHRPLHSARVRPPAHLAAPPGSR>sp|P07307|ASGR2_HUMAN Asialoglycoprotein receptor 2 OS=Homo sapiensOX=9606 GN=ASGR2 PE=1 SV=2MAKDFQDIQQLSSEENDHPFHQGEGPGTRRLNPRRGNPFLKGPPPAQPLAQRLCSMVCFSLLALSFNILLLVVICVTGSQSEGHGGAQLQAELRSLKEAFSNFSSSTLTEVQAISTHGGSVGDKITSLGAKLEKQQQDLKADHDALLFHLKHFPVDLRFVACQMELLHSNGSQRTCCPVNWVEHQGSCYWFSHSGKAWAEAEKYCQLENAHLVVINSWEEQKFIVQHTNPFNTWIGLTDSDGSWKWVDGTDYRHNYKNWAVTQPDNWHGHELGGSEDCVEVQPDGRWNDDFCLQVYRWVCEKRRNATGEVA>sp|P07307-2|ASGR2_HUMAN Isoform 2 of Asialoglycoprotein receptor 2OS=Homo sapiens OX=9606 GN=ASGR2MAKDFQDIQQLSSEENDHPFHQGPPPAQPLAQRLCSMVCFSLLALSFNILLLVVICVTGSQSEGHGGAQLQAELRSLKEAFSNFSSSTLTEVQAISTHGGSVGDKITSLGAKLEKQQQDLKADHDALLFHLKHFPVDLRFVACQMELLHSNGSQRTCCPVNWVEHQGSCYWFSHSGKAWAEAEKYCQLENAHLVVINSWEEQKFIVQHTNPFNTWIGLTDSDGSWKWVDGTDYRHNYKNWAVTQPDNWHGHELGGSEDCVEVQPDGRWNDDFCLQVYRWVCEKRRNATGEVA>sp|P07307-3|ASGR2_HUMAN Isoform 3 of Asialoglycoprotein receptor 2OS=Homo sapiens OX=9606 GN=ASGR2MAKDFQDIQQLSSEENDHPFHQGPPPAQPLAQRLCSMVCFSLLALSFNILLLVVICVTGSQSAQLQAELRSLKEAFSNFSSSTLTEVQAISTHGGSVGDKITSLGAKLEKQQQDLKADHDALLFHLKHFPVDLRFVACQMELLHSNGSQRTCCPVNWVEHQGSCYWFSHSGKAWAEAEKYCQLENAHLVVINSWEEQKFIVQHTNPFNTWIGLTDSDGSWKWVDGTDYRHNYKNWAVTQPDNWHGHELGGSEDCVEVQPDGRWNDDFCLQVYRWVCEKRRNATGEVA>sp|Q9BVC5|ASHWN_HUMAN Ashwin OS=Homo sapiens OX=9606 GN=C2orf49 PE=1SV=1MAGDVGGRSCTDSELLLHPELLSQEFLLLTLEQKNIAVETDVRVNKDSLTDLYVQHAIPLPQRDLPKNRWGKMMEKKREQHEIKNETKRSSTVDGLRKRPLIVFDGSSTSTSIKVKKTENGDNDRLKPPPQASFTSNAFRKLSNSSSSVSPLILSSNLPVNNKTEHNNNDAKQNHDLTHRKSPSGPVKSPPLSPVGTTPVKLKRAAPKEEAEAMNNLKPPQAKRKIQHVTWP>sp|Q9BVC5-2|ASHWN_HUMAN Isoform 2 of Ashwin OS=Homo sapiens OX=9606GN=C2orf49MRRLRVTTHASLRPSTSLPQRFLRGALWVADWGLLATTMAGDVGGRSCTDSELLLHPELLSQEFLLLTLEQKNIAVETDVRVNKDSLTDLYVQHAIPLPQRDLPKNRWGKMMEKKREQHEIKNETKRSSTVDGLRKRPLIVFDGSSTSTSIKVKKTENGDNDRLKPPPQNHDLTHRKSPSGPVKSPPLSPVGTTPVKLKRAAPKEEAEAMNNLKPPQAKRKIQHVTWP>sp|P78357|CNTP1_HUMAN Contactin-associated protein 1 OS=Homo sapiensOX=9606 GN=CNTNAP1 PE=1 SV=1MMHLRLFCILLAAVSGAEGWGYYGCDEELVGPLYARSLGASSYYSLLTAPRFARLHGISGWSPRIGDPNPWLQIDLMKKHRIRAVATQGSFNSWDWVTRYMLLYGDRVDSWTPFYQRGHNSTFFGNVNESAVVRHDLHFHFTARYIRIVPLAWNPRGKIGLRLGLYGCPYKADILYFDGDDAISYRFPRGVSRSLWDVFAFSFKTEEKDGLLLHAEGAQGDYVTLELEGAHLLLHMSLGSSPIQPRPGHTTVSAGGVLNDQHWHYVRVDRFGRDVNFTLDGYVQRFILNGDFERLNLDTEMFIGGLVGAARKNLAYRHNFRGCIENVIFNRVNIADLAVRRHSRITFEGKVAFRCLDPVPHPINFGGPHNFVQVPGFPRRGRLAVSFRFRTWDLTGLLLFSRLGDGLGHVELTLSEGQVNVSIAQSGRKKLQFAAGYRLNDGFWHEVNFVAQENHAVISIDDVEGAEVRVSYPLLIRTGTSYFFGGCPKPASRWDCHSNQTAFHGCMELLKVDGQLVNLTLVEGRRLGFYAEVLFDTCGITDRCSPNMCEHDGRCYQSWDDFICYCELTGYKGETCHTPLYKESCEAYRLSGKTSGNFTIDPDGSGPLKPFVVYCDIRENRAWTVVRHDRLWTTRVTGSSMERPFLGAIQYWNASWEEVSALANASQHCEQWIEFSCYNSRLLNTAGGYPYSFWIGRNEEQHFYWGGSQPGIQRCACGLDRSCVDPALYCNCDADQPQWRTDKGLLTFVDHLPVTQVVIGDTNRSTSEAQFFLRPLRCYGDRNSWNTISFHTGAALRFPPIRANHSLDVSFYFRTSAPSGVFLENMGGPYCQWRRPYVRVELNTSRDVVFAFDVGNGDENLTVHSDDFEFNDDEWHLVRAEINVKQARLRVDHRPWVLRPMPLQTYIWMEYDQPLYVGSAELKRRPFVGCLRAMRLNGVTLNLEGRANASEGTSPNCTGHCAHPRLPCFHGGRCVERYSYYTCDCDLTAFDGPYCNHDIGGFFEPGTWMRYNLQSALRSAAREFSHMLSRPVPGYEPGYIPGYDTPGYVPGYHGPGYRLPDYPRPGRPVPGYRGPVYNVTGEEVSFSFSTSSAPAVLLYVSSFVRDYMAVLIKDDGTLQLRYQLGTSPYVYQLTTRPVTDGQPHSINITRVYRNLFIQVDYFPLTEQKFSLLVDSQLDSPKALYLGRVMETGVIDPEIQRYNTPGFSGCLSGVRFNNVAPLKTHFRTPRPMTAELAEALRVQGELSESNCGAMPRLVSEVPPELDPWYLPPDFPYYHDEGWVAILLGFLVAFLLLGLVGMLVLFYLQNHRYKGSYHTNEPKAAHEYHPGSKPPLPTSGPAQVPTPTAAPNQAPASAPAPAPTPAPAPGPRDQNLPQILEESRSE>sp|Q5T686|AVPI1_HUMAN Arginine vasopressin-induced protein 1 OS=Homosapiens OX=9606 GN=AVPI1 PE=1 SV=3MGTPASVVSEPPPWQAPIEARGRKQASANIFQDAELLQIQALFQRSGDQLAEERAQIIWECAGDHRVAEALKRLRRKRPPRQKPLGHSLHHCSRLRILEPHSALANPQSATETASSEQYLHSRKKSARIRRNWRKSGPTSYLHQIRH>sp|Q13825|AUHM_HUMAN Methylglutaconyl-CoA hydratase, mitochondrialOS=Homo sapiens OX=9606 GN=AUH PE=1 SV=1MAAAVAAAPGALGSLHAGGARLVAACSAWLCPGLRLPGSLAGRRAGPAIWAQGWVPAAGGPAPKRGYSSEMKTEDELRVRHLEEENRGIVVLGINRAYGKNSLSKNLIKMLSKAVDALKSDKKVRTIIIRSEVPGIFCAGADLKERAKMSSSEVGPFVSKIRAVINDIANLPVPTIAAIDGLALGGGLELALACDIRVAASSAKMGLVETKLAIIPGGGGTQRLPRAIGMSLAKELIFSARVLDGKEAKAVGLISHVLEQNQEGDAAYRKALDLAREFLPQGPVAMRVAKLAINQGMEVDLVTGLAIEEACYAQTIPTKDRLEGLLAFKEKRPPRYKGE>sp|Q13825-2|AUHM_HUMAN Isoform 2 of Methylglutaconyl-CoA hydratase,mitochondrial OS=Homo sapiens OX=9606 GN=AUHMAAAVAAAPGALGSLHAGGARLVAACSAWLCPGLRLPGSLAGRRAGPAIWAQGWVPAAGGPAPKRGYSSEMKTEDELRVRHLEEENRGIVVLGINRAYGKNSLSKNLIKMLSKAVDALKSDKKVRTIIIRSEVPGIFCAANLPVPTIAAIDGLALGGGLELALACDIRVAASSAKMGLVETKLAIIPGGGGTQRLPRAIGMSLAKELIFSARVLDGKEAKAVGLISHVLEQNQEGDAAYRKALDLAREFLPQGPVAMRVAKLAINQGMEVDLVTGLAIEEACYAQTIPTKDRLEGLLAFKEKRPPRYKGE>sp|P18859|ATP5J_HUMAN ATP synthase-coupling factor 6, mitochondrialOS=Homo sapiens OX=9606 GN=ATP5PF PE=1 SV=1MILQRLFRFSSVIRSAVSVHLRRNIGVTAVAFNKELDPIQKLFVDKIREYKSKRQTSGGPVDASSEYQQELERELFKLKQMFGNADMNTFPTFKFEDPKFEVIEKPQA>sp|P18859-2|ATP5J_HUMAN Isoform 2 of ATP synthase-coupling factor 6,mitochondrial OS=Homo sapiens OX=9606 GN=ATP5PFMHCDGGISMILQRLFRFSSVIRSAVSVHLRRNIGVTAVAFNKELDPIQKLFVDKIREYKSKRQTSGGPVDASSEYQQELERELFKLKQMFGNADMNTFPTFKFEDPKFEVIEKPQA>sp|O43313|ATMIN_HUMAN ATM interactor OS=Homo sapiens OX=9606 GN=ATMINPE=1 SV=2MAASEAAAAAGSAALAAGARAVPAATTGAAAAASGPWVPPGPRLRGSRPRPAGATQQPAVPAPPAGELIQPSVSELSRAVRTNILCTVRGCGKILPNSPALNMHLVKSHRLQDGIVNPTIRKDLKTGPKFYCCPIEGCPRGPERPFSQFSLVKQHFMKMHAEKKHKCSKCSNSYGTEWDLKRHAEDCGKTFRCTCGCPYASRTALQSHIYRTGHEIPAEHRDPPSKKRKMENCAQNQKLSNKTIESLNNQPIPRPDTQELEASEIKLEPSFEDSCGSNTDKQTLTTPPRYPQKLLLPKPKVALVKLPVMQFSVMPVFVPTADSSAQPVVLGVDQGSATGAVHLMPLSVGTLILGLDSEACSLKESLPLFKIANPIAGEPISTGVQVNFGKSPSNPLQELGNTCQKNSISSINVQTDLSYASQNFIPSAQWATADSSVSSCSQTDLSFDSQVSLPISVHTQTFLPSSKVTSSIAAQTDAFMDTCFQSGGVSRETQTSGIESPTDDHVQMDQAGMCGDIFESVHSSYNVATGNIISNSLVAETVTHSLLPQNEPKTLNQDIEKSAPIINFSAQNSMLPSQNMTDNQTQTIDLLSDLENILSSNLPAQTLDHRSLLSDTNPGPDTQLPSGPAQNPGIDFDIEEFFSASNIQTQTEESELSTMTTEPVLESLDIETQTDFLLADTSAQSYGCRGNSNFLGLEMFDTQTQTDLNFFLDSSPHLPLGSILKHSSFSVSTDSSDTETQTEGVSTAKNIPALESKVQLNSTETQTMSSGFETLGSLFFTSNETQTAMDDFLLADLAWNTMESQFSSVETQTSAEPHTVSNF>sp|O43313-2|ATMIN_HUMAN Isoform 2 of ATM interactor OS=Homo sapiensOX=9606 GN=ATMINMKMHAEKKHKCSKCSNSYGTEWDLKRHAEDCGKTFRCTCGCPYASRTALQSHIYRTGHEIPAEHRDPPSKKRKMENCAQNQKLSNKTIESLNNQPIPRPDTQELEASEIKLEPSFEDSCGSNTDKQTLTTPPRYPQKLLLPKPKVALVKLPVMQFSVMPVFVPTADSSAQPVVLGVDQGSATGAVHLMPLSVGTLILGLDSEACSLKESLPLFKIANPIAGEPISTGVQVNFGKSPSNPLQELGNTCQKNSISSINVQTDLSYASQNFIPSAQWATADSSVSSCSQTDLSFDSQVSLPISVHTQTFLPSSKVTSSIAAQTDAFMDTCFQSGGVSRETQTSGIESPTDDHVQMDQAGMCGDIFESVHSSYNVATGNIISNSLVAETVTHSLLPQNEPKTLNQDIEKSAPIINFSAQNSMLPSQNMTDNQTQTIDLLSDLENILSSNLPAQTLDHRSLLSDTNPGPDTQLPSGPAQNPGIDFDIEEFFSASNIQTQTEESELSTMTTEPVLESLDIETQTDFLLADTSAQSYGCRGNSNFLGLEMFDTQTQTDLNFFLDSSPHLPLGSILKHSSFSVSTDSSDTETQTEGVSTAKNIPALESKVQLNSTETQTMSSGFETLGSLFFTSNETQTAMDDFLLADLAWNTMESQFSSVETQTSAEPHTVSNF>sp|Q3ZCQ2|AX2R_HUMAN Annexin-2 receptor OS=Homo sapiens OX=9606GN=ANXA2R PE=1 SV=2MEQHFLGCVKRAWDSAEVAPEPQPPPIVSSEDRGPWPLPLYPVLGEYSLDSCDLGLLSSPCWRLPGVYWQNGLSPGVQSTLEPSTAKPTEFSWPGTQKQQEAPVEEVGQAEEPDRLRLQQLPWSSPLHPWDRQQDTEVCDSGCLLERRHPPALQPWRHLPGFSDCLEWILRVGFAAFSVLWACCSRICGAKQP>sp|Q92523|CPT1B_HUMAN Carnitine O-palmitoyltransferase 1, muscle isoformOS=Homo sapiens OX=9606 GN=CPT1B PE=1 SV=2MAEAHQAVAFQFTVTPDGVDFRLSREALKHVYLSGINSWKKRLIRIKNGILRGVYPGSPTSWLVVIMATVGSSFCNVDISLGLVSCIQRCLPQGCGPYQTPQTRALLSMAIFSTGVWVTGIFFFRQTLKLLLCYHGWMFEMHGKTSNLTRIWAMCIRLLSSRHPMLYSFQTSLPKLPVPRVSATIQRYLESVRPLLDDEEYYRMELLAKEFQDKTAPRLQKYLVLKSWWASNYVSDWWEEYIYLRGRSPLMVNSNYYVMDLVLIKNTDVQAARLGNIIHAMIMYRRKLDREEIKPVMALGIVPMCSYQMERMFNTTRIPGKDTDVLQHLSDSRHVAVYHKGRFFKLWLYEGARLLKPQDLEMQFQRILDDPSPPQPGEEKLAALTAGGRVEWAQARQAFFSSGKNKAALEAIERAAFFVALDEESYSYDPEDEASLSLYGKALLHGNCYNRWFDKSFTLISFKNGQLGLNAEHAWADAPIIGHLWEFVLGTDSFHLGYTETGHCLGKPNPALAPPTRLQWDIPKQCQAVIESSYQVAKALADDVELYCFQFLPFGKGLIKKCRTSPDAFVQIALQLAHFRDRGKFCLTYEASMTRMFREGRTETVRSCTSESTAFVQAMMEGSHTKADLRDLFQKAAKKHQNMYRLAMTGAGIDRHLFCLYLVSKYLGVSSPFLAEVLSEPWRLSTSQIPQSQIRMFDPEQHPNHLGAGGGFGPVADDGYGVSYMIAGENTIFFHISSKFSSSETNAQRFGNHIRKALLDIADLFQVPKAYS>sp|Q92523-2|CPT1B_HUMAN Isoform 2 of Carnitine O-palmitoyltransferase 1,muscle isoform OS=Homo sapiens OX=9606 GN=CPT1BMAEAHQAVAFQFTVTPDGVDFRLSREALKHVYLSGINSWKKRLIRIKNGILRGVYPGSPTSWLVVIMATVGSSFCNVDISLGLVSCIQRCLPQGCGPYQTPQTRALLSMAIFSTGVWVTGIFFFRQTLKLLLCYHGWMFEMHGKTSNLTRIWAMCIRLLSSRHPMLYSFQTSLPKLPVPRVSATIQRYLESVRPLLDDEEYYRMELLAKEFQDKTAPRLQKYLVLKSWWASNYVSDWWEEYIYLRGRSPLMVNSNYYVMDLVLIKNTDVQAARLGNIIHAMIMYRRKLDREEIKPVMALGIVPMCSYQMERMFNTTRIPGKDTDVLQHLSDSRHVAVYHKGRFFKLWLYEGARLLKPQDLEMQFQRILDDPSPPQPGEEKLAALTAGGRVEWAQARQAFFSSGKNKAALEAIERAAFFVALDEESYSYDPEDEASLSLYGKALLHGNCYNRWFDKSFTLISFKNGQLGLNAEHAWADAPIIGHLWEFVLGTDSFHLGYTETGHCLGKPNPALAPPTRLQWDIPKQCQAVIESSYQVAKALADDVELYCFQFLPFGKGLIKKCRTSPDAFVQIALQLAHFRG>sp|Q92523-3|CPT1B_HUMAN Isoform 3 of Carnitine O-palmitoyltransferase 1,muscle isoform OS=Homo sapiens OX=9606 GN=CPT1BMAEAHQAVAFQFTVTPDGVDFRLSREALKHVYLSGINSWKKRLIRIKNGILRGVYPGSPTSWLVVIMATVGSSFCNVDISLGLVSCIQRCLPQGCGPYQTPQTRALLSMAIFSTGVWVTGIFFFRQTLKLLLCYHGWMFEMHGKTSNLTRIWAYLESVRPLLDDEEYYRMELLAKEFQDKTAPRLQKYLVLKSWWASNYVSDWWEEYIYLRGRSPLMVNSNYYVMDLVLIKNTDVQAARLGNIIHAMIMYRRKLDREEIKPVMALGIVPMCSYQMERMFNTTRIPGKDTDVLQHLSDSRHVAVYHKGRFFKLWLYEGARLLKPQDLEMQFQRILDDPSPPQPGEEKLAALTAGGRVEWAQARQAFFSSGKNKAALEAIERAAFFVALDEESYSYDPEDEASLSLYGKALLHGNCYNRWFDKSFTLISFKNGQLGLNAEHAWADAPIIGHLWEFVLGTDSFHLGYTETGHCLGKPNPALAPPTRLQWDIPKQCQAVIESSYQVAKALADDVELYCFQFLPFGKGLIKKCRTSPDAFVQIALQLAHFRDRGKFCLTYEASMTRMFREGRTETVRSCTSESTAFVQAMMEGSHTKADLRDLFQKAAKKHQNMYRLAMTGAGIDRHLFCLYLVSKYLGVSSPFLAEVLSEPWRLSTSQIPQSQIRMFDPEQHPNHLGAGGGFGPVADDGYGVSYMIAGENTIFFHISSKFSSSETNAQRFGNHIRKALLDIADLFQVPKAYS>sp|Q92523-4|CPT1B_HUMAN Isoform 4 of Carnitine O-palmitoyltransferase 1,muscle isoform OS=Homo sapiens OX=9606 GN=CPT1BMAEAHQAVAFQFTVTPDGVDFRLSREALKHVYLSGINSWKKRLIRIKNGILRGVYPGSPTSWLVVIMATVGSSFCNVDISLGLVSCIQRCLPQGCGPYQTPQTRALLSMAIFSTGVWVTGIFFFRQTLKLLLCYHGWMFEMHGKTSNLTRIWAMCIRLLSSRHPMLYSFQTSLPKLPVPRVSATIQRYLESVRPLLDDEEYYRMELLAKEFQDKTAPRLQKYLVLKSWWASNYVSDWWEEYIYLRGRSPLMVNSNYYVMDLVLIKNTDVQAARLGNIIHAMIMYRRKLDREEIKPVMALGIVPMCSYQMERMFNTTRIPGKDTDVLQHLSDSRHVAVYHKGRFFKLWLYEGARLLSLYGKALLHGNCYNRWFDKSFTLISFKNGQLGLNAEHAWADAPIIGHLWEFVLGTDSFHLGYTETGHCLGKPNPALAPPTRLQWDIPKQCQAVIESSYQVAKALADDVELYCFQFLPFGKGLIKKCRTSPDAFVQIALQLAHFRDRGKFCLTYEASMTRMFREGRTETVRSCTSESTAFVQAMMEGSHTKADLRDLFQKAAKKHQNMYRLAMTGAGIDRHLFCLYLVSKYLGVSSPFLAEVLSEPWRLSTSQIPQSQIRMFDPEQHPNHLGAGGGFGPVADDGYGVSYMIAGENTIFFHISSKFSSSETNAQRFGNHIRKALLDIADLFQVPKAYS>sp|Q9UQB9|AURKC_HUMAN Aurora kinase C OS=Homo sapiens OX=9606 GN=AURKCPE=1 SV=1MSSPRAVVQLGKAQPAGEELATANQTAQQPSSPAMRRLTVDDFEIGRPLGKGKFGNVYLARLKESHFIVALKVLFKSQIEKEGLEHQLRREIEIQAHLQHPNILRLYNYFHDARRVYLILEYAPRGELYKELQKSEKLDEQRTATIIEELADALTYCHDKKVIHRDIKPENLLLGFRGEVKIADFGWSVHTPSLRRKTMCGTLDYLPPEMIEGRTYDEKVDLWCIGVLCYELLVGYPPFESASHSETYRRILKVDVRFPLSMPLGARDLISRLLRYQPLERLPLAQILKHPWVQAHSRRVLPPCAQMAS>sp|Q9UQB9-2|AURKC_HUMAN Isoform 2 of Aurora kinase C OS=Homo sapiensOX=9606 GN=AURKCMRRLTVDDFEIGRPLGKGKFGNVYLARLKESHFIVALKVLFKSQIEKEGLEHQLRREIEIQAHLQHPNILRLYNYFHDARRVYLILEYAPRGELYKELQKSEKLDEQRTATIIEELADALTYCHDKKVIHRDIKPENLLLGFRGEVKIADFGWSVHTPSLRRKTMCGTLDYLPPEMIEGRTYDEKVDLWCIGVLCYELLVGYPPFESASHSETYRRILKVDVRFPLSMPLGARDLISRLLRYQPLERLPLAQILKHPWVQAHSRRVLPPCAQMAS>sp|Q9UQB9-3|AURKC_HUMAN Isoform 3 of Aurora kinase C OS=Homo sapiensOX=9606 GN=AURKCMATANQTAQQPSSPAMRRLTVDDFEIGRPLGKGKFGNVYLARLKESHFIVALKVLFKSQIEKEGLEHQLRREIEIQAHLQHPNILRLYNYFHDARRVYLILEYAPRGELYKELQKSEKLDEQRTATIIEELADALTYCHDKKVIHRDIKPENLLLGFRGEVKIADFGWSVHTPSLRRKTMCGTLDYLPPEMIEGRTYDEKVDLWCIGVLCYELLVGYPPFESASHSETYRRILKVDVRFPLSMPLGARDLISRLLRYQPLERLPLAQILKHPWVQAHSRRVLPPCAQMAS>sp|O15169|AXIN1_HUMAN Axin-1 OS=Homo sapiens OX=9606 GN=AXIN1 PE=1 SV=2MNIQEQGFPLDLGASFTEDAPRPPVPGEEGELVSTDPRPASYSFCSGKGVGIKGETSTATPRRSDLDLGYEPEGSASPTPPYLKWAESLHSLLDDQDGISLFRTFLKQEGCADLLDFWFACTGFRKLEPCDSNEEKRLKLARAIYRKYILDNNGIVSRQTKPATKSFIKGCIMKQLIDPAMFDQAQTEIQATMEENTYPSFLKSDIYLEYTRTGSESPKVCSDQSSGSGTGKGISGYLPTLNEDEEWKCDQDMDEDDGRDAAPPGRLPQKLLLETAAPRVSSSRRYSEGREFRYGSWREPVNPYYVNAGYALAPATSANDSEQQSLSSDADTLSLTDSSVDGIPPYRIRKQHRREMQESVQVNGRVPLPHIPRTYRVPKEVRVEPQKFAEELIHRLEAVQRTREAEEKLEERLKRVRMEEEGEDGDPSSGPPGPCHKLPPAPAWHHFPPRCVDMGCAGLRDAHEENPESILDEHVQRVLRTPGRQSPGPGHRSPDSGHVAKMPVALGGAASGHGKHVPKSGAKLDAAGLHHHRHVHHHVHHSTARPKEQVEAEATRRAQSSFAWGLEPHSHGARSRGYSESVGAAPNASDGLAHSGKVGVACKRNAKKAESGKSASTEVPGASEDAEKNQKIMQWIIEGEKEISRHRRTGHGSSGTRKPQPHENSRPLSLEHPWAGPQLRTSVQPSHLFIQDPTMPPHPAPNPLTQLEEARRRLEEEEKRASRAPSKQRYVQEVMRRGRACVRPACAPVLHVVPAVSDMELSETETRSQRKVGGGSAQPCDSIVVAYYFCGEPIPYRTLVRGRAVTLGQFKELLTKKGSYRYYFKKVSDEFDCGVVFEEVREDEAVLPVFEEKIIGKVEKVD>sp|O15169-2|AXIN1_HUMAN Isoform 2 of Axin-1 OS=Homo sapiens OX=9606GN=AXIN1MNIQEQGFPLDLGASFTEDAPRPPVPGEEGELVSTDPRPASYSFCSGKGVGIKGETSTATPRRSDLDLGYEPEGSASPTPPYLKWAESLHSLLDDQDGISLFRTFLKQEGCADLLDFWFACTGFRKLEPCDSNEEKRLKLARAIYRKYILDNNGIVSRQTKPATKSFIKGCIMKQLIDPAMFDQAQTEIQATMEENTYPSFLKSDIYLEYTRTGSESPKVCSDQSSGSGTGKGISGYLPTLNEDEEWKCDQDMDEDDGRDAAPPGRLPQKLLLETAAPRVSSSRRYSEGREFRYGSWREPVNPYYVNAGYALAPATSANDSEQQSLSSDADTLSLTDSSVDGIPPYRIRKQHRREMQESVQVNGRVPLPHIPRTYRVPKEVRVEPQKFAEELIHRLEAVQRTREAEEKLEERLKRVRMEEEGEDGDPSSGPPGPCHKLPPAPAWHHFPPRCVDMGCAGLRDAHEENPESILDEHVQRVLRTPGRQSPGPGHRSPDSGHVAKMPVALGGAASGHGKHVPKSGAKLDAAGLHHHRHVHHHVHHSTARPKEQVEAEATRRAQSSFAWGLEPHSHGARSRGYSESVGAAPNASDGLAHSGKVGVACKRNAKKAESGKSASTEVPGASEDAEKNQKIMQWIIEGEKEISRHRRTGHGSSGTRKPQPHENSRPLSLEHPWAGPQLRTSVQPSHLFIQDPTMPPHPAPNPLTQLEEARRRLEEEEKRASRAPSKQRTRSQRKVGGGSAQPCDSIVVAYYFCGEPIPYRTLVRGRAVTLGQFKELLTKKGSYRYYFKKVSDEFDCGVVFEEVREDEAVLPVFEEKIIGKVEKVD>sp|Q9Y2T1|AXIN2_HUMAN Axin-2 OS=Homo sapiens OX=9606 GN=AXIN2 PE=1 SV=1MSSAMLVTCLPDPSSSFREDAPRPPVPGEEGETPPCQPGVGKGQVTKPMSVSSNTRRNEDGLGEPEGRASPDSPLTRWTKSLHSLLGDQDGAYLFRTFLEREKCVDTLDFWFACNGFRQMNLKDTKTLRVAKAIYKRYIENNSIVSKQLKPATKTYIRDGIKKQQIDSIMFDQAQTEIQSVMEENAYQMFLTSDIYLEYVRSGGENTAYMSNGGLGSLKVVCGYLPTLNEEEEWTCADFKCKLSPTVVGLSSKTLRATASVRSTETVDSGYRSFKRSDPVNPYHIGSGYVFAPATSANDSEISSDALTDDSMSMTDSSVDGIPPYRVGSKKQLQREMHRSVKANGQVSLPHFPRTHRLPKEMTPVEPATFAAELISRLEKLKLELESRHSLEERLQQIREDEEREGSELTLNSREGAPTQHPLSLLPSGSYEEDPQTILDDHLSRVLKTPGCQSPGVGRYSPRSRSPDHHHHHHSQYHSLLPPGGKLPPAAASPGACPLLGGKGFVTKQTTKHVHHHYIHHHAVPKTKEEIEAEATQRVHCFCPGGSEYYCYSKCKSHSKAPETMPSEQFGGSRGSTLPKRNGKGTEPGLALPAREGGAPGGAGALQLPREEGDRSQDVWQWMLESERQSKPKPHSAQSTKKAYPLESARSSPGERASRHHLWGGNSGHPRTTPRAHLFTQDPAMPPLTPPNTLAQLEEACRRLAEVSKPPKQRCCVASQQRDRNHSATVQTGATPFSNPSLAPEDHKEPKKLAGVHALQASELVVTYFFCGEEIPYRRMLKAQSLTLGHFKEQLSKKGNYRYYFKKASDEFACGAVFEEIWEDETVLPMYEGRILGKVERID>sp|Q9NR63|CP26B_HUMAN Cytochrome P450 26B1 OS=Homo sapiens OX=9606GN=CYP26B1 PE=1 SV=1MLFEGLDLVSALATLAACLVSVTLLLAVSQQLWQLRWAATRDKSCKLPIPKGSMGFPLIGETGHWLLQGSGFQSSRREKYGNVFKTHLLGRPLIRVTGAENVRKILMGEHHLVSTEWPRSTRMLLGPNTVSNSIGDIHRNKRKVFSKIFSHEALESYLPKIQLVIQDTLRAWSSHPEAINVYQEAQKLTFRMAIRVLLGFSIPEEDLGHLFEVYQQFVDNVFSLPVDLPFSGYRRGIQARQILQKGLEKAIREKLQCTQGKDYLDALDLLIESSKEHGKEMTMQELKDGTLELIFAAYATTASASTSLIMQLLKHPTVLEKLRDELRAHGILHSGGCPCEGTLRLDTLSGLRYLDCVIKEVMRLFTPISGGYRTVLQTFELDGFQIPKGWSVMYSIRDTHDTAPVFKDVNVFDPDRFSQARSEDKDGRFHYLPFGGGVRTCLGKHLAKLFLKVLAVELASTSRFELATRTFPRITLVPVLHPVDGLSVKFFGLDSNQNEILPETEAMLSATV>sp|Q9NR63-2|CP26B_HUMAN Isoform 2 of Cytochrome P450 26B1 OS=Homosapiens OX=9606 GN=CYP26B1MLFEGLDLVSALATLAACLVSVTLLLAVSQQLWQLRWAATRDKSCKLPIPKGSMGFPLIGETGHWLLQVFSKIFSHEALESYLPKIQLVIQDTLRAWSSHPEAINVYQEAQKLTFRMAIRVLLGFSIPEEDLGHLFEVYQQFVDNVFSLPVDLPFSGYRRGIQARQILQKGLEKAIREKLQCTQGKDYLDALDLLIESSKEHGKEMTMQELKDGTLELIFAAYATTASASTSLIMQLLKHPTVLEKLRDELRAHGILHSGGCPCEGTLRLDTLSGLRYLDCVIKEVMRLFTPISGGYRTVLQTFELDGFQIPKGWSVMYSIRDTHDTAPVFKDVNVFDPDRFSQARSEDKDGRFHYLPFGGGVRTCLGKHLAKLFLKVLAVELASTSRFELATRTFPRITLVPVLHPVDGLSVKFFGLDSNQNEILPETEAMLSATV>sp|Q9NR63-3|CP26B_HUMAN Isoform 3 of Cytochrome P450 26B1 OS=Homosapiens OX=9606 GN=CYP26B1MKNKTCVLVCVSVFGGERGQVTVPRVGVRRPSLAGPLQKCTLRETRVWLPQGSGFQSSRREKYGNVFKTHLLGRPLIRVTGAENVRKILMGEHHLVSTEWPRSTRMLLGPNTVSNSIGDIHRNKRKVFSKIFSHEALESYLPKIQLVIQDTLRAWSSHPEAINVYQEAQKLTFRMAIRVLLGFSIPEEDLGHLFEVYQQFVDNVFSLPVDLPFSGYRRGIQARQILQKGLEKAIREKLQCTQGKDYLDALDLLIESSKEHGKEMTMQELKDGTLELIFAAYATTASASTSLIMQLLKHPTVLEKLRDELRAHGILHSGGCPCEGTLRLDTLSGLRYLDCVIKEVMRLFTPISGGYRTVLQTFELDGFQIPKGWSVMYSIRDTHDTAPVFKDVNVFDPDRFSQARSEDKDGRFHYLPFGGGVRTCLGKHLAKLFLKVLAVELASTSRFELATRTFPRITLVPVLHPVDGLSVKFFGLDSNQNEILPETEAMLSATV>sp|P54710|ATNG_HUMAN Sodium/potassium-transporting ATPase subunit gammaOS=Homo sapiens OX=9606 GN=FXYD2 PE=1 SV=3MTGLSMDGGGSPKGDVDPFYYDYETVRNGGLIFAGLAFIVGLLILLSRRFRCGGNKKRRQINEDEP>sp|P54710-2|ATNG_HUMAN Isoform 2 of Sodium/potassium-transporting ATPasesubunit gamma OS=Homo sapiens OX=9606 GN=FXYD2MDRWYLGGSPKGDVDPFYYDYETVRNGGLIFAGLAFIVGLLILLSRRFRCGGNKKRRQINEDEP>sp|Q9UPA5|BSN_HUMAN Protein bassoon OS=Homo sapiens OX=9606 GN=BSN PE=1SV=4MGNEVSLEGGAGDGPLPPGGAGPGPGPGPGPGAGKPPSAPAGGGQLPAAGAARSTAVPPVPGPGPGPGPGPGPGSTSRRLDPKEPLGNQRAASPTPKQASATTPGHESPRETRAQGPAGQEADGPRRTLQVDSRTQRSGRSPSVSPDRGSTPTSPYSVPQIAPLPSSTLCPICKTSDLTSTPSQPNFNTCTQCHNKVCNQCGFNPNPHLTQVKEWLCLNCQMQRALGMDMTTAPRSKSQQQLHSPALSPAHSPAKQPLGKPDQERSRGPGGPQPGSRQAETARATSVPGPAQAAAPPEVGRVSPQPPQPTKPSTAEPRPPAGEAPAKSATAVPAGLGATEQTQEGLTGKLFGLGASLLTQASTLMSVQPEADTQGQPAPSKGTPKIVFNDASKEAGPKPLGSGPGPGPAPGAKTEPGARMGPGSGPGALPKTGGTTSPKHGRAEHQAASKAAAKPKTMPKERAICPLCQAELNVGSKSPANYNTCTTCRLQVCNLCGFNPTPHLVEKTEWLCLNCQTKRLLEGSLGEPTPLPPPTSQQPPVGAPHRASGTSPLKQKGPQGLGQPSGPLPAKASPLSTKASPLPSKASPQAKPLRASEPSKTPSSVQEKKTRVPTKAEPMPKPPPETTPTPATPKVKSGVRRAEPATPVVKAVPEAPKGGEAEDLVGKPYSQDASRSPQSLSDTGYSSDGISSSQSEITGVVQQEVEQLDSAGVTGPHPPSPSEIHKVGSSMRPLLQAQGLAPSERSKPLSSGTGEEQKQRPHSLSITPEAFDSDEELEDILEEDEDSAEWRRRREQQDTAESSDDFGSQLRHDYVEDSSEGGLSPLPPQPPARAAELTDEDFMRRQILEMSAEEDNLEEDDTATSGRGLAKHGTQKGGPRPRPEPSQEPAALPKRRLPHNATTGYEELLPEGGSAEATDGSGTLQGGLRRFKTIELNSTGSYGHELDLGQGPDPSLDREPELEMESLTGSPEDRSRGEHSSTLPASTPSYTSGTSPTSLSSLEEDSDSSPSRRQRLEEAKQQRKARHRSHGPLLPTIEDSSEEEELREEEELLREQEKMREVEQQRIRSTARKTRRDKEELRAQRRRERSKTPPSNLSPIEDASPTEELRQAAEMEELHRSSCSEYSPSPSLDSEAEALDGGPSRLYKSGSEYNLPTFMSLYSPTETPSGSSTTPSSGRPLKSAEEAYEEMMRKAELLQRQQGQAAGARGPHGGPSQPTGPRGLGSFEYQDTTDREYGQAAQPAAEGTPASLGAAVYEEILQTSQSIVRMRQASSRDLAFAEDKKKEKQFLNAESAYMDPMKQNGGPLTPGTSPTQLAAPVSFSTPTSSDSSGGRVIPDVRVTQHFAKETQDPLKLHSSPASPSSASKEIGMPFSQGPGTPATTAVAPCPAGLPRGYMTPASPAGSERSPSPSSTAHSYGHSPTTANYGSQTEDLPQAPSGLAAAGRAAREKPLSASDGEGGTPQPSRAYSYFASSSPPLSPSSPSESPTFSPGKMGPRATAEFSTQTPSPAPASDMPRSPGAPTPSPMVAQGTQTPHRPSTPRLVWQESSQEAPFMVITLASDASSQTRMVHASASTSPLCSPTETQPTTHGYSQTTPPSVSQLPPEPPGPPGFPRVPSAGADGPLALYGWGALPAENISLCRISSVPGTSRVEPGPRTPGTAVVDLRTAVKPTPIILTDQGMDLTSLAVEARKYGLALDPIPGRQSTAVQPLVINLNAQEHTFLATATTVSITMASSVFMAQQKQPVVYGDPYQSRLDFGQGGGSPVCLAQVKQVEQAVQTAPYRSGPRGRPREAKFARYNLPNQVAPLARRDVLITQMGTAQSIGLKPGPVPEPGAEPHRATPAELRSHALPGARKPHTVVVQMGEGTAGTVTTLLPEEPAGALDLTGMRPESQLACCDMVYKLPFGSSCTGTFHPAPSVPEKSMADAAPPGQSSSPFYGPRDPEPPEPPTYRAQGVVGPGPHEEQRPYPQGLPGRLYSSMSDTNLAEAGLNYHAQRIGQLFQGPGRDSAMDLSSLKHSYSLGFADGRYLGQGLQYGSVTDLRHPTDLLAHPLPMRRYSSVSNIYSDHRYGPRGDAVGFQEASLAQYSATTAREISRMCAALNSMDQYGGRHGSGGGGPDLVQYQPQHGPGLSAPQSLVPLRPGLLGNPTFPEGHPSPGNLAQYGPAAGQGTAVRQLLPSTATVRAADGMIYSTINTPIAATLPITTQPASVLRPMVRGGMYRPYASGGITAVPLTSLTRVPMIAPRVPLGPTGLYRYPAPSRFPIASSVPPAEGPVYLGKPAAAKAPGAGGPSRPEMPVGAAREEPLPTTTPAAIKEAAGAPAPAPLAGQKPPADAAPGGGSGALSRPGFEKEEASQEERQRKQQEQLLQLERERVELEKLRQLRLQEELERERVELQRHREEEQLLVQRELQELQTIKHHVLQQQQEERQAQFALQREQLAQQRLQLEQIQQLQQQLQQQLEEQKQRQKAPFPAACEAPGRGPPLAAAELAQNGQYWPPLTHAAFIAMAGPEGLGQPREPVLHRGLPSSASDMSLQTEEQWEASRSGIKKRHSMPRLRDACELESGTEPCVVRRIADSSVQTDDEDGESRYLLSRRRRARRSADCSVQTDDEDSAEWEQPVRRRRSRLPRHSDSGSDSKHDATASSSSAAATVRAMSSVGIQTISDCSVQTEPDQLPRVSPAIHITAATDPKVEIVRYISAPEKTGRGESLACQTEPDGQAQGVAGPQLVGPTAISPYLPGIQIVTPGPLGRFEKKKPDPLEIGYQAHLPPESLSQLVSRQPPKSPQVLYSPVSPLSPHRLLDTSFASSERLNKAHVSPQKHFTADSALRQQTLPRPMKTLQRSLSDPKPLSPTAEESAKERFSLYQHQGGLGSQVSALPPNSLVRKVKRTLPSPPPEEAHLPLAGQASPQLYAASLLQRGLTGPTTVPATKASLLRELDRDLRLVEHESTKLRKKQAELDEEEKEIDAKLKYLELGITQRKESLAKDRGGRDYPPLRGLGEHRDYLSDSELNQLRLQGCTTPAGQFVDFPATAAAPATPSGPTAFQQPRFQPPAPQYSAGSGGPTQNGFPAHQAPTYPGPSTYPAPAFPPGASYPAEPGLPNQQAFRPTGHYAGQTPMPTTQSTLFPVPADSRAPLQKPRQTSLADLEQKVPTNYEVIASPVVPMSSAPSETSYSGPAVSSGYEQGKVPEVPRAGDRGSVSQSPAPTYPSDSHYTSLEQNVPRNYVMIDDISELTKDSTSTAPDSQRLEPLGPGSSGRPGKEPGEPGVLDGPTLPCCYARGEEESEEDSYDPRGKGGHLRSMESNGRPASTHYYGDSDYRHGARVEKYGPGPMGPKHPSKSLAPAAISSKRSKHRKQGMEQKISKFSPIEEAKDVESDLASYPPPAVSSSLVSRGRKFQDEITYGLKKNVYEQQKYYGMSSRDAVEDDRIYGGSSRSRAPSAYSGEKLSSHDFSGWGKGYEREREAVERLQKAGPKPSSLSMAHSRVRPPMRSQASEEESPVSPLGRPRPAGGPLPPGGDTCPQFCSSHSMPDVQEHVKDGPRAHAYKREEGYILDDSHCVVSDSEAYHLGQEETDWFDKPRDARSDRFRHHGGHAVSSSSQKRGPARHSYHDYDEPPEEGLWPHDEGGPGRHASAKEHRHGDHGRHSGRHTGEEPGRRAAKPHARDLGRHEARPHSQPSSAPAMPKKGQPGYPSSAEYSQPSRASSAYHHASDSKKGSRQAHSGPAALQSKAEPQAQPQLQGRQAAPGPQQSQSPSSRQIPSGAASRQPQTQQQQQGLGLQPPQQALTQARLQQQSQPTTRGSAPAASQPAGKPQPGPSTATGPQPAGPPRAEQTNGSKGTAKAPQQGRAPQAQPAPGPGPAGVKAGARPGGTPGAPAGQPGADGESVFSKILPGGAAEQAGKLTEAVSAFGKKFSSFW>sp|O43303|CP110_HUMAN Centriolar coiled-coil protein of 110 kDa OS=Homosapiens OX=9606 GN=CCP110 PE=1 SV=3MEEYEKFCEKSLARIQEASLSTESFLPAQSESISLIRFHGVAILSPLLNIEKRKEMQQEKQKALDVEARKQVNRKKALLTRVQEILDNVQVRKAPNASDFDQWEMETVYSNSEVRNLNVPATFPNSFPSHTEHSTAAKLDKIAGILPLDNEDQCKTDGIDLARDSEGFNSPKQCDSSNISHVENEAFPKTSSATPQETLISDGPFSVNEQQDLPLLAEVIPDPYVMSLQNLMKKSKEYIEREQSRRSLRGSINRIVNESHLDKEHDAVEVADCVKEKGQLTGKHCVSVIPDKPSLNKSNVLLQGASTQASSMSMPVLASFSKVDIPIRTGHPTVLESNSDFKVIPTFVTENNVIKSLTGSYAKLPSPEPSMSPKMHRRRSRTSSACHILINNPINACELSPKGKEQAMDLIIQDTDENTNVPEIMPKLPTDLAGVCSSKVYVGKNTSEVKEDVVLGKSNQVCQSSGNHLENKVTHGLVTVEGQLTSDERGAHIMNSTCAAMPKLHEPYASSQCIASPNFGTVSGLKPASMLEKNCSLQTELNKSYDVKNPSPLLMQNQNTRQQMDTPMVSCGNEQFLDNSFEKVKRRLDLDIDGLQKENCPYVITSGITEQERQHLPEKRYPKGSGFVNKNKMLGTSSKESEELLKSKMLAFEEMRKRLEEQHAQQLSLLIAEQEREQERLQKEIEEQEKMLKEKKAMTAEASELDINNAVELEWRKISDSSLLETMLSQADSLHTSNSNSSGFTNSAMQYSFVSANEAPFYLWGSSTSGLTKLSVTRPFGRAKTRWSQVFSLEIQAKFNKITAVAKGFLTRRLMQTDKLKQLRQTVKDTMEFIRSFQSEAPLKRGIVSAQDASLQERVLAQLRAALYGIHDIFFVMDAAERMSILHHDREVRKEKMLRQMDKMKSPRVALSAATQKSLDRKKYMKAAEMGMPNKKFLVKQNPSETRVLQPNQGQNAPVHRLLSRQGTPKTSVKGVVQNRQKPSQSRVPNRVPVSGVYAGKIQRKRPNVATI>sp|O43303-2|CP110_HUMAN Isoform 2 of Centriolar coiled-coil protein of110 kDa OS=Homo sapiens OX=9606 GN=CCP110MEEYEKFCEKSLARIQEASLSTESFLPAQSESISLIRFHGVAILSPLLNIEKRKEMQQEKQKALDVEARKQVNRKKALLTRVQEILDNVQVRKAPNASDFDQWEMETVYSNSEVRNLNVPATFPNSFPSHTEHSTAAKLDKIAGILPLDNEDQCKTDGIDLARDSEGFNSPKQCDSSNISHVENEAFPKTSSATPQETLISDGPFSVNEQQDLPLLAEVIPDPYVMSLQNLMKKSKEYIEREQSRRSLRGSINRIVNESHLDKEHDAVEVADCVKEKGQLTGKHCVSVIPDKPSLNKSNVLLQGASTQASSMSMPVLASFSKVDIPIRTGHPTVLESNSDFKVIPTFVTENNVIKSLTGSYAKLPSPEPSMSPKMHRRRSRTSSACHILINNPINACELSPKGKEQAMDLIIQDTDENTNVPEIMPKLPTDLAGVCSSKVYVGKNTSEVKEDVVLGKSNQVCQSSGNHLENKVTHGLVTVEGQLTSDERGAHIMNSTCAAMPKLHEPYASSQCIASPNFGTVSGLKPASMLEKNCSLQTELNKSYDVKNPSPLLMQNQNTRQQMDTPMVSCGNEQFLDNSFEKVKRRLDLDIDGLQKENCPYVITSGITEQERQHLPEKRYPKGSGFVNKNKMLGTSSKESEELLKSKMLAFEEMRKRLEEQHAQQLSLLIAEQEREQERLQKEIEEQEKMLKEKKAMTAEASELDINNAVELEWRKISDSSLLETMLSQADSLHTSNSNSSGFTNSAMQYSFVSANEAPFYLWGSSTSGLTKLSVTRPFGRAKTRWSQVFSLEIQAKFNKITAVAKGFLTRRLMQTDKLKQLRQTVKDTMEFIRSFQSEAPLKRGIVSAQDASLQERVLAQLRAALYGIHDIFFVMDAAERMSILHHDREVRKEKMLRQMDKMKSPRVALSAATQKSLDRKKYMKAAEMGMPNKKFLVKQNPSETRVLQPNQGQNAPVHRLLSRQGSICRKNPKKAAKCCDNLRRQHSLG>sp|P07315|CRGC_HUMAN Gamma-crystallin C OS=Homo sapiens OX=9606 GN=CRYGCPE=1 SV=2MGKITFYEDRAFQGRSYETTTDCPNLQPYFSRCNSIRVESGCWMLYERPNYQGQQYLLRRGEYPDYQQWMGLSDSIRSCCLIPQTVSHRLRLYEREDHKGLMMELSEDCPSIQDRFHLSEIRSLHVLEGCWVLYELPNYRGRQYLLRPQEYRRCQDWGAMDAKAGSLRRVVDLY>sp|Q7Z569|BRAP_HUMAN BRCA1-associated protein OS=Homo sapiens OX=9606GN=BRAP PE=1 SV=2MSVSLVVIRLELAEHSPVPAGFGFSAAAGEMSDEEIKKTTLASAVACLEGKSPGEKVAIIHQHLGRREMTDVIIETMKSNPDELKTTVEERKSSEASPTAQRSKDHSKECINAAPDSPSKQLPDQISFFSGNPSVEIVHGIMHLYKTNKMTSLKEDVRRSAMLCILTVPAAMTSHDLMKFVAPFNEVIEQMKIIRDSTPNQYMVLIKFRAQADADSFYMTCNGRQFNSIEDDVCQLVYVERAEVLKSEDGASLPVMDLTELPKCTVCLERMDESVNGILTTLCNHSFHSQCLQRWDDTTCPVCRYCQTPEPVEENKCFECGVQENLWICLICGHIGCGRYVSRHAYKHFEETQHTYAMQLTNHRVWDYAGDNYVHRLVASKTDGKIVQYECEGDTCQEEKIDALQLEYSYLLTSQLESQRIYWENKIVRIEKDTAEEINNMKTKFKETIEKCDNLEHKLNDLLKEKQSVERKCTQLNTKVAKLTNELKEEQEMNKCLRANQVLLQNKLKEEERVLKETCDQKDLQITEIQEQLRDVMFYLETQQKINHLPAETRQEIQEGQINIAMASASSPASSGGSGKLPSRKGRSKRGK>sp|Q7Z569-2|BRAP_HUMAN Isoform 2 of BRCA1-associated protein OS=Homosapiens OX=9606 GN=BRAPMHLYKTNKMTSLKEDVRRSAMLCILTVPAAMTSHDLMKFVAPFNEVIEQMKIIRDSTPNQYMVLIKFRAQGASLPVMDLTELPKCTVCLERMDESVNGILTTLCNHSFHSQCLQRWDDTTCPVCRYCQTPEPVEENKCFECGVQENLWICLICGHIGCGRYVSRHAYKHFEETQHTYAMQLTNHRVWDYAGDNYVHRLVASKTDGKIVQYECEGDTCQEEKIDALQLEYSYLLTSQLESQRIYWENKIVRIEKDTAEEINNMKTKFKETIEKCDNLEHKLNDLLKEKQSVERKCTQLNTKVAKLTNELKEEQEMNKCLRANQVLLQNKLKEEERVLKETCDQKDLQITEIQEQLRDVMFYLETQQKINHLPAETRQEIQEGQINIAMASASSPASSGGSGKLPSRKGRSKRGK>sp|O14548|COX7R_HUMAN Cytochrome c oxidase subunit 7A-related protein,mitochondrial OS=Homo sapiens OX=9606 GN=COX7A2L PE=1 SV=2MYYKFSGFTQKLAGAWASEAYSPQGLKPVVSTEAPPIIFATPTKLTSDSTVYDYAGKNKVPELQKFFQKADGVPVYLKRGLPDQMLYRTTMALTVGGTIYCLIALYMASQPKNK>sp|Q9BU40|CRDL1_HUMAN Chordin-like protein 1 OS=Homo sapiens OX=9606GN=CHRDL1 PE=1 SV=2MRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVRCPNVHCLSPVHIPHLCCPRCPDSLPPVNNKVTSKSCEYNGTTYQHGELFVAEGLFQNRQPNQCTQCSCSEGNVYCGLKTCPKLTCAFPVSVPDSCCRVCRGDGELSWEHSDGDIFRQPANREARHSYHRSHYDPPPSRQAGGLSRFPGARSHRGALMDSQQASGTIVQIVINNKHKHGQVCVSNGKTYSHGESWHPNLRAFGIVECVLCTCNVTKQECKKIHCPNRYPCKYPQKIDGKCCKVCPGKKAKELPGQSFDNKGYFCGEETMPVYESVFMEDGETTRKIALETERPPQVEVHVWTIRKGILQHFHIEKISKRMFEELPHFKLVTRTTLSQWKIFTEGEAQISQMCSSRVCRTELEDLVKVLYLERSEKGHC>sp|Q9BU40-3|CRDL1_HUMAN Isoform 2 of Chordin-like protein 1 OS=Homosapiens OX=9606 GN=CHRDL1MRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVRCPNVHCLSPVHIPHLCCPRCPGDGELSWEHSDGDIFRQPANREARHSYHRSHYDPPPSRQAGGLSRFPGARSHRGALMDSQQASGTIVQIVINNKHKHGQVCVSNGKTYSHGESWHPNLRAFGIVECVLCTCNVTKQECKKIHCPNRYPCKYPQKIDGKCCKVCPGKKAKEELPGQSFDNKGYFCGEETMPVYESVFMEDGETTRKIALETERPPQVEVHVWTIRKGILQHFHIEKISKRMFEELPHFKLVTRTTLSQWKIFTEGEAQISQMCSSRVCRTELEDLVKVLYLERSEKGHC>sp|Q9BU40-4|CRDL1_HUMAN Isoform 3 of Chordin-like protein 1 OS=Homosapiens OX=9606 GN=CHRDL1MRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVRCPNVHCLSPVHIPHLCCPRCPEDSLPPVNNKVTSKSCEYNGTTYQHGELFVAEGLFQNRQPNQCTQCSCSEGNVYCGLKTCPKLTCAFPVSVPDSCCRVCRGDGELSWEHSDGDIFRQPANREARHSYHRSHYDPPPSRQAGGLSRFPGARSHRGALMDSQQASGTIVQIVINNKHKHGQVCVSNGKTYSHGESWHPNLRAFGIVECVLCTCNVTKQECKKIHCPNRYPCKYPQKIDGKCCKVCPGKKAKEELPGQSFDNKGYFCGEETMPVYESVFMEDGETTRKIALETERPPQVEVHVWTIRKGILQHFHIEKISKRMFEELPHFKLVTRTTLSQWKIFTEGEAQISQMCSSRVCRTELEDLVKVLYLERSEKGHC>sp|Q9BU40-5|CRDL1_HUMAN Isoform 4 of Chordin-like protein 1 OS=Homosapiens OX=9606 GN=CHRDL1MRKKWKMGGMKYIFSLLFFLLLEGGKTEQVKHSETYCMFQDKKYRVGERWHPYLEPYGLVYCVNCICSENGNVLCSRVRCPNVHCLSPVHIPHLCCPRCPDSLPPVNNKVTSKSCEYNGTTYQHGELFVAEGLFQNRQPNQCTQCSCSEGNVYCGLKTCPKLTCAFPVSVPDSCCRVCRGDGELSWEHSDGDIFRQPANREARHSYHRSHYDPPPSRQAGGLSRFPGARSHRGALMDSQQASGTIVQIVINNKHKHGQVCVSNGKTYSHGESWHPNLRAFGIVECVLCTCNVTKQECKKIHCPNRYPCKYPQKIDGKCCKVCPGKKAKEELPGQSFDNKGYFCGEETMPVYESVFMEDGETTRKIALETERPPQVEVHVWTIRKGILQHFHIEKISKRMFEELPHFKLVTRTTLSQWKIFTEGEAQISQMCSSRVCRTELEDLVKVLYLERSEKGHC>sp|Q6Q6R5|CRIP3_HUMAN Cysteine-rich protein 3 OS=Homo sapiens OX=9606GN=CRIP3 PE=1 SV=2MSWTCPRCQQPVFFAEKVSSLGKNWHRFCLKCERCHSILSPGGHAEHNGRPYCHKPCYGALFGPRGVNIGGVGSYLYNPPTPSPGCTTPLSPSSFSPPRPRTGLPQGKKSPPHMKTFTGETSLCPGCGEPVYFAEKVMSLGRNWHRPCLRCQRCHKTLTAGSHAEHDGVPYCHVPCYGYLFGPKGGQPHPRHWDGMYMPEVWHVHGLWVCVDNFPCG>sp|Q6Q6R5-2|CRIP3_HUMAN Isoform 2 of Cysteine-rich protein 3 OS=Homosapiens OX=9606 GN=CRIP3MSWTCPRCQQPVFFAEKVSSLGKNWHRFCLKCERCHSILSPGGHAEHNGRPYCHKPCYGALFGPRGVNIGGVGSYLYNPPTPSPGCTTPLSPSSFSPPRPRTGLPQGKKSPPHMKTFTGETSLCPGCGEPVYFAEKVMSLGRNWHRPCLRCQRCHKTLTAGSHAEHDGVPYCHVPCYGYLFGPKGGQPHPRHWDGMYMPEVWHVV>sp|Q6Q6R5-3|CRIP3_HUMAN Isoform 3 of Cysteine-rich protein 3 OS=Homosapiens OX=9606 GN=CRIP3MSWTCPRCQQPVFFAEKVSSLGKNWHRFCLKCERCHSILSPGGHAEHNGRPYCHKPCYGALFGPRGVNIGGVGSYLYNPPTPSPGCTTPLSPSSFSPPRPRTGLPQGKKSPPHMKTFTGETSLCPGCGEPVYFAEKVMSLGRNWHRPCLRCQRCHKTLTAGSHAEHDGVPYCHVPCYGYLFGPKGVNIGDVGCYIYDPVKIKFK>sp|Q6Q6R5-4|CRIP3_HUMAN Isoform 4 of Cysteine-rich protein 3 OS=Homosapiens OX=9606 GN=CRIP3MSWTCPRCQQPVFFAEKVSSLGKNWHRFCLKCERCHSILSPGGHAEHNGRPYCHKPCYGALFGPRGVNIGGVGSYLYNPPTPSPGCTTPLSPSSFSPPRPRTGLPQGKKSPPHMKTFTGETSLCPGCGEPVYFAEKVMSLGRNWHRPCLRCQRCHKTLTAGSHAEV>sp|Q10588|BST1_HUMAN ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 2OS=Homo sapiens OX=9606 GN=BST1 PE=1 SV=2MAAQGCAASRLLQLLLQLLLLLLLLAAGGARARWRGEGTSAHLRDIFLGRCAEYRALLSPEQRNKNCTAIWEAFKVALDKDPCSVLPSDYDLFINLSRHSIPRDKSLFWENSHLLVNSFADNTRRFMPLSDVLYGRVADFLSWCRQKNDSGLDYQSCPTSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEKRLKDMGFQYSCINDYRPVKLLQCVDHSTHPDCALKSAAAATQRKAPSLYTEQRAGLIIPLFLVLASRTQL>sp|Q10588-2|BST1_HUMAN Isoform 2 of ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 2 OS=Homo sapiens OX=9606 GN=BST1MAAQGNKNCTAIWEAFKVALDKDPCSVLPSDYDLFINLSRHSIPRDKSLFWENSHLLVNSFADNTRRFMPLSDVLYGRVADFLSWCRQKNDSGLDYQSCPTSEDCENNPVDSFWKRASIQYSKDSSGVIHVMLNGSEPTGAYPIKGFFADYEIPNLQKEKITRIEIWVMHEIGGPNVESCGEGSMKVLEKRLKDMGFQYSCINDYRPVKLLQCVDHSTHPDCALKSAAAATQRKAPSLYTEQRAGLIIPLFLVLASRTQL>sp|Q6PJG6|BRAT1_HUMAN BRCA1-associated ATM activator 1 OS=Homo sapiensOX=9606 GN=BRAT1 PE=1 SV=2MDPECAQLLPALCAVLVDPRQPVADDTCLEKLLDWFKTVTEGESSVVLLQEHPCLVELLSHVLKVQDLSSGVLSFSLRLAGTFAAQENCFQYLQQGELLPGLFGEPGPLGRATWAVPTVRSGWIQGLRSLAQHPSALRFLADHGAVDTIFSLQGDSSLFVASAASQLLVHVLALSMRGGAEGQPCLPGGDWPACAQKIMDHVEESLCSAATPKVTQALNVLTTTFGRCQSPWTEALWVRLSPRVACLLERDPIPAAHSFVDLLLCVARSPVFSSSDGSLWETVARALSCLGPTHMGPLALGILKLEHCPQALRTQAFQVLLQPLACVLKATVQAPGPPGLLDGTADDATTVDTLLASKSSCAGLLCRTLAHLEELQPLPQRPSPWPQASLLGATVTVLRLCDGSAAPASSVGGHLCGTLAGCVRVQRAALDFLGTLSQGTGPQELVTQALAVLLECLESPGSSPTVLKKAFQATLRWLLSSPKTPGCSDLGPLIPQFLRELFPVLQKRLCHPCWEVRDSALEFLTQLSRHWGGQADFRCALLASEVPQLALQLLQDPESYVRASAVTAMGQLSSQGLHAPTSPEHAEARQSLFLELLHILSVDSEGFPRRAVMQVFTEWLRDGHADAAQDTEQFVATVLQAASRDLDWEVRAQGLELALVFLGQTLGPPRTHCPYAVALPEVAPAQPLTEALRALCHVGLFDFAFCALFDCDRPVAQKSCDLLLFLRDKIASYSSLREARGSPNTASAEATLPRWRAGEQAQPPGDQEPEAVLAMLRSLDLEGLRSTLAESSDHVEKSPQSLLQDMLATGGFLQGDEADCY>sp|Q6PJG6-2|BRAT1_HUMAN Isoform 2 of BRCA1-associated ATM activator 1OS=Homo sapiens OX=9606 GN=BRAT1MDPECAQLLPALCAVLVDPRQPVADDTCLEKLLDWFKTVTEGESSVVLLQEHPCLVELLSHVLKVQDLSSGVLSFSLRLAGTFAAQENCFQYLQQGELLPGLFGEPGPLGRATWAVPTVRSGWIQGLRSLAQHPSALRFLADHGAVDTIFSLQGDSSLFVASAASQLLVHVLALSMRGGAEGQPCLPGGDWPACAQKIMDHVEESLCSAATPKVTQALNVLTTTFGRCQSPWTEALWVRLSPRVACLLERDPIPAAHSFVDLLLCVARSGPRDAAGGPGWATVFLG>sp|Q6PJG6-3|BRAT1_HUMAN Isoform 3 of BRCA1-associated ATM activator 1OS=Homo sapiens OX=9606 GN=BRAT1MGKLRIGGPCAHCAAWEGVRAGCGPRLHVRGQPPSCTGVLLREPRSCHPTNHPHLLPVPQSLFLELLHILSVDSEGFPRRAVMQVFTEWLRDGHADAAQDTEQFVATVLQAASRDLDWEVRAQGLELALVFLGQTLGPPRTHCPYAVALPEVAPAQPLTEALRALCHVGLFDFAFCALFDCDRPVAQKSCDLLLFLRDKIASYSSLREARGSPNTASAEATLPRWRAGEQAQPPGDQEPEAVLAMLRSLDLEGLRSTLAESSDHVEKSPQSLLQDMLATGGFLQGDEADCY>sp|Q6P5X5|CV039_HUMAN UPF0545 protein C22orf39 OS=Homo sapiens OX=9606GN=C22orf39 PE=1 SV=2MCRCSLVLLSVDHEVPFSSFFIGWRTEGRAWRAGRPDMADGSGWQPPRPCEAYRAEWKLCRSARHFLHHYYVHGERPACEQWQRDLASCRDWEERRNAEAQQSLCESERARVRAARKHILVWAPRQSPPPDWHLPLPQEKDE>sp|Q6P5X5-2|CV039_HUMAN Isoform 2 of UPF0545 protein C22orf39 OS=Homosapiens OX=9606 GN=C22orf39MCRCSLVLLSVDHEVPFSSFFIGWRTEGRAWRAGRPDMADGSGWQPPRPCEAYRAEWKLCRSARHFLHHYYVHGERPACEQWQRDLASCRDWEERRNAEAQVLSVVAHTCNLSYLGG>sp|O14981|BTAF1_HUMAN TATA-binding protein-associated factor 172 OS=Homosapiens OX=9606 GN=BTAF1 PE=1 SV=2MAVSRLDRLFILLDTGTTPVTRKAAAQQLGEVVKLHPHELNNLLSKVLIYLRSANWDTRIAAGQAVEAIVKNVPEWNPVPRTRQEPTSESSMEDSPTTERLNFDRFDICRLLQHGASLLGSAGAEFEVQDEKSGEVDPKERIARQRKLLQKKLGLNMGEAIGMSTEELFNDEDLDYTPTSASFVNKQPTLQAAELIDSEFRAGMSNRQKNKAKRMAKLFAKQRSRDAVETNEKSNDSTDGEPEEKRRKIANVVINQSANDSKVLIDNIPDSSSLIEETNEWPLESFCEELCNDLFNPSWEVRHGAGTGLREILKAHGKSGGKMGDSTLEEMIQQHQEWLEDLVIRLLCVFALDRFGDFVSDEVVAPVRETCAQTLGVVLKHMNETGVHKTVDVLLKLLTQEQWEVRHGGLLGIKYALAVRQDVINTLLPKVLTRIIEGLQDLDDDVRAVAAASLVPVVESLVYLQTQKVPFIINTLWDALLELDDLTASTNSIMTLLSSLLTYPQVQQCSIQQSLTVLVPRVWPFLHHTISSVRRAALETLFTLLSTQDQNSSSWLIPILPDMLRHIFQFCVLESSQEILDLIHKVWMELLSKASVQYVVAAACPWMGAWLCLMMQPSHLPIDLNMLLEVKARAKEKTGGKVRQGQSQNKEVLQEYIAGADTIMEDPATRDFVVMRARMMAAKLLGALCCCICDPGVNVVTQEIKPAESLGQLLLFHLNSKSALQRISVALVICEWAALQKECKAVTLAVQPRLLDILSEHLYYDEIAVPFTRMQNECKQLISSLADVHIEVGNRVNNNVLTIDQASDLVTTVFNEATSSFDLNPQVLQQLDSKRQQVQMTVTETNQEWQVLQLRVHTFAACAVVSLQQLPEKLNPIIKPLMETIKKEENTLVQNYAAQCIAKLLQQCTTRTPCPNSKIIKNLCSSLCVDPYLTPCVTCPVPTQSGQENSKGSTSEKDGMHHTVTKHRGIITLYRHQKAAFAITSRRGPTPKAVKAQIADLPAGSSGNILVELDEAQKPYLVQRRGAEFALTTIVKHFGGEMAVKLPHLWDAMVGPLRNTIDINNFDGKSLLDKGDSPAQELVNSLQVFETAAASMDSELHPLLVQHLPHLYMCLQYPSTAVRHMAARCVGVMSKIATMETMNIFLEKVLPWLGAIDDSVKQEGAIEALACVMEQLDVGIVPYIVLLVVPVLGRMSDQTDSVRFMATQCFATLIRLMPLEAGIPDPPNMSAELIQLKAKERHFLEQLLDGKKLENYKIPVPINAELRKYQQDGVNWLAFLNKYKLHGILCDDMGLGKTLQSICILAGDHCHRAQEYARSKLAECMPLPSLVVCPPTLTGHWVDEVGKFCSREYLNPLHYTGPPTERIRLQHQVKRHNLIVASYDVVRNDIDFFRNIKFNYCILDEGHVIKNGKTKLSKAVKQLTANYRIILSGTPIQNNVLELWSLFDFLMPGFLGTERQFAARYGKPILASRDARSSSREQEAGVLAMDALHRQVLPFLLRRMKEDVLQDLPPKIIQDYYCTLSPLQVQLYEDFAKSRAKCDVDETVSSATLSEETEKPKLKATGHVFQALQYLRKLCNHPALVLTPQHPEFKTTAEKLAVQNSSLHDIQHAPKLSALKQLLLDCGLGNGSTSESGTESVVAQHRILIFCQLKSMLDIVEHDLLKPHLPSVTYLRLDGSIPPGQRHSIVSRFNNDPSIDVLLLTTHVGGLGLNLTGADTVVFVEHDWNPMRDLQAMDRAHRIGQKRVVNVYRLITRGTLEEKIMGLQKFKMNIANTVISQENSSLQSMGTDQLLDLFTLDKDGKAEKADTSTSGKASMKSILENLSDLWDQEQYDSEYSLENFMHSLK>sp|O14981-2|BTAF1_HUMAN Isoform 2 of TATA-binding protein-associatedfactor 172 OS=Homo sapiens OX=9606 GN=BTAF1MEQLDVGIVPYIVLLVVPVLGRMSDQTDSVRFMATQCFATLIRLMPLEAGIPDPPNMSAELIQLKAKERHFLEQLLDGKKLENYKIPVPINAELRKYQQDGVNWLAFLNKYKLHGILCDDMGLGKTLQSICILAGDHCHRAQEYARSKLAECMPLPSLVVCPPTLTGHWVDEVGKFCSREYLNPLHYTGPPTERIRLQHQVKRHNLIVASYDVVRNDIDFFRNIKFNYCILDEGHVIKNGKTKLSKAVKQLTANYRIILSGTPIQNNVLELWSLFDFLMPGFLGTERQFAARYGKPILASRDARSSSREQEAGVLAMDALHRQVLPFLLRRMKEDVLQDLPPKIIQDYYCTLSPLQVQLYEDFAKSRAKCDVDETVSSATLSEETEKPKLKATGHVFQALQYLRKLCNHPALVLTPQHPEFKTTAEKLAVQNSSLHDIQHAPKLSALKQLLLDCGLGNGSTSESGTESVVAQHRILIFCQLKSMLDIVEHDLLKPHLPSVTYLRLDGSIPPGQRHSIVSRFNNDPSIDVLLLTTHVGGLGLNLTGADTVVFVEHDWNPMRDLQAMDRAHRIGQKRVVNVYRLITRGTLEEKIMGLQKFKMNIANTVISQENSSLQSMGTDQLLDLFTLDKDGKAEKADTSTSGKASMKSILENLSDLWDQEQYDSEYSLENFMHSLK>sp|Q9H0C5|BTBD1_HUMAN BTB/POZ domain-containing protein 1 OS=Homosapiens OX=9606 GN=BTBD1 PE=1 SV=1MASLGPAAAGEQASGAEAEPGPAGPPPPPSPSSLGPLLPLQREPLYNWQATKASLKERFAFLFNSELLSDVRFVLGKGRGAAAAGGPQRIPAHRFVLAAGSAVFDAMFNGGMATTSAEIELPDVEPAAFLALLRFLYSDEVQIGPETVMTTLYTAKKYAVPALEAHCVEFLTKHLRADNAFMLLTQARLFDEPQLASLCLDTIDKSTMDAISAEGFTDIDIDTLCAVLERDTLSIRESRLFGAVVRWAEAECQRQQLPVTFGNKQKVLGKALSLIRFPLMTIEEFAAGPAQSGILSDREVVNLFLHFTVNPKPRVEYIDRPRCCLRGKECCINRFQQVESRWGYSGTSDRIRFTVNRRISIVGFGLYGSIHGPTDYQVNIQIIEYEKKQTLGQNDTGFSCDGTANTFRVMFKEPIEILPNVCYTACATLKGPDSHYGTKGLKKVVHETPAASKTVFFFFSSPGNNNGTSIEDGQIPEIIFYT>sp|Q9H0C5-2|BTBD1_HUMAN Isoform 2 of BTB/POZ domain-containing protein 1OS=Homo sapiens OX=9606 GN=BTBD1MASLGPAAAGEQASGAEAEPGPAGPPPPPSPSSLGPLLPLQREPLYNWQATKASLKERFAFLFNSELLSDVRFVLGKGRGAAAAGGPQRIPAHRFVLAAGSAVFDAMFNGGMATTSAEIELPDVEPAAFLALLRFLYSDEVQIGPETVMTTLYTAKKYAVPALEAHCVEFLTKHLRADNAFMLLTQARLFDEPQLASLCLDTIDKSTMDAISAEGFTDIDIDTLCAVLERDTLSIRESRLFGAVVRWAEAECQRQQLPVTFGNKQKVLGKALSLIRFPLMTIEEFAAGPAQSGILSDREVVNLFLHFTVNPKPRVEYIDRPRCCLRGKECCINRFQQVESRWGYSGTSDRIRSLNMRKSKPWDRMIPALVVMGQLTHSGSCSRNP>sp|O75752|B3GL1_HUMAN UDP-GalNAc:beta-1,3-N-acetylgalactosaminyltransferase 1 OS=Homo sapiens OX=9606 GN=B3GALNT1PE=1 SV=1MASALWTVLPSRMSLRSLKWSLLLLSLLSFFVMWYLSLPHYNVIERVNWMYFYEYEPIYRQDFHFTLREHSNCSHQNPFLVILVTSHPSDVKARQAIRVTWGEKKSWWGYEVLTFFLLGQEAEKEDKMLALSLEDEHLLYGDIIRQDFLDTYNNLTLKTIMAFRWVTEFCPNAKYVMKTDTDVFINTGNLVKYLLNLNHSEKFFTGYPLIDNYSYRGFYQKTHISYQEYPFKVFPPYCSGLGYIMSRDLVPRIYEMMGHVKPIKFEDVYVGICLNLLKVNIHIPEDTNLFFLYRIHLDVCQLRRVIAAHGFSSKEIITFWQVMLRNTTCHY>sp|Q8NCR0|B3GL2_HUMAN UDP-GalNAc:beta-1,3-N-acetylgalactosaminyltransferase 2 OS=Homo sapiens OX=9606 GN=B3GALNT2PE=1 SV=1MRNWLVLLCPCVLGAALHLWLRLRSPPPACASGAGPADQLALFPQWKSTHYDVVVGVLSARNNHELRNVIRSTWMRHLLQHPTLSQRVLVKFIIGAHGCEVPVEDREDPYSCKLLNITNPVLNQEIEAFSLSEDTSSGLPEDRVVSVSFRVLYPIVITSLGVFYDANDVGFQRNITVKLYQAEQEEALFIARFSPPSCGVQVNKLWYKPVEQFILPESFEGTIVWESQDLHGLVSRNLHKVTVNDGGGVLRVITAGEGALPHEFLEGVEGVAGGFIYTIQEGDALLHNLHSRPQRLIDHIRNLHEEDALLKEESSIYDDIVFVDVVDTYRNVPAKLLNFYRWTVETTSFNLLLKTDDDCYIDLEAVFNRIVQKNLDGPNFWWGNFRLNWAVDRTGKWQELEYPSPAYPAFACGSGYVISKDIVKWLASNSGRLKTYQGEDVSMGIWMAAIGPKRYQDSLWLCEKTCETGMLSSPQYSPWELTELWKLKERCGDPCRCQAR>sp|Q8NCR0-2|B3GL2_HUMAN Isoform 2 of UDP-GalNAc:beta-1,3-N-acetylgalactosaminyltransferase 2 OS=Homo sapiens OX=9606 GN=B3GALNT2MRNWLVLLCPCVLGAALHLWLRLRSPPPACASGAGPAGGVSLLLPRLECNGAVSAHPNLHLPGSRDSPASASQVAGITDQLALFPQWKSTHYDVVVGVLSARNNHELRNVIRSTWMRHLLQHPTLSQRVLVKFIIGAHGCEVPVEDREDPYSCKLLNITNPVLNQEIEAFSLSEDTSSGLPEDRVVSVSFRVLYPIVITSLGVFYDANDVGFQRNITVKLYQAEQEEALFIARFSPPSCGVQVNKLWYKPVEQFILPESFEGTIVWESQDLHGLVSRNLHKVTVNDGGGVLRVITAGEGALPHEFLEGVEGVAGGFIYTIQGKFAS>sp|Q9BSF8|BTBDA_HUMAN BTB/POZ domain-containing protein 10 OS=Homosapiens OX=9606 GN=BTBD10 PE=1 SV=2MAGRPHPYDGNSSDPENWDRKLHSRPRKLYKHSSTSSRIAKGGVDHTKMSLHGASGGHERSRDRRRSSDRSRDSSHERTESQLTPCIRNVTSPTRQHHVEREKDHSSSRPSSPRPQKASPNGSISSAGNSSRNSSQSSSDGSCKTAGEMVFVYENAKEGARNIRTSERVTLIVDNTRFVVDPSIFTAQPNTMLGRMFGSGREHNFTRPNEKGEYEVAEGIGSTVFRAILDYYKTGIIRCPDGISIPELREACDYLCISFEYSTIKCRDLSALMHELSNDGARRQFEFYLEEMILPLMVASAQSGERECHIVVLTDDDVVDWDEEYPPQMGEEYSQIIYSTKLYRFFKYIENRDVAKSVLKERGLKKIRLGIEGYPTYKEKVKKRPGGRPEVIYNYVQRPFIRMSWEKEEGKSRHVDFQCVKSKSITNLAAAAADIPQDQLVVMHPTPQVDELDILPIHPPSGNSDLDPDAQNPML>sp|Q9BSF8-2|BTBDA_HUMAN Isoform 2 of BTB/POZ domain-containing protein10 OS=Homo sapiens OX=9606 GN=BTBD10MPKDADLAFSASLFERAESLYTLISKFFSCFCVSTLAYTKGSTSSRIAKGGVDHTKMSLHGASGGHERSRDRRRSSDRSRDSSHERTESQLTPCIRNVTSPTRQHHVEREKDHSSSRPSSPRPQKASPNGSISSAGNSSRNSSQSSSDGSCKTAGEMVFVYENAKEGARNIRTSERVTLIVDNTRFVVDPSIFTAQPNTMLGRMFGSGREHNFTRPNEKGEYEVAEGIGSTVFRAILDYYKTGIIRCPDGISIPELREACDYLCISFEYSTIKCRDLSALMHELSNDGARRQFEFYLEEMILPLMVASAQSGERECHIVVLTDDDVVDWDEEYPPQMGEEYSQIIYSTKLYRFFKYIENRDVAKSVLKERGLKKIRLGIEGYPTYKEKVKKRPGGRPEVIYNYVQRPFIRMSWEKEEGKSRHVDFQCVKSKSITNLAAAAADIPQDQLVVMHPTPQVDELDILPIHPPSGNSDLDPDAQNPML>sp|A6NE02|BTBDH_HUMAN BTB/POZ domain-containing protein 17 OS=Homosapiens OX=9606 GN=BTBD17 PE=3 SV=1MPRRGYSKPGSWGSFWAMLTLVGLVTHAAQRADVGGEAAGTSINHSQAVLQRLQELLRQGNASDVVLRVQAAGTDEVRVFHAHRLLLGLHSELFLELLSNQSEAVLQEPQDCAAVFDKFIRYLYCGELTVLLTQAIPLHRLATKYGVSSLQRGVADYMRAHLAGGAGPAVGWYHYAVGTGDEALRESCLQFLAWNLSAVAASTEWGAVSPELLWQLLQRSDLVLQDELELFHALEAWLGRARPPPAVAERALRAIRYPMIPPAQLFQLQARSAALARHGPAVADLLLQAYQFHAASPLHYAKFFDVNGSAFLPRNYLAPAWGAPWVINNPARDDRSTSFQTQLGPSGHDAGRRVTWNVLFSPRWLPVSLRPVYADAAGTALPAARPEDGRPRLVVTPASSGGDAAGVSFQKTVLVGARQQGRLLVRHAYSFHQSSEEAGDFLAHADLQRRNSEYLVENALHLHLIVKPVYHTLIRTPK>sp|Q6ZMB0|B3GN6_HUMAN Acetylgalactosaminyl-O-glycosyl-glycoprotein beta-1,3-N-acetylglucosaminyltransferase OS=Homo sapiens OX=9606 GN=B3GNT6PE=1 SV=2MAFPCRRSLTAKTLACLLVGVSFLALQQWFLQAPRSPREERSPQEETPEGPTDAPAADEPPSELVPGPPCVANASANATADFEQLPARIQDFLRYRHCRHFPLLWDAPAKCAGGRGVFLLLAVKSAPEHYERRELIRRTWGQERSYGGRPVRRLFLLGTPGPEDEARAERLAELVALEAREHGDVLQWAFADTFLNLTLKHLHLLDWLAARCPHARFLLSGDDDVFVHTANVVRFLQAQPPGRHLFSGQLMEGSVPIRDSWSKYFVPPQLFPGSAYPVYCSGGGFLLSGPTARALRAAARHTPLFPIDDAYMGMCLERAGLAPSGHEGIRPFGVQLPGAQQSSFDPCMYRELLLVHRFAPYEMLLMWKALHSPALSCDRGHRVS>sp|Q6ZMB0-2|B3GN6_HUMAN Isoform 2 of Acetylgalactosaminyl-O-glycosyl-glycoprotein beta-1,3-N-acetylglucosaminyltransferase OS=Homo sapiensOX=9606 GN=B3GNT6MAFPCRRSLTAKTLACLLVGVSFLVLQRRRLPPVRPHGPGPARGRPPHPALPHRRRLHGRPVRRLFLLGTPGPEDEARAERLAELVALEAREHGDVLQWAFADTFLNLTLKHLHLLDWLAARCPHARFLLSGDDDVFVHTANVVRFLQAQPPGRHLFSGQLMEGSVPIRDSWSKYFVPPQLFPGSAYPVYCSGGGFLLSGLAPSGHEGIRPFGVQLPGAQQSSFDPCMYRELLLVHRFAPYEMLLMWKALHSPALSCDRGHRVS>sp|Q6ZMB0-3|B3GN6_HUMAN Isoform 3 of Acetylgalactosaminyl-O-glycosyl-glycoprotein beta-1,3-N-acetylglucosaminyltransferase OS=Homo sapiensOX=9606 GN=B3GNT6MAFPCRRSLTAKTLACLLVGVSFLALQQWFLQAPRSPREERSPQEETPEGPTDAPAADEPPSELVPGPPCVANASANATADFEQLPARIQDFLRYRHCRHFPLLWDAPAKCAGGRGVFLLLAVKSAPEHYERRELIRRTWGQERSYGGRPVRRLFLLGTPGPEDEARAERLAELVALEAREHGDVLQWAFADTFLNLTLKHLHLLDWLAARCPHARFLLSGDDDVFVHTANVVRFLQAQPPGRHLFSGQLMEGSVPIRDSWSKYFVPPQLFPGSAYPVYCSGGGFLLSGPTARALRAAARHTPLFPIDDAYMGMCLGARRPGAQRPRGHPGPSACSLPGAQQSSFDPCMYRELLLVHRFAPYEMLLMWKALHSPALSCDRGHRVS>sp|P25440|BRD2_HUMAN Bromodomain-containing protein 2 OS=Homo sapiensOX=9606 GN=BRD2 PE=1 SV=2MLQNVTPHNKLPGEGNAGLLGLGPEAAAPGKRIRKPSLLYEGFESPTMASVPALQLTPANPPPPEVSNPKKPGRVTNQLQYLHKVVMKALWKHQFAWPFRQPVDAVKLGLPDYHKIIKQPMDMGTIKRRLENNYYWAASECMQDFNTMFTNCYIYNKPTDDIVLMAQTLEKIFLQKVASMPQEEQELVVTIPKNSHKKGAKLAALQGSVTSAHQVPAVSSVSHTALYTPPPEIPTTVLNIPHPSVISSPLLKSLHSAGPPLLAVTAAPPAQPLAKKKGVKRKADTTTPTPTAILAPGSPASPPGSLEPKAARLPPMRRESGRPIKPPRKDLPDSQQQHQSSKKGKLSEQLKHCNGILKELLSKKHAAYAWPFYKPVDASALGLHDYHDIIKHPMDLSTVKRKMENRDYRDAQEFAADVRLMFSNCYKYNPPDHDVVAMARKLQDVFEFRYAKMPDEPLEPGPLPVSTAMPPGLAKSSSESSSEESSSESSSEEEEEEDEEDEEEEESESSDSEEERAHRLAELQEQLRAVHEQLAALSQGPISKPKRKREKKEKKKKRKAEKHRGRAGADEDDKGPRAPRPPQPKKSKKASGSGGGSAALGPSGFGPSGGSGTKLPKKATKTAPPALPTGYDSEEEEESRPMSYDEKRQLSLDINKLPGEKLGRVVHIIQAREPSLRDSNPEEIEIDFETLKPSTLRELERYVLSCLRKKPRKPYTIKKPVGKTKEELALEKKRELEKRLQDVSGQLNSTKKPPKKANEKTESSSAQQVAVSRLSASSSSSDSSSSSSSSSSSDTSDSDSG>sp|P25440-2|BRD2_HUMAN Isoform 2 of Bromodomain-containing protein 2OS=Homo sapiens OX=9606 GN=BRD2MLQNVTPHNKLPGEGNAGLLGLGPEAAAPGKRIRKPSLLYEGFESPTMASVPALQLTPANPPPPEVSNPKKPGRVTNQLQYLHKVVMKALWKHQFAWPFRQPVDAVKLGLPDYHKIIKQPMDMGTIKRRLENNYYWAASECMQDFNTMFTNCYIYNKPTDDIVLMAQTLEKIFLQKVASMPQEEQELVVTIPKNSHKKGAKLAALQGSVTSAHQVPAVSSVSHTALYTPPPEIPTTVLNIPHPSVISSPLLKSLHSAGPPLLAVTAAPPAQPLAKKKGVKRKADTTTPTPTAILAPGSPASPPGSLEPKAARLPPMRRESGRPIKPPRKDLPDSQQQHQSSKKGKLSEQLKHCNGILKELLSKKHAAYAWPFYKPVDASALGLHDYHDIIKHPMDLSTVKRKMENRDYRDAQEFAADVRLMFSNCYKYNPPDHDVVAMARKLQDVFEFRYAKMPDEPLEPGPLPVSTAMPPGLAKSSSESSSEESSSESSSEEEEEEDEEDEEEEESESSDSEEERAHRLAELQEQLRAVHEQLAALSQGPISKPKRKREKKEKKKKRKAEKHRGRAGADEDDKGPRAPRPPQPKKSKKASGSGGGSAALGPSGFGPSGGSGTKLQAGVQWRDLGLLQPPLLGFKRFSCLSLPSSQDYRLPKKATKTAPPALPTGYDSEEEEESRPMSYDEKRQLSLDINKLPGEKLGRVVHIIQAREPSLRDSNPEEIEIDFETLKPSTLRELERYVLSCLRKKPRKPYTIKKPVGKTKEELALEKKRELEKRLQDVSGQLNSTKKPPKKANEKTESSSAQQVAVSRLSASSSSSDSSSSSSSSSSSDTSDSDSG>sp|P25440-3|BRD2_HUMAN Isoform 3 of Bromodomain-containing protein 2OS=Homo sapiens OX=9606 GN=BRD2MASVPALQLTPANPPPPEVSNPKKPGRVTNQLQYLHKVVMKALWKHQFAWPFRQPVDAVKLGLPDYHKIIKQPMDMGTIKRRLENNYYWAASECMQDFNTMFTNCYIYNKPTDDIVLMAQTLEKIFLQKVASMPQEEQELVVTIPKNSHKKGAKLAALQGSVTSAHQVPAVSSVSHTALYTPPPEIPTTVLNIPHPSVISSPLLKSLHSAGPPLLAVTAAPPAQPLAKKKGVKRKADTTTPTPTAILAPGSPASPPGSLEPKAARLPPMRRESGRPIKPPRKDLPDSQQQHQSSKKGKLSEQLKHCNGILKELLSKKHAAYAWPFYKPVDASALGLHDYHDIIKHPMDLSTVKRKMENRDYRDAQEFAADVRLMFSNCYKYNPPDHDVVAMARKLQDVFEFRYAKMPDEPLEPGPLPVSTAMPPGLAKSSSESSSEESSSESSSEEEEEEDEEDEEEEESESSDSEEERAHRLAELQEQLRAVHEQLAALSQGPISKPKRKREKKEKKKKRKAEKHRGRAGADEDDKGPRAPRPPQPKKSKKASGSGGGSAALGPSGFGPSGGSGTKLPKKATKTAPPALPTGYDSEEEEESRPMSYDEKRQLSLDINKLPGEKLGRVVHIIQAREPSLRDSNPEEIEIDFETLKPSTLRELERYVLSCLRKKPRKPYTIKKPVGKTKEELALEKKRELEKRLQDVSGQLNSTKKPPKKANEKTESSSAQQVAVSRLSASSSSSDSSSSSSSSSSSDTSDSDSG>sp|P25440-4|BRD2_HUMAN Isoform 4 of Bromodomain-containing protein 2OS=Homo sapiens OX=9606 GN=BRD2MDMGTIKRRLENNYYWAASECMQDFNTMFTNCYIYNKPTDDIVLMAQTLEKIFLQKVASMPQEEQELVVTIPKNSHKKGAKLAALQGSVTSAHQVPAVSSVSHTALYTPPPEIPTTVLNIPHPSVISSPLLKSLHSAGPPLLAVTAAPPAQPLAKKKGVKRKADTTTPTPTAILAPGSPASPPGSLEPKAARLPPMRRESGRPIKPPRKDLPDSQQQHQSSKKGKLSEQLKHCNGILKELLSKKHAAYAWPFYKPVDASALGLHDYHDIIKHPMDLSTVKRKMENRDYRDAQEFAADVRLMFSNCYKYNPPDHDVVAMARKLQDVFEFRYAKMPDEPLEPGPLPVSTAMPPGLAKSSSESSSEESSSESSSEEEEEEDEEDEEEEESESSDSEEERAHRLAELQEQLRAVHEQLAALSQGPISKPKRKREKKEKKKKRKAEKHRGRAGADEDDKGPRAPRPPQPKKSKKASGSGGGSAALGPSGFGPSGGSGTKLPKKATKTAPPALPTGYDSEEEEESRPMSYDEKRQLSLDINKLPGEKLGRVVHIIQAREPSLRDSNPEEIEIDFETLKPSTLRELERYVLSCLRKKPRKPYTIKKPVGKTKEELALEKKRELEKRLQDVSGQLNSTKKPPKKANEKTESSSAQQVAVSRLSASSSSSDSSSSSSSSSSSDTSDSDSG>sp|Q9NPI1|BRD7_HUMAN Bromodomain-containing protein 7 OS=Homo sapiensOX=9606 GN=BRD7 PE=1 SV=1MGKKHKKHKSDKHLYEEYVEKPLKLVLKVGGNEVTELSTGSSGHDSSLFEDKNDHDKHKDRKRKKRKKGEKQIPGEEKGRKRRRVKEDKKKRDRDRVENEAEKDLQCHAPVRLDLPPEKPLTSSLAKQEEVEQTPLQEALNQLMRQLQRKDPSAFFSFPVTDFIAPGYSMIIKHPMDFSTMKEKIKNNDYQSIEELKDNFKLMCTNAMIYNKPETIYYKAAKKLLHSGMKILSQERIQSLKQSIDFMADLQKTRKQKDGTDTSQSGEDGGCWQREREDSGDAEAHAFKSPSKENKKKDKDMLEDKFKSNNLEREQEQLDRIVKESGGKLTRRLVNSQCEFERRKPDGTTTLGLLHPVDPIVGEPGYCPVRLGMTTGRLQSGVNTLQGFKEDKRNKVTPVLYLNYGPYSSYAPHYDSTFANISKDDSDLIYSTYGEDSDLPSDFSIHEFLATCQDYPYVMADSLLDVLTKGGHSRTLQEMEMSLPEDEGHTRTLDTAKEMEITEVEPPGRLDSSTQDRLIALKAVTNFGVPVEVFDSEEAEIFQKKLDETTRLLRELQEAQNERLSTRPPPNMICLLGPSYREMHLAEQVTNNLKELAQQVTPGDIVSTYGVRKAMGISIPSPVMENNFVDLTEDTEEPKKTDVAECGPGGS>sp|Q9NPI1-2|BRD7_HUMAN Isoform 2 of Bromodomain-containing protein 7OS=Homo sapiens OX=9606 GN=BRD7MGKKHKKHKSDKHLYEEYVEKPLKLVLKVGGNEVTELSTGSSGHDSSLFEDKNDHDKHKDRKRKKRKKGEKQIPGEEKGRKRRRVKEDKKKRDRDRVENEAEKDLQCHAPVRLDLPPEKPLTSSLAKQEEVEQTPLQEALNQLMRQLQRKDPSAFFSFPVTDFIAPGYSMIIKHPMDFSTMKEKIKNNDYQSIEELKDNFKLMCTNAMIYNKPETIYYKAAKKLLHSGMKILSQERIQSLKQSIDFMADLQKTRKQKDGTDTSQSGEDGGCWQREREDSGDAEAHAFKSPSKENKKKDKDMLEDKFKSNNLEREQEQLDRIVKESGGKLTRRLVNSQCEFERRKPDGTTTLGLLHPVDPIVGEPGYCPVRLGMTTGRLQSGVNTLQGFKEDKRNKVTPVLYLNYGPYSSYAPHYDSTFANISKDDSDLIYSTYGEDSDLPSDFSIHEFLATCQDYPYVMADSLLDVLTKGGHSRTLQEMEMSLPEDEGHTRTLDTAKEMEQITEVEPPGRLDSSTQDRLIALKAVTNFGVPVEVFDSEEAEIFQKKLDETTRLLRELQEAQNERLSTRPPPNMICLLGPSYREMHLAEQVTNNLKELAQQVTPGDIVSTYGVRKAMGISIPSPVMENNFVDLTEDTEEPKKTDVAECGPGGS>sp|Q07812|BAX_HUMAN Apoptosis regulator BAX OS=Homo sapiens OX=9606GN=BAX PE=1 SV=1MDGSGEQPRGGGPTSSEQIMKTGALLLQGFIQDRAGRMGGEAPELALDPVPQDASTKKLSECLKRIGDELDSNMELQRMIAAVDTDSPREVFFRVAADMFSDGNFNWGRVVALFYFASKLVLKALCTKVPELIRTIMGWTLDFLRERLLGWIQDQGGWDGLLSYFGTPTWQTVTIFVAGVLTASLTIWKKMG>sp|Q07812-2|BAX_HUMAN Isoform Beta of Apoptosis regulator BAX OS=Homosapiens OX=9606 GN=BAXMDGSGEQPRGGGPTSSEQIMKTGALLLQGFIQDRAGRMGGEAPELALDPVPQDASTKKLSECLKRIGDELDSNMELQRMIAAVDTDSPREVFFRVAADMFSDGNFNWGRVVALFYFASKLVLKALCTKVPELIRTIMGWTLDFLRERLLGWIQDQGGWVRLLKPPHPHHRALTTAPAPPSLPPATPLGPWAFWSRSQWCPLPIFRSSDVVYNAFSLRV>sp|Q07812-3|BAX_HUMAN Isoform Gamma of Apoptosis regulator BAX OS=Homosapiens OX=9606 GN=BAXMDGSGEQPRGGVSSRIEQGEWGGRHPSWPWTRCLRMRPPRS>sp|Q07812-4|BAX_HUMAN Isoform Delta of Apoptosis regulator BAX OS=Homosapiens OX=9606 GN=BAXMDGSGEQPRGGGPTSSEQIMKTGALLLQGMIAAVDTDSPREVFFRVAADMFSDGNFNWGRVVALFYFASKLVLKALCTKVPELIRTIMGWTLDFLRERLLGWIQDQGGWDGLLSYFGTPTWQTVTIFVAGVLTASLTIWKKMG>sp|Q07812-5|BAX_HUMAN Isoform Epsilon of Apoptosis regulator BAX OS=Homosapiens OX=9606 GN=BAXMDGSGEQPRGGGPTSSEQIMKTGALLLQGFIQDRAGRMGGEAPELALDPVPQDASTKKLSECLKRIGDELDSNMELQRMIAAVDTDSPREVFFRVAADMFSDGNFNWGRVVALFYFASKLVLKAGVKWRDLGSLQPLPPGFKRFTCLSIPRSWDYRPCAPRCRN>sp|Q07812-6|BAX_HUMAN Isoform Zeta of Apoptosis regulator BAX OS=Homosapiens OX=9606 GN=BAXMIAAVDTDSPREVFFRVAADMFSDGNFNWGRVVALFYFASKLVLKALCTKVPELIRTIMGWTLDFLRERLLGWIQDQGGWDGLLSYFGTPTWQTVTIFVAGVLTASLTIWKKMG>sp|Q07812-7|BAX_HUMAN Isoform Psi of Apoptosis regulator BAX OS=Homosapiens OX=9606 GN=BAXMKTGALLLQGFIQDRAGRMGGEAPELALDPVPQDASTKKLSECLKRIGDELDSNMELQRMIAAVDTDSPREVFFRVAADMFSDGNFNWGRVVALFYFASKLVLKALCTKVPELIRTIMGWTLDFLRERLLGWIQDQGGWDGLLSYFGTPTWQTVTIFVAGVLTASLTIWKKMG>sp|Q07812-8|BAX_HUMAN Isoform Sigma of Apoptosis regulator BAX OS=Homosapiens OX=9606 GN=BAXMDGSGEQPRGGGPTSSEQIMKTGALLLQGFIQDRAGRMGGEAPELALDPVPQDASTKKLSECLKRIGDELDSNMELQRMIAAVDTDSPREVFFRVAADMFSDGNFNWGRVVALFYFASKLVLKALCTKVPELIRTIMGWTLDFLRERLLGWIQDQGGWTVTIFVAGVLTASLTIWKKMG>sp|Q76KP1|B4GN4_HUMAN N-acetyl-beta-glucosaminyl-glycoprotein 4-beta-N-acetylgalactosaminyltransferase 1 OS=Homo sapiens OX=9606 GN=B4GALNT4PE=1 SV=1MPRLPVKKIRKQMKLLLLLLLLSCAAWLTYVHLGLVRQGRALRQRLGYGRDGEKLTSETDGRGVHAAPSTQRAEDSSESREEEQAPEGRDLDMLFPGGAGRLPLNFTHQTPPWREEYKGQVNLHVFEDWCGGAVGHLRRNLHFPLFPHTRTTVKKLAVSPKWKNYGLRIFGFIHPARDGDVQFSVASDDNSEFWLSLDESPAAAQLVAFVGKTGSEWTAPGEFTKFSSQVSKPRRLMASRRYYFELLHKQDDRGSDHVEVGWRAFLPGLKFEVISSAHISLYTDESALKMDHVAHVPQSPASHVGGRPPQEETSADMLRPDPRDTFFLTPRMESSSLENVLEPCAYAPTYVVKDFPIARYQGLQFVYLSFVYPNDYTRLTHMETDNKCFYRESPLYLERFGFYKYMKMDKEEGDEDEEDEVQRRAFLFLNPDDFLDDEDEGELLDSLEPTEAAPPRSGPQSPAPAAPAQPGATLAPPTPPRPRDGGTPRHSRALSWAARAARPLPLFLGRAPPPRPAVEQPPPKVYVTRVRPGQRASPRAPAPRAPWPPFPGVFLHPRPLPRVQLRAPPRPPRPHGRRTGGPQATQPRPPARAQATQGGREGQARTLGPAAPTVDSNLSSEARPVTSFLSLSQVSGPQLPGEGEEEEEGEDDGAPGDEAASEDSEEAAGPALGRWREDAIDWQRTFSVGAVDFELLRSDWNDLRCNVSGNLQLPEAEAVDVTAQYMERLNARHGGRFALLRIVNVEKRRDSARGSRFLLELELQERGGGRLRLSEYVFLRLPGARVGDADGESPEPAPAASVRPDGRPELCRPLRLAWRQDVMVHFIVPVKNQARWVAQFLADMAALHARTGDSRFSVVLVDFESEDMDVERALRAARLPRYQYLRRTGNFERSAGLQAGVDAVEDASSIVFLCDLHIHFPPNILDGIRKHCVEGRLAFAPVVMRLSCGSSPRDPHGYWEVNGFGLFGIYKSDFDRVGGMNTEEFRDQWGGEDWELLDRVLQAGLEVERLRLRNFYHHYHSKRGMWSVRSRKGSRTGAS>sp|Q8WWI5|CTL1_HUMAN Choline transporter-like protein 1 OS=Homo sapiensOX=9606 GN=SLC44A1 PE=1 SV=1MGCCSSASSAAQSSKREWKPLEDRSCTDIPWLLLFILFCIGMGFICGFSIATGAAARLVSGYDSYGNICGQKNTKLEAIPNSGMDHTQRKYVFFLDPCNLDLINRKIKSVALCVAACPRQELKTLSDVQKFAEINGSALCSYNLKPSEYTTSPKSSVLCPKLPVPASAPIPFFHRCAPVNISCYAKFAEALITFVSDNSVLHRLISGVMTSKEIILGLCLLSLVLSMILMVIIRYISRVLVWILTILVILGSLGGTGVLWWLYAKQRRSPKETVTPEQLQIAEDNLRALLIYAISATVFTVILFLIMLVMRKRVALTIALFHVAGKVFIHLPLLVFQPFWTFFALVLFWVYWIMTLLFLGTTGSPVQNEQGFVEFKISGPLQYMWWYHVVGLIWISEFILACQQMTVAGAVVTYYFTRDKRNLPFTPILASVNRLIRYHLGTVAKGSFIITLVKIPRMILMYIHSQLKGKENACARCVLKSCICCLWCLEKCLNYLNQNAYTATAINSTNFCTSAKDAFVILVENALRVATINTVGDFMLFLGKVLIVCSTGLAGIMLLNYQQDYTVWVLPLIIVCLFAFLVAHCFLSIYEMVVDVLFLCFAIDTKYNDGSPGREFYMDKVLMEFVENSRKAMKEAGKGGVADSRELKPMASGASSA>sp|Q8WWI5-2|CTL1_HUMAN Isoform 2 of Choline transporter-like protein 1OS=Homo sapiens OX=9606 GN=SLC44A1MGCCSSASSAAQSSKREWKPLEDRSCTDIPWLLLFILFCIGMGFICGFSIATGAAARLVSGYDSYGNICGQKNTKLEAIPNSGMDHTQRKYVFFLDPCNLDLINRKIKSVALCVAACPRQELKTLSDVQKFAEINGSALCSYNLKPSEYTTSPKSSVLCPKLPVPASAPIPFFHRCAPVNISCYAKFAEALITFVSDNSVLHRLISGVMTSKEIILGLCLLSLVLSMILMVIIRYISRVLVWILTILVILGSLGGTGVLWWLYAKQRRSPKETVTPEQLQIAEDNLRALLIYAISATVFTVILFLIMLVMRKRVALTIALFHVAGKVFIHLPLLVFQPFWTFFALVLFWVYWIMTLLFLGTTGSPVQNEQGFVEFKISGPLQYMWWYHVVGLIWISEFILACQQMTVAGAVVTYYFTRDKRNLPFTPILASVNRLIRYHLGTVAKGSFIITLVKIPRMILMYIHSQLKGKENACARCVLKSCICCLWCLEKCLNYLNQNAYTATAINSTNFCTSAKDAFVILVENALRVATINTVGDFMLFLGKVLIVCSTGLAGIMLLNYQQDYTVWVLPLIIVCLFAFLVAHCFLSIYEMVVDVLFLCFAIDTKYNDGSPGREFYMDKVLMEFVENSRKAMKEAGKGGVADSRELKPMLKKR>sp|Q8WWI5-3|CTL1_HUMAN Isoform 3 of Choline transporter-like protein 1OS=Homo sapiens OX=9606 GN=SLC44A1MGCCSSASSAAQSSKREWKPLEDRSCTDIPWLLLFILFCIGMGFICGFSIATGAAARLVSGYDSYGNICGQKNTKLEAIPNSGMDHTQRKYVFFLDPCNLDLINRKIKSVALCVAACPRQELKTLSDVQKFAEINGSALCSYNLKPSEYTTSPKSSVLCPKLPVPASAPIPFFHRCAPVNISCYAKFAEALITFVSDNSVLHRLISGVMTSKEIILGLCLLSLVLSMILMVIIRYISRVLVWILTILVILGSLGGTGVLWWLYAKQRRSPKETVTPEQLQIAEDNLRALLIYAISATVFTVILFLIMLVMRKRVALTIALFHVAGKVFIHLPLLVFQPFWTFFALVLFWVYWIMTLLFLGTTGSPVQNEQGFVEFKISGPLQYMWWYHVVGLIWISEFILACQQMTVAGAVVTYYFTRDKRNLPFTPILASVNRLIRYHLGTVAKGSFIITLVKIPRMILMYIHSQLKGKENACARCVLKSCICCLWCLEKCLNYLNQNAYTATAINSTNFCTSAKDAFVILVENALRVATINTVGDFMLFLGKVLIVCSTGLAGIMLLNYQQDYTVWVLPLIIVCLFAFLVAHCFLSIYEMVVDVLFLCFAIDTKYNDGSPGREFYMDKVLMEFVENSRKAMKEAGKGGVADSRELKPMIK>sp|P51451|BLK_HUMAN Tyrosine-protein kinase Blk OS=Homo sapiens OX=9606GN=BLK PE=1 SV=3MGLVSSKKPDKEKPIKEKDKGQWSPLKVSAQDKDAPPLPPLVVFNHLTPPPPDEHLDEDKHFVVALYDYTAMNDRDLQMLKGEKLQVLKGTGDWWLARSLVTGREGYVPSNFVARVESLEMERWFFRSQGRKEAERQLLAPINKAGSFLIRESETNKGAFSLSVKDVTTQGELIKHYKIRCLDEGGYYISPRITFPSLQALVQHYSKKGDGLCQRLTLPCVRPAPQNPWAQDEWEIPRQSLRLVRKLGSGQFGEVWMGYYKNNMKVAIKTLKEGTMSPEAFLGEANVMKALQHERLVRLYAVVTKEPIYIVTEYMARGCLLDFLKTDEGSRLSLPRLIDMSAQIAEGMAYIERMNSIHRDLRAANILVSEALCCKIADFGLARIIDSEYTAQEGAKFPIKWTAPEAIHFGVFTIKADVWSFGVLLMEVVTYGRVPYPGMSNPEVIRNLERGYRMPRPDTCPPELYRGVIAECWRSRPEERPTFEFLQSVLEDFYTATERQYELQP>sp|Q13489|BIRC3_HUMAN Baculoviral IAP repeat-containing protein 3OS=Homo sapiens OX=9606 GN=BIRC3 PE=1 SV=2MNIVENSIFLSNLMKSANTFELKYDLSCELYRMSTYSTFPAGVPVSERSLARAGFYYTGVNDKVKCFCCGLMLDNWKRGDSPTEKHKKLYPSCRFVQSLNSVNNLEATSQPTFPSSVTNSTHSLLPGTENSGYFRGSYSNSPSNPVNSRANQDFSALMRSSYHCAMNNENARLLTFQTWPLTFLSPTDLAKAGFYYIGPGDRVACFACGGKLSNWEPKDNAMSEHLRHFPKCPFIENQLQDTSRYTVSNLSMQTHAARFKTFFNWPSSVLVNPEQLASAGFYYVGNSDDVKCFCCDGGLRCWESGDDPWVQHAKWFPRCEYLIRIKGQEFIRQVQASYPHLLEQLLSTSDSPGDENAESSIIHFEPGEDHSEDAIMMNTPVINAAVEMGFSRSLVKQTVQRKILATGENYRLVNDLVLDLLNAEDEIREEERERATEEKESNDLLLIRKNRMALFQHLTCVIPILDSLLTAGIINEQEHDVIKQKTQTSLQARELIDTILVKGNIAATVFRNSLQEAEAVLYEHLFVQQDIKYIPTEDVSDLPVEEQLRRLQEERTCKVCMDKEVSIVFIPCGHLVVCKDCAPSLRKCPICRSTIKGTVRTFLS>sp|O15255|CXX1_HUMAN CAAX box protein 1 OS=Homo sapiens OX=9606 GN=RTL8CPE=2 SV=1MGGGRGLLGRETLGPGGGCSGEGPLCYWPPPGSPPAPSLRASLPLEPPRCPLRSCSLPRSACLCSRNSAPGSCCRPWASLWSEPPPSPSSQPAPPMYIWTLSCAPAASWAPVTHWTDHPLPPLPSPLLPTRLPDDYIILPTDLRCHSHRHPSHPTDRLLLLVIWTHLGGIWAGHSPWTVIQTAGRPPRDLSPSARPISSPPPETSCVLA>sp|Q13490|BIRC2_HUMAN Baculoviral IAP repeat-containing protein 2OS=Homo sapiens OX=9606 GN=BIRC2 PE=1 SV=2MHKTASQRLFPGPSYQNIKSIMEDSTILSDWTNSNKQKMKYDFSCELYRMSTYSTFPAGVPVSERSLARAGFYYTGVNDKVKCFCCGLMLDNWKLGDSPIQKHKQLYPSCSFIQNLVSASLGSTSKNTSPMRNSFAHSLSPTLEHSSLFSGSYSSLSPNPLNSRAVEDISSSRTNPYSYAMSTEEARFLTYHMWPLTFLSPSELARAGFYYIGPGDRVACFACGGKLSNWEPKDDAMSEHRRHFPNCPFLENSLETLRFSISNLSMQTHAARMRTFMYWPSSVPVQPEQLASAGFYYVGRNDDVKCFCCDGGLRCWESGDDPWVEHAKWFPRCEFLIRMKGQEFVDEIQGRYPHLLEQLLSTSDTTGEENADPPIIHFGPGESSSEDAVMMNTPVVKSALEMGFNRDLVKQTVQSKILTTGENYKTVNDIVSALLNAEDEKREEEKEKQAEEMASDDLSLIRKNRMALFQQLTCVLPILDNLLKANVINKQEHDIIKQKTQIPLQARELIDTILVKGNAAANIFKNCLKEIDSTLYKNLFVDKNMKYIPTEDVSGLSLEEQLRRLQEERTCKVCMDKEVSVVFIPCGHLVVCQECAPSLRKCPICRGIIKGTVRTFLS>sp|Q13490-2|BIRC2_HUMAN Isoform 2 of Baculoviral IAP repeat-containingprotein 2 OS=Homo sapiens OX=9606 GN=BIRC2MSTYSTFPAGVPVSERSLARAGFYYTGVNDKVKCFCCGLMLDNWKLGDSPIQKHKQLYPSCSFIQNLVSASLGSTSKNTSPMRNSFAHSLSPTLEHSSLFSGSYSSLSPNPLNSRAVEDISSSRTNPYSYAMSTEEARFLTYHMWPLTFLSPSELARAGFYYIGPGDRVACFACGGKLSNWEPKDDAMSEHRRHFPNCPFLENSLETLRFSISNLSMQTHAARMRTFMYWPSSVPVQPEQLASAGFYYVGRNDDVKCFCCDGGLRCWESGDDPWVEHAKWFPRCEFLIRMKGQEFVDEIQGRYPHLLEQLLSTSDTTGEENADPPIIHFGPGESSSEDAVMMNTPVVKSALEMGFNRDLVKQTVQSKILTTGENYKTVNDIVSALLNAEDEKREEEKEKQAEEMASDDLSLIRKNRMALFQQLTCVLPILDNLLKANVINKQEHDIIKQKTQIPLQARELIDTILVKGNAAANIFKNCLKEIDSTLYKNLFVDKNMKYIPTEDVSGLSLEEQLRRLQEERTCKVCMDKEVSVVFIPCGHLVVCQECAPSLRKCPICRGIIKGTVRTFLS>sp|Q9HAW0|BRF2_HUMAN Transcription factor IIIB 50 kDa subunit OS=Homosapiens OX=9606 GN=BRF2 PE=1 SV=1MPGRGRCPDCGSTELVEDSHYSQSQLVCSDCGCVVTEGVLTTTFSDEGNLREVTYSRSTGENEQVSRSQQRGLRRVRDLCRVLQLPPTFEDTAVAYYQQAYRHSGIRAARLQKKEVLVGCCVLITCRQHNWPLTMGAICTLLYADLDVFSSTYMQIVKLLGLDVPSLCLAELVKTYCSSFKLFQASPSVPAKYVEDKEKMLSRTMQLVELANETWLVTGRHPLPVITAATFLAWQSLQPADRLSCSLARFCKLANVDLPYPASSRLQELLAVLLRMAEQLAWLRVLRLDKRSVVKHIGDLLQHRQSLVRSAFRDGTAEVETREKEPPGWGQGQGEGEVGNNSLGLPQGKRPASPALLLPPCMLKSPKRICPVPPVSTVTGDENISDSEIEQYLRTPQEVRDFQRAQAARQAATSVPNPP>sp|Q9HAW0-2|BRF2_HUMAN Isoform 2 of Transcription factor IIIB 50 kDasubunit OS=Homo sapiens OX=9606 GN=BRF2MPGRGRCPDCVVTEGVLTTTFSDEGNLREVTYSRSTGENEQVSRSQQRGLRRVRDLCRVLQLPPTFEDTAVAYYQQAYRHSGIRAARLQKKEVLVGCCVLITCRQHNWPLTMGAICTLLYADLDVFSSTYMQIVKLLGLDVPSLCLAELVKTYCSSFKLFQASPSVPAKYVEDKEKMLSRTMQLVELANETWLVTGRHPLPVITAATFLAWQSLQPADRLSCSLARFCKLANVDLPYPASSRLQELLAVLLRMAEQLAWLRVLRLDKRSVVKHIGDLLQHRQSLVRSAFRDGTAEVETREKEPPGWGQGQGEGEVGNNSLGLPQGKRPASPALLLPPCMLKSPKRICPVPPVSTVTGDENISDSEIEQYLRTPQEVRDFQRAQAARQAATSVPNPP>sp|A8MY62|BLML_HUMAN Putative beta-lactamase-like 1 OS=Homo sapiensOX=9606 GN=LACTBL1 PE=2 SV=2MCPRHPEPVPLAHPLPVLKEALEKVDQILRQAMSAPGVAAMSAVVIHNDTVLWTGNFGKKNGSDPASGAPNEYTMYRISSISKIFPVLMLYRLWEEGIVASLDDPLERYASTFTINNPLGLASAEQQGLILRRMASQLSGLPRRLRSTSLLWKGSTQEALNLLKDDVLVVDPGTRCHYSTLAFSLLAHVLAAHTAQGDYQRWVSENVLEPLGMADTGFDLTPDVRARLAAGFYGSGRPAPLYDLGWYRPSGQMYSTAADLAKLAVALLGGGPRRLLRPDAAKTLLAPLLACPGAYFANETGTPWEFHAQRGYRVVRKDGDLDGYAATFSLVPPLRLGLVLLLAGPRPPGPDLVARAYDELLPALERALREAEPGPAPPPTAHPFAGYFTFANLTFYEVRAGPAGELRLRQFGPRVEALVPPAFRTLALRHLHGRVFQLHVAHEFPCALPLGDAWLSLEAQHGQLVNFYPLDHHGLSPGFDVPGLNTYRVLRLRGKPVFKT>sp|Q92843|B2CL2_HUMAN Bcl-2-like protein 2 OS=Homo sapiens OX=9606GN=BCL2L2 PE=1 SV=2MATPASAPDTRALVADFVGYKLRQKGYVCGAGPGEGPAADPLHQAMRAAGDEFETRFRRTFSDLAAQLHVTPGSAQQRFTQVSDELFQGGPNWGRLVAFFVFGAALCAESVNKEMEPLVGQVQEWMVAYLETQLADWIHSSGGWAEFTALYGDGALEEARRLREGNWASVRTVLTGAVALGALVTVGAFFASK>sp|Q92843-2|B2CL2_HUMAN Isoform 3 of Bcl-2-like protein 2 OS=Homosapiens OX=9606 GN=BCL2L2MATPASAPDTRALVADFVGYKLRQKGYVCGAGPGEGPAADPLHQAMRAAGDEFETRFRRTFSDLAAQLHVTPGSAQQRFTQVSDELFQGGPNWGRLVAFFVFGAALCAESVNKEMEPLVGQVQEWMVAYLETQLADWIHSSGGWELEAIKARVREMEEEAEKLKELQNEVEKQMNMSPPPGNAGPVIMSIEEKMEADARSIYVGNVDYGATAEELEAHFHGCGSVNRVTILCDKFSGHPKGFAYIEFSDKESVRTSLALDESLFRGRQIKVIPKRTNRPGISTTDRGFPRARYRARTTNYNSSRSRFYSGFNSRPRGRVYRGRARATSWYSPY>sp|Q8N3I7|BBS5_HUMAN Bardet-Biedl syndrome 5 protein OS=Homo sapiensOX=9606 GN=BBS5 PE=1 SV=1MSVLDALWEDRDVRFDLSAQQMKTRPGEVLIDCLDSIEDTKGNNGDRGRLLVTNLRILWHSLALSRVNVSVGYNCILNITTRTANSKLRGQTEALYILTKCNSTRFEFIFTNLVPGSPRLFTSVMAVHRAYETSKMYRDFKLRSALIQNKQLRLLPQEHVYDKINGVWNLSSDQGNLGTFFITNVRIVWHANMNDSFNVSIPYLQIRSIKIRDSKFGLALVIESSQQSGGYVLGFKIDPVEKLQESVKEINSLHKVYSASPIFGVDYEMEEKPQPLEALTVEQIQDDVEIDSDGHTDAFVAYFADGNKQQDREPVFSEELGLAIEKLKDGFTLQGLWEVMS>sp|Q8N3I7-2|BBS5_HUMAN Isoform 2 of Bardet-Biedl syndrome 5 proteinOS=Homo sapiens OX=9606 GN=BBS5MSVLDALWEDRDVRFDLSAQQMKTRPGEVLIDCLDSIEDTKGNNGDRGRLLVTNLRILWHSLALSRVNVSVGYNCILNITTRTANSKLRGQTEALYILTKCNSTRFEFIFTNLVPGSPRLFTSVMAVHRAYETSKMYRDFKLRSALIQNKQLRLLPQEHVYDKINGVWNLSSDQGNLGTFFITNVRIVWHANMNDSFNVSIPYLQISGGYVLGFKIDPVEKLQESVKEINSLHKVYSASPIFGVDYEMEEKPQPLEALTVEQIQDDVEIDSDGHTDAFVAYFADGNKQQDREPVFSEELGLAIEKLKDGFTLQGLWEVMS>sp|P08311|CATG_HUMAN Cathepsin G OS=Homo sapiens OX=9606 GN=CTSG PE=1SV=2MQPLLLLLAFLLPTGAEAGEIIGGRESRPHSRPYMAYLQIQSPAGQSRCGGFLVREDFVLTAAHCWGSNINVTLGAHNIQRRENTQQHITARRAIRHPQYNQRTIQNDIMLLQLSRRVRRNRNVNPVALPRAQEGLRPGTLCTVAGWGRVSMRRGTDTLREVQLRVQRDRQCLRIFGSYDPRRQICVGDRRERKAAFKGDSGGPLLCNNVAHGIVSYGKSSGVPPEVFTRVSSFLPWIRTTMRSFKLLDQMETPL>sp|O14944|EREG_HUMAN Proepiregulin OS=Homo sapiens OX=9606 GN=EREG PE=1SV=1MTAGRRMEMLCAGRVPALLLCLGFHLLQAVLSTTVIPSCIPGESSDNCTALVQTEDNPRVAQVSITKCSSDMNGYCLHGQCIYLVDMSQNYCRCEVGYTGVRCEHFFLTVHQPLSKEYVALTVILIILFLITVVGSTYYFCRWYRNRKSKEPKKEYERVTSGDPELPQV>sp|Q6NT32|EST5A_HUMAN Carboxylesterase 5A OS=Homo sapiens OX=9606GN=CES5A PE=2 SV=1MSGNWVHPGQILIWAIWVLAAPTKGPSAEGPQRNTRLGWIQGKQVTVLGSPVPVNVFLGVPFAAPPLGSLRFTNPQPASPWDNLREATSYPNLCLQNSEWLLLDQHMLKVHYPKFGVSEDCLYLNIYAPAHADTGSKLPVLVWFPGGAFKTGSASIFDGSALAAYEDVLVVVVQYRLGIFGFFTTWDQHAPGNWAFKDQVAALSWVQKNIEFFGGDPSSVTIFGESAGAISVSSLILSPMAKGLFHKAIMESGVAIIPYLEAHDYEKSEDLQVVAHFCGNNASDSEALLRCLRTKPSKELLTLSQKTKSFTRVVDGAFFPNEPLDLLSQKAFKAIPSIIGVNNHECGFLLPMKEAPEILSGSNKSLALHLIQNILHIPPQYLHLVANEYFHDKHSLTEIRDSLLDLLGDVFFVVPALITARYHRDAGAPVYFYEFRHRPQCFEDTKPAFVKADHADEVRFVFGGAFLKGDIVMFEGATEEEKLLSRKMMKYWATFARTGNPNGNDLSLWPAYNLTEQYLQLDLNMSLGQRLKEPRVDFWTSTIPLILSASDMLHSPLSSLTFLSLLQPFFFFCAP>sp|Q6NT32-2|EST5A_HUMAN Isoform 2 of Carboxylesterase 5A OS=Homo sapiensOX=9606 GN=CES5AMSGNWVHPGQILIWAIWVLAAPTKGPSAEGPQRNTRLGWIQGKQVTVLGSPVPVNVFLGVPFAAPPLGSLRFTNPQPASPWDNLREATSYPNLCLQNSEWLLLDQHMLKVHYPKFGVSEDCLYLNIYAPAHADTGSKLPVLVWFPGGAFKTGSASIFDGSALAAYEDVLVVVVQYRLGIFGFFTTWDQHAPGNWAFKDQVAALSWVQKNIEFFGGDPSSVTIFGESAGAISVSSLILSPMAKGLFHKAIMESGVAIIPYLEAHDYEKSEDLQVVAHFCGNNASDSEALLRCLRTKPSKELLTLSQKTKSFTRVVDGAFFPNEPLDLLSQKAFKAIPSIIGVNNHECGFLLPMKEAPEILSGSNKSLALHLIQNILHIPPQYLHLVANEYFHDKHSLTEIRDSLLDLLGDVFFVVPALITARYHREGATEEEKLLSRKMMKYWATFARTGNPNGNDLSLWPAYNLTEQYLQLDLNMSLGQRLKEPRVDFWTSTIPLILSASDMLHSPLSSLTFLSLLQPFFFFCAP>sp|Q6NT32-3|EST5A_HUMAN Isoform 3 of Carboxylesterase 5A OS=Homo sapiensOX=9606 GN=CES5AMLKVHYPKFGVSEDCLYLNIYAPAHADTGSKLPVLVWFPGGAFKTGSASIFDGSALAAYEDVLVVVVQYRLGIFGFFTTWDQHAPGNWAFKDQVAALSWVQKNIEFFGGDPSSVTIFGESAGAISVSSLILSPMAKGLFHKAIMESGVAIIPYLEAHDYEKSEDLQVVAHFCGNNASDSEALLRCLRTKPSKELLTLSQKTKSFTRVVDGAFFPNEPLDLLSQKAFKAIPSIIGVNNHECGFLLPMKEAPEILSGSNKSLALHLIQNILHIPPQYLHLVANEYFHDKHSLTEIRDSLLDLLGDVFFVVPALITARYHRDAGAPVYFYEFRHRPQCFEDTKPAFVKADHADEVRFVFGGAFLKGDIVMFEGATEEEKLLSRKMMKYWATFARTGNPNGNDLSLWPAYNLTEQYLQLDLNMSLGQRLKEPRVDFWTSTIPLILSASDMLHSPLSSLTFLSLLQPFFFFCAP>sp|Q6NT32-4|EST5A_HUMAN Isoform 4 of Carboxylesterase 5A OS=Homo sapiensOX=9606 GN=CES5AMAVLVCPASCHGLKEFRIRRGMWRLCLVYYFYPASSTLYVLRIDVLNYTSKDEGPSAEGPQRNTRLGWIQGKQVTVLGSPVPVNVFLGVPFAAPPLGSLRFTNPQPASPWDNLREATSYPNLCLQNSEWLLLDQHMLKVHYPKFGVSEDCLYLNIYAPAHADTGSKLPVLVWFPGGAFKTGSASIFDGSALAAYEDVLVVVVQYRLGIFGFFTTWDQHAPGNWAFKDQVAALSWVQKNIEFFGGDPSSVTIFGESAGAISVSSLILSPMAKGLFHKAIMESGVAIIPYLEAHDYEKSEDLQVVAHFCGNNASDSEALLRCLRTKPSKELLTLSQKTKSFTRVVDGAFFPNEPLDLLSQKAFKAIPSIIGVNNHECGFLLPMKEAPEILSGSNKSLALHLIQNILHIPPQYLHLVANEYFHDKHSLTEIRDSLLDLLGDVFFVVPALITARYHRDAGAPVYFYEFRHRPQCFEDTKPAFVKADHADEVRFVFGGAFLKGDIVMFEGATEEEKLLSRKMMKYWATFARTGNPNGNDLSLWPAYNLTEQYLQLDLNMSLGQRLKEPRVDFWTSTIPLILSASDMLHSPLSSLTFLSLLQPFFFFCAP>sp|A8MVW0|F1712_HUMAN Protein FAM171A2 OS=Homo sapiens OX=9606GN=FAM171A2 PE=1 SV=1MPPASGPSVLARLLPLLGLLLGSASRAPGKSPPEPPSPQEILIKVQVYVSGELVPLARASVDVFGNRTLLAAGTTDSEGVATLPLSYRLGTWVLVTAARPGFLTNSVPWRVDKLPLYASVSLYLLPERPATLILYEDLVHILLGSPGARSQPLVQFQRRAARLPVSSTYSQLWASLTPASTQQEMRAFPAFLGTEASSSGNGSWLELMPLTAVSVHLLTGNGTEVPLSGPIHLSLPVPSETRALTVGTSIPAWRFDPKSGLWVRNGTGVIRKEGRQLYWTFVSPQLGYWVAAMASPTAGLVTITSGIQDIGTYHTIFLLTILAALALLVLILLCLLIYYCRRRCLKPRQQHRKLQLSGPSDGNKRDQATSMSQLHLICGGPLEPAPSGDPEAPPPGPLHSAFSSSRDLASSRDDFFRTKPRSASRPAAEPSGARGGESAGLKGARSAEGPGGLEPGLEEHRRGPSGAAAFLHEPPSPPPPFDHYLGHKGAAEGKTPDFLLSQSVDQLARPPSLGQAGQLIFCGSIDHLKDNVYRNVMPTLVIPAHYVRLGGEAGAAGVGDEPAPPEGTAPGPARAFPQPDPQRPQMPGHSGPGGEGGGGGGEGWGAGRAAPVSGSVTIPVLFNESTMAQLNGELQALTEKKLLELGVKPHPRAWFVSLDGRSNSQVRHSYIDLQAGGGARSTDASLDSGVDVHEARPARRRPAREERERAPPAAPPPPPAPPRLALSEDTEPSSSESRTGLCSPEDNSLTPLLDEVAAPEGRAATVPRGRGRSRGDSSRSSASELRRDSLTSPEDELGAEVGDEAGDKKSPWQRREERPLMVFNVK>sp|Q8N9W8|FA71D_HUMAN Protein FAM71D OS=Homo sapiens OX=9606 GN=FAM71DPE=2 SV=2MKKNTSKTTMRINKQDALCTPHSHDPRDLQNMLDGGEYAPFVSPPMLESNFIQVNRRGESIYLHNRANWVTVGICFSSSTHKIPNVMLLAHLTPGAQKDTETLFKSLLTSPPAEKLVLTRFLPLQFVTLSVHDAENMSLKVKLVSGRAYYLQLCTSAYKQDTLFSQWVALISLLNQEKAKVSKVSEVSSLSGITNSTDITGSMDVTDVTTFTAILTPYMYAGTGPEHVRDSIDFPEFTDITDITDVTDLPENEVPEVPDVRIVTEVIEVREATEVTDSSDITNCSGVTVVFENNDLIRAKQEEKEKLKNILKPGCLQDTKSKSELKESSKHVTISNITLTFEGKRYFQTTLTPVESEANTSKEMKDKTSEEKMPDFQSTALKAEESRSLRTESNTSVLSPHIKSPSNFLKLVPHLSAPFSRE>sp|Q8N9W8-2|FA71D_HUMAN Isoform 2 of Protein FAM71D OS=Homo sapiensOX=9606 GN=FAM71DMKKNTSKTTMRINKQDALCTPHSHDPRDLQNMLDGGEYAPFVSPPMLESNFIQVNRRGESIYLHNRANWVTVGICFSSSTHKIPNVMLLAHLTPGAQKDTETLFKSLLTSPPAEKLVLTRFLPLQFVTLSVHDAENMSLKVKLVSGRAYYLQLCTSAYKQDTLFSQWVALISLLNQEKAKVSKVSEVSSLSGITNSTDITGSMDVTDVTTFTAILTPYMYAGTGPEHVRDSIDFPEFTDITDITDVTDLPENEVPEVPDVRIVTEVIEVREATEVTDSSDITNCSGVTVVFENNDLIRAKQEEKEKLKNILKPGCLQDTKSKRYFQTTLTPVESEANTSKEMKDKTSEEKMPDFQSTALKAEESRSLRTESNTSVLSPHIKSPSNFLKLVPHLSAPFSRE>sp|P29323|EPHB2_HUMAN Ephrin type-B receptor 2 OS=Homo sapiens OX=9606GN=EPHB2 PE=1 SV=5MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYDENMNTIRTYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSIPSVPGSCKETFNLYYYEADFDSATKTFPNWMENPWVKVDTIAADESFSQVDLGGRVMKINTEVRSFGPVSRSGFYLAFQDYGGCMSLIAVRVFYRKCPRIIQNGAIFQETLSGAESTSLVAARGSCIANAEEVDVPIKLYCNGDGEWLVPIGRCMCKAGFEAVENGTVCRGCPSGTFKANQGDEACTHCPINSRTTSEGATNCVCRNGYYRADLDPLDMPCTTIPSAPQAVISSVNETSLMLEWTPPRDSGGREDLVYNIICKSCGSGRGACTRCGDNVQYAPRQLGLTEPRIYISDLLAHTQYTFEIQAVNGVTDQSPFSPQFASVNITTNQAAPSAVSIMHQVSRTVDSITLSWSQPDQPNGVILDYELQYYEKELSEYNATAIKSPTNTVTVQGLKAGAIYVFQVRARTVAGYGRYSGKMYFQTMTEAEYQTSIQEKLPLIIGSSAAGLVFLIAVVVIAIVCNRRGFERADSEYTDKLQHYTSGHMTPGMKIYIDPFTYEDPNEAVREFAKEIDISCVKIEQVIGAGEFGEVCSGHLKLPGKREIFVAIKTLKSGYTEKQRRDFLSEASIMGQFDHPNVIHLEGVVTKSTPVMIITEFMENGSLDSFLRQNDGQFTVIQLVGMLRGIAAGMKYLADMNYVHRDLAARNILVNSNLVCKVSDFGLSRFLEDDTSDPTYTSALGGKIPIRWTAPEAIQYRKFTSASDVWSYGIVMWEVMSYGERPYWDMTNQDVINAIEQDYRLPPPMDCPSALHQLMLDCWQKDRNHRPKFGQIVNTLDKMIRNPNSLKAMAPLSSGINLPLLDRTIPDYTSFNTVDEWLEAIKMGQYKESFANAGFTSFDVVSQMMMEDILRVGVTLAGHQKKILNSIQVMRAQMNQIQSVEGQPLARRPRATGRTKRCQPRDVTKKTCNSNDGKKKGMGKKKTDPGRGREIQGIFFKEDSHKESNDCSCGG>sp|P29323-2|EPHB2_HUMAN Isoform 2 of Ephrin type-B receptor 2 OS=Homosapiens OX=9606 GN=EPHB2MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYDENMNTIRTYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSIPSVPGSCKETFNLYYYEADFDSATKTFPNWMENPWVKVDTIAADESFSQVDLGGRVMKINTEVRSFGPVSRSGFYLAFQDYGGCMSLIAVRVFYRKCPRIIQNGAIFQETLSGAESTSLVAARGSCIANAEEVDVPIKLYCNGDGEWLVPIGRCMCKAGFEAVENGTVCRGCPSGTFKANQGDEACTHCPINSRTTSEGATNCVCRNGYYRADLDPLDMPCTTIPSAPQAVISSVNETSLMLEWTPPRDSGGREDLVYNIICKSCGSGRGACTRCGDNVQYAPRQLGLTEPRIYISDLLAHTQYTFEIQAVNGVTDQSPFSPQFASVNITTNQAAPSAVSIMHQVSRTVDSITLSWSQPDQPNGVILDYELQYYEKELSEYNATAIKSPTNTVTVQGLKAGAIYVFQVRARTVAGYGRYSGKMYFQTMTEAEYQTSIQEKLPLIIGSSAAGLVFLIAVVVIAIVCNRRGFERADSEYTDKLQHYTSGHMTPGMKIYIDPFTYEDPNEAVREFAKEIDISCVKIEQVIGAGEFGEVCSGHLKLPGKREIFVAIKTLKSGYTEKQRRDFLSEASIMGQFDHPNVIHLEGVVTKSTPVMIITEFMENGSLDSFLRQNDGQFTVIQLVGMLRGIAAGMKYLADMNYVHRDLAARNILVNSNLVCKVSDFGLSRFLEDDTSDPTYTSALGGKIPIRWTAPEAIQYRKFTSASDVWSYGIVMWEVMSYGERPYWDMTNQDVINAIEQDYRLPPPMDCPSALHQLMLDCWQKDRNHRPKFGQIVNTLDKMIRNPNSLKAMAPLSSGINLPLLDRTIPDYTSFNTVDEWLEAIKMGQYKESFANAGFTSFDVVSQMMMEDILRVGVTLAGHQKKILNSIQVMRAQMNQIQSVEV>sp|P29323-3|EPHB2_HUMAN Isoform 3 of Ephrin type-B receptor 2 OS=Homosapiens OX=9606 GN=EPHB2MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYDENMNTIRTYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSIPSVPGSCKETFNLYYYEADFDSATKTFPNWMENPWVKVDTIAADESFSQVDLGGRVMKINTEVRSFGPVSRSGFYLAFQDYGGCMSLIAVRVFYRKCPRIIQNGAIFQETLSGAESTSLVAARGSCIANAEEVDVPIKLYCNGDGEWLVPIGRCMCKAGFEAVENGTVCRGCPSGTFKANQGDEACTHCPINSRTTSEGATNCVCRNGYYRADLDPLDMPCTTIPSAPQAVISSVNETSLMLEWTPPRDSGGREDLVYNIICKSCGSGRGACTRCGDNVQYAPRQLGLTEPRIYISDLLAHTQYTFEIQAVNGVTDQSPFSPQFASVNITTNQAAPSAVSIMHQVSRTVDSITLSWSQPDQPNGVILDYELQYYEKELSEYNATAIKSPTNTVTVQGLKAGAIYVFQVRARTVAGYGRYSGKMYFQTMTEAEYQTSIQEKLPLIIGSSAAGLVFLIAVVVIAIVCNRRRGFERADSEYTDKLQHYTSGHMTPGMKIYIDPFTYEDPNEAVREFAKEIDISCVKIEQVIGAGEFGEVCSGHLKLPGKREIFVAIKTLKSGYTEKQRRDFLSEASIMGQFDHPNVIHLEGVVTKSTPVMIITEFMENGSLDSFLRQNDGQFTVIQLVGMLRGIAAGMKYLADMNYVHRDLAARNILVNSNLVCKVSDFGLSRFLEDDTSDPTYTSALGGKIPIRWTAPEAIQYRKFTSASDVWSYGIVMWEVMSYGERPYWDMTNQDVINAIEQDYRLPPPMDCPSALHQLMLDCWQKDRNHRPKFGQIVNTLDKMIRNPNSLKAMAPLSSGINLPLLDRTIPDYTSFNTVDEWLEAIKMGQYKESFANAGFTSFDVVSQMMMEDILRVGVTLAGHQKKILNSIQVMRAQMNQIQSVEV>sp|Q2M2I3|FA83E_HUMAN Protein FAM83E OS=Homo sapiens OX=9606 GN=FAM83EPE=1 SV=2MAASQLAALEGVDSGPRVPGASPGFLYSEGQRLALEALLSKGAEAFQTCVQREELWPFLSADEVQGLAAAAEDWTVAKQEPSGMAEGATTTDVDAGSLSYWPGQSEQPAPVLRLGWPVDSAWKGITRAQLYTQPPGEGQPPLKELVRLEIQAAHKLVAVVMDVFTDPDLLLDLVDAATRRWVPVYLLLDRQQLPAFLELAQQLGVNPWNTENVDVRVVRGCSFQSRWRRQVSGTVREKFVLLDGERVISGSYSFTWSDARLHRGLVTLLTGEIVDAFSLEFRTLYAASCPLPPAPPQKPSVIGGLQRGRSPHRVSRRRSVAPASPPPPDGPLAHRLAACRVSPATPGPALSDILRSVQRARTPSGPPARPSRSMWDLSRLSQLSGSSDGDNELKKSWGSKDTPAKALMRQRGTGGGPWGEVDSRPPWGGALPLPPAHRLRYLSPARRRFGGDATFKLQEPRGVRPSDWAPRAGLGGQP>sp|Q96GI7|FA89A_HUMAN Protein FAM89A OS=Homo sapiens OX=9606 GN=FAM89APE=1 SV=1MSGARAAPGAAGNGAVRGLRVDGLPPLPKSLSGLLHSASGGGASGGWRHLERLYAQKSRIQDELSRGGPGGGGARAAALPAKPPNLDAALALLRKEMVGLRQLDMSLLCQLYSLYESIQEYKGACQAASSPDCTYALENGFFDEEEEYFQEQNSLHDRRDRGPPRDLSLPVSSLSSSDWILESI>sp|P54764|EPHA4_HUMAN Ephrin type-A receptor 4 OS=Homo sapiens OX=9606GN=EPHA4 PE=1 SV=1MAGIFYFALFSCLFGICDAVTGSRVYPANEVTLLDSRSVQGELGWIASPLEGGWEEVSIMDEKNTPIRTYQVCNVMEPSQNNWLRTDWITREGAQRVYIEIKFTLRDCNSLPGVMGTCKETFNLYYYESDNDKERFIRENQFVKIDTIAADESFTQVDIGDRIMKLNTEIRDVGPLSKKGFYLAFQDVGACIALVSVRVFYKKCPLTVRNLAQFPDTITGADTSSLVEVRGSCVNNSEEKDVPKMYCGADGEWLVPIGNCLCNAGHEERSGECQACKIGYYKALSTDATCAKCPPHSYSVWEGATSCTCDRGFFRADNDAASMPCTRPPSAPLNLISNVNETSVNLEWSSPQNTGGRQDISYNVVCKKCGAGDPSKCRPCGSGVHYTPQQNGLKTTKVSITDLLAHTNYTFEIWAVNGVSKYNPNPDQSVSVTVTTNQAAPSSIALVQAKEVTRYSVALAWLEPDRPNGVILEYEVKYYEKDQNERSYRIVRTAARNTDIKGLNPLTSYVFHVRARTAAGYGDFSEPLEVTTNTVPSRIIGDGANSTVLLVSVSGSVVLVVILIAAFVISRRRSKYSKAKQEADEEKHLNQGVRTYVDPFTYEDPNQAVREFAKEIDASCIKIEKVIGVGEFGEVCSGRLKVPGKREICVAIKTLKAGYTDKQRRDFLSEASIMGQFDHPNIIHLEGVVTKCKPVMIITEYMENGSLDAFLRKNDGRFTVIQLVGMLRGIGSGMKYLSDMSYVHRDLAARNILVNSNLVCKVSDFGMSRVLEDDPEAAYTTRGGKIPIRWTAPEAIAYRKFTSASDVWSYGIVMWEVMSYGERPYWDMSNQDVIKAIEEGYRLPPPMDCPIALHQLMLDCWQKERSDRPKFGQIVNMLDKLIRNPNSLKRTGTESSRPNTALLDPSSPEFSAVVSVGDWLQAIKMDRYKDNFTAAGYTTLEAVVHVNQEDLARIGITAITHQNKILSSVQAMRTQMQQMHGRMVPV>sp|P54764-2|EPHA4_HUMAN Isoform 2 of Ephrin type-A receptor 4 OS=Homosapiens OX=9606 GN=EPHA4MKWEEVSIMDEKNTPIRTYQVCNVMEPSQNNWLRTDWITREGAQRVYIEIKFTLRDCNSLPGVMGTCKETFNLYYYESDNDKERFIRENQFVKIDTIAADESFTQVDIGDRIMKLNTEIRDVGPLSKKGFYLAFQDVGACIALVSVRVFYKKCPLTVRNLAQFPDTITGADTSSLVEVRGSCVNNSEEKDVPKMYCGADGEWLVPIGNCLCNAGHEERSGECQACKIGYYKALSTDATCAKCPPHSYSVWEGATSCTCDRGFFRADNDAASMPCTRPPSAPLNLISNVNETSVNLEWSSPQNTGGRQDISYNVVCKKCGAGDPSKCRPCGSGVHYTPQQNGLKTTKVSITDLLAHTNYTFEIWAVNGVSKYNPNPDQSVSVTVTTNQAAPSSIALVQAKEVTRYSVALAWLEPDRPNGVILEYEVKYYEKDQNERSYRIVRTAARNTDIKGLNPLTSYVFHVRARTAAGYGDFSEPLEVTTNTVPSRIIGDGANSTVLLVSVSGSVVLVVILIAAFVISRRRSKYSKAKQEADEEKHLNQGVRTYVDPFTYEDPNQAVREFAKEIDASCIKIEKVIGVGEFGEVCSGRLKVPGKREICVAIKTLKAGYTDKQRRDFLSEASIMGQFDHPNIIHLEGVVTKCKPVMIITEYMENGSLDAFLRKNDGRFTVIQLVGMLRGIGSGMKYLSDMSYVHRDLAARNILVNSNLVCKVSDFGMSRVLEDDPEAAYTTRGGKIPIRWTAPEAIAYRKFTSASDVWSYGIVMWEVMSYGERPYWDMSNQDVIKAIEEGYRLPPPMDCPIALHQLMLDCWQKERSDRPKFGQIVNMLDKLIRNPNSLKRTGTESSRPNTALLDPSSPEFSAVVSVGDWLQAIKMDRYKDNFTAAGYTTLEAVVHVNQEDLARIGITAITHQNKILSSVQAMRTQMQQMHGRMVPV>sp|Q17R55|F187B_HUMAN Protein FAM187B OS=Homo sapiens OX=9606 GN=FAM187BPE=2 SV=2MPPMLWLLLHFAAPALGFYFSISCPSGKQCQQALLSGNDILLYCNSSGAHWYYLFTQGKKGRLTSLTNISNMEIMPEGSLLIKDPLPSQTGLYHCWNKNGRQVVQYEIDFQDVTTLHITHKDLGQRPLQNETLHLGSKQLIFTWWEPWQDCNRCEEPGECKRLGYRYIEEPLEEAMPCWLYLGEVLVWSSRLRPELQVEACHVQCTNNTQLRVDYVIFDNFRLDEKTEFVWLDCPLGSMYRPVNWRANDTPLTWESQLSGQDFTTFLDPSTGGRQLQVFQPAVYKCFVQQELVAQFKPAASLETLEAQWRENDAQWREARKALRGRADSVLKGLKLVLLVVTVLALLGALLKCIHPSPGRRSTQVLVVK>sp|A6NHQ4|EPOP_HUMAN Elongin BC and Polycomb repressive complex 2-associated protein OS=Homo sapiens OX=9606 GN=EPOP PE=1 SV=1METLCPAPRLAVPASPRGSPCSPTPRKPCRGTQEFSPLCLRALAFCALAKPRASSLGPGPGELAARSPVLRGPQAPLRPGGWAPDGLKHLWAPTGRPGVPNTAAGEDADVAACPRRGEEEEGGGGFPHFGVRSCAPPGRCPAPPHPRESTTSFASAPPRPAPGLEPQRGPAASPPQEPSSRPPSPPAGLSTEPAGPGTAPRPFLPGQPAEVDGNPPPAAPEAPAASPSTASPAPAAPGDLRQEHFDRLIRRSKLWCYAKGFALDTPSLRRGPERPPAKGPARGAAKKRRLPAPPPRTAQPRRPAPTLPTTSTFSLLNCFPCPPALVVGEDGDLKPASSLRLQGDSKPPPAHPLWRWQMGGPAVPEPPGLKFWGINMDES>sp|Q8IYD1|ERF3B_HUMAN Eukaryotic peptide chain release factor GTP-binding subunit ERF3B OS=Homo sapiens OX=9606 GN=GSPT2 PE=1 SV=2MDSGSSSSDSAPDCWDQVDMESPGSAPSGDGVSSAVAEAQREPLSSAFSRKLNVNAKPFVPNVHAAEFVPSFLRGPTQPPTLPAGSGSNDETCTGAGYPQGKRMGRGAPVEPSREEPLVSLEGSNSAVTMELSEPVVENGEVEMALEESWEHSKEVSEAEPGGGSSGDSGPPEESGQEMMEEKEEIRKSKSVIVPSGAPKKEHVNVVFIGHVDAGKSTIGGQIMFLTGMVDKRTLEKYEREAKEKNRETWYLSWALDTNQEERDKGKTVEVGRAYFETERKHFTILDAPGHKSFVPNMIGGASQADLAVLVISARKGEFETGFEKGGQTREHAMLAKTAGVKHLIVLINKMDDPTVNWSIERYEECKEKLVPFLKKVGFSPKKDIHFMPCSGLTGANIKEQSDFCPWYTGLPFIPYLDNLPNFNRSIDGPIRLPIVDKYKDMGTVVLGKLESGSIFKGQQLVMMPNKHNVEVLGILSDDTETDFVAPGENLKIRLKGIEEEEILPGFILCDPSNLCHSGRTFDVQIVIIEHKSIICPGYNAVLHIHTCIEEVEITALISLVDKKSGEKSKTRPRFVKQDQVCIARLRTAGTICLETFKDFPQMGRFTLRDEGKTIAIGKVLKLVPEKD>sp|Q9NQ60|EQTN_HUMAN Equatorin OS=Homo sapiens OX=9606 GN=EQTN PE=2 SV=2MNFILFIFIPGVFSLKSSTLKPTIEALPNVLPLNEDVNKQEEKNEDHTPNYAPANEKNGNYYKDIKQYVFTTQNPNGTESEISVRATTDLNFALKNDKTVNATTYEKSTIEEETTTSEPSHKNIQRSTPNVPAFWTMLAKAINGTAVVMDDKDQLFHPIPESDVNATQGENQPDLEDLKIKIMLGISLMTLLLFVVLLAFCSATLYKLRHLSYKSCESQYSVNPELATMSYFHPSEGVSDTSFSKSAESSTFLGTTSSDMRRSGTRTSESKIMTDIISIGSDNEMHENDESVTR>sp|Q9NQ60-2|EQTN_HUMAN Isoform 2 of Equatorin OS=Homo sapiens OX=9606GN=EQTNMNFILFIFIPGVFSLKSSTLKPTIEALPNVLPLNEDVNKQEEKNEDHTPNYAPANEKNGNYYKDIKQYVFTTQNPNGTESEISVRATTDLNFALKNDKTVNATTYEKSTIEEETTTSEPSHKNIQSI>sp|Q9NQ60-3|EQTN_HUMAN Isoform 3 of Equatorin OS=Homo sapiens OX=9606GN=EQTNMNFILFIFIPGVFSLKSSTLKPTIEALPNVLPLNEDVNKQEEKNEDHTPNYAPANEKNGNYYKDIKQYVFTTQNPNGTESEISVRATTDLNFALKNGSTPNVPAFWTMLAKAINGTAVVMDDKDQLFHPIPESDVNATQGENQPDLEDLKIKIMLGISLMTLLLFVVLLAFCSATLYKLRHLSYKSCESQYSVNPELATMSYFHPSEGVSDTSFSKSAESSTFLGTTSSDMRRSGTRTSESKIMTDIISIGSDNEMHENDESVTR>sp|P00488|F13A_HUMAN Coagulation factor XIII A chain OS=Homo sapiensOX=9606 GN=F13A1 PE=1 SV=4MSETSRTAFGGRRAVPPNNSNAAEDDLPTVELQGVVPRGVNLQEFLNVTSVHLFKERWDTNKVDHHTDKYENNKLIVRRGQSFYVQIDFSRPYDPRRDLFRVEYVIGRYPQENKGTYIPVPIVSELQSGKWGAKIVMREDRSVRLSIQSSPKCIVGKFRMYVAVWTPYGVLRTSRNPETDTYILFNPWCEDDAVYLDNEKEREEYVLNDIGVIFYGEVNDIKTRSWSYGQFEDGILDTCLYVMDRAQMDLSGRGNPIKVSRVGSAMVNAKDDEGVLVGSWDNIYAYGVPPSAWTGSVDILLEYRSSENPVRYGQCWVFAGVFNTFLRCLGIPARIVTNYFSAHDNDANLQMDIFLEEDGNVNSKLTKDSVWNYHCWNEAWMTRPDLPVGFGGWQAVDSTPQENSDGMYRCGPASVQAIKHGHVCFQFDAPFVFAEVNSDLIYITAKKDGTHVVENVDATHIGKLIVTKQIGGDGMMDITDTYKFQEGQEEERLALETALMYGAKKPLNTEGVMKSRSNVDMDFEVENAVLGKDFKLSITFRNNSHNRYTITAYLSANITFYTGVPKAEFKKETFDVTLEPLSFKKEAVLIQAGEYMGQLLEQASLHFFVTARINETRDVLAKQKSTVLTIPEIIIKVRGTQVVGSDMTVTVQFTNPLKETLRNVWVHLDGPGVTRPMKKMFREIRPNSTVQWEEVCRPWVSGHRKLIASMSSDSLRHVYGELDVQIQRRPSM>sp|Q9BPY3|F118B_HUMAN Protein FAM118B OS=Homo sapiens OX=9606 GN=FAM118BPE=1 SV=1MASTGSQASDIDEIFGFFNDGEPPTKKPRKLLPSLKTKKPRELVLVIGTGISAAVAPQVPALKSWKGLIQALLDAAIDFDLLEDEESKKFQKCLHEDKNLVHVAHDLIQKLSPRTSNVRSTFFKDCLYEVFDDLESKMEDSGKQLLQSVLHLMENGALVLTTNFDNLLELYAADQGKQLESLDLTDEKKVLEWAQEKRKLSVLHIHGVYTNPSGIVLHPAGYQNVLRNTEVMREIQKLYENKSFLFLGCGWTVDDTTFQALFLEAVKHKSDLEHFMLVRRGDVDEFKKLRENMLDKGIKVISYGDDYADLPEYFKRLTCEISTRGTSAGMVREGQLNGSSAAHSEIRGCST>sp|Q8N7L0|F216B_HUMAN Protein FAM216B OS=Homo sapiens OX=9606 GN=FAM216BPE=2 SV=1MGQNWKRQQKLWNVPQLPFIRVPPSIYDTSLLKALNQGQQRYFYSIMRIYNSRPQWEALQTRYIHSLQHQQLLGYITQREALSYALVLRDSTKRASAKVAPQRTIPRKTSAMTRRCPSVLPVSVVLPRAQSKRRQVLRN>sp|Q9NWS6|F118A_HUMAN Protein FAM118A OS=Homo sapiens OX=9606 GN=FAM118APE=1 SV=2MDSVEKTTNRSEQKSRKFLKSLIRKQPQELLLVIGTGVSAAVAPGIPALCSWRSCIEAVIEAAEQLEVLHPGDVAEFRRKVTKDRDLLVVAHDLIRKMSPRTGDAKPSFFQDCLMEVFDDLEQHIRSPVVLQSILSLMDRGAMVLTTNYDNLLEAFGRRQNKPMESLDLKDKTKVLEWARGHMKYGVLHIHGLYTDPCGVVLDPSGYKDVTQDAEVMEVLQNLYRTKSFLFVGCGETLRDQIFQALFLYSVPNKVDLEHYMLVLKENEDHFFKHQADMLLHGIKVVSYGDCFDHFPGYVQDLATQICKQQSPDADRVDSTTLLGNACQDCAKRKLEENGIEVSKKRTQSDTDDAGGS>sp|Q9NWS6-2|F118A_HUMAN Isoform 2 of Protein FAM118A OS=Homo sapiensOX=9606 GN=FAM118AMKYGVLHIHGLYTDPCGVVLDPSGYKDVTQDAEVMEVLQNLYRTKSFLFVGCGETLRDQIFQALFLYSVPNKVDLEHYMLVLKENEDHFFKHQADMLLHGIKVVSYGDCFDHFPGYVQDLATQICKQQSPDADRVDSTTLLGNACQDCAKRKLEENGIEVSKKRTQSDTDDAGGS>sp|Q96BN6|F149B_HUMAN Primary cilium assembly protein FAM149B1 OS=Homosapiens OX=9606 GN=FAM149B1 PE=1 SV=2MISRYTRKAVPQSLELKGITKHALNHHPPPEKLEEISPTSDSHEKDTSSQSKSDITRESSFTSADTGNSLSAFPSYTGAGISTEGSSDFSWGYGELDQNATEKVQTMFTAIDELLYEQKLSVHTKSLQEECQQWTASFPHLRILGRQIITPSEGYRLYPRSPSAVSASYETTLSQERDSTIFGIRGKKLHFSSSYAHKASSIAKSSSFCSMERDEEDSIIVSEGIIEEYLAFDHIDIEEGFHGKKSEAATEKQKLGYPPIAPFYCMKEDVLAYVFDSVWCKVVSCMEQLTRSHWEGFASDDESNVAVTRPDSESSCVLSELHPLVLPRVPQSKVLYITSNPMSLCQASRHQPNVNDLLVHGMPLQPRNLSLMDKLLDLDDKLLMRPGSSTILSTRNWPNRAVEFSTSSLSYTVQSTRRRNPPPRTLHPISTSHSCAETPRSVEEILRGARVPVAPDSLSSPSPTPLSRNNLLPPIGTAEVEHVSTVGPQRQMKPHGDSSRAQSAVVDEPNYQQPQERLLLPDFFPRPNTTQSFLLDTQYRRSCAVEYPHQARPGRGSAGPQLHGSTKSQSGGRPVSRTRQGP>sp|Q96BN6-2|F149B_HUMAN Isoform 2 of Primary cilium assembly proteinFAM149B1 OS=Homo sapiens OX=9606 GN=FAM149B1MISRYTRKAVPQSLELKGITKHALNHHPPPEKLEEISPTSDSHEKDTSSQSKSDITRESSFTSADTGNSLSAFPSYTGAGISTEGSSDFSWGYGELDQNATEKVQTMFTAIDELLYEQKLSVHTKSLQEECQQWTASFPHLRILGRQIITPSEGYRLYPRSPSAVSASYETTLSQERDSTIFGIRGKKLHFSSSYAHKASSIAKSSSFCSMERDEEDSIIVSEGIIEEYLAFDHIDIEEGFHGKKSEAATEKQKLGYPPIAPFYCMKEDVLAYVFDSVWCKVVSCMEQLTRSHWEGFASDDESNVAVTRPDSESSCVLSELHPLVLPRVPQSKMSLCQASRHQPNVNDLLVHGMPLQPRNLSLMDKLLDLDDKLLMRPGSSTILSTRNWPNRAVEFSTSSLSYTVQSTRRRNPPPRTLHPISTSHSCAETPRSVEEILRGARVPVAPDSLSSPSPTPLSRNNLLPPIGTAEVEHVSTVGPQRQMKPHGDSSRAQSAVVDEPNYQQPQERLLLPDFFPRPNTTQSFLVE>sp|B1ANY3|F220P_HUMAN Putative protein FAM220BP OS=Homo sapiens OX=9606GN=FAM220BP PE=5 SV=1MRDRRGPLGTCLAQVQWAGGGDSDKLSYSLKKRMPTEGPWPADAPSWMNKPAVDGNSQSEALSLEMAGLSLPSGGPVLPYVKESARRNPASAATPSAAVGLFPAPTEYFARVSCSGVEALGRDWLGGGPRATHGHRGQCPKGEPRVSRLTRHQKLPEMGSFWDDPPSAFPSGLGSELEPSCLHSILSATLHACPEVLLKDETKRIFLDLLNPMFSKQTIEFKKMFKSTSDGLQITLGLLALQHFELANSLCHSLKYKQNNASRLILRVVLE>sp|Q13158|FADD_HUMAN FAS-associated death domain protein OS=Homo sapiensOX=9606 GN=FADD PE=1 SV=1MDPFLVLLHSVSSSLSSSELTELKFLCLGRVGKRKLERVQSGLDLFSMLLEQNDLEPGHTELLRELLASLRRHDLLRRVDDFEAGAAAGAAPGEEDLCAAFNVICDNVGKDWRRLARQLKVSDTKIDSIEDRYPRNLTERVRESLRIWKNTEKENATVAHLVGALRSCQMNLVADLVQEVQQARDLQNRSGAMSPMSWNSDASTSEAS>sp|A4D161|F221A_HUMAN Protein FAM221A OS=Homo sapiens OX=9606 GN=FAM221APE=1 SV=1MERLTLPLGGAAAVDEYLEYRRIVGEDDGGKLFTPEEYEEYKRKVLPLRLQNRLFVSWRSPTGMDCKLVGPETLCFCTHRYKQHKTDLEAIPQQCPIDLPCQVTGCQCRAYLYVPLNGSQPIRCRCKHFADQHSAAPGFTCNTCSKCSGFHSCFTCACGQPAYAHDTVVETKQERLAQEKPVGQDIPYAAMGGLTGFSSLAEGYMRLDDSGIGVPSVEFLESPITAVDSPFLKAFQASSSSSPETLTDVGTSSQVSSLRRPEEDDMAFFERRYQERMKMEKAAKWKGKAPLPSATKPS>sp|A4D161-2|F221A_HUMAN Isoform 2 of Protein FAM221A OS=Homo sapiensOX=9606 GN=FAM221AMERLTLPLGGAAAVDEYLEYRRIVGEDDGGKLFTPEEYEEYKRKVLPLRLQNRLFVSWRSPTGMDCKLVGPETLCFCTHRYKQHKTDLEAIPQQCPIDLPCQVTGCQCRAYLYVPLNGSQPIRCRCKHFADQHSAAPGFTCNTCSKCSGFHSCFTCACGQPAYAHDTVVETKQERLAQEKPVGQDIPYAAMGGLTGFSSLAEGYMRLDDSGIVGTSSQVSSLRRPEEDDMAFFERRYQERMKMEKAAKWKGKAPLPSATKPS>sp|A4D161-3|F221A_HUMAN Isoform 3 of Protein FAM221A OS=Homo sapiensOX=9606 GN=FAM221AMERLTLPLGGAAAVDEYLEYRRYKQHKTDLEAIPQQCPIDLPCQVTGCQCRAYLYVPLNGSQPIRCRCKHFADQHSAAPGFTCNTCSKCSGFHSCFTCACGQPAYAHDTVVETKQERLAQEKPVGQDIPYAAMGGLTGFSSLAEGYMRLDDSGIVGTSSQVSSLRRPEEDDMAFFERRYQERMKMEKAAKWKGKAPLPSATKPS>sp|Q8IW50|F219A_HUMAN Protein FAM219A OS=Homo sapiens OX=9606 GN=FAM219APE=1 SV=3MMEEIDRFQVPTAHSEMQPLDPAAASISDGDCDAREGESVAMNYKPSPLQVKLEKQRELARKGSLKNGSMGSPVNQQPKKNNVMARTRLVVPNKGYSSLDQSPDEKPLVALDTDSDDDFDMSRYSSSGYSSAEQINQDLNIQLLKDGYRLDEIPDDEDLDLIPPKSVNPTCMCCQATSSTACHIQ>sp|Q8IW50-2|F219A_HUMAN Isoform 2 of Protein FAM219A OS=Homo sapiensOX=9606 GN=FAM219AMMEEIDRFQDPAAASISDGDCDAREEKQRELARKGSLKNGSMGSPVNQQPKKNNVMARTRLVVPNKGYSSLDQSPDEKPLVALDTDSDDDFDMSRYSSSGYSSAEQINQDLNIQLLKDGYRLDEIPDDEDLDLIPPKSVNPTCMCCQATSSTACHIQ>sp|Q8IW50-3|F219A_HUMAN Isoform 3 of Protein FAM219A OS=Homo sapiensOX=9606 GN=FAM219AMMEEIDRFQDPAAASISDGDCDAREEKQRELARKGSLKNGSMGSPVNQQPKKNNVMARTRLVVPNKGYSSLDQSPDEKPLVALDTDSDDDFDMSRYSSSGYSSAEINQDLNIQLLKDGYRLDEIPDDEDLDLIPPKSVNPTCMCCQATSSTACHIQ>sp|Q8IW50-4|F219A_HUMAN Isoform 4 of Protein FAM219A OS=Homo sapiensOX=9606 GN=FAM219AMMEEIDRFQDPAAASISDGDCDAREGESVAMNYKPSPLQVKLEKQRELARKGSLKNGSMGSPVNQQPKKNNVMARTRLVVPNKGYSSLDQSPDEKPLVALDTDSDDDFDMSRYSSSGYSSAEINQDLNIQLLKDGYRLDEIPDDEDLDLIPPKSVNPTCMCCQATSSTACHIQ>sp|Q8IW50-5|F219A_HUMAN Isoform 5 of Protein FAM219A OS=Homo sapiensOX=9606 GN=FAM219AMMEEIDRFQVPTAHSEMQPLDPAAASISDGDCDAREEKQRELARKGSLKNGSMGSPVNQQPKKNNVMARTRLVVPNKGYSSLDQSPDEKPLVALDTDSDDDFDMSRYSSSGYSSAEINQDLNIQLLKDGYRLDEIPDDEDLDLIPPKSVNPTCMCCQATSSTACHIQ>sp|Q8IW50-6|F219A_HUMAN Isoform 6 of Protein FAM219A OS=Homo sapiensOX=9606 GN=FAM219AMMEEIDRFQVPTAHSEMQPLDPAAASISDGDCDAREEKQRELARKGSLKNGSMGSPVNQQPKKNNVMARTRLVVPNKGYSSLDQSPDEKPLVALDTDSDDDFDMSRYSSSGYSSAEQINQDLNIQLLKDGYRLDEIPDDEDLDLIPPKSVNPTCMCCQATSSTACHIQ>sp|Q8IW50-7|F219A_HUMAN Isoform 7 of Protein FAM219A OS=Homo sapiensOX=9606 GN=FAM219AMMEEIDRFQVPTAHSEMQPLDPAAASISDGDCDAREGESVAMNYKPSPLQVKLEKQRELARKGSLKNGSMGSPVNQQPKKNNVMARTRLVVPNKGYSSLDQSPDEKPLVALDTDRCVWGLGGSWAAQRNLYSTSGLYRPHLLYCQNWDILQPESLQG>sp|Q96GL9|F163A_HUMAN Protein FAM163A OS=Homo sapiens OX=9606 GN=FAM163APE=1 SV=1MTAGTVVITGGILATVILLCIIAVLCYCRLQYYCCKKSGTEVADEEEEREHDLPTHPRGPTCNACSSQALDGRGSLAPLTSEPCSQPCGVAASHCTTCSPYSSPFYIRTADMVPNGGGGERLSFAPTYYKEGGPPSLKLAAPQSYPVTWPGSGREAFTNPRAISTDV>sp|A0A1B0GTK4|F237A_HUMAN Protein FAM237A OS=Homo sapiens OX=9606GN=FAM237A PE=3 SV=1MADPGNRGGIHRPLSFTCSLLIVGMCCVSPFFCHSQTDLLALSQADPQCWESSSVLLLEMWKPRVSNTVSGFWDFMIYLKSSENLKHGALFWDLAQLFWDIYVDCVLSRNHGLGRRQLVGEEEKISAAQPQHTRSKQGTYSQLLRTSFLKKKELIEDLISMHVRRSGSSVIGKVNLEIKRK>sp|A6NKX1|F223B_HUMAN Protein FAM223B OS=Homo sapiens OX=9606 GN=FAM223BPE=3 SV=1MYVQEHRLWGLMDKPHSAPCLMSLSLSFLICNKGRNAIRVQQSTDERMDAMLLRQCPTQGTRKNHESNSSLHHVPNWIFHSTIIPPNKGSKRCLRKVDWLLPRAGGVGGKRGVTADGDRVSF>sp|A0A494C0Y3|F246A_HUMAN Protein FAM246A OS=Homo sapiens OX=9606GN=FAM246A PE=3 SV=1MATPGRPWAQARSAYRASEVLRRVTGRRRDPGPQSNGPGQEDARAPGRLARLLGQLRAEAASRSEVPRLLKLVERAGAGAAGAGERTGAHSRGSVCSVCGEPRGRATYPAGVLEVSERRLQEGLAAVREELGAEIEALRAELRAELDALRALLPPPPPSPPARREPRAVPRATPRGPTLLRTLGTVSALVAASRPADDAPDGPAECGAHRAPVRKNHKKMPVPPGAPQGGGD>sp|Q96L91|EP400_HUMAN E1A-binding protein p400 OS=Homo sapiens OX=9606GN=EP400 PE=1 SV=4MHHGTGPQNVQHQLQRSRACPGSEGEEQPAHPNPPPSPAAPFAPSASPSAPQSPSYQIQQLMNRSPATGQNVNITLQSVGPVVGGNQQITLAPLPLPSPTSPGFQFSAQPRRFEHGSPSYIQVTSPLSQQVQTQSPTQPSPGPGQALQNVRAGAPGPGLGLCSSSPTGGFVDASVLVRQISLSPSSGGHFVFQDGSGLTQIAQGAQVQLQHPGTPITVRERRPSQPHTQSGGTIHHLGPQSPAAAGGAGLQPLASPSHITTANLPPQISSIIQGQLVQQQQVLQGPPLPRPLGFERTPGVLLPGAGGAAGFGMTSPPPPTSPSRTAVPPGLSSLPLTSVGNTGMKKVPKKLEEIPPASPEMAQMRKQCLDYHYQEMQALKEVFKEYLIELFFLQHFQGNMMDFLAFKKKHYAPLQAYLRQNDLDIEEEEEEEEEEEEKSEVINDEVKVVTGKDGQTGTPVAIATQLPPKVSAAFSSQQQPFQQALAGSLVAGAGSTVETDLFKRQQAMPSTGMAEQSKRPRLEVGHQGVVFQHPGADAGVPLQQLMPTAQGGMPPTPQAAQLAGQRQSQQQYDPSTGPPVQNAASLHTPLPQLPGRLPPAGVPTAALSSALQFAQQPQVVEAQTQLQIPVKTQQPNVPIPAPPSSQLPIPPSQPAQLALHVPTPGKVQVQASQLSSLPQMVASTRLPVDPAPPCPRPLPTSSTSSLAPVSGSGPGPSPARSSPVNRPSSATNKALSPVTSRTPGVVASAPTKPQSPAQNATSSQDSSQDTLTEQITLENQVHQRIAELRKAGLWSQRRLPKLQEAPRPKSHWDYLLEEMQWMATDFAQERRWKVAAAKKLVRTVVRHHEEKQLREERGKKEEQSRLRRIAASTAREIECFWSNIEQVVEIKLRVELEEKRKKALNLQKVSRRGKELRPKGFDALQESSLDSGMSGRKRKASISLTDDEVDDEEETIEEEEANEGVVDHQTELSNLAKEAELPLLDLMKLYEGAFLPSSQWPRPKPDGEDTSGEEDADDCPGDRESRKDLVLIDSLFIMDQFKAAERMNIGKPNAKDIADVTAVAEAILPKGSARVTTSVKFNAPSLLYGALRDYQKIGLDWLAKLYRKNLNGILADEAGLGKTVQIIAFFAHLACNEGNWGPHLVVVRSCNILKWELELKRWCPGLKILSYIGSHRELKAKRQEWAEPNSFHVCITSYTQFFRGLTAFTRVRWKCLVIDEMQRVKGMTERHWEAVFTLQSQQRLLLIDSPLHNTFLELWTMVHFLVPGISRPYLSSPLRAPSEESQDYYHKVVIRLHRVTQPFILRRTKRDVEKQLTKKYEHVLKCRLSNRQKALYEDVILQPGTQEALKSGHFVNVLSILVRLQRICNHPGLVEPRHPGSSYVAGPLEYPSASLILKALERDFWKEADLSMFDLIGLENKITRHEAELLSKKKIPRKLMEEISTSAAPAARPAAAKLKASRLFQPVQYGQKPEGRTVAFPSTHPPRTAAPTTASAAPQGPLRGRPPIATFSANPEAKAAAAPFQTSQASASAPRHQPASASSTAASPAHPAKLRAQTTAQASTPGQPPPQPQAPSHAAGQSALPQRLVLPSQAQARLPSGEVVKIAQLASITGPQSRVAQPETPVTLQFQGSKFTLSHSQLRQLTAGQPLQLQGSVLQIVSAPGQPYLRAPGPVVMQTVSQAGAVHGALGSKPPAGGPSPAPLTPQVGVPGRVAVNALAVGEPGTASKPASPIGGPTQEEKTRLLKERLDQIYLVNERRCSQAPVYGRDLLRICALPSHGRVQWRGSLDGRRGKEAGPAHSYTSSSESPSELMLTLCRCGESLQDVIDRVAFVIPPVVAAPPSLRVPRPPPLYSHRMRILRQGLREHAAPYFQQLRQTTAPRLLQFPELRLVQFDSGKLEALAILLQKLKSEGRRVLILSQMILMLDILEMFLNFHYLTYVRIDENASSEQRQELMRSFNRDRRIFCAILSTHSRTTGINLVEADTVVFYDNDLNPVMDAKAQEWCDRIGRCKDIHIYRLVSGNSIEEKLLKNGTKDLIREVAAQGNDYSMAFLTQRTIQELFEVYSPMDDAGFPVKAEEFVVLSQEPSVTETIAPKIARPFIEALKSIEYLEEDAQKSAQEGVLGPHTDALSSDSENMPCDEEPSQLEELADFMEQLTPIEKYALNYLELFHTSIEQEKERNSEDAVMTAVRAWEFWNLKTLQEREARLRLEQEEAELLTYTREDAYSMEYVYEDVDGQTEVMPLWTPPTPPQDDSDIYLDSVMCLMYEATPIPEAKLPPVYVRKERKRHKTDPSAAGRKKKQRHGEAVVPPRSLFDRATPGLLKIRREGKEQKKNILLKQQVPFAKPLPTFAKPTAEPGQDNPEWLISEDWALLQAVKQLLELPLNLTIVSPAHTPNWDLVSDVVNSCSRIYRSSKQCRNRYENVIIPREEGKSKNNRPLRTSQIYAQDENATHTQLYTSHFDLMKMTAGKRSPPIKPLLGMNPFQKNPKHASVLAESGINYDKPLPPIQVASLRAERIAKEKKALADQQKAQQPAVAQPPPPQPQPPPPPQQPPPPLPQPQAAGSQPPAGPPAVQPQPQPQPQTQPQPVQAPAKAQPAITTGGSAAVLAGTIKTSVTGTSMPTGAVSGNVIVNTIAGVPAATFQSINKRLASPVAPGALTTPGGSAPAQVVHTQPPPRAVGSPATATPDLVSMATTQGVRAVTSVTASAVVTTNLTPVQTPARSLVPQVSQATGVQLPGKTITPAHFQLLRQQQQQQQQQQQQQQQQQQQQQQQQQQQQQTTTTSQVQVPQIQGQAQSPAQIKAVGKLTPEHLIKMQKQKLQMPPQPPPPQAQSAPPQPTAQVQVQTSQPPQQQSPQLTTVTAPRPGALLTGTTVANLQVARLTRVPTSQLQAQGQMQTQAPQPAQVALAKPPVVSVPAAVVSSPGVTTLPMNVAGISVAIGQPQKAAGQTVVAQPVHMQQLLKLKQQAVQQQKAIQPQAAQGPAAVQQKITAQQITTPGAQQKVAYAAQPALKTQFLTTPISQAQKLAGAQQVQTQIQVAKLPQVVQQQTPVASIQQVASASQQASPQTVALTQATAAGQQVQMIPAVTATAQVVQQKLIQQQVVTTASAPLQTPGAPNPAQVPASSDSPSQQPKLQMRVPAVRLKTPTKPPCQ>sp|Q96L91-2|EP400_HUMAN Isoform 2 of E1A-binding protein p400 OS=Homosapiens OX=9606 GN=EP400MHHGTGPQNVQHQLQRSRACPGSEGEEQPAHPNPPPSPAAPFAPSASPSAPQSPSYQIQQLMNRSPATGQNVNITLQSVGPVVGGNQQITLAPLPLPSPTSPGFQFSAQPRRFEHGSPSYIQVTSPLSQQVQTQSPTQPSPGPGQALQNVRAGAPGPGLGLCSSSPTGGFVDASVLVRQISLSPSSGGHFVFQDGSGLTQIAQGAQVQLQHPGTPITVRERRPSQPHTQSGGTIHHLGPQSPAAAGGAGLQPLASPSHITTANLPPQISSIIQGQLVQQQQVLQGPPLPRPLGFERTPGVLLPGAGGAAGFGMTSPPPPTSPSRTAVPPGLSSLPLTSVGNTGMKKVPKKLEEIPPASPEMAQMRKQCLDYHYQEMQALKEVFKEYLIELFFLQHFQGNMMDFLAFKKKHYAPLQAYLRQNDLDIEEEEEEEEEEEEKSEVINDEQQALAGSLVAGAGSTVETDLFKRQQAMPSTGMAEQSKRPRLEVGHQGVVFQHPGADAGVPLQQLMPTAQGGMPPTPQAAQLAGQRQSQQQYDPSTGPPVQNAASLHTPLPQLPGRLPPAGVPTAALSSALQFAQQPQVVEAQTQLQIPVKTQQPNVPIPAPPSSQLPIPPSQPAQLALHVPTPGKVQVQASQLSSLPQMVASTRLPVDPAPPCPRPLPTSSTSSLAPVSGSGPGPSPARSSPVNRPSSATNKALSPVTSRTPGVVASAPTKPQSPAQNATSSQDSSQDTLTEQITLENQVHQRIAELRKAGLWSQRRLPKLQEAPRPKSHWDYLLEEMQWMATDFAQERRWKVAAAKKLVRTVVRHHEEKQLREERGKKEEQSRLRRIAASTAREIECFWSNIEQVVEIKLRVELEEKRKKALNLQKVSRRGKELRPKGFDALQESSLDSGMSGRKRKASISLTDDEVDDEEETIEEEEANEGVVDHQTELSNLAKEAELPLLDLMKLYEGAFLPSSQWPRPKPDGEDTSGEEDADDCPGDRESRKDLVLIDSLFIMDQFKAAERMNIGKPNAKDIADVTAVAEAILPKGSARVTTSVKFNAPSLLYGALRDYQKIGLDWLAKLYRKNLNGILADEAGLGKTVQIIAFFAHLACNEGNWGPHLVVVRSCNILKWELELKRWCPGLKILSYIGSHRELKAKRQEWAEPNSFHVCITSYTQFFRGLTAFTRVRWKCLVIDEMQRVKGMTERHWEAVFTLQSQQRLLLIDSPLHNTFLELWTMVHFLVPGISRPYLSSPLRAPSEESQDYYHKVVIRLHRVTQPFILRRTKRDVEKQLTKKYEHVLKCRLSNRQKALYEDVILQPGTQEALKSGHFVNVLSILVRLQRICNHPGLVEPRHPGSSYVAGPLEYPSASLILKALERDFWKEADLSMFDLIGLENKITRHEAELLSKKKIPRKLMEEISTSAAPAARPAAAKLKASRLFQPVQYGQKPEGRTVAFPSTHPPRTAAPTTASAAPQGPLRGRPPIATFSANPEAKAAAAPFQTSQASASAPRHQPASASSTAASPAHPAKLRAQTTAQASTPGQPPPQPQAPSHAAGQSALPQRLVLPSQAQARLPSGEVVKIAQLASITGPQSRVAQPETPVTLQFQGSKFTLSHSQLRQLTAGQPLQLQGSVLQIVSAPGQPYLRAPGPVVMQTVSQAGAVHGALGSKPPAGGPSPAPLTPQVGVPGRVAVNALAVGEPGTASKPASPIGGPTQEEKTRLLKERLDQIYLVNERRCSQAPVYGRDLLRICALPSHGRVQWRGSLDGRRGKEAGPAHSYTSSSESPSELMLTLCRCGESLQDVIDRVAFVIPPVVAAPPSLRVPRPPPLYSHRMRILRQGLREHAAPYFQQLRQTTAPRLLQFPELRLVQFDSGKLEALAILLQKLKSEGRRVLILSQMILMLDILEMFLNFHYLTYVRIDENASSEQRQELMRSFNRDRRIFCAILSTHSRTTGINLVEADTVVFYDNDLNPVMDAKAQEWCDRIGRCKDIHIYRLVSGNSIEEKLLKNGTKDLIREVAAQGNDYSMAFLTQRTIQELFEVYSPMDDAGFPVKAEEFVVLSQEPSVTETIAPKIARPFIEALKSIEYLEEDAQKSAQEGVLGPHTDALSSDSENMPCDEEPSQLEELADFMEQLTPIEKYALNYLELFHTSIEQEKERNSEDAVMTAVRAWEFWNLKTLQEREARLRLEQEEAELLTYTREDAYSMEYVYEDVDGQTEVMPLWTPPTPPQDDSDIYLDSVMCLMYEATPIPEAKLPPVYVRKERKRHKTDPSAAGRKKKQRHGEAVVPPRSLFDRATPGLLKIRREGKEQKKNILLKQQVPFAKPLPTFAKPTAEPGQDNPEWLISEDWALLQAVKQLLELPLNLTIVSPAHTPNWDLVSDVVNSCSRIYRSSKQCRNRYENVIIPREEGKSKNNRPLRTSQIYAQDENATHTQLYTSHFDLMKMTAGKRSPPIKPLLGMNPFQKNPKHASVLAESGINYDKPLPPIQVASLRAERIAKEKKALADQQKAQQPAVAQPPPPQPQPPPPPQQPPPPLPQPQAAGSQPPAGPPAVQPQPQPQPQTQPQPVQAPAKAQPAITTGGSAAVLAGTIKTSVTGTSMPTGAVSGNVIVNTIAGVPAATFQSINKRLASPVAPGALTTPGGSAPAQVVHTQPPPRAVGSPATATPDLVSMATTQGVRAVTSVTASAVVTTNLTPVQTPARSLVPQVSQATGVQLPGKTITPAHFQLLRQQQQQQQQQQQQQQQQQQQQQQQQQQQQQTTTTSQVQVPQIQGQAQSPAQIKAVGKLTPEHLIKMQKQKLQMPPQPPPPQAQSAPPQPTAQVQVQTSQPPQQQSPQLTTVTAPRPGALLTGTTVANLQVARLTRVPTSQLQAQGQMQTQAPQPAQVALAKPPVVSVPAAVVSSPGVTTLPMNVAGISVAIGQPQKAAGQTVVAQPVHMQQLLKLKQQAVQQQKAIQPQAAQGPAAVQQKITAQQITTPGAQQKVAYAAQPALKTQFLTTPISQAQKLAGAQQVQTQIQVAKLPQVVQQQTPVASIQQVASASQQASPQTVALTQATAAGQQVQMIPAVTATAQVVQQKLIQQQVVTTASAPLQTPGAPNPAQVPASSDSPSQQPKLQMRVPAVRLKTPTKPPCQ>sp|Q96L91-3|EP400_HUMAN Isoform 3 of E1A-binding protein p400 OS=Homosapiens OX=9606 GN=EP400MHHGTGPQNVQHQLQRSRACPGSEGEEQPAHPNPPPSPAAPFAPSASPSAPQSPSYQIQQLMNRSPATGQNVNITLQSVGPVVGGNQQITLAPLPLPSPTSPGFQFSAQPRRFEHGSPSYIQVTSPLSQQVQTQSPTQPSPGPGQALQNVRAGAPGPGLGLCSSSPTGGFVDASVLVRQISLSPSSGGHFVFQDGSGLTQIAQGAQVQLQHPGTPITVRERRPSQPHTQSGGTIHHLGPQSPAAAGGAGLQPLASPSHITTANLPPQISSIIQGQLVQQQQVLQGPPLPRPLGFERTPGVLLPGAGGAAGFGMTSPPPPTSPSRTAVPPGLSSLPLTSVGNTGMKKVPKKLEEIPPASPEMAQMRKQCLDYHYQEMQALKEVFKEYLIELFFLQHFQGNMMDFLAFKKKHYAPLQAYLRQNDLDIEEEEEEEEEEEEKSEVINDEQALAGSLVAGAGSTVETDLFKRQQAMPSTGMAGGMPPTPQAAQLAGQRQSQQQYDPSTGPPVQNAASLHTPLPQLPGRLPPAGVPTAALSSALQFAQQPQVVEAQTQLQIPVKTQQPNVPIPAPPSSQLPIPPSQPAQLALHVPTPGKVQVQASQLSSLPQMVASTRLPVDPAPPCPRPLPTSSTSSLAPVSGSGPGPSPARSSPVNRPSSATNKALSPVTSRTPGVVASAPTKPQSPAQNATSSQDSSQDTLTEQITLENQVHQRIAELRKAGLWSQRRLPKLQEAPRPKSHWDYLLEEMQWMATDFAQERRWKVAAAKKLVRTVVRHHEEKQLREERGKKEEQSRLRRIAASTAREIECFWSNIEQVVEIKLRVELEEKRKKALNLQKVSRRGKELRPKGFDALQESSLDSGMSGRKRKASISLTDDEVDDEEETIEEEEANEGVVDHQTELSNLAKEAELPLLDLMKLYEGAFLPSSQWPRPKPDGEDTSGEEDADDCPGDRESRKDLVLIDSLFIMDQFKAAERMNIGKPNAKDIADVTAVAEAILPKGSARVTTSVKFNAPSLLYGALRDYQKIGLDWLAKLYRKNLNGILADEAGLGKTVQIIAFFAHLACNEGNWGPHLVVVRSCNILKWELELKRWCPGLKILSYIGSHRELKAKRQEWAEPNSFHVCITSYTQFFRGLTAFTRVRWKCLVIDEMQRVKGMTERHWEAVFTLQSQQRLLLIDSPLHNTFLELWTMVHFLVPGISRPYLSSPLRAPSEESQDYYHKVVIRLHRVTQPFILRRTKRDVEKQLTKKYEHVLKCRLSNRQKALYEDVILQPGTQEALKSGHFVNVLSILVRLQRICNHPGLVEPRHPGSSYVAGPLEYPSASLILKALERDFWKEADLSMFDLIGLENKITRHEAELLSKKKIPRKLMEEISTSAAPAARPAAAKLKASRLFQPVQYGQKPEGRTVAFPSTHPPRTAAPTTASAAPQGPLRGRPPIATFSANPEAKAAAAPFQTSQASASAPRHQPASASSTAASPAHPAKLRAQTTAQASTPGQPPPQPQAPSHAAGQSALPQRLVLPSQAQARLPSGEVVKIAQLASITGPQSRVAQPETPVTLQFQGSKFTLSHSQLRQLTAGQPLQLQGSVLQIVSAPGQPYLRAPGPVVMQTVSQAGAVHGALGSKPPAGGPSPAPLTPQVGVPGRVAVNALAVGEPGTASKPASPIGGPTQEEKTRLLKERLDQIYLVNERRCSQAPVYGRDLLRICALPSHGRVQWRGSLDGRRGKEAGPAHSYTSSSESPSELMLTLCRCGESLQDVIDRVAFVIPPVVAAPPSLRVPRPPPLYSHRMRILRQGLREHAAPYFQQLRQTTAPRLLQFPELRLVQFDSGKLEALAILLQKLKSEGRRVLILSQMILMLDILEMFLNFHYLTYVRIDENASSEQRQELMRSFNRDRRIFCAILSTHSRTTGINLVEADTVVFYDNDLNPVMDAKAQEWCDRIGRCKDIHIYRLVSGNSIEEKLLKNGTKDLIREVAAQGNDYSMAFLTQRTIQELFEVYSPMDDAGFPVKAEEFVVLSQEPSVTETIAPKIARPFIEALKSIEYLEEDAQKSAQEGVLGPHTDALSSDSENMPCDEEPSQLEELADFMEQLTPIEKYALNYLELFHTSIEQEKERNSEDAVMTAVRAWEFWNLKTLQEREARLRLEQEEAELLTYTREDAYSMEYVYEDVDGQTEVMPLWTPPTPPQDDSDIYLDSVMCLMYEATPIPEAKLPPVYVRKERKRHKTDPSAAGRKKKQRHGEAVVPPRSLFDRATPGLLKIRREGKEQKKNILLKQQVPFAKPLPTFAKPTAEPGQDNPEWLISEDWALLQAVKQLLELPLNLTIVSPAHTPNWDLVSDVVNSCSRIYRSSKQCRNRYENVIIPREEGKSKNNRPLRTSQIYAQDENATHTQLYTSHFDLMKMTAGKRSPPIKPLLGMNPFQKNPKHASVLAESGINYDKPLPPIQVASLRAERIAKEKKALADQQKAQQPAVAQPPPPQPQPPPPPQQPPPPLPQPQAAGSQPPAGPPAVQPQPQPQPQTQPQPVQAPAKAQPAITTGGSAAVLAGTIKTSVTGTSMPTGAVSGNVIVNTIAGVPAATFQSINKRLASPVAPGALTTPGGSAPAQVVHTQPPPRAVGSPATATPDLVSMATTQGVRAVTSVTASAVVTTNLTPVQTPARSLVPQVSQATGVQLPGKTITPAHFQLLRQQQQQQQQQQQQQQQQQQQQQQQQQQQQQTTTTSQVQVPQIQGQAQSPAQIKAVGKLTPEHLIKMQKQKLQMPPQPPPPQAQSAPPQPTAQVQVQTSQPPQQQSPQLTTVTAPRPGALLTGTTVANLQVARLTRVPTSQLQAQGQMQTQAPQPAQVALAKPPVVSVPAAVVSSPGVTTLPMNVAGISVAIGQPQKAAGQTVVAQPVHMQQLLKLKQQAVQQQKAIQPQAAQGPAAVQQKITAQQITTPGAQQKVAYAAQPALKTQFLTTPISQAQKLAGAQQVQTQIQVAKLPQVVQQQTPVASIQQVASASQQASPQTVALTQATAAGQQVQMIPAVTATAQVVQQKLIQQQVVTTASAPLQTPGAPNPAQVPASSDSPSQQPKLQMRVPAVRLKTPTKPPCQ>sp|Q96L91-4|EP400_HUMAN Isoform 4 of E1A-binding protein p400 OS=Homosapiens OX=9606 GN=EP400MHHGTGPQNVQHQLQRSRACPGSEGEEQPAHPNPPPSPAAPFAPSASPSAPQSPSYQIQQLMNRSPATGQNVNITLQSVGPVVGGNQQITLAPLPLPSPTSPGFQFSAQPRRFEHGSPSYIQVTSPLSQQVQTQSPTQPSPGPGQALQNVRAGAPGPGLGLCSSSPTGGFVDASVLVRQISLSPSSGGHFVFQDGSGLTQIAQGAQVQLQHPGTPITVRERRPSQPHTQSGGTIHHLGPQSPAAAGGAGLQPLASPSHITTANLPPQISSIIQGQLVQQQQVLQGPPLPRPLGFERTPGVLLPGAGGAAGFGMTSPPPPTSPSRTAVPPGLSSLPLTSVGNTGMKKVPKKLEEIPPASPEMAQMRKQCLDYHYQEMQALKEVFKEYLIELFFLQHFQGNMMDFLAFKKKHYAPLQAYLRQNDLDIEEEEEEEEEEEEKSEVINDEQQALAGSLVAGAGSTVETDLFKRQQAMPSTGMAEQSKRPRLEVGHQGVVFQHPGADAGVPLQQLMPTAQGGMPPTPQAAQLAGQRQSQQQYDPSTGPPVQNAASLHTPLPQLPGRLPPAGVPTAALSSALQFAQQPQVVEAQTQLQIPVKTQQPNVPIPAPPSSQLPIPPSQPAQLALHVPTPGKVQVQASQLSSLPQMVASTRLPVDPAPPCPRPLPTSSTSSLAPVSGSGPGPSPARSSPVNRPSSATNKALSPVTSRTPGVVASAPTKPQSPAQNATSSQDSSQDTLTEQITLENQVHQRIAELRKAGLWSQRRLPKLQEAPRPKSHWDYLLEEMQWMATDFAQERRWKVAAAKKLVRTVVRHHEEKQLREERGKKEEQSRLRRIAASTAREIECFWSNIEQVVEIKLRVELEEKRKKALNLQKVSRRGKELRPKGFDALQESSLDSGMSGRKRKASISLTDDEVDDEEETIEEEEANEGVVDHQTELSNLAKEAELPLLDLMKLYEGAFLPSSQWPRPKPDGEDTSGEEDADDCPGDRESRKDLVLIDSLFIMDQFKAAERMNIGKPNAKDIADVTAVAEAILPKGSARVTTSVKFNAPSLLYGALRDYQKIGLDWLAKLYRKNLNGILADEAGLGKTVQIIAFFAHLACNEGNWGPHLVVVRSCNILKWELELKRWCPGLKILSYIGSHRELKAKRQEWAEPNSFHVCITSYTQFFRGLTAFTRVRWKCLVIDEMQRVKGMTERHWEAVFTLQSQQRLLLIDSPLHNTFLELWTMVHFLVPGISRPYLSSPLRAPSEESQDYYHKVVIRLHRVTQPFILRRTKRDVEKQLTKKYEHVLKCRLSNRQKALYEDVILQPGTQEALKSGHFVNVLSILVRLQRICNHPGLVEPRHPGSSYVAGPLEYPSASLILKALERDFWKEADLSMFDLIGLENKITRHEAELLSKKKIPRKLMEEISTSAAPAARPAAAKLKASRLFQPVQYGQKPEGRTVAFPSTHPPRTAAPTTASAAPQGPLRGRPPIATFSANPEAKGGEVVKIAQLASITGPQSRVAQPETPVTLQFQGSKFTLSHSQLRQLTAGQPLQLQGSVLQIVSAPGQPYLRAPGPVVMQTVSQAGAVHGALGSKPPAGGPSPAPLTPQVGVPGRVAVNALAVGEPGTASKPASPIGGPTQEEKTRLLKERLDQIYLVNERRCSQAPVYGRDLLRICALPSHGRVQWRGSLDGRRGKEAGPAHSYTSSSESPSELMLTLCRCGESLQDVIDRVAFVIPPVVAAPPSLRVPRPPPLYSHRMRILRQGLREHAAPYFQQLRQTTAPRLLQFPELRLVQFDSGKLEALAILLQKLKSEGRRVLILSQMILMLDILEMFLNFHYLTYVRIDENASSEQRQELMRSFNRDRRIFCAILSTHSRTTGINLVEADTVVFYDNDLNPVMDAKAQEWCDRIGRCKDIHIYRLVSGNSIEEKLLKNGTKDLIREVAAQGNDYSMAFLTQRTIQELFEVYSPMDDAGFPVKAEEFVVLSQEPSVTETIAPKIARPFIEALKSIEYLEEDAQKSAQEGVLGPHTDALSSDSENMPCDEEPSQLEELADFMEQLTPIEKYALNYLELFHTSIEQEKERNSEDAVMTAVRAWEFWNLKTLQEREARLRLEQEEAELLTYTREDAYSMEYVYEDVDGQTEVMPLWTPPTPPQDDSDIYLDSVMCLMYEATPIPEAKLPPVYVRKERKRHKTDPSAAGRKKKQRHGEAVVPPRSLFDRATPGLLKIRREGKEQKKNILLKQQVPFAKPLPTFAKPTAEPGQDNPEWLISEDWALLQAVKQLLELPLNLTIVSPAHTPNWDLVSDVVNSCSRIYRSSKQCRNRYENVIIPREEGKSKNNRPLRTSQIYAQDENATHTQLYTSHFDLMKMTAGKRSPPIKPLLGMNPFQKNPKHASVLAESGINYDKPLPPIQVASLRAERIAKEKKALADQQKAQQPAVAQPPPPQPQPPPPPQQPPPPLPQPQAAGSQPPAGPPAVQPQPQPQPQTQPQPVQAPAKAQPAITTGGSAAVLAGTIKTSVTGTSMPTGAVSGNVIVNTIAGVPAATFQSINKRLASPVAPGALTTPGGSAPAQVVHTQPPPRAVGSPATATPDLVSMATTQGVRAVTSVTASAVVTTNLTPVQTPARSLVPQVSQATGVQLPGKTITPAHFQLLRQQQQQQQQQQQQQQQQQQQQQQQQQQQQQTTTTSQVQVPQIQGQAQSPAQIKAVGKLTPEHLIKMQKQKLQMPPQPPPPQAQSAPPQPTAQVQVQTSQPPQQQSPQLTTVTAPRPGALLTGTTVANLQVARLTRVPTSQLQAQGQMQTQAPQPAQVALAKPPVVSVPAAVVSSPGVTTLPMNVAGISVAIGQPQKAAGQTVVAQPVHMQQLLKLKQQAVQQQKAIQPQAAQGPAAVQQKITAQQITTPGAQQKVAYAAQPALKTQFLTTPISQAQKLAGAQQVQTQIQVAKLPQVVQQQTPVASIQQVASASQQASPQTVALTQATAAGQQVQMIPAVTATAQVVQQKLIQQQVVTTASAPLQTPGAPNPAQVPASSDSPSQQPKLQMRVPAVRLKTPTKPPCQ>sp|Q96L91-5|EP400_HUMAN Isoform 5 of E1A-binding protein p400 OS=Homosapiens OX=9606 GN=EP400MHHGTGPQNVQHQLQRSRACPGSEGEEQPAHPNPPPSPAAPFAPSASPSAPQSPSYQIQQLMNRSPATGQNVNITLQSVGPVVGGNQQITLAPLPLPSPTSPGFQFSAQPRRFEHGSPSYIQVTSPLSQQVQTQSPTQPSPGPGQALQNVRAGAPGPGLGLCSSSPTGGFVDASVLVRQISLSPSSGGHFVFQDGSGLTQIAQGAQVQLQHPGTPITVRERRPSQPHTQSGGTIHHLGPQSPAAAGGAGLQPLASPSHITTANLPPQISSIIQGQLVQQQQVLQGPPLPRPLGFERTPGVLLPGAGGAAGFGMTSPPPPTSPSRTAVPPGLSSLPLTSVGNTGMKKVPKKLEEIPPASPEMAQMRKQCLDYHYQEMQALKEVFKEYLIELFFLQHFQGNMMDFLAFKKKHYAPLQAYLRQNDLDIEEEEEEEEEEEEKSEVINDEQALAGSLVAGAGSTVETDLFKRQQAMPSTGMAEQSKRPRLEVGHQGVVFQHPGADAGVPLQQLMPTAQGGMPPTPQAAQLAGQRQSQQQYDPSTGPPVQNAASLHTPLPQLPGRLPPAGVPTAALSSALQFAQQPQVVEAQTQLQIPVKTQQPNVPIPAPPSSQLPIPPSQPAQLALHVPTPGKVQVQASQLSSLPQMVASTRLPVDPAPPCPRPLPTSSTSSLAPVSGSGPGPSPARSSPVNRPSSATNKALSPVTSRTPGVVASAPTKPQSPAQNATSSQDSSQDTLTEQITLENQVHQRIAELRKAGLWSQRRLPKLQEAPRPKSHWDYLLEEMQWMATDFAQERRWKVAAAKKLVRTVVRHHEEKQLREERGKKEEQSRLRRIAASTAREIECFWSNIEQVVEIKLRVELEEKRKKALNLQKVSRRGKELRPKGFDALQESSLDSGMSGRKRKASISLTDDEVDDEEETIEEEEANEGVVDHQTELSNLAKEAELPLLDLMKLYEGAFLPSSQWPRPKPDGEDTSGEEDADDCPGDRESRKDLVLIDSLFIMDQFKAAERMNIGKPNAKDIADVTAVAEAILPKGSARVTTSVKFNAPSLLYGALRDYQKIGLDWLAKLYRKNLNGILADEAGLGKTVQIIAFFAHLACNEGNWGPHLVVVRSCNILKWELELKRWCPGLKILSYIGSHRELKAKRQEWAEPNSFHVCITSYTQFFRGLTAFTRVRWKCLVIDEMQRVKGMTERHWEAVFTLQSQQRLLLIDSPLHNTFLELWTMVHFLVPGISRPYLSSPLRAPSEESQDYYHKVVIRLHRVTQPFILRRTKRDVEKQLTKKYEHVLKCRLSNRQKALYEDVILQPGTQEALKSGHFVNVLSILVRLQRICNHPGLVEPRHPGSSYVAGPLEYPSASLILKALERDFWKEADLSMFDLIGLENKITRHEAELLSKKKIPRKLMEEISTSAAPAARPAAAKLKASRLFQPVQYGQKPEGRTVAFPSTHPPRTAAPTTASAAPQGPLRGRPPIATFSANPEAKAAAAPFQTSQASASAPRHQPASASSTAASPAHPAKLRAQTTAQASTPGQPPPQPQAPSHAAGQSALPQRLVLPSQAQARLPSGEVVKIAQLASITGPQSRVAQPETPVTLQFQGSKFTLSHSQLRQLTAGQPLQLQGSVLQIVSAPGQPYLRAPGPVVMQTVSQAGAVHGALGSKPPAGGPSPAPLTPQVGVPGRVAVNALAVGEPGTASKPASPIGGPTQEEKTRLLKERLDQIYLVNERRCSQAPVYGRDLLRICALPSHGRVQWRGSLDGRRGKEAGPAHSYTSSSESPSELMLTLCRCGESLQDVIDRVAFVIPPVVAAPPSLRVPRPPPLYSHRMRILRQGLREHAAPYFQQLRQTTAPRLLQFPELRLVQFDSGKLEALAILLQKLKSEGRRVLILSQMILMLDILEMFLNFHYLTYVRIDENASSEQRQELMRSFNRDRRIFCAILSTHSRTTGINLVEADTVVFYDNDLNPVMDAKAQEWCDRIGRCKDIHIYRLVSGNSIEEKLLKNGTKDLIREVAAQGNDYSMAFLTQRTIQELFEVYSPMDDAGFPVKAEEFVVLSQEPSVTETIAPKIARPFIEALKSIEYLEEDAQKSAQEGVLGPHTDALSSDSENMPCDEEPSQLEELADFMEQLTPIEKYALNYLELFHTSIEQEKERNSEDAVMTAVRAWEFWNLKTLQEREARLRLEQEEAELLTYTREDAYSMEYVYEDVDGQTEVMPLWTPPTPPQDDSDIYLDSVMCLMYEATPIPEAKLPPVYVRKERKRHKTDPSAAGRKKKQRHGEAVVPPRSLFDRATPGLLKIRREGKEQKKNILLKQQVPFAKPLPTFAKPTAEPGQDNPEWLISEDWALLQAVKQLLELPLNLTIVSPAHTPNWDLVSDVVNSCSRIYRSSKQCRNRYENVIIPREEGKSKNNRPLRTSQIYAQDENATHTQLYTSHFDLMKMTAGKRSPPIKPLLGMNPFQKNPKHASVLAESGINYDKPLPPIQVASLRAERIAKEKKALADQQKAQQPAVAQPPPPQPQPPPPPQQPPPPLPQPQAAGSQPPAGPPAVQPQPQPQPQTQPQPVQAPAKAQPAITTGGSAAVLAGTIKTSVTGTSMPTGAVSGNVIVNTIAGVPAATFQSINKRLASPVAPGALTTPGGSAPAQVVHTQPPPRAVGSPATATPDLVSMATTQGVRAVTSVTASAVVTTNLTPVQTPARSLVPQVSQATGVQLPGKTITPAHFQLLRQQQQQQQQQQQQQQQQQQQQQQQQQQQQQTTTTSQVQVPQIQGQAQSPAQIKAVGKLTPEHLIKMQKQKLQMPPQPPPPQAQSAPPQPTAQVQVQTSQPPQQQSPQLTTVTAPRPGALLTGTTVANLQVARLTRVPTSQLQAQGQMQTQAPQPAQVALAKPPVVSVPAAVVSSPGVTTLPMNVAGISVAIGQPQKAAGQTVVAQPVHMQQLLKLKQQAVQQQKAIQPQAAQGPAAVQQKITAQQITTPGAQQKVAYAAQPALKTQFLTTPISQAQKLAGAQQVQTQIQVAKLPQVVQQQTPVASIQQVASASQQASPQTVALTQATAAGQQVQMIPAVTATAQVVQQKLIQQQVVTTASAPLQTPGAPNPAQVPASSDSPSQQPKLQMRVPAVRLKTPTKPPCQ>sp|P11171|EPB41_HUMAN Protein 4.1 OS=Homo sapiens OX=9606 GN=EPB41 PE=1SV=4MTTEKSLVTEAENSQHQQKEEGEEAINSGQQEPQQEESCQTAAEGDNWCEQKLKASNGDTPTHEDLTKNKERTSESRGLSRLFSSFLKRPKSQVSEEEGKEVESDKEKGEGGQKEIEFGTSLDEEIILKAPIAAPEPELKTDPSLDLHSLSSAETQPAQEELREDPDFEIKEGEGLEECSKIEVKEESPQSKAETELKASQKPIRKHRNMHCKVSLLDDTVYECVVEKHAKGQDLLKRVCEHLNLLEEDYFGLAIWDNATSKTWLDSAKEIKKQVRGVPWNFTFNVKFYPPDPAQLTEDITRYYLCLQLRQDIVAGRLPCSFATLALLGSYTIQSELGDYDPELHGVDYVSDFKLAPNQTKELEEKVMELHKSYRSMTPAQADLEFLENAKKLSMYGVDLHKAKDLEGVDIILGVCSSGLLVYKDKLRINRFPWPKVLKISYKRSSFFIKIRPGEQEQYESTIGFKLPSYRAAKKLWKVCVEHHTFFRLTSTDTIPKSKFLALGSKFRYSGRTQAQTRQASALIDRPAPHFERTASKRASRSLDGAAAVDSADRSPRPTSAPAITQGQVAEGGVLDASAKKTVVPKAQKETVKAEVKKEDEPPEQAEPEPTEAWKVEKTHIEVTVPTSNGDQTQKLAEKTEDLIRMRKKKRERLDGENIYIRHSNLMLEDLDKSQEEIKKHHASISELKKNFMESVPEPRPSEWDKRLSTHSPFRTLNINGQIPTGEGPPLVKTQTVTISDNANAVKSEIPTKDVPIVHTETKTITYEAAQTDDNSGDLDPGVLLTAQTITSETPSSTTTTQITKTVKGGISETRIEKRIVITGDADIDHDQVLVQAIKEAKEQHPDMSVTKVVVHQETEIADE>sp|P11171-2|EPB41_HUMAN Isoform 2 of Protein 4.1 OS=Homo sapiens OX=9606GN=EPB41MTTEKSLVTEAENSQHQQKEEGEEAINSGQQEPQQEESCQTAAEGDNWCEQKLKASNGDTPTHEDLTKNKERTSESRGLSRLFSSFLKRPKSQVSEEEGKEVESDKEKGEGGQKEIEFGTSLDEEIILKAPIAAPEPELKTDPSLDLHSLSSAETQPAQEELREDPDFEIKEGEGLEECSKIEVKEESPQSKAETELKASQKPIRKHRNMHCKVSLLDDTVYECVVEKHAKGQDLLKRVCEHLNLLEEDYFGLAIWDNATSKTWLDSAKEIKKQVRGVPWNFTFNVKFYPPDPAQLTEDITRYYLCLQLRQDIVAGRLPCSFATLALLGSYTIQSELGDYDPELHGVDYVSDFKLAPNQTKELEEKVMELHKSYRSMTPAQADLEFLENAKKLSMYGVDLHKAKDLEGVDIILGVCSSGLLVYKDKLRINRFPWPKVLKISYKRSSFFIKIRPGEQEQYESTIGFKLPSYRAAKKLWKVCVEHHTFFRLTSTDTIPKSKFLALGSKFRYSGRTQAQTRQASALIDRPAPHFERTASKRASRSLDGAAAVDSADRSPRPTSAPAITQGQVAEGGVLDASAKKTVVPKAQKETVKAEVKKEDEPPEQAEPEPTEAWKKKRERLDGENIYIRHSNLMLEDLDKSQEEIKKHHASISELKKNFMESVPEPRPSEWDKRLSTHSPFRTLNINGQIPTGEGPPLVKTQTVTISDNANAVKSEIPTKDVPIVHTETKTITYEAAQTDDNSGDLDPGVLLTAQTITSETPSSTTTTQITKTVKGGISETRIEKRIVITGDADIDHDQVLVQAIKEAKEQHPDMSVTKVVVHQETEIADE>sp|P11171-3|EPB41_HUMAN Isoform 3 of Protein 4.1 OS=Homo sapiens OX=9606GN=EPB41MHCKVSLLDDTVYECVVEKHAKGQDLLKRVCEHLNLLEEDYFGLAIWDNATSKTWLDSAKEIKKQVRGVPWNFTFNVKFYPPDPAQLTEDITRYYLCLQLRQDIVAGRLPCSFATLALLGSYTIQSELGDYDPELHGVDYVSDFKLAPNQTKELEEKVMELHKSYRSMTPAQADLEFLENAKKLSMYGVDLHKAKDLEGVDIILGVCSSGLLVYKDKLRINRFPWPKVLKISYKRSSFFIKIRPGEQEQYESTIGFKLPSYRAAKKLWKVCVEHHTFFRLTSTDTIPKSKFLALGSKFRYSGRTQAQTRQASALIDRPAPHFERTASKRASRSLDGAAAVDSADRSPRPTSAPAITQGQVAEGGVLDASAKKTVVPKAQKETVKAEVKKEDEPPEQAEPEPTEAWKVEKTHIEVTVPTSNGDQTQKKRERLDGENIYIRHSNLMLEDLDKSQEEIKKHHASISELKKNFMESVPEPRPSEWDKRLSTHSPFRTLNINGQIPTGEGPPLVKTQTVTISDNANAVKSEIPTKDVPIVHTETKTITYEAAQTDDNSGDLDPGVLLTAQTITSETPSSTTTTQITKTVKGGISETRIEKRIVITGDADIDHDQVLVQAIKEAKEQHPDMSVTKVVVHQETEIADE>sp|P11171-4|EPB41_HUMAN Isoform 4 of Protein 4.1 OS=Homo sapiens OX=9606GN=EPB41MHCKVSLLDDTVYECVVEKHAKGQDLLKRVCEHLNLLEEDYFGLAIWDNATSKTWLDSAKEIKKQVRGVPWNFTFNVKFYPPDPAQLTEDITRYYLCLQLRQDIVAGRLPCSFATLALLGSYTIQSELGDYDPELHGVDYVSDFKLAPNQTKELEEKVMELHKSYRSMTPAQADLEFLENAKKLSMYGVDLHKAKDLEGVDIILGVCSSGLLVYKDKLRINRFPWPKVLKISYKRSSFFIKIRPGEQEQYESTIGFKLPSYRAAKKLWKVCVEHHTFFRLTSTDTIPKSKFLALGSKFRYSGRTQAQTRQASALIDRPAPHFERTASKRASRSLDGAAAVDSADRSPRPTSAPAITQGQVAEGGVLDASAKKTVVPKAQKETVKAEVKKEDEPPEQAEPEPTEAWKKKRERLDGENIYIRHSNLMLEDLDKSQEEIKKHHASISELKKNFMESVPEPRPSEWDKRLSTHSPFRTLNINGQIPTGEGPPLVKTQTVTISDNANAVKSEIPTKDVPIVHTETKTITYEAAQTVKGGISETRIEKRIVITGDADIDHDQVLVQAIKEAKEQHPDMSVTKVVVHQETEIADE>sp|P11171-5|EPB41_HUMAN Isoform 5 of Protein 4.1 OS=Homo sapiens OX=9606GN=EPB41MTTEKSLVTEAENSQHQQKEEGEEAINSGQQEPQQEESCQTAAEGDNWCEQKLKASNGDTPTHEDLTKNKERTSESRGLSRLFSSFLKRPKSQVSEEEGKEVESDKEKGEGGQKEIEFGTSLDEEIILKAPIAAPEPELKTDPSLDLHSLSSAETQPAQEELREDPDFEIKEGEGLEECSKIEVKEESPQSKAETELKASQKPIRKHRNMHCKVSLLDDTVYECVVETWLDSAKEIKKQVRGVPWNFTFNVKFYPPDPAQLTEDITRYYLCLQLRQDIVAGRLPCSFATLALLGSYTIQSELGDYDPELHGVDYVSDFKLAPNQTKELEEKVMELHKSYRSMTPAQADLEFLENAKKLSMYGVDLHKAKDLEGVDIILGVCSSGLLVYKDKLRINRFPWPKVLKISYKRSSFFIKIRPGEQEQYESTIGFKLPSYRAAKKLWKVCVEHHTFFRLTSTDTIPKSKFLALGSKFRYSGRTQAQTRQASALIDRPAPHFERTASKRASRSLDGAAAVDSADRSPRPTSAPAITQGQVAEGGVLDASAKKTVVPKAQKETVKAEVKKEDEPPEQAEPEPTEAWKDLDKSQEEIKKHHASISELKKNFMESVPEPRPSEWDKRLSTHSPFRTLNINGQIPTGEGPPLVKTQTVTISDNANAVKSEIPTKDVPIVHTETKTITYEAAQTDDNSGDLDPGVLLTAQTITSETPSSTTTTQITKTVKGGISETRIEKRIVITGDADIDHDQVLVQAIKEAKEQHPDMSVTKVVVHQETEIADE>sp|P11171-6|EPB41_HUMAN Isoform 6 of Protein 4.1 OS=Homo sapiens OX=9606GN=EPB41MHCKVSLLDDTVYECVVETWLDSAKEIKKQVRGVPWNFTFNVKFYPPDPAQLTEDITRYYLCLQLRQDIVAGRLPCSFATLALLGSYTIQSELGDYDPELHGVDYVSDFKLAPNQTKELEEKVMELHKSYRSMTPAQADLEFLENAKKLSMYGVDLHKAKDLEGVDIILGVCSSGLLVYKDKLRINRFPWPKVLKISYKRSSFFIKIRPGEQEQYESTIGFKLPSYRAAKKLWKVCVEHHTFFRLTSTDTIPKSKFLALGSKFRYSGRTQAQTRQASALIDRPAPHFERTASKRASRSLDGAAAVDSADRSPRPTSAPAITQGQVAEGGVLDASAKKTVVPKAQKETVKAEVKKEDEPPEQAEPEPTEAWKDLDKSQEEIKKHHASISELKKNFMESVPEPRPSEWDKRLSTHSPFRTLNINGQIPTGEGPPLVKTQTVTISDNANAVKSEIPTKDVPIVHTETKTITYEAAQTDDNSGDLDPGVLLTAQTITSETPSSTTTTQITKTVKGGISETRIEKRIVITGDADIDHDQVLVQAIKEAKEQHPDMSVTKVVVHQETEIADE>sp|P11171-7|EPB41_HUMAN Isoform 7 of Protein 4.1 OS=Homo sapiens OX=9606GN=EPB41MTTEKSLVTEAENSQHQQKEEGEEAINSGQQEPQQEESCQTAAEGDNWCEQKLKASNGDTPTHEDLTKNKERTSESRGLSRLFSSFLKRPKSQVSEEEGKEVESDKEKGEGGQKEIEFGTSLDEEIILKAPIAAPEPELKTDPSLDLHSLSSAETQPAQEELREDPDFEIKEGEGLEECSKIEVKEESPQSKAETELKASQKPIRKHRNMHCKVSLLDDTVYECVVEKHAKGQDLLKRVCEHLNLLEEDYFGLAIWDNATSKTWLDSAKEIKKQVRGVPWNFTFNVKFYPPDPAQLTEDITRYYLCLQLRQDIVAGRLPCSFATLALLGSYTIQSELGDYDPELHGVDYVSDFKLAPNQTKELEEKVMELHKSYRSMTPAQADLEFLENAKKLSMYGVDLHKAKDLEGVDIILGVCSSGLLVYKDKLRINRFPWPKVLKISYKRSSFFIKIRPGEQEQYESTIGFKLPSYRAAKKLWKVCVEHHTFFRLTSTDTIPKSKFLALGSKFRYSGRTQAQTRQASALIDRPAPHFERTASKRASRSLDGAAAVDSADRSPRPTSAPAITQGQVAEGGVLDASAKKTVVPKAQKETVKAEVKKEDEPPEQAEPEPTEAWKVEKTHIEVTVPTSNGDQTQKKRERLDGENIYIRHSNLMLEDLDKSQEEIKKHHASISELKKNFMESVPEPRPSEWDKRLSTHSPFRTLNINGQIPTGEGVSTLST>sp|O95528|GTR10_HUMAN Solute carrier family 2, facilitated glucosetransporter member 10 OS=Homo sapiens OX=9606 GN=SLC2A10 PE=1 SV=2MGHSPPVLPLCASVSLLGGLTFGYELAVISGALLPLQLDFGLSCLEQEFLVGSLLLGALLASLVGGFLIDCYGRKQAILGSNLVLLAGSLTLGLAGSLAWLVLGRAVVGFAISLSSMACCIYVSELVGPRQRGVLVSLYEAGITVGILLSYALNYALAGTPWGWRHMFGWATAPAVLQSLSLLFLPAGTDETATHKDLIPLQGGEAPKLGPGRPRYSFLDLFRARDNMRGRTTVGLGLVLFQQLTGQPNVLCYASTIFSSVGFHGGSSAVLASVGLGAVKVAATLTAMGLVDRAGRRALLLAGCALMALSVSGIGLVSFAVPMDSGPSCLAVPNATGQTGLPGDSGLLQDSSLPPIPRTNEDQREPILSTAKKTKPHPRSGDPSAPPRLALSSALPGPPLPARGHALLRWTALLCLMVFVSAFSFGFGPVTWLVLSEIYPVEIRGRAFAFCNSFNWAANLFISLSFLDLIGTIGLSWTFLLYGLTAVLGLGFIYLFVPETKGQSLAEIDQQFQKRRFTLSFGHRQNSTGIPYSRIEISAAS>sp|P61550|ENVT1_HUMAN Endogenous retrovirus group S71 member 1 Envpolyprotein OS=Homo sapiens OX=9606 GN=ERVS71-1 PE=2 SV=1MGPEAWVRPLKTAPKPGEAIRLILFIYLSCFFLPVMSSEPSYSFLLTSFTTGRVFANTTWRAGTSKEVSFAVDLCVLFPEPARTHEEQHNLPVIGAGSVDLAAGFGHSGSQTGCGSSKGAEKGLQNVDFYLCPGNHPDASCRDTYQFFCPDWTCVTLATYSGGSTRSSTLSISRVPHPKLCTRKNCNPLTITVHDPNAAQWYYGMSWGLRLYIPGFDVGTMFTIQKKILVSWSSPKPIGPLTDLGDPIFQKHPDKVDLTVPLPFLVPRPQLQQQHLQPSLMSILGGVHHLLNLTQPKLAQDCWLCLKAKPPYYVGLGVEATLKRGPLSCHTRPRALTIGDVSGNASCLISTGYNLSASPFQATCNQSLLTSISTSVSYQAPNNTWLACTSGLTRCINGTEPGPLLCVLVHVLPQVYVYSGPEGRQLIAPPELHPRLHQAVPLLVPLLAGLSIAGSAAIGTAALVQGETGLISLSQQVDADFSNLQSAIDILHSQVESLAEVVLQNCRCLDLLFLSQGGLCAALGESCCFYANQSGVIKGTVKKVRENLDRHQQERENNIPWYQSMFNWNPWLTTLITGLAGPLLILLLSLIFGPCILNSFLNFIKQRIASVKLTYLKTQYDTLVNN>sp|Q05397|FAK1_HUMAN Focal adhesion kinase 1 OS=Homo sapiens OX=9606GN=PTK2 PE=1 SV=2MAAAYLDPNLNHTPNSSTKTHLGTGMERSPGAMERVLKVFHYFESNSEPTTWASIIRHGDATDVRGIIQKIVDSHKVKHVACYGFRLSHLRSEEVHWLHVDMGVSSVREKYELAHPPEEWKYELRIRYLPKGFLNQFTEDKPTLNFFYQQVKSDYMLEIADQVDQEIALKLGCLEIRRSYWEMRGNALEKKSNYEVLEKDVGLKRFFPKSLLDSVKAKTLRKLIQQTFRQFANLNREESILKFFEILSPVYRFDKECFKCALGSSWIISVELAIGPEEGISYLTDKGCNPTHLADFTQVQTIQYSNSEDKDRKGMLQLKIAGAPEPLTVTAPSLTIAENMADLIDGYCRLVNGTSQSFIIRPQKEGERALPSIPKLANSEKQGMRTHAVSVSETDDYAEIIDEEDTYTMPSTRDYEIQRERIELGRCIGEGQFGDVHQGIYMSPENPALAVAIKTCKNCTSDSVREKFLQEALTMRQFDHPHIVKLIGVITENPVWIIMELCTLGELRSFLQVRKYSLDLASLILYAYQLSTALAYLESKRFVHRDIAARNVLVSSNDCVKLGDFGLSRYMEDSTYYKASKGKLPIKWMAPESINFRRFTSASDVWMFGVCMWEILMHGVKPFQGVKNNDVIGRIENGERLPMPPNCPPTLYSLMTKCWAYDPSRRPRFTELKAQLSTILEEEKAQQEERMRMESRRQATVSWDSGGSDEAPPKPSRPGYPSPRSSEGFYPSPQHMVQTNHYQVSGYPGSHGITAMAGSIYPGQASLLDQTDSWNHRPQEIAMWQPNVEDSTVLDLRGIGQVLPTHLMEERLIRQQQEMEEDQRWLEKEERFLKPDVRLSRGSIDREDGSLQGPIGNQHIYQPVGKPDPAAPPKKPPRPGAPGHLGSLASLSSPADSYNEGVKLQPQEISPPPTANLDRSNDKVYENVTGLVKAVIEMSSKIQPAPPEEYVPMVKEVGLALRTLLATVDETIPLLPASTHREIEMAQKLLNSDLGELINKMKLAQQYVMTSLQQEYKKQMLTAAHALAVDAKNLLDVIDQARLKMLGQTRPH>sp|Q05397-2|FAK1_HUMAN Isoform 2 of Focal adhesion kinase 1 OS=Homosapiens OX=9606 GN=PTK2MSDYWVVGKKSNYEVLEKDVGLKRFFPKSLLDSVKAKTLRKLIQQTFRQFANLNREESILKFFEILSPVYRFDKECFKCALGSSWIISVELAIGPEEGISYLTDKGCNPTHLADFTQVQTIQYSNSEDKDRKGMLQLKIAGAPEPLTVTAPSLTIAENMADLIDGYCRLVNGTSQSFIIRPQKEGERALPSIPKLANSEKQGMRTHAVSVSETDDYAEIIDEEDTYTMPSTRDYEIQRERIELGRCIGEGQFGDVHQGIYMSPENPALAVAIKTCKNCTSDSVREKFLQEACHYTSLHWNWCRYISDPNVDACPDPRNAELTMRQFDHPHIVKLIGVITENPVWIIMELCTLGELRSFLQVRKYSLDLASLILYAYQLSTALAYLESKRFVHRDIAARNVLVSSNDCVKLGDFGLSRYMEDSTYYKASKGKLPIKWMAPESINFRRFTSASDVWMFGVCMWEILMHGVKPFQGVKNNDVIGRIENGERLPMPPNCPPTLYSLMTKCWAYDPSRRPRFTELKAQLSTILEEEKAQQEERMRMESRRQATVSWDSGGSDEAPPKPSRPGYPSPRSSEGFYPSPQHMVQTNHYQVSGYPGSHGITAMAGSIYPGQASLLDQTDSWNHRPQEIAMWQPNVEDSTVLDLRGIGQVLPTHLMEERLIRQQQEMEEDQRWLEKEERFLIGNQHIYQPVGKPDPAAPPKKPPRPGAPGHLGSLASLSSPADSYNEGVKLQPQEISPPPTANLDRSNDKVYENVTGLVKAVIEMSSKIQPAPPEEYVPMVKEVGLALRTLLATVDETIPLLPASTHREIEMAQKLLNSDLGELINKMKLAQQYVMTSLQQEYKKQMLTAAHALAVDAKNLLDVIDQARLKMLGQTRPH>sp|Q05397-3|FAK1_HUMAN Isoform 3 of Focal adhesion kinase 1 OS=Homosapiens OX=9606 GN=PTK2MSDYWVVGKKSNYEVLEKDVGLKRFFPKSLLDSVKAKTLRKLIQQTFRQFANLNREESILKFFEILSPVYRFDKECFKCALGSSWIISVELAIGPEEGISYLTDKGCNPTHLADFTQVQTIQYSNSEDKDRKGMLQLKIAGAPEPLTVTAPSLTIAENMADLIDGYCRLVNGTSQSFIIRPQKEGERALPSIPKLANSEKQGMRTHAVSVSETDDYAEIIDEEDTYTMPSTRDYEIQRERIELGRCIGEGQFGDVHQGIYMSPENPALAVAIKTCKNCTSDSVREKFLQEACHYTSLHWNWCRYISDPNVDACPDPRNAELTMRQFDHPHIVKLIGVITENPVWIIMELCTLGELRSFLQVRKYSLDLASLILYAYQLSTALAYLESKRFVHRDIAARNVLVSSNDCVKLGDFGLSRYMEDSTYYKASKGKLPIKWMAPESINFRRFTSASDVWMFGVCMWEILMHGVKPFQGVKNNDVIGRIENGERLPMPPNCPPTLYSLMTKCWAYDPSRRPRFTELKAQLFQNPAQMLPASGRLPNQPCPERENYSFATF>sp|Q05397-4|FAK1_HUMAN Isoform 4 of Focal adhesion kinase 1 OS=Homosapiens OX=9606 GN=PTK2MSDYWVVGKKSNYEVLEKDVGLKRFFPKSLLDSVKAKTLRKLIQQTFRQFANLNREESILKFFEILSPVYRFDKECFKCALGSSWIISVELAIGPEEGISYLTDKGCNPTHLADFTQVQTIQYSNSEDKDRKGMLQLKIAGAPEPLTVTAPSLTIAENMADLIDGYCRLVNGTSQSFIIRPQKEGERALPSIPKLANSEKQGMRTHAVSVSETDDYAEIIDEEDTYTMPSTRDYEIQRERIELGRCIGEGQFGDVHQGIYMSPENPALAVAIKTCKNCTSDSVREKFLQEACHYTSLHWNWCRYISDPNVDACPDPRNAELTMRQFDHPHIVKLIGVITENPVWIIMELCTLGELRSFLQVRKYSLDLASLILYAYQLSTALAYLESKRFVHRDIAARNVLVSSNDCVKLGDFGLSRYMEDSTYYKGKKSG>sp|Q05397-5|FAK1_HUMAN Isoform 5 of Focal adhesion kinase 1 OS=Homosapiens OX=9606 GN=PTK2MAAAYLDPNLNHTPNSSTKTHLGTGMERSPGAMERVLKVFHYFESNSEPTTWASIIRHGDATDVRGIIQKIVDSHKVKHVACYGFRLSHLRSEEVHWLHVDMGVSSVREKYELAHPPEEWKYELRIRYLPKGFLNQFTEDKPTLNFFYQQVKSDYMLEIADQVDQEIALKLGCLEIRRSYWEMRGNALEKKSNYEVLEKDVGLKRFFPKSLLDSVKAKTLRKLIQQTFRQFANLNREESILKFFEILSPVYRFDKECFKCALGSSWIISVELAIGPEEGISYLTDKGCNPTHLADFTQVQTIQYSNSEDKDRKGMLQLKIAGAPEPLTVTAPSLTIAENMADLIDGYCRLVNGTSQSFIIRPQKEGERALPSIPKLANSEKQGMRTHAVSVSETDDYAEIIDEEDTYTMPSTRDYEIQRERIELGRCIGEGQFGDVHQGIYMSPENPALAVAIKTCKNCTSDSVREKFLQEALTMRQFDHPHIVKLIGVITENPVWIIMELCTLGELRSFLQVRKYSLDLASLILYAYQLSTALAYLESKRFVHRDIAARNVLVSSNDCVKLGDFGLSRYMEDSTYYKASKGKLPIKWMAPESINFRRFTSASDVWMFGVCMWEILMHGVKPFQGVKNNDVIGRIENGERLPMPPNCPPTLYSLMTKCWAYDPSRRPRFTELKAQLSTILEEEKAQQEERMRMESRRQATVSWDSGGSDEAPPKPSRPGYPSPRSSEGFYPSPQHMVQTNHYQVSGYPGSHGITAMAGSIYPGQASLLDQTDSWNHRPQEIAMWQPNVEDSTVLDLRGIGQVLPTHLMEERLIRQQQEMEEDQRWLEKEERFLKPDVRLSRGSIDREDGSLQGPIGNQHIYQPVGKPGKEEKNWAERNPAAPPKKPPRPGAPGHLGSLASLSSPADSYNEGVKPWRLQPQEISPPPTANLDRSNDKVYENVTGLVKAVIEMSSKIQPAPPEEYVPMVKEVGLALRTLLATVDETIPLLPASTHREIEMAQKLLNSDLGELINKMKLAQQYVMTSLQQEYKKQMLTAAHALAVDAKNLLDVIDQARLKMLGQTRPH>sp|Q05397-6|FAK1_HUMAN Isoform 6 of Focal adhesion kinase 1 OS=Homosapiens OX=9606 GN=PTK2MESRRQATVSWDSGGSDEAPPKPSRPGYPSPRSSEGFYPSPQHMVQTNHYQVSGYPGSHGITAMAGSIYPGQASLLDQTDSWNHRPQEIAMWQPNVEDSTVLDLRGIGQVLPTHLMEERLIRQQQEMEEDQRWLEKEERFLKPDVRLSRGSIDREDGSLQGPIGNQHIYQPVGKPDPAAPPKKPPRPGAPGHLGSLASLSSPADSYNEGVKLQPQEISPPPTANLDRSNDKVYENVTGLVKAVIEMSSKIQPAPPEEYVPMVKEVGLALRTLLATVDETIPLLPASTHREIEMAQKLLNSDLGELINKMKLAQQYVMTSLQQEYKKQMLTAAHALAVDAKNLLDVIDQARLKMLGQTRPH>sp|Q05397-7|FAK1_HUMAN Isoform 7 of Focal adhesion kinase 1 OS=Homosapiens OX=9606 GN=PTK2MAAAYLDPNLNHTPNSSTKTHLGTGMERSPGAMERVLKVFHYFESNSEPTTWASIIRHGDATDVRGIIQKIVDSHKVKHVACYGFRLSHLRSEEVHWLHVDMGVSSVREKYELAHPPEEWKYELRIRYLPKGFLNQFTEDKPTLNFFYQQVKSDYMLEIADQVDQEIALKLGCLEIRRSYWEMRGNALEKKSNYEVLEKDVGLKRFFPKSLLDSVKAKTLRKLIQQTFRQFANLNREESILKFFEILSPVYRFDKECFKCALGSSWIISVELAIGPEEGISYLTDKGCNPTHLADFTQVQTIQYSNSEDKDRKGMLQLKIAGAPEPLTVTAPSLTIAENMADLIDGYCRLVNGTSQSFIIRPQKEGERALPSIPKLANSEKQGMRTHAVSVSETDDYAEIIDEEDTYTMPSTRDYEIQRERIELGRCIGEGQFGDVHQGIYMSPENPALAVAIKTCKNCTSDSVREKFLQEALTMRQFDHPHIVKLIGVITENPVWIIMELCTLGELRSFLQVRKYSLDLASLILYAYQLSTALAYLESKRFVHRDIAARNVLVSSNDCVKLGDFGLSRYMEDSTYYKASKGKLPIKWMAPESINFRRFTSASDVWMFGVCMWEILMHGVKPFQGVKNNDVIGRIENGERLPMPPNCPPTLYSLMTKCWAYDPSRRPRFTELKAQLSTILEEEKAQQEERMRMESRRQATVSWDSGGSDEAPPKPSRPGYPSPRSSEGFYPSPQHMVQTNHYQDSTVLDLRGIGQVLPTHLMEERLIRQQQEMEEDQRWLEKEERFLKPDVRLSRGSIDREDGSLQGPIGNQHIYQPVGKPDPAAPPKKPPRPGAPGHLGSLASLSSPADSYNEGVKLQPQEISPPPTANLDRSNDKVYENVTGLVKAVIEMSSKIQPAPPEEYVPMVKEVGLALRTLLATVDETIPLLPASTHREIEMAQKLLNSDLGELINKMKLAQQYVMTSLQQEYKKQMLTAAHALAVDAKNLLDVIDQARLKMLGQTRPH>sp|Q53RD9|FBLN7_HUMAN Fibulin-7 OS=Homo sapiens OX=9606 GN=FBLN7 PE=2SV=1MVPSSPRALFLLLLILACPEPRASQNCLSKQQLLSAIRQLQQLLKGQETRFAEGIRHMKSRLAALQNSVGRVGPDALPVSCPALNTPADGRKFGSKYLVDHEVHFTCNPGFRLVGPSSVVCLPNGTWTGEQPHCRGISECSSQPCQNGGTCVEGVNQYRCICPPGRTGNRCQHQAQTAAPEGSVAGDSAFSRAPRCAQVERAQHCSCEAGFHLSGAAGDSVCQDVNECELYGQEGRPRLCMHACVNTPGSYRCTCPGGYRTLADGKSCEDVDECVGLQPVCPQGTTCINTGGSFQCVSPECPEGSGNVSYVKTSPFQCERNPCPMDSRPCRHLPKTISFHYLSLPSNLKTPITLFRMATASAPGRAGPNSLRFGIVGGNSRGHFVMQRSDRQTGDLILVQNLEGPQTLEVDVDMSEYLDRSFQANHVSKVTIFVSPYDF>sp|Q53RD9-2|FBLN7_HUMAN Isoform 2 of Fibulin-7 OS=Homo sapiens OX=9606GN=FBLN7MVPSSPRALFLLLLILACPEPRASQNCLSKQQLLSAIRQLQQLLKGQETRFAEGIRHMKSRLAALQNSVGRVGPDALPVSCPALNTPADGRKFGSKYLVDHEVHFTCNPGFRLVGPSSVVCLPNGTWTGEQPHCRGISECSSQPCQNGGTCVEGVNQYRCICPPGRTGNRCQHQAQTDVNECELYGQEGRPRLCMHACVNTPGSYRCTCPGGYRTLADGKSCEDVDECVGLQPVCPQGTTCINTGGSFQCVSPECPEGSGNVSYVKTSPFQCERNPCPMDSRPCRHLPKTISFHYLSLPSNLKTPITLFRMATASAPGRAGPNSLRFGIVGGNSRGHFVMQRSDRQTGDLILVQNLEGPQTLEVDVDMSEYLDRSFQANHVSKVTIFVSPYDF>sp|Q53RD9-3|FBLN7_HUMAN Isoform 3 of Fibulin-7 OS=Homo sapiens OX=9606GN=FBLN7MKSRLAALQNSVGRVGPDALPVSCPALNTPADGRKFGSKYLVDHEVHFTCNPGFRLVGPSSVVCLPNGTWTGEQPHCRGISECSSQPCQNGGTCVEGVNQYRCICPPGRTGNRCQHQAQTAAPEGSVAGDSAFSRAPRCAQVERAQHCSCEAGFHLSGAAGDSVCQDVNECELYGQEGRPRLCMHACVNTPGSYRCTCPGGYRTLADGKSCEDVDECVGLQPVCPQGTTCINTGGSFQCVSPECPEGSGNVSYVKTSPFQCERNPCPMDSRPCRHLPKTISFHYLSLPSNLKTPITLFRMATASAPGRAGPNSLRFGIVGGNSRGHFVMQRSDRQTGDLILVQNLEGPQTLEVDVDMSEYLDRSFQANHVSKVTIFVSPYDF>sp|Q53RD9-4|FBLN7_HUMAN Isoform 4 of Fibulin-7 OS=Homo sapiens OX=9606GN=FBLN7MVPSSPRALFLLLLILACPEPRASQNCLSKQQLLSAIRQLQQLLKGQETRFAEGIRHMKSRLAALQNSVGRVGPDALPVSCPALNTPADGRKFGSKYLVDHEVHFTCNPGFRLVGPSSVVCLPNGTWTGEQPHCRDVDECVGLQPVCPQGTTCINTGGSFQCVSPECPEGSGNVSYVKTSPFQCERNPCPMDSRPCRHLPKTISFHYLSLPSNLKTPITLFRMATASAPGRAGPNSLRFGIVGGNSRGHFVMQRSDRQTGDLILVQNLEGPQTLEVDVDMSEYLDRSFQANHVSKVTIFVSPYDF>sp|P58499|FAM3B_HUMAN Protein FAM3B OS=Homo sapiens OX=9606 GN=FAM3BPE=1 SV=2MRPLAGGLLKVVFVVFASLCAWYSGYLLAELIPDAPLSSAAYSIRSIGERPVLKAPVPKRQKCDHWTPCPSDTYAYRLLSGGGRSKYAKICFEDNLLMGEQLGNVARGINIAIVNYVTGNVTATRCFDMYEGDNSGPMTKFIQSAAPKSLLFMVTYDDGSTRLNNDAKNAIEALGSKEIRNMKFRSSWVFIAAKGLELPSEIQREKINHSDAKNNRYSGWPAEIQIEGCIPKERS>sp|P58499-2|FAM3B_HUMAN Isoform A of Protein FAM3B OS=Homo sapiensOX=9606 GN=FAM3BMRPLAGGSRWACWLTRCLISCFDINVQGRLLVKLRPKPTANTTCPGLLKVVFVVFASLCAWYSGYLLAELIPDAPLSSAAYSIRSIGERPVLKAPVPKRQKCDHWTPCPSDTYAYRLLSGGGRSKYAKICFEDNLLMGEQLGNVARGINIAIVNYVTGNVTATRCFDMYEGDNSGPMTKFIQSAAPKSLLFMVTYDDGSTRLNNDAKNAIEALGSKEIRNMKFRSSWVFIAAKGLELPSEIQREKINHSDAKNNRYSGWPAEIQIEGCIPKERS>sp|P58499-3|FAM3B_HUMAN Isoform C of Protein FAM3B OS=Homo sapiensOX=9606 GN=FAM3BMRPLAGAPVPKRQKCDHWTPCPSDTYAYRLLSGGGRSKYAKICFEDNLLMGEQLGNVARGINIAIVNYVTGNVTATRCFDMYEGDNSGPMTKFIQSAAPKSLLFMVTYDDGSTRLNNDAKNAIEALGSKEIRNMKFRSSWVFIAAKGLELPSEIQREKINHSDAKNNRYSGWPAEIQIEGCIPKERS>sp|O60427|FADS1_HUMAN Acyl-CoA (8-3)-desaturase OS=Homo sapiens OX=9606GN=FADS1 PE=1 SV=3MAPDPVAAETAAQGPTPRYFTWDEVAQRSGCEERWLVIDRKVYNISEFTRRHPGGSRVISHYAGQDATDPFVAFHINKGLVKKYMNSLLIGELSPEQPSFEPTKNKELTDEFRELRATVERMGLMKANHVFFLLYLLHILLLDGAAWLTLWVFGTSFLPFLLCAVLLSAVQAQAGWLQHDFGHLSVFSTSKWNHLLHHFVIGHLKGAPASWWNHMHFQHHAKPNCFRKDPDINMHPFFFALGKILSVELGKQKKKYMPYNHQHKYFFLIGPPALLPLYFQWYIFYFVIQRKKWVDLAWMITFYVRFFLTYVPLLGLKAFLGLFFIVRFLESNWFVWVTQMNHIPMHIDHDRNMDWVSTQLQATCNVHKSAFNDWFSGHLNFQIEHHLFPTMPRHNYHKVAPLVQSLCAKHGIEYQSKPLLSAFADIIHSLKESGQLWLDAYLHQ>sp|O60427-2|FADS1_HUMAN Isoform 2 of Acyl-CoA (8-3)-desaturase OS=Homosapiens OX=9606 GN=FADS1MNSLLIGELSPEQPSFEPTKNKELTDEFRELRATVERMGLMKANHVFFLLYLLHILLLDGAAWLTLWVFGTSFLPFLLCAVLLSAVQAQAGWLQHDFGHLSVFSTSKWNHLLHHFVIGHLKGAPASWWNHMHFQHHAKPNCFRKDPDINMHPFFFALGKILSVELGKQKKKYMPYNHQHKYFFLIGPPALLPLYFQWYIFYFVIQRKKWVDLAWMITFYVRFFLTYVPLLGLKAFLGLFFIVRFLESNWFVWVTQMNHIPMHIDHDRNMDWVSTQLQATCNVHKSAFNDWFSGHLNFQIEHHLFPTMPRHNYHKVAPLVQSLCAKHGIEYQSKPLLSAFADIIHSLKESGQLWLDAYLHQ>sp|O15360|FANCA_HUMAN Fanconi anemia group A protein OS=Homo sapiensOX=9606 GN=FANCA PE=1 SV=2MSDSWVPNSASGQDPGGRRRAWAELLAGRVKREKYNPERAQKLKESAVRLLRSHQDLNALLLEVEGPLCKKLSLSKVIDCDSSEAYANHSSSFIGSALQDQASRLGVPVGILSAGMVASSVGQICTAPAETSHPVLLTVEQRKKLSSLLEFAQYLLAHSMFSRLSFCQELWKIQSSLLLEAVWHLHVQGIVSLQELLESHPDMHAVGSWLFRNLCCLCEQMEASCQHADVARAMLSDFVQMFVLRGFQKNSDLRRTVEPEKMPQVTVDVLQRMLIFALDALAAGVQEESSTHKIVRCWFGVFSGHTLGSVISTDPLKRFFSHTLTQILTHSPVLKASDAVQMQREWSFARTHPLLTSLYRRLFVMLSAEELVGHLQEVLETQEVHWQRVLSFVSALVVCFPEAQQLLEDWVARLMAQAFESCQLDSMVTAFLVVRQAALEGPSAFLSYADWFKASFGSTRGYHGCSKKALVFLFTFLSELVPFESPRYLQVHILHPPLVPGKYRSLLTDYISLAKTRLADLKVSIENMGLYEDLSSAGDITEPHSQALQDVEKAIMVFEHTGNIPVTVMEASIFRRPYYVSHFLPALLTPRVLPKVPDSRVAFIESLKRADKIPPSLYSTYCQACSAAEEKPEDAALGVRAEPNSAEEPLGQLTAALGELRASMTDPSQRDVISAQVAVISERLRAVLGHNEDDSSVEISKIQLSINTPRLEPREHMAVDLLLTSFCQNLMAASSVAPPERQGPWAALFVRTMCGRVLPAVLTRLCQLLRHQGPSLSAPHVLGLAALAVHLGESRSALPEVDVGPPAPGAGLPVPALFDSLLTCRTRDSLFFCLKFCTAAISYSLCKFSSQSRDTLCSCLSPGLIKKFQFLMFRLFSEARQPLSEEDVASLSWRPLHLPSADWQRAALSLWTHRTFREVLKEEDVHLTYQDWLHLELEIQPEADALSDTERQDFHQWAIHEHFLPESSASGGCDGDLQAACTILVNALMDFHQSSRSYDHSENSDLVFGGRTGNEDIISRLQEMVADLELQQDLIVPLGHTPSQEHFLFEIFRRRLQALTSGWSVAASLQRQRELLMYKRILLRLPSSVLCGSSFQAEQPITARCEQFFHLVNSEMRNFCSHGGALTQDITAHFFRGLLNACLRSRDPSLMVDFILAKCQTKCPLILTSALVWWPSLEPVLLCRWRRHCQSPLPRELQKLQEGRQFASDFLSPEAASPAPNPDWLSAAALHFAIQQVREENIRKQLKKLDCEREELLVFLFFFSLMGLLSSHLTSNSTTDLPKAFHVCAAILECLEKRKISWLALFQLTESDLRLGRLLLRVAPDQHTRLLPFAFYSLLSYFHEDAAIREEAFLHVAVDMYLKLVQLFVAGDTSTVSPPAGRSLELKGQGNPVELITKARLFLLQLIPRCPKKSFSHVAELLADRGDCDPEVSAALQSRQQAAPDADLSQEPHLF>sp|O15360-2|FANCA_HUMAN Isoform 2 of Fanconi anemia group A proteinOS=Homo sapiens OX=9606 GN=FANCAMSDSWVPNSASGQDPGGRRRAWAELLAGRVKREKYNPERAQKLKESAVRLLRSHQDLNALLLEVEGPLCKKLSLSKVIDCDSSEAYANHSSSFIGSALQDQASRLGVPVGILSAGMVASSVGQICTAPAETSHPVLLTVEQRKKLSSLLEFAQYLLAHSMFSRLSFCQELWKIQSSLLLEAVWHLHVQGIVSLQELLESHPDMHAVGSWLFRNLCCLCEQMEASCQHADVARAMLSDFVQMFVLRGFQKNSDLRRTVEPEKMPQVTVDVLQRMLIFALDALAAGVQEESSTHKIVRC>sp|O15360-3|FANCA_HUMAN Isoform 3 of Fanconi anemia group A proteinOS=Homo sapiens OX=9606 GN=FANCAMSDSWVPNSASGQDPGGRRRAWAELLAGRVKREKYNPERAQKLKESAVRLLRSHQDLNALLLEVEGPLCKKLSLSKVIDCDSSEAYANHSSSFIGSALQDQASRLGVPVGILSAGMVASSVGQICTAPAETSHPVLLTVEQRKKLSSLLEFAQYLLAHSMFSRLSFCQELWKIQSSLLLEAVWHLHVQGIVSLQELLESHPDMHAVGSWLFRNLCCLCEQMEASCQHADVARAMLSDFVQMFVLRGFQKNSDLRRTVEPEKMPQVTVDVLQRMLIFALDALAAGVQEESSTHKIVRCWFGVFSGHTLGSVISTDPLKRFFSHTLTQILTHSPVLKASDAVQMQREWSFARTHPLLTSLYRRLFVMLSAEELVGHLQEVLETQEVHWQRVLSFVSALVVCFPEAQQLLEDWVARLMAQAFESCQLDSMVTAFLVVRQAALEGPSAFLSYADWFKASFGSTRGYHGCSKKALVFLFTFLSELVPFESPRYLQVHILHPPLVPGKYRSLLTDYISLAKTRLADLKVSIENMGLYEDLSSAGDITEPHSQALQDVEKAIMVFEHTGNIPVTVMEASIFRRPYYVSHFLPALLTPRVLPKVPDSRVAFIESLKRADKIPPSLYSTYCQACSAAEEKPEDAALGVRAEPNSAEEPLGQLTAALGELRASMTDPSQRDVISAQVAVISERLRAVLGHNEDDSSVEISKIQLSINTPRLEPREHMAVDLLLTSFCQNLMAASSVAPPERQGPWAALFVRTMCGRVLPAVLTRLCQLLRHQGPSLSAPHVLGLAALAVHLGESRSALPEVDVGPPAPGAGLPVPALFDSLLTCRTRDSLFFCLKFCTAAISYSLCKFSSQSRDTLCSCLSPGLIKKFQFLMFRLFSEARQPLSEEDVASLSWRPLHLPSADWQRAALSLWTHRTFREVLKEEDVHLTYQDWLHLELEIQPEADALSDTERQDFHQWAIHEHFLPESSASGGCDGDLQAACTILVNALMDFHQSSRSYDHSENSDLVFGGRTGNEDIISRLQEMVADLELQQDLIVPLGHTPSQEHFLFEIFRRRLQALTSGWSVAASLQRQRELLMYKRILLRLPSSVLCGSSFQAEQPITARCEQFFHLVNSEMRNFCSHGGALTQDITAHFFRGLLNACLRSRDPSLMVDFILAKCQTKCPLILTSALVWWPSLEPVLLCRWRRHCQSPLPRELQKLQEGRQFASDFLSPEAASPAPNPDWLSAAALHFAIQQVREENIRKQLKKLDCEREELLVFLFFFSLMGLLSSHLTSNSTTDLPKAFHVCAAILECLEKRKISWLALFQLTESDLRLGRLLLRVAPDQHTRLLPFAFYSLLSYFHEDAAIREEAFLHVAVDMYLKLVQLFVAGDTSTVSPPAGRSLELKGQAGQPRGTDNKSSSFSAAVNTSVPEKELLTRGRAAG>sp|Q11128|FUT5_HUMAN 4-galactosyl-N-acetylglucosaminide 3-alpha-L-fucosyltransferase FUT5 OS=Homo sapiens OX=9606 GN=FUT5 PE=1 SV=1MDPLGPAKPQWLWRRCLAGLLFQLLVAVCFFSYLRVSRDDATGSPRPGLMAVEPVTGAPNGSRCQDSMATPAHPTLLILLWTWPFNTPVALPRCSEMVPGAADCNITADSSVYPQADAVIVHHWDIMYNPSANLPPPTRPQGQRWIWFSMESPSNCRHLEALDGYFNLTMSYRSDSDIFTPYGWLEPWSGQPAHPPLNLSAKTELVAWAVSNWKPDSARVRYYQSLQAHLKVDVYGRSHKPLPKGTMMETLSRYKFYLAFENSLHPDYITEKLWRNALEAWAVPVVLGPSRSNYERFLPPDAFIHVDDFQSPKDLARYLQELDKDHARYLSYFRWRETLRPRSFSWALAFCKACWKLQQESRYQTVRSIAAWFT>sp|Q96NE9|FRMD6_HUMAN FERM domain-containing protein 6 OS=Homo sapiensOX=9606 GN=FRMD6 PE=1 SV=1MNKLNFHNNRVMQDRRSVCIFLPNDESLNIIINVKILCHQLLVQVCDLLRLKDCHLFGLSVIQNNEHVYMELSQKLYKYCPKEWKKEASKVRQYEVTWGIDQFGPPMIIHFRVQYYVENGRLISDRAARYYYYWHLRKQVLHSQCVLREEAYFLLAAFALQADLGNFKRNKHYGKYFEPEAYFPSWVVSKRGKDYILKHIPNMHKDQFALTASEAHLKYIKEAVRLDDVAVHYYRLYKDKREIEASLTLGLTMRGIQIFQNLDEEKQLLYDFPWTNVGKLVFVGKKFEILPDGLPSARKLIYYTGCPMRSRHLLQLLSNSHRLYMNLQPVLRHIRKLEENEEKKQYRESYISDNLDLDMDQLEKRSRASGSSAGSMKHKRLSRHSTASHSSSHTSGIEADTKPRDTGPEDSYSSSAIHRKLKTCSSMTSHGSSHTSGVESGGKDRLEEDLQDDEIEMLVDDPRDLEQMNEESLEVSPDMCIYITEDMLMSRKLNGHSGLIVKEIGSSTSSSSETVVKLRGQSTDSLPQTICRKPKTSTDRHSLSLDDIRLYQKDFLRIAGLCQDTAQSYTFGCGHELDEEGLYCNSCLAQQCINIQDAFPVKRTSKYFSLDLTHDEVPEFVV>sp|Q96NE9-2|FRMD6_HUMAN Isoform 2 of FERM domain-containing protein 6OS=Homo sapiens OX=9606 GN=FRMD6MNKLNFHNNRVMQDRRSVCIFLPNDESLNIIINVKILCHQLLVQVCDLLRLKDCHLFGLSVIQNNEHVYMELSQKLYKYCPKEWKKEASKGIDQFGPPMIIHFRVQYYVENGRLISDRAARYYYYWHLRKQVLHSQCVLREEAYFLLAAFALQADLGNFKRNKHYGKYFEPEAYFPSWVVSKRGKDYILKHIPNMHKDQFALTASEAHLKYIKEAVRLDDVAVHYYRLYKDKREIEASLTLGLTMRGIQIFQNLDEEKQLLYDFPWTNVGKLVFVGKKFEILPDGLPSARKLIYYTGCPMRSRHLLQLLSNSHRLYMNLQPVLRHIRKLEENEEKKQYRESYISDNLDLDMDQLEKRSRASGSSAGSMKHKRLSRHSTASHSSSHTSGIEADTKPRDTGPEDSYSSSAIHRKLKTCSSMTSHGSSHTSGVESGGKDRLEEDLQDDEIEMLVDDPRDLEQMNEESLEVSPDMCIYITEDMLMSRKLNGHSGLIVKEIGSSTSSSSETVVKLRGQSTDSLPQTICRKPKTSTDRHSLSLDDIRLYQKDFLRIAGLCQDTAQSYTFGCGHELDEEGLYCNSCLAQQCINIQDAFPVKRTSKYFSLDLTHDEVPEFVV>sp|Q96NE9-3|FRMD6_HUMAN Isoform 3 of FERM domain-containing protein 6OS=Homo sapiens OX=9606 GN=FRMD6MDQLEKRSRASGSSAGSMKHKRLSRHSTASHSSSHTSGIEADTKPRDTGPEDSYSSSAIHRKLKTCSSMTSHGSSHTSGVESGGKDRLEEDLQDDEIEMLVDDPRDLEQMNEESLEVSPDMCIYITEDMLMSRKLNGHSGLIVKEIGSSTSSSSETVVKLRGQSTDSLPQTICRKPKTSTDRHSLSLDDIRLYQKDFLRIAGLCQDTAQSYTFGCGHELDEEGLYCNSCLAQQCINIQDAFPVKRTSKYFSLDLTHDEVPEFVV>sp|Q8N4A0|GALT4_HUMAN Polypeptide N-acetylgalactosaminyltransferase 4OS=Homo sapiens OX=9606 GN=GALNT4 PE=1 SV=2MAVRWTWAGKSCLLLAFLTVAYIFVELLVSTFHASAGAGRARELGSRRLSDLQKNTEDLSRPLYKKPPADSRALGEWGKASKLQLNEDELKQQEELIERYAINIYLSDRISLHRHIEDKRMYECKSQKFNYRTLPTTSVIIAFYNEAWSTLLRTIHSVLETSPAVLLKEIILVDDLSDRVYLKTQLETYISNLDRVRLIRTNKREGLVRARLIGATFATGDVLTFLDCHCECNSGWLEPLLERIGRDETAVVCPVIDTIDWNTFEFYMQIGEPMIGGFDWRLTFQWHSVPKQERDRRISRIDPIRSPTMAGGLFAVSKKYFQYLGTYDTGMEVWGGENLELSFRVWQCGGKLEIHPCSHVGHVFPKRAPYARPNFLQNTARAAEVWMDEYKEHFYNRNPPARKEAYGDISERKLLRERLRCKSFDWYLKNVFPNLHVPEDRPGWHGAIRSRGISSECLDYNSPDNNPTGANLSLFGCHGQGGNQFFEYTSNKEIRFNSVTELCAEVPEQKNYVGMQNCPKDGFPVPANIIWHFKEDGTIFHPHSGLCLSAYRTPEGRPDVQMRTCDALDKNQIWSFEK>sp|Q8N4A0-2|GALT4_HUMAN Isoform 2 of Polypeptide N-acetylgalactosaminyltransferase 4 OS=Homo sapiens OX=9606 GN=GALNT4MAWCVATADPAHTSRPLFTGLAVSRGSAGHAWSAGFDWAAVVVVTGRRCRSGQTVPGAARSPLLPHPLPSPLRVPPPTGALGRPLPRWPQPRRTPFWSVISKATKLRSPPWTSAPTASNLERDRRISRIDPIRSPTMAGGLFAVSKKYFQYLGTYDTGMEVWGGENLELSFRVWQCGGKLEIHPCSHVGHVFPKRAPYARPNFLQNTARAAEVWMDEYKEHFYNRNPPARKEAYGDISERKLLRERLRCKSFDWYLKNVFPNLHVPEDRPGWHGAIRSRGISSECLDYNSPDNNPTGANLSLFGCHGQGGNQFFEYTSNKEIRFNSVTELCAEVPEQKNYVGMQNCPKDGFPVPANIIWHFKEDGTIFHPHSGLCLSAYRTPEGRPDVQMRTCDALDKNQIWSFEK>sp|O43826|G6PT1_HUMAN Glucose-6-phosphate exchanger SLC37A4 OS=Homosapiens OX=9606 GN=SLC37A4 PE=1 SV=1MAAQGYGYYRTVIFSAMFGGYSLYYFNRKTFSFVMPSLVEEIPLDKDDLGFITSSQSAAYAISKFVSGVLSDQMSARWLFSSGLLLVGLVNIFFAWSSTVPVFAALWFLNGLAQGLGWPPCGKVLRKWFEPSQFGTWWAILSTSMNLAGGLGPILATILAQSYSWRSTLALSGALCVVVSFLCLLLIHNEPADVGLRNLDPMPSEGKKGSLKEESTLQELLLSPYLWVLSTGYLVVFGVKTCCTDWGQFFLIQEKGQSALVGSSYMSALEVGGLVGSIAAGYLSDRAMAKAGLSNYGNPRHGLLLFMMAGMTVSMYLFRVTVTSDSPKLWILVLGAVFGFSSYGPIALFGVIANESAPPNLCGTSHAIVGLMANVGGFLAGLPFSTIAKHYSWSTAFWVAEVICAASTAAFFLLRNIRTKMGRVSKKAE>sp|O43826-2|G6PT1_HUMAN Isoform 2 of Glucose-6-phosphate exchangerSLC37A4 OS=Homo sapiens OX=9606 GN=SLC37A4MAAQGYGYYRTVIFSAMFGGYSLYYFNRKTFSFVMPSLVEEIPLDKDDLGFITSSQSAAYAISKFVSGVLSDQMSARWLFSSGLLLVGLVNIFFAWSSTVPVFAALWFLNGLAQGLGWPPCGKVLRKWFEPSQFGTWWAILSTSMNLAGGLGPILATILAQSYSWRSTLALSGALCVVVSFLCLLLIHNEPADVGLRNLDPMPSEGKKGSLKEESTLQELLLSPYLWVLSTGYLVVFGVKTCCTDWGQFFLIQEKGQSALVGSSYMSALEVGGLVGSIAAGYLSDRAMAKAGLSNYGNPRHGLLLFMMAGMTVSMYLFRVTVTSDSPKDVAFWTLALHPLAELTGFTEHELWILVLGAVFGFSSYGPIALFGVIANESAPPNLCGTSHAIVGLMANVGGFLAGLPFSTIAKHYSWSTAFWVAEVICAASTAAFFLLRNIRTKMGRVSKKAE>sp|P07902|GALT_HUMAN Galactose-1-phosphate uridylyltransferase OS=Homosapiens OX=9606 GN=GALT PE=1 SV=3MSRSGTDPQQRQQASEADAAAATFRANDHQHIRYNPLQDEWVLVSAHRMKRPWQGQVEPQLLKTVPRHDPLNPLCPGAIRANGEVNPQYDSTFLFDNDFPALQPDAPSPGPSDHPLFQAKSARGVCKVMCFHPWSDVTLPLMSVPEIRAVVDAWASVTEELGAQYPWVQIFENKGAMMGCSNPHPHCQVWASSFLPDIAQREERSQQAYKSQHGEPLLMEYSRQELLRKERLVLTSEHWLVLVPFWATWPYQTLLLPRRHVRRLPELTPAERDDLASIMKKLLTKYDNLFETSFPYSMGWHGAPTGSEAGANWNHWQLHAHYYPPLLRSATVRKFMVGYEMLAQAQRDLTPEQAAERLRALPEVHYHLGQKDRETATIA>sp|P07902-2|GALT_HUMAN Isoform 2 of Galactose-1-phosphateuridylyltransferase OS=Homo sapiens OX=9606 GN=GALTMTLSTLCVLGPSEPTESKVMCFHPWSDVTLPLMSVPEIRAVVDAWASVTEELGAQYPWVQIFENKGAMMGCSNPHPHCQVWASSFLPDIAQREERSQQAYKSQHGEPLLMEYSRQELLRKERLVLTSEHWLVLVPFWATWPYQTLLLPRRHVRRLPELTPAERDDLASIMKKLLTKYDNLFETSFPYSMGWHGAPTGSEAGANWNHWQLHAHYYPPLLRSATVRKFMVGYEMLAQAQRDLTPEQAAERLRALPEVHYHLGQKDRETATIA>sp|Q96D09|GASP2_HUMAN G-protein coupled receptor-associated sortingprotein 2 OS=Homo sapiens OX=9606 GN=GPRASP2 PE=1 SV=1MTGAEIEPSAQAKPEKKAGEEVIAGPERENDVPLVVRPKVRTQATTGARPKTETKSVPAARPKTEAQAMSGARPKTEVQVMGGARPKTEAQGITGARPKTDARAVGGARSKTDAKAIPGARPKDEAQAWAQSEFGTEAVSQAEGVSQTNAVAWPLATAESGSVTKSKGLSMDRELVNVDAETFPGTQGQKGIQPWFGPGEETNMGSWCYSRPRAREEASNESGFWSADETSTASSFWTGEETSVRSWPREESNTRSRHRAKHQTNPRSRPRSKQEAYVDSWSGSEDEASNPFSFWVGENTNNLFRPRVREEANIRSKLRTNREDCFESESEDEFYKQSWVLPGEEANSRFRHRDKEDPNTALKLRAQKDVDSDRVKQEPRFEEEVIIGSWFWAEKEASLEGGASAICESEPGTEEGAIGGSAYWAEEKSSLGAVAREEAKPESEEEAIFGSWFWDRDEACFDLNPCPVYKVSDRFRDAAEELNASSRPQTWDEVTVEFKPGLFHGVGFRSTSPFGIPEEASEMLEAKPKNLELSPEGEEQESLLQPDQPSPEFTFQYDPSYRSVREIREHLRARESAESESWSCSCIQCELKIGSEEFEEFLLLMDKIRDPFIHEISKIAMGMRSASQFTRDFIRDSGVVSLIETLLNYPSSRVRTSFLENMIHMAPPYPNLNMIETFICQVCEETLAHSVDSLEQLTGIRMLRHLTMTIDYHTLIANYMSGFLSLLTTANARTKFHVLKMLLNLSENPAVAKKLFSAKALSIFVGLFNIEETNDNIQIVIKMFQNISNIIKSGKMSLIDDDFSLEPLISAFREFEELAKQLQAQIDNQNDPEVGQQS>sp|Q14CM0|FRPD4_HUMAN FERM and PDZ domain-containing protein 4 OS=Homosapiens OX=9606 GN=FRMPD4 PE=1 SV=1MDVFSFVKIAKLSSHRTKSSGWPPPSGTWGLSQVPPYGWEMTANRDGRDYFINHMTQAIPFDDPRLESCQIIPPAPRKVEMRRDPVLGFGFVAGSEKPVVVRSVTPGGPSEGKLIPGDQIVMINDEPVSAAPRERVIDLVRSCKESILLTVIQPYPSPKSAFISAAKKARLKSNPVKVRFSEEVIINGQVSETVKDNSLLFMPNVLKVYLENGQTKSFRFDCSTSIKDVILTLQEKLSIKGIEHFSLMLEQRTEGAGTKLLLLHEQETLTQVTQRPSSHKMRCLFRISFVPKDPIDLLRRDPVAFEYLYVQSCNDVVQERFGPELKYDIALRLAALQMYIATVTTKQTQKISLKYIEKEWGLETFLPSAVLQSMKEKNIKKALSHLVKANQNLVPPGKKLSALQAKVHYLKFLSDLRLYGGRVFKATLVQAEKRSEVTLLVGPRYGISHVINTKTNLVALLADFSHVNRIEMFSEEESLVRVELHVLDVKPITLLMESSDAMNLACLTAGYYRLLVDSRRSIFNMANKKNTATQETGPENKGKHNLLGPDWNCIPQMTTFIGEGEQEAQITYIDSKQKTVEITDSTMCPKEHRHLYIDNAYSSDGLNQQLSQPGEAPCEADYRSLAQRSLLTLSGPETLKKAQESPRGAKVSFIFGDFALDDGISPPTLGYETLLDEGPEMLEKQRNLYIGSANDMKGLDLTPEAEGIQFVENSVYANIGDVKSFQAAEGIEEPLLHDICYAENTDDAEDEDEVSCEEDLVVGEMNQPAILNLSGSSDDIIDLTSLPPPEGDDNEDDFLLRSLNMAIAAPPPGFRDSSDEEDSQSQAASFPEDKEKGSSLQNDEIPVSLIDAVPTSAEGKCEKGLDNAVVSTLGALEALSVSEEQQTSDNSGVAILRAYSPESSSDSGNETNSSEMTESSELATAQKQSENLSRMFLATHEGYHPLAEEQTEFPASKTPAGGLPPKSSHALAARPATDLPPKVVPSKQLLHSDHMEMEPETMETKSVTDYFSKLHMGSVAYSCTSKRKSKLADGEGKAPPNGNTTGKKQQGTKTAEMEEEASGKFGTVSSRDSQHLSTFNLERTAFRKDSQRWYVATEGGMAEKSGLEAATGKTFPRASGLGAREAEGKEEGAPDGETSDGSGLGQGDRFLTDVTCASSAKDLDNPEDADSSTCDHPSKLPEADESVARLCDYHLAKRMSSLQSEGHFSLQSSQGSSVDAGCGTGSSGSACATPVESPLCPSLGKHLIPDASGKGVNYIPSEERAPGLPNHGATFKELHPQTEGMCPRMTVPALHTAINTEPLFGTLRDGCHRLPKIKETTV>sp|Q13480|GAB1_HUMAN GRB2-associated-binding protein 1 OS=Homo sapiensOX=9606 GN=GAB1 PE=1 SV=2MSGGEVVCSGWLRKSPPEKKLKRYAWKRRWFVLRSGRLTGDPDVLEYYKNDHAKKPIRIIDLNLCQQVDAGLTFNKKEFENSYIFDINTIDRIFYLVADSEEEMNKWVRCICDICGFNPTEEDPVKPPGSSLQAPADLPLAINTAPPSTQADSSSATLPPPYQLINVPPHLETLGIQEDPQDYLLLINCQSKKPEPTRTHADSAKSTSSETDCNDNVPSHKNPASSQSKHGMNGFFQQQMIYDSPPSRAPSASVDSSLYNLPRSYSHDVLPKVSPSSTEADGELYVFNTPSGTSSVETQMRHVSISYDIPPTPGNTYQIPRTFPEGTLGQTSKLDTIPDIPPPRPPKPHPAHDRSPVETCSIPRTASDTDSSYCIPTAGMSPSRSNTISTVDLNKLRKDASSQDCYDIPRAFPSDRSSSLEGFHNHFKVKNVLTVGSVSSEELDENYVPMNPNSPPRQHSSSFTEPIQEANYVPMTPGTFDFSSFGMQVPPPAHMGFRSSPKTPPRRPVPVADCEPPPVDRNLKPDRKVKPAPLEIKPLPEWEELQAPVRSPITRSFARDSSRFPMSPRPDSVHSTTSSSDSHDSEENYVPMNPNLSSEDPNLFGSNSLDGGSSPMIKPKGDKQVEYLDLDLDSGKSTPPRKQKSSGSGSSVADERVDYVVVDQQKTLALKSTREAWTDGRQSTESETPAKSVK>sp|Q13480-2|GAB1_HUMAN Isoform 2 of GRB2-associated-binding protein 1OS=Homo sapiens OX=9606 GN=GAB1MSGGEVVCSGWLRKSPPEKKLKRYAWKRRWFVLRSGRLTGDPDVLEYYKNDHAKKPIRIIDLNLCQQVDAGLTFNKKEFENSYIFDINTIDRIFYLVADSEEEMNKWVRCICDICGFNPTEEDPVKPPGSSLQAPADLPLAINTAPPSTQADSSSATLPPPYQLINVPPHLETLGIQEDPQDYLLLINCQSKKPEPTRTHADSAKSTSSETDCNDNVPSHKNPASSQSKHGMNGFFQQQMIYDSPPSRAPSASVDSSLYNLPRSYSHDVLPKVSPSSTEADGELYVFNTPSGTSSVETQMRHVSISYDIPPTPGNTYQIPRTFPEGTLGQTSKLDTIPDIPPPRPPKPHPAHDRSPVETCSIPRTASDTDSSYCIPTAGMSPSRSNTISTVDLNKLRKDASSQDCYDIPRAFPSDRSSSLEGFHNHFKVKNVLTVGSVSSEELDENYVPMNPNSPPRQHSSSFTEPIQEANYVPMTPGTFDFSSFGMQVPPPAHMGFRSSPKTPPRRPVPVADCEPPPVDRNLKPDRKGQSPKILRLKPHGLERTDSQTIGDFATRRKVKPAPLEIKPLPEWEELQAPVRSPITRSFARDSSRFPMSPRPDSVHSTTSSSDSHDSEENYVPMNPNLSSEDPNLFGSNSLDGGSSPMIKPKGDKQVEYLDLDLDSGKSTPPRKQKSSGSGSSVADERVDYVVVDQQKTLALKSTREAWTDGRQSTESETPAKSVK>sp|P01350|GAST_HUMAN Gastrin OS=Homo sapiens OX=9606 GN=GAST PE=1 SV=1MQRLCVYVLIFALALAAFSEASWKPRSQQPDAPLGTGANRDLELPWLEQQGPASHHRRQLGPQGPPHLVADPSKKQGPWLEEEEEAYGWMDFGRRSAEDEN>sp|O94915|FRYL_HUMAN Protein furry homolog-like OS=Homo sapiens OX=9606GN=FRYL PE=1 SV=2MSNITIDPDVKPGEYVIKSLFAEFAVQAEKKIEVVMAEPLEKLLSRSLQRGEDLQFDQLISSMSSVAEHCLPSLLRTLFDWYRRQNGTEDESYEYRPRSSTKSKGDEQQRERDYLLERRDLAVDFIFCLVLVEVLKQIPVHPVPDPLVHEVLNLAFKHFKHKEGYSGTNTGNVHIIADLYAEVIGVLAQSKFQAVRKKFVTELKELRQKEQSPHVVQSVISLIMGMKFFRVKMYPVEDFEASFQFMQECAQYFLEVKDKDIKHALAGLFVEILIPVAAAVKNEVNVPCLKNFVEMLYQTTFELSSRKKHSLALYPLITCLLCVSQKQFFLNNWHIFLQNCLSHLKNKDPKMSRVALESLYRLLWVYVIRIKCESNTVTQSRLMSIVSALFPKGSRSVVPRDTPLNIFVKIIQFIAQERLDFAMKEIIFDLLSVGKSTKTFTINPERMNIGLRVFLVIADSLQQKDGEPPMPTTGVILPSGNTLRVKKIFLNKTLTDEEAKVIGMSVYYPQVRKALDSILRHLDKEVGRPMCMTSVQMSNKEPEDMITGERKPKIDLFRTCIAAIPRLIPDGMSRTDLIELLARLTIHMDEELRALAFNTLQALMLDFPDWREDVLSGFVYFIVREVTDVHPTLLDNAVKMLVQLINQWKQAAQMHNKNQDTQHGVANGASHPPPLERSPYSNVFHVVEGFALVILCSSRPATRRLAVSVLREIRALFALLEIPKGDDELAIDVMDRLSPSILESFIHLTGADQTTLLYCPSSIDLQTLAEWNSSPISHQFDVISPSHIWIFAHVTQGQDPWIISLSSFLKQENLPKHCSTAVSYAWMFAYTRLQLLSPQVDINSPINAKKVNTTTSSDSYIGLWRNYLILCCSAATSSSSTSAGSVRCSPPETLASTPDSGYSIDSKIIGIPSPSSLFKHIVPMMRSESMEITESLVLGLGRTNPGAFRELIEELHPIIKEALERRPENMKRRRRRDILRVQLVRIFELLADAGVISHSASGGLDNETHFLNNTLLEYVDLTRQLLEAENEKDSDTLKDIRCHFSALVANIIQNVPVHQRRSIFPQQSLRHSLFMLFSHWAGPFSIMFTPLDRYSDRNMQINRHQYCALKAMSAVLCCGPVADNVGLSSDGYLYKWLDNILDSLDKKVHQLGCEAVTLLLELNPDQSNLMYWAVDRCYTGSGRVAAGCFKAIANVFQNRDYQCDTVMLLNLILFKAADSSRSIYEVAMQLLQILEPKMFRYAHKLEVQRTDGVLSQLSPLPHLYSVSYYQLSEELARAYPELTLAIFSEISQRIQTAHPAGRQVMLHYLLPWMNNIELVDLKPLPTARRHDEDEDDSLKDRELMVTSRRWLRGEGWGSPQATAMVLNNLMYMTAKYGDELAWSEVENVWTTLADGWPKNLKIILHFLISICGVNSEPSLLPYVKKVIVYLGRDKTMQLLEELVSELQLTDPVSSGVTHMDNPPYYRITSSYKIPSVTSGTTSSSNTMVAPTDGNPDNKPIKENIEESYVHLDIYSGLNSHLNRQHHRLESRYSSSSGGSYEEEKSDSMPLYSNWRLKVMEHNQGEPLPFPPAGGCWSPLVDYVPETSSPGLPLHRCNIAVILLTDLIIDHSVKVEWGSYLHLLLHAIFIGFDHCHPEVYEHCKRLLLHLLIVMGPNSNIRTVASVLLRNKEFNEPRVLTVKQVAHLDYNFTAGINDFIPDYQPSPMTDSGLSSSSTSSSISLGNNSAAISHLHTTILNEVDISVEQDGKVKTLMEFITSRKRGPLWNHEDVSAKNPSIKSAEQLTTFLKHVVSVFKQSSSEGIHLEHHLSEVALQTALSCSSRHYAGRSFQIFRALKQPLTATTLSDVLSRLVETVGDPGEDAQGFVIELLLTLESAIDTLAETMKHYDLLSALSQTSYHDPIMGNKYAANRKSTGQLNLSTSPINSSSYLGYNSNARSNSLRLSLIGDRRGDRRRSNTLDIMDGRINHSSSLARTRSLSSLREKGMYDVQSTTEPTNLMATIFWIAASLLESDYEYEYLLALRLLNKLLIHLPLDKSESREKIENVQSKLKWTNFPGLQQLFLKGFTSASTQEMTVHLLSKLISVSKHTLVDPSQLSGFPLNILCLLPHLIQHFDSPTQFCKETASRIAKVCAEEKCPTLVNLAHMMSLYSTHTYSRDCSNWINVVCRYLHDSFSDTTFNLVTYLAELLEKGLSSMQQSLLQIIYSLLSHIDLSAAPAKQFNLEIIKIIGKYVQSPYWKEALNILKLVVSRSASLVVPSDIPKTYGGDTGSPEISFTKIFNNVSKELPGKTLDFHFDISETPIIGNKYGDQHSAAGRNGKPKVIAVTRSTSSTSSGSNSNALVPVSWKRPQLSQRRTREKLMNVLSLCGPESGLPKNPSVVFSSNEDLEVGDQQTSLISTTEDINQEEEVAVEDNSSEQQFGVFKDFDFLDVELEDAEGESMDNFNWGVRRRSLDSIDKGDTPSLQEYQCSSSTPSLNLTNQEDTDESSEEEAALTASQILSRTQMLNSDSATDETIPDHPDLLLQSEDSTGSITTEEVLQIRDETPTLEASLDNANSRLPEDTTSVLKEEHVTTFEDEGSYIIQEQQESLVCQGILDLEETEMPEPLAPESYPESVCEEDVTLALKELDERCEEEEADFSGLSSQDEEEQDGFPEVQTSPLPSPFLSAIIAAFQPVAYDDEEEAWRCHVNQMLSDTDGSSAVFTFHVFSRLFQTIQRKFGEITNEAVSFLGDSLQRIGTKFKSSLEVMMLCSECPTVFVDAETLMSCGLLETLKFGVLELQEHLDTYNVKREAAEQWLDDCKRTFGAKEDMYRINTDAQQMEILAELELCRRLYKLHFQLLLLFQAYCKLINQVNTIKNEAEVINMSEELAQLESILKEAESASENEEIDISKAAQTTIETAIHSLIETLKNKEFISAVAQVKAFRSLWPSDIFGSCEDDPVQTLLHIYFHHQTLGQTGSFAVIGSNLDMSEANYKLMELNLEIRESLRMVQSYQLLAQAKPMGNMVSTGF>sp|O94915-2|FRYL_HUMAN Isoform 2 of Protein furry homolog-like OS=Homosapiens OX=9606 GN=FRYLMPEPLAPESYPESVCEEDVTLALKELDERCEEEEADFSGLSSQDEEEQDGFPEVQTSPLPSPFLSAIIAAFQPVAYDDEEEAWRCHVNQMLSDTDGSSAVFTFHVFSRLFQTIQRKFGEITNEAVSFLGDSLQRIGTKFKSSLEVMMLCSECPTVFVDAETLMSCGLLETLKFGVLELQEHLDTYNVKREAAEQWLDDCKRTFGAKEDMYRINTDAQELELCRRLYKLHFQLLLLFQAYCKLINQVNTIKNEAEVINMSEELAQLESILKEAESASENEEIDISKAAQTTIETAIHSLIETLKNKEFISAVAQVKAFRSLWPSDIFGSCEDDPVQTLLHIYFHHQTLGQTGSFAVIGSNLDMSEANYKLMELNLEIRESLRMVQSYQLLAQAKPMGNMVSTGF>sp|Q8N1C3|GBRG1_HUMAN Gamma-aminobutyric acid receptor subunit gamma-1OS=Homo sapiens OX=9606 GN=GABRG1 PE=1 SV=2MGPLKAFLFSPFLLRSQSRGVRLVFLLLTLHLGNCVDKADDEDDEDLTVNKTWVLAPKIHEGDITQILNSLLQGYDNKLRPDIGVRPTVIETDVYVNSIGPVDPINMEYTIDIIFAQTWFDSRLKFNSTMKVLMLNSNMVGKIWIPDTFFRNSRKSDAHWITTPNRLLRIWNDGRVLYTLRLTINAECYLQLHNFPMDEHSCPLEFSSYGYPKNEIEYKWKKPSVEVADPKYWRLYQFAFVGLRNSTEITHTISGDYVIMTIFFDLSRRMGYFTIQTYIPCILTVVLSWVSFWINKDAVPARTSLGITTVLTMTTLSTIARKSLPKVSYVTAMDLFVSVCFIFVFAALMEYGTLHYFTSNQKGKTATKDRKLKNKASMTPGLHPGSTLIPMNNISVPQEDDYGYQCLEGKDCASFFCCFEDCRTGSWREGRIHIRIAKIDSYSRIFFPTAFALFNLVYWVGYLYL>sp|P14653|HXB1_HUMAN Homeobox protein Hox-B1 OS=Homo sapiens OX=9606GN=HOXB1 PE=1 SV=2MDYNRMNSFLEYPLCNRGPSAYSAHSAPTSFPPSSAQAVDSYASEGRYGGGLSSPAFQQNSGYPAQQPPSTLGVPFPSSAPSGYAPAACSPSYGPSQYYPLGQSEGDGGYFHPSSYGAQLGGLSDGYGAGGAGPGPYPPQHPPYGNEQTASFAPAYADLLSEDKETPCPSEPNTPTARTFDWMKVKRNPPKTAKVSEPGLGSPSGLRTNFTTRQLTELEKEFHFNKYLSRARRVEIAATLELNETQVKIWFQNRRMKQKKREREEGRVPPAPPGCPKEAAGDASDQSTCTSPEASPSSVTS>sp|P14653-2|HXB1_HUMAN Isoform 2 of Homeobox protein Hox-B1 OS=Homosapiens OX=9606 GN=HOXB1MDYNRMNSFLEYPLCNRGPSAYSAHSAPTSFPPSSAQAVDSYASEGRYGGGLSSPAFQQNSGYPAQQPPSTLGVPFPSSAPSGYAPAACSPSYGPSQYYPLGQSEGDGGYFHPSSYGAQLGGLSDGYGAGGAGPGPYPPQHPPYGNEQTASFAPAYADLLSEDKETPCPSEPNTPTARTFDWMKVKRNPPKTGRAQMWPPLLRGPKHLCFPCSDMSWVWAGFFSFSGSGRHR>sp|P48506|GSH1_HUMAN Glutamate--cysteine ligase catalytic subunitOS=Homo sapiens OX=9606 GN=GCLC PE=1 SV=2MGLLSQGSPLSWEETKRHADHVRRHGILQFLHIYHAVKDRHKDVLKWGDEVEYMLVSFDHENKKVRLVLSGEKVLETLQEKGERTNPNHPTLWRPEYGSYMIEGTPGQPYGGTMSEFNTVEANMRKRRKEATSILEENQALCTITSFPRLGCPGFTLPEVKPNPVEGGASKSLFFPDEAINKHPRFSTLTRNIRHRRGEKVVINVPIFKDKNTPSPFIETFTEDDEASRASKPDHIYMDAMGFGMGNCCLQVTFQACSISEARYLYDQLATICPIVMALSAASPFYRGYVSDIDCRWGVISASVDDRTREERGLEPLKNNNYRISKSRYDSIDSYLSKCGEKYNDIDLTIDKEIYEQLLQEGIDHLLAQHVAHLFIRDPLTLFEEKIHLDDANESDHFENIQSTNWQTMRFKPPPPNSDIGWRVEFRPMEVQLTDFENSAYVVFVVLLTRVILSYKLDFLIPLSKVDENMKVAQKRDAVLQGMFYFRKDICKGGNAVVDGCGKAQNSTELAAEEYTLMSIDTIINGKEGVFPGLIPILNSYLENMEVDVDTRCSILNYLKLIKKRASGELMTVARWMREFIANHPDYKQDSVITDEMNYSLILKCNQIANELCECPELLGSAFRKVKYSGSKTDSSN>sp|X6R8D5|GUCNB_HUMAN Putative uncharacterized protein GUCA1ANB OS=Homosapiens OX=9606 GN=GUCA1ANB PE=5 SV=2MGRKEHESPSQPHMCGWEDSQKPSVPSHGPKTPSCKGVKAPHSSRPRAWKQDLEQSLAAAYVPVVVDSKGQNPDKLRFNFYTSQYSNSLNPFYTLQKPTCGYLYRRDTDHTRKRFDVPPANLVLWRS>sp|P16401|H15_HUMAN Histone H1.5 OS=Homo sapiens OX=9606 GN=H1-5 PE=1SV=3MSETAPAETATPAPVEKSPAKKKATKKAAGAGAAKRKATGPPVSELITKAVAASKERNGLSLAALKKALAAGGYDVEKNNSRIKLGLKSLVSKGTLVQTKGTGASGSFKLNKKAASGEAKPKAKKAGAAKAKKPAGATPKKAKKAAGAKKAVKKTPKKAKKPAAAGVKKVAKSPKKAKAAAKPKKATKSPAKPKAVKPKAAKPKAAKPKAAKPKAAKAKKAAAKKK>sp|A4D1S0|KLRG2_HUMAN Killer cell lectin-like receptor subfamily Gmember 2 OS=Homo sapiens OX=9606 GN=KLRG2 PE=1 SV=3MEESWEAAPGGQAGAELPMEPVGSLVPTLEQPQVPAKVRQPEGPESSPSPAGAVEKAAGAGLEPSSKKKPPSPRPGSPRVPPLSLGYGVCPEPPSPGPALVKLPRNGEAPGAEPAPSAWAPMELQVDVRVKPVGAAGGSSTPSPRPSTRFLKVPVPESPAFSRHADPAHQLLLRAPSQGGTWGRRSPLAAARTESGCDAEGRASPAEGSAGSPGSPTCCRCKELGLEKEDAALLPRAGLDGDEKLPRAVTLTGLPMYVKSLYWALAFMAVLLAVSGVVIVVLASRAGARCQQCPPGWVLSEEHCYYFSAEAQAWEASQAFCSAYHATLPLLSHTQDFLGRYPVSRHSWVGAWRGPQGWHWIDEAPLPPQLLPEDGEDNLDINCGALEEGTLVAANCSTPRPWVCAKGTQ>sp|A4D1S0-2|KLRG2_HUMAN Isoform 2 of Killer cell lectin-like receptorsubfamily G member 2 OS=Homo sapiens OX=9606 GN=KLRG2MEESWEAAPGGQAGAELPMEPVGSLVPTLEQPQVPAKVRQPEGPESSPSPAGAVEKAAGAGLEPSSKKKPPSPRPGSPRVPPLSLGYGVCPEPPSPGPALVKLPRNGEAPGAEPAPSAWAPMELQVDVRVKPVGAAGGSSTPSPRPSTRFLKVPVPESPAFSRHADPAHQLLLRAPSQGGTWGRRSPLAAARTESGCDAEGRASPAEGSAGSPGSPTCCRCKELGLEKEDAALLPRAGLDGDEKLPRAVTLTDSLRTARTIWISTVGPWRKARWWLQTAALQDPGSVPRGPSDLGSAWSSACQADAAPPTGEAS>sp|Q5TEC6|H3PS2_HUMAN Histone HIST2H3PS2 OS=Homo sapiens OX=9606 GN=H3-2PE=1 SV=1MARTKQTARKSTGGKAPRKQLATKAARKSAPATGGVKKPHRYRPGTVALREIRRYQKSTELLIRKLPFQRLVREIAQEFKTDLRFQSSAVMALQEAREAYLVGLFEDTNLCAIHAKRVTIMPKDIQLVSRIRGERA>sp|Q15486|GUSP1_HUMAN Putative inactive beta-glucuronidase-like proteinSMA3 OS=Homo sapiens OX=9606 GN=GUSBP1 PE=5 SV=3MDRSNPVKPALDYFSNRLVNYQISVKCSNQFKLEVCLLNAENKVVDNQAGTQGQLKVLGANLWWPYLMHEHPASLYSWEDGDCSHQSLGPLPACDLCDQLHLRSRQGGSVCGCDPCEQLLLLVSQLRAPGVDSAAAGRPV>sp|Q16695|H31T_HUMAN Histone H3.1t OS=Homo sapiens OX=9606 GN=H3-4 PE=1SV=3MARTKQTARKSTGGKAPRKQLATKVARKSAPATGGVKKPHRYRPGTVALREIRRYQKSTELLIRKLPFQRLMREIAQDFKTDLRFQSSAVMALQEACESYLVGLFEDTNLCVIHAKRVTIMPKDIQLARRIRGERA>sp|P0C5Z0|H2AB2_HUMAN Histone H2A-Bbd type 2/3 OS=Homo sapiens OX=9606GN=H2AB2 PE=1 SV=1MPRRRRRRGSSGAGGRGRTCSRTVRAELSFSVSQVERSLREGHYAQRLSRTAPVYLAAVIEYLTAKVLELAGNEAQNSGERNITPLLLDMVVHNDRLLSTLFNTTTISQVAPGED>sp|P16104|H2AX_HUMAN Histone H2AX OS=Homo sapiens OX=9606 GN=H2AX PE=1SV=2MSGRGKTGGKARAKAKSRSSRAGLQFPVGRVHRLLRKGHYAERVGAGAPVYLAAVLEYLTAEILELAGNAARDNKKTRIIPRHLQLAIRNDEELNKLLGGVTIAQGGVLPNIQAVLLPKKTSATVGPKAPSGGKKATQASQEY>sp|P84243|H33_HUMAN Histone H3.3 OS=Homo sapiens OX=9606 GN=H3-3A PE=1SV=2MARTKQTARKSTGGKAPRKQLATKAARKSAPSTGGVKKPHRYRPGTVALREIRRYQKSTELLIRKLPFQRLVREIAQDFKTDLRFQSAAIGALQEASEAYLVGLFEDTNLCAIHAKRVTIMPKDIQLARRIRGERA>sp|Q8TAA5|GRPE2_HUMAN GrpE protein homolog 2, mitochondrial OS=Homosapiens OX=9606 GN=GRPEL2 PE=1 SV=1MAVRSLWAGRLRVQRLLAWSAAWESKGWPLPFSTATQRTAGEDCRSEDPPDELGPPLAERALRVKAVKLEKEVQDLTVRYQRAIADCENIRRRTQRCVEDAKIFGIQSFCKDLVEVADILEKTTECISEESEPEDQKLTLEKVFRGLLLLEAKLKSVFAKHGLEKLTPIGDKYDPHEHELICHVPAGVGVQPGTVALVRQDGYKLHGRTIRLARVEVAVESQRRL>sp|Q8TAA5-2|GRPE2_HUMAN Isoform 2 of GrpE protein homolog 2,mitochondrial OS=Homo sapiens OX=9606 GN=GRPEL2MAVRSLWAGRLRVQRLLAWSAAWESKGWPLPFSTATQRTAGEDCRSEDPPDELGPPLAERALRVKAVKLEKEVQDLTESRVSVRTWWRWLTFWRRLQSAFLKNRSLRTKSSLWRRSSEGCCF>sp|Q14943|KI3S1_HUMAN Killer cell immunoglobulin-like receptor 3DS1OS=Homo sapiens OX=9606 GN=KIR3DS1 PE=1 SV=2MLLMVVSMACVGLFLVQRAGPHMGGQDKPFLSAWPSAVVPRGGHVTLRCHYRHRFNNFMLYKEDRIHVPIFHGRIFQEGFNMSPVTTAHAGNYTCRGSHPHSPTGWSAPSNPMVIMVTGNHRKPSLLAHPGPLVKSGERVILQCWSDIMFEHFFLHREWISKDPSRLVGQIHDGVSKANFSIGSMMRALAGTYRCYGSVTHTPYQLSAPSDPLDIVVTGLYEKPSLSAQPGPKVQAGESVTLSCSSRSSYDMYHLSREGGAHERRLPAVRKVNRTFQADFPLGPATHGGTYRCFGSFRHSPYEWSDPSDPLLVSVTGNPSSSWPSPTEPSSKSGNLRHLHILIGTSVVKIPFTILLFFLLHRWCSNKKKCCCNGPRACREQK>sp|P41594|GRM5_HUMAN Metabotropic glutamate receptor 5 OS=Homo sapiensOX=9606 GN=GRM5 PE=1 SV=2MVLLLILSVLLLKEDVRGSAQSSERRVVAHMPGDIIIGALFSVHHQPTVDKVHERKCGAVREQYGIQRVEAMLHTLERINSDPTLLPNITLGCEIRDSCWHSAVALEQSIEFIRDSLISSEEEEGLVRCVDGSSSSFRSKKPIVGVIGPGSSSVAIQVQNLLQLFNIPQIAYSATSMDLSDKTLFKYFMRVVPSDAQQARAMVDIVKRYNWTYVSAVHTEGNYGESGMEAFKDMSAKEGICIAHSYKIYSNAGEQSFDKLLKKLTSHLPKARVVACFCEGMTVRGLLMAMRRLGLAGEFLLLGSDGWADRYDVTDGYQREAVGGITIKLQSPDVKWFDDYYLKLRPETNHRNPWFQEFWQHRFQCRLEGFPQENSKYNKTCNSSLTLKTHHVQDSKMGFVINAIYSMAYGLHNMQMSLCPGYAGLCDAMKPIDGRKLLESLMKTNFTGVSGDTILFDENGDSPGRYEIMNFKEMGKDYFDYINVGSWDNGELKMDDDEVWSKKSNIIRSVCSEPCEKGQIKVIRKGEVSCCWTCTPCKENEYVFDEYTCKACQLGSWPTDDLTGCDLIPVQYLRWGDPEPIAAVVFACLGLLATLFVTVVFIIYRDTPVVKSSSRELCYIILAGICLGYLCTFCLIAKPKQIYCYLQRIGIGLSPAMSYSALVTKTNRIARILAGSKKKICTKKPRFMSACAQLVIAFILICIQLGIIVALFIMEPPDIMHDYPSIREVYLICNTTNLGVVTPLGYNGLLILSCTFYAFKTRNVPANFNEAKYIAFTMYTTCIIWLAFVPIYFGSNYKIITMCFSVSLSATVALGCMFVPKVYIILAKPERNVRSAFTTSTVVRMHVGDGKSSSAASRSSSLVNLWKRRGSSGETLRYKDRRLAQHKSEIECFTPKGSMGNGGRATMSSSNGKSVTWAQNEKSSRGQHLWQRLSIHINKKENPNQTAVIKPFPKSTESRGLGAGAGAGGSAGGVGATGGAGCAGAGPGGPESPDAGPKALYDVAEAEEHFPAPARPRSPSPISTLSHRAGSASRTDDDVPSLHSEPVARSSSSQGSLMEQISSVVTRFTANISELNSMMLSTAAPSPGVGAPLCSSYLIPKEIQLPTTMTTFAEIQPLPAIEVTGGAQPAAGAQAAGDAARESPAAGPEAAAAKPDLEELVALTPPSPFRDSVDSGSTTPNSPVSESALCIPSSPKYDTLIIRDYTQSSSSL>sp|P41594-2|GRM5_HUMAN Isoform 1 of Metabotropic glutamate receptor 5OS=Homo sapiens OX=9606 GN=GRM5MVLLLILSVLLLKEDVRGSAQSSERRVVAHMPGDIIIGALFSVHHQPTVDKVHERKCGAVREQYGIQRVEAMLHTLERINSDPTLLPNITLGCEIRDSCWHSAVALEQSIEFIRDSLISSEEEEGLVRCVDGSSSSFRSKKPIVGVIGPGSSSVAIQVQNLLQLFNIPQIAYSATSMDLSDKTLFKYFMRVVPSDAQQARAMVDIVKRYNWTYVSAVHTEGNYGESGMEAFKDMSAKEGICIAHSYKIYSNAGEQSFDKLLKKLTSHLPKARVVACFCEGMTVRGLLMAMRRLGLAGEFLLLGSDGWADRYDVTDGYQREAVGGITIKLQSPDVKWFDDYYLKLRPETNHRNPWFQEFWQHRFQCRLEGFPQENSKYNKTCNSSLTLKTHHVQDSKMGFVINAIYSMAYGLHNMQMSLCPGYAGLCDAMKPIDGRKLLESLMKTNFTGVSGDTILFDENGDSPGRYEIMNFKEMGKDYFDYINVGSWDNGELKMDDDEVWSKKSNIIRSVCSEPCEKGQIKVIRKGEVSCCWTCTPCKENEYVFDEYTCKACQLGSWPTDDLTGCDLIPVQYLRWGDPEPIAAVVFACLGLLATLFVTVVFIIYRDTPVVKSSSRELCYIILAGICLGYLCTFCLIAKPKQIYCYLQRIGIGLSPAMSYSALVTKTNRIARILAGSKKKICTKKPRFMSACAQLVIAFILICIQLGIIVALFIMEPPDIMHDYPSIREVYLICNTTNLGVVTPLGYNGLLILSCTFYAFKTRNVPANFNEAKYIAFTMYTTCIIWLAFVPIYFGSNYKIITMCFSVSLSATVALGCMFVPKVYIILAKPERNVRSAFTTSTVVRMHVGDGKSSSAASRSSSLVNLWKRRGSSGETLSSNGKSVTWAQNEKSSRGQHLWQRLSIHINKKENPNQTAVIKPFPKSTESRGLGAGAGAGGSAGGVGATGGAGCAGAGPGGPESPDAGPKALYDVAEAEEHFPAPARPRSPSPISTLSHRAGSASRTDDDVPSLHSEPVARSSSSQGSLMEQISSVVTRFTANISELNSMMLSTAAPSPGVGAPLCSSYLIPKEIQLPTTMTTFAEIQPLPAIEVTGGAQPAAGAQAAGDAARESPAAGPEAAAAKPDLEELVALTPPSPFRDSVDSGSTTPNSPVSESALCIPSSPKYDTLIIRDYTQSSSSL>sp|P41594-3|GRM5_HUMAN Isoform 3 of Metabotropic glutamate receptor 5OS=Homo sapiens OX=9606 GN=GRM5MVLLLILSVLLLKEDVRGSAQSSERRVVAHMPGDIIIGALFSVHHQPTVDKVHERKCGAVREQYGIQRVEAMLHTLERINSDPTLLPNITLGCEIRDSCWHSAVALEQSIEFIRDSLISSEEEEGLVRCVDGSSSSFRSKKPIVGVIGPGSSSVAIQVQNLLQLFNIPQIAYSATSMDLSDKTLFKYFMRVVPSDAQQARAMVDIVKRYNWTYVSAVHTEGNYGESGMEAFKDMSAKEGICIAHSYKIYSNAGEQSFDKLLKKLTSHLPKARVVACFCEGMTVRGLLMAMRRLGLAGEFLLLGSDGWADRYDVTDGYQREAVGGITIKLQSPDVKWFDDYYLKLRPETNHRNPWFQEFWQHRFQCRLEGFPQENSKYNKTCNSSLTLKTHHVQDSKMGFVINAIYSMAYGLHNMQMSLCPGYAGLCDAMKPIDGRKLLESLMKTNFTGVSGDTILFDENGDSPGRYEIMNFKEMGKDYFDYINVGSWDNGELKMDDDEVWSKKSNIIRSVCSEPCEKGQIKVIRKGEVSCCWTCTPCKENEYVFDEYTCKACQLGSWPTDDLTGCDLIPVQYLRWGDPEPIAAVVFACLGLLATLFVTVVFIIYRDTPVVKSSSRELCYIILAGICLGYLCTFCLIAKPKQIYCYLQRIGIGLSPAMSYSALVTKTNRIARILAGSKKKICTKKPRFMSACAQLVIAFILICIQLGIIVALFIMEPPDIMHDYPSIREVYLICNTTNLGVVTPLGYNGLLILSCTFYAFKTRNVPANFNEAKYIAFTMYTTCIIWLAFVPIYFGSNYKIITMCFSVSLSATVALGCMFVPKVYIILAKPERNVRSAFTTSTVVRMHVGDGKSSSAASRSSSLVNLWKRRGSSGETLRYKDRRLAQHKSEIECFTPPSPFRDSVDSGSTTPNSPVSESALCIPSSPKYDTLIIRDYTQSSSSL>sp|Q8WUI4|HDAC7_HUMAN Histone deacetylase 7 OS=Homo sapiens OX=9606GN=HDAC7 PE=1 SV=2MDLRVGQRPPVEPPPEPTLLALQRPQRLHHHLFLAGLQQQRSVEPMRLSMDTPMPELQVGPQEQELRQLLHKDKSKRSAVASSVVKQKLAEVILKKQQAALERTVHPNSPGIPYRTLEPLETEGATRSMLSSFLPPVPSLPSDPPEHFPLRKTVSEPNLKLRYKPKKSLERRKNPLLRKESAPPSLRRRPAETLGDSSPSSSSTPASGCSSPNDSEHGPNPILGSEALLGQRLRLQETSVAPFALPTVSLLPAITLGLPAPARADSDRRTHPTLGPRGPILGSPHTPLFLPHGLEPEAGGTLPSRLQPILLLDPSGSHAPLLTVPGLGPLPFHFAQSLMTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-2|HDAC7_HUMAN Isoform 2 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MQACVGVRGVYPPGSMWVPAVAVLACSLQPRPWGVRTPWVPALTLAPAGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-3|HDAC7_HUMAN Isoform 3 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MDLRVGQRPPVEPPPEPTLLALQRPQRLHHHLFLAGLQQQRSVEPMRLSMDTPMPELQVGPQEQELRQLLHKDKSKRSAVASSVVKQKLAEVILKKQQAALERTVHPNSPGIPYRTLEPLETEGATRSMLSSFLPPVPSLPSDPPEHFPLRKTVSEPNLKLRYKPKKSLERRKNPLLRKESAPPSLRRRPAETLGDSSPSSSSTPASGCSSPNDSEHGPNPILGSEADSDRRTHPTLGPRGPILGSPHTPLFLPHGLEPEAGGTLPSRLQPILLLDPSGSHAPLLTVPGLGPLPFHFAQSLMTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-4|HDAC7_HUMAN Isoform 4 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MDLRVGQRPPVEPPPEPTLLALQRPQRLHHHLFLAGLQQQRSVEPMRLSMDTPMPELQVGPQEQELRQLLHKDKSKRSAVASSVVKQKLAEVILKKQQAALERTVHPNSPGIPYRTLEPLETEGATRSMLSSFLPPVPSLPSDPPEHFPLRKTVSEPNLKLRYKPKKSLERRKNPLLRKESAPPSLRRRPAETLGDSSPSSSSTPASGCSSPNDSEHGPNPILGSEGLPAPARADSDRRTHPTLGPRGPILGSPHTPLFLPHGLEPEAGGTLPSRLQPILLLDPSGSHAPLLTVPGLGPLPFHFAQSLMTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-5|HDAC7_HUMAN Isoform 5 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MHSPGADGTQVSPGAHYCSPTGAGCPRPCADTPGPQPQPMDLRVGQRPPVEPPPEPTLLALQRPQRLHHHLFLAGLQQQRSVEPMRLSMDTPMPELQVGPQEQELRQLLHKDKSKRSAVASSVVKQKLAEVILKKQQAALERTVHPNSPGIPYRTLEPLETEGATRSMLSSFLPPVPSLPSDPPEHFPLRKTVSEPNLKLRYKPKKSLERRKNPLLRKESAPPSLRRRPAETLGDSSPSSSSTPASGCSSPNDSEHGPNPILGSEALLGQRLRLQETSVAPFALPTVSLLPAITLGLPAPARADSDRRTHPTLGPRGPILGSPHTPLFLPHGLEPEAGGTLPSRLQPILLLDPSGSHAPLLTVPGLGPLPFHFAQSLMTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-6|HDAC7_HUMAN Isoform 6 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MHSPGAGCPRPCADTPGPQPQPMDLRVGQRPPVEPPPEPTLLALQRPQRLHHHLFLAGLQQQRSVEPMRLSMDTPMPELQVGPQEQELRQLLHKDKSKRSAVASSVVKQKLAEVILKKQQAALERTVHPNSPGIPYRTLEPLETEGATRSMLSSFLPPVPSLPSDPPEHFPLRKTVSEPNLKLRYKPKKSLERRKNPLLRKESAPPSLRRRPAETLGDSSPSSSSTPASGCSSPNDSEHGPNPILGSEALLGQRLRLQETSVAPFALPTVSLLPAITLGLPAPARADSDRRTHPTLGPRGPILGSPHTPLFLPHGLEPEAGGTLPSRLQPILLLDPSGSHAPLLTVPGLGPLPFHFAQSLMTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-7|HDAC7_HUMAN Isoform 7 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MHSPGADGTQVSPGAHYCSPTGAGCPRPCADTPGPQPQPMDLRVGQRPPVEPPPEPTLLALQRPQRLHHHLFLAGLQQQRSVEPMRLSMDTPMPELQVGPQEQELRQLLHKDKSKRSAVASSVVKQKLAEVILKKQQAALERTVHPNSPGIPYRTLEPLETEGATRSMLSSFLPPVPSLPSDPPEHFPLRKTVSEPNLKLRYKPKKSLERRKNPLLRKESAPPSLRRRPAETLGDSSPSSSSTPASGCSSPNDSEHGPNPILGSEADSDRRTHPTLGPRGPILGSPHTPLFLPHGLEPEAGGTLPSRLQPILLLDPSGSHAPLLTVPGLGPLPFHFAQSLMTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-8|HDAC7_HUMAN Isoform 8 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MSDLRKRELGALFTSRGTGGVEWDGTQVSPGAHYCSPTGAGCPRPCADTPGPQPQPMDLRVGQRPPVEPPPEPTLLALQRPQRLHHHLFLAGLQQQRSVEPMRLSMDTPMPELQVGPQEQELRQLLHKDKSKRSAVASSVVKQKLAEVILKKQQAALERTVHPNSPGIPYRTLEPLETEGATRSMLSSFLPPVPSLPSDPPEHFPLRKTVSEPNLKLRYKPKKSLERRKNPLLRKESAPPSLRRRPAETLGDSSPSSSSTPASGCSSPNDSEHGPNPILGSEALLGQRLRLQETSVAPFALPTVSLLPAITLGLPAPARADSDRRTHPTLGPRGPILGSPHTPLFLPHGLEPEAGGTLPSRLQPILLLDPSGSHAPLLTVPGLGPLPFHFAQSLMTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHMGALTLSQIPGHGSSQQQAGGAFSRPGHPCRAAVVMVNTGAACSAWPPVQTPGCLECQGLTKKKWRQ>sp|Q8WUI4-9|HDAC7_HUMAN Isoform 9 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q8WUI4-10|HDAC7_HUMAN Isoform 10 of Histone deacetylase 7 OS=Homosapiens OX=9606 GN=HDAC7MTTERLSGSGLHWPLSRTRSEPLPPSATAPPPPGPMQPRLEQLKTHVQVIKRSAKPSEKPRLRQIPSAEDLETDGGGPGQVVDDGLEHRELGHGQPEARGPAPLQQHPQVLLWEQQRLAGRLPRGSTGDTVLLPLAQGGHRPLSRAQSSPAAPASLSAPEPASQARVLSSSETPARTLPFTTGLIYDSVMLKHQCSCGDNSRHPEHAGRIQSIWSRLQERGLRSQCECLRGRKASLEELQSVHSERHVLLYGTNPLSRLKLDNGKLAGLLAQRMFVMLPCGGVGVDTDTIWNELHSSNAARWAAGSVTDLAFKVASRELKNGFAVVRPPGHHADHSTAMGFCFFNSVAIACRQLQQQSKASKILIVDWDVHHGNGTQQTFYQDPSVLYISLHRHDDGNFFPGSGAVDEVGAGSGEGFNVNVAWAGGLDPPMGDPEYLAAFRIVVMPIAREFSPDLVLVSAGFDAAEGHPAPLGGYHVSAKCFGYMTQQLMNLAGGAVVLALEGGHDLTAICDASEACVAALLGNRVDPLSEEGWKQKPNLNAIRSLEAVIRVHSKYWGCMQRLASCPDSWVPRVPGADKEEVEAVTALASLSVGILAEDRPSEQLVEEEEPMNL>sp|Q9UQL6|HDAC5_HUMAN Histone deacetylase 5 OS=Homo sapiens OX=9606GN=HDAC5 PE=1 SV=2MNSPNESDGMSGREPSLEILPRTSLHSIPVTVEVKPVLPRAMPSSMGGGGGGSPSPVELRGALVGSVDPTLREQQLQQELLALKQQQQLQKQLLFAEFQKQHDHLTRQHEVQLQKHLKQQQEMLAAKQQQEMLAAKRQQELEQQRQREQQRQEELEKQRLEQQLLILRNKEKSKESAIASTEVKLRLQEFLLSKSKEPTPGGLNHSLPQHPKCWGAHHASLDQSSPPQSGPPGTPPSYKLPLPGPYDSRDDFPLRKTASEPNLKVRSRLKQKVAERRSSPLLRRKDGTVISTFKKRAVEITGAGPGASSVCNSAPGSGPSSPNSSHSTIAENGFTGSVPNIPTEMLPQHRALPLDSSPNQFSLYTSPSLPNISLGLQATVTVTNSHLTASPKLSTQQEAERQALQSLRQGGTLTGKFMSTSSIPGCLLGVALEGDGSPHGHASLLQHVLLLEQARQQSTLIAVPLHGQSPLVTGERVATSMRTVGKLPRHRPLSRTQSSPLPQSPQALQQLVMQQQHQQFLEKQKQQQLQLGKILTKTGELPRQPTTHPEETEEELTEQQEVLLGEGALTMPREGSTESESTQEDLEEEDEEDDGEEEEDCIQVKDEEGESGAEEGPDLEEPGAGYKKLFSDAQPLQPLQVYQAPLSLATVPHQALGRTQSSPAAPGGMKSPPDQPVKHLFTTGVVYDTFMLKHQCMCGNTHVHPEHAGRIQSIWSRLQETGLLSKCERIRGRKATLDEIQTVHSEYHTLLYGTSPLNRQKLDSKKLLGPISQKMYAVLPCGGIGVDSDTVWNEMHSSSAVRMAVGCLLELAFKVAAGELKNGFAIIRPPGHHAEESTAMGFCFFNSVAITAKLLQQKLNVGKVLIVDWDIHHGNGTQQAFYNDPSVLYISLHRYDNGNFFPGSGAPEEVGGGPGVGYNVNVAWTGGVDPPIGDVEYLTAFRTVVMPIAHEFSPDVVLVSAGFDAVEGHLSPLGGYSVTARCFGHLTRQLMTLAGGRVVLALEGGHDLTAICDASEACVSALLSVELQPLDEAVLQQKPNINAVATLEKVIEIQSKHWSCVQKFAAGLGRSLREAQAGETEEAETVSAMALLSVGAEQAQAAAAREHSPRPAEEPMEQEPAL>sp|Q9UQL6-2|HDAC5_HUMAN Isoform 2 of Histone deacetylase 5 OS=Homosapiens OX=9606 GN=HDAC5MNSPNESDGMSGREPSLEILPRTSLHSIPVTVEVKPVLPRAMPSSMGGGGGGSPSPVELRGALVGSVDPTLREQQLQQELLALKQQQQLQKQLLFAEFQKQHDHLTRQHEVQLQKHLKQQQEMLAAKQQQEMLAAKRQQELEQQRQREQQRQEELEKQRLEQQLLILRNKEKSKESAIASTEVKLRLQEFLLSKSKEPTPGGLNHSLPQHPKCWGAHHASLDQSSPPQSGPPGTPPSYKLPLPGPYDSRDDFPLRKTASEPNLKVRSRLKQKVAERRSSPLLRRKDGTVISTFKKRAVEITGAGPGASSVCNSAPGSGPSSPNSSHSTIAENGFTGSVPNIPTEMLPQHRALPLDSSPNQFSLYTSPSLPNISLGLQATVTVTNSHLTASPKLSTQQEAERQALQSLRQGGTLTGKFMSTSSIPGCLLGVALEGDGSPHGHASLLQHVLLLEQARQQSTLIAVPLHGQSPLVTGERVATSMRTVGKLPRHRPLSRTQSSPLPQSPQALQQLVMQQQHQQFLEKQKQQQLQLGKILTKTGELPRQPTTHPEETEEELTEQQEVLLGEGALTMPREGSTESESTQEDLEEEDEEDDGEEEEDCIQVKDEEGESGAEEGPDLEEPGAGYKKLFSDAQPLQPLQVYQAPLSLATVPHQALGRTQSSPAAPGGMKSPPDQPVKHLFTTGPISQKMYAVLPCGGIGVDSDTVWNEMHSSSAVRMAVGCLLELAFKVAAGELKNGFAIIRPPGHHAEESTAMGFCFFNSVAITAKLLQQKLNVGKVLIVDWDIHHGNGTQQAFYNDPSVLYISLHRYDNGNFFPGSGAPEEVGGGPGVGYNVNVAWTGGVDPPIGDVEYLTAFRTVVMPIAHEFSPDVVLVSAGFDAVEGHLSPLGGYSVTARCFGHLTRQLMTLAGGRVVLALEGGHDLTAICDASEACVSALLSVELQPLDEAVLQQKPNINAVATLEKVIEIQSKHWSCVQKFAAGLGRSLREAQAGETEEAETVSAMALLSVGAEQAQAAAAREHSPRPAEEPMEQEPAL>sp|Q9UQL6-3|HDAC5_HUMAN Isoform 3 of Histone deacetylase 5 OS=Homosapiens OX=9606 GN=HDAC5MNSPNESADGMSGREPSLEILPRTSLHSIPVTVEVKPVLPRAMPSSMGGGGGGSPSPVELRGALVGSVDPTLREQQLQQELLALKQQQQLQKQLLFAEFQKQHDHLTRQHEVQLQKHLKQQQEMLAAKQQQEMLAAKRQQELEQQRQREQQRQEELEKQRLEQQLLILRNKEKSKESAIASTEVKLRLQEFLLSKSKEPTPGGLNHSLPQHPKCWGAHHASLDQSSPPQSGPPGTPPSYKLPLPGPYDSRDDFPLRKTASEPNLKVRSRLKQKVAERRSSPLLRRKDGTVISTFKKRAVEITGAGPGASSVCNSAPGSGPSSPNSSHSTIAENGFTGSVPNIPTEMLPQHRALPLDSSPNQFSLYTSPSLPNISLGLQATVTVTNSHLTASPKLSTQQEAERQALQSLRQGGTLTGKFMSTSSIPGCLLGVALEGDGSPHGHASLLQHVLLLEQARQQSTLIAVPLHGQSPLVTGERVATSMRTVGKLPRHRPLSRTQSSPLPQSPQALQQLVMQQQHQQFLEKQKQQQLQLGKILTKTGELPRQPTTHPEETEEELTEQQEVLLGEGALTMPREGSTESESTQEDLEEEDEEDDGEEEEDCIQVKDEEGESGAEEGPDLEEPGAGYKKLFSDAQPLQPLQVYQAPLSLATVPHQALGRTQSSPAAPGGMKSPPDQPVKHLFTTGVVYDTFMLKHQCMCGNTHVHPEHAGRIQSIWSRLQETGLLSKCERIRGRKATLDEIQTVHSEYHTLLYGTSPLNRQKLDSKKLLGPISQKMYAVLPCGGIGVDSDTVWNEMHSSSAVRMAVGCLLELAFKVAAGELKNGFAIIRPPGHHAEESTAMGFCFFNSVAITAKLLQQKLNVGKVLIVDWDIHHGNGTQQAFYNDPSVLYISLHRYDNGNFFPGSGAPEEVGGGPGVGYNVNVAWTGGVDPPIGDVEYLTAFRTVVMPIAHEFSPDVVLVSAGFDAVEGHLSPLGGYSVTARCFGHLTRQLMTLAGGRVVLALEGGHDLTAICDASEACVSALLSVELQPLDEAVLQQKPNINAVATLEKVIEIQSKHWSCVQKFAAGLGRSLREAQAGETEEAETVSAMALLSVGAEQAQAAAAREHSPRPAEEPMEQEPAL>sp|Q4VC39|HIG2B_HUMAN Putative HIG1 domain family member 2B OS=Homosapiens OX=9606 GN=HIGD2B PE=5 SV=1MATLGFVTPEAPFESSKPPIFEGLSPTVYSNPEGFKEKFLRKTRENPVVPIGFLCTAAVLTNGLYCFHQGNSQCSRLMMHTQIAAQGFTIAAILLGLAATAMKSPP>sp|Q6UX52|IL40_HUMAN Protein IL-40 OS=Homo sapiens OX=9606 GN=C17orf99PE=1 SV=2MGLPGLFCLAVLAASSFSKAREEEITPVVSIAYKVLEVFPKGRWVLITCCAPQPPPPITYSLCGTKNIKVAKKVVKTHEPASFNLNVTLKSSPDLLTYFCWASSTSGAHVDSARLQMHWELWSKPVSELRANFTLQDRGAGPRVEMICQASSGSPPITNSLIGKDGQVHLQQRPCHRQPANFSFLPSQTSDWFWCQAANNANVQHSALTVVPPGGDQKMEDWQGPLESPILALPLYRSTRRLSEEEFGGFRIGNGEVRGRKAAAM>sp|Q01101|INSM1_HUMAN Insulinoma-associated protein 1 OS=Homo sapiensOX=9606 GN=INSM1 PE=1 SV=1MPRGFLVKRSKKSTPVSYRVRGGEDGDRALLLSPSCGGARAEPPAPSPVPGPLPPPPPAERAHAALAAALACAPGPQPPPQGPRAAHFGNPEAAHPAPLYSPTRPVSREHEKHKYFERSFNLGSPVSAESFPTPAALLGGGGGGGASGAGGGGTCGGDPLLFAPAELKMGTAFSAGAEAARGPGPGPPLPPAAALRPPGKRPPPPTAAEPPAKAVKAPGAKKPKAIRKLHFEDEVTTSPVLGLKIKEGPVEAPRGRAGGAARPLGEFICQLCKEEYADPFALAQHKCSRIVRVEYRCPECAKVFSCPANLASHRRWHKPRPAPAAARAPEPEAAARAEAREAPGGGSDRDTPSPGGVSESGSEDGLYECHHCAKKFRRQAYLRKHLLAHHQALQAKGAPLAPPAEDLLALYPGPDEKAPQEAAGDGEGAGVLGLSASAECHLCPVCGESFASKGAQERHLRLLHAAQVFPCKYCPATFYSSPGLTRHINKCHPSENRQVILLQVPVRPAC>sp|Q96LR2|LURA1_HUMAN Leucine rich adaptor protein 1 OS=Homo sapiensOX=9606 GN=LURAP1 PE=1 SV=1MEGTVESQTPDLRDVEGKVGRKTPEGLLRGLRGECELGTSGALLLPGASSTGHDLGDKIMALKMELAYLRAIDVKILQQLVTLNEGIEAVRWLLEERGTLTSHCSSLTSSQYSLTGGSPGRSRRGSWDSLPDTSTTDRLDSVSIGSFLDTVAPSELDEQGPPGAPRSEMDWAKVIAGGERARTEVDVAATRLGSLRAVWKPPGERLQGGPPESPEDESAKLGFEAHWFWEQCQDDVTFL>sp|A8MYZ5|IQCF6_HUMAN IQ domain-containing protein F6 OS=Homo sapiensOX=9606 GN=IQCF6 PE=4 SV=3MVRRTLLQAALRAWVIQCWWRSMQAKMLEQRRRLALRLYTCQEWAVVKVQAQVRMWQARRRFLQARQAACIIQSHWRWHASQTRGLIRGHYEVRASRLELDIEILMT>sp|Q9H9V9|JMJD4_HUMAN 2-oxoglutarate and iron-dependent oxygenase JMJD4OS=Homo sapiens OX=9606 GN=JMJD4 PE=1 SV=2MRAGPEPQALAGQKRGALRLLVPRLVLTVSAPAEVRRRVLRPVLSWMDRETRALADSHFRGLGVDVPGVGQAPGRVAFVSEPGAFSYADFVRGFLLPNLPCVFSSAFTQGWGSRRRWVTPAGRPDFDHLLRTYGDVVVPVANCGVQEYNSNPKEHMTLRDYITYWKEYIQAGYSSPRGCLYLKDWHLCRDFPVEDVFTLPVYFSSDWLNEFWDALDVDDYRFVYAGPAGSWSPFHADIFRSFSWSVNVCGRKKWLLFPPGQEEALRDRHGNLPYDVTSPALCDTHLHPRNQLAGPPLEITQEAGEMVFVPSGWHHQVHNLDDTISINHNWVNGFNLANMWRFLQQELCAVQEEVSEWRDSMPDWHHHCQVIMRSCSGINFEEFYHFLKVIAEKRLLVLREAAAEDGAGLGFEQAAFDVGRITEVLASLVAHPDFQRVDTSAFSPQPKELLQQLREAVDAAAAP>sp|Q9H9V9-2|JMJD4_HUMAN Isoform 2 of 2-oxoglutarate and iron-dependentoxygenase JMJD4 OS=Homo sapiens OX=9606 GN=JMJD4MRAGPEPQALAGQKRGALRLLVPRLVLTVSAPAEVRRRVLRPVLSWMDRETRALADSHFRGLGVDVPGVGQAPGRVAFVSEPGAFSYADFVRGFLLPNLPCVFSSAFTQGWGSRRRWVTPAGRPDFDHLLRTYGDVVVPVANCGVQEYNSNPKEHMTLRDYITYWKEYIQAGYSSPRGCLYLKDWHLCRDFPVEDVFTLPVYFSSDWLNEFWDALDVDDYRFVYAGPAGSWSPFHADIFRSFSWSVNVCGRKKWLLFPPGQEEALRDRHGNLPYDVTSPALCDTHLHPRNQLAGPPLEITQEAGEMVFVPSGWHHQVHNLDDTISINHNWVNGFNLANMWRFLQQELCAVQEEVIMRSCSGINFEEFYHFLKVIAEKRLLVLREAAAEDGAGLGFEQAAFDVGRITEVLASLVAHPDFQRVDTSAFSPQPKELLQQLREAVDAAAAP>sp|Q6DN90|IQEC1_HUMAN IQ motif and SEC7 domain-containing protein 1OS=Homo sapiens OX=9606 GN=IQSEC1 PE=1 SV=1MWCLHCNSERTQSLLELELDSGVEGEAPSSETGTSLDSPSAYPQGPLVPGSSLSPDHYEHTSVGAYGLYSGPPGQQQRTRRPKLQHSTSILRKQAEEEAIKRSRSLSESYELSSDLQDKQVEMLERKYGGRLVTRHAARTIQTAFRQYQMNKNFERLRSSMSENRMSRRIVLSNMRMQFSFEGPEKVHSSYFEGKQVSVTNDGSQLGALVSPECGDLSEPTTLKSPAPSSDFADAITELEDAFSRQVKSLAESIDDALNCRSLHTEEAPALDAARARDTEPQTALHGMDHRKLDEMTASYSDVTLYIDEEELSPPLPLSQAGDRPSSTESDLRLRAGGAAPDYWALAHKEDKADTDTSCRSTPSLERQEQRLRVEHLPLLTIEPPSDSSVDLSDRSERGSLKRQSAYERSLGGQQGSPKHGPHSGAPKSLPREEPELRPRPPRPLDSHLAINGSANRQSKSESDYSDGDNDSINSTSNSNDTINCSSESSSRDSLREQTLSKQTYHKEARNSWDSPAFSNDVIRKRHYRIGLNLFNKKPEKGVQYLIERGFVPDTPVGVAHFLLQRKGLSRQMIGEFLGNRQKQFNRDVLDCVVDEMDFSTMELDEALRKFQAHIRVQGEAQKVERLIEAFSQRYCICNPGVVRQFRNPDTIFILAFAIILLNTDMYSPNVKPERKMKLEDFIKNLRGVDDGEDIPREMLMGIYERIRKRELKTNEDHVSQVQKVEKLIVGKKPIGSLHPGLGCVLSLPHRRLVCYCRLFEVPDPNKPQKLGLHQREIFLFNDLLVVTKIFQKKKNSVTYSFRQSFSLYGMQVLLFENQYYPNGIRLTSSVPGADIKVLINFNAPNPQDRKKFTDDLRESIAEVQEMEKHRIESELEKQKGVVRPSMSQCSSLKKESGNGTLSRACLDDSYASGEGLKRSALSSSLRDLSEAGKRGRRSSAGSLESNVEFQPFEPLQPSVLCS>sp|Q6DN90-2|IQEC1_HUMAN Isoform 2 of IQ motif and SEC7 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=IQSEC1MLERKYGGRLVTRHAARTIQTAFRQYQMNKNFERLRSSMSENRMSRRIVLSNMRMQFSFEGPEKVHSSYFEGKQVSVTNDGSQLGALVSPECGDLSEPTTLKSPAPSSDFADAITELEDAFSRQVKSLAESIDDALNCRSLHTEEAPALDAARARDTEPQTALHGMDHRKLDEMTASYSDVTLYIDEEELSPPLPLSQAGDRPSSTESDLRLRAGGAAPDYWALAHKEDKADTDTSCRSTPSLERQEQRLRVEHLPLLTIEPPSDSSVDLSDRSERGSLKRQSAYERSLGGQQGSPKHGPHSGAPKSLPREEPELRPRPPRPLDSHLAINGSANRQSKSESDYSDGDNDSINSTSNSNDTINCSSESSSRDSLREQTLSKQTYHKEARNSWDSPAFSNDVIRKRHYRIGLNLFNKKPEKGVQYLIERGFVPDTPVGVAHFLLQRKGLSRQMIGEFLGNRQKQFNRDVLDCVVDEMDFSTMELDEALRKFQAHIRVQGEAQKVERLIEAFSQRYCICNPGVVRQFRNPDTIFILAFAIILLNTDMYSPNVKPERKMKLEDFIKNLRGVDDGEDIPREMLMGIYERIRKRELKTNEDHVSQVQKVEKLIVGKKPIGSLHPGLGCVLSLPHRRLVCYCRLFEVPDPNKPQKLGLHQREIFLFNDLLVVTKIFQKKKNSVTYSFRQSFSLYGMQVLLFENQYYPNGIRLTSSVPGADIKVLINFNAPNPQDRKKFTDDLRESIAEVQEMEKHRIESELEKQKGVVRPSMSQCSSLKKESGNGTLSRACLDDSYASGEGLKRSALSSSLRDLSEAGKRGRRSSAGSLESNVEFQPFEPLQPSVLCS>sp|Q6DN90-3|IQEC1_HUMAN Isoform 3 of IQ motif and SEC7 domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=IQSEC1MACRRRYFVEGEAPSSETGTSLDSPSAYPQGPLVPGSSLSPDHYEHTSVGAYGLYSGPPGQQQRTRRPKLQHSTSILRKQAEEEAIKRSRSLSESYELSSDLQDKQVEMLERKYGGRLVTRHAARTIQTAFRQYQMNKNFERLRSSMSENRMSRRIVLSNMRMQFSFEGPEKVHSSYFEGKQVSVTNDGSQLGALVSPECGDLSEPTTLKSPAPSSDFADAITELEDAFSRQVKSLAESIDDALNCRSLHTEEAPALDAARARDTEPQTALHGMDHRKLDEMTASYSDVTLYIDEEELSPPLPLSQAGDRPSSTESDLRLRAGGAAPDYWALAHKEDKADTDTSCRSTPSLERQEQRLRVEHLPLLTIEPPSDSSVDLSDRSERGSLKRQSAYERSLGGQQGSPKHGPHSGAPKSLPREEPELRPRPPRPLDSHLAINGSANRQSKSESDYSDGDNDSINSTSNSNDTINCSSESSSRDSLREQTLSKQTYHKEARNSWDSPAFSNDVIRKRHYRIGLNLFNKKPEKGVQYLIERGFVPDTPVGVAHFLLQRKGLSRQMIGEFLGNRQKQFNRDVLDCVVDEMDFSTMELDEALRKFQAHIRVQGEAQKVERLIEAFSQRYCICNPGVVRQFRNPDTIFILAFAIILLNTDMYSPNVKPERKMKLEDFIKNLRGVDDGEDIPREMLMGIYERIRKRELKTNEDHVSQVQKVEKLIVGKKPIGSLHPGLGCVLSLPHRRLVCYCRLFEVPDPNKPQKLGLHQREIFLFNDLLVVTKIFQKKKNSVTYSFRQSFSLYGMQVLLFENQYYPNGIRLTSSVPGADIKVLINFNAPNPQDRKKFTDDLRESIAEVQEMEKHRIESELEKQKGVVRPSMSQCSSLKKESGNGTLSRACLDDSYASGEGLKRSALSSSLRDLSEAGKRGRRSSAGSLESNVEGSIISSPHMRRRATSTRECPSRPHQTMPNSSSLLGSLFGSKRGKPPPQAHLPSAPALPPPHPPVVLPHLQHSVAGHHLGPPEGLPQAAMHGHHTQYCHMQNPPPYHHHHHHHPPQHIQHAHQYHHGPHGGHPAYGAHAHGHPPLPSAHVGHTVHHHGQPPAPPPPTSSKAKPSGISTIV>sp|Q96JJ6|JPH4_HUMAN Junctophilin-4 OS=Homo sapiens OX=9606 GN=JPH4 PE=1SV=2MSPGGKFDFDDGGCYVGGWEAGRAHGYGVCTGPGAQGEYSGCWAHGFESLGVFTGPGGHSYQGHWQQGKREGLGVERKSRWTYRGEWLGGLKGRSGVWESVSGLRYAGLWKDGFQDGYGTETYSDGGTYQGQWQAGKRHGYGVRQSVPYHQAALLRSPRRTSLDSGHSDPPTPPPPLPLPGDEGGSPASGSRGGFVLAGPGDADGASSRKRTPAAGGFFRRSLLLSGLRAGGRRSSLGSKRGSLRSEVSSEVGSTGPPGSEASGPPAAAPPALIEGSATEVYAGEWRADRRSGFGVSQRSNGLRYEGEWLGNRRHGYGRTTRPDGSREEGKYKRNRLVHGGRVRSLLPLALRRGKVKEKVDRAVEGARRAVSAARQRQEIAAARAADALLKAVAASSVAEKAVEAARMAKLIAQDLQPMLEAPGRRPRQDSEGSDTEPLDEDSPGVYENGLTPSEGSPELPSSPASSRQPWRPPACRSPLPPGGDQGPFSSPKAWPEEWGGAGAQAEELAGYEAEDEAGMQGPGPRDGSPLLGGCSDSSGSLREEEGEDEEPLPPLRAPAGTEPEPIAMLVLRGSSSRGPDAGCLTEELGEPAATERPAQPGAANPLVVGAVALLDLSLAFLFSQLLT>sp|Q9Y2B9|IPKG_HUMAN cAMP-dependent protein kinase inhibitor gammaOS=Homo sapiens OX=9606 GN=PKIG PE=1 SV=1MMEVESSYSDFISCDRTGRRNAVPDIQGDSEAVSVRKLAGDMGELALEGAEGQVEGSAPDKEAGNQPQSSDGTTSS>sp|Q9BT40|INP5K_HUMAN Inositol polyphosphate 5-phosphatase K OS=Homosapiens OX=9606 GN=INPP5K PE=1 SV=3MSSRKLSGPKGRRLSIHVVTWNVASAAPPLDLSDLLQLNNRNLNLDIYVIGLQELNSGIISLLSDAAFNDSWSSFLMDVLSPLSFIKVSHVRMQGILLLVFAKYQHLPYIQILSTKSTPTGLFGYWGNKGGVNICLKLYGYYVSIINCHLPPHISNNYQRLEHFDRILEMQNCEGRDIPNILDHDLIIWFGDMNFRIEDFGLHFVRESIKNRCYGGLWEKDQLSIAKKHDPLLREFQEGRLLFPPTYKFDRNSNDYDTSEKKRKPAWTDRILWRLKRQPCAGPDTPIPPASHFSLSLRGYSSHMTYGISDHKPVSGTFDLELKPLVSAPLIVLMPEDLWTVENDMMVSYSSTSDFPSSPWDWIGLYKVGLRDVNDYVSYAWVGDSKVSCSDNLNQVYIDISNIPTTEDEFLLCYYSNSLRSVVGISRPFQIPPGSLREDPLGEAQPQI>sp|Q9BT40-2|INP5K_HUMAN Isoform 2 of Inositol polyphosphate 5-phosphatase K OS=Homo sapiens OX=9606 GN=INPP5KMDVLSPLSFIKVSHVRMQGILLLVFAKYQHLPYIQILSTKSTPTGLFGYWGNKGGVNICLKLYGYYVSIINCHLPPHISNNYQRLEHFDRILEMQNCEGRDIPNILDHDLIIWFGDMNFRIEDFGLHFVRESIKNRCYGGLWEKDQLSIAKKHDPLLREFQEGRLLFPPTYKFDRNSNDYDTSEKKRKPAWTDRILWRLKRQPCAGPDTPIPPASHFSLSLRGYSSHMTYGISDHKPVSGTFDLELKPLVSAPLIVLMPEDLWTVENDMMVSYSSTSDFPSSPWDWIGLYKVGLRDVNDYVSYAWVGDSKVSCSDNLNQVYIDISNIPTTEDEFLLCYYSNSLRSVVGISRPFQIPPGSLREDPLGEAQPQI>sp|Q17R60|IMPG1_HUMAN Interphotoreceptor matrix proteoglycan 1 OS=Homosapiens OX=9606 GN=IMPG1 PE=1 SV=2MYLETRRAIFVFWIFLQVQGTKDISINIYHSETKDIDNPPRNETTESTEKMYKMSTMRRIFDLAKHRTKRSAFFPTGVKVCPQESMKQILDSLQAYYRLRVCQEAVWEAYRIFLDRIPDTGEYQDWVSICQQETFCLFDIGKNFSNSQEHLDLLQQRIKQRSFPDRKDEISAEKTLGEPGETIVISTDVANVSLGPFPLTPDDTLLNEILDNTLNDTKMPTTERETEFAVLEEQRVELSVSLVNQKFKAELADSQSPYYQELAGKSQLQMQKIFKKLPGFKKIHVLGFRPKKEKDGSSSTEMQLTAIFKRHSAEAKSPASDLLSFDSNKIESEEVYHGTMEEDKQPEIYLTATDLKRLISKALEEEQSLDVGTIQFTDEIAGSLPAFGPDTQSELPTSFAVITEDATLSPELPPVEPQLETVDGAEHGLPDTSWSPPAMASTSLSEAPPFFMASSIFSLTDQGTTDTMATDQTMLVPGLTIPTSDYSAISQLALGISHPPASSDDSRSSAGGEDMVRHLDEMDLSDTPAPSEVPELSEYVSVPDHFLEDTTPVSALQYITTSSMTIAPKGRELVVFFSLRVANMAFSNDLFNKSSLEYRALEQQFTQLLVPYLRSNLTGFKQLEILNFRNGSVIVNSKMKFAKSVPYNLTKAVHGVLEDFRSAAAQQLHLEIDSYSLNIEPADQADPCKFLACGEFAQCVKNERTEEAECRCKPGYDSQGSLDGLEPGLCGPGTKECEVLQGKGAPCRLPDHSENQAYKTSVKKFQNQQNNKVISKRNSELLTVEYEEFNHQDWEGN>sp|Q17R60-2|IMPG1_HUMAN Isoform 2 of Interphotoreceptor matrixproteoglycan 1 OS=Homo sapiens OX=9606 GN=IMPG1MYLETRRAIFVFWIFLQVQGTKVCQEAVWEAYRIFLDRIPDTGEYQDWVSICQQETFCLFDIGKNFSNSQEHLDLLQQRIKQRSFPDRKDEISAEKTLGEPGETIVISTEKNKGKTKPFNILQFGNNHHEHLLPIFCLLSSIIYTYY>sp|Q92833|JARD2_HUMAN Protein Jumonji OS=Homo sapiens OX=9606 GN=JARID2PE=1 SV=2MSKERPKRNIIQKKYDDSDGIPWSEERVVRKVLYLSLKEFKNSQKRQHAEGIAGSLKTVNGLLGNDQSKGLGPASEQSENEKDDASQVSSTSNDVSSSDFEEGPSRKRPRLQAQRKFAQSQPNSPSTTPVKIVEPLLPPPATQISDLSKRKPKTEDFLTFLCLRGSPALPNSMVYFGSSQDEEEVEEEDDETEDVKTATNNASSSCQSTPRKGKTHKHVHNGHVFNGSSRSTREKEPVQKHKSKEATPAKEKHSDHRADSRREQASANHPAAAPSTGSSAKGLAATHHHPPLHRSAQDLRKQVSKVNGVTRMSSLGAGVTSAKKMREVRPSPSKTVKYTATVTKGAVTYTKAKRELVKDTKPNHHKPSSAVNHTISGKTESSNAKTRKQVLSLGGASKSTGPAVNGLKVSGRLNPKSCTKEVGGRQLREGLQLREGLRNSKRRLEEAHQAEKPQSPPKKMKGAAGPAEGPGKKAPAERGLLNGHVKKEVPERSLERNRPKRATAGKSTPGRQAHGKADSASCENRSTSQPESVHKPQDSGKAEKGGGKAGWAAMDEIPVLRPSAKEFHDPLIYIESVRAQVEKFGMCRVIPPPDWRPECKLNDEMRFVTQIQHIHKLGRRWGPNVQRLACIKKHLKSQGITMDELPLIGGCELDLACFFRLINEMGGMQQVTDLKKWNKLADMLRIPRTAQDRLAKLQEAYCQYLLSYDSLSPEEHRRLEKEVLMEKEILEKRKGPLEGHTENDHHKFHPLPRFEPKNGLIHGVAPRNGFRSKLKEVGQAQLKTGRRRLFAQEKEVVKEEEEDKGVLNDFHKCIYKGRSVSLTTFYRTARNIMSMCFSKEPAPAEIEQEYWRLVEEKDCHVAVHCGKVDTNTHGSGFPVGKSEPFSRHGWNLTVLPNNTGSILRHLGAVPGVTIPWLNIGMVFSTSCWSRDQNHLPYIDYLHTGADCIWYCIPAEEENKLEDVVHTLLQANGTPGLQMLESNVMISPEVLCKEGIKVHRTVQQSGQFVVCFPGSFVSKVCCGYSVSETVHFATTQWTSMGFETAKEMKRRHIAKPFSMEKLLYQIAQAEAKKENGPTLSTISALLDELRDTELRQRRQLFEAGLHSSARYGSHDGSSTVADGKKKPRKWLQLETSERRCQICQHLCYLSMVVQENENVVFCLECALRHVEKQKSCRGLKLMYRYDEEQIISLVNQICGKVSGKNGSIENCLSKPTPKRGPRKRATVDVPPSRLSASSSSKSASSSS>sp|Q92833-2|JARD2_HUMAN Isoform 2 of Protein Jumonji OS=Homo sapiensOX=9606 GN=JARID2MAAPRVCQVQFLVAYLEEPGIEGLLGNDQSKGLGPASEQSENEKDDASQVSSTSNDVSSSDFEEGPSRKRPRLQAQRKFAQSQPNSPSTTPVKIVEPLLPPPATQISDLSKRKPKTEDFLTFLCLRGSPALPNSMVYFGSSQDEEEVEEEDDETEDVKTATNNASSSCQSTPRKGKTHKHVHNGHVFNGSSRSTREKEPVQKHKSKEATPAKEKHSDHRADSRREQASANHPAAAPSTGSSAKGLAATHHHPPLHRSAQDLRKQVSKVNGVTRMSSLGAGVTSAKKMREVRPSPSKTVKYTATVTKGAVTYTKAKRELVKDTKPNHHKPSSAVNHTISGKTESSNAKTRKQVLSLGGASKSTGPAVNGLKVSGRLNPKSCTKEVGGRQLREGLQLREGLRNSKRRLEEAHQAEKPQSPPKKMKGAAGPAEGPGKKAPAERGLLNGHVKKEVPERSLERNRPKRATAGKSTPGRQAHGKADSASCENRSTSQPESVHKPQDSGKAEKGGGKAGWAAMDEIPVLRPSAKEFHDPLIYIESVRAQVEKFGMCRVIPPPDWRPECKLNDEMRFVTQIQHIHKLGRRWGPNVQRLACIKKHLKSQGITMDELPLIGGCELDLACFFRLINEMGGMQQVTDLKKWNKLADMLRIPRTAQDRLAKLQEAYCQYLLSYDSLSPEEHRRLEKEVLMEKEILEKRKGPLEGHTENDHHKFHPLPRFEPKNGLIHGVAPRNGFRSKLKEVGQAQLKTGRRRLFAQEKEVVKEEEEDKGVLNDFHKCIYKGRSVSLTTFYRTARNIMSMCFSKEPAPAEIEQEYWRLVEEKDCHVAVHCGKVDTNTHGSGFPVGKSEPFSRHGWNLTVLPNNTGSILRHLGAVPGVTIPWLNIGMVFSTSCWSRDQNHLPYIDYLHTGADCICLSVEPVFPHLSVAVGSIVDLGISFLPCGDTRVMYPVESVAWRGVLGPRL>sp|Q92833-3|JARD2_HUMAN Isoform 3 of Protein Jumonji OS=Homo sapiensOX=9606 GN=JARID2MVYFGSSQDEEEVEEEDDETEDVKTATNNASSSCQSTPRKGKTHKHVHNGHVFNGSSRSTREKEPVQKHKSKEATPAKEKHSDHRADSRREQASANHPAAAPSTGSSAKGLAATHHHPPLHRSAQDLRKQVSKVNGVTRMSSLGAGVTSAKKMREVRPSPSKTVKYTATVTKGAVTYTKAKRELVKDTKPNHHKPSSAVNHTISGKTESSNAKTRKQVLSLGGASKSTGPAVNGLKVSGRLNPKSCTKEVGGRQLREGLQLREGLRNSKRRLEEAHQAEKPQSPPKKMKGAAGPAEGPGKKAPAERGLLNGHVKKEVPERSLERNRPKRATAGKSTPGRQAHGKADSASCENRSTSQPESVHKPQDSGKAEKGGGKAGWAAMDEIPVLRPSAKEFHDPLIYIESVRAQVEKFGMCRVIPPPDWRPECKLNDEMRFVTQIQHIHKLGRRWGPNVQRLACIKKHLKSQGITMDELPLIGGCELDLACFFRLINEMGGMQQVTDLKKWNKLADMLRIPRTAQDRLAKLQEAYCQYLLSYDSLSPEEHRRLEKEVLMEKEILEKRKGPLEGHTENDHHKFHPLPRFEPKNGLIHGVAPRNGFRSKLKEVGQAQLKTGRRRLFAQEKEVVKEEEEDKGVLNDFHKCIYKGRSVSLTTFYRTARNIMSMCFSKEPAPAEIEQEYWRLVEEKDCHVAVHCGKVDTNTHGSGFPVGKSEPFSRHGWNLTVLPNNTGSILRHLGAVPGVTIPWLNIGMVFSTSCWSRDQNHLPYIDYLHTGADCIWYCIPAEEENKLEDVVHTLLQANGTPGLQMLESNVMISPEVLCKEGIKVHRTVQQSGQFVVCFPGSFVSKVCCGYSVSETVHFATTQWTSMGFETAKEMKRRHIAKPFSMEKLLYQIAQAEAKKENGPTLSTISALLDELRDTELRQRRQLFEAGLHSSARYGSHDGSSTVADGKKKPRKWLQLETSERRCQICQHLCYLSMVVQENENVVFCLECALRHVEKQKSCRGLKLMYRYDEEQIISLVNQICGKVSGKNGSIENCLSKPTPKRGPRKRATVDVPPSRLSASSSSKSASSSS>sp|O15397|IPO8_HUMAN Importin-8 OS=Homo sapiens OX=9606 GN=IPO8 PE=1SV=2MDLNRIIQALKGTIDPKLRIAAENELNQSYKIINFAPSLLRIIVSDHVEFPVRQAAAIYLKNMVTQYWPDREPPPGEAIFPFNIHENDRQQIRDNIVEGIIRSPDLVRVQLTMCLRAIIKHDFPGHWPGVVDKIDYYLQSQSSASWLGSLLCLYQLVKTYEYKKAEEREPLIIAMQIFLPRIQQQIVQLLPDSSYYSVLLQKQILKIFYALVQYALPLQLVNNQTMTTWMEIFRTIIDRTVPPETLHIDEDDRPELVWWKCKKWALHIVARLFERYGSPGNVTKEYFEFSEFFLKTYAVGIQQVLLKILDQYRQKEYVAPRVLQQAFNYLNQGVVHSITWKQMKPHIQNISEDVIFSVMCYKDEDEELWQEDPYEYIRMKFDIFEDYASPTTAAQTLLYTAAKKRKEVLPKMMAFCYQILTDPNFDPRKKDGALHVIGSLAEILLKKSLFKDQMELFLQNHVFPLLLSNLGYLRARSCWVLHAFSSLKFHNELNLRNAVELAKKSLIEDKEMPVKVEAALALQSLISNQIQAKEYMKPHVRPIMQELLHIVRETENDDVTNVIQKMICEYSQEVASIAVDMTQHLAEIFGKVLQSDEYEEVEDKTVMAMGILHTIDTILTVVEDHKEITQQLENICLRIIDLVLQKHVIEFYEEILSLAYSLTCHSISPQMWQLLGILYEVFQQDCFEYFTDMMPLLHNYVTIDTDTLLSNAKHLEILFTMCRKVLCGDAGEDAECHAAKLLEVIILQCKGRGIDQCIPLFVQLVLERLTRGVKTSELRTMCLQVAIAALYYNPDLLLHTLERIQLPHNPGPITVQFINQWMNDTDCFLGHHDRKMCIIGLSILLELQNRPPAVDAVVGQIVPSILFLFLGLKQVCATRQLVNREDRSKAEKADMEENEEISSDEEETNVTAQAMQSNNGRGEDEEEEDDDWDEEVLEETALEGFSTPLDLDNSVDEYQFFTQALITVQSRDAAWYQLLMAPLSEDQRTALQEVYTLAEHRRTVAEAKKKIEQQGGFTFENKGVLSAFNFGTVPSNN>sp|O15397-2|IPO8_HUMAN Isoform 2 of Importin-8 OS=Homo sapiens OX=9606GN=IPO8MESLTLKGYALPLQLVNNQTMTTWMEIFRTIIDRTVPPETLHIDEDDRPELVWWKCKKWALHIVARLFERYGSPGNVTKEYFEFSEFFLKTYAVGIQQVLLKILDQYRQKEYVAPRVLQQAFNYLNQGVVHSITWKQMKPHIQNISEDVIFSVMCYKDEDEELWQEDPYEYIRMKFDIFEDYASPTTAAQTLLYTAAKKRKEVLPKMMAFCYQILTDPNFDPRKKDGALHVIGSLAEILLKKSLFKDQMELFLQNHVFPLLLSNLGYLRARSCWVLHAFSSLKFHNELNLRNAVELAKKSLIEDKEMPVKVEAALALQSLISNQIQAKEYMKPHVRPIMQELLHIVRETENDDVTNVIQKMICEYSQEVASIAVDMTQHLAEIFGKVLQSDEYEEVEDKTVMAMGILHTIDTILTVVEDHKEITQQLENICLRIIDLVLQKHVIEFYEEILSLAYSLTCHSISPQMWQLLGILYEVFQQDCFEYFTDMMPLLHNYVTIDTDTLLSNAKHLEILFTMCRKVLCGDAGEDAECHAAKLLEVIILQCKGRGIDQCIPLFVQLVLERLTRGVKTSELRTMCLQVAIAALYYNPDLLLHTLERIQLPHNPGPITVQFINQWMNDTDCFLGHHDRKMCIIGLSILLELQNRPPAVDAVVGQIVPSILFLFLGLKQVCATRQLVNREDRSKAEKADMEENEEISSDEEETNVTAQAMQSNNGRGEDEEEEDDDWDEEVLEETALEGFSTPLDLDNSVDEYQFFTQALITVQSRDAAWYQLLMAPLSEDQRTALQEVYTLAEHRRTVAEAKKKIEQQGGFTFENKGVLSAFNFGTVPSNN>sp|O94829|IPO13_HUMAN Importin-13 OS=Homo sapiens OX=9606 GN=IPO13 PE=1SV=3MERREEQPGAAGAGAAPALDFTVENVEKALHQLYYDPNIENKNLAQKWLMQAQVSPQAWHFSWQLLQPDKVPEIQYFGASALHIKISRYWSDIPTDQYESLKAQLFTQITRFASGSKIVLTRLCVALASLALSMMPDAWPCAVADMVRLFQAEDSPVDGQGRCLALLELLTVLPEEFQTSRLPQYRKGLVRTSLAVECGAVFPLLEQLLQQPSSPSCVRQKVLKCFSSWVQLEVPLQDCEALIQAAFAALQDSELFDSSVEAIVNAISQPDAQRYVNTLLKLIPLVLGLQEQLRQAVQNGDMETSHGICRIAVALGENHSRALLDQVEHWQSFLALVNMIMFCTGIPGHYPVNETTSSLTLTFWYTLQDDILSFEAEKQAVYQQVYRPVYFQLVDVLLHKAQFPSDEEYGFWSSDEKEQFRIYRVDISDTLMYVYEMLGAELLSNLYDKLGRLLTSSEEPYSWQHTEALLYGFQSIAETIDVNYSDVVPGLIGLIPRISISNVQLADTVMFTIGALSEWLADHPVMINSVLPLVLHALGNPELSVSSVSTLKKICRECKYDLPPYAANIVAVSQDVLMKQIHKTSQCMWLMQALGFLLSALQVEEILKNLHSLISPYIQQLEKLAEEIPNPSNKLAIVHILGLLSNLFTTLDISHHEDDHEGPELRKLPVPQGPNPVVVVLQQVFQLIQKVLSKWLNDAQVVEAVCAIFEKSVKTLLDDFAPMVPQLCEMLGRMYSTIPQASALDLTRQLVHIFAHEPAHFPPIEALFLLVTSVTLTLFQQGPRDHPDIVDSFMQLLAQALKRKPDLFLCERLDVKAVFQCAVLALKFPEAPTVKASCGFFTELLPRCGEVESVGKVVQEDGRMLLIAVLEAIGGQASRSLMDCFADILFALNKHCFSLLSMWIKEALQPPGFPSARLSPEQKDTFSQQILRERVNKRRVKEMVKEFTLLCRGLHGTDYTADY>sp|Q96P70|IPO9_HUMAN Importin-9 OS=Homo sapiens OX=9606 GN=IPO9 PE=1SV=3MAAAAAAGAASGLPGPVAQGLKEALVDTLTGILSPVQEVRAAAEEQIKVLEVTEEFGVHLAELTVDPQGALAIRQLASVILKQYVETHWCAQSEKFRPPETTERAKIVIRELLPNGLRESISKVRSSVAYAVSAIAHWDWPEAWPQLFNLLMEMLVSGDLNAVHGAMRVLTEFTREVTDTQMPLVAPVILPEMYKIFTMAEVYGIRTRSRAVEIFTTCAHMICNMEELEKGAAKVLIFPVVQQFTEAFVQALQIPDGPTSDSGFKMEVLKAVTALVKNFPKHMVSSMQQILPIVWNTLTESAAFYVRTEVNYTEEVEDPVDSDGEVLGFENLVFSIFEFVHALLENSKFKSTVKKALPELIYYIILYMQITEEQIKVWTANPQQFVEDEDDDTFSYTVRIAAQDLLLAVATDFQNESAAALAAAATRHLQEAEQTKNSGTEHWWKIHEACMLALGSVKAIITDSVKNGRIHFDMHGFLTNVILADLNLSVSPFLLGRALWAASRFTVAMSPELIQQFLQATVSGLHETQPPSVRISAVRAIWGYCDQLKVSESTHVLQPFLPSILDGLIHLAAQFSSEVLNLVMETLCIVCTVDPEFTASMESKICPFTIAIFLKYSNDPVVASLAQDIFKELSQIEACQGPMQMRLIPTLVSIMQAPADKIPAGLCATAIDILTTVVRNTKPPLSQLLICQAFPAVAQCTLHTDDNATMQNGGECLRAYVSVTLEQVAQWHDEQGHNGLWYVMQVVSQLLDPRTSEFTAAFVGRLVSTLISKAGRELGENLDQILRAILSKMQQAETLSVMQSLIMVFAHLVHTQLEPLLEFLCSLPGPTGKPALEFVMAEWTSRQHLFYGQYEGKVSSVALCKLLQHGINADDKRLQDIRVKGEEIYSMDEGIRTRSKSAKNPERWTNIPLLVKILKLIINELSNVMEANAARQATPAEWSQDDSNDMWEDQEEEEEEEEDGLAGQLLSDILATSKYEEDYYEDDEEDDPDALKDPLYQIDLQAYLTDFLCQFAQQPCYIMFSGHLNDNERRVLQTIGI>sp|P80217|IN35_HUMAN Interferon-induced 35 kDa protein OS=Homo sapiensOX=9606 GN=IFI35 PE=1 SV=5MSAPLDAALHALQEEQARLKMRLWDLQQLRKELGDSPKDKVPFSVPKIPLVFRGHTQQDPEVPKSLVSNLRIHCPLLAGSALITFDDPKVAEQVLQQKEHTINMEECRLRVQVQPLELPMVTTIQMSSQLSGRRVLVTGFPASLRLSEEELLDKLEIFFGKTRNGGGDVDVRELLPGSVMLGFARDGVAQRLCQIGQFTVPLGGQQVPLRVSPYVNGEIQKAEIRSQPVPRSVLVLNIPDILDGPELHDVLEIHFQKPTRGGGEVEALTVVPQGQQGLAVFTSESG>sp|P80217-2|IN35_HUMAN Isoform 2 of Interferon-induced 35 kDa proteinOS=Homo sapiens OX=9606 GN=IFI35MSAPLDAALHALQEEQARLKMRLWDLQQLRKELGDSPKDKVPFSVPKIPLVFRGHTQQDPEVPKSLVSNLRIHCPLLAGSALITFDDPKVAEQVLQQKEHTINMEECRLRVQVQPLELPMVTTIQVMMSSQLSGRRVLVTGFPASLRLSEEELLDKLEIFFGKTRNGGGDVDVRELLPGSVMLGFARDGVAQRLCQIGQFTVPLGGQQVPLRVSPYVNGEIQKAEIRSQPVPRSVLVLNIPDILDGPELHDVLEIHFQKPTRGGGEVEALTVVPQGQQGLAVFTSESG>sp|Q04695|K1C17_HUMAN Keratin, type I cytoskeletal 17 OS=Homo sapiensOX=9606 GN=KRT17 PE=1 SV=2MTTSIRQFTSSSSIKGSSGLGGGSSRTSCRLSGGLGAGSCRLGSAGGLGSTLGGSSYSSCYSFGSGGGYGSSFGGVDGLLAGGEKATMQNLNDRLASYLDKVRALEEANTELEVKIRDWYQRQAPGPARDYSQYYRTIEELQNKILTATVDNANILLQIDNARLAADDFRTKFETEQALRLSVEADINGLRRVLDELTLARADLEMQIENLKEELAYLKKNHEEEMNALRGQVGGEINVEMDAAPGVDLSRILNEMRDQYEKMAEKNRKDAEDWFFSKTEELNREVATNSELVQSGKSEISELRRTMQALEIELQSQLSMKASLEGNLAETENRYCVQLSQIQGLIGSVEEQLAQLRCEMEQQNQEYKILLDVKTRLEQEIATYRRLLEGEDAHLTQYKKEPVTTRQVRTIVEEVQDGKVISSREQVHQTTR>sp|Q99456|K1C12_HUMAN Keratin, type I cytoskeletal 12 OS=Homo sapiensOX=9606 GN=KRT12 PE=1 SV=1MDLSNNTMSLSVRTPGLSRRLSSQSVIGRPRGMSASSVGSGYGGSAFGFGASCGGGFSAASMFGSSSGFGGGSGSSMAGGLGAGYGRALGGGSFGGLGMGFGGSPGGGSLGILSGNDGGLLSGSEKETMQNLNDRLASYLDKVRALEEANTELENKIREWYETRGTGTADASQSDYSKYYPLIEDLRNKIISASIGNAQLLLQIDNARLAAEDFRMKYENELALRQGVEADINGLRRVLDELTLTRTDLEMQIESLNEELAYMKKNHEDELQSFRVGGPGEVSVEMDAAPGVDLTRLLNDMRAQYETIAEQNRKDAEAWFIEKSGELRKEISTNTEQLQSSKSEVTDLRRAFQNLEIELQSQLAMKKSLEDSLAEAEGDYCAQLSQVQQLISNLEAQLLQVRADAERQNVDHQRLLNVKARLELEIETYRRLLDGEAQGDGLEESLFVTDSKSQAQSTDSSKDPTKTRKIKTVVQEMVNGEVVSSQVQEIEELM>sp|Q86Y46|K2C73_HUMAN Keratin, type II cytoskeletal 73 OS=Homo sapiensOX=9606 GN=KRT73 PE=1 SV=1MSRQFTYKSGAAAKGGFSGCSAVLSGGSSSSYRAGGKGLSGGFSSRSLYSLGGARSISFNVASGSGWAGGYGFGRGRASGFAGSMFGSVALGSVCPSLCPPGGIHQVTINKSLLAPLNVELDPEIQKVRAQEREQIKVLNNKFASFIDKVRFLEQQNQVLETKWELLQQLDLNNCKNNLEPILEGYISNLRKQLETLSGDRVRLDSELRSVREVVEDYKKRYEEEINKRTTAENEFVVLKKDVDAAYTSKVELQAKVDALDGEIKFFKCLYEGETAQIQSHISDTSIILSMDNNRNLDLDSIIAEVRAQYEEIARKSKAEAEALYQTKFQELQLAAGRHGDDLKHTKNEISELTRLIQRLRSEIESVKKQCANLETAIADAEQRGDCALKDARAKLDELEGALQQAKEELARMLREYQELLSVKLSLDIEIATYRKLLEGEECRMSGEYTNSVSISVINSSMAGMAGTGAGFGFSNAGTYGYWPSSVSGGYSMLPGGCVTGSGNCSPRGEARTRLGSASEFRDSQGKTLALSSPTKKTMR>sp|Q86Y46-2|K2C73_HUMAN Isoform 2 of Keratin, type II cytoskeletal 73OS=Homo sapiens OX=9606 GN=KRT73MSRQFTYKSGAAAKGGFSGCSAVLSGGSSSSYRAGGKGLSGGFSSRSLYSLGGARSISFNVASGSGWAGGYGFGRGRASGFAGSMFGSVALGSVCPSLCPPGGIHQVTINKSLLAPLNVELDPEIQKVRAQEREQIKVLNNKFASFIDKVRFLEQQNQVLETKWELLQQLDLNNCKNNLEPILEGYISNLRKQLETLSGDRVRLDSELRSVREVVEDYKKRYEEEINKRTTAENEFVVLKKDVDAAYTSKVELQAKVDALDGEIKFFKCLYEGETAQIQSHISDTSIILSMDNNRNLDLDSIIAEVRAQYEEIARKSKAEAEALYQTKFQELQLAAGRHGDDLKHTKNEISELTRLIQRLRSEIESVKKQVKGTGAFLTHS>sp|P13645|K1C10_HUMAN Keratin, type I cytoskeletal 10 OS=Homo sapiensOX=9606 GN=KRT10 PE=1 SV=6MSVRYSSSKHYSSSRSGGGGGGGGCGGGGGVSSLRISSSKGSLGGGFSSGGFSGGSFSRGSSGGGCFGGSSGGYGGLGGFGGGSFRGSYGSSSFGGSYGGIFGGGSFGGGSFGGGSFGGGGFGGGGFGGGFGGGFGGDGGLLSGNEKVTMQNLNDRLASYLDKVRALEESNYELEGKIKEWYEKHGNSHQGEPRDYSKYYKTIDDLKNQILNLTTDNANILLQIDNARLAADDFRLKYENEVALRQSVEADINGLRRVLDELTLTKADLEMQIESLTEELAYLKKNHEEEMKDLRNVSTGDVNVEMNAAPGVDLTQLLNNMRSQYEQLAEQNRKDAEAWFNEKSKELTTEIDNNIEQISSYKSEITELRRNVQALEIELQSQLALKQSLEASLAETEGRYCVQLSQIQAQISALEEQLQQIRAETECQNTEYQQLLDIKIRLENEIQTYRSLLEGEGSSGGGGRGGGSFGGGYGGGSSGGGSSGGGHGGGHGGSSGGGYGGGSSGGGSSGGGYGGGSSSGGHGGSSSGGYGGGSSGGGGGGYGGGSSGGGSSSGGGYGGGSSSGGHKSSSSGSVGESSSKGPRY>sp|Q7RTS7|K2C74_HUMAN Keratin, type II cytoskeletal 74 OS=Homo sapiensOX=9606 GN=KRT74 PE=1 SV=2MSRQLNIKSSGDKGNFSVHSAVVPRKAVGSLASYCAAGRGAGAGFGSRSLYSLGGNRRISFNVAGGGVRAGGYGFRPGSGYGGGRASGFAGSMFGSVALGPACLSVCPPGGIHQVTVNKSLLAPLNVELDPEIQKVRAQEREQIKVLNDKFASFIDKVRFLEQQNQVLETKWELLQQLDLNNCKKNLEPILEGYISNLRKQLETLSGDRVRLDSELRSMRDLVEDYKKRYEVEINRRTTAENEFVVLKKDADAAYAVKVELQAKVDSLDKEIKFLKCLYDAEIAQIQTHASETSVILSMDNNRDLDLDSIIAEVRMHYEEIALKSKAEAEALYQTKIQELQLAASRHGDDLKHTRSEMVELNRLIQRIRCEIGNVKKQRASLETAIADAEQRGDNALKDAQAKLDELEGALHQAKEELARMLREYQELMSLKLALDMEIATYRKLLEGEECRMSGENPSSVSISVISSSSYSYHHPSSAGVDLGASAVAGSSGSTQSGQTKTTEARGGDLKDTQGKSTPASIPARKATR>sp|Q75QN2|INT8_HUMAN Integrator complex subunit 8 OS=Homo sapiensOX=9606 GN=INTS8 PE=1 SV=1MSAEAADREAATSSRPCTPPQTCWFEFLLEESLLEKHLRKPCPDPAPVQLIVQFLEQASKPSVNEQNQVQPPPDNKRNRILKLLALKVAAHLKWDLDILEKSLSVPVLNMLLNELLCISKVPPGTKHVDMDLATLPPTTAMAVLLYNRWAIRTIVQSSFPVKQAKPGPPQLSVMNQMQQEKELTENILKVLKEQAADSILVLEAALKLNKDLYVHTMRTLDLLAMEPGMVNGETESSTAGLKVKTEEMQCQVCYDLGAAYFQQGSTNSAVYENAREKFFRTKELIAEIGSLSLHCTIDEKRLAGYCQACDVLVPSSDSTSQQLTPYSQVHICLRSGNYQEVIQIFIEDNLTLSLPVQFRQSVLRELFKKAQQGNEALDEICFKVCACNTVRDILEGRTISVQFNQLFLRPNKEKIDFLLEVCSRSVNLEKASESLKGNMAAFLKNVCLGLEDLQYVFMISSHELFITLLKDEERKLLVDQMRKRSPRVNLCIKPVTSFYDIPASASVNIGQLEHQLILSVDPWRIRQILIELHGMTSERQFWTVSNKWEVPSVYSGVILGIKDNLTRDLVYILMAKGLHCSTVKDFSHAKQLFAACLELVTEFSPKLRQVMLNEMLLLDIHTHEAGTGQAGERPPSDLISRVRGYLEMRLPDIPLRQVIAEECVAFMLNWRENEYLTLQVPAFLLQSNPYVKLGQLLAATCKELPGPKESRRTAKDLWEVVVQICSVSSQHKRGNDGRVSLIKQRESTLGIMYRSELLSFIKKLREPLVLTIILSLFVKLHNVREDIVNDITAEHISIWPSSIPNLQSVDFEAVAITVKELVRYTLSINPNNHSWLIIQADIYFATNQYSAALHYYLQAGAVCSDFFNKAVPPDVYTDQVIKRMIKCCSLLNCHTQVAILCQFLREIDYKTAFKSLQEQNSHDAMDSYYDYIWDVTILEYLTYLHHKRGETDKRQIAIKAIGQTELNASNPEEVLQLAAQRRKKKFLQAMAKLYF>sp|Q75QN2-2|INT8_HUMAN Isoform 2 of Integrator complex subunit 8 OS=Homosapiens OX=9606 GN=INTS8MSAEAADREAATSSRPCTPPQTCWFEFLLEESLLEKHLRKPCPDPAPVQLIVQFLEQASKPSVNEQNQVQPPPDNKRNRILKLLALKVAAHLKWDLDILEKSLSVPVLNMLLNELLCISKVPPGTKHVDMDLATLPPTTAMAVLLYNRWAIRTIVQSSFPVKQAKPGPPQLSVMNQMQQEKELTENILKVLKEQAADSILVLEAALKLNKDLYVHTMRTLDLLAMEPGMVNGETESSTAGLKVKTEEMQCQVCYDLGAAYFQQGSTNSAVYENAREKFFRTKELIAEIGSLSLHCTIDEKRLAGYCQACDVLVPSSDSTSQQLTPYSQVHICLRSGNYQEVIQIFIEDNLTLSLPVQFRQSVLRELFKKAQQGNEALDEICFKVCACNTVRDILEGRTISVQFNQLFLRPNKEKIDFLLEVCSRSVNLEKASESLKGNMAAFLKNVCLGLEDLQYVFMISSHELFITLLKDEERKLLVDQMRKRSPRVNLCIKPVTSFYDIPASASVNIGQLEHQLILSVDPWRIRQILIELHGMTSERQFWTVSNKWEVPSVYSGVILGIKDNLTRDLVYILMAKGLHCSTVKDFSHAKQLFAACLELVTEFSPKLRQVMLNEMLLLDIHTHEAGTGQAGERPPSDLISRVRGYLEMRLPDIPLRQVIAEECVAFMLNWRENEYLTLQVPAFLLQSNPYVKLGQLLAATCKELPGPKESRRTAKDLWEVVVQICSVSSQHKRGNDGRVSLIKQRESTLGIMYRSELLSFIKKLREPLVLTIILSLFVKLHNVREDIVNDITAEHISIWPSSIPNLQSVDFEAVAITVKELVRYTLSINPNNHSWLIIQADIYFATNQYSAALHYYLQAGAVCSDFFNKAVPPDVYTDQVAILCQFLREIDYKTAFKSLQEQNSHDAMDSYYDYIWDVTILEYLTYLHHKRGETDKRQIAIKAIGQTELNASNPEEVLQLAAQRRKKKFLQAMAKLYF>sp|Q96MP8|KCTD7_HUMAN BTB/POZ domain-containing protein KCTD7 OS=Homosapiens OX=9606 GN=KCTD7 PE=1 SV=1MVVVTGREPDSRRQDGAMSSSDAEDDFLEPATPTATQAGHALPLLPQEFPEVVPLNIGGAHFTTRLSTLRCYEDTMLAAMFSGRHYIPTDSEGRYFIDRDGTHFGDVLNFLRSGDLPPRERVRAVYKEAQYYAIGPLLEQLENMQPLKGEKVRQAFLGLMPYYKDHLERIVEIARLRAVQRKARFAKLKVCVFKEEMPITPYECPLLNSLRFERSESDGQLFEHHCEVDVSFGPWEAVADVYDLLHCLVTDLSAQGLTVDHQCIGVCDKHLVNHYYCKRPIYEFKITWW>sp|Q96MP8-2|KCTD7_HUMAN Isoform 2 of BTB/POZ domain-containing proteinKCTD7 OS=Homo sapiens OX=9606 GN=KCTD7MVVVTGREPDSRRQDGAMSSSDAEDDFLEPATPTATQAGHALPLLPQEFPEVVPLNIGGAHFTTRLSTLRCYEDTMLAAMFSGRHYIPTDSEGRYFIDRDGTHFGDVLNFLRSGDLPPRERVRAVYKEAQYYAIGPLLEQLENMQPLKGEKVRQAFLGLMPYYKDHLERIVEIARLRAVQRKARFAKLKVCVFKEEMPITPYECPLLNSLRFERSESDGQLFEHHCEVDVSFGPWEAVADVYDLLHCLVTDLSAQGLTVDHQCIGVCDKHLVNHYYCKRPIYEFKITW>sp|Q9BYR5|KRA42_HUMAN Keratin-associated protein 4-2 OS=Homo sapiensOX=9606 GN=KRTAP4-2 PE=1 SV=2MVNSCCGSVCSDQGCGLENCCRPSCCQTTCCRTTCCRPSCCVSSCCRPQCCQSVCCQPTCCSPSCCQTTCCRTTCCRPSCCVSSCFRPQCCQSVYCQPTCCRPSCGQTTCCRTTCYRPSCCVSTCCRPTCSSGSCC>sp|Q9BYR0|KRA47_HUMAN Keratin-associated protein 4-7 OS=Homo sapiensOX=9606 GN=KRTAP4-7 PE=1 SV=2MVSSCCGSVCSDQGCSQDLCQETCCRPSCCQTTCCRTTCYRPSCCVSSCCRPQCCQSVCCQPTCCRPTCCETTCCHPRCCISSCCRPSCCMSSCCKPQCCQSVCCQPTCCHPSCCISSCCRPSCCVSRCCRPQCCQSVCCQPTCCRPSCCISSCCRPSCCESSCCRPSCCRPCCCLRPVCGRVSCHTTCYRPTCVISTCPRPLCCASSCC>sp|P59990|KR121_HUMAN Keratin-associated protein 12-1 OS=Homo sapiensOX=9606 GN=KRTAP12-1 PE=1 SV=1MCHTSCSSGCQPACCAPSPCQASCYIPVGCQSSVCVPVSFKPAVCVPVRCQSSVCVPVSCRPVVYAAPSCQSSGCCQPSCTSVLCRPISCSTPSCC>sp|Q9BYR8|KRA31_HUMAN Keratin-associated protein 3-1 OS=Homo sapiensOX=9606 GN=KRTAP3-1 PE=1 SV=1MYCCALRSCSVPTGPATTFCSFDKSCRCGVCLPSTCPHEISLLQPICCDTCPPPCCKPDTYVPTCWLLNNCHPTPGLSGINLTTYVQPGCESPCEPRC>sp|Q9BYR3|KRA44_HUMAN Keratin-associated protein 4-4 OS=Homo sapiensOX=9606 GN=KRTAP4-4 PE=1 SV=1MVNSCCGSVCSDQGCGLENCCRPSYCQTTCCRTTCCRPSCCVSSCCRPQCCQTTCCRTTCCHPSCCVSSCCRPQCCQSVCCQPTCCRPQCCQTTCCRTTCCRPSCCRPQCCQSVCCQPTCCCPSYCVSSCCRPQCCQTTCCRTTCCRPSCCVSRCYRPHCGQSLCC>sp|Q9BYR7|KRA32_HUMAN Keratin-associated protein 3-2 OS=Homo sapiensOX=9606 GN=KRTAP3-2 PE=1 SV=1MDCCASRSCSVPTGPATTICSSDKSCRCGVCLPSTCPHTVWLLEPICCDNCPPPCHIPQPCVPTCFLLNSCQPTPGLETLNLTTFTQPCCEPCLPRGC>sp|O75690|KRA58_HUMAN Keratin-associated protein 5-8 OS=Homo sapiensOX=9606 GN=KRTAP5-8 PE=1 SV=2MGCCGCSGGCGSGCGGCGSGCGGCGSSCCVPICCCKPVCCCVPACSCSSCGSCGGSKGGRGSCGGSKGDCGSCGGSKGGCGSCGCSQCSCYKPCCCSSGCGSSCCQSSCCKPCCSQSSCCKPCSCSSGCGSSCCQSSCCKPCCSQSSCCKPCCCSSGCGSSCCQSSCCKPCCSQSSCCVPICCQCKI>sp|Q5VTJ3|KLD7A_HUMAN Kelch domain-containing protein 7A OS=Homo sapiensOX=9606 GN=KLHDC7A PE=1 SV=5MFPRGAEAQDWHLDMQLTGKVVLSAAALLLVTVAYRLYKSRPAPAQRWGGNGQAEAKEEAEGSGQPAVQEASPGVLLRGPRRRRSSKRAEAPQGCSCENPRGPYVLVTGATSTDRKPQRKGSGEERGGQGSDSEQVPPCCPSQETRTAVGSNPDPPHFPRLGSEPKSSPAGLIAAADGSCAGGEPSPWQDSKPREHPGLGQLEPPHCHYVAPLQGSSDMNQSWVFTRVIGVSREEAGALEAASDVDLTLHQQEGAPNSSYTFSSIARVRMEEHFIQKAEGVEPRLKGKVYDYYVESTSQAIFQGRLAPRTAALTEVPSPRPPPGSLGTGAASGGQAGDTKGAAERAASPQTGPWPSTRGFSRKESLLQIAENPELQLQPDGFRLPAPPCPDPGALPGLGRSSREPHVQPVAGTNFFHIPLTPASAPQVRLDLGNCYEVLTLAKRQNLEALKEAAYKVMSENYLQVLRSPDIYGCLSGAERELILQRRLRGRQYLVVADVCPKEDSGGLCCYDDEQDVWRPLARMPPEAVSRGCAICSLFNYLFVVSGCQGPGHQPSSRVFCYNPLTGIWSEVCPLNQARPHCRLVALDGHLYAIGGECLNSVERYDPRLDRWDFAPPLPSDTFALAHTATVRAKEIFVTGGSLRFLLFRFSAQEQRWWAGPTGGSKDRTAEMVAVNGFLYRFDLNRSLGIAVYRCSASTRLWYECATYRTPYPDAFQCAVVDNLIYCVGRRSTLCFLADSVSPRFVPKELRSFPAPQGTLLPTVLTLPTPDLPQTRV>sp|Q9P2N7|KLH13_HUMAN Kelch-like protein 13 OS=Homo sapiens OX=9606GN=KLHL13 PE=1 SV=3MPLKWKTSSPAIWKFPVPVLKTSRSTPLSPAYISLVEEEDQHMKLSLGGSEMGLSSHLQSSKAGPTRIFTSNTHSSVVLQGFDQLRLEGLLCDVTLMPGDTDDAFPVHRVMMASASDYFKAMFTGGMKEQDLMCIKLHGVSKVGLRKIIDFIYTAKLSLNMDNLQDTLEAASFLQILPVLDFCKVFLISGVTLDNCVEVGRIANTYNLTEVDKYVNSFVLKNFPALLSTGEFLKLPFERLAFVLSSNSLKHCTELELFKATCRWLRLEEPRMDFAAKLMKNIRFPLMTPQELINYVQTVDFMRTDNTCVNLLLEASNYQMMPYMQPVMQSDRTAIRSDTTHLVTLGGVLRQQLVVSKELRMYDEKAHEWKSLAPMDAPRYQHGIAVIGNFLYVVGGQSNYDTKGKTAVDTVFRFDPRYNKWMQVASLNEKRTFFHLSALKGYLYAVGGRNAAGELPTVECYNPRTNEWTYVAKMSEPHYGHAGTVYGGVMYISGGITHDTFQKELMCFDPDTDKWIQKAPMTTVRGLHCMCTVGERLYVIGGNHFRGTSDYDDVLSCEYYSPILDQWTPIAAMLRGQSDVGVAVFENKIYVVGGYSWNNRCMVEIVQKYDPDKDEWHKVFDLPESLGGIRACTLTVFPPEETTPSPSRESPLSAP>sp|Q9P2N7-2|KLH13_HUMAN Isoform 2 of Kelch-like protein 13 OS=Homosapiens OX=9606 GN=KLHL13MKLSLGGSEMGLSSHLQSSKAGPTRIFTSNTHSSVVLQGFDQLRLEGLLCDVTLMPGDTDDAFPVHRVMMASASDYFKAMFTGGMKEQDLMCIKLHGVSKVGLRKIIDFIYTAKLSLNMDNLQDTLEAASFLQILPVLDFCKVFLISGVTLDNCVEVGRIANTYNLTEVDKYVNSFVLKNFPALLSTGEFLKLPFERLAFVLSSNSLKHCTELELFKATCRWLRLEEPRMDFAAKLMKNIRFPLMTPQELINYVQTVDFMRTDNTCVNLLLEASNYQMMPYMQPVMQSDRTAIRSDTTHLVTLGGVLRQQLVVSKELRMYDEKAHEWKSLAPMDAPRYQHGIAVIGNFLYVVGGQSNYDTKGKTAVDTVFRFDPRYNKWMQVASLNEKRTFFHLSALKGYLYAVGGRNAAGELPTVECYNPRTNEWTYVAKMSEPHYGHAGTVYGGVMYISGGITHDTFQKELMCFDPDTDKWIQKAPMTTVRGLHCMCTVGERLYVIGGNHFRGTSDYDDVLSCEYYSPILDQWTPIAAMLRGQSDVGVAVFENKIYVVGGYSWNNRCMVEIVQKYDPDKDEWHKVFDLPESLGGIRACTLTVFPPEETTPSPSRESPLSAP>sp|Q9P2N7-3|KLH13_HUMAN Isoform 3 of Kelch-like protein 13 OS=Homosapiens OX=9606 GN=KLHL13MDHLHRGELVAAILRNRSLVEEEDQHMKLSLGGSEMGLSSHLQSSKAGPTRIFTSNTHSSVVLQGFDQLRLEGLLCDVTLMPGDTDDAFPVHRVMMASASDYFKAMFTGGMKEQDLMCIKLHGVSKVGLRKIIDFIYTAKLSLNMDNLQDTLEAASFLQILPVLDFCKVFLISGVTLDNCVEVGRIANTYNLTEVDKYVNSFVLKNFPALLSTGEFLKLPFERLAFVLSSNSLKHCTELELFKATCRWLRLEEPRMDFAAKLMKNIRFPLMTPQELINYVQTVDFMRTDNTCVNLLLEASNYQMMPYMQPVMQSDRTAIRSDTTHLVTLGGVLRQQLVVSKELRMYDEKAHEWKSLAPMDAPRYQHGIAVIGNFLYVVGGQSNYDTKGKTAVDTVFRFDPRYNKWMQVASLNEKRTFFHLSALKGYLYAVGGRNAAGELPTVECYNPRTNEWTYVAKMSEPHYGHAGTVYGGVMYISGGITHDTFQKELMCFDPDTDKWIQKAPMTTVRGLHCMCTVGERLYVIGGNHFRGTSDYDDVLSCEYYSPILDQWTPIAAMLRGQSDVGVAVFENKIYVVGGYSWNNRCMVEIVQKYDPDKDEWHKVFDLPESLGGIRACTLTVFPPEETTPSPSRESPLSAP>sp|Q9P2N7-4|KLH13_HUMAN Isoform 4 of Kelch-like protein 13 OS=Homosapiens OX=9606 GN=KLHL13MLRFISHLYCCSSKEDCSEDDKCILSRSLVEEEDQHMKLSLGGSEMGLSSHLQSSKAGPTRIFTSNTHSSVVLQGFDQLRLEGLLCDVTLMPGDTDDAFPVHRVMMASASDYFKAMFTGGMKEQDLMCIKLHGVSKVGLRKIIDFIYTAKLSLNMDNLQDTLEAASFLQILPVLDFCKVFLISGVTLDNCVEVGRIANTYNLTEVDKYVNSFVLKNFPALLSTGEFLKLPFERLAFVLSSNSLKHCTELELFKATCRWLRLEEPRMDFAAKLMKNIRFPLMTPQELINYVQTVDFMRTDNTCVNLLLEASNYQMMPYMQPVMQSDRTAIRSDTTHLVTLGGVLRQQLVVSKELRMYDEKAHEWKSLAPMDAPRYQHGIAVIGNFLYVVGGQSNYDTKGKTAVDTVFRFDPRYNKWMQVASLNEKRTFFHLSALKGYLYAVGGRNAAGELPTVECYNPRTNEWTYVAKMSEPHYGHAGTVYGGVMYISGGITHDTFQKELMCFDPDTDKWIQKAPMTTVRGLHCMCTVGERLYVIGGNHFRGTSDYDDVLSCEYYSPILDQWTPIAAMLRGQSDVGVAVFENKIYVVGGYSWNNRCMVEIVQKYDPDKDEWHKVFDLPESLGGIRACTLTVFPPEETTPSPSRESPLSAP>sp|Q9P2N7-5|KLH13_HUMAN Isoform 5 of Kelch-like protein 13 OS=Homosapiens OX=9606 GN=KLHL13MMRVQTLREKWAYWRRRQLSLKQADFKDIFKKSTSGSLVEEEDQHMKLSLGGSEMGLSSHLQSSKAGPTRIFTSNTHSSVVLQGFDQLRLEGLLCDVTLMPGDTDDAFPVHRVMMASASDYFKAMFTGGMKEQDLMCIKLHGVSKVGLRKIIDFIYTAKLSLNMDNLQDTLEAASFLQILPVLDFCKVFLISGVTLDNCVEVGRIANTYNLTEVDKYVNSFVLKNFPALLSTGEFLKLPFERLAFVLSSNSLKHCTELELFKATCRWLRLEEPRMDFAAKLMKNIRFPLMTPQELINYVQTVDFMRTDNTCVNLLLEASNYQMMPYMQPVMQSDRTAIRSDTTHLVTLGGVLRQQLVVSKELRMYDEKAHEWKSLAPMDAPRYQHGIAVIGNFLYVVGGQSNYDTKGKTAVDTVFRFDPRYNKWMQVASLNEKRTFFHLSALKGYLYAVGGRNAAGELPTVECYNPRTNEWTYVAKMSEPHYGHAGTVYGGVMYISGGITHDTFQKELMCFDPDTDKWIQKAPMTTVRGLHCMCTVGERLYVIGGNHFRGTSDYDDVLSCEYYSPILDQWTPIAAMLRGQSDVGVAVFENKIYVVGGYSWNNRCMVEIVQKYDPDKDEWHKVFDLPESLGGIRACTLTVFPPEETTPSPSRESPLSAP>sp|P30085|KCY_HUMAN UMP-CMP kinase OS=Homo sapiens OX=9606 GN=CMPK1 PE=1SV=3MKPLVVFVLGGPGAGKGTQCARIVEKYGYTHLSAGELLRDERKNPDSQYGELIEKYIKEGKIVPVEITISLLKREMDQTMAANAQKNKFLIDGFPRNQDNLQGWNKTMDGKADVSFVLFFDCNNEICIERCLERGKSSGRSDDNRESLEKRIQTYLQSTKPIIDLYEEMGKVKKIDASKSVDEVFDEVVQIFDKEG>sp|P30085-2|KCY_HUMAN Isoform 2 of UMP-CMP kinase OS=Homo sapiensOX=9606 GN=CMPK1MKPLVVFVLGGPGAGKGTQCARIVEEMDQTMAANAQKNKFLIDGFPRNQDNLQGWNKTMDGKADVSFVLFFDCNNEICIERCLERGKSSGRSDDNRESLEKRIQTYLQSTKPIIDLYEEMGKVKKIDASKSVDEVFDEVVQIFDKEG>sp|P30085-3|KCY_HUMAN Isoform 3 of UMP-CMP kinase OS=Homo sapiensOX=9606 GN=CMPK1MLSRCRSGLLHVLGLSFLLQTRRPILLCSPRLMKPLVVFVLGGPGAGKGTQCARIVEKYGYTHLSAGELLRDERKNPDSQYGELIEKYIKEGKIVPVEITISLLKREMDQTMAANAQKNKFLIDGFPRNQDNLQGWNKTMDGKADVSFVLFFDCNNEICIERCLERGKSSGRSDDNRESLEKRIQTYLQSTKPIIDLYEEMGKVKKIDASKSVDEVFDEVVQIFDKEG>sp|O43474|KLF4_HUMAN Krueppel-like factor 4 OS=Homo sapiens OX=9606GN=KLF4 PE=1 SV=3MRQPPGESDMAVSDALLPSFSTFASGPAGREKTLRQAGAPNNRWREELSHMKRLPPVLPGRPYDLAAATVATDLESGGAGAACGGSNLAPLPRRETEEFNDLLDLDFILSNSLTHPPESVAATVSSSASASSSSSPSSSGPASAPSTCSFTYPIRAGNDPGVAPGGTGGGLLYGRESAPPPTAPFNLADINDVSPSGGFVAELLRPELDPVYIPPQQPQPPGGGLMGKFVLKASLSAPGSEYGSPSVISVSKGSPDGSHPVVVAPYNGGPPRTCPKIKQEAVSSCTHLGAGPPLSNGHRPAAHDFPLGRQLPSRTTPTLGLEEVLSSRDCHPALPLPPGFHPHPGPNYPSFLPDQMQPQVPPLHYQGQSRGFVARAGEPCVCWPHFGTHGMMLTPPSSPLELMPPGSCMPEEPKPKRGRRSWPRKRTATHTCDYAGCGKTYTKSSHLKAHLRTHTGEKPYHCDWDGCGWKFARSDELTRHYRKHTGHRPFQCQKCDRAFSRSDHLALHMKRHF>sp|O43474-1|KLF4_HUMAN Isoform 2 of Krueppel-like factor 4 OS=Homosapiens OX=9606 GN=KLF4MRQPPGESDMAVSDALLPSFSTFASGPAGREKTLRQAGAPNNRWREELSHMKRLPPVLPGRPYDLAAATVATDLESGGAGAACGGSNLAPLPRRETEEFNDLLDLDFILSNSLTHPPESVAATVSSSASASSSSSPSSSGPASAPSTCSFTYPIRAGNDPGVAPGGTGGGLLYGRESAPPPTAPFNLADINDVSPSGGFVAELLRPELDPVYIPPQQPQPPGGGLMGKFVLKASLSAPGSEYGSPSVISVSKGSPDGSHPVVVAPYNGGPPRTCPKIKQEAVSSCTHLGAGPPLSNGHRPAAHDFPLGRQLPSRTTPTLGLEEVLSSRDCHPALPLPPGFHPHPGPNYPSFLPDQMQPQVPPLHYQELMPPGSCMPEEPKPKRGRRSWPRKRTATHTCDYAGCGKTYTKSSHLKAHLRTHTGEKPYHCDWDGCGWKFARSDELTRHYRKHTGHRPFQCQKCDRAFSRSDHLALHMKRHF>sp|O43474-4|KLF4_HUMAN Isoform 3 of Krueppel-like factor 4 OS=Homosapiens OX=9606 GN=KLF4MKRLPPVLPGRPYDLAAATVATDLESGGAGAACGGSNLAPLPRRETEEFNDLLDLDFILSNSLTHPPESVAATVSSSASASSSSSPSSSGPASAPSTCSFTYPIRAGNDPGVAPGGTGGGLLYGRESAPPPTAPFNLADINDVSPSGGFVAELLRPELDPVYIPPQQPQPPGGGLMGKFVLKASLSAPGSEYGSPSVISVSKGSPDGSHPVVVAPYNGGPPRTCPKIKQEAVSSCTHLGAGPPLSNGHRPAAHDFPLGRQLPSRTTPTLGLEEVLSSRDCHPALPLPPGFHPHPGPNYPSFLPDQMQPQVPPLHYQELMPPGSCMPEEPKPKRGRRSWPRKRTATHTCDYAGCGKTYTKSSHLKAHLRTHTGEKPYHCDWDGCGWKFARSDELTRHYRKHTGHRPFQCQKCDRAFSRSDHLALHMKRHF>sp|O43474-5|KLF4_HUMAN Isoform 4 of Krueppel-like factor 4 OS=Homosapiens OX=9606 GN=KLF4MRQPPGESDMAVSDALLPSFSTFASGPAGREKTLRQAGAPNNSSCHPVPACQRSPSQRGEDDRGPGKGPPPTLVITRAAAKPTQRVPISRHTCEPTQVRNLTTVTGTAVDGNSPAQMN>sp|O43474-6|KLF4_HUMAN Isoform 5 of Krueppel-like factor 4 OS=Homosapiens OX=9606 GN=KLF4MRQPPGESDMAVSDALLPSFSTFASGPAGREKTLRQAGAPNNVRNLTTVTGTAVDGNSPAQMN>sp|A6PVL3|KNCN_HUMAN Kinocilin OS=Homo sapiens OX=9606 GN=KNCN PE=2 SV=1MDIPISSRDFRGLQLACVALGLVAGSIIIGISVSKAAAAMGGVFIGAAVLGLLILAYPFLKARFNLDHILPTIGSLRIHPHPGADHGEGRSSTNGNKEGARSSLSTVSRTLEKLKPGTRGAEEC>sp|A6PVL3-2|KNCN_HUMAN Isoform 2 of Kinocilin OS=Homo sapiens OX=9606GN=KNCNMDIPISSRDFRGLQLACVALGLVAGSIIIGISVSKAAAAMGGVFIGAAVLGSLRIHPHPGADHGEGRSSTNGNKEGARSSLSTVSRTLEKLKPGTRGAEEC>sp|Q8NG31|KNL1_HUMAN Kinetochore scaffold 1 OS=Homo sapiens OX=9606GN=KNL1 PE=1 SV=3MDGVSSEANEENDNIERPVRRRHSSILKPPRSPLQDLRGGNERVQESNALRNKKNSRRVSFADTIKVFQTESHMKIVRKSEMEGCSAMVPSQLQLLPPGFKRFSCLSLPETETGENLLLIQNKKLEDNYCEITGMNTLLSAPIHTQMQQKEFSIIEHTRERKHANDQTVIFSDENQMDLTSSHTVMITKGLLDNPISEKSTKIDTTSFLANLKLHTEDSRMKKEVNFSVDQNTSSENKIDFNDFIKRLKTGKCSAFPDVPDKENFEIPIYSKEPNSASSTHQMHVSLKEDENNSNITRLFREKDDGMNFTQCHTANIQTLIPTSSETNSRESKGNDITIYGNDFMDLTFNHTLQILPATGNFSEIENQTQNAMDVTTGYGTKASGNKTVFKSKQNTAFQDLSINSADKIHITRSHIMGAETHIVSQTCNQDARILAMTPESIYSNPSIQGCKTVFYSSCNDAMEMTKCLSNMREEKNLLKHDSNYAKMYCNPDAMSSLTEKTIYSGEENMDITKSHTVAIDNQIFKQDQSNVQIAAAPTPEKEMMLQNLMTTSEDGKMNVNCNSVPHVSKERIQQSLSNPLSISLTDRKTELLSGENMDLTESHTSNLGSQVPLAAYNLAPESTSESHSQSKSSSDECEEITKSRNEPFQRSDIIAKNSLTDTWNKDKDWVLKILPYLDKDSPQSADCNQEIATSHNIVYCGGVLDKQITNRNTVSWEQSLFSTTKPLFSSGQFSMKNHDTAISSHTVKSVLGQNSKLAEPLRKSLSNPTPDYCHDKMIICSEEEQNMDLTKSHTVVIGFGPSELQELGKTNLEHTTGQLTTMNRQIAVKVEKCGKSPIEKSGVLKSNCIMDVLEDESVQKPKFPKEKQNVKIWGRKSVGGPKIDKTIVFSEDDKNDMDITKSYTIEINHRPLLEKRDCHLVPLAGTSETILYTCRQDDMEITRSHTTALECKTVSPDEITTRPMDKTVVFVDNHVELEMTESHTVFIDYQEKERTDRPNFELSQRKSLGTPTVICTPTEESVFFPGNGESDRLVANDSQLTPLEEWSNNRGPVEVADNMELSKSATCKNIKDVQSPGFLNEPLSSKSQRRKSLKLKNDKTIVFSENHKNDMDITQSCMVEIDNESALEDKEDFHLAGASKTILYSCGQDDMEITRSHTTALECKTLLPNEIAIRPMDKTVLFTDNYSDLEVTDSHTVFIDCQATEKILEENPKFGIGKGKNLGVSFPKDNSCVQEIAEKQALAVGNKIVLHTEQKQQLFAATNRTTNEIIKFHSAAMDEKVIGKVVDQACTLEKAQVESCQLNNRDRRNVDFTSSHATAVCGSSDNYSCLPNVISCTDNLEGSAMLLCDKDEEKANYCPVQNDLAYANDFASEYYLESEGQPLSAPCPLLEKEEVIQTSTKGQLDCVITLHKDQDLIKDPRNLLANQTLVYSQDLGEMTKLNSKRVSFKLPKDQMKVYVDDIYVIPQPHFSTDQPPLPKKGQSSINKEEVILSKAGNKSLNIIENSSAPICENKPKILNSEEWFAAACKKELKENIQTTNYNTALDFHSNSDVTKQVIQTHVNAGEAPDPVITSNVPCFHSIKPNLNNLNGKTGEFLAFQTVHLPPLPEQLLELGNKAHNDMHIVQATEIHNINIISSNAKDSRDEENKKSHNGAETTSLPPKTVFKDKVRRCSLGIFLPRLPNKRNCSVTGIDDLEQIPADTTDINHLETQPVSSKDSGIGSVAGKLNLSPSQYINEENLPVYPDEINSSDSINIETEEKALIETYQKEISPYENKMGKTCNSQKRTWVQEEEDIHKEKKIRKNEIKFSDTTQDREIFDHHTEEDIDKSANSVLIKNLSRTPSSCSSSLDSIKADGTSLDFSTYRSSQMESQFLRDTICEESLREKLQDGRITIREFFILLQVHILIQKPRQSNLPGNFTVNTPPTPEDLMLSQYVYRPKIQIYREDCEARRQKIEELKLSASNQDKLLVDINKNLWEKMRHCSDKELKAFGIYLNKIKSCFTKMTKVFTHQGKVALYGKLVQSAQNEREKLQIKIDEMDKILKKIDNCLTEMETETKNLEDEEKNNPVEEWDSEMRAAEKELEQLKTEEEELQRNLLELEVQKEQTLAQIDFMQKQRNRTEELLDQLSLSEWDVVEWSDDQAVFTFVYDTIQLTITFEESVVGFPFLDKRYRKIVDVNFQSLLDEDQAPPSSLLVHKLIFQYVEEKESWKKTCTTQHQLPKMLEEFSLVVHHCRLLGEEIEYLKRWGPNYNLMNIDINNNELRLLFSSSAAFAKFEITLFLSAYYPSVPLPSTIQNHVGNTSQDDIATILSKVPLENNYLKNVVKQIYQDLFQDCHFYH>sp|Q8NG31-2|KNL1_HUMAN Isoform 2 of Kinetochore scaffold 1 OS=Homosapiens OX=9606 GN=KNL1MDGVSSEANEENDNIERPVRRRHSSILKPPRSPLQDLRGGNERVQESNALRNKKNSRRVSFADTIKVFQTESHMKIVRKSEMEETETGENLLLIQNKKLEDNYCEITGMNTLLSAPIHTQMQQKEFSIIEHTRERKHANDQTVIFSDENQMDLTSSHTVMITKGLLDNPISEKSTKIDTTSFLANLKLHTEDSRMKKEVNFSVDQNTSSENKIDFNDFIKRLKTGKCSAFPDVPDKENFEIPIYSKEPNSASSTHQMHVSLKEDENNSNITRLFREKDDGMNFTQCHTANIQTLIPTSSETNSRESKGNDITIYGNDFMDLTFNHTLQILPATGNFSEIENQTQNAMDVTTGYGTKASGNKTVFKSKQNTAFQDLSINSADKIHITRSHIMGAETHIVSQTCNQDARILAMTPESIYSNPSIQGCKTVFYSSCNDAMEMTKCLSNMREEKNLLKHDSNYAKMYCNPDAMSSLTEKTIYSGEENMDITKSHTVAIDNQIFKQDQSNVQIAAAPTPEKEMMLQNLMTTSEDGKMNVNCNSVPHVSKERIQQSLSNPLSISLTDRKTELLSGENMDLTESHTSNLGSQVPLAAYNLAPESTSESHSQSKSSSDECEEITKSRNEPFQRSDIIAKNSLTDTWNKDKDWVLKILPYLDKDSPQSADCNQEIATSHNIVYCGGVLDKQITNRNTVSWEQSLFSTTKPLFSSGQFSMKNHDTAISSHTVKSVLGQNSKLAEPLRKSLSNPTPDYCHDKMIICSEEEQNMDLTKSHTVVIGFGPSELQELGKTNLEHTTGQLTTMNRQIAVKVEKCGKSPIEKSGVLKSNCIMDVLEDESVQKPKFPKEKQNVKIWGRKSVGGPKIDKTIVFSEDDKNDMDITKSYTIEINHRPLLEKRDCHLVPLAGTSETILYTCRQDDMEITRSHTTALECKTVSPDEITTRPMDKTVVFVDNHVELEMTESHTVFIDYQEKERTDRPNFELSQRKSLGTPTVICTPTEESVFFPGNGESDRLVANDSQLTPLEEWSNNRGPVEVADNMELSKSATCKNIKDVQSPGFLNEPLSSKSQRRKSLKLKNDKTIVFSENHKNDMDITQSCMVEIDNESALEDKEDFHLAGASKTILYSCGQDDMEITRSHTTALECKTLLPNEIAIRPMDKTVLFTDNYSDLEVTDSHTVFIDCQATEKILEENPKFGIGKGKNLGVSFPKDNSCVQEIAEKQALAVGNKIVLHTEQKQQLFAATNRTTNEIIKFHSAAMDEKVIGKVVDQACTLEKAQVESCQLNNRDRRNVDFTSSHATAVCGSSDNYSCLPNVISCTDNLEGSAMLLCDKDEEKANYCPVQNDLAYANDFASEYYLESEGQPLSAPCPLLEKEEVIQTSTKGQLDCVITLHKDQDLIKDPRNLLANQTLVYSQDLGEMTKLNSKRVSFKLPKDQMKVYVDDIYVIPQPHFSTDQPPLPKKGQSSINKEEVILSKAGNKSLNIIENSSAPICENKPKILNSEEWFAAACKKELKENIQTTNYNTALDFHSNSDVTKQVIQTHVNAGEAPDPVITSNVPCFHSIKPNLNNLNGKTGEFLAFQTVHLPPLPEQLLELGNKAHNDMHIVQATEIHNINIISSNAKDSRDEENKKSHNGAETTSLPPKTVFKDKVRRCSLGIFLPRLPNKRNCSVTGIDDLEQIPADTTDINHLETQPVSSKDSGIGSVAGKLNLSPSQYINEENLPVYPDEINSSDSINIETEEKALIETYQKEISPYENKMGKTCNSQKRTWVQEEEDIHKEKKIRKNEIKFSDTTQDREIFDHHTEEDIDKSANSVLIKNLSRTPSSCSSSLDSIKADGTSLDFSTYRSSQMESQFLRDTICEESLREKLQDGRITIREFFILLQVHILIQKPRQSNLPGNFTVNTPPTPEDLMLSQYVYRPKIQIYREDCEARRQKIEELKLSASNQDKLLVDINKNLWEKMRHCSDKELKAFGIYLNKIKSCFTKMTKVFTHQGKVALYGKLVQSAQNEREKLQIKIDEMDKILKKIDNCLTEMETETKNLEDEEKNNPVEEWDSEMRAAEKELEQLKTEEEELQRNLLELEVQKEQTLAQIDFMQKQRNRTEELLDQLSLSEWDVVEWSDDQAVFTFVYDTIQLTITFEESVVGFPFLDKRYRKIVDVNFQSLLDEDQAPPSSLLVHKLIFQYVEEKESWKKTCTTQHQLPKMLEEFSLVVHHCRLLGEEIEYLKRWGPNYNLMNIDINNNELRLLFSSSAAFAKFEITLFLSAYYPSVPLPSTIQNHVGNTSQDDIATILSKVPLENNYLKNVVKQIYQDLFQDCHFYH>sp|Q8NG31-3|KNL1_HUMAN Isoform 3 of Kinetochore scaffold 1 OS=Homosapiens OX=9606 GN=KNL1MDGVSSEANEENDNIERPVRRRHSSILKPPRSPLQDLRGGNERVQESNALRNKKNSRRVSFADTIKVFQTESHMKIVRKSEMEETETGENLLLIQNKKLEDNYCEITGMNTLLSAPIHTQMQQKEFSIIEHTRERKHANDQTVIFSDENQMDLTSSHTVMITKGLLDNPISEKSTKIDTTSFLANLKLHTEDSRMKKEVNFSVDQNTSSENKIDFNDFIKRLKTGKCSAFPDVPDKENFEIPIYSKEPNSASSTHQMHVSLKEDENNSNITRLFREKDDGMNFTQCHTANIQTLIPTSSETNSRESKGNDITIYGNDFMDLTFNHTLQILPATGNFSEIENQTQNAMDVTTGYGTKASGNKTVFKSKQNTAFQDLSINSADKIHITRSHIMGAETHIVSQTCNQDARILAMTPESIYSNPSIQGCKTVFYSSCNDAMEMTKCLSNMREEKNLLKHDSNYAKMYCNPDAMSSLTEKTIYSGEENMDITKSHTVAIDNQIFKQDQSNVQIAAAPTPEKEMMLQNLMTTSEDGKMNVNCNSVPHVSKERIQQSLSNPLSISLTDRKTELLSGENMDLTESHTSNLGSQVPLAAYNLAPESTSESHSQSKSSSDECEEITKSRNEPFQRSDIIAKNSLTDTWNKDKDWVLKILPYLDKDSPQSADCNQEIATSHNIVYCGGVLDKQITNRNTVSWEQSLFSTTKPLFSSGQFSMKNHDTAISSHTVKSVLGQNSKLAEPLRKSLSNPTPDYCHDKMIICSEEEQNMDLTKSHTVVIGFGPSELQELGKTNLEHTTGQLTTMNRQIAVKVEKCGKSPIEKSGVLKSNCIMDVLEDESVQKPKFPKEKQNVKIWGRKSVGGPKIDKTIVFSEDDKNDMDITKSYTIEINHRPLLEKRDCHLVPLAGTSETILYTCRQDDMEITRSHTTALECKTVSPDEITTRPMDKTVVFVDNHVELEMTESHTVFIDYQEKERTDRPNFELSQRKSLGTPTVICTPTEESVFFPGNGESDRLVANDSQLTPLEEWSNNRGPVEVADNMELSKSATCKNIKDVQSPGFLNEPLSSKSQRRKSLKLKNDKTIVFSENHKNDMDITQSCMVEIDNESALEDKEDFHLAGASKTILYSCGQDDMEITRSHTTALECKTLLPNEIAIRPMDKTVLFTDNYSDLEVTDSHTVFIDCQATEKILEENPKFGIGKGKNLGVSFPKDNSCVQEIAEKQALAVGNKIVLHTEQKQQLFAATNRTTNEIIKFHSAAMDEKVIGKVVDQACTLEKAQVESCQLNNRDRRNVDFTSSHATAVCGSSDNYSCLPNVISCTDNLEGSAMLLCDKDEEKANYCPVQNDLAYANDFASEYYLESEGQPLSAPCPLLEKEEVIQTSTKGQLDCVITLHKDQDLIKDPRNLLANQTLVYSQDLGEMTKLNSKRVSFKLPKDQMKVYVDDIYVIPQPHFSTDQPPLPKKGQSSINKEEVILSKAGNKSLNIIENSSAPICENKPKILNSEEWFAAACKKELKENIQTTNYNTALDFHSNSDVTKQVIQTHVNAGEAPDPVITSNVPCFHSIKPNLNNLNGKTGEFLAFQTVHLPPLPEQLLELGNKAHNDMHIVQATEIHNINIISSNAKDSRDEENKKSHNGAETTSLPPKTVFKDKVRRCSLGIFLPRLPNKRNCSVTGIDDLEQIPADTTDINHLETQPVSSKDSGIGSVAGKLNLSPSQYINEENLPVYPDEINSSDSINIETEEKAVGTRRRRYS>sp|Q8NG31-4|KNL1_HUMAN Isoform 4 of Kinetochore scaffold 1 OS=Homosapiens OX=9606 GN=KNL1MDGVSSEANEENDNIERPVRRRHSSILKPPRSPLQDLRGGNERVQESNALRNKKNSRRVSFADTIKVFQTESHMKIVRKSEMEETETGENLLLIQNKKLEDNYCEITGMNTLLSAPIHTQMQQKEFSIIEHTRERKHANDQTVIFSDENQMDLTSSHTVMITKGLLDNPISEKSTKIDTTSFLANLKLHTEDSRMKKEVNFSVDQNTSSENKIDFNDFIKRLKTGKCSAFPDVPDKENFEIPIYSKEPNSASSTHQMHVSLKEDENNSNITRLFREKDDGMNFTQCHTANIQTLIPTSSETNSRESKGNDITIYGNDFMDLTFNHTLQILPATGNFSEIENQTQNAMDVTTGYGTKASGNKTVFKSKQNTAFQDLSINSADKIHITRSHIMGAETHIVSQTCNQDARILAMTPESIYSNPSIQGCKTVFYSSCNDAMEMTKCLSNMREEKNLLKHDSNYAKMYCNPDAMSSLTEKTIYSGEENMDITKSHTVAIDNQIFKQDQSNVQIAAAPTPEKEMMLQNLMTTSEDGKMNVNCNSVPHVSKERIQQSLSNPLSISLTDRKTELLSGENMDLTESHTSNLGSQVPLAAYNLAPESTSESHSQSKSSSDECEEITKSRNEPFQRSDIIAKNSLTDTWNKDKDWVLKILPYLDKDSPQSADCNQEIATSHNIVYCGGVLDKQITNRNTVSWEQSLFSTTKPLFSSGQFSMKNHDTAISSHTVKSVLGQNSKLAEPLRKSLSNPTPDYCHDKMIICSEEEQNMDLTKSHTVVIGFGPSELQELGKTNLEHTTGQLTTMNRQIAVKVEKCGKSPIEKSGVLKSNCIMDVLEDESVQKPKFPKEKQNVKIWGRKSVGGPKIDKTIVFSEDDKNDMDITKSYTIEINHRPLLEKRDCHLVPLAGTSETILYTCRQDDMEITRSHTTALECKTVSPDEITTRPMDKTVVFVDNHVELEMTESHTVFIDYQEKERTDRPNFELSQRKSLGTPTVICTPTEESVFFPGNGESDRLVANDSQLTPLEEWSNNRGPVEVADNMELSKSATCKNIKDVQSPGFLNEPLSSKSQRRKSLKLKNDKTIVFSENHKNDMDITQSCMVEIDNESALEDKEDFHLAGASKTILYSCGQDDMEITRSHTTALECKTLLPNEIAIRPMDKTVLFTDNYSDLEVTDSHTVFIDCQATEKILEENPKFGIGKGKNLGVSFPKDNSCVQEIAEKQALAVGNKIVLHTEQKQQLFAATNRTTNEIIKFHSAAMDEKVIGKVVDQACTLEKAQVESCQLNNRDRRNVDFTSSHATAVCGSSDNYSCLPNVISCTDNLEGSAMLLCDKDEEKANYCPVQNDLAYANDFASEYYLESEGQPLSAPCPLLEKEEVIQTSTKGQLDCVITLHKDQDLIKDPRNLLANQTLVYSQDLGEMTKLNSKRVSFKLPKDQMKVYVDDIYVIPQPHFSTDQPPLPKKGQSSINKEEVILSKAGNKSLNIIENSSAPICENKPKILNSEEWFAAACKKELKENIQTTNYNTALDFHSNSDVTKQVIQTHVNAGEAPDPVITSNVPCFHSIKPNLNNLNGKTGEFLAFQTVHLPPLPEQLLELGNKAHNDMHIVQATEIHNINIISSNAKDSRDEENKKSHNGAETTSLPPKTVFKDKVRRCSLGIFLPRLPNKRNCSVTGIDDLEQIPADTTDINHLETQPVSSKDSGIGSVAGKLNLSPSQYINEENLPVYPDEINSSDSINIETEEKALIETYQKEISPYENKMGKTCNSQKRTWVQEEEDIHKEKKIRKNEIKFSDTTQDREVSSVLNQRMFLNFGFCFVFLNCGYSQILILVSGRQKIIIST>sp|A6NCF5|KLH33_HUMAN Kelch-like protein 33 OS=Homo sapiens OX=9606GN=KLHL33 PE=4 SV=2MLLSGMRESQGTEVSLRTISTQDLRLLVSFAYSGVVRARWPGLLRAAQAALQYQSSSCLDLCQKGLARGLSPARCLALFPMAEAPGLERLWSKARHYLLTHLPAVALCPAFPSLPAACLAELLDSDELHVQEEFEAFVAARCWLAANPETQESEAKALLRCVRFGRMSTRELRRVRAAGLLPPLTPDLLHQLMVEADVPGQERRREPDRALVVIGGDGLRPDMALRQPSRAVWWARAFRCGVGLVRTVEWGQLPALPAPGRFRHGAASLAGSELYVCGGQDFYSHSNTLASTLRWEPSQEDWEEMAPLSQARSLFSLVALDGKLYALGGRHNDVALDSVETYNPELNVWRPAPALPAPCFAHAAAILEGQLYVSGGCGGTGQYLASLMHYDPKLEKPGTFLSPMGVPRAGHVMAALGGRLYVAGGLGETEDLLSFEAYELRTDSWTHLAPLPSPHVGAASAVLQGELLVLGGYSHRTYALSHLIHAYCPGLGRWLCLGTLPRPRAEMPACILTLPAVQHIALVPTPHQTKPAG>sp|A8MV57|MPTX_HUMAN Putative mucosal pentraxin homolog OS=Homo sapiensOX=9606 GN=MPTX1 PE=5 SV=2MGMYLLHIGNAAVTFNGPTPCPRSPYASTHVNVSWESASGIATLWANGKLVGRKGVWKGYSVGEEAKIILGQEQDSFGGHFDENQSFVGVIWDVFLWDHVLPPKEMCDSCYSGSLLNRHTLTYEDNGYVVTKPKVWA>sp|Q9P2K6|KLH42_HUMAN Kelch-like protein 42 OS=Homo sapiens OX=9606GN=KLHL42 PE=1 SV=2MSAEEMVQIRLEDRCYPVSKRKLIEQSDYFRALYRSGMREALSQEAGGPEVQQLRGLSAPGLRLVLDFINAGGAREGWLLGPRGEKGGGVDEDEEMDEVSLLSELVEAASFLQVTSLLQLLLSQVRLNNCLEMYRLAQVYGLPDLQEACLRFMVVHFHEVLCKPQFHLLGSPPQAPGDVSLKQRLREARMTGTPVLVALGDFLGGPLAPHPYQGEPPSMLRYEEMTERWFPLANNLPPDLVNVRGYGSAILDNYLFIVGGYRITSQEISAAHSYNPSTNEWLQVASMNQKRSNFKLVAVNSKLYAIGGQAVSNVECYNPEQDAWNFVAPLPNPLAEFSACECKGKIYVIGGYTTRDRNMNILQYCPSSDMWTLFETCDVHIRKQQMVSVEETIYIVGGCLHELGPNRRSSQSEDMLTVQSYNTVTRQWLYLKENTSKSGLNLTCALHNDGIYIMSRDVTLSTSLEHRVFLKYNIFSDSWEAFRRFPAFGHNLLVSSLYLPNKAET>sp|P11801|KPSH1_HUMAN Serine/threonine-protein kinase H1 OS=Homo sapiensOX=9606 GN=PSKH1 PE=1 SV=4MGCGTSKVLPEPPKDVQLDLVKKVEPFSGTKSDVYKHFITEVDSVGPVKAGFPAASQYAHPCPGPPTAGHTEPPSEPPRRARVAKYRAKFDPRVTAKYDIKALIGRGSFSRVVRVEHRATRQPYAIKMIETKYREGREVCESELRVLRRVRHANIIQLVEVFETQERVYMVMELATGGELFDRIIAKGSFTERDATRVLQMVLDGVRYLHALGITHRDLKPENLLYYHPGTDSKIIITDFGLASARKKGDDCLMKTTCGTPEYIAPEVLVRKPYTNSVDMWALGVIAYILLSGTMPFEDDNRTRLYRQILRGKYSYSGEPWPSVSNLAKDFIDRLLTVDPGARMTALQALRHPWVVSMAASSSMKNLHRSISQNLLKRASSRCQSTKSAQSTRSSRSTRSNKSRRVRERELRELNLRYQQQYNG>sp|Q53HC5|KLH26_HUMAN Kelch-like protein 26 OS=Homo sapiens OX=9606GN=KLHL26 PE=1 SV=2MAESGGSSGGAGGGGAFGAGPGPERPNSTADKNGALKCTFSAPSHSTSLLQGLATLRAQGQLLDVVLTINREAFPAHKVVLAACSDYFRAMFTGGMREASQDVIELKGVSARGLRHIIDFAYSAEVTLDLDCVQDVLGAAVFLQMLPVVELCEEFLKAAMSVETCLNIGQMATTFSLASLRESVDAFTFRHFLQIAEEEDFLRLPLERLVFFLQSNRLQSCAEIDLFRAAVRWLQHDPARRPRASHVLCHIRFPLMQSSELVDSVQTLDIMVEDVLCRQYLLEAFNYQVLPFRQHEMQSPRTAVRSDVPSLVTFGGTPYTDSDRSVSSKVYQLPEPGARHFRELTEMEVGCSHTCVAVLDNFVYVAGGQHLQYRSGEGAVDACYRYDPHLNRWLRLQAMQESRIQFQLNVLCGMVYATGGRNRAGSLASVERYCPRRNEWGYACSLKRRTWGHAGAASGGRLYISGGYGISVEDKKALHCYDPVADQWEFKAPMSEPRVLHAMVGAGGRIYALGGRMDHVDRCFDVLAVEYYVPETDQWTSVSPMRAGQSEAGCCLLERKIYIVGGYNWRLNNVTGIVQVYNTDTDEWERDLHFPESFAGIACAPVLLPRAGTRR>sp|Q2TBA0|KLH40_HUMAN Kelch-like protein 40 OS=Homo sapiens OX=9606GN=KLHL40 PE=1 SV=2MALGLEQAEEQRLYQQTLLQDGLKDMLDHGKFLDCVVRAGEREFPCHRLVLAACSPYFRARFLAEPERAGELHLEEVSPDVVAQVLHYLYTSEIALDEASVQDLFAAAHRFQIPSIFTICVSFLQKRLCLSNCLAVFRLGLLLDCARLAVAARDFICAHFTLVARDADFLGLSADELIAIISSDGLNVEKEEAVFEAVMRWAGSGDAEAQAERQRALPTVFESVRCRLLPRAFLESRVERHPLVRAQPELLRKVQMVKDAHEGRITTLRKKKKGKDGAGAKEADKGTSKAKAEEDEEAERILPGILNDTLRFGMFLQDLIFMISEEGAVAYDPAANECYCASLSNQVPKNHVSLVTKENQVFVAGGLFYNEDNKEDPMSAYFLQFDHLDSEWLGMPPLPSPRCLFGLGEALNSIYVVGGREIKDGERCLDSVMCYDRLSFKWGESDPLPYVVYGHTVLSHMDLVYVIGGKGSDRKCLNKMCVYDPKKFEWKELAPMQTARSLFGATVHDGRIIVAAGVTDTGLTSSAEVYSITDNKWAPFEAFPQERSSLSLVSLVGTLYAIGGFATLETESGELVPTELNDIWRYNEEEKKWEGVLREIAYAAGATFLPVRLNVLCLTKM>sp|Q2TBA0-2|KLH40_HUMAN Isoform 2 of Kelch-like protein 40 OS=Homosapiens OX=9606 GN=KLHL40MALGLEQAEEQRLYQQTLLQDGLKDMLDHGKFLDCVVRAGEREFPCHRLVLAACSPYFRARFLAEPERAGELHLEEVSPDVVAQVLHYLYTSEIALDEASVQDLFAAAHRFQIPSIFTICVSFLQKRLCLSNCLAVFRLGLLLDCARLAVAARDFICAHFTLVARDADFLGLSADELIAIISSDGLNVEKEEAVFEAVMRWAGSGDAEAQAERQRALPTVFESVRCRLLPRAFLESRVERHPLVRAQPELLRKVQMVKDAHEGRITTLRKKKKGKDGAGAKEADKGTSKAKAEEDEEAERILPGILNDTLRFGMFLQDLIFMISEEGAVAYDPAANECYCASLSNQVPKNHVSLVTKENQVFVAGGLFYNEDNKEDPMSAYFLQFDHLDSEWLGMPPLPSPRCLFGLGEALNSIYVVGGREIKDGERCLDSVMCYDRLSFKWGHRHRADQFCRSVQHHRQQVGTLRGLPTGA>sp|Q9P2J3|KLHL9_HUMAN Kelch-like protein 9 OS=Homo sapiens OX=9606GN=KLHL9 PE=1 SV=2MKVSLGNGEMGVSAHLQPCKAGTTRFFTSNTHSSVVLQGFDQLRIEGLLCDVTLVPGDGDEIFPVHRAMMASASDYFKAMFTGGMKEQDLMCIKLHGVNKVGLKKIIDFIYTAKLSLNMDNLQDTLEAASFLQILPVLDFCKVFLISGVSLDNCVEVGRIANTYNLIEVDKYVNNFILKNFPALLSTGEFLKLPFERLAFVLSSNSLKHCTELELFKAACRWLRLEDPRMDYAAKLMKNIRFPLMTPQDLINYVQTVDFMRTDNTCVNLLLEASNYQMMPYMQPVMQSDRTAIRSDSTHLVTLGGVLRQQLVVSKELRMYDERAQEWRSLAPMDAPRYQHGIAVIGNFLYVVGGQSNYDTKGKTAVDTVFRFDPRYNKWMQVASLNEKRTFFHLSALKGHLYAVGGRSAAGELATVECYNPRMNEWSYVAKMSEPHYGHAGTVYGGLMYISGGITHDTFQNELMCFDPDTDKWMQKAPMTTVRGLHCMCTVGDKLYVIGGNHFRGTSDYDDVLSCEYYSPTLDQWTPIAAMLRGQSDVGVAVFENKIYVVGGYSWNNRCMVEIVQKYDPEKDEWHKVFDLPESLGGIRACTLTVFPPEENPGSPSRESPLSAPSDHS>sp|Q09470|KCNA1_HUMAN Potassium voltage-gated channel subfamily A member1 OS=Homo sapiens OX=9606 GN=KCNA1 PE=1 SV=2MTVMSGENVDEASAAPGHPQDGSYPRQADHDDHECCERVVINISGLRFETQLKTLAQFPNTLLGNPKKRMRYFDPLRNEYFFDRNRPSFDAILYYYQSGGRLRRPVNVPLDMFSEEIKFYELGEEAMEKFREDEGFIKEEERPLPEKEYQRQVWLLFEYPESSGPARVIAIVSVMVILISIVIFCLETLPELKDDKDFTGTVHRIDNTTVIYNSNIFTDPFFIVETLCIIWFSFELVVRFFACPSKTDFFKNIMNFIDIVAIIPYFITLGTEIAEQEGNQKGEQATSLAILRVIRLVRVFRIFKLSRHSKGLQILGQTLKASMRELGLLIFFLFIGVILFSSAVYFAEAEEAESHFSSIPDAFWWAVVSMTTVGYGDMYPVTIGGKIVGSLCAIAGVLTIALPVPVIVSNFNYFYHRETEGEEQAQLLHVSSPNLASDSDLSRRSSSTMSKSEYMEIEEDMNNSIAHYRQVNIRTANCTTANQNCVNKSKLLTDV>sp|Q9ULD8|KCNH3_HUMAN Potassium voltage-gated channel subfamily H member3 OS=Homo sapiens OX=9606 GN=KCNH3 PE=1 SV=2MPAMRGLLAPQNTFLDTIATRFDGTHSNFVLGNAQVAGLFPVVYCSDGFCDLTGFSRAEVMQRGCACSFLYGPDTSELVRQQIRKALDEHKEFKAELILYRKSGLPFWCLLDVIPIKNEKGEVALFLVSHKDISETKNRGGPDRWKETGGGRRRYGRARSKGFNANRRRSRAVLYHLSGHLQKQPKGKHKLNKGVFGEKPNLPEYKVAAIRKSPFILLHCGALRATWDGFILLATLYVAVTVPYSVCVSTAREPSAARGPPSVCDLAVEVLFILDIVLNFRTTFVSKSGQVVFAPKSICLHYVTTWFLLDVIAALPFDLLHAFKVNVYFGAHLLKTVRLLRLLRLLPRLDRYSQYSAVVLTLLMAVFALLAHWVACVWFYIGQREIESSESELPEIGWLQELARRLETPYYLVGRRPAGGNSSGQSDNCSSSSEANGTGLELLGGPSLRSAYITSLYFALSSLTSVGFGNVSANTDTEKIFSICTMLIGALMHAVVFGNVTAIIQRMYARRFLYHSRTRDLRDYIRIHRIPKPLKQRMLEYFQATWAVNNGIDTTELLQSLPDELRADIAMHLHKEVLQLPLFEAASRGCLRALSLALRPAFCTPGEYLIHQGDALQALYFVCSGSMEVLKGGTVLAILGKGDLIGCELPRREQVVKANADVKGLTYCVLQCLQLAGLHDSLALYPEFAPRFSRGLRGELSYNLGAGGGSAEVDTSSLSGDNTLMSTLEEKETDGEQGPTVSPAPADEPSSPLLSPGCTSSSSAAKLLSPRRTAPRPRLGGRGRPGRAGALKAEAGPSAPPRALEGLRLPPMPWNVPPDLSPRVVDGIEDGCGSDQPKFSFRVGQSGPECSSSPSPGPESGLLTVPHGPSEARNTDTLDKLRQAVTELSEQVLQMREGLQSLRQAVQLVLAPHREGPCPRASGEGPCPASTSGLLQPLCVDTGASSYCLQPPAGSVLSGTWPHPRPGPPPLMAPWPWGPPASQSSPWPRATAFWTSTSDSEPPASGDLCSEPSTPASPPPSEEGARTGPAEPVSQAEATSTGEPPPGSGGLALPWDPHSLEMVLIGCHGSGTVQWTQEEGTGV>sp|Q9H7Z6|KAT8_HUMAN Histone acetyltransferase KAT8 OS=Homo sapiensOX=9606 GN=KAT8 PE=1 SV=2MAAQGAAAAVAAGTSGVAGEGEPGPGENAAAEGTAPSPGRVSPPTPARGEPEVTVEIGETYLCRRPDSTWHSAEVIQSRVNDQEGREEFYVHYVGFNRRLDEWVDKNRLALTKTVKDAVQKNSEKYLSELAEQPERKITRNQKRKHDEINHVQKTYAEMDPTTAALEKEHEAITKVKYVDKIHIGNYEIDAWYFSPFPEDYGKQPKLWLCEYCLKYMKYEKSYRFHLGQCQWRQPPGKEIYRKSNISVYEVDGKDHKIYCQNLCLLAKLFLDHKTLYFDVEPFVFYILTEVDRQGAHIVGYFSKEKESPDGNNVACILTLPPYQRRGYGKFLIAFSYELSKLESTVGSPEKPLSDLGKLSYRSYWSWVLLEILRDFRGTLSIKDLSQMTSITQNDIISTLQSLNMVKYWKGQHVICVTPKLVEEHLKSAQYKKPPITVDSVCLKWAPPKHKQVKLSKK>sp|Q9H7Z6-2|KAT8_HUMAN Isoform 2 of Histone acetyltransferase KAT8OS=Homo sapiens OX=9606 GN=KAT8MAAQGAAAAVAAGTSGVAGEGEPGPGENAAAEGTAPSPGRVSPPTPARGEPEVTVEIGETYLCRRPDSTWHSAEVIQSRVNDQEGREEFYVHYVGFNRRLDEWVDKNRLALTKTVKDAVQKNSEKYLSELAEQPERKITRNQKRKHDEINHVQKTYAEMDPTTAALEKEHEAITKVKYVDKIHIGNYEIDAWYFSPFPEDYGKQPKLWLCEYCLKYMKYEKSYRFHLGQCQWRQPPGKEIYRKSNISVYEVDGKDHKIYCQNLCLLAKLFLDHKTLYFDVEPFVFYILTEVDRQGAHIVGYFSKEKESPDGNNVACILTLPPYQRRGYGKFLIAFSYELSKLESTVGSPEKPLSDLGKLSYRSYWSWVLLEILRDFRGTLSIKDLSQMTSITQNDIISTLQSLNMVKYWKGQHVICVTPKLVEEHLKSAQYKKPPITGGWGAAVCRGRWGSVSIWTGRSQGLLIAVT>sp|Q9Y2U2|KCNK7_HUMAN Potassium channel subfamily K member 7 OS=Homosapiens OX=9606 GN=KCNK7 PE=1 SV=1MGGLRPWSRYGLLVVAHLLALGLGAVVFQALEGPPACRLQAELRAELAAFQAEHRACLPPGALEELLGTALATQAHGVSTLGNSSEGRTWDLPSALLFAASILTTTGYGHMAPLSPGGKAFCMVYAALGLPASLALVATLRHCLLPVLSRPRAWVAVHWQLSPARAALLQAVALGLLVASSFVLLPALVLWGLQGDCSLLGAVYFCFSSLSTIGLEDLLPGRGRSLHPVIYHLGQLALLGYLLLGLLAMLLAVETFSELPQVRAMGKFFRPSGPVTAEDQGGILGQDELALSTLPPAAPASGQAPAC>sp|Q9Y2U2-2|KCNK7_HUMAN Isoform B of Potassium channel subfamily Kmember 7 OS=Homo sapiens OX=9606 GN=KCNK7MGGLRPWSRYGLLVVAHLLALGLGAVVFQALEGPPACRLQAELRAELAAFQAEHRACLPPGALEELLGTALATQAHGVSTLGNSSEGRTWDLPSALLFAASILTTTGYGHMAPLSPGGKAFCMVYAALGLPASLALVATLRHCLLPVLSRPRAWVAVHWQLSPARAALLQAVALGLLVASSFVLLPALVLWGLQGDCSLLGAVYFCFSSLSTIGLEDLLPGRGRSLHPVIYHLGQLALLGGGTSLQGTAWEG>sp|Q9Y2U2-3|KCNK7_HUMAN Isoform C of Potassium channel subfamily Kmember 7 OS=Homo sapiens OX=9606 GN=KCNK7MGGLRPWSRYGLLVVAHLLALGLGAVVFQALEGPPACRLQAELRAELAAFQAEHRACLPPGALEELLGTALATQAHGVSTLGNSSEGRTWDLPSALLFAASILTTTGYGHMAPLSPGGKAFCMVYAALGLPASLALVATLRHCLLPVLSRPRAWVAVHWQLSPARAALLQAVALGLLVASSFVLLPALVLWGLQGDCSLLGAVYFCFSSLSTIGLEDLLPGRGRSLHPVIYHLGQLALLGKSSHLTACGGRGKRSLD>sp|Q13241|KLRD1_HUMAN Natural killer cells antigen CD94 OS=Homo sapiensOX=9606 GN=KLRD1 PE=1 SV=2MAVFKTTLWRLISGTLGIICLSLMSTLGILLKNSFTKLSIEPAFTPGPNIELQKDSDCCSCQEKWVGYRCNCYFISSEQKTWNESRHLCASQKSSLLQLQNTDELDFMSSSQQFYWIGLSYSEEHTAWLWENGSALSQYLFPSFETFNTKNCIAYNPNGNALDESCEDKNRYICKQQLI>sp|Q13241-2|KLRD1_HUMAN Isoform 2 of Natural killer cells antigen CD94OS=Homo sapiens OX=9606 GN=KLRD1MAVFKTTLWRLISGTLGIICLSLMSTLGILLKNSFTKLSIEPAFTPGPNIELQKDSDCCSCQEKWVGYRCNCYFISSEQKTWNESRHLCASQKSSLLQLQNTDELQDFMSSSQQFYWIGLSYSEEHTAWLWENGSALSQYLFPSFETFNTKNCIAYNPNGNALDESCEDKNRYICKQQLI>sp|Q13241-3|KLRD1_HUMAN Isoform 3 of Natural killer cells antigen CD94OS=Homo sapiens OX=9606 GN=KLRD1MAAFTKLSIEPAFTPGPNIELQKDSDCCSCQEKWVGYRCNCYFISSEQKTWNESRHLCASQKSSLLQLQNTDELDFMSSSQQFYWIGLSYSEEHTAWLWENGSALSQYLFPSFETFNTKNCIAYNPNGNALDESCEDKNRYICKQQLI>sp|Q9NQT8|KI13B_HUMAN Kinesin-like protein KIF13B OS=Homo sapiensOX=9606 GN=KIF13B PE=1 SV=2MGDSKVKVAVRIRPMNRRETDLHTKCVVDVDANKVILNPVNTNLSKGDARGQPKVFAYDHCFWSMDESVKEKYAGQDIVFKCLGENILQNAFDGYNACIFAYGQTGSGKSYTMMGTADQPGLIPRLCSGLFERTQKEENEEQSFKVEVSYMEIYNEKVRDLLDPKGSRQTLKVREHSVLGPYVDGLSKLAVTSYKDIESLMSEGNKSRTVAATNMNEESSRSHAVFKITLTHTLYDVKSGTSGEKVGKLSLVDLAGSERATKTGAAGDRLKEGSNINKSLTTLGLVISALADQSAGKNKNKFVPYRDSVLTWLLKDSLGGNSKTAMVATVSPAADNYDETLSTLRYADRAKHIVNHAVVNEDPNARIIRDLREEVEKLREQLTKAEAMKSPELKDRLEESEKLIQEMTVTWEEKLRKTEEIAQERQKQLESLGISLQSSGIKVGDDKCFLVNLNADPALNELLVYYLKEHTLIGSANSQDIQLCGMGILPEHCIIDITSEGQVMLTPQKNTRTFVNGSSVSSPIQLHHGDRILWGNNHFFRLNLPKKKKKAEREDEDQDPSMKNENSSEQLDVDGDSSSEVSSEVNFNYEYAQMEVTMKALGSNDPMQSILNSLEQQHEEEKRSALERQRLMYEHELEQLRRRLSPEKQNCRSMDRFSFHSPSAQQRLRQWAEEREATLNNSLMRLREQIVKANLLVREANYIAEELDKRTEYKVTLQIPASSLDANRKRGSLLSEPAIQVRRKGKGKQIWSLEKLDNRLLDMRDLYQEWKECEEDNPVIRSYFKRADPFYDEQENHSLIGVANVFLESLFYDVKLQYAVPIINQKGEVAGRLHVEVMRLSGDVGERIAGGDEVAEVSFEKETQENKLVCMVKILQATGLPQHLSHFVFCKYSFWDQQEPVIVAPEVDTSSSSVSKEPHCMVVFDHCNEFSVNITEDFIEHLSEGALAIEVYGHKINDPRKNPALWDLGIIQAKTRSLRDRWSEVTRKLEFWVQILEQNENGEYCPVEVISAKDVPTGGIFQLRQGQSRRVQVEVKSVQESGTLPLMEECILSVGIGCVKVRPLRAPRTHETFHEEEEDMDSYQDRDLERLRRKWLNALTKRQEYLDQQLQKLVSKRDKTEDDADREAQLLEMRLTLTEERNAVMVPSAGSGIPGAPAEWTPVPGMETHIPVIFLDLNADDFSSQDNLDDPEAGGWDATLTGEEEEEFFELQIVKQHDGEVKAEASWDSAVHGCPQLSRGTPVDERLFLIVRVTVQLSHPADMQLVLRKRICVNVHGRQGFAQSLLKKMSHRSSIPGCGVTFEIVSNIPEDAQGVEEREALARMAANVENPASADSEAYIEKYLRSVLAVENLLTLDRLRQEVAVKEQLTGKGKLSRRSISSPNVNRLSGSRQDLIPSYSLGSNKGRWESQQDVSQTTVSRGIAPAPALSVSPQNNHSPDPGLSNLAASYLNPVKSFVPQMPKLLKSLFPVRDEKRGKRPSPLAHQPVPRIMVQSASPDIRVTRMEEAQPEMGPDVLVQTMGAPALKICDKPAKVPSPPPVIAVTAVTPAPEAQDGPPSPLSEASSGYFSHSVSTATLSDALGPGLDAAAPPGSMPTAPEAEPEAPISHPPPPTAVPAEEPPGPQQLVSPGRERPDLEAPAPGSPFRVRRVRASELRSFSRMLAGDPGCSPGAEGNAPAPGAGGQALASDSEEADEVPEWLREGEFVTVGAHKTGVVRYVGPADFQEGTWVGVELDLPSGKNDGSIGGKQYFRCNPGYGLLVRPSRVRRATGPVRRRSTGLRLGAPEARRSATLSGSATNLASLTAALAKADRSHKNPENRKSWAS>sp|Q9NQT8-2|KI13B_HUMAN Isoform 2 of Kinesin-like protein KIF13B OS=Homosapiens OX=9606 GN=KIF13BMPKLLKSLFPVRDEKRGKRPSPLAHQAQPEMGPDVLVQTMGAPALKICDKPAKVPSPPPVIAVTAVTPAPEAQDGPPSPLSEASSGYFSHSVSTATLSDALGPGLDAAAPPGSMPTAPEAEPEAPISHPPPPTAVPAEEPPGPQQLVSPGRERPDLEAPAPGSPFRVRRVRASELRSFSRMLAGDPGCSPGAEGNAPAPGAGGQALASDSEEADEVPEWLREGEFVTVGAHKTGVVRYVGPADFQEGTWVGVELDLPSGKNDGSIGGKQYFRCNPGYGLLVRPSRVRRATGPVRRRSTGLRLGAPEARRSATLSGSATNLASLTAALAKADRSHKNPENRKSWAS>sp|Q8N5Z5|KCD17_HUMAN BTB/POZ domain-containing protein KCTD17 OS=Homosapiens OX=9606 GN=KCTD17 PE=1 SV=3MQTPRPAMRMEAGEAAPPAGAGGRAAGGWGKWVRLNVGGTVFLTTRQTLCREQKSFLSRLCQGEELQSDRDETGAYLIDRDPTYFGPILNFLRHGKLVLDKDMAEEGVLEEAEFYNIGPLIRIIKDRMEEKDYTVTQVPPKHVYRVLQCQEEELTQMVSTMSDGWRFEQLVNIGSSYNYGSEDQAEFLCVVSKELHSTPNGLSSESSRKTKSTEEQLEEQQQQEEEVEEVEVEQVQVEADAQEKAQSSQDPANLFSLPPLPPPPLPAGGSRPHPLRPEAELAVRASPRPLARPQSCHPCCYKPEAPGCEAPDHLQGLGVPI>sp|Q8N5Z5-2|KCD17_HUMAN Isoform 2 of BTB/POZ domain-containing proteinKCTD17 OS=Homo sapiens OX=9606 GN=KCTD17MQTPRPAMRMEAGEAAPPAGAGGRAAGGWGKWVRLNVGGTVFLTTRQTLCREQKSFLSRLCQGEELQSDRDETGAYLIDRDPTYFGPILNFLRHGKLVLDKDMAEEGVLEEAEFYNIGPLIRIIKDRMEEKDYTVTQVPPKHVYRVLQCQEEELTQMVSTMSDGWRFEQLVNIGSSYNYGSEDQAEFLCVVSKELHSTPNGLSSESSRKTKSTEEQLEEQQQQEEEVEEVEVEQVQVEADAQEKGSRPHPLRPEAELAVRASPRPLARPQSCHPCCYKPEAPGCEAPDHLQGLGVPI>sp|O43525|KCNQ3_HUMAN Potassium voltage-gated channel subfamily KQTmember 3 OS=Homo sapiens OX=9606 GN=KCNQ3 PE=1 SV=2MGLKARRAAGAAGGGGDGGGGGGGAANPAGGDAAAAGDEERKVGLAPGDVEQVTLALGAGADKDGTLLLEGGGRDEGQRRTPQGIGLLAKTPLSRPVKRNNAKYRRIQTLIYDALERPRGWALLYHALVFLIVLGCLILAVLTTFKEYETVSGDWLLLLETFAIFIFGAEFALRIWAAGCCCRYKGWRGRLKFARKPLCMLDIFVLIASVPVVAVGNQGNVLATSLRSLRFLQILRMLRMDRRGGTWKLLGSAICAHSKELITAWYIGFLTLILSSFLVYLVEKDVPEVDAQGEEMKEEFETYADALWWGLITLATIGYGDKTPKTWEGRLIAATFSLIGVSFFALPAGILGSGLALKVQEQHRQKHFEKRRKPAAELIQAAWRYYATNPNRIDLVATWRFYESVVSFPFFRKEQLEAASSQKLGLLDRVRLSNPRGSNTKGKLFTPLNVDAIEESPSKEPKPVGLNNKERFRTAFRMKAYAFWQSSEDAGTGDPMAEDRGYGNDFPIEDMIPTLKAAIRAVRILQFRLYKKKFKETLRPYDVKDVIEQYSAGHLDMLSRIKYLQTRIDMIFTPGPPSTPKHKKSQKGSAFTFPSQQSPRNEPYVARPSTSEIEDQSMMGKFVKVERQVQDMGKKLDFLVDMHMQHMERLQVQVTEYYPTKGTSSPAEAEKKEDNRYSDLKTIICNYSETGPPEPPYSFHQVTIDKVSPYGFFAHDPVNLPRGGPSSGKVQATPPSSATTYVERPTVLPILTLLDSRVSCHSQADLQGPYSDRISPRQRRSITRDSDTPLSLMSVNHEELERSPSGFSISQDRDDYVFGPNGGSSWMREKRYLAEGETDTDTDPFTPSGSMPLSSTGDGISDSVWTPSNKPI>sp|O43525-2|KCNQ3_HUMAN Isoform 2 of Potassium voltage-gated channelsubfamily KQT member 3 OS=Homo sapiens OX=9606 GN=KCNQ3MKPAEHATMFLIVLGCLILAVLTTFKEYETVSGDWLLLLETFAIFIFGAEFALRIWAAGCCCRYKGWRGRLKFARKPLCMLDIFVLIASVPVVAVGNQGNVLATSLRSLRFLQILRMLRMDRRGGTWKLLGSAICAHSKELITAWYIGFLTLILSSFLVYLVEKDVPEVDAQGEEMKEEFETYADALWWGLITLATIGYGDKTPKTWEGRLIAATFSLIGVSFFALPAGILGSGLALKVQEQHRQKHFEKRRKPAAELIQAAWRYYATNPNRIDLVATWRFYESVVSFPFFRKEQLEAASSQKLGLLDRVRLSNPRGSNTKGKLFTPLNVDAIEESPSKEPKPVGLNNKERFRTAFRMKAYAFWQSSEDAGTGDPMAEDRGYGNDFPIEDMIPTLKAAIRAVRILQFRLYKKKFKETLRPYDVKDVIEQYSAGHLDMLSRIKYLQTRIDMIFTPGPPSTPKHKKSQKGSAFTFPSQQSPRNEPYVARPSTSEIEDQSMMGKFVKVERQVQDMGKKLDFLVDMHMQHMERLQVQVTEYYPTKGTSSPAEAEKKEDNRYSDLKTIICNYSETGPPEPPYSFHQVTIDKVSPYGFFAHDPVNLPRGGPSSGKVQATPPSSATTYVERPTVLPILTLLDSRVSCHSQADLQGPYSDRISPRQRRSITRDSDTPLSLMSVNHEELERSPSGFSISQDRDDYVFGPNGGSSWMREKRYLAEGETDTDTDPFTPSGSMPLSSTGDGISDSVWTPSNKPI>sp|Q9NPI9|KCJ16_HUMAN Inward rectifier potassium channel 16 OS=Homosapiens OX=9606 GN=KCNJ16 PE=1 SV=1MSYYGSSYHIINADAKYPGYPPEHIIAEKRRARRRLLHKDGSCNVYFKHIFGEWGSYVVDIFTTLVDTKWRHMFVIFSLSYILSWLIFGSVFWLIAFHHGDLLNDPDITPCVDNVHSFTGAFLFSLETQTTIGYGYRCVTEECSVAVLMVILQSILSCIINTFIIGAALAKMATARKRAQTIRFSYFALIGMRDGKLCLMWRIGDFRPNHVVEGTVRAQLLRYTEDSEGRMTMAFKDLKLVNDQIILVTPVTIVHEIDHESPLYALDRKAVAKDNFEILVTFIYTGDSTGTSHQSRSSYVPREILWGHRFNDVLEVKRKYYKVNCLQFEGSVEVYAPFCSAKQLDWKDQQLHIEKAPPVRESCTSDTKARRRSFSAVAIVSSCENPEETTTSATHEYRETPYQKALLTLNRISVESQM>sp|P23352|KALM_HUMAN Anosmin-1 OS=Homo sapiens OX=9606 GN=ANOS1 PE=1SV=3MVPGVPGAVLTLCLWLAASSGCLAAGPGAAAARRLDESLSAGSVQRARCASRCLSLQITRISAFFQHFQNNGSLVWCQNHKQCSKCLEPCKESGDLRKHQCQSFCEPLFPKKSYECLTSCEFLKYILLVKQGDCPAPEKASGFAAACVESCEVDNECSGVKKCCSNGCGHTCQVPKTLYKGVPLKPRKELRFTELQSGQLEVKWSSKFNISIEPVIYVVQRRWNYGIHPSEDDATHWQTVAQTTDERVQLTDIRPSRWYQFRVAAVNVHGTRGFTAPSKHFRSSKDPSAPPAPANLRLANSTVNSDGSVTVTIVWDLPEEPDIPVHHYKVFWSWMVSSKSLVPTKKKRRKTTDGFQNSVILEKLQPDCDYVVELQAITYWGQTRLKSAKVSLHFTSTHATNNKEQLVKTRKGGIQTQLPFQRRRPTRPLEVGAPFYQDGQLQVKVYWKKTEDPTVNRYHVRWFPEACAHNRTTGSEASSGMTHENYIILQDLSFSCKYKVTVQPIRPKSHSKAEAVFFTTPPCSALKGKSHKPVGCLGEAGHVLSKVLAKPENLSASFIVQDVNITGHFSWKMAKANLYQPMTGFQVTWAEVTTESRQNSLPNSIISQSQILPSDHYVLTVPNLRPSTLYRLEVQVLTPGGEGPATIKTFRTPELPPSSAHRSHLKHRHPHHYKPSPERY>sp|P01597|KV139_HUMAN Immunoglobulin kappa variable 1-39 OS=Homo sapiensOX=9606 GN=IGKV1-39 PE=1 SV=2MDMRVPAQLLGLLLLWLRGARCDIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSYSTP>sp|P04433|KV311_HUMAN Immunoglobulin kappa variable 3-11 OS=Homo sapiensOX=9606 GN=IGKV3-11 PE=1 SV=1MEAPAQLLFLLLLWLPDTTGEIVLTQSPATLSLSPGERATLSCRASQSVSSYLAWYQQKPGQAPRLLIYDASNRATGIPARFSGSGSGTDFTLTISSLEPEDFAVYYCQQRSNWP>sp|P06315|KV502_HUMAN Immunoglobulin kappa variable 5-2 OS=Homo sapiensOX=9606 GN=IGKV5-2 PE=1 SV=1MGSQVHLLSFLLLWISDTRAETTLTQSPAFMSATPGDKVNISCKASQDIDDDMNWYQQKPGEAAIFIIQEATTLVPGIPPRFSGSGYGTDFTLTINNIESEDAAYYFCLQHDNFP>sp|A0A087WSZ0|KVD08_HUMAN Immunoglobulin kappa variable 1D-8 OS=Homosapiens OX=9606 GN=IGKV1D-8 PE=3 SV=6MDMRVPAQLLGLLLLWLPGARCAIWMTQSPSLLSASTGDRVTISCRMSQGISSYLAWYQQKPGKAPELLIYAASTLQSGVPSRFSGSGSGTDFTLTISCLQSEDFATYYCQQYYSFP>sp|A0A075B6R9|KVD24_HUMAN Probable non-functional immunoglobulin kappavariable 2D-24 OS=Homo sapiens OX=9606 GN=IGKV2D-24 PE=1 SV=1MRLLAQLLGLLMLWVPGSSGDIVMTQTPLSSPVTLGQPASISFRSSQSLVHSDGNTYLSWLQQRPGQPPRLLIYKVSNRFSGVPDRFSGSGAGTDFTLKISRVEAEDVGVYYCTQATQFP>sp|P24043|LAMA2_HUMAN Laminin subunit alpha-2 OS=Homo sapiens OX=9606GN=LAMA2 PE=1 SV=4MPGAAGVLLLLLLSGGLGGVQAQRPQQQRQSQAHQQRGLFPAVLNLASNALITTNATCGEKGPEMYCKLVEHVPGQPVRNPQCRICNQNSSNPNQRHPITNAIDGKNTWWQSPSIKNGIEYHYVTITLDLQQVFQIAYVIVKAANSPRPGNWILERSLDDVEYKPWQYHAVTDTECLTLYNIYPRTGPPSYAKDDEVICTSFYSKIHPLENGEIHISLINGRPSADDPSPELLEFTSARYIRLRFQRIRTLNADLMMFAHKDPREIDPIVTRRYYYSVKDISVGGMCICYGHARACPLDPATNKSRCECEHNTCGDSCDQCCPGFHQKPWRAGTFLTKTECEACNCHGKAEECYYDENVARRNLSLNIRGKYIGGGVCINCTQNTAGINCETCTDGFFRPKGVSPNYPRPCQPCHCDPIGSLNEVCVKDEKHARRGLAPGSCHCKTGFGGVSCDRCARGYTGYPDCKACNCSGLGSKNEDPCFGPCICKENVEGGDCSRCKSGFFNLQEDNWKGCDECFCSGVSNRCQSSYWTYGKIQDMSGWYLTDLPGRIRVAPQQDDLDSPQQISISNAEARQALPHSYYWSAPAPYLGNKLPAVGGQLTFTISYDLEEEEEDTERVLQLMIILEGNDLSISTAQDEVYLHPSEEHTNVLLLKEESFTIHGTHFPVRRKEFMTVLANLKRVLLQITYSFGMDAIFRLSSVNLESAVSYPTDGSIAAAVEVCQCPPGYTGSSCESCWPRHRRVNGTIFGGICEPCQCFGHAESCDDVTGECLNCKDHTGGPYCDKCLPGFYGEPTKGTSEDCQPCACPLNIPSNNFSPTCHLDRSLGLICDGCPVGYTGPRCERCAEGYFGQPSVPGGSCQPCQCNDNLDFSIPGSCDSLSGSCLICKPGTTGRYCELCADGYFGDAVDAKNCQPCRCNAGGSFSEVCHSQTGQCECRANVQGQRCDKCKAGTFGLQSARGCVPCNCNSFGSKSFDCEESGQCWCQPGVTGKKCDRCAHGYFNFQEGGCTACECSHLGNNCDPKTGRCICPPNTIGEKCSKCAPNTWGHSITTGCKACNCSTVGSLDFQCNVNTGQCNCHPKFSGAKCTECSRGHWNYPRCNLCDCFLPGTDATTCDSETKKCSCSDQTGQCTCKVNVEGIHCDRCRPGKFGLDAKNPLGCSSCYCFGTTTQCSEAKGLIRTWVTLKAEQTILPLVDEALQHTTTKGIVFQHPEIVAHMDLMREDLHLEPFYWKLPEQFEGKKLMAYGGKLKYAIYFEAREETGFSTYNPQVIIRGGTPTHARIIVRHMAAPLIGQLTRHEIEMTEKEWKYYGDDPRVHRTVTREDFLDILYDIHYILIKATYGNFMRQSRISEISMEVAEQGRGTTMTPPADLIEKCDCPLGYSGLSCEACLPGFYRLRSQPGGRTPGPTLGTCVPCQCNGHSSLCDPETSICQNCQHHTAGDFCERCALGYYGIVKGLPNDCQQCACPLISSSNNFSPSCVAEGLDDYRCTACPRGYEGQYCERCAPGYTGSPGNPGGSCQECECDPYGSLPVPCDPVTGFCTCRPGATGRKCDGCKHWHAREGWECVFCGDECTGLLLGDLARLEQMVMSINLTGPLPAPYKMLYGLENMTQELKHLLSPQRAPERLIQLAEGNLNTLVTEMNELLTRATKVTADGEQTGQDAERTNTRAKSLGEFIKELARDAEAVNEKAIKLNETLGTRDEAFERNLEGLQKEIDQMIKELRRKNLETQKEIAEDELVAAEALLKKVKKLFGESRGENEEMEKDLREKLADYKNKVDDAWDLLREATDKIREANRLFAVNQKNMTALEKKKEAVESGKRQIENTLKEGNDILDEANRLADEINSIIDYVEDIQTKLPPMSEELNDKIDDLSQEIKDRKLAEKVSQAESHAAQLNDSSAVLDGILDEAKNISFNATAAFKAYSNIKDYIDEAEKVAKEAKDLAHEATKLATGPRGLLKEDAKGCLQKSFRILNEAKKLANDVKENEDHLNGLKTRIENADARNGDLLRTLNDTLGKLSAIPNDTAAKLQAVKDKARQANDTAKDVLAQITELHQNLDGLKKNYNKLADSVAKTNAVVKDPSKNKIIADADATVKNLEQEADRLIDKLKPIKELEDNLKKNISEIKELINQARKQANSIKVSVSSGGDCIRTYKPEIKKGSYNNIVVNVKTAVADNLLFYLGSAKFIDFLAIEMRKGKVSFLWDVGSGVGRVEYPDLTIDDSYWYRIVASRTGRNGTISVRALDGPKASIVPSTHHSTSPPGYTILDVDANAMLFVGGLTGKLKKADAVRVITFTGCMGETYFDNKPIGLWNFREKEGDCKGCTVSPQVEDSEGTIQFDGEGYALVSRPIRWYPNISTVMFKFRTFSSSALLMYLATRDLRDFMSVELTDGHIKVSYDLGSGMASVVSNQNHNDGKWKSFTLSRIQKQANISIVDIDTNQEENIATSSSGNNFGLDLKADDKIYFGGLPTLRNLSMKARPEVNLKKYSGCLKDIEISRTPYNILSSPDYVGVTKGCSLENVYTVSFPKPGFVELSPVPIDVGTEINLSFSTKNESGIILLGSGGTPAPPRRKRRQTGQAYYAILLNRGRLEVHLSTGARTMRKIVIRPEPNLFHDGREHSVHVERTRGIFTVQVDENRRYMQNLTVEQPIEVKKLFVGGAPPEFQPSPLRNIPPFEGCIWNLVINSVPMDFARPVSFKNADIGRCAHQKLREDEDGAAPAEIVIQPEPVPTPAFPTPTPVLTHGPCAAESEPALLIGSKQFGLSRNSHIAIAFDDTKVKNRLTIELEVRTEAESGLLFYMARINHADFATVQLRNGLPYFSYDLGSGDTHTMIPTKINDGQWHKIKIMRSKQEGILYVDGASNRTISPKKADILDVVGMLYVGGLPINYTTRRIGPVTYSIDGCVRNLHMAEAPADLEQPTSSFHVGTCFANAQRGTYFDGTGFAKAVGGFKVGLDLLVEFEFRTTTTTGVLLGISSQKMDGMGIEMIDEKLMFHVDNGAGRFTAVYDAGVPGHLCDGQWHKVTANKIKHRIELTVDGNQVEAQSPNPASTSADTNDPVFVGGFPDDLKQFGLTTSIPFRGCIRSLKLTKGTGKPLEVNFAKALELRGVQPVSCPAN>sp|Q9Y383|LC7L2_HUMAN Putative RNA-binding protein Luc7-like 2 OS=Homosapiens OX=9606 GN=LUC7L2 PE=1 SV=2MSAQAQMRAMLDQLMGTSRDGDTTRQRIKFSDDRVCKSHLLNCCPHDVLSGTRMDLGECLKVHDLALRADYEIASKEQDFFFELDAMDHLQSFIADCDRRTEVAKKRLAETQEEISAEVAAKAERVHELNEEIGKLLAKVEQLGAEGNVEESQKVMDEVEKARAKKREAEEVYRNSMPASSFQQQKLRVCEVCSAYLGLHDNDRRLADHFGGKLHLGFIEIREKLEELKRVVAEKQEKRNQERLKRREEREREEREKLRRSRSHSKNPKRSRSREHRRHRSRSMSRERKRRTRSKSREKRHRHRSRSSSRSRSRSHQRSRHSSRDRSRERSKRRSSKERFRDQDLASCDRDRSSRDRSPRDRDRKDKKRSYESANGRSEDRRSSEEREAGEI>sp|Q9Y383-2|LC7L2_HUMAN Isoform 2 of Putative RNA-binding protein Luc7-like 2 OS=Homo sapiens OX=9606 GN=LUC7L2MPAYLNLQGSVRKAPHSPSRDTTRQRIKFSDDRVCKSHLLNCCPHDVLSGTRMDLGECLKVHDLALRADYEIASKEQDFFFELDAMDHLQSFIADCDRRTEVAKKRLAETQEEISAEVAAKAERVHELNEEIGKLLAKVEQLGAEGNVEESQKVMDEVEKARAKKREAEEVYRNSMPASSFQQQKLRVCEVCSAYLGLHDNDRRLADHFGGKLHLGFIEIREKLEELKRVVAEKQEKRNQERLKRREEREREEREKLRRSRSHSKNPKRSRSREHRRHRSRSMSRERKRRTRSKSREKRHRHRSRSSSRSRSRSHQRSRHSSRDRSRERSKRRSSKERFRDQDLASCDRDRSSRDRSPRDRDRKDKKRSYESANGRSEDRRSSEEREAGEI>sp|Q9Y383-3|LC7L2_HUMAN Isoform 3 of Putative RNA-binding protein Luc7-like 2 OS=Homo sapiens OX=9606 GN=LUC7L2MVIHSQLKKIQGASERMGDTTRQRIKFSDDRVCKSHLLNCCPHDVLSGTRMDLGECLKVHDLALRADYEIASKEQDFFFELDAMDHLQSFIADCDRRTEVAKKRLAETQEEISAEVAAKAERVHELNEEIGKLLAKVEQLGAEGNVEESQKVMDEVEKARAKKREAEEVYRNSMPASSFQQQKLRVCEVCSAYLGLHDNDRRLADHFGGKLHLGFIEIREKLEELKRVVAEKQEKRNQERLKRREEREREEREKLRRSRSHSKNPKRSRSREHRRHRSRSMSRERKRRTRSKSREKRHRHRSRSSSRSRSRSHQRSRHSSRDRSRERSKRRSSKERFRDQDLASCDRDRSSRDRSPRDRDRKDKKRSYESANGRSEDRRSSEEREAGEI>sp|P01611|KVD12_HUMAN Immunoglobulin kappa variable 1D-12 OS=Homosapiens OX=9606 GN=IGKV1D-12 PE=1 SV=2MDMMVPAQLLGLLLLWFPGSRCDIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQANSFP>sp|A0A075B6H7|KV37_HUMAN Probable non-functional immunoglobulin kappavariable 3-7 OS=Homo sapiens OX=9606 GN=IGKV3-7 PE=1 SV=1MEAPAQLLFLLLLWLPDTTREIVMTQSPPTLSLSPGERVTLSCRASQSVSSSYLTWYQQKPGQAPRLLIYGASTRATSIPARFSGSGSGTDFTLTISSLQPEDFAVYYCQQDYNLP>sp|P04180|LCAT_HUMAN Phosphatidylcholine-sterol acyltransferase OS=Homosapiens OX=9606 GN=LCAT PE=1 SV=1MGPPGSPWQWVTLLLGLLLPPAAPFWLLNVLFPPHTTPKAELSNHTRPVILVPGCLGNQLEAKLDKPDVVNWMCYRKTEDFFTIWLDLNMFLPLGVDCWIDNTRVVYNRSSGLVSNAPGVQIRVPGFGKTYSVEYLDSSKLAGYLHTLVQNLVNNGYVRDETVRAAPYDWRLEPGQQEEYYRKLAGLVEEMHAAYGKPVFLIGHSLGCLHLLYFLLRQPQAWKDRFIDGFISLGAPWGGSIKPMLVLASGDNQGIPIMSSIKLKEEQRITTTSPWMFPSRMAWPEDHVFISTPSFNYTGRDFQRFFADLHFEEGWYMWLQSRDLLAGLPAPGVEVYCLYGVGLPTPRTYIYDHGFPYTDPVGVLYEDGDDTVATRSTELCGLWQGRQPQPVHLLPLHGIQHLNMVFSNLTLEHINAILLGAYRQGPPASPTASPEPPPPE>sp|O76015|KRT38_HUMAN Keratin, type I cuticular Ha8 OS=Homo sapiensOX=9606 GN=KRT38 PE=1 SV=3MTSSYSSSSCPLGCTMAPGARNVSVSPIDIGCQPGAEANIAPMCLLANVAHANRVRVGSTPLGRPSLCLPPTCHTACPLPGTCHIPGNIGICGAYGENTLNGHEKETMQFLNDRLANYLEKVRQLEQENAELEATLLERSKCHESTVCPDYQSYFHTIEELQQKILCSKAENARLIVQIDNAKLAADDFRIKLESERSLRQLVEADKCGTQKLLDDATLAKADLEAQQESLKEEQLSLKSNHEQEVKILRSQLGEKLRIELDIEPTIDLNRVLGEMRAQYEAMLETNRQDVEQWFQAQSEGISLQDMSCSEELQCCQSEILELRCTVNALEVERQAQHTLKDCLQNSLCEAEDRFGTELAQMQSLISNVEEQLSEIRADLERQNQEYQVLLDVKTRLENEIATYRNLLESEDCKLPCNPCSTSPSCVTAPCAPRPSCGPCTTCGPTCGASTTGSRF>sp|Q9NSB2|KRT84_HUMAN Keratin, type II cuticular Hb4 OS=Homo sapiensOX=9606 GN=KRT84 PE=2 SV=2MSCRSYRVSSGHRVGNFSSCSAMTPQNLNRFRANSVSCWSGPGFRGLGSFGSRSVITFGSYSPRIAAVGSRPIHCGVRFGAGCGMGFGDGRGVGLGPRADSCVGLGFGAGSGIGYGFGGPGFGYRVGGVGVPAAPSITAVTVNKSLLTPLNLEIDPNAQRVKKDEKEQIKTLNNKFASFIDKVRFLEQQNKLLETKWSFLQEQKCIRSNLEPLFESYITNLRRQLEVLVSDQARLQAERNHLQDVLEGFKKKYEEEVVCRANAENEFVALKKDVDAAFMNKSDLEANVDTLTQEIDFLKTLYMEEIQLLQSHISETSVIVKMDNSRDLNLDGIIAEVKAQYEEVARRSRADAEAWYQTKYEEMQVTAGQHCDNLRNIRNEINELTRLIQRLKAEIEHAKAQRAKLEAAVAEAEQQGEATLSDAKCKLADLECALQQAKQDMARQLCEYQELMNAKLGLDIEIATYRRLLEGEESRLCEGVGPVNISVSSSRGGLVCGPEPLVAGSTLSRGGVTFSGSSSVCATSGVLASCGPSLGGARVAPATGDLLSTGTRSGSMLISEACVPSVPCPLPTQGGFSSCSGGRSSSVRFVSTTTSCRTKY>sp|P23443|KS6B1_HUMAN Ribosomal protein S6 kinase beta-1 OS=Homo sapiensOX=9606 GN=RPS6KB1 PE=1 SV=2MRRRRRRDGFYPAPDFRDREAEDMAGVFDIDLDQPEDAGSEDELEEGGQLNESMDHGGVGPYELGMEHCEKFEISETSVNRGPEKIRPECFELLRVLGKGGYGKVFQVRKVTGANTGKIFAMKVLKKAMIVRNAKDTAHTKAERNILEEVKHPFIVDLIYAFQTGGKLYLILEYLSGGELFMQLEREGIFMEDTACFYLAEISMALGHLHQKGIIYRDLKPENIMLNHQGHVKLTDFGLCKESIHDGTVTHTFCGTIEYMAPEILMRSGHNRAVDWWSLGALMYDMLTGAPPFTGENRKKTIDKILKCKLNLPPYLTQEARDLLKKLLKRNAASRLGAGPGDAGEVQAHPFFRHINWEELLARKVEPPFKPLLQSEEDVSQFDSKFTRQTPVDSPDDSTLSESANQVFLGFTYVAPSVLESVKEKFSFEPKIRSPRRFIGSPRTPVSPVKFSPGDFWGRGASASTANPQTPVEYPMETSGIEQMDVTMSGEASAPLPIRQPNSGPYKKQAFPMISKRPEHLRMNL>sp|P23443-2|KS6B1_HUMAN Isoform Alpha II of Ribosomal protein S6 kinasebeta-1 OS=Homo sapiens OX=9606 GN=RPS6KB1MAGVFDIDLDQPEDAGSEDELEEGGQLNESMDHGGVGPYELGMEHCEKFEISETSVNRGPEKIRPECFELLRVLGKGGYGKVFQVRKVTGANTGKIFAMKVLKKAMIVRNAKDTAHTKAERNILEEVKHPFIVDLIYAFQTGGKLYLILEYLSGGELFMQLEREGIFMEDTACFYLAEISMALGHLHQKGIIYRDLKPENIMLNHQGHVKLTDFGLCKESIHDGTVTHTFCGTIEYMAPEILMRSGHNRAVDWWSLGALMYDMLTGAPPFTGENRKKTIDKILKCKLNLPPYLTQEARDLLKKLLKRNAASRLGAGPGDAGEVQAHPFFRHINWEELLARKVEPPFKPLLQSEEDVSQFDSKFTRQTPVDSPDDSTLSESANQVFLGFTYVAPSVLESVKEKFSFEPKIRSPRRFIGSPRTPVSPVKFSPGDFWGRGASASTANPQTPVEYPMETSGIEQMDVTMSGEASAPLPIRQPNSGPYKKQAFPMISKRPEHLRMNL>sp|P23443-3|KS6B1_HUMAN Isoform 2 of Ribosomal protein S6 kinase beta-1OS=Homo sapiens OX=9606 GN=RPS6KB1MDHGGVGPYELGMEHCEKFEISETSVNRGPEKIRPECFELLRVLGKGGYGKVFQVRKVTGANTGKIFAMKVLKKAMIVRNAKDTAHTKAERNILEEVKHPFIVDLIYAFQTGGKLYLILEYLSGGELFMQLEREGIFMEDTACFYLAEISMALGHLHQKGIIYRDLKPENIMLNHQGHVKLTDFGLCKESIHDGTVTHTFCGTIEYMAPEILMRSGHNRAVDWWSLGALMYDMLTGAPPFTGENRKKTIDKILKCKLNLPPYLTQEARDLLKKLLKRNAASRLGAGPGDAGEVQAHPFFRHINWEELLARKVEPPFKPLLQSEEDVSQFDSKFTRQTPVDSPDDSTLSESANQVFLGFTYVAPSVLESVKEKFSFEPKIRSPRRFIGSPRTPVSPVKFSPGDFWGRGASASTANPQTPVEYPMETSGIEQMDVTMSGEASAPLPIRQPNSGPYKKQAFPMISKRPEHLRMNL>sp|P23443-5|KS6B1_HUMAN Isoform 4 of Ribosomal protein S6 kinase beta-1OS=Homo sapiens OX=9606 GN=RPS6KB1MRRRRRRDGFYPAPDFRDREAEDMAGVFDIDLDQPEDAGSEDELEEGGQLNESMDHGGVGPYELGMEHCEKFEISETSVNRGPEKIRPECFELLRVLGKGGYGKAMIVRNAKDTAHTKAERNILEEVKHPFIVDLIYAFQTGGKLYLILEYLSGGELFMQLEREGIFMEDTACFYLAEISMALGHLHQKGIIYRDLKPENIMLNHQGHVKLTDFGLCKESIHDGTVTHTFCGTIEYMAPEILMRSGHNRAVDWWSLGALMYDMLTGAPPFTGENRKKTIDKILKCKLNLPPYLTQEARDLLKKLLKRNAASRLGAGPGDAGEVQAHPFFRHINWEELLARKVEPPFKPLLQSEEDVSQFDSKFTRQTPVDSPDDSTLSESANQVFLGFTYVAPSVLESVKEKFSFEPKIRSPRRFIGSPRTPVSPVKFSPGDFWGRGASASTANPQTPVEYPMETSGIEQMDVTMSGEASAPLPIRQPNSGPYKKQAFPMISKRPEHLRMNL>sp|P23443-4|KS6B1_HUMAN Isoform 3 of Ribosomal protein S6 kinase beta-1OS=Homo sapiens OX=9606 GN=RPS6KB1MRRRRRRDGFYPAPDFRDREAEDMAGVFDIDLDQPEDAGSEDELEEGGQLNESMDHGGVGPYELGMEHCEKFEISETSVNRGPEKIRPECFELLRVLGKGGYGKVFQVRKVTGANTGKIFAMKVLKKAMIVRNAKDTAHTKAERNILEEVKHPFIVDLIYAFQTGGKLYLILEYLSGGELFMQLEREGIFMEDTACFYLAEISMALGHLHQKGIIYRDLKPENIMLNHQGHVKLTDFGLCKESIHDGTVTHTFCGTIEYMAPEILMRSGHNRAVDWWSLGALMYDMLTGAPPFTGENRKKTIDKILKCKLNLPPYLTQEARDLLKKLLKRNAASRLGAGPGDAGEVQAHPFFRHINWEELLARKVEPPFKPLLQSEEDVSQFDSKFTRQTPVDSPDDSTLSESANQVFLGFTYVAPSVLESVKEKFSFEPKIRSPRRFIGSPRTPVSTAMC>sp|Q96LW2|KS6R_HUMAN Ribosomal protein S6 kinase-related protein OS=Homosapiens OX=9606 GN=RSKR PE=1 SV=2MGAVSCRQGQHTQQGEHTRVAVPHKQGGNIRGPWARGWKSLWTGLGTIRSDLEELWELRGHHYLHQESLKPAPVLVEKPLPEWPVPQFINLFLPEFPIRPIRGQQQLKILGLVAKGSFGTVLKVLDCTQKAVFAVKVVPKVKVLQRDTVRQCKEEVSIQRQINHPFVHSLGDSWQGKRHLFIMCSYCSTDLYSLWSAVGCFPEASIRLFAAELVLVLCYLHDLGIMHRDVKVENILLDERGHLKLTDFGLSRHVPQGAQAYTICGTLQYMAPEVLSGGPYNHAADWWSLGVLLFSLATGKFPVAAERDHVAMLASVTHSDSEIPASLNQGLSLLLHELLCQNPLHRLRYLHHFQVHPFFRGVAFDPELLQKQPVNFVTETQATQPSSAETMPFDDFDCDLESFLLYPIPA>sp|Q96LW2-2|KS6R_HUMAN Isoform 2 of Ribosomal protein S6 kinase-relatedprotein OS=Homo sapiens OX=9606 GN=RSKRMGAVSCRQGQHTQQGEHTRVAVPHKQGGNIRGPWARGWKSLWTGLGTIRSDLEELWELRGHHYLHQESLKPAPVLVEKPLPEWPVPQFINLFLPEFPIRPIRGQQQLKILGLVAKGSFGTVLKVLDCTQKAVFAVKVVPKVKVLQRDTVRQCKEEVSIQVISMTWASCIEM>sp|Q96LW2-3|KS6R_HUMAN Isoform 3 of Ribosomal protein S6 kinase-relatedprotein OS=Homo sapiens OX=9606 GN=RSKRMGAVSCRQGQHTQQGEHTRVAVPHKQGGNIRGPWARGWKSLWTGLGTIRSDLEELWELRGHHYLHQESLKPAPVLVEKPLPEWPVPQFINLFLPEFPIRPIRGQQQLKILGLVAKGSFGTVLKVLDCTQKAVFAVKVVPKVKVLQRDTVRQCKEEVSIQRQINHPFVHSLGDSWQGKRHLFIMCSYCSTDLYSLWSAVGCFPEASIRLFAAELVLVLCYLHDLGIMHRDVKVENILLDERGHLKLTDFGLSRHVPQGAQAYTICGTLQYMGERG>sp|Q9BVA0|KTNB1_HUMAN Katanin p80 WD40 repeat-containing subunit B1OS=Homo sapiens OX=9606 GN=KATNB1 PE=1 SV=1MATPVVTKTAWKLQEIVAHASNVSSLVLGKASGRLLATGGDDCRVNLWSINKPNCIMSLTGHTSPVESVRLNTPEELIVAGSQSGSIRVWDLEAAKILRTLMGHKANICSLDFHPYGEFVASGSQDTNIKLWDIRRKGCVFRYRGHSQAVRCLRFSPDGKWLASAADDHTVKLWDLTAGKMMSEFPGHTGPVNVVEFHPNEYLLASGSSDRTIRFWDLEKFQVVSCIEGEPGPVRSVLFNPDGCCLYSGCQDSLRVYGWEPERCFDVVLVNWGKVADLAICNDQLIGVAFSQSNVSSYVVDLTRVTRTGTVARDPVQDHRPLAQPLPNPSAPLRRIYERPSTTCSKPQRVKQNSESERRSPSSEDDRDERESRAEIQNAEDYNEIFQPKNSISRTPPRRSEPFPAPPEDDAATAKEAAKPSPAMDVQFPVPNLEVLPRPPVVASTPAPKAEPAIIPATRNEPIGLKASDFLPAVKIPQQAELVDEDAMSQIRKGHDTMCVVLTSRHKNLDTVRAVWTMGDIKTSVDSAVAINDLSVVVDLLNIVNQKASLWKLDLCTTVLPQIEKLLQSKYESYVQTGCTSLKLILQRFLPLITDMLAAPPSVGVDISREERLHKCRLCYKQLKSISGLVKSKSGLSGRHGSTFRELHLLMASLD>sp|Q9BTC8|MTA3_HUMAN Metastasis-associated protein MTA3 OS=Homo sapiensOX=9606 GN=MTA3 PE=1 SV=2MAANMYRVGDYVYFENSSSNPYLIRRIEELNKTASGNVEAKVVCFYRRRDISNTLIMLADKHAKEIEEESETTVEADLTDKQKHQLKHRELFLSRQYESLPATHIRGKCSVALLNETESVLSYLDKEDTFFYSLVYDPSLKTLLADKGEIRVGPRYQADIPEMLLEGESDEREQSKLEVKVWDPNSPLTDRQIDQFLVVARAVGTFARALDCSSSVRQPSLHMSAAAASRDITLFHAMDTLYRHSYDLSSAISVLVPLGGPVLCRDEMEEWSASEASLFEEALEKYGKDFNDIRQDFLPWKSLTSIIEYYYMWKTTDRYVQQKRLKAAEAESKLKQVYIPTYSKPNPNQISTSNGKPGAVNGAVGTTFQPQNPLLGRACESCYATQSHQWYSWGPPNMQCRLCAICWLYWKKYGGLKMPTQSEEEKLSPSPTTEDPRVRSHVSRQAMQGMPVRNTGSPKSAVKTRQAFFLHTTYFTKFARQVCKNTLRLRQAARRPFVAINYAAIRAEYADRHAELSGSPLKSKSTRKPLACIIGYLEIHPAKKPNVIRSTPSLQTPTTKRMLTTPNHTSLSILGKRNYSHHNGLDELTCCVSD>sp|Q9BTC8-2|MTA3_HUMAN Isoform 2 of Metastasis-associated protein MTA3OS=Homo sapiens OX=9606 GN=MTA3MAANMYRVGDYVYFENSSSNPYLIRRIEELNKTASGNVEAKVVCFYRRRDISNTLIMLADKHAKEIEEESETTVEADLTDKQKHQLKHRELFLSRQYESLPATHIRGKCSVALLNETESVLSYLDKEDTFFYSLVYDPSLKTLLADKGEIRVGPRYQADIPEMLLEGESDEREQSKLEVKVWDPNSPLTDRQIDQFLVVARAVGTFARALDCSSSVRQPSLHMSAAAASRDITLFHAMDTLYRHSYDLSSAISVLVPLGGPVLCRDEMEEWSASEASLFEEALEKYGKDFNDIRQDFLPWKSLTSIIEYYYMWKTTDRYVQQKRLKAAEAESKLKQVYIPTYSKPNPNQISTSNGKPGAVNGAVGTTFQPQNPLLGRACESCYATQSHQWYSWGPPNMQCRLCAICWLYWKKYGGLKMPTQSEEEKLSPSPTTEDPRVRSHVSRQAMQGMPVRNTGSPKSAVKTRQAFFLHTTYFTKFARQVCKNTLRLRQAARRPFVAINYAAIRAECKMLLNS>sp|Q9UK32|KS6A6_HUMAN Ribosomal protein S6 kinase alpha-6 OS=Homosapiens OX=9606 GN=RPS6KA6 PE=1 SV=1MLPFAPQDEPWDREMEVFSGGGASSGEVNGLKMVDEPMEEGEADSCHDEGVVKEIPITHHVKEGYEKADPAQFELLKVLGQGSFGKVFLVRKKTGPDAGQLYAMKVLKKASLKVRDRVRTKMERDILVEVNHPFIVKLHYAFQTEGKLYLILDFLRGGDVFTRLSKEVLFTEEDVKFYLAELALALDHLHQLGIVYRDLKPENILLDEIGHIKLTDFGLSKESVDQEKKAYSFCGTVEYMAPEVVNRRGHSQSADWWSYGVLMFEMLTGTLPFQGKDRNETMNMILKAKLGMPQFLSAEAQSLLRMLFKRNPANRLGSEGVEEIKRHLFFANIDWDKLYKREVQPPFKPASGKPDDTFCFDPEFTAKTPKDSPGLPASANAHQLFKGFSFVATSIAEEYKITPITSANVLPIVQINGNAAQFGEVYELKEDIGVGSYSVCKRCIHATTNMEFAVKIIDKSKRDPSEEIEILMRYGQHPNIITLKDVFDDGRYVYLVTDLMKGGELLDRILKQKCFSEREASDILYVISKTVDYLHCQGVVHRDLKPSNILYMDESASADSIRICDFGFAKQLRGENGLLLTPCYTANFVAPEVLMQQGYDAACDIWSLGVLFYTMLAGYTPFANGPNDTPEEILLRIGNGKFSLSGGNWDNISDGAKDLLSHMLHMDPHQRYTAEQILKHSWITHRDQLPNDQPKRNDVSHVVKGAMVATYSALTHKTFQPVLEPVAASSLAQRRSMKKRTSTGL>sp|Q9UK32-2|KS6A6_HUMAN Isoform 2 of Ribosomal protein S6 kinase alpha-6OS=Homo sapiens OX=9606 GN=RPS6KA6MGLSTSAIWKNTRVEIVNPYEVKRKVKVNGLKMVDEPMEEGEADSCHDEGVVKEIPITHHVKEGYEKADPAQFELLKVLGQGSFGKVFLVRKKTGPDAGQLYAMKVLKKASLKVRDRVRTKMERDILVEVNHPFIVKLHYAFQTEGKLYLILDFLRGGDVFTRLSKEVLFTEEDVKFYLAELALALDHLHQLGIVYRDLKPENILLDEIGHIKLTDFGLSKESVDQEKKAYSFCGTVEYMAPEVVNRRGHSQSADWWSYGVLMFEMLTGTLPFQGKDRNETMNMILKAKLGMPQFLSAEAQSLLRMLFKRNPANRLGSEGVEEIKRHLFFANIDWDKLYKREVQPPFKPASGKPDDTFCFDPEFTAKTPKDSPGLPASANAHQLFKGFSFVATSIAEEYKITPITSANVLPIVQINGNAAQFGEVYELKEDIGVGSYSVCKRCIHATTNMEFAVKIIDKSKRDPSEEIEILMRYGQHPNIITLKDVFDDGRYVYLVTDLMKGGELLDRILKQKCFSEREASDILYVISKTVDYLHCQGVVHRDLKPSNILYMDESASADSIRICDFGFAKQLRGENGLLLTPCYTANFVAPEVLMQQGYDAACDIWSLGVLFYTMLAGYTPFANGPNDTPEEILLRIGNGKFSLSGGNWDNISDGAKDLLSHMLHMDPHQRYTAEQILKHSWITHRDQLPNDQPKRNDVSHVVKGAMVATYSALTHKTFQPVLEPVAASSLAQRRSMKKRTSTGL>sp|P20585|MSH3_HUMAN DNA mismatch repair protein Msh3 OS=Homo sapiensOX=9606 GN=MSH3 PE=1 SV=4MSRRKPASGGLAASSSAPARQAVLSRFFQSTGSLKSTSSSTGAADQVDPGAAAAAAAAAAAAPPAPPAPAFPPQLPPHIATEIDRRKKRPLENDGPVKKKVKKVQQKEGGSDLGMSGNSEPKKCLRTRNVSKSLEKLKEFCCDSALPQSRVQTESLQERFAVLPKCTDFDDISLLHAKNAVSSEDSKRQINQKDTTLFDLSQFGSSNTSHENLQKTASKSANKRSKSIYTPLELQYIEMKQQHKDAVLCVECGYKYRFFGEDAEIAARELNIYCHLDHNFMTASIPTHRLFVHVRRLVAKGYKVGVVKQTETAALKAIGDNRSSLFSRKLTALYTKSTLIGEDVNPLIKLDDAVNVDEIMTDTSTSYLLCISENKENVRDKKKGNIFIGIVGVQPATGEVVFDSFQDSASRSELETRMSSLQPVELLLPSALSEQTEALIHRATSVSVQDDRIRVERMDNIYFEYSHAFQAVTEFYAKDTVDIKGSQIISGIVNLEKPVICSLAAIIKYLKEFNLEKMLSKPENFKQLSSKMEFMTINGTTLRNLEILQNQTDMKTKGSLLWVLDHTKTSFGRRKLKKWVTQPLLKLREINARLDAVSEVLHSESSVFGQIENHLRKLPDIERGLCSIYHKKCSTQEFFLIVKTLYHLKSEFQAIIPAVNSHIQSDLLRTVILEIPELLSPVEHYLKILNEQAAKVGDKTELFKDLSDFPLIKKRKDEIQGVIDEIRMHLQEIRKILKNPSAQYVTVSGQEFMIEIKNSAVSCIPTDWVKVGSTKAVSRFHSPFIVENYRHLNQLREQLVLDCSAEWLDFLEKFSEHYHSLCKAVHHLATVDCIFSLAKVAKQGDYCRPTVQEERKIVIKNGRHPVIDVLLGEQDQYVPNNTDLSEDSERVMIITGPNMGGKSSYIKQVALITIMAQIGSYVPAEEATIGIVDGIFTRMGAADNIYKGQSTFMEELTDTAEIIRKATSQSLVILDELGRGTSTHDGIAIAYATLEYFIRDVKSLTLFVTHYPPVCELEKNYSHQVGNYHMGFLVSEDESKLDPGAAEQVPDFVTFLYQITRGIAARSYGLNVAKLADVPGEILKKAAHKSKELEGLINTKRKRLKYFAKLWTMHNAQDLQKWTEEFNMEETQTSLLH>sp|P55157|MTP_HUMAN Microsomal triglyceride transfer protein largesubunit OS=Homo sapiens OX=9606 GN=MTTP PE=1 SV=1MILLAVLFLCFISSYSASVKGHTTGLSLNNDRLYKLTYSTEVLLDRGKGKLQDSVGYRISSNVDVALLWRNPDGDDDQLIQITMKDVNVENVNQQRGEKSIFKGKSPSKIMGKENLEALQRPTLLHLIHGKVKEFYSYQNEAVAIENIKRGLASLFQTQLSSGTTNEVDISGNCKVTYQAHQDKVIKIKALDSCKIARSGFTTPNQVLGVSSKATSVTTYKIEDSFVIAVLAEETHNFGLNFLQTIKGKIVSKQKLELKTTEAGPRLMSGKQAAAIIKAVDSKYTAIPIVGQVFQSHCKGCPSLSELWRSTRKYLQPDNLSKAEAVRNFLAFIQHLRTAKKEEILQILKMENKEVLPQLVDAVTSAQTSDSLEAILDFLDFKSDSSIILQERFLYACGFASHPNEELLRALISKFKGSIGSSDIRETVMIITGTLVRKLCQNEGCKLKAVVEAKKLILGGLEKAEKKEDTRMYLLALKNALLPEGIPSLLKYAEAGEGPISHLATTALQRYDLPFITDEVKKTLNRIYHQNRKVHEKTVRTAAAAIILNNNPSYMDVKNILLSIGELPQEMNKYMLAIVQDILRFEMPASKIVRRVLKEMVAHNYDRFSRSGSSSAYTGYIERSPRSASTYSLDILYSGSGILRRSNLNIFQYIGKAGLHGSQVVIEAQGLEALIAATPDEGEENLDSYAGMSAILFDVQLRPVTFFNGYSDLMSKMLSASGDPISVVKGLILLIDHSQELQLQSGLKANIEVQGGLAIDISGAMEFSLWYRESKTRVKNRVTVVITTDITVDSSFVKAGLETSTETEAGLEFISTVQFSQYPFLVCMQMDKDEAPFRQFEKKYERLSTGRGYVSQKRKESVLAGCEFPLHQENSEMCKVVFAPQPDSTSSGWF>sp|P55157-2|MTP_HUMAN Isoform 2 of Microsomal triglyceride transferprotein large subunit OS=Homo sapiens OX=9606 GN=MTTPMILLAVLFLCFISSYSASVKGHTTGLSLNNDRLYKLTYSTEVLLDRGKGKLQDSVGYRISSNVDVALLWRNPDGDDDQLIQITMKDVNVENVNQQRGEKSIFKGKSPSKIMGKENLEALQRPTLLHLIHGKVKGRLDSTTFSPTSYFSSLQ>sp|Q9HAT1|LMA1L_HUMAN Protein ERGIC-53-like OS=Homo sapiens OX=9606GN=LMAN1L PE=2 SV=2MPAVSGPGPLFCLLLLLLDPHSPETGCPPLRRFEYKLSFKGPRLALPGAGIPFWSHHGDAILGLEEVRLTPSMRNRSGAVWSRASVPFSAWEVEVQMRVTGLGRRGAQGMAVWYTRGRGHVGSVLGGLASWDGIGIFFDSPAEDTQDSPAIRVLASDGHIPSEQPGDGASQGLGSCHWDFRNRPHPFRARITYWGQRLRMSLNSGLTPSDPGEFCVDVGPLLLVPGGFFGVSAATGTLADDHDVLSFLTFSLSEPSPEVPPQPFLEMQQLRLARQLEGLWARLGLGTREDVTPKSDSEAQGEGERLFDLEETLGRHRRILQALRGLSKQLAQAERQWKKQLGPPGQARPDGGWALDASCQIPSTPGRGGHLSMSLNKDSAKVGALLHGQWTLLQALQEMRDAAVRMAAEAQVSYLPVGIEHHFLELDHILGLLQEELRGPAKAAAKAPRPPGQPPRASSCLQPGIFLFYLLIQTVGFFGYVHFRQELNKSLQECLSTGSLPLGPAPHTPRALGILRRQPLPASMPA>sp|Q9HAT1-3|LMA1L_HUMAN Isoform 3 of Protein ERGIC-53-like OS=Homosapiens OX=9606 GN=LMAN1LMPAVSGPGPLFCLLLLLLDPHSPETGCPPLRRFEYKLSFKGPRLALPGAGIPFWSHHGDAILGLEEVRLTPSMRNRSGAVWSRASVPFSAWEVEVQMRVTGLGRRGAQGMAVWYTRGRGHVGSVLGGLASWDGIGIFFDSPAEDTQDSPAIRVLASDGHIPSEQPGDGASQGLGSCHWDFRNRPHPFRARITYWGQRLRMSLNSGLTPSDPGEFCVDVGPLLLVPGGFFGVSAATGTLAGEDPTGQVPPQPFLEMQQLRLARQLEGLWARLGLGTREDVTPKSDSEAQGEGERLFDLEETLGRHRRILQALRGLSKQLAQAERQWKKQLGPPGQARPDGGWALDASCQIPSTPGRGGHLSMSLNKDSAKVGALLHGQWTLLQALQEMRDAAVRMAAEAQVSYLPVGIEHHFLELDHILGLLQEELRGPAKAAAKAPRPPGQPPRASSCLQPGIFLFYLLIQTVGFFGYVHFRQELNKSLQECLSTGSLPLGPAPHTPRALGILRRQPLPASMPA>sp|P36776|LONM_HUMAN Lon protease homolog, mitochondrial OS=Homo sapiensOX=9606 GN=LONP1 PE=1 SV=2MAASTGYVRLWGAARCWVLRRPMLAAAGGRVPTAAGAWLLRGQRTCDASPPWALWGRGPAIGGQWRGFWEASSRGGGAFSGGEDASEGGAEEGAGGAGGSAGAGEGPVITALTPMTIPDVFPHLPLIAITRNPVFPRFIKIIEVKNKKLVELLRRKVRLAQPYVGVFLKRDDSNESDVVESLDEIYHTGTFAQIHEMQDLGDKLRMIVMGHRRVHISRQLEVEPEEPEAENKHKPRRKSKRGKKEAEDELSARHPAELAMEPTPELPAEVLMVEVENVVHEDFQVTEEVKALTAEIVKTIRDIIALNPLYRESVLQMMQAGQRVVDNPIYLSDMGAALTGAESHELQDVLEETNIPKRLYKALSLLKKEFELSKLQQRLGREVEEKIKQTHRKYLLQEQLKIIKKELGLEKDDKDAIEEKFRERLKELVVPKHVMDVVDEELSKLGLLDNHSSEFNVTRNYLDWLTSIPWGKYSNENLDLARAQAVLEEDHYGMEDVKKRILEFIAVSQLRGSTQGKILCFYGPPGVGKTSIARSIARALNREYFRFSVGGMTDVAEIKGHRRTYVGAMPGKIIQCLKKTKTENPLILIDEVDKIGRGYQGDPSSALLELLDPEQNANFLDHYLDVPVDLSKVLFICTANVTDTIPEPLRDRMEMINVSGYVAQEKLAIAERYLVPQARALCGLDESKAKLSSDVLTLLIKQYCRESGVRNLQKQVEKVLRKSAYKIVSGEAESVEVTPENLQDFVGKPVFTVERMYDVTPPGVVMGLAWTAMGGSTLFVETSLRRPQDKDAKGDKDGSLEVTGQLGEVMKESARIAYTFARAFLMQHAPANDYLVTSHIHLHVPEGATPKDGPSAGCTIVTALLSLAMGRPVRQNLAMTGEVSLTGKILPVGGIKEKTIAAKRAGVTCIVLPAENKKDFYDLAAFITEGLEVHFVEHYREIFDIAFPDEQAEALAVER>sp|P36776-2|LONM_HUMAN Isoform 2 of Lon protease homolog, mitochondrialOS=Homo sapiens OX=9606 GN=LONP1MAASTGYVRLWGAARCWVLRRPMLAAAGGRVPTAAGAWLLRGPVITALTPMTIPDVFPHLPLIAITRNPVFPRFIKIIEVKNKKLVELLRRKVRLAQPYVGVFLKRDDSNESDVVESLDEIYHTGTFAQIHEMQDLGDKLRMIVMGHRRVHISRQLEVEPEEPEAENKHKPRRKSKRGKKEAEDELSARHPAELAMEPTPELPAEVLMVEVENVVHEDFQVTEEVKALTAEIVKTIRDIIALNPLYRESVLQMMQAGQRVVDNPIYLSDMGAALTGAESHELQDVLEETNIPKRLYKALSLLKKEFELSKLQQRLGREVEEKIKQTHRKYLLQEQLKIIKKELGLEKDDKDAIEEKFRERLKELVVPKHVMDVVDEELSKLGLLDNHSSEFNVTRNYLDWLTSIPWGKYSNENLDLARAQAVLEEDHYGMEDVKKRILEFIAVSQLRGSTQGKILCFYGPPGVGKTSIARSIARALNREYFRFSVGGMTDVAEIKGHRRTYVGAMPGKIIQCLKKTKTENPLILIDEVDKIGRGYQGDPSSALLELLDPEQNANFLDHYLDVPVDLSKVLFICTANVTDTIPEPLRDRMEMINVSGYVAQEKLAIAERYLVPQARALCGLDESKAKLSSDVLTLLIKQYCRESGVRNLQKQVEKVLRKSAYKIVSGEAESVEVTPENLQDFVGKPVFTVERMYDVTPPGVVMGLAWTAMGGSTLFVETSLRRPQDKDAKGDKDGSLEVTGQLGEVMKESARIAYTFARAFLMQHAPANDYLVTSHIHLHVPEGATPKDGPSAGCTIVTALLSLAMGRPVRQNLAMTGEVSLTGKILPVGGIKEKTIAAKRAGVTCIVLPAENKKDFYDLAAFITEGLEVHFVEHYREIFDIAFPDEQAEALAVER>sp|P36776-3|LONM_HUMAN Isoform 3 of Lon protease homolog, mitochondrialOS=Homo sapiens OX=9606 GN=LONP1MQDLGDKLRMIVMGHRRVHISRQLEVEPEEPEAENKHKPRRKSKRGKKEAEDELSARHPAELAMEPTPELPAEVLMVEVENVVHEDFQVTEEVKALTAEIVKTIRDIIALNPLYRESVLQMMQAGQRVVDNPIYLSDMGAALTGAESHELQDVLEETNIPKRLYKALSLLKKEFELSKLQQRLGREVEEKIKQTHRKYLLQEQLKIIKKELGLEKDDKDAIEEKFRERLKELVVPKHVMDVVDEELSKLGLLDNHSSEFNVTRNYLDWLTSIPWGKYSNENLDLARAQAVLEEDHYGMEDVKKRILEFIAVSQLRGSTQGKILCFYGPPGVGKTSIARSIARALNREYFRFSVGGMTDVAEIKGHRRTYVGAMPGKIIQCLKKTKTENPLILIDEVDKIGRGYQGDPSSALLELLDPEQNANFLDHYLDVPVDLSKVLFICTANVTDTIPEPLRDRMEMINVSGYVAQEKLAIAERYLVPQARALCGLDESKAKLSSDVLTLLIKQYCRESGVRNLQKQVEKVLRKSAYKIVSGEAESVEVTPENLQDFVGKPVFTVERMYDVTPPGVVMGLAWTAMGGSTLFVETSLRRPQDKDAKGDKDGSLEVTGQLGEVMKESARIAYTFARAFLMQHAPANDYLVTSHIHLHVPEGATPKDGPSAGCTIVTALLSLAMGRPVRQNLAMTGEVSLTGKILPVGGIKEKTIAAKRAGVTCIVLPAENKKDFYDLAAFITEGLEVHFVEHYREIFDIAFPDEQAEALAVER>sp|Q68DH5|LMBD2_HUMAN G-protein coupled receptor-associated proteinLMBRD2 OS=Homo sapiens OX=9606 GN=LMBRD2 PE=1 SV=1MSGAALGLEIVFVFFLALFLLHRYGDFKKQHRLVIIGTLLAWYLCFLIVFILPLDVSTTIYNRCKHAAANSSPPENSNITGLYATANPVPSQHPCFKPWSYIPDGIMPIFWRVVYWTSQFLTWILLPFMQSYARSGGFSITGKIKTALIENAIYYGTYLLIFGAFLIYVAVNPHLHLEWNQLQTIGIAAANTWGLFLLVLLLGYGLVEIPRSYWNGAKRGYLLMKTYFKAAKLMTEKADAEENLEDAMEEVRKVNESIKYNHPLRKCVDTILKKCPTEYQEKMGRNMDDYEDFDEKHSIYPSEKSLVKLHKQVIYSVQRHRRTQVQWQILLEQAFYLEDVAKNETSATHQFVHTFQSPEPENRFIQYFYNPTFEWYWECLLRPWFYKILAVVLSIFSVIVVWSECTFFSTTPVLSLFAVFIQLAEKTYNYIYIEIACFLSIFFLSICVYSTVFRIRVFNYYYLASHHQTDAYSLLFSGMLFCRLTPPLCLNFLGLTHMDSSISHKNTQPTAYTSIMGSMKVLSFIADGFYIYYPMLVVILCIATYFSLGTRCLNLLGFQQFMGDDDMTSDLVNEGKELIRKEKRKRQRQEEGENRRREWKERYGHNREDSTRNRNIHTDPKESNFSDVNTNRSAFKYTRANNRTERDRIELLQDAEPLDFNAETFTDDPLESESGRYQPGGRYLSMSRSDIFNDV>sp|Q9Y468|LMBL1_HUMAN Lethal(3)malignant brain tumor-like protein 1OS=Homo sapiens OX=9606 GN=L3MBTL1 PE=1 SV=4MHLVAGDSPGSGPHLPATAFIIPASSATLGLPSSALDVSCFPREPIHVGAPEQVAGCEPVSATVLPQLSAGPASSSTSTVRLLEWTEAAAPPPGGGLRFRISEYKPLNMAGVEQPPSPELRQEGVTEYEDGGAPAGDGEAGPQQAEDHPQNPPEDPNQDPPEDDSTCQCQACGPHQAAGPDLGSSNDGCPQLFQERSVIVENSSGSTSASELLKPMKKRKRREYQSPSEEESEPEAMEKQEEGKDPEGQPTASTPESEEWSSSQPATGEKKECWSWESYLEEQKAITAPVSLFQDSQAVTHNKNGFKLGMKLEGIDPQHPSMYFILTVAEVCGYRLRLHFDGYSECHDFWVNANSPDIHPAGWFEKTGHKLQPPKGYKEEEFSWSQYLRSTRAQAAPKHLFVSQSHSPPPLGFQVGMKLEAVDRMNPSLVCVASVTDVVDSRFLVHFDNWDDTYDYWCDPSSPYIHPVGWCQKQGKPLTPPQDYPDPDNFCWEKYLEETGASAVPTWAFKVRPPHSFLVNMKLEAVDRRNPALIRVASVEDVEDHRIKIHFDGWSHGYDFWIDADHPDIHPAGWCSKTGHPLQPPLGPREPSSASPGGCPPLSYRSLPHTRTSKYSFHHRKCPTPGCDGSGHVTGKFTAHHCLSGCPLAERNQSRLKAELSDSEASARKKNLSGFSPRKKPRHHGRIGRPPKYRKIPQEDFQTLTPDVVHQSLFMSALSAHPDRSLSVCWEQHCKLLPGVAGISASTVAKWTIDEVFGFVQTLTGCEDQARLFKDEARIVRVTHVSGKTLVWTVAQLGDLVCSDHLQEGKGILETGVHSLLCSLPTHLLAKLSFASDSQY>sp|Q9Y468-1|LMBL1_HUMAN Isoform 1 of Lethal(3)malignant brain tumor-likeprotein 1 OS=Homo sapiens OX=9606 GN=L3MBTL1MRRREGHGTDSEMGQGPVRESQSSDPPALQFRISEYKPLNMAGVEQPPSPELRQEGVTEYEDGGAPAGDGEAGPQQAEDHPQNPPEDPNQDPPEDDSTCQCQACGPHQAAGPDLGSSNDGCPQLFQERSVIVENSSGSTSASELLKPMKKRKRREYQSPSEEESEPEAMEKQEEGKDPEGQPTASTPESEEWSSSQPATGEKKECWSWESYLEEQKAITAPVSLFQDSQAVTHNKNGFKLGMKLEGIDPQHPSMYFILTVAEVCGYRLRLHFDGYSECHDFWVNANSPDIHPAGWFEKTGHKLQPPKGYKEEEFSWSQYLRSTRAQAAPKHLFVSQSHSPPPLGFQVGMKLEAVDRMNPSLVCVASVTDVVDSRFLVHFDNWDDTYDYWCDPSSPYIHPVGWCQKQGKPLTPPQDYPDPDNFCWEKYLEETGASAVPTWAFKVRPPHSFLVNMKLEAVDRRNPALIRVASVEDVEDHRIKIHFDGWSHGYDFWIDADHPDIHPAGWCSKTGHPLQPPLGPREPSSASPGGCPPLSYRSLPHTRTSKYSFHHRKCPTPGCDGSGHVTGKFTAHHCLSGCPLAERNQSRLKAELSDSEASARKKNLSGFSPRKKPRHHGRIGRPPKYRKIPQEDFQTLTPDVVHQSLFMSALSAHPDRSLSVCWEQHCKLLPGVAGISASTVAKWTIDEVFGFVQTLTGCEDQARLFKDEARIVRVTHVSGKTLVWTVAQLGDLVCSDHLQEGKGILETGVHSLLCSLPTHLLAKLSFASDSQY>sp|Q9Y468-2|LMBL1_HUMAN Isoform 2 of Lethal(3)malignant brain tumor-likeprotein 1 OS=Homo sapiens OX=9606 GN=L3MBTL1MRRREGHGTDSEMGQGPVRESQSSDPPALQFRISEYKPLNMAGVEQPPSPELRQEGVTEYEDGGAPAGDGEAGPQQAEDHPQNPPEDPNQDPPEDDSTCQCQACGPHQAAGPDLGSSNDGCPQLFQERSVIVENSSGSTSASELLKPMKKRKRREYQSPSEEESEPEAMEKQEEGKDPEGQPTASTPESEEWSSSQPATGEKKECWSWESYLEEQKAITAPVSLFQDSQAVTHNKNGFKLGMKLEGIDPQHPSMYFILTVAEVCGYRLRLHFDGYSECHDFWVNANSPDIHPAGWFEKTGHKLQPPKGYKEEEFSWSQYLRSTRAQAAPKHLFVSQSHSPPPLGFQVGMKLEAVDRMNPSLVCVASVTDVVDSRFLVHFDNWDDTYDYWCDPSSPYIHPVGWCQKQGKPLTPPQDYPDPDNFCWEKYLEETGASAVPTWAFKVRPPHSFLVNMKLEAVDRRNPALIRVASVEDVEDHRIKIHFDGWSHGYDFWIDADHPDIHPAGWCSKTGHPLQPPLGPREPSSASPGGCPPLSYRSLPHTRTSKYSFHHRKCPTPGCDGSGHVTGKFTAHHCLSGCPLAERNQSRLKAELSDSEASARKKNLSGFSPRKKPRHHGRIGRPPKYRKIPQEDFQTLTPDVVHQSLFMSALSAHPDRSLSVCWEQHCKLLPGVAGISASTVAKWTIDEVFGFVQTLTGCEDQARLFKDEVRCKCRVGDRAGVTVLKTAGSRCPPQRHFC>sp|Q9Y468-3|LMBL1_HUMAN Isoform 3 of Lethal(3)malignant brain tumor-likeprotein 1 OS=Homo sapiens OX=9606 GN=L3MBTL1MKLEAVDRMNPSLVCVASVTDVVDSRFLVHFDNWDDTYDYWCDPSSPYIHPVGWCQKQGKPLTPPQDYPDPDNFCWEKYLEETGASAVPTWAFKVRPPHSFLVNMKLEAVDRRNPALIRVASVEDVEDHRIKIHFDGWSHGYDFWIDADHPDIHPAGWCSKTGHPLQPPLGPREPSSASPGGCPPLSYRSLPHTRTSKYSFHHRKCPTPGCDGSGHVTGKFTAHHCLSGCPLAERNQSRLKAELSDSEASARKKNLSGFSPRKKPRHHGRIGRPPKYRKIPQEDFQTLTPDVVHQSLFMSALSAHPDRSLSVCWEQHCKLLPGVAGISASTVAKWTIDEVFGFVQTLTGCEDQARLFKDEVRCKCRVGDRAGVTVLKTAGSRCPPQRHFC>sp|Q9Y468-4|LMBL1_HUMAN Isoform 4 of Lethal(3)malignant brain tumor-likeprotein 1 OS=Homo sapiens OX=9606 GN=L3MBTL1MRRREGHGTDSEMGQGPVRESQSSDPPALQFRISEYKPLNMAGVEQPPSPELRQEGVTEYEDGGAPAGDGEAGPQQAEDHPQNPPEDPNQDPPEDDSTCQCQACGPHQAAGPDLGSSNDGCPQLFQERSVIVENSSGSTSASELLKPMKKRKRREYQSPSEEESEPEAMEKQEEGKDPEGQPTASTPESEEWSSSQPATGEKKECWSWESYLEEQKAITAPVSLFQDSQAVTHNKNGFKLGMKLEGIDPQHPSMYFILTVAEVCGYRLRLHFDGYSECHDFWVNANSPDIHPAGWFEKTGHKLQPPKGYKEEEFSWSQYLRSTRAQAAPKHLFVSQSHSPPPLGFQVGMKLEAVDRMNPSLVCVASVTDVVDSRFLVHFDNWDDTYDYWCDPSSPYIHPVGWCQKQGKPLTPPQDYPDPDNFCWEKYLEETGASAVPTWAFKVRPPHSFLVNMKLEAVDRRNPALIRVASVEDVEDHRIKIHFDGWSHGYDFWIDADHPDIHPAGWCSKTGHPLQPPLGPREPSSASPGGCPPLSYRSLPHTRTSKYSFHHRKCPTPGCDGSGHVTGKFTAHHCLSGCPLAERNQSRLKAELSDSEASARKKNLSGFSPRKKPRHHGRIGRPPKYRKIPQEDFQTLTPDVVHQSLFMSALSAHPDRSLSVCWEQHCKLLPGVAGISASTVAKWTIDEVFGFVQTLTGCEDQARLFKDEMIDGEAFLLLTQADIVKIMSVKLGPALKIYNAILMFKNADDTLK>sp|Q8WVP7|LMBR1_HUMAN Limb region 1 protein homolog OS=Homo sapiensOX=9606 GN=LMBR1 PE=1 SV=1MEGQDEVSAREQHFHSQVRESTICFLLFAILYVVSYFIITRYKRKSDEQEDEDAIVNRISLFLSTFTLAVSAGAVLLLPFSIISNEILLSFPQNYYIQWLNGSLIHGLWNLASLFSNLCLFVLMPFAFFFLESEGFAGLKKGIRARILETLVMLLLLALLILGIVWVASALIDNDAASMESLYDLWEFYLPYLYSCISLMGCLLLLLCTPVGLSRMFTVMGQLLVKPTILEDLDEQIYIITLEEEALQRRLNGLSSSVEYNIMELEQELENVKTLKTKLERRKKASAWERNLVYPAVMVLLLIETSISVLLVACNILCLLVDETAMPKGTRGPGIGNASLSTFGFVGAALEIILIFYLMVSSVVGFYSLRFFGNFTPKKDDTTMTKIIGNCVSILVLSSALPVMSRTLGITRFDLLGDFGRFNWLGNFYIVLSYNLLFAIVTTLCLVRKFTSAVREELFKALGLHKLHLPNTSRDSETAKPSVNGHQKAL>sp|Q8WVP7-2|LMBR1_HUMAN Isoform 2 of Limb region 1 protein homologOS=Homo sapiens OX=9606 GN=LMBR1MEGQDEVSAREQHFHSQVRESTICFLLFAILYVVSYFIITRYKRKSDEQEDEDAIVNRISLFLSTFTLAVSAGAVLLLPFSIISNEILLSFPQNYYIQWLNGSLIHGLWNLASLFSNLCLFVLMPFAFFFLESEGFAGLKKGIRARILETLVMLLLLALLILGIVWVASALIDNDAASMESLYDLWEFYLPYLYSCISLMGCLLLHLPNTSRDSETAKPSVNGHQKAL>sp|Q8WVP7-3|LMBR1_HUMAN Isoform 3 of Limb region 1 protein homologOS=Homo sapiens OX=9606 GN=LMBR1MEGQDEVSAREQHFHSQVRESTICFLLFAILYVVSYFIITRYKRKSDEQEDEDAIVNRISLFLSTFTLAVSAGAVLLLPFSIISNEILLSFPQNYYIQWLNGSLIHGLWNLASLFSNLCLFVLMPFAFFFLESEGFAGLKKGIRARILETLVMLLLLALLILGIVWVASALIDNDAASMESLYDLWEFYLPYLYSCISLMGCLLLLLCTPVGLSRMFTVMGQLLVKPTILEDLDEQIYIITLEEEALQRRLNVGMLCAGNPEVATGRQVPEEQAGQLLLGKWIQEGGDMIANPRLSSSVEYNIMELEQELENVKTLKTKLERRKKASAWERNLVYPAVMVLLLIETSISVLLVACNILCLLVDETAMPKGTRGPGIGNASLSTFGFVGAALEIILIFYLMVSSVVGFYSLRFFGNFTPKKDDTTMTKIIGNCVSILVLSSALPVMSRTLGITRFDLLGDFGRFNWLGNFYIVLSYNLLFAIVTTLCLVRKFTSAVREELFKALGLHKLHLPNTSRDSETAKPSVNGHQKAL>sp|Q9BT23|LIMD2_HUMAN LIM domain-containing protein 2 OS=Homo sapiensOX=9606 GN=LIMD2 PE=1 SV=1MFQAAGAAQATPSHDAKGGGSSTVQRSKSFSLRAQVKETCAACQKTVYPMERLVADKLIFHNSCFCCKHCHTKLSLGSYAALHGEFYCKPHFQQLFKSKGNYDEGFGRKQHKELWAHKEVDPGTKTA>sp|Q8WV35|LRC29_HUMAN Leucine-rich repeat-containing protein 29 OS=Homosapiens OX=9606 GN=LRRC29 PE=1 SV=1MYSSGWPAGAAEPRHGRGRELAQALGCMHGAPSQLASLSLAHCSSLKSRPELEHQASGTKDACPEPQGPSLLTLRALQELDLTACSKLTDASLAKVLQFLQLRQLSLSLLPELTDNGLVAVARGCPSLEHLALSHCSRLSDKGWAQAASSWPRLQHLNLSSCSQLIEQTLDAIGQACRQLRVLDVATCPGINMAAVRRFQAQLPQVSCVQSRFVGGADLTLTL>sp|Q8NGG6|OR8BC_HUMAN Olfactory receptor 8B12 OS=Homo sapiens OX=9606GN=OR8B12 PE=2 SV=1MAAKNSSVTEFILEGLTHQPGLRIPLFFLFLGFYTVTVVGNLGLITLIGLNSHLHTPMYFFLFNLSLIDFCFSTTITPKMLMSFVSRKNIISFTGCMTQLFFFCFFVVSESFILSAMAYDRYVAICNPLLYTVTMSCQVCLLLLLGAYGMGFAGAMAHTGSIMNLTFCADNLVNHFMCDILPLLELSCNSSYMNELVVFIVVAVDVGMPIVTVFISYALILSSILHNSSTEGRSKAFSTCSSHIIVVSLFFGSGAFMYLKPLSILPLEQGKVSSLFYTIIVPVLNPLIYSLRNKDVKVALRRTLGRKIFS>sp|O15374|MOT5_HUMAN Monocarboxylate transporter 5 OS=Homo sapiensOX=9606 GN=SLC16A4 PE=1 SV=1MLKREGKVQPYTKTLDGGWGWMIVIHFFLVNVFVMGMTKTFAIFFVVFQEEFEGTSEQIGWIGSIMSSLRFCAGPLVAIICDILGEKTTSILGAFVVTGGYLISSWATSIPFLCVTMGLLPGLGSAFLYQVAAVVTTKYFKKRLALSTAIARSGMGLTFLLAPFTKFLIDLYDWTGALILFGAIALNLVPSSMLLRPIHIKSENNSGIKDKGSSLSAHGPEAHATETHCHETEESTIKDSTTQKAGLPSKNLTVSQNQSEEFYNGPNRNRLLLKSDEESDKVISWSCKQLFDISLFRNPFFYIFTWSFLLSQLAYFIPTFHLVARAKTLGIDIMDASYLVSVAGILETVSQIISGWVADQNWIKKYHYHKSYLILCGITNLLAPLATTFPLLMTYTICFAIFAGGYLALILPVLVDLCRNSTVNRFLGLASFFAGMAVLSGPPIAGWLYDYTQTYNGSFYFSGICYLLSSVSFFFVPLAERWKNSLT>sp|O15374-2|MOT5_HUMAN Isoform 2 of Monocarboxylate transporter 5OS=Homo sapiens OX=9606 GN=SLC16A4MGMDDCDSFFPGPLVAIICDILGEKTTSILGAFVVTGGYLISSWATSIPFLCVTMGLLPGLGSAFLYQVAAVVTTKYFKKRLALSTAIARSGMGLTFLLAPFTKFLIDLYDWTGALILFGAIALNLVPSSMLLRPIHIKSENNSGIKDKGSSLSAHGPEAHATETHCHETEESTIKDSTTQKAGLPSKNLTVSQNQSEEFYNGPNRNRLLLKSDEESDKVISWSCKQLFDISLFRNPFFYIFTWSFLLSQLAYFIPTFHLVARAKTLGIDIMDASYLVSVAGILETVSQIISGWVADQNWIKKYHYHKSYLILCGITNLLAPLATTFPLLMTYTICFAIFAGGYLALILPVLVDLCRNSTVNRFLGLASFFAGMAVLSGPPIAGWLYDYTQTYNGSFYFSGICYLLSSVSFFFVPLAERWKNSLT>sp|O15374-3|MOT5_HUMAN Isoform 3 of Monocarboxylate transporter 5OS=Homo sapiens OX=9606 GN=SLC16A4MLKREGKVQPYTKTLDGGWGWMIVIHFFLVNVFVMGMTKTFAIFFVVFQEEFEGTSEQIGWIGSIMSSLRFCAGPLVAIICDILGEKTTSILGAFVVTGGYLISSWATSIPFLCVTMGLLPGLGSAFLYQVAAVVTTKYFKKRLALSTAIARSGMGLTFLLAPFTKFLIDLYDWTGILETVSQIISGWVADQNWIKKYHYHKSYLILCGITNLLAPLATTFPLLMTYTICFAIFAGGYLALILPVLVDLCRNSTVNRFLGLASFFAGMAVLSGPPIAGWLYDYTQTYNGSFYFSGICYLLSSVSFFFVPLAERWKNSLT>sp|O15374-4|MOT5_HUMAN Isoform 4 of Monocarboxylate transporter 5OS=Homo sapiens OX=9606 GN=SLC16A4MGMDDCDSFFPGLGSAFLYQVAAVVTTKYFKKRLALSTAIARSGMGLTFLLAPFTKFLIDLYDWTGALILFGAIALNLVPSSMLLRPIHIKSENNSGIKDKGSSLSAHGPEAHATETHCHETEESTIKDSTTQKAGLPSKNLTVSQNQSEEFYNGPNRNRLLLKSDEESDKVISWSCKQLFDISLFRNPFFYIFTWSFLLSQLAYFIPTFHLVARAKTLGIDIMDASYLVSVAGILETVSQIISGWVADQNWIKKYHYHKSYLILCGITNLLAPLATTFPLLMTYTICFAIFAGGYLALILPVLVDLCRNSTVNRFLGLASFFAGMAVLSGPPIAEIIPSFQAGYMIIPRHTMALSTSLAYAISSLQFPFFLYHWPKDGKTV>sp|O15374-5|MOT5_HUMAN Isoform 5 of Monocarboxylate transporter 5OS=Homo sapiens OX=9606 GN=SLC16A4MLKREGKVQPYTKTLDGGWGWMIVIHFFLVNVFVMGMTKTFAIFFVVFQEEFEGTSEQIGWIGSIMSSLRFCAGLGSAFLYQVAAVVTTKYFKKRLALSTAIARSGMGLTFLLAPFTKFLIDLYDWTGALILFGAIALNLVPSSMLLRPIHIKSENNSGIKDKGSSLSAHGPEAHATETHCHETEESTIKDSTTQKAGLPSKNLTVSQNQSEEFYNGPNRNRLLLKSDEESDKVISWSCKQLFDISLFRNPFFYIFTWSFLLSQLAYFIPTFHLVARAKTLGIDIMDASYLVSVAGILETVSQIISGWVADQNWIKKYHYHKSYLILCGITNLLAPLATTFPLLMTYTICFAIFAGGYLALILPVLVDLCRNSTVNRFLGLASFFAGMAVLSGPPIAGWLYDYTQTYNGSFYFSGICYLLSSVSFFFVPLAERWKNSLT>sp|O15442|MPPD1_HUMAN Metallophosphoesterase domain-containing protein 1OS=Homo sapiens OX=9606 GN=MPPED1 PE=1 SV=3MWRSRWDASVLKAEALALLPCGLGMAFSQSHVMAARRHQHSRLIIEVDEYSSNPTQAFTFYNINQGRFQPPHVQMVDPVPHDAPKPPGYTRFVCVSDTHSRTDPIQMPYGDVLIHAGDFTELGLPSEVKKFNEWLGSLPYEYKIVIAGNHELTFDQEFMADLIKQDFYYFPSVSKLKPENYENVQSLLTNCIYLQDSEVTVRGFRIYGSPWQPWFYGWGFNLPRGQALLEKWNLIPEGVDILITHGPPLGFLDWVPKKMQRVGCVELLNTVQRRVQPRLHVFGHIHEGYGVMADGTTTYVNASVCTVNYQPVNPPIVIDLPTPRNS>sp|O15442-2|MPPD1_HUMAN Isoform 2 of Metallophosphoesterase domain-containing protein 1 OS=Homo sapiens OX=9606 GN=MPPED1MNGRETQSVSRSGGGPGCGGGSGGRCRGGRRRSMWRSRWDASVLKAEALALLPCGLGMAFSQSHVMAARRHQHSRLIIEVDEYSSNPTQAFTFYNINQGRFQPPHVQMVDPVPHDAPKPPGYTRFVCVSDTHSRTDPIQMPYGDVLIHAGDFTELGLPSEVKKFNEWLGSLPYEYKIVIAGNHELTFDQEFMADLIKQDFYYFPSVSKLKPENYENVQSLLTNCIYLQDSEVTVRGFRIYGSPWQPWFYGWGFNLPRGQALLEKWNLIPEGVDILITHGPPLGFLDWVPKKMQRVGCVELLNTVQRRVQPRLHVFGHIHEGYGVMADGTTTYVNASVCTVNYQPVNPPIVIDLPTPRNS>sp|Q99542|MMP19_HUMAN Matrix metalloproteinase-19 OS=Homo sapiensOX=9606 GN=MMP19 PE=1 SV=1MNCQQLWLGFLLPMTVSGRVLGLAEVAPVDYLSQYGYLQKPLEGSNNFKPEDITEALRAFQEASELPVSGQLDDATRARMRQPRCGLEDPFNQKTLKYLLLGRWRKKHLTFRILNLPSTLPPHTARAALRQAFQDWSNVAPLTFQEVQAGAADIRLSFHGRQSSYCSNTFDGPGRVLAHADIPELGSVHFDEDEFWTEGTYRGVNLRIIAAHEVGHALGLGHSRYSQALMAPVYEGYRPHFKLHPDDVAGIQALYGKKSPVIRDEEEEETELPTVPPVPTEPSPMPDPCSSELDAMMLGPRGKTYAFKGDYVWTVSDSGPGPLFRVSALWEGLPGNLDAAVYSPRTQWIHFFKGDKVWRYINFKMSPGFPKKLNRVEPNLDAALYWPLNQKVFLFKGSGYWQWDELARTDFSSYPKPIKGLFTGVPNQPSAAMSWQDGRVYFFKGKVYWRLNQQLRVEKGYPRNISHNWMHCRPRTIDTTPSGGNTTPSGTGITLDTTLSATETTFEY>sp|Q99542-3|MMP19_HUMAN Isoform 2 of Matrix metalloproteinase-19 OS=Homosapiens OX=9606 GN=MMP19MGVTWDFSMSNGGPRGKTYAFKGDYVWTVSDSGPGPLFRVSALWEGLPGNLDAAVYSPRTQWIHFFKGDKVWRYINFKMSPGFPKKLNRVEPNLDAALYWPLNQKVFLFKGSGYWQWDELARTDFSSYPKPIKGLFTGVPNQPSAAMSWQDGRVYFFKGKVYWRLNQQLRVEKGYPRNISHNWMHCRPRTIDTTPSGGNTTPSGTGITLDTTLSATETTFEY>sp|Q99542-4|MMP19_HUMAN Isoform 3 of Matrix metalloproteinase-19 OS=Homosapiens OX=9606 GN=MMP19MNCQQLWLGFLLPMTVSGRVLGLAEVAPVDYLSQYGYLQKPLEGSNNFKPEDITEALSLRSAG>sp|Q99542-5|MMP19_HUMAN Isoform 4 of Matrix metalloproteinase-19 OS=Homosapiens OX=9606 GN=MMP19MNCQQLWLGFLLPMTVSGRVLGLAEVAPVDYLSQYGYLQKPLEGSNNFKPEDITEALRAFQEASELPVSGQLDDATRARMRQPRCGLEDPFNQKTLKYLLLGRWRKKHLTFRILNLPSTLPPHTARAALRQAFQDWSNVAPLTFQEVQAGAADIRLSFHGRQSSYCSNTFDGPGKKSPVIRDEEEEETELPTVPPVPTEPSPMPDPCSSELDAMMLGEAPPLQAVGRRWGQPADPEAWTNGSDMGLQHEQWRAPWEDLCFQGGLCVDCIRFRTGPLVPSVCPLGGAPRKPGCCCLLASNTMDSLL>sp|P09238|MMP10_HUMAN Stromelysin-2 OS=Homo sapiens OX=9606 GN=MMP10PE=1 SV=1MMHLAFLVLLCLPVCSAYPLSGAAKEEDSNKDLAQQYLEKYYNLEKDVKQFRRKDSNLIVKKIQGMQKFLGLEVTGKLDTDTLEVMRKPRCGVPDVGHFSSFPGMPKWRKTHLTYRIVNYTPDLPRDAVDSAIEKALKVWEEVTPLTFSRLYEGEADIMISFAVKEHGDFYSFDGPGHSLAHAYPPGPGLYGDIHFDDDEKWTEDASGTNLFLVAAHELGHSLGLFHSANTEALMYPLYNSFTELAQFRLSQDDVNGIQSLYGPPPASTEEPLVPTKSVPSGSEMPAKCDPALSFDAISTLRGEYLFFKDRYFWRRSHWNPEPEFHLISAFWPSLPSYLDAAYEVNSRDTVFIFKGNEFWAIRGNEVQAGYPRGIHTLGFPPTIRKIDAAVSDKEKKKTYFFAADKYWRFDENSQSMEQGFPRLIADDFPGVEPKVDAVLQAFGFFYFFSGSSQFEFDPNARMVTHILKSNSWLHC>sp|P37198|NUP62_HUMAN Nuclear pore glycoprotein p62 OS=Homo sapiensOX=9606 GN=NUP62 PE=1 SV=3MSGFNFGGTGAPTGGFTFGTAKTATTTPATGFSFSTSGTGGFNFGAPFQPATSTPSTGLFSLATQTPATQTTGFTFGTATLASGGTGFSLGIGASKLNLSNTAATPAMANPSGFGLGSSNLTNAISSTVTSSQGTAPTGFVFGPSTTSVAPATTSGGFSFTGGSTAQPSGFNIGSAGNSAQPTAPATLPFTPATPAATTAGATQPAAPTPTATITSTGPSLFASIATAPTSSATTGLSLCTPVTTAGAPTAGTQGFSLKAPGAASGTSTTTSTAATATATTTSSSSTTGFALNLKPLAPAGIPSNTAAAVTAPPGPGAAAGAAASSAMTYAQLESLINKWSLELEDQERHFLQQATQVNAWDRTLIENGEKITSLHREVEKVKLDQKRLDQELDFILSQQKELEDLLSPLEELVKEQSGTIYLQHADEEREKTYKLAENIDAQLKRMAQDLKDIIEHLNTSGAPADTSDPLQQICKILNAHMDSLQWIDQNSALLQRKVEEVTKVCEGRRKEQERSFRITFD>sp|Q9UKD2|MRT4_HUMAN mRNA turnover protein 4 homolog OS=Homo sapiensOX=9606 GN=MRTO4 PE=1 SV=2MPKSKRDKKVSLTKTAKKGLELKQNLIEELRKCVDTYKYLFIFSVANMRNSKLKDIRNAWKHSRMFFGKNKVMMVALGRSPSDEYKDNLHQVSKRLRGEVGLLFTNRTKEEVNEWFTKYTEMDYARAGNKAAFTVSLDPGPLEQFPHSMEPQLRQLGLPTALKRGVVTLLSDYEVCKEGDVLTPEQARVLKLFGYEMAEFKVTIKYMWDSQSGRFQQMGDDLPESASESTEESDSEDDD>sp|Q8NB16|MLKL_HUMAN Mixed lineage kinase domain-like protein OS=Homosapiens OX=9606 GN=MLKL PE=1 SV=1MENLKHIITLGQVIHKRCEEMKYCKKQCRRLGHRVLGLIKPLEMLQDQGKRSVPSEKLTTAMNRFKAALEEANGEIEKFSNRSNICRFLTASQDKILFKDVNRKLSDVWKELSLLLQVEQRMPVSPISQGASWAQEDQQDADEDRRAFQMLRRDNEKIEASLRRLEINMKEIKETLRQYLPPKCMQEIPQEQIKEIKKEQLSGSPWILLRENEVSTLYKGEYHRAPVAIKVFKKLQAGSIAIVRQTFNKEIKTMKKFESPNILRIFGICIDETVTPPQFSIVMEYCELGTLRELLDREKDLTLGKRMVLVLGAARGLYRLHHSEAPELHGKIRSSNFLVTQGYQVKLAGFELRKTQTSMSLGTTREKTDRVKSTAYLSPQELEDVFYQYDVKSEIYSFGIVLWEIATGDIPFQGCNSEKIRKLVAVKRQQEPLGEDCPSELREIIDECRAHDPSVRPSVDEILKKLSTFSK>sp|Q8NB16-2|MLKL_HUMAN Isoform 2 of Mixed lineage kinase domain-likeprotein OS=Homo sapiens OX=9606 GN=MLKLMENLKHIITLGQVIHKRCEEMKYCKKQCRRLGHRVLGLIKPLEMLQDQGKRSVPSEKLTTAMNRFKAALEEANGEIEKFSNRSNICRFLTASQDKILFKDVNRKLSDVWKELSLLLQVEQRMPVSPISQGASWAQEDQQDADEDRRAFQMLRRDNEKIEASLRRLEINMKEIKETLRQSLESSSGKSPLEISRFKVKNVKTGSASGCNSEKIRKLVAVKRQQEPLGEDCPSELREIIDECRAHDPSVRPSVDEILKKLSTFSK>sp|Q96J66|MRP8_HUMAN ATP-binding cassette sub-family C member 11 OS=Homosapiens OX=9606 GN=ABCC11 PE=1 SV=1MTRKRTYWVPNSSGGLVNRGIDIGDDMVSGLIYKTYTLQDGPWSQQERNPEAPGRAAVPPWGKYDAALRTMIPFRPKPRFPAPQPLDNAGLFSYLTVSWLTPLMIQSLRSRLDENTIPPLSVHDASDKNVQRLHRLWEEEVSRRGIEKASVLLVMLRFQRTRLIFDALLGICFCIASVLGPILIIPKILEYSEEQLGNVVHGVGLCFALFLSECVKSLSFSSSWIINQRTAIRFRAAVSSFAFEKLIQFKSVIHITSGEAISFFTGDVNYLFEGVCYGPLVLITCASLVICSISSYFIIGYTAFIAILCYLLVFPLAVFMTRMAVKAQHHTSEVSDQRIRVTSEVLTCIKLIKMYTWEKPFAKIIEDLRRKERKLLEKCGLVQSLTSITLFIIPTVATAVWVLIHTSLKLKLTASMAFSMLASLNLLRLSVFFVPIAVKGLTNSKSAVMRFKKFFLQESPVFYVQTLQDPSKALVFEEATLSWQQTCPGIVNGALELERNGHASEGMTRPRDALGPEEEGNSLGPELHKINLVVSKGMMLGVCGNTGSGKSSLLSAILEEMHLLEGSVGVQGSLAYVPQQAWIVSGNIRENILMGGAYDKARYLQVLHCCSLNRDLELLPFGDMTEIGERGLNLSGGQKQRISLARAVYSDRQIYLLDDPLSAVDAHVGKHIFEECIKKTLRGKTVVLVTHQLQYLEFCGQIILLENGKICENGTHSELMQKKGKYAQLIQKMHKEATSDMLQDTAKIAEKPKVESQALATSLEESLNGNAVPEHQLTQEEEMEEGSLSWRVYHHYIQAAGGYMVSCIIFFFVVLIVFLTIFSFWWLSYWLEQGSGTNSSRESNGTMADLGNIADNPQLSFYQLVYGLNALLLICVGVCSSGIFTKVTRKASTALHNKLFNKVFRCPMSFFDTIPIGRLLNCFAGDLEQLDQLLPIFSEQFLVLSLMVIAVLLIVSVLSPYILLMGAIIMVICFIYYMMFKKAIGVFKRLENYSRSPLFSHILNSLQGLSSIHVYGKTEDFISQFKRLTDAQNNYLLLFLSSTRWMALRLEIMTNLVTLAVALFVAFGISSTPYSFKVMAVNIVLQLASSFQATARIGLETEAQFTAVERILQYMKMCVSEAPLHMEGTSCPQGWPQHGEIIFQDYHMKYRDNTPTVLHGINLTIRGHEVVGIVGRTGSGKSSLGMALFRLVEPMAGRILIDGVDICSIGLEDLRSKLSVIPQDPVLLSGTIRFNLDPFDRHTDQQIWDALERTFLTKAISKFPKKLHTDVVENGGNFSVGERQLLCIARAVLRNSKIILIDEATASIDMETDTLIQRTIREAFQGCTVLVIAHRVTTVLNCDHILVMGNGKVVEFDRPEVLRKKPGSLFAALMATATSSLR>sp|Q96J66-2|MRP8_HUMAN Isoform 2 of ATP-binding cassette sub-family Cmember 11 OS=Homo sapiens OX=9606 GN=ABCC11MTRKRTYWVPNSSGGLVNRGIDIGDDMVSGLIYKTYTLQDGPWSQQERNPEAPGRAAVPPWGKYDAALRTMIPFRPKPRFPAPQPLDNAGLFSYLTVSWLTPLMIQSLRSRLDENTIPPLSVHDASDKNVQRLHRLWEEEVSRRGIEKASVLLVMLRFQRTRLIFDALLGICFCIASVLGPILIIPKILEYSEEQLGNVVHGVGLCFALFLSECVKSLSFSSSWIINQRTAIRFRAAVSSFAFEKLIQFKSVIHITSGEAISFFTGDVNYLFEGVCYGPLVLITCASLVICSISSYFIIGYTAFIAILCYLLVFPLAVFMTRMAVKAQHHTSEVSDQRIRVTSEVLTCIKLIKMYTWEKPFAKIIEDLRRKERKLLEKCGLVQSLTSITLFIIPTVATAVWVLIHTSLKLKLTASMAFSMLASLNLLRLSVFFVPIAVKGLTNSKSAVMRFKKFFLQESPVFYVQTLQDPSKALVFEEATLSWQQTCPGIVNGALELERNGHASEGMTRPRDALGPEEEGNSLGPELHKINLVVSKGMMLGVCGNTGSGKSSLLSAILEEMHLLEGSVGVQGSLAYVPQQAWIVSGNIRENILMGGAYDKARYLQVLHCCSLNRDLELLPFGDMTEIGERGLNLSGGQKQRISLARAVYSDRQIYLLDDPLSAVDAHVGKHIFEECIKKTLRGKTVVLVTHQLQYLEFCGQIILLENGKICENGTHSELMQKKGKYAQLIQKMHKEATSDMLQDTAKIAEKPKVESQALATSLEESLNGNAVPEHQLTQEEEMEEGSLSWRVYHHYIQAAGGYMVSCIIFFFVVLIVFLTIFSFWWLSYWLEQGSGTNSSRESNGTMADLGNIADNPQLSFYQLVYGLNALLLICVGVCSSGIFTKVTRKASTALHNKLFNKVFRCPMSFFDTIPIGRLLNCFAGDLEQLDQLLPIFSEQFLVLSLMVIAVLLIVSVLSPYILLMGAIIMVICFIYYMMFKKAIGVFKRLENYSRSPLFSHILNSLQGLSSIHVYGKTEDFISQFKRLTDAQNNYLLLFLSSTRWMALRLEIMTNLVTLAVALFVAFGISSTPYSFKVMAVNIVLQLASSFQATARIGLETEAQFTAVERILQYMKMCVSEAPLHMEGTSCPQGWPQHGEIIFQDYHMKYRDNTPTVLHGINLTIRGHEVVGIVGRTGSGKSSLGMALFRLVEPMAGRILIDGVDICSIGLEDLRSKLSVIPQDPVLLSGTIRFNLDPFDRHTDQQIWDALERTFLTKAIILIDEATASIDMETDTLIQRTIREAFQGCTVLVIAHRVTTVLNCDHILVMGNGKVVEFDRPEVLRKKPGSLFAALMATATSSLR>sp|Q147X3|NAA30_HUMAN N-alpha-acetyltransferase 30 OS=Homo sapiensOX=9606 GN=NAA30 PE=1 SV=1MAEVPPGPSSLLPPPAPPAPAAVEPRCPFPAGAALACCSEDEEDDEEHEGGGSRSPAGGESATVAAKGHPCLRCPQPPQEQQQLNGLISPELRHLRAAASLKSKVLSVAEVAATTATPDGGPRATATKGAGVHSGERPPHSLSSNARTAVPSPVEAAAASDPAAARNGLAEGTEQEEEEEDEQVRLLSSSLTADCSLRSPSGREVEPGEDRTIRYVRYESELQMPDIMRLITKDLSEPYSIYTYRYFIHNWPQLCFLAMVGEECVGAIVCKLDMHKKMFRRGYIAMLAVDSKYRRNGIGTNLVKKAIYAMVEGDCDEVVLETEITNKSALKLYENLGFVRDKRLFRYYLNGVDALRLKLWLR>sp|Q147X3-2|NAA30_HUMAN Isoform 2 of N-alpha-acetyltransferase 30OS=Homo sapiens OX=9606 GN=NAA30MAEVPPGPSSLLPPPAPPAPAAVEPRCPFPAGAALACCSEDEEQQQLNGLISPELRHLRAAASLKSKVLSVAEVAATTATPDGGPRATATKGAGVHSGERPPHSLSSNARTAVPSPVEAAAASDPAAARNGLAEGTEQEEEEEDEQVRLLSSSLTADCSLRSPSGREVEPGEDRTIRYVRYESELQMPDIMRLITKDLSEPYSIYTYRYFIHNWPQLCFLAMVGEECVGAIVCKLDMHKKMFRRGYIAMLAVDSKYRRNGIGTNLVKKAIYAMVEGDCDEVVLETEITNKSALKLYENLGFVRDKRLFRYYLNGVDALRLKLWLR>sp|Q6PIF6|MYO7B_HUMAN Unconventional myosin-VIIb OS=Homo sapiens OX=9606GN=MYO7B PE=1 SV=2MSGFRLGDHVWLEPPSTHKTGVAIGGIIKEAKPGKVLVEDDEGKEHWIRAEDFGVLSPMHPNSVQGVDDMIRLGDLNEAGMVHNLLIRYQQHKIYTYTGSILVAVNPFQVLPLYTLEQVQLYYSRHMGELPPHVFAIANNCYFSMKRNKRDQCCIISGESGAGKTETTKLILQFLATISGQHSWIEQQVLEANPILEAFGNAKTIRNDNSSRFGKYIDIYFNPSGVIEGARIEQFLLEKSRVCRQAPEERNYHIFYCMLMGVSAEDKQLLSLGTPSEYHYLTMGNCTSCEGLNDAKDYAHIRSAMKILQFSDSESWDVIKLLAAILHLGNVGFMASVFENLDASDVMETPAFPTVMKLLEVQHQELRDCLIKHTILIRGEFVTRSLNIAQAADRRDAFVKGIYGHLFLWIVKKINAAIFTPPAQDPKNVRRAIGLLDIFGFENFENNSFEQLCINFANEHLQQFFVQHVFTMEQEEYRSENISWDYIHYTDNRPTLDLLALKPMSIISLLDEESRFPQGTDLTMLQKLNSVHANNKAFLQPKNIHDARFGIAHFAGEVYYQAEGFLEKNRDVLSTDILTLVYSSKNKFLREIFNLELAETKLGHGTIRQAKAGNHLFKSADSNKRPSTLGSQFKQSLDQLMKILTNCQPYFIRCIKPNEYKKPLLFDRELCLRQLRYSGMMETVHIRKSGFPIRYTFEEFSQRFGVLLPNAMRMQLQGKLRQMTLGITDVWLRTDKDWKAGKTKIFLRDHQDTLLEVQRSQVLDRAALSIQKVLRGYRYRKEFLRQRRAAVTLQAWWRGYCNRRNFKLILVGFERLQAIARSQPLARQYQAMRQRTVQLQALCRGYLVRQQVQAKRRAVVVIQAHARGMAARRNFQQRKANAPLVIPAEGQKSQGALPAKKRRSIYDTVTDTEMVEKVFGFLPAMIGGQEGQASPHFEDLESKTQKLLEVDLDTVPMAEEPEEDVDGLAEYTFPKFAVTYFQKSASHTHIRRPLRYPLLYHEDDTDCLAALVIWNVILRFMGDLPEPVLYARSSQQGSSVMRQIHDTLGREHGAQVPQHSRSAQVASQLNIGEEALEPDGLGADRPMSNLEKVHFIVGYAILRPSLRDEIYCQICKQLSENFKTSSLARGWILLSLCLGCFPPSERFMKYLLNFIGQGPATYGPFCAERLRRTYANGVRAEPPTWLELQAVKSKKHIPIQVILATGESLTVPVDSASTSREMCMHIAHKQGLSDHLGFSLQVAVYDKFWSLGSGRDHMMDAIARCEQMAQERGESQRQSPWRIYFRKEFFTPWHDSREDPVSTELIYRQVLRGVWSGEYSFEKEEELVELLARHCYVQLGASAESKAVQELLPSCIPHKLYRTKPPDRWASLVTAACAKAPYTQKQVTPLAVREQVVDAARLQWPLLFSRLFEVITLSGPRLPKTQLILAVNWKGLCFLDQQEKMLLELSFPEVMGLATNREAQGGQRLLLSTMHEEYEFVSPSSVAIAELVALFLEGLKERSIFAMALQDRKATDDTTLLAFKKGDLLVLTKKQGLLASENWTLGQNDRTGKTGLVPMACLYTIPTVTKPSAQLLSLLAMSPEKRKLAAQEGQFTEPRPEEPPKEKLHTLEEFSYEFFRAPEKDMVSMAVLPLARARGHLWAYSCEPLRQPLLKRVHANVDLWDIACQIFVAILRYMGDYPSRQAWPTLELTDQIFTLALQHPALQDEVYCQILKQLTHNSNRHSEERGWQLLWLCTGLFPPSKGLLPHAQKFIDTRRGKLLAPDCSRRIQKVLRTGPRKQPPHQVEVEAAEQNVSRICHKIYFPNDTSEMLEVVANTRVRDVCDSIATRLQLASWEGCSLFIKISDKVISQKEGDFFFDSLREVSDWVKKNKPQKEGAPVTLPYQVYFMRKLWLNISPGKDVNADTILHYHQELPKYLRGFHKCSREDAIHLAGLIYKAQFNNDRSQLASVPKILRELVPENLTRLMSSEEWKKSILLAYDKHKDKTVEEAKVAFLKWICRWPTFGSAFFEVKQTSEPSYPDVILIAINRHGVLLIHPKTKDLLTTYPFTKISSWSSGSTYFHMALGSLGRGSRLLCETSLGYKMDDLLTSYVQQLLSAMNKQRGSKAPALAST>sp|Q6PIF6-2|MYO7B_HUMAN Isoform 2 of Unconventional myosin-VIIb OS=Homosapiens OX=9606 GN=MYO7BMSGFRLGDHVWLEPPSTHKTGVAIGGIIKEAKPGKVLVEDDEGKEHWIRAEDFGVLSPMHPNSVQGVDDMIRLGDLNEAGMVHNLLIRYQQHKIYTYTGSILVAVNPFQVLPLYTLEQVQLYYSRHMGELPPHVFAIANNCYFSMKRNKRDQCCIISGESGAGKTETTKLILQFLATISGQHSWIEQQVLEANPILEAFGNAKTIRNDNSSRFGKYIDIYFNPSGVIEGARIEQFLLEKSRVCRQAPEERNYHIFYCMLMGVSAEDKQLLSLGTPSEYHYLTMGNCTSCEGLNDAKDYAHIRSAMKILQFSDSESWDVIKLLAAILHLGNVGFMASVFENLDASDVMETPAFPTVMKLLEVQHQELRDCLIKHTILIRGEFVTRSLNIAQAADRRDAFVKGIYGHLFLWIVKKINAAIFTPPAQDPKNVRRAIGLLDIFGFENFENNSFEQLCINFANEHLQQFFVQHVFTMEQEEYRSENISWDYIHYTDNRPTLDLLALKPMSIISLLDEESRFPQGTDLTMLQKLNSVHANNKAFLQPKNIHDARFGIAHFAGEVYYQAEGFLEKNRDVLSTDILTLVYSSKNKFLREIFNLELAETKLGHGTIRQAKAGNHLFKSADSNKRPSTLGSQFKQSLDQLMKILTNCQPYFIRCIKPNEYKKPLLFDRELCLRQLRYSGMMETVHIRKSGFPIRYTFEEFSQRFGVLLPNAMRMQLQGKLRQMTLGITDVWLRTDKDWKAGKTKIFLRDHQDTLLEVQRSQVLDRAALSIQKVLRGYRYRKEFLRQRRAAVTLQAWWRGYCNRRNFKLILVGFERLQAIARSQPLARQYQAMRQRTVQLQALCRGYLVRQQVQAKRRAVVVIQAHARGMAARRNFQQRKANAPLVIPAEGQKSQGALPAKKRRSIYDTVTDTEMVEKVFGFLPAMIGGQEGQASPHFEDLESKTQKLLEVDLDTVPMAEEPEEDVDGLAEYTFPKFAVTYFQKSASHTHIRRPLRYPLLYHEDDTDCLAALVIWNVILRFMGDLPEPVLYARSSQQGSSVMRQIHDTLGREHGAQVPQHSRSAQVASQLNIGEEALEPDGLGADRPMSNLEKVHFIVGYAILRPSLRDEIYCQICKQLSENFKTSSLARGWILLSLCLGCFPPSERFMKYLLNFIGQGPATYGPFCAERLRRTYANGVRAEPPTWLELQAVKSKKHIPIQVILATGESLTVPVDSASTSREMCMHIAHKQGLSDHLGFSLQVAVYDKFWSLGSGRDHMMDAIARCEQMAQERGESQRQSPWRIYFRKEFFTPWHDSREDPVSTELIYRQVLRGVWSGEYSFEKEEELVELLARHCYVQLGASAESKAVQELLPSCIPHKLYRTKPPDRWASLVTAACAKAPYTQKQVTPLAVREQVVDAARLQWPLLFSRLFEVITLSGPRLPKTQLILAVNWKGLCFLDQQEKMLLELSFPEVMGLATNREAQGGQRLLLSTMHEEYEFVSPSSVAIAELVALFLEGLKERSIFAMALQDRKATDDTTLLAFKKGDLLVLTKKQGLLASENWTLGQNDRTGKTGLVPMACLYTIPTVTKPSAQLLSLLAMSPEKRKLAAQEGQFTEPRPEEPPKEKLHTLEEFSYEFFRAPEKDMVSMAVLPLARARGHLWAYSCEPLRQPLLKRVHANVDLWDIACQIFVAILRYMGDYPSRQAWPTLELTDQIFTLALQHPALQDEVYCQILKQLTHNSNRHSEERGWQLLWLCTGLFPPSKGLLPHAQKFIDTRRGKLLAPDCSRRIQKVLRTGPRKQPPHQVEVEAAEQNVSRICHKIYFPNDTSEMLEVVANTRVRDVCDSIATRLQLASWEGCSLFIKISDKVGRAGAGQTVGGRAVSEALGAACGGLSLPGAPMLDQAAGTEVGGVLEQSQLHTPIAHAQPTPAQHPGRRRPLDQNPAGSQEDSPRKPPNFPVPSPSPGHQPEGGRLLL>sp|Q8TBZ2|MYBPP_HUMAN MYCBP-associated protein OS=Homo sapiens OX=9606GN=MYCBPAP PE=1 SV=2MVPGGTMKSLKKDSRLRITPTRLLEASENVKEKKRAKGPEQPTPTIQEEPEPVSNVLQGDDILALAIKKEDLKEQHIPRLTEKEDKRVITQKFIIRKLKPMDPRRKVCHLVARPANPDEATKPLDYSGPGDSFDGSDQILPHHILGSLQDFKRIALARGNTQLAERIPTSPCLMTLISAEGESKQKAPKEEKRPPWAPPPQHNFLKNWQRNTALRKKQQEALSEHLKKPVSELLMHTGETYRRIQEERELIDCTLPTRRDRKSWENSGFWSRLEYLGDEMTGLVMTKTKTQRGLMEPITHIRKPHSIRVETGLPAQRDASYRYTWDRSLFLIYRRKELQRIMEELDFSQQDIDGLEVVGKGWPFSAVTVEDYTVFERSQGSSSEDTAYLGTLASSSDVSMPILGPSLLFCGKPACWIRGSNPQDKRQVGIAAHLTFETLEGEKTSSELTVVNNGTVAIWYDWRRQHQPDTFQDLKKNRMQRFYFDNREGVILPGEIKTFTFFFKSLTAGVFREFWEFRTHPTLLGGAILQVNLHAVSLTQDVFEDERKVLESKLTAHEAVTVVREVLQELLMGVLTPERTPSPVDAYLTEEDLFRHRNPPLHYEHQVVQSLHQLWRQYMTLPAKAEEARPGDKEHVSPIATEKASVNAELLPRFRSPISETQVPRPENEALRESGSQKARVGTKSPQRKSIMEEILVEESPDVDSTKSPWEPDGLPLLEWNLCLEDFRKAVMVLPDENHREDALMRLNKAALELCQKPRPLQSNLLHQMCLQLWRDVIDSLVGHSMWLRSVLGLPEKETIYLNVPEEQDQKSPPIMEVKVPVGKAGKEERKGAAQEKKQLGIKDKEDKKGAKLLGKEDRPNSKKHKAKDDKKVIKSASQDRFSLEDPTPDIILSSQEPIDPLVMGKYTQSLHSEVRGLLDTLVTDLMVLADELSPIKNVEEALRLCR>sp|Q9BXD5|NPL_HUMAN N-acetylneuraminate lyase OS=Homo sapiens OX=9606GN=NPL PE=1 SV=1MAFPKKKLQGLVAATITPMTENGEINFSVIGQYVDYLVKEQGVKNIFVNGTTGEGLSLSVSERRQVAEEWVTKGKDKLDQVIIHVGALSLKESQELAQHAAEIGADGIAVIAPFFLKPWTKDILINFLKEVAAAAPALPFYYYHIPALTGVKIRAEELLDGILDKIPTFQGLKFSDTDLLDFGQCVDQNRQQQFAFLFGVDEQLLSALVMGATGAVGSTYNYLGKKTNQMLEAFEQKDFSLALNYQFCIQRFINFVVKLGFGVSQTKAIMTLVSGIPMGPPRLPLQKASREFTDSAEAKLKSLDFLSFTDLKDGNLEAGS>sp|Q9BXD5-2|NPL_HUMAN Isoform 2 of N-acetylneuraminate lyase OS=Homosapiens OX=9606 GN=NPLMSRAPGILASWRRAPSLSVQKGSQTARHTCHPEVPLGNCFLPVYKASPLTVTRLWAERLDQVIIHVGALSLKESQELAQHAAEIGADGIAVIAPFFLKPWTKDILINFLKEVAAAAPALPFYYYHIPALTGVKIRAEELLDGILDKIPTFQGLKFSDTDLLDFGQCVDQNRQQQFAFLFGVDEQLLSALVMGATGAVGSTYNYLGKKTNQMLEAFEQKDFSLALNYQFCIQRFINFVVKLGFGVSQTKAIMTLVSGIPMGPPRLPLQKASREFTDSAEAKLKSLDFLSFTDLKDGNLEAGS>sp|Q9BXD5-3|NPL_HUMAN Isoform 3 of N-acetylneuraminate lyase OS=Homosapiens OX=9606 GN=NPLMAFPKKKLQGLVAATITPMTENGEINFSVIGQYVDYLVKEQGVKNIFVNGTTGEGLSLSVSERRQVAEEWVTKGKDKLDQVIIHVGALSLKESQELAQHAAEIGADGIAVIAPFFLKPWTKDILINFLKEVAAAAPALPFYYYHIPALTGVKIRAEELLDGILDKIPTFQGLKFSDTDLLDFGQCVDQNRQQQFAFLFGVDEQLLSALVMGATGAVGSTYNYLGKKTNQMLEAFEQKDFSLALNYQFCIQRFINFVVKLENSKLKVSKNQRTLPLGTTNFPFLH>sp|Q9BXD5-4|NPL_HUMAN Isoform 4 of N-acetylneuraminate lyase OS=Homosapiens OX=9606 GN=NPLMAFPKKKLQGLVAATITPMTENGEINFSVIGQYVDYLVKEQGVKNIFVNGTTGEGLSLSVSERRQVAEEWVTKGKDKLDQVIIHVGALSLKESQELAQHAAEIGADGIAVIAPFFLKPWTKDILINFLKEVAAAAPALPFYYYHIPALTGVKIRAEELLDGILDKIPTFQGLKFSDTDLLDFGQCVDQNRQQQFAFLFGVDEFCIQRFINFVVKLENSKLKVSKNQRTLPLGTTNFPFLH>sp|Q9BXD5-5|NPL_HUMAN Isoform 5 of N-acetylneuraminate lyase OS=Homosapiens OX=9606 GN=NPLMAFPKKKLQGLVAATITPMTENGEINFSVIGQYVDYLVKEQGVKNIFVNGTTGEGLSLSVSERRQVAEEWVTKGKDKSNHHKLGTIRTTQSRQSSFRRQLKAWHSGSHL>sp|Q9H607|OCEL1_HUMAN Occludin/ELL domain-containing protein 1 OS=Homosapiens OX=9606 GN=OCEL1 PE=2 SV=1MHNPDGSASPTADPGSELQTLGQAARRPPPPRAGHDAPRRTRPSARKPLSCFSRRPMPTREPPKTRGSRGHLHTHPPGPGPPLQGLAPRGLKTSAPRPPCQPQPGPHKAKTKKIVFEDELLSQALLGAKKPIGAIPKGHKPRPHPVPDYELKYPPVSSERERSRYVAVFQDQYGEFLELQHEVGCAQAKLRQLEALLSSLPPPQSQKEAQVAARVWREFEMKRMDPGFLDKQARCHYLKGKLRHLKTQIQKFDDQGDSEGSVYF>sp|O15243|OBRG_HUMAN Leptin receptor gene-related protein OS=Homosapiens OX=9606 GN=LEPROT PE=1 SV=1MAGVKALVALSFSGAIGLTFLMLGCALEDYGVYWPLFVLIFHAISPIPHFIAKRVTYDSDATSSACRELAYFFTTGIVVSAFGFPVILARVAVIKWGACGLVLAGNAVIFLTIQGFFLIFGRGDDFSWEQW>sp|Q8N148|OR6V1_HUMAN Olfactory receptor 6V1 OS=Homo sapiens OX=9606GN=OR6V1 PE=2 SV=1MANLSQPSEFVLLGFSSFGELQALLYGPFLMLYLLAFMGNTIIIVMVIADTHLHTPMYFFLGNFSLLEILVTMTAVPRMLSDLLVPHKVITFTGCMVQFYFHFSLGSTSFLILTDMALDRFVAICHPLRYGTLMSRAMCVQLAGAAWAAPFLAMVPTVLSRAHLDYCHGDVINHFFCDNEPLLQLSCSDTRLLEFWDFLMALTFVLSSFLVTLISYGYIVTTVLRIPSASSCQKAFSTCGSHLTLVFIGYSSTIFLYVRPGKAHSVQVRKVVALVTSVLTPFLNPFILTFCNQTVKTVLQGQMQRLKGLCKAQ>sp|Q8TAK6|OLIG1_HUMAN Oligodendrocyte transcription factor 1 OS=Homosapiens OX=9606 GN=OLIG1 PE=1 SV=2MYYAVSQARVNAVPGTMLRPQRPGDLQLGASLYELVGYRQPPSSSSSSTSSTSSTSSSSTTAPLLPKAAREKPEAPAEPPGPGPGSGAHPGGSARPDAKEEQQQQLRRKINSRERKRMQDLNLAMDALREVILPYSAAHCQGAPGRKLSKIATLLLARNYILLLGSSLQELRRALGEGAGPAAPRLLLAGLPLLAAAPGSVLLAPGAVGPPDALRPAKYLSLALDEPPCGQFALPGGGAGGPGLCTCAVCKFPHLVPASLGLAAVQAQFSK>sp|Q8NGA0|OR7G1_HUMAN Olfactory receptor 7G1 OS=Homo sapiens OX=9606GN=OR7G1 PE=3 SV=2MGPRNQTAVSEFLLMKVTEDPELKLIPFSLFLSMYLVTILGNLLILLAVISDSHLHTPMYFLLFNLSFTDICLTTTTVPKILVNIQAQNQSITYTGCLTQICLVLVFAGLESCFLAVMAYDRYVAICHPLRYTVLMNVHFWGLLILLSMFMSTMDALVQSLMVLQLSFCKNVEIPLFFCEVVQVIKLACSDTLINNILIYFASSVFGAIPLSGIIFSYSQIVTSVLRMPSARGKYKAFSTCGCHLSVFSLFYGTAFGVYISSAVAESSRITAVASVMYTVVPQMMNPFIYSLRNKEMKKALRKLIGRLFPF>sp|Q8NH08|O10AC_HUMAN Olfactory receptor 10AC1 OS=Homo sapiens OX=9606GN=OR10AC1 PE=3 SV=2MDSPSNATVPCGFLLQGFSEFPHLRPVLFLLLLGVHLATLGGNLLILVAVASMPSRQPMLLFLCQLSAIELCYTLVVVPRSLVDLSTPGHRRGSPISFLSCAFQMQMFVALGGAECFLLAAMAYDRYVAICHPLRYAAVVTPGLCARLALACCLRGLAVSVGLTVAIFHLPFCGSRLLLHFFCDITALLHLACTRSYADELPLLGACLVLLLLPSVLILASYGAIAAALRRLRCPKGRGKAASTCALHLAVTFLHYGCATFMYVRPRASYSPRLDRTLALVYTNVTPLLCPLIYSLRNREITAALSRVLGRRRPGQAPGGDLREL>sp|Q5T2S8|ODAD2_HUMAN Outer dynein arm-docking complex subunit 2 OS=Homosapiens OX=9606 GN=ODAD2 PE=1 SV=1MGVALRKLTQWTAAGHGTGILEITPLNEAILKEIIVFVESFIYKHPQEAKFVFVEPLEWNTSLAPSAFESGYVVSETTVKSEEVDKNGQPLLFLSVPQIKIRSFGQLSRLLLIAKTGKLKEAQACVEANRDPIVKILGSDYNTMKENSIALNILGKITRDDDPESEIKMKIAMLLKQLDLHLLNHSLKHISLEISLSPMTVKKDIELLKRFSGKGNQTVLESIEYTSDYEFSNGCRAPPWRQIRGEICYVLVKPHDGETLCITCSAGGVFLNGGKTDDEGDVNYERKGSIYKNLVTFLREKSPKFSENMSKLGISFSEDQQKEKDQLGKAPKKEEAAALRKDISGSDKRSLEKNQINFWRNQMTKRWEPSLNWKTTVNYKGKGSAKEIQEDKHTGKLEKPRPSVSHGRAQLLRKSAEKIEETVSDSSSESEEDEEPPDHRQEASADLPSEYWQIQKLVKYLKGGNQTATVIALCSMRDFSLAQETCQLAIRDVGGLEVLINLLETDEVKCKIGSLKILKEISHNPQIRQNIVDLGGLPIMVNILDSPHKSLKCLAAETIANVAKFKRARRVVRQHGGITKLVALLDCAHDSTKPAQSSLYEARDVEVARCGALALWSCSKSHTNKEAIRKAGGIPLLARLLKTSHENMLIPVVGTLQECASEENYRAAIKAERIIENLVKNLNSENEQLQEHCAMAIYQCAEDKETRDLVRLHGGLKPLASLLNNTDNKERLAAVTGAIWKCSISKENVTKFREYKAIETLVGLLTDQPEEVLVNVVGALGECCQERENRVIVRKCGGIQPLVNLLVGINQALLVNVTKAVGACAVEPESMMIIDRLDGVRLLWSLLKNPHPDVKASAAWALCPCIKNAKDAGEMVRSFVGGLELIVNLLKSDNKEVLASVCAAITNIAKDQENLAVITDHGVVPLLSKLANTNNNKLRHHLAEAISRCCMWGRNRVAFGEHKAVAPLVRYLKSNDTNVHRATAQALYQLSEDADNCITMHENGAVKLLLDMVGSPDQDLQEAAAGCISNIRRLALATEKARYT>sp|Q5T2S8-2|ODAD2_HUMAN Isoform 2 of Outer dynein arm-docking complexsubunit 2 OS=Homo sapiens OX=9606 GN=ODAD2MRDFSLAQETCQLAIRDVGGLEVLINLLETDEVKCKIGSLKILKEISHNPQIRQNIVDLGGLPIMVNILDSPHKSLKCLAAETIANVAKFKRARRVVRQHGGITKLVALLDCAHDSTKPAQSSLYEARDVEVARCGALALWSCSKSHTNKEAIRKAGGIPLLARLLKTSHENMLIPVVGTLQECASEENYRAAIKAERIIENLVKNLNSENEQLQEHCAMAIYQCAEDKETRDLVRLHGGLKPLASLLNNTDNKERLAAVTGAIWKCSISKENVTKFREYKAIETLVGLLTDQPEEVLVNVVGALGECCQERENRVIVRKCGGIQPLVNLLVGINQALLVNVTKAVGACAVEPESMMIIDRLDGVRLLWSLLKNPHPDVKASAAWALCPCIKNAKDAGEMVRSFVGGLELIVNLLKSDNKEVLASVCAAITNIAKDQENLAVITDHGVVPLLSKLANTNNNKLRHHLAEAISRCCMWGRNRVAFGEHKAVAPLVRYLKSNDTNVHRATAQALYQLSEDADNCITMHENGAVKTESRHVARLECSDNDLGSLQPPPPGFKRFSCLSLLSSWDYSFYWIWLGPLTRISRKLQLVVYPISAGWLLLQRRQDTLEI>sp|Q9UND3|NPIA1_HUMAN Nuclear pore complex-interacting protein familymember A1 OS=Homo sapiens OX=9606 GN=NPIPA1 PE=2 SV=3MFCCLGYEWLSGGCKTWHSAWVINTLADHRHRGTDFGGSPWLLIITVFLRSYKFAISLCTSYLCVSFLKTIFPSQNGHDGSTDVQQRARRSNRRRQEGIKIVLEDIFTLWRQVETKVRAKIRKMKVTTKVNRHDKINGKRKTAKEHLRKLSMKEREHGEKERQVSEAEENGKLDMKEIHTYMEMFQRAQALRRRAEDYYRCKITPSARKPLCNRVRMAAVEHRHSSGLPYWPYLTAETLKNRMGHQPPPPTQQHSIIDNSLSLKTPSECLLTPLPPSALPSADDNLKTPAECLLYPLPPSADDNLKTPPECLLTPLPPSAPPSVDDNLKTPPECVCSLPFHPQRMIISRN>sp|Q8IZS5|OFCC1_HUMAN Orofacial cleft 1 candidate gene 1 protein OS=Homosapiens OX=9606 GN=OFCC1 PE=1 SV=1MEREKFQQKALKQTKQKKSKSAEFLMVKEDREATEGTGNPAFNMSSPDLSACQTAEKKVIRHDMPDRTLAAHQQKFRLPASAEPKGNEYGRNYFDPLMDEEINPRQCATEVSREDDDRIFYNRLTKLFDESRQGEPQDESGREETLNSEAPGSSNKSHEIHKEASEATTAHLEEFQRSQKTIILLGSSPLEQEIRSTSLHCMEDEMSHPWILLLKVTAVIRSRRYYREQRF>sp|Q8IZS5-2|OFCC1_HUMAN Isoform 2 of Orofacial cleft 1 candidate gene 1protein OS=Homo sapiens OX=9606 GN=OFCC1MWITSLITMKDEDIFDLAGDPQDSLIPGPSPTPKQNPVCNEAFFGHQTFSLRETGLKSVHCQGQEAENMEREKFQQKALKQTKQKKSKSAEFLMVKEDREATEGTGNPAFNMSSPDLSACQTAEKKVIRHDMPDRTLAAHQQKFRLPASAEPKGNEYGRNYFDPLMDEEINPRQCATEVSREDESGREETLNSEAPGSSNKSHEIHKEASEATTAHLEEFQRSQKTIILLGSSPLEQEIRSTSLHCMEDEMSHPWILLLKVTAVIRSRRYYREQRF>sp|Q8IZS5-3|OFCC1_HUMAN Isoform 3 of Orofacial cleft 1 candidate gene 1protein OS=Homo sapiens OX=9606 GN=OFCC1MEREKFQQKALKQTKQKKSKSAEFLMVKEDREATEGTGNPAFNMSSPDLSACQTAEKKVIRHDMPDRTLAAHQQKFRLPASAEPKGNEYGRNYFDPLMDEEINPRQCATEVSREGSIPKKIGPCSMDYDPNLLEEDDELHSQGDSLTDHSVKGKSTVWRIGEAEDYSQDISYLEELEEHRFSV>sp|Q8IZS5-4|OFCC1_HUMAN Isoform 4 of Orofacial cleft 1 candidate gene 1protein OS=Homo sapiens OX=9606 GN=OFCC1MEREKFQQKALKQTKQKKSKSAEFLMVKEDREATEGTGNPAFNMSSPDLSACQTAEKKVIRHDMPDRTLAAHQQKFRLPASAEPKGNEYGRNYFDPLMDEEINPRQCATEVSREAF>sp|Q8IZS5-5|OFCC1_HUMAN Isoform 5 of Orofacial cleft 1 candidate gene 1protein OS=Homo sapiens OX=9606 GN=OFCC1MEREKFQQKALKQTKQKKSKSAEFLMVKEDREATEGTGNPAFNMSSPDLSACQTAEKKVIRHDMPDRTLAAHQQKFRLPASAEPKGNEYGRNYFDPLMDEEINPRQCATEVSREGFEIRRGRPQRIHSYVTFKDW>sp|Q9UKL2|O52A1_HUMAN Olfactory receptor 52A1 OS=Homo sapiens OX=9606GN=OR52A1 PE=2 SV=2MSISNITVYMPSVLTLVGIPGLESVQCWIGIPFCAIYLIAMIGNSLLLSIIKSERSLHEPLYIFLGMLGATDIALASSIMPKMLGIFWFNVPEIYFDSCLLQMWFIHTLQGIESGILVAMALDRYVAICYPLRHANIFTHQLVIQIGTMVVLRAAILVAPCLVLIKCRFQFYHTTVISHSYCEHMAIVKLAAANVQVNKIYGLFVAFTVAGFDLTFITLSYIQIFITVFRLPQKEARFKAFNTCIAHICVFLQFYLLAFFSFFTHRFGSHISPYIHILFSSIYLLVPPFLNPLVYGAKTTQIRIHVVKMFCS>sp|P47883|OR3A4_HUMAN Putative olfactory receptor 3A4 OS=Homo sapiensOX=9606 GN=OR3A4P PE=5 SV=4MDLGNSGNDSVVTKFVLLGLTETAALQPILFVIFLLAYVTTIGGTLSILAAILMETKLHSPMYFFLGNLSLPDVGCVSVTVPAMLSHFISNDRSIPYKACLSELFFFHLLAGADCFLLTIMAYDRYLAICQSLTYSSRMSWGIQQALVGMSCVFSFTNALTQTVALSPLNFCGPNVINHFYCDLPQPFQLSCSSVHLNGQLLFVAAAFMGVAPLVLITVSYAHVAAAVLRIRSAEGRKKAFSTCSSHLTVVGIFYGTGVFSYTRLGSVESSDKDKGIGILNTVISPMLNPLIYWTSLLDVGCISHCSSDAGVSPGPPVQSSLCCLQFTALLSPPPGWGGLSPLNSHGL>sp|Q9H0J9|PAR12_HUMAN Protein mono-ADP-ribosyltransferase PARP12 OS=Homosapiens OX=9606 GN=PARP12 PE=1 SV=1MAQAGVVGEVTQVLCAAGGALELPELRRRLRMGLSADALERLLRQRGRFVVAVRAGGAAAAPERVVLAASPLRLCRAHQGSKPGCVGLCAQLHLCRFMVYGACKFLRAGKNCRNSHSLTTEHNLSVLRTHGVDHLSYNELCQLLFQNDPWLLPEICQHYNKGDGPHGSCAFQKQCIKLHICQYFLQGECKFGTSCKRSHDFSNSENLEKLEKLGMSSDLVSRLPTIYRNAHDIKNKSSAPSRVPPLFVPQGTSERKDSSGSVSPNTLSQEEGDQICLYHIRKSCSFQDKCHRVHFHLPYRWQFLDRGKWEDLDNMELIEEAYCNPKIERILCSESASTFHSHCLNFNAMTYGATQARRLSTASSVTKPPHFILTTDWIWYWSDEFGSWQEYGRQGTVHPVTTVSSSDVEKAYLAYCTPGSDGQAATLKFQAGKHNYELDFKAFVQKNLVYGTTKKVCRRPKYVSPQDVTTMQTCNTKFPGPKSIPDYWDSSALPDPGFQKITLSSSSEEYQKVWNLFNRTLPFYFVQKIERVQNLALWEVYQWQKGQMQKQNGGKAVDERQLFHGTSAIFVDAICQQNFDWRVCGVHGTSYGKGSYFARDAAYSHHYSKSDTQTHTMFLARVLVGEFVRGNASFVRPPAKEGWSNAFYDSCVNSVSDPSIFVIFEKHQVYPEYVIQYTTSSKPSVTPSILLALGSLFSSRQ>sp|Q8NG83|OR2M3_HUMAN Olfactory receptor 2M3 OS=Homo sapiens OX=9606GN=OR2M3 PE=2 SV=1MARENSTFNSDFILLGIFNHSPTHTFLFFLVLAIFSVAFMGNSVMVLLIYLDTQLHTPMYLLLSQLSLMDLMLICTTVPKMAFNYLSGSKSISMAGCATQIFFYTSLLGSECFLLAVMAYDRYTAICHPLRYTNLMSPKICGLMTAFSWILGSTDGIIDVVATFSFSYCGSREIAHFFCDFPSLLILSCSDTSIFEKILFICCIVMIVFPVAIIIASYARVILAVIHMGSGEGRRKAFTTCSSHLLVVGMYYGAALFMYIRPTSDRSPTQDKMVSVFYTILTPMLNPLIYSLRNKEVTRAFMKILGKGKSGE>sp|Q9Y5P1|O51B2_HUMAN Olfactory receptor 51B2 OS=Homo sapiens OX=9606GN=OR51B2 PE=1 SV=4MWPNITAAPFLLTGFPGLEAAHHWISIPFFAVYVCILLGNGMLLYLIKHDHSLHEPMYYFLTMLAGTDLMVTLTTMPTVMGILWVNHREISSVGCFLQAYFIHSLSVVESGSLLAMAYDCFIAIRNPLRYASILTNTRVIALGVGVFLRGFVSILPVILRLFSFSYCKSHVITRAFCLHQEIMRLACADITFNRLYPVILISLTIFLDCLIILFSYILILNTVIGIASGEERAKALNTCISHISCVLIFYVTVMGLTFIYRFGKNVPEVVHIIMSYIYFLFPPLMNPVIYSIKTKQIQYGIIRLLSKHRFSS>sp|Q86WS3|OOSP2_HUMAN Oocyte-secreted protein 2 OS=Homo sapiens OX=9606GN=OOSP2 PE=1 SV=1MALEVLMLLAVLIWTGAENLHVKISCSLDWLMVSVIPVAESRNLYIFADELHLGMGCPANRIHTYVYEFIYLVRDCGIRTRVVSEETLLFQTELYFTPRNIDHDPQEIHLECSTSRKSVWLTPVSTENEIKLDPSPFIADFQTTAEELGLLSSSPNLL>sp|Q8NH04|O2T27_HUMAN Olfactory receptor 2T27 OS=Homo sapiens OX=9606GN=OR2T27 PE=3 SV=1MEQSNYSVYADFILLGLFSNARFPWLLFALILLVFLTSIASNVVKIILIHIDSRLHTPMYFLLSQLSLRDILYISTIVPKMLVDQVMSQRAISFAGCTAQHFLYLTLAGAEFFLLGLMSYDRYVAICNPLHYPVLMSRKICWLIVAAAWLGGSIDGFLLTPVTMQFPFCASREINHFFCEVPALLKLSCTDTSAYETAMYVCCIMMLLIPFSVISGSYTRILITVYRMSEAEGRGKAVATCSSHMVVVSLFYGAAMYTYVLPHSYHTPEQDKAVSAFYTILTPMLNPLIYSLRNKDVTGALQKVVGRCVSSGKVTTF>sp|Q8NGI2|O52N4_HUMAN Olfactory receptor 52N4 OS=Homo sapiens OX=9606GN=OR52N4 PE=2 SV=2MLTLNKTDLIPASFILNGVPGLEDTQLWISFPFCSMYVVAMVGNCGLLYLIHYEDALHKPMYYFLAMLSFTDLVMCSSTIPKALCIFWFHLKDIGFDECLVQMFFTHTFTGMESGVLMLMALDRYVAICYPLRYSTILTNPVIAKVGTATFLRGVLLIIPFTFLTKLLPYCRGNILPHTYCDHMSVAKLSCGNVKVNAIYGLMVALLIWGFDILCITNSYTMILRAVVSLSSADARQKAFNTCTAHICAIVFSYTPAFFSFFSHRFGEHIIPPSCHIIVANIYLLLPPTMNPIVYGVKTKQIRDCVIRILSGSKDTKSYSM>sp|P23760|PAX3_HUMAN Paired box protein Pax-3 OS=Homo sapiens OX=9606GN=PAX3 PE=1 SV=2MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKQVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERASAPQSDEGSDIDSEPDLPLKRKQRRSRTTFTAEQLEELERAFERTHYPDIYTREELAQRAKLTEARVQVWFSNRRARWRKQAGANQLMAFNHLIPGGFPPTAMPTLPTYQLSETSYQPTSIPQAVSDPSSTVHRPQPLPPSTVHQSTIPSNPDSSSAYCLPSTRHGFSSYTDSFVPPSGPSNPMNPTIGNGLSPQVMGLLTNHGGVPHQPQTDYALSPLTGGLEPTTTVSASCSQRLDHMKSLDSLPTSQSYCPPTYSTTGYSMDPVTGYQYGQYGQSKPWTF>sp|P23760-2|PAX3_HUMAN Isoform Pax3A of Paired box protein Pax-3 OS=Homosapiens OX=9606 GN=PAX3MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKQVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERGKRWRLGRRTCWVTWRASAS>sp|P23760-3|PAX3_HUMAN Isoform Pax3B of Paired box protein Pax-3 OS=Homosapiens OX=9606 GN=PAX3MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKQVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERGKALVSGVSSH>sp|P23760-4|PAX3_HUMAN Isoform Pax3G of Paired box protein Pax-3 OS=Homosapiens OX=9606 GN=PAX3MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKQVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERASAPQSDEGSDIDSEPDLPLKRKQRRSRTTFTAEQLEELERAFERTHYPDIYTREELAQRAKLTEARVQVWFSNRRARWRKQAGANQLMAFNHLIPGGFPPTAMPTLPTYQLSETSYQPTSIPQAVSDPSSTVHRPQPLPPSTVHQSTIPSNPDSSSAYCLPSTRHGFSSYTDSFVPPSGPSNPMNPTIGNGLSPQVPFIISSQISRK>sp|P23760-5|PAX3_HUMAN Isoform Pax3H of Paired box protein Pax-3 OS=Homosapiens OX=9606 GN=PAX3MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKQVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERASAPQSDEGSDIDSEPDLPLKRKQRRSRTTFTAEQLEELERAFERTHYPDIYTREELAQRAKLTEARVQVWFSNRRARWRKQAGANQLMAFNHLIPGGFPPTAMPTLPTYQLSETSYQPTSIPQAVSDPSSTVHRPQPLPPSTVHQSTIPSNPDSSSAYCLPSTRHGFSSYTDSFVPPSGPSNPMNPTIGNGLSPQVPFIISSQISLGFKSF>sp|P23760-6|PAX3_HUMAN Isoform 6 of Paired box protein Pax-3 OS=Homosapiens OX=9606 GN=PAX3MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERASAPQSDEGSDIDSEPDLPLKRKQRRSRTTFTAEQLEELERAFERTHYPDIYTREELAQRAKLTEARVQVWFSNRRARWRKQAGANQLMAFNHLIPGGFPPTAMPTLPTYQLSETSYQPTSIPQAVSDPSSTVHRPQPLPPSTVHQSTIPSNPDSSSAYCLPSTRHGFSSYTDSFVPPSGPSNPMNPTIGNGLSPQVMGLLTNHGGVPHQPQTDYALSPLTGGLEPTTTVSASCSQRLDHMKSLDSLPTSQSYCPPTYSTTGYSMDPVTGYQYGQYGQSAFHYLKPDIA>sp|P23760-7|PAX3_HUMAN Isoform 7 of Paired box protein Pax-3 OS=Homosapiens OX=9606 GN=PAX3MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKQVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERASAPQSDEGSDIDSEPDLPLKRKQRRSRTTFTAEQLEELERAFERTHYPDIYTREELAQRAKLTEARVQVWFSNRRARWRKQAGANQLMAFNHLIPGGFPPTAMPTLPTYQLSETSYQPTSIPQAVSDPSSTVHRPQPLPPSTVHQSTIPSNPDSSSAYCLPSTRHGFSSYTDSFVPPSGPSNPMNPTIGNGLSPQVMGLLTNHGGVPHQPQTDYALSPLTGGLEPTTTVSASCSQRLDHMKSLDSLPTSQSYCPPTYSTTGYSMDPVTGYQYGQYGQSAFHYLKPDIA>sp|P23760-8|PAX3_HUMAN Isoform Pax3E of Paired box protein Pax-3 OS=Homosapiens OX=9606 GN=PAX3MTTLAGAVPRMMRPGPGQNYPRSGFPLEVSTPLGQGRVNQLGGVFINGRPLPNHIRHKIVEMAHHGIRPCVISRQLRVSHGCVSKILCRYQETGSIRPGAIGGSKPKQVTTPDVEKKIEEYKRENPGMFSWEIRDKLLKDAVCDRNTVPSVSSISRILRSKFGKGEEEEADLERKEAEESEKKAKHSIDGILSERASAPQSDEGSDIDSEPDLPLKRKQRRSRTTFTAEQLEELERAFERTHYPDIYTREELAQRAKLTEARVQVWFSNRRARWRKQAGANQLMAFNHLIPGGFPPTAMPTLPTYQLSETSYQPTSIPQAVSDPSSTVHRPQPLPPSTVHQSTIPSNPDSSSAYCLPSTRHGFSSYTDSFVPPSGPSNPMNPTIGNGLSPQVMGLLTNHGGVPHQPQTDYALSPLTGGLEPTTTVSASCSQRLDHMKSLDSLPTSQSYCPPTYSTTGYSMDPVTGYQYGQYGQSAFHYLKPDIAWFQILLNTFDKSSGEEEDLEQ>sp|Q8NGV7|OR5H2_HUMAN Olfactory receptor 5H2 OS=Homo sapiens OX=9606GN=OR5H2 PE=3 SV=3MSNEDMEQDNTTLLTEFVLTGLTYQPEWKMPLFLVFLVIYLITIVWNLGLIALIWNDPQLHIPMYFFLGSLAFVDAWISSTVTPKMLVNFLAKNRMISLSECMIQFFSFAFGGTTECFLLATMAYDRYVAICKPLLYPVIMNNSLCIRLLAFSFLGGFLHALIHEVLIFRLTFCNSNIIHHFYCDIIPLFMISCTDPSINFLMVFILSGSIQVFTIVTVLNSYTFALFTILKKKSVRGVRKAFSTCGAHLLSVSLYYGPLIFMYLRPASPQADDQDMIDSVFYTIIIPLLNPIIYSLRNKQVIDSFTKMVKRNV>sp|Q9NR21|PAR11_HUMAN Protein mono-ADP-ribosyltransferase PARP11 OS=Homosapiens OX=9606 GN=PARP11 PE=1 SV=2MWEANPEMFHKAEELFSKTTNNEVDDMDTSDTQWGWFYLAECGKWHMFQPDTNSQCSVSSEDIEKSFKTNPCGSISFTTSKFSYKIDFAEMKQMNLTTGKQRLIKRAPFSISAFSYICENEAIPMPPHWENVNTQVPYQLIPLHNQTHEYNEVANLFGKTMDRNRIKRIQRIQNLDLWEFFCRKKAQLKKKRGVPQINEQMLFHGTSSEFVEAICIHNFDWRINGIHGAVFGKGTYFARDAAYSSRFCKDDIKHGNTFQIHGVSLQQRHLFRTYKSMFLARVLIGDYINGDSKYMRPPSKDGSYVNLYDSCVDDTWNPKIFVVFDANQIYPEYLIDFH>sp|Q9NR21-2|PAR11_HUMAN Isoform 2 of Protein mono-ADP-ribosyltransferasePARP11 OS=Homo sapiens OX=9606 GN=PARP11MWEVAHVSEMKQMNLTTGKQRLIKRAPFSISAFSYICENEAIPMPPHWENVNTQVPYQLIPLHNQTHEYNEVANLFGKTMDRNRIKRIQRIQNLDLWEFFCRKKAQLKKKRGVPQINEQMLFHGTSSEFVEAICIHNFDWRINGIHGAVFGKGTYFARDAAYSSRFCKDDIKHGNTFQIHGVSLQQRHLFRTYKSMFLARVLIGDYINGDSKYMRPPSKDGSYVNLYDSCVDDTWNPKIFVVFDANQIYPEYLIDFH>sp|Q9NR21-1|PAR11_HUMAN Isoform 3 of Protein mono-ADP-ribosyltransferasePARP11 OS=Homo sapiens OX=9606 GN=PARP11MFHKAEELFSKTTNNEVDDMDTSDTQWGWFYLAECGKWHMFQPDTNSQCSVSSEDIEKSFKTNPCGSISFTTSKFSYKIDFAEMKQMNLTTGKQRLIKRAPFSISAFSYICENEAIPMPPHWENVNTQVPYQLIPLHNQTHEYNEVANLFGKTMDRNRIKRIQRIQNLDLWEFFCRKKAQLKKKRGVPQINEQMLFHGTSSEFVEAICIHNFDWRINGIHGAVFGKGTYFARDAAYSSRFCKDDIKHGNTFQIHGVSLQQRHLFRTYKSMFLARVLIGDYINGDSKYMRPPSKDGSYVNLYDSCVDDTWNPKIFVVFDANQIYPEYLIDFH>sp|Q9NR21-5|PAR11_HUMAN Isoform 4 of Protein mono-ADP-ribosyltransferasePARP11 OS=Homo sapiens OX=9606 GN=PARP11MWEANPEMFHKAEELFSKTTNNEVDDMDTSDTQWGWFYLAECGKWHMFQPDTNSQCSVSSEDIEKSFKTNPCGSISFTTSKFSYKIDFAEMKQMNLTTGKQRLIKRAPFSISAFSYICENEAIPMPPHWENVNTQVPYQLIPLHNQTHEYNEVANLFGKTMDRNRIKRIQRIQNLDLWEFFCRKKAQLKKKRGVPQINEQMLFHGTSSEFVEAICIHNFDWRINGIHGAVFGKDNMWKL>sp|Q96FW1|OTUB1_HUMAN Ubiquitin thioesterase OTUB1 OS=Homo sapiensOX=9606 GN=OTUB1 PE=1 SV=2MAAEEPQQQKQEPLGSDSEGVNCLAYDEAIMAQQDRIQQEIAVQNPLVSERLELSVLYKEYAEDDNIYQQKIKDLHKKYSYIRKTRPDGNCFYRAFGFSHLEALLDDSKELQRFKAVSAKSKEDLVSQGFTEFTIEDFHNTFMDLIEQVEKQTSVADLLASFNDQSTSDYLVVYLRLLTSGYLQRESKFFEHFIEGGRTVKEFCQQEVEPMCKESDHIHIIALAQALSVSIQVEYMDRGEGGTTNPHIFPEGSEPKVYLLYRPGHYDILYK>sp|Q96FW1-2|OTUB1_HUMAN Isoform 2 of Ubiquitin thioesterase OTUB1OS=Homo sapiens OX=9606 GN=OTUB1MMKPSWLSRTEFSKRLLCRTLWCQSGWSSRSYTRSMLKMTTSINRRSRTSTKSTRTSARPGLTATVSIGLSDSPTWRHCWMTARSCSGEKGGHWAPRQVGVYLLPGRVGCVSSRVSPSFPGDGLDSGLARRGSAVSALASGLVEEPMLGPPFHPTPRFKAVSAKSKEDLVSQGFTEFTIEDFHNTFMDLIEQVEKQTSVADLLASFNDQSTSDYLVVYLRLLTSGYLQRESKFFEHFIEGGRTVKEFCQQEVEPMCKESDHIHIIALAQALSVSIQVEYMDRGEGGTTNPHIFPEGSEPKVYLLYRPGHYDILYK>sp|Q9UN73|PCDA6_HUMAN Protocadherin alpha-6 OS=Homo sapiens OX=9606GN=PCDHA6 PE=2 SV=1MVFTPEDRLGKQCLLLPLLLLAAWKVGSGQLHYSVPEEAKHGTFVGRIAQDLGLELAELVPRLFRMASKDREDLLEVNLQNGILFVNSRIDREELCGRSAECSIHLEVIVDRPLQVFHVDVEVRDINDNPPLFPVEEQRVLIYESRLPDSVFPLEGASDADVGSNSILTYKLSSSEYFGLDVKINSDDNKQIGLLLKKSLDREEAPAHNLFLTATDGGKPELTGTVQLLVTVLDVNDNAPTFEQSEYEVRIFENADNGTTVIRLNASDRDEGANGAISYSFNSLVAAMVIDHFSIDRNTGEIVIRGNLDFEQENLYKILIDATDKGHPPMAGHCTVLVRILDKNDNVPEIALTSLSLPVREDAQFGTVIALISVNDLDSGANGQVNCSLTPHVPFKLVSTFKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATASLSVEVADMNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERALSSYISVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLAPRVGGTGGAVSELVPRSLGAGQVVAKVRAVDADSGYNAWLSYELQPPASSARFPFRVGLYTGEISTTRVLDEADSPRHRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRASVGAAGPEAALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSAPPTEGACTADKPTLVCSSAVGSWSYSQQRRQRVCSGEGPPKMDLMAFSPSLSPCPIMMGKAENQDLNEDHDAKPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9UN73-2|PCDA6_HUMAN Isoform 2 of Protocadherin alpha-6 OS=Homosapiens OX=9606 GN=PCDHA6MVFTPEDRLGKQCLLLPLLLLAAWKVGSGQLHYSVPEEAKHGTFVGRIAQDLGLELAELVPRLFRMASKDREDLLEVNLQNGILFVNSRIDREELCGRSAECSIHLEVIVDRPLQVFHVDVEVRDINDNPPLFPVEEQRVLIYESRLPDSVFPLEGASDADVGSNSILTYKLSSSEYFGLDVKINSDDNKQIGLLLKKSLDREEAPAHNLFLTATDGGKPELTGTVQLLVTVLDVNDNAPTFEQSEYEVRIFENADNGTTVIRLNASDRDEGANGAISYSFNSLVAAMVIDHFSIDRNTGEIVIRGNLDFEQENLYKILIDATDKGHPPMAGHCTVLVRILDKNDNVPEIALTSLSLPVREDAQFGTVIALISVNDLDSGANGQVNCSLTPHVPFKLVSTFKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATASLSVEVADMNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERALSSYISVHAESGKVYALQPLDHEELELLQFQPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9UN73-3|PCDA6_HUMAN Isoform 3 of Protocadherin alpha-6 OS=Homosapiens OX=9606 GN=PCDHA6MVFTPEDRLGKQCLLLPLLLLAAWKVGSGQLHYSVPEEAKHGTFVGRIAQDLGLELAELVPRLFRMASKDREDLLEVNLQNGILFVNSRIDREELCGRSAECSIHLEVIVDRPLQVFHVDVEVRDINDNPPLFPVEEQRVLIYESRLPDSVFPLEGASDADVGSNSILTYKLSSSEYFGLDVKINSDDNKQIGLLLKKSLDREEAPAHNLFLTATDGGKPELTGTVQLLVTVLDVNDNAPTFEQSEYEVRIFENADNGTTVIRLNASDRDEGANGAISYSFNSLVAAMVIDHFSIDRNTGEIVIRGNLDFEQENLYKILIDATDKGHPPMAGHCTVLVRILDKNDNVPEIALTSLSLPVREDAQFGTVIALISVNDLDSGANGQVNCSLTPHVPFKLVSTFKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATASLSVEVADMNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERALSSYISVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLAPRVGGTGGAVSELVPRSLGAGQVVAKVRAVDADSGYNAWLSYELQPPASSARFPFRVGLYTGEISTTRVLDEADSPRHRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRASVGAAGPEAALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSAPPTEGACTADKPTLVCSSAVGSWSYSQQRRQRVCSGEGPPKMDLMAFSPSLSPCPIMMGKAENQDLNEDHDAKVSEFS>sp|Q9Y5H6|PCDA8_HUMAN Protocadherin alpha-8 OS=Homo sapiens OX=9606GN=PCDHA8 PE=2 SV=1MDYHWRGELGSWRLLLLLLLLAAWKVGSGQLHYSVPEEAKHGTFVGRIAQDLGLELAELVPRLFRVASKRHRDLLEVSLQNGILFVNSRIDREELCGRSAECSIHLEVIVDRPLQVFHVDVEVKDVNDNPPVFRVKDQKLFVSESRMPDSRFPLEGASDADVGANSVLTYRLSSHDYFMLDVNSKNDENKLVELVLRKSLDREDAPAHHLFLTATDGGKPELTGTVQLLVTVLDVNDNAPTFEQSEYEVRIFENADNGTTVIKLNASDPDEGANGAISYSFNSLVETMVIDHFSIDRNTGEIVIRGNLDFEQENLYKILIDATDKGHPPMAGHCTVLVRILDKNDNVPEIALTSLSLPVREDAQFGTVIALISVNDLDSGANGQVTCSLMPHVPFKLVSTFKNYYSLVLDSALDRERVSAYELVVTARDGGSPSLWATASLSVEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERSLSSYISVHTESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLEPRVGGTGGAASKLVPRSVGAGHVVAKVRAVDADSGYNAWLSYELQPAASSPRIPFRVGLYTGEISTTRVLDEADSPRHRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRQSAGVLGPEAALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSALPTEGGCRAGKPTLVCSSAVGSWSYSQQQPQRVCSGEGPPKTDLMAFSPCLPPDLGSVDVGEEQDLNVDHGLKPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9Y5H6-2|PCDA8_HUMAN Isoform 2 of Protocadherin alpha-8 OS=Homosapiens OX=9606 GN=PCDHA8MDYHWRGELGSWRLLLLLLLLAAWKVGSGQLHYSVPEEAKHGTFVGRIAQDLGLELAELVPRLFRVASKRHRDLLEVSLQNGILFVNSRIDREELCGRSAECSIHLEVIVDRPLQVFHVDVEVKDVNDNPPVFRVKDQKLFVSESRMPDSRFPLEGASDADVGANSVLTYRLSSHDYFMLDVNSKNDENKLVELVLRKSLDREDAPAHHLFLTATDGGKPELTGTVQLLVTVLDVNDNAPTFEQSEYEVRIFENADNGTTVIKLNASDPDEGANGAISYSFNSLVETMVIDHFSIDRNTGEIVIRGNLDFEQENLYKILIDATDKGHPPMAGHCTVLVRILDKNDNVPEIALTSLSLPVREDAQFGTVIALISVNDLDSGANGQVTCSLMPHVPFKLVSTFKNYYSLVLDSALDRERVSAYELVVTARDGGSPSLWATASLSVEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRVGERSLSSYISVHTESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLEPRVGGTGGAASKLVPRSVGAGHVVAKVRAVDADSGYNAWLSYELQPAASSPRIPFRVGLYTGEISTTRVLDEADSPRHRLLVLVKDHGEPALTATATVLVSLVESGQAPKASSRQSAGVLGPEAALVDVNVYLIIAICAVSSLLVLTLLLYTALRCSALPTEGGCRAGKPTLVCSSAVGSWSYSQQQPQRVCSGEGPPKTDLMAFSPCLPPDLGSVDVGEEQDLNVDHGLKVSPFKFRTHKFYLWKL>sp|P32243|OTX2_HUMAN Homeobox protein OTX2 OS=Homo sapiens OX=9606GN=OTX2 PE=1 SV=1MMSYLKQPPYAVNGLSLTTSGMDLLHPSVGYPATPRKQRRERTTFTRAQLDVLEALFAKTRYPDIFMREEVALKINLPESRVQVWFKNRRAKCRQQQQQQQNGGQNKVRPAKKKTSPAREVSSESGTSGQFTPPSSTSVPTIASSSAPVSIWSPASISPLSDPLSTSSSCMQRSYPMTYTQASGYSQGYAGSTSYFGGMDCGSYLTPMHHQLPGPGATLSPMGTNAVTSHLNQSPASLSTQGYGASSLGFNSTTDCLDYKDQTASWKLNFNADCLDYKDQTSSWKFQVL>sp|P32243-2|OTX2_HUMAN Isoform 2 of Homeobox protein OTX2 OS=Homosapiens OX=9606 GN=OTX2MMSYLKQPPYAVNGLSLTTSGMDLLHPSVGYPGPWASCPAATPRKQRRERTTFTRAQLDVLEALFAKTRYPDIFMREEVALKINLPESRVQVWFKNRRAKCRQQQQQQQNGGQNKVRPAKKKTSPAREVSSESGTSGQFTPPSSTSVPTIASSSAPVSIWSPASISPLSDPLSTSSSCMQRSYPMTYTQASGYSQGYAGSTSYFGGMDCGSYLTPMHHQLPGPGATLSPMGTNAVTSHLNQSPASLSTQGYGASSLGFNSTTDCLDYKDQTASWKLNFNADCLDYKDQTSSWKFQVL>sp|Q9H714|PACER_HUMAN Protein associated with UVRAG as autophagyenhancer OS=Homo sapiens OX=9606 GN=RUBCNL PE=1 SV=3MVSQSTVRQDSPVEPWEGISDHSGIIDGSPRLLNTDHPPCQLDIRLMRHKAVWINPQDVQQQPQDLQSQVPAAGNSGTHFVTDAASPSGPSPSCLGDSLAETTLSEDTTDSVGSASPHGSSEKSSSFSLSSTEVHMVRPGYSHRVSLPTSPGILATSPYPETDSAFFEPSHLTSAADEGAVQVSRRTISSNSFSPEVFVLPVDVEKENAHFYVADMIISAMEKMKCNILSQQQTESWSKEVSGLLGSDQPDSEMTFDTNIKQESGSSTSSYSGYEGCAVLQVSPVTETRTYHDVKEICKCDVDEFVILELGDFNDITETCSCSCSSSKSVTYEPDFNSAELLAKELYRVFQKCWILSVVNSQLAGSLSAAGSIVVNEECVRKDFESSMNVVQEIKFKSRIRGTEDWAPPRFQIIFNIHPPLKRDLVVAAQNFFCAGCGTPVEPKFVKRLRYCEYLGKYFCDCCHSYAESCIPARILMMWDFKKYYVSNFSKQLLDSIWHQPIFNLLSIGQSLYAKAKELDRVKEIQEQLFHIKKLLKTCRFANSALKEFEQVPGHLTDELHLFSLEDLVRIKKGLLAPLLKDILKASLAHVAGCELCQGKGFICEFCQNTTVIFPFQTATCRRCSACRACFHKQCFQSSECPRCARITARRKLLESVASAAT>sp|Q9H714-4|PACER_HUMAN Isoform 5 of Protein associated with UVRAG asautophagy enhancer OS=Homo sapiens OX=9606 GN=RUBCNLMVSQSTVRQDSPVEPWEGISDHSGIIDGSPRLLNTDHPPCQLDIRLMRHKAVWINPQDVQQQPQDLQSQVPAAGNSGTHFVTDAASPSGPSPSCLGDSLAETTLSEDTTDSVGSASPHGSSEKSSSFSLSSTEVHMVRPGYSHRVSLPTSPGILATSPYPETDSAFFEPSHLTSAADEGAVQVSRRTISSNSFSPEVFVLPVDVEKENAHFYVADMIISAMEKMKCNILSQQQTESWSKEVSGLLGSDQPDSEMTFDTNIKQESGSSTSSYSGYEGCAVLQVSPVTETRTYHDVKEICKCDVDEFVILELGDFNDITETCSCSCSSSKSVTYEPDFNSAELLAKELYRVFQKCWILSVVNSQLAGSLSAAGSIVVNEECVRKDFESSMNVVQEIKFKSRIRGTEDWAPPRFQIIFNIHPPLKRDLVVAAQNFFCAGCGTPVEPKFVKRLRYCEYLGKYFCDCCHSYAESCIPARILMMWDFKKYYVSNFSKQLLDSIWHQPIFNLLSIGQSLYAKAKELDRVKEIQEQLFHIKKLLKTCRFANSCVKERALFVNFARIRLSSSHFRQQHVEDVQRAGLAFTNSASSPPSAPGVRGSQRGENFWKVWPLQQHDAPEYCEKDCSTCLMITPICVYYW>sp|Q9H714-3|PACER_HUMAN Isoform 2 of Protein associated with UVRAG asautophagy enhancer OS=Homo sapiens OX=9606 GN=RUBCNLMVSNHYFLLCVNLPLREIHTPGPSPSCLGDSLAETTLSEDTTDSVGSASPHGSSEKSSSFSLSSTEVHMVRPGYSHRVSLPTSPGILATSPYPETDSAFFEPSHLTSAADEGAVQVSRRTISSNSFSPEVFVLPVDVEKENAHFYVADMIISAMEKMKCNILSQQQTESWSKEVSGLLGSDQPDSEMTFDTNIKQESGSSTSSYSGYEGCAVLQVSPVTETRTYHDVKEICKCDVDEFVILELGDFNDITETCSCSCSSSKSVTYEPDFNSAELLAKELYRVFQKCWILSVVNSQLAGSLSAAGSIVVNEECVRKDFESSMNVVQEIKFKSRIRGTEDWAPPRFQIIFNIHPPLKRDLVVAAQNFFCAGCGTPVEPKFVKRLRYCEYLGKYFCDCCHSYAESCIPARILMMWDFKKYYVSNFSKQLLDSIWHQPIFNLLSIGQSLYAKAKELDRVKEIQEQLFHIKKLLKTCRFANSALKEFEQVPGHLTDELHLFSLEDLVRIKKGLLAPLLKDILKASLAHVAGCELCQGKGFICEFCQNTTVIFPFQTATCRRCSACRACFHKQCFQSSECPRCARITARRKLLESVASAAT>sp|Q9H714-1|PACER_HUMAN Isoform 3 of Protein associated with UVRAG asautophagy enhancer OS=Homo sapiens OX=9606 GN=RUBCNLMVSQSTVRQDSPVEPWEGISDHSGIIDGSPRLLNTDHPPCQLDIRLMRHKAVWINPQDVQQQPQDLQSQVPAAGNSGTHFVTDAASPSGPSPSCLGDSLAETTLSEDTTDSVGSASPHGSSEKSSSFSLSSTEVHMVRPGYSHRVSLPTSPGILATSPYPETDSAFFEPSHLTSAADEGAVQVSRRTISSNSFSPEVFVLPVDVEKENAHFYVADMIISAMEKMKCNILSQQQTESWSKEVSGLLGSDQPDSEMTFDTNIKQESGSSTSSYSGYEGCAVLQVSPVTETRTYHDVKEICKCDVDEFVILVSLMSQTSILQNY>sp|Q9H714-2|PACER_HUMAN Isoform 4 of Protein associated with UVRAG asautophagy enhancer OS=Homo sapiens OX=9606 GN=RUBCNLMVSQSTVRQDSPVEPWEGISDHSGIIDGSPRLLNTDHPPCQLDIRLMRHKAVWINPQDVQQQPQDLQSQVPAAGNSGTHFVTDAASPSGPSPSCLGDSLAETTLSEDTTDSVGSASPHGSSEKSSSFSLSSTEVHKACMRKPRSWTE>sp|Q9H714-6|PACER_HUMAN Isoform 6 of Protein associated with UVRAG asautophagy enhancer OS=Homo sapiens OX=9606 GN=RUBCNLMVRPGYSHRVSLPTSPGILATSPYPETDSAFFEPSHLTSAADEGAVQVSRRTISSNSFSPEVFVLPVDVEKENAHFYVADMIISAMEKMKCNILSQQQTESWSKEVSGLLGSDQPDSEMTFDTNIKQESGSSTSSYSGYEGCAVLQVSPVTETRTYHDVKEICKCDVDEFVILELGDFNDITETCSCSCSSSKSVTYEPDFNSAELLAKELYRVFQKCWILSVVNSQLAGSLSAAGSIVVNEECVRKDFESSMNVVQEIKFKSRIRGTEDWAPPRFQIIFNIHPPLKRDLVVAAQNFFCAGCGTPVEPKFVKRLRYCEYLGKYFCDCCHSYAESCIPARILMMWDFKKYYVSNFSKQLLDSIWHQPIFNLLSIGQSLYAKAKELDRVKEIQEQLFHIKKLLKTCRFANSALKEFEQVPGHLTDELHLFSLEDLVRIKKGLLAPLLKDILKASLAHVAGCELCQGKGFICEFCQNTTVIFPFQTATCRRCSACRACFHKQCFQSSECPRCARITARRKLLESVASAAT>sp|Q9Y5H5|PCDA9_HUMAN Protocadherin alpha-9 OS=Homo sapiens OX=9606GN=PCDHA9 PE=2 SV=1MLYSSRGDPEGQPLLLSLLILAMWVVGSGQLHYSVPEEAEHGTFVGRIAQDLGLELAELVPRLFQLDSKGRGDLLEVNLQNGILFVNSRIDREELCGRSAECSIHLEVIVDRPLQVFHVDVEVKDINDNPPVFPATQKNLFIAESRPLDSRFPLEGASDADIGENALLTYRLSPNEYFFLDVPTSNQQVKPLGLVLRKLLDREETPELHLLLTATDGGKPELTGTVQLLITVLDNNDNAPVFDRTLYTVKLPENVSIGTLVIHPNASDLDEGLNGDIIYSFSSDVSPDIKSKFHMDPLSGAITVIGHMDFEESRAHKIPVEAVDKGFPPLAGHCTLLVEVVDVNDNAPQLTIKTLSVPVKEDAQLGTVIALISVIDLDADANGQVTCSLTPHVPFKLVSTYKNYYSLVLDRALDRESVSAYELVVTARDGGSPSLWATARVSVEVADVNDNAPAFAQSEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRLGERSLSSYVSVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLTPRMRGTDGAVSEMVLRSVGAGVVVGKVRAVDADSGYNAWLSYELQPETASASIPFRVGLYTGEISTTRALDETDAPRQRLLVLVKDHGEPALTATATVLVSLVESGQAPKSSSRASVGATGPEVTLVDVNVYLIIAICAVSSLLVLTLLLYTVLRCSAMPTEGECAPGKPTLVCSSAVGSWSYSQQRRQRVCSGEGKQKTDLMAFSPGLSPCAGSTERTGEPSASSDSTGKPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9Y5H5-2|PCDA9_HUMAN Isoform 2 of Protocadherin alpha-9 OS=Homosapiens OX=9606 GN=PCDHA9MLYSSRGDPEGQPLLLSLLILAMWVVGSGQLHYSVPEEAEHGTFVGRIAQDLGLELAELVPRLFQLDSKGRGDLLEVNLQNGILFVNSRIDREELCGRSAECSIHLEVIVDRPLQVFHVDVEVKDINDNPPVFPATQKNLFIAESRPLDSRFPLEGASDADIGENALLTYRLSPNEYFFLDVPTSNQQVKPLGLVLRKLLDREETPELHLLLTATDGGKPELTGTVQLLITVLDNNDNAPVFDRTLYTVKLPENVSIGTLVIHPNASDLDEGLNGDIIYSFSSDVSPDIKSKFHMDPLSGAITVIGHMDFEESRAHKIPVEAVDKGFPPLAGHCTLLVEVVDVNDNAPQLTIKTLSVPVKEDAQLGTVIALISVIDLDADANGQVTCSLTPHVPFKLVSTYKNYYSLVLDRALDRESVSAYELVVTARDGGSPSLWATARVSVEVADVNDNAPAFAQSEYTVFVKENNPPGCHIFTVSARDADAQENALVSYSLVERRLGERSLSSYVSVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLTPRMRGTDGAVSEMVLRSVGAGVVVGKVRAVDADSGYNAWLSYELQPETASASIPFRVGLYTGEISTTRALDETDAPRQRLLVLVKDHGEPALTATATVLVSLVESGQAPKSSSRASVGATGPEVTLVDVNVYLIIAICAVSSLLVLTLLLYTVLRCSAMPTEGECAPGKPTLVCSSAVGSWSYSQQRRQRVCSGEGKQKTDLMAFSPGLSPCAGSTERTGEPSASSDSTGKVGFSSILFIYIIFFLERYYRLLPGAVQIVLFIFLEIQQIFFLIK>sp|Q9H244|P2Y12_HUMAN P2Y purinoceptor 12 OS=Homo sapiens OX=9606GN=P2RY12 PE=1 SV=1MQAVDNLTSAPGNTSLCTRDYKITQVLFPLLYTVLFFVGLITNGLAMRIFFQIRSKSNFIIFLKNTVISDLLMILTFPFKILSDAKLGTGPLRTFVCQVTSVIFYFTMYISISFLGLITIDRYQKTTRPFKTSNPKNLLGAKILSVVIWAFMFLLSLPNMILTNRQPRDKNVKKCSFLKSEFGLVWHEIVNYICQVIFWINFLIVIVCYTLITKELYRSYVRTRGVGKVPRKKVNVKVFIIIAVFFICFVPFHFARIPYTLSQTRDVFDCTAENTLFYVKESTLWLTSLNACLDPFIYFFLCKSFRNSLISMLKCPNSATSLSQDNRKKEQDGGDPNEETPM>sp|Q9UN75|PCDAC_HUMAN Protocadherin alpha-12 OS=Homo sapiens OX=9606GN=PCDHA12 PE=2 SV=1MVIIGPRGPGSQRLLLSLLLLAAWEVGSGQLHYSVYEEAKHGTFVGRIAQDLGLELAELVPRLFRVASKRHGDLLEVNLQNGILFVNSRIDREKLCGRSAECSIHLEVIVDRPLQVFHVDVEVKDINDNPPVFREREQKVPVSESAPLDSHFPLEGASDADIGVNSLLTYALSLNENFELKIKTKKDKSILPELVLRKLLDREQTPKLNLLLMVIDGGKPELTGSVQIQITVLDVNDNGPAFDKPSYKVVLSENVQNDTRVIQLNASDPDEGLNGEISYGIKMILPVSEKCMFSINPDTGEIRIYGELDFEENNAYEIQVNAIDKGIPSMAGHSMVLVEVLDVNDNVPEVMVTSLSLPVQEDAQVGTVIALISVSDRDSGANGQVICSLTPHVPFKLVSTYKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATARVSVEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSAWDADAQKNALVSYSLVERRVGEHALSSYVSVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLATPAGSAGGAVSELVPRSVGAGHVVAKVRAVDADSGYNAWLSYELQPAAVGAHIPFHVGLYTGEISTTRILDEADAPRHRLLVLVKDHGEPALTSTATVLVSLVENGQAPKTSSRASVGAVDPEAALVDINVYLIIAICAVSSLLVLTLLLYTALRCSAPPTVSRCAPGKPTLVCSSAVGSWSYSQQRRQRVCSAESPPKTDLMAFSPSLQLSREDCLNPPSEPRQPNPDWRYSASLRAGMHSSVHLEEAGILRAGPGGPDQQWPTVSSATPEPEAGEVSPPVGAGVNSNSWTFKYGPGNPKQSGPGELPDKFIIPGSPAIISIRQEPTNSQIDKSDFITFGKKEETKKKKKKKKGNKTQEKKEKGNSTTDNSDQ>sp|Q9UN75-2|PCDAC_HUMAN Isoform 2 of Protocadherin alpha-12 OS=Homosapiens OX=9606 GN=PCDHA12MVIIGPRGPGSQRLLLSLLLLAAWEVGSGQLHYSVYEEAKHGTFVGRIAQDLGLELAELVPRLFRVASKRHGDLLEVNLQNGILFVNSRIDREKLCGRSAECSIHLEVIVDRPLQVFHVDVEVKDINDNPPVFREREQKVPVSESAPLDSHFPLEGASDADIGVNSLLTYALSLNENFELKIKTKKDKSILPELVLRKLLDREQTPKLNLLLMVIDGGKPELTGSVQIQITVLDVNDNGPAFDKPSYKVVLSENVQNDTRVIQLNASDPDEGLNGEISYGIKMILPVSEKCMFSINPDTGEIRIYGELDFEENNAYEIQVNAIDKGIPSMAGHSMVLVEVLDVNDNVPEVMVTSLSLPVQEDAQVGTVIALISVSDRDSGANGQVICSLTPHVPFKLVSTYKNYYSLVLDSALDRESVSAYELVVTARDGGSPSLWATARVSVEVADVNDNAPAFAQPEYTVFVKENNPPGCHIFTVSAWDADAQKNALVSYSLVERRVGEHALSSYVSVHAESGKVYALQPLDHEELELLQFQVSARDAGVPPLGSNVTLQVFVLDENDNAPALLATPAGSAGGAVSELVPRSVGAGHVVAKVRAVDADSGYNAWLSYELQPAAVGAHIPFHVGLYTGEISTTRILDEADAPRHRLLVLVKDHGEPALTSTATVLVSLVENGQAPKTSSRASVGAVDPEAALVDINVYLIIAICAVSSLLVLTLLLYTALRCSAPPTVSRCAPGKPTLVCSSAVGSWSYSQQRRQRVCSAESPPKTDLMAFSPSLQLSREDCLNPPSEVSY>sp|Q8WZ82|OVCA2_HUMAN Esterase OVCA2 OS=Homo sapiens OX=9606 GN=OVCA2PE=1 SV=1MAAQRPLRVLCLAGFRQSERGFREKTGALRKALRGRAELVCLSGPHPVPDPPGPEGARSDFGSCPPEEQPRGWWFSEQEADVFSALEEPAVCRGLEESLGMVAQALNRLGPFDGLLGFSQGAALAALVCALGQAGDPRFPLPRFILLVSGFCPRGIGFKESILQRPLSLPSLHVFGDTDKVIPSQESVQLASQFPGAITLTHSGGHFIPAAAPQRQAYLKFLDQFAE>sp|Q9Y5E6|PCDB3_HUMAN Protocadherin beta-3 OS=Homo sapiens OX=9606GN=PCDHB3 PE=1 SV=2MEAGGERFLRQRQVLLLFVFLGGSLAGSESRRYSVAEEKEKGFLIANLAKDLGLRVEELAARGAQVVSKGNKQHFQLSHQTGDLLLNEKLDREELCGPTEPCILHFQILLQNPLQFVTNELRIIDVNDHSPVFFENEMHLKILESTLPGTVIPLGNAEDLDVGRNSLQNYTITPNSHFHVLTRSRRDGRKYPELVLDKALDPEEQPELSLTLTALDGGSPPRSGTAQINIQVLDINDNAPEFAQPLYEVAVLENTPVNSVIVTVSASDLDTGSFGTISYAFFHASEEIRKTFQLNPITGDMQLVKYLNFEAINSYEVDIEAKDGGGLSGKSTVIVQVVDVNDNPPELTLSSVNSPIPENSGETVLAVFSVSDLDSGDNGRVMCSIENNLPFFLKPSVENFYTLVSEGALDRETRSEYNITITITDLGTPRLKTKYNITVLVSDVNDNAPAFTQISYTLFVRENNSPALHIGSVSATDRDSGTNAQVTYSLLPPQDPHLPLSSLVSINADNGHLFALRSLDYEALQAFEFRVGATDRGSPALSSEALVRVLVLDANDNSPFVLYPLQNGSAPCTELVPRAAEPGYLVTKVVAVDGDSGQNAWLSYQLLKATEPGLFGVWAHNGEVRTARLLSERDAAKHRLVVLVKDNGEPPRSATATLHVLLVDGFSQPYLPLPEAAPAQAQADLLTVYLVVALASVSSLFLFSVLLFVAVRLCRRSRAASVGRCSVPEGPFPGQMVDVSGTGTLSQSYQYEVCLTGGSGTNEFKFLKPIIPNFVAQGAERVSEANPSFRKSFEFS>sp|Q15391|P2Y14_HUMAN P2Y purinoceptor 14 OS=Homo sapiens OX=9606GN=P2RY14 PE=2 SV=1MINSTSTQPPDESCSQNLLITQQIIPVLYCMVFIAGILLNGVSGWIFFYVPSSKSFIIYLKNIVIADFVMSLTFPFKILGDSGLGPWQLNVFVCRVSAVLFYVNMYVSIVFFGLISFDRYYKIVKPLWTSFIQSVSYSKLLSVIVWMLMLLLAVPNIILTNQSVREVTQIKCIELKSELGRKWHKASNYIFVAIFWIVFLLLIVFYTAITKKIFKSHLKSSRNSTSVKKKSSRNIFSIVFVFFVCFVPYHIARIPYTKSQTEAHYSCQSKEILRYMKEFTLLLSAANVCLDPIIYFFLCQPFREILCKKLHIPLKAQNDLDISRIKRGNTTLESTDTL>sp|Q9UKS6|PACN3_HUMAN Protein kinase C and casein kinase substrate inneurons protein 3 OS=Homo sapiens OX=9606 GN=PACSIN3 PE=1 SV=2MAPEEDAGGEALGGSFWEAGNYRRTVQRVEDGHRLCGDLVSCFQERARIEKAYAQQLADWARKWRGTVEKGPQYGTLEKAWHAFFTAAERLSALHLEVREKLQGQDSERVRAWQRGAFHRPVLGGFRESRAAEDGFRKAQKPWLKRLKEVEASKKSYHAARKDEKTAQTRESHAKADSAVSQEQLRKLQERVERCAKEAEKTKAQYEQTLAELHRYTPRYMEDMEQAFETCQAAERQRLLFFKDMLLTLHQHLDLSSSEKFHELHRDLHQGIEAASDEEDLRWWRSTHGPGMAMNWPQFEEWSLDTQRTISRKEKGGRSPDEVTLTSIVPTRDGTAPPPQSPGSPGTGQDEEWSDEESPRKAATGVRVRALYDYAGQEADELSFRAGEELLKMSEEDEQGWCQGQLQSGRIGLYPANYVECVGA>sp|Q9Y5E5|PCDB4_HUMAN Protocadherin beta-4 OS=Homo sapiens OX=9606GN=PCDHB4 PE=2 SV=1MKKLGRIHPNRQVLAFILMVFLSQVRLEPIRYSVLEETESGSFVAHLAKDLGLGIGELASRSARVLSDDDKQRLQLDRQTGDLLLREKLDREELCGPIEPCVLHFQVFLEMPVQFFQGELLIQDINDHSPIFPEREVLLKILENSQPGTLFPLLIAEDLDVGSNGLQKYTISPNSHFHILTRNHSEGKKYPDLVQDKPLDREEQPEFSLTLVALDGGSPPRSGTVMVRILIMDINDNAPEFVHTPYGVQVLENSPLDSPIVRVLARDIDAGNFGSVSYGLFQASDEIKQTFSINEVTGEILLKKKLDFEKIKSYHVEIEATDGGGLSGKGTVVIEVVDVNDNPPELIISSLTSSIPENAPETVVSIFRIRDRDSGENGKMICSIPDNLPFILKPTLKNFYTLVTERPLDRETSAEYNITIAVTDLGTPRLKTQQNITVQVSDVNDNAPAFTQTSYTLFVRENNSPALHIGSVSATDRDSGTNAQVTYSLLPPQDPHLPLASLVSINADNGHLFALRSLDYEALQAFEFRVGASDRGSPALSSEALVRVLVLDTNDNSPFVLYPLQNGSAPCTELVPRAAEPGYLVTKVVAVDGDSGQNAWLSYQLLKATEPGLFGVWAHNGEVRTARLLSERDAAKHRLVVLVKDNGEPPRSATATLHVLLVDGFSQPYLPLPEAAPAQAQADSLTVYLVVALASVSSLFLFSVLLFVAVRLCRRSRAASVGRCSVPEGPFPGHLVDVSGTGTLSQSYQYEVCLTGDSGTGEFKFLKPIFPNLLVQDTGREVKENPKFRNSLVFS>sp|P17706|PTN2_HUMAN Tyrosine-protein phosphatase non-receptor type 2OS=Homo sapiens OX=9606 GN=PTPN2 PE=1 SV=2MPTTIEREFEELDTQRRWQPLYLEIRNESHDYPHRVAKFPENRNRNRYRDVSPYDHSRVKLQNAENDYINASLVDIEEAQRSYILTQGPLPNTCCHFWLMVWQQKTKAVVMLNRIVEKESVKCAQYWPTDDQEMLFKETGFSVKLLSEDVKSYYTVHLLQLENINSGETRTISHFHYTTWPDFGVPESPASFLNFLFKVRESGSLNPDHGPAVIHCSAGIGRSGTFSLVDTCLVLMEKGDDINIKQVLLNMRKYRMGLIQTPDQLRFSYMAIIEGAKCIKGDSSIQKRWKELSKEDLSPAFDHSPNKIMTEKYNGNRIGLEEEKLTGDRCTGLSSKMQDTMEENSESALRKRIREDRKATTAQKVQQMKQRLNENERKRKRWLYWQPILTKMGFMSVILVGAFVGWTLFFQQNAL>sp|P17706-2|PTN2_HUMAN Isoform 2 of Tyrosine-protein phosphatase non-receptor type 2 OS=Homo sapiens OX=9606 GN=PTPN2MPTTIEREFEELDTQRRWQPLYLEIRNESHDYPHRVAKFPENRNRNRYRDVSPYDHSRVKLQNAENDYINASLVDIEEAQRSYILTQGPLPNTCCHFWLMVWQQKTKAVVMLNRIVEKESVKCAQYWPTDDQEMLFKETGFSVKLLSEDVKSYYTVHLLQLENINSGETRTISHFHYTTWPDFGVPESPASFLNFLFKVRESGSLNPDHGPAVIHCSAGIGRSGTFSLVDTCLVLMEKGDDINIKQVLLNMRKYRMGLIQTPDQLRFSYMAIIEGAKCIKGDSSIQKRWKELSKEDLSPAFDHSPNKIMTEKYNGNRIGLEEEKLTGDRCTGLSSKMQDTMEENSESALRKRIREDRKATTAQKVQQMKQRLNENERKRKRPRLTDT>sp|P17706-3|PTN2_HUMAN Isoform 3 of Tyrosine-protein phosphatase non-receptor type 2 OS=Homo sapiens OX=9606 GN=PTPN2MPTTIEREFEELDTQRRWQPLYLEIRNESHDYPHRVAKFPENRNRNRYRDVSPYDHSRVKLQNAENDYINASLVDIEEAQRSYILTQGPLPNTCCHFWLMVWQQKTKAVVMLNRIVEKESVKCAQYWPTDDQEMLFKETGFSVKLLSEDVKSYYTVHLLQLENINSGETRTISHFHYTTWPDFGVPESPASFLNFLFKVRESGSLNPDHGPAVIHCSAGIGRSGTFSLVDTCLVLMEKGDDINIKQVLLNMRKYRMGLIQTPDQLRFSYMAIIEGAKCIKGDSSIQKRWKELSKEDLSPAFDHSPNKIMTEKYNGNRIGLEEEKLTGDRCTGLSSKMQDTMEENSERPRLTDT>sp|P17706-4|PTN2_HUMAN Isoform 4 of Tyrosine-protein phosphatase non-receptor type 2 OS=Homo sapiens OX=9606 GN=PTPN2MPTTIEREFEELDTQRRWQPLYLEIRNESHDYPHRVAKFPENRNRNRYRDVSPYDHSRVKLQNAENDYINASLVDIEEAQRSYILTQGPLPNTCCHFWLMVWQQKTKAVVMLNRIVEKESVKCAQYWPTDDQEMLFKETGFSVKLLSEDVKSYYTVHLLQLENINYIENLWITLYLKLLMLDVKRSLKSGETRTISHFHYTTWPDFGVPESPASFLNFLFKVRESGSLNPDHGPAVIHCSAGIGRSGTFSLVDTCLVLMEKGDDINIKQVLLNMRKYRMGLIQTPDQLRFSYMAIIEGAKCIKGDSSIQKRWKELSKEDLSPAFDHSPNKIMTEKYNGNRIGLEEEKLTGDRCTGLSSKMQDTMEENSESALRKRIREDRKATTAQKVQQMKQRLNENERKRKRPRLTDT>sp|Q6ISU1|PTCRA_HUMAN Pre T-cell antigen receptor alpha OS=Homo sapiensOX=9606 GN=PTCRA PE=1 SV=1MAGTWLLLLLALGCPALPTGVGGTPFPSLAPPIMLLVDGKQQMVVVCLVLDVAPPGLDSPIWFSAGNGSALDAFTYGPSPATDGTWTNLAHLSLPSEELASWEPLVCHTGPGAEGHSRSTQPMHLSGEASTARTCPQEPLRGTPGGALWLGVLRLLLFKLLLFDLLLTCSCLCDPAGPLPSPATTTRLRALGSHRLHPATETGGREATSSPRPQPRDRRWGDTPPGRKPGSPVWGEGSYLSSYPTCPAQAWCSRSALRAPSSSLGAFFAGDLPPPLQAGAA>sp|Q6ISU1-2|PTCRA_HUMAN Isoform 2 of Pre T-cell antigen receptor alphaOS=Homo sapiens OX=9606 GN=PTCRAMAGTWLLLLLALGCPALPTGEASTARTCPQEPLRGTPGGALWLGVLRLLLFKLLLFDLLLTCSCLCDPAGPLPSPATTTRLRALGSHRLHPATETGGREATSSPRPQPRDRRWGDTPPGRKPGSPVWGEGSYLSSYPTCPAQAWCSRSALRAPSSSLGAFFAGDLPPPLQAGAA>sp|Q6ISU1-3|PTCRA_HUMAN Isoform 3 of Pre T-cell antigen receptor alphaOS=Homo sapiens OX=9606 GN=PTCRAMAGTWLLLLLALGCPALPTGPVSFPSSPEAATTGPIWFSAGNGSALDAFTYGPSPATDGTWTNLAHLSLPSEELASWEPLVCHTGPGAEGHSRSTQPMHLSGEASTARTCPQEPLRGTPGGALWLGVLRLLLFKLLLFDLLLTCSCLCDPAGPLPSPATTTRLRALGSHRLHPATETGGREATSSPRPQPRDRRWGDTPPGRKPGSPVWGEGSYLSSYPTCPAQAWCSRSALRAPSSSLGAFFAGDLPPPLQAGAA>sp|Q96M98|PACRG_HUMAN Parkin coregulated gene protein OS=Homo sapiensOX=9606 GN=PACRG PE=1 SV=2MVAEKETLSLNKCPDKMPKRTKLLAQQPLPVHQPHSLVSEGFTVKAMMKNSVVRGPPAAGAFKERPTKPTAFRKFYERGDFPIALEHDSKGNKIAWKVEIEKLDYHHYLPLFFDGLCEMTFPYEFFARQGIHDMLEHGGNKILPVLPQLIIPIKNALNLRNRQVICVTLKVLQHLVVSAEMVGKALVPYYRQILPVLNIFKNMNGSYSLPRLECSGAIMARCNLDHLGSSDPPTSASQVAEIIVNSGDGIDYSQQKRENIGDLIQETLEAFERYGGENAFINIKYVVPTYESCLLN>sp|Q96M98-2|PACRG_HUMAN Isoform 2 of Parkin coregulated gene proteinOS=Homo sapiens OX=9606 GN=PACRGMVAEKETLSLNKCPDKMPKRTKLLAQQPLPVHQPHSLVSEGFTVKAMMKNSVVRGPPAAGAFKERPTKPTAFRKFYERGDFPIALEHDSKGNKIAWKVEIEKLDYHHYLPLFFDGLCEMTFPYEFFARQGIHDMLEHGGNKILPVLPQLIIPIKNALNLRNRQVICVTLKVLQHLVVSAEMVGKALVPYYRQILPVLNIFKNMNVNSGDGIDYSQQKRENIGDLIQETLEAFERYGGENAFINIKYVVPTYESCLLN>sp|Q9Y5E3|PCDB6_HUMAN Protocadherin beta-6 OS=Homo sapiens OX=9606GN=PCDHB6 PE=2 SV=1MMQTKVQNKKRQVAFFILLMLWGEVGSESIQYSVLEETESGTFVANLTKDLGLRVGELASRGARVVFKGNRQHLQFDPQTHDLLLNEKLDREELCGSTEPCVLPFQVLLENPLQFFQASLRVRDINDHAPEFPAREMLLKISEITMPGKIFPLKMAHDLDTGSNGLQRYTISSNPHFHVLTRNRSEGRKFPELVLDKPLDREEQPQLRLTLIALDGGSPPRSGTSEIQIQVLDINDNVPEFAQELYEAQVPENNPLGSLVITVSARDLDAGSFGKVSYALFQVDDVNQPFEINAITGEIRLRKALDFEEIQSYDVDVEATDGGGLSGKCSLVVRVLDVNDNAPELTMSFFISLIPENLPEITVAVFSVSDADSGHNQQVICSIENNLPFLLRPSVENFYTLVTEGALDRESRAEYNITITVTDLGTPRLKTQQSITVQVSDVNDNVPAFTQTSYTLFVRENNSPALHIGSVSATDRDSGINAQVTYSLLPPQDPHLPLSSLVSINADNGHLFALRSLDYEALQSFEFRVGATDRGSPALSSEALVRLLVLDANDNSPFVLYPLQNGSAPCTELVPRAAEPGYLVTKVVAVDGDSGQNAWLSYQLLKATELGLFGVWAHNGEVRTARLLSERDAAKHRLVVLVKDNGEPPRSATATLHVLLVDGFSQPYLPLPEAAPAQAQADSLTVYLVVALASVSSLFLFSVLLFVAVRLCRRSRAASVGRYSVPEGPFPGHLVDVSGTGTLSQSYQYKVCLTGGSETNEFKFLKPIMPNFPPQGTEREMEETPTSRNSFPFS>sp|O00110|OVOL3_HUMAN Putative transcription factor ovo-like protein 3OS=Homo sapiens OX=9606 GN=OVOL3 PE=3 SV=3MPRAFLVRSRRPQPPNWGHLPDQLRGDAYIPGGPLTVPGGKGQERRSVTIWLFSSDCSSLGGPPAQQSSSVRDPWTAQPTQGNLTSAPRGPGTLGCPLCPKAFPLQRMLTRHLKCHSPVRRHLCRCCGKGFHDAFDLKRHMRTHTGIRPFRCSACGKAFTQRCSLEAHLAKVHGQPASYAYRERREKLHVCEDCGFTSSRPDTYAQHRALHRAA>sp|Q9NWS1|PARI_HUMAN PCNA-interacting partner OS=Homo sapiens OX=9606GN=PARPBP PE=1 SV=3MAVFNQKSVSDMIKEFRKNWRALCNSERTTLCGADSMLLALQLSMAENNKQHSGEFTVSLSDVLLTWKYLLHEKLNLPVENMDVTDHYEDVRKIYDDFLKNSNMLDLIDVYQKCRALTSNCENYNTVSPSQLLDFLSGKQYAVGDETDLSIPTSPTSKYNRDNEKVQLLARKIIFSYLNLLVNSKNDLAVAYILNIPDRGLGREAFTDLKHAAREKQMSIFLVATSFIRTIELGGKGYAPPPSDPLRTHVKGLSNFINFIDKLDEILGEIPNPSIAGGQILSVIKMQLIKGQNSRDPFCKAIEEVAQDLDLRIKNIINSQEGVVALSTTDISPARPKSHAINHGTAYCGRDTVKALLVLLDEEAANAPTKNKAELLYDEENTIHHHGTSILTLFRSPTQVNNSIKPLRERICVSMQEKKIKMKQTLIRSQFACTYKDDYMISKDNWNNVNLASKPLCVLYMENDLSEGVNPSVGRSTIGTSFGNVHLDRSKNEKVSRKSTSQTGNKSSKRKQVDLDGENILCDNRNEPPQHKNAKIPKKSNDSQNRLYGKLAKVAKSNKCTAKDKLISGQAKLTQFFRL>sp|Q9NWS1-2|PARI_HUMAN Isoform 2 of PCNA-interacting partner OS=Homosapiens OX=9606 GN=PARPBPMDVTDHYEDVRKIYDDFLKNSNMLDLIDVYQKCRALTSNCENYNTVSPSQLLDFLSGKQYAVGDETDLSIPTSPTSKYNRDNEKVQLLARKIIFSYLNLLVNSKNDLAVAYILNIPDRGLGREAFTDLKHAAREKQMSIFLVATSFIRTIELGGKGYAPPPSDPLRTHVKGLSNFINFIDKLDEILGEIPNPSIAGGQILSVIKMQLIKGQNSRDPFCKAIEEVAQDLDLRIKNIINSQEGVVALSTTDISPARPKSHAINHGTAYCGRDTVKALLVLLDEEAANAPTKNKAELLYDEENTIHHHGTSILTLFRSPTQVNNSIKPLRERICVSMQEKKIKMKQTLIRSQFACTYKDDYMISKDNWNNVNLASKPLCVLYMENDLSEGVNPSVGRSTIGTSFGNVHLDRSKNEKVSRKSTSQTGNKSSKRKQVDLDGENILCDNRNEPPQHKNAKIPKKSNDSQNRLYGKLAKVAKSNKCTAKDKLISGQAKLTQFFRL>sp|Q9NWS1-3|PARI_HUMAN Isoform 3 of PCNA-interacting partner OS=Homosapiens OX=9606 GN=PARPBPMAVFNQKSVSDMIKEFRKNWRALCNSERTTLCGADSMLLALQLSMAENNKQHSGEFTVSLSDVLLTWKYLLHEKLNLPVENMDVTDHYEDVRKIYDDFLKNSNMLDLIDVYQKCRALTSNCENYNTVSPSQLLDFLSGKQYAVGDETDLSIPTSPTSKYNRDNEKALPVLKR>sp|Q9NWS1-4|PARI_HUMAN Isoform 4 of PCNA-interacting partner OS=Homosapiens OX=9606 GN=PARPBPMAVFNQKSVSDMIKEFRKNWRALCNSERTTLCGADSMLLALQLSMAENNKQHSGEFTVSLSDVLLTWKYLLHEKLNLPVENMDVTDHYEDVRKIYDDFLKNSNMLDLIDVYQKCRALTSNCENYNTVSPVSIF>sp|Q9NWS1-5|PARI_HUMAN Isoform 5 of PCNA-interacting partner OS=Homosapiens OX=9606 GN=PARPBPMQLIKGQNSRDPFCKAIEEVAQDLDLRIKNIINSQEGVVALSTTDISPARPKSHAINHGTAYCGRDTVKALLVLLDEEAANAPTKNKAELLYDEENTIHHHGTSILTLFRSPTQVNNSIKPLRERICVSMQEKKIKMKQTLIRSQFACTYKDDYMISKDNWNNVNLASKPLCVLYMENDLSEGVNPSVGRSTIGTSFGNVHLDRSKNEKVSRKSTSQTGNKSSKRKQVDLDGENILCDNRNEPPQHKNAKIPKKSNDSQNRLYGKLAKVAKSNKCTAKDKLISGQAKLTQFFRL>sp|Q9NWS1-6|PARI_HUMAN Isoform 6 of PCNA-interacting partner OS=Homosapiens OX=9606 GN=PARPBPMAVFNQKSVSDMIKEFRKNWRALCNSERTTLCGADSMLLALQLSMAENNKQHSGEFTVSLSDVLLTWKYLLHEKLNLPVENMDVTDHYEDVRKIYDDFLKNSNMLDLIDVYQKCRALTSNCENYNTVSPSQLLDFLSGKQYAVGDETDLSIPTSPTSKYNRDNEKVQLLARKIIFSYLNLLVNSKNDLAVAYILNIPDRGLGREAFTDLKHAAREKQMSIFLVATSFIRTIELGGKGYAPPPSDPLRTHVKGLSNFINFIDKLDEILGEIPNPRGCKSICWKINNWNEFWKCSSGQK>sp|Q9NWS1-7|PARI_HUMAN Isoform 7 of PCNA-interacting partner OS=Homosapiens OX=9606 GN=PARPBPMAVFNQKSVSDMIKEFRKNWRALCNSERTTLCGADSMLLALQLSMAENNKQHSGEFTVSLSDVLLTWKYLLHEKLNLPVENMDVTDHYEDVRKIYDDFLKNSNMLDLIDVYQKCRALTSNCENYNTVSPSQLLDFLSGKQYAVGDETDLSIPTSPTSKYNRDNEKVQLLARKIIFSYLNLLVNSKNDLAVAYILNIPDRGLGREAFTDLKHAAREKQMSIFLVATSFIRTIELGGKGYAPPPSDPLRTHVKGLSNFINFIDKLDEILGEIPNPRSPTQVNNSIKPLRERICVSMQEKKIKRV>sp|Q9Y5F0|PCDBD_HUMAN Protocadherin beta-13 OS=Homo sapiens OX=9606GN=PCDHB13 PE=2 SV=1MEASGKLICRQRQVLFSFLLLGLSLAGAAEPRSYSVVEETEGSSFVTNLAKDLGLEQREFSRRGVRVVSRGNKLHLQLNQETADLLLNEKLDREDLCGHTEPCVLRFQVLLESPFEFFQAELQVIDINDHSPVFLDKQMLVKVSESSPPGTTFPLKNAEDLDVGQNNIENYIISPNSYFRVLTRKRSDGRKYPELVLDKALDREEEAELRLTLTALDGGSPPRSGTAQVYIEVLDVNDNAPEFEQPFYRVQISEDSPVGFLVVKVSATDVDTGVNGEISYSLFQASEEIGKTFKINPLTGEIELKKQLDFEKLQSYEVNIEARDAGTFSGKCTVLIQVIDVNDHAPEVTMSAFTSPIPENAPETVVALFSVSDLDSGENGKISCSIQEDLPFLLKSAENFYTLLTERPLDRESRAEYNITITVTDLGTPMLITQLNMTVLIADVNDNAPAFTQTSYTLFVRENNSPALHIRSVSATDRDSGTNAQVTYSLLPPQDPHLPLTSLVSINADNGHLFALRSLDYEALQGFQFRVGASDHGSPALSSEALVRVVVLDANDNSPFVLYPLQNGSAPCTELVPRAAEPGYLVTKVVAVDGDSGQNAWLSYQLLKATELGLFGVWAHNGEVRTARLLSERDAAKHRLVVLVKDNGEPPRSATATLHVLLVDGFSQPYLPLPEAAPTQAQADLLTVYLVVALASVSSLFLFSVLLFVAVRLCRRSRAASVGRCLVPEGPLPGHLVDMSGTRTLSQSYQYEVCLAGGSGTNEFKFLKPIIPNFPPQCPGKEIQGNSTFPNNFGFNIQ>sp|Q9NRJ7|PCDBG_HUMAN Protocadherin beta-16 OS=Homo sapiens OX=9606GN=PCDHB16 PE=1 SV=4MEIGWMHNRRQRQVLVFFVLLSLSGAGAELGSYSVVEETERGSFVANLGKDLGLGLTEMSTRKARIISQGNKQHLQLKAQTGDLLINEKLDREELCGPTEPCILHFQVLMENPLEIFQAELRVIDINDHSPMFTEKEMILKIPENSPLGTEFPLNHALDLDVGSNNVQNYKISPSSHFRVLIHEFRDGRKYPELVLDKELDREEEPQLRLTLTALDGGSPPRSGTAQVRIEVVDINDNAPEFEQPIYKVQIPENSPLGSLVATVSARDLDGGANGKISYTLFQPSEDISKTLEVNPMTGEVRLRKQVDFEMVTSYEVRIKATDGGGLSGKCTLLLQVVDVNDNPPQVTMSALTSPIPENSPEIVVAVFSVSDPDSGNNGKTISSIQEDLPFLLKPSVKNFYTLVTERALDREARAEYNITLTVTDMGTPRLKTEHNITVQISDVNDNAPTFTQTSYTLFVRENNSPALHIGSVSATDRDSGTNAQVTYSLLPPQDPHLPLASLVSINADNGHLFALRSLDYEALQAFEFRVGATDRGSPALSREALVRVLVLDANDNSPFVLYPLQNGSAPCTELVPRAAEPGYLVTKVVAVDGDSGQNAWLSYQLLKATEPGLFGVWAHNGEVRTARLLSERDAAKQRLVVLVKDNGEPPRSATATLHVLLVDGFSQPFLPLPEAAPGQTQANSLTVYLVVALASVSSLFLFSVLLFVAVRLCRRSRAASVGRCSMPEGPFPGRLVDVSGTGTLSQSYQYEVCLTGGSETSEFKFLKPIIPNFSP>sp|P83859|OX26_HUMAN Orexigenic neuropeptide QRFP OS=Homo sapiensOX=9606 GN=QRFP PE=2 SV=1MVRPYPLIYFLFLPLGACFPLLDRREPTDAMGGLGAGERWADLAMGPRPHSVWGSSRWLRASQPQALLVIARGLQTSGREHAGCRFRFGRQDEGSEATGFLPAAGEKTSGPLGNLAEELNGYSRKKGGFSFRFGRR>sp|P29350|PTN6_HUMAN Tyrosine-protein phosphatase non-receptor type 6OS=Homo sapiens OX=9606 GN=PTPN6 PE=1 SV=1MVRWFHRDLSGLDAETLLKGRGVHGSFLARPSRKNQGDFSLSVRVGDQVTHIRIQNSGDFYDLYGGEKFATLTELVEYYTQQQGVLQDRDGTIIHLKYPLNCSDPTSERWYHGHMSGGQAETLLQAKGEPWTFLVRESLSQPGDFVLSVLSDQPKAGPGSPLRVTHIKVMCEGGRYTVGGLETFDSLTDLVEHFKKTGIEEASGAFVYLRQPYYATRVNAADIENRVLELNKKQESEDTAKAGFWEEFESLQKQEVKNLHQRLEGQRPENKGKNRYKNILPFDHSRVILQGRDSNIPGSDYINANYIKNQLLGPDENAKTYIASQGCLEATVNDFWQMAWQENSRVIVMTTREVEKGRNKCVPYWPEVGMQRAYGPYSVTNCGEHDTTEYKLRTLQVSPLDNGDLIREIWHYQYLSWPDHGVPSEPGGVLSFLDQINQRQESLPHAGPIIVHCSAGIGRTGTIIVIDMLMENISTKGLDCDIDIQKTIQMVRAQRSGMVQTEAQYKFIYVAIAQFIETTKKKLEVLQSQKGQESEYGNITYPPAMKNAHAKASRTSSKHKEDVYENLHTKNKREEKVKKQRSADKEKSKGSLKRK>sp|P29350-3|PTN6_HUMAN Isoform 2 of Tyrosine-protein phosphatase non-receptor type 6 OS=Homo sapiens OX=9606 GN=PTPN6MLSRGWFHRDLSGLDAETLLKGRGVHGSFLARPSRKNQGDFSLSVRVGDQVTHIRIQNSGDFYDLYGGEKFATLTELVEYYTQQQGVLQDRDGTIIHLKYPLNCSDPTSERWYHGHMSGGQAETLLQAKGEPWTFLVRESLSQPGDFVLSVLSDQPKAGPGSPLRVTHIKVMCEGGRYTVGGLETFDSLTDLVEHFKKTGIEEASGAFVYLRQPYYATRVNAADIENRVLELNKKQESEDTAKAGFWEEFESLQKQEVKNLHQRLEGQRPENKGKNRYKNILPFDHSRVILQGRDSNIPGSDYINANYIKNQLLGPDENAKTYIASQGCLEATVNDFWQMAWQENSRVIVMTTREVEKGRNKCVPYWPEVGMQRAYGPYSVTNCGEHDTTEYKLRTLQVSPLDNGDLIREIWHYQYLSWPDHGVPSEPGGVLSFLDQINQRQESLPHAGPIIVHCSAGIGRTGTIIVIDMLMENISTKGLDCDIDIQKTIQMVRAQRSGMVQTEAQYKFIYVAIAQFIETTKKKLEVLQSQKGQESEYGNITYPPAMKNAHAKASRTSSKHKEDVYENLHTKNKREEKVKKQRSADKEKSKGSLKRK>sp|P29350-2|PTN6_HUMAN Isoform 3 of Tyrosine-protein phosphatase non-receptor type 6 OS=Homo sapiens OX=9606 GN=PTPN6MLSRGVGDQVTHIRIQNSGDFYDLYGGEKFATLTELVEYYTQQQGVLQDRDGTIIHLKYPLNCSDPTSERWYHGHMSGGQAETLLQAKGEPWTFLVRESLSQPGDFVLSVLSDQPKAGPGSPLRVTHIKVMCEGGRYTVGGLETFDSLTDLVEHFKKTGIEEASGAFVYLRQPYYATRVNAADIENRVLELNKKQESEDTAKAGFWEEFESLQKQEVKNLHQRLEGQRPENKGKNRYKNILPFDHSRVILQGRDSNIPGSDYINANYIKNQLLGPDENAKTYIASQGCLEATVNDFWQMAWQENSRVIVMTTREVEKGRNKCVPYWPEVGMQRAYGPYSVTNCGEHDTTEYKLRTLQVSPLDNGDLIREIWHYQYLSWPDHGVPSEPGGVLSFLDQINQRQESLPHAGPIIVHCSAGIGRTGTIIVIDMLMENISTKGLDCDIDIQKTIQMVRAQRSGMVQTEAQYKFIYVAIAQFIETTKKKLEVLQSQKGQESEYGNITYPPAMKNAHAKASRTSSKHKEDVYENLHTKNKREEKVKKQRSADKEKSKGSLKRK>sp|P29350-4|PTN6_HUMAN Isoform 4 of Tyrosine-protein phosphatase non-receptor type 6 OS=Homo sapiens OX=9606 GN=PTPN6MVRWFHRDLSGLDAETLLKGRGVHGSFLARPSRKNQGDFSLSVRVGDQVTHIRIQNSGDFYDLYGGEKFATLTELVEYYTQQQGVLQDRDGTIIHLKYPLNCSDPTSERWYHGHMSGGQAETLLQAKGEPWTFLVRESLSQPGDFVLSVLSDQPKAGPGSPLRVTHIKVMCEGGRYTVGGLETFDSLTDLVEHFKKTGIEEASGAFVYLRQPYYATRVNAADIENRVLELNKKQESEDTAKAGFWEEFESLQKQEVKNLHQRLEGQRPENKGKNRYKNILPFDHSRVILQGRDSNIPGSDYINANYIKNQLLGPDENAKTYIASQGCLEATVNDFWQMAWQENSRVIVMTTREVEKGRNKCVPYWPEVGMQRAYGPYSVTNCGEHDTTEYKLRTLQVSPLDNGDLIREIWHYQYLSWPDHGVPSEPGGVLSFLDQINQRQESLPHAGPIIVHCSAGIGRTGTIIVIDMLMENISTKGLDCDIDIQKTIQMVRAQRSGMVQTEAQYKFIYVAIAQFIETTKKKLEVLQSQKGQESEYGNITYPPAMKNAHAKASRTSSKSLESSAGTVAASPVRRGGQRGLPVPGPPVLSPDLHQLPVLAPLHPAADTRRMCMRTCTLRTRGRRK>sp|P35236|PTN7_HUMAN Tyrosine-protein phosphatase non-receptor type 7OS=Homo sapiens OX=9606 GN=PTPN7 PE=1 SV=3MVQAHGGRSRAQPLTLSLGAAMTQPPPEKTPAKKHVRLQERRGSNVALMLDVRSLGAVEPICSVNTPREVTLHFLRTAGHPLTRWALQRQPPSPKQLEEEFLKIPSNFVSPEDLDIPGHASKDRYKTILPNPQSRVCLGRAQSQEDGDYINANYIRGYDGKEKVYIATQGPMPNTVSDFWEMVWQEEVSLIVMLTQLREGKEKCVHYWPTEEETYGPFQIRIQDMKECPEYTVRQLTIQYQEERRSVKHILFSAWPDHQTPESAGPLLRLVAEVEESPETAAHPGPIVVHCSAGIGRTGCFIATRIGCQQLKARGEVDILGIVCQLRLDRGGMIQTAEQYQFLHHTLALYAGQLPEEPSP>sp|P35236-2|PTN7_HUMAN Isoform 2 of Tyrosine-protein phosphatase non-receptor type 7 OS=Homo sapiens OX=9606 GN=PTPN7MGASFWPIRQAREQQRRALSFRQTSWLSEPPLGPAPHLSMVQAHGGRSRAQPLTLSLGAAMTQPPPEKTPAKKHVRLQERRGSNVALMLDVRSLGAVEPICSVNTPREVTLHFLRTAGHPLTRWALQRQPPSPKQLEEEFLKIPSNFVSPEDLDIPGHASKDRYKTILPNPQSRVCLGRAQSQEDGDYINANYIRGYDGKEKVYIATQGPMPNTVSDFWEMVWQEEVSLIVMLTQLREGKEKCVHYWPTEEETYGPFQIRIQDMKECPEYTVRQLTIQYQEERRSVKHILFSAWPDHQTPESAGPLLRLVAEVEESPETAAHPGPIVVHCSAGIGRTGCFIATRIGCQQLKARGEVDILGIVCQLRLDRGGMIQTAEQYQFLHHTLALYAGQLPEEPSP>sp|P35236-3|PTN7_HUMAN Isoform 3 of Tyrosine-protein phosphatase non-receptor type 7 OS=Homo sapiens OX=9606 GN=PTPN7MVGKAWPLTHSQGTGPWAPEGHRREAADPWWQRQQAQEGRMQLGCAWVAARRGGGRKLASWSLLSPQRQTDRQTDSWQEAAWGPQLLQQTSWLSEPPLGPAPHLSMVQAHGGRSRAQPLTLSLGAAMTQPPPEKTPAKKHVRLQERRGSNVALMLDVRSLGAVEPICSVNTPREVTLHFLRTAGHPLTRWALQRQPPSPKQLEEEFLKIPSNFVSPEDLDIPGHASKDRYKTILPNPQSRVCLGRAQSQEDGDYINANYIRGYDGKEKVYIATQGPMPNTVSDFWEMVWQEEVSLIVMLTQLREGKEKCVHYWPTEEETYGPFQIRIQDMKECPEYTVRQLTIQYQEERRSVKHILFSAWPDHQTPESAGPLLRLVAEVEESPETAAHPGPIVVHCSAGIGRTGCFIATRIGCQQLKARGEVDILGIVCQLRLDRGGMIQTAEQYQFLHHTLALYAGQLPEEPSP>sp|P43378|PTN9_HUMAN Tyrosine-protein phosphatase non-receptor type 9OS=Homo sapiens OX=9606 GN=PTPN9 PE=1 SV=1MEPATAPRPDMAPELTPEEEQATKQFLEEINKWTVQYNVSPLSWNVAVKFLMARKFDVLRAIELFHSYRETRRKEGIVKLKPHEEPLRSEILSGKFTILNVRDPTGASIALFTARLHHPHKSVQHVVLQALFYLLDRAVDSFETQRNGLVFIYDMCGSNYANFELDLGKKVLNLLKGAFPARLKKVLIVGAPIWFRVPYSIISLLLKDKVRERIQILKTSEVTQHLPRECLPENLGGYVKIDLATWNFQFLPQVNGHPDPFDEIILFSLPPALDWDSVHVPGPHAMTIQELVDYVNARQKQGIYEEYEDIRRENPVGTFHCSMSPGNLEKNRYGDVPCLDQTRVKLTKRSGHTQTDYINASFMDGYKQKNAYIGTQGPLENTYRDFWLMVWEQKVLVIVMTTRFEEGGRRKCGQYWPLEKDSRIRFGFLTVTNLGVENMNHYKKTTLEIHNTEERQKRQVTHFQFLSWPDYGVPSSAASLIDFLRVVRNQQSLAVSNMGARSKGQCPEPPIVVHCSAGIGRTGTFCSLDICLAQLEELGTLNVFQTVSRMRTQRAFSIQTPEQYYFCYKAILEFAEKEGMVSSGQNLLAVESQ>sp|P60484|PTEN_HUMAN Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN OS=Homo sapiensOX=9606 GN=PTEN PE=1 SV=1MTAIIKEIVSRNKRRYQEDGFDLDLTYIYPNIIAMGFPAERLEGVYRNNIDDVVRFLDSKHKNHYKIYNLCAERHYDTAKFNCRVAQYPFEDHNPPQLELIKPFCEDLDQWLSEDDNHVAAIHCKAGKGRTGVMICAYLLHRGKFLKAQEALDFYGEVRTRDKKGVTIPSQRRYVYYYSYLLKNHLDYRPVALLFHKMMFETIPMFSGGTCNPQFVVCQLKVKIYSSNSGPTRREDKFMYFEFPQPLPVCGDIKVEFFHKQNKMLKKDKMFHFWVNTFFIPGPEETSEKVENGSLCDQEIDSICSIERADNDKEYLVLTLTKNDLDKANKDKANRYFSPNFKVKLYFTKTVEEPSNPEASSSTSVTPDVSDNEPDHYRYSDTTDSDPENEPFDEDQHTQITKV>sp|P60484-2|PTEN_HUMAN Isoform alpha of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTENOS=Homo sapiens OX=9606 GN=PTENMERGGEAAAAAAAAAAAPGRGSESPVTISRAGNAGELVSPLLLPPTRRRRRRHIQGPGPVLNLPSAAAAPPVARAPEAAGGGSRSEDYSSSPHSAAAAARPLAAEEKQAQSLQPSSSRRSSHYPAAVQSQAAAERGASATAKSRAISILQKKPRHQQLLPSLSSFFFSHRLPDMTAIIKEIVSRNKRRYQEDGFDLDLTYIYPNIIAMGFPAERLEGVYRNNIDDVVRFLDSKHKNHYKIYNLCAERHYDTAKFNCRVAQYPFEDHNPPQLELIKPFCEDLDQWLSEDDNHVAAIHCKAGKGRTGVMICAYLLHRGKFLKAQEALDFYGEVRTRDKKGVTIPSQRRYVYYYSYLLKNHLDYRPVALLFHKMMFETIPMFSGGTCNPQFVVCQLKVKIYSSNSGPTRREDKFMYFEFPQPLPVCGDIKVEFFHKQNKMLKKDKMFHFWVNTFFIPGPEETSEKVENGSLCDQEIDSICSIERADNDKEYLVLTLTKNDLDKANKDKANRYFSPNFKVKLYFTKTVEEPSNPEASSSTSVTPDVSDNEPDHYRYSDTTDSDPENEPFDEDQHTQITKV>sp|P60484-3|PTEN_HUMAN Isoform 3 of Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTENOS=Homo sapiens OX=9606 GN=PTENMTAIIKEIVSRNKRRYQEDGFDLDLTYIYPNIIAMGFPAERLEGVYRNNIDDVVSCAERHYDTAKFNCRVAQYPFEDHNPPQLELIKPFCEDLDQWLSEDDNHVAAIHCKAGKGRTGVMICAYLLHRGKFLKAQEALDFYGEVRTRDKKADPTGGIPDKGIIVIGDGSSMDVIAP>sp|Q96BW5|PTER_HUMAN Phosphotriesterase-related protein OS=Homo sapiensOX=9606 GN=PTER PE=1 SV=1MSSLSGKVQTVLGLVEPSKLGRTLTHEHLAMTFDCCYCPPPPCQEAISKEPIVMKNLYWIQKNAYSHKENLQLNQETEAIKEELLYFKANGGGALVENTTTGISRDTQTLKRLAEETGVHIISGAGFYVDATHSSETRAMSVEQLTDVLMNEILHGADGTSIKCGIIGEIGCSWPLTESERKVLQATAHAQAQLGCPVIIHPGRSSRAPFQIIRILQEAGADISKTVMSHLDRTILDKKELLEFAQLGCYLEYDLFGTELLHYQLGPDIDMPDDNKRIRRVRLLVEEGCEDRILVAHDIHTKTRLMKYGGHGYSHILTNVVPKMLLRGITENVLDKILIENPKQWLTFK>sp|Q96BW5-2|PTER_HUMAN Isoform 2 of Phosphotriesterase-related proteinOS=Homo sapiens OX=9606 GN=PTERMSSLSGKVQTVLGLVEPSKLGRTLTHEHLAMTFDCCYCPPPPCQEAISKEPIVMKNLYWIQKNAYSHKENLQLNQETEAIKEELLYFKANGGGALVENTTTGISRDTQTLKRLAEETGVHIISGAGFYVDATHSSETRAMSVEQLTDVLMNEILHGADGTSIKCGIIGEIGCSWPLTESERKVLQATAHAQAQLGCPVIIHPGRSSRAPFQIIRILQEAGADISKTVMSHLDRVRLLVEEGCEDRILVAHDIHTKTRLMKYGGHGYSHILTNVVPKMLLRGITENVLDKILIENPKQWLTFK>sp|P21246|PTN_HUMAN Pleiotrophin OS=Homo sapiens OX=9606 GN=PTN PE=1SV=1MQAQQYQQQRRKFAAAFLAFIFILAAVDTAEAGKKEKPEKKVKKSDCGEWQWSVCVPTSGDCGLGTREGTRTGAECKQTMKTQRCKIPCNWKKQFGAECKYQFQAWGECDLNTALKTRTGSLKRALHNAECQKTVTISKPCGKLTKPKPQAESKKKKKEGKKQEKMLD>sp|Q7RTS3|PTF1A_HUMAN Pancreas transcription factor 1 subunit alphaOS=Homo sapiens OX=9606 GN=PTF1A PE=1 SV=1MDAVLLEHFPGGLDAFPSSYFDEDDFFTDQSSRDPLEDGDELLADEQAEVEFLSHQLHEYCYRDGACLLLQPAPPAAPLALAPPSSGGLGEPDDGGGGGYCCETGAPPGGFPYSPGSPPSCLAYPCAGAAVLSPGARLRGLSGAAAAAARRRRRVRSEAELQQLRQAANVRERRRMQSINDAFEGLRSHIPTLPYEKRLSKVDTLRLAIGYINFLSELVQADLPLRGGGAGGCGGPGGGGRLGGDSPGSQAQKVIICHRGTRSPSPSDPDYGLPPLAGHSLSWTDEKQLKEQNIIRTAKVWTPEDPRKLNSKSSFNNIENEPPFEFVS>sp|Q86YD1|PTOV1_HUMAN Prostate tumor-overexpressed gene 1 proteinOS=Homo sapiens OX=9606 GN=PTOV1 PE=1 SV=1MVRPRRAPYRSGAGGPLGGRGRPPRPLVVRAVRSRSWPASPRGPQPPRIRARSAPPMEGARVFGALGPIGPSSPGLTLGGLAVSEHRLSNKLLAWSGVLEWQEKRRPYSDSTAKLKRTLPCQAYVNQGENLETDQWPQKLIMQLIPQQLLTTLGPLFRNSQLAQFHFTNRDCDSLKGLCRIMGNGFAGCMLFPHISPCEVRVLMLLYSSKKKIFMGLIPYDQSGFVSAIRQVITTRKQAVGPGGVNSGPVQIVNNKFLAWSGVMEWQEPRPEPNSRSKRWLPSHVYVNQGEILRTEQWPRKLYMQLIPQQLLTTLVPLFRNSRLVQFHFTKDLETLKSLCRIMDNGFAGCVHFSYKASCEIRVLMLLYSSEKKIFIGLIPHDQGNFVNGIRRVIANQQQVLQRNLEQEQQQRGMGG>sp|Q86YD1-2|PTOV1_HUMAN Isoform 2 of Prostate tumor-overexpressed gene 1protein OS=Homo sapiens OX=9606 GN=PTOV1MRSPAVPTPARGQLGVAFVLLPPHSEGARVFGALGPIGPSSPGLTLGGLAVSEHRLSNKLLAWSGVLEWQEKRRPYSDSTAKLKRTLPCQAYVNQGENLETDQWPQKLIMQLIPQQLLTTLGPLFRNSQLAQFHFTNRDCDSLKGLCRIMGNGFAGCMLFPHISPCEVRVLMLLYSSKKKIFMGLIPYDQSGFVSAIRQVITTRKQAVGPGGVNSGPVQIVNNKFLAWSGVMEWQEPRPEPNSRSKRWLPSHVYVNQGEILRTEQWPRKLYMQLIPQQLLTTLVPLFRNSRLVQFHFTKDLETLKSLCRIMDNGFRRKSSLASSPMTRATLSTASGVSLPTSSRSCSGTWSRSNSNEGWGGSGYPQQVLQRNLEQEQQQRGMGG>sp|Q86YD1-3|PTOV1_HUMAN Isoform 3 of Prostate tumor-overexpressed gene 1protein OS=Homo sapiens OX=9606 GN=PTOV1MLFPHISPCEVRVLMLLYSSKKKIFMGLIPYDQSGFVSAIRQVITTRKQAVGPGGVNSGPVQIVNNKFLAWSGVMEWQEPRPEPNSRSKRWLPSHVYVNQGEILRTEQWPRKLYMQLIPQQLLTTLVPLFRNSRLVQFHFTKDLETLKSLCRIMDNGFAGCVHFSYKASCEIRVLMLLYSSEKKIFIGLIPHDQGNFVNGIRRVIANQQQVLQRNLEQEQQQRGMGG>sp|P30566|PUR8_HUMAN Adenylosuccinate lyase OS=Homo sapiens OX=9606GN=ADSL PE=1 SV=2MAAGGDHGSPDSYRSPLASRYASPEMCFVFSDRYKFRTWRQLWLWLAEAEQTLGLPITDEQIQEMKSNLENIDFKMAAEEEKRLRHDVMAHVHTFGHCCPKAAGIIHLGATSCYVGDNTDLIILRNALDLLLPKLARVISRLADFAKERASLPTLGFTHFQPAQLTTVGKRCCLWIQDLCMDLQNLKRVRDDLRFRGVKGTTGTQASFLQLFEGDDHKVEQLDKMVTEKAGFKRAFIITGQTYTRKVDIEVLSVLASLGASVHKICTDIRLLANLKEMEEPFEKQQIGSSAMPYKRNPMRSERCCSLARHLMTLVMDPLQTASVQWFERTLDDSANRRICLAEAFLTADTILNTLQNISEGLVVYPKVIERRIRQELPFMATENIIMAMVKAGGSRQDCHEKIRVLSQQAASVVKQEGGDNDLIERIQVDAYFSPIHSQLDHLLDPSSFTGRASQQVQRFLEEEVYPLLKPYESVMKVKAELCL>sp|P30566-2|PUR8_HUMAN Isoform 2 of Adenylosuccinate lyase OS=Homosapiens OX=9606 GN=ADSLMAAGGDHGSPDSYRSPLASRYASPEMCFVFSDRYKFRTWRQLWLWLAEAEQTLGLPITDEQIQEMKSNLENIDFKMAAEEEKRLRHDVMAHVHTFGHCCPKAAGIIHLGATSCYVGDNTDLIILRNALDLLLPKLARVISRLADFAKERASLPTLGFTHFQPAQLTTVGKRCCLWIQDLCMDLQNLKRVRDDLRFRGVKGTTGTQASFLQLFEGDDHKVEQLDKMVTEKAGFKRAFIITGQTYTRKVDIEVLSVLASLGASVHKICTDIRLLANLKEMEEPFEKQQIGSSAMPYKRNPMRSERCCSLARHLMTLVMDPLQTASVQWFERTLDDSANRRICLAEAFLTADTILNTLQNISEGLVVYPKVIERRIRQELPFMATENIIMAMVKAGGSRQVQRFLEEEVYPLLKPYESVMKVKAELCL>sp|Q06203|PUR1_HUMAN Amidophosphoribosyltransferase OS=Homo sapiensOX=9606 GN=PPAT PE=1 SV=1MELEELGIREECGVFGCIASGEWPTQLDVPHVITLGLVGLQHRGQESAGIVTSDGSSVPTFKSHKGMGLVNHVFTEDNLKKLYVSNLGIGHTRYATTGKCELENCQPFVVETLHGKIAVAHNGELVNAARLRKKLLRHGIGLSTSSDSEMITQLLAYTPPQEQDDTPDWVARIKNLMKEAPTAYSLLIMHRDVIYAVRDPYGNRPLCIGRLIPVSDINDKEKKTSETEGWVVSSESCSFLSIGARYYREVLPGEIVEISRHNVQTLDIISRSEGNPVAFCIFEYVYFARPDSMFEDQMVYTVRYRCGQQLAIEAPVDADLVSTVPESATPAALAYAGKCGLPYVEVLCKNRYVGRTFIQPNMRLRQLGVAKKFGVLSDNFKGKRIVLVDDSIVRGNTISPIIKLLKESGAKEVHIRVASPPIKYPCFMGINIPTKEELIANKPEFDHLAEYLGANSVVYLSVEGLVSSVQEGIKFKKQKEKKHDIMIQENGNGLECFEKSGHCTACLTGKYPVELEW>sp|Q8IV42|PSTK_HUMAN L-seryl-tRNA(Sec) kinase OS=Homo sapiens OX=9606GN=PSTK PE=1 SV=2MKTAENIRGTGSDGPRKRGLCVLCGLPAAGKSTFARALAHRLQQEQGWAIGVVAYDDVMPDAFLAGARARPAPSQWKLLRQELLKYLEYFLMAVINGCQMSVPPNRTEAMWEDFITCLKDQDLIFSAAFEAQSCYLLTKTAVSRPLFLVLDDNFYYQSMRYEVYQLARKYSLGFCQLFLDCPLETCLQRNGQRPQALPPETIHLMGRKLEKPNPEKNAWEHNSLTIPSPACASEASLEVTDLLLTALENPVKYAEDNMEQKDTDRIICSTNILHKTDQTLRRIVSQTMKEAKGNQEAFSEMTFKQRWVRANHAAIWRIILGNEHIKCRSAKVGWLQCCRIEKRPLSTG>sp|Q8IV42-2|PSTK_HUMAN Isoform 2 of L-seryl-tRNA(Sec) kinase OS=Homosapiens OX=9606 GN=PSTKMKTAENIRGTGSDGPRKRGLCVLCGLPAAGKSTFARALAHRLQQEQGWAIGVVAYDDVMPDAFLAGARARPAPSQWKLLRQELLKYLEYFLMAVINGCQMSVPPNRTEAMWEDFITCLKDQDLIFSAAFEAQSCYLLTKTAVSRPLFLVLDDNFYYQSMRYEVYQLARKYSLGFCQLFLDCPLETCLQRNGQRPQALPPETIHLMGRKLEKPNPEKNAWEHNSLTIPSPACASEASLEVTDLLLTALENPVKYAEDNMEQKVNFQCKFNVNEKEQLFVGRSFEPIIKCE>sp|O75475|PSIP1_HUMAN PC4 and SFRS1-interacting protein OS=Homo sapiensOX=9606 GN=PSIP1 PE=1 SV=1MTRDFKPGDLIFAKMKGYPHWPARVDEVPDGAVKPPTNKLPIFFFGTHETAFLGPKDIFPYSENKEKYGKPNKRKGFNEGLWEIDNNPKVKFSSQQAATKQSNASSDVEVEEKETSVSKEDTDHEEKASNEDVTKAVDITTPKAARRGRKRKAEKQVETEEAGVVTTATASVNLKVSPKRGRPAATEVKIPKPRGRPKMVKQPCPSESDIITEEDKSKKKGQEEKQPKKQPKKDEEGQKEEDKPRKEPDKKEGKKEVESKRKNLAKTGVTSTSDSEEEGDDQEGEKKRKGGRNFQTAHRRNMLKGQHEKEAADRKRKQEEQMETEQQNKDEGKKPEVKKVEKKRETSMDSRLQRIHAEIKNSLKIDNLDVNRCIEALDELASLQVTMQQAQKHTEMITTLKKIRRFKVSQVIMEKSTMLYNKFKNMFLVGEGDSVITQVLNKSLAEQRQHEEANKTKDQGKKGPNKKLEKEQTGSKTLNGGSDAQDGNQPQHNGESNEDSKDNHEASTKKKPSSEERETEISLKDSTLDN>sp|O75475-2|PSIP1_HUMAN Isoform 2 of PC4 and SFRS1-interacting proteinOS=Homo sapiens OX=9606 GN=PSIP1MTRDFKPGDLIFAKMKGYPHWPARVDEVPDGAVKPPTNKLPIFFFGTHETAFLGPKDIFPYSENKEKYGKPNKRKGFNEGLWEIDNNPKVKFSSQQAATKQSNASSDVEVEEKETSVSKEDTDHEEKASNEDVTKAVDITTPKAARRGRKRKAEKQVETEEAGVVTTATASVNLKVSPKRGRPAATEVKIPKPRGRPKMVKQPCPSESDIITEEDKSKKKGQEEKQPKKQPKKDEEGQKEEDKPRKEPDKKEGKKEVESKRKNLAKTGVTSTSDSEEEGDDQEGEKKRKGGRNFQTAHRRNMLKGQHEKEAADRKRKQEEQMETEHQTTCNLQ>sp|O75475-3|PSIP1_HUMAN Isoform 3 of PC4 and SFRS1-interacting proteinOS=Homo sapiens OX=9606 GN=PSIP1MTRDFKPGDLIFAKMKGYPHWPARVDEVPDGAVKPPTNKLPIFFFGTHETAFLGPKDIFPYSENKEKYGKPNKRKGFNEGLWEIDNNPKVKFSSQQAATKQSNASSDVEVEEKETSVSKEDTDHEEKASNEDVTKAVDITTPKAARRGRKRKAEKQVETEEAGVVTTATASVNLKVSPKRGRPAATEVKIPKPRGRPKMVKQPCPSESDIITEEDKSKKKGQEEKQPKKQPKKDEEGQKEEDKPRKEPDKKEGKKEVESKRKNLAKTGVTSTSDSEEEGDDQEGEKKRKGGRNFQTAHRRNMLKGQHEKEAADRKRKQEEQMETEHFAL>sp|Q8IXQ6|PARP9_HUMAN Protein mono-ADP-ribosyltransferase PARP9 OS=Homosapiens OX=9606 GN=PARP9 PE=1 SV=2MDFSMVAGAAAYNEKSGRITSLSLLFQKVFAQIFPQWRKGNTEECLPYKCSETGALGENYSWQIPINHNDFKILKNNERQLCEVLQNKFGCISTLVSPVQEGNSKSLQVFRKMLTPRIELSVWKDDLTTHAVDAVVNAANEDLLHGGGLALALVKAGGFEIQEESKQFVARYGKVSAGEIAVTGAGRLPCKQIIHAVGPRWMEWDKQGCTGKLQRAIVSILNYVIYKNTHIKTVAIPALSSGIFQFPLNLCTKTIVETIRVSLQGKPMMSNLKEIHLVSNEDPTVAAFKAASEFILGKSELGQETTPSFNAMVVNNLTLQIVQGHIEWQTADVIVNSVNPHDITVGPVAKSILQQAGVEMKSEFLATKAKQFQRSQLVLVTKGFNLFCKYIYHVLWHSEFPKPQILKHAMKECLEKCIEQNITSISFPALGTGNMEIKKETAAEILFDEVLTFAKDHVKHQLTVKFVIFPTDLEIYKAFSSEMAKRSKMLSLNNYSVPQSTREEKRENGLEARSPAINLMGFNVEEMYEAHAWIQRILSLQNHHIIENNHILYLGRKEHDILSQLQKTSSVSITEIISPGRTELEIEGARADLIEVVMNIEDMLCKVQEEMARKKERGLWRSLGQWTIQQQKTQDEMKENIIFLKCPVPPTQELLDQKKQFEKCGLQVLKVEKIDNEVLMAAFQRKKKMMEEKLHRQPVSHRLFQQVPYQFCNVVCRVGFQRMYSTPCDPKYGAGIYFTKNLKNLAEKAKKISAADKLIYVFEAEVLTGFFCQGHPLNIVPPPLSPGAIDGHDSVVDNVSSPETFVIFSGMQAIPQYLWTCTQEYVQSQDYSSGPMRPFAQHPWRGFASGSPVD>sp|Q8IXQ6-2|PARP9_HUMAN Isoform 2 of Protein mono-ADP-ribosyltransferasePARP9 OS=Homo sapiens OX=9606 GN=PARP9MDFSMVAGAAAYNEKSETGALGENYSWQIPINHNDFKILKNNERQLCEVLQNKFGCISTLVSPVQEGNSKSLQVFRKMLTPRIELSVWKDDLTTHAVDAVVNAANEDLLHGGGLALALVKAGGFEIQEESKQFVARYGKVSAGEIAVTGAGRLPCKQIIHAVGPRWMEWDKQGCTGKLQRAIVSILNYVIYKNTHIKTVAIPALSSGIFQFPLNLCTKTIVETIRVSLQGKPMMSNLKEIHLVSNEDPTVAAFKAASEFILGKSELGQETTPSFNAMVVNNLTLQIVQGHIEWQTADVIVNSVNPHDITVGPVAKSILQQAGVEMKSEFLATKAKQFQRSQLVLVTKGFNLFCKYIYHVLWHSEFPKPQILKHAMKECLEKCIEQNITSISFPALGTGNMEIKKETAAEILFDEVLTFAKDHVKHQLTVKFVIFPTDLEIYKAFSSEMAKRSKMLSLNNYSVPQSTREEKRENGLEARSPAINLMGFNVEEMYEAHAWIQRILSLQNHHIIENNHILYLGRKEHDILSQLQKTSSVSITEIISPGRTELEIEGARADLIEVVMNIEDMLCKVQEEMARKKERGLWRSLGQWTIQQQKTQDEMKENIIFLKCPVPPTQELLDQKKQFEKCGLQVLKVEKIDNEVLMAAFQRKKKMMEEKLHRQPVSHRLFQQVPYQFCNVVCRVGFQRMYSTPCDPKYGAGIYFTKNLKNLAEKAKKISAADKLIYVFEAEVLTGFFCQGHPLNIVPPPLSPGAIDGHDSVVDNVSSPETFVIFSGMQAIPQYLWTCTQEYVQSQDYSSGPMRPFAQHPWRGFASGSPVD>sp|Q8IXQ6-3|PARP9_HUMAN Isoform 3 of Protein mono-ADP-ribosyltransferasePARP9 OS=Homo sapiens OX=9606 GN=PARP9MDFSMVAGAAAYNEKSETGALGENYSWQIPINHNDFKILKNNERQLCEVLQNKFGCISTLVSPVQEGNSKSLQVFRKMLTPRIELSVWKDDLTTHAVDAVVNAANEDLLHGGGLALALVKAGGFEIQEESKQFVARYGKVSAGEIAVTGAGRLPCKQIIHAVGPRWMEWDKQGCTGKLQRAIVSILNYVIYKNTHIKTVAIPALSSGIFQFPLNLCTKTIVETIRVSLQGKPMMSNLKEIHLVSNEDPTVAAFKAASEFILGKSELGQETTPSFNAMVVNNLTLQIVQGHIEWQTADVIVNSVNPHDITVGPVAKSILQQAGVEMKSEFLATKAKQFQRSQLVLVTKGFNLFCKYIYHVLWHSEFPKPQILKHAMKECLEKCIEQNITSISFPALGTGNMEIKKETAAEILFDEVLTFAKDHVKHQLTVKFVIFPTDLEIYKAFSSEMAKRSKMLSLNNYSVPQSTREEKRENGLEARSPAINLMGFNVEEMYEAHAWIQRILSLQNHHIIENNHILYLGRKEHDILSQLQKTSSVSITEIISPGRTELEIEGARADLIEVVMNIEDMLCKVQEEMARKKERGLWRSLGQWTIQQQKTQDEMKENIIFLKCPVPPTQELLDQKKQFEKCGLQVLKVEKIDNEVLMAAFQRKKKMMEEKLHRQPVSHRLFQQVPYQFCNVVCRVGFQRMYSTPCGRCQCLIIGATLWNLVS>sp|Q9Y5H3|PCDGA_HUMAN Protocadherin gamma-A10 OS=Homo sapiens OX=9606GN=PCDHGA10 PE=2 SV=1MAAQRNRSKESKDCSGLVLLCLFFGIPWEAGARQISYSIPEELEKGSFVGNISKDLGLAPRELAERGVRIVSRGRTQLFSLNPRSGSLITAGRIDREELCAQSARCVVSFNILVEDRVKLFGIEIEVTDINDNAPKFQAENLDVKINENVAAGMRFPLPEAIDPDVGVNSLQSYQLSPNKHFSLRVQSRANGVKYPELVLEHSLDREEEAIHHLVLTASDGGDPLRSGTVLVSVTVFDANDNAPVFTLPEYRVSVPENLPVGTQLLTVTATDRDEGANGEVTYSFRKLPDTQLLKFQLNKYTGEIKISENLDYEETGFYEIEIQAEDGGAYLATAKVLITVEDVNDNSPELTITSLFSPVTEDSPLGTVVALLNVHDLDSEQNGQVTCSILAYLPFKLEKSIDSYYRLVIHRALDREQVSSYNITVTATDGGSPPLSTEAHFMLQVADINDNPPTFSQVSYFTYIPENNARGASIFSVTALDPDSKENAQIIYSLAEDTIQGVPLSSYISINSDTGVLYALRSFDYEQFHELQMQVTASDSGDPPLSSNVSLSLFVLDQNDNAPEILYPALPTDGSTGVELAPRSAEPGYLVTKVVAVDRDSGQNAWLSYRLLKASEPGLFAVGEHTGEVRTARALLDRDALKQSLVVAVQDHGQPPLSATVTLTVAVADSIPQVLADLGSFESPANSETSDLTLYLVVAVAAVSCVFLAFVIVLLAHRLRRWHKSRLLQASGGGLTGVSGSHFVGVDGVRAFLQTYSHEVSLTADSRKSHLIFPQPNYADTLISQESCEKNDPLSLLDDSKFPIEDTPLVPQAPPNTDWRFSQAQRPGTSGSQNGDDTGTWPNNQFDTEMLQAMILASASEAADGSSTLGGGAGTMGLSARYGPQFTLQHVPDYRQNVYIPGSNATLTNAAGKRDGKAPAGGNGNKKKSGKKEKK>sp|Q9Y5H3-2|PCDGA_HUMAN Isoform 2 of Protocadherin gamma-A10 OS=Homosapiens OX=9606 GN=PCDHGA10MAAQRNRSKESKDCSGLVLLCLFFGIPWEAGARQISYSIPEELEKGSFVGNISKDLGLAPRELAERGVRIVSRGRTQLFSLNPRSGSLITAGRIDREELCAQSARCVVSFNILVEDRVKLFGIEIEVTDINDNAPKFQAENLDVKINENVAAGMRFPLPEAIDPDVGVNSLQSYQLSPNKHFSLRVQSRANGVKYPELVLEHSLDREEEAIHHLVLTASDGGDPLRSGTVLVSVTVFDANDNAPVFTLPEYRVSVPENLPVGTQLLTVTATDRDEGANGEVTYSFRKLPDTQLLKFQLNKYTGEIKISENLDYEETGFYEIEIQAEDGGAYLATAKVLITVEDVNDNSPELTITSLFSPVTEDSPLGTVVALLNVHDLDSEQNGQVTCSILAYLPFKLEKSIDSYYRLVIHRALDREQVSSYNITVTATDGGSPPLSTEAHFMLQVADINDNPPTFSQVSYFTYIPENNARGASIFSVTALDPDSKENAQIIYSLAEDTIQGVPLSSYISINSDTGVLYALRSFDYEQFHELQMQVTASDSGDPPLSSNVSLSLFVLDQNDNAPEILYPALPTDGSTGVELAPRSAEPGYLVTKVVAVDRDSGQNAWLSYRLLKASEPGLFAVGEHTGEVRTARALLDRDALKQSLVVAVQDHGQPPLSATVTLTVAVADSIPQVLADLGSFESPANSETSDLTLYLVVAVAAVSCVFLAFVIVLLAHRLRRWHKSRLLQASGGGLTGVSGSHFVGVDGVRAFLQTYSHEVSLTADSRKSHLIFPQPNYADTLISQESCEKNDPLSLLDDSKFPIEDTPLVPVSFIFIFTFVKKKKIGFYFEVCGMMVESVNAKTLMSRI>sp|Q7Z3E1|PARPT_HUMAN Protein mono-ADP-ribosyltransferase TIPARP OS=Homosapiens OX=9606 GN=TIPARP PE=1 SV=1MEMETTEPEPDCVVQPPSPPDDFSCQMRLSEKITPLKTCFKKKDQKRLGTGTLRSLRPILNTLLESGSLDGVFRSRNQSTDENSLHEPMMKKAMEINSSCPPAENNMSVLIPDRTNVGDQIPEAHPSTEAPERVVPIQDHSFPSETLSGTVADSTPAHFQTDLLHPVSSDVPTSPDCLDKVIDYVPGIFQENSFTIQYILDTSDKLSTELFQDKSEEASLDLVFELVNQLQYHTHQENGIEICMDFLQGTCIYGRDCLKHHTVLPYHWQIKRTTTQKWQSVFNDSQEHLERFYCNPENDRMRMKYGGQEFWADLNAMNVYETTEFDQLRRLSTPPSSNVNSIYHTVWKFFCRDHFGWREYPESVIRLIEEANSRGLKEVRFMMWNNHYILHNSFFRREIKRRPLFRSCFILLPYLQTLGGVPTQAPPPLEATSSSQIICPDGVTSANFYPETWVYMHPSQDFIQVPVSAEDKSYRIIYNLFHKTVPEFKYRILQILRVQNQFLWEKYKRKKEYMNRKMFGRDRIINERHLFHGTSQDVVDGICKHNFDPRVCGKHATMFGQGSYFAKKASYSHNFSKKSSKGVHFMFLAKVLTGRYTMGSHGMRRPPPVNPGSVTSDLYDSCVDNFFEPQIFVIFNDDQSYPYFVIQYEEVSNTVSI>sp|Q9UN71|PCDGG_HUMAN Protocadherin gamma-B4 OS=Homo sapiens OX=9606GN=PCDHGB4 PE=2 SV=1MGSGAGELGRAERLPVLFLFLLSLFCPALCEQIRYRIPEEMPKGSVVGNLATDLGFSVQELPTRKLRVSSEKPYFTVSAESGELLVSSRLDREEICGKKPACALEFEAVAENPLNFYHVNVEIEDINDHTPKFTQNSFELQISESAQPGTRFILGSAHDADIGSNTLQNYQLSPSDHFSLINKEKSDGSKYPEMVLKTPLDREKQKSYHLTLTALDFGAPPLSSTAQIHVLVTDANDNAPVFSQDVYRVSLSENVYPGTTVLQVTATDQDEGVNAEITFSFSEASQITQFDLNSNTGEITVLNTLDFEEVKEYSIVLEARDGGGMIAQCTVEVEVIDENDNAPEVIFQSLPNLIMEDAELGTHIALLKVRDKDSRHNGEVTCKLEGDVPFKILTSSRNTYKLVTDAVLDREQNPEYNITVTATDRGKPPLSSSSSITLHIGDVNDNAPVFSQSSYIVHVAENNPPGASISQVRASDPDLGPNGQVSYCIMASDLEQRELSSYVSISAESGVVFAQRAFDHEQLRAFELTLQARDQGSPALSANVSLRVLVDDRNDNAPRVLYPALGPDGSALFDMVPHAAEPGYLVTKVVAVDADSGHNAWLSYHVLQASEPGLFSLGLRTGEVRTARALGDRDAVRQRLLVAVRDGGQPPLSATATLHLVFADSLQEVLPDITDRPDPSDLQAELQFYLVVALALISVLFLVAMILAIALRLRRSSSPASWSCFQPGLCVKSESVVPPNYSEGTLPYSYNLCVAHTGKTEFNFLKCSEQLSSGQDILCGDSSGALFPLCNSSELTSHQQAPPNTDWRFSQAQRPGTSGSQNGDDTGTWPNNQFDTEMLQAMILASASEAADGSSTLGGGAGTMGLSARYGPQFTLQHVPDYRQNVYIPGSNATLTNAAGKRDGKAPAGGNGNKKKSGKKEKK>sp|Q9UN71-2|PCDGG_HUMAN Isoform 2 of Protocadherin gamma-B4 OS=Homosapiens OX=9606 GN=PCDHGB4MGSGAGELGRAERLPVLFLFLLSLFCPALCEQIRYRIPEEMPKGSVVGNLATDLGFSVQELPTRKLRVSSEKPYFTVSAESGELLVSSRLDREEICGKKPACALEFEAVAENPLNFYHVNVEIEDINDHTPKFTQNSFELQISESAQPGTRFILGSAHDADIGSNTLQNYQLSPSDHFSLINKEKSDGSKYPEMVLKTPLDREKQKSYHLTLTALDFGAPPLSSTAQIHVLVTDANDNAPVFSQDVYRVSLSENVYPGTTVLQVTATDQDEGVNAEITFSFSEASQITQFDLNSNTGEITVLNTLDFEEVKEYSIVLEARDGGGMIAQCTVEVEVIDENDNAPEVIFQSLPNLIMEDAELGTHIALLKVRDKDSRHNGEVTCKLEGDVPFKILTSSRNTYKLVTDAVLDREQNPEYNITVTATDRGKPPLSSSSSITLHIGDVNDNAPVFSQSSYIVHVAENNPPGASISQVRASDPDLGPNGQVSYCIMASDLEQRELSSYVSISAESGVVFAQRAFDHEQLRAFELTLQARDQGSPALSANVSLRVLVDDRNDNAPRVLYPALGPDGSALFDMVPHAAEPGYLVTKVVAVDADSGHNAWLSYHVLQASEPGLFSLGLRTGEVRTARALGDRDAVRQRLLVAVRDGGQPPLSATATLHLVFADSLQEVLPDITDRPDPSDLQAELQFYLVVALALISVLFLVAMILAIALRLRRSSSPASWSCFQPGLCVKSESVVPPNYSEGTLPYSYNLCVAHTGKTEFNFLKCSEQLSSGQDILCGDSSGALFPLCNSSELTSHQVSFL>sp|Q9UKK3|PARP4_HUMAN Protein mono-ADP-ribosyltransferase PARP4 OS=Homosapiens OX=9606 GN=PARP4 PE=1 SV=3MVMGIFANCIFCLKVKYLPQQQKKKLQTDIKENGGKFSFSLNPQCTHIILDNADVLSQYQLNSIQKNHVHIANPDFIWKSIREKRLLDVKNYDPYKPLDITPPPDQKASSSEVKTEGLCPDSATEEEDTVELTEFGMQNVEIPHLPQDFEVAKYNTLEKVGMEGGQEAVVVELQCSRDSRDCPFLISSHFLLDDGMETRRQFAIKKTSEDASEYFENYIEELKKQGFLLREHFTPEATQLASEQLQALLLEEVMNSSTLSQEVSDLVEMIWAEALGHLEHMLLKPVNRISLNDVSKAEGILLLVKAALKNGETAEQLQKMMTEFYRLIPHKGTMPKEVNLGLLAKKADLCQLIRDMVNVCETNLSKPNPPSLAKYRALRCKIEHVEQNTEEFLRVRKEVLQNHHSKSPVDVLQIFRVGRVNETTEFLSKLGNVRPLLHGSPVQNIVGILCRGLLLPKVVEDRGVQRTDVGNLGSGIYFSDSLSTSIKYSHPGETDGTRLLLICDVALGKCMDLHEKDFSLTEAPPGYDSVHGVSQTASVTTDFEDDEFVVYKTNQVKMKYIIKFSMPGDQIKDFHPSDHTELEEYRPEFSNFSKVEDYQLPDAKTSSSTKAGLQDASGNLVPLEDVHIKGRIIDTVAQVIVFQTYTNKSHVPIEAKYIFPLDDKAAVCGFEAFINGKHIVGEIKEKEEAQQEYLEAVTQGHGAYLMSQDAPDVFTVSVGNLPPKAKVLIKITYITELSILGTVGVFFMPATVAPWQQDKALNENLQDTVEKICIKEIGTKQSFSLTMSIEMPYVIEFIFSDTHELKQKRTDCKAVISTMEGSSLDSSGFSLHIGLSAAYLPRMWVEKHPEKESEACMLVFQPDLDVDLPDLASESEVIICLDCSSSMEGVTFLQAKQIALHALSLVGEKQKVNIIQFGTGYKELFSYPKHITSNTMAAEFIMSATPTMGNTDFWKTLRYLSLLYPARGSRNILLVSDGHLQDESLTLQLVKRSRPHTRLFACGIGSTANRHVLRILSQCGAGVFEYFNAKSKHSWRKQIEDQMTRLCSPSCHSVSVKWQQLNPDVPEALQAPAQVPSLFLNDRLLVYGFIPHCTQATLCALIQEKEFRTMVSTTELQKTTGTMIHKLAARALIRDYEDGILHENETSHEMKKQTLKSLIIKLSKENSLITQFTSFVAVEKRDENESPFPDIPKVSELIAKEDVDFLPYMSWQGEPQEAVRNQSLLASSEWPELRLSKRKHRKIPFSKRKMELSQPEVSEDFEEDGLGVLPAFTSNLERGGVEKLLDLSWTESCKPTATEPLFKKVSPWETSTSSFFPILAPAVGSYLPPTARAHSPASLSFASYRQVASFGSAAPPRQFDASQFSQGPVPGTCADWIPQSASCPTGPPQNPPSSPYCGIVFSGSSLSSAQSAPLQHPGGFTTRPSAGTFPELDSPQLHFSLPTDPDPIRGFGSYHPSASSPFHFQPSAASLTANLRLPMASALPEALCSQSRTTPVDLCLLEESVGSLEGSRCPVFAFQSSDTESDELSEVLQDSCFLQIKCDTKDDSILCFLEVKEEDEIVCIQHWQDAVPWTELLSLQTEDGFWKLTPELGLILNLNTNGLHSFLKQKGIQSLGVKGRECLLDLIATMLVLQFIRTRLEKEGIVFKSLMKMDDASISRNIPWAFEAIKQASEWVRRTEGQYPSICPRLELGNDWDSATKQLLGLQPISTVSPLHRVLHYSQG>sp|O60330|PCDGC_HUMAN Protocadherin gamma-A12 OS=Homo sapiens OX=9606GN=PCDHGA12 PE=2 SV=1MIPARLHRDYKGLVLLGILLGTLWETGCTQIRYSVPEELEKGSRVGDISRDLGLEPRELAERGVRIIPRGRTQLFALNPRSGSLVTAGRIDREELCMGAIKCQLNLDILMEDKVKIYGVEVEVRDINDNAPYFRESELEIKISENAATEMRFPLPHAWDPDIGKNSLQSYELSPNTHFSLIVQNGADGSKYPELVLKRALDREEKAAHHLVLTASDGGDPVRTGTARIRVMVLDANDNAPAFAQPEYRASVPENLALGTQLLVVNATDPDEGVNAEVRYSFRYVDDKAAQVFKLDCNSGTISTIGELDHEESGFYQMEVQAMDNAGYSARAKVLITVLDVNDNAPEVVLTSLASSVPENSPRGTLIALLNVNDQDSEENGQVICFIQGNLPFKLEKSYGNYYSLVTDIVLDREQVPSYNITVTATDRGTPPLSTETHISLNVADTNDNPPVFPQASYSAYIPENNPRGVSLVSVTAHDPDCEENAQITYSLAENTIQGASLSSYVSINSDTGVLYALSSFDYEQFRDLQVKVMARDNGHPPLSSNVSLSLFVLDQNDNAPEILYPALPTDGSTGVELAPRSAEPGYLVTKVVAVDRDSGQNAWLSYRLLKASEPGLFSVGLHTGEVRTARALLDRDALKQSLVVAVQDHGQPPLSATVTLTVAVADSIPQVLADLGSLESPANSETSDLTLYLVVAVAAVSCVFLAFVILLLALRLRRWHKSRLLQASGGGLTGAPASHFVGVDGVQAFLQTYSHEVSLTTDSRKSHLIFPQPNYADMLVSQESFEKSEPLLLSGDSVFSKDSHGLIEQAPPNTDWRFSQAQRPGTSGSQNGDDTGTWPNNQFDTEMLQAMILASASEAADGSSTLGGGAGTMGLSARYGPQFTLQHVPDYRQNVYIPGSNATLTNAAGKRDGKAPAGGNGNKKKSGKKEKK>sp|O60330-2|PCDGC_HUMAN Isoform 2 of Protocadherin gamma-A12 OS=Homosapiens OX=9606 GN=PCDHGA12MIPARLHRDYKGLVLLGILLGTLWETGCTQIRYSVPEELEKGSRVGDISRDLGLEPRELAERGVRIIPRGRTQLFALNPRSGSLVTAGRIDREELCMGAIKCQLNLDILMEDKVKIYGVEVEVRDINDNAPYFRESELEIKISENAATEMRFPLPHAWDPDIGKNSLQSYELSPNTHFSLIVQNGADGSKYPELVLKRALDREEKAAHHLVLTASDGGDPVRTGTARIRVMVLDANDNAPAFAQPEYRASVPENLALGTQLLVVNATDPDEGVNAEVRYSFRYVDDKAAQVFKLDCNSGTISTIGELDHEESGFYQMEVQAMDNAGYSARAKVLITVLDVNDNAPEVVLTSLASSVPENSPRGTLIALLNVNDQDSEENGQVICFIQGNLPFKLEKSYGNYYSLVTDIVLDREQVPSYNITVTATDRGTPPLSTETHISLNVADTNDNPPVFPQASYSAYIPENNPRGVSLVSVTAHDPDCEENAQITYSLAENTIQGASLSSYVSINSDTGVLYALSSFDYEQFRDLQVKVMARDNGHPPLSSNVSLSLFVLDQNDNAPEILYPALPTDGSTGVELAPRSAEPGYLVTKVVAVDRDSGQNAWLSYRLLKASEPGLFSVGLHTGEVRTARALLDRDALKQSLVVAVQDHGQPPLSATVTLTVAVADSIPQVLADLGSLESPANSETSDLTLYLVVAVAAVSCVFLAFVILLLALRLRRWHKSRLLQASGGGLTGAPASHFVGVDGVQAFLQTYSHEVSLTTDSRKSHLIFPQPNYADMLVSQESFEKSEPLLLSGDSVFSKDSHGLIEVSLYQIFFLFFF>sp|Q8IVL5|P3H2_HUMAN Prolyl 3-hydroxylase 2 OS=Homo sapiens OX=9606GN=P3H2 PE=1 SV=1MRERIWAPPLLLLLPLLLPPPLWGGPPDSPRRELELEPGPLQPFDLLYASGAAAYYSGDYERAVRDLEAALRSHRRLREIRTRCARHCAARHPLPPPPPGEGPGAELPLFRSLLGRARCYRSCETQRLGGPASRHRVSEDVRSDFQRRVPYNYLQRAYIKLNQLEKAVEAAHTFFVANPEHMEMQQNIENYRATAGVEALQLVDREAKPHMESYNAGVKHYEADDFEMAIRHFEQALREYFVEDTECRTLCEGPQRFEEYEYLGYKAGLYEAIADHYMQVLVCQHECVRELATRPGRLSPIENFLPLHYDYLQFAYYRVGEYVKALECAKAYLLCHPDDEDVLDNVDYYESLLDDSIDPASIEAREDLTMFVKRHKLESELIKSAAEGLGFSYTEPNYWIRYGGRQDENRVPSGVNVEGAEVHGFSMGKKLSPKIDRDLREGGPLLYENITFVYNSEQLNGTQRVLLDNVLSEEQCRELHSVASGIMLVGDGYRGKTSPHTPNEKFEGATVLKALKSGYEGRVPLKSARLFYDISEKARRIVESYFMLNSTLYFSYTHMVCRTALSGQQDRRNDLSHPIHADNCLLDPEANECWKEPPAYTFRDYSALLYMNDDFEGGEFIFTEMDAKTVTASIKPKCGRMISFSSGGENPHGVKAVTKGKRCAVALWFTLDPLYRELERIQADEVIAILDQEQQGKHELNINPKDEL>sp|Q8IVL5-2|P3H2_HUMAN Isoform 2 of Prolyl 3-hydroxylase 2 OS=Homosapiens OX=9606 GN=P3H2MEMQQNIENYRATAGVEALQLVDREAKPHMESYNAGVKHYEADDFEMAIRHFEQALREYFVEDTECRTLCEGPQRFEEYEYLGYKAGLYEAIADHYMQVLVCQHECVRELATRPGRLSPIENFLPLHYDYLQFAYYRVGEYVKALECAKAYLLCHPDDEDVLDNVDYYESLLDDSIDPASIEAREDLTMFVKRHKLESELIKSAAEGLGFSYTEPNYWIRYGGRQDENRVPSGVNVEGAEVHGFSMGKKLSPKIDRDLREGGPLLYENITFVYNSEQLNGTQRVLLDNVLSEEQCRELHSVASGIMLVGDGYRGKTSPHTPNEKFEGATVLKALKSGYEGRVPLKSARLFYDISEKARRIVESYFMLNSTLYFSYTHMVCRTALSGQQDRRNDLSHPIHADNCLLDPEANECWKEPPAYTFRDYSALLYMNDDFEGGEFIFTEMDAKTVTASIKPKCGRMISFSSGGENPHGVKAVTKGKRCAVALWFTLDPLYRELERIQADEVIAILDQEQQGKHELNINPKDEL>sp|Q96RD7|PANX1_HUMAN Pannexin-1 OS=Homo sapiens OX=9606 GN=PANX1 PE=1SV=4MAIAQLATEYVFSDFLLKEPTEPKFKGLRLELAVDKMVTCIAVGLPLLLISLAFAQEISIGTQISCFSPSSFSWRQAAFVDSYCWAAVQQKNSLQSESGNLPLWLHKFFPYILLLFAILLYLPPLFWRFAAAPHICSDLKFIMEELDKVYNRAIKAAKSARDLDMRDGACSVPGVTENLGQSLWEVSESHFKYPIVEQYLKTKKNSNNLIIKYISCRLLTLIIILLACIYLGYYFSLSSLSDEFVCSIKSGILRNDSTVPDQFQCKLIAVGIFQLLSVINLVVYVLLAPVVVYTLFVPFRQKTDVLKVYEILPTFDVLHFKSEGYNDLSLYNLFLEENISEVKSYKCLKVLENIKSSGQGIDPMLLLTNLGMIKMDVVDGKTPMSAEMREEQGNQTAELQGMNIDSETKANNGEKNARQRLLDSSC>sp|Q96RD7-2|PANX1_HUMAN Isoform 2 of Pannexin-1 OS=Homo sapiens OX=9606GN=PANX1MAIAQLATEYVFSDFLLKEPTEPKFKGLRLELAVDKMVTCIAVGLPLLLISLAFAQEISIGTQISCFSPSSFSWRQAAFVDSYCWAAVQQKNSLQSESGNLPLWLHKFFPYILLLFAILLYLPPLFWRFAAAPHICSDLKFIMEELDKVYNRAIKAAKSARDLDMRDGACSVPGVTENLGQSLWEVSESHFKYPIVEQYLKTKKNSNNLIIKYISCRLLTLIIILLACIYLGYYFSLSSLSDEFVCSIKSGILRNDSTVPDQFQCKLIAVGIFQLLSVINLVVYVLLAPVVVYTLFVPFRQKTDVLKVYEILPTFDVLHFKSEGYNDLSLYNLFLEENISEVKSYKCLKVLENIKSSGQGIDPMLLLTNLGMIKMDVVDGKTPMSAEMREEQGNQTAELQDSETKANNGEKNARQRLLDSSC>sp|Q9UM07|PADI4_HUMAN Protein-arginine deiminase type-4 OS=Homo sapiensOX=9606 GN=PADI4 PE=1 SV=2MAQGTLIRVTPEQPTHAVCVLGTLTQLDICSSAPEDCTSFSINASPGVVVDIAHGPPAKKKSTGSSTWPLDPGVEVTLTMKVASGSTGDQKVQISYYGPKTPPVKALLYLTGVEISLCADITRTGKVKPTRAVKDQRTWTWGPCGQGAILLVNCDRDNLESSAMDCEDDEVLDSEDLQDMSLMTLSTKTPKDFFTNHTLVLHVARSEMDKVRVFQATRGKLSSKCSVVLGPKWPSHYLMVPGGKHNMDFYVEALAFPDTDFPGLITLTISLLDTSNLELPEAVVFQDSVVFRVAPWIMTPNTQPPQEVYACSIFENEDFLKSVTTLAMKAKCKLTICPEEENMDDQWMQDEMEIGYIQAPHKTLPVVFDSPRNRGLKEFPIKRVMGPDFGYVTRGPQTGGISGLDSFGNLEVSPPVTVRGKEYPLGRILFGDSCYPSNDSRQMHQALQDFLSAQQVQAPVKLYSDWLSVGHVDEFLSFVPAPDRKGFRLLLASPRSCYKLFQEQQNEGHGEALLFEGIKKKKQQKIKNILSNKTLREHNSFVERCIDWNRELLKRELGLAESDIIDIPQLFKLKEFSKAEAFFPNMVNMLVLGKHLGIPKPFGPVINGRCCLEEKVCSLLEPLGLQCTFINDFFTYHIRHGEVHCGTNVRRKPFSFKWWNMVP>sp|O00750|P3C2B_HUMAN Phosphatidylinositol 4-phosphate 3-kinase C2domain-containing subunit beta OS=Homo sapiens OX=9606 GN=PIK3C2B PE=1SV=2MSSTQGNGEHWKSLESVGISRKELAMAEALQMEYDALSRLRHDKEENRAKQNADPSLISWDEPGVDFYSKPAGRRTDLKLLRGLSGSDPTLNYNSLSPQEGPPNHSTSQGPQPGSDPWPKGSLSGDYLYIFDGSDGGVSSSPGPGDIEGSCKKLSPPPLPPRASIWDTPPLPPRKGSPSSSKISQPSDINTFSLVEQLPGKLLEHRILEEEEVLGGGGQGRLLGSVDYDGINDAITRLNLKSTYDAEMLRDATRGWKEGRGPLDFSKDTSGKPVARSKTMPPQVPPRTYASRYGNRKNATPGKNRRISAAPVGSRPHTVANGHELFEVSEERDEEVAAFCHMLDILRSGSDIQDYFLTGYVWSAVTPSPEHLGDEVNLKVTVLCDRLQEALTFTCNCSSTVDLLIYQTLCYTHDDLRNVDVGDFVLKPCGLEEFLQNKHALGSHEYIQYCRKFDIDIRLQLMEQKVVRSDLARTVNDDQSPSTLNYLVHLQERPVKQTISRQALSLLFDTYHNEVDAFLLADGDFPLKADRVVQSVKAICNALAAVETPEITSALNQLPPCPSRMQPKIQKDPSVLAVRENREKVVEALTAAILDLVELYCNTFNADFQTAVPGSRKHDLVQEACHFARSLAFTVYATHRIPIIWATSYEDFYLSCSLSHGGKELCSPLQTRRAHFSKYLFHLIVWDQQICFPVQVNRLPRETLLCATLYALPIPPPGSSSEANKQRRVPEALGWVTTPLFNFRQVLTCGRKLLGLWPATQENPSARWSAPNFHQPDSVILQIDFPTSAFDIKFTSPPGDKFSPRYEFGSLREEDQRKLKDIMQKESLYWLTDADKKRLWEKRYYCHSEVSSLPLVLASAPSWEWACLPDIYVLLKQWTHMNHQDALGLLHATFPDQEVRRMAVQWIGSLSDAELLDYLPQLVQALKYECYLDSPLVRFLLKRAVSDLRVTHYFFWLLKDGLKDSQFSIRYQYLLAALLCCCGKGLREEFNRQCWLVNALAKLAQQVREAAPSARQGILRTGLEEVKQFFALNGSCRLPLSPSLLVKGIVPRDCSYFNSNAVPLKLSFQNVDPLGENIRVIFKCGDDLRQDMLTLQMIRIMSKIWVQEGLDMRMVIFRCFSTGRGRGMVEMIPNAETLRKIQVEHGVTGSFKDRPLADWLQKHNPGEDEYEKAVENFIYSCAGCCVATYVLGICDRHNDNIMLKTTGHMFHIDFGRFLGHAQMFGNIKRDRAPFVFTSDMAYVINGGDKPSSRFHDFVDLCCQAYNLIRKHTHLFLNLLGLMLSCGIPELSDLEDLKYVYDALRPQDTEANATTYFTRLIESSLGSVATKLNFFIHNLAQMKFTGSDDRLTLSFASRTHTLKSSGRISDVFLCRHEKIFHPNKGYIYVVKVMRENTHEATYIQRTFEEFQELHNKLRLLFPSSHLPSFPSRFVIGRSRGEAVAERRREELNGYIWHLIHAPPEVAECDLVYTFFHPLPRDEKAMGTSPAPKSSDGTWARPVGKVGGEVKLSISYKNNKLFIMVMHIRGLQLLQDGNDPDPYVKIYLLPDPQKTTKRKTKVARKTCNPTYNEMLVYDGIPKGDLQQRELQLSVLSEQGFWENVLLGEVNIRLRELDLAQEKTGWFALGSRSHGTL>sp|P09466|PAEP_HUMAN Glycodelin OS=Homo sapiens OX=9606 GN=PAEP PE=1SV=2MLCLLLTLGVALVCGVPAMDIPQTKQDLELPKLAGTWHSMAMATNNISLMATLKAPLRVHITSLLPTPEDNLEIVLHRWENNSCVEKKVLGEKTENPKKFKINYTVANEATLLDTDYDNFLFLCLQDTTTPIQSMMCQYLARVLVEDDEIMQGFIRAFRPLPRHLWYLLDLKQMEEPCRF>sp|P09466-2|PAEP_HUMAN Isoform 2 of Glycodelin OS=Homo sapiens OX=9606GN=PAEPMLCLLLTLGVALVCGVPAMDIPQTKQDLELPKAPLRVHITSLLPTPEDNLEIVLHRWENNSCVEKKVLGEKTENPKKFKINYTVANEATLLDTDYDNFLFLCLQDTTTPIQSMMCQYLARVLVEDDEIMQGFIRAFRPLPRHLWYLLDLKQMEEPCRF>sp|P09466-3|PAEP_HUMAN Isoform 3 of Glycodelin OS=Homo sapiens OX=9606GN=PAEPMLCLLLTLGVALVCGVPAMDIPQTKQDLELPKDTTTPIQSMMCQYLARVLVEDDEIMQGFIRAFRPLPRHLWYLLDLKQMEEPCRF>sp|O94913|PCF11_HUMAN Pre-mRNA cleavage complex 2 protein Pcf11 OS=Homosapiens OX=9606 GN=PCF11 PE=1 SV=3MSEQTPAEAGAAGAREDACRDYQSSLEDLTFNSKPHINMLTILAEENLPFAKEIVSLIEAQTAKAPSSEKLPVMYLMDSIVKNVGREYLTAFTKNLVATFICVFEKVDENTRKSLFKLRSTWDEIFPLKKLYALDVRVNSLDPAWPIKPLPPNVNTSSIHVNPKFLNKSPEEPSTPGTVVSSPSISTPPIVPDIQKNLTQEQLIRQQLLAKQKQLLELQQKKLELELEQAKAQLAVSLSVQQETSNLGPGSAPSKLHVSQIPPMAVKAPHQVPVQSEKSRPGPSLQIQDLKGTNRDPRLNRISQHSHGKDQSHRKEFLMNTLNQSDTKTSKTIPSEKLNSSKQEKSKSGEKITKKELDQLDSKSKSKSKSPSPLKNKLSHTKDLKNQESESMRLSDMNKRDPRLKKHLQDKTDGKDDDVKEKRKTAEKKDKDEHMKSSEHRLAGSRNKIINGIVQKQDTITEESEKQGTKPGRSSTRKRSRSRSPKSRSPIIHSPKRRDRRSPKRRQRSMSPTSTPKAGKIRQSGAKQSHMEEFTPPSREDRNAKRSTKQDIRDPRRMKKTEEERPQETTNQHSTKSGTEPKENVENWQSSKSAKRWKSGWEENKSLQQVDEHSKPPHLRHRESWSSTKGILSPRAPKQQQHRLSVDANLQIPKELTLASKRELLQKTSERLASGEITQDDFLVVVHQIRQLFQYQEGVREEQRSPFNDRFPLKRPRYEDSDKPFVDSPASRFAGLDTNQRLTALAEDRPLFDGPSRPSVARDGPTKMIFEGPNKLSPRIDGPPTPASLRFDGSPGQMGGGGPLRFEGPQGQLGGGCPLRFEGPPGPVGTPLRFEGPIGQAGGGGFRFEGSPGLRFEGSPGGLRFEGPGGQPVGGLRFEGHRGQPVGGLRFEGPHGQPVGGLRFDNPRGQPVGGLRFEGGHGPSGAAIRFDGPHGQPGGGIRFEGPLLQQGVGMRFEGPHGQSVAGLRFEGQHNQLGGNLRFEGPHGQPGVGIRFEGPLVQQGGGMRFEGPSVPGGGLRIEGPLGQGGPRFEGCHALRFDGQPGQPSLLPRFDGLHGQPGPRFERTPGQPGPQRFDGPPGQQVQPRFDGVPQRFDGPQHQQASRFDIPLGLQGTRFDNHPSQRLESVSFNQTGPYNDPPGNAFNAPSQGLQFQRHEQIFDSPQGPNFNGPHGPGNQSFSNPLNRASGHYFDEKNLQSSQFGNFGNIPAPMTVGNIQASQQVLSGVAQPVAFGQGQQFLPVHPQNPGFVQNPSGALPKAYPDNHLSQVDVNELFSKLLKTGILKLSQTDSATTQVSEVTAQPPPEEEEDQNEDQDVPDLTNFTVEELKQRYDSVINRLYTGIQCYSCGMRFTTSQTDVYADHLDWHYRQNRTEKDVSRKVTHRRWYYSLTDWIEFEEIADLEERAKSQFFEKVHEEVVLKTQEAAKEKEFQSVPAGPAGAVESCEICQEQFEQYWDEEEEEWHLKNAIRVDGKIYHPSCYEDYQNTSSFDCTPSPSKTPVENPLNIMLNIVKNELQEPCDSPKVKEERIDTPPACTEESIATPSEIKTENDTVESV>sp|Q8WXA2|PATE1_HUMAN Prostate and testis expressed protein 1 OS=Homosapiens OX=9606 GN=PATE1 PE=1 SV=1MDKSLLLELPILLCCFRALSGSLSMRNDAVNEIVAVKNNFPVIEIVQCRMCHLQFPGEKCSRGRGICTATTEEACMVGRMFKRDGNPWLTFMGCLKNCADVKGIRWSVYLVNFRCCRSHDLCNEDL>sp|Q8WXA2-2|PATE1_HUMAN Isoform 2 of Prostate and testis expressedprotein 1 OS=Homo sapiens OX=9606 GN=PATE1MDKSLLLELPILLCCFRALSGSLSMRNDAVIEIVQCRMCHLQFPGEKCSRGRGICTATTEEACMVGRMFKRDGNPWLTFMGCLKNCADVKGIRWSVYLVNFRCCRSHDLCNEDL>sp|Q08174|PCDH1_HUMAN Protocadherin-1 OS=Homo sapiens OX=9606 GN=PCDH1PE=1 SV=2MDSGAGGRRCPEAALLILGPPRMEHLRHSPGPGGQRLLLPSMLLALLLLLAPSPGHATRVVYKVPEEQPPNTLIGSLAADYGFPDVGHLYKLEVGAPYLRVDGKTGDIFTTETSIDREGLRECQNQLPGDPCILEFEVSITDLVQNGSPRLLEGQIEVQDINDNTPNFASPVITLAIPENTNIGSLFPIPLASDRDAGPNGVASYELQAGPEAQELFGLQVAEDQEEKQPQLIVMGNLDRERWDSYDLTIKVQDGGSPPRASSALLRVTVLDTNDNAPKFERPSYEAELSENSPIGHSVIQVKANDSDQGANAEIEYTFHQAPEVVRRLLRLDRNTGLITVQGPVDREDLSTLRFSVLAKDRGTNPKSARAQVVVTVKDMNDNAPTIEIRGIGLVTHQDGMANISEDVAEETAVALVQVSDRDEGENAAVTCVVAGDVPFQLRQASETGSDSKKKYFLQTTTPLDYEKVKDYTIEIVAVDSGNPPLSSTNSLKVQVVDVNDNAPVFTQSVTEVAFPENNKPGEVIAEITASDADSGSNAELVYSLEPEPAAKGLFTISPETGEIQVKTSLDREQRESYELKVVAADRGSPSLQGTATVLVNVLDCNDNDPKFMLSGYNFSVMENMPALSPVGMVTVIDGDKGENAQVQLSVEQDNGDFVIQNGTGTILSSLSFDREQQSTYTFQLKAVDGGVPPRSAYVGVTINVLDENDNAPYITAPSNTSHKLLTPQTRLGETVSQVAAEDFDSGVNAELIYSIAGGNPYGLFQIGSHSGAITLEKEIERRHHGLHRLVVKVSDRGKPPRYGTALVHLYVNETLANRTLLETLLGHSLDTPLDIDIAGDPEYERSKQRGNILFGVVAGVVAVALLIALAVLVRYCRQREAKSGYQAGKKETKDLYAPKPSGKASKGNKSKGKKSKSPKPVKPVEDEDEAGLQKSLKFNLMSDAPGDSPRIHLPLNYPPGSPDLGRHYRSNSPLPSIQLQPQSPSASKKHQVVQDLPPANTFVGTGDTTSTGSEQYSDYSYRTNPPKYPSKQVGQPFQLSTPQPLPHPYHGAIWTEVWE>sp|Q08174-2|PCDH1_HUMAN Isoform 2 of Protocadherin-1 OS=Homo sapiensOX=9606 GN=PCDH1MDSGAGGRRCPEAALLILGPPRMEHLRHSPGPGGQRLLLPSMLLALLLLLAPSPGHATRVVYKVPEEQPPNTLIGSLAADYGFPDVGHLYKLEVGAPYLRVDGKTGDIFTTETSIDREGLRECQNQLPGDPCILEFEVSITDLVQNGSPRLLEGQIEVQDINDNTPNFASPVITLAIPENTNIGSLFPIPLASDRDAGPNGVASYELQAGPEAQELFGLQVAEDQEEKQPQLIVMGNLDRERWDSYDLTIKVQDGGSPPRASSALLRVTVLDTNDNAPKFERPSYEAELSENSPIGHSVIQVKANDSDQGANAEIEYTFHQAPEVVRRLLRLDRNTGLITVQGPVDREDLSTLRFSVLAKDRGTNPKSARAQVVVTVKDMNDNAPTIEIRGIGLVTHQDGMANISEDVAEETAVALVQVSDRDEGENAAVTCVVAGDVPFQLRQASETGSDSKKKYFLQTTTPLDYEKVKDYTIEIVAVDSGNPPLSSTNSLKVQVVDVNDNAPVFTQSVTEVAFPENNKPGEVIAEITASDADSGSNAELVYSLEPEPAAKGLFTISPETGEIQVKTSLDREQRESYELKVVAADRGSPSLQGTATVLVNVLDCNDNDPKFMLSGYNFSVMENMPALSPVGMVTVIDGDKGENAQVQLSVEQDNGDFVIQNGTGTILSSLSFDREQQSTYTFQLKAVDGGVPPRSAYVGVTINVLDENDNAPYITAPSNTSHKLLTPQTRLGETVSQVAAEDFDSGVNAELIYSIAGGNPYGLFQIGSHSGAITLEKEIERRHHGLHRLVVKVSDRGKPPRYGTALVHLYVNETLANRTLLETLLGHSLDTPLDIDIAGDPEYERSKQRGNILFGVVAGVVAVALLIALAVLVRYCRQREAKSGYQAGKKETKDLYAPKPSGKASKGNKSKGKKSKSPKPVKPVEDEDEAGLQKSLKFNLMSDAPGDSPRIHLPLNYPPGSPDLGRHYRSNSPLPSIQLQPQSPSASKKHQVVQDLPPANTFVGTGDTTSTGSEQYSDYSYRTNPPKYPSKQLPHRRVTFSATSQAQELQDPSQHSYYDSGLEESETPSSKSSSGPRLGPLALPEDHYERTTPDGSIGEMEHPENDLRPLPDVAMTGTCTRECSEFGHSDTCWMPGQSSPSRRTKSSALKLSTFVPYQDRGGQEPAGAGSPSPPEDRNTKTAPVRLLPSYSAFSHSSHDSCKDSATLEEIPLTQTSDFPPAATPASAQTAKREIYL>sp|Q96RD6|PANX2_HUMAN Pannexin-2 OS=Homo sapiens OX=9606 GN=PANX2 PE=2SV=2MHHLLEQSADMATALLAGEKLRELILPGAQDDKAGALAALLLQLKLELPFDRVVTIGTVLVPILLVTLVFTKNFAEEPIYCYTPHNFTRDQALYARGYCWTELRDALPGVDASLWPSLFEHKFLPYALLAFAAIMYVPALGWEFLASTRLTSELNFLLQEIDNCYHRAAEGRAPKIEKQIQSKGPGITEREKREIIENAEKEKSPEQNLFEKYLERRGRSNFLAKLYLARHVLILLLSAVPISYLCTYYATQKQNEFTCALGASPDGAAGAGPAVRVSCKLPSVQLQRIIAGVDIVLLCVMNLIILVNLIHLFIFRKSNFIFDKLHKVGIKTRRQWRRSQFCDINILAMFCNENRDHIKSLNRLDFITNESDLMYDNVVRQLLAALAQSNHDATPTVRDSGVQTVDPSANPAEPDGAAEPPVVKRPRKKMKWIPTSNPLPQPFKEPLAIMRVENSKAEKPKPARRKTATDTLIAPLLDRSAHHYKGGGGDPGPGPAPAPAPPPAPDKKHARHFSLDVHPYILGTKKAKAEAVPAALPASRSQEGGFLSQAEDCGLGLAPAPIKDAPLPEKEIPYPTEPARAGLPSGGPFHVRSPPAAPAVAPLTPASLGKAEPLTILSRNATHPLLHINTLYEAREEEDGGPRLPQDVGDLIAIPAPQQILIATFDEPRTVVSTVEF>sp|Q96RD6-1|PANX2_HUMAN Isoform 1 of Pannexin-2 OS=Homo sapiens OX=9606GN=PANX2MHHLLEQSADMATALLAGEKLRELILPGAQDDKAGALAALLLQLKLELPFDRVVTIGTVLVPILLVTLVFTKNFAEEPIYCYTPHNFTRDQALYARGYCWTELRDALPGVDASLWPSLFEHKFLPYALLAFAAIMYVPALGWEFLASTRLTSELNFLLQEIDNCYHRAAEGRAPKIEKQIQSKGPGITEREKREIIENAEKEKSPEQNLFEKYLERRGRSNFLAKLYLARHVLILLLSAVPISYLCTYYATQKQNEFTCALGASPDGAAGAGPAVRVSCKLPSVQLQRIIAGVDIVLLCVMNLIILVNLIHLFIFRKSNFIFDKLHKVGIKTRRQWRRSQFCDINILAMFCNENRDHIKSLNRLDFITNESDLMYDNVVRQLLAALAQSNHDATPTVRDSGVQTVDPSANPAEPDGAAEPPVVKRPRKKMKWIPTSNPLPQPFKEPLAIMRVENSKAEKPKPARRKTATDTLIAPLLDRSAHHYKGGGGDPGPGPAPAPAPPPAPDKKHARHFSLDVHPYILGTKKAKAEAVPAALPASRSQEGGFLSQAEDCGLGLAPAPIKDAPLPEKEIPYPTEPARAGLPSGGPFHVRSPPAAPAVAPLTPASLGKAEPLTILSRNATHPLLHINTLSSSPPSTSRERS>sp|Q96RD6-2|PANX2_HUMAN Isoform 2 of Pannexin-2 OS=Homo sapiens OX=9606GN=PANX2MYVPALGWEFLASTRLTSELNFLLQEIDNCYHRAAEGRAPKIEKQIQSKGPGITEREKREIIENAEKEKSPEQNLFEKYLERRGRSNFLAKLYLARHVLILLLSAVPISYLCTYYATQKQNEFTCALGASPDGAAGAGPAVRVSCKLPSVQLQRIIAGVDIVLLCVMNLIILVNLIHLFIFRKSNFIFDKLHKVGIKTRRQWRRSQFCDINILAMFCNENRDHIKSLNRLDFITNESDLMYDNVVRQLLAALAQSNHDATPTVRDSGVQTVDPSANPAEPDGAAEPPVVKRPRKKMKWIPTSNPLPQPFKEPLAIMRVENSKAEKPKPARRKTATDTLIAPLLDRSAHHYKGGGGDPGPGPAPAPAPPPAPDKKHARHFSLDVHPYILGTKKAKAEAVPAALPASRSQEGGFLSQAEDCGLGLAPAPIKDAPLPEKEIPYPTEPARAGLPSGGPFHVRSPPAAPAVAPLTPASLGKAEPLTILSRNATHPLLHINTLSSSPPSTSRERS>sp|O60245|PCDH7_HUMAN Protocadherin-7 OS=Homo sapiens OX=9606 GN=PCDH7PE=1 SV=2MLRMRTAGWARGWCLGCCLLLPLSLSLAAAKQLLRYRLAEEGPADVRIGNVASDLGIVTGSGEVTFSLESGSEYLKIDNLTGELSTSERRIDREKLPQCQMIFDENECFLDFEVSVIGPSQSWVDLFEGQVIVLDINDNTPTFPSPVLTLTVEENRPVGTLYLLPTATDRDFGRNGIERYELLQEPGGGGSGGESRRAGAADSAPYPGGGGNGASGGGSGGSKRRLDASEGGGGTNPGGRSSVFELQVADTPDGEKQPQLIVKGALDREQRDSYELTLRVRDGGDPPRSSQAILRVLITDVNDNSPRFEKSVYEADLAENSAPGTPILQLRAADLDVGVNGQIEYVFGAATESVRRLLRLDETSGWLSVLHRIDREEVNQLRFTVMARDRGQPPKTDKATVVLNIKDENDNVPSIEIRKIGRIPLKDGVANVAEDVLVDTPIALVQVSDRDQGENGVVTCTVVGDVPFQLKPASDTEGDQNKKKYFLHTSTPLDYEATREFNVVIVAVDSGSPSLSSNNSLIVKVGDTNDNPPMFGQSVVEVYFPENNIPGERVATVLATDADSGKNAEIAYSLDSSVMGIFAIDPDSGDILVNTVLDREQTDRYEFKVNAKDKGIPVLQGSTTVIVQVADKNDNDPKFMQDVFTFYVKENLQPNSPVGMVTVMDADKGRNAEMSLYIEENNNIFSIENDTGTIYSTMSFDREHQTTYTFRVKAVDGGDPPRSATATVSLFVMDENDNAPTVTLPKNISYTLLPPSSNVRTVVATVLATDSDDGINADLNYSIVGGNPFKLFEIDPTSGVVSLVGKLTQKHYGLHRLVVQVNDSGQPSQSTTTLVHVFVNESVSNATAIDSQIARSLHIPLTQDIAGDPSYEISKQRLSIVIGVVAGIMTVILIILIVVMARYCRSKNKNGYEAGKKDHEDFFTPQQHDKSKKPKKDKKNKKSKQPLYSSIVTVEASKPNGQRYDSVNEKLSDSPSMGRYRSVNGGPGSPDLARHYKSSSPLPTVQLHPQSPTAGKKHQAVQDLPPANTFVGAGDNISIGSDHCSEYSCQTNNKYSKQMRLHPYITVFG>sp|O60245-2|PCDH7_HUMAN Isoform B of Protocadherin-7 OS=Homo sapiensOX=9606 GN=PCDH7MLRMRTAGWARGWCLGCCLLLPLSLSLAAAKQLLRYRLAEEGPADVRIGNVASDLGIVTGSGEVTFSLESGSEYLKIDNLTGELSTSERRIDREKLPQCQMIFDENECFLDFEVSVIGPSQSWVDLFEGQVIVLDINDNTPTFPSPVLTLTVEENRPVGTLYLLPTATDRDFGRNGIERYELLQEPGGGGSGGESRRAGAADSAPYPGGGGNGASGGGSGGSKRRLDASEGGGGTNPGGRSSVFELQVADTPDGEKQPQLIVKGALDREQRDSYELTLRVRDGGDPPRSSQAILRVLITDVNDNSPRFEKSVYEADLAENSAPGTPILQLRAADLDVGVNGQIEYVFGAATESVRRLLRLDETSGWLSVLHRIDREEVNQLRFTVMARDRGQPPKTDKATVVLNIKDENDNVPSIEIRKIGRIPLKDGVANVAEDVLVDTPIALVQVSDRDQGENGVVTCTVVGDVPFQLKPASDTEGDQNKKKYFLHTSTPLDYEATREFNVVIVAVDSGSPSLSSNNSLIVKVGDTNDNPPMFGQSVVEVYFPENNIPGERVATVLATDADSGKNAEIAYSLDSSVMGIFAIDPDSGDILVNTVLDREQTDRYEFKVNAKDKGIPVLQGSTTVIVQVADKNDNDPKFMQDVFTFYVKENLQPNSPVGMVTVMDADKGRNAEMSLYIEENNNIFSIENDTGTIYSTMSFDREHQTTYTFRVKAVDGGDPPRSATATVSLFVMDENDNAPTVTLPKNISYTLLPPSSNVRTVVATVLATDSDDGINADLNYSIVGGNPFKLFEIDPTSGVVSLVGKLTQKHYGLHRLVVQVNDSGQPSQSTTTLVHVFVNESVSNATAIDSQIARSLHIPLTQDIAGDPSYEISKQRLSIVIGVVAGIMTVILIILIVVMARYCRSKNKNGYEAGKKDHEDFFTPQQHDKSKKPKKDKKNKKSKQPLYSSIVTVEASKPNGQRYDSVNEKLSDSPSMGRYRSVNGGPGSPDLARHYKSSSPLPTVQLHPQSPTAGKKHQAVQDLPPANTFVGAGDNISIGSDHCSEYSCQTNNKYSKQVRCIPNIFKYPREG>sp|Q9HBI0|PARVG_HUMAN Gamma-parvin OS=Homo sapiens OX=9606 GN=PARVG PE=1SV=1MEPEFLYDLLQLPKGVEPPAEEELSKGGKKKYLPPTSRKDPKFEELQKVLMEWINATLLPEHIVVRSLEEDMFDGLILHHLFQRLAALKLEAEDIALTATSQKHKLTVVLEAVNRSLQLEEWQAKWSVESIFNKDLLSTLHLLVALAKRFQPDLSLPTNVQVEVITIESTKSGLKSEKLVEQLTEYSTDKDEPPKDVFDELFKLAPEKVNAVKEAIVNFVNQKLDRLGLSVQNLDTQFADGVILLLLIGQLEGFFLHLKEFYLTPNSPAEMLHNVTLALELLKDEGLLSCPVSPEDIVNKDAKSTLRVLYGLFCKHTQKAHRDRTPHGAPN>sp|Q9HBI0-2|PARVG_HUMAN Isoform 2 of Gamma-parvin OS=Homo sapiensOX=9606 GN=PARVGMEPEFLYDLLQLPKGVEPPAEEELSKGGKKKYLPPTSRKDPKFEELQKVLMEWINATLLPEHIVVRSLEEDMFDGLILHHLFQRLAALKLEAEDIALTATSQKHKLTVVLEAVNRSLQLEEWQAKWSVESIFNKDLLSTLHLLVALAKRFQPDLSLPTNVQVEVITIESTKSGLKSEKLVEQLTEYSTDKDEPPKDVFDELFKLAPEKVNAVKEAIVNFVNQKLDRLGLSVQNLDTQFADGVILLLLIGQLEGFFLHLKEFYLTPNSPAEMIS>sp|Q9HBI0-3|PARVG_HUMAN Isoform 3 of Gamma-parvin OS=Homo sapiensOX=9606 GN=PARVGMEPEFLYDLLQLPKGVEPPAEEELSKGGKKKYLPPTSRKDPKFEELQKVLMEWINATLLPEHIVVRSLEEDMFDGLILHHLFQRLAALKLEAEDIALTATSQKHKLTVVLEAVNRSLQLEEWQAKWSVESIFNKDLLSTLHLLVALAKRFQPDLSLPTNVQVEVITIESTKSGLKSEKLVEQLTEYR>sp|Q9HBI0-4|PARVG_HUMAN Isoform 4 of Gamma-parvin OS=Homo sapiensOX=9606 GN=PARVGMVPAKEQVPGRCDSTQRCFPGPSNWTGAGGRAGSQPFVGDGTLGTPNFCWDHKEKRAAESQLQAWEAMEPEFLYDLLQLPKGVEPPAEEELSKGGKKKYLPPTSRKDPKFEELQKHTWPSPVTGTGDTICGLARKTW>sp|Q9HBI0-5|PARVG_HUMAN Isoform 5 of Gamma-parvin OS=Homo sapiensOX=9606 GN=PARVGMEPEFLYDLLQLPKGVEPPAEEELSKGGKKKYLPPTSRKDPKFEELQKHTWPSPVTGTGDTICGLARKTW>sp|Q96QZ0|PANX3_HUMAN Pannexin-3 OS=Homo sapiens OX=9606 GN=PANX3 PE=2SV=1MSLAHTAAEYMLSDALLPDRRGPRLKGLRLELPLDRIVKFVAVGSPLLLMSLAFAQEFSSGSPISCFSPSNFSIRQAAYVDSSCWDSLLHHKQDGPGQDKMKSLWPHKALPYSLLALALLMYLPVLLWQYAAVPALSSDLLFIISELDKSYNRSIRLVQHMLKIRQKSSDPYVFWNELEKARKERYFEFPLLERYLACKQRSHSLVATYLLRNSLLLIFTSATYLYLGHFHLDVFFQEEFSCSIKTGLLSDETHVPNLITCRLTSLSIFQIVSLSSVAIYTILVPVIIYNLTRLCRWDKRLLSVYEMLPAFDLLSRKMLGCPINDLNVILLFLRANISELISFSWLSVLCVLKDTTTQKHNIDTVVDFMTLLAGLEPSKPKHLTNSACDEHP>sp|O95206|PCDH8_HUMAN Protocadherin-8 OS=Homo sapiens OX=9606 GN=PCDH8PE=1 SV=2MSPVRRWGSPCLFPLQLFSLCWVLSVAQSKTVRYSTFEEDAPGTVIGTLAEDLHMKVSGDTSFRLMKQFNSSLLRVREGDGQLTVGDAGLDRERLCGQAPQCVLAFDVVSFSQEQFRLVHVEVEVRDVNDHAPRFPRAQIPVEVSEGAAVGTRIPLEVPVDEDVGANGLQTVRLAEPHSPFRVELQTRADGAQCADLVLLQELDRESQAAYSLELVAQDGGRPPRSATAALSVRVLDANDHSPAFPQGAVAEVELAEDAPVGSLLLDLDAADPDEGPNGDVVFAFGARTPPEARRLFRLDPRSGRLTLAGPVDYERQDTYELDVRAQDRGPGPRAATCKVIVRIRDVNDNAPDIAITPLAAPGAPATSPFAAAAAAAALGGADASSPAGAGTPEAGATSLVPEGAARESLVALVSTSDRDSGANGQVRCALYGHEHFRLQPAYAGSYLVVTAASLDRERIAEYNLTLVAEDRGAPPLRTVRPYTVRVGDENDNAPLFTRPVYEVSVRENNPPGAYLATVAARDRDLGRNGQVTYRLLEAEVGRAGGAVSTYVSVDPATGAIYALRSFDYETLRQLDVRIQASDGGSPQLSSSALVQVRVLDQNDHAPVLVHPAPANGSLEVAVPGRTAKDTVVARVQARDADEGANGELAFELQQQEPREAFAIGRRTGEILLTGDLSQEPPGRVFRALLVISDGGRPPLTTTATVSFVVTAGGGRGPAAPASAGSPERSRPPGSRLGVSGSVLQWDTPLIVIIVLAGSCTLLLAAIIAIATTCNRRKKEVRKGGALREERPGAAGGGASAPGSPEEAARGAGPRPNMFDVLTFPGTGKAPFGSPAADAPPPAVAAAEVPGSEGGSATGESACHFEGQQRLRGAHAEPYGASPGFGKEPAPPVAVWKGHSFNTISGREAEKFSGKDSGKGDSDFNDSDSDISGDALKKDLINHMQSGLWACTAECKILGHSDRCWSPSCSGPNAHPSPHPPAQMSTFCKSTSLPRDPLRRDNYYQAQLPKTVGLQSVYEKVLHRDYDRTVTLLSPPRPGRLPDLQEIGVPLYQSPPGRYLSPKKGANENV>sp|O95206-2|PCDH8_HUMAN Isoform 2 of Protocadherin-8 OS=Homo sapiensOX=9606 GN=PCDH8MSPVRRWGSPCLFPLQLFSLCWVLSVAQSKTVRYSTFEEDAPGTVIGTLAEDLHMKVSGDTSFRLMKQFNSSLLRVREGDGQLTVGDAGLDRERLCGQAPQCVLAFDVVSFSQEQFRLVHVEVEVRDVNDHAPRFPRAQIPVEVSEGAAVGTRIPLEVPVDEDVGANGLQTVRLAEPHSPFRVELQTRADGAQCADLVLLQELDRESQAAYSLELVAQDGGRPPRSATAALSVRVLDANDHSPAFPQGAVAEVELAEDAPVGSLLLDLDAADPDEGPNGDVVFAFGARTPPEARRLFRLDPRSGRLTLAGPVDYERQDTYELDVRAQDRGPGPRAATCKVIVRIRDVNDNAPDIAITPLAAPGAPATSPFAAAAAAAALGGADASSPAGAGTPEAGATSLVPEGAARESLVALVSTSDRDSGANGQVRCALYGHEHFRLQPAYAGSYLVVTAASLDRERIAEYNLTLVAEDRGAPPLRTVRPYTVRVGDENDNAPLFTRPVYEVSVRENNPPGAYLATVAARDRDLGRNGQVTYRLLEAEVGRAGGAVSTYVSVDPATGAIYALRSFDYETLRQLDVRIQASDGGSPQLSSSALVQVRVLDQNDHAPVLVHPAPANGSLEVAVPGRTAKDTVVARVQARDADEGANGELAFELQQQEPREAFAIGRRTGEILLTGDLSQEPPGRVFRALLVISDGGRPPLTTTATVSFVVTAGGGRGPAAPASAGSPERSRPPGSRLGVSGSVLQWDTPLIVIIVLAGSCTLLLAAIIAIATTCNRRKKEPYGASPGFGKEPAPPVAVWKGHSFNTISGREAEKFSGKDSGKGDSDFNDSDSDISGDALKKDLINHMQSGLWACTAECKILGHSDRCWSPSCSGPNAHPSPHPPAQMSTFCKSTSLPRDPLRRDNYYQAQLPKTVGLQSVYEKVLHRDYDRTVTLLSPPRPGRLPDLQEIGVPLYQSPPGRYLSPKKGANENV>sp|Q8WUM4|PDC6I_HUMAN Programmed cell death 6-interacting proteinOS=Homo sapiens OX=9606 GN=PDCD6IP PE=1 SV=1MATFISVQLKKTSEVDLAKPLVKFIQQTYPSGGEEQAQYCRAAEELSKLRRAAVGRPLDKHEGALETLLRYYDQICSIEPKFPFSENQICLTFTWKDAFDKGSLFGGSVKLALASLGYEKSCVLFNCAALASQIAAEQNLDNDEGLKIAAKHYQFASGAFLHIKETVLSALSREPTVDISPDTVGTLSLIMLAQAQEVFFLKATRDKMKDAIIAKLANQAADYFGDAFKQCQYKDTLPKEVFPVLAAKHCIMQANAEYHQSILAKQQKKFGEEIARLQHAAELIKTVASRYDEYVNVKDFSDKINRALAAAKKDNDFIYHDRVPDLKDLDPIGKATLVKSTPVNVPISQKFTDLFEKMVPVSVQQSLAAYNQRKADLVNRSIAQMREATTLANGVLASLNLPAAIEDVSGDTVPQSILTKSRSVIEQGGIQTVDQLIKELPELLQRNREILDESLRLLDEEEATDNDLRAKFKERWQRTPSNELYKPLRAEGTNFRTVLDKAVQADGQVKECYQSHRDTIVLLCKPEPELNAAIPSANPAKTMQGSEVVNVLKSLLSNLDEVKKEREGLENDLKSVNFDMTSKFLTALAQDGVINEEALSVTELDRVYGGLTTKVQESLKKQEGLLKNIQVSHQEFSKMKQSNNEANLREEVLKNLATAYDNFVELVANLKEGTKFYNELTEILVRFQNKCSDIVFARKTERDELLKDLQQSIAREPSAPSIPTPAYQSSPAGGHAPTPPTPAPRTMPPTKPQPPARPPPPVLPANRAPSATAPSPVGAGTAAPAPSQTPGSAPPPQAQGPPYPTYPGYPGYCQMPMPMGYNPYAYGQYNMPYPPVYHQSPGQAPYPGPQQPSYPFPQPPQQSYYPQQ>sp|Q8WUM4-2|PDC6I_HUMAN Isoform 2 of Programmed cell death 6-interactingprotein OS=Homo sapiens OX=9606 GN=PDCD6IPMATFISVQLKKTSEVDLAKPLVKFIQQTYPSGGEEQAQYCRAAEELSKLRRAAVGRPLDKHEGALETLLRYYDQICSIEPKFPFSENQICLTFTWKDAFDKGSLFGGSVKLALASLGYEKSCVLFNCAALASQIAAEQNLDNDEGLKIAAKHYQFASGAFLHIKETVLSALSREPTVDISPDTVGTLSLIMLAQAQEVFFLKATRDKMKDAIIAKLANQAADYFGDAFKQCQYKDTLPKYFYFQEVFPVLAAKHCIMQANAEYHQSILAKQQKKFGEEIARLQHAAELIKTVASRYDEYVNVKDFSDKINRALAAAKKDNDFIYHDRVPDLKDLDPIGKATLVKSTPVNVPISQKFTDLFEKMVPVSVQQSLAAYNQRKADLVNRSIAQMREATTLANGVLASLNLPAAIEDVSGDTVPQSILTKSRSVIEQGGIQTVDQLIKELPELLQRNREILDESLRLLDEEEATDNDLRAKFKERWQRTPSNELYKPLRAEGTNFRTVLDKAVQADGQVKECYQSHRDTIVLLCKPEPELNAAIPSANPAKTMQGSEVVNVLKSLLSNLDEVKKEREGLENDLKSVNFDMTSKFLTALAQDGVINEEALSVTELDRVYGGLTTKVQESLKKQEGLLKNIQVSHQEFSKMKQSNNEANLREEVLKNLATAYDNFVELVANLKEGTKFYNELTEILVRFQNKCSDIVFARKTERDELLKDLQQSIAREPSAPSIPTPAYQSSPAGGHAPTPPTPAPRTMPPTKPQPPARPPPPVLPANRAPSATAPSPVGAGTAAPAPSQTPGSAPPPQAQGPPYPTYPGYPGYCQMPMPMGYNPYAYGQYNMPYPPVYHQSPGQAPYPGPQQPSYPFPQPPQQSYYPQQ>sp|Q8WUM4-3|PDC6I_HUMAN Isoform 3 of Programmed cell death 6-interactingprotein OS=Homo sapiens OX=9606 GN=PDCD6IPMATFISVQLKKTSEVDLAKPLVKFIQQTYPSGGEEQAQYCRAAEELSKLRRAAVGRPLDKHEGALETLLRYYDQICSIEPKFPFSENQICLTFTWKDAFDKGSLFGGSVKLALASLGYEKSCVLFNCAALASQIAAEQNLDNDEGLKIAAKHYQFASGAFLHIKETVLSALSREPTVDISPDTVGTLSLIMLAQAQEVFFLKATRDKMKDAIIAKLANQAADYFGDAFKQCQYKDTLPKVSYCFYKHLLTLHVKYLDFFVYKKQVETYKEI>sp|Q8NBR0|P5I13_HUMAN Tumor protein p53-inducible protein 13 OS=Homosapiens OX=9606 GN=TP53I13 PE=1 SV=1MAPPPPSPQLLLLAALARLLGPSEVMAGPAEEAGAHCPESLWPLPPQVSPRVTYTRVSPGQAEDVTFLYHPCAHPWLKLQLALLAYACMANPSLTPDFSLTQDRPLVLTAWGLALEMAWVEPAWAAHWLMRRRRRKQRKKKAWIYCESLSGPAPSEPTPGRGRLCRRGCVQALALAFALRSWRPPGTEVTSQGPRQPSSSGAKRRRLRAALGPQPTRSALRFPSASPGSLKAKQSMAGIPGRESNAPSVPTVSLLPGAPGGNASSRTEAQVPNGQGSPGGCVCSSQASPAPRAAAPPRAARGPTPRTEEAAWAAMALTFLLVLLTLATLCTRLHRNFRRGESIYWGPTADSQDTVAAVLKRRLLQPSRRVKRSRRRPLLPPTPDSGPEGESSE>sp|Q86V24|PAQR2_HUMAN Adiponectin receptor protein 2 OS=Homo sapiensOX=9606 GN=ADIPOR2 PE=1 SV=1MNEPTENRLGCSRTPEPDIRLRKGHQLDGTRRGDNDSHQGDLEPILEASVLSSHHKKSSEEHEYSDEAPQEDEGFMGMSPLLQAHHAMEKMEEFVCKVWEGRWRVIPHDVLPDWLKDNDFLLHGHRPPMPSFRACFKSIFRIHTETGNIWTHLLGCVFFLCLGIFYMFRPNISFVAPLQEKVVFGLFFLGAILCLSFSWLFHTVYCHSEGVSRLFSKLDYSGIALLIMGSFVPWLYYSFYCNPQPCFIYLIVICVLGIAAIIVSQWDMFATPQYRGVRAGVFLGLGLSGIIPTLHYVISEGFLKAATIGQIGWLMLMASLYITGAALYAARIPERFFPGKCDIWFHSHQLFHIFVVAGAFVHFHGVSNLQEFRFMIGGGCSEEDAL>sp|O14683|P5I11_HUMAN Tumor protein p53-inducible protein 11 OS=Homosapiens OX=9606 GN=TP53I11 PE=1 SV=2MAAKQPPPLMKKHSQTDLVSRLKTRKILGVGGEDDDGEVHRSKISQVLGNEIKFTIREPLGLRVWQFVSAVLFSGIAIMALAFPDQLYDAVFDGAQVTSKTPIRLYGGALLSISLIMWNALYTAEKVIIRWTLLTEACYFGVQFLVVTATLAETGLMSLGILLLLVSRLLFVVISIYYYYQVGRRPKKA>sp|O14737|PDCD5_HUMAN Programmed cell death protein 5 OS=Homo sapiensOX=9606 GN=PDCD5 PE=1 SV=3MADEELEALRRQRLAELQAKHGDPGDAAQQEAKHREAEMRNSILAQVLDQSARARLSNLALVKPEKTKAVENYLIQMARYGQLSEKVSEQGLIEILKKVSQQTEKTTTVKFNRRKVMDSDEDDDY>sp|O14737-2|PDCD5_HUMAN Isoform 2 of Programmed cell death protein 5OS=Homo sapiens OX=9606 GN=PDCD5MADEELEALRRQRLAELQAKHGDPGDAAQQEAKHREAEMRNSILAQVLDQSARARLSNLALVKPEKTKAVENYLIQMARYGQLSEKVSLDSLEELYCYLLYQNMASKGQLHLHWITEFLLTLRRNCWRE>sp|O00459|P85B_HUMAN Phosphatidylinositol 3-kinase regulatory subunitbeta OS=Homo sapiens OX=9606 GN=PIK3R2 PE=1 SV=2MAGPEGFQYRALYPFRRERPEDLELLPGDVLVVSRAALQALGVAEGGERCPQSVGWMPGLNERTRQRGDFPGTYVEFLGPVALARPGPRPRGPRPLPARPRDGAPEPGLTLPDLPEQFSPPDVAPPLLVKLVEAIERTGLDSESHYRPELPAPRTDWSLSDVDQWDTAALADGIKSFLLALPAPLVTPEASAEARRALREAAGPVGPALEPPTLPLHRALTLRFLLQHLGRVASRAPALGPAVRALGATFGPLLLRAPPPPSSPPPGGAPDGSEPSPDFPALLVEKLLQEHLEEQEVAPPALPPKPPKAKPASTVLANGGSPPSLQDAEWYWGDISREEVNEKLRDTPDGTFLVRDASSKIQGEYTLTLRKGGNNKLIKVFHRDGHYGFSEPLTFCSVVDLINHYRHESLAQYNAKLDTRLLYPVSKYQQDQIVKEDSVEAVGAQLKVYHQQYQDKSREYDQLYEEYTRTSQELQMKRTAIEAFNETIKIFEEQGQTQEKCSKEYLERFRREGNEKEMQRILLNSERLKSRIAEIHESRTKLEQQLRAQASDNREIDKRMNSLKPDLMQLRKIRDQYLVWLTQKGARQKKINEWLGIKNETEDQYALMEDEDDLPHHEERTWYVGKINRTQAEEMLSGKRDGTFLIRESSQRGCYACSVVVDGDTKHCVIYRTATGFGFAEPYNLYGSLKELVLHYQHASLVQHNDALTVTLAHPVRAPGPGPPPAAR>sp|O75781|PALM_HUMAN Paralemmin-1 OS=Homo sapiens OX=9606 GN=PALM PE=1SV=2MEVLAAETTSQQERLQAIAEKRKRQAEIENKRRQLEDERRQLQHLKSKALRERWLLEGTPSSASEGDEDLRRQMQDDEQKTRLLEDSVSRLEKEIEVLERGDSAPATAKENAAAPSPVRAPAPSPAKEERKTEVVMNSQQTPVGTPKDKRVSNTPLRTVDGSPMMKAAMYSVEITVEKDKVTGETRVLSSTTLLPRQPLPLGIKVYEDETKVVHAVDGTAENGIHPLSSSEVDELIHKADEVTLSEAGSTAGAAETRGAVEGAARTTPSRREITGVQAQPGEATSGPPGIQPGQEPPVTMIFMGYQNVEDEAETKKVLGLQDTITAELVVIEDAAEPKEPAPPNGSAAEPPTEAASREENQAGPEATTSDPQDLDMKKHRCKCCSIM>sp|O75781-2|PALM_HUMAN Isoform 2 of Paralemmin-1 OS=Homo sapiens OX=9606GN=PALMMEVLAAETTSQQERLQAIAEKRKRQAEIENKRRQLEDERRQLQHLKSKALRERWLLEGTPSSASEGDEDLRRQMQDDEQKTRLLEDSVSRLEKEIEVLERGDSAPATAKENAAAPSPVRAPAPSPAKEERKTEVVMNSQQTPVGTPKDKRVSNTPLRTVDGSPMMKAVVHAVDGTAENGIHPLSSSEVDELIHKADEVTLSEAGSTAGAAETRGAVEGAARTTPSRREITGVQAQPGEATSGPPGIQPGQEPPVTMIFMGYQNVEDEAETKKVLGLQDTITAELVVIEDAAEPKEPAPPNGSAAEPPTEAASREENQAGPEATTSDPQDLDMKKHRCKCCSIM>sp|Q9NZW5|PALS2_HUMAN Protein PALS2 OS=Homo sapiens OX=9606 GN=PALS2PE=1 SV=2MQQVLENLTELPSSTGAEEIDLIFLKGIMENPIVKSLAKAHERLEDSKLEAVSDNNLELVNEILEDITPLINVDENVAELVGILKEPHFQSLLEAHDIVASKCYDSPPSSPEMNNSSINNQLLPVDAIRILGIHKRAGEPLGVTFRVENNDLVIARILHGGMIDRQGLLHVGDIIKEVNGHEVGNNPKELQELLKNISGSVTLKILPSYRDTITPQQVFVKCHFDYNPYNDNLIPCKEAGLKFSKGEILQIVNREDPNWWQASHVKEGGSAGLIPSQFLEEKRKAFVRRDWDNSGPFCGTISSKKKKKMMYLTTRNAEFDRHEIQIYEEVAKMPPFQRKTLVLIGAQGVGRRSLKNRFIVLNPTRFGTTVPFTSRKPREDEKDGQAYKFVSRSEMEADIKAGKYLEHGEYEGNLYGTKIDSILEVVQTGRTCILDVNPQALKVLRTSEFMPYVVFIAAPELETLRAMHKAVVDAGITTKLLTDSDLKKTVDESARIQRAYNHYFDLIIINDNLDKAFEKLQTAIEKLRMEPQWVPISWVY>sp|Q8N3R9|PALS1_HUMAN Protein PALS1 OS=Homo sapiens OX=9606 GN=PALS1PE=1 SV=3MTTSHMNGHVTEESDSEVKNVDLASPEEHQKHREMAVDCPGDLGTRMMPIRRSAQLERIRQQQEDMRRRREEEGKKQELDLNSSMRLKKLAQIPPKTGIDNPMFDTEEGIVLESPHYAVKILEIEDLFSSLKHIQHTLVDSQSQEDISLLLQLVQNKDFQNAFKIHNAITVHMNKASPPFPLISNAQDLAQEVQTVLKPVHHKEGQELTALLNTPHIQALLLAHDKVAEQEMQLEPITDERVYESIGQYGGETVKIVRIEKARDIPLGATVRNEMDSVIISRIVKGGAAEKSGLLHEGDEVLEINGIEIRGKDVNEVFDLLSDMHGTLTFVLIPSQQIKPPPAKETVIHVKAHFDYDPSDDPYVPCRELGLSFQKGDILHVISQEDPNWWQAYREGDEDNQPLAGLVPGKSFQQQREAMKQTIEEDKEPEKSGKLWCAKKNKKKRKKVLYNANKNDDYDNEEILTYEEMSLYHQPANRKRPIILIGPQNCGQNELRQRLMNKEKDRFASAVPHTTRSRRDQEVAGRDYHFVSRQAFEADIAAGKFIEHGEFEKNLYGTSIDSVRQVINSGKICLLSLRTQSLKTLRNSDLKPYIIFIAPPSQERLRALLAKEGKNPKPEELREIIEKTREMEQNNGHYFDTAIVNSDLDKAYQELLRLINKLDTEPQWVPSTWLR>sp|Q8N3R9-2|PALS1_HUMAN Isoform 2 of Protein PALS1 OS=Homo sapiensOX=9606 GN=PALS1MAVDCPGDLGTRMMPIRRSAQLERIRQQQEDMRRRREEEGKKQELDLNSSMRLKKLAQIPPKTGIDNPMFDTEEGIVLESPHYAVKILEIEDLFSSLKHIQHTLVDSQSQEDISLLLQLVQNKDFQNAFKIHNAITVHMNKASPPFPLISNAQDLAQEVQTVLKPVHHKEGQELTALLNTPHIQALLLAHDKVAEQEMQLEPITDERVYESIGQYGGETVKIVRIEKARDIPLGATVRNEMDSVIISRIVKGGAAEKSGLLHEGDEVLEINGIEIRGKDVNEVFDLLSDMHGTLTFVLIPSQQIKPPPAKETVIHVKAHFDYDPSDDPYVPCRELGLSFQKGDILHVISQEDPNWWQAYREGDEDNQPLAGLVPGKSFQQQREAMKQTIEEDKEPEKSGKLWCAKKNKKKRKKVLYNANKNDDYDNEEILTYEEMSLYHQPANRKRPIILIGPQNCGQNELRQRLMNKEKDRFASAVPHTTRSRRDQEVAGRDYHFVSRQAFEADIAAGKFIEHGEFEKNLYGTSIDSVRQVINSGKICLLSLRTQSLKTLRNSDLKPYIIFIAPPSQERLRALLAKEGKNPKPEELREIIEKTREMEQNNGHYFDTAIVNSDLDKAYQELLRLINKLDTEPQWVPSTWLR>sp|Q14432|PDE3A_HUMAN cGMP-inhibited 3',5'-cyclic phosphodiesterase AOS=Homo sapiens OX=9606 GN=PDE3A PE=1 SV=3MAVPGDAARVRDKPVHSGVSQAPTAGRDCHHRADPASPRDSGCRGCWGDLVLQPLRSSRKLSSALCAGSLSFLLALLVRLVRGEVGCDLEQCKEAAAAEEEEAAPGAEGGVFPGPRGGAPGGGARLSPWLQPSALLFSLLCAFFWMGLYLLRAGVRLPLAVALLAACCGGEALVQIGLGVGEDHLLSLPAAGVVLSCLAAATWLVLRLRLGVLMIALTSAVRTVSLISLERFKVAWRPYLAYLAGVLGILLARYVEQILPQSAEAAPREHLGSQLIAGTKEDIPVFKRRRRSSSVVSAEMSGCSSKSHRRTSLPCIPREQLMGHSEWDHKRGPRGSQSSGTSITVDIAVMGEAHGLITDLLADPSLPPNVCTSLRAVSNLLSTQLTFQAIHKPRVNPVTSLSENYTCSDSEESSEKDKLAIPKRLRRSLPPGLLRRVSSTWTTTTSATGLPTLEPAPVRRDRSTSIKLQEAPSSSPDSWNNPVMMTLTKSRSFTSSYAISAANHVKAKKQSRPGALAKISPLSSPCSSPLQGTPASSLVSKISAVQFPESADTTAKQSLGSHRALTYTQSAPDLSPQILTPPVICSSCGRPYSQGNPADEPLERSGVATRTPSRTDDTAQVTSDYETNNNSDSSDIVQNEDETECLREPLRKASACSTYAPETMMFLDKPILAPEPLVMDNLDSIMEQLNTWNFPIFDLVENIGRKCGRILSQVSYRLFEDMGLFEAFKIPIREFMNYFHALEIGYRDIPYHNRIHATDVLHAVWYLTTQPIPGLSTVINDHGSTSDSDSDSGFTHGHMGYVFSKTYNVTDDKYGCLSGNIPALELMALYVAAAMHDYDHPGRTNAFLVATSAPQAVLYNDRSVLENHHAAAAWNLFMSRPEYNFLINLDHVEFKHFRFLVIEAILATDLKKHFDFVAKFNGKVNDDVGIDWTNENDRLLVCQMCIKLADINGPAKCKELHLQWTDGIVNEFYEQGDEEASLGLPISPFMDRSAPQLANLQESFISHIVGPLCNSYDSAGLMPGKWVEDSDESGDTDDPEEEEEEAPAPNEEETCENNESPKKKTFKRRKIYCQITQHLLQNHKMWKKVIEEEQRLAGIENQSLDQTPQSHSSEQIQAIKEEEEEKGKPRGEEIPTQKPDQ>sp|O15460|P4HA2_HUMAN Prolyl 4-hydroxylase subunit alpha-2 OS=Homosapiens OX=9606 GN=P4HA2 PE=1 SV=1MKLWVSALLMAWFGVLSCVQAEFFTSIGHMTDLIYAEKELVQSLKEYILVEEAKLSKIKSWANKMEALTSKSAADAEGYLAHPVNAYKLVKRLNTDWPALEDLVLQDSAAGFIANLSVQRQFFPTDEDEIGAAKALMRLQDTYRLDPGTISRGELPGTKYQAMLSVDDCFGMGRSAYNEGDYYHTVLWMEQVLKQLDAGEEATTTKSQVLDYLSYAVFQLGDLHRALELTRRLLSLDPSHERAGGNLRYFEQLLEEEREKTLTNQTEAELATPEGIYERPVDYLPERDVYESLCRGEGVKLTPRRQKRLFCRYHHGNRAPQLLIAPFKEEDEWDSPHIVRYYDVMSDEEIERIKEIAKPKLARATVRDPKTGVLTVASYRVSKSSWLEEDDDPVVARVNRRMQHITGLTVKTAELLQVANYGVGGQYEPHFDFSRNDERDTFKHLGTGNRVATFLNYMSDVEAGGATVFPDLGAAIWPKKGTAVFWYNLLRSGEGDYRTRHAACPVLVGCKWVSNKWFHERGQEFLRPCGSTEVD>sp|O15460-2|P4HA2_HUMAN Isoform IIa of Prolyl 4-hydroxylase subunitalpha-2 OS=Homo sapiens OX=9606 GN=P4HA2MKLWVSALLMAWFGVLSCVQAEFFTSIGHMTDLIYAEKELVQSLKEYILVEEAKLSKIKSWANKMEALTSKSAADAEGYLAHPVNAYKLVKRLNTDWPALEDLVLQDSAAGFIANLSVQRQFFPTDEDEIGAAKALMRLQDTYRLDPGTISRGELPGTKYQAMLSVDDCFGMGRSAYNEGDYYHTVLWMEQVLKQLDAGEEATTTKSQVLDYLSYAVFQLGDLHRALELTRRLLSLDPSHERAGGNLRYFEQLLEEEREKTLTNQTEAELATPEGIYERPVDYLPERDVYESLCRGEGVKLTPRRQKRLFCRYHHGNRAPQLLIAPFKEEDEWDSPHIVRYYDVMSDEEIERIKEIAKPKLARATVRDPKTGVLTVASYRVSKSSWLEEDDDPVVARVNRRMQHITGLTVKTAELLQVANYGVGGQYEPHFDFSRRPFDSGLKTEGNRLATFLNYMSDVEAGGATVFPDLGAAIWPKKGTAVFWYNLLRSGEGDYRTRHAACPVLVGCKWVSNKWFHERGQEFLRPCGSTEVD>sp|P04054|PA21B_HUMAN Phospholipase A2 OS=Homo sapiens OX=9606GN=PLA2G1B PE=1 SV=3MKLLVLAVLLTVAAADSGISPRAVWQFRKMIKCVIPGSDPFLEYNNYGCYCGLGGSGTPVDELDKCCQTHDNCYDQAKKLDSCKFLLDNPYTHTYSYSCSGSAITCSSKNKECEAFICNCDRNAAICFSKAPYNKAHKNLDTKKYCQS>sp|Q16549|PCSK7_HUMAN Proprotein convertase subtilisin/kexin type 7OS=Homo sapiens OX=9606 GN=PCSK7 PE=1 SV=2MPKGRQKVPHLDAPLGLPTCLWLELAGLFLLVPWVMGLAGTGGPDGQGTGGPSWAVHLESLEGDGEEETLEQQADALAQAAGLVNAGRIGELQGHYLFVQPAGHRPALEVEAIRQQVEAVLAGHEAVRWHSEQRLLRRAKRSVHFNDPKYPQQWHLNNRRSPGRDINVTGVWERNVTGRGVTVVVVDDGVEHTIQDIAPNYSPEGSYDLNSNDPDPMPHPDVENGNHHGTRCAGEIAAVPNNSFCAVGVAYGSRIAGIRVLDGPLTDSMEAVAFNKHYQINDIYSCSWGPDDDGKTVDGPHQLGKAALQHGVIAGRQGFGSIFVVASGNGGQHNDNCNYDGYANSIYTVTIGAVDEEGRMPFYAEECASMLAVTFSGGDKMLRSIVTTDWDLQKGTGCTEGHTGTSAAAPLAAGMIALMLQVRPCLTWRDVQHIIVFTATRYEDRRAEWVTNEAGFSHSHQHGFGLLNAWRLVNAAKIWTSVPYLASYVSPVLKENKAIPQSPRSLEVLWNVSRMDLEMSGLKTLEHVAVTVSITHPRRGSLELKLFCPSGMMSLIGAPRSMDSDPNGFNDWTFSTVRCWGERARGTYRLVIRDVGDESFQVGILRQWQLTLYGSVWSAVDIRDRQRLLESAMSGKYLHDDFALPCPPGLKIPEEDGYTITPNTLKTLVLVGCFTVFWTVYYMLEVYLSQRNVASNQVCRSGPCHWPHRSRKAKEEGTELESVPLCSSKDPDEVETESRGPPTTSDLLAPDLLEQGDWSLSQNKSALDCPHQHLDVPHGKEEQIC>sp|O43422|P52K_HUMAN 52 kDa repressor of the inhibitor of the proteinkinase OS=Homo sapiens OX=9606 GN=THAP12 PE=1 SV=2MPNFCAAPNCTRKSTQSDLAFFRFPRDPARCQKWVENCRRADLEDKTPDQLNKHYRLCAKHFETSMICRTSPYRTVLRDNAIPTIFDLTSHLNNPHSRHRKRIKELSEDEIRTLKQKKIDETSEQEQKHKETNNSNAQNPSEEEGEGQDEDILPLTLEEKENKEYLKSLFEILILMGKQNIPLDGHEADEIPEGLFTPDNFQALLECRINSGEEVLRKRFETTAVNTLFCSKTQQRQMLEICESCIREETLREVRDSHFFSIITDDVVDIAGEEHLPVLVRFVDESHNLREEFIGFLPYEADAEILAVKFHTMITEKWGLNMEYCRGQAYIVSSGFSSKMKVVASRLLEKYPQAIYTLCSSCALNMWLAKSVPVMGVSVALGTIEEVCSFFHRSPQLLLELDNVISVLFQNSKERGKELKEICHSQWTGRHDAFEILVELLQALVLCLDGINSDTNIRWNNYIAGRAFVLCSAVSDFDFIVTIVVLKNVLSFTRAFGKNLQGQTSDVFFAAGSLTAVLHSLNEVMENIEVYHEFWFEEATNLATKLDIQMKLPGKFRRAHQGNLESQLTSESYYKETLSVPTVEHIIQELKDIFSEQHLKALKCLSLVPSVMGQLKFNTSEEHHADMYRSDLPNPDTLSAELHCWRIKWKHRGKDIELPSTIYEALHLPDIKFFPNVYALLKVLCILPVMKVENERYENGRKRLKAYLRNTLTDQRSSNLALLNINFDIKHDLDLMVDTYIKLYTSKSELPTDNSETVENT>sp|O43422-2|P52K_HUMAN Isoform Short of 52 kDa repressor of theinhibitor of the protein kinase OS=Homo sapiens OX=9606 GN=THAP12MPNFCAAPNCTRKSTQSDLAFFRFPRDPARCQKWVENCRRADLEDKTPDQLNKHYRLCAKHFETSMICRTSPYRTVLRDNAIPTIFDLTSHLNNPHSRHRKRIKELSEDEIRTLKQKKIDETSEQEQKHKETNNSNAQNPSEEEGEGQDEDILPLTLEEKENKEYLKSLFEILILMGKQNIPLDGHEADEIPEGLFTPDNFQALLECRINSGEEVLRKRFETTAVNTLFCSKTQQRQMLEICESCIREETLREVRDSHFFSIITDDVVDIAGEEHLPVLVRFVDESHNLREEFIGFLPYEADAEILAVKFHTMITEKWGLNMEYCRGQAYIVSSGFSSKMKVVASRLLEKYPQAIYTLCSSCALNMWLAKSVPVMGVSVALGTIEEVCSFFHRSPQLLLELDNVISVLFQNSKERGKELKEICHSQWTGRHDAFEILVELLQALVLCLDGINSDTNIRWNNYIAGRAFVLCSAVSDFDFIVTIVVLKNEIKI>sp|Q9UHG2|PCS1N_HUMAN ProSAAS OS=Homo sapiens OX=9606 GN=PCSK1N PE=1SV=1MAGSPLLWGPRAGGVGLLVLLLLGLFRPPPALCARPVKEPRGLSAASPPLAETGAPRRFRRSVPRGEAAGAVQELARALAHLLEAERQERARAEAQEAEDQQARVLAQLLRVWGAPRNSDPALGLDDDPDAPAAQLARALLRARLDPAALAAQLVPAPVPAAALRPRPPVYDDGPAGPDAEEAGDETPDVDPELLRYLLGRILAGSADSEGVAAPRRLRRAADHDVGSELPPEGVLGALLRVKRLETPAPQVPARRLLPP>sp|P40426|PBX3_HUMAN Pre-B-cell leukemia transcription factor 3 OS=Homosapiens OX=9606 GN=PBX3 PE=1 SV=1MDDQSRMLQTLAGVNLAGHSVQGGMALPPPPHGHEGADGDGRKQDIGDILHQIMTITDQSLDEAQAKKHALNCHRMKPALFSVLCEIKEKTGLSIRGAQEEDPPDPQLMRLDNMLLAEGVSGPEKGGGSAAAAAAAAASGGSSDNSIEHSDYRAKLTQIRQIYHTELEKYEQACNEFTTHVMNLLREQSRTRPISPKEIERMVGIIHRKFSSIQMQLKQSTCEAVMILRSRFLDARRKRRNFSKQATEILNEYFYSHLSNPYPSEEAKEELAKKCSITVSQVSNWFGNKRIRYKKNIGKFQEEANLYAAKTAVTAAHAVAAAVQNNQTNSPTTPNSGSSGSFNLPNSGDMFMNMQSLNGDSYQGSQVGANVQSQVDTLRHVINQTGGYSDGLGGNSLYSPHNLNANGGWQDATTPSSVTSPTEGPGSVHSDTSN>sp|P40426-2|PBX3_HUMAN Isoform PBX3b of Pre-B-cell leukemiatranscription factor 3 OS=Homo sapiens OX=9606 GN=PBX3MDDQSRMLQTLAGVNLAGHSVQGGMALPPPPHGHEGADGDGRKQDIGDILHQIMTITDQSLDEAQAKKHALNCHRMKPALFSVLCEIKEKTGLSIRGAQEEDPPDPQLMRLDNMLLAEGVSGPEKGGGSAAAAAAAAASGGSSDNSIEHSDYRAKLTQIRQIYHTELEKYEQACNEFTTHVMNLLREQSRTRPISPKEIERMVGIIHRKFSSIQMQLKQSTCEAVMILRSRFLDARRKRRNFSKQATEILNEYFYSHLSNPYPSEEAKEELAKKCSITVSQVSNWFGNKRIRYKKNIGKFQEEANLYAAKTAVTAAHAVAAAVQNNQTNSPTTPNSGGYPPSCYQSDGRLQ>sp|P40426-3|PBX3_HUMAN Isoform PBX3c of Pre-B-cell leukemiatranscription factor 3 OS=Homo sapiens OX=9606 GN=PBX3MNLLREQSRTRPISPKEIERMVGIIHRKFSSIQMQLKQSTCEAVMILRSRFLDARRKRRNFSKQATEILNEYFYSHLSNPYPSEEAKEELAKKCSITVSQVSNWFGNKRIRYKKNIGKFQEEANLYAAKTAVTAAHAVAAAVQNNQTNSPTTPNSGSSGSFNLPNSGDMFMNMQSLNGDSYQGSQVGANVQSQVDTLRHVINQTGGYSDGLGGNSLYSPHNLNANGGWQDATTPSSVTSPTEGPGSVHSDTSN>sp|P40426-4|PBX3_HUMAN Isoform PBX3d of Pre-B-cell leukemiatranscription factor 3 OS=Homo sapiens OX=9606 GN=PBX3MNLLREQSRTRPISPKEIERMVGIIHRKFSSIQMQLKQSTCEAVMILRSRFLDARRKRRNFSKQATEILNEYFYSHLSNPYPSEEAKEELAKKCSITVSQVSNWFGNKRIRYKKNIGKFQEEANLYAAKTAVTAAHAVAAAVQNNQTNSPTTPNSGGYPPSCYQSDGRLQ>sp|P40426-5|PBX3_HUMAN Isoform 5 of Pre-B-cell leukemia transcriptionfactor 3 OS=Homo sapiens OX=9606 GN=PBX3MKPALFSVLCEIKEKTGLSIRGAQEEDPPDPQLMRLDNMLLAEGVSGPEKGGGSAAAAAAAAASGGSSDNSIEHSDYRAKLTQIRQIYHTELEKYEQACNEFTTHVMNLLREQSRTRPISPKEIERMVGIIHRKFSSIQMQLKQSTCEAVMILRSRFLDARRKRRNFSKQATEILNEYFYSHLSNPYPSEEAKEELAKKCSITVSQVSNWFGNKRIRYKKNIGKFQEEANLYAAKTAVTAAHAVAAAVQNNQTNSPTTPNSGSSGSFNLPNSGDMFMNMQSLNGDSYQGSQVGANVQSQVDTLRHVINQTGGYSDGLGGNSLYSPHNLNANGGWQDATTPSSVTSPTEGPGSVHSDTSN>sp|P0DJD9|PEPA5_HUMAN Pepsin A-5 OS=Homo sapiens OX=9606 GN=PGA5 PE=1SV=1MKWLLLLGLVALSECIMYKVPLIRKKSLRRTLSERGLLKDFLKKHNLNPARKYFPQWEAPTLVDEQPLENYLDMEYFGTIGIGTPAQDFTVVFDTGSSNLWVPSVYCSSLACTNHNRFNPEDSSTYQSTSETVSITYGTGSMTGILGYDTVQVGGISDTNQIFGLSETEPGSFLYYAPFDGILGLAYPSISSSGATPVFDNIWNQGLVSQDLFSVYLSADDKSGSVVIFGGIDSSYYTGSLNWVPVTVEGYWQITVDSITMNGETIACAEGCQAIVDTGTSLLTGPTSPIANIQSDIGASENSDGDMVVSCSAISSLPDIVFTINGVQYPVPPSAYILQSEGSCISGFQGMNVPTESGELWILGDVFIRQYFTVFDRANNQVGLAPVA>sp|P78562|PHEX_HUMAN Phosphate-regulating neutral endopeptidase PHEXOS=Homo sapiens OX=9606 GN=PHEX PE=1 SV=1MEAETGSSVETGKKANRGTRIALVVFVGGTLVLGTILFLVSQGLLSLQAKQEYCLKPECIEAAAAILSKVNLSVDPCDNFFRFACDGWISNNPIPEDMPSYGVYPWLRHNVDLKLKELLEKSISRRRDTEAIQKAKILYSSCMNEKAIEKADAKPLLHILRHSPFRWPVLESNIGPEGVWSERKFSLLQTLATFRGQYSNSVFIRLYVSPDDKASNEHILKLDQATLSLAVREDYLDNSTEAKSYRDALYKFMVDTAVLLGANSSRAEHDMKSVLRLEIKIAEIMIPHENRTSEAMYNKMNISELSAMIPQFDWLGYIKKVIDTRLYPHLKDISPSENVVVRVPQYFKDLFRILGSERKKTIANYLVWRMVYSRIPNLSRRFQYRWLEFSRVIQGTTTLLPQWDKCVNFIESALPYVVGKMFVDVYFQEDKKEMMEELVEGVRWAFIDMLEKENEWMDAGTKRKAKEKARAVLAKVGYPEFIMNDTHVNEDLKAIKFSEADYFGNVLQTRKYLAQSDFFWLRKAVPKTEWFTNPTTVNAFYSASTNQIRFPAGELQKPFFWGTEYPRSLSYGAIGVIVGHEFTHGFDNNGRKYDKNGNLDPWWSTESEEKFKEKTKCMINQYSNYYWKKAGLNVKGKRTLGENIADNGGLREAFRAYRKWINDRRQGLEEPLLPGITFTNNQLFFLSYAHVRCNSYRPEAAREQVQIGAHSPPQFRVNGAISNFEEFQKAFNCPPNSTMNRGMDSCRLW>sp|P41238|ABEC1_HUMAN C->U-editing enzyme APOBEC-1 OS=Homo sapiensOX=9606 GN=APOBEC1 PE=1 SV=3MTSEKGPSTGDPTLRRRIEPWEFDVFYDPRELRKEACLLYEIKWGMSRKIWRSSGKNTTNHVEVNFIKKFTSERDFHPSMSCSITWFLSWSPCWECSQAIREFLSRHPGVTLVIYVARLFWHMDQQNRQGLRDLVNSGVTIQIMRASEYYHCWRNFVNYPPGDEAHWPQYPPLWMMLYALELHCIILSLPPCLKISRRWQNHLTFFRLHLQNCHYQTIPPHILLATGLIHPSVAWR>sp|O75061|AUXI_HUMAN Putative tyrosine-protein phosphatase auxilinOS=Homo sapiens OX=9606 GN=DNAJC6 PE=1 SV=3MKDSENKGASSPDMEPSYGGGLFDMVKGGAGRLFSNLKDNLKDTLKDTSSRVIQSVTSYTKGDLDFTYVTSRIIVMSFPLDNVDIGFRNQVDDIRSFLDSRHLDHYTVYNLSPKSYRTAKFHSRVSECSWPIRQAPSLHNLFAVCRNMYNWLLQNPKNVCVVHCLDGRAASSILVGAMFIFCNLYSTPGPAIRLLYAKRPGIGLSPSHRRYLGYMCDLLADKPYRPHFKPLTIKSITVSPIPFFNKQRNGCRPYCDVLIGETKIYSTCTDFERMKEYRVQDGKIFIPLNITVQGDVVVSMYHLRSTIGSRLQAKVTNTQIFQLQFHTGFIPLDTTVLKFTKPELDACDVPEKYPQLFQVTLDVELQPHDKVIDLTPPWEHYCTKDVNPSILFSSHQEHQDTLALGGQAPIDIPPDNPRHYGQSGFFASLCWQDQKSEKSFCEEDHAALVNQESEQSDDELLTLSSPHGNANGDKPHGVKKPSKKQQEPAAPPPPEDVDLLGLEGSAMSNSFSPPAAPPTNSELLSDLFGGGGAAGPTQAGQSGVEDVFHPSGPASTQSTPRRSATSTSASPTLRVGEGATFDPFGAPSKPSGQDLLGSFLNTSSASSDPFLQPTRSPSPTVHASSTPAVNIQPDVSGGWDWHAKPGGFGMGSKSAATSPTGSSHGTPTHQSKPQTLDPFADLGTLGSSSFASKPTTPTGLGGGFPPLSSPQKASPQPMGGGWQQGGAYNWQQPQPKPQPSMPHSSPQNRPNYNVSFSAMPGGQNERGKGSSNLEGKQKAADFEDLLSGQGFNAHKDKKGPRTIAEMRKEEMAKEMDPEKLKILEWIEGKERNIRALLSTMHTVLWAGETKWKPVGMADLVTPEQVKKVYRKAVLVVHPDKATGQPYEQYAKMIFMELNDAWSEFENQGQKPLY>sp|O75061-2|AUXI_HUMAN Isoform 2 of Putative tyrosine-proteinphosphatase auxilin OS=Homo sapiens OX=9606 GN=DNAJC6MSLLGSYRKKTSNDGYESLQLVDSNGDLSAGSGGVGGKQRVNAGAAARSPARQPPDRASTMDSSGASSPDMEPSYGGGLFDMVKGGAGRLFSNLKDNLKDTLKDTSSRVIQSVTSYTKGDLDFTYVTSRIIVMSFPLDNVDIGFRNQVDDIRSFLDSRHLDHYTVYNLSPKSYRTAKFHSRVSECSWPIRQAPSLHNLFAVCRNMYNWLLQNPKNVCVVHCLDGRAASSILVGAMFIFCNLYSTPGPAIRLLYAKRPGIGLSPSHRRYLGYMCDLLADKPYRPHFKPLTIKSITVSPIPFFNKQRNGCRPYCDVLIGETKIYSTCTDFERMKEYRVQDGKIFIPLNITVQGDVVVSMYHLRSTIGSRLQAKVTNTQIFQLQFHTGFIPLDTTVLKFTKPELDACDVPEKYPQLFQVTLDVELQPHDKVIDLTPPWEHYCTKDVNPSILFSSHQEHQDTLALGGQAPIDIPPDNPRHYGQSGFFASLCWQDQKSEKSFCEEDHAALVNQESEQSDDELLTLSSPHGNANGDKPHGVKKPSKKQQEPAAPPPPEDVDLLGLEGSAMSNSFSPPAAPPTNSELLSDLFGGGGAAGPTQAGQSGVEDVFHPSGPASTQSTPRRSATSTSASPTLRVGEGATFDPFGAPSKPSGQDLLGSFLNTSSASSDPFLQPTRSPSPTVHASSTPAVNIQPDVSGGWDWHAKPGGFGMGSKSAATSPTGSSHGTPTHQSKPQTLDPFADLGTLGSSSFASKPTTPTGLGGGFPPLSSPQKASPQPMGGGWQQGGAYNWQQPQPKPQPSMPHSSPQNRPNYNVSFSAMPGGQNERGKGSSNLEGKQKAADFEDLLSGQGFNAHKDKKGPRTIAEMRKEEMAKEMDPEKLKILEWIEGKERNIRALLSTMHTVLWAGETKWKPVGMADLVTPEQVKKVYRKAVLVVHPDKATGQPYEQYAKMIFMELNDAWSEFENQGQKPLY>sp|O75061-3|AUXI_HUMAN Isoform 3 of Putative tyrosine-proteinphosphatase auxilin OS=Homo sapiens OX=9606 GN=DNAJC6MEPSYGGGLFDMVKGGAGRLFSNLKDNLKDTLKDTSSRVIQSVTSYTKGDLDFTYVTSRIIVMSFPLDNVDIGFRNQVDDIRSFLDSRHLDHYTVYNLSPKSYRTAKFHSRVSECSWPIRQAPSLHNLFAVCRNMYNWLLQNPKNVCVVHCLDGRAASSILVGAMFIFCNLYSTPGPAIRLLYAKRPGIGLSPSHRRYLGYMCDLLADKPYRPHFKPLTIKSITVSPIPFFNKQRNGCRPYCDVLIGETKIYSTCTDFERMKEYRVQDGKIFIPLNITVQGDVVVSMYHLRSTIGSRLQAKVTNTQIFQLQFHTGFIPLDTTVLKFTKPELDACDVPEKYPQLFQVTLDVELQPHDKVIDLTPPWEHYCTKDVNPSILFSSHQEHQDTLALGGQAPIDIPPDNPRHYGQSGFFASLCWQDQKSEKSFCEEDHAALVNQESEQ>sp|O75061-4|AUXI_HUMAN Isoform 4 of Putative tyrosine-proteinphosphatase auxilin OS=Homo sapiens OX=9606 GN=DNAJC6MEPSYGGGLFDMVKGGAGRLFSNLKDNLKDTLKDTSSRVIQSVTSYTKGDLDFTYVTSRIIVMSFPLDNVDIGFRNQVDDIRSFLDSRHLDHYTVYNLSPKSYRTAKFHSRVSECSWPIRQAPSLHNLFAVCRNMYNWLLQNPKNVCVVHCLDGRAASSILVGAMFIFCNLYSTPGPAIRLLYAKRPGIGLSPSHRRYLGYMCDLLADKPYRPHFKPLTIKSITVSPIPFFNKQRNGCRPYCDVLIGETKIYSTCTDFERMKEYRVQDGKIFIPLNITVQGDVVVSMYHLRSTIGSRLQAKVTNTQIFQLQFHTGFIPLDTTVLKFTKPELDACDVPEKYPQLFQVTLDVELQPHDKVIDLTPPWEHYCTKDVNPSILFSSHQEHQDTLALGGQAPIDIPPDNPRHYGQSGFFASLCWQDQKSEKSFCEEDHAALVNQESEQSDDELLTLSSPHGNANGDKPHGVKKPSKKQQEPAAPPPPEDVDLLGLEGSAMSNSFSPPAAPPTNSELLSDLFGGGGAAGPTQAGQSGVEDVFHPSGPASTQSTPRRSATSTSASPTLRVGEGATFDPFGAPSKPSGQDLLGSFLNTSSASSDPFLQPTRSPSPTVHASSTPAVNIQPDVSGGWDWHAKPGGFGMGSKSAATSPTGSSHGTPTHQSKPQTLDPFADLGTLGSSSFASKPTTPTGLGGGFPPLSSPQKASPQPMGGGWQQGGAYNWQQPQPKPQPSMPHSSPQNRPNYNVSFSAMPGGQNERGKGSSNLEGKQKAADFEDLLSGQGFNAHKDKKGPRTIAEMRKEEMAKEMDPEKLKILEWIEGKERNIRALLSTMHTVLWAGETKWKPVGMADLVTPEQVKKVYRKAVLVVHPDKATGQPYEQYAKMIFMELNDAWSEFENQGQKPLY>sp|Q9UII2|ATIF1_HUMAN ATPase inhibitor, mitochondrial OS=Homo sapiensOX=9606 GN=ATP5IF1 PE=1 SV=1MAVTALAARTWLGVWGVRTMQARGFGSDQSENVDRGAGSIREAGGAFGKREQAEEERYFRAQSREQLAALKKHHEEEIVHHKKEIERLQKEIERHKQKIKMLKHDD>sp|Q9UII2-2|ATIF1_HUMAN Isoform 2 of ATPase inhibitor, mitochondrialOS=Homo sapiens OX=9606 GN=ATP5IF1MAVTALAARTWLGVWGVRTMQARGFGSDQSENVDRGAGSIREAGGAFGKREQAEEERYFRHYRLCFEISLG>sp|Q9UII2-3|ATIF1_HUMAN Isoform 3 of ATPase inhibitor, mitochondrialOS=Homo sapiens OX=9606 GN=ATP5IF1MAVTALAARTWLGVWGVRTMQARGFGSDQSENVDRGAGSIREAGGAFGKREQAEEERYFR>sp|P19652|A1AG2_HUMAN Alpha-1-acid glycoprotein 2 OS=Homo sapiensOX=9606 GN=ORM2 PE=1 SV=2MALSWVLTVLSLLPLLEAQIPLCANLVPVPITNATLDRITGKWFYIASAFRNEEYNKSVQEIQATFFYFTPNKTEDTIFLREYQTRQNQCFYNSSYLNVQRENGTVSRYEGGREHVAHLLFLRDTKTLMFGSYLDDEKNWGLSFYADKPETTKEQLGEFYEALDCLCIPRSDVMYTDWKKDKCEPLEKQHEKERKQEEGES>sp|Q5TBC7|B2L15_HUMAN Bcl-2-like protein 15 OS=Homo sapiens OX=9606GN=BCL2L15 PE=1 SV=1MKSSQTFEEQTECIVNTLLMDFLSPTLQVASRNLCCVDEVDSGEPCSFDVAIIAGRLRMLGDQFNGELEASAKNVIAETIKGQTGAILQDTVESLSKTWCAQDSSLAYERAFLAVSVKLLEYMAHIAPEVVGQVAIPMTGMINGNQAIREFIQGQGGWENLES>sp|Q5TBC7-2|B2L15_HUMAN Isoform 2 of Bcl-2-like protein 15 OS=Homosapiens OX=9606 GN=BCL2L15MKSSQTFEEQTECIVNTLLMDFLSPTLQVASRNLCCVDEVDSGKSGELKSWSYSRD>sp|Q96SE0|ABHD1_HUMAN Protein ABHD1 OS=Homo sapiens OX=9606 GN=ABHD1PE=1 SV=2MLSSFLSPQNGTWADTFSLLLALAVALYLGYYWACVLQRPRLVAGPQFLAFLEPHCSITTETFYPTLWCFEGRLQSIFQVLLQSQPLVLYQSDILQTPDGGQLLLDWAKQPDSSQDPDPTTQPIVLLLPGITGSSQDTYVLHLVNQALRDGYQAVVFNNRGCRGEELRTHRAFCASNTEDLETVVNHIKHRYPQAPLLAVGISFGGILVLNHLAQARQAAGLVAALTLSACWDSFETTRSLETPLNSLLFNQPLTAGLCQLVERNRKVIEKVVDIDFVLQARTIRQFDERYTSVAFGYQDCVTYYKAASPRTKIDAIRIPVLYLSAADDPFSPVCALPIQAAQHSPYVALLITARGGHIGFLEGLLPWQHWYMSRLLHQYAKAIFQDPEGLPDLRALLPSEDRNS>sp|Q96SE0-3|ABHD1_HUMAN Isoform 2 of Protein ABHD1 OS=Homo sapiensOX=9606 GN=ABHD1MLSSFLSPQNGTWADTFSLLLALAVALYLGYYWACVLQRPRLVAGPQFLAFLEPHCSITTETFYPTLWCFEGRLQSIFQVLLQSQPLVLYQSDILQTPDGGQLLLDWAKQPDSSQDPDPTTQPIVLLLPGITGSSQDTYVLHLVNQALRDGYQAVVFNNRGCRGEELRTHRAFCASNTEDLETVVNHIKHRYPQAPLLAVGISFGGILVLNHLAQARQAAGLVAALTLSACWDSFETTRSLETPLNSLLFNQPLTAGLCQLVERLSYGKTCRPVQSASLMSATHLWPLDIKTVLPTTKQQALEPR>sp|Q5W0U4|BSPRY_HUMAN B box and SPRY domain-containing protein OS=Homosapiens OX=9606 GN=BSPRY PE=2 SV=1MSAEGAEPGPGSGSGPGPGPLCPEHGQALSWFCGSERRPVCAACAGLGGRCRGHRIRRAEERAEELRNKIVDQCERLQLQSAAITKYVADVLPGKNQRAVSMASAARELVIQRLSLVRSLCESEEQRLLEQVHGEEERAHQSILTQRVHWAEALQKLDTIRTGLVGMLTHLDDLQLIQKEQEIFERTEEAEGILDPQESEMLNFNEKCTRSPLLTQLWATAVLGSLSGTEDIRIDERTVSPFLQLSDDRKTLTFSTKKSKACADGPERFDHWPNALAATSFQNGLHAWMVNVQNSCAYKVGVASGHLPRKGSGSDCRLGHNAFSWVFSRYDQEFRFSHNGQHEPLGLLRGPAQLGVVLDLQVQELLFYEPASGTVLCAHHVSFPGPLFPVFAVADQTISIVR>sp|Q5W0U4-2|BSPRY_HUMAN Isoform 2 of B box and SPRY domain-containingprotein OS=Homo sapiens OX=9606 GN=BSPRYMSAEGAEPGPGSGSGPGPGPLCPEHGQALSWFCGSERRPVCAACAGLGGRCRGHRIRRAEERAEELRNKIVDQCERLQLQSAAITKYVADVLPGKNQRAVSMASAARELVIQRLSLVRSLCESEEQRLLEQVHGEEERAHQSILTQRVHWAEALQKLDTIRTGLVGMLTHLDDLQLIQKEQEIFERHRGHTDR>sp|Q6JQN1|ACD10_HUMAN Acyl-CoA dehydrogenase family member 10 OS=Homosapiens OX=9606 GN=ACAD10 PE=1 SV=1MCVRSCFQSPRLQWVWRTAFLKHTQRRHQGSHRWTHLGGSTYRAVIFDMGGVLIPSPGRVAAEWEVQNRIPSGTILKALMEGGENGPWMRFMRAEITAEGFLREFGRLCSEMLKTSVPVDSFFSLLTSERVAKQFPVMTEAITQIRAKGLQTAVLSNNFYLPNQKSFLPLDRKQFDVIVESCMEGICKPDPRIYKLCLEQLGLQPSESIFLDDLGTNLKEAARLGIHTIKVNDPETAVKELEALLGFTLRVGVPNTRPVKKTMEIPKDSLQKYLKDLLGIQTTGPLELLQFDHGQSNPTYYIRLANRDLVLRKKPPGTLLPSAHAIEREFRIMKALANAGVPVPNVLDLCEDSSVIGTPFYVMEYCPGLIYKDPSLPGLEPSHRRAIYTAMNTVLCKIHSVDLQAVGLEDYGKQGDYIPRQVRTWVKQYRASETSTIPAMERLIEWLPLHLPRQQRTTVVHGDFRLDNLVFHPEEPEVLAVLDWELSTLGDPLADVAYSCLAHYLPSSFPVLRGINDCDLTQLGIPAAEEYFRMYCLQMGLPPTENWNFYMAFSFFRVAAILQGVYKRSLTGQASSTYAEQTGKLTEFVSNLAWDFAVKEGFRVFKEMPFTNPLTRSYHTWARPQSQWCPTGSRSYSSVPEASPAHTSRGGLVISPESLSPPVRELYHRLKHFMEQRVYPAEPELQSHQASAARWSPSPLIEDLKEKAKAEGLWNLFLPLEADPEKKYGAGLTNVEYAHLCELMGTSLYAPEVCNCSAPDTGNMELLVRYGTEAQKARWLIPLLEGKARSCFAMTEPQVASSDATNIEASIREEDSFYVINGHKWWITGILDPRCQLCVFMGKTDPHAPRHRQQSVLLVPMDTPGIKIIRPLTVYGLEDAPGGHGEVRFEHVRVPKENMVLGPGRGFEIAQGRLGPGRIHHCMRLIGFSERALALMKARVKSRLAFGKPLVEQGTVLADIAQSRVEIEQARLLVLRAAHLMDLAGNKAAALDIAMIKMVAPSMASRVIDRAIQAFGAAGLSSDYPLAQFFTWARALRFADGPDEVHRATVAKLELKHRI>sp|Q6JQN1-2|ACD10_HUMAN Isoform 2 of Acyl-CoA dehydrogenase familymember 10 OS=Homo sapiens OX=9606 GN=ACAD10MCVRSCFQSPRLQWVWRTAFLKHTQRRHQGSHRWTHLGGSTYRAVIFDMGGVLIPSPGRVAAEWEVQNRIPSGTILKALMEGGENGPWMRFMRAEITAEGFLREFGRLCSEMLKTSVPVDSFFSLLTSERVAKQFPVMTEAITQIRAKGLQTAVLSNNFYLPNQKSFLPLDRKQFDVIVESCMEGICKPDPRIYKLCLEQLGLQPSESIFLDDLGTNLKEAARLGIHTIKVNDPETAVKELEALLGFTLRVGVPNTRPVKKTMEIPKDSLQKYLKDLLGIQTTGPLELLQFDHGQSNPTYYIRLANRDLVLRKKPPGTLLPSAHAIEREFRIMKALANAGVPVPNVLDLCEDSSVIGTPFYVMEYCPGLIYKDPSLPGLEPSHRRAIYTAMNTVLCKIHSVDLQAVGLEDYGKQGDYIPRQVRTWVKQYRASETSTIPAMERLIEWLPLHLPRQQRTTVVHGDFRLDNLVFHPEEPEVLAVLDWELSTLGDPLADVAYSCLAHYLPSSFPVLRGINDCDLTQLGIPAAEEYFRMYCLQMGLPPTENWNFYMAFSFFRVAAILQGVYKRSLTGQASSTYAEQTGKLTEFVSNLAWDFAVKEGFRVFKEMPFTNPLTRSYHTWARPQSQWCPTGSRSYSSVPEASPAHTSRGGLVISPESLSPPVRELYHRLKHFMEQRVYPAEPELQSHQASAARWSPSPLIEDLKEKAKAEGLWNLFLPLEADPEKKYGAGLTNVEYAHLCELMGTSLYAPEVCNCSAPDTGNMELLVRYGTEAQKARWLIPLLEGKARSCFAMTEPQVASSDATNIEASIREEDSFYVINGHKWWITGILDPRCQLCVFMGKTDPHAPRHRQQSVLLVPMDTPGIKIIRPLTVYGLEDAPGCFLPSFSL>sp|Q6JQN1-3|ACD10_HUMAN Isoform 3 of Acyl-CoA dehydrogenase familymember 10 OS=Homo sapiens OX=9606 GN=ACAD10MLEYLSLTFLISVKIQGDYIPRQVRTWVKQYRASETSTIPAMERLIEWLPLHLPRQQRTTVVHGDFRLDNLVFHPEEPEVLAVLDWELSTLGDPLADVAYSCLAHYLPSSFPVLRGINDCDLTQLGIPAAEEYFRMYCLQMGLPPTENWNFYMAFSFFRVAAILQGVYKRSLTGQASSTYAEQTGKLTEFVSNLAWDFAVKEGFRVFKEMPFTNPLTRSYHTWARPQSQWCPTGSRSYSSVPEASPAHTSRGGLVISPESLSPPVRELYHRLKHFMEQRVYPAEPELQSHQASAARWSPSPLIEDLKEKAKAEGLWNLFLPLEADPEKKYGAGLTNVEYAHLCELMGTSLYAPEVCNCSAPDTGNMELLVRYGTEAQKARWLIPLLEGKARSCFAMTEPQVASSDATNIEASIREEDSFYVINGHKWWITGILDPRCQLCVFMGKTDPHAPRHRQQSVLLVPMDTPGIKIIRPLTVYGLEDAPGCFLPSFSL>sp|Q6JQN1-4|ACD10_HUMAN Isoform 4 of Acyl-CoA dehydrogenase familymember 10 OS=Homo sapiens OX=9606 GN=ACAD10MCVRSCFQSPRLQWVWRTAFLKHTQRRHQGSHRWTHLGGSTYRAVIFDMGGVLIPSPGRVAAEWEVQNRIPSGTILKALMEGGENGPWMRFMRAEITAEGFLREFGRLCSEMLKTSVPVDSFFSLLTSERVAKQFPVMTEAITQIRAKGLQTAVLSNNFYLPNQKSFLPLDRKQFDVIVESCMEGICKPDPRIYKLCLEQLGLQPSESIFLDDLGTNLKEAARLGIHTIKVNDPETAVKELEALLGFTLRVGVPNTRPVKKTMEIPKDSLQKYLKDLLGIQTTGL>sp|Q6JQN1-5|ACD10_HUMAN Isoform 5 of Acyl-CoA dehydrogenase familymember 10 OS=Homo sapiens OX=9606 GN=ACAD10MCVRSCFQSPRLQWVWRTAFLKHTQRRHQGSHRWTHLGGSTYRAVIFDMGGVLIPSPGRVAAEWEVQNRIPSGTILKALMEGGENGPWMRFMRAEITAEGFLREFGRLCSEMLKTSVPVDSFFSLLTSERVAKQFPVMTEAITQIRAKGLQTAVLSNNFYLPNQKSFLPLDRKQFDVIVESCMEGICKPDPRIYKLCLEQLGLQPSESIFLDDLGTNLKEAARLGIHTIKRQGFAVLPKLVSNSWAQAIYPPYPPKVVRLQVNDPETAVKELEALLGFTLRVGVPNTRPVKKTMEIPKDSLQKYLKDLLGIQTTGPLELLQFDHGQSNPTYYIRLANRDLVLRKKPPGTLLPSAHAIEREFRIMKALANAGVPVPNVLDLCEDSSVIGTPFYVMEYCPGLIYKDPSLPGLEPSHRRAIYTAMNTVLCKIHSVDLQAVGLEDYGKQGDYIPRQVRTWVKQYRASETSTIPAMERLIEWLPLHLPRQQRTTVVHGDFRLDNLVFHPEEPEVLAVLDWELSTLGDPLADVAYSCLAHYLPSSFPVLRGINDCDLTQLGIPAAEEYFRMYCLQMGLPPTENWNFYMAFSFFRVAAILQGVYKRSLTGQASSTYAEQTGKLTEFVSNLAWDFAVKEGFRVFKEMPFTNPLTRSYHTWARPQSQWCPTGSRSYSSVPEASPAHTSRGGLVISPESLSPPVRELYHRLKHFMEQRVYPAEPELQSHQASAARWSPSPLIEDLKEKAKAEGLWNLFLPLEADPEKKYGAGLTNVEYAHLCELMGTSLYAPEVCNCSAPDTGNMELLVRYGTEAQKARWLIPLLEGKARSCFAMTEPQVASSDATNIEASIREEDSFYVINGHKWWITGILDPRCQLCVFMGKTDPHAPRHRQQSVLLVPMDTPGIKIIRPLTVYGLEDAPGGHGEVRFEHVRVPKENMVLGPGRGFEIAQGRLGPGRIHHCMRLIGFSERALALMKARVKSRLAFGKPLVEQGTVLADIAQSRVEIEQARLLVLRAAHLMDLAGNKAAALDIAMIKMVAPSMASRVIDRAIQAFGAAGLSSDYPLAQFFTWARALRFADGPDEVHRATVAKLELKHRI>sp|P08910|ABHD2_HUMAN Monoacylglycerol lipase ABHD2 OS=Homo sapiensOX=9606 GN=ABHD2 PE=1 SV=1MNAMLETPELPAVFDGVKLAAVAAVLYVIVRCLNLKSPTAPPDLYFQDSGLSRFLLKSCPLLTKEYIPPLIWGKSGHIQTALYGKMGRVRSPHPYGHRKFITMSDGATSTFDLFEPLAEHCVGDDITMVICPGIANHSEKQYIRTFVDYAQKNGYRCAVLNHLGALPNIELTSPRMFTYGCTWEFGAMVNYIKKTYPLTQLVVVGFSLGGNIVCKYLGETQANQEKVLCCVSVCQGYSALRAQETFMQWDQCRRFYNFLMADNMKKIILSHRQALFGDHVKKPQSLEDTDLSRLYTATSLMQIDDNVMRKFHGYNSLKEYYEEESCMRYLHRIYVPLMLVNAADDPLVHESLLTIPKSLSEKRENVMFVLPLHGGHLGFFEGSVLFPEPLTWMDKLVVEYANAICQWERNKLQCSDTEQVEADLE>sp|Q8WWZ7|ABCA5_HUMAN Cholesterol transporter ABCA5 OS=Homo sapiensOX=9606 GN=ABCA5 PE=1 SV=2MSTAIREVGVWRQTRTLLLKNYLIKCRTKKSSVQEILFPLFFLFWLILISMMHPNKKYEEVPNIELNPMDKFTLSNLILGYTPVTNITSSIMQKVSTDHLPDVIITEEYTNEKEMLTSSLSKPSNFVGVVFKDSMSYELRFFPDMIPVSSIYMDSRAGCSKSCEAAQYWSSGFTVLQASIDAAIIQLKTNVSLWKELESTKAVIMGETAVVEIDTFPRGVILIYLVIAFSPFGYFLAIHIVAEKEKKIKEFLKIMGLHDTAFWLSWVLLYTSLIFLMSLLMAVIATASLLFPQSSSIVIFLLFFLYGLSSVFFALMLTPLFKKSKHVGIVEFFVTVAFGFIGLMIILIESFPKSLVWLFSPFCHCTFVIGIAQVMHLEDFNEGASFSNLTAGPYPLIITIIMLTLNSIFYVLLAVYLDQVIPGEFGLRRSSLYFLKPSYWSKSKRNYEELSEGNVNGNISFSEIIEPVSSEFVGKEAIRISGIQKTYRKKGENVEALRNLSFDIYEGQITALLGHSGTGKSTLMNILCGLCPPSDGFASIYGHRVSEIDEMFEARKMIGICPQLDIHFDVLTVEENLSILASIKGIPANNIIQEVQKVLLDLDMQTIKDNQAKKLSGGQKRKLSLGIAVLGNPKILLLDEPTAGMDPCSRHIVWNLLKYRKANRVTVFSTHFMDEADILADRKAVISQGMLKCVGSSMFLKSKWGIGYRLSMYIDKYCATESLSSLVKQHIPGATLLQQNDQQLVYSLPFKDMDKFSGLFSALDSHSNLGVISYGVSMTTLEDVFLKLEVEAEIDQADYSVFTQQPLEEEMDSKSFDEMEQSLLILSETKAALVSTMSLWKQQMYTIAKFHFFTLKRESKSVRSVLLLLLIFFTVQIFMFLVHHSFKNAVVPIKLVPDLYFLKPGDKPHKYKTSLLLQNSADSDISDLISFFTSQNIMVTMINDSDYVSVAPHSAALNVMHSEKDYVFAAVFNSTMVYSLPILVNIISNYYLYHLNVTETIQIWSTPFFQEITDIVFKIELYFQAALLGIIVTAMPPYFAMENAENHKIKAYTQLKLSGLLPSAYWIGQAVVDIPLFFIILILMLGSLLAFHYGLYFYTVKFLAVVFCLIGYVPSVILFTYIASFTFKKILNTKEFWSFIYSVAALACIAITEITFFMGYTIATILHYAFCIIIPIYPLLGCLISFIKISWKNVRKNVDTYNPWDRLSVAVISPYLQCVLWIFLLQYYEKKYGGRSIRKDPFFRNLSTKSKNRKLPEPPDNEDEDEDVKAERLKVKELMGCQCCEEKPSIMVSNLHKEYDDKKDFLLSRKVKKVATKYISFCVKKGEILGLLGPNGAGKSTIINILVGDIEPTSGQVFLGDYSSETSEDDDSLKCMGYCPQINPLWPDTTLQEHFEIYGAVKGMSASDMKEVISRITHALDLKEHLQKTVKKLPAGIKRKLCFALSMLGNPQITLLDEPSTGMDPKAKQHMWRAIRTAFKNRKRAAILTTHYMEEAEAVCDRVAIMVSGQLRCIGTVQHLKSKFGKGYFLEIKLKDWIENLEVDRLQREIQYIFPNASRQESFSSILAYKIPKEDVQSLSQSFFKLEEAKHAFAIEEYSFSQATLEQVFVELTKEQEEEDNSCGTLNSTLWWERTQEDRVVF>sp|Q8WWZ7-2|ABCA5_HUMAN Isoform 2 of Cholesterol transporter ABCA5OS=Homo sapiens OX=9606 GN=ABCA5MSTAIREVGVWRQTRTLLLKNYLIKCRTKKSSVQEILFPLFFLFWLILISMMHPNKKYEEVPNIELNPMDKFTLSNLILGYTPVTNITSSIMQKVSTDHLPDVIITEEYTNEKEMLTSSLSKPSNFVGVVFKDSMSYELRFFPDMIPVSSIYMDSRAGCSKSCEAAQYWSSGFTVLQASIDAAIIQLKTNVSLWKELESTKAVIMGETAVVEIDTFPRGVILIYLVIAFSPFGYFLAIHIVAEKEKKIKEFLKIMGLHDTAFWLSWVLLYTSLIFLMSLLMAVIATASLLFPQSSSIVIFLLFFLYGLSSVFFALMLTPLFKKSKHVGIVEFFVTVAFGFIGLMIILIESFPKSLVWLFSPFCHCTFVIGIAQVMHLEDFNEGASFSNLTAGPYPLIITIIMLTLNSIFYVLLAVYLDQVIPGEFGLRRSSLYFLKPSYWSKSKRNYEELSEGNVNGNISFSEIIEPVSSEFVGKEAIRISGIQKTYRKKGENVEALRNLSFDIYEGQITALLGHSGTGKSTLMNILCGLCPPSDGFASIYGHRVSEIDEMFEARKMIGICPQLDIHFDVLTVEENLSILASIKGIPANNIIQEVQKVLLDLDMQTIKDNQAKKLSGGQKRKLSLGIAVLGNPKILLLDEPTAGMDPCSRHIVWNLLKYRKANRVTVFSTHFMDEADILADRKAVISQGMLKCVGSSMFLKSKWGIGYRLSMYIDKYCATESLSSLVKQHIPGATLLQQNDQQLVYSLPFKDMDKFSGLFSALDSHSNLGVISYGVSMTTLEDVFLKLEVEAEIDQADYSVFTQQPLEEEMDSKSFDEMEQSLLILSETKAALVSTMSLWKQQMYTIAKFHFFTLKRESKSVRSVLLLLLIFFTVQIFMFLVHHSFKNAVVPIKLVPDLYFLKPGDKPHKYKTSLLLQNSAGESV>sp|Q8WWZ7-3|ABCA5_HUMAN Isoform 3 of Cholesterol transporter ABCA5OS=Homo sapiens OX=9606 GN=ABCA5MTTLEDVFLKLEVEAEIDQADYSVFTQQPLEEEMDSKSFDEMEQSLLILSETKAALVSTMSLWKQQMYTIAKFHFFTLKRESKSVRSVLLLLLIFFTVQIFMFLVHHSFKNAVVPIKLVPDLYFLKPGDKPHKYKTSLLLQNSADSDISDLISFFTSQNIMVTMINDSDYVSVAPHSAALNVMHSEKDYVFAAVFNSTMVYSLPILVNIISNYYLYHLNVTETIQIWSTPFFQEITDIVFKIELYFQAALLGIIVTAMPPYFAMENAENHKIKAYTQLKLSGLLPSAYWIGQAVVDIPLFFIILILMLGSLLAFHYGLYFYTVKFLAVVFCLIGYVPSVILFTYIASFTFKKILNTKEFWSFIYSVAALACIAITEITFFMGYTIATILHYAFCIIIPIYPLLGCLISFIKISWKNVRKNVDTYNPWDRLSVAVISPYLQCVLWIFLLQYYEKKYGGRSIRKDPFFRNLSTKSKNRKLPEPPDNEDEDEDVKAERLKVKELMGCQCCEEKPSIMVSNLHKEYDDKKDFLLSRKVKKVATKYISFCVKKGEILGLLGPNGAGKSTIINILVGDIEPTSGQVFLGDYSSETSEDDDSLKCMGYCPQINPLWPDTTLQEHFEIYGAVKGMSASDMKEVISRITHALDLKEHLQKTVKKLPAGIKRKLCFALSMLGNPQITLLDEPSTGMDPKAKQHMWRAIRTAFKNRKRAAILTTHYMEEAEAVCDRVAIMVSGQLRCIGTVQHLKSKFGKGYFLEIKLKDWIENLEVDRLQREIQYIFPNASRQESFSSILAYKIPKEDVQSLSQSFFKLEEAKHAFAIEEYSFSQATLEQVFVELTKEQEEEDNSCGTLNSTLWWERTQEDRVVF>sp|Q9GZN4|BSSP4_HUMAN Brain-specific serine protease 4 OS=Homo sapiensOX=9606 GN=PRSS22 PE=1 SV=1MVVSGAPPALGGGCLGTFTSLLLLASTAILNAARIPVPPACGKPQQLNRVVGGEDSTDSEWPWIVSIQKNGTHHCAGSLLTSRWVITAAHCFKDNLNKPYLFSVLLGAWQLGNPGSRSQKVGVAWVEPHPVYSWKEGACADIALVRLERSIQFSERVLPICLPDASIHLPPNTHCWISGWGSIQDGVPLPHPQTLQKLKVPIIDSEVCSHLYWRGAGQGPITEDMLCAGYLEGERDACLGDSGGPLMCQVDGAWLLAGIISWGEGCAERNRPGVYISLSAHRSWVEKIVQGVQLRGRAQGGGALRAPSQGSGAAARS>sp|O94911|ABCA8_HUMAN ABC-type organic anion transporter ABCA8 OS=Homosapiens OX=9606 GN=ABCA8 PE=1 SV=4MRKRKISVCQQTWALLCKNFLKKWRMKRESLMEWLNSLLLLLCLYIYPHSHQVNDFSSLLTMDLGRVDTFNESRFSVVYTPVTNTTQQIMNKVASTPFLAGKEVLGLPDEESIKEFTANYPEEIVRVTFTNTYSYHLKFLLGHGMPAKKEHKDHTAHCYETNEDVYCEVSVFWKEGFVALQAAINAAIIEITTNHSVMEELMSVTGKNMKMHSFIGQSGVITDLYLFSCIISFSSFIYYASVNVTRERKRMKALMTMMGLRDSAFWLSWGLLYAGFIFIMALFLALVIRSTQFIILSGFMVVFSLFLLYGLSLVALAFLMSILVKKSFLTGLVVFLLTVFWGCLGFTSLYRHLPASLEWILSLLSPFAFMLGMAQLLHLDYDLNSNAFPHPSDGSNLIVATNFMLAFDTCLYLALAIYFEKILPNEYGHRRPPLFFLKSSFWSQTQKTDHVALEDEMDADPSFHDSFEQAPPEFQGKEAIRIRNVTKEYKGKPDKIEALKDLVFDIYEGQITAILGHSGAGKSTLLNILSGLSVPTKGSVTIYNNKLSEMADLENLSKLTGVCPQSNVQFDFLTVRENLRLFAKIKGILPQEVDKEIQRVLLELEMKNIQDVLAQNLSGGQKRKLTFGIAILGDPQIFLLDEPTAGLDPFSRHQVWNLLKERKTDRVILFSTQFMDEADILADRKVFLSQGKLKCAGSSLFLKKKWGIGYHLSLQLNEICVEENITSLVKQHIPDAKLSAKSEGKLIYTLPLERTNKFPELYKDLDSYPDLGIENYGVSMTTLNEVFLKLEGKSTINESDIAILGEVQAEKADDTERLVEMEQVLSSLNKMRKTIGGVALWRQQICAIARVRLLKLKHERKALLALLLILMAGFCPLLVEYTMVKIYQNSYTWELSPHLYFLAPGQQPHDPLTQLLIINKTGASIDDFIQSVEHQNIALEVDAFGTRNGTDDPSYNGAITVCCNEKNYSFSLACNAKRLNCFPVLMDIVSNGLLGMVKPSVHIRTERSTFLENGQDNPIGFLAYIMFWLVLTSSCPPYIAMSSIDDYKNRARSQLRISGLSPSAYWFGQALVDVSLYFLVFVFIYLMSYISNFEDMLLTIIHIIQIPCAVGYSFSLIFMTYVISFIFRKGRKNSGIWSFCFYVVTVFSVAGFAFSIFESDIPFIFTFLIPPATMIGCLFLSSHLLFSSLFSEERMDVQPFLVFLIPFLHFIIFLFTLRCLEWKFGKKSMRKDPFFRISPRSSDVCQNPEEPEGEDEDVQMERVRTANALNSTNFDEKPVIIASCLRKEYAGKRKGCFSKRKNKIATRNVSFCVRKGEVLGLLGHNGAGKSTSIKVITGDTKPTAGQVLLKGSGGGDALEFLGYCPQENALWPNLTVRQHLEVYAAVKGLRKGDAEVAITRLVDALKLQDQLKSPVKTLSEGIKRKLCFVLSILGNPSVVLLDEPSTGMDPEGQQQMWQAIRATFRNTERGALLTTHYMAEAEAVCDRVAIMVSGRLRCIGSIQHLKSKFGKDYLLEMKVKNLAQVEPLHAEILRLFPQAARQERYSSLMVYKLPVEDVQPLAQAFFKLEKVKQSFDLEEYSLSQSTLEQVFLELSKEQELGDFEEDFDPSVKWKLLPQEEP>sp|O94911-1|ABCA8_HUMAN Isoform 1 of ABC-type organic anion transporterABCA8 OS=Homo sapiens OX=9606 GN=ABCA8MRKRKISVCQQTWALLCKNFLKKWRMKRESLMEWLNSLLLLLCLYIYPHSHQVNDFSSLLTMDLGRVDTFNESRFSVVYTPVTNTTQQIMNKVASTPFLAGKEVLGLPDEESIKEFTANYPEEIVRVTFTNTYSYHLKFLLGHGMPAKKEHKDHTAHCYETNEDVYCEVSVFWKEGFVALQAAINAAIIEITTNHSVMEELMSVTGKNMKMHSFIGQSGVITDLYLFSCIISFSSFIYYASVNVTRERKRMKALMTMMGLRDSAFWLSWGLLYAGFIFIMALFLALVIRSTQFIILSGFMVVFSLFLLYGLSLVALAFLMSILVKKSFLTGLVVFLLTVFWGCLGFTSLYRHLPASLEWILSLLSPFAFMLGMAQLLHLDYDLNSNAFPHPSDGSNLIVATNFMLAFDTCLYLALAIYFEKILPNEYGHRRPPLFFLKSSFWSQTQKTDHVALEDEMDADPSFHDSFEQAPPEFQGKEAIRIRNVTKEYKGKPDKIEALKDLVFDIYEGQITAILGHSGAGKSTLLNILSGLSVPTKGSVTIYNNKLSEMADLENLSKLTGVCPQSNVQFDFLTVRENLRLFAKIKGILPQEVDKEIFLLDEPTAGLDPFSRHQVWNLLKERKTDRVILFSTQFMDEADILADRKVFLSQGKLKCAGSSLFLKKKWGIGYHLSLQLNEICVEENITSLVKQHIPDAKLSAKSEGKLIYTLPLERTNKFPELYKDLDSYPDLGIENYGVSMTTLNEVFLKLEGKSTINESDIAILGEVQAEKADDTERLVEMEQVLSSLNKMRKTIGGVALWRQQICAIARVRLLKLKHERKALLALLLILMAGFCPLLVEYTMVKIYQNSYTWELSPHLYFLAPGQQPHDPLTQLLIINKTGASIDDFIQSVEHQNIALEVDAFGTRNGTDDPSYNGAITVCCNEKNYSFSLACNAKRLNCFPVLMDIVSNGLLGMVKPSVHIRTERSTFLENGQDNPIGFLAYIMFWLVLTSSCPPYIAMSSIDDYKNRARSQLRISGLSPSAYWFGQALVDVSLYFLVFVFIYLMSYISNFEDMLLTIIHIIQIPCAVGYSFSLIFMTYVISFIFRKGRKNSGIWSFCFYVVTVFSVAGFAFSIFESDIPFIFTFLIPPATMIGCLFLSSHLLFSSLFSEERMDVQPFLVFLIPFLHFIIFLFTLRCLEWKFGKKSMRKDPFFRISPRSSDVCQNPEEPEGEDEDVQMERVRTANALNSTNFDEKPVIIASCLRKEYAGKRKGCFSKRKNKIATRNVSFCVRKGEVLGLLGHNGAGKSTSIKVITGDTKPTAGQVLLKGSGGGDALEFLGYCPQENALWPNLTVRQHLEVYAAVKGLRKGDAEVAITRLVDALKLQDQLKSPVKTLSEGIKRKLCFVLSILGNPSVVLLDEPSTGMDPEGQQQMWQAIRATFRNTERGALLTTHYMAEAEAVCDRVAIMVSGRLRCIGSIQHLKSKFGKDYLLEMKVKNLAQVEPLHAEILRLFPQAARQERYSSLMVYKLPVEDVQPLAQAFFKLEKVKQSFDLEEYSLSQSTLEQVFLELSKEQELGDFEEDFDPSVKWKLLPQEEP>sp|O94911-2|ABCA8_HUMAN Isoform 2 of ABC-type organic anion transporterABCA8 OS=Homo sapiens OX=9606 GN=ABCA8MRKRKISVCQQTWALLCKNFLKKWRMKRESLMEWLNSLLLLLCLYIYPHSHQVNDFSSLLTMDLGRVDTFNESRFSVVYTPVTNTTQQIMNKVASTPFLAGKEVLGLPDEESIKEFTANYPEEIVRVTFTNTYSYHLKFLLGHGMPAKKEHKDHTAHCYETNEDVYCEVSVFWKEGFVALQAAINAAIIEITTNHSVMEELMSVTGKNMKMHSFIGQSGVITDLYLFSCIISFSSFIYYASVNVTRERKRMKALMTMMGLRDSAFW>sp|Q8WWZ4|ABCAA_HUMAN ATP-binding cassette sub-family A member 10OS=Homo sapiens OX=9606 GN=ABCA10 PE=2 SV=3MNKMALASFMKGRTVIGTPDEETMDIELPKKYHEMVGVIFSDTFSYRLKFNWGYRIPVIKEHSEYTEHCWAMHGEIFCYLAKYWLKGFVAFQAAINAAIIEVTTNHSVMEELTSVIGINMKIPPFISKGEIMNEWFHFTCLVSFSSFIYFASLNVARERGKFKKLMTVMGLRESAFWLSWGLTYICFIFIMSIFMALVITSIPIVFHTGFMVIFTLYSLYGLSLIALAFLMSVLIRKPMLAGLAGFLFTVFWGCLGFTVLYRQLPLSLGWVLSLLSPFAFTAGMAQITHLDNYLSGVIFPDPSGDSYKMIATFFILAFDTLFYLIFTLYFERVLPDKDGHGDSPLFFLKSSFWSKHQNTHHEIFENEINPEHSSDDSFEPVSPEFHGKEAIRIRNVIKEYNGKTGKVEALQGIFFDIYEGQITAILGHNGAGKSTLLNILSGLSVSTEGSATIYNTQLSEITDMEEIRKNIGFCPQFNFQFDFLTVRENLRVFAKIKGIQPKEVEQEVKRIIMELDMQSIQDIIAKKLSGGQKRKLTLGIAILGDPQVLLLDEPTAGLDPFSRHRVWSLLKEHKVDRLILFSTQFMDEADILADRKVFLSNGKLKCAGSSLFLKRKWGIGYHLSLHRNEMCDTEKITSLIKQHIPDAKLTTESEEKLVYSLPLEKTNKFPDLYSDLDKCSDQGIRNYAVSVTSLNEVFLNLEGKSAIDEPDFDIGKQEKIHVTRNTGDESEMEQVLCSLPETRKAVSSAALWRRQIYAVATLRFLKLRRERRALLCLLLVLGIAFIPIILEKIMYKVTRETHCWEFSPSMYFLSLEQIPKTPLTSLLIVNNTGSNIEDLVHSLKCQDIVLEIDDFRNRNGSDDPSYNGAIIVSGDQKDYRFSVACNTKKLNCFPVLMGIVSNALMGIFNFTELIQMESTSFSRDDIVLDLGFIDGSIFLLLITNCVSPFIGMSSISDYKKNVQSQLWISGLWPSAYWCGQALVDIPLYFLILFSIHLIYYFIFLGFQLSWELMFVLVVCIIGCAVSLIFLTYVLSFIFRKWRKNNGFWSFGFFIILICVSTIMVSTQYEKLNLILCMIFIPSFTLLGYVMLLIQLDFMRNLDSLDNRINEVNKTILLTTLIPYLQSVIFLFVIRCLEMKYGNEIMNKDPVFRISPRSRETHPNPEEPEEEDEDVQAERVQAANALTAPNLEEEPVITASCLHKEYYETKKSCFSTRKKKIAIRNVSFCVKKGEVLGLLGHNGAGKSTSIKMITGCTKPTAGVVVLQGSRASVRQQHDNSLKFLGYCPQENSLWPKLTMKEHLELYAAVKGLGKEDAALSISRLVEALKLQEQLKAPVKTLSEGIKRKLCFVLSILGNPSVVLLDEPFTGMDPEGQQQMWQILQATVKNKERGTLLTTHYMSEAEAVCDRMAMMVSGTLRCIGSIQHLKNKFGRDYLLEIKMKEPTQVEALHTEILKLFPQAAWQERYSSLMAYKLPVEDVHPLSRAFFKLEAMKQTFNLEEYSLSQATLEQVFLELCKEQELGNVDDKIDTTVEWKLLPQEDP>sp|Q8WWZ4-2|ABCAA_HUMAN Isoform 2 of ATP-binding cassette sub-family Amember 10 OS=Homo sapiens OX=9606 GN=ABCA10MDIELPKKYHEMVGVIFSDTFSYRLKFNWGYRIPVIKEHSEYTEHCWAMHGEIFCYLAKYWLKGFVAFQAAINAAIIEVTTNHSVMEELTSVIGINMKIPPFISKGEIMNEWFHFTCLVSFSSFIYFASLNVARERGKFKKLMTVMGLRESAFWLSWGLTYICFIFIMSIFMALVITSIPIVFHTGFMVIFTLYSLYGLSLIALAFLMSVLIRKPMLAGLAGFLFTVFWGCLGFTVLYRQLPLSLGWVLSLLSPFAFTAGMAQITHLDNYLSGVIFPDPSGDSYKMIATFFILAFDTLFYLIFTLYFERVLPDKDGHGDSPLFFLKSSFWSKHQNTHHEIFENEINPEHSSDDSFEPVSPEFHGKEAIRIRNVIKEYNGKTGKVEALQGIFFDIYEGQITAILGHNGAGKSTLLNILSGLSVSTEGSATIYNTQLSEITDMEEIRKNIGFCPQFNFQFDFLTVRENLRVFAKIKGIQPKEVEQEVKRIIMELDMQSIQDIIAKKLSGGQKRKLTLGIAILGDPQVLLLDEPTAGLDPFSRHRVWSLLKEHKVDRLILFSTQFMDEADILADRKVFLSNGKLKCAGSSLFLKRKWGIGYHLSLHRNEMCDTEKITSLIKQHIPDAKLTTESEEKLVYSLPLEKTNKFPDLYSDLDKCSDQGIRNYAVSVTSLNEVFLNLEGKSAIDEPDFDIGKQEKIHVTRNTGDESEMEQVLCSLPETRKAVSSAALWRRQIYAVATLRFLKLRRERRALLCLLLVLGIAFIPIILEKIMYKVTRETHCWEFSPSMYFLSLEQIPKTPLTSLLIVNNTGSNIEDLVHSLKCQDIVLEIDDFRNRNGSDDPSYNGAIIVSGDQKDYRFSVACNTKKLNCFPVLMGIVSNALMGIFNFTELIQMESTSFSRDDIVLDLGFIDGSIFLLLITNCVSPFIGMSSISDYKKNVQSQLWISGLWPSAYWCGQALVDIPLYFLILFSIHLIYYFIFLGFQLSWELMFVLVVCIIGCAVSLIFLTYVLSFIFRKWRKNNGFWSFGFFIILICVSTIMVSTQYEKLNLILCMIFIPSFTLLGYVMLLIQLDFMRNLDSLDNRINEVNKTILLTTLIPYLQSVIFLFVIRCLEMKYGNEIMNKDPVFRISPRSRETHPNPEEPEEEDEDVQAERVQAANALTAPNLEEEPVITASCLHKEYYETKKSCFSTRKKKIAIRNVSFCVKKGEVLGLLGHNGAGKSTSIKMITGCTKPTAGVVVLQGSRASVRQQHDNSLKFLGYCPQENSLWPKLTMKEHLELYAAVKGLGKEDAALSISRLVEALKLQEQLKAPVKTLSEGIKRKLCFVLSILGNPSVVLLDEPFTGMDPEGQQQMWQILQATVKNKERGTLLTTHYMSEAEAVCDRMAMMVSGTLRCIGSIQHLKNKFGRDYLLEIKMKEPTQVEALHTEILKLFPQAAWQERYSSLMAYKLPVEDVHPLSRAFFKLEAMKQTFNLEEYSLSQATLEQVFLELCKEQELGNVDDKIDTTVEWKLLPQEDP>sp|Q8WWZ4-3|ABCAA_HUMAN Isoform 3 of ATP-binding cassette sub-family Amember 10 OS=Homo sapiens OX=9606 GN=ABCA10MNKMALASFMKGRTVIGTPDEETMDIELPKKYHEMVGVIFSDTFSYRLKFNWGYRIPVIKEHSEYTGHNKSFCNGGVDISYWNKYEDTTFHF>sp|Q8WWZ4-4|ABCAA_HUMAN Isoform 4 of ATP-binding cassette sub-family Amember 10 OS=Homo sapiens OX=9606 GN=ABCA10MNKMALASFMKGRTVIGTPDEETMDIELPKKYHEMVGVIFSDTFSYRLKFNWGYRIPVIKEHSEYTEHCWAMHGEIFCYLAKYWLKGFVAFQAAINAAIIEVTTNHSVMEELTSVIGINMKIPPFISKGEIMNEWFHFTCLVSFSSFIYFASLNVARERGKFKKLMTVMGLRESAFWLSWGLTYICFIFIMSIFMALVITSIPIVFHTGFMVIFTLYSLYGLSLIALAFLMSVLIRKPMLAGLAGFLFTVFWGCLGFTVLYRQLPLSLGWVLSLLSPFAFTAGMAQITHLDNYLSGVIFPDPSGDSYKMIATFFILAFDTLFYLIFTLYFERVLPDKDGHGDSPLFFLKSSFWSKHQNTHHEIFENEINPEHSSDDSFEPVSPEFHGKEAIRIRNVIKEYNGKTGKVEALQGIFFDIYEGQITAILGHNGAGKSTLLNILSGLSVSTEGKKNYNGIRHAKHSRHYC>sp|Q8WWZ4-5|ABCAA_HUMAN Isoform 5 of ATP-binding cassette sub-family Amember 10 OS=Homo sapiens OX=9606 GN=ABCA10MNKMALASFMKGRTVIGTPDEETMDIELPKKYHEMVGVIFSDTFSYRLKFNWGYRIPVIKEHSEYTEHCWAMHGEIFCYLAKYWLKGFVAFQAAINAAIIEVTTNHSVMEELTSVIGINMKIPPFISKGEIMNEWFHFTCLVSFSSFIYFASLNVARERGKFKKLMTVMGLRESAFWLSWGLTYICFIFIMSIFMALVITSIPIVFHTGFMVIFTLYSLYGLSLIALAFLMSVLIRKPMLAGLAGFLFTVFWGCLGFTVLYRQLPLSLGWVLSLLSPFAFTAGMAQITHLDNYLSGVIFPDPSGDSYKMIATFFILAFDTLFYLIFTLYFERVLPDKDGHGDSPLFFLKSSFWSKHQNTHHEIFENEINPEHSSDDSFEPVSPEFHGKEAIRIRNVIKEYNGKTGKVEALQGSEERLCPAAHRLRCGERLCPAAHHLGCEERPCPAATPSGN>sp|Q9BWV1|BOC_HUMAN Brother of CDO OS=Homo sapiens OX=9606 GN=BOC PE=1SV=1MLRGTMTAWRGMRPEVTLACLLLATAGCFADLNEVPQVTVQPASTVQKPGGTVILGCVVEPPRMNVTWRLNGKELNGSDDALGVLITHGTLVITALNNHTVGRYQCVARMPAGAVASVPATVTLANLQDFKLDVQHVIEVDEGNTAVIACHLPESHPKAQVRYSVKQEWLEASRGNYLIMPSGNLQIVNASQEDEGMYKCAAYNPVTQEVKTSGSSDRLRVRRSTAEAARIIYPPEAQTIIVTKGQSLILECVASGIPPPRVTWAKDGSSVTGYNKTRFLLSNLLIDTTSEEDSGTYRCMADNGVGQPGAAVILYNVQVFEPPEVTMELSQLVIPWGQSAKLTCEVRGNPPPSVLWLRNAVPLISSQRLRLSRRALRVLSMGPEDEGVYQCMAENEVGSAHAVVQLRTSRPSITPRLWQDAELATGTPPVSPSKLGNPEQMLRGQPALPRPPTSVGPASPQCPGEKGQGAPAEAPIILSSPRTSKTDSYELVWRPRHEGSGRAPILYYVVKHRKVTNSSDDWTISGIPANQHRLTLTRLDPGSLYEVEMAAYNCAGEGQTAMVTFRTGRRPKPEIMASKEQQIQRDDPGASPQSSSQPDHGRLSPPEAPDRPTISTASETSVYVTWIPRGNGGFPIQSFRVEYKKLKKVGDWILATSAIPPSRLSVEITGLEKGTSYKFRVRALNMLGESEPSAPSRPYVVSGYSGRVYERPVAGPYITFTDAVNETTIMLKWMYIPASNNNTPIHGFYIYYRPTDSDNDSDYKKDMVEGDKYWHSISHLQPETSYDIKMQCFNEGGESEFSNVMICETKARKSSGQPGRLPPPTLAPPQPPLPETIERPVGTGAMVARSSDLPYLIVGVVLGSIVLIIVTFIPFCLWRAWSKQKHTTDLGFPRSALPPSCPYTMVPLGGLPGHQASGQPYLSGISGRACANGIHMNRGCPSAAVGYPGMKPQQHCPGELQQQSDTSSLLRQTHLGNGYDPQSHQITRGPKSSPDEGSFLYTLPDDSTHQLLQPHHDCCQRQEQPAAVGQSGVRRAPDSPVLEAVWDPPFHSGPPCCLGLVPVEEVDSPDSCQVSGGDWCPQHPVGAYVGQEPGMQLSPGPLVRVSFETPPLTI>sp|Q9BWV1-2|BOC_HUMAN Isoform 2 of Brother of CDO OS=Homo sapiensOX=9606 GN=BOCKTRNGCLIPSPCSLGLPPGHALQDILVHTPSVLALLAPPGSTAEAARIIYPPEAQTIIVTKGQSLILECVASGIPPPRVTWAKDGSSVTGYNKTRFLLSNLLIDTTSEEDSGTYRCMADNGVGQPGAAVILYNVQVFEPPEVTMELSQLVIPWGQSAKLTCEVRGNPPPSVLWLRNAVPLISSQRLRLSRRALRVLSMGPEDEGVYQCMAENEVGSAHAVVQLRTSRPSITPRLWQDAELATGTPPVSPSKLGNPEQMLRGQPALPRPPTSVGPASPQCPGEKGQGAPAEAPIILSSPRTSKTDSYELVWRPRHEGSGRAPILYYVVKHRKVTNSSDDWTISGIPANQHRLTLTRLDPGSLYEVEMAAYNCAGEGQTAMVTFRTGRRPKPEIMASKEQQIQRDDPGASPQSSSQPDHGRLSPPEAPDRPTISTASETSVYVTWIPRGNGGFPIQSFRVEYKKLKKVGDWILATSAIPPSRLSVEITGLEKGTSYKFRVRALNMLGESEPSAPSRPYVVSGYSGRVYERPVAGPYITFTDAVNETTIMLKWMYIPASNNNTPIHGFYIYYRPTDSDNDSDYKKDMVEGDKYWHSISHLQPETSYDIKMQCFNEGGESEFSNVMICETKARKSSGQPGRLPPPTLAPPQPPLPETIERPVGTGAMVARSSDLPYLIVGVVLGSIVLIIVTFIPFCLWRAWSKQKHTTDLGFPRSALPPSCPYTMVPLGGLPGHQASGQPYLSGISGRACANGIHMNRGCPSAAVGYPGMKPQQHCPGELQQQSDTSSLLRQTHLGNGYDPQSHQITRGPKSSPDEGSFLYTLPDDSTHQLLQPHHDCCQRQEQPAAVGQSGVRRAPDSPVLEAVWDPPFHSGPPCCLGLVPVEEVDSPDSCQVSGGDWCPQHPVGAYVGQEPGMQLSPGPLVRVSFETPPLTI>sp|Q9BWV1-3|BOC_HUMAN Isoform 3 of Brother of CDO OS=Homo sapiensOX=9606 GN=BOCMLRGTMTAWRGMRPEVTLACLLLATAGCFADLNEVPQVTVQPASTVQKPGGTVILGCVVEPPRMNVTWRLNGKELNGSDDALGVLITHGTLVITALNNHTVGRYQCVARMPAGAVASVPATVTLANLQDFKLDVQHVIEVDEGNTAVIACHLPESHPKAQVRYSVKQEWLEASRGNYLIMPSGNLQIVNASQEDEGMYKCAAYNPVTQEVKTSGSSDRLRVRRSTAEAARIIYPPEAQTIIVTKGQSLILECVASGIPPPRVTWAKDGSSVTGYNKTRFLLSNLLIDTTSEEDSGTYRCMADNGVGQPGAAVILYNVQVFEPPEVTMELSQLVIPWGQSAKLTCEVRGNPPPSVLWLRNAVPLISSQRLRLSRRALRVLSMGPEDEGVYQCMAENEVGSAHAVVQLRTSRPSITPRLWQDAELATGTPPVSPSKLGNPEQMLRGQPALPRPPTSVGPASPQCPGEKGQGAPAEAPIILSSPRTSKTDSYELVWRPRHEGSGRAPILYYVVKHRKQVTNSSDDWTISGIPANQHRLTLTRLDPGSLYEVEMAAYNCAGEGQTAMVTFRTGRRPKPEIMASKEQQIQRDDPGASPQSSSQPDHGRLSPPEAPDRPTISTASETSVYVTWIPRGNGGFPIQSFRVEYKKLKKVGDWILATSAIPPSRLSVEITGLEKGTSYKFRVRALNMLGESEPSAPSRPYVVSGYSGRVYERPVAGPYITFTDAVNETTIMLKWMYIPASNNNTPIHGFYIYYRPTDSDNDSDYKKDMVEGDKYWHSISHLQPETSYDIKMQCFNEGGESEFSNVMICETKARKSSGQPGRLPPPTLAPPQPPLPETIERPVGTGAMVARSSDLPYLIVGVVLGSIVLIIVTFIPFCLWRAWSKQKHTTDLGFPRSALPPSCPYTMVPLGGLPGHQASGQPYLSGISGRACANGIHMNRGCPSAAVGYPGMKPQQHCPGELQQQSDTSSLLRQTHLGNGYDPQSHQITRGPKSSPDEGSFLYTLPDDSTHQLLQPHHDCCQRQEQPAAVGQSGVRRAPDSPVLEAVWDPPFHSGPPCCLGLVPVEEVDSPDSCQVSGGDWCPQHPVGAYVGQEPGMQLSPGPLVRVSFETPPLTI>sp|P14060|3BHS1_HUMAN 3 beta-hydroxysteroid dehydrogenase/Delta 5-->4-isomerase type 1 OS=Homo sapiens OX=9606 GN=HSD3B1 PE=1 SV=2MTGWSCLVTGAGGFLGQRIIRLLVKEKELKEIRVLDKAFGPELREEFSKLQNKTKLTVLEGDILDEPFLKRACQDVSVIIHTACIIDVFGVTHRESIMNVNVKGTQLLLEACVQASVPVFIYTSSIEVAGPNSYKEIIQNGHEEEPLENTWPAPYPHSKKLAEKAVLAANGWNLKNGGTLYTCALRPMYIYGEGSRFLSASINEALNNNGILSSVGKFSTVNPVYVGNVAWAHILALRALQDPKKAPSIRGQFYYISDDTPHQSYDNLNYTLSKEFGLRLDSRWSFPLSLMYWIGFLLEIVSFLLRPIYTYRPPFNRHIVTLSNSVFTFSYKKAQRDLAYKPLYSWEEAKQKTVEWVGSLVDRHKETLKSKTQ>sp|Q96G01|BICD1_HUMAN Protein bicaudal D homolog 1 OS=Homo sapiensOX=9606 GN=BICD1 PE=1 SV=3MAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEAFGQSFSIHRKVAEDGETREETLLQESASKEAYYLGKILEMQNELKQSRAVVTNVQAENERLTAVVQDLKENNEMVELQRIRMKDEIREYKFREARLLQDYTELEEENITLQKLVSTLKQNQVEYEGLKHEIKRFEEETVLLNSQLEDAIRLKEIAEHQLEEALETLKNEREQKNNLRKELSQYISLNDNHISISVDGLKFAEDGSEPNNDDKMNGHIHGPLVKLNGDYRTPTLRKGESLNPVSDLFSELNISEIQKLKQQLMQVEREKAILLANLQESQTQLEHTKGALTEQHERVHRLTEHVNAMRGLQSSKELKAELDGEKGRDSGEEAHDYEVDINGLEILECKYRVAVTEVIDLKAEIKALKEKYNKSVENYTDEKAKYESKIQMYDEQVTSLEKTTKESGEKMAHMEKELQKMTSIANENHSTLNTAQDELVTFSEELAQLYHHVCLCNNETPNRVMLDYYRQSRVTRSGSLKGPDDPRGLLSPRLARRGVSSPVETRTSSEPVAKESTEASKEPSPTKTPTISPVITAPPSSPVLDTSDIRKEPMNIYNLNAIIRDQIKHLQKAVDRSLQLSRQRAAARELAPMIDKDKEALMEEILKLKSLLSTKREQIATLRAVLKANKQTAEVALANLKNKYENEKAMVTETMTKLRNELKALKEDAATFSSLRAMFATRCDEYVTQLDEMQRQLAAAEDEKKTLNTLLRMAIQQKLALTQRLEDLEFDHEQSRRSKGKLGKSKIGSPKVSGEASVTVPTIDTYLLHSQGPQTPNIRVSSGTQRKRQFSPSLCDQSRPRTSGASYLQNLLRVPPDPTSTESFLLKGPPSMSEFIQGHRLSKEKRLTVAPPDCQQPAASVPPQCSQLAGRQDCPTVSPDTALPEEQPHSSSQCAPLHCLSKPPHP>sp|Q96G01-2|BICD1_HUMAN Isoform 2 of Protein bicaudal D homolog 1OS=Homo sapiens OX=9606 GN=BICD1MAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVSCLSPLPFLALTPPTRKAHSS>sp|Q96G01-3|BICD1_HUMAN Isoform 3 of Protein bicaudal D homolog 1OS=Homo sapiens OX=9606 GN=BICD1MAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEAFGQSFSIHRKVAEDGETREETLLQESASKEAYYLGKILEMQNELKQSRAVVTNVQAENERLTAVVQDLKENNEMVELQRIRMKDEIREYKFREARLLQDYTELEEENITLQKLVSTLKQNQVEYEGLKHEIKRFEEETVLLNSQLEDAIRLKEIAEHQLEEALETLKNEREQKNNLRKELSQYISLNDNHISISVDGLKFAEDGSEPNNDDKMNGHIHGPLVKLNGDYRTPTLRKGESLNPVSDLFSELNISEIQKLKQQLMQVEREKAILLANLQESQTQLEHTKGALTEQHERVHRLTEHVNAMRGLQSSKELKAELDGEKGRDSGEEAHDYEVDINGLEILECKYRVAVTEVIDLKAEIKALKEKYNKSVENYTDEKAKYESKIQMYDEQVTSLEKTTKESGEKMAHMEKELQKMTSIANENHSTLNTAQDELVTFSEELAQLYHHVCLCNNETPNRVMLDYYRQSRVTRSGSLKGPDDPRGLLSPRLARRGVSSPVETRTSSEPVAKESTEASKEPSPTKTPTISPVITAPPSSPVLDTSDIRKEPMNIYNLNAIIRDQIKHLQKAVDRSLQLSRQRAAARELAPMIDKDKEALMEEILKLKSLLSTKREQIATLRAVLKANKQTAEVALANLKNKYENEKAMVTETMTKLRNELKALKEDAATFSSLRAMFATRCDEYVTQLDEMQRQLAAAEDEKKTLNTLLRMAIQQKLALTQRLEDLEFDHEQSRRSKGKLGKSKIGSPKVSGEASVTVPTIDTYLLHSQGPQTPNIRVSSGTQRKRYACSDLHSTVQWPDFS>sp|Q96G01-4|BICD1_HUMAN Isoform 4 of Protein bicaudal D homolog 1OS=Homo sapiens OX=9606 GN=BICD1MAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEAFGQSFSIHRKVAEDGETREETLLQESASKEAYYLGKILEMQNELKQSRAVVTNVQAENERLTAVVQDLKENNEMVELQRIRMKDEIREYKFREARLLQDYTELEEENITLQKLVSTLKQNQVEYEGLKHEIKRFEEETVLLNSQLEDAIRLKEIAEHQLEEALETLKNEREQKNNLRKELSQYISLNDNHISISVDGLKFAEDGSEPNNDDKMNGHIHGPLVKLNGDYRTPTLRKGESLNPVSDLFSELNISEIQKLKQQLMQVEREKAILLANLQESQTQLEHTKGALTEQHERVHRLTEHVNAMRGLQSSKELKAELDGEKGRDSGEEAHDYEVDINGLEILECKYRVAVTEVIDLKAEIKALKEKYNKSVENYTDEKAKYESKIQMYDEQVTSLEKTTKESGEKMAHMEKELQKMTSIANENHSTLNTAQDELVTFSEELAQLYHHVCLCNNETPNRVMLDYYRQSRVTRSGSLKGPDDPRGLLSPRLARRGVSSPVETRTSSEPVAKESTEASKEPSPTKTPTISPVITAPPSSPVLDTSDIRKEPMNIYNLNAIIRDQIKHLQKAVDRSLQLSRQRAAARELAPMIDKDKEALMEEILKLKSLLSTKREQIATLRAVLKANKQTAEVALANLKNKYENEKAMVTETMTKLRNELKALKEDAATFSSLRAMFATRCDEYVTQLDEMQRQLAAAEDEKKTLNTLLRMAIQQKLALTQRLEDLEFDHEQSRRSKGKLGKSKIGSPKIVSSLLPPYRHSAHN>sp|O60239|3BP5_HUMAN SH3 domain-binding protein 5 OS=Homo sapiensOX=9606 GN=SH3BP5 PE=1 SV=2MDAALKRSRSEEPAEILPPARDEEEEEEEGMEQGLEEEEEVDPRIQGELEKLNQSTDDINRRETELEDARQKFRSVLVEATVKLDELVKKIGKAVEDSKPYWEARRVARQAQLEAQKATQDFQRATEVLRAAKETISLAEQRLLEDDKRQFDSAWQEMLNHATQRVMEAEQTKTRSELVHKETAARYNAAMGRMRQLEKKLKRAINKSKPYFELKAKYYVQLEQLKKTVDDLQAKLTLAKGEYKMALKNLEMISDEIHERRRSSAMGPRGCGVGAEGSSTSVEDLPGSKPEPDAISVASEAFEDDSCSNFVSEDDSETQSVSSFSSGPTSPSEMPDQFPAVVRPGSLDLPSPVSLSEFGMMFPVLGPRSECSGASSPECEVERGDRAEGAENKTSDKANNNRGLSSSSGSGGSSKSQSSTSPEGQALENRMKQLSLQCSKGRDGIIADIKMVQIG>sp|O60239-2|3BP5_HUMAN Isoform 2 of SH3 domain-binding protein 5 OS=Homosapiens OX=9606 GN=SH3BP5MLNHATQRVMEAEQTKTRSELVHKETAARYNAAMGRMRQLEKKLKRAINKSKPYFELKAKYYVQLEQLKKTVDDLQAKLTLAKGEYKMALKNLEMISDEIHERRRSSAMGPRGCGVGAEGSSTSVEDLPGSKPEPDAISVASEAFEDDSCSNFVSEDDSETQSVSSFSSGPTSPSEMPDQFPAVVRPGSLDLPSPVSLSEFGMMFPVLGPRSECSGASSPECEVERGDRAEGAENKTSDKANNNRGLSSSSGSGGSSKSQSSTSPEGQALENRMKQLSLQCSKGRDGIIADIKMVQIG>sp|O60516|4EBP3_HUMAN Eukaryotic translation initiation factor 4E-binding protein 3 OS=Homo sapiens OX=9606 GN=EIF4EBP3 PE=1 SV=1MSTSTSCPIPGGRDQLPDCYSTTPGGTLYATTPGGTRIIYDRKFLLECKNSPIARTPPCCLPQIPGVTTPPTAPLSKLEELKEQETEEEIPDDAQFEMDI>sp|Q8N9W6|BOLL_HUMAN Protein boule-like OS=Homo sapiens OX=9606 GN=BOLLPE=1 SV=2MQTDSLSPSPNPVSPVPLNNPTSAPRYGTVIPNRIFVGGIDFKTNESDLRKFFSQYGSVKEVKIVNDRAGVSKGYGFVTFETQEDAQKILQEAEKLNYKDKKLNIGPAIRKQQVGIPRSSIMPAAGTMYLTTSTGYPYTYHNGVAYFHTPEVTSVPPPWPSRSVCSSPVMVAQPIYQQPAYHYQATTQYLPGQWQWSVPQPSASSAPFLYLQPSEVIYQPVEIAQDGGCVPPPLSLMETSVPEPYSDHGVQATYHQVYAPSAITMPAPVMQPEPIKTVWSIHY>sp|Q8N9W6-2|BOLL_HUMAN Isoform 2 of Protein boule-like OS=Homo sapiensOX=9606 GN=BOLLMQTSNQMQTDSLSPSPNPVSPVPLNNPTSAPRYGTVIPNRIFVGGIDFKTNESDLRKFFSQYGSVKEVKIVNDRAGVSKGYGFVTFETQEDAQKILQEAEKLNYKDKKLNIGPAIRKQQVGIPRSSIMPAAGTMYLTTSTGYPYTYHNGVAYFHTPEVTSVPPPWPSRSVCSSPVMVAQPIYQQPAYHYQGIKQCHTRRWMDSLLPFTKCDEATTQYLPGQWQWSVPQPSASSAPFLYLQPSEVIYQPVEIAQDGGCVPPPLSLMETSVPEPYSDHGVQATYHQVYAPSAITMPAPVMQPEPIKCGAFIIKTIGQLYSSSTDFLSNDPCVAEIQLQRTS>sp|Q8N9W6-3|BOLL_HUMAN Isoform 3 of Protein boule-like OS=Homo sapiensOX=9606 GN=BOLLMETESGPQTSNQMQTDSLSPSPNPVSPVPLNNPTSAPRYGTVIPNRIFVGGIDFKTNESDLRKFFSQYGSVKEVKIVNDRAGVSKGYGFVTFETQEDAQKILQEAEKLNYKDKKLNIGPAIRKQQVGIPRSSIMPAAGTMYLTTSTGYPYTYHNGVAYFHTPEVTSVPPPWPSRSVCSSPVMVAQPIYQQPAYHYQATTQYLPGQWQWSVPQPSASSAPFLYLQPSEVIYQPVEIAQDGGCVPPPLSLMETSVPEPYSDHGVQATYHQVYAPSAITMPAPVMQPEPIKTVWSIHY>sp|Q8N9W6-4|BOLL_HUMAN Isoform 4 of Protein boule-like OS=Homo sapiensOX=9606 GN=BOLLMQTSNQMQTDSLSPSPNPVSPVPLNNPTSAPRYGTVIPNRIFVGGIDFKTNESDLRKFFSQYGSVKEVKIVNDRAGVSKGYGFVTFETQEDAQKILQEAEKLNYKDKKLNIGPAIRKQQVGIPRSSIMPAAGTMYLTTSTGYPYTYHNGVAYFHTPEVTSVPPPWPSRSVCSSPVMVAQPIYQQPAYHYQATTQYLPGQWQWSVPQPSASSAPFLYLQPSEVIYQPVEIAQDGGCVPPPLSLMETSVPEPYSDHGVQATYHQVYAPSAITMPAPVMQPEPIKTVWSIHY>sp|Q8N9W6-5|BOLL_HUMAN Isoform 5 of Protein boule-like OS=Homo sapiensOX=9606 GN=BOLLMTELEYPKGSSIMPAAGTMYLTTSTGYPYTYHNGVAYFHTPEVTSVPPPWPSRSVCSSPVMVAQPIYQQPAYHYQATTQYLPGQWQWSVPQPSASSAPFLYLQPSEVIYQPVEIAQDGGCVPPPLSLMETSVPEPYSDHGVQATYHQVYAPSAITMPAPVMQPEPIKTVWSIHY>sp|A8MW95|BECN2_HUMAN Beclin-2 OS=Homo sapiens OX=9606 GN=BECN2 PE=1SV=2MSSIRFLCQRCHQALKLSGSSESRSLPAAPAPTSGQAEPGDTREPGVTTREVTDAEEQQDGASSRSPPGDGSVSKGHANIFTLLGELGAMHMLSSIQKAAGDIFDIVSGQAVVDHPLCEECTDSLLEQLDIQLALTEADSQNYQRCLETGELATSEDEAAALRAELRDLELEEARLVQELEDVDRNNARAAADLQAAQAEAAELDQQERQHYRDYSALKRQQLELLDQLGNVENQLQYARVQRDRLKEINCFTATFEIWVEGPLGVINNFRLGRLPTVRVGWNEINTAWGQAALLLLTLANTIGLQFQRYRLIPCGNHSYLKSLTDDRTELPLFCYGGQDVFLNNKYDRAMVAFLDCMQQFKEEAEKGELGLSLPYGIQVETGLMEDVGGRGECYSIRTHLNTQELWTKALKFMLINFKWSLIWVASRYQK>sp|P08195|4F2_HUMAN 4F2 cell-surface antigen heavy chain OS=Homo sapiensOX=9606 GN=SLC3A2 PE=1 SV=3MELQPPEASIAVVSIPRQLPGSHSEAGVQGLSAGDDSELGSHCVAQTGLELLASGDPLPSASQNAEMIETGSDCVTQAGLQLLASSDPPALASKNAEVTGTMSQDTEVDMKEVELNELEPEKQPMNAASGAAMSLAGAEKNGLVKIKVAEDEAEAAAAAKFTGLSKEELLKVAGSPGWVRTRWALLLLFWLGWLGMLAGAVVIIVRAPRCRELPAQKWWHTGALYRIGDLQAFQGHGAGNLAGLKGRLDYLSSLKVKGLVLGPIHKNQKDDVAQTDLLQIDPNFGSKEDFDSLLQSAKKKSIRVILDLTPNYRGENSWFSTQVDTVATKVKDALEFWLQAGVDGFQVRDIENLKDASSFLAEWQNITKGFSEDRLLIAGTNSSDLQQILSLLESNKDLLLTSSYLSDSGSTGEHTKSLVTQYLNATGNRWCSWSLSQARLLTSFLPAQLLRLYQLMLFTLPGTPVFSYGDEIGLDAAALPGQPMEAPVMLWDESSFPDIPGAVSANMTVKGQSEDPGSLLSLFRRLSDQRSKERSLLHGDFHAFSAGPGLFSYIRHWDQNERFLVVLNFGDVGLSAGLQASDLPASASLPAKADLLLSTQPGREEGSPLELERLKLEPHEGLLLRFPYAA>sp|P08195-2|4F2_HUMAN Isoform 2 of 4F2 cell-surface antigen heavy chainOS=Homo sapiens OX=9606 GN=SLC3A2MSQDTEVDMKEVELNELEPEKQPMNAASGAAMSLAGAEKNGLVKIKVAEDEAEAAAAAKFTGLSKEELLKVAGSPGWVRTRWALLLLFWLGWLGMLAGAVVIIVRAPRCRELPAQKWWHTGALYRIGDLQAFQGHGAGNLAGLKGRLDYLSSLKVKGLVLGPIHKNQKDDVAQTDLLQIDPNFGSKEDFDSLLQSAKKKSIRVILDLTPNYRGENSWFSTQVDTVATKVKDALEFWLQAGVDGFQVRDIENLKDASSFLAEWQNITKGFSEDRLLIAGTNSSDLQQILSLLESNKDLLLTSSYLSDSGSTGEHTKSLVTQYLNATGNRWCSWSLSQARLLTSFLPAQLLRLYQLMLFTLPGTPVFSYGDEIGLDAAALPGQPMEAPVMLWDESSFPDIPGAVSANMTVKGQSEDPGSLLSLFRRLSDQRSKERSLLHGDFHAFSAGPGLFSYIRHWDQNERFLVVLNFGDVGLSAGLQASDLPASASLPAKADLLLSTQPGREEGSPLELERLKLEPHEGLLLRFPYAA>sp|P08195-3|4F2_HUMAN Isoform 3 of 4F2 cell-surface antigen heavy chainOS=Homo sapiens OX=9606 GN=SLC3A2MELQPPEASIAVVSIPRQLPGSHSEAGVQGLSAGDDSGTMSQDTEVDMKEVELNELEPEKQPMNAASGAAMSLAGAEKNGLVKIKVAEDEAEAAAAAKFTGLSKEELLKVAGSPGWVRTRWALLLLFWLGWLGMLAGAVVIIVRAPRCRELPAQKWWHTGALYRIGDLQAFQGHGAGNLAGLKGRLDYLSSLKVKGLVLGPIHKNQKDDVAQTDLLQIDPNFGSKEDFDSLLQSAKKKSIRVILDLTPNYRGENSWFSTQVDTVATKVKDALEFWLQAGVDGFQVRDIENLKDASSFLAEWQNITKGFSEDRLLIAGTNSSDLQQILSLLESNKDLLLTSSYLSDSGSTGEHTKSLVTQYLNATGNRWCSWSLSQARLLTSFLPAQLLRLYQLMLFTLPGTPVFSYGDEIGLDAAALPGQPMEAPVMLWDESSFPDIPGAVSANMTVKGQSEDPGSLLSLFRRLSDQRSKERSLLHGDFHAFSAGPGLFSYIRHWDQNERFLVVLNFGDVGLSAGLQASDLPASASLPAKADLLLSTQPGREEGSPLELERLKLEPHEGLLLRFPYAA>sp|P08195-4|4F2_HUMAN Isoform 4 of 4F2 cell-surface antigen heavy chainOS=Homo sapiens OX=9606 GN=SLC3A2MELQPPEASIAVVSIPRQLPGSHSEAGVQGLSAGDDSELGSHCVAQTGLELLASGDPLPSASQNAEMIETGSDCVTQAGLQLLASSDPPALASKNAEVTETGFHHVSQADIEFLTSIDPTASASGSAGITGTMSQDTEVDMKEVELNELEPEKQPMNAASGAAMSLAGAEKNGLVKIKVAEDEAEAAAAAKFTGLSKEELLKVAGSPGWVRTRWALLLLFWLGWLGMLAGAVVIIVRAPRCRELPAQKWWHTGALYRIGDLQAFQGHGAGNLAGLKGRLDYLSSLKVKGLVLGPIHKNQKDDVAQTDLLQIDPNFGSKEDFDSLLQSAKKKSIRVILDLTPNYRGENSWFSTQVDTVATKVKDALEFWLQAGVDGFQVRDIENLKDASSFLAEWQNITKGFSEDRLLIAGTNSSDLQQILSLLESNKDLLLTSSYLSDSGSTGEHTKSLVTQYLNATGNRWCSWSLSQARLLTSFLPAQLLRLYQLMLFTLPGTPVFSYGDEIGLDAAALPGQPMEAPVMLWDESSFPDIPGAVSANMTVKGQSEDPGSLLSLFRRLSDQRSKERSLLHGDFHAFSAGPGLFSYIRHWDQNERFLVVLNFGDVGLSAGLQASDLPASASLPAKADLLLSTQPGREEGSPLELERLKLEPHEGLLLRFPYAA>sp|Q76B58|BRNP3_HUMAN BMP/retinoic acid-inducible neural-specificprotein 3 OS=Homo sapiens OX=9606 GN=BRINP3 PE=1 SV=1MIWRSRAGAELFSLMALWEWIALSLHCWVLAVAAVSDQHATSPFDWLLSDKGPFHRSQEYTDFVDRSRQGFSTRYKIYREFGRWKVNNLAVERRNFLGSPLPLAPEFFRNIRLLGRRPTLQQITENLIKKYGTHFLLSATLGGEESLTIFVDKRKLSKRAEGSDSTTNSSSVTLETLHQLAASYFIDRDSTLRRLHHIQIASTAIKVTETRTGPLGCSNYDNLDSVSSVLVQSPENKIQLQGLQVLLPDYLQERFVQAALSYIACNSEGEFICKENDCWCHCGPKFPECNCPSMDIQAMEENLLRITETWKAYNSDFEESDEFKLFMKRLPMNYFLNTSTIMHLWTMDSNFQRRYEQLENSMKQLFLKAQKIVHKLFSLSKRCHKQPLISLPRQRTSTYWLTRIQSFLYCNENGLLGSFSEETHSCTCPNDQVVCTAFLPCTVGDASACLTCAPDNRTRCGTCNTGYMLSQGLCKPEVAESTDHYIGFETDLQDLEMKYLLQKTDRRIEVHAIFISNDMRLNSWFDPSWRKRMLLTLKSNKYKSSLVHMILGLSLQICLTKNSTLEPVLAVYVNPFGGSHSESWFMPVNENSFPDWERTKLDLPLQCYNWTLTLGNKWKTFFETVHIYLRSRIKSNGPNGNESIYYEPLEFIDPSRNLGYMKINNIQVFGYSMHFDPEAIRDLILQLDYPYTQGSQDSALLQLLEIRDRVNKLSPPGQRRLDLFSCLLRHRLKLSTSEVVRIQSALQAFNAKLPNTMDYDTTKLCS>sp|Q76B58-2|BRNP3_HUMAN Isoform 2 of BMP/retinoic acid-inducible neural-specific protein 3 OS=Homo sapiens OX=9606 GN=BRINP3MPQAPSTGSSLIRDPSIAHRNTQILWTEAGRDLAQDTRYTGEESLTIFVDKRKLSKRAEGSDSTTNSSSVTLETLHQLAASYFIDRDSTLRRLHHIQIASTAIKVTETRTGPLGCSNYDNLDSVSSVLVQSPENKIQLQGLQVLLPDYLQERFVQAALSYIACNSEGEFICKENDCWCHCGPKFPECNCPSMDIQAMEENLLRITETWKAYNSDFEESDEFKLFMKRLPMNYFLNTSTIMHLWTMDSNFQRRYEQLENSMKQLFLKAQKIVHKLFSLSKRCHKQPLISLPRQRTSTYWLTRIQSFLYCNENGLLGSFSEETHSCTCPNDQVVCTAFLPCTVGDASACLTCAPDNRTRCGTCNTGYMLSQGLCKPEVAESTDHYIGFETDLQDLEMKYLLQKTDRRIEVHAIFISNDMRLNSWFDPSWRKRMLLTLKSNKYKSSLVHMILGLSLQICLTKNSTLEPVLAVYVNPFGGSHSESWFMPVNENSFPDWERTKLDLPLQCYNWTLTLGNKWKTFFETVHIYLRSRIKSNGPNGNESIYYEPLEFIDPSRNLGYMKINNIQVFGYSMHFDPEAIRDLILQLDYPYTQGSQDSALLQLLEIRDRVNKLSPPGQRRLDLFSCLLRHRLKLSTSEVVRIQSALQAFNAKLPNTMDYDTTKLCS>sp|P35226|BMI1_HUMAN Polycomb complex protein BMI-1 OS=Homo sapiensOX=9606 GN=BMI1 PE=1 SV=2MHRTTRIKITELNPHLMCVLCGGYFIDATTIIECLHSFCKTCIVRYLETSKYCPICDVQVHKTRPLLNIRSDKTLQDIVYKLVPGLFKNEMKRRRDFYAAHPSADAANGSNEDRGEVADEDKRIITDDEIISLSIEFFDQNRLDRKVNKDKEKSKEEVNDKRYLRCPAAMTVMHLRKFLRSKMDIPNTFQIDVMYEEEPLKDYYTLMDIAYIYTWRRNGPLPLKYRVRPTCKRMKISHQRDGLTNAGELESDSGSDKANSPAGGIPSTSSCLPSPSTPVQSPHPQFPHISSTMNGTSNSPSGNHQSSFANRPRKSSVNGSSATSSG>sp|Q96GX2|A7L3B_HUMAN Ataxin-7-like protein 3B OS=Homo sapiens OX=9606GN=ATXN7L3B PE=1 SV=2MEEISLANLDTNKLEAIAQEIYVDLIEDSCLGFCFEVHRAVKCGYFYLEFAETGSVKDFGIQPVEDKGACRLPLCSLPGEPGNGPDQQLQRSPPEFQ>sp|Q15825|ACHA6_HUMAN Neuronal acetylcholine receptor subunit alpha-6OS=Homo sapiens OX=9606 GN=CHRNA6 PE=1 SV=1MLTSKGQGFLHGGLCLWLCVFTPFFKGCVGCATEERLFHKLFSHYNQFIRPVENVSDPVTVHFEVAITQLANVDEVNQIMETNLWLRHIWNDYKLRWDPMEYDGIETLRVPADKIWKPDIVLYNNAVGDFQVEGKTKALLKYNGMITWTPPAIFKSSCPMDITFFPFDHQNCSLKFGSWTYDKAEIDLLIIGSKVDMNDFWENSEWEIIDASGYKHDIKYNCCEEIYTDITYSFYIRRLPMFYTINLIIPCLFISFLTVLVFYLPSDCGEKVTLCISVLLSLTVFLLVITETIPSTSLVVPLVGEYLLFTMIFVTLSIVVTVFVLNIHYRTPTTHTMPRWVKTVFLKLLPQVLLMRWPLDKTRGTGSDAVPRGLARRPAKGKLASHGEPRHLKECFHCHKSNELATSKRRLSHQPLQWVVENSEHSPEVEDVINSVQFIAENMKSHNETKEVEDDWKYVAMVVDRVFLWVFIIVCVFGTAGLFLQPLLGNTGKS>sp|Q15825-2|ACHA6_HUMAN Isoform 2 of Neuronal acetylcholine receptorsubunit alpha-6 OS=Homo sapiens OX=9606 GN=CHRNA6MLTSKGQGFLHGGLCLWLCVFTPFFKGCVGCATEERLFHKLFSHYNQFIRPVENVSDPVTVHFEVAITQLANVIWNDYKLRWDPMEYDGIETLRVPADKIWKPDIVLYNNAVGDFQVEGKTKALLKYNGMITWTPPAIFKSSCPMDITFFPFDHQNCSLKFGSWTYDKAEIDLLIIGSKVDMNDFWENSEWEIIDASGYKHDIKYNCCEEIYTDITYSFYIRRLPMFYTINLIIPCLFISFLTVLVFYLPSDCGEKVTLCISVLLSLTVFLLVITETIPSTSLVVPLVGEYLLFTMIFVTLSIVVTVFVLNIHYRTPTTHTMPRWVKTVFLKLLPQVLLMRWPLDKTRGTGSDAVPRGLARRPAKGKLASHGEPRHLKECFHCHKSNELATSKRRLSHQPLQWVVENSEHSPEVEDVINSVQFIAENMKSHNETKEVEDDWKYVAMVVDRVFLWVFIIVCVFGTAGLFLQPLLGNTGKS>sp|O00590|ACKR2_HUMAN Atypical chemokine receptor 2 OS=Homo sapiensOX=9606 GN=ACKR2 PE=1 SV=2MAATASPQPLATEDADSENSSFYYYDYLDEVAFMLCRKDAVVSFGKVFLPVFYSLIFVLGLSGNLLLLMVLLRYVPRRRMVEIYLLNLAISNLLFLVTLPFWGISVAWHWVFGSFLCKMVSTLYTINFYSGIFFISCMSLDKYLEIVHAQPYHRLRTRAKSLLLATIVWAVSLAVSIPDMVFVQTHENPKGVWNCHADFGGHGTIWKLFLRFQQNLLGFLLPLLAMIFFYSRIGCVLVRLRPAGQGRALKIAAALVVAFFVLWFPYNLTLFLHTLLDLQVFGNCEVSQHLDYALQVTESIAFLHCCFSPILYAFSSHRFRQYLKAFLAAVLGWHLAPGTAQASLSSCSESSILTAQEEMTGMNDLGERQSENYPNKEDVGNKSA>sp|P25106|ACKR3_HUMAN Atypical chemokine receptor 3 OS=Homo sapiensOX=9606 GN=ACKR3 PE=1 SV=3MDLHLFDYSEPGNFSDISWPCNSSDCIVVDTVMCPNMPNKSVLLYTLSFIYIFIFVIGMIANSVVVWVNIQAKTTGYDTHCYILNLAIADLWVVLTIPVWVVSLVQHNQWPMGELTCKVTHLIFSINLFGSIFFLTCMSVDRYLSITYFTNTPSSRKKMVRRVVCILVWLLAFCVSLPDTYYLKTVTSASNNETYCRSFYPEHSIKEWLIGMELVSVVLGFAVPFSIIAVFYFLLARAISASSDQEKHSSRKIIFSYVVVFLVCWLPYHVAVLLDIFSILHYIPFTCRLEHALFTALHVTQCLSLVHCCVNPVLYSFINRNYRYELMKAFIFKYSAKTGLTKLIDASRVSETEYSALEQSTK>sp|Q9NPB9|ACKR4_HUMAN Atypical chemokine receptor 4 OS=Homo sapiensOX=9606 GN=ACKR4 PE=1 SV=1MALEQNQSTDYYYEENEMNGTYDYSQYELICIKEDVREFAKVFLPVFLTIVFVIGLAGNSMVVAIYAYYKKQRTKTDVYILNLAVADLLLLFTLPFWAVNAVHGWVLGKIMCKITSALYTLNFVSGMQFLACISIDRYVAVTKVPSQSGVGKPCWIICFCVWMAAILLSIPQLVFYTVNDNARCIPIFPRYLGTSMKALIQMLEICIGFVVPFLIMGVCYFITARTLMKMPNIKISRPLKVLLTVVIVFIVTQLPYNIVKFCRAIDIIYSLITSCNMSKRMDIAIQVTESIALFHSCLNPILYVFMGASFKNYVMKVAKKYGSWRRQRQSVEEFPFDSEGPTEPTSTFSI>sp|Q96GS6|AB17A_HUMAN Alpha/beta hydrolase domain-containing protein 17AOS=Homo sapiens OX=9606 GN=ABHD17A PE=1 SV=1MNGLSLSELCCLFCCPPCPGRIAAKLAFLPPEATYSLVPEPEPGPGGAGAAPLGTLRASSGAPGRWKLHLTERADFQYSQRELDTIEVFPTKSARGNRVSCMYVRCVPGARYTVLFSHGNAVDLGQMSSFYIGLGSRLHCNIFSYDYSGYGASSGRPSERNLYADIDAAWQALRTRYGISPDSIILYGQSIGTVPTVDLASRYECAAVVLHSPLTSGMRVAFPDTKKTYCFDAFPNIEKVSKITSPVLIIHGTEDEVIDFSHGLALYERCPKAVEPLWVEGAGHNDIELYSQYLERLRRFISQELPSQRA>sp|Q96GS6-2|AB17A_HUMAN Isoform 2 of Alpha/beta hydrolase domain-containing protein 17A OS=Homo sapiens OX=9606 GN=ABHD17AMNGLSLSELCCLFCCPPCPGRIAAKLAFLPPEATYSLVPEPEPGPGGAGAAPLGTLRASSGAPGRWKLHLTERADFQYSQRELDTIEVFPTKSARGNRVSCMYVRCVPGARQGHQAQGGHPQLAWVGRLGDSNNPAPGGCLLGKSWGTGAALACGYIHLLARYTVLFSHGNAVDLGQMSSFYIGLGSRLHCNIFSYDYSGYGASSGRPSERNLYADIDAAWQALRTRYGISPDSIILYGQSIGTVPTVDLASRYECAAVVLHSPLTSGMRVAFPDTKKTYCFDAFPNIEKVSKITSPVLIIHGTEDEVIDFSHGLALYERCPKAVEPLWVEGAGHNDIELYSQYLERLRRFISQELPSQRA>sp|Q96GS6-3|AB17A_HUMAN Isoform 3 of Alpha/beta hydrolase domain-containing protein 17A OS=Homo sapiens OX=9606 GN=ABHD17AMNGLSLSELCCLFCCPPCPGRIAAKLAFLPPEATYSLVPEPEPGPGGAGAAPLGTLRASSGAPGRWKLHLTERADFQYSQRELDTIEVFPTKSARGNRVSCMYVRCVPGARYTVLFSHGNAVDLGQMSSFYIGLGSRLHCNIFSYDYSGYGASSGRPSERNLYADIDAAWQALRTRYGISPDSIILYGQSIGTVPTVDLASRYECAAVVLHSPLTSGMRVAFPDTKKTYCFDAFPK>sp|Q96GS6-4|AB17A_HUMAN Isoform 4 of Alpha/beta hydrolase domain-containing protein 17A OS=Homo sapiens OX=9606 GN=ABHD17AMNGLSLSELCCLFCCPPCPGRIAAKLAFLPPEATYSLVPEPEPGPGGAGAAPLGTLRASSGAPGRWKLHLTERADFQYSQRELDTIEVFPTKSARGNRVSCMYVRCVPGARYTVLFSHGNAVDLGQMSSFYIGLGSRLHCNIFSYDYSGYGASSGRPSERNLYADIDAAWQALRTR>sp|Q9NY61|AATF_HUMAN Protein AATF OS=Homo sapiens OX=9606 GN=AATF PE=1SV=1MAGPQPLALQLEQLLNPRPSEADPEADPEEATAARVIDRFDEGEDGEGDFLVVGSIRKLASASLLDTDKRYCGKTTSRKAWNEDHWEQTLPGSSDEEISDEEGSGDEDSEGLGLEEYDEDDLGAAEEQECGDHRESKKSRSHSAKTPGFSVQSISDFEKFTKGMDDLGSSEEEEDEESGMEEGDDAEDSQGESEEDRAGDRNSEDDGVVMTFSSVKVSEEVEKGRAVKNQIALWDQLLEGRIKLQKALLTTNQLPQPDVFPLFKDKGGPEFSSALKNSHKALKALLRSLVGLQEELLFQYPDTRYLVDGTKPNAGSEEISSEDDELVEEKKQQRRRVPAKRKLEMEDYPSFMAKRFADFTVYRNRTLQKWHDKTKLASGKLGKGFGAFERSILTQIDHILMDKERLLRRTQTKRSVYRVLGKPEPAAQPVPESLPGEPEILPQAPANAHLKDLDEEIFDDDDFYHQLLRELIERKTSSLDPNDQVAMGRQWLAIQKLRSKIHKKVDRKASKGRKLRFHVLSKLLSFMAPIDHTTMNDDARTELYRSLFGQLHPPDEGHGD>sp|Q7Z5R6|AB1IP_HUMAN Amyloid beta A4 precursor protein-binding family Bmember 1-interacting protein OS=Homo sapiens OX=9606 GN=APBB1IP PE=1 SV=1MGESSEDIDQMFSTLLGEMDLLTQSLGVDTLPPPDPNPPRAEFNYSVGFKDLNESLNALEDQDLDALMADLVADISEAEQRTIQAQKESLQNQHHSASLQASIFSGAASLGYGTNVAATGISQYEDDLPPPPADPVLDLPLPPPPPEPLSQEEEEAQAKADKIKLALEKLKEAKVKKLVVKVHMNDNSTKSLMVDERQLARDVLDNLFEKTHCDCNVDWCLYEIYPELQIERFFEDHENVVEVLSDWTRDTENKILFLEKEEKYAVFKNPQNFYLDNRGKKESKETNEKMNAKNKESLLEESFCGTSIIVPELEGALYLKEDGKKSWKRRYFLLRASGIYYVPKGKTKTSRDLACFIQFENVNIYYGTQHKMKYKAPTDYCFVLKHPQIQKESQYIKYLCCDDTRTLNQWVMGIRIAKYGKTLYDNYQRAVAKAGLASRWTNLGTVNAAAPAQPSTGPKTGTTQPNGQIPQATHSVSAVLQEAQRHAETSKDKKPALGNHHDPAVPRAPHAPKSSLPPPPPVRRSSDTSGSPATPLKAKGTGGGGLPAPPDDFLPPPPPPPPLDDPELPPPPPDFMEPPPDFVPPPPPSYAGIAGSELPPPPPPPPAPAPAPVPDSARPPPAVAKRPPVPPKRQENPGHPGGAGGGEQDFMSDLMKALQKKRGNVS>sp|Q7Z5R6-2|AB1IP_HUMAN Isoform 2 of Amyloid beta A4 precursor protein-binding family B member 1-interacting protein OS=Homo sapiens OX=9606GN=APBB1IPMGESSEDIDQMFSTLLGEMDLLTQSLGVDTLPPPDPNPPRAEFNYSVGFKDLNESLNALEDQDLDALMADLVADISEAEQRTIQAQKESLQNQHHSASLQASIFSGAASLGYGTNVAATGISQYEDDLPPPPADPVLDLPLPPPPPEPLSQVSMWDQRWQDHQPLLPITDVP>sp|A5X5Y0|5HT3E_HUMAN 5-hydroxytryptamine receptor 3E OS=Homo sapiensOX=9606 GN=HTR3E PE=1 SV=1MEGSWFHRKRFSFYLLLGFLLQGRGVTFTINCSGFGQHGADPTALNSVFNRKPFRPVTNISVPTQVNISFAMSAILDVNEQLHLLSSFLWLEMVWDNPFISWNPEECEGITKMSMAAKNLWLPDIFIIELMDVDKTPKGLTAYVSNEGRIRYKKPMKVDSICNLDIFYFPFDQQNCTLTFSSFLYTVDSMLLDMEKEVWEITDASRNILQTHGEWELLGLSKATAKLSRGGNLYDQIVFYVAIRRRPSLYVINLLVPSGFLVAIDALSFYLPVKSGNRVPFKITLLLGYNVFLLMMSDLLPTSGTPLIGVYFALCLSLMVGSLLETIFITHLLHVATTQPPPLPRWLHSLLLHCNSPGRCCPTAPQKENKGPGLTPTHLPGVKEPEVSAGQMPGPAEAELTGGSEWTRAQREHEAQKQHSVELWLQFSHAMDAMLFRLYLLFMASSIITVICLWNT>sp|A5X5Y0-2|5HT3E_HUMAN Isoform 2 of 5-hydroxytryptamine receptor 3EOS=Homo sapiens OX=9606 GN=HTR3EMEGSWFHRKRFSFYLLLGFLLQGRGVTFTINCSGFGQHGADPTALNSVFNRKPFRPVTNISVPTQVNISFAMSAILDVVWDNPFISWNPEECEGITKMSMAAKNLWLPDIFIIELMDVDKTPKGLTAYVSNEGRIRYKKPMKVDSICNLDIFYFPFDQQNCTLTFSSFLYTVDSMLLDMEKEVWEITDASRNILQTHGEWELLGLSKATAKLSRGGNLYDQIVFYVAIRRRPSLYVINLLVPSGFLVAIDALSFYLPVKSGNRVPFKITLLLGYNVFLLMMSDLLPTSGTPLIGVYFALCLSLMVGSLLETIFITHLLHVATTQPPPLPRWLHSLLLHCNSPGRCCPTAPQKENKGPGLTPTHLPGVKEPEVSAGQMPGPAEAELTGGSEWTRAQREHEAQKQHSVELWLQFSHAMDAMLFRLYLLFMASSIITVICLWNT>sp|A5X5Y0-3|5HT3E_HUMAN Isoform 3 of 5-hydroxytryptamine receptor 3EOS=Homo sapiens OX=9606 GN=HTR3EMLAFILSRATPRPALGPLSYREHRVALLHLTHSMSTTGRGVTFTINCSGFGQHGADPTALNSVFNRKPFRPVTNISVPTQVNISFAMSAILDVNEQLHLLSSFLWLEMVWDNPFISWNPEECEGITKMSMAAKNLWLPDIFIIELMDVDKTPKGLTAYVSNEGRIRYKKPMKVDSICNLDIFYFPFDQQNCTLTFSSFLYTVDSMLLDMEKEVWEITDASRNILQTHGEWELLGLSKATAKLSRGGNLYDQIVFYVAIRRRPSLYVINLLVPSGFLVAIDALSFYLPVKSGNRVPFKITLLLGYNVFLLMMSDLLPTSGTPLIGVYFALCLSLMVGSLLETIFITHLLHVATTQPPPLPRWLHSLLLHCNSPGRCCPTAPQKENKGPGLTPTHLPGVKEPEVSAGQMPGPAEAELTGGSEWTRAQREHEAQKQHSVELWLQFSHAMDAMLFRLYLLFMASSIITVICLWNT>sp|A5X5Y0-4|5HT3E_HUMAN Isoform 4 of 5-hydroxytryptamine receptor 3EOS=Homo sapiens OX=9606 GN=HTR3EMLAFILSRATPRPALGPLSYREHRVALLHLTHSMSTTGRGVTFTINCSGFGQHGADPTALNSVFNRKPFRPVTNISVPTQVNISFAMSAILDVVWDNPFISWNPEECEGITKMSMAAKNLWLPDIFIIELMDVDKTPKGLTAYVSNEGRIRYKKPMKVDSICNLDIFYFPFDQQNCTLTFSSFLYTVDSMLLDMEKEVWEITDASRNILQTHGEWELLGLSKATAKLSRGGNLYDQIVFYVAIRRRPSLYVINLLVPSGFLVAIDALSFYLPVKSGNRVPFKITLLLGYNVFLLMMSDLLPTSGTPLIGVYFALCLSLMVGSLLETIFITHLLHVATTQPPPLPRWLHSLLLHCNSPGRCCPTAPQKENKGPGLTPTHLPGVKEPEVSAGQMPGPAEAELTGGSEWTRAQREHEAQKQHSVELWLQFSHAMDAMLFRLYLLFMASSIITVICLWNT>sp|A5X5Y0-6|5HT3E_HUMAN Isoform 5 of 5-hydroxytryptamine receptor 3EOS=Homo sapiens OX=9606 GN=HTR3EMLAFILSRATPRPALGPLSYREHRVALLHLTHSMSTTGRGVTFTINCSGFGQHGADPTALNSVFNRKPFRPVTNISVPTQVNISFAMSAILDVVWDNPFISWNPEECEGITKMSMAAKNLWLPDIFIIELCVSRAGQREVPSPGSHRDHSLPLGPLMDVDKTPKGLTAYVSNEGRIRYKKPMKVDSICNLDIFYFPFDQQNCTLTFSSFLYTVDSMLLDMEKEVWEITDASRNILQTHGEWELLGLSKATAKLSRGGNLYDQIVFYVAIRRRPSLYVINLLVPSGFLVAIDALSFYLPVKSGNRVPFKITLLLGYNVFLLMMSDLLPTSGTPLIGVYFALCLSLMVGSLLETIFITHLLHVATTQPPPLPRWLHSLLLHCNSPGRCCPTAPQKENKGPGLTPTHLPGVKEPEVSAGQMPGPAEAELTGGSEWTRAQREHEAQKQHSVELWLQFSHAMDAMLFRLYLLFMASSIITVICLWNT>sp|P46098|5HT3A_HUMAN 5-hydroxytryptamine receptor 3A OS=Homo sapiensOX=9606 GN=HTR3A PE=1 SV=1MLLWVQQALLALLLPTLLAQGEARRSRNTTRPALLRLSDYLLTNYRKGVRPVRDWRKPTTVSIDVIVYAILNVDEKNQVLTTYIWYRQYWTDEFLQWNPEDFDNITKLSIPTDSIWVPDILINEFVDVGKSPNIPYVYIRHQGEVQNYKPLQVVTACSLDIYNFPFDVQNCSLTFTSWLHTIQDINISLWRLPEKVKSDRSVFMNQGEWELLGVLPYFREFSMESSNYYAEMKFYVVIRRRPLFYVVSLLLPSIFLMVMDIVGFYLPPNSGERVSFKITLLLGYSVFLIIVSDTLPATAIGTPLIGVYFVVCMALLVISLAETIFIVRLVHKQDLQQPVPAWLRHLVLERIAWLLCLREQSTSQRPPATSQATKTDDCSAMGNHCSHMGGPQDFEKSPRDRCSPPPPPREASLAVCGLLQELSSIRQFLEKRDEIREVARDWLRVGSVLDKLLFHIYLLAVLAYSITLVMLWSIWQYA>sp|P46098-2|5HT3A_HUMAN Isoform 2 of 5-hydroxytryptamine receptor 3AOS=Homo sapiens OX=9606 GN=HTR3AMLLWVQQALLALLLPTLLAQGEARRSRNTTRPALLRLSDYLLTNYRKGVRPVRDWRKPTTVSIDVIVYAILNVDEKNQVLTTYIWYRQYWTDEFLQWNPEDFDNITKLSIPTDSIWVPDILINEFVDVGKSPNIPYVYIRHQGEVQNYKPLQVVTACSLDIYNFPFDVQNCSLTFTSWLHTIQDINISLWRLPEKVKSDRSVFMNQGEWELLGVLPYFREFSMESSNYYAEMKFYVVIRRRPLFYVVSLLLPSIFLMVMDIVGFYLPPNSGERVSFKITLLLGYSVFLIIVSDTLPATAIGTPLIGKAPPGSRAQSGEKPAPSHLLHVSLASALGCTGVYFVVCMALLVISLAETIFIVRLVHKQDLQQPVPAWLRHLVLERIAWLLCLREQSTSQRPPATSQATKTDDCSAMGNHCSHMGGPQDFEKSPRDRCSPPPPPREASLAVCGLLQELSSIRQFLEKRDEIREVARDWLRVGSVLDKLLFHIYLLAVLAYSITLVMLWSIWQYA>sp|P46098-3|5HT3A_HUMAN Isoform 3 of 5-hydroxytryptamine receptor 3AOS=Homo sapiens OX=9606 GN=HTR3AMHRSFLQARRSRNTTRPALLRLSDYLLTNYRKGVRPVRDWRKPTTVSIDVIVYAILNVDEKNQVLTTYIWYRQYWTDEFLQWNPEDFDNITKLSIPTDSIWVPDILINEFVDVGKSPNIPYVYIRHQGEVQNYKPLQVVTACSLDIYNFPFDVQNCSLTFTSWLHTIQDINISLWRLPEKVKSDRSVFMNQGEWELLGVLPYFREFSMESSNYYAEMKFYVVIRRRPLFYVVSLLLPSIFLMVMDIVGFYLPPNSGERVSFKITLLLGYSVFLIIVSDTLPATAIGTPLIGVYFVVCMALLVISLAETIFIVRLVHKQDLQQPVPAWLRHLVLERIAWLLCLREQSTSQRPPATSQATKTDDCSAMGNHCSHMGGPQDFEKSPRDRCSPPPPPREASLAVCGLLQELSSIRQFLEKRDEIREVARDWLRVGSVLDKLLFHIYLLAVLAYSITLVMLWSIWQYA>sp|P46098-4|5HT3A_HUMAN Isoform 4 of 5-hydroxytryptamine receptor 3AOS=Homo sapiens OX=9606 GN=HTR3AMLGKLAMLLWVQQALLALLLPTLLAQGEARRSRNTTRPALLRLSDYLLTNYRKGVRPVRDWRKPTTVSIDVIVYAILNVDEKNQVLTTYIWYRQYWTDEFLQWNPEDFDNITKLSIPTDSIWVPDILINEFVDVGKSPNIPYVYIRHQGEVQNYKPLQVVTACSLDIYNFPFDVQNCSLTFTSWLHTIQDINISLWRLPEKVKSDRSVFMNQGEWELLGVLPYFREFSMESSNYYAEMKFYVVIRRRPLFYVVSLLLPSIFLMVMDIVGFYLPPNSGERVSFKITLLLGYSVFLIIVSDTLPATAIGTPLIGVYFVVCMALLVISLAETIFIVRLVHKQDLQQPVPAWLRHLVLERIAWLLCLREQSTSQRPPATSQATKTDDCSAMGNHCSHMGGPQDFEKSPRDRCSPPPPPREASLAVCGLLQELSSIRQFLEKRDEIREVARDWLRVGSVLDKLLFHIYLLAVLAYSITLVMLWSIWQYA>sp|P46098-5|5HT3A_HUMAN Isoform 5 of 5-hydroxytryptamine receptor 3AOS=Homo sapiens OX=9606 GN=HTR3AMLGKLAMLLWVQQALLALLLPTLLAQGEARRSRNTTRPALLRLSDYLLTNYRKGVRPVRDWRKPTTVSIDVIVYAILNVDEKNQVLTTYIWYRQYWTDEFLQWNPEDFDNITKLSIPTDSIWVPDILINEFVDVGKSPNIPYVYIRHQGEVQNYKPLQVVTACSLDIYNFPFDVQNCSLTFTSWLHTIQDINISLWRLPEKVKSDRSVFMNQGEWELLGVLPYFREFSMESSNYYAEMKFYVVIRRRPLFYVVSLLLPSIFLMVMDIVGFYLPPNSGERVSFKITLLLGYSVFLIIVSDTLPATAIGTPLIGKAPPGSRAQSGEKPAPSHLLHVSLASALGCTGVYFVVCMALLVISLAETIFIVRLVHKQDLQQPVPAWLRHLVLERIAWLLCLREQSTSQRPPATSQATKTDDCSAMGNHCSHMGGPQDFEKSPRDRCSPPPPPREASLAVCGLLQELSSIRQFLEKRDEIREVARDWLRVGSVLDKLLFHIYLLAVLAYSITLVMLWSIWQYA>sp|P29274|AA2AR_HUMAN Adenosine receptor A2a OS=Homo sapiens OX=9606GN=ADORA2A PE=1 SV=2MPIMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKNHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESQPLPGERARSTLQKEVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQQEPFKAAGTSARVLAAHGSDGEQVSLRLNGHPPGVWANGSAPHPERRPNGYALGLVSGGSAQESQGNTGLPDVELLSHELKGVCPEPPGLDDPLAQDGAGVS>sp|Q96AP0|ACD_HUMAN Adrenocortical dysplasia protein homolog OS=Homosapiens OX=9606 GN=ACD PE=1 SV=4MAGSGRLVLRPWIRELILGSETPSSPRAGQLLEVLQDAEAAVAGPSHAPDTSDVGATLLVSDGTHSVRCLVTREALDTSDWEEKEFGFRGTEGRLLLLQDCGVHVQVAEGGAPAEFYLQVDRFSLLPTEQPRLRVPGCNQDLDVQKKLYDCLEEHLSESTSSNAGLSLSQLLDEMREDQEHQGALVCLAESCLTLEGPCTAPPVTHWAASRCKATGEAVYTVPSSMLCISENDQLILSSLGPCQRTQGPELPPPDPALQDLSLTLIASPPSSPSSSGTPALPGHMSSEESGTSISLLPALSLAAPDPGQRSSSQPSPAICSAPATLTPRSPHASRTPSSPLQSCTPSLSPRSHVPSPHQALVTRPQKPSLEFKEFVGLPCKNRPPFPRTGATRGAQEPCSVWEPPKRHRDGSAFQYEYEPPCTSLCARVQAVRLPPQLMAWALHFLMDAQPGSEPTPM>sp|Q96AP0-2|ACD_HUMAN Isoform 2 of Adrenocortical dysplasia proteinhomolog OS=Homo sapiens OX=9606 GN=ACDMAGSGRLVLRPWIRELILGSETPSSPRAGQLLEDAEAAVAGPSHAPDTSDVGATLLVSDGTHSVRCLVTREALDTSDWEEKEFGFRGTEGRLLLLQDCGVHVQVAEGGAPAEFYLQVDRFSLLPTEQPRLRVPGCNQDLDVQKKLYDCLEEHLSESTSSNAGLSLSQLLDEMREDQEHQGALVCLAESCLTLEGPCTAPPVTHWAASRCKATGEAVYTVPSSMLCISENDQLILSSLGPCQRTQGPELPPPDPALQDLSLTLIASPPSSPSSSGTPALPGHMSSEESGTSISLLPALSLAAPDPGQRSSSQPSPAICSAPATLTPRSPHASRTPSSPLQSCTPSLSPRSHVPSPHQALVTRPQKPSLEFKEFVGLPCKNRPPFPRTGATRGAQEPCSVWEPPKRHRDGSAFQYEYEPPCTSLCARVQAVRLPPQLMAWALHFLMDAQPGSEPTPM>sp|Q9H161|ALX4_HUMAN Homeobox protein aristaless-like 4 OS=Homo sapiensOX=9606 GN=ALX4 PE=1 SV=2MNAETCVSYCESPAAAMDAYYSPVSQSREGSSPFRAFPGGDKFGTTFLSAAAKAQGFGDAKSRARYGAGQQDLATPLESGAGARGSFNKFQPQPSTPQPQPPPQPQPQQQQPQPQPPAQPHLYLQRGACKTPPDGSLKLQEGSSGHSAALQVPCYAKESSLGEPELPPDSDTVGMDSSYLSVKEAGVKGPQDRASSDLPSPLEKADSESNKGKKRRNRTTFTSYQLEELEKVFQKTHYPDVYAREQLAMRTDLTEARVQVWFQNRRAKWRKRERFGQMQQVRTHFSTAYELPLLTRAENYAQIQNPSWLGNNGAASPVPACVVPCDPVPACMSPHAHPPGSGASSVTDFLSVSGAGSHVGQTHMGSLFGAASLSPGLNGYELNGEPDRKTSSIAALRMKAKEHSAAISWAT>sp|Q9BUW7|BBLN_HUMAN Bublin coiled-coil protein OS=Homo sapiens OX=9606GN=BBLN PE=1 SV=1MSGPNGDLGMPVEAGAEGEEDGFGEAEYAAINSMLDQINSCLDHLEEKNDHLHARLQELLESNRQTRLEFQQQLGEAPSDASP>sp|O95490|AGRL2_HUMAN Adhesion G protein-coupled receptor L2 OS=Homosapiens OX=9606 GN=ADGRL2 PE=1 SV=2MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKLQKREKTCRAYLKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENIKSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQSRIRRMWNDTVRKQSESSFISGDINSTSTLNQGMTGNYLLTNPLLRPHGTNNPYNTLLAETVVCNAPSAPVFNSPGHSLNNARDTSAMDTLPLNGNFNNSYSLHKGDYNDSVQVVDCGLSLNDTAFEKMIISELVHNNLRGSSKTHNLELTLPVKPVIGGSSSEDDAIVADASSLMHSDNPGLELHHKELEAPLIPQRTHSLLYQPQKKVKSEGTDSYVSQLTAEAEDHLQSPNRDSLYTSMPNLRDSPYPESSPDMEEDLSPSRRSENEDIYYKSMPNLGAGHQLQMCYQISRGNSDGYIIPINKEGCIPEGDVREGQMQLVTSL>sp|O95490-2|AGRL2_HUMAN Isoform 2 of Adhesion G protein-coupled receptorL2 OS=Homo sapiens OX=9606 GN=ADGRL2MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENIKSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQSRIRRMWNDTVRKQSESSFISGDINSTSTLNQGHSLNNARDTSAMDTLPLNGNFNNSYSLHKGDYNDSVQVVDCGLSLNDTAFEKMIISELVHNNLRGSSKTHNLELTLPVKPVIGGSSSEDDAIVADASSLMHSDNPGLELHHKELEAPLIPQRTHSLLYQPQKKVKSEGTDSYVSQLTAEAEDHLQSPNRDSLYTSMPNLRDSPYPESSPDMEEDLSPSRRSENEDIYYKSMPNLGAGHQLQMCYQISRGNSDGYIIPINKEGCIPEGDVREGQMQLVTSL>sp|O95490-3|AGRL2_HUMAN Isoform 3 of Adhesion G protein-coupled receptorL2 OS=Homo sapiens OX=9606 GN=ADGRL2MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENIKSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQDIH>sp|O95490-4|AGRL2_HUMAN Isoform 4 of Adhesion G protein-coupled receptorL2 OS=Homo sapiens OX=9606 GN=ADGRL2MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENIKSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQSRIRRMWNDTVRKQSESSFISGDINSTSTLNQGLTSHGLRAHLQDLYHLELLLGQIA>sp|O95490-5|AGRL2_HUMAN Isoform 5 of Adhesion G protein-coupled receptorL2 OS=Homo sapiens OX=9606 GN=ADGRL2MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKLQKREKTCRAYLKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENIKSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQSRIRRMWNDTVRKQSESSFISGDINSTSTLNQGHSLNNARDTSAMDTLPLNGNFNNSYSLHKGDYNDSVQVVDCGLSLNDTAFEKMIISELVHNNLRGSSKTHNLELTLPVKPVIGGSSSEDDAIVADASSLMHSDNPGLELHHKELEAPLIPQRTHSLLYQPQKKVKSEGTDSYVSQLTAEAEDHLQSPNRDSLYTSMPNLRDSPYPESSPDMEEDLSPSRRSENEDIYYKSMPNLGAGHQLQMCYQISRGNSDGYIIPINKEGCIPEGDVREGQMQLVTSL>sp|O95490-6|AGRL2_HUMAN Isoform 6 of Adhesion G protein-coupled receptorL2 OS=Homo sapiens OX=9606 GN=ADGRL2MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKLQKREKTCRAYLKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENINNYRVCDGYYNTDLPGSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQSRIRRMWNDTVRKQSESSFISGDINSTSTLNQGMTGNYLLTNPLLRPHGTNNPYNTLLAETVVCNAPSAPVFNSPGHSLNNARDTSAMDTLPLNGNFNNSYSLHKGDYNDSVQVVDCGLSLNDTAFEKMIISELVHNNLRGSSKTHNLELTLPVKPVIGGSSSEDDAIVADASSLMHSDNPGLELHHKELEAPLIPQRTHSLLYQPQKKVKSEGTDSYVSQLTAEAEDHLQSPNRDSLYTSMPNLRDSPYPESSPDMEEDLSPSRRSENEDIYYKSMPNLGAGHQLQMCYQISRGNSDGYIIPINKEGCIPEGDVREGQMQLVTSL>sp|O95490-7|AGRL2_HUMAN Isoform 7 of Adhesion G protein-coupled receptorL2 OS=Homo sapiens OX=9606 GN=ADGRL2MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENINNYRVCDGYYNTDLPGSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQSRIRRMWNDTVRKQSESSFISGDINSTSTLNQGMTGNYLLTNPLLRPHGTNNPYNTLLAETVVCNAPSAPVFNSPGHSLNNARDTSAMDTLPLNGNFNNSYSLHKGDYNDSVQVVDCGLSLNDTAFEKMIISELVHNNLRGSSKTHNLELTLPVKPVIGGSSSEDDAIVADASSLMHSDNPGLELHHKELEAPLIPQRTHSLLYQPQKKVKSEGTDSYVSQLTAEAEDHLQSPNRDSLYTSMPNLRDSPYPESSPDMEEDLSPSRRSENEDIYYKSMPNLGAGHQLQMCYQISRGNSDGYIIPINKEGCIPEGDVREGQMQLVTSL>sp|Q9HAR2|AGRL3_HUMAN Adhesion G protein-coupled receptor L3 OS=Homosapiens OX=9606 GN=ADGRL3 PE=1 SV=2MWPSQLLIFMMLLAPIIHAFSRAPIPMAVVRRELSCESYPIELRCPGTDVIMIESANYGRTDDKICDSDPAQMENIRCYLPDAYKIMSQRCNNRTQCAVVAGPDVFPDPCPGTYKYLEVQYECVPYKVEQKVFLCPGLLKGVYQSEHLFESDHQSGAWCKDPLQASDKIYYMPWTPYRTDTLTEYSSKDDFIAGRPTTTYKLPHRVDGTGFVVYDGALFFNKERTRNIVKFDLRTRIKSGEAIIANANYHDTSPYRWGGKSDIDLAVDENGLWVIYATEQNNGKIVISQLNPYTLRIEGTWDTAYDKRSASNAFMICGILYVVKSVYEDDDNEATGNKIDYIYNTDQSKDSLVDVPFPNSYQYIAAVDYNPRDNLLYVWNNYHVVKYSLDFGPLDSRSGQAHHGQVSYISPPIHLDSELERPSVKDISTTGPLGMGSTTTSTTLRTTTLSPGRSTTPSVSGRRNRSTSTPSPAVEVLDDMTTHLPSASSQIPALEESCEAVEAREIMWFKTRQGQIAKQPCPAGTIGVSTYLCLAPDGIWDPQGPDLSNCSSPWVNHITQKLKSGETAANIARELAEQTRNHLNAGDITYSVRAMDQLVGLLDVQLRNLTPGGKDSAARSLNKAMVETVNNLLQPQALNAWRDLTTSDQLRAATMLLHTVEESAFVLADNLLKTDIVRENTDNIKLEVARLSTEGNLEDLKFPENMGHGSTIQLSANTLKQNGRNGEIRVAFVLYNNLGPYLSTENASMKLGTEALSTNHSVIVNSPVITAAINKEFSNKVYLADPVVFTVKHIKQSEENFNPNCSFWSYSKRTMTGYWSTQGCRLLTTNKTHTTCSCNHLTNFAVLMAHVEVKHSDAVHDLLLDVITWVGILLSLVCLLICIFTFCFFRGLQSDRNTIHKNLCISLFVAELLFLIGINRTDQPIACAVFAALLHFFFLAAFTWMFLEGVQLYIMLVEVFESEHSRRKYFYLVGYGMPALIVAVSAAVDYRSYGTDKVCWLRLDTYFIWSFIGPATLIIMLNVIFLGIALYKMFHHTAILKPESGCLDNIKSWVIGAIALLCLLGLTWAFGLMYINESTVIMAYLFTIFNSLQGMFIFIFHCVLQKKVRKEYGKCLRTHCCSGKSTESSIGSGKTSGSRTPGRYSTGSQSRIRRMWNDTVRKQSESSFITGDINSSASLNREGLLNNARDTSVMDTLPLNGNHGNSYSIASGEYLSNCVQIIDRGYNHNETALEKKILKELTSNYIPSYLNNHERSSEQNRNLMNKLVNNLGSGREDDAIVLDDATSFNHEESLGLELIHEESDAPLLPPRVYSTENHQPHHYTRRRIPQDHSESFFPLLTNEHTEDLQSPHRDSLYTSMPTLAGVAATESVTTSTQTEPPPAKCGDAEDVYYKSMPNLGSRNHVHQLHTYYQLGRGSSDGFIVPPNKDGTPPEGSSKGPAHLVTSL>sp|Q9HAR2-2|AGRL3_HUMAN Isoform 2 of Adhesion G protein-coupled receptorL3 OS=Homo sapiens OX=9606 GN=ADGRL3MWPSQLLIFMMLLAPIIHAFSRAPIPMAVVRRELSCESYPIELRCPGTDVIMIESANYGRTDDKICDSDPAQMENIRCYLPDAYKIMSQRCNNRTQCAVVAGPDVFPDPCPGTYKYLEVQYECVPYKVEQKVFLCPGLLKGVYQSEHLFESDHQSGAWCKDPLQASDKIYYMPWTPYRTDTLTEYSSKDDFIAGRPTTTYKLPHRVDGTGFVVYDGALFFNKERTRNIVKFDLRTRIKSGEAIIANANYHDTSPYRWGGKSDIDLAVDENGLWVIYATEQNNGKIVISQLNPYTLRIEGTWDTAYDKRSASNAFMICGILYVVKSVYEDDDNEATGNKIDYIYNTDQSKDSLVDVPFPNSYQYIAAVDYNPRDNLLYVWNNYHVVKYSLDFGPLDSRSGQAHHGQVSYISPPIHLDSELERPSVKDISTTGPLGMGSTTTSTTLRTTTLSPGRSTTPSVSGRRNRSTSTPSPAVEVLDDMTTHLPSASSQIPALEESCEAVEAREIMWFKTRQGQIAKQPCPAGTIGVSTYLCLAPDGIWDPQGPDLSNCSSPWVNHITQKLKSGETAANIARELAEQTRNHLNAGDITYSVRAMDQLVGLLDVQLRNLTPGGKDSAARSLNKLQKRERSCRAYVQAMVETVNNLLQPQALNAWRDLTTSDQLRAATMLLHTVEESAFVLADNLLKTDIVRENTDNIKLEVARLSTEGNLEDLKFPENMGHGSTIQLSANTLKQNGRNGEIRVAFVLYNNLGPYLSTENASMKLGTEALSTNHSVIVNSPVITAAINKEFSNKVYLADPVVFTVKHIKQSEENFNPNCSFWSYSKRTMTGYWSTQGCRLLTTNKTHTTCSCNHLTNFAVLMAHVEVKHSDAVHDLLLDVITWVGILLSLVCLLICIFTFCFFRGLQSDRNTIHKNLCISLFVAELLFLIGINRTDQPIACAVFAALLHFFFLAAFTWMFLEGVQLYIMLVEVFESEHSRRKYFYLVGYGMPALIVAVSAAVDYRSYGTDKVCWLRLDTYFIWSFIGPATLIIMLNVIFLGIALYKMFHHTAILKPESGCLDNINYEDNRPFIKSWVIGAIALLCLLGLTWAFGLMYINESTVIMAYLFTIFNSLQGMFIFIFHCVLQKKVRKEYGKCLRTHCCSGKSTESSIGSGKTSGSRTPGRYSTGSQSRIRRMWNDTVRKQSESSFITGDINSSASLNREPYRETSMGVKLNIAYQIGASEQCQGYKCHGYSTTEW>sp|Q9HAR2-3|AGRL3_HUMAN Isoform 3 of Adhesion G protein-coupled receptorL3 OS=Homo sapiens OX=9606 GN=ADGRL3MWPSQLLIFMMLLAPIIHAFSRAPIPMAVVRRELSCESYPIELRCPGTDVIMIESANYGRTDDKICDSDPAQMENIRCYLPDAYKIMSQRCNNRTQCAVVAGPDVFPDPCPGTYKYLEVQYECVPYKVEQKVFLCPGLLKGVYQSEHLFESDHQSGAWCKDPLQASDKIYYMPWTPYRTDTLTEYSSKDDFIAGRPTTTYKLPHRVDGTGFVVYDGALFFNKERTRNIVKFDLRTRIKSGEAIIANANYHDTSPYRWGGKSDIDLAVDENGLWVIYATEQNNGKIVISQLNPYTLRIEGTWDTAYDKRSASNAFMICGILYVVKSVYEDDDNEATGNKIDYIYNTDQSKDSLVDVPFPNSYQYIAAVDYNPRDNLLYVWNNYHVVKYSLDFGPLDSRSGQAHHGQVSYISPPIHLDSELERPSVKDISTTGPLGMGSTTTSTTLRTTTLSPGRSTTPSVSGRRNRSTSTPSPAVEVLDDMTTHLPSASSQIPALEESCEAVEAREIMWFKTRQGQIAKQPCPAGTIGVSTYLCLAPDGIWDPQGPDLSNCSSPWVNHITQKLKSGETAANIARELAEQTRNHLNAGDITYSVRAMDQLVGLLDVQLRNLTPGGKDSAARSLNKAMVETVNNLLQPQALNAWRDLTTSDQLRAATMLLHTVEESAFVLVLQVCLPVREQSFLPFFSFFIFFFSFLPFIPLKFRLAKNK>sp|Q9HAR2-4|AGRL3_HUMAN Isoform 4 of Adhesion G protein-coupled receptorL3 OS=Homo sapiens OX=9606 GN=ADGRL3MWPSQLLIFMMLLAPIIHAFSRAPIPMAVVRRELSCESYPIELRCPGTDVIMIESANYGRTDDKICDSDPAQMENIRCYLPDAYKIMSQRCNNRTQCAVVAGPDVFPDPCPGTYKYLEVQYECVPYKVEQKVFLCPGLLKGVYQSEHLFESDHQSGAWCKDPLQASDKIYYMPWTPYRTDTLTEYSSKDDFIAGRPTTTYKLPHRVDGTGFVVYDGALFFNKERTRNIVKFDLRTRIKSGEAIIANANYHDTSPYRWGGKSDIDLAVDENGLWVIYATEQNNGKIVISQLNPYTLRIEGTWDTAYDKRSASNAFMICGILYVVKSVYEDDDNEATGNKIDYIYNTDQSKDSLVDVPFPNSYQYIAAVDYNPRDNLLYVWNNYHVVKYSLDFGPLDSRSGQAHHGQVSYISPPIHLDSELERPSVKDISTTGPLGMGSTTTSTTLRTTTLSPGRSTTPSVSGRRNRSTSTPSPAVEVLDDMTTHLPSASSQIPALEESCEAVEAREIMWFKTRQGQIAKQPCPAGTIGVSTYLCLAPDGIWDPQGPDLSNCSSPWVNHITQKLKSGETAANIARELAEQTRNHLNAGDITYSVRAMDQLVGLLDVQLRNLTPGGKDSAARSLNKLQKRERSCRAYVQAMVETVNNLLQPQALNAWRDLTTSDQLRAATMLLHTVEESAFVLADNLLKTDIVRENTDNIKLEVARLSTEGNLEDLKFPENMGHGSTIQLSANTLKQNGRNGEIRVAFVLYNNLGPYLSTENASMKLGTEALSTNHSVIVNSPVITAAINKEFSNKVYLADPVVFTVKHIKQSEENFNPNCSFWSYSKRTMTGYWSTQGCRLLTTNKTHTTCSCNHLTNFAVLMAHVEVKHSDAVHDLLLDVITWVGILLSLVCLLICIFTFCFFRGLQSDRNTIHKNLCISLFVAELLFLIGINRTDQPIACAVFAALLHFFFLAAFTWMFLEGVQLYIMLVEVFESEHSRRKYFYLVGYGMPALIVAVSAAVDYRSYGTDKVCWLRLDTYFIWSFIGPATLIIMLNVIFLGIALYKMFHHTAILKPESGCLDNINYEDNRPFIKSWVIGAIALLCLLGLTWAFGLMYINESTVIMAYLFTIFNSLQGMFIFIFHCVLQKKVRKEYGKCLRTHCCSGKSTESSIGSGKTSGSRTPGRYSTGSQSRIRRMWNDTVRKQSESSFITGDINSSASLNREGLLNNARDTSVMDTLPLNGNHGNSYSIASGEYLSNCVQIIDRGYNHNETALEKKILKELTSNYIPSYLNNHERSSEQNRNLMNKLVNNLGSGREDDAIVLDDATSFNHEESLGLELIHEESDAPLLPPRVYSTENHQPHHYTRRRIPQDHSESFFPLLTNEHTEDLQSPHRDSLYTSMPTLAGVAATESVTTSTQTEPPPAKCGDAEDVYYKSMPNLGSRNHVHQLHTYYQLGRGSSDGFIVPPNKDGTPPEGSSKGPAHLVTSL>sp|Q9H2A2|AL8A1_HUMAN 2-aminomuconic semialdehyde dehydrogenase OS=Homosapiens OX=9606 GN=ALDH8A1 PE=1 SV=1MAGTNALLMLENFIDGKFLPCSSYIDSYDPSTGEVYCRVPNSGKDEIEAAVKAAREAFPSWSSRSPQERSRVLNQVADLLEQSLEEFAQAESKDQGKTLALARTMDIPRSVQNFRFFASSSLHHTSECTQMDHLGCMHYTVRAPVGVAGLISPWNLPLYLLTWKIAPAMAAGNTVIAKPSELTSVTAWMLCKLLDKAGVPPGVVNIVFGTGPRVGEALVSHPEVPLISFTGSQPTAERITQLSAPHCKKLSLELGGKNPAIIFEDANLDECIPATVRSSFANQGEICLCTSRIFVQKSIYSEFLKRFVEATRKWKVGIPSDPLVSIGALISKAHLEKVRSYVKRALAEGAQIWCGEGVDKLSLPARNQAGYFMLPTVITDIKDESCCMTEEIFGPVTCVVPFDSEEEVIERANNVKYGLAATVWSSNVGRVHRVAKKLQSGLVWTNCWLIRELNLPFGGMKSSGIGREGAKDSYDFFTEIKTITVKH>sp|Q9H2A2-2|AL8A1_HUMAN Isoform 2 of 2-aminomuconic semialdehydedehydrogenase OS=Homo sapiens OX=9606 GN=ALDH8A1MAGTNALLMLENFIDGKFLPCSSYIDSYDPSTGEVYCRVPNSGKDEIEAAVKAAREAFPSWSSRSPQERSRVLNQVADLLEQSLEEFAQAESKDQGKTLALARTMDIPRSVQNFRFFASSSLHHTSECTQMDHLGCMHYTVRAPVGVAGLISPWNLPLYLLTWKIAPAMAAGNTVIAKPSELTSVTAWMLCKLLDKAGVPPGVVNIVFGTGPRVGEALVSHPEVPLISFTGSQPTAERITQLSAPHCKKLSLELGGKNPAIIFEDANLDECIPATVRSSFANQVRSYVKRALAEGAQIWCGEGVDKLSLPARNQAGYFMLPTVITDIKDESCCMTEEIFGPVTCVVPFDSEEEVIERANNVKYGLAATVWSSNVGRVHRVAKKLQSGLVWTNCWLIRELNLPFGGMKSSGIGREGAKDSYDFFTEIKTITVKH>sp|Q9H2A2-3|AL8A1_HUMAN Isoform 3 of 2-aminomuconic semialdehydedehydrogenase OS=Homo sapiens OX=9606 GN=ALDH8A1MAGTNALLMLENFIDGKFLPCSSYIDSYDPSTGEVYCRVPNSGKDEIEAAVKAAREAFPSWSSRSPQERSRVLNQVADLLEQSLEEFAQAESKDQGKTLALARTMDIPRSVQNFRFFASSSLHHTSECTQMDHLGCMHYTVRAPVGVVPGYTCRTCRFVT>sp|Q9H2A2-4|AL8A1_HUMAN Isoform 4 of 2-aminomuconic semialdehydedehydrogenase OS=Homo sapiens OX=9606 GN=ALDH8A1MAGTNALLMLENFIDGKFLPCSSYIDSYDPSTGEVYCRVPNSGKDEIEAAVKAAREAFPSWSSRSPQERSRVLNQVADLLEQSLEEFAQAESKDQGKTLALARTMDIPRSVQNFRFFASSSLHHTSECTQMDHLGCMHYTVRAPVGVGVPPGVVNIVFGTGPRVGEALVSHPEVPLISFTGSQPTAERITQLSAPHCKKLSLELGGKNPAIIFEDANLDECIPATVRSSFANQGEICLCTSRIFVQKSIYSEFLKRFVEATRKWKVGIPSDPLVSIGALISKAHLEKVRSYVKRALAEGAQIWCGEGVDKLSLPARNQAGYFMLPTVITDIKDESCCMTEEIFGPVTCVVPFDSEEEVIERANNVKYGLAATVWSSNVGRVHRVAKKLQSGLVWTNCWLIRELNLPFGGMKSSGIGREGAKDSYDFFTEIKTITVKH>sp|P17516|AK1C4_HUMAN Aldo-keto reductase family 1 member C4 OS=Homosapiens OX=9606 GN=AKR1C4 PE=1 SV=3MDPKYQRVELNDGHFMPVLGFGTYAPPEVPRNRAVEVTKLAIEAGFRHIDSAYLYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWCTFFQPQMVQPALESSLKKLQLDYVDLYLLHFPMALKPGETPLPKDENGKVIFDTVDLSATWEVMEKCKDAGLAKSIGVSNFNCRQLEMILNKPGLKYKPVCNQVECHPYLNQSKLLDFCKSKDIVLVAHSALGTQRHKLWVDPNSPVLLEDPVLCALAKKHKQTPALIALRYQLQRGVVVLAKSYNEQRIRENIQVFEFQLTSEDMKVLDGLNRNYRYVVMDFLMDHPDYPFSDEY>sp|Q86UN6|AKA28_HUMAN A-kinase anchor protein 14 OS=Homo sapiens OX=9606GN=AKAP14 PE=1 SV=1MSETQNSTSQKAMDEDNKAASQTMPNTQDKNYEDELTQVALALVEDVINYAVKIVEEERNPLKNIKWMTHGEFTVEKGLKQIDEYFSKCVSKKCWAHGVEFVERKDLIHSFLYIYYVHWSISTADLPVARISAGTYFTMKVSKTKPPDAPIVVSYVGDHQALVHRPGMVRFRENWQKNLTDAKYSFMESFPFLFNRV>sp|Q86UN6-2|AKA28_HUMAN Isoform 2 of A-kinase anchor protein 14 OS=Homosapiens OX=9606 GN=AKAP14MSETQNSTSQKAMDEDNKAASQTMPNTQDKNYEDELTQVALALVEDVINYAVKIVEEERNPLKNIKWMTHGEFTVEKGLKQIDEYFSDAPIVVSYVGDHQALVHRPGMVRFRENWQKNLTDAKYSFMESFPFLFNRV>sp|Q86UN6-3|AKA28_HUMAN Isoform 3 of A-kinase anchor protein 14 OS=Homosapiens OX=9606 GN=AKAP14MSETQNSTSQKAMDEDNKAASQTMPNTQDKNYEDELTQVALALVEDVINYAVKIVEEERNPLKNIKWMTHGEFTVEKGLKQIDEYFSVS>sp|O75969|AKAP3_HUMAN A-kinase anchor protein 3 OS=Homo sapiens OX=9606GN=AKAP3 PE=1 SV=2MSEKVDWLQSQNGVCKVDVYSPGDNQAQDWKMDTSTDPVRVLSWLRRDLEKSTAEFQDVRFKPGESFGGETSNSGDPHKGFSVDYYNTTTKGTPERLHFEMTHKEIPCQGPRAQLGNGSSVDEVSFYANRLTNLVIAMARKEINEKIDGSENKCVYQSLYMGNEPTPTKSLSKIASELVNETVSACSRNAAPDKAPGSGDRVSGSSQSPPNLKYKSTLKIKESTKERQGPDDKPPSKKSFFYKEVFESRNGDYAREGGRFFPRERKRFRGQERPDDFTASVSEGIMTYANSVVSDMMVSIMKTLKIQVKDTTIATILLKKVLLKHAKEVVSDLIDSFLRNLHSVTGTLMTDTQFVSAVKRTVFSHGSQKATDIMDAMLRKLYNVMFAKKVPEHVRKAQDKAESYSLISMKGMGDPKNRNVNFAMKSETKLREKMYSEPKSEEETCAKTLGEHIIKEGLTLWHKTQQKECKSLGFQHAAFEAPNTQRKPASDISFEYPEDIGNLSLPPYPPEKPENFMYDSDSWAEDLIVSALLLIQYHLAQGGRRDARSFVEAAGTTNFPANEPPVAPDESCLKSAPIVGDQEQAEKKDLRSVFFNFIRNLLSETIFKRDQSPEPKVPEQPVKEDRKLCERPLASSPPRLYEDDETPGALSGLTKMAVSQIDGHMSGQMVEHLMNSVMKLCVIIAKSCDASLAELGDDKSGDASRLTSAFPDSLYECLPAKGTGSAEAVLQNAYQAIHNEMRGTSGQPPEGCAAPTVIVSNHNLTDTVQNKQLQAVLQWVAASELNVPILYFAGDDEGIQEKLLQLSAAAVDKGCSVGEVLQSVLRYEKERQLNEAVGNVTPLQLLDWLMVNL>sp|O43572|AKA10_HUMAN A-kinase anchor protein 10, mitochondrial OS=Homosapiens OX=9606 GN=AKAP10 PE=1 SV=2MRGAGPSPRQSPRTLRPDPGPAMSFFRRKVKGKEQEKTSDVKSIKASISVHSPQKSTKNHALLEAAGPSHVAINAISANMDSFSSSRTATLKKQPSHMEAAHFGDLGRSCLDYQTQETKSSLSKTLEQVLHDTIVLPYFIQFMELRRMEHLVKFWLEAESFHSTTWSRIRAHSLNTVKQSSLAEPVSPSKKHETTASFLTDSLDKRLEDSGSAQLFMTHSEGIDLNNRTNSTQNHLLLSQECDSAHSLRLEMARAGTHQVSMETQESSSTLTVASRNSPASPLKELSGKLMKSIEQDAVNTFTKYISPDAAKPIPITEAMRNDIIARICGEDGQVDPNCFVLAQSIVFSAMEQEHFSEFLRSHHFCKYQIEVLTSGTVYLADILFCESALFYFSEYMEKEDAVNILQFWLAADNFQSQLAAKKGQYDGQEAQNDAMILYDKYFSLQATHPLGFDDVVRLEIESNICREGGPLPNCFTTPLRQAWTTMEKVFLPGFLSSNLYYKYLNDLIHSVRGDEFLGGNVSLTAPGSVGPPDESHPGSSDSSASQSSVKKASIKILKNFDEAIIVDAASLDPESLYQRTYAGKMTFGRVSDLGQFIRESEPEPDVRKSKGSMFSQAMKKWVQGNTDEAQEELAWKIAKMIVSDIMQQAQYDQPLEKSTKL>sp|Q13023|AKAP6_HUMAN A-kinase anchor protein 6 OS=Homo sapiens OX=9606GN=AKAP6 PE=1 SV=3MLTMSVTLSPLRSQDLDPMATDASPMAINMTPTVEQGEGEEAMKDMDSDQQYEKPPPLHTGADWKIVLHLPEIETWLRMTSERVRDLTYSVQQDSDSKHVDVHLVQLKDICEDISDHVEQIHALLETEFSLKLLSYSVNVIVDIHAVQLLWHQLRVSVLVLRERILQGLQDANGNYTRQTDILQAFSEETKEGRLDSLTEVDDSGQLTIKCSQNYLSLDCGITAFELSDYSPSEDLLSGLGDMTSSQVKTKPFDSWSYSEMEKEFPELIRSVGLLTVAADSISTNGSEAVTEEVSQVSLSVDDKGGCEEDNASAVEEQPGLTLGVSSSSGEALTNAAQPSSETVQQESSSSSHHDAKNQQPVPCENATPKRTIRDCFNYNEDSPTQPTLPKRGLFLKEETFKNDLKGNGGKRQMVDLKPEMSRSTPSLVDPPDRSKLCLVLQSSYPNSPSAASQSYECLHKVGNGNLENTVKFHIKEISSSLGRLNDCYKEKSRLKKPHKTSEEVPPCRTPKRGTGSGKQAKNTKSSAVPNGELSYTSKAIEGPQTNSASTSSLEPCNQRSWNAKLQLQSETSSSPAFTQSSESSVGSDNIMSPVPLLSKHKSKKGQASSPSHVTRNGEVVEAWYGSDEYLALPSHLKQTEVLALKLENLTKLLPQKPRGETIQNIDDWELSEMNSDSEIYPTYHVKKKHTRLGRVSPSSSSDIASSLGESIESGPLSDILSDEESSMPLAGMKKYADEKSERASSSEKNESHSATKSALIQKLMQDIQHQDNYEAIWEKIEGFVNKLDEFIQWLNEAMETTENWTPPKAEMDDLKLYLETHLSFKLNVDSHCALKEAVEEEGHQLLELIASHKAGLKDMLRMIASQWKELQRQIKRQHSWILRALDTIKAEILATDVSVEDEEGTGSPKAEVQLCYLEAQRDAVEQMSLKLYSEQYTSSSKRKEEFADMSKVHSVGSNGLLDFDSEYQELWDWLIDMESLVMDSHDLMMSEEQQQHLYKRYSVEMSIRHLKKTELLSKVEALKKGGVLLPNDLLEKVDSINEKWELLGKTLGEKIQDTMAGHSGSSPRDLLSPESGSLVRQLEVRIKELKGWLRDTELFIFNSCLRQEKEGTMNTEKQLQYFKSLCREIKQRRRGVASILRLCQHLLDDRETCNLNADHQPMQLIIVNLERRWEAIVMQAVQWQTRLQKKMGKESETLNVIDPGLMDLNGMSEDALEWDEMDISNKLISLNEESNDLDQELQPVIPSLKLGETSNEDPGYDEEADNHGGSQYASNITAPSSPHIYQVYSLHNVELYEDNHMPFLKNNPKVTGMTQPNVLTKSLSKDSSFSSTKSLPDLLGGSNLVKPCACHGGDMSQNSGSESGIVSEGDTETTTNSEMCLLNAVDGSPSNLETEHLDPQMGDAVNVLKQKFTDEGESIKLPNSSQSSISPVGCVNGKVGDLNSITKHTPDCLGEELQGKHDVFTFYDYSYLQGSKLKLPMIMKQSQSEKAHVEDPLLRGFYFDKKSCKSKHQTTELQPDVPPHERILASASHEMDRISYKSGNIEKTFTGMQNAKQLSLLSHSSSIESLSPGGDLFGLGIFKNGSDSLQRSTSLESWLTSYKSNEDLFSCHSSGDISVSSGSVGELSKRTLDLLNRLENIQSPSEQKIKRSVSDITLQSSSQKMSFTGQMSLDIASSINEDSAASLTELSSSDELSLCSEDIVLHKNKIPESNASFRKRLTRSVADESDVNVSMIVNVSCTSACTDDEDDSDLLSSSTLTLTEEELCIKDEDDDSSIATDDEIYEDCTLMSGLDYIKNELQTWIRPKLSLTRDKKRCNVSDEMKGSKDISSSEMTNPSDTLNIETLLNGSVKRVSENNGNGKNSSHTHELGTKRENKKTIFKVNKDPYVADMENGNIEGIPERQKGKPNVTSKVSENLGSHGKEISESEHCKCKALMDSLDDSNTAGKEFVSQDVRHLPKKCPNHHHFENQSTASTPTEKSFSELALETRFNNRQDSDALKSSDDAPSMAGKSAGCCLALEQNGTEENASISNISCCNCEPDVFHQKDAEDCSVHNFVKEIIDMASTALKSKSQPENEVAAPTSLTQIKEKVLEHSHRPIQLRKGDFYSYLSLSSHDSDCGEVTNYIEEKSSTPLPLDTTDSGLDDKEDIECFFEACVEGDSDGEEPCFSSAPPNESAVPSEAAMPLQATACSSEFSDSSLSADDADTVALSSPSSQERAEVGKEVNGLPQTSSGCAENLEFTPSKLDSEKESSGKPGESGMPEEHNAASAKSKVQDLSLKANQPTDKAALHPSPKTLTCEENLLNLHEKRHRNMHR>sp|Q13023-2|AKAP6_HUMAN Isoform 2 of A-kinase anchor protein 6 OS=Homosapiens OX=9606 GN=AKAP6MLTMSVTLSPLRSQDLDPMATDASPMAINMTPTVEQGEGEEAMKDMDSDQQYEKPPPLHTGADWKIVLHLPEIETWLRMTSERVRDLTYSVQQDSDSKHVDVHLVQLKDICEDISDHVEQIHALLETEFSLKLLSYSVNVIVDIHAVQLLWHQLRVSVLVLRERILQGLQDANGNYTRQTDILQAFSEETKEGRLDSLTEVDDSGQLTIKCSQNYLSLDCGITAFELSDYSPSEDLLSGLGDMTSSQVKTKPFDSWSYSEMEKEFPELIRSVGLLTVAADSISTNGSEAVTEEVSQVSLSVDDKGGCEEDNASAVEEQPGLTLGVSSSSGEALTNAAQPSSETVQQESSSSSHHDAKNQQPVPCENATPKRTIRDCFNYNEDSPTQPTLPKRGLFLKEETFKNDLKGNGGKRQMVDLKPEMSRSTPSLVDPPDRSKLCLVLQSSYPNSPSAASQSYECLHKVGNGNLENTVKFHIKEISSSLGRLNDCYKEKSRLKKPHKTSEEVPPCRTPKRGTGSGKQAKNTKSSAVPNGELSYTSKAIEGPQTNSASTSSLEPCNQRSWNAKLQLQSETSSSPAFTQSSESSVGSDNIMSPVPLLSKHKSKKGQASSPSHVTRNGEVVEAWYGSDEYLALPSHLKQTEVLALKLENLTKLLPQKPRGETIQNIDDWELSEMNSDSEIYPTYHVKKKHTRLGRVSPSSSSDIASSLGESIESGPLSDILSDEESSMPLAGMKKYADEKSERASSSEKNESHSATKSALIQKLMQDIQHQDNYEAIWEKIEGFVNKLDEFIQWLNEAMETTENWTPPKAEMDDLKLYLETHLSFKLNVDSHCALKEAVEEEGHQLLELIASHKAGLKDMLRMIASQWKELQRQIKRQHSWILRALDTIKAEILATDVSVEDEEGTGSPKAEVQLCYLEAQRDAVEQMSLKLYSEQYTSSSKRKEEFADMSKVHSVGSNGLLDFDSEYQELWDWLIDMESLVMDSHDLMMSEEQQQHLYKRYSVEMSIRHLKKTELLSKVEALKKGGVLLPNDLLEKVDSINEKWELLGVFAFLLLFVGYVYIFCVVKYSVRFLI>sp|P40145|ADCY8_HUMAN Adenylate cyclase type 8 OS=Homo sapiens OX=9606GN=ADCY8 PE=1 SV=1MELSDVRCLTGSEELYTIHPTPPAGDGRSASRPQRLLWQTAVRHITEQRFIHGHRGGSGSGSGGSGKASDPAGGGPNHHAPQLSGDSALPLYSLGPGERAHSTCGTKVFPERSGSGSASGSGGGGDLGFLHLDCAPSNSDFFLNGGYSYRGVIFPTLRNSFKSRDLERLYQRYFLGQRRKSEVVMNVLDVLTKLTLLVLHLSLASAPMDPLKGILLGFFTGIEVVICALVVVRKDTTSHTYLQYSGVVTWVAMTTQILAAGLGYGLLGDGIGYVLFTLFATYSMLPLPLTWAILAGLGTSLLQVILQVVIPRLAVISINQVVAQAVLFMCMNTAGIFISYLSDRAQRQAFLETRRCVEARLRLETENQRQERLVLSVLPRFVVLEMINDMTNVEDEHLQHQFHRIYIHRYENVSILFADVKGFTNLSTTLSAQELVRMLNELFARFDRLAHEHHCLRIKILGDCYYCVSGLPEPRQDHAHCCVEMGLSMIKTIRYVRSRTKHDVDMRIGIHSGSVLCGVLGLRKWQFDVWSWDVDIANKLESGGIPGRIHISKATLDCLNGDYNVEEGHGKERNEFLRKHNIETYLIKQPEDSLLSLPEDIVKESVSSSDRRNSGATFTEGSWSPELPFDNIVGKQNTLAALTRNSINLLPNHLAQALHVQSGPEEINKRIEHTIDLRSGDKLRREHIKPFSLMFKDSSLEHKYSQMRDEVFKSNLVCAFIVLLFITAIQSLLPSSRVMPMTIQFSILIMLHSALVLITTAEDYKCLPLILRKTCCWINETYLARNVIIFASILINFLGAILNILWCDFDKSIPLKNLTFNSSAVFTDICSYPEYFVFTGVLAMVTCAVFLRLNSVLKLAVLLIMIAIYALLTETVYAGLFLRYDNLNHSGEDFLGTKEVSLLLMAMFLLAVFYHGQQLEYTARLDFLWRVQAKEEINEMKELREHNENMLRNILPSHVARHFLEKDRDNEELYSQSYDAVGVMFASIPGFADFYSQTEMNNQGVECLRLLNEIIADFDELLGEDRFQDIEKIKTIGSTYMAVSGLSPEKQQCEDKWGHLCALADFSLALTESIQEINKHSFNNFELRIGISHGSVVAGVIGAKKPQYDIWGKTVNLASRMDSTGVSGRIQVPEETYLILKDQGFAFDYRGEIYVKGISEQEGKIKTYFLLGRVQPNPFILPPRRLPGQYSLAAVVLGLVQSLNRQRQKQLLNENNNTGIIKGHYNRRTLLSPSGTEPGAQAEGTDKSDLP>sp|O60566|BUB1B_HUMAN Mitotic checkpoint serine/threonine-protein kinaseBUB1 beta OS=Homo sapiens OX=9606 GN=BUB1B PE=1 SV=3MAAVKKEGGALSEAMSLEGDEWELSKENVQPLRQGRIMSTLQGALAQESACNNTLQQQKRAFEYEIRFYTGNDPLDVWDRYISWTEQNYPQGGKESNMSTLLERAVEALQGEKRYYSDPRFLNLWLKLGRLCNEPLDMYSYLHNQGIGVSLAQFYISWAEEYEARENFRKADAIFQEGIQQKAEPLERLQSQHRQFQARVSRQTLLALEKEEEEEVFESSVPQRSTLAELKSKGKKTARAPIIRVGGALKAPSQNRGLQNPFPQQMQNNSRITVFDENADEASTAELSKPTVQPWIAPPMPRAKENELQAGPWNTGRSLEHRPRGNTASLIAVPAVLPSFTPYVEETARQPVMTPCKIEPSINHILSTRKPGKEEGDPLQRVQSHQQASEEKKEKMMYCKEKIYAGVGEFSFEEIRAEVFRKKLKEQREAELLTSAEKRAEMQKQIEEMEKKLKEIQTTQQERTGDQQEETMPTKETTKLQIASESQKIPGMTLSSSVCQVNCCARETSLAENIWQEQPHSKGPSVPFSIFDEFLLSEKKNKSPPADPPRVLAQRRPLAVLKTSESITSNEDVSPDVCDEFTGIEPLSEDAIITGFRNVTICPNPEDTCDFARAARFVSTPFHEIMSLKDLPSDPERLLPEEDLDVKTSEDQQTACGTIYSQTLSIKKLSPIIEDSREATHSSGFSGSSASVASTSSIKCLQIPEKLELTNETSENPTQSPWCSQYRRQLLKSLPELSASAELCIEDRPMPKLEIEKEIELGNEDYCIKREYLICEDYKLFWVAPRNSAELTVIKVSSQPVPWDFYINLKLKERLNEDFDHFCSCYQYQDGCIVWHQYINCFTLQDLLQHSEYITHEITVLIIYNLLTIVEMLHKAEIVHGDLSPRCLILRNRIHDPYDCNKNNQALKIVDFSYSVDLRVQLDVFTLSGFRTVQILEGQKILANCSSPYQVDLFGIADLAHLLLFKEHLQVFWDGSFWKLSQNISELKDGELWNKFFVRILNANDEATVSVLGELAAEMNGVFDTTFQSHLNKALWKVGKLTSPGALLFQ>sp|O60566-2|BUB1B_HUMAN Isoform 2 of Mitotic checkpointserine/threonine-protein kinase BUB1 beta OS=Homo sapiens OX=9606GN=BUB1BMAAVKKEGGALSEAMSLEGDEWELSKENVQPLRQGRIMSTLQGALAQESACNNTLQQQKRAFEYEIRFYTGNDPLDVWDRYISWTEQNYPQGGKESNMSTLLERAVEALQGENFRKADAIFQEGIQQKAEPLERLQSQHRQFQARVSRQTLLALEKEEEEEVFESSVPQRSTLAELKSKGKKTARAPIIRVGGALKAPSQNRGLQNPFPQQMQNNSRITVFDENADEASTAELSKPTVQPWIAPPMPRAKENELQAGPWNTGRSLEHRPRGNTASLIAVPAVLPSFTPYVEETARQPVMTPCKIEPSINHILSTRKPGKEEGDPLQRVQSHQQASEEKKEKMMYCKEKIYAGVGEFSFEEIRAEVFRKKLKEQREAELLTSAEKRAEMQKQIEEMEKKLKEIQTTQQERTGDQQEETMPTKETTKLQIASESQKIPGMTLSSSVCQVNCCARETSLAENIWQEQPHSKVSLSLGPSVPFSIFDEFLLSEKKNKSPPADPPRVLAQRRPLAVLKTSESITSNEDVSPDVCDEFTGIEPLSEDAIITGFRNVTICPNPEDSREATHSSGFSGSSASVASTSSIKCLQIPEKLELTNETSENPTQSPWCSQYRRQLLKSLPELSASAELCIEDRPMPKLEIEKEIELGNEDYCIKREYLICEDYKLFWVAPRNSAELTVIKVSSQPVPWDFYINLKLKERLNEDFDHFCSCYQYQDGCIVWHQYINCFTLQDLLQHSEYITHEITVLIIYNLLTIVEMLHKAEIVHGDLSPRCLILRNRIHDPYDCNKNNQALKIVDFSYSVDLRVQLDVFTLSGFRTVQILEGQKILANCSSPYQVDLFGIADLAHLLLFKEHLQVFWDGSFWKLSQNISELKDGELWNKFFVRILNANDEATVSVLGELAAEMNGVFDTTFQSHLNKALWKVGKLTSPGALLFQ>sp|O60566-3|BUB1B_HUMAN Isoform 3 of Mitotic checkpointserine/threonine-protein kinase BUB1 beta OS=Homo sapiens OX=9606GN=BUB1BMAAVKKEGGALSEAMSLEGDEWELSKENVQPLRQGRIMSTLQGALAQESACNNTLQQQKRAFEYEIRFYTGNDPLDVWDRWVFLFHKDNRNINRYISWTEQNYPQGGKESNMSTLLERAVEALQGEKRYYSDPRFLNLWLKLGRLCNEPLDMYSYLHNQGIGVSLAQFYISWAEEYEARENFRKADAIFQEGIQQKAEPLERLQSQHRQFQARVSRQTLLALEKEEEEEVFESSVPQRSTLAELKSKGKKTARAPIIRVGGALKAPSQNRGLQNPFPQQMQNNSRITVFDENADEASTAELSKPTVQPWIAPPMPRAKENELQAGPWNTGRSLEHRPRGNTASLIAVPAVLPSFTPYVEETARQPVMTPCKIEPSINHILSTRKPGKEEGDPLQRVQSHQQASEEKKEKMMYCKEKIYAGVGEFSFEEIRAEVFRKKLKEQREAELLTSAEKRAEMQKQIEEMEKKLKEIQTTQQERTGDQQEETMPTKETTKLQIASESQKIPGMTLSSSVCQVNCCARETSLAENIWQEQPHSKGPSVPFSIFDEFLLSEKKNKSPPADPPRVLAQRRPLAVLKTSESITSNEDVSPDVCDEFTGIEPLSEDAIITGFRNVTICPNPEDTCDFARAARFVSTPFHEIMSLKDLPSDPERLLPEEDLDVKTSEDQQTACGTIYSQTLSIKKLSPIIEDSREATHSSGFSGSSASVASTSSIKCLQIPEKLELTNETSENPTQSPWCSQYRRQLLKSLPELSASAELCIEDRPMPKLEIEKEIELGNEDYCIKREYLICEDYKLFWVAPRNSAELTVIKVSSQPVPWDFYINLKLKERLNEDFDHFCSCYQYQDGCIVWHQYINCFTLQDLLQHSEYITHEITVLIIYNLLTIVEMLHKAEIVHGDLSPRCLILRNRIHDPYDCNKNNQALKIVDFSYSVDLRVQLDVFTLSGFRTVQILEGQKILANCSSPYQVDLFGIADLAHLLLFKEHLQVFWDGSFWKLSQNISELKDGELWNKFFVRILNANDEATVSVLGELAAEMNGVFDTTFQSHLNKALWKVGKLTSPGALLFQ>sp|Q8IUZ5|AT2L2_HUMAN 5-phosphohydroxy-L-lysine phospho-lyase OS=Homosapiens OX=9606 GN=PHYKPL PE=1 SV=1MAADQRPKADTLALRQRLISSSCRLFFPEDPVKIVRAQGQYMYDEQGAEYIDCISNVAHVGHCHPLVVQAAHEQNQVLNTNSRYLHDNIVDYAQRLSETLPEQLCVFYFLNSGSEANDLALRLARHYTGHQDVVVLDHAYHGHLSSLIDISPYKFRNLDGQKEWVHVAPLPDTYRGPYREDHPNPAMAYANEVKRVVSSAQEKGRKIAAFFAESLPSVGGQIIPPAGYFSQVAEHIRKAGGVFVADEIQVGFGRVGKHFWAFQLQGKDFVPDIVTMGKSIGNGHPVACVAATQPVARAFEATGVEYFNTFGGSPVSCAVGLAVLNVLEKEQLQDHATSVGSFLMQLLGQQKIKHPIVGDVRGVGLFIGVDLIKDEATRTPATEEAAYLVSRLKENYVLLSTDGPGRNILKFKPPMCFSLDNARQVVAKLDAILTDMEEKVRSCETLRLQP>sp|Q8IUZ5-2|AT2L2_HUMAN Isoform 2 of 5-phosphohydroxy-L-lysine phospho-lyase OS=Homo sapiens OX=9606 GN=PHYKPLMQLLGQQKIKHPIVGDVRGVGLFIGVDLIKDEATRTPATEEAAYLVSRLKENYVLLSTDGPGRNILKFKPPMCFSLDNARQVVAKLDAILTDMEEKVRSCETLRLQP>sp|Q8IUZ5-3|AT2L2_HUMAN Isoform 3 of 5-phosphohydroxy-L-lysine phospho-lyase OS=Homo sapiens OX=9606 GN=PHYKPLMGKSIGNGHPVACVAATQPVARAFEATGVEYFNTFGGSPVSCAVGLAVLNVLEKEQLQDHATSVGSFLMQLLGQQKIKHPIVGDVRGVGLFIGVDLIKDEATRTPATEEAAYLVSRLKENYVLLSTDGPGRNILKFKPPMCFSLDNARQVVAKLDAILTDMEEKVRSCETLRLQP>sp|Q9Y2D1|ATF5_HUMAN Cyclic AMP-dependent transcription factor ATF-5OS=Homo sapiens OX=9606 GN=ATF5 PE=1 SV=4MSLLATLGLELDRALLPASGLGWLVDYGKLPPAPAPLAPYEVLGGALEGGLPVGGEPLAGDGFSDWMTERVDFTALLPLEPPLPPGTLPQPSPTPPDLEAMASLLKKELEQMEDFFLDAPPLPPPSPPPLPPPPLPPAPSLPLSLPSFDLPQPPVLDTLDLLAIYCRNEAGQEEVGMPPLPPPQQPPPPSPPQPSRLAPYPHPATTRGDRKQKKRDQNKSAALRYRQRKRAEGEALEGECQGLEARNRELKERAESVEREIQYVKDLLIEVYKARSQRTRSC>sp|Q14CW9|AT7L3_HUMAN Ataxin-7-like protein 3 OS=Homo sapiens OX=9606GN=ATXN7L3 PE=1 SV=1MKMEEMSLSGLDNSKLEAIAQEIYADLVEDSCLGFCFEVHRAVKCGYFFLDDTDPDSMKDFEIVDQPGLDIFGQVFNQWKSKECVCPNCSRSIAASRFAPHLEKCLGMGRNSSRIANRRIANSNNMNKSESDQEDNDDINDNDWSYGSEKKAKKRKSDKNPNSPRRSKSLKHKNGELSNSDPFKYNNSTGISYETLGPEELRSLLTTQCGVISEHTKKMCTRSLRCPQHTDEQRRTVRIYFLGPSAVLPEVESSLDNDSFDMTDSQALISRLQWDGSSDLSPSDSGSSKTSENQGWGLGTNSSESRKTKKKKSHLSLVGTASGLGSNKKKKPKPPAPPTPSIYDDIN>sp|Q14CW9-2|AT7L3_HUMAN Isoform 2 of Ataxin-7-like protein 3 OS=Homosapiens OX=9606 GN=ATXN7L3MKMEEMSLSGLDNSKLEAIAQEIYADLVEDSCLGFCFEVHRAVKCGYFFLDDTDPDSMKDFEIVDQPGLDIFGQVFNQWKSKECVCPNCSRSIAASRFAPHLEKCLGMGRNSSRIANRRIANSNNMNKSESDQEDNDDINDNDWSYGSEKKAKKRKSDKLWYLPFQNPNSPRRSKSLKHKNGELSNSDPFKYNNSTGISYETLGPEELRSLLTTQCGVISEHTKKMCTRSLRCPQHTDEQRRTVRIYFLGPSAVLPEVESSLDNDSFDMTDSQALISRLQWDGSSDLSPSDSGSSKTSENQGWGLGTNSSESRKTKKKKSHLSLVGTASGLGSNKKKKPKPPAPPTPSIYDDIN>sp|Q6XD76|ASCL4_HUMAN Achaete-scute homolog 4 OS=Homo sapiens OX=9606GN=ASCL4 PE=1 SV=1METRKPAERLALPYSLRTAPLGVPGTLPGLPRRDPLRVALRLDAACWEWARSGCARGWQYLPVPLDSAFEPAFLRKRNERERQRVRCVNEGYARLRDHLPRELADKRLSKVETLRAAIDYIKHLQELLERQAWGLEGAAGAVPQRRAECNSDGESKASSAPSPSSEPEEGGS>sp|P13637|AT1A3_HUMAN Sodium/potassium-transporting ATPase subunitalpha-3 OS=Homo sapiens OX=9606 GN=ATP1A3 PE=1 SV=3MGDKKDDKDSPKKNKGKERRDLDDLKKEVAMTEHKMSVEEVCRKYNTDCVQGLTHSKAQEILARDGPNALTPPPTTPEWVKFCRQLFGGFSILLWIGAILCFLAYGIQAGTEDDPSGDNLYLGIVLAAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIREGEKMQVNAEEVVVGDLVEIKGGDRVPADLRIISAHGCKVDNSSLTGESEPQTRSPDCTHDNPLETRNITFFSTNCVEGTARGVVVATGDRTVMGRIATLASGLEVGKTPIAIEIEHFIQLITGVAVFLGVSFFILSLILGYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTEDQSGTSFDKSSHTWVALSHIAGLCNRAVFKGGQDNIPVLKRDVAGDASESALLKCIELSSGSVKLMRERNKKVAEIPFNSTNKYQLSIHETEDPNDNRYLLVMKGAPERILDRCSTILLQGKEQPLDEEMKEAFQNAYLELGGLGERVLGFCHYYLPEEQFPKGFAFDCDDVNFTTDNLCFVGLMSMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTITILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTVNDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKPSWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY>sp|P13637-2|AT1A3_HUMAN Isoform 2 of Sodium/potassium-transportingATPase subunit alpha-3 OS=Homo sapiens OX=9606 GN=ATP1A3MGGWEEERNRRATDKKDDKDSPKKNKGKERRDLDDLKKEVAMTEHKMSVEEVCRKYNTDCVQGLTHSKAQEILARDGPNALTPPPTTPEWVKFCRQLFGGFSILLWIGAILCFLAYGIQAGTEDDPSGDNLYLGIVLAAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIREGEKMQVNAEEVVVGDLVEIKGGDRVPADLRIISAHGCKVDNSSLTGESEPQTRSPDCTHDNPLETRNITFFSTNCVEGTARGVVVATGDRTVMGRIATLASGLEVGKTPIAIEIEHFIQLITGVAVFLGVSFFILSLILGYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTEDQSGTSFDKSSHTWVALSHIAGLCNRAVFKGGQDNIPVLKRDVAGDASESALLKCIELSSGSVKLMRERNKKVAEIPFNSTNKYQLSIHETEDPNDNRYLLVMKGAPERILDRCSTILLQGKEQPLDEEMKEAFQNAYLELGGLGERVLGFCHYYLPEEQFPKGFAFDCDDVNFTTDNLCFVGLMSMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTITILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTVNDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKPSWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY>sp|P13637-3|AT1A3_HUMAN Isoform 3 of Sodium/potassium-transportingATPase subunit alpha-3 OS=Homo sapiens OX=9606 GN=ATP1A3MGSGGSDSYRIATSQDKKDDKDSPKKNKGKERRDLDDLKKEVAMTEHKMSVEEVCRKYNTDCVQGLTHSKAQEILARDGPNALTPPPTTPEWVKFCRQLFGGFSILLWIGAILCFLAYGIQAGTEDDPSGDNLYLGIVLAAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIREGEKMQVNAEEVVVGDLVEIKGGDRVPADLRIISAHGCKVDNSSLTGESEPQTRSPDCTHDNPLETRNITFFSTNCVEGTARGVVVATGDRTVMGRIATLASGLEVGKTPIAIEIEHFIQLITGVAVFLGVSFFILSLILGYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTEDQSGTSFDKSSHTWVALSHIAGLCNRAVFKGGQDNIPVLKRDVAGDASESALLKCIELSSGSVKLMRERNKKVAEIPFNSTNKYQLSIHETEDPNDNRYLLVMKGAPERILDRCSTILLQGKEQPLDEEMKEAFQNAYLELGGLGERVLGFCHYYLPEEQFPKGFAFDCDDVNFTTDNLCFVGLMSMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTITILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTVNDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKPSWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY>sp|Q13733|AT1A4_HUMAN Sodium/potassium-transporting ATPase subunitalpha-4 OS=Homo sapiens OX=9606 GN=ATP1A4 PE=1 SV=3MGLWGKKGTVAPHDQSPRRRPKKGLIKKKMVKREKQKRNMEELKKEVVMDDHKLTLEELSTKYSVDLTKGHSHQRAKEILTRGGPNTVTPPPTTPEWVKFCKQLFGGFSLLLWTGAILCFVAYSIQIYFNEEPTKDNLYLSIVLSVVVIVTGCFSYYQEAKSSKIMESFKNMVPQQALVIRGGEKMQINVQEVVLGDLVEIKGGDRVPADLRLISAQGCKVDNSSLTGESEPQSRSPDFTHENPLETRNICFFSTNCVEGTARGIVIATGDSTVMGRIASLTSGLAVGQTPIAAEIEHFIHLITVVAVFLGVTFFALSLLLGYGWLEAIIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDMTVYEADTTEEQTGKTFTKSSDTWFMLARIAGLCNRADFKANQEILPIAKRATTGDASESALLKFIEQSYSSVAEMREKNPKVAEIPFNSTNKYQMSIHLREDSSQTHVLMMKGAPERILEFCSTFLLNGQEYSMNDEMKEAFQNAYLELGGLGERVLGFCFLNLPSSFSKGFPFNTDEINFPMDNLCFVGLISMIDPPRAAVPDAVSKCRSAGIKVIMVTGDHPITAKAIAKGVGIISEGTETAEEVAARLKIPISKVDASAAKAIVVHGAELKDIQSKQLDQILQNHPEIVFARTSPQQKLIIVEGCQRLGAVVAVTGDGVNDSPALKKADIGIAMGISGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIMYTLTSNIPEITPFLMFIILGIPLPLGTITILCIDLGTDMVPAISLAYESAESDIMKRLPRNPKTDNLVNHRLIGMAYGQIGMIQALAGFFTYFVILAENGFRPVDLLGIRLHWEDKYLNDLEDSYGQQWTYEQRKVVEFTCQTAFFVTIVVVQWADLIISKTRRNSLFQQGMRNKVLIFGILEETLLAAFLSYTPGMDVALRMYPLKITWWLCAIPYSILIFVYDEIRKLLIRQHPDGWVERETYY>sp|Q13733-2|AT1A4_HUMAN Isoform 2 of Sodium/potassium-transportingATPase subunit alpha-4 OS=Homo sapiens OX=9606 GN=ATP1A4MIQALAGFFTYFVILAENGFRPVDLLGIRLHWEDKYLNDLEDSYGQQWTYEQRKVVEFTCQTAFFVTIVVVQWADLIISKTRRNSLFQQGMRNKVLIFGILEETLLAAFLSYTPGMDVALRMYPLKITWWLCAIPYSILIFVYDEIRKLLIRQHPDGWVERETYY>sp|Q12797|ASPH_HUMAN Aspartyl/asparaginyl beta-hydroxylase OS=Homosapiens OX=9606 GN=ASPH PE=1 SV=3MAQRKNAKSSGNSSSSGSGSGSTSAGSSSPGARRETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHVEGEDLQQEDGPTGEPQQEDDEFLMATDVDDRFETLEPEVSHEETEHSYHVEETVSQDCNQDMEEMMSEQENPDSSEPVVEDERLHHDTDDVTYQVYEEQAVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPETNRKTDDPEQKAKVKKKKPKLLNKFDKTIKAELDAAEKLRKRGKIEEAVNAFKELVRKYPQSPRARYGKAQCEDDLAEKRRSNEVLRGAIETYQEVASLPDVPADLLKLSLKRRSDRQQFLGHMRGSLLTLQRLVQLFPNDTSLKNDLGVGYLLIGDNDNAKKVYEEVLSVTPNDGFAKVHYGFILKAQNKIAESIPYLKEGIESGDPGTDDGRFYFHLGDAMQRVGNKEAYKWYELGHKRGHFASVWQRSLYNVNGLKAQPWWTPKETGYTELVKSLERNWKLIRDEGLAVMDKAKGLFLPEDENLREKGDWSQFTLWQQGRRNENACKGAPKTCTLLEKFPETTGCRRGQIKYSIMHPGTHVWPHTGPTNCRLRMHLGLVIPKEGCKIRCANETKTWEEGKVLIFDDSFEHEVWQDASSFRLIFIVDVWHPELTPQQRRSLPAI>sp|Q12797-2|ASPH_HUMAN Isoform 2 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAQRKNAKSSGNSSSSGSGSGSTSAGSSSPGARRETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHVEGEDLQQEDGPTGEPQQEDDEFLMATDVDDRFETLEPEVSHEETEHSYHVEETVSQDCNQDMEEMMSEQENPDSSEPVVEDERLHHDTDDVTYQVYEEQAVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPDT>sp|Q12797-3|ASPH_HUMAN Isoform 3 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAEDKETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLAKAKDFRYNLSEVLQGKLGIYDADGDGDFDVDDAKVLLEGPSGVAKRKTKAKVKELTKEELKKEKEKPESRKESKNEERKKGKKEDVRKDKKIADADLSRKESPKGKKDREKEKVDLEKSAKTKENRKKSTNMKDVSSKMASRDKDDRKESRSSTRYAHLTKGNTQKRNG>sp|Q12797-4|ASPH_HUMAN Isoform 4 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAEDKETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLGKLGIYDADGDGDFDVDDAKVLLEGPSGVAKRKTKAKVKELTKEELKKEKEKPESRKESKNEERKKGKKEDVRKDKKIADADLSRKESPKGKKDREKEKVDLEKSAKTKENRKKSTNMKDVSSKMASRDKDDRKESRSSTRYAHLTKGNTQKRNG>sp|Q12797-5|ASPH_HUMAN Isoform 5 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAEDKETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLAKAKDFRYNLSEVLQGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHVEGEDLQQEDGPTGEPQQEDDEFLMATDVDDRFETLEPEVSHEETEHSYHVEETVSQDCNQDMEEMMSEQENPDSSEPVVEDERLHHDTDDVTYQVYEEQVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPDT>sp|Q12797-10|ASPH_HUMAN Isoform 10 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAEDKETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHVEGEDLQQEDGPTGEPQQEDDEFLMATDVDDRFETLEPEVSHEETEHSYHVEETVSQDCNQDMEEMMSEQENPDSSEPVVEDERLHHDTDDVTYQVYEEQAVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPETNRKTDDPEQKAKVKKKKPKLLNKFDKTIKAELDAAEKLRKRGKIEEAVNAFKELVRKYPQSPRARYGKAQCEDDLAEKRRSNEVLRGAIETYQEVASLPDVPADLLKLSLKRRSDRQQFLGHMRGSLLTLQRLVQLFPNDTSLKNDLGVGYLLIGDNDNAKKVYEEVLSVTPNDGFAKVHYGFILKAQNKIAESIPYLKEGIESGDPGTDDGRFYFHLGDAMQRVGNKEAYKWYELGHKRGHFASVWQRSLYNVNGLKAQPWWTPKETGYTELVKSLERNWKLIRDEGLAVMDKAKGLFLPEDENLREKGDWSQFTLWQQGRRNENACKGAPKTCTLLEKFPETTGCRRGQIKYSIMHPGTHVWPHTGPTNCRLRMHLGLVIPKEGCKIRCANETKTWEEGKVLIFDDSFEHEVWQDASSFRLIFIVDVWHPELTPQQRRSLPAI>sp|Q12797-6|ASPH_HUMAN Isoform 6 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAQRKNAKSSGNSSSSGSGSGSTSAGSSSPGARRETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHETEHSYHVEETVSQDCNQDMEEMMSEQENPDSSEPVVEDERLHHDTDDVTYQVYEEQAVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPDT>sp|Q12797-7|ASPH_HUMAN Isoform 7 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAQRKNAKSSGNSSSSGSGSGSTSAGSSSPGARRETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLAKAKDFRYNLSEVLQGKLGIYDADGDGDFDVDDAKVLLGLTKDGSNENIDSLEEVLNILAEESSDWFYGFLSFLYDIMTPFEMLEEEEEESETADGVDGTSQNEGVQGKTCVILDLHNQ>sp|Q12797-8|ASPH_HUMAN Isoform 8 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAEDKETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLAKAKDFRYNLSEVLQGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHVEGEDLQQEDGPTGEPQQEDDEFLMATDVDDRFETLEPEVSHEETEHSYHVEETVSQDCNQDMEEMMSEQENPDSSEPVVEDERLHHDTDDVTYQVYEEQAVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPDT>sp|Q12797-9|ASPH_HUMAN Isoform 9 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAEDKETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLAKAKDFRYNLSEVLQGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHETEHSYHVEETVSQDCNQDMEEMMSEQENPDSSEPVVEDERLHHDTDDVTYQVYEEQAVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPDT>sp|Q12797-11|ASPH_HUMAN Isoform 11 of Aspartyl/asparaginyl beta-hydroxylase OS=Homo sapiens OX=9606 GN=ASPHMAQRKNAKSSGNSSSSGSGSGSTSAGSSSPGARRETKHGGHKNGRKGGLSGTSFFTWFMVIALLGVWTSVAVVWFDLVDYEEVLGKLGIYDADGDGDFDVDDAKVLLGLKERSTSEPAVPPEEAEPHTEPEEQVPVEAEPQNIEDEAKEQIQSLLHEMVHAEHVEGEDLQQEDGPTGEPQQEDDEFLMATDVDDRFETLEPEVSHEETEHSYHVEETDSSEPVVEDERLHHDTDDVTYQVYEEQAVYEPLENEGIEITEVTAPPEDNPVEDSQVIVEEVSIFPVEEQQEVPPDT>sp|Q8IZT6|ASPM_HUMAN Abnormal spindle-like microcephaly-associatedprotein OS=Homo sapiens OX=9606 GN=ASPM PE=1 SV=2MANRRVGRGCWEVSPTERRPPAGLRGPAAEEEASSPPVLSLSHFCRSPFLCFGDVLLGASRTLSLALDNPNEEVAEVKISHFPAADLGFSVSQRCFVLQPKEKIVISVNWTPLKEGRVREIMTFLVNDVLKHQAILLGNAEEQKKKKRSLWDTIKKKKISASTSHNRRVSNIQNVNKTFSVSQKVDRVRSPLQACENLAMNEGGPPTENNSLILEENKIPISPISPAFNECHGATCLPLSVRRSTTYSSLHASENRELLNVHSANVSKVSFNEKAVTETSFNSVNVNGQRGENSKLSLTPNCSSTLNITQSQIHFLSPDSFVNNSHGANNELELVTCLSSDMFMKDNSQPVHLESTIAHEIYQKILSPDSFIKDNYGLNQDLESESVNPILSPNQFLKDNMAYMCTSQQTCKVPLSNENSQVPQSPEDWRKSEVSPRIPECQGSKSPKAIFEELVEMKSNYYSFIKQNNPKFSAVQDISSHSHNKQPKRRPILSATVTKRKATCTRENQTEINKPKAKRCLNSAVGEHEKVINNQKEKEDFHSYLPIIDPILSKSKSYKNEVTPSSTTASVARKRKSDGSMEDANVRVAITEHTEVREIKRIHFSPSEPKTSAVKKTKNVTTPISKRISNREKLNLKKKTDLSIFRTPISKTNKRTKPIIAVAQSSLTFIKPLKTDIPRHPMPFAAKNMFYDERWKEKQEQGFTWWLNFILTPDDFTVKTNISEVNAATLLLGIENQHKISVPRAPTKEEMSLRAYTARCRLNRLRRAACRLFTSEKMVKAIKKLEIEIEARRLIVRKDRHLWKDVGERQKVLNWLLSYNPLWLRIGLETTYGELISLEDNSDVTGLAMFILNRLLWNPDIAAEYRHPTVPHLYRDGHEEALSKFTLKKLLLLVCFLDYAKISRLIDHDPCLFCKDAEFKASKEILLAFSRDFLSGEGDLSRHLGLLGLPVNHVQTPFDEFDFAVTNLAVDLQCGVRLVRTMELLTQNWDLSKKLRIPAISRLQKMHNVDIVLQVLKSRGIELSDEHGNTILSKDIVDRHREKTLRLLWKIAFAFQVDISLNLDQLKEEIAFLKHTKSIKKTISLLSCHSDDLINKKKGKRDSGSFEQYSENIKLLMDWVNAVCAFYNKKVENFTVSFSDGRVLCYLIHHYHPCYVPFDAICQRTTQTVECTQTGSVVLNSSSESDDSSLDMSLKAFDHENTSELYKELLENEKKNFHLVRSAVRDLGGIPAMINHSDMSNTIPDEKVVITYLSFLCARLLDLRKEIRAARLIQTTWRKYKLKTDLKRHQEREKAARIIQLAVINFLAKQRLRKRVNAALVIQKYWRRVLAQRKLLMLKKEKLEKVQNKAASLIQGYWRRYSTRQRFLKLKYYSIILQSRIRMIIAVTSYKRYLWATVTIQRHWRAYLRRKQDQQRYEMLKSSTLIIQSMFRKWKQRKMQSQVKATVILQRAFREWHLRKQAKEENSAIIIQSWYRMHKELRKYIYIRSCVVIIQKRFRCFQAQKLYKRRKESILTIQKYYKAYLKGKIERTNYLQKRAAAIQLQAAFRRLKAHNLCRQIRAACVIQSYWRMRQDRVRFLNLKKTIIKFQAHVRKHQQRQKYKKMKKAAVIIQTHFRAYIFAMKVLASYQKTRSAVIVLQSAYRGMQARKMYIHILTSVIKIQSYYRAYVSKKEFLSLKNATIKLQSTVKMKQTRKQYLHLRAAALFIQQCYRSKKIAAQKREEYMQMRESCIKLQAFVRGYLVRKQMRLQRKAVISLQSYFRMRKARQYYLKMYKAIIVIQNYYHAYKAQVNQRKNFLQVKKAATCLQAAYRGYKVRQLIKQQSIAALKIQSAFRGYNKRVKYQSVLQSIIKIQRWYRAYKTLHDTRTHFLKTKAAVISLQSAYRGWKVRKQIRREHQAALKIQSAFRMAKAQKQFRLFKTAALVIQQNFRAWTAGRKQCMEYIELRHAVLVLQSMWKGKTLRRQLQRQHKCAIIIQSYYRMHVQQKKWKIMKKAALLIQKYYRAYSIGREQNHLYLKTKAAVVTLQSAYRGMKVRKRIKDCNKAAVTIQSKYRAYKTKKKYATYRASAIIIQRWYRGIKITNHQHKEYLNLKKTAIKIQSVYRGIRVRRHIQHMHRAATFIKAMFKMHQSRISYHTMRKAAIVIQVRCRAYYQGKMQREKYLTILKAVKVLQASFRGVRVRRTLRKMQTAATLIQSNYRRYRQQTYFNKLKKITKTVQQRYWAMKERNIQFQRYNKLRHSVIYIQAIFRGKKARRHLKMMHIAATLIQRRFRTLMMRRRFLSLKKTAILIQRKYRAHLCTKHHLQFLQVQNAVIKIQSSYRRWMIRKRMREMHRAATFIQSTFRMHRLHMRYQALKQASVVIQQQYQANRAAKLQRQHYLRQRHSAVILQAAFRGMKTRRHLKSMHSSATLIQSRFRSLLVRRRFISLKKATIFVQRKYRATICAKHKLYQFLHLRKAAITIQSSYRRLMVKKKLQEMQRAAVLIQATFRMYRTYITFQTWKHASILIQQHYRTYRAAKLQRENYIRQWHSAVVIQAAYKGMKARQLLREKHKASIVIQSTYRMYRQYCFYQKLQWATKIIQEKYRANKKKQKVFQHNELKKETCVQAGFQDMNIKKQIQEQHQAAIIIQKHCKAFKIRKHYLHLRATVVSIQRRYRKLTAVRTQAVICIQSYYRGFKVRKDIQNMHRAATLIQSFYRMHRAKVDYETKKTAIVVIQNYYRLYVRVKTERKNFLAVQKSVRTIQAAFRGMKVRQKLKNVSEEKMAAIVNQSALCCYRSKTQYEAVQSEGVMIQEWYKASGLACSQEAEYHSQSRAAVTIQKAFCRMVTRKLETQKCAALRIQFFLQMAVYRRRFVQQKRAAITLQHYFRTWQTRKQFLLYRKAAVVLQNHYRAFLSAKHQRQVYLQIRSSVIIIQARSKGFIQKRKFQEIKNSTIKIQAMWRRYRAKKYLCKVKAACKIQAWYRCWRAHKEYLAILKAVKIIQGCFYTKLERTRFLNVRASAIIIQRKWRAILPAKIAHEHFLMIKRHRAACLIQAHYRGYKGRQVFLRQKSAALIIQKYIRAREAGKHERIKYIEFKKSTVILQALVRGWLVRKRFLEQRAKIRLLHFTAAAYYHLNAVRIQRAYKLYLAVKNANKQVNSVICIQRWFRARLQEKRFIQKYHSIKKIEHEGQECLSQRNRAASVIQKAVRHFLLRKKQEKFTSGIIKIQALWRGYSWRKKNDCTKIKAIRLSLQVVNREIREENKLYKRTALALHYLLTYKHLSAILEALKHLEVVTRLSPLCCENMAQSGAISKIFVLIRSCNRSIPCMEVIRYAVQVLLNVSKYEKTTSAVYDVENCIDILLELLQIYREKPGNKVADKGGSIFTKTCCLLAILLKTTNRASDVRSRSKVVDRIYSLYKLTAHKHKMNTERILYKQKKNSSISIPFIPETPVRTRIVSRLKPDWVLRRDNMEEITNPLQAIQMVMDTLGIPY>sp|Q8IZT6-2|ASPM_HUMAN Isoform 2 of Abnormal spindle-like microcephaly-associated protein OS=Homo sapiens OX=9606 GN=ASPMMANRRVGRGCWEVSPTERRPPAGLRGPAAEEEASSPPVLSLSHFCRSPFLCFGDVLLGASRTLSLALDNPNEEVAEVKISHFPAADLGFSVSQRCFVLQPKEKIVISVNWTPLKEGRVREIMTFLVNDVLKHQAILLGNAEEQKKKKRSLWDTIKKKKISASTSHNRRVSNIQNVNKTFSVSQKVDRVRSPLQACENLAMNEGGPPTENNSLILEENKIPISPISPAFNECHGATCLPLSVRRSTTYSSLHASENRELLNVHSANVSKVSFNEKAVTETSFNSVNVNGQRGENSKLSLTPNCSSTLNITQSQIHFLSPDSFVNNSHGANNELELVTCLSSDMFMKDNSQPVHLESTIAHEIYQKILSPDSFIKDNYGLNQDLESESVNPILSPNQFLKDNMAYMCTSQQTCKVPLSNENSQVPQSPEDWRKSEVSPRIPECQGSKSPKAIFEELVEMKSNYYSFIKQNNPKFSAVQDISSHSHNKQPKRRPILSATVTKRKATCTRENQTEINKPKAKRCLNSAVGEHEKVINNQKEKEDFHSYLPIIDPILSKSKSYKNEVTPSSTTASVARKRKSDGSMEDANVRVAITEHTEVREIKRIHFSPSEPKTSAVKKTKNVTTPISKRISNREKLNLKKKTDLSIFRTPISKTNKRTKPIIAVAQSSLTFIKPLKTDIPRHPMPFAAKNMFYDERWKEKQEQGFTWWLNFILTPDDFTVKTNISEVNAATLLLGIENQHKISVPRAPTKEEMSLRAYTARCRLNRLRRAACRLFTSEKMVKAIKKLEIEIEARRLIVRKDRHLWKDVGERQKVLNWLLSYNPLWLRIGLETTYGELISLEDNSDVTGLAMFILNRLLWNPDIAAEYRHPTVPHLYRDGHEEALSKFTLKKLLLLVCFLDYAKISRLIDHDPCLFCKDAEFKASKEILLAFSRDFLSGEGDLSRHLGLLGLPVNHVQTPFDEFDFAVTNLAVDLQCGVRLVRTMELLTQNWDLSKKLRIPAISRLQKMHNVDIVLQVLKSRGIELSDEHGNTILSKDIVDRHREKTLRLLWKIAFAFQVDISLNLDQLKEEIAFLKHTKSIKKTISLLSCHSDDLINKKKGKRDSGSFEQYSENIKLLMDWVNAVCAFYNKKVENFTVSFSDGRVLCYLIHHYHPCYVPFDAICQRTTQTVECTQTGSVVLNSSSESDDSSLDMSLKAFDHENTSELYKELLENEKKNFHLVRSAVRDLGGIPAMINHSDMSNTIPDEKVVITYLSFLCARLLDLRKEIRAARLIQTTWRKYKLKTDLKRHQEREKAARIIQLAVINFLAKQRLRKRVNAALVIQKYWRRVLAQRKLLMLKKEKLEKVQNKAASLIQAMWRRYRAKKYLCKVKAACKIQAWYRCWRAHKEYLAILKAVKIIQGCFYTKLERTRFLNVRASAIIIQRKWRAILPAKIAHEHFLMIKRHRAACLIQAHYRGYKGRQVFLRQKSAALIIQKYIRAREAGKHERIKYIEFKKSTVILQALVRGWLVRKRFLEQRAKIRLLHFTAAAYYHLNAVRIQRAYKLYLAVKNANKQVNSVICIQRWFRARLQEKRFIQKYHSIKKIEHEGQECLSQRNRAASVIQKAVRHFLLRKKQEKFTSGIIKIQALWRGYSWRKKNDCTKIKAIRLSLQVVNREIREENKLYKRTALALHYLLTYKHLSAILEALKHLEVVTRLSPLCCENMAQSGAISKIFVLIRSCNRSIPCMEVIRYAVQVLLNVSKYEKTTSAVYDVENCIDILLELLQIYREKPGNKVADKGGSIFTKTCCLLAILLKTTNRASDVRSRSKVVDRIYSLYKLTAHKHKMNTERILYKQKKNSSISIPFIPETPVRTRIVSRLKPDWVLRRDNMEEITNPLQAIQMVMDTLGIPY>sp|O75746|CMC1_HUMAN Calcium-binding mitochondrial carrier proteinAralar1 OS=Homo sapiens OX=9606 GN=SLC25A12 PE=1 SV=2MAVKVQTTKRGDPHELRNIFLQYASTEVDGERYMTPEDFVQRYLGLYNDPNSNPKIVQLLAGVADQTKDGLISYQEFLAFESVLCAPDSMFIVAFQLFDKSGNGEVTFENVKEIFGQTIIHHHIPFNWDCEFIRLHFGHNRKKHLNYTEFTQFLQELQLEHARQAFALKDKSKSGMISGLDFSDIMVTIRSHMLTPFVEENLVSAAGGSISHQVSFSYFNAFNSLLNNMELVRKIYSTLAGTRKDVEVTKEEFAQSAIRYGQVTPLEIDILYQLADLYNASGRLTLADIERIAPLAEGALPYNLAELQRQQSPGLGRPIWLQIAESAYRFTLGSVAGAVGATAVYPIDLVKTRMQNQRGSGSVVGELMYKNSFDCFKKVLRYEGFFGLYRGLIPQLIGVAPEKAIKLTVNDFVRDKFTRRDGSVPLPAEVLAGGCAGGSQVIFTNPLEIVKIRLQVAGEITTGPRVSALNVLRDLGIFGLYKGAKACFLRDIPFSAIYFPVYAHCKLLLADENGHVGGLNLLAAGAMAGVPAASLVTPADVIKTRLQVAARAGQTTYSGVIDCFRKILREEGPSAFWKGTAARVFRSSPQFGVTLVTYELLQRWFYIDFGGLKPAGSEPTPKSRIADLPPANPDHIGGYRLATATFAGIENKFGLYLPKFKSPSVAVVQPKAAVAATQ>sp|O75746-2|CMC1_HUMAN Isoform 2 of Calcium-binding mitochondrialcarrier protein Aralar1 OS=Homo sapiens OX=9606 GN=SLC25A12MENVKEIFGQTIIHHHIPFNWDCEFIRLHFGHNRKKHLNYTEFTQFLQELQLEHARQAFALKDKSKSGMISGLDFSDIMVTIRSHMLTPFVEENLVSAAGGSISHQVSFSYFNAFNSLLNNMELVRKIYSTLAGTRKDVEVTKEEFAQSAIRYGQVTPLEIDILYQLADLYNASGRLTLADIERIAPLAEGALPYNLAELQRQQSPGLGRPIWLQIAESAYRFTLGSVAGAVGATAVYPIDLVKTRMQNQRGSGSVVGELMYKNSFDCFKKVLRYEGFFGLYRGLIPQLIGVAPEKAIKLTVNDFVRDKFTRRDGSVPLPAEVLAGGCAGGSQVIFTNPLEIVKIRLQVAGEITTGPRVSALNVLRDLGIFGLYKGAKACFLRDIPFSAIYFPVYAHCKLLLADENGHVGGLNLLAAGAMAGVPAASLVTPADVIKTRLQVAARAGQTTYSGVIDCFRKILREEGPSAFWKGTAARVFRSSPQFGVTLVTYELLQRWFYIDFGGLKPAGSEPTPKSRIADLPPANPDHIGGYRLATATFAGIENKFGLYLPKFKSPSVAVVQPKAAVAATQ>sp|Q9H2U6|CO005_HUMAN Putative uncharacterized protein encoded byLINC00597 OS=Homo sapiens OX=9606 GN=LINC00597 PE=5 SV=1MLKNRELLKIFEQASHMMKLIEEHCICDCIWMEWEDLEAKTLDRRPPEQTRRERCSCGNGKRWAKPKITTEKKNHPDFMIDWMYFETPLSIQMK>sp|Q8N910|CO056_HUMAN Putative uncharacterized protein PAK6-AS1 OS=Homosapiens OX=9606 GN=PAK6-AS1 PE=5 SV=1MPRAGRAPAEGGPAPGTRSSRCLRPRPLAWRRLVPNFGAWAPRKGAARVGRPVLSPRTSGAAGEPTCGAGSPGTLEEGVASGRTRRRTQSAGEVAKCRWGLGQEPLCPRGAVLLNSFSPPAWPQFPPALRLRALAWPQPRGPACGSTAQWPPRGDPTWRIS>sp|P56211|ARP19_HUMAN cAMP-regulated phosphoprotein 19 OS=Homo sapiensOX=9606 GN=ARPP19 PE=1 SV=2MSAEVPEAASAEEQKEMEDKVTSPEKAEEAKLKARYPHLGQKPGGSDFLRKRLQKGQKYFDSGDYNMAKAKMKNKQLPTAAPDKTEVTGDHIPTPQDLPQRKPSLVASKLAG>sp|P56211-2|ARP19_HUMAN Isoform ARPP-16 of cAMP-regulated phosphoprotein19 OS=Homo sapiens OX=9606 GN=ARPP19MEDKVTSPEKAEEAKLKARYPHLGQKPGGSDFLRKRLQKGQKYFDSGDYNMAKAKMKNKQLPTAAPDKTEVTGDHIPTPQDLPQRKPSLVASKLAG>sp|Q9C0K3|ARP3C_HUMAN Actin-related protein 3C OS=Homo sapiens OX=9606GN=ACTR3C PE=2 SV=1MFESFNVPGLYIAVQAVLALAASWTSRQVGERTLTGIVIDSGDGVTHVIPVAEGYVIGSCIKHIPIAGRDITYFIQQLLREREVGIPPEQSLETAKAIKEKYCYICPDIVKEFAKYDVDPQKWIKQYTGINAINQKKFVIDVGYERFLGPEIFFHPEFANPDSMESISDVVDEVIQNCPIDVRRPLYKMEQIPLSYPQGHGFHPLSPPFH>sp|Q9C0K3-2|ARP3C_HUMAN Isoform 2 of Actin-related protein 3C OS=Homosapiens OX=9606 GN=ACTR3CMESISDVVDEVIQNCPIDVRRPLYKMEQIPLSYPQGHGFHPLSPPFH>sp|Q9UKP5|ATS6_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 6 OS=Homo sapiens OX=9606 GN=ADAMTS6 PE=2 SV=2MEILWKTLTWILSLIMASSEFHSDHRLSYSSQEEFLTYLEHYQLTIPIRVDQNGAFLSFTVKNDKHSRRRRSMDPIDPQQAVSKLFFKLSAYGKHFHLNLTLNTDFVSKHFTVEYWGKDGPQWKHDFLDNCHYTGYLQDQRSTTKVALSNCVGLHGVIATEDEEYFIEPLKNTTEDSKHFSYENGHPHVIYKKSALQQRHLYDHSHCGVSDFTRSGKPWWLNDTSTVSYSLPINNTHIHHRQKRSVSIERFVETLVVADKMMVGYHGRKDIEHYILSVMNIVAKLYRDSSLGNVVNIIVARLIVLTEDQPNLEINHHADKSLDSFCKWQKSILSHQSDGNTIPENGIAHHDNAVLITRYDICTYKNKPCGTLGLASVAGMCEPERSCSINEDIGLGSAFTIAHEIGHNFGMNHDGIGNSCGTKGHEAAKLMAAHITANTNPFSWSACSRDYITSFLDSGRGTCLDNEPPKRDFLYPAVAPGQVYDADEQCRFQYGATSRQCKYGEVCRELWCLSKSNRCVTNSIPAAEGTLCQTGNIEKGWCYQGDCVPFGTWPQSIDGGWGPWSLWGECSRTCGGGVSSSLRHCDSPAPSGGGKYCLGERKRYRSCNTDPCPLGSRDFREKQCADFDNMPFRGKYYNWKPYTGGGVKPCALNCLAEGYNFYTERAPAVIDGTQCNADSLDICINGECKHVGCDNILGSDAREDRCRVCGGDGSTCDAIEGFFNDSLPRGGYMEVVQIPRGSVHIEVREVAMSKNYIALKSEGDDYYINGAWTIDWPRKFDVAGTAFHYKRPTDEPESLEALGPTSENLIVMVLLQEQNLGIRYKFNVPITRTGSGDNEVGFTWNHQPWSECSATCAGGVQRQEVVCKRLDDNSIVQNNYCDPDSKPPENQRACNTEPCPPEWFIGDWLECSKTCDGGMRTRAVLCIRKIGPSEEETLDYSGCLTHRPVEKEPCNNQSCPPQWVALDWSECTPKCGPGFKHRIVLCKSSDLSKTFPAAQCPEESKPPVRIRCSLGRCPPPRWVTGDWGQCSAQCGLGQQMRTVQCLSYTGQASSDCLETVRPPSMQQCESKCDSTPISNTEECKDVNKVAYCPLVLKFKFCSRAYFRQMCCKTCQGH>sp|Q9UKP5-2|ATS6_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 6 OS=Homo sapiens OX=9606 GN=ADAMTS6MEILWKTLTWILSLIMASSEFHSDHRLSYSSQEEFLTYLEHYQLTIPIRVDQNGAFLSFTVKNDKHSRRRRSMDPIDPQQAVSKLFFKLSAYGKHFHLNLTLNTDFVSKHFTVEYWGKDGPQWKHDFLDNCHYTGYLQDQRSTTKVALSNCVGLHGVIATEDEEYFIEPLKNTTEDSKHFSYENGHPHVIYKKSALQQRHLYDHSHCGVSDFTRSGKPWWLNDTSTVSYSLPINNTHIHHRQKRSVSIERFVETLVVADKMMVGYHGRKDIEHYILSVMNIVAKLYRDSSLGNVVNIIVARLIVLTEDQPNLEINHHADKSLDSFCKWQKSILSHQSDGNTIPENGIAHHDNAVLITRYDICTYKNKPCGTLGLASVAGMCEPERSCSINEDIGLGSAFTIAHEIGHNFGMNHDGIGNSCGRKVMKQQNYGSSHYCEYQSFFLVCLQSRFHHQLFREVCRELWCLSKSNRCVTNSIPAAEGTLCQTGNIEKGWCYQGDCVPFGTWPQSIDGGWGPWSLWGECSRTCGGGVSSSLRHCDSPAPSGGGKYCLGERKRYRSCNTDPCPLGSRDFREKQCADFDNMPFRGKYYNWKPYTGGGVKPCALNCLAEGYNFYTERAPAVIDGTQCNADSLDICINGECKHVGCDNILGSDAREDRCRVCGGDGSTCDAIEGFFNDSLPRGGYMEVVQIPRGSVHIEVREVAMSKNYIALKSEGDDYYINGAWTIDWPRKFDVAGTAFHYKRPTDEPESLEALGPTSENLIVMVLLQEQNLGIRYKFNVPITRTGSGDNEVGFTWNHQPWSECSATCAGGKMPTRQPTQRARWRTKHILSYALCLLKKLIGNISCRFASSCNLAKETLL>sp|Q9UKP5-3|ATS6_HUMAN Isoform 3 of A disintegrin and metalloproteinasewith thrombospondin motifs 6 OS=Homo sapiens OX=9606 GN=ADAMTS6MEILWKTLTWILSLIMASSEFHSDHRLSYSSQEEFLTYLEHYQLTIPIRVDQNGAFLSFTVKNDKHSRRRRSMDPIDPQQAVSKLFFKLSAYGKHFHLNLTLNTDFVSKHFTVEYWGKDGPQWKHDFLDNCHYTGYLQDQRSTTKVALSNCVGLHGVIATEDEEYFIEPLKNTTEDSKHFSYENGHPHVIYKKSALQQRHLYDHSHCGVSDFTRSGKPWWLNDTSTVSYSLPINNTHIHHRQKRSVSIERFVETLVVADKMMVGYHGRKDIEHYILSVMNIVAKLYRDSSLGNVVNIIVARLIVLTEDQPNLEINHHADKSLDSFCKWQKSILSHQSDGNTIPENGIAHHDNAVLITRYDICTYKNKPCGTLGLASVAGMCEPERSCSINEDIGLGSAFTIAHEIGHNFGMNHDGIGNSCGTKGHEAAKLMAAHITANTNPFSWSACSRDYITSFLEFLKLGDSISGS>sp|Q9UKP5-4|ATS6_HUMAN Isoform 4 of A disintegrin and metalloproteinasewith thrombospondin motifs 6 OS=Homo sapiens OX=9606 GN=ADAMTS6MEILWKTLTWILSLIMASSEFHSDHRLSYSSQEEFLTYLEHYQLTIPIRVDQNGAFLSFTVKNDKHSRRRRSMDPIDPQQAVSKLFFKLSAYGKHFHLNLTLNTDFVSKHFTVEYWGKDGPQWKHDFLDNCHYTGYLQDQRSTTKVALSNCVGLHGVIATEDEEYFIEPLKNTTEDSKHFSYENGHPHVIYKKSALQQRHLYDHSHCGVSDFTRSGKPWWLNDTSTVSYSLPINNTHIHHRQKRSVSIERFVETLVVADKMMVGYHGRKDIEHYILSVMNIVRLPNFTVIPA>sp|Q9NVT9|ARMC1_HUMAN Armadillo repeat-containing protein 1 OS=Homosapiens OX=9606 GN=ARMC1 PE=1 SV=1MNSSTSTMSEEPDALSVVNQLRDLAADPLNRRAIVQDQGCLPGLILFMDHPNPPVVHSALLALRYLAECRANREKMKGELGMMLSLQNVIQKTTTPGETKLLASEIYDILQSSNMADGDSFNEMNSRRRKAQFFLGTTNKRAKTVVLHIDGLDDTSRRNLCEEALLKIKGVISFTFQMAVQRCVVRIRSDLKAEALASAIASTKVMKAQQVVKSESGEEMLVPFQDTPVEVEQNTELPDYLPEDESPTKEQDKAVSRVGSHPEGGASWLSTAANFLSRSFYW>sp|Q9NVT9-2|ARMC1_HUMAN Isoform 2 of Armadillo repeat-containing protein1 OS=Homo sapiens OX=9606 GN=ARMC1MSAWPYFIYGPSQPSSRPLRFACSSILGRMPCKQRKDERRTGYDVELTKCYTESRRNLCEEALLKIKGVISFTFQMAVQRCVVRIRSDLKAEALASAIASTKVMKAQQVVKSESGEEMLVPFQDTPVEVEQNTELPDYLPEDESPTKEQDKAVSRVGSHPEGGASWLSTAANFLSRSFYW>sp|Q9H9F9|ARP5_HUMAN Actin-related protein 5 OS=Homo sapiens OX=9606GN=ACTR5 PE=1 SV=2MAANVFPFRDARAAPDPVLEAGPVAHGPLPVPLVLDNGSFQVRAGWACPGQDPGPEPRLQFRAVCARGRGGARGASGPQVGNALGSLEPLRWMLRSPFDRNVPVNLELQELLLDYSFQHLGVSSQGCVDHPIVLTEAVCNPLYSRQMMSELLFECYGIPKVAYGIDSLFSFYHNKPKNSMCSGLIISSGYQCTHVLPILEGRLDAKNCKRINLGGSQAAGYLQRLLQLKYPGHLAAITLSRMEEILHEHSYIAEDYVEELHKWRCPDYYENNVHKMQLPFSSKLLGSTLTSEEKQERRQQQLRRLQELNARRREEKLQLDQERLDRLLYVQELLEDGQMDQFHKALIELNMDSPEELQSYIQKLSIAVEQAKQKILQAEVNLEVDVVDSKPETPDLEQLEPSLEDVESMNDFDPLFSEETPGVEKPVTTVQPVFNLAAYHQLFVGTERIRAPEIIFQPSLIGEEQAGIAETLQYILDRYPKDIQEMLVQNVFLTGGNTMYPGMKARMEKELLEMRPFRSSFQVQLASNPVLDAWYGARDWALNHLDDNEVWITRKEYEEKGGEYLKEHCASNIYVPIRLPKQASRSSDAQASSKGSAAGGGGAGEQA>sp|P51689|ARSD_HUMAN Arylsulfatase D OS=Homo sapiens OX=9606 GN=ARSDPE=1 SV=2MRSAARRGRAAPAARDSLPVLLFLCLLLKTCEPKTANAFKPNILLIMADDLGTGDLGCYGNNTLRTPNIDQLAEEGVRLTQHLAAAPLCTPSRAAFLTGRHSFRSGMDASNGYRALQWNAGSGGLPENETTFARILQQHGYATGLIGKWHQGVNCASRGDHCHHPLNHGFDYFYGMPFTLTNDCDPGRPPEVDAALRAQLWGYTQFLALGILTLAAGQTCGFFSVSARAVTGMAGVGCLFFISWYSSFGFVRRWNCILMRNHDVTEQPMVLEKTASLMLKEAVSYIERHKHGPFLLFLSLLHVHIPLVTTSAFLGKSQHGLYGDNVEEMDWLIGKVLNAIEDNGLKNSTFTYFTSDHGGHLEARDGHSQLGGWNGIYKGGKGMGGWEGGIRVPGIFHWPGVLPAGRVIGEPTSLMDVFPTVVQLVGGEVPQDRVIDGHSLVPLLQGAEARSAHEFLFHYCGQHLHAARWHQKDSGSVWKVHYTTPQFHPEGAGACYGRGVCPCSGEGVTHHRPPLLFDLSRDPSEARPLTPDSEPLYHAVIARVGAAVSEHRQTLSPVPQQFSMSNILWKPWLQPCCGHFPFCSCHEDGDGTP>sp|P51689-2|ARSD_HUMAN Isoform 2 of Arylsulfatase D OS=Homo sapiensOX=9606 GN=ARSDMRSAARRGRAAPAARDSLPVLLFLCLLLKTCEPKTANAFKPNILLIMADDLGTGDLGCYGNNTLRTPNIDQLAEEGVRLTQHLAAAPLCTPSRAAFLTGRHSFRSGMDASNGYRALQWNAGSGGLPENETTFARILQQHGYATGLIGKWHQGVNCASRGDHCHHPLNHGFDYFYGMPFTLTNDCDPGRPPEVDAALRAQLWGYTQFLALGILTLAAGQTCGFFSVSARAVTGMAGVGCLFFISWYSSFGFVRRWNCILMRNHDVTEQPMVLEKTASLMLKEAVSYIERHKHGPFLLFLSLLHVHIPLVTTSAFLGKSQHGLYGDNVEEMDWLIASDFMSSSEVTESEAIKLMFRTMQRRCLPSMAFKKPWRGPVRLQILKRA>sp|P51689-3|ARSD_HUMAN Isoform 3 of Arylsulfatase D OS=Homo sapiensOX=9606 GN=ARSDMRSAARRGRAAPAARDSLPVLLFLCLLLKTCEPKTANAFKPNILLIMADDLGTGDLGCYGNNTLRTPNIDQLAEEGVRLTQHLAAAPLCTPSRAAFLTGRHSFRSGMDASNGYRALQWNAGSGGLPENETTFARILQQHGYATGLIGKWHQGVNCASRGDHCHHPLNHGFDYFYGMPFTLTNDCDPGRPPEVDAALRAQLWGYTQFLALGILTLAAGQTCGFFSVSARAVTGMAGVGCLFFISWYSSFGFVRRWNCILMRNHDVTEQPMVLEKTASLMLKEAVSYIERHKHGPFLLFLSLLHVHIPLVTTSAFLGKSQHGLYGDNVEEMDWLIGKVLNAIEDNGLKNSTFTYFTSDHGGHLEARDGHSQLGGWNGIYKGGKGMGGWEGGIRVPGIFHWPGVLPAGRVIGEPTSLMDVFPTVVQLVGGEVPQDRVIDGHSLVPLLQGAEARSAHEFLFHYCGQHLHAARWHQKDSGSVWKVHYTTPQFHPEGAGACYGRGVCPC>sp|P54793|ARSF_HUMAN Arylsulfatase F OS=Homo sapiens OX=9606 GN=ARSFPE=1 SV=4MRPRRPLVFMSLVCALLNTCQAHRVHDDKPNIVLIMVDDLGIGDLGCYGNDTMRTPHIDRLAREGVRLTQHISAASLCSPSRSAFLTGRYPIRSGMVSSGNRRVIQNLAVPAGLPLNETTLAALLKKQGYSTGLIGKWHQGLNCDSRSDQCHHPYNYGFDYYYGMPFTLVDSCWPDPSRNTELAFESQLWLCVQLVAIAILTLTFGKLSGWVSVPWLLIFSMILFIFLLGYAWFSSHTSPLYWDCLLMRGHEITEQPMKAERAGSIMVKEAISFLERHSKETFLLFFSFLHVHTPLPTTDDFTGTSKHGLYGDNVEEMDSMVGKILDAIDDFGLRNNTLVYFTSDHGGHLEARRGHAQLGGWNGIYKGGKGMGGWEGGIRVPGIVRWPGKVPAGRLIKEPTSLMDILPTVASVSGGSLPQDRVIDGRDLMPLLQGNVRHSEHEFLFHYCGSYLHAVRWIPKDDSGSVWKAHYVTPVFQPPASGGCYVTSLCRCFGEQVTYHNPPLLFDLSRDPSESTPLTPATEPLHDFVIKKVANALKEHQETIVPVTYQLSELNQGRTWLKPCCGVFPFCLCDKEEEVSQPRGPNEKR>sp|Q5FYB0|ARSJ_HUMAN Arylsulfatase J OS=Homo sapiens OX=9606 GN=ARSJPE=2 SV=1MAPRGCAGHPPPPSPQACVCPGKMLAMGALAGFWILCLLTYGYLSWGQALEEEEEGALLAQAGEKLEPSTTSTSQPHLIFILADDQGFRDVGYHGSEIKTPTLDKLAAEGVKLENYYVQPICTPSRSQFITGKYQIHTGLQHSIIRPTQPNCLPLDNATLPQKLKEVGYSTHMVGKWHLGFYRKECMPTRRGFDTFFGSLLGSGDYYTHYKCDSPGMCGYDLYENDNAAWDYDNGIYSTQMYTQRVQQILASHNPTKPIFLYIAYQAVHSPLQAPGRYFEHYRSIININRRRYAAMLSCLDEAINNVTLALKTYGFYNNSIIIYSSDNGGQPTAGGSNWPLRGSKGTYWEGGIRAVGFVHSPLLKNKGTVCKELVHITDWYPTLISLAEGQIDEDIQLDGYDIWETISEGLRSPRVDILHNIDPIYTKAKNGSWAAGYGIWNTAIQSAIRVQHWKLLTGNPGYSDWVPPQSFSNLGPNRWHNERITLSTGKSVWLFNITADPYERVDLSNRYPGIVKKLLRRLSQFNKTAVPVRYPPKDPRSNPRLNGGVWGPWYKEETKKKKPSKNQAEKKQKKSKKKKKKQQKAVSGSTCHSGVTCG>sp|Q9H993|ARMT1_HUMAN Damage-control phosphatase ARMT1 OS=Homo sapiensOX=9606 GN=ARMT1 PE=1 SV=1MAVVPASLSGQDVGSFAYLTIKDRIPQILTKVIDTLHRHKSEFFEKHGEEGVEAEKKAISLLSKLRNELQTDKPFIPLVEKFVDTDIWNQYLEYQQSLLNESDGKSRWFYSPWLLVECYMYRRIHEAIIQSPPIDYFDVFKESKEQNFYGSQESIIALCTHLQQLIRTIEDLDENQLKDEFFKLLQISLWGNKCDLSLSGGESSSQNTNVLNSLEDLKPFILLNDMEHLWSLLSNCKKTREKASATRVYIVLDNSGFELVTDLILADFLLSSELATEVHFYGKTIPWFVSDTTIHDFNWLIEQVKHSNHKWMSKCGADWEEYIKMGKWVYHNHIFWTLPHEYCAMPQVAPDLYAELQKAHLILFKGDLNYRKLTGDRKWEFSVPFHQALNGFHPAPLCTIRTLKAEIQVGLQPGQGEQLLASEPSWWTTGKYGIFQYDGPL>sp|Q9UH62|ARMX3_HUMAN Armadillo repeat-containing X-linked protein 3OS=Homo sapiens OX=9606 GN=ARMCX3 PE=1 SV=1MGYARKVGWVTAGLVIGAGACYCIYRLTRGRKQNKEKMAEGGSGDVDDAGDCSGARYNDWSDDDDDSNESKSIVWYPPWARIGTEAGTRARARARARATRARRAVQKRASPNSDDTVLSPQELQKVLCLVEMSEKPYILEAALIALGNNAAYAFNRDIIRDLGGLPIVAKILNTRDPIVKEKALIVLNNLSVNAENQRRLKVYMNQVCDDTITSRLNSSVQLAGLRLLTNMTVTNEYQHMLANSISDFFRLFSAGNEETKLQVLKLLLNLAENPAMTRELLRAQVPSSLGSLFNKKENKEVILKLLVIFENINDNFKWEENEPTQNQFGEGSLFFFLKEFQVCADKVLGIESHHDFLVKVKVGKFMAKLAEHMFPKSQE>sp|Q9UPZ9|CILK1_HUMAN Serine/threonine-protein kinase ICK OS=Homosapiens OX=9606 GN=CILK1 PE=1 SV=1MNRYTTIRQLGDGTYGSVLLGRSIESGELIAIKKMKRKFYSWEECMNLREVKSLKKLNHANVVKLKEVIRENDHLYFIFEYMKENLYQLIKERNKLFPESAIRNIMYQILQGLAFIHKHGFFHRDLKPENLLCMGPELVKIADFGLAREIRSKPPYTDYVSTRWYRAPEVLLRSTNYSSPIDVWAVGCIMAEVYTLRPLFPGASEIDTIFKICQVLGTPKKTDWPEGYQLSSAMNFRWPQCVPNNLKTLIPNASSEAVQLLRDMLQWDPKKRPTASQALRYPYFQVGHPLGSTTQNLQDSEKPQKGILEKAGPPPYIKPVPPAQPPAKPHTRISSRQHQASQPPLHLTYPYKAEVSRTDHPSHLQEDKPSPLLFPSLHNKHPQSKITAGLEHKNGEIKPKSRRRWGLISRSTKDSDDWADLDDLDFSPSLSRIDLKNKKRQSDDTLCRFESVLDLKPSEPVGTGNSAPTQTSYQRRDTPTLRSAAKQHYLKHSRYLPGISIRNGILSNPGKEFIPPNPWSSSGLSGKSSGTMSVISKVNSVGSSSTSSSGLTGNYVPSFLKKEIGSAMQRVHLAPIPDPSPGYSSLKAMRPHPGRPFFHTQPRSTPGLIPRPPAAQPVHGRTDWASKYASRR>sp|Q9UPZ9-2|CILK1_HUMAN Isoform 2 of Serine/threonine-protein kinase ICKOS=Homo sapiens OX=9606 GN=CILK1MNRYTTIRQLGDGTYGSVLLGRSIESGELIAIKKMKRKFYSWEECMNLREVKSLKKLNHANVVKLKEVIRENDHLYFIFEYMKENLYQLIKERNKLFPESAIRNIMYQILQGLAFIHKHGFFHRDLKPENLLCMGPELVKIADFGLAREIRSKPPYTDYVSTRWYRAPEVLLRSTNYSSPIDVWAVGCIMAEVYTLRPLFPGASEIDTIFKICQVLGTPKKTDWPEGYQLSSAMNFRWPQCVPNNLKTLIPNASSEAVQLLRDMLQWDPKKRPTASQVFFHFLVITFISNSE>sp|Q5K131|CLLU1_HUMAN Chronic lymphocytic leukemia up-regulated protein1 OS=Homo sapiens OX=9606 GN=CLLU1 PE=2 SV=1MFNKCSFHSSIYRPAADNSASSLCAIICFLNLVIECDLETNSEINKLIIYLFSQNNRIRFSKLLLKILFYISIFSYPELMCEQYVTFIKPGIHYGQVSKKHIIYSTFLSKNFKFQLLRVCW>sp|Q96CD2|COAC_HUMAN Phosphopantothenoylcysteine decarboxylase OS=Homosapiens OX=9606 GN=PPCDC PE=1 SV=2MEPKASCPAAAPLMERKFHVLVGVTGSVAALKLPLLVSKLLDIPGLEVAVVTTERAKHFYSPQDIPVTLYSDADEWEIWKSRSDPVLHIDLRRWADLLLVAPLDANTLGKVASGICDNLLTCVMRAWDRSKPLLFCPAMNTAMWEHPITAQQVDQLKAFGYVEIPCVAKKLVCGDEGLGAMAEVGTIVDKVKEVLFQHSGFQQS>sp|Q96CD2-2|COAC_HUMAN Isoform 2 of Phosphopantothenoylcysteinedecarboxylase OS=Homo sapiens OX=9606 GN=PPCDCMWKSRSDPVLHIDLRRWADLLLVAPLDANTLGKVASGICDNLLTCVMRAWDRSKPLLFCPAMNTAMWEHPITAQQVDQLKAFGYVEIPCVAKKLVCGDEGLGAMAEVGTIVDKVKEVLFQHSGFQQS>sp|Q8TDQ1|CLM1_HUMAN CMRF35-like molecule 1 OS=Homo sapiens OX=9606GN=CD300LF PE=1 SV=3MPLLTLYLLLFWLSGYSIVTQITGPTTVNGLERGSLTVQCVYRSGWETYLKWWCRGAIWRDCKILVKTSGSEQEVKRDRVSIKDNQKNRTFTVTMEDLMKTDADTYWCGIEKTGNDLGVTVQVTIDPAPVTQEETSSSPTLTGHHLDNRHKLLKLSVLLPLIFTILLLLLVAASLLAWRMMKYQQKAAGMSPEQVLQPLEGDLCYADLTLQLAGTSPQKATTKLSSAQVDQVEVEYVTMASLPKEDISYASLTLGAEDQEPTYCNMGHLSSHLPGRGPEEPTEYSTISRP>sp|Q8TDQ1-2|CLM1_HUMAN Isoform 2 of CMRF35-like molecule 1 OS=Homosapiens OX=9606 GN=CD300LFMWLPQLDLMRVISAKSQGYSIVTQITGPTTVNGLERGSLTVQCVYRSGWETYLKWWCRGAIWRDCKILVKTSGSEQEVKRDRVSIKDNQKNRTFTVTMEDLMKTDADTYWCGIEKTGNDLGVTVQVTIDPASTPAPTTPTSTTFTAPVTQEETSSSPTLTGHHLDNRHKLLKLSVLLPLIFTILLLLLVAASLLAWRMMKYQQKGTAAPGGRPLLCRPDPAAGRNLPAKGYHEAFLCPG>sp|Q8TDQ1-3|CLM1_HUMAN Isoform 3 of CMRF35-like molecule 1 OS=Homosapiens OX=9606 GN=CD300LFMWLPQLDLMRVISAKSQGYSIVTQITGPTTVNGLERGSLTVQCVYRSGWETYLKWWCRGAIWRDCKILVKTSGSEQEVKRDRVSIKDNQKNRTFTVTMEDLMKTDADTYWCGIEKTGNDLGVTVQVTIDPAPVTQEETSSSPTLTGHHLDNRYCSPWRATSAMQT>sp|Q8TDQ1-4|CLM1_HUMAN Isoform 4 of CMRF35-like molecule 1 OS=Homosapiens OX=9606 GN=CD300LFMWLPQLDLMRVISAKSQGYSIVTQITGPTTVNGLERGSLTVQCVYRSGWETYLKWWCRGAIWRDCKILVKTSGSEQEVKRDRVSIKDNQKNRTFTVTMEDLMKTDADTYWCGIEKTGNDLGVTVQVTIDPAPVTQEETSSSPTLTGHHLDNSSRDVPRAGTAAPGGRPLLCRPDPAAGRNLPAKGYHEAFLCPG>sp|Q8TDQ1-5|CLM1_HUMAN Isoform 5 of CMRF35-like molecule 1 OS=Homosapiens OX=9606 GN=CD300LFMPLLTLYLLLFWLSGYSIVTQITGPTTVNGLERGSLTVQCVYRSGWETYLKWWCRGAIWRDCKILVKTSGSEQEVKRDRVSIKDNQKNRTFTVTMEDLMKTDADTYWCGIEKTGNDLGVTVQVTIDPAPVTQEETSSSPTLTGHHLDNRSEGSQAANYRPAAHQAQAPEAQCPPAPHLHHIAAAFGGRLTLGLEDDEVPAESSRDVPRAGTAAPGGRPLLCRPDPAAGRNLPAKGYHEAFLCPG>sp|Q8TDQ1-6|CLM1_HUMAN Isoform 6 of CMRF35-like molecule 1 OS=Homosapiens OX=9606 GN=CD300LFMWLPQLDLMRVISAKSQGYSIVTQITGPTTVNGLERGSLTVQCVYRSGWETYLKWWCRGAIWRDCKILVKTSGSEQEVKRDRVSIKDNQKNRTFTVTMEDLMKTDADTYWCGIEKTGNDLGVTVQVTIDPAPVTQEETSSSPTLTGHHLDNRHKLLKLSVLLPLIFTILLLLLVAASLLAWRMMKYQQKAAGMSPEQVLQPLEGDLCYADLTLQLAGTSPQKATTKLSSAQVDQVEVEYVTMASLPKEDISYASLTLGAEDQEPTYCNMGHLSSHLPGRGPEEPTEYSTISRP>sp|Q8IV77|CNGA4_HUMAN Cyclic nucleotide-gated cation channel alpha-4OS=Homo sapiens OX=9606 GN=CNGA4 PE=1 SV=3MSQDTKVKTTESSPPAPSKARKLLPVLDPSGDYYYWWLNTMVFPVMYNLIILVCRACFPDLQHGYLVAWLVLDYTSDLLYLLDMVVRFHTGFLEQGILVVDKGRISSRYVRTWSFFLDLASLMPTDVVYVRLGPHTPTLRLNRFLRAPRLFEAFDRTETRTAYPNAFRIAKLMLYIFVVIHWNSCLYFALSRYLGFGRDAWVYPDPAQPGFERLRRQYLYSFYFSTLILTTVGDTPPPAREEEYLFMVGDFLLAVMGFATIMGSMSSVIYNMNTADAAFYPDHALVKKYMKLQHVNRKLERRVIDWYQHLQINKKMTNEVAILQHLPERLRAEVAVSVHLSTLSRVQIFQNCEASLLEELVLKLQPQTYSPGEYVCRKGDIGQEMYIIREGQLAVVADDGITQYAVLGAGLYFGEISIINIKGNMSGNRRTANIKSLGYSDLFCLSKEDLREVLSEYPQAQTIMEEKGREILLKMNKLDVNAEAAEIALQEATESRLRGLDQQLDDLQTKFARLLAELESSALKIAYRIERLEWQTREWPMPEDLAEADDEGEPEEGTSKDEEGRASQEGPPGPE>sp|Q8IV77-2|CNGA4_HUMAN Isoform 2 of Cyclic nucleotide-gated cationchannel alpha-4 OS=Homo sapiens OX=9606 GN=CNGA4MVFPVMYNLIILVCRACFPDLQHGYLVAWLVLDYTSDLLYLLDMVVRFHTGFLEQGILVVDKGRISSRYVRTWSFFLDLASLMPTDVVYVRLGPHTPTLRLNRFLRAPRLFEAFDRTETRTAYPNAFRIAKLMLYIFVVIHWNSCLYFALSRYLGFGRDAWVYPDPAQPGFERLRRQYLYSFYFSTLILTTVGDTPPPAREEEYLFMVGDFLLAVMGFATIMGSMSSVIYNMNTADAAFYPDHALVKKYMKLQHVNRKLERRVIDWYQHLQINKKMTNEVAILQHLPERLRAEVAVSVHLSTLSRVQIFQNCEASLLEELVLKLQPQTYSPGEYVCRKGDIGQEMYIIREGQLAVVADDGITQYAVLGAGLYFGEISIINIKGGYPSICSRDKDGWGRGEQQSPVLGPDSTSGLNF>sp|Q6UXZ3|CLM5_HUMAN CMRF35-like molecule 5 OS=Homo sapiens OX=9606GN=CD300LD PE=1 SV=1MWLSPSLLLLILPGYSIAAKITGPTTVNGSEQGSLTVQCAYGSGWETYLKWRCQGADWNYCNILVKTNGSEQEVKKNRVSIRDNQKNHVFTVTMENLKRDDADSYWCGTERPGIDLGVKVQVTINPGTQTAVSEWTTTTASLAFTAAATQKTSSPLTRSPLKSTHFLFLFLLELPLLLSMLGTVLWVNRPQRRS>sp|P09496|CLCA_HUMAN Clathrin light chain A OS=Homo sapiens OX=9606GN=CLTA PE=1 SV=1MAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQESNGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNRVADEAFYKQPFADVIGYVTNINHPCYSLEQAAEEAFVNDIDESSPGTEWERVARLCDFNPKSSKQAKDVSRMRSVLISLKQAPLVH>sp|P09496-2|CLCA_HUMAN Isoform Non-brain of Clathrin light chain AOS=Homo sapiens OX=9606 GN=CLTAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQESNGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNRAAEEAFVNDIDESSPGTEWERVARLCDFNPKSSKQAKDVSRMRSVLISLKQAPLVH>sp|P09496-3|CLCA_HUMAN Isoform 3 of Clathrin light chain A OS=Homosapiens OX=9606 GN=CLTAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQESNGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNRVADEAFYKQPFADVIGYVAAEEAFVNDIDESSPGTEWERVARLCDFNPKSSKQAKDVSRMRSVLISLKQAPLVH>sp|P09496-4|CLCA_HUMAN Isoform 4 of Clathrin light chain A OS=Homosapiens OX=9606 GN=CLTAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQESNGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNSTNINHPCYSLEQAAEEAFVNDIDESSPGTEWERVARLCDFNPKSSKQAKDVSRMRSVLISLKQAPLVH>sp|P09496-5|CLCA_HUMAN Isoform 5 of Clathrin light chain A OS=Homosapiens OX=9606 GN=CLTAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNRAAEEAFVNDIDESSPGTEWERVARLCDFNPKSSKQAKDVSRMRSVLISLKQAPLVH>sp|O43861|ATP9B_HUMAN Probable phospholipid-transporting ATPase IIBOS=Homo sapiens OX=9606 GN=ATP9B PE=2 SV=4MADQIPLYPVRSAAAAAANRKRAAYYSAAGPRPGADRHSRYQLEDESAHLDEMPLMMSEEGFENEESDYHTLPRARIMQRKRGLEWFVCDGWKFLCTSCCGWLINICRRKKELKARTVWLGCPEKCEEKHPRNSIKNQKYNVFTFIPGVLYEQFKFFLNLYFLVISCSQFVPALKIGYLYTYWAPLGFVLAVTMTREAIDEFRRFQRDKEVNSQLYSKLTVRGKVQVKSSDIQVGDLIIVEKNQRIPSDMVFLRTSEKAGSCFIRTDQLDGETDWKLKVAVSCTQQLPALGDLFSISAYVYAQKPQMDIHSFEGTFTREDSDPPIHESLSIENTLWASTIVASGTVIGVVIYTGKETRSVMNTSNPKNKVGLLDLELNRLTKALFLALVALSIVMVTLQGFVGPWYRNLFRFLLLFSYIIPISLRVNLDMGKAVYGWMMMKDENIPGTVVRTSTIPEELGRLVYLLTDKTGTLTQNEMIFKRLHLGTVSYGADTMDEIQSHVRDSYSQMQSQAGGNNTGSTPLRKAQSSAPKVRKSVSSRIHEAVKAIVLCHNVTPVYESRAGVTEETEFAEADQDFSDENRTYQASSPDEVALVQWTESVGLTLVSRDLTSMQLKTPSGQVLSFCILQLFPFTSESKRMGVIVRDESTAEITFYMKGADVAMSPIVQYNDWLEEECGNMAREGLRTLVVAKKALTEEQYQDFESRYTQAKLSMHDRSLKVAAVVESLEREMELLCLTGVEDQLQADVRPTLEMLRNAGIKIWMLTGDKLETATCIAKSSHLVSRTQDIHIFRQVTSRGEAHLELNAFRRKHDCALVISGDSLEVCLKYYEHEFVELACQCPAVVCCRCSPTQKARIVTLLQQHTGRRTCAIGDGGNDVSMIQAADCGIGIEGKEGKQASLAADFSITQFRHIGRLLMVHGRNSYKRSAALGQFVMHRGLIISTMQAVFSSVFYFASVPLYQGFLMVGYATIYTMFPVFSLVLDQDVKPEMAMLYPELYKDLTKGRSLSFKTFLIWVLISIYQGGILMYGALVLFESEFVHVVAISFTALILTELLMVALTVRTWHWLMVVAEFLSLGCYVSSLAFLNEYFGIGRVSFGAFLDVAFITTVTFLWKVSAITVVSCLPLYVLKYLRRKLSPPSYCKLAS>sp|O43861-2|ATP9B_HUMAN Isoform 2 of Probable phospholipid-transportingATPase IIB OS=Homo sapiens OX=9606 GN=ATP9BMADQIPLYPVRSAAAAAANRKRAAYYSAAGPRPGADRHSRYQLEDESAHLDEMPLMMSEEGFENEESDYHTLPRARIMQRKRGLEWFVCDGWKFLCTSCCGWLINICRRKKELKARTVWLGCPEKCEEKHPRNSIKNQKYNVFTFIPGVLYEQFKFFLNLYFLVISCSQFVPALKIGYLYTYWAPLGFVLAVTMTREAIDEFRRFQRDKEVNSQLYSKLTVRGKVQVKSSDIQVGDLIIVEKNQRIPSDMVFLRTSEKAGSCFIRTDQLDGETDWKLKVAVSCTQQLPALGDLFSISAYVYAQKPQMDIHSFEGTFTREDSDPPIHESLSIENTLWASTIVASGTVIGVVIYTGKETRSVMNTSNPKNKVGLLDLELNRLTKALFLALVALSIVMVTLQGFVGPWYRNLFRFLLLFSYIIPISLRVNLDMGKAVYGWMMMKDENIPGTVVRTSTIPEELGRLVYLLTDKTGTLTQNEMIFKRLHLGTVSYGADTMDEIQSHVRDSYSQMQSQAGGNNTGSTPLRKAQSSAPKVRKSVSSRIHEAVKAIVLCHNVTPVYESRAGVTEETEFAEADQDFSDENRTYQASSPDEVALVQWTESVGLTLVSRDLTSMQLKTPSGQVLSFCILQLFPFTSESKRMGVIVRDESTAEITFYMKGADVAMSPIVQYNDWLEEECGNMAREGLRTLVVAKKALTEEQYQDFESRYTQAKLSMHDRSLKVAAVVESLEREMELLCLTGVEDQLQADVRPTLEMLRNAGIKIWMLTGDKLETATCIAKSSHLVSRTQDIHIFRQVTSRGEAHLELNAFRRKHDCALVISGDSLEVCLKYYEHEFVELACQCPAVVCCRCSPTQKARIVTLLQQHTGRRTCAIGDGGNDVSMIQAADCGIGIEGKEGKQASLAADFSITQFRHIGRLLMVHGRNSYKRSAALGQFVMHRGLIISTMQAVFSSVFYFASVPLYQGFLMVGYATIYTMFPVFSLVLDQDVKPEMAMLYPELYKDLTKGRSLSFKTFLIWVLISIYQGGILMYGALVLFESEFVHVVAISFTALILTELLMVALTVRTWHWLMVVAEFLSLGCYVSSLAFLNEYFDVAFITTVTFLWKVSAITVVSCLPLYVLKYLRRKLSPPSYCKLAS>sp|Q96KA5|CLP1L_HUMAN Cleft lip and palate transmembrane protein 1-likeprotein OS=Homo sapiens OX=9606 GN=CLPTM1L PE=1 SV=1MWSGRSSFTSLVVGVFVVYVVHTCWVMYGIVYTRPCSGDANCIQPYLARRPKLQLSVYTTTRSHLGAENNIDLVLNVEDFDVESKFERTVNVSVPKKTRNNGTLYAYIFLHHAGVLPWHDGKQVHLVSPLTTYMVPKPEEINLLTGESDTQQIEAEKKPTSALDEPVSHWRPRLALNVMADNFVFDGSSLPADVHRYMKMIQLGKTVHYLPILFIDQLSNRVKDLMVINRSTTELPLTVSYDKVSLGRLRFWIHMQDAVYSLQQFGFSEKDADEVKGIFVDTNLYFLALTFFVAAFHLLFDFLAFKNDISFWKKKKSMIGMSTKAVLWRCFSTVVIFLFLLDEQTSLLVLVPAGVGAAIELWKVKKALKMTIFWRGLMPEFQFGTYSESERKTEEYDTQAMKYLSYLLYPLCVGGAVYSLLNIKYKSWYSWLINSFVNGVYAFGFLFMLPQLFVNYKLKSVAHLPWKAFTYKAFNTFIDDVFAFIITMPTSHRLACFRDDVVFLVYLYQRWLYPVDKRRVNEFGESYEEKATRAPHTD>sp|Q96KA5-2|CLP1L_HUMAN Isoform 2 of Cleft lip and palate transmembraneprotein 1-like protein OS=Homo sapiens OX=9606 GN=CLPTM1LMWSGRSSFTSLVVGVFVVYVVHTCWVMYGIVYTRPCSGDANCIQPYLARRPKLQLSVYTTTRSHLGAENNIDLVLNVEDFDVESKFERTVNVSVPKKTRNNGTLYAYIFLHHAGVLPWHDGKQVHLVSPLTTYMVPKPEEINLLTGESDTQQIEAEKKPTSALDEPVSHWRPRLALNVMADNFVFDGSSLPADVHRYMKMIQLGKTVHYLPILFIDQLSNRVKDLMVINRSTTELPLTVSYDKVSLGRLRFWIHMQDAVYSLQQFGFSEKDADEVKGIFVDTNLYFLALTFFVAAFHLLFDFLAFKNDISFWKKKKSMIGMSTKLWKVKKALKMTIFWRGLMPEFQFGTYSESERKTEEYDTQAMKYLSYLLYPLCVGGAVYSLLNIKYKSWYSWLINSFVNGVYAFGFLFMLPQLFVNYKLKSVAHLPWKAFTYKAFNTFIDDVFAFIITMPTSHRLACFRDDVVFLVYLYQRWLYPVDKRRVNEFGESYEEKATRAPHTD>sp|Q9BW66|CINP_HUMAN Cyclin-dependent kinase 2-interacting proteinOS=Homo sapiens OX=9606 GN=CINP PE=1 SV=1MEAKTLGTVTPRKPVLSVSARKIKDNAADWHNLILKWETLNDAGFTTANNIANLKISLLNKDKIELDSSSPASKENEEKVCLEYNEELEKLCEELQATLDGLTKIQVKMEKLSSTTKGICELENYHYGEESKRPPLFHTWPTTHFYEVSHKLLEMYRKELLLKRTVAKELAHTGDPDLTLSYLSMWLHQPYVESDSRLHLESMLLETGHRAL>sp|Q9BW66-2|CINP_HUMAN Isoform 2 of Cyclin-dependent kinase 2-interacting protein OS=Homo sapiens OX=9606 GN=CINPMEAKTLGTVTPRKPVLSVSARKIKDNAADWHNLILKWETLNDAGFTTANNIANLKISLLNKDKIELDSSSPASKENEEKVCLEYNEELEKLCEELQATLDGLMRFRISSWRCTGRSCS>sp|Q9BW66-3|CINP_HUMAN Isoform 3 of Cyclin-dependent kinase 2-interacting protein OS=Homo sapiens OX=9606 GN=CINPMNGTIYANECQQIRHPNSKTLGTVTPRKPVLSVSARKIKDNAADWHNLILKWETLNDAGFTTANNIANLKISLLNKDKIELDSSSPASKENEEKVCLEYNEELEKLCEELQATLDGLTKIQVKMEKLSSTTKGICELENYHYGEESKRPPLFHTWPTTHFYEVSHKLLEMYRKELLLKRTVAKELAHTGDPDLTLSYLSMWLHQPYVESDSRLHLESMLLETGHRAL>sp|Q5VV63|ATRN1_HUMAN Attractin-like protein 1 OS=Homo sapiens OX=9606GN=ATRNL1 PE=2 SV=2METGGRARTGTPQPAAPGVWRARPAGGGGGGASSWLLDGNSWLLCYGFLYLALYAQVSQSKPCERTGSCFSGRCVNSTCLCDPGWVGDQCQHCQGRFKLTEPSGYLTDGPINYKYKTKCTWLIEGYPNAVLRLRFNHFATECSWDHMYVYDGDSIYAPLIAVLSGLIVPEIRGNETVPEVVTTSGYALLHFFSDAAYNLTGFNIFYSINSCPNNCSGHGKCTTSVSVPSQVYCECDKYWKGEACDIPYCKANCGSPDHGYCDLTGEKLCVCNDSWQGPDCSLNVPSTESYWILPNVKPFSPSVGRASHKAVLHGKFMWVIGGYTFNYSSFQMVLNYNLESSIWNVGTPSRGPLQRYGHSLALYQENIFMYGGRIETNDGNVTDELWVFNIHSQSWSTKTPTVLGHGQQYAVEGHSAHIMELDSRDVVMIIIFGYSAIYGYTSSIQEYHISSNTWLVPETKGAIVQGGYGHTSVYDEITKSIYVHGGYKALPGNKYGLVDDLYKYEVNTKTWTILKESGFARYLHSAVLINGAMLIFGGNTHNDTSLSNGAKCFSADFLAYDIACDEWKILPKPNLHRDVNRFGHSAVVINGSMYIFGGFSSVLLNDILVYKPPNCKAFRDEELCKNAGPGIKCVWNKNHCESWESGNTNNILRAKCPPKTAASDDRCYRYADCASCTANTNGCQWCDDKKCISANSNCSMSVKNYTKCHVRNEQICNKLTSCKSCSLNLNCQWDQRQQECQALPAHLCGEGWSHIGDACLRVNSSRENYDNAKLYCYNLSGNLASLTTSKEVEFVLDEIQKYTQQKVSPWVGLRKINISYWGWEDMSPFTNTTLQWLPGEPNDSGFCAYLERAAVAGLKANPCTSMANGLVCEKPVVSPNQNARPCKKPCSLRTSCSNCTSNGMECMWCSSTKRCVDSNAYIISFPYGQCLEWQTATCSPQNCSGLRTCGQCLEQPGCGWCNDPSNTGRGHCIEGSSRGPMKLIGMHHSEMVLDTNLCPKEKNYEWSFIQCPACQCNGHSTCINNNVCEQCKNLTTGKQCQDCMPGYYGDPTNGGQCTACTCSGHANICHLHTGKCFCTTKGIKGDQCQLCDSENRYVGNPLRGTCYYSLLIDYQFTFSLLQEDDRHHTAINFIANPEQSNKNLDISINASNNFNLNITWSVGSTAGTISGEETSIVSKNNIKEYRDSFSYEKFNFRSNPNITFYVYVSNFSWPIKIQIAFSQHNTIMDLVQFFVTFFSCFLSLLLVAAVVWKIKQTCWASRRREQLLRERQQMASRPFASVDVALEVGAEQTEFLRGPLEGAPKPIAIEPCAGNRAAVLTVFLCLPRGSSGAPPPGQSGLAIASALIDISQQKASDSKDKTSGVRNRKHLSTRQGTCV>sp|Q5VV63-2|ATRN1_HUMAN Isoform 2 of Attractin-like protein 1 OS=Homosapiens OX=9606 GN=ATRNL1METGGRARTGTPQPAAPGVWRARPAGGGGGGASSWLLDGNSWLLCYGFLYLALYAQVSQSKPCERTGSCFSGRCVNSTCLCDPGWVGDQCQHCQGRFKLTEPSGYLTDGPINYKYKTKCTWLIEGYPNAVLRLRFNHFATECSWDHMYVYDGDSIYAPLIAVLSGLIVPEIRGNETVPEVVTTSGYALLHFFSDAAYNLTGFNIFYSINSCPNNCSGHGKCTTSVSVPSQVYCECDKYWKGEACDIPYCKANCGSPDHGYCDLTGEKLCVCNDSWQGPDCSLNVPSTESYWILPNVKPFSPSVGRASHKAVLHGKFMWVIGGYTFNYSSFQMVLNYNLESSIWNVGTPSRGPLQRYGHSLALYQENIFMYGGRIETNDGNVTDELWVFNIHSQSWSTKTPTVLGHGQQYAVEGHSAHIMELDSRDVVMIIIFGYSAIYGYTSSIQEYHICELLKNCNFFIDWECFSL>sp|P35523|CLCN1_HUMAN Chloride channel protein 1 OS=Homo sapiens OX=9606GN=CLCN1 PE=1 SV=3MEQSRSQQRGGEQSWWGSDPQYQYMPFEHCTSYGLPSENGGLQHRLRKDAGPRHNVHPTQIYGHHKEQFSDREQDIGMPKKTGSSSTVDSKDEDHYSKCQDCIHRLGQVVRRKLGEDGIFLVLLGLLMALVSWSMDYVSAKSLQAYKWSYAQMQPSLPLQFLVWVTFPLVLILFSALFCHLISPQAVGSGIPEMKTILRGVVLKEYLTMKAFVAKVVALTAGLGSGIPVGKEGPFVHIASICAAVLSKFMSVFCGVYEQPYYYSDILTVGCAVGVGCCFGTPLGGVLFSIEVTSTYFAVRNYWRGFFAATFSAFVFRVLAVWNKDAVTITALFRTNFRMDFPFDLKELPAFAAIGICCGLLGAVFVYLHRQVMLGVRKHKALSQFLAKHRLLYPGIVTFVIASFTFPPGMGQFMAGELMPREAISTLFDNNTWVKHAGDPESLGQSAVWIHPRVNVVIIIFLFFVMKFWMSIVATTMPIPCGGFMPVFVLGAAFGRLVGEIMAMLFPDGILFDDIIYKILPGGYAVIGAAALTGAVSHTVSTAVICFELTGQIAHILPMMVAVILANMVAQSLQPSLYDSIIQVKKLPYLPDLGWNQLSKYTIFVEDIMVRDVKFVSASYTYGELRTLLQTTTVKTLPLVDSKDSMILLGSVERSELQALLQRHLCPERRLRAAQEMARKLSELPYDGKARLAGEGLPGAPPGRPESFAFVDEDEDEDLSGKSELPPSLALHPSTTAPLSPEEPNGPLPGHKQQPEAPEPAGQRPSIFQSLLHCLLGRARPTKKKTTQDSTDLVDNMSPEEIEAWEQEQLSQPVCFDSCCIDQSPFQLVEQTTLHKTHTLFSLLGLHLAYVTSMGKLRGVLALEELQKAIEGHTKSGVQLRPPLASFRNTTSTRKSTGAPPSSAENWNLPEDRPGATGTGDVIAASPETPVPSPSPEPPLSLAPGKVEGELEELELVESPGLEEELADILQGPSLRSTDEEDEDELIL>sp|P56880|CLD20_HUMAN Claudin-20 OS=Homo sapiens OX=9606 GN=CLDN20 PE=1SV=1MASAGLQLLAFILALSGVSGVLTATLLPNWKVNVDVDSNIITAIVQLHGLWMDCTWYSTGMFSCALKHSILSLPIHVQAARATMVLACVLSALGICTSTVGMKCTRLGGDRETKSHASFAGGVCFMSAGISSLISTVWYTKEIIANFLDLTVPESNKHEPGGAIYIGFISAMLLFISGMIFCTSCIKRNPEARLDPPTQQPISNTQLENNSTHNLKDYV>sp|Q8N7P3|CLD22_HUMAN Claudin-22 OS=Homo sapiens OX=9606 GN=CLDN22 PE=1SV=3MALVFRTVAQLAGVSLSLLGWVLSCLTNYLPHWKNLNLDLNEMENWTMGLWQTCVIQEEVGMQCKDFDSFLALPAELRVSRILMFLSNGLGFLGLLVSGFGLDCLRIGESQRDLKRRLLILGGILSWASGVTALVPVSWVAHKTVQEFWDENVPDFVPRWEFGEALFLGWFAGLSLLLGGCLLHCAACSSHAPLASGHYAVAQTQDHHQELETRNTNLKH>sp|Q96B33|CLD23_HUMAN Claudin-23 OS=Homo sapiens OX=9606 GN=CLDN23 PE=1SV=2MRTPVVMTLGMVLAPCGLLLNLTGTLAPGWRLVKGFLNQPVDVELYQGLWDMCREQSSRERECGQTDQWGYFEAQPVLVARALMVTSLAATVLGLLLASLGVRCWQDEPNFVLAGLSGVVLFVAGLLGLIPVSWYNHFLGDRDVLPAPASPVTVQVSYSLVLGYLGSCLLLLGGFSLALSFAPWCDERCRRRRKGPSAGPRRSSVSTIQVEWPEPDLAPAIKYYSDGQHRPPPAQHRKPKPKPKVGFPMPRPRPKAYTNSVDVLDGEGWESQDAPSCSTHPCDSSLPCDSDL>sp|P58397|ATS12_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 12 OS=Homo sapiens OX=9606 GN=ADAMTS12 PE=1 SV=2MPCAQRSWLANLSVVAQLLNFGALCYGRQPQPGPVRFPDRRQEHFIKGLPEYHVVGPVRVDASGHFLSYGLHYPITSSRRKRDLDGSEDWVYYRISHEEKDLFFNLTVNQGFLSNSYIMEKRYGNLSHVKMMASSAPLCHLSGTVLQQGTRVGTAALSACHGLTGFFQLPHGDFFIEPVKKHPLVEGGYHPHIVYRRQKVPETKEPTCGLKDSVNISQKQELWREKWERHNLPSRSLSRRSISKERWVETLVVADTKMIEYHGSENVESYILTIMNMVTGLFHNPSIGNAIHIVVVRLILLEEEEQGLKIVHHAEKTLSSFCKWQKSINPKSDLNPVHHDVAVLLTRKDICAGFNRPCETLGLSHLSGMCQPHRSCNINEDSGLPLAFTIAHELGHSFGIQHDGKENDCEPVGRHPYIMSRQLQYDPTPLTWSKCSEEYITRFLDRGWGFCLDDIPKKKGLKSKVIAPGVIYDVHHQCQLQYGPNATFCQEVENVCQTLWCSVKGFCRSKLDAAADGTQCGEKKWCMAGKCITVGKKPESIPGGWGRWSPWSHCSRTCGAGVQSAERLCNNPEPKFGGKYCTGERKRYRLCNVHPCRSEAPTFRQMQCSEFDTVPYKNELYHWFPIFNPAHPCELYCRPIDGQFSEKMLDAVIDGTPCFEGGNSRNVCINGICKMVGCDYEIDSNATEDRCGVCLGDGSSCQTVRKMFKQKEGSGYVDIGLIPKGARDIRVMEIEGAGNFLAIRSEDPEKYYLNGGFIIQWNGNYKLAGTVFQYDRKGDLEKLMATGPTNESVWIQLLFQVTNPGIKYEYTIQKDGLDNDVEQQMYFWQYGHWTECSVTCGTGIRRQTAHCIKKGRGMVKATFCDPETQPNGRQKKCHEKACPPRWWAGEWEACSATCGPHGEKKRTVLCIQTMVSDEQALPPTDCQHLLKPKTLLSCNRDILCPSDWTVGNWSECSVSCGGGVRIRSVTCAKNHDEPCDVTRKPNSRALCGLQQCPSSRRVLKPNKGTISNGKNPPTLKPVPPPTSRPRMLTTPTGPESMSTSTPAISSPSPTTASKEGDLGGKQWQDSSTQPELSSRYLISTGSTSQPILTSQSLSIQPSEENVSSSDTGPTSEGGLVATTTSGSGLSSSRNPITWPVTPFYNTLTKGPEMEIHSGSGEEREQPEDKDESNPVIWTKIRVPGNDAPVESTEMPLAPPLTPDLSRESWWPPFSTVMEGLLPSQRPTTSETGTPRVEGMVTEKPANTLLPLGGDHQPEPSGKTANRNHLKLPNNMNQTKSSEPVLTEEDATSLITEGFLLNASNYKQLTNGHGSAHWIVGNWSECSTTCGLGAYWRRVECSTQMDSDCAAIQRPDPAKRCHLRPCAGWKVGNWSKCSRNCSGGFKIREIQCVDSRDHRNLRPFHCQFLAGIPPPLSMSCNPEPCEAWQVEPWSQCSRSCGGGVQERGVFCPGGLCDWTKRPTSTMSCNEHLCCHWATGNWDLCSTSCGGGFQKRTVQCVPSEGNKTEDQDQCLCDHKPRPPEFKKCNQQACKKSADLLCTKDKLSASFCQTLKAMKKCSVPTVRAECCFSCPQTHITHTQRQRRQRLLQKSKEL>sp|P58397-2|ATS12_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 12 OS=Homo sapiens OX=9606 GN=ADAMTS12MPCAQRSWLANLSVVAQLLNFGALCYGRQPQPGPVRFPDRRQEHFIKGLPEYHVVGPVRVDASGHFLSYGLHYPITSSRRKRDLDGSEDWVYYRISHEEKDLFFNLTVNQGFLSNSYIMEKRYGNLSHVKMMASSAPLCHLSGTVLQQGTRVGTAALSACHGLTGFFQLPHGDFFIEPVKKHPLVEGGYHPHIVYRRQKVPETKEPTCGLKGIVTHMSSWVEESVLFFW>sp|P58397-3|ATS12_HUMAN Isoform 3 of A disintegrin and metalloproteinasewith thrombospondin motifs 12 OS=Homo sapiens OX=9606 GN=ADAMTS12MPCAQRSWLANLSVVAQLLNFGALCYGRQPQPGPVRFPDRRQEHFIKGLPEYHVVGPVRVDASGHFLSYGLHYPITSSRRKRDLDGSEDWVYYRISHEEKDLFFNLTVNQGFLSNSYIMEKRYGNLSHVKMMASSAPLCHLSGTVLQQGTRVGTAALSACHGLTGFFQLPHGDFFIEPVKKHPLVEGGYHPHIVYRRQKVPETKEPTCGLKDSVNISQKQELWREKWERHNLPSRSLSRRSISKERWVETLVVADTKMIEYHGSENVESYILTIMNMVTGLFHNPSIGNAIHIVVVRLILLEEEEQGLKIVHHAEKTLSSFCKWQKSINPKSDLNPVHHDVAVLLTRKDICAGFNRPCETLGLSHLSGMCQPHRSCNINEDSGLPLAFTIAHELGHSFGIQHDGKENDCEPVGRHPYIMSRQLQYDPTPLTWSKCSEEYITRFLDRGWGFCLDDIPKKKGLKSKVIAPGVIYDVHHQCQLQYGPNATFCQEVENVCQTLWCSVKGFCRSKLDAAADGTQCGEKKWCMAGKCITVGKKPESIPGGWGRWSPWSHCSRTCGAGVQSAERLCNNPEPKFGGKYCTGERKRYRLCNVHPCRSEAPTFRQMQCSEFDTVPYKNELYHWFPIFNPGYVDIGLIPKGARDIRVMEIEGAGNFLAIRSEDPEKYYLNGGFIIQWNGNYKLAGTVFQYDRKGDLEKLMATGPTNESVWIQLLFQVTNPGIKYEYTIQKDGLDNDVEQQMYFWQYGHWTECSVTCGTGIRRQTAHCIKKGRGMVKATFCDPETQPNGRQKKCHEKACPPRWWAGEWEACSATCGPHGEKKRTVLCIQTMVSDEQALPPTDCQHLLKPKTLLSCNRDILCPSDWTVGNWSECSVSCGGGVRIRSVTCAKNHDEPCDVTRKPNSRALCGLQQCPSSRRVLKPNKGTISNGKNPPTLKPVPPPTSRPRMLTTPTGPESMSTSTPAISSPSPTTASKEGDLGGKQWQDSSTQPELSSRYLISTGSTSQPILTSQSLSIQPSEENVSSSDTGPTSEGGLVATTTSGSGLSSSRNPITWPVTPFYNTLTKGPEMEIHSGSGEEREQPEDKDESNPVIWTKIRVPGNDAPVESTEMPLAPPLTPDLSRESWWPPFSTVMEGLLPSQRPTTSETGTPRVEGMVTEKPANTLLPLGGDHQPEPSGKTANRNHLKLPNNMNQTKSSEPVLTEEDATSLITEGFLLNASNYKQLTNGHGSAHWIVGNWSECSTTCGLGAYWRRVECSTQMDSDCAAIQRPDPAKRCHLRPCAGWKVGNWSKCSRNCSGGFKIREIQCVDSRDHRNLRPFHCQFLAGIPPPLSMSCNPEPCEAWQVEPWSQCSRSCGGGVQERGVFCPGGLCDWTKRPTSTMSCNEHLCCHWATGNWDLCSTSCGGGFQKRTVQCVPSEGNKTEDQDQCLCDHKPRPPEFKKCNQQACKKSADLLCTKDKLSASFCQTLKAMKKCSVPTVRAECCFSCPQTHITHTQRQRRQRLLQKSKEL>sp|A6NM45|CLD24_HUMAN Putative claudin-24 OS=Homo sapiens OX=9606GN=CLDN24 PE=5 SV=2MALIFRTAMQSVGLLLSLLGWILSIITTYLPHWKNLNLDLNEMENWTMGLWQTCVIQEEVGMQCKDFDSFLALPAELRVSRILMFLSNGLGFLGLLVSGFGLDCLRIGESQRDLKRRLLILGGILSWASGITALVPVSWVAHKTVQEFWDENVPDFVPRWEFGEALFLGWFAGLSLLLGGCLLNCAACSSHAPLALGHYAVAQMQTQCPYLEDGTADPQV>sp|P51790|CLCN3_HUMAN H(+)/Cl(-) exchange transporter 3 OS=Homo sapiensOX=9606 GN=CLCN3 PE=1 SV=2MESEQLFHRGYYRNSYNSITSASSDEELLDGAGVIMDFQTSEDDNLLDGDTAVGTHYTMTNGGSINSSTHLLDLLDEPIPGVGTYDDFHTIDWVREKCKDRERHRRINSKKKESAWEMTKSLYDAWSGWLVVTLTGLASGALAGLIDIAADWMTDLKEGICLSALWYNHEQCCWGSNETTFEERDKCPQWKTWAELIIGQAEGPGSYIMNYIMYIFWALSFAFLAVSLVKVFAPYACGSGIPEIKTILSGFIIRGYLGKWTLMIKTITLVLAVASGLSLGKEGPLVHVACCCGNIFSYLFPKYSTNEAKKREVLSAASAAGVSVAFGAPIGGVLFSLEEVSYYFPLKTLWRSFFAALVAAFVLRSINPFGNSRLVLFYVEYHTPWYLFELFPFILLGVFGGLWGAFFIRANIAWCRRRKSTKFGKYPVLEVIIVAAITAVIAFPNPYTRLNTSELIKELFTDCGPLESSSLCDYRNDMNASKIVDDIPDRPAGIGVYSAIWQLCLALIFKIIMTVFTFGIKVPSGLFIPSMAIGAIAGRIVGIAVEQLAYYHHDWFIFKEWCEVGADCITPGLYAMVGAAACLGGVTRMTVSLVVIVFELTGGLEYIVPLMAAVMTSKWVGDAFGREGIYEAHIRLNGYPFLDAKEEFTHTTLAADVMRPRRNDPPLAVLTQDNMTVDDIENMINETSYNGFPVIMSKESQRLVGFALRRDLTIAIESARKKQEGIVGSSRVCFAQHTPSLPAESPRPLKLRSILDMSPFTVTDHTPMEIVVDIFRKLGLRQCLVTHNGRLLGIITKKDILRHMAQTANQDPASIMFN>sp|P51790-2|CLCN3_HUMAN Isoform 2 of H(+)/Cl(-) exchange transporter 3OS=Homo sapiens OX=9606 GN=CLCN3MESEQLFHRGYYRNSYNSITSASSDEELLDGAGVIMDFQTSEDDNLLDGDTAVGTHYTMTNGGSINSSTHLLDLLDEPIPGVGTYDDFHTIDWVREKCKDRERHRRINSKKKESAWEMTKSLYDAWSGWLVVTLTGLASGALAGLIDIAADWMTDLKEGICLSALWYNHEQCCWGSNETTFEERDKCPQWKTWAELIIGQAEGPGSYIMNYIMYIFWALSFAFLAVSLVKVFAPYACGSGIPEIKTILSGFIIRGYLGKWTLMIKTITLVLAVASGLSLGKEGPLVHVACCCGNIFSYLFPKYSTNEAKKREVLSAASAAGVSVAFGAPIGGVLFSLEEVSYYFPLKTLWRSFFAALVAAFVLRSINPFGNSRLVLFYVEYHTPWYLFELFPFILLGVFGGLWGAFFIRANIAWCRRRKSTKFGKYPVLEVIIVAAITAVIAFPNPYTRLNTSELIKELFTDCGPLESSSLCDYRNDMNASKIVDDIPDRPAGIGVYSAIWQLCLALIFKIIMTVFTFGIKVPSGLFIPSMAIGAIAGRIVGIAVEQLAYYHHDWFIFKEWCEVGADCITPGLYAMVGAAACLGGVTRMTVSLVVIVFELTGGLEYIVPLMAAVMTSKWVGDAFGREGIYEAHIRLNGYPFLDAKEEFTHTTLAADVMRPRRNDPPLAVLTQDNMTVDDIENMINETSYNGFPVIMSKESQRLVGFALRRDLTIAIESARKKQEGIVGSSRVCFAQHTPSLPAESPRPLKLRSILDMSPFTVTDHTPMEIVVDIFRKLGLRQCLVTHNGIVLGIITKKNILEHLEQLKQHVEPLAPPWHYNKKRYPPAYGPDGKPRPRFNNVQLNLTDEEREETEEEVYLLNSTTL>sp|P51790-4|CLCN3_HUMAN Isoform 3 of H(+)/Cl(-) exchange transporter 3OS=Homo sapiens OX=9606 GN=CLCN3MESEQLFHRGYYRNSYNSITSASSDEELLDGAGVIMDFQTSEDDNLLDGDTAVGTHYTMTNGGSINSSTHLLDLLDEPIPGVGTYDDFHTIDWVREKCKDRERHRRINSKKKESAWEMTKSLYDAWSGWLVVTLTGLASGALAGLIDIAADWMTDLKEGICLSALWYNHEQCCWGSNETTFEERDKCPQWKTWAELIIGQAEGPGSYIMNYIMYIFWALSFAFLAVSLVKVFAPYACGSGIPEIKTILSGFIIRGYLGKWTLMIKTITLVLAVASGLSLGKEGPLVHVACCCGNIFSYLFPKYSTNEAKKREVSYYFPLKTLWRSFFAALVAAFVLRSINPFGNSRLVLFYVEYHTPWYLFELFPFILLGVFGGLWGAFFIRANIAWCRRRKSTKFGKYPVLEVIIVAAITAVIAFPNPYTRLNTSELIKELFTDCGPLESSSLCDYRNDMNASKIVDDIPDRPAGIGVYSAIWQLCLALIFKIIMTVFTFGIKVPSGLFIPSMAIGAIAGRIVGIAVEQLAYYHHDWFIFKEWCEVGADCITPGLYAMVGAAACLGGVTRMTVSLVVIVFELTGGLEYIVPLMAAVMTSKWVGDAFGREGIYEAHIRLNGYPFLDAKEEFTHTTLAADVMRPRRNDPPLAVLTQDNMTVDDIENMINETSYNGFPVIMSKESQRLVGFALRRDLTIAIESARKKQEGIVGSSRVCFAQHTPSLPAESPRPLKLRSILDMSPFTVTDHTPMEIVVDIFRKLGLRQCLVTHNGRLLGIITKKDILRHMAQTANQDPASIMFN>sp|P51790-5|CLCN3_HUMAN Isoform 4 of H(+)/Cl(-) exchange transporter 3OS=Homo sapiens OX=9606 GN=CLCN3MVTLQLGESHYVVQAGLQLLGSSNPPALASQVAEITGTHYTMTNGGSINSSTHLLDLLDEPIPGVGTYDDFHTIDWVREKCKDRERHRRINSKKKESAWEMTKSLYDAWSGWLVVTLTGLASGALAGLIDIAADWMTDLKEGICLSALWYNHEQCCWGSNETTFEERDKCPQWKTWAELIIGQAEGPGSYIMNYIMYIFWALSFAFLAVSLVKVFAPYACGSGIPEIKTILSGFIIRGYLGKWTLMIKTITLVLAVASGLSLGKEGPLVHVACCCGNIFSYLFPKYSTNEAKKREVLSAASAAGVSVAFGAPIGGVLFSLEEVSYYFPLKTLWRSFFAALVAAFVLRSINPFGNSRLVLFYVEYHTPWYLFELFPFILLGVFGGLWGAFFIRANIAWCRRRKSTKFGKYPVLEVIIVAAITAVIAFPNPYTRLNTSELIKELFTDCGPLESSSLCDYRNDMNASKIVDDIPDRPAGIGVYSAIWQLCLALIFKIIMTVFTFGIKVPSGLFIPSMAIGAIAGRIVGIAVEQLAYYHHDWFIFKEWCEVGADCITPGLYAMVGAAACLGGVTRMTVSLVVIVFELTGGLEYIVPLMAAVMTSKWVGDAFGREGIYEAHIRLNGYPFLDAKEEFTHTTLAADVMRPRRNDPPLAVLTQDNMTVDDIENMINETSYNGFPVIMSKESQRLVGFALRRDLTIAIESARKKQEGIVGSSRVCFAQHTPSLPAESPRPLKLRSILDMSPFTVTDHTPMEIVVDIFRKLGLRQCLVTHNGRLLGIITKKDILRHMAQTANQDPASIMFN>sp|H7C241|CLD34_HUMAN Claudin-34 OS=Homo sapiens OX=9606 GN=CLDN34 PE=3SV=2MVWFCNSADCQFSVFALTTIGWILSSTSTGLVEWRIWYMKDTSLYPPGIACVGIFRVCIYRRRTNSTTTKFCYRYSYQDTFLPFEISMAQRFLLTASIFGFFGRAFNMFALRNMSMRMFEEDTYNSFVVSGILNIAAGVFNLIAVLQNYDAVINSQGITFLPSLQMPFKPDVQEVGTAIQVAGIGVLPMLLTGMFSLFYKCPPYGQVHPGISEM>sp|Q76LX8|ATS13_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 13 OS=Homo sapiens OX=9606 GN=ADAMTS13 PE=1 SV=1MHQRHPRARCPPLCVAGILACGFLLGCWGPSHFQQSCLQALEPQAVSSYLSPGAPLKGRPPSPGFQRQRQRQRRAAGGILHLELLVAVGPDVFQAHQEDTERYVLTNLNIGAELLRDPSLGAQFRVHLVKMVILTEPEGAPNITANLTSSLLSVCGWSQTINPEDDTDPGHADLVLYITRFDLELPDGNRQVRGVTQLGGACSPTWSCLITEDTGFDLGVTIAHEIGHSFGLEHDGAPGSGCGPSGHVMASDGAAPRAGLAWSPCSRRQLLSLLSAGRARCVWDPPRPQPGSAGHPPDAQPGLYYSANEQCRVAFGPKAVACTFAREHLDMCQALSCHTDPLDQSSCSRLLVPLLDGTECGVEKWCSKGRCRSLVELTPIAAVHGRWSSWGPRSPCSRSCGGGVVTRRRQCNNPRPAFGGRACVGADLQAEMCNTQACEKTQLEFMSQQCARTDGQPLRSSPGGASFYHWGAAVPHSQGDALCRHMCRAIGESFIMKRGDSFLDGTRCMPSGPREDGTLSLCVSGSCRTFGCDGRMDSQQVWDRCQVCGGDNSTCSPRKGSFTAGRAREYVTFLTVTPNLTSVYIANHRPLFTHLAVRIGGRYVVAGKMSISPNTTYPSLLEDGRVEYRVALTEDRLPRLEEIRIWGPLQEDADIQVYRRYGEEYGNLTRPDITFTYFQPKPRQAWVWAAVRGPCSVSCGAGLRWVNYSCLDQARKELVETVQCQGSQQPPAWPEACVLEPCPPYWAVGDFGPCSASCGGGLRERPVRCVEAQGSLLKTLPPARCRAGAQQPAVALETCNPQPCPARWEVSEPSSCTSAGGAGLALENETCVPGADGLEAPVTEGPGSVDEKLPAPEPCVGMSCPPGWGHLDATSAGEKAPSPWGSIRTGAQAAHVWTPAAGSCSVSCGRGLMELRFLCMDSALRVPVQEELCGLASKPGSRREVCQAVPCPARWQYKLAACSVSCGRGVVRRILYCARAHGEDDGEEILLDTQCQGLPRPEPQEACSLEPCPPRWKVMSLGPCSASCGLGTARRSVACVQLDQGQDVEVDEAACAALVRPEASVPCLIADCTYRWHVGTWMECSVSCGDGIQRRRDTCLGPQAQAPVPADFCQHLPKPVTVRGCWAGPCVGQGTPSLVPHEEAAAPGRTTATPAGASLEWSQARGLLFSPAPQPRRLLPGPQENSVQSSACGRQHLEPTGTIDMRGPGQADCAVAIGRPLGEVVTLRVLESSLNCSAGDMLLLWGRLTWRKMCRKLLDMTFSSKTNTLVVRQRCGRPGGGVLLRYGSQLAPETFYRECDMQLFGPWGEIVSPSLSPATSNAGGCRLFINVAPHARIAIHALATNMGAGTEGANASYILIRDTHSLRTTAFHGQQVLYWESESSQAEMEFSEGFLKAQASLRGQYWTLQSWVPEMQDPQSWKGKEGT>sp|Q76LX8-2|ATS13_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 13 OS=Homo sapiens OX=9606 GN=ADAMTS13MHQRHPRARCPPLCVAGILACGFLLGCWGPSHFQQSCLQALEPQAVSSYLSPGAPLKGRPPSPGFQRQRQRQRRAAGGILHLELLVAVGPDVFQAHQEDTERYVLTNLNIGAELLRDPSLGAQFRVHLVKMVILTEPEGAPNITANLTSSLLSVCGWSQTINPEDDTDPGHADLVLYITRFDLELPDGNRQVRGVTQLGGACSPTWSCLITEDTGFDLGVTIAHEIGHSFGLEHDGAPGSGCGPSGHVMASDGAAPRAGLAWSPCSRRQLLSLLSAGRARCVWDPPRPQPGSAGHPPDAQPGLYYSANEQCRVAFGPKAVACTFAREHLDMCQALSCHTDPLDQSSCSRLLVPLLDGTECGVEKWCSKGRCRSLVELTPIAAVHGRWSSWGPRSPCSRSCGGGVVTRRRQCNNPRPAFGGRACVGADLQAEMCNTQACEKTQLEFMSQQCARTDGQPLRSSPGGASFYHWGAAVPHSQGDALCRHMCRAIGESFIMKRGDSFLDGTRCMPSGPREDGTLSLCVSGSCRTFGCDGRMDSQQVWDRCQVCGGDNSTCSPRKGSFTAGRAREYVTFLTVTPNLTSVYIANHRPLFTHLAVRIGGRYVVAGKMSISPNTTYPSLLEDGRVEYRVALTEDRLPRLEEIRIWGPLQEDADIQVYRRYGEEYGNLTRPDITFTYFQPKPRQAWVWAAVRGPCSVSCGAGLRWVNYSCLDQARKELVETVQCQGSQQPPAWPEACVLEPCPPYWAVGDFGPCSASCGGGLRERPVRCVEAQGSLLKTLPPARCRAGAQQPAVALETCNPQPCPARWEVSEPSSCTSAGGAGLALENETCVPGADGLEAPVTEGPGSVDEKLPAPEPCVGMSCPPGWGHLDATSAGEKAPSPWGSIRTGAQAAHVWTPAAGSCSVSCGRGLMELRFLCMDSALRVPVQEELCGLASKPGSRREVCQAVPCPARWQYKLAACSVSCGRGVVRRILYCARAHGEDDGEEILLDTQCQGLPRPEPQEACSLEPCPPRWKVMSLGPCSASCGLGTARRSVACVQLDQGQDVEVDEAACAALVRPEASVPCLIADCTYRWHVGTWMECSVSCGDGIQRRRDTCLGPQAQAPVPADFCQHLPKPVTVRGCWAGPCVGQGACGRQHLEPTGTIDMRGPGQADCAVAIGRPLGEVVTLRVLESSLNCSAGDMLLLWGRLTWRKMCRKLLDMTFSSKTNTLVVRQRCGRPGGGVLLRYGSQLAPETFYRECDMQLFGPWGEIVSPSLSPATSNAGGCRLFINVAPHARIAIHALATNMGAGTEGANASYILIRDTHSLRTTAFHGQQVLYWESESSQAEMEFSEGFLKAQASLRGQYWTLQSWVPEMQDPQSWKGKEGT>sp|Q76LX8-3|ATS13_HUMAN Isoform 3 of A disintegrin and metalloproteinasewith thrombospondin motifs 13 OS=Homo sapiens OX=9606 GN=ADAMTS13MHQRHPRARCPPLCVAGILACGFLLGCWGPSHFQQSCLQALEPQAVSSYLSPGAPLKGRPPSPGFQRQRQRQRRAAGGILHLELLVAVGPDVFQAHQEDTERYVLTNLNIGAELLRDPSLGAQFRVHLVKMVILTEPEGAPNITANLTSSLLSVCGWSQTINPEDDTDPGHADLVLYITRFDLELPDGNRQVRGVTQLGGACSPTWSCLITEDTGFDLGVTIAHEIGHSFGLEHDGAPGSGCGPSGHVMASDGAAPRAGLAWSPCSRRQLLSLLSANEQCRVAFGPKAVACTFAREHLDMCQALSCHTDPLDQSSCSRLLVPLLDGTECGVEKWCSKGRCRSLVELTPIAAVHGRWSSWGPRSPCSRSCGGGVVTRRRQCNNPRPAFGGRACVGADLQAEMCNTQACEKTQLEFMSQQCARTDGQPLRSSPGGASFYHWGAAVPHSQGDALCRHMCRAIGESFIMKRGDSFLDGTRCMPSGPREDGTLSLCVSGSCRTFGCDGRMDSQQVWDRCQVCGGDNSTCSPRKGSFTAGRAREYVTFLTVTPNLTSVYIANHRPLFTHLAVRIGGRYVVAGKMSISPNTTYPSLLEDGRVEYRVALTEDRLPRLEEIRIWGPLQEDADIQVYRRYGEEYGNLTRPDITFTYFQPKPRQAWVWAAVRGPCSVSCGAGLRWVNYSCLDQARKELVETVQCQGSQQPPAWPEACVLEPCPPYWAVGDFGPCSASCGGGLRERPVRCVEAQGSLLKTLPPARCRAGAQQPAVALETCNPQPCPARWEVSEPSSCTSAGGAGLALENETCVPGADGLEAPVTEGPGSVDEKLPAPEPCVGMSCPPGWGHLDATSAGEKAPSPWGSIRTGAQAAHVWTPAAGSCSVSCGRGLMELRFLCMDSALRVPVQEELCGLASKPGSRREVCQAVPCPARWQYKLAACSVSCGRGVVRRILYCARAHGEDDGEEILLDTQCQGLPRPEPQEACSLEPCPPRWKVMSLGPCSASCGLGTARRSVACVQLDQGQDVEVDEAACAALVRPEASVPCLIADCTYRWHVGTWMECSVSCGDGIQRRRDTCLGPQAQAPVPADFCQHLPKPVTVRGCWAGPCVGQGACGRQHLEPTGTIDMRGPGQADCAVAIGRPLGEVVTLRVLESSLNCSAGDMLLLWGRLTWRKMCRKLLDMTFSSKTNTLVVRQRCGRPGGGVLLRYGSQLAPETFYRECDMQLFGPWGEIVSPSLSPATSNAGGCRLFINVAPHARIAIHALATNMGAGTEGANASYILIRDTHSLRTTAFHGQQVLYWESESSQAEMEFSEGFLKAQASLRGQYWTLQSWVPEMQDPQSWKGKEGT>sp|Q76LX8-4|ATS13_HUMAN Isoform 4 of A disintegrin and metalloproteinasewith thrombospondin motifs 13 OS=Homo sapiens OX=9606 GN=ADAMTS13MDMCQALSCHTDPLDQSSCSRLLVPLLDGTECGVEKWCSKGRCRSLVELTPIAAVHGRWSSWGPRSPCSRSCGGGVVTRRRQCNNPRPAFGGRACVGADLQAEMCNTQACEKTQLEFMSQQCARTDGQPLRSSPGGASFYHWGAAVPHSQGDALCRHMCRAIGESFIMKRGDSFLDGTRCMPSGPREDGTLSLCVSGSCRTFGCDGRMDSQQVWDRCQVCGGDNSTCSPRKGSFTAGRAREYVTFLTVTPNLTSVYIANHRPLFTHLAVRIGGRYVVAGKMSISPNTTYPSLLEDGRVEYRVALTEDRLPRLEEIRIWGPLQEDADIQVGGVRAQLMHISWWSRPGLGERDLCARGRWPGGSSD>sp|Q8TE58|ATS15_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 15 OS=Homo sapiens OX=9606 GN=ADAMTS15 PE=2 SV=1MLLLGILTLAFAGRTAGGSEPEREVVVPIRLDPDINGRRYYWRGPEDSGDQGLIFQITAFQEDFYLHLTPDAQFLAPAFSTEHLGVPLQGLTGGSSDLRRCFYSGDVNAEPDSFAAVSLCGGLRGAFGYRGAEYVISPLPNASAPAAQRNSQGAHLLQRRGVPGGPSGDPTSRCGVASGWNPAILRALDPYKPRRAGFGESRSRRRSGRAKRFVSIPRYVETLVVADESMVKFHGADLEHYLLTLLATAARLYRHPSILNPINIVVVKVLLLRDRDSGPKVTGNAALTLRNFCAWQKKLNKVSDKHPEYWDTAILFTRQDLCGATTCDTLGMADVGTMCDPKRSCSVIEDDGLPSAFTTAHELGHVFNMPHDNVKVCEEVFGKLRANHMMSPTLIQIDRANPWSACSAAIITDFLDSGHGDCLLDQPSKPISLPEDLPGASYTLSQQCELAFGVGSKPCPYMQYCTKLWCTGKAKGQMVCQTRHFPWADGTSCGEGKLCLKGACVERHNLNKHRVDGSWAKWDPYGPCSRTCGGGVQLARRQCTNPTPANGGKYCEGVRVKYRSCNLEPCPSSASGKSFREEQCEAFNGYNHSTNRLTLAVAWVPKYSGVSPRDKCKLICRANGTGYFYVLAPKVVDGTLCSPDSTSVCVQGKCIKAGCDGNLGSKKRFDKCGVCGGDNKSCKKVTGLFTKPMHGYNFVVAIPAGASSIDIRQRGYKGLIGDDNYLALKNSQGKYLLNGHFVVSAVERDLVVKGSLLRYSGTGTAVESLQASRPILEPLTVEVLSVGKMTPPRVRYSFYLPKEPREDKSSHPKDPRGPSVLHNSVLSLSNQVEQPDDRPPARWVAGSWGPCSASCGSGLQKRAVDCRGSAGQRTVPACDAAHRPVETQACGEPCPTWELSAWSPCSKSCGRGFQRRSLKCVGHGGRLLARDQCNLHRKPQELDFCVLRPC>sp|O15551|CLD3_HUMAN Claudin-3 OS=Homo sapiens OX=9606 GN=CLDN3 PE=1SV=1MSMGLEITGTALAVLGWLGTIVCCALPMWRVSAFIGSNIITSQNIWEGLWMNCVVQSTGQMQCKVYDSLLALPQDLQAARALIVVAILLAAFGLLVALVGAQCTNCVQDDTAKAKITIVAGVLFLLAALLTLVPVSWSANTIIRDFYNPVVPEAQKREMGAGLYVGWAAAALQLLGGALLCCSCPPREKKYTATKVVYSAPRSTGPGASLGTGYDRKDYV>sp|O00501|CLD5_HUMAN Claudin-5 OS=Homo sapiens OX=9606 GN=CLDN5 PE=1SV=1MGSAALEILGLVLCLVGWGGLILACGLPMWQVTAFLDHNIVTAQTTWKGLWMSCVVQSTGHMQCKVYDSVLALSTEVQAARALTVSAVLLAFVALFVTLAGAQCTTCVAPGPAKARVALTGGVLYLFCGLLALVPLCWFANIVVREFYDPSVPVSQKYELGAALYIGWAATALLMVGGCLLCCGAWVCTGRPDLSFPVKYSAPRRPTATGDYDKKNYV>sp|P56747|CLD6_HUMAN Claudin-6 OS=Homo sapiens OX=9606 GN=CLDN6 PE=1SV=2MASAGMQILGVVLTLLGWVNGLVSCALPMWKVTAFIGNSIVVAQVVWEGLWMSCVVQSTGQMQCKVYDSLLALPQDLQAARALCVIALLVALFGLLVYLAGAKCTTCVEEKDSKARLVLTSGIVFVISGVLTLIPVCWTAHAIIRDFYNPLVAEAQKRELGASLYLGWAASGLLLLGGGLLCCTCPSGGSQGPSHYMARYSTSAPAISRGPSEYPTKNYV>sp|O95484|CLD9_HUMAN Claudin-9 OS=Homo sapiens OX=9606 GN=CLDN9 PE=1SV=1MASTGLELLGMTLAVLGWLGTLVSCALPLWKVTAFIGNSIVVAQVVWEGLWMSCVVQSTGQMQCKVYDSLLALPQDLQAARALCVIALLLALLGLLVAITGAQCTTCVEDEGAKARIVLTAGVILLLAGILVLIPVCWTAHAIIQDFYNPLVAEALKRELGASLYLGWAAAALLMLGGGLLCCTCPPPQVERPRGPRLGYSIPSRSGASGLDKRDYV>sp|P56134|ATPK_HUMAN ATP synthase subunit f, mitochondrial OS=Homosapiens OX=9606 GN=ATP5MF PE=1 SV=3MASVGECPAPVPVKDKKLLEVKLGELPSWILMRDFSPSGIFGAFQRGYYRYYNKYINVKKGSISGITMVLACYVLFSYSFSYKHLKHERLRKYH>sp|P56134-2|ATPK_HUMAN Isoform 2 of ATP synthase subunit f,mitochondrial OS=Homo sapiens OX=9606 GN=ATP5MFMASVVPVKDKKLLEVKLGELPSWILMRDFSPSGIFGAFQRGYYRYYNKYINVKKGSISGITMVLACYVLFSYSFSYKHLKHERLRKYH>sp|P56134-3|ATPK_HUMAN Isoform 3 of ATP synthase subunit f,mitochondrial OS=Homo sapiens OX=9606 GN=ATP5MFMASVGECPAPVPVKDKKLLEVKLGELPSWILMRDFSPSGIFGAFQREHERLRKYH>sp|P56134-4|ATPK_HUMAN Isoform 4 of ATP synthase subunit f,mitochondrial OS=Homo sapiens OX=9606 GN=ATP5MFMASVVPVKDKKLLEVKLGELPSWILMRDFSPSGIFGAFQREHERLRKYH>sp|P0C0L4|CO4A_HUMAN Complement C4-A OS=Homo sapiens OX=9606 GN=C4A PE=1SV=2MRLLWGLIWASSFFTLSLQKPRLLLFSPSVVHLGVPLSVGVQLQDVPRGQVVKGSVFLRNPSRNNVPCSPKVDFTLSSERDFALLSLQVPLKDAKSCGLHQLLRGPEVQLVAHSPWLKDSLSRTTNIQGINLLFSSRRGHLFLQTDQPIYNPGQRVRYRVFALDQKMRPSTDTITVMVENSHGLRVRKKEVYMPSSIFQDDFVIPDISEPGTWKISARFSDGLESNSSTQFEVKKYVLPNFEVKITPGKPYILTVPGHLDEMQLDIQARYIYGKPVQGVAYVRFGLLDEDGKKTFFRGLESQTKLVNGQSHISLSKAEFQDALEKLNMGITDLQGLRLYVAAAIIESPGGEMEEAELTSWYFVSSPFSLDLSKTKRHLVPGAPFLLQALVREMSGSPASGIPVKVSATVSSPGSVPEVQDIQQNTDGSGQVSIPIIIPQTISELQLSVSAGSPHPAIARLTVAAPPSGGPGFLSIERPDSRPPRVGDTLNLNLRAVGSGATFSHYYYMILSRGQIVFMNREPKRTLTSVSVFVDHHLAPSFYFVAFYYHGDHPVANSLRVDVQAGACEGKLELSVDGAKQYRNGESVKLHLETDSLALVALGALDTALYAAGSKSHKPLNMGKVFEAMNSYDLGCGPGGGDSALQVFQAAGLAFSDGDQWTLSRKRLSCPKEKTTRKKRNVNFQKAINEKLGQYASPTAKRCCQDGVTRLPMMRSCEQRAARVQQPDCREPFLSCCQFAESLRKKSRDKGQAGLQRALEILQEEDLIDEDDIPVRSFFPENWLWRVETVDRFQILTLWLPDSLTTWEIHGLSLSKTKGLCVATPVQLRVFREFHLHLRLPMSVRRFEQLELRPVLYNYLDKNLTVSVHVSPVEGLCLAGGGGLAQQVLVPAGSARPVAFSVVPTAAAAVSLKVVARGSFEFPVGDAVSKVLQIEKEGAIHREELVYELNPLDHRGRTLEIPGNSDPNMIPDGDFNSYVRVTASDPLDTLGSEGALSPGGVASLLRLPRGCGEQTMIYLAPTLAASRYLDKTEQWSTLPPETKDHAVDLIQKGYMRIQQFRKADGSYAAWLSRDSSTWLTAFVLKVLSLAQEQVGGSPEKLQETSNWLLSQQQADGSFQDPCPVLDRSMQGGLVGNDETVALTAFVTIALHHGLAVFQDEGAEPLKQRVEASISKANSFLGEKASAGLLGAHAAAITAYALTLTKAPVDLLGVAHNNLMAMAQETGDNLYWGSVTGSQSNAVSPTPAPRNPSDPMPQAPALWIETTAYALLHLLLHEGKAEMADQASAWLTRQGSFQGGFRSTQDTVIALDALSAYWIASHTTEERGLNVTLSSTGRNGFKSHALQLNNRQIRGLEEELQFSLGSKINVKVGGNSKGTLKVLRTYNVLDMKNTTCQDLQIEVTVKGHVEYTMEANEDYEDYEYDELPAKDDPDAPLQPVTPLQLFEGRRNRRRREAPKVVEEQESRVHYTVCIWRNGKVGLSGMAIADVTLLSGFHALRADLEKLTSLSDRYVSHFETEGPHVLLYFDSVPTSRECVGFEAVQEVPVGLVQPASATLYDYYNPERRCSVFYGAPSKSRLLATLCSAEVCQCAEGKCPRQRRALERGLQDEDGYRMKFACYYPRVEYGFQVKVLREDSRAAFRLFETKITQVLHFTKDVKAAANQMRNFLVRASCRLRLEPGKEYLIMGLDGATYDLEGHPQYLLDSNSWIEEMPSERLCRSTRQRAACAQLNDFLQEYGTQGCQV>sp|P0C0L4-2|CO4A_HUMAN Isoform 2 of Complement C4-A OS=Homo sapiensOX=9606 GN=C4AMRLLWGLIWASSFFTLSLQKPRLLLFSPSVVHLGVPLSVGVQLQDVPRGQVVKGSVFLRNPSRNNVPCSPKVDFTLSSERDFALLSLQVPLKDAKSCGLHQLLRGPEVQLVAHSPWLKDSLSRTTNIQGINLLFSSRRGHLFLQTDQPIYNPGQRVRYRVFALDQKMRPSTDTITVMVENSHGLRVRKKEVYMPSSIFQDDFVIPDISEPGTWKISARFSDGLESNSSTQFEVKKYVLPNFEVKITPGKPYILTVPGHLDEMQLDIQARYIYGKPVQGVAYVRFGLLDEDGKKTFFRGLESQTKLVNGQSHISLSKAEFQDALEKLNMGITDLQGLRLYVAAAIIESPGGEMEEAELTSWYFVSSPFSLDLSKTKRHLVPGAPFLLQALVREMSGSPASGIPVKVSATVSSPGSVPEVQDIQQNTDGSGQVSIPIIIPQTISELQLSVSAGSPHPAIARLTVAAPPSGGPGFLSIERPDSRPPRVGDTLNLNLRAVGSGATFSHYYYMILSRGQIVFMNREPKRTLTSVSVFVDHHLAPSFYFVAFYYHGDHPVANSLRVDVQAGACEGKLELSVDGAKQYRNGESVKLHLETDSLALVALGALDTALYAAGSKSHKPLNMGKVFEAMNSYDLGCGPGGGDSALQVFQAAGLAFSDGDQWTLSRKRLSCPKEKTTRKKRNVNFQKAINEKLGQYASPTAKRCCQDGVTRLPMMRSCEQRAARVQQPDCREPFLSCCQFAESLRKKSRDKGQAGLQRALEILQEEDLIDEDDIPVRSFFPENWLWRVETVDRFQILTLWLPDSLTTWEIHGLSLSKTKGLCVATPVQLRVFREFHLHLRLPMSVRRFEQLELRPVLYNYLDKNLTVSVHVSPVEGLCLAGGGGLAQQVLVPAGSARPVAFSVVPTAAAAVSLKVVARGSFEFPVGDAVSKVLQIEKEGAIHREELVYELNPLDHRGRTLEIPGNSDPNMIPDGDFNSYVRVTASDPLDTLGSEGALSPGGVASLLRLPRGCGEQTMIYLAPTLAASRYLDKTEQWSTLPPETKDHAVDLIQKGYMRIQQFRKADGSYAAWLSRDSSTWLTAFVLKVLSLAQEQVGGSPEKLQETSNWLLSQQQADGSFQDPCPVLDRSMQGGLVGNDETVALTAFVTIALHHGLAVFQDEGAEPLKQRVEASISKANSFLGEKASAGLLGAHAAAITAYALTLTKAPVDLLGVAHNNLMAMAQETGDNLYWGSVTGSQSNAVSPTPAPRNPSDPMPQAPALWIETTAYALLHLLLHEGKAEMADQASAWLTRQGSFQGGFRSTQDTVIALDALSAYWIASHTTEERGLNVTLSSTGRNGFKSHALQLNNRQIRGLEEELQFSLGSKINVKVGGNSKGTLKVLRTYNVLDMKNTTCQDLQIEVTVKGHVEYTMEANEDYEDYEYDELPAKDDPDAPLQPVTPLQLFEGRRNRRRREAPKLTSLSDRYVSHFETEGPHVLLYFDSVPTSRECVGFEAVQEVPVGLVQPASATLYDYYNPERRCSVFYGAPSKSRLLATLCSAEVCQCAEGKCPRQRRALERGLQDEDGYRMKFACYYPRVEYGFQVKVLREDSRAAFRLFETKITQVLHFTKDVKAAANQMRNFLVRASCRLRLEPGKEYLIMGLDGATYDLEGHPQYLLDSNSWIEEMPSERLCRSTRQRAACAQLNDFLQEYGTQGCQV>sp|Q2KHT3|CL16A_HUMAN Protein CLEC16A OS=Homo sapiens OX=9606 GN=CLEC16APE=1 SV=2MFGRSRSWVGGGHGKTSRNIHSLDHLKYLYHVLTKNTTVTEQNRNLLVETIRSITEILIWGDQNDSSVFDFFLEKNMFVFFLNILRQKSGRYVCVQLLQTLNILFENISHETSLYYLLSNNYVNSIIVHKFDFSDEEIMAYYISFLKTLSLKLNNHTVHFFYNEHTNDFALYTEAIKFFNHPESMVRIAVRTITLNVYKVSLDNQAMLHYIRDKTAVPYFSNLVWFIGSHVIELDDCVQTDEEHRNRGKLSDLVAEHLDHLHYLNDILIINCEFLNDVLTDHLLNRLFLPLYVYSLENQDKGGERPKISLPVSLYLLSQVFLIIHHAPLVNSLAEVILNGDLSEMYAKTEQDIQRSSAKPSIRCFIKPTETLERSLEMNKHKGKRRVQKRPNYKNVGEEEDEEKGPTEDAQEDAEKAKGTEGGSKGIKTSGESEEIEMVIMERSKLSELAASTSVQEQNTTDEEKSAAATCSESTQWSRPFLDMVYHALDSPDDDYHALFVLCLLYAMSHNKGMDPEKLERIQLPVPNAAEKTTYNHPLAERLIRIMNNAAQPDGKIRLATLELSCLLLKQQVLMSAGCIMKDVHLACLEGAREESVHLVRHFYKGEDIFLDMFEDEYRSMTMKPMNVEYLMMDASILLPPTGTPLTGIDFVKRLPCGDVEKTRRAIRVFFMLRSLSLQLRGEPETQLPLTREEDLIKTDDVLDLNNSDLIACTVITKDGGMVQRFLAVDIYQMSLVEPDVSRLGWGVVKFAGLLQDMQVTGVEDDSRALNITIHKPASSPHSKPFPILQATFIFSDHIRCIIAKQRLAKGRIQARRMKMQRIAALLDLPIQPTTEVLGFGLGSSTSTQHLPFRFYDQGRRGSSDPTVQRSVFASVDKVPGFAVAQCINQHSSPSLSSQSPPSASGSPSGSGSTSHCDSGGTSSSSTPSTAQSPADAPMSPELPKPHLPDQLVIVNETEADSKPSKNVARSAAVETASLSPSLVPARQPTISLLCEDTADTLSVESLTLVPPVDPHSLRSLTGMPPLSTPAAACTEPVGEEAACAEPVGTAED>sp|Q2KHT3-2|CL16A_HUMAN Isoform 2 of Protein CLEC16A OS=Homo sapiensOX=9606 GN=CLEC16AMFGRSRSWVGGGHGKTSRNIHSLDHLKYLYHVLTKNTTVTEQNRNLLVETIRSITEILIWGDQNDSSVFDFFLEKNMFVFFLNILRQKSGRYVCVQLLQTLNILFENISHETSLYYLLSNNYVNSIIVHKFDFSDEEIMAYYISFLKTLSLKLNNHTVHFFYNEHTNDFALYTEAIKFFNHPESMVRIAVRTITLNVYKVDNQAMLHYIRDKTAVPYFSNLVWFIGSHVIELDDCVQTDEEHRNRGKLSDLVAEHLDHLHYLNDILIINCEFLNDVLTDHLLNRLFLPLYVYSLENQDKGGERPKISLPVSLYLLSQVFLIIHHAPLVNSLAEVILNGDLSEMYAKTEQDIQRSSAKPSIRCFIKPTETLERSLEMNKHKGKRRVQKRPNYKNVGEEEDEEKGPTEDAQEDAEKAKEIEMVIMERSKLSELAASTSVQEQNTTDEEKSAAATCSESTQWSRPFLDMVYHALDSPDDDYHALFVLCLLYAMSHNKGMDPEKLERIQLPVPNAAEKTTYNHPLAERLIRIMNNAAQPDGKIRLATLELSCLLLKQQVLMSAGCIMKDVHLACLEGAREESVHLVRHFYKGEDIFLDMFEDEYRSMTMKPMNVEYLMMDASILLPPTGTPLTGIDFVKRLPCGDVEKTRRAIRVFFMLRSLSLQLRGEPETQLPLTREEDLIKTDDVLDLNNSDLIACTVITKDGGMVQRFLAVDIYQMSLVEPDVSRLGWGVVKFAGLLQDMQVTGVEDDSRALNITIHKPASSPHSKPFPILQATFIFSDHIRCIIAKQRLAKGRIQARRMKMQRIAALLDLPIQPTTEVLGFGLGSSTSTQHLPFRFYDQGRRGSSDPTVQRSVFASVDKVPGEPAPRPAPQLVHHGGRSRSFSLWSLCELPFLSQKPRRLAAPAS>sp|Q2KHT3-3|CL16A_HUMAN Isoform 3 of Protein CLEC16A OS=Homo sapiensOX=9606 GN=CLEC16AMAATGFSAPNGSCHGTSRTVNSDAPMSPELPKPHLPDQLVIVNETEADSKPSKNVARSAAVETASLSPSLVPARQPTISLLCEDTADTLSVESLTLVPPVDPHSLRSLTGMPPLSTPAAACTEPVGEEAACAEPVGTAED>sp|Q8N100|ATOH7_HUMAN Protein atonal homolog 7 OS=Homo sapiens OX=9606GN=ATOH7 PE=1 SV=1MKSCKPSGPPAGARVAPPCAGGTECAGTCAGAGRLESAARRRLAANARERRRMQGLNTAFDRLRRVVPQWGQDKKLSKYETLQMALSYIMALTRILAEAERFGSERDWVGLHCEHFGRDHYLPFPGAKLPGESELYSQRLFGFQPEPFQMAT>sp|Q8WXX7|AUTS2_HUMAN Autism susceptibility gene 2 protein OS=Homosapiens OX=9606 GN=AUTS2 PE=1 SV=1MDGPTRGHGLRKKRRSRSQRDRERRSRGGLGAGAAGGGGAGRTRALSLASSSGSDKEDNGKPPSSAPSRPRPPRRKRRESTSAEEDIIDGFAMTSFVTFEALEKDVALKPQERVEKRQTPLTKKKREALTNGLSFHSKKSRLSHPHHYSSDRENDRNLCQHLGKRKKMPKALRQLKPGQNSCRDSDSESASGESKGFHRSSSRERLSDSSAPSSLGTGYFCDSDSDQEEKASDASSEKLFNTVIVNKDPELGVGTLPEHDSQDAGPIVPKISGLERSQEKSQDCCKEPIFEPVVLKDPCPQVAQPIPQPQTEPQLRAPSPDPDLVQRTEAPPQPPPLSTQPPQGPPEAQLQPAPQPQVQRPPRPQSPTQLLHQNLPPVQAHPSAQSLSQPLSAYNSSSLSLNSLSSSRSSTPAKTQPAPPHISHHPSASPFPLSLPNHSPLHSFTPTLQPPAHSHHPNMFAPPTALPPPPPLTSGSLQVAGHPAGSTYSEQDILRQELNTRFLASQSADRGASLGPPPYLRTEFHQHQHQHQHTHQHTHQHTFTPFPHAIPPTAIMPTPAPPMFDKYPTKVDPFYRHSLFHSYPPAVSGIPPMIPPTGPFGSLQGAFQPKTSNPIDVAARPGTVPHTLLQKDPRLTDPFRPMLRKPGKWCAMHVHIAWQIYHHQQKVKKQMQSDPHKLDFGLKPEFLSRPPGPSLFGAIHHPHDLARPSTLFSAAGAAHPTGTPFGPPPHHSNFLNPAAHLEPFNRPSTFTGLAAVGGNAFGGLGNPSVTPNSMFGHKDGPSVQNFSNPHEPWNRLHRTPPSFPTPPPWLKPGELERSASAAAHDRDRDVDKRDSSVSKDDKERESVEKRHSSHPSPAPVLPVNALGHTRSSTEQIRAHLNTEAREKDKPKERERDHSESRKDLAADEHKAKEGHLPEKDGHGHEGRAAGEEAKQLARVPSPYVRTPVVESARPNSTSSREAEPRKGEPAYENPKKSSEVKVKEERKEDHDLPPEAPQTHRASEPPPPNSSSSVHPGPLASMPMTVGVTGIHPMNSISSLDRTRMMTPFMGISPLPGGERFPYPSFHWDPIRDPLRDPYRELDIHRRDPLGRDFLLRNDPLHRLSTPRLYEADRSFRDREPHDYSHHHHHHHHPLSVDPRREHERGGHLDERERLHMLREDYEHTRLHSVHPASLDGHLPHPSLITPGLPSMHYPRISPTAGNQNGLLNKTPPTAALSAPPPLISTLGGRPVSPRRTTPLSAEIRERPPSHTLKDIEAR>sp|Q8WXX7-2|AUTS2_HUMAN Isoform 2 of Autism susceptibility gene 2protein OS=Homo sapiens OX=9606 GN=AUTS2MDGPTRGHGLRKKRRSRSQRDRERRSRGGLGAGAAGGGGAGRTRALSLASSSGSDKEDNGKPPSSAPSRPRPPRRKRRESTSAEEDIIDGFAMTSFVTFEALEKDVALKPQERVEKRQTPLTKKKREALTNGLSFHSKKSRLSHPHHYSSDRENDRNLCQHLGKRKKMPKALRQLKPGQNSCRDSDSESASGESKGFHRSSSRERLSDSSAPSSLGTGYFCDSDSDQEEKASDASSEKLFNTVIVNKDPELGVGTLPEHDSQDAGPIVPKISGLERSQEKSQDCCKEPIFEPVVLKDPCPQVAQPIPQPQTEPQLRAPSPDPDLVQRTEAPPQPPPLSTQPPQGPPEAQLQPAPQPQVQRPPRPQSPTQLLHQNLPPVQAHPSAQSLSQPLSAYNSSSLSLNSLSSSRSSTPAKTQPAPPHISHHPSASPFPLSLPNHSPLHSFTPTLQPPAHSHHPNMFAPPTALPPPPPLTSGSLQVAGHPAGSTYSEQDILRQELNTRFLASQSADRGASLGPPPYLRTEFHQHQHQHQHTHQHTHQHTFTPFPHAIPPTAIMPTPAPPMFDKYPTKVDPFYRHSLFHSYPPAVSGIPPMIPPTGPFGSLQGAFQPKLTDPFRPMLRKPGKWCAMHVHIAWQIYHHQQKVKKQMQSDPHKLDFGLKPEFLSRPPGPSLFGAIHHPHDLARPSTLFSAAGAAHPTGTPFGPPPHHSNFLNPAAHLEPFNRPSTFTGLAAVGGNAFGGLGNPSVTPNSMFGHKDGPSVQNFSNPHEPWNRLHRTPPSFPTPPPWLKPGELERSASAAAHDRDRDVDKRDSSVSKDDKERESVEKRHSSHPSPAPVLPVNALGHTRSSTEQIRAHLNTEAREKDKPKERERDHSESRKDLAADEHKAKEGHLPEKDGHGHEGRAAGEEAKQLARVPSPYVRTPVVESARPNSTSSREAEPRKGEPAYENPKKSSEVKVKEERKEDHDLPPEAPQTHRASEPPPPNSSSSVHPGPLASMPMTVGVTGIHPMNSISSLDRTRMMTPFMGISPLPGGERFPYPSFHWDPIRDPLRDPYRELDIHRRDPLGRDFLLRNDPLHRLSTPRLYEADRSFRDREPHDYSHHHHHHHHPLSVDPRREHERGGHLDERERLHMLREDYEHTRLHSVHPASLDGHLPHPSLITPGLPSMHYPRISPTAGNQNGLLNKTPPTAALSAPPPLISTLGGRPVSPRRTTPLSAEIRERPPSHTLKDIEAR>sp|Q8WXX7-3|AUTS2_HUMAN Isoform 3 of Autism susceptibility gene 2protein OS=Homo sapiens OX=9606 GN=AUTS2MDGPTRGHGLRKKRRSRSQRDRERRSRGGLGAGAAGGGGAGRTRALSLASSSGSDKEDNGKPPSSAPSRPRPPRRKRRESTSAEEDIIDGFAMTSFVTFEALEKDVALKPQERVEKRQTPLTKKKREALTNGLSFHSKKSRLSHPHHYSSDRENDRNLCQHLGKRKKMPKALRQLKPGQNSCRDSDSESASGESKGFHRSSSRERLSDSSAPSSLGTGYFRSGKMCLGEEACLKSGNDMKRDVSNTSSWASNRESFFSLVKLLKGF>sp|Q8WXX7-5|AUTS2_HUMAN Isoform 5 of Autism susceptibility gene 2protein OS=Homo sapiens OX=9606 GN=AUTS2MPTPAPPMFDKYPTKVDPFYRHSLFHSYPPAVSGIPPMIPPTGPFGSLQGAFQPKLTDPFRPMLRKPGKWCAMHVHIAWQIYHHQQKVKKQMQSDPHKLDFGLKPEFLSRPPGPSLFGAIHHPHDLARPSTLFSAAGAAHPTGTPFGPPPHHSNFLNPAAHLEPFNRPSTFTGLAAVGGNAFGGLGNPSVTPNSMFGHKDGPSVQNFSNPHEPWNRLHRTPPSFPTPPPWLKPGELERSASAAAHDRDRDVDKRDSSVSKDDKERESVEKRHSSHPSPAPVLPVNALGHTRSSTEQIRAHLNTEAREKDKPKERERDHSESRKDLAADEHKAKEGHLPEKDGHGHEGRAAGEEAKQLARVPSPYVRTPVVESARPNSTSSREAEPRKGEPAYENPKKSSEVKVKEERKEDHDLPPEAPQTHRASEPPPPNSSSSVHPGPLASMPMTVGVTGIHPMNSISSLDRTRMMTPFMGISPLPGGERFPYPSFHWDPIRDPLRDPYRELDIHRRDPLGRDFLLRNDPLHRLSTPRLYEADRSFRDREPHDYSHHHHHHHHPLSVDPRREHERGGHLDERERLHMLREDYEHTRLHSVHPASLDGHLPHPSLITPGLPSMHYPRISPTAGNQNGLLNKTPPTAALSAPPPLISTLGGRPVSPRRTTPLSAEIRERPPSHTLKDIEAR>sp|O14977|AZIN1_HUMAN Antizyme inhibitor 1 OS=Homo sapiens OX=9606GN=AZIN1 PE=1 SV=2MKGFIDDANYSVGLLDEGTNLGNVIDNYVYEHTLTGKNAFFVGDLGKIVKKHSQWQNVVAQIKPFYTVKCNSAPAVLEILAALGTGFACSSKNEMALVQELGVPPENIIYISPCKQVSQIKYAAKVGVNILTCDNEIELKKIARNHPNAKVLLHIATEDNIGGEEGNMKFGTTLKNCRHLLECAKELDVQIIGVKFHVSSACKESQVYVHALSDARCVFDMAGEIGFTMNMLDIGGGFTGTEFQLEEVNHVISPLLDIYFPEGSGVKIISEPGSYYVSSAFTLAVNIIAKKVVENDKFPSGVEKTGSDEPAFMYYMNDGVYGSFASKLSEDLNTIPEVHKKYKEDEPLFTSSLWGPSCDELDQIVESCLLPELNVGDWLIFDNMGADSFHEPSAFNDFQRPAIYYMMSFSDWYEMQDAGITSDSMMKNFFFVPSCIQLSQEDSFSAEA>sp|O95833|CLIC3_HUMAN Chloride intracellular channel protein 3 OS=Homosapiens OX=9606 GN=CLIC3 PE=1 SV=2MAETKLQLFVKASEDGESVGHCPSCQRLFMVLLLKGVPFTLTTVDTRRSPDVLKDFAPGSQLPILLYDSDAKTDTLQIEDFLEETLGPPDFPSLAPRYRESNTAGNDVFHKFSAFIKNPVPAQDEALYQQLLRALARLDSYLRAPLEHELAGEPQLRESRRRFLDGDRLTLADCSLLPKLHIVDTVCAHFRQAPIPAELRGVRRYLDSAMQEKEFKYTCPHSAEILAAYRPAVHPR>sp|Q96SQ7|ATOH8_HUMAN Protein atonal homolog 8 OS=Homo sapiens OX=9606GN=ATOH8 PE=1 SV=2MKHIPVLEDGPWKTVCVKELNGLKKLKRKGKEPARRANGYKTFRLDLEAPEPRAVATNGLRDRTHRLQPVPVPVPVPVPVAPAVPPRGGTDTAGERGGSRAPEVSDARKRCFALGAVGPGLPTPPPPPPPAPQSQAPGGPEAQPFREPGLRPRILLCAPPARPAPSAPPAPPAPPESTVRPAPPTRPGESSYSSISHVIYNNHQDSSASPRKRPGEATAASSEIKALQQTRRLLANARERTRVHTISAAFEALRKQVPCYSYGQKLSKLAILRIACNYILSLARLADLDYSADHSNLSFSECVQRCTRTLQAEGRAKKRKE>sp|Q96SQ7-2|ATOH8_HUMAN Isoform 2 of Protein atonal homolog 8 OS=Homosapiens OX=9606 GN=ATOH8MKHIPVLEDGPWKTVCVKELNGLKKLKRKGKEPARRANGYKTFRLDLEAPEPRAVATNGLRDRTHRLQPVPVPVPVPVPVAPAVPPRGGTDTAGERGGSRAPEVSDARKRCFALGAVGPGLPTPPPPPPPAPQSQAPGGPEAQPFREPGLRPRILLCAPPARPAPSAPPAPPAPPESTVRPAPPTRPGESSYSSISHVIYNNHQDSSASPRKRPGEATAASSEIKALQQTRRLLANARERTRVHTISAAFEALRKQVPCYSYGQKLSKLAILRIACNYILSLARLADLDYSADHSNLSFSECVQRCTRTLQAEGRAKKRKSLIITQDTTARAAGLEAAGKTVQKVLCERGNSLMNNRTGRRKSWRLEFLFLRRRCFLLTFYLWFLFFSRFLLMLFLPLLTSVVTFLPPLRARRPPH>sp|Q6ZU45|CL20A_HUMAN Putative C-type lectin domain family 20 member AOS=Homo sapiens OX=9606 GN=CLEC20A PE=2 SV=2MLPRALLLSFCAAALQLVSSKRDLVLVKEALSWYDAQQHCRLHYTDLADLQPSGLWKLYSLMTSTPAWIGLFFDASTSGLRWSSGSTFTALEWGQKLPEFGVGFCATLYTWLKLPSIGAASCTAQKPFLCYCDPDVGHLISTKPSLSLTTSPKPAVVQISGQTFMRFDQVMTWSSALLYCRSHHTDLADLQMVTDETGKEALRSIMSETEAWIGLYLNANSGSLSWSSDLGASIPSWLQVPMMVRGLCTALGIYMTYSPKVYSVNCSSLLPFFCFYDSSTGHRASAELPPLFHTSPTEMTEETTPRPGRAVASVGSGTDRRDTAAATEAQHLSSESKEKTSAQKSGHPFGILKADFTISTLMDPEEMKDQFLRQIQEVLKLTLGHEQFRLKWVSFEVNKK>sp|A8TX70|CO6A5_HUMAN Collagen alpha-5(VI) chain OS=Homo sapiens OX=9606GN=COL6A5 PE=1 SV=1MKILLIIFVLIIWTETLADQSPGPGPVYADVVFLVDSSDHLGPKSFPFVKTFINKMINSLPIEANKYRVALAQYSDEFHSEFHLSTFKGRSPMLNHLKKNFQFIGGSLQIGKALQEAHRTYFSAPINGRDRKQFPPILVVLASAESEDEVEEASKALQKDGVKIISVGVQKASEENLKAMATSHFHFNLRTIRDLSTFSQNMTQIIKDVTKYKEGAVDADMQVHFPISCQKDSLADLVFLVDESLGTGGNLRHLQTFLENITSSMDVKENCMRLGLMSYSNSAKTISFLKSSTTQSEFQQQIKNLSIQVGKSNTGAAIDQMRRDGFSESYGSRRAQGVPQIAVLVTHRPSDDEVHDAALNLRLEDVNVFALSIQGANNTQLEEIVSYPPEQTISTLKSYADLETYSTKFLKKLQNEIWSQISTYAEQRNLDKTGCVDTKEADIHFLIDGSSSIQEKQFEQIKRFMLEVTEMFSIGPDKVRVGVVQYSDDTEVEFYITDYSNDIDLRKAIFNIKQLTGGTYTGKALDYILQIIKNGMKDRMSKVPCYLIVLTDGMSTDRVVEPAKRLRAEQITVHAVGIGAANKIELQEIAGKEERVSFGQNFDALKSIKNEVVREICAEKGCEDMKADIMFLVDSSWSIGNENFRKMKIFMKNLLTKIQIGADKTQIGVVQFSDKTKEEFQLNRYFTQQEISDAIDRMSLINEGTLTGKALNFVGQYFTHSKGARLGAKKFLILITDGVAQDDVRDPARILRGKDVTIFSVGVYNANRSQLEEISGDSSLVFHVENFDHLKALERKLIFRVCALHDCKRITLLDVVFVLDHSGSIKKQYQDHMINLTIHLVKKADVGRDRVQFGALKYSDQPNILFYLNTYSNRSAIIENLRKRRDTGGNTYTAKALKHANALFTEEHGSRIKQNVKQMLIVITDGESHDHDQLNDTALELRNKGITIFAVGVGKANQKELEGMAGNKNNTIYVDNFDKLKDVFTLVQERMCTEAPEVCHLQEADVIFLCDGSDRVSNSDFVTMTTFLSDLIDNFDIQSQRMKIGMAQFGSNYQSIIELKNSLTKTQWKTQIQNVSKSGGFPRIDFALKKVSNMFNLHAGGRRNAGVPQTLVVITSGDPRYDVADAVKTLKDLGICVLVLGIGDVYKEHLLPITGNSEKIITFQDFDKLKNVDVKKRIIREICQSCGKTNCFMDIVVGFDISTHVQGQPLFQGHPQLESYLPGILEDISSIKGVSCGAGTEAQVSLAFKVNSDQGFPAKFQIYQKAVFDSLLQVNVSGPTHLNAQFLRSLWDTFKDKSASRGQVLLIFSDGLQSESNIMLENQSDRLREAGLDALLVVSLNTTAHHEFSSFEFGKRFDYRTHLTIGMRELGKKLSQYLGNIAERTCCCTFCKCPGIPGPHGTRGLQAMKGSQGLKGSRGHRGEDGNPGVRGDTGPQGDKGIAGCPGAWGQKGLKGFSGPKGGHGDDGIDGLDGEEGCHGFPGIKGEKGDPGSQGSPGSRGAPGQYGEKGFPGDPGNPGQNNNIKGQKGSKGEQGRQGRSGQKGVQGSPSSRGSRGREGQRGLRGVSGEPGNPGPTGTLGAEGLQGPQGSQGNPGRKGEKGSQGQKGPQGSPGLMGAKGSTGRPGLLGKKGEPGLPGDLGPVGQTGQRGRQGDSGIPGYGQMGRKGVKGPRGFPGDAGQKGDIGNPGIPGGPGPKGFRGLALTVGLKGEEGSRGLPGPPGQRGIKGMAGQPVYSQCDLIRFLREHSPCWKEKCPAYPTELVFALDNSYDVTEESFNKTRDIITSIVNDLNIRENNCPVGARVAMVSYNSGTSYLIRWSDYNRKKQLLQQLSQIKYQDTTEPRDVGNAMRFVTRNVFKRTYAGANVRRVAVFFSNGQTASRSSIITATMEFSALDISPTVFAFDERVFLEAFGFDNTGTFQVIPVPPNGENQTLERLRRCALCYDKCFPNACIREAFLPEDSYMDVVFLIDNSRNIAKDEFKAVKALVSSVIDNFNIASDPLISDSGDRIALLSYSPWESSRRKMGTVKTEFDFITYDNQLLMKNHIQTSFQQLNGEATIGRALLWTTENLFPETPYLRKHKVIFVVSAGENYERKEFVKMMALRAKCQGYVIFVISLGSTRKDDMEELASYPLDQHLIQLGRIHKPDLNYIAKFLKPFLYSVRRGFNQYPPPMLEDACRLINLGGENIQNDGFQFVTELQEDFLGGNGFIGQELNSGRESPFVKTEDNGSDYLVYLPSQMFEPQKLMINYEKDQKSAEIASLTSGHENYGRKEEPDHTYEPGDVSLQEYYMDVAFLIDASQRVGSDEFKEVKAFITSVLDYFHIAPTPLTSTLGDRVAVLSYSPPGYMPNTEECPVYLEFDLVTYNSIHQMKHHLQDSQQLNGDVFIGHALQWTIDNVFVGTPNLRKNKVIFVISAGETNSLDKDVLRNVSLRAKCQGYSIFVFSFGPKHNDKELEELASHPLDHHLVQLGRTHKPDWNYIIKFVKPFVHLIRRAINKYPTEDMKATCVNMTSPNPENGGTENTVLLLPGIYEIKTENGDLFDEFDSQAQHLLVLGNNHSSGSETATDLMQKLYLLFSTEKLAMKDKEKAHLEEISALVVDKQQEKEDKEMEATDI>sp|A8TX70-2|CO6A5_HUMAN Isoform 2 of Collagen alpha-5(VI) chain OS=Homosapiens OX=9606 GN=COL6A5MKILLIIFVLIIWTETLADQSPGPGPVYADVVFLVDSSDHLGPKSFPFVKTFINKMINSLPIEANKYRVALAQYSDEFHSEFHLSTFKGRSPMLNHLKKNFQFIGGSLQIGKALQEAHRTYFSAPINGRDRKQFPPILVVLASAESEDEVEEASKALQKDGVKIISVGVQKASEENLKAMATSHFHFNLRTIRDLSTFSQNMTQIIKDVTKYKEGAVDADMQVHFPISCQKDSLADLVFLVDESLGTGGNLRHLQTFLENITSSMDVKENCMRLGLMSYSNSAKTISFLKSSTTQSEFQQQIKNLSIQVGKSNTGAAIDQMRRDGFSESYGSRRAQGVPQIAVLVTHRPSDDEVHDAALNLRLEDVNVFALSIQGANNTQLEEIVSYPPEQTISTLKSYADLETYSTKFLKKLQNEIWSQISTYAEQRNLDKTGCVDTKEADIHFLIDGSSSIQEKQFEQIKRFMLEVTEMFSIGPDKVRVGVVQYSDDTEVEFYITDYSNDIDLRKAIFNIKQLTGGTYTGKALDYILQIIKNGMKDRMSKVPCYLIVLTDGMSTDRVVEPAKRLRAEQITVHAVGIGAANKIELQEIAGKEERVSFGQNFDALKSIKNEVVREICAEKGCEDMKADIMFLVDSSWSIGNENFRKMKIFMKNLLTKIQIGADKTQIGVVQFSDKTKEEFQLNRYFTQQEISDAIDRMSLINEGTLTGKALNFVGQYFTHSKGARLGAKKFLILITDGVAQDDVRDPARILRGKDVTIFSVGVYNANRSQLEEISGDSSLVFHVENFDHLKALERKLIFRVCALHDCKRITLLDVVFVLDHSGSIKKQYQDHMINLTIHLVKKADVGRDRVQFGALKYSDQPNILFYLNTYSNRSAIIENLRKRRDTGGNTYTAKALKHANALFTEEHGSRIKQNVKQMLIVITDGESHDHDQLNDTALELRNKGITIFAVGVGKANQKELEGMAGNKNNTIYVDNFDKLKDVFTLVQERMCTEAPEVCHLQEADVIFLCDGSDRVSNSDFVTMTTFLSDLIDNFDIQSQRMKIGMAQFGSNYQSIIELKNSLTKTQWKTQIQNVSKSGGFPRIDFALKKVSNMFNLHAGGRRNAGVPQTLVVITSGDPRYDVADAVKTLKDLGICVLVLGIGDVYKEHLLPITGNSEKIITFQDFDKLKNVDVKKRIIREICQSCGKTNCFMDIVVGFDISTHVQGQPLFQGHPQLESYLPGILEDISSIKGVSCGAGTEAQVSLAFKVNSDQGFPAKFQIYQKAVFDSLLQVNVSGPTHLNAQFLRSLWDTFKDKSASRGQVLLIFSDGLQSESNIMLENQSDRLREAGLDALLVVSLNTTAHHEFSSFEFGKRFDYRTHLTIGMRELGKKLSQYLGNIAERTCCCTFCKCPGIPGPHGTRGLQAMKGSQGLKGSRGHRGEDGNPGVRGDTGPQGDKGIAGCPGAWGQKGLKGFSGPKGGHGDDGIDGLDGEEGCHGFPGIKGEKGDPGSQGSPGSRGAPGQYGEKGFPGDPGNPGQNNNIKGQKGSKGEQGRQGRSGQKGVQGSPSSRGSRGREGQRGLRGVSGEPGNPGPTGTLGAEGLQGPQGSQGNPGRKGEKGSQGQKGPQGSPGLMGAKGSTGRPGLLGKKGEPGLPGDLGPVGQTGQRGRQGDSGIPGYGQMGRKGVKGPRGFPGDAGQKGDIGNPGIPGGPGPKGFRGLALTVGLKGEEGSRGLPGPPGQRGIKGMAGQPVYSQCDLIRFLREHSPCWKEKCPAYPTELVFALDNSYDVTEESFNKTRDIITSIVNDLNIRENNCPVGARVAMVSYNSGTSYLIRWSDYNRKKQLLQQLSQIKYQDTTEPRDVGNAMRFVTRNVFKRTYAGANVRRVAVFFSNGQTASRSSIITATMEFSALDISPTVFAFDERVFLEAFGFDNTGTFQVIPVPPNGENQTLERLRRCALCYDKCFPNACIREAFLPEDSYMDVVFLIDNSRNIAKDEFKAVKALVSSVIDNFNIASDPLISDSGDRIALLSYSPWESSRRKMGTVKTEFDFITYDNQLLMKNHIQTSFQQLNGEATIGRALLWTTENLFPETPYLRKHKVIFVVSAGENYERKEFVKMMALRAKCQGYVIFVISLGSTRKDDMEELASYPLDQHLIQLGRIHKPDLNYIAKFLKPFLYSVRRGFNQYPPPMLEDACRLINLGGENIQNDGFQFVTELQEDFLGGNGFIGQELNSGRESPFVKTEDNGSDYLVYLPSQMFEPQKLMINYEKDQKSAEIASLTSGHENYGRKEEPDHTYEPGDVSLQEYYMDVAFLIDASQRVGSDEFKEVKAFITSVLDYFHIAPTPLTSTLGDRVAVLSYSPPGYMPNTEECPVYLEFDLVTYNSIHQMKHHLQDSQQLNGDVFIGHALQWTIDNVFVGTPNLRKNKVIFVISAGETNSLDKDVLRNVSLRAKCQGYSIFVFSFGPKHNDKELEELASHPLDHHLVQLGRTHKPDWNYIIKFVKPFVHLIRRAINKYPTEDMKATCVNMTSPNPENGGTENTVLW>sp|Q5JTJ3|COA6_HUMAN Cytochrome c oxidase assembly factor 6 homologOS=Homo sapiens OX=9606 GN=COA6 PE=1 SV=1MGPGGPLLSPSRGFLLCKTGWHSNRLLGDCGPHTPVSTALSFIAVGMAAPSMKERQVCWGARDEYWKCLDENLEDASQCKKLRSSFESSCPQQWIKYFDKRRDYLKFKEKFEAGQFEPSETTAKS>sp|Q5JTJ3-2|COA6_HUMAN Isoform 2 of Cytochrome c oxidase assembly factor6 homolog OS=Homo sapiens OX=9606 GN=COA6MVARKGQKSPRFRRVSCFLRLGRSTLLELEPAGRPCSGRTRHRALHRRLVACVTVSSRRHRKEAGRGRAESFIAVGMAAPSMKERQVCWGARDEYWKCLDENLEDASQCKKLRSSFESSCPQQWIKYFDKRRDYLKFKEKFEAGQFEPSETTAKS>sp|Q5JTJ3-3|COA6_HUMAN Isoform 3 of Cytochrome c oxidase assembly factor6 homolog OS=Homo sapiens OX=9606 GN=COA6MAAPSMKERQVCWGARDEYWKCLDENLEDASQCKKLRSSFESSCPQQWIKYFDKRRDYLKFKEKFEAGQFEPSETTAKS>sp|P20853|CP2A7_HUMAN Cytochrome P450 2A7 OS=Homo sapiens OX=9606GN=CYP2A7 PE=2 SV=2MLASGLLLVALLACLTVMVLMSVWQQRKSRGKLPPGPTPLPFIGNYLQLNTEHICDSIMKFSECYGPVFTIHLGPRRVVVLCGHDAVREALVDQAEEFSGRGEQATFDWVFKGYGVAFSNGERAKQLLRFAIATLRDFGVGKRGIEERIQEESGFLIEAIRSTHGANIDPTFFLSRTVSNVISSIVFGDRFDYEDKEFLSLLSMMLGIFQFTSTSTGQLYEMFSSVMKHLPGPQQQAFKLLQGLEDFIAKKVEHNQRTLDPNSPQDFIDSFLIHMQEEEKNPNTEFYLKNLMMSTLNLFIAGTETVSTTLRYGFLLLMKHPEVEAKVHEEIDRVIGKNRQPKFEDRTKMPYMEAVIHEIQRFGDVIPMSLARRVKKDTKFRDFFLPKGTEVFPMLGSVLRDPSFFSNPQDFNPQHFLDDKGQFKKSDAFVPFSIGKRNCFGEGLARMELFLFFTTVMQNFRLKSSQSPKDIDVSPKHVVFATIPRNYTMSFLPR>sp|P17735|ATTY_HUMAN Tyrosine aminotransferase OS=Homo sapiens OX=9606GN=TAT PE=1 SV=1MDPYMIQMSSKGNLPSILDVHVNVGGRSSVPGKMKGRKARWSVRPSDMAKKTFNPIRAIVDNMKVKPNPNKTMISLSIGDPTVFGNLPTDPEVTQAMKDALDSGKYNGYAPSIGFLSSREEIASYYHCPEAPLEAKDVILTSGCSQAIDLCLAVLANPGQNILVPRPGFSLYKTLAESMGIEVKLYNLLPEKSWEIDLKQLEYLIDEKTACLIVNNPSNPCGSVFSKRHLQKILAVAARQCVPILADEIYGDMVFSDCKYEPLATLSTDVPILSCGGLAKRWLVPGWRLGWILIHDRRDIFGNEIRDGLVKLSQRILGPCTIVQGALKSILCRTPGEFYHNTLSFLKSNADLCYGALAAIPGLRPVRPSGAMYLMVGIEMEHFPEFENDVEFTERLVAEQSVHCLPATCFEYPNFIRVVITVPEVMMLEACSRIQEFCEQHYHCAEGSQEECDK>sp|Q16696|CP2AD_HUMAN Cytochrome P450 2A13 OS=Homo sapiens OX=9606GN=CYP2A13 PE=1 SV=3MLASGLLLVTLLACLTVMVLMSVWRQRKSRGKLPPGPTPLPFIGNYLQLNTEQMYNSLMKISERYGPVFTIHLGPRRVVVLCGHDAVKEALVDQAEEFSGRGEQATFDWLFKGYGVAFSNGERAKQLRRFSIATLRGFGVGKRGIEERIQEEAGFLIDALRGTHGANIDPTFFLSRTVSNVISSIVFGDRFDYEDKEFLSLLRMMLGSFQFTATSTGQLYEMFSSVMKHLPGPQQQAFKELQGLEDFIAKKVEHNQRTLDPNSPRDFIDSFLIRMQEEEKNPNTEFYLKNLVMTTLNLFFAGTETVSTTLRYGFLLLMKHPEVEAKVHEEIDRVIGKNRQPKFEDRAKMPYTEAVIHEIQRFGDMLPMGLAHRVNKDTKFRDFFLPKGTEVFPMLGSVLRDPRFFSNPRDFNPQHFLDKKGQFKKSDAFVPFSIGKRYCFGEGLARMELFLFFTTIMQNFRFKSPQSPKDIDVSPKHVGFATIPRNYTMSFLPR>sp|Q8WW18|CQ050_HUMAN Uncharacterized protein C17orf50 OS=Homo sapiensOX=9606 GN=C17orf50 PE=1 SV=2MDKHGVKTPLWKKETEELRAEDAEQEEGKEGSEDEDEDNQRPLEDSATEGEEPPRVAEEGEGRERRSVSYCPLRQESSTQQVALLRRADSGFWGWLGPLALLGGLTAPTDRKRSLPEEPCVLEIRRRPPRRGGCACCELLFCKKCRSLHSHPAYVAHCVLDHPDLGKAGAAGNS>sp|Q8N7U9|CQ054_HUMAN Putative uncharacterized protein encoded byLINC00469 OS=Homo sapiens OX=9606 GN=LINC00469 PE=5 SV=1MTSSAPTLPDVTIRNVSRHIQMSLMGKGEPPWLCRLQLEPLLQAMEEQQLGNLEARWEVEKHGNEVSGSTSREVWEDADFICPVLKQCTNPKLNENKNIHQAKECEKSPFLSLSPHQQWKPGLPRRNDALPTSLCLCCSEN>sp|Q8N7U9-2|CQ054_HUMAN Isoform 2 of Putative uncharacterized proteinencoded by LINC00469 OS=Homo sapiens OX=9606 GN=LINC00469MTSSAPTLPDVTIRNVSRHIQMSLMGKGEPPWLCRLQLEPLLQAMEEQQLGNLEARWEVEKHGNEVSGSTSKSEPLPRYYLYNQTELQGALWSGQHPPEGQGEIFQTVFQQRSLGRC>sp|Q2M2W7|CQ058_HUMAN UPF0450 protein C17orf58 OS=Homo sapiens OX=9606GN=C17orf58 PE=3 SV=2MNRLYLTPDGFFFRVHMLALDSSSCNKPCPEFKPGSRYIVMGHIYHKRRQLPTALLQVLRGRLRPGDGLLRSSSSYVKRFNRKREGQIQGAIHTQCI>sp|Q2M2W7-2|CQ058_HUMAN Isoform 2 of UPF0450 protein C17orf58 OS=Homosapiens OX=9606 GN=C17orf58MNRLYLTPDGFFFRVHMLALDSSSCNKPCPEFKPGIETDLNDAAYVLYTTVCNVGATARAVGRPAFFWERWETMT>sp|A2RUQ5|CQ102_HUMAN Uncharacterized protein TMEM132E-DT OS=Homosapiens OX=9606 GN=TMEM132E-DT PE=2 SV=1MFDFSFPTPASAGTRMGPASCGGRSLHLPQLRFSRVDATAVTDVPFQRMHAPHRAPEVFCSRSSRGAGRGHPTPTPRVRWALAGNQPRCCAQLLSGRGGSGAQLRAGWVRGAAVGNLFILLLGKEDGEEEGTVLSYSSMVHISNITGIVGTTVSRTKPALVLMELTF>sp|Q99700|ATX2_HUMAN Ataxin-2 OS=Homo sapiens OX=9606 GN=ATXN2 PE=1 SV=2MRSAAAAPRSPAVATESRRFAAARWPGWRSLQRPARRSGRGGGGAAPGPYPSAAPPPPGPGPPPSRQSSPPSASDCFGSNGNGGGAFRPGSRRLLGLGGPPRPFVVLLLPLASPGAPPAAPTRASPLGARASPPRSGVSLARPAPGCPRPACEPVYGPLTMSLKPQQQQQQQQQQQQQQQQQQQQQQQPPPAAANVRKPGGSGLLASPAAAPSPSSSSVSSSSATAPSSVVAATSGGGRPGLGRGRNSNKGLPQSTISFDGIYANMRMVHILTSVVGSKCEVQVKNGGIYEGVFKTYSPKCDLVLDAAHEKSTESSSGPKREEIMESILFKCSDFVVVQFKDMDSSYAKRDAFTDSAISAKVNGEHKEKDLEPWDAGELTANEELEALENDVSNGWDPNDMFRYNEENYGVVSTYDSSLSSYTVPLERDNSEEFLKREARANQLAEEIESSAQYKARVALENDDRSEEEKYTAVQRNSSEREGHSINTRENKYIPPGQRNREVISWGSGRQNSPRMGQPGSGSMPSRSTSHTSDFNPNSGSDQRVVNGGVPWPSPCPSPSSRPPSRYQSGPNSLPPRAATPTRPPSRPPSRPSRPPSHPSAHGSPAPVSTMPKRMSSEGPPRMSPKAQRHPRNHRVSAGRGSISSGLEFVSHNPPSEAATPPVARTSPSGGTWSSVVSGVPRLSPKTHRPRSPRQNSIGNTPSGPVLASPQAGIIPTEAVAMPIPAASPTPASPASNRAVTPSSEAKDSRLQDQRQNSPAGNKENIKPNETSPSFSKAENKGISPVVSEHRKQIDDLKKFKNDFRLQPSSTSESMDQLLNKNREGEKSRDLIKDKIEPSAKDSFIENSSSNCTSGSSKPNSPSISPSILSNTEHKRGPEVTSQGVQTSSPACKQEKDDKEEKKDAAEQVRKSTLNPNAKEFNPRSFSQPKPSTTPTSPRPQAQPSPSMVGHQQPTPVYTQPVCFAPNMMYPVPVSPGVQPLYPIPMTPMPVNQAKTYRAVPNMPQQRQDQHHQSAMMHPASAAGPPIAATPPAYSTQYVAYSPQQFPNQPLVQHVPHYQSQHPHVYSPVIQGNARMMAPPTHAQPGLVSSSATQYGAHEQTHAMYACPKLPYNKETSPSFYFAISTGSLAQQYAHPNATLHPHTPHPQPSATPTGQQQSQHGGSHPAPSPVQHHQHQAAQALHLASPQQQSAIYHAGLAPTPPSMTPASNTQSPQNSFPAAQQTVFTIHPSHVQPAYTNPPHMAHVPQAHVQSGMVPSHPTAHAPMMLMTTQPPGGPQAALAQSALQPIPVSTTAHFPYMTHPSVQAHHQQQL>sp|Q99700-2|ATX2_HUMAN Isoform 2 of Ataxin-2 OS=Homo sapiens OX=9606GN=ATXN2MRSAAAAPRSPAVATESRRFAAARWPGWRSLQRPARRSGRGGGGAAPGPYPSAAPPPPGPGPPPSRQSSPPSASDCFGSNGNGGGAFRPGSRRLLGLGGPPRPFVVLLLPLASPGAPPAAPTRASPLGARASPPRSGVSLARPAPGCPRPACEPVYGPLTMSLKPQQQQQQQQQQQQQQQQQQQQQQQPPPAAANVRKPGGSGLLASPAAAPSPSSSSVSSSSATAPSSVVAATSGGGRPGLGRGRNSNKGLPQSTISFDGIYANMRMVHILTSVVGSKCEVQVKNGGIYEGVFKTYSPKCDLVLDAAHEKSTESSSGPKREEIMESILFKCSDFVVVQFKDMDSSYAKRDAFTDSAISAKVNGEHKEKDLEPWDAGELTANEELEALENDVSNGWDPNDMFRYNEENYGVVSTYDSSLSSYTVPLERDNSEEFLKREARANQLAEEIESSAQYKARVALENDDRSEEEKYTAVQRNSSEREGHSINTRENKYIPPGQRNREVISWGSGRQNSPRMGQPGSGSMPSRSTSHTSDFNPNSGSDQRVVNGGVPWPSPCPSPSSRPPSRYQSGPNSLPPRAATPTRPPSRPPSRPSRPPSHPSAHGSPAPVSTMPKRMSSEGPPRMSPKAQRHPRNHRVSAGRGSISSGLEFVSHNPPSEAATPPVARTSPSGGTWSSVVSGVPRLSPKTHRPRSPRQNSIGNTPSGPVLASPQAGIIPTEAVAMPIPAASPTPASPASNRAVTPSSEAKDSRLQDQRQNSPAGNKENIKPNETSPSFSKAENKGISPVVSEHRKQIDDLKKFKNDFRLQPSSTSESMDQLLNKNREGEKSRDLIKDKIEPSAKDSFIENSSSNCTSGSSKPNSPSISPSILSNTEHKRGPEVTSQGVQTSSPACKQEKDDKEEKKDAAEQVRKSTLNPNAKEFNPRSFSQPKPSTTPTSPRPQAQPSPSMVGHQQPTPVYTQPVCFAPNMMYPVPVSPGVQYQICPNSGKTSIIRVP>sp|Q99700-3|ATX2_HUMAN Isoform 3 of Ataxin-2 OS=Homo sapiens OX=9606GN=ATXN2MYYAVEILFNRQSAFFSAVPNMPQQRQDQHHQSAMMHPASAAGPPIAATPPAYSTQYVAYSPQQFPNQPLVQHVPHYQSQHPHVYSPVIQGNARMMAPPTHAQPGLVSSSATQYGAHEQTHAMYVSTGSLAQQYAHPNATLHPHTPHPQPSATPTGQQQSQHGGSHPAPSPVQHHQHQAAQALHLASPQQQSAIYHAGLAPTPPSMTPASNTQSPQNSFPAAQQTVFTIHPSHVQPAYTNPPHMAHVPQVIPALANFL>sp|Q99700-4|ATX2_HUMAN Isoform 4 of Ataxin-2 OS=Homo sapiens OX=9606GN=ATXN2MRSAAAAPRSPAVATESRRFAAARWPGWRSLQRPARRSGRGGGGAAPGPYPSAAPPPPGPGPPPSRQSSPPSASDCFGSNGNGGGAFRPGSRRLLGLGGPPRPFVVLLLPLASPGAPPAAPTRASPLGARASPPRSGVSLARPAPGCPRPACEPVYGPLTMSLKPQQQQQQQQQQQQQQQQQQQQQQQPPPAAANVRKPGGSGLLASPAAAPSPSSSSVSSSSATAPSSVVAATSGGGRPGLGRGRNSNKGLPQSTISFDGIYANMRMVHILTSVVGSKCEVQVKNGGIYEGVFKTYSPKCDLVLDAAHEKSTESSSGPKREEIMESILFKCSDFVVVQFKDMDSSYAKRDAFTDSAISAKVNGEHKEKDLEPWDAGELTANEELEALENDVSNGWDPNDMFRYNEENYGVVSTYDSSLSSYTVPLERDNSEEFLKREARANQLAEEIESSAQYKARVALENDDRSEEEKYTAVQRNSSEREGHSINTRENKYIPPGQRNREVISWGSGRQNSPRMGQPGSGSMPSRSTSHTSDFNPNSGSDQRVVNGGVPWPSPCPSPSSRPPSRYQSGPNSLPPRAATPTRPPSRPPSRPSRPPSHPSAHGSPAPVSTMPKRMSSEGPPRMSPKAQRHPRNHRVSAGRGSISSGLEFVSHNPPSEAATPPVARTSPSGGTWSSVVSGVPRLSPKTHRPRSPRQNSIGNTPSGPVLASPQAGIIPTEAVAMPIPAASPTPASPASNRAVTPSSEAKDSRLQDQRQNSPAGNKENIKPNETSPSFSKAENKGISPVVSEHRKQIDDLKKFKNDFRLQPSSTSESMDQLLNKNREGEKSRDLIKDKIEPSAKDSFIENSSSNCTSGSSKPNSPSISPSILSNTEHKRGPEVTSQGVQTSSPACKQEKDDKEEKKDAAEQVRKSTLNPNAKEFNPRSFSQPKPSTTPTSPRPQAQPSPSMVGHQQPTPVYTQPVCFAPNMMYPVPVSPGVQPLYPIPMTPMPVNQAKTYRAVPNMPQQRQDQHHQSAMMHPASAAGPPIAATPPAYSTQYVAYSPQQFPNQPLVQHVPHYQSQHPHVYSPVIQGNARMMAPPTHAQPGLVSSSATQYGAHEQTHAMYACPKLPYNKETSPSFYFAISTGSLAQQYAHPNATLHPHTPHPQPSATPTGQQQSQHGGSHPAPSPVQHHQHQAAQALHLASPQQQSAIYHAGLAPTPPSMTPASNTQSPQNSFPAAQQTVFTIHPSHVQPAYTNPPHM>sp|Q99700-5|ATX2_HUMAN Isoform 5 of Ataxin-2 OS=Homo sapiens OX=9606GN=ATXN2MRMVHILTSVVCDLVLDAAHEKSTESSSGPKREEIMESILFKCSDFVVVQFKDMDSSYAKRDAFTDSAISAKVNGEHKEKDLEPWDAGELTANEELEALENDVSNGWDPNDMFRYNEENYGVVSTYDSSLSSYTVPLERDNSEEFLKREARANQLAEEIESSAQYKARVALENDDRSEEEKYTAVQRNSSEREGHSINTRENKYIPPGQRNREVISWGSGRQNSPRMGQPGSGSMPSRSTSHTSDFNPNSGSDQRVVNGGVPWPSPCPSPSSRPPSRYQSGPNSLPPRAATPTRPPSRPPSRPSRPPSHPSAHGSPAPVSTMPKRMSSEGPPRMSPKAQRHPRNHRVSAGRGSISSGLEFVSHNPPSEAATPPVARTSPSGGTWSSVVSGVPRLSPKTHRPRSPRQNSIGNTPSGPVLASPQAGIIPTEAVAMPIPAASPTPASPASNRAVTPSSEAKDSRLQDQRQNSPAGNKENIKPNETSPSFSKAENKGISPVVSEHRKQIDDLKKFKNDFRLQPSSTSESMDQLLNKNREGEKSRDLIKDKIEPSAKDSFIENSSSNCTSGSSKPNSPSISPSILSNTEHKRGPEVTSQGVQTSSPACKQEKDDKEEKKDAAEQVRKSTLNPNAKEFNPRSFSQPKPSTTPTSPRPQAQPSPSMVGHQQPTPVYTQPVCFAPNMMYPVPVSPGVQPLYPIPMTPMPVNQAKTYRAVPNMPQQRQDQHHQSAMMHPASAAGPPIAATPPAYSTQYVAYSPQQFPNQPLVQHVPHYQSQHPHVYSPVIQGNARMMAPPTHAQPGLVSSSATQYGAHEQTHAMYVSTGSLAQQYAHPNATLHPHTPHPQPSATPTGQQQSQHGGSHPAPSPVQHHQHQAAQALHLASPQQQSAIYHAGLAPTPPSMTPASNTQSPQNSFPAAQQTVFTIHPSHVQPAYTNPPHMAHVPQAHVQSGMVPSHPTAHAPMMLMTTQPPGGPQAALAQSALQPIPVSTTAHFPYMTHPSVQAHHQQQL>sp|Q58HT5|AWAT1_HUMAN Acyl-CoA wax alcohol acyltransferase 1 OS=Homosapiens OX=9606 GN=AWAT1 PE=1 SV=1MAHSKQPSHFQSLMLLQWPLSYLAIFWILQPLFVYLLFTSLWPLPVLYFAWLFLDWKTPERGGRRSAWVRNWCVWTHIRDYFPITILKTKDLSPEHNYLMGVHPHGLLTFGAFCNFCTEATGFSKTFPGITPHLATLSWFFKIPFVREYLMAKGVCSVSQPAINYLLSHGTGNLVGIVVGGVGEALQSVPNTTTLILQKRKGFVRTALQHGAHLVPTFTFGETEVYDQVLFHKDSRMYKFQSCFRRIFGFYCCVFYGQSFCQGSTGLLPYSRPIVTVVGEPLPLPQIEKPSQEMVDKYHALYMDALHKLFDQHKTHYGCSETQKLFFL>sp|O14965|AURKA_HUMAN Aurora kinase A OS=Homo sapiens OX=9606 GN=AURKAPE=1 SV=2MDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRVPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATYITELANALSYCHSKRVIHRDIKPENLLLGSAGELKIADFGWSVHAPSSRRTTLCGTLDYLPPEMIEGRMHDEKVDLWSLGVLCYEFLVGKPPFEANTYQETYKRISRVEFTFPDFVTEGARDLISRLLKHNPSQRPMLREVLEHPWITANSSKPSNCQNKESASKQS>sp|Q7Z4G1|COMD6_HUMAN COMM domain-containing protein 6 OS=Homo sapiensOX=9606 GN=COMMD6 PE=1 SV=1MEASSEPPLDAKSDVTNQLVDFQWKLGMAVSSDTCRSLKYPYVAVMLKVADHSGQVKTKCFEMTIPQFQNFYRQFKEIAAVIETV>sp|Q7Z4G1-2|COMD6_HUMAN Isoform 2 of COMM domain-containing protein 6OS=Homo sapiens OX=9606 GN=COMMD6MEASSEPPLDAKSDVTNQLVDFQWKLGMAVSSDTCRSLKYPYVAVMLKVADHSGQVKTKCFEMTIPQFQPQLLATSSLLSASNFYRQFKEIAAVIETV>sp|K7EIQ3|CS082_HUMAN Uncharacterized protein ZNF561-AS1 OS=Homo sapiensOX=9606 GN=ZNF561-AS1 PE=4 SV=1MGRIPGGCSSKAFIGRAQWLTPVIPALWEAKGLTLLSRLECSDVIMDHCSPQLTGLRMKGFLAQTPPLEFPVHQYQPGDHVLIKSWKRESLNQLRRTSSGTLDE>sp|K7EIQ3-2|CS082_HUMAN Isoform 2 of Uncharacterized protein ZNF561-AS1OS=Homo sapiens OX=9606 GN=ZNF561-AS1MGRIPGGCSSKAFIGRAQWLTPVIPALWEAKDERLPSTNTTPGVPGTSIPAWGSRSHQELEEGKLEPA>sp|P00846|ATP6_HUMAN ATP synthase subunit a OS=Homo sapiens OX=9606GN=MT-ATP6 PE=1 SV=1MNENLFASFIAPTILGLPAAVLIILFPPLLIPTSKYLINNRLITTQQWLIKLTSKQMMTMHNTKGRTWSLMLVSLIIFIATTNLLGLLPHSFTPTTQLSMNLAMAIPLWAGTVIMGFRSKIKNALAHFLPQGTPTPLIPMLVIIETISLLIQPMALAVRLTANITAGHLLMHLIGSATLAMSTINLPSTLIIFTILILLTILEIAVALIQAYVFTLLVSLYLHDNT>sp|Q6V0L0|CP26C_HUMAN Cytochrome P450 26C1 OS=Homo sapiens OX=9606GN=CYP26C1 PE=2 SV=2MFPWGLSCLSVLGAAGTALLCAGLLLSLAQHLWTLRWMLSRDRASTLPLPKGSMGWPFFGETLHWLVQGSRFHSSRRERYGTVFKTHLLGRPVIRVSGAENVRTILLGEHRLVRSQWPQSAHILLGSHTLLGAVGEPHRRRRKVLARVFSRAALERYVPRLQGALRHEVRSWCAAGGPVSVYDASKALTFRMAARILLGLRLDEAQCATLARTFEQLVENLFSLPLDVPFSGLRKGIRARDQLHRHLEGAISEKLHEDKAAEPGDALDLIIHSARELGHEPSMQELKESAVELLFAAFFTTASASTSLVLLLLQHPAAIAKIREELVAQGLGRACGCAPGAAGGSEGPPPDCGCEPDLSLAALGRLRYVDCVVKEVLRLLPPVSGGYRTALRTFELDGYQIPKGWSVMYSIRDTHETAAVYRSPPEGFDPERFGAAREDSRGASSRFHYIPFGGGARSCLGQELAQAVLQLLAVELVRTARWELATPAFPAMQTVPIVHPVDGLRLFFHPLTPSVAGNGLCL>sp|Q92905|CSN5_HUMAN COP9 signalosome complex subunit 5 OS=Homo sapiensOX=9606 GN=COPS5 PE=1 SV=4MAASGSGMAQKTWELANNMQEAQSIDEIYKYDKKQQQEILAAKPWTKDHHYFKYCKISALALLKMVMHARSGGNLEVMGLMLGKVDGETMIIMDSFALPVEGTETRVNAQAAAYEYMAAYIENAKQVGRLENAIGWYHSHPGYGCWLSGIDVSTQMLNQQFQEPFVAVVIDPTRTISAGKVNLGAFRTYPKGYKPPDEGPSEYQTIPLNKIEDFGVHCKQYYALEVSYFKSSLDRKLLELLWNKYWVNTLSSSSLLTNADYTTGQVFDLSEKLEQSEAQLGRGSFMLGLETHDRKSEDKLAKATRDSCKTTIEAIHGLMSQVIKDKLFNQINIS>sp|Q96A70|AZIN2_HUMAN Antizyme inhibitor 2 OS=Homo sapiens OX=9606GN=AZIN2 PE=1 SV=1MAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSPGVLKVLAQLGLGFSCANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKMVLCIATDDSHSLSCLSLKFGVSLKSCRHLLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGAKVRFEEIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPTPILQKKPSTEQPLYSSSLWGPAVDGCDCVAEGLWLPQLHVGDWLVFDNMGAYTVGMGSPFWGTQACHITYAMSRVAWEALRRQLMAAEQEDDVEGVCKPLSCGWEITDTLCVGPVFTPASIM>sp|Q96A70-2|AZIN2_HUMAN Isoform 2 of Antizyme inhibitor 2 OS=Homosapiens OX=9606 GN=AZIN2MAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSPGVLKVLAQLGLGFSCANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKMVLCIATDDSHSLSCLSLKFGVSLKSCRHLLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGAKVRFEEIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREAPLPPPHIATCAASEPSPPAEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPTPILQKKPSTEQPLYSSSLWGPAVDGCDCVAEGLWLPQLHVGDWLVFDNMGAYTVGMGSPFWGTQACHITYAMSRVAWEALRRQLMAAEQEDDVEGVCKPLSCGWEITDTLCVGPVFTPASIM>sp|Q96A70-3|AZIN2_HUMAN Isoform 3 of Antizyme inhibitor 2 OS=Homosapiens OX=9606 GN=AZIN2MAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSPGVLKVLAQLGLGFSCANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKMVLCIATDDSHSLSCLSLKFGVSLKSCRHLLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGAKVRFEEIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPTPILQKSKNHSPCYMSLESIHFIAV>sp|Q96A70-4|AZIN2_HUMAN Isoform 4 of Antizyme inhibitor 2 OS=Homosapiens OX=9606 GN=AZIN2MAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSPGVLKVLAQLGLGFSCANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKFVQQRGTACLIRMVLCIATDDSHSLSCLSLKFGVSLKSCRHLLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGAKVRFEEIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPTPILQKSKNHSPCYMSLESIHFIAV>sp|Q96A70-5|AZIN2_HUMAN Isoform 6 of Antizyme inhibitor 2 OS=Homosapiens OX=9606 GN=AZIN2MAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSPGVLKVLAQLGLGFSCANKIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPTPILQKSKNHSPCYMSLESIHFIAV>sp|Q9H6S1|AZI2_HUMAN 5-azacytidine-induced protein 2 OS=Homo sapiensOX=9606 GN=AZI2 PE=1 SV=1MDALVEDDICILNHEKAHKRDTVTPVSIYSGDESVASHFALVTAYEDIKKRLKDSEKENSLLKKRIRFLEEKLIARFEEETSSVGREQVNKAYHAYREVCIDRDNLKSKLDKMNKDNSESLKVLNEQLQSKEVELLQLRTEVETQQVMRNLNPPSSNWEVEKLSCDLKIHGLEQELELMRKECSDLKIELQKAKQTDPYQEDNLKSRDLQKLSISSDNMQHAYWELKREMSNLHLVTQVQAELLRKLKTSTAIKKACAPVGCSEDLGRDSTKLHLMNFTATYTRHPPLLPNGKALCHTTSSPLPGDVKVLSEKAILQSWTDNERSIPNDGTCFQEHSSYGRNSLEDNSWVFPSPPKSSETAFGETKTKTLPLPNLPPLHYLDQHNQNCLYKN>sp|Q9H6S1-3|AZI2_HUMAN Isoform 2 of 5-azacytidine-induced protein 2OS=Homo sapiens OX=9606 GN=AZI2MDALVEDDICILNHEKAHKRDTVTPVSIYSGDESVASHFALVTAYEDIKKRLKDSEKENSLLKKRIRFLEEKLIARFEEETSSVGREQVNKAYHAYREVCIDRDNLKSKLDKMNKDNSESLKVLNEQLQSKEVELLQLRTEVETQQVMRNLNPPSSNWEVEKLSCDLKIHGLEQELELMRKECSDLKIELQKAKQTDPYQEDNLKSRDLQKLSISTQPGVQWRNHGIA>sp|Q9H6S1-4|AZI2_HUMAN Isoform 3 of 5-azacytidine-induced protein 2OS=Homo sapiens OX=9606 GN=AZI2MDALVEDDICILNHEKAHKRDTVTPVSIYSGDESVASHFALVTAYEDIKKRLKDSEKENSLLKKRIRFLEEKLIARFEEETSSVGREQVNKAYHAYREVCIDRDNLKSKLDKMNKDNSESLKVLNEQLQSKEVELLQLRTEVETQQVMRNLNPPSSNWEVEKLSCDLKIHGLEQELELMRKECSDLKIELQKAKQTDPYQEDNLKSRDLQKLSISRQSICSTAWSAVAQSWDSMNFEDCSLFA>sp|Q9H6S1-5|AZI2_HUMAN Isoform 4 of 5-azacytidine-induced protein 2OS=Homo sapiens OX=9606 GN=AZI2MDALVEDDICILNHEKAHKRDTVTPVSIYSGDESVASHFALVTAYEDIKKRLKDSEKENSLLKKRIRFLEEKLIARFEEETSSVGREQVNKAYHAYREVCIDRDNLKSKLDKMNKDNSESLKVLNEQLQSKEVELLQLRTEVETQQVMRNLNPPSSNWEVEKLSCDLKIHGLEQELELMRKECSDLKIELQKAKQTDPYQEDNLKSRDLQKLSISRVSVAQPGVQWRNHGIA>sp|Q92858|ATOH1_HUMAN Protein atonal homolog 1 OS=Homo sapiens OX=9606GN=ATOH1 PE=2 SV=1MSRLLHAEEWAEVKELGDHHRQPQPHHLPQPPPPPQPPATLQAREHPVYPPELSLLDSTDPRAWLAPTLQGICTARAAQYLLHSPELGASEAAAPRDEVDGRGELVRRSSGGASSSKSPGPVKVREQLCKLKGGVVVDELGCSRQRAPSSKQVNGVQKQRRLAANARERRRMHGLNHAFDQLRNVIPSFNNDKKLSKYETLQMAQIYINALSELLQTPSGGEQPPPPPASCKSDHHHLRTAASYEGGAGNATAAGAQQASGGSQRPTPPGSCRTRFSAPASAGGYSVQLDALHFSTFEDSALTAMMAQKNLSPSLPGSILQPVQEENSKTSPRSHRSDGEFSPHSHYSDSDEAS>sp|Q8WZ55|BSND_HUMAN Barttin OS=Homo sapiens OX=9606 GN=BSND PE=1 SV=1MADEKTFRIGFIVLGLFLLALGTFLMSHDRPQVYGTFYAMGSVMVIGGIIWSMCQCYPKITFVPADSDFQGILSPKAMGLLENGLAAEMKSPSPQPPYVRLWEEAAYDQSLPDFSHIQMKVMSYSEDHRSLLAPEMGQPKLGTSDGGEGGPGDVQAWMEAAVVIHKGSDESEGERRLTQSWPGPLACPQGPAPLASFQDDLDMDSSEGSSPNASPHDREEACSPQQEPQGCRCPLDRFQDFALIDAPTLEDEPQEGQQWEIALPNNWQRYPRTKVEEKEASDTGGEEPEKEEEDLYYGLPDGAGDLLPDKELGFEPDTQG>sp|Q16548|B2LA1_HUMAN Bcl-2-related protein A1 OS=Homo sapiens OX=9606GN=BCL2A1 PE=1 SV=1MTDCEFGYIYRLAQDYLQCVLQIPQPGSGPSKTSRVLQNVAFSVQKEVEKNLKSCLDNVNVVSVDTARTLFNQVMEKEFEDGIINWGRIVTIFAFEGILIKKLLRQQIAPDVDTYKEISYFVAEFIMNNTGEWIRQNGGWENGFVKKFEPKSGWMTFLEVTGKICEMLSLLKQYC>sp|Q16548-2|B2LA1_HUMAN Isoform 2 of Bcl-2-related protein A1 OS=Homosapiens OX=9606 GN=BCL2A1MTDCEFGYIYRLAQDYLQCVLQIPQPGSGPSKTSRVLQNVAFSVQKEVEKNLKSCLDNVNVVSVDTARTLFNQVMEKEFEDGIINWGRIVTIFAFEGILIKKLLRQQIAPDVDTYKEISYFVAEFIMNNTGEWIRQNGGWGKWHNHTPMLVESVAHKKRKMAL>sp|Q075Z2|BSPH1_HUMAN Binder of sperm protein homolog 1 OS=Homo sapiensOX=9606 GN=BSPH1 PE=2 SV=1MGSLMLLFVETTRNSSACIFPVILNELSSTVETITHFPEVTDGECVFPFHYKNGTYYDCIKSKARHKWCSLNKTYEGYWKFCSAEDFANCVFPFWYRRLIYWECTDDGEAFGKKWCSLTKNFNKDRIWKYCE>sp|Q13324|CRFR2_HUMAN Corticotropin-releasing factor receptor 2 OS=Homosapiens OX=9606 GN=CRHR2 PE=1 SV=2MDAALLHSLLEANCSLALAEELLLDGWGPPLDPEGPYSYCNTTLDQIGTCWPRSAAGALVERPCPEYFNGVKYNTTRNAYRECLENGTWASKINYSQCEPILDDKQRKYDLHYRIALVVNYLGHCVSVAALVAAFLLFLALRSIRCLRNVIHWNLITTFILRNVMWFLLQLVDHEVHESNEVWCRCITTIFNYFVVTNFFWMFVEGCYLHTAIVMTYSTERLRKCLFLFIGWCIPFPIIVAWAIGKLYYENEQCWFGKEPGDLVDYIYQGPIILVLLINFVFLFNIVRILMTKLRASTTSETIQYRKAVKATLVLLPLLGITYMLFFVNPGEDDLSQIMFIYFNSFLQSFQGFFVSVFYCFFNGEVRSAVRKRWHRWQDHHSLRVPMARAMSIPTSPTRISFHSIKQTAAV>sp|Q13324-2|CRFR2_HUMAN Isoform CRF2-beta of Corticotropin-releasingfactor receptor 2 OS=Homo sapiens OX=9606 GN=CRHR2MRGPSGPPGLLYVPHLLLCLLCLLPPPLQYAAGQSQMPKDQPLWALLEQYCHTIMTLTNLSGPYSYCNTTLDQIGTCWPRSAAGALVERPCPEYFNGVKYNTTRNAYRECLENGTWASKINYSQCEPILDDKQRKYDLHYRIALVVNYLGHCVSVAALVAAFLLFLALRSIRCLRNVIHWNLITTFILRNVMWFLLQLVDHEVHESNEVWCRCITTIFNYFVVTNFFWMFVEGCYLHTAIVMTYSTERLRKCLFLFIGWCIPFPIIVAWAIGKLYYENEQCWFGKEPGDLVDYIYQGPIILVLLINFVFLFNIVRILMTKLRASTTSETIQYRKAVKATLVLLPLLGITYMLFFVNPGEDDLSQIMFIYFNSFLQSFQGFFVSVFYCFFNGEVRSAVRKRWHRWQDHHSLRVPMARAMSIPTSPTRISFHSIKQTAAV>sp|Q13324-3|CRFR2_HUMAN Isoform CRF2-gamma of Corticotropin-releasingfactor receptor 2 OS=Homo sapiens OX=9606 GN=CRHR2MGREPWPEDRDLGFPQLFCQGPYSYCNTTLDQIGTCWPRSAAGALVERPCPEYFNGVKYNTTRNAYRECLENGTWASKINYSQCEPILDDKQRKYDLHYRIALVVNYLGHCVSVAALVAAFLLFLALRSIRCLRNVIHWNLITTFILRNVMWFLLQLVDHEVHESNEVWCRCITTIFNYFVVTNFFWMFVEGCYLHTAIVMTYSTERLRKCLFLFIGWCIPFPIIVAWAIGKLYYENEQCWFGKEPGDLVDYIYQGPIILVLLINFVFLFNIVRILMTKLRASTTSETIQYRKAVKATLVLLPLLGITYMLFFVNPGEDDLSQIMFIYFNSFLQSFQGFFVSVFYCFFNGEVRSAVRKRWHRWQDHHSLRVPMARAMSIPTSPTRISFHSIKQTAAV>sp|Q13324-4|CRFR2_HUMAN Isoform D of Corticotropin-releasing factorreceptor 2 OS=Homo sapiens OX=9606 GN=CRHR2MDAALLHSLLEANCSLALAEELLLDGWGPPLDPEGPYSYCNTTLDQIGTCWPRSAAGALVERPCPEYFNGVKYNTTRNAYRECLENGTWASKINYSQCEPILDDKQRKYDLHYRIALVVNYLGHCVSVAALVAAFLLFLALRSIRCLRNVIHWNLITTFILRNVMWFLLQLVDHEVHESNEVWCRCITTIFNYFVVTNFFWMFVEGCYLHTAIVMTYSTERLRKCLFLFIGWCIPFPIIVAWAIGKLYYENEQCWFGKEPGDLVDYIYQGPIILVLLINFVFLFNIVRILMTKLRASTTSETIQYRKAVKATLVLLPLLGITYMLFFVNPGEDDLSQIMFIYFNSFLQSFQGFFVSVFYCFFNGESWVSKEAQAAGPHGREKPEQRW>sp|Q13324-5|CRFR2_HUMAN Isoform E of Corticotropin-releasing factorreceptor 2 OS=Homo sapiens OX=9606 GN=CRHR2MDAALLHSLLEANCSLALAEELLLDGWGPPLDPEGPYSYCNTTLDQIGTCWPRSAAGALVERPCPEYFNGVKYNTTRNAYRECLENGTWASKINYSQCEPILDDKQRKYDLHYRIALVVNYLGHCVSVAALVAAFLLFLALRSIRCLRNVIHWNLITTFILRNVMWFLLQLVDHEVHESNEVWCRCITTIFNYFVVTNFFWMFVEGCYLHTAIVMTYSTERLRKCLFLFIGWCIPFPIIVAWAIGKLYYENEQCWFGKEPGDLVDYIYQGPIILVLLINFVFLFNIVRILMTKLRASTTSETIQYRKAVKATLVLLPLLGITYMLFFVNPGEDDLSQIMFIYFNSFLQSFQGFFVSVFYCFFNGEGLEPV>sp|Q13324-6|CRFR2_HUMAN Isoform F of Corticotropin-releasing factorreceptor 2 OS=Homo sapiens OX=9606 GN=CRHR2MDAALLHSLLEANCSLALAEELLLDGWGPPLDPEGPYSYCNTTLDQIGTCWPRSAAGALVERPCPEYFNGVKYNTTRNAYRECLENGTWASKINYSQCEPILDDKQRKYDLHYRIALVVNYLGHCVSVAALVAAFLLFLALRSIRCLRNVIHWNLITTFILRNVMWFLLQLVDHEVHESNEVWCRCITTIFNYFVVTNFFWMFVEGCYLHTAIVMTYSTERLRKCLFLFIGWCIPFPIIVAWAIGKLYYENEQCWFGKEPGDLVDYIYQGPIILVLLINFVFLFNIVRILMTKLRASTTSETIQYRKAVKATLVLLPLLGITYMLFFVNPGEDDLSQIMFIYFNSFLQSFQGFFVSVFYCFFNGEV>sp|Q13324-7|CRFR2_HUMAN Isoform desQ of Corticotropin-releasing factorreceptor 2 OS=Homo sapiens OX=9606 GN=CRHR2MDAALLHSLLEANCSLALAEELLLDGWGPPLDPEGPYSYCNTTLDQIGTCWPRSAAGALVERPCPEYFNGVKYNTTRNAYRECLENGTWASKINYSQCEPILDDKRKYDLHYRIALVVNYLGHCVSVAALVAAFLLFLALRSIRCLRNVIHWNLITTFILRNVMWFLLQLVDHEVHESNEVWCRCITTIFNYFVVTNFFWMFVEGCYLHTAIVMTYSTERLRKCLFLFIGWCIPFPIIVAWAIGKLYYENEQCWFGKEPGDLVDYIYQGPIILVLLINFVFLFNIVRILMTKLRASTTSETIQYRKAVKATLVLLPLLGITYMLFFVNPGEDDLSQIMFIYFNSFLQSFQGFFVSVFYCFFNGEVRSAVRKRWHRWQDHHSLRVPMARAMSIPTSPTRISFHSIKQTAAV>sp|A8MUP2|CSKMT_HUMAN Citrate synthase-lysine N-methyltransferase CSKMT,mitochondrial OS=Homo sapiens OX=9606 GN=CSKMT PE=1 SV=1MAALRRMLHLPSLMMGTCRPFAGSLADSCLADRCLWDRLHAQPRLGTVPTFDWFFGYDEVQGLLLPLLQEAQAASPLRVLDVGCGTSSLCTGLYTKSPHPVDVLGVDFSPVAVAHMNSLLEGGPGQTPLCPGHPASSLHFMHADAQNLGAVASSGSFQLLLDKGTWDAVARGGLPRAYQLLSECLRVLNPQGTLIQFSDEDPDVRLPCLEQGSYGWTVTVQELGPFRGITYFAYLIQGSH>sp|Q9BXS0|COPA1_HUMAN Collagen alpha-1(XXV) chain OS=Homo sapiensOX=9606 GN=COL25A1 PE=1 SV=2MLLKKHAGKGGGREPRSEDPTPAEQHCARTMPPCAVLAALLSVVAVVSCLYLGVKTNDLQARIAALESAKGAPSIHLLPDTLDHLKTMVQEKVERLLAQKSYEHMAKIRIAREAPSECNCPAGPPGKRGKRGRRGESGPPGQPGPQGPPGPKGDKGEQGDQGPRMVFPKINHGFLSADQQLIKRRLIKGDQGQAGPPGPPGPPGPRGPPGDTGKDGPRGMPGVPGEPGKPGEQGLMGPLGPPGQKGSIGAPGIPGMNGQKGEPGLPGAVGQNGIPGPKGEPGEQGEKGDAGENGPKGDTGEKGDPGSSAAGIKGEPGESGRPGQKGEPGLPGLPGLPGIKGEPGFIGPQGEPGLPGLPGTKGERGEAGPPGRGERGEPGAPGPKGKQGESGTRGPKGSKGDRGEKGDSGAQGPRGPPGQKGDQGATEIIDYNGNLHEALQRITTLTVTGPPGPPGPQGLQGPKGEQGSPGIPGMDGEQGLKGSKGDMGDPGMTGEKGGIGLPGLPGANGMKGEKGDSGMPGPQGPSIIGPPGPPGPHGPPGPMGPHGLPGPKGTDGPMGPHGPAGPKGERGEKGAMGEPGPRGPYGLPGKDGEPGLDGFPGPRGEKGDLGEKGEKGFRGVKGEKGEPGQPGLDGLDAPCQLGPDGLPMPGCWQK>sp|Q9BXS0-2|COPA1_HUMAN Isoform 2 of Collagen alpha-1(XXV) chain OS=Homosapiens OX=9606 GN=COL25A1MLLKKHAGKGGGREPRSEDPTPAEQHCARTMPPCAVLAALLSVVAVVSCLYLGVKTNDLQARIAALESAKGAPSIHLLPDTLDHLKTMVQEKVERLLAQKSYEHMAKIRIAREAPSECNCPAGPPGKRGKRGRRGESGPPGQPGPQGPPGPKGDKGEQGDQGPRMVFPKINHGFLSADQQLIKRRLIKGDQGQAGPPGPPGPPGPRGPPGDTGKDGPRGMPGVPGEPGKPGEQGLMGPLGPPGQKGSIGAPGIPGMNGQKGEPGLPGAVGQNGIPGPKGEPGEQGEKGDAGENGPKGDTGEKGDPGSSAAGIKGEPGESGRPGQKGEPGLPGLPGLPGIKGEPGFIGPQGEPGLPGLPGTKGERGEAGPPGRGERGEPGAPGPKGKQGESGTRGPKGSKGDRGEKGDSGAQGPRGPPGQKGDQGATEIIDYNGNLHEALQRITTLTVTGPPGPPGPQGLQGPKGEQGSPGIPGMDGEQGLKGSKGDMGDPGMTGEKGGIGLPGLPGANGMKGEKGDSGMPGPQGPSIIGPPGPPGPHGPPGPMGPHGLPGPKGTDGPMGPHGPAGPKGERGEKGAMGEPGPRGPYGLPGKDGEPGLDGFPGPRGEKGDLGEKGEKVTSPSQHVPCLILLLLSALLFSLCDSI>sp|Q9BXS0-3|COPA1_HUMAN Isoform 3 of Collagen alpha-1(XXV) chain OS=Homosapiens OX=9606 GN=COL25A1MLLKKHAGKGGGREPRSEDPTPAEQHCARTMPPCAVLAALLSVVAVVSCLYLGVKTNDLQARIAALESAKGAPSIHLLPDTLDHLKTMVQEKVERLLAQKSYEHMAKIRIAREAPSECNCPAGPPGKRGKRGRRGESGPPGPPGPKGDKGEQGDQGPRMVFPKINHGFLSADQQLIKRRLIKGDQGQAGPPGPPGPPGPRGPPGDTGKDGPRGMPGVPGEPGKPGEQGLMGPLGPPGQKGSIGAPGIPGMNGQKGEPGLPGAVGQNGIPGPKGEPGEQGEKGDAGENGPKGDTGEKGDPGSSAAGIKGEPGESGRPGQKGEPGFIGPQGEPGLPGLPGTKGERGEAGPPGRGERGEPGAPGPKGKQGESGTRGPKGSKGDRGEKGDSGAQGPRGPPGQKGDQGATEIIDYNGNLHEALQRITTLTVTGPPGPPGPQGLQGPKGEQGSPGIPGMDGEQGLKGSKGDMGDPGMTGEKGGIGLPGLPGANGMKGEKGDSGMPGPQGPSIIGPPGPPGPHGPPGPMGPHGLPGPKGTDGPMGPHGPAGPKGERGEKGAMGEPGPRGPYGLPLGPDGLPMPGCWQK>sp|A6NNT2|CP096_HUMAN Uncharacterized protein C16orf96 OS=Homo sapiensOX=9606 GN=C16orf96 PE=4 SV=3MSFSLTFTELANIAIPQCGVLNFKALHLLLHGILEHIHMAELKKVLSGDEDFLQTSQVVIMPREGDAQPILNPMKRLSNVFDHVVSRLDKLENQLALLQDLPSTAQLLEASQGTARPVQDLWHLIKLRKMVEGHDEVMAKSMQTLQDLLTDLHALQVTITALRKEVDMLKNMLDKVHPERMDIFAEDFKIQNWKMVALQREVASLQNKFKTIPKTEDMVLWSGLHDAMFTSEIGSSPLDLWQSVEQLPEAALAQTTKYLEATRAIQVSEPVQNPQLLQTVWHYEVPELLPEGSSAQAVSLSRAQEPAQPPALTPESAPGCTTEFAPGPAPGTEPVPGLELGLELEPVPALGPVPGPSVTPGSLPAPWPVLGPVPAPGAQPPPLGDWPALPRRWPLPQGWPRVGSWPLWDLGVLRPTQPQPSRAPPPATEFGSLWPRPLQPYQSRQGEALQLAAVQVKGEENDVPSLRGLRERARKDGAPKDRTRKDGVPKDRGGKDVDPKDRAHKDDVPKDRGGKDVDPKDRAHKDDVPKDRGGKDGDPKDRVGKDGAPKEAQPKAPQSALHRLKTTAAIAAAAAAAYAAATSSAAQAAKVAAKFVKDAPATKMAAIATDTAAAGPLGVFADVLGAGPSRGATESQILGDDSEIYEILSPSYSAASIGPDPALSQAMVATKQAMSPEDKKRAVKYSMSHIAQIPVKHDSLKEEFAQLSCNLNQRLSYLANMGGPSSLGTTVDILQKKIGSLQKSRLKEEELERIWGNQIEMMKDRYITLDKAVENLQIRMDEFKTLQAQIKRLEMNKVNKSTMEEELREKADRSALAGKASRVDLETVALELNEMIQGILFKVTIHEDSWKKAMEELSKDVNTKLVHSDLDPLKKEMEEVWKIVRKLLIEGLRLDPDSAAGFRRKLFKRVKCISCDRPVEMMTGPQLITIRKAHLLSRLRPASANSCEYLQRQQMREQQWLQLQDLGIQEDCQQDWGDGPQNATSLKCKSCNLLTLYPYGDPHVIDYDSAEVDILGVDGILYKGRVNSQRGAQPLAVAKELAAVKAPSPPSQSLYDRVHSSALFGAICPPLCPRSSACSAASGPHLTMPARPPSLPPLLLLPPLIPSLRDPQQAPGSTRLSRAPHIESRVGRKPPEEPANP>sp|O75208|COQ9_HUMAN Ubiquinone biosynthesis protein COQ9, mitochondrialOS=Homo sapiens OX=9606 GN=COQ9 PE=1 SV=1MAAAAVSGALGRAGWRLLQLRCLPVARCRQALVPRAFHASAVGLRSSDEQKQQPPNSFSQQHSETQGAEKPDPESSHSPPRYTDQGGEEEEDYESEEQLQHRILTAALEFVPAHGWTAEAIAEGAQSLGLSSAAASMFGKDGSELILHFVTQCNTRLTRVLEEEQKLVQLGQAEKRKTDQFLRDAVETRLRMLIPYIEHWPRALSILMLPHNIPSSLSLLTSMVDDMWHYAGDQSTDFNWYTRRAMLAAIYNTTELVMMQDSSPDFEDTWRFLENRVNDAMNMGHTAKQVKSTGEALVQGLMGAAVTLKNLTGLNQRR>sp|O75208-2|COQ9_HUMAN Isoform 2 of Ubiquinone biosynthesis proteinCOQ9, mitochondrial OS=Homo sapiens OX=9606 GN=COQ9MAAAAVSGALGRAGWRLLQLRCLPVARCRQALVPRAFHASAVGLRSSDEQKQQPPNSFSQQHSETQGAEKPDPESSHSPPRYTDQGGEEEEDYESEEQLQHRILTAALEFVPAHGWTAEAIAEGAQVCIGEGGAT>sp|P07316|CRGB_HUMAN Gamma-crystallin B OS=Homo sapiens OX=9606 GN=CRYGBPE=1 SV=3MGKITFYEDRAFQGRSYECTTDCPNLQPYFSRCNSIRVESGCWMIYERPNYQGHQYFLRRGEYPDYQQWMGLSDSIRSCCLIPPHSGAYRMKIYDRDELRGQMSELTDDCISVQDRFHLTEIHSLNVLEGSWILYEMPNYRGRQYLLRPGEYRRFLDWGAPNAKVGSLRRVMDLY>sp|Q494V2|CP100_HUMAN Cilia- and flagella-associated protein 100 OS=Homosapiens OX=9606 GN=CFAP100 PE=1 SV=1MSEIPSTIVSKNMTNDKNSLESMNISSSSSTEENPKKQARKNEEHGPDPSANPFHLSGDVDFFLLRDQERNKALSERQQQKTMRVHQKMTYSSKVSAKHTSLRRQLQLEDKQEDLEARAEAEHQRAFRDYTTWKLTLTKEKNVEPENMSGYIKQKRQMFLLQYALDVKRREIQRLETLATKEEARLERAEKSLEKDAALFDEFVRENDCSSVQAMRAAEKETKAKIEKILEIRDLTTQIVNIKSEISRFEDTLKHYKVYKDFLYKLSPKEWLEEQEKKHSFLKKAKEVSEASKESSVNSTPGDKGPGIKGKASSMWAKEGQGTKKPWRFLQTMRLGRSPSYLSSPQQGSQPSESSGGDSRGSNSPIPPTQEDTDSDGEEPQLYFTEPQQLLDVFRELEEQNLSLIQNSQETEKTLEELSHTLKHTQIRMDREVNQLKQWVTTMMMSITKEEDTAAELELKARVFHFGEYKGDQQDKLLESLNCKVLDVYRHCTGTQQEANLGTVQMLTIIEHQLDELLENLEHVPQVKIEQAERAKEKERRIRLREEKLQMQKILQEEHLQRARARAQAEIKKKRGRTLVCRSRPPAHRIKQQSEHTLMDKEEEELLFFFT>sp|Q494V2-2|CP100_HUMAN Isoform 2 of Cilia- and flagella-associatedprotein 100 OS=Homo sapiens OX=9606 GN=CFAP100MSEIPSTIVSKNMTNDKNSLESMNISSSSSTEENPKKQARKNEEHGPDPSANPFHLSGDVDFFLLRDQERNKALSERQQQKTMRVHQKMTYSSKVSAKHTSLRRQLQLEDKQEDLEARAEAEHQRAFRDYTTWKLTLTKAEKNVEPENMSGYIKQKRQMFLLQYALDVKRREIQRLETLATKEEARLERAEKSLEKDAALFDEFVRENDCSSVQAMRAAEKETKAKIEKILEIRDLTTQIVNIKSEISRFEDTLKHYKVYKDFLYKLSPKEWLEEQEKKHSFLKKAKEVSEASKESSVNSTPGDKGPGIKGKASSMWAKEGQGTKKPWRFLQTMRLGRSPSYLSSPQQGSQPSESSGGDSRGSNSPIPPTQEDTDSDGEEPQLYFTEPQQLLDVFRELEEQNLSLIQNSQETEKTLEELSHTLKHTQIRMDREVNQLKQWVTTMMMSITKEEDTAAELELKARVFHFGEYKGDQQDKLLESLNCKVLDVYRHCTGTQQEANLGTVQMLTIIEHQLDELLENLEHVPQVKIEQAERAKEKERRIRLREEKLQMQKILQEEHLQRARARAQAEIKKKRGRTLVCRSRPPAHRIKQQSEHTLMDKEEEELLFFFT>sp|Q8TDH9|BL1S5_HUMAN Biogenesis of lysosome-related organelles complex1 subunit 5 OS=Homo sapiens OX=9606 GN=BLOC1S5 PE=1 SV=1MSGGGTETPVGCEAAPGGGSKKRDSLGTAGSAHLIIKDLGEIHSRLLDHRPVIQGETRYFVKEFEEKRGLREMRVLENLKNMIHETNEHTLPKCRDTMRDSLSQVLQRLQAANDSVCRLQQREQERKKIHSDHLVASEKQHMLQWDNFMKEQPNKRAEVDEEHRKAMERLKEQYAEMEKDLAKFSTF>sp|Q8TDH9-2|BL1S5_HUMAN Isoform 2 of Biogenesis of lysosome-relatedorganelles complex 1 subunit 5 OS=Homo sapiens OX=9606 GN=BLOC1S5MSGGGTETPVGCEAAPGGGSKKRDSLGTAGSAHLIIKDLGEIHSRLLDHRPVIQGETRYFVKEFEEKRGLREMRVLENLKNMIHETNEHTLPKCRDTMRDSLSQVLQRYS>sp|Q8TDH9-3|BL1S5_HUMAN Isoform 3 of Biogenesis of lysosome-relatedorganelles complex 1 subunit 5 OS=Homo sapiens OX=9606 GN=BLOC1S5MEKRGLREMRVLENLKNMIHETNEHTLPKCRDTMRDSLSQVLQRLQAANDSVCRLQQREQERKKIHSDHLVASEKQHMLQWDNFMKEQPNKRAEVDEEHRKAMERLKEQYAEMEKDLAKFSTF>sp|Q96A83|COQA1_HUMAN Collagen alpha-1(XXVI) chain OS=Homo sapiensOX=9606 GN=COL26A1 PE=1 SV=1MKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSETVVQRVYQSCRWPGPCANLVSYRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEECMNCTRLSDMSERLTTLEAKVLLLEAAERPSSPDNDLPAPESTPPTWNEDFLPDAIPLAHPVPRQRRPTGPAGPPGQTGPPGPAGPPGSKGDRGQTGEKGPAGPPGLLGPPGPRGLPGEMGRPGPPGPPGPAGNPGPSPNSPQGALYSLQPPTDKDNGDSRLASAIVDTVLAGVPGPRGPPGPPGPPGPRGPPGPPGTPGSQGLAGERGTVGPSGEPGVKGEEGEKAATAEGEGVQQLREALKILAERVLILEHMIGIHDPLASPEGGSGQDAALRANLKMKRGGAQPDGVLAALLGPDPGQKSVDQASSRK>sp|Q96A83-2|COQA1_HUMAN Isoform 2 of Collagen alpha-1(XXVI) chainOS=Homo sapiens OX=9606 GN=COL26A1MKLALLLPWACCCLCGSALATGFLYPFSAAALQQHGYPEPGAGSPGSGYASRRHWCHHTVTRTVSCQVQNGSETVVQRVYQSCRWPGPCANLVRTLIRPTYRVSYRTVTVLEWRCCPGFTGSNCDEECMNCTRLSDMSERLTTLEAKVLLLEAAERPSSPDNDLPAPESTPPTWNEDFLPDAIPLAHPVPRQRRPTGPAGPPGQTGPPGPAGPPGSKGDRGQTGEKGPAGPPGLLGPPGPRGLPGEMGRPGPPGPPGPAGNPGPSPNSPQGALYSLQPPTDKDNGDSRLASAIVDTVLAGVPGPRGPPGPPGPPGPRGPPGPPGTPGSQGLAGERGTVGPSGEPGVKGEEGEKAATAEGEGVQQLREALKILAERVLILEHMIGIHDPLASPEGGSGQDAALRANLKMKRGGAQPDGVLAALLGPDPGQKSVDQASSRK>sp|Q8N9N5|BANP_HUMAN Protein BANP OS=Homo sapiens OX=9606 GN=BANP PE=1SV=3MMSEHDLADVVQIAVEDLSPDHPVVLENHVVTDEDEPALKRQRLEINCQDPSIKTICLRLDSIEAKLQALEATCKSLEEKLDLVTNKQHSPIQVPMVAGSPLGATQTCNKVRCVVPQTTVILNNDRQNAIVAKMEDPLSNRAPDSLENVISNAVPGRRQNTIVVKVPGQEDSHHEDGESGSEASDSVSSCGQAGSQSIGSNVTLITLNSEEDYPNGTWLGDENNPEMRVRCAIIPSDMLHISTNCRTAEKMALTLLDYLFHREVQAVSNLSGQGKHGKKQLDPLTIYGIRCHLFYKFGITESDWYRIKQSIDSKCRTAWRRKQRGQSLAVKSFSRRTPNSSSYCPSEPMMSTPPPASELPQPQPQPQALHYALANAQQVQIHQIGEDGQVQVGHLHIAQVPQGEQVQITQDSEGNLQIHHVGQDGQLLEATRIPCLLAPSVFKASSGQVLQGAQLIAVASSDPAAAGVDGSPLQGSDIQVQYVQLAPVSDHTAGAQTAEALQPTLQPEMQLEHGAIQIQ>sp|Q8N9N5-2|BANP_HUMAN Isoform 2 of Protein BANP OS=Homo sapiens OX=9606GN=BANPMMSEHDLADVVQIAVEDLSPDHPVVLENHVVTDEDEPALKRQRLEINCQDPSIKSFLYSINQTICLRLDSIEAKLQALEATCKSLEEKLDLVTNKQHSPIQVPMVAGSPLGATQTCNKVRCAVPGRRQNTIVVKVPGQEDSHHEDGESGSEASDSVSSCGQAGSQSIGSNVTLITLNSEEDYPNGTWLGDENNPEMRVRCAIIPSDMLHISTNCRTAEKMALTLLDYLFHREVQAVSNLSGQGKHGKKQLDPLTIYGIRCHLFYKFGITESDWYRIKQSIDSKCRTAWRRKQRGQSLAVKSFSRRTPNSSSYCPSEPMMSTPPPASELPQPQPQPQALHYALANAQQVQIHQIGEDGQVQVIPQGHLHIAQVPQGEQVQITQDSEGNLQIHHVGQDGQVLQGAQLIAVASSDPAAAGVDGSPLQGSDIQVQYVQLAPVSDHTAGAQTAEALQPTLQPEMQLEHGAIQIQ>sp|Q8N9N5-3|BANP_HUMAN Isoform 3 of Protein BANP OS=Homo sapiens OX=9606GN=BANPMTREFVKRSIFLPALKRQRLEINCQDPSIKSFLYSINQTICLRLDSIEAKLQALEATCKSLEEKLDLVTNKQHSPIQVPMVAGSPLGATQTCNKVRCAVPGRRQNTIVVKVPGQEDSHHEDGESGSEASDSVSSCGQAGSQSIGSNVTLITLNSEEDYPNGTWLGDENNPEMRVRCAIIPSDMLHISTNCRTAEKMALTLLDYLFHREVQAVSNLSGQGKHGKKQLDPLTIYGIRCHLFYKFGITESDWYRIKQSIDSKCRTAWRRKQRGQSLAVKSFSRRTPNSSSYCPSEPMMSTPPPASELPQPQPQPQALHYALANAQQVQIHQIGEDGQVQVGHLHIAQVPQGEQVQITQDSEGNLQIHHVGQDGQVLQGAQLIAVASSDPAAAGVDGSPLQGSDIQVQYVQLAPVSDHTAGAQTAEALQPTLQPEMQLEHGAIQIQ>sp|Q8N9N5-4|BANP_HUMAN Isoform 4 of Protein BANP OS=Homo sapiens OX=9606GN=BANPMMSEHDLADVVQIAVEDLSPDHPVVLENHVVTDEDEPALKRQRLEINCQDPSIKSFLYSINQTICLRLDSIEAKLQALEATCKSLEEKLDLVTNKQHSPIQVPMVAGSPLGATQTCNKVRCAVPGRRQNTIVVKVPGQEDSHHEDGESGSEASDSVSSCGQAGSQSIGSNVTLITLNSEEDYPNGTWLGDENNPEMRVRCAIIPSDMLHISTNCRTAEKMALTLLDYLFHREVQAVSNLSGQGKHGKKQLDPLTIYGIRCHLFYKFGITESDWYRIKQSIDSKCRTAWRRKQRGQSLAVKSFSRRTPNSSSYCPSEPMMSTPPPASELPQPQPQPQALHYALANAQQVQIHQIGEDGQVQVIPQGHLHIAQVPQGEQVQITQDSEGNLQIHHVGQDGQLLEATRIPCLLAPSVFKASSGQVLQGAQLIAVASSDPAAAGVDGSPLQGSDIQVQYVQLAPVSDHTAGAQTAEALQPTLQPEMQLEHGAIQIQ>sp|Q8N9N5-5|BANP_HUMAN Isoform 5 of Protein BANP OS=Homo sapiens OX=9606GN=BANPMMSEHDLADVVQIAVEDLSPDHPGTELWDIVLENHVVTDEDEPALKRQRLEINCQDPSIKSFLYSINQTICLRLDSIEAKLQALEATCKSLEEKLDLVTNKQHSPIQVPMVAGSPLGATQTCNKVRCAVPGRRQNTIVVKVPGQEDSHHEDGESGSEASDSVSSCGQAGSQSIGSNVTLITLNSEEDYPNGTWLGDENNPEMRVRCAIIPSDMLHISTNCRTAEKMALTLLDYLFHREVQAVSNLSGQGKHGKKQLDPLTIYGIRCHLFYKFGITESDWYRIKQSIDSKCRTAWRRKQRGQSLAVKSFSRRTPNSSSYCPSEPMMSTPPPASELPQPQPQPQALHYALANAQQVQIHQIGEDGQVQVIPQGHLHIAQVPQGEQVQITQDSEGNLQIHHVGQDGQLLEATRIPCLLAPSVFKASSGQVLQGAQLIAVASSDPAAAGVDGSPLQGSDIQVQYVQLAPVSDHTAGAQTAEALQPTLQPEMQLEHGAIQIQ>sp|Q8N9N5-6|BANP_HUMAN Isoform 6 of Protein BANP OS=Homo sapiens OX=9606GN=BANPMMSEHDLADVVQIAVEDLSPDHPVVLENHVVTDEDEPALKRQRLEINCQDPSIKSFLYSINQTICLRLDSIEAKLQALEATCKSLEEKLDLVTNKQHSPIQVPMVAGSPLGATQTCNKVRCAVPGRRQNTIVVKVPGQEDSHHEDGESGSEASDSVSSCGQAGSQSIGSNVTLITLNSEEDYPNGTWLGDENNPEMRVRCAIIPSDMLHISTNCRTAEKMALTLLDYLFHREVQAVSNLSGQGKHGKKQLDPLTIYGIRCHLFYKFGITESDWYRIKQSIDSKCRTAWRRKQRGQSLAVKSFSRRTPNSSSYCPSEPMMSTPPPASELPQPQPQPQALHYALANAQQVQIHQIGEDGQVQVGHLHIAQVPQGEQVQITQDSEGNLQIHHVGQDGQVLQGAQLIAVASSDPAAAGVDGSPLQGSDIQVQYVQLAPVSDHTAGAQTAEALQPTLQPEMQLEHGAIQIQ>sp|Q8N9N5-7|BANP_HUMAN Isoform 7 of Protein BANP OS=Homo sapiens OX=9606GN=BANPMMSEHDLADVVQIAVEDLSPDHPVVLENHVVTDEDEPALKRQRLEINCQDPSIKSFLYSINQTICLRLDSIEAKLQALEATCKSLEEKLDLVTNKQHSPIQVPMVAGSPLGATQTCNKVRCVVPQTTVILNNDRQNAIVAKMEDPLSNRAPDSLENVISNAVPGRRQNTIVVKVPGQEDSHHEDGESGSEASDSVSSCGQAGSQSIGSNVTLITLNSEEDYPNGTWLGDENNPEMRVRCAIIPSDMLHISTNCRTAEKMALTLLDYLFHREVQAVSNLSGQGKHGKKQLDPLTIYGIRCHLFYKFGITESDWYRIKQSIDSKCRTAWRRKQRGQSLAVKSFSRRTPNSSSYCPSEPMMSTPPPASELPQPQPQPQALHYALANAQQVQIHQIGEDGQVQVIPQGHLHIAQVPQGEQVQITQDSEGNLQIHHVGQDGQVLQGAQLIAVASSDPAAAGVDGSPLQGSDIQVQYVQLAPVSDHTAGAQTAEALQPTLQPEMQLEHGAIQIQ>sp|P50238|CRIP1_HUMAN Cysteine-rich protein 1 OS=Homo sapiens OX=9606GN=CRIP1 PE=1 SV=3MPKCPKCNKEVYFAERVTSLGKDWHRPCLKCEKCGKTLTSGGHAEHEGKPYCNHPCYAAMFGPKGFGRGGAESHTFK>sp|P59051|BRAS2_HUMAN Putative uncharacterized protein encoded by BRWD1-AS2 OS=Homo sapiens OX=9606 GN=BRWD1-AS2 PE=5 SV=1MLGWIQPSRQPQLRAAPPTRTPSAKRCILCNFLPGCWLVGDVAGSRQPSAPQTLRQRQHTRPPPQERGSGRRSPLREARRANPHFKSFPVLEARGLPCGARRTGPRRPVREMTLPSDPERATLPNPRLGAPAVPRRGPRSHGGRR>sp|Q86UP6|CUZD1_HUMAN CUB and zona pellucida-like domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=CUZD1 PE=2 SV=1MELVRRLMPLTLLILSCLAELTMAEAEGNASCTVSLGGANMAETHKAMILQLNPSENCTWTIERPENKSIRIIFSYVQLDPDGSCESENIKVFDGTSSNGPLLGQVCSKNDYVPVFESSSSTLTFQIVTDSARIQRTVFVFYYFFSPNISIPNCGGYLDTLEGSFTSPNYPKPHPELAYCVWHIQVEKDYKIKLNFKEIFLEIDKQCKFDFLAIYDGPSTNSGLIGQVCGRVTPTFESSSNSLTVVLSTDYANSYRGFSASYTSIYAENINTTSLTCSSDRMRVIISKSYLEAFNSNGNNLQLKDPTCRPKLSNVVEFSVPLNGCGTIRKVEDQSITYTNIITFSASSTSEVITRQKQLQIIVKCEMGHNSTVEIIYITEDDVIQSQNALGKYNTSMALFESNSFEKTILESPYYVDLNQTLFVQVSLHTSDPNLVVFLDTCRASPTSDFASPTYDLIKSGCSRDETCKVYPLFGHYGRFQFNAFKFLRSMSSVYLQCKVLICDSSDHQSRCNQGCVSRSKRDISSYKWKTDSIIGPIRLKRDRSASGNSGFQHETHAEETPNQPFNSVHLFSFMVLALNVVTVATITVRHFVNQRADYKYQKLQNY>sp|Q86UP6-2|CUZD1_HUMAN Isoform 2 of CUB and zona pellucida-like domain-containing protein 1 OS=Homo sapiens OX=9606 GN=CUZD1MRVIISKSYLEAFNSNGNNLQLKDPTCRPKLSNVVEFSVPLNGCGTIRKVEDQSITYTNIITFSASSTSEVITRQKQLQIIVKCEMGHNSTVEIIYITEDDVIQSQNALGKYNTSMALFESNSFEKTILESPYYVDLNQTLFVQVSLHTSDPNLVVFLDTCRASPTSDFASPTYDLIKSGCSRDETCKVYPLFGHYGRFQFNAFKFLRSMSSVYLQCKVLICDSSDHQSRCNQGCVSRSKRDISSYKWKTDSIIGPIRLKRDRSASGNSGFQHETHAEETPNQPFNSVHLFSFMVLALNVVTVATITVRHFVNQRADYKYQKLQNY>sp|Q86UP6-3|CUZD1_HUMAN Isoform 3 of CUB and zona pellucida-like domain-containing protein 1 OS=Homo sapiens OX=9606 GN=CUZD1MGHNSTVEIIYITEDDVIQSQNALGKYNTSMALFESNSFEKTILESPYYVDLNQTLFVQVSLHTSDPNLVVFLDTCRASPTSDFASPTYDLIKSGCSRDETCKVYPLFGHYGRFQFNAFKFLRSMSSVYLQCKVLICDSSDHQSRCNQGCVSRSKRDISSYKWKTDSIIGPIRLKRDRSASGNSGFQHETHAEETPNQPFNSVHLFSFMVLALNVVTVATITVRHFVNQRADYKYQKLQNY>sp|P56545|CTBP2_HUMAN C-terminal-binding protein 2 OS=Homo sapiensOX=9606 GN=CTBP2 PE=1 SV=1MALVDKHKVKRQRLDRICEGIRPQIMNGPLHPRPLVALLDGRDCTVEMPILKDLATVAFCDAQSTQEIHEKVLNEAVGAMMYHTITLTREDLEKFKALRVIVRIGSGYDNVDIKAAGELGIAVCNIPSAAVEETADSTICHILNLYRRNTWLYQALREGTRVQSVEQIREVASGAARIRGETLGLIGFGRTGQAVAVRAKAFGFSVIFYDPYLQDGIERSLGVQRVYTLQDLLYQSDCVSLHCNLNEHNHHLINDFTIKQMRQGAFLVNAARGGLVDEKALAQALKEGRIRGAALDVHESEPFSFAQGPLKDAPNLICTPHTAWYSEQASLEMREAAATEIRRAITGRIPESLRNCVNKEFFVTSAPWSVIDQQAIHPELNGATYRYPPGIVGVAPGGLPAAMEGIIPGGIPVTHNLPTVAHPSQAPSPNQPTKHGDNREHPNEQ>sp|P56545-2|CTBP2_HUMAN Isoform 2 of C-terminal-binding protein 2OS=Homo sapiens OX=9606 GN=CTBP2MPVPSRHINIGRSQSWDAAGWYEGPWENAESLRPLGRRSSLTYGTAEGTWFEPNHRPQDAALPVAAEPYLYREAVYNSVAARKGSTPDFTFYDSRQAVMSGRSPLLPREYYSDPSGAARVPKEPPLYRDPGVSRPVPSYGVLGSRTSWDPMQGRSPALQDAGHLYRDPGGKMIPQGRQTQSRAASPGRYGREQPDTRYGAEVPAYPLSQVFSDISERPIDPAPARQVAPTCLVVDPSSAAAPEGSTGVAPGALNRGYGPARESIPSKMAYETYEADLSTFQGPGGKRTVLPEFLAFLRAEGLAEATLGALLQQGFDSPAVLATLEDADIKSVAPNLGQARVLSRLANSCRTEMQLRRQDRGGPLPRARSSSFSHRSELLHGDLASLGAAAPLQTASPRAGDPARRPSSAPSQHLLETAATYSAPGVGTHAPHFPSNSGYSSPTPCALTARLSPTYPLQAGVALTNPGPSNPLHPGPRTAYSTAYTVPMELLKRERNVAASPLPSPHGSPQVLRKPGAPLGPSTLPPASQSLHTPHSPYQKVARRTGAPIIVSTMLAPEPSIRPQIMNGPLHPRPLVALLDGRDCTVEMPILKDLATVAFCDAQSTQEIHEKVLNEAVGAMMYHTITLTREDLEKFKALRVIVRIGSGYDNVDIKAAGELGIAVCNIPSAAVEETADSTICHILNLYRRNTWLYQALREGTRVQSVEQIREVASGAARIRGETLGLIGFGRTGQAVAVRAKAFGFSVIFYDPYLQDGIERSLGVQRVYTLQDLLYQSDCVSLHCNLNEHNHHLINDFTIKQMRQGAFLVNAARGGLVDEKALAQALKEGRIRGAALDVHESEPFSFAQGPLKDAPNLICTPHTAWYSEQASLEMREAAATEIRRAITGRIPESLRNCVNKEFFVTSAPWSVIDQQAIHPELNGATYRYPPGIVGVAPGGLPAAMEGIIPGGIPVTHNLPTVAHPSQAPSPNQPTKHGDNREHPNEQ>sp|P56545-3|CTBP2_HUMAN Isoform 3 of C-terminal-binding protein 2OS=Homo sapiens OX=9606 GN=CTBP2MRPGLPGPTGLCAQTSSRGQKSVLKQKESCGIWQLYHFLSRKQEPRWEPCVSGSSSGDGAVADLADELRGYPALCCTLPVHSYRSWAGIRPQIMNGPLHPRPLVALLDGRDCTVEMPILKDLATVAFCDAQSTQEIHEKVLNEAVGAMMYHTITLTREDLEKFKALRVIVRIGSGYDNVDIKAAGELGIAVCNIPSAAVEETADSTICHILNLYRRNTWLYQALREGTRVQSVEQIREVASGAARIRGETLGLIGFGRTGQAVAVRAKAFGFSVIFYDPYLQDGIERSLGVQRVYTLQDLLYQSDCVSLHCNLNEHNHHLINDFTIKQMRQGAFLVNAARGGLVDEKALAQALKEGRIRGAALDVHESEPFSFAQGPLKDAPNLICTPHTAWYSEQASLEMREAAATEIRRAITGRIPESLRNCVNKEFFVTSAPWSVIDQQAIHPELNGATYRYPPGIVGVAPGGLPAAMEGIIPGGIPVTHNLPTVAHPSQAPSPNQPTKHGDNREHPNEQ>sp|P48751|B3A3_HUMAN Anion exchange protein 3 OS=Homo sapiens OX=9606GN=SLC4A3 PE=1 SV=2MANGVIPPPGGASPLPQVRVPLEEPPLSPDVEEEDDDLGKTLAVSRFGDLISKPPAWDPEKPSRSYSERDFEFHRHTSHHTHHPLSARLPPPHKLRRLPPTSARHTRRKRKKEKTSAPPSEGTPPIQEEGGAGVDEEEEEEEEEEGESEAEPVEPPHSGTPQKAKFSIGSDEDDSPGLPGRAAVTKPLPSVGPHTDKSPQHSSSSPSPRARASRLAGEKSRPWSPSASYDLRERLCPGSALGNPGGPEQQVPTDEAEAQMLGSADLDDMKSHRLEDNPGVRRHLVKKPSRTQGGRGSPSGLAPILRRKKKKKKLDRRPHEVFVELNELMLDRSQEPHWRETARWIKFEEDVEEETERWGKPHVASLSFRSLLELRRTIAHGAALLDLEQTTLPGIAHLVVETMIVSDQIRPEDRASVLRTLLLKHSHPNDDKDSGFFPRNPSSSSMNSVLGNHHPTPSHGPDGAVPTMADDLGEPAPLWPHDPDAKEKPLHMPGGDGHRGKSLKLLEKIPEDAEATVVLVGCVPFLEQPAAAFVRLNEAVLLESVLEVPVPVRFLFVMLGPSHTSTDYHELGRSIATLMSDKLFHEAAYQADDRQDLLSAISEFLDGSIVIPPSEVEGRDLLRSVAAFQRELLRKRREREQTKVEMTTRGGYTAPGKELSLELGGSEATPEDDPLLRTGSVFGGLVRDVRRRYPHYPSDLRDALHSQCVAAVLFIYFAALSPAITFGGLLGEKTEGLMGVSELIVSTAVLGVLFSLLGAQPLLVVGFSGPLLVFEEAFFKFCRAQDLEYLTGRVWVGLWLVVFVLALVAAEGSFLVRYISPFTQEIFAFLISLIFIYETFYKLYKVFTEHPLLPFYPPEGALEGSLDAGLEPNGSALPPTEGPPSPRNQPNTALLSLILMLGTFFIAFFLRKFRNSRFLGGKARRIIGDFGIPISILVMVLVDYSITDTYTQKLTVPTGLSVTSPDKRSWFIPPLGSARPFPPWMMVAAAVPALLVLILIFMETQITALIVSQKARRLLKGSGFHLDLLLIGSLGGLCGLFGLPWLTAATVRSVTHVNALTVMRTAIAPGDKPQIQEVREQRVTGVLIASLVGLSIVMGAVLRRIPLAVLFGIFLYMGVTSLSGIQLSQRLLLILMPAKHHPEQPYVTKVKTWRMHLFTCIQLGCIALLWVVKSTAASLAFPFLLLLTVPLRHCLLPRLFQDRELQALDSEDAEPNFDEDGQDEYNELHMPV>sp|P48751-2|B3A3_HUMAN Isoform CAE3 of Anion exchange protein 3 OS=Homosapiens OX=9606 GN=SLC4A3MPAGLAPILRRKKKKKKLDRRPHEVFVELNELMLDRSQEPHWRETARWIKFEEDVEEETERWGKPHVASLSFRSLLELRRTIAHGAALLDLEQTTLPGIAHLVVETMIVSDQIRPEDRASVLRTLLLKHSHPNDDKDSGFFPRNPSSSSMNSVLGNHHPTPSHGPDGAVPTMADDLGEPAPLWPHDPDAKEKPLHMPGGDGHRGKSLKLLEKIPEDAEATVVLVGCVPFLEQPAAAFVRLNEAVLLESVLEVPVPVRFLFVMLGPSHTSTDYHELGRSIATLMSDKLFHEAAYQADDRQDLLSAISEFLDGSIVIPPSEVEGRDLLRSVAAFQRELLRKRREREQTKVEMTTRGGYTAPGKELSLELGGSEATPEDDPLLRTGSVFGGLVRDVRRRYPHYPSDLRDALHSQCVAAVLFIYFAALSPAITFGGLLGEKTEGLMGVSELIVSTAVLGVLFSLLGAQPLLVVGFSGPLLVFEEAFFKFCRAQDLEYLTGRVWVGLWLVVFVLALVAAEGSFLVRYISPFTQEIFAFLISLIFIYETFYKLYKVFTEHPLLPFYPPEGALEGSLDAGLEPNGSALPPTEGPPSPRNQPNTALLSLILMLGTFFIAFFLRKFRNSRFLGGKARRIIGDFGIPISILVMVLVDYSITDTYTQKLTVPTGLSVTSPDKRSWFIPPLGSARPFPPWMMVAAAVPALLVLILIFMETQITALIVSQKARRLLKGSGFHLDLLLIGSLGGLCGLFGLPWLTAATVRSVTHVNALTVMRTAIAPGDKPQIQEVREQRVTGVLIASLVGLSIVMGAVLRRIPLAVLFGIFLYMGVTSLSGIQLSQRLLLILMPAKHHPEQPYVTKVKTWRMHLFTCIQLGCIALLWVVKSTAASLAFPFLLLLTVPLRHCLLPRLFQDRELQALDSEDAEPNFDEDGQDEYNELHMPV>sp|P48751-3|B3A3_HUMAN Isoform 3 of Anion exchange protein 3 OS=Homosapiens OX=9606 GN=SLC4A3MANGVIPPPGGASPLPQVRVPLEEPPLSPDVEEEDDDLGKTLAVSRFGDLISKPPAWDPEKPSRSYSERDFEFHRHTSHHTHHPLSARLPPPHKLRRLPPTSARHTRRKRKKEKTSAPPSEGTPPIQEEGGAGVDEEEEEEEEEEGESEAEPVEPPHSGTPQKAKFSIGSDEDDSPGLPGRAAVTKPLPSVGPHTDKSPQHSSRPCSELRDGDGTTDLALSSPRLLCCLPSSPSPRARASRLAGEKSRPWSPSASYDLRERLCPGSALGNPGGPEQQVPTDEAEAQMLGSADLDDMKSHRLEDNPGVRRHLVKKPSRTQGGRGSPSGLAPILRRKKKKKKLDRRPHEVFVELNELMLDRSQEPHWRETARWIKFEEDVEEETERWGKPHVASLSFRSLLELRRTIAHGAALLDLEQTTLPGIAHLVVETMIVSDQIRPEDRASVLRTLLLKHSHPNDDKDSGFFPRNPSSSSMNSVLGNHHPTPSHGPDGAVPTMADDLGEPAPLWPHDPDAKEKPLHMPGGDGHRGKSLKLLEKIPEDAEATVVLVGCVPFLEQPAAAFVRLNEAVLLESVLEVPVPVRFLFVMLGPSHTSTDYHELGRSIATLMSDKLFHEAAYQADDRQDLLSAISEFLDGSIVIPPSEVEGRDLLRSVAAFQRELLRKRREREQTKVEMTTRGGYTAPGKELSLELGGSEATPEDDPLLRTGSVFGGLVRDVRRRYPHYPSDLRDALHSQCVAAVLFIYFAALSPAITFGGLLGEKTEGLMGVSELIVSTAVLGVLFSLLGAQPLLVVGFSGPLLVFEEAFFKFCRAQDLEYLTGRVWVGLWLVVFVLALVAAEGSFLVRYISPFTQEIFAFLISLIFIYETFYKLYKVFTEHPLLPFYPPEGALEGSLDAGLEPNGSALPPTEGPPSPRNQPNTALLSLILMLGTFFIAFFLRKFRNSRFLGGKARRIIGDFGIPISILVMVLVDYSITDTYTQKLTVPTGLSVTSPDKRSWFIPPLGSARPFPPWMMVAAAVPALLVLILIFMETQITALIVSQKARRLLKGSGFHLDLLLIGSLGGLCGLFGLPWLTAATVRSVTHVNALTVMRTAIAPGDKPQIQEVREQRVTGVLIASLVGLSIVMGAVLRRIPLAVLFGIFLYMGVTSLSGIQLSQRLLLILMPAKHHPEQPYVTKVKTWRMHLFTCIQLGCIALLWVVKSTAASLAFPFLLLLTVPLRHCLLPRLFQDRELQALDSEDAEPNFDEDGQDEYNELHMPV>sp|Q8WVV5|BT2A2_HUMAN Butyrophilin subfamily 2 member A2 OS=Homo sapiensOX=9606 GN=BTN2A2 PE=1 SV=2MEPAAALHFSLPASLLLLLLLLLLSLCALVSAQFTVVGPANPILAMVGENTTLRCHLSPEKNAEDMEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRITFVSKDINRGSVALVIHNVTAQENGIYRCYFQEGRSYDEAILRLVVAGLGSKPLIEIKAQEDGSIWLECISGGWYPEPLTVWRDPYGEVVPALKEVSIADADGLFMVTTAVIIRDKYVRNVSCSVNNTLLGQEKETVIFIPESFMPSASPWMVALAVILTASPWMVSMTVILAVFIIFMAVSICCIKKLQREKKILSGEKKVEQEEKEIAQQLQEELRWRRTFLHAADVVLDPDTAHPELFLSEDRRSVRRGPYRQRVPDNPERFDSQPCVLGWESFASGKHYWEVEVENVMVWTVGVCRHSVERKGEVLLIPQNGFWTLEMFGNQYRALSSPERILPLKESLCRVGVFLDYEAGDVSFYNMRDRSHIYTCPRSAFTVPVRPFFRLGSDDSPIFICPALTGASGVMVPEEGLKLHRVGTHQSL>sp|Q8WVV5-2|BT2A2_HUMAN Isoform 2 of Butyrophilin subfamily 2 member A2OS=Homo sapiens OX=9606 GN=BTN2A2MEPAAALHFSLPASLLLLLLLLLLSLCALVSAQFTVVGPANPILAMVGENTTLRCHLSPEKNAEDMEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRITFVSKDINRGSVALVIHNVTAQENGIYRCYFQEGRSYDEAILRLVVAGLGSKPLIEIKAQEDGSIWLECISGGWYPEPLTVWRDPYGEVVPALKEVSIADADGLFMVTTAVIIRDKYVRNVSCSVNNTLLGQEKETVIFIPESFMPSASPWMVALAVILTASPWMVSMTVILAVFIIFMAVSICCIKKLQREKKILSGEKKVEQEEKEIAQQLQEELRWRRTFLHADVNLTGLRNT>sp|Q8WVV5-3|BT2A2_HUMAN Isoform 3 of Butyrophilin subfamily 2 member A2OS=Homo sapiens OX=9606 GN=BTN2A2MEPAAALHFSLPASLLLLLLLLLLSLCALVSAQFTVVGPANPILAMVGENTTLRCHLSPEKNAEDMEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRITFVSKDINRGSVALVIHNVTAQENGIYRCYFQEGRSYDEAILRLVVAESFMPSASPWMVALAVILTASPWMVSMTVILAVFIIFMAVSICCIKKLQREKKILSGEKKVEQEEKEIAQQLQEELRWRRTFLHAGYELPGIRGPSWKRPLHGEPPSAF>sp|Q8WVV5-4|BT2A2_HUMAN Isoform 4 of Butyrophilin subfamily 2 member A2OS=Homo sapiens OX=9606 GN=BTN2A2MEPAAALHFSLPASLLLLLLLLLLSLCALVSGLGSKPLIEIKAQEDGSIWLECISGGWYPEPLTVWRDPYGEVVPALKEVSIADADGLFMVTTAVIIRDKYVRNVSCSVNNTLLGQEKETVIFIPESFMPSASPWMVALAVILTASPWMVSMTVILAVFIIFMAVSICCIKKLQREKKILSGEKKVEQEEKEIAQQLQEELRWRRTFLHAADVVLDPDTAHPELFLSEDRRSVRRGPYRQRVPDNPERFDSQPCVLGWESFASGKHYWEVEVENVMVWTVGVCRHSVERKGEVLLIPQNGFWTLEMFGNQYRALSSPERILPLKESLCRVGVFLDYEAGDVSFYNMRDRSHIYTCPRSAFTVPVRPFFRLGSDDSPIFICPALTGASGVMVPEEGLKLHRVGTHQSL>sp|Q8WVV5-5|BT2A2_HUMAN Isoform 5 of Butyrophilin subfamily 2 member A2OS=Homo sapiens OX=9606 GN=BTN2A2MEPAAALHFSLPASLLLLLLLLLLSLCALVSESFMPSASPWMVALAVILTASPWMVSMTVILAVFIIFMAVSICCIKKLQREKKILSGEKKVEQEEKEIAQQLQEELRWRRTFLHAADVVLDPDTAHPELFLSEDRRSVRRGPYRQRVPDNPERFDSQPCVLGWESFASGKHYWEVEVENVMVWTVGVCRHSVERKGEVLLIPQNGFWTLEMFGNQYRALSSPERILPLKESLCRVGVFLDYEAGDVSFYNMRDRSHIYTCPRSAFTVPVRPFFRLGSDDSPIFICPALTGASGVMVPEEGLKLHRVGTHQSL>sp|Q6IC83|CV042_HUMAN Uncharacterized protein C22orf42 OS=Homo sapiensOX=9606 GN=C22orf42 PE=2 SV=1MGSKLTCCLGPSGGLNCDCCRPDVGPCHECEIPETVAATAPASTTAKPAKLDLKAKKAQLMQYLSLPKTPKMLKMSKGLDARSKRWLKIIWRRHGIWPLENIGPTEDVQASAHGGVEENMTSDIEIPEAKHDHRPTEDVQVSAHGGVEENITSDIEISEAKHDHHLVEDLSESLSVCLEDFMTSDLSESLSVSLEDFMTSGLSESLSVSLEDLMTPEMAKERYEDYLCWVKMARSRLNEPISSQVLGLLRL>sp|Q2NKJ3|CTC1_HUMAN CST complex subunit CTC1 OS=Homo sapiens OX=9606GN=CTC1 PE=1 SV=2MAAGRAQVPSSEQAWLEDAQVFIQKTLCPAVKEPNVQLTPLVIDCVKTVWLSQGRNQGSTLPLSYSFVSVQDLKTHQRLPCCSHLSWSSSAYQAWAQEAGPNGNPLPREQLLLLGTLTDLSADLEQECRNGSLYVRDNTGVLSCELIDLDLSWLGHLFLFPRWSYLPPARWNSSGEGHLELWDAPVPVFPLTISPGPVTPIPVLYPESASCLLRLRNKLRGVQRNLAGSLVRLSALVKSKQKAYFILSLGRSHPAVTHVSIIVQVPAQLVWHRALRPGTAYVLTELRVSKIRGQRQHVWMTSQSSRLLLLKPECVQELELELEGPLLEADPKPLPMPSNSEDKKDPESLVRYSRLLSYSGAVTGVLNEPAGLYELDGQLGLCLAYQQFRGLRRVMRPGVCLQLQDVHLLQSVGGGTRRPVLAPCLRGAVLLQSFSRQKPGAHSSRQAYGASLYEQLVWERQLGLPLYLWATKALEELACKLCPHVLRHHQFLQHSSPGSPSLGLQLLAPTLDLLAPPGSPVRNAHNEILEEPHHCPLQKYTRLQTPSSFPTLATLKEEGQRKAWASFDPKALLPLPEASYLPSCQLNRRLAWSWLCLLPSAFCPAQVLLGVLVASSHKGCLQLRDQSGSLPCLLLAKHSQPLSDPRLIGCLVRAERFQLIVERDVRSSFPSWKELSMPGFIQKQQARVYVQFFLADALILPVPRPCLHSATPSTPQTDPTGPEGPHLGQSRLFLLCHKEALMKRNFCVPPGASPEVPKPALSFYVLGSWLGGTQRKEGTGWGLPEPQGNDDNDQKVHLIFFGSSVRWFEFLHPGQVYRLIAPGPATPMLFEKDGSSCISRRPLELAGCASCLTVQDNWTLELESSQDIQDVLDANKSLPESSLTDLLSDNFTDSLVSFSAEILSRTLCEPLVASLWMKLGNTGAMRRCVKLTVALETAECEFPPHLDVYIEDPHLPPSLGLLPGARVHFSQLEKRVSRSHNVYCCFRSSTYVQVLSFPPETTISIPLPHIYLAELLQGGQSPFQATASCHIVSVFSLQLFWVCAYCTSICRQGKCTRLGSTCPTQTAISQAIIRLLVEDGTAEAVVTCRNHHVAAALGLCPREWASLLDFVQVPGRVVLQFAGPGAQLESSARVDEPMTMFLWTLCTSPSVLRPIVLSFELERKPSKIVPLEPPRLQRFQCGELPFLTHVNPRLRLSCLSIRESEYSSSLGILASSC>sp|Q2NKJ3-2|CTC1_HUMAN Isoform 2 of CST complex subunit CTC1 OS=Homosapiens OX=9606 GN=CTC1MAAGRAQVPSSEQAWLEDAQVFIQKTLCPAVKEPNVQLTPLVIDCVKTVWLSQGRNQGSTLPLSYSFVSVQDLKTHQRLPCCSHLSWSSSAYQAWAQEAGPNGNPLPREQLLLLGTLTDLSADLEQECRNGSLYVRDNTGVLSCELIDLDLSWLGHLFLFPRWSYLPPARWNSSGEGHLELWDAPVPVFPLTISPGPVTPIPVLYPESASCLLRLRSHPAVTHVSIIVQVPAQLVWHRALRPGTAYVLTELRVSKIRGQRQHVWMTSQSSRLLLLKPECVQELELELEGPLLEADPKPLPMPSNSEDKKDPESLVRYSRLLSYSGAVTGVLNEPAGLYELDGQLGLCLAYQQFRGLRRVMRPGVCLQLQDVHLLQSVGGGTRRPVLAPCLRGAVLLQSFSRQKPGAHSSRQAYGASLYEQLVWERQLGLPLYLWATKALEELACKLCPHVLRHHQFLQHSSPGSPSLGLQLLAPTLDLLAPPGSPVRNAHNEILEEPHHCPLQKYTRLQTPSSFPTLATLKEEGQRKAWASFDPKALLPLPEASYLPSCQLNRRLAWSWLCLLPSAFCPAQVLLGVLVASSHKGCLQLRDQSGSLPCLLLAKHSQPLSDPRLIGCLVRAERFQLIVERDVRSSFPSWKELSMPGFIQKQQARVYVQFFLADALILPVPRPCLHSATPSTPQTDPTGPEGPHLGQSRLFLLCHKEALMKRNFCVPPGASPEVPKPALSFYVLGSWLGGTQRKEGTGWGLPEPQGNDDNDQKVHLIFFGSSVRWFEFLHPGQVYRLIAPGPATPMLFEKDGSSCISRRPLELAGCASCLTVQDNWTLELESSQDIQDVLDANKSLPESSLTDLLSDNFTDSLVSFSAEILSRTLCEPLVASLWMKLGNTGAMRRCVKLTVALETAECEFPPHLDVYIEDPHLPPSLGLLPGARVHFSQLEKRVSRSHNVYCCFRSSTYVQVLSFPPETTISIPLPHIYLAELLQGGQSPFQATASCHIVSVFSLQLFWVCAYCTSICRQAPGGGWDCRSRGDL>sp|Q7KYR7|BT2A1_HUMAN Butyrophilin subfamily 2 member A1 OS=Homo sapiensOX=9606 GN=BTN2A1 PE=1 SV=3MESAAALHFSRPASLLLLLLSLCALVSAQFIVVGPTDPILATVGENTTLRCHLSPEKNAEDMEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRTTFVSKDISRGSVALVIHNITAQENGTYRCYFQEGRSYDEAILHLVVAGLGSKPLISMRGHEDGGIRLECISRGWYPKPLTVWRDPYGGVAPALKEVSMPDADGLFMVTTAVIIRDKSVRNMSCSINNTLLGQKKESVIFIPESFMPSVSPCAVALPIIVVILMIPIAVCIYWINKLQKEKKILSGEKEFERETREIALKELEKERVQKEEELQVKEKLQEELRWRRTFLHAVDVVLDPDTAHPDLFLSEDRRSVRRCPFRHLGESVPDNPERFDSQPCVLGRESFASGKHYWEVEVENVIEWTVGVCRDSVERKGEVLLIPQNGFWTLEMHKGQYRAVSSPDRILPLKESLCRVGVFLDYEAGDVSFYNMRDRSHIYTCPRSAFSVPVRPFFRLGCEDSPIFICPALTGANGVTVPEEGLTLHRVGTHQSL>sp|Q7KYR7-1|BT2A1_HUMAN Isoform 2 of Butyrophilin subfamily 2 member A1OS=Homo sapiens OX=9606 GN=BTN2A1MESAAALHFSRPASLLLLLLSLCALVSAQFIVVGPTDPILATVGENTTLRCHLSPEKNAEDMEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRTTFVSKDISRGSVALVIHNITAQENGTYRCYFQEGRSYDEAILHLVVAGLGSKPLISMRGHEDGGIRLECISRGWYPKPLTVWRDPYGGVAPALKEVSMPDADGLFMVTTAVIIRDKSVRNMSCSINNTLLGQKKESVIFIPESFMPSVSPLAVCIYWINKLQKEKKILSGEKEFERETREIALKELEKERVQKEEELQVKEKLQEELRWRRTFLHAVDVVLDPDTAHPDLFLSEDRRSVRRCPFRHLGESVPDNPERFDSQPCVLGRESFASGKHYWEVEVENVIEWTVGVCRDSVERKGEVLLIPQNGFWTLEMHKGQYRAVSSPDRILPLKESLCRVGVFLDYEAGDVSFYNMRDRSHIYTCPRSAFSGPDTSQSGDPPEPIESIPWSHSHVDKPWSFQQPPHNTHLPAASFTPTTDLSPSFLLLTRLCF>sp|Q7KYR7-3|BT2A1_HUMAN Isoform 3 of Butyrophilin subfamily 2 member A1OS=Homo sapiens OX=9606 GN=BTN2A1MRGHEDGGIRLECISRGWYPKPLTVWRDPYGGVAPALKEVSMPDADGLFMVTTAVIIRDKSVRNMSCSINNTLLGQKKESVIFIPESFMPSVSPCAVALPIIVVILMIPIAVCIYWINKLQKEKKILSGEKEFERETREIALKELEKERVQKEEELQVKEKLQEELRWRRTFLHAVDVVLDPDTAHPDLFLSEDRRSVRRCPFRHLGESVPDNPERFDSQPCVLGRESFASGKHYWEVEVENVIEWTVGVCRDSVERKGEVLLIPQNGFWTLEMHKGQYRAVSSPDRILPLKESLCRVGVFLDYEAGDVSFYNMRDRSHIYTCPRSAFSVPVRPFFRLGCEDSPIFICPALTGANGVTVPEEGLTLHRVGTHQSL>sp|Q7KYR7-4|BT2A1_HUMAN Isoform 4 of Butyrophilin subfamily 2 member A1OS=Homo sapiens OX=9606 GN=BTN2A1MESAAALHFSRPASLLLLLLSLCALVSAQFIVVGPTDPILATVGENTTLRCHLSPEKNAEDMEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRTTFVSKDISRGSVALVIHNITAQENGTYRCYFQEGRSYDEAILHLVVAGLGSKPLISMRGHEDGGIRLECISRGWYPKPLTVWRDPYGGVAPALKEVSMPDADGLFMVTTAVIIRDKSVRNMSCSINNTLLGQKKESVIFIPESFMPSVSPCAVALPIIVVILMIPIAVCIYWINKLQKEKKILSGEKEFERETREIALKELEKERVQKEEELQVKEKLQEELRWRRTFLHAELQFFSN>sp|Q7KYR7-5|BT2A1_HUMAN Isoform 5 of Butyrophilin subfamily 2 member A1OS=Homo sapiens OX=9606 GN=BTN2A1MEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRTTFVSKDISRGSVALVIHNITAQENGTYRCYFQEGRSYDEAILHLVVAGLGSKPLISMRGHEDGGIRLECISRGWYPKPLTVWRDPYGGVAPALKEVSMPDADGLFMVTTAVIIRDKSVRNMSCSINNTLLGQKKESVIFIPESFMPSVSPCAVALPIIVVILMIPIAVCIYWINKLQKEKKILSGEKEFERETREIALKELEKERVQKEEELQVKEKLQEELRWRRTFLHAVDVVLDPDTAHPDLFLSEDRRSVRRCPFRHLGESVPDNPERFDSQPCVLGRESFASGKHYWEVEVENVIEWTVGVCRDSVERKGEVLLIPQNGFWTLEMHKGQYRAVSSPDRILPLKESLCRVGVFLDYEAGDVSFYNMRDRSHIYTCPRSAFSVPVRPFFRLGCEDSPIFICPALTGANGVTVPEEGLTLHRVGTHQSL>sp|Q7KYR7-6|BT2A1_HUMAN Isoform 6 of Butyrophilin subfamily 2 member A1OS=Homo sapiens OX=9606 GN=BTN2A1MESAAALHFSRPASLLLLLLSLCALVSAQFIVVGPTDPILATVGENTTLRCHLSPEKNAEDMEVRWFRSQFSPAVFVYKGGRERTEEQMEEYRGRTTFVSKDISRGSVALVIHNITAQENGTYRCYFQEGRSYDEAILHLVVAGLGSKPLISMRGHEDGGIRLECISRGWYPKPLTVWRDPYGGVAPALKEVSMPDADGLFMVTTAVIIRDKSVRNMSCSINNTLLGQKKESVIFIPESFMPSVSPCAVALPIIVVILMIPIAVCIYWINKLQKEKKILSGEKEFERETREIALKELEKERVQKEEELQVKEKLQEELRWRRTFLHAGPV>sp|Q8NI51|CTCFL_HUMAN Transcriptional repressor CTCFL OS=Homo sapiensOX=9606 GN=CTCFL PE=1 SV=2MAATEISVLSEQFTKIKELELMPEKGLKEEEKDGVCREKDHRSPSELEAERTSGAFQDSVLEEEVELVLAPSEESEKYILTLQTVHFTSEAVELQDMSLLSIQQQEGVQVVVQQPGPGLLWLEEGPRQSLQQCVAISIQQELYSPQEMEVLQFHALEENVMVASEDSKLAVSLAETTGLIKLEEEQEKNQLLAERTKEQLFFVETMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWINLHRHSEKCGSGEAKSAASGKGRRTRKRKQTILKEATKGQKEAAKGWKEAANGDEAAAEEASTTKGEQFPGEMFPVACRETTARVKEEVDEGVTCEMLLNTMDK>sp|Q8NI51-2|CTCFL_HUMAN Isoform 2 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMAATEISVLSEQFTKIKELELMPEKGLKEEEKDGVCREKDHRSPSELEAERTSGAFQDSVLEEEVELVLAPSEESEKYILTLQTVHFTSEAVELQDMSLLSIQQQEGVQVVVQQPGPGLLWLEEGPRQSLQQCVAISIQQELYSPQEMEVLQFHALEENVMVASEDSKLAVSLAETTGLIKLEEEQEKNQLLAERTKEQLFFVETMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWITSKWSGLKPQTFIT>sp|Q8NI51-3|CTCFL_HUMAN Isoform 3 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMAATEISVLSEQFTKIKELELMPEKGLKEEEKDGVCREKDHRSPSELEAERTSGAFQDSVLEEEVELVLAPSEESEKYILTLQTVHFTSEAVELQDMSLLSIQQQEGVQVVVQQPGPGLLWLEEGPRQSLQQCVAISIQQELYSPQEMEVLQFHALEENVMVASEDSKLAVSLAETTGLIKLEEEQEKNQLLAERTKEQLFFVETMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWINLHRHSEKCGSGEAKSAASGKGRRTRKRKQTILKEATKGQKEAAKGWKEAANGDGVISAHRNLCLLGSSDSHASVSGAGITDARHHAWLIVLLFLVEMGFYHVSHS>sp|Q8NI51-4|CTCFL_HUMAN Isoform 4 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMAATEISVLSEQFTKIKELELMPEKGLKEEEKDGVCREKDHRSPSELEAERTSGAFQDSVLEEEVELVLAPSEESEKYILTLQTVHFTSEAVELQDMSLLSIQQQEGVQVVVQQPGPGLLWLEEGPRQSLQQCVAISIQQELYSPQEMEVLQFHALEENVMVASEDSKLAVSLAETTGLIKLEEEQEKNQLLAERTKEQLFFVETMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWILWVGNSEVAELGGPGSGPLLRLQSGCPPGLHHPKAGLGPEDPLPGQLRHTTAGTGLSSLLQGPLCRAA>sp|Q8NI51-5|CTCFL_HUMAN Isoform 5 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWILWVGNSEVAELGGPGSGPLLRLQSGCPPGLHHPKAGLGPEDPLPGQLRHTTAGTGLSSLLQGPLCRAA>sp|Q8NI51-6|CTCFL_HUMAN Isoform 6 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWINLHRHSEKCGSGEAKSAASGKGRRTRKRKQTILKEATKGQKEAAKGWKEAANGDGVISAHRNLCLLGSSDSHASVSGAGITDARHHAWLIVLLFLVEMGFYHVSHS>sp|Q8NI51-7|CTCFL_HUMAN Isoform 7 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMAATEISVLSEQFTKIKELELMPEKGLKEEEKDGVCREKDHRSPSELEAERTSGAFQDSVLEEEVELVLAPSEESEKYILTLQTVHFTSEAVELQDMSLLSIQQQEGVQVVVQQPGPGLLWLEEGPRQSLQQCVAISIQQELYSPQEMEVLQFHALEENVMVASEDSKLAVSLAETTGLIKLEEEQEKNQLLAERTKEQLFFVETMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWINLHRHSEKCGSGEAKSAASGKGRRTRKRKQTILKEATKGQKEAAKGWKEAANGDEAAAEEASTTKGEQFPGEMFPVACRETTARVKEEVDEGVTCEMLLNTMDNSAGCTGRMMLVSAWLLGRPQETYNQGRRRRGSRRVTW>sp|Q8NI51-8|CTCFL_HUMAN Isoform 8 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMAATEISVLSEQFTKIKELELMPEKGLKEEEKDGVCREKDHRSPSELEAERTSGAFQDSVLEEEVELVLAPSEESEKYILTLQTVHFTSEAVELQDMSLLSIQQQEGVQVVVQQPGPGLLWLEEGPRQSLQQCVAISIQQELYSPQEMEVLQFHALEENVMVASEDSKLAVSLAETTGLIKLEEEQEKNQLLAERTKEQLFFVETMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWINLHRHSEKCGSGEAKSAASGKGRRTRKRKQTILKEATKGQKEAAKGWKEAANGDEAAAEEASTTKGEQFPGEMFPVACRETTARVKEEVDEGVTCEMLLNTMDK>sp|Q8NI51-9|CTCFL_HUMAN Isoform 9 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMAATEISVLSEQFTKIKELELMPEKGLKEEEKDGVCREKDHRSPSELEAERTSGAFQDSVLEEEVELVLAPSEESEKYILTLQTVHFTSEAVELQDMSLLSIQQQEGVQVVVQQPGPGLLWLEEGPRQSLQQCVAISIQQELYSPQEMEVLQFHALEENVMVASEDSKLAVSLAETTGLIKLEEEQEKNQLLAERTKEQLFFVETMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSEATSKRSLQEIPRCKFHPDCLQMLQVWQRLFPLD>sp|Q8NI51-10|CTCFL_HUMAN Isoform 10 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMSGDERSDEIVLTVSNSNVEEQEDQPTAGQADAEKAKSTKNQRKTKGAKGTFHCDVCMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWINLHRHSEKCGSGEAKSAASGKGRRTRKRKQTILKEATKGQKEAAKGWKEAANGDGVISAHRNLCLLGSSDSHASVSGAGITDARHHAWLIVLLFLVEMGFYHVSHS>sp|Q8NI51-11|CTCFL_HUMAN Isoform 11 of Transcriptional repressor CTCFLOS=Homo sapiens OX=9606 GN=CTCFLMFTSSRMSSFNRHMKTHTSEKPHLCHLCLKTFRTVTLLRNHVNTHTGTRPYKCNDCNMAFVTSGELVRHRRYKHTHEKPFKCSMCKYASVEASKLKRHVRSHTGERPFQCCQCSYASRDTYKLKRHMRTHSGEKPYECHICHTRFTQSGTMKIHILQKHGENVPKYQCPHCATIIARKSDLRVHMRNLHAYSAAELKCRYCSAVFHERYALIQHQKTHKNEKRFKCKHCSYACKQERHMTAHIRTHTGEKPFTCLSCNKCFRQKQLLNAHFRKYHDANFIPTVYKCSKCGKGFSRWVLY>sp|Q9GZU7|CTDS1_HUMAN Carboxy-terminal domain RNA polymerase IIpolypeptide A small phosphatase 1 OS=Homo sapiens OX=9606 GN=CTDSP1 PE=1SV=1MDSSAVITQISKEEARGPLRGKGDQKSAASQKPRSRGILHSLFCCVCRDDGEALPAHSGAPLLVEENGAIPKQTPVQYLLPEAKAQDSDKICVVIDLDETLVHSSFKPVNNADFIIPVEIDGVVHQVYVLKRPHVDEFLQRMGELFECVLFTASLAKYADPVADLLDKWGAFRARLFRESCVFHRGNYVKDLSRLGRDLRRVLILDNSPASYVFHPDNAVPVASWFDNMSDTELHDLLPFFEQLSRVDDVYSVLRQPRPGS>sp|Q9GZU7-2|CTDS1_HUMAN Isoform 2 of Carboxy-terminal domain RNApolymerase II polypeptide A small phosphatase 1 OS=Homo sapiens OX=9606GN=CTDSP1MDSSAVITQISKEEARGPLRGKGDQKSAASQKPRSRGILHSLFCCVCRDDGEALPAHSGAPLLVEENGAIPKTPVQYLLPEAKAQDSDKICVVIDLDETLVHSSFKPVNNADFIIPVEIDGVVHQVYVLKRPHVDEFLQRMGELFECVLFTASLAKYADPVADLLDKWGAFRARLFRESCVFHRGNYVKDLSRLGRDLRRVLILDNSPASYVFHPDNAVPVASWFDNMSDTELHDLLPFFEQLSRVDDVYSVLRQPRPGS>sp|Q9GZU7-3|CTDS1_HUMAN Isoform 3 of Carboxy-terminal domain RNApolymerase II polypeptide A small phosphatase 1 OS=Homo sapiens OX=9606GN=CTDSP1MVAAPWATQEQEEGRGIQPGDRGDQKSAASQKPRSRGILHSLFCCVCRDDGEALPAHSGAPLLVEENGAIPKTPVQYLLPEAKAQDSDKICVVIDLDETLVHSSFKPVNNADFIIPVEIDGVVHQVYVLKRPHVDEFLQRMGELFECVLFTASLAKYADPVADLLDKWGAFRARLFRESCVFHRGNYVKDLSRLGRDLRRVLILDNSPASYVFHPDNAVPVASWFDNMSDTELHDLLPFFEQLSRVDDVYSVLRQPRPGS>sp|Q9BX70|BTBD2_HUMAN BTB/POZ domain-containing protein 2 OS=Homosapiens OX=9606 GN=BTBD2 PE=1 SV=1MAAGGSGGRASCPPGVGVGPGTGGSPGPSANAAATPAPGNAAAAAAAAAAAAAAPGPTPPAPPGPGTDAQAAGAERAEEAAGPGAAALQREAAYNWQASKPTVQERFAFLFNNEVLCDVHFLVGKGLSSQRIPAHRFVLAVGSAVFDAMFNGGMATTSTEIELPDVEPAAFLALLKFLYSDEVQIGPETVMTTLYTAKKYAVPALEAHCVEFLKKNLRADNAFMLLTQARLFDEPQLASLCLENIDKNTADAITAEGFTDIDLDTLVAVLERDTLGIREVRLFNAVVRWSEAECQRQQLQVTPENRRKVLGKALGLIRFPLMTIEEFAAGPAQSGILVDREVVSLFLHFTVNPKPRVEFIDRPRCCLRGKECSINRFQQVESRWGYSGTSDRIRFSVNKRIFVVGFGLYGSIHGPTDYQVNIQIIHTDSNTVLGQNDTGFSCDGSASTFRVMFKEPVEVLPNVNYTACATLKGPDSHYGTKGLRKVTHESPTTGAKTCFTFCYAAGNNNGTSVEDGQIPEVIFYT>sp|Q9BX70-2|BTBD2_HUMAN Isoform 2 of BTB/POZ domain-containing protein 2OS=Homo sapiens OX=9606 GN=BTBD2MTIEEFAAGPAQSGILVDREVVSLFLHFTVNPKPRVEFIDRPRCCLRGKECSINRFQQVESRWGYSGTSDRIRFSVNKRIFVVGFGLYGSIHGPTDYQVNIQIIHTDSNTVLGQNDTGFSCDGSASTFRVMFKEPVEVLPNVNYTACATLKGPDSHYGTKGLRKVTHESPTTGAKTCFTFCYAAGNNNGTSVEDGQIPEVIFYT>sp|P51587|BRCA2_HUMAN Breast cancer type 2 susceptibility proteinOS=Homo sapiens OX=9606 GN=BRCA2 PE=1 SV=3MPIGSKERPTFFEIFKTRCNKADLGPISLNWFEELSSEAPPYNSEPAEESEHKNNNYEPNLFKTPQRKPSYNQLASTPIIFKEQGLTLPLYQSPVKELDKFKLDLGRNVPNSRHKSLRTVKTKMDQADDVSCPLLNSCLSESPVVLQCTHVTPQRDKSVVCGSLFHTPKFVKGRQTPKHISESLGAEVDPDMSWSSSLATPPTLSSTVLIVRNEEASETVFPHDTTANVKSYFSNHDESLKKNDRFIASVTDSENTNQREAASHGFGKTSGNSFKVNSCKDHIGKSMPNVLEDEVYETVVDTSEEDSFSLCFSKCRTKNLQKVRTSKTRKKIFHEANADECEKSKNQVKEKYSFVSEVEPNDTDPLDSNVANQKPFESGSDKISKEVVPSLACEWSQLTLSGLNGAQMEKIPLLHISSCDQNISEKDLLDTENKRKKDFLTSENSLPRISSLPKSEKPLNEETVVNKRDEEQHLESHTDCILAVKQAISGTSPVASSFQGIKKSIFRIRESPKETFNASFSGHMTDPNFKKETEASESGLEIHTVCSQKEDSLCPNLIDNGSWPATTTQNSVALKNAGLISTLKKKTNKFIYAIHDETSYKGKKIPKDQKSELINCSAQFEANAFEAPLTFANADSGLLHSSVKRSCSQNDSEEPTLSLTSSFGTILRKCSRNETCSNNTVISQDLDYKEAKCNKEKLQLFITPEADSLSCLQEGQCENDPKSKKVSDIKEEVLAAACHPVQHSKVEYSDTDFQSQKSLLYDHENASTLILTPTSKDVLSNLVMISRGKESYKMSDKLKGNNYESDVELTKNIPMEKNQDVCALNENYKNVELLPPEKYMRVASPSRKVQFNQNTNLRVIQKNQEETTSISKITVNPDSEELFSDNENNFVFQVANERNNLALGNTKELHETDLTCVNEPIFKNSTMVLYGDTGDKQATQVSIKKDLVYVLAEENKNSVKQHIKMTLGQDLKSDISLNIDKIPEKNNDYMNKWAGLLGPISNHSFGGSFRTASNKEIKLSEHNIKKSKMFFKDIEEQYPTSLACVEIVNTLALDNQKKLSKPQSINTVSAHLQSSVVVSDCKNSHITPQMLFSKQDFNSNHNLTPSQKAEITELSTILEESGSQFEFTQFRKPSYILQKSTFEVPENQMTILKTTSEECRDADLHVIMNAPSIGQVDSSKQFEGTVEIKRKFAGLLKNDCNKSASGYLTDENEVGFRGFYSAHGTKLNVSTEALQKAVKLFSDIENISEETSAEVHPISLSSSKCHDSVVSMFKIENHNDKTVSEKNNKCQLILQNNIEMTTGTFVEEITENYKRNTENEDNKYTAASRNSHNLEFDGSDSSKNDTVCIHKDETDLLFTDQHNICLKLSGQFMKEGNTQIKEDLSDLTFLEVAKAQEACHGNTSNKEQLTATKTEQNIKDFETSDTFFQTASGKNISVAKESFNKIVNFFDQKPEELHNFSLNSELHSDIRKNKMDILSYEETDIVKHKILKESVPVGTGNQLVTFQGQPERDEKIKEPTLLGFHTASGKKVKIAKESLDKVKNLFDEKEQGTSEITSFSHQWAKTLKYREACKDLELACETIEITAAPKCKEMQNSLNNDKNLVSIETVVPPKLLSDNLCRQTENLKTSKSIFLKVKVHENVEKETAKSPATCYTNQSPYSVIENSALAFYTSCSRKTSVSQTSLLEAKKWLREGIFDGQPERINTADYVGNYLYENNSNSTIAENDKNHLSEKQDTYLSNSSMSNSYSYHSDEVYNDSGYLSKNKLDSGIEPVLKNVEDQKNTSFSKVISNVKDANAYPQTVNEDICVEELVTSSSPCKNKNAAIKLSISNSNNFEVGPPAFRIASGKIVCVSHETIKKVKDIFTDSFSKVIKENNENKSKICQTKIMAGCYEALDDSEDILHNSLDNDECSTHSHKVFADIQSEEILQHNQNMSGLEKVSKISPCDVSLETSDICKCSIGKLHKSVSSANTCGIFSTASGKSVQVSDASLQNARQVFSEIEDSTKQVFSKVLFKSNEHSDQLTREENTAIRTPEHLISQKGFSYNVVNSSAFSGFSTASGKQVSILESSLHKVKGVLEEFDLIRTEHSLHYSPTSRQNVSKILPRVDKRNPEHCVNSEMEKTCSKEFKLSNNLNVEGGSSENNHSIKVSPYLSQFQQDKQQLVLGTKVSLVENIHVLGKEQASPKNVKMEIGKTETFSDVPVKTNIEVCSTYSKDSENYFETEAVEIAKAFMEDDELTDSKLPSHATHSLFTCPENEEMVLSNSRIGKRRGEPLILVGEPSIKRNLLNEFDRIIENQEKSLKASKSTPDGTIKDRRLFMHHVSLEPITCVPFRTTKERQEIQNPNFTAPGQEFLSKSHLYEHLTLEKSSSNLAVSGHPFYQVSATRNEKMRHLITTGRPTKVFVPPFKTKSHFHRVEQCVRNINLEENRQKQNIDGHGSDDSKNKINDNEIHQFNKNNSNQAAAVTFTKCEEEPLDLITSLQNARDIQDMRIKKKQRQRVFPQPGSLYLAKTSTLPRISLKAAVGGQVPSACSHKQLYTYGVSKHCIKINSKNAESFQFHTEDYFGKESLWTGKGIQLADGGWLIPSNDGKAGKEEFYRALCDTPGVDPKLISRIWVYNHYRWIIWKLAAMECAFPKEFANRCLSPERVLLQLKYRYDTEIDRSRRSAIKKIMERDDTAAKTLVLCVSDIISLSANISETSSNKTSSADTQKVAIIELTDGWYAVKAQLDPPLLAVLKNGRLTVGQKIILHGAELVGSPDACTPLEAPESLMLKISANSTRPARWYTKLGFFPDPRPFPLPLSSLFSDGGNVGCVDVIIQRAYPIQWMEKTSSGLYIFRNEREEEKEAAKYVEAQQKRLEALFTKIQEEFEEHEENTTKPYLPSRALTRQQVRALQDGAELYEAVKNAADPAYLEGYFSEEQLRALNNHRQMLNDKKQAQIQLEIRKAMESAEQKEQGLSRDVTTVWKLRIVSYSKKEKDSVILSIWRPSSDLYSLLTEGKRYRIYHLATSKSKSKSERANIQLAATKKTQYQQLPVSDEILFQIYQPREPLHFSKFLDPDFQPSCSEVDLIGFVVSVVKKTGLAPFVYLSDECYNLLAIKFWIDLNEDIIKPHMLIAASNLQWRPESKSGLLTLFAGDFSVFSASPKEGHFQETFNKMKNTVENIDILCNEAENKLMHILHANDPKWSTPTKDCTSGPYTAQIIPGTGNKLLMSSPNCEIYYQSPLSLCMAKRKSVSTPVSAQMTSKSCKGEKEIDDQKNCKKRRALDFLSRLPLPPPVSPICTFVSPAAQKAFQPPRSCGTKYETPIKKKELNSPQMTPFKKFNEISLLESNSIADEELALINTQALLSGSTGEKQFISVSESTRTAPTSSEDYLRLKRRCTTSLIKEQESSQASTEECEKNKQDTITTKKYI>sp|O60885|BRD4_HUMAN Bromodomain-containing protein 4 OS=Homo sapiensOX=9606 GN=BRD4 PE=1 SV=2MSAESGPGTRLRNLPVMGDGLETSQMSTTQAQAQPQPANAASTNPPPPETSNPNKPKRQTNQLQYLLRVVLKTLWKHQFAWPFQQPVDAVKLNLPDYYKIIKTPMDMGTIKKRLENNYYWNAQECIQDFNTMFTNCYIYNKPGDDIVLMAEALEKLFLQKINELPTEETEIMIVQAKGRGRGRKETGTAKPGVSTVPNTTQASTPPQTQTPQPNPPPVQATPHPFPAVTPDLIVQTPVMTVVPPQPLQTPPPVPPQPQPPPAPAPQPVQSHPPIIAATPQPVKTKKGVKRKADTTTPTTIDPIHEPPSLPPEPKTTKLGQRRESSRPVKPPKKDVPDSQQHPAPEKSSKVSEQLKCCSGILKEMFAKKHAAYAWPFYKPVDVEALGLHDYCDIIKHPMDMSTIKSKLEAREYRDAQEFGADVRLMFSNCYKYNPPDHEVVAMARKLQDVFEMRFAKMPDEPEEPVVAVSSPAVPPPTKVVAPPSSSDSSSDSSSDSDSSTDDSEEERAQRLAELQEQLKAVHEQLAALSQPQQNKPKKKEKDKKEKKKEKHKRKEEVEENKKSKAKEPPPKKTKKNNSSNSNVSKKEPAPMKSKPPPTYESEEEDKCKPMSYEEKRQLSLDINKLPGEKLGRVVHIIQSREPSLKNSNPDEIEIDFETLKPSTLRELERYVTSCLRKKRKPQAEKVDVIAGSSKMKGFSSSESESSSESSSSDSEDSETEMAPKSKKKGHPGREQKKHHHHHHQQMQQAPAPVPQQPPPPPQQPPPPPPPQQQQQPPPPPPPPSMPQQAAPAMKSSPPPFIATQVPVLEPQLPGSVFDPIGHFTQPILHLPQPELPPHLPQPPEHSTPPHLNQHAVVSPPALHNALPQQPSRPSNRAAALPPKPARPPAVSPALTQTPLLPQPPMAQPPQVLLEDEEPPAPPLTSMQMQLYLQQLQKVQPPTPLLPSVKVQSQPPPPLPPPPHPSVQQQLQQQPPPPPPPQPQPPPQQQHQPPPRPVHLQPMQFSTHIQQPPPPQGQQPPHPPPGQQPPPPQPAKPQQVIQHHHSPRHHKSDPYSTGHLREAPSPLMIHSPQMSQFQSLTHQSPPQQNVQPKKQELRAASVVQPQPLVVVKEEKIHSPIIRSEPFSPSLRPEPPKHPESIKAPVHLPQRPEMKPVDVGRPVIRPPEQNAPPPGAPDKDKQKQEPKTPVAPKKDLKIKNMGSWASLVQKHPTTPSSTAKSSSDSFEQFRRAAREKEEREKALKAQAEHAEKEKERLRQERMRSREDEDALEQARRAHEEARRRQEQQQQQRQEQQQQQQQQAAAVAAAATPQAQSSQPQSMLDQQRELARKREQERRRREAMAATIDMNFQSDLLSIFEENLF>sp|O60885-2|BRD4_HUMAN Isoform C of Bromodomain-containing protein 4OS=Homo sapiens OX=9606 GN=BRD4MSAESGPGTRLRNLPVMGDGLETSQMSTTQAQAQPQPANAASTNPPPPETSNPNKPKRQTNQLQYLLRVVLKTLWKHQFAWPFQQPVDAVKLNLPDYYKIIKTPMDMGTIKKRLENNYYWNAQECIQDFNTMFTNCYIYNKPGDDIVLMAEALEKLFLQKINELPTEETEIMIVQAKGRGRGRKETGTAKPGVSTVPNTTQASTPPQTQTPQPNPPPVQATPHPFPAVTPDLIVQTPVMTVVPPQPLQTPPPVPPQPQPPPAPAPQPVQSHPPIIAATPQPVKTKKGVKRKADTTTPTTIDPIHEPPSLPPEPKTTKLGQRRESSRPVKPPKKDVPDSQQHPAPEKSSKVSEQLKCCSGILKEMFAKKHAAYAWPFYKPVDVEALGLHDYCDIIKHPMDMSTIKSKLEAREYRDAQEFGADVRLMFSNCYKYNPPDHEVVAMARKLQDVFEMRFAKMPDEPEEPVVAVSSPAVPPPTKVVAPPSSSDSSSDSSSDSDSSTDDSEEERAQRLAELQEQLKAVHEQLAALSQPQQNKPKKKEKDKKEKKKEKHKRKEEVEENKKSKAKEPPPKKTKKNNSSNSNVSKKEPAPMKSKPPPTYESEEEDKCKPMSYEEKRQLSLDINKLPGEKLGRVVHIIQSREPSLKNSNPDEIEIDFETLKPSTLRELERYVTSCLRKKRKPQAEKVDVIAGSSKMKGFSSSESESSSESSSSDSEDSETGPA>sp|O60885-3|BRD4_HUMAN Isoform B of Bromodomain-containing protein 4OS=Homo sapiens OX=9606 GN=BRD4MSAESGPGTRLRNLPVMGDGLETSQMSTTQAQAQPQPANAASTNPPPPETSNPNKPKRQTNQLQYLLRVVLKTLWKHQFAWPFQQPVDAVKLNLPDYYKIIKTPMDMGTIKKRLENNYYWNAQECIQDFNTMFTNCYIYNKPGDDIVLMAEALEKLFLQKINELPTEETEIMIVQAKGRGRGRKETGTAKPGVSTVPNTTQASTPPQTQTPQPNPPPVQATPHPFPAVTPDLIVQTPVMTVVPPQPLQTPPPVPPQPQPPPAPAPQPVQSHPPIIAATPQPVKTKKGVKRKADTTTPTTIDPIHEPPSLPPEPKTTKLGQRRESSRPVKPPKKDVPDSQQHPAPEKSSKVSEQLKCCSGILKEMFAKKHAAYAWPFYKPVDVEALGLHDYCDIIKHPMDMSTIKSKLEAREYRDAQEFGADVRLMFSNCYKYNPPDHEVVAMARKLQDVFEMRFAKMPDEPEEPVVAVSSPAVPPPTKVVAPPSSSDSSSDSSSDSDSSTDDSEEERAQRLAELQEQLKAVHEQLAALSQPQQNKPKKKEKDKKEKKKEKHKRKEEVEENKKSKAKEPPPKKTKKNNSSNSNVSKKEPAPMKSKPPPTYESEEEDKCKPMSYEEKRQLSLDINKLPGEKLGRVVHIIQSREPSLKNSNPDEIEIDFETLKPSTLRELERYVTSCLRKKRKPQAEKVDVIAGSSKMKGFSSSESESSSESSSSDSEDSETAFCTSGDFVSPGPSPYHSHVQCGRFREMLRWFLVDVEQTAAGQPHRQSAAGPAITWAPAIAYPSPECARCCVGCS>sp|Q8NHY0|B4GN2_HUMAN Beta-1,4 N-acetylgalactosaminyltransferase 2OS=Homo sapiens OX=9606 GN=B4GALNT2 PE=1 SV=2MGSAGFSVGKFHVEVASRGRECVSGTPECGNRLGSAGFGALCLELRGADPAWGPFAAHGRSRRQGSRFLWLLKILVIILVLGIVGFMFGSMFLQAVFSSPKPELPSPAPGVQKLKLLPEERLRNLFSYDGIWLFPKNQCKCEANKEQGGYNFQDAYGQSDLPAVKARRQAEFEHFQRREGLPRPLPLLVQPNLPFGYPVHGVEVMPLHTVPIPGLQFEGPDAPVYEVTLTASLGTLNTLADVPDSVVQGRGQKQLIISTSDRKLLKFILQHVTYTSTGYQHQKVDIVSLESRSSVAKFPVTIRHPVIPKLYDPGPERKLRNLVTIATKTFLRPHKLMIMLRSIREYYPDLTVIVADDSQKPLEIKDNHVEYYTMPFGKGWFAGRNLAISQVTTKYVLWVDDDFLFNEETKIEVLVDVLEKTELDVVGGSVLGNVFQFKLLLEQSENGACLHKRMGFFQPLDGFPSCVVTSGVVNFFLAHTERLQRVGFDPRLQRVAHSEFFIDGLGTLLVGSCPEVIIGHQSRSPVVDSELAALEKTYNTYRSNTLTRVQFKLALHYFKNHLQCAA>sp|Q8NHY0-2|B4GN2_HUMAN Isoform 2 of Beta-1,4 N-acetylgalactosaminyltransferase 2 OS=Homo sapiens OX=9606 GN=B4GALNT2MTSGGSRFLWLLKILVIILVLGIVGFMFGSMFLQAVFSSPKPELPSPAPGVQKLKLLPEERLRNLFSYDGIWLFPKNQCKCEANKEQGGYNFQDAYGQSDLPAVKARRQAEFEHFQRREGLPRPLPLLVQPNLPFGYPVHGVEVMPLHTVPIPGLQFEGPDAPVYEVTLTASLGTLNTLADVPDSVVQGRGQKQLIISTSDRKLLKFILQHVTYTSTGYQHQKVDIVSLESRSSVAKFPVTIRHPVIPKLYDPGPERKLRNLVTIATKTFLRPHKLMIMLRSIREYYPDLTVIVADDSQKPLEIKDNHVEYYTMPFGKGWFAGRNLAISQVTTKYVLWVDDDFLFNEETKIEVLVDVLEKTELDVVGGSVLGNVFQFKLLLEQSENGACLHKRMGFFQPLDGFPSCVVTSGVVNFFLAHTERLQRVGFDPRLQRVAHSEFFIDGLGTLLVGSCPEVIIGHQSRSPVVDSELAALEKTYNTYRSNTLTRVQFKLALHYFKNHLQCAA>sp|Q8NHY0-3|B4GN2_HUMAN Isoform 3 of Beta-1,4 N-acetylgalactosaminyltransferase 2 OS=Homo sapiens OX=9606 GN=B4GALNT2MFGSMFLQAVFSSPKPELPSPAPGVQKLKLLPEERLRNLFSYDGIWLFPKNQCKCEANKEQGGYNFQDAYGQSDLPAVKARRQAEFEHFQRREGLPRPLPLLVQPNLPFGYPVHGVEVMPLHTVPIPGLQFEGPDAPVYEVTLTASLGTLNTLADVPDSVVQGRGQKQLIISTSDRKLLKFILQHVTYTSTGYQHQKVDIVSLESRSSVAKFPVTIRHPVIPKLYDPGPERKLRNLVTIATKTFLRPHKLMIMLRSIREYYPDLTVIVADDSQKPLEIKDNHVEYYTMPFGKGWFAGRNLAISQVTTKYVLWVDDDFLFNEETKIEVLVDVLEKTELDVVGGSVLGNVFQFKLLLEQSENGACLHKRMGFFQPLDGFPSCVVTSGVVNFFLAHTERLQRVGFDPRLQRVAHSEFFIDGLGTLLVGSCPEVIIGHQSRSPVVDSELAALEKTYNTYRSNTLTRVQFKLALHYFKNHLQCAA>sp|O60909|B4GT2_HUMAN Beta-1,4-galactosyltransferase 2 OS=Homo sapiensOX=9606 GN=B4GALT2 PE=1 SV=1MSRLLGGTLERVCKAVLLLCLLHFLVAVILYFDVYAQHLAFFSRFSARGPAHALHPAASSSSSSSNCSRPNATASSSGLPEVPSALPGPTAPTLPPCPDSPPGLVGRLLIEFTSPMPLERVQRENPGVLMGGRYTPPDCTPAQTVAVIIPFRHREHHLRYWLHYLHPILRRQRLRYGVYVINQHGEDTFNRAKLLNVGFLEALKEDAAYDCFIFSDVDLVPMDDRNLYRCGDQPRHFAIAMDKFGFRLPYAGYFGGVSGLSKAQFLRINGFPNEYWGWGGEDDDIFNRISLTGMKISRPDIRIGRYRMIKHDRDKHNEPNPQRFTKIQNTKLTMKRDGIGSVRYQVLEVSRQPLFTNITVDIGRPPSWPPRG>sp|O60909-2|B4GT2_HUMAN Isoform 2 of Beta-1,4-galactosyltransferase 2OS=Homo sapiens OX=9606 GN=B4GALT2MPSTQLLAAAAAAATAPGPTPPPLAPGSLRSPVPCPVPRLPRCHPVLTRHLVLRVQRENPGVLMGGRYTPPDCTPAQTVAVIIPFRHREHHLRYWLHYLHPILRRQRLRYGVYVINQHGEDTFNRAKLLNVGFLEALKEDAAYDCFIFSDVDLVPMDDRNLYRCGDQPRHFAIAMDKFGFRLPYAGYFGGVSGLSKAQFLRINGFPNEYWGWGGEDDDIFNRISLTGMKISRPDIRIGRYRMIKHDRDKHNEPNPQRFTKIQNTKLTMKRDGIGSVRYQVLEVSRQPLFTNITVDIGRPPSWPPRG>sp|O60909-3|B4GT2_HUMAN Isoform 3 of Beta-1,4-galactosyltransferase 2OS=Homo sapiens OX=9606 GN=B4GALT2MAVEVQEQWPCLPAAGCPGPLGGPVAACGMSRLLGGTLERVCKAVLLLCLLHFLVAVILYFDVYAQHLAFFSRFSARGPAHALHPAASSSSSSSNCSRPNATASSSGLPEVPSALPGPTAPTLPPCPDSPPGLVGRLLIEFTSPMPLERVQRENPGVLMGGRYTPPDCTPAQTVAVIIPFRHREHHLRYWLHYLHPILRRQRLRYGVYVINQHGEDTFNRAKLLNVGFLEALKEDAAYDCFIFSDVDLVPMDDRNLYRCGDQPRHFAIAMDKFGFRLPYAGYFGGVSGLSKAQFLRINGFPNEYWGWGGEDDDIFNRISLTGMKISRPDIRIGRYRMIKHDRDKHNEPNPQRFTKIQNTKLTMKRDGIGSVRYQVLEVSRQPLFTNITVDIGRPPSWPPRG>sp|Q58F21|BRDT_HUMAN Bromodomain testis-specific protein OS=Homo sapiensOX=9606 GN=BRDT PE=1 SV=4MSLPSRQTAIIVNPPPPEYINTKKNGRLTNQLQYLQKVVLKDLWKHSFSWPFQRPVDAVKLQLPDYYTIIKNPMDLNTIKKRLENKYYAKASECIEDFNTMFSNCYLYNKPGDDIVLMAQALEKLFMQKLSQMPQEEQVVGVKERIKKGTQQNIAVSSAKEKSSPSATEKVFKQQEIPSVFPKTSISPLNVVQGASVNSSSQTAAQVTKGVKRKADTTTPATSAVKASSEFSPTFTEKSVALPPIKENMPKNVLPDSQQQYNVVKTVKVTEQLRHCSEILKEMLAKKHFSYAWPFYNPVDVNALGLHNYYDVVKNPMDLGTIKEKMDNQEYKDAYKFAADVRLMFMNCYKYNPPDHEVVTMARMLQDVFETHFSKIPIEPVESMPLCYIKTDITETTGRENTNEASSEGNSSDDSEDERVKRLAKLQEQLKAVHQQLQVLSQVPFRKLNKKKEKSKKEKKKEKVNNSNENPRKMCEQMRLKEKSKRNQPKKRKQQFIGLKSEDEDNAKPMNYDEKRQLSLNINKLPGDKLGRVVHIIQSREPSLSNSNPDEIEIDFETLKASTLRELEKYVSACLRKRPLKPPAKKIMMSKEELHSQKKQELEKRLLDVNNQLNSRKRQTKSDKTQPSKAVENVSRLSESSSSSSSSSESESSSSDLSSSDSSDSESEMFPKFTEVKPNDSPSKENVKKMKNECIPPEGRTGVTQIGYCVQDTTSANTTLVHQTTPSHVMPPNHHQLAFNYQELEHLQTVKNISPLQILPPSGDSEQLSNGITVMHPSGDSDTTMLESECQAPVQKDIKIKNADSWKSLGKPVKPSGVMKSSDELFNQFRKAAIEKEVKARTQELIRKHLEQNTKELKASQENQRDLGNGLTVESFSNKIQNKCSGEEQKEHQQSSEAQDKSKLWLLKDRDLARQKEQERRRREAMVGTIDMTLQSDIMTMFENNFD>sp|Q58F21-2|BRDT_HUMAN Isoform 2 of Bromodomain testis-specific proteinOS=Homo sapiens OX=9606 GN=BRDTMTCTCRQDSKQLRMSLPSRQTAIIVNPPPPEYINTKKNGRLTNQLQYLQKVVLKDLWKHSFSWPFQRPVDAVKLQLPDYYTIIKNPMDLNTIKKRLENKYYAKASECIEDFNTMFSNCYLYNKPGDDIVLMAQALEKLFMQKLSQMPQEEQVVGVKERIKKGTQQNIAVSSAKEKSSPSATEKVFKQQEIPSVFPKTSISPLNVVQGASVNSSSQTAAQVTKGVKRKADTTTPATSAVKASSEFSPTFTEKSVALPPIKENMPKNVLPDSQQQYNVVKTVKVTEQLRHCSEILKEMLAKKHFSYAWPFYNPVDVNALGLHNYYDVVKNPMDLGTIKEKMDNQEYKDAYKFAADVRLMFMNCYKYNPPDHEVVTMARMLQDVFETHFSKIPIEPVESMPLCYIKTDITETTGRENTNEASSEGNSSDDSEDERVKRLAKLQEQLKAVHQQLQVLSQVPFRKLNKKKEKSKKEKKKEKVNNSNENPRKMCEQMRLKEKSKRNQPKKRKQQFIGLKSEDEDNAKPMNYDEKRQLSLNINKLPGDKLGRVVHIIQSREPSLSNSNPDEIEIDFETLKASTLRELEKYVSACLRKRPLKPPAKKIMMSKEELHSQKKQELEKRLLDVNNQLNSRKRQTKSDKTQPSKAVENVSRLSESSSSSSSSSESESSSSDLSSSDSSDSESEMFPKFTEVKPNDSPSKENVKKMKNECIPPEGRTGVTQIGYCVQDTTSANTTLVHQTTPSHVMPPNHHQLAFNYQELEHLQTVKNISPLQILPPSGDSEQLSNGITVMHPSGDSDTTMLESECQAPVQKDIKIKNADSWKSLGKPVKPSGVMKSSDELFNQFRKAAIEKEVKARTQELIRKHLEQNTKELKASQENQRDLGNGLTVESFSNKIQNKCSGEEQKEHQQSSEAQDKSKLWLLKDRDLARQKEQERRRREAMVGTIDMTLQSDIMTMFENNFD>sp|Q58F21-3|BRDT_HUMAN Isoform 3 of Bromodomain testis-specific proteinOS=Homo sapiens OX=9606 GN=BRDTMSLPSRQTAIIVNPPPPEYINTKKNGRLTNQLQYLQKVVLKDLWKHSFSWPFQRPVDAVKLQLPDYYTIIKNPMDLNTIKKRLENKYYAKASECIEDFNTMFSNCYLYNKPGDDIVLMAQALEKLFMQKLSQMPQEEQVVGVKERIKKGKAGGTQQNIAVSSAKEKSSPSATEKVFKQQEIPSVFPKTSISPLNVVQGASVNSSSQTAAQVTKGVKRKADTTTPATSAVKASSEFSPTFTEKSVALPPIKENMPKNVLPDSQQQYNVVKTVKVTEQLRHCSEILKEMLAKKHFSYAWPFYNPVDVNALGLHNYYDVVKNPMDLGTIKEKMDNQEYKDAYKFAADVRLMFMNCYKYNPPDHEVVTMARMLQDVFETHFSKIPIEPVESMPLCYIKTDITETTGRENTNEASSEGNSSDDSEDERVKRLAKLQEQLKAVHQQLQVLSQVPFRKLNKKKEKSKKEKKKEKVNNSNENPRKMCEQMRLKEKSKRNQPKKRKQQFIGLKSEDEDNAKPMNYDEKRQLSLNINKLPGDKLGRVVHIIQSREPSLSNSNPDEIEIDFETLKASTLRELEKYVSACLRKRPLKPPAKKIMMSKEELHSQKKQELEKRLLDVNNQLNSRKRQTKSDKTQPSKAVENVSRLSESSSSSSSSSESESSSSDLSSSDSSDSESEMFPKFTEVKPNDSPSKENVKKMKNECIPPEGRTGVTQIGYCVQDTTSANTTLVHQTTPSHVMPPNHHQLAFNYQELEHLQTVKNISPLQILPPSGDSEQLSNGITVMHPSGDSDTTMLESECQAPVQKDIKIKNADSWKSLGKPVKPSGVMKSSDELFNQFRKAAIEKEVKARTQELIRKHLEQNTKELKASQENQRDLGNGLTVESFSNKIQNKCSGEEQKEHQQSSEAQDKSKLWLLKDRDLARQKEQERRRREAMVGTIDMTLQSDIMTMFENNFD>sp|Q58F21-4|BRDT_HUMAN Isoform 4 of Bromodomain testis-specific proteinOS=Homo sapiens OX=9606 GN=BRDTMSLPSRQTAIIVNPPPPEYINTKKNGRLTNQLQYLQKVVLKDLWKHSFSWPFQRPVDAVKLQLPPGDDIVLMAQALEKLFMQKLSQMPQEEQVVGVKERIKKGTQQNIAVSSAKEKSSPSATEKVFKQQEIPSVFPKTSISPLNVVQGASVNSSSQTAAQVTKGVKRKADTTTPATSAVKASSEFSPTFTEKSVALPPIKENMPKNVLPDSQQQYNVVKTVKVTEQLRHCSEILKEMLAKKHFSYAWPFYNPVDVNALGLHNYYDVVKNPMDLGTIKEKMDNQEYKDAYKFAADVRLMFMNCYKYNPPDHEVVTMARMLQDVFETHFSKIPIEPVESMPLCYIKTDITETTGRENTNEASSEGNSSDDSEDERVKRLAKLQEQLKAVHQQLQVLSQVPFRKLNKKKEKSKKEKKKEKVNNSNENPRKMCEQMRLKEKSKRNQPKKRKQQFIGLKSEDEDNAKPMNYDEKRQLSLNINKLPGDKLGRVVHIIQSREPSLSNSNPDEIEIDFETLKASTLRELEKYVSACLRKRPLKPPAKKIMMSKEELHSQKKQELEKRLLDVNNQLNSRKRQTKSDKTQPSKAVENVSRLSESSSSSSSSSESESSSSDLSSSDSSDSESEMFPKFTEVKPNDSPSKENVKKMKNECIPPEGRTGVTQIGYCVQDTTSANTTLVHQTTPSHVMPPNHHQLAFNYQELEHLQTVKNISPLQILPPSGDSEQLSNGITVMHPSGDSDTTMLESECQAPVQKDIKIKNADSWKSLGKPVKPSGVMKSSDELFNQFRKAAIEKEVKARTQELIRKHLEQNTKELKASQENQRDLGNGLTVESFSNKIQNKCSGEEQKEHQQSSEAQDKSKLWLLKDRDLARQKEQERRRREAMVGTIDMTLQSDIMTMFENNFD>sp|Q58F21-5|BRDT_HUMAN Isoform 5 of Bromodomain testis-specific proteinOS=Homo sapiens OX=9606 GN=BRDTMDLNTIKKRLENKYYAKASECIEDFNTMFSNCYLYNKPGDDIVLMAQALEKLFMQKLSQMPQEEQVVGVKERIKKGTQQNIAVSSAKEKSSPSATEKVFKQQEIPSVFPKTSISPLNVVQGASVNSSSQTAAQVTKGVKRKADTTTPATSAVKASSEFSPTFTEKSVALPPIKENMPKNVLPDSQQQYNVVKTVKVTEQLRHCSEILKEMLAKKHFSYAWPFYNPVDVNALGLHNYYDVVKNPMDLGTIKEKMDNQEYKDAYKFAADVRLMFMNCYKYNPPDHEVVTMARMLQDVFETHFSKIPIEPVESMPLCYIKTDITETTGRENTNEASSEGNSSDDSEDERVKRLAKLQEQLKAVHQQLQVLSQVPFRKLNKKKEKSKKEKKKEKVNNSNENPRKMCEQMRLKEKSKRNQPKKRKQQFIGLKSEDEDNAKPMNYDEKRQLSLNINKLPGDKLGRVVHIIQSREPSLSNSNPDEIEIDFETLKASTLRELEKYVSACLRKRPLKPPAKKIMMSKEELHSQKKQELEKRLLDVNNQLNSRKRQTKSDKTQPSKAVENVSRLSESSSSSSSSSESESSSSDLSSSDSSDSESEMFPKFTEVKPNDSPSKENVKKMKNECIPPEGRTGVTQIGYCVQDTTSANTTLVHQTTPSHVMPPNHHQLAFNYQELEHLQTVKNISPLQILPPSGDSEQLSNGITVMHPSGDSDTTMLESECQAPVQKDIKIKNADSWKSLGKPVKPSGVMKSSDELFNQFRKAAIEKEVKARTQELIRKHLEQNTKELKASQENQRDLGNGLTVESFSNKIQNKCSGEEQKEHQQSSEAQDKSKLWLLKDRDLARQKEQERRRREAMVGTIDMTLQSDIMTMFENNFD>sp|P11021|BIP_HUMAN Endoplasmic reticulum chaperone BiP OS=Homo sapiensOX=9606 GN=HSPA5 PE=1 SV=2MKLSLVAAMLLLLSAARAEEEDKKEDVGTVVGIDLGTTYSCVGVFKNGRVEIIANDQGNRITPSYVAFTPEGERLIGDAAKNQLTSNPENTVFDAKRLIGRTWNDPSVQQDIKFLPFKVVEKKTKPYIQVDIGGGQTKTFAPEEISAMVLTKMKETAEAYLGKKVTHAVVTVPAYFNDAQRQATKDAGTIAGLNVMRIINEPTAAAIAYGLDKREGEKNILVFDLGGGTFDVSLLTIDNGVFEVVATNGDTHLGGEDFDQRVMEHFIKLYKKKTGKDVRKDNRAVQKLRREVEKAKRALSSQHQARIEIESFYEGEDFSETLTRAKFEELNMDLFRSTMKPVQKVLEDSDLKKSDIDEIVLVGGSTRIPKIQQLVKEFFNGKEPSRGINPDEAVAYGAAVQAGVLSGDQDTGDLVLLDVCPLTLGIETVGGVMTKLIPRNTVVPTKKSQIFSTASDNQPTVTIKVYEGERPLTKDNHLLGTFDLTGIPPAPRGVPQIEVTFEIDVNGILRVTAEDKGTGNKNKITITNDQNRLTPEEIERMVNDAEKFAEEDKKLKERIDTRNELESYAYSLKNQIGDKEKLGGKLSSEDKETMEKAVEEKIEWLESHQDADIEDFKAKKKELEEIVQPIISKLYGSAGPPPTGEEDTAEKDEL>sp|P32247|BRS3_HUMAN Bombesin receptor subtype-3 OS=Homo sapiens OX=9606GN=BRS3 PE=1 SV=1MAQRQPHSPNQTLISITNDTESSSSVVSNDNTNKGWSGDNSPGIEALCAIYITYAVIISVGILGNAILIKVFFKTKSMQTVPNIFITSLAFGDLLLLLTCVPVDATHYLAEGWLFGRIGCKVLSFIRLTSVGVSVFTLTILSADRYKAVVKPLERQPSNAILKTCVKAGCVWIVSMIFALPEAIFSNVYTFRDPNKNMTFESCTSYPVSKKLLQEIHSLLCFLVFYIIPLSIISVYYSLIARTLYKSTLNIPTEEQSHARKQIESRKRIARTVLVLVALFALCWLPNHLLYLYHSFTSQTYVDPSAMHFIFTIFSRVLAFSNSCVNPFALYWLSKSFQKHFKAQLFCCKAERPEPPVADTSLTTLAVMGTVPGTGSIQMSEISVTSFTGCSVKQAEDRF>sp|P46379|BAG6_HUMAN Large proline-rich protein BAG6 OS=Homo sapiensOX=9606 GN=BAG6 PE=1 SV=2MEPNDSTSTAVEEPDSLEVLVKTLDSQTRTFIVGAQMNVKEFKEHIAASVSIPSEKQRLIYQGRVLQDDKKLQEYNVGGKVIHLVERAPPQTHLPSGASSGTGSASATHGGGSPPGTRGPGASVHDRNANSYVMVGTFNLPSDGSAVDVHINMEQAPIQSEPRVRLVMAQHMIRDIQTLLSRMETLPYLQCRGGPQPQHSQPPPQPPAVTPEPVALSSQTSEPVESEAPPREPMEAEEVEERAPAQNPELTPGPAPAGPTPAPETNAPNHPSPAEYVEVLQELQRLESRLQPFLQRYYEVLGAAATTDYNNNHEGREEDQRLINLVGESLRLLGNTFVALSDLRCNLACTPPRHLHVVRPMSHYTTPMVLQQAAIPIQINVGTTVTMTGNGTRPPPTPNAEAPPPGPGQASSVAPSSTNVESSAEGAPPPGPAPPPATSHPRVIRISHQSVEPVVMMHMNIQDSGTQPGGVPSAPTGPLGPPGHGQTLGQQVPGFPTAPTRVVIARPTPPQARPSHPGGPPVSGTLQGAGLGTNASLAQMVSGLVGQLLMQPVLVAQGTPGMAPPPAPATASASAGTTNTATTAGPAPGGPAQPPPTPQPSMADLQFSQLLGNLLGPAGPGAGGSGVASPTITVAMPGVPAFLQGMTDFLQATQTAPPPPPPPPPPPPAPEQQTMPPPGSPSGGAGSPGGLGLESLSPEFFTSVVQGVLSSLLGSLGARAGSSESIAAFIQRLSGSSNIFEPGADGALGFFGALLSLLCQNFSMVDVVMLLHGHFQPLQRLQPQLRSFFHQHYLGGQEPTPSNIRMATHTLITGLEEYVRESFSLVQVQPGVDIIRTNLEFLQEQFNSIAAHVLHCTDSGFGARLLELCNQGLFECLALNLHCLGGQQMELAAVINGRIRRMSRGVNPSLVSWLTTMMGLRLQVVLEHMPVGPDAILRYVRRVGDPPQPLPEEPMEVQGAERASPEPQRENASPAPGTTAEEAMSRGPPPAPEGGSRDEQDGASAETEPWAAAVPPEWVPIIQQDIQSQRKVKPQPPLSDAYLSGMPAKRRKTMQGEGPQLLLSEAVSRAAKAAGARPLTSPESLSRDLEAPEVQESYRQQLRSDIQKRLQEDPNYSPQRFPNAQRAFADDP>sp|P46379-2|BAG6_HUMAN Isoform 2 of Large proline-rich protein BAG6OS=Homo sapiens OX=9606 GN=BAG6MEPNDSTSTAVEEPDSLEVLVKTLDSQTRTFIVGAQMNVKEFKEHIAASVSIPSEKQRLIYQGRVLQDDKKLQEYNVGGKVIHLVERAPPQTHLPSGASSGTGSASATHGGGSPPGTRGPGASVHDRNANSYVMVGTFNLPSDGSAVDVHINMEQAPIQSEPRVRLVMAQHMIRDIQTLLSRMECRGGPQPQHSQPPPQPPAVTPEPVALSSQTSEPVESEAPPREPMEAEEVEERAPAQNPELTPGPAPAGPTPAPETNAPNHPSPAEYVEVLQELQRLESRLQPFLQRYYEVLGAAATTDYNNNHEGREEDQRLINLVGESLRLLGNTFVALSDLRCNLACTPPRHLHVVRPMSHYTTPMVLQQAAIPIQINVGTTVTMTGNGTRPPPTPNAEAPPPGPGQASSVAPSSTNVESSAEGAPPPGPAPPPATSHPRVIRISHQSVEPVVMMHMNIQDSGTQPGGVPSAPTGPLGPPGHGQTLGQQVPGFPTAPTRVVIARPTPPQARPSHPGGPPVSGTLQGAGLGTNASLAQMVSGLVGQLLMQPVLVAQGTPGMAPPPAPATASASAGTTNTATTAGPAPGGPAQPPPTPQPSMADLQFSQLLGNLLGPAGPGAGGSGVASPTITVAMPGVPAFLQGMTDFLQATQTAPPPPPPPPPPPPAPEQQTMPPPGSPSGGAGSPGGLGLESLSPEFFTSVVQGVLSSLLGSLGARAGSSESIAAFIQRLSGSSNIFEPGADGALGFFGALLSLLCQNFSMVDVVMLLHGHFQPLQRLQPQLRSFFHQHYLGGQEPTPSNIRMATHTLITGLEEYVRESFSLVQVQPGVDIIRTNLEFLQEQFNSIAAHVLHCTDSGFGARLLELCNQGLFECLALNLHCLGGQQMELAAVINGRIRRMSRGVNPSLVSWLTTMMGLRLQVVLEHMPVGPDAILRYVRRVGDPPQPLPEEPMEVQGAERASPEPQRENASPAPGTTAEEAMSRGPPPAPEGGSRDEQDGASAETEPWAAAVPPEWVPIIQQDIQSQRKVKPQPPLSDAYLSGMPAKRRKTMQGEGPQLLLSEAVSRAAKAAGARPLTSPESLSRDLEAPEVQESYRQQLRSDIQKRLQEDPNYSPQRFPNAQRAFADDP>sp|P46379-3|BAG6_HUMAN Isoform 3 of Large proline-rich protein BAG6OS=Homo sapiens OX=9606 GN=BAG6MEPNDSTSTAVEEPDSLEVLVKTLDSQTRTFIVGAQMNVKEFKEHIAASVSIPSEKQRLIYQGRVLQDDKKLQEYNVGGKVIHLVERAPPQTHLPSGASSGTGSASATHGGGSPPGTRGPGASVHDRNANSYVMVGTFNLPSDGSAVDVHINMEQAPIQSEPRVRLVMAQHMIRDIQTLLSRMECRGGPQPQHSQPPPQPPAVTPEPVALSSQTSEPVESEAPPREPMEAEEVEERAPAQNPELTPGPAPAGPTPAPETNAPNHPSPAEYVEVLQELQRLESRLQPFLQRYYEVLGAAATTDYNNNHEGREEDQRLINLVGESLRLLGNTFVALSDLRCNLACTPPRHLHVVRPMSHYTTPMVLQQAAIPIQINVGTTVTMTGNGTRPPPTPNAEAPPPGPGQASSVAPSSTNVESSAEGAPPPGPAPPPATSHPRVIRISHQSVEPVVMMHMNIQDSGTQPGGVPSAPTGPLGPPGHGQTLGSTLIQLPSLPPEFMHAVAHQITHQAMVAAVASAAAGQQVPGFPTAPTRVVIARPTPPQARPSHPGGPPVSGTLQGAGLGTNASLAQMVSGLVGQLLMQPVLVAQGTPGMAPPPAPATASASAGTTNTATTAGPAPGGPAQPPPTPQPSMADLQFSQLLGNLLGPAGPGAGGSGVASPTITVAMPGVPAFLQGMTDFLQATQTAPPPPPPPPPPPPAPEQQTMPPPGSPSGGAGSPGGLGLESLSPEFFTSVVQGVLSSLLGSLGARAGSSESIAAFIQRLSGSSNIFEPGADGALGFFGALLSLLCQNFSMVDVVMLLHGHFQPLQRLQPQLRSFFHQHYLGGQEPTPSNIRMATHTLITGLEEYVRESFSLVQVQPGVDIIRTNLEFLQEQFNSIAAHVLHCTDSGFGARLLELCNQGLFECLALNLHCLGGQQMELAAVINGRIRRMSRGVNPSLVSWLTTMMGLRLQVVLEHMPVGPDAILRYVRRVGDPPQPLPEEPMEVQGAERASPEPQRENASPAPGTTAEEAMSRGPPPAPEGGSRDEQDGASAETEPWAAAVPPEWVPIIQQDIQSQRKVKPQPPLSDAYLSGMPAKRRKTMQGEGPQLLLSEAVSRAAKAAGARPLTSPESLSRDLEAPEVQESYRQQLRSDIQKRLQEDPNYSPQRFPNAQRAFADDP>sp|P46379-4|BAG6_HUMAN Isoform 4 of Large proline-rich protein BAG6OS=Homo sapiens OX=9606 GN=BAG6MEPNDSTSTAVEEPDSLEVLVKTLDSQTRTFIVGAQMNVKEFKEHIAASVSIPSEKQRLIYQGRVLQDDKKLQEYNVGGKVIHLVERAPPQTHLPSGASSGTGSASATHGGGSPPGTRGPGASVHDRNANSYVMVGTFNLPSDGSAVDVHINMEQAPIQSEPRVRLVMAQHMIRDIQTLLSRMECRGGPQPQHSQPPPQPPAVTPEPVALSSQTSEPVESEAPPREPMEAEEVEERAPAQNPELTPGPAPAGPTPAPETNAPNHPSPAEYVEVLQELQRLESRLQPFLQRYYEVLGAAATTDYNNNHEGREEDQRLINLVGESLRLLGNTFVALSDLRCNLACTPPRHLHVVRPMSHYTTPMVLQQAAIPIQINVGTTVTMTGNGTRPPPTPNAEAPPPGPGQASSVAPSSTNVESSAEGAPPPGPAPPPATSHPRVIRISHQSVEPVVMMHMNIQDSGTQPGGVPSAPTGPLGPPGHGQTLGQQVPGFPTAPTRVVIARPTPPQARPSHPGGPPVSGTLGAGLGTNASLAQMVSGLVGQLLMQPVLVAQGTPGSPGGLGLESLSPEFFTSVVQGVLSSLLGSLGARAGSSESIAAFIQRLSGSSNIFEPGADGALGFFGALLSLLCQNFSMVDVVMLLHGHFQPLQRLQPQLRSFFHQHYLGGQEPTPSNIRMATHTLITGLEEYVRESFSLVQVQPGVDIIRTNLEFLQEQFNSIAAHVLHCTDSGFGARLLELCNQGLFECLALNLHCLGGQQMELAAVINGRIRRMSRGVNPSLVSWLTTMMGLRLQVVLEHMPVGPDAILRYVRRVGDPPQPLPEEPMEVQGAERASPEPQEWVPIIQQDIQSQRKVKPQPPLSDAYLSGMPAKRRKLRSDIQKRLQEDPNYSPQRFPNAQRAFADDP>sp|P46379-5|BAG6_HUMAN Isoform 5 of Large proline-rich protein BAG6OS=Homo sapiens OX=9606 GN=BAG6MEPNDSTSTAVEEPDSLEVLVKTLDSQTRTFIVGAQMNVKEFKEHIAASVSIPSEKQRLIYQGRVLQDDKKLQEYNVGGKVIHLVERAPPQTHLPSGASSGTGSASATHGGGSPPGTRGPGASVHDRNANSYVMVGTFNLPSDGSAVDVHINMEQAPIQSEPRVRLVMAQHMIRDIQTLLSRMECRGGPQPQHSQPPPQPPAVTPEPVALSSQTSEPVESEAPPREPMEAEEVEERAPAQNPELTPGPAPAGPTPAPETNAPNHPSPAEYVEVLQELQRLESRLQPFLQRYYEVLGAAATTDYNNNHEGREEDQRLINLVGESLRLLGNTFVALSDLRCNLACTPPRHLHVVRPMSHYTTPMVLQQAAIPIQINVGTTVTMTGNGTRPPPTPNAEAPPPGPGQASSVAPSSTNVESSAEGAPPPGPAPPPATSHPRVIRISHQSVEPVVMMHMNIQDSGTQPGGVPSAPTGPLGPPGHGQTLGQQVPGFPTAPTRVVIARPTPPQARPSHPGGPPVSGTLQGAGLGTNASLAQMVSGLVGQLLMQPVLVAQGTPGMAPPPAPATASASAGTTNTATTAGPAPGGPAQPPPTPQPSMADLQFSQLLGNLLGPAGPGAGGSGVASPTITVAMPGVPAFLQGMTDFLQATQTAPPPPPPPPPPPPAPEQQTMPPPGSPSGGAGSPGGLGLESLSPEFFTSVVQGVLSSLLGSLGARAGSSESIAAFIQRLSGSSNIFEPGADGALGFFGALLSLLCQNFSMVDVVMLLHGHFQPLQRLQPQLRSFFHQHYLGGQEPTPSNIRMATHTLITGLEEYVRESFSLVQVQPGVDIIRTNLEFLQEQFNSIAAHVLHCTDSGFGARLLELCNQGLFECLALNLHCLGGQQMELAAVINGRIRRMSRGVNPSLVSWLTTMMGLRLQVVLEHMPVGPDAILRYVRRVGDPPQPLPEEPMEVQGAERASPEPQRENASPAPGTTAEEAMSRGPPPAPEGGSRDEQDGASAETEPWAAAVPPEWVPIIQQDIQSQRKVKPQPPLSDAYLSGMPAKRRKLRSDIQKRLQEDPNYSPQRFPNAQRAFADDP>sp|Q9H3F6|BACD3_HUMAN BTB/POZ domain-containing adapter for CUL3-mediated RhoA degradation protein 3 OS=Homo sapiens OX=9606 GN=KCTD10PE=1 SV=1MEEMSGESVVSSAVPAAATRTTSFKGTSPSSKYVKLNVGGALYYTTMQTLTKQDTMLKAMFSGRMEVLTDSEGWILIDRCGKHFGTILNYLRDGAVPLPESRREIEELLAEAKYYLVQGLVEECQAALQNKDTYEPFCKVPVITSSKEEQKLIATSNKPAVKLLYNRSNNKYSYTSNSDDNMLKNIELFDKLSLRFNGRVLFIKDVIGDEICCWSFYGQGRKIAEVCCTSIVYATEKKQTKVEFPEARIYEETLNILLYEAQDGRGPDNALLEATGGAAGRSHHLDEDEERERIERVRRIHIKRPDDRAHLHQ>sp|Q9H3F6-2|BACD3_HUMAN Isoform 2 of BTB/POZ domain-containing adapterfor CUL3-mediated RhoA degradation protein 3 OS=Homo sapiens OX=9606GN=KCTD10MEEMSGESVVSSAVPAAATRTTSFKGTSPSSKYVKLNVGGALYYTTMQTLTKQDTMLKAMFSGRMEVLTDSEGWILIDRCGKHFGTILNYLRDGAVPLPESRREIEELLAEAKYYLVQGLVEECQAALQNKDTYEPFCKVPVITSSKEEQKLIATSNKPAVKLLYNRSNNKYSYTRVLFIKDVIGDEICCWSFYGQGRKIAEVCCTSIVYATEKKQTKVEFPEARIYEETLNILLYEAQDGRGPDNALLEATGGAAGRSHHLDEDEERERIERVRRIHIKRPDDRAHLHQ>sp|Q9H3F6-3|BACD3_HUMAN Isoform 3 of BTB/POZ domain-containing adapterfor CUL3-mediated RhoA degradation protein 3 OS=Homo sapiens OX=9606GN=KCTD10MMAVFTSLWSPYQMLFCSNSDDNMLKNIELFDKLSLRFNGRVLFIKDVIGDEICCWSFYGQGRKIAEVCCTSIVYATEKKQTKVEFPEARIYEETLNILLYEAQDGRGPDNALLEATGGAAGRSHHLDEDEERERIERVRRIHIKRPDDRAHLHQ>sp|Q6PI77|BHLH9_HUMAN Protein BHLHb9 OS=Homo sapiens OX=9606 GN=BHLHB9PE=1 SV=1MAGTKNKTRAQAKTEKKAAIQAKAGAEREATGVVRPVAKTRAKAKAKTGSKTDAVAEMKAVSKNKVVAETKEGALSEPKTLGKAMGDFTPKAGNESTSSTCKNEAGTDAWFWAGEEATINSWFWNGEEAGNSFSTKNDKPEIGAQVCAEELEPAAGADCKPRSGAEEEEEENVIGNWFWEGDDTSFDPNPKPVSRIVKPQPVYEINEKNRPKDWSEVTIWPNAPAVTPAVLGFRSQAPSEASPPSYIVLASAEENACSLPVATACRPSRNTRSCSQPIPECRFDSDPCIQTIDEIRRQIRIREVNGIKPFACPCKMECYMDSEEFEKLVSLLKSTTDPLIHKIARIAMGVHNVHPFAQEFINEVGVVTLIESLLSFPSPEMRKKTVITLNPPSGDERQRKIELHVKHMCKETMSFPLNSPGQQSGLKILGQLTTDFVHHYIVANYFSELFHLLSSGNCKTRNLVLKLLLNMSENPTAARDMINMKALAALKLIFNQKEAKANLVSGVAIFINIKEHIRKGSIVVVDHLSYNTLMAIFREVKEIIETM>sp|Q9H7X2|CA115_HUMAN Uncharacterized protein C1orf115 OS=Homo sapiensOX=9606 GN=C1orf115 PE=2 SV=1MTVGARLRSKAESSLLRRGPRGRGRTEGDEEAAAILEHLEYADEAEAAAESGTSAADERGPGTRGARRVHFALLPERYEPLEEPAPSEQPRKRYRRKLKKYGKNVGKVIIKGCRYVVIGLQGFAAAYSAPFAVATSVVSFVR>sp|Q8TD86|CALL6_HUMAN Calmodulin-like protein 6 OS=Homo sapiens OX=9606GN=CALML6 PE=1 SV=2MGLQQEISLQPWCHHPAESCQTTTDMTERLSAEQIKEYKGVFEMFDEEGNGEVKTGELEWLMSLLGINPTKSELASMAKDVDRDNKGFFNCDGFLALMGVYHEKAQNQESELRAAFRVFDKEGKGYIDWNTLKYVLMNAGEPLNEVEAEQMMKEADKDGDRTIDYEEFVAMMTGESFKLIQ>sp|P27797|CALR_HUMAN Calreticulin OS=Homo sapiens OX=9606 GN=CALR PE=1SV=1MLLSVPLLLGLLGLAVAEPAVYFKEQFLDGDGWTSRWIESKHKSDFGKFVLSSGKFYGDEEKDKGLQTSQDARFYALSASFEPFSNKGQTLVVQFTVKHEQNIDCGGGYVKLFPNSLDQTDMHGDSEYNIMFGPDICGPGTKKVHVIFNYKGKNVLINKDIRCKDDEFTHLYTLIVRPDNTYEVKIDNSQVESGSLEDDWDFLPPKKIKDPDASKPEDWDERAKIDDPTDSKPEDWDKPEHIPDPDAKKPEDWDEEMDGEWEPPVIQNPEYKGEWKPRQIDNPDYKGTWIHPEIDNPEYSPDPSIYAYDNFGVLGLDLWQVKSGTIFDNFLITNDEAYAEEFGNETWGVTKAAEKQMKDKQDEEQRLKEEEEDKKRKEEEEAEDKEDDEDKDEDEEDEEDKEEDEEEDVPGQAKDEL>sp|Q9NY47|CA2D2_HUMAN Voltage-dependent calcium channel subunit alpha-2/delta-2 OS=Homo sapiens OX=9606 GN=CACNA2D2 PE=1 SV=2MAVPARTCGASRPGPARTARPWPGCGPHPGPGTRRPTSGPPRPLWLLLPLLPLLAAPGASAYSFPQQHTMQHWARRLEQEVDGVMRIFGGVQQLREIYKDNRNLFEVQENEPQKLVEKVAGDIESLLDRKVQALKRLADAAENFQKAHRWQDNIKEEDIVYYDAKADAELDDPESEDVERGSKASTLRLDFIEDPNFKNKVNYSYAAVQIPTDIYKGSTVILNELNWTEALENVFMENRRQDPTLLWQVFGSATGVTRYYPATPWRAPKKIDLYDVRRRPWYIQGASSPKDMVIIVDVSGSVSGLTLKLMKTSVCEMLDTLSDDDYVNVASFNEKAQPVSCFTHLVQANVRNKKVFKEAVQGMVAKGTTGYKAGFEYAFDQLQNSNITRANCNKMIMMFTDGGEDRVQDVFEKYNWPNRTVRVFTFSVGQHNYDVTPLQWMACANKGYYFEIPSIGAIRINTQEYLDVLGRPMVLAGKEAKQVQWTNVYEDALGLGLVVTGTLPVFNLTQDGPGEKKNQLILGVMGIDVALNDIKRLTPNYTLGANGYVFAIDLNGYVLLHPNLKPQTTNFREPVTLDFLDAELEDENKEEIRRSMIDGNKGHKQIRTLVKSLDERYIDEVTRNYTWVPIRSTNYSLGLVLPPYSTFYLQANLSDQILQVKLPISKLKDFEFLLPSSFESEGHVFIAPREYCKDLNASDNNTEFLKNFIELMEKVTPDSKQCNNFLLHNLILDTGITQQLVERVWRDQDLNTYSLLAVFAATDGGITRVFPNKAAEDWTENPEPFNASFYRRSLDNHGYVFKPPHQDALLRPLELENDTVGILVSTAVELSLGRRTLRPAVVGVKLDLEAWAEKFKVLASNRTHQDQPQKCGPNSHCEMDCEVNNEDLLCVLIDDGGFLVLSNQNHQWDQVGRFFSEVDANLMLALYNNSFYTRKESYDYQAACAPQPPGNLGAAPRGVFVPTVADFLNLAWWTSAAAWSLFQQLLYGLIYHSWFQADPAEAEGSPETRESSCVMKQTQYYFGSVNASYNAIIDCGNCSRLFHAQRLTNTNLLFVVAEKPLCSQCEAGRLLQKETHSDGPEQCELVQRPRYRRGPHICFDYNATEDTSDCGRGASFPPSLGVLVSLQLLLLLGLPPRPQPQVLVHASRRL>sp|Q9NY47-2|CA2D2_HUMAN Isoform 2 of Voltage-dependent calcium channelsubunit alpha-2/delta-2 OS=Homo sapiens OX=9606 GN=CACNA2D2MAVPARTCGASRPGPARTARPWPGCGPHPGPGTRRPTSGPPRPLWLLLPLLPLLAAPGASAYSFPQQHTMQHWARRLEQEVDGVMRIFGGVQQLREIYKDNRNLFEVQENEPQKLVEKVAGDIESLLDRKVQALKRLADAAENFQKAHRWQDNIKEEDIVYYDAKADAELDDPESEDVERGSKASTLRLDFIEDPNFKNKVNYSYAAVQIPTDIYKGSTVILNELNWTEALENVFMENRRQDPTLLWQVFGSATGVTRYYPATPWRAPKKIDLYDVRRRPWYIQGASSPKDMVIIVDVSGSVSGLTLKLMKTSVCEMLDTLSDDDYVNVASFNEKAQPVSCFTHLVQANVRNKKVFKEAVQGMVAKGTTGYKAGFEYAFDQLQNSNITRANCNKMIMMFTDGGEDRVQDVFEKYNWPNRTVRVFTFSVGQHNYDVTPLQWMACANKGYYFEIPSIGAIRINTQEYLDVLGRPMVLAGKEAKQVQWTNVYEDALGLGLVVTGTLPVFNLTQDGPGEKKNQLILGVMGIDVALNDIKRLTPNYTLGANGYVFAIDLNGYVLLHPNLKPQTTNFREPVTLDFLDAELEDENKEEIRRSMIDGNKGHKQIRTLVKSLDERYIDEVTRNYTWVPIRSTNYSLGLVLPPYSTFYLQANLSDQILQVKYFEFLLPSSFESEGHVFIAPREYCKDLNASDNNTEFLKNFIELMEKVTPDSKQCNNFLLHNLILDTGITQQLVERVWRDQDLNTYSLLAVFAATDGGITRVFPNKAAEDWTENPEPFNASFYRRSLDNHGYVFKPPHQDALLRPLELENDTVGILVSTAVELSLGRRTLRPAVVGVKLDLEAWAEKFKVLASNRTHQDQPQKCGPNSHCEMDCEVNNEDLLCVLIDDGGFLVLSNQNHQWDQVGRFFSEVDANLMLALYNNSFYTRKESYDYQAACAPQPPGNLGAAPRGVFVPTVADFLNLAWWTSAAAWSLFQQLLYGLIYHSWFQADPAEAEGSPETRESSCVMKQTQYYFGSVNASYNAIIDCGNCSRLFHAQRLTNTNLLFVVAEKPLCSQCEAGRLLQKETHSDGPEQCELVQRPRYRRGPHICFDYNATEDTSDCGRGASFPPSLGVLVSLQLLLLLGLPPRPQPQVLVHASRRL>sp|Q9NY47-3|CA2D2_HUMAN Isoform 3 of Voltage-dependent calcium channelsubunit alpha-2/delta-2 OS=Homo sapiens OX=9606 GN=CACNA2D2MAVPARTCGASRPGPARTARPWPGCGPHPGPGTRRPTSGPPRPLWLLLPLLPLLAAPGASAYSFPQQHTMQHWARRLEQEVDGVMRIFGGVQQLREIYKDNRNLFEVQENEPQKLVEKVAGDIESLLDRKVQALKRLADAAENFQKAHRWQDNIKEEDIVYYDAKADAELDDPESEDVERGSKASTLRLDFIEDPNFKNKVNYSYAAVQIPTDIYKGSTVILNELNWTEALENVFMENRRQDPTLLWQVFGSATGVTRYYPATPWRAPKKIDLYDVRRRPWYIQGASSPKDMVIIVDVSGSVSGLTLKLMKTSVCEMLDTLSDDDYVNVASFNEKAQPVSCFTHLVQANVRNKKVFKEAVQGMVAKGTTGYKAGFEYAFDQLQNSNITRANCNKMIMMFTDGGEDRVQDVFEKYNWPNRTVRVFTFSVGQHNYDVTPLQWMACANKGYYFEIPSIGAIRINTQEYLDVLGRPMVLAGKEAKQVQWTNVYEDALGLGLVVTGTLPVFNLTQDGPGEKKNQLILGVMGIDVALNDIKRLTPNYTLGANGYVFAIDLNGYVLLHPNLKPQTTNFREPVTLDFLDAELEDENKEEIRRSMIDGNKGHKQIRTLVKSLDERYIDEVTRNYTWVPIRSTNYSLGLVLPPYSTFYLQANLSDQILQVKYFEFLLPSSFESEGHVFIAPREYCKDLNASDNNTEFLKNFIELMEKVTPDSKQCNNFLLHNLILDTGITQQLVERVWRDQDLNTYSLLAVFAATDGGITRVFPNKAAEDWTENPEPFNASFYRRSLDNHGYVFKPPHQDALLRPLELENDTVGILVSTAVELSLGRRTLRPAVVGVKLDLEAWAEKFKVLASNRTHQDQPQKCGPNSHCEMDCEVNNEDLLCVLIDDGGFLVLSNQNHQWDQVGRFFSEVDANLMLALYNNSFYTRKESYDYQAACAPQPPGNLGAAPRGVFVPTVADFLNLAWWTSAAAWSLFQQLLYGLIYHSWFQADPAEAEGSPETRESSCVMKQTQYYFGSVNASYNAIIDCGNCSRLFHAQRLTNTNLLFVVAEKPLCSQCEAGRLLQKETHCPADGPEQCELVQRPRYRRGPHICFDYNATEDTSDCGRGASFPPSLGVLVSLQLLLLLGLPPRPQPQVLVHASRRL>sp|Q9NY47-4|CA2D2_HUMAN Isoform 4 of Voltage-dependent calcium channelsubunit alpha-2/delta-2 OS=Homo sapiens OX=9606 GN=CACNA2D2MQHWARRLEQEVDGVMRIFGGVQQLREIYKDNRNLFEVQENEPQKLVEKVAGDIESLLDRKVQALKRLADAAENFQKAHRWQDNIKEEDIVYYDAKADAELDDPESEDVERGSKASTLRLDFIEDPNFKNKVNYSYAAVQIPTDIYKGSTVILNELNWTEALENVFMENRRQDPTLLWQVFGSATGVTRYYPATPWRAPKKIDLYDVRRRPWYIQGASSPKDMVIIVDVSGSVSGLTLKLMKTSVCEMLDTLSDDDYVNVASFNEKAQPVSCFTHLVQANVRNKKVFKEAVQGMVAKGTTGYKAGFEYAFDQLQNSNITRANCNKMIMMFTDGGEDRVQDVFEKYNWPNRTVRVFTFSVGQHNYDVTPLQWMACANKGYYFEIPSIGAIRINTQEYLDVLGRPMVLAGKEAKQVQWTNVYEDALGLGLVVTGTLPVFNLTQDGPGEKKNQLILGVMGIDVALNDIKRLTPNYTLGANGYVFAIDLNGYVLLHPNLKPQTTNFREPVTLDFLDAELEDENKEEIRRSMIDGNKGHKQIRTLVKSLDERYIDEVTRNYTWVPIRSTNYSLGLVLPPYSTFYLQANLSDQILQVKYFEFLLPSSFESEGHVFIAPREYCKDLNASDNNTEFLKNFIELMEKVTPDSKQCNNFLLHNLILDTGITQQLVERVWRDQDLNTYSLLAVFAATDGGITRVFPNKAAEDWTENPEPFNASFYRRSLDNHGYVFKPPHQDALLRPLELENDTVGILVSTAVELSLGRRTLRPAVVGVKLDLEAWAEKFKVLASNRTHQDQPQKCGPNSHCEMDCEVNNEDLLCVLIDDGGFLVLSNQNHQWDQVGRFFSEVDANLMLALYNNSFYTRKESYDYQAACAPQPPGNLGAAPRGVFVPTVADFLNLAWWTSAAAWSLFQQLLYGLIYHSWFQADPAEAEGSPETRESSCVMKQTQYYFGSVNASYNAIIDCGNCSRLFHAQRLTNTNLLFVVAEKPLCSQCEAGRLLQKETHCPADGPEQCELVQRPRYRRGPHICFDYNATEDTSDCGRGASFPPSLGVLVSLQLLLLLGLPPRPQPQVLVHASRRL>sp|Q9NY47-5|CA2D2_HUMAN Isoform 5 of Voltage-dependent calcium channelsubunit alpha-2/delta-2 OS=Homo sapiens OX=9606 GN=CACNA2D2MAVPARTCGASRPGPARTARPWPGCGPHPGPGTRRPTSGPPRPLWLLLPLLPLLAAPGASAYSFPQQHTMQHWARRLEQEVDGVMRIFGGVQQLREIYKDNRNLFEVQENEPQKLVEKVAGDIESLLDRKVQALKRLADAAENFQKAHRWQDNIKEEDIVYYDAKADAELDDPESEDVERGSKASTLRLDFIEDPNFKNKVNYSYAAVQIPTDIYKGSTVILNELNWTEALENVFMENRRQDPTLLWQVFGSATGVTRYYPATPWRAPKKIDLYDVRRRPWYIQGASSPKDMVIIVDVSGSVSGLTLKLMKTSVCEMLDTLSDDDYVNVASFNEKAQPVSCFTHLVQANVRNKKVFKEAVQGMVAKGTTGYKAGFEYAFDQLQNSNITRANCNKMIMMFTDGGEDRVQDVFEKYNWPNRTVRVFTFSVGQHNYDVTPLQWMACANKGYYFEIPSIGAIRINTQEYLDVLGRPMVLAGKEAKQVQWTNVYEDALGLGLVVTGTLPVFNLTQDGPGEKKNQLILGVMGIDVALNDIKRLTPNYTLGANGYVFAIDLNGYVLLHPNLKPQTTNFREPVTLDFLDAELEDENKEEIRRSMIDGNKGHKQIRTLVKSLDERYIDEVTRNYTWVPIRSTNYSLGLVLPPYSTFYLQANLSDQILQVKLPISKLKDFEFLLPSSFESEGHVFIAPREYCKDLNASDNNTEFLKNFIELMEKVTPDSKQCNNFLLHNLILDTGITQQLVERVWRDQDLNTYSLLAVFAATDGGITRVFPNKAAEDWTENPEPFNASFYRRSLDNHGYVFKPPHQDALLRPLELENDTVGILVSTAVELSLGRRTLRPAVVGVKLDLEAWAEKFKVLASNRTHQDQPQKCGPNSHCEMDCEVNNEDLLCVLIDDGGFLVLSNQNHQWDQVGRFFSEVDANLMLALYNNSFYTRKESYDYQAACAPQPPGNLGAAPRGVFVPTVADFLNLAWWTSAAAWSLFQQLLYGLIYHSWFQADPAEAEGSPETRESSCVMKQTQYYFGSVNASYNAIIDCGNCSRLFHAQRLTNTNLLFVVAEKPLCSQCEAGRLLQKETHCPADGPEQCELVQRPRYRRGPHICFDYNATEDTSDCGRGASFPPSLGVLVSLQLLLLLGLPPRPQPQVLVHASRRL>sp|Q6P1W5|CA094_HUMAN Uncharacterized protein C1orf94 OS=Homo sapiensOX=9606 GN=C1orf94 PE=1 SV=2MRGGGGCVLALGGQRGFQKERRRMASGNGLPSSSALVAKGPCALGPFPRYIWIHQDTPQDSLDKTCHEIWKRVQGLPEASQPWTSMEQLSVPVVGTLRGNELSFQEEALELSSGKDEISLLVEQEFLSLTKEHSILVEESSGELEVPGSSPEGTRELAPCILAPPLVAGSNERPRASIIVGDKLLKQKVAMPVISSRQDCDSATSTVTDILCAAEVKSSKGTEDRGRILGDSNLQVSKLLSQFPLKSTETSKVPDNKNVLDKTRVTKDFLQDNLFSGPGPKEPTGLSPFLLLPPRPPPARPDKLPELPAQKRQLPVFAKICSKPKADPAVERHHLMEWSPGTKEPKKGQGSLFLSQWPQSQKDACGEEGCCDAVGTASLTLPPKKPTCPAEKNLLYEFLGATKNPSGQPRLRNKVEVDGPELKFNAPVTVADKNNPKYTGNVFTPHFPTAMTSATLNQPLWLNLNYPPPPVFTNHSTFLQYQGLYPQQAARMPYQQALHPQLGCYSQQVMPYNPQQMGQQIFRSSYTPLLSYIPFVQPNYPYPQRTPPKMSANPRDPPLMAGDGPQYLFPQGYGFGSTSGGPLMHSPYFSSSGNGINF>sp|Q6P1W5-2|CA094_HUMAN Isoform 2 of Uncharacterized protein C1orf94OS=Homo sapiens OX=9606 GN=C1orf94MPVISSRQDCDSATSTVTDILCAAEVKSSKGTEDRGRILGDSNLQVSKLLSQFPLKSTETSKVPDNKNVLDKTRVTKDFLQDNLFSGPGPKEPTGLSPFLLLPPRPPPARPDKLPELPAQKRQLPVFAKICSKPKADPAVERHHLMEWSPGTKEPKKGQGSLFLSQWPQSQKDACGEEGCCDAVGTASLTLPPKKPTCPAEKNLLYEFLGATKNPSGQPRLRNKVEVDGPELKFNAPVTVADKNNPKYTGNVFTPHFPTAMTSATLNQPLWLNLNYPPPPVFTNHSTFLQYQGLYPQQAARMPYQQALHPQLGCYSQQVMPYNPQQMGQQIFRSSYTPLLSYIPFVQPNYPYPQRTPPKMSANPRDPPLMAGDGPQYLFPQGYGFGSTSGGPLMHSPYFSSSGNGINF>sp|Q8N4F0|BPIB2_HUMAN BPI fold-containing family B member 2 OS=Homosapiens OX=9606 GN=BPIFB2 PE=1 SV=2MAWASRLGLLLALLLPVVGASTPGTVVRLNKAALSYVSEIGKAPLQRALQVTVPHFLDWSGEALQPTRIRILNVHVPRLHLKFIAGFGVRLLAAANFTFKVFRAPEPLELTLPVELLADTRVTQSSIRTPVVSISACSLFSGHANEFDGSNSTSHALLVLVQKHIKAVLSNKLCLSISNLVQGVNVHLGTLIGLNPVGPESQIRYSMVSVPTVTSDYISLEVNAVLFLLGKPIILPTDATPFVLPRHVGTEGSMATVGLSQQLFDSALLLLQKAGALNLDITGQLRSDDNLLNTSALGRLIPEVARQFPEPMPVVLKVRLGATPVAMLHTNNATLRLQPFVEVLATASNSAFQSLFSLDVVVNLRLQLSVSKVKLQGTTSVLGDVQLTVASSNVGFIDTDQVRTLMGTVFEKPLLDHLNALLAMGIALPGVVNLHYVAPEIFVYEGYVVISSGLFYQS>sp|Q5XLA6|CAR17_HUMAN Caspase recruitment domain-containing protein 17OS=Homo sapiens OX=9606 GN=CARD17 PE=1 SV=1MADKVLKEKRKQFIRSVGEGTINGLLGELLETRVLSQEEIEIVKCENATVMDKARALLDSVIRKGAPACQICITYICEEDSHLAGTLGLSAGPTSGNHLTTQDSQIVLPS>sp|O75155|CAND2_HUMAN Cullin-associated NEDD8-dissociated protein 2OS=Homo sapiens OX=9606 GN=CAND2 PE=1 SV=3MSTAAFHISSLLEKMTSSDKDFRFMATSDLMSELQKDSIQLDEDSERKVVKMLLRLLEDKNGEVQNLAVKCLGPLVVKVKEYQVETIVDTLCTNMRSDKEQLRDIAGIGLKTVLSELPPAATGSGLATNVCRKITGQLTSAIAQQEDVAVQLEALDILSDMLSRLGVPLGAFHASLLHCLLPQLSSPRLAVRKRAVGALGHLAAACSTDLFVELADHLLDRLPGPRVPTSPTAIRTLIQCLGSVGRQAGHRLGAHLDRLVPLVEDFCNLDDDELRESCLQAFEAFLRKCPKEMGPHVPNVTSLCLQYIKHDPNYNYDSDEDEEQMETEDSEFSEQESEDEYSDDDDMSWKVRRAAAKCIAALISSRPDLLPDFHCTLAPVLIRRFKEREENVKADVFTAYIVLLRQTQPPKGWLEAMEEPTQTGSNLHMLRGQVPLVVKALQRQLKDRSVRARQGCFSLLTELAGVLPGSLAEHMPVLVSGIIFSLADRSSSSTIRMDALAFLQGLLGTEPAEAFHPHLPILLPPVMACVADSFYKIAAEALVVLQELVRALWPLHRPRMLDPEPYVGEMSAVTLARLRATDLDQEVKERAISCMGHLVGHLGDRLGDDLEPTLLLLLDRLRNEITRLPAIKALTLVAVSPLQLDLQPILAEALHILASFLRKNQRALRLATLAALDALAQSQGLSLPPSAVQAVLAELPALVNESDMHVAQLAVDFLATVTQAQPASLVEVSGPVLSELLRLLRSPLLPAGVLAAAEGFLQALVGTRPPCVDYAKLISLLTAPVYEQAVDGGPGLHKQVFHSLARCVAALSAACPQEAASTASRLVCDARSPHSSTGVKVLAFLSLAEVGQVAGPGHQRELKAVLLEALGSPSEDVRAAASYALGRVGAGSLPDFLPFLLEQIEAEPRRQYLLLHSLREALGAAQPDSLKPYAEDIWALLFQRCEGAEEGTRGVVAECIGKLVLVNPSFLLPRLRKQLAAGRPHTRSTVITAVKFLISDQPHPIDPLLKSFIGEFMESLQDPDLNVRRATLAFFNSAVHNKPSLVRDLLDDILPLLYQETKIRRDLIREVEMGPFKHTVDDGLDVRKAAFECMYSLLESCLGQLDICEFLNHVEDGLKDHYDIRMLTFIMVARLATLCPAPVLQRVDRLIEPLRATCTAKVKAGSVKQEFEKQDELKRSAMRAVAALLTIPEVGKSPIMADFSSQIRSNPELAALFESIQKDSASAPSTDSMELS>sp|O75155-2|CAND2_HUMAN Isoform 2 of Cullin-associated NEDD8-dissociatedprotein 2 OS=Homo sapiens OX=9606 GN=CAND2MSTAAFHISSLLEKMTSSDKDFRFMATSDLMSELQKDSIQLDEDSERKVVKMLLRLLEDKNGEVQNLAVKWLGVPLGAFHASLLHCLLPQLSSPRLAVRKRAVGALGHLAAACSTDLFVELADHLLDRLPGPRVPTSPTAIRTLIQCLGSVGRQAGHRLGAHLDRLVPLVEDFCNLDDDELRESCLQAFEAFLRKCPKEMGPHVPNVTSLCLQYIKHDPNYNYDSDEDEEQMETEDSEFSEQESEDEYSDDDDMSWKVRRAAAKCIAALISSRPDLLPDFHCTLAPVLIRRFKEREENVKADVFTAYIVLLRQTQPPKGWLEAMEEPTQTGSNLHMLRGQVPLVVKALQRQLKDRSVRARQGCFSLLTELAGVLPGSLAEHMPVLVSGIIFSLADRSSSSTIRMDALAFLQGLLGTEPAEAFHPHLPILLPPVMACVADSFYKIAAEALVVLQELVRALWPLHRPRMLDPEPYVGEMSAVTLARLRATDLDQEVKERAISCMGHLVGHLGDRLGDDLEPTLLLLLDRLRNEITRLPAIKALTLVAVSPLQLDLQPILAEALHILASFLRKNQRALRLATLAALDALAQSQGLSLPPSAVQAVLAELPALVNESDMHVAQLAVDFLATVTQAQPASLVEVSGPVLSELLRLLRSPLLPAGVLAAAEGFLQALVGTRPPCVDYAKLISLLTAPVYEQAVDGGPGLHKQVFHSLARCVAALSAACPQEAASTASRLVCDARSPHSSTGVKVLAFLSLAEVGQVAGPGHQRELKAVLLEALGSPSEDVRAAASYALGRVGAGSLPDFLPFLLEQIEAEPRRQYLLLHSLREALGAAQPDSLKPYAEDIWALLFQRCEGAEEGTRGVVAECIGKLVLVNPSFLLPRLRKQLAAGRPHTRSTVITAVKFLISDQPHPIDPLLKSFIAVHNKPSLVRDLLDDILPLLYQETKIRRDLIREVEMGPFKHTVDDGLDVRKAAFECMYSLLESCLGQLDICEFLNHVEDGLKDHYDIRMLTFIMVARLATLCPAPVLQRVDRLIEPLRATCTAKVKAGSVKQEFEKQDELKRSAMRAVAALLTIPEVGKSPIMADFSSQIRSNPELAALFESIQKDSASAPSTDSMELS>sp|Q6ZUS5|CC121_HUMAN Coiled-coil domain-containing protein 121 OS=Homosapiens OX=9606 GN=CCDC121 PE=1 SV=1MTDLNKHIKQAQTQRKQLLEESRELHREKLLVQAENRFFLEYLTNKTEEYTEQPEKVWNSYLQKSGEIERRRQESASRYAEQISVLKTALLQKENIQSSLKRKLQAMRDIAILKEKQEKEIQTLQEETKKVQAETASKTREVQAQLLQEKRLLEKQLSEPDRRLLGKRKRRELNMKAQALKLAAKRFIFEYSCGINRENQQFKKELLQLIEQAQKLTATQSHLENRKQQLQQEQWYLESLIQARQRLQGSHNQCLNRQDVPKTTPSLPQGTKSRINPK>sp|Q6ZUS5-2|CC121_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 121 OS=Homo sapiens OX=9606 GN=CCDC121MGSRGQGSHSKKTRSMPVILSPQRTGSGATGGPAARAYSVAEAVKQFRAGPAGTGAGCSLQGCWAAPRPFEHRTNKLRELSTLAHCSRELQTQVPDASAHSLAVTLSELHSCRDLQDECLDSRFAEGPRRLLPPYHSLINNFVKPEKLTKVETRLKEKIVAEMTDLNKHIKQAQTQRKQLLEESRELHREKLLVQAENRFFLEYLTNKTEEYTEQPEKVWNSYLQKSGEIERRRQESASRYAEQISVLKTALLQKENIQSSLKRKLQAMRDIAILKEKQEKEIQTLQEETKKVQAETASKTREVQAQLLQEKRLLEKQLSEPDRRLLGKRKRRELNMKAQALKLAAKRFIFEYSCGINRENQQFKKELLQLIEQAQKLTATQSHLENRKQQLQQEQWYLESLIQARQRLQGSHNQCLNRQDVPKTTPSLPQGTKSRINPK>sp|Q5JPI3|CC038_HUMAN Uncharacterized protein C3orf38 OS=Homo sapiensOX=9606 GN=C3orf38 PE=1 SV=1MEMSGLSFSEMEGCRNLLGLLDNDEIMALCDTVTNRLVQPQDRQDAVHAILAYSQSAEELLRRRKVHREVIFKYLATQGIVIPPATEKHNLIQHAKDYWQKQPQLKLKETPEPVTKTEDIHLFQQQVKEDKKAEKVDFRRLGEEFCHWFFGLLNSQNPFLGPPQDEWGPQHFWHDVKLRFYYNTSEQNVMDYHGAEIVSLRLLSLVKEEFLFLSPNLDSHGLKCASSPHGLVMVGVAGTVHRGNTCLGIFEQIFGLIRCPFVENTWKIKFINLKIMGESSLAPGTLPKPSVKFEQSDLEAFYNVITVCGTNEVRHNVKQASDSGTGDQV>sp|Q5JPI3-2|CC038_HUMAN Isoform 2 of Uncharacterized protein C3orf38OS=Homo sapiens OX=9606 GN=C3orf38MSGLSFSEMEGCRNLLGLLDNDEIMALCDTVTNRLVQPQDRQDAVHAILAYSQSAEELLRRRKVHREVIFKYLATQGIVIPPATEKHNLIQHAKDYWQKQPQLKLKETPEPVTKTEDIHLFQQQVKEDKKAEKVDFRRLGEEFCHWFFGLLNSQNPFLGPPQDEWGPQHFWHDVKLRFYYNTSEQNVMDYHGAEIVSLRLLSLVKEEFLFLSPNLDSHGLKCASSPHGLVMVGVAGTVHRGNTCLGIFEQIFGLIRCPFVENTWKIKFINLKIMGESSLAPGTLPKPSVKFEQSDLEAFYNVITVCGTNEVRHNVKQASDSGTGDQV>sp|Q8IU99|CAHM1_HUMAN Calcium homeostasis modulator protein 1 OS=Homosapiens OX=9606 GN=CALHM1 PE=1 SV=2MMDKFRMIFQFLQSNQESFMNGICGIMALASAQMYSAFDFNCPCLPGYNAAYSAGILLAPPLVLFLLGLVMNNNVSMLAEEWKRPLGRRAKDPAVLRYMFCSMAQRALIAPVVWVAVTLLDGKCFLCAFCTAVPVSALGNGSLAPGLPAPELARLLARVPCPEIYDGDWLLAREVAVRYLRCISQALGWSFVLLTTLLAFVVRSVRPCFTQAAFLKSKYWSHYIDIERKLFDETCTEHAKAFAKVCIQQFFEAMNHDLELGHTHGTLATAPASAAAPTTPDGAEEEREKLRGITDQGTMNRLLTSWHKCKPPLRLGQEEPPLMGNGWAGGGPRPPRKEVATYFSKV>sp|Q5VVM6|CCD30_HUMAN Coiled-coil domain-containing protein 30 OS=Homosapiens OX=9606 GN=CCDC30 PE=2 SV=1MSQEKNEMFESEWSKEREREKQLASGLDTAEKALKVESEELQKSKSELICLYNEVHNLPGESESKDHFLIACDLLQRENSELETKVLKLSQEFAQLNHFTLGGKTAPSNLITSENTCKDPESNEPILETEIQSRKEETEELCPKLGERKQKEIPEESVKEGSFPREGQKEEGSQQNRDMKDEEKEQQLTMKPEEIVRLREELSHINQSLLQSQSSGDSSDDSGAQHPSSGEKLKYNQQGEVQQLHQNLHRLQILCNSAENELRYERGQNLDLKQHNSLLQEENIKIKIELKHAQQKLLDSTKMCSSLTAEYKHCQQKIKELELEVLKHTQSIKSQNNLQEKLVQEKSKVADAEEKILDLQRKLEHAHKVCLTDTCISEKQQLEEKIKEATQNEAKVKQQYQEEQQKRKLLYQNVDELHRQVRTLQDKENLLEMTCSQQQSRIQQQEALLKQLENEKRKYDEHVKSNQELSEKLSKLQQEKEALREEYLRLLKLLNVHVRNYNEKHHQQKVKLQKVKYRLTNEVELRDKRINQFEDEIGILQHKIEKEKAIQDQITAQNDTLLLEKRKLQEQVIEQEQLIHSNKWTISSIQSRVLYMDKENKQLQENSLRLTQQIGFLERIIRSIHIRRGENLKEFPVPKWWHRGKLASLPPTKKQKEIYSTEVFTSNNAELQHEDESVPEATEKWKHSEQMETTISDILESEVVNEILPLSNSSFSGKGLVESFASLQETEEIKSKEAMASSKSPEKSPENLVCSQNSEAGYINVASLKETHGIQEQDQKSEL>sp|Q5VVM6-2|CCD30_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 30 OS=Homo sapiens OX=9606 GN=CCDC30MIHPPRPPKVLGLQHPSSGEKLKYNQQGEVQQLHQNLHRLQILCNSAENELRYERGQNLDLKQHNSLLQEENIKIKIELKHAQQKLLDSTKMCSSLTAEYKHCQQKIKELELEVLKHTQSIKSQNNLQEKLVQEKSKVADAEEKILDLQRKLEHAHKVCLTDTCISEKQQLEEKIKEATQNEAKVKQQYQEEQQKRKLLYQNVDELHRQVRTLQDKENLLEMTCSQQQSRIQQQEALLKQLENEKRKYDEHVKSNQELSEKLSKLQQEKEALREEYLRLLKLLNVHVRNYNEKHHQQKVKLQKVKYRLTNEVELRDKRINQFEDEIGILQHKIEKEKAIQDQITAQNDTLLLEKRKLQEQVIEQEQLIHSNKWTISSIQSRVLYMDKENKQLQENSLRLTQQIGFLERIIRSIHIRRGENLKEFPVPKWWHRGKLASLPPTKKQKEIYSTEVFTSNNAELQHEDESVPEATEKWKHSEQMETTISDILESEVVNEILPLSNSSFSGKGLVESFASLQETEEIKSKEAMASSKSPEKSPENLVCSQNSEAGYINVASLKETHGIQEQDQKSEL>sp|Q86Z20|CC125_HUMAN Coiled-coil domain-containing protein 125 OS=Homosapiens OX=9606 GN=CCDC125 PE=1 SV=2MSKVARSSSESDVQLWETEEDDMTEGDLGYGLGRKPGGIYEIEFSHRSRKRSDGKNFSPPPFPRKGEERNEASFQYSKHKSQQDTFPQVSRISNYRRQSSTVDSNSELSNEELRQCLNETLEEVEMLKTELEASQRQLRGKEEALKILQSMAILGKATSHTQAVLQKTMEQNRSLEKEINALQWEIEFDHNRFKNIEESWIQKYDRLNCENAVLKENLKVKTEEIKMLKSDNAVLNQRYLEALAMLDIKQQKMAQENMCCDKSGFAEASGLELAVLGACLCHGPGGNPCSCARMAASTRKLLLQLKQELEILQKSKEEAYVMADAFRIAFEQQLMRKNDQALQLTQMDKMHKKATKWMNWKHLKEDGFPSPRSKKTFGQRLLGMLPSENSSKRMEDQDSPQEVLKMLIDLLNDKEEALAHQRKVSYMLARALEDKDTASNENKEKNPIKENFPFNNPWRKTSEFSVLGDPIHSSVCILNSVGCICSIQHSQIDPNYRTLKRSHSLPSSIIF>sp|Q86Z20-2|CC125_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 125 OS=Homo sapiens OX=9606 GN=CCDC125MLKTELEASQRQLRGKEEALKILQSMAILGKATSHTQAVLQKTMEQNRSLEKEINALQWEIEFDHNRFKNIEESWIQKYDRLNCENAVLKENLKVKTEEIKMLKSDNAVLNQRYLEALAMLDIKQQKMAQENMCCDKSGFAEASGLELAVLGACLCHGPGGNPCSCARMAASTRKLLLQLKQELEILQKSKEEAYVMADAFRIAFEQQLMRKNDQALQLTQMDKMHKKATKWMNWKHLKEDGFPSPRSKKTFGQRLLGMLPSENSSKRMEDQDSPQEVLKMLIDLLNDKEEALAHQRKVSYMLARALEDKDTASNENKEKNPIKENFPFNNPWRKTSEFSVLGDPIHSSVCILNSVGCICSIQHSQIDPNYRTLKRSHSLPSSIIF>sp|Q96CT7|CC124_HUMAN Coiled-coil domain-containing protein 124 OS=Homosapiens OX=9606 GN=CCDC124 PE=1 SV=1MPKKFQGENTKSAAARARRAEAKAAADAKKQKELEDAYWKDDDKHVMRKEQRKEEKEKRRLDQLERKKETQRLLEEEDSKLKGGKAPRVATSSKVTRAQIEDTLRRDHQLREAPDTAEKAKSHLEVPLEENVNRRVLEEGSVEARTIEDAIAVLSVAEEAADRHPERRMRAAFTAFEEAQLPRLKQENPNMRLSQLKQLLKKEWLRSPDNPMNQRAVPFNAPK>sp|P35218|CAH5A_HUMAN Carbonic anhydrase 5A, mitochondrial OS=Homosapiens OX=9606 GN=CA5A PE=1 SV=1MLGRNTWKTSAFSFLVEQMWAPLWSRSMRPGRWCSQRSCAWQTSNNTLHPLWTVPVSVPGGTRQSPINIQWRDSVYDPQLKPLRVSYEAASCLYIWNTGYLFQVEFDDATEASGISGGPLENHYRLKQFHFHWGAVNEGGSEHTVDGHAYPAELHLVHWNSVKYQNYKEAVVGENGLAVIGVFLKLGAHHQTLQRLVDILPEIKHKDARAAMRPFDPSTLLPTCWDYWTYAGSLTTPPLTESVTWIIQKEPVEVAPSQLSAFRTLLFSALGEEEKMMVNNYRPLQPLMNRKVWASFQATNEGTRS>sp|P98082|DAB2_HUMAN Disabled homolog 2 OS=Homo sapiens OX=9606 GN=DAB2PE=1 SV=3MSNEVETSATNGQPDQQAAPKAPSKKEKKKGPEKTDEYLLARFKGDGVKYKAKLIGIDDVPDARGDKMSQDSMMKLKGMAAAGRSQGQHKQRIWVNISLSGIKIIDEKTGVIEHEHPVNKISFIARDVTDNRAFGYVCGGEGQHQFFAIKTGQQAEPLVVDLKDLFQVIYNVKKKEEEKKKIEEASKAVENGSEALMILDDQTNKLKSGVDQMDLFGDMSTPPDLNSPTESKDILLVDLNSEIDTNQNSLRENPFLTNGITSCSLPRPTPQASFLPENAFSANLNFFPTPNPDPFRDDPFTQPDQSTPSSFDSLKSPDQKKENSSSSSTPLSNGPLNGDVDYFGQQFDQISNRTGKQEAQAGPWPFSSSQTQPAVRTQNGVSEREQNGFSVKSSPNPFVGSPPKGLSIQNGVKQDLESSVQSSPHDSIAIIPPPQSTKPGRGRRTAKSSANDLLASDIFAPPVSEPSGQASPTGQPTALQPNPLDLFKTSAPAPVGPLVGLGGVTVTLPQAGPWNTASLVFNQSPSMAPGAMMGGQPSGFSQPVIFGTSPAVSGWNQPSPFAASTPPPVPVVWGPSASVAPNAWSTTSPLGNPFQSNIFPAPAVSTQPPSMHSSLLVTPPQPPPRAGPPKDISSDAFTALDPLGDKEIKDVKEMFKDFQLRQPPAVPARKGEQTSSGTLSAFASYFNSKVGIPQENADHDDFDANQLLNKINEPPKPAPRQVSLPVTKSTDNAFENPFFKDSFGSSQASVASSQPVSSEMYRDPFGNPFA>sp|P98082-2|DAB2_HUMAN Isoform 2 of Disabled homolog 2 OS=Homo sapiensOX=9606 GN=DAB2MSNEVETSATNGQPDQQAAPKAPSKKEKKKGPEKTDEYLLARFKGDGVKYKAKLIGIDDVPDARGDKMSQDSMMKLKGMAAAGRSQGQHKQRIWVNISLSGIKIIDEKTGVIEHEHPVNKISFIARDVTDNRAFGYVCGGEGQHQFFAIKTGQQAEPLVVDLKDLFQVIYNVKKKEEEKKKIEEASKAVENGSEALMILDDQTNKLKSGVDQMDLFGDMSTPPDLNSPTSSANDLLASDIFAPPVSEPSGQASPTGQPTALQPNPLDLFKTSAPAPVGPLVGLGGVTVTLPQAGPWNTASLVFNQSPSMAPGAMMGGQPSGFSQPVIFGTSPAVSGWNQPSPFAASTPPPVPVVWGPSASVAPNAWSTTSPLGNPFQSNIFPAPAVSTQPPSMHSSLLVTPPQPPPRAGPPKDISSDAFTALDPLGDKEIKDVKEMFKDFQLRQPPAVPARKGEQTSSGTLSAFASYFNSKVGIPQENADHDDFDANQLLNKINEPPKPAPRQVSLPVTKSTDNAFENPFFKDSFGSSQASVASSQPVSSEMYRDPFGNPFA>sp|P98082-3|DAB2_HUMAN Isoform 3 of Disabled homolog 2 OS=Homo sapiensOX=9606 GN=DAB2MSNEVETSATNGQPDQQAAPKAPSKKEKKKGPEKTDEYLLARFKGDGVKYKAKLIGIDDVPDARGDKMSQDSMMKLKGMAAAGRSQGQHKQRIWVNISLSGIKIIDEKTGVIEHEHPVNKISFIARDVTDNRAFGYVCGGEGQHQFFAIKTGQQAEPLVVDLKDLFQVIYNVKKKEEEKKKIEEASKAVENGSEALMILDDQTNKLKSESKDILLVDLNSEIDTNQNSLRENPFLTNGITSCSLPRPTPQASFLPENAFSANLNFFPTPNPDPFRDDPFTQPDQSTPSSFDSLKSPDQKKENSSSSSTPLSNGPLNGDVDYFGQQFDQISNRTGKQEAQAGPWPFSSSQTQPAVRTQNGVSEREQNGFSVKSSPNPFVGSPPKGLSIQNGVKQDLESSVQSSPHDSIAIIPPPQSTKPGRGRRTAKSSANDLLASDIFAPPVSEPSGQASPTGQPTALQPNPLDLFKTSAPAPVGPLVGLGGVTVTLPQAGPWNTASLVFNQSPSMAPGAMMGGQPSGFSQPVIFGTSPAVSGWNQPSPFAASTPPPVPVVWGPSASVAPNAWSTTSPLGNPFQSNIFPAPAVSTQPPSMHSSLLVTPPQPPPRAGPPKDISSDAFTALDPLGDKEIKDVKEMFKDFQLRQPPAVPARKGEQTSSGTLSAFASYFNSKVGIPQENADHDDFDANQLLNKINEPPKPAPRQVSLPVTKSTDNAFENPFFKDSFGSSQASVASSQPVSSEMYRDPFGNPFA>sp|Q13137|CACO2_HUMAN Calcium-binding and coiled-coil domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=CALCOCO2 PE=1 SV=1MEETIKDPPTSAVLLDHCHFSQVIFNSVEKFYIPGGDVTCHYTFTQHFIPRRKDWIGIFRVGWKTTREYYTFMWVTLPIDLNNKSAKQQEVQFKAYYLPKDDEYYQFCYVDEDGVVRGASIPFQFRPENEEDILVVTTQGEVEEIEQHNKELCKENQELKDSCISLQKQNSDMQAELQKKQEELETLQSINKKLELKVKEQKDYWETELLQLKEQNQKMSSENEKMGIRVDQLQAQLSTQEKEMEKLVQGDQDKTEQLEQLKKENDHLFLSLTEQRKDQKKLEQTVEQMKQNETTAMKKQQELMDENFDLSKRLSENEIICNALQRQKERLEGENDLLKRENSRLLSYMGLDFNSLPYQVPTSDEGGARQNPGLAYGNPYSGIQESSSPSPLSIKKCPICKADDICDHTLEQQQMQPLCFNCPICDKIFPATEKQIFEDHVFCHSL>sp|Q13137-2|CACO2_HUMAN Isoform 2 of Calcium-binding and coiled-coildomain-containing protein 2 OS=Homo sapiens OX=9606 GN=CALCOCO2MEETIKDPPTSAVLLDHCHFSQVIFNSVEKFYIPGGDVTCHYTFTQHFIPRRKDWIGIFRVGWKTTREYYTFMWVTLPIDLNNKSAKQQEVQFKAYYLPKDDEYYQFCYVDEDGVVRGASIPFQFRPENEEDILVVTTQEELETLQSINKKLELKVKEQKDYWETELLQLKEQNQKMSSENEKMGIRVDQLQAQLSTQEKEMEKLVQGDQDKTEQLEQLKKENDHLFLSLTEQRKDQKKLEQTVEQMKQNETTAMKKQQELMDENFDLSKRLSENEIICNALQRQKERLEGENDLLKRENSRLLSYMGLDFNSLPYQVPTSDEGGARQNPGLAYGNPYSGIQESSSPSPLSIKKCPICKADDICDHTLEQQQMQPLCFNCPICDKIFPATEKQIFEDHVFCHSL>sp|Q13137-3|CACO2_HUMAN Isoform 3 of Calcium-binding and coiled-coildomain-containing protein 2 OS=Homo sapiens OX=9606 GN=CALCOCO2MEETIKDPPTSAVLLDHCHFSQVIFNSVEKFYIPGGDVTCHYTFTQHFIPRRKDWIGIFRCSLNQTIQLLITPDTGSIWHQVGWKTTREYYTFMWVTLPIDLNNKSAKQQEVQFKAYYLPKDDEYYQFCYVDEDGVVRGASIPFQFRPENEEDILVVTTQGEVEEIEQHNKELCKENQELKDSCISLQKQNSDMQAELQKKQEELETLQSINKKLELKVKEQKDYWETELLQLKEQNQKMSSENEKMGIRVDQLQAQLSTQEKEMEKLVQGDQDKTEQLEQLKKENDHLFLSLTEQRKDQKKLEQTVEQMKQNETTAMKKQQELMDENFDLSKRLSENEIICNALQRQKERLEGENDLLKRENSRLLSYMGLDFNSLPYQVPTSDEGGARQNPGLAYGNPYSGIQESSSPSPLSIKKCPICKADDICDHTLEQQQMQPLCFNCPICDKIFPATEKQIFEDHVFCHSL>sp|Q13137-4|CACO2_HUMAN Isoform 4 of Calcium-binding and coiled-coildomain-containing protein 2 OS=Homo sapiens OX=9606 GN=CALCOCO2MEETIKDPPTSAVLLDHCHFSQVIFNSVEKFYIPGGDVTCHYTFTQHFIPRRKDWIGIFRAFKCFQDKLEQELLKWRSQGQKLQVGWKTTREYYTFMWVTLPIDLNNKSAKQQEVQFKAYYLPKDDEYYQFCYVDEDGVVRGASIPFQFRPENEEDILVVTTQGEVEEIEQHNKELCKENQELKDSCISLQKQNSDMQAELQKKQEELETLQSINKKLELKVKEQKDYWETELLQLKEQNQKMSSENEKMGIRVDQLQAQLSTQEKEMEKLVQGDQDKTEQLEQLKKENDHLFLSLTEQRKDQKKLEQTVEQMKQNETTAMKKQQELMDENFDLSKRLSENEIICNALQRQKERLEGENDLLKRENSRLLSYMGLDFNSLPYQVPTSDEGGARQNPGLAYGNPYSGIQESSSPSPLSIKKCPICKADDICDHTLEQQQMQPLCFNCPICDKIFPATEKQIFEDHVFCHSL>sp|Q13137-5|CACO2_HUMAN Isoform 5 of Calcium-binding and coiled-coildomain-containing protein 2 OS=Homo sapiens OX=9606 GN=CALCOCO2MWVTLPIDLNNKSAKQQEVQFKAYYLPKDDEYYQFCYVDEDGVVRGASIPFQFRPENEEDILVVTTQGEVEEIEQHNKELCKENQELKDSCISLQKQNSDMQAELQKKQEELETLQSINKKLELKVKEQKDYWETELLQLKEQNQKMSSENEKMGIRVDQLQAQLSTQEKEMEKLVQGDQDKTEQLEQLKKENDHLFLSLTEQRKDQKKLEQTVEQMKQNETTAMKKQQELMDENFDLSKRLSENEIICNALQRQKERLEGENDLLKRENSRLLSYMGLDFNSLPYQVPTSDEGGARQNPGLAYGNPYSGIQESSSPSPLSIKKCPICKADDICDHTLEQQQMQPLCFNCPICDKIFPATEKQIFEDHVFCHSL>sp|Q9BXJ0|C1QT5_HUMAN Complement C1q tumor necrosis factor-relatedprotein 5 OS=Homo sapiens OX=9606 GN=C1QTNF5 PE=1 SV=1MRPLLVLLLLGLAAGSPPLDDNKIPSLCPGHPGLPGTPGHHGSQGLPGRDGRDGRDGAPGAPGEKGEGGRPGLPGPRGDPGPRGEAGPAGPTGPAGECSVPPRSAFSAKRSESRVPPPSDAPLPFDRVLVNEQGHYDAVTGKFTCQVPGVYYFAVHATVYRASLQFDLVKNGESIASFFQFFGGWPKPASLSGGAMVRLEPEDQVWVQVGVGDYIGIYASIKTDSTFSGFLVYSDWHSSPVFA>sp|Q53HC0|CCD92_HUMAN Coiled-coil domain-containing protein 92 OS=Homosapiens OX=9606 GN=CCDC92 PE=1 SV=2MTSPHFSSYDEGPLDVSMAATNLENQLHSAQKNLLFLQREHASTLKGLHSEIRRLQQHCTDLTYELTVKSSEQTGDGTSKSSELKKRCEELEAQLKVKENENAELLKELEQKNAMITVLENTIKEREKKYLEELKAKSHKLTLLSSELEQRASTIAYLTSQLHAAKKKLMSSSGTSDASPSGSPVLASYKPAPPKDKLPETPRRRMKKSLSAPLHPEFEEVYRFGAESRKLLLREPVDAMPDPTPFLLARESAEVHLIKERPLVIPPIASDRSGEQHSPAREKPHKAHVGVAHRIHHATPPQAQPEVKTLAVDQVNGGKVVRKHSGTDRTV>sp|Q53HC0-2|CCD92_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 92 OS=Homo sapiens OX=9606 GN=CCDC92MAATNLENQLHSAQKNLLFLQREHASTLKGLHSEIRRLQQHCTDLTYELTVKSSEQTGDGTSKSSELKKRCEELEAQLKVKENENAELLKELEQKNAMITVLENTIKEREKKYLEELKAKSHKLTLLSSELEQRASTIAYLTSQLHAAKKKLMSSSGTSDASPSGSPVLASYKPAPPKDKLPETPRRRMKKSLSAPLHPEFEEVYRFGAESRKLLLREPVDAMPDPTPFLLARESAEVHLIKERPLVIPPIASDRSGEQHSPAREKPHKAHVGVAHRIHHATPPQAQPEVKTLAVDQVNGGKVVRKHSGTDRTV>sp|P55287|CAD11_HUMAN Cadherin-11 OS=Homo sapiens OX=9606 GN=CDH11 PE=1SV=2MKENYCLQAALVCLGMLCHSHAFAPERRGHLRPSFHGHHEKGKEGQVLQRSKRGWVWNQFFVIEEYTGPDPVLVGRLHSDIDSGDGNIKYILSGEGAGTIFVIDDKSGNIHATKTLDREERAQYTLMAQAVDRDTNRPLEPPSEFIVKVQDINDNPPEFLHETYHANVPERSNVGTSVIQVTASDADDPTYGNSAKLVYSILEGQPYFSVEAQTGIIRTALPNMDREAKEEYHVVIQAKDMGGHMGGLSGTTKVTITLTDVNDNPPKFPQSVYQMSVSEAAVPGEEVGRVKAKDPDIGENGLVTYNIVDGDGMESFEITTDYETQEGVIKLKKPVDFETKRAYSLKVEAANVHIDPKFISNGPFKDTVTVKISVEDADEPPMFLAPSYIHEVQENAAAGTVVGRVHAKDPDAANSPIRYSIDRHTDLDRFFTINPEDGFIKTTKPLDREETAWLNITVFAAEIHNRHQEAKVPVAIRVLDVNDNAPKFAAPYEGFICESDQTKPLSNQPIVTISADDKDDTANGPRFIFSLPPEIIHNPNFTVRDNRDNTAGVYARRGGFSRQKQDLYLLPIVISDGGIPPMSSTNTLTIKVCGCDVNGALLSCNAEAYILNAGLSTGALIAILACIVILLVIVVLFVTLRRQKKEPLIVFEEEDVRENIITYDDEGGGEEDTEAFDIATLQNPDGINGFIPRKDIKPEYQYMPRPGLRPAPNSVDVDDFINTRIQEADNDPTAPPYDSIQIYGYEGRGSVAGSLSSLESATTDSDLDYDYLQNWGPRFKKLADLYGSKDTFDDDS>sp|P55287-2|CAD11_HUMAN Isoform 2 of Cadherin-11 OS=Homo sapiens OX=9606GN=CDH11MKENYCLQAALVCLGMLCHSHAFAPERRGHLRPSFHGHHEKGKEGQVLQRSKRGWVWNQFFVIEEYTGPDPVLVGRLHSDIDSGDGNIKYILSGEGAGTIFVIDDKSGNIHATKTLDREERAQYTLMAQAVDRDTNRPLEPPSEFIVKVQDINDNPPEFLHETYHANVPERSNVGTSVIQVTASDADDPTYGNSAKLVYSILEGQPYFSVEAQTGIIRTALPNMDREAKEEYHVVIQAKDMGGHMGGLSGTTKVTITLTDVNDNPPKFPQSVYQMSVSEAAVPGEEVGRVKAKDPDIGENGLVTYNIVDGDGMESFEITTDYETQEGVIKLKKPVDFETKRAYSLKVEAANVHIDPKFISNGPFKDTVTVKISVEDADEPPMFLAPSYIHEVQENAAAGTVVGRVHAKDPDAANSPIRYSIDRHTDLDRFFTINPEDGFIKTTKPLDREETAWLNITVFAAEIHNRHQEAKVPVAIRVLDVNDNAPKFAAPYEGFICESDQTKPLSNQPIVTISADDKDDTANGPRFIFSLPPEIIHNPNFTVRDNRDNTAGVYARRGGFSRQKQDLYLLPIVISDGGIPPMSSTNTLTIKVCGCDVNGALLSCNAEAYILNAGLSTGALIAILACIVILLGCPSLMEPPSPREDMRLLYLGFQLMLFSYVKVNRRFCLLGVFIKLPFLYVVATESPTTLTSL>sp|P00736|C1R_HUMAN Complement C1r subcomponent OS=Homo sapiens OX=9606GN=C1R PE=1 SV=2MWLLYLLVPALFCRAGGSIPIPQKLFGEVTSPLFPKPYPNNFETTTVITVPTGYRVKLVFQQFDLEPSEGCFYDYVKISADKKSLGRFCGQLGSPLGNPPGKKEFMSQGNKMLLTFHTDFSNEENGTIMFYKGFLAYYQAVDLDECASRSKSGEEDPQPQCQHLCHNYVGGYFCSCRPGYELQEDTHSCQAECSSELYTEASGYISSLEYPRSYPPDLRCNYSIRVERGLTLHLKFLEPFDIDDHQQVHCPYDQLQIYANGKNIGEFCGKQRPPDLDTSSNAVDLLFFTDESGDSRGWKLRYTTEIIKCPQPKTLDEFTIIQNLQPQYQFRDYFIATCKQGYQLIEGNQVLHSFTAVCQDDGTWHRAMPRCKIKDCGQPRNLPNGDFRYTTTMGVNTYKARIQYYCHEPYYKMQTRAGSRESEQGVYTCTAQGIWKNEQKGEKIPRCLPVCGKPVNPVEQRQRIIGGQKAKMGNFPWQVFTNIHGRGGGALLGDRWILTAAHTLYPKEHEAQSNASLDVFLGHTNVEELMKLGNHPIRRVSVHPDYRQDESYNFEGDIALLELENSVTLGPNLLPICLPDNDTFYDLGLMGYVSGFGVMEEKIAHDLRFVRLPVANPQACENWLRGKNRMDVFSQNMFCAGHPSLKQDACQGDSGGVFAVRDPNTDRWVATGIVSWGIGCSRGYGFYTKVLNYVDWIKKEMEEED>sp|P55291|CAD15_HUMAN Cadherin-15 OS=Homo sapiens OX=9606 GN=CDH15 PE=1SV=1MDAAFLLVLGLLAQSLCLSLGVPGWRRPTTLYPWRRAPALSRVRRAWVIPPISVSENHKRLPYPLVQIKSDKQQLGSVIYSIQGPGVDEEPRGVFSIDKFTGKVFLNAMLDREKTDRFRLRAFALDLGGSTLEDPTDLEIVVVDQNDNRPAFLQEAFTGRVLEGAVPGTYVTRAEATDADDPETDNAALRFSILQQGSPELFSIDELTGEIRTVQVGLDREVVAVYNLTLQVADMSGDGLTATASAIITLDDINDNAPEFTRDEFFMEAIEAVSGVDVGRLEVEDRDLPGSPNWVARFTILEGDPDGQFTIRTDPKTNEGVLSIVKALDYESCEHYELKVSVQNEAPLQAAALRAERGQAKVRVHVQDTNEPPVFQENPLRTSLAEGAPPGTLVATFSARDPDTEQLQRLSYSKDYDPEDWLQVDAATGRIQTQHVLSPASPFLKGGWYRAIVLAQDDASQPRTATGTLSIEILEVNDHAPVLAPPPPGSLCSEPHQGPGLLLGATDEDLPPHGAPFHFQLSPRLPELGRNWSLSQVNVSHARLRPRHQVPEGLHRLSLLLRDSGQPPQQREQPLNVTVCRCGKDGVCLPGAAALLAGGTGLSLGALVIVLASALLLLVLVLLVALRARFWKQSRGKGLLHGPQDDLRDNVLNYDEQGGGEEDQDAYDISQLRHPTALSLPLGPPPLRRDAPQGRLHPQPPRVLPTSPLDIADFINDGLEAADSDPSVPPYDTALIYDYEGDGSVAGTLSSILSSQGDEDQDYDYLRDWGPRFARLADMYGHPCGLEYGARWDHQAREGLSPGALLPRHRGRTA>sp|B2RNN3|C1T9B_HUMAN Complement C1q and tumor necrosis factor-relatedprotein 9B OS=Homo sapiens OX=9606 GN=C1QTNF9B PE=1 SV=1MRIWWLLLAIEICTGNINSQDTCRQGHPGIPGNPGHNGLPGRDGRDGAKGDKGDAGEPGCPGSPGKDGTSGEKGERGADGKVEAKGIKGDQGSRGSPGKHGPKGLAGPMGEKGLRGETGPQGQKGNKGDVGPTGPEGPRGNIGPLGPTGLPGPMGPIGKPGPKGEAGPTGPQGEPGVRGIRGWKGDRGEKGKIGETLVLPKSAFTVGLTVLSKFPSSDVPIKFDKILYNEFNHYDTAVGKFTCHIAGVYYFTYHITVFSRNVQVSLVKNGVKILHTRDAYVSSEDQASGSIVLQLKLGDEMWLQVTGGERFNGLFADEDDDTTFTGFLLFSSQ>sp|B2RNN3-2|C1T9B_HUMAN Isoform 2 of Complement C1q and tumor necrosisfactor-related protein 9B OS=Homo sapiens OX=9606 GN=C1QTNF9BMRIWWLLLAIEICTGNINSQDTCRQGHPGIPGNPGHNGLPGRDGRDGAKGDKGDAGEPGCPGSPGKDGTSGEKGERGADGKVEAKGIKEMFRCLWSKME>sp|P43155|CACP_HUMAN Carnitine O-acetyltransferase OS=Homo sapiensOX=9606 GN=CRAT PE=1 SV=5MLAFAARTVVKPLGFLKPFSLMKASSRFKAHQDALPRLPVPPLQQSLDHYLKALQPIVSEEEWAHTKQLVDEFQASGGVGERLQKGLERRARKTENWLSEWWLKTAYLQYRQPVVIYSSPGVMLPKQDFVDLQGQLRFAAKLIEGVLDFKVMIDNETLPVEYLGGKPLCMNQYYQILSSCRVPGPKQDTVSNFSKTKKPPTHITVVHNYQFFELDVYHSDGTPLTADQIFVQLEKIWNSSLQTNKEPVGILTSNHRNSWAKAYNTLIKDKVNRDSVRSIQKSIFTVCLDATMPRVSEDVYRSHVAGQMLHGGGSRLNSGNRWFDKTLQFIVAEDGSCGLVYEHAAAEGPPIVTLLDYVIEYTKKPELVRSPLVPLPMPKKLRFNITPEIKSDIEKAKQNLSIMIQDLDITVMVFHHFGKDFPKSEKLSPDAFIQMALQLAYYRIYGQACATYESASLRMFHLGRTDTIRSASMDSLTFVKAMDDSSVTEHQKVELLRKAVQAHRGYTDRAIRGEAFDRHLLGLKLQAIEDLVSMPDIFMDTSYAIAMHFHLSTSQVPAKTDCVMFFGPVVPDGYGVCYNPMEAHINFSLSAYNSCAETNAARLAHYLEKALLDMRALLQSHPRAKL>sp|P43155-2|CACP_HUMAN Isoform 2 of Carnitine O-acetyltransferaseOS=Homo sapiens OX=9606 GN=CRATMKASSRFKAHQDALPRLPVPPLQQSLDHYLKALQPIVSEEEWAHTKQLVDEFQASGGVGERLQKGLERRARKTENWLSEWWLKTAYLQYRQPVVIYSSPGVMLPKQDFVDLQGQLRFAAKLIEGVLDFKVMIDNETLPVEYLGGKPLCMNQYYQILSSCRVPGPKQDTVSNFSKTKKPPTHITVVHNYQFFELDVYHSDGTPLTADQIFVQLEKIWNSSLQTNKEPVGILTSNHRNSWAKAYNTLIKDKVNRDSVRSIQKSIFTVCLDATMPRVSEDVYRSHVAGQMLHGGGSRLNSGNRWFDKTLQFIVAEDGSCGLVYEHAAAEGPPIVTLLDYVIEYTKKPELVRSPLVPLPMPKKLRFNITPEIKSDIEKAKQNLSIMIQDLDITVMVFHHFGKDFPKSEKLSPDAFIQMALQLAYYRIYGQACATYESASLRMFHLGRTDTIRSASMDSLTFVKAMDDSSVTEHQKVELLRKAVQAHRGYTDRAIRGEAFDRHLLGLKLQAIEDLVSMPDIFMDTSYAIAMHFHLSTSQVPAKTDCVMFFGPVVPDGYGVCYNPMEAHINFSLSAYNSCAETNAARLAHYLEKALLDMRALLQSHPRAKL>sp|P43155-3|CACP_HUMAN Isoform 3 of Carnitine O-acetyltransferaseOS=Homo sapiens OX=9606 GN=CRATMLAFAARTVVKPLGFLKPFSLMKASSRFKAHQDALPRLPVPPLQQSLDHYLKALQPIVSEEEWAHTKQLVDEFQASGGVGERLQKGLERRARKTENWLSEWWLKTAYLQYRQPVVIYSSPGVMLPKQDFVDLQGQLRFAAKLIEGVLDFKVMIDNETLPVEYLGGKPLCMNQYYQILSSCRVPGPKQDTVSNFSKTKKPPTHITVVHNYQFFELDVYHSDGTPLTADQIFVQLEKIWNSSLQTNKEPVGILTSNHRNSWAKAYNTLIKDKVNRDSVRSIQKKPELVRSPLVPLPMPKKLRFNITPEIKSDIEKAKQNLSIMIQDLDITVMVFHHFGKDFPKSEKLSPDAFIQMALQLAYYRIYGQACATYESASLRMFHLGRTDTIRSASMDSLTFVKAMDDSSVTEHQKVELLRKAVQAHRGYTDRAIRGEAFDRHLLGLKLQAIEDLVSMPDIFMDTSYAIAMHFHLSTSQVPAKTDCVMFFGPVVPDGYGVCYNPMEAHINFSLSAYNSCAETNAARLAHYLEKALLDMRALLQSHPRAKL>sp|Q9BXJ2|C1QT7_HUMAN Complement C1q tumor necrosis factor-relatedprotein 7 OS=Homo sapiens OX=9606 GN=C1QTNF7 PE=2 SV=1MFVLLYVTSFAICASGQPRGNQLKGENYSPRYICSIPGLPGPPGPPGANGSPGPHGRIGLPGRDGRDGRKGEKGEKGTAGLRGKTGPLGLAGEKGDQGETGKKGPIGPEGEKGEVGPIGPPGPKGDRGEQGDPGLPGVCRCGSIVLKSAFSVGITTSYPEERLPIIFNKVLFNEGEHYNPATGKFICAFPGIYYFSYDITLANKHLAIGLVHNGQYRIKTFDANTGNHDVASGSTVIYLQPEDEVWLEIFFTDQNGLFSDPGWADSLFSGFLLYVDTDYLDSISEDDEL>sp|Q9BXJ2-2|C1QT7_HUMAN Isoform 2 of Complement C1q tumor necrosisfactor-related protein 7 OS=Homo sapiens OX=9606 GN=C1QTNF7MSRQEPKMFVLLYVTSFAICASGQPRGNQLKGENYSPRYICSIPGLPGPPGPPGANGSPGPHGRIGLPGRDGRDGRKGEKGEKGTAGLRGKTGPLGLAGEKGDQGETGKKGPIGPEGEKGEVGPIGPPGPKGDRGEQGDPGLPGVCRCGSIVLKSAFSVGITTSYPEERLPIIFNKVLFNEGEHYNPATGKFICAFPGIYYFSYDITLANKHLAIGLVHNGQYRIKTFDANTGNHDVASGSTVIYLQPEDEVWLEIFFTDQNGLFSDPGWADSLFSGFLLYVDTDYLDSISEDDEL>sp|Q9P296|C5AR2_HUMAN C5a anaphylatoxin chemotactic receptor 2 OS=Homosapiens OX=9606 GN=C5AR2 PE=1 SV=1MGNDSVSYEYGDYSDLSDRPVDCLDGACLAIDPLRVAPLPLYAAIFLVGVPGNAMVAWVAGKVARRRVGATWLLHLAVADLLCCLSLPILAVPIARGGHWPYGAVGCRALPSIILLTMYASVLLLAALSADLCFLALGPAWWSTVQRACGVQVACGAAWTLALLLTVPSAIYRRLHQEHFPARLQCVVDYGGSSSTENAVTAIRFLFGFLGPLVAVASCHSALLCWAARRCRPLGTAIVVGFFVCWAPYHLLGLVLTVAAPNSALLARALRAEPLIVGLALAHSCLNPMLFLYFGRAQLRRSLPAACHWALRESQGQDESVDSKKSTSHDLVSEMEV>sp|Q13634|CAD18_HUMAN Cadherin-18 OS=Homo sapiens OX=9606 GN=CDH18 PE=2SV=1MKITSTSCICPVLVCLCFVQRCYGTAHHSSIKVMRNQTKHIEGETEVHHRPKRGWVWNQFFVLEEHMGPDPQYVGKLHSNSDKGDGSVKYILTGEGAGTIFIIDDTTGDIHSTKSLDREQKTHYVLHAQAIDRRTNKPLEPESEFIIKVQDINDNAPKFTDGPYIVTVPEMSDMGTSVLQVTATDADDPTYGNSARVVYSILQGQPYFSVDPKTGVIRTALHNMDREAREHYSVVIQAKDMAGQVGGLSGSTTVNITLTDVNDNPPRFPQKHYQLYVPESAQVGSAVGKIKANDADTGSNADMTYSIINGDGMGIFSISTDKETREGILSLKKPLNYEKKKSYTLNIEGANTHLDFRFSHLGPFKDATMLKIIVGDVDEPPLFSMPSYLMEVYENAKIGTVVGTVLAQDPDSTNSLVRYFINYNVEDDRFFNIDANTGTIRTTKVLDREETPWYNITVTASEIDNPDLLSHVTVGIRVLDVNDNPPELAREYDIIVCENSKPGQVIHTISATDKDDFANGPRFNFFLDERLPVNPNFTLKDNEDNTASILTRRRRFSRTVQDVYYLPIMISDGGIPSLSSSSTLTIRVCACERDGRVRTCHAEAFLSSAGLSTGALIAILLCVLILLAIVVLFITLRRSKKEPLIISEEDVRENVVTYDDEGGGEEDTEAFDITALRNPSAAEELKYRRDIRPEVKLTPRHQTSSTLESIDVQEFIKQRLAEADLDPSVPPYDSLQTYAYEGQRSEAGSISSLDSATTQSDQDYHYLGDWGPEFKKLAELYGEIESERTT>sp|Q13634-2|CAD18_HUMAN Isoform 2 of Cadherin-18 OS=Homo sapiens OX=9606GN=CDH18MKITSTSCICPVLVCLCFVQRCYGTAHHSSIKVMRNQTKHIEGETEVHHRPKRGWVWNQFFVLEEHMGPDPQYVGKLHSNSDKGDGSVKYILTGEGAGTIFIIDDTTGDIHSTKSLDREQKTHYVLHAQAIDRRTNKPLEPESEFIIKVQDINDNAPKFTDGPYIVTVPEMSDMGTSVLQVTATDADDPTYGNSARVVYSILQGQPYFSVDPKTGVIRTALHNMDREAREHYSVVIQAKDMAGQVGGLSGSTTVNITLTDVNDNPPRFPQKHYQLYVPESAQVGSAVGKIKANDADTGSNADMTYSIINGDGMGIFSISTDKETREGILSLKKPLNYEKKKSYTLNIEGANTHLDFRFSHLGPFKDATMLKIIVGDVDEPPLFSMPSYLMEVYENAKIGTVVGTVLAQDPDSTNSLVRYFINYNVEDDRFFNIDANTGTIRTTKVLDREETPWYNITVTASEIDNPDLLSHVTVGIRVLDVNDNPPELAREYDIIVCENSKPGQVIHTISATDKDDFANGPRFNFFLDERLPVNPNFTLKDNEAAAPSPSGFVHAREMGVCGPAMQKPSCPRLV>sp|Q99622|C10_HUMAN Protein C10 OS=Homo sapiens OX=9606 GN=C12orf57 PE=1SV=1MASASTQPAALSAEQAKVVLAEVIQAFSAPENAVRMDEARDNACNDMGKMLQFVLPVATQIQQEVIKAYGFSCDGEGVLKFARLVKSYEAQDPEIASLSGKLKALFLPPMTLPPHGPAAGGSVAAS>sp|Q9UJ99|CAD22_HUMAN Cadherin-22 OS=Homo sapiens OX=9606 GN=CDH22 PE=2SV=2MRPRPEGRGLRAGVALSPALLLLLLLPPPPTLLGRLWAAGTPSPSAPGARQDGALGAGRVKRGWVWNQFFVVEEYTGTEPLYVGKIHSDSDEGDGAIKYTISGEGAGTIFLIDELTGDIHAMERLDREQKTFYTLRAQARDRATNRLLEPESEFIIKVQDINDSEPRFLHGPYIGSVAELSPTGTSVMQVMASDADDPTYGSSARLVYSVLDGEHHFTVDPKTGVIRTAVPDLDRESQERYEVVIQATDMAGQLGGLSGSTTVTIVVTDVNDNPPRFPQKMYQFSIQESAPIGTAVGRVKAEDSDVGENTDMTYHLKDESSSGGDVFKVTTDSDTQEAIIVVQKRLDFESQPVHTVILEALNKFVDPRFADLGTFRDQAIVRVAVTDVDEPPEFRPPSGLLEVQEDAQVGSLVGVVTARDPDAANRPVRYAIDRESDLDQIFDIDADTGAIVTGKGLDRETAGWHNITVLAMEADNHAQLSRASLRIRILDVNDNPPELATPYEAAVCEDAKPGQLIQTISVVDRDEPQGGHRFYFRLVPEAPSNPHFSLLDIQDNTAAVHTQHVGFNRQEQDVFFLPILVVDSGPPTLSSTGTLTIRICGCDSSGTIQSCNTTAFVMAASLSPGALIALLVCVLILVVLVLLILTLRRHHKSHLSSDEDEDMRDNVIKYNDEGGGEQDTEAYDMSALRSLYDFGELKGGDGGGSAGGGAGGGSGGGAGSPPQAHLPSERHSLPQGPPSPEPDFSVFRDFISRKVALADGDLSVPPYDAFQTYAFEGADSPAASLSSLHSGSSGSEQDFAYLSSWGPRFRPLAALYAGHRGDDEAQAS>sp|Q6YHK3|CD109_HUMAN CD109 antigen OS=Homo sapiens OX=9606 GN=CD109PE=1 SV=2MQGPPLLTAAHLLCVCTAALAVAPGPRFLVTAPGIIRPGGNVTIGVELLEHCPSQVTVKAELLKTASNLTVSVLEAEGVFEKGSFKTLTLPSLPLNSADEIYELRVTGRTQDEILFSNSTRLSFETKRISVFIQTDKALYKPKQEVKFRIVTLFSDFKPYKTSLNILIKDPKSNLIQQWLSQQSDLGVISKTFQLSSHPILGDWSIQVQVNDQTYYQSFQVSEYVLPKFEVTLQTPLYCSMNSKHLNGTITAKYTYGKPVKGDVTLTFLPLSFWGKKKNITKTFKINGSANFSFNDEEMKNVMDSSNGLSEYLDLSSPGPVEILTTVTESVTGISRNVSTNVFFKQHDYIIEFFDYTTVLKPSLNFTATVKVTRADGNQLTLEERRNNVVITVTQRNYTEYWSGSNSGNQKMEAVQKINYTVPQSGTFKIEFPILEDSSELQLKAYFLGSKSSMAVHSLFKSPSKTYIQLKTRDENIKVGSPFELVVSGNKRLKELSYMVVSRGQLVAVGKQNSTMFSLTPENSWTPKACVIVYYIEDDGEIISDVLKIPVQLVFKNKIKLYWSKVKAEPSEKVSLRISVTQPDSIVGIVAVDKSVNLMNASNDITMENVVHELELYNTGYYLGMFMNSFAVFQECGLWVLTDANLTKDYIDGVYDNAEYAERFMEENEGHIVDIHDFSLGSSPHVRKHFPETWIWLDTNMGYRIYQEFEVTVPDSITSWVATGFVISEDLGLGLTTTPVELQAFQPFFIFLNLPYSVIRGEEFALEITIFNYLKDATEVKVIIEKSDKFDILMTSNEINATGHQQTLLVPSEDGATVLFPIRPTHLGEIPITVTALSPTASDAVTQMILVKAEGIEKSYSQSILLDLTDNRLQSTLKTLSFSFPPNTVTGSERVQITAIGDVLGPSINGLASLIRMPYGCGEQNMINFAPNIYILDYLTKKKQLTDNLKEKALSFMRQGYQRELLYQREDGSFSAFGNYDPSGSTWLSAFVLRCFLEADPYIDIDQNVLHRTYTWLKGHQKSNGEFWDPGRVIHSELQGGNKSPVTLTAYIVTSLLGYRKYQPNIDVQESIHFLESEFSRGISDNYTLALITYALSSVGSPKAKEALNMLTWRAEQEGGMQFWVSSESKLSDSWQPRSLDIEVAAYALLSHFLQFQTSEGIPIMRWLSRQRNSLGGFASTQDTTVALKALSEFAALMNTERTNIQVTVTGPSSPSPVKFLIDTHNRLLLQTAELAVVQPTAVNISANGFGFAICQLNVVYNVKASGSSRRRRSIQNQEAFDLDVAVKENKDDLNHVDLNVCTSFSGPGRSGMALMEVNLLSGFMVPSEAISLSETVKKVEYDHGKLNLYLDSVNETQFCVNIPAVRNFKVSNTQDASVSIVDYYEPRRQAVRSYNSEVKLSSCDLCSDVQGCRPCEDGASGSHHHSSVIFIFCFKLLYFMELWL>sp|Q6YHK3-2|CD109_HUMAN Isoform 2 of CD109 antigen OS=Homo sapiensOX=9606 GN=CD109MQGPPLLTAAHLLCVCTAALAVAPGPRFLVTAPGIIRPGGNVTIGVELLEHCPSQVTVKAELLKTASNLTVSVLEAEGVFEKGSFKTLTLPSDPKSNLIQQWLSQQSDLGVISKTFQLSSHPILGDWSIQVQVNDQTYYQSFQVSEYVLPKFEVTLQTPLYCSMNSKHLNGTITAKYTYGKPVKGDVTLTFLPLSFWGKKKNITKTFKINGSANFSFNDEEMKNVMDSSNGLSEYLDLSSPGPVEILTTVTESVTGISRNVSTNVFFKQHDYIIEFFDYTTVLKPSLNFTATVKVTRADGNQLTLEERRNNVVITVTQRNYTEYWSGSNSGNQKMEAVQKINYTVPQSGTFKIEFPILEDSSELQLKAYFLGSKSSMAVHSLFKSPSKTYIQLKTRDENIKVGSPFELVVSGNKRLKELSYMVVSRGQLVAVGKQNSTMFSLTPENSWTPKACVIVYYIEDDGEIISDVLKIPVQLVFKNKIKLYWSKVKAEPSEKVSLRISVTQPDSIVGIVAVDKSVNLMNASNDITMENVVHELELYNTGYYLGMFMNSFAVFQECGLWVLTDANLTKDYIDGVYDNAEYAERFMEENEGHIVDIHDFSLGSSPHVRKHFPETWIWLDTNMGYRIYQEFEVTVPDSITSWVATGFVISEDLGLGLTTTPVELQAFQPFFIFLNLPYSVIRGEEFALEITIFNYLKDATEVKVIIEKSDKFDILMTSNEINATGHQQTLLVPSEDGATVLFPIRPTHLGEIPITVTALSPTASDAVTQMILVKAEGIEKSYSQSILLDLTDNRLQSTLKTLSFSFPPNTVTGSERVQITAIGDVLGPSINGLASLIRMPYGCGEQNMINFAPNIYILDYLTKKKQLTDNLKEKALSFMRQGYQRELLYQREDGSFSAFGNYDPSGSTWLSAFVLRCFLEADPYIDIDQNVLHRTYTWLKGHQKSNGEFWDPGRVIHSELQGGNKSPVTLTAYIVTSLLGYRKYQPNIDVQESIHFLESEFSRGISDNYTLALITYALSSVGSPKAKEALNMLTWRAEQEGGMQFWVSSESKLSDSWQPRSLDIEVAAYALLSHFLQFQTSEGIPIMRWLSRQRNSLGGFASTQDTTVALKALSEFAALMNTERTNIQVTVTGPSSPSPVKFLIDTHNRLLLQTAELAVVQPTAVNISANGFGFAICQLNVVYNVKASGSSRRRRSIQNQEAFDLDVAVKENKDDLNHVDLNVCTSFSGPGRSGMALMEVNLLSGFMVPSEAISLSETVKKVEYDHGKLNLYLDSVNETQFCVNIPAVRNFKVSNTQDASVSIVDYYEPRRQAVRSYNSEVKLSSCDLCSDVQGCRPCEDGASGSHHHSSVIFIFCFKLLYFMELWL>sp|Q6YHK3-3|CD109_HUMAN Isoform 3 of CD109 antigen OS=Homo sapiensOX=9606 GN=CD109MQGPPLLTAAHLLCVCTAALAVAPGPRFLVTAPGIIRPGGNVTIGVELLEHCPSQVTVKAELLKTASNLTVSVLEAEGVFEKGSFKTLTLPSLPLNSADEIYELRVTGRTQDEILFSNSTRLSFETKRISVFIQTDKALYKPKQEVKFRIVTLFSDFKPYKTSLNILIKDPKSNLIQQWLSQQSDLGVISKTFQLSSHPILGDWSIQVQVNDQTYYQSFQVSEYVLPKFEVTLQTPLYCSMNSKHLNGTITAKYTYGKPVKGDVTLTFLPLSFWGKKKNITKTFKINGSANFSFNDEEMKNVMDSSNGLSEYLDLSSPGPVEILTTVTESVTGISRNVSTNVFFKQHDYIIEFFDYTTVLKPSLNFTATVKVTRADGNQLTLEERRNNVVITVTQRNYTEYWSGSNSGNQKMEAVQKINYTVPQSGTFKIEFPILEDSSELQLKAYFLGSKSSMAVHSLFKSPSKTYIQLKTRDENIKVGSPFELVVSGNKRLKELSYMVVSRGQLVAVGKQNSTMFSLTPENSWTPKACVIVYYIEDDGEIISDVLKIPVQLVFKNKIKLYWSKVKAEPSEKVSLRISVTQPDSIVGIVAVDKSVNLMNASNDITMENVVHELELYNTGYYLGMFMNSFAVFQECGLWVLTDANLTKDYIDGVYDNLFGTQEAL>sp|Q6YHK3-4|CD109_HUMAN Isoform 4 of CD109 antigen OS=Homo sapiensOX=9606 GN=CD109MQGPPLLTAAHLLCVCTAALAVAPGPRFLVTAPGIIRPGGNVTIGVELLEHCPSQVTVKAELLKTASNLTVSVLEAEGVFEKGSFKTLTLPSLPLNSADEIYELRVTGRTQDEILFSNSTRLSFETKRISVFIQTDKALYKPKQEVKFRIVTLFSDFKPYKTSLNILIKDPKSNLIQQWLSQQSDLGVISKTFQLSSHPILGDWSIQVQVNDQTYYQSFQVSEYVLPKFEVTLQTPLYCSMNSKHLNGTITAKYTYGKPVKGDVTLTFLPLSFWGKKKNITKTFKINGSANFSFNDEEMKNVMDSSNGLSEYLDLSSPGPVEILTTVTESVTGISRNVSTNVFFKQHDYIIEFFDYTTVLKPSLNFTATVKVTRADGNQLTLEERRNNVVITVTQRNYTEYWSGSNSGNQKMEAVQKINYTVPQSGTFKIEFPILEDSSELQLKAYFLGSKSSMAVHSLFKSPSKTYIQLKTRDENIKVGSPFELVVSGNKRLKELSYMVVSRGQLVAVGKQNSTMFSLTPENSWTPKACVIVYYIEDDGEIISDVLKIPVQLVFKNKIKLYWSKVKAEPSEKVSLRISVTQPDSIVGIVAVDKSVNLMNASNDITMENVVHELELYNTGYYLGMFMNSFAVFQECGLWVLTDANLTKDYIDGVYDNAEYAERFMEENEGHIVDIHDFSLGSSPHVRKHFPETWIWLDTNMGYRIYQEFEVTVPDSITSWVATGFVISEDLGLGLTTTPVELQAFQPFFIFLNLPYSVIRGEEFALEITIFNYLKDATEVKVIIEKSDKFDILMTSNEINATGHQQTLLVPSEDGATVLFPIRPTHLGEIPITVTALSPTASDAVTQMILVKAEGIEKSYSQSILLDLTDNRLQSTLKTLSFSFPPNTVTGSERVQITAIGDVLGPSINGLASLIRMPYGCGEQNMINFAPNIYILDYLTKKKQLTDNLKEKALSFMRQGYQRELLYQREDGSFSAFGNYDPSGSTWLSAFVLRCFLEADPYIDIDQNVLHRTYTWLKGHQKSNGEFWDPGRVIHSELQGGNKSPVTLTAYIVTSLLGYRKYQPNIDVQESIHFLESEFSRGISDNYTLALITYALSSVGSPKAKEALNMLTWRAEQEGGMQFWVSSESKLSDSWQPRSLDIEVAAYALLSHFLQFQTSEGIPIMRWLSRQRNSLGGFASTQDTTVALKALSEFAALMNTERTNIQVTVTGPSSPSPLAVVQPTAVNISANGFGFAICQLNVVYNVKASGSSRRRRSIQNQEAFDLDVAVKENKDDLNHVDLNVCTSFSGPGRSGMALMEVNLLSGFMVPSEAISLSETVKKVEYDHGKLNLYLDSVNETQFCVNIPAVRNFKVSNTQDASVSIVDYYEPRRQAVRSYNSEVKLSSCDLCSDVQGCRPCEDGASGSHHHSSVIFIFCFKLLYFMELWL>sp|Q9C0F1|CEP44_HUMAN Centrosomal protein of 44 kDa OS=Homo sapiensOX=9606 GN=CEP44 PE=1 SV=2MATGDLKRSLRNLEQVLRLLNYPEEVDCVGLIKGDPAASLPIISYSFTSYSPYVTELIMESNVELIAKNDLRFIDAVYKLLRDQFNYKPILTKKQFIQCGFAEWKIQIVCDILNCVMKKHKELSSLQKIPSQQRKKISSGKSEPPLGNEKISAEAVGVDISGRFMTSGKKKAVVIRHLYNEDNVDISEDTLSPITDVNEAVDVSDLNATEIKMPEVKVPEIKAEQQDVNVNPEITALQTMLAECQENLKKLTSIEKRLDCLEQKMKGKVMVDENTWTNLLSRVTLLETEMLLSKKNDEFIEFNEVSEDYASCSDMDLLNPHRKSEVERPASIPLSSGYSTASSDSTPRASTVNYCGLNEISEETTIQKMERMKKMFEETAELLKCPNHYL>sp|Q9C0F1-2|CEP44_HUMAN Isoform 2 of Centrosomal protein of 44 kDaOS=Homo sapiens OX=9606 GN=CEP44MATGDLKRSLRNLEQVLRLLNYPEEVDCVGLIKGDPAASLPIISYSFTSYSPYVTELIMESNVELIAKNDLRFIDAVYKLLRDQFNYKPILTKKQFIQCGFAEWKIQIVCDILNCVMKKHKELSSLQKIPSQQRKKISSGKSEPPLGNEKISAEAVGVDISGRFMTSGKKKAVVIRHLYNEDNVDISEDTLSPITDVNEAVDVSDLNATEIKMPEVKVPEIKAEQQDVNVNPEITALQTMLAECQENLKKLTSIEKRLDCLEQKMKGKVMVDENTWTNLLSRVTLLETEMLLSKKNDEFIEFNEVSEDYASCSDMDLLNPHRKSEVERPASIPLSSGYSTASSDSTPRASTVNYCGLNEISENFPAWSATSSCSSLSWLLRGHTSYLSSQSFAWPLSCV>sp|P51659|DHB4_HUMAN Peroxisomal multifunctional enzyme type 2 OS=Homosapiens OX=9606 GN=HSD17B4 PE=1 SV=3MGSPLRFDGRVVLVTGAGAGLGRAYALAFAERGALVVVNDLGGDFKGVGKGSLAADKVVEEIRRRGGKAVANYDSVEEGEKVVKTALDAFGRIDVVVNNAGILRDRSFARISDEDWDIIHRVHLRGSFQVTRAAWEHMKKQKYGRIIMTSSASGIYGNFGQANYSAAKLGLLGLANSLAIEGRKSNIHCNTIAPNAGSRMTQTVMPEDLVEALKPEYVAPLVLWLCHESCEENGGLFEVGAGWIGKLRWERTLGAIVRQKNHPMTPEAVKANWKKICDFENASKPQSIQESTGSIIEVLSKIDSEGGVSANHTSRATSTATSGFAGAIGQKLPPFSYAYTELEAIMYALGVGASIKDPKDLKFIYEGSSDFSCLPTFGVIIGQKSMMGGGLAEIPGLSINFAKVLHGEQYLELYKPLPRAGKLKCEAVVADVLDKGSGVVIIMDVYSYSEKELICHNQFSLFLVGSGGFGGKRTSDKVKVAVAIPNRPPDAVLTDTTSLNQAALYRLSGDWNPLHIDPNFASLAGFDKPILHGLCTFGFSARRVLQQFADNDVSRFKAIKARFAKPVYPGQTLQTEMWKEGNRIHFQTKVQETGDIVISNAYVDLAPTSGTSAKTPSEGGKLQSTFVFEEIGRRLKDIGPEVVKKVNAVFEWHITKGGNIGAKWTIDLKSGSGKVYQGPAKGAADTTIILSDEDFMEVVLGKLDPQKAFFSGRLKARGNIMLSQKLQMILKDYAKL>sp|P51659-2|DHB4_HUMAN Isoform 2 of Peroxisomal multifunctional enzymetype 2 OS=Homo sapiens OX=9606 GN=HSD17B4MVILEAPHLLRRKEPETPGLSSRIGPSLCPGFCRKRSVSCCFQNLCNNPMEKIISQCRFFVSMNDLGGDFKGVGKGSLAADKVVEEIRRRGGKAVANYDSVEEGEKVVKTALDAFGRIDVVVNNAGILRDRSFARISDEDWDIIHRVHLRGSFQVTRAAWEHMKKQKYGRIIMTSSASGIYGNFGQANYSAAKLGLLGLANSLAIEGRKSNIHCNTIAPNAGSRMTQTVMPEDLVEALKPEYVAPLVLWLCHESCEENGGLFEVGAGWIGKLRWERTLGAIVRQKNHPMTPEAVKANWKKICDFENASKPQSIQESTGSIIEVLSKIDSEGGVSANHTSRATSTATSGFAGAIGQKLPPFSYAYTELEAIMYALGVGASIKDPKDLKFIYEGSSDFSCLPTFGVIIGQKSMMGGGLAEIPGLSINFAKVLHGEQYLELYKPLPRAGKLKCEAVVADVLDKGSGVVIIMDVYSYSEKELICHNQFSLFLVGSGGFGGKRTSDKVKVAVAIPNRPPDAVLTDTTSLNQAALYRLSGDWNPLHIDPNFASLAGFDKPILHGLCTFGFSARRVLQQFADNDVSRFKAIKARFAKPVYPGQTLQTEMWKEGNRIHFQTKVQETGDIVISNAYVDLAPTSGTSAKTPSEGGKLQSTFVFEEIGRRLKDIGPEVVKKVNAVFEWHITKGGNIGAKWTIDLKSGSGKVYQGPAKGAADTTIILSDEDFMEVVLGKLDPQKAFFSGRLKARGNIMLSQKLQMILKDYAKL>sp|P51659-3|DHB4_HUMAN Isoform 3 of Peroxisomal multifunctional enzymetype 2 OS=Homo sapiens OX=9606 GN=HSD17B4MGSPLRFDGRVVLVTGAGAVNDLGGDFKGVGKGSLAADKVVEEIRRRGGKAVANYDSVEEGEKVVKTALDAFGRIDVVVNNAGILRDRSFARISDEDWDIIHRVHLRGSFQVTRAAWEHMKKQKYGRIIMTSSASGIYGNFGQANYSAAKLGLLGLANSLAIEGRKSNIHCNTIAPNAGSRMTQTVMPEDLVEALKPEYVAPLVLWLCHESCEENGGLFEVGAGWIGKLRWERTLGAIVRQKNHPMTPEAVKANWKKICDFENASKPQSIQESTGSIIEVLSKIDSEGGVSANHTSRATSTATSGFAGAIGQKLPPFSYAYTELEAIMYALGVGASIKDPKDLKFIYEGSSDFSCLPTFGVIIGQKSMMGGGLAEIPGLSINFAKVLHGEQYLELYKPLPRAGKLKCEAVVADVLDKGSGVVIIMDVYSYSEKELICHNQFSLFLVGSGGFGGKRTSDKVKVAVAIPNRPPDAVLTDTTSLNQAALYRLSGDWNPLHIDPNFASLAGFDKPILHGLCTFGFSARRVLQQFADNDVSRFKAIKARFAKPVYPGQTLQTEMWKEGNRIHFQTKVQETGDIVISNAYVDLAPTSGTSAKTPSEGGKLQSTFVFEEIGRRLKDIGPEVVKKVNAVFEWHITKGGNIGAKWTIDLKSGSGKVYQGPAKGAADTTIILSDEDFMEVVLGKLDPQKAFFSGRLKARGNIMLSQKLQMILKDYAKL>sp|P04234|CD3D_HUMAN T-cell surface glycoprotein CD3 delta chain OS=Homosapiens OX=9606 GN=CD3D PE=1 SV=1MEHSTFLSGLVLATLLSQVSPFKIPIEELEDRVFVNCNTSITWVEGTVGTLLSDITRLDLGKRILDPRGIYRCNGTDIYKDKESTVQVHYRMCQSCVELDPATVAGIIVTDVIATLLLALGVFCFAGHETGRLSGAADTQALLRNDQVYQPLRDRDDAQYSHLGGNWARNK>sp|P04234-2|CD3D_HUMAN Isoform 2 of T-cell surface glycoprotein CD3delta chain OS=Homo sapiens OX=9606 GN=CD3DMEHSTFLSGLVLATLLSQVSPFKIPIEELEDRVFVNCNTSITWVEGTVGTLLSDITRLDLGKRILDPRGIYRCNGTDIYKDKESTVQVHYRTADTQALLRNDQVYQPLRDRDDAQYSHLGGNWARNK>sp|Q96EP1|CHFR_HUMAN E3 ubiquitin-protein ligase CHFR OS=Homo sapiensOX=9606 GN=CHFR PE=1 SV=2MERPEEGKQSPPPQPWGRLLRLGAEEGEPHVLLRKREWTIGRRRGCDLSFPSNKLVSGDHCRIVVDEKSGQVTLEDTSTSGTVINKLKVVKKQTCPLQTGDVIYLVYRKNEPEHNVAYLYESLSEKQGMTQESFEANKENVFHGTKDTSGAGAGRGADPRVPPSSPATQVCFEEPQPSTSTSDLFPTASASSTEPSPAGRERSSSCGSGGGGISPKGSGPSVASDEVSSFASALPDRKTASFSSLEPQDQEDLEPVKKKMRGDGDLDLNGQLLVAQPRRNAQTVHEDVRAAAGKPDKMEETLTCIICQDLLHDCVSLQPCMHTFCAACYSGWMERSSLCPTCRCPVERICKNHILNNLVEAYLIQHPDKSRSEEDVQSMDARNKITQDMLQPKVRRSFSDEEGSSEDLLELSDVDSESSDISQPYVVCRQCPEYRRQAAQPPHCPAPEGEPGAPQALGDAPSTSVSLTTAVQDYVCPLQGSHALCTCCFQPMPDRRAEREQDPRVAPQQCAVCLQPFCHLYWGCTRTGCYGCLAPFCELNLGDKCLDGVLNNNSYESDILKNYLATRGLTWKNMLTESLVALQRGVFLLSDYRVTGDTVLCYCCGLRSFRELTYQYRQNIPASELPVAVTSRPDCYWGRNCRTQVKAHHAMKFNHICEQTRFKN>sp|Q96EP1-2|CHFR_HUMAN Isoform 2 of E3 ubiquitin-protein ligase CHFROS=Homo sapiens OX=9606 GN=CHFRMERPEEGKQSPPPQPWGRLLRLGAEEGEPHVLLRKREWTIGRRRGCDLSFPSNKLVSGDHCRIVVDEKSGQVTLEDTSTSGTVINKLKVVKKQTCPLQTGDVIYLVYRKNEPEHNVAYLYESLSEKQGMTQESFDTSGAGAGRGADPRVPPSSPATQVCFEEPQPSTSTSDLFPTASASSTEPSPAGRERSSSCGSGGGGISPKGSGPSVASDEVSSFASALPDRKTASFSSLEPQDQEDLEPVKKKMRGDGDLDLNGQLLVAQPRRNAQTVHEDVRAAAGKPDKMEETLTCIICQDLLHDCVSLQPCMHTFCAACYSGWMERSSLCPTCRCPVERICKNHILNNLVEAYLIQHPDKSRSEEDVQSMDARNKITQDMLQPKVRRSFSDEEGSSEDLLELSDVDSESSDISQPYVVCRQCPEYRRQAAQPPHCPAPEGEPGAPQALGDAPSTSVSLTTAVQDYVCPLQGSHALCTCCFQPMPDRRAEREQDPRVAPQQCAVCLQPFCHLYWGCTRTGCYGCLAPFCELNLGDKCLDGVLNNNSYESDILKNYLATRGLTWKNMLTESLVALQRGVFLLSDYRVTGDTVLCYCCGLRSFRELTYQYRQNIPASELPVAVTSRPDCYWGRNCRTQVKAHHAMKFNHICEQTRFKN>sp|Q96EP1-3|CHFR_HUMAN Isoform 3 of E3 ubiquitin-protein ligase CHFROS=Homo sapiens OX=9606 GN=CHFRMERPEEGKQSPPPQPWGRLLRLGAEEGEPHVLLRKREWTIGRRRGCDLSFPSNKLVSGDHCRIVVDEKSGQVTLEDTSTSGTVINKLKVVKKQTCPLQTGDVIYLVYRKNEPEHNVAYLYESLSEKQGMTQESFEMVPCCVAQAGLKLLGSSDPPTLASQSIVITGSGGGGISPKGSGPSVASDEVSSFASALPDRKTASFSSLEPQDQEDLEPVKKKMRGDGDLDLNGQLLVAQPRRNAQTVHEDVRAAAGKPDKMEETLTCIICQDLLHDCVSLQPCMHTFCAACYSGWMERSSLCPTCRCPVERICKNHILNNLVEAYLIQHPDKSRSEEDVQSMDARNKITQDMLQPKVRRSFSDEEGSSEDLLELSDVDSESSDISQPYVVCRQCPEYRRQAAQPPHCPAPEGEPGAPQALGDAPSTSVSLTTAVQDYVCPLQGSHALCTCCFQPMPDRRAEREQDPRVAPQQCAVCLQPFCHLYWGCTRTGCYGCLAPFCELNLGDKCLDGVLNNNSYESDILKNYLATRGLTWKNMLTESLVALQRGVFLLSDYRVTGDTVLCYCCGLRSFRELTYQYRQNIPASELPVAVTSRPDCYWGRNCRTQVKAHHAMKFNHICEQTRFKN>sp|Q96EP1-4|CHFR_HUMAN Isoform 4 of E3 ubiquitin-protein ligase CHFROS=Homo sapiens OX=9606 GN=CHFRMERPEEGKQSPPPQPWGRLLRLGAEEGEPHVLLRKREWTIGRRRGCDLSFPSNKLVSGDHCRIVVDEKSGQVTLEDTSTSGTVINKLKVVKKQTCPLQTGDVIYLVYRKNEPEHNVAYLYESLSEKQGMTQESFEANKENVFHGTKDTSGAGAGRGADPRVPPSSPATQVCFEEPQPSTSTSDLFPTASASSTEPSPAGRERSSSCGSGGGGISPKGSGPSVASDEVSSFASALPDRKTASFSSLEPQDQEDLEPVKKKMRGDGDLDLNGQLLVAQPRRNAQTVHEDVRAAAGKPDKMEETLTCIICQDLLHDCVSLQPCMHTFCAACYSGWMERSSLCPTCRCPVERICKNHILNNLVEAYLIQHPDKSRSEEDVQSMDARNKITQDMLQPKVRRSFSDEEGSSEDLLELSDVDSESSDISQPYVVCRQCPEYRRQAAQPPHCPAPEGEPGAPQALGDAPSTSVSLTTVQDYVCPLQGSHALCTCCFQPMPDRRAEREQDPRVAPQQCAVCLQPFCHLYWGCTRTGCYGCLAPFCELNLGDKCLDGVLNNNSYESDILKNYLATRGLTWKNMLTESLVALQRGVFLLSDYRVTGDTVLCYCCGLRSFRELTYQYRQNIPASELPVAVTSRPDCYWGRNCRTQVKAHHAMKFNHICEQTRFKN>sp|Q96EP1-5|CHFR_HUMAN Isoform 5 of E3 ubiquitin-protein ligase CHFROS=Homo sapiens OX=9606 GN=CHFRMERPEEGKQSPPPQPWGRLLRLGAEEGEPHVLLRKREWTIGRRRGCDLSFPSNKLVSGDHCRIVVDEKSGQVTLEDTSTSGTVINKLKVVKKQTCPLQTGDVIYLVYRKNEPEHRSGGGGISPKGSGPSVASDEVSSFASALPDRKTASFSSLEPQDQEDLEPVKKKMRGDGDLDLNGQLLVAQPRRNAQTVHEDVRAAAGKPDKMEETLTCIICQDLLHDCVSLQPCMHTFCAACYSGWMERSSLCPTCRCPVERICKNHILNNLVEAYLIQHPDKSRSEEDVQSMDARNKITQDMLQPKVRRSFSDEEGSSEDLLELSDVDSESSDISQPYVVCRQCPEYRRQAAQPPHCPAPEGEPGAPQALGDAPSTSVSLTTAVQDYVCPLQGSHALCTCCFQPMPDRRAEREQDPRVAPQQCAVCLQPFCHLYWGCTRTGCYGCLAPFCELNLGDKCLDGVLNNNSYESDILKNYLATRGLTWKNMLTESLVALQRGVFLLSDYRVTGDTVLCYCCGLRSFRELTYQYRQNIPASELPVAVTSRPDCYWGRNCRTQVKAHHAMKFNHICEQTRFKN>sp|P09693|CD3G_HUMAN T-cell surface glycoprotein CD3 gamma chain OS=Homosapiens OX=9606 GN=CD3G PE=1 SV=1MEQGKGLAVLILAIILLQGTLAQSIKGNHLVKVYDYQEDGSVLLTCDAEAKNITWFKDGKMIGFLTEDKKKWNLGSNAKDPRGMYQCKGSQNKSKPLQVYYRMCQNCIELNAATISGFLFAEIVSIFVLAVGVYFIAGQDGVRQSRASDKQTLLPNDQLYQPLKDREDDQYSHLQGNQLRRN>sp|P00450|CERU_HUMAN Ceruloplasmin OS=Homo sapiens OX=9606 GN=CP PE=1SV=1MKILILGIFLFLCSTPAWAKEKHYYIGIIETTWDYASDHGEKKLISVDTEHSNIYLQNGPDRIGRLYKKALYLQYTDETFRTTIEKPVWLGFLGPIIKAETGDKVYVHLKNLASRPYTFHSHGITYYKEHEGAIYPDNTTDFQRADDKVYPGEQYTYMLLATEEQSPGEGDGNCVTRIYHSHIDAPKDIASGLIGPLIICKKDSLDKEKEKHIDREFVVMFSVVDENFSWYLEDNIKTYCSEPEKVDKDNEDFQESNRMYSVNGYTFGSLPGLSMCAEDRVKWYLFGMGNEVDVHAAFFHGQALTNKNYRIDTINLFPATLFDAYMVAQNPGEWMLSCQNLNHLKAGLQAFFQVQECNKSSSKDNIRGKHVRHYYIAAEEIIWNYAPSGIDIFTKENLTAPGSDSAVFFEQGTTRIGGSYKKLVYREYTDASFTNRKERGPEEEHLGILGPVIWAEVGDTIRVTFHNKGAYPLSIEPIGVRFNKNNEGTYYSPNYNPQSRSVPPSASHVAPTETFTYEWTVPKEVGPTNADPVCLAKMYYSAVDPTKDIFTGLIGPMKICKKGSLHANGRQKDVDKEFYLFPTVFDENESLLLEDNIRMFTTAPDQVDKEDEDFQESNKMHSMNGFMYGNQPGLTMCKGDSVVWYLFSAGNEADVHGIYFSGNTYLWRGERRDTANLFPQTSLTLHMWPDTEGTFNVECLTTDHYTGGMKQKYTVNQCRRQSEDSTFYLGERTYYIAAVEVEWDYSPQREWEKELHHLQEQNVSNAFLDKGEFYIGSKYKKVVYRQYTDSTFRVPVERKAEEEHLGILGPQLHADVGDKVKIIFKNMATRPYSIHAHGVQTESSTVTPTLPGETLTYVWKIPERSGAGTEDSACIPWAYYSTVDQVKDLYSGLIGPLIVCRRPYLKVFNPRRKLEFALLFLVFDENESWYLDDNIKTYSDHPEKVNKDDEEFIESNKMHAINGRMFGNLQGLTMHVGDEVNWYLMGMGNEIDLHTVHFHGHSFQYKHRGVYSSDVFDIFPGTYQTLEMFPRTPGIWLLHCHVTDHIHAGMETTYTVLQNEDTKSG>sp|Q6UWT4|CE046_HUMAN Uncharacterized protein C5orf46 OS=Homo sapiensOX=9606 GN=C5orf46 PE=1 SV=2MAVSVLRLTVVLGLLVLFLTCYADDKPDKPDDKPDDSGKDPKPDFPKFLSLLGTEIIENAVEFILRSMSRSTGFMEFDDNEGKHSSK>sp|Q6UWT4-2|CE046_HUMAN Isoform 2 of Uncharacterized protein C5orf46OS=Homo sapiens OX=9606 GN=C5orf46MAVSVLRLTVVLGLLVLFLTCYADDKPDKPDDKPDDSGKDPKPDFPKFLSLLGTEIIENAVEFILRSMSRST>sp|Q9UKJ5|CHIC2_HUMAN Cysteine-rich hydrophobic domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=CHIC2 PE=1 SV=1MADFDEIYEEEEDEERALEEQLLKYSPDPVVVRGSGHVTVFGLSNKFESEFPSSLTGKVAPEEFKASINRVNSCLKKNLPVNVRWLLCGCLCCCCTLGCSMWPVICLSKRTRRSIEKLLEWENNRLYHKLCLHWRLSKRKCETNNMMEYVILIEFLPKTPIFRPD>sp|Q569G3|CE047_HUMAN Uncharacterized protein C5orf47 OS=Homo sapiensOX=9606 GN=C5orf47 PE=2 SV=2MAAAGRGREQDSARFVYVTRFGSHQCSGVLQLGGRGAQGLWGQGPGAGCRQEKPREAMAVAGVQGGSELPLGSQLRVPTTPGVEAAASASSQLRASRVQSGTRQSARAGLIQKDAAKKYDFPIPLNEASKIMKKKKKVLVWNRVYKVISRMLEENEKYRHRLKCQRLSSESSNYTR>sp|O95661|DIRA3_HUMAN GTP-binding protein Di-Ras3 OS=Homo sapiensOX=9606 GN=DIRAS3 PE=1 SV=1MGNASFGSKEQKLLKRLRLLPALLILRAFKPHRKIRDYRVVVVGTAGVGKSTLLHKWASGNFRHEYLPTIENTYCQLLGCSHGVLSLHITDSKSGDGNRALQRHVIARGHAFVLVYSVTKKETLEELKAFYELICKIKGNNLHKFPIVLVGNKSDDTHREVALNDGATCAMEWNCAFMEISAKTDVNVQELFHMLLNYKKKPTTGLQEPEKKSQMPNTTEKLLDKCIIM>sp|Q96KT6|CH014_HUMAN Putative uncharacterized protein encoded byLINC00208 OS=Homo sapiens OX=9606 GN=LINC00208 PE=5 SV=1MGQSLQEGRKQGRLLPAPSAHFLKHAHLASPSEVGGEPEIGSLCASHVLHMSPLYSVNLQVSPGSLTFHSLSLRSTSTRLQPQSTYIVGPLC>sp|Q6P047|CH074_HUMAN Uncharacterized protein C8orf74 OS=Homo sapiensOX=9606 GN=C8orf74 PE=1 SV=3MALLTPQGVKEVFQLQRPQGRERLRRLLNWEEFDEQRDSRRSILLDTLYESIIFAVGKGFPWVEVAQVVKFTEELLRETKGCSITEAVTILGNKLRDYRGHFNTTHLLALCDYFHHTFIRHYKLYQYVLGQDQQVDLTVAHLEVCMPPHPLPLAEGMDRDLWIHEQQVATLTEAEAQKRADVLLLKEALRLERENSLQKAFAAAAPAQPGQVLERQELESLICQAVHTQMELLQELLQRQIQNTFAILDLKLQKKTLNLNAPTPIPPPITSHAGQEEALKPQRASKGKKAKARK>sp|Q0VF96|CGNL1_HUMAN Cingulin-like protein 1 OS=Homo sapiens OX=9606GN=CGNL1 PE=1 SV=2MELYFGEYQHVQQEYGVHLRLASDDTQKSRSSQNSKAGSYGVSIRVQGIDGHPYIVLNNTERCLAGTSFSENGPPFPPPVINNLPLHSSNGSVPKENSEELQLPENPYAQPSPIRNLKQPLLHEGKNGVLDRKDGSVKPSHLLNFQRHPELLQPYDPEKNELNLQNHQPSESNWLKTLTEEGINNKKPWTCFPKPSNSQPTSPSLEDPAKSGVTAIRLCSSVVIEDPKKQTSVCVNVQSCTKERVGEEALFTSGRPLTAHSPHAHPETKKTRPDVLPFRRQDSAGPVLDGARSRRSSSSSTTPTSANSLYRFLLDDQECAIHADNVNRHENRRYIPFLPGTGRDIDTGSIPGVDQLIEKFDQKPGLQRRGRSGKRNRINTDDRKRSRSVDSAFPFGLQGNSEYLIEFSRNLGKSSEHLLRPSQVCPQRPLSQERRGKQSVGRTFAKLQGAAHGASCAHSRPPQPNIDGKVLETEGSQESTVIRAPSLGAQSKKEEEVKTATATLMLQNRATATSPDSGAKKISVKTFPSASNTQATPDLLKGQQELTQQTNEETAKQILYNYLKEGSTDNDDATKRKVNLVFEKIQTLKSRAAGSAQGNNQACNSTSEVKDLLEQKSKLTIEVAELQRQLQLEVKNQQNIKEERERMRANLEELRSQHNEKVEENSTLQQRLEESEGELRKNLEELFQVKMEREQHQTEIRDLQDQLSEMHDELDSAKRSEDREKGALIEELLQAKQDLQDLLIAKEEQEDLLRKRERELTALKGALKEEVSSHDQEMDKLKEQYDAELQALRESVEEATKNVEVLASRSNTSEQDQAGTEMRVKLLQEENEKLQGRSEELERRVAQLQRQIEDLKGDEAKAKETLKKYEGEIRQLEEALVHARKEEKEAVSARRALENELEAAQGNLSQTTQEQKQLSEKLKEESEQKEQLRRLKNEMENERWHLGKTIEKLQKEMADIVEASRTSTLELQNQLDEYKEKNRRELAEMQRQLKEKTLEAEKSRLTAMKMQDEMRLMEEELRDYQRAQDEALTKRQLLEQTLKDLEYELEAKSHLKDDRSRLVKQMEDKVSQLEMELEEERNNSDLLSERISRSREQMEQLRNELLQERAARQDLECDKISLERQNKDLKSRIIHLEGSYRSSKEGLVVQMEARIAELEDRLESEERDRANLQLSNRRLERKVKELVMQVDDEHLSLTDQKDQLSLRLKAMKRQVEEAEEEIDRLESSKKKLQRELEEQMDMNEHLQGQLNSMKKDLRLKKLPSKVLDDMDDDDDLSTDGGSLYEAPVSYTFSKDSTVASQI>sp|Q0VF96-2|CGNL1_HUMAN Isoform 2 of Cingulin-like protein 1 OS=Homosapiens OX=9606 GN=CGNL1MEREQHQTEIRDLQDQLSEMHDELDSAKRSEDREKGALIEELLQAKQDLQDLLIAKEEQEDLLRKRERELTALKGALKEEVSSHDQEMDKLKEQYDAELQALRESVEEATKNVEVLASRSNTSEQDQAGTEMRVKLLQEENEKLQGRSEELERRVAQLQRQIEDLKGDEAKAKETLKKYEGEIRQLEEALVHARKEEKEAVSARRALENELEAAQGNLSQTTQEQKQLSEKLKEESEQKEQLRRLKNEMENERWHLGKTIEKLQKEMADIVEASRTSTLELQNQLDEYKEKNRRELAEMQRQLKEKTLEAEKSRLTAMKMQDEMRLMEEELRDYQRAQDEALTKRQLLEQTLKDLEYELEAKSHLKDDRSRLVKQMEDKVSQLEMELEEERNNSDLLSERISRSREQMEQLRNELLQERAARQDLECDKISLERQNKDLKSRIIHLEGSYRSSKEGLVVQMEARIAELEDRLESEERDRANLQLSNRRLERKVKELVMQVDDEHLSLTDQKDQLSLRLKAMKRQVEEAEEEIDRLESSKKKLQRELEEQMDMNEHLQGQLNSMKKDLRLKKLPSKVLDDMDDDDDLSTDGGSLYEAPVSYTFSKDSTVASQI>sp|Q15131|CDK10_HUMAN Cyclin-dependent kinase 10 OS=Homo sapiens OX=9606GN=CDK10 PE=1 SV=1MAEPDLECEQIRLKCIRKEGFFTVPPEHRLGRCRSVKEFEKLNRIGEGTYGIVYRARDTQTDEIVALKKVRMDKEKDGIPISSLREITLLLRLRHPNIVELKEVVVGNHLESIFLVMGYCEQDLASLLENMPTPFSEAQVKCIVLQVLRGLQYLHRNFIIHRDLKVSNLLMTDKGCVKTADFGLARAYGVPVKPMTPKVVTLWYRAPELLLGTTTQTTSIDMWAVGCILAELLAHRPLLPGTSEIHQIDLIVQLLGTPSENIWPGFSKLPLVGQYSLRKQPYNNLKHKFPWLSEAGLRLLHFLFMYDPKKRATAGDCLESSYFKEKPLPCEPELMPTFPHHRNKRAAPATSEGQSKRCKP>sp|Q15131-2|CDK10_HUMAN Isoform 2 of Cyclin-dependent kinase 10 OS=Homosapiens OX=9606 GN=CDK10MDKEKDGIPISSLREITLLLRLRHPNIVELKEVVVGNHLESIFLVMGYCEQDLASLLENMPTPFSEAQVKCIVLQVLRGLQYLHRNFIIHRDLKVSNLLMTDKGCVKTADFGLARAYGVPVKPMTPKVVTLWYRAPELLLGTTTQTTSIDMWAVGCILAELLAHRPLLPGTSEIHQIDLIVQLLGTPSENIWPGFSKLPLVGQYSLRKQPYNNLKHKFPWLSEAGLRLLHFLFMYDPKKRATAGDCLESSYFKEKPLPCEPELMPTFPHHRNKRAAPATSEGQSKRCKP>sp|Q15131-3|CDK10_HUMAN Isoform 3 of Cyclin-dependent kinase 10 OS=Homosapiens OX=9606 GN=CDK10MDKEKDGIPISSLREITLLLRLRHPNIVELKEVVVGNHLESIFLVMGYCEQDLASLLENMPTPFSEAQVKCIVLQVLRGLQYLHRNFIIHRDLKVSNLLMTDKGCVKTADFGLARAYGVPVKPMTPKVVTLWYRAPELLLGTTTQTTSIDMWAVGCILAELLAHRPLLPGTSEIHQIDLIVQLLGTPSENIWPGFSKLPLVGQYSLRKQPYNNLKHKFPWLSEAGLRLLHFLFMATAGDCLESSYFKEKPLPCEPELMPTFPHHRNKRAAPATSEGQSKRCKP>sp|Q15131-4|CDK10_HUMAN Isoform 4 of Cyclin-dependent kinase 10 OS=Homosapiens OX=9606 GN=CDK10MDKEKDGIPISSLREITLLLRLRHPNIVELKEVVVGNHLESIFLVMGYCEQDLASLLENMPTPFSEAQVKCIVLQVLRGLQYLHRNFIIHRDLKVSNLLMTDKGCVKTADFGLARAYGVPVKPMTPKVVTLWYRAPELLLGTTTQTTSIDMWAVGCILAELLAHRPLLPGTSEIHQIDLIVQLLGTPSENIWPGFSKLPLVGQYSLRKQPYNNLKHKFPWLSEAGLRLLHFLFMYDPKKRATAGDCLESSYFKEKPLRLPISGVCEGCREPG>sp|Q15131-5|CDK10_HUMAN Isoform 5 of Cyclin-dependent kinase 10 OS=Homosapiens OX=9606 GN=CDK10MAEPDLECEQIRLKCIRKEGFFTVPPEHRLGRCRSVKEFEKLNRIGEDRARDTQTDEIVALKKVRMDKEKDGIPISSLREITLLLRLRHPNIVELKEVVVGNHLESIFLVMGYCEQDLASLLENMPTPFSEAQVKCIVLQVLRGLQYLHRNFIIHRDLKVSNLLMTDKGCVKTGGCNLGQALSLDGTW>sp|Q15131-6|CDK10_HUMAN Isoform 6 of Cyclin-dependent kinase 10 OS=Homosapiens OX=9606 GN=CDK10MAEPDLECEQIRLKCIRKEGFFTVPPEHRLGRCRSVKEFEKLNRIGEDRARDTQTDEIVALKKVRMDKEKDGIPISSLREITLLLRLRHPNIVELKEVVVGNHLESIFLVMGYCEQDLASLLENMPTPFSEAQVRGRGAWGGGMGFMGPCGAHL>sp|Q15131-7|CDK10_HUMAN Isoform 7 of Cyclin-dependent kinase 10 OS=Homosapiens OX=9606 GN=CDK10MDKEKDGIPISSLREITLLLRLRHPNIVELKEVVVGNHLESIFLVMGYCEQDLASLLENMPTPFSEAQVKCIVLQVLRGLQYLHRNFIIHRDLKVSNLLMTDKGCVKTGGCNLGQALSLDGTWMTPKVVTLWYRAPELLLGTTTQTTSIDMWAVGCILAELLAHRPLLPGTSEIHQIDLIVQLLGTPSENIWPGFSKLPLVGQYSLRKQPYNNLKHKFPWLSEAGLRLLHFLFMYDPKKRATAGDCLESSYFKEKPLPCEPELMPTFPHHRNKRAAPATSEGQSKRCKP>sp|O14646|CHD1_HUMAN Chromodomain-helicase-DNA-binding protein 1 OS=Homosapiens OX=9606 GN=CHD1 PE=1 SV=2MNGHSDEESVRNSSGESSQSDDDSGSASGSGSGSSSGSSSDGSSSQSGSSDSDSGSESGSQSESESDTSRENKVQAKPPKVDGAEFWKSSPSILAVQRSAILKKQQQQQQQQQHQASSNSGSEEDSSSSEDSDDSSSEVKRKKHKDEDWQMSGSGSPSQSGSDSESEEEREKSSCDETESDYEPKNKVKSRKPQNRSKSKNGKKILGQKKRQIDSSEEDDDEEDYDNDKRSSRRQATVNVSYKEDEEMKTDSDDLLEVCGEDVPQPEEEEFETIERFMDCRIGRKGATGATTTIYAVEADGDPNAGFEKNKEPGEIQYLIKWKGWSHIHNTWETEETLKQQNVRGMKKLDNYKKKDQETKRWLKNASPEDVEYYNCQQELTDDLHKQYQIVERIIAHSNQKSAAGYPDYYCKWQGLPYSECSWEDGALISKKFQACIDEYFSRNQSKTTPFKDCKVLKQRPRFVALKKQPSYIGGHEGLELRDYQLNGLNWLAHSWCKGNSCILADEMGLGKTIQTISFLNYLFHEHQLYGPFLLVVPLSTLTSWQREIQTWASQMNAVVYLGDINSRNMIRTHEWTHHQTKRLKFNILLTTYEILLKDKAFLGGLNWAFIGVDEAHRLKNDDSLLYKTLIDFKSNHRLLITGTPLQNSLKELWSLLHFIMPEKFSSWEDFEEEHGKGREYGYASLHKELEPFLLRRVKKDVEKSLPAKVEQILRMEMSALQKQYYKWILTRNYKALSKGSKGSTSGFLNIMMELKKCCNHCYLIKPPDNNEFYNKQEALQHLIRSSGKLILLDKLLIRLRERGNRVLIFSQMVRMLDILAEYLKYRQFPFQRLDGSIKGELRKQALDHFNAEGSEDFCFLLSTRAGGLGINLASADTVVIFDSDWNPQNDLQAQARAHRIGQKKQVNIYRLVTKGSVEEDILERAKKKMVLDHLVIQRMDTTGKTVLHTGSAPSSSTPFNKEELSAILKFGAEELFKEPEGEEQEPQEMDIDEILKRAETHENEPGPLTVGDELLSQFKVANFSNMDEDDIELEPERNSKNWEEIIPEDQRRRLEEEERQKELEEIYMLPRMRNCAKQISFNGSEGRRSRSRRYSGSDSDSISEGKRPKKRGRPRTIPRENIKGFSDAEIRRFIKSYKKFGGPLERLDAIARDAELVDKSETDLRRLGELVHNGCIKALKDSSSGTERTGGRLGKVKGPTFRISGVQVNAKLVISHEEELIPLHKSIPSDPEERKQYTIPCHTKAAHFDIDWGKEDDSNLLIGIYEYGYGSWEMIKMDPDLSLTHKILPDDPDKKPQAKQLQTRADYLIKLLSRDLAKKEALSGAGSSKRRKARAKKNKAMKSIKVKEEIKSDSSPLPSEKSDEDDDKLSESKSDGRERSKKSSVSDAPVHITASGEPVPISEESEELDQKTFSICKERMRPVKAALKQLDRPEKGLSEREQLEHTRQCLIKIGDHITECLKEYTNPEQIKQWRKNLWIFVSKFTEFDARKLHKLYKHAIKKRQESQQNSDQNSNLNPHVIRNPDVERLKENTNHDDSSRDSYSSDRHLTQYHDHHKDRHQGDSYKKSDSRKRPYSSFSNGKDHRDWDHYKQDSRYYSDREKHRKLDDHRSRDHRSNLEGSLKDRSHSDHRSHSDHRLHSDHRSSSEYTHHKSSRDYRYHSDWQMDHRASSSGPRSPLDQRSPYGSRSPFEHSVEHKSTPEHTWSSRKT>sp|O14646-2|CHD1_HUMAN Isoform 2 of Chromodomain-helicase-DNA-bindingprotein 1 OS=Homo sapiens OX=9606 GN=CHD1MNGHSDEESVRNSSGESSQSDDDSGSASGSGSGSSSGSSSDGSSSQSGSSDSDSGSESGSQSESESDTSRENKVQAKPPKVDGAEFWKSSPSILAVQRSAILKKQQQQQQQQQHQASSNSGSEEDSSSSEDSDDSSSEVKRKKHKDEDWQMSGSGSPSQSGSDSESEEEREKSSCDETESDYEPKNKVKSRKPQNRSKSKNGKKILGQKKRQIDSSEEDDDEEDYDNDKRSSRRQATVNVSYKEDEEMKTDSDDLLEVCGEDVPQPEEEEFETIERFMDCRIGRKGATGATTTIYAVEADGDPNAGFEKNKEPGEIQYLIKWKGWSHIHNTWETEETLKQQNVRGMKKLDNYKKKDQETKRWLKNASPEDVEYYNCQQELTDDLHKQYQIVERIIAHSNQKSAAGYPDYYCKWQGLPYSECSWEDGALISKKFQACIDEYFSRNQSKTTPFKDCKVLKQRPRFVALKKQPSYIGGHEGLELRDYQLNGLNWLAHSWCKGNSCILADEMGLGKTIQTISFLNYLFHEHQLYGPFLLVVPLSTLTSWQREIQTWASQMNAVVYLGDINSRNMIRTHEWTHHQTKRLKFNILLTTYEILLKDKAFLGGLNWAFIGVDEAHRLKNDDSLLYKTLIDFKSNHRLLITGTPLQNSLKELWSLLHFIMPEKFSSWEDFEEEHGKGREYGYASLHKELEPFLLRRVKKDVEKSLPAKVEQILRMEMSALQKQYYKWILTRNYKALSKGSKGSTSGFLNIMMELKKCCNHCYLIKPPDNNEFYNKQEALQHLIRSSGKLILLDKLLIRLRERGNRVLIFSQMVRMLDILAEYLKYRQFPFQRLDGSIKGELRKQALDHFNAEGSEDFCFLLSTRAGGLGINLASADTVVIFDSDWNPQNDLQAQARAHRIGQKKQVNIYRLVTKGSVEEDILERAKKKMVLDHLVIQRMDTTGKTVLHTGSAPSSSTPFNKEELSAILKFGAEELFKEPEGEEQEPQEMDIDEILKRAETHENEPGPLTVGDELLSQFKVANFSNMDEDDIELEPERNSKNWEEIIPEDQRRRLEEEERQKELEEIYMLPRMRNCAKQISFNGSEGRRSRSRRYSGSDSDSISEGKRPKKRGRPRTIPRENIKGFSDAEIRRFIKSYKKFGGPLERLDAIARDAELVDKSETDLRRLGELVHNGCIKALKDSSSGTERTGGRLGKVKGPTFRISGVQVNAKLVISHEEELIPLHKSIPSDPEERKQYTIPCHTKAAHFDIDWGKEDDSNLLIGIYEYGYGSWEMIKMDPDLSLTHKILPDDPDKKPQAKQLQTRADYLIKLLSRDLAKKEALSGAGSSKRRKARAKKNKAMKSIKVKEEIKSDSSPLPSEKSDEDDDKLSESKSDGRERSKKSSVSDAPVHITASGEPVPISEESEELDQKTFSICKERMRPVKAALKQLDRPEKGLSEREQLEHTRQCLIKIGDHITECLKEYTNPEQIKQWRKNLWIFVSKFTEFDARKLHKLYKHAIKKRQESQQNSDQNSNLNPHVIRNPDVERLKENTNHDDSSRDSYSSDRHLTQYHDHHKDRHQGDSYKKSDSRKRPYSSFSNGKDHRDWDHYKQDSRYYSDREKHRKLDDHRSRDHRSNLEGSLKDRSHSDHRSHSDHRLHSDHRSSSEYTHHKSSRDYRYHSDWQMDHRASSSGPRSPLDQRSYGSRSPFEHSVEHKSTPEHTWSSRKT>sp|Q00537|CDK17_HUMAN Cyclin-dependent kinase 17 OS=Homo sapiens OX=9606GN=CDK17 PE=1 SV=2MKKFKRRLSLTLRGSQTIDESLSELAEQMTIEENSSKDNEPIVKNGRPPTSHSMHSFLHQYTGSFKKPPLRRPHSVIGGSLGSFMAMPRNGSRLDIVHENLKMGSDGESDQASGTSSDEVQSPTGVCLRNRIHRRISMEDLNKRLSLPADIRIPDGYLEKLQINSPPFDQPMSRRSRRASLSEIGFGKMETYIKLEKLGEGTYATVYKGRSKLTENLVALKEIRLEHEEGAPCTAIREVSLLKDLKHANIVTLHDIVHTDKSLTLVFEYLDKDLKQYMDDCGNIMSMHNVKLFLYQILRGLAYCHRRKVLHRDLKPQNLLINEKGELKLADFGLARAKSVPTKTYSNEVVTLWYRPPDVLLGSSEYSTQIDMWGVGCIFFEMASGRPLFPGSTVEDELHLIFRLLGTPSQETWPGISSNEEFKNYNFPKYKPQPLINHAPRLDSEGIELITKFLQYESKKRVSAEEAMKHVYFRSLGPRIHALPESVSIFSLKEIQLQKDPGFRNSSYPETGHGKNRRQSMLF>sp|Q00537-2|CDK17_HUMAN Isoform 2 of Cyclin-dependent kinase 17 OS=Homosapiens OX=9606 GN=CDK17MKKFKRRLSLTLRGSQTIDESLSELAEQMTIEENSSKDNEPIVKNGRPPTSHSMHSFLHQYTGSFKKPPLRRPHSVIGGSLGSFMAMPRNGSRLDIVHENLKMGSDGESDQASGTSSDEVQSPTGVCLRNRIHRRISMEDLNKRLSLPADIRIPDGYLEKLQINSPPFDQPMSRRSRRASLSEIGFGKMETYIKLEKLGEGTYATVYKGRSKLTENLVALKEIRLEHEEGAPCTAIREVSLLKDLKHANIVTLHDIVHTDKSLTLVFEYLDKDLKQYMDDCGNIMSMHNVKLFLYQILRGLAYCHRRKVLHRDLKPQNLLINEKGELKLADFGLARAKSVPTKTYSNEVVTLWYRPPDVLLGSSEYSTQIDMWGVGCIFFEMASGRPLFPGSTVEDELHLIFRLLGTPSQETWPGISSNEEFKNYNFPKYKPQPLINHAPRLDSEGIELITKFLQYESKKRVSAEEAMKHVYFRSLGPRIHALPESVSIFSLKEIQLQKDPGFRNSSYPETGVFVINHFTCRS>sp|Q14839|CHD4_HUMAN Chromodomain-helicase-DNA-binding protein 4 OS=Homosapiens OX=9606 GN=CHD4 PE=1 SV=2MASGLGSPSPCSAGSEEEDMDALLNNSLPPPHPENEEDPEEDLSETETPKLKKKKKPKKPRDPKIPKSKRQKKERMLLCRQLGDSSGEGPEFVEEEEEVALRSDSEGSDYTPGKKKKKKLGPKKEKKSKSKRKEEEEEEDDDDDSKEPKSSAQLLEDWGMEDIDHVFSEEDYRTLTNYKAFSQFVRPLIAAKNPKIAVSKMMMVLGAKWREFSTNNPFKGSSGASVAAAAAAAVAVVESMVTATEVAPPPPPVEVPIRKAKTKEGKGPNARRKPKGSPRVPDAKKPKPKKVAPLKIKLGGFGSKRKRSSSEDDDLDVESDFDDASINSYSVSDGSTSRSSRSRKKLRTTKKKKKGEEEVTAVDGYETDHQDYCEVCQQGGEIILCDTCPRAYHMVCLDPDMEKAPEGKWSCPHCEKEGIQWEAKEDNSEGEEILEEVGGDLEEEDDHHMEFCRVCKDGGELLCCDTCPSSYHIHCLNPPLPEIPNGEWLCPRCTCPALKGKVQKILIWKWGQPPSPTPVPRPPDADPNTPSPKPLEGRPERQFFVKWQGMSYWHCSWVSELQLELHCQVMFRNYQRKNDMDEPPSGDFGGDEEKSRKRKNKDPKFAEMEERFYRYGIKPEWMMIHRILNHSVDKKGHVHYLIKWRDLPYDQASWESEDVEIQDYDLFKQSYWNHRELMRGEEGRPGKKLKKVKLRKLERPPETPTVDPTVKYERQPEYLDATGGTLHPYQMEGLNWLRFSWAQGTDTILADEMGLGKTVQTAVFLYSLYKEGHSKGPFLVSAPLSTIINWEREFEMWAPDMYVVTYVGDKDSRAIIRENEFSFEDNAIRGGKKASRMKKEASVKFHVLLTSYELITIDMAILGSIDWACLIVDEAHRLKNNQSKFFRVLNGYSLQHKLLLTGTPLQNNLEELFHLLNFLTPERFHNLEGFLEEFADIAKEDQIKKLHDMLGPHMLRRLKADVFKNMPSKTELIVRVELSPMQKKYYKYILTRNFEALNARGGGNQVSLLNVVMDLKKCCNHPYLFPVAAMEAPKMPNGMYDGSALIRASGKLLLLQKMLKNLKEGGHRVLIFSQMTKMLDLLEDFLEHEGYKYERIDGGITGNMRQEAIDRFNAPGAQQFCFLLSTRAGGLGINLATADTVIIYDSDWNPHNDIQAFSRAHRIGQNKKVMIYRFVTRASVEERITQVAKKKMMLTHLVVRPGLGSKTGSMSKQELDDILKFGTEELFKDEATDGGGDNKEGEDSSVIHYDDKAIERLLDRNQDETEDTELQGMNEYLSSFKVAQYVVREEEMGEEEEVEREIIKQEESVDPDYWEKLLRHHYEQQQEDLARNLGKGKRIRKQVNYNDGSQEDRDWQDDQSDNQSDYSVASEEGDEDFDERSEAPRRPSRKGLRNDKDKPLPPLLARVGGNIEVLGFNARQRKAFLNAIMRYGMPPQDAFTTQWLVRDLRGKSEKEFKAYVSLFMRHLCEPGADGAETFADGVPREGLSRQHVLTRIGVMSLIRKKVQEFEHVNGRWSMPELAEVEENKKMSQPGSPSPKTPTPSTPGDTQPNTPAPVPPAEDGIKIEENSLKEEESIEGEKEVKSTAPETAIECTQAPAPASEDEKVVVEPPEGEEKVEKAEVKERTEEPMETEPKGAADVEKVEEKSAIDLTPIVVEDKEEKKEEEEKKEVMLQNGETPKDLNDEKQKKNIKQRFMFNIADGGFTELHSLWQNEERAATVTKKTYEIWHRRHDYWLLAGIINHGYARWQDIQNDPRYAILNEPFKGEMNRGNFLEIKNKFLARRFKLLEQALVIEEQLRRAAYLNMSEDPSHPSMALNTRFAEVECLAESHQHLSKESMAGNKPANAVLHKVLKQLEELLSDMKADVTRLPATIARIPPVAVRLQMSERNILSRLANRAPEPTPQQVAQQQ>sp|Q14839-2|CHD4_HUMAN Isoform 2 of Chromodomain-helicase-DNA-bindingprotein 4 OS=Homo sapiens OX=9606 GN=CHD4MASGLGSPSPCSAGSEEEDMDALLNNSLPPPHPENEEDPEEDLSETETPKLKKKKKPKKPRDPKIPKSKRQKKERMLLCRQLGDSSGEGPEFVEEEEEVALRSDSEGSDYTPGKKKKKKLGPKKEKKSKSKRKEEEEEEDDDDDSKEPKSSAQLLEDWGMEDIDHVFSEEDYRTLTNYKAFSQFVRPLIAAKNPKIAVSKMMMVLGAKWREFSTNNPFKGSSGASVAAAAAAAVAVVESMVTATEVAPPPPPVEVPIRKAKTKEGKGPNARRKPKGSPRVPDAKKPKPKKVAPLKIKLGGFGSKRKRSSSEDDDLDVESDFDDASINSYSVSDGSTSRSSRSRKKLRTTKKKKKGEEEVTAVDGYETDHQDYCEVCQQGGEIILCDTCPRAYHMVCLDPDMEKAPEGKWSCPHCEKEGIQWEAKEDNSEGEEILEEVGGDLEEEDDHHMEFCRVCKDGGELLCCDTCPSSYHIHCLNPPLPEIPNGEWLCPRCTCPALKGKVQKILIWKWGQPPSPTPVPRPPDADPNTPSPKPLEGRPERQFFVKWQGMSYWHCSWVSELQLELHCQVMFRNYQRKNDMDEPPSGDFGGDEEKSRKRKNKDPKFAEMEERFYRYGIKPEWMMIHRILNHSVDKKGHVHYLIKWRDLPYDQASWESEDVEIQDYDLFKQSYWNHRELMRGEEGRPGKKLKKVKLRKLERPPETPTVDPTVKYERQPEYLDATGGTLHPYQMEGLNWLRFSWAQGTDTILADEMGLGKTVQTAVFLYSLYKEGHSKGPFLVSAPLSTIINWEREFEMWAPDMYVVTYVGDKDSRAIIRENEFSFEDNAIRGGKKASRMKKEASVKFHVLLTSYELITIDMAILGSIDWACLIVDEAHRLKNNQSKFFRVLNGYSLQHKLLLTGTPLQNNLEELFHLLNFLTPERFHNLEGFLEEFADIAKEDQIKKLHDMLGPHMLRRLKADVFKNMPSKTELIVRVELSPMQKKYYKYILTRNFEALNARGGGNQVSLLNVVMDLKKCCNHPYLFPVAAMEAPKMPNGMYDGSALIRASGKLLLLQKMLKNLKEGGHRVLIFSQMTKMLDLLEDFLEHEGYKYERIDGGITGNMRQEAIDRFNAPGAQQFCFLLSTRAGGLGINLATADTVIIYDSDWNPHNDIQAFSRAHRIGQNKKVMIYRFVTRASVEERITQVAKKKMMLTHLVVRPGLGSKTGSMSKQELDDILKFGTEELFKDEATDGGGDNKEGEDSSVIHYDDKAIERLLDRNQDETEDTELQGMNEYLSSFKVAQYVVREEEMGEEEEVEREIIKQEESVDPDYWEKLLRHHYEQQQEDLARNLGKGKRIRKQVNYNDGSQEDRGVCGRPRPPPMGRSTRAVGPAHLPSLPPDWQDDQSDNQSDYSVASEEGDEDFDERSEAPRRPSRKGLRNDKDKPLPPLLARVGGNIEVLGFNARQRKAFLNAIMRYGMPPQDAFTTQWLVRDLRGKSEKEFKAYVSLFMRHLCEPGADGAETFADGVPREGLSRQHVLTRIGVMSLIRKKVQEFEHVNGRWSMPELAEVEENKKMSQPGSPSPKTPTPSTPGDTQPNTPAPVPPAEDGIKIEENSLKEEESIEGEKEVKSTAPETAIECTQAPAPASEDEKVVVEPPEGEEKVEKAEVKERTEEPMETEPKGAADVEKVEEKSAIDLTPIVVEDKEEKKEEEEKKEVMLQNGETPKDLNDEKQKKNIKQRFMFNIADGGFTELHSLWQNEERAATVTKKTYEIWHRRHDYWLLAGIINHGYARWQDIQNDPRYAILNEPFKGEMNRGNFLEIKNKFLARRFKLLEQALVIEEQLRRAAYLNMSEDPSHPSMALNTRFAEVECLAESHQHLSKESMAGNKPANAVLHKVLKQLEELLSDMKADVTRLPATIARIPPVAVRLQMSERNILSRLANRAPEPTPQQVAQQQ>sp|Q96FZ7|CHMP6_HUMAN Charged multivesicular body protein 6 OS=Homosapiens OX=9606 GN=CHMP6 PE=1 SV=3MGNLFGRKKQSRVTEQDKAILQLKQQRDKLRQYQKRIAQQLERERALARQLLRDGRKERAKLLLKKKRYQEQLLDRTENQISSLEAMVQSIEFTQIEMKVMEGLQFGNECLNKMHQVMSIEEVERILDETQEAVEYQRQIDELLAGSFTQEDEDAILEELSAITQEQIELPEVPSEPLPEKIPENVPVKARPRQAELVAAS>sp|P0CG37|CFC1_HUMAN Cryptic protein OS=Homo sapiens OX=9606 GN=CFC1PE=1 SV=1MTWRHHVRLLFTVSLALQIINLGNSYQREKHNGGREEVTKVATQKHRQSPLNWTSSHFGEVTGSAEGWGPEEPLPYSRAFGEGASARPRCCRNGGTCVLGSFCVCPAHFTGRYCEHDQRRSECGALEHGAWTLRACHLCRCIFGALHCLPLQTPDRCDPKDFLASHAHGPSAGGAPSLLLLLPCALLHRLLRPDAPAHPRSLVPSVLQRERRPCGRPGLGHRL>sp|Q8WWL7|CCNB3_HUMAN G2/mitotic-specific cyclin-B3 OS=Homo sapiensOX=9606 GN=CCNB3 PE=1 SV=2MLLPLPPQSSKPVPKKSQSSKIVPSHHDPSEKTGENCQTKISPSSLQESPSSLQGALKKRSAFEDLTNASQCQPVQPKKEANKEFVKVVSKKINRNTHALGLAKKNKRNLKWHKLEVTPVVASTTVVPNIMEKPLILDISTTSKTPNTEEASLFRKPLVLKEEPTIEDETLINKSLSLKKCSNHEEVSLLEKLQPLQEESDSDDAFVIEPMTFKKTHKTEEAAITKKTLSLKKKMCASQRKQSCQEESLAVQDVNMEEDSFFMESMSFKKKPKTEESIPTHKLSSLKKKCTIYGKICHFRKPPVLQTTICGAMSSIKKPTTEKETLFQELSVLQEKHTTEHEMSILKKSLALQKTNFKEDSLVKESLAFKKKPSTEEAIMMPVILKEQCMTEGKRSRLKPLVLQEITSGEKSLIMKPLSIKEKPSTEKESFSQEPSALQKKHTTQEEVSILKEPSSLLKSPTEESPFDEALAFTKKCTIEEAPPTKKPLILKRKHATQGTMSHLKKPLILQTTSGEKSLIKEPLPFKEEKVSLKKKCTTQEMMSICPELLDFQDMIGEDKNSFFMEPMSFRKNPTTEETVLTKTSLSLQEKKITQGKMSHLKKPLVLQKITSEEESFYKKLLPFKMKSTTEEKFLSQEPSALKEKHTTLQEVSLSKESLAIQEKATTEEEFSQELFSLHVKHTNKSGSLFQEALVLQEKTDAEEDSLKNLLALQEKSTMEEESLINKLLALKEELSAEAATNIQTQLSLKKKSTSHGKVFFLKKQLALNETINEEEFLNKQPLALEGYPSIAEGETLFKKLLAMQEEPSIEKEAVLKEPTIDTEAHFKEPLALQEEPSTEKEAVLKEPSVDTEAHFKETLALQEKPSIEQEALFKRHSALWEKPSTEKETIFKESLDLQEKPSIKKETLLKKPLALKMSTINEAVLFEDMIALNEKPTTGKELSFKEPLALQESPTYKEDTFLKTLLVPQVGTSPNVSSTAPESITSKSSIATMTSVGKSGTINEAFLFEDMITLNEKPTTGKELSFKEPLALQESPTCKEDTFLETFLIPQIGTSPYVFSTTPESITEKSSIATMTSVGKSRTTTESSACESASDKPVSPQAKGTPKEITPREDIDEDSSDPSFNPMYAKEIFSYMKEREEQFILTDYMNRQIEITSDMRAILVDWLVEVQVSFEMTHETLYLAVKLVDLYLMKAVCKKDKLQLLGATAFMIAAKFEEHNSPRVDDFVYICDDNYQRSEVLSMEINILNVLKCDINIPIAYHFLRRYARCIHTNMKTLTLSRYICEMTLQEYHYVQEKASKLAAASLLLALYMKKLGYWVPFLEHYSGYSISELHPLVRQLNKLLTFSSYDSLKAVYYKYSHPVFFEVAKIPALDMLKLEEILNCDCEAQGLVL>sp|Q8WWL7-2|CCNB3_HUMAN Isoform 2 of G2/mitotic-specific cyclin-B3OS=Homo sapiens OX=9606 GN=CCNB3MLLPLPPQSSKPVPKKSQSSKIVPSHHDPSEKTGENCQTKISPSSLQESPSSLQGALKKRSAFEDLTNVSFEMTHETLYLAVKLVDLYLMKAVCKKDKLQLLGATAFMIAAKFEEHNSPRVDDFVYICDDNYQRSEVLSMEINILNVLKCDINIPIAYHFLRRYARCIHTNMKTLTLSRYICEMTLQEYHYVQEKASKLAAASLLLALYMKKLGYWVPFLEHYSGYSISELHPLVRQLNKLLTFSSYDSLKAVYYKYSHPVFFEVAKIPALDMLKLEEILNCDCEAQGLVL>sp|Q8WWL7-3|CCNB3_HUMAN Isoform 3 of G2/mitotic-specific cyclin-B3OS=Homo sapiens OX=9606 GN=CCNB3MLLPLPPQSSKPVPKKSQSSKIVPSHHDPSEKTGENCQTKISPSSLQESPSSLQGALKKRSAFEDLTNASQCQPVQPKKEANKEFVKVVSKKINRNTHALGLAKKNKRNLK>sp|Q92879|CELF1_HUMAN CUGBP Elav-like family member 1 OS=Homo sapiensOX=9606 GN=CELF1 PE=1 SV=2MNGTLDHPDQPDLDAIKMFVGQVPRTWSEKDLRELFEQYGAVYEINVLRDRSQNPPQSKGCCFVTFYTRKAALEAQNALHNMKVLPGMHHPIQMKPADSEKNNAVEDRKLFIGMISKKCTENDIRVMFSSFGQIEECRILRGPDGLSRGCAFVTFTTRAMAQTAIKAMHQAQTMEGCSSPMVVKFADTQKDKEQKRMAQQLQQQMQQISAASVWGNLAGLNTLGPQYLALYLQLLQQTASSGNLNTLSSLHPMGGLNAMQLQNLAALAAAASAAQNTPSGTNALTTSSSPLSVLTSSGSSPSSSSSNSVNPIASLGALQTLAGATAGLNVGSLAGMAALNGGLGSSGLSNGTGSTMEALTQAYSGIQQYAAAALPTLYNQNLLTQQSIGAAGSQKEGPEGANLFIYHLPQEFGDQDLLQMFMPFGNVVSAKVFIDKQTNLSKCFGFVSYDNPVSAQAAIQSMNGFQIGMKRLKVQLKRSKNDSKPY>sp|Q92879-2|CELF1_HUMAN Isoform 2 of CUGBP Elav-like family member 1OS=Homo sapiens OX=9606 GN=CELF1MNGTLDHPDQPDLDAIKMFVGQVPRTWSEKDLRELFEQYGAVYEINVLRDRSQNPPQSKGCCFVTFYTRKAALEAQNALHNMKVLPGMHHPIQMKPADSEKNNAVEDRKLFIGMISKKCTENDIRVMFSSFGQIEECRILRGPDGLSRGCAFVTFTTRAMAQTAIKAMHQAQTMEGCSSPMVVKFADTQKDKEQKRMAQQLQQQMQQISAASVWGNLAGLNTLGPQYLALLQQTASSGNLNTLSSLHPMGGLNAMQLQNLAALAAAASAAQNTPSGTNALTTSSSPLSVLTSSGSSPSSSSSNSVNPIASLGALQTLAGATAGLNVGSLAGMAALNGGLGSSGLSNGTGSTMEALTQAYSGIQQYAAAALPTLYNQNLLTQQSIGAAGSQKEGPEGANLFIYHLPQEFGDQDLLQMFMPFGNVVSAKVFIDKQTNLSKCFGFVSYDNPVSAQAAIQSMNGFQIGMKRLKVQLKRSKNDSKPY>sp|Q92879-3|CELF1_HUMAN Isoform 3 of CUGBP Elav-like family member 1OS=Homo sapiens OX=9606 GN=CELF1MNGTLDHPDQPDLDAIKMFVGQVPRTWSEKDLRELFEQYGAVYEINVLRDRSQNPPQSKGCCFVTFYTRKAALEAQNALHNMKVLPGMHHPIQMKPADSEKNNAVEDRKLFIGMISKKCTENDIRVMFSSFGQIEECRILRGPDGLSRGCAFVTFTTRAMAQTAIKAMHQAQTMEGCSSPMVVKFADTQKDKEQKRMAQQLQQQMQQISAASVWGNLAGLNTLGPQYLALLQQTASSGNLNTLSSLHPMGGLNAMQLQNLAALAAAASAAQNTPSGTNALTTSSSPLSVLTSSAGSSPSSSSSNSVNPIASLGALQTLAGATAGLNVGSLAGMAALNGGLGSSGLSNGTGSTMEALTQAYSGIQQYAAAALPTLYNQNLLTQQSIGAAGSQKEGPEGANLFIYHLPQEFGDQDLLQMFMPFGNVVSAKVFIDKQTNLSKCFGFVSYDNPVSAQAAIQSMNGFQIGMKRLKVQLKRSKNDSKPY>sp|Q92879-4|CELF1_HUMAN Isoform 4 of CUGBP Elav-like family member 1OS=Homo sapiens OX=9606 GN=CELF1MAAFKLDFLPEMMVDHCSLNSSPVSKKMNGTLDHPDQPDLDAIKMFVGQVPRTWSEKDLRELFEQYGAVYEINVLRDRSQNPPQSKGCCFVTFYTRKAALEAQNALHNMKVLPGMHHPIQMKPADSEKNNVEDRKLFIGMISKKCTENDIRVMFSSFGQIEECRILRGPDGLSRGCAFVTFTTRAMAQTAIKAMHQAQTMEGCSSPMVVKFADTQKDKEQKRMAQQLQQQMQQISAASVWGNLAGLNTLGPQYLALYLQLLQQTASSGNLNTLSSLHPMGGLNAMQLQNLAALAAAASAAQNTPSGTNALTTSSSPLSVLTSSGSSPSSSSSNSVNPIASLGALQTLAGATAGLNVGSLAGMAALNGGLGSSGLSNGTGSTMEALTQAYSGIQQYAAAALPTLYNQNLLTQQSIGAAGSQKEGPEGANLFIYHLPQEFGDQDLLQMFMPFGNVVSAKVFIDKQTNLSKCFGFVSYDNPVSAQAAIQSMNGFQIGMKRLKVQLKRSKNDSKPY>sp|Q92879-5|CELF1_HUMAN Isoform 5 of CUGBP Elav-like family member 1OS=Homo sapiens OX=9606 GN=CELF1MFVGQVPRTWSEKDLRELFEQYGAVYEINVLRDRSQNPPQSKGCCFVTFYTRKAALEAQNALHNMKVLPGMHHPIQMKPADSEKNNVEDRKLFIGMISKKCTENDIRVMFSSFGQIEECRILRGPDGLSRGCAFVTFTTRAMAQTAIKAMHQAQTMEGCSSPMVVKFADTQKDKEQKRMAQQLQQQMQQISAASVWGNLAGLNTLGPQYLALYLQLLQQTASSGNLNTLSSLHPMGGLNAMQLQNLAALAAAASAAQNTPSGTNALTTSSSPLSVLTSSGSSPSSSSSNSVNPIASLGALQTLAGATAGLNVGSLAGMAALNGGLGSSGLSNGTGSTMEALTQAYSGIQQYAAAALPTLYNQNLLTQQSIGAAGSQKEGPEGANLFIYHLPQEFGDQDLLQMFMPFGNVVSAKVFIDKQTNLSKCFGFVSYDNPVSAQAAIQSMNGFQIGMKRLKVQLKRSKNDSKPY>sp|Q92879-6|CELF1_HUMAN Isoform 6 of CUGBP Elav-like family member 1OS=Homo sapiens OX=9606 GN=CELF1MNGTLDHPDQPDLDAIKMFVGQVPRTWSEKDLRELFEQYGAVYEINVLRDRSQNPPQSKGCCFVTFYTRKAALEAQNALHNMKVLPGMHHPIQMKPADSEKNNVEDRKLFIGMISKKCTENDIRVMFSSFGQIEECRILRGPDGLSRGCAFVTFTTRAMAQTAIKAMHQAQTMEGCSSPMVVKFADTQKDKEQKRMAQQLQQQMQQISAASVWGNLAGLNTLGPQYLALYLQLLQQTASSGNLNTLSSLHPMGGLNAMQLQNLAALAAAASAAQNTPSGTNALTTSSSPLSVLTSSGSSPSSSSSNSVNPIASLGALQTLAGATAGLNVGSLAGMAALNGGLGSSGLSNGTGSTMEALTQAYSGIQQYAAAALPTLYNQNLLTQQSIGAAGSQKEGPEGANLFIYHLPQEFGDQDLLQMFMPFGNVVSAKVFIDKQTNLSKCFGFVSYDNPVSAQAAIQSMNGFQIGMKRLKVQLKRSKNDSKPY>sp|Q96F85|CNRP1_HUMAN CB1 cannabinoid receptor-interacting protein 1OS=Homo sapiens OX=9606 GN=CNRIP1 PE=1 SV=1MGDLPGLVRLSIALRIQPNDGPVFYKVDGQRFGQNRTIKLLTGSSYKVEVKIKPSTLQVENISIGGVLVPLELKSKEPDGDRVVYTGTYDTEGVTPTKSGERQPIQITMPFTDIGTFETVWQVKFYNYHKRDHCQWGSPFSVIEYECKPNETRSLMWVNKESFL>sp|Q96F85-2|CNRP1_HUMAN Isoform 2 of CB1 cannabinoid receptor-interacting protein 1 OS=Homo sapiens OX=9606 GN=CNRIP1MGDLPGLVRLSIALRIQPNDGPVFYKVDGQRFGQNRTIKLLTGSSYKVEVKIKPSTLQVENISIGGVLVPLELKSKEPDGDRVVYTGTYDTEGVTPTKSGERQPIQITMPECLEQRPQEISLTYECEE>sp|P13584|CP4B1_HUMAN Cytochrome P450 4B1 OS=Homo sapiens OX=9606GN=CYP4B1 PE=1 SV=2MVPSFLSLSFSSLGLWASGLILVLGFLKLIHLLLRRQTLAKAMDKFPGPPTHWLFGHALEIQETGSLDKVVSWAHQFPYAHPLWFGQFIGFLNIYEPDYAKAVYSRGDPKAPDVYDFFLQWIGRGLLVLEGPKWLQHRKLLTPGFHYDVLKPYVAVFTESTRIMLDKWEEKAREGKSFDIFCDVGHMALNTLMKCTFGRGDTGLGHRDSSYYLAVSDLTLLMQQRLVSFQYHNDFIYWLTPHGRRFLRACQVAHDHTDQVIRERKAALQDEKVRKKIQNRRHLDFLDILLGARDEDDIKLSDADLRAEVDTFMFEGHDTTTSGISWFLYCMALYPEHQHRCREEVREILGDQDFFQWDDLGKMTYLTMCIKESFRLYPPVPQVYRQLSKPVTFVDGRSLPAGSLISMHIYALHRNSAVWPDPEVFDSLRFSTENASKRHPFAFMPFSAGPRNCIGQQFAMSEMKVVTAMCLLRFEFSLDPSRLPIKMPQLVLRSKNGFHLHLKPLGPGSGK>sp|P13584-2|CP4B1_HUMAN Isoform 2 of Cytochrome P450 4B1 OS=Homo sapiensOX=9606 GN=CYP4B1MVPSFLSLSFSSLGLWASGLILVLGFLKLIHLLLRRQTLAKAMDKFPGPPTHWLFGHALEIQETGSLDKVVSWAHQFPYAHPLWFGQFIGFLNIYEPDYAKAVYSRGDPKAPDVYDFFLQWIGRGLLVLEGPKWLQHRKLLTPGFHYDVLKPYVAVFTESTRIMLDKWEEKAREGKSFDIFCDVGHMALNTLMKCTFGRGDTGLGHSRDSSYYLAVSDLTLLMQQRLVSFQYHNDFIYWLTPHGRRFLRACQVAHDHTDQVIRERKAALQDEKVRKKIQNRRHLDFLDILLGARDEDDIKLSDADLRAEVDTFMFEGHDTTTSGISWFLYCMALYPEHQHRCREEVREILGDQDFFQWDDLGKMTYLTMCIKESFRLYPPVPQVYRQLSKPVTFVDGRSLPAGSLISMHIYALHRNSAVWPDPEVFDSLRFSTENASKRHPFAFMPFSAGPRNCIGQQFAMSEMKVVTAMCLLRFEFSLDPSRLPIKMPQLVLRSKNGFHLHLKPLGPGSGK>sp|Q8IUI8|CRLF3_HUMAN Cytokine receptor-like factor 3 OS=Homo sapiensOX=9606 GN=CRLF3 PE=1 SV=2MRGAMELEPELLLQEARENVEAAQSYRRELGHRLEGLREARRQIKESASQTRDVLKQHFNDLKGTLGKLLDERLVTLLQEVDTIEQETIKPLDDCQKLIEHGVNTAEDLVREGEIAMLGGVGEENEKLWSFTKKASHIQLDSLPEVPLLVDVPCLSAQLDDSILNIVKDHIFKHGTVASRPPVQIEELIEKPGGIIVRWCKVDDDFTAQDYRLQFRKCTSNHFEDVYVGSETEFIVLHIDPNVDYQFRVCARGDGRQEWSPWSVPQIGHSTLVPHEWTAGFEGYSLSSRRNIALRNDSESSGVLYSRAPTYFCGQTLTFRVETVGQPDRRDSIGVCAEKQDGYDSLQRDQAVCISTNGAVFVNGKEMTNQLPAVTSGSTVTFDIEAVTLGTTSNNEGGHFKLRVTISSNNREVVFDWLLDQSCGSLYFGCSFFYPGWKVLVF>sp|Q8IUI8-2|CRLF3_HUMAN Isoform 2 of Cytokine receptor-like factor 3OS=Homo sapiens OX=9606 GN=CRLF3MELEPELLLQEARENVEAAQSYRRELGHRLEGLREARRQIKESASQTRDVLKQHFNDLKGTLGKLLDERLVTLLQEVDTIEQETIKPLDDCQKLIEHGVNTAEDLVREGEIAMLGGVGEENEKLWSFTKKASHIQLDSLPEVPLLVDVPCLSAQLDDSILNIVKDHIFKHGTVASRPPVQIEELIEKPGGIIVRWCKVDDDFTAQDYRLQFRKCTSNHFEDVYVGSETEFIVLHIDPNVDYQFRVCARGDGRQEWSPWSVPQIGHSTLVPHEWTAGFEGYSLSSRRNIALRNDSESSGVLYSRAPTYFCGQTLTFRVETVGQPDRRDSIGVCAEKQDGYDSLQRDQAVCISTNGAVFVNGKEMTNQLPAVTSGSTVTFDIEAVTLGTTSNNEGGHFKLRVTISSNNREVVFDWLLDQSCGSLYFGCSFFYPGWKVLVF>sp|P50416|CPT1A_HUMAN Carnitine O-palmitoyltransferase 1, liver isoformOS=Homo sapiens OX=9606 GN=CPT1A PE=1 SV=2MAEAHQAVAFQFTVTPDGIDLRLSHEALRQIYLSGLHSWKKKFIRFKNGIITGVYPASPSSWLIVVVGVMTTMYAKIDPSLGIIAKINRTLETANCMSSQTKNVVSGVLFGTGLWVALIVTMRYSLKVLLSYHGWMFTEHGKMSRATKIWMGMVKIFSGRKPMLYSFQTSLPRLPVPAVKDTVNRYLQSVRPLMKEEDFKRMTALAQDFAVGLGPRLQWYLKLKSWWATNYVSDWWEEYIYLRGRGPLMVNSNYYAMDLLYILPTHIQAARAGNAIHAILLYRRKLDREEIKPIRLLGSTIPLCSAQWERMFNTSRIPGEETDTIQHMRDSKHIVVYHRGRYFKVWLYHDGRLLKPREMEQQMQRILDNTSEPQPGEARLAALTAGDRVPWARCRQAYFGRGKNKQSLDAVEKAAFFVTLDETEEGYRSEDPDTSMDSYAKSLLHGRCYDRWFDKSFTFVVFKNGKMGLNAEHSWADAPIVAHLWEYVMSIDSLQLGYAEDGHCKGDINPNIPYPTRLQWDIPGECQEVIETSLNTANLLANDVDFHSFPFVAFGKGIIKKCRTSPDAFVQLALQLAHYKDMGKFCLTYEASMTRLFREGRTETVRSCTTESCDFVRAMVDPAQTVEQRLKLFKLASEKHQHMYRLAMTGSGIDRHLFCLYVVSKYLAVESPFLKEVLSEPWRLSTSQTPQQQVELFDLENNPEYVSSGGGFGPVADDGYGVSYILVGENLINFHISSKFSCPETDSHRFGRHLKEAMTDIITLFGLSSNSKK>sp|P50416-2|CPT1A_HUMAN Isoform 2 of Carnitine O-palmitoyltransferase 1,liver isoform OS=Homo sapiens OX=9606 GN=CPT1AMAEAHQAVAFQFTVTPDGIDLRLSHEALRQIYLSGLHSWKKKFIRFKNGIITGVYPASPSSWLIVVVGVMTTMYAKIDPSLGIIAKINRTLETANCMSSQTKNVVSGVLFGTGLWVALIVTMRYSLKVLLSYHGWMFTEHGKMSRATKIWMGMVKIFSGRKPMLYSFQTSLPRLPVPAVKDTVNRYLQSVRPLMKEEDFKRMTALAQDFAVGLGPRLQWYLKLKSWWATNYVSDWWEEYIYLRGRGPLMVNSNYYAMDLLYILPTHIQAARAGNAIHAILLYRRKLDREEIKPIRLLGSTIPLCSAQWERMFNTSRIPGEETDTIQHMRDSKHIVVYHRGRYFKVWLYHDGRLLKPREMEQQMQRILDNTSEPQPGEARLAALTAGDRVPWARCRQAYFGRGKNKQSLDAVEKAAFFVTLDETEEGYRSEDPDTSMDSYAKSLLHGRCYDRWFDKSFTFVVFKNGKMGLNAEHSWADAPIVAHLWEYVMSIDSLQLGYAEDGHCKGDINPNIPYPTRLQWDIPGECQEVIETSLNTANLLANDVDFHSFPFVAFGKGIIKKCRTSPDAFVQLALQLAHYKDMGKFCLTYEASMTRLFREGRTETVRSCTTESCDFVRAMVDPAQTVEQRLKLFKLASEKHQHMYRLAMTGSGIDRHLFCLYVVSKYLAVESPFLKEVLSEPWRLSTSQTPQQQVELFDLENNPEYVSSGGGFGPVADDGYGVSYILVGENLINFHISSKFSCPETGIISQGPSSDT>sp|Q16850|CP51A_HUMAN Lanosterol 14-alpha demethylase OS=Homo sapiensOX=9606 GN=CYP51A1 PE=1 SV=4MAAAAGMLLLGLLQAGGSVLGQAMEKVTGGNLLSMLLIACAFTLSLVYLIRLAAGHLVQLPAGVKSPPYIFSPIPFLGHAIAFGKSPIEFLENAYEKYGPVFSFTMVGKTFTYLLGSDAAALLFNSKNEDLNAEDVYSRLTTPVFGKGVAYDVPNPVFLEQKKMLKSGLNIAHFKQHVSIIEKETKEYFESWGESGEKNVFEALSELIILTASHCLHGKEIRSQLNEKVAQLYADLDGGFSHAAWLLPGWLPLPSFRRRDRAHREIKDIFYKAIQKRRQSQEKIDDILQTLLDATYKDGRPLTDDEVAGMLIGLLLAGQHTSSTTSAWMGFFLARDKTLQKKCYLEQKTVCGENLPPLTYDQLKDLNLLDRCIKETLRLRPPIMIMMRMARTPQTVAGYTIPPGHQVCVSPTVNQRLKDSWVERLDFNPDRYLQDNPASGEKFAYVPFGAGRHRCIGENFAYVQIKTIWSTMLRLYEFDLIDGYFPTVNYTTMIHTPENPVIRYKRRSK>sp|Q16850-2|CP51A_HUMAN Isoform 2 of Lanosterol 14-alpha demethylaseOS=Homo sapiens OX=9606 GN=CYP51A1MVGKTFTYLLGSDAAALLFNSKNEDLNAEDVYSRLTTPVFGKGVAYDVPNPVFLEQKKMLKSGLNIAHFKQHVSIIEKETKEYFESWGESGEKNVFEALSELIILTASHCLHGKEIRSQLNEKVAQLYADLDGGFSHAAWLLPGWLPLPSFRRRDRAHREIKDIFYKAIQKRRQSQEKIDDILQTLLDATYKDGRPLTDDEVAGMLIGLLLAGQHTSSTTSAWMGFFLARDKTLQKKCYLEQKTVCGENLPPLTYDQLKDLNLLDRCIKETLRLRPPIMIMMRMARTPQTVAGYTIPPGHQVCVSPTVNQRLKDSWVERLDFNPDRYLQDNPASGEKFAYVPFGAGRHRCIGENFAYVQIKTIWSTMLRLYEFDLIDGYFPTVNYTTMIHTPENPVIRYKRRSK>sp|P83436|COG7_HUMAN Conserved oligomeric Golgi complex subunit 7OS=Homo sapiens OX=9606 GN=COG7 PE=1 SV=1MDFSKFLADDFDVKEWINAAFRAGSKEAASGKADGHAATLVMKLQLFIQEVNHAVEETSHQALQNMPKVLRDVEALKQEASFLKEQMILVKEDIKKFEQDTSQSMQVLVEIDQVKSRMQLAAESLQEADKWSTLSADIEETFKTQDIAVISAKLTGMQNSLMMLVDTPDYSEKCVHLEALKNRLEALASPQIVAAFTSQAVDQSKVFVKVFTEIDRMPQLLAYYYKCHKVQLLAAWQELCQSDLSLDRQLTGLYDALLGAWHTQIQWATQVFQKPHEVVMVLLIQTLGALMPSLPSCLSNGVERAGPEQELTRLLEFYDATAHFAKGLEMALLPHLHEHNLVKVTELVDAVYDPYKPYQLKYGDMEESNLLIQMSAVPLEHGEVIDCVQELSHSVNKLFGLASAAVDRCVRFTNGLGTCGLLSALKSLFAKYVSDFTSTLQSIRKKCKLDHIPPNSLFQEDWTAFQNSIRIIATCGELLRHCGDFEQQLANRILSTAGKYLSDSCSPRSLAGFQESILTDKKNSAKNPWQEYNYLQKDNPAEYASLMEILYTLKEKGSSNHNLLAAPRAALTRLNQQAHQLAFDSVFLRIKQQLLLISKMDSWNTAGIGETLTDELPAFSLTPLEYISNIGQYIMSLPLNLEPFVTQEDSALELALHAGKLPFPPEQGDELPELDNMADNWLGSIARATMQTYCDAILQIPELSPHSAKQLATDIDYLINVMDALGLQPSRTLQHIVTLLKTRPEDYRQVSKGLPRRLATTVATMRSVNY>sp|O75131|CPNE3_HUMAN Copine-3 OS=Homo sapiens OX=9606 GN=CPNE3 PE=1SV=1MAAQCVTKVALNVSCANLLDKDIGSKSDPLCVLFLNTSGQQWYEVERTERIKNCLNPQFSKTFIIDYYFEVVQKLKFGVYDIDNKTIELSDDDFLGECECTLGQIVSSKKLTRPLVMKTGRPAGKGSITISAEEIKDNRVVLFEMEARKLDNKDLFGKSDPYLEFHKQTSDGNWLMVHRTEVVKNNLNPVWRPFKISLNSLCYGDMDKTIKVECYDYDNDGSHDLIGTFQTTMTKLKEASRSSPVEFECINEKKRQKKKSYKNSGVISVKQCEITVECTFLDYIMGGCQLNFTVGVDFTGSNGDPRSPDSLHYISPNGVNEYLTALWSVGLVIQDYDADKMFPAFGFGAQIPPQWQVSHEFPMNFNPSNPYCNGIQGIVEAYRSCLPQIKLYGPTNFSPIINHVARFAAAATQQQTASQYFVLLIITDGVITDLDETRQAIVNASRLPMSIIIVGVGGADFSAMEFLDGDGGSLRSPLGEVAIRDIVQFVPFRQFQNAPKEALAQCVLAEIPQQVVGYFNTYKLLPPKNPATKQQKQ>sp|O00230|CORT_HUMAN Cortistatin OS=Homo sapiens OX=9606 GN=CORT PE=1SV=1MPLSPGLLLLLLSGATATAALPLEGGPTGRDSEHMQEAAGIRKSSLLTFLAWWFEWTSQASAGPLIGEEAREVARRQEGAPPQQSARRDRMPCRNFFWKTFSSCK>sp|O95727|CRTAM_HUMAN Cytotoxic and regulatory T-cell molecule OS=Homosapiens OX=9606 GN=CRTAM PE=1 SV=2MWWRVLSLLAWFPLQEASLTNHTETITVEEGQTLTLKCVTSLRKNSSLQWLTPSGFTIFLNEYPALKNSKYQLLHHSANQLSITVPNVTLQDEGVYKCLHYSDSVSTKEVKVIVLATPFKPILEASVIRKQNGEEHVVLMCSTMRSKPPPQITWLLGNSMEVSGGTLHEFETDGKKCNTTSTLIIHTYGKNSTVDCIIRHRGLQGRKLVAPFRFEDLVTDEETASDALERNSLSSQDPQQPTSTVSVTEDSSTSEIDKEEKEQTTQDPDLTTEANPQYLGLARKKSGILLLTLVSFLIFILFIIVQLFIMKLRKAHVIWKKENEVSEHTLESYRSRSNNEETSSEEKNGQSSHPMRCMNYITKLYSEAKTKRKENVQHSKLEEKHIQVPESIV>sp|O95727-2|CRTAM_HUMAN Isoform 2 of Cytotoxic and regulatory T-cellmolecule OS=Homo sapiens OX=9606 GN=CRTAMMWVKLLSIVAEFCFSPFLVTDEETASDALERNSLSSQDPQQPTSTVSVTEDSSTSEIDKEEKEQTTQDPDLTTEANPQYLGLARKKSGILLLTLVSFLIFILFIIVQLFIMKLRKAHVIWKKENEVSEHTLESYRSRSNNEETSSEEKNGQSSHPMRCMNYITKLYSEAKTKRKENVQHSKLEEKHIQVPESIV>sp|Q9NX08|COMD8_HUMAN COMM domain-containing protein 8 OS=Homo sapiensOX=9606 GN=COMMD8 PE=1 SV=1MEPEEGTPLWRLQKLPAELGPQLLHKIIDGICGRAYPVYQDYHTVWESEEWMHVLEDIAKFFKAIVGKNLPDEEIFQQLNQLNSLHQETIMKCVKSRKDEIKQALSREIVAISSAQLQDFDWQVKLALSSDKIAALRMPLLSLHLDVKENGEVKPYSIEMSREELQNLIQSLEAANKVVLQLK>sp|Q07973|CP24A_HUMAN 1,25-dihydroxyvitamin D(3) 24-hydroxylase,mitochondrial OS=Homo sapiens OX=9606 GN=CYP24A1 PE=1 SV=2MSSPISKSRSLAAFLQQLRSPRQPPRLVTSTAYTSPQPREVPVCPLTAGGETQNAAALPGPTSWPLLGSLLQILWKGGLKKQHDTLVEYHKKYGKIFRMKLGSFESVHLGSPCLLEALYRTESAYPQRLEIKPWKAYRDYRKEGYGLLILEGEDWQRVRSAFQKKLMKPGEVMKLDNKINEVLADFMGRIDELCDERGHVEDLYSELNKWSFESICLVLYEKRFGLLQKNAGDEAVNFIMAIKTMMSTFGRMMVTPVELHKSLNTKVWQDHTLAWDTIFKSVKACIDNRLEKYSQQPSADFLCDIYHQNRLSKKELYAAVTELQLAAVETTANSLMWILYNLSRNPQVQQKLLKEIQSVLPENQVPRAEDLRNMPYLKACLKESMRLTPSVPFTTRTLDKATVLGEYALPKGTVLMLNTQVLGSSEDNFEDSSQFRPERWLQEKEKINPFAHLPFGVGKRMCIGRRLAELQLHLALCWIVRKYDIQATDNEPVEMLHSGTLVPSRELPIAFCQR>sp|Q07973-2|CP24A_HUMAN Isoform 2 of 1,25-dihydroxyvitamin D(3) 24-hydroxylase, mitochondrial OS=Homo sapiens OX=9606 GN=CYP24A1MSSPISKSRSLAAFLQQLRSPRQPPRLVTSTAYTSPQPREVPVCPLTAGGETQNAAALPGPTSWPLLGSLLQILWKGGLKKQHDTLVEYHKKYGKIFRMKLGSFESVHLGSPCLLEALYRTESAYPQRLEIKPWKAYRDYRKEGYGLLILEGEDWQRVRSAFQKKLMKPGEVMKLDNKINEVLADFMGRIDELCDERGHVEDLYSELNKWSFESICLVLYEKRFGLLQKNAGDEAVNFIMAIKTMMSTFGRMMVTPVELHKSLNTKVWQDHTLAWDTIFKSVKACIDNRLEKYSQQPSADFLCDIYHQNRLSKKELYAAVTELQLAAVETTANSLMWILYNLSRNPQVQQKLLKEIQSVLPENQVPRAEDLRNMPYLKACLKESMRLTPSVPFTTRTLDKATVLGEYALPKGIVRKYDIQATDNEPVEMLHSGTLVPSRELPIAFCQR>sp|Q07973-3|CP24A_HUMAN Isoform 3 of 1,25-dihydroxyvitamin D(3) 24-hydroxylase, mitochondrial OS=Homo sapiens OX=9606 GN=CYP24A1MYSCFSHREGEDWQRVRSAFQKKLMKPGEVMKLDNKINEVLADFMGRIDELCDERGHVEDLYSELNKWSFESICLVLYEKRFGLLQKNAGDEAVNFIMAIKTMMSTFGRMMVTPVELHKSLNTKVWQDHTLAWDTIFKSVKACIDNRLEKYSQQPSADFLCDIYHQNRLSKKELYAAVTELQLAAVETTANSLMWILYNLSRNPQVQQKLLKEIQSVLPENQVPRAEDLRNMPYLKACLKESMRLTPSVPFTTRTLDKATVLGEYALPKGTVLMLNTQVLGSSEDNFEDSSQFRPERWLQEKEKINPFAHLPFGVGKRMCIGRRLAELQLHLALCWIVRKYDIQATDNEPVEMLHSGTLVPSRELPIAFCQR>sp|Q14232|EI2BA_HUMAN Translation initiation factor eIF-2B subunit alphaOS=Homo sapiens OX=9606 GN=EIF2B1 PE=1 SV=1MDDKELIEYFKSQMKEDPDMASAVAAIRTLLEFLKRDKGETIQGLRANLTSAIETLCGVDSSVAVSSGGELFLRFISLASLEYSDYSKCKKIMIERGELFLRRISLSRNKIADLCHTFIKDGATILTHAYSRVVLRVLEAAVAAKKRFSVYVTESQPDLSGKKMAKALCHLNVPVTVVLDAAVGYIMEKADLVIVGAEGVVENGGIINKIGTNQMAVCAKAQNKPFYVVAESFKFVRLFPLNQQDVPDKFKYKADTLKVAQTGQDLKEEHPWVDYTAPSLITLLFTDLGVLTPSAVSDELIKLYL>sp|Q14232-2|EI2BA_HUMAN Isoform 2 of Translation initiation factor eIF-2B subunit alpha OS=Homo sapiens OX=9606 GN=EIF2B1MDDKELIEYFKSQMKEDPDMASAVAAIRTLLEFLKRDKGETIQGLRANLTSAIETLCGVDSSVAVSSGGELFLRFISLASLEYSDYSKCKKIMIERGELFLRRISLSRNKIADLCHTFIKDGATILTHAYSRVVLRVLEAAVAAKKRFSVYVTESQPDLSGQVPFCSVMCPAIILQSKLRITVQQDQNQNVPPACQQSALPFIVPFPAFGRKITEFAAGRSI>sp|A8MQ03|CRTP1_HUMAN Cysteine-rich tail protein 1 OS=Homo sapiensOX=9606 GN=CYSRT1 PE=1 SV=1MDPQEMVVKNPYAHISIPRAHLRPDLGQQLEVASTCSSSSEMQPLPVGPCAPEPTHLLQPTEVPGPKGAKGNQGAAPIQNQQAWQQPGNPYSSSQRQAGLTYAGPPPAGRGDDIAHHCCCCPCCHCCHCPPFCRCHSCCCCVIS>sp|P82279|CRUM1_HUMAN Protein crumbs homolog 1 OS=Homo sapiens OX=9606GN=CRB1 PE=1 SV=2MALKNINYLLIFYLSFSLLIYIKNSFCNKNNTRCLSNSCQNNSTCKDFSKDNDCSCSDTANNLDKDCDNMKDPCFSNPCQGSATCVNTPGERSFLCKCPPGYSGTICETTIGSCGKNSCQHGGICHQDPIYPVCICPAGYAGRFCEIDHDECASSPCQNGAVCQDGIDGYSCFCVPGYQGRHCDLEVDECASDPCKNEATCLNEIGRYTCICPHNYSGVNCELEIDECWSQPCLNGATCQDALGAYFCDCAPGFLGDHCELNTDECASQPCLHGGLCVDGENRYSCNCTGSGFTGTHCETLMPLCWSKPCHNNATCEDSVDNYTCHCWPGYTGAQCEIDLNECNSNPCQSNGECVELSSEKQYGRITGLPSSFSYHEASGYVCICQPGFTGIHCEEDVNECSSNPCQNGGTCENLPGNYTCHCPFDNLSRTFYGGRDCSDILLGCTHQQCLNNGTCIPHFQDGQHGFSCLCPSGYTGSLCEIATTLSFEGDGFLWVKSGSVTTKGSVCNIALRFQTVQPMALLLFRSNRDVFVKLELLSGYIHLSIQVNNQSKVLLFISHNTSDGEWHFVEVIFAEAVTLTLIDDSCKEKCIAKAPTPLESDQSICAFQNSFLGGLPVGMTSNGVALLNFYNMPSTPSFVGCLQDIKIDWNHITLENISSGSSLNVKAGCVRKDWCESQPCQSRGRCINLWLSYQCDCHRPYEGPNCLREYVAGRFGQDDSTGYVIFTLDESYGDTISLSMFVRTLQPSGLLLALENSTYQYIRVWLERGRLAMLTPNSPKLVVKFVLNDGNVHLISLKIKPYKIELYQSSQNLGFISASTWKIEKGDVIYIGGLPDKQETELNGGFFKGCIQDVRLNNQNLEFFPNPTNNASLNPVLVNVTQGCAGDNSCKSNPCHNGGVCHSRWDDFSCSCPALTSGKACEEVQWCGFSPCPHGAQCQPVLQGFECIANAVFNGQSGQILFRSNGNITRELTNITFGFRTRDANVIILHAEKEPEFLNISIQDSRLFFQLQSGNSFYMLSLTSLQSVNDGTWHEVTLSMTDPLSQTSRWQMEVDNETPFVTSTIATGSLNFLKDNTDIYVGDRAIDNIKGLQGCLSTIEIGGIYLSYFENVHGFINKPQEEQFLKISTNSVVTGCLQLNVCNSNPCLHGGNCEDIYSSYHCSCPLGWSGKHCELNIDECFSNPCIHGNCSDRVAAYHCTCEPGYTGVNCEVDIDNCQSHQCANGATCISHTNGYSCLCFGNFTGKFCRQSRLPSTVCGNEKTNLTCYNGGNCTEFQTELKCMCRPGFTGEWCEKDIDECASDPCVNGGLCQDLLNKFQCLCDVAFAGERCEVDLADDLISDIFTTIGSVTVALLLILLLAIVASVVTSNKRATQGTYSPSRQEKEGSRVEMWNLMPPPAMERLI>sp|P82279-2|CRUM1_HUMAN Isoform 2 of Protein crumbs homolog 1 OS=Homosapiens OX=9606 GN=CRB1MALKNINYLLIFYLSFSLLIYIKNSFCNKNNTRCLSNSCQNNSTCKDFSKDNDCSCSDTANNLDKDCDNMKDPCFSNPCQGSATCVNTPGERSFLCKCPPGYSGTICETTIGSCGKNSCQHGGICHQDPIYPVCICPAGYAGRFCEIDHDECASSPCQNGAVCQDGIDGYSCFCVPGYQGRHCDLEVDECASDPCKNEATCLNEIGRYTCICPHNYSGVNCELEIDECWSQPCLNGATCQDALGAYFCDCAPGFLGDHCELNTDECASQPCLHGGLCVDGENRYSCNCTGSGFTGTHCETLMPLCWSKPCHNNATCEDSVDNYTCHCWPGYTGAQCEIDLNECNSNPCQSNGECVELSSEKQYGRITGLPSSFSYHEASGYVCICQPGFTGIHCEEDVNECSSNPCQNGGTCENLPGNYTCHCPFDNLSRTFYGGRDCSDILLGCTHQQCLNNGTCIPHFQDGQHGFSCLCPSGYTGSLCEIATTLSFEGDGFLWVKSGSVTTKGSVCNIALRFQTVQPMALLLFRSNRDVFVKLELLSGYIHLSIQVNNQSKVLLFISHNTSDGEWHFVEVIFAEAVTLTLIDDSCKEKCIAKAPTPLESDQSICAFQNSFLGGLPVGMTSNGVALLNFYNMPSTPSFVGCLQDIKIDWNHITLENISSGSSLNVKAGCVRKDWCESQPCQSRGRCINLWLSYQCDCHRPYEGPNCLREYVAGRFGQDDSTGYVIFTLDESYGDTISLSMFVRTLQPSGLLLALENSTYQYIRVWLERGRLAMLTPNSPKLVVKFVLNDGNVHLISLKIKPYKIELYQSSQNLGFISASTWKIEKGDVIYIGGLPDKQETELNGGFFKGCIQDVRLNNQNLEFFPNPTNNASLNPVLVNVTQGCAGDNSCKSNPCHNGGVCHSRWDDFSCSCPALTSGKACEEVQWCGFSPCPHGAQCQPVLQGFECIANAVFNGQSGQILFRSNGNITRELTNITFGFRTRDANVIILHAEKEPEFLNISIQDSRLFFQLQSGNSFYMLSLTSLQSVNDGTWHEVTLSMTDPLSQTSRWQMEVDNETPFVTSTIATGSLNFLKDNTDIYVGDRAIDNIKGLQGCLSTIEIGGIYLSYFENVHGFINKPQEEQFLKISTNSVVTGCLQLNVCNSNPCLHGGNCEDIYSSYHCSCPLGWSGKHCELNIDECFSNPCIHGNCSDRVAAYHCTCEPGYTGVNCEVDIDNCQSHQCANGATCISHTNGYSCLCFGNFTGKFCRQSRLPSTVCGNEKTNLTCYNGGNCTEFQTELKCMCRPGFTGEWCEKDIDECASDPCVNGGLCQDLLNKFQCLCDVAFAGERCEVDVSSLSFYVSLLFWQNLFQLLSYLILRMNDEPVVEWGEQEDY>sp|P82279-3|CRUM1_HUMAN Isoform 3 of Protein crumbs homolog 1 OS=Homosapiens OX=9606 GN=CRB1MALKNINYLLIFYLSFSLLIYIKNSFCNKNNTRCLSNSCQNNSTCKDFSKDNDCSCSDTANNLDKDCDNMKDPCFSNPCQGSATCVNTPGERSFLCKCPPGYSGTICETTIGSCGKNSCQHGGICHQDPIYPVCICPAGYAGRFCEIDHDECASSPCQNGAVCQDGIDGYSCFCVPGYQGRHCDLEVDECASDPCKNEATCLNEIGRYTCICPHNYSGYTGAQCEIDLNECNSNPCQSNGECVELSSEKQYGRITGLPSSFSYHEASGYVCICQPGFTGIHCEEDVNECSSNPCQNGGTCENLPGNYTCHCPFDNLSRTFYGGRDCSDILLGCTHQQCLNNGTCIPHFQDGQHGFSCLCPSGYTGSLCEIATTLSFEGDGFLWVKSGSVTTKGSVCNIALRFQTVQPMALLLFRSNRDVFVKLELLSGYIHLSIQVNNQSKVLLFISHNTSDGEWHFVEVIFAEAVTLTLIDDSCKEKCIAKAPTPLESDQSICAFQNSFLGGLPVGMTSNGVALLNFYNMPSTPSFVGCLQDIKIDWNHITLENISSGSSLNVKAGCVRKDWCESQPCQSRGRCINLWLSYQCDCHRPYEGPNCLREYVAGRFGQDDSTGYVIFTLDESYGDTISLSMFVRTLQPSGLLLALENSTYQYIRVWLERGRLAMLTPNSPKLVVKFVLNDGNVHLISLKIKPYKIELYQSSQNLGFISASTWKIEKGDVIYIGGLPDKQETELNGGFFKGCIQDVRLNNQNLEFFPNPTNNASLNPVLVNVTQGCAGDNSCKSNPCHNGGVCHSRWDDFSCSCPALTSGKACEEVQWCGFSPCPHGAQCQPVLQGFECIANAVFNGQSGQILFRSNGNITRELTNITFGFRTRDANVIILHAEKEPEFLNISIQDSRLFFQLQSGNSFYMLSLTSLQSVNDGTWHEVTLSMTDPLSQTSRWQMEVDNETPFVTSTIATGSLNFLKDNTDIYVGDRAIDNIKGLQGCLSTIEIGGIYLSYFENVHGFINKPQEEQFLKISTNSVVTGCLQLNVCNSNPCLHGGNCEDIYSSYHCSCPLGWSGKHCELNIDECFSNPCIHGNCSDRVAAYHCTCEPGYTGVNCEVDIDNCQSHQCANGATCISHTNGYSCLCFGNFTGKFCRQSRLPSTVCGNEKTNLTCYNGGNCTEFQTELKCMCRPGFTGEWCEKDIDECASDPCVNGGLCQDLLNKFQCLCDVAFAGERCEVDLADDLISDIFTTIGSVTVALLLILLLAIVASVVTSNKRATQGTYSPSRQEKEGSRVEMWNLMPPPAMERLI>sp|P82279-4|CRUM1_HUMAN Isoform 4 of Protein crumbs homolog 1 OS=Homosapiens OX=9606 GN=CRB1MIRNSLCQPSRCLDEYLFFNRKMFGARTHGFHILMAMLIGIHCEEDVNECSSNPCQNGGTCENLPGNYTCHCPFDNLSRTFYGGRDCSDILLGCTHQQCLNNGTCIPHFQDGQHGFSCLCPSGYTGSLCEIATTLSFEGDGFLWVKSGSVTTKGSVCNIALRFQTVQPMALLLFRSNRDVFVKLELLSGYIHLSIQVNNQSKVLLFISHNTSDGEWHFVEVIFAEAVTLTLIDDSCKEKCIAKAPTPLESDQSICAFQNSFLGGLPVGMTSNGVALLNFYNMPSTPSFVGCLQDIKIDWNHITLENISSGSSLNVKAGCVRKDWCESQPCQSRGRCINLWLSYQCDCHRPYEGPNCLREYVAGRFGQDDSTGYVIFTLDESYGDTISLSMFVRTLQPSGLLLALENSTYQYIRVWLERGRLAMLTPNSPKLVVKFVLNDGNVHLISLKIKPYKIELYQSSQNLGFISASTWKIEKGDVIYIGGLPDKQETELNGGFFKGCIQDVRLNNQNLEFFPNPTNNASLNPVLVNVTQGCAGDNSCKSNPCHNGGVCHSRWDDFSCSCPALTSGKACEEVQWCGFSPCPHGAQCQPVLQGFECIANAVFNGQSGQILFRSNGNITRELTNITFGFRTRDANVIILHAEKEPEFLNISIQDSRLFFQLQSGNSFYMLSLTSLQSVNDGTWHEVTLSMTDPLSQTSRWQMEVDNETPFVTSTIATGSLNFLKDNTDIYVGDRAIDNIKGLQGCLSTIEIGGIYLSYFENVHGFINKPQEEQFLKISTNSVVTGCLQLNVCNSNPCLHGGNCEDIYSSYHCSCPLGWSGKHCELNIDECFSNPCIHGNCSDRVAAYHCTCEPGYTGVNCEVDIDNCQSHQCANGATCISHTNGYSCLCFGNFTGKFCRQSRLPSTVCGNEKTNLTCYNGGNCTEFQTELKCMCRPGFTGEW>sp|P82279-5|CRUM1_HUMAN Isoform 5 of Protein crumbs homolog 1 OS=Homosapiens OX=9606 GN=CRB1MALKNINYLLIFYLSFSLLIYIKNSFCNKNNTRCLSNSCQNNSTCKDFSKDNDCSCSDTANNLDKDCDNMKDPCFSNPCQGSATCVNTPGERSFLCKCPPGYSGTICETTIGSCGKNSCQHGGICHQDPIYPVCICPAGYAGRFCEIDHDECASSPCQNGAVCQDGIDGYSCFCVPGYQGRHCDLEVDECASDPCKNEATCLNEIGRYTCICPHNYSGVNCELEIDECWSQPCLNGATCQDALGAYFCDCAPGFLGDHCELNTDECASQPCLHGGLCVDGENRYSCNCTGSGFTGTHCETLMPLCWSKPCHNNATCEDSVDNYTCHCWPGYTGAQCEIDLNECNSNPCQSNGECVELSSEKQYGRITGLPSSFSYHEASGYVCICQPGFTGIHCEEDVNECSSNPCQNGGTCENLPGNYTCHCPFDNLSRTFYGGRDCSDILLGCTHQQCLNNGTCIPHFQDGQHGFSCLCPSGYTGSLCEIATTLSFEGDGFLWVKSGSVTTKGSVCNIALRFQTVQPMALLLFRSNRDVFVKLELLSGYIHLSIQVNNQSKVLLFISHNTSDGEWHFVEVIFAEAVTLTLIDDSCKEKCIAKAPTPLESDQSICAFQNSFLGGLPVGMTSNGVALLNFYNMPSTPSFVGCLQDIKIDWNHITLENISSGSSLNVKAGCVRKDWCESQPCQSRGRCINLWLSYQCDCHRPYEGPNCLRGKFCRQSRLPSTVCGNEKTNLTCYNGGNCTEFQTELKCMCRPGFTGEWCEKDIDECASDPCVNGGLCQDLLNKFQCLCDVAFAGERCEVDLADDLISDIFTTIGSVTVALLLILLLAIVASVVTSNKRATQGTYSPSRQEKEGSRVEMWNLMPPPAMERLI>sp|P67870|CSK2B_HUMAN Casein kinase II subunit beta OS=Homo sapiensOX=9606 GN=CSNK2B PE=1 SV=1MSSSEEVSWISWFCGLRGNEFFCEVDEDYIQDKFNLTGLNEQVPHYRQALDMILDLEPDEELEDNPNQSDLIEQAAEMLYGLIHARYILTNRGIAQMLEKYQQGDFGYCPRVYCENQPMLPIGLSDIPGEAMVKLYCPKCMDVYTPKSSRHHHTDGAYFGTGFPHMLFMVHPEYRPKRPANQFVPRLYGFKIHPMAYQLQLQAASNFKSPVKTIR>sp|Q6UWD8|CP054_HUMAN Transmembrane protein C16orf54 OS=Homo sapiensOX=9606 GN=C16orf54 PE=1 SV=1MPLTPEPPSGRVEGPPAWEAAPWPSLPCGPCIPIMLVLATLAALFILTTAVLAERLFRRALRPDPSHRAPTLVWRPGGELWIEPMGTARERSEDWYGSAVPLLTDRAPEPPTQVGTLEARATAPPAPSAPNSAPSNLGPQTVLEVPARSTFWGPQPWEGRPPATGLVSWAEPEQRPEASVQFGSPQARRQRPGSPDPEWGLQPRVTLEQISAFWKREGRTSVGF>sp|Q8WTQ4|CP078_HUMAN Uncharacterized protein C16orf78 OS=Homo sapiensOX=9606 GN=C16orf78 PE=2 SV=1MSEQQMDLKDLMPTKRKYMWKTAEDRRMSDLTCVLEWLERRQGKKKQAPEKQKPKVVTVLKRNKKKEEKKGKGLMTARGGNRRDTETSQQALGKRFRKDAASYRSLYGVEQKGKHLSMVPGSYIKDGPKKSDTDIKDAVDPESTQRPNPFRRQSIVLDPMLQEGTFNSQRATFIRDWSNKMPDMAYERKLKSLMEKSTEPKMETMRMLKPEEVLSCRYLRLSKENIRTLLKLCKDAGMNVDIHPHMVEEDIDAKKVFTGIPSMAL>sp|Q8NI60|COQ8A_HUMAN Atypical kinase COQ8A, mitochondrial OS=Homosapiens OX=9606 GN=COQ8A PE=1 SV=1MAAILGDTIMVAKGLVKLTQAAVETHLQHLGIGGELIMAARALQSTAVEQIGMFLGKVQGQDKHEEYFAENFGGPEGEFHFSVPHAAGASTDFSSASAPDQSAPPSLGHAHSEGPAPAYVASGPFREAGFPGQASSPLGRANGRLFANPRDSFSAMGFQRRFFHQDQSPVGGLTAEDIEKARQAKARPENKQHKQTLSEHARERKVPVTRIGRLANFGGLAVGLGFGALAEVAKKSLRSEDPSGKKAVLGSSPFLSEANAERIVRTLCKVRGAALKLGQMLSIQDDAFINPHLAKIFERVRQSADFMPLKQMMKTLNNDLGPNWRDKLEYFEERPFAAASIGQVHLARMKGGREVAMKIQYPGVAQSINSDVNNLMAVLNMSNMLPEGLFPEHLIDVLRRELALECDYQREAACARKFRDLLKGHPFFYVPEIVDELCSPHVLTTELVSGFPLDQAEGLSQEIRNEICYNILVLCLRELFEFHFMQTDPNWSNFFYDPQQHKVALLDFGATREYDRSFTDLYIQIIRAAADRDRETVRAKSIEMKFLTGYEVKVMEDAHLDAILILGEAFASDEPFDFGTQSTTEKIHNLIPVMLRHRLVPPPEETYSLHRKMGGSFLICSKLKARFPCKAMFEEAYSNYCKRQAQQ>sp|Q8NI60-2|COQ8A_HUMAN Isoform 2 of Atypical kinase COQ8A,mitochondrial OS=Homo sapiens OX=9606 GN=COQ8AMQTDPNWSNFFYDPQQHKVALLDFGATREYDRSFTDLYIQIIRAAADRDRETVRAKSIEMKFLTGYEVKVMEDAHLDAILILGEAFASDEPFDFGTQSTTEKIHNLIPVMLRHRLVPPPEETYSLHRKMGGSFLICSKLKARFPCKAMFEEAYSNYCKRQAQQ>sp|Q8NI60-3|COQ8A_HUMAN Isoform 3 of Atypical kinase COQ8A,mitochondrial OS=Homo sapiens OX=9606 GN=COQ8AMFLGKVQGQDKHEEYFAENFGGPEGEFHFSVPHAAGASTDFSSASAPDQSAPPSLGHAHSEGPAPAYVASGPFREAGFPGQASSPLGRANGRLFANPRDSFSAMGFQRRFFHQDQSPVGGLTAEDIEKARQAKARPENKQHKQTLSEHARERKVPVTRIGRLANFGGLAVGLGFGALAEVAKKSLRSEDPSGKKAVLGSSPFLSEANAERIVRTLCKVRGAALKLGQMLSIQDDAFINPHLAKIFERVRQSADFMPLKQMMKTLNNDLGPNWRDKLEYFEERPFAAASIGQVHLARMKGGREVAMKIQYPGVAQSINSDVNNLMAVLNMSNMLPEGLFPEHLIDVLRRELALECDYQREAACARKFRDLLKGHPFFYVPEIVDELCSPHVLTTELVSGFPLDQAEGLSQEIRNEICYNILVLCLRELFEFHFMQTDPNWSNFFYDPQQHKVALLDFGATREYDRSFTDLYIQIIRAAADRDRETVRAKSIEMKFLTGYEVKVMEDAHLDAILILGEAFASDEPFDFGTQSTTEKIHNLIPVMLRHRLVPPPEETYSLHRKMGGSFLICSKLKARFPCKAMFEEAYSNYCKRQAQQ>sp|Q8NI60-4|COQ8A_HUMAN Isoform 4 of Atypical kinase COQ8A,mitochondrial OS=Homo sapiens OX=9606 GN=COQ8AMLSIQDDAFINPHLAKIFERVRQSADFMPLKQMMKTLNNDLGPNWRDKLEYFEERPFAAASIGQVHLARMKGGREVAMKIQYPGVAQSINSDVNNLMAVLNMSNMLPEGLFPEHLIDVLRRELALECDYQREAACARKFRDLLKGHPFFYVPEIVDELCSPHVLTTELVSGFPLDQAEGLSQEIRNEICYNILVLCLRELFEFHFMQTDPNWSNFFYDPQQHKVALLDFGATREYDRSFTDLYIQIIRAAADRDRETVRAKSIEMKFLTGYEVKVMEDAHLDAILILGEAFASDEPFDFGTQSTTEKIHNLIPVMLRHRLVPPPEETYSLHRKMGGSFLICSKLKARFPCKAMFEEAYSNYCKRQAQQ>sp|Q6ZW13|CP086_HUMAN Uncharacterized protein C16orf86 OS=Homo sapiensOX=9606 GN=C16orf86 PE=2 SV=2MASAGAERRPGVQEATVVGQGQLTEEPGSAQTSECPVAGDQFLVPAHEARGTQSEDQRPAGAASESELQEEGPKLGEERPKPHAGALEERGPRPVVSIVRPRHGPKRKPVKSLSLPGLRAHLKAEAELPPKLPLQEEEPEDSQSEPSPSAKQHKKAKKRKSLGAPVLHAVASMVSAPLETLRLERKAQRLRPLYQYVNYCNPELNQAGKGDGEAEVEAEAELAPVPEEGGVEQLQALLPLAGELGPGLALPCPSPLVTPTHALAPLGEEAGEEPGGLPSLGVSDHKAEVDKSTQVDIDKMLSVCTAPLVPPLSPQYK>sp|Q0D2K5|EGFEM_HUMAN Putative EGF-like and EMI domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=EGFEM1P PE=5 SV=1MDELRWYHITVCLDHIFGHNCSLSCKDCMNGGKCQEGKSECSCPAGCRVILCNENCLEGAYGAGCTSECQCVEENTLECSAKNGSCTCKSGYQGNRCQKDGLWGPEGWFSSAPCENGGQCNKKTGNCDCTPDYTRKSCTILRCISLTNLALSRRSSPMKYQQNVSSHREVRQRQQCSSDRPFKKLLCKFSFKIGM>sp|A8MWE9|EFCB8_HUMAN EF-hand calcium-binding domain-containing protein8 OS=Homo sapiens OX=9606 GN=EFCAB8 PE=4 SV=2MSSEDLAEIPQLQKLSIPHGFQNKEAASSPTPSITLSQVPDLQPGSQLFTEIHLAKIEKMFEEDINSTGALGMDAFIKAMKKVLSSVSDEMLKELFLKVDSDCEGFVTWQKYVDYMMREFQGKEDMRKSQYRLHFYLPMTVVPL>sp|Q6P2E9|EDC4_HUMAN Enhancer of mRNA-decapping protein 4 OS=Homosapiens OX=9606 GN=EDC4 PE=1 SV=1MASCASIDIEDATQHLRDILKLDRPAGGPSAESPRPSSAYNGDLNGLLVPDPLCSGDSTSANKTGLRTMPPINLQEKQVICLSGDDSSTCIGILAKEVEIVASSDSSISSKARGSNKVKIQPVAKYDWEQKYYYGNLIAVSNSFLAYAIRAANNGSAMVRVISVSTSERTLLKGFTGSVADLAFAHLNSPQLACLDEAGNLFVWRLALVNGKIQEEILVHIRQPEGTPLNHFRRIIWCPFIPEESEDCCEESSPTVALLHEDRAEVWDLDMLRSSHSTWPVDVSQIKQGFIVVKGHSTCLSEGALSPDGTVLATASHDGYVKFWQIYIEGQDEPRCLHEWKPHDGRPLSCLLFCDNHKKQDPDVPFWRFLITGADQNRELKMWCTVSWTCLQTIRFSPDIFSSVSVPPSLKVCLDLSAEYLILSDVQRKVLYVMELLQNQEEGHACFSSISEFLLTHPVLSFGIQVVSRCRLRHTEVLPAEEENDSLGADGTHGAGAMESAAGVLIKLFCVHTKALQDVQIRFQPQLNPDVVAPLPTHTAHEDFTFGESRPELGSEGLGSAAHGSQPDLRRIVELPAPADFLSLSSETKPKLMTPDAFMTPSASLQQITASPSSSSSGSSSSSSSSSSSLTAVSAMSSTSAVDPSLTRPPEELTLSPKLQLDGSLTMSSSGSLQASPRGLLPGLLPAPADKLTPKGPGQVPTATSALSLELQEVEPLGLPQASPSRTRSPDVISSASTALSQDIPEIASEALSRGFGSSAPEGLEPDSMASAASALHLLSPRPRPGPELGPQLGLDGGPGDGDRHNTPSLLEAALTQEASTPDSQVWPTAPDITRETCSTLAESPRNGLQEKHKSLAFHRPPYHLLQQRDSQDASAEQSDHDDEVASLASASGGFGTKVPAPRLPAKDWKTKGSPRTSPKLKRKSKKDDGDAAMGSRLTEHQVAEPPEDWPALIWQQQRELAELRHSQEELLQRLCTQLEGLQSTVTGHVERALETRHEQEQRRLERALAEGQQRGGQLQEQLTQQLSQALSSAVAGRLERSIRDEIKKTVPPCVSRSLEPMAGQLSNSVATKLTAVEGSMKENISKLLKSKNLTDAIARAAADTLQGPMQAAYREAFQSVVLPAFEKSCQAMFQQINDSFRLGTQEYLQQLESHMKSRKAREQEAREPVLAQLRGLVSTLQSATEQMAATVAGSVRAEVQHQLHVAVGSLQESILAQVQRIVKGEVSVALKEQQAAVTSSIMQAMRSAAGTPVPSAHLDCQAQQAHILQLLQQGHLNQAFQQALTAADLNLVLYVCETVDPAQVFGQPPCPLSQPVLLSLIQQLASDLGTRTDLKLSYLEEAVMHLDHSDPITRDHMGSVMAQVRQKLFQFLQAEPHNSLGKAARRLSLMLHGLVTPSLP>sp|Q6P2E9-2|EDC4_HUMAN Isoform 2 of Enhancer of mRNA-decapping protein 4OS=Homo sapiens OX=9606 GN=EDC4MWCTVSWTCLQTIRFSPDIFSSVSVPPSLKVCLDLSAEYLILSDVQRKVLYVMELLQNQEEGHACFSSISEFLLTHPVLSFGIQVVSRCRLRHTEVLPAEEENDSLGADGTHGAGAMESAAGVLIKLFCVHTKALQDVQIRFQPQLNPDVVAPLPTHTAHEDFTFGESRPELGSEGLGSAAHGSQPDLRRIVELPAPADFLSLSSETKPKLMTPDAFMTPSASLQQITASPSSSSSGSSSSSSSSSSSLTAVSAMSSTSAVDPSLTRPPEELTLSPKLQLDGSLTMSSSGSLQASPRGLLPGLLPAPADKLTPKGPGQVPTATSALSLELQEVEPLGLPQASPSRTRSPDVISSASTALSQDIPEIASEALSRGFGSSAPEGLEPDSMASAASALHLLSPRPRPGPELGPQLGLDGGPGDGDRHNTPSLLEAALTQEASTPDSQVWPTAPDITRETCSTLAESPRNGLQEKHKSLAFHRPPYHLLQQRDSQDASAEQSDHDDEVASLASASGGFGTKVPAPRLPAKDWKTKGSPRTSPKLKRKSKKDDGDAAMGSRLTEHQVAEPPEDWPALIWQQQRELAELRHSQEELLQRLCTQLEGLQSTVTGHVERALETRHEQEQRRLERALAEGQQRGGQLQEQLTQQLSQALSSAVAGRLERSIRDEIKKTVPPCVSRSLEPMAGQLSNSVATKLTAVEGSMKENISKLLKSKNLTDAIARAAADTLQGPMQAAYREAFQSVVLPAFEKSCQAMFQQINDSFRLGTQEYLQQLESHMKSRKAREQEAREPVLAQLRGLVSTLQSATEQMAATVAGSVRAEVQHQLHVAVGSLQESILAQVQRIVKGEVSVALKEQQAAVTSSIMQAMRSAAGTPVPSAHLDCQAQQAHILQLLQQGHLNQAFQQALTAADLNLVLYVCETVDPAQVFGQPPCPLSQPVLLSLIQQLASDLGTRTDLKLSYLEEAVMHLDHSDPITRDHMGSVMAQVRQKLFQFLQAEPHNSLGKAARRLSLMLHGLVTPSLP>sp|A8MZ26|EFCB9_HUMAN EF-hand calcium-binding domain-containing protein9 OS=Homo sapiens OX=9606 GN=EFCAB9 PE=3 SV=2MRLKQGSFLWYLYLDKIYCLLSVRNVKALAEYFHILDVHGKNTLNDVLFYHFLHHVTDLKKAQINIVFDMLDWNAVGEIDFEKFYMLVCMLLAHQNHLEGQFMYRHSRPVFDLLDLKGDLRIGAKNFEMYRFLFNIQKQELKDLFRDFDITGDNRLNYQEFKLYTIIYTDKLQKRQKTEEKEKGERKRSLYSKCHIK>sp|Q9HA90|EFCC1_HUMAN EF-hand and coiled-coil domain-containing protein1 OS=Homo sapiens OX=9606 GN=EFCC1 PE=2 SV=2MEPVSTGAEAGMEGAGGDPYRRPARRTQWLLSALAHHYGLDRGVENEIVVLATGLDQYLQEVFHHLDCRGAGRLPRADFRALCAVLGLRAEGATTAGQAAGDGNSRDVTPGDAAAELATDGDSDTDEEARLALRAEPPELTFRQFHARLCGYFGTRAGPRLPRGALSEHIETQIRLRRPRRRRRPPCAPGPDSGPDCERVARLEEENSSLRELVEDLRAALQSSDARCLALQVGLWKSQASTHEMGHGGPEAAVRELRQAQGALAAAEARAGRLRRGQAEVRRRAEEARQVVLRSLHRVRELEALAQQVPGLQRWVRRLEAELQRYRSEDSQLPTPQLANPEPGDKSNEPEDAGTRDPDPTPEGAWQSDSSSGSRALDEVDEQLFRSVEGQAASDEEEVEEERWQEEKKTPAAEAKTLLARLSSCRGRCDDQTAEKLMTYFGHFGGANHAHTLGELEACIAMLVEQLRTQGCGGRTLGTSEEEAELQQKVEENEHLRLELQMVETERVRLSLLEEKLVDVLQLLQRLRDLNISKRALGKILLSTLDAFRDPTHEGRPSPAAILDALHQALAACQLLRRQPSAPASAAAALTNPLLVSC>sp|Q9HA90-2|EFCC1_HUMAN Isoform 2 of EF-hand and coiled-coil domain-containing protein 1 OS=Homo sapiens OX=9606 GN=EFCC1MTYFGHFGGANHAHTLGELEACIAMLVEQLRTQGCGGRTLGTSEEEAELQQKVEENEHLRLELQMVETERVRLSLLEEKLVDVLQLLQRLRDLNISKRALGKILLSTLDAFRDPTHEGRPSPAAILDALHQALAACQLLRRQPSAPASAAAALTNPLLVSC>sp|Q96D31|CRCM1_HUMAN Calcium release-activated calcium channel protein1 OS=Homo sapiens OX=9606 GN=ORAI1 PE=1 SV=2MHPEPAPPPSRSSPELPPSGGSTTSGSRRSRRRSGDGEPPGAPPPPPSAVTYPDWIGQSYSEVMSLNEHSMQALSWRKLYLSRAKLKASSRTSALLSGFAMVAMVEVQLDADHDYPPGLLIAFSACTTVLVAVHLFALMISTCILPNIEAVSNVHNLNSVKESPHERMHRHIELAWAFSTVIGTLLFLAEVVLLCWVKFLPLKKQPGQPRPTSKPPASGAAANVSTSGITPGQAAAIASTTIMVPFGLIFIVFAVHFYRSLVSHKTDRQFQELNELAEFARLQDQLDHRGDHPLTPGSHYA>sp|Q96D31-2|CRCM1_HUMAN Isoform beta of Calcium release-activatedcalcium channel protein 1 OS=Homo sapiens OX=9606 GN=ORAI1MQALSWRKLYLSRAKLKASSRTSALLSGFAMVAMVEVQLDADHDYPPGLLIAFSACTTVLVAVHLFALMISTCILPNIEAVSNVHNLNSVKESPHERMHRHIELAWAFSTVIGTLLFLAEVVLLCWVKFLPLKKQPGQPRPTSKPPASGAAANVSTSGITPGQAAAIASTTIMVPFGLIFIVFAVHFYRSLVSHKTDRQFQELNELAEFARLQDQLDHRGDHPLTPGSHYA>sp|P15954|COX7C_HUMAN Cytochrome c oxidase subunit 7C, mitochondrialOS=Homo sapiens OX=9606 GN=COX7C PE=1 SV=1MLGQSIRRFTTSVVRRSHYEEGPGKNLPFSVENKWSLLAKMCLYFGSAFATPFLVVRHQLLKT>sp|P23508|CRCM_HUMAN Colorectal mutant cancer protein OS=Homo sapiensOX=9606 GN=MCC PE=1 SV=2MNSGVAMKYGNDSSAELSELHSAALASLKGDIVELNKRLQQTERERDLLEKKLAKAQCEQSHLMREHEDVQERTTLRYEERITELHSVIAELNKKIDRLQGTTIREEDEYSELRSELSQSQHEVNEDSRSMDQDQTSVSIPENQSTMVTADMDNCSDLNSELQRVLTGLENVVCGRKKSSCSLSVAEVDKHIEQLTTASEHCDLAIKTVEEIEGVLGRDLYPNLAEERSRWEKELAGLREENESLTAMLCSKEEELNRTKATMNAIREERDRLRRRVRELQTRLQSVQATGPSSPGRLTSTNRPINPSTGELSTSSSSNDIPIAKIAERVKLSKTRSESSSSDRPVLGSEISSIGVSSSVAEHLAHSLQDCSNIQEIFQTLYSHGSAISESKIREFEVETERLNSRIEHLKSQNDLLTITLEECKSNAERMSMLVGKYESNATALRLALQYSEQCIEAYELLLALAESEQSLILGQFRAAGVGSSPGDQSGDENITQMLKRAHDCRKTAENAAKALLMKLDGSCGGAFAVAGCSVQPWESLSSNSHTSTTSSTASSCDTEFTKEDEQRLKDYIQQLKNDRAAVKLTMLELESIHIDPLSYDVKPRGDSQRLDLENAVLMQELMAMKEEMAELKAQLYLLEKEKKALELKLSTREAQEQAYLVHIEHLKSEVEEQKEQRMRSLSSTSSGSKDKPGKECADAASPALSLAELRTTCSENELAAEFTNAIRREKKLKARVQELVSALERLTKSSEIRHQQSAEFVNDLKRANSNLVAAYEKAKKKHQNKLKKLESQMMAMVERHETQVRMLKQRIALLEEENSRPHTNETSL>sp|P23508-2|CRCM_HUMAN Isoform 2 of Colorectal mutant cancer proteinOS=Homo sapiens OX=9606 GN=MCCMMAAAAAAAAGSSSSGGGGGGSGSSSSSSDTSSTGEEERMRRLFQTCDGDGDGYISRNDLLMVCRQLNMEESVAEIMNQLGADENGKISFQDFTRCRMQLVREIRKEEVDLSAKSDNSCTKKLRDRIASWPTSSDNSLGALSAARESWEYDSGARDLQSPDVQSQSALQKLLEYGGSSLHQQAALHKLLTQSPHIGNSVGGSYLELANTLHSAALASLKGDIVELNKRLQQTERERDLLEKKLAKAQCEQSHLMREHEDVQERTTLRYEERITELHSVIAELNKKIDRLQGTTIREEDEYSELRSELSQSQHEVNEDSRSMDQDQTSVSIPENQSTMVTADMDNCSDLNSELQRVLTGLENVVCGRKKSSCSLSVAEVDKHIEQLTTASEHCDLAIKTVEEIEGVLGRDLYPNLAEERSRWEKELAGLREENESLTAMLCSKEEELNRTKATMNAIREERDRLRRRVRELQTRLQSVQATGPSSPGRLTSTNRPINPSTGELSTSSSSNDIPIAKIAERVKLSKTRSESSSSDRPVLGSEISSIGVSSSVAEHLAHSLQDCSNIQEIFQTLYSHGSAISESKIREFEVETERLNSRIEHLKSQNDLLTITLEECKSNAERMSMLVGKYESNATALRLALQYSEQCIEAYELLLALAESEQSLILGQFRAAGVGSSPGDQSGDENITQMLKRAHDCRKTAENAAKALLMKLDGSCGGAFAVAGCSVQPWESLSSNSHTSTTSSTASSCDTEFTKEDEQRLKDYIQQLKNDRAAVKLTMLELESIHIDPLSYDVKPRGDSQRLDLENAVLMQELMAMKEEMAELKAQLYLLEKEKKALELKLSTREAQEQAYLVHIEHLKSEVEEQKEQRMRSLSSTSSGSKDKPGKECADAASPALSLAELRTTCSENELAAEFTNAIRREKKLKARVQELVSALERLTKSSEIRHQQSAEFVNDLKRANSNLVAAYEKAKKKHQNKLKKLESQMMAMVERHETQVRMLKQRIALLEEENSRPHTNETSL>sp|O43889|CREB3_HUMAN Cyclic AMP-responsive element-binding protein 3OS=Homo sapiens OX=9606 GN=CREB3 PE=1 SV=2MELELDAGDQDLLAFLLEESGDLGTAPDEAVRAPLDWALPLSEVPSDWEVDDLLCSLLSPPASLNILSSSNPCLVHHDHTYSLPRETVSMDLESESCRKEGTQMTPQHMEELAEQEIARLVLTDEEKSLLEKEGLILPETLPLTKTEEQILKRVRRKIRNKRSAQESRRKKKVYVGGLESRVLKYTAQNMELQNKVQLLEEQNLSLLDQLRKLQAMVIEISNKTSSSSTCILVLLVSFCLLLVPAMYSSDTRGSLPAEHGVLSRQLRALPSEDPYQLELPALQSEVPKDSTHQWLDGSDCVLQAPGNTSCLLHYMPQAPSAEPPLEWPFPDLFSEPLCRGPILPLQANLTRKGGWLPTGSPSVILQDRYSG>sp|O43889-3|CREB3_HUMAN Isoform 2 of Cyclic AMP-responsive element-binding protein 3 OS=Homo sapiens OX=9606 GN=CREB3MELELDAGDQDLLAFLLEESGDLGTAPDEAVRAPLDWALPLSEVPSDWEVDDLLCSLLSPPASLNILSSSNPCLVHHDHTYSLPRETVSMDLESESCRKEGTQMTPQHMEELAEQEIARLVLTDEEKSLLEKEGLILPETLPLTKTEEQILKRVRRKIRNKRSAQESRRKKKVYVGGLESRVLKYTAQNMELQNKVQLLEEQNLSLLDQLRKLQAMVIEISNKTSSSSMYSSDTRGSLPAEHGVLSRQLRALPSEDPYQLELPALQSEVPKDSTHQWLDGSDCVLQAPGNTSCLLHYMPQAPSAEPPLEWPFPDLFSEPLCRGPILPLQANLTRKGGWLPTGSPSVILQDRYSG>sp|Q03060|CREM_HUMAN cAMP-responsive element modulator OS=Homo sapiensOX=9606 GN=CREM PE=1 SV=6MTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVSVAGSGTRRGSPAVTLVQLPSGQTIHVQGVIQTPQPWVIQSSEIHTVQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQDEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-1|CREM_HUMAN Isoform 2 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVSVAGSGTRRGSPAVTLVQLPSGQTIHVQGVIQTPQPWVIQSSEIHTVQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-6|CREM_HUMAN Isoform 3 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVSVAGSGTRRGSPAVTLVQLPSGQTIHVQGVIQTPQPWVIQSSEIHTVQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-2|CREM_HUMAN Isoform 4 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYTATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-7|CREM_HUMAN Isoform 5 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-8|CREM_HUMAN Isoform 6 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMAVTGDDTDEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-9|CREM_HUMAN Isoform 7 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMAVTGDDTAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-10|CREM_HUMAN Isoform 8 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMAVTGDDTDEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-11|CREM_HUMAN Isoform 9 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMAVTGDDTAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-12|CREM_HUMAN Isoform 10 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMWWHQHNLCFRRPIEEDYSSGDVEEKVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-13|CREM_HUMAN Isoform 11 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMWWHQHNLCFRRPIEEDYSSGDVEEKVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYDEETELAPSHMATATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-14|CREM_HUMAN Isoform 12 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYDEETELAPSHMATATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-15|CREM_HUMAN Isoform 13 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQDEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-16|CREM_HUMAN Isoform 14 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-17|CREM_HUMAN Isoform 15 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-19|CREM_HUMAN Isoform 16 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVDEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-20|CREM_HUMAN Isoform 17 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVSVAGSGTRRGSPAVTLVQLPSGQTIHVQGVIQTPQPWVIQSSEIHTVQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-21|CREM_HUMAN Isoform 18 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVSVAGSGTRRGSPAVTLVQLPSGQTIHVQGVIQTPQPWVIQSSEIHTVQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-22|CREM_HUMAN Isoform 19 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMWWHQHNLCFRRPIEEDYSSGDVEEKVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQDEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-23|CREM_HUMAN Isoform 20 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-24|CREM_HUMAN Isoform 21 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMNRTQELSGQLSAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-25|CREM_HUMAN Isoform 22 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYSMYAAIRYDTVLALSLL>sp|Q03060-26|CREM_HUMAN Isoform 23 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYNEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-27|CREM_HUMAN Isoform 24 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMNRTQELSGQLSAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-28|CREM_HUMAN Isoform 25 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-29|CREM_HUMAN Isoform 26 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMNRTQELSGQLSDEETELAPSHMAAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-30|CREM_HUMAN Isoform 27 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYTATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAAKECRRRKKEYVKCLESRVAVLEVQNKKLIEELETLKDICSPKTDY>sp|Q03060-31|CREM_HUMAN Isoform 28 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYIAIAQGGTIQISNPGSDGVQGLQALTMTNSGAPPPGATIVQYAAQSADGTQQFFVPGSQVVVQAATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q03060-32|CREM_HUMAN Isoform 29 of cAMP-responsive element modulatorOS=Homo sapiens OX=9606 GN=CREMMSKCARKKYIKTNPRQMTMETVESQHDGSITASLTESKSAHVQTQTGQNSIPALAQVAAIAETDESAESEGVIDSHKRREILSRRPSYRKILNELSSDVPGVPKIEEERSEEEGTPPSIATMAVPTSIYQTSTGQYTATGDMPTYQIRAPTAALPQGVVMAASPGSLHSPQQLAEEATRKRELRLMKNREAARECRRKKKEYVKCLENRVAVLENQNKTLIEELKALKDLYCHKVE>sp|Q13363|CTBP1_HUMAN C-terminal-binding protein 1 OS=Homo sapiensOX=9606 GN=CTBP1 PE=1 SV=2MGSSHLLNKGLPLGVRPPIMNGPLHPRPLVALLDGRDCTVEMPILKDVATVAFCDAQSTQEIHEKVLNEAVGALMYHTITLTREDLEKFKALRIIVRIGSGFDNIDIKSAGDLGIAVCNVPAASVEETADSTLCHILNLYRRATWLHQALREGTRVQSVEQIREVASGAARIRGETLGIIGLGRVGQAVALRAKAFGFNVLFYDPYLSDGVERALGLQRVSTLQDLLFHSDCVTLHCGLNEHNHHLINDFTVKQMRQGAFLVNTARGGLVDEKALAQALKEGRIRGAALDVHESEPFSFSQGPLKDAPNLICTPHAAWYSEQASIEMREEAAREIRRAITGRIPDSLKNCVNKDHLTAATHWASMDPAVVHPELNGAAYRYPPGVVGVAPTGIPAAVEGIVPSAMSLSHGLPPVAHPPHAPSPGQTVKPEADRDHASDQL>sp|Q13363-2|CTBP1_HUMAN Isoform 2 of C-terminal-binding protein 1OS=Homo sapiens OX=9606 GN=CTBP1MSGVRPPIMNGPLHPRPLVALLDGRDCTVEMPILKDVATVAFCDAQSTQEIHEKVLNEAVGALMYHTITLTREDLEKFKALRIIVRIGSGFDNIDIKSAGDLGIAVCNVPAASVEETADSTLCHILNLYRRATWLHQALREGTRVQSVEQIREVASGAARIRGETLGIIGLGRVGQAVALRAKAFGFNVLFYDPYLSDGVERALGLQRVSTLQDLLFHSDCVTLHCGLNEHNHHLINDFTVKQMRQGAFLVNTARGGLVDEKALAQALKEGRIRGAALDVHESEPFSFSQGPLKDAPNLICTPHAAWYSEQASIEMREEAAREIRRAITGRIPDSLKNCVNKDHLTAATHWASMDPAVVHPELNGAAYRYPPGVVGVAPTGIPAAVEGIVPSAMSLSHGLPPVAHPPHAPSPGQTVKPEADRDHASDQL>sp|Q8WYQ4|CV015_HUMAN Uncharacterized protein C22orf15 OS=Homo sapiensOX=9606 GN=C22orf15 PE=1 SV=1MFIKVMFGAGCSVLVNTSCRLVNLTAHLRQKAGLPPDATIALLAEDGNLVSLEEDLKEGASRAQTMGNSLLKERAIYVLVRIIKGEDMASTRYESLLENLDDHYPELAEELRRLSGLSSVGHNWRKRMGTRRGRHEQSPTSRPRKGPD>sp|Q8WYQ4-2|CV015_HUMAN Isoform 2 of Uncharacterized protein C22orf15OS=Homo sapiens OX=9606 GN=C22orf15MFIKVMFGAGCSVLVNTSCRLVNLTAHLRQKAGLPPDATIALLAEDGNLVSLEEDLKEGASRAQTMGNSLLKERAIYVLVRIISKVAQEGEDMASTRYESLLENLDDHYPELAGANRQQPSRTPLAESGIAEKLHQQEGQGP>sp|Q8N1L1|CV037_HUMAN Putative uncharacterized protein encoded byLINC00528 OS=Homo sapiens OX=9606 GN=LINC00528 PE=5 SV=1MALLLSDWCPDGDADTHTGTDPGRTTHRLCARERGVRGTQPCPRIYLRLPAQNCEETRFCCASPGSVVLGHGAPRTASPPSALSHPSPLEGLSFSPFPPSVLSHPSPPEGLSFSLFHCLCSGKLSESPGCFWNSLGWSFSVLTEPGVWKVGEAIWVAENLAQPLTSPCAC>sp|Q6P0A1|F180B_HUMAN Protein FAM180B OS=Homo sapiens OX=9606 GN=FAM180BPE=1 SV=3MAATLQFLVCLVVAICLLSGVTTTQPHAGQPMDSTSVGGGLQEPEAPEVMFELLWAGLELDVMGQLHIQDEELASTHPGRRLRLLLQHHVPSDLEGTEQWLQQLQDLRKGPPLSTWDFEHLLLTGLSCVYRLHAASEAEERGRWAQVFALLAQETLWDLCKGFCPQDRPPSLGSWASILDPFP>sp|Q717R9|CYS1_HUMAN Cystin-1 OS=Homo sapiens OX=9606 GN=CYS1 PE=1 SV=1MGSGSSRSSRTLRRRRSPESLPAGPGAAALEGGTRRRVPVAAAEVPGAAAEEAPGRDPSPVAPPDGRDETLRLLDELLAESAAWGPPEPAPRRPARLRPTAVAGSAVCAEQSTEGHPGSGNVSEAPGSGRKKPERPAAISYDHSEEGLMASIEREYCR>sp|A0FGR8|ESYT2_HUMAN Extended synaptotagmin-2 OS=Homo sapiens OX=9606GN=ESYT2 PE=1 SV=1MTANRDAALSSHRHPGCAQRPRTPTFASSSQRRSAFGFDDGNFPGLGERSHAPGSRLGARRRAKTARGLRGHRQRGAGAGLSRPGSARAPSPPRPGGPENPGGVLSVELPGLLAQLARSFALLLPVYALGYLGLSFSWVLLALALLAWCRRSRGLKALRLCRALALLEDEERVVRLGVRACDLPAWVHFPDTERAEWLNKTVKHMWPFICQFIEKLFRETIEPAVRGANTHLSTFSFTKVDVGQQPLRINGVKVYTENVDKRQIILDLQISFVGNCEIDLEIKRYFCRAGVKSIQIHGTMRVILEPLIGDMPLVGALSIFFLRKPLLEINWTGLTNLLDVPGLNGLSDTIILDIISNYLVLPNRITVPLVSEVQIAQLRFPVPKGVLRIHFIEAQDLQGKDTYLKGLVKGKSDPYGIIRVGNQIFQSRVIKENLSPKWNEVYEALVYEHPGQELEIELFDEDPDKDDFLGSLMIDLIEVEKERLLDEWFTLDEVPKGKLHLRLEWLTLMPNASNLDKVLTDIKADKDQANDGLSSALLILYLDSARNLPSGKKISSNPNPVVQMSVGHKAQESKIRYKTNEPVWEENFTFFIHNPKRQDLEVEVRDEQHQCSLGNLKVPLSQLLTSEDMTVSQRFQLSNSGPNSTIKMKIALRVLHLEKRERPPDHQHSAQVKRPSVSKEGRKTSIKSHMSGSPGPGGSNTAPSTPVIGGSDKPGMEEKAQPPEAGPQGLHDLGRSSSSLLASPGHISVKEPTPSIASDISLPIATQELRQRLRQLENGTTLGQSPLGQIQLTIRHSSQRNKLIVVVHACRNLIAFSEDGSDPYVRMYLLPDKRRSGRRKTHVSKKTLNPVFDQSFDFSVSLPEVQRRTLDVAVKNSGGFLSKDKGLLGKVLVALASEELAKGWTQWYDLTEDGTRPQAMT>sp|A0FGR8-2|ESYT2_HUMAN Isoform 2 of Extended synaptotagmin-2 OS=Homosapiens OX=9606 GN=ESYT2MTPPSRAEAGVRRSRVPSEGRWRGAEPPGISASTQPASAGRAARHCGAMSGARGEGPEAGAGGAGGRAAPENPGGVLSVELPGLLAQLARSFALLLPVYALGYLGLSFSWVLLALALLAWCRRSRGLKALRLCRALALLEDEERVVRLGVRACDLPAWVHFPDTERAEWLNKTVKHMWPFICQFIEKLFRETIEPAVRGANTHLSTFSFTKVDVGQQPLRINGVKVYTENVDKRQIILDLQISFVGNCEIDLEIKRYFCRAGVKSIQIHGTMRVILEPLIGDMPLVGALSIFFLRKPLLEINWTGLTNLLDVPGLNGLSDTIILDIISNYLVLPNRITVPLVSEVQIAQLRFPVPKGVLRIHFIEAQDLQGKDTYLKGLVKGKSDPYGIIRVGNQIFQSRVIKENLSPKWNEVYEALVYEHPGQELEIELFDEDPDKDDFLGSLMIDLIEVEKERLLDEWFTLDEVPKGKLHLRLEWLTLMPNASNLDKVLTDIKADKDQANDGLSSALLILYLDSARNLPSGKKISSNPNPVVQMSVGHKAQESKIRYKTNEPVWEENFTFFIHNPKRQDLEVEVRDEQHQCSLGNLKVPLSQLLTSEDMTVSQRFQLSNSGPNSTIKMKIALRVLHLEKRERPPDHQHSAQVKRPSVSKEGRKTSIKSHMSGSPGPGGSNTAPSTPVIGGSDKPGMEEKAQPPEAGPQGLHDLGRSSSSLLASPGHISVKEPTPSIASDISLPIATQELRQRLRQLENGTTLGQSPLGQIQLTIRHSSQRNKLIVVVHACRNLIAFSEDGSDPYVRMYLLPDKRRSGRRKTHVSKKTLNPVFDQSFDFSVSLPEVQRRTLDVAVKNSGGFLSKDKGLLGKVLVALASEELAKGWTQWYDLTEDGTRPQAMT>sp|A0FGR8-4|ESYT2_HUMAN Isoform 4 of Extended synaptotagmin-2 OS=Homosapiens OX=9606 GN=ESYT2MWPFICQFIEKLFRETIEPAVRGANTHLSTFSFTKVDVGQQPLRINGVKVYTENVDKRQIILDLQISFVGNCEIDLEIKRYFCRAGVKSIQIHGTMRVILEPLIGDMPLVGALSIFFLRKPLLEINWTGLTNLLDVPGLNGLSDTIILDIISNYLVLPNRITVPLVSEVQIAQLRFPVPKGVLRIHFIEAQDLQGKDTYLKGLVKGKSDPYGIIRVGNQIFQSRVIKENLSPKWNEVYEALVYEHPGQELEIELFDEDPDKDDFLGSLMIDLIEVEKERLLDEWFTLDEVPKGKLHLRLEWLTLMPNASNLDKVLTDIKADKDQANDGLSSALLILYLDSARNLPSGKKISSNPNPVVQMSVGHKAQESKIRYKTNEPVWEENFTFFIHNPKRQDLEVEVRDEQHQCSLGNLKVPLSQLLTSEDMTVSQRFQLSNSGPNSTIKMKIALRVLHLEKRERPPDHQHSAQVKRPSVSKEGRKTSIKSHMSGSPGPGGSNTAPSTSQSRSRPPASPRTSRCPSPPRSCGKG>sp|A0FGR8-5|ESYT2_HUMAN Isoform 5 of Extended synaptotagmin-2 OS=Homosapiens OX=9606 GN=ESYT2MPVLPPCVLQVRDEQHQCSLGNLKVPLSQLLTSEDMTVSQRFQLSNSGPNSTIKMKIALRVLHLEKRERPPDHQHSAQVKRPSVSKEGRKTSIKSHMSGSPGPGGSNTAPSTPVIGGSDKPGMEEKAQPPEAGPQGLHDLGRSSSSLLASPGHISVKEPTPSIASDISLPIATQELRQRLRQLENGTTLGQSPLGQIQLTIRHSSQRNKLIVVVHACRNLIAFSEDGSDPYVRMYLLPDKRRSGRRKTHVSKKTLNPVFDQSFDFSVSLPEVQRRTLDVAVKNSGGFLSKDKGLLGKVLVALASEELAKGWTQWYDLTEDGTRPQAMT>sp|A0FGR8-6|ESYT2_HUMAN Isoform 6 of Extended synaptotagmin-2 OS=Homosapiens OX=9606 GN=ESYT2MTANRDAALSSHRHPGCAQRPRTPTFASSSQRRSAFGFDDGNFPGLGERSHAPGSRLGARRRAKTARGLRGHRQRGAGAGLSRPGSARAPSPPRPGGPENPGGVLSVELPGLLAQLARSFALLLPVYALGYLGLSFSWVLLALALLAWCRRSRGLKALRLCRALALLEDEERVVRLGVRACDLPAWVHFPDTERAEWLNKTVKHMWPFICQFIEKLFRETIEPAVRGANTHLSTFSFTKVDVGQQPLRINGVKVYTENVDKRQIILDLQISFVGNCEIDLEIKRYFCRAGVKSIQIHGTMRVILEPLIGDMPLVGALSIFFLRKPLLEINWTGLTNLLDVPGLNGLSDTIILDIISNYLVLPNRITVPLVSEVQIAQLRFPVPKGVLRIHFIEAQDLQGKDTYLKGLVKGKSDPYGIIRVGNQIFQSRVIKENLSPKWNEVYEALVYEHPGQELEIELFDEDPDKDDFLGSLMIDLIEVEKERLLDEWFTLDEVPKGKLHLRLEWLTLMPNASNLDKVLTDIKADKDQANDGLSSALLILYLDSARNLPSNPLEFNPDVLKKTAVQRALKSGKKISSNPNPVVQMSVGHKAQESKIRYKTNEPVWEENFTFFIHNPKRQDLEVEVRDEQHQCSLGNLKVPLSQLLTSEDMTVSQRFQLSNSGPNSTIKMKIALRVLHLEKRERPPDHQHSAQVKRPSVSKEGRKTSIKSHMSGSPGPGGSNTAPSTPVIGGSDKPGMEEKAQPPEAGPQGLHDLGRSSSSLLASPGHISVKEPTPSIASDISLPIATQELRQRLRQLENGTTLGQSPLGQIQLTIRHSSQRNKLIVVVHACRNLIAFSEDGSDPYVRMYLLPDKRRSGRRKTHVSKKTLNPVFDQSFDFSVSLPEVQRRTLDVAVKNSGGFLSKDKGLLGKVLVALASEELAKGWTQWYDLTEDGTRPQAMT>sp|Q8N4M1|CTL3_HUMAN Choline transporter-like protein 3 OS=Homo sapiensOX=9606 GN=SLC44A3 PE=1 SV=4MHCLGAEYLVSAEGAPRQREWRPQIYRKCTDTAWLFLFFLFWTGLVFIMGYSVVAGAAGRLLFGYDSFGNMCGKKNSPVEGAPLSGQDMTLKKHVFFMNSCNLEVKGTQLNRMALCVSNCPEEQLDSLEEVQFFANTSGSFLCVYSLNSFNYTHSPKADSLCPRLPVPPSKSFPLFNRCVPQTPECYSLFASVLINDVDTLHRILSGIMSGRDTILGLCILALALSLAMMFTFRFITTLLVHIFISLVILGLLFVCGVLWWLYYDYTNDLSIELDTERENMKCVLGFAIVSTGITAVLLVLIFVLRKRIKLTVELFQITNKAISSAPFLLFQPLWTFAILIFFWVLWVAVLLSLGTAGAAQVMEGGQVEYKPLSGIRYMWSYHLIGLIWTSEFILACQQMTIAGAVVTCYFNRSKNDPPDHPILSSLSILFFYHQGTVVKGSFLISVVRIPRIIVMYMQNALKEQQHGALSRYLFRCCYCCFWCLDKYLLHLNQNAYTTTAINGTDFCTSAKDAFKILSKNSSHFTSINCFGDFIIFLGKVLVVCFTVFGGLMAFNYNRAFQVWAVPLLLVAFFAYLVAHSFLSVFETVLDALFLCFAVDLETNDGSSEKPYFMDQEFLSFVKRSNKLNNARAQQDKHSLRNEEGTELQAIVR>sp|Q8N4M1-2|CTL3_HUMAN Isoform 2 of Choline transporter-like protein 3OS=Homo sapiens OX=9606 GN=SLC44A3MGYSVVAGAAGRLLFGYDSFGNMCGKKNSPVEGAPLSGQDMTLKKHVFFMNSCNLEVKGTQLNRMALCVSNCPEEQLDSLEEVQFFANTSGSFLCVYSLNSFNYTHSPKADSLCPRLPVPPSKSFPLFNRCVPQTPECYSLFASVLINDVDTLHRILSGIMSGRDTILGLCILALALSLAMMFTFRFITTLLVHIFISLVILGLLFVCGVLWWLYYDYTNDLSIELDTERENMKCVLGFAIVSTGITAVLLVLIFVLRKRIKLTVELFQITNKAISSAPFLLFQPLWTFAILIFFWVLWVAVLLSLGTAGAAQVMEGGQVEYKPLSGIRYMWSYHLIGLIWTSEFILACQQMTIAGAVVTCYFNRSKNDPPDHPILSSLSILFFYHQGTVVKGSFLISVVRIPRIIVMYMQNALKEQQHGALSRYLFRCCYCCFWCLDKYLLHLNQNAYTTTAINGTDFCTSAKDAFKILSKNSSHFTSINCFGDFIIFLGKVLVVCFTVFGGLMAFNYNRAFQVWAVPLLLVAFFAYLVAHSFLSVFETVLDALFLCFAVDLETNDGSSEKPYFMDQEFLSFVKRSNKLNNARAQQDKHSLRNEEGTELQAIVR>sp|Q8N4M1-3|CTL3_HUMAN Isoform 3 of Choline transporter-like protein 3OS=Homo sapiens OX=9606 GN=SLC44A3MHCLGAEYLVFIMGYSVVAGAAGRLLFGYDSFGNMCGKKNSPVEGAPLSGQDMTLKKHVFFMNSCNLEVKGTQLNRMALCVSNCPEEQLDSLEEVQFFANTSGSFLCVYSLNSFNYTHSPKADSLCPRLPVPPSKSFPLFNRCVPQTPECYSLFASVLINDVDTLHRILSGIMSGRDTILGLCILALALSLAMMFTFRFITTLLVHIFISLVILGLLFVCGVLWWLYYDYTNDLSIELDTERENMKCVLGFAIVSTGITAVLLVLIFVLRKRIKLTVELFQITNKAISSAPFLLFQPLWTFAILIFFWVLWVAVLLSLGTAGAAQVMEGGQVEYKPLSGIRYMWSYHLIGLIWTSEFILACQQMTIAGAVVTCYFNRSKNDPPDHPILSSLSILFFYHQGTVVKGSFLISVVRIPRIIVMYMQNALKEQQHGALSRYLFRCCYCCFWCLDKYLLHLNQNAYTTTAINGTDFCTSAKDAFKILSKNSSHFTSINCFGDFIIFLGKVLVVCFTVFGGLMAFNYNRAFQVWAVPLLLVAFFAYLVAHSFLSVFETVLDALFLCFAVDLETNDGSSEKPYFMDQEFLSFVKRSNKLNNARAQQDKHSLRNEEGTELQAIVR>sp|Q8N4M1-4|CTL3_HUMAN Isoform 4 of Choline transporter-like protein 3OS=Homo sapiens OX=9606 GN=SLC44A3MHCLGAEYLVFIMGYSVVAGAAGRLLFGYDSFGNMCGKKNSPVEGAPLSGQDMTLKKHVFFMNSCNLEVKGSFLCVYSLNSFNYTHSPKADSLCPRLPVPPSKSFPLFNRCVPQTPECYSLFASVLINDVDTLHRILSGIMSGRDTILGLCILALALSLAMMFTFRFITTLLVHIFISLVILGLLFVCGVLWWLYYDYTNDLSIELDTERENMKCVLGFAIVSTGITAVLLVLIFVLRKRIKLTVELFQITNKAISSAPFLLFQPLWTFAILIFFWVLWVAVLLSLGTAGAAQVMEGGQVEYKPLSGIRYMWSYHLIGLIWTSEFILACQQMTIAGAVVTCYFNRSKNDPPDHPILSSLSILFFYHQGTVVKGSFLISVVRIPRIIVMYMQNALKEQQHGALSRYLFRCCYCCFWCLDKYLLHLNQNAYTTTAINGTDFCTSAKDAFKILSKNSSHFTSINCFGDFIIFLGKVLVVCFTVFGGLMAFNYNRAFQVWAVPLLLVAFFAYLVAHSFLSVFETVLDALFLCFAVDLETNDGSSEKPYFMDQEFLSFVKRSNKLNNARAQQDKHSLRNEEGTELQAIVR>sp|Q8N4M1-5|CTL3_HUMAN Isoform 5 of Choline transporter-like protein 3OS=Homo sapiens OX=9606 GN=SLC44A3MGYSVVAGAAGRLLFGYDSFGNMCGKKNSPVEGAPLSGQDMTLKKHVFFMNSCNLEVKGSFLCVYSLNSFNYTHSPKADSLCPRLPVPPSKSFPLFNRCVPQTPECYSLFASVLINDVDTLHRILSGIMSGRDTILGLCILALALSLAMMFTFRFITTLLVHIFISLVILGLLFVCGVLWWLYYDYTNDLSIELDTERENMKCVLGFAIVSTGITAVLLVLIFVLRKRIKLTVELFQITNKAISSAPFLLFQPLWTFAILIFFWVLWVAVLLSLGTAGAAQVMEGGQVEYKPLSGIRYMWSYHLIGLIWTSEFILACQQMTIAGAVVTCYFNRSKNDPPDHPILSSLSILFFYHQGTVVKGSFLISVVRIPRIIVMYMQNALKEQHGALSRYLFRCCYCCFWCLDKYLLHLNQNAYTTTAINGTDFCTSAKDAFKILSKNSSHFTSINCFGDFIIFLGKVLVVCFTVFGGLMAFNYNRAFQVWAVPLLLVAFFAYLVAHSFLSVFETVLDALFLCFAVDLETNDGSSEKPYFMDQEFLSFVKRSNKLNNARAQQDKHSLRNEEGTELQAIVR>sp|Q8N4M1-6|CTL3_HUMAN Isoform 6 of Choline transporter-like protein 3OS=Homo sapiens OX=9606 GN=SLC44A3MHCLGAEYLVSAEGAPRQREWRPQIYRKCTDTAWLFLFFLFWTGLVFIMGYSVVAGAAGRLLFGYDSFGNMCGKKNSPVEGAPLSGQDMTLKKHVFFMNSCNLEVKGSFLCVYSLNSFNYTHSPKADSLCPRLPVPPSKSFPLFNRCVPQTPECYSLFASVLINDVDTLHRILSGIMSGRDTILGLCILALALSLAMMFTFRFITTLLVHIFISLVILGLLFVCGVLWWLYYDYTNDLSIELDTERENMKCVLGFAIVSTGITAVLLVLIFVLRKRIKLTVELFQITNKAISSAPFLLFQPLWTFAILIFFWVLWVAVLLSLGTAGAAQVMEGGQVEYKPLSGIRYMWSYHLIGLIWTSEFILACQQMTIAGAVVTCYFNRSKNDPPDHPILSSLSILFFYHQGTVVKGSFLISVVRIPRIIVMYMQNALKEQHGALSRYLFRCCYCCFWCLDKYLLHLNQNAYTTTAINGTDFCTSAKDAFKILSKNSSHFTSINCFGDFIIFLGKVLVVCFTVFGGLMAFNYNRAFQVWAVPLLLVAFFAYLVAHSFLSVFETVLDALFLCFAVDLETNDGSSEKPYFMDQEFLSFVKRSNKLNNARAQQDKHSLRNEEGTELQAIVR>sp|Q9NWM3|CUED1_HUMAN CUE domain-containing protein 1 OS=Homo sapiensOX=9606 GN=CUEDC1 PE=1 SV=1MTSLFRRSSSGSGGGGTAGARGGGGGTAAPQELNNSRPARQVRRLEFNQAMDDFKTMFPNMDYDIIECVLRANSGAVDATIDQLLQMNLEGGGSSGGVYEDSSDSEDSIPPEILERTLEPDSSDEEPPPVYSPPAYHMHVFDRPYPLAPPTPPPRIDALGSGAPTSQRRYRNWNPPLLGNLPDDFLRILPQQLDSIQGNAGGPKPGSGEGCPPAMAGPGPGDQESRWKQYLEDERIALFLQNEEFMKELQRNRDFLLALERDRLKYESQKSKSSSVAVGNDFGFSSPVPGTGDANPAVSEDALFRDKLKHMGKSTRRKLFELARAFSEKTKMRKSKRKHLLKHQSLGAAASTANLLDDVEGHACDEDFRGRRQEAPKVEEGLREGQ>sp|Q9NWM3-2|CUED1_HUMAN Isoform 2 of CUE domain-containing protein 1OS=Homo sapiens OX=9606 GN=CUEDC1MTSLFRRSSSGSGGGGTAGARGGGGGTAAPQELNNSRPARQVRRLEFNQAMDDFKTMFPNMDYDIIECVLRANSGAVDATIDQLLQMNLEGGGSSGGVYEDSSDSEDSIPPEILERTLEPDSSDEEPPPVYSPPAYHMHVFDRPYPLAPPTPPPRIDALGSGAPTSQRRYRNWNPPLLGNLPDDFLRILPQQLDSIQGNAGGPKPGSGEGCPPAMAGPGPGDQESRWKQYLERDRLKYESQKSKSSSVAVGNDFGFSSPVPGTGDANPAVSEDALFRDKLKHMGKSTRRKLFELARAFSEKTKMRKSKRKHLLKHQSLGAAASTANLLDDVEGHACDEDFRGRRQEAPKVEEGLREGQ>sp|P35212|CXA4_HUMAN Gap junction alpha-4 protein OS=Homo sapiensOX=9606 GN=GJA4 PE=1 SV=3MGDWGFLEKLLDQVQEHSTVVGKIWLTVLFIFRILILGLAGESVWGDEQSDFECNTAQPGCTNVCYDQAFPISHIRYWVLQFLFVSTPTLVYLGHVIYLSRREERLRQKEGELRALPAKDPQVERALAAVERQMAKISVAEDGRLRIRGALMGTYVASVLCKSVLEAGFLYGQWRLYGWTMEPVFVCQRAPCPYLVDCFVSRPTEKTIFIIFMLVVGLISLVLNLLELVHLLCRCLSRGMRARQGQDAPPTQGTSSDPYTDQVFFYLPVGQGPSSPPCPTYNGLSSSEQNWANLTTEERLASSRPPLFLDPPPQNGQKPPSRPSSSASKKQYV>sp|Q13616|CUL1_HUMAN Cullin-1 OS=Homo sapiens OX=9606 GN=CUL1 PE=1 SV=2MSSTRSQNPHGLKQIGLDQIWDDLRAGIQQVYTRQSMAKSRYMELYTHVYNYCTSVHQSNQARGAGVPPSKSKKGQTPGGAQFVGLELYKRLKEFLKNYLTNLLKDGEDLMDESVLKFYTQQWEDYRFSSKVLNGICAYLNRHWVRRECDEGRKGIYEIYSLALVTWRDCLFRPLNKQVTNAVLKLIEKERNGETINTRLISGVVQSYVELGLNEDDAFAKGPTLTVYKESFESQFLADTERFYTRESTEFLQQNPVTEYMKKAEARLLEEQRRVQVYLHESTQDELARKCEQVLIEKHLEIFHTEFQNLLDADKNEDLGRMYNLVSRIQDGLGELKKLLETHIHNQGLAAIEKCGEAALNDPKMYVQTVLDVHKKYNALVMSAFNNDAGFVAALDKACGRFINNNAVTKMAQSSSKSPELLARYCDSLLKKSSKNPEEAELEDTLNQVMVVFKYIEDKDVFQKFYAKMLAKRLVHQNSASDDAEASMISKLKQACGFEYTSKLQRMFQDIGVSKDLNEQFKKHLTNSEPLDLDFSIQVLSSGSWPFQQSCTFALPSELERSYQRFTAFYASRHSGRKLTWLYQLSKGELVTNCFKNRYTLQASTFQMAILLQYNTEDAYTVQQLTDSTQIKMDILAQVLQILLKSKLLVLEDENANVDEVELKPDTLIKLYLGYKNKKLRVNINVPMKTEQKQEQETTHKNIEEDRKLLIQAAIVRIMKMRKVLKHQQLLGEVLTQLSSRFKPRVPVIKKCIDILIEKEYLERVDGEKDTYSYLA>sp|P0C2S0|CTXN2_HUMAN Cortexin-2 OS=Homo sapiens OX=9606 GN=CTXN2 PE=3SV=1MSSTYCGNSSAKMSVNEVSAFSLTLEQKTGFAFVGILCIFLGLLIIRCFKILLDPYSSMPSSTWEDEVEEFDKGTFEYALA>sp|Q2VPK5|CTU2_HUMAN Cytoplasmic tRNA 2-thiolation protein 2 OS=Homosapiens OX=9606 GN=CTU2 PE=1 SV=1MCQVGEDYGEPAPEEPPPAPRPSREQKCVKCKEAQPVVVIRAGDAFCRDCFKAFYVHKFRAMLGKNRLIFPGEKVLLAWSGGPSSSSMVWQVLEGLSQDSAKRLRFVAGVIFVDEGAACGQSLEERSKTLAEVKPILQATGFPWHVVALEEVFSLPPSVLWCSAQELVGSEGAYKAAVDSFLQQQHVLGAGGGPGPTQGEEQPPQPPLDPQNLARPPAPAQTEALSQLFCSVRTLTAKEELLQTLRTHLILHMARAHGYSKVMTGDSCTRLAIKLMTNLALGRGAFLAWDTGFSDERHGDVVVVRPMRDHTLKEVAFYNRLFSVPSVFTPAVDTKAPEKASIHRLMEAFILRLQTQFPSTVSTVYRTSEKLVKGPRDGPAAGDSGPRCLLCMCALDVDAADSATAFGAQTSSRLSQMQSPIPLTETRTPPGPCCSPGVGWAQRCGQGACRREDPQACIEEQLCYSCRVNMKDLPSLDPLPPYILAEAQLRTQRAWGLQEIRDCLIEDSDDEAGQS>sp|Q2VPK5-3|CTU2_HUMAN Isoform 2 of Cytoplasmic tRNA 2-thiolationprotein 2 OS=Homo sapiens OX=9606 GN=CTU2MVWQVLEGLSQDSAKRLRFVAGVIFVDEGAACGQSLEERSKTLAEVKPILQATGFPWHVVALEEVFSLPPSVLWCSAQELVGSEGAYKAAVDSFLQQQHVLGAGGGPGPTQGEEQPPQPPLDPQNLARPPAPAQTEALSQLFCSVRTLTAKEELLQTLRTHLILHMARAHGYSKVMTGDSCTRLAIKLMTNLALGRGAFLAWDTGFSDERHGDVVVVRPMRDHTLKEVAFYNRLFSVPSVFTPAVDTKAPEKASIHRLMEAFILRLQTQFPSTVSTVYRTSEKLVKGPRDGPAAGDSGPRCLLCMCALDVDAADSATAFGAQTSSRLSQMQSPIPLTETRTPPGPCCSPGVGWAQRCGQGACRREDPQACIEEQLCYSCRVNMKDLPSLDPLPPYILAEAQLRTQRAWGLQEIRDCLIEDSDDEAGQS>sp|Q2VPK5-5|CTU2_HUMAN Isoform 3 of Cytoplasmic tRNA 2-thiolationprotein 2 OS=Homo sapiens OX=9606 GN=CTU2MCQVGEDYGEPAPEEPPPAPRPSREQKCVKCKEAQPVVVIRAGDAFCRDCFKAFYVHKFRAMLGKNRLIFPGEKVLLAWSGGPSSSSMVWQVLEGLSQDSAKRLRFVAGVIFVDEGAACGQSLEERSKTLAEVKPILQATGFPWHVVALEEVFSLPPSVLWCSAQELVGSEGAYKAAVDSFLQQQHVLGAGGGPGPTQGEEQPPQPPLDPQNLARPPAPAQTEALSQLFCSVRTLTAKEELLQTLRTHLILHMARAHGYSKVMTGDSCTRLAIKLMTNLALGRGAFLAWDTGFSDERHGDVVVVRPMRDHTLKEVAFYNRLFSVPSVFTPAVDTKAPEKASIHRLMEAFILRLQTQFPSTVSTVYRTSEKLVKGPRDGPAAGDSGPRCLLCMCALDVDAADSATAFGAQTSSRLSQMQSPIPLTETRTPPGPCCSPGVGWAQRCGQGACRREDPQACIEEQLCYSCRVNMKDLGLGLAGDPGLSD>sp|A2VCK2|DCD2B_HUMAN Doublecortin domain-containing protein 2B OS=Homosapiens OX=9606 GN=DCDC2B PE=1 SV=1MAGGSPAAKRVVVYRNGDPFFPGSQLVVTQRRFPTMEAFLCEVTSAVQAPLAVRALYTPCHGHPVTNLADLKNRGQYVAAGFERFHKLHYLPHRGKDPGGKSCRLQGPPVTRHLCDGAIGRQLPAGAPSYIHVFRNGDLVSPPFSLKLSQAASQDWETVLKLLTEKVKLQSGAVCKLCTLEGLPLSAGKELVTGHYYVAVGEDEFKDLPYLELLVPSPSLPRGCWQPPGSKSRPHRQGAQGHRAQVTQPSPKEPDRIKPSAFYARPQQTIQPRSKLPTLSFPSGVIGVYGAPHRRKETAGALEVADDEDTQTEEPLDQRAAQIVEEALSLENQPGAGAAISASAPALPS>sp|Q96PD2|DCBD2_HUMAN Discoidin, CUB and LCCL domain-containing protein2 OS=Homo sapiens OX=9606 GN=DCBLD2 PE=1 SV=1MASRAVVRARRCPQCPQVRAAAAAPAWAALPLSRSLPPCSNSSSFSMPLFLLLLLVLLLLLEDAGAQQGDGCGHTVLGPESGTLTSINYPQTYPNSTVCEWEIRVKMGERVRIKFGDFDIEDSDSCHFNYLRIYNGIGVSRTEIGKYCGLGLQMNHSIESKGNEITLLFMSGIHVSGRGFLASYSVIDKQDLITCLDTASNFLEPEFSKYCPAGCLLPFAEISGTIPHGYRDSSPLCMAGVHAGVVSNTLGGQISVVISKGIPYYESSLANNVTSVVGHLSTSLFTFKTSGCYGTLGMESGVIADPQITASSVLEWTDHTGQENSWKPKKARLKKPGPPWAAFATDEYQWLQIDLNKEKKITGIITTGSTMVEHNYYVSAYRILYSDDGQKWTVYREPGVEQDKIFQGNKDYHQDVRNNFLPPIIARFIRVNPTQWQQKIAMKMELLGCQFIPKGRPPKLTQPPPPRNSNDLKNTTAPPKIAKGRAPKFTQPLQPRSSNEFPAQTEQTTASPDIRNTTVTPNVTKDVALAAVLVPVLVMVLTTLILILVCAWHWRNRKKKTEGTYDLPYWDRAGWWKGMKQFLPAKAVDHEETPVRYSSSEVNHLSPREVTTVLQADSAEYAQPLVGGIVGTLHQRSTFKPEEGKEAGYADLDPYNSPGQEVYHAYAEPLPITGPEYATPIIMDMSGHPTTSVGQPSTSTFKATGNQPPPLVGTYNTLLSRTDSCSSAQAQYDTPKAGKPGLPAPDELVYQVPQSTQEVSGAGRDGECDVFKEIL>sp|Q96PD2-2|DCBD2_HUMAN Isoform 2 of Discoidin, CUB and LCCL domain-containing protein 2 OS=Homo sapiens OX=9606 GN=DCBLD2MASRAVVRARRCPQCPQVRAAAAAPAWAALPLSRSLPPCSNSSSFSMPLFLLLLLVLLLLLEDAGAQQGDGCGHTVLGPESGTLTSINYPQTYPNSTVCEWEIRVKMGERVRIKFGDFDIEDSDSCHFNYLRIYNGIGVSRTEIGKYCGLGLQMNHSIESKGNEITLLFMSGIHVSGRGFLASYSVIDKQDLITCLDTASNFLEPEFSKYCPAGCLLPFAEISGTIPHGYRDSSPLCMAGVHAGVVSNTLGGQISVVISKGIPYYESSLANNVTSVVGHLSTSLFTFKTSGCYGTLGMESGVIADPQITASSVLEWTDHTGQENSWKPKKARLKKPGPPWAAFATDEYQWLQIDLNKEKKITGIITTGSTMVEHNYYVSAYRILYSDDGQKWTVYREPGVEQDKIFQGNKDYHQDVRNNFLPPIIARFIRVNPTQWQQKIAMKMELLGCQFIPKGRPPKLTQPPPPRNSNDLKNTTAPPKIAKGRAPKFTQPLQPRSSNEFPAQTEQTTASPDIRNTTVTPNVTKDVALAAVLVPVLVMVLTTLILILVCAWHWRNRKKKTEGTYDLPYWDRAGFYLMVSLACRHNEGWWKGMKQFLPAKAVDHEETPVRYSSSEVNHLSPREVTTVLQADSAEYAQPLVGGIVGTLHQRSTFKPEEGKEAGYADLDPYNSPGQEVYHAYAEPLPITGPEYATPIIMDMSGHPTTSVGQPSTSTFKATGNQPPPLVGTYNTLLSRTDSCSSAQAQYDTPKAGKPGLPAPDELVYQVPQSTQEVSGAGRDGECDVFKEIL>sp|O95786|DDX58_HUMAN Antiviral innate immune response receptor RIG-IOS=Homo sapiens OX=9606 GN=DDX58 PE=1 SV=2MTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREEEVQYIQAEKNNKGPMEAATLFLKFLLELQEEGWFRGFLDALDHAGYSGLYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSECLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLALEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPECQNLSENSCPPSEVSDTNLYSPFKPRNYQLELALPAMKGKNTIICAPTGCGKTFVSLLICEHHLKKFPQGQKGKVVFFANQIPVYEQQKSVFSKYFERHGYRVTGISGATAENVPVEQIVENNDIIILTPQILVNNLKKGTIPSLSIFTLMIFDECHNTSKQHPYNMIMFNYLDQKLGGSSGPLPQVIGLTASVGVGDAKNTDEALDYICKLCASLDASVIATVKHNLEELEQVVYKPQKFFRKVESRISDKFKYIIAQLMRDTESLAKRICKDLENLSQIQNREFGTQKYEQWIVTVQKACMVFQMPDKDEESRICKALFLYTSHLRKYNDALIISEHARMKDALDYLKDFFSNVRAAGFDEIEQDLTQRFEEKLQELESVSRDPSNENPKLEDLCFILQEEYHLNPETITILFVKTRALVDALKNWIEGNPKLSFLKPGILTGRGKTNQNTGMTLPAQKCILDAFKASGDHNILIATSVADEGIDIAQCNLVILYEYVGNVIKMIQTRGRGRARGSKCFLLTSNAGVIEKEQINMYKEKMMNDSILRLQTWDEAVFREKILHIQTHEKFIRDSQEKPKPVPDKENKKLLCRKCKALACYTADVRVIEECHYTVLGDAFKECFVSRPHPKPKQFSSFEKRAKIFCARQNCSHDWGIHVKYKTFEIPVIKIESFVVEDIATGVQTLYSKWKDFHFEKIPFDPAEMSK>sp|O95786-2|DDX58_HUMAN Isoform 2 of Antiviral innate immune responsereceptor RIG-I OS=Homo sapiens OX=9606 GN=DDX58MTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREGYSGLYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSECLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLALEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPECQNLSENSCPPSEVSDTNLYSPFKPRNYQLELALPAMKGKNTIICAPTGCGKTFVSLLICEHHLKKFPQGQKGKVVFFANQIPVYEQQKSVFSKYFERHGYRVTGISGATAENVPVEQIVENNDIIILTPQILVNNLKKGTIPSLSIFTLMIFDECHNTSKQHPYNMIMFNYLDQKLGGSSGPLPQVIGLTASVGVGDAKNTDEALDYICKLCASLDASVIATVKHNLEELEQVVYKPQKFFRKVESRISDKFKYIIAQLMRDTESLAKRICKDLENLSQIQNREFGTQKYEQWIVTVQKACMVFQMPDKDEESRICKALFLYTSHLRKYNDALIISEHARMKDALDYLKDFFSNVRAAGFDEIEQDLTQRFEEKLQELESVSRDPSNENPKLEDLCFILQEEYHLNPETITILFVKTRALVDALKNWIEGNPKLSFLKPGILTGRGKTNQNTGMTLPAQKCILDAFKASGDHNILIATSVADEGIDIAQCNLVILYEYVGNVIKMIQTRGRGRARGSKCFLLTSNAGVIEKEQINMYKEKMMNDSILRLQTWDEAVFREKILHIQTHEKFIRDSQEKPKPVPDKENKKLLCRKCKALACYTADVRVIEECHYTVLGDAFKECFVSRPHPKPKQFSSFEKRAKIFCARQNCSHDWGIHVKYKTFEIPVIKIESFVVEDIATGVQTLYSKWKDFHFEKIPFDPAEMSK>sp|P81534|D103A_HUMAN Beta-defensin 103 OS=Homo sapiens OX=9606GN=DEFB103A PE=1 SV=2MRIHYLLFALLFLFLVPVPGHGGIINTLQKYYCRVRGGRCAVLSCLPKEEQIGKCSTRGRKCCRRKK>sp|Q8N9W5|DAAF3_HUMAN Dynein axonemal assembly factor 3 OS=Homo sapiensOX=9606 GN=DNAAF3 PE=1 SV=4MTTPAGSGSGFGSVSWWGLSPALDLQAESPPVDPDSQADTVHSNPELDVLLLGSVDGRHLLRTLSRAKFWPRRRFNFFVLENNLEAVARHMLIFSLALEEPEKMGLQERSETFLEVWGNALLRPPVAAFVRAQADLLAHLVPEPDRLEEQLPWLSLRALKFRERDALEAVFRFWAGGEKGPQAFPMSRLWDSRLRHYLGSRYDARRGVSDWDLRMKLHDRGAQVIHPQEFRRWRDTGVAFELRDSSAYHVPNRTLASGRLLSYRGERVAARGYWGDIATGPFVAFGIEADDESLLRTSNGQPVKTAGEITQHNVTELLRDVAAWGRARATGGDLEEQQHAEGSPEPGTPAAPTPESFTVHFLPLNSAQTLHHKSCYNGRFQLLYVACGMVHLLIPELGACVAPGGNLIVELARYLVDVRQEQLQGFNTRVRELAQAAGFAPQTGARPSETFARFCKSQESALGNTVPAVEPGTPPLDILAQPLEASNPALEGLTQPLQGGTPHCEPCQLPSESPGSLSEVLAQPQGALAPPNCESDSKTGV>sp|Q8N9W5-5|DAAF3_HUMAN Isoform 2 of Dynein axonemal assembly factor 3OS=Homo sapiens OX=9606 GN=DNAAF3MTTPAGSGSGFGSVSWWGLSPALDLQAESPPVDPDSQADTVHSNPELDVLLLGSVDGRHLLRTLSRAKFWPRRRFNVSWDEDESPDSRVLEGGRD>sp|Q8N9W5-3|DAAF3_HUMAN Isoform 3 of Dynein axonemal assembly factor 3OS=Homo sapiens OX=9606 GN=DNAAF3MLPLLDSSKRAGTLGSGCGVPRVHSAALSREEGASRDIWRIKVWARVMTTPAGSGSGFGSVSWWGLSPALDLQAERDATVDALPTTMVPQPAVILPGPPVDPDSQADTVHSNPELDVLLLGSVDGRHLLRTLSRAKFWPRRRFNFFVLENNLEAVARHMLIFSLALEEPEKMGLQERSETFLEVWGNALLRPPVAAFVRAQADLLAHLVPEPDRLEEQLPWLSLRALKFRERDALEAVFRFWAGGEKGPQAFPMSRLWDSRLRHYLGSRYDARRGVSDWDLRMKLHDRGAQVIHPQEFRRWRDTGVAFELRDSSAYHVPNRTLASGRLLSYRGERVAARGYWGDIATGPFVAFGIEADDESLLRTSNGQPVKTAGEITQHNVTELLRDVAAWGRARATGGDLEEQQHAEGSPEPGTPAPTPESFTVHFLPLNSAQTLHHKSCYNGRFQLLYVACGMVHLLIPELGACVAPGGNLIVELARYLVDVRQEQLQGFNTRVRELAQAAGFAPQTGARPSETFARFCKSQESALGNTVPAVEPGTPPLDILAQPLEASNPALEGLTQPLQGGTPHCEPCQLPSESPGSLSEVLAQPQGALAPPNCESDSKTGV>sp|Q8N9W5-6|DAAF3_HUMAN Isoform 4 of Dynein axonemal assembly factor 3OS=Homo sapiens OX=9606 GN=DNAAF3MLPLLDSSKRAGTLGSGCGVPRVHSAALSREEGASRDIWRIKVWARVMTTPAGSGSGFGSVSWWGLSPALDLQAESPPVDPDSQADTVHSNPELDVLLLGSVDGRHLLRTLSRAKFWPRRRFNFFVLENNLEAVARHMLIFSLALEEPEKMGLQERSETFLEVWGNALLRPPVAAFVRAQADLLAHLVPEPDRLEEQLPWLSLRALKFRERDALEAVFRFWAGGEKGPQAFPMSRLWDSRLRHYLGSRYDARRGVSDWDLRMKLHDRGAQVIHPQEFRRWRDTGVAFELRDSSAYHVPNRTLASGRLLSYRGERVAARGYWGDIATGPFVAFGIEADDESLLRTSNGQPVKTAGEITQHNVTELLRDVAAWGRARATGGDLEEQQHAEGSPEPGTPAAPTPESFTVHFLPLNSAQTLHHKSCYNGRFQLLYVACGMVHLLIPELGACVAPGGNLIVELARYLVDVRQEQLQGFNTRVRELAQAAGFAPQTGARPSETFARFCKSQESALGNTVPAVEPGTPPLDILAQPLEASNPALEGLTQPLQGGTPHCEPCQLPSESPGSLSEVLAQPQGALAPPNCESDSKTGV>sp|Q8N9W5-7|DAAF3_HUMAN Isoform 5 of Dynein axonemal assembly factor 3OS=Homo sapiens OX=9606 GN=DNAAF3MKMRAQIPESLREEGIEILKPQFFVLENNLEAVARHMLIFSLALEEPEKMGLQERSETFLEVWGNALLRPPVAAFVRAQADLLAHLVPEPDRLEEQLPWLSLRALKFRERDALEAVFRFWAGGEKGPQAFPMSRLWDSRLRHYLGSRYDARRGVSDWDLRMKLHDRGAQVIHPQEFRRWRDTGVAFELRDSSAYHVPNRTLASGRLLSYRGERVAARGYWGDIATGPFVAFGIEADDESLLRTSNGQPVKTAGEITQHNVTELLRDVAAWGRARATGGDLEEQQHAEGSPEPGTPAAPTPESFTVHFLPLNSAQTLHHKSCYNGRFQLLYVACGMVHLLIPELGACVAPGGNLIVELARYLVDVRQEQLQGFNTRVRELAQAAGFAPQTGARPSETFARFCKSQESALGNTVPAVEPGTPPLDILAQPLEASNPALEGLTQPLQGGTPHCEPCQLPSESPGSLSEVLAQPQGALAPPNCESDSKTGV>sp|B0L3A2|DEAR_HUMAN Dual endothelin-1(VEGFsp)/angiotensin II receptorOS=Homo sapiens OX=9606 GN=FBXW7-AS1 PE=1 SV=1MTMFKGSNEMKSRWNWGSITCIICFTCVGSQLSMSSSKASNFSGPLQLYQRELEIFIVLTDVPNYRLIKENSHLHTTIVDQGRTV>sp|Q9Y3I1|FBX7_HUMAN F-box only protein 7 OS=Homo sapiens OX=9606GN=FBXO7 PE=1 SV=1MRLRVRLLKRTWPLEVPETEPTLGHLRSHLRQSLLCTWGYSSNTRFTITLNYKDPLTGDEETLASYGIVSGDLICLILQDDIPAPNIPSSTDSEHSSLQNNEQPSLATSSNQTSMQDEQPSDSFQGQAAQSGVWNDDSMLGPSQNFEAESIQDNAHMAEGTGFYPSEPMLCSESVEGQVPHSLETLYQSADCSDANDALIVLIHLLMLESGYIPQGTEAKALSMPEKWKLSGVYKLQYMHPLCEGSSATLTCVPLGNLIVVNATLKINNEIRSVKRLQLLPESFICKEKLGENVANIYKDLQKLSRLFKDQLVYPLLAFTRQALNLPDVFGLVVLPLELKLRIFRLLDVRSVLSLSAVCRDLFTASNDPLLWRFLYLRDFRDNTVRVQDTDWKELYRKRHIQRKESPKGRFVMLLPSSTHTIPFYPNPLHPRPFPSSRLPPGIIGGEYDQRPTLPYVGDPISSLIPGPGETPSQFPPLRPRFDPVGPLPGPNPILPGRGGPNDRFPFRPSRGRPTDGRLSFM>sp|Q9Y3I1-2|FBX7_HUMAN Isoform 2 of F-box only protein 7 OS=Homo sapiensOX=9606 GN=FBXO7MARPPGGSGPLLDSEHSSLQNNEQPSLATSSNQTSMQDEQPSDSFQGQAAQSGVWNDDSMLGPSQNFEAESIQDNAHMAEGTGFYPSEPMLCSESVEGQVPHSLETLYQSADCSDANDALIVLIHLLMLESGYIPQGTEAKALSMPEKWKLSGVYKLQYMHPLCEGSSATLTCVPLGNLIVVNATLKINNEIRSVKRLQLLPESFICKEKLGENVANIYKDLQKLSRLFKDQLVYPLLAFTRQALNLPDVFGLVVLPLELKLRIFRLLDVRSVLSLSAVCRDLFTASNDPLLWRFLYLRDFRDNTVRVQDTDWKELYRKRHIQRKESPKGRFVMLLPSSTHTIPFYPNPLHPRPFPSSRLPPGIIGGEYDQRPTLPYVGDPISSLIPGPGETPSQFPPLRPRFDPVGPLPGPNPILPGRGGPNDRFPFRPSRGRPTDGRLSFM>sp|Q9Y3I1-3|FBX7_HUMAN Isoform 3 of F-box only protein 7 OS=Homo sapiensOX=9606 GN=FBXO7MQDEQPSDSFQGQAAQSGVWNDDSMLGPSQNFEAESIQDNAHMAEGTGFYPSEPMLCSESVEGQVPHSLETLYQSADCSDANDALIVLIHLLMLESGYIPQGTEAKALSMPEKWKLSGVYKLQYMHPLCEGSSATLTCVPLGNLIVVNATLKINNEIRSVKRLQLLPESFICKEKLGENVANIYKDLQKLSRLFKDQLVYPLLAFTRQALNLPDVFGLVVLPLELKLRIFRLLDVRSVLSLSAVCRDLFTASNDPLLWRFLYLRDFRDNTVRVQDTDWKELYRKRHIQRKESPKGRFVMLLPSSTHTIPFYPNPLHPRPFPSSRLPPGIIGGEYDQRPTLPYVGDPISSLIPGPGETPSQFPPLRPRFDPVGPLPGPNPILPGRGGPNDRFPFRPSRGRPTDGRLSFM>sp|Q9BVV2|FND11_HUMAN Fibronectin type III domain-containing protein 11OS=Homo sapiens OX=9606 GN=FNDC11 PE=1 SV=1MSTHVAGLGLDKMKLGNPQSFLDQEEADDQQLLEPEAWKTYTERRNALREFLTSDLSPHLLKRHHARMQLLRKCSYYIEVLPKHLALGDQNPLVLPSALFQLIDPWKFQRMKKVGTAQTKIQLLLLGDLLEQLDHGRAELDALLRSPDPRPFLADWALVERRLADVSAVMDSFLTMMVPGRLHVKHRLVSDVSATKIPHIWLMLSTKMPVVFDRKASAAHQDWARLRWFVTIQPATSEQYELRFRLLDPRTQQECAQCGVIPVAACTFDVRNLLPNRSYKFTIKRAETSTLVYEPWRDSLTLHTKPEPLEGPALSHSV>sp|O94760|DDAH1_HUMAN N(G),N(G)-dimethylarginine dimethylaminohydrolase1 OS=Homo sapiens OX=9606 GN=DDAH1 PE=1 SV=3MAGLGHPAAFGRATHAVVRALPESLGQHALRSAKGEEVDVARAERQHQLYVGVLGSKLGLQVVELPADESLPDCVFVEDVAVVCEETALITRPGAPSRRKEVDMMKEALEKLQLNIVEMKDENATLDGGDVLFTGREFFVGLSKRTNQRGAEILADTFKDYAVSTVPVADGLHLKSFCSMAGPNLIAIGSSESAQKALKIMQQMSDHRYDKLTVPDDIAANCIYLNIPNKGHVLLHRTPEEYPESAKVYEKLKDHMLIPVSMSELEKVDGLLTCCSVLINKKVDS>sp|O94760-2|DDAH1_HUMAN Isoform 2 of N(G),N(G)-dimethylargininedimethylaminohydrolase 1 OS=Homo sapiens OX=9606 GN=DDAH1MMKEALEKLQLNIVEMKDENATLDGGDVLFTGREFFVGLSKRTNQRGAEILADTFKDYAVSTVPVADGLHLKSFCSMAGPNLIAIGSSESAQKALKIMQQMSDHRYDKLTVPDDIAANCIYLNIPNKGHVLLHRTPEEYPESAKVYEKLKDHMLIPVSMSELEKVDGLLTCCSVLINKKVDS>sp|Q8IYS4|DAAF8_HUMAN Dynein axonemal assembly factor 8 OS=Homo sapiensOX=9606 GN=DNAAF8 PE=1 SV=3MASNDKGMAPSLGSPWASQMGPWDAILKAVKDQLPSLDSDSPLSDYGEEELFIFQRNQTSLIPDLSEELAEDPADGDKSRAWVAAAEESLPEPVLVPAELATEPGCRQNTRTKDASSQEGRDPGRPFESSGEVSALLGMAEEPPRWLEGDLGSLSFNTKGSQGPPWDPQAEATLSCHEGDPKAEPLSTASQESVNRRALRQERRKMIETDILQKVTRDACGPTSSDKGGVKEAPCHAAESAPRSKMPLVEPPEGPPVLSLQQLEAWDLDDILQSLAGQEDNQGNRAPGTVWWAADHRQVQDRMVPSAHNRLMEQLALLCTTQSKASACARKVPADTPQDTKEADSGSRCASRKQGSQAGPGPQLAQGMRLNAESPTIFIDLRQMELPDHLSPESSSHSSSDSEEEEEEEMAALGDAEGASPSSLGLRTCTGKSQLLQQLRAFQKGTAQPELPASKGPAGGRAQAPEDTAGSRTGRKQHMKLCAKGQSAQARLPRGRPRALGDVPEPGAAREALMPPLEQL>sp|O75553|DAB1_HUMAN Disabled homolog 1 OS=Homo sapiens OX=9606 GN=DAB1PE=1 SV=3MSTETELQVAVKTSAKKDSRKKGQDRSEATLIKRFKGEGVRYKAKLIGIDEVSAARGDKLCQDSMMKLKGVVAGARSKGEHKQKIFLTISFGGIKIFDEKTGALQHHHAVHEISYIAKDITDHRAFGYVCGKEGNHRFVAIKTAQAAEPVILDLRDLFQLIYELKQREELEKKAQKDKQCEQAVYQTILEEDVEDPVYQYIVFEAGHEPIRDPETEENIYQVPTSQKKEGVYDVPKSQPVSNGYSFEDFEERFAAATPNRNLPTDFDEIFEATKAVTQLELFGDMSTPPDITSPPTPATPGDAFIPSSSQTLPASADVFSSVPFGTAAVPSGYVAMGAVLPSFWGQQPLVQQQMVMGAQPPVAQVMPGAQPIAWGQPGLFPATQQPWPTVAGQFPPAAFMPTQTVMPLPAAMFQGPLTPLATVPGTSDSTRSSPQTDKPRQKMGKETFKDFQMAQPPPVPSRKPDQPSLTCTSEAFSSYFNKVGVAQDTDDCDDFDISQLNLTPVTSTTPSTNSPPTPAPRQSSPSKSSASHASDPTTDDIFEEGFESPSKSEEQEAPDGSQASSNSDPFGEPSGEPSGDNISPQAGS>sp|O75553-2|DAB1_HUMAN Isoform DAB213 of Disabled homolog 1 OS=Homosapiens OX=9606 GN=DAB1MSTETELQVAVKTSAKKDSRKKGQDRSEATLIKRFKGEGVRYKAKLIGIDEVSAARGDKLCQDSMMKLKGVVAGARSKGEHKQKIFLTISFGGIKIFDEKTGALQHHHAVHEISYIAKDITDHRAFGYVCGKEGNHRFVAIKTAQAAEPVILDLRDLFQLIYELKQREELEKKAQKDKQCEQAVYQTILEEDVEDPVYQVISETSRGFRFKSD>sp|O75553-3|DAB1_HUMAN Isoform DAB469 of Disabled homolog 1 OS=Homosapiens OX=9606 GN=DAB1MSTETELQVAVKTSAKKDSRKKGQDRSEATLIKRFKGEGVRYKAKLIGIDEVSAARGDKLCQDSMMKLKGVVAGARSKGEHKQKIFLTISFGGIKIFDEKTGVPTSQKKEGVYDVPKSQPVSNGYSFEDFEERFAAATPNRNLPTDFDEIFEATKAVTQLELFGDMSTPPDITSPPTPATPGDAFIPSSSQTLPASADVFSSVPFGTAAVPSGYVAMGAVLPSFWGQQPLVQQQMVMGAQPPVAQVMPGAQPIAWGQPGLFPATQQPWPTVAGQFPPAAFMPTQTVMPLPAAMFQGPLTPLATVPGTSDSTRSSPQTDKPRQKMGKETFKDFQMAQPPPVPSRKPDQPSLTCTSEAFSSYFNKVGVAQDTDDCDDFDISQLNLTPVTSTTPSTNSPPTPAPRQSSPSKSSASHASDPTTDDIFEEGFESPSKSEEQEAPDGSQASSNSDPFGEPSGEPSGDNISPQAGS>sp|O75553-4|DAB1_HUMAN Isoform DAB537 of Disabled homolog 1 OS=Homosapiens OX=9606 GN=DAB1MSTETELQVAVKTSAKKDSRKKGQDRSEATLIKRFKGEGVRYKAKLIGIDEVSAARGDKLCQDSMMKLKGVVAGARSKGEHKQKIFLTISFGGIKIFDEKTGALQHHHAVHEISYIAKDITDHRAFGYVCGKEGNHRFVAIKTAQAAEPVILDLRDLFQLIYELKQREELEKKAQKDKQCEQAVYQVPTSQKKEGVYDVPKSQPVSNGYSFEDFEERFAAATPAVTQLELFGDMSTPPDITSPPTPATPGDAFIPSSSQTLPASADVFSSVPFGTAAVPSGYVAMGAVLPSFWGQQPLVQQQMVMGAQPPVAQVMPGAQPIAWGQPGLFPATQQPWPTVAGQFPPAAFMPTQTVMPLPAAMFQGPLTPLATVPGTSDSTRSSPQTDKPRQKMGKETFKDFQMAQPPPVPSRKPDQPSLTCTSEAFSSYFNKVGVAQDTDDCDDFDISQLNLTPVTSTTPSTNSPPTPAPRQSSPSKSSASHASDPTTDDIFEEGFESPSKSEEQEAPDGSQASSNSDPFGEPSGEPSGDNISPQAGS>sp|O75553-5|DAB1_HUMAN Isoform DAB553 of Disabled homolog 1 OS=Homosapiens OX=9606 GN=DAB1MSTETELQVAVKTSAKKDSRKKGQDRSEATLIKRFKGEGVRYKAKLIGIDEVSAARGDKLCQDSMMKLKGVVAGARSKGEHKQKIFLTISFGGIKIFDEKTGALQHHHAVHEISYIAKDITDHRAFGYVCGKEGNHRFVAIKTAQAAEPVILDLRDLFQLIYELKQREELEKKAQKDKQCEQAVYQVPTSQKKEGVYDVPKSQPVSNGYSFEDFEERFAAATPNRNLPTDFDEIFEATKAVTQLELFGDMSTPPDITSPPTPATPGDAFIPSSSQTLPASADVFSSVPFGTAAVPSGYVAMGAVLPSFWGQQPLVQQQMVMGAQPPVAQVMPGAQPIAWGQPGLFPATQQPWPTVAGQFPPAAFMPTQTVMPLPAAMFQGPLTPLATVPGTSDSTRSSPQTDKPRQKMGKETFKDFQMAQPPPVPSRKPDQPSLTCTSEAFSSYFNKVGVAQDTDDCDDFDISQLNLTPVTSTTPSTNSPPTPAPRQSSPSKSSASHASDPTTDDIFEEGFESPSKSEEQEAPDGSQASSNSDPFGEPSGEPSGDNISPQAGS>sp|O75553-6|DAB1_HUMAN Isoform DAB555 of Disabled homolog 1 OS=Homosapiens OX=9606 GN=DAB1MSTETELQVAVKTSAKKDSRKKGQDRSEATLIKRFKGEGVRYKAKLIGIDEVSAARGDKLCQDSMMKLKGVVAGARSKGEHKQKIFLTISFGGIKIFDEKTGALQHHHAVHEISYIAKDITDHRAFGYVCGKEGNHRFVAIKTAQAAEPVILDLRDLFQLIYELKQREELEKKAQKDKQCEQAVYQTILEEDVEDPVYQYIVFEAGHEPIRDPETEENIYQVPTSQKKEGVYDVPKSQPVSAVTQLELFGDMSTPPDITSPPTPATPGDAFIPSSSQTLPASADVFSSVPFGTAAVPSGYVAMGAVLPSFWGQQPLVQQQMVMGAQPPVAQVMPGAQPIAWGQPGLFPATQQPWPTVAGQFPPAAFMPTQTVMPLPAAMFQGPLTPLATVPGTSDSTRSSPQTDKPRQKMGKETFKDFQMAQPPPVPSRKPDQPSLTCTSEAFSSYFNKVGVAQDTDDCDDFDISQLNLTPVTSTTPSTNSPPTPAPRQSSPSKSSASHASDPTTDDIFEEGFESPSKSEEQEAPDGSQASSNSDPFGEPSGEPSGDNISPQAGS>sp|Q9NRR1|CYTL1_HUMAN Cytokine-like protein 1 OS=Homo sapiens OX=9606GN=CYTL1 PE=1 SV=1MRTPGPLPVLLLLLAGAPAARPTPPTCYSRMRALSQEITRDFNLLQVSEPSEPCVRYLPRLYLDIHNYCVLDKLRDFVASPPCWKVAQVDSLKDKARKLYTIMNSFCRRDLVFLLDDCNALEYPIPVTTVLPDRQR>sp|Q5VW00|DC122_HUMAN DDB1- and CUL4-associated factor 12-like protein 2OS=Homo sapiens OX=9606 GN=DCAF12L2 PE=2 SV=1MAQQQTGSRKRKAPAVEAGAGSSSSQGLAAADGEGPLLPKKQKRPATRRRLVHYLKGREVGARGPAGLQGFEGELRGYAVQRLPELLTERQLDLGTLNKVFASQWLNARQVVCGTKCNTLFVVDVQSGHITRIPLMRDKEAGLAQAHQGCGIHAIELNPSKTLLATGGENPNSLAIYQLPTLDPLCLGDRHGHKDWIFAVAWLSDTVAVSGSRDGTVALWRMDPDMFNGSIAWHSEVGLPVYAHIRPRDVEAIPRASTNPSNRKVRALAFSGKNQELGAVSLDGYFHLWKARSTLSRLLSIRLPYCRENVCLTYCDELSLYAVGSQSHVSFLDPRQRQQNIRPLCSREGGTGVRSLSFYQHIITVGTGHGSLLFYDIRAQKFLEERASSSLDSMPGPAGRKLKLACGRGWLNQDDVWVNYFGGMGEFPNALYTHCYNWPEMKLFVAGGPLPSGLHGNYAGLWS>sp|P49789|FHIT_HUMAN Bis(5'-adenosyl)-triphosphatase OS=Homo sapiensOX=9606 GN=FHIT PE=1 SV=3MSFRFGQHLIKPSVVFLKTELSFALVNRKPVVPGHVLVCPLRPVERFHDLRPDEVADLFQTTQRVGTVVEKHFHGTSLTFSMQDGPEAGQTVKHVHVHVLPRKAGDFHRNDSIYEELQKHDKEDFPASWRSEEEMAAEAAALRVYFQ>sp|Q9H1C7|CYTM1_HUMAN Cysteine-rich and transmembrane domain-containingprotein 1 OS=Homo sapiens OX=9606 GN=CYSTM1 PE=1 SV=1MNQENPPPYPGPGPTAPYPPYPPQPMGPGPMGGPYPPPQGYPYQGYPQYGWQGGPQEPPKTTVYVVEDQRRDELGPSTCLTACWTALCCCCLWDMLT>sp|Q96GE9|DMAC1_HUMAN Distal membrane-arm assembly complex protein 1OS=Homo sapiens OX=9606 GN=DMAC1 PE=1 SV=1MGSRLSQPFESYITAPPGTAAAPAKPAPPATPGAPTSPAEHRLLKTCWSCRVLSGLGLMGAGGYVYWVARKPMKMGYPPSPWTITQMVIGLSENQGIATWGIVVMADPKGKAYRVV>sp|Q96GE9-2|DMAC1_HUMAN Isoform 2 of Distal membrane-arm assemblycomplex protein 1 OS=Homo sapiens OX=9606 GN=DMAC1MGSRLSQPFESYITAPPGTAAAPAKPAPPATPGAPTSPAEHRLLKTCWSCRVLSGLGLMGAGGYVYWVARKPMKMGYPPSPWTITQMVIGLSIATWGIVVMADPKGKAYRVV>sp|Q9H7Y0|DIK2B_HUMAN Divergent protein kinase domain 2B OS=Homo sapiensOX=9606 GN=DIPK2B PE=2 SV=3MEPQLGPEAAALRPGWLALLLWVSALSCSFSLPASSLSSLVPQVRTSYNFGRTFLGLDKCNACIGTSICKKFFKEEIRSDNWLASHLGLPPDSLLSYPANYSDDSKIWRPVEIFRLVSKYQNEISDRRICASASAPKTCSIERVLRKTERFQKWLQAKRLTPDLVQGLASPLLRCPSQRLLDRVVRRYAEVADAGSIFMDHFTDRDKLRLLYTLAVNSHPILLQIFPGAEGWPLPKYLGSCGRFLVSTSTRPLQEFYDAPPDQAADLAYQLLGVLESLRSNDLNYFFYFTHIDAGMFGVFNNGHLFIRDASAVGVIDKQEGSQEANRAGENKDIFSCLVSGCQAQLPSCESISEKQSLVLVCQKLLPRLLQGRFPSPVQDDIDSILVQCGDSIRPDPEVLGAASQLKDILRPLRTCDSRFAYRYPDCKYNDKF>sp|Q9H7Y0-2|DIK2B_HUMAN Isoform 2 of Divergent protein kinase domain 2BOS=Homo sapiens OX=9606 GN=DIPK2BMEPQLGPEAAALRPGWLALLLWVSALSCSFSLPASSLSSLVPQVRTSYNFGRTFLGLDKCNACIGTSICKKFFKEEIRSDNWLASHLGLPPDSLLSYPANYSDDSKIWRPVEIFRLVSKYQNEISDRRICASASAPKTCSIERVLRKTERFQKWLQAKRLTPDLVQDCHQGQRELKFLCMLR>sp|P28068|DMB_HUMAN HLA class II histocompatibility antigen, DM betachain OS=Homo sapiens OX=9606 GN=HLA-DMB PE=1 SV=1MITFLPLLLGLSLGCTGAGGFVAHVESTCLLDDAGTPKDFTYCISFNKDLLTCWDPEENKMAPCEFGVLNSLANVLSQHLNQKDTLMQRLRNGLQNCATHTQPFWGSLTNRTRPPSVQVAKTTPFNTREPVMLACYVWGFYPAEVTITWRKNGKLVMPHSSAHKTAQPNGDWTYQTLSHLALTPSYGDTYTCVVEHIGAPEPILRDWTPGLSPMQTLKVSVSAVTLGLGLIIFSLGVISWRRAGHSSYTPLPGSNYSEGWHIS>sp|P37058|DHB3_HUMAN Testosterone 17-beta-dehydrogenase 3 OS=Homosapiens OX=9606 GN=HSD17B3 PE=1 SV=2MGDVLEQFFILTGLLVCLACLAKCVRFSRCVLLNYWKVLPKSFLRSMGQWAVITGAGDGIGKAYSFELAKRGLNVVLISRTLEKLEAIATEIERTTGRSVKIIQADFTKDDIYEHIKEKLAGLEIGILVNNVGMLPNLLPSHFLNAPDEIQSLIHCNITSVVKMTQLILKHMESRQKGLILNISSGIALFPWPLYSMYSASKAFVCAFSKALQEEYKAKEVIIQVLTPYAVSTAMTKYLNTNVITKTADEFVKESLNYVTIGGETCGCLAHEILAGFLSLIPAWAFYSGAFQRLLLTHYVAYLKLNTKVR>sp|P37058-2|DHB3_HUMAN Isoform 2 of Testosterone 17-beta-dehydrogenase 3OS=Homo sapiens OX=9606 GN=HSD17B3MGDVLEQFFILTGLLVCLACLAKCVRFSRCVLLNYWKVLPKSFLRSMGQWAVITGAGDGIGKAYSFELAKRGLNVVLISRTLEKLEAIATEIERTTGRSVKIIQADFTKDDIYEHIKEKLAGLEIGILVNNVGMLPNLLPSHFLNAPDEIQSLIHCNITSVVKMTQLILKHMESRQKGLILNISSGIALFPWPLYSMYSASKAFVCAFSKALQEEYKAKEVIIQAGFLSLIPAWAFYSGAFQRLLLTHYVAYLKLNTKVR>sp|Q9H3Z4|DNJC5_HUMAN DnaJ homolog subfamily C member 5 OS=Homo sapiensOX=9606 GN=DNAJC5 PE=1 SV=1MADQRQRSLSTSGESLYHVLGLDKNATSDDIKKSYRKLALKYHPDKNPDNPEAADKFKEINNAHAILTDATKRNIYDKYGSLGLYVAEQFGEENVNTYFVLSSWWAKALFVFCGLLTCCYCCCCLCCCFNCCCGKCKPKAPEGEETEFYVSPEDLEAQLQSDEREATDTPIVIQPASATETTQLTADSHPSYHTDGFN>sp|Q9H3Z4-2|DNJC5_HUMAN Isoform 2 of DnaJ homolog subfamily C member 5OS=Homo sapiens OX=9606 GN=DNAJC5MADQRQRSLSTSGESLYHVLGLDKNATSDDIKKSYRKLALKYHPDKNPDNPEAADKFKEINNAHAILTDATKRNIYDKYGSLGLYVAEQFGEENVNTYFVLSSWWAKALFVFCGLLTCCYCCCCLCCCFNCCCGKCKPKAPEGEETEFYVSPEDLEAQLQSDERGGH>sp|Q92506|DHB8_HUMAN (3R)-3-hydroxyacyl-CoA dehydrogenase OS=Homosapiens OX=9606 GN=HSD17B8 PE=1 SV=2MASQLQNRLRSALALVTGAGSGIGRAVSVRLAGEGATVAACDLDRAAAQETVRLLGGPGSKEGPPRGNHAAFQADVSEARAARCLLEQVQACFSRPPSVVVSCAGITQDEFLLHMSEDDWDKVIAVNLKGTFLVTQAAAQALVSNGCRGSIINISSIVGKVGNVGQTNYAASKAGVIGLTQTAARELGRHGIRCNSVLPGFIATPMTQKVPQKVVDKITEMIPMGHLGDPEDVADVVAFLASEDSGYITGTSVEVTGGLFM>sp|Q86SQ9|DHDDS_HUMAN Dehydrodolichyl diphosphate synthase complexsubunit DHDDS OS=Homo sapiens OX=9606 GN=DHDDS PE=1 SV=3MSWIKEGELSLWERFCANIIKAGPMPKHIAFIMDGNRRYAKKCQVERQEGHSQGFNKLAETLRWCLNLGILEVTVYAFSIENFKRSKSEVDGLMDLARQKFSRLMEEKEKLQKHGVCIRVLGDLHLLPLDLQELIAQAVQATKNYNKCFLNVCFAYTSRHEISNAVREMAWGVEQGLLDPSDISESLLDKCLYTNRSPHPDILIRTSGEVRLSDFLLWQTSHSCLVFQPVLWPEYTFWNLFEAILQFQMNHSVLQKARDMYAEERKRQQLERDQATVTEQLLREGLQASGDAQLRRTRLHKLSARREERVQGFLQALELKRADWLARLGTASA>sp|Q86SQ9-2|DHDDS_HUMAN Isoform 2 of Dehydrodolichyl diphosphatesynthase complex subunit DHDDS OS=Homo sapiens OX=9606 GN=DHDDSMSWIKEGELSLWERFCANIIKAGPMPKHIAFIMDGNRRYAKKCQVERQEGHSQGFNKLAETLRWCLNLGILEVTVYAFSIENFKRSKSEVDGLMDLARQKFSRLMEEKEKLQKHGVCIRVLGDLHLLPLDLQELIAQAVQATKNYNKCFLNVCFAYTSRHEISNAVREMAWGVEQGLLDPSDISESLLDKCLYTNRSPHPDILIRTSGEVRLSDFLLWQTSHSCLVFQPVLWPEYTFWNLFEAILQFQMNHSVLQQKARDMYAEERKRQQLERDQATVTEQLLREGLQASGDAQLRRTRLHKLSARREERVQGFLQALELKRADWLARLGTASA>sp|Q86SQ9-3|DHDDS_HUMAN Isoform 3 of Dehydrodolichyl diphosphatesynthase complex subunit DHDDS OS=Homo sapiens OX=9606 GN=DHDDSMSWIKEGELSLWERFCANIIKAGPMPKHIAFIMDGNRRYAKKCQVERQEGHSQGFNKLAETLRWCLNLGILEVTVYAFSIENFKRSKSEVDGLMDLARQKFSRLMEEKCFLNVCFAYTSRHEISNAVREMAWGVEQGLLDPSDISESLLDKCLYTNRSPHPDILIRTSGEVRLSDFLLWQTSHSCLVFQPVLWPEYTFWNLFEAILQFQMNHSVLQKARDMYAEERKRQQLERDQATVTEQLLREGLQASGDAQLRRTRLHKLSARREERVQGFLQALELKRADWLARLGTASA>sp|Q86SQ9-4|DHDDS_HUMAN Isoform 4 of Dehydrodolichyl diphosphatesynthase complex subunit DHDDS OS=Homo sapiens OX=9606 GN=DHDDSMSWIKEGELSLWERFCANIIKAGPMPKHIAFIMDGNRRYAKKCQVERQEGHSQGFNKLAETLRWCLNLGILEVTVYAFSIENFKRSKSEVDGLMDLARQKFSRLMEEKEKLQKHGVCIRVLGDLHLLPLDLQELIAQAVQATKNYNNDISESLLDKCLYTNRSPHPDILIRTSGEVRLSDFLLWQTSHSCLVFQPVLWPEYTFWNLFEAILQFQMNHSVLQKARDMYAEERKRQQLERDQATVTEQLLREGLQASGDAQLRRTRLHKLSARREERVQGFLQALELKRADWLARLGTASA>sp|Q6PK57|DMP34_HUMAN Putative GED domain-containing protein DNM1P34OS=Homo sapiens OX=9606 GN=DNM1P34 PE=5 SV=1MPSCSPQQASKAEENGSNSFMHSMVPQLEWQMETTQSLVDSYVAIVNKTVWDLMVGLTPKTIMHLMINNNKEFIFSELLANLYLHGDKNMLMEESAEQAQRS>sp|O95633|FSTL3_HUMAN Follistatin-related protein 3 OS=Homo sapiensOX=9606 GN=FSTL3 PE=1 SV=1MRPGAPGPLWPLPWGALAWAVGFVSSMGSGNPAPGGVCWLQQGQEATCSLVLQTDVTRAECCASGNIDTAWSNLTHPGNKINLLGFLGLVHCLPCKDSCDGVECGPGKACRMLGGRPRCECAPDCSGLPARLQVCGSDGATYRDECELRAARCRGHPDLSVMYRGRCRKSCEHVVCPRPQSCVVDQTGSAHCVVCRAAPCPVPSSPGQELCGNNNVTYISSCHMRQATCFLGRSIGVRHAGSCAGTPEEPPGGESAEEEENFV>sp|O95633-2|FSTL3_HUMAN Isoform 2 of Follistatin-related protein 3OS=Homo sapiens OX=9606 GN=FSTL3MGSGNPAPGGVCWLQQGQEATCSLVLQTDVTRAECCASGNIDTAWSNLTHPGNKINLLGFLGLVHCLPCKDSCDGVECGPGKACRMLGGRPRCECAPDCSGLPARLQVCGSDGATYRDECELRAARCRGHPDLSVMYRGRCRKSCEHVVCPRPQSCVVDQTGSAHCVVCRAAPCPVPSSPGQELCGNNNVTYISSCHMRQATCFLGRSIGVRHAGSCAGTPEEPPGGESAEEEENFV>sp|A6NGK3|GAG10_HUMAN G antigen 10 OS=Homo sapiens OX=9606 GN=GAGE10PE=1 SV=1MSWRGRSTYRSRPRLYVEPPEMIGPMLPEQFSDEVEPATPEEGEPATQRQDPAAAQEGEDEGASAGQGPKPEADSQEQVHPKTGCECGDGPDGQEMGLPNPEEVKRPEEGEKQSQC>sp|Q96IV6|FXDC2_HUMAN Fatty acid hydroxylase domain-containing protein 2OS=Homo sapiens OX=9606 GN=FAXDC2 PE=1 SV=1MKGEAGHMLHNEKSKQEGHIWGSMRRTAFILGSGLLSFVAFWNSVTWHLQRFWGASGYFWQAQWERLLTTFEGKEWILFFIGAIQVPCLFFWSFNGLLLVVDTTGKPNFISRYRIQVGKNEPVDPVKLRQSIRTVLFNQCMISFPMVVFLYPFLKWWRDPCRRELPTFHWFLLELAIFTLIEEVLFYYSHRLLHHPTFYKKIHKKHHEWTAPIGVISLYAHPIEHAVSNMLPVIVGPLVMGSHLSSITMWFSLALIITTISHCGYHLPFLPSPEFHDYHHLKFNQCYGVLGVLDHLHGTDTMFKQTKAYERHVLLLGFTPLSESIPDSPKRME>sp|Q96IV6-2|FXDC2_HUMAN Isoform 2 of Fatty acid hydroxylase domain-containing protein 2 OS=Homo sapiens OX=9606 GN=FAXDC2MRRTAFILGSGLLSFVAFWNSVTWHLQRFWGASGYFWQAQWERLLTTFEGKEWILFFIGAIQVPCLFFWSFNGLLLVVDTTGKPNFISRYRIQVGKNEPVDPVKLRQSIRTVLFNQCMISFPMVVFLYPFLKWWRDPCRRELPTFHWFLLELAIFTLIEEVLFYYSHRLLHHPTFYKKIHKKHHEWTAPIGVISLYAHPIEHAVSNMLPVIVGPLVMGSHLSSITMWFSLALIITTISHCGYHLPFLPSPEFHDYHHLKFNQCYGVLGVLDHLHGTDTMFKQTKAYERHVLLLGFTPLSESIPDSPKRME>sp|Q4V321|GAG13_HUMAN G antigen 13 OS=Homo sapiens OX=9606 GN=GAGE13PE=3 SV=2MSWRGRSTYYWPRPRRYVEPPEMIGPMRPEQFSDEVEPATPEEGEPATQRQDPAAAQEGEDEGASAGQGPKPEADSQEQGHPQTGCECEDGPDGQEMDPPNPEEVKTPEEGEKQSQC>sp|Q6NT46|GAG2A_HUMAN G antigen 2A OS=Homo sapiens OX=9606 GN=GAGE2APE=1 SV=1MSWRGRSTYRPRPRRYVEPPEMIGPMRPEQFSDEVEPATPEEGEPATQRQDPAAAQEGQDEGASAGQGPKPEAHSQEQGHPQTGCECEDGPDGQEMDPPNPEEVKTPEEGEKQSQC>sp|Q9Y5R5|DMRT2_HUMAN Doublesex- and mab-3-related transcription factor2 OS=Homo sapiens OX=9606 GN=DMRT2 PE=1 SV=2MADPQAGSAAGDWEIDVESLELEEDVCGAPRSTPPGPSPPPADGDCEDDEDDDGVDEDAEEEGDGEEAGASPGMPGQPEQRGGPQPRPPLAPQASPAGTGPRERCTPAGGGAEPRKLSRTPKCARCRNHGVVSCLKGHKRFCRWRDCQCANCLLVVERQRVMAAQVALRRQQATEDKKGLSGKQNNFERKAVYQRQVRAPSLLAKSILEGYRPIPAETYVGGTFPLPPPVSDRMRKRRAFADKELENIMLEREYKEREMLETSQAAALFLPNRMVPGPDYNSYKSAYSPSPVEPPSKDFCNFLPTCLDLTMQYSGSGNMELISSNVSVATTYRQYPLSSRFLVWPKCGPISDTLLYQQCLLNATTSVQALKPGASWDLKGARVQDGLSAEQDMMPSKLEGSLVLPHTPEIQTTRSDLQGHQAVPERSAFSPPRRNFSPIVDTDSLAAQGHVLTKISKENTRHPLPLRHNPFHSLFQQTLTDKSGPELKTPFVKEAFEETPKKHRECLVKDNQKYTFTIDRCAKDLFVAKQVGTKLSVNEPLSFSVESILKRPSSAITRVSQ>sp|Q9Y5R5-2|DMRT2_HUMAN Isoform 2 of Doublesex- and mab-3-relatedtranscription factor 2 OS=Homo sapiens OX=9606 GN=DMRT2MADPQAGSAAGDWEIDVESLELEEDVCGAPRSTPPGPSPPPADGDCEDDEDDDGVDEDAEEEGDGEEAGASPGMPGQPEQRGGPQPRPPLAPQASPAGTGPRERCTPAGGGAEPRKLSRTPKCARCRNHGVVSCLKGHKRFCRWRDCQCANCLLVVERQRVMAAQVALRRQQATEDKKGLSGKQNNFERKAVYQRQVRAPSLLAKSILEVLLGLFYSYYVYIMNHL>sp|Q9Y5R5-3|DMRT2_HUMAN Isoform 3 of Doublesex- and mab-3-relatedtranscription factor 2 OS=Homo sapiens OX=9606 GN=DMRT2MRKRRAFADKELENIMLEREYKEREMLETSQAAALFLPNRMVPGPDYNSYKSAYSPSPVEPPSKDFCNFLPTCLDLTMQYSGSGNMELISSNVSVATTYRQYPLSSRFLVWPKCGPISDTLLYQQCLLNATTSVQALKPGASWDLKGARVQDGLSAEQDMMPSKLEGSLVLPHTPEIQTTRSDLQGHQAVPERSAFSPPRRNFSPIVDTDSLAAQGHVLTKISKENTRHPLPLRHNPFHSLFQQTLTDKSGPELKTPFVKEAFEETPKKHRECLVKDNQKYTFTIDRCAKDLFVAKQVGTKLSVNEPLSFSVESILKRPSSAITRVSQ>sp|Q6MZW2|FSTL4_HUMAN Follistatin-related protein 4 OS=Homo sapiensOX=9606 GN=FSTL4 PE=2 SV=3MKPGGFWLHLTLLGASLPAALGWMDPGTSRGPDVGVGESQAEEPRSFEVTRREGLSSHNELLASCGKKFCSRGSRCVLSRKTGEPECQCLEACRPSYVPVCGSDGRFYENHCKLHRAACLLGKRITVIHSKDCFLKGDTCTMAGYARLKNVLLALQTRLQPLQEGDSRQDPASQKRLLVESLFRDLDADGNGHLSSSELAQHVLKKQDLDEDLLGCSPGDLLRFDDYNSDSSLTLREFYMAFQVVQLSLAPEDRVSVTTVTVGLSTVLTCAVHGDLRPPIIWKRNGLTLNFLDLEDINDFGEDDSLYITKVTTIHMGNYTCHASGHEQLFQTHVLQVNVPPVIRVYPESQAQEPGVAASLRCHAEGIPMPRITWLKNGVDVSTQMSKQLSLLANGSELHISSVRYEDTGAYTCIAKNEVGVDEDISSLFIEDSARKTLANILWREEGLSVGNMFYVFSDDGIIVIHPVDCEIQRHLKPTEKIFMSYEEICPQREKNATQPCQWVSAVNVRNRYIYVAQPALSRVLVVDIQAQKVLQSIGVDPLPAKLSYDKSHDQVWVLSWGDVHKSRPSLQVITEASTGQSQHLIRTPFAGVDDFFIPPTNLIINHIRFGFIFNKSDPAVHKVDLETMMPLKTIGLHHHGCVPQAMAHTHLGGYFFIQCRQDSPASAARQLLVDSVTDSVLGPNGDVTGTPHTSPDGRFIVSAAADSPWLHVQEITVRGEIQTLYDLQINSGISDLAFQRSFTESNQYNIYAALHTEPDLLFLELSTGKVGMLKNLKEPPAGPAQPWGGTHRIMRDSGLFGQYLLTPARESLFLINGRQNTLRCEVSGIKGGTTVVWVGEV>sp|Q6MZW2-2|FSTL4_HUMAN Isoform 2 of Follistatin-related protein 4OS=Homo sapiens OX=9606 GN=FSTL4MKPGGFWLHLTLLGASLPAALGWMDPGTSRGPDVGVGESQAEEPRSFEVTRREGLSSHNELLASCGKKFCSRGSRCVLSLAPEDRVSVTTVTVGLSTVLTCAVHGDLRPPIIWKRNGLTLNFLDLEDINDFGEDDSLYITKVTTIHMGNYTCHASGHEQLFQTHVLQVNVPPVIRVYPESQAQEPGVAASLRCHAEGIPMPRITWLKNGVDVSTQMSKQLSLLANGSELHISSVRYEDTGAYTCIAKNEVGVDEDISSLFIEDSARKTLANILWREEGLSVGNMFYVFSDDGIIVIHPVDCEIQRHLKPTEKIFMSYEEICPQREKNATQPCQWVSAVNVRNRYIYVAQPALSRVLVVDIQAQKVLQSIGVDPLPAKLSYDKSHDQVWVLSWGDVHKSRPSLQVITEASTGQSQHLIRTPFAGVDDFFIPPTNLIINHIRFGFIFNKSDPAVHKVDLETMMPLKTIGLHHHGCVPQAMAHTHLGGYFFIQCRQDSPASAARQLLVDSVTDSVLGPNGDVTGTPHTSPDGRFIVSAAADSPWLHVQEITVRGEIQTLYDLQINSGISDLAFQRSFTESNQYNIYAALHTEPDLLFLELSTGKVGMLKNLKEPPAGPAQPWGGTHRIMRDSGLFGQYLLTPARESLFLINGRQNTLRCEVSGIKGGTTVVWVGEV>sp|Q6MZW2-3|FSTL4_HUMAN Isoform 3 of Follistatin-related protein 4OS=Homo sapiens OX=9606 GN=FSTL4MKPGGFWLHLTLLGASLPAALGWMDPGTSRGPDVGVGESQAEEPRSFEVTRREGLSSHNELLASCGKKFCSRGSRCVLSRKTGEPECQCLEACRPSYVPVCGSDGRFYENHCKLHRAACLLGKRITVIHSKDCFLKGDTCTMAGYARLKNVLLALQTRLQPLQEGDSRQDPASQKRLLVESLFRDLDADGNGHLSSSELAQHVLKKQDLDEDLLGCSPGDLLRFDDYNSDSSLTLREFYMAFQVVQLSLAPEDRVSVTTVTVGLSTVLTCAVHGDLRPPIIWKRNGLTLNFLDLEDINDFGEDDSLYITKVTTIHMGNYTCHASGHEQLFQTHVLQVNVPPVIRVYPESQAQEPGVAASLRCHAEGIPMPRITWLKNGVDVSTQMSKQLSLLANGSELHISSVRYEDTGAYTCIAKNEVGVDEDISSLFIEDSARKTLANILWREEGLSVGNMFYVFSDDGIIVIHPVDCEIQRHLKPTEKIFMSYEEICPQREKNATQPCQWVSAVNVRNRYIYVAQPALSRVLVVDIQAQKVLQSIGVDPLPAKLSYDKSHDQVWVLSWGDVHKSRPSLQVITEASTGQSQHLIRTPFAGVDDFFIPPINLEQ>sp|Q9NRI5|DISC1_HUMAN Disrupted in schizophrenia 1 protein OS=Homosapiens OX=9606 GN=DISC1 PE=1 SV=3MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRSLQERIKSLNLSLKEITTKVCMSEKFCSTLRKKVNDIETQLPALLEAKMHAISGNHFWTAKDLTEEIRSLTSEREGLEGLLSKLLVLSSRNVKKLGSVKEDYNRLRREVEHQETAYETSVKENTMKYMETLKNKLCSCKCPLLGKVWEADLEACRLLIQSLQLQEARGSLSVEDERQMDDLEGAAPPIPPRLHSEDKRKTPLKVLEEWKTHLIPSLHCAGGEQKEESYILSAELGEKCEDIGKKLLYLEDQLHTAIHSHDEDLIQSLRRELQMVKETLQAMILQLQPAKEAGEREAAASCMTAGVHEAQA>sp|Q9NRI5-2|DISC1_HUMAN Isoform 2 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRSLQERIKSLNLSLKEITTKVCMSEKFCSTLRKKVNDIETQLPALLEAKMHAISGNHFWTAKDLTEEIRSLTSEREGLEGLLSKLLVLSSRNVKKLGSVKEDYNRLRREVEHQETAYETSVKENTMKYMETLKNKLCSCKCPLLGKVWEADLEACRLLIQSLQLQEARGSLSVEDERQMDDLEGAAPPIPPRLHSEDKRKTPLKESYILSAELGEKCEDIGKKLLYLEDQLHTAIHSHDEDLIQSLRRELQMVKETLQAMILQLQPAKEAGEREAAASCMTAGVHEAQA>sp|Q9NRI5-3|DISC1_HUMAN Isoform 3 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRSLQERIKSLNLSLKEITTKVCMSEKFCSTLRKKVNDIETQLPALLEAKMHAISGNHFWTAKDLTEEIRSLTSEREGLEGLLSKLLVLSSRNVKKLGSVKEDYNRLRREVEHQETAYGYKYCDAESWTQRSQQLA>sp|Q9NRI5-4|DISC1_HUMAN Isoform 4 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMELEPIALDPPWKPRHPEPNSY>sp|Q9NRI5-5|DISC1_HUMAN Isoform 5 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRSLQERIKSLNLSLKEITTKVCMSEKFCSTLRKKVNDIETQLPALLEAKMHAISGNHFWTAKDLTEEIRSLTSEREGLEGLLSKLLVLSSRNVKKLGSVKEDYNRLRREVEHQETAYDGVSLCRPVWSAVVRSCSLQPLPPEFKQFSCLSLRSSWDYRCPPPCLANFVFLVEMGFYHVDQTGLKLLTSSDPPSSASQSAGITDMSHCAWPLQ>sp|Q9NRI5-6|DISC1_HUMAN Isoform 6 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRSLQERIKSLNLSLKEITTKETISGRLKTSPRRLDH>sp|Q9NRI5-7|DISC1_HUMAN Isoform 7 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRRNKCEGKYYEVHGNT>sp|Q9NRI5-8|DISC1_HUMAN Isoform 8 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRSLQERIKSLNLSLKEITTKVCMSEKFCSTLRKKVNDIETQLPALLEAKMHAISGNHFWTAKDLTEEIRSLTSEREGLEGLLSKLLVLSSRNVKKLGSVKEDYNRLRREVEHQETAYAASVHCLGKCGKLTWKLVDCLSRAYSSRKPGEACL>sp|Q9NRI5-9|DISC1_HUMAN Isoform 9 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMEVISLRLKLQKLQEDAVENDDYDKAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRSLQERIKSLNLSLKEITTKVCMSEKFCSTLRKKVNDIETQLPALLEAKMHAISGNHFWTAKDLTEEIRSLTSEREGLEGLLSKLLVLSSRNVKKLGSVKEDYNRLRREVEHQETAYGR>sp|Q9NRI5-10|DISC1_HUMAN Isoform 10 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAGSRDCLPPAACFRRRRLARRPGYMRSSTGPGIGFLSPAVGTLFRFPGGVSGEESHHSESRARQCGLDSRGLLVRSPVSKSAAAPTVTSVRGTSAHFGIQLRGGTRLPDRLSWPCGPGSAGWQQEFAAMDSSETLDASWEAACSDGARRVRAAGSLPSAELSSNSCSPGCGPEVPPTPPGSHSAFTSSFSFIRLSLGSAGERGEAEGCPPSREAESHCQSPQEMGAKAASLDGPHEDPRCLSRPFSLLATRVSADLAQAARNSSRPERDMHSLPDMDPGSSSSLDPSLAGCGGDGSSGSGDAHSWDTLLRKWEPVLRDCLLRNRRQMELRRYNKD>sp|Q9NRI5-11|DISC1_HUMAN Isoform 11 of Disrupted in schizophrenia 1protein OS=Homo sapiens OX=9606 GN=DISC1MPGGGPQGAPAAAGGGGVSHRAAETLQQRLEDLEQEKISLHFQLPSRQPALSSFLGHLAAQVQAALRRGATQQASGDDTHTPLRMEPRLLEPTAQDSLHVSITRRDWLLQEKQQLQKEIEALQARMFVLEAKDQQLRREIEEQEQQLQWQGCDLTPLVGQLSLGQLQEVSKALQDTLASAGQIPFHAEPPETIRRKPFLDG>sp|P00367|DHE3_HUMAN Glutamate dehydrogenase 1, mitochondrial OS=Homosapiens OX=9606 GN=GLUD1 PE=1 SV=2MYRYLGEALLLSRAGPAALGSASADSAALLGWARGQPAAAPQPGLALAARRHYSEAVADREDDPNFFKMVEGFFDRGASIVEDKLVEDLRTRESEEQKRNRVRGILRIIKPCNHVLSLSFPIRRDDGSWEVIEGYRAQHSQHRTPCKGGIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAGVTFT>sp|P00367-2|DHE3_HUMAN Isoform 2 of Glutamate dehydrogenase 1,mitochondrial OS=Homo sapiens OX=9606 GN=GLUD1MTYKCAVVDVPFGGAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAGVTFT>sp|P00367-3|DHE3_HUMAN Isoform 3 of Glutamate dehydrogenase 1,mitochondrial OS=Homo sapiens OX=9606 GN=GLUD1MTCPCDNASSVFLGFCIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYTMERSARQIMRTAMKYNLGLDLRTAAYVNAIEKVFKVYNEAGVTFT>sp|Q9P2K9|DISP3_HUMAN Protein dispatched homolog 3 OS=Homo sapiensOX=9606 GN=DISP3 PE=2 SV=2MDTEDDPLLQDVWLEEEQEEEEATGETFLGAQKPGPQPGAGGQCCWRHWPLASRPPASGFWSTLGWAFTNPCCAGLVLFLGCSIPMALSAFMFLYYPPLDIDISYNAFEIRNHEASQRFDALTLALKSQFGSWGRNRRDLADFTSETLQRLISEQLQQLHLGNRSRQASRAPRVIPAASLGGPGPYRDTSAAQKPTANRSGRLRRETPPLEDLAANQSEDPRNQRLSKNGRYQPSIPPHAAVAANQSRARRGASRWDYSRAYVSANTQTHAHWRIELIFLARGDAERNIFTSERLVTIHEIERKIMDHPGFREFCWKPHEVLKDLPLGSYSYCSPPSSLMTYFFPTERGGKIYYDGMGQDLADIRGSLELAMTHPEFYWYVDEGLSADNLKSSLLRSEILFGAPLPNYYSVDDRWEEQRAKFQSFVVTYVAMLAKQSTSKVQVLYGGTDLFDYEVRRTFNNDMLLAFISSSCIAALVYILTSCSVFLSFFGIASIGLSCLVALFLYHVVFGIQYLGILNGVAAFVIVGIGVDDVFVFINTYRQATHLEDPQLRMIHTVQTAGKATFFTSLTTAAAYAANVFSQIPAVHDFGLFMSLIVSCCWLAVLVTMPAALGLWSLYLAPLESSCQTSCHQNCSRKTSLHFPGDVFAAPEQVGGSPAQGPIPYLDDDIPLLEVEEEPVSLELGDVSLVSVSPEGLQPASNTGSRGHLIVQLQELLHHWVLWSAVKSRWVIVGLFVSILILSLVFASRLRPASRAPLLFRPDTNIQVLLDLKYNLSAEGISCITCSGLFQEKPHSLQNNIRTSLEKKRRGSGVPWASRPEATLQDFPGTVYISKVKSQGHPAVYRLSLNASLPAPWQAVSPGDGEVPSFQVYRAPFGNFTKKLTACMSTVGLLQAASPSRKWMLTTLACDAKRGWKFDFSFYVATKEQQHTRKLYFAQSHKPPFHGRVCMAPPGCLLSSSPDGPTKGFFFVPSEKVPKARLSATFGFNPCVNTGCGKPAVRPLVDTGAMVFVVFGIIGVNRTRQVDNHVIGDPGSVVYDSSFDLFKEIGHLCHLCKAIAANSELVKPGGAQCLPSGYSISSFLQMLHPECKELPEPNLLPGQLSHGAVGVREGRVQWISMAFESTTYKGKSSFQTYSDYLRWESFLQQQLQALPEGSVLRRGFQTCEHWKQIFMEIVGVQSALCGLVLSLLICVAAVAVFTTHILLLLPVLLSILGIVCLVVTIMYWSGWEMGAVEAISLSILVGSSVDYCVHLVEGYLLAGENLPPHQAEDARTQRQWRTLEAVRHVGVAIVSSALTTVIATVPLFFCIIAPFAKFGKIVALNTGVSILYTLTVSTALLGIMAPSSFTRTRTSFLKALGAVLLAGALGLGACLVLLQSGYKIPLPAGASL>sp|Q9P2K9-2|DISP3_HUMAN Isoform 2 of Protein dispatched homolog 3OS=Homo sapiens OX=9606 GN=DISP3MDTEDDPLLQDVWLEEEQEEEEATGETFLGAQKPGPQPGAGGQCCWRHWPLASRPPASGFWSTLGWAFTNPCCAGLVLFLGCSIPMALSAFMFLYYPPLDIDISYNAFEIRNHEASQRFDALTLALKSQFGSWGRNRRDLADFTSETLQRLISEQLQQLHLGNRSRQASRAPRVIPAASLGGPGPYRDTSAAQKPTANRSGRLRRETPPLEDLAANQSEDPRNQRLSKNGRYQPSIPPHAAVAANQSRARRGASRWDYSRAYVSANTQTHAHWRIELIFLARGDAERNIFTSERLVTIHEIERKIMDHPGFREFCWKPHEVLKDLPLGSYSYCSPPSSLMTYFFPTERGGKIYYDGMGQDLADIRGSLELAMTHPEFYWYVDEGLSADNLKSSLLRSEILFGAPLPNYYSVDDRWEEQRAKFQSFVVTYVAMLAKQSTSKVQVLYGGTDLFDYEVRRTFNNDMLLAFISSSCIAALVYILTSCSVFLSFFGIASIGLSCLVALFLYHVVFGIQYLGILNGVAAFVIVGIGVDDVFVFINTYRQATHLEDPQLRMIHTVQTAGKATFFTSLTTAAAYAANVFSQIPAVHDFGLFMSLIVSCCWLAVLVTMPAALGLWSLYLAPLESSCQTSCHQNCSRKTSLHFPGDVFAAPEQVGGSPAQGPIPYLDDDIPLLEVEEEPVSLELGDVSLVSVSPEGLQPASNTGSRGHLIVQLQELLHHWVLWSAVKSRWVIVGLFVSILILSLVFASRLRPASRAPLLFRPDTNIQVLLDLKYNLSAEGISCITCSGLFQEKPHSLQNNIRTSLEKKRRGSGVPWASRPEATLQDFPGTVYISKVKSQGHPAVYRLSLNASLPAPWQAVSPGDGEVPSFQVYRAPFGNFTKKLTACMSTVGLLQAASPSRKWMLTTLACDAKRGWKFDFSFYVATKEQQHTR>sp|Q8N475|FSTL5_HUMAN Follistatin-related protein 5 OS=Homo sapiensOX=9606 GN=FSTL5 PE=2 SV=2MFKCWSVVLVLGFIFLESEGRPTKEGGYGLKSYQPLMRLRHKQEKNQESSRVKGFMIQDGPFGSCENKYCGLGRHCVTSRETGQAECACMDLCKRHYKPVCGSDGEFYENHCEVHRAACLKKQKITIVHNEDCFFKGDKCKTTEYSKMKNMLLDLQNQKYIMQENENPNGDDISRKKLLVDQMFKYFDADSNGLVDINELTQVIKQEELGKDLFDCTLYVLLKYDDFNADKHLALEEFYRAFQVIQLSLPEDQKLSITAATVGQSAVLSCAIQGTLRPPIIWKRNNIILNNLDLEDINDFGDDGSLYITKVTTTHVGNYTCYADGYEQVYQTHIFQVNVPPVIRVYPESQAREPGVTASLRCHAEGIPKPQLGWLKNGIDITPKLSKQLTLQANGSEVHISNVRYEDTGAYTCIAKNEAGVDEDISSLFVEDSARKTLANILWREEGLGIGNMFYVFYEDGIKVIQPIECEFQRHIKPSEKLLGFQDEVCPKAEGDEVQRCVWASAVNVKDKFIYVAQPTLDRVLIVDVQSQKVVQAVSTDPVPVKLHYDKSHDQVWVLSWGTLEKTSPTLQVITLASGNVPHHTIHTQPVGKQFDRVDDFFIPTTTLIITHMRFGFILHKDEAALQKIDLETMSYIKTINLKDYKCVPQSLAYTHLGGYYFIGCKPDSTGAVSPQVMVDGVTDSVIGFNSDVTGTPYVSPDGHYLVSINDVKGLVRVQYITIRGEIQEAFDIYTNLHISDLAFQPSFTEAHQYNIYGSSSTQTDVLFVELSSGKVKMIKSLKEPLKAEEWPWNRKNRQIQDSGLFGQYLMTPSKDSLFILDGRLNKLNCEITEVEKGNTVIWVGDA>sp|Q8N475-2|FSTL5_HUMAN Isoform 2 of Follistatin-related protein 5OS=Homo sapiens OX=9606 GN=FSTL5MFKCWSVVLVLGFIFLESEGRPTKEGGYGLKSYQPLMRLRHKEKNQESSRVKGFMIQDGPFGSCENKYCGLGRHCVTSRETGQAECACMDLCKRHYKPVCGSDGEFYENHCEVHRAACLKKQKITIVHNEDCFFKGDKCKTTEYSKMKNMLLDLQNQKYIMQENENPNGDDISRKKLLVDQMFKYFDADSNGLVDINELTQVIKQEELGKDLFDCTLYVLLKYDDFNADKHLALEEFYRAFQVIQLSLPEDQKLSITAATVGQSAVLSCAIQGTLRPPIIWKRNNIILNNLDLEDINDFGDDGSLYITKVTTTHVGNYTCYADGYEQVYQTHIFQVNVPPVIRVYPESQAREPGVTASLRCHAEGIPKPQLGWLKNGIDITPKLSKQLTLQANGSEVHISNVRYEDTGAYTCIAKNEAGVDEDISSLFVEDSARKTLANILWREEGLGIGNMFYVFYEDGIKVIQPIECEFQRHIKPSEKLLGFQDEVCPKAEGDEVQRCVWASAVNVKDKFIYVAQPTLDRVLIVDVQSQKVVQAVSTDPVPVKLHYDKSHDQVWVLSWGTLEKTSPTLQVITLASGNVPHHTIHTQPVGKQFDRVDDFFIPTTTLIITHMRFGFILHKDEAALQKIDLETMSYIKTINLKDYKCVPQSLAYTHLGGYYFIGCKPDSTGAVSPQVMVDGVTDSVIGFNSDVTGTPYVSPDGHYLVSINDVKGLVRVQYITIRGEIQEAFDIYTNLHISDLAFQPSFTEAHQYNIYGSSSTQTDVLFVELSSGKVKMIKSLKEPLKAEEWPWNRKNRQIQDSGLFGQYLMTPSKDSLFILDGRLNKLNCEITEVEKGNTVIWVGDA>sp|Q8N475-3|FSTL5_HUMAN Isoform 3 of Follistatin-related protein 5OS=Homo sapiens OX=9606 GN=FSTL5MFKCWSVVLVLGFIFLESEGRPTKEGGYGLKSYQPLMRLRHKEKNQESSRVKGFMIQDGPFGSCENKYCGLGRHCVTSRETGQAECACMDLCKRHYKPVCGSDGEFYENHCEVHRAACLKKQKITIVHNEDCFFKGDKCKTTEYSKMKNMLLDLQNQKYIMQENENPNGDDISRKKLLVDQMFKYFDADSNGLVDINELTQVIKQEELGKDLFDCTLYVLLKYDDFNADKHLALEEFYRAFQVIQLSLPEDQKLSITAATVGQSAVLSCAIQGTLRPPIIWKRNNIILNNLDLEDINDFGDDGSLYITKVTTTHVGNYTCYADGYEQVYQTHIFQVNVPPVIRVYPESQAREPGVTASLRCHAEGIPKPQLGWLKNGIDITPKLSKQLTLQANGSEVHISNVRYEDTGAYTCIAKNEAGVDEDISSLFVEDSARKTRLGIGNMFYVFYEDGIKVIQPIECEFQRHIKPSEKLLGFQDEVCPKAEGDEVQRCVWASAVNVKDKFIYVAQPTLDRVLIVDVQSQKVVQAVSTDPVPVKLHYDKSHDQVWVLSWGTLEKTSPTLQVITLASGNVPHHTIHTQPVGKQFDRVDDFFIPTTTLIITHMRFGFILHKDEAALQKIDLETMSYIKTINLKDYKCVPQSLAYTHLGGYYFIGCKPDSTGAVSPQVMVDGVTDSVIGFNSDVTGTPYVSPDGHYLVSINDVKGLVRVQYITIRGEIQEAFDIYTNLHISDLAFQPSFTEAHQYNIYGSSSTQTDVLFVELSSGKVKMIKSLKEPLKAEEWPWNRKNRQIQDSGLFGQYLMTPSKDSLFILDGRLNKLNCEITEVEKGNTVIWVGDA>sp|P33316|DUT_HUMAN Deoxyuridine 5'-triphosphate nucleotidohydrolase,mitochondrial OS=Homo sapiens OX=9606 GN=DUT PE=1 SV=4MTPLCPRPALCYHFLTSLLRSAMQNARGARQRAEAAVLSGPGPPLGRAAQHGIPRPLSSAGRLSQGCRGASTVGAAGWKGELPKAGGSPAPGPETPAISPSKRARPAEVGGMQLRFARLSEHATAPTRGSARAAGYDLYSAYDYTIPPMEKAVVKTDIQIALPSGCYGRVAPRSGLAAKHFIDVGAGVIDEDYRGNVGVVLFNFGKEKFEVKKGDRIAQLICERIFYPEIEEVQALDDTERGSGGFGSTGKN>sp|P33316-2|DUT_HUMAN Isoform 2 of Deoxyuridine 5'-triphosphatenucleotidohydrolase, mitochondrial OS=Homo sapiens OX=9606 GN=DUTMPCSEETPAISPSKRARPAEVGGMQLRFARLSEHATAPTRGSARAAGYDLYSAYDYTIPPMEKAVVKTDIQIALPSGCYGRVAPRSGLAAKHFIDVGAGVIDEDYRGNVGVVLFNFGKEKFEVKKGDRIAQLICERIFYPEIEEVQALDDTERGSGGFGSTGKN>sp|Q13838|DX39B_HUMAN Spliceosome RNA helicase DDX39B OS=Homo sapiensOX=9606 GN=DDX39B PE=1 SV=1MAENDVDNELLDYEDDEVETAAGGDGAEAPAKKDVKGSYVSIHSSGFRDFLLKPELLRAIVDCGFEHPSEVQHECIPQAILGMDVLCQAKSGMGKTAVFVLATLQQLEPVTGQVSVLVMCHTRELAFQISKEYERFSKYMPNVKVAVFFGGLSIKKDEEVLKKNCPHIVVGTPGRILALARNKSLNLKHIKHFILDECDKMLEQLDMRRDVQEIFRMTPHEKQVMMFSATLSKEIRPVCRKFMQDPMEIFVDDETKLTLHGLQQYYVKLKDNEKNRKLFDLLDVLEFNQVVIFVKSVQRCIALAQLLVEQNFPAIAIHRGMPQEERLSRYQQFKDFQRRILVATNLFGRGMDIERVNIAFNYDMPEDSDTYLHRVARAGRFGTKGLAITFVSDENDAKILNDVQDRFEVNISELPDEIDISSYIEQTR>sp|Q13838-2|DX39B_HUMAN Isoform 2 of Spliceosome RNA helicase DDX39BOS=Homo sapiens OX=9606 GN=DDX39BMAENDVDNELLDYEDDEVETAAGGDGAEAPAKKDVKGSYVSIHSSGFRDFLLKPELLRAIVDCGFEHPSEVQHECIPQAILGMDVLCQAKSGMGKTAVFVLATLQQLEPVTGQVYLGRVLGRGFWLGLVSVLVMCHTRELAFQISKEYERFSKYMPNVKVAVFFGGLSIKKDEEVLKKNCPHIVVGTPGRILALARNKSLNLKHIKHFILDECDKMLEQLDMRRDVQEIFRMTPHEKQVMMFSATLSKEIRPVCRKFMQDPMEIFVDDETKLTLHGLQQYYVKLKDNEKNRKLFDLLDVLEFNQVVIFVKSVQRCIALAQLLVEQNFPAIAIHRGMPQEERLSRYQQFKDFQRRILVATNLFGRGMDIERVNIAFNYDMPEDSDTYLHRVARAGRFGTKGLAITFVSDENDAKILNDVQDRFEVNISELPDEIDISSYIEQTR>sp|Q9BY08|EBPL_HUMAN Emopamil-binding protein-like OS=Homo sapiensOX=9606 GN=EBPL PE=1 SV=1MGAEWELGAEAGGSLLLCAALLAAGCALGLRLGRGQGAADRGALIWLCYDALVHFALEGPFVYLSLVGNVANSDGLIASLWKEYGKADARWVYFDPTIVSVEILTVALDGSLALFLIYAIVKEKYYRHFLQITLCVCELYGCWMTFLPEWLTRSPNLNTSNWLYCWLYLFFFNGVWVLIPGLLLWQSWLELKKMHQKETSSVKKFQ>sp|Q9BY08-2|EBPL_HUMAN Isoform 2 of Emopamil-binding protein-likeOS=Homo sapiens OX=9606 GN=EBPLMGAEWELGAEAGGSLLLCAALLAAGCALGLRLGRGQGAADRGALIWLCYDALVHFALEGPFVYLSLVGNVANSDGLIASLCESRSVPQAGAQWHHLGSLQAPPPRFTPFSCLSLPSSWDYRRPPPRLANFFVFLVETGFHHVSQDGLDLLTS>sp|Q9BY08-3|EBPL_HUMAN Isoform 3 of Emopamil-binding protein-likeOS=Homo sapiens OX=9606 GN=EBPLMGAEWELGAEAGGSLLLCAALLAAGCALGLRLGRGQGAADRGALIWLCYDALVHFALAFPADHPVRVRAVWLLDDLPPRVAHQKPQPQHQQLAVLLALPVFF>sp|Q9BY08-4|EBPL_HUMAN Isoform 4 of Emopamil-binding protein-likeOS=Homo sapiens OX=9606 GN=EBPLMGAEWELGAEAGGSLLLCAALLAAGCALGLRLGRGQGAADRGALIWLCYDALVHFALEGPFVYLSLVGNVANSDGLIASLCISCRSPCACASCMAAG>sp|Q9BY08-5|EBPL_HUMAN Isoform 5 of Emopamil-binding protein-likeOS=Homo sapiens OX=9606 GN=EBPLMGAEWELGAEAGGSLLLCAALLAAGCALGLRLGRGQGAADRGALIWLCYDALVHFALEGPFVYLSLVGNVANSDGLIASLSDARWVYFDPTIVSVEILTVALDGSLALFLIYAIVKEKYYRDRVAWGE>sp|Q9NRD9|DUOX1_HUMAN Dual oxidase 1 OS=Homo sapiens OX=9606 GN=DUOX1PE=1 SV=1MGFCLALAWTLLVGAWTPLGAQNPISWEVQRFDGWYNNLMEHRWGSKGSRLQRLVPASYADGVYQPLGEPHLPNPRDLSNTISRGPAGLASLRNRTVLGVFFGYHVLSDLVSVETPGCPAEFLNIRIPPGDPMFDPDQRGDVVLPFQRSRWDPETGRSPSNPRDPANQVTGWLDGSAIYGSSHSWSDALRSFSRGQLASGPDPAFPRDSQNPLLMWAAPDPATGQNGPRGLYAFGAERGNREPFLQALGLLWFRYHNLWAQRLARQHPDWEDEELFQHARKRVIATYQNIAVYEWLPSFLQKTLPEYTGYRPFLDPSISSEFVAASEQFLSTMVPPGVYMRNASCHFQGVINRNSSVSRALRVCNSYWSREHPSLQSAEDVDALLLGMASQIAEREDHVLVEDVRDFWPGPLKFSRTDHLASCLQRGRDLGLPSYTKARAALGLSPITRWQDINPALSRSNDTVLEATAALYNQDLSWLELLPGGLLESHRDPGPLFSTIVLEQFVRLRDGDRYWFENTRNGLFSKKEIEEIRNTTLQDVLVAVINIDPSALQPNVFVWHKGDPCPQPRQLSTEGLPACAPSVVRDYFEGSGFGFGVTIGTLCCFPLVSLLSAWIVARLRMRNFKRLQGQDRQSIVSEKLVGGMEALEWQGHKEPCRPVLVYLQPGQIRVVDGRLTVLRTIQLQPPQKVNFVLSSNRGRRTLLLKIPKEYDLVLLFNLEEERQALVENLRGALKESGLSIQEWELREQELMRAAVTREQRRHLLETFFRHLFSQVLDINQADAGTLPLDSSQKVREALTCELSRAEFAESLGLKPQDMFVESMFSLADKDGNGYLSFREFLDILVVFMKGSPEEKSRLMFRMYDFDGNGLISKDEFIRMLRSFIEISNNCLSKAQLAEVVESMFRESGFQDKEELTWEDFHFMLRDHNSELRFTQLCVKGVEVPEVIKDLCRRASYISQDMICPSPRVSARCSRSDIETELTPQRLQCPMDTDPPQEIRRRFGKKVTSFQPLLFTEAHREKFQRSCLHQTVQQFKRFIENYRRHIGCVAVFYAIAGGLFLERAYYYAFAAHHTGITDTTRVGIILSRGTAASISFMFSYILLTMCRNLITFLRETFLNRYVPFDAAVDFHRLIASTAIVLTVLHSVGHVVNVYLFSISPLSVLSCLFPGLFHDDGSELPQKYYWWFFQTVPGLTGVVLLLILAIMYVFASHHFRRRSFRGFWLTHHLYILLYVLLIIHGSFALIQLPRFHIFFLVPAIIYGGDKLVSLSRKKVEISVVKAELLPSGVTHLRFQRPQGFEYKSGQWVRIACLALGTTEYHPFTLTSAPHEDTLSLHIRAAGPWTTRLREIYSAPTGDRCARYPKLYLDGPFGEGHQEWHKFEVSVLVGGGIGVTPFASILKDLVFKSSVSCQVFCKKIYFIWVTRTQRQFEWLADIIREVEENDHQDLVSVHIYITQLAEKFDLRTTMLYICERHFQKVLNRSLFTGLRSITHFGRPPFEPFFNSLQEVHPQVRKIGVFSCGPPGMTKNVEKACQLINRQDRTHFSHHYENF>sp|Q9NRD9-2|DUOX1_HUMAN Isoform 2 of Dual oxidase 1 OS=Homo sapiensOX=9606 GN=DUOX1MWMHCCWAWPPRSQSERTMCWLKMCGVSLRLSLQVVNSWPLGRGSAGLPEPDFWPGPLKFSRTDHLASCLQRGRDLGLPSYTKARAALGLSPITRWQDINPALSRSNDTVLEATAALYNQDLSWLELLPGGLLESHRDPGPLFSTIVLEQFVRLRDGDRYWFENTRNGLFSKKEIEEIRNTTLQDVLVAVINIDPSALQPNVFVWHKGDPCPQPRQLSTEGLPACAPSVVRDYFEGSGFGFGVTIGTLCCFPLVSLLSAWIVARLRMRNFKRLQGQDRQSIVSEKLVGGMEALEWQGHKEPCRPVLVYLQPGQIRVVDGRLTVLRTIQLQPPQKVNFVLSSNRGRRTLLLKIPKEYDLVLLFNLEEERQALVENLRGALKESGLSIQEWELREQELMRAAVTREQRRHLLETFFRHLFSQVLDINQADAGTLPLDSSQKVREALTCELSRAEFAESLGLKPQDMFVESMFSLADKDGNGYLSFREFLDILVVFMKGSPEEKSRLMFRMYDFDGNGLISKDEFIRMLRSFIEISNNCLSKAQLAEVVESMFRESGFQDKEELTWEDFHFMLRDHNSELRFTQLCVKGVEVPEVIKDLCRRASYISQDMICPSPRVSARCSRSDIETELTPQRLQCPMDTDPPQEIRRRFGKKVTSFQPLLFTEAHREKFQRSCLHQTVQQFKRFIENYRRHIGCVAVFYAIAGGLFLERAYYYAFAAHHTGITDTTRVGIILSRGTAASISFMFSYILLTMCRNLITFLRETFLNRYVPFDAAVDFHRLIASTAIVLTVLHSVGHVVNVYLFSISPLSVLSCLFPGLFHDDGSELPQKYYWWFFQTVPGLTGVVLLLILAIMYVFASHHFRRRSFRGFWLTHHLYILLYVLLIIHGSFALIQLPRFHIFFLVPAIIYGGDKLVSLSRKKVEISVVKAELLPSGVTHLRFQRPQGFEYKSGQWVRIACLALGTTEYHPFTLTSAPHEDTLSLHIRAAGPWTTRLREIYSAPTGDRCARYPKLYLDGPFGEGHQEWHKFEVSVLVGGGIGVTPFASILKDLVFKSSVSCQVFCKKIYFIWVTRTQRQFEWLADIIREVEENDHQDLVSVHIYITQLAEKFDLRTTMLYICERHFQKVLNRSLFTGLRSITHFGRPPFEPFFNSLQEVHPQVRKIGVFSCGPPGMTKNVEKACQLINRQDRTHFSHHYENF>sp|O60762|DPM1_HUMAN Dolichol-phosphate mannosyltransferase subunit 1OS=Homo sapiens OX=9606 GN=DPM1 PE=1 SV=1MASLEVSRSPRRSRRELEVRSPRQNKYSVLLPTYNERENLPLIVWLLVKSFSESGINYEIIIIDDGSPDGTRDVAEQLEKIYGSDRILLRPREKKLGLGTAYIHGMKHATGNYIIIMDADLSHHPKFIPEFIRKQKEGNFDIVSGTRYKGNGGVYGWDLKRKIISRGANFLTQILLRPGASDLTGSFRLYRKEVLEKLIEKCVSKGYVFQMEMIVRARQLNYTIGEVPISFVDRVYGESKLGGNEIVSFLKGLLTLFATT>sp|Q8IZU8|DSEL_HUMAN Dermatan-sulfate epimerase-like protein OS=Homosapiens OX=9606 GN=DSEL PE=2 SV=2MALMFTGHLLFLALLMFAFSTFEESVSNYSEWAVFTDDIDQFKTQKVQDFRPNQKLKKSMLHPSLYFDAGEIQAMRQKSRASHLHLFRAIRSAVTVMLSNPTYYLPPPKHADFAAKWNEIYGNNLPPLALYCLLCPEDKVAFEFVLEYMDRMVGYKDWLVENAPGDEVPIGHSLTGFATAFDFLYNLLDNHRRQKYLEKIWVITEEMYEYSKVRSWGKQLLHNHQATNMIALLTGALVTGVDKGSKANIWKQAVVDVMEKTMFLLNHIVDGSLDEGVAYGSYTAKSVTQYVFLAQRHFNINNLDNNWLKMHFWFYYATLLPGFQRTVGIADSNYNWFYGPESQLVFLDKFILKNGAGNWLAQQIRKHRPKDGPMVPSTAQRWSTLHTEYIWYDPQLTPQPPADYGTAKIHTFPNWGVVTYGAGLPNTQTNTFVSFKSGKLGGRAVYDIVHFQPYSWIDGWRSFNPGHEHPDQNSFTFAPNGQVFVSEALYGPKLSHLNNVLVFAPSPSSQCNKPWEGQLGECAQWLKWTGEEVGDAAGEIITASQHGEMVFVSGEAVSAYSSAMRLKSVYRALLLLNSQTLLVVDHIERQEDSPINSVSAFFHNLDIDFKYIPYKFMNRYNGAMMDVWDAHYKMFWFDHHGNSPMASIQEAEQAAEFKKRWTQFVNVTFQMEPTITRIAYVFYGPYINVSSCRFIDSSNPGLQISLNVNNTEHVVSIVTDYHNLKTRFNYLGFGGFASVADQGQITRFGLGTQAIVKPVRHDRIIFPFGFKFNIAVGLILCISLVILTFQWRFYLSFRKLMRWILILVIALWFIELLDVWSTCSQPICAKWTRTEAEGSKKSLSSEGHHMDLPDVVITSLPGSGAEILKQLFFNSSDFLYIRVPTAYIDIPETELEIDSFVDACEWKVSDIRSGHFRLLRGWLQSLVQDTKLHLQNIHLHEPNRGKLAQYFAMNKDKKRKFKRRESLPEQRSQMKGAFDRDAEYIRALRRHLVYYPSARPVLSLSSGSWTLKLHFFQEVLGASMRALYIVRDPRAWIYSMLYNSKPSLYSLKNVPEHLAKLFKIEGGKGKCNLNSGYAFEYEPLRKELSKSKSNAVSLLSHLWLANTAAALRINTDLLPTSYQLVKFEDIVHFPQKTTERIFAFLGIPLSPASLNQILFATSTNLFYLPYEGEISPTNTNVWKQNLPRDEIKLIENICWTLMDRLGYPKFMD>sp|Q9HAF1|EAF6_HUMAN Chromatin modification-related protein MEAF6OS=Homo sapiens OX=9606 GN=MEAF6 PE=1 SV=1MAMHNKAAPPQIPDTRRELAELVKRKQELAETLANLERQIYAFEGSYLEDTQMYGNIIRGWDRYLTNQKNSNSKNDRRNRKFKEAERLFSKSSVTSAAAVSALAGVQDQLIEKREPGSGTESDTSPDFHNQENEPSQEDPEDLDGSVQGVKPQKAASSTSSGSHHSSHKKRKNKNRHRIDLKLNKKPRADY>sp|Q9HAF1-2|EAF6_HUMAN Isoform 2 of Chromatin modification-relatedprotein MEAF6 OS=Homo sapiens OX=9606 GN=MEAF6MAMHNKAAPPQIPDTRRELAELVKRKQELAETLANLERQIYAFEGSYLEDTQMYGNIIRGWDRYLTNQKNSNSKNDRRNRKFKEAERLFSKSSVTSAAAVSALAGVQDQLIEKREPGSGTESDTSPDFHNQENEPSQEDPEDLDGSVQGVKPQKAASSTSSGSHHSSHKKRKNKNRHSPSGMFDYDFEYVY>sp|Q9HAF1-3|EAF6_HUMAN Isoform 3 of Chromatin modification-relatedprotein MEAF6 OS=Homo sapiens OX=9606 GN=MEAF6MAMHNKAAPPQIPDTRRELAELVKRKQELAETLANLERQIYAFEGSYLEDTQMYGNIIRGWDRYLTNQKNSNSKNDRRNRKFKEAERLFSKSSVTSAAAVSALAGVQDQLIEKREPGSGTESDTSPDFHNQENEPSQEDPEDLDGSVQGVKPQKAASSTSSGSHHSSHKKRKNKNRHSPSGMFDYDFEIDLKLNKKPRADY>sp|Q9HAF1-4|EAF6_HUMAN Isoform 4 of Chromatin modification-relatedprotein MEAF6 OS=Homo sapiens OX=9606 GN=MEAF6MAMHNKAAPPQIPDTRRELAELVKRKQELAETLANLERQIYAFEGSYLEDTQMYGNIIRGWDRYLTNQKNSNSKNDRRNRKFKEAERLFSKSSVTSAAAVSALAGVQDQLIEKREPGSGTESDTSPDFHNQENEPSQEDPEDLDGSVQGVKPQKAASSTSSGSHHSSHKKRKNKNRHRMNVSPKTGWHQLHL>sp|Q9NR33|DPOE4_HUMAN DNA polymerase epsilon subunit 4 OS=Homo sapiensOX=9606 GN=POLE4 PE=1 SV=2MAAAAAAGSGTPREEEGPAGEAAASQPQAPTSVPGARLSRLPLARVKALVKADPDVTLAGQEAIFILARAAELFVETIAKDAYCCAQQGKRKTLQRRDLDNAIEAVDEFAFLEGTLD>sp|Q6UXV0|GFRAL_HUMAN GDNF family receptor alpha-like OS=Homo sapiensOX=9606 GN=GFRAL PE=1 SV=2MIVFIFLAMGLSLENEYTSQTNNCTYLREQCLRDANGCKHAWRVMEDACNDSDPGDPCKMRNSSYCNLSIQYLVESNFQFKECLCTDDFYCTVNKLLGKKCINKSDNVKEDKFKWNLTTRSHHGFKGMWSCLEVAEACVGDVVCNAQLASYLKACSANGNPCDLKQCQAAIRFFYQNIPFNIAQMLAFCDCAQSDIPCQQSKEALHSKTCAVNMVPPPTCLSVIRSCQNDELCRRHYRTFQSKCWQRVTRKCHEDENCISTLSKQDLTCSGSDDCKAAYIDILGTVLQVQCTCRTITQSEESLCKIFQHMLHRKSCFNYPTLSNVKGMALYTRKHANKITLTGFHSPFNGEVIYAAMCMTVTCGILLLVMVKLRTSRISSKARDPSSIQIPGEL>sp|P00374|DYR_HUMAN Dihydrofolate reductase OS=Homo sapiens OX=9606GN=DHFR PE=1 SV=2MVGSLNCIVAVSQNMGIGKNGDLPWPPLRNEFRYFQRMTTTSSVEGKQNLVIMGKKTWFSIPEKNRPLKGRINLVLSRELKEPPQGAHFLSRSLDDALKLTEQPELANKVDMVWIVGGSSVYKEAMNHPGHLKLFVTRIMQDFESDTFFPEIDLEKYKLLPEYPGVLSDVQEEKGIKYKFEVYEKND>sp|P00374-2|DYR_HUMAN Isoform 2 of Dihydrofolate reductase OS=Homosapiens OX=9606 GN=DHFRMGKKTWFSIPEKNRPLKGRINLVLSRELKEPPQGAHFLSRSLDDALKLTEQPELANKVDMVWIVGGSSVYKEAMNHPGHLKLFVTRIMQDFESDTFFPEIDLEKYKLLPEYPGVLSDVQEEKGIKYKFEVYEKND>sp|P52566|GDIR2_HUMAN Rho GDP-dissociation inhibitor 2 OS=Homo sapiensOX=9606 GN=ARHGDIB PE=1 SV=3MTEKAPEPHVEEDDDDELDSKLNYKPPPQKSLKELQEMDKDDESLIKYKKTLLGDGPVVTDPKAPNVVVTRLTLVCESAPGPITMDLTGDLEALKKETIVLKEGSEYRVKIHFKVNRDIVSGLKYVQHTYRTGVKVDKATFMVGSYGPRPEEYEFLTPVEEAPKGMLARGTYHNKSFFTDDDKQDHLSWEWNLSIKKEWTE>sp|Q8TF65|GIPC2_HUMAN PDZ domain-containing protein GIPC2 OS=Homosapiens OX=9606 GN=GIPC2 PE=1 SV=1MPLKLRGKKKAKSKETAGLVEGEPTGAGGGSLSASRAPARRLVFHAQLAHGSATGRVEGFSSIQELYAQIAGAFEISPSEILYCTLNTPKIDMERLLGGQLGLEDFIFAHVKGIEKEVNVYKSEDSLGLTITDNGVGYAFIKRIKDGGVIDSVKTICVGDHIESINGENIVGWRHYDVAKKLKELKKEELFTMKLIEPKKAFEIELRSKAGKSSGEKIGCGRATLRLRSKGPATVEEMPSETKAKAIEKIDDVLELYMGIRDIDLATTMFEAGKDKVNPDEFAVALDETLGDFAFPDEFVFDVWGVIGDAKRRGL>sp|Q14194|DPYL1_HUMAN Dihydropyrimidinase-related protein 1 OS=Homosapiens OX=9606 GN=CRMP1 PE=1 SV=1MSYQGKKSIPHITSDRLLIKGGRIINDDQSLYADVYLEDGLIKQIGENLIVPGGVKTIEANGRMVIPGGIDVNTYLQKPSQGMTAADDFFQGTRAALVGGTTMIIDHVVPEPGSSLLTSFEKWHEAADTKSCCDYSLHVDITSWYDGVREELEVLVQDKGVNSFQVYMAYKDVYQMSDSQLYEAFTFLKGLGAVILVHAENGDLIAQEQKRILEMGITGPEGHALSRPEELEAEAVFRAITIAGRINCPVYITKVMSKSAADIIALARKKGPLVFGEPIAASLGTDGTHYWSKNWAKAAAFVTSPPLSPDPTTPDYLTSLLACGDLQVTGSGHCPYSTAQKAVGKDNFTLIPEGVNGIEERMTVVWDKAVATGKMDENQFVAVTSTNAAKIFNLYPRKGRIAVGSDADVVIWDPDKLKTITAKSHKSAVEYNIFEGMECHGSPLVVISQGKIVFEDGNINVNKGMGRFIPRKAFPEHLYQRVKIRNKVFGLQGVSRGMYDGPVYEVPATPKYATPAPSAKSSPSKHQPPPIRNLHQSNFSLSGAQIDDNNPRRTGHRIVAPPGGRSNITSLG>sp|Q14194-2|DPYL1_HUMAN Isoform LCRMP-1 of Dihydropyrimidinase-relatedprotein 1 OS=Homo sapiens OX=9606 GN=CRMP1MADRRRAWNTEDDLPVYLARPGSAAQTPRQKYGGMFAAVEGAYENKTIDFDAYSVGRRGSARTPRSAGRPDAVGLPGPGGSEDTASDVSEPSGSAVSSPGERDERPPTLRIRRPAPRDLPLGRDNGQSDRLLIKGGRIINDDQSLYADVYLEDGLIKQIGENLIVPGGVKTIEANGRMVIPGGIDVNTYLQKPSQGMTAADDFFQGTRAALVGGTTMIIDHVVPEPGSSLLTSFEKWHEAADTKSCCDYSLHVDITSWYDGVREELEVLVQDKGVNSFQVYMAYKDVYQMSDSQLYEAFTFLKGLGAVILVHAENGDLIAQEQKRILEMGITGPEGHALSRPEELEAEAVFRAITIAGRINCPVYITKVMSKSAADIIALARKKGPLVFGEPIAASLGTDGTHYWSKNWAKAAAFVTSPPLSPDPTTPDYLTSLLACGDLQVTGSGHCPYSTAQKAVGKDNFTLIPEGVNGIEERMTVVWDKAVATGKMDENQFVAVTSTNAAKIFNLYPRKGRIAVGSDADVVIWDPDKLKTITAKSHKSAVEYNIFEGMECHGSPLVVISQGKIVFEDGNINVNKGMGRFIPRKAFPEHLYQRVKIRNKVFGLQGVSRGMYDGPVYEVPATPKYATPAPSAKSSPSKHQPPPIRNLHQSNFSLSGAQIDDNNPRRTGHRIVAPPGGRSNITSLG>sp|Q14195|DPYL3_HUMAN Dihydropyrimidinase-related protein 3 OS=Homosapiens OX=9606 GN=DPYSL3 PE=1 SV=1MSYQGKKNIPRITSDRLLIKGGRIVNDDQSFYADIYMEDGLIKQIGDNLIVPGGVKTIEANGKMVIPGGIDVHTHFQMPYKGMTTVDDFFQGTKAALAGGTTMIIDHVVPEPESSLTEAYEKWREWADGKSCCDYALHVDITHWNDSVKQEVQNLIKDKGVNSFMVYMAYKDLYQVSNTELYEIFTCLGELGAIAQVHAENGDIIAQEQTRMLEMGITGPEGHVLSRPEELEAEAVFRAITIASQTNCPLYVTKVMSKSAADLISQARKKGNVVFGEPITASLGIDGTHYWSKNWAKAAAFVTSPPLSPDPTTPDYINSLLASGDLQLSGSAHCTFSTAQKAIGKDNFTAIPEGTNGVEERMSVIWDKAVATGKMDENQFVAVTSTNAAKIFNLYPRKGRISVGSDSDLVIWDPDAVKIVSAKNHQSAAEYNIFEGMELRGAPLVVICQGKIMLEDGNLHVTQGAGRFIPCSPFSDYVYKRIKARRKMADLHAVPRGMYDGPVFDLTTTPKGGTPAGSARGSPTRPNPPVRNLHQSGFSLSGTQVDEGVRSASKRIVAPPGGRSNITSLS>sp|Q14195-2|DPYL3_HUMAN Isoform LCRMP-4 of Dihydropyrimidinase-relatedprotein 3 OS=Homo sapiens OX=9606 GN=DPYSL3MASGRRGWDSSHEDDLPVYLARPGTTDQVPRQKYGGMFCNVEGAFESKTLDFDALSVGQRGAKTPRSGQGSDRGSGSRPGIEGDTPRRGQGREESREPAPASPAPAGVEIRSATGKEVLQNLGPKDKSDRLLIKGGRIVNDDQSFYADIYMEDGLIKQIGDNLIVPGGVKTIEANGKMVIPGGIDVHTHFQMPYKGMTTVDDFFQGTKAALAGGTTMIIDHVVPEPESSLTEAYEKWREWADGKSCCDYALHVDITHWNDSVKQEVQNLIKDKGVNSFMVYMAYKDLYQVSNTELYEIFTCLGELGAIAQVHAENGDIIAQEQTRMLEMGITGPEGHVLSRPEELEAEAVFRAITIASQTNCPLYVTKVMSKSAADLISQARKKGNVVFGEPITASLGIDGTHYWSKNWAKAAAFVTSPPLSPDPTTPDYINSLLASGDLQLSGSAHCTFSTAQKAIGKDNFTAIPEGTNGVEERMSVIWDKAVATGKMDENQFVAVTSTNAAKIFNLYPRKGRISVGSDSDLVIWDPDAVKIVSAKNHQSAAEYNIFEGMELRGAPLVVICQGKIMLEDGNLHVTQGAGRFIPCSPFSDYVYKRIKARRKMADLHAVPRGMYDGPVFDLTTTPKGGTPAGSARGSPTRPNPPVRNLHQSGFSLSGTQVDEGVRSASKRIVAPPGGRSNITSLS>sp|Q03001|DYST_HUMAN Dystonin OS=Homo sapiens OX=9606 GN=DST PE=1 SV=4MAGYLSPAAYLYVEEQEYLQAYEDVLERYKDERDKVQKKTFTKWINQHLMKVRKHVNDLYEDLRDGHNLISLLEVLSGDTLPREKGRMRFHRLQNVQIALDYLKRRQVKLVNIRNDDITDGNPKLTLGLIWTIILHFQISDIHVTGESEDMSAKERLLLWTQQATEGYAGIRCENFTTCWRDGKLFNAIIHKYRPDLIDMNTVAVQSNLANLEHAFYVAEKIGVIRLLDPEDVDVSSPDEKSVITYVSSLYDAFPKVPEGGEGIGANDVEVKWIEYQNMVNYLIQWIRHHVTTMSERTFPNNPVELKALYNQYLQFKETEIPPKETEKSKIKRLYKLLEIWIEFGRIKLLQGYHPNDIEKEWGKLIIAMLEREKALRPEVERLEMLQQIANRVQRDSVICEDKLILAGNALQSDSKRLESGVQFQNEAEIAGYILECENLLRQHVIDVQILIDGKYYQADQLVQRVAKLRDEIMALRNECSSVYSKGRILTTEQTKLMISGITQSLNSGFAQTLHPSLTSGLTQSLTPSLTSSSMTSGLSSGMTSRLTPSVTPAYTPGFPSGLVPNFSSGVEPNSLQTLKLMQIRKPLLKSSLLDQNLTEEEINMKFVQDLLNWVDEMQVQLDRTEWGSDLPSVESHLENHKNVHRAIEEFESSLKEAKISEIQMTAPLKLTYAEKLHRLESQYAKLLNTSRNQERHLDTLHNFVSRATNELIWLNEKEEEEVAYDWSERNTNIARKKDYHAELMRELDQKEENIKSVQEIAEQLLLENHPARLTIEAYRAAMQTQWSWILQLCQCVEQHIKENTAYFEFFNDAKEATDYLRNLKDAIQRKYSCDRSSSIHKLEDLVQESMEEKEELLQYKSTIANLMGKAKTIIQLKPRNSDCPLKTSIPIKAICDYRQIEITIYKDDECVLANNSHRAKWKVISPTGNEAMVPSVCFTVPPPNKEAVDLANRIEQQYQNVLTLWHESHINMKSVVSWHYLINEIDRIRASNVASIKTMLPGEHQQVLSNLQSRFEDFLEDSQESQVFSGSDITQLEKEVNVCKQYYQELLKSAEREEQEESVYNLYISEVRNIRLRLENCEDRLIRQIRTPLERDDLHESVFRITEQEKLKKELERLKDDLGTITNKCEEFFSQAAASSSVPTLRSELNVVLQNMNQVYSMSSTYIDKLKTVNLVLKNTQAAEALVKLYETKLCEEEAVIADKNNIENLISTLKQWRSEVDEKRQVFHALEDELQKAKAISDEMFKTYKERDLDFDWHKEKADQLVERWQNVHVQIDNRLRDLEGIGKSLKYYRDTYHPLDDWIQQVETTQRKIQENQPENSKTLATQLNQQKMLVSEIEMKQSKMDECQKYAEQYSATVKDYELQTMTYRAMVDSQQKSPVKRRRMQSSADLIIQEFMDLRTRYTALVTLMTQYIKFAGDSLKRLEEEEKSLEEEKKEHVEKAKELQKWVSNISKTLKDAEKAGKPPFSKQKISSEEISTKKEQLSEALQTIQLFLAKHGDKMTDEERNELEKQVKTLQESYNLLFSESLKQLQESQTSGDVKVEEKLDKVIAGTIDQTTGEVLSVFQAVLRGLIDYDTGIRLLETQLMISGLISPELRKCFDLKDAKSHGLIDEQILCQLKELSKAKEIISAASPTTIPVLDALAQSMITESMAIKVLEILLSTGSLVIPATGEQLTLQKAFQQNLVSSALFSKVLERQNMCKDLIDPCTSEKVSLIDMVQRSTLQENTGMWLLPVRPQEGGRITLKCGRNISILRAAHEGLIDRETMFRLLSAQLLSGGLINSNSGQRMTVEEAVREGVIDRDTASSILTYQVQTGGIIQSNPAKRLTVDEAVQCDLITSSSALLVLEAQRGYVGLIWPHSGEIFPTSSSLQQELITNELAYKILNGRQKIAALYIPESSQVIGLDAAKQLGIIDNNTASILKNITLPDKMPDLGDLEACKNARRWLSFCKFQPSTVHDYRQEEDVFDGEEPVTTQTSEETKKLFLSYLMINSYMDANTGQRLLLYDGDLDEAVGMLLEGCHAEFDGNTAIKECLDVLSSSGVFLNNASGREKDECTATPSSFNKCHCGEPEHEETPENRKCAIDEEFNEMRNTVINSEFSQSGKLASTISIDPKVNSSPSVCVPSLISYLTQTELADISMLRSDSENILTNYENQSRVETNERANECSHSKNIQNFPSDLIENPIMKSKMSKFCGVNETENEDNTNRDSPIFDYSPRLSALLSHDKLMHSQGSFNDTHTPESNGNKCEAPALSFSDKTMLSGQRIGEKFQDQFLGIAAINISLPGEQYGQKSLNMISSNPQVQYHNDKYISNTSGEDEKTHPGFQQMPEDKEDESEIEEYSCAVTPGGDTDNAIVSLTCATPLLDETISASDYETSLLNDQQNNTGTDTDSDDDFYDTPLFEDDDHDSLLLDGDDRDCLHPEDYDTLQEENDETASPADVFYDVSKENENSMVPQGAPVGSLSVKNKAHCLQDFLMDVEKDELDSGEKIHLNPVGSDKVNGQSLETGSERECTNILEGDESDSLTDYDIVGGKESFTASLKFDDSGSWRGRKEEYVTGQEFHSDTDHLDSMQSEESYGDYIYDSNDQDDDDDDGIDEEGGGIRDENGKPRCQNVAEDMDIQLCASILNENSDENENINTMILLDKMHSCSSLEKQQRVNVVQLASPSENNLVTEKSNLPEYTTEIAGKSKENLLNHEMVLKDVLPPIIKDTESEKTFGPASISHDNNNISSTSELGTDLANTKVKLIQGSELPELTDSVKGKDEYFKNMTPKVDSSLDHIICTEPDLIGKPAEESHLSLIASVTDKDPQGNGSDLIKGRDGKSDILIEDETSIQKMYLGEGEVLVEGLVEEENRHLKLLPGKNTRDSFKLINSQFPFPQITNNEELNQKGSLKKATVTLKDEPNNLQIIVSKSPVQFENLEEIFDTSVSKEISDDITSDITSWEGNTHFEESFTDGPEKELDLFTYLKHCAKNIKAKDVAKPNEDVPSHVLITAPPMKEHLQLGVNNTKEKSTSTQKDSPLNDMIQSNDLCSKESISGGGTEISQFTPESIEATLSILSRKHVEDVGKNDFLQSERCANGLGNDNSSNTLNTDYSFLEINNKKERIEQQLPKEQALSPRSQEKEVQIPELSQVFVEDVKDILKSRLKEGHMNPQEVEEPSACADTKILIQNLIKRITTSQLVNEASTVPSDSQMSDSSGVSPMTNSSELKPESRDDPFCIGNLKSELLLNILKQDQHSQKITGVFELMRELTHMEYDLEKRGITSKVLPLQLENIFYKLLADGYSEKIEHVGDFNQKACSTSEMMEEKPHILGDIKSKEGNYYSPNLETVKEIGLESSTVWASTLPRDEKLKDLCNDFPSHLECTSGSKEMASGDSSTEQFSSELQQCLQHTEKMHEYLTLLQDMKPPLDNQESLDNNLEALKNQLRQLETFELGLAPIAVILRKDMKLAEEFLKSLPSDFPRGHVEELSISHQSLKTAFSSLSNVSSERTKQIMLAIDSEMSKLAVSHEEFLHKLKSFSDWVSEKSKSVKDIEIVNVQDSEYVKKRLEFLKNVLKDLGHTKMQLETTAFDVQFFISEYAQDLSPNQSKQLLRLLNTTQKCFLDVQESVTTQVERLETQLHLEQDLDDQKIVAERQQEYKEKLQGICDLLTQTENRLIGHQEAFMIGDGTVELKKYQSKQEELQKDMQGSAQALAEVVKNTENFLKENGEKLSQEDKALIEQKLNEAKIKCEQLNLKAEQSKKELDKVVTTAIKEETEKVAAVKQLEESKTKIENLLDWLSNVDKDSERAGTKHKQVIEQNGTHFQEGDGKSAIGEEDEVNGNLLETDVDGQVGTTQENLNQQYQKVKAQHEKIISQHQAVIIATQSAQVLLEKQGQYLSPEEKEKLQKNMKELKVHYETALAESEKKMKLTHSLQEELEKFDADYTEFEHWLQQSEQELENLEAGADDINGLMTKLKRQKSFSEDVISHKGDLRYITISGNRVLEAAKSCSKRDGGKVDTSATHREVQRKLDHATDRFRSLYSKCNVLGNNLKDLVDKYQHYEDASCGLLAGLQACEATASKHLSEPIAVDPKNLQRQLEETKALQGQISSQQVAVEKLKKTAEVLLDARGSLLPAKNDIQKTLDDIVGRYEDLSKSVNERNEKLQITLTRSLSVQDGLDEMLDWMGNVESSLKEQGQVPLNSTALQDIISKNIMLEQDIAGRQSSINAMNEKVKKFMETTDPSTASSLQAKMKDLSARFSEASHKHKETLAKMEELKTKVELFENLSEKLQTFLETKTQALTEVDVPGKDVTELSQYMQESTSEFLEHKKHLEVLHSLLKEISSHGLPSDKALVLEKTNNLSKKFKEMEDTIKEKKEAVTSCQEQLDAFQVLVKSLKSWIKETTKKVPIVQPSFGAEDLGKSLEDTKKLQEKWSLKTPEIQKVNNSGISLCNLISAVTTPAKAIAAVKSGGAVLNGEGTATNTEEFWANKGLTSIKKDMTDISHGYEDLGLLLKDKIAELNTKLSKLQKAQEESSAMMQWLQKMNKTATKWQQTPAPTDTEAVKTQVEQNKSFEAELKQNVNKVQELKDKLTELLEENPDTPEAPRWKQMLTEIDSKWQELNQLTIDRQQKLEESSNNLTQFQTVEAQLKQWLVEKELMVSVLGPLSIDPNMLNTQRQQVQILLQEFATRKPQYEQLTAAGQGILSRPGEDPSLRGIVKEQLAAVTQKWDSLTGQLSDRCDWIDQAIVKSTQYQSLLRSLSDKLSDLDNKLSSSLAVSTHPDAMNQQLETAQKMKQEIQQEKKQIKVAQALCEDLSALVKEEYLKAELSRQLEGILKSFKDVEQKAENHVQHLQSACASSHQFQQMSRDFQAWLDTKKEEQNKSHPISAKLDVLESLIKDHKDFSKTLTAQSHMYEKTIAEGENLLLKTQGSEKAALQLQLNTIKTNWDTFNKQVKERENKLKESLEKALKYKEQVETLWPWIDKCQNNLEEIKFCLDPAEGENSIAKLKSLQKEMDQHFGMVELLNNTANSLLSVCEIDKEVVTDENKSLIQKVDMVTEQLHSKKFCLENMTQKFKEFQEVSKESKRQLQCAKEQLDIHDSLGSQAYSNKYLTMLQTQQKSLQALKHQVDLAKRLAQDLVVEASDSKGTSDVLLQVETIAQEHSTLSQQVDEKCSFLETKLQGIGHFQNTIREMFSQFAEFDDELDSMAPVGRDAETLQKQKETIKAFLKKLEALMASNDNANKTCKMMLATEETSPDLVGIKRDLEALSKQCNKLLDRAQAREEQVEGTIKRLEEFYSKLKEFSILLQKAEEHEESQGPVGMETETINQQLNMFKVFQKEEIEPLQGKQQDVNWLGQGLIQSAAKSTSTQGLEHDLDDVNARWKTLNKKVAQRAAQLQEALLHCGRFQDALESLLSWMVDTEELVANQKPPSAEFKVVKAQIQEQKLLQRLLDDRKSTVEVIKREGEKIATTAEPADKVKILKQLSLLDSRWEALLNKAETRNRQLEGISVVAQQFHETLEPLNEWLTTIEKRLVNCEPIGTQASKLEEQIAQHKALEDDIINHNKHLHQAVSIGQSLKVLSSREDKDMVQSKLDFSQVWYIEIQEKSHSRSELLQQALCNAKIFGEDEVELMNWLNEVHDKLSKLSVQDYSTEGLWKQQSELRVLQEDILLRKQNVDQALLNGLELLKQTTGDEVLIIQDKLEAIKARYKDITKLSTDVAKTLEQALQLARRLHSTHEELCTWLDKVEVELLSYETQVLKGEEASQAQMRPKELKKEAKNNKALLDSLNEVSSALLELVPWRAREGLEKMVAEDNERYRLVSDTITQKVEEIDAAILRSQQFDQAADAELSWITETEKKLMSLGDIRLEQDQTSAQLQVQKTFTMEILRHKDIIDDLVKSGHKIMTACSEEEKQSMKKKLDKVLKNYDTICQINSERYLQLERAQSLVNQFWETYEELWPWLTETQSIISQLPAPALEYETLRQQQEEHRQLRELIAEHKPHIDKMNKTGPQLLELSPGEGFSIQEKYVAADTLYSQIKEDVKKRAVALDEAISQSTQFHDKIDQILESLERIVERLRQPPSISAEVEKIKEQISENKNVSVDMEKLQPLYETLKQRGEEMIARSGGTDKDISAKAVQDKLDQMVFIWENIHTLVEEREAKLLDVMELAEKFWCDHMSLIVTIKDTQDFIRDLEDPGIDPSVVKQQQEAAETIREEIDGLQEELDIVINLGSELIAACGEPDKPIVKKSIDELNSAWDSLNKAWKDRIDKLEEAMQAAVQYQDGLQAVFDWVDIAGGKLASMSPIGTDLETVKQQIEELKQFKSEAYQQQIEMERLNHQAELLLKKVTEESDKHTVQDPLMELKLIWDSLEERIINRQHKLEGALLALGQFQHALDELLAWLTHTEGLLSEQKPVGGDPKAIEIELAKHHVLQNDVLAHQSTVEAVNKAGNDLIESSAGEEASNLQNKLEVLNQRWQNVLEKTEQRKQQLDGALRQAKGFHGEIEDLQQWLTDTERHLLASKPLGGLPETAKEQLNVHMEVCAAFEAKEETYKSLMQKGQQMLARCPKSAETNIDQDINNLKEKWESVETKLNERKTKLEEALNLAMEFHNSLQDFINWLTQAEQTLNVASRPSLILDTVLFQIDEHKVFANEVNSHREQIIELDKTGTHLKYFSQKQDVVLIKNLLISVQSRWEKVVQRLVERGRSLDDARKRAKQFHEAWSKLMEWLEESEKSLDSELEIANDPDKIKTQLAQHKEFQKSLGAKHSVYDTTNRTGRSLKEKTSLADDNLKLDDMLSELRDKWDTICGKSVERQNKLEEALLFSGQFTDALQALIDWLYRVEPQLAEDQPVHGDIDLVMNLIDNHKAFQKELGKRTSSVQALKRSARELIEGSRDDSSWVKVQMQELSTRWETVCALSISKQTRLEAALRQAEEFHSVVHALLEWLAEAEQTLRFHGVLPDDEDALRTLIDQHKEFMKKLEEKRAELNKATTMGDTVLAICHPDSITTIKHWITIIRARFEEVLAWAKQHQQRLASALAGLIAKQELLEALLAWLQWAETTLTDKDKEVIPQEIEEVKALIAEHQTFMEEMTRKQPDVDKVTKTYKRRAADPSSLQSHIPVLDKGRAGRKRFPASSLYPSGSQTQIETKNPRVNLLVSKWQQVWLLALERRRKLNDALDRLEELREFANFDFDIWRKKYMRWMNHKKSRVMDFFRRIDKDQDGKITRQEFIDGILSSKFPTSRLEMSAVADIFDRDGDGYIDYYEFVAALHPNKDAYKPITDADKIEDEVTRQVAKCKCAKRFQVEQIGDNKYRFFLGNQFGDSQQLRLVRILRSTVMVRVGGGWMALDEFLVKNDPCRVHHHGSKMLRSESNSSITTTQPTIAKGRTNMELREKFILADGASQGMAAFRPRGRRSRPSSRGASPNRSTSVSSQAAQAASPQVPATTTPKGTPIQGSKLRLPGYLSGKGFHSGEDSGLITTAAARVRTQFADSKKTPSRPGSRAGSKAGSRASSRRGSDASDFDISEIQSVCSDVETVPQTHRPTPRAGSRPSTAKPSKIPTPQRKSPASKLDKSSKR>sp|Q03001-8|DYST_HUMAN Isoform 2 of Dystonin OS=Homo sapiens OX=9606GN=DSTMHSSSYSYRSSDSVFSNTTSTRTSLDSNENLLLVHCGPTLINSCISFGSESFDGHRLEMLQQIANRVQRDSVICEDKLILAGNALQSDSKRLESGVQFQNEAEIAGYILECENLLRQHVIDVQILIDGKYYQADQLVQRVAKLRDEIMALRNECSSVYSKGRILTTEQTKLMISGITQSLNSGFAQTLHPSLTSGLTQSLTPSLTSSSMTSGLSSGMTSRLTPSVTPAYTPGFPSGLVPNFSSGVEPNSLQTLKLMQIRKPLLKSSLLDQNLTEEEINMKFVQDLLNWVDEMQVQLDRTEWGSDLPSVESHLENHKNVHRAIEEFESSLKEAKISEIQMTAPLKLTYAEKLHRLESQYAKLLNTSRNQERHLDTLHNFVSRATNELIWLNEKEEEEVAYDWSERNTNIARKKDYHAELMRELDQKEENIKSVQEIAEQLLLENHPARLTIEAYRAAMQTQWSWILQLCQCVEQHIKENTAYFEFFNDAKEATDYLRNLKDAIQRKYSCDRSSSIHKLEDLVQESMEEKEELLQYKSTIANLMGKAKTIIQLKPRNSDCPLKTSIPIKAICDYRQIEITIYKDDECVLANNSHRAKWKVISPTGNEAMVPSVCFTVPPPNKEAVDLANRIEQQYQNVLTLWHESHINMKSVVSWHYLINEIDRIRASNVASIKTMLPGEHQQVLSNLQSRFEDFLEDSQESQVFSGSDITQLEKEVNVCKQYYQELLKSAEREEQEESVYNLYISEVRNIRLRLENCEDRLIRQIRTPLERDDLHESVFRITEQEKLKKELERLKDDLGTITNKCEEFFSQAAASSSVPTLRSELNVVLQNMNQVYSMSSTYIDKLKTVNLVLKNTQAAEALVKLYETKLCEEEAVIADKNNIENLISTLKQWRSEVDEKRQVFHALEDELQKAKAISDEMFKTYKERDLDFDWHKEKADQLVERWQNVHVQIDNRLRDLEGIGKSLKYYRDTYHPLDDWIQQVETTQRKIQENQPENSKTLATQLNQQKMLVSEIEMKQSKMDECQKYAEQYSATVKDYELQTMTYRAMVDSQQKSPVKRRRMQSSADLIIQEFMDLRTRYTALVTLMTQYIKFAGDSLKRLEEEEKSLEEEKKEHVEKAKELQKWVSNISKTLKDAEKAGKPPFSKQKISSEEISTKKEQLSEALQTIQLFLAKHGDKMTDEERNELEKQVKTLQESYNLLFSESLKQLQESQTSGDVKVEEKIVAERQQEYKEKLQGICDLLTQTENRLIGHQEAFMIGDGTVELKKYQSKQEELQKDMQGSAQALAEVVKNTENFLKENGEKLSQEDKALIEQKLNEAKIKCEQLNLKAEQSKKELDKVVTTAIKEETEKVAAVKQLEESKTKIENLLDWLSNVDKDSERAGTKHKQVIEQNGTHFQEGDGKSAIGEEDEVNGNLLETDVDGQVGTTQENLNQQYQKVKAQHEKIISQHQAVIIATQSAQVLLEKQGQYLSPEEKEKLQKNMKELKVHYETALAESEKKMKLTHSLQEELEKFDADYTEFEHWLQQSEQELENLEAGADDINGLMTKLKRQKSFSEDVISHKGDLRYITISGNRVLEAAKSCSKRDGGKVDTSATHREVQRKLDHATDRFRSLYSKCNVLGNNLKDLVDKYQHYEDASCGLLAGLQACEATASKHLSEPIAVDPKNLQRQLEETKALQGQISSQQVAVEKLKKTAEVLLDARGSLLPAKNDIQKTLDDIVGRYEDLSKSVNERNEKLQITLTRSLSVQDGLDEMLDWMGNVESSLKEQGQVPLNSTALQDIISKNIMLEQDIAGRQSSINAMNEKVKKFMETTDPSTASSLQAKMKDLSARFSEASHKHKETLAKMEELKTKVELFENLSEKLQTFLETKTQALTEVDVPGKDVTELSQYMQESTSEFLEHKKHLEVLHSLLKEISSHGLPSDKALVLEKTNNLSKKFKEMEDTIKEKKEAVTSCQEQLDAFQVLVKSLKSWIKETTKKVPIVQPSFGAEDLGKSLEDTKKLQEKWSLKTPEIQKVNNSGISLCNLISAVTTPAKAIAAVKSGGAVLNGEGTATNTEEFWANKGLTSIKKDMTDISHGYEDLGLLLKDKIAELNTKLSKLQKAQEESSAMMQWLQKMNKTATKWQQTPAPTDTEAVKTQVEQNKSFEAELKQNVNKVQELKDKLTELLEENPDTPEAPRWKQMLTEIDSKWQELNQLTIDRQQKLEESSNNLTQFQTVEAQLKQWLVEKELMVSVLGPLSIDPNMLNTQRQQVQILLQEFATRKPQYEQLTAAGQGILSRPGEDPSLRGIVKEQLAAVTQKWDSLTGQLSDRCDWIDQAIVKSTQYQSLLRSLSDKLSDLDNKLSSSLAVSTHPDAMNQQLETAQKMKQEIQQEKKQIKVAQALCEDLSALVKEEYLKAELSRQLEGILKSFKDVEQKAENHVQHLQSACASSHQFQQMSRDFQAWLDTKKEEQNKSHPISAKLDVLESLIKDHKDFSKTLTAQSHMYEKTIAEGENLLLKTQGSEKAALQLQLNTIKTNWDTFNKQVKERENKLKESLEKALKYKEQVETLWPWIDKCQNNLEEIKFCLDPAEGENSIAKLKSLQKEMDQHFGMVELLNNTANSLLSVCEIDKEVVTDENKSLIQKVDMVTEQLHSKKFCLENMTQKFKEFQEVSKESKRQLQCAKEQLDIHDSLGSQAYSNKYLTMLQTQQKSLQALKHQVDLAKRLAQDLVVEASDSKGTSDVLLQVETIAQEHSTLSQQVDEKCSFLETKLQGIGHFQNTIREMFSQFAEFDDELDSMAPVGRDAETLQKQKETIKAFLKKLEALMASNDNANKTCKMMLATEETSPDLVGIKRDLEALSKQCNKLLDRAQAREEQVEGTIKRLEEFYSKLKEFSILLQKAEEHEESQGPVGMETETINQQLNMFKVFQKEEIEPLQGKQQDVNWLGQGLIQSAAKSTSTQGLEHDLDDVNARWKTLNKKVAQRAAQLQEALLHCGRFQDALESLLSWMVDTEELVANQKPPSAEFKVVKAQIQEQKLLQRLLDDRKSTVEVIKREGEKIATTAEPADKVKILKQLSLLDSRWEALLNKAETRNRQLEGISVVAQQFHETLEPLNEWLTTIEKRLVNCEPIGTQASKLEEQIAQHKALEDDIINHNKHLHQAVSIGQSLKVLSSREDKDMVQSKLDFSQVWYIEIQEKSHSRSELLQQALCNAKIFGEDEVELMNWLNEVHDKLSKLSVQDYSTEGLWKQQSELRVLQEDILLRKQNVDQALLNGLELLKQTTGDEVLIIQDKLEAIKARYKDITKLSTDVAKTLEQALQLARRLHSTHEELCTWLDKVEVELLSYETQVLKGEEASQAQMRPKELKKEAKNNKALLDSLNEVSSALLELVPWRAREGLEKMVAEDNERYRLVSDTITQKVEEIDAAILRSQQFDQAADAELSWITETEKKLMSLGDIRLEQDQTSAQLQVQKTFTMEILRHKDIIDDLVKSGHKIMTACSEEEKQSMKKKLDKVLKNYDTICQINSERYLQLERAQSLVNQFWETYEELWPWLTETQSIISQLPAPALEYETLRQQQEEHRQLRELIAEHKPHIDKMNKTGPQLLELSPGEGFSIQEKYVAADTLYSQIKEDVKKRAVALDEAISQSTQFHDKIDQILESLERIVERLRQPPSISAEVEKIKEQISENKNVSVDMEKLQPLYETLKQRGEEMIARSGGTDKDISAKAVQDKLDQMVFIWENIHTLVEEREAKLLDVMELAEKFWCDHMSLIVTIKDTQDFIRDLEDPGIDPSVVKQQQEAAETIREEIDGLQEELDIVINLGSELIAACGEPDKPIVKKSIDELNSAWDSLNKAWKDRIDKLEEAMQAAVQYQDGLQAVFDWVDIAGGKLASMSPIGTDLETVKQQIEELKQFKSEAYQQQIEMERLNHQAELLLKKVTEESDKHTVQDPLMELKLIWDSLEERIINRQHKLEGALLALGQFQHALDELLAWLTHTEGLLSEQKPVGGDPKAIEIELAKHHVLQNDVLAHQSTVEAVNKAGNDLIESSAGEEASNLQNKLEVLNQRWQNVLEKTEQRKQQLDGALRQAKGFHGEIEDLQQWLTDTERHLLASKPLGGLPETAKEQLNVHMEVCAAFEAKEETYKSLMQKGQQMLARCPKSAETNIDQDINNLKEKWESVETKLNERKTKLEEALNLAMEFHNSLQDFINWLTQAEQTLNVASRPSLILDTVLFQIDEHKVFANEVNSHREQIIELDKTGTHLKYFSQKQDVVLIKNLLISVQSRWEKVVQRLVERGRSLDDARKRAKQFHEAWSKLMEWLEESEKSLDSELEIANDPDKIKTQLAQHKEFQKSLGAKHSVYDTTNRTGRSLKEKTSLADDNLKLDDMLSELRDKWDTICGKSVERQNKLEEALLFSGQFTDALQALIDWLYRVEPQLAEDQPVHGDIDLVMNLIDNHKAFQKELGKRTSSVQALKRSARELIEGSRDDSSWVKVQMQELSTRWETVCALSISKQTRLEAALRQAEEFHSVVHALLEWLAEAEQTLRFHGVLPDDEDALRTLIDQHKEFMKKLEEKRAELNKATTMGDTVLAICHPDSITTIKHWITIIRARFEEVLAWAKQHQQRLASALAGLIAKQELLEALLAWLQWAETTLTDKDKEVIPQEIEEVKALIAEHQTFMEEMTRKQPDVDKVTKTYKRRAADPSSLQSHIPVLDKGRAGRKRFPASSLYPSGSQTQIETKNPRVNLLVSKWQQVWLLALERRRKLNDALDRLEELREFANFDFDIWRKKYMRWMNHKKSRVMDFFRRIDKDQDGKITRQEFIDGILSSKFPTSRLEMSAVADIFDRDGDGYIDYYEFVAALHPNKDAYKPITDADKIEDEVTRQVAKCKCAKRFQVEQIGDNKYRFFLGNQFGDSQQLRLVRILRSTVMVRVGGGWMALDEFLVKNDPCRAKGRTNMELREKFILADGASQGMAAFRPRGRRSRPSSRGASPNRSTSVSSQAAQAASPQVPATTTPKILHPLTRNYGKPWLTNSKMSTPCKAAECSDFPVPSAEGTPIQGSKLRLPGYLSGKGFHSGEDSGLITTAAARVRTQFADSKKTPSRPGSRAGSKAGSRASSRRGSDASDFDISEIQSVCSDVETVPQTHRPTPRAGSRPSTAKPSKIPTPQRKSPASKLDKSSKR>sp|Q03001-3|DYST_HUMAN Isoform 3 of Dystonin OS=Homo sapiens OX=9606GN=DSTMHSSSYSYRSSDSVFSNTTSTRTSLDSNENLLLVHCGPTLINSCISFGSESFDGHRLEMLQQIANRVQRDSVICEDKLILAGNALQSDSKRLESGVQFQNEAEIAGYILECENLLRQHVIDVQILIDGKYYQADQLVQRVAKLRDEIMALRNECSSVYSKGRILTTEQTKLMISGITQSLNSGFAQTLHPSLTSGLTQSLTPSLTSSSMTSGLSSGMTSRLTPSVTPAYTPGFPSGLVPNFSSGVEPNSLQTLKLMQIRKPLLKSSLLDQNLTEEEINMKFVQDLLNWVDEMQVQLDRTEWGSDLPSVESHLENHKNVHRAIEEFESSLKEAKISEIQMTAPLKLTYAEKLHRLESQYAKLLNTSRNQERHLDTLHNFVSRATNELIWLNEKEEEEVAYDWSERNTNIARKKDYHAELMRELDQKEENIKSVQEIAEQLLLENHPARLTIEAYRAAMQTQWSWILQLCQCVEQHIKENTAYFEFFNDAKEATDYLRNLKDAIQRKYSCDRSSSIHKLEDLVQESMEEKEELLQYKSTIANLMGKAKTIIQLKPRNSDCPLKTSIPIKAICDYRQIEITIYKDDECVLANNSHRAKWKVISPTGNEAMVPSVCFTVPPPNKEAVDLANRIEQQYQNVLTLWHESHINMKSVVSWHYLINEIDRIRASNVASIKTMLPGEHQQVLSNLQSRFEDFLEDSQESQVFSGSDITQLEKEVNVCKQYYQELLKSAEREEQEESVYNLYISEVRNIRLRLENCEDRLIRQIRTPLERDDLHESVFRITEQEKLKKELERLKDDLGTITNKCEEFFSQAAASSSVPTLRSELNVVLQNMNQVYSMSSTYIDKLKTVNLVLKNTQAAEALVKLYETKLCEEEAVIADKNNIENLISTLKQWRSEVDEKRQVFHALEDELQKAKAISDEMFKTYKERDLDFDWHKEKADQLVERWQNVHVQIDNRLRDLEGIGKSLKYYRDTYHPLDDWIQQVETTQRKIQENQPENSKTLATQLNQQKMLVSEIEMKQSKMDECQKYAEQYSATVKDYELQTMTYRAMVDSQQKSPVKRRRMQSSADLIIQEFMDLRTRYTALVTLMTQYIKFAGDSLKRLEEEEIKRCKETSEHGAYSDLLQRQKATVLENSKLTGKISELERMVAELKKQKSRVEEELPKVREAAENELRKQQRNVEDISLQKIRAESEAKQYRRELETIVREKEAAERELERVRQLTIEAEAKRAAVEENLLNFRNQLEENTFTRRTLEDHLKRKDLSLNDLEQQKNKLMEELRRKRDNEEELLKLIKQMEKDLAFQKQVAEKQLKEKQKIELEARRKITEIQYTCRENALPVCPITQATSCRAVTGLQQEHDKQKAEELKQQVDELTAANRKAEQDMRELTYELNALQLEKTSSEEKARLLKDKLDETNNTLRCLKLELERKDQAEKGYSQQLRELGRQLNQTTGKAEEAMQEASDLKKIKRNYQLELESLNHEKGKLQREVDRITRAHAVAEKNIQHLNSQIHSFRDEKELERLQICQRKSDHLKEQFEKSHEQLLQNIKAEKENNDKIQRLNEELEKSNECAEMLKQKVEELTRQNNETKLMMQRIQAESENIVLEKQTIQQRCEALKIQADGFKDQLRSTNEHLHKQTKTEQDFQRKIKCLEEDLAKSQNLVSEFKQKCDQQNIIIQNTKKEVRNLNAELNASKEEKRRGEQKVQLQQAQVQELNNRLKKVQDELHLKTIEEQMTHRKMVLFQEESGKFKQSAEEFRKKMEKLMESKVITENDISGIRLDFVSLQQENSRAQENAKLCETNIKELERQLQQYREQMQQGQHMEANHYQKCQKLEDELIAQKREVENLKQKMDQQIKEHEHQLVLLQCEIQKKSTAKDCTFKPDFEMTVKECQHSGELSSRNTGHLHPTPRSPLLRWTQEPQPLEEKWQHRVVEQIPKEVQFQPPGAPLEKEKSQQCYSEYFSQTSTELQITFDETNPITRLSEIEKIRDQALNNSRPPVRYQDNACEMELVKVLTPLEIAKNKQYDMHTEVTTLKQEKNPVPSAEEWMLEGCRASGGLKKGDFLKKGLEPETFQNFDGDHACSVRDDEFKFQGLRHTVTARQLVEAKLLDMRTIEQLRLGLKTVEEVQKTLNKFLTKATSIAGLYLESTKEKISFASAAERIIIDKMVALAFLEAQAATGFIIDPISGQTYSVEDAVLKGVVDPEFRIRLLEAEKAAVGYSYSSKTLSVFQAMENRMLDRQKGKHILEAQIASGGVIDPVRGIRVPPEIALQQGLLNNAILQFLHEPSSNTRVFPNPNNKQALYYSELLRMCVFDVESQCFLFPFGERNISNLNVKKTHRISVVDTKTGSELTVYEAFQRNLIEKSIYLELSGQQYQWKEAMFFESYGHSSHMLTDTKTGLHFNINEAIEQGTIDKALVKKYQEGLITLTELADSLLSRLVPKKDLHSPVAGYWLTASGERISVLKASRRNLVDRITALRCLEAQVSTGGIIDPLTGKKYRVAEALHRGLVDEGFAQQLRQCELVITGIGHPITNKMMSVVEAVNANIINKEMGIRCLEFQYLTGGLIEPQVHSRLSIEEALQVGIIDVLIATKLKDQKSYVRNIICPQTKRKLTYKEALEKADFDFHTGLKLLEVSEPLMTGISSLYYSS>sp|Q03001-9|DYST_HUMAN Isoform 4 of Dystonin OS=Homo sapiens OX=9606GN=DSTMHSSSYSYRSSDSVFSNTTSTRTSLDSNENLLLVHCGPTLINSCISFGSESFDGHRLEMLQQIANRVQRDSVICEDKLILAGNALQSDSKRLESGVQFQNEAEIAGYILECENLLRQHVIDVQILIDGKYYQADQLVQRVAKLRDEIMALRNECSSVYSKGRILTTEQTKLMISGITQSLNSGFAQTLHPSLTSGLTQSLTPSLTSSSMTSGLSSGMTSRLTPSVTPAYTPGFPSGLVPNFSSGVEPNSLQTLKLMQIRKPLLKSSLLDQNLTEEEINMKFVQDLLNWVDEMQVQLDRTEWGSDLPSVESHLENHKNVHRAIEEFESSLKEAKISEIQMTAPLKLTYAEKLHRLESQYAKLLNTSRNQERHLDTLHNFVSRATNELIWLNEKEEEEVAYDWSERNTNIARKKDYHAELMRELDQKEENIKSVQEIAEQLLLENHPARLTIEAYRAAMQTQWSWILQLCQCVEQHIKENTAYFEFFNDAKEATDYLRNLKDAIQRKYSCDRSSSIHKLEDLVQESMEEKEELLQYKSTIANLMGKAKTIIQLKPRNSDCPLKTSIPIKAICDYRQIEITIYKDDECVLANNSHRAKWKVISPTGNEAMVPSVCFTVPPPNKEAVDLANRIEQQYQNVLTLWHESHINMKSVVSWHYLINEIDRIRASNVASIKTMLPGEHQQVLSNLQSRFEDFLEDSQESQVFSGSDITQLEKEVNVCKQYYQELLKSAEREEQEESVYNLYISEVRNIRLRLENCEDRLIRQIRTPLERDDLHESVFRITEQEKLKKELERLKDDLGTITNKCEEFFSQAAASSSVPTLRSELNVVLQNMNQVYSMSSTYIDKLKTVNLVLKNTQAAEALVKLYETKLCEEEAVIADKNNIENLISTLKQWRSEVDEKRQVFHALEDELQKAKAISDEMFKTYKERDLDFDWHKEKADQLVERWQNVHVQIDNRLRDLEGIGKSLKYYRDTYHPLDDWIQQVETTQRKIQENQPENSKTLATQLNQQKMLVSEIEMKQSKMDECQKYAEQYSATVKDYELQTMTYRAMVDSQQKSPVKRRRMQSSADLIIQEFMDLRTRYTALVTLMTQYIKFAGDSLKRLEEEEKSLEEEKKEHVEKAKELQKWVSNISKTLKDAEKAGKPPFSKQKISSEEISTKKEQLSEALQTIQLFLAKHGDKMTDEERNELEKQVKTLQESYNLLFSESLKQLQESQTSGDVKVEEKLDKVIAGTIDQTTGEVLSVFQAVLRGLIDYDTGIRLLETQLMISGLISPELRKCFDLKDAKSHGLIDEQILCQLKELSKAKEIISAASPTTIPVLDALAQSMITESMAIKVLEILLSTGSLVIPATGEQLTLQKAFQQNLVSSALFSKVLERQNMCKDLIDPCTSEKVSLIDMVQRSTLQENTGMWLLPVRPQEGGRITLKCGRNISILRAAHEGLIDRETMFRLLSAQLLSGGLINSNSGQRMTVEEAVREGVIDRDTASSILTYQVQTGGIIQSNPAKRLTVDEAVQCDLITSSSALLVLEAQRGYVGLIWPHSGEIFPTSSSLQQELITNELAYKILNGRQKIAALYIPESSQVIGLDAAKQLGIIDNNTASILKNITLPDKMPDLGDLEACKNARRWLSFCKFQPSTVHDYRQEEDVFDGEEPVTTQTSEETKKLFLSYLMINSYMDANTGQRLLLYDGDLDEAVGMLLEGCHAEFDGNTAIKECLDVLSSSGVFLNNASGREKDECTATPSSFNKCHCGEPEHEETPENRKCAIDEEFNEMRNTVINSEFSQSGKLASTISIDPKVNSSPSVCVPSLISYLTQTELADISMLRSDSENILTNYENQSRVETNERANECSHSKNIQNFPSDLIENPIMKSKMSKFCGVNETENEDNTNRDSPIFDYSPRLSALLSHDKLMHSQGSFNDTHTPESNGNKCEAPALSFSDKTMLSGQRIGEKFQDQFLGIAAINISLPGEQYGQKSLNMISSNPQVQYHNDKYISNTSGEDEKTHPGFQQMPEDKEDESEIEEYSCAVTPGGDTDNAIVSLTCATPLLDETISASDYETSLLNDQQNNTGTDTDSDDDFYDTPLFEDDDHDSLLLDGDDRDCLHPEDYDTLQEENDETASPADVFYDVSKENENSMVPQGAPVGSLSVKNKAHCLQDFLMDVEKDELDSGEKIHLNPVGSDKVNGQSLETGSERECTNILEGDESDSLTDYDIVGGKESFTASLKFDDSGSWRGRKEEYVTGQEFHSDTDHLDSMQSEESYGDYIYDSNDQDDDDDDGIDEEGGGIRDENGKPRCQNVAEDMDIQLCASILNENSDENENINTMILLDKMHSCSSLEKQQRVNVVQLASPSENNLVTEKSNLPEYTTEIAGKSKENLLNHEMVLKDVLPPIIKDTESEKTFGPASISHDNNNISSTSELGTDLANTKVKLIQGSELPELTDSVKGKDEYFKNMTPKVDSSLDHIICTEPDLIGKPAEESHLSLIASVTDKDPQGNGSDLIKGRDGKSDILIEDETSIQKMYLGEGEVLVEGLVEEENRHLKLLPGKNTRDSFKLINSQFPFPQITNNEELNQKGSLKKATVTLKDEPNNLQIIVSKSPVQFENLEEIFDTSVSKEISDDITSDITSWEGNTHFEESFTDGPEKELDLFTYLKHCAKNIKAKDVAKPNEDVPSHVLITAPPMKEHLQLGVNNTKEKSTSTQKDSPLNDMIQSNDLCSKESISGGGTEISQFTPESIEATLSILSRKHVEDVGKNDFLQSERCANGLGNDNSSNTLNTDYSFLEINNKKERIEQQLPKEQALSPRSQEKEVQIPELSQVFVEDVKDILKSRLKEGHMNPQEVEEPSACADTKILIQNLIKRITTSQLVNEASTVPSDSQMSDSSGVSPMTNSSELKPESRDDPFCIGNLKSELLLNILKQDQHSQKITGVFELMRELTHMEYDLEKRGITSKVLPLQLENIFYKLLADGYSEKIEHVGDFNQKACSTSEMMEEKPHILGDIKSKEGNYYSPNLETVKEIGLESSTVWASTLPRDEKLKDLCNDFPSHLECTSGSKEMASGDSSTEQ>sp|Q03001-10|DYST_HUMAN Isoform 5 of Dystonin OS=Homo sapiens OX=9606GN=DSTVVTTAIKEETEKVAAVKQLEESKTKIENLLDWLSNVDKDSERAGTKHKQVIEQNGTHFQEGDGKSAIGEEDEVNGNLLETDVDGQVGTTQENLNQQYQKVKAQHEKIISQHQAVIIATQSAQVLLEKQGQYLSPEEKEKLQKNMKELKVHYETALAESEKKMKLTHSLQEELEKFDADYTEFEHWLQQSEQELENLEAGADDINGLMTKLKRQKSFSEDVISHKGDLRYITISGNRVLEAAKSCSKRDGGKVDTSATHREVQRKLDHATDRFRSLYSKCNVLGNNLKDLVDKYQHYEDASCGLLAGLQACEATASKHLSEPIAVDPKNLQRQLEETKALQGQISSQQVAVEKLKKTAEVLLDARGSLLPAKNDIQKTLDDIVGRYEDLSKSVNERNEKLQITLTRSLSVQDGLDEMLDWMGNVESSLKEQDVGTGYCRSSEQYKCHE>sp|Q03001-11|DYST_HUMAN Isoform 6 of Dystonin OS=Homo sapiens OX=9606GN=DSTMIAAAFLVLLRPYSIQCALFLLLLLLGTIATIVFFCCWHRKLQKGRHPMKSVFSGRSRSRDAVLRSHHFRSEGFRASPRHLRRRVAAAAAARLEEVKPVVEVHHQSEQETSVRKRRIKKSSRVQPEFYHSVQGASIRRPSSGNASYRCSMSSSADFSDEDDFSQKSGSASPAPGDTLPWNLPKHERSKRKIQGGSVLDPAERAVLRIADERDKVQKKTFTKWIN>sp|Q03001-12|DYST_HUMAN Isoform 7 of Dystonin OS=Homo sapiens OX=9606GN=DSTMQHSIFSLKKKRCHSLYTSMSSVSKDTDGNEISDIHVTGESEDMSAKERLLLWTQQATEGYAGIRCENFTTCWRDGKLFNA>sp|Q03001-13|DYST_HUMAN Isoform 8 of Dystonin OS=Homo sapiens OX=9606GN=DSTMGNVCGCVRAEKEEQYVDPAKTPLNPEKYSPGRKYFRRKPIKKTGGDKESVGANNENEGKKKSSSQPSKEQPAPLSRGLVQQESVTLNSALGDGIQQKKTEVVADSVKQKLLPSAVSSWSDCVNTSPAKDSETEVKVSELDERISEKDSTPYCAKRKKHLDDVNTSEITFQEKTDVFSFRKAASLSSIPSGIERSLEKGGFPEDPPKSYSSIQEKQNTERFCPHATQHFQFKKKRCHSLYTSMSSVSKDTDGNEISDIHVTGESEDMSAKERLLLWTQQATEGYAGIRCENFTTCWRDGKLFNAIIHKYRPDLIDMNTVAVQSNLANLEHAFYVAEKIGVIRLLDPEDVDVSSPDEKSVITYVSSLYDAFPKVPEGGEGIGANDVEVKWIEYQNMVNYLIQWIRHHVTTMSERTFPNNPVELKALYNQYLQFKETEIPPKETEKSKIKRLYKLLEIWIEFGRIKLLQGYHPNDIEKEWGKLIIAMLEREKALRPEVERLEMLQQIANRVQRDSVICEDKLILAGNALQSDSKRLESGVQFQNEAEIAGYILECENLLRQHVIDVQILIDGKYYQADQLVQRVAKLRDEIMALRNECSSVYSKGRILTTEQTKLMISGITQSLNSGFAQTLHPSLTSGLTQSLTPSLTSSSMTSGLSSGMTSRLTPSVTPAYTPGFPSGLVPNFSSGVEPNSLQTLKLMQIRKPLLKSSLLDQNLTEEEINMKFVQDLLNWVDEMQVQLDRTEWGSDLPSVESHLENHKNVHRAIEEFESSLKEAKISEIQMTAPLKLTYAEKLHRLESQYAKLLNTSRNQERHLDTLHNFVSRATNELIWLNEKEEEEVAYDWSERNTNIARKKDYHAELMRELDQKEENIKSVQEIAEQLLLENHPARLTIEVKLESVMVLVEY>sp|Q03001-14|DYST_HUMAN Isoform 9 of Dystonin OS=Homo sapiens OX=9606GN=DSTMAGYLSPAAYLYVEEQEYLQAYEDVLERYKDERDKVQKKTFTKWINQHLMKVRKHVNDLYEDLRDGHNLISLLEVLSGDTLPREKGRMRFHRLQNVQIALDYLKRRQVKLVNIRNDDITDGNPKLTLGLIWTIILHFQISDIHVTGESEDMSAKERLLLWTQQATEGYAGIRCENFTTCWRDGKLFNAIIHKYRPDLIDMNTVAVQSNLANLEHAFYVAEKIGVIRLLDPEDVDVSSPDEKSVITYVSSLYDAFPKVPEGGEGIGANDVEVKWIEYQNMVNYLIQWIRHHVTTMSERTFPNNPVELKALYNQYLQFKETEIPPKETEKSKIKRLYKLLEIWIEFGRIKLLQGYHPNDIEKEWGKLIIAMLEREKALRPEVERLEMLQQIANRVQRDSVICEDKLILAGNALQSDSKRLESGVQFQNEAEIAGYILECENLLRQHVIDVQILIDGKYYQADQLVQRVAKLRDEIMALRNECSSVYSKGRILTTEQTKLMISGITQSLNSGFAQTLHPSLTSGLTQSLTPSLTSSSMTSGLSSGMTSRLTPSVTPAYTPGFPSGLVPNFSSGVEPNSLQTLKLMQIRKPLLKSSLLDQNLTEEEINMKFVQDLLNWVDEMQVQLDRTEWGSDLPSVESHLENHKNVHRAIEEFESSLKEAKISEIQMTAPLKLTYAEKLHRLESQYAKLLNTSRNQERHLDTLHNFVSRATNELIWLNEKEEEEVAYDWSERNTNIARKKDYHAELMRELDQKEENIKSVQEIAEQLLLENHPARLTIEAYRAAMQTQWSWILQLCQCVEQHIKENTAYFEFFNDAKEATDYLRNLKDAIQRKYSCDRSSSIHKLEDLVQESMEEKEELLQYKSTIANLMGKAKTIIQLKPRNSDCPLKTSIPIKAICDYRQIEITIYKDDECVLANNSHRAKWKVISPTGNEAMVPSVCFTVPPPNKEAVDLANRIEQQYQNVLTLWHESHINMKSVVSWHYLINEIDRIRASNVASIKTMLPGEHQQVLSNLQSRFEDFLEDSQESQVFSGSDITQLEKEVNVCKQYYQELLKSAEREEQEESVYNLYISEVRNIRLRLENCEDRLIRQIRTPLERDDLHESVFRITEQEKLKKELERLKDDLGTITNKCEEFFSQAAASSSVPTLRSELNVVLQNMNQVYSMSSTYIDKLKTVNLVLKNTQAAEALVKLYETKLCEEEAVIADKNNIENLISTLKQWRSEVDEKRQVFHALEDELQKAKAISDEMFKTYKERDLDFDWHKEKADQLVERWQNVHVQIDNRLRDLEGIGKSLKYYRDTYHPLDDWIQQVETTQRKIQENQPENSKTLATQLNQQKMLVSEIEMKQSKMDECQKYAEQYSATVKDYELQTMTYRAMVDSQQKSPVKRRRMQSSADLIIQEFMDLRTRYTALVTLMTQYIKFAGDSLKRLEEEEKSLEEEKKEHVEKAKELQKWVSNISKTLKDAEKAGKPPFSKQKISSEEISTKKEQLSEALQTIQLFLAKHGDKMTDEERNELEKQVKTLQESYNLLFSESLKQLQESQTSGDVKVEEKIVAERQQEYKEKLQGICDLLTQTENRLIGHQEAFMIGDGTVELKKYQSKQEELQKDMQGSAQALAEVVKNTENFLKENGEKLSQEDKALIEQKLNEAKIKCEQLNLKAEQSKKELDKVVTTAIKEETEKVAAVKQLEESKTKIENLLDWLSNVDKDSERAGTKHKQVIEQNGTHFQEGDGKSAIGEEDEVNGNLLETDVDGQVGTTQENLNQQYQKVKAQHEKIISQHQAVIIATQSAQVLLEKQGQYLSPEEKEKLQKNMKELKVHYETALAESEKKMKLTHSLQEELEKFDADYTEFEHWLQQSEQELENLEAGADDINGLMTKLKRQKSFSEDVISHKGDLRYITISGNRVLEAAKSCSKRDGGKVDTSATHREVQRKLDHATDRFRSLYSKCNVLGNNLKDLVDKYQHYEDASCGLLAGLQACEATASKHLSEPIAVDPKNLQRQLEETKALQGQISSQQVAVEKLKKTAEVLLDARGSLLPAKNDIQKTLDDIVGRYEDLSKSVNERNEKLQITLTRSLSVQDGLDEMLDWMGNVESSLKEQGQVPLNSTALQDIISKNIMLEQDIAGRQSSINAMNEKVKKFMETTDPSTASSLQAKMKDLSARFSEASHKHKETLAKMEELKTKVELFENLSEKLQTFLETKTQALTEVDVPGKDVTELSQYMQESTSEFLEHKKHLEVLHSLLKEISSHGLPSDKALVLEKTNNLSKKFKEMEDTIKEKKEAVTSCQEQLDAFQVLVKSLKSWIKETTKKVPIVQPSFGAEDLGKSLEDTKKLQEKWSLKTPEIQKVNNSGISLCNLISAVTTPAKAIAAVKSGGAVLNGEGTATNTEEFWANKGLTSIKKDMTDISHGYEDLGLLLKDKIAELNTKLSKLQKAQEESSAMMQWLQKMNKTATKWQQTPAPTDTEAVKTQVEQNKSFEAELKQNVNKVQELKDKLTELLEENPDTPEAPRWKQMLTEIDSKWQELNQLTIDRQQKLEESSNNLTQFQTVEAQLKQWLVEKELMVSVLGPLSIDPNMLNTQRQQVQILLQEFATRKPQYEQLTAAGQGILSRPGEDPSLRGIVKEQLAAVTQKWDSLTGQLSDRCDWIDQAIVKSTQYQSLLRSLSDKLSDLDNKLSSSLAVSTHPDAMNQQLETAQKMKQEIQQEKKQIKVAQALCEDLSALVKEEYLKAELSRQLEGILKSFKDVEQKAENHVQHLQSACASSHQFQQMSRDFQAWLDTKKEEQNKSHPISAKLDVLESLIKDHKDFSKTLTAQSHMYEKTIAEGENLLLKTQGSEKAALQLQLNTIKTNWDTFNKQVKERENKLKESLEKALKYKEQVETLWPWIDKCQNNLEEIKFCLDPAEGENSIAKLKSLQKEMDQHFGMVELLNNTANSLLSVCEIDKEVVTDENKSLIQKVDMVTEQLHSKKFCLENMTQKFKEFQEVSKESKRQLQCAKEQLDIHDSLGSQAYSNKYLTMLQTQQKSLQALKHQVDLAKRLAQDLVVEASDSKGTSDVLLQVETIAQEHSTLSQQVDEKCSFLETKLQGIGHFQNTIREMFSQFAEFDDELDSMAPVGRDAETLQKQKETIKAFLKKLEALMASNDNANKTCKMMLATEETSPDLVGIKRDLEALSKQCNKLLDRAQAREEQVEGTIKRLEEFYSKLKEFSILLQKAEEHEESQGPVGMETETINQQLNMFKVFQKEEIEPLQGKQQDVNWLGQGLIQSAAKSTSTQGLEHDLDDVNARWKTLNKKVAQRAAQLQEALLHCGRFQDALESLLSWMVDTEELVANQKPPSAEFKVVKAQIQEQKLLQRLLDDRKSTVEVIKREGEKIATTAEPADKVKILKQLSLLDSRWEALLNKAETRNRQLEGISVVAQQFHETLEPLNEWLTTIEKRLVNCEPIGTQASKLEEQIAQHKVLQEDILLRKQNVDQALLNGLELLKQTTGDEVLIIQDKLEAIKARYKDITKLSTDVAKTLEQALQLARRLHSTHEELCTWLDKVEVELLSYETQVLKGEEASQAQMRPKELKKEAKNNKALLDSLNEVSSALLELVPWRAREGLEKMVAEDNERYRLVSDTITQKVEEIDAAILRSQQFDQAADAELSWITETEKKLMSLGDIRLEQDQTSAQLQVQKTFTMEILRHKDIIDDLVKSGHKIMTACSEEEKQSMKKKLDKVLKNYDTICQINSERYLQLERAQSLVNQFWETYEELWPWLTETQSIISQLPAPALEYETLRQQQEEHRQLRELIAEHKPHIDKMNKTGPQLLELSPGEGFSIQEKYVAADTLYSQIKEDVKKRAVALDEAISQSTQFHDKIDQILESLERIVERLRQPPSISAEVEKIKEQISENKNVSVDMEKLQPLYETLKQRGEEMIARSGGTDKDISAKAVQDKLDQMVFIWENIHTLVEEREAKLLDVMELAEKFWCDHMSLIVTIKDTQDFIRDLEDPGIDPSVVKQQQEAAETIREEIDGLQEELDIVINLGSELIAACGEPDKPIVKKSIDELNSAWDSLNKAWKDRIDKLEEAMQAAVQYQDGLQAVFDWVDIAGGKLASMSPIGTDLETVKQQIEELKQFKSEAYQQQIEMERLNHQAELLLKKVTEESDKHTVQDPLMELKLIWDSLEERIINRQHKLEGALLALGQFQHALDELLAWLTHTEGLLSEQKPVGGDPKAIEIELAKHHVLQNDVLAHQSTVEAVNKAGNDLIESSAGEEASNLQNKLEVLNQRWQNVLEKTEQRKQQLDGALRQAKGFHGEIEDLQQWLTDTERHLLASKPLGGLPETAKEQLNVHMEVCAAFEAKEETYKSLMQKGQQMLARCPKSAETNIDQDINNLKEKWESVETKLNERKTKLEEALNLAMEFHNSLQDFINWLTQAEQTLNVASRPSLILDTVLFQIDEHKVFANEVNSHREQIIELDKTGTHLKYFSQKQDVVLIKNLLISVQSRWEKVVQRLVERGRSLDDARKRAKQFHEAWSKLMEWLEESEKSLDSELEIANDPDKIKTQLAQHKEFQKSLGAKHSVYDTTNRTGRSLKEKTSLADDNLKLDDMLSELRDKWDTICGKSVERQNKLEEALLFSGQFTDALQALIDWLYRVEPQLAEDQPVHGDIDLVMNLIDNHKAFQKELGKRTSSVQALKRSARELIEGSRDDSSWVKVQMQELSTRWETVCALSISKQTRLEAALRQAEEFHSVVHALLEWLAEAEQTLRFHGVLPDDEDALRTLIDQHKEFMKKLEEKRAELNKATTMGDTVLAICHPDSITTIKHWITIIRARFEEVLAWAKQHQQRLASALAGLIAKQELLEALLAWLQWAETTLTDKDKEVIPQEIEEVKALIAEHQTFMEEMTRKQPDVDKVTKTYKRRAADPSSLQSHIPVLDKGRAGRKRFPASSLYPSGSQTQIETKNPRVNLLVSKWQQVWLLALERRRKLNDALDRLEELREFANFDFDIWRKKYMRWMNHKKSRVMDFFRRIDKDQDGKITRQEFIDGILSSKFPTSRLEMSAVADIFDRDGDGYIDYYEFVAALHPNKDAYKPITDADKIEDEVTRQVAKCKCAKRFQVEQIGDNKYRFFLGNQFGDSQQLRLVRILRSTVMVRVGGGWMALDEFLVKNDPCRVHHHGSKMLRSESNSSITTTQPTIAKGRTNMELREKFILADGASQGMAAFRPRGRRSRPSSRGASPNRSTSVSSQAAQAASPQVPATTTPKGTPIQGSKLRLPGYLSGKGFHSGEDSGLITTAAARVRTQFADSKKTPSRPGSRAGSKAGSRASSRRGSDASDFDISEIQSVCSDVETVPQTHRPTPRAGSRPSTAKPSKIPTPQRKSPASKLDKSSKR>sp|P01906|DQA2_HUMAN HLA class II histocompatibility antigen, DQ alpha 2chain OS=Homo sapiens OX=9606 GN=HLA-DQA2 PE=1 SV=2MILNKALLLGALALTAVMSPCGGEDIVADHVASYGVNFYQSHGPSGQYTHEFDGDEEFYVDLETKETVWQLPMFSKFISFDPQSALRNMAVGKHTLEFMMRQSNSTAATNEVPEVTVFSKFPVTLGQPNTLICLVDNIFPPVVNITWLSNGHSVTEGVSETSFLSKSDHSFFKISYLTFLPSADEIYDCKVEHWGLDEPLLKHWEPEIPAPMSELTETLVCALGLSVGLMGIVVGTVFIIQGLRSVGASRHQGLL>sp|Q9NP87|DPOLM_HUMAN DNA-directed DNA/RNA polymerase mu OS=Homo sapiensOX=9606 GN=POLM PE=1 SV=1MLPKRRRARVGSPSGDAASSTPPSTRFPGVAIYLVEPRMGRSRRAFLTGLARSKGFRVLDACSSEATHVVMEETSAEEAVSWQERRMAAAPPGCTPPALLDISWLTESLGAGQPVPVECRHRLEVAGPRKGPLSPAWMPAYACQRPTPLTHHNTGLSEALEILAEAAGFEGSEGRLLTFCRAASVLKALPSPVTTLSQLQGLPHFGEHSSRVVQELLEHGVCEEVERVRRSERYQTMKLFTQIFGVGVKTADRWYREGLRTLDDLREQPQKLTQQQKAGLQHHQDLSTPVLRSDVDALQQVVEEAVGQALPGATVTLTGGFRRGKLQGHDVDFLITHPKEGQEAGLLPRVMCRLQDQGLILYHQHQHSCCESPTRLAQQSHMDAFERSFCIFRLPQPPGAAVGGSTRPCPSWKAVRVDLVVAPVSQFPFALLGWTGSKLFQRELRRFSRKEKGLWLNSHGLFDPEQKTFFQAASEEDIFRHLGLEYLPPEQRNA>sp|Q9NP87-2|DPOLM_HUMAN Isoform 2 of DNA-directed DNA/RNA polymerase muOS=Homo sapiens OX=9606 GN=POLMMLPKRRRARVGSPSGDAASSTPPSTRFPGVAIYLVEPRMGRSRRAFLTGLARSKGFRVLDACSSEATHVVMEETSAEEAVSWQERRMAAAPPGCTPPALLDISWLTESLGAGQPVPVECRHRLEVAGPRKGPLSPAWMPAYACQRPTPLTHHNTGLSEALEILAEAAGFEGSEGRLLTFCRAASVLKALPSPVTTLSQLQGLPHFGEHSSRVVQELLEHGVCEEVERVRRSERYQTMKLFTQIFGVGVKTADRWYREGLRTLDDLREQPQKLTQQQKAAPPGPEHPSPAVRCRCPAAGGGGSCGAGPAWGHRHADRRLPQGLILYHQHQHSCCESPTRLAQQSHMDAFERSFCIFRLPQPPGAAVGGSTRPCPSWKAVRVDLVVAPVSQFPFALLGWTGSKLFQRELRRFSRKEKGLWLNSHGLFDPEQKTFFQAASEEDIFRHLGLEYLPPEQRNA>sp|Q9NP87-3|DPOLM_HUMAN Isoform 3 of DNA-directed DNA/RNA polymerase muOS=Homo sapiens OX=9606 GN=POLMMLPKRRRARVGSPSGDAASSTPPSTRFPGVAIYLVEPRMGRSRRAFLTGLARSKGFRVLDACSSEATHVVMEETSAEEAVSWQERRMAAAPPGCTPPALLDISWLTESLGAGQPVPVECRHRLEVAGPRKGPLSPAWMPAYACQRPTPLTHHNTGLSEALEILAEAAGFEGSEGRLLTFCRAASVLKALPSPVTTLSQLQGLPHFGEHSSRVVQELLEHGVCEEVERVRRSERAPAPPGPEHPSPAVRCRCPAAGGGGSCGAGPAWGHRHADRRLPQGLILYHQHQHSCCESPTRLAQQSHMDAFERSFCIFRLPQPPGAAVGGSTRPCPSWKAVRVDLVVAPVSQFPFALLGWTGSKLFQRELRRFSRKEKGLWLNSHGLFDPEQGSSSGKTPRSRKSCFCCRRHFSKRLQRKTSSDTWALSTFLQSRETPEPACVPHFHSGNWAAPNLATECLQADMLPPDPHLHPSPPRPGSSGGQLCLQDQLSPCWCAAGCDEVGALSASLITV>sp|Q96FN9|DTD2_HUMAN D-aminoacyl-tRNA deacylase 2 OS=Homo sapiensOX=9606 GN=DTD2 PE=1 SV=1MAEGSRIPQARALLQQCLHARLQIRPADGDVAAQWVEVQRGLVIYVCFFKGADKELLPKMVNTLLNVKLSETENGKHVSILDLPGNILIIPQATLGGRLKGRNMQYHSNSGKEEGFELYSQFVTLCEKEVAANSKCAEARVVVEHGTYGNRQVLKLDTNGPFTHLIEF>sp|P05538|DQB2_HUMAN HLA class II histocompatibility antigen, DQ beta 2chain OS=Homo sapiens OX=9606 GN=HLA-DQB2 PE=1 SV=2MSWKMALQIPGGFWAAAVTVMLVMLSTPVAEARDFPKDFLVQFKGMCYFTNGTERVRGVARYIYNREEYGRFDSDVGEFQAVTELGRSIEDWNNYKDFLEQERAAVDKVCRHNYEAELRTTLQRQVEPTVTISPSRTEALNHHNLLVCSVTDFYPAQIKVRWFRNDQEETAGVVSTSLIRNGDWTFQILVMLEITPQRGDIYTCQVEHPSLQSPITVEWRAQSESAQSKMLSGIGGFVLGLIFLGLGLIIRHRGQKGPRGPPPAGLLH>sp|P05538-2|DQB2_HUMAN Isoform 2 of HLA class II histocompatibilityantigen, DQ beta 2 chain OS=Homo sapiens OX=9606 GN=HLA-DQB2MALQIPGGFWAAAVTVMLVMLSTPVAEARDFPKDFLVQFKGMCYFTNGTERVRGVARYIYNREEYGRFDSDVGEFQAVTELGRSIEDWNNYKDFLEQERAAVDKVCRHNYEAELRTTLQRQVEPTVTISPSRTEALNHHNLLVCSVTDFYPAQIKVRWFRNDQEETAGVVSTSLIRNGDWTFQILVMLEITPQRGDIYTCQVEHPSLQSPITVEWRPRGPPPAGLLH>sp|Q8TEA8|DTD1_HUMAN D-aminoacyl-tRNA deacylase 1 OS=Homo sapiensOX=9606 GN=DTD1 PE=1 SV=2MKAVVQRVTRASVTVGGEQISAIGRGICVLLGISLEDTQKELEHMVRKILNLRVFEDESGKHWSKSVMDKQYEILCVSQFTLQCVLKGNKPDFHLAMPTEQAEGFYNSFLEQLRKTYRPELIKDGKFGAYMQVHIQNDGPVTIELESPAPGTATSDPKQLSKLEKQQQRKEKTRAKGPSESSKERNTPRKEDRSASSGAEGDVSSEREP>sp|Q8WW35|DYT2B_HUMAN Dynein light chain Tctex-type protein 2B OS=Homosapiens OX=9606 GN=DYNLT2B PE=1 SV=2MATSIGVSFSVGDGVPEAEKNAGEPENTYILRPVFQQRFRPSVVKDCIHAVLKEELANAEYSPEEMPQLTKHLSENIKDKLKEMGFDRYKMVVQVVIGEQRGEGVFMASRCFWDADTDNYTHDVFMNDSLFCVVAAFGCFYY>sp|Q8IY82|DRC7_HUMAN Dynein regulatory complex subunit 7 OS=Homo sapiensOX=9606 GN=DRC7 PE=1 SV=3MEVLREKVEEEEEAEREEAAEWAEWARMEKMMRPVEVRKEEITLKQETLRDLEKKLSEIQITVSAELPAFTKDTIDISKLPISYKTNTPKEEHLLQVADNFSRQYSHLCPDRVPLFLHPLNECEVPKFVSTTLRPTLMPYPELYNWDSCAQFVSDFLTMVPLPDPLKPPSHLYSSTTVLKYQKGNCFDFSTLLCSMLIGSGYDAYCVNGYGSLDLCHMDLTREVCPLTVKPKETIKKEEKVLPKKYTIKPPRDLCSRFEQEQEVKKQQEIRAQEKKRLREEEERLMEAEKAKPDALHGLRVHSWVLVLSGKREVPENFFIDPFTGHSYSTQDEHFLGIESLWNHKNYWINMQDCWNCCKDLIFDLGDPVRWEYMLLGTDKSQLSLTEEDDSGINDEDDVENLGKEDEDKSFDMPHSWVEQIEISPEAFETRCPNGKKVIQYKRAKLEKWAPYLNSNGLVSRLTTYEDLQCTNILEIKEWYQNREDMLELKHINKTTDLKTDYFKPGHPQALRVHSYKSMQPEMDRVIEFYETARVDGLMKREETPRTMTEYYQGRPDFLSYRHASFGPRVKKLTLSSAESNPRPIVKITERFFRNPAKPAEEDVAERVFLVAEERIQLRYHCREDHITASKREFLRRTEVDSKGNKIIMTPDMCISFEVEPMEHTKKLLYQYEAMMHLKREEKLSRHQVWESELEVLEILKLREEEEAAHTLTISIYDTKRNEKSKEYREAMERMMHEEHLRQVETQLDYLAPFLAQLPPGEKLTCWQAVRLKDECLSDFKQRLINKANLIQARFEKETQELQKKQQWYQENQVTLTPEDEDLYLSYCSQAMFRIRILEQRLNRHKELAPLKYLALEEKLYKDPRLGELQKIFA>sp|Q8IY82-2|DRC7_HUMAN Isoform 2 of Dynein regulatory complex subunit 7OS=Homo sapiens OX=9606 GN=DRC7MEVLREKVEEEEEAEREEAAEWAEWARMEKMMRPVEVRKEEITLKQETLRDLEKKLSEIQITVSAELPAFTKDTIDISKLPISYKTNTPKEEHLLQVADNFSRQYSHLCPDRVPLFLHPLNECEVPKFVSTTLRPTLMPYPELYNWDSCAQFVSDFLTMVPLPDPLKPTIKKEEKVLPKKYTIKPPRDLCSRFEQEQEVKKQQEIRAQEKKRLREEEERLMEAEKAKPDALHGLRVHSWVLVLSGKREVPENFFIDPFTGHSYSTQDEHFLGIESLWNHKNYWINMQDCWNCCKDLIFDLGDPVRWEYMLLGTDKSQLSLTEEDDSGINDEDDVENLGKEDEDKSFDMPHSWVEQIEISPEAFETRCPNGKKVIQYKRAKLEKWAPYLNSNGLVSRLTTYEDLQCTNILEIKEWYQNREDMLELKHINKTTDLKTDYFKPGHPQALRVHSYKSMQPEMDRVIEFYETARVDGLMKREETPRTMTEYYQGRPDFLSYRHASFGPRVKKLTLSSAESNPRPIVKITERFFRNPAKPAEEDVAERVFLVAEERIQLRYHCREDHITASKREFLRRTEVDSKGNKIIMTPDMCISFEVEPMEHTKKLLYQYEAMMHLKREEKLSRHQVWESELEVLEILKLREEEEAAHTLTISIYDTKRNEKSKEYREAMERMMHEEHLRQVETQLDYLAPFLAQLPPGEKLTCWQAVRLKDECLSDFKQRLINKANLIQARFEKETQELQKKQQWYQENQVTLTPEDEDLYLSYCSQAMFRIRILEQRLNRHKELAPLKYLALEEKLYKDPRLGELQKIFA>sp|P41567|EIF1_HUMAN Eukaryotic translation initiation factor 1 OS=Homosapiens OX=9606 GN=EIF1 PE=1 SV=1MSAIQNLHSFDPFADASKGDDLLPAGTEDYIHIRIQQRNGRKTLTTVQGIADDYDKKKLVKAFKKKFACNGTVIEHPEYGEVIQLQGDQRKNICQFLVEIGLAKDDQLKVHGF>sp|Q92784|DPF3_HUMAN Zinc finger protein DPF3 OS=Homo sapiens OX=9606GN=DPF3 PE=1 SV=3MATVIHNPLKALGDQFYKEAIEHCRSYNSRLCAERSVRLPFLDSQTGVAQNNCYIWMEKRHRGPGLAPGQLYTYPARCWRKKRRLHPPEDPKLRLLEIKPEVELPLKKDGFTSESTTLEALLRGEGVEKKVDAREEESIQEIQRVLENDENVEEGNEEEDLEEDIPKRKNRTRGRARGSAGGRRRHDAASQEDHDKPYVCDICGKRYKNRPGLSYHYAHTHLASEEGDEAQDQETRSPPNHRNENHRPQKGPDGTVIPNNYCDFCLGGSNMNKKSGRPEELVSCADCGRSGHPTCLQFTLNMTEAVKTYKWQCIECKSCILCGTSENDDQLLFCDDCDRGYHMYCLNPPVAEPPEGSWSCHLCWELLKEKASAFGCQA>sp|Q92784-2|DPF3_HUMAN Isoform 2 of Zinc finger protein DPF3 OS=Homosapiens OX=9606 GN=DPF3MATVIHNPLKALGDQFYKEAIEHCRSYNSRLCAERSVRLPFLDSQTGVAQNNCYIWMEKRHRGPGLAPGQLYTYPARCWRKKRRLHPPEDPKLRLLEIKPEVELPLKKDGFTSESTTLEALLRGEGVEKKVDAREEESIQEIQRVLENDENVEEGNEEEDLEEDIPKRKNRTRGRARGSAGGRRRHDAASQEDHDKPYVCDICGKRYKNRPGLSYHYAHTHLASEEGDEAQDQETRSPPNHRNENHRPQKGPDGTVIPNNYCDFCLGGSNMNKKSGRPEELVSCADCGRSAHLGGEGRKEKEAAAAARTTEDLFGSTSESDTSTFHGFDEDDLEEPRSCRGRRSGRGSPTADKKGSC>sp|Q92784-3|DPF3_HUMAN Isoform 3 of Zinc finger protein DPF3 OS=Homosapiens OX=9606 GN=DPF3MFYGRINGRNFAASSLPVAFAATPLMLFLPNPQLICSFPISSRNHITGLMPPGKLKLENLFHMCTRLGDQFYKEAIEHCRSYNSRLCAERSVRLPFLDSQTGVAQNNCYIWMEKRHRGPGLAPGQLYTYPARCWRKKRRLHPPEDPKLRLLEIKPEVELPLKKDGFTSESTTLEALLRGEGVEKKVDAREEESIQEIQRVLENDENVEEGNEEEDLEEDIPKRKNRTRGRARGSAGGRRRHDAASQEDHDKPYVCDICGKRYKNRPGLSYHYAHTHLASEEGDEAQDQETRSPPNHRNENHRPQKGPDGTVIPNNYCDFCLGGSNMNKKSGRPEELVSCADCGRSAHLGGEGRKEKEAAAAARTTEDLFGSTSESDTSTFHGFDEDDLEEPRSCRGRRSGRGSPTADKKGSC>sp|Q92784-4|DPF3_HUMAN Isoform 4 of Zinc finger protein DPF3 OS=Homosapiens OX=9606 GN=DPF3MATVIHNPLKALGDQFYKEAIEHCRSYNSRLCAERSVRLPFLDSQTGVAQNNCYIWMEKRHRGPGLAPGQLYTYPARCWRKKRRLHPPEDPKLRLLEIKPEVELPLKKDGFTSESTTLEALLRGEGVEKKVDAREEESIQEIQRVLENDENVEEGNEEEDLEEDIPKRKNRTRGRARCPLPSLHCFLPSLCRDRC>sp|Q92784-5|DPF3_HUMAN Isoform 5 of Zinc finger protein DPF3 OS=Homosapiens OX=9606 GN=DPF3MGFTDLEEPISGCPGGPWALGLGDQFYKEAIEHCRSYNSRLCAERSVRLPFLDSQTGVAQNNCYIWMEKRHRGPGLAPGQLYTYPARCWRKKRRLHPPEDPKLRLLEIKPEVELPLKKDGFTSESTTLEALLRGEGVEKKVDAREEESIQEIQRVLENDENVEEGNEEEDLEEDIPKRKNRTRGRARGSAGGRRRHDAASQEDHDKPYVCDICGKRYKNRPGLSYHYAHTHLASEEGDEAQDQETRSPPNHRNENHRPQKGPDGTVIPNNYCDFCLGGSNMNKKSGRPEELVSCADCGRSAHLGGEGRKEKEAAAAARTTEDLFGSTSESDTSTFHGFDEDDLEEPRSCRGRRSGRGSPTADKKGSC>sp|A8MWY0|ELAP2_HUMAN Endosome/lysosome-associated apoptosis andautophagy regulator family member 2 OS=Homo sapiens OX=9606 GN=ELAPOR2PE=1 SV=2MLFRARGPVRGRGWGRPAEAPRRGRSPPWSPAWICCWALAGCQAAWAGDLPSSSSRPLPPCQEKDYHFEYTECDSSGSRWRVAIPNSAVDCSGLPDPVRGKECTFSCASGEYLEMKNQVCSKCGEGTYSLGSGIKFDEWDELPAGFSNIATFMDTVVGPSDSRPDGCNNSSWIPRGNYIESNRDDCTVSLIYAVHLKKSGYVFFEYQYVDNNIFFEFFIQNDQCQEMDTTTDKWVKLTDNGEWGSHSVMLKSGTNILYWRTTGILMGSKAVKPVLVKNITIEGVAYTSECFPCKPGTFSNKPGSFNCQVCPRNTYSEKGAKECIRCKDDSQFSEEGSSECTERPPCTTKDYFQIHTPCDEEGKTQIMYKWIEPKICREDLTDAIRLPPSGEKKDCPPCNPGFYNNGSSSCHPCPPGTFSDGTKECRPCPAGTEPALGFEYKWWNVLPGNMKTSCFNVGNSKCDGMNGWEVAGDHIQSGAGGSDNDYLILNLHIPGFKPPTSMTGATGSELGRITFVFETLCSADCVLYFMVDINRKSTNVVESWGGTKEKQAYTHIIFKNATFTFTWAFQRTNQGQDNRRFINDMVKIYSITATNAVDGVASSCRACALGSEQSGSSCVPCPPGHYIEKETNQCKECPPDTYLSIHQVYGKEACIPCGPGSKNNQDHSVCYSDCFFYHEKENQSLHYDFSNLSSVGSLMNGPSFTSKGTKYFHFFNISLCGHEGKKMALCTNNITDFTVKEIVAGSDDYTNLVGAFVCQSTIIPSESKGFRAALSSQSIILADTFIGVTVETTLKNINIKEDMFPVPTSQIPDVHFFYKSSTATTSCINGRSTAVKMRCNPTKSGAGVISVPSKCPAGTCDGCTFYFLWESAEACPLCTEHDFHEIEGACKRGFQETLYVWNEPKWCIKGISLPEKKLATCETVDFWLKVGAGVGAFTAVLLVALTCYFWKKNQKLEYKYSKLVMTTNSKECELPAADSCAIMEGEDNEEEVVYSNKQSLLGKLKSLATKEKEDHFESVQLKTSRSPNI>sp|A8MWY0-2|ELAP2_HUMAN Isoform 2 of Endosome/lysosome-associatedapoptosis and autophagy regulator family member 2 OS=Homo sapiens OX=9606GN=ELAPOR2MLEGNYQVMLKSGTNILYWRTTGILMGSKAVKPVLVKNITIEGVAYTSECFPCKPGTFSNKPGSFNCQVCPRNTYSEKGAKECIRCKDDSQFSEEGSSECTERPPCTTKDYFQIHTPCDEEGKTQIMYKWIEPKICREDLTDAIRLPPSGEKKDCPPCNPGFYNNGSSSCHPCPPGTFSDGTKECRPCPAGTEPALGFEYKWWNVLPGNMKTSCFNVGNSKCDGMNGWEVAGDHIQSGAGGSDNDYLILNLHIPGFKPPTSMTGATGSELGRITFVFETLCSADCVLYFMVDINRKSTNVVESWGGTKEKQAYTHIIFKNATFTFTWAFQRTNQGQDNRRFINDMVKIYSITATNAVDGVASSCRACALGSEQSGSSCVPCPPGHYIEKETNQCKECPPDTYLSIHQVYGKEACIPCGPGSKNNQDHSVCYSDCFFYHEKENQSLHYDFSNLSSVGSLMNGPSFTSKGTKYFHFFNISLCGHEGKKMALCTNNITDFTVKEIVAGSDDYTNLVGAFVCQSTIIPSESKGFRAALSSQSIILADTFIGVTVETTLKNINIKEDMFPVPTSQIPDVHFFYKSSTATTSCINGRSTAVKMRCNPTKSGAGVISVPSKCPAGTCDGCTFYFLWESAEACPLCTEHDFHEIEGACKRGFQETLYVWNEPKWCIKGISLPEKKLATCETVDFWLKVGAGVGAFTAVLLVALTCYFWKKNQKLEYKYSKLVMTTNSKECELPAADSCAIMEGEDNEEEVVYSNKQSLLGKLKSLATKEKEDHFESVQLKTSRSPNI>sp|A8MWY0-3|ELAP2_HUMAN Isoform 3 of Endosome/lysosome-associatedapoptosis and autophagy regulator family member 2 OS=Homo sapiens OX=9606GN=ELAPOR2MHSSWIPRGNYIESNRDDCTVSLIYAVHLKKSGYVFFEYQYVDNNIFFEFFIQNDQCQEMDTTTDKWVKLTDNGEWGSHSVMLKSGTNILYWRTTGILMGSKAVKPVLVKNITIEGVAYTSECFPCKPGTFSNKPGSFNCQVCPRNTYSEKGAKECIRCKDDSQFSEEGSSECTERPPCTTKDYFQIHTPCDEEGKTQIMYKWIEPKICREDLTDAIRLPPSGEKKDCPPCNPGFYNNGSSSCHPCPPGTFSDGTKECRPCPAGTEPALGFEYKWWNVLPGNMKTSCFNVGNSKCDGMNGWEVAGDHIQSGAGGSDNDYLILNLHIPGFKPPTSMTGATGSELGRITFVFETLCSADCVLYFMVDINRKSTNVVESWGGTKEKQAYTHIIFKNATFTFTWAFQRTNQGQDNRRFINDMVKIYSITATNAVDGVASSCRACALGSEQSGSSCVPCPPGHYIEKETNQCKECPPDTYLSIHQVYGKEACIPCGPGSKNNQDHSVCYSDCFFYHEKENQSLHYDFSNLSSVGSLMNGPSFTSKGTKYFHFFNISLCGHEGKKMALCTNNITDFTVKEIVAGSDDYTNLVGAFVCQSTIIPSESKGFRAALSSQSIILADTFIGVTVETTLKNINIKEDMFPVPTSQIPDVHFFYKSSTATTSCINGRSTAVKMRCNPTKSGAGVISVPSKCPAGTCDGCTFYFLWESAEACPLCTEHDFHEIEGACKRGFQETLYVWNEPKWCIKGISLPEKKLATCETVDFWLKVGAGVGAFTAVLLVALTCYFWKKNQKLEYKYSKLVMTTNSKECELPAADSCAIMEGEDNEEEVVYSNKQSLLGKLKSLATKEKEDHFESVQLKTSRSPNI>sp|A6NLF2|ELB3D_HUMAN Elongin-A3 member D OS=Homo sapiens OX=9606GN=ELOA3DP PE=3 SV=1MAAGSTTLRAVGKLQVRLATKTEPKKLEKYLQKLSALPMTADILAETGIRKTVKRLRKHQHVGDFARDLAARWKKLVLVDRNTGPDPQDPEESASRQRFGEALQEREKAWGFPENATAPRSPSHSPEHRRTARRTPPGQQRPHPRSPSREPRAERKRPRMAPADSGPHRDPPTRTAPLPMPEGPEPAVPGEQPGRGHAHAAQGGPLLGQGCQGQPQGEAVGSHSKGHKSSRGASAQKSPPVQESQSERLQAAVADSAGPKTVPSHVFSELWDPSEAWMQANYDLLSAFEAMTSQANPEALSAPTLQEEAAFPGRRVNAKMPVYSGSRPACQLQVPTLRQQCLRVPRNNPDALGDVEGVPYSALEPVLEGWTPDQPYRTEKDNAALARETDELWRIHCLQDFKEEKPQEHESWRELYLRLRDAREQRLRVVTTKIRSARENKPSGRQTKMICFNSVAKTPYDASRRQEKSAGAADPGNGEMEPAPKPAGSSQAPSGLGDGDGGSVSGGGSSNRHAAPADKTRKQAAKKVAPLMAKAIRDYKGRFSRR>sp|Q8N1I0|DOCK4_HUMAN Dedicator of cytokinesis protein 4 OS=Homo sapiensOX=9606 GN=DOCK4 PE=1 SV=3MWIPTEHEKYGVVIASFRGTVPYGLSLEIGDTVQILEKCDGWYRGFALKNPNIKGIFPSSYVHLKNACVKNKGQFEMVIPTEDSVITEMTSTLRDWGTMWKQLYVRNEGDLFHRLWHIMNEILDLRRQVLVGHLTHDRMKDVKRHITARLDWGNEQLGLDLVPRKEYAMVDPEDISITELYRLMEHRHRKKDTPVQASSHHLFVQMKSLMCSNLGEELEVIFSLFDSKENRPISERFFLRLNRNGLPKAPDKPERHCSLFVDLGSSELRKDIYITVHIIRIGRMGAGEKKNACSVQYRRPFGCAVLSIADLLTGETKDDLILKVYMCNTESEWYQIHENIIKKLNARYNLTGSNAGLAVSLQLLHGDIEQIRREYSSVFSHGVSITRKLGFSNIIMPGEMRNDLYITIERGEFEKGGKSVARNVEVTMFIVDSSGQTLKDFISFGSGEPPASEYHSFVLYHNNSPRWSELLKLPIPVDKFRGAHIRFEFRHCSTKEKGEKKLFGFSFVPLMQEDGRTLPDGTHELIVHKCEENTNLQDTTRYLKLPFSKGIFLGNNNQAMKATKESFCITSFLCSTKLTQNGDMLDLLKWRTHPDKITGCLSKLKEIDGSEIVKFLQDTLDTLFGILDENSQKYGSKVFDSLVHIINLLQDSKFHHFKPVMDTYIESHFAGALAYRDLIKVLKWYVDRITEAERQEHIQEVLKAQEYIFKYIVQSRRLFSLATGGQNEEEFRCCIQELLMSVRFFLSQESKGSGALSQSQAVFLSSFPAVYSELLKLFDVREVANLVQDTLGSLPTILHVDDSLQAIKLQCIGKTVESQLYTNPDSRYILLPVVLHHLHIHLQEQKDLIMCARILSNVFCLIKKNSSEKSVLEEIDVIVASLLDILLRTILEITSRPQPSSSAMRFQFQDVTGEFVACLLSLLRQMTDRHYQQLLDSFNTKEELRDFLLQIFTVFRILIRPEMFPKDWTVMRLVANNVIITTVLYLSDALRKNFLNENFDYKIWDSYFYLAVIFINQLCLQLEMFTPSKKKKVLEKYGDMRVTMGCEIFSMWQNLGEHKLHFIPALIGPFLEVTLIPQPDLRNVMIPIFHDMMDWEQRRSGNFKQVEAKLIDKLDSLMSEGKGDETYRELFNSILLKKIERETWRESGVSLIATVTRLMERLLDYRDCMKMGEVDGKKIGCTVSLLNFYKTELNKEEMYIRYIHKLYDLHLKAQNFTEAAYTLLLYDELLEWSDRPLREFLTYPMQTEWQRKEHLHLTIIQNFDRGKCWENGIILCRKIAEQYESYYDYRNLSKMRMMEASLYDKIMDQQRLEPEFFRVGFYGKKFPFFLRNKEFVCRGHDYERLEAFQQRMLNEFPHAIAMQHANQPDETIFQAEAQYLQIYAVTPIPESQEVLQREGVPDNIKSFYKVNHIWKFRYDRPFHKGTKDKENEFKSLWVERTSLYLVQSLPGISRWFEVEKREVVEMSPLENAIEVLENKNQQLKTLISQCQTRQMQNINPLTMCLNGVIDAAVNGGVSRYQEAFFVKEYILSHPEDGEKIARLRELMLEQAQILEFGLAVHEKFVPQDMRPLHKKLVDQFFVMKSSLGIQEFSACMQASPVHFPNGSPRVCRNSAPASVSPDGTRVIPRRSPLSYPAVNRYSSSSLSSQASAEVSNITGQSESSDEVFNMQPSPSTSSLSSTHSASPNVTSSAPSSARASPLLSDKHKHSRENSCLSPRERPCSAIYPTPVEPSQRMLFNHIGDGALPRSDPNLSAPEKAVNPTPSSWSLDSGKEAKNMSDSGKLISPPVPPRPTQTASPARHTTSVSPSPAGRSPLKGSVQSFTPSPVEYHSPGLISNSPVLSGSYSSGISSLSRCSTSETSGFENQVNEQSAPLPVPVPVPVPSYGGEEPVRKESKTPPPYSVYERTLRRPVPLPHSLSIPVTSEPPALPPKPLAARSSHLENGARRTDPGPRPRPLPRKVSQL>sp|Q8N1I0-2|DOCK4_HUMAN Isoform 2 of Dedicator of cytokinesis protein 4OS=Homo sapiens OX=9606 GN=DOCK4MWIPTEHEKYGVVIASFRGTVPYGLSLEIGDTVQILEKCDGWYRGFALKNPNIKGIFPSSYVHLKNACVKNKGQFEMVIPTEDSVITEMTSTLRDWGTMWKQLYVRNEGDLFHRLWHIMNEILDLRRQVLVGHLTHDRMKDVKRHITARLDWGNEQLGLDLVPRKEYAMVDPEDISITELYRLMEHRHRKKDTPVQASSHHLFVQMKSLMCSNLGEELEVIFSLFDSKENRPISERFFLRLNRNGLPKAPDKPERHCSLFVDLGSSELRKDIYITVHIIRIGRMGAGEKKNACSVQYRRPFGCAVLSIADLLTGETKDDLILKVYMCNTESEWYQIHENIIKKLNARYNLTGSNAGLAVSLQLLHGDIEQIRREYSSVFSHGVSITRKLGFSNIIMPGEMRNDLYITIERGEFEKGGKSVARNVEVTMFIVDSSGQTLKDFISFGSGEPPASEYHSFVLYHNNSPRWSELLKLPIPVDKFRGAHIRFEFRHCSTKEKGEKKLFGFSFVPLMQEDGRTLPDGTHELIVHKCEENTNLQDTTRYLKLPFSKGIFLGNNNQAMKATKESFCITSFLCSTKLTQNGDMLDLLKWRTHPDKITGCLSKLKEIDGSEIVKFLQDTLDTLFGILDENSQKYGSKVFDSLVHIINLLQDSKFHHFKPVMDTYIESHFAGALAYRDLIKVLKWYVDRITEAERQEHIQEVLKAQEYIFKYIVQSRRLFSLATGGQNEEEFRCCIQELLMSVRFFLSQESKGSGALSQSQAVFLSSFPAVYSELLKLFDVREVANLVQDTLGSLPTILHVDDSLQAIKLQCIGKTVESQLYTNPDSRYILLPVVLHHLHIHLQEQKDLIMCARILSNVFCLIKKNSSEKSVLEEIDVIVASLLDILLRTILEITSRPQPSSSAMRFQFQDVTGEFVACLLSLLRQMTDRHYQQLLDSFNTKEELRDFLLQIFTVFRILIRPEMFPKDWTVMRLVANNVIITTVLYLSDALRKNFLNENFDYKIWDSYFYLAVIFINQLCLQLEMFTPSKKKKVLEKYGDMRVTMGCEIFSMWQNLGEHKLHFIPALIGPFLEVTLIPQPDLRNVMIPIFHDMMDWEQRRSGNFKQVEAKLIDKLDSLMSEGKGDETYRELFNSIIPLFGPYPSLLKKIERETWRESGVSLIATVTRLMERLLDYRDCMKMGEVDGKKIGCTVSLLNFYKTELNKEEMYIRYIHKLYDLHLKAQNFTEAAYTLLLYDELLEWSDRPLREFLTYPMQTEWQRKEHLHLTIIQNFDRGKCWENGIILCRKIAEQYESYYDYRNLSKMRMMEASLYDKIMDQQRLEPEFFRVGFYGKKFPFFLRNKEFVCRGHDYERLEAFQQRMLNEFPHAIAMQHANQPDETIFQAEAQYLQIYAVTPIPESQEVLQREGVPDNIKSFYKVNHIWKFRYDRPFHKGTKDKENEFKSLWVERTSLYLVQSLPGISRWFEVEKREVVEMSPLENAIEVLENKNQQLKTLISQCQTRQMQNINPLTMCLNGVIDAAVNGGVSRYQEAFFVKEYILSHPEDGEKIARLRELMLEQAQILEFGLAVHEKFVPQDMRPLHKKLVDQFFVMKSSLGIQEFSACMQASPVHFPNGSPRVCRNSAPASVSPDGTRVIPRRSPLSYPAVNRYSSSSLSSQASAEVSNITGQSESSDEVFNMQPSPSTSSLSSTHSASPNVTSSAPSSARASPLLSDKHKHSRENSCLSPRERPCSAIYPTPVEPSQRMLFNHIGDGALPRSDPNLSAPEKASPARHTTSVSPSPAGRSPLKGSVQSFTPSPVEYHSPGLISNSPVLSGSYSSGISSLSRCSTSETSGFENQVNEQSAPLPVPVPVPVPSYGGEEPVRKESKTPPPYSVYERTLRRPVPLPHSLSIPVTSEPPALPPKPLAARSSHLENGARRTDPGPRPRPLPRKVSQL>sp|Q8N1I0-3|DOCK4_HUMAN Isoform 3 of Dedicator of cytokinesis protein 4OS=Homo sapiens OX=9606 GN=DOCK4MWIPTEHEKYGVVIASFRGTVPYGLSLEIGDTVQILEKCDGWYRGFALKNPNIKGIFPSSYVHLKNACVKNKGQFEMVIPTEDSVITEMTSTLRDWGTMWKQLYVRNEGDLFHRLWHIMNEILDLRRQVLVGHLTHDRMKDVKRHITARLDWGNEQLGLDLVPRKEYAMVDPEDISITELYRLMEHRHRKKDTPVQASSHHLFVQMKSLMCSNLGEELEVIFSLFDSKENRPISERFFLRLNRNGLPKAPDKPERHCSLFVDLGSSELRKDIYITVHIIRIGRMGAGEKKNACSVQYRRPFGCAVLSIADLLTGETKDDLILKVYMCNTESEWYQIHENIIKKLNARYNLTGSNAGLAVSLQLLHGDIEQIRREYSSVFSHGVSITRKLGFSNIIMPGEMRNDLYITIERGEFEKGGKSVARNVEVTMFIVDSSGQTLKDFISFGSGEPPASEYHSFVLYHNNSPRWSELLKLPIPVDKFRGAHIRFEFRHCSTKEKGEKKLFGFSFVPLMQEDGRTLPDGTHELIVHKCEENTNLQDTTRYLKLPFSKGIFLGNNNQAMKATKESFCITSFLCSTKLTQNGDMLDLLKWRTHPDKITGCLSKLKEIDGSEIVKFLQDTLDTLFGILDENSQKYGSKVFDSLVHIINLLQDSKFHHFKPVMDTYIESHFAGALAYRDLIKVLKWYVDRITEAERQEHIQEVLKAQEYIFKYIVQSRRLFSLATGGQNEEEFRCCIQELLMSVRFFLSQESKGSGALSQSQAVFLSSFPAVYSELLKLFDVREVANLVQDTLGSLPTILHVDDSLQAIKLQCIGKTVESQLYTNPDSRYILLPVVLHHLHIHLQEQKDLIMCARILSNVFCLIKKNSSEKSVLEEIDVIVASLLDILLRTILEITSRPQPSSSAMRFQFQDVTGEFVACLLSLLRQMTDRHYQQLLDSFNTKEELRDFLLQIFTVFRILIRPEMFPKDWTVMRLVANNVIITTVLYLSDALRKNFLNENFDYKIWDSYFYLAVIFINQLCLQLEMFTPSKKKKVLEKYGDMRVTMGCEIFSMWQNLGEHKLHFIPALIGPFLEVTLIPQPDLRNVMIPIFHDMMDWEQRRSGNFKQVEAKLIDKLDSLMSEGKGDETYRELFNSIIPLFGPYPSLLKKIERETWRESGVSLIATVTRLMERLLDYRDCMKMGEVDGKKIGCTVSLLNFYKTELNKEEMYIRYIHKLYDLHLKAQNFTEAAYTLLLYDELLEWSDRPLREFLTYPMQTEWQRKEHLHLTIIQNFDRGKCWENGIILCRKIAEQYESYYDYRNLSKMRMMEASLYDKIMDQQRLEPEFFRVGFYGKKFPFFLRNKEFVCRGHDYERLEAFQQRMLNEFPHAIAMQHANQPDETIFQAEAQYLQIYAVTPIPESQEVLQREGVPDNIKSFYKVNHIWKFRYDRPFHKGTKDKENEFKSLWVERTSLYLVQSLPGISRWFEVEKREVVEMSPLENAIEVLENKNQQLKTLISQCQTRQMQNINPLTMCLNGVIDAAVNGGVSRYQEAFFVKEYILSHPEDGEKIARLRELMLEQAQILEFGLAVHEKFVPQDMRPLHKKLVDQFFVMKSSLGIQEFSACMQASPVHFPNGSPRVCRNSAPASVSPDGTRVIPRRSPLSYPAVNRYSSSSLSSQASAEVSNITGQSESSDEVFNMQPSPSTSSLSSTHSASPNVTSSAPSSARASPLLSDKHKHSRENSCLSPRERPCSAIYPTPVEPSQRMLFNHIGDGALPRSDPNLSAPEKAVNPTPSSWSLDSGKEAKNMSDSGKLISPPVPPRPTQTASPARHTTSVSPSPAGRSPLKGSVQSFTPSPVEYHSPGLISNSPVLSGSYSSGISSLSRCSTSETSGFENQVNEQSAPLPVPVPVPVPSYGGEEPVRKESKTPPPYSVYERTLRRPVPLPHSLSIPVTSEPPALPPKPLAARSSHLENGARRTDPGPRPRPLPRKVSQL>sp|Q8N1I0-4|DOCK4_HUMAN Isoform 4 of Dedicator of cytokinesis protein 4OS=Homo sapiens OX=9606 GN=DOCK4MLMILSLLLFPASPLLSDKHKHSRENSCLSPRERPCSAIYPTPVEPSQRMLFNHIGDGALPRSDPNLSAPEKAVNPTPSSWSLDSGKEAKNMSDSGKLISPPVPPRPTQTASPARHTTSVSPSPAGRSPLKGSVQSFTPSPVEYHSPGLISNSPVLSGSYSSGISSLSRCSTSETSGFENQVNEQSAPLPVPVPVPVPSYGGEEPVRKESKTPPPYSVYERTLRRPVPLPHSLSIPVTSEPPALPPKPLAARSSHLENGARRTDPGPRPRPLPRKVSQL>sp|Q9HB65|ELL3_HUMAN RNA polymerase II elongation factor ELL3 OS=Homosapiens OX=9606 GN=ELL3 PE=1 SV=2MEELQEPLRGQLRLCFTQAARTSLLLLRLNDAALRALQECQRQQVRPVIAFQGHRGYLRLPGPGWSCLFSFIVSQCCQEGAGGSLDLVCQRFLRSGPNSLHCLGSLRERLIIWAAMDSIPAPSSVQGHNLTEDARHPESWQNTGGYSEGDAVSQPQMALEEVSVSDPLASNQGQSLPGSSREHMAQWEVRSQTHVPNREPVQALPSSASRKRLDKKRSVPVATVELEEKRFRTLPLVPSPLQGLTNQDLQEGEDWEQEDEDMDPRLEHSSSVQEDSESPSPEDIPDYLLQYRAIHSAEQQHAYEQDFETDYAEYRILHARVGTASQRFIELGAEIKRVRRGTPEYKVLEDKIIQEYKKFRKQYPSYREEKRRCEYLHQKLSHIKGLILEFEEKNRGS>sp|Q9HB65-2|ELL3_HUMAN Isoform 2 of RNA polymerase II elongation factorELL3 OS=Homo sapiens OX=9606 GN=ELL3MGLTVSFHPQYLRLPGPGWSCLFSFIVSQCCQEGAGGSLDLVCQRFLRSGPNSLHCLGSLRERLIIWAAMDSIPAPSSVQGHNLTEDARHPESWQNTGGYSEGDAVSQPQMALEEVSVSDPLASNQGQSLPGSSREHMAQWEVRSQTHVPNREPVQALPSSASRKRLDKKRSVPVATVELEEKRFRTLPLVPSPLQGLTNQDLQEGEDWEQEDEDMDPRLEHSSSVQEDSESPSPEDIPDYLLQYRAIHSAEQQHAYEQDFETDYAEYRILHARVGTASQRFIELGAEIKRVRRGTPEYKVLEDKIIQEYKKFRKQYPSYREEKRRCEYLHQKLSHIKGLILEFEEKNRGS>sp|Q9UKW6|ELF5_HUMAN ETS-related transcription factor Elf-5 OS=Homosapiens OX=9606 GN=ELF5 PE=1 SV=2MPSLPHSHRVMLDSVTHSTFLPNASFCDPLMSWTDLFSNEEYYPAFEHQTACDSYWTSVHPEYWTKRHVWEWLQFCCDQYKLDTNCISFCNFNISGLQLCSMTQEEFVEAAGLCGEYLYFILQNIRTQGYSFFNDAEESKATIKDYADSNCLKTSGIKSQDCHSHSRTSLQSSHLWEFVRDLLLSPEENCGILEWEDREQGIFRVVKSEALAKMWGQRKKNDRMTYEKLSRALRYYYKTGILERVDRRLVYKFGKNAHGWQEDKL>sp|Q9UKW6-2|ELF5_HUMAN Isoform 2 of ETS-related transcription factorElf-5 OS=Homo sapiens OX=9606 GN=ELF5MLDSVTHSTFLPNASFCDPLMSWTDLFSNEEYYPAFEHQTACDSYWTSVHPEYWTKRHVWEWLQFCCDQYKLDTNCISFCNFNISGLQLCSMTQEEFVEAAGLCGEYLYFILQNIRTQGYSFFNDAEESKATIKDYADSNCLKTSGIKSQDCHSHSRTSLQSSHLWEFVRDLLLSPEENCGILEWEDREQGIFRVVKSEALAKMWGQRKKNDRMTYEKLSRALRYYYKTGILERVDRRLVYKFGKNAHGWQEDKL>sp|Q9UKW6-3|ELF5_HUMAN Isoform 3 of ETS-related transcription factorElf-5 OS=Homo sapiens OX=9606 GN=ELF5MLDSVTHSTFLPNASFCDPLMSWTDLFSNEEYYPAFEHQTACDSYWTSVHPEYWTKRHVWEWLQFCCDQYKLDTNCISFCNFNISGLQLCSMTQEEFVEAAGLCGEYLYFILQNIRTQGQCSEGQTSRGGTRIRTKQL>sp|Q9UKW6-4|ELF5_HUMAN Isoform 4 of ETS-related transcription factorElf-5 OS=Homo sapiens OX=9606 GN=ELF5MLDSVTHSTFLPNASFCDPLMSWTDLFSNEEYYPAFEHQTDADSNCLKTSGIKSQDCHSHSRTSLQSSHLWEFVRDLLLSPEENCGILEWEDREQGIFRVVKSEALAKMWGQRKKNDRMTYEKLSRALRYYYKTGILERVDRRLVYKFGKNAHGWQEDKL>sp|P15502|ELN_HUMAN Elastin OS=Homo sapiens OX=9606 GN=ELN PE=1 SV=4MAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGAAGAGVLGGLVPGAPGAVPGVPGTGGVPGVGTPAAAAAKAAAKAAQFGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAGADEGVRRSLSPELREGDPSSSQHLPSTPSSPRVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGAAGLGGVLGGAGQFPLGGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-1|ELN_HUMAN Isoform 1 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGVGTPAAAAAKAAAKAAQFALLNLAGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGAAGLGGVLGGAGQFPLGGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-2|ELN_HUMAN Isoform 2 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGVGTPAAAAAKAAAKAAQFGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGAAGLGGVLGGAGQFPLGGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-4|ELN_HUMAN Isoform 4 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGVGTPAAAAAKAAAKAAQFGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAGADEGVRRSLSPELREGDPSSSQHLPSTPSSPRVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGAAGLGGVLGGAGQFPLGGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-5|ELN_HUMAN Isoform 5 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAAPSVPGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGVGTPAAAAAKAAAKAAQFGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-6|ELN_HUMAN Isoform 6 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-7|ELN_HUMAN Isoform 7 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-8|ELN_HUMAN Isoform 8 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAGAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-9|ELN_HUMAN Isoform 9 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGAAGAGVLGGLVPGAPGAVPGVPGTGGVPGVGTPAAAAAKAAAKAAQFALLNLAGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAGADEGVRRSLSPELREGDPSSSQHLPSTPSSPRVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGAAGLGGVLGGAGQFPLGGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-10|ELN_HUMAN Isoform 10 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGAAGAGVLGGLVPGAPGAVPGVPGTGGVPGVGTPAAAAAKAAAKAAQFALLNLAGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGAAGLGGVLGGAGQFPLGGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-11|ELN_HUMAN Isoform 11 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-12|ELN_HUMAN Isoform 12 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAAPSVPGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|P15502-13|ELN_HUMAN Isoform 13 of Elastin OS=Homo sapiens OX=9606GN=ELNMAGLTAAAPRPGVLLLLLSILHPSRPGGVPGAIPGGVPGGVFYPGAGLGALGGGALGPGGKPLKPVPGGLAGAGLGAGLGAFPAVTFPGALVPGGVADAAAAYKAAKAGAGLGGVPGVGGLGVSAGAVVPQPGAGVKPGKVPGVGLPGVYPGGVLPGARFPGVGVLPGVPTGAGVKPKAPGVGGAFAGIPGVGPFGGPQPGVPLGYPIKAPKLPGGYGLPYTTGKLPYGYGPGGVAGAAGKAGYPTGTGVGPQAAAAAAAKAAAKFGAGAAGVLPGVGGAGVPGVPGAIPGIGGIAGVGTPAAAAAAAAAAKAAKYGAAAGLVPGGPGFGPGVVGVPGAGVPGVGVPGAGIPVVPGAGIPGAAVPGVVSPEAAAKAAAKAAKYGARPGVGVGGIPTYGVGAGGFPGFGVGVGGIPGVAGVPGVGGVPGVGGVPGVGISPEAQAAAAAKAAKYGLVPGVGVAPGVGVAPGVGVAPGVGLAPGVGVAPGVGVAPGVGVAPGIGPGGVAAAAKSAAKVAAKAQLRAAAGLGAGIPGLGVGVGVPGLGVGAGVPGLGVGAGVPGFGAVPGALAAAKAAKYGAAVPGVLGGLGALGGVGIPGGVVGAGPAAAAAAAKAAAKAAQFGLVGAAGLGGLGVGGLGVPGVGGLGGIPPAAAAKAAKYGAAGLGGVLGGAGQFPLGGVAARPGFGLSPIFPGGACLGKACGRKRK>sp|O42043|ENK18_HUMAN Endogenous retrovirus group K member 18 Envpolyprotein OS=Homo sapiens OX=9606 GN=ERVK-18 PE=1 SV=2MVTPVTWMDNPIEVYVNDSVWVPGPTDDRCPAKPEEEGMMINISIGYHYPPICLGRAPGCLMPAVQNWLVEVPTVSPNSRFTYHMVSGMSLRPRVNCLQDFSYQRSLKFRPKGKTCPKEIPKGSKNTEVLVWEECVANSVVILQNNEFGTIIDWAPRGQFYHNCSGQTQSCPSAQVSPAVDSDLTESLDKHKHKKLQSFYLWEWEEKGISTPRPKIISPVSGPEHPELWRLTVASHHIRIWSGNQTLETRYRKPFYTIDLNSILTVPLQSCVKPPYMLVVGNIVIKPASQTITCENCRLFTCIDSTFNWQHRILLVRAREGMWIPVSTDRPWEASPSIHILTEILKGVLNRSKRFIFTLIAVIMGLIAVTATAAVAGVALHSSVQSVNFVNYWQKNSTRLWNSQSSIDQKLASQINDLRQTVIWMGDRLMTLEHHFQLQCDWNTSDFCITPQIYNESEHHWDMVRRHLQGREDNLTLDISKLKEQIFEASKAHLNLVPGTEAIAGVADGLANLNPVTWIKTIRSTMIINLILIVVCLFCLLLVCRCTQQLRRDSDIENGP>sp|P52797|EFNA3_HUMAN Ephrin-A3 OS=Homo sapiens OX=9606 GN=EFNA3 PE=1SV=1MAAAPLLLLLLLVPVPLLPLLAQGPGGALGNRHAVYWNSSNQHLRREGYTVQVNVNDYLDIYCPHYNSSGVGPGAGPGPGGGAEQYVLYMVSRNGYRTCNASQGFKRWECNRPHAPHSPIKFSEKFQRYSAFSLGYEFHAGHEYYYISTPTHNLHWKCLRMKVFVCCASTSHSGEKPVPTLPQFTMGPNVKINVLEDFEGENPQVPKLEKSISGTSPKREHLPLAVGIAFFLMTFLAS>sp|P52797-2|EFNA3_HUMAN Isoform 2 of Ephrin-A3 OS=Homo sapiens OX=9606GN=EFNA3MAAAPLLLLLLLVPVPLLPLLAQGPGGALGNRHAVYWNSSNQHLRREGYTVQVNVNDYLDIYCPHYNSSGVGPGAGPGPGGGAEQYVLYMVSRNGYRTCNASQGFKRWECNRPHAPHSPIKFSEKFQRYSAFSLGYEFHAGHEYYYISTPTHNLHWKCLRMKVFVCCASKDFEGENPQVPKLEKSISGTSPKREHLPLAVGIAFFLMTFLAS>sp|Q902F8|ENK8_HUMAN Endogenous retrovirus group K member 8 Envpolyprotein OS=Homo sapiens OX=9606 GN=ERVK-8 PE=1 SV=1MNPSEMQRKAPPRRRRHRNRAPLTHKMNKMVTSEEQMKLPSTKKAEPPTWAQLKKLTQLATKYLENTKVTQTPESMLLAALMIVSMVVSLPMPAGAAVANYTNWAYVPFPPLIRAVTWMDNPIEVYVNDSVWVPGPIDDRCPAKPEEEGMMINISIGYRYPPICLGRAPGCLMPAVQNWLVEVPTVSPISRFTYHMVSGMSLRPRVNYLQDFSYQRSLKFRPKGKPCPKEIPKESKNTEVLVWEECVANSAVILQNNEFGTIIDWAPRGQFYHNCSGQTQSCPSAQVSPAVDSDLTESLDKHKHKKLQSFYPWEWGEKRISTPRPKIVSPVSGPEHPELWRLTVASHHIRIWSGNQTLETRDRKPFYTVDLNSSLTLPLQSCVKPPYMLVVGNIVIKPDSQTITCENCRLLTCIDSTFNWQHRILLVRAREGVWIPVSMDRPWEASPSVHILTEVLKGVLNRSKRFIFTLIAVIMGLIAVTATAAVAGVALHSSVQSVNFVNDGQKNSTRLWNSQSSIDQKLANQINDLRQTVIWMGDRLMSLEHRFQLQCDWNTSDFCITPQIYNDSEHHWDMVRRHLQGREDNLTLDISKLKEQIFEASKAHLNLVPGTEAIAGVADGLANLNPVTWVKTIGSTTIINLILILVCLFCLLLVCRCTQQLRRDSDHRERAMMTMAVLSKRKGGNVGKSKRDQIVTVSV>sp|Q9NR50|EI2BG_HUMAN Translation initiation factor eIF-2B subunit gammaOS=Homo sapiens OX=9606 GN=EIF2B3 PE=1 SV=1MEFQAVVMAVGGGSRMTDLTSSIPKPLLPVGNKPLIWYPLNLLERVGFEEVIVVTTRDVQKALCAEFKMKMKPDIVCIPDDADMGTADSLRYIYPKLKTDVLVLSCDLITDVALHEVVDLFRAYDASLAMLMRKGQDSIEPVPGQKGKKKAVEQRDFIGVDSTGKRLLFMANEADLDEELVIKGSILQKHPRIRFHTGLVDAHLYCLKKYIVDFLMENGSITSIRSELIPYLVRKQFSSASSQQGQEEKEEDLKKKELKSLDIYSFIKEANTLNLAPYDACWNACRGDRWEDLSRSQVRCYVHIMKEGLCSRVSTLGLYMEANRQVPKLLSALCPEEPPVHSSAQIVSKHLVGVDSLIGPETQIGEKSSIKRSVIGSSCLIKDRVTITNCLLMNSVTVEEGSNIQGSVICNNAVIEKGADIKDCLIGSGQRIEAKAKRVNEVIVGNDQLMEI>sp|Q9NR50-2|EI2BG_HUMAN Isoform 2 of Translation initiation factor eIF-2B subunit gamma OS=Homo sapiens OX=9606 GN=EIF2B3MEFQAVVMAVGGGSRMTDLTSSIPKPLLPVGNKPLIWYPLNLLERVGFEEVIVVTTRDVQKALCAEFKMKMKPDIVCIPDDADMGTADSLRYIYPKLKTDVLVLSCDLITDVALHEVVDLFRAYDASLAMLMRKGQDSIEPVPGQKGKKKAVEQRDFIGVDSTGKRLLFMANEADLDEELVIKGSILQKHPRIRFHTGLVDAHLYCLKKYIVDFLMENGSITSIRSELIPYLVRKQFSSASSQQGQEEKEEDLKKKELKSLDIYSFIKEANTLNLAPYDACWNACRGDRWEDLSRSQVRCYVHIMKEGLCSRVSTLGLYMEANRQVPKLLSALCPEEPPVHSSAQIVSKHLVGVDSLIGPETQIGEKSSIKRSVIGSSCLIKDRVTITNCLLMNSVTVEEGYVSPCTHLRQR>sp|Q9NR50-3|EI2BG_HUMAN Isoform 3 of Translation initiation factor eIF-2B subunit gamma OS=Homo sapiens OX=9606 GN=EIF2B3MEFQAVVMAVGGGSRMTDLTSSIPKPLLPVGNKPLIWYPLNLLERVGFEEVIVVTTRDVQKALCAEFKMKMKPDIVCIPDDADMGTADSLRYIYPKLKTDVLVLSCDLITDVALHEVVDLFRAYDASLAMLMRKGQDSIEPVPGQKGKKKAVEQRDFIGVDSTGKRLLFMANEADLDEELVIKGSILQKHPRIRFHTGLVDAHLYCLKKYIVDFLMENGSITSIRSELIPYLVRKQFSSASSQQGQEEKEEDLKKKELKSLDIYSFIKEANTLNLAPYDACWNACRGDRWEDLSRSQVRCYVHIMKEGLCSRVSTLGLYMEANRQVPKLLSALCPEEPPVHSSAQIVSKHLVGVDSLIGPETQIGEKSSIKRSVIGSSCLIKDRVTITNCLLMNSVTVEEG>sp|Q6UWT2|ENHO_HUMAN Adropin OS=Homo sapiens OX=9606 GN=ENHO PE=2 SV=2MGAAISQGALIAIVCNGLVGFLLLLLWVILCWACHSRSADVDSLSESSPNSSPGPCPEKAPPPQKPSHEGSYLLQP>sp|Q6UWT2-2|ENHO_HUMAN Isoform 2 of Adropin OS=Homo sapiens OX=9606GN=ENHOMGAAISQGALIAIVCNGLVGFLLLLLWVILCWACHSRSADVDSLSESRTQESACLELDPAAQSLASLAPIGAQWP>sp|P13639|EF2_HUMAN Elongation factor 2 OS=Homo sapiens OX=9606 GN=EEF2PE=1 SV=4MVNFTVDQIRAIMDKKANIRNMSVIAHVDHGKSTLTDSLVCKAGIIASARAGETRFTDTRKDEQERCITIKSTAISLFYELSENDLNFIKQSKDGAGFLINLIDSPGHVDFSSEVTAALRVTDGALVVVDCVSGVCVQTETVLRQAIAERIKPVLMMNKMDRALLELQLEPEELYQTFQRIVENVNVIISTYGEGESGPMGNIMIDPVLGTVGFGSGLHGWAFTLKQFAEMYVAKFAAKGEGQLGPAERAKKVEDMMKKLWGDRYFDPANGKFSKSATSPEGKKLPRTFCQLILDPIFKVFDAIMNFKKEETAKLIEKLDIKLDSEDKDKEGKPLLKAVMRRWLPAGDALLQMITIHLPSPVTAQKYRCELLYEGPPDDEAAMGIKSCDPKGPLMMYISKMVPTSDKGRFYAFGRVFSGLVSTGLKVRIMGPNYTPGKKEDLYLKPIQRTILMMGRYVEPIEDVPCGNIVGLVGVDQFLVKTGTITTFEHAHNMRVMKFSVSPVVRVAVEAKNPADLPKLVEGLKRLAKSDPMVQCIIEESGEHIIAGAGELHLEICLKDLEEDHACIPIKKSDPVVSYRETVSEESNVLCLSKSPNKHNRLYMKARPFPDGLAEDIDKGEVSARQELKQRARYLAEKYEWDVAEARKIWCFGPDGTGPNILTDITKGVQYLNEIKDSVVAGFQWATKEGALCEENMRGVRFDVHDVTLHADAIHRGGGQIIPTARRCLYASVLTAQPRLMEPIYLVEIQCPEQVVGGIYGVLNRKRGHVFEESQVAGTPMFVVKAYLPVNESFGFTADLRSNTGGQAFPQCVFDHWQILPGDPFDNSSRPSQVVAETRKRKGLKEGIPALDNFLDKL>sp|Q8TDU6|GPBAR_HUMAN G-protein coupled bile acid receptor 1 OS=Homosapiens OX=9606 GN=GPBAR1 PE=1 SV=1MTPNSTGEVPSPIPKGALGLSLALASLIITANLLLALGIAWDRRLRSPPAGCFFLSLLLAGLLTGLALPTLPGLWNQSRRGYWSCLLVYLAPNFSFLSLLANLLLVHGERYMAVLRPLQPPGSIRLALLLTWAGPLLFASLPALGWNHWTPGANCSSQAIFPAPYLYLEVYGLLLPAVGAAAFLSVRVLATAHRQLQDICRLERAVCRDEPSALARALTWRQARAQAGAMLLFGLCWGPYVATLLLSVLAYEQRPPLGPGTLLSLLSLGSASAAAVPVAMGLGDQRYTAPWRAAAQRCLQGLWGRASRDSPGPSIAYHPSSQSSVDLDLN>sp|Q69384|ENK6_HUMAN Endogenous retrovirus group K member 6 Envpolyprotein OS=Homo sapiens OX=9606 GN=ERVK-6 PE=1 SV=1MNPSEMQRKAPPRRRRHRNRAPLTHKMNKMVTSEEQMKLPSTKKAEPPTWAQLKKLTQLATKYLENTKVTQTPESMLLAALMIVSMVVSLPMPAGAAAANYTYWAYVPFPPLIRAVTWMDNPTEVYVNDSVWVPGPIDDRCPAKPEEEGMMINISIGYHYPPICLGRAPGCLMPAVQNWLVEVPTVSPICRFTYHMVSGMSLRPRVNYLQDFSYQRSLKFRPKGKPCPKEIPKESKNTEVLVWEECVANSAVILQNNEFGTIIDWAPRGQFYHNCSGQTQSCPSAQVSPAVDSDLTESLDKHKHKKLQSFYPWEWGEKGISTPRPKIVSPVSGPEHPELWRLTVASHHIRIWSGNQTLETRDRKPFYTIDLNSSLTVPLQSCVKPPYMLVVGNIVIKPDSQTITCENCRLLTCIDSTFNWQHRILLVRAREGVWIPVSMDRPWEASPSVHILTEVLKGVLNRSKRFIFTLIAVIMGLIAVTATAAVAGVALHSSVQSVNFVNDWQKNSTRLWNSQSSIDQKLANQINDLRQTVIWMGDRLMSLEHRFQLQCDWNTSDFCITPQIYNESEHHWDMVRRHLQGREDNLTLDISKLKEQIFEASKAHLNLVPGTEAIAGVADGLANLNPVTWVKTIGSTTIINLILILVCLFCLLLVCRCTQQLRRDSDHRERAMMTMAVLSKRKGGNVGKSKRDQIVTVSV>sp|Q9N2K0|ENH1_HUMAN HERV-H_2q24.3 provirus ancestral Env polyproteinOS=Homo sapiens OX=9606 PE=2 SV=1MIFAGKAPSNTSTLMKFYSLLLYSLLFSFPFLCHPLPLPSYLHHTINLTHSLLAASNPSLVNNCWLCISLSSSAYTAVPAVQTDWATSPISLHLRTSFNSPHLYPPEELIYFLDRSSKTSPDISHQQAAALLRTYLKNLSPYINSTPPIFGPLTTQTTIPVAAPLCISWQRPTGIPLGNLSPSRCSFTLHLRSPTTNINETIGAFQLHITDKPSINTDKLKNISSNYCLGRHLPCISLHPWLSSPCSSDSPPRPSSCLLIPSPENNSERLLVDTRRFLIHHENRTFPSTQLPHQSPLQPLTAAALAGSLGVWVQDTPFSTPSHLFTLHLQFCLAQGLFFLCGSSTYMCLPANWTGTCTLVFLTPKIQFANGTEELPVPLMTPTQQKRVIPLIPLMVGLGLSASTVALGTGIAGISTSVMTFRSLSNDFSASITDISQTLSVLQAQVDSLAAVVLQNRRGLDLLTAEKGGLCIFLNEECCFYLNQSGLVYDNIKKLKDRAQKLANQASNYAEPPWALSNWMSWVLPIVSPLIPIFLLLLFGPCIFRLVSQFIQNRIQAITNHSIRQMFLLTSPQYHPLPQDLPSA>sp|Q8N6R0|EFNMT_HUMAN eEF1A lysine and N-terminal methyltransferaseOS=Homo sapiens OX=9606 GN=METTL13 PE=1 SV=1MNLLPKSSREFGSVDYWEKFFQQRGKKAFEWYGTYLELCGVLHKYIKPREKVLVIGCGNSELSEQLYDVGYRDIVNIDISEVVIKQMKECNATRRPQMSFLKMDMTQMEFPDASFQVVLDKGTLDAVLTDEEEKTLQQVDRMLAEVGRVLQVGGRYLCISLAQAHILKKAVGHFSREGWMVRVHQVANSQDQVLEAEPQFSLPVFAFIMTKFRPVPGSALQIFELCAQEQRKPVRLESAERLAEAVQERQQYAWLCSQLRRKARLGSVSLDLCDGDTGEPRYTLHVVDSPTVKPSRDNHFAIFIIPQGRETEWLFGMDEGRKQLAASAGFRRLITVALHRGQQYESMDHIQAELSARVMELAPAGMPTQQQVPFLSVGGDIGVRTVQHQDCSPLSGDYVIEDVQGDDKRYFRRLIFLSNRNVVQSEARLLKDVSHKAQKKRKKDRKKQRPADAEDLPAAPGQSIDKSYLCCEHHKAMIAGLALLRNPELLLEIPLALLVVGLGGGSLPLFVHDHFPKSCIDAVEIDPSMLEVATQWFGFSQSDRMKVHIADGLDYIASLAGGGEARPCYDVIMFDVDSKDPTLGMSCPPPAFVEQSFLQKVKSILTPEGVFILNLVCRDLGLKDSVLAGLKAVFPLLYVRRIEGEVNEILFCQLHPEQKLATPELLETAQALERTLRKPGRGWDDTYVLSDMLKTVKIV>sp|Q8N6R0-4|EFNMT_HUMAN Isoform 2 of eEF1A lysine and N-terminalmethyltransferase OS=Homo sapiens OX=9606 GN=METTL13MNLLPKSSREFGSVDYWEKFFQQRGKKAFEWYGTYLELCGVLHKYIKPREKVLVIGCGNSELSEQLYDVGYRDIVNIDISEVVIKQMKECNATRRPQMSFLKMDMTQMEFPDASFQVVLDKGTLDAVLTDEEEKTLQQVDRMLAEVGRVLQVGGRYLCISLAQAHILKKAVGHFSREGWMVRVHQVANSQDQVLEAEPQFSLPVFAFIMTKFRPVPGSALQIFELCAQEQRKPVRLESAERLAEAVQERQQYAWLCSQLRRKARLGSVSLDLCDGDTGEPRYTLHVVDSPTVKPSRDNHFAIFIIPQGRETEWLFGMDEGRKQLAASAGFRRLITVALHRGQQYESMDHIQAELSARVMELAPAGMPTQQQVPFLSVGGDIGVRTVQHQDCSPLSGDYVIEDVQGDDKRYFRRLIFLSNRNVVQSEARLLKDVSHKAQKKRKKDRKKQRPADAEDLPAAPGQSIDKSYLCCEHHKAMIAGLALLRNPELLLEIPLALLVVGLGGGSLPLFVHDHFPKSCIDAVEIDPSMLEVATQWFGFSQSDRMKVHIADGLDYIASLAGGGEARPCYDVIMFDVDSKDPTLGMSCPPPAFVEQSFLQKVKSILTPEGVFILNLVCRDLGLKDSVLAGLKAVFPLLYVRRI>sp|Q8N6R0-3|EFNMT_HUMAN Isoform 3 of eEF1A lysine and N-terminalmethyltransferase OS=Homo sapiens OX=9606 GN=METTL13MKECNATRRPQMSFLKMDMTQMEFPDASFQVVLDKGTLDAVLTDEEEKTLQQVDRMLAEVGRVLQVGGRYLCISLAQAHILKKAVGHFSREGWMVRVHQVANSQDQVLEAEPQFSLPVFAFIMTKFRPVPGSALQIFELCAQEQRKPVRLESAERLAEAVQERQQYAWLCSQLRRKARLGSVSLDLCDGDTGEPRYTLHVVDSPTVKPSRDNHFAIFIIPQGRETEWLFGMDEGRKQLAASAGFRRLITVALHRGQQYESMDHIQAELSARVMELAPAGMPTQQQVPFLSVGGDIGVRTVQHQDCSPLSGDYVIEDVQGDDKRYFRRLIFLSNRNVVQSEARLLKDVSHKAQKKRKKDRKKQRPADAEDLPAAPGQSIDKSYLCCEHHKAMIAGLALLRNPELLLEIPLALLVVGLGGGSLPLFVHDHFPKSCIDAVEIDPSMLEVATQWFGFSQSDRMKVHIADGLDYIASLAGGGEARPCYDVIMFDVDSKDPTLGMSCPPPAFVEQSFLQKVKSILTPEGVFILNLVCRDLGLKDSVLAGLKAVFPLLYVRRIEGEVNEILFCQLHPEQKLATPELLETAQALERTLRKPGRGWDDTYVLSDMLKTVKIV>sp|Q8N6R0-1|EFNMT_HUMAN Isoform 4 of eEF1A lysine and N-terminalmethyltransferase OS=Homo sapiens OX=9606 GN=METTL13MNLLPKSSREFGSVDYWEKFFQQRGKKAFEWYGTYLELCGVLHKYIKPREKVLVIGCGNSELSEQLYDVGYRDIVNIDISEVVIKQMKECNATRRPQMSFLKMDMTQMEFPDASFQVVLDKGTLDAVLTDEEEKTLQQVDRMLAEVGRVLQGRETEWLFGMDEGRKQLAASAGFRRLITVALHRGQQYESMDHIQAELSARVMELAPAGMPTQQQVPFLSVGGDIGVRTVQHQDCSPLSGDYVIEDVQGDDKRYFRRLIFLSNRNVVQSEARLLKDVSHKAQKKRKKDRKKQRPADAEDLPAAPGQSIDKSYLCCEHHKAMIAGLALLRNPELLLEIPLALLVVGLGGGSLPLFVHDHFPKSCIDAVEIDPSMLEVATQWFGFSQSDRMKVHIADGLDYIASLAGGGEARPCYDVIMFDVDSKDPTLGMSCPPPAFVEQSFLQKVKSILTPEGVFILNLVCRDLGLKDSVLAGLKAVFPLLYVRRIEGEVNEILFCQLHPEQKLATPELLETAQALERTLRKPGRGWDDTYVLSDMLKTVKIV>sp|Q8N6R0-2|EFNMT_HUMAN Isoform 5 of eEF1A lysine and N-terminalmethyltransferase OS=Homo sapiens OX=9606 GN=METTL13MKECNATRRPQMSFLKMDMTQMEFPDASFQVVLDKGTLDAVLTDEEEKTLQQVDRMLAEVGRVLQVGGRYLCISLAQAHILKKAVGHFSREGWMVRVHQVANSQDQVLEAEPQFSLPVFAFIMTKFRPVPGSALQIFELCAQEQRKPVRLESAERLAEAVQERQQYAWLCSQLRRKARLGSVSLDLCDGDTGEPRYTLHVVDSLPLFVHDHFPKSCIDAVEIDPSMLEVATQWFGFSQSDRMKVHIADGLDYIASLAGGGEARPCYDVIMFDVDSKDPTLGMSCPPPAFVEQSFLQKVKSILTPEGVFILNLVCRDLGLKDSVLAGLKAVFPLLYVRRIEGEVNEILFCQLHPEQKLATPELLETAQALERTLRKPGRGWDDTYVLSDMLKTVKIV>sp|Q9H9Y4|GPN2_HUMAN GPN-loop GTPase 2 OS=Homo sapiens OX=9606 GN=GPN2PE=1 SV=2MAGAAPTTAFGQAVIGPPGSGKTTYCLGMSEFLRALGRRVAVVNLDPANEGLPYECAVDVGELVGLGDVMDALRLGPNGGLLYCMEYLEANLDWLRAKLDPLRGHYFLFDCPGQVELCTHHGALRSIFSQMAQWDLRLTAVHLVDSHYCTDPAKFISVLCTSLATMLHVELPHINLLSKMDLIEHYGKLAFNLDYYTEVLDLSYLLDHLASDPFFRHYRQLNEKLVQLIEDYSLVSFIPLNIQDKESIQRVLQAVDKANGYCFRAQEQRSLEAMMSAAMGADFHFSSTLGIQEKYLAPSNQSVEQEAMQL>sp|Q15303|ERBB4_HUMAN Receptor tyrosine-protein kinase erbB-4 OS=Homosapiens OX=9606 GN=ERBB4 PE=1 SV=1MKPATGLWVWVSLLVAAGTVQPSDSQSVCAGTENKLSSLSDLEQQYRALRKYYENCEVVMGNLEITSIEHNRDLSFLRSVREVTGYVLVALNQFRYLPLENLRIIRGTKLYEDRYALAIFLNYRKDGNFGLQELGLKNLTEILNGGVYVDQNKFLCYADTIHWQDIVRNPWPSNLTLVSTNGSSGCGRCHKSCTGRCWGPTENHCQTLTRTVCAEQCDGRCYGPYVSDCCHRECAGGCSGPKDTDCFACMNFNDSGACVTQCPQTFVYNPTTFQLEHNFNAKYTYGAFCVKKCPHNFVVDSSSCVRACPSSKMEVEENGIKMCKPCTDICPKACDGIGTGSLMSAQTVDSSNIDKFINCTKINGNLIFLVTGIHGDPYNAIEAIDPEKLNVFRTVREITGFLNIQSWPPNMTDFSVFSNLVTIGGRVLYSGLSLLILKQQGITSLQFQSLKEISAGNIYITDNSNLCYYHTINWTTLFSTINQRIVIRDNRKAENCTAEGMVCNHLCSSDGCWGPGPDQCLSCRRFSRGRICIESCNLYDGEFREFENGSICVECDPQCEKMEDGLLTCHGPGPDNCTKCSHFKDGPNCVEKCPDGLQGANSFIFKYADPDRECHPCHPNCTQGCNGPTSHDCIYYPWTGHSTLPQHARTPLIAAGVIGGLFILVIVGLTFAVYVRRKSIKKKRALRRFLETELVEPLTPSGTAPNQAQLRILKETELKRVKVLGSGAFGTVYKGIWVPEGETVKIPVAIKILNETTGPKANVEFMDEALIMASMDHPHLVRLLGVCLSPTIQLVTQLMPHGCLLEYVHEHKDNIGSQLLLNWCVQIAKGMMYLEERRLVHRDLAARNVLVKSPNHVKITDFGLARLLEGDEKEYNADGGKMPIKWMALECIHYRKFTHQSDVWSYGVTIWELMTFGGKPYDGIPTREIPDLLEKGERLPQPPICTIDVYMVMVKCWMIDADSRPKFKELAAEFSRMARDPQRYLVIQGDDRMKLPSPNDSKFFQNLLDEEDLEDMMDAEEYLVPQAFNIPPPIYTSRARIDSNRSEIGHSPPPAYTPMSGNQFVYRDGGFAAEQGVSVPYRAPTSTIPEAPVAQGATAEIFDDSCCNGTLRKPVAPHVQEDSSTQRYSADPTVFAPERSPRGELDEEGYMTPMRDKPKQEYLNPVEENPFVSRRKNGDLQALDNPEYHNASNGPPKAEDEYVNEPLYLNTFANTLGKAEYLKNNILSMPEKAKKAFDNPDYWNHSLPPRSTLQHPDYLQEYSTKYFYKQNGRIRPIVAENPEYLSEFSLKPGTVLPPPPYRHRNTVV>sp|Q15303-2|ERBB4_HUMAN Isoform JM-B CYT-1 of Receptor tyrosine-proteinkinase erbB-4 OS=Homo sapiens OX=9606 GN=ERBB4MKPATGLWVWVSLLVAAGTVQPSDSQSVCAGTENKLSSLSDLEQQYRALRKYYENCEVVMGNLEITSIEHNRDLSFLRSVREVTGYVLVALNQFRYLPLENLRIIRGTKLYEDRYALAIFLNYRKDGNFGLQELGLKNLTEILNGGVYVDQNKFLCYADTIHWQDIVRNPWPSNLTLVSTNGSSGCGRCHKSCTGRCWGPTENHCQTLTRTVCAEQCDGRCYGPYVSDCCHRECAGGCSGPKDTDCFACMNFNDSGACVTQCPQTFVYNPTTFQLEHNFNAKYTYGAFCVKKCPHNFVVDSSSCVRACPSSKMEVEENGIKMCKPCTDICPKACDGIGTGSLMSAQTVDSSNIDKFINCTKINGNLIFLVTGIHGDPYNAIEAIDPEKLNVFRTVREITGFLNIQSWPPNMTDFSVFSNLVTIGGRVLYSGLSLLILKQQGITSLQFQSLKEISAGNIYITDNSNLCYYHTINWTTLFSTINQRIVIRDNRKAENCTAEGMVCNHLCSSDGCWGPGPDQCLSCRRFSRGRICIESCNLYDGEFREFENGSICVECDPQCEKMEDGLLTCHGPGPDNCTKCSHFKDGPNCVEKCPDGLQGANSFIFKYADPDRECHPCHPNCTQGCIGSSIEDCIGLMDRTPLIAAGVIGGLFILVIVGLTFAVYVRRKSIKKKRALRRFLETELVEPLTPSGTAPNQAQLRILKETELKRVKVLGSGAFGTVYKGIWVPEGETVKIPVAIKILNETTGPKANVEFMDEALIMASMDHPHLVRLLGVCLSPTIQLVTQLMPHGCLLEYVHEHKDNIGSQLLLNWCVQIAKGMMYLEERRLVHRDLAARNVLVKSPNHVKITDFGLARLLEGDEKEYNADGGKMPIKWMALECIHYRKFTHQSDVWSYGVTIWELMTFGGKPYDGIPTREIPDLLEKGERLPQPPICTIDVYMVMVKCWMIDADSRPKFKELAAEFSRMARDPQRYLVIQGDDRMKLPSPNDSKFFQNLLDEEDLEDMMDAEEYLVPQAFNIPPPIYTSRARIDSNRSEIGHSPPPAYTPMSGNQFVYRDGGFAAEQGVSVPYRAPTSTIPEAPVAQGATAEIFDDSCCNGTLRKPVAPHVQEDSSTQRYSADPTVFAPERSPRGELDEEGYMTPMRDKPKQEYLNPVEENPFVSRRKNGDLQALDNPEYHNASNGPPKAEDEYVNEPLYLNTFANTLGKAEYLKNNILSMPEKAKKAFDNPDYWNHSLPPRSTLQHPDYLQEYSTKYFYKQNGRIRPIVAENPEYLSEFSLKPGTVLPPPPYRHRNTVV>sp|Q15303-3|ERBB4_HUMAN Isoform JM-A CYT-2 of Receptor tyrosine-proteinkinase erbB-4 OS=Homo sapiens OX=9606 GN=ERBB4MKPATGLWVWVSLLVAAGTVQPSDSQSVCAGTENKLSSLSDLEQQYRALRKYYENCEVVMGNLEITSIEHNRDLSFLRSVREVTGYVLVALNQFRYLPLENLRIIRGTKLYEDRYALAIFLNYRKDGNFGLQELGLKNLTEILNGGVYVDQNKFLCYADTIHWQDIVRNPWPSNLTLVSTNGSSGCGRCHKSCTGRCWGPTENHCQTLTRTVCAEQCDGRCYGPYVSDCCHRECAGGCSGPKDTDCFACMNFNDSGACVTQCPQTFVYNPTTFQLEHNFNAKYTYGAFCVKKCPHNFVVDSSSCVRACPSSKMEVEENGIKMCKPCTDICPKACDGIGTGSLMSAQTVDSSNIDKFINCTKINGNLIFLVTGIHGDPYNAIEAIDPEKLNVFRTVREITGFLNIQSWPPNMTDFSVFSNLVTIGGRVLYSGLSLLILKQQGITSLQFQSLKEISAGNIYITDNSNLCYYHTINWTTLFSTINQRIVIRDNRKAENCTAEGMVCNHLCSSDGCWGPGPDQCLSCRRFSRGRICIESCNLYDGEFREFENGSICVECDPQCEKMEDGLLTCHGPGPDNCTKCSHFKDGPNCVEKCPDGLQGANSFIFKYADPDRECHPCHPNCTQGCNGPTSHDCIYYPWTGHSTLPQHARTPLIAAGVIGGLFILVIVGLTFAVYVRRKSIKKKRALRRFLETELVEPLTPSGTAPNQAQLRILKETELKRVKVLGSGAFGTVYKGIWVPEGETVKIPVAIKILNETTGPKANVEFMDEALIMASMDHPHLVRLLGVCLSPTIQLVTQLMPHGCLLEYVHEHKDNIGSQLLLNWCVQIAKGMMYLEERRLVHRDLAARNVLVKSPNHVKITDFGLARLLEGDEKEYNADGGKMPIKWMALECIHYRKFTHQSDVWSYGVTIWELMTFGGKPYDGIPTREIPDLLEKGERLPQPPICTIDVYMVMVKCWMIDADSRPKFKELAAEFSRMARDPQRYLVIQGDDRMKLPSPNDSKFFQNLLDEEDLEDMMDAEEYLVPQAFNIPPPIYTSRARIDSNRNQFVYRDGGFAAEQGVSVPYRAPTSTIPEAPVAQGATAEIFDDSCCNGTLRKPVAPHVQEDSSTQRYSADPTVFAPERSPRGELDEEGYMTPMRDKPKQEYLNPVEENPFVSRRKNGDLQALDNPEYHNASNGPPKAEDEYVNEPLYLNTFANTLGKAEYLKNNILSMPEKAKKAFDNPDYWNHSLPPRSTLQHPDYLQEYSTKYFYKQNGRIRPIVAENPEYLSEFSLKPGTVLPPPPYRHRNTVV>sp|Q15303-4|ERBB4_HUMAN Isoform JM-B CYT-2 of Receptor tyrosine-proteinkinase erbB-4 OS=Homo sapiens OX=9606 GN=ERBB4MKPATGLWVWVSLLVAAGTVQPSDSQSVCAGTENKLSSLSDLEQQYRALRKYYENCEVVMGNLEITSIEHNRDLSFLRSVREVTGYVLVALNQFRYLPLENLRIIRGTKLYEDRYALAIFLNYRKDGNFGLQELGLKNLTEILNGGVYVDQNKFLCYADTIHWQDIVRNPWPSNLTLVSTNGSSGCGRCHKSCTGRCWGPTENHCQTLTRTVCAEQCDGRCYGPYVSDCCHRECAGGCSGPKDTDCFACMNFNDSGACVTQCPQTFVYNPTTFQLEHNFNAKYTYGAFCVKKCPHNFVVDSSSCVRACPSSKMEVEENGIKMCKPCTDICPKACDGIGTGSLMSAQTVDSSNIDKFINCTKINGNLIFLVTGIHGDPYNAIEAIDPEKLNVFRTVREITGFLNIQSWPPNMTDFSVFSNLVTIGGRVLYSGLSLLILKQQGITSLQFQSLKEISAGNIYITDNSNLCYYHTINWTTLFSTINQRIVIRDNRKAENCTAEGMVCNHLCSSDGCWGPGPDQCLSCRRFSRGRICIESCNLYDGEFREFENGSICVECDPQCEKMEDGLLTCHGPGPDNCTKCSHFKDGPNCVEKCPDGLQGANSFIFKYADPDRECHPCHPNCTQGCIGSSIEDCIGLMDRTPLIAAGVIGGLFILVIVGLTFAVYVRRKSIKKKRALRRFLETELVEPLTPSGTAPNQAQLRILKETELKRVKVLGSGAFGTVYKGIWVPEGETVKIPVAIKILNETTGPKANVEFMDEALIMASMDHPHLVRLLGVCLSPTIQLVTQLMPHGCLLEYVHEHKDNIGSQLLLNWCVQIAKGMMYLEERRLVHRDLAARNVLVKSPNHVKITDFGLARLLEGDEKEYNADGGKMPIKWMALECIHYRKFTHQSDVWSYGVTIWELMTFGGKPYDGIPTREIPDLLEKGERLPQPPICTIDVYMVMVKCWMIDADSRPKFKELAAEFSRMARDPQRYLVIQGDDRMKLPSPNDSKFFQNLLDEEDLEDMMDAEEYLVPQAFNIPPPIYTSRARIDSNRNQFVYRDGGFAAEQGVSVPYRAPTSTIPEAPVAQGATAEIFDDSCCNGTLRKPVAPHVQEDSSTQRYSADPTVFAPERSPRGELDEEGYMTPMRDKPKQEYLNPVEENPFVSRRKNGDLQALDNPEYHNASNGPPKAEDEYVNEPLYLNTFANTLGKAEYLKNNILSMPEKAKKAFDNPDYWNHSLPPRSTLQHPDYLQEYSTKYFYKQNGRIRPIVAENPEYLSEFSLKPGTVLPPPPYRHRNTVV>sp|Q9UM22|EPDR1_HUMAN Mammalian ependymin-related protein 1 OS=Homosapiens OX=9606 GN=EPDR1 PE=1 SV=2MPGRAPLRTVPGALGAWLLGGLWAWTLCGLCSLGAVGAPRPCQAPQQWEGRQVMYQQSSGRNSRALLSYDGLNQRVRVLDERKALIPCKRLFEYILLYKDGVMFQIDQATKQCSKMTLTQPWDPLDIPQNSTFEDQYSIGGPQEQITVQEWSDRKSARSYETWIGIYTVKDCYPVQETFTINYSVILSTRFFDIQLGIKDPSVFTPPSTCQMAQLEKMSEDCSW>sp|Q9UM22-2|EPDR1_HUMAN Isoform 2 of Mammalian ependymin-related protein1 OS=Homo sapiens OX=9606 GN=EPDR1MPGRAPLRTVPGALGAWLLGGLWAWTLCGLCSLGAVGAPRPCQAPQQWEGRQVMYQQSSGRNSRALLSYDGLNQRVRVLDERKALIPCKR>sp|Q9UM22-3|EPDR1_HUMAN Isoform 3 of Mammalian ependymin-related protein1 OS=Homo sapiens OX=9606 GN=EPDR1MVRDWEGRCAHRGRPAGGGLSNTQRGGGRLFEYILLYKDGVMFQIDQATKQCSKMTLTQPWDPLDIPQNSTFEDQYSIGGPQEQITVQEWSDRKSARSYETWIGIYTVKDCYPVQETFTINYSVILSTRFFDIQLGIKDPSVFTPPSTCQMAQLEKMSEDCSW>sp|Q5TYM5|FA72A_HUMAN Protein FAM72A OS=Homo sapiens OX=9606 GN=FAM72APE=1 SV=1MSTNICSFKDRCVSILCCKFCKQVLSSRGMKAVLLADTEIDLFSTDIPPTNAVDFTGRCYFTKICKCKLKDIACLKCGNIVGYHVIVPCSSCLLSCNNGHFWMFHSQAVYDINRLDSTGVNVLLWGNLPEIEESTDEDVLNISAEECIR>sp|Q5TYM5-2|FA72A_HUMAN Isoform 2 of Protein FAM72A OS=Homo sapiensOX=9606 GN=FAM72AMSTNICSFKDSAVDFTGRCYFTKICKCKLKDIACLKCGNIVGYHVIVPCSSCLLSCNNGHFWMFHSQAVYDINRLDSTGVNVLLWGNLPEIEESTDEDVLNISAEECIR>sp|P03951|FA11_HUMAN Coagulation factor XI OS=Homo sapiens OX=9606GN=F11 PE=1 SV=1MIFLYQVVHFILFTSVSGECVTQLLKDTCFEGGDITTVFTPSAKYCQVVCTYHPRCLLFTFTAESPSEDPTRWFTCVLKDSVTETLPRVNRTAAISGYSFKQCSHQISACNKDIYVDLDMKGINYNSSVAKSAQECQERCTDDVHCHFFTYATRQFPSLEHRNICLLKHTQTGTPTRITKLDKVVSGFSLKSCALSNLACIRDIFPNTVFADSNIDSVMAPDAFVCGRICTHHPGCLFFTFFSQEWPKESQRNLCLLKTSESGLPSTRIKKSKALSGFSLQSCRHSIPVFCHSSFYHDTDFLGEELDIVAAKSHEACQKLCTNAVRCQFFTYTPAQASCNEGKGKCYLKLSSNGSPTKILHGRGGISGYTLRLCKMDNECTTKIKPRIVGGTASVRGEWPWQVTLHTTSPTQRHLCGGSIIGNQWILTAAHCFYGVESPKILRVYSGILNQSEIKEDTSFFGVQEIIIHDQYKMAESGYDIALLKLETTVNYTDSQRPICLPSKGDRNVIYTDCWVTGWGYRKLRDKIQNTLQKAKIPLVTNEECQKRYRGHKITHKMICAGYREGGKDACKGDSGGPLSCKHNEVWHLVGITSWGEGCAQRERPGVYTNVVEYVDWILEKTQAV>sp|P03951-2|FA11_HUMAN Isoform 2 of Coagulation factor XI OS=Homosapiens OX=9606 GN=F11MIFLYQVVHFILFTSVSGECVTQLLKDTCFEGGDITTVFTPSAKYCQVVCTYHPRCLLFTFTAESPSEDPTRWFTCVLKDSVTETLPRVNRTAAISGYSFKQCSHQISNICLLKHTQTGTPTRITKLDKVVSGFSLKSCALSNLACIRDIFPNTVFADSNIDSVMAPDAFVCGRICTHHPGCLFFTFFSQEWPKESQRNLCLLKTSESGLPSTRIKKSKALSGFSLQSCRHSIPVFCHSSFYHDTDFLGEELDIVAAKSHEACQKLCTNAVRCQFFTYTPAQASCNEGKGKCYLKLSSNGSPTKILHGRGGISGYTLRLCKMDNECTTKIKPRIVGGTASVRGEWPWQVTLHTTSPTQRHLCGGSIIGNQWILTAAHCFYGVESPKILRVYSGILNQSEIKEDTSFFGVQEIIIHDQYKMAESGYDIALLKLETTVNYTDSQRPICLPSKGDRNVIYTDCWVTGWGYRKLRDKIQNTLQKAKIPLVTNEECQKRYRGHKITHKMICAGYREGGKDACKGDSGGPLSCKHNEVWHLVGITSWGEGCAQRERPGVYTNVVEYVDWILEKTQAV>sp|Q8N257|H2B3B_HUMAN Histone H2B type 3-B OS=Homo sapiens OX=9606GN=H2BU1 PE=1 SV=3MPDPSKSAPAPKKGSKKAVTKAQKKDGKKRKRGRKESYSIYVYKVLKQVHPDTGISSKAMGIMNSFVNDIFERIASEASRLAHYNKRSTITSREVQTAVRLLLPGELAKHAVSEGTKAVTKYTSSK>sp|Q92908|GATA6_HUMAN Transcription factor GATA-6 OS=Homo sapiensOX=9606 GN=GATA6 PE=1 SV=2MALTDGGWCLPKRFGAAGADASDSRAFPAREPSTPPSPISSSSSSCSRGGERGPGGASNCGTPQLDTEAAAGPPARSLLLSSYASHPFGAPHGPSAPGVAGPGGNLSSWEDLLLFTDLDQAATASKLLWSSRGAKLSPFAPEQPEEMYQTLAALSSQGPAAYDGAPGGFVHSAAAAAAAAAAASSPVYVPTTRVGSMLPGLPYHLQGSGSGPANHAGGAGAHPGWPQASADSPPYGSGGGAAGGGAAGPGGAGSAAAHVSARFPYSPSPPMANGAAREPGGYAAAGSGGAGGVSGGGSSLAAMGGREPQYSSLSAARPLNGTYHHHHHHHHHHPSPYSPYVGAPLTPAWPAGPFETPVLHSLQSRAGAPLPVPRGPSADLLEDLSESRECVNCGSIQTPLWRRDGTGHYLCNACGLYSKMNGLSRPLIKPQKRVPSSRRLGLSCANCHTTTTTLWRRNAEGEPVCNACGLYMKLHGVPRPLAMKKEGIQTRKRKPKNINKSKTCSGNSNNSIPMTPTSTSSNSDDCSKNTSPTTQPTASGAGAPVMTGAGESTNPENSELKYSGQDGLYIGVSLASPAEVTSSVRPDSWCALALA>sp|Q92908-2|GATA6_HUMAN Isoform 2 of Transcription factor GATA-6 OS=Homosapiens OX=9606 GN=GATA6MYQTLAALSSQGPAAYDGAPGGFVHSAAAAAAAAAAASSPVYVPTTRVGSMLPGLPYHLQGSGSGPANHAGGAGAHPGWPQASADSPPYGSGGGAAGGGAAGPGGAGSAAAHVSARFPYSPSPPMANGAAREPGGYAAAGSGGAGGVSGGGSSLAAMGGREPQYSSLSAARPLNGTYHHHHHHHHHHPSPYSPYVGAPLTPAWPAGPFETPVLHSLQSRAGAPLPVPRGPSADLLEDLSESRECVNCGSIQTPLWRRDGTGHYLCNACGLYSKMNGLSRPLIKPQKRVPSSRRLGLSCANCHTTTTTLWRRNAEGEPVCNACGLYMKLHGVPRPLAMKKEGIQTRKRKPKNINKSKTCSGNSNNSIPMTPTSTSSNSDDCSKNTSPTTQPTASGAGAPVMTGAGESTNPENSELKYSGQDGLYIGVSLASPAEVTSSVRPDSWCALALA>sp|Q8NB91|FANCB_HUMAN Fanconi anemia group B protein OS=Homo sapiensOX=9606 GN=FANCB PE=1 SV=1MTSKQAMSSNEQERLLCYNGEVLVFQLSKGNFADKEPTKTPILHVRRMVFDRGTKVFVQKSTGFFTIKEENSHLKIMCCNCVSDFRTGINLPYIVIEKNKKNNVFEYFLLILHSTNKFEMRLSFKLGYEMKDGLRVLNGPLILWRHVKAFFFISSQTGKVVSVSGNFSSIQWAGEIENLGMVLLGLKECCLSEEECTQEPSKSDYAIWNTKFCVYSLESQEVLSDIYIIPPAYSSVVTYVHICATEIIKNQLRISLIALTRKNQLISFQNGTPKNVCQLPFGDPCAVQLMDSGGGNLFFVVSFISNNACAVWKESFQVAAKWEKLSLVLIDDFIGSGTEQVLLLFKDSLNSDCLTSFKITDLGKINYSSEPSDCNEDDLFEDKQENRYLVVPPLETGLKVCFSSFRELRQHLLLKEKIISKSYKALINLVQGKDDNTSSAEEKECLVPLCGEEENSVHILDEKLSDNFQDSEQLVEKIWYRVIDDSLVVGVKTTSSLKLSLNDVTLSLLMDQAHDSRFRLLKCQNRVIKLSTNPFPAPYLMPCEIGLEAKRVTLTPDSKKEESFVCEHPSKKECVQIITAVTSLSPLLTFSKFCCTVLLQIMERESGNCPKDRYVVCGRVFLSLEDLSTGKYLLTFPKKKPIEHMEDLFALLAAFHKSCFQITSPGYALNSMKVWLLEHMKCEIIKEFPEVYFCERPGSFYGTLFTWKQRTPFEGILIIYSRNQTVMFQCLHNLIRILPINCFLKNLKSGSENFLIDNMAFTLEKELVTLSSLSSAIAKHESNFMQRCEVSKGKSSVVAAALSDRRENIHPYRKELQREKKKMLQTNLKVSGALYREITLKVAEVQLKSDFAAQKLSNL>sp|P51993|FUT6_HUMAN 4-galactosyl-N-acetylglucosaminide 3-alpha-L-fucosyltransferase FUT6 OS=Homo sapiens OX=9606 GN=FUT6 PE=1 SV=1MDPLGPAKPQWSWRCCLTTLLFQLLMAVCFFSYLRVSQDDPTVYPNGSRFPDSTGTPAHSIPLILLWTWPFNKPIALPRCSEMVPGTADCNITADRKVYPQADAVIVHHREVMYNPSAQLPRSPRRQGQRWIWFSMESPSHCWQLKAMDGYFNLTMSYRSDSDIFTPYGWLEPWSGQPAHPPLNLSAKTELVAWAVSNWGPNSARVRYYQSLQAHLKVDVYGRSHKPLPQGTMMETLSRYKFYLAFENSLHPDYITEKLWRNALEAWAVPVVLGPSRSNYERFLPPDAFIHVDDFQSPKDLARYLQELDKDHARYLSYFRWRETLRPRSFSWALAFCKACWKLQEESRYQTRGIAAWFT>sp|P51993-2|FUT6_HUMAN Isoform 2 of 4-galactosyl-N-acetylglucosaminide3-alpha-L-fucosyltransferase FUT6 OS=Homo sapiens OX=9606 GN=FUT6MDPLGPAKPQWSWRCCLTTLLFQLLMAVCFFSYLRVSQDDPTVYPNGSRFPDSTGTPAHSIPLILLWTWPFNKPIALPRCSEMVPGTADCNITADRKVYPQADAVIVHHREVMYNPSAQLPRSPRRQGQRWIWFSMESPSHCWQLKAMDGYFNLTMSYRSDSDIFTPYGWLEPWSGQPAHPPLNLSAKTELVAWAVSNWGPNSARVRYYQSLQAHLKVDVYGRSHKPLPQGTMMETLSRYKFYLAFENSLHPDYITEKLWRNALEAWAVPVVLGPSRSNYERFLPPDAFIHVDDFQSPKDLARYLQELDKDHARYLSYFRWRETLRPRSFSWALAFCKACWKLQEESSGGLIYLRTRLPEASPA>sp|Q6IN97|FRP2L_HUMAN Putative protein FRMPD2-like OS=Homo sapiensOX=9606 GN=FRMPD2B PE=5 SV=1MTSIPFPGDRLLQVDGVILCGLTHKQAVQCLKGPGQVARLVLERRVPRSTQQCPSANDSMGDERTAVSLVTALPGRPSSCVSVTDGPKFEVKLKKNANGLGFSFVQMEKESCSHLKSDLVRIKRLFPGQPAEENGAIAAGDIILAVNGRSTEGLIFQEVLHLLRGAPQEVTLLLCRPPPGALPEMEQEWQTPELSADKEFTRATCTDSCTSPILDQEDSWRDSASPDAGEGLGLRPESSQKAIREAQWGQNRERPWASSLTHSPESHPHLCKLHQERDESTLATSLEKDVRQNCYSVCDIMRLGRYSFSSPLTRLSTDIF>sp|P62684|GA113_HUMAN Endogenous retrovirus group K member 113 Gagpolyprotein OS=Homo sapiens OX=9606 GN=HERVK_113 PE=1 SV=2MGQTKSKIKSKYASYLSFIKILLKRGGVKVSTKNLIKLFQIIEQFCPWFPEQGTLDLKDWKRIGKELKQAGRKGNIIPLTVWNDWAIIKAALEPFQTEEDSVSVSDAPGSCIIDCNEKTRKKSQKETESLHCEYVAEPVMAQSTQNADYNQLQEVIYPETLKLEGKGPELMGPSESKPRGTSPLPAGQVPVTLQPQKQVKENKTQPPVAYQYWPPAELQYQPPPESQYGYPGMPPAPQGRAPYPQPPTRRLNPTAPPSRQGSELHEIIDKSRKEGDTEAWQFPVTLELMPPGEGAQEGEPPTVEARYKSFSIKMLKDMKEGVKQYGPNSPYMRTLLDSIAHGHRLIPYDWEILAKSSLSPSQFLQFKTWWIDGVQEQVRRNRAANPPVNIDADQLLGIGQNWSTISQQALMQNEAIEQVRAICLRAWEKIQDPGSTCPSFNTVRQGSKEPYPDFVARLQDVAQKSIADEKARKVIVELMAYENANPECQSAIKPLKGKVPAGSDVISEYVKACDGMGGAMHKAMLMAQAITGVVLGGQVRTFGGKCYNCGQIGHLKKNCPVLNKQNITIQATTTGREPPDLCPRCKKGKHWASQCRSKFDKNGQPLSGNEQRGQPQAPQQTGAFPIQPFVPQGFQGQQPPLSQVFQGISQLPQYNNCPPPQAAVQQ>sp|Q9C0B1|FTO_HUMAN Alpha-ketoglutarate-dependent dioxygenase FTOOS=Homo sapiens OX=9606 GN=FTO PE=1 SV=3MKRTPTAEEREREAKKLRLLEELEDTWLPYLTPKDDEFYQQWQLKYPKLILREASSVSEELHKEVQEAFLTLHKHGCLFRDLVRIQGKDLLTPVSRILIGNPGCTYKYLNTRLFTVPWPVKGSNIKHTEAEIAAACETFLKLNDYLQIETIQALEELAAKEKANEDAVPLCMSADFPRVGMGSSYNGQDEVDIKSRAAYNVTLLNFMDPQKMPYLKEEPYFGMGKMAVSWHHDENLVDRSAVAVYSYSCEGPEEESEDDSHLEGRDPDIWHVGFKISWDIETPGLAIPLHQGDCYFMLDDLNATHQHCVLAGSQPRFSSTHRVAECSTGTLDYILQRCQLALQNVCDDVDNDDVSLKSFEPAVLKQGEEIHNEVEFEWLRQFWFQGNRYRKCTDWWCQPMAQLEALWKKMEGVTNAVLHEVKREGLPVEQRNEILTAILASLTARQNLRREWHARCQSRIARTLPADQKPECRPYWEKDDASMPLPFDLTDIVSELRGQLLEAKP>sp|Q9C0B1-2|FTO_HUMAN Isoform 2 of Alpha-ketoglutarate-dependentdioxygenase FTO OS=Homo sapiens OX=9606 GN=FTOMEWRKVSECNSVEPCREVKKWPYRCIHHGKNFSRMTNAVLHEVKREGLPVEQRNEILTAILASLTARQNLRREWHARCQSRIARTLPADQKPECRPYWEKDDASMPLPFDLTDIVSELRGQLLEAKP>sp|Q9C0B1-3|FTO_HUMAN Isoform 3 of Alpha-ketoglutarate-dependentdioxygenase FTO OS=Homo sapiens OX=9606 GN=FTOMACQGREECWCQSRIARTLPADQKPECRPYWEKDDASMPLPFDLTDIVSELRGQLLEAKP>sp|Q9C0B1-4|FTO_HUMAN Isoform 4 of Alpha-ketoglutarate-dependentdioxygenase FTO OS=Homo sapiens OX=9606 GN=FTOMAQLEALWKKMEGVTNAVLHEVKREGLPVEQRNEILTAILASLTARQNLRREWHARCQSRIARTLPADQKPECRPYWEKDDASMPLPFDLTDIVSELRGQLLEAKP>sp|Q6P4F1|FUT10_HUMAN Alpha-(1,3)-fucosyltransferase 10 OS=Homo sapiensOX=9606 GN=FUT10 PE=2 SV=2MVRIQRRKLLASCLCVTATVFLLVTLQVMVELGKFERKEFKSSSLQDGHTKMEEAPTHLNSFLKKEGLTFNRKRKWELDSYPIMLWWSPLTGETGRLGQCGADACFFTINRTYLHHHMTKAFLFYGTDFNIDSLPLPRKAHHDWAVFHEESPKNNYKLFHKPVITLFNYTATFSRHSHLPLTTQYLESIEVLKSLRYLVPLQSKNKLRKRLAPLVYVQSDCDPPSDRDSYVRELMTYIEVDSYGECLRNKDLPQQLKNPASMDADGFYRIIAQYKFILAFENAVCDDYITEKFWRPLKLGVVPVYYGSPSITDWLPSNKSAILVSEFSHPRELASYIRRLDSDDRLYEAYVEWKLKGEISNQRLLTALRERKWGVQDVNQDNYIDAFECMVCTKVWANIRLQEKGLPPKRWEAEDTHLSCPEPTVFAFSPLRTPPLSSLREMWISSFEQSKKEAQALRWLVDRNQNFSSQEFWGLVFKD>sp|Q6P4F1-2|FUT10_HUMAN Isoform 2 of Alpha-(1,3)-fucosyltransferase 10OS=Homo sapiens OX=9606 GN=FUT10MVRIQRRKLLASCLCVTATVFLLVTLALDTVENLMKVTGPPQGVTDSMQCFNDQRPLSNTRSSEHIKEVMVELGKFERKEFKSSSLQDGHTKMEEAPTHLNSFLKKEGLTFNRKRKWELDSYPIMLWWSPLTGETGRLGQCGADACFFTINRTYLHHHMTKAFLFYGTDFNIDSLPLPRKAHHDWAVFHEESPKNNYKLFHKPVITLFNYTATFSRHSHLPLTTQYLESIEVLKSLRYLVPLQSKNKLRKRLAPLVYVQSDCDPPSDRDSYVRELMTYIEVDSYGECLRNKDLPQQLKNPASMDADGFYRIIAQYKFILAFENAVCDDYITEKFWRPLKLGVVPVYYGSPSITDWLPSNKSAILVSEFSHPRELASYIRRLDSDDRLYEAYVEWKLKGEISNQRLLTALRERKWGVQDVNQDNYIDAFECMVCTKVWANIRLQEKGLPPKRWEAEDTHLSCPEPTVFAFSPLRTPPLSSLREMWISSFEQSKKEAQALRWLVDRNQNFSSQEFWGLVFKD>sp|Q6P4F1-3|FUT10_HUMAN Isoform 3 of Alpha-(1,3)-fucosyltransferase 10OS=Homo sapiens OX=9606 GN=FUT10MGIGQLPHYALVVPADGGDWEVRPMWSRCLFLHHQPDLPPSSHDQSIPLLWSQEESPPLAENDGTDFNIDSLPLPRKAHHDWAVFHEESPKNNYKLFHKPVITLFNYTATFSRHSHLPLTTQYLESIEVLKSLRYLVPLQSKNKLRKRLAPLVYVQSDCDPPSDRDSYVRELMTYIEVDSYGECLRNKDLPQQLKNPASMDADGFYRIIAQYKFILAFENAVCDDYITEKFWRPLKLGVVPVYYGSPSITDWLPSNKSAILVSEFSHPRELASYIRRLDSDDRLYEAYVEWKLKGEISNQRLLTALRERKWGVQDVNQDNYIDAFECMVCTKVWANIRLQEKVSKSKVGIEPAGWPS>sp|Q6P4F1-4|FUT10_HUMAN Isoform 4 of Alpha-(1,3)-fucosyltransferase 10OS=Homo sapiens OX=9606 GN=FUT10MVELGKFERKEFKSSSLQDGHTKMEEAPTHLNSFLKKEGLTFNRKRKWELDSYPIMLWWSPLTGETGRLGQCGADACFFTINRTYLHHHMTKAFLFYGTDFNIDSLPLPRKAHHDWAVFHEESPKNNYKLFHKPVITLFNYTATFSRHSHLPLTTQYLESIEVLKSLRYLVPLQSKNKLRKRLAPLVYVQSDCDPPSDRDSYVRELMTYIEVDSYGECLRNKDLPQQLKNPASMDADGFYRIIAQYKFILAFENAVCDDYITEKFWRPLKLGVVPVYYGSPSITDWLPSNKSAILVSEFSHPRELASYIRRLDSDDRLYEAYVEWKLKGEISNQRLLTALRERKWGVQDVNQDNYIDAFECMVCTKVWANIRLQEKVSKSKVGIEPAGWPS>sp|Q6P4F1-5|FUT10_HUMAN Isoform 5 of Alpha-(1,3)-fucosyltransferase 10OS=Homo sapiens OX=9606 GN=FUT10MVRIQRRKLLASCLCVTATVFLLVTLQVMVELGKFERKEFKSSSLQDGHTKMEEAPTHLNSFLKKEGLTFNRKRKWELDSYPIMLWWSPLTGETGRLGQCGADACFFTINRTYLHHHMTKAFLFYGTDFNIDSLPLPRKAHHDWAVFHEESPKNNYKLFHKPVITLFNYTATFSRHSHLPLTTQYLESIEVLKSLRYLVPLQSKNKLRKRLAPLVYVQSDCDPPSDRDSYVRELMTYIEVDSYGECLRNKDLPQQLKNPASMDADGFYRIIAQYKFILAFENAVCDDYITEKFWRPLKLGVVPVYYGSPSITDWLPSNKSAILVSEFSHPRELASYIRRLDSDDRLYEAYVEWKLKGEISNQRLLTALRERKWGVQDVNQDNYIDAFECMVCTKVWANIRLQEKVSKSKVGIEPAGWPS>sp|Q6P4F1-6|FUT10_HUMAN Isoform 6 of Alpha-(1,3)-fucosyltransferase 10OS=Homo sapiens OX=9606 GN=FUT10MVELGKFERKEFKSSSLQDGHTKMEEAPTHLNSFLKKEGLTFNRKRKWELDSYPIMLWWSPLTGETGRLGQCGADACFFTINRTYLHHHMTKAFLFYGTDFNIDSLPLPRKAHHDWAVFHEESPKNNYKLFHKPVITLFNYTATFSRHSHLPLTTQYLESIEVLKSLRYLVPLQSKNKLRKRLAPLVYVQSDCDPPSDRDSYVRELMTYIEVDSYGECLRNKDLPQQLKNPASMDADGFYRIIAQYKFILAFENAVCDDYITEKFWRPLKLGVVPVYYGSPSITDWLPSNKSAILVSEFSHPRELASYIRRLDSDDRLYEAYVEWKLKGEISNQRLLTALRERKWGVQDVNQDNYIDAFECMVCTKVWANIRLQEKGLPPKRWEAEDTHLSCPEPTVFAFSPLRTPPLSSLREMWISSFEQSKKEAQALRWLVDRNQNFSSQEFWGLVFKD>sp|Q6P4F1-7|FUT10_HUMAN Isoform 7 of Alpha-(1,3)-fucosyltransferase 10OS=Homo sapiens OX=9606 GN=FUT10MEEAPTHLNSFLKKEGLTFNRKRKWELDSYPIMLWWSPLTGETGRLGQCGADACFFTINRTYLHHHMTKAFLFYGKQDFRLSPLFAVVFLQS>sp|Q10981|FUT2_HUMAN Galactoside alpha-(1,2)-fucosyltransferase 2OS=Homo sapiens OX=9606 GN=FUT2 PE=1 SV=1MLVVQMPFSFPMAHFILFVFTVSTIFHVQQRLAKIQAMWELPVQIPVLASTSKALGPSQLRGMWTINAIGRLGNQMGEYATLYALAKMNGRPAFIPAQMHSTLAPIFRITLPVLHSATASRIPWQNYHLNDWMEEEYRHIPGEYVRFTGYPCSWTFYHHLRQEILQEFTLHDHVREEAQKFLRGLQVNGSRPGTFVGVHVRRGDYVHVMPKVWKGVVADRRYLQQALDWFRARYSSLIFVVTSNGMAWCRENIDTSHGDVVFAGDGIEGSPAKDFALLTQCNHTIMTIGTFGIWAAYLTGGDTIYLANYTLPDSPFLKIFKPEAAFLPEWTGIAADLSPLLKH>sp|Q2WGJ9|FR1L6_HUMAN Fer-1-like protein 6 OS=Homo sapiens OX=9606GN=FER1L6 PE=2 SV=2MFGLKVKKKRNKAEKGLILANKAAKDSQGDTEALQEEPSHQEGPRGDLVHDDASIFPVPSASPKRRSKLLTKIHDGEVRSQNYQIAITITEARQLVGENIDPVVTIEIGDEKKQSTVKEGTNSPFYNEYFVFDFIGPQVHLFDKIIKISVFHHKLIGSVLIGSFKVDLGTVYNQPGHQFCNKWALLTDPGDIRTGTKGYLKCDISVMGKGDVLKTSPKTSDTEEPIEKNLLIPNGFPLERPWARFYVRLYKAEGLPKMNSSIMANVTKAFVGDSKDLVDPFVEVSFAGQMGRTTVQKNCADPVWHEQVIFKEMFPPLCRRVKIQVWDEGSMNDVALATHFIDLKKISNEQDGDKGFLPTFGPAWINLYGSPRNHSLMDDYQEMNEGFGEGVSFRGRILVEIAVEILSGRAQESKFSKALKELKLPSKDKDSKSSKGKDKADKTEDGKSQQASNKTNSTEVEVESFDVPPEIVPEKNEEFLLFGAFFEATMIDRKIGDKPISFEVSIGNFGNLIDGGSHHGSKKSAESAEEDLLPLLHEGQGDVAHDVPIPMASTTHPEKPLVTEGNRNYNYLPFEAKKPCVYFISSWGDQTFRLHWSNMLEKMADFLEESIEEVRELIKISQEAPEEKMKTVLSDFISRSSAFISEAEKKPKMLNQTTLDKKRLTLCWQELEAMCKEAKGIIQQQKKKLSVDEMIHEAQNFVEKIRFLVDEPQHTIPDVFIWMLSNNRRVAYARIASKDLLYSPVAGQMGKHCGKIKTHFLKPPGKRPAGWSVQAKVDVYLWLGSIKHASAILDNLPVGYEAEMSSKGAGTNHPPSNLLYQEQHVFQLRAHMYQARGLIAADSNGLSDPFAKVTFLSHCQTTKIISQTLSPTWNQMLLFNDLVLHGDVKELAESPPLVVVELYDSDAVGKPEYLGATVAAPVVKLADQDYEPPRLCYHPIFCGNLSGGDLLAVFELLQVPPSGLQGLPPVEPPDITQIYPVPANIRPVLSKYRVEVLFWGVREMKKVQLLSVDRPQALIECGGQGVKSCVIQSYKNNPNFSIQADAFEVELPENELLHPPLSICVVDWRAFGRSTLVGTYTINYLKQFLCKLREPLAPITQVDGTQPGHDISDSLTATESSGAHSSSQDPPADHIYVDVEPPPTVVPDSAQAQPAILVDVPDSSPMLEPEHTPVAQEPPKDGKPKDPRKPSRRSTKRRKRTIADESAENVIDWWSKYYASLKKAQKAKERNPKGKKGNTEAKPDEVVVDIEDGPKKKKDKMLKKKPKDDGIPNLAILQIYDGDLESEFNNFEDWVKTFELFRGKSTEDDHGLDGDRVIGKFKGSFCIYKSPQDSSSEDSGQLRIQQGIPPNHPVTVLIRVYIVAAFNLSPADPDGKSDPYIVIKLGKTEIKDRDKYIPKQLNPVFGRSFEIQATFPKESLLSILIYDHDMIGTDDLIGETKIDLENRFYSKHRAICGLQSQYEIEGYNAWRDTSKPTEILTKLCKDNKLDGPYFHPGKIQIGNQVFSGKTIFTEEDTDETVESYEHLALKVLHSWEDIPEVGCRLVPEHIETRPLYHKDKPGMEQGRLQMWVDMFPKDMPQPGPPVDISPRRPKGYELRVTIWNTEDVILEDENIFTGQKSSDIYVKGWLKGLEDDKQETDVHYNSLTGEGNFNWRFLFPFQYLPAEKQMVITKRENIFSLEKMECKTPAVLVLQVWDFERLSSDDFLGTLEMNLNSFPRAAKSAKACDLAKFENASEETKISIFQQKRVRGWWPFSKSKELTGKVEAEFHLVTAEEAEKNPVGKARKEPEPLAKPNRPDTSFSWFMSPFKCLYYLIWKNYKKYIIIAFILIILIIFLVLFIYTLPGAISRRIVVGS>sp|Q96NZ1|FOXN4_HUMAN Forkhead box protein N4 OS=Homo sapiens OX=9606GN=FOXN4 PE=1 SV=2MIESDTSSIMSGIIRNSGQNHHPSPQEYRLLATTSDDDLPGDLQSLSWLTAVDVPRLQQMASGRVDLGGPCVPHPHPGALAGVADLHVGATPSPLLHGPAGMAPRGMPGLGPITGHRDSMSQFPVGGQPSSGLQDPPHLYSPATQPQFPLPPGAQQCPPVGLYGPPFGVRPPYPQPHVAVHSSQELHPKHYPKPIYSYSCLIAMALKNSKTGSLPVSEIYSFMKEHFPYFKTAPDGWKNSVRHNLSLNKCFEKVENKMSGSSRKGCLWALNLARIDKMEEEMHKWKRKDLAAIHRSMANPEELDKLISDRPESCRRPGKPGEPEAPVLTHATTVAVAHGCLAVSQLPPQPLMTLSLQSVPLHHQVQPQAHLAPDSPAPAQTPPLHALPDLSPSPLPHPAMGRAPVDFINISTDMNTEVDALDPSIMDFALQGNLWEEMKDEGFSLDTLGAFADSPLGCDLGASGLTPASGGSDQSFPDLQVTGLYTAYSTPDSVAASGTSSSSQYLGAQGNKPIALL>sp|Q96NZ1-2|FOXN4_HUMAN Isoform 2 of Forkhead box protein N4 OS=Homosapiens OX=9606 GN=FOXN4MIESDTSSIMSGIIRNSGQNHHPSPQEYRLLATTSDDDLPGDLQSLSWLTAVDVPRLQQMASGRVDLGGPCVPHPHPGALAGVADLHVGATPSPLLHGPAGMAPRGMPGLGPITGHRDSQMSQFPVGGQPSSGLQDPPHLYSPATQPQFPLPPGAQQLSDRHGPEEQQDRQPACERDLQLHEGALPLLQDGPRRVEELGAAQPVSEQVLREGGEQDERLLPQGLPVGSEPGPHRQDGGGDAQVEEEGPGCHPPEYGQP>sp|Q96NZ1-3|FOXN4_HUMAN Isoform 3 of Forkhead box protein N4 OS=Homosapiens OX=9606 GN=FOXN4MPGLPCPALPCPAPPPAPSCLIAMALKNSKTGSLPVSEIYSFMKEHFPYFKTAPDGWKNSVRHNLSLNKCFEKVENKMSGSSRKGCLWALNLARIDKMEEEMHKWKRKDLAAIHRSMANPEELDKLISDRPESCRRPGKPGEPEAPVLTHATTVAVAHGCLAVSQLPPQPLMTLSLQSVPLHHQVQPQAHLAPDSPAPAQTPPLHALPDLSPSPLPHPAMGRAPVDFINISTDMNTEVDALDPSIMDFALQGNLWEEMKDEGFSLDTLGAFADSPLGCDLGASGLTPASGGSDQSFPDLQVTGLYTAYSTPDSVAASGTSSSSQYLGAQGNKPIALL>sp|O43524|FOXO3_HUMAN Forkhead box protein O3 OS=Homo sapiens OX=9606GN=FOXO3 PE=1 SV=1MAEAPASPAPLSPLEVELDPEFEPQSRPRSCTWPLQRPELQASPAKPSGETAADSMIPEEEDDEDDEDGGGRAGSAMAIGGGGGSGTLGSGLLLEDSARVLAPGGQDPGSGPATAAGGLSGGTQALLQPQQPLPPPQPGAAGGSGQPRKCSSRRNAWGNLSYADLITRAIESSPDKRLTLSQIYEWMVRCVPYFKDKGDSNSSAGWKNSIRHNLSLHSRFMRVQNEGTGKSSWWIINPDGGKSGKAPRRRAVSMDNSNKYTKSRGRAAKKKAALQTAPESADDSPSQLSKWPGSPTSRSSDELDAWTDFRSRTNSNASTVSGRLSPIMASTELDEVQDDDAPLSPMLYSSSASLSPSVSKPCTVELPRLTDMAGTMNLNDGLTENLMDDLLDNITLPPSQPSPTGGLMQRSSSFPYTTKGSGLGSPTSSFNSTVFGPSSLNSLRQSPMQTIQENKPATFSSMSHYGNQTLQDLLTSDSLSHSDVMMTQSDPLMSQASTAVSAQNSRRNVMLRNDPMMSFAAQPNQGSLVNQNLLHHQHQTQGALGGSRALSNSVSNMGLSESSSLGSAKHQQQSPVSQSMQTLSDSLSGSSLYSTSANLPVMGHEKFPSDLDLDMFNGSLECDMESIIRSELMDADGLDFNFDSLISTQNVVGLNVGNFTGAKQASSQSWVPG>sp|O43524-2|FOXO3_HUMAN Isoform 2 of Forkhead box protein O3 OS=Homosapiens OX=9606 GN=FOXO3MRVQNEGTGKSSWWIINPDGGKSGKAPRRRAVSMDNSNKYTKSRGRAAKKKAALQTAPESADDSPSQLSKWPGSPTSRSSDELDAWTDFRSRTNSNASTVSGRLSPIMASTELDEVQDDDAPLSPMLYSSSASLSPSVSKPCTVELPRLTDMAGTMNLNDGLTENLMDDLLDNITLPPSQPSPTGGLMQRSSSFPYTTKGSGLGSPTSSFNSTVFGPSSLNSLRQSPMQTIQENKPATFSSMSHYGNQTLQDLLTSDSLSHSDVMMTQSDPLMSQASTAVSAQNSRRNVMLRNDPMMSFAAQPNQGSLVNQNLLHHQHQTQGALGGSRALSNSVSNMGLSESSSLGSAKHQQQSPVSQSMQTLSDSLSGSSLYSTSANLPVMGHEKFPSDLDLDMFNGSLECDMESIIRSELMDADGLDFNFDSLISTQNVVGLNVGNFTGAKQASSQSWVPG>sp|Q12952|FOXL1_HUMAN Forkhead box protein L1 OS=Homo sapiens OX=9606GN=FOXL1 PE=2 SV=2MSHLFDPRLPALAASPMLYLYGPERPGLPLAFAPAAALAASGRAETPQKPPYSYIALIAMAIQDAPEQRVTLNGIYQFIMDRFPFYHDNRQGWQNSIRHNLSLNDCFVKVPREKGRPGKGSYWTLDPRCLDMFENGNYRRRKRKPKPGPGAPEAKRPRAETHQRSAEAQPEAGSGAGGSGPAISRLQAAPAGPSPLLDGPSPPAPLHWPGTASPNEDAGDAAQGAAAVAVGQAARTGDGPGSPLRPASRSSPKSSDKSKSFSIDSILAGKQGQKPPSGDELLGGAKPGPGGRLGASLLAASSSLRPPFNASLMLDPHVQGGFYQLGIPFLSYFPLQVPDTVLHFQ>sp|O43638|FOXS1_HUMAN Forkhead box protein S1 OS=Homo sapiens OX=9606GN=FOXS1 PE=2 SV=2MQQQPLPGPGAPTTEPTKPPYSYIALIAMAIQSSPGQRATLSGIYRYIMGRFAFYRHNRPGWQNSIRHNLSLNECFVKVPRDDRKPGKGSYWTLDPDCHDMFEHGSFLRRRRRFTRQTGAEGTRGPAKARRGPLRATSQDPGVPNATTGRQCSFPPELPDPKGLSFGGLVGAMPASMCPATTDGRPRPPMEPKEISTPKPACPGELPVATSSSSCPAFGFPAGFSEAESFNKAPTPVLSPESGIGSSYQCRLQALNFCMGADPGLEHLLASAAPSPAPPTPPGSLRAPLPLPTDHKEPWVAGGFPVQGGSGYPLGLTPCLYRTPGMFFFE>sp|Q8IVH2|FOXP4_HUMAN Forkhead box protein P4 OS=Homo sapiens OX=9606GN=FOXP4 PE=1 SV=1MMVESASETIRSAPSGQNGVGSLSGQADGSSGGATGTTASGTGREVTTGADSNGEMSPAELLHFQQQQALQVARQFLLQQASGLSSPGNNDSKQSASAVQVPVSVAMMSPQMLTPQQMQQILSPPQLQALLQQQQALMLQQLQEYYKKQQEQLHLQLLTQQQAGKPQPKEALGNKQLAFQQQLLQMQQLQQQHLLNLQRQGLVSLQPNQASGPLQTLPQAAVCPTDLPQLWKGEGAPGQPAEDSVKQEGLDLTGTAATATSFAAPPKVSPPLSHHTLPNGQPTVLTSRRDSSSHEETPGSHPLYGHGECKWPGCETLCEDLGQFIKHLNTEHALDDRSTAQCRVQMQVVQQLEIQLAKESERLQAMMAHLHMRPSEPKPFSQPLNPVPGSSSFSKVTVSAADSFPDGLVHPPTSAAAPVTPLRPPGLGSASLHGGGPARRRSSDKFCSPISSELAQNHEFYKNADVRPPFTYASLIRQAILETPDRQLTLNEIYNWFTRMFAYFRRNTATWKNAVRHNLSLHKCFVRVENVKGAVWTVDEREYQKRRPPKMTGSPTLVKNMISGLSYGALNASYQAALAESSFPLLNSPGMLNPGSASSLLPLSHDDVGAPVEPLPSNGSSSPPRLSPPQYSHQVQVKEEPAEAEEDRQPGPPLGAPNPSASGPPEDRDLEEELPGEELS>sp|Q8IVH2-2|FOXP4_HUMAN Isoform 2 of Forkhead box protein P4 OS=Homosapiens OX=9606 GN=FOXP4MMVESASETIRSAPSGQNGVGSLSGQADGSSGGATGTTASGTGREVTTGADSNGEMSPAELLHFQQQQALQVARQFLLQQASGLSSPGNNDSKQSASAVQVPVSVAMMSPQMLTPQQMQQILSPPQLQALLQQQQALMLQQEYYKKQQEQLHLQLLTQQQAGKPQPKEALGNKQLAFQQQLLQMQQLQQQHLLNLQRQGLVSLQPNQASGPLQTLPQAAVCPTDLPQLWKGEGAPGQPAEDSVKQEGLDLTGTAATATSFAAPPKVSPPLSHHTLPNGQPTVLTSRRDSSSHEETPGSHPLYGHGECKWPGCETLCEDLGQFIKHLNTEHALDDRSTAQCRVQMQVVQQLEIQLAKESERLQAMMAHLHMRPSEPKPFSQPLNPVPGSSSFSKVTVSAADSFPDGLVHPPTSAAAPVTPLRPPGLGSASLHGGGPARRRSSDKFCSPISSELAQNHEFYKNADVRPPFTYASLIRQAILETPDRQLTLNEIYNWFTRMFAYFRRNTATWKNAVRHNLSLHKCFVRVENVKGAVWTVDEREYQKRRPPKMTGSPTLVKNMISGLSYGALNASYQAALAESSFPLLNSPGMLNPGSASSLLPLSHDDVGAPVEPLPSNGSSSPPRLSPPQYSHQVQVKEEPAEAEEDRQPGPPLGAPNPSASGPPEDRDLEEELPGEELS>sp|Q8IVH2-3|FOXP4_HUMAN Isoform 3 of Forkhead box protein P4 OS=Homosapiens OX=9606 GN=FOXP4MMVESASETIRSAPSGQNGVGSLSGQADGSSGGATGTTASGTGREVTTGADSNGEMSPAELLHFQQQQALQVARQFLLQQASGLSSPGNNDSKQSASAVQVPVSVAMMSPQMLTPQQMQQILSPPQLQALLQQQQALMLQQLQEYYKKQQEQLHLQLLTQQQAGKPQPKEALGNKQLAFQQQLLQMQQLQQQHLLNLQRQGLVSLQPNQASGPLQTLPQAVCPTDLPQLWKGEGAPGQPAEDSVKQEGLDLTGTAATATSFAAPPKVSPPLSHHTLPNGQPTVLTSRRDSSSHEETPGSHPLYGHGECKWPGCETLCEDLGQFIKHLNTEHALDDRSTAQCRVQMQVVQQLEIQLAKESERLQAMMAHLHMRPSEPKPFSQPVTVSAADSFPDGLVHPPTSAAAPVTPLRPPGLGSASLHGGGPARRRSSDKFCSPISSELAQNHEFYKNADVRPPFTYASLIRQAILETPDRQLTLNEIYNWFTRMFAYFRRNTATWKNAVRHNLSLHKCFVRVENVKGAVWTVDEREYQKRRPPKMTGSPTLVKNMISGLSYGALNASYQAALAESSFPLLNSPGMLNPGSASSLLPLSHDDVGAPVEPLPSNGSSSPPRLSPPQYSHQVQVKEEPAEAEEDRQPGPPLGAPNPSASGPPEDRDLEEELPGEELS>sp|Q96FZ2|HMCES_HUMAN Abasic site processing protein HMCES OS=Homosapiens OX=9606 GN=HMCES PE=1 SV=1MCGRTSCHLPRDVLTRACAYQDRRGQQRLPEWRDPDKYCPSYNKSPQSNSPVLLSRLHFEKDADSSERIIAPMRWGLVPSWFKESDPSKLQFNTTNCRSDTVMEKRSFKVPLGKGRRCVVLADGFYEWQRCQGTNQRQPYFIYFPQIKTEKSGSIGAADSPENWEKVWDNWRLLTMAGIFDCWEPPEGGDVLYSYTIITVDSCKGLSDIHHRMPAILDGEEAVSKWLDFGEVSTQEALKLIHPTENITFHAVSSVVNNSRNNTPECLAPVDLVVKKELRASGSSQRMLQWLATKSPKKEDSKTPQKEESDVPQWSSQFLQKSPLPTKRGTAGLLEQWLKREKEEEPVAKRPYSQ>sp|P08151|GLI1_HUMAN Zinc finger protein GLI1 OS=Homo sapiens OX=9606GN=GLI1 PE=1 SV=1MFNSMTPPPISSYGEPCCLRPLPSQGAPSVGTEGLSGPPFCHQANLMSGPHSYGPARETNSCTEGPLFSSPRSAVKLTKKRALSISPLSDASLDLQTVIRTSPSSLVAFINSRCTSPGGSYGHLSIGTMSPSLGFPAQMNHQKGPSPSFGVQPCGPHDSARGGMIPHPQSRGPFPTCQLKSELDMLVGKCREEPLEGDMSSPNSTGIQDPLLGMLDGREDLEREEKREPESVYETDCRWDGCSQEFDSQEQLVHHINSEHIHGERKEFVCHWGGCSRELRPFKAQYMLVVHMRRHTGEKPHKCTFEGCRKSYSRLENLKTHLRSHTGEKPYMCEHEGCSKAFSNASDRAKHQNRTHSNEKPYVCKLPGCTKRYTDPSSLRKHVKTVHGPDAHVTKRHRGDGPLPRAPSISTVEPKREREGGPIREESRLTVPEGAMKPQPSPGAQSSCSSDHSPAGSAANTDSGVEMTGNAGGSTEDLSSLDEGPCIAGTGLSTLRRLENLRLDQLHQLRPIGTRGLKLPSLSHTGTTVSRRVGPPVSLERRSSSSSSISSAYTVSRRSSLASPFPPGSPPENGASSLPGLMPAQHYLLRARYASARGGGTSPTAASSLDRIGGLPMPPWRSRAEYPGYNPNAGVTRRASDPAQAADRPAPARVQRFKSLGCVHTPPTVAGGGQNFDPYLPTSVYSPQPPSITENAAMDARGLQEEPEVGTSMVGSGLNPYMDFPPTDTLGYGGPEGAAAEPYGARGPGSLPLGPGPPTNYGPNPCPQQASYPDPTQETWGEFPSHSGLYPGPKALGGTYSQCPRLEHYGQVQVKPEQGCPVGSDSTGLAPCLNAHPSEGPPHPQPLFSHYPQPSPPQYLQSGPYTQPPPDYLPSEPRPCLDFDSPTHSTGQLKAQLVCNYVQSQQELLWEGGGREDAPAQEPSYQSPKFLGGSQVSPSRAKAPVNTYGPGFGPNLPNHKSGSYPTPSPCHENFVVGANRASHRAAAPPRLLPPLPTCYGPLKVGGTNPSCGHPEVGRLGGGPALYPPPEGQVCNPLDSLDLDNTQLDFVAILDEPQGLSPPPSHDQRGSSGHTPPPSGPPNMAVGNMSVLLRSLPGETEFLNSSA>sp|P08151-2|GLI1_HUMAN Isoform 2 of Zinc finger protein GLI1 OS=Homosapiens OX=9606 GN=GLI1MFNSMTPPPISSYGEPCCLRPLPSQGAPSVGTEVKLTKKRALSISPLSDASLDLQTVIRTSPSSLVAFINSRCTSPGGSYGHLSIGTMSPSLGFPAQMNHQKGPSPSFGVQPCGPHDSARGGMIPHPQSRGPFPTCQLKSELDMLVGKCREEPLEGDMSSPNSTGIQDPLLGMLDGREDLEREEKREPESVYETDCRWDGCSQEFDSQEQLVHHINSEHIHGERKEFVCHWGGCSRELRPFKAQYMLVVHMRRHTGEKPHKCTFEGCRKSYSRLENLKTHLRSHTGEKPYMCEHEGCSKAFSNASDRAKHQNRTHSNEKPYVCKLPGCTKRYTDPSSLRKHVKTVHGPDAHVTKRHRGDGPLPRAPSISTVEPKREREGGPIREESRLTVPEGAMKPQPSPGAQSSCSSDHSPAGSAANTDSGVEMTGNAGGSTEDLSSLDEGPCIAGTGLSTLRRLENLRLDQLHQLRPIGTRGLKLPSLSHTGTTVSRRVGPPVSLERRSSSSSSISSAYTVSRRSSLASPFPPGSPPENGASSLPGLMPAQHYLLRARYASARGGGTSPTAASSLDRIGGLPMPPWRSRAEYPGYNPNAGVTRRASDPAQAADRPAPARVQRFKSLGCVHTPPTVAGGGQNFDPYLPTSVYSPQPPSITENAAMDARGLQEEPEVGTSMVGSGLNPYMDFPPTDTLGYGGPEGAAAEPYGARGPGSLPLGPGPPTNYGPNPCPQQASYPDPTQETWGEFPSHSGLYPGPKALGGTYSQCPRLEHYGQVQVKPEQGCPVGSDSTGLAPCLNAHPSEGPPHPQPLFSHYPQPSPPQYLQSGPYTQPPPDYLPSEPRPCLDFDSPTHSTGQLKAQLVCNYVQSQQELLWEGGGREDAPAQEPSYQSPKFLGGSQVSPSRAKAPVNTYGPGFGPNLPNHKSGSYPTPSPCHENFVVGANRASHRAAAPPRLLPPLPTCYGPLKVGGTNPSCGHPEVGRLGGGPALYPPPEGQVCNPLDSLDLDNTQLDFVAILDEPQGLSPPPSHDQRGSSGHTPPPSGPPNMAVGNMSVLLRSLPGETEFLNSSA>sp|P08151-3|GLI1_HUMAN Isoform 3 of Zinc finger protein GLI1 OS=Homosapiens OX=9606 GN=GLI1MSPSLGFPAQMNHQKGPSPSFGVQPCGPHDSARGGMIPHPQSRGPFPTCQLKSELDMLVGKCREEPLEGDMSSPNSTGIQDPLLGMLDGREDLEREEKREPESVYETDCRWDGCSQEFDSQEQLVHHINSEHIHGERKEFVCHWGGCSRELRPFKAQYMLVVHMRRHTGEKPHKCTFEGCRKSYSRLENLKTHLRSHTGEKPYMCEHEGCSKAFSNASDRAKHQNRTHSNEKPYVCKLPGCTKRYTDPSSLRKHVKTVHGPDAHVTKRHRGDGPLPRAPSISTVEPKREREGGPIREESRLTVPEGAMKPQPSPGAQSSCSSDHSPAGSAANTDSGVEMTGNAGGSTEDLSSLDEGPCIAGTGLSTLRRLENLRLDQLHQLRPIGTRGLKLPSLSHTGTTVSRRVGPPVSLERRSSSSSSISSAYTVSRRSSLASPFPPGSPPENGASSLPGLMPAQHYLLRARYASARGGGTSPTAASSLDRIGGLPMPPWRSRAEYPGYNPNAGVTRRASDPAQAADRPAPARVQRFKSLGCVHTPPTVAGGGQNFDPYLPTSVYSPQPPSITENAAMDARGLQEEPEVGTSMVGSGLNPYMDFPPTDTLGYGGPEGAAAEPYGARGPGSLPLGPGPPTNYGPNPCPQQASYPDPTQETWGEFPSHSGLYPGPKALGGTYSQCPRLEHYGQVQVKPEQGCPVGSDSTGLAPCLNAHPSEGPPHPQPLFSHYPQPSPPQYLQSGPYTQPPPDYLPSEPRPCLDFDSPTHSTGQLKAQLVCNYVQSQQELLWEGGGREDAPAQEPSYQSPKFLGGSQVSPSRAKAPVNTYGPGFGPNLPNHKSGSYPTPSPCHENFVVGANRASHRAAAPPRLLPPLPTCYGPLKVGGTNPSCGHPEVGRLGGGPALYPPPEGQVCNPLDSLDLDNTQLDFVAILDEPQGLSPPPSHDQRGSSGHTPPPSGPPNMAVGNMSVLLRSLPGETEFLNSSA>sp|Q86UU5|GGN_HUMAN Gametogenetin OS=Homo sapiens OX=9606 GN=GGN PE=1SV=2MGNLQSEPSAGGGSRKVQPSDRAPDSRRTSLVEPEMTSQAMRLTRGLGVWFPGSATPPGLMVPREPQASPSTLPLTLERPSPVMPPPEEAAAVSAPPPAPAGTLLPGPSKWQKPAGTPVPRIRRLLEASHRGQGDPPSLRPLKPPPPPRQLSVKDTVPRAPSQFPPPLETWKPPPPLPSERQPADRRITPALATPASPPTESQAGPRNQGQTAGRARGGAPPHAGEGEMAQPADSESGLSLLCKITFKSRPSLAPPAASSSLAAKASLGGGGGGGLFAASGAISYAEVLKQGPLPPGAARPLGEVSRGAQEAEGGDGDGEGCSGPPSAPASQARALPPPPYTTFPGSKPKFDWVSAPDGPERHFRFNGAGGGIGAPRRRAAALSGPWGSPPPPPEQIHSAPGPRRPAPALLAPPTFIFPAPTNGEPMRPGPPGLQELPPLPPPTPPPTLQPPALQPTPLPVAPPLTPGLGHKESALAPTAAPALPPALAADQAPAPSPAPAPTVAEPSPPVSAPAPAAAPIKTRTRRNKGSRAARGATRKDGLHGDGPRERATATVPDSSGGGGGGSGASQTGAANTRAARHWLPFQVLNSCPCKCYCHHQPRHRRLPRNVSAWLSTSTNHLGEPPWVATIKLSGSLVAKLEHYDLQATHSN>sp|Q86UU5-2|GGN_HUMAN Isoform 2 of Gametogenetin OS=Homo sapiens OX=9606GN=GGNMPPPEEAAAVSAPPPAPAGTLLPGPSKWQKPAGTPVPRIRRLLEASHRGQGDPPSLRPLKPPPPPRQLSVKDTVPRAPSQFPPPLETWKPPPPLPSERQPADRRITPALATPASPPTESQAGPRNQGQTAGRARGGAPPHAGEGEMAQPADSESGLSLLCKITFKSRPSLAPPAASSSLAAKASLGGGGGGGLFAASGAISYAEVLKQGPLPPGAARPLGEVSRGAQEAEGGDGDGEGCSGPPSAPASQARALPPPPYTTFPGSKPKFDWVSAPDGPERHFRFNGAGGGIGAPRRRAAALSGPWGSPPPPPEQIHSAPGPRRPAPALLAPPTFIFPAPTNGEPMRPGPPGLQELPPLPPPTPPPTLQPPALQPTPLPVAPPLTPGLGHKESALAPTAAPALPPALAADQAPAPSPAPAPTVAEPSPPVSAPAPAAAPIKTRTRRNKGSRAARGATRA>sp|Q86UU5-3|GGN_HUMAN Isoform 3 of Gametogenetin OS=Homo sapiens OX=9606GN=GGNMGNLQSEPSAGGGSRKVQPSDRAPDSRRTSLVEPEMTSQAMRLTRGLGVWFPGSATPPGLMVPREPQASPSTLPLTLERPSPVMPPPEEAAAVSAPPPAPAGTLLPGPSKWQKPAGTPVPRIRRLLEASHRGQGDPPSLRPLKPPPPPRQLSVKDTVPRAPSQFPPPLETWKPPPPLPSERQPADRRITPALATPACVRARTRGCAHQDPHAQEQGFPCSPGRD>sp|P01859|IGHG2_HUMAN Immunoglobulin heavy constant gamma 2 OS=Homosapiens OX=9606 GN=IGHG2 PE=1 SV=2ASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSNFGTQTYTCNVDHKPSNTKVDKTVERKCCVECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDISVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK>sp|Q9Y6W8|ICOS_HUMAN Inducible T-cell costimulator OS=Homo sapiensOX=9606 GN=ICOS PE=1 SV=1MKSGLWYFFLFCLRIKVLTGEINGSANYEMFIFHNGGVQILCKYPDIVQQFKMQLLKGGQILCDLTKTKGSGNTVSIKSLKFCHSQLSNNSVSFFLYNLDHSHANYYFCNLSIFDPPPFKVTLTGGYLHIYESQLCCQLKFWLPIGCAAFVVVCILGCILICWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL>sp|Q9Y6W8-2|ICOS_HUMAN Isoform 2 of Inducible T-cell costimulatorOS=Homo sapiens OX=9606 GN=ICOSMKSGLWYFFLFCLRIKVLTGEINGSANYEMFIFHNGGVQILCKYPDIVQQFKMQLLKGGQILCDLTKTKGSGNTVSIKSLKFCHSQLSNNSVSFFLYNLDHSHANYYFCNLSIFDPPPFKVTLTGGYLHIYESQLCCQLKFWLPIGCAAFVVVCILGCILICWLTKKM>sp|P51553|IDH3G_HUMAN Isocitrate dehydrogenase [NAD] subunit gamma,mitochondrial OS=Homo sapiens OX=9606 GN=IDH3G PE=1 SV=1MALKVATVAGSAAKAVLGPALLCRPWEVLGAHEVPSRNIFSEQTIPPSAKYGGRHTVTMIPGDGIGPELMLHVKSVFRHACVPVDFEEVHVSSNADEEDIRNAIMAIRRNRVALKGNIETNHNLPPSHKSRNNILRTSLDLYANVIHCKSLPGVVTRHKDIDILIVRENTEGEYSSLEHESVAGVVESLKIITKAKSLRIAEYAFKLAQESGRKKVTAVHKANIMKLGDGLFLQCCREVAARYPQITFENMIVDNTTMQLVSRPQQFDVMVMPNLYGNIVNNVCAGLVGGPGLVAGANYGHVYAVFETATRNTGKSIANKNIANPTATLLASCMMLDHLKLHSYATSIRKAVLASMDNENMHTPDIGGQGTTSEAIQDVIRHIRVINGRAVEA>sp|P51553-2|IDH3G_HUMAN Isoform 2 of Isocitrate dehydrogenase [NAD]subunit gamma, mitochondrial OS=Homo sapiens OX=9606 GN=IDH3GMALKVATVAGSAAKAVLGPALLCRPWEVLGAHEVPSRNIFSEQTIPPSAKYGGRHTVTMIPGDGIGPELMLHVKSVFRHACVPVDFEEVHVSSNADEEDIRNAIMAIRRNRVALKGNIETNHNLPPSHKSRNNILRTSLDLYANVIHCKSLPGVVTRHKDIDILIVRENTEGEYSSLEHESVAGVVESLKIITKAKSLRIAEYAFKLAQESGRKKVTAVHKANIMKLGDGLFLQCCREVAARYPQITFENMIVDNTTMQLVSRPQQFDVMVMPNLYGNIVNNVCAGLVGGPGLVAGANYGHVYAVFETATRNTGKSIANKNIANPTATLLASCMMLDHLKLHSYATSIRKAVLASMDNENVRFPSHPTLLPRPVSPCSLL>sp|Q9NX55|HYPK_HUMAN Huntingtin-interacting protein K OS=Homo sapiensOX=9606 GN=HYPK PE=1 SV=2MRRRGEIDMATEGDVELELETETSGPERPPEKPRKHDSGAADLERVTDYAEEKEIQSSNLETAMSVIGDRRSREQKAKQEREKELAKVTIKKEDLELIMTEMEISRAAAERSLREHMGNVVEALIALTN>sp|Q9NX55-3|HYPK_HUMAN Isoform 3 of Huntingtin-interacting protein KOS=Homo sapiens OX=9606 GN=HYPKMRRRGEIDMATEGDVELELETETSGPERPPEKPRKHDSGAADLERVTDYAEEKEIQSSNLETGERTGKSHYQEGRSGANSEWKEL>sp|B5MD39|GGTL3_HUMAN Putative glutathione hydrolase light chain 3OS=Homo sapiens OX=9606 GN=GGTLC3 PE=5 SV=1MTSEFFAAQLRSQISDHTTHPISYYKPEFYTPDDGGTAHLSVVAEDGSAVSATSTINLYFGSKVCSPVSGILFNNEWTTSALPAFTNEFGAPPSPANFIQPGKQPLLSMCPTIMVGQDGQVRMVVGAAGGTQITTDTALAIIYNLWFGYDVKRAVEEPRLHNKLLPNVTTVERNIDQAVTAALETRHHHTQIASTFIAVVQAIVRTAGGWAAASDSRKGGEPAGY>sp|Q9BX51|GGTL1_HUMAN Glutathione hydrolase light chain 1 OS=Homosapiens OX=9606 GN=GGTLC1 PE=2 SV=2MTSEFFSAQLRAQISDDTTHPISYYKPEFYMPDDGGTAHLSVVAEDGSAVSATSTINLYFGSKVRSPVSGILLNNEMDDFSSTSITNEFGVPPSPANFIQPGKQPLSSMCPTIMVGQDGQVRMVVGAAGGTQITMATALAIIYNLWFGYDVKWAVEEPRLHNQLLPNVTTVERNIDQEVTAALETRHHHTQITSTFIAVVQAIVRMAGGWAAASDSRKGGEPAGY>sp|A6NCL1|GEMC1_HUMAN Geminin coiled-coil domain-containing protein 1OS=Homo sapiens OX=9606 GN=GMNC PE=1 SV=2MNTILPCQDQYFVGGQSYNCPYSTTTSESSVDVSTETWVSFWAAGLLDNRELQQAPQAQESFSDSNFPLPDLCSWEEAQLSSQLYRNKQLQDTLVQKEEELARLHEENNHLRQYLNSALVKCLEEKAKKLLSSDEFSKAYGKFRKGKRKSKEQRYSPAEIPHPKNAKRNLSSEFANCEEQAGPPVDPWVLQTLGLKDLDTIDDTSSANYSALASHPRRVASTFSQFPDDAVDYKNIPREDMPIDYRGDRTTPLHSTATHGEDFHILSQLSNPPVGLKTLPYYTAHVSPNKTEMAFSTSLSPHCNVKTHSFHQGQAFVRRDEEGGWKFTWVPKQS>sp|P40305|IFI27_HUMAN Interferon alpha-inducible protein 27,mitochondrial OS=Homo sapiens OX=9606 GN=IFI27 PE=1 SV=4MEASALTSSAVTSVAKVVRVASGSAVVLPLARIATVVIGGVVAMAAVPMVLSAMGFTAAGIASSSIAAKMMSAAAIANGGGVASGSLVATLQSLGATGLSGLTKFILGSIGSAIAAVIARFY>sp|P40305-1|IFI27_HUMAN Isoform 2 of Interferon alpha-inducible protein27, mitochondrial OS=Homo sapiens OX=9606 GN=IFI27MEASALTSSAVTSVAKVVRVASGSAVVLPLARIATVVIGGVVAVPMVLSAMGFTAAGIASSSIAAKMMSAAAIANGGGVASGSLVATLQSLGATGLSGLTKFILGSIGSAIAAVIARFY>sp|P40305-3|IFI27_HUMAN Isoform 3 of Interferon alpha-inducible protein27, mitochondrial OS=Homo sapiens OX=9606 GN=IFI27MAAVPMVLSAMGFTAAGIASSSIAAKMMSAAAIANGGGVASGSLVATLQSLGATGLSGLTKFILGSIGSAIAAVIARFY>sp|P40305-4|IFI27_HUMAN Isoform 4 of Interferon alpha-inducible protein27, mitochondrial OS=Homo sapiens OX=9606 GN=IFI27MVLSAMGFTAAGIASSSIAAKMMSAAAIANGGGVASGSLVATLQSLGATGLSGLTKFILGSIGSAIAAVIARFY>sp|Q7L5D6|GET4_HUMAN Golgi to ER traffic protein 4 homolog OS=Homosapiens OX=9606 GN=GET4 PE=1 SV=1MAAAAAMAEQESARNGGRNRGGVQRVEGKLRASVEKGDYYEAHQMYRTLFFRYMSQSKHTEARELMYSGALLFFSHGQQNSAADLSMLVLESLEKAEVEVADELLENLAKVFSLMDPNSPERVTFVSRALKWSSGGSGKLGHPRLHQLLALTLWKEQNYCESRYHFLHSADGEGCANMLVEYSTSRGFRSEVDMFVAQAVLQFLCLKNKSSASVVFTTYTQKHPSIEDGPPFVEPLLNFIWFLLLAVDGGKLTVFTVLCEQYQPSLRRDPMYNEYLDRIGQLFFGVPPKQTSSYGGLLGNLLTSLMGSSEQEDGEESPSDGSPIELD>sp|Q7L5D6-2|GET4_HUMAN Isoform 2 of Golgi to ER traffic protein 4homolog OS=Homo sapiens OX=9606 GN=GET4MSQSKHTEARELMYSGALLFFSHGQQNSAADLSMLVLESLEKAEVEVADELLENLAKVFSLMDPNSPERVTFVSRALKWSSGGSGKLGHPRLHQLLALTLWKEQNYCESRYHFLHSADGEGCANMLVEYSTSRGFRSEVDMFVAQAVLQFLCLKNKSSASVVFTTYTQKHPSIEDGPPFVEPLLNFIWFLLLAVDGGKLTVFTVLCEQYQPSLRRDPMYNEYLDRIGQLFFGVPPKQTSSYGGLLGNLLTSLMGSSEQEDGEESPSDGSPIELD>sp|Q8TB36|GDAP1_HUMAN Ganglioside-induced differentiation-associatedprotein 1 OS=Homo sapiens OX=9606 GN=GDAP1 PE=1 SV=3MAERQEEQRGSPPLRAEGKADAEVKLILYHWTHSFSSQKVRLVIAEKALKCEEHDVSLPLSEHNEPWFMRLNSTGEVPVLIHGENIICEATQIIDYLEQTFLDERTPRLMPDKESMYYPRVQHYRELLDSLPMDAYTHGCILHPELTVDSMIPAYATTRIRSQIGNTESELKKLAEENPDLQEAYIAKQKRLKSKLLDHDNVKYLKKILDELEKVLDQVETELQRRNEETPEEGQQPWLCGESFTLADVSLAVTLHRLKFLGFARRNWGNGKRPNLETYYERVLKRKTFNKVLGHVNNILISAVLPTAFRVAKKRAPKVLGTTLVVGLLAGVGYFAFMLFRKRLGSMILAFRPRPNYF>sp|Q8TB36-2|GDAP1_HUMAN Isoform 2 of Ganglioside-induceddifferentiation-associated protein 1 OS=Homo sapiens OX=9606 GN=GDAP1MRLNSTGEVPVLIHGENIICEATQIIDYLEQTFLDERTPRLMPDKESMYYPRVQHYRELLDSLPMDAYTHGCILHPELTVDSMIPAYATTRIRSQIGNTESELKKLAEENPDLQEAYIAKQKRLKSKLLDHDNVKYLKKILDELEKVLDQVETELQRRNEETPEEGQQPWLCGESFTLADVSLAVTLHRLKFLGFARRNWGNGKRPNLETYYERVLKRKTFNKVLGHVNNILISAVLPTAFRVAKKRAPKVLGTTLVVGLLAGVGYFAFMLFRKRLGSMILAFRPRPNYF>sp|Q9HCG7|GBA2_HUMAN Non-lysosomal glucosylceramidase OS=Homo sapiensOX=9606 GN=GBA2 PE=1 SV=2MGTQDPGNMGTGVPASEQISCAKEDPQVYCPEETGGTKDVQVTDCKSPEDSRPPKETDCCNPEDSGQLMVSYEGKAMGYQVPPFGWRICLAHEFTEKRKPFQANNVSLSNMIKHIGMGLRYLQWWYRKTHVEKKTPFIDMINSVPLRQIYGCPLGGIGGGTITRGWRGQFCRWQLNPGMYQHRTVIADQFTVCLRREGQTVYQQVLSLERPSVLRSWNWGLCGYFAFYHALYPRAWTVYQLPGQNVTLTCRQITPILPHDYQDSSLPVGVFVWDVENEGDEALDVSIMFSMRNGLGGGDDAPGGLWNEPFCLERSGETVRGLLLHHPTLPNPYTMAVAARVTAATTVTHITAFDPDSTGQQVWQDLLQDGQLDSPTGQSTPTQKGVGIAGAVCVSSKLRPRGQCRLEFSLAWDMPRIMFGAKGQVHYRRYTRFFGQDGDAAPALSHYALCRYAEWEERISAWQSPVLDDRSLPAWYKSALFNELYFLADGGTVWLEVLEDSLPEELGRNMCHLRPTLRDYGRFGYLEGQEYRMYNTYDVHFYASFALIMLWPKLELSLQYDMALATLREDLTRRRYLMSGVMAPVKRRNVIPHDIGDPDDEPWLRVNAYLIHDTADWKDLNLKFVLQVYRDYYLTGDQNFLKDMWPVCLAVMESEMKFDKDHDGLIENGGYADQTYDGWVTTGPSAYCGGLWLAAVAVMVQMAALCGAQDIQDKFSSILSRGQEAYERLLWNGRYYNYDSSSRPQSRSVMSDQCAGQWFLKACGLGEGDTEVFPTQHVVRALQTIFELNVQAFAGGAMGAVNGMQPHGVPDKSSVQSDEVWVGVVYGLAATMIQEGLTWEGFQTAEGCYRTVWERLGLAFQTPEAYCQQRVFRSLAYMRPLSIWAMQLALQQQQHKKASWPKVKQGTGLRTGPMFGPKEAMANLSPE>sp|Q9HCG7-2|GBA2_HUMAN Isoform 2 of Non-lysosomal glucosylceramidaseOS=Homo sapiens OX=9606 GN=GBA2MGTQDPGNMGTGVPASEQISCAKEDPQVYCPEETGGTKDVQVTDCKSPEDSRPPKETDCCNPEDSGQLMVSYEGKAMGYQVPPFGWRICLAHEFTEKRKPFQANNVSLSNMIKHIGMGLRYLQWWYRKTHVEKKTPFIDMINSVPLRQIYGCPLGGIGGGTITRGWRGQFCRWQLNPGMYQHRTVIADQFTVCLRREGQTVYQQVLSLERPSVLRSWNWGLCGYFAFYHALYPRAWTVYQLPGQNVTLTCRQITPILPHDYQDSSLPVGVFVWDVENEGDEALDVSIMFSMRNGLGGGDDAPGGLWNEPFCLERSGETVRGLLLHHPTLPNPYTMAVAARVTAATTVTHITAFDPDSTGQQVWQDLLQDGQLDSPTGQSTPTQKGVGIAGAVCVSSKLRPRGQCRLEFSLAWDMPRIMFGAKGQVHYRRYTRFFGQDGDAAPALSHYALCRYAEWEERISAWQSPVLDDRSLPAWYKSALFNELYFLADGGTVWLEVLEDSLPEELGRNMCHLRPTLRDYGRFGYLEGQEYRMYNTYDVHFYASFALIMLWPKLELSLQYDMALATLREDLTRRRYLMSGVMAPVKRRNVIPHDIGDPDDEPWLRVNAYLIHDTADWKDLNLKFVLQVYRDYYLTGDQNFLKDMWPVCLAVMESEMKFDKDHDGLIENGGYADQTYDGWVTTGPSAYCGGLWLAAVAVMVQMAALCGAQDIQDKFSSILSRGQEAYERLLWNGRYYNYDSSSRPQSRSVMSDQCAGQWFLKACGLGEGDTEVFPTQHVVRALQTIFELNVQAFAGGAMGAVNGMQPHGVPDKSSVQSDEVWVGVVYGLAATMIQELLPSGFCLWVIVISSTCWELLEGKDSTASIYPVEVALQRVPS>sp|Q9HCG7-3|GBA2_HUMAN Isoform 3 of Non-lysosomal glucosylceramidaseOS=Homo sapiens OX=9606 GN=GBA2MFSMRNGLGGGDDAPGGLWNEPFCLERSGETVRGLLLHHPTLPNPYTMAVAARVTAATTVTHITAFDPDSTGQQVWQDLLQDGQLDSPTGQSTPTQKGVGIAGAVCVSSKLRPRGQCRLEFSLAWDMPRIMFGAKGQVHYRRYTRFFGQDGDAAPALSHYALCRYAEWEERISAWQSPVLDDRSLPAWYKSALFNELYFLADGGTVWLEVLEDSLPEELGRNMCHLRPTLRDYGRFGYLEGQEYRMYNTYDVHFYASFALIMLWPKLELSLQYDMALATLREDLTRRRYLMSGVMAPVKRRNVIPHDIGDPDDEPWLRVNAYLIHDTADWKDLNLKFVLQVYRDYYLTGDQNFLKDMWPVCLAVMESEMKFDKDHDGLIENGGYADQTYDGWVTTGPSAYCGGLWLAAVAVMVQMAALCGAQDIQDKFSSILSRGQEAYERLLWNGRYYNYDSSSRPQSRSVMSDQCAGQWFLKACGLGEGDTEVFPTQHVVRALQTIFELNVQAFAGGAMGAVNGMQPHGVPDKSSVQSDEVWVGVVYGLAATMIQEGLTWEGFQTAEGCYRTVWERLGLAFQTPEAYCQQRVFRSLAYMRPLSIWAMQLALQQQQHKKASWPKVKQGTGLRTGPMFGPKEAMANLSPE>sp|P57678|GEMI4_HUMAN Gem-associated protein 4 OS=Homo sapiens OX=9606GN=GEMIN4 PE=1 SV=2MDLGPLNICEEMTILHGGFLLAEQLFHPKALAELTKSDWERVGRPIVEALREISSAAAHSQPFAWKKKALIIIWAKVLQPHPVTPSDTETRWQEDLFFSVGNMIPTINHTILFELLKSLEASGLFIQLLMALPTTICHAELERFLEHVTVDTSAEDVAFFLDVWWEVMKHKGHPQDPLLSQFSAMAHKYLPALDEFPHPPKRLRSDPDACPTMPLLAMLLRGLTQIQSRILGPGRKCCALANLADMLTVFALTEDDPQEVSATVYLDKLATVISVWNSDTQNPYHQQALAEKVKEAERDVSLTSLAKLPSETIFVGCEFLHHLLREWGEELQAVLRSSQGTSYDSYRLCDSLTSFSQNATLYLNRTSLSKEDRQVVSELAECVRDFLRKTSTVLKNRALEDITASIAMAVIQQKMDRHMEVCYIFASEKKWAFSDEWVACLGSNRALFRQPDLVLRLLETVIDVSTADRAIPESQIRQVIHLILECYADLSLPGKNKVLAGILRSWGRKGLSEKLLAYVEGFQEDLNTTFNQLTQSASEQGLAKAVASVARLVIVHPEVTVKKMCSLAVVNLGTHKFLAQILTAFPALRFVEEQGPNSSATFMVSCLKETVWMKFSTPKEEKQFLELLNCLMSPVKPQGIPVAALLEPDEVLKEFVLPFLRLDVEEVDLSLRIFIQTLEANACREEYWLQTCSPFPLLFSLCQLLDRFSKYWQLPKEKRCLSLDRKDLAIHILELLCEIVSANAETFSPDVWIKSLSWLHRKLEQLDWTVGLRLKSFFEGHFKCEVPATLFEICKLSEDEWTSQAHPGYGAGTGLLAWMECCCVSSGISERMLSLLVVDVGNPEEVRLFSKGFLVALVQVMPWCSPQEWQRLHQLTRRLLEKQLLHVPYSLEYIQFVPLLNLKPFAQELQLSVLFLRTFQFLCSHSCRDWLPLEGWNHVVKLLCGSLTRLLDSVRAIQAAGPWVQGPEQDLTQEALFVYTQVFCHALHIMAMLHPEVCEPLYVLALETLTCYETLSKTNPSVSSLLQRAHEQRFLKSIAEGIGPEERRQTLLQKMSSF>sp|P16260|GDC_HUMAN Graves disease carrier protein OS=Homo sapiensOX=9606 GN=SLC25A16 PE=1 SV=3MAAATAAAALAAADPPPAMPQAAGAGGPTTRRDFYWLRSFLAGGIAGCCAKTTVAPLDRVKVLLQAHNHHYKHLGVFSALRAVPQKEGFLGLYKGNGAMMIRIFPYGAIQFMAFEHYKTLITTKLGISGHVHRLMAGSMAGMTAVICTYPLDMVRVRLAFQVKGEHSYTGIIHAFKTIYAKEGGFFGFYRGLMPTILGMAPYAGVSFFTFGTLKSVGLSHAPTLLGRPSSDNPNVLVLKTHVNLLCGGVAGAIAQTISYPFDVTRRRMQLGTVLPEFEKCLTMRDTMKYVYGHHGIRKGLYRGLSLNYIRCIPSQAVAFTTYELMKQFFHLN>sp|P55107|GDF10_HUMAN Growth/differentiation factor 10 OS=Homo sapiensOX=9606 GN=GDF10 PE=2 SV=1MAHVPARTSPGPGPQLLLLLLPLFLLLLRDVAGSHRAPAWSALPAAADGLQGDRDLQRHPGDAAATLGPSAQDMVAVHMHRLYEKYSRQGARPGGGNTVRSFRARLEVVDQKAVYFFNLTSMQDSEMILTATFHFYSEPPRWPRALEVLCKPRAKNASGRPLPLGPPTRQHLLFRSLSQNTATQGLLRGAMALAPPPRGLWQAKDISPIVKAARRDGELLLSAQLDSEERDPGVPRPSPYAPYILVYANDLAISEPNSVAVTLQRYDPFPAGDPEPRAAPNNSADPRVRRAAQATGPLQDNELPGLDERPPRAHAQHFHKHQLWPSPFRALKPRPGRKDRRKKGQEVFMAASQVLDFDEKTMQKARRKQWDEPRVCSRRYLKVDFADIGWNEWIISPKSFDAYYCAGACEFPMPKIVRPSNHATIQSIVRAVGIIPGIPEPCCVPDKMNSLGVLFLDENRNVVLKVYPNMSVDTCACR>sp|P14136|GFAP_HUMAN Glial fibrillary acidic protein OS=Homo sapiensOX=9606 GN=GFAP PE=1 SV=1MERRRITSAARRSYVSSGEMMVGGLAPGRRLGPGTRLSLARMPPPLPTRVDFSLAGALNAGFKETRASERAEMMELNDRFASYIEKVRFLEQQNKALAAELNQLRAKEPTKLADVYQAELRELRLRLDQLTANSARLEVERDNLAQDLATVRQKLQDETNLRLEAENNLAAYRQEADEATLARLDLERKIESLEEEIRFLRKIHEEEVRELQEQLARQQVHVELDVAKPDLTAALKEIRTQYEAMASSNMHEAEEWYRSKFADLTDAAARNAELLRQAKHEANDYRRQLQSLTCDLESLRGTNESLERQMREQEERHVREAASYQEALARLEEEGQSLKDEMARHLQEYQDLLNVKLALDIEIATYRKLLEGEENRITIPVQTFSNLQIRETSLDTKSVSEGHLKRNIVVKTVEMRDGEVIKESKQEHKDVM>sp|P14136-3|GFAP_HUMAN Isoform 2 of Glial fibrillary acidic proteinOS=Homo sapiens OX=9606 GN=GFAPMERRRITSAARRSYVSSGEMMVGGLAPGRRLGPGTRLSLARMPPPLPTRVDFSLAGALNAGFKETRASERAEMMELNDRFASYIEKVRFLEQQNKALAAELNQLRAKEPTKLADVYQAELRELRLRLDQLTANSARLEVERDNLAQDLATVRQKLQDETNLRLEAENNLAAYRQEADEATLARLDLERKIESLEEEIRFLRKIHEEEVRELQEQLARQQVHVELDVAKPDLTAALKEIRTQYEAMASSNMHEAEEWYRSKFADLTDAAARNAELLRQAKHEANDYRRQLQSLTCDLESLRGTNESLERQMREQEERHVREAASYQEALARLEEEGQSLKDEMARHLQEYQDLLNVKLALDIEIATYRKLLEGEENRITIPVQTFSNLQIRGGKSTKDGENHKVTRYLKSLTIRVIPIQAHQIVNGTPPARG>sp|P14136-2|GFAP_HUMAN Isoform 3 of Glial fibrillary acidic proteinOS=Homo sapiens OX=9606 GN=GFAPMERRRITSAARRSYVSSGEMMVGGLAPGRRLGPGTRLSLARMPPPLPTRVDFSLAGALNAGFKETRASERAEMMELNDRFASYIEKVRFLEQQNKALAAELNQLRAKEPTKLADVYQAELRELRLRLDQLTANSARLEVERDNLAQDLATVRQKLQDETNLRLEAENNLAAYRQEADEATLARLDLERKIESLEEEIRFLRKIHEEEVRELQEQLARQQVHVELDVAKPDLTAALKEIRTQYEAMASSNMHEAEEWYRSKFADLTDAAARNAELLRQAKHEANDYRRQLQSLTCDLESLRGTNESLERQMREQEERHVREAASYQEALARLEEEGQSLKDEMARHLQEYQDLLNVKLALDIEIATYRKLLEGEENRITIPVQTFSNLQIRGQYSRASWEGHWSPAPSSRACRLLQTGTEDQGKGIQLSLGAFVTLQRS>sp|Q08334|I10R2_HUMAN Interleukin-10 receptor subunit beta OS=Homosapiens OX=9606 GN=IL10RB PE=1 SV=2MAWSLGSWLGGCLLVSALGMVPPPENVRMNSVNFKNILQWESPAFAKGNLTFTAQYLSYRIFQDKCMNTTLTECDFSSLSKYGDHTLRVRAEFADEHSDWVNITFCPVDDTIIGPPGMQVEVLADSLHMRFLAPKIENEYETWTMKNVYNSWTYNVQYWKNGTDEKFQITPQYDFEVLRNLEPWTTYCVQVRGFLPDRNKAGEWSEPVCEQTTHDETVPSWMVAVILMASVFMVCLALLGCFALLWCVYKKTKYAFSPRNSLPQHLKEFLGHPHHNTLLFFSFPLSDENDVFDKLSVIAEDSESGKQNPGDSCSLGTPPGQGPQS>sp|Q6KF10|GDF6_HUMAN Growth/differentiation factor 6 OS=Homo sapiensOX=9606 GN=GDF6 PE=1 SV=1MDTPRVLLSAVFLISFLWDLPGFQQASISSSSSSAELGSTKGMRSRKEGKMQRAPRDSDAGREGQEPQPRPQDEPRAQQPRAQEPPGRGPRVVPHEYMLSIYRTYSIAEKLGINASFFQSSKSANTITSFVDRGLDDLSHTPLRRQKYLFDVSMLSDKEELVGAELRLFRQAPSAPWGPPAGPLHVQLFPCLSPLLLDARTLDPQGAPPAGWEVFDVWQGLRHQPWKQLCLELRAAWGELDAGEAEARARGPQQPPPPDLRSLGFGRRVRPPQERALLVVFTRSQRKNLFAEMREQLGSAEAAGPGAGAEGSWPPPSGAPDARPWLPSPGRRRRRTAFASRHGKRHGKKSRLRCSKKPLHVNFKELGWDDWIIAPLEYEAYHCEGVCDFPLRSHLEPTNHAIIQTLMNSMDPGSTPPSCCVPTKLTPISILYIDAGNNVVYKQYEDMVVESCGCR>sp|P62879|GBB2_HUMAN Guanine nucleotide-binding protein G(I)/G(S)/G(T)subunit beta-2 OS=Homo sapiens OX=9606 GN=GNB2 PE=1 SV=3MSELEQLRQEAEQLRNQIRDARKACGDSTLTQITAGLDPVGRIQMRTRRTLRGHLAKIYAMHWGTDSRLLVSASQDGKLIIWDSYTTNKVHAIPLRSSWVMTCAYAPSGNFVACGGLDNICSIYSLKTREGNVRVSRELPGHTGYLSCCRFLDDNQIITSSGDTTCALWDIETGQQTVGFAGHSGDVMSLSLAPDGRTFVSGACDASIKLWDVRDSMCRQTFIGHESDINAVAFFPNGYAFTTGSDDATCRLFDLRADQELLMYSHDNIICGITSVAFSRSGRLLLAGYDDFNCNIWDAMKGDRAGVLAGHDNRVSCLGVTDDGMAVATGSWDSFLKIWN>sp|P62879-2|GBB2_HUMAN Isoform 2 of Guanine nucleotide-binding proteinG(I)/G(S)/G(T) subunit beta-2 OS=Homo sapiens OX=9606 GN=GNB2MTCAYAPSGNFVACGGLDNICSIYSLKTREGNVRVSRELPGHTGYLSCCRFLDDNQIITSSGDTTCALWDIETGQQTVGFAGHSGDVMSLSLAPDGRTFVSGACDASIKLWDVRDSMCRQTFIGHESDINAVAFFPNGYAFTTGSDDATCRLFDLRADQELLMYSHDNIICGITSVAFSRSGRLLLAGYDDFNCNIWDAMKGDRAGVLAGHDNRVSCLGVTDDGMAVATGSWDSFLKIWN>sp|Q9UK05|GDF2_HUMAN Growth/differentiation factor 2 OS=Homo sapiensOX=9606 GN=GDF2 PE=1 SV=1MCPGALWVALPLLSLLAGSLQGKPLQSWGRGSAGGNAHSPLGVPGGGLPEHTFNLKMFLENVKVDFLRSLNLSGVPSQDKTRVEPPQYMIDLYNRYTSDKSTTPASNIVRSFSMEDAISITATEDFPFQKHILLFNISIPRHEQITRAELRLYVSCQNHVDPSHDLKGSVVIYDVLDGTDAWDSATETKTFLVSQDIQDEGWETLEVSSAVKRWVRSDSTKSKNKLEVTVESHRKGCDTLDISVPPGSRNLPFFVVFSNDHSSGTKETRLELREMISHEQESVLKKLSKDGSTEAGESSHEEDTDGHVAAGSTLARRKRSAGAGSHCQKTSLRVNFEDIGWDSWIIAPKEYEAYECKGGCFFPLADDVTPTKHAIVQTLVHLKFPTKVGKACCVPTKLSPISVLYKDDMGVPTLKYHYEGMSVAECGCR>sp|Q14397|GCKR_HUMAN Glucokinase regulatory protein OS=Homo sapiensOX=9606 GN=GCKR PE=1 SV=6MPGTKRFQHVIETPEPGKWELSGYEAAVPITEKSNPLTQDLDKADAENIVRLLGQCDAEIFQEEGQALSTYQRLYSESILTTMVQVAGKVQEVLKEPDGGLVVLSGGGTSGRMAFLMSVSFNQLMKGLGQKPLYTYLIAGGDRSVVASREGTEDSALHGIEELKKVAAGKKRVIVIGISVGLSAPFVAGQMDCCMNNTAVFLPVLVGFNPVSMARNDPIEDWSSTFRQVAERMQKMQEKQKAFVLNPAIGPEGLSGSSRMKGGSATKILLETLLLAAHKTVDQGIAASQRCLLEILRTFERAHQVTYSQSPKIATLMKSVSTSLEKKGHVYLVGWQTLGIIAIMDGVECIHTFGADFRDVRGFLIGDHSDMFNQKAELTNQGPQFTFSQEDFLTSILPSLTEIDTVVFIFTLDDNLTEVQTIVEQVKEKTNHIQALAHSTVGQTLPIPLKKLFPSIISITWPLLFFEYEGNFIQKFQRELSTKWVLNTVSTGAHVLLGKILQNHMLDLRISNSKLFWRALAMLQRFSGQSKARCIESLLRAIHFPQPLSDDIRAAPISCHVQVAHEKEQVIPIALLSLLFRCSITEAQAHLAAAPSVCEAVRSALAGPGQKRTADPLEILEPDVQ>sp|Q14397-2|GCKR_HUMAN Isoform 2 of Glucokinase regulatory proteinOS=Homo sapiens OX=9606 GN=GCKRMPGTKRFQHVIETPEPGKWELSGYEAAVPITEKSNPLTQDLDKADAENIVRLLGQCDAEIFQEEGQALSTYQRLYSESILTTMVQVAGKVQEVLKEPDGGLVVLSGGGTSGRMAFLMSVSFNQLMKGLGQKPLYTYLIAGGDRWLPGRRE>sp|Q7Z4P5|GDF7_HUMAN Growth/differentiation factor 7 OS=Homo sapiensOX=9606 GN=GDF7 PE=2 SV=2MDLSAAAALCLWLLSACRPRDGLEAAAVLRAAGAGPVRSPGGGGGGGGGGRTLAQAAGAAAVPAAAVPRARAARRAAGSGFRNGSVVPHHFMMSLYRSLAGRAPAGAAAVSASGHGRADTITGFTDQATQDESAAETGQSFLFDVSSLNDADEVVGAELRVLRRGSPESGPGSWTSPPLLLLSTCPGAARAPRLLYSRAAEPLVGQRWEAFDVADAMRRHRREPRPPRAFCLLLRAVAGPVPSPLALRRLGFGWPGGGGSAAEERAVLVVSSRTQRKESLFREIRAQARALGAALASEPLPDPGTGTASPRAVIGGRRRRRTALAGTRTAQGSGGGAGRGHGRRGRSRCSRKPLHVDFKELGWDDWIIAPLDYEAYHCEGLCDFPLRSHLEPTNHAIIQTLLNSMAPDAAPASCCVPARLSPISILYIDAANNVVYKQYEDMVVEACGCR>sp|Q9NXP7|GIN1_HUMAN Gypsy retrotransposon integrase-like protein 1OS=Homo sapiens OX=9606 GN=GIN1 PE=1 SV=3MVRSGKNGDLHLKQIAYYKRTGEYHSTTLPSERSGIRRAAKKFVFKEKKLFYVGKDRKQNRLVIVSEEEKKKVLRECHENDSGAHHGISRTLTLVESNYYWTSVTNDVKQWVYACQHCQVAKNTVIVAPKQHLLKVENPWSLVTVDLMGPFHTSNRSHVYAIIMTDLFTKWIVILPLCDVSASEVSKAIINIFFLYGPPQKIIMDQRDEFIQQINIELYRLFGIKQIVISHTSGTVNPTESTPNTIKAFLSKHCADHPNNWDDHLSAVSFAFNVTHLEPTKNTPYFQMFSRNPYMPETSDSLHEVDGDNTSMFAKILDAIKEADKIMENKTTSLGQMENNNLDELNKSKIIVKKKPKQLNPFHLKVGHEVLRQRKNWWKDGRFQSEWVGPCVIDYITESGCAVLRDNTGVRLKRPIKMSHLKPYIRESSEQESLYLLQGSVVADHDYIGLPEIPIGAYQANILVEDATIGIVDNELLTSSKDRELLEYRNTKISPLIDDHSSLEKQTFSLLDSSNQVLEYLS>sp|Q9NXP7-2|GIN1_HUMAN Isoform 2 of Gypsy retrotransposon integrase-likeprotein 1 OS=Homo sapiens OX=9606 GN=GIN1MVRSGKNGDLHLKQIAYYKRTGEYHSTTLPSERSGIRRAAKKFVFKGICLSALPSGKKYSYCSTETAPSQGGKSMEFSYC>sp|Q9NXP7-3|GIN1_HUMAN Isoform 3 of Gypsy retrotransposon integrase-likeprotein 1 OS=Homo sapiens OX=9606 GN=GIN1MVRSGKNGDLHLKQIAYYKRTGEYHSTTLPSERSGIRRAAKKFVFKEKKLFYVGKDRKQNRLVIVSEEEKKKVLRECHENDSGAHHGISRTLTLVESNYYWTSVTNDVKQWVYACQHCQVAKNTVIVAPKQHLLKVENPWSLVTVDLMGPFHTSNRSHVYAIIMTDLFTKWIVILPLCDVSASEVSKAIINIFFLYGPPQKIIMDQRDEFIQQKVFISCKVQ>sp|Q8WWP7|GIMA1_HUMAN GTPase IMAP family member 1 OS=Homo sapiensOX=9606 GN=GIMAP1 PE=1 SV=1MGGRKMATDEENVYGLEENAQSRQESTRRLILVGRTGAGKSATGNSILGQRRFFSRLGATSVTRACTTGSRRWDKCHVEVVDTPDIFSSQVSKTDPGCEERGHCYLLSAPGPHALLLVTQLGRFTAQDQQAVRQVRDMFGEDVLKWMVIVFTRKEDLAGGSLHDYVSNTENRALRELVAECGGRVCAFDNRATGREQEAQVEQLLGMVEGLVLEHKGAHYSNEVYELAQVLRWAGPEERLRRVAERVAARVQRRPWGAWLSARLWKWLKSPRSWRLGLALLLGGALLFWVLLHRRWSEAVAEVGPD>sp|P0DJR0|GIMD1_HUMAN GTPase IMAP family member GIMD1 OS=Homo sapiensOX=9606 GN=GIMD1 PE=2 SV=1MTDPNKMIINLALFGMTQSGKSSAGNILLGSTDFHSSFAPCSVTTCCSLGRSCHLHSFMRRGGLEVALQVQVLDTPGYPHSRLSKKYVKQEVKEALAHHFGQGGLHLALLVQRADVPFCGQEVTDPVQMIQELLGHAWMNYTAILFTHAEKIEEAGLTEDKYLHEASDTLKTLLNSIQHKYVFQYKKGKSLNEQRMKILERIMEFIKENCYQVLTFK>sp|Q92616|GCN1_HUMAN eIF-2-alpha kinase activator GCN1 OS=Homo sapiensOX=9606 GN=GCN1 PE=1 SV=6MAADTQVSETLKRFAGKVTTASVKERREILSELGKCVAGKDLPEGAVKGLCKLFCLTLHRYRDAASRRALQAAIQQLAEAQPEATAKNLLHSLQSSGIGSKAGVPSKSSGSAALLALTWTCLLVRIVFPSRAKRQGDIWNKLVEVQCLLLLEVLGGSHKHAVDGAVKKLTKLWKENPGLVEQYLSAILSLEPNQNYAGMLGLLVQFCTSHKEMDVVSQHKSALLDFYMKNILMSKVKPPKYLLDSCAPLLRYLSHSEFKDLILPTIQKSLLRSPENVIETISSLLASVTLDLSQYAMDIVKGLAGHLKSNSPRLMDEAVLALRNLARQCSDSSAMESLTKHLFAILGGSEGKLTVVAQKMSVLSGIGSVSHHVVSGPSSQVLNGIVAELFIPFLQQEVHEGTLVHAVSVLALWCNRFTMEVPKKLTEWFKKAFSLKTSTSAVRHAYLQCMLASYRGDTLLQALDLLPLLIQTVEKAASQSTQVPTITEGVAAALLLLKLSVADSQAEAKLSSFWQLIVDEKKQVFTSEKFLVMASEDALCTVLHLTERLFLDHPHRLTGNKVQQYHRALVAVLLSRTWHVRRQAQQTVRKLLSSLGGFKLAHGLLEELKTVLSSHKVLPLEALVTDAGEVTEAGKAYVPPRVLQEALCVISGVPGLKGDVTDTEQLAQEMLIISHHPSLVAVQSGLWPALLARMKIDPEAFITRHLDQIIPRMTTQSPLNQSSMNAMGSLSVLSPDRVLPQLISTITASVQNPALRLVTREEFAIMQTPAGELYDKSIIQSAQQDSIKKANMKRENKAYSFKEQIIELELKEEIKKKKGIKEEVQLTSKQKEMLQAQLDREAQVRRRLQELDGELEAALGLLDIILAKNPSGLTQYIPVLVDSFLPLLKSPLAAPRIKNPFLSLAACVMPSRLKALGTLVSHVTLRLLKPECVLDKSWCQEELSVAVKRAVMLLHTHTITSRVGKGEPGAAPLSAPAFSLVFPFLKMVLTEMPHHSEEEEEWMAQILQILTVQAQLRASPNTPPGRVDENGPELLPRVAMLRLLTWVIGTGSPRLQVLASDTLTTLCASSSGDDGCAFAEQEEVDVLLCALQSPCASVRETVLRGLMELHMVLPAPDTDEKNGLNLLRRLWVVKFDKEEEIRKLAERLWSMMGLDLQPDLCSLLIDDVIYHEAAVRQAGAEALSQAVARYQRQAAEVMGRLMEIYQEKLYRPPPVLDALGRVISESPPDQWEARCGLALALNKLSQYLDSSQVKPLFQFFVPDALNDRHPDVRKCMLDAALATLNTHGKENVNSLLPVFEEFLKNAPNDASYDAVRQSVVVLMGSLAKHLDKSDPKVKPIVAKLIAALSTPSQQVQESVASCLPPLVPAIKEDAGGMIQRLMQQLLESDKYAERKGAAYGLAGLVKGLGILSLKQQEMMAALTDAIQDKKNFRRREGALFAFEMLCTMLGKLFEPYVVHVLPHLLLCFGDGNQYVREAADDCAKAVMSNLSAHGVKLVLPSLLAALEEESWRTKAGSVELLGAMAYCAPKQLSSCLPNIVPKLTEVLTDSHVKVQKAGQQALRQIGSVIRNPEILAIAPVLLDALTDPSRKTQKCLQTLLDTKFVHFIDAPSLALIMPIVQRAFQDRSTDTRKMAAQIIGNMYSLTDQKDLAPYLPSVTPGLKASLLDPVPEVRTVSAKALGAMVKGMGESCFEDLLPWLMETLTYEQSSVDRSGAAQGLAEVMAGLGVEKLEKLMPEIVATASKVDIAPHVRDGYIMMFNYLPITFGDKFTPYVGPIIPCILKALADENEFVRDTALRAGQRVISMYAETAIALLLPQLEQGLFDDLWRIRFSSVQLLGDLLFHISGVTGKMTTETASEDDNFGTAQSNKAIITALGVERRNRVLAGLYMGRSDTQLVVRQASLHVWKIVVSNTPRTLREILPTLFGLLLGFLASTCADKRTIAARTLGDLVRKLGEKILPEIIPILEEGLRSQKSDERQGVCIGLSEIMKSTSRDAVLYFSESLVPTARKALCDPLEEVREAAAKTFEQLHSTIGHQALEDILPFLLKQLDDEEVSEFALDGLKQVMAIKSRVVLPYLVPKLTTPPVNTRVLAFLSSVAGDALTRHLGVILPAVMLALKEKLGTPDEQLEMANCQAVILSVEDDTGHRIIIEYLLEATRSPEVGMRQAAAIILNIYCSRSKADYTSHLRSLVSGLIRLFNDSSPVVLEESWDALNAITKKLDAGNQLALIEELHKEIRLIGNESKGEHVPGFCLPKKGVTSILPVLREGVLTGSPEQKEEAAKALGLVIRLTSADALRPSVVSITGPLIRILGDRFSWNVKAALLETLSLLLAKVGIALKPFLPQLQTTFTKALQDSNRGVRLKAADALGKLISIHIKVDPLFTELLNGIRAMEDPGVRDTMLQALRFVIQGAGAKVDAVIRKNIVSLLLSMLGHDEDNTRISSAGCLGELCAFLTEEELSAVLQQCLLADVSGIDWMVRHGRSLALSVAVNVAPGRLCAGRYSSDVQEMILSSATADRIPIAVSGVRGMGFLMRHHIETGGGQLPAKLSSLFVKCLQNPSSDIRLVAEKMIWWANKDPLPPLDPQAIKPILKALLDNTKDKNTVVRAYSDQAIVNLLKMRQGEEVFQSLSKILDVASLEVLNEVNRRSLKKLASQADSTEQVDDTILT>sp|Q15056|IF4H_HUMAN Eukaryotic translation initiation factor 4H OS=Homosapiens OX=9606 GN=EIF4H PE=1 SV=5MADFDTYDDRAYSSFGGGRGSRGSAGGHGSRSQKELPTEPPYTAYVGNLPFNTVQGDIDAIFKDLSIRSVRLVRDKDTDKFKGFCYVEFDEVDSLKEALTYDGALLGDRSLRVDIAEGRKQDKGGFGFRKGGPDDRGMGSSRESRGGWDSRDDFNSGFRDDFLGGRGGSRPGDRRTGPPMGSRFRDGPPLRGSNMDFREPTEEERAQRPRLQLKPRTVATPLNQVANPNSAIFGGARPREEVVQKEQE>sp|Q15056-2|IF4H_HUMAN Isoform Short of Eukaryotic translationinitiation factor 4H OS=Homo sapiens OX=9606 GN=EIF4HMADFDTYDDRAYSSFGGGRGSRGSAGGHGSRSQKELPTEPPYTAYVGNLPFNTVQGDIDAIFKDLSIRSVRLVRDKDTDKFKGFCYVEFDEVDSLKEALTYDGALLGDRSLRVDIAEGRKQDKGGFGFRKGGPDDRGFRDDFLGGRGGSRPGDRRTGPPMGSRFRDGPPLRGSNMDFREPTEEERAQRPRLQLKPRTVATPLNQVANPNSAIFGGARPREEVVQKEQE>sp|Q9BTL4|IER2_HUMAN Immediate early response gene 2 protein OS=Homosapiens OX=9606 GN=IER2 PE=1 SV=1MEVQKEAQRIMTLSVWKMYHSRMQRGGLRLHRSLQLSLVMRSARELYLSAKVEALEPEVSLPAALPSDPRLHPPREAESTAETATPDGEHPFPEPMDTQEAPTAEETSACCAPRPAKVSRKRRSSSLSDGGDAGLVPSKKARLEEKEEEEGASSEVADRLQPPPAQAEGAFPNLARVLQRRFSGLLNCSPAAPPTAPPACEAKPACRPADSMLNVLVRAVVAF>sp|Q8TDY8|IGDC4_HUMAN Immunoglobulin superfamily DCC subclass member 4OS=Homo sapiens OX=9606 GN=IGDCC4 PE=1 SV=1MARGDAGRGRGLLALTFCLLAARGELLLPQETTVELSCGVGPLQVILGPEQAAVLNCSLGAAAAGPPTRVTWSKDGDTLLEHDHLHLLPNGSLWLSQPLAPNGSDESVPEAVGVIEGNYSCLAHGPLGVLASQTAVVKLATLADFSLHPESQTVEENGTARFECHIEGLPAPIITWEKDQVTLPEEPRLIVLPNGVLQILDVQESDAGPYRCVATNSARQHFSQEALLSVAHRGSLASTRGQDVVIVAAPENTTVVSGQSVVMECVASADPTPFVSWVRQDGKPISTDVIVLGRTNLLIANAQPWHSGVYVCRANKPRTRDFATAAAELRVLAAPAITQAPEALSRTRASTARFVCRASGEPRPALRWLHNGAPLRPNGRVKVQGGGGSLVITQIGLQDAGYYQCVAENSAGMACAAASLAVVVREGLPSAPTRVTATPLSSSAVLVAWERPEMHSEQIIGFSLHYQKARGMDNVEYQFAVNNDTTELQVRDLEPNTDYEFYVVAYSQLGASRTSTPALVHTLDDVPSAAPQLSLSSPNPSDIRVAWLPLPPSLSNGQVVKYKIEYGLGKEDQIFSTEVRGNETQLMLNSLQPNKVYRVRISAGTAAGFGAPSQWMHHRTPSMHNQSHVPFAPAELKVQAKMESLVVSWQPPPHPTQISGYKLYWREVGAEEEANGDRLPGGRGDQAWDVGPVRLKKKVKQYELTQLVPGRLYEVKLVAFNKHEDGYAAVWKGKTEKAPAPDMPIQRGPPLPPAHVHAESNSSTSIWLRWKKPDFTTVKIVNYTVRFSPWGLRNASLVTYYTSSGEDILIGGLKPFTKYEFAVQSHGVDMDGPFGSVVERSTLPDRPSTPPSDLRLSPLTPSTVRLHWCPPTEPNGEIVEYLILYSSNHTQPEHQWTLLTTQGNIFSAEVHGLESDTRYFFKMGARTEVGPGPFSRLQDVITLQEKLSDSLDMHSVTGIIVGVCLGLLCLLACMCAGLRRSPHRESLPGLSSTATPGNPALYSRARLGPPSPPAAHELESLVHPHPQDWSPPPSDVEDRAEVHSLMGGGVSEGRSHSKRKISWAQPSGLSWAGSWAGCELPQAGPRPALTRALLPPAGTGQTLLLQALVYDAIKGNGRKKSPPACRNQVEAEVIVHSDFSASNGNPDLHLQDLEPEDPLPPEAPDLISGVGDPGQGAAWLDRELGGCELAAPGPDRLTCLPEAASASCSYPDLQPGEVLEETPGDSCQLKSPCPLGASPGLPRSPVSSSA>sp|Q8TDY8-2|IGDC4_HUMAN Isoform 2 of Immunoglobulin superfamily DCCsubclass member 4 OS=Homo sapiens OX=9606 GN=IGDCC4MGRRKGRSALSRSSLERVNQGEVKVIGRGAREGGGGQAWGTGGGGRDLSCGIPRSASPLAPLAAPAITQAPEALSRTRASTARFVCRASGEPRPALRWLHNGAPLRPNGRVKVQGGGGSLVITQIGLQDAGYYQCVAENSAGMACAAASLAVVVREGLPSAPTRVTATPLSSSAVLVAWERPEMHSEQIIGFSLHYQKARGMDNVEYQFAVNNDTTELQVRDLEPNTDYEFYVVAYSQLGASRTSTPALVHTLDDVPSAAPQLSLSSPNPSDIRVAWLPLPPSLSNGQVVKYKIEYGLGKEDQIFSTEVRGNETQLMLNSLQPNKVYRVRISAGTAAGFGAPSQWMHHRTPSMHNQSHVPFAPAELKVQAKMESLVVSWQPPPHPTQISGYKLYWREVGAEEEANGDRLPGGRGDQAWDVGPVRLKKKVKQYELTQLVPGRLYEVKLVAFNKHEDGYAAVWKGKTEKAPAPDMPIQRGPPLPPAHVHAESNSSTSIWLRWKKPDFTTVKIVNYTVRFSPWGLRNASLVTYYTSSGEDILIGGLKPFTKYEFAVQSHGVDMDGPFGSVVERSTLPDRPSTPPSDLRLSPLTPSTVRLHWCPPTEPNGEIVEYLILYSSNHTQPEHQWTLLTTQGNIFSAEVHGLESDTRYFFKMGARTEVGPGPFSRLQDVITLQEKLSDSLDMHSVTGIIVGVCLGLLCLLACMCAGLRRSPHRESLPGLSSTATPGNPALYSRARLGPPSPPAAHELESLVHPHPQDWSPPPSDVEDRAEVHSLMGGGVSEGRSHSKRKISWAQPSGLSWAGSWAGCELPQAGPRPALTRALLPPAGTGQTLLLQALVYDAIKGNGRKKSPPACRNQVEAEVIVHSDFSASNGNPDLHLQDLEPEDPLPPEAPDLISGVGDPGQGAAWLDRELGGCELAAPGPDRLTCLPEAASASCSYPDLQPGEVLEETPGDSCQLKSPCPLGASPGLPRSPVSSSA>sp|P08069|IGF1R_HUMAN Insulin-like growth factor 1 receptor OS=Homosapiens OX=9606 GN=IGF1R PE=1 SV=1MKSGSGGGSPTSLWGLLFLSAALSLWPTSGEICGPGIDIRNDYQQLKRLENCTVIEGYLHILLISKAEDYRSYRFPKLTVITEYLLLFRVAGLESLGDLFPNLTVIRGWKLFYNYALVIFEMTNLKDIGLYNLRNITRGAIRIEKNADLCYLSTVDWSLILDAVSNNYIVGNKPPKECGDLCPGTMEEKPMCEKTTINNEYNYRCWTTNRCQKMCPSTCGKRACTENNECCHPECLGSCSAPDNDTACVACRHYYYAGVCVPACPPNTYRFEGWRCVDRDFCANILSAESSDSEGFVIHDGECMQECPSGFIRNGSQSMYCIPCEGPCPKVCEEEKKTKTIDSVTSAQMLQGCTIFKGNLLINIRRGNNIASELENFMGLIEVVTGYVKIRHSHALVSLSFLKNLRLILGEEQLEGNYSFYVLDNQNLQQLWDWDHRNLTIKAGKMYFAFNPKLCVSEIYRMEEVTGTKGRQSKGDINTRNNGERASCESDVLHFTSTTTSKNRIIITWHRYRPPDYRDLISFTVYYKEAPFKNVTEYDGQDACGSNSWNMVDVDLPPNKDVEPGILLHGLKPWTQYAVYVKAVTLTMVENDHIRGAKSEILYIRTNASVPSIPLDVLSASNSSSQLIVKWNPPSLPNGNLSYYIVRWQRQPQDGYLYRHNYCSKDKIPIRKYADGTIDIEEVTENPKTEVCGGEKGPCCACPKTEAEKQAEKEEAEYRKVFENFLHNSIFVPRPERKRRDVMQVANTTMSSRSRNTTAADTYNITDPEELETEYPFFESRVDNKERTVISNLRPFTLYRIDIHSCNHEAEKLGCSASNFVFARTMPAEGADDIPGPVTWEPRPENSIFLKWPEPENPNGLILMYEIKYGSQVEDQRECVSRQEYRKYGGAKLNRLNPGNYTARIQATSLSGNGSWTDPVFFYVQAKTGYENFIHLIIALPVAVLLIVGGLVIMLYVFHRKRNNSRLGNGVLYASVNPEYFSAADVYVPDEWEVAREKITMSRELGQGSFGMVYEGVAKGVVKDEPETRVAIKTVNEAASMRERIEFLNEASVMKEFNCHHVVRLLGVVSQGQPTLVIMELMTRGDLKSYLRSLRPEMENNPVLAPPSLSKMIQMAGEIADGMAYLNANKFVHRDLAARNCMVAEDFTVKIGDFGMTRDIYETDYYRKGGKGLLPVRWMSPESLKDGVFTTYSDVWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEIISSIKEEMEPGFREVSFYYSEENKLPEPEELDLEPENMESVPLDPSASSSSLPLPDRHSGHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALPLPQSSTC>sp|P01817|HV205_HUMAN Immunoglobulin heavy variable 2-5 OS=Homo sapiensOX=9606 GN=IGHV2-5 PE=1 SV=2MDTLCSTLLLLTIPSWVLSQITLKESGPTLVKPTQTLTLTCTFSGFSLSTSGVGVGWIRQPPGKALEWLALIYWDDDKRYSPSLKSRLTITKDTSKNQVVLTMTNMDPVDTATYYCAHR>sp|A0A0B4J1V2|HV226_HUMAN Immunoglobulin heavy variable 2-26 OS=Homosapiens OX=9606 GN=IGHV2-26 PE=3 SV=1MDTLCYTLLLLTTPSWVLSQVTLKESGPVLVKPTETLTLTCTVSGFSLSNARMGVSWIRQPPGKALEWLAHIFSNDEKSYSTSLKSRLTISKDTSKSQVVLTMTNMDPVDTATYYCARI>sp|Q5VVH5|IKBP1_HUMAN Interleukin-1 receptor-associated kinase 1-bindingprotein 1 OS=Homo sapiens OX=9606 GN=IRAK1BP1 PE=1 SV=1MSLQKTPPTRVFVELVPWADRSRENNLASGRETLPGLRHPLSSTQAQTATREVQVSGTSEVSAGPDRAQVVVRVSSTKEAAAEAKKSVCRRLDYITQSLQQQGVQAENITVTKDFRRVENAYHMEAEVCITFTEFGKMQNICNFLVEKLDSSVVISPPQFYHTPGSVENLRRQACLVAVENAWRKAQEVCNLVGQTLGKPLLIKEEETKEWEGQIDDHQSSRLSSSLTVQQKIKSATIHAASKVFITFEVKGKEKRKKHL>sp|Q9HBG6|IF122_HUMAN Intraflagellar transport protein 122 homologOS=Homo sapiens OX=9606 GN=IFT122 PE=1 SV=2MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDGKRFASGSADKSVIIWTSKLEGILKYTHNDAIQCVSYNPITHQLASCSSSDFGLWSPEQKSVSKHKSSSKIICCSWTNDGQYLALGMFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSSRWESFWMNRENEDAEDVIVNRYIQEIPSTLKSAVYSSQGSEAEEEEPEEEDDSPRDDNLEERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQDPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-3|IF122_HUMAN Isoform 3 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDGKRFASGSADKSVIIWTSKLEGILKYTHNDAIQCVSYNPITHQLASCSSSDFGLWSPEQKSVSKHKSSSKIICCSWTNDGQYLALGMFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSREERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQDPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-4|IF122_HUMAN Isoform 4 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDGLWSPEQKSVSKHKSSSKIICCSWTNDGQYLALGMFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSREERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQADPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-5|IF122_HUMAN Isoform 5 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDGKRFASGSADKSVIIWTSKLEGILKYTSWSVMSSLHLHLPFLGLHKTVRVTATDKAPKGQGGRIDCLRPSVQNQPGQKHNDAIQCVSYNPITHQLASCSSSDFGLWSPEQKSVSKHKSSSKIICCSWTNDGQYLALGMFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSSRWESFWMNRENEDAEDVIVNRYIQEIPSTLKSAVYSSQGSEAEEEEPEEEDDSPRDDNLEERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQDPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-6|IF122_HUMAN Isoform 6 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDGKRFASGSADKSVIIWTSKLEGILKYTSWSVMSSLHLHLPFLGLHKTVRVTATDKAPKGQGGRIDCLRPSVQNQPGQKHNDAIQCVSYNPITHQLASCSSSDFGLWSPEQKSVSKHKSSSKIICCSWTNDGQYLALGMFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSREERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQADPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-7|IF122_HUMAN Isoform 7 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSREERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQDPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-8|IF122_HUMAN Isoform 8 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSSRWESFWMNRENEDAEDVIVNRYIQEIPSTLKSAVYSSQGSEAEEEEPEEEDDSPRDDNLEERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQDPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-9|IF122_HUMAN Isoform 9 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDVLCIEGLWSPEQKSVSKHKSSSKIICCSWTNDGQYLALGMFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSREERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQADPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-10|IF122_HUMAN Isoform 10 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDGLWSPEQKSVSKHKSSSKIICCREERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQADPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEELVPLCYRCSTNNPLLNNLGNVCINCRQPFIFSASSYDVLHLVEFYLEEGITDEEAISLIDLEVLRPKRDDRQLEIANNSSQILRLVETKDSIGDEDPFTAKLSFEQGGSEFVPVVVSRLVLRSMSRRDVLIKRWPPPLRWQYFRSLLPDASITMCPSCFQMFHSEDYELLVLQHGCCPYCRRCKDDPGP>sp|Q9HBG6-11|IF122_HUMAN Isoform 11 of Intraflagellar transport protein122 homolog OS=Homo sapiens OX=9606 GN=IFT122MRAVLTWRDKAEHCINDIAFKPDGTQLILAAGSRLLVYDTSDGTLLQPLKGHKDTVYCVAYAKDGKRFASGSADKSVIIWTSKLEGILKYTHNDAIQCVSYNPITHQLASCSSSDFGLWSPEQKSVSKHKSSSKIICCSWTNDGQYLALGMFNGIISIRNKNGEEKVKIERPGGSLSPIWSICWNPSREERNDILAVADWGQKVSFYQLSGKQIGKDRALNFDPCCISYFTKGEYILLGGSDKQVSLFTKDGVRLGTVGEQNSWVWTCQAKPDSNYVVVGCQDGTISFYQLIFSTVHGLYKDRYAYRDSMTDVIVQHLITEQKVRIKCKELVKKIAIYRNRLAIQLPEKILIYELYSEDLSDMHYRVKEKIIKKFECNLLVVCANHIILCQEKRLQCLSFSGVKEREWQMESLIRYIKVIGGPPGREGLLVGLKNGQILKIFVDNLFAIVLLKQATAVRCLDMSASRKKLAVVDENDTCLVYDIDTKELLFQEPNANSVAWNTQCEDMLCFSGGGYLNIKASTFPVHRQKLQGFVVGYNGSKIFCLHVFSISAVEVPQSAPMYQYLDRKLFKEAYQIACLGVTDTDWRELAMEALEGLDFETAKKAFIRVQDLRYLELISSIEERKKRGETNNDLFLADVFSYQGKFHEAAKLYKRSGHENLALEMYTDLCMFEYAKDFLGSGDPKETKMLITKQADWARNIKEPKAAVEMYISAGEHVKAIEICGDHGWVDMLIDIARKLDKAEREPLLLCATYLKKLDSPGYAAETYLKMGDLKSLVQLHVETQRWDEAFALGEKHPEFKDDIYMPYAQWLAENDRFEEAQKAFHKAGRQREAVQVLEQLTNNAVAESRFNDAAYYYWMLSMQCLDIAQDPAQKDTMLGKFYHFQRLAELYHGYHAIHRHTEDPFSVHRPETLFNISRFLLHSLPKDTPSGISKVKILFTLAKQSKALGAYRLARHAYDKLRGLYIPARFQKSIELGTLTIRAKPFHDSEE>sp|P01814|HV270_HUMAN Immunoglobulin heavy variable 2-70 OS=Homo sapiensOX=9606 GN=IGHV2-70 PE=1 SV=2MDILCSTLLLLTVPSWVLSQVTLRESGPALVKPTQTLTLTCTFSGFSLSTSGMCVSWIRQPPGKALEWLALIDWDDDKYYSTSLKTRLTISKDTSKNQVVLTMTNMDPVDTATYYCARI>sp|P01780|HV307_HUMAN Immunoglobulin heavy variable 3-7 OS=Homo sapiensOX=9606 GN=IGHV3-7 PE=1 SV=2MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSSYWMSWVRQAPGKGLEWVANIKQDGSEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR>sp|P01782|HV309_HUMAN Immunoglobulin heavy variable 3-9 OS=Homo sapiensOX=9606 GN=IGHV3-9 PE=1 SV=2MELGLSWIFLLAILKGVQCEVQLVESGGGLVQPGRSLRLSCAASGFTFDDYAMHWVRQAPGKGLEWVSGISWNSGSIGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTALYYCAKD>sp|Q9BYH8|IKBZ_HUMAN NF-kappa-B inhibitor zeta OS=Homo sapiens OX=9606GN=NFKBIZ PE=1 SV=1MIVDKLLDDSRGGEGLRDAAGGCGLMTSPLNLSYFYGASPPAAAPGACDASCSVLGPSAPGSPGSDSSDFSSASSVSSCGAVESRSRGGARAERQPVEPHMGVGRQQRGPFQGVRVKNSVKELLLHIRSHKQKASGQAVDDFKTQGVNIEQFRELKNTVSYSGKRKGPDSLSDGPACKRPALLHSQFLTPPQTPTPGESMEDVHLNEPKQESSADLLQNIINIKNECSPVSLNTVQVSWLNPVVVPQSSPAEQCQDFHGGQVFSPPQKCQPFQVRGSQQMIDQASLYQYSPQNQHVEQQPHYTHKPTLEYSPFPIPPQSPAYEPNLFDGPESQFCPNQSLVSLLGDQRESENIANPMQTSSSVQQQNDAHLHSFSMMPSSACEAMVGHEMASDSSNTSLPFSNMGNPMNTTQLGKSLFQWQVEQEESKLANISQDQFLSKDADGDTFLHIAVAQGRRALSYVLARKMNALHMLDIKEHNGQSAFQVAVAANQHLIVQDLVNIGAQVNTTDCWGRTPLHVCAEKGHSQVLQAIQKGAVGSNQFVDLEATNYDGLTPLHCAVIAHNAVVHELQRNQQPHSPEVQELLLKNKSLVDTIKCLIQMGAAVEAKDRKSGRTALHLAAEEANLELIRLFLELPSCLSFVNAKAYNGNTALHVAASLQYRLTQLDAVRLLMRKGADPSTRNLENEQPVHLVPDGPVGEQIRRILKGKSIQQRAPPY>sp|Q9BYH8-2|IKBZ_HUMAN Isoform 2 of NF-kappa-B inhibitor zeta OS=Homosapiens OX=9606 GN=NFKBIZMGVGRQQRGPFQGVRVKNSVKELLLHIRSHKQKASGQAVDDFKTQGVNIEQFRELKNTVSYSGKRKGPDSLSDGPACKRPALLHSQFLTPPQTPTPGESMEDVHLNEPKQESSADLLQNIINIKNECSPVSLNTVQVSWLNPVVVPQSSPAEQCQDFHGGQVFSPPQKCQPFQVRGSQQMIDQASLYQYSPQNQHVEQQPHYTHKPTLEYSPFPIPPQSPAYEPNLFDGPESQFCPNQSLVSLLGDQRESENIANPMQTSSSVQQQNDAHLHSFSMMPSSACEAMVGHEMASDSSNTSLPFSNMGNPMNTTQLGKSLFQWQVEQEESKLANISQDQFLSKDADGDTFLHIAVAQGRRALSYVLARKMNALHMLDIKEHNGQSAFQVAVAANQHLIVQDLVNIGAQVNTTDCWGRTPLHVCAEKGHSQVLQAIQKGAVGSNQFVDLEATNYDGLTPLHCAVIAHNAVVHELQRNQQPHSPEVQELLLKNKSLVDTIKCLIQMGAAVEAKDRKSGRTALHLAAEEANLELIRLFLELPSCLSFVNAKAYNGNTALHVAASLQYRLTQLDAVRLLMRKGADPSTRNLENEQPVHLVPDGPVGEQIRRILKGKSIQQRAPPY>sp|Q9BYH8-3|IKBZ_HUMAN Isoform 3 of NF-kappa-B inhibitor zeta OS=Homosapiens OX=9606 GN=NFKBIZMIVDKLLDDSRGGEGLRDAAGGCGLMTSPLNLSYFYGASPPAAAPGACDASCSVLGPSAPGSPGSDSSDFSSASSVSSCGAVESRSRGGARAERQPVEPHMGVGRQQRGPFQGVRVKNSVKELLLHIRSHKQKASGQAVDDFKTQGVNIEQFRELKNTVSYSGKRKGPDSLSDGPACKRPALLHSQFLTPPQTPTPGESMEDVHLNEPKQESSADLLQNIINIKNECSPVSLNTVQTSSSVQQQNDAHLHSFSMMPSSACEAMVGHEMASDSSNTSLPFSNMGNPMNTTQLGKSLFQWQVEQEESKLANISQDQFLSKDADGDTFLHIAVAQGRRALSYVLARKMNALHMLDIKEHNGQSAFQVAVAANQHLIVQDLVNIGAQVNTTDCWGRTPLHVCAEKGHSQVLQAIQKGAVGSNQFVDLEATNYDGLTPLHCAVIAHNAVVHELQRNQQPHSPEVQELLLKNKSLVDTIKCLIQMGAAVEAKDRKSGRTALHLAAEEANLELIRLFLELPSCLSFVNAKAYNGNTALHVAASLQYRLTQLDAVRLLMRKGADPSTRNLENEQPVHLVPDGPVGEQIRRILKGKSIQQRAPPY>sp|P01762|HV311_HUMAN Immunoglobulin heavy variable 3-11 OS=Homo sapiensOX=9606 GN=IGHV3-11 PE=1 SV=2MEFGLSWVFLVAIIKGVQCQVQLVESGGGLVKPGGSLRLSCAASGFTFSDYYMSWIRQAPGKGLEWVSYISSSSSYTNYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR>sp|P01766|HV313_HUMAN Immunoglobulin heavy variable 3-13 OS=Homo sapiensOX=9606 GN=IGHV3-13 PE=1 SV=2MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMHWVRQATGKGLEWVSAIGTAGDPYYPGSVKGRFTISRENAKNSLYLQMNSLRAGDTAVYYCAR>sp|A0A0B4J1V0|HV315_HUMAN Immunoglobulin heavy variable 3-15 OS=Homosapiens OX=9606 GN=IGHV3-15 PE=3 SV=1MEFGLSWIFLAAILKGVQCEVQLVESGGGLVKPGGSLRLSCAASGFTFSNAWMSWVRQAPGKGLEWVGRIKSKTDGGTTDYAAPVKGRFTISRDDSKNTLYLQMNSLKTEDTAVYYCTT>sp|A0A0C4DH30|HV316_HUMAN Probable non-functional immunoglobulin heavyvariable 3-16 OS=Homo sapiens OX=9606 GN=IGHV3-16 PE=1 SV=1MEFGLSWVFLAGILKGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSNSDMNWARKAPGKGLEWVSGVSWNGSRTHYVDSVKRRFIISRDNSRNSLYLQKNRRRAEDMAVYYCVR>sp|Q70UQ0|IKIP_HUMAN Inhibitor of nuclear factor kappa-B kinase-interacting protein OS=Homo sapiens OX=9606 GN=IKBIP PE=1 SV=1MSEVKSRKKSGPKGAPAAEPGKRSEGGKTPVARSSGGGGWADPRTCLSLLSLGTCLGLAWFVFQQSEKFAKVENQYQLLKLETNEFQQLQSKISLISEKWQKSEAIMEQLKSFQIIAHLKRLQEEINEVKTWSNRITEKQDILNNSLTTLSQDITKVDQSTTSMAKDVGLKITSVKTDIRRISGLVTDVISLTDSVQELENKIEKVEKNTVKNIGDLLSSSIDRTATLRKTASENSQRINSVKKTLTELKSDFDKHTDRFLSLEGDRAKVLKTVTFANDLKPKVYNLKKDFSRLEPLVNDLTLRIGRLVTDLLQREKEIAFLSEKISNLTIVQAEIKDIKDEIAHISDMN>sp|Q70UQ0-2|IKIP_HUMAN Isoform 2 of Inhibitor of nuclear factor kappa-Bkinase-interacting protein OS=Homo sapiens OX=9606 GN=IKBIPMEQLKSFQIIAHLKRLQEEINEVKTWSNRITEKQDILNNSLTTLSQDITKVDQSTTSMAKDVGLKITSVKTDIRRISGLVTDVISLTDSVQELENKIEKVEKNTVKNIGDLLSSSIDRTATLRKTASENSQRINSVKKTLTELKSDFDKHTDRFLSLEGDRAKVLKTVTFANDLKPKVYNLKKDFSRLEPLVNDLTLRIGRLVTDLLQREKEIAFLSEKISNLTIVQAEIKDIKDEIAHISDMN>sp|Q70UQ0-3|IKIP_HUMAN Isoform 3 of Inhibitor of nuclear factor kappa-Bkinase-interacting protein OS=Homo sapiens OX=9606 GN=IKBIPMSEVKSRKKSGPKGAPAAEPGKRSEGGKTPVARSSGGGGWADPRTCLSLLSLGTCLGLACGRNLKLSWNN>sp|Q70UQ0-4|IKIP_HUMAN Isoform 4 of Inhibitor of nuclear factor kappa-Bkinase-interacting protein OS=Homo sapiens OX=9606 GN=IKBIPMSEVKSRKKSGPKGAPAAEPGKRSEGGKTPVARSSGGGGWADPRTCLSLLSLGTCLGLAWFVFQQSEKFAKVENQYQLLKLETNEFQQLQSKISLISEKLESTESILQEATSSMSLMTQFEQEVSNLQDIMHDIQNNEEVLTQRMQSLNEKFQNITDFWKRSLEEMNINTDIFKSEAKHIHSQVTVQINSAEQEIKLLTERLKDLEDSTLRNIRTVKRQEEEDLLRVEEQLGSDTKAIEKLEEEQHALFARDEDLTNKLSDYEPKVEECKTHLPTIESAIHSVLRVSQDLIETEKKMEDLTMQMFNMEDDMLKAVSEIMEMQKTLEGIQYDNSILKMQNELDILKEKVHDFIAYSSTGEKGTLKEYNIENKGIGGDF>sp|A0A0C4DH32|HV320_HUMAN Immunoglobulin heavy variable 3-20 OS=Homosapiens OX=9606 GN=IGHV3-20 PE=3 SV=2MEFGLSWVFLVAILKGVQCEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTALYHCAR>sp|A0A0B4J1V1|HV321_HUMAN Immunoglobulin heavy variable 3-21 OS=Homosapiens OX=9606 GN=IGHV3-21 PE=1 SV=1MELGLRWVFLVAILEGVQCEVQLVESGGGLVKPGGSLRLSCAASGFTFSSYSMNWVRQAPGKGLEWVSSISSSSSYIYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR>sp|P01764|HV323_HUMAN Immunoglobulin heavy variable 3-23 OS=Homo sapiensOX=9606 GN=IGHV3-23 PE=1 SV=2MEFGLSWLFLVAILKGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSAISGSGGSTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAK>sp|P01768|HV330_HUMAN Immunoglobulin heavy variable 3-30 OS=Homo sapiensOX=9606 GN=IGHV3-30 PE=1 SV=2MEFGLSWVFLVALLRGVQCQVQLVESGGGVVQPGRSLRLSCAASGFTFSSYGMHWVRQAPGKGLEWVAVISYDGSNKYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAK>sp|P01772|HV333_HUMAN Immunoglobulin heavy variable 3-33 OS=Homo sapiensOX=9606 GN=IGHV3-33 PE=1 SV=2MEFGLSWVFLVALLRGVQCQVQLVESGGGVVQPGRSLRLSCAASGFTFSSYGMHWVRQAPGKGLEWVAVIWYDGSNKYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAR>sp|A0A0C4DH35|HV335_HUMAN Probable non-functional immunoglobulin heavyvariable 3-35 OS=Homo sapiens OX=9606 GN=IGHV3-35 PE=1 SV=1MEFGLSWVFLAAILKGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSNSDMNWVHQAPGKGLEWVSGVSWNGSRTHYADSVKGRFIISRDNSRNTLYLQTNSLRAEDTAVYYCVR>sp|A0A0C4DH36|HV338_HUMAN Probable non-functional immunoglobulin heavyvariable 3-38 OS=Homo sapiens OX=9606 GN=IGHV3-38 PE=1 SV=1MQFVLSWVFLVGILKGVQCEVQLVESGGGLVQPRGSLRLSCAASGFTVSSNEMSWIRQAPGKGLEWVSSISGGSTYYADSRKGRFTISRDNSKNTLYLQMNNLRAEGTAVYYCARY>sp|A0A0B4J1X8|HV343_HUMAN Immunoglobulin heavy variable 3-43 OS=Homosapiens OX=9606 GN=IGHV3-43 PE=3 SV=1MEFGLSWVFLVAILKGVQCEVQLVESGGVVVQPGGSLRLSCAASGFTFDDYTMHWVRQAPGKGLEWVSLISWDGGSTYYADSVKGRFTISRDNSKNSLYLQMNSLRTEDTALYYCAKD>sp|O15111|IKKA_HUMAN Inhibitor of nuclear factor kappa-B kinase subunitalpha OS=Homo sapiens OX=9606 GN=CHUK PE=1 SV=2MERPPGLRPGAGGPWEMRERLGTGGFGNVCLYQHRELDLKIAIKSCRLELSTKNRERWCHEIQIMKKLNHANVVKACDVPEELNILIHDVPLLAMEYCSGGDLRKLLNKPENCCGLKESQILSLLSDIGSGIRYLHENKIIHRDLKPENIVLQDVGGKIIHKIIDLGYAKDVDQGSLCTSFVGTLQYLAPELFENKPYTATVDYWSFGTMVFECIAGYRPFLHHLQPFTWHEKIKKKDPKCIFACEEMSGEVRFSSHLPQPNSLCSLVVEPMENWLQLMLNWDPQQRGGPVDLTLKQPRCFVLMDHILNLKIVHILNMTSAKIISFLLPPDESLHSLQSRIERETGINTGSQELLSETGISLDPRKPASQCVLDGVRGCDSYMVYLFDKSKTVYEGPFASRSLSDCVNYIVQDSKIQLPIIQLRKVWAEAVHYVSGLKEDYSRLFQGQRAAMLSLLRYNANLTKMKNTLISASQQLKAKLEFFHKSIQLDLERYSEQMTYGISSEKMLKAWKEMEEKAIHYAEVGVIGYLEDQIMSLHAEIMELQKSPYGRRQGDLMESLEQRAIDLYKQLKHRPSDHSYSDSTEMVKIIVHTVQSQDRVLKELFGHLSKLLGCKQKIIDLLPKVEVALSNIKEADNTVMFMQGKRQKEIWHLLKIACTQSSARSLVGSSLEGAVTPQTSAWLPPTSAEHDHSLSCVVTPQDGETSAQMIEENLNCLGHLSTIIHEANEEQGNSMMNLDWSWLTE>sp|P01763|HV348_HUMAN Immunoglobulin heavy variable 3-48 OS=Homo sapiensOX=9606 GN=IGHV3-48 PE=1 SV=2MELGLCWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSSYEMNWVRQAPGKGLEWVSYISSSGSTIYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR>sp|P10997|IAPP_HUMAN Islet amyloid polypeptide OS=Homo sapiens OX=9606GN=IAPP PE=1 SV=1MGILKLQVFLIVLSVALNHLKATPIESHQVEKRKCNTATCATQRLANFLVHSSNNFGAILSSTNVGSNTYGKRNAVEVLKREPLNYLPL>sp|A0A0A0MS15|HV349_HUMAN Immunoglobulin heavy variable 3-49 OS=Homosapiens OX=9606 GN=IGHV3-49 PE=3 SV=1MEFGLSWVFLVAILKGVQCEVQLVESGGGLVQPGRSLRLSCTASGFTFGDYAMSWVRQAPGKGLEWVGFIRSKAYGGTTEYAASVKGRFTISRDDSKSIAYLQMNSLKTEDTAVYYCTR>sp|P01767|HV353_HUMAN Immunoglobulin heavy variable 3-53 OS=Homo sapiensOX=9606 GN=IGHV3-53 PE=1 SV=2MEFWLSWVFLVAISKGVQCEVQLVETGGGLIQPGGSLRLSCAASGFTVSSNYMSWVRQAPGKGLEWVSVIYSGGSTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAR>sp|Q96RY7|IF140_HUMAN Intraflagellar transport protein 140 homologOS=Homo sapiens OX=9606 GN=IFT140 PE=1 SV=1MALYYDHQIEAPDAAGSPSFISWHPVHPFLAVAYISTTSTGSVDIYLEQGECVPDTHVERPFRVASLCWHPTRLVLAVGWETGEVTVFNKQDKEQHTMPLTHTADITVLRWSPSGNCLLSGDRLGVLLLWRLDQRGRVQGTPLLKHEYGKHLTHCIFRLPPPGEDLVQLAKAAVSGDEKALDMFNWKKSSSGSLLKMGSHEGLLFFVSLMDGTVHYVDEKGKTTQVVSADSTIQMLFYMEKREALVVVTENLRLSLYTVPPEGKAEEVMKVKLSGKTGRRADIALIEGSLLVMAVGEAALRFWDIERGENYILSPDEKFGFEKGENMNCVCYCKVKGLLAAGTDRGRVAMWRKVPDFLGSPGAEGKDRWALQTPTELQGNITQIQWGSRKNLLAVNSVISVAILSERAMSSHFHQQVAAMQVSPSLLNVCFLSTGVAHSLRTDMHISGVFATKDAVAVWNGRQVAIFELSGAAIRSAGTFLCETPVLAMHEENVYTVESNRVQVRTWQGTVKQLLLFSETEGNPCFLDICGNFLVVGTDLAHFKSFDLSRREAKAHCSCRSLAELVPGVGGIASLRCSSSGSTISILPSKADNSPDSKICFYDVEMDTVTVFDFKTGQIDRRETLSFNEQETNKSHLFVDEGLKNYVPVNHFWDQSEPRLFVCEAVQETPRSQPQSANGQPQDGRAGPAADVLILSFFISEEHGFLLHESFPRPATSHSLLGMEVPYYYFTRKPEEADREDEVEPGCHHIPQMVSRRPLRDFVGLEDCDKATRDAMLHFSFFVTIGDMDEAFKSIKLIKSEAVWENMARMCVKTQRLDVAKVCLGNMGHARGARALREAEQEPELEARVAVLATQLGMLEDAEQLYRKCKRHDLLNKFYQAAGRWQEALQVAEHHDRVHLRSTYHRYAGHLEASADCSRALSYYEKSDTHRFEVPRMLSEDLPSLELYVNKMKDKTLWRWWAQYLESQGEMDAALHYYELARDHFSLVRIHCFQGNVQKAAQIANETGNLAASYHLARQYESQEEVGQAVHFYTRAQAFKNAIRLCKENGLDDQLMNLALLSSPEDMIEAARYYEEKGVQMDRAVMLYHKAGHFSKALELAFATQQFVALQLIAEDLDETSDPALLARCSDFFIEHSQYERAVELLLAARKYQEALQLCLGQNMSITEEMAEKMTVAKDSSDLPEESRRELLEQIADCCMRQGSYHLATKKYTQAGNKLKAMRALLKSGDTEKITFFASVSRQKEIYIMAANYLQSLDWRKEPEIMKNIIGFYTKGRALDLLAGFYDACAQVEIDEYQNYDKAHGALTEAYKCLAKAKAKSPLDQETRLAQLQSRMALVKRFIQARRTYTEDPKESIKQCELLLEEPDLDSTIRIGDVYGFLVEHYVRKEEYQTAYRFLEEMRRRLPLANMSYYVSPQAVDAVHRGLGLPLPRTVPEQVRHNSMEDARELDEEVVEEADDDP>sp|Q96RY7-2|IF140_HUMAN Isoform 2 of Intraflagellar transport protein140 homolog OS=Homo sapiens OX=9606 GN=IFT140MARMCVKTQRLDVAKVCLGNMGHARGARALREAEQEPELEARVAVLATQLGMLEDAEQLYRKCKRHDLLNKFYQAAGRWQEALQVAEHHDRVHLRSTYHRYAGHLEASADCSRALSYYEKSDTHRFEVPRMLSEDLPSLELYVNKMKDKTLWRWWAQYLESQGEMDAALHYYELARDHFSLVRIHCFQGNVQKAAQIANETGNLAASYHLARQYESQEEVGQAVHFYTRAQAFKNAIRLCKENGLDDQLMNLALLSSPEDMIEAARYYEEKGVQMDRAVMLYHKAGHFSKALELAFATQQFVALQLIAEDLDETSDPALLARCSDFFIEHSQYERAVELLLAARKYQEALQLCLGQNMSITEEMAEKMTVAKDSSDLPEESRRELLEQIADCCMRQGSYHLATKKYTQAGNKLKAMRALLKSGDTEKITFFASVSRQKEIYIMAANYLQSLDWRKEPEIMKNIIGFYTKGRALDLLAGFYDACAQVEIDEYQNYDKAHGALTEAYKCLAKAKAKSPLDQETRLAQLQSRMALVKRFIQARRTYTEDPKESIKQCELLLEEPDLDSTIRIGDVYGFLVEHYVRKEEYQTAYRFLEEMRRRLPLANMSYYVSPQAVDAVHRGLGLPLPRTVPEQVRHNSMEDARELDEEVVEEADDDP>sp|A0A075B6Q5|HV364_HUMAN Immunoglobulin heavy variable 3-64 OS=Homosapiens OX=9606 GN=IGHV3-64 PE=3 SV=1MMEFGLSWVFLVAIFKGVQCEVQLVESGEGLVQPGGSLRLSCAASGFTFSSYAMHWVRQAPGKGLEYVSAISSNGGSTYYADSVKGRFTISRDNSKNTLYLQMGSLRAEDMAVYYCAR>sp|A0A0C4DH42|HV366_HUMAN Immunoglobulin heavy variable 3-66 OS=Homosapiens OX=9606 GN=IGHV3-66 PE=3 SV=1MEFGLSWVFLVAILKGVQCEVQLVESGGGLIQPGGSLRLSCAASGFTVSSNYMSWVRQAPGKGLEWVSVIYSCGSTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAR>sp|A0A0B4J1Y9|HV372_HUMAN Immunoglobulin heavy variable 3-72 OS=Homosapiens OX=9606 GN=IGHV3-72 PE=3 SV=1MEFGLSWVFLVVILQGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSDHYMDWVRQAPGKGLEWVGRTRNKANSYTTEYAASVKGRFTISRDDSKNSLYLQMNSLKTEDTAVYYCAR>sp|A0A0B4J1V6|HV373_HUMAN Immunoglobulin heavy variable 3-73 OS=Homosapiens OX=9606 GN=IGHV3-73 PE=3 SV=1MEFGLSWVFLVAILKGVQCEVQLVESGGGLVQPGGSLKLSCAASGFTFSGSAMHWVRQASGKGLEWVGRIRSKANSYATAYAASVKGRFTISRDDSKNTAYLQMNSLKTEDTAVYYCTR>sp|A0A0B4J1X5|HV374_HUMAN Immunoglobulin heavy variable 3-74 OS=Homosapiens OX=9606 GN=IGHV3-74 PE=3 SV=1MEFGLSWVFLVAILKGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSSYWMHWVRQAPGKGLVWVSRINSDGSSTSYADSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCAR>sp|P0DTE1|HV383_HUMAN Probable non-functional immunoglobulin heavyvariable 3-38-3 OS=Homo sapiens OX=9606 GN=IGHV3-38-3 PE=1 SV=1MQFVLSWVFLVAILKGVQCEVQLVESRGVLVQPGGSLRLSCAASGFTVSSNEMSWVRQAPGKGLEWVSSISGGSTYYADSRKGRFTISRDNSKNTLHLQMNSLRAEDTAVYYCKK>sp|P0DTW3|HV384_HUMAN Probable non-functional immunoglobulin heavyvariable 1-38-4 OS=Homo sapiens OX=9606 GN=IGHV1-38-4 PE=1 SV=1MDWNWRILFLVVATTGAHSQVQLVQSWAEVRKSGASVKVSCSFSGFTITSYGIHWVQQSPGQGLEWMGWINPGNGSPSYAKKFQGRFTMTRDMSTTTAYTDLSSLTSEDMAVYYYAR>sp|A0A075B6R2|HV404_HUMAN Immunoglobulin heavy variable 4-4 OS=Homosapiens OX=9606 GN=IGHV4-4 PE=3 SV=2MKHLWFFLLLVAAPRWVLSQVQLQESGPGLVKPSGTLSLTCAVSGGSISSSNWWSWVRQPPGKGLEWIGEIYHSGSTNYNPSLKSRVTISVDKSKNQFSLKLSSVTAADTAVYYCAR>sp|Q16666|IF16_HUMAN Gamma-interferon-inducible protein 16 OS=Homosapiens OX=9606 GN=IFI16 PE=1 SV=3MGKKYKNIVLLKGLEVINDYHFRMVKSLLSNDLKLNLKMREEYDKIQIADLMEEKFRGDAGLGKLIKIFEDIPTLEDLAETLKKEKLKVKGPALSRKRKKEVDATSPAPSTSSTVKTEGAEATPGAQKRKKSTKEKAGPKGSKVSEEQTQPPSPAGAGMSTAMGRSPSPKTSLSAPPNSSSTENPKTVAKCQVTPRRNVLQKRPVIVKVLSTTKPFEYETPEMEKKIMFHATVATQTQFFHVKVLNTSLKEKFNGKKIIIISDYLEYDSLLEVNEESTVSEAGPNQTFEVPNKIINRAKETLKIDILHKQASGNIVYGVFMLHKKTVNQKTTIYEIQDDRGKMDVVGTGQCHNIPCEEGDKLQLFCFRLRKKNQMSKLISEMHSFIQIKKKTNPRNNDPKSMKLPQEQRQLPYPSEASTTFPESHLRTPQMPPTTPSSSFFTKKSEDTISKMNDFMRMQILKEGSHFPGPFMTSIGPAESHPHTPQMPPSTPSSSFLTTKSEDTISKMNDFMRMQILKEGSHFPGPFMTSIGPAESHPHTPQMPPSTPSSSFLTTLKPRLKTEPEEVSIEDSAQSDLKEVMVLNATESFVYEPKEQKKMFHATVATENEVFRVKVFNIDLKEKFTPKKIIAIANYVCRNGFLEVYPFTLVADVNADRNMEIPKGLIRSASVTPKINQLCSQTKGSFVNGVFEVHKKNVRGEFTYYEIQDNTGKMEVVVHGRLTTINCEEGDKLKLTCFELAPKSGNTGELRSVIHSHIKVIKTRKNKKDILNPDSSMETSPDFFF>sp|Q16666-2|IF16_HUMAN Isoform 2 of Gamma-interferon-inducible protein16 OS=Homo sapiens OX=9606 GN=IFI16MGKKYKNIVLLKGLEVINDYHFRMVKSLLSNDLKLNLKMREEYDKIQIADLMEEKFRGDAGLGKLIKIFEDIPTLEDLAETLKKEKLKVKGPALSRKRKKEVDATSPAPSTSSTVKTEGAEATPGAQKRKKSTKEKAGPKGSKVSEEQTQPPSPAGAGMSTAMGRSPSPKTSLSAPPNSSSTENPKTVAKCQVTPRRNVLQKRPVIVKVLSTTKPFEYETPEMEKKIMFHATVATQTQFFHVKVLNTSLKEKFNGKKIIIISDYLEYDSLLEVNEESTVSEAGPNQTFEVPNKIINRAKETLKIDILHKQASGNIVYGVFMLHKKTVNQKTTIYEIQDDRGKMDVVGTGQCHNIPCEEGDKLQLFCFRLRKKNQMSKLISEMHSFIQIKKKTNPRNNDPKSMKLPQEQRQLPYPSEASTTFPESHLRTPQMPPTTPSSSFFTKKSEDTISKMNDFMRMQILKEGSHFPGPFMTSIGPAESHPHTPQMPPSTPSSSFLTTLKPRLKTEPEEVSIEDSAQSDLKEVMVLNATESFVYEPKEQKKMFHATVATENEVFRVKVFNIDLKEKFTPKKIIAIANYVCRNGFLEVYPFTLVADVNADRNMEIPKGLIRSASVTPKINQLCSQTKGSFVNGVFEVHKKNVRGEFTYYEIQDNTGKMEVVVHGRLTTINCEEGDKLKLTCFELAPKSGNTGELRSVIHSHIKVIKTRKNKKDILNPDSSMETSPDFFF>sp|Q16666-3|IF16_HUMAN Isoform 3 of Gamma-interferon-inducible protein16 OS=Homo sapiens OX=9606 GN=IFI16MGKKYKNIVLLKGLEVINDYHFRMVKSLLSNDLKLNLKMREEYDKIQIADLMEEKFRGDAGLGKLIKIFEDIPTLEDLAETLKKEKLKVKGPALSRKRKKEVDATSPAPSTSSTVKTEGAEATPGAQKRKKSTKEKAGPKGSKVSEEQTQPPSPAGAGMSTAMGRSPSPKTSLSAPPNSSSTENPKTVAKCQVTPRRNVLQKRPVIVKVLSTTKPFEYETPEMEKKIMFHATVATQTQFFHVKVLNTSLKEKFNGKKIIIISDYLEYDSLLEVNEESTVSEAGPNQTFEVPNKIINRAKETLKIDILHKQASGNIVYGVFMLHKKTVNQKTTIYEIQDDRGKMDVVGTGQCHNIPCEEGDKLQLFCFRLRKKNQMSKLISEMHSFIQIKKKTNPRNNDPKSMKLPQEQRQLPYPSEASTTFPESHLRTPQMPPTTPSSSFFTKLKPRLKTEPEEVSIEDSAQSDLKEVMVLNATESFVYEPKEQKKMFHATVATENEVFRVKVFNIDLKEKFTPKKIIAIANYVCRNGFLEVYPFTLVADVNADRNMEIPKGLIRSASVTPKINQLCSQTKGSFVNGVFEVHKKNVRGEFTYYEIQDNTGKMEVVVHGRLTTINCEEGDKLKLTCFELAPKSGNTGELRSVIHSHIKVIKTRKNKKDILNPDSSMETSPDFFF>sp|Q16666-6|IF16_HUMAN Isoform 4 of Gamma-interferon-inducible protein16 OS=Homo sapiens OX=9606 GN=IFI16MGKKYKNIVLLKGLEVINDYHFRMVKSLLSNDLKLNLKMREEYDKIQIADLMEEKFRGDAGLGKLIKIFEDIPTLEDLAETLKKEKLKVKGPALSRKRKKEVDATSPAPSTSSTVKTEGAEATPGAQNPKTVAKCQVTPRRNVLQKRPVIVKVLSTTKPFEYETPEMEKKIMFHATVATQTQFFHVKVLNTSLKEKFNGKKIIIISDYLEYDSLLEVNEESTVSEAGPNQTFEVPNKIINRAKETLKIDILHKQASGNIVYGVFMLHKKTVNQKTTIYEIQDDRGKMDVVGTGQCHNIPCEEGDKLQLFCFRLRKKNQMSKLISEMHSFIQIKKKTNPRNNDPKSMKLPQEQRQLPYPSEASTTFPESHLRTPQMPPTTPSSSFFTKKSEDTISKMNDFMRMQILKEGSHFPGPFMTSIGPAESHPHTPQMPPSTPSSSFLTTKSEDTISKMNDFMRMQILKEGSHFPGPFMTSIGPAESHPHTPQMPPSTPSSSFLTTLKPRLKTEPEEVSIEDSAQSDLKEVMVLNATESFVYEPKEQKKMFHATVATENEVFRVKVFNIDLKEKFTPKKIIAIANYVCRNGFLEVYPFTLVADVNADRNMEIPKGLIRSASVTPKINQLCSQTKGSFVNGVFEVHKKNVRGEFTYYEIQDNTGKMEVVVHGRLTTINCEEGDKLKLTCFELAPKSGNTGELRSVIHSHIKVIKTRKNKKDILNPDSSMETSPDFFF>sp|A0A0C4DH34|HV428_HUMAN Immunoglobulin heavy variable 4-28 OS=Homosapiens OX=9606 GN=IGHV4-28 PE=3 SV=1MKHLWFFLLLVAAPRWVLSQVQLQESGPGLVKPSDTLSLTCAVSGYSISSSNWWGWIRQPPGKGLEWIGYIYYSGSTYYNPSLKSRVTMSVDTSKNQFSLKLSSVTAVDTAVYYCAR>sp|P0DP07|HV431_HUMAN Immunoglobulin heavy variable 4-31 OS=Homo sapiensOX=9606 GN=IGHV4-31 PE=3 SV=1MKHLWFFLLLVAAPRWVLSQVQLQESGPGLVKPSQTLSLTCTVSGGSISSGGYYWSWIRQHPGKGLEWIGYIYYSGSTYYNPSLKSLVTISVDTSKNQFSLKLSSVTAADTAVYYCAR>sp|A0A087WSY4|HV432_HUMAN Immunoglobulin heavy variable 4-30-2 OS=Homosapiens OX=9606 GN=IGHV4-30-2 PE=3 SV=1MKHLWFFLLLVAAPRWVLSQLQLQESGSGLVKPSQTLSLTCAVSGGSISSGGYSWSWIRQPPGKGLEWIGYIYHSGSTYYNPSLKSRVTISVDRSKNQFSLKLSSVTAADTAVYYCAR>sp|O14920|IKKB_HUMAN Inhibitor of nuclear factor kappa-B kinase subunitbeta OS=Homo sapiens OX=9606 GN=IKBKB PE=1 SV=1MSWSPSLTTQTCGAWEMKERLGTGGFGNVIRWHNQETGEQIAIKQCRQELSPRNRERWCLEIQIMRRLTHPNVVAARDVPEGMQNLAPNDLPLLAMEYCQGGDLRKYLNQFENCCGLREGAILTLLSDIASALRYLHENRIIHRDLKPENIVLQQGEQRLIHKIIDLGYAKELDQGSLCTSFVGTLQYLAPELLEQQKYTVTVDYWSFGTLAFECITGFRPFLPNWQPVQWHSKVRQKSEVDIVVSEDLNGTVKFSSSLPYPNNLNSVLAERLEKWLQLMLMWHPRQRGTDPTYGPNGCFKALDDILNLKLVHILNMVTGTIHTYPVTEDESLQSLKARIQQDTGIPEEDQELLQEAGLALIPDKPATQCISDGKLNEGHTLDMDLVFLFDNSKITYETQISPRPQPESVSCILQEPKRNLAFFQLRKVWGQVWHSIQTLKEDCNRLQQGQRAAMMNLLRNNSCLSKMKNSMASMSQQLKAKLDFFKTSIQIDLEKYSEQTEFGITSDKLLLAWREMEQAVELCGRENEVKLLVERMMALQTDIVDLQRSPMGRKQGGTLDDLEEQARELYRRLREKPRDQRTEGDSQEMVRLLLQAIQSFEKKVRVIYTQLSKTVVCKQKALELLPKVEEVVSLMNEDEKTVVRLQEKRQKELWNLLKIACSKVRGPVSGSPDSMNASRLSQPGQLMSQPSTASNSLPEPAKKSEELVAEAHNLCTLLENAIQDTVREQDQSFTALDWSWLQTEEEEHSCLEQAS>sp|O14920-2|IKKB_HUMAN Isoform 2 of Inhibitor of nuclear factor kappa-Bkinase subunit beta OS=Homo sapiens OX=9606 GN=IKBKBMFSGGCHSPGFGRPSPAFPAPGSPPPAPRPCRQETGEQIAIKQCRQELSPRNRERWCLEIQIMRRLTHPNVVAARDVPEGMQNLAPNDLPLLAMEYCQGGDLRKYLNQFENCCGLREGAILTLLSDIASALRYLHENRIIHRDLKPENIVLQQGEQRLIHKIIDLGYAKELDQGSLCTSFVGTLQYLAPELLEQQKYTVTVDYWSFGTLAFECITGFRPFLPNWQPVQWHSKVRQKSEVDIVVSEDLNGTVKFSSSLPYPNNLNSVLAERLEKWLQLMLMWHPRQRGTDPTYGPNGCFKALDDILNLKLVHILNMVTGTIHTYPVTEDESLQSLKARIQQDTGIPEEDQELLQEAGLALIPDKPATQCISDGKLNEGHTLDMDLVFLFDNSKITYETQISPRPQPESVSCILQEPKRNLAFFQLRKVWGQVWHSIQTLKEDCNRLQQGQRAAMMNLLRNNSCLSKMKNSMASMSQQLKAKLDFFKTSIQIDLEKYSEQTEFGITSDKLLLAWREMEQAVELCGRENEVKLLVERMMALQTDIVDLQRSPMGRKQGGTLDDLEEQARELYRRLREKPRDQRTEGDSQEMVRLLLQAIQSFEKKVRVIYTQLSKTVVCKQKALELLPKVEEVVSLMNEDEKTVVRLQEKRQKELWNLLKIACSKVRGPVSGSPDSMNASRLSQPGQLMSQPSTASNSLPEPAKKSEELVAEAHNLCTLLENAIQDTVREQDQSFTALDWSWLQTEEEEHSCLEQAS>sp|O14920-3|IKKB_HUMAN Isoform 3 of Inhibitor of nuclear factor kappa-Bkinase subunit beta OS=Homo sapiens OX=9606 GN=IKBKBMSWSPSLTTQTCGAWEMKERLGTGGFGNVIRWHNQETGEQIAIKQCRQELSPRNRERWCLEIQIMRRLTHPNVVAARDVPEGMQNLAPNDLPLLAMEYCQGGDLRKYLNQFENCCGLREGAILTLLSDIASALRYLHENRIIHRDLKPENIVLQQGEQRLIHKIIDLGYAKELDQGSLCTSFVGTLQYLAPELLEQQKYTVTVDYWSFGTLAFECITGFRPFLPNWQPVQCVRMWPGTVAHSCNPSTLGGRGRWIS>sp|O14920-4|IKKB_HUMAN Isoform 4 of Inhibitor of nuclear factor kappa-Bkinase subunit beta OS=Homo sapiens OX=9606 GN=IKBKBMSSDGTIRLTHPNVVAARDVPEGMQNLAPNDLPLLAMEYCQGGDLRKYLNQFENCCGLREGAILTLLSDIASALRYLHENRIIHRDLKPENIVLQQGEQRLIHKIIDLGYAKELDQGSLCTSFVGTLQYLAPELLEQQKYTVTVDYWSFGTLAFECITGFRPFLPNWQPVQWHSKVRQKSEVDIVVSEDLNGTVKFSSSLPYPNNLNSVLAERLEKWLQLMLMWHPRQRGTDPTYGPNGCFKALDDILNLKLVHILNMVTGTIHTYPVTEDESLQSLKARIQQDTGIPEEDQELLQEAGLALIPDKPATQCISDGKLNEGHTLDMDLVFLFDNSKITYETQISPRPQPESVSCILQEPKRNLAFFQLRKVWGQVWHSIQTLKEDCNRLQQGQRAAMMNLLRNNSCLSKMKNSMASMSQQLKAKLDFFKTSIQIDLEKYSEQTEFGITSDKLLLAWREMEQAVELCGRENEVKLLVERMMALQTDIVDLQRSPMGRKQGGTLDDLEEQARELYRRLREKPRDQRTEGDSQEMVRLLLQAIQSFEKKVRVIYTQLSKTVVCKQKALELLPKVEEVVSLMNEDEKTVVRLQEKRQKELWNLLKIACSKVRGPVSGSPDSMNASRLSQPGQLMSQPSTASNSLPEPAKKSEELVAEAHNLCTLLENAIQDTVREQDQSFTALDWSWLQTEEEEHSCLEQAS>sp|Q8WUF5|IASPP_HUMAN RelA-associated inhibitor OS=Homo sapiens OX=9606GN=PPP1R13L PE=1 SV=4MDSEAFQSARDFLDMNFQSLAMKHMDLKQMELDTAAAKVDELTKQLESLWSDSPAPPGPQAGPPSRPPRYSSSSIPEPFGSRGSPRKAATDGADTPFGRSESAPTLHPYSPLSPKGRPSSPRTPLYLQPDAYGSLDRATSPRPRAFDGAGSSLGRAPSPRPGPGPLRQQGPPTPFDFLGRAGSPRGSPLAEGPQAFFPERGPSPRPPATAYDAPASAFGSSLLGSGGSAFAPPLRAQDDLTLRRRPPKAWNESDLDVAYEKKPSQTASYERLDVFARPASPSLQLLPWRESSLDGLGGTGKDNLTSATLPRNYKVSPLASDRRSDAGSYRRSLGSAGPSGTLPRSWQPVSRIPMPPSSPQPRGAPRQRPIPLSMIFKLQNAFWEHGASRAMLPGSPLFTRAPPPKLQPQPQPQPQPQSQPQPQLPPQPQTQPQTPTPAPQHPQQTWPPVNEGPPKPPTELEPEPEIEGLLTPVLEAGDVDEGPVARPLSPTRLQPALPPEAQSVPELEEVARVLAEIPRPLKRRGSMEQAPAVALPPTHKKQYQQIISRLFHRHGGPGPGGPEPELSPITEGSEARAGPPAPAPPAPIPPPAPSQSSPPEQPQSMEMRSVLRKAGSPRKARRARLNPLVLLLDAALTGELEVVQQAVKEMNDPSQPNEEGITALHNAICGANYSIVDFLITAGANVNSPDSHGWTPLHCAASCNDTVICMALVQHGAAIFATTLSDGATAFEKCDPYREGYADCATYLADVEQSMGLMNSGAVYALWDYSAEFGDELSFREGESVTVLRRDGPEETDWWWAALHGQEGYVPRNYFGLFPRVKPQRSKV>sp|P06331|HV434_HUMAN Immunoglobulin heavy variable 4-34 OS=Homo sapiensOX=9606 GN=IGHV4-34 PE=1 SV=2MDLLHKNMKHLWFFLLLVAAPRWVLSQVQLQQWGAGLLKPSETLSLTCAVYGGSFSGYYWSWIRQPPGKGLEWIGEINHSGSTNYNPSLKSRVTISVDTSKNQFSLKLSSVTAADTAVYYCAR>sp|P01824|HV439_HUMAN Immunoglobulin heavy variable 4-39 OS=Homo sapiensOX=9606 GN=IGHV4-39 PE=1 SV=2MDLMCKKMKHLWFFLLLVAAPRWVLSQLQLQESGPGLVKPSETLSLTCTVSGGSISSSSYYWGWIRQPPGKGLEWIGSIYYSGSTYYNPSLKSRVTISVDTSKNQFSLKLSSVTAADTAVYYCAR>sp|Q9UG01|IF172_HUMAN Intraflagellar transport protein 172 homologOS=Homo sapiens OX=9606 GN=IFT172 PE=1 SV=2MHLKHLRTLLSPQDGAAKVTCMAWSQNNAKFAVCTVDRVVLLYDEHGERRDKFSTKPADMKYGRKSYMVKGMAFSPDSTKIAIGQTDNIIYVYKIGEDWGDKKVICNKFIQTSAVTCLQWPAEYIIVFGLAEGKVRLANTKTNKSSTIYGTESYVVSLTTNCSGKGILSGHADGTIVRYFFDDEGSGESQGKLVNHPCPPYALAWATNSIVAAGCDRKIVAYGKEGHMLQTFDYSRDPQEREFTTAVSSPGGQSVVLGSYDRLRVFNWIPRRSIWEEAKPKEITNLYTITALAWKRDGSRLCVGTLCGGVEQFDCCLRRSIYKNKFELTYVGPSQVIVKNLSSGTRVVLKSHYGYEVEEVKILGKERYLVAHTSETLLLGDLNTNRLSEIAWQGSGGNEKYFFENENVCMIFNAGELTLVEYGNNDTLGSVRTEFMNPHLISVRINERCQRGTEDNKKLAYLIDIKTIAIVDLIGGYNIGTVSHESRVDWLELNETGHKLLFRDRKLRLHLYDIESCSKTMILNFCSYMQWVPGSDVLVAQNRNSLCVWYNIEAPERVTMFTIRGDVIGLERGGGKTEVMVMEGVTTVAYTLDEGLIEFGTAIDDGNYIRATAFLETLEMTPETEAMWKTLSKLALEARQLHIAERCFSALGQVAKARFLHETNEIADQVSREYGGEGTDFYQVRARLAMLEKNYKLAEMIFLEQNAVEEAMGMYQELHRWDECIAVAEAKGHPALEKLRRSYYQWLMDTQQEERAGELQESQGDGLAAISLYLKAGLPAKAARLVLTREELLANTELVEHITAALIKGELYERAGDLFEKIHNPQKALECYRKGNAFMKAVELARLAFPVEVVKLEEAWGDHLVQQKQLDAAINHYIEARCSIKAIEAALGARQWKKAIYILDLQDRNTASKYYPLVAQHYASLQEYEIAEELYTKGDRTKDAIDMYTQAGRWEQAHKLAMKCMRPEDVSVLYITQAQEMEKQGKYREAERLYVTVQEPDLAITMYKKHKLYDDMIRLVGKHHPDLLSDTHLHLGKELEAEGRLQEAEYHYLEAQEWKATVNMYRASGLWEEAYRVARTQGGANAHKHVAYLWAKSLGGEAAVRLLNKLGLLEAAVDHAADNCSFEFAFELSRLALKHKTPEVHLKYAMFLEDEGKFEEAEAEFIRAGKPKEAVLMFVHNQDWEAAQRVAEAHDPDSVAEVLVGQARGALEEKDFQKAEGLLLRAQRPGLALNYYKEAGLWSDALRICKDYVPSQLEALQEEYEREATKKGARGVEGFVEQARHWEQAGEYSRAVDCYLKVRDSGNSGLAEKCWMKAAELSIKFLPPQRNMEVVLAVGPQLIGIGKHSAAAELYLNLDLVKEAIDAFIEGEEWNKAKRVAKELDPRYEDYVDQHYKEFLKNQGKVDSLVGVDVIAALDLYVEQGQWDKCIETATKQNYKILHKYVALYATHLIREGSSAQALALYVQHGAPANPQNFNIYKRIFTDMVSSPGTNCAEAYHSWADLRDVLFNLCENLVKSSEANSPAHEEFKTMLLIAHYYATRSAAQSVKQLETVAARLSVSLLRHTQLLPVDKAFYEAGIAAKAVGWDNMAFIFLNRFLDLTDAIEEGTLDGLDHSDFQDTDIPFEVPLPAKQHVPEAEREEVRDWVLTVSMDQRLEQVLPRDERGAYEASLVAASTGVRALPCLITGYPILRNKIEFKRPGKAANKDNWNKFLMAIKTSHSPVCQDVLKFISQWCGGLPSTSFSFQ>sp|Q9UG01-2|IF172_HUMAN Isoform 2 of Intraflagellar transport protein172 homolog OS=Homo sapiens OX=9606 GN=IFT172MHLKHLRTLLSPQDGAAKVTCMAWSQNNAKFAVCTVDRVVLLYDEHGERRDKFSTKPADMKYGRKSYMVKGMAFSPDSTKIAIGQTDNIIYVYKIGEDWGDKKVICNKFIQTSAVTCLQWPAEYIIVFGLAEGKVRLANTKTNKSSTIYGTESYVVSLTTNCSGKGILSGHADGTIVRYFFDDEGSGESQGKLVNHPCPPYALAWATNSIVAAGCDRKIVAYGKEGHMLQTFDYSRDPQEREFTTAVSSPGGQSVVLGSYDRLRVFNWIPRRSIWEEAKPKEITNLYTITALAWKRDGSRLCVGTLCGGVEQFDCCLRRSIYKNKFELTYVGPSQVIVKNLSSGTRVVLKSHYGYEVEEVKILGKERYLVAHTSETLLLGDLNTNRLSEIAWQGSGGNEKYFFENENVCMIFNAGELTLVEYGNNDTLGSVRTEFMNPHLISVRINERCQRGTEDNKKLAYLIDIKTIAIVDLIGGYNIGTVSHESRVDWLELNETGHKLLFRDRKLRLHLYDIESCSKTMILNFCSYMQWVPGSDVLVAQNRNSLCVWYNIEAPERVTMFTIRGDVIGLERGGGKTEVMVMEGVTTVAYTLDEGLIEFGTAIDDGNYIRATAFLETLEMTPETEAMWKTLSKLALEARQLHIAERCFSALGQVAKARFLHETNEIADQVSREYGGEGTDFYQVRARLAMLEKNYKLAEMIFLEQNAVEEAMGMYQELHRWDECIAVAEAKGHPALEKLRRSYYQWLMDTQQEERAGELQESQGDGLAAISLYLKAGLPAKAARLVLTREELLANTELVEHITAALIKGELYERAGDLFEKIHNPQKALECYRKGNAFMKAVELARLAFPVEVVKLEEAWGDHLVQQKQLDAAINHYIEARCSIKAIEAALGARQWKKAIYILDLQDRNTASKYYPLVAQHYASLQEYEIAEELYTKGDRTKDAIDMYTQAGRWEQAHKLAMKCMRPEDVSVLYITQAQEMEKQGKYREAERLYVTVQEPDLAITMYKKHKLYDDMIRLVGKHHPDLLSDTHLHLGKELEAEGRLQEAEYHYLEAQEWKATVNMYRASGLWEEAYRVARTQGGANAHKHVAYLWAKSLGGEAAVRLLNKLGLLEAAVDHAADNCSFEFAFELSRLALKHKTPEVHLKYAMFLEDEGKFEEAEAEFIRAGKPKEAVLMFVHNQDWEAAQRVAEAHDPDSVAEVLVGQARGALEEKDFQKAEGLLLRAQRPGLALNYYKEAGLWSDALRICKDYVPSQLEALQEEYEREATKKGARGVEGFVEQARHWEQAGEYSRAVDCYLKVRDSGNSGLAEKCWMKAAELSIKFLPPQRNMEVVLAVGPQLIGIGKHSAAAELYLNLDLVKEAIDAFIEGEEWNKAKRVAKELDPRYEDYVDQHYKEFLKNQGKVDSLVGVDVIAALDLYVEQGQWDKCIETATKQNYKILHKYVALYATHLIREGSSAQALALYVQHGAPANPQNFNIYKRIFTDMVSSPGTNCAEAYHSWADLRDVLFNLAVLSPSSSVKTW>sp|Q9UG01-3|IF172_HUMAN Isoform 3 of Intraflagellar transport protein172 homolog OS=Homo sapiens OX=9606 GN=IFT172MHLKHLRTLLSPQDGAAKVTCMAWSQNNAKFAVCTVDRVVLLYDEHGERRDKFSTKPADMKYGRKSYMVKGMAFSPDSTKIAIGQTDNIIYVYKIGEDWGDKKVICNKFIQTSAVTCLQWPAEYIIVFGLAEGKVRLANTKTNKSSTIYGTESYVVSLTTNCSGKGILSGHADGTIVRYFFDDEGSGESQGKLVNHPCPPYALAWATNSIVAAGCDRKIVAYGKEGHMLQTFDYSRDPQEREFTTAVSSPGGQSVVLGSYDRLRVFNWIPRRSIWEEAKPKEITNLYTITALAWKRDGSRLCVGTLCGGVEQFDCCLRRSIYKNKFELTYVGPSQVIVKNLSSGTRVVLKSHYGYEVEEVKILGKERYLVAHTSETLLLGDLNTNRLSEIAWQGSGGNEKYFFENENVCMIFNAGELTLVEYGNNDTLGSVRTEFMNPHLISVRINERCQRGTEDNKKLAYLIDIKTIAIVDLIGGYNIGTVSHESRVDWLELNETGHKLLFRDRKLRVRRATKALGIGWPTEGVRQAATRD>sp|P0DP04|HV43D_HUMAN Immunoglobulin heavy variable 3-43D OS=Homosapiens OX=9606 GN=IGHV3-43D PE=3 SV=1MEFGLSWVFLVAILKGVQCEVQLVESGGVVVQPGGSLRLSCAASGFTFDDYAMHWVRQAPGKGLEWVSLISWDGGSTYYADSVKGRFTISRDNSKNSLYLQMNSLRAEDTALYYCAKD>sp|B1ANH7|IBADT_HUMAN Putative uncharacterized protein IBA57-DT OS=Homosapiens OX=9606 GN=IBA57-DT PE=5 SV=1MTYPPHRAFSRSDVPYPLLSSPVQWPLSLVVGDTSTRWPQQPSALESDCPGPSHPCLAGLLGPMHPVDIPLSTALHSKHQRRLTQCVLMVQSPSKQRSLYLLNKKIPHDA>sp|P01825|HV459_HUMAN Immunoglobulin heavy variable 4-59 OS=Homo sapiensOX=9606 GN=IGHV4-59 PE=1 SV=2MKHLWFFLLLVAAPRWVLSQVQLQESGPGLVKPSETLSLTCTVSGGSISSYYWSWIRQPPGKGLEWIGYIYYSGSTNYNPSLKSRVTISVDTSKNQFSLKLSSVTAADTAVYYCAR>sp|A0A0C4DH41|HV461_HUMAN Immunoglobulin heavy variable 4-61 OS=Homosapiens OX=9606 GN=IGHV4-61 PE=1 SV=1MKHLWFFLLLVAAPRWVLSQVQLQESGPGLVKPSETLSLTCTVSGGSVSSGSYYWSWIRQPPGKGLEWIGYIYYSGSTNYNPSLKSRVTISVDTSKNQFSLKLSSVTAADTAVYYCAR>sp|O14764|GBRD_HUMAN Gamma-aminobutyric acid receptor subunit deltaOS=Homo sapiens OX=9606 GN=GABRD PE=1 SV=2MDAPARLLAPLLLLCAQQLRGTRAMNDIGDYVGSNLEISWLPNLDGLIAGYARNFRPGIGGPPVNVALALEVASIDHISEANMEYTMTVFLHQSWRDSRLSYNHTNETLGLDSRFVDKLWLPDTFIVNAKSAWFHDVTVENKLIRLQPDGVILYSIRITSTVACDMDLAKYPMDEQECMLDLESYGYSSEDIVYYWSESQEHIHGLDKLQLAQFTITSYRFTTELMNFKSAGQFPRLSLHFHLRRNRGVYIIQSYMPSVLLVAMSWVSFWISQAAVPARVSLGITTVLTMTTLMVSARSSLPRASAIKALDVYFWICYVFVFAALVEYAFAHFNADYRKKQKAKVKVSRPRAEMDVRNAIVLFSLSAAGVTQELAISRRQRRVPGNLMGSYRSVGVETGETKKEGAARSGGQGGIRARLRPIDADTIDIYARAVFPAAFAAVNVIYWAAYAM>sp|Q96N76|HUTU_HUMAN Urocanate hydratase OS=Homo sapiens OX=9606GN=UROC1 PE=1 SV=1MSSLQALCSGLPLRPLPENRGRQAGVPHAPVRTPSLSPVEKQLALRNALRYFPPDVQELLAPEFAQELQLYGHIYMYRFCPDIEMRAYPIEQYPCQTKVAAAIMHMIMNNLDPAVAQFPQELVTYGGNGQVFSNWAQFWLTMFYLSKMTEEQTLVMYSGHPLGLFPSSRSAPRLVITNGMVIPNYSSRTEYEKLFALGVTMYGQMTAGSYCYIGPQGIVHGTVLTVLNAARRYLGIEDLAGKVFVTSGLGGMSGAQAKAAVIVGCIGVIAEVDKAALEKRHRQGWLMEVTDSLDRCIQRLREARKKKEVLSLGYHGNVVALWERLVHELDTTGECLVDLGSDQTSCHNPFNGGYYPVQLSFTEAQSLMASNPAVFKDLVQESLRRQVSAINRLAEEKFFFWDYGNAFLLEAQRAGADVEKKGAGRTEFRYPSYVQHIMGDIFSQGFGPFRWVCTSGDPQDLAVTDELATSVLEEAIADGVKVSVKLQYMDNIRWIREAARHRLVVGSQARILYSDQKGRVAIAVAINQAIACRRIKAPVVLSRDHHDVSGTDSPFRETSNIYDGSAFCADMAVQNFVGDACRGATWVALHNGGGVGWGEVINGGFGLVLDGTPEAEGRARLMLSWDVSNGVARRCWSGNQKAYEIICQTMQENSTLVVTLPHKVEDERVLQQALQL>sp|Q96N76-2|HUTU_HUMAN Isoform 2 of Urocanate hydratase OS=Homo sapiensOX=9606 GN=UROC1MSSLQALCSGLPLRPLPENRGRQAGVPHAPVRTPSLSPVEKQLALRNALRYFPPDVQELLAPEFAQELQLYGHIYMYRFCPDIEMRAYPIEQYPCQTKVAAAIMHMIMNNLDPAVAQFPQELVTYGGNGQVFSNWAQFWLTMFYLSKMTEEQTLVMYSGHPLGLFPSSRSAPRLVITNGMVIPNYSSRTEYEKLFALGVTMYGQMTAGSYCYIGPQGIVHGTVLTVLNAARRYLGIEDLAGKVFVTSGLGGMSGAQAKAAVIVGCIGVIAEVDKAALEKRHRQGWLMEVTDSLDRCIQRLRVLQLGLQQALGWAGLPAALGLCVLSCFVNLAPLGEGRCLAPSGFSRPLLGAPVLLLCPSREARKKKEVLSLGYHGNVVALWERLVHELDTTGECLVDLGSDQTSCHNPFNGGYYPVQLSFTEAQSLMASNPAVFKDLVQESLRRQVSAINRLAEEKFFFWDYGNAFLLEAQRAGADVEKKGAGRTEFRYPSYVQHIMGDIFSQGFGPFRWVCTSGDPQDLAVTDELATSVLEEAIADGVKVSVKLQYMDNIRWIREAARHRLVVGSQARILYSDQKGRVAIAVAINQAIACRRIKAPVVLSRDHHDVSGTDSPFRETSNIYDGSAFCADMAVQNFVGDACRGATWVALHNGGGVGWGEVINGGFGLVLDGTPEAEGRARLMLSWDVSNGVARRCWSGNQKAYEIICQTMQENSTLVVTLPHKVEDERVLQQALQL>sp|P60520|GBRL2_HUMAN Gamma-aminobutyric acid receptor-associatedprotein-like 2 OS=Homo sapiens OX=9606 GN=GABARAPL2 PE=1 SV=1MKWMFKEDHSLEHRCVESAKIRAKYPDRVPVIVEKVSGSQIVDIDKRKYLVPSDITVAQFMWIIRKRIQLPSEKAIFLFVDKTVPQSSLTMGQLYEKEKDEDGFLYVAYSGENTFGF>sp|Q9H0R8|GBRL1_HUMAN Gamma-aminobutyric acid receptor-associatedprotein-like 1 OS=Homo sapiens OX=9606 GN=GABARAPL1 PE=1 SV=1MKFQYKEDHPFEYRKKEGEKIRKKYPDRVPVIVEKAPKARVPDLDKRKYLVPSDLTVGQFYFLIRKRIHLRPEDALFFFVNNTIPPTSATMGQLYEDNHEEDYFLYVAYSDESVYGK>sp|Q9H0R8-2|GBRL1_HUMAN Isoform 2 of Gamma-aminobutyric acid receptor-associated protein-like 1 OS=Homo sapiens OX=9606 GN=GABARAPL1MKFQYKEDHPFEYRKKEGEKIRKKYPDRVPVIVEKAPKARVPDLDKRKYLVPSDLTVGQFYFLIRKRIHLRPEDALFFFVNNTIPPTSATMGQLYEVMVLVAQYWMPSSAVWHPLALVLDALITHLRSGAEGVIYPDPLTYGSVRL>sp|Q9BY60|GBRL3_HUMAN Gamma-aminobutyric acid receptor-associatedprotein-like 3 OS=Homo sapiens OX=9606 GN=GABARAPL3 PE=2 SV=1MKFQYKEVHPFEYRKKEGEKIRKKYPDRVPLIVEKAPKARVPDLDRRKYLVPSDLTDGQFYLLIRKRIHLRPEDALFFFVNNTIPPTSATMGQLYEDSHEEDDFLYVAYSNESVYGK>sp|P01275|GLUC_HUMAN Pro-glucagon OS=Homo sapiens OX=9606 GN=GCG PE=1SV=3MKSIYFVAGLFVMLVQGSWQRSLQDTEEKSRSFSASQADPLSDPDQMNEDKRHSQGTFTSDYSKYLDSRRAQDFVQWLMNTKRNRNNIAKRHDEFERHAEGTFTSDVSSYLEGQAAKEFIAWLVKGRGRRDFPEEVAIVEELGRRHADGSFSDEMNTILDNLAARDFINWLIQTKITDRK>sp|P14672|GLUT4_HUMAN Solute carrier family 2, facilitated glucosetransporter member 4 OS=Homo sapiens OX=9606 GN=SLC2A4 PE=1 SV=1MPSGFQQIGSEDGEPPQQRVTGTLVLAVFSAVLGSLQFGYNIGVINAPQKVIEQSYNETWLGRQGPEGPSSIPPGTLTTLWALSVAIFSVGGMISSFLIGIISQWLGRKRAMLVNNVLAVLGGSLMGLANAAASYEMLILGRFLIGAYSGLTSGLVPMYVGEIAPTHLRGALGTLNQLAIVIGILIAQVLGLESLLGTASLWPLLLGLTVLPALLQLVLLPFCPESPRYLYIIQNLEGPARKSLKRLTGWADVSGVLAELKDEKRKLERERPLSLLQLLGSRTHRQPLIIAVVLQLSQQLSGINAVFYYSTSIFETAGVGQPAYATIGAGVVNTVFTLVSVLLVERAGRRTLHLLGLAGMCGCAILMTVALLLLERVPAMSYVSIVAIFGFVAFFEIGPGPIPWFIVAELFSQGPRPAAMAVAGFSNWTSNFIIGMGFQYVAEAMGPYVFLLFAVLLLGFFIFTFLRVPETRGRTFDQISAAFHRTPSLLEQEVKPSTELEYLGPDEND>sp|P14672-2|GLUT4_HUMAN Isoform 2 of Solute carrier family 2,facilitated glucose transporter member 4 OS=Homo sapiens OX=9606GN=SLC2A4MPSGFQQIGSEDGEPPQQRVTGTLVLAVFSAVLGSLQFGYNIGVINAPQKVIEQSYNETWLGRQGPEGPSSIPPGTLTTLWALSVAIFSVGGMISSFLIGIISQWLGRKRAMLVNNVLAVLGGSLMGLANAAASYEMLILGRFLIGAYSGLTSGLVPMYVGEIAPTHLRGALGTLNQLAIVIGILIAQVLGLESLLGTASLWPLLLGLTVLPALLQLVLLPFCPESPRYLYIIQNLEGPARKSLKRLTGWADVSGVLAELKDEKRKLERERPLSLLQLLGSRTHRQPLIIAVVLQLSQQLSGINAVFYYSTSIFETAGVGQPAYATIGAGVVNTVFTLVSVTAHLWNGPSHWLHLPGCPGGVVGGAGGAPDAPSPGPGGHVWLCHPDDCGSAPAGASSSHELRLHCGHLWLRGIF>sp|P16383|GCFC2_HUMAN Intron Large complex component GCFC2 OS=Homosapiens OX=9606 GN=GCFC2 PE=1 SV=2MAHRPKRTFRQRAADSSDSDGAEESPAEPGAPRELPVPGSAEEEPPSGGGRAQVAGLPHRVRGPRGRGRVWASSRRATKAAPRADEGSESRTLDVSTDEEDKIHHSSESKDDQGLSSDSSSSLGEKELSSTVKIPDAAFIQAARRKRELARAQDDYISLDVQHTSSISGMKRESEDDPESEPDDHEKRIPFTLRPQTLRQRMAEESISRNEETSEESQEDEKQDTWEQQQMRKAVKIIEERDIDLSCGNGSSKVKKFDTSISFPPVNLEIIKKQLNTRLTLLQETHRSHLREYEKYVQDVKSSKSTIQNLESSSNQALNCKFYKSMKIYVENLIDCLNEKIINIQEIESSMHALLLKQAMTFMKRRQDELKHESTYLQQLSRKDETSTSGNFSVDEKTQWILEEIESRRTKRRQARVLSGNCNHQEGTSSDDELPSAEMIDFQKSQGDILQKQKKVFEEVQDDFCNIQNILLKFQQWREKFPDSYYEAFISLCIPKLLNPLIRVQLIDWNPLKLESTGLKEMPWFKSVEEFMDSSVEDSKKESSSDKKVLSAIINKTIIPRLTDFVEFLWDPLSTSQTTSLITHCRVILEEHSTCENEVSKSRQDLLKSIVSRMKKAVEDDVFIPLYPKSAVENKTSPHSKFQERQFWSGLKLFRNILLWNGLLTDDTLQELGLGKLLNRYLIIALLNATPGPDVVKKCNQVAACLPEKWFENSAMRTSIPQLENFIQFLLQSAHKLSRSEFRDEVEEIILILVKIKALNQAESFIGEHHLDHLKSLIKED>sp|P16383-2|GCFC2_HUMAN Isoform 2 of Intron Large complex componentGCFC2 OS=Homo sapiens OX=9606 GN=GCFC2MAHRPKRTFRQRAADSSDSDGAEESPAEPGAPRELPVPGSAEEEPPSGGGRAQVAGLPHRVRGPRGRGRVWASSRRATKAAPRADEGSESRTLDVSTDEEDKIHHSSESKDDQGLSSDSSSSLGEKELSSTVKIPDAAFIQAARRKRELARAQDDYISLDVQHTSSISVSRNEETSEESQEDEKQDTWEQQQMRKAVKIIEERDIDLSCGNGSSKVKKFDTSISFPPVNLEIIKKQLNTRLTLLQETHRSHLREYEKYVQDVKSSKSTIQNLESSSNQALNCKFYKSMKIYVENLIDCLNEKIINIQEIESSMHALLLKQAMTFMKRRQDELKHESTYLQQLSRKDETSTSGNFSVDEKTQWILEEIESRRTKRRQARVLSGNCNHQEGTSSDDELPSAEMIDFQKSQGDILQKQKKVFEEVQDDFCNIQNILLKFQQWREKFPDSYYEAFISLCIPKLLNPLIRVQLIDWNPLKLESTGLKEMPWFKSVEEFMDSSVEDSKKESSSDKKVLSAIINKTIIPRLTDFVEFLWDPLSTSQTTSLITHCRVILEEHSTCENEVSKSRQDLLKSIVSRMKKAVEDDVFIPLYPKSAVENKTSPHSKFQERQFWSGLKLFRNILLWNGLLTDDTLQELGLGKLLNRYLIIALLNATPGPDVVKKCNQVAACLPEKWFENSAMRTSIPQLENFIQFLLQSAHKLSRSEFRDEVEEIILILVKIKALNQAESFIGEHHLDHLKSLIKED>sp|P16383-3|GCFC2_HUMAN Isoform 3 of Intron Large complex componentGCFC2 OS=Homo sapiens OX=9606 GN=GCFC2MAHRPKRTFRQRAADSSDSDGAEESPAEPGAPRELPVPGSAEEEPPSGGGRAQVAGLPHRVRGPRGRGRVWASSRRATKAAPRADEGSESRTLDVSTDEEDKIHHSSESKDDQGLSSDSSSSLGEKELSSTVKIPDAAFIQAARRKRELARAQDDYISLDVQHTSSISGMKRESEDDPESEPDDHEKRIPFTLRPQTLRQRMAEESSMDLPIYED>sp|P16383-4|GCFC2_HUMAN Isoform 4 of Intron Large complex componentGCFC2 OS=Homo sapiens OX=9606 GN=GCFC2MAHRPKRTFRQRAADSSDSDGAEESPAEPGAPRELPVPGSAEEEPPSGGGRAQVAGLPHRVRGPRGRGRVWASSRRATKAAPRADEGSESRTLDVSTDEEDKIHHSSESKDDQGLSSDSSSSLGEKELSSTVKIPDAAFIQAARRKRELARAQDDYISLDVQHTSSISGMKRESEDDPESEPDDHEKRIPFTLRPQTLRQRMAEESISRNEETSEESQEDEKQDTWEQQQMRKAVKIIEINITTGNSPLTPEGV>sp|Q9BXV9|GON7_HUMAN EKC/KEOPS complex subunit GON7 OS=Homo sapiensOX=9606 GN=GON7 PE=1 SV=2MELLGEYVGQEGKPQKLRVSCEAPGDGDPFQGLLSGVAQMKDMVTELFDPLVQGEVQHRVAAAPDEDLDGDDEDDAEDENNIDNRTNFDGPSAKRPKTPS>sp|Q9Y5U9|IR3IP_HUMAN Immediate early response 3-interacting protein 1OS=Homo sapiens OX=9606 GN=IER3IP1 PE=1 SV=1MAFTLYSLLQAALLCVNAIAVLHEERFLKNIGWGTDQGIGGFGEEPGIKSQLMNLIRSVRTVMRVPLIIVNSIAIVLLLLFG>sp|P05111|INHA_HUMAN Inhibin alpha chain OS=Homo sapiens OX=9606 GN=INHAPE=1 SV=1MVLHLLLFLLLTPQGGHSCQGLELARELVLAKVRALFLDALGPPAVTREGGDPGVRRLPRRHALGGFTHRGSEPEEEEDVSQAILFPATDASCEDKSAARGLAQEAEEGLFRYMFRPSQHTRSRQVTSAQLWFHTGLDRQGTAASNSSEPLLGLLALSPGGPVAVPMSLGHAPPHWAVLHLATSALSLLTHPVLVLLLRCPLCTCSARPEATPFLVAHTRTRPPSGGERARRSTPLMSWPWSPSALRLLQRPPEEPAAHANCHRVALNISFQELGWERWIVYPPSFIFHYCHGGCGLHIPPNLSLPVPGAPPTPAQPYSLLPGAQPCCAALPGTMRPLHVRTTSDGGYSFKYETVPNLLTQHCACI>sp|Q9UK76|JUPI1_HUMAN Jupiter microtubule associated homolog 1 OS=Homosapiens OX=9606 GN=JPT1 PE=1 SV=3MTTTTTFKGVDPNSRNSSRVLRPPGGGSNFSLGFDEPTEQPVRKNKMASNIFGTPEENQASWAKSAGAKSSGGREDLESSGLQRRNSSEASSGDFLDLKGEGDIHENVDTDLPGSLGQSEEKPVPAAPVPSPVAPAPVPSRRNPPGGKSSLVLG>sp|Q9UK76-2|JUPI1_HUMAN Isoform 2 of Jupiter microtubule associatedhomolog 1 OS=Homo sapiens OX=9606 GN=JPT1MTTTTTFKGVDPNSRNSSRVLRPPGGGSNFSLGFDEPTEQPVRKNKMASNIFGTPEENQASWAKSAGAKSSGGREDLESSGLQRRNSSEASSGDFLDLKKMWTQTCQAAWGRVKRSPCLLRLCPARWPRPQCHPEEIPLAASPASSWVSSDCPERCRSVCFLHACELHNLSLTVHLLDLFH>sp|Q9UK76-3|JUPI1_HUMAN Isoform 3 of Jupiter microtubule associatedhomolog 1 OS=Homo sapiens OX=9606 GN=JPT1MASNIFGTPEENQASWAKSAGAKSSGGREDLESSGLQRRNSSEASSGDFLDLKGEGDIHENVDTDLPGSLGQSEEKPVPAAPVPSPVAPAPVPSRRNPPGGKSSLVLG>sp|Q9H910|JUPI2_HUMAN Jupiter microtubule associated homolog 2 OS=Homosapiens OX=9606 GN=JPT2 PE=1 SV=1MFQVPDSEGGRAGSRAMKPPGGESSNLFGSPEEATPSSRPNRMASNIFGPTEEPQNIPKRTNPPGGKGSGIFDESTPVQTRQHLNPPGGKTSDIFGSPVTATSRLAHPNKPKDHVFLCEGEEPKSDLKAARSIPAGAEPGEKGSARKAGPAKEQEPMPTVDSHEPRLGPRPRSHNKVLNPPGGKSSISFY>sp|Q9H910-2|JUPI2_HUMAN Isoform 2 of Jupiter microtubule associatedhomolog 2 OS=Homo sapiens OX=9606 GN=JPT2MKPPGGESSNLFGSPEEATPSSRPNRMASNIFGPTEEPQNIPKRTNPPGGKGSGIFDESTPVQTRQHLNPPGGKTSDIFGSPVTATSRLAHPNKPKDHVFLCEGEEPKSDLKAARSIPAGAEPGEKGSARKAGPAKEQEPMPTVDSHEPRLGPRPRSHNKVLNPPGGKSSISFY>sp|Q9H910-3|JUPI2_HUMAN Isoform 3 of Jupiter microtubule associatedhomolog 2 OS=Homo sapiens OX=9606 GN=JPT2MFQVPDSEGGRAGSRKWQLLTGSLASTSPSLLSGQGPWAPLQRAMKPPGGESSNLFGSPEEATPSSRPNRMASNIFGPTEEPQNIPKRTNPPGGKGSGIFDESTPVQTRQHLNPPGGKTSDIFGSPVTATSRLAHPNKPKDHVFLCEGEEPKSDLKAARSIPAGAEPGEKGSARKAGPAKEQEPMPTVDSHEPRLGPRPRSHNKVLNPPGGKSSISFY>sp|P05161|ISG15_HUMAN Ubiquitin-like protein ISG15 OS=Homo sapiensOX=9606 GN=ISG15 PE=1 SV=5MGWDLTVKMLAGNEFQVSLSSSMSVSELKAQITQKIGVHAFQQRLAVHPSGVALQDRVPLASQGLGPGSTVLLVVDKCDEPLSILVRNNKGRSSTYEVRLTQTVAHLKQQVSGLEGVQDDLFWLTFEGKPLEDQLPLGEYGLKPLSTVFMNLRLRGGGTEPGGRS>sp|Q96AZ6|ISG20_HUMAN Interferon-stimulated gene 20 kDa protein OS=Homosapiens OX=9606 GN=ISG20 PE=1 SV=2MAGSREVVAMDCEMVGLGPHRESGLARCSLVNVHGAVLYDKFIRPEGEITDYRTRVSGVTPQHMVGATPFAVARLEILQLLKGKLVVGHDLKHDFQALKEDMSGYTIYDTSTDRLLWREAKLDHCRRVSLRVLSERLLHKSIQNSLLGHSSVEDARATMELYQISQRIRARRGLPRLAVSD>sp|Q96AZ6-2|ISG20_HUMAN Isoform 2 of Interferon-stimulated gene 20 kDaprotein OS=Homo sapiens OX=9606 GN=ISG20MAGSREVVAMDCEMVGLGPHRESGLARCSLVNVHGAVLYDKFIRPEGEITDYRTRVSGVTPQHMVGATPFAVARLEVPFPSSPTAA>sp|Q6NUI2|GPAT2_HUMAN Glycerol-3-phosphate acyltransferase 2,mitochondrial OS=Homo sapiens OX=9606 GN=GPAT2 PE=2 SV=2MATMLEGRCQTQPRSSPSGREASLWSSGFGMKLEAVTPFLGKYRPFVGRCCQTCTPKSWESLFHRSITDLGFCNVILVKEENTRFRGWLVRRLCYFLWSLEQHIPPCQDVPQKIMESTGVQNLLSGRVPGGTGEGQVPDLVKKEVQRILGHIQAPPRPFLVRLFSWALLRFLNCLFLNVQLHKGQMKMVQKAAQAGLPLVLLSTHKTLLDGILLPFMLLSQGLGVLRVAWDSRACSPALRALLRKLGGLFLPPEASLSLDSSEGLLARAVVQAVIEQLLVSGQPLLIFLEEPPGALGPRLSALGQAWVGFVVQAVQVGIVPDALLVPVAVTYDLVPDAPCDIDHASAPLGLWTGALAVLRSLWSRWGCSHRICSRVHLAQPFSLQEYIVSARSCWGGRQTLEQLLQPIVLGQCTAVPDTEKEQEWTPITGPLLALKEEDQLLVRRLSCHVLSASVGSSAVMSTAIMATLLLFKHQKLLGEFSWLTEEILLRGFDVGFSGQLRSLLQHSLSLLRAHVALLRIRQGDLLVVPQPGPGLTHLAQLSAELLPVFLSEAVGACAVRGLLAGRVPPQGPWELQGILLLSQNELYRQILLLMHLLPQDLLLLKPCQSSYCYCQEVLDRLIQCGLLVAEETPGSRPACDTGRQRLSRKLLWKPSGDFTDSDSDDFGEADGRYFRLSQQSHCPDFFLFLCRLLSPLLKAFAQAAAFLRQGQLPDTELGYTEQLFQFLQATAQEEGIFECADPKLAISAVWTFRDLGVLQQTPSPAGPRLHLSPTFASLDNQEKLEQFIRQFICS>sp|Q6NUI2-3|GPAT2_HUMAN Isoform 2 of Glycerol-3-phosphateacyltransferase 2, mitochondrial OS=Homo sapiens OX=9606 GN=GPAT2MATMLEGRCQTQPRSSPSGREASLWSSGFGMKLEAVTPFLGKYRPFVGRCCQTCTPKSWESLFHRSITDLGFCNVILVKEENTRFRGWLVRRLCYFLWSLEQHIPPCQDVPQKIMESTGVQNLLSGRVPGGTGEGQVPDLVKKEVQRILGHIQAPPRPFLVRLFSWALLRFLNCLFLNVQLHKGQMKMVQKAAQAGLPLVLLSTHKTLLDGILLPFMLLSQGLGVLRVAWDSRACSPALRALLRKLGGLFLPPEASLSLDSSEGLLARAVVQAVIEQLLVSGQPLLIFLEEPPGALGPRLSALGQAWVGFVVQAVQVGIVPDALLVPVAVTYDLVPDAPCDIDHASAPLGLWTGALAVLRSLWSRWGCSHRICSRVHLAQPFSLQEYIVSARSCWGGRQTLEQLLQPIVLGQCTAVPDTEKEQEWTPITGPLLALKEEDQLLVRRLSCHVLSASVGSSAVMSTAIMATLLLFKHQKLLGEFSWLTEEILLRGFDVGFSGQLRSLLQHSLSLLRAHVALLRIRQGDLLVVPQPGPGLTHLAQLSAELLPVFLSEAVGACAVRGLLAGRVPPQGPWELQGILLLSQNELYRQILLLMHLLPQDLLLLKPCQSSYCYCQEVLDRLIQCGLLVAEESWATQSSCSSSCRPPPRKKGSSSVRTQSSPSVLSGPSET>sp|Q6NUI2-4|GPAT2_HUMAN Isoform 3 of Glycerol-3-phosphateacyltransferase 2, mitochondrial OS=Homo sapiens OX=9606 GN=GPAT2MATMLEGRCQTQPRSSPSGREASLWSSGFGMKLEAVTPFLGKYRPFVGRCCQTCTPKSWESLFHRSITDLGFCNVILVKEENTRFRGWLVRRLCYFLWSLEQHIPPCQDVPQKIMESTGVQNLLSGRVPGGTGEGQVPDLVKKEVQRILGHIQAPPRPFLVRLFSWALLRFLNCLFLNVQLHKGQMKMVQKAAQAGLPLVLLSTHKTLLDGILLPFMLLSQGLGVLRVAWDSRACSPALRALLRKLGGLFLPPEASLSLDSSEGLLARAVVQAVIEQLLVSGQPLLIFLEEPPGALGPRLSALGQAWVGFVVQAVQVGIVPDALLVPVAVTYDLVPDAPCDIDHASAPLGLWTGALAVLRSLWSRWGCSHRICSRVHLAQPFSLQEYIVSARSCWGGRQTLEQLLQPIVLGQCTAVPDTEKEQEWTPITGPLLALKEEDQLLVRRLSCHVLSASVGSSAVMSTAIMATLLLFKHQKGVFLSQLLGEFSWLTEEILLRGFDVGFSGQLRSLLQHSLSLLRAHVALLRIRQGDLLVVPQPGPGLTHLAQLSAELLPVFLSEAVGACAVRGLLAGRVPPQGPWELQGILLLSQNELYRQILLLMHLLPQDLLLLKPCQSSYCYCQEVLDRLIQCGLLVAEETPGSRPACDTGRQRLSRKLLWKPSGDFTDSDSDDFGEADGRYFRLSQQSHCPDFFLFLCRLLSPLLKAFAQAAAFLRQGQLPDTELGYTEQLFQFLQATAQEEGIFECADPKLAISAVWTFRDLGVLQQTPSPAGPRLHLSPTFASLDNQEKLEQFIRQFICS>sp|Q6NUI2-5|GPAT2_HUMAN Isoform 4 of Glycerol-3-phosphateacyltransferase 2, mitochondrial OS=Homo sapiens OX=9606 GN=GPAT2MLLSQGLGVLRVAWDSRACSPALRALLRKLGGLFLPPEASLSLDSSEGLLARAVVQAASAPLGLWTGALAVLRSLWSRWGCSHRICSRVHLAQPFSLQEYIVSARSCWGGRQTLEQLLQPIVLGQCTAVPDTEKEQEWTPITGPLLALKEEDQLLVRRLSCHVLSASVGSSAVMSTAIMATLLLFKHQKLLGEFSWLTEEILLRGFDVGFSGQLRSLLQHSLSLLRAHVALLRIRQGDLLVVPQPGPGLTHLAQLSAELLPVFLSEAVGACAVRGLLAGRVPPQGPWELQGILLLSQNELYRQILLLMHLLPQDLLLLKPCQSSYCYCQEVLDRLIQCGLLVAEETPGSRPACDTGRQRLSRKLLWKPSGDFTDSDSDDFGEADGRYFRLSQQSHCPDFFLFLCRLLSPLLKAFAQAAAFLRQGQLPDTELGYTEQLFQFLQATAQEEGIFECADPKLAISAVWTFRDLGVLQQTPSPAGPRLHLSPTFASLDNQEKLEQFIRQFICS>sp|Q16538|GP162_HUMAN Probable G-protein coupled receptor 162 OS=Homosapiens OX=9606 GN=GPR162 PE=1 SV=1MARGGAGAEEASLRSNALSWLACGLLALLANAWIILSISAKQQKHKPLELLLCFLAGTHILMAAVPLTTFAVVQLRRQASSDYDWNESICKVFVSTYYTLALATCFTVASLSYHRMWMVRWPVNYRLSNAKKQALHAVMGIWMVSFILSTLPSIGWHNNGERYYARGCQFIVSKIGLGFGVCFSLLLLGGIVMGLVCVAITFYQTLWARPRRARQARRVGGGGGTKAGGPGALGTRPAFEVPAIVVEDARGKRRSSLDGSESAKTSLQVTNLVSAIVFLYDSLTGVPILVVSFFSLKSDSAPPWMVLAVLWCSMAQTLLLPSFIWSCERYRADVRTVWEQCVAIMSEEDGDDDGGCDDYAEGRVCKVRFDANGATGPGSRDPAQVKLLPGRHMLFPPLERVHYLQVPLSRRLSHDETNIFSTPREPGSFLHKWSSSDDIRVLPAQSRALGGPPEYLGQRHRLEDEEDEEEAEGGGLASLRQFLESGVLGSGGGPPRGPGFFREEITTFIDETPLPSPTASPGHSPRRPRPLGLSPRRLSLGSPESRAVGLPLGLSAGRRCSLTGGEESARAWGGSWGPGNPIFPQLTL>sp|Q16538-2|GP162_HUMAN Isoform 2 of Probable G-protein coupled receptor162 OS=Homo sapiens OX=9606 GN=GPR162MLSTGVVSFFSLKSDSAPPWMVLAVLWCSMAQTLLLPSFIWSCERYRADVRTVWEQCVAIMSEEDGDDDGGCDDYAEGRVCKVRFDANGATGPGSRDPAQVKLLPGRHMLFPPLERVHYLQVPLSRRLSHDETNIFSTPREPGSFLHKWSSSDDIRVLPAQSRALGGPPEYLGQRHRLEDEEDEEEAEGGGLASLRQFLESGVLGSGGGPPRGPGFFREEITTFIDETPLPSPTASPGHSPRRPRPLGLSPRRLSLGSPESRAVGLPLGLSAGRRCSLTGGEESARAWGGSWGPGNPIFPQLTL>sp|Q86UL3|GPAT4_HUMAN Glycerol-3-phosphate acyltransferase 4 OS=Homosapiens OX=9606 GN=GPAT4 PE=1 SV=1MFLLLPFDSLIVNLLGISLTVLFTLLLVFIIVPAIFGVSFGIRKLYMKSLLKIFAWATLRMERGAKEKNHQLYKPYTNGIIAKDPTSLEEEIKEIRRSGSSKALDNTPEFELSDIFYFCRKGMETIMDDEVTKRFSAEELESWNLLSRTNYNFQYISLRLTVLWGLGVLIRYCFLLPLRIALAFTGISLLVVGTTVVGYLPNGRFKEFMSKHVHLMCYRICVRALTAIITYHDRENRPRNGGICVANHTSPIDVIILASDGYYAMVGQVHGGLMGVIQRAMVKACPHVWFERSEVKDRHLVAKRLTEHVQDKSKLPILIFPEGTCINNTSVMMFKKGSFEIGATVYPVAIKYDPQFGDAFWNSSKYGMVTYLLRMMTSWAIVCSVWYLPPMTREADEDAVQFANRVKSAIARQGGLVDLLWDGGLKREKVKDTFKEEQQKLYSKMIVGNHKDRSRS>sp|Q96AB3|ISOC2_HUMAN Isochorismatase domain-containing protein 2OS=Homo sapiens OX=9606 GN=ISOC2 PE=1 SV=1MAAARPSLGRVLPGSSVLFLCDMQEKFRHNIAYFPQIVSVAARMLKVARLLEVPVMLTEQYPQGLGPTVPELGTEGLRPLAKTCFSMVPALQQELDSRPQLRSVLLCGIEAQACILNTTLDLLDRGLQVHVVVDACSSRSQVDRLVALARMRQSGAFLSTSEGLILQLVGDAVHPQFKEIQKLIKEPAPDSGLLGLFQGQNSLLH>sp|Q96AB3-2|ISOC2_HUMAN Isoform 2 of Isochorismatase domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=ISOC2MAAARPSLGRVLPGSSVLFLCDMQEKFRHNIAYFPQIVSVAARMLKVARLLEVPVMLTEQYPQGLGPTVPELGTEGLRPLAKTCFSMVPALQQELDSRPQLRSVLLCGIEAQACILDPRSYPGLALTSLYPQNTTLDLLDRGLQVHVVVDACSSRSQVDRLVALARMRQSGAFLSTSEGLILQLVGDAVHPQFKEIQKLIKEPAPDSGLLGLFQGQNSLLH>sp|Q96AB3-3|ISOC2_HUMAN Isoform 3 of Isochorismatase domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=ISOC2MAAARPSLGRVLPGSSVLFLCDMQEKFRHNIAYFPQIVSVAARMLKNTTLDLLDRGLQVHVVVDACSSRSQVDRLVALARMRQSGAFLSTSEGLILQLVGDAVHPQFKEIQKLIKEPAPDSGLLGLFQGQNSLLH>sp|O15218|GP182_HUMAN G-protein coupled receptor 182 OS=Homo sapiensOX=9606 GN=GPR182 PE=2 SV=1MSVKPSWGPGPSEGVTAVPTSDLGEIHNWTELLDLFNHTLSECHVELSQSTKRVVLFALYLAMFVVGLVENLLVICVNWRGSGRAGLMNLYILNMAIADLGIVLSLPVWMLEVTLDYTWLWGSFSCRFTHYFYFVNMYSSIFFLVCLSVDRYVTLTSASPSWQRYQHRVRRAMCAGIWVLSAIIPLPEVVHIQLVEGPEPMCLFMAPFETYSTWALAVALSTTILGFLLPFPLITVFNVLTACRLRQPGQPKSRRHCLLLCAYVAVFVMCWLPYHVTLLLLTLHGTHISLHCHLVHLLYFFYDVIDCFSMLHCVINPILYNFLSPHFRGRLLNAVVHYLPKDQTKAGTCASSSSCSTQHSIIITKGDSQPAAAAPHPEPSLSFQAHHLLPNTSPISPTQPLTPS>sp|Q6IE38|ISK14_HUMAN Serine protease inhibitor Kazal-type 14 OS=Homosapiens OX=9606 GN=SPINK14 PE=3 SV=1MAKSFPVFSLLSFILIHLVLSSVSGPRHWWPPRGIIKVKCPYEKVNLSWYNGTVNPCPGLYQPICGTNFITYDNPCILCVESLKSHGRIRFYHDGKC>sp|P27987|IP3KB_HUMAN Inositol-trisphosphate 3-kinase B OS=Homo sapiensOX=9606 GN=ITPKB PE=1 SV=5MAVYCYALNSLVIMNSANEMKSGGGPGPSGSETPPPPRRAVLSPGSVFSPGRGASFLFPPAESLSPEEPRSPGGWRSGRRRLNSSSGSGSGSSGSSVSSPSWAGRLRGDRQQVVAAGTLSPPGPEEAKRKLRILQRELQNVQVNQKVGMFEAHIQAQSSAIQAPRSPRLGRARSPSPCPFRSSSQPPGRVLVQGARSEERRTKSWGEQCPETSGTDSGRKGGPSLCSSQVKKGMPPLPGRAAPTGSEAQGPSAFVRMEKGIPASPRCGSPTAMEIDKRGSPTPGTRSCLAPSLGLFGASLTMATEVAARVTSTGPHRPQDLALTEPSGRARELEDLQPPEALVERQGQFLGSETSPAPERGGPRDGEPPGKMGKGYLPCGMPGSGEPEVGKRPEETTVSVQSAESSDSLSWSRLPRALASVGPEEARSGAPVGGGRWQLSDRVEGGSPTLGLLGGSPSAQPGTGNVEAGIPSGRMLEPLPCWDAAKDLKEPQCPPGDRVGVQPGNSRVWQGTMEKAGLAWTRGTGVQSEGTWESQRQDSDALPSPELLPQDPDKPFLRKACSPSNIPAVIITDMGTQEDGALEETQGSPRGNLPLRKLSSSSASSTGFSSSYEDSEEDISSDPERTLDPNSAFLHTLDQQKPRVSKSWRKIKNMVHWSPFVMSFKKKYPWIQLAGHAGSFKAAANGRILKKHCESEQRCLDRLMVDVLRPFVPAYHGDVVKDGERYNQMDDLLADFDSPCVMDCKMGIRTYLEEELTKARKKPSLRKDMYQKMIEVDPEAPTEEEKAQRAVTKPRYMQWRETISSTATLGFRIEGIKKEDGTVNRDFKKTKTREQVTEAFREFTKGNHNILIAYRDRLKAIRTTLEVSPFFKCHEVIGSSLLFIHDKKEQAKVWMIDFGKTTPLPEGQTLQHDVPWQEGNREDGYLSGLNNLVDILTEMSQDAPLA>sp|P27987-2|IP3KB_HUMAN Isoform 2 of Inositol-trisphosphate 3-kinase BOS=Homo sapiens OX=9606 GN=ITPKBMAVYCYALNSLVIMNSANEMKSGGGPGPSGSETPPPPRRAVLSPGSVFSPGRGASFLFPPAESLSPEEPRSPGGWRSGRRRLNSSSGSGSGSSGSSVSSPSWAGRLRGDRQQVVAAGTLSPPGPEEAKRKLRILQRELQNVQVNQKVGMFEAHIQAQSSAIQAPRSPRLGRARSPSPCPFRSSSQPPGRVLVQGARSEERRTKSWGEQCPETSGTDSGRKGGPSLCSSQVKKGMPPLPGRAAPTGSEAQGPSAFVRMEKGIPASPRCGSPTAMEIDKRGSPTPGTRSCLAPSLGLFGASLTMATEVAARVTSTGPHRPQDLALTEPSGRARELEDLQPPEALVERQGQFLGSETSPAPERGGPRDGEPPGKMGKGYLPCGMPGSGEPEVGKRPEETTVSVQSAESSDSLSWSRLPRALASVGPEEARSGAPVGGGRWQLSDRVEGGSPTLGLLGGSPSAQPGTGNVEAGIPSGRMLEPLPCWDAAKDLKEPQCPPGDRVGVQPGNSRVWQGTMEKAGLAWTRGTGVQSEGTWESQRQDSDALPSPELLPQDPDKPFLRKACSPSNIPAVIITDMGTQEDGALEETQGSPRGNLPLRKLSSSSASSTGFSSSYEDSEEDISSDPERTLDPNSAFLHTLDQQKPRV>sp|P07359|GP1BA_HUMAN Platelet glycoprotein Ib alpha chain OS=Homosapiens OX=9606 GN=GP1BA PE=1 SV=2MPLLLLLLLLPSPLHPHPICEVSKVASHLEVNCDKRNLTALPPDLPKDTTILHLSENLLYTFSLATLMPYTRLTQLNLDRCELTKLQVDGTLPVLGTLDLSHNQLQSLPLLGQTLPALTVLDVSFNRLTSLPLGALRGLGELQELYLKGNELKTLPPGLLTPTPKLEKLSLANNNLTELPAGLLNGLENLDTLLLQENSLYTIPKGFFGSHLLPFAFLHGNPWLCNCEILYFRRWLQDNAENVYVWKQGVDVKAMTSNVASVQCDNSDKFPVYKYPGKGCPTLGDEGDTDLYDYYPEEDTEGDKVRATRTVVKFPTKAHTTPWGLFYSWSTASLDSQMPSSLHPTQESTKEQTTFPPRWTPNFTLHMESITFSKTPKSTTEPTPSPTTSEPVPEPAPNMTTLEPTPSPTTPEPTSEPAPSPTTPEPTSEPAPSPTTPEPTSEPAPSPTTPEPTPIPTIATSPTILVSATSLITPKSTFLTTTKPVSLLESTKKTIPELDQPPKLRGVLQGHLESSRNDPFLHPDFCCLLPLGFYVLGLFWLLFASVVLILLLSWVGHVKPQALDSGQGAALTTATQTTHLELQRGRQVTVPRAWLLFLRGSLPTFRSSLFLWVRPNGRVGPLVAGRRPSALSQGRGQDLLSTVSIRYSGHSL>sp|Q9H2G9|GO45_HUMAN Golgin-45 OS=Homo sapiens OX=9606 GN=BLZF1 PE=1SV=2MTTKNLETKVTVTSSPIRGAGDGMETEEPPKSVEVTSGVQSRKHHSLQSPWKKAVPSESPGVLQLGKMLTEKAMEVKAVRILVPKAAITHDIPNKNTKVKSLGHHKGEFLGQSEGVIEPNKELSEVKNVLEKLKNSERRLLQDKEGLSNQLRVQTEVNRELKKLLVASVGDDLQYHFERLAREKNQLILENEALGRNTAQLSEQLERMSIQCDVWRSKFLASRVMADELTNSRAALQRQNRDAHGAIQDLLSEREQFRQEMIATQKLLEELLVSLQWGREQTYSPSVQPHSTAELALTNHKLAKAVNSHLLGNVGINNQKKIPSTVEFCSTPAEKMAETVLRILDPVTCKESSPDNPFFESSPTTLLATKKNIGRFHPYTRYENITFNCCNHCRGELIAL>sp|Q9H2G9-2|GO45_HUMAN Isoform 2 of Golgin-45 OS=Homo sapiens OX=9606GN=BLZF1MTTKNLETKVTVTSSPIRGAGDGMETEEPPKSVEVTSGVQSRKHHSLQSPWKKAVPSESPGVLQLGKMLTEKAMEVKAVRILVPKAAITHDIPNKNTKVKSLGHHKGEFLGQSEGVIEPNKELSEVKNVLEKLKNSERRLLQDKEGLSNQLRVQTEVRRALIDKMSTTLYVWTF>sp|Q9NW75|GPTC2_HUMAN G patch domain-containing protein 2 OS=Homosapiens OX=9606 GN=GPATCH2 PE=1 SV=1MFGAAGRQPIGAPAAGNSWHFSRTMEELVHDLVSALEESSEQARGGFAETGDHSRSISCPLKRQARKRRGRKRRSYNVHHPWETGHCLSEGSDSSLEEPSKDYRENHNNNKKDHSDSDDQMLVAKRRPSSNLNNNVRGKRPLWHESDFAVDNVGNRTLRRRRKVKRMAVDLPQDISNKRTMTQPPEGCRDQDMDSDRAYQYQEFTKNKVKKRKLKIIRQGPKIQDEGVVLESEETNQTNKDKMECEEQKVSDELMSESDSSSLSSTDAGLFTNDEGRQGDDEQSDWFYEKESGGACGITGVVPWWEKEDPTELDKNVPDPVFESILTGSFPLMSHPSRRGFQARLSRLHGMSSKNIKKSGGTPTSMVPIPGPVGNKRMVHFSPDSHHHDHWFSPGARTEHDQHQLLRDNRAERGHKKNCSVRTASRQTSMHLGSLCTGDIKRRRKAAPLPGPTTAGFVGENAQPILENNIGNRMLQNMGWTPGSGLGRDGKGISEPIQAMQRPKGLGLGFPLPKSTSATTTPNAGKSA>sp|Q9NW75-2|GPTC2_HUMAN Isoform 2 of G patch domain-containing protein 2OS=Homo sapiens OX=9606 GN=GPATCH2MFGAAGRQPIGAPAAGNSWHFSRTMEELVHDLVSALEESSEQARGGFAETGDHSRSISCPLKRQARKRRGRKRRSYNVHHPWETGHCLSEGSDSSLEEPSKDYRENHNNNKKDHSDSDDQMLVAKRRPSSNLNNNVRGKRPLWHESDFAVDNVGNRTLRRRRKVKRMAVDLPQDISNKRTMTQPPEGCRDQDMDSDRAYQYQEFTKNKVKKRKLKIIRQGPKIQDEGVVLESEETNQTNKDKMECEEQKVSDELMSESDSSSLSSTDAGLFTNDEGRQGDDEQSDWFYEKESGGACGITGVVPWWEKEDPTELDKNVPDPVFESILTGSFPLMSHPSRRGFQARLSRLHGMSSKNIKKSGGTPTSMATNWTSEIPL>sp|O43187|IRAK2_HUMAN Interleukin-1 receptor-associated kinase-like 2OS=Homo sapiens OX=9606 GN=IRAK2 PE=1 SV=2MACYIYQLPSWVLDDLCRNMDALSEWDWMEFASYVITDLTQLRKIKSMERVQGVSITRELLWWWGMRQATVQQLVDLLCRLELYRAAQIILNWKPAPEIRCPIPAFPDSVKPEKPLAASVRKAEDEQEEGQPVRMATFPGPGSSPARAHQPAFLQPPEEDAPHSLRSDLPTSSDSKDFSTSIPKQEKLLSLAGDSLFWSEADVVQATDDFNQNRKISQGTFADVYRGHRHGKPFVFKKLRETACSSPGSIERFFQAELQICLRCCHPNVLPVLGFCAARQFHSFIYPYMANGSLQDRLQGQGGSDPLPWPQRVSICSGLLCAVEYLHGLEIIHSNVKSSNVLLDQNLTPKLAHPMAHLCPVNKRSKYTMMKTHLLRTSAAYLPEDFIRVGQLTKRVDIFSCGIVLAEVLTGIPAMDNNRSPVYLKDLLLSDIPSSTASLCSRKTGVENVMAKEICQKYLEKGAGRLPEDCAEALATAACLCLRRRNTSLQEVCGSVAAVEERLRGRETLLPWSGLSEGTGSSSNTPEETDDVDNSSLDASSSMSVAPWAGAATPLLPTENGEGRLRVIVGREADSSSEACVGLEPPQDVTETSWQIEINEAKRKLMENILLYKEEKVDSIELFGP>sp|Q9NWQ4|GPT2L_HUMAN G patch domain-containing protein 2-like OS=Homosapiens OX=9606 GN=GPATCH2L PE=1 SV=3MDELVHDLASALEQTSEQNKLGELWEEMALSPRQQRRQLRKRRGRKRRSDFTHLAEHTCCYSEASESSLDEATKDCREVAPVTNFSDSDDTMVAKRHPALNAIVKSKQHSWHESDSFTENAPCRPLRRRRKVKRVTSEVAASLQQKLKVSDWSYERGCRFKSAKKQRLSRWKENTPWTSSGHGLCESAENRTFLSKTGRKERMECETDEQKQGSDENMSECETSSVCSSSDTGLFTNDEGRQGDDEQSDWFYEGECVPGFTVPNLLPKWAPDHCSEVERMDSGLDKFSDSTFLLPSRPAQRGYHTRLNRLPGAAARCLRKGRRRLVGKETSINTLGTERISHIISDPRQKEKNKALASDFPHISACAHEFNPLSPLYSLDVLADASHRRCSPAHCSARQANVHWGPPCSRDIKRKRKPVATASLSSPSAVHMDAVEPTTPASQAPKSPSSEWLVRTSAAEKATDATTATFFKMPQEKSPGYS>sp|Q9NWQ4-1|GPT2L_HUMAN Isoform 2 of G patch domain-containing protein2-like OS=Homo sapiens OX=9606 GN=GPATCH2LMDELVHDLASALEQTSEQNKLGELWEEMALSPRQQRRQLRKRRGRKRRSDFTHLAEHTCCYSEASESSLDEATKDCREVAPVTNFSDSDDTMVAKRHPALNAIVKSKQHSWHESDSFTENAPCRPLRRRRKVKRVTSEVAASLQQKLKVSDWSYERGCRFKSAKKQRLSRWKENTPWTSSGHGLCESAENRTFLSKTGRKERMECETDEQKQGSDENMSECETSSVCSSSDTGLFTNDEGRQGDDEQSDWFYEGECVPGFTVPNLLPKWAPDHCSEVERMDSGLDKFSDSTFLLPSRPAQRGYHTRLNRLPGAAARCLRKGRRRLVGKVIPLTVSLAQWGDNIPYGSCVSY>sp|Q9NWQ4-4|GPT2L_HUMAN Isoform 4 of G patch domain-containing protein2-like OS=Homo sapiens OX=9606 GN=GPATCH2LMDELVHDLASALEQTSEQNKLGELWEEMALSPRQQRRQLRKRRGRKRRSDFTHLAEHTCCYSEASESSLDEATKDCREVAPVTNFSDSDDTMVAKRHPALNAIVKSKQHSWHESDSFTENAPCRPLRRRRKVKRVTSEVAASLQQKLKVSDWSYERGCRFKSAKKQRLSRWKENTPWTSSGHGLCESAENRTFLSKTGRKERMECETDEQKQGSDENMSECETSSVCSSSDTGLFTNDEGRQGDDEQSDWFYEGECVPGFTVPNLLPKWAPDHCSEVERMDSGLDKFSDSTFLLPSRPAQRGYHTRLNRLPGAAARCLRKGRRRLVGKETSINTLGTERISHIISDPRQKDFWLPSAGKRERNQFNPLSPLYSLDVLADASHRRCSPAHCSARQANVHWGPPCSRDIKRKRKPVATASLSSPSAVHMDAVEPTTPASQAPKSPSSEWLVRTSAAEKATDATTATFFKMPQEKSPGYS>sp|P55259|GP2_HUMAN Pancreatic secretory granule membrane majorglycoprotein GP2 OS=Homo sapiens OX=9606 GN=GP2 PE=1 SV=3MPHLMERMVGSGLLWLALVSCILTQASAVQRGYGNPIEASSYGLDLDCGAPGTPEAHVCFDPCQNYTLLDEPFRSTENSAGSQGCDKNMSGWYRFVGEGGVRMSETCVQVHRCQTDAPMWLNGTHPALGDGITNHTACAHWSGNCCFWKTEVLVKACPGGYHVYRLEGTPWCNLRYCTVPRDPSTVEDKCEKACRPEEECLALNSTWGCFCRQDLNSSDVHSLQPQLDCGPREIKVKVDKCLLGGLGLGEEVIAYLRDPNCSSILQTEERNWVSVTSPVQASACRNILERNQTHAIYKNTLSLVNDFIIRDTILNINFQCAYPLDMKVSLQAALQPIVSSLNVSVDGNGEFIVRMALFQDQNYTNPYEGDAVELSVESVLYVGAILEQGDTSRFNLVLRNCYATPTEDKADLVKYFIIRNSCSNQRDSTIHVEENGQSSESRFSVQMFMFAGHYDLVFLHCEIHLCDSLNEQCQPSCSRSQVRSEVPAIDLARVLDLGPITRRGAQSPGVMNGTPSTAGFLVAWPMVLLTVLLAWLF>sp|P55259-2|GP2_HUMAN Isoform Beta of Pancreatic secretory granulemembrane major glycoprotein GP2 OS=Homo sapiens OX=9606 GN=GP2MPHLMERMVGSGLLWLALVSCILTQASAVQRVPRDPSTVEDKCEKACRPEEECLALNSTWGCFCRQDLNSSDVHSLQPQLDCGPREIKVKVDKCLLGGLGLGEEVIAYLRDPNCSSILQTEERNWVSVTSPVQASACRNILERNQTHAIYKNTLSLVNDFIIRDTILNINFQCAYPLDMKVSLQAALQPIVSSLNVSVDGNGEFIVRMALFQDQNYTNPYEGDAVELSVESVLYVGAILEQGDTSRFNLVLRNCYATPTEDKADLVKYFIIRNSCSNQRDSTIHVEENGQSSESRFSVQMFMFAGHYDLVFLHCEIHLCDSLNEQCQPSCSRSQVRSEVPAIDLARVLDLGPITRRGAQSPGVMNGTPSTAGFLVAWPMVLLTVLLAWLF>sp|P55259-3|GP2_HUMAN Isoform Alpha of Pancreatic secretory granulemembrane major glycoprotein GP2 OS=Homo sapiens OX=9606 GN=GP2MPHLMERMVGSGLLWLALVSCILTQASAVQRGYGNPIEASSYGLDLDCGAPGTPEAHVCFDPCQNYTLLDEPFRSTENSAGSQGCDKNMSGWYRFVGEGGVRMSETCVQVHRCQTDAPMWLNGTHPALGDGITNHTACAHWSGNCCFWKTEVLVKACPGGYHVYRLEGTPWCNLRYCTDPSTVEDKCEKACRPEEECLALNSTWGCFCRQDLNSSDVHSLQPQLDCGPREIKVKVDKCLLGGLGLGEEVIAYLRDPNCSSILQTEERNWVSVTSPVQASACRNILERNQTHAIYKNTLSLVNDFIIRDTILNINFQCAYPLDMKVSLQAALQPIVSSLNVSVDGNGEFIVRMALFQDQNYTNPYEGDAVELSVESVLYVGAILEQGDTSRFNLVLRNCYATPTEDKADLVKYFIIRNSCSNQRDSTIHVEENGQSSESRFSVQMFMFAGHYDLVFLHCEIHLCDSLNEQCQPSCSRSQVRSEVPAIDLARVLDLGPITRRGAQSPGVMNGTPSTAGFLVAWPMVLLTVLLAWLF>sp|P55259-4|GP2_HUMAN Isoform 2 of Pancreatic secretory granule membranemajor glycoprotein GP2 OS=Homo sapiens OX=9606 GN=GP2MPHLMERMVGSGLLWLALVSCILTQASAVQRDPSTVEDKCEKACRPEEECLALNSTWGCFCRQDLNSSDVHSLQPQLDCGPREIKVKVDKCLLGGLGLGEEVIAYLRDPNCSSILQTEERNWVSVTSPVQASACRNILERNQTHAIYKNTLSLVNDFIIRDTILNINFQCAYPLDMKVSLQAALQPIVSSLNVSVDGNGEFIVRMALFQDQNYTNPYEGDAVELSVESVLYVGAILEQGDTSRFNLVLRNCYATPTEDKADLVKYFIIRNSCSNQRDSTIHVEENGQSSESRFSVQMFMFAGHYDLVFLHCEIHLCDSLNEQCQPSCSRSQVRSEVPAIDLARVLDLGPITRRGAQSPGVMNGTPSTAGFLVAWPMVLLTVLLAWLF>sp|Q9NZD1|GPC5D_HUMAN G-protein coupled receptor family C group 5 memberD OS=Homo sapiens OX=9606 GN=GPRC5D PE=1 SV=1MYKDCIESTGDYFLLCDAEGPWGIILESLAILGIVVTILLLLAFLFLMRKIQDCSQWNVLPTQLLFLLSVLGLFGLAFAFIIELNQQTAPVRYFLFGVLFALCFSCLLAHASNLVKLVRGCVSFSWTTILCIAIGCSLLQIIIATEYVTLIMTRGMMFVNMTPCQLNVDFVVLLVYVLFLMALTFFVSKATFCGPCENWKQHGRLIFITVLFSIIIWVVWISMLLRGNPQFQRQPQWDDPVVCIALVTNAWVFLLLYIVPELCILYRSCRQECPLQGNACPVTAYQHSFQVENQELSRARDSDGAEEDVALTSYGTPIQPQTVDPTQECFIPQAKLSPQQDAGGV>sp|Q9NZD1-2|GPC5D_HUMAN Isoform 2 of G-protein coupled receptor family Cgroup 5 member D OS=Homo sapiens OX=9606 GN=GPRC5DMYKDCIESTGDYFLLCDAEGPWGIILESLAILGIVVTILLLLAFLFLMRKIQDCSQWNVLPTQLLFLLSVLGLFGLAFAFIIELNQQTAPVRYFLFGVLFALCFSCLLAHASNLVKLVRGCVSFSWTTILCIAIGCSLLQIIIATEYVTLIMTRGMMFVNMTPCQLNVDFVVLLVYVLFLMALTFFVSKATFCGPCENWKQHGRLIFITVLFSIIIWVVWISMLLRGNPQFQRQPQWDDPVVCIALVTNAWVFLLLYIVPELCILYRSCRQECPLQGNACPVTAYQHSFQVENQELSRDC>sp|Q9NZD1-3|GPC5D_HUMAN Isoform 3 of G-protein coupled receptor family Cgroup 5 member D OS=Homo sapiens OX=9606 GN=GPRC5DMYKDCIESTGDYFLLCDAEGPWGIILESLAILGIVVTILLLLAFLFLMRKIQDCSQWNVLPTQLLFLLSVLGLFGLAFAFIIELNQQTAPVRYFLFGVLFALCFSCLLAHASNLVKLVRGCVSFSWTTILCIAIGCSLLQIIIATEYVTLIMTRGMMFVNMTPCQLNVDFVVLLVYVLFLMALTFFVSKATFCGPCENWKQHGRLIFITVLFSIIIWVVWISMLLRGNPQFQRQPQWDDPVVCIALVTNAWVFLLLYIVPELCILYRSCRQECPLQGNACPVTAYQHSFQVENQELSRGTFLGDSGSREVLLQEKQEKNHAVG>sp|Q96I76|GPTC3_HUMAN G patch domain-containing protein 3 OS=Homosapiens OX=9606 GN=GPATCH3 PE=1 SV=1MAVPGEAEEEATVYLVVSGIPSVLRSAHLRSYFSQFREERGGGFLCFHYRHRPERAPPQAAPNSALIPTDPAAEGQLLSQTSATDVRPLSTRDSTPIQTRTCCCVISVRGLAQAQRLIRMYSGRRWLDSHGTWLPGRCLIRRLRLPTEASGLGSFPFKTRKELQSWKAENEAFTLADLKQLPELNPPVLMPRGNVGTPLRVFLELIRACRLPPRIITQLQLQFPKTGSSRRYGNVPFEYEDSETVEQEELVYTAEGEEIPQGTYLADIPASPCGEPEEEVGKEEEEESHSDEDDDRGEEWERHEALHEDVTGQERTTEQLFEEEIELKWEKGGSGLVFYTDAQFWQEEEGDFDEQTADDWDVDMSVYYDRDGGDKDARDSVQMRLEQRLRDGQEDGSVIERQVGTFERHTKGIGRKVMERQGWAEGQGLGCRCSGVPEALDSDGQHPRCKRGLGYHGEKLQPFGQLKRPRRNGLGLISTIYDEPLPQDQTESLLRRQPPTSMKFRTDMAFVRGSSCASDSPSLPD>sp|P43220|GLP1R_HUMAN Glucagon-like peptide 1 receptor OS=Homo sapiensOX=9606 GN=GLP1R PE=1 SV=2MAGAPGPLRLALLLLGMVGRAGPRPQGATVSLWETVQKWREYRRQCQRSLTEDPPPATDLFCNRTFDEYACWPDGEPGSFVNVSCPWYLPWASSVPQGHVYRFCTAEGLWLQKDNSSLPWRDLSECEESKRGERSSPEEQLLFLYIIYTVGYALSFSALVIASAILLGFRHLHCTRNYIHLNLFASFILRALSVFIKDAALKWMYSTAAQQHQWDGLLSYQDSLSCRLVFLLMQYCVAANYYWLLVEGVYLYTLLAFSVLSEQWIFRLYVSIGWGVPLLFVVPWGIVKYLYEDEGCWTRNSNMNYWLIIRLPILFAIGVNFLIFVRVICIVVSKLKANLMCKTDIKCRLAKSTLTLIPLLGTHEVIFAFVMDEHARGTLRFIKLFTELSFTSFQGLMVAILYCFVNNEVQLEFRKSWERWRLEHLHIQRDSSMKPLKCPTSSLSSGATAGSSMYTATCQASCS>sp|P40197|GPV_HUMAN Platelet glycoprotein V OS=Homo sapiens OX=9606GN=GP5 PE=1 SV=1MLRGTLLCAVLGLLRAQPFPCPPACKCVFRDAAQCSGGDVARISALGLPTNLTHILLFGMGRGVLQSQSFSGMTVLQRLMISDSHISAVAPGTFSDLIKLKTLRLSRNKITHLPGALLDKMVLLEQLFLDHNALRGIDQNMFQKLVNLQELALNQNQLDFLPASLFTNLENLKLLDLSGNNLTHLPKGLLGAQAKLERLLLHSNRLVSLDSGLLNSLGALTELQFHRNHIRSIAPGAFDRLPNLSSLTLSRNHLAFLPSALFLHSHNLTLLTLFENPLAELPGVLFGEMGGLQELWLNRTQLRTLPAAAFRNLSRLRYLGVTLSPRLSALPQGAFQGLGELQVLALHSNGLTALPDGLLRGLGKLRQVSLRRNRLRALPRALFRNLSSLESVQLDHNQLETLPGDVFGALPRLTEVLLGHNSWRCDCGLGPFLGWLRQHLGLVGGEEPPRCAGPGAHAGLPLWALPGGDAECPGPRGPPPRPAADSSSEAPVHPALAPNSSEPWVWAQPVTTGKGQDHSPFWGFYFLLLAVQAMITVIIVFAMIKIGQLFRKLIRERALG>sp|Q14330|GPR18_HUMAN N-arachidonyl glycine receptor OS=Homo sapiensOX=9606 GN=GPR18 PE=1 SV=2MITLNNQDQPVPFNSSHPDEYKIAALVFYSCIFIIGLFVNITALWVFSCTTKKRTTVTIYMMNVALVDLIFIMTLPFRMFYYAKDEWPFGEYFCQILGALTVFYPSIALWLLAFISADRYMAIVQPKYAKELKNTCKAVLACVGVWIMTLTTTTPLLLLYKDPDKDSTPATCLKISDIIYLKAVNVLNLTRLTFFFLIPLFIMIGCYLVIIHNLLHGRTSKLKPKVKEKSIRIIITLLVQVLVCFMPFHICFAFLMLGTGENSYNPWGAFTTFLMNLSTCLDVILYYIVSKQFQARVISVMLYRNYLRSMRRKSFRSGSLRSLSNINSEML>sp|Q9Y243|AKT3_HUMAN RAC-gamma serine/threonine-protein kinase OS=Homosapiens OX=9606 GN=AKT3 PE=1 SV=1MSDVTIVKEGWVQKRGEYIKNWRPRYFLLKTDGSFIGYKEKPQDVDLPYPLNNFSVAKCQLMKTERPKPNTFIIRCLQWTTVIERTFHVDTPEEREEWTEAIQAVADRLQRQEEERMNCSPTSQIDNIGEEEMDASTTHHKRKTMNDFDYLKLLGKGTFGKVILVREKASGKYYAMKILKKEVIIAKDEVAHTLTESRVLKNTRHPFLTSLKYSFQTKDRLCFVMEYVNGGELFFHLSRERVFSEDRTRFYGAEIVSALDYLHSGKIVYRDLKLENLMLDKDGHIKITDFGLCKEGITDAATMKTFCGTPEYLAPEVLEDNDYGRAVDWWGLGVVMYEMMCGRLPFYNQDHEKLFELILMEDIKFPRTLSSDAKSLLSGLLIKDPNKRLGGGPDDAKEIMRHSFFSGVNWQDVYDKKLVPPFKPQVTSETDTRYFDEEFTAQTITITPPEKYDEDGMDCMDNERRPHFPQFSYSASGRE>sp|Q9Y243-2|AKT3_HUMAN Isoform 2 of RAC-gamma serine/threonine-proteinkinase OS=Homo sapiens OX=9606 GN=AKT3MSDVTIVKEGWVQKRGEYIKNWRPRYFLLKTDGSFIGYKEKPQDVDLPYPLNNFSVAKCQLMKTERPKPNTFIIRCLQWTTVIERTFHVDTPEEREEWTEAIQAVADRLQRQEEERMNCSPTSQIDNIGEEEMDASTTHHKRKTMNDFDYLKLLGKGTFGKVILVREKASGKYYAMKILKKEVIIAKDEVAHTLTESRVLKNTRHPFLTSLKYSFQTKDRLCFVMEYVNGGELFFHLSRERVFSEDRTRFYGAEIVSALDYLHSGKIVYRDLKLENLMLDKDGHIKITDFGLCKEGITDAATMKTFCGTPEYLAPEVLEDNDYGRAVDWWGLGVVMYEMMCGRLPFYNQDHEKLFELILMEDIKFPRTLSSDAKSLLSGLLIKDPNKRLGGGPDDAKEIMRHSFFSGVNWQDVYDKKLVPPFKPQVTSETDTRYFDEEFTAQTITITPPEKCQQSDCGMLGNWKK>sp|Q8N7X0|ADGB_HUMAN Androglobin OS=Homo sapiens OX=9606 GN=ADGB PE=2SV=3MASKQTKKKEVHRINSAHGSDKSKDFYPFGSNVQSGSTEQKKGKFPLWPEWSEADINSEKWDAGKGAKEKDKTGKSPVFHFFEDPEGKIELPPSLKIYSWKRPQDILFSQTPVVVKNEITFDLFSANEHLLCSELMRWIISEIYAVWKIFNGGILSNYFKGTSGEPPLLPWKPWEHIYSLCKAVKGHMPLFNSYGKYVVKLYWMGCWRKITIDDFLPFDEDNNLLLPATTYEFELWPMLLSKAIIKLANIDIHVADRRELGEFTVIHALTGWLPEVISLHPGYMDKVWELLKEILPEFKLSDEASSESKIAVLDSKLKEPGKEGKEGKEIKDGKEVKDVKEFKPESSLTTLKAPEKSDKVPKEKADARDIGKKRSKDGEKEKFKFSLHGSRPSSEVQYSVQSLSDCSSAIQTSHMVVYATFTPLYLFENKIFSLEKMADSAEKLREYGLSHICSHPVLVTRSRSCPLVAPPKPPPLPPWKLIRQKKETVITDEAQELIVKKPERFLEISSPFLNYRMTPFTIPTEMHFVRSLIKKGIPPGSDLPSVSETDETATHSQTDLSQITKATSQGNTASQVILGKGTDEQTDFGLGDAHQSDGLNLEREIVSQTTATQEKSQEELPTTNNSVSKEIWLDFEDFCVCFQNIYIFHKPSSYCLNFQKSEFKFSEERVSYYLFVDSLKPIELLVCFSALVRWGEYGALTKDSPPIEPGLLTAETFSWKSLKPGSLVLKIHTYATKATVVRLPVGRHMLLFNAYSPVGHSIHICSMVSFVIGDEHVVLPNFEPESCRFTEQSLLIMKAIGNVIANFKDKGKLSAALKDLQTAHYPVPFHDKELTAQHFRVFHLSLWRLMKKVQITKPPPNFKFAFRAMVLDLELLNSSLEEVSLVEWLDVKYCMPTSDKEYSAEEVAAAIKIQAMWRGTYVRLLMKARIPDTKENISVADTLQKVWAVLEMNLEQYAVSLLRLMFKSKCKSLESYPCYQDEETKIAFADYTVTYQEQPPNSWFIVFRETFLVHQDMILVPKVYTTLPICILHIVNNDTMEQVPKVFQKVVPYLYTKNKKGYTFVAEAFTGDTYVAASRWKLRLIGSSAPLPCLSRDSPCNSFAIKEIRDYYIPNDKKILFRYSVKVLTPQPATIQVRTSKPDAFIKLQVLENEETMVSSTGKGQAIIPAFHFLKSEKGLSSQSSKHILSFHSASKKEQEVYVKKKAAQGIQKSPKGRAVSAIQDIGLPLVEEETTSTPTREDSSSTPLQNYKYIIQCSVLYNSWPLTESQLTFVQALKDLKKSNTKAYGERHEELINLGSPDSHTISEGQKSSVTSKTTRKGKEKSSEKEKTAKEKQAPRFEPQISTVHPQQEDPNKPYWILRLVTEHNESELFEVKKDTERADEIRAMKQAWETTEPGRAIKASQARLHYLSGFIKKTSDAESPPISESQTKPKEEVETAARGVKEPNSKNSAGSESKEMTQTGSGSAVWKKWQLTKGLRDVAKSTSSESGGVSSPGKEEREQSTRKENIQTGPRTRSPTILETSPRLIRKALEFMDLSQYVRKTDTDPLLQTDELNQQQAMQKAEEIHQFRQHRTRVLSIRNIDQEERLKLKDEVLDMYKEMQDSLDEARQKIFDIREEYRNKLLEAEHLKLETLAAQEAAMKLETEKMTPAPDTQKKKKGKKK>sp|Q8N7X0-2|ADGB_HUMAN Isoform 2 of Androglobin OS=Homo sapiens OX=9606GN=ADGBMNLEQYAVSLLRLMFKSKCKSLESYPCYQDEETKIAFADYTVTYQEQPPNSWFIVFRETFLVHQDMILVPKVYTTLPICILHIVNNDTMEQVPKVFQKVVPYLYTKNKKGYTFVAEAFTGDTYVAASRWKLRLIGSSAPLPCLSRDSPCNSFAIKEIRDYYIPNDKKILFRYSVKVLTPQPATIQVRTSKPDAFIKLQVLENEETMVSSTGKGQAIIPAFHFLKSEKGLSSQSYGERHEELINLGSPDSHTISEGQKSSVTSKTTRKGKEKSSEKEKTAKEKQAPRFEPQISTVHPQQEDPNKPYWILRLVTEHNESELFEVKKDTERADEIRAMKQAWETTEPGRAIKASQARLHYLSGFIKKTSDAESPPISESQTKPKEEVETAARGVKEPNSKNSAGSESKEMTQTGSGSAVWKKWQLTKGLRDVAKSTSSESGGVSSPGKEEREQSTRKENIQTGPRTRSPTILETSPRLIRKALEFMDLSQYVRKTDTDPLLQTDELNQQQAMQKAEEIHQFRQHRTRVLSIRNIDQEERLKLKDEVLDMYKEMQDSLDEARQKIFDIREEYRNKLLEAEHLKLETLAAQEAAMKLETEKMTPAPDTQKKKKGKKK>sp|Q9NVV5|AIG1_HUMAN Androgen-induced gene 1 protein OS=Homo sapiensOX=9606 GN=AIG1 PE=1 SV=3MALVPCQVLRMAILLSYCSILCNYKAIEMPSHQTYGGSWKFLTFIDLVIQAVFFGICVLTDLSSLLTRGSGNQEQERQLKKLISLRDWMLAVLAFPVGVFVVAVFWIIYAYDREMIYPKLLDNFIPGWLNHGMHTTVLPFILIEMRTSHHQYPSRSSGLTAICTFSVGYILWVCWVHHVTGMWVYPFLEHIGPGARIIFFGSTTILMNFLYLLGEVLNNYIWDTQKSMEEEKEKPKLE>sp|Q9NVV5-1|AIG1_HUMAN Isoform 2 of Androgen-induced gene 1 proteinOS=Homo sapiens OX=9606 GN=AIG1MALVPCQVLRMAILLSYCSILCNYKAIEMPSHQTYGGSWKFLTFIDLVIQAVFFGICVLTDLSSLLTRGSGNQEQERQLKKLISLRDWMLAVLAFPVGVFVVAVFWIIYAYDREMIYPKLLDNFIPGWLNHGMHTTVLPFILIEMRTSHHQYPSRSSGLTAICTFSVGYILWVCWVHHVTGMWVYPFLEHIGPGARIIFFGSTTILMNFLYLLGEVLNNYIWDTQKKPPSWQDMKIKFMYLGPSS>sp|Q9NVV5-3|AIG1_HUMAN Isoform 3 of Androgen-induced gene 1 proteinOS=Homo sapiens OX=9606 GN=AIG1MALVPCQVLRMAILLSYCSILCNYKAIEMPSHQTYGGSWKFLTFIDLFVVAVFWIIYAYDREMIYPKLLDNFIPGWLNHGMHTTVLPFILIEMRTSHHQYPSRSSGLTAICTFSVGYILWVCWVHHVTGMWVYPFLEHIGPGARIIFFGSTTILMNFLYLLGEVLNNYIWDTQKSMEEEKEKPKLE>sp|Q9NVV5-4|AIG1_HUMAN Isoform 4 of Androgen-induced gene 1 proteinOS=Homo sapiens OX=9606 GN=AIG1MAILLSYCSILCNYKAIEMPSHQTYGGSWKFLTFIDLVIQAVFFGICVLTDLSSLLTRGSGNQEQERQLKKLISLRDWMLAVLAFPVGVFVVAVFWIIYAYDREMIYPKLLDNFIPGWLNHGMHTTVLPFILIEMRTSHHQYPSRSSGLTAICTFSVGYILWVCWVHHVTGMWVYPFLEHIGPGARIIFFGSTTILMNFLYLLGEVLNNYIWDTQKSMEEEKEKPKLE>sp|Q9NVV5-5|AIG1_HUMAN Isoform 5 of Androgen-induced gene 1 proteinOS=Homo sapiens OX=9606 GN=AIG1MALVPCQVLRMAILLSYCSILCNYKAIEMPSHQTYGGSWKFLTFIDLVIQAVFFGICVLTDLSSLLTRGSGNQEQERQLKKLISLRDWMLAVLAFPVGVFVVAVFWIIYAYDREMIYPKLLDNFIPGWLNHGMHFKA>sp|Q9NVV5-6|AIG1_HUMAN Isoform 6 of Androgen-induced gene 1 proteinOS=Homo sapiens OX=9606 GN=AIG1MALVPCQVLRMAILLSYCSILCNYKAIEMPSHQTYGGSWKFLTFIDLVIQAVFFGICVLTDLSSLLTRGSGNQEQERQLKKLISLRDWMLAVLAFPVGVFVVAVFWIIYAYDREMIYPKLLDNFIPGWLNHGML>sp|Q8WXG9|AGRV1_HUMAN Adhesion G-protein coupled receptor V1 OS=Homosapiens OX=9606 GN=ADGRV1 PE=1 SV=2MSVFLGPGMPSASLLVNLLSALLILFVFGETEIRFTGQTEFVVNETSTTVIRLIIERIGEPANVTAIVSLYGEDAGDFFDTYAAAFIPAGETNRTVYIAVCDDDLPEPDETFIFHLTLQKPSANVKLGWPRTVTVTILSNDNAFGIISFNMLPSIAVSEPKGRNESMPLTLIREKGTYGMVMVTFEVEGGPNPPDEDLSPVKGNITFPPGRATVIYNLTVLDDEVPENDEIFLIQLKSVEGGAEINTSRNSIEIIIKKNDSPVRFLQSIYLVPEEDHILIIPVVRGKDNNGNLIGSDEYEVSISYAVTTGNSTAHAQQNLDFIDLQPNTTVVFPPFIHESHLKFQIVDDTIPEIAESFHIMLLKDTLQGDAVLISPSVVQVTIKPNDKPYGVLSFNSVLFERTVIIDEDRISRYEEITVVRNGGTHGNVSANWVLTRNSTDPSPVTADIRPSSGVLHFAQGQMLATIPLTVVDDDLPEEAEAYLLQILPHTIRGGAEVSEPAELLFYIQDSDDVYGLITFFPMENQKIESSPGERYLSLSFTRLGGTKGDVRLLYSVLYIPAGAVDPLQAKEGILNISRRNDLIFPEQKTQVTTKLPIRNDAFLQNGAHFLVQLETVELLNIIPLIPPISPRFGEICNISLLVTPAIANGEIGFLSNLPIILHEPEDFAAEVVYIPLHRDGTDGQATVYWSLKPSGFNSKAVTPDDIGPFNGSVLFLSGQSDTTINITIKGDDIPEMNETVTLSLDRVNVENQVLKSGYTSRDLIILENDDPGGVFEFSPASRGPYVIKEGESVELHIIRSRGSLVKQFLHYRVEPRDSNEFYGNTGVLEFKPGEREIVITLLARLDGIPELDEHYWVVLSSHGERESKLGSATIVNITILKNDDPHGIIEFVSDGLIVMINESKGDAIYSAVYDVVRNRGNFGDVSVSWVVSPDFTQDVFPVQGTVVFGDQEFSKNITIYSLPDEIPEEMEEFTVILLNGTGGAKVGNRTTATLRIRRNDDPIYFAEPRVVRVQEGETANFTVLRNGSVDVTCMVQYATKDGKATARERDFIPVEKGETLIFEVGSRQQSISIFVNEDGIPETDEPFYIILLNSTGDTVVYQYGVATVIIEANDDPNGIFSLEPIDKAVEEGKTNAFWILRHRGYFGSVSVSWQLFQNDSALQPGQEFYETSGTVNFMDGEEAKPIILHAFPDKIPEFNEFYFLKLVNISGGSPGPGGQLAETNLQVTVMVPFNDDPFGVFILDPECLEREVAEDVLSEDDMSYITNFTILRQQGVFGDVQLGWEILSSEFPAGLPPMIDFLLVGIFPTTVHLQQHMRRHHSGTDALYFTGLEGAFGTVNPKYHPSRNNTIANFTFSAWVMPNANTNGFIIAKDDGNGSIYYGVKIQTNESHVTLSLHYKTLGSNATYIAKTTVMKYLEESVWLHLLIILEDGIIEFYLDGNAMPRGIKSLKGEAITDGPGILRIGAGINGNDRFTGLMQDVRSYERKLTLEEIYELHAMPAKSDLHPISGYLEFRQGETNKSFIISARDDNDEEGEELFILKLVSVYGGARISEENTTARLTIQKSDNANGLFGFTGACIPEIAEEGSTISCVVERTRGALDYVHVFYTISQIETDGINYLVDDFANASGTITFLPWQRSEVLNIYVLDDDIPELNEYFRVTLVSAIPGDGKLGSTPTSGASIDPEKETTDITIKASDHPYGLLQFSTGLPPQPKDAMTLPASSVPHITVEEEDGEIRLLVIRAQGLLGRVTAEFRTVSLTAFSPEDYQNVAGTLEFQPGERYKYIFINITDNSIPELEKSFKVELLNLEGGVAELFRVDGSGSGDGDMEFFLPTIHKRASLGVASQILVTIAASDHAHGVFEFSPESLFVSGTEPEDGYSTVTLNVIRHHGTLSPVTLHWNIDSDPDGDLAFTSGNITFEIGQTSANITVEILPDEDPELDKAFSVSVLSVSSGSLGAHINATLTVLASDDPYGIFIFSEKNRPVKVEEATQNITLSIIRLKGLMGKVLVSYATLDDMEKPPYFPPNLARATQGRDYIPASGFALFGANQSEATIAISILDDDEPERSESVFIELLNSTLVAKVQSRSIPNSPRLGPKVETIAQLIIIANDDAFGTLQLSAPIVRVAENHVGPIINVTRTGGAFADVSVKFKAVPITAIAGEDYSIASSDVVLLEGETSKAVPIYVINDIYPELEESFLVQLMNETTGGARLGALTEAVIIIEASDDPYGLFGFQITKLIVEEPEFNSVKVNLPIIRNSGTLGNVTVQWVATINGQLATGDLRVVSGNVTFAPGETIQTLLLEVLADDVPEIEEVIQVQLTDASGGGTIGLDRIANIIIPANDDPYGTVAFAQMVYRVQEPLERSSCANITVRRSGGHFGRLLLFYSTSDIDVVALAMEEGQDLLSYYESPIQGVPDPLWRTWMNVSAVGEPLYTCATLCLKEQACSAFSFFSASEGPQCFWMTSWISPAVNNSDFWTYRKNMTRVASLFSGQAVAGSDYEPVTRQWAIMQEGDEFANLTVSILPDDFPEMDESFLISLLEVHLMNISASLKNQPTIGQPNISTVVIALNGDAFGVFVIYNISPNTSEDGLFVEVQEQPQTLVELMIHRTGGSLGQVAVEWRVVGGTATEGLDFIGAGEILTFAEGETKKTVILTILDDSEPEDDESIIVSLVYTEGGSRILPSSDTVRVNILANDNVAGIVSFQTASRSVIGHEGEILQFHVIRTFPGRGNVTVNWKIIGQNLELNFANFSGQLFFPEGSLNTTLFVHLLDDNIPEEKEVYQVILYDVRTQGVPPAGIALLDAQGYAAVLTVEASDEPHGVLNFALSSRFVLLQEANITIQLFINREFGSLGAINVTYTTVPGMLSLKNQTVGNLAEPEVDFVPIIGFLILEEGETAAAINITILEDDVPELEEYFLVNLTYVGLTMAASTSFPPRLDSEGLTAQVIIDANDGARGVIEWQQSRFEVNETHGSLTLVAQRSREPLGHVSLFVYAQNLEAQVGLDYIFTPMILHFADGERYKNVNIMILDDDIPEGDEKFQLILTNPSPGLELGKNTIALIIVLANDDGPGVLSFNNSEHFFLREPTALYVQESVAVLYIVREPAQGLFGTVTVQFIVTEVNSSNESKDLTPSKGYIVLEEGVRFKALQISAILDTEPEMDEYFVCTLFNPTGGARLGVHVQTLITVLQNQAPLGLFSISAVENRATSIDIEEANRTVYLNVSRTNGIDLAVSVQWETVSETAFGMRGMDVVFSVFQSFLDESASGWCFFTLENLIYGIMLRKSSVTVYRWQGIFIPVEDLNIENPKTCEAFNIGFSPYFVITHEERNEEKPSLNSVFTFTSGFKLFLVQTIIILESSQVRYFTSDSQDYLIIASQRDDSELTQVFRWNGGSFVLHQKLPVRGVLTVALFNKGGSVFLAISQANARLNSLLFRWSGSGFINFQEVPVSGTTEVEALSSANDIYLIFAENVFLGDQNSIDIFIWEMGQSSFRYFQSVDFAAVNRIHSFTPASGIAHILLIGQDMSALYCWNSERNQFSFVLEVPSAYDVASVTVKSLNSSKNLIALVGAHSHIYELAYISSHSDFIPSSGELIFEPGEREATIAVNILDDTVPEKEESFKVQLKNPKGGAEIGINDSVTITILSNDDAYGIVAFAQNSLYKQVEEMEQDSLVTLNVERLKGTYGRITIAWEADGSISDIFPTSGVILFTEGQVLSTITLTILADNIPELSEVVIVTLTRITTEGVEDSYKGATIDQDRSKSVITTLPNDSPFGLVGWRAASVFIRVAEPKENTTTLQLQIARDKGLLGDIAIHLRAQPNFLLHVDNQATENEDYVLQETIIIMKENIKEAHAEVSILPDDLPELEEGFIVTITEVNLVNSDFSTGQPSVRRPGMEIAEIMIEENDDPRGIFMFHVTRGAGEVITAYEVPPPLNVLQVPVVRLAGSFGAVNVYWKASPDSAGLEDFKPSHGILEFADKQVTAMIEITIIDDAEFELTETFNISLISVAGGGRLGDDVVVTVVIPQNDSPFGVFGFEEKTVMIDESLSSDDPDSYVTLTVVRSPGGKGTVRLEWTIDEKAKHNLSPLNGTLHFDETESQKTIVLHTLQDTVLEEDRRFTIQLISIDEVEISPVKGSASIIIRGDKRASGEVGIAPSSRHILIGEPSAKYNGTAIISLVRGPGILGEVTVFWRIFPPSVGEFAETSGKLTMRDEQSAVIVVIQALNDDIPEEKSFYEFQLTAVSEGGVLSESSSTANITVVASDSPYGRFAFSHEQLRVSEAQRVNITIIRSSGDFGHVRLWYKTMSGTAEAGLDFVPAAGELLFEAGEMRKSLHVEILDDDYPEGPEEFSLTITKVELQGRGYDFTIQENGLQIDQPPEIGNISIVRIIIMKNDNAEGIIEFDPKYTAFEVEEDVGLIMIPVVRLHGTYGYVTADFISQSSSASPGGVDYILHGSTVTFQHGQNLSFINISIIDDNESEFEEPIEILLTGATGGAVLGRHLVSRIIIAKSDSPFGVIRFLNQSKISIANPNSTMILSLVLERTGGLLGEIQVNWETVGPNSQEALLPQNRDIADPVSGLFYFGEGEGGVRTIILTIYPHEEIEVEETFIIKLHLVKGEAKLDSRAKDVTLTIQEFGDPNGVVQFAPETLSKKTYSEPLALEGPLLITFFVRRVKGTFGEIMVYWELSSEFDITEDFLSTSGFFTIADGESEASFDVHLLPDEVPEIEEDYVIQLVSVEGGAELDLEKSITWFSVYANDDPHGVFALYSDRQSILIGQNLIRSIQINITRLAGTFGDVAVGLRISSDHKEQPIVTENAERQLVVKDGATYKVDVVPIKNQVFLSLGSNFTLQLVTVMLVGGRFYGMPTILQEAKSAVLPVSEKAANSQVGFESTAFQLMNITAGTSHVMISRRGTYGALSVAWTTGYAPGLEIPEFIVVGNMTPTLGSLSFSHGEQRKGVFLWTFPSPGWPEAFVLHLSGVQSSAPGGAQLRSGFIVAEIEPMGVFQFSTSSRNIIVSEDTQMIRLHVQRLFGFHSDLIKVSYQTTAGSAKPLEDFEPVQNGELFFQKFQTEVDFEITIINDQLSEIEEFFYINLTSVEIRGLQKFDVNWSPRLNLDFSVAVITILDNDDLAGMDISFPETTVAVAVDTTLIPVETESTTYLSTSKTTTILQPTNVVAIVTEATGVSAIPEKLVTLHGTPAVSEKPDVATVTANVSIHGTFSLGPSIVYIEEEMKNGTFNTAEVLIRRTGGFTGNVSITVKTFGERCAQMEPNALPFRGIYGISNLTWAVEEEDFEEQTLTLIFLDGERERKVSVQILDDDEPEGQEFFYVFLTNPQGGAQIVEEKDDTGFAAFAMVIITGSDLHNGIIGFSEESQSGLELREGAVMRRLHLIVTRQPNRAFEDVKVFWRVTLNKTVVVLQKDGVNLVEELQSVSGTTTCTMGQTKCFISIELKPEKVPQVEVYFFVELYEATAGAAINNSARFAQIKILESDESQSLVYFSVGSRLAVAHKKATLISLQVARDSGTGLMMSVNFSTQELRSAETIGRTIISPAISGKDFVITEGTLVFEPGQRSTVLDVILTPETGSLNSFPKRFQIVLFDPKGGARIDKVYGTANITLVSDADSQAIWGLADQLHQPVNDDILNRVLHTISMKVATENTDEQLSAMMHLIEKITTEGKIQAFSVASRTLFYEILCSLINPKRKDTRGFSHFAEVTENFAFSLLTNVTCGSPGEKSKTILDSCPYLSILALHWYPQQINGHKFEGKEGDYIRIPERLLDVQDAEIMAGKSTCKLVQFTEYSSQQWFISGNNLPTLKNKVLSLSVKGQSSQLLTNDNEVLYRIYAAEPRIIPQTSLCLLWNQAAASWLSDSQFCKVVEETADYVECACSHMSVYAVYARTDNLSSYNEAFFTSGFICISGLCLAVLSHIFCARYSMFAAKLLTHMMAASLGTQILFLASAYASPQLAEESCSAMAAVTHYLYLCQFSWMLIQSVNFWYVLVMNDEHTERRYLLFFLLSWGLPAFVVILLIVILKGIYHQSMSQIYGLIHGDLCFIPNVYAALFTAALVPLTCLVVVFVVFIHAYQVKPQWKAYDDVFRGRTNAAEIPLILYLFALISVTWLWGGLHMAYRHFWMLVLFVIFNSLQGLYVFMVYFILHNQMCCPMKASYTVEMNGHPGPSTAFFTPGSGMPPAGGEISKSTQNLIGAMEEVPPDWERASFQQGSQASPDLKPSPQNGATFPSSGGYGQGSLIADEESQEFDDLIFALKTGAGLSVSDNESGQGSQEGGTLTDSQIVELRRIPIADTHL>sp|Q8WXG9-2|AGRV1_HUMAN Isoform 2 of Adhesion G-protein coupled receptorV1 OS=Homo sapiens OX=9606 GN=ADGRV1MQLCIFCCCCILFYFDLYDFGRGYDFTIQENGLQIDQPPEIGNISIVRIIIMKNDNAEGIIEFDPKYTAFEVEEDVGLIMIPVVRLHGTYGYVTADFISQSSSASPGGVDYILHGSTVTFQHGQNLSFINISIIDDNESEFEEPIEILLTGATGGAVLGRHLVSRIIIAKSDSPFGVIRFLNQSKISIANPNSTMILSLVLERTGGLLGEIQVNWETVGPNSQEALLPQNRDIADPVSGLFYFGEGEGGVRTIILTIYPHEEIEVEETFIIKLHLVKGEAKLDSRAKDVTLTIQEFGDPNGVVQFAPETLSKKTYSEPLALEGPLLITFFVRRVKGTFGEIMVYWELSSEFDITEDFLSTSGFFTIADGESEASFDVHLLPDEVPEIEEDYVIQLVSVEGGAELDLEKSITWFSVYANDDPHGVFALYSDRQSILIGQNLIRSIQINITRLAGTFGDVAVGLRISSDHKEQPIVTENAERQLVVKDGATYKVDVVPIKNQVFLSLGSNFTLQLVTVMLVGGRFYGMPTILQEAKSAVLPVSEKAANSQVGFESTAFQLMNITAGTSHVMISRRGTYGALSVAWTTGYAPGLEIPEFIVVGNMTPTLGSLSFSHGEQRKGVFLWTFPSPGWPEAFVLHLSGVQSSAPGGAQLRSGFIVAEIEPMGVFQFSTSSRNIIVSEDTQMIRLHVQRLFGFHSDLIKVSYQTTAGSAKPLEDFEPVQNGELFFQKFQTEVDFEITIINDQLSEIEEFFYINLTSVEIRGLQKFDVNWSPRLNLDFSVAVITILDNDDLAGMDISFPETTVAVAVDTTLIPVETESTTYLSTSKTTTILQPTNVVAIVTEATGVSAIPEKLVTLHGTPAVSEKPDVATVTANVSIHGTFSLGPSIVYIEEEMKNGTFNTAEVLIRRTGGFTGNVSITVKTFGERCAQMEPNALPFRGIYGISNLTWAVEEEDFEEQTLTLIFLDGERERKVSVQILDDDEPEGQEFFYVFLTNPQGGAQIVEEKDDTGFAAFAMVIITGSDLHNGIIGFSEESQSGLELREGAVMRRLHLIVTRQPNRAFEDVKVFWRVTLNKTVVVLQKDGVNLVEELQSVSGTTTCTMGQTKCFISIELKPEKVPQVEVYFFVELYEATAGAAINNSARFAQIKILESDESQSLVYFSVGSRLAVAHKKATLISLQVARDSGTGLMMSVNFSTQELRSAETIGRTIISPAISGKDFVITEGTLVFEPGQRSTVLDVILTPETGSLNSFPKRFQIVLFDPKGGARIDKVYGTANITLVSDADSQAIWGLADQLHQPVNDDILNRVLHTISMKVATENTDEQLSAMMHLIEKITTEGKIQAFSVASRTLFYEILCSLINPKRKDTRGFSHFAEVTENFAFSLLTNVTCGSPGEKSKTILDSCPYLSILALHWYPQQINGHKFEGKEGDYIRIPERLLDVQDAEIMAGKSTCKLVQFTEYSSQQWFISGNNLPTLKNKVLSLSVKGQSSQLLTNDNEVLYRIYAAEPRIIPQTSLCLLWNQAAASWLSDSQFCKVVEETADYVECACSHMSVYAVYARTDNLSSYNEAFFTSGFICISGLCLAVLSHIFCARYSMFAAKLLTHMMAASLGTQILFLASAYASPQLAEESCSAMAAVTHYLYLCQFSWMLIQSVNFWYVLVMNDEHTERRYLLFFLLSWGLPAFVVILLIVILKGIYHQSMSQIYGLIHGDLCFIPNVYAALFTAALVPLTCLVVVFVVFIHAYQVKPQWKAYDDVFRGRTNAAEIPLILYLFALISVTWLWGGLHMAYRHFWMLVLFVIFNSLQGLYVFMVYFILHNQMCCPMKASYTVEMNGHPGPSTAFFTPGSGMPPAGGEISKSTQNLIGAMEEVPPDWERASFQQGSQASPDLKPSPQNGATFPSSGGYGQGSLIADEESQEFDDLIFALKTGAGLSVSDNESGQGSQEGGTLTDSQIVELRRIPIADTHL>sp|Q8WXG9-3|AGRV1_HUMAN Isoform 3 of Adhesion G-protein coupled receptorV1 OS=Homo sapiens OX=9606 GN=ADGRV1MSVFLGPGMPSASLLVNLLSALLILFVFGETEIRFTGQTEFVVNETSTTVIRLIIERIGEPANVTAIVSLYGEDAGDFFDTYAAAFIPAGETNRTVYIAVCDDDLPEPDETFIFHLTLQKPSANVKLGWPRTVTVTILSNDNAFGIISFNMLPSIAVSEPKGRNESMPLTLIREKGTYGMVMVTFEVEGGPNPPDEDLSPVKGNITFPPGRATVIYNLTVLDDEVPENDEIFLIQLKSVEGGAEINTSRNSIEIIIKKNDSPVRFLQSIYLVPEEDHILIIPVVRGKDNNGNLIGSDEYEVSISYAVTTGNSTAHAQQNLDFIDLQPNTTVVFPPFIHESHLKFQIVDDTIPEIAESFHIMLLKDTLQGDAVLISPSVVQVTIKPNDKPYGVLSFNSVLFERTVIIDEDRISRYEEITVVRNGGTHGNVSANWVLTRNSTDPSPVTADIRPSSGVLHFAQGQMLATIPLTVVDDDLPEEAEAYLLQILPHTIRGGAEVSEPAELLFYIQDSDDVYGLITFFPMENQKIESSPGERYLSLSFTRLGGTKGDVRLLYSVLYIPAGAVDPLQAKEGILNISRRNDLIFPEQKTQVTTKLPIRNDAFLQNGAHFLVQLETVELLNIIPLIPPISPRFGEICNISLLVTPAIANGEIGFLSNLPIILHEPEDFAAEVVYIPLHRDGTDGQATVYWSLKPSGFNSKAVTPDDIGPFNGSVLFLSGQSDTTINITIKGDDIPEMNETVTLSLDRVNVENQVLKSGYTSRDLIILENDDPGGVFEFSPASRGPYVIKEGESVELHIIRSRGSLVKQFLHYRVEPRDSNEFYGNTGVLEFKPGEREIVITLLARLDGIPELDEHYWVVLSSHGERESKLGSATIVNITILKNDDPHGIIEFVSDGLIVMINESKGDAIYSAVYDVVRNRGNFGDVSVSWVVSPDFTQDVFPVQGTVVFGDQEFSKNITIYSLPDEIPEEMEEFTVILLNGTGGAKVGNRTTATLRIRRNDDPIYFAEPRVVRVQEGETANFTVLRNGSVDVTCMVQYATKDGKATARERDFIPVEKGETLIFEVGSRQQSISIFVNEDGIPETDEPFYIILLNSTGDTVVYQYGVATVIIEANDDPNGIFSLEPIDKAVEEGKTNAFWILRHRGYFGSVSVSWQLFQNDSALQPGQEFYETSGTVNFMDGEEAKPIILHAFPDKIPEFNEFYFLKLVNISGGSPGPGGQLAETNLQVTVMVPFNDDPFGVFILDPECLEREVAEDVLSEDDMSYITNFTILRQQGVFGDVQLGWEILSSEFPAGLPPMIDFLLVGIFPTTVHLQQHMRRHHSGTDALYFTGLEGAFGTVNPKYHPSRNNTIANFTFSAWVMPNANTNGFIIAKDDGNGSIYYGVKIQTNESHVTLSLHYKTLGSNATYIAKTTVMKYLEESVWLHLLIILEDGIIEFYLDGNAMPRGIKSLKGEAITDGPGILRIGAGINGNDRFTGLMQDVRSYERKLTLEEIYELHAMPAKSDLHPISGYLEFRQGETNKSFIISARDDNDEEGEELFILKLVSVYGGARISEENTTARLTIQKSDNANGLFGFTGACIPEIAEEGSTISCVVERTRGALDYVHVFYTISQIETDGINYLVDDFANASGTITFLPWQRSEVLNIYVLDDDIPELNEYFRVTLVSAIPGDGKLGSTPTSGASIDPEKETTDITIKASDHPYGLLQFSTGLPPQPKDAMTLPASSVPHITVEEEDGEIRLLVIRAQGLLGRVTAEFRTVSLTAFSPEDYQNVAGTLEFQPGERYKYIFINITDNSIPELEKSFKVELLNLEGGVAELFRVDGSGSGDGDMEFFLPTIHKRASLGVASQILVTIAASDHAHGVFEFSPESLFVSGTEPEDGYSTVTLNVIRHHGTLSPVTLHWNIDSDPDGDLAFTSGNITFEIGQTSANITVEILPDEDPELDKAFSVSVLSVSSGSLGAHINATLTVLASDDPYGIFIFSEKNRPVKVEEATQNITLSIIRLKGLMGKVLVSYATLDDMEKPPYFPPNLARATQGRDYIPASGFALFGANQSEATIAISILDDDEPERSESVFIELLNSTLVAKVQSRSIPNSPRLGPKVETIAQLIIIANDDAFGTLQLSAPIVRVAENHVGPIINVTRTGGAFADVSVKFKAVPITAIAGEDYSIASSDVVLLEGETSKAVPIYVINDIYPELEESFLVQLMNETTGGARLGALTEAVIIIEASDDPYGLFGFQITKLIVEEPEFNSVKVNLPIIRNSGTLGNVTVQWVATINGQLATGDLRVVSGNVTFARVVSGYPSATN>sp|Q8WXG9-4|AGRV1_HUMAN Isoform 4 of Adhesion G-protein coupled receptorV1 OS=Homo sapiens OX=9606 GN=ADGRV1MSVFLGPGMPSASLLVNLLSALLILFVFGETEIRFTGQTEFVVNETSTTVIRLIIERIGEPANVTAIVSLYGEDAGDFFDTYAAAFIPAGETNRTVYIAVCDDDLPEPDETFIFHLTLQKPSANVKLGWPRTVTVTILSNDNAFGIISFNMLPSIAVSEPKGRNESMPLTLIREKGTYGMVMVTFEVEGGPNPPDEDLSPVKGNITFPPGRATVIYNLTVLDDEVPENDEIFLIQLKSVEGGAEINTSRNSIEIIIKKNDSPVRFLQSIYLVPEEDHILIIPVVRGKDNNGNLIGSDEYEVSISYAVTTGNSTAHAQQNLDFIDLQPNTTVVFPPFIHESHLKFQIVDDTIPEIAESFHIMLLKDTLQGDAVLISPSVVQVTIKPNDKPYGVLSFNSVLFERTVIIDEDRISRYEEITVVRNGGTHGNVSANWVLTRNSTDPSPVTADIRPSSGVLHFAQGQMLATIPLTVVDDDLPEEAEAYLLQILPHTIRGGAEVSEPAELLFYIQDSDDVYGLITFFPMENQKIESSPGERYLSLSFTRLGGTKGDVRLLYSVLYIPAGAVDPLQAKEGILNISRRNDLIFPEQKTQVTTKLPIRNDAFLQNGAHFLVQLETVELLNIIPLIPPISPRFGEICNISLLVTPAIANGEIGFLSNLPIILHEPEDFAAEVVYIPLHRDGTDGQATVYWSLKPSGFNSKAVTPDDIGPFNGSVLFLSGQSDTTINITIKGDDIPEMNETVTLSLDRVNVENQVLKSGYTSRDLIILENDDPGGVFEFSPASRGPYVIKEGESVELHIIRSRGSLVKQFLHYRVEPRDSNEFYGNTGVLEFKPGEREIVITLLARLDGIPELDEHYWVVLSSHGERESKLGSATIVNITILKNDDPHGIIEFVSDGLIVMINESKGDAIYSAVYDVVRNRGNFGDVSVSWVVSPDFTQDVFPVQGTVVFGDQEFSKNITIYSLPDEIPEEMEEFTVILLNGTGGAKVGNRTTATLRIRRNDDPIYFAEPRVVRVQEGETANFTVLRNGSVDVTCMVQYATKDGKATARERDFIPVEKGETLIFEVGSRQQSISIFVNEDGIPETDEPFYIILLNSTGDTVVYQYGVATVIIEANDDPNGIFSLEPIDKAVEEGKTNAFWILRHRGYFGSVSVSWQLFQNDSALQPGQEFYETSGTVNFMDGEEAKPIILHAFPDKIPEFNEFYFLKLVNISGGSPGPGGQLAETNLQVTVMVPFNDDPFGVFILDPECLEREVAEDVLSEDDMSYITNFTILRQQGVFGDVQLGWEILSSEFPAGLPPMIDFLLVGIFPTTVHLQQHMRRHHSGTDALYFTGLEGAFGTVNPKYHPSRNNTIANFTFSAWVMPNANTNGFIIAKDDGNGSIYYGVKIQTNESHVTLSLHYKTLGSNATYIAKTTVMKYLEESVWLHLLIILEDGIIEFYLDGNAMPRGIKSLKGEAITDGEGHHHN>sp|O43506|ADA20_HUMAN Disintegrin and metalloproteinase domain-containing protein 20 OS=Homo sapiens OX=9606 GN=ADAM20 PE=2 SV=2MAVGEPLVHIRVTLLLLWFGMFLSISGHSQARPSQYFTSPEVVIPLKVISRGRGAKAPGWLSYSLRFGGQRYIVHMRVNKLLFAAHLPVFTYTEQHALLQDQPFIQDDCYYHGYVEGVPESLVALSTCSGGFLGMLQINDLVYEIKPISVSATFEHLVYKIDSDDTQFPPMRCGLTEEKIAHQMELQLSYNFTLKQSSFVGWWTHQRFVELVVVVDNIRYLFSQSNATTVQHEVFNVVNIVDSFYHPLEVDVILTGIDIWTASNPLPTSGDLDNVLEDFSIWKNYNLNNRLQHDVAHLFIKDTQGMKLGVAYVKGICQNPFNTGVDVFEDNRLVVFAITLGHELGHNLGMQHDTQWCVCELQWCIMHAYRKVTTKFSNCSYAQYWDSTISSGLCIQPPPYPGNIFRLKYCGNLVVEEGEECDCGTIRQCAKDPCCLLNCTLHPGAACAFGICCKDCKFLPSGTLCRQQVGECDLPEWCNGTSHQCPDDVYVQDGISCNVNAFCYEKTCNNHDIQCKEIFGQDARSASQSCYQEINTQGNRFGHCGIVGTTYVKCWTPDIMCGRVQCENVGVIPNLIEHSTVQQFHLNDTTCWGTDYHLGMAIPDIGEVKDGTVCGPEKICIRKKCASMVHLSQACQPKTCNMRGICNNKQHCHCNHEWAPPYCKDKGYGGSADSGPPPKNNMEGLNVMGKLRYLSLLCLLPLVAFLLFCLHVLFKKRTKSKEDEEG>sp|P52895|AK1C2_HUMAN Aldo-keto reductase family 1 member C2 OS=Homosapiens OX=9606 GN=AKR1C2 PE=1 SV=3MDSKYQCVKLNDGHFMPVLGFGTYAPAEVPKSKALEAVKLAIEAGFHHIDSAHVYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSNSHRPELVRPALERSLKNLQLDYVDLYLIHFPVSVKPGEEVIPKDENGKILFDTVDLCATWEAMEKCKDAGLAKSIGVSNFNHRLLEMILNKPGLKYKPVCNQVECHPYFNQRKLLDFCKSKDIVLVAYSALGSHREEPWVDPNSPVLLEDPVLCALAKKHKRTPALIALRYQLQRGVVVLAKSYNEQRIRQNVQVFEFQLTSEEMKAIDGLNRNVRYLTLDIFAGPPNYPFSDEY>sp|P52895-2|AK1C2_HUMAN Isoform 2 of Aldo-keto reductase family 1 memberC2 OS=Homo sapiens OX=9606 GN=AKR1C2MDSKYQCVKLNDGHFMPVLGFGTYAPAEVPKSKALEAVKLAIEAGFHHIDSAHVYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSNSHRPELVRPALERSLKNLQLDYVDLYLIHFPVSVKEDIGILTWKKSPKHNS>sp|P14550|AK1A1_HUMAN Aldo-keto reductase family 1 member A1 OS=Homosapiens OX=9606 GN=AKR1A1 PE=1 SV=3MAASCVLLHTGQKMPLIGLGTWKSEPGQVKAAVKYALSVGYRHIDCAAIYGNEPEIGEALKEDVGPGKAVPREELFVTSKLWNTKHHPEDVEPALRKTLADLQLEYLDLYLMHWPYAFERGDNPFPKNADGTICYDSTHYKETWKALEALVAKGLVQALGLSNFNSRQIDDILSVASVRPAVLQVECHPYLAQNELIAHCQARGLEVTAYSPLGSSDRAWRDPDEPVLLEEPVVLALAEKYGRSPAQILLRWQVQRKVICIPKSITPSRILQNIKVFDFTFSPEEMKQLNALNKNWRYIVPMLTVDGKRVPRDAGHPLYPFNDPY>sp|Q9UKF5|ADA29_HUMAN Disintegrin and metalloproteinase domain-containing protein 29 OS=Homo sapiens OX=9606 GN=ADAM29 PE=1 SV=3MKMLLLLHCLGVFLSCSGHIQDEHPQYHSPPDVVIPVRITGTTRGMTPPGWLSYILPFGGQKHIIHIKVKKLLFSKHLPVFTYTDQGAILEDQPFVQNNCYYHGYVEGDPESLVSLSTCFGGFQGILQINDFAYEIKPLAFSTTFEHLVYKMDSEEKQFSTMRSGFMQNEITCRMEFEEIDNSTQKQSSYVGWWIHFRIVEIVVVIDNYLYIRYERNDSKLLEDLYVIVNIVDSILDVIGVKVLLFGLEIWTNKNLIVVDDVRKSVHLYCKWKSENITPRMQHDTSHLFTTLGLRGLSGIGAFRGMCTPHRSCAIVTFMNKTLGTFSIAVAHHLGHNLGMNHDEDTCRCSQPRCIMHEGNPPITKFSNCSYGDFWEYTVERTKCLLETVHTKDIFNVKRCGNGVVEEGEECDCGPLKHCAKDPCCLSNCTLTDGSTCAFGLCCKDCKFLPSGKVCRKEVNECDLPEWCNGTSHKCPDDFYVEDGIPCKERGYCYEKSCHDRNEQCRRIFGAGANTASETCYKELNTLGDRVGHCGIKNATYIKCNISDVQCGRIQCENVTEIPNMSDHTTVHWARFNDIMCWSTDYHLGMKGPDIGEVKDGTECGIDHICIHRHCVHITILNSNCSPAFCNKRGICNNKHHCHCNYLWDPPNCLIKGYGGSVDSGPPPKRKKKKKFCYLCILLLIVLFILLCCLYRLCKKSKPIKKQQDVQTPSAKEEEKIQRRPHELPPQSQPWVMPSQSQPPVTPSQSHPQVMPSQSQPPVTPSQSQPRVMPSQSQPPVMPSQSHPQLTPSQSQPPVTPSQRQPQLMPSQSQPPVTPS>sp|Q9UKF5-2|ADA29_HUMAN Isoform Beta of Disintegrin andmetalloproteinase domain-containing protein 29 OS=Homo sapiens OX=9606GN=ADAM29MKMLLLLHCLGVFLSCSGHIQDEHPQYHSPPDVVIPVRITGTTRGMTPPGWLSYILPFGGQKHIIHIKVKKLLFSKHLPVFTYTDQGAILEDQPFVQNNCYYHGYVEGDPESLVSLSTCFGGFQGILQINDFAYEIKPLAFSTTFEHLVYKMDSEEKQFSTMRSGFMQNEITCRMEFEEIDNSTQKQSSYVGWWIHFRIVEIVVVIDNYLYIRYERNDSKLLEDLYVIVNIVDSILDVIGVKVLLFGLEIWTNKNLIVVDDVRKSVHLYCKWKSENITPRMQHDTSHLFTTLGLRGLSGIGAFRGMCTPHRSCAIVTFMNKTLGTFSIAVAHHLGHNLGMNHDEDTCRCSQPRCIMHEGNPPITKFSNCSYGDFWEYTVERTKCLLETVHTKDIFNVKRCGNGVVEEGEECDCGPLKHCAKDPCCLSNCTLTDGSTCAFGLCCKDCKFLPSGKVCRKEVNECDLPEWCNGTSHKCPDDFYVEDGIPCKERGYCYEKSCHDRNEQCRRIFGAGANTASETCYKELNTLGDRVGHCGIKNATYIKCNISDVQCGRIQCENVTEIPNMSDHTTVHWARFNDIMCWSTDYHLGMKGPDIGEVKDGTECGIDHICIHRHCVHITILNSNCSPAFCNKRGICNNKHHCHCNYLWDPPNCLIKGYGGSVDSGPPPKRKKKKKFCYLCILLLIVLFILLCCLYRLCKKSKPIKKQQDVQTPSAKEEEKIQRRPHELPPQSQPWVMPSQSQPPVTPSQRQPQLMPSQSQPPVTPS>sp|Q9UKF5-3|ADA29_HUMAN Isoform Gamma of Disintegrin andmetalloproteinase domain-containing protein 29 OS=Homo sapiens OX=9606GN=ADAM29MKMLLLLHCLGVFLSCSGHIQDEHPQYHSPPDVVIPVRITGTTRGMTPPGWLSYILPFGGQKHIIHIKVKKLLFSKHLPVFTYTDQGAILEDQPFVQNNCYYHGYVEGDPESLVSLSTCFGGFQGILQINDFAYEIKPLAFSTTFEHLVYKMDSEEKQFSTMRSGFMQNEITCRMEFEEIDNSTQKQSSYVGWWIHFRIVEIVVVIDNYLYIRYERNDSKLLEDLYVIVNIVDSILDVIGVKVLLFGLEIWTNKNLIVVDDVRKSVHLYCKWKSENITPRMQHDTSHLFTTLGLRGLSGIGAFRGMCTPHRSCAIVTFMNKTLGTFSIAVAHHLGHNLGMNHDEDTCRCSQPRCIMHEGNPPITKFSNCSYGDFWEYTVERTKCLLETVHTKDIFNVKRCGNGVVEEGEECDCGPLKHCAKDPCCLSNCTLTDGSTCAFGLCCKDCKFLPSGKVCRKEVNECDLPEWCNGTSHKCPDDFYVEDGIPCKERGYCYEKSCHDRNEQCRRIFGAGANTASETCYKELNTLGDRVGHCGIKNATYIKCNISDVQCGRIQCENVTEIPNMSDHTTVHWARFNDIMCWSTDYHLGMKGPDIGEVKDGTECGIDHICIHRHCVHITILNSNCSPAFCNKRGICNNKHHCHCNYLWDPPNCLIKGYGGSVDSGPPPKRKKKKKFCYLCILLLIVLFILLCCLYRLCKKSKPIKKQQDVQTPSAKEEEKIQRRPHELPPQSQPWVMPSQSQPPVTPSQSHPQVMPSQSQPPQNLFLFSFSISDCVLNFRLLYLQAT>sp|Q04771|ACVR1_HUMAN Activin receptor type-1 OS=Homo sapiens OX=9606GN=ACVR1 PE=1 SV=1MVDGVMILPVLIMIALPSPSMEDEKPKVNPKLYMCVCEGLSCGNEDHCEGQQCFSSLSINDGFHVYQKGCFQVYEQGKMTCKTPPSPGQAVECCQGDWCNRNITAQLPTKGKSFPGTQNFHLEVGLIILSVVFAVCLLACLLGVALRKFKRRNQERLNPRDVEYGTIEGLITTNVGDSTLADLLDHSCTSGSGSGLPFLVQRTVARQITLLECVGKGRYGEVWRGSWQGENVAVKIFSSRDEKSWFRETELYNTVMLRHENILGFIASDMTSRHSSTQLWLITHYHEMGSLYDYLQLTTLDTVSCLRIVLSIASGLAHLHIEIFGTQGKPAIAHRDLKSKNILVKKNGQCCIADLGLAVMHSQSTNQLDVGNNPRVGTKRYMAPEVLDETIQVDCFDSYKRVDIWAFGLVLWEVARRMVSNGIVEDYKPPFYDVVPNDPSFEDMRKVVCVDQQRPNIPNRWFSDPTLTSLAKLMKECWYQNPSARLTALRIKKTLTKIDNSLDKLKTDC>sp|Q96Q83|ALKB3_HUMAN Alpha-ketoglutarate-dependent dioxygenase alkBhomolog 3 OS=Homo sapiens OX=9606 GN=ALKBH3 PE=1 SV=1MEEKRRRARVQGAWAAPVKSQAIAQPATTAKSHLHQKPGQTWKNKEHHLSDREFVFKEPQQVVRRAPEPRVIDREGVYEISLSPTGVSRVCLYPGFVDVKEADWILEQLCQDVPWKQRTGIREDITYQQPRLTAWYGELPYTYSRITMEPNPHWHPVLRTLKNRIEENTGHTFNSLLCNLYRNEKDSVDWHSDDEPSLGRCPIIASLSFGATRTFEMRKKPPPEENGDYTYVERVKIPLDHGTLLIMEGATQADWQHRVPKEYHSREPRVNLTFRTVYPDPRGAPW>sp|Q96Q83-2|ALKB3_HUMAN Isoform 2 of Alpha-ketoglutarate-dependentdioxygenase alkB homolog 3 OS=Homo sapiens OX=9606 GN=ALKBH3MEEKRRRARVQGAWAAPVKSQAIAQPATTAKSHLHQKPGQTWKNKEHHLSDREFVFKEPQQVVRRAPEPRVIEEGVYEISLSPTGVSRVCLYPGFVDVKEADWILEQLCQDVPWKQRTGIREDSILQLTFKKSAPVSGTATAPQSCWYERPSPPHIPGPAILTRTRLWAP>sp|P14621|ACYP2_HUMAN Acylphosphatase-2 OS=Homo sapiens OX=9606 GN=ACYP2PE=1 SV=2MSTAQSLKSVDYEVFGRVQGVCFRMYTEDEARKIGVVGWVKNTSKGTVTGQVQGPEDKVNSMKSWLSKVGSPSSRIDRTNFSNEKTISKLEYSNFSIRY>sp|Q9BZ11|ADA33_HUMAN Disintegrin and metalloproteinase domain-containing protein 33 OS=Homo sapiens OX=9606 GN=ADAM33 PE=1 SV=2MGWRPRRARGTPLLLLLLLLLLWPVPGAGVLQGHIPGQPVTPHWVLDGQPWRTVSLEEPVSKPDMGLVALEAEGQELLLELEKNHRLLAPGYIETHYGPDGQPVVLAPNHTDHCHYQGRVRGFPDSWVVLCTCSGMSGLITLSRNASYYLRPWPPRGSKDFSTHEIFRMEQLLTWKGTCGHRDPGNKAGMTSLPGGPQSRGRREARRTRKYLELYIVADHTLFLTRHRNLNHTKQRLLEVANYVDQLLRTLDIQVALTGLEVWTERDRSRVTQDANATLWAFLQWRRGLWAQRPHDSAQLLTGRAFQGATVGLAPVEGMCRAESSGGVSTDHSELPIGAAATMAHEIGHSLGLSHDPDGCCVEAAAESGGCVMAAATGHPFPRVFSACSRRQLRAFFRKGGGACLSNAPDPGLPVPPALCGNGFVEAGEECDCGPGQECRDLCCFAHNCSLRPGAQCAHGDCCVRCLLKPAGALCRQAMGDCDLPEFCTGTSSHCPPDVYLLDGSPCARGSGYCWDGACPTLEQQCQQLWGPGSHPAPEACFQVVNSAGDAHGNCGQDSEGHFLPCAGRDALCGKLQCQGGKPSLLAPHMVPVDSTVHLDGQEVTCRGALALPSAQLDLLGLGLVEPGTQCGPRMVCQSRRCRKNAFQELQRCLTACHSHGVCNSNHNCHCAPGWAPPFCDKPGFGGSMDSGPVQAENHDTFLLAMLLSVLLPLLPGAGLAWCCYRLPGAHLQRCSWGCRRDPACSGPKDGPHRDHPLGGVHPMELGPTATGQPWPLDPENSHEPSSHPEKPLPAVSPDPQADQVQMPRSCLW>sp|Q9BZ11-2|ADA33_HUMAN Isoform 2 of Disintegrin and metalloproteinasedomain-containing protein 33 OS=Homo sapiens OX=9606 GN=ADAM33MGWRPRRARGTPLLLLLLLLLLWPVPGAGVLQGHIPGQPVTPHWVLDGQPWRTVSLEEPVSKPDMGLVALEAEGQELLLELEKNHRLLAPGYIETHYGPDGQPVVLAPNHTDHCHYQGRVRGFPDSWVVLCTCSGMSGLITLSRNASYYLRPWPPRGSKDFSTHEIFRMEQLLTWKGTCGHRDPGNKAGMTSLPGGPQSRGRREARRTRKYLELYIVADHTLFLTRHRNLNHTKQRLLEVANYVDQLLRTLDIQVALTGLEVWTERDRSRVTQDANATLWAFLQWRRGLWAQRPHDSAQLLTGRAFQGATVGLAPVEGMCRAESSGGVSTDHSELPIGAAATMAHEIGHSLGLSHDPDGCCVEAAAESGGCVMAAATGHPFPRVFSACSRRQLRAFFRKGGGACLSNAPDPGLPVPPALCGNGFVEAGEECDCGPGQECRDLCCFAHNCSLRPGAQCAHGDCCVRCLLKPAGALCRQAMGDCDLPEFCTGTSSHCPPDVYLLDGSPCARGSGYCWDGACPTLEQQCQQLWGPGSHPAPEACFQVVNSAGDAHGNCGQDSEGHFLPCAGRDALCGKLQCQGGKPSLLAPHMVPVDSTVHLDGQEVTCRGALALPSAQLDLLGLGLVEPGTQCGPRMVCNSNHNCHCAPGWAPPFCDKPGFGGSMDSGPVQAENHDTFLLAMLLSVLLPLLPGAGLAWCCYRLPGAHLQRCSWGCRRDPACSGPKDGPHRDHPLGGVHPMELGPTATGQPWPLDPENSHEPSSHPEKPLPAVSPDPQADQVQMPRSCLW>sp|Q9BZ11-3|ADA33_HUMAN Isoform 3 of Disintegrin and metalloproteinasedomain-containing protein 33 OS=Homo sapiens OX=9606 GN=ADAM33MGDCDLPEFCTGTSSHCPPDVYLLDGSPCARGSGYCWDGACPTLEQQCQQLWGPGSHPAPEACFQVVNSAGDAHGNCGQDSEGHFLPCAGRDALCGKLQCQGGKPSLLAPHMVPVDSTVHLDGQEVTCRGALALPSAQLDLLGLGLVEPGTQCGPRMVCNSNHNCHCAPGWAPPFCDKPGFGGSMDSGPVQAENHDTFLLAMLLSVLLPLLPGAGLAWCCYRLPGAHLQRCSWGCRRDPACSGPKDGPHRDHPLGGVHPMELGPTATGQPWPLDPENSHEPSSHPEKPLPAVSPDPQADQVQMPRSCLW>sp|Q5JQC9|AKAP4_HUMAN A-kinase anchor protein 4 OS=Homo sapiens OX=9606GN=AKAP4 PE=1 SV=1MMAYSDTTMMSDDIDWLRSHRGVCKVDLYNPEGQQDQDRKVICFVDVSTLNVEDKDYKDAASSSSEGNLNLGSLEEKEIIVIKDTEKKDQSKTEGSVCLFKQAPSDPVSVLNWLLSDLQKYALGFQHALSPSTSTCKHKVGDTEGEYHRASSENCYSVYADQVNIDYLMNRPQNLRLEMTAAKNTNNNQSPSAPPAKPPSTQRAVISPDGECSIDDLSFYVNRLSSLVIQMAHKEIKEKLEGKSKCLHHSICPSPGNKERISPRTPASKIASEMAYEAVELTAAEMRGTGEESREGGQKSFLYSELSNKSKSGDKQMSQRESKEFADSISKGLMVYANQVASDMMVSLMKTLKVHSSGKPIPASVVLKRVLLRHTKEIVSDLIDSCMKNLHNITGVLMTDSDFVSAVKRNLFNQWKQNATDIMEAMLKRLVSALIGEEKETKSQSLSYASLKAGSHDPKCRNQSLEFSTMKAEMKERDKGKMKSDPCKSLTSAEKVGEHILKEGLTIWNQKQGNSCKVATKACSNKDEKGEKINASTDSLAKDLIVSALKLIQYHLTQQTKGKDTCEEDCPGSTMGYMAQSTQYEKCGGGQSAKALSVKQLESHRAPGPSTCQKENQHLDSQKMDMSNIVLMLIQKLLNENPFKCEDPCEGENKCSEPRASKAASMSNRSDKAEEQCQEHQELDCTSGMKQANGQFIDKLVESVMKLCLIMAKYSNDGAALAELEEQAASANKPNFRGTRCIHSGAMPQNYQDSLGHEVIVNNQCSTNSLQKQLQAVLQWIAASQFNVPMLYFMGDKDGQLEKLPQVSAKAAEKGYSVGGLLQEVMKFAKERQPDEAVGKVARKQLLDWLLANL>sp|Q5JQC9-2|AKAP4_HUMAN Isoform 2 of A-kinase anchor protein 4 OS=Homosapiens OX=9606 GN=AKAP4MSDDIDWLRSHRGVCKVDLYNPEGQQDQDRKVICFVDVSTLNVEDKDYKDAASSSSEGNLNLGSLEEKEIIVIKDTEKKDQSKTEGSVCLFKQAPSDPVSVLNWLLSDLQKYALGFQHALSPSTSTCKHKVGDTEGEYHRASSENCYSVYADQVNIDYLMNRPQNLRLEMTAAKNTNNNQSPSAPPAKPPSTQRAVISPDGECSIDDLSFYVNRLSSLVIQMAHKEIKEKLEGKSKCLHHSICPSPGNKERISPRTPASKIASEMAYEAVELTAAEMRGTGEESREGGQKSFLYSELSNKSKSGDKQMSQRESKEFADSISKGLMVYANQVASDMMVSLMKTLKVHSSGKPIPASVVLKRVLLRHTKEIVSDLIDSCMKNLHNITGVLMTDSDFVSAVKRNLFNQWKQNATDIMEAMLKRLVSALIGEEKETKSQSLSYASLKAGSHDPKCRNQSLEFSTMKAEMKERDKGKMKSDPCKSLTSAEKVGEHILKEGLTIWNQKQGNSCKVATKACSNKDEKGEKINASTDSLAKDLIVSALKLIQYHLTQQTKGKDTCEEDCPGSTMGYMAQSTQYEKCGGGQSAKALSVKQLESHRAPGPSTCQKENQHLDSQKMDMSNIVLMLIQKLLNENPFKCEDPCEGENKCSEPRASKAASMSNRSDKAEEQCQEHQELDCTSGMKQANGQFIDKLVESVMKLCLIMAKYSNDGAALAELEEQAASANKPNFRGTRCIHSGAMPQNYQDSLGHEVIVNNQCSTNSLQKQLQAVLQWIAASQFNVPMLYFMGDKDGQLEKLPQVSAKAAEKGYSVGGLLQEVMKFAKERQPDEAVGKVARKQLLDWLLANL>sp|P24588|AKAP5_HUMAN A-kinase anchor protein 5 OS=Homo sapiens OX=9606GN=AKAP5 PE=1 SV=3METTISEIHVENKDEKRSAEGSPGAERQKEKASMLCFKRRKKAAKALKPKAGSEAADVARKCPQEAGASDQPEPTRGAWASLKRLVTRRKRSESSKQQKPLEGEMQPAINAEDADLSKKKAKSRLKIPCIKFPRGPKRSNHSKIIEDSDCSIKVQEEAEILDIQTQTPLNDQATKAKSTQDLSEGISRKDGDEVCESNVSNSTTSGEKVISVELGLDNGHSAIQTGTLILEEIETIKEKQDVQPQQASPLETSETDHQQPVLSDVPPLPAIPDQQIVEEASNSTLESAPNGKDYESTEIVAEETKPKDTELSQESDFKENGITEEKSKSEESKRMEPIAIIITDTEISEFDVTKSKNVPKQFLISAENEQVGVFANDNGFEDRTSEQYETLLIETASSLVKNAIQLSIEQLVNEMASDDNKINNLLQ>sp|Q99965|ADAM2_HUMAN Disintegrin and metalloproteinase domain-containing protein 2 OS=Homo sapiens OX=9606 GN=ADAM2 PE=2 SV=2MWRVLFLLSGLGGLRMDSNFDSLPVQITVPEKIRSIIKEGIESQASYKIVIEGKPYTVNLMQKNFLPHNFRVYSYSGTGIMKPLDQDFQNFCHYQGYIEGYPKSVVMVSTCTGLRGVLQFENVSYGIEPLESSVGFEHVIYQVKHKKADVSLYNEKDIESRDLSFKLQSVEPQQDFAKYIEMHVIVEKQLYNHMGSDTTVVAQKVFQLIGLTNAIFVSFNITIILSSLELWIDENKIATTGEANELLHTFLRWKTSYLVLRPHDVAFLLVYREKSNYVGATFQGKMCDANYAGGVVLHPRTISLESLAVILAQLLSLSMGITYDDINKCQCSGAVCIMNPEAIHFSGVKIFSNCSFEDFAHFISKQKSQCLHNQPRLDPFFKQQAVCGNAKLEAGEECDCGTEQDCALIGETCCDIATCRFKAGSNCAEGPCCENCLFMSKERMCRPSFEECDLPEYCNGSSASCPENHYVQTGHPCGLNQWICIDGVCMSGDKQCTDTFGKEVEFGPSECYSHLNSKTDVSGNCGISDSGYTQCEADNLQCGKLICKYVGKFLLQIPRATIIYANISGHLCIAVEFASDHADSQKMWIKDGTSCGSNKVCRNQRCVSSSYLGYDCTTDKCNDRGVCNNKKHCHCSASYLPPDCSVQSDLWPGGSIDSGNFPPVAIPARLPERRYIENIYHSKPMRWPFFLFIPFFIIFCVLIAIMVKVNFQRKKWRTEDYSSDEQPESESEPKG>sp|Q99965-2|ADAM2_HUMAN Isoform 2 of Disintegrin and metalloproteinasedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=ADAM2MWRVLFLLSGLGGLRMDSNFDSLPVQITVPEKIRSIIKEGIESQASYKIVIEGKPYTVNLMQKNFLPHNFRVYSYSGTGIMKPLDQDFQNFCHYQGYIEGYPKSVVMVSTCTGLRGVLQFENVSYGIEPLESSVGFEHVIYQVKHKKADVSLYNEKDIESRDLSFKLQSVEYNHMGSDTTVVAQKVFQLIGLTNAIFVSFNITIILSSLELWIDENKIATTGEANELLHTFLRWKTSYLVLRPHDVAFLLVYREKSNYVGATFQGKMCDANYAGGVVLHPRTISLESLAVILAQLLSLSMGITYDDINKCQCSGAVCIMNPEAIHFSGVKIFSNCSFEDFAHFISKQKSQCLHNQPRLDPFFKQQAVCGNAKLEAGEECDCGTEQDCALIGETCCDIATCRFKAGSNCAEGPCCENCLFMSKERMCRPSFEECDLPEYCNGSSASCPENHYVQTGHPCGLNQWICIDGVCMSGDKQCTDTFGKEVEFGPSECYSHLNSKTDVSGNCGISDSGYTQCEADNLQCGKLICKYVGKFLLQIPRATIIYANISGHLCIAVEFASDHADSQKMWIKDGTSCGSNKVCRNQRCVSSSYLGYDCTTDKCNDRGVCNNKKHCHCSASYLPPDCSVQSDLWPGGSIDSGNFPPVAIPARLPERRYIENIYHSKPMRWPFFLFIPFFIIFCVLIAIMVKVNFQRKKWRTEDYSSDEQPESESEPKG>sp|Q96DR5|BPIA2_HUMAN BPI fold-containing family A member 2 OS=Homosapiens OX=9606 GN=BPIFA2 PE=1 SV=2MLQLWKLVLLCGVLTGTSESLLDNLGNDLSNVVDKLEPVLHEGLETVDNTLKGILEKLKVDLGVLQKSSAWQLAKQKAQEAEKLLNNVISKLLPTNTDIFGLKISNSLILDVKAEPIDDGKGLNLSFPVTANVTVAGPIIGQIINLKASLDLLTAVTIETDPQTHQPVAVLGECASDPTSISLSLLDKHSQIINKFVNSVINTLKSTVSSLLQKEICPLIRIFIHSLDVNVIQQVVDNPQHKTQLQTLI>sp|Q8WV93|AFG1L_HUMAN AFG1-like ATPase OS=Homo sapiens OX=9606 GN=AFG1LPE=1 SV=2MAASWSLLVTLRPLAQSPLRGRCVGCGAWAAALAPLATAPGKPFWKAYTVQTSESMTPTATSETYLKALAVCHGPLDHYDFLIKAHELKDDEHQRRVIQCLQKLHEDLKGYNIEAEGLFSKLFSRSKPPRGLYVYGDVGTGKTMVMDMFYAYVEMKRKKRVHFHGFMLDVHKRIHRLKQSLPKRKPGFMAKSYDPIAPIAEEISEEACLLCFDEFQVTDIADAMILKQLFENLFKNGVVVVATSNRPPEDLYKNGLQRANFVPFIAVLKEYCNTVQLDSGIDYRKRELPAAGKLYYLTSEADVEAVMDKLFDELAQKQNDLTRPRILKVQGRELRLNKACGTVADCTFEELCERPLGASDYLELSKNFDTIFLRNIPQFTLANRTQGRRFITLIDNFYDLKVRIICSASTPISSLFLHQHHDSELEQSRILMDDLGLSQDSAEGLSMFTGEEEIFAFQRTISRLTEMQTEQYWNEGDRTKK>sp|Q9UKV8|AGO2_HUMAN Protein argonaute-2 OS=Homo sapiens OX=9606 GN=AGO2PE=1 SV=3MYSGAGPALAPPAPPPPIQGYAFKPPPRPDFGTSGRTIKLQANFFEMDIPKIDIYHYELDIKPEKCPRRVNREIVEHMVQHFKTQIFGDRKPVFDGRKNLYTAMPLPIGRDKVELEVTLPGEGKDRIFKVSIKWVSCVSLQALHDALSGRLPSVPFETIQALDVVMRHLPSMRYTPVGRSFFTASEGCSNPLGGGREVWFGFHQSVRPSLWKMMLNIDVSATAFYKAQPVIEFVCEVLDFKSIEEQQKPLTDSQRVKFTKEIKGLKVEITHCGQMKRKYRVCNVTRRPASHQTFPLQQESGQTVECTVAQYFKDRHKLVLRYPHLPCLQVGQEQKHTYLPLEVCNIVAGQRCIKKLTDNQTSTMIRATARSAPDRQEEISKLMRSASFNTDPYVREFGIMVKDEMTDVTGRVLQPPSILYGGRNKAIATPVQGVWDMRNKQFHTGIEIKVWAIACFAPQRQCTEVHLKSFTEQLRKISRDAGMPIQGQPCFCKYAQGADSVEPMFRHLKNTYAGLQLVVVILPGKTPVYAEVKRVGDTVLGMATQCVQMKNVQRTTPQTLSNLCLKINVKLGGVNNILLPQGRPPVFQQPVIFLGADVTHPPAGDGKKPSIAAVVGSMDAHPNRYCATVRVQQHRQEIIQDLAAMVRELLIQFYKSTRFKPTRIIFYRDGVSEGQFQQVLHHELLAIREACIKLEKDYQPGITFIVVQKRHHTRLFCTDKNERVGKSGNIPAGTTVDTKITHPTEFDFYLCSHAGIQGTSRPSHYHVLWDDNRFSSDELQILTYQLCHTYVRCTRSVSIPAPAYYAHLVAFRARYHLVDKEHDSAEGSHTSGQSNGRDHQALAKAVQVHQDTLRTMYFA>sp|Q9UKV8-2|AGO2_HUMAN Isoform 2 of Protein argonaute-2 OS=Homo sapiensOX=9606 GN=AGO2MYSGAGPALAPPAPPPPIQGYAFKPPPRPDFGTSGRTIKLQANFFEMDIPKIDIYHYELDIKPEKCPRRVNREIVEHMVQHFKTQIFGDRKPVFDGRKNLYTAMPLPIGRDKVELEVTLPGEGKDRIFKVSIKWVSCVSLQALHDALSGRLPSVPFETIQALDVVMRHLPSMRYTPVGRSFFTASEGCSNPLGGGREVWFGFHQSVRPSLWKMMLNIDVSATAFYKAQPVIEFVCEVLDFKSIEEQQKPLTDSQRVKFTKEIKGLKVEITHCGQMKRKYRVCNVTRRPASHQTFPLQQESGQTVECTVAQYFKDRHKLVLRYPHLPCLQVGQEQKHTYLPLEVCNIVAGQRCIKKLTDNQTSTMIRATARSAPDRQEEISKLMRSASFNTDPYVREFGIMVKDEMTDVTGRVLQPPSILYGGRNKAIATPVQGVWDMRNKQFHTGIEIKVWAIACFAPQRQCTEVHLKSFTEQLRKISRDAGMPIQGQPCFCKYAQGADSVEPMFRHLKNTYAGLQLVVVILPGKTPVYAEVKRVGDTVLGMATQCVQMKNVQRTTPQTLSNLCLKINVKLGGVNNILLPQGRPPVFQQPVIFLGADVTHPPAGDGKKPSIAAVVGSMDAHPNRYCATVRVQQHRQEIIQDLAAMVRELLIQFYKSTRFKPTRIIFYRDGVSEGQFQQVLHHELLAIREACIKLEKDYQPGITFIVVQKRHHTRLFCTDKNERGTSRPSHYHVLWDDNRFSSDELQILTYQLCHTYVRCTRSVSIPAPAYYAHLVAFRARYHLVDKEHDSAEGSHTSGQSNGRDHQALAKAVQVHQDTLRTMYFA>sp|Q96IZ2|ADTRP_HUMAN Androgen-dependent TFPI-regulating protein OS=Homosapiens OX=9606 GN=ADTRP PE=1 SV=1MTKTSTCIYHFLVLSWYTFLNYYISQEGKDEVKPKILANGARWKYMTLLNLLLQTIFYGVTCLDDVLKRTKGGKDIKFLTAFRDLLFTTLAFPVSTFVFLAFWILFLYNRDLIYPKVLDTVIPVWLNHAMHTFIFPITLAEVVLRPHSYPSKKTGLTLLAAASIAYISRILWLYFETGTWVYPVFAKLSLLGLAAFFSLSYVFIASIYLLGEKLNHWKWGDMRQPRKKRK>sp|Q96IZ2-2|ADTRP_HUMAN Isoform 2 of Androgen-dependent TFPI-regulatingprotein OS=Homo sapiens OX=9606 GN=ADTRPMTKTSTCIYHFLVLSWYTFLNYYISQEGKDEVKPKILANGARWKYMTLLNLLKNRTAGFDIYQPGSFRQLLQTIFYGVTCLDDVLKRTKGGKDIKFLTAFRDLLFTTLAFPVSTFVFLAFWILFLYNRDLIYPKVLDTVIPVWLNHAMHTFIFPITLAEVVLRPHSYPSKKTGLTLLAAASIAYISRILWLYFETGTWVYPVFAKLSLLGLAAFFSLSYVFIASIYLLGEKLNHWKWGDMRQPRKKRK>sp|Q96IZ2-3|ADTRP_HUMAN Isoform 3 of Androgen-dependent TFPI-regulatingprotein OS=Homo sapiens OX=9606 GN=ADTRPMTKTSTCIYHFLVLSWYTFLNYYISQEGKDEVKPKILANGARWKYMTLLNLLLQTIFYGVTCLDDVLKRTKGGKDIKFLTAFRDLLFTTLAFPVSTFVFLAFWILFLYNRDLIYPKVLDTVIPVWLNHAMHTFIFPITLAEVVLRPHSYPSKKTGLTLLAAASIAYISRILWLYFETGTWVYPVFAKLSLLGLAAFFSLSYVFIASIYLLGEKLNHWKWVSVQILQRWRLESVGICFQWPDWKSPAKHQLVKNIR>sp|Q08828|ADCY1_HUMAN Adenylate cyclase type 1 OS=Homo sapiens OX=9606GN=ADCY1 PE=1 SV=2MAGAPRGGGGGGGGAGEPGGAERAAGTSRRRGLRACDEEFACPELEALFRGYTLRLEQAATLKALAVLSLLAGALALAELLGAPGPAPGLAKGSHPVHCVLFLALLVVTNVRSLQVPQLQQVGQLALLFSLTFALLCCPFALGGPARGSAGAAGGPATAEQGVWQLLLVTFVSYALLPVRSLLAIGFGLVVAASHLLVTATLVPAKRPRLWRTLGANALLFVGVNMYGVFVRILTERSQRKAFLQARSCIEDRLRLEDENEKQERLLMSLLPRNVAMEMKEDFLKPPERIFHKIYIQRHDNVSILFADIVGFTGLASQCTAQELVKLLNELFGKFDELATENHCRRIKILGDCYYCVSGLTQPKTDHAHCCVEMGLDMIDTITSVAEATEVDLNMRVGLHTGRVLCGVLGLRKWQYDVWSNDVTLANVMEAAGLPGKVHITKTTLACLNGDYEVEPGYGHERNSFLKTHNIETFFIVPSHRRKIFPGLILSDIKPAKRMKFKTVCYLLVQLMHCRKMFKAEIPFSNVMTCEDDDKRRALRTASEKLRNRSSFSTNVVYTTPGTRVNRYISRLLEARQTELEMADLNFFTLKYKHVEREQKYHQLQDEYFTSAVVLTLILAALFGLVYLLIFPQSVVVLLLLVFCICFLVACVLYLHITRVQCFPGCLTIQIRTVLCIFIVVLIYSVAQGCVVGCLPWAWSSKPNSSLVVLSSGGQRTALPTLPCESTHHALLCCLVGTLPLAIFFRVSSLPKMILLSGLTTSYILVLELSGYTRTGGGAVSGRSYEPIVAILLFSCALALHARQVDIRLRLDYLWAAQAEEEREDMEKVKLDNRRILFNLLPAHVAQHFLMSNPRNMDLYYQSYSQVGVMFASIPNFNDFYIELDGNNMGVECLRLLNEIIADFDELMEKDFYKDIEKIKTIGSTYMAAVGLAPTSGTKAKKSISSHLSTLADFAIEMFDVLDEINYQSYNDFVLRVGINVGPVVAGVIGARRPQYDIWGNTVNVASRMDSTGVQGRIQVTEEVHRLLRRCPYHFVCRGKVSVKGKGEMLTYFLEGRTDGNGSQIRSLGLDRKMCPFGRAGLQGRRPPVCPMPGVSVRAGLPPHSPGQYLPSAAAGKEA>sp|Q7Z695|ADCK2_HUMAN Uncharacterized aarF domain-containing proteinkinase 2 OS=Homo sapiens OX=9606 GN=ADCK2 PE=1 SV=1MVAPWRVSVRVCLSHLRCFELRQGLSLLRPSECPRDARLCWLLLGTLPKVVSLCGDVGEGAPDVLSRRRVRCSGAAGAGPAESLPRAGPLGGVFLHLRLWLRAGALLVKFFPLLLLYPLTYLAPSVSTLWLHLLLKATETSGPTYIKLGQWASTRRDLFSEAFCAQFSKLHVRVTPHPWTHTERFLRQAFGDDWGSILSFENREPVGSGCVAQVYKAYANTAFLETDSVQRLGRASCLPPFSHTGAVGGLRELFGYLGNGRKPPENLADQSFLERLLLPKADLVGSNAGVSRAQVPGHQPEATNLISVAVKVLHPGLLAQVHMDLLLMKIGSRVLGVLPGIKWLSLPEIVEEFEKLMVQQIDLRYEAQNLEHFQVNFRNVKAVKFPTPLRPFVTREVLVETYEESVPVSSYQQAGIPVDLKRKIARLGINMLLKMIFVDNFVHADLHPGNILVQGANGLSSSQEAQLQQADICDTLVVAVPSSLCPLRLVLLDAGIVAELQAPDLRNFRAVFMAVVMGQGQRVAELILHHARASECRDVEGFKTEMAMLVTQARKNTITLEKLHVSSLLSSVFKLLMTHKVKLESNFASIVFAIMVLEGLGRSLDPKLDILEAARPFLLTGPVCPP>sp|P17213|BPI_HUMAN Bactericidal permeability-increasing protein OS=Homosapiens OX=9606 GN=BPI PE=1 SV=4MRENMARGPCNAPRWASLMVLVAIGTAVTAAVNPGVVVRISQKGLDYASQQGTAALQKELKRIKIPDYSDSFKIKHLGKGHYSFYSMDIREFQLPSSQISMVPNVGLKFSISNANIKISGKWKAQKRFLKMSGNFDLSIEGMSISADLKLGSNPTSGKPTITCSSCSSHINSVHVHISKSKVGWLIQLFHKKIESALRNKMNSQVCEKVTNSVSSELQPYFQTLPVMTKIDSVAGINYGLVAPPATTAETLDVQMKGEFYSENHHNPPPFAPPVMEFPAAHDRMVYLGLSDYFFNTAGLVYQEAGVLKMTLRDDMIPKESKFRLTTKFFGTFLPEVAKKFPNMKIQIHVSASTPPHLSVQPTGLTFYPAVDVQAFAVLPNSSLASLFLIGMHTTGSMEVSAESNRLVGELKLDRLLLELKHSNIGPFPVELLQDIMNYIVPILVLPRVNEKLQKGFPLPTPARVQLYNVVLQPHQNFLLFGADVVYK>sp|Q6P093|ADCL2_HUMAN Arylacetamide deacetylase-like 2 OS=Homo sapiensOX=9606 GN=AADACL2 PE=2 SV=3MGLKALCLGLLCVLFVSHFYTPMPDNIEESWKIMALDAIAKTCTFTAMCFENMRIMRYEEFISMIFRLDYTQPLSDEYITVTDTTFVDIPVRLYLPKRKSETRRRAVIYFHGGGFCFGSSKQRAFDFLNRWTANTLDAVVVGVDYRLAPQHHFPAQFEDGLAAVKFFLLEKILTKYGVDPTRICIAGDSSGGNLATAVTQQVQNDAEIKHKIKMQVLLYPGLQITDSYLPSHRENEHGIVLTRDVAIKLVSLYFTKDEALPWAMRRNQHMPLESRHLFKFVNWSILLPEKYRKDYVYTEPILGGLSYSLPGLTDSRALPLLANDSQLQNLPLTYILTCQHDLLRDDGLMYVTRLRNVGVQVVHEHIEDGIHGALSFMTSPFYLRLGLRIRDMYVSWLDKNL>sp|Q6P093-3|ADCL2_HUMAN Isoform 2 of Arylacetamide deacetylase-like 2OS=Homo sapiens OX=9606 GN=AADACL2MGLKALCLGLLCVLFVSHFYTPMPDNIEESWKIMALDAIAKTCTFTNRGPLTS>sp|P0C7M7|ACSM4_HUMAN Acyl-coenzyme A synthetase ACSM4, mitochondrialOS=Homo sapiens OX=9606 GN=ACSM4 PE=2 SV=1MKIFFRYQTFRFIWLTKPPGRRLHKDHQLWTPLTLADFEAINRCNRPLPKNFNFAADVLDQWSQKEKTGERPANPALWWVNGKGDEVKWSFRELGSLSRKAANVLTKPCGLQRGDRLAVILPRIPEWWLVNVACIRTGIIFMPGTIQLTAKDILYRLRASKAKCIVASEEVAPAVESIVLECPDLKTKLLVSPQSWNGWLSFQELFQFASEEHSCVETGSQEPMTIYFTSGTTGFPKMAQHSQSSLGIGFTLCGRYWLDLKSSDIIWNMSDTGWVKAAIGSVFSSWLCGACVFVHRMAQFDTDTFLDTLTTYPITTLCSPPTVYRMLVQKDLKRYKFKSLRHCLTGGEPLNPEVLEQWRVQTGLELYEGYGQTEVGMICANQKGQEIKPGSMGKGMLPYDVQIIDENGNVLPPGKEGEIALRLKPTRPFCFFSKYVDNPQKTAATIRGDFYVTGDRGVMDSDGYFWFVGRADDVIISSGYRIGPFEVESALIEHPAVVESAVVSSPDQIRGEVVKAFVVLAAPFKSYNPEKLTLELQDHVKKSTAPYKYPRKVEFVQELPKTITGKIKRNVLRDQEWRGR>sp|O43707|ACTN4_HUMAN Alpha-actinin-4 OS=Homo sapiens OX=9606 GN=ACTN4PE=1 SV=2MVDYHAANQSYQYGPSSAGNGAGGGGSMGDYMAQEDDWDRDLLLDPAWEKQQRKTFTAWCNSHLRKAGTQIENIDEDFRDGLKLMLLLEVISGERLPKPERGKMRVHKINNVNKALDFIASKGVKLVSIGAEEIVDGNAKMTLGMIWTIILRFAIQDISVEETSAKEGLLLWCQRKTAPYKNVNVQNFHISWKDGLAFNALIHRHRPELIEYDKLRKDDPVTNLNNAFEVAEKYLDIPKMLDAEDIVNTARPDEKAIMTYVSSFYHAFSGAQKAETAANRICKVLAVNQENEHLMEDYEKLASDLLEWIRRTIPWLEDRVPQKTIQEMQQKLEDFRDYRRVHKPPKVQEKCQLEINFNTLQTKLRLSNRPAFMPSEGKMVSDINNGWQHLEQAEKGYEEWLLNEIRRLERLDHLAEKFRQKASIHEAWTDGKEAMLKHRDYETATLSDIKALIRKHEAFESDLAAHQDRVEQIAAIAQELNELDYYDSHNVNTRCQKICDQWDALGSLTHSRREALEKTEKQLEAIDQLHLEYAKRAAPFNNWMESAMEDLQDMFIVHTIEEIEGLISAHDQFKSTLPDADREREAILAIHKEAQRIAESNHIKLSGSNPYTTVTPQIINSKWEKVQQLVPKRDHALLEEQSKQQSNEHLRRQFASQANVVGPWIQTKMEEIGRISIEMNGTLEDQLSHLKQYERSIVDYKPNLDLLEQQHQLIQEALIFDNKHTNYTMEHIRVGWEQLLTTIARTINEVENQILTRDAKGISQEQMQEFRASFNHFDKDHGGALGPEEFKACLISLGYDVENDRQGEAEFNRIMSLVDPNHSGLVTFQAFIDFMSRETTDTDTADQVIASFKVLAGDKNFITAEELRRELPPDQAEYCIARMAPYQGPDAVPGALDYKSFSTALYGESDL>sp|O43707-2|ACTN4_HUMAN Isoform ACTN4ISO of Alpha-actinin-4 OS=Homosapiens OX=9606 GN=ACTN4MVDYHAANQSYQYGPSSAGNGAGGGGSMGDYMAQEDDWDRDLLLDPAWEKQQRKAETAANRICKVLAVNQENEHLMEDYEKLASDLLEWIRRTIPWLEDRVPQKTIQEMQQKLEDFRDYRRVHKPPKVQEKCQLEINFNTLQTKLRLSNRPAFMPSEGKMVSDINNGWQHLEQAEKGYEEWLLNEIRRLERLDHLAEKFRQKASIHEAWTDGKEAMLKHRDYETATLSDIKALIRKHEAFESDLAAHQDRVEQIAAIAQELNELDYYDSHNVNTRCQKICDQWDALGSLTHSRREALEKTEKQLEAIDQLHLEYAKRAAPFNNWMESAMEDLQDMFIVHTIEEIEGLISAHDQFKSTLPDADREREAILAIHKEAQRIAESNHIKLSGSNPYTTVTPQIINSKWEKVQQLVPKRDHALLEEQSKQQSNEHLRRQFASQANVVGPWIQTKMEEIGRISIEMNGTLEDQLSHLKQYERSIVDYKPNLDLLEQQHQLIQEALIFDNKHTNYTMEHIRVGWEQLLTTIARTINEVENQILTRDAKGISQEQMQEFRASFNHFDKDHGGALGPEEFKACLISLGYDVENDRQGEAEFNRIMSLVDPNHSGLVTFQAFIDFMSRETTDTDTADQVIASFKVLAGDKNFITAEELRRELPPDQAEYCIARMAPYQGPDAVPGALDYKSFSTALYGESDL>sp|O43707-3|ACTN4_HUMAN Isoform 3 of Alpha-actinin-4 OS=Homo sapiensOX=9606 GN=ACTN4MVDYHAANQSYQYGPSSAGNGAGGGGSMGDYMAQEDDWDRDLLLDPAWEKQQRKTFTAWCNSHLRKAGTQIENIDEDFRDGLKLMLLLELNELDYYDSHNVNTRCQKICDQWDALGSLTHSRREALEKTEKQLEAIDQLHLEYAKRAAPFNNWMESAMEDLQDMFIVHTIEEIEGLISAHDQFKSTLPDADREREAILAIHKEAQRIAESNHIKLSGSNPYTTVTPQIINSKWEKVQQLVPKRDHALLEEQSKQQSNEHLRRQFASQANVVGPWIQTKMEEIGRISIEMNGTLEDQLSHLKQYERSIVDYKPNLDLLEQQHQLIQEALIFDNKHTNYTMEHIRVGWEQLLTTIARTINEVENQILTRDAKGISQEQMQEFRASFNHFDKDHGGALGPEEFKACLISLGYDVENDRQGEAEFNRIMSLVDPNHSGLVTFQAFIDFMSRETTDTDTADQVIASFKVLAGDKNFITAEELRRELPPDQAEYCIARMAPYQGPDAVPGALDYKSFSTALYGESDL>sp|Q2TAA5|ALG11_HUMAN GDP-Man:Man(3)GlcNAc(2)-PP-Dol alpha-1,2-mannosyltransferase OS=Homo sapiens OX=9606 GN=ALG11 PE=1 SV=2MAAGERSWCLCKLLRFFYSLFFPGLIVCGTLCVCLVIVLWGIRLLLQRKKKLVSTSKNGKNQMVIAFFHPYCNAGGGGERVLWCALRALQKKYPEAVYVVYTGDVNVNGQQILEGAFRRFNIRLIHPVQFVFLRKRYLVEDSLYPHFTLLGQSLGSIFLGWEALMQCVPDVYIDSMGYAFTLPLFKYIGGCQVGSYVHYPTISTDMLSVVKNQNIGFNNAAFITRNPFLSKVKLIYYYLFAFIYGLVGSCSDVVMVNSSWTLNHILSLWKVGNCTNIVYPPCDVQTFLDIPLHEKKMTPGHLLVSVGQFRPEKNHPLQIRAFAKLLNKKMVESPPSLKLVLIGGCRNKDDELRVNQLRRLSEDLGVQEYVEFKINIPFDELKNYLSEATIGLHTMWNEHFGIGVVECMAAGTIILAHNSGGPKLDIVVPHEGDITGFLAESEEDYAETIAHILSMSAEKRLQIRKSARASVSRFSDQEFEVTFLSSVEKLFK>sp|Q96PE1|AGRA2_HUMAN Adhesion G protein-coupled receptor A2 OS=Homosapiens OX=9606 GN=ADGRA2 PE=1 SV=2MGAGGRRMRGAPARLLLPLLPWLLLLLAPEARGAPGCPLSIRSCKCSGERPKGLSGGVPGPARRRVVCSGGDLPEPPEPGLLPNGTVTLLLSNNKITGLRNGSFLGLSLLEKLDLRNNIISTVQPGAFLGLGELKRLDLSNNRIGCLTSETFQGLPRLLRLNISGNIFSSLQPGVFDELPALKVVDLGTEFLTCDCHLRWLLPWAQNRSLQLSEHTLCAYPSALHAQALGSLQEAQLCCEGALELHTHHLIPSLRQVVFQGDRLPFQCSASYLGNDTRIRWYHNRAPVEGDEQAGILLAESLIHDCTFITSELTLSHIGVWASGEWECTVSMAQGNASKKVEIVVLETSASYCPAERVANNRGDFRWPRTLAGITAYQSCLQYPFTSVPLGGGAPGTRASRRCDRAGRWEPGDYSHCLYTNDITRVLYTFVLMPINASNALTLAHQLRVYTAEAASFSDMMDVVYVAQMIQKFLGYVDQIKELVEVMVDMASNLMLVDEHLLWLAQREDKACSRIVGALERIGGAALSPHAQHISVNARNVALEAYLIKPHSYVGLTCTAFQRREGGVPGTRPGSPGQNPPPEPEPPADQQLRFRCTTGRPNVSLSSFHIKNSVALASIQLPPSLFSSLPAALAPPVPPDCTLQLLVFRNGRLFHSHSNTSRPGAAGPGKRRGVATPVIFAGTSGCGVGNLTEPVAVSLRHWAEGAEPVAAWWSQEGPGEAGGWTSEGCQLRSSQPNVSALHCQHLGNVAVLMELSAFPREVGGAGAGLHPVVYPCTALLLLCLFATIITYILNHSSIRVSRKGWHMLLNLCFHIAMTSAVFAGGITLTNYQMVCQAVGITLHYSSLSTLLWMGVKARVLHKELTWRAPPPQEGDPALPTPSPMLRFYLIAGGIPLIICGITAAVNIHNYRDHSPYCWLVWRPSLGAFYIPVALILLITWIYFLCAGLRLRGPLAQNPKAGNSRASLEAGEELRGSTRLRGSGPLLSDSGSLLATGSARVGTPGPPEDGDSLYSPGVQLGALVTTHFLYLAMWACGALAVSQRWLPRVVCSCLYGVAASALGLFVFTHHCARRRDVRASWRACCPPASPAAPHAPPRALPAAAEDGSPVFGEGPPSLKSSPSGSSGHPLALGPCKLTNLQLAQSQVCEAGAAAGGEGEPEPAGTRGNLAHRHPNNVHHGRRAHKSRAKGHRAGEACGKNRLKALRGGAAGALELLSSESGSLHNSPTDSYLGSSRNSPGAGLQLEGEPMLTPSEGSDTSAAPLSEAGRAGQRRSASRDSLKGGGALEKESHRRSYPLNAASLNGAPKGGKYDDVTLMGAEVASGGCMKTGLWKSETTV>sp|Q96PE1-2|AGRA2_HUMAN Isoform 2 of Adhesion G protein-coupled receptorA2 OS=Homo sapiens OX=9606 GN=ADGRA2MGAGGRRMRGAPARLLLPLLPWLLLLLAPEARGAPGCPLSIRSCKCSGERPKGLSGGVPGPARRRVVCSGGDLPEPPEPGLLPNGTVTLLLSNNKITGLRNGSFLGLSLLEKLDLRNNIISTVQPGAFLGLGELKRLDLSNNRIGCLTSETFQGLPRLLRLNISGNIFSSLQPGVFDELPALKVVDLGTEFLTCDCHLRWLLPWAQNRSLQLSEHTLCAYPSALHAQALGSLQEAQLCCEGALELHTHHLIPSLRQVVFQGDRLPFQCSASYLGNDTRIRWYHNRAPVEGDEQAGILLAESLIHDCTFITSELTLSHIGVWASGEWECTVSMAQGNASKKVEIVVLETSASYCPAERVANNRGDFRWPRTLAGITAYQSCLQYPFTSVPLGGGAPGTRASRRCDRAGRWEPGDYSHCLYTNDITRVLYTFVLMPINASNALTLAHQLRVYTAEAASFSDMMDVVYVAQMIQKFLGYVDQIKELVEVMVDMASNLMLVDEHLLWLAQREDKACSRIVGALERIGGAALSPHAQHISVELSAFPREVGGAGAGLHPVVYPCTALLLLCLFATIITYILNHSSIRVSRKGWHMLLNLCFHIAMTSAVFAGGITLTNYQMVCQAVGITLHYSSLSTLLWMGVKARVLHKELTWRAPPPQEGDPALPTPSPMLRFYLIAGGIPLIICGITAAVNIHNYRDHSPYCWLVWRPSLGAFYIPVALILLITWIYFLCAGLRLRGPLAQNPKAGNSRASLEAGEELRGSTRLRGSGPLLSDSGSLLATGSARVGTPGPPEDGDSLYSPGVQLGALVTTHFLYLAMWACGALAVSQRWLPRVVCSCLYGVAASALGLFVFTHHCARRRDVRASWRACCPPASPAAPHAPPRALPAAAEDGSPVFGEGPPSLKSSPSGSSGHPLALGPCKLTNLQLAQSQVCEAGAAAGGEGEPEPAGTRGNLAHRHPNNVHHGRRAHKSRAKGHRAGEACGKNRLKALRGGAAGALELLSSESGSLHNSPTDSYLGSSRNSPGAGLQLEGEPMLTPSEGSDTSAAPLSEAGRAGQRRSASRDSLKGGGALEKESHRRSYPLNAASLNGAPKGGKYDDVTLMGAEVASGGCMKTGLWKSETTV>sp|Q96PE1-3|AGRA2_HUMAN Isoform 3 of Adhesion G protein-coupled receptorA2 OS=Homo sapiens OX=9606 GN=ADGRA2MGAGGRRMRGAPARLLLPLLPWLLLLLAPEARGAPGCPLSIRSCKCSGERPKGLSGGVPGPARRRVVCSGGDLPEPPEPGLLPNGTVTLLLSNNKITGLRNGSFLGLSLLEKLDLRNNIISTVQPGAFLGLGELKRLDLSNNRIGCLTSETFQGLPRLLRLNISGNIFSSLQPGVFDELPALKVV>sp|P06280|AGAL_HUMAN Alpha-galactosidase A OS=Homo sapiens OX=9606GN=GLA PE=1 SV=1MQLRNPELHLGCALALRFLALVSWDIPGARALDNGLARTPTMGWLHWERFMCNLDCQEEPDSCISEKLFMEMAELMVSEGWKDAGYEYLCIDDCWMAPQRDSEGRLQADPQRFPHGIRQLANYVHSKGLKLGIYADVGNKTCAGFPGSFGYYDIDAQTFADWGVDLLKFDGCYCDSLENLADGYKHMSLALNRTGRSIVYSCEWPLYMWPFQKPNYTEIRQYCNHWRNFADIDDSWKSIKSILDWTSFNQERIVDVAGPGGWNDPDMLVIGNFGLSWNQQVTQMALWAIMAAPLFMSNDLRHISPQAKALLQDKDVIAINQDPLGKQGYQLRQGDNFEVWERPLSGLAWAVAMINRQEIGGPRSYTIAVASLGKGVACNPACFITQLLPVKRKLGFYEWTSRLRSHINPTGTVLLQLENTMQMSLKDLL>sp|Q7Z4H4|ADM2_HUMAN Protein ADM2 OS=Homo sapiens OX=9606 GN=ADM2 PE=1SV=1MARIPTAALGCISLLCLQLPGSLSRSLGGDPRPVKPREPPARSPSSSLQPRHPAPRPVVWKLHRALQAQRGAGLAPVMGQPLRDGGRQHSGPRRHSGPRRTQAQLLRVGCVLGTCQVQNLSHRLWQLMGPAGRQDSAPVDPSSPHSYG>sp|C9JUS6|ADM5_HUMAN Putative adrenomedullin-5-like protein OS=Homosapiens OX=9606 GN=ADM5 PE=2 SV=1MTIHILILLLLLAFSAQGDLDTAARRGQHQVPQHRGHVCYLGVCRTHRLAEIIYWIRCLHQGALGEGQPRAPGPLQLWAPPVARGGSPARFPGFRPAARGLAQCPARWVTSGTARPLLGFSLPICMLELLLHISSPLTPAPETVFPSPSPGCD>sp|P0DO97|CC192_HUMAN Coiled-coil domain-containing protein 192 OS=Homosapiens OX=9606 GN=CCDC192 PE=4 SV=1MMPVDVCPRDRGSQWVWLEMGQCYSKKSVVPESDTSERSSMTSGSSESDIPQENKVSKASLDTGQMAFTLAQLESLEICLKEAEEKAKALSEQLSVSEGTKSKLLEQVSRLEEKLEAVDHKEASGGPYEKMVLVKDQCIQKLQAEVKASQEQLIAQKLKHEKKVKKLQTDLATANAITVLELNEKIKTLYEGKPAPREDSLLEGFCGGLPPVEEGDRKISLIMELSTQVSLQTERITQLKEVLEEKERKIQQLEAERSPHPPQEVKDPPGCLPEAPVFSTHDIPPVVSDENL>sp|A0A1B0GVG4|CC194_HUMAN Coiled-coil domain-containing protein 194OS=Homo sapiens OX=9606 GN=CCDC194 PE=3 SV=1MAEPGPEPGRAWRVLALCGVAVFLAAAAAGGALVAWNLAASAARGPRCPEPGANATAPPGDPPPGVDDLRRRLAEAAEREEALARQLDQAESIRHELEKALKACEGRQSRLQTQLTTLKIEMDEAKAQGTQMGAENGALTEALARWEAAATESTRRLDEALRRAGVAEAEGEACAAREAALRERLNVLEAEMSPQRRVPRPRPRSGSRPRPSPRSRSRSGPSGGCRRPARRARG>sp|Q9BVK2|ALG8_HUMAN Probable dolichyl pyrophosphate Glc1Man9GlcNAc2alpha-1,3-glucosyltransferase OS=Homo sapiens OX=9606 GN=ALG8 PE=1 SV=2MAALTIATGTGNWFSALALGVTLLKCLLIPTYHSTDFEVHRNWLAITHSLPISQWYYEATSEWTLDYPPFFAWFEYILSHVAKYFDQEMLNVHNLNYSSSRTLLFQRFSVIFMDVLFVYAVRECCKCIDGKKVGKELTEKPKFILSVLLLWNFGLLIVDHIHFQYNGFLFGLMLLSIARLFQKRHMEGAFLFAVLLHFKHIYLYVAPAYGVYLLRSYCFTANKPDGSIRWKSFSFVRVISLGLVVFLVSALSLGPFLALNQLPQVFSRLFPFKRGLCHAYWAPNFWALYNALDKVLSVIGLKLKFLDPNNIPKASMTSGLVQQFQHTVLPSVTPLATLICTLIAILPSIFCLWFKPQGPRGFLRCLTLCALSSFMFGWHVHEKAILLAILPMSLLSVGKAGDASIFLILTTTGHYSLFPLLFTAPELPIKILLMLLFTIYSISSLKTLFRKEKPLFNWMETFYLLGLGPLEVCCEFVFPFTSWKVKYPFIPLLLTSVYCAVGITYAWFKLYVSVLIDSAIGKTKKQ>sp|Q9BVK2-2|ALG8_HUMAN Isoform 2 of Probable dolichyl pyrophosphateGlc1Man9GlcNAc2 alpha-1,3-glucosyltransferase OS=Homo sapiens OX=9606GN=ALG8MAALTIATGTGNWFSALALGVTLLKCLLIPTYHSTDFEVHRNWLAITHSLPISQWYYEATSEWTLDYPPFFAWFEYILSHVAKYFDQEMLNVHNLNYSSSRTLLFQRFSVIFMDVLFVYAVRECCKCIDGKKVGKELTEKPKFILSVLLLWNFGLLIVDHIHFQYNGFLFGLMLLSIARLFQKRHMEGAFLFAVLLHFKHIYLYVAPAYGVYLLRSYCFTANKPDGSIRWKSFSFVRVISLGLVVFLVSALSLGPFLALNQLPQVFSRLFPFKRGLCHAYWAPNFWALYNALDKVLSVIGLKLKFLDPNNIPKASMTSGLVQQFQHTVLPSVTPLATLICTLIAILPSIFCLWFKPQGPRGFLRCLTLCALSSFMFGWHVHEKAILLAILPMSLLSVGKAGDASIFLILTTTGHYSLFPLLFTAPELPIKILLMLLFTIYSISSLKTLFRRSFTLVAQAGVQWHDLS>sp|O75078|ADA11_HUMAN Disintegrin and metalloproteinase domain-containing protein 11 OS=Homo sapiens OX=9606 GN=ADAM11 PE=2 SV=3MRLLRRWAFAALLLSLLPTPGLGTQGPAGALRWGGLPQLGGPGAPEVTEPSRLVRESSGGEVRKQQLDTRVRQEPPGGPPVHLAQVSFVIPAFNSNFTLDLELNHHLLSSQYVERHFSREGTTQHSTGAGDHCYYQGKLRGNPHSFAALSTCQGLHGVFSDGNLTYIVEPQEVAGPWGAPQGPLPHLIYRTPLLPDPLGCREPGCLFAVPAQSAPPNRPRLRRKRQVRRGHPTVHSETKYVELIVINDHQLFEQMRQSVVLTSNFAKSVVNLADVIYKEQLNTRIVLVAMETWADGDKIQVQDDLLETLARLMVYRREGLPEPSDATHLFSGRTFQSTSSGAAYVGGICSLSHGGGVNEYGNMGAMAVTLAQTLGQNLGMMWNKHRSSAGDCKCPDIWLGCIMEDTGFYLPRKFSRCSIDEYNQFLQEGGGSCLFNKPLKLLDPPECGNGFVEAGEECDCGSVQECSRAGGNCCKKCTLTHDAMCSDGLCCRRCKYEPRGVSCREAVNECDIAETCTGDSSQCPPNLHKLDGYYCDHEQGRCYGGRCKTRDRQCQVLWGHAAADRFCYEKLNVEGTERGSCGRKGSGWVQCSKQDVLCGFLLCVNISGAPRLGDLVGDISSVTFYHQGKELDCRGGHVQLADGSDLSYVEDGTACGPNMLCLDHRCLPASAFNFSTCPGSGERRICSHHGVCSNEGKCICQPDWTGKDCSIHNPLPTSPPTGETERYKGPSGTNIIIGSIAGAVLVAAIVLGGTGWGFKNIRRGRSGGA>sp|O75078-2|ADA11_HUMAN Isoform Short of Disintegrin andmetalloproteinase domain-containing protein 11 OS=Homo sapiens OX=9606GN=ADAM11MCWLSHHLLSSQYVERHFSREGTTQHSTGAGDHCYYQGKLRGNPHSFAALSTCQGLHGVFSDGNLTYIVEPQEVAGPWGAPQGPLPHLIYRTPLLPDPLGCREPGCLFAVPAQSAPPNRPRLRRKRQVRRGHPTVHSETKYVELIVINDHQLFEQMRQSVVLTSNFAKSVVNLADVIYKEQLNTRIVLVAMETWADGDKIQVQDDLLETLARLMVYRREGLPEPSDATHLFSGRTFQSTSSGAAYVGGICSLSHGGGVNEYGNMGAMAVTLAQTLGQNLGMMWNKHRSSAGDCKCPDIWLGCIMEDTGFYLPRKFSRCSIDEYNQFLQEGGGSCLFNKPLKLLDPPECGNGFVEAGEECDCGSVQECSRAGGNCCKKCTLTHDAMCSDGLCCRRCKYEPRGVSCREAVNECDIAETCTGDSSQCPPNLHKLDGYYCDHEQGRCYGGRCKTRDRQCQVLWGHAAADRFCYEKLNVEGTERGSCGRKGSGWVQCSKQPQQGRAVWLPPLCQHLWSSSARGPGGRHQ>sp|P42568|AF9_HUMAN Protein AF-9 OS=Homo sapiens OX=9606 GN=MLLT3 PE=1SV=2MASSCAVQVKLELGHRAQVRKKPTVEGFTHDWMVFVRGPEHSNIQHFVEKVVFHLHESFPRPKRVCKDPPYKVEESGYAGFILPIEVYFKNKEEPRKVRFDYDLFLHLEGHPPVNHLRCEKLTFNNPTEDFRRKLLKAGGDPNRSIHTSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSTSFSKPHKLMKEHKEKPSKDSREHKSAFKEPSRDHNKSSKESSKKPKENKPLKEEKIVPKMAFKEPKPMSKEPKPDSNLLTITSGQDKKAPSKRPPISDSEELSAKKRKKSSSEALFKSFSSAPPLILTCSADKKQIKDKSHVKMGKVKIESETSEKKKSTLPPFDDIVDPNDSDVEENISSKSDSEQPSPASSSSSSSSSFTPSQTRQQGPLRSIMKDLHSDDNEEESDEVEDNDNDSEMERPVNRGGSRSRRVSLSDGSDSESSSASSPLHHEPPPPLLKTNNNQILEVKSPIKQSKSDKQIKNGECDKAYLDELVELHRRLMTLRERHILQQIVNLIEETGHFHITNTTFDFDLCSLDKTTVRKLQSYLETSGTS>sp|P42568-2|AF9_HUMAN Isoform 2 of Protein AF-9 OS=Homo sapiens OX=9606GN=MLLT3MCAVQVKLELGHRAQVRKKPTVEGFTHDWMVFVRGPEHSNIQHFVEKVVFHLHESFPRPKRVCKDPPYKVEESGYAGFILPIEVYFKNKEEPRKVRFDYDLFLHLEGHPPVNHLRCEKLTFNNPTEDFRRKLLKAGGDPNRSIHTSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSTSFSKPHKLMKEHKEKPSKDSREHKSAFKEPSRDHNKSSKESSKKPKENKPLKEEKIVPKMAFKEPKPMSKEPKPDSNLLTITSGQDKKAPSKRPPISDSEELSAKKRKKSSSEALFKSFSSAPPLILTCSADKKQIKDKSHVKMGKVKIESETSEKKKSTLPPFDDIVDPNDSDVEENISSKSDSEQPSPASSSSSSSSSFTPSQTRQQGPLRSIMKDLHSDDNEEESDEVEDNDNDSEMERPVNRGGSRSRRVSLSDGSDSESSSASSPLHHEPPPPLLKTNNNQILEVKSPIKQSKSDKQIKNGECDKAYLDELVELHRRLMTLRERHILQQIVNLIEETGHFHITNTTFDFDLCSLDKTTVRKLQSYLETSGTS>sp|Q9H2P0|ADNP_HUMAN Activity-dependent neuroprotector homeobox proteinOS=Homo sapiens OX=9606 GN=ADNP PE=1 SV=1MFQLPVNNLGSLRKARKTVKKILSDIGLEYCKEHIEDFKQFEPNDFYLKNTTWEDVGLWDPSLTKNQDYRTKPFCCSACPFSSKFFSAYKSHFRNVHSEDFENRILLNCPYCTFNADKKTLETHIKIFHAPNASAPSSSLSTFKDKNKNDGLKPKQADSVEQAVYYCKKCTYRDPLYEIVRKHIYREHFQHVAAPYIAKAGEKSLNGAVPLGSNAREESSIHCKRCLFMPKSYEALVQHVIEDHERIGYQVTAMIGHTNVVVPRSKPLMLIAPKPQDKKSMGLPPRIGSLASGNVRSLPSQQMVNRLSIPKPNLNSTGVNMMSSVHLQQNNYGVKSVGQGYSVGQSMRLGLGGNAPVSIPQQSQSVKQLLPSGNGRSYGLGSEQRSQAPARYSLQSANASSLSSGQLKSPSLSQSQASRVLGQSSSKPAAAATGPPPGNTSSTQKWKICTICNELFPENVYSVHFEKEHKAEKVPAVANYIMKIHNFTSKCLYCNRYLPTDTLLNHMLIHGLSCPYCRSTFNDVEKMAAHMRMVHIDEEMGPKTDSTLSFDLTLQQGSHTNIHLLVTTYNLRDAPAESVAYHAQNNPPVPPKPQPKVQEKADIPVKSSPQAAVPYKKDVGKTLCPLCFSILKGPISDALAHHLRERHQVIQTVHPVEKKLTYKCIHCLGVYTSNMTASTITLHLVHCRGVGKTQNGQDKTNAPSRLNQSPSLAPVKRTYEQMEFPLLKKRKLDDDSDSPSFFEEKPEEPVVLALDPKGHEDDSYEARKSFLTKYFNKQPYPTRREIEKLAASLWLWKSDIASHFSNKRKKCVRDCEKYKPGVLLGFNMKELNKVKHEMDFDAEWLFENHDEKDSRVNASKTADKKLNLGKEDDSSSDSFENLEEESNESGSPFDPVFEVEPKISNDNPEEHVLKVIPEDASESEEKLDQKEDGSKYETIHLTEEPTKLMHNASDSEVDQDDVVEWKDGASPSESGPGSQQVSDFEDNTCEMKPGTWSDESSQSEDARSSKPAAKKKATMQGDREQLKWKNSSYGKVEGFWSKDQSQWKNASENDERLSNPQIEWQNSTIDSEDGEQFDNMTDGVAEPMHGSLAGVKLSSQQA>sp|P78536|ADA17_HUMAN Disintegrin and metalloproteinase domain-containing protein 17 OS=Homo sapiens OX=9606 GN=ADAM17 PE=1 SV=1MRQSLLFLTSVVPFVLAPRPPDDPGFGPHQRLEKLDSLLSDYDILSLSNIQQHSVRKRDLQTSTHVETLLTFSALKRHFKLYLTSSTERFSQNFKVVVVDGKNESEYTVKWQDFFTGHVVGEPDSRVLAHIRDDDVIIRINTDGAEYNIEPLWRFVNDTKDKRMLVYKSEDIKNVSRLQSPKVCGYLKVDNEELLPKGLVDREPPEELVHRVKRRADPDPMKNTCKLLVVADHRFYRYMGRGEESTTTNYLIELIDRVDDIYRNTSWDNAGFKGYGIQIEQIRILKSPQEVKPGEKHYNMAKSYPNEEKDAWDVKMLLEQFSFDIAEEASKVCLAHLFTYQDFDMGTLGLAYVGSPRANSHGGVCPKAYYSPVGKKNIYLNSGLTSTKNYGKTILTKEADLVTTHELGHNFGAEHDPDGLAECAPNEDQGGKYVMYPIAVSGDHENNKMFSNCSKQSIYKTIESKAQECFQERSNKVCGNSRVDEGEECDPGIMYLNNDTCCNSDCTLKEGVQCSDRNSPCCKNCQFETAQKKCQEAINATCKGVSYCTGNSSECPPPGNAEDDTVCLDLGKCKDGKCIPFCEREQQLESCACNETDNSCKVCCRDLSGRCVPYVDAEQKNLFLRKGKPCTVGFCDMNGKCEKRVQDVIERFWDFIDQLSINTFGKFLADNIVGSVLVFSLIFWIPFSILVHCVDKKLDKQYESLSLFHPSNVEMLSSMDSASVRIIKPFPAPQTPGRLQPAPVIPSAPAAPKLDHQRMDTIQEDPSTDSHMDEDGFEKDPFPNSSTAAKSFEDLTDHPVTRSEKAASFKLQRQNRVDSKETEC>sp|P78536-2|ADA17_HUMAN Isoform B of Disintegrin and metalloproteinasedomain-containing protein 17 OS=Homo sapiens OX=9606 GN=ADAM17MRQSLLFLTSVVPFVLAPRPPDDPGFGPHQRLEKLDSLLSDYDILSLSNIQQHSVRKRDLQTSTHVETLLTFSALKRHFKLYLTSSTERFSQNFKVVVVDGKNESEYTVKWQDFFTGHVVGEPDSRVLAHIRDDDVIIRINTDGAEYNIEPLWRFVNDTKDKRMLVYKSEDIKNVSRLQSPKVCGYLKVDNEELLPKGLVDREPPEELVHRVKRRADPDPMKNTCKLLVVADHRFYRYMGRGEESTTTNYLIELIDRVDDIYRNTSWDNAGFKGYGIQIEQIRILKSPQEVKPGEKHYNMAKSYPNEEKDAWDVKMLLEQFSFDIAEEASKVCLAHLFTYQDFDMGTLGLAYVGSPRANSHGGVCPKAYYSPVGKKNIYLNSGLTSTKNYGKTILTKEADLVTTHELGHNFGAEHDPDGLAECAPNEDQGGKYVMYPIAVSGDHENNKMFSNCSKQSIYKTIESKAQECFQERSNKVCGNSRVDEGEECDPGIMYLNNDTCCNSDCTLKEGVQCSDRNSPCCKNCQFETAQKKCQEAINATCKGVSYCTGNSSECPPPGNAEDDTVCLDLGKCKDGKCIPFCEREQQLESCACNETDNSCKVCCRDLSGRCVPYVDAEQKNLFLRKGKPCTVGFCDMNGKCEKRVQDVIERFWDFIDQLSINTFGKFLADNIVGSVLVFSLIFWIPFSILVHCV>sp|P55196|AFAD_HUMAN Afadin OS=Homo sapiens OX=9606 GN=AFDN PE=1 SV=3MSAGGRDEERRKLADIIHHWNANRLDLFEISQPTEDLEFHGVMRFYFQDKAAGNFATKCIRVSSTATTQDVIETLAEKFRPDMRMLSSPKYSLYEVHVSGERRLDIDEKPLVVQLNWNKDDREGRFVLKNENDAIPPKKAQSNGPEKQEKEGVIQNFKRTLSKKEKKEKKKREKEALRQASDKDDRPFQGEDVENSRLAAEVYKDMPETSFTRTISNPEVVMKRRRQQKLEKRMQEFRSSDGRPDSGGTLRIYADSLKPNIPYKTILLSTTDPADFAVAEALEKYGLEKENPKDYCIARVMLPPGAQHSDEKGAKEIILDDDECPLQIFREWPSDKGILVFQLKRRPPDHIPKKTKKHLEGKTPKGKERADGSGYGSTLPPEKLPYLVELSPGRRNHFAYYNYHTYEDGSDSRDKPKLYRLQLSVTEVGTEKLDDNSIQLFGPGIQPHHCDLTNMDGVVTVTPRSMDAETYVEGQRISETTMLQSGMKVQFGASHVFKFVDPSQDHALAKRSVDGGLMVKGPRHKPGIVQETTFDLGGDIHSGTALPTSKSTTRLDSDRVSSASSTAERGMVKPMIRVEQQPDYRRQESRTQDASGPELILPASIEFRESSEDSFLSAIINYTNSSTVHFKLSPTYVLYMACRYVLSNQYRPDISPTERTHKVIAVVNKMVSMMEGVIQKQKNIAGALAFWMANASELLNFIKQDRDLSRITLDAQDVLAHLVQMAFKYLVHCLQSELNNYMPAFLDDPEENSLQRPKIDDVLHTLTGAMSLLRRCRVNAALTIQLFSQLFHFINMWLFNRLVTDPDSGLCSHYWGAIIRQQLGHIEAWAEKQGLELAADCHLSRIVQATTLLTMDKYAPDDIPNINSTCFKLNSLQLQALLQNYHCAPDEPFIPTDLIENVVTVAENTADELARSDGREVQLEEDPDLQLPFLLPEDGYSCDVVRNIPNGLQEFLDPLCQRGFCRLIPHTRSPGTWTIYFEGADYESHLLRENTELAQPLRKEPEIITVTLKKQNGMGLSIVAAKGAGQDKLGIYVKSVVKGGAADVDGRLAAGDQLLSVDGRSLVGLSQERAAELMTRTSSVVTLEVAKQGAIYHGLATLLNQPSPMMQRISDRRGSGKPRPKSEGFELYNNSTQNGSPESPQLPWAEYSEPKKLPGDDRLMKNRADHRSSPNVANQPPSPGGKSAYASGTTAKITSVSTGNLCTEEQTPPPRPEAYPIPTQTYTREYFTFPASKSQDRMAPPQNQWPNYEEKPHMHTDSNHSSIAIQRVTRSQEELREDKAYQLERHRIEAAMDRKSDSDMWINQSSSLDSSTSSQEHLNHSSKSVTPASTLTKSGPGRWKTPAAIPATPVAVSQPIRTDLPPPPPPPPVHYAGDFDGMSMDLPLPPPPSANQIGLPSAQVAAAERRKREEHQRWYEKEKARLEEERERKRREQERKLGQMRTQSLNPAPFSPLTAQQMKPEKPSTLQRPQETVIRELQPQQQPRTIERRDLQYITVSKEELSSGDSLSPDPWKRDAKEKLEKQQQMHIVDMLSKEIQELQSKPDRSAEESDRLRKLMLEWQFQKRLQESKQKDEDDEEEEDDDVDTMLIMQRLEAERRARLQDEERRRQQQLEEMRKREAEDRARQEEERRRQEEERTKRDAEEKRRQEEGYYSRLEAERRRQHDEAARRLLEPEAPGLCRPPLPRDYEPPSPSPAPGAPPPPPQRNASYLKTQVLSPDSLFTAKFVAYNEEEEEEDCSLAGPNSYPGSTGAAVGAHDACRDAKEKRSKSQDADSPGSSGAPENLTFKERQRLFSQGQDVSNKVKASRKLTELENELNTK>sp|P55196-2|AFAD_HUMAN Isoform 1 of Afadin OS=Homo sapiens OX=9606GN=AFDNMSAGGRDEERRKLADIIHHWNANRLDLFEISQPTEDLEFHGVMRFYFQDKAAGNFATKCIRVSSTATTQDVIETLAEKFRPDMRMLSSPKYSLYEVHVSGERRLDIDEKPLVVQLNWNKDDREGRFVLKNENDAIPPKAQSNGPEKQEKEGVIQNFKRTLSKKEKKEKKKREKEALRQASDKDDRPFQGEDVENSRLAAEVYKDMPETSFTRTISNPEVVMKRRRQQKLEKRMQEFRSSDGRPDSGGTLRIYADSLKPNIPYKTILLSTTDPADFAVAEALEKYGLEKENPKDYCIARVMLPPGAQHSDEKGAKEIILDDDECPLQIFREWPSDKGILVFQLKRRPPDHIPKKTKKHLEGKTPKGKERADGSGYGSTLPPEKLPYLVELSPDGSDSRDKPKLYRLQLSVTEVGTEKLDDNSIQLFGPGIQPHHCDLTNMDGVVTVTPRSMDAETYVEGQRISETTMLQSGMKVQFGASHVFKFVDPSQDHALAKRSVDGGLMVKGPRHKPGIVQETTFDLGGDIHSGTALPTSKSTTRLDSDRVSSASSTAERGMVKPMIRVEQQPDYRRQESRTQDASGPELILPASIEFRESSEDSFLSAIINYTNSSTVHFKLSPTYVLYMACRYVLSNQYRPDISPTERTHKVIAVVNKMVSMMEGVIQKQKNIAGALAFWMANASELLNFIKQDRDLSRITLDAQDVLAHLVQMAFKYLVHCLQSELNNYMPAFLDDPEENSLQRPKIDDVLHTLTGAMSLLRRCRVNAALTIQLFSQLFHFINMWLFNRLVTDPDSGLCSHYWGAIIRQQLGHIEAWAEKQGLELAADCHLSRIVQATTLLTMDKYAPDDIPNINSTCFKLNSLQLQALLQNYHCAPDEPFIPTDLIENVVTVAENTADELARSDGREVQLEEDPDLQLPFLLPEDGYSCDVVRNIPNGLQEFLDPLCQRGFCRLIPHTRSPGTWTIYFEGADYESHLLRENTELAQPLRKEPEIITVTLKKQNGMGLSIVAAKGAGQDKLGIYVKSVVKGGAADVDGRLAAGDQLLSVDGRSLVGLSQERAAELMTRTSSVVTLEVAKQGAIYHGLATLLNQPSPMMQRISDRRGSGKPRPKSEGFELYNNSTQNGSPESPQLPWAEYSEPKKLPGDDRLMKNRADHRSSPNVANQPPSPGGKSAYASGTTAKITSVSTGNLCTEEQTPPPRPEAYPIPTQTYTREYFTFPASKSQDRMAPPQNQWPNYEEKPHMHTDSNHSSIAIQRVTRSQEELREDKAYQLERHRIEAAMDRKSDSDMWINQSSSLDSSTSSQEHLNHSSKSVTPASTLTKSGPGRWKTPAAIPATPVAVSQPIRTDLPPPPPPPPVHYAGDFDGMSMDLPLPPPPSANQIGLPSAQVAAAERRKREEHQRWYEKEKARLEEERERKRREQERKLGQMRTQSLNPAPFSPLTAQQMKPEKPSTLQRPQETVIRELQPQQQPRTIERRDLQYITVSKEELSSGDSLSPDPWKRDAKEKLEKQQQMHIVDMLSKEIQELQSKPDRSAEESDRLRKLMLEWQFQKRLQESKQKDEDDEEEEDDDVDTMLIMQRLEAERRARVKGGVLWLCPSVVPILASACFPWG>sp|P55196-1|AFAD_HUMAN Isoform 2 of Afadin OS=Homo sapiens OX=9606GN=AFDNMSAGGRDEERRKLADIIHHWNANRLDLFEISQPTEDLEFHGVMRFYFQDKAAGNFATKCIRVSSTATTQDVIETLAEKFRPDMRMLSSPKYSLYEVHVSGERRLDIDEKPLVVQLNWNKDDREGRFVLKNENDAIPPKAQSNGPEKQEKEGVIQNFKRTLSKKEKKEKKKREKEALRQASDKDDRPFQGEDVENSRLAAEVYKDMPETSFTRTISNPEVVMKRRRQQKLEKRMQEFRSSDGRPDSGGTLRIYADSLKPNIPYKTILLSTTDPADFAVAEALEKYGLEKENPKDYCIARVMLPPGAQHSDEKGAKEIILDDDECPLQIFREWPSDKGILVFQLKRRPPDHIPKKTKKHLEGKTPKGKERADGSGYGSTLPPEKLPYLVELSPDGSDSRDKPKLYRLQLSVTEVGTEKLDDNSIQLFGPGIQPHHCDLTNMDGVVTVTPRSMDAETYVEGQRISETTMLQSGMKVQFGASHVFKFVDPSQDHALAKRSVDGGLMVKGPRHKPGIVQETTFDLGGDIHSGTALPTSKSTTRLDSDRVSSASSTAERGMVKPMIRVEQQPDYRRQESRTQDASGPELILPASIEFRESSEDSFLSAIINYTNSSTVHFKLSPTYVLYMACRYVLSNQYRPDISPTERTHKVIAVVNKMVSMMEGVIQKQKNIAGALAFWMANASELLNFIKQDRDLSRITLDAQDVLAHLVQMAFKYLVHCLQSELNNYMPAFLDDPEENSLQRPKIDDVLHTLTGAMSLLRRCRVNAALTIQLFSQLFHFINMWLFNRLVTDPDSGLCSHYWGAIIRQQLGHIEAWAEKQGLELAADCHLSRIVQATTLLTMDKYAPDDIPNINSTCFKLNSLQLQALLQNYHCAPDEPFIPTDLIENVVTVAENTADELARSDGREVQLEEDPDLQLPFLLPEDGYSCDVVRNIPNGLQEFLDPLCQRGFCRLIPHTRSPGTWTIYFEGADYESHLLRENTELAQPLRKEPEIITVTLKKQNGMGLSIVAAKGAGQDKLGIYVKSVVKGGAADDGRLAAGDQLLSVDGRSLVGLSQERAAELMTRTSSVVTLEVAKQGAIYHGLATLLNQPSPMMQRISDRRGSGKPRPKSEGFELYNNSTQNGSPESPQLPWAEYSEPKKLPGDDRLMKNRADHRSSPNVANQPPSPGGKSAYASGTTAKITSVSTGNLCTEEQTPPPRPEAYPIPTQTYTREYFTFPASKSQDRMAPPQNQWPNYEEKPHMHTDSNHSSIAIQRVTRSQEELREDKAYQLERHRIEAAMDRKSDSDMWINQSSSLDSSTSSQEHLNHSSKSVTPASTLTKSGPGRWKTPAAIPATPVAVSQPIRTDLPPPPPPPPVHYAGDFDGMSMDLPLPPPPSANQIGLPSAQVAAAERRKREEHQRWYEKEKARLEEERERKRREQERKLGQMRTQSLNPAPFSPLTAQQMKPEKPSTLQRPQETVIRELQPQQQPRTIERRDLQYITVSKEELSSGDSLSPDPWKRDAKEKLEKQQQMHIVDMLSKEIQELQSKPDRSAEESDRLRKLMLEWQFQKRLQESKQKDEDDEEEEDDDVDTMLIMQRLEAERRARLQDEERRRQQQLEEMRKREAEDRARQEEERRRQEEERTKRDAEEKRRQEEGYYSRLEAERRRQHDEAARRLLEPEAPGLCRPPLPRDYEPPSPSPAPGAPPPPPQRNASYLKTQVLSPDSLFTAKFVAYNEEEEEEDCSLAGQDKYSSTRKSHGDLLPAPLKPRPPPCQPRPASDGVFLSNSFQPPSAKANSTAHKKGQPLPPPKKSSSYHPSHCKGRGKRVTNQLSLS>sp|P55196-3|AFAD_HUMAN Isoform 3 of Afadin OS=Homo sapiens OX=9606GN=AFDNMSAGGRDEERRKLADIIHHWNANRLDLFEISQPTEDLEFHGVMRFYFQDKAAGNFATKCIRVSSTATTQDVIETLAEKFRPDMRMLSSPKYSLYEVHVSGERRLDIDEKPLVVQLNWNKDDREGRFVLKNENDAIPPKAQSNGPEKQEKEGVIQNFKRTLSKKEKKEKKKREKEALRQASDKDDRPFQGEDVENSRLAAEVYKDMPETSFTRTISNPEVVMKRRRQQKLEKRMQEFRSSDGRPDSGGTLRIYADSLKPNIPYKTILLSTTDPADFAVAEALEKYGLEKENPKDYCIARVMLPPGAQHSDEKGAKEIILDDDECPLQIFREWPSDKGILVFQLKRRPPDHIPKKTKKHLEGKTPKGKERADGSGYGSTLPPEKLPYLVELSPDGSDSRDKPKLYRLQLSVTEVGTEKLDDNSIQLFGPGIQPHHCDLTNMDGVVTVTPRSMDAETYVEGQRISETTMLQSGMKVQFGASHVFKFVDPSQDHALAKRSVDGGLMVKGPRHKPGIVQETTFDLGGDIHSGTALPTSKSTTRLDSDRVSSASSTAERGMVKPMIRVEQQPDYRRQESRTQDASGPELILPASIEFRESSEDSFLSAIINYTNSSTVHFKLSPTYVLYMACRYVLSNQYRPDISPTERTHKVIAVVNKMVSMMEGVIQKQKNIAGALAFWMANASELLNFIKQDRDLSRITLDAQDVLAHLVQMAFKYLVHCLQSELNNYMPAFLDDPEENSLQRPKIDDVLHTLTGAMSLLRRCRVNAALTIQLFSQLFHFINMWLFNRLVTDPDSGLCSHYWGAIIRQQLGHIEAWAEKQGLELAADCHLSRIVQATTLLTMDKYAPDDIPNINSTCFKLNSLQLQALLQNYHCAPDEPFIPTDLIENVVTVAENTADELARSDGREVQLEEDPDLQLPFLLPEDGYSCDVVRNIPNGLQEFLDPLCQRGFCRLIPHTRSPGTWTIYFEGADYESHLLRENTELAQPLRKEPEIITVTLKKQNGMGLSIVAAKGAGQDKLGIYVKSVVKGGAADDGRLAAGDQLLSVDGRSLVGLSQERAAELMTRTSSVVTLEVAKQGAIYHGLATLLNQPSPMMQRISDRRGSGKPRPKSEGFELYNNSTQNGSPESPQLPWAEYSEPKKLPGDDRLMKNRADHRSSPNVANQPPSPGGKSAYASGTTAKITSVSTGNLCTEEQTPPPRPEAYPIPTQTYTREYFTFPASKSQDRMAPPQNQWPNYEEKPHMHTDSNHSSIAIQRVTRSQEELREDKAYQLERHRIEAAMDRKSDSDMWINQSSSLDSSTSSQEHLNHSSKSVTPASTLTKSGPGRWKTPAAIPATPVAVSQPIRTDLPPPPPPPPVHYAGDFDGMSMDLPLPPPPSANQIGLPSAQVAAAERRKREEHQRWYEKEKARLEEERERKRREQERKLGQMRTQSLNPAPFSPLTAQQMKPEKPSTLQRPQETVIRELQPQQQPRTIERRDLQYITVSKEELSSGDSLSPDPWKRDAKEKLEKQQQMHIVDMLSKEIQELQSKPDRSAEESDRLRKLMLEWQFQKRLQESKQKDEDDEEEEDDDVDTMLIMQRLEAERRARLQDEERRRQQQLEEMRKREAEDRARQEEERRRQEEERTKRDAEEKRRQEEGYYSRLEAERRRQHDEAARRLLEPEAPGPNSYPGSTGAAVGAHDACRDAKEKRSKSQDADSPGSSGAPENLTFKERQRLFSQGQDVSNKVKASRKLTELENELNTK>sp|P55196-6|AFAD_HUMAN Isoform 6 of Afadin OS=Homo sapiens OX=9606GN=AFDNMSAGGRDEERRKLADIIHHWNANRLDLFEISQPTEDLEFHGVMRFYFQDKAAGNFATKCIRVSSTATTQDVIETLAEKFRPDMRMLSSPKYSLYEVHVSGERRLDIDEKPLVVQLNWNKDDREGRFVLKNENDAIPPKKAQSNGPEKQEKEGVIQNFKRTLSKKEKKEKKKREKEALRQASDKDDRPFQGEDVENSRLAAEVYKDMPETSFTRTISNPEVVMKRRRQQKLEKRMQEFRSSDGRPDSGGTLRIYADSLKPNIPYKTILLSTTDPADFAVAEALEKYGLEKENPKDYCIARVMLPPGAQHSDEKGAKEIILDDDECPLQIFREWPSDKGILVFQLKRRPPDHIPKKTKKHLEGKTPKGKERADGSGYGSTLPPEKLPYLVELSPGRRNHFAYYNYHTYEDGSDSRDKPKLYRLQLSVTEVGTEKLDDNSIQLFGPGIQPHHCDLTNMDGVVTVTPRSMDAETYVEGQRISETTMLQSGMKVQFGASHVFKFVDPSQDHALAKRSVDGGLMVKGPRHKPGIVQETTFDLGGDIHSGTALPTSKSTTRLDSDRVSSASSTAERGMVKPMIRVEQQPDYRRQESRTQDASGPELILPASIEFRESSEDSFLSAIINYTNSSTVHFKLSPTYVLYMACRYVLSNQYRPDISPTERTHKVIAVVNKMVSMMEGVIQKQKNIAGALAFWMANASELLNFIKQDRDLSRITLDAQDVLAHLVQMAFKYLVHCLQSELNNYMPAFLDDPEENSLQRPKIDDVLHTLTGAMSLLRRCRVNAALTIQLFSQLFHFINMWLFNRLVTDPDSGLCSHYWGAIIRQQLGHIEAWAEKQGLELAADCHLSRIVQATTLLTMDKYAPDDIPNINSTCFKLNSLQLQALLQNYHCAPDEPFIPTDLIENVVTVAENTADELARSDGREVQLEEDPDLQLPFLLPEDGYSCDVVRNIPNGLQEFLDPLCQRGFCRLIPHTRSPGTWTIYFEGADYESHLLRENTELAQPLRKEPEIITVTLKKQNGMGLSIVAAKGAGQDKLGIYVKSVVKGGAADVDGRLAAGDQLLSVDGRSLVGLSQERAAELMTRTSSVVTLEVAKQGAIYHGLATLLNQPSPMMQRISDRRGSGKPRPKSEGFELYNNSTQNGSPESPQLPWAEYSEPKKLPGDDRLMKNRADHRSSPNVANQPPSPGGKSAYASGTTAKITSVSTGNLCTEEQTPPPRPEAYPIPTQTYTREYFTFPASKSQDRMAPPQNQWPNYEEKPHMHTDSNHSSIAIQRVTRSQEELREDKAYQLERHRIEAAMDRKSDSDMWINQSSSLDSSTSSQEHLNHSSKSVTPASTLTKSGPGRWKTPAAIPATPVAVSQPIRTDLPPPPPPPPVHYAGDFDGMSMDLPLPPPPSANQIGLPSAQVAAAERRKREEHQRWYEKEKARLEEERERKRREQERKLGQMRTQSLNPAPFSPLTAQQMKPEKPSTLQRPQETVIRELQPQQQPRTIERRDLQYITVSKEELSSGDSLSPDPWKRDAKEKLEKQQQMHIVDMLSKEIQELQSKPDRSAEESDRLRKLMLEWQFQKRLQESKQKDEDDEEEEDDDVDTMLIMQRLEAERRARDEERRRQQQLEEMRKREAEDRARQEEERRRQEEERTKRDAEEKVMVL>sp|P55196-5|AFAD_HUMAN Isoform 5 of Afadin OS=Homo sapiens OX=9606GN=AFDNMSAGGRDEERRKLADIIHHWNANRLDLFEISQPTEDLEFHGVMRFYFQDKAAGNFATKCIRVSSTATTQDVIETLAEKFRPDMRMLSSPKYSLYEVHVSGERRLDIDEKPLVVQLNWNKDDREGRFVLKNENDAIPPKAQSNGPEKQEKEGVIQNFKRTLSKKEKKEKKKREKEALRQASDKDDRPFQGEDVENSRLAAEVYKDMPETSFTRTISNPEVVMKRRRQQKLEKRMQEFRSSDGRPDSGGTLRIYADSLKPNIPYKTILLSTTDPADFAVAEALEKYGLEKENPKDYCIARVMLPPGAQHSDEKGAKEIILDDDECPLQIFREWPSDKGILVFQLKRRPPDHIPKKTKKHLEGKTPKGKERADGSGYGSTLPPEKLPYLVELSPGRRNHFAYYNYHTYEDGSDSRDKPKLYRLQLSVTEVGTEKLDDNSIQLFGPGIQPHHCDLTNMDGVVTVTPRSMDAETYVEGQRISETTMLQSGMKVQFGASHVFKFVDPSQDHALAKRSVDGGLMVKGPRHKPGIVQETTFDLGGDIHSGTALPTSKSTTRLDSDRVSSASSTAERGMVKPMIRVEQQPDYRRQESRTQDASGPELILPASIEFRESSEDSFLSAIINYTNSSTVHFKLSPTYVLYMACRYVLSNQYRPDISPTERTHKVIAVVNKMVSMMEGVIQKQKNIAGALAFWMANASELLNFIKQDRDLSRITLDAQDVLAHLVQMAFKYLVHCLQSELNNYMPAFLDDPEENSLQRPKIDDVLHTLTGAMSLLRRCRVNAALTIQLFSQLFHFINMWLFNRLVTDPDSGLCSHYWGAIIRQQLGHIEAWAEKQGLELAADCHLSRIVQATTLLTMDKYAPDDIPNINSTCFKLNSLQLQALLQNYHCAPDEPFIPTDLIENVVTVAENTADELARSDGREVQLEEDPDLQLPFLLPEDGYSCDVVRNIPNGLQEFLDPLCQRGFCRLIPHTRSPGTWTIYFEGADYESHLLRENTELAQPLRKEPEIITVTLKKQNGMGLSIVAAKGAGQDKLGIYVKSVVKGGAADVDGRLAAGDQLLSVDGRSLVGLSQERAAELMTRTSSVVTLEVAKQGAIYHGLATLLNQPSPMMQRISDRRGSGKPRPKSEGFELYNNSTQNGSPESPQLPWAEYSEPKKLPGDDRLMKNRADHRSSPNVANQPPSPGGKSAYASGTTAKITSVSTGNLCTEEQTPPPRPEAYPIPTQTYTREYFTFPASKSQDRMAPPQNQWPNYEEKPHMHTDSNHSSIAIQRVTRSQEELREDKAYQLERHRIEAAMDRKSDSDMWINQSSSLDSSTSSQEHLNHSSKSVTPASTLTKSGPGRWKTPAAIPATPVAVSQPIRTDLPPPPPPPPVHYAGDFDGMSMDLPLPPPPSANQIGLPSAQVAAAERRKREEHQRWYEKEKARLEEERERKRREQERKLGQMRTQSLNPAPFSPLTAQQMKPEKPSTLQRPQETVIRELQPQQQPRTIERRDLQYITVSKEELSSGDSLSPDPWKRDAKEKLEKQQQMHIVDMLSKEIQELQSKPDRSAEESDRLRKLMLEWQFQKRLQESKQKDEDDEEEEDDDVDTMLIMQRLEAERRARTAMPAISVLDLLQDEERRRQQQLEEMRKREAEDRARQEEERRRQEEERTKRDAEEKRRQEEGYYSRLEAERRRQHDEAARRLLEPEAPGLCRPPLPRDYEPPSPSPAPGAPPPPPQRNASYLKTQVLSPDSLFTAKFVAYNEEEEEEDCSLAGPNSYPGSTGAAVGAHDACRDAKEKRSKSQDADSPGSSGAPENLTFKERQRLFSQGQDVSNKVKASRKLTELENELNTK>sp|P52594|AGFG1_HUMAN Arf-GAP domain and FG repeat-containing protein 1OS=Homo sapiens OX=9606 GN=AGFG1 PE=1 SV=2MAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQSPVVGRSQGQQQEKKQFDLLSDLGSDIFAAPAPQSTATANFANFAHFNSHAAQNSANADFANFDAFGQSSGSSNFGGFPTASHSPFQPQTTGGSAASVNANFAHFDNFPKSSSADFGTFNTSQSHQTASAVSKVSTNKAGLQTADKYAALANLDNIFSAGQGGDQGSGFGTTGKAPVGSVVSVPSQSSASSDKYAALAELDSVFSSAATSSNAYTSTSNASSNVFGTVPVVASAQTQPASSSVPAPFGATPSTNPFVAAAGPSVASSTNPFQTNARGATAATFGTASMSMPTGFGTPAPYSLPTSFSGSFQQPAFPAQAAFPQQTAFSQQPNGAGFAAFGQTKPVVTPFGQVAAAGVSSNPFMTGAPTGQFPTGSSSTNPFL>sp|P52594-2|AGFG1_HUMAN Isoform 2 of Arf-GAP domain and FG repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=AGFG1MAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQSPVVGRSQGQQQEKKQFDLLSDLGSDIFAAPAPQSTATANFANFAHFNSHAGGSAASVNANFAHFDNFPKSSSADFGTFNTSQSHQTASAVSKVSTNKAGLQTADKYAALANLDNIFSAGQGGDQGSGFGTTGKAPVGSVVSVPSQSSASSDKYAALAELDSVFSSAATSSNAYTSTSNASSNVFGTVPVVASAQTQPASSSVPAPFGATPSTNPFVAAAGPSVASSTNPFQTNARGATAATFGTASMSMPTGFGTPAPYSLPTSFSGSFQQPAFPAQAAFPQQTAFSQQPNGAGFAAFGQTKPVVTPFGQVAAAGVSSNPFMTGAPTGQFPTGSSSTNPFL>sp|P52594-3|AGFG1_HUMAN Isoform 3 of Arf-GAP domain and FG repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=AGFG1MAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQSPVVGRSQGQQQEKKQFDLLSDLGSDIFAAPAPQSTATANFANFAHFNSHAAQNSANADFANFDAFGQSSGSSNFGGFPTASHSPFQPQTTGGSAASVNANFAHFDNFPKSSSADFGTFNTSQSHQTASAVSKVSTNKAGLQTADKYAALANLDNIFSAGQGGDQGSGFGTTGKAPVGSVVSVPSQSSASSDKYAALAELDSVFSSAATSSNAYTSTSNASSNVFGTVPVVASAQTQPASSSVPAPFGATPSTNPFVAAAGPSVASSTNPFQTNARGATAATFGTASMSMPTGFGTPAPYSLPTSFSGSFQQPAFPAQAAFPQQTAFSQQPNGFAAFGQTKPVVTPFGQVAAAGVSSNPFMTGAPTGQFPTGSSSTNPFL>sp|P52594-4|AGFG1_HUMAN Isoform 4 of Arf-GAP domain and FG repeat-containing protein 1 OS=Homo sapiens OX=9606 GN=AGFG1MAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQSPVVGRSQGQQQEKKQFDLLSDLGSDIFAAPAPQSTATANFANFAHFNSHAAQNSANADFANFDAFGQSSGSSNFGGFPTASHSPFQPQTTAFRMLSSSCSFGEFTSAFPLQATHSGSAASVNANFAHFDNFPKSSSADFGTFNTSQSHQTASAVSKVSTNKAGLQTADKYAALANLDNIFSAGQGGDQGSGFGTTGKAPVGSVVSVPSQSSASSDKYAALAELDSVFSSAATSSNAYTSTSNASSNVFGTVPVVASAQTQPASSSVPAPFGATPSTNPFVAAAGPSVASSTNPFQTNARGATAATFGTASMSMPTGFGTPAPYSLPTSFSGSFQQPAFPAQAAFPQQTAFSQQPNGFAAFGQTKPVVTPFGQVAAAGVSSNPFMTGAPTGQFPTGSSSTNPFL>sp|P54922|ADPRH_HUMAN [Protein ADP-ribosylarginine] hydrolase OS=Homosapiens OX=9606 GN=ADPRH PE=1 SV=1MEKYVAAMVLSAAGDALGYYNGKWEFLQDGEKIHRQLAQLGGLDALDVGRWRVSDDTVMHLATAEALVEAGKAPKLTQLYYLLAKHYQDCMEDMDGRAPGGASVHNAMQLKPGKPNGWRIPFNSHEGGCGAAMRAMCIGLRFPHHSQLDTLIQVSIESGRMTHHHPTGYLGALASALFTAYAVNSRPPLQWGKGLMELLPEAKKYIVQSGYFVEENLQHWSYFQTKWENYLKLRGILDGESAPTFPESFGVKERDQFYTSLSYSGWGGSSGHDAPMIAYDAVLAAGDSWKELAHRAFFHGGDSDSTAAIAGCWWGVMYGFKGVSPSNYEKLEYRNRLEETARALYSLGSKEDTVISL>sp|Q53H12|AGK_HUMAN Acylglycerol kinase, mitochondrial OS=Homo sapiensOX=9606 GN=AGK PE=1 SV=2MTVFFKTLRNHWKKTTAGLCLLTWGGHWLYGKHCDNLLRRAACQEAQVFGNQLIPPNAQVKKATVFLNPAACKGKARTLFEKNAAPILHLSGMDVTIVKTDYEGQAKKLLELMENTDVIIVAGGDGTLQEVVTGVLRRTDEATFSKIPIGFIPLGETSSLSHTLFAESGNKVQHITDATLAIVKGETVPLDVLQIKGEKEQPVFAMTGLRWGSFRDAGVKVSKYWYLGPLKIKAAHFFSTLKEWPQTHQASISYTGPTERPPNEPEETPVQRPSLYRRILRRLASYWAQPQDALSQEVSPEVWKDVQLSTIELSITTRNNQLDPTSKEDFLNICIEPDTISKGDFITIGSRKVRNPKLHVEGTECLQASQCTLLIPEGAGGSFSIDSEEYEAMPVEVKLLPRKLQFFCDPRKREQMLTSPTQ>sp|Q53H12-2|AGK_HUMAN Isoform 2 of Acylglycerol kinase, mitochondrialOS=Homo sapiens OX=9606 GN=AGKMTVFFKTLRNHWKKTTAGLCLLTWGGHWLYGKHCDNLLRRAACQEAQHYQDESRWEPTLSRTPGS>sp|Q15327|ANKR1_HUMAN Ankyrin repeat domain-containing protein 1 OS=Homosapiens OX=9606 GN=ANKRD1 PE=1 SV=2MMVLKVEELVTGKKNGNGEAGEFLPEDFRDGEYEAAVTLEKQEDLKTLLAHPVTLGEQQWKSEKQREAELKKKKLEQRSKLENLEDLEIIIQLKKRKKYRKTKVPVVKEPEPEIITEPVDVPTFLKAALENKLPVVEKFLSDKNNPDVCDEYKRTALHRACLEGHLAIVEKLMEAGAQIEFRDMLESTAIHWASRGGNLDVLKLLLNKGAKISARDKLLSTALHVAVRTGHYECAEHLIACEADLNAKDREGDTPLHDAVRLNRYKMIRLLIMYGADLNIKNCAGKTPMDLVLHWQNGTKAIFDSLRENSYKTSRIATF>sp|A6NH57|ARL5C_HUMAN Putative ADP-ribosylation factor-like protein 5COS=Homo sapiens OX=9606 GN=ARL5C PE=3 SV=4MGQLIAKLMSIFGNQEHTVIIVGLDNEGKTTILYRFLTNEVVHMCPTIGSNVEEIILPKTHFFMWDIVRPEALSFIWNTYYSNTEFIILVIDSTDRDRLLTTREELYKMLAHEALQDASVLIFANKQDVKDSMRMVEISHFLTLSTIKDHSWHIQGCCALTREGLPARLQWMESQAAAN>sp|P04424|ARLY_HUMAN Argininosuccinate lyase OS=Homo sapiens OX=9606GN=ASL PE=1 SV=4MASESGKLWGGRFVGAVDPIMEKFNASIAYDRHLWEVDVQGSKAYSRGLEKAGLLTKAEMDQILHGLDKVAEEWAQGTFKLNSNDEDIHTANERRLKELIGATAGKLHTGRSRNDQVVTDLRLWMRQTCSTLSGLLWELIRTMVDRAEAERDVLFPGYTHLQRAQPIRWSHWILSHAVALTRDSERLLEVRKRINVLPLGSGAIAGNPLGVDRELLRAELNFGAITLNSMDATSERDFVAEFLFWASLCMTHLSRMAEDLILYCTKEFSFVQLSDAYSTGSSLMPQKKNPDSLELIRSKAGRVFGRCAGLLMTLKGLPSTYNKDLQEDKEAVFEVSDTMSAVLQVATGVISTLQIHQENMGQALSPDMLATDLAYYLVRKGMPFRQAHEASGKAVFMAETKGVALNQLSLQELQTISPLFSGDVICVWDYGHSVEQYGALGGTARSSVDWQIRQVRALLQAQQA>sp|P04424-2|ARLY_HUMAN Isoform 2 of Argininosuccinate lyase OS=Homosapiens OX=9606 GN=ASLMASESGKLWGGRFVGAVDPIMEKFNASIAYDRHLWEVDVQGSKAYSRGLEKAGLLTKAEMDQILHGLDKVAEEWAQGTFKLNSNDEDIHTANERRLKELIGATAGKLHTGRSRNDQVVTDLRLWMRQTCSTLSGLLWELIRTMVDRAEAERDVLFPGYTHLQRAQPIRWSHWILSHAVALTRDSERLLEVRKRINVLPLGSGAIAGNPLGVDRELLRAELNFGAITLNSMDATSERDFVAEFLFWASLCMTHLSRMAEDLILYCTKEFSFVQLSDAYSTGSSLMPQKKNPDSLELIRSKAGRVFGREDKEAVFEVSDTMSAVLQVATGVISTLQIHQENMGQALSPDMLATDLAYYLVRKGMPFRQAHEASGKAVFMAETKGVALNQLSLQELQTISPLFSGDVICVWDYGHSVEQYGALGGTARSSVDWQIRQVRALLQAQQA>sp|P04424-3|ARLY_HUMAN Isoform 3 of Argininosuccinate lyase OS=Homosapiens OX=9606 GN=ASLMASESGKLWGGRFVGAVDPIMEKFNASIAYDRHLWEVDVQGSKAYSRGLEKAGLLTKAEMDQILHGLDKVAEEWAQGTFKLNSNDEDIHTANERRLKELIGATAGKLHTGRSRNDQVVTDLRLWMRQTCSTLSGLLWELIRTMVDRAEAERDVLFPGYTHLQRAQPIRWSHWILSGAIAGNPLGVDRELLRAELNFGAITLNSMDATSERDFVAEFLFWASLCMTHLSRMAEDLILYCTKEFSFVQLSDAYSTGSSLMPQKKNPDSLELIRSKAGRVFGRCAGLLMTLKGLPSTYNKDLQEDKEAVFEVSDTMSAVLQVATGVISTLQIHQENMGQALSPDMLATDLAYYLVRKGMPFRQAHEASGKAVFMAETKGVALNQLSLQELQTISPLFSGDVICVWDYGHSVEQYGALGGTARSSVDWQIRQVRALLQAQQA>sp|Q9NR81|ARHG3_HUMAN Rho guanine nucleotide exchange factor 3 OS=Homosapiens OX=9606 GN=ARHGEF3 PE=1 SV=1MVAKDYPFYLTVKRANCSLELPPASGPAKDAEEPSNKRVKPLSRVTSLANLIPPVKATPLKRFSQTLQRSISFRSESRPDILAPRPWSRNAAPSSTKRRDSKLWSETFDVCVNQMLTSKEIKRQEAIFELSQGEEDLIEDLKLAKKAYHDPMLKLSIMTEQELNQIFGTLDSLIPLHEELLSQLRDVRKPDGSTEHVGPILVGWLPCLSSYDSYCSNQVAAKALLDHKKQDHRVQDFLQRCLESPFSRKLDLWNFLDIPRSRLVKYPLLLREILRHTPNDNPDQQHLEEAINIIQGIVAEINTKTGESECRYYKERLLYLEEGQKDSLIDSSRVLCCHGELKNNRGVKLHVFLFQEVLVITRAVTHNEQLCYQLYRQPIPVKDLLLEDLQDGEVRLGGSLRGAFSNNERIKNFFRVSFKNGSQSQTHSLQANDTFNKQQWLNCIRQAKETVLCAAGQAGVLDSEGSFLNPTTGSRELQGETKLEQMDQSDSESDCSMDTSEVSLDCERMEQTDSSCGNSRHGESNV>sp|Q9NR81-2|ARHG3_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor 3 OS=Homo sapiens OX=9606 GN=ARHGEF3MDSSTAMNQCSCRGMEENKERPKRQRQNNFPMFPSPKAWNFRGRKRKQSTQDEDAVSLCSLDISEPSNKRVKPLSRVTSLANLIPPVKATPLKRFSQTLQRSISFRSESRPDILAPRPWSRNAAPSSTKRRDSKLWSETFDVCVNQMLTSKEIKRQEAIFELSQGEEDLIEDLKLAKKAYHDPMLKLSIMTEQELNQIFGTLDSLIPLHEELLSQLRDVRKPDGSTEHVGPILVGWLPCLSSYDSYCSNQVAAKALLDHKKQDHRVQDFLQRCLESPFSRKLDLWNFLDIPRSRLVKYPLLLREILRHTPNDNPDQQHLEEAINIIQGIVAEINTKTGESECRYYKERLLYLEEGQKDSLIDSSRVLCCHGELKNNRGVKLHVFLFQEVLVITRAVTHNEQLCYQLYRQPIPVKDLLLEDLQDGEVRLGGSLRGAFSNNERIKNFFRVSFKNGSQSQTHSLQANDTFNKQQWLNCIRQAKETVLCAAGQAGVLDSEGSFLNPTTGSRELQGETKLEQMDQSDSESDCSMDTSEVSLDCERMEQTDSSCGNSRHGESNV>sp|Q9NR81-3|ARHG3_HUMAN Isoform 3 of Rho guanine nucleotide exchangefactor 3 OS=Homo sapiens OX=9606 GN=ARHGEF3MIEVCHHNWLLWLCPSKFGIFMCCLASTTGQMELRRTREPSNKRVKPLSRVTSLANLIPPVKATPLKRFSQTLQRSISFRSESRPDILAPRPWSRNAAPSSTKRRDSKLWSETFDVCVNQMLTSKEIKRQEAIFELSQGEEDLIEDLKLAKKAYHDPMLKLSIMTEQELNQIFGTLDSLIPLHEELLSQLRDVRKPDGSTEHVGPILVGWLPCLSSYDSYCSNQVAAKALLDHKKQDHRVQDFLQRCLESPFSRKLDLWNFLDIPRSRLVKYPLLLREILRHTPNDNPDQQHLEEAINIIQGIVAEINTKTGESECRYYKERLLYLEEGQKDSLIDSSRVLCCHGELKNNRGVKLHVFLFQEVLVITRAVTHNEQLCYQLYRQPIPVKDLLLEDLQDGEVRLGGSLRGAFSNNERIKNFFRVSFKNGSQSQTHSLQANDTFNKQQWLNCIRQAKETVLCAAGQAGVLDSEGSFLNPTTGSRELQGETKLEQMDQSDSESDCSMDTSEVSLDCERMEQTDSSCGNSRHGESNV>sp|Q9NR81-4|ARHG3_HUMAN Isoform 4 of Rho guanine nucleotide exchangefactor 3 OS=Homo sapiens OX=9606 GN=ARHGEF3MKLPCLSSYDSYCSNQVAAKALLDHKKQDHRVQDFLQRCLESPFSRKLDLWNFLDIPRSRLVKYPLLLREILRHTPNDNPDQQHLEEAINIIQGIVAEINTKTGESECRYYKERLLYLEEGQKDSLIDSSRVLCCHGELKNNRGVKLHVFLFQEVLVITRAVTHNEQLCYQLYRQPIPVKDLLLEDLQDGEVRLGGSLRGAFSNNERIKNFFRVSFKNGSQSQTHSLQANDTFNKQQWLNCIRQAKETVLCAAGQAGVLDSEGSFLNPTTGSRELQGETKLEQMDQSDSESDCSMDTSEVSLDCERMEQTDSSCGNSRHGESNV>sp|O75808|CAN15_HUMAN Calpain-15 OS=Homo sapiens OX=9606 GN=CAPN15 PE=1SV=1MATVGEWSCVRCTFLNPAGQRQCSICEAPRHKPDLNHILRLSVEEQKWPCARCTFRNFLGKEACEVCGFTPEPAPGAAFLPVLNGVLPKPPAILGEPKGSCQEEAGPVRTAGLVATEPARGQCEDKDEEEKEEQEEEEGAAEPRGGWACPRCTLHNTPVASSCSVCGGPRRLSLPRIPPEALVVPEVVAPAGFHVVPAAPPPGLPGEGAEANPPATSQGPAAEPEPPRVPPFSPFSSTLQNNPVPRSRREVPPQLQPPVPEAAQPSPSAGCRGAPQGSGWAGASRLAELLSGKRLSVLEEEATEGGTSRVEAGSSTSGSDIIDLAGDTVRYTPASPSSPDFTTWSCAKCTLRNPTVAPRCSACGCSKLHGFQEHGEPPTHCPDCGADKPSPCGRSCGRVSSAQKAARVLPERPGQWACPACTLLNALRAKHCAACHTPQLLVAQRRGAAPLRRRESMHVEQRRQTDEGEAKALWENIVAFCRENNVSFVDDSFPPGPESVGFPAGDSVQQRVRQWLRPQEINCSVFRDHRATWSVFHTLRPSDILQGLLGNCWFLSALAVLAERPDLVERVMVTRSLCAEGAYQVRLCKDGTWTTVLVDDMLPCDEAGCLLFSQAQRKQLWVALIEKALAKLHGSYFALQAGRAIEGLATLTGAPCESLALQLSSTNPREEPVDTDLIWAKMLSSKEAGFLMGASCGGGNMKVDDSAYESLGLRPRHAYSILDVRDVQGTRLLRLRNPWGRFSWNGSWSDEWPHWPGHLRGELMPHGSSEGVFWMEYGDFVRYFDSVDICKVHSDWQEARVQGCFPSSASAPVGVTALTVLERASLEFALFQEGSRRSDAVDSHLLDLCILVFRATFGSGGHLSLGRLLAHSKRAVKKFVSCDVMLEPGEYAVVCCAFNHWGPPLPGTPAPQASSPSAGVPRASPEPPGHVLAVYSSRLVMVEPVEAQPTTLADAIILLTESRGERHEGREGMTCYYLTHGWAGLIVVVENRHPKAYLHVQCDCTDSFNVVSTRGSLRTQDSVPPLHRQVLVILSQLEGNAGFSITHRLAHRKAAQAFLSDWTASKGTHSPPLTPEVAGLHGPRPL>sp|O75808-2|CAN15_HUMAN Isoform 2 of Calpain-15 OS=Homo sapiens OX=9606GN=CAPN15MATVGEWSCVRCTFLNPAGQRQCSICEAPRHKPDLNHILRLSVEEQKWPCARCTFRNFLGKEACEVCGFTPEPAPGAAFLPVLNGVLPKPPAILGEPKGSCQEEAGPVRTAGLVATEPARGQCEDKDEEEKEEQEEEEGAAEPRGGWACPRCTLHNTPVASSCSVCGGPRRLSLPRIPPEALVVPEVVAPAGFHVVPAAPPPGLPGEGAEANPPATSQGPAAEPEPPRVPPFSPFSSTLQNNPVPRSRREVPPQLQPPVPEAAQPSPSAGCRGAPQGSGWAGASRLAELLSGKRLSVLEEEATEGGTSRVEAGSSTSGSDIIDLAGDTVRYTPASPSSPDFTTWSCAKCTLRNPCPPGLQPLGRGPESLPRAAGPRAGCVQLEAGHGGARGSPADHAGRRHHPAHREPRRAARGP>sp|Q15052|ARHG6_HUMAN Rho guanine nucleotide exchange factor 6 OS=Homosapiens OX=9606 GN=ARHGEF6 PE=1 SV=2MNPEEQIVTWLISLGVLESPKKTICDPEEFLKSSLKNGVVLCKLINRLMPGSVEKFCLDPQTEADCINNINDFLKGCATLQVEIFDPDDLYSGVNFSKVLSTLLAVNKATEDQLSERPCGRSSSLSAANTSQTNPQGAVSSTVSGLQRQSKTVEMTENGSHQLIVKARFNFKQTNEDELSVCKGDIIYVTRVEEGGWWEGTLNGRTGWFPSNYVREIKSSERPLSPKAVKGFETAPLTKNYYTVVLQNILDTEKEYAKELQSLLVTYLRPLQSNNNLSTVEVTSLLGNFEEVCTFQQTLCQALEECSKFPENQHKVGGCLLSLMPHFKSMYLAYCANHPSAVNVLTQHSDELEQFMENQGASSPGILILTTNLSKPFMRLEKYVTLLQELERHMEDTHPDHQDILKAIVAFKTLMGQCQDLRKRKQLELQILSEPIQAWEGEDIKNLGNVIFMSQVMVQYGACEEKEERYLMLFSNVLIMLSASPRMSGFIYQGKIPIAGTVVTRLDEIEGNDCTFEITGNTVERIVVHCNNNQDFQEWLEQLNRLIRGPASCSSLSKTSSSSCSAHSSFSSTGQPRGPLEPPQIIKPWSLSCLRPAPPLRPSAALGYKERMSYILKESSKSPKTMKKFLHKRKTERKPSEEEYVIRKSTAALEEDAQILKVIEAYCTSANFQQGHGSSTRKDSIPQVLLPEEEKLIIEETRSNGQTIMEEKSLVDTVYALKDEVRELKQENKRMKQCLEEELKSRRDLEKLVRRLLKQTDECIRGESSSKTSILP>sp|Q15052-2|ARHG6_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor 6 OS=Homo sapiens OX=9606 GN=ARHGEF6MTENGSHQLIVKARFNFKQTNEDELSVCKGDIIYVTRVEEGGWWEGTLNGRTGWFPSNYVREIKSSERPLSPKAVKGFETAPLTKNYYTVVLQNILDTEKEYAKELQSLLVTYLRPLQSNNNLSTVEVTSLLGNFEEVCTFQQTLCQALEECSKFPENQHKVGGCLLSLMPHFKSMYLAYCANHPSAVNVLTQHSDELEQFMENQGASSPGILILTTNLSKPFMRLEKYVTLLQELERHMEDTHPDHQDILKAIVAFKTLMGQCQDLRKRKQLELQILSEPIQAWEGEDIKNLGNVIFMSQVMVQYGACEEKEERYLMLFSNVLIMLSASPRMSGFIYQGKIPIAGTVVTRLDEIEGNDCTFEITGNTVERIVVHCNNNQDFQEWLEQLNRLIRGPASCSSLSKTSSSSCSAHSSFSSTGQPRGPLEPPQIIKPWSLSCLRPAPPLRPSAALGYKERMSYILKESSKSPKTMKKFLHKRKTERKPSEEEYVIRKSTAALEEDAQILKVIEAYCTSANFQQGHGSSTRKDSIPQVLLPEEEKLIIEETRSNGQTIMEEKSLVDTVYALKDEVRELKQENKRMKQCLEEELKSRRDLEKLVRRLLKQTDECIRGESSSKTSILP>sp|Q14511|CASL_HUMAN Enhancer of filamentation 1 OS=Homo sapiens OX=9606GN=NEDD9 PE=1 SV=1MKYKNLMARALYDNVPECAEELAFRKGDILTVIEQNTGGLEGWWLCSLHGRQGIVPGNRVKLLIGPMQETASSHEQPASGLMQQTFGQQKLYQVPNPQAAPRDTIYQVPPSYQNQGIYQVPTGHGTQEQEVYQVPPSVQRSIGGTSGPHVGKKVITPVRTGHGYVYEYPSRYQKDVYDIPPSHTTQGVYDIPPSSAKGPVFSVPVGEIKPQGVYDIPPTKGVYAIPPSACRDEAGLREKDYDFPPPMRQAGRPDLRPEGVYDIPPTCTKPAGKDLHVKYNCDIPGAAEPVARRHQSLSPNHPPPQLGQSVGSQNDAYDVPRGVQFLEPPAETSEKANPQERDGVYDVPLHNPPDAKGSRDLVDGINRLSFSSTGSTRSNMSTSSTSSKESSLSASPAQDKRLFLDPDTAIERLQRLQQALEMGVSSLMALVTTDWRCYGYMERHINEIRTAVDKVELFLKEYLHFVKGAVANAACLPELILHNKMKRELQRVEDSHQILSQTSHDLNECSWSLNILAINKPQNKCDDLDRFVMVAKTVPDDAKQLTTTINTNAEALFRPGPGSLHLKNGPESIMNSTEYPHGGSQGQLLHPGDHKAQAHNKALPPGLSKEQAPDCSSSDGSERSWMDDYDYVHLQGKEEFERQQKELLEKENIMKQNKMQLEHHQLSQFQLLEQEITKPVENDISKWKPSQSLPTTNSGVSAQDRQLLCFYYDQCETHFISLLNAIDALFSCVSSAQPPRIFVAHSKFVILSAHKLVFIGDTLTRQVTAQDIRNKVMNSSNQLCEQLKTIVMATKMAALHYPSTTALQEMVHQVTDLSRNAQLFKRSLLEMATF>sp|Q14511-2|CASL_HUMAN Isoform 2 of Enhancer of filamentation 1 OS=Homosapiens OX=9606 GN=NEDD9MKYKNLMARALYDNVPECAEELAFRKGDILTVIEQNTGGLEGWWLCSLHGRQGIVPGNRVKLLIGPMQETASSHEQPASGLMQQTFGQQKLYQVPNPQAAPRDTIYQVPPSYQNQGIYQVPTGHGTQEQEVYQVPPSVQRSIGGTSGPHVGKKVFQRDGQVSYFLVRASKQTSL>sp|Q14511-3|CASL_HUMAN Isoform 3 of Enhancer of filamentation 1 OS=Homosapiens OX=9606 GN=NEDD9MWTRNLMARALYDNVPECAEELAFRKGDILTVIEQNTGGLEGWWLCSLHGRQGIVPGNRVKLLIGPMQETASSHEQPASGLMQQTFGQQKLYQVPNPQAAPRDTIYQVPPSYQNQGIYQVPTGHGTQEQEVYQVPPSVQRSIGGTSGPHVGKKVITPVRTGHGYVYEYPSRYQKDVYDIPPSHTTQGVYDIPPSSAKGPVFSVPVGEIKPQGVYDIPPTKGVYAIPPSACRDEAGLREKDYDFPPPMRQAGRPDLRPEGVYDIPPTCTKPAGKDLHVKYNCDIPGAAEPVARRHQSLSPNHPPPQLGQSVGSQNDAYDVPRGVQFLEPPAETSEKANPQERDGVYDVPLHNPPDAKGSRDLVDGINRLSFSSTGSTRSNMSTSSTSSKESSLSASPAQDKRLFLDPDTAIERLQRLQQALEMGVSSLMALVTTDWRCYGYMERHINEIRTAVDKVELFLKEYLHFVKGAVANAACLPELILHNKMKRELQRVEDSHQILSQTSHDLNECSWSLNILAINKPQNKCDDLDRFVMVAKTVPDDAKQLTTTINTNAEALFRPGPGSLHLKNGPESIMNSTEYPHGGSQGQLLHPGDHKAQAHNKALPPGLSKEQAPDCSSSDGSERSWMDDYDYVHLQGKEEFERQQKELLEKENIMKQNKMQLEHHQLSQFQLLEQEITKPVENDISKWKPSQSLPTTNSGVSAQDRQLLCFYYDQCETHFISLLNAIDALFSCVSSAQPPRIFVAHSKFVILSAHKLVFIGDTLTRQVTAQDIRNKVMNSSNQLCEQLKTIVMATKMAALHYPSTTALQEMVHQVTDLSRNAQLFKRSLLEMATF>sp|Q9H246|CA021_HUMAN Uncharacterized protein C1orf21 OS=Homo sapiensOX=9606 GN=C1orf21 PE=1 SV=1MGCASAKHVATVQNEEEAQKGKNYQNGDVFGDEYRIKPVEEVKYMKNGAEEEQKIAARNQENLEKSASSNVRLKTNKEVPGLVHQPRANMHISESQQEFFRMLDEKIEKGRDYCSEEEDIT>sp|O96018|APBA3_HUMAN Amyloid-beta A4 precursor protein-binding family Amember 3 OS=Homo sapiens OX=9606 GN=APBA3 PE=1 SV=1MDFPTISRSPSGPPAMDLEGPRDILVPSEDLTPDSQWDPMPGGPGSLSRMELDESSLQELVQQFEALPGDLVGPSPGGAPCPLHIATGHGLASQEIADAHGLLSAEAGRDDLLGLLHCEECPPSQTGPEEPLEPAPRLLQPPEDPDEDSDSPEWVEGASAEQEGSRSSSSSPEPWLETVPLVTPEEPPAGAQSPETLASYPAPQEVPGPCDHEDLLDGVIFGARYLGSTQLVSERNPPTSTRMAQAREAMDRVKAPDGETQPMTEVDLFVSTKRIKVLTADSQEAMMDHALHTISYTADIGCVLVLMARRRLARRPAPQDHGRRLYKMLCHVFYAEDAQLIAQAIGQAFAAAYSQFLRESGIDPSQVGVHPSPGACHLHNGDLDHFSNSDNCREVHLEKRRGEGLGVALVESGWGSLLPTAVIANLLHGGPAERSGALSIGDRLTAINGTSLVGLPLAACQAAVRETKSQTSVTLSIVHCPPVTTAIIHRPHAREQLGFCVEDGIICSLLRGGIAERGGIRVGHRIIEINGQSVVATPHARIIELLTEAYGEVHIKTMPAATYRLLTGQEQPVYL>sp|Q14444|CAPR1_HUMAN Caprin-1 OS=Homo sapiens OX=9606 GN=CAPRIN1 PE=1SV=2MPSATSHSGSGSKSSGPPPPSGSSGSEAAAGAGAAAPASQHPATGTGAVQTEAMKQILGVIDKKLRNLEKKKGKLDDYQERMNKGERLNQDQLDAVSKYQEVTNNLEFAKELQRSFMALSQDIQKTIKKTARREQLMREEAEQKRLKTVLELQYVLDKLGDDEVRTDLKQGLNGVPILSEEELSLLDEFYKLVDPERDMSLRLNEQYEHASIHLWDLLEGKEKPVCGTTYKVLKEIVERVFQSNYFDSTHNHQNGLCEEEEAASAPAVEDQVPEAEPEPAEEYTEQSEVESTEYVNRQFMAETQFTSGEKEQVDEWTVETVEVVNSLQQQPQAASPSVPEPHSLTPVAQADPLVRRQRVQDLMAQMQGPYNFIQDSMLDFENQTLDPAIVSAQPMNPTQNMDMPQLVCPPVHSESRLAQPNQVPVQPEATQVPLVSSTSEGYTASQPLYQPSHATEQRPQKEPIDQIQATISLNTDQTTASSSLPAASQPQVFQAGTSKPLHSSGINVNAAPFQSMQTVFNMNAPVPPVNEPETLKQQNQYQASYNQSFSSQPHQVEQTELQQEQLQTVVGTYHGSPDQSHQVTGNHQQPPQQNTGFPRSNQPYYNSRGVSRGGSRGARGLMNGYRGPANGFRGGYDGYRPSFSNTPNSGYTQSQFSAPRDYSGYQRDGYQQNFKRGSGQSGPRGAPRGRGGPPRPNRGMPQMNTQQVN>sp|Q14444-2|CAPR1_HUMAN Isoform 2 of Caprin-1 OS=Homo sapiens OX=9606GN=CAPRIN1MPSATSHSGSGSKSSGPPPPSGSSGSEAAAGAGAAAPASQHPATGTGAVQTEAMKQILGVIDKKLRNLEKKKGKLDDYQERMNKGERLNQDQLDAVSKYQEVTNNLEFAKELQRSFMALSQDIQKTIKKTARREQLMREEAEQKRLKTVLELQYVLDKLGDDEVRTDLKQGLNGVPILSEEELSLLDEFYKLVDPERDMSLRLNEQYEHASIHLWDLLEGKEKPVCGTTYKVLKEIVERVFQSNYFDSTHNHQNGLCEEEEAASAPAVEDQVPEAEPEPAEEYTEQSEVESTEYVNRQFMAETQFTSGEKEQVDEWTVETVEVVNSLQQQPQAASPSVPEPHSLTPVAQADPLVRRQRVQDLMAQMQGPYNFIQDSMLDFENQTLDPAIVSAQPMNPTQNMDMPQLVCPPVHSESRLAQPNQVPVQPEATQVPLVSSTSEGYTASQPLYQPSHATEQRPQKEPIDQIQATISLNTDQTTASSSLPAASQPQVFQAGTSKPLHSSGINVNAAPFQSMQTVFNMNAPVPPVNEPETLKQQNQYQASYNQSFSSQPHQVEQTELQQEQLQTVVGTYHGSPDQSHQVTGNHQQPPQQNTGFPRSNQPYYNSRGVSRGGSRGARGLMNGYRGPANGFRGGYDGYRPSFSNTPNSGYTQSQFSAPRDYSGYQRDGYQQNFKRGSGQSGPRGAPRGNILWW>sp|P52907|CAZA1_HUMAN F-actin-capping protein subunit alpha-1 OS=Homosapiens OX=9606 GN=CAPZA1 PE=1 SV=3MADFDDRVSDEEKVRIAAKFITHAPPGEFNEVFNDVRLLLNNDNLLREGAAHAFAQYNMDQFTPVKIEGYEDQVLITEHGDLGNSRFLDPRNKISFKFDHLRKEASDPQPEEADGGLKSWRESCDSALRAYVKDHYSNGFCTVYAKTIDGQQTIIACIESHQFQPKNFWNGRWRSEWKFTITPPTAQVVGVLKIQVHYYEDGNVQLVSHKDVQDSLTVSNEAQTAKEFIKIIENAENEYQTAISENYQTMSDTTFKALRRQLPVTRTKIDWNKILSYKIGKEMQNA>sp|Q5VV41|ARHGG_HUMAN Rho guanine nucleotide exchange factor 16 OS=Homosapiens OX=9606 GN=ARHGEF16 PE=1 SV=1MAQRHSDSSLEEKLLGHRFHSELRLDAGGNPASGLPMVRGSPRVRDDAAFQPQVPAPPQPRPPGHEEPWPIVLSTESPAALKLGTQQLIPKSLAVASKAKTPARHQSFGAAVLSREAARRDPKLLPAPSFSLDDMDVDKDPGGMLRRNLRNQSYRAAMKGLGKPGGQGDAIQLSPKLQALAEEPSQPHTRSPAKNKKTLGRKRGHKGSFKDDPQLYQEIQERGLNTSQESDDDILDESSSPEGTQKVDATIVVKSYRPAQVTWSQLPEVVELGILDQLSTEERKRQEAMFEILTSEFSYQHSLSILVEEFLQSKELRATVTQMEHHHLFSNILDVLGASQRFFEDLEQRHKAQVLVEDISDILEEHAEKHFHPYIAYCSNEVYQQRTLQKLISSNAAFREALREIERRPACGGLPMLSFLILPMQRVTRLPLLMDTLCLKTQGHSERYKAASRALKAISKLVRQCNEGAHRMERMEQMYTLHTQLDFSKVKSLPLISASRWLLKRGELFLVEETGLFRKIASRPTCYLFLFNDVLVVTKKKSEESYMVQDYAQMNHIQVEKIEPSELPLPGGGNRSSSVPHPFQVTLLRNSEGRQEQLLLSSDSASDRARWIVALTHSERQWQGLSSKGDLPQVEITKAFFAKQADEVTLQQADVVLVLQQEDGWLYGERLRDGETGWFPEDFARFITSRVAVEGNVRRMERLRVETDV>sp|Q5VV41-2|ARHGG_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor 16 OS=Homo sapiens OX=9606 GN=ARHGEF16MFEILTSEFSYQHSLSILVEEFLQSKELRATVTQMEHHHLFSNILDVLGASQRFFEDLEQRHKAQVLVEDISDILEEHAEKHFHPYIAYCSNEVYQQRTLQKLISSNAAFREALREIERRPACGGLPMLSFLILPMQRVTRLPLLMDTLCLKTQGHSERYKAASRALKAISKLVRQCNEGAHRMERMEQMYTLHTQLDFSKVKSLPLISASRWLLKRGELFLVEETGLFRKIASRPTCYLFLFNDVLVVTKKKSEESYMVQDYAQMNHIQVEKIEPSELPLPGGGNRSSSVPHPFQVTLLRNSEGRQEQLLLSSDSASDRARWIVALTHSERQWQGLSSKGDLPQVEITKAFFAKQADEVTLQQADVVLVLQQEDGWLYGERLRDGETGWFPEDFARFITSRVAVEGNVRRMERLRVETDV>sp|Q6IMN6|CAPR2_HUMAN Caprin-2 OS=Homo sapiens OX=9606 GN=CAPRIN2 PE=1SV=1MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLSVEDQMEQSSLYFWDLLEGSEKAVVGTTYKHLKDLLSKLLNSGYFESIPVPKNAKEKEVPLEEEMLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVPKPVHQPVGSSSTLPKDPVLRKEKLQDLMTQIQGTCNFMQESVLDFDKPSSAIPTSQPPSATPGSPVASKEQNLSSQSDFLQEPLQATSSPVTCSSNACLVTTDQASSGSETEFMTSETPEAAIPPGKQPSSLASPNPPMAKGSEQGFQSPPASSSSVTINTAPFQAMQTVFNVNAPLPPRKEQEIKESPYSPGYNQSFTTASTQTPPQCQLPSIHVEQTVHSQETAANYHPDGTIQVSNGSLAFYPAQTNVFPRPTQPFVNSRGSVRGCTRGGRLITNSYRSPGGYKGFDTYRGLPSISNGNYSQLQFQAREYSGAPYSQRDNFQQCYKRGGTSGGPRANSRAGWSDSSQVSSPERDNETFNSGDSGQGDSRSMTPVDVPVTNPAATILPVHVYPLPQQMRVAFSAARTSNLAPGTLDQPIVFDLLLNNLGETFDLQLGRFNCPVNGTYVFIFHMLKLAVNVPLYVNLMKNEEVLVSAYANDGAPDHETASNHAILQLFQGDQIWLRLHRGAIYGSSWKYSTFSGYLLYQD>sp|Q6IMN6-2|CAPR2_HUMAN Isoform 2 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLSVEDQMEQSSLYFWDLLEGSEKAVVGTTYKHLKDLLSKLLNSGYFESIPVPKNAKEKEVPLEEEMLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVPKPVHQPVGSSSTLPKDPVLRKEKLQDLMTQIQGTCNFMQESVLDFDKPSSAIPTSQPPSATPGSPVASKEQNLSSQSDFLQEPLQATSSPVTCSSNACLVTTDQASSGSETEFMTSETPEVFNVNAPLPPRKEQEIKESPYSPGYNQSFTTASTQTPPQCQLPSIHVEQTVHSQETANYHPDGTIQVSNGSLAFYPAQTNVFPRPTQPFVNSRGSVRGCTRGGRLITNSYRSPGGYKGFDTYRGLPSISNGNYSQLQFQAREYSGAPYSQRDNFQQCYKRGGTSGGPRANSRAGWSDSSQVSSPERDNETFNSGDSGQGDSRSMTPVDVPVTNPAATILPVHVYPLPQQMRVAFSAARTSNLAPGTLDQPIVFDLLLNNLGETFDLQLGRFNCPVNGTYVFIFHMLKLAVNVPLYVNLMKNEEVLVSAYANDGAPDHETASNHAILQLFQGDQIWLRLHRGAIYGSSWKYSTFSGYLLYQD>sp|Q6IMN6-3|CAPR2_HUMAN Isoform 3 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLSVEDQMEQSSLYFWDLLEGSEKAVVGTTYKHLKDLLSKLLNSGYFESIPVPKNAKEKEVPLEEEMLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVPKPVHQPVGSSSTLPKDPVLRKEKLQDLMTQIQGTCNFMQESVLDFDKPSSAIPTSQPPSATPGSPVASKEQNLSSQSDFLQEPLQATSSPVTCSSNACLVTTDQASSGSETEFMTSETPEAAIPPGKQPSSLASPNPPMAKGSEQGFQSPPASSSSVTINTAPFQAMQTVFNVNAPLPPRKEQEIKESPYSPGYNQSFTTASTQTPPQCQLPSIHVEQTVHSQETANYHPDGTIQVSNGSLAFYPAQTNVFPRPTQPFVNSRGSVRGCTRGGRLITNSYRSPGGYKGFDTYRGLPSISNGNYSQLQFQAREYSGAPYSQRDNFQQCYKRGGTSGGPRANSRANCFIMRNSLLLIKQQGGVILLR>sp|Q6IMN6-4|CAPR2_HUMAN Isoform 4 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVPKPVHQPVGSSSTLPKDPVLRKEKLQDLMTQIQGTCNFMQESVLDFDKPSSAIPTSQPPSATPGSPVASKEQNLSSQSDFLQEPLQATSSPVTCSSNACLVTTDQASSGSETEFMTSETPEAAIPPGKQPSSLASPNPPMAKGSEQGFQSPPASSSSVTINTAPFQAMQTVFNVNAPLPPRKEQEIKESPYSPGYNQSFTTASTQTPPQCQLPSIHVEQTVHSQETAANYHPDGTIQVSNGSLAFYPAQTNVFPRPTQPFVNSRGSVRGCTRGGRLITNSYRSPGGYKGFDTYRGLPSISNGNYSQLQFQAREYSGAPYSQRDNFQQCYKRGGTSGGPRANSRAGWSDSSQVSSPERDNETFNSGDSGQGDSRSMTPVDVPVTNPAATILPVHVYPLPQQMRVAFSAARTSNLAPGTLDQPIVFDLLLNNLGETFDLQLGRFNCPVNGTYVFIFHMLKLAVNVPLYVNLMKNEEVLVSAYANDGAPDHETASNHAILQLFQGDQIWLRLHRGAIYGSSWKYSTFSGYLLYQD>sp|Q6IMN6-5|CAPR2_HUMAN Isoform 5 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLRQTLEGSTV>sp|Q6IMN6-6|CAPR2_HUMAN Isoform 6 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLSVEDQMEQSSLYFWDLLEGSEKAVVGTTYKHLKDLLSKLLNSGYFESIPVPKNAKEKEVPLEEEMLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVS>sp|Q6IMN6-7|CAPR2_HUMAN Isoform 7 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLSVEDQMEQSSLYFWDLLEGSEKAVVGTTYKHLKDLLSKLLNSGYFESIPVPKNAKEKEVPLEEEMLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVPKPVHQPVGSSSTLPKDPVLRKEKLQDLMTQIQGTCNFMQESVLDFDKPSSAIPTSQPPSATPGSPVASKEQNLSSQSDFLQEPLQATSSPVTCSSNACLVTTDQASSGSETEFMTSETPEAAIPPGKQPSSLASPNPPMAKGSEQGFQSPPASSSSVTINTAPFQAMQTVFNVNAPLPPRKEQEIKESPYSPGYNQSFTTASTQTPPQCQLPSIHVEQTVHSQETAQTNVFPRPTQPFVNSRGSVRGCTRGGRLITNSYRSPGGYKGFDTYRGLPSISNGNYSQLQFQAREYSGAPYSQRDNFQQCYKRGGTSGGPRANSRANCFIMRNSLLLIKQQGGVILLR>sp|Q6IMN6-9|CAPR2_HUMAN Isoform 9 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLSVEDQMEQSSLYFWDLLEGSEKAVVGTTYKHLKDLLSKLLNSGYFESIPVPKNAKEKEVPLEEEMLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVPKPVHQPVGSSSTLPKDPVLRKEKLQDLMTQIQGTCNFMQESVLDFDKPSSAIPTSQPPSATPGSPVASKEQNLSSQSDFLQEPLQATSSPVTCSSNACLVTTDQASSGSETEFMTSETPEAAIPPGKQPSSLASPNPPMAKGSEQGFQSPPASSSSVTINTAPFQAMQTVFNVNAPLPPRKEQEIKESPYSPGYNQSFTTASTQTPPQCQLPSIHVEQTVHSQETANYHPDGTIQVSNGSLAFYPAQTNVFPRPTQPFVNSRGSVRGCTRGGRLITNSYRSPGGYKGFDTYRGLPSISNGNYSQLQFQAREYSGAPYSQRDNFQQCYKRGGTSGGPRANSRAGWSDSSQVSSPERDNETFNSGDSGQGDSRSMTPVDVPVTNPAATILPVHVYPLPQQMRVAFSAARTSNLAPGTLDQPIVFDLLLNNLGETFDLQLGRFNCPVNGTYVFIFHMLKLAVNVPLYVNLMKNEEVLVSAYANDGAPDHETASNHAILQLFQGDQIWLRLHRGAIYGSSWKYSTFSGYLLYQD>sp|Q6IMN6-10|CAPR2_HUMAN Isoform 10 of Caprin-2 OS=Homo sapiens OX=9606GN=CAPRIN2MEVQVSQASLGFELTSVEKSLREWSRLSREVIAWLCPSSPNFILNFPPPPSASSVSMVQLFSSPFGYQSPSGHSEEEREGNMKSAKPQVNHSQHGESQRALSPLQSTLSSAASPSQAYETYIENGLICLKHKIRNIEKKKLKLEDYKDRLKSGEHLNPDQLEAVEKYEEVLHNLEFAKELQKTFSGLSLDLLKAQKKAQRREHMLKLEAEKKKLRTILQVQYVLQNLTQEHVQKDFKGGLNGAVYLPSKELDYLIKFSKLTCPERNESLSVEDQMEQSSLYFWDLLEGSEKAVVGTTYKHLKDLLSKLLNSGYFESIPVPKNAKEKEVPLEEEMLIQSEKKTQLSKTESVKESESLMEFAQPEIQPQEFLNRRYMTEVDYSNKQGEEQPWEADYARKPNLPKRWDMLTEPDGQEKKQESFKSWEASGKHQEVSKPAVSLEQRKQDTSKLRSTLPEEQKKQEISKSKPSPSQWKQDTPKSKAGYVQEEQKKQETPKLWPVQLQKEQDPKKQTPKSWTPSMQSEQNTTKSWTTPMCEEQDSKQPETPKSWENNVESQKHSLTSQSQISPKSWGVATASLIPNDQLLPRKLNTEPKDVPKPVHQPVGSSSTLPKDPVLRKEKLQDLMTQIQGTCNFMQESVLDFDKPSSAIPTSQPPSATPGSPVASKEQNLSSQSDFLQEPLQAAIPPGKQPSSLASPNPPMAKGSEQGFQSPPASSSSVTINTAPFQAMQTVFNVNAPLPPRKEQEIKESPYSPGYNQSFTTASTQTPPQCQLPSIHVEQTVHSQETAQTNVFPRPTQPFVNSRGSVRGCTRGGRLITNSYRSPGGYKGFDTYRGLPSISNGNYSQLQFQAREYSGAPYSQRDNFQQCYKRGGTSGGPRANSRANCFIMRNSLLLIKQQGGVILLR>sp|Q92870|APBB2_HUMAN Amyloid beta precursor protein binding family Bmember 2 OS=Homo sapiens OX=9606 GN=APBB2 PE=1 SV=3MSEVLPADSGVDTLAVFMASSGTTDVTNRNSPATPPNTLNLRSSHNELLNAEIKHTETKNSTPPKCRKKYALTNIQAAMGLSDPAAQPLLGNGSANIKLVKNGENQLRKAAEQGQQDPNKNLSPTAVINITSEKLEGKEPHPQDSSSCEILPSQPRRTKSFLNYYADLETSARELEQNRGNHHGTAEEKSQPVQGQASTIIGNGDLLLQKPNRPQSSPEDGQVATVSSSPETKKDHPKTGAKTDCALHRIQNLAPSDEESSWTTLSQDSASPSSPDETDIWSDHSFQTDPDLPPGWKRVSDIAGTYYWHIPTGTTQWERPVSIPADLQGSRKGSLSSVTPSPTPENEKQPWSDFAVLNGGKINSDIWKDLHAATVNPDPSLKEFEGATLRYASLKLRNAPHPDDDDSCSINSDPEAKCFAVRSLGWVEMAEEDLAPGKSSVAVNNCIRQLSYCKNDIRDTVGIWGEGKDMYLILENDMLSLVDPMDRSVLHSQPIVSIRVWGVGRDNGRDFAYVARDKDTRILKCHVFRCDTPAKAIATSLHEICSKIMAERKNAKALACSSLQERANVNLDVPLQVDFPTPKTELVQKFHVQYLGMLPVDKPVGMDILNSAIENLMTSSNKEDWLSVNMNVADATVTVISEKNEEEVLVECRVRFLSFMGVGKDVHTFAFIMDTGNQRFECHVFWCEPNAGNVSEAVQAACMLRYQKCLVARPPSQKVRPPPPPADSVTRRVTTNVKRGVLSLIDTLKQKRPVTEMP>sp|Q92870-2|APBB2_HUMAN Isoform 2 of Amyloid beta precursor proteinbinding family B member 2 OS=Homo sapiens OX=9606 GN=APBB2MSEVLPADSGVDTLAVFMASSGTTDVTNRNSPATPPNTLNLRSSHNELLNAEIKHTETKNSTPPKCRKKYALTNIQAAMGLSDPAAQPLLGNGSANIKLVKNGENQLRKAAEQGQQDPNKNLSPTAVINITSEKLEGKEPHPQDSSSCEILPSQPRRTKSFLNYYADLETSARELEQNRGNHHGTAEEKSQPVQGQASTIIGNGDLLLQKPNRPQSSPEDGQVATVSSSPETKKDHPKTGAKTDCALHRIQNLAPSDEESSWTTLSQDSASPSSPDETDIWSDHSFQTDPDLPPGWKRVSDIAGTYYWHIPTGTTQWERPVSIPADLQGSRKGSLSSVTPSPTPENEDLHAATVNPDPSLKEFEGATLRYASLKLRNAPHPDDDDSCSINSDPEAKCFAVRSLGWVEMAEEDLAPGKSSVAVNNCIRQLSYCKNDIRDTVGIWGEGKDMYLILENDMLSLVDPMDRSVLHSQPIVSIRVWGVGRDNGRDFAYVARDKDTRILKCHVFRCDTPAKAIATSLHEICSKIMAERKNAKALACSSLQERANVNLDVPLQDFPTPKTELVQKFHVQYLGMLPVDKPVGMDILNSAIENLMTSSNKEDWLSVNMNVADATVTVISEKNEEEVLVECRVRFLSFMGVGKDVHTFAFIMDTGNQRFECHVFWCEPNAGNVSEAVQAACMLRYQKCLVARPPSQKVRPPPPPADSVTRRVTTNVKRGVLSLIDTLKQKRPVTEMP>sp|Q92870-3|APBB2_HUMAN Isoform 3 of Amyloid beta precursor proteinbinding family B member 2 OS=Homo sapiens OX=9606 GN=APBB2MAERKNAKALACSSLQERANVNLDVPLQVDFPTPKTELVQKFHVQYLGMLPVDKPVGMDILNSAIENLMTSSNKEDWLSVNMNVADATVTVISEKNEEEVLVECRVRFLSFMGVGKDVHTFAFIMDTGNQRFECHVFWCEPNAGNVSEAVQAACMLRYQKCLVARPPSQKVRPPPPPADSVTRRVTTNVKRGVLSLIDTLKQKRPVTEMP>sp|Q92870-4|APBB2_HUMAN Isoform 4 of Amyloid beta precursor proteinbinding family B member 2 OS=Homo sapiens OX=9606 GN=APBB2MSEVLPADSGVDTLAVFMASSGTTDVTNRNSPATPPNTLNLRSSHNELLNAEIKHTETKNSTPPKCRKKYALTNIQAAMGLSDPAAQPLLGNGSANIKLVKNGENQLRKAAEQGQQDPNKNLSPTAVINITSEKLEGKEPHPQDSSSCEILPSQPRRTKSFLNYYADLETSARELEQNRGNHHGTAEEKSQPVQGQASTIIGNGDLLLQKPNRPQSSPEDGQVATVSSSPETKKDHPKTGAKTDCALHRIQNLAPSDEESSWTTLSQDSASPSSPDETADIWSDHSFQTDPDLPPGWKRVSDIAGTYYWHIPTGTTQWERPVSIPADLQGSRKGSLSSVTPSPTPENEKQPWSDFAVLNGGKINSDIWKDLHAATVNPDPSLKEFEGATLRYASLKLRNAPHPDDDDSCSINSDPEAKCFAVRSLGWVEMAEEDLAPGKSSVAVNNCIRQLSYCKNDIRDTVGIWGEGKDMYLILENDMLSLVDPMDRSVLHSQPIVSIRVWGVGRDNGRDFAYVARDKDTRILKCHVFRCDTPAKAIATSLHEICSKIMAERKNAKALACSSLQERANVNLDVPLQVDFPTPKTELVQKFHVQYLGMLPVDKPVGMDILNSAIENLMTSSNKEDWLSVNMNVADATVTVISEKNEEEVLVECRVRFLSFMGVGKDVHTFAFIMDTGNQRFECHVFWCEPNAGNVSEAVQAACMLRYQKCLVARPPSQKVRPPPPPADSVTRRVTTNVKRGVLSLIDTLKQKRPVTEMP>sp|Q86V15|CASZ1_HUMAN Zinc finger protein castor homolog 1 OS=Homosapiens OX=9606 GN=CASZ1 PE=1 SV=4MDLGTAEGTRCTDPPAGKPAMAPKRKGGLKLNAICAKLSRQVVVEKRADAGSHTEGSPSQPRDQERSGPESGAARAPRSEEDKRRAVIEKWVNGEYSEEPAPTPVLGRIAREGLELPPEGVYMVQPQGCSDEEDHAEEPSKDGGALEEKDSDGAASKEDSGPSTRQASGEASSLRDYAASTMTEFLGMFGYDDQNTRDELARKISFEKLHAGSTPEAATSSMLPTSEDTLSKRARFSKYEEYIRKLKAGEQLSWPAPSTKTEERVGKEVVGTLPGLRLPSSTAHLETKATILPLPSHSSVQMQNLVARASKYDFFIQKLKTGENLRPQNGSTYKKPSKYDLENVKYLHLFKPGEGSPDMGGAIAFKTGKVGRPSKYDVRGIQKPGPAKVPPTPSLAPAPLASVPSAPSAPGPGPEPPASLSFNTPEYLKSTFSKTDSITTGTVSTVKNGLPTDKPAVTEDVNIYQKYIARFSGSQHCGHIHCAYQYREHYHCLDPECNYQRFTSKQDVIRHYNMHKKRDNSLQHGFMRFSPLDDCSVYYHGCHLNGKSTHYHCMQVGCNKVYTSTSDVMTHENFHKKNTQLINDGFQRFRATEDCGTADCQFYGQKTTHFHCRRPGCTFTFKNKCDIEKHKSYHIKDDAYAKDGFKKFYKYEECKYEGCVYSKATNHFHCIRAGCGFTFTSTSQMTSHKRKHERRHIRSSGALGLPPSLLGAKDTEHEESSNDDLVDFSALSSKNSSLSASPTSQQSSASLAAATAATEAGPSATKPPNSKISGLLPQGLPGSIPLALALSNSGLPTPTPYFPILAGRGSTSLPVGTPSLLGAVSSGSAASATPDTPTLVASGAGDSAPVAAASVPAPPASIMERISASKGLISPMMARLAAAALKPSATFDPGSGQQVTPARFPPAQVKPEPGESTGAPGPHEASQDRSLDLTVKEPSNESNGHAVPANSSLLSSLMNKMSQGNPGLGSLLNIKAEAEGSPAAEPSPFLGKAVKALVQEKLAEPWKVYLRRFGTKDFCDGQCDFLHKAHFHCVVEECGALFSTLDGAIKHANFHFRTEGGAAKGNTEAAFPASAAETKPPMAPSSPPVPPVTTATVSSLEGPAPSPASVPSTPTLLAWKQLASTIPQMPQIPASVPHLPASPLATTSLENAKPQVKPGFLQFQENDPCLATDCKYANKFHFHCLFGNCKYVCKTSGKAESHCLDHINPNNNLVNVRDQFAYYSLQCLCPNQHCEFRMRGHYHCLRTGCYFVTNITTKLPWHIKKHEKAERRAANGFKYFTKREECGRLGCKYNQVNSHFHCIREGCQFSFLLKHQMTSHARKHMRRMLGKNFDRVPPSQGPPGLMDAETDECMDYTGCSPGAMSSESSTMDRSCSSTPVGNESTAAGNTISMPTASGAKKRFWIIEDMSPFGKRRKTASSRKMLDEGMMLEGFRRFDLYEDCKDAACQFSLKVTHYHCTRENCGYKFCGRTHMYKHAQHHDRVDNLVLDDFKRFKASLSCHFADCPFSGTSTHFHCLRCRFRCTDSTKVTAHRKHHGKQDVISAAGFCQFSSSADCAVPDCKYKLKCSHFHCTFPGCRHTVVGMSQMDSHKRKHEKQERGEPAAEGPAPGPPISLDGSLSLGAEPGSLLFLQSAAAGLGLALGDAGDPGPPDAAAPGPREGAAAAAAAAGESSQEDEEEELELPEEEAEDDEDEDDDEDDDDEDDDEDDDDEDLRTDSEESLPEAAAEAAGAGARTPALAALAALGAPGPAPTAASSP>sp|Q86V15-2|CASZ1_HUMAN Isoform 2 of Zinc finger protein castor homolog1 OS=Homo sapiens OX=9606 GN=CASZ1MDLGTAEGTRCTDPPAGKPAMAPKRKGGLKLNAICAKLSRQVVVEKRADAGSHTEGSPSQPRDQERSGPESGAARAPRSEEDKRRAVIEKWVNGEYSEEPAPTPVLGRIAREGLELPPEGVYMVQPQGCSDEEDHAEEPSKDGGALEEKDSDGAASKEDSGPSTRQASGEASSLRDYAASTMTEFLGMFGYDDQNTRDELARKISFEKLHAGSTPEAATSSMLPTSEDTLSKRARFSKYEEYIRKLKAGEQLSWPAPSTKTEERVGKEVVGTLPGLRLPSSTAHLETKATILPLPSHSSVQMQNLVARASKYDFFIQKLKTGENLRPQNGSTYKKPSKYDLENVKYLHLFKPGEGSPDMGGAIAFKTGKVGRPSKYDVRGIQKPGPAKVPPTPSLAPAPLASVPSAPSAPGPGPEPPASLSFNTPEYLKSTFSKTDSITTGTVSTVKNGLPTDKPAVTEDVNIYQKYIARFSGSQHCGHIHCAYQYREHYHCLDPECNYQRFTSKQDVIRHYNMHKKRDNSLQHGFMRFSPLDDCSVYYHGCHLNGKSTHYHCMQVGCNKVYTSTSDVMTHENFHKKNTQLINDGFQRFRATEDCGTADCQFYGQKTTHFHCRRPGCTFTFKNKCDIEKHKSYHIKDDAYAKDGFKKFYKYEECKYEGCVYSKATNHFHCIRAGCGFTFTSTSQMTSHKRKHERRHIRSSGALGLPPSLLGAKDTEHEESSNDDLVDFSALSSKNSSLSASPTSQQSSASLAAATAATEAGPSATKPPNSKISGLLPQGLPGSIPLALALSNSGLPTPTPYFPILAGRGSTSLPVGTPSLLGAVSSGSAASATPDTPTLVASGAGDSAPVAAASVPAPPASIMERISASKGLISPMMARLAAAALKPSATFDPGSGQQVTPARFPPAQVKPEPGESTGAPGPHEASQDRSLDLTVKEPSNESNGHAVPANSSLLSSLMNKMSQGNPGLGSLLNIKAEAEGSPAAEPSPFLGKAVKALVQEKLAEPWKVYLRRFGTKDFCDGQCDFLHKAHFHCVVEECGALFSTLDGAIKHANFHFRTEGGAAKGNTEAAFPASAAETKPPMAPSSPPVPPVTTATVSSLEGPAPSPASVPSTPTLLAWKQLASTIPQMPQIPASVPHLPASPLATTSLENAKPQVKPGFLQFQEK>sp|P53367|ARFP1_HUMAN Arfaptin-1 OS=Homo sapiens OX=9606 GN=ARFIP1 PE=1SV=2MAQESPKNSAAEIPVTSNGEVDDSREHSFNRDLKHSLPSGLGLSETQITSHGFDNTKEGVIEAGAFQGSPAPPLPSVMSPSRVAASRLAQQGSDLIVPAGGQRTQTKSGPVILADEIKNPAMEKLELVRKWSLNTYKCTRQIISEKLGRGSRTVDLELEAQIDILRDNKKKYENILKLAQTLSTQLFQMVHTQRQLGDAFADLSLKSLELHEEFGYNADTQKLLAKNGETLLGAINFFIASVNTLVNKTIEDTLMTVKQYESARIEYDAYRTDLEELNLGPRDANTLPKIEQSQHLFQAHKEKYDKMRNDVSVKLKFLEENKVKVLHNQLVLFHNAIAAYFAGNQKQLEQTLKQFHIKLKTPGVDAPSWLEEQ>sp|P53367-2|ARFP1_HUMAN Isoform A of Arfaptin-1 OS=Homo sapiens OX=9606GN=ARFIP1MAQESPKNSAAEIPVTSNGEVDDSREHSFNRDLKHSLPSGLGLSETQITSHGFDNTKEGVIEAGAFQGGQRTQTKSGPVILADEIKNPAMEKLELVRKWSLNTYKCTRQIISEKLGRGSRTVDLELEAQIDILRDNKKKYENILKLAQTLSTQLFQMVHTQRQLGDAFADLSLKSLELHEEFGYNADTQKLLAKNGETLLGAINFFIASVNTLVNKTIEDTLMTVKQYESARIEYDAYRTDLEELNLGPRDANTLPKIEQSQHLFQAHKEKYDKMRNDVSVKLKFLEENKVKVLHNQLVLFHNAIAAYFAGNQKQLEQTLKQFHIKLKTPGVDAPSWLEEQ>sp|P53367-3|ARFP1_HUMAN Isoform 3 of Arfaptin-1 OS=Homo sapiens OX=9606GN=ARFIP1MAQESPKNSAAEIPVTSNGEVDDSREHSFNREEFGYNADTQKLLAKNGETLLGAINFFIASVNTLVNKTIEDTLMTVKQYESARIEYDAYRTDLEELNLGPRDANTLPKIEQSQHLFQAHKEKYDKMRNDVSVKLKFLEENKVKVLHNQLVLFHNAIAAYFAGNQKQLEQTLKQFHIKLKTPGVDAPSWLEEQ>sp|P53365|ARFP2_HUMAN Arfaptin-2 OS=Homo sapiens OX=9606 GN=ARFIP2 PE=1SV=1MTDGILGKAATMEIPIHGNGEARQLPEDDGLEQDLQQVMVSGPNLNETSIVSGGYGGSGDGLIPTGSGRHPSHSTTPSGPGDEVARGIAGEKFDIVKKWGINTYKCTKQLLSERFGRGSRTVDLELELQIELLRETKRKYESVLQLGRALTAHLYSLLQTQHALGDAFADLSQKSPELQEEFGYNAETQKLLCKNGETLLGAVNFFVSSINTLVTKTMEDTLMTVKQYEAARLEYDAYRTDLEELSLGPRDAGTRGRLESAQATFQAHRDKYEKLRGDVAIKLKFLEENKIKVMHKQLLLFHNAVSAYFAGNQKQLEQTLQQFNIKLRPPGAEKPSWLEEQ>sp|P53365-2|ARFP2_HUMAN Isoform 2 of Arfaptin-2 OS=Homo sapiens OX=9606GN=ARFIP2MKPALCLVAMGALVMDSSPQCTKQLLSERFGRGSRTVDLELELQIELLRETKRKYESVLQLGRALTAHLYSLLQTQHALGDAFADLSQKSPELQEEFGYNAETQKLLCKNGETLLGAVNFFVSSINTLVTKTMEDTLMTVKQYEAARLEYDAYRTDLEELSLGPRDAGTRGRLESAQATFQAHRDKYEKLRGDVAIKLKFLEENKIKVMHKQLLLFHNAVSAYFAGNQKQLEQTLQQFNIKLRPPGAEKPSWLEEQ>sp|P53365-3|ARFP2_HUMAN Isoform 3 of Arfaptin-2 OS=Homo sapiens OX=9606GN=ARFIP2MVSGPNLNETSIVSGGYGGSGDGLIPTGSGRHPSHSTTPSGPGDEVARGIAGEKFDIVKKWGINTYKCTKQLLSERFGRGSRTVDLELELQIELLRETKRKYESVLQLGRALTAHLYSLLQTQHALGDAFADLSQKSPELQEEFGYNAETQKLLCKNGETLLGAVNFFVSSINTLVTKTMEDTLMTVKQYEAARLEYDAYRTDLEELSLGPRDAGTRGRLESAQATFQAHRDKYEKLRGDVAIKLKFLEENKIKVMHKQLLLFHNAVSAYFAGNQKQLEQTLQQFNIKLRPPGAEKPSWLEEQ>sp|Q96LR7|CB050_HUMAN Uncharacterized protein C2orf50 OS=Homo sapiensOX=9606 GN=C2orf50 PE=1 SV=1MGSHPTPGLQRTTSAGYRLPPTRPPASVSPAARGGPMASRGLAGGCQAPQALKAQRVAQGAACDGVQQDQLWRELLEAERRGQQRWIQNWSFLKDYDPMGNKKEPEKLPDHVPLFSDTVPSSTNQVVGSRLDTPLGQTLIRMDFFFTEGARKKKLEDQMQPI>sp|Q8N535|CB052_HUMAN Putative uncharacterized protein encoded byLINC00471 OS=Homo sapiens OX=9606 GN=LINC00471 PE=5 SV=1MSEAKDNGSRDEVLVPHKNCRKNTTVPGKKGEEKSLAPVFAEKLISPSRRGAKLKDRESHQENEDRNSELDQDEEDKESFCRGFPMSGCELETSCCVCHSTALGERFC>sp|Q8N5S3|CB073_HUMAN Uncharacterized protein C2orf73 OS=Homo sapiensOX=9606 GN=C2orf73 PE=2 SV=3MEEKEDKHQQHKIEDAAITYVSENEEIKHEEKPGKSIHHSKSHVGRGRIYYAKFINTNARTYNEPFPYIDPKKGPEIQGDWWSHGKALEPVFLPPYDSKSTQRSDFQKPSCPLVLPVKHSKMQKPSCGIVPLASPGTSAELQNNFIEYISFIHQYDARKTPNEPLQGKRHGAFVQREIKPGSRPTVPKGAEVLLNTPGSRSSEQSKKTEKGNSAESRMISPGLCQQNSQELLEPKTHLSETDVRQAAKACPSTPESREKTSGATQTTVGDALFTRHKPLNPPIKKSE>sp|Q8N5S3-2|CB073_HUMAN Isoform 2 of Uncharacterized protein C2orf73OS=Homo sapiens OX=9606 GN=C2orf73MQKPSCGIVPLASPGTSAELQNNFIEYISFIHQYDARKTPNEPLQGKRHGAFVQREIKPGSRPTVPKGAEVLLNTPGSRSSEQSKKTEKGNSAESRMISPGLCQQNSQELLEPKTHLSETDVRQAAKACPSTPESREKTSGATQTTVGDALFTRHKPLNPPIKKSE>sp|A8MZ97|CB074_HUMAN Uncharacterized protein C2orf74 OS=Homo sapiensOX=9606 GN=C2orf74 PE=1 SV=3MSLLAKPMSFETTAITFFIILLICLICILLLLVVFLYKCFQGRKGKETKKVPCTDANGGVDCAAAKVVTSNPEDHERILMQVMNLNVPMRPGILVQRQSKEVLATPLENRRDMEAEEENQINEKQEPENAGETGQEEDDGLQKIHTSVTRTPSVVESQKRPLKGVTFSREVIVVDLGNEYPTPRSYTREHKERK>sp|Q96DR7|ARHGQ_HUMAN Rho guanine nucleotide exchange factor 26 OS=Homosapiens OX=9606 GN=ARHGEF26 PE=1 SV=4MDGESEVDFSSNSITPLWRRRSIPQPHQVLGRSKPRPQSYQSPNGLLITDFPVEDGGTLLAAQIPAQVPTASDSRTVHRSPLLLGAQRRAVANGGTASPEYRAASPRLRRPKSPKLPKAVPGGSPKSPANGAVTLPAPPPPPVLRPPRTPNAPAPCTPEEDLTGLTASPVPSPTANGLAANNDSPGSGSQSGRKAKDPERGLFPGPQKSSSEQKLPLQRLPSQENELLENPSVVLSTNSPAALKVGKQQIIPKSLASEIKISKSNNQNVEPHKRLLKVRSMVEGLGGPLGHAGEESEVDNDVDSPGSLRRGLRSTSYRRAVVSGFDFDSPTSSKKKNRMSQPVLKVVMEDKEKFSSLGRIKKKMLKGQGTFDGEENAVLYQNYKEKALDIDSDEESEPKEQKSDEKIVIHHKPLRSTWSQLSAVKRKGLSQTVSQEERKRQEAIFEVISSEHSYLLSLEILIRMFKNSKELSDTMTKTERHHLFSNITDVCEASKKFFIELEARHQNNIFIDDISDIVEKHTASTFDPYVKYCTNEVYQQRTLQKLLATNPSFKEVLSRIESHEDCRNLPMISFLILPMQRVTRLPLLMDTICQKTPKDSPKYEVCKRALKEVSKLVRLCNEGARKMERTEMMYTINSQLEFKIKPFPLVSSSRWLVKRGELTAYVEDTVLFSRRTSKQQVYFFLFNDVLIITKKKSEESYNVNDYSLRDQLLVESCDNEELNSSPGKNSSTMLYSRQSSASHLFTLTVLSNHANEKVEMLLGAETQSERARWITALGHSSGKPPADRTSLTQVEIVRSFTAKQPDELSLQVADVVLIYQRVSDGWYEGERLRDGERGWFPMECAKEITCQATIDKNVERMGRLLGLETNV>sp|Q96DR7-3|ARHGQ_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor 26 OS=Homo sapiens OX=9606 GN=ARHGEF26MDGESEVDFSSNSITPLWRRRSIPQPHQVLGRSKPRPQSYQSPNGLLITDFPVEDGGTLLAAQIPAQVPTASDSRTVHRSPLLLGAQRRAVANGGTASPEYRAASPRLRRPKSPKLPKAVPGGSPKSPANGAVTLPAPPPPPVLRPPRTPNAPAPCTPEEDLTGLTASPVPSPTANGLAANNDSPGSGSQSGRKAKDPERGLFPGPQKSSSEQKLPLQRLPSQENELLENPSVVLSTNSPAALKVGKQQIIPKSLASEIKISKSNNQNVEPHKRLLKVRSMVEGLGGPLGHAGEESEVDNDVDSPGSLRRGLRSTSYRRAVVSGFDFDSPTSSKKKNRMSQPVLKVVMEDKEKFSSLGRIKKKMLKGQGTFDGEENAVLYQNYKEKALDIDSDEESEPKEQKSDEKIVIHHKPLRSTWSQLSAVKRKVILIVGFMEMKDGRLRGGK>sp|Q96DR7-4|ARHGQ_HUMAN Isoform 3 of Rho guanine nucleotide exchangefactor 26 OS=Homo sapiens OX=9606 GN=ARHGEF26MDGESEVDFSSNSITPLWRRRSIPQPHQVLGRSKPRPQSYQSPNGLLITDFPVEDGGTLLAAQIPAQVPTASDSRTVHRSPLLLGAQRRAVANGGTASPEYRAASPRLRRPKSPKLPKAVPGGSPKSPANGAVTLPAPPPPPVLRPPRTPNAPAPCTPEEDLTGLTASPVPSPTANGLAANNDSPGSGSQSGRKAKDPERGLFPGPQKSSSEQKLPLQRLPSQENELLENPSVVLSTNSPAALKVGKQQIIPKSLASEIKISKSNNQNVEPHKRLLKVRSMVEGLGGPLGHAGEESEVDNDVDSPGSLRRGLRSTSYRRAVVSGFDFDSPTSSKKKNRMSQPVLKVVMEDKEKFSSLGRIKKKMLKGQGTFDGEENAVLYQNYKEKALDIDSDEESEPKEQKSDEKIVIHHKPLRSTWSQLSAVKRKGLSQTVSQEERKRQEAIFEVISSEHSYLLSLEILIRMFKNSKELSDTMTKTERHHLFSNITDVCEASKKFFIELEARHQNNIFIDDISDIVEKHTASTFDPYVKYCTNEVYQQRTLQKLLATNPSFKEVLSRIESHEDCRNLPMISFLILPMQRVTRLPLLMDTICQKTPKDSPKYEVCKRALKEVSKLVRLCNEGARKMERTEMMYTINSQLEFKIKPFPLVSSSRWLVKRGELTAYVEDTVLFSRRTSKQQVYFFLFNDVLIITKKKSEESYNVNDYSLRDQLLVESCDNEELNSSPGKNSSTMLYSRQSSASHLFTLTVLSNHANEKVEMLLGAETQSERARWITALGHSSGKPPADRTCG>sp|Q9BY67|CADM1_HUMAN Cell adhesion molecule 1 OS=Homo sapiens OX=9606GN=CADM1 PE=1 SV=2MASVVLPSGSQCAAAAAAAAPPGLRLRLLLLLFSAAALIPTGDGQNLFTKDVTVIEGEVATISCQVNKSDDSVIQLLNPNRQTIYFRDFRPLKDSRFQLLNFSSSELKVSLTNVSISDEGRYFCQLYTDPPQESYTTITVLVPPRNLMIDIQKDTAVEGEEIEVNCTAMASKPATTIRWFKGNTELKGKSEVEEWSDMYTVTSQLMLKVHKEDDGVPVICQVEHPAVTGNLQTQRYLEVQYKPQVHIQMTYPLQGLTREGDALELTCEAIGKPQPVMVTWVRVDDEMPQHAVLSGPNLFINNLNKTDNGTYRCEASNIVGKAHSDYMLYVYDPPTTIPPPTTTTTTTTTTTTTILTIITDSRAGEEGSIRAVDHAVIGGVVAVVVFAMLCLLIILGRYFARHKGTYFTHEAKGADDAADADTAIINAEGGQNNSEEKKEYFI>sp|Q9BY67-2|CADM1_HUMAN Isoform 2 of Cell adhesion molecule 1 OS=Homosapiens OX=9606 GN=CADM1MASVVLPSGSQCAAAAAAAAPPGLRLRLLLLLFSAAALIPTGDGQNLFTKDVTVIEGEVATISCQVNKSDDSVIQLLNPNRQTIYFRDFRPLKDSRFQLLNFSSSELKVSLTNVSISDEGRYFCQLYTDPPQESYTTITVLVPPRNLMIDIQKDTAVEGEEIEVNCTAMASKPATTIRWFKGNTELKGKSEVEEWSDMYTVTSQLMLKVHKEDDGVPVICQVEHPAVTGNLQTQRYLEVQYKPQVHIQMTYPLQGLTREGDALELTCEAIGKPQPVMVTWVRVDDEMPQHAVLSGPNLFINNLNKTDNGTYRCEASNIVGKAHSDYMLYVYGT>sp|Q9BY67-3|CADM1_HUMAN Isoform 3 of Cell adhesion molecule 1 OS=Homosapiens OX=9606 GN=CADM1MASVVLPSGSQCAAAAAAAAPPGLRLRLLLLLFSAAALIPTGDGQNLFTKDVTVIEGEVATISCQVNKSDDSVIQLLNPNRQTIYFRDFRPLKDSRFQLLNFSSSELKVSLTNVSISDEGRYFCQLYTDPPQESYTTITVLVPPRNLMIDIQKDTAVEGEEIEVNCTAMASKPATTIRWFKGNTELKGKSEVEEWSDMYTVTSQLMLKVHKEDDGVPVICQVEHPAVTGNLQTQRYLEVQYKPQVHIQMTYPLQGLTREGDALELTCEAIGKPQPVMVTWVRVDDEMPQHAVLSGPNLFINNLNKTDNGTYRCEASNIVGKAHSDYMLYVYDPPTTIPPPTTTTTTTTTTTTTILTIITDTTATTEPAVHGLTQLPNSAEELDSEDLSDSRAGEEGSIRAVDHAVIGGVVAVVVFAMLCLLIILGRYFARHKGTYFTHEAKGADDAADADTAIINAEGGQNNSEEKKEYFI>sp|Q9BY67-4|CADM1_HUMAN Isoform 4 of Cell adhesion molecule 1 OS=Homosapiens OX=9606 GN=CADM1MASVVLPSGSQCAAAAAAAAPPGLRLRLLLLLFSAAALIPTGDGQNLFTKDVTVIEGEVATISCQVNKSDDSVIQLLNPNRQTIYFRDFRPLKDSRFQLLNFSSSELKVSLTNVSISDEGRYFCQLYTDPPQESYTTITVLVPPRNLMIDIQKDTAVEGEEIEVNCTAMASKPATTIRWFKGNTELKGKSEVEEWSDMYTVTSQLMLKVHKEDDGVPVICQVEHPAVTGNLQTQRYLEVQYKPQVHIQMTYPLQGLTREGDALELTCEAIGKPQPVMVTWVRVDDEMPQHAVLSGPNLFINNLNKTDNGTYRCEASNIVGKAHSDYMLYVYDPPTTIPPPTTTTTTTTTTTTTILTIITDTTATTEPAVHDSRAGEEGSIRAVDHAVIGGVVAVVVFAMLCLLIILGRYFARHKGTYFTHEAKGADDAADADTAIINAEGGQNNSEEKKEYFI>sp|Q9BY67-5|CADM1_HUMAN Isoform 5 of Cell adhesion molecule 1 OS=Homosapiens OX=9606 GN=CADM1MASVVLPSGSQCAAAAAAAAPPGLRLRLLLLLFSAAALIPTGDGQNLFTKDVTVIEGEVATISCQVNKSDDSVIQLLNPNRQTIYFRDFRPLKDSRFQLLNFSSSELKVSLTNVSISDEGRYFCQLYTDPPQESYTTITVLVPPRNLMIDIQKDTAVEGEEIEVNCTAMASKPATTIRWFKGNTELKGKSEVEEWSDMYTVTSQLMLKVHKEDDGVPVICQVEHPAVTGNLQTQRYLEVQYKPQVHIQMTYPLQGLTREGDALELTCEAIGKPQPVMVTWVRVDDEMPQHAVLSGPNLFINNLNKTDNGTYRCEASNIVGKAHSDYMLYVYDSRAGEEGSIRAVDHAVIGGVVAVVVFAMLCLLIILGRYFARHKGTYFTHEAKGADDAADADTAIINAEGGQNNSEEKKEYFI>sp|A8MVX0|ARG33_HUMAN Rho guanine nucleotide exchange factor 33 OS=Homosapiens OX=9606 GN=ARHGEF33 PE=2 SV=2MEKTKTKQGENEHMPVNNPSTQIYQLQALASELKTGFTEAMQELSRIQHGEYALEEKVKSCRCSMEEKVTEMKNSLNYFKEELSNAMSMIQAITSKQEEMQQKIEQLQQEKRRESRKVKAKKTQKEEHSSQAGPAQAQGSPFRSINIPEPVLPSEDFTNLLPSQAYEKAQESRSVHVGDSNVKGMMGPGVNPTTPEAEENLKSCLSADIQSKGHLPSGMWRQPKDGKEWGEEYVTKDHPDKLKEAGQGRHSSLENVLCETSLAAKRQTVALELLESERKYVINISLILKIKATFQGSDGKRNSKERSLFPGSLRYLVQQHLDLLHALQERVLKWPRQGVLGDLFLKLTNDENNFLDYYVAYLRDLPECISLVHVVVLKEGDEEIKSDIYTLFFHIVQRIPEYLIHLQNVLKFTEQEHPDYYLLLVCVQRLRVFISHYTLLFQCNEDLLIQKRKKLKKSSMAKLYKGLASQCANAGQDASPTAGPEAVRDTGIHSEELLQPYPSAPSSGPAITHLMPPVKKSQQQQSLMESMQPGKPSDWELEGRKHERPESLLAPTQFCAAEQDVKALAGPLQAIPEMDFESSPAEPLGNVERSLRAPAELLPDARGFVPAAYEEFEYGGEIFALPAPYDEEPFQAPALFENCSPASSESSLDICFLRPVSFAMEAERPEHPLQPLPKSATSPAGSSSAYKLEAAAQAHGKAKPLSRSLKEFPRAPPADGVAPRLYSTRSSSGGRAPIKAERAAQAHGPAAAAVAARGASRTFFPQQRSQSEKQTYLEVRREMHLEDTTRFCPKEERESEQTSFSDQNPRQDQKGGFRSSFRKLFKKKNGNATGEDFCGPWGWW>sp|A8MVX0-2|ARG33_HUMAN Isoform 2 of Rho guanine nucleotide exchangefactor 33 OS=Homo sapiens OX=9606 GN=ARHGEF33MEKTKTKQGENEHMPVNNPSTQIYQLQALASELKTGFTEAMQELSRIQHGEYALEEKVKSCRCSMEEKVTEMKNSLNYFKEELSNAMSMIQAITSKQEEMQQKIEQLQQEKRRESRKVKAKKTQKEEHSSQAGPAQAQGSPFRSINIPEPVLPSEDFTNLLPSQAYEKAQESRSVHVGDSNVKGMMGPGVNPTTPEAEENLKSCLSADIQSKGHLPSGMWRQPKDGKEWGEEYVTKDHPDKLKEAGQGRHSSLENVLCETSLAAKRQTVALELLESERKYVINISLILKIKATFQGSDGKRNSKERSLFPGSLRYLVQQHLDLLHALQERVLKWPRQGVLGDLFLKLTNDENNFLDYYVAYLRDLPECISLVHVVVLKEGDEEIKSDIYTLFFHIVQRIPEYLIHLQNVLKFTEQEHPDYYLLLVCVQRLRVFISHYTLLFQCNEDLLIQKRKKLKKSSMAKLYKGLASQCANAGQDASPTAGPEAVRDTGIHSEELLQPYPSAPSSGPAITHLMPPVKKSQQQQSLMESMQPGKPSDWELEGRKHERPESLLAPTQFCAAEQDVKALAGPLQAIPEMDFESSPAEPLGNVERSLRAPAELLPDARGFVPAAYEEFEYGGEIFALPAPYDEEPFQAPALFENCSPASSESSLDICFLRPVSFAMEAERPEHPLQPLPKSATSPAGSSSAYKLEAAAQAHGKAKPLSRSLKEFPRAPPADGVAPRLYSTRSSSGGRAPIKAERAAQAHGPAAAAVAARGASRTFFPQQRSQSEKQTYLEVRREMHLEDTTRFCPKEERESEQTSFSDQNPRQDQKGGFRSSFRKLFKKKSSGSEYREKTNENPSMDPSPTKQDFFRNRLALANDLDQGTAV>sp|Q9HCE9|ANO8_HUMAN Anoctamin-8 OS=Homo sapiens OX=9606 GN=ANO8 PE=1SV=3MAEAASGAGGTSLEGERGKRPPPEGEPAAPASGVLDKLFGKRLLQAGRYLVSHKAWMKTVPTENCDVLMTFPDTTDDHTLLWLLNHIRVGIPELIVQVRHHRHTRAYAFFVTATYESLLRGADELGLRKAVKAEFGGGTRGFSCEEDFIYENVESELRFFTSQERQSIIRFWLQNLRAKQGEALHNVRFLEDQPIIPELAARGIIQQVFPVHEQRILNRLMKSWVQAVCENQPLDDICDYFGVKIAMYFAWLGFYTSAMVYPAVFGSVLYTFTEADQTSRDVSCVVFALFNVIWSTLFLEEWKRRGAELAYKWGTLDSPGEAVEEPRPQFRGVRRISPITRAEEFYYPPWKRLLFQLLVSLPLCLACLVCVFLLMLGCFQLQELVLSVKGLPRLARFLPKVMLALLVSVSAEGYKKLAIWLNDMENYRLESAYEKHLIIKVVLFQFVNSYLSLFYIGFYLKDMERLKEMLATLLITRQFLQNVREVLQPHLYRRLGRGELGLRAVWELARALLGLLSLRRPAPRRLEPQADEGGGGGSGGGGRRCLSGGCGAPEEEEEAALVERRRAGEGGEEGDGPPGGKEEDEDDEEEEDEEEEEDEEEGEEGGLLDCGLRLKKVSFAERGAGRRRPGPSPEALLEEGSPTMVEKGLEPGVFTLAEEDDEAEGAPGSPEREPPAILFRRAGGEGRDQGPDGGPDPEPGSNSDSTRRQRRQNRSSWIDPPEEEHSPQLTQAELESCMKKYEDTFQDYQEMFVQFGYVVLFSSAFPLAALCALVNNLIEIRSDAFKLCTGLQRPFGQRVESIGQWQKVMEAMGVLAIVVNCYLIGQCGQLQRLFPWLSPEAAIVSVVVLEHFALLLKYLIHVAIPDIPGWVAEEMAKLEYQRREAFKRHERQAQHRYQQQQRRRREEEERQRHAEHHARREHDSGGREEARAEGSGLDPATSSEKASAKAKGSTAGGHGPERPKRPGSLLAPNNVMKLKQIIPLQGKFLSSGATSSLAAAGAGATTRPPPAQSPTGSDTRLPAFLSFKFLKSPETRRDSERSHSPPKAFHAGKLFPFGGTRAEPGSNGAGGQARPDGTPSSGSSRVQRSGPVDEALAEELEAPRPEEEGSGTALAPVGAPALRTRRSRSPAPPPPMPLPRPPTPPAGCWQWDGPWGCGGEGAAPRQALAAAECPPCAMAGPPPAPQPLPGDASFYSLPPPPLPPTSDPLETPAPSPSPSPSPQAVCWPSGWH>sp|Q9HCE9-2|ANO8_HUMAN Isoform 2 of Anoctamin-8 OS=Homo sapiens OX=9606GN=ANO8MAEAASGAGGTSLEGERGKRPPPEGEPAAPASGVLDKLFGKRLLQAGRYLVSHKAWMKTVPTENCDVLMTFPDTTDDHTLLWLLNHIRVGIPELIVQVRHHRHTRAYAFFVTATYESLLRGADELGLRKAVKAEFGGGTRGFSCEEDFIYENVESELRFFTSQERQSIIRFWLQNLRAKQGEALHNVRFLEDQPIIPELAARGIIQQVFPVHEQRILNRLMKSWVQAVCENQPLDDICDYFGVKIAMYFAWLGFYTSAMVYPAVFGSVLYTFTEADQTSRDVSCVVFALFNVIWSTLFLEEWKRRGAELAYKWGTLDSPGEAVEEPRPQFRGVRRISPITRAEEFYYPPWKRLLFQLLVSLPLCLACLVCVFLLMLGCFQLQELVLSVKGLPRLARFLPKVMLALLVSVSAEGYKKLAIWLNDMENYRLESAYEKHLIIKVVLFQFVNSYLSLFYIGFYLKDMERLKEMLATLLITRQFLQNVREVLQPHLYRRLGRGELGLRAVWELARALLGLLSLRRPAPRRLEPQADEGGGGGSGGGGRRCLSGGCGAPEEEEEAALVERRRAGEGGEEGDGPPGGKEEDEDDEEEEDEEEEEDEEEGEEGGLLDCGLRLKKVSFAERGAGRRRPGPSPEALLEEGSPTMVEKGLEPGVFTLAEEDDEAEGAPGSPEREPPAILFRRAGGEGRDQGPDGGPDPEPGSNSDSTRRQRRQNRSSWIDPPEEEHSPQLTQAELESCMKKYEDTFQDYQEMFVQFGYVVLFSSAFPLAALCALVNNLIEIRSDAFKLCTGLQRPFGQRVESIGQWQKVMEAMGVLAIVVNCYLIGQCGQLQRLFPWLSPEAAIVSVVVLEHFALLLKYLIHVAIPDIPGWVAEEMAKLEYQRREAFKRHERQAQHRYQQQQRRRREEEERQRHAEHHARREHDSGGREEARAEGSGLDPATSSEKASAKAKGSTAGGHGPERPKRPGSLLAPNNVMKLKQIIPLQGKFLSSGATSSLAAAGAGATTRPPPAQSPTGSDTRLPAFLSFKFLKSPETRRDSERSHSPPKAFHAGKLFPFGGTRAEPGSNGAGGQARPDGTPSSGSSRVQRSGPVDEALAEELEAPRPEEEGSGHKL>sp|Q96MI9|CBPC4_HUMAN Cytosolic carboxypeptidase 4 OS=Homo sapiensOX=9606 GN=AGBL1 PE=1 SV=3MAEQEASGLQVLLHTLQSSSDKESILTILKVLGDLLSVGTDRRIHYMISKGGSEALLQTLVDTARTAPPDYDILLPLFRLLAKVGLRDKKIGRKALELEALDVTLILARKNLSHGQNLLHCLWALRVFASSVSMGAMLGINGAMELLFKVITPYTRKRTQAIRAATEVLAALLKSKSNGRRAVNRGYVTSLLGLHQDWHSHDTANAYVQIRRGLLLCLRHIAALRSGREAFLAAQGMEILFSTTQNCLDDKSMEPVISVVLQILRQCYPTSPLPLVTASSAYAFPVPGCITTEPPHDLPEEDFEDDGDDEVDKDSDTEDGKVEDDDLETDVNKLSSKPGLDRPEEELMQYEVMCLELSYSFEELQSKLGDDLNSEKTQYANHHHIPAAASSKQHCYSKDQSSCGQEREYAVQTSLLCRVKTGRSTVHLGSKKNPGVNLYQNVQSNSLRRDSSESEIPDIQASPKADAWDVDAIFCPRMSASFSNSTRTREVVKVIDKLLQTHLKRVPFHDPYLYMAKARRTSSVVDFKMMAFPDVWGHCPPPTTQPMLERKCGVQRIRIFEDIRRLIQPSDVINKVVFSLDEPWPLQDNASNCLRFFSKFESGNLRKAIQVREFEYDLLVNADVNSTQHQQWFYFKVSGMQAAIPYHFNIINCEKPNSQFNYGMQPTLYSVKEALLGKPTWIRTGHEICYYKNHYRQSTAVAGGASGKCYYTLTFAVTFPHSEDVCYLAYHYPYTYTALMTHLDILEKSVNLKEVYFRQDVLCQTLGGNPCPLVTITAMPESNSDEHLEQFRHRPYQVITARVHPGESNASWVMKGTLEFLVSSDPVARLLRENFIFKIIPMLNPDGVINGNHRCSLSGEDLNRQWLSPSAHLQPTIYHAKGLLYHLSSIGRSPVVFCDFHGHSQKKNVFLYGCSIKETLWQAACTVGTSTILEEVNYRTLPKILDKLAPAFTMSSCSFLVEKSRASTARVVVWREMGVSRSYTMESSYCGCNQGPYQCTQRLLERTKNERAHPVDGLQGLQFGTRELEEMGAMFCLGLLILELKSASCSHQLLAQAATLLSAEEDALDQHLQRLKSSNFLPKHIWFAYHFFAITNFFKMNLLLHVSPVCDT>sp|P51671|CCL11_HUMAN Eotaxin OS=Homo sapiens OX=9606 GN=CCL11 PE=1 SV=1MKVSAALLWLLLIAAAFSPQGLAGPASVPTTCCFNLANRKIPLQRLESYRRITSGKCPQKAVIFKTKLAKDICADPKKKWVQDSMKYLDQKSPTPKP>sp|Q9Y4X5|ARI1_HUMAN E3 ubiquitin-protein ligase ARIH1 OS=Homo sapiensOX=9606 GN=ARIH1 PE=1 SV=2MDSDEGYNYEFDEDEECSEEDSGAEEEEDEDDDEPDDDTLDLGEVELVEPGLGVGGERDGLLCGETGGGGGSALGPGGGGGGGGGGGGGGPGHEQEEDYRYEVLTAEQILQHMVECIREVNEVIQNPATITRILLSHFNWDKEKLMERYFDGNLEKLFAECHVINPSKKSRTRQMNTRSSAQDMPCQICYLNYPNSYFTGLECGHKFCMQCWSEYLTTKIMEEGMGQTISCPAHGCDILVDDNTVMRLITDSKVKLKYQHLITNSFVECNRLLKWCPAPDCHHVVKVQYPDAKPVRCKCGRQFCFNCGENWHDPVKCKWLKKWIKKCDDDSETSNWIAANTKECPKCHVTIEKDGGCNHMVCRNQNCKAEFCWVCLGPWEPHGSAWYNCNRYNEDDAKAARDAQERSRAALQRYLFYCNRYMNHMQSLRFEHKLYAQVKQKMEEMQQHNMSWIEVQFLKKAVDVLCQCRATLMYTYVFAFYLKKNNQSIIFENNQADLENATEVLSGYLERDISQDSLQDIKQKVQDKYRYCESRRRVLLQHVHEGYEKDLWEYIED>sp|Q8WWN8|ARAP3_HUMAN Arf-GAP with Rho-GAP domain, ANK repeat and PHdomain-containing protein 3 OS=Homo sapiens OX=9606 GN=ARAP3 PE=1 SV=1MAAPQDLDIAVWLATVHLEQYADTFRRHGLATAGAARGLGHEELKQLGISATGHRKRILRLLQTGTEEGSLDPKSDSAMEPSPSPAPQAQPPKPVPKPRTVFGGLSGPATTQRPGLSPALGGPGVSRSPEPSPRPPPLPTSSSEQSSALNTVEMMPNSIYFGLDSRGRAQAAQDKAPDSSQISAPTPALRPTTGTVHIMDPGCLYYGVQPVGTPGAPDRRESRGVCQGRAEHRLSRQDLEAREDAGYASLELPGDSTLLSPTLETEETSDDLISPYASFSFTADRLTPLLSGWLDKLSPQGNYVFQRRFVQFNGRSLMYFGSDKDPFPKGVIPLTAIEMTRSSKDNKFQVITGQRVFVFRTESEAQRDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYKSEQAFSLGIGICFIELQGCSVRETKSRSFDLLTPHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPDWAAVNLGVVICKQCAGQHRALGSGISKVQSLKLDTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLFRKPHPQYPDHSQLLQALCAAVARPNLLKNMTQLLCVEAFEGEEPWFPPAPDGSCPGLLPSDPSPGVYNEVVVRATYSGFLYCSPVSNKAGPSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTDPGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVGKWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCSAPGPGPPAPEDMVHLRRLQEISVVSAADTPDKKEHLVLVETGRTLYLQGEGRLDFTAWNAAIGGAAGGGGTGLQEQQMSRGDIPIIVDACISFVTQHGLRLEGVYRKGGARARSLRLLAEFRRDARSVKLRPGEHFVEDVTDTLKRFFRELDDPVTSARLLPRWREAAELPQKNQRLEKYKDVIGCLPRVNRRTLATLIGHLYRVQKCAALNQMCTRNLALLFAPSVFQTDGRGEHEVRVLQELIDGYISVFDIDSDQVAQIDLEVSLITTWKDVQLSQAGDLIMEVYIEQQLPDNCVTLKVSPTLTAEELTNQVLEMRGTAAGMDLWVTFEIREHGELERPLHPKEKVLEQALQWCQLPEPCSASLLLKKVPLAQAGCLFTGIRRESPRVGLLRCREEPPRLLGSRFQERFFLLRGRCLLLLKEKKSSKPEREWPLEGAKVYLGIRKKLKPPTPWGFTLILEKMHLYLSCTDEDEMWDWTTSILKAQHDDQQPVVLRRHSSSDLARQKFGTMPLLPIRGDDSGATLLSANQTLRRLHNRRTLSMFFPMKSSQGSVEEQEELEEPVYEEPVYEEVGAFPELIQDTSTSFSTTREWTVKPENPLTSQKSLDQPFLSKSSTLGQEERPPEPPPGPPSKSSPQARGSLEEQLLQELSSLILRKGETTAGLGSPSQPSSPQSPSPTGLPTQTPGFPTQPPCTSSPPSSQPLT>sp|Q8WWN8-2|ARAP3_HUMAN Isoform 2 of Arf-GAP with Rho-GAP domain, ANKrepeat and PH domain-containing protein 3 OS=Homo sapiens OX=9606GN=ARAP3MTRSSKDNKFQVITGQRVFVFRTESEAQRDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYKSEQAFSLGIGICFIELQGCSVRETKSRSFDLLTPHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPDWAAVNLGVVICKQCAGQHRALGSGISKVQSLKLDTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLFRKPHPQYPDHSQLLQALCAAVARPNLLKNMTQLLCVEAFEGEEPWFPPAPDGSCPGLLPSDPSPGVYNEVVVRATYSGFLYCSPVSNKAGPSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTDPGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVGKWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCSAPGPGPPAPEDMVHLRRLQEISVVSAADTPDKKEHLVLVETGRTLYLQGEGRLDFTAWNAAIGGAAGGGGTGLQEQQMSRGDIPIIVDACISFVTQHGLRLEGVYRKGGARARSLRLLAEFRRDARSVKLRPGEHFVEDVTDTLKRFFRELDDPVTSARLLPRWREAAELPQKNQRLEKYKDVIGCLPRVNRRTLATLIGHLYRVQKCAALNQMCTRNLALLFAPSVFQTDGRGEHEVRVLQELIDGYISVFDIDSDQVAQIDLEVSLITTWKDVQLSQAGDLIMEVYIEQQLPDNCVTLKVSPTLTAEELTNQVLEMRGTAAGMDLWVTFEIREHGELERPLHPKEKVLEQALQWCQLPEPCSASLLLKKVPLAQAGCLFTGIRRESPRVGLLRCREEPPRLLGSRFQERFFLLRGRCLLLLKEKKSSKPEREWPLEGAKVYLGIRKKLKPPTPWGFTLILEKMHLYLSCTDEDEMWDWTTSILKAQHDDQQPVVLRRHSSSDLARQKFGTMPLLPIRGDDSGATLLSANQTLPMKSSQGSVEEQEELEEPVYEEPVYEEVGAFPELIQDTSTSFSTTREWTVKPENPLTSQKSLDQPFLSKSSTLGQEERPPEPPPGPPSKSSPQARGSLEEQLLQELSSLILRKGETTAGLGSPSQPSSPQSPSPTGLPTQTPGFPTQPPCTSSPPSSQPLT>sp|O75052|CAPON_HUMAN Carboxyl-terminal PDZ ligand of neuronal nitricoxide synthase protein OS=Homo sapiens OX=9606 GN=NOS1AP PE=1 SV=3MPSKTKYNLVDDGHDLRIPLHNEDAFQHGICFEAKYVGSLDVPRPNSRVEIVAAMRRIRYEFKAKNIKKKKVSIMVSVDGVKVILKKKKKLLLLQKKEWTWDESKMLVMQDPIYRIFYVSHDSQDLKIFSYIARDGASNIFRCNVFKSKKKSQAMRIVRTVGQAFEVCHKLSLQHTQQNADGQEDGESERNSNSSGDPGRQLTGAERASTATAEETDIDAVEVPLPGNDVLEFSRGVTDLDAVGKEGGSHTGSKVSHPQEPMLTASPRMLLPSSSSKPPGLGTETPLSTHHQMQLLQQLLQQQQQQTQVAVAQVHLLKDQLAAEAAARLEAQARVHQLLLQNKDMLQHISLLVKQVQELELKLSGQNAMGSQDSLLEITFRSGALPVLCDPTTPKPEDLHSPPLGAGLADFAHPAGSPLGRRDCLVKLECFRFLPPEDTPPPAQGEALLGGLELIKFRESGIASEYESNTDESEERDSWSQEELPRLLNVLQRQELGDGLDDEIAV>sp|O75052-2|CAPON_HUMAN Isoform 2 of Carboxyl-terminal PDZ ligand ofneuronal nitric oxide synthase protein OS=Homo sapiens OX=9606 GN=NOS1APMSLSSLCPVFSAAASSLQVHLLKDQLAAEAAARLEAQARVHQLLLQNKDMLQHISLLVKQVQELELKLSGQNAMGSQDSLLEITFRSGALPVLCDPTTPKPEDLHSPPLGAGLADFAHPAGSPLGRRDCLVKLECFRFLPPEDTPPPAQGEALLGGLELIKFRESGIASEYESNTDESEERDSWSQEELPRLLNVLQRQELGDGLDDEIAV>sp|O75052-3|CAPON_HUMAN Isoform 3 of Carboxyl-terminal PDZ ligand ofneuronal nitric oxide synthase protein OS=Homo sapiens OX=9606 GN=NOS1APMPSKTKYNLVDDGHDLRIPLHNEDAFQHGICFEAKYVGSLDVPRPNSRVEIVAAMRRIRYEFKAKNIKKKKVSIMVSVDGVKVILKKKKKKKEWTWDESKMLVMQDPIYRIFYVSHDSQDLKIFSYIARDGASNIFRCNVFKSKKKSQAMRIVRTVGQAFEVCHKLSLQHTQQNADGQEDGESERNSNSSGDPGRQLTGAERASTATAEETDIDAVEVPLPGNDVLEFSRGVTDLDAVGKEGGSHTGSKVSHPQEPMLTASPRMLLPSSSSKPPGLGTETPLSTHHQMQLLQQLLQQQQQQTQVAVAQVHLLKDQLAAEAAARLEAQARVHQLLLQNKDMLQHISLLVKQVQELELKLSGQNAMGSQDSLLEITFRSGALPVLCDPTTPKPEDLHSPPLGAGLADFAHPAGSPLGRRDCLVKLECFRFLPPEDTPPPAQGEALLGGLELIKFRESGIASEYESNTDESEERDSWSQEELPRLLNVLQRQELGDGLDDEIAV>sp|Q99616|CCL13_HUMAN C-C motif chemokine 13 OS=Homo sapiens OX=9606GN=CCL13 PE=1 SV=1MKVSAVLLCLLLMTAAFNPQGLAQPDALNVPSTCCFTFSSKKISLQRLKSYVITTSRCPQKAVIFRTKLGKEICADPKEKWVQNYMKHLGRKAHTLKT>sp|Q96IT6|ARAS1_HUMAN Putative uncharacterized protein ARHGAP5-AS1OS=Homo sapiens OX=9606 GN=ARHGAP5-AS1 PE=5 SV=1MQAPDSVRSVKVEREAKTWIEKPRGAGLRVAQKTPVHATTSLTLGTVVHLAFIILP>sp|Q9UJX5|APC4_HUMAN Anaphase-promoting complex subunit 4 OS=Homosapiens OX=9606 GN=ANAPC4 PE=1 SV=2MLRFPTCFPSFRVVGEKQLPQEIIFLVWSPKRDLIALANTAGEVLLHRLASFHRVWSFPPNENTGKEVTCLAWRPDGKLLAFALADTKKIVLCDVEKPESLHSFSVEAPVSCMHWMEVTVESSVLTSFYNAEDESNLLLPKLPTLPKNYSNTSKIFSEENSDEIIKLLGDVRLNILVLGGSSGFIELYAYGMFKIARVTGIAGTCLALCLSSDLKSLSVVTEVSTNGASEVSYFQLETNLLYSFLPEVTRMARKFTHISALLQYINLSLTCMCEAWEEILMQMDSRLTKFVQEKNTTTSVQDEFMHLLLWGKASAELQTLLMNQLTVKGLKKLGQSIESSYSSIQKLVISHLQSGSESLLYHLSELKGMASWKQKYEPLGLDAAGIEEAITAVGSFILKANELLQVIDSSMKNFKAFFRWLYVAMLRMTEDHVLPELNKMTQKDITFVAEFLTEHFNEAPDLYNRKGKYFNVERVGQYLKDEDDDLVSPPNTEGNQWYDFLQNSSHLKESPLLFPYYPRKSLHFVKRRMENIIDQCLQKPADVIGKSMNQAICIPLYRDTRSEDSTRRLFKFPFLWNNKTSNLHYLLFTILEDSLYKMCILRRHTDISQSVSNGLIAIKFGSFTYATTEKVRRSIYSCLDAQFYDDETVTVVLKDTVGREGRDRLLVQLPLSLVYNSEDSAEYQFTGTYSTRLDEQCSAIPTRTMHFEKHWRLLESMKAQYVAGNGFRKVSCVLSSNLRHVRVFEMDIDDEWELDESSDEEEEASNKPVKIKEEVLSESEAENQQAGAAALAPEIVIKVEKLDPELDS>sp|Q9UJX5-2|APC4_HUMAN Isoform 2 of Anaphase-promoting complex subunit 4OS=Homo sapiens OX=9606 GN=ANAPC4MLRFPTCFPSFRVVGEKQLPQEIIFLVWSPKRDLIALANTAGEVLLHRLASFHRVWSFPPNENTGKEVTCLAWRPDGKLLAFALADTKKIVLCDVEKPESLHSFSVEAPVSCMHWMEVTVESSVLTSFYNAEDESNLLLPKLPTLPKNYSNTSKIFSEENSDEIIKLLGDVRLNILVLGGSSGFIELYAYGMFKIARVTGIAGTCLALCLSSDLKSLSVVTEVSTNGASEVSYFQLETNLLYSFLPEVTRMARKFTHISALLQYINLSLTCMCEAWEEILMQMDSRLTKFVQEKNTTTSVQDEFMHLLLWGKASAELQTLLMNQLTVKGLKKLGQSIESSYSSIQKLVISHLQSGSESLLYHLSELKGMASWKQKYEPLGLDAAGIEEAITAVGSFILKANELLQVIDSSMKNFKAFFRWLYVAMLRMTEDHVLPELNKMTQKDITFVAEFLTEHFNEAPDLYNRKGKYFNVERVGQYLKDEDDDLVSPPNTEGNQWYDFLQNSSHLKESPLLFPYYPRKSLHFVKRRMENIIDQCLQKPAVSLKEMHVFV>sp|Q9UJX5-3|APC4_HUMAN Isoform 3 of Anaphase-promoting complex subunit 4OS=Homo sapiens OX=9606 GN=ANAPC4MLRFPTCFPSFRVVGEKQLPQEIIFLVWSPKRDLIALANTAGEVLLHRLASFHRVWSFPPNENTGKEVTCLAWRPDGKLLAFALADTKKIVLCDVEKPESLHSFSVEAPVSCMHWMEVTVESSVLTSFYNAEDESNLLLPKLPTLPKNYSNTSKIFSEENSDEIIKLLGDVRLNILVLGGSSGFIELYAYGMFKIARVTGIAGTCLALCLSSDLKSLSVVTEVSTNGASEVSYFQLETNLLYSFLPEVTRMARKFTHISALLQYINLSLTCMCEAWEEILMQMDSRLTKFVQEKNTTTSVQDEFMHLLLWGKASAELQTLLMNQLTVKGLKKLGQSIESSYSSIQKLVISHLQSGSESLLYHLSELKGMASWKQKYEPLGLDAAGIEEAITAVGSFILKANELLQVIDSSMKNFKAFFRWLYVAMLRMTEDHVLPELNKVMTQKDITFVAEFLTEHFNEAPDLYNRKGKYFNVERVGQYLKDEDDDLVSPPNTEGNQWYDFLQNSSHLKESPLLFPYYPRKSLHFVKRRMENIIDQCLQKPADVIGKSMNQAICIPLYRDTRSEDSTRRLFKFPFLWNNKTSNLHYLLFTILEDSLYKMCILRRHTDISQSVSNGLIAIKFGSFTYATTEKVRRSIYSCLDAQFYDDETVTVVLKDTVGREGRDRLLVQLPLSLVYNSEDSAEYQFTGTYSTRLDEQCSAIPTRTMHFEKHWRLLESMKAQYVAGNGFRKVSCVLSSNLRHVRVFEMDIDDEWELDESSDEEEEASNKPVKIKEEVLSESEAENQQAGAAALAPEIVIKVEKLDPELDS>sp|Q16663|CCL15_HUMAN C-C motif chemokine 15 OS=Homo sapiens OX=9606GN=CCL15 PE=1 SV=2MKVSVAALSCLMLVAVLGSQAQFINDAETELMMSKLPLENPVVLNSFHFAADCCTSYISQSIPCSLMKSYFETSSECSKPGVIFLTKKGRQVCAKPSGPGVQDCMKKLKPYSI>sp|Q5VU57|CBPC6_HUMAN Cytosolic carboxypeptidase 6 OS=Homo sapiensOX=9606 GN=AGBL4 PE=2 SV=3MAEGSQSAPEAGNDMGNDDAIGGNVSKYIVLPTGYCGQPKKGHLIFDACFESGNLGRVDQVSEFEYDLFIRPDTCNPRFRVWFNFTVENVKESQRVIFNIVNFSKTKSLYRDGMAPMVKSTSRPKWQRLPPKNVYYYRCPDHRKNYVMSFAFCFDREEDIYQFAYCYPYTYTRFQHYLDSLQKRNMDYFFREQLGQSVQQRKLDLLTITSPDNLREGAEQKVVFITGRVHPGETPSSFVCQGIIDFLVSQHPIACVLREYLVFKIAPMLNPDGVYLGNYRCSLMGFDLNRHWLDPSPWVHPTLHGVKQLIVQMYNDPKTSLEFYIDIHAHSTMMNGFMYGNIFEDEERFQRQAIFPKLLCQNAEDFSYSSTSFNRDAVKAGTGRRFLGGLLDHTSYCYTLEVSFYSYIISGTTAAVPYTEEAYMKLGRNVARTFLDYYRLNPVVEKVAIPMPRLRNKEIEVQRRKEKSPPYKHPLLRGPASNYPNSKGDKKSSVNHKDPSTPF>sp|Q5VU57-2|CBPC6_HUMAN Isoform 2 of Cytosolic carboxypeptidase 6OS=Homo sapiens OX=9606 GN=AGBL4MAEGSQSAPEAGNDMGNDDAIGGNVSKYIVLPTGYCGQPKKGHLIFDACFESGNLGRVDQVSEFEYDLFIRPDTCNPRFRVWFNFTVENVKESQVREIVDTFRVVLRVIFNIVNFSKTKSLYRDGMAPMVKSTSRPKWQRLPPKNVYYYRCPDHRKNYVMSFAFCFDREEDIYQFAYCYPYTYTRFQHYLDSLQKRNMDYFFREQLGQSVQQRKLDLLTITSPDNLREGAEQKVVFITGRVHPGETPSSFVCQGIIDFLVSQHPIACVLREYLVFKIAPMLNPDGVYLGNYRCSLMGFDLNRHWLDPSPWVHPTLHGVKQLIVQMYNDPKTSLEFYIDIHAHSTMMNGFMYGNIFEDEERFQRQAIFPKLLCQNAEDFSYSSTSFNRDAVKAGTGRRFLGGLLDHTSYCYTLEVSFYSYIISGTTAAVPYTEEAYMKLGRNVARTFLDYYRLNPVVEKVAIPMPRLRKEKSPPYKHPLLRGPASNYPNSKGDKKSSVNHKDPSTPF>sp|P16066|ANPRA_HUMAN Atrial natriuretic peptide receptor 1 OS=Homosapiens OX=9606 GN=NPR1 PE=1 SV=1MPGPRRPAGSRLRLLLLLLLPPLLLLLRGSHAGNLTVAVVLPLANTSYPWSWARVGPAVELALAQVKARPDLLPGWTVRTVLGSSENALGVCSDTAAPLAAVDLKWEHNPAVFLGPGCVYAAAPVGRFTAHWRVPLLTAGAPALGFGVKDEYALTTRAGPSYAKLGDFVAALHRRLGWERQALMLYAYRPGDEEHCFFLVEGLFMRVRDRLNITVDHLEFAEDDLSHYTRLLRTMPRKGRVIYICSSPDAFRTLMLLALEAGLCGEDYVFFHLDIFGQSLQGGQGPAPRRPWERGDGQDVSARQAFQAAKIITYKDPDNPEYLEFLKQLKHLAYEQFNFTMEDGLVNTIPASFHDGLLLYIQAVTETLAHGGTVTDGENITQRMWNRSFQGVTGYLKIDSSGDRETDFSLWDMDPENGAFRVVLNYNGTSQELVAVSGRKLNWPLGYPPPDIPKCGFDNEDPACNQDHLSTLEVLALVGSLSLLGILIVSFFIYRKMQLEKELASELWRVRWEDVEPSSLERHLRSAGSRLTLSGRGSNYGSLLTTEGQFQVFAKTAYYKGNLVAVKRVNRKRIELTRKVLFELKHMRDVQNEHLTRFVGACTDPPNICILTEYCPRGSLQDILENESITLDWMFRYSLTNDIVKGMLFLHNGAICSHGNLKSSNCVVDGRFVLKITDYGLESFRDLDPEQGHTVYAKKLWTAPELLRMASPPVRGSQAGDVYSFGIILQEIALRSGVFHVEGLDLSPKEIIERVTRGEQPPFRPSLALQSHLEELGLLMQRCWAEDPQERPPFQQIRLTLRKFNRENSSNILDNLLSRMEQYANNLEELVEERTQAYLEEKRKAEALLYQILPHSVAEQLKRGETVQAEAFDSVTIYFSDIVGFTALSAESTPMQVVTLLNDLYTCFDAVIDNFDVYKVETIGDAYMVVSGLPVRNGRLHACEVARMALALLDAVRSFRIRHRPQEQLRLRIGIHTGPVCAGVVGLKMPRYCLFGDTVNTASRMESNGEALKIHLSSETKAVLEEFGGFELELRGDVEMKGKGKVRTYWLLGERGSSTRG>sp|O15467|CCL16_HUMAN C-C motif chemokine 16 OS=Homo sapiens OX=9606GN=CCL16 PE=1 SV=1MKVSEAALSLLVLILIITSASRSQPKVPEWVNTPSTCCLKYYEKVLPRRLVVGYRKALNCHLPAIIFVTKRNREVCTNPNDDWVQEYIKDPNLPLLPTRNLSTVKIITAKNGQPQLLNSQ>sp|Q5T440|CAF17_HUMAN Putative transferase CAF17, mitochondrial OS=Homosapiens OX=9606 GN=IBA57 PE=1 SV=1MATAALLRGATPGRGGPVWRWRLRAAPRCRLAHSSCSPGGDPTAGAAWACFRLDGRTLLRVRGPDAAPFLLGLLTNELPLPSPAAAGAPPAARAGYAHFLNVQGRTLYDVILYGLQEHSEVSGFLLECDSSVQGALQKHLALYRIRRKVTVEPHPELRVWAVLPSSPEACGAASLQERAGAAAILIRDPRTARMGWRLLTQDEGPALVPGGRLGDLWDYHQHRYLQGVPEGVRDLPPGVALPLESNLAFMNGVSFTKGCYIGQELTARTHHMGVIRKRLFPVRFLDPLPTSGITPGATVLTASGQTVGKFRAGQGNVGLALLWSEKIKGPLHIRASEGAQVALAASVPDWWPTVSK>sp|Q9UJX3|APC7_HUMAN Anaphase-promoting complex subunit 7 OS=Homosapiens OX=9606 GN=ANAPC7 PE=1 SV=4MDPGDAAILESSLRILYRLFESVLPPLPAALQSRMNVIDHVRDMAAAGLHSNVRLLSSLLLTMSNNNPELFSPPQKYQLLVYHADSLFHDKEYRNAVSKYTMALQQKKALSKTSKVRPSTGNSASTPQSQCLPSEIEVKYKMAECYTMLKQDKDAIAILDGIPSRQRTPKINMMLANLYKKAGQERPSVTSYKEVLRQCPLALDAILGLLSLSVKGAEVASMTMNVIQTVPNLDWLSVWIKAYAFVHTGDNSRAISTICSLEKKSLLRDNVDLLGSLADLYFRAGDNKNSVLKFEQAQMLDPYLIKGMDVYGYLLAREGRLEDVENLGCRLFNISDQHAEPWVVSGCHSFYSKRYSRALYLGAKAIQLNSNSVQALLLKGAALRNMGRVQEAIIHFREAIRLAPCRLDCYEGLIECYLASNSIREAMVMANNVYKTLGANAQTLTLLATVCLEDPVTQEKAKTLLDKALTQRPDYIKAVVKKAELLSREQKYEDGIALLRNALANQSDCVLHRILGDFLVAVNEYQEAMDQYSIALSLDPNDQKSLEGMQKMEKEESPTDATQEEDVDDMEGSGEEGDLEGSDSEAAQWADQEQWFGMQ>sp|Q9UJX3-2|APC7_HUMAN Isoform 2 of Anaphase-promoting complex subunit 7OS=Homo sapiens OX=9606 GN=ANAPC7MDPGDAAILESSLRILYRLFESVLPPLPAALQSRMNVIDHVRDMAAAGLHSNVRLLSSLLLTMSNNNPELFSPPQKYQLLVYHADSLFHDKEYRNAVSKYTMALQQKKALSKTSKVRPSTGNSASTPQSQCLPSEIEVKYKMAECYTMLKQDKDAIAILDGIPSRQRTPKINMMLANLYKKAGQERPSVTSYKEVLRQCPLALDAILGLLSLSVKGAEVASMTMNVIQTVPNLDWLSVWIKAYAFVHTGDNSRAISTICSLEKKSLLRDNVDLLGSLADLYFRAGDNKNSVLKFEQAQMLDPYLIKGMDVYGYLLAREGRLEDVENLGCRLFNISDQHAEPWVVSGCHSFYSKRYSRALYLGAKAIQLNSNSVQALLLKGAALRNMGRVQEAIIHFREAIRLAPCRLDCYEGLIECYLASNSIREAMVMANNVYKTLGANAQTLTLLATVCLEDPVTQEKAKTLLDKALTQRPDYIKAVVKKAELLSREQKYEDGIALLRNALANQSDCVLHRILGDFLVAVNEYQEAMDQYSIALR>sp|A6NKF2|ARI3C_HUMAN AT-rich interactive domain-containing protein 3COS=Homo sapiens OX=9606 GN=ARID3C PE=1 SV=1MEALQKQQAARLAQGVGPLAPACPLLPPQPPLPDHRTLQAPEGALGNVGAEEEEDAEEDEEKREEAGAEEEAAEESRPGAQGPSSPSSQPPGLHPHEWTYEEQFKQLYELDADPKRKEFLDDLFSFMQKRGTPVNRVPIMAKQVLDLYALFRLVTAKGGLVEVINRKVWREVTRGLSLPTTITSAAFTLRTQYMKYLYPYECETRALSSPGELQAAIDSNRREGRRQAYTATPLFGLAGPPPRGAQDPALGPGPAPPATQSSPGPAQGSTSGLPAHACAQLSPSPIKKEESGIPNPCLALPVGLALGPTREKLAPEEPPEKRAVLMGPMDPPRPCMPPSFLPRGKVPLREERLDGPLNLAGSGISSINMALEINGVVYTGVLFARRQPVPASQGPTNPAPPPSTGPPSSILP>sp|Q8J025|APCD1_HUMAN Protein APCDD1 OS=Homo sapiens OX=9606 GN=APCDD1PE=1 SV=1MSWPRRLLLRYLFPALLLHGLGEGSALLHPDSRSHPRSLEKSAWRAFKESQCHHMLKHLHNGARITVQMPPTIEGHWVSTGCEVRSGPEFITRSYRFYHNNTFKAYQFYYGSNRCTNPTYTLIIRGKIRLRQASWIIRGGTEADYQLHNVQVICHTEAVAEKLGQQVNRTCPGFLADGGPWVQDVAYDLWREENGCECTKAVNFAMHELQLIRVEKQYLHHNLDHLVEELFLGDIHTDATQRMFYRPSSYQPPLQNAKNHDHACIACRIIYRSDEHHPPILPPKADLTIGLHGEWVSQRCEVRPEVLFLTRHFIFHDNNNTWEGHYYHYSDPVCKHPTFSIYARGRYSRGVLSSRVMGGTEFVFKVNHMKVTPMDAATASLLNVFNGNECGAEGSWQVGIQQDVTHTNGCVALGIKLPHTEYEIFKMEQDARGRYLLFNGQRPSDGSSPDRPEKRATSYQMPLVQCASSSPRAEDLAEDSGSSLYGRAPGRHTWSLLLAALACLVPLLHWNIRR>sp|Q8NFD2|ANKK1_HUMAN Ankyrin repeat and protein kinase domain-containing protein 1 OS=Homo sapiens OX=9606 GN=ANKK1 PE=1 SV=1MAADPTELRLGSLPVFTRDDFEGDWRLVASGGFSQVFQARHRRWRTEYAIKCAPCLPPDAASSDVNYLIEEAAKMKKIKFQHIVSIYGVCKQPLGIVMEFMANGSLEKVLSTHSLCWKLRFRIIHETSLAMNFLHSIKPPLLHLDLKPGNILLDSNMHVKISDFGLSKWMEQSTRMQYIERSALRGMLSYIPPEMFLESNKAPGPKYDVYSFAIVIWELLTQKKPYSGFNMMMIIIRVAAGMRPSLQPVSDQWPSEAQQMVDLMKRCWDQDPKKRPCFLDITIETDILLSLLQSRVAVPESKALARKVSCKLSLRQPGEVNEDISQELMDSDSGNYLKRALQLSDRKNLVPRDEELCIYENKVTPLHFLVAQGSVEQVRLLLAHEVDVDCQTASGYTPLLIAAQDQQPDLCALLLAHGADANRVDEDGWAPLHFAAQNGDDGTARLLLDHGACVDAQEREGWTPLHLAAQNNFENVARLLVSRQADPNLHEAEGKTPLHVAAYFGHVSLVKLLTSQGAELDAQQRNLRTPLHLAVERGKVRAIQHLLKSGAVPDALDQSGYGPLHTAAARGKYLICKMLLRYGASLELPTHQGWTPLHLAAYKGHLEIIHLLAESHANMGALGAVNWTPLHLAARHGEEAVVSALLQCGADPNAAEQSGWTPLHLAVQRSTFLSVINLLEHHANVHARNKVGWTPAHLAALKGNTAILKVLVEAGAQLDVQDGVSCTPLQLALRSRKQGIMSFLEGKEPSVATLGGSKPGAEMEI>sp|P57796|CABP4_HUMAN Calcium-binding protein 4 OS=Homo sapiens OX=9606GN=CABP4 PE=1 SV=2MTTEQARGQQGPNLAIGRQKPPAGVVTPKSDAEEPPLTRKRSKKERGLRGSRKRTGSSGEQTGPEAPGSSNNPPSTGEGPAGAPPASPGPASSRQSHRHRPDSLHDAAQRTYGPLLNRVFGKDRELGPEELDELQAAFEEFDTDRDGYISHRELGDCMRTLGYMPTEMELLEVSQHIKMRMGGRVDFEEFVELIGPKLREETAHMLGVRELRIAFREFDRDRDGRITVAELREAVPALLGEPLAGPELDEMLREVDLNGDGTVDFDEFVMMLSRH>sp|P57796-2|CABP4_HUMAN Isoform 2 of Calcium-binding protein 4 OS=Homosapiens OX=9606 GN=CABP4MTEPWLALGTSWTLPLQDRELGPEELDELQAAFEEFDTDRDGYISHRELGDCMRTLGYMPTEMELLEVSQHIKMRMGGRVDFEEFVELIGPKLREETAHMLGVRELRIAFREFDRDRDGRITVAELREAVPALLGEPLAGPELDEMLREVDLNGDGTVDFDEFVMMLSRH>sp|Q0P5N6|ARL16_HUMAN ADP-ribosylation factor-like protein 16 OS=Homosapiens OX=9606 GN=ARL16 PE=1 SV=1MRVAGGRALSRGAELRVPGGAKHGMCLLLGATGVGKTLLVKRLQEVSSRDGKGDLGEPPPTRPTVGTNLTDIVAQRKITIRELGGCMGPIWSSYYGNCRSLLFVMDASDPTQLSASCVQLLGLLSAEQLAEASVLILFNKIDLPCYMSTEEMKSLIRLPDIIACAKQNITTAEISAREGTGLAGVLAWLQATHRAND>sp|P0CE67|CC079_HUMAN Putative uncharacterized protein encoded byLINC02877 OS=Homo sapiens OX=9606 GN=LINC02877 PE=5 SV=1MHVCDLQKLVRIQLAFTTFPWMFSCHLLPTPELSSKRNQCLLYKTSGCLTQMPILYGHPATLLKDYILQAILQPGKKIQGGTEIQRGSFANQYQTDASHL>sp|P40616|ARL1_HUMAN ADP-ribosylation factor-like protein 1 OS=Homosapiens OX=9606 GN=ARL1 PE=1 SV=1MGGFFSSIFSSLFGTREMRILILGLDGAGKTTILYRLQVGEVVTTIPTIGFNVETVTYKNLKFQVWDLGGQTSIRPYWRCYYSNTDAVIYVVDSCDRDRIGISKSELVAMLEEEELRKAILVVFANKQDMEQAMTSSEMANSLGLPALKDRKWQIFKTSATKGTGLDEAMEWLVETLKSRQ>sp|P40616-2|ARL1_HUMAN Isoform 2 of ADP-ribosylation factor-like protein1 OS=Homo sapiens OX=9606 GN=ARL1MRILILGLDGAGKTTILYRLQVGEVVTTIPTIGFNVETVTYKNLKFQVWDLGGQTSIRPYWRCYYSNTDAVIYVVDSCDRDRIGISKSELVAMLEEEELRKAILVVFANKQDMEQAMTSSEMANSLGLPALKDRKWQIFKTSATKGTGLDEAMEWLVETLKSRQ>sp|A0A1B0GTC6|CC085_HUMAN Uncharacterized protein C3orf85 OS=Homosapiens OX=9606 GN=C3orf85 PE=3 SV=1MAYKMLQVVLCSTLLIGALGAPFLLEDPANQFLRLKRHVNLQDYWDPDHSSDVWVNTLAKQARETWIALKTTAQYYLDMNTFTFDMSTAQ>sp|P55064|AQP5_HUMAN Aquaporin-5 OS=Homo sapiens OX=9606 GN=AQP5 PE=1SV=1MKKEVCSVAFLKAVFAEFLATLIFVFFGLGSALKWPSALPTILQIALAFGLAIGTLAQALGPVSGGHINPAITLALLVGNQISLLRAFFYVAAQLVGAIAGAGILYGVAPLNARGNLAVNALNNNTTQGQAMVVELILTFQLALCIFASTDSRRTSPVGSPALSIGLSVTLGHLVGIYFTGCSMNPARSFGPAVVMNRFSPAHWVFWVGPIVGAVLAAILYFYLLFPNSLSLSERVAIIKGTYEPDEDWEEQREERKKTMELTTR>sp|Q96BM9|ARL8A_HUMAN ADP-ribosylation factor-like protein 8A OS=Homosapiens OX=9606 GN=ARL8A PE=1 SV=1MIALFNKLLDWFKALFWKEEMELTLVGLQYSGKTTFVNVIASGQFNEDMIPTVGFNMRKITKGNVTIKLWDIGGQPRFRSMWERYCRGVSAIVYMVDAADQEKIEASKNELHNLLDKPQLQGIPVLVLGNKRDLPGALDEKELIEKMNLSAIQDREICCYSISCKEKDNIDITLQWLIQHSKSRRS>sp|P84077|ARF1_HUMAN ADP-ribosylation factor 1 OS=Homo sapiens OX=9606GN=ARF1 PE=1 SV=2MGNIFANLFKGLFGKKEMRILMVGLDAAGKTTILYKLKLGEIVTTIPTIGFNVETVEYKNISFTVWDVGGQDKIRPLWRHYFQNTQGLIFVVDSNDRERVNEAREELMRMLAEDELRDAVLLVFANKQDLPNAMNAAEITDKLGLHSLRHRNWYIQATCATSGDGLYEGLDWLSNQLRNQK>sp|Q6PK04|CC137_HUMAN Coiled-coil domain-containing protein 137 OS=Homosapiens OX=9606 GN=CCDC137 PE=1 SV=1MAGAGRGAAVSRVQAGPGSPRRARGRQQVQPLGKQRPAPWPGLRSKEKKKVNCKPKNQDEQEIPFRLREIMRSRQEMKNPISNKKRKKAAQVTFRKTLEKEAKGEEPDIAVPKFKQRKGESDGAYIHRMQQEAQHVLFLSKNQAIRQPEVQAAPKEKSEQKKAKKAFQKRRLDKVRRKKEEKAADRLEQELLRDTVKFGEVVLQPPELTARPQRSVSKDQPGRRSQMLRMLLSPGGVSQPLTASLARQRIVEEERERAVQAYRALKQRQQQLHGERPHLTSRKKPEPQL>sp|Q6NSX1|CCD70_HUMAN Coiled-coil domain-containing protein 70 OS=Homosapiens OX=9606 GN=CCDC70 PE=1 SV=1MATPPFRLIRKMFSFKVSRWMGLACFRSLAASSPSIRQKKLMHKLQEEKAFREEMKIFREKIEDFREEMWTFRGKIHAFRGQILGFWEEERPFWEEEKTFWKEEKSFWEMEKSFREEEKTFWKKYRTFWKEDKAFWKEDNALWERDRNLLQEDKALWEEEKALWVEERALLEGEKALWEDKTSLWEEENALWEEERAFWMENNGHIAGEQMLEDGPHNANRGQRLLAFSRGRA>sp|O15084|ANR28_HUMAN Serine/threonine-protein phosphatase 6 regulatoryankyrin repeat subunit A OS=Homo sapiens OX=9606 GN=ANKRD28 PE=1 SV=5MAFLKLRDQPSLVQAIFNGDPDEVRALIFKKEDVNFQDNEKRTPLHAAAYLGDAEIIELLILSGARVNAKDSKWLTPLHRAVASCSEEAVQVLLKHSADVNARDKNWQTPLHIAAANKAVKCAEALVPLLSNVNVSDRAGRTALHHAAFSGHGEMVKLLLSRGANINAFDKKDRRAIHWAAYMGHIEVVKLLVSHGAEVTCKDKKSYTPLHAAASSGMISVVKYLLDLGVDMNEPNAYGNTPLHVACYNGQDVVVNELIDCGAIVNQKNEKGFTPLHFAAASTHGALCLELLVGNGADVNMKSKDGKTPLHMTALHGRFSRSQTIIQSGAVIDCEDKNGNTPLHIAARYGHELLINTLITSGADTAKRGIHGMFPLHLAALSGFSDCCRKLLSSGFDIDTPDDFGRTCLHAAAAGGNLECLNLLLNTGADFNKKDKFGRSPLHYAAANCNYQCLFALVGSGASVNDLDERGCTPLHYAATSDTDGKCLEYLLRNDANPGIRDKQGYNAVHYSAAYGHRLCLQLIASETPLDVLMETSGTDMLSDSDNRATISPLHLAAYHGHHQALEVLVQSLLDLDVRNSSGRTPLDLAAFKGHVECVDVLINQGASILVKDYILKRTPIHAAATNGHSECLRLLIGNAEPQNAVDIQDGNGQTPLMLSVLNGHTDCVYSLLNKGANVDAKDKWGRTALHRGAVTGHEECVDALLQHGAKCLLRDSRGRTPIHLSAACGHIGVLGALLQSAASMDANPATADNHGYTALHWACYNGHETCVELLLEQEVFQKTEGNAFSPLHCAVINDNEGAAEMLIDTLGASIVNATDSKGRTPLHAAAFTDHVECLQLLLSHNAQVNSVDSTGKTPLMMAAENGQTNTVEMLVSSASAELTLQDNSKNTALHLACSKGHETSALLILEKITDRNLINATNAALQTPLHVAARNGLTMVVQELLGKGASVLAVDENGYTPALACAPNKDVADCLALILATMMPVSSSSPLSSLTFNAINRYTNTSKTVSFEALPIMRNEPSSYCSFNNIGGEQEYLYTDVDELNDSDSETY>sp|O15084-2|ANR28_HUMAN Isoform 2 of Serine/threonine-proteinphosphatase 6 regulatory ankyrin repeat subunit A OS=Homo sapiens OX=9606GN=ANKRD28MVKLLLSRGANINAFDKKDRRAIHWAAYMGHIEVVKLLVSHGAEVTCKDKKSYTPLHAAASSGMISVVKYLLDLGVDMNEPNAYGNTPLHVACYNGQDVVVNELIDCGAIVNQKNEKGFTPLHFAAASTHGALCLELLVGNGADVNMKSKDGKTPLHMTALHGRFSRSQTIIQSGAVIDCEDKNGNTPLHIAARYGHELLINTLITSGADTAKRGIHGMFPLHLAALSGFSDCCRKLLSSGFDIDTPDDFGRTCLHAAAAGGNLECLNLLLNTGADFNKKDKFGRSPLHYAAANCNYQCLFALVGSGASVNDLDERGCTPLHYAATSDTDGKCLEYLLRNDANPGIRDKQGYNAVHYSAAYGHRLCLQLIASETPLDVLMETSGTDMLSDSDNRATISPLHLAAYHGHHQALEVLVQSLLDLDVRNSSGRTPLDLAAFKGHVECVDVLINQGASILVKDYILKRTPIHAAATNGHSECLRLLIGNAEPQNAVDIQDGNGQTPLMLSVLNGHTDCVYSLLNKGANVDAKDKWGRTALHRGAVTGHEECVDALLQHGAKCLLRDSRGRTPIHLSAACGHIGVLGALLQSAASMDANPATADNHGYTALHWACYNGHETCVELLLEQEVFQKTEGNAFSPLHCAVINDNEGAAEMLIDTLGASIVNATDSKGRTPLHAAAFTDHVECLQLLLSHNAQVNSVDSTGKTPLMMAAENGQTNTVEMLVSSASAELTLQDNSKNTALHLACSKGHETSALLILEKITDRNLINATNAALQTPLHVAARNGLTMVVQELLGKGASVLAVDENGYTPALACAPNKDVADCLALILATMMPVSSSSPLSSLTFNAINRYTNTSKTVSFEALPIMRNEPSSYCSFNNIGGEQEYLYTDVDELNDSDSETY>sp|O15084-1|ANR28_HUMAN Isoform 3 of Serine/threonine-proteinphosphatase 6 regulatory ankyrin repeat subunit A OS=Homo sapiens OX=9606GN=ANKRD28MSRVCIVVLEEVEDESPAFISKLPQENKSLHSPPSGNVLVRYPSLVQAIFNGDPDEVRALIFKKEDVNFQDNEKRTPLHAAAYLGDAEIIELLILSGARVNAKDSKWLTPLHRAVASCSEEAVQVLLKHSADVNARDKNWQTPLHIAAANKAVKCAEALVPLLSNVNVSDRAGRTALHHAAFSGHGEMVKLLLSRGANINAFDKKDRRAIHWAAYMGHIEVVKLLVSHGAEVTCKDKKSYTPLHAAASSGMISVVKYLLDLGVDMNEPNAYGNTPLHVACYNGQDVVVNELIDCGAIVNQKNEKGFTPLHFAAASTHGALCLELLVGNGADVNMKSKDGKTPLHMTALHGRFSRSQTIIQSGAVIDCEDKNGNTPLHIAARYGHELLINTLITSGADTAKRGIHGMFPLHLAALSGFSDCCRKLLSSGFDIDTPDDFGRTCLHAAAAGGNLECLNLLLNTGADFNKKDKFGRSPLHYAAANCNYQCLFALVGSGASVNDLDERGCTPLHYAATSDTDGKCLEYLLRNDANPGIRDKQGYNAVHYSAAYGHRLCLQLIASETPLDVLMETSGTDMLSDSDNRATISPLHLAAYHGHHQALEVLVQSLLDLDVRNSSGRTPLDLAAFKGHVECVDVLINQGASILVKDYILKRTPIHAAATNGHSECLRLLIGNAEPQNAVDIQDGNGQTPLMLSVLNGHTDCVYSLLNKGANVDAKDKWGRTALHRGAVTGHEECVDALLQHGAKCLLRDSRGRTPIHLSAACGHIGVLGALLQSAASMDANPATADNHGYTALHWACYNGHETCVELLLEQEVFQKTEGNAFSPLHCAVINDNEGAAEMLIDTLGASIVNATDSKGRTPLHAAAFTDHVECLQLLLSHNAQVNSVDSTGKTPLMMAAENGQTNTVEMLVSSASAELTLQDNSKNTALHLACSKGHETSALLILEKITDRNLINATNAALQTPLHVAARNGLTMVVQELLGKGASVLAVDENGYTPALACAPNKDVADCLALILATMMPVSSSSPLSSLTFNAINRYTNTSKTVSFEALPIMRNEPSSYCSFNNIGGEQEYLYTDVDELNDSDSETY>sp|O15084-4|ANR28_HUMAN Isoform 4 of Serine/threonine-proteinphosphatase 6 regulatory ankyrin repeat subunit A OS=Homo sapiens OX=9606GN=ANKRD28MSRVCIVVLEEVEDESPAFISKLPQENKSLHSPPSGNVLPSLVQAIFNGDPDEVRALIFKKEDVNFQDNEKRTPLHAAAYLGDAEIIELLILSGARVNAKDSKWLTPLHRAVASCSEEAVQVLLKHSADVNARDKNWQTPLHIAAANKAVKCAEALVPLLSNVNVSDRAGRTALHHAAFSGHGEMVKLLLSRGANINAFDKKDRRAIHWAAYMGHIEVVKLLVSHGAEVTCKDKKSYTPLHAAASSGMISVVKYLLDLGVDMNEPNAYGNTPLHVACYNGQDVVVNELIDCGAIVNQKNEKGFTPLHFAAASTHGALCLELLVGNGADVNMKSKDGKTPLHMTALHGRFSRSQTIIQSGAVIDCEDKNGNTPLHIAARYGHELLINTLITSGADTAKRGIHGMFPLHLAALSGFSDCCRKLLSSGFDIDTPDDFGRTCLHAAAAGGNLECLNLLLNTGADFNKKDKFGRSPLHYAAANCNYQCLFALVGSGASVNDLDERGCTPLHYAATSDTDGKCLEYLLRNDANPGIRDKQGYNAVHYSAAYGHRLCLQLIASETPLDVLMETSGTDMLSDSDNRATISPLHLAAYHGHHQALEVLVQSLLDLDVRNSSGRTPLDLAAFKGHVECVDVLINQGASILVKDYILKRTPIHAAATNGHSECLRLLIGNAEPQNAVDIQDGNGQTPLMLSVLNGHTDCVYSLLNKGANVDAKDKWGRTALHRGAVTGHEECVDALLQHGAKCLLRDSRGRTPIHLSAACGHIGVLGALLQSAASMDANPATADNHGYTALHWACYNGHETCVELLLEQEVFQKTEGNAFSPLHCAVINDNEGAAEMLIDTLGASIVNATDSKGRTPLHAAAFTDHVECLQLLLSHNAQVNSVDSTGKTPLMMAAENGQTNTVEMLVSSASAELTLQDNSKNTALHLACSKGHETSALLILEKITDRNLINATNAALQTPLHVAARNGLTMVVQELLGKGASVLAVDENGYTPALACAPNKDVADCLALILATMMPVSSSSPLSSLTFNAINRYTNTSKTVSFEALPIMRNEPSSYCSFNNIGGEQEYLYTDVDELNDSDSETY>sp|Q8N6D5|ANR29_HUMAN Ankyrin repeat domain-containing protein 29OS=Homo sapiens OX=9606 GN=ANKRD29 PE=1 SV=2MCRMSFKKETPLANAAFWAARRGNLALLKLLLNSGRVDVDCRDSHGTTLLMVAAYAGHIDCVRELVLQGADINLQRESGTTALFFAAQQGHNDVVRFLFGFGASTEFRTKDGGTALLAASQYGHMQVVETLLKHGANIHDQLYDGATALFLAAQGGYLDVIRLLLASGAKVNQPRQDGTAPLWIASQMGHSEVVRVMLLRGADRDAARNDGTTALLKAANKGYNDVIKELLKFSPTLGILKNGTSALHAAVLSGNIKTVALLLEAGADPSLRNKANELPAELTKNERILRLLRSKEGPRKS>sp|Q8N6D5-3|ANR29_HUMAN Isoform 3 of Ankyrin repeat domain-containingprotein 29 OS=Homo sapiens OX=9606 GN=ANKRD29MCRMSFKKETPLANAAFWAARRGNLALLKLLLNSGRVDVDCRDSHGTTLLMVAAYAGHIDCVRELVLQGADINLQRESGTTALFFAAQQGHNDVVRFLFGFGASTEFRTKDGGTALLAASQYGHMQVVETLLKHGANIHDQLYDGATALFLAAQGGYLDVIRLLLASGAKVNQPRQDGTAPLWIASQMGHSEVVRVMLLRGADRDAARNDGTTALLKAANKGYNDVIKELLKFSPTLGILKANELPAELTKNERILRLLRSKEGPRKS>sp|P0DTE7|AMY1B_HUMAN Alpha-amylase 1B OS=Homo sapiens OX=9606 GN=AMY1BPE=1 SV=1MKLFWLLFTIGFCWAQYSSNTQQGRTSIVHLFEWRWVDIALECERYLAPKGFGGVQVSPPNENVAIHNPFRPWWERYQPVSYKLCTRSGNEDEFRNMVTRCNNVGVRIYVDAVINHMCGNAVSAGTSSTCGSYFNPGSRDFPAVPYSGWDFNDGKCKTGSGDIENYNDATQVRDCRLSGLLDLALGKDYVRSKIAEYMNHLIDIGVAGFRIDASKHMWPGDIKAILDKLHNLNSNWFPEGSKPFIYQEVIDLGGEPIKSSDYFGNGRVTEFKYGAKLGTVIRKWNGEKMSYLKNWGEGWGFMPSDRALVFVDNHDNQRGHGAGGASILTFWDARLYKMAVGFMLAHPYGFTRVMSSYRWPRYFENGKDVNDWVGPPNDNGVTKEVTINPDTTCGNDWVCEHRWRQIRNMVNFRNVVDGQPFTNWYDNGSNQVAFGRGNRGFIVFNNDDWTFSLTLQTGLPAGTYCDVISGDKINGNCTGIKIYVSDDGKAHFSISNSAEDPFIAIHAESKL>sp|Q8N7Z5|ANR31_HUMAN Ankyrin repeat domain-containing protein 31OS=Homo sapiens OX=9606 GN=ANKRD31 PE=2 SV=2MEEGVQAPDWDSDETVIEGSVTESDLEEKELPWRRLLFDQDASLKSEFSLHPDTRGMCKGMPSPEIQLGFKLREDLQEQMNKNKMMPVLSEDTILQSQDETERNQALLQTRKNCSMFIGSFRQSGLSLNHQNIEGPEAESPEVLPHIEKELSEGRDSPEVSLLSGTAITVSDTVAVKETSLVEPEKILAAPNTFFEPRKEVTMTMTSEETKDEESSLETFVSALESLLTSPESTQEERLFELVSDFDRKELMNPLSDSLSSISIPLNSWSACHRDLLEDAKDDALPAELLEALNTLSEAKVETICHRKEGGSSLIARNECLEVEFNTSQTNEDCTQIAETLQDPNPSGLQTLAHQNITSCEPLSNKRNSNSVTNSSDQETACVLRRSSRLEKLKVSRDAKYSDHMYKMPEKILPKILGCEDLTNNNSSAQNFRMQDPALMIDGKEKNMHSARFKNGKQIRKNEQFSGKKEKMKVNKISLHSINRRNIFGENLVYKAALHDDADLVHHCIKKGGNVNQPSYAGWTALHEASVGGFYRTASELLKGGADVNIKGLYQITPLHDAVMNGHYKVAELLLLNGADPLFRNDDGKCALDEAKDLCMKRLLERYIPKHQKCLTSAQRSSIDPLDIEDVYQHKKPKFSSKSHIWHVYNENSNRQKLEHVKVNKGSKASLFINKEDVYEYYQKDPKNTKFGKSKHKQSTLDQIYSTGLRKGNLHNVKDPNTNVPKGIGRRKTQHKRTQVDDVDCNPRKILAVSPSRRINRLVTYQQHIPETHNDLPEELCEPSSLTLSSLRNGLDSSTEACSVSKEKHIQNLDLSDSQEVQCLELESVDQTEAVSFPGLLLHKEIKLPVVTTDKQPHTLQEQHHVLYKSHENSNLVPKDERFNKWENSFLSFVKENSDNDDDDDCSTSEKAITSKKVLCSTGGKKHYNFKENLTNKKEMGFQQFLLSEDHLSQENELKAVSLTTLPEQEAVNFSYSDNAVISEHVANYEQCIFGPSFDHSNGNPEQNSLACMRTLLTHEASKLTNHVELFKKPQDYIPRAPTFLMNQTDTHIVEKMAKNCDTERNYIDRDQKIIYSNEPLSIVAHSQVIETTKVEKRRQNHLESETIHNIDSHSTDNMSKELANISKLSQREKKEISHKPGMKAGRINKRNARGESQLHLAVRRGNLPLVKALIESGADVNLNDNAGWTPLHEASNEGSIDIIVELLKAGAKVNCENIDGILPLHDAVANNHLKAAEILLQNGANPNQKDQKQKSALDEADDEKMKELLRSYGAIETVNRDESDAIVNEKIPAVRSKRHKQCFCDDGKTIDSSSLSHQERSRESLSVHQTLSAILQDIEEKQEYLLEFEIRNPEDAEQYIEKMLKIKKIMDNVLAKQKAERDDLAKKYRVSIESFKHGALREQLANLAARQKSLLVVAKKQKKISLKIQNCRNVTSLPCLSLRKLPPRSEISSEKDSQELTSLENLEHPQSGSLSPVSGSMQETQLSLETWNYSQNTNICLNSEAVRRGEFSGNDMNSKQNGSDCTLDGFPKSRHSDGTEKNKLPSQPVAFIGQTEYSQKENDLTEATDKDHEFYVSSPVIGKLNISETASVLAENAAHPSNIICDQDLSNYDPKRGNRKTSSQQSPTGASESLAHQGIAVLGSDTVHQMKPYLKKSVSVVPCADDSQISSSSGSGQQDTIKKALNYSTAPKKKCIQIKDLILLGRINPGNNILEFKTQETTHKASILLNGKLKVESGQIYKNPVTWLKDLLGGNSYVTWNYAWSKVTYLGKELLRYVSEDAPILPEPNSVPQQYQPCLPEVACLDDPVQEPNKSMFEKTKFGQGTSRESMQSSPRYLQINEILLISDQEFLPCHIMDQHWKFCVECEELTP>sp|Q17RM4|CC142_HUMAN Coiled-coil domain-containing protein 142 OS=Homosapiens OX=9606 GN=CCDC142 PE=2 SV=1MAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYEADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGPGETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVASRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQALGQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPADPAPVALGLCTLQTTLLWFLGRAQQYLAAWDPASFLLLIQKDLPPLLHEAEALYSLASEESLALEVEQQLGLEIQKLTAQIQLLPEESLSVFSQECHKQAMQGFKLYMPRGRYWRLRLCPEPPSAPSEYAGLVVRTVLEPVLQGLQGLPPQAQAPALGQALTAIVGAWLDHILTHGIRFSLQGALQLKQDFGVVRELLEEEQWSLSPDLRQTLLMLSIFQQLDGALLCLLQQPLPKSQVHRRPPCCCACQEVQTTKLPSSCLNSLESLEPPLQPGTSPAQTGQLQSTLGGRGPSPEGYLVGNQQAWLALRQHQRPRWHLPFFSCLGTSPES>sp|Q17RM4-2|CC142_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 142 OS=Homo sapiens OX=9606 GN=CCDC142MAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYEADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGPGETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVASRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQALGQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPAGLCTLQTTLLWFLGRAQQYLAAWDPASFLLLIQKDLPPLLHEAEALYSLASEESLALEVEQQLGLEIQKLTAQIQLLPEESLSVFSQECHKQAMQGFKLYMPRGRYWRLRLCPEPPSAPSEYAGLVVRTVLEPVLQGLQGLPPQAQAPALGQALTAIVGAWLDHILTHGIRFSLQGALQLKQDFGVVRELLEEEQWSLSPDLRQTLLMLSIFQQLDGALLCLLQQPLPKSQVHRRPPCCCACQEVQTTKLPSSCLNSLESLEPPLQPGTSPAQTGQLQSTLGGRGPSPEGYLVGNQQAWLALRQHQRPRWHLPFFSCLGTSPES>sp|Q17RM4-3|CC142_HUMAN Isoform 3 of Coiled-coil domain-containingprotein 142 OS=Homo sapiens OX=9606 GN=CCDC142MAQASRSGSLPPLVIVPPLRAQPGGTGEEQWERSRTGGLRWEVHCWPSGTSGGTPWWPTPADVSEDYEADAAAWRRGPAGGGPIPPALQRLRAVLLRLHREREQLLQARDCAYHLQSAVRLMKTLSPGSPSGGPSPLPQWCRDLQLHPSQGAVLRIGPGETLEPLLLARPIGLAAQCLEAVIEMQLRALGREPASPGLSSQLAELLFALPAYHTLQRKALSHVPGAARPFPTSRVLRLLTGERGCQVASRLDEALQGSALRDQLRRRCQEEGDLLPGLLGLVGGVAGSASCGLGLGGAGALWSQYWTLLWAACAQSLDLNLGPWRDPRATAQQLSQALGQASLPQECEKELASLCHRLLHQSLIWSWDQGFCQALGSALGGQSSLPTSSGTAELLQQLFPPLLDALREPRLRRIFCQPADPAPVALGLCTLQTTLLWFLGRAQQYLAAWDPASFLLLIQKDLPPLLHEAEALYSLASEESLALEVEQQLGLEIQKLTAQIQLLPEESLSVFSQECHKQAMQGFKLYMPRGRYWRLRLCPEPPSAPSEYAGLVVRTVLEPVLQGLQGLPPQAQAPALGQALTAIVGAWLDHILTHGIRFSLQGALQLKQDFGVVRELLEEEQWSLSPDLRQTLLMLSIFQQLDGALLCLLQQPLPKSQVHRRPPCC>sp|Q6ZRK6|CCD73_HUMAN Coiled-coil domain-containing protein 73 OS=Homosapiens OX=9606 GN=CCDC73 PE=2 SV=2MESNFNTESSSTFTLQSSSETLFSIQLLDFKTSLLEALEELRMRREAEIHYEEQIGKIIVETQELKWQKETLQNQKETLAEQHKEAMAVFKKQLQMKMCALEEEKGKYQLATEIKEKEIEGLKETLKALQVSKYSLQKKVSEMEQKVQLHLLAKEDYHKQLSEIEKYYATITGQFGLVKENHEKLEQNVREAIQSNKRLSALNKKQEAEICSLKKELKKAASDLIKSKVTCQYKMGEENINLTIKEQKFQELQERLNMELELNEKINEEITHIQEEKQDIIISFQHMQQLLRQQIQANTEMEAELKVLKENNQTLERDNELQREKVKENEEKFLNLQNEHEKALGTWKRHAEELNGEINKIKNELSSLKETHIKLQEHYNKLCNQKTFEEDKKFQNVPEVNNENSEMSTEKSENTIIQKYNTEQEIREENMENFCSDTEYREKEEKKEGSFIEEIIIDDLQLFEKSFKNEIDTVVSQDENQSEISLSKTLSLDKEVISQGQTSNVTDNRKSVTTEIKDKICLEKDNGCTEFKSPNNHFVVLDTAIETEKIHLERTRGLDVHHTDVNLEVENNKTSFNSILNETAHNTYHNNNKDVSENEPFKQFRLLPGTREHALEKEITNSDQTKADLDSSLDIKKNPVPCQKYSLRNSSNVMLDDKQCKIKQIQLLTKKSECSILLSKQTSDFLQVCNDTLEKSELTVPCDIVIDHHVSYAAFSANSKLLLKNSDKNVHSMSMLVKPNSSPGGKTMCKNMSDMQNSQFNNCLGYLENTNVNISHLHLNNENSHASQAKDVKTAVHMKTCTETEFSNKKNQIDENQVTEATKNDLFLFVSINERQHTLLNNTEKTESLNDIVSGKMFSEGQLEESHSFHIEPSGDLVNRSGRSTFDLSTSDKKTEKTPVYMNFSDPGPWSKVNHIESQTASSSTPCISLLLKERPLDPSENKKIISMALCKNIGVDDVGKDIGPDTTSINRVADTLNNWSIHPDPKGEPSEEKNAMAKTFYDSSFPTEHVKTKPLISTPLQSHLQAIKTTKNTSGDDDWQSLITNQLNKSENLLSLENDNQPKKRKAEETLEKNNRLK>sp|Q6ZRK6-2|CCD73_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 73 OS=Homo sapiens OX=9606 GN=CCDC73MESNFNTESSSTFTLQSSSETLFSIQLLDFKTSLLEALEELRMRREAEIHYEEQIGKIIVETQELKWQKETLQNQKETLAEQHKEAMAVFKKQLQMKMCALEEEKGKYQLATEIKEKEIEGLKETLKALQVSKYSLQKKVSEMEQKVQLHLLAKEDYHKQLSEIEKYYATITGQFGLVKENHEKLEQNVREAIQSNKRLSALNKKQEAEICSLKKELKKAASDLIKSKVTCQYKMGEENINLTIKEQKFQELQERLNMELELNEKINEEITHIQEEKQQLLRQQIQANTEMEAELKVLKENNQTLERDNELQREKVKENEEKFLNLQNEHEKALGTWKRHAEELNGEINKIKNELSSLKETHIKLQEHYNKLCNQKTFEEDKKFQNVPEVNNENSEMSTEKSENTIIQKYNTEQEIREENMENFCSDTEYREKEEKKEGSFIEEIIIDGNLKIILIFSNLYVDIYSKYF>sp|P61204|ARF3_HUMAN ADP-ribosylation factor 3 OS=Homo sapiens OX=9606GN=ARF3 PE=1 SV=2MGNIFGNLLKSLIGKKEMRILMVGLDAAGKTTILYKLKLGEIVTTIPTIGFNVETVEYKNISFTVWDVGGQDKIRPLWRHYFQNTQGLIFVVDSNDRERVNEAREELMRMLAEDELRDAVLLVFANKQDLPNAMNAAEITDKLGLHSLRHRNWYIQATCATSGDGLYEGLDWLANQLKNKK>sp|P61204-2|ARF3_HUMAN Isoform 2 of ADP-ribosylation factor 3 OS=Homosapiens OX=9606 GN=ARF3MGNIFGNLLKSLIGKKEMRILMVGLDAAGKTTILYKLKLGEIVTTIPTIGLIFVVDSNDRERVNEAREELMRMLAEDELRDAVLLVFANKQDLPNAMNAAEITDKLGLHSLRHRNWYIQATCATSGDGLYEGLDWLANQLKNKK>sp|Q7Z713|ANR37_HUMAN Ankyrin repeat domain-containing protein 37OS=Homo sapiens OX=9606 GN=ANKRD37 PE=1 SV=1MLLLDCNPEVDGLKHLLETGASVNAPPDPCKQSPVHLAAGSGLACFLLWQLQTGADLNQQDVLGEAPLHKAAKVGSLECLSLLVASDAQIDLCNKNGQTAEDLAWSCGFPDCAKFLTTIKCMQTIKASEHPDRNDCVAVLRQKRSLGSVENTSGKRKC>sp|O94778|AQP8_HUMAN Aquaporin-8 OS=Homo sapiens OX=9606 GN=AQP8 PE=1SV=2MSGEIAMCEPEFGNDKAREPSVGGRWRVSWYERFVQPCLVELLGSALFIFIGCLSVIENGTDTGLLQPALAHGLALGLVIATLGNISGGHFNPAVSLAAMLIGGLNLVMLLPYWVSQLLGGMLGAALAKAVSPEERFWNASGAAFVTVQEQGQVAGALVAEIILTTLLALAVCMGAINEKTKGPLAPFSIGFAVTVDILAGGPVSGGCMNPARAFGPAVVANHWNFHWIYWLGPLLAGLLVGLLIRCFIGDGKTRLILKAR>sp|Q53RE8|ANR39_HUMAN Ankyrin repeat domain-containing protein 39OS=Homo sapiens OX=9606 GN=ANKRD39 PE=1 SV=1MATPRPCADGPCCSHPSAVLGVQQTLEEMDFERGIWSAALNGDLGRVKHLIQKAEDPSQPDSAGYTALHYASRNGHYAVCQFLLESGAKCDAQTHGGATALHRASYCGHTEIARLLLSHGSNPRVVDDDGMTSLHKAAERGHGDICSLLLQHSPALKAIRDRKARLACDLLPCNSDLRDLLSS>sp|O43315|AQP9_HUMAN Aquaporin-9 OS=Homo sapiens OX=9606 GN=AQP9 PE=1SV=2MQPEGAEKGKSFKQRLVLKSSLAKETLSEFLGTFILIVLGCGCVAQAILSRGRFGGVITINVGFSMAVAMAIYVAGGVSGGHINPAVSLAMCLFGRMKWFKLPFYVGAQFLGAFVGAATVFGIYYDGLMSFAGGKLLIVGENATAHIFATYPAPYLSLANAFADQVVATMILLIIVFAIFDSRNLGAPRGLEPIAIGLLIIVIASSLGLNSGCAMNPARDLSPRLFTALAGWGFEVFRAGNNFWWIPVVGPLVGAVIGGLIYVLVIEIHHPEPDSVFKTEQSEDKPEKYELSVIM>sp|Q4G0S7|CC152_HUMAN Coiled-coil domain-containing protein 152 OS=Homosapiens OX=9606 GN=CCDC152 PE=1 SV=3MDQSSEGCMKKISSVNLDKLINDFSQIEKKMVETNGKNNILDIQLEKSNCLLKVMQAKEVSIKEECATLHNIIKGLQQTIEYQQNLKGENEQLKISADLIKEKLKSHEQEYKNNIAKLVSEMKIKEEGYKKEISKLYQDMQRKVELNEEKHKELIEKKEMEISELNAKLRSQEKEKQNEIIKLQLEFDAKLARVQTKSKSYQDSTVLPQSIYRRKLQHFQEEKNKEIAILRNTIRDLEQRLSVGKDSHLKRRRF>sp|Q4G0S7-2|CC152_HUMAN Isoform 2 of Coiled-coil domain-containingprotein 152 OS=Homo sapiens OX=9606 GN=CCDC152MDQSSEGCMKKISSVNLDKLINDFSQIEKKMVETNGKNNILDIQLEKSNCLLKVMQAKEVSIKEECATLHNIIKGLQQTIEYQQNLKVELNEEKHKELIEKKEMEISELNAKLRSQEKEKQNEIIKLQLEFDAKLARVQTKSKSYQDSTVLPQSIYRRKLQHFQEEKNKEIAILRNTIRDLEQRLSVGKDSHLKRRRF>sp|Q96BI3|APH1A_HUMAN Gamma-secretase subunit APH-1A OS=Homo sapiensOX=9606 GN=APH1A PE=1 SV=1MGAAVFFGCTFVAFGPAFALFLITVAGDPLRVIILVAGAFFWLVSLLLASVVWFILVHVTDRSDARLQYGLLIFGAAVSVLLQEVFRFAYYKLLKKADEGLASLSEDGRSPISIRQMAYVSGLSFGIISGVFSVINILADALGPGVVGIHGDSPYYFLTSAFLTAAIILLHTFWGVVFFDACERRRYWALGLVVGSHLLTSGLTFLNPWYEASLLPIYAVTVSMGLWAFITAGGSLRSIQRSLLCRRQEDSRVMVYSALRIPPED>sp|Q96BI3-2|APH1A_HUMAN Isoform 2 of Gamma-secretase subunit APH-1AOS=Homo sapiens OX=9606 GN=APH1AMGAAVFFGCTFVAFGPAFALFLITVAGDPLRVIILVAGAFFWLVSLLLASVVWFILVHVTDRSDARLQYGLLIFGAAVSVLLQEVFRFAYYKLLKKADEGLASLSEDGRSPISIRQMAYVSGLSFGIISGVFSVINILADALGPGVVGIHGDSPYYFLTSAFLTAAIILLHTFWGVVFFDACERRRYWALGLVVGSHLLTSGLTFLNPWYEASLLPIYAVTVSMGLWAFITAGGSLRSIQRSLLCKD>sp|Q96BI3-3|APH1A_HUMAN Isoform 3 of Gamma-secretase subunit APH-1AOS=Homo sapiens OX=9606 GN=APH1AMGAAVFFGCTFVAFGPAFALFLITVAGDPLRVIILVAGRCSALPTTSCLISGLSFGIISGVFSVINILADALGPGVVGIHGDSPYYFLTSAFLTAAIILLHTFWGVVFFDACERRRYWALGLVVGSHLLTSGLTFLNPWYEASLLPIYAVTVSMGLWAFITAGGSLRSIQRSLLCRRQEDSRVMVYSALRIPPED>sp|Q86Z23|C1QL4_HUMAN Complement C1q-like protein 4 OS=Homo sapiensOX=9606 GN=C1QL4 PE=1 SV=1MVLLLLVAIPLLVHSSRGPAHYEMLGRCRMVCDPHGPRGPGPDGAPASVPPFPPGAKGEVGRRGKAGLRGPPGPPGPRGPPGEPGRPGPPGPPGPGPGGVAPAAGYVPRIAFYAGLRRPHEGYEVLRFDDVVTNVGNAYEAASGKFTCPMPGVYFFAYHVLMRGGDGTSMWADLMKNGQVRASAIAQDADQNYDYASNSVILHLDVGDEVFIKLDGGKVHGGNTNKYSTFSGFIIYPD>sp|Q7Z2E3|APTX_HUMAN Aprataxin OS=Homo sapiens OX=9606 GN=APTX PE=1 SV=2MSNVNLSVSDFWRVMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVQLKAECNKGYVKVKQVGVNPTSIDSVVIGKDQEVKLQPGQVLHMVNELYPYIVEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-2|APTX_HUMAN Isoform 2 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-3|APTX_HUMAN Isoform 3 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMSNVNLSVSDFWRVMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVQLKAECNKGYVKVKQVGVNPTSIDSVVIGKDQEVKLQPGQVLHMESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-4|APTX_HUMAN Isoform 4 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMVNELYPYIVEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-5|APTX_HUMAN Isoform 5 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-6|APTX_HUMAN Isoform 6 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQE>sp|Q7Z2E3-7|APTX_HUMAN Isoform 7 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVQLKAECNKGYVKVKQVGVNPTSIDSVVIGKDQEVKLQPGQVLHMVNELYPYIVEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-8|APTX_HUMAN Isoform 8 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMSNVNLSVSDFWRVMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVQLKAECNKGYVKVKQVGVNPTSIDSVVIGKDQEVKLQPGQVLHMVNELYPYIVEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-9|APTX_HUMAN Isoform 9 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVQLKAECNKGYVKVKQVGVNPTSIDSVVIGKDQEVKLQPGQVLHMVNELYPYIVEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQE>sp|Q7Z2E3-10|APTX_HUMAN Isoform 10 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMSNVNLSVSDFWRVMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQAVIEMVQEAGRVTVRDGMPELLKLPLRCHECQQLLPSIPQLKEHLRKHWTQ>sp|Q7Z2E3-11|APTX_HUMAN Isoform 11 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMSNVNLSVSDFWRVMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVQLKAECNKGYVKVKQVGVNPTSIDSVVIGKDQEVKLQPGQVLHMVNELYPYIVEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQVYKDEQVVVIKDKYPKARYHWLVLPWTSISSLKAVAREHLELLKHMHTVGEKVIVDFAGSSKLRFRLGYHAIPSMSHVHLHVISQDFDSPCLKNKKHWNSFNTEYFLESQE>sp|Q7Z2E3-12|APTX_HUMAN Isoform 12 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVESRV>sp|Q7Z2E3-13|APTX_HUMAN Isoform 13 of Aprataxin OS=Homo sapiens OX=9606GN=APTXMMRVCWLVRQDSRHQRIRLPHLEAVVIGRGPETKITDKKCSRQQVQLKAECNKGYVKVKQVGVNPTSIDSVVIGKDQEVKLQPGQVLHMVNELYPYIVEFEEEAKNPGLETHRKRKRSGNSDSIERDAAQEAEAGTGLEPGSNSGQCSVPLKKGKDAPIKKESLGHWSQGLKISMQDPKMQPCTSSCDQPGF>sp|Q9NVM4|ANM7_HUMAN Protein arginine N-methyltransferase 7 OS=Homosapiens OX=9606 GN=PRMT7 PE=1 SV=1MKIFCSRANPTTGSVEWLEEDEHYDYHQEIARSSYADMLHDKDRNVKYYQGIRAAVSRVKDRGQKALVLDIGTGTGLLSMMAVTAGADFCYAIEVFKPMADAAVKIVEKNGFSDKIKVINKHSTEVTVGPEGDMPCRANILVTELFDTELIGEGALPSYEHAHRHLVEENCEAVPHRATVYAQLVESGRMWSWNKLFPIHVQTSLGEQVIVPPVDVESCPGAPSVCDIQLNQVSPADFTVLSDVLPMFSIDFSKQVSSSAACHSRRFEPLTSGRAQVVLSWWDIEMDPEGKIKCTMAPFWAHSDPEEMQWRDHWMQCVYFLPQEEPVVQGSALYLVAHHDDYCVWYSLQRTSPEKNERVRQMRPVCDCQAHLLWNRPRFGEINDQDRTDRYVQALRTVLKPDSVCLCVSDGSLLSVLAHHLGVEQVFTVESSAASHKLLRKIFKANHLEDKINIIEKRPELLTNEDLQGRKVSLLLGEPFFTTSLLPWHNLYFWYVRTAVDQHLGPGAMVMPQAASLHAVVVEFRDLWRIRSPCGDCEGFDVHIMDDMIKRALDFRESREAEPHPLWEYPCRSLSEPWQILTFDFQQPVPLQPLCAEGTVELRRPGQSHAAVLWMEYHLTPECTLSTGLLEPADPEGGCCWNPHCKQAVYFFSPAPDPRALLGGPRTVSYAVEFHPDTGDIIMEFRHADTPD>sp|Q9NVM4-2|ANM7_HUMAN Isoform 2 of Protein arginine N-methyltransferase7 OS=Homo sapiens OX=9606 GN=PRMT7MKIFCSRANPTTGSVEWLEEDEHYDYHQEIARSSYADMLHDKDRNVKYYQGIRAAVSRVKDRGQKALVLDIGTGTGLLSMMAVTAGADFCYAIEENCEAVPHRATVYAQLVESGRMWSWNKLFPIHVQTSLGEQVIVPPVDVESCPGAPSVCDIQLNQVSPADFTVLSDVLPMFSIDFSKQVSSSAACHSRRFEPLTSGRAQVVLSWWDIEMDPEGKIKCTMAPFWAHSDPEEMQWRDHWMQCVYFLPQEEPVVQGSALYLVAHHDDYCVWYSLQRTSPEKNERVRQMRPVCDCQAHLLWNRPRFGEINDQDRTDRYVQALRTVSLLLGEPFFTTSLLPWHNLYFWYVRTAVDQHLGPGAMVMPQAASLHAVVVEFRDLWRIRSPCGDCEGFDVHIMDDMIKRALDFRESREAEPHPLWEYPCRSLSEPWQILTFDFQQPVPLQPLCAEGTVELRRPGQSHAAVLWMEYHLTPECTLSTGLLEPADPEGGCCWNPHCKQAVYFFSPAPDPRALLGGPRTVSYAVEFHPDTGDIIMEFRHADTPD>sp|Q9NVM4-3|ANM7_HUMAN Isoform 3 of Protein arginine N-methyltransferase7 OS=Homo sapiens OX=9606 GN=PRMT7MKIFCSRANPTTGSVEWLEEDEHYDYHQEIARSSYADMLHDKDRVFKPMADAAVKIVEKNGFSDKIKVINKHSTEVTVGPEGDMPCRANILVTELFDTELIGEGALPSYEHAHRHLVEENCEAVPHRATVYAQLVESGRMWSWNKLFPIHVQTSLGEQVIVPPVDVESCPGAPSVCDIQLNQVSPADFTVLSDVLPMFSIDFSKQVSSSAACHSRRFEPLTSGRAQVVLSWWDIEMDPEGKIKCTMAPFWAHSDPEEMQWRDHWMQCVYFLPQEEPVVQGSALYLVAHHDDYCVWYSLQRTSPEKNERVRQMRPVCDCQAHLLWNRPRFGEINDQDRTDRYVQALRTVLKPDSVCLCVSDGSLLSVLAHHLGVEQVFTVESSAASHKLLRKIFKANHLEDKINIIEKRPELLTNEDLQGRKVSLLLGEPFFTTSLLPWHNLYFWYVRTAVDQHLGPGAMVMPQAASLHAVVVEFRDLWRIRSPCGDCEGFDVHIMDDMIKRALDFRESREAEPHPLWEYPCRSLSEPWQILTFDFQQPVPLQPLCAEGTVELRRPGQSHAAVLWMEYHLTPECTLSTGLLEPADPEGGCCWNPHCKQAVYFFSPAPDPRALLGGPRTVSYAVEFHPDTGDIIMEFRHADTPD>sp|Q9NVM4-4|ANM7_HUMAN Isoform 4 of Protein arginine N-methyltransferase7 OS=Homo sapiens OX=9606 GN=PRMT7MKIFCSRANPTTGSVEWLEEDEHYDYHQEIARSSYADMLHDKDRNVKYYQGIRAAVSRVKDRGQKALVLDIGTGTGLLSMMAVTAGADFCYAIEVFKPMADAAVKIVEKNGFSDKIKVINKHSTEVTVGPEGDMPCRANILVTELFDTELIGEGALPSYEHAHRHLVEENCEAVPHRATVYAQLVESGRMWSWNKLFPIHVQTSLGEQVIVPPVDVESCPGAPSVCDIQLNQVSPADFTVLSDVLPMFSIDFSKQVSSSAACHSRRFEPLTSGRAQVVLSWWDIEMDPEGKIKCTMAPFWAHSDPEEMQWRDHWMQCVYFLPQEEPVVQGSALYLVAHHDDYCVWYSLQRTSPEKNERVRQMRPVCDCQAHLLWNRPRFGEINDQDRTDRYVQALRTVLKPDSVCLCVSDGSLLSVLAHHLGVEQVFTVESSAASHKLLRKIFKANHLEDKINIIEKRPELLTNEDLQGRKVSLLLGEPFFTTSLLPWHNLYFWYVRTAVDQHLGPGAMVMPQAASLHAVVVEFRVCREQQDVPLVLAATLPCVLAGGCGWGCSFLTGPVADPEPLW>sp|A1IGU5|ARH37_HUMAN Rho guanine nucleotide exchange factor 37 OS=Homosapiens OX=9606 GN=ARHGEF37 PE=2 SV=2MAKHGADEPSSRSGSPDREGRASEDRSLLHQRLAVRELIDTEVSYLHMLQLCASDIRSRLQQLPQGDLDVLFSNIDDIIKVNSRFLHDLQETASKEEEQVQLVGNIFLEFQEELEQVYKVYCASYDQALLLVDTYRKEPELQRHIQGIVEAVVPQAGSSGLSFLLVIPLQRITRYPLLLQKILENTVPDASAYPVLQRAVSALQDVNTNINEYKMRKEVASKYTKVEQLTLRERLARINTHTLSKKTTRLSQLLKQEAGLIPRTEDKEFDDLEERFQWVSLCVTELKNNVAAYLDNLQAFLYFRPHEYNLDIPEGPAVQYCNLARDLHLEAFLKFKQRLEGLVWQPLCSLAKALLGPQNLIKKRLDKLLDFERVEEKLLEVGSVTYQEEAARHTYQALNSLLVAELPQFNQLVMQWLGQIMCTFVTLQRDLAKQVLQRAEGSMAQLPHHHVPEPAFRKLVEDALGRTSNQLRSFQETFEKVQPPPTTQPLLPGSERQVQALLSRYGPGKLYQVTSNISGTGTLDLTLPRGQIVAILQNKDTKGNSGRWLVDTGGHRGYVPAGKLQLYHVVPSAEELRRQAGLNKDPRCLTPEPSPALVPSIPTMNQVIAAYPFVARSSHEVSLQAGQPVTILEAQDKKGNPEWSLVEVNGQRGYVPSGFLARARSPVLWGWSLPS>sp|O95684|CEP43_HUMAN Centrosomal protein 43 OS=Homo sapiens OX=9606GN=CEP43 PE=1 SV=1MAATAAAVVAEEDTELRDLLVQTLENSGVLNRIKAELRAAVFLALEEQEKVENKTPLVNESLKKFLNTKDGRLVASLVAEFLQFFNLDFTLAVFQPETSTLQGLEGRENLARDLGIIEAEGTVGGPLLLEVIRRCQQKEKGPTTGEGALDLSDVHSPPKSPEGKTSAQTTPSKIPRYKGQGKKKTSGQKAGDKKANDEANQSDTSVSLSEPKSKSSLHLLSHETKIGSFLSNRTLDGKDKAGLCPDEDDMEGDSFFDDPIPKPEKTYGLRKEPRKQAGSLASLSDAPPLKSGLSSLAGAPSLKDSESKRGNTVLKDLKLISDKIGSLGLGTGEDDDYVDDFNSTSHRSEKSEISIGEEIEEDLSVEIDDINTSDKLDDLTQDLTVSQLSDVADYLEDVA>sp|O95684-2|CEP43_HUMAN Isoform 2 of Centrosomal protein 43 OS=Homosapiens OX=9606 GN=CEP43MAATAAAVVAEEDTELRDLLVQTLENSGVLNRIKAELRAAVFLALEEQEKVENKTPLVNESLKKFLNTKDGRLVASLVAEFLQFFNLDFTLAVFQPETSTLQGLEGRENLARDLGIIEAEGTVGGPLLLEVIRRCQQKEKGPTTGEGALDLSDVHSPPKSPEGKTSAQTTPSKKANDEANQSDTSVSLSEPKSKSSLHLLSHETKIGSFLSNRTLDGKDKAGLCPDEDDMEGDSFFDDPIPKPEKTYGLRKEPRKQAGSLASLSDAPPLKSGLSSLAGAPSLKDSESKRGNTVLKDLKLISDKIGSLGLGTGEDDDYVDDFNSTSHRSEKSEISIGEEIEEDLSVEIDDINTSDKLDDLTQDLTVSQLSDVADYLEDVA>sp|O95684-3|CEP43_HUMAN Isoform 3 of Centrosomal protein 43 OS=Homosapiens OX=9606 GN=CEP43MEGDSFFDDPIPKPEKTYGLRKEPRKQAGSLASLSDAPPLKSGLSSLAGAPSLKDSESKRGNTVLKDLKLISDKIGSLGLGTGEDDDYVDDFNSTSHRSEKSEISIGEEIEEDLSVEIDDINTSDKTITQLECLLSIGALHFKNTADIF>sp|Q9Y2Y0|AR2BP_HUMAN ADP-ribosylation factor-like protein 2-bindingprotein OS=Homo sapiens OX=9606 GN=ARL2BP PE=1 SV=1MDALEGESFALSFSSASDAEFDAVVGYLEDIIMDDEFQLLQRNFMDKYYLEFEDTEENKLIYTPIFNEYISLVEKYIEEQLLQRIPEFNMAAFTTTLQHHKDEVAGDIFDMLLTFTDFLAFKEMFLDYRAEKEGRGLDLSSGLVVTSLCKSSSLPASQNNLRH>sp|Q9Y2Y0-2|AR2BP_HUMAN Isoform 2 of ADP-ribosylation factor-likeprotein 2-binding protein OS=Homo sapiens OX=9606 GN=ARL2BPMRSSASDAEFDAVVGYLEDIIMDDEFQLLQRNFMDKYYLEFEDTEENKLIYTPIFNEYISLVEKYIEEQLLQRIPEFNMAAFTTTLQHHKDEVAGDIFDMLLTFTDFLAFKEMFLDYRAEKEGRGLDLSSGLVVTSLCKSSSLPASQNNLRH>sp|Q92754|AP2C_HUMAN Transcription factor AP-2 gamma OS=Homo sapiensOX=9606 GN=TFAP2C PE=1 SV=1MLWKITDNVKYEEDCEDRHDGSSNGNPRVPHLSSAGQHLYSPAPPLSHTGVAEYQPPPYFPPPYQQLAYSQSADPYSHLGEAYAAAINPLHQPAPTGSQQQAWPGRQSQEGAGLPSHHGRPAGLLPHLSGLEAGAVSARRDAYRRSDLLLPHAHALDAAGLAENLGLHDMPHQMDEVQNVDDQHLLLHDQTVIRKGPISMTKNPLNLPCQKELVGAVMNPTEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAAHVTLLTSLVEGEAVHLARDFAYVCEAEFPSKPVAEYLTRPHLGGRNEMAARKNMLLAAQQLCKEFTELLSQDRTPHGTSRLAPVLETNIQNCLSHFSLITHGFGSQAICAAVSALQNYIKEALIVIDKSYMNPGDQSPADSNKTLEKMEKHRK>sp|Q92754-2|AP2C_HUMAN Isoform 2 of Transcription factor AP-2 gammaOS=Homo sapiens OX=9606 GN=TFAP2CMPHQMDEVQNVDDQHLLLHDQTVIRKGPISMTKNPLNLPCQKELVGAVMNPTEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAAHVTLLTSLVEGEAVHLARDFAYVCEAEFPSKPVAEYLTRPHLGGRNEMAARKNMLLAAQQLCKEFTELLSQDRTPHGTSRLAPVLETNIQNCLSHFSLITHGFGSQAICAAVSALQNYIKEALIVIDKSYMNPGDQSPADSNKTLEKMEKHRK>sp|P19801|AOC1_HUMAN Amiloride-sensitive amine oxidase [copper-containing] OS=Homo sapiens OX=9606 GN=AOC1 PE=1 SV=4MPALGWAVAAILMLQTAMAEPSPGTLPRKAGVFSDLSNQELKAVHSFLWSKKELRLQPSSTTTMAKNTVFLIEMLLPKKYHVLRFLDKGERHPVREARAVIFFGDQEHPNVTEFAVGPLPGPCYMRALSPRPGYQSSWASRPISTAEYALLYHTLQEATKPLHQFFLNTTGFSFQDCHDRCLAFTDVAPRGVASGQRRSWLIIQRYVEGYFLHPTGLELLVDHGSTDAGHWAVEQVWYNGKFYGSPEELARKYADGEVDVVVLEDPLPGGKGHDSTEEPPLFSSHKPRGDFPSPIHVSGPRLVQPHGPRFRLEGNAVLYGGWSFAFRLRSSSGLQVLNVHFGGERIAYEVSVQEAVALYGGHTPAGMQTKYLDVGWGLGSVTHELAPGIDCPETATFLDTFHYYDADDPVHYPRALCLFEMPTGVPLRRHFNSNFKGGFNFYAGLKGQVLVLRTTSTVYNYDYIWDFIFYPNGVMEAKMHATGYVHATFYTPEGLRHGTRLHTHLIGNIHTHLVHYRVDLDVAGTKNSFQTLQMKLENITNPWSPRHRVVQPTLEQTQYSWERQAAFRFKRKLPKYLLFTSPQENPWGHKRTYRLQIHSMADQVLPPGWQEEQAITWARYPLAVTKYRESELCSSSIYHQNDPWHPPVVFEQFLHNNENIENEDLVAWVTVGFLHIPHSEDIPNTATPGNSVGFLLRPFNFFPEDPSLASRDTVIVWPRDNGPNYVQRWIPEDRDCSMPPPFSYNGTYRPV>sp|P19801-2|AOC1_HUMAN Isoform 2 of Amiloride-sensitive amine oxidase[copper-containing] OS=Homo sapiens OX=9606 GN=AOC1MPALGWAVAAILMLQTAMAEPSPGTLPRKAGVFSDLSNQELKAVHSFLWSKKELRLQPSSTTTMAKNTVFLIEMLLPKKYHVLRFLDKGERHPVREARAVIFFGDQEHPNVTEFAVGPLPGPCYMRALSPRPGYQSSWASRPISTAEYALLYHTLQEATKPLHQFFLNTTGFSFQDCHDRCLAFTDVAPRGVASGQRRSWLIIQRYVEGYFLHPTGLELLVDHGSTDAGHWAVEQVWYNGKFYGSPEELARKYADGEVDVVVLEDPLPGGKGHDSTEEPPLFSSHKPRGDFPSPIHVSGPRLVQPHGPRFRLEGNAVLYGGWSFAFRLRSSSGLQVLNVHFGGERIAYEVSVQEAVALYGGHTPAGMQTKYLDVGWGLGSVTHELAPGIDCPETATFLDTFHYYDADDPVHYPRALCLFEMPTGVPLRRHFNSNFKGGFNFYAGLKGQVLVLRTTSTVYNYDYIWDFIFYPNGVMEAKMHATGYVHATFYTPEGLRHGTRLHTHLIGNIHTHLVHYRVDLDVAGTKNSFQTLQMKLENITNPWSPRHRVVQPTLEQTQYSWERQAAFRFKRKLPKYLLFTSPQENPWGHKRTYRLQIHSMADQVLPPGWQEEQAITWARTEGGQPRALSQAASPVPGRYPLAVTKYRESELCSSSIYHQNDPWHPPVVFEQFLHNNENIENEDLVAWVTVGFLHIPHSEDIPNTATPGNSVGFLLRPFNFFPEDPSLASRDTVIVWPRDNGPNYVQRWIPEDRDCSMPPPFSYNGTYRPV>sp|P04746|AMYP_HUMAN Pancreatic alpha-amylase OS=Homo sapiens OX=9606GN=AMY2A PE=1 SV=2MKFFLLLFTIGFCWAQYSPNTQQGRTSIVHLFEWRWVDIALECERYLAPKGFGGVQVSPPNENVAIYNPFRPWWERYQPVSYKLCTRSGNEDEFRNMVTRCNNVGVRIYVDAVINHMCGNAVSAGTSSTCGSYFNPGSRDFPAVPYSGWDFNDGKCKTGSGDIENYNDATQVRDCRLTGLLDLALEKDYVRSKIAEYMNHLIDIGVAGFRLDASKHMWPGDIKAILDKLHNLNSNWFPAGSKPFIYQEVIDLGGEPIKSSDYFGNGRVTEFKYGAKLGTVIRKWNGEKMSYLKNWGEGWGFVPSDRALVFVDNHDNQRGHGAGGASILTFWDARLYKMAVGFMLAHPYGFTRVMSSYRWPRQFQNGNDVNDWVGPPNNNGVIKEVTINPDTTCGNDWVCEHRWRQIRNMVIFRNVVDGQPFTNWYDNGSNQVAFGRGNRGFIVFNNDDWSFSLTLQTGLPAGTYCDVISGDKINGNCTGIKIYVSDDGKAHFSISNSAEDPFIAIHAESKL>sp|P04746-2|AMYP_HUMAN Isoform 2 of Pancreatic alpha-amylase OS=Homosapiens OX=9606 GN=AMY2AMKFFLLLFTIGFCWAQYSPNTQQGRTSIVHLFEWRWVDIALECERYLAPKGFGGVQVSPPNENVAIYNPFRPWWERYQPVSYKLCTRSGNEDEFRNMVTRCNNVGVRIYVDAVINHMCGNAVSAGTSSTCGSYFNPGSRDFPAVPYSGWDFNDGKCKTGSGDIENYNDATQVRDCRLTGLLDLALEKDYVRSKIAEYMNHLIDIGVAGFRLDASKHMWPGDIKAILDKLHNLNSNWFPAGSKPFIYQEVHQYLYAYKISSYSLEN>sp|Q6ZMG9|CERS6_HUMAN Ceramide synthase 6 OS=Homo sapiens OX=9606GN=CERS6 PE=1 SV=1MAGILAWFWNERFWLPHNVTWADLKNTEEATFPQAEDLYLAFPLAFCIFMVRLIFERFVAKPCAIALNIQANGPQIAPPNAILEKVFTAITKHPDEKRLEGLSKQLDWDVRSIQRWFRQRRNQEKPSTLTRFCESMWRFSFYLYVFTYGVRFLKKTPWLWNTRHCWYNYPYQPLTTDLHYYYILELSFYWSLMFSQFTDIKRKDFGIMFLHHLVSIFLITFSYVNNMARVGTLVLCLHDSADALLEAAKMANYAKFQKMCDLLFVMFAVVFITTRLGIFPLWVLNTTLFESWEIVGPYPSWWVFNLLLLLVQGLNCFWSYLIVKIACKAVSRGKVSKDDRSDIESSSDEEDSEPPGKNPHTATTTNGTSGTNGYLLTGSCSMDD>sp|Q6ZMG9-2|CERS6_HUMAN Isoform 2 of Ceramide synthase 6 OS=Homo sapiensOX=9606 GN=CERS6MAGILAWFWNERFWLPHNVTWADLKNTEEATFPQAEDLYLAFPLAFCIFMVRLIFERFVAKPCAIALNIQANGPQIAPPNAILEKVFTAITKHPDEKRLEGLSKQLDWDVRSIQRWFRQRRNQEKPSTLTRFCESMWRFSFYLYVFTYGVRFLKKTPWLWNTRHCWYNYPYQPLTTDLHYYYILELSFYWSLMFSQFTDIKRKDFGIMFLHHLVSIFLITFSYVNNMARVGTLVLCLHDSADALLEAAKMANYAKFQKMCDLLFVMFAVVFITTRLGIFPLWVLNTTLFESWEIVGPYPSWWVFNLLLLLVQGLNCFWSYLIVKIACKAVSRGKAGKWNPLHVSKDDRSDIESSSDEEDSEPPGKNPHTATTTNGTSGTNGYLLTGSCSMDD>sp|P53677|AP3M2_HUMAN AP-3 complex subunit mu-2 OS=Homo sapiens OX=9606GN=AP3M2 PE=1 SV=1MIHSLFLINSSGDIFLEKHWKSVVSRSVCDYFFEAQERATEAENVPPVIPTPHHYLLSVYRHKIFFVAVIQTEVPPLFVIEFLHRVVDTFQDYFGVCSEPVIKDNVVVVYEVLEEMLDNGFPLATESNILKELIKPPTILRTVVNTITGSTNVGDQLPTGQLSVVPWRRTGVKYTNNEAYFDVIEEIDAIIDKSGSTITAEIQGVIDACVKLTGMPDLTLSFMNPRLLDDVSFHPCVRFKRWESERILSFIPPDGNFRLLSYHVSAQNLVAIPVYVKHNISFRDSSSLGRFEITVGPKQTMGKTIEGVTVTSQMPKGVLNMSLTPSQGTHTFDPVTKMLSWDVGKINPQKLPSLKGTMSLQAGASKPDENPTINLQFKIQQLAISGLKVNRLDMYGEKYKPFKGIKYMTKAGKFQVRT>sp|P53677-2|AP3M2_HUMAN Isoform 2 of AP-3 complex subunit mu-2 OS=Homosapiens OX=9606 GN=AP3M2MIHSLFLINSSGDIFLEKHWKSVVSRSVCDYFFEAQERATEAENVPPVIPTPHHYLLSVYRHKIFFVAVIQTEVPPLFVIEFLHRVVDTFQDYFGVCSEPVIKDNVVVVYEVLEEMLDNGFPLATESNILKELIKPPTILRTVVNTITGSTNVGDQLPTGQLSVVPWRRTGVKYTNNEAYFDVIEEIDAIIDKSGSTITAEIQGVIDACVKLTGMPDLTLSFMNPRLLDDVSFHPCVRFKRWESERILSFIPPDGNFRLLSYHVSAQKCCLGM>sp|Q96N21|AP4AT_HUMAN AP-4 complex accessory subunit Tepsin OS=Homosapiens OX=9606 GN=TEPSIN PE=1 SV=1MAAAPPLRDRLSFLHRLPILLKGTSDDDVPCPGYLFEEIAKISHESPGSSQCLLEYLLSRLHSSSGHGKLKVLKILLYLCSHGSSFFLLILKRNSAFIQEAAAFAGPPDPLHGNSLYQKVRAAAQDLGSTLFSDTVLPLAPSQPLGTPPATGMGSQARPHSTLQGFGYSKEHGRTAVRHQPGQAGGGWDELDSGPSSQNSSQNSDLSRVSDSGSHSGSDSHSGASREPGDLAERVEVVALSDCQQELSLVRTVTRGPRAFLSREEAQHFIKACGLLNCEAVLQLLTCHLRGTSECTQLRALCAIASLGSSDLLPQEHILLRTRPWLQELSMGSPGPVTNKATKILRHFEASCGQLSPARGTSAEPGPTAALPGPSDLLTDAVPLPGSQVFLQPLSSTPVSSRSPAPSSGMPSSPVPTPPPDASPIPAPGDPSEAEARLAESRRWRPERIPGGTDSPKRGPSSCAWSRDSLFAGMELVACPRLVGAGAAAGESCPDAPRAPQTSSQRTAAKEPPGSEPSAFAFLNA>sp|Q96N21-2|AP4AT_HUMAN Isoform 2 of AP-4 complex accessory subunitTepsin OS=Homo sapiens OX=9606 GN=TEPSINMGSQARPHSTLQGFGYSKEHGRTGSAGEAFLSTIQKAAEVVASAMRPGPESPSTRRLLPRGDTYQPAMMPSASHGPPTLGNLLPGAIPGPRAVRHQPGQAGGGWDELDSGPSSQNSSQNSDLSRVSDSGSHSGSDSHSGASREPGDLAERVEVVALSDCQQELSLVRTVTRGPRAFLSREEAQHFIKACGLLNCEAVLQLLTCHLRGTSECTQLRALCAIASLGSSDLLPQEHILLRTRPWLQELSMGSPGPVTNKATKILRHFEASCGQLSPARGTSAEPGPTAALPGPSDLLTDAVPLPGSQVFLQPLSSTPVSSRSPAPSSGMPSSPVPTPPPDASPIPAPGDPSEAEARLAESRRWRPERIPGGTDSPKRGPSSCAWSRDSLFAGMELVACPRLVGAGAAAGESCPDAPRAPQTSSQRTAAKEPPGSEPSAFAFLNA>sp|Q8N6S4|AN13C_HUMAN Ankyrin repeat domain-containing protein 13COS=Homo sapiens OX=9606 GN=ANKRD13C PE=1 SV=2MTGEKIRSLRRDHKPSKEEGDLLEPGDEEAAAALGGTFTRSRIGKGGKACHKIFSNHHHRLQLKAAPASSNPPGAPALPLHNSSVTANSQSPALLAGTNPVAVVADGGSCPAHYPVHECVFKGDVRRLSSLIRTHNIGQKDNHGNTPLHLAVMLGNKECAHLLLAHNAPVKVKNAQGWSPLAEAISYGDRQMITALLRKLKQQSRESVEEKRPRLLKALKELGDFYLELHWDFQSWVPLLSRILPSDACKIYKQGINIRLDTTLIDFTDMKCQRGDLSFIFNGDAAPSESFVVLDNEQKVYQRIHHEESEMETEEEVDILMSSDIYSATLSTKSISFTRAQTGWLFREDKTERVGNFLADFYLVNGLVLESRKRREHLSEEDILRNKAIMESLSKGGNIMEQNFEPIRRQSLTPPPQNTITWEEYISAENGKAPHLGRELVCKESKKTFKATIAMSQEFPLGIELLLNVLEVVAPFKHFNKLREFVQMKLPPGFPVKLDIPVFPTITATVTFQEFRYDEFDGSIFTIPDDYKEDPSRFPDL>sp|Q8N6S4-2|AN13C_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 13C OS=Homo sapiens OX=9606 GN=ANKRD13CMTGEKIRSLRRDHKPSKEEGDLLEPGDEEAAAALGGTFTRSRIGKGGKACHKIFSNHHHRLQLKAAPASSNPPGAPALPLHNSSVTANSQSPALLAGTNPVAVVADGGSCPAHYPVHECVFKGDVRRLSSLIRTHNIGQKDNHGNTPLHLAVMLGNKVTALLRKLKQQSRESVEEKRPRLLKALKELGDFYLELHWDFQSWVPLLSRILPSDACKIYKQGINIRLDTTLIDFTDMKCQRGDLSFIFNGDAAPSESFVVLDNEQKVYQRIHHEESEMETEEEVDILMSSDIYSATLSTKSISFTRAQTGWLFREDKTERVGNFLADFYLVNGLVLESRKRREHLSEEDILRNKAIMESLSKGGNIMEQNFEPIRRQSLTPPPQNTITWEEYISAENGKAPHLGRELVCKESKKTFKATIAMSQEFPLGIELLLNVLEVVAPFKHFNKLREFVQMKLPPGFPVKLDIPVFPTITATVTFQEFRYDEFDGSIFTIPDDYKEDPSRFPDL>sp|Q8N6S4-3|AN13C_HUMAN Isoform 3 of Ankyrin repeat domain-containingprotein 13C OS=Homo sapiens OX=9606 GN=ANKRD13CMTGEKIRSLRRDHKPSKEEGDLLEPGDEEAAAALGGTFTRSRIGKGGKACHKIFSNHHHRLQLKAAPASSNPPGAPALPLHNSSVTANSQSPALLAGTNPVAVVADGGSCPAHYPVHECVFKGDVRRLSSLIRTHNIGQKDNHGEEC>sp|O43299|AP5Z1_HUMAN AP-5 complex subunit zeta-1 OS=Homo sapiensOX=9606 GN=AP5Z1 PE=1 SV=2MFSAGAESLLHQAREIQDEELKKFCSRICKLLQAEDLGPDTLDSLQRLFLIISATKYSRRLEKTCVDLLQATLGLPACPEQLQVLCAAILREMSPSDSLSLAWDHTQNSRQLSLVASVLLAQGDRNEEVRAVGQGVLRALESRQPEGPSLRHLLPVMAKVVVLSPGTLQEDQATLLSKRLVDWLRYASLQQGLPHSGGFFSTPRARQPGPVTEVDGAVATDFFTVLSSGHRFTDDQWLNVQAFSMLRAWLLHSGPEGPGTLDTDDRSEQEGSTLSVISATSSAGRLLPPRERLREVAFEYCQRLIEQSNRRALRKGDSDLQKACLVEAVLVLDVLCRQDPSFLYRSLSCLKALHGRVRGDPASVRVLLPLAHFFLSHGEAAAVDSEAVYQHLFTRIPVEQFHSPMLAFEFIQFCRDNLHLFSGHLSTLRLSFPNLFKFLAWNSPPLTSEFVALLPALVDAGTALEMLHALLDLPCLTAVLDLQLRSAPAASERPLWDTSLRAPSCLEAFRDPQFQGLFQYLLRPKASGATERLAPLHQLLQPMAGCARVAQCAQAVPTLLQAFFSAVTQVADGSLINQLALLLLGRSDSLYPAPGYAAGVHSVLSSQFLALCTLKPSLVVELARDLLEFLGSVNGLCSRASLVTSVVWAIGEYLSVTYDRRCTVEQINKFFEALEALLFEVTQCRPSAALPRCPPQVVTVLMTTLTKLASRSQDLIPRASLLLSKMRTLAHSPATSSTHSEEGAEAIRTRATELLTLLKMPSVAQFVLTPSTEVCSPRYHRDANTALPLALRTVSRLVEREAGLMPG>sp|O43299-2|AP5Z1_HUMAN Isoform 2 of AP-5 complex subunit zeta-1 OS=Homosapiens OX=9606 GN=AP5Z1MFSAGAESLLHQAREIQDEELKKFCSRICKLLQAEDLGPDTLDSLQRLFLIISATKYSRRLEKTCVDLLQATLGLPACPEQLQVLCAAILREMSPSDSLSLAWDHTQNSRQLSLVASVLLAQGDRNEEVRAVGQGVLRALESRQPEGPSLRHLLPVMAKVVVLSPGTLQEDQATLLSKRLVDWLRYASLQQGLPHSGGFFSTPRARQPGPVTEVDGAVATDFFTVLSSGHRFTDDQWLNVQAFSMLRAWLLHSGPEGPGTLDTDDRSEQEGSTLSVISATSSAGRLLPPRERLREVAFEYCQRLIEQSNRRALRKGDSDLQKACLVEAVLVLDVLCRQDPSFLYRSLSCLKALHGRVRGDPASVRVLLPLAHFFLSHGEAAAVDSEAVYQHLFTRIPVEQFHSPMLAFEFIQFCRDNLHLFSGHLSTLRLSFPNLFKFLAWNSPPLTSEFVALLPALVDAGTALEMLHALLDLPCLTAVLDLQLRSAPAASERPLWDTSLRAPSCLEAFRDPQFQGLFQYLLRPKASGATERLAPLHQLLQPMAGCARVAQCAQAVPTLLQAFFSAVTQVADGSLINQLALLLLGRSDSLYPAPGYAAGVHRPDACRPILVPL>sp|O43299-3|AP5Z1_HUMAN Isoform 3 of AP-5 complex subunit zeta-1 OS=Homosapiens OX=9606 GN=AP5Z1MAKVVVLSPGTLQEDQATLLSKRLVDWLRYASLQQGLPHSGGFFSTPRARQPGPVTEVDGAVATDFFTVLSSGHRFTDDQWLNVQAFSMLRAWLLHSGPEGPGTLDTDDRSEQEGSTLSVISATSSAGRLLPPRERLREVAFEYCQRLIEQSNRRALRKGDSDLQKACLVEAVLVLDVLCRQDPSFLYRSLSCLKALHGRVRGDPASVRVLLPLAHFFLSHGEAAAVDSEAVYQHLFTRIPVEQFHSPMLAFEFIQFCRDNLHLFSGHLSTLRLSFPNLFKFLAWNSPPLTSEFVALLPALVDAGTALEMLHALLDLPCLTAVLDLQLRSAPAASERPLWDTSLRAPSCLEAFRDPQFQGLFQYLLRPKASGATERLAPLHQLLQPMAGCARVAQCAQAVPTLLQAFFSAVTQVADGSLINQLALLLLGRSDSLYPAPGYAAGVHR>sp|Q8TDI0|CHD5_HUMAN Chromodomain-helicase-DNA-binding protein 5 OS=Homosapiens OX=9606 GN=CHD5 PE=1 SV=1MRGPVGTEEELPRLFAEEMENEDEMSEEEDGGLEAFDDFFPVEPVSLPKKKKPKKLKENKCKGKRKKKEGSNDELSENEEDLEEKSESEGSDYSPNKKKKKKLKDKKEKKAKRKKKDEDEDDNDDGCLKEPKSSGQLMAEWGLDDVDYLFSEEDYHTLTNYKAFSQFLRPLIAKKNPKIPMSKMMTVLGAKWREFSANNPFKGSSAAAAAAAVAAAVETVTISPPLAVSPPQVPQPVPIRKAKTKEGKGPGVRKKIKGSKDGKKKGKGKKTAGLKFRFGGISNKRKKGSSSEEDEREESDFDSASIHSASVRSECSAALGKKSKRRRKKKRIDDGDGYETDHQDYCEVCQQGGEIILCDTCPRAYHLVCLDPELEKAPEGKWSCPHCEKEGIQWEPKDDDDEEEEGGCEEEEDDHMEFCRVCKDGGELLCCDACPSSYHLHCLNPPLPEIPNGEWLCPRCTCPPLKGKVQRILHWRWTEPPAPFMVGLPGPDVEPSLPPPKPLEGIPEREFFVKWAGLSYWHCSWVKELQLELYHTVMYRNYQRKNDMDEPPPFDYGSGDEDGKSEKRKNKDPLYAKMEERFYRYGIKPEWMMIHRILNHSFDKKGDVHYLIKWKDLPYDQCTWEIDDIDIPYYDNLKQAYWGHRELMLGEDTRLPKRLLKKGKKLRDDKQEKPPDTPIVDPTVKFDKQPWYIDSTGGTLHPYQLEGLNWLRFSWAQGTDTILADEMGLGKTVQTIVFLYSLYKEGHSKGPYLVSAPLSTIINWEREFEMWAPDFYVVTYTGDKESRSVIRENEFSFEDNAIRSGKKVFRMKKEVQIKFHVLLTSYELITIDQAILGSIEWACLVVDEAHRLKNNQSKFFRVLNSYKIDYKLLLTGTPLQNNLEELFHLLNFLTPERFNNLEGFLEEFADISKEDQIKKLHDLLGPHMLRRLKADVFKNMPAKTELIVRVELSQMQKKYYKFILTRNFEALNSKGGGNQVSLLNIMMDLKKCCNHPYLFPVAAVEAPVLPNGSYDGSSLVKSSGKLMLLQKMLKKLRDEGHRVLIFSQMTKMLDLLEDFLEYEGYKYERIDGGITGGLRQEAIDRFNAPGAQQFCFLLSTRAGGLGINLATADTVIIYDSDWNPHNDIQAFSRAHRIGQNKKVMIYRFVTRASVEERITQVAKRKMMLTHLVVRPGLGSKSGSMTKQELDDILKFGTEELFKDDVEGMMSQGQRPVTPIPDVQSSKGGNLAASAKKKHGSTPPGDNKDVEDSSVIHYDDAAISKLLDRNQDATDDTELQNMNEYLSSFKVAQYVVREEDGVEEVEREIIKQEENVDPDYWEKLLRHHYEQQQEDLARNLGKGKRIRKQVNYNDASQEDQEWQDELSDNQSEYSIGSEDEDEDFEERPEGQSGRRQSRRQLKSDRDKPLPPLLARVGGNIEVLGFNARQRKAFLNAIMRWGMPPQDAFNSHWLVRDLRGKSEKEFRAYVSLFMRHLCEPGADGAETFADGVPREGLSRQHVLTRIGVMSLVRKKVQEFEHVNGKYSTPDLIPEGPEGKKSGEVISSDPNTPVPASPAHLLPAPLGLPDKMEAQLGYMDEKDPGAQKPRQPLEVQALPAALDRVESEDKHESPASKERAREERPEETEKAPPSPEQLPREEVLPEKEKILDKLELSLIHSRGDSSELRPDDTKAEEKEPIETQQNGDKEEDDEGKKEDKKGKFKFMFNIADGGFTELHTLWQNEERAAVSSGKIYDIWHRRHDYWLLAGIVTHGYARWQDIQNDPRYMILNEPFKSEVHKGNYLEMKNKFLARRFKLLEQALVIEEQLRRAAYLNMTQDPNHPAMALNARLAEVECLAESHQHLSKESLAGNKPANAVLHKVLNQLEELLSDMKADVTRLPSMLSRIPPVAARLQMSERSILSRLTNRAGDPTIQQGAFGSSQMYSNNFGPNFRGPGPGGIVNYNQMPLGPYVTDI>sp|A6NCL7|AN33B_HUMAN Ankyrin repeat domain-containing protein 33BOS=Homo sapiens OX=9606 GN=ANKRD33B PE=3 SV=1MVLLAGTGPEGGGARCMTPPPPSPPRGAQVEEDPADYEEFEDFSSLPDTRSIASDDSFYPFEDEEEHGVESAESVPEGVPESVPETATLLRAACANNVGLLRTLVRRGVSVEEAQETDRNGRTGLIVACYHGFVDTVVALAECPHVDVNWQDSEGNTALITAAQAGHAIITNYLLNYFPGLDLERRNAFGFTALMKAAMQGRTDCIRALMLAGADVHARDPRRGMSPQEWATYTGRVDAVRLMQRLLERPCPEQFWEKYRPELPPPPEAARKPAGSKNCLQRLTDCVLSVLTPRSVRGPEDGGVLDHMVRMTTSLYSPAVAIVCQTVCPESPPSVGKRRLAVQEILAARAARGPQAQEEDEVGGAGQRGRTGQEDADSREGSPRAGLPPALGSRGPAAPAPRKASLLPLQRLRRRSVRPGVVVPRVRVSKAPAPTFQPERPARKGSTKDSGHLQIPKWRYKEAKEEKRKAEEAEKKRQAEAQKERRTAPWKKRT>sp|Q9Y6Q5|AP1M2_HUMAN AP-1 complex subunit mu-2 OS=Homo sapiens OX=9606GN=AP1M2 PE=1 SV=4MSASAVFILDVKGKPLISRNYKGDVAMSKIEHFMPLLVQREEEGALAPLLSHGQVHFLWIKHSNLYLVATTSKNANASLVYSFLYKTIEVFCEYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQQSNKLETGKSRVPPTVTNAVSWRSEGIKYKKNEVFIDVIESVNLLVNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGRSKNKSVELEDVKFHQCVRLSRFDNDRTISFIPPDGDFELMSYRLSTQVKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVPVPSDADSPRFKTSVGSAKYVPERNVVIWSIKSFPGGKEYLMRAHFGLPSVEKEEVEGRPPIGVKFEIPYFTVSGIQVRYMKIIEKSGYQALPWVRYITQSGDYQLRTS>sp|Q9Y6Q5-2|AP1M2_HUMAN Isoform 2 of AP-1 complex subunit mu-2 OS=Homosapiens OX=9606 GN=AP1M2MSASAVFILDVKGKPLISRNYKGDVAMSKIEHFMPLLVQREEEGALAPLLSHGQVHFLWIKHSNLYLVATTSKNANASLVYSFLYKTIEVFCEYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQQSNKLETGKSRVPPTVTNAVSWRSEGIKYKKNEVFIDVIESVNLLVNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGLSGSKNKSVELEDVKFHQCVRLSRFDNDRTISFIPPDGDFELMSYRLSTQVKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVPVPSDADSPRFKTSVGSAKYVPERNVVIWSIKSFPGGKEYLMRAHFGLPSVEKEEVEGRPPIGVKFEIPYFTVSGIQVRYMKIIEKSGYQALPWVRYITQSGDYQLRTS>sp|P53567|CEBPG_HUMAN CCAAT/enhancer-binding protein gamma OS=Homosapiens OX=9606 GN=CEBPG PE=1 SV=1MSKISQQNSTPGVNGISVIHTQAHASGLQQVPQLVPAGPGGGGKAVAPSKQSKKSSPMDRNSDEYRQRRERNNMAVKKSRLKSKQKAQDTLQRVNQLKEENERLEAKIKLLTKELSVLKDLFLEHAHNLADNVQSISTENTTADGDNAGQ>sp|Q9C0C7|AMRA1_HUMAN Activating molecule in BECN1-regulated autophagyprotein 1 OS=Homo sapiens OX=9606 GN=AMBRA1 PE=1 SV=2MKVVPEKNAVRILWGRERGARAMGAQRLLQELVEDKTRWMKWEGKRVELPDSPRSTFLLAFSPDRTLLASTHVNHNIYITEVKTGKCVHSLIGHRRTPWCVTFHPTISGLIASGCLDGEVRIWDLHGGSESWFTDSNNAIASLAFHPTAQLLLIATANEIHFWDWSRREPFAVVKTASEMERVRLVRFDPLGHYLLTAIVNPSNQQGDDEPEIPIDGTELSHYRQRALLQSQPVRRTPLLHNFLHMLSSRSSGIQVGEQSTVQDSATPSPPPPPPQPSTERPRTSAYIRLRQRVSYPTAECCQHLGILCLCSRCSGTRVPSLLPHQDSVPPASARATTPSFSFVQTEPFHPPEQASSTQQDQGLLNRPSAFSTVQSSTAGNTLRNLSLGPTRRSLGGPLSSHPSRYHREIAPGLTGSEWTRTVLSLNSRSEAESMPPPRTSASSVSLLSVLRQQEGGSQASVYTSATEGRGFPASGLATESDGGNGSSQNNSGSIRHELQCDLRRFFLEYDRLQELDQSLSGEAPQTQQAQEMLNNNIESERPGPSHQPTPHSSENNSNLSRGHLNRCRACHNLLTFNNDTLRWERTTPNYSSGEASSSWQVPSSFESVPSSGSQLPPLERTEGQTPSSSRLELSSSASPQEERTVGVAFNQETGHWERIYTQSSRSGTVSQEALHQDMPEESSEEDSLRRRLLESSLISLSRYDGAGSREHPIYPDPARLSPAAYYAQRMIQYLSRRDSIRQRSMRYQQNRLRSSTSSSSSDNQGPSVEGTDLEFEDFEDNGDRSRHRAPRNARMSAPSLGRFVPRRFLLPEYLPYAGIFHERGQPGLATHSSVNRVLAGAVIGDGQSAVASNIANTTYRLQWWDFTKFDLPEISNASVNVLVQNCKIYNDASCDISADGQLLAAFIPSSQRGFPDEGILAVYSLAPHNLGEMLYTKRFGPNAISVSLSPMGRYVMVGLASRRILLHPSTEHMVAQVFRLQQAHGGETSMRRVFNVLYPMPADQRRHVSINSARWLPEPGLGLAYGTNKGDLVICRPEALNSGVEYYWDQLNETVFTVHSNSRSSERPGTSRATWRTDRDMGLMNAIGLQPRNPATSVTSQGTQTLALQLQNAETQTEREVPEPGTAASGPGEGEGSEYGASGEDALSRIQRLMAEGGMTAVVQREQSTTMASMGGFGNNIIVSHRIHRSSQTGTEPGAAHTSSPQPSTSRGLLPEAGQLAERGLSPRTASWDQPGTPGREPTQPTLPSSSPVPIPVSLPSAEGPTLHCELTNNNHLLDGGSSRGDAAGPRGEPRNR>sp|Q9C0C7-2|AMRA1_HUMAN Isoform 2 of Activating molecule in BECN1-regulated autophagy protein 1 OS=Homo sapiens OX=9606 GN=AMBRA1MKVVPEKNAVRILWGRERGARAMGAQRLLQELVEDKTRWMKWEGKRVELPDSPRSTFLLAFSPDRTLLASTHVNHNIYITEVKTGKCVHSLIGHRRTPWCVTFHPTISGLIASGCLDGEVRIWDLHGGSESWFTDSNNAIASLAFHPTAQLLLIATANEIHFWDWSRREPFAVVKTASEMERVRLVRFDPLGHYLLTAIVNPSNQQGDDEPEIPIDGTELSHYRQRALLQSQPVRRTPLLHNFLHMLSSRSSGIQVGEQSTVQDSATPSPPPPPPQPSTERPRTSAYIRLRQRVSYPTAECCQHLGILCLCSRCSGTRVPSLLPHQDSVPPASARATTPSFSFVQTEPFHPPEQASSTQQDQGLLNRPSAFSTVQSSTAGNTLRNLSLGPTRRSLGGPLSSHPSRYHREIAPGLTGSEWTRTVLSLNSRSEAESMPPPRTSASSVSLLSVLRQQEGGSQASVYTSATEGRGFPASGLATESDGGNGSSQNNSGSIRHELQCDLRRFFLEYDRLQELDQSLSGEAPQTQQAQEMLNNNIESERPGPSHQPTPHSSENNSNLSRGHLNRCRACHNLLTFNNDTLRWERTTPNYSSGEASSSWQVPSSFESVPSSGSQLPPLERTEGQTPSSSRLELSSSASPQEERTVGVAFNQETGHWERIYTQSSRSGTVSQEALHQDMPEESSEEDSLRRRLLESSLISLSRYDGAGSREHPIYPDPARDNGDRSRHRAPRNARMSAPSLGRFVPRRFLLPEYLPYAGIFHERGQPGLATHSSVNRVLAGAVIGDGQSAVASNIANTTYRLQWWDFTKFDLPEISNASVNVLVQNCKIYNDASCDISADGQLLAAFIPSSQRGFPDEGILAVYSLAPHNLGEMLYTKRFGPNAISVSLSPMGRYVMVGLASRRILLHPSTEHMVAQVFRLQQAHGGETSMRRVFNVLYPMPADQRRHVSINSARWLPEPGLGLAYGTNKGDLVICRPEALNSGVEYYWDQLNETVFTVHSNSRSSERPGTSRATWRTDRDMGLMNAIGLQPRNPATSVTSQGTQTLALQLQNAETQTEREVPEPGTAASGPGEGEGSEYGASGEDALSRIQRLMAEGGMTAVVQREQSTTMASMGGFGNNIIVSHRIHRSSQTGTEPGAAHTSSPQPSTSRGLLPEAGQLAERGLSPRTASWDQPGTPGREPTQPTLPSSSPVPIPVSLPSAEGPTLHCELTNNNHLLDGGSSRGDAAGPRGEPRNR>sp|Q9C0C7-3|AMRA1_HUMAN Isoform 3 of Activating molecule in BECN1-regulated autophagy protein 1 OS=Homo sapiens OX=9606 GN=AMBRA1MKVVPEKNAVRILWGRERGARAMGAQRLLQELVEDKTRWMKWEGKRVELPDSPRSTFLLAFSPDRTLLASTHVNHNIYITEVKTGKCVHSLIGHRRTPWCVTFHPTISGLIASGCLDGEVRIWDLHGGSESWFTDSNNAIASLAFHPTAQLLLIATANEIHFWDWSRREPFAVVKTASEMERVRLVRFDPLGHYLLTAIVNPSNQQGDDEPEIPIDGTELSHYRQRALLQSQPVRRTPLLHNFLHMLSSRSSGIQVGEQSTVQDSATPSPPPPPPQPSTERPRTSAYIRLRQRVSYPTAECCQHLGILCLCSRCSGTRVPSLLPHQDSVPPASARATTPSFSFVQTEPFHPPEQASSTQQDQGLLNRPSAFSTVQSSTAGNTLRNLSLGPTRRSLGGPLSSHPSRYHREIAPGLTGSEWTRTVLSLNSRSEAESMPPPRTSASSVSLLSVLRQQEGGSQASVYTSATEGRGFPASGLATESDGGNGSSQNNSGSIRHELQCDLRRFFLEYDRLQELDQSLSGEAPQTQQAQEMLNNNIESERPGPSHQPTPHSSENNSNLSRGHLNRCRACHNLLTFNNDTLRWERTTPNYSSGEASSSWQVPSSFESVPSSGSQLPPLERTEGQTPSSSRLELSSSASPQEERTVGVAFNQETGHWERIYTQSSRSGTVSQEALHQDMPEESSEEDSLRRLSPAAYYAQRMIQYLSRRDSIRQRSMRYQQNRLRSSTSSSSSDNQGPSVEGTDLEFEDFEDNGDRSRHRAPRNARMSAPSLGRFVPRRFLLPEYLPYAGIFHERGQPGLATHSSVNRVLAGAVIGDGQSAVASNIANTTYRLQWWDFTKFDLPEISNASVNVLVQNCKIYNDASCDISADGQLLAAFIPSSQRGFPDEGILAVYSLAPHNLGEMLYTKRFGPNAISVSLSPMGRYVMVGLASRRILLHPSTEHMVAQVFRLQQAHGGETSMRRVFNVLYPMPADQRRHVSINSARWLPEPGLGLAYGTNKGDLVICRPEALNSGVEYYWDQLNETVFTVHSNSRSSERPGTSRATWRTDRDMGLMNAIGLQPRNPATSVTSQGTQTLALQLQNAETQTEREVPEPGTAASGPGEGEGSEYGASGEDALSRIQRLMAEGGMTAVVQREQSTTMASMGGFGNNIIVSHRIHRSSQTGTEPGAAHTSSPQPSTSRGLLPEAGQLAERGLSPRTASWDQPGTPGREPTQPTLPSSSPVPIPVSLPSAEGPTLHCELTNNNHLLDGGSSRGDAAGPRGEPRNR>sp|Q9C0C7-4|AMRA1_HUMAN Isoform 4 of Activating molecule in BECN1-regulated autophagy protein 1 OS=Homo sapiens OX=9606 GN=AMBRA1MKVVPEKNAVRILWGRERGARAMGAQRLLQELVEDKTRWMKWEGKRVELPDSPRSTFLLAFSPDRTLLASTHVNHNIYITEVKTGKCVHSLIGHRRTPWCVTFHPTISGLIASGCLDGEVRIWDLHGGSESWFTDSNNAIASLAFHPTAQLLLIATANEIHFWDWSRREPFAVVKTASEMERVRLVRFDPLGHYLLTAIVNPSNQQGDDEPEIPIDGTELSHYRQRALLQSQPVRRTPLLHNFLHMLSSRSSGIQTEPFHPPEQASSTQQDQGLLNRPSAFSTVQSSTAGNTLRNLSLGPTRRSLGGPLSSHPSRYHREIAPGLTGSEWTRTVLSLNSRSEAESMPPPRTSASSVSLLSVLRQQEGGSQASVYTSATEGRGFPASGLATESDGGNGSSQNNSGSIRHELQCDLRRFFLEYDRLQELDQSLSGEAPQTQQAQEMLNNNIESERPGPSHQPTPHSSENNSNLSRGHLNRCRACHNLLTFNNDTLRWERTTPNYSSGEASSSWQVPSSFESVPSSGSQLPPLERTEGQTPSSSRLELSSSASPQEERTVGVAFNQETGHWERIYTQSSRSGTVSQEALHQDMPEESSEEDSLRRRLLESSLISLSRYDGAGSREHPIYPDPARLSPAAYYAQRMIQYLSRRDSIRQRSMRYQQNRLRSSTSSSSSDNQGPSVEGTDLEFEDFEDNGDRSRHRAPRNARMSAPSLGRFVPRRFLLPEYLPYAGIFHERGQPGLATHSSVNRVLAGAVIGDGQSAVASNIANTTYRLQWWDFTKFDLPEISNASVNVLVQNCKIYNDASCDISADGQLLAAFIPSSQRGFPDEGILAVYSLAPHNLGEMLYTKRFGPNAISVSLSPMGRYVMVGLASRRILLHPSTEHMVAQVFRLQQAHGGETSMRRVFNVLYPMPADQRRHVSINSARWLPEPGLGLAYGTNKGDLVICRPEALNSGVEYYWDQLNETVFTVHSNSRSSERPGTSRATWRTDRDMGLMNAIGLQPRNPATSVTSQGTQTLALQLQNAETQTEREVPEPGTAASGPGEGEGSEYGASGEDALSRIQRLMAEGGMTAVVQREQSTTMASMGGFGNNIIVSHRIHRSSQTGTEPGAAHTSSPQPSTSRGLLPEAGQLAERGLSPRTASWDQPGTPGREPTQPTLPSSSPVPIPVSLPSAEGPTLHCELTNNNHLLDGGSSRGDAAGPRGEPRNR>sp|Q9C0C7-5|AMRA1_HUMAN Isoform 5 of Activating molecule in BECN1-regulated autophagy protein 1 OS=Homo sapiens OX=9606 GN=AMBRA1MKVVPEKNAVRILWGRERGARAMGAQRLLQELVEDKTRWMKWEGKRVELPDSPRSTFLLAFSPDRTLLASTHVNHNIYITEVKTGKCVHSLIGHRRTPWCVTFHPTISGLIASGCLDGEVRIWDLHGGSESWFTDSNNAIASLAFHPTAQLLLIATANEIHFWDWSRREPFAVVKTASEMERVRLVRFDPLGHYLLTAIVNPSNQQGDDEPEIPIDGTELSHYRQRALLQSQPVRRTPLLHNFLHMLSSRSSGIQTEPFHPPEQASSTQQDQGLLNRPSAFSTVQSSTAGNTLRNLSLGPTRRSLGGPLSSHPSRYHREIAPGLTGSEWTRTVLSLNSRSEAESMPPPRTSASSVSLLSVLRQQEGGSQASVYTSATEGRGFPASGLATESDGGNGSSQNNSGSIRHELQCDLRRFFLEYDRLQELDQSLSGEAPQTQQAQEMLNNNIESERPGPSHQPTPHSSENNSNLSRGHLNRCRACHNLLTFNNDTLRWERTTPNYSSGEASSSWQVPSSFESVPSSGSQLPPLERTEGQTPSSSRLELSSSASPQEERTVGVAFNQETGHWERIYTQSSRSGTVSQEALHQDMPEESSEEDSLRRRSLALSPRLEYSGAILAHCKLRLPGSCHSPASASQVAGTTGAHHHARLIFAFLVEMEFHHVSQAGLELLTSGDLPTSASQSAGITGVSHRAWPRLLESSLISLSRYDGAGSREHPIYPDPARLSPAAYYAQRMIQYLSRRDSIRQRSMRYQQNRLRSSTSSSSSDNQGPSVEGTDLEFEDFEDNGDRSRHRAPRNARMSAPSLGRFVPRRFLLPEYLPYAGIFHERGQPGLATHSSVNRVLAGAVIGDGQSAVASNIANTTYRLQWWDFTKFDLPEISNASVNVLVQNCKIYNDASCDISADGQLLAAFIPSSQRGFPDEGILAVYSLAPHNLGEMLYTKRFGPNAISVSLSPMGRYVMVGLASRRILLHPSTEHMVAQVFRLQQAHGGETSMRRVFNVLYPMPADQRRHVSINSARWLPEPGLGLAYGTNKGDLVICRPEALNSGVEYYWDQLNETVFTVHSNSRSSERPGTSRATWRTDRDMGLMNAIGLQPRNPATSVTSQGTQTLALQLQNAETQTEREVPEPGTAASGPGEGEGSEYGASGEDALSRIQRLMAEGGMTAVVQREQSTTMASMGGFGNNIIVSHRIHRSSQTGTEPGAAHTSSPQPSTSRGLLPEAGQLAERGLSPRTASWDQPGTPGREPTQPTLPSSSPVPIPVSLPSAEGPTLHCELTNNNHLLDGGSSRGDAAGPRGEPRNR>sp|Q9C0C7-6|AMRA1_HUMAN Isoform 6 of Activating molecule in BECN1-regulated autophagy protein 1 OS=Homo sapiens OX=9606 GN=AMBRA1MKVVPEKNAVRILWGRERGARAMGAQRLLQELVEDKTRWMKWEGKRVELPDSPRSTFLLAFSPDRTLLASTHVNHNIYITEVKTGKCVHSLIGHRRTPWCVTFHPTISGLIASGCLDGEVRIWDLHGGSESWFTDSNNAIASLAFHPTAQLLLIATANEIHFWDWSRREPFAVVKTASEMERVRLVRFDPLGHYLLTAIVNPSNQQGDDEPEIPIDGTELSHYRQRALLQSQPVRRTPLLHNFLHMLSSRSSGIQTEPFHPPEQASSTQQDQGLLNRPSAFSTVQSSTAGNTLRNLSLGPTRRSLGGPLSSHPSRYHREIAPGLTGSEWTRTVLSLNSRSEAESMPPPRTSASSVSLLSVLRQQEGGSQASVYTSATEGRGFPASGLATESDGGNGSSQNNSGSIRHELQCDLRRFFLEYDRLQELDQSLSGEAPQTQQAQEMLNNNIESERPGPSHQPTPHSSENNSNLSRGHLNRCRACHNLLTFNNDTLRWERTTPNYSSGEASSSWQVPSSFESVPSSGSQLPPLERTEGQTPSSSRLELSSSASPQEERTVGVAFNQETGHWERIYTQSSRSGTVSQEALHQDMPEESSEEDSLRRLSPAAYYAQRMIQYLSRRDSIRQRSMRYQQNRLRSSTSSSSSDNQGPSVEGTDLEFEDFEDNGDRSRHRAPRNARMSAPSLGRFVPRRFLLPEYLPYAGIFHERGQPGLATHSSVNRVLAGAVIGDGQSAVASNIANTTYRLQGGGTSLSLTSLKSVMLP>sp|P61966|AP1S1_HUMAN AP-1 complex subunit sigma-1A OS=Homo sapiensOX=9606 GN=AP1S1 PE=1 SV=1MMRFMLLFSRQGKLRLQKWYLATSDKERKKMVRELMQVVLARKPKMCSFLEWRDLKVVYKRYASLYFCCAIEGQDNELITLELIHRYVELLDKYFGSVCELDIIFNFEKAYFILDEFLMGGDVQDTSKKSVLKAIEQADLLQEEDESPRSVLEEMGLA>sp|P61966-2|AP1S1_HUMAN Isoform 2 of AP-1 complex subunit sigma-1AOS=Homo sapiens OX=9606 GN=AP1S1MMRFMLLFSRQGKLRLQKWYLATSDKERKKMVRELMQVVLARKPKMCSFLEWRDLKVVYKRYASLYFCCAIEGQDNELITLELIHRYVELLDKYFGSVCELDIIFNFEKAYFILDEFLMGGDVQDTSTFPFSH>sp|P05090|APOD_HUMAN Apolipoprotein D OS=Homo sapiens OX=9606 GN=APODPE=1 SV=1MVMLLLLLSALAGLFGAAEGQAFHLGKCPNPPVQENFDVNKYLGRWYEIEKIPTTFENGRCIQANYSLMENGKIKVLNQELRADGTVNQIEGEATPVNLTEPAKLEVKFSWFMPSAPYWILATDYENYALVYSCTCIIQLFHVDFAWILARNPNLPPETVDSLKNILTSNNIDVKKMTVTDQVNCPKLS>sp|Q9BXX2|AN30B_HUMAN Ankyrin repeat domain-containing protein 30BOS=Homo sapiens OX=9606 GN=ANKRD30B PE=2 SV=3MKRLLAAAGKGVRGPEPPNPFSERVYTEKDYGTIYFGDLGKIHTAASRGQVQKLEKMTVGKKPVNLNKRDMKKRTALHWACVNGHAEVVTFLVDRKCQLNVLDGEGRTPLMKALQCEREACANILIDAGADLNYVDVYGNTALHYAVYSENLLMVATLLSYGAVIEVQNKASLTPLLLAIQKRSKQTVEFLLTKNANANAFNESKCTALMLAICEGSSEIVGMLLQQNVDVFAEDIHGITAERYAAACGVNYIHQQLLEHIRKLPKNPQNTNPEGTSTGTPDEAAPLAERTPDTAESLLEKTPDEAARLVEGTSAKIQCLGKATSGKFEQSTEETPRKILRPTKETSEKFSWPAKERSRKITWEEKETSVKTECVAGVTPNKTEVLEKGTSNMIACPTKETSTKASTNVDVSSVEPIFSLFGTRTIENSQCTKVEEDFNLATKIISKSAAQNYTCLPDATYQKDIKTINHKIEDQMFPSESKREEDEEYSWDSGSLFESSAKTQVCIPESMYQKVMEINREVEELPEKPSAFKPAVEMQKTVPNKAFELKNEQTLRAAQMFPSESKQKDDEENSWDSESPCETVSQKDVYLPKATHQKEFDTLSGKLEESPVKDGLLKPTCGRKVSLPNKALELKDRETFKAESPDKDGLLKPTCGRKVSLPNKALELKDRETLKAESPDNDGLLKPTCGRKVSLPNKALELKDRETFKAAQMFPSESKQKDDEENSWDFESFLETLLQNDVCLPKATHQKEFDTLSGKLEESPDKDGLLKPTCGMKISLPNKALELKDRETFKAEDVSSVESTFSLFGKPTTENSQSTKVEEDFNLTTKEGATKTVTGQQERDIGIIERAPQDQTNKMPTSELGRKEDTKSTSDSEIISVSDTQNYECLPEATYQKEIKTTNGKIEESPEKPSHFEPATEMQNSVPNKGLEWKNKQTLRADSTTLSKILDALPSCERGRELKKDNCEQITAKMEQTKNKFCVLQKELSEAKEIKSQLENQKAKWEQELCSVRLTLNQEEEKRRNVDILKEKIRPEEQLRKKLEVKQQLEQTLRIQDIELKSVTSNLNQVSHTHESENDLFHENCMLKKEIAMLKLEVATLKHQHQVKENKYFEDIKILQEKNAELQMTLKLKQKTVTKRASQYREQLKVLTAENTMLTSKLKEKQDKEILETEIESHHPRLASALQDHDQSVTSRKNQELAFHSAGDAPLQGIMNVDVSNTIYNNEVLHQPLYEAQRKSKSPKINLNYAGDDLRENALVSEHAQRDRCETQCQMKKAEHMYQNEQDNVDKHTEQQESLEQKLFQLESKNRWLRQQLVYAHKKVNKSKVTINIQFPEMKMQRHLNEKNEEVFNYGNHLKERIDQYEKEKAEREVSIKKYKYFSNFLKESGLG>sp|Q9BXX2-2|AN30B_HUMAN Isoform 2 of Ankyrin repeat domain-containingprotein 30B OS=Homo sapiens OX=9606 GN=ANKRD30BMKRLLAAAGKGVRGPEPPNPFSERVYTEKDYGTIYFGDLGKIHTAASRGQVQKLEKMTVGKKPVNLNKRDMKKRTALHWACVNGHAEVVTFLVDRKCQLNVLDGEGRTPLMKALQCEREACANILIDAGADLNYVDVYGNTALHYAVYSENLLMVATLLSYGAVIEVQNKASLTPLLLAIQKRSKQTVEFLLTKNANANAFNESKCTALMLAICEGSSEIVGMLLQQNVDVFAEDIHGITAERYAAACGVNYIHQQLLEHIRKLPKNPQNTNPEGTSTGTPDEAAPLAERTPDTAESLLEKTPDEAARLVEGTSAKIQCLGKATSGKFEQSTEETPRKILRPTKETSEKFSWPAKERSRKITWEEKETSVKTECVAGVTPNKTEVLEKGTSNMIACPTKETSTKASTNVDVSSVEPIFSLFGTRTIENSQCTKVEEDFNLATKIISKSAAQNYTCLPDATYQKDIKTINHKIEDQMFPSESKREEDEEYSWDSGSLFESSAKTQVCIPESMYQKVMEINREVEELPEKPSAFKPAVEMQKTVPNKAFELKNEQTLRAAQMFPSESKQKDDEENSWDSESPCETVSQKDVYLPKATHQKEFDTLSGKLEAYLWKESFSSK>sp|Q9Y6B7|AP4B1_HUMAN AP-4 complex subunit beta-1 OS=Homo sapiensOX=9606 GN=AP4B1 PE=1 SV=2MPYLGSEDVVKELKKALCNPHIQADRLRYRNVIQRVIRYMTQGLDMSGVFMEMVKASATVDIVQKKLVYLYMCTYAPLKPDLALLAINTLCKDCSDPNPMVRGLALRSMCSLRMPGVQEYIQQPILNGLRDKASYVRRVAVLGCAKMHNLHGDSEVDGALVNELYSLLRDQDPIVVVNCLRSLEEILKQEGGVVINKPIAHHLLNRMSKLDQWGQAEVLNFLLRYQPRSEEELFDILNLLDSFLKSSSPGVVMGATKLFLILAKMFPHVQTDVLVRVKGPLLAACSSESRELCFVALCHVRQILHSLPGHFSSHYKKFFCSYSEPHYIKLQKVEVLCELVNDENVQQVLEELRGYCTDVSADFAQAAIFAIGGIARTYTDQCVQILTELLGLRQEHITTVVVQTFRDLVWLCPQCTEAVCQALPGCEENIQDSEGKQALIWLLGVHGERIPNAPYVLEDFVENVKSETFPAVKMELLTALLRLFLSRPAECQDMLGRLLYYCIEEEKDMAVRDRGLFYYRLLLVGIDEVKRILCSPKSDPTLGLLEDPAERPVNSWASDFNTLVPVYGKAHWATISKCQGAERCDPELPKTSSFAASGPLIPEENKERVQELPDSGALMLVPNRQLTADYFEKTWLSLKVAHQQVLPWRGEFHPDTLQMALQVVNIQTIAMSRAGSRPWKAYLSAQDDTGCLFLTELLLEPGNSEMQISVKQNEARTETLNSFISVLETVIGTIEEIKS>sp|Q9Y6B7-2|AP4B1_HUMAN Isoform 2 of AP-4 complex subunit beta-1 OS=Homosapiens OX=9606 GN=AP4B1MPYLGSEDVVKELKKALCNPHIQADRLRYRNVIQRVIRYMTQGLDMSGVFMEMVKASATVDIVQKKLVYLYMCTYAPLKPDLALLAINTLCKDCSDPNPMVRGLALRSMCSLRMSKLDQWGQAEVLNFLLRYQPRSEEELFDILNLLDSFLKSSSPGVVMGATKLFLILAKMFPHVQTDVLVRVKGPLLAACSSESRELCFVALCHVRQILHSLPGHFSSHYKKFFCSYSEPHYIKLQKVEVLCELVNDENVQQVLEELRGYCTDVSADFAQAAIFAIGRCLLLFLLENLDQPARKLWLEEP>sp|Q9HDC9|APMAP_HUMAN Adipocyte plasma membrane-associated proteinOS=Homo sapiens OX=9606 GN=APMAP PE=1 SV=2MSEADGLRQRRPLRPQVVTDDDGQAPEAKDGSSFSGRVFRVTFLMLAVSLTVPLLGAMMLLESPIDPQPLSFKEPPLLLGVLHPNTKLRQAERLFENQLVGPESIAHIGDVMFTGTADGRVVKLENGEIETIARFGSGPCKTRDDEPVCGRPLGIRAGPNGTLFVADAYKGLFEVNPWKREVKLLLSSETPIEGKNMSFVNDLTVTQDGRKIYFTDSSSKWQRRDYLLLVMEGTDDGRLLEYDTVTREVKVLLDQLRFPNGVQLSPAEDFVLVAETTMARIRRVYVSGLMKGGADLFVENMPGFPDNIRPSSSGGYWVGMSTIRPNPGFSMLDFLSERPWIKRMIFKLFSQETVMKFVPRYSLVLELSDSGAFRRSLHDPDGLVATYISEVHEHDGHLYLGSFRSPFLCRLSLQAV>sp|Q9HDC9-2|APMAP_HUMAN Isoform 2 of Adipocyte plasma membrane-associated protein OS=Homo sapiens OX=9606 GN=APMAPMSEADGLRQRRPLRPQVVTDDDGQAPEAKDGSSFSGRVFRVTFLMLAVSLTVPLLGAMMLLESPIDPQPLSFKEPPLLLGVLHPNTKLRQAERLFENQLVGPESIAHIGDVMFTGTADGRVVKLENGEIETIARFGSGPCKTRDDEPVCGRPLGIRAGPNGTLFVADAYKGLFEVNPWKREVKLLLSSETPIEGKNMSFVNDLTVTQDGRKIYFTDSSSKWQRRDYLLLVMEGTDDGRLLEYDTVTREVKVLLDQLRFPNGVQLSPAEDFVLVAETTMARIRSSLVKRR>sp|B4E2M5|ANR66_HUMAN Ankyrin repeat domain-containing protein 66OS=Homo sapiens OX=9606 GN=ANKRD66 PE=2 SV=2MDTTLRMVRTACQHRAPQISHKTGCSHISMHSPGGLTTTKMAGPLPRVSDSLFSAMELAKMSDMTKLHQAVAAGDYSLVKKILKKGLCDPNYKDVDWNDRTPLHWAAIKGQMEVIRLLIEYGARPCLVTSVGWTPAHFAAEAGHLNILKTLHALHAAIDAPDFFGDTPKRIAQIYGQKACVAFLEKAEPECQDHRCAAQQKGLPLDERDEDWDAKKRELELSLPSLNQNMNKKNKKSRGPTRPSNTKGRRV>sp|P02749|APOH_HUMAN Beta-2-glycoprotein 1 OS=Homo sapiens OX=9606GN=APOH PE=1 SV=3MISPVLILFSSFLCHVAIAGRTCPKPDDLPFSTVVPLKTFYEPGEEITYSCKPGYVSRGGMRKFICPLTGLWPINTLKCTPRVCPFAGILENGAVRYTTFEYPNTISFSCNTGFYLNGADSAKCTEEGKWSPELPVCAPIICPPPSIPTFATLRVYKPSAGNNSLYRDTAVFECLPQHAMFGNDTITCTTHGNWTKLPECREVKCPFPSRPDNGFVNYPAKPTLYYKDKATFGCHDGYSLDGPEEIECTKLGNWSAMPSCKASCKVPVKKATVVYQGERVKIQEKFKNGMLHGDKVSFFCKNKEKKCSYTEDAQCIDGTIEVPKCFKEHSSLAFWKTDASDVKPC>sp|P48745|CCN3_HUMAN CCN family member 3 OS=Homo sapiens OX=9606 GN=CCN3PE=1 SV=1MQSVQSTSFCLRKQCLCLTFLLLHLLGQVAATQRCPPQCPGRCPATPPTCAPGVRAVLDGCSCCLVCARQRGESCSDLEPCDESSGLYCDRSADPSNQTGICTAVEGDNCVFDGVIYRSGEKFQPSCKFQCTCRDGQIGCVPRCQLDVLLPEPNCPAPRKVEVPGECCEKWICGPDEEDSLGGLTLAAYRPEATLGVEVSDSSVNCIEQTTEWTACSKSCGMGFSTRVTNRNRQCEMLKQTRLCMVRPCEQEPEQPTDKKGKKCLRTKKSLKAIHLQFKNCTSLHTYKPRFCGVCSDGRCCTPHNTKTIQAEFQCSPGQIVKKPVMVIGTCTCHTNCPKNNEAFLQELELKTTRGKM>sp|P27216|ANX13_HUMAN Annexin A13 OS=Homo sapiens OX=9606 GN=ANXA13 PE=1SV=3MGNRHAKASSPQGFDVDRDAKKLNKACKGMGTNEAAIIEILSGRTSDERQQIKQKYKATYGKELEEVLKSELSGNFEKTALALLDRPSEYAARQLQKAMKGLGTDESVLIEVLCTRTNKEIIAIKEAYQRLFDRSLESDVKGDTSGNLKKILVSLLQANRNEGDDVDKDLAGQDAKDLYDAGEGRWGTDELAFNEVLAKRSYKQLRATFQAYQILIGKDIEEAIEEETSGDLQKAYLTLVRCAQDCEDYFAERLYKSMKGAGTDEETLIRIVVTRAEVDLQGIKAKFQEKYQKSLSDMVRSDTSGDFRKLLVALLH>sp|P27216-2|ANX13_HUMAN Isoform B of Annexin A13 OS=Homo sapiens OX=9606GN=ANXA13MGNRHSQSYTLSEGSQQLPKGDSQPSTVVQPLSHPSRNGEPEAPQPAKASSPQGFDVDRDAKKLNKACKGMGTNEAAIIEILSGRTSDERQQIKQKYKATYGKELEEVLKSELSGNFEKTALALLDRPSEYAARQLQKAMKGLGTDESVLIEVLCTRTNKEIIAIKEAYQRLFDRSLESDVKGDTSGNLKKILVSLLQANRNEGDDVDKDLAGQDAKDLYDAGEGRWGTDELAFNEVLAKRSYKQLRATFQAYQILIGKDIEEAIEEETSGDLQKAYLTLVRCAQDCEDYFAERLYKSMKGAGTDEETLIRIVVTRAEVDLQGIKAKFQEKYQKSLSDMVRSDTSGDFRKLLVALLH>sp|P58335|ANTR2_HUMAN Anthrax toxin receptor 2 OS=Homo sapiens OX=9606GN=ANTXR2 PE=1 SV=5MVAERSPARSPGSWLFPGLWLLVLSGPGGLLRAQEQPSCRRAFDLYFVLDKSGSVANNWIEIYNFVQQLAERFVSPEMRLSFIVFSSQATIILPLTGDRGKISKGLEDLKRVSPVGETYIHEGLKLANEQIQKAGGLKTSSIIIALTDGKLDGLVPSYAEKEAKISRSLGASVYCVGVLDFEQAQLERIADSKEQVFPVKGGFQALKGIINSILAQSCTEILELQPSSVCVGEEFQIVLSGRGFMLGSRNGSVLCTYTVNETYTTSVKPVSVQLNSMLCPAPILNKAGETLDVSVSFNGGKSVISGSLIVTATECSNGIAAIIVILVLLLLLGIGLMWWFWPLCCKVVIKDPPPPPAPAPKEEEEEPLPTKKWPTVDASYYGGRGVGGIKRMEVRWGDKGSTEEGARLEKAKNAVVKIPEETEEPIRPRPPRPKPTHQPPQTKWYTPIKGRLDALWALLRRQYDRVSLMRPQEGDEVCIWECIEKELTA>sp|P58335-2|ANTR2_HUMAN Isoform 2 of Anthrax toxin receptor 2 OS=Homosapiens OX=9606 GN=ANTXR2MVAERSPARSPGSWLFPGLWLLVLSGPGGLLRAQEQPSCRRAFDLYFVLDKSGSVANNWIEIYNFVQQLAERFVSPEMRLSFIVFSSQATIILPLTGDRGKISKGLEDLKRVSPVGETYIHEGLKLANEQIQKAGGLKTSSIIIALTDGKLDGLVPSYAEKEAKISRSLGASVYCVGVLDFEQAQLERIADSKEQVFPVKGGFQALKGIINSSNGIAAIIVILVLLLLLGIGLMWWFWPLCCKVVIKDPPPPPAPAPKEEEEEPLPTKKWPTVDASYYGGRGVGGIKRMEVRWGDKGSTEEGARLEKAKNAVVKIPEETEEPIRPRPPRPKPTHQPPQTKWYTPIKGRLDALWALLRRQYDRVSLMRPQEGDEVCIWECIEKELTA>sp|P58335-3|ANTR2_HUMAN Isoform 3 of Anthrax toxin receptor 2 OS=Homosapiens OX=9606 GN=ANTXR2MVAERSPARSPGSWLFPGLWLLVLSGPGGLLRAQEQPSCRRAFDLYFVLDKSGSVANNWIEIYNFVQQLAERFVSPEMRLSFIVFSSQATIILPLTGDRGKISKGLEDLKRVSPVGETYIHEGLKLANEQIQKAGGLKTSSIIIALTDGKLDGLVPSYAEKEAKISRSLGASVYCVGVLDFEQAQLERIADSKEQVFPVKGGFQALKGIINSILAQSCTEILELQPSSVCVGEEFQIVLSGRGFMLGSRNGSVLCTYTVNETYTTSVKPVSVQLNSMLCPAPILNKAGEWGLTVTQAGVKWHDLTHCTFGLSGSGDPPTSAS>sp|P58335-4|ANTR2_HUMAN Isoform 4 of Anthrax toxin receptor 2 OS=Homosapiens OX=9606 GN=ANTXR2MVAERSPARSPGSWLFPGLWLLVLSGPGGLLRAQEQPSCRRAFDLYFVLDKSGSVANNWIEIYNFVQQLAERFVSPEMRLSFIVFSSQATIILPLTGDRGKISKGLEDLKRVSPVGETYIHEGLKLANEQIQKAGGLKTSSIIIALTDGKLDGLVPSYAEKEAKISRSLGASVYCVGVLDFEQAQLERIADSKEQVFPVKGGFQALKGIINSILAQSCTEILELQPSSVCVGEEFQIVLSGRGFMLGSRNGSVLCTYTVNETYTTSVKPVSVQLNSMLCPAPILNKAGETLDVSVSFNGGKSVISGSLIVTATECSNGIAAIIVILVLLLLLGIGLMWWFWPLCCKVVIKDPPPPPAPAPKEEEEEPLPTKKWPTVDASYYGGRGVGGIKRMEVRWGDKGSTEEGARLEKAKNAVVKIPEETEEPIRPRPPRPKPTHQPPQTKWYTPIKGRLDALWALLRRQYDRVSLMRPQEGDEGRCINFSRVPSQ>sp|P20073|ANXA7_HUMAN Annexin A7 OS=Homo sapiens OX=9606 GN=ANXA7 PE=1SV=3MSYPGYPPTGYPPFPGYPPAGQESSFPPSGQYPYPSGFPPMGGGAYPQVPSSGYPGAGGYPAPGGYPAPGGYPGAPQPGGAPSYPGVPPGQGFGVPPGGAGFSGYPQPPSQSYGGGPAQVPLPGGFPGGQMPSQYPGGQPTYPSQINTDSFSSYPVFSPVSLDYSSEPATVTQVTQGTIRPAANFDAIRDAEILRKAMKGFGTDEQAIVDVVANRSNDQRQKIKAAFKTSYGKDLIKDLKSELSGNMEELILALFMPPTYYDAWSLRKAMQGAGTQERVLIEILCTRTNQEIREIVRCYQSEFGRDLEKDIRSDTSGHFERLLVSMCQGNRDENQSINHQMAQEDAQRLYQAGEGRLGTDESCFNMILATRSFPQLRATMEAYSRMANRDLLSSVSREFSGYVESGLKTILQCALNRPAFFAERLYYAMKGAGTDDSTLVRIVVTRSEIDLVQIKQMFAQMYQKTLGTMIAGDTSGDYRRLLLAIVGQ>sp|P20073-2|ANXA7_HUMAN Isoform 2 of Annexin A7 OS=Homo sapiens OX=9606GN=ANXA7MSYPGYPPTGYPPFPGYPPAGQESSFPPSGQYPYPSGFPPMGGGAYPQVPSSGYPGAGGYPAPGGYPAPGGYPGAPQPGGAPSYPGVPPGQGFGVPPGGAGFSGYPQPPSQSYGGGPAQVPLPGGFPGGQMPSQYPGGQPTYPSQPATVTQVTQGTIRPAANFDAIRDAEILRKAMKGFGTDEQAIVDVVANRSNDQRQKIKAAFKTSYGKDLIKDLKSELSGNMEELILALFMPPTYYDAWSLRKAMQGAGTQERVLIEILCTRTNQEIREIVRCYQSEFGRDLEKDIRSDTSGHFERLLVSMCQGNRDENQSINHQMAQEDAQRLYQAGEGRLGTDESCFNMILATRSFPQLRATMEAYSRMANRDLLSSVSREFSGYVESGLKTILQCALNRPAFFAERLYYAMKGAGTDDSTLVRIVVTRSEIDLVQIKQMFAQMYQKTLGTMIAGDTSGDYRRLLLAIVGQ>sp|P16860|ANFB_HUMAN Natriuretic peptides B OS=Homo sapiens OX=9606GN=NPPB PE=1 SV=1MDPQTAPSRALLLLLFLHLAFLGGRSHPLGSPGSASDLETSGLQEQRNHLQGKLSELQVEQTSLEPLQESPRPTGVWKSREVATEGIRGHRKMVLYTLRAPRSPKMVQGSGCFGRKMDRISSSSGLGCKVLRRH>sp|Q7Z5J8|ANKAR_HUMAN Ankyrin and armadillo repeat-containing proteinOS=Homo sapiens OX=9606 GN=ANKAR PE=2 SV=3MLRLPKKGLPRFEQVQDEDTYLENLAIQRNASAFFEKYDRSEIQELLTTALVSWLSAKEDVRSQVDLPCGIMSQMNNVGFSTAILLTPVDPTALLDYREVHQMIRELAIGIYCLNQIPSISLEANYDQSSSCQLPPAYYDTRIGQILINIDYMLKALWHGIYMPKEKRARFSELWRAIMDIDPDGKPQTNKDIFSEFSSAGLTDITKDPDFNEIYDEDVNEDPTYDPNSPEETAVFMKYAENIMLKLTFSTTQIQQYENVFIFETGYWLTNAIKYNQDYLDICTYQRLQQRLYLQKKIIQKHFEKKKDIRRGIGYLKLICFLIPFLLSLKKKMKVPYLSSLLQPFSDDKVKTERELPPFIYGRDFKCQNFHYKENQYFHVHGGIEFDISTPSIENALEDFQKNLEKIRDCAANTFIEDSGYKEYYSIPVMEFHGKSYYVIYFELETFYQQLYKTQWWGAINEIVNNLRLKRLPLTDAQLHEQFKKKLGFKRAMKCKSIPFGMKSAVERGLSAVFHTFSRKTSSSTINVSDEAGYTIFHHAALHNRVSIICQLCNANFKVNQRRFVTFSQGPTPLHLAAQACSLETTVCLLCSKADYTLSEKRGWMPIHFAAFYDNVCIIIALCRKDPSLLEAEATAENQCTPLLLAATSGALDTIQYLFSIGANWRKTDIKGNNIIHLSVLTFHTEVLKYIIKLNIPELPVWKTLVEMLQCESYKRRMMAVMSLEVICLANDQYWRCILDAGTIPALINLLKSSKIKLQCKTVGLLSNISTHKSAVHALVEAGGIPSLINLLVCDEPEVHSRCAVILYDIAQCENKDVIAKYNGIPSLINLLNLNIENVLVNVMNCIRVLCIGNENNQRAVREHKGLPYLIRFLSSDSDVLKAVSSAAIAEVGRDNKEIQDAIAMEGAIPPLVALFKGKQISVQMKGAMAVESLASHNALIQKAFLEKSLTKYLLKLLKAFQIDVKEQGAVALWALAGQTLKQQKYMAEQIGYSFIINMLLSPSAKMQYVGGEAVIALSKDSRMHQNQICEGNGIAPLVRLLRISTIAEGTLLSVIRAVGSICIGVAHTSNPVSQQLVVDENAFPVLIQLLRNHPSPNIKVEVAFSLACIVLGNDVLQKDLHENEGFEYADVLYLLHSTEKDICLRAGYALTLFAFNNRFQQYLILESGIMTISIFERFLESTVETEKAMAAFQIVVLAKVIRDMDHITLSARGVTILVDSLYSVQTSTIVLTGNLIASLAHSRAGIPEAFTTLGTIQRLCYHLYSGIEEVRAACSSALGYLTYNANAFRILLKECRNKPNQFIRIKNNISRDASINPAFLKEFQMQQTLVGLPSLSLEKNGGPSIIPIFKRGKEHRRKLKPKIQPKDSLTLLPPVTNFMGLFKATKKTKDSHNIFSFSSTITSDITNVSRPRIVCLNQLGKHVQKANPEPAEG>sp|Q7Z5J8-2|ANKAR_HUMAN Isoform 2 of Ankyrin and armadillo repeat-containing protein OS=Homo sapiens OX=9606 GN=ANKARMLRLPKKGLPRFEQVQDEDTYLENLAIQRNASAFFEKYDRSEIQELLTTALVSWLSAKEDVRSQVDLPCGIMSQMNNVGFSTAILLTPVDPTALLDYREVHQMIRELAIGIYCLNQIPSISLEANYDQSSSCQLPPAYYDTRIGQILINIDYMLKALWHGIYMPKEKRARFSELWRAIMDIDPDGKPQTNKDIFSEFSSAGLTDITKDPDFNEIYDEDVNEDPTYDPNSPEETAVFMKYAENIMLKLTFSTTQIQQYENVFIFETGYWLTNAIKYNQDYLDICTYQRLQQRLYLQKKIIQKHFEKKKDIRRGIGYLKLICFLIPFLLSLKKKMKVPYLSSLLQPFSDDKVKTERELPPFIYGRDFKCQNFHYKENQYFHVHGGIEFDISTPSIENALEDFQKNLEKIRDCAANTFIEDSGYKEYYSIPVMEFHGKSYYVIYFELETFYQQLYKTQWWGAINEIVNNLRLKRLPLTDAQLHEQFKKKLGFKRAMKCKSIPFGMKSAVERGLSAVFHTFSRKTSSSTINVSDEAGYTIFHHAALHNRVSIICQLCNANFKVNQRRFVTFSQGPTPLHLAAQACSLETTVCLLCSKADYTLSEKRGWMPIHFAAFYDNVCIIIALCRKDPSLLEAEATAENQCTPLLLAATSGALDTIQYLFSIGANWRKTDIKGNNIIHLSVLTFHTEVLKYIIKLNIPELPVWKTLVEMLQCESYKRRMMAVMSLEVICLANDQYWRCILDAGTIPALINLLKSSKIKLQCKTVGLLSNISTHKSAVHALVEAGGIPSLINLLVCDEPEVHSRCAVILYDIAQCENKDVIAKYNGIPSLINLLNLNIENVLVNVMNCIRVLCIGNENNQRAVREHKGLPYLIRFLSSDSDVLKAVSSAAIAEVGRDNKEIQDAIAMEGAIPPLVALFKGKQISVQMKGAMAVESLASHNALIQKAFLEKSLTKYLLKLLKAFQIDVKEQGAVALWALAGQTLKQQKYMAEQIGYSFIINMLLSPSAKMQYVGGEAVIALSKDSRMHQNQICEGNGIAPLVRLLRISTIAEGTLLSVIRAVGSICIGYLLKSRLCINTFCLQ>sp|Q7Z5J8-3|ANKAR_HUMAN Isoform 3 of Ankyrin and armadillo repeat-containing protein OS=Homo sapiens OX=9606 GN=ANKARMKYAENIMLKLTFSTTQIQQYENVFIFETGYWLTNAIKYNQDYLDICTYQRLQQRLYLQKKIIQKHFEKKKDIRRGIGYLKLICFLIPFLLSLKKKMKVPYLSSLLQPFSDDKVKTERELPPFIYGRDFKCQNFHYKENQYFHVHGGIEFDISTPSIENALEDFQKNLEKIRDCAANTFIEDSGYKEYYSIPVMEFHGKSYYVIYFELETFYQQLYKTQWWGAINEIVNNLRLKRLPLTDAQLHEQFKKKLGFKRAMKCKSIPFGMKSAVERGLSAVFHTFSRKTSSSTINVSDEAGYTIFHHAALHNRVSIICQLCNANFKVNQRRFVTFSQGPTPLHLAAQACSLETTVCLLCSKADYTLSEKRGWMPIHFAAFYDNVCIIIALCRKDPSLLEAEATAENQCTPLLLAATSGALDTIQYLFSIGANWRKTDIKGNNIIHLSVLTFHTEVLKYIIKLNIPELPVWKTLVEMLQCESYKRRMMAVMSLEVICLANDQYWRCILDAGTIPALINLLKSSKIKLQCKTVGLLSNISTHKSAVHALVEAGGIPSLINLLVCDEPEVHSRCAVILYDIAQCENKDVIAKYNGIPSLINLLNLNIENVLVNVMNCIRVLCIGNENNQRAVREHKGLPYLIRFLSSDSGLFNLFLNSFEDVLKAVSSAAIAEVGRDNKEIQDAIAMEGAIPPLVALFKGKQISVQMKGAMAVESLASHNALIQKAFLEKSLTKYLLKLLKAFQIDVKEQGAVALWALAGQTLKQQKYMAEQIGYSFIINMLLSPSAKMQYVGYLLKSRLCINTFCLQ>sp|Q7Z5J8-4|ANKAR_HUMAN Isoform 4 of Ankyrin and armadillo repeat-containing protein OS=Homo sapiens OX=9606 GN=ANKARMKVPYLSSLLQPFSDDKVKTERELPPFIYGRDFKCQNFHYKENQYFHVHGGIEFDISTPSIENALEDFQKNLEKIRDCAANTFIEDSGYKEYYSIPVMEFHGKSYYVIYFELETFYQQLYKTQWWGAINEIVNNLRLKRLPLTDAQLHEQFKKKLGFKRAMKCKSIPFGMKSAVERGLSAVFHTFSRKTSSSTINVSDEAGYTIFHHAALHNRVSIICQLCNANFKVNQRRFVTFSQGPTPLHLAAQACSLETTVCLLCSKADYTLSEKRGWMPIHFAAFYDNVCIIIALCRKDPSLLEAEATAENQCTPLLLAATSGALDTIQYLFSIGANWRKTDIKGNNIIHLSVLTFHTEVLKYIIKLNIPELPVWKTLKCYSVKAINEG>sp|P20248|CCNA2_HUMAN Cyclin-A2 OS=Homo sapiens OX=9606 GN=CCNA2 PE=1SV=2MLGNSAPGPATREAGSALLALQQTALQEDQENINPEKAAPVQQPRTRAALAVLKSGNPRGLAQQQRPKTRRVAPLKDLPVNDEHVTVPPWKANSKQPAFTIHVDEAEKEAQKKPAESQKIEREDALAFNSAISLPGPRKPLVPLDYPMDGSFESPHTMDMSIILEDEKPVSVNEVPDYHEDIHTYLREMEVKCKPKVGYMKKQPDITNSMRAILVDWLVEVGEEYKLQNETLHLAVNYIDRFLSSMSVLRGKLQLVGTAAMLLASKFEEIYPPEVAEFVYITDDTYTKKQVLRMEHLVLKVLTFDLAAPTVNQFLTQYFLHQQPANCKVESLAMFLGELSLIDADPYLKYLPSVIAGAAFHLALYTVTGQSWPESLIRKTGYTLESLKPCLMDLHQTYLKAPQHAQQSIREKYKNSKYHGVSLLNPPETLNL>sp|P08243|ASNS_HUMAN Asparagine synthetase [glutamine-hydrolyzing]OS=Homo sapiens OX=9606 GN=ASNS PE=1 SV=4MCGIWALFGSDDCLSVQCLSAMKIAHRGPDAFRFENVNGYTNCCFGFHRLAVVDPLFGMQPIRVKKYPYLWLCYNGEIYNHKKMQQHFEFEYQTKVDGEIILHLYDKGGIEQTICMLDGVFAFVLLDTANKKVFLGRDTYGVRPLFKAMTEDGFLAVCSEAKGLVTLKHSATPFLKVEPFLPGHYEVLDLKPNGKVASVEMVKYHHCRDVPLHALYDNVEKLFPGFEIETVKNNLRILFNNAVKKRLMTDRRIGCLLSGGLDSSLVAATLLKQLKEAQVQYPLQTFAIGMEDSPDLLAARKVADHIGSEHYEVLFNSEEGIQALDEVIFSLETYDITTVRASVGMYLISKYIRKNTDSVVIFSGEGSDELTQGYIYFHKAPSPEKAEEESERLLRELYLFDVLRADRTTAAHGLELRVPFLDHRFSSYYLSLPPEMRIPKNGIEKHLLRETFEDSNLIPKEILWRPKEAFSDGITSVKNSWFKILQEYVEHQVDDAMMANAAQKFPFNTPKTKEGYYYRQVFERHYPGRADWLSHYWMPKWINATDPSARTLTHYKSAVKA>sp|P08243-2|ASNS_HUMAN Isoform 2 of Asparagine synthetase [glutamine-hydrolyzing] OS=Homo sapiens OX=9606 GN=ASNSMKIAHRGPDAFRFENVNGYTNCCFGFHRLAVVDPLFGMQPIRVKKYPYLWLCYNGEIYNHKKMQQHFEFEYQTKVDGEIILHLYDKGGIEQTICMLDGVFAFVLLDTANKKVFLGRDTYGVRPLFKAMTEDGFLAVCSEAKGLVTLKHSATPFLKVEPFLPGHYEVLDLKPNGKVASVEMVKYHHCRDVPLHALYDNVEKLFPGFEIETVKNNLRILFNNAVKKRLMTDRRIGCLLSGGLDSSLVAATLLKQLKEAQVQYPLQTFAIGMEDSPDLLAARKVADHIGSEHYEVLFNSEEGIQALDEVIFSLETYDITTVRASVGMYLISKYIRKNTDSVVIFSGEGSDELTQGYIYFHKAPSPEKAEEESERLLRELYLFDVLRADRTTAAHGLELRVPFLDHRFSSYYLSLPPEMRIPKNGIEKHLLRETFEDSNLIPKEILWRPKEAFSDGITSVKNSWFKILQEYVEHQVDDAMMANAAQKFPFNTPKTKEGYYYRQVFERHYPGRADWLSHYWMPKWINATDPSARTLTHYKSAVKA>sp|P08243-3|ASNS_HUMAN Isoform 3 of Asparagine synthetase [glutamine-hydrolyzing] OS=Homo sapiens OX=9606 GN=ASNSMQQHFEFEYQTKVDGEIILHLYDKGGIEQTICMLDGVFAFVLLDTANKKVFLGRDTYGVRPLFKAMTEDGFLAVCSEAKGLVTLKHSATPFLKVEPFLPGHYEVLDLKPNGKVASVEMVKYHHCRDVPLHALYDNVEKLFPGFEIETVKNNLRILFNNAVKKRLMTDRRIGCLLSGGLDSSLVAATLLKQLKEAQVQYPLQTFAIGMEDSPDLLAARKVADHIGSEHYEVLFNSEEGIQALDEVIFSLETYDITTVRASVGMYLISKYIRKNTDSVVIFSGEGSDELTQGYIYFHKAPSPEKAEEESERLLRELYLFDVLRADRTTAAHGLELRVPFLDHRFSSYYLSLPPEMRIPKNGIEKHLLRETFEDSNLIPKEILWRPKEAFSDGITSVKNSWFKILQEYVEHQVDDAMMANAAQKFPFNTPKTKEGYYYRQVFERHYPGRADWLSHYWMPKWINATDPSARTLTHYKSAVKA>sp|O95260|ATE1_HUMAN Arginyl-tRNA--protein transferase 1 OS=Homo sapiensOX=9606 GN=ATE1 PE=1 SV=2MAFWAGGSPSVVDYFPSEDFYRCGYCKNESGSRSNGMWAHSMTVQDYQDLIDRGWRRSGKYVYKPVMNQTCCPQYTIRCRPLQFQPSKSHKKVLKKMLKFLAKGEVPKGSCEDEPMDSTMDDAVAGDFALINKLDIQCDLKTLSDDIKESLESEGKNSKKEEPQELLQSQDFVGEKLGSGEPSHSVKVHTVPKPGKGADLSKPPCRKAKEIRKERKRLKLMQQNPAGELEGFQAQGHPPSLFPPKAKSNQPKSLEDLIFESLPENASHKLEVRVVRSSPPSSQFKATLLESYQVYKRYQMVIHKNPPDTPTESQFTRFLCSSPLEAETPPNGPDCGYGSFHQQYWLDGKIIAVGVIDILPNCVSSVYLYYDPDYSFLSLGVYSALREIAFTRQLHEKTSQLSYYYMGFYIHSCPKMKYKGQYRPSDLLCPETYVWVPIEQCLPSLENSKYCRFNQDPEAVDEDRSTEPDRLQVFHKRAIMPYGVYKKQQKDPSEEAAVLQYASLVGQKCSERMLLFRN>sp|O95260-2|ATE1_HUMAN Isoform ATE1-2 of Arginyl-tRNA--proteintransferase 1 OS=Homo sapiens OX=9606 GN=ATE1MAFWAGGSPSVVDYFPSEDFYRCGYCKNESGSRSNGMWAHSMTVQDYQDLIDRGWRRSGKYVYKPVMNQTCCPQYTIRCRPLQFQPSKSHKKVLKKMLKFLAKGEVPKGSCEDEPMDSTMDDAVAGDFALINKLDIQCDLKTLSDDIKESLESEGKNSKKEEPQELLQSQDFVGEKLGSGEPSHSVKVHTVPKPGKGADLSKPPCRKAKEIRKERKRLKLMQQNPAGELEGFQAQGHPPSLFPPKAKSNQPKSLEDLIFESLPENASHKLEVRLVPVSFEDPEFKSSFSQSFSLYVKYQVAIHQDPPDECGKTEFTRFLCSSPLEAETPPNGPDCGYGSFHQQYWLDGKIIAVGVIDILPNCVSSVYLYYDPDYSFLSLGVYSALREIAFTRQLHEKTSQLSYYYMGFYIHSCPKMKYKGQYRPSDLLCPETYVWVPIEQCLPSLENSKYCRFNQDPEAVDEDRSTEPDRLQVFHKRAIMPYGVYKKQQKDPSEEAAVLQYASLVGQKCSERMLLFRN>sp|P05496|AT5G1_HUMAN ATP synthase F(0) complex subunit C1,mitochondrial OS=Homo sapiens OX=9606 GN=ATP5MC1 PE=1 SV=2MQTAGALFISPALIRCCTRGLIRPVSASFLNSPVNSSKQPSYSNFPLQVARREFQTSVVSRDIDTAAKFIGAGAATVGVAGSGAGIGTVFGSLIIGYARNPSLKQQLFSYAILGFALSEAMGLFCLMVAFLILFAM>sp|Q9BZE9|ASPC1_HUMAN Tether containing UBX domain for GLUT4 OS=Homosapiens OX=9606 GN=ASPSCR1 PE=1 SV=1MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLFITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGALVPPEPIPGTAQPVKRSLGKVPKWLKLPASKR>sp|Q9BZE9-2|ASPC1_HUMAN Isoform 2 of Tether containing UBX domain forGLUT4 OS=Homo sapiens OX=9606 GN=ASPSCR1MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLFITPPKTVLDDHTQTLFQPQLGDRVAPFTLGPSLKRCLGPEQRTRLPVVGDGGDVDSGRLLFWGPSRGRASPSTGQPPCHPVCRPSSPPSPRPSSGDPSRVKAGHKHVGTGRANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGALVPPEPIPGTAQPVKRSLGKVPKWLKLPASKR>sp|Q9BZE9-3|ASPC1_HUMAN Isoform 3 of Tether containing UBX domain forGLUT4 OS=Homo sapiens OX=9606 GN=ASPSCR1MVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLCLSSFGRMDGRGPRCFLTRRCLLSSVITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGALVPPEPIPGTAQPVKRSLGKVPKWLKLPASKR>sp|Q9BZE9-4|ASPC1_HUMAN Isoform 4 of Tether containing UBX domain forGLUT4 OS=Homo sapiens OX=9606 GN=ASPSCR1MVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPRRSLSLSPRLESVVPSQLTASSASRVQVVLLPQPPK>sp|Q5VTU8|AT5EL_HUMAN ATP synthase subunit epsilon-like protein,mitochondrial OS=Homo sapiens OX=9606 GN=ATP5F1EP2 PE=1 SV=1MVAYWRQAGLSYIRYSQICAKVVRDALKTEFKANAKKTSGNSVKIVKVKKE>sp|Q9Y574|ASB4_HUMAN Ankyrin repeat and SOCS box protein 4 OS=Homosapiens OX=9606 GN=ASB4 PE=1 SV=1MDGTTAPVTKSGAAKLVKRNFLEALKSNDFGKLKAILIQRQIDVDTVFEVEDENMVLASYKQGYWLPSYKLKSSWATGLHLSVLFGHVECLLVLLDHNATINCRPNGKTPLHVACEMANVDCVKILCDRGAKLNCYSLSGHTALHFCTTPSSILCAKQLVWRGANVNMKTNNQDEETPLHTAAHFGLSELVAFYVEHGAIVDSVNAHMETPLAIAAYWALRFKEQEYSTEHHLVCRMLLDYKAEVNARDDDFKSPLHKAAWNCDHVLMHMMLEAGAEANLMDINGCAAIQYVLKVTSVRPAAQPEICYQLLLNHGAARIYPPQFHKVIQACHSCPKAIEVVVNAYEHIRWNTKWRRAIPDDDLEKYWDFYHSLFTVCCNSPRTLMHLSRCAIRRTLHNRCHRAIPLLSLPLSLKKYLLLEPEGIIY>sp|Q9Y574-2|ASB4_HUMAN Isoform 2 of Ankyrin repeat and SOCS box protein4 OS=Homo sapiens OX=9606 GN=ASB4MDGTTAPVTKSGAAKLVKRNFLEALKSNDFGKLKAILIQRQIDVDTVFEVEDENMVLASYKQGYWLPSYKLKSSWATGLHLSVLFGHVECLLVLLDHNATINCRPNGKTPLHVACEMANVDCVKILCDRGAKLNCYSLSGHTALHFCTTPSSILCAKQLVWRGANVNMKTNNQDEETPLHTAAHFGLSELVAFYVEHGAIVDSVNAHMETPLAIAAYWALRFKEQEYSTEHHLVCRMLLDYKAEVNARDDDFKSPLHKAAWNCDHVLMHMMLEAGAEANLMDINGCAAIQYVLKVTSVRPAAQPEICYQLLLNHGAARIYPPQFHKVRLCPVVSRLRKIQMAALSEISK>sp|P17405|ASM_HUMAN Sphingomyelin phosphodiesterase OS=Homo sapiensOX=9606 GN=SMPD1 PE=1 SV=5MPRYGASLRQSCPRSGREQGQDGTAGAPGLLWMGLVLALALALALALALSDSRVLWAPAEAHPLSPQGHPARLHRIVPRLRDVFGWGNLTCPICKGLFTAINLGLKKEPNVARVGSVAIKLCNLLKIAPPAVCQSIVHLFEDDMVEVWRRSVLSPSEACGLLLGSTCGHWDIFSSWNISLPTVPKPPPKPPSPPAPGAPVSRILFLTDLHWDHDYLEGTDPDCADPLCCRRGSGLPPASRPGAGYWGEYSKCDLPLRTLESLLSGLGPAGPFDMVYWTGDIPAHDVWHQTRQDQLRALTTVTALVRKFLGPVPVYPAVGNHESTPVNSFPPPFIEGNHSSRWLYEAMAKAWEPWLPAEALRTLRIGGFYALSPYPGLRLISLNMNFCSRENFWLLINSTDPAGQLQWLVGELQAAEDRGDKVHIIGHIPPGHCLKSWSWNYYRIVARYENTLAAQFFGHTHVDEFEVFYDEETLSRPLAVAFLAPSATTYIGLNPGYRVYQIDGNYSGSSHVVLDHETYILNLTQANIPGAIPHWQLLYRARETYGLPNTLPTAWHNLVYRMRGDMQLFQTFWFLYHKGHPPSEPCGTPCRLATLCAQLSARADSPALCRHLMPDGSLPEAQSLWPRPLFC>sp|P17405-2|ASM_HUMAN Isoform 2 of Sphingomyelin phosphodiesteraseOS=Homo sapiens OX=9606 GN=SMPD1MPRYGASLRQSCPRSGREQGQDGTAGAPGLLWMGLVLALALALALALALSDSRVLWAPAEAHPLSPQGHPARLHRIVPRLRDVFGWGNLTCPICKGLFTAINLGLKKEPNVARVGSVAIKLCNLLKIAPPAVCQSIVHLFEDDMVEVWRRSVLSPSEACGLLLGSTCGHWDIFSSWNISLPTVPKPPPKPPSPPAPGAPVSRILFLTDLHWDHDYLEGTDPDCADPLCCRRGSGLPPASRPGAGYWGEYSKCDLPLRTLESLLSGLGPAGPFDMVYWTGDIPAHDVWHQTRQDQLRALTTVTALVRKFLGPVPVYPAVGNHESTPVNSFPPPFIEGNHSSRWLYEAMAKAWEPWLPAEALRTLRYLSSVETQEGKRKVHIIGHIPPGHCLKSWSWNYYRIVARYENTLAAQFFGHTHVDEFEVFYDEETLSRPLAVAFLAPSATTYIGLNPGYRVYQIDGNYSGSSHVVLDHETYILNLTQANIPGAIPHWQLLYRARETYGLPNTLPTAWHNLVYRMRGDMQLFQTFWFLYHKGHPPSEPCGTPCRLATLCAQLSARADSPALCRHLMPDGSLPEAQSLWPRPLFC>sp|P17405-3|ASM_HUMAN Isoform 3 of Sphingomyelin phosphodiesteraseOS=Homo sapiens OX=9606 GN=SMPD1MPRYGASLRQSCPRSGREQGQDGTAGAPGLLWMGLVLALALALALALALSDSRVLWAPAEAHPLSPQGHPARLHRIVPRLRDVFGWGNLTCPICKGLFTAINLGLKKEPNVARVGSVAIKLCNLLKIAPPAVCQSIVHLFEDDMVEVWRRSVLSPSEACGLLLGSTCGHWDIFSSWNISLPTVPKPPPKPPSPPAPGAPVSRILFLTDLHWDHDYLEGTDPDCADPLCCRRGSGLPPASRPGAGYWGEYSKCDLPLRTLESLLSGLGPAGPFDMVYWTGDIPAHDVWHQTRQDQLRALTTVTALVRKFLGPVPVYPAVGNHESTPVNSFPPPFIEGNHSSRWLYEAMAKAWEPWLPAEALRTLRKVHIIGHIPPGHCLKSWSWNYYRIVARYENTLAAQFFGHTHVDEFEVFYDEETLSRPLAVAFLAPSATTYIGLNPGYRVYQIDGNYSGSSHVVLDHETYILNLTQANIPGAIPHWQLLYRARETYGLPNTLPTAWHNLVYRMRGDMQLFQTFWFLYHKGHPPSEPCGTPCRLATLCAQLSARADSPALCRHLMPDGSLPEAQSLWPRPLFC>sp|P17405-4|ASM_HUMAN Isoform 4 of Sphingomyelin phosphodiesteraseOS=Homo sapiens OX=9606 GN=SMPD1MPRYGASLRQSCPRSGREQGQDGTAGAPGLLWMGLVLALALALALALALSDSRVLWAPAEAHPLSPQGHPARLHRIVPRLRDVFGWGNLTCPICKGLFTAINLGLKEPNVARVGSVAIKLCNLLKIAPPAVCQSIVHLFEDDMVEVWRRSVLSPSEACGLLLGSTCGHWDIFSSWNISLPTVPKPPPKPPSPPAPGAPVSRILFLTDLHWDHDYLEGTDPDCADPLCCRRGSGLPPASRPGAGYWGEYSKCDLPLRTLESLLSGLGPAGPFDMVYWTGDIPAHDVWHQTRQDQLRALTTVTALVRKFLGPVPVYPAVGNHESTPVNSFPPPFIEGNHSSRWLYEAMAKAWEPWLPAEALRTLRIGGFYALSPYPGLRLISLNMNFCSRENFWLLINSTDPAGQLQWLVGELQAAEDRGDKVHIIGHIPPGHCLKSWSWNYYRIVARYENTLAAQFFGHTHVDEFEVFYDEETLSRPLAVAFLAPSATTYIGLNPGYRVYQIDGNYSGSSHVVLDHETYILNLTQANIPGAIPHWQLLYRARETYGLPNTLPTAWHNLVYRMRGDMQLFQTFWFLYHKGHPPSEPCGTPCRLATLCAQLSARADSPALCRHLMPDGSLPEAQSLWPRPLFC>sp|P46597|ASMT_HUMAN Acetylserotonin O-methyltransferase OS=Homo sapiensOX=9606 GN=ASMT PE=1 SV=1MGSSEDQAYRLLNDYANGFMVSQVLFAACELGVFDLLAEAPGPLDVAAVAAGVRASAHGTELLLDICVSLKLLKVETRGGKAFYRNTELSSDYLTTVSPTSQCSMLKYMGRTSYRCWGHLADAVREGRNQYLETFGVPAEELFTAIYRSEGERLQFMQALQEVWSVNGRSVLTAFDLSVFPLMCDLGGGAGALAKECMSLYPGCKITVFDIPEVVWTAKQHFSFQEEEQIDFQEGDFFKDPLPEADLYILARVLHDWADGKCSHLLERIYHTCKPGGGILVIESLLDEDRRGPLLTQLYSLNMLVQTEGQERTPTHYHMLLSSAGFRDFQFKKTGAIYDAILARK>sp|P46597-2|ASMT_HUMAN Isoform 2 of Acetylserotonin O-methyltransferaseOS=Homo sapiens OX=9606 GN=ASMTMGSSEDQAYRLLNDYANGFMVSQVLFAACELGVFDLLAEAPGPLDVAAVAAGVRASAHGTELLLDICVSLKLLKVETRGGKAFYRNTELSSDYLTTVSPTSQCSMLKYMGRTSYRCWGHLADAVREGRNQYLETFGVPAEELFTAIYRSEGERLQFMQALQEVWSVNGRSVLTAFDLSVFPLMCDLGGDFFKDPLPEADLYILARVLHDWADGKCSHLLERIYHTCKPGGGILVIESLLDEDRRGPLLTQLYSLNMLVQTEGQERTPTHYHMLLSSAGFRDFQFKKTGAIYDAILARK>sp|P46597-3|ASMT_HUMAN Isoform 3 of Acetylserotonin O-methyltransferaseOS=Homo sapiens OX=9606 GN=ASMTMGSSEDQAYRLLNDYANGFMVSQVLFAACELGVFDLLAEAPGPLDVAAVAAGVRASAHGTELLLDICVSLKLLKVETRGGKAFYRNTELSSDYLTTVSPTSQCSMLKYMGRTSYRCWGHLADAVREGRNQYLETFGVPAEELFTAIYRSEGERLQFMQALQEVWSVNGRSVLTAFDLSVFPLMCDLGGTWIKLETIILSKLSQGQKTKHRVFSLIGGAGALAKECMSLYPGCKITVFDIPEVVWTAKQHFSFQEEEQIDFQEGDFFKDPLPEADLYILARVLHDWADGKCSHLLERIYHTCKPGGGILVIESLLDEDRRGPLLTQLYSLNMLVQTEGQERTPTHYHMLLSSAGFRDFQFKKTGAIYDAILARK>sp|Q7RTU5|ASCL5_HUMAN Achaete-scute homolog 5 OS=Homo sapiens OX=9606GN=ASCL5 PE=3 SV=2MPMGAAERGAGPQSSAAPWAGSEKAAKRGPSKSWYPRAAASDVTCPTGGDGADPKPGPFGGGLALGPAPRGTMNNNFCRALVDRRPLGPPSCMQLGVMPPPRQAPLPPAEPLGNVPFLLYPGPAEPPYYDAYAGVFPYVPFPGAFGVYEYPFEPAFIQKRNERERQRVKCVNEGYARLRGHLPGALAEKRLSKVETLRAAIRYIKYLQELLSSAPDGSTPPASRGLPGTGPCPAPPATPRPDRPGDGEARAPSSLVPESSESSCFSPSPFLESEESWH>sp|Q6ICH7|ASPH2_HUMAN Aspartate beta-hydroxylase domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=ASPHD2 PE=2 SV=1MVWAPLGPPRTDCLTLLHTPSKDSPKMSLEWLVAWSWSLDGLRDCIATGIQSVRDCDTTAVITVACLLVLFVWYCYHVGREQPRPYVSVNSLMQAADANGLQNGYVYCQSPECVRCTHNEGLNQKLYHNLQEYAKRYSWSGMGRIHKGIREQGRYLNSRPSIQKPEVFFLPDLPTTPYFSRDAQKHDVEVLERNFQTILCEFETLYKAFSNCSLPQGWKMNSTPSGEWFTFYLVNQGVCVPRNCRKCPRTYRLLGSLRTCIGNNVFGNACISVLSPGTVITEHYGPTNIRIRCHLGLKTPNGCELVVGGEPQCWAEGRCLLFDDSFLHAAFHEGSAEDGPRVVFMVDLWHPNVAAAERQALDFIFAPGR>sp|Q07065|CKAP4_HUMAN Cytoskeleton-associated protein 4 OS=Homo sapiensOX=9606 GN=CKAP4 PE=1 SV=2MPSAKQRGSKGGHGAASPSEKGAHPSGGADDVAKKPPPAPQQPPPPPAPHPQQHPQQHPQNQAHGKGGHRGGGGGGGKSSSSSSASAAAAAAAASSSASCSRRLGRALNFLFYLALVAAAAFSGWCVHHVLEEVQQVRRSHQDFSRQREELGQGLQGVEQKVQSLQATFGTFESILRSSQHKQDLTEKAVKQGESEVSRISEVLQKLQNEILKDLSDGIHVVKDARERDFTSLENTVEERLTELTKSINDNIAIFTEVQKRSQKEINDMKAKVASLEESEGNKQDLKALKEAVKEIQTSAKSREWDMEALRSTLQTMESDIYTEVRELVSLKQEQQAFKEAADTERLALQALTEKLLRSEESVSRLPEEIRRLEEELRQLKSDSHGPKEDGGFRHSEAFEALQQKSQGLDSRLQHVEDGVLSMQVASARQTESLESLLSKSQEHEQRLAALQGRLEGLGSSEADQDGLASTVRSLGETQLVLYGDVEELKRSVGELPSTVESLQKVQEQVHTLLSQDQAQAARLPPQDFLDRLSSLDNLKASVSQVEADLKMLRTAVDSLVAYSVKIETNENNLESAKGLLDDLRNDLDRLFVKVEKIHEKV>sp|O15145|ARPC3_HUMAN Actin-related protein 2/3 complex subunit 3OS=Homo sapiens OX=9606 GN=ARPC3 PE=1 SV=3MPAYHSSLMDPDTKLIGNMALLPIRSQFKGPAPRETKDTDIVDEAIYYFKANVFFKNYEIKNEADRTLIYITLYISECLKKLQKCNSKSQGEKEMYTLGITNFPIPGEPGFPLNAIYAKPANKQEDEVMRAYLQQLRQETGLRLCEKVFDPQNDKPSKWWTCFVKRQFMNKSLSGPGQ>sp|P59998|ARPC4_HUMAN Actin-related protein 2/3 complex subunit 4OS=Homo sapiens OX=9606 GN=ARPC4 PE=1 SV=3MTATLRPYLSAVRATLQAALCLENFSSQVVERHNKPEVEVRSSKELLLQPVTISRNEKEKVLIEGSINSVRVSIAVKQADEIEKILCHKFMRFMMMRAENFFILRRKPVEGYDISFLITNFHTEQMYKHKLVDFVIHFMEEIDKEISEMKLSVNARARIVAEEFLKNF>sp|P59998-2|ARPC4_HUMAN Isoform 2 of Actin-related protein 2/3 complexsubunit 4 OS=Homo sapiens OX=9606 GN=ARPC4MTATLRPYLSAVRATLQAALCLENFSSQVVERHNKPEVEVRSSKELLLQPVTISRNEKEKVLIEGSINSVRVSIAVKQADEIEKILCHKFMRFMMMRAENFFILRRKPVEQKKIFTIQGCYPVIRCLLRRRGWVEKKMVHRSGPTLLPPQKDLDSSAMGDSDTTEDEDEDEDEEFQPSQLFDFDDLLKFDDLDGTHALMVGLCLNLRNLPWFDEVDANSFFPRCYCLGAEDDKKAFIGDKQPKKQEKNPVLVSPEFVDEALCACEEYLSNLAHMDIDKDLEAPLYLTPEGWSLFLQRYYQVVHEGAELRHLDTQVQRCEDILQQLQAVVPQIDMEGDRNIWIVKPGAKSRGRGIMCMDHLEEMLKLVNGNPVVMKDGKWVVQKYIERPLLIFGTKFDLRQWFLVTDWNPLTVWFYRDSYIRFSTQPFSLKNLDNSVHLCNNSIQKHLENSCHRHPLLPPDNMWSSQRFQAHLQEMGAPNAWSTIIVPGMKDAVIHALQTSQDTVQCRKASFELYGADFVFGEDFQPWLIEINASPTMAPSTAVTARLCAGVQADTLRVVIDRMLDRNCDTGAFELIYKQPVTTSPASTPRPSCLLPMYSDTRARSSDDSTASWWALRPCRPQARP>sp|P59998-3|ARPC4_HUMAN Isoform 3 of Actin-related protein 2/3 complexsubunit 4 OS=Homo sapiens OX=9606 GN=ARPC4MVREPGPRPGTPGCSASGQWTATLRPYLSAVRATLQAALCLENFSSQVVERHNKPEVEVRSSKELLLQPVTISRNEKEKVLIEGSINSVRVSIAVKQADEIEKILCHKFMRFMMMRAENFFILRRKPVEGYDISFLITNFHTEQMYKHKLVDFVIHFMEEIDKEISEMKLSVNARARIVAEEFLKNF>sp|P59998-4|ARPC4_HUMAN Isoform 4 of Actin-related protein 2/3 complexsubunit 4 OS=Homo sapiens OX=9606 GN=ARPC4MRFMMMRAENFFILRRKPVEGYDISFLITNFHTEQMYKHKLVDFVIHFMEEIDKEISEMKLSVNARARIVAEEFLKNF>sp|Q7Z6K5|ARPIN_HUMAN Arpin OS=Homo sapiens OX=9606 GN=ARPIN PE=1 SV=1MSRIYHDGALRNKAVQSVRLPGAWDPAAHQGGNGVLLEGELIDVSRHSILDTHGRKERYYVLYIRPSHIHRRKFDAKGNEIEPNFSATRKVNTGFLMSSYKVEAKGDTDRLTPEALKGLVNKPELLALTESLTPDHTVAFWMPESEMEVMELELGAGVRLKTRGDGPFLDSLAKLEAGTVTKCNFTGDGKTGASWTDNIMAQKCSKGAAAEIREQGDGAEDEEWDD>sp|Q7Z6K5-2|ARPIN_HUMAN Isoform C15orf38-AP3S2 of Arpin OS=Homo sapiensOX=9606 GN=ARPINMSRIYHDGALRNKAVQSVRLPGAWDPAAHQGGNGVLLEGELIDVSRHSILDTHGRKERYYVLYIRPSHIHRRKFDAKGNEIEPNFSATRKVNTGFLMSSYKVEAKGDTDRLTPEALKGLVNKPELLALTESLTPDHTVAFWMPESEMEVMELELGAGVRLKTRGDGPFLDSLAKLEAGTVTKCNFTGDGKTGASWTDNIMAQKCSKGAAAEIREQGDGAEDEEWPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSESELGILDLIQVFVETLDKCFENVCELDLIFHMDKVHYILQEVVMGGMVLETNMNEIVAQIEAQNRLEKSEGGLSAAPARAVSAVKNINLPEIPRNINIGDLNIKVPNLSQFV>sp|Q32M92|CO032_HUMAN Uncharacterized protein C15orf32 OS=Homo sapiensOX=9606 GN=C15orf32 PE=1 SV=2MNKRTSVDASKEDLHPADPQSGEGVPPNRKNTKTSPRGEGTAPPFSARPCVWTLCEMLSILALVGVLHPFYRSNNQVYQKLKTHLRCQSSRVDGLMLKPTLLTPSQLKSPEGHLILPTFNHLVIRHILDPKQIFCVADVCTDCKFNCGSIERHQKRHLMRVSQDWEHLIRYRNQICLS>sp|Q32M92-2|CO032_HUMAN Isoform 2 of Uncharacterized protein C15orf32OS=Homo sapiens OX=9606 GN=C15orf32MNKRTSVDASKEDLHPADPQSGEGVPPNRKNTKTSPRGEGTAPPFSARPCVWTLCEMLSILALVGVLHPFYRSNNQVYQKLKTHLRCQSSRVDGLMLKPTLLTPSQLKSPEGHLILPTFNHLVIRHILDPKQIFCVADVCTDCKFNCGSIERHQKRHLMRVSQDW>sp|Q8TBH0|ARRD2_HUMAN Arrestin domain-containing protein 2 OS=Homosapiens OX=9606 GN=ARRDC2 PE=1 SV=2MLFDKVKAFSVQLDGATAGVEPVFSGGQAVAGRVLLELSSAARVGALRLRARGRAHVHWTESRSAGSSTAYTQSYSERVEVVSHRATLLAPDTGETTTLPPGRHEFLFSFQLPPTLVTSFEGKHGSVRYCIKATLHRPWVPARRARKVFTVIEPVDINTPALLAPQAGAREKVARSWYCNRGLVSLSAKIDRKGYTPGEVIPVFAEIDNGSTRPVLPRAAVVQTQTFMARGARKQKRAVVASLAGEPVGPGQRALWQGRALRIPPVGPSILHCRVLHVDYALKVCVDIPGTSKLLLELPLVIGTIPLHPFGSRSSSVGSHASFLLDWRLGALPERPEAPPEYSEVVADTEEAALGQSPFPLPQDPDMSLEGPFFAYIQEFRYRPPPLYSEEDPNPLLGDMRPRCMTC>sp|Q8TBH0-2|ARRD2_HUMAN Isoform 2 of Arrestin domain-containing protein2 OS=Homo sapiens OX=9606 GN=ARRDC2MRSGGVRSFALELARGPGGAYRGGERLCGRVLLEAAAPLRVRALEVKARGGAATHWLEGRSVGVNAVSSDYAAAETYLRRRQLLLRDTGETTTLPPGRHEFLFSFQLPPTLVTSFEGKHGSVRYCIKATLHRPWVPARRARKVFTVIEPVDINTPALLAPQAGAREKVARSWYCNRGLVSLSAKIDRKGYTPGEVIPVFAEIDNGSTRPVLPRAAVVQTQTFMARGARKQKRAVVASLAGEPVGPGQRALWQGRALRIPPVGPSILHCRVLHVDYALKVCVDIPGTSKLLLELPLVIGTIPLHPFGSRSSSVGSHASFLLDWRLGALPERPEAPPEYSEVVADTEEAALGQSPFPLPQDPDMSLEGPFFAYIQEFRYRPPPLYSEEDPNPLLGDMRPRCMTC>sp|H3BNL8|ARMD2_HUMAN Armadillo-like helical domain-containing protein 2OS=Homo sapiens OX=9606 GN=ARMH2 PE=4 SV=1MANSRFSCTQIWVKMYGYFAGLCRRLQKFWRVTVKGFFVKKKEKKIPSAETYFHEEKIVVLGQVLMNESLPIEKRAQAAQKIGLLAFTGGPPAGNFAAEYMEEVAHLLQDEELAPKIKILLLQSVACWCYLNPVSQKRAKSLQFIPILISFFEGRFESTIKSETNSYLLLKFWTCYVLSVMTCNNLSCVKELKDHSALKYHLQMLAAENWSGWTENFAEVLYFLIGFHRN>sp|P15848|ARSB_HUMAN Arylsulfatase B OS=Homo sapiens OX=9606 GN=ARSBPE=1 SV=1MGPRGAASLPRGPGPRRLLLPVVLPLLLLLLLAPPGSGAGASRPPHLVFLLADDLGWNDVGFHGSRIRTPHLDALAAGGVLLDNYYTQPLCTPSRSQLLTGRYQIRTGLQHQIIWPCQPSCVPLDEKLLPQLLKEAGYTTHMVGKWHLGMYRKECLPTRRGFDTYFGYLLGSEDYYSHERCTLIDALNVTRCALDFRDGEEVATGYKNMYSTNIFTKRAIALITNHPPEKPLFLYLALQSVHEPLQVPEEYLKPYDFIQDKNRHHYAGMVSLMDEAVGNVTAALKSSGLWNNTVFIFSTDNGGQTLAGGNNWPLRGRKWSLWEGGVRGVGFVASPLLKQKGVKNRELIHISDWLPTLVKLARGHTNGTKPLDGFDVWKTISEGSPSPRIELLHNIDPNFVDSSPCPRNSMAPAKDDSSLPEYSAFNTSVHAAIRHGNWKLLTGYPGCGYWFPPPSQYNVSEIPSSDPPTKTLWLFDIDRDPEERHDLSREYPHIVTKLLSRLQFYHKHSVPVYFPAQDPRCDPKATGVWGPWM>sp|P15848-2|ARSB_HUMAN Isoform 2 of Arylsulfatase B OS=Homo sapiensOX=9606 GN=ARSBMGPRGAASLPRGPGPRRLLLPVVLPLLLLLLLAPPGSGAGASRPPHLVFLLADDLGWNDVGFHGSRIRTPHLDALAAGGVLLDNYYTQPLCTPSRSQLLTGRYQIRTGLQHQIIWPCQPSCVPLDEKLLPQLLKEAGYTTHMVGKWHLGMYRKECLPTRRGFDTYFGYLLGSEDYYSHERCTLIDALNVTRCALDFRDGEEVATGYKNMYSTNIFTKRAIALITNHPPEKPLFLYLALQSVHEPLQVPEEYLKPYDFIQDKNRHHYAGMVSLMDEAVGNVTAALKSSGLWNNTVFIFSTDNGGQTLAGGNNWPLRGRKWSLWEGGVRGVGFVASPLLKQKGVKNRELIHISDWLPTLVKLARGHTNGTKPLDGFDVWKTISEGSPSPRIELLHNIDPNFVDSSPYWPECSLLL>sp|Q8IY22|CMIP_HUMAN C-Maf-inducing protein OS=Homo sapiens OX=9606GN=CMIP PE=1 SV=3MDVTSSSGGGGDPRQIEETKPLLGGDVSAPEGTKMGAVPCRRALLLCNGMRYKLLQEGDIQVCVIRHPRTFLSKILTSKFLRRWEPHHLTLADNSLASATPTGYMENSVSYSAIEDVQLLSWENAPKYCLQLTIPGGTVLLQAANSYLRDQWFHSLQWKKKIYKYKKVLSNPSRWEVVLKEIRTLVDMALTSPLQDDSINQAPLEIVSKLLSENTNLTTQEHENIIVAIAPLLENNHPPPDLCEFFCKHCRERPRSMVVIEVFTPVVQRILKHNMDFGKCPRLRLFTQEYILALNELNAGMEVVKKFIQSMHGPTGHCPHPRVLPNLVAVCLAAIYSCYEEFINSRDNSPSLKEIRNGCQQPCDRKPTLPLRLLHPSPDLVSQEATLSEARLKSVVVASSEIHVEVERTSTAKPALTASAGNDSEPNLIDCLMVSPACSTMSIELGPQADRTLGCYVEILKLLSDYDDWRPSLASLLQPIPFPKEALAHEKFTKELKYVIQRFAEDPRQEVHSCLLSVRAGKDGWFQLYSPGGVACDDDGELFASMVHILMGSCYKTKKFLLSLAENKLGPCMLLALRGNQTMVEILCLMLEYNIIDNNDTQLQIISTLESTDVGKRMYEQLCDRQRELKELQRKGGPTRLTLPSKSTDADLARLLSSGSFGNLENLSLAFTNVTSACAEHLIKLPSLKQLNLWSTQFGDAGLRLLSEHLTMLQVLNLCETPVTDAGLLALSSMKSLCSLNMNSTKLSADTYEDLKAKLPNLKEVDVRYTEAW>sp|Q8IY22-2|CMIP_HUMAN Isoform 2 of C-Maf-inducing protein OS=Homosapiens OX=9606 GN=CMIPMGQAAEPTGYMENSVSYSAIEDVQLLSWENAPKYCLQLTIPGGTVLLQAANSYLRDQWFHSLQWKKKIYKYKKVLSNPSRWEVVLKEIRTLVDMALTSPLQDDSINQAPLEIVSKLLSENTNLTTQEHENIIVAIAPLLENNHPPPDLCEFFCKHCRERPRSMVVIEVFTPVVQRILKHNMDFGKCPRLRLFTQEYILALNELNAGMEVVKKFIQSMHGPTGHCPHPRVLPNLVAVCLAAIYSCYEEFINSRDNSPSLKEIRNGCQQPCDRKPTLPLRLLHPSPDLVSQEATLSEARLKSVVVASSEIHVEVERTSTAKPALTASAGNDSEPNLIDCLMVSPACSTMSIELGPQADRTLGCYVEILKLLSDYDDWRPSLASLLQPIPFPKEALAHEKFTKELKYVIQRFAEDPRQEVHSCLLSVRAGKDGWFQLYSPGGVACDDDGELFASMVHILMGSCYKTKKFLLSLAENKLGPCMLLALRGNQTMVEILCLMLEYNIIDNNDTQLQIISTLESTDVGKRMYEQLCDRQRELKELQRKGGPTRLTLPSKSTDADLARLLSSGSFGNLENLSLAFTNVTSACAEHLIKLPSLKQLNLWSTQFGDAGLRLLSEHLTMLQVLNLCETPVTDAGLLALSSMKSLCSLNMNSTKLSADTYEDLKAKLPNLKEVDVRYTEAW>sp|Q8IY22-3|CMIP_HUMAN Isoform 3 of C-Maf-inducing protein OS=Homosapiens OX=9606 GN=CMIPMASVAQKKIYKYKKVLSNPSRWEVVLKEIRTLVDMALTSPLQDDSINQAPLEIVSKLLSENTNLTTQEHENIIVAIAPLLENNHPPPDLCEFFCKHCRERPRSMVVIEVFTPVVQRILKHNMDFGKCPRLRLFTQEYILALNELNAGMEVVKKFIQSMHGPTGHCPHPRVLPNLVAVCLAAIYSCYEEFINSRDNSPSLKEIRNGCQQPCDRKPTLPLRLLHPSPDLVSQEATLSEARLKSVVVASSEIHVEVERTSTAKPALTASAGNDSEPNLIDCLMVSPACSTMSIELGPQADRTLGCYVEILKLLSDYDDWRPSLASLLQPIPFPKEALAHEKFTKELKYVIQRFAEDPRQEVHSCLLSVRAGKDGWFQLYSPGGVACDDDGELFASMVHILMGSCYKTKKFLLSLAENKLGPCMLLALRGNQTMVEILCLMLEYNIIDNNDTQLQIISTLESTDVGKRMYEQLCDRQRELKELQRKGGPTRLTLPSKSTDADLARLLSSGSFGNLENLSLAFTNVTSACAEHLIKLPSLKQLNLWSTQFGDAGLRLLSEHLTMLQVLNLCETPVTDAGLLALSSMKSLCSLNMNSTKLSADTYEDLKAKLPNLKEVDVRYTEAW>sp|Q86TY3|ARMD4_HUMAN Armadillo-like helical domain-containing protein 4OS=Homo sapiens OX=9606 GN=ARMH4 PE=1 SV=1MRGPIVLHICLAFCSLLLFSVATQCLAFPKIERRREIAHVHAEKGQSDKMNTDDLENSSVTSKQTPQLVVSEDPMMMSAVPSATSLNKAFSINKETQPGQAGLMQTERPGVSTPTESGVPSAEEVFGSSQPERISPESGLAKAMLTIAITATPSLTVDEKEELLTSTNFQPIVEEITETTKGFLKYMDNQSFATESQEGVGLGHSPSSYVNTKEMLTTNPKTEKFEADTDHRTTSFPGAESTAGSEPGSLTPDKEKPSQMTADNTQAAATKQPLETSEYTLSVEPETDSLLGAPEVTVSVSTAVPAASALSDEWDDTKLESVSRIRTPKLGDNEETQVRTEMSQTAQVSHEGMEGGQPWTEAAQVALGLPEGETHTGTALLIAHGNERSPAFTDQSSFTPTSLMEDMKVSIVNLLQSTGDFTESTKENDALFFLETTVSVSVYESEADQLLGNTMKDIITQEMTTAVQEPDATLSMVTQEQVATLELIRDSGKTEEEKEDPSPVSDVPGVTQLSRRWEPLATTISTTVVPLSFEVTPTVEEQMDTVTGPNEEFTPVLGSPVTPPGIMVGEPSISPALPALEASSERRTVVPSITRVNTAASYGLDQLESEEGQEDEDEEDEEDEDEEEEDEEEDEEDKDADSLDEGLDGDTELPGFTLPGITSQEPGLEEGNMDLLEGATYQVPDALEWEQQNQGLVRSWMEKLKDKAGYMSGMLVPVGVGIAGALFILGALYSIKVMNRRRRNGFKRHKRKQREFNSMQDRVMLLADSSEDEF>sp|Q86TY3-2|ARMD4_HUMAN Isoform 2 of Armadillo-like helical domain-containing protein 4 OS=Homo sapiens OX=9606 GN=ARMH4MRGPIVLHICLAFCSLLLFSVATQCLAFPKIERRREIAHVHAEKGQSDKMNTDDLENSSVTSKQTPQLVVSEDPMMMSAVPSATSLNKAFSINKETQPGQAGLMQTERPGVSTPTESGVPSAEEVFGSSQPERISPESGLAKAMLTIAITATPSLTVDEKEELLTSTNFQPIVEEITETTKGFLKYMDNQSFATESQEGVGLGHSPSSYVNTKEMLTTNPKTEKFEADTDHRTTSFPGAESTAGSEPGSLTPDKEKPSQMTADNTQAAATKQPLETSEYTLSVEPETDSLLGAPEVTVSVSTAVPAASALSDEWDDTKLESVSRIRTPKLGDNEETQVRTEMSQTAQVSHEGMEGGQPWTEAAQVALGLPEGETHTGTALLIAHGNERSPAFTDQSSFTPTSLMEDMKVSIVNLLQSTGDFTESTKENDALFFLETTVSVSVYESEADQLLGNTMKDIITQEMTTAVQEPDATLSMVTQEQVATLELIRDSGKTEEEKEDPSPVSDVPGVTQLSRRWEPLATTISTTVVPLSFEVTPTVEEQMDTVTGPNEEFTPVLGSPVTPPGIMVGEPSISPALPALEASSERRTVVPSITRVNTAASYGLDQLESEETGFHHVAQARLKLLGLRSLPASASQSVGITSVNSCTQPRKYLNSCLKWKLNPKHFATGV>sp|Q86TY3-3|ARMD4_HUMAN Isoform 3 of Armadillo-like helical domain-containing protein 4 OS=Homo sapiens OX=9606 GN=ARMH4MDTVTGPNEEFTPVLGSPVTPPGIMVGEPSISPALPALEASSERRTVVPSITRVNTAASYGLDQLESEEGQEDEDEEDEEDEDEEEEDEEEDEEDKDADSLDEGLDGDTELPGFTLPGITSQEPGLEEGNMDLLEGATYQVPDALEWEQQNQGLVRSWMEKLKDKAGYMSGMLVPVGVGIAGALFILGALYSIKVMNRRRRNGFKRHKRKQREFNSMQDRVMLLADSSEDEF>sp|Q96EG1|ARSG_HUMAN Arylsulfatase G OS=Homo sapiens OX=9606 GN=ARSGPE=1 SV=1MGWLFLKVLLAGVSFSGFLYPLVDFCISGKTRGQKPNFVIILADDMGWGDLGANWAETKDTANLDKMASEGMRFVDFHAAASTCSPSRASLLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPACPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYGAGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQGGSPAKQTTWEGGHRVPALAYWPGRVPVNVTSTALLSVLDIFPTVVALAQASLPQGRRFDGVDVSEVLFGRSQPGHRVLFHPNSGAAGEFGALQTVRLERYKAFYITGGARACDGSTGPELQHKFPLIFNLEDDTAEAVPLERGGAEYQAVLPEVRKVLADVLQDIANDNISSADYTQDPSVTPCCNPYQIACRCQAA>sp|P62633|CNBP_HUMAN CCHC-type zinc finger nucleic acid binding proteinOS=Homo sapiens OX=9606 GN=CNBP PE=1 SV=1MSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRGGFTSDRGFQFVSSSLPDICYRCGESGHLAKDCDLQEDACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|P62633-2|CNBP_HUMAN Isoform 2 of CCHC-type zinc finger nucleic acidbinding protein OS=Homo sapiens OX=9606 GN=CNBPMSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRGFQFVSSSLPDICYRCGESGHLAKDCDLQEDACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|P62633-3|CNBP_HUMAN Isoform 3 of CCHC-type zinc finger nucleic acidbinding protein OS=Homo sapiens OX=9606 GN=CNBPMSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRGGFTSDRDICYRCGESGHLAKDCDLQEDACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|P62633-4|CNBP_HUMAN Isoform 4 of CCHC-type zinc finger nucleic acidbinding protein OS=Homo sapiens OX=9606 GN=CNBPMSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRGGFTSDRGFQFVSSSLPDICYRCGESGHLAKDCDLQEDEACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|P62633-5|CNBP_HUMAN Isoform 5 of CCHC-type zinc finger nucleic acidbinding protein OS=Homo sapiens OX=9606 GN=CNBPMSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRGFQFVSSSLPDICYRCGESGHLAKDCDLQEDVEACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|P62633-6|CNBP_HUMAN Isoform 6 of CCHC-type zinc finger nucleic acidbinding protein OS=Homo sapiens OX=9606 GN=CNBPMSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRGGFTSDRGFQFVSSSLPDICYRCGESGHLAKDCDLQEDVEACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|P62633-7|CNBP_HUMAN Isoform 7 of CCHC-type zinc finger nucleic acidbinding protein OS=Homo sapiens OX=9606 GN=CNBPMSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRDICYRCGESGHLAKDCDLQEDACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|P62633-8|CNBP_HUMAN Isoform 8 of CCHC-type zinc finger nucleic acidbinding protein OS=Homo sapiens OX=9606 GN=CNBPMSSNECFKCGRSGHWARECPTGGGRGRGMRSRGRGFQFVSSSLPDICYRCGESGHLAKDCDLQEDEACYNCGRGGHIAKDCKEPKREREQCCYNCGKPGHLARDCDHADEQKCYSCGEFGHIQKDCTKVKCYRCGETGHVAINCSKTSEVNCYRCGESGHLARECTIEATA>sp|Q5FYB1|ARSI_HUMAN Arylsulfatase I OS=Homo sapiens OX=9606 GN=ARSIPE=1 SV=1MHTLTGFSLVSLLSFGYLSWDWAKPSFVADGPGEAGEQPSAAPPQPPHIIFILTDDQGYHDVGYHGSDIETPTLDRLAAKGVKLENYYIQPICTPSRSQLLTGRYQIHTGLQHSIIRPQQPNCLPLDQVTLPQKLQEAGYSTHMVGKWHLGFYRKECLPTRRGFDTFLGSLTGNVDYYTYDNCDGPGVCGFDLHEGENVAWGLSGQYSTMLYAQRASHILASHSPQRPLFLYVAFQAVHTPLQSPREYLYRYRTMGNVARRKYAAMVTCMDEAVRNITWALKRYGFYNNSVIIFSSDNGGQTFSGGSNWPLRGRKGTYWEGGVRGLGFVHSPLLKRKQRTSRALMHITDWYPTLVGLAGGTTSAADGLDGYDVWPAISEGRASPRTEILHNIDPLYNHAQHGSLEGGFGIWNTAVQAAIRVGEWKLLTGDPGYGDWIPPQTLATFPGSWWNLERMASVRQAVWLFNISADPYEREDLAGQRPDVVRTLLARLAEYNRTAIPVRYPAENPRAHPDFNGGAWGPWASDEEEEEEEGRARSFSRGRRKKKCKICKLRSFFRKLNTRLMSQRI>sp|Q5FYB1-2|ARSI_HUMAN Isoform 2 of Arylsulfatase I OS=Homo sapiensOX=9606 GN=ARSIMVGKWHLGFYRKECLPTRRGFDTFLGSLTGNVDYYTYDNCDGPGVCGFDLHEGENVAWGLSGQYSTMLYAQRASHILASHSPQRPLFLYVAFQAVHTPLQSPREYLYRYRTMGNVARRKYAAMVTCMDEAVRNITWALKRYGFYNNSVIIFSSDNGGQTFSGGSNWPLRGRKGTYWEGGVRGLGFVHSPLLKRKQRTSRALMHITDWYPTLVGLAGGTTSAADGLDGYDVWPAISEGRASPRTEILHNIDPLYNHAQHGSLEGGFGIWNTAVQAAIRVGEWKLLTGDPGYGDWIPPQTLATFPGSWWNLERMASVRQAVWLFNISADPYEREDLAGQRPDVVRTLLARLAEYNRTAIPVRYPAENPRAHPDFNGGAWGPWASDEEEEEEEGRARSFSRGRRKKKCKICKLRSFFRKLNTRLMSQRI>sp|Q6UWY0|ARSK_HUMAN Arylsulfatase K OS=Homo sapiens OX=9606 GN=ARSKPE=1 SV=1MLLLWVSVVAALALAVLAPGAGEQRRRAAKAPNVVLVVSDSFDGRLTFHPGSQVVKLPFINFMKTRGTSFLNAYTNSPICCPSRAAMWSGLFTHLTESWNNFKGLDPNYTTWMDVMERHGYRTQKFGKLDYTSGHHSISNRVEAWTRDVAFLLRQEGRPMVNLIRNRTKVRVMERDWQNTDKAVNWLRKEAINYTEPFVIYLGLNLPHPYPSPSSGENFGSSTFHTSLYWLEKVSHDAIKIPKWSPLSEMHPVDYYSSYTKNCTGRFTKKEIKNIRAFYYAMCAETDAMLGEIILALHQLDLLQKTIVIYSSDHGELAMEHRQFYKMSMYEASAHVPLLMMGPGIKAGLQVSNVVSLVDIYPTMLDIAGIPLPQNLSGYSLLPLSSETFKNEHKVKNLHPPWILSEFHGCNVNASTYMLRTNHWKYIAYSDGASILPQLFDLSSDPDELTNVAVKFPEITYSLDQKLHSIINYPKVSASVHQYNKEQFIKWKQSIGQNYSNVIANLRWHQDWQKEPRKYENAIDQWLKTHMNPRAV>sp|Q6UVW9|CLC2A_HUMAN C-type lectin domain family 2 member A OS=Homosapiens OX=9606 GN=CLEC2A PE=1 SV=2MINPELRDGRADGFIHRIVPKLIQNWKIGLMCFLSIIITTVCIIMIATWSKHAKPVACSGDWLGVRDKCFYFSDDTRNWTASKIFCSLQKAELAQIDTQEDMEFLKRYAGTDMHWIGLSRKQGDSWKWTNGTTFNGWFEIIGNGSFAFLSADGVHSSRGFIDIKWICSKPKYFL>sp|Q6UVW9-2|CLC2A_HUMAN Isoform 2 of C-type lectin domain family 2member A OS=Homo sapiens OX=9606 GN=CLEC2AMINPELRDGRADGFIHRIVPKLIQNWKIGLMCFLSIIITTVCIIMIATWSKHAKPVACSGDWLGVRDKCFYFSDDTRNWTASKIFCSLQKAELAQIDTQEDMEFLKRYAGTDMHWIGLSRKQGDSWKWTNGTTFNGWPSNSKWSCNWSLRQWLLLLGPLR>sp|Q6P1M9|ARMX5_HUMAN Armadillo repeat-containing X-linked protein 5OS=Homo sapiens OX=9606 GN=ARMCX5 PE=1 SV=1MVDSGTEARARGKAEAGLQDGISGPATARVNGKTQAEAVAEAELKTESVTQAKAGDGAMTRTHTVTYREAMAVTREVIKVEDTTKTRVMVETKTKPLAERSIVPQTKSKAMPMSRVSTVTKSEVKVVAVIEANIRSYAKSHDKANTGSRPDRREETSIGMKSSDEDEENICSWFWTGEEPSVGSWFWPEEETSLQVYKPLPKIQEKPKPTHKPTLTIKQKVIAWSRARYIVLVPVEGGEQSLPPEGNWTLVETLIETPLGIRPLTKIPPYHGPYYQTLAEIKKQIRQREKYGPNPKACHCKSRGFSLEPKEFDKLVALLKLTKDPFIHEIATMIMGISPAYPFTQDIIHDVGITVMIENLVNNPNVKEHPGALSMVDDSSESSEEPKSGESYIHQVCKGIISCPLNSPVQLAGLKLLGHLSIKFEDHYVITSYIPDFLTLLNKGSVKTKFYVLKVFSCLSKNHANTRELISAKVLSSLVAPFNKNESKANILNIIEIFENINFQFKTKAKLFTKEKFTKSELISIFQEAKQFGQKLQDLAEHSDPEVRDKVIRLILKL>sp|O75596|CLC3A_HUMAN C-type lectin domain family 3 member A OS=Homosapiens OX=9606 GN=CLEC3A PE=1 SV=1MAKNGLVICILVITLLLDQTTSHTSRLKARKHSKRRVRDKDGDLKTQIEKLWTEVNALKEIQALQTVCLRGTKVHKKCYLASEGLKHFHEANEDCISKGGILVIPRNSDEINALQDYGKRSLPGVNDFWLGINDMVTEGKFVDVNGIAISFLNWDRAQPNGGKRENCVLFSQSAQGKWSDEACRSSKRYICEFTIPQ>sp|Q16281|CNGA3_HUMAN Cyclic nucleotide-gated cation channel alpha-3OS=Homo sapiens OX=9606 GN=CNGA3 PE=1 SV=2MAKINTQYSHPSRTHLKVKTSDRDLNRAENGLSRAHSSSEETSSVLQPGIAMETRGLADSGQGSFTGQGIARLSRLIFLLRRWAARHVHHQDQGPDSFPDRFRGAELKEVSSQESNAQANVGSQEPADRGRSAWPLAKCNTNTSNNTEEEKKTKKKDAIVVDPSSNLYYRWLTAIALPVFYNWYLLICRACFDELQSEYLMLWLVLDYSADVLYVLDVLVRARTGFLEQGLMVSDTNRLWQHYKTTTQFKLDVLSLVPTDLAYLKVGTNYPEVRFNRLLKFSRLFEFFDRTETRTNYPNMFRIGNLVLYILIIIHWNACIYFAISKFIGFGTDSWVYPNISIPEHGRLSRKYIYSLYWSTLTLTTIGETPPPVKDEEYLFVVVDFLVGVLIFATIVGNVGSMISNMNASRAEFQAKIDSIKQYMQFRKVTKDLETRVIRWFDYLWANKKTVDEKEVLKSLPDKLKAEIAINVHLDTLKKVRIFQDCEAGLLVELVLKLRPTVFSPGDYICKKGDIGKEMYIINEGKLAVVADDGVTQFVVLSDGSYFGEISILNIKGSKSGNRRTANIRSIGYSDLFCLSKDDLMEALTEYPEAKKALEEKGRQILMKDNLIDEELARAGADPKDLEEKVEQLGSSLDTLQTRFARLLAEYNATQMKMKQRLSQLESQVKGGGDKPLADGEVPGDATKTEDKQQ>sp|Q16281-2|CNGA3_HUMAN Isoform 2 of Cyclic nucleotide-gated cationchannel alpha-3 OS=Homo sapiens OX=9606 GN=CNGA3MAKINTQYSHPSRTHLKVKTSDRDLNRAENGLSRAHSSSEETSSVLQPGIAMETRGLADSGQGSFTGQGIARLSRLIFLLRRWAARHVHHQDQGPDSFPDRFRGAELKEVSSQESNAQANVGSQEPADRGRRKKTKKKDAIVVDPSSNLYYRWLTAIALPVFYNWYLLICRACFDELQSEYLMLWLVLDYSADVLYVLDVLVRARTGFLEQGLMVSDTNRLWQHYKTTTQFKLDVLSLVPTDLAYLKVGTNYPEVRFNRLLKFSRLFEFFDRTETRTNYPNMFRIGNLVLYILIIIHWNACIYFAISKFIGFGTDSWVYPNISIPEHGRLSRKYIYSLYWSTLTLTTIGETPPPVKDEEYLFVVVDFLVGVLIFATIVGNVGSMISNMNASRAEFQAKIDSIKQYMQFRKVTKDLETRVIRWFDYLWANKKTVDEKEVLKSLPDKLKAEIAINVHLDTLKKVRIFQDCEAGLLVELVLKLRPTVFSPGDYICKKGDIGKEMYIINEGKLAVVADDGVTQFVVLSDGSYFGEISILNIKGSKSGNRRTANIRSIGYSDLFCLSKDDLMEALTEYPEAKKALEEKGRQILMKDNLIDEELARAGADPKDLEEKVEQLGSSLDTLQTRFARLLAEYNATQMKMKQRLSQLESQVKGGGDKPLADGEVPGDATKTEDKQQ>sp|Q16281-3|CNGA3_HUMAN Isoform 3 of Cyclic nucleotide-gated cationchannel alpha-3 OS=Homo sapiens OX=9606 GN=CNGA3METRGLADSGQGSFTGQGIARFGRIQKKSQPEKVVRAASRGRPLIGWTQWCAEDGGDESEMALAGSPGCSSGPQGRLSRLIFLLRRWAARHVHHQDQGPDSFPDRFRGAELKEVSSQESNAQANVGSQEPADRGRSAWPLAKCNTNTSNNTEEEKKTKKKDAIVVDPSSNLYYRWLTAIALPVFYNWYLLICRACFDELQSEYLMLWLVLDYSADVLYVLDVLVRARTGFLEQGLMVSDTNRLWQHYKTTTQFKLDVLSLVPTDLAYLKVGTNYPEVRFNRLLKFSRLFEFFDRTETRTNYPNMFRIGNLVLYILIIIHWNACIYFAISKFIGFGTDSWVYPNISIPEHGRLSRKYIYSLYWSTLTLTTIGETPPPVKDEEYLFVVVDFLVGVLIFATIVGNVGSMISNMNASRAEFQAKIDSIKQYMQFRKVTKDLETRVIRWFDYLWANKKTVDEKEVLKSLPDKLKAEIAINVHLDTLKKVRIFQDCEAGLLVELVLKLRPTVFSPGDYICKKGDIGKEMYIINEGKLAVVADDGVTQFVVLSDGSYFGEISILNIKGSKSGNRRTANIRSIGYSDLFCLSKDDLMEALTEYPEAKKALEEKGRQILMKDNLIDEELARAGADPKDLEEKVEQLGSSLDTLQTRFARLLAEYNATQMKMKQRLSQLESQVKGGGDKPLADGEVPGDATKTEDKQQ>sp|Q6ZP68|ATPUN_HUMAN Putative protein ATP11AUN OS=Homo sapiens OX=9606GN=ATP11AUN PE=2 SV=1MNSPEARLCVAQCRDSYPGCQPLKDTRAWASSLKMDPAGLEGGPRDESRDEPPIRAQAASWDQPQGCLTYKGRRSASGTQKQLQLPDTLSSLLCWRGAIMVYIKVTVQTDDSNKLLSLLYR>sp|Q9UMR7|CLC4A_HUMAN C-type lectin domain family 4 member A OS=Homosapiens OX=9606 GN=CLEC4A PE=1 SV=1MTSEITYAEVRFKNEFKSSGINTASSAASKERTAPHKSNTGFPKLLCASLLIFFLLLAISFFIAFVIFFQKYSQLLEKKTTKELVHTTLECVKKNMPVEETAWSCCPKNWKSFSSNCYFISTESASWQDSEKDCARMEAHLLVINTQEEQDFIFQNLQEESAYFVGLSDPEGQRHWQWVDQTPYNESSTFWHPREPSDPNERCVVLNFRKSPKRWGWNDVNCLGPQRSVCEMMKIHL>sp|Q9UMR7-2|CLC4A_HUMAN Isoform 2 of C-type lectin domain family 4member A OS=Homo sapiens OX=9606 GN=CLEC4AMTSEITYAEVRFKNEFKSSGINTASSAASKERTAPHKSNTGFPKLLCASLLIFFLLLAISFFIAFVKTAWSCCPKNWKSFSSNCYFISTESASWQDSEKDCARMEAHLLVINTQEEQDFIFQNLQEESAYFVGLSDPEGQRHWQWVDQTPYNESSTFWHPREPSDPNERCVVLNFRKSPKRWGWNDVNCLGPQRSVCEMMKIHL>sp|Q9UMR7-3|CLC4A_HUMAN Isoform 3 of C-type lectin domain family 4member A OS=Homo sapiens OX=9606 GN=CLEC4AMTSEITYAEVRFKNEFKSSGINTASSAVFFQKYSQLLEKKTTKELVHTTLECVKKNMPVEETAWSCCPKNWKSFSSNCYFISTESASWQDSEKDCARMEAHLLVINTQEEQDFIFQNLQEESAYFVGLSDPEGQRHWQWVDQTPYNESSTFWHPREPSDPNERCVVLNFRKSPKRWGWNDVNCLGPQRSVCEMMKIHL>sp|Q9UMR7-4|CLC4A_HUMAN Isoform 4 of C-type lectin domain family 4member A OS=Homo sapiens OX=9606 GN=CLEC4AMTSEITYAEVRFKNEFKSSGINTASSAETAWSCCPKNWKSFSSNCYFISTESASWQDSEKDCARMEAHLLVINTQEEQDFIFQNLQEESAYFVGLSDPEGQRHWQWVDQTPYNESSTFWHPREPSDPNERCVVLNFRKSPKRWGWNDVNCLGPQRSVCEMMKIHL>sp|Q9NQW8|CNGB3_HUMAN Cyclic nucleotide-gated cation channel beta-3OS=Homo sapiens OX=9606 GN=CNGB3 PE=1 SV=2MFKSLTKVNKVKPIGENNENEQSSRRNEEGSHPSNQSQQTTAQEENKGEEKSLKTKSTPVTSEEPHTNIQDKLSKKNSSGDLTTNPDPQNAAEPTGTVPEQKEMDPGKEGPNSPQNKPPAAPVINEYADAQLHNLVKRMRQRTALYKKKLVEGDLSSPEASPQTAKPTAVPPVKESDDKPTEHYYRLLWFKVKKMPLTEYLKRIKLPNSIDSYTDRLYLLWLLLVTLAYNWNCCFIPLRLVFPYQTADNIHYWLIADIICDIIYLYDMLFIQPRLQFVRGGDIIVDSNELRKHYRTSTKFQLDVASIIPFDICYLFFGFNPMFRANRMLKYTSFFEFNHHLESIMDKAYIYRVIRTTGYLLFILHINACVYYWASNYEGIGTTRWVYDGEGNEYLRCYYWAVRTLITIGGLPEPQTLFEIVFQLLNFFSGVFVFSSLIGQMRDVIGAATANQNYFRACMDDTIAYMNNYSIPKLVQKRVRTWYEYTWDSQRMLDESDLLKTLPTTVQLALAIDVNFSIISKVDLFKGCDTQMIYDMLLRLKSVLYLPGDFVCKKGEIGKEMYIIKHGEVQVLGGPDGTKVLVTLKAGSVFGEISLLAAGGGNRRTANVVAHGFANLLTLDKKTLQEILVHYPDSERILMKKARVLLKQKAKTAEATPPRKDLALLFPPKEETPKLFKTLLGGTGKASLARLLKLKREQAAQKKENSEGGEEEGKENEDKQKENEDKQKENEDKGKENEDKDKGREPEEKPLDRPECTASPIAVEEEPHSVRRTVLPRGTSRQSLIISMAPSAEGGEEVLTIEVKEKAKQ>sp|Q9NQW8-2|CNGB3_HUMAN Isoform 2 of Cyclic nucleotide-gated cationchannel beta-3 OS=Homo sapiens OX=9606 GN=CNGB3MFKSLTKVNKVKPIGENNENEQSSRRNEEGSHPSNQSQQTTAQEENKGEEKSLKTKSTPVTSEEPHTNIQDKLSKKNSSGDLTTNPDPQNAAEPTGTVPEQKEMDPGKEGPNSPQNKPPAAPVINEYADAQLHNLVKRMRQRTALYKKKLVEGDLSSPEASPQTAKPTAVPPVKESDDKPTEHYYRLLWFKVKKMPLTEYLKRIKLPNSIDSYTDRLYLLWLLLVTLAYNWNCCFIPLRLVFPYQTADNIHYWLIADIICDIIYLYDMLFIQPRLQFVRGGDIIVDSNELRKHYRTSTKFQLDVASIIPFDICYLFFGFNPMFRANRMLKYTSFFEFNHHLESIMDKAYIYRVIRTTGYLLFILHINACVYYWASNYEGIGTTRWVYDGEGNEYLRCYYWAVRTLITIGGLPEPQTLFEIVFQLLNFFSGVFVFSSLIGQMRDVIGAATANQNYFRACMDDTIAYMNNYSIPKLVQKRVRTWYEYTWDSQRMLDESDLLKTLPTTVQLALAIDVNFSIISKVDLFKGCDTQMIYDMLLRLKSVLYLPGDFVCKKGEIGKEMYIIKHGEVQVLGGPDGTKVLVTLKAGSVLLAAGGGNRRTANVVAHGFANLLTLDKKTLQEILVHYPDSERILMKKARVLLKQKAKTAEATPPRKDLALLFPPKEETPKLFKTLLGGTGKASLARLLKLKREQAAQKKENSEGGEEEGKENEDKQKENEDKQKENEDKGKENEDKDKGREPEEKPLDRPECTASPIAVEEEPHSVRRTVLPRGTSRQSLIISMAPSAEGGEEVLTIEVKEKAKQ>sp|Q8N1N0|CLC4F_HUMAN C-type lectin domain family 4 member F OS=Homosapiens OX=9606 GN=CLEC4F PE=2 SV=2MDGEAVRFCTDNQCVSLHPQEVDSVAMAPAAPKIPRLVQATPAFMAVTLVFSLVTLFVVVQQQTRPVPKPVQAVILGDNITGHLPFEPNNHHHFGREAEMRELIQTFKGHMENSSAWVVEIQMLKCRVDNVNSQLQVLGDHLGNTNADIQMVKGVLKDATTLSLQTQMLRSSLEGTNAEIQRLKEDLEKADALTFQTLNFLKSSLENTSIELHVLSRGLENANSEIQMLNASLETANTQAQLANSSLKNANAEIYVLRGHLDSVNDLRTQNQVLRNSLEGANAEIQGLKENLQNTNALNSQTQAFIKSSFDNTSAEIQFLRGHLERAGDEIHVLKRDLKMVTAQTQKANGRLDQTDTQIQVFKSEMENVNTLNAQIQVLNGHMKNASREIQTLKQGMKNASALTSQTQMLDSNLQKASAEIQRLRGDLENTKALTMEIQQEQSRLKTLHVVITSQEQLQRTQSQLLQMVLQGWKFNGGSLYYFSSVKKSWHEAEQFCVSQGAHLASVASKEEQAFLVEFTSKVYYWIGLTDRGTEGSWRWTDGTPFNAAQNKAPGSKGSCPLRKYIIVNSGMGACSFIDTPPCPWILSN>sp|Q8N1N0-2|CLC4F_HUMAN Isoform 2 of C-type lectin domain family 4member F OS=Homo sapiens OX=9606 GN=CLEC4FMDGEAVRFCTDNQCVSLHPQEVDSVAMAPAAPKIPRLVQATPAFMAVTLVFSLVTLFVVVQQQTRPVPKPVQAVILGDNITGHLPFEPNNHHHFGREAEMRELIQTFKGHMENSSAWVVEIQMLKCRVDNVNSQLQVLGDHLGNTNADIQMVKGVLKDATTLSLQTQMLRSSLEGTNAEIQRLKEDLEKADALTFQTLNFLKSSLENTSIELHVLSRGLENANSEIQMLNASLETANTQAQLANSSLKNANAEIYVLRGHLDSVNDLRTQNQVLRNSLEGANAEIQGLKENLQNTNALNSQTQAFIKSSFDNTSAEIQFLRGHLERAGDEIHVLKRDLKMVTAQTQKANGRLDQTDTQIQVFKSEMENVNTLNAQIQVLNGHMKNASREIQTLKQGMKNASALTSQTQMLDSNLQKASAEIQRLRGDLENTKALTMEIQQEQSRLKTLHVVITSQEQLQRTQSQLLQMVLQGWKFNGGSLYYFSSVKKSWHEAEQFCVSQGAHLASVASKEEQAFLVEFTSKVYYWIGLTDRGTEGSWRWTDGTPFNAAQNKASHSTRKGCCLHLTV>sp|Q9UGN4|CLM8_HUMAN CMRF35-like molecule 8 OS=Homo sapiens OX=9606GN=CD300A PE=1 SV=2MWLPWALLLLWVPGCFALSKCRTVAGPVGGSLSVQCPYEKEHRTLNKYWCRPPQIFLCDKIVETKGSAGKRNGRVSIRDSPANLSFTVTLENLTEEDAGTYWCGVDTPWLRDFHDPVVEVEVSVFPASTSMTPASITAAKTSTITTAFPPVSSTTLFAVGATHSASIQEETEEVVNSQLPLLLSLLALLLLLLVGASLLAWRMFQKWIKAGDHSELSQNPKQAATQSELHYANLELLMWPLQEKPAPPREVEVEYSTVASPREELHYASVVFDSNTNRIAAQRPREEEPDSDYSVIRKT>sp|Q9UGN4-2|CLM8_HUMAN Isoform 2 of CMRF35-like molecule 8 OS=Homosapiens OX=9606 GN=CD300AMWLPWALLLLWVPASTSMTPASITAAKTSTITTAFPPVSSTTLFAVGATHSASIQEETEEVVNSQLPLLLSLLALLLLLLVGASLLAWRMFQKWIKAGDHSELSQNPKQAATQSELHYANLELLMWPLQEKPAPPREVEVEYSTVASPREELHYASVVFDSNTNRIAAQRPREEEPDSDYSVIRKT>sp|Q9UGN4-3|CLM8_HUMAN Isoform 3 of CMRF35-like molecule 8 OS=Homosapiens OX=9606 GN=CD300AMWLPWALLLLWVPAGDHSELSQNPKQAATQSELHYANLELLMWPLQEKPAPPREVEVEYSTVASPREELHYASVVFDSNTNRIAAQRPREEEPDSDYSVIRKT>sp|Q9UGN4-4|CLM8_HUMAN Isoform 4 of CMRF35-like molecule 8 OS=Homosapiens OX=9606 GN=CD300AMWLPWALLLLWVPASTSMTPASITAAKTSTITTAFPPVSSTTLFAVGATHSASIQEETEEVVNSQLPLLLSLLALLLLLLVGASLLAWRMFQKWIKAGDHSELSQNPKQASPREELHYASVVFDSNTNRIAAQRPREEEPDSDYSVIRKT>sp|Q6UXB4|CLC4G_HUMAN C-type lectin domain family 4 member G OS=Homosapiens OX=9606 GN=CLEC4G PE=1 SV=1MDTTRYSKWGGSSEEVPGGPWGRWVHWSRRPLFLALAVLVTTVLWAVILSILLSKASTERAALLDGHDLLRTNASKQTAALGALKEEVGDCHSCCSGTQAQLQTTRAELGEAQAKLMEQESALRELRERVTQGLAEAGRGREDVRTELFRALEAVRLQNNSCEPCPTSWLSFEGSCYFFSVPKTTWAAAQDHCADASAHLVIVGGLDEQGFLTRNTRGRGYWLGLRAVRHLGKVQGYQWVDGVSLSFSHWNQGEPNDAWGRENCVMMLHTGLWNDAPCDSEKDGWICEKRHNC>sp|Q96JQ2|CLMN_HUMAN Calmin OS=Homo sapiens OX=9606 GN=CLMN PE=1 SV=1MAAHEWDWFQREELIGQISDIRVQNLQVERENVQKRTFTRWINLHLEKCNPPLEVKDLFVDIQDGKILMALLEVLSGRNLLHEYKSSSHRIFRLNNIAKALKFLEDSNVKLVSIDAAEIADGNPSLVLGLIWNIILFFQIKELTGNLSRNSPSSSLSPGSGGTDSDSSFPPTPTAERSVAISVKDQRKAIKALLAWVQRKTRKYGVAVQDFAGSWRSGLAFLAVIKAIDPSLVDMKQALENSTRENLEKAFSIAQDALHIPRLLEPEDIMVDTPDEQSIMTYVAQFLERFPELEAEDIFDSDKEVPIESTFVRIKETPSEQESKVFVLTENGERTYTVNHETSHPPPSKVFVCDKPESMKEFRLDGVSSHALSDSSTEFMHQIIDQVLQGGPGKTSDISEPSPESSILSSRKENGRSNSLPIKKTVHFEADTYKDPFCSKNLSLCFEGSPRVAKESLRQDGHVLAVEVAEEKEQKQESSKIPESSSDKVAGDIFLVEGTNNNSQSSSCNGALESTARHDEESHSLSPPGENTVMADSFQIKVNLMTVEALEEGDYFEAIPLKASKFNSDLIDFASTSQAFNKVPSPHETKPDEDAEAFENHAEKLGKRSIKSAHKKKDSPEPQVKMDKHEPHQDSGEEAEGCPSAPEETPVDKKPEVHEKAKRKSTRPHYEEEGEDDDLQGVGEELSSSPPSSCVSLETLGSHSEEGLDFKPSPPLSKVSVIPHDLFYFPHYEVPLAAVLEAYVEDPEDLKNEEMDLEEPEGYMPDLDSREEEADGSQSSSSSSVPGESLPSASDQVLYLSRGGVGTTPASEPAPLAPHEDHQQRETKENDPMDSHQSQESPNLENIANPLEENVTKESISSKKKEKRKHVDHVESSLFVAPGSVQSSDDLEEDSSDYSIPSRTSHSDSSIYLRRHTHRSSESDHFSYVQLRNAADLDDRRNRILTRKANSSGEAMSLGSHSPQSDSLTQLVQQPDMMYFILFLWLLVYCLLLFPQLDVSRL>sp|Q9H2X3|CLC4M_HUMAN C-type lectin domain family 4 member M OS=Homosapiens OX=9606 GN=CLEC4M PE=1 SV=1MSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTGCLGHGALVLQLLSFMLLAGVLVAILVQVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVGELPDQSKQQQIYQELTDLKTAFERLCRHCPKDWTFFQGNCYFMSNSQRNWHDSVTACQEVRAQLVVIKTAEEQNFLQLQTSRSNRFSWMGLSDLNQEGTWQWVDGSPLSPSFQRYWNSGEPNNSGNEDCAEFSGSGWNDNRCDVDNYWICKKPAACFRDE>sp|Q9H2X3-2|CLC4M_HUMAN Isoform 2 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTGCLGHGALVLQLLSFMLLAGVLVAILVQVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVGELPDQSKQQQIYQELTDLKTAFGEFLHIKGPWA>sp|Q9H2X3-3|CLC4M_HUMAN Isoform 3 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTGCLGHGALVLQLLSFMLLAGVLVAILVQVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVGELPDQSKQQQIYQELTDLKTAFERLCRHCPKDWTFFQGNCYFMSNSQRNWHDSVTACQEVRAQLVVIKTAEEQLPAVLEQWRTQQ>sp|Q9H2X3-4|CLC4M_HUMAN Isoform 4 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTGCLGHGALVLQLLSFMLLAGVLVAILVQVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVERLCRHCPKDWTFFQGNCYFMSNSQRNWHDSVTACQEVRAQLVVIKTAEEQLPAVLEQWRTQQ>sp|Q9H2X3-5|CLC4M_HUMAN Isoform 5 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTVPFLLGPVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVERLCRHCPKDWTFFQGNCYFMSNSQRNWHDSVTACQEVRAQLVVIKTAEEQNFLQLQTSRSNRFSWMGLSDLNQEGTWQWVDGSPLSPSFQRYWNSGEPNNSGNEDCAEFSGSGWNDNRCDVDNYWICKKPAACFRDE>sp|Q9H2X3-6|CLC4M_HUMAN Isoform 6 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTVPFLLGPVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVGELPDQSKQQQIYQELTDLKTAFGEFLHIKGPWA>sp|Q9H2X3-7|CLC4M_HUMAN Isoform 7 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTVPFLLGPVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVERLCRHCPKDWTFFQGNCYFMSNSQRNWHDSVTACQEVRAQLVVIKTAEEQNFLQLQTSRSNRFSWMGLSDLNQEGTWQWVDGSPLSPSFQRYWNSGEPNNSGNEDCAEFSGSGWNDNRCDVDNYWICKKPAACFRDE>sp|Q9H2X3-8|CLC4M_HUMAN Isoform 8 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLEEDPTTSGIRLFPRDFQFQQIHGHKSSTGCLGHGALVLQLLSFMLLAGVLVAILVQVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVGELPDQSKQQQIYQELTDLKTAFERLCRHCPKDWTFFQGNCYFMSNSQRNWHDSVTACQEVRAQLVVIKTAEEQNFLQLQTSRSNRFSWMGLSDLNQEGTWQWVDGSPLSPSFQRYWNSGEPNNSGNEDCAEFSGSGWNDNRCDVDNYWICKKPAACFRDE>sp|Q9H2X3-9|CLC4M_HUMAN Isoform 9 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLGCLGHGALVLQLLSFMLLAGVLVAILVQVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVGELPDQSKQQQIYQELTDLKTAFERLCRHCPKDWTFFQGNCYFMSNSQRNWHDSVTACQEVRAQLVVIKTAEEQLPAVLEQWRTQQ>sp|Q9H2X3-10|CLC4M_HUMAN Isoform 10 of C-type lectin domain family 4member M OS=Homo sapiens OX=9606 GN=CLEC4MMSDSKEPRVQQLGLLVSKVPSSLSQEQSEQDAIYQNLTQLKAAVGELSEKSKLQEIYQELTQLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTRLKAAVGELPEKSKLQEIYQELTELKAAVGELPEKSKLQEIYQELTQLKAAVGELPDQSKQQQIYQELTDLKTAFGEFLHIKGPWA>sp|O95406|CNIH1_HUMAN Protein cornichon homolog 1 OS=Homo sapiensOX=9606 GN=CNIH1 PE=1 SV=1MAFTFAAFCYMLALLLTAALIFFAIWHIIAFDELKTDYKNPIDQCNTLNPLVLPEYLIHAFFCVMFLCAAEWLTLGLNMPLLAYHIWRYMSRPVMSGPGLYDPTTIMNADILAYCQKEGWCKLAFYLLAFFYYLYGMIYVLVSS>sp|Q6EIG7|CLC6A_HUMAN C-type lectin domain family 6 member A OS=Homosapiens OX=9606 GN=CLEC6A PE=1 SV=1MMQEQQPQSTEKRGWLSLRLWSVAGISIALLSACFIVSCVVTYHFTYGETGKRLSELHSYHSSLTCFSEGTKVPAWGCCPASWKSFGSSCYFISSEEKVWSKSEQNCVEMGAHLVVFNTEAEQNFIVQQLNESFSYFLGLSDPQGNNNWQWIDKTPYEKNVRFWHLGEPNHSAEQCASIVFWKPTGWGWNDVICETRRNSICEMNKIYL>sp|Q6EIG7-2|CLC6A_HUMAN Isoform 2 of C-type lectin domain family 6member A OS=Homo sapiens OX=9606 GN=CLEC6AMMQEQQPQSTVTYHFTYGETGKRLSELHSYHSSLTCFSEGTKVPAWGCCPASWKSFGSSCYFISSEEKVWSKSEQNCVEMGAHLVVFNTEAEQNFIVQQLNESFSYFLGLSDPQGNNNWQWIDKTPYEKNVRFWHLGEPNHSAEQCASIVFWKPTGWGWNDVICETRRNSICEMNKIYL>sp|Q8TBE1|CNIH3_HUMAN Protein cornichon homolog 3 OS=Homo sapiensOX=9606 GN=CNIH3 PE=1 SV=1MAFTFAAFCYMLSLVLCAALIFFAIWHIIAFDELRTDFKSPIDQCNPVHARERLRNIERICFLLRKLVLPEYSIHSLFCIMFLCAQEWLTLGLNVPLLFYHFWRYFHCPADSSELAYDPPVVMNADTLSYCQKEAWCKLAFYLLSFFYYLYCMIYTLVSS>sp|Q9BXN2|CLC7A_HUMAN C-type lectin domain family 7 member A OS=Homosapiens OX=9606 GN=CLEC7A PE=1 SV=1MEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMAIWRSNSGSNTLENGYFLSRNKENHSQPTQSSLEDSVTPTKAVKTTGVLSSPCPPNWIIYEKSCYLFSMSLNSWDGSKRQCWQLGSNLLKIDSSNELGFIVKQVSSQPDNSFWIGLSRPQTEVPWLWEDGSTFSSNLFQIRTTATQENPSPNCVWIHVSVIYDQLCSVPSYSICEKKFSM>sp|Q9BXN2-2|CLC7A_HUMAN Isoform 2 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMGVLSSPCPPNWIIYEKSCYLFSMSLNSWDGSKRQCWQLGSNLLKIDSSNELGFIVKQVSSQPDNSFWIGLSRPQTEVPWLWEDGSTFSSNLFQIRTTATQENPSPNCVWIHVSVIYDQLCSVPSYSICEKKFSM>sp|Q9BXN2-3|CLC7A_HUMAN Isoform 3 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMAIWRSNSGSNTLENGYFLSRNKENHSQPTQSSLEDSVTPTKAVKTTGVLSSPCPPNWIIYEKSCYLFSMSLNSWDGSKRQCWQLGSNLLKIDSSNELISDQNHSYPRKPISKLCMDSRVSHL>sp|Q9BXN2-4|CLC7A_HUMAN Isoform 4 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMAIWRSNSGSNTLENGYFLSRNKENHSQPTQSSLEDSVTPTKAVKTTGVLSSPCPPNWIIYEKSCYLFSMSLNSWDGSKRQCWQLGSNLLKIDSSNELSLTLLPKLECSEAATSQAQVILPPQLPE>sp|Q9BXN2-5|CLC7A_HUMAN Isoform 5 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGVLSSPCPPNWIIYEKSCYLFSMSLNSWDGSKRQCWQLGSNLLKIDSSNELGFIVKQVSSQPDNSFWIGLSRPQTEVPWLWEDGSTFSSNLFQIRTTATQENPSPNCVWIHVSVIYDQLCSVPSYSICEKKFSM>sp|Q9BXN2-6|CLC7A_HUMAN Isoform 6 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMGVLSSPCPPNWIIYEKSCYLFSMSLNSWDGSKRQCWQLGSNLLKIDSSNELVSVDFCYDYLWCVS>sp|Q9BXN2-7|CLC7A_HUMAN Isoform 7 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMGVLSSPCPPNWIIYEKSCYLFSMSLNSWDGSKRQCWQLGSNLLKIDSSNELISDQNHSYPRKPISKLCMDSRVSHL>sp|Q9BXN2-8|CLC7A_HUMAN Isoform 8 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGIYSKTSVFPT>sp|Q9BXN2-9|CLC7A_HUMAN Isoform 9 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMAGFKAVEFKG>sp|Q9BXN2-10|CLC7A_HUMAN Isoform 10 of C-type lectin domain family 7member A OS=Homo sapiens OX=9606 GN=CLEC7AMEYHPDLENLDEDGYTQLHFDSQSNTRIAVVSEKGSCAASPPWRLIAVILGILCLVILVIAVVLGTMGTGQFLKDLSFLNNRRKLFGDPIQEATHWRMATFYQEIKRTTVNPHNHL>sp|Q03692|COAA1_HUMAN Collagen alpha-1(X) chain OS=Homo sapiens OX=9606GN=COL10A1 PE=1 SV=2MLPQIPFLLLVSLNLVHGVFYAERYQMPTGIKGPLPNTKTQFFIPYTIKSKGIAVRGEQGTPGPPGPAGPRGHPGPSGPPGKPGYGSPGLQGEPGLPGPPGPSAVGKPGVPGLPGKPGERGPYGPKGDVGPAGLPGPRGPPGPPGIPGPAGISVPGKPGQQGPTGAPGPRGFPGEKGAPGVPGMNGQKGEMGYGAPGRPGERGLPGPQGPTGPSGPPGVGKRGENGVPGQPGIKGDRGFPGEMGPIGPPGPQGPPGERGPEGIGKPGAAGAPGQPGIPGTKGLPGAPGIAGPPGPPGFGKPGLPGLKGERGPAGLPGGPGAKGEQGPAGLPGKPGLTGPPGNMGPQGPKGIPGSHGLPGPKGETGPAGPAGYPGAKGERGSPGSDGKPGYPGKPGLDGPKGNPGLPGPKGDPGVGGPPGLPGPVGPAGAKGMPGHNGEAGPRGAPGIPGTRGPIGPPGIPGFPGSKGDPGSPGPPGPAGIATKGLNGPTGPPGPPGPRGHSGEPGLPGPPGPPGPPGQAVMPEGFIKAGQRPSLSGTPLVSANQGVTGMPVSAFTVILSKAYPAIGTPIPFDKILYNRQQHYDPRTGIFTCQIPGIYYFSYHVHVKGTHVWVGLYKNGTPVMYTYDEYTKGYLDQASGSAIIDLTENDQVWLQLPNAESNGLYSSEYVHSSFSGFLVAPM>sp|G9CGD6|CNIPF_HUMAN CNK3/IPCEF1 fusion protein OS=Homo sapiens OX=9606GN=CNK3/IPCEF1 PE=1 SV=1MEPVTKWSPKQVVDWTRGLDDCLQQYVHKFEREKINGEQLLQISHQDLEELGVTRIGHQELVLEAVDLLCALNYGLETDNMKNLVLKLRASSHNLQNYISSRRKSPAYDGNTSRKAPNEFLTSVVELIGAAKALLAWLDRAPFTGITDFSVTKNKIIQLCLDLTTTVQKDCFVAEMEDKVLTVVKVLNGICDKTIRSTTDPVMSQCACLEEVHLPNIKPGEGLGMYIKSTYDGLHVITGTTENSPADRSQKIHAGDEVIQVNQQTVVGWQLKNLVKKLRENPTGVVLLLKKRPTGSFNFTPAPLKNLRWKPPLVQTSPPPATTQSPESTMDTSLKKEKSAILDLYIPPPPAVPYSPRDENGSFVYGGSSKCKQPLPGPKGSESPNSFLDQESRRRRFTIADSDQLPGYSVETNILPTKMREKTPSYGKPRPLSMPADGNWMGIVDPFARPRGHGRKAFVSTKMTSYMAIDGSALVPLRQKPRRKTQGFLTMSRRRISCKDLGHADCQGWLYKKKEKGSFLSNKWKKFWVILKGSSLYWYSNQMAEKADGFVNLPDFTVERASECKKKHAFKISHPQIKTFYFAAENVQEMNVWLNKLGSAVIHQESTTKDEECYSESEQEDPEIAAETPPPPHASQTQSLTAQQASSSSPSLSGTSYSFSSLENTVKTPSSFPSSLSKERQSLPDTVNSLSAAEDEGQPITFAVQVHSPVPSEAGIHKALENSFVTSESGFLNSLSSDDTSSLSSNHDHLTVPDKPAGSKIMDKEETKVSEDDEMEKLYKSLEQASLSPLGDRRPSTKKELRKSFVKRCKNPSINEKLHKIRTLNSTLKCKEHDLAMINQLLDDPKLTARKYREWKVMNTLLIQDIYQQQRASPAPDDTDDTPQELKKSPSSPSVENSI>sp|G9CGD6-2|CNIPF_HUMAN Isoform CNK3-IPCEF1-2 of CNK3/IPCEF1 fusionprotein OS=Homo sapiens OX=9606 GN=CNK3/IPCEF1MEPVTKWSPKQVVDWTRGLDDCLQQYVHKFEREKINGEQLLQISHQDLEELGVTRIGHQELVLEAVDLLCALNYGLETDNMKNLVLKLRASSHNLQNYISSRRKSPAYDGNTSRKAPNEFLTSVVELIGAAKALLAWLDRAPFTGITDFSVTKNKIIQLCLDLTTTVQKDCFVAEMEDKVLTVVKVLNGICDKTIRSTTDPVMSQCACLEEVHLPNIKPGEGLGMYIKSTYDGLHVITGTTENSPADRSQKIHAGDEVIQVNQQTVVGWQLKNLVKKLRENPTGVVLLLKKRPTGSFNFTPAPLKNLRWKPPLVQTSPPPATTQSPESTMDTSLKKEKSAILDLYIPPPPAVPYSPRDENGSFVYGGSSKCKQPLPGPKGSESPNSFLDQESRRRRFTIADSDQLPGYSVETNILPTKMREKTPSYGKPRPLSMPADGNWMGIVDPFARPRGHGRKAFVSTKMTSYMAIDGSALQVPLRQKPRRKTQGFLTMSRRRISCKDLGHADCQGWLYKKKEKGSFLSNKWKKFWVILKGSSLYWYSNQMAEKADGFVNLPDFTVERASECKKKHAFKISHPQIKTFYFAAENVQEMNVWLNKLGSAVIHQESTTKDEECYSESEQEDPEIAAETPPPPHASQTQSLTAQQASSSSPSLSGTSYSFSSLENTVKTPSSFPSSLSKERQSLPDTVNSLSAAEDEGQPITFAVQVHSPVPSEAGIHKALENSFVTSESGFLNSLSSDDTSSLSSNHDHLTVPDKPAGSKIMDKEETKVSEDDEMEKLYKSLEQASLSPLGDRRPSTKKELRKSFVKRCKNPSINEKLHKIRTLNSTLKCKEHDLAMINQLLDDPKLTARKYREWKVMNTLLIQDIYQQQRASPAPDDTDDTPQELKKSPSSPSVENSI>sp|G9CGD6-3|CNIPF_HUMAN Isoform CNK3-IPCEF1-3 of CNK3/IPCEF1 fusionprotein OS=Homo sapiens OX=9606 GN=CNK3/IPCEF1MEPVTKWSPKQVVDWTRGLDDCLQQYVHKFEREKINGEQLLQISHQDLEELGVTRIGHQELVLEAVDLLCALNYGLETDNMKNLVLKLRASSHNLQNYISSRRKSPAYDGNTSRKAPNEFLTSVVELIGAAKALLAWLDRAPFTGITDFSVTKNKIIQLCLDLTTTVQKDCFVAEMEDKVLTVVKVLNGICDKTIRSTTDPVMSQCACLEEVHLPNIKPGEGLGMYIKSTYDGLHVITGTTENSPADRSQKIHAGDEVIQVNQQTVVGWQLKNLVKKLRENPTGVVLLLKKRPTGSFNFTPAPLKNLRWKPPLVQTSPPPATTQSPESTMDTSLKKEKSAILDLYIPPPPAVPYSPRDENGSFVYGGSSKCKQPLPGPKGSESPNSFLDQESRRRRFTIADSDQLPGYSVETNILPTKMREKTPSYGKPRPLSMPADGNWMGIVDPFARPRGHGRKAFVSTKMTSYMAIDGSALAEKADGFVNLPDFTVERASECKKKHAFKISHPQIKTFYFAAENVQEMNVWLNKLGSAVIHQESTTKDEECYSESEQEDPEIAAETPPPPHASQTQSLTAQQASSSSPSLSGTSYSFSSLENTVKTPSSFPSSLSKERQSLPDTVNSLSAAEDEGQPITFAVQVHSPVPSEAGIHKALENSFVTSESGFLNSLSSDDTSSLSSNHDHLTVPDKPAGSKIMDKEETKVSEDDEMEKLYKSLEQASLSPLGDRRPSTKKELRKSFVKRCKNPSINEKLHKIRTLNSTLKCKEHDLAMINQLLDDPKLTARKYREWKVMNTLLIQDIYQQQRASPAPDDTDDTPQELKKSPSSPSVENSI>sp|Q16740|CLPP_HUMAN ATP-dependent Clp protease proteolytic subunit,mitochondrial OS=Homo sapiens OX=9606 GN=CLPP PE=1 SV=1MWPGILVGGARVASCRYPALGPRLAAHFPAQRPPQRTLQNGLALQRCLHATATRALPLIPIVVEQTGRGERAYDIYSRLLRERIVCVMGPIDDSVASLVIAQLLFLQSESNKKPIHMYINSPGGVVTAGLAIYDTMQYILNPICTWCVGQAASMGSLLLAAGTPGMRHSLPNSRIMIHQPSGGARGQATDIAIQAEEIMKLKKQLYNIYAKHTKQSLQVIESAMERDRYMSPMEAQEFGILDKVLVHPPQDGEDEPTLVQKEPVEAAPAAEPVPAST>sp|Q99439|CNN2_HUMAN Calponin-2 OS=Homo sapiens OX=9606 GN=CNN2 PE=1SV=4MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSNFIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKAKTKGLQSGVDIGVKYSEKQERNFDDATMKAGQCVIGLQMGTNKCASQSGMTAYGTRRHLYDPKNHILPPMDHSTISLQMGTNKCASQVGMTAPGTRRHIYDTKLGTDKCDNSSMSLQMGYTQGANQSGQVFGLGRQIYDPKYCPQGTVADGAPSGTGDCPDPGEVPEYPPYYQEEAGY>sp|Q99439-2|CNN2_HUMAN Isoform 2 of Calponin-2 OS=Homo sapiens OX=9606GN=CNN2MSSTQFNKGPSYGLSAEVKNRLLSKYDPQKEAELRTWIEGLTGLSIGPDFQKGLKDGTILCTLMNKLQPGSVPKINRSMQNWHQLENLSNFIKAMVSYGMNPVDLFEANDLFESGNMTQVQVSLLALAGKMGTNKCASQSGMTAYGTRRHLYDPKNHILPPMDHSTISLQMGTNKCASQVGMTAPGTRRHIYDTKLGTDKCDNSSMSLQMGYTQGANQSGQVFGLGRQIYDPKYCPQGTVADGAPSGTGDCPDPGEVPEYPPYYQEEAGY>sp|A5YKK6|CNOT1_HUMAN CCR4-NOT transcription complex subunit 1 OS=Homosapiens OX=9606 GN=CNOT1 PE=1 SV=2MNLDSLSLALSQISYLVDNLTKKNYRASQQEIQHIVNRHGPEADRHLLRCLFSHVDFSGDGKSSGKDFHQTQFLIQECALLITKPNFISTLSYAIDNPLHYQKSLKPAPHLFAQLSKVLKLSKVQEVIFGLALLNSSSSDLRGFAAQFIKQKLPDLLRSYIDADVSGNQEGGFQDIAIEVLHLLLSHLLFGQKGAFGVGQEQIDAFLKTLRRDFPQERCPVVLAPLLYPEKRDILMDRILPDSGGVAKTMMESSLADFMQEVGYGFCASIEECRNIIVQFGVREVTAAQVARVLGMMARTHSGLTDGIPLQSISAPGSGIWSDGKDKSDGAQAHTWNVEVLIDVLKELNPSLNFKEVTYELDHPGFQIRDSKGLHNVVYGIQRGLGMEVFPVDLIYRPWKHAEGQLSFIQHSLINPEIFCFADYPCHTVATDILKAPPEDDNREIATWKSLDLIESLLRLAEVGQYEQVKQLFSFPIKHCPDMLVLALLQINTSWHTLRHELISTLMPIFLGNHPNSAIILHYAWHGQGQSPSIRQLIMHAMAEWYMRGEQYDQAKLSRILDVAQDLKALSMLLNGTPFAFVIDLAALASRREYLKLDKWLTDKIREHGEPFIQACMTFLKRRCPSILGGLAPEKDQPKSAQLPPETLATMLACLQACAGSVSQELSETILTMVANCSNVMNKARQPPPGVMPKGRPPSASSLDAISPVQIDPLAGMTSLSIGGSAAPHTQSMQGFPPNLGSAFSTPQSPAKAFPPLSTPNQTTAFSGIGGLSSQLPVGGLGTGSLTGIGTGALGLPAVNNDPFVQRKLGTSGLNQPTFQQSKMKPSDLSQVWPEANQHFSKEIDDEANSYFQRIYNHPPHPTMSVDEVLEMLQRFKDSTIKREREVFNCMLRNLFEEYRFFPQYPDKELHITACLFGGIIEKGLVTYMALGLALRYVLEALRKPFGSKMYYFGIAALDRFKNRLKDYPQYCQHLASISHFMQFPHHLQEYIEYGQQSRDPPVKMQGSITTPGSIALAQAQAQAQVPAKAPLAGQVSTMVTTSTTTTVAKTVTVTRPTGVSFKKDVPPSINTTNIDTLLVATDQTERIVEPPENIQEKIAFIFNNLSQSNMTQKVEELKETVKEEFMPWVSQYLVMKRVSIEPNFHSLYSNFLDTLKNPEFNKMVLNETYRNIKVLLTSDKAAANFSDRSLLKNLGHWLGMITLAKNKPILHTDLDVKSLLLEAYVKGQQELLYVVPFVAKVLESSIRSVVFRPPNPWTMAIMNVLAELHQEHDLKLNLKFEIEVLCKNLALDINELKPGNLLKDKDRLKNLDEQLSAPKKDVKQPEELPPITTTTTSTTPATNTTCTATVPPQPQYSYHDINVYSLAGLAPHITLNPTIPLFQAHPQLKQCVRQAIERAVQELVHPVVDRSIKIAMTTCEQIVRKDFALDSEESRMRIAAHHMMRNLTAGMAMITCREPLLMSISTNLKNSFASALRTASPQQREMMDQAAAQLAQDNCELACCFIQKTAVEKAGPEMDKRLATEFELRKHARQEGRRYCDPVVLTYQAERMPEQIRLKVGGVDPKQLAVYEEFARNVPGFLPTNDLSQPTGFLAQPMKQAWATDDVAQIYDKCITELEQHLHAIPPTLAMNPQAQALRSLLEVVVLSRNSRDAIAALGLLQKAVEGLLDATSGADADLLLRYRECHLLVLKALQDGRAYGSPWCNKQITRCLIECRDEYKYNVEAVELLIRNHLVNMQQYDLHLAQSMENGLNYMAVAFAMQLVKILLVDERSVAHVTEADLFHTIETLMRINAHSRGNAPEGLPQLMEVVRSNYEAMIDRAHGGPNFMMHSGISQASEYDDPPGLREKAEYLLREWVNLYHSAAAGRDSTKAFSAFVGQMHQQGILKTDDLITRFFRLCTEMCVEISYRAQAEQQHNPAANPTMIRAKCYHNLDAFVRLIALLVKHSGEATNTVTKINLLNKVLGIVVGVLLQDHDVRQSEFQQLPYHRIFIMLLLELNAPEHVLETINFQTLTAFCNTFHILRPTKAPGFVYAWLELISHRIFIARMLAHTPQQKGWPMYAQLLIDLFKYLAPFLRNVELTKPMQILYKGTLRVLLVLLHDFPEFLCDYHYGFCDVIPPNCIQLRNLILSAFPRNMRLPDPFTPNLKVDMLSEINIAPRILTNFTGVMPPQFKKDLDSYLKTRSPVTFLSDLRSNLQVSNEPGNRYNLQLINALVLYVGTQAIAHIHNKGSTPSMSTITHSAHMDIFQNLAVDLDTEGRYLFLNAIANQLRYPNSHTHYFSCTMLYLFAEANTEAIQEQITRVLLERLIVNRPHPWGLLITFIELIKNPAFKFWNHEFVHCAPEIEKLFQSVAQCCMGQKQAQQVMEGTGAS>sp|A5YKK6-2|CNOT1_HUMAN Isoform 2 of CCR4-NOT transcription complexsubunit 1 OS=Homo sapiens OX=9606 GN=CNOT1MNLDSLSLALSQISYLVDNLTKKNYRASQQEIQHIVNRHGPEADRHLLRCLFSHVDFSGDGKSSGKDFHQTQFLIQECALLITKPNFISTLSYAIDNPLHYQKSLKPAPHLFAQLSKVLKLSKVQEVIFGLALLNSSSSDLRGFAAQFIKQKLPDLLRSYIDADVSGNQEGGFQDIAIEVLHLLLSHLLFGQKGAFGVGQEQIDAFLKTLRRDFPQERCPVVLAPLLYPEKRDILMDRILPDSGGVAKTMMESSLADFMQEVGYGFCASIEECRNIIVQFGVREVTAAQVARVLGMMARTHSGLTDGIPLQSISAPGSGIWSDGKDKSDGAQAHTWNVEVLIDVLKELNPSLNFKEVTYELDHPGFQIRDSKGLHNVVYGIQRGLGMEVFPVDLIYRPWKHAEGQLSFIQHSLINPEIFCFADYPCHTVATDILKAPPEDDNREIATWKSLDLIESLLRLAEVGQYEQVKQLFSFPIKHCPDMLVLALLQINTSWHTLRHELISTLMPIFLGNHPNSAIILHYAWHGQGQSPSIRQLIMHAMAEWYMRGEQYDQAKLSRILDVAQDLKALSMLLNGTPFAFVIDLAALASRREYLKLDKWLTDKIREHGEPFIQACMTFLKRRCPSILGGLAPEKDQPKSAQLPPETLATMLACLQACAGSVSQELSETILTMVANCSNVMNKARQPPPGVMPKGRPPSASSLDAISPVQIDPLAGMTSLSIGGSAAPHTQSMQGFPPNLGSAFSTPQSPAKAFPPLSTPNQTTAFSGIGGLSSQLPVGGLGTGSLTGIGTGALGLPAVNNDPFVQRKLGTSGLNQPTFQQTDLSQVWPEANQHFSKEIDDEANSYFQRIYNHPPHPTMSVDEVLEMLQRFKDSTIKREREVFNCMLRNLFEEYRFFPQYPDKELHITACLFGGIIEKGLVTYMALGLALRYVLEALRKPFGSKMYYFGIAALDRFKNRLKDYPQYCQHLASISHFMQFPHHLQEYIEYGQQSRDPPVKMQGSITTPGSIALAQAQAQAQVPAKAPLAGQVSTMVTTSTTTTVAKTVTVTRPTGVSFKKDVPPSINTTNIDTLLVATDQTERIVEPPENIQEKIAFIFNNLSQSNMTQKVEELKETVKEEFMPWVSQYLVMKRVSIEPNFHSLYSNFLDTLKNPEFNKMVLNETYRNIKVLLTSDKAAANFSDRSLLKNLGHWLGMITLAKNKPILHTDLDVKSLLLEAYVKGQQELLYVVPFVAKVLESSIRSVVFRPPNPWTMAIMNVLAELHQEHDLKLNLKFEIEVLCKNLALDINELKPGNLLKDKDRLKNLDEQLSAPKKDVKQPEELPPITTTTTSTTPATNTTCTATVPPQPQYSYHDINVYSLAGLAPHITLNPTIPLFQAHPQLKQCVRQAIERAVQELVHPVVDRSIKIAMTTCEQIVRKDFALDSEESRMRIAAHHMMRNLTAGMAMITCREPLLMSISTNLKNSFASALRTASPQQREMMDQAAAQLAQDNCELACCFIQKTAVEKAGPEMDKRLATEFELRKHARQEGRRYCDPVVLTYQAERMPEQIRLKVGGVDPKQLAVYEEFARNVPGFLPTNDLSQPTGFLAQPMKQAWATDDVAQIYDKCITELEQHLHAIPPTLAMNPQAQALRSLLEVVVLSRNSRDAIAALGLLQKAVEGLLDATSGADADLLLRYRECHLLVLKALQDGRAYGSPWCNKQITRCLIECRDEYKYNVEAVELLIRNHLVNMQQYDLHLAQSMENGLNYMAVAFAMQLVKILLVDERSVAHVTEADLFHTIETLMRINAHSRGNAPEGLPQLMEVVRSNYEAMIDRAHGGPNFMMHSGISQASEYDDPPGLREKAEYLLREWVNLYHSAAAGRDSTKAFSAFVGQMHQQGILKTDDLITRFFRLCTEMCVEISYRAQAEQQHNPAANPTMIRAKCYHNLDAFVRLIALLVKHSGEATNTVTKINLLNKVLGIVVGVLLQDHDVRQSEFQQLPYHRIFIMLLLELNAPEHVLETINFQTLTAFCNTFHILRPTKAPGFVYAWLELISHRIFIARMLAHTPQQKGWPMYAQLLIDLFKYLAPFLRNVELTKPMQILYKGTLRVLLVLLHDFPEFLCDYHYGFCDVIPPNCIQLRNLILSAFPRNMRLPDPFTPNLKVDMLSEINIAPRILTNFTGVMPPQFKKDLDSYLKTRSPVTFLSDLRSNLQVSNEPGNRYNLQLINALVLYVGTQAIAHIHNKGSTPSMSTITHSAHMDIFQNLAVDLDTEGRYLFLNAIANQLRYPNSHTHYFSCTMLYLFAEANTEAIQEQITRVLLERLIVNRPHPWGLLITFIELIKNPAFKFWNHEFVHCAPEIEKLFQSVAQCCMGQKQAQQVMEGTGAS>sp|A5YKK6-3|CNOT1_HUMAN Isoform 3 of CCR4-NOT transcription complexsubunit 1 OS=Homo sapiens OX=9606 GN=CNOT1MNLDSLSLALSQISYLVDNLTKKNYRASQQEIQHIVNRHGPEADRHLLRCLFSHVDFSGDGKSSGKDFHQTQFLIQECALLITKPNFISTLSYAIDNPLHYQKSLKPAPHLFAQLSKVLKLSKVQEVIFGLALLNSSSSDLRGFAAQFIKQKLPDLLRSYIDADVSGNQEGGFQDIAIEVLHLLLSHLLFGQKGAFGVGQEQIDAFLKTLRRDFPQERCPVVLAPLLYPEKRDILMDRILPDSGGVAKTMMESSLADFMQEVGYGFCASIEECRNIIVQFGVREVTAAQVARVLGMMARTHSGLTDGIPLQSISAPGSGIWSDGKDKSDGAQAHTWNVEVLIDVLKELNPSLNFKEVTYELDHPGFQIRDSKGLHNVVYGIQRGLGMEVFPVDLIYRPWKHAEGQLSFIQHSLINPEIFCFADYPCHTVATDILKAPPEDDNREIATWKSLDLIESLLRLAEVGQYEQVKQLFSFPIKHCPDMLVLALLQINTSWHTLRHELISTLMPIFLGNHPNSAIILHYAWHGQGQSPSIRQLIMHAMAEWYMRGEQYDQAKLSRILDVAQDLKALSMLLNGTPFAFVIDLAALASRREYLKLDKWLTDKIREHGEPFIQACMTFLKRRCPSILGGLAPEKDQPKSAQLPPETLATMLACLQACAGSVSQELSETILTMVANCSNVMNKARQPPPGVMPKGRPPSASSLDAISPVQIDPLAGMTSLSIGGSAAPHTQSMQGFPPNLGSAFSTPQSPAKAFPPLSTPNQTTAFSGIGGLSSQLPVGGLGTGSLTGIGTGALGLPAVNNDPFVQRKLGTSGLNQPTFQQTDLSQVWPEANQHFSKEIDDEANSYFQRIYNHPPHPTMSVDEVLEMLQRFKDSTIKREREVFNCMLRNLFEEYRFFPQYPDKELHITACLFGGIIEKGLVTYMALGLALRYVLEALRKPFGSKMYYFGIAALDRFKNRLKDYPQYCQHLASISHFMQFPHHLQEYIEYGQQSRDPPVKMQGSITTPGSIALAQAQAQAQVPAKAPLAGQVSTMVTTSTTTTVAKTVTVTRPTGVSFKKDVPPSINTTNIDTLLVATDQTERIVEPPENIQEKIAFIFNNLSQSNMTQKVEELKETVKEEFMPWVSQYLVMKRVSIEPNFHSLYSNFLDTLKNPEFNKMVLNETYRNIKVLLTSDKAAANFSDRSLLKNLGHWLGMITLAKNKPILHTDLDVKSLLLEAYVKGQQELLYVVPFVAKVLESSIRSVVFRPPNPWTMAIMNVLAELHQEHDLKLNLKFEIEVLCKNLALDINELKPGNLLKDKDRLKNLDEQLSAPKKDVKQPEELPPITTTTTSTTPATNTTCTATVPPQPQYSYHDINVYSLAGLAPHITLNPTIPLFQAHPQLKQCVRQAIERAVQELVHPVVDRSIKIAMTTCEQIVRKDFALDSEESRMRIAAHHMMRNLTAGMAMITCREPLLMSISTNLKNSFASALRTASPQQREMMDQAAAQLAQDNCELACCFIQKTAVEKAGPEMDKRLATEFELRKHARQEGRRYCDPVVLTYQAERMPEQIRLKVGGVDPKQLAVYEEFARNVPGFLPTNDLSQPTGFLAQPMKQAWATDDVAQIYDKCITELEQHLHAIPPTLAMNPQAQALRSLLEVVVLSRNSRDAIAALGLLQKAVEGLLDATSGADADLLLRYRECHLLVLKALQDGRAYGSPWCNKQITRCLIECRDEYKYNVEAVELLIRNHLVNMQQYDLHLAQSMENGLNYMAVAFAMQLVKILLVDERSVAHVTEADLFHTIETLMRINAHSRGNAPEGLPQLMEVVRSNYEAMIDRAHGGPNFMMHSGISQASEYDDPPGLREKAEYLLREWVNLYHSAAAGRDSTKAFSAFVGQMHQQGILKTDDLITRFFRLCTEMCVEISYRAQAEQQHNPAANPTMIRAKCYHNLDAFVRLIALLVKHSGEATNTVTKINLLNKVLGIVVGVLLQDHDVRQSEFQQLPYHRIFIMLLLELNAPEHVLETINFQTLTAFCNTFHILRPTKAPGFVYAWLELISHRIFIARMLAHTPQQKGWPMYAQLLIDLFKYLAPFLRNVELTKPMQILYKGTLRVLLVLLHDFPEFLCDYHYGFCDVIPPNCIQLRNLILSAFPRNMRLPDPFTPNLKSLTL>sp|A5YKK6-4|CNOT1_HUMAN Isoform 4 of CCR4-NOT transcription complexsubunit 1 OS=Homo sapiens OX=9606 GN=CNOT1MNLDSLSLALSQISYLVDNLTKKNYRASQQEIQHIVNRHGPEADRHLLRCLFSHVDFSGDGKSSGKDFHQTQFLIQECALLITKPNFISTLSYAIDNPLHYQKSLKPAPHLFAQLSKVLKLSKVQEVIFGLALLNSSSSDLRGFAAQFIKQKLPDLLRSYIDADVSGNQEGGFQDIAIEVLHLLLSHLLFGQKGAFGVGQEQIDAFLKTLRRDFPQERCPVVLAPLLYPEKRDILMDRILPDSGGVAKTMMESSLADFMQEVGYGFCASIEECRNIIVQFGVREVTAAQVARVLGMMARTHSGLTDGIPLQSISAPGSGIWSDGKDKSDGAQAHTWNVEVLIDVLKELNPSLNFKEVTYELDHPGFQIRDSKGLHNVVYGIQRGLGMEVFPVDLIYRPWKHAEGQLSFIQHSLINPEIFCFADYPCHTVATDILKAPPEDDNREIATWKSLDLIESLLRLAEVGQYEQVKQLFSFPIKHCPDMLVLALLQINTSWHTLRHELISTLMPIFLGNHPNSAIILHYAWHGQGQSPSIRQLIMHAMAEWYMRGEQYDQAKLSRILDVAQDLKALSMLLNGTPFAFVIDLAALASRREYLKLDKWLTDKIREHGEPFIQACMTFLKRRCPSILGGLAPEKDQPKSAQLPPETLATMLACLQACAGSVSQELSETILTMVANCSNVMNKARQPPPGVMPKGRPPSASSLDAISPVQIDPLAGMTSLSIGGSAAPHTQSMQGFPPNLGSAFSTPQSPAKAFPPLSTPNQTTAFSGIGGLSSQLPVGGLGTGSLTGIGTGALGLPAVNNDPFVQRKLGTSGLNQPTFQQSKMKPSDLSQVWPEANQHFSKEIDDEANSYFQRIYNHPPHPTMSVDEVLEMLQRFKDSTIKREREVFNCMLRNLFEEYRFFPQYPDKELHITACLFGGIIEKGLVTYMALGLALRYVLEALRKPFGSKMYYFGIAALDRFKNRLKDYPQYCQHLASISHFMQFPHHLQEYIEYGQQSRDPPVKMQGSITTPGSIALAQAQAQAQVPAKAPLAGQVSTMVTTSTTTTVAKTVTVTRPTGVSFKKDVPPSINTTNIDTLLVATDQTERIVEPPENIQEKIAFIFNNLSQSNMTQKVEELKETVKEEFMPWVSQYLVMKRVSIEPNFHSLYSNFLDTLKNPEFNKMVLNETYRNIKVLLTSDKAAANFSDRSLLKNLGHWLGMITLAKNKPILHTDLDVKSLLLEAYVKGQQELLYVVPFVAKVLESSIRSVVFRPPNPWTMAIMNVLAELHQEHDLKLNLKFEIEVLCKNLALDINELKPGNLLKDKDRLKNLDEQLSAPKKDVKQPEELPPITTTTTSTTPATNTTCTATVPPQPQYSYHDINVYSLAGLAPHITLNPTIPLFQAHPQLKQCVRQAIERAVQELVHPVVDRSIKIAMTTCEQIVRKDFALDSEESRMRIAAHHMMRNLTAGMAMITCREPLLMSISTNLKNSFASALRVSWLFPWYRYKTYYCLSVIIFFFVYIWHWALPLILNNHHICLMSSIILDCNSVRQSIMSVCFFFFLLYSQHDV>sp|P46100|ATRX_HUMAN Transcriptional regulator ATRX OS=Homo sapiensOX=9606 GN=ATRX PE=1 SV=5MTAEPMSESKLNTLVQKLHDFLAHSSEESEETSSPPRLAMNQNTDKISGSGSNSDMMENSKEEGTSSSEKSKSSGSSRSKRKPSIVTKYVESDDEKPLDDETVNEDASNENSENDITMQSLPKGTVIVQPEPVLNEDKDDFKGPEFRSRSKMKTENLKKRGEDGLHGIVSCTACGQQVNHFQKDSIYRHPSLQVLICKNCFKYYMSDDISRDSDGMDEQCRWCAEGGNLICCDFCHNAFCKKCILRNLGRKELSTIMDENNQWYCYICHPEPLLDLVTACNSVFENLEQLLQQNKKKIKVDSEKSNKVYEHTSRFSPKKTSSNCNGEEKKLDDSCSGSVTYSYSALIVPKEMIKKAKKLIETTANMNSSYVKFLKQATDNSEISSATKLRQLKAFKSVLADIKKAHLALEEDLNSEFRAMDAVNKEKNTKEHKVIDAKFETKARKGEKPCALEKKDISKSEAKLSRKQVDSEHMHQNVPTEEQRTNKSTGGEHKKSDRKEEPQYEPANTSEDLDMDIVSVPSSVPEDIFENLETAMEVQSSVDHQGDGSSGTEQEVESSSVKLNISSKDNRGGIKSKTTAKVTKELYVKLTPVSLSNSPIKGADCQEVPQDKDGYKSCGLNPKLEKCGLGQENSDNEHLVENEVSLLLEESDLRRSPRVKTTPLRRPTETNPVTSNSDEECNETVKEKQKLSVPVRKKDKRNSSDSAIDNPKPNKLPKSKQSETVDQNSDSDEMLAILKEVSRMSHSSSSDTDINEIHTNHKTLYDLKTQAGKDDKGKRKRKSSTSGSDFDTKKGKSAKSSIISKKKRQTQSESSNYDSELEKEIKSMSKIGAARTTKKRIPNTKDFDSSEDEKHSKKGMDNQGHKNLKTSQEGSSDDAERKQERETFSSAEGTVDKDTTIMELRDRLPKKQQASASTDGVDKLSGKEQSFTSLEVRKVAETKEKSKHLKTKTCKKVQDGLSDIAEKFLKKDQSDETSEDDKKQSKKGTEEKKKPSDFKKKVIKMEQQYESSSDGTEKLPEREEICHFPKGIKQIKNGTTDGEKKSKKIRDKTSKKKDELSDYAEKSTGKGDSCDSSEDKKSKNGAYGREKKRCKLLGKSSRKRQDCSSSDTEKYSMKEDGCNSSDKRLKRIELRERRNLSSKRNTKEIQSGSSSSDAEESSEDNKKKKQRTSSKKKAVIVKEKKRNSLRTSTKRKQADITSSSSSDIEDDDQNSIGEGSSDEQKIKPVTENLVLSSHTGFCQSSGDEALSKSVPVTVDDDDDDNDPENRIAKKMLLEEIKANLSSDEDGSSDDEPEEGKKRTGKQNEENPGDEEAKNQVNSESDSDSEESKKPRYRHRLLRHKLTVSDGESGEEKKTKPKEHKEVKGRNRRKVSSEDSEDSDFQESGVSEEVSESEDEQRPRTRSAKKAELEENQRSYKQKKKRRRIKVQEDSSSENKSNSEEEEEEKEEEEEEEEEEEEEEEDENDDSKSPGKGRKKIRKILKDDKLRTETQNALKEEEERRKRIAEREREREKLREVIEIEDASPTKCPITTKLVLDEDEETKEPLVQVHRNMVIKLKPHQVDGVQFMWDCCCESVKKTKKSPGSGCILAHCMGLGKTLQVVSFLHTVLLCDKLDFSTALVVCPLNTALNWMNEFEKWQEGLKDDEKLEVSELATVKRPQERSYMLQRWQEDGGVMIIGYEMYRNLAQGRNVKSRKLKEIFNKALVDPGPDFVVCDEGHILKNEASAVSKAMNSIRSRRRIILTGTPLQNNLIEYHCMVNFIKENLLGSIKEFRNRFINPIQNGQCADSTMVDVRVMKKRAHILYEMLAGCVQRKDYTALTKFLPPKHEYVLAVRMTSIQCKLYQYYLDHLTGVGNNSEGGRGKAGAKLFQDFQMLSRIWTHPWCLQLDYISKENKGYFDEDSMDEFIASDSDETSMSLSSDDYTKKKKKGKKGKKDSSSSGSGSDNDVEVIKVWNSRSRGGGEGNVDETGNNPSVSLKLEESKATSSSNPSSPAPDWYKDFVTDADAEVLEHSGKMVLLFEILRMAEEIGDKVLVFSQSLISLDLIEDFLELASREKTEDKDKPLIYKGEGKWLRNIDYYRLDGSTTAQSRKKWAEEFNDETNVRGRLFIISTKAGSLGINLVAANRVIIFDASWNPSYDIQSIFRVYRFGQTKPVYVYRFLAQGTMEDKIYDRQVTKQSLSFRVVDQQQVERHFTMNELTELYTFEPDLLDDPNSEKKKKRDTPMLPKDTILAELLQIHKEHIVGYHEHDSLLDHKEEEELTEEERKAAWAEYEAEKKGLTMRFNIPTGTNLPPVSFNSQTPYIPFNLGALSAMSNQQLEDLINQGREKVVEATNSVTAVRIQPLEDIISAVWKENMNLSEAQVQALALSRQASQELDVKRREAIYNDVLTKQQMLISCVQRILMNRRLQQQYNQQQQQQMTYQQATLGHLMMPKPPNLIMNPSNYQQIDMRGMYQPVAGGMQPPPLQRAPPPMRSKNPGPSQGKSM>sp|P46100-2|ATRX_HUMAN Isoform 1 of Transcriptional regulator ATRXOS=Homo sapiens OX=9606 GN=ATRXMSDDISRDSDGMDEQCRWCAEGGNLICCDFCHNAFCKKCILRNLGRKELSTIMDENNQWYCYICHPEPLLDLVTACNSVFENLEQLLQQNKKKIKVDSEKSNKVYEHTSRFSPKKTSSNCNGEEKKLDDSCSGSVTYSYSALIVPKEMIKKAKKLIETTANMNSSYVKFLKQATDNSEISSATKLRQLKAFKSVLADIKKAHLALEEDLNSEFRAMDAVNKEKNTKEHKVIDAKFETKARKGEKPCALEKKDISKSEAKLSRKQVDSEHMHQNVPTEEQRTNKSTGGEHKKSDRKEEPQYEPANTSEDLDMDIVSVPSSVPEDIFENLETAMEVQSSVDHQGDGSSGTEQEVESSSVKLNISSKDNRGGIKSKTTAKVTKELYVKLTPVSLSNSPIKGADCQEVPQDKDGYKSCGLNPKLEKCGLGQENSDNEHLVENEVSLLLEESDLRRSPRVKTTPLRRPTETNPVTSNSDEECNETVKEKQKLSVPVRKKDKRNSSDSAIDNPKPNKLPKSKQSETVDQNSDSDEMLAILKEVSRMSHSSSSDTDINEIHTNHKTLYDLKTQAGKDDKGKRKRKSSTSGSDFDTKKGKSAKSSIISKKKRQTQSESSNYDSELEKEIKSMSKIGAARTTKKRIPNTKDFDSSEDEKHSKKGMDNQGHKNLKTSQEGSSDDAERKQERETFSSAEGTVDKDTTIMELRDRLPKKQQASASTDGVDKLSGKEQSFTSLEVRKVAETKEKSKHLKTKTCKKVQDGLSDIAEKFLKKDQSDETSEDDKKQSKKGTEEKKKPSDFKKKVIKMEQQYESSSDGTEKLPEREEICHFPKGIKQIKNGTTDGEKKSKKIRDKTSKKKDELSDYAEKSTGKGDSCDSSEDKKSKNGAYGREKKRCKLLGKSSRKRQDCSSSDTEKYSMKEDGCNSSDKRLKRIELRERRNLSSKRNTKEIQSGSSSSDAEESSEDNKKKKQRTSSKKKAVIVKEKKRNSLRTSTKRKQADITSSSSSDIEDDDQNSIGEGSSDEQKIKPVTENLVLSSHTGFCQSSGDEALSKSVPVTVDDDDDDNDPENRIAKKMLLEEIKANLSSDEDGSSDDEPEEGKKRTGKQNEENPGDEEAKNQVNSESDSDSEESKKPRYRHRLLRHKLTVSDGESGEEKKTKPKEHKEVKGRNRRKVSSEDSEDSDFQESGVSEEVSESEDEQRPRTRSAKKAELEENQRSYKQKKKRRRIKVQEDSSSENKSNSEEEEEEKEEEEEEEEEEEEEEEDENDDSKSPGKGRKKIRKILKDDKLRTETQNALKEEEERRKRIAEREREREKLREVIEIEDASPTKCPITTKLVLDEDEETKEPLVQVHRNMVIKLKPHQVDGVQFMWDCCCESVKKTKKSPGSGCILAHCMGLGKTLQVVSFLHTVLLCDKLDFSTALVVCPLNTALNWMNEFEKWQEGLKDDEKLEVSELATVKRPQERSYMLQRWQEDGGVMIIGYEMYRNLAQGRNVKSRKLKEIFNKALVDPGPDFVVCDEGHILKNEASAVSKAMNSIRSRRRIILTGTPLQNNLIEYHCMVNFIKENLLGSIKEFRNRFINPIQNGQCADSTMVDVRVMKKRAHILYEMLAGCVQRKDYTALTKFLPPKHEYVLAVRMTSIQCKLYQYYLDHLTGVGNNSEGGRGKAGAKLFQDFQMLSRIWTHPWCLQLDYISKENKGYFDEDSMDEFIASDSDETSMSLSSDDYTKKKKKGKKGKKDSSSSGSGSDNDVEVIKVWNSRSRGGGEGNVDETGNNPSVSLKLEESKATSSSNPSSPAPDWYKDFVTDADAEVLEHSGKMVLLFEILRMAEEIGDKVLVFSQSLISLDLIEDFLELASREKTEDKDKPLIYKGEGKWLRNIDYYRLDGSTTAQSRKKWAEEFNDETNVRGRLFIISTKAGSLGINLVAANRVIIFDASWNPSYDIQSIFRVYRFGQTKPVYVYRFLAQGTMEDKIYDRQVTKQSLSFRVVDQQQVERHFTMNELTELYTFEPDLLDDPNSEKKKKRDTPMLPKDTILAELLQIHKEHIVGYHEHDSLLDHKEEEELTEEERKAAWAEYEAEKKGLTMRFNIPTGTNLPPVSFNSQTPYIPFNLGALSAMSNQQLEDLINQGREKVVEATNSVTAVRIQPLEDIISAVWKENMNLSEAQVQALALSRQASQELDVKRREAIYNDVLTKQQMLISCVQRILMNRRLQQQYNQQQQQQMTYQQATLGHLMMPKPPNLIMNPSNYQQIDMRGMYQPVAGGMQPPPLQRAPPPMRSKNPGPSQGKSM>sp|P46100-3|ATRX_HUMAN Isoform 2 of Transcriptional regulator ATRXOS=Homo sapiens OX=9606 GN=ATRXMQSLPKGTVIVQPEPVLNEDKDDFKGPEFRSRSKMKTENLKKRGEDGLHGIVSCTACGQQVNHFQKDSIYRHPSLQVLICKNCFKYYMSDDISRDSDGMDEQCRWCAEGGNLICCDFCHNAFCKKCILRNLGRKELSTIMDENNQWYCYICHPEPLLDLVTACNSVFENLEQLLQQNKKKIKVDSEKSNKVYEHTSRFSPKKTSSNCNGEEKKLDDSCSGSVTYSYSALIVPKEMIKKAKKLIETTANMNSSYVKFLKQATDNSEISSATKLRQLKAFKSVLADIKKAHLALEEDLNSEFRAMDAVNKEKNTKEHKVIDAKFETKARKGEKPCALEKKDISKSEAKLSRKQVDSEHMHQNVPTEEQRTNKSTGGEHKKSDRKEEPQYEPANTSEDLDMDIVSVPSSVPEDIFENLETAMEVQSSVDHQGDGSSGTEQEVESSSVKLNISSKDNRGGIKSKTTAKVTKELYVKLTPVSLSNSPIKGADCQEVPQDKDGYKSCGLNPKLEKCGLGQENSDNEHLVENEVSLLLEESDLRRSPRVKTTPLRRPTETNPVTSNSDEECNETVKEKQKLSVPVRKKDKRNSSDSAIDNPKPNKLPKSKQSETVDQNSDSDEMLAILKEVSRMSHSSSSDTDINEIHTNHKTLYDLKTQAGKDDKGKRKRKSSTSGSDFDTKKGKSAKSSIISKKKRQTQSESSNYDSELEKEIKSMSKIGAARTTKKRIPNTKDFDSSEDEKHSKKGMDNQGHKNLKTSQEGSSDDAERKQERETFSSAEGTVDKDTTIMELRDRLPKKQQASASTDGVDKLSGKEQSFTSLEVRKVAETKEKSKHLKTKTCKKVQDGLSDIAEKFLKKDQSDETSEDDKKQSKKGTEEKKKPSDFKKKVIKMEQQYESSSDGTEKLPEREEICHFPKGIKQIKNGTTDGEKKSKKIRDKTSKKKDELSDYAEKSTGKGDSCDSSEDKKSKNGAYGREKKRCKLLGKSSRKRQDCSSSDTEKYSMKEDGCNSSDKRLKRIELRERRNLSSKRNTKEIQSGSSSSDAEESSEDNKKKKQRTSSKKKAVIVKEKKRNSLRTSTKRKQADITSSSSSDIEDDDQNSIGEGSSDEQKIKPVTENLVLSSHTGFCQSSGDEALSKSVPVTVDDDDDDNDPENRIAKKMLLEEIKANLSSDEDGSSDDEPEEGKKRTGKQNEENPGDEEAKNQVNSESDSDSEESKKPRYRHRLLRHKLTVSDGESGEEKKTKPKEHKEVKGRNRRKVSSEDSEDSDFQESGVSEEVSESEDEQRPRTRSAKKAELEENQRSYKQKKKRRRIKVQEDSSSENKSNSEEEEEEKEEEEEEEEEEEEEEEDENDDSKSPGKGRKKIRKILKDDKLRTETQNALKEEEERRKRIAEREREREKLREVIEIEDASPTKCPITTKLVLDEDEETKEPLVQVHRNMVIKLKPHQVDGVQFMWDCCCESVKKTKKSPGSGCILAHCMGLGKTLQVVSFLHTVLLCDKLDFSTALVVCPLNTALNWMNEFEKWQEGLKDDEKLEVSELATVKRPQERSYMLQRWQEDGGVMIIGYEMYRNLAQGRNVKSRKLKEIFNKALVDPGPDFVVCDEGHILKNEASAVSKAMNSIRSRRRIILTGTPLQNNLIEYHCMVNFIKENLLGSIKEFRNRFINPIQNGQCADSTMVDVRVMKKRAHILYEMLAGCVQRKDYTALTKFLPPKHEYVLAVRMTSIQCKLYQYYLDHLTGVGNNSEGGRGKAGAKLFQDFQMLSRIWTHPWCLQLDYISKENKGYFDEDSMDEFIASDSDETSMSLSSDDYTKKKKKGKKGKKDSSSSGSGSDNDVEVIKVWNSRSRGGGEGNVDETGNNPSVSLKLEESKATSSSNPSSPAPDWYKDFVTDADAEVLEHSGKMVLLFEILRMAEEIGDKVLVFSQSLISLDLIEDFLELASREKTEDKDKPLIYKGEGKWLRNIDYYRLDGSTTAQSRKKWAEEFNDETNVRGRLFIISTKAGSLGINLVAANRVIIFDASWNPSYDIQSIFRVYRFGQTKPVYVYRFLAQGTMEDKIYDRQVTKQSLSFRVVDQQQVERHFTMNELTELYTFEPDLLDDPNSEKKKKRDTPMLPKDTILAELLQIHKEHIVGYHEHDSLLDHKEEEELTEEERKAAWAEYEAEKKGLTMRFNIPTGTNLPPVSFNSQTPYIPFNLGALSAMSNQQLEDLINQGREKVVEATNSVTAVRIQPLEDIISAVWKENMNLSEAQVQALALSRQASQELDVKRREAIYNDVLTKQQMLISCVQRILMNRRLQQQYNQQQQQQMTYQQATLGHLMMPKPPNLIMNPSNYQQIDMRGMYQPVAGGMQPPPLQRAPPPMRSKNPGPSQGKSM>sp|P46100-4|ATRX_HUMAN Isoform 3 of Transcriptional regulator ATRXOS=Homo sapiens OX=9606 GN=ATRXMTAEPMSESKLNTLVQKLHDFLAHSSEESEETSSPPRLAMNQNTDKISGSGSNSDMMENSKEEGTSSSEKSKSSGSSRSKRKPSIVTKYVESDDEKPLDDETVNEDASNENSENDITMQSLPKEDGLHGIVSCTACGQQVNHFQKDSIYRHPSLQVLICKNCFKYYMSDDISRDSDGMDEQCRWCAEGGNLICCDFCHNAFCKKCILRNLGRKELSTIMDENNQWYCYICHPEPLLDLVTACNSVFENLEQLLQQNKKKIKVDSEKSNKVYEHTSRFSPKKTSSNCNGEEKKLDDSCSGSVTYSYSALIVPKEMIKKAKKLIETTANMNSSYVKFLKQATDNSEISSATKLRQLKAFKSVLADIKKAHLALEEDLNSEFRAMDAVNKEKNTKEHKVIDAKFETKARKGEKPCALEKKDISKSEAKLSRKQVDSEHMHQNVPTEEQRTNKSTGGEHKKSDRKEEPQYEPANTSEDLDMDIVSVPSSVPEDIFENLETAMEVQSSVDHQGDGSSGTEQEVESSSVKLNISSKDNRGGIKSKTTAKVTKELYVKLTPVSLSNSPIKGADCQEVPQDKDGYKSCGLNPKLEKCGLGQENSDNEHLVENEVSLLLEESDLRRSPRVKTTPLRRPTETNPVTSNSDEECNETVKEKQKLSVPVRKKDKRNSSDSAIDNPKPNKLPKSKQSETVDQNSDSDEMLAILKEVSRMSHSSSSDTDINEIHTNHKTLYDLKTQAGKDDKGKRKRKSSTSGSDFDTKKGKSAKSSIISKKKRQTQSESSNYDSELEKEIKSMSKIGAARTTKKRIPNTKDFDSSEDEKHSKKGMDNQGHKNLKTSQEGSSDDAERKQERETFSSAEGTVDKDTTIMELRDRLPKKQQASASTDGVDKLSGKEQSFTSLEVRKVAETKEKSKHLKTKTCKKVQDGLSDIAEKFLKKDQSDETSEDDKKQSKKGTEEKKKPSDFKKKVIKMEQQYESSSDGTEKLPEREEICHFPKGIKQIKNGTTDGEKKSKKIRDKTSKKKDELSDYAEKSTGKGDSCDSSEDKKSKNGAYGREKKRCKLLGKSSRKRQDCSSSDTEKYSMKEDGCNSSDKRLKRIELRERRNLSSKRNTKEIQSGSSSSDAEESSEDNKKKKQRTSSKKKAVIVKEKKRNSLRTSTKRKQADITSSSSSDIEDDDQNSIGEGSSDEQKIKPVTENLVLSSHTGFCQSSGDEALSKSVPVTVDDDDDDNDPENRIAKKMLLEEIKANLSSDEDGSSDDEPEEGKKRTGKQNEENPGDEEAKNQVNSESDSDSEESKKPRYRHRLLRHKLTVSDGESGEEKKTKPKEHKEVKGRNRRKVSSEDSEDSDFQESGVSEEVSESEDEQRPRTRSAKKAELEENQRSYKQKKKRRRIKVQEDSSSENKSNSEEEEEEKEEEEEEEEEEEEEEEDENDDSKSPGKGRKKIRKILKDDKLRTETQNALKEEEERRKRIAEREREREKLREVIEIEDASPTKCPITTKLVLDEDEETKEPLVQVHRNMVIKLKPHQVDGVQFMWDCCCESVKKTKKSPGSGCILAHCMGLGKTLQVVSFLHTVLLCDKLDFSTALVVCPLNTALNWMNEFEKWQEGLKDDEKLEVSELATVKRPQERSYMLQRWQEDGGVMIIGYEMYRNLAQGRNVKSRKLKEIFNKALVDPGPDFVVCDEGHILKNEASAVSKAMNSIRSRRRIILTGTPLQNNLIEYHCMVNFIKENLLGSIKEFRNRFINPIQNGQCADSTMVDVRVMKKRAHILYEMLAGCVQRKDYTALTKFLPPKHEYVLAVRMTSIQCKLYQYYLDHLTGVGNNSEGGRGKAGAKLFQDFQMLSRIWTHPWCLQLDYISKENKGYFDEDSMDEFIASDSDETSMSLSSDDYTKKKKKGKKGKKDSSSSGSGSDNDVEVIKVWNSRSRGGGEGNVDETGNNPSVSLKLEESKATSSSNPSSPAPDWYKDFVTDADAEVLEHSGKMVLLFEILRMAEEIGDKVLVFSQSLISLDLIEDFLELASREKTEDKDKPLIYKGEGKWLRNIDYYRLDGSTTAQSRKKWAEEFNDETNVRGRLFIISTKAGSLGINLVAANRVIIFDASWNPSYDIQSIFRVYRFGQTKPVYVYRFLAQGTMEDKIYDRQVTKQSLSFRVVDQQQVERHFTMNELTELYTFEPDLLDDPNSEKKKKRDTPMLPKDTILAELLQIHKEHIVGYHEHDSLLDHKEEEELTEEERKAAWAEYEAEKKGLTMRFNIPTGTNLPPVSFNSQTPYIPFNLGALSAMSNQQLEDLINQGREKVVEATNSVTAVRIQPLEDIISAVWKENMNLSEAQVQALALSRQASQELDVKRREAIYNDVLTKQQMLISCVQRILMNRRLQQQYNQQQQQQMTYQQATLGHLMMPKPPNLIMNPSNYQQIDMRGMYQPVAGGMQPPPLQRAPPPMRSKNPGPSQGKSM>sp|P46100-5|ATRX_HUMAN Isoform 5 of Transcriptional regulator ATRXOS=Homo sapiens OX=9606 GN=ATRXMQSLPKEDGLHGIVSCTACGQQVNHFQKDSIYRHPSLQVLICKNCFKYYMSDDISRDSDGMDEQCRWCAEGGNLICCDFCHNAFCKKCILRNLGRKELSTIMDENNQWYCYICHPEPLLDLVTACNSVFENLEQLLQQNKKKIKVDSEKSNKVYEHTSRFSPKKTSSNCNGEEKKLDDSCSGSVTYSYSALIVPKEMIKKAKKLIETTANMNSSYVKFLKQATDNSEISSATKLRQLKAFKSVLADIKKAHLALEEDLNSEFRAMDAVNKEKNTKEHKVIDAKFETKARKGEKPCALEKKDISKSEAKLSRKQVDSEHMHQNVPTEEQRTNKSTGGEHKKSDRKEEPQYEPANTSEDLDMDIVSVPSSVPEDIFENLETAMEVQSSVDHQGDGSSGTEQEVESSSVKLNISSKDNRGGIKSKTTAKVTKELYVKLTPVSLSNSPIKGADCQEVPQDKDGYKSCGLNPKLEKCGLGQENSDNEHLVENEVSLLLEESDLRRSPRVKTTPLRRPTETNPVTSNSDEECNETVKEKQKLSVPVRKKDKRNSSDSAIDNPKPNKLPKSKQSETVDQNSDSDEMLAILKEVSRMSHSSSSDTDINEIHTNHKTLYDLKTQAGKDDKGKRKRKSSTSGSDFDTKKGKSAKSSIISKKKRQTQSESSNYDSELEKEIKSMSKIGAARTTKKRIPNTKDFDSSEDEKHSKKGMDNQGHKNLKTSQEGSSDDAERKQERETFSSAEGTVDKDTTIMELRDRLPKKQQASASTDGVDKLSGKEQSFTSLEVRKVAETKEKSKHLKTKTCKKVQDGLSDIAEKFLKKDQSDETSEDDKKQSKKGTEEKKKPSDFKKKVIKMEQQYESSSDGTEKLPEREEICHFPKGIKQIKNGTTDGEKKSKKIRDKTSKKKDELSDYAEKSTGKGDSCDSSEDKKSKNGAYGREKKRCKLLGKSSRKRQDCSSSDTEKYSMKEDGCNSSDKRLKRIELRERRNLSSKRNTKEIQSGSSSSDAEESSEDNKKKKQRTSSKKKAVIVKEKKRNSLRTSTKRKQADITSSSSSDIEDDDQNSIGEGSSDEQKIKPVTENLVLSSHTGFCQSSGDEALSKSVPVTVDDDDDDNDPENRIAKKMLLEEIKANLSSDEDGSSDDEPEEGKKRTGKQNEENPGDEEAKNQVNSESDSDSEESKKPRYRHRLLRHKLTVSDGESGEEKKTKPKEHKEVKGRNRRKVSSEDSEDSDFQESGVSEEVSESEDEQRPRTRSAKKAELEENQRSYKQKKKRRRIKVQEDSSSENKSNSEEEEEEKEEEEEEEEEEEEEEEDENDDSKSPGKGRKKIRKILKDDKLRTETQNALKEEEERRKRIAEREREREKLREVIEIEDASPTKCPITTKLVLDEDEETKEPLVQVHRNMVIKLKPHQVDGVQFMWDCCCESVKKTKKSPGSGCILAHCMGLGKTLQVVSFLHTVLLCDKLDFSTALVVCPLNTALNWMNEFEKWQEGLKDDEKLEVSELATVKRPQERSYMLQRWQEDGGVMIIGYEMYRNLAQGRNVKSRKLKEIFNKALVDPGPDFVVCDEGHILKNEASAVSKAMNSIRSRRRIILTGTPLQNNLIEYHCMVNFIKENLLGSIKEFRNRFINPIQNGQCADSTMVDVRVMKKRAHILYEMLAGCVQRKDYTALTKFLPPKHEYVLAVRMTSIQCKLYQYYLDHLTGVGNNSEGGRGKAGAKLFQDFQMLSRIWTHPWCLQLDYISKENKGYFDEDSMDEFIASDSDETSMSLSSDDYTKKKKKGKKGKKDSSSSGSGSDNDVEVIKVWNSRSRGGGEGNVDETGNNPSVSLKLEESKATSSSNPSSPAPDWYKDFVTDADAEVLEHSGKMVLLFEILRMAEEIGDKVLVFSQSLISLDLIEDFLELASREKTEDKDKPLIYKGEGKWLRNIDYYRLDGSTTAQSRKKWAEEFNDETNVRGRLFIISTKAGSLGINLVAANRVIIFDASWNPSYDIQSIFRVYRFGQTKPVYVYRFLAQGTMEDKIYDRQVTKQSLSFRVVDQQQVERHFTMNELTELYTFEPDLLDDPNSEKKKKRDTPMLPKDTILAELLQIHKEHIVGYHEHDSLLDHKEEEELTEEERKAAWAEYEAEKKGLTMRFNIPTGTNLPPVSFNSQTPYIPFNLGALSAMSNQQLEDLINQGREKVVEATNSVTAVRIQPLEDIISAVWKENMNLSEAQVQALALSRQASQELDVKRREAIYNDVLTKQQMLISCVQRILMNRRLQQQYNQQQQQQMTYQQATLGHLMMPKPPNLIMNPSNYQQIDMRGMYQPVAGGMQPPPLQRAPPPMRSKNPGPSQGKSM>sp|P46100-6|ATRX_HUMAN Isoform 6 of Transcriptional regulator ATRXOS=Homo sapiens OX=9606 GN=ATRXMTAEPMSESKLNTLVQKLHDFLAHSSEESEETSSPPRLAMNQNTDKISGSGSNSDMMENSKEEGTSSSEKSKSSGSSRSKRKPSIVTKYVESDDEKPLDDETVNEDASNENSENDITMQSLPKDGLHGIVSCTACGQQVNHFQKDSIYRHPSLQVLICKNCFKYYMSDDISRDSDGMDEQCRWCAEGGNLICCDFCHNAFCKKCILRNLGRKELSTIMDENNQWYCYICHPEPLLDLVTACNSVFENLEQLLQQNKKKIKVDSEKSNKVYEHTSRFSPKKTSSNCNGEEKKLDDSCSGSVTYSYSALIVPKEMIKKAKKLIETTANMNSSYVKFLKQATDNSEISSATKLRQLKAFKSVLADIKKAHLALEEDLNSEFRAMDAVNKEKNTKEHKVIDAKFETKARKGEKPCALEKKDISKSEAKLSRKQVDSEHMHQNVPTEEQRTNKSTGGEHKKSDRKEEPQYEPANTSEDLDMDIVSVPSSVPEDIFENLETAMEVQSSVDHQGDGSSGTEQEVESSSVKLNISSKDNRGGADCQEVPQDKDGYKSCGLNPKLEKCGLGQENSDNEHLVENEVSLLLEESDLRRSPRVKTTPLRRPTETNPVTSNSDEECNETVKEKQKLSVPVRKKDKRNSSDSAIDNPKPNKLPKSKQSETVDQNSDSDEMLAILKEVSRMSHSSSSDTDINEIHTNHKTLYDLKTQAGKDDKGKRKRKSSTSGSDFDTKKGKSAKSSIISKKKRQTQSESSNYDSELEKEIKSMSKIGAARTTKKRIPNTKDFDSSEDEKHSKKGMDNQGHKNLKTSQEGSSDDAERKQERETFSSAEGTVDKDTTIMELRDRLPKKQQASASTDGVDKLSGKEQSFTSLEVRKVAETKEKSKHLKTKTCKKVQDGLSDIAEKFLKKDQSDETSEDDKKQSKKGTEEKKKPSDFKKKVIKMEQQYESSSDGTEKLPEREEICHFPKGIKQIKNGTTDGEKKSKKIRDKTSKKKDELSDYAEKSTGKGDSCDSSEDKKSKNGAYGREKKRCKLLGKSSRKRQDCSSSDTEKYSMKEDGCNSSDKRLKRIELRERRNLSSKRNTKEIQSGSSSSDAEESSEDNKKKKQRTSSKKKAVIVKEKKRNSLRTSTKRKQADITSSSSSDIEDDDQNSIGEGSSDEQKIKPVTENLVLSSHTGFCQSSGDEALSKSVPVTVDDDDDDNDPENRIAKKMLLEEIKANLSSDEDGSSDDEPEEGKKRTGKQNEENPGDEEAKNQVNSESDSDSEESKKPRYRHRLLRHKLTVSDGESGEEKKTKPKEHKEVKGRNRRKVSSEDSEDSDFQESGVSEEVSESEDEQRPRTRSAKKAELEENQRS>sp|P56856|CLD18_HUMAN Claudin-18 OS=Homo sapiens OX=9606 GN=CLDN18 PE=1SV=1MSTTTCQVVAFLLSILGLAGCIAATGMDMWSTQDLYDNPVTSVFQYEGLWRSCVRQSSGFTECRPYFTILGLPAMLQAVRALMIVGIVLGAIGLLVSIFALKCIRIGSMEDSAKANMTLTSGIMFIVSGLCAIAGVSVFANMLVTNFWMSTANMYTGMGGMVQTVQTRYTFGAALFVGWVAGGLTLIGGVMMCIACRGLAPEETNYKAVSYHASGHSVAYKPGGFKASTGFGSNTKNKKIYDGGARTEDEVQSYPSKHDYV>sp|P56856-2|CLD18_HUMAN Isoform A2 of Claudin-18 OS=Homo sapiens OX=9606GN=CLDN18MAVTACQGLGFVVSLIGIAGIIAATCMDQWSTQDLYNNPVTAVFNYQGLWRSCVRESSGFTECRGYFTLLGLPAMLQAVRALMIVGIVLGAIGLLVSIFALKCIRIGSMEDSAKANMTLTSGIMFIVSGLCAIAGVSVFANMLVTNFWMSTANMYTGMGGMVQTVQTRYTFGAALFVGWVAGGLTLIGGVMMCIACRGLAPEETNYKAVSYHASGHSVAYKPGGFKASTGFGSNTKNKKIYDGGARTEDEVQSYPSKHDYV>sp|Q9C0C6|CIPC_HUMAN CLOCK-interacting pacemaker OS=Homo sapiens OX=9606GN=CIPC PE=1 SV=2MERKNPSRESPRRLSAKVGKGTEMKKVARQLGMAAAESDKDSGFSDGSSECLSSAEQMESEDMLSALGWSREDRPRQNSKTAKNAFPTLSPMVVMKNVLVKQGSSSSQLQSWTVQPSFEVISAQPQLLFLHPPVPSPVSPCHTGEKKSDSRNYLPILNSYTKIAPHPGKRGLSLGPEEKGTSGVQKKICTERLGPSLSSSEPTKAGAVPSSPSTPAPPSAKLAEDSALQGVPSLVAGGSPQTLQPVSSSHVAKAPSLTFASPASPVCASDSTLHGLESNSPLSPLSANYSSPLWAAEHLCRSPDIFSEQRQSKHRRFQNTLVVLHKSGLLEITLKTKELIRQNQATQVELDQLKEQTQLFIEATKSRAPQAWAKLQASLTPGSSNTGSDLEAFSDHPAI>sp|P36542|ATPG_HUMAN ATP synthase subunit gamma, mitochondrial OS=Homosapiens OX=9606 GN=ATP5F1C PE=1 SV=1MFSRAGVAGLSAWTLQPQWIQVRNMATLKDITRRLKSIKNIQKITKSMKMVAAAKYARAERELKPARIYGLGSLALYEKADIKGPEDKKKHLLIGVSSDRGLCGAIHSSIAKQMKSEVATLTAAGKEVMLVGIGDKIRGILYRTHSDQFLVAFKEVGRKPPTFGDASVIALELLNSGYEFDEGSIIFNKFRSVISYKTEEKPIFSLNTVASADSMSIYDDIDADVLQNYQEYNLANIIYYSLKESTTSEQSARMTAMDNASKNASEMIDKLTLTFNRTRQAVITKELIEIISGAAALD>sp|P36542-2|ATPG_HUMAN Isoform Heart of ATP synthase subunit gamma,mitochondrial OS=Homo sapiens OX=9606 GN=ATP5F1CMFSRAGVAGLSAWTLQPQWIQVRNMATLKDITRRLKSIKNIQKITKSMKMVAAAKYARAERELKPARIYGLGSLALYEKADIKGPEDKKKHLLIGVSSDRGLCGAIHSSIAKQMKSEVATLTAAGKEVMLVGIGDKIRGILYRTHSDQFLVAFKEVGRKPPTFGDASVIALELLNSGYEFDEGSIIFNKFRSVISYKTEEKPIFSLNTVASADSMSIYDDIDADVLQNYQEYNLANIIYYSLKESTTSEQSARMTAMDNASKNASEMIDKLTLTFNRTRQAVITKELIEIISGAAAL>sp|O95832|CLD1_HUMAN Claudin-1 OS=Homo sapiens OX=9606 GN=CLDN1 PE=1SV=1MANAGLQLLGFILAFLGWIGAIVSTALPQWRIYSYAGDNIVTAQAMYEGLWMSCVSQSTGQIQCKVFDSLLNLSSTLQATRALMVVGILLGVIAIFVATVGMKCMKCLEDDEVQKMRMAVIGGAIFLLAGLAILVATAWYGNRIVQEFYDPMTPVNARYEFGQALFTGWAAASLCLLGGALLCCSCPRKTTSYPTPRPYPKPAPSSGKDYV>sp|Q9H7T9|AUNIP_HUMAN Aurora kinase A and ninein-interacting proteinOS=Homo sapiens OX=9606 GN=AUNIP PE=1 SV=1MRRTGPEEEACGVWLDAAALKRRKVQTHLIKPGTKMLTLLPGERKANIYFTQRRAPSTGIHQRSIASFFTLQPGKTNGSDQKSVSSHTESQINKESKKNATQLDHLIPGLAHDCMASPLATSTTADIQEAGLSPQSLQTSGHHRMKTPFSTELSLLQPDTPDCAGDSHTPLAFSFTEDLESSCLLDRKEEKGDSARKWEWLHESKKNYQSMEKHTKLPGDKCCQPLGKTKLERKVSAKENRQAPVLLQTYRESWNGENIESVKQSRSPVSVFSWDNEKNDKDSWSQLFTEDSQGQRVIAHNTRAPFQDVTNNWNWDLGPFPNSPWAQCQEDGPTQNLKPDLLFTQDSEGNQVIRHQF>sp|Q9H7T9-2|AUNIP_HUMAN Isoform 2 of Aurora kinase A and ninein-interacting protein OS=Homo sapiens OX=9606 GN=AUNIPMRRTGPEEEACGVWLDAAALKRRKVQTHLIKPGTKMLTLLPGERKANIYFTQRRAPSTGIHQRSIASFFTLQPGKTNGSDQKSVSSHTESQINKESKKNATQLDHLIPGLAHDCMASPLATSTTADIQEAGLSPQSLQTSGHHRMKTPFSTELSLLQPDTPDCAGDSHTPLAFSFTEDLESSCLLDRKEEKGDSARKWEWLHESKKNYQSMEKHTKLPGDKCCQPLGKTKLERKVSAKENRQAPVLLQTYRESWNGENIESVKQSRSPVSVFSWDNEKNDKDSWSQLFTEDSQGQRVIAHNTRAPFQDVTNNWNWDLGPFPNSPWAQCQEDGPTQNLKPDLLFTQDSEVQALACQQDCCRRSILKRQKHLR>sp|Q13535|ATR_HUMAN Serine/threonine-protein kinase ATR OS=Homo sapiensOX=9606 GN=ATR PE=1 SV=3MGEHGLELASMIPALRELGSATPEEYNTVVQKPRQILCQFIDRILTDVNVVAVELVKKTDSQPTSVMLLDFIQHIMKSSPLMFVNVSGSHEAKGSCIEFSNWIITRLLRIAATPSCHLLHKKICEVICSLLFLFKSKSPAIFGVLTKELLQLFEDLVYLHRRNVMGHAVEWPVVMSRFLSQLDEHMGYLQSAPLQLMSMQNLEFIEVTLLMVLTRIIAIVFFRRQELLLWQIGCVLLEYGSPKIKSLAISFLTELFQLGGLPAQPASTFFSSFLELLKHLVEMDTDQLKLYEEPLSKLIKTLFPFEAEAYRNIEPVYLNMLLEKLCVMFEDGVLMRLKSDLLKAALCHLLQYFLKFVPAGYESALQVRKVYVRNICKALLDVLGIEVDAEYLLGPLYAALKMESMEIIEEIQCQTQQENLSSNSDGISPKRRRLSSSLNPSKRAPKQTEEIKHVDMNQKSILWSALKQKAESLQISLEYSGLKNPVIEMLEGIAVVLQLTALCTVHCSHQNMNCRTFKDCQHKSKKKPSVVITWMSLDFYTKVLKSCRSLLESVQKLDLEATIDKVVKIYDALIYMQVNSSFEDHILEDLCGMLSLPWIYSHSDDGCLKLTTFAANLLTLSCRISDSYSPQAQSRCVFLLTLFPRRIFLEWRTAVYNWALQSSHEVIRASCVSGFFILLQQQNSCNRVPKILIDKVKDDSDIVKKEFASILGQLVCTLHGMFYLTSSLTEPFSEHGHVDLFCRNLKATSQHECSSSQLKASVCKPFLFLLKKKIPSPVKLAFIDNLHHLCKHLDFREDETDVKAVLGTLLNLMEDPDKDVRVAFSGNIKHILESLDSEDGFIKELFVLRMKEAYTHAQISRNNELKDTLILTTGDIGRAAKGDLVPFALLHLLHCLLSKSASVSGAAYTEIRALVAAKSVKLQSFFSQYKKPICQFLVESLHSSQMTALPNTPCQNADVRKQDVAHQREMALNTLSEIANVFDFPDLNRFLTRTLQVLLPDLAAKASPAASALIRTLGKQLNVNRREILINNFKYIFSHLVCSCSKDELERALHYLKNETEIELGSLLRQDFQGLHNELLLRIGEHYQQVFNGLSILASFASSDDPYQGPRDIISPELMADYLQPKLLGILAFFNMQLLSSSVGIEDKKMALNSLMSLMKLMGPKHVSSVRVKMMTTLRTGLRFKDDFPELCCRAWDCFVRCLDHACLGSLLSHVIVALLPLIHIQPKETAAIFHYLIIENRDAVQDFLHEIYFLPDHPELKKIKAVLQEYRKETSESTDLQTTLQLSMKAIQHENVDVRIHALTSLKETLYKNQEKLIKYATDSETVEPIISQLVTVLLKGCQDANSQARLLCGECLGELGAIDPGRLDFSTTETQGKDFTFVTGVEDSSFAYGLLMELTRAYLAYADNSRAQDSAAYAIQELLSIYDCREMETNGPGHQLWRRFPEHVREILEPHLNTRYKSSQKSTDWSGVKKPIYLSKLGSNFAEWSASWAGYLITKVRHDLASKIFTCCSIMMKHDFKVTIYLLPHILVYVLLGCNQEDQQEVYAEIMAVLKHDDQHTINTQDIASDLCQLSTQTVFSMLDHLTQWARHKFQALKAEKCPHSKSNRNKVDSMVSTVDYEDYQSVTRFLDLIPQDTLAVASFRSKAYTRAVMHFESFITEKKQNIQEHLGFLQKLYAAMHEPDGVAGVSAIRKAEPSLKEQILEHESLGLLRDATACYDRAIQLEPDQIIHYHGVVKSMLGLGQLSTVITQVNGVHANRSEWTDELNTYRVEAAWKLSQWDLVENYLAADGKSTTWSVRLGQLLLSAKKRDITAFYDSLKLVRAEQIVPLSAASFERGSYQRGYEYIVRLHMLCELEHSIKPLFQHSPGDSSQEDSLNWVARLEMTQNSYRAKEPILALRRALLSLNKRPDYNEMVGECWLQSARVARKAGHHQTAYNALLNAGESRLAELYVERAKWLWSKGDVHQALIVLQKGVELCFPENETPPEGKNMLIHGRAMLLVGRFMEETANFESNAIMKKYKDVTACLPEWEDGHFYLAKYYDKLMPMVTDNKMEKQGDLIRYIVLHFGRSLQYGNQFIYQSMPRMLTLWLDYGTKAYEWEKAGRSDRVQMRNDLGKINKVITEHTNYLAPYQFLTAFSQLISRICHSHDEVFVVLMEIIAKVFLAYPQQAMWMMTAVSKSSYPMRVNRCKEILNKAIHMKKSLEKFVGDATRLTDKLLELCNKPVDGSSSTLSMSTHFKMLKKLVEEATFSEILIPLQSVMIPTLPSILGTHANHASHEPFPGHWAYIAGFDDMVEILASLQKPKKISLKGSDGKFYIMMCKPKDDLRKDCRLMEFNSLINKCLRKDAESRRRELHIRTYAVIPLNDECGIIEWVNNTAGLRPILTKLYKEKGVYMTGKELRQCMLPKSAALSEKLKVFREFLLPRHPPIFHEWFLRTFPDPTSWYSSRSAYCRSTAVMSMVGYILGLGDRHGENILFDSLTGECVHVDFNCLFNKGETFEVPEIVPFRLTHNMVNGMGPMGTEGLFRRACEVTMRLMRDQREPLMSVLKTFLHDPLVEWSKPVKGHSKAPLNETGEVVNEKAKTHVLDIEQRLQGVIKTRNRVTGLPLSIEGHVHYLIQEATDENLLCQMYLGWTPYM>sp|Q13535-2|ATR_HUMAN Isoform 2 of Serine/threonine-protein kinase ATROS=Homo sapiens OX=9606 GN=ATRMGEHGLELASMIPALRELGSATPEEYNTVVQKPRQILCQFIDRILTDVNVVAVELVKKTDSQPTSVMLLDFIQHIMKSSPLMFVNVSGSHEAKGSCIEFSNWIITRLLRIAATPSCHLLHKKICEVICSLLFLFKSKSPAIFGVLTKELLQLFEDLVYLHRRNVMGHAVEWPVVMSRFLSQLDEHMGYLQSAPLQLMSMQNLEFIEVTLLMVLTRIIAIVFFRRQELLLWQIGCVLLEYGSPKIKSLAISFLTELFQLGGLPAQPASTFFSSFLELLKHLVEMDTDQLKLYEEPLSKLIKTLFPFEAEAYRNIEPVYLNMLLEKLCVMFEDGVLMRLKSDLLKAALCHLLQYFLKFVPAGYESALQVRKVYVRNICKALLDVLGIEVDAEYLLGPLYAALKMESMEIIEEIQCQTQQENLSSNSDGISPKRRRLSSSLNPSKRAPKQTEDRTFKDCQHKSKKKPSVVITWMSLDFYTKVLKSCRSLLESVQKLDLEATIDKVVKIYDALIYMQVNSSFEDHILEDLCGMLSLPWIYSHSDDGCLKLTTFAANLLTLSCRISDSYSPQAQSRCVFLLTLFPRRIFLEWRTAVYNWALQSSHEVIRASCVSGFFILLQQQNSCNRVPKILIDKVKDDSDIVKKEFASILGQLVCTLHGMFYLTSSLTEPFSEHGHVDLFCRNLKATSQHECSSSQLKASVCKPFLFLLKKKIPSPVKLAFIDNLHHLCKHLDFREDETDVKAVLGTLLNLMEDPDKDVRVAFSGNIKHILESLDSEDGFIKELFVLRMKEAYTHAQISRNNELKDTLILTTGDIGRAAKGDLVPFALLHLLHCLLSKSASVSGAAYTEIRALVAAKSVKLQSFFSQYKKPICQFLVESLHSSQMTALPNTPCQNADVRKQDVAHQREMALNTLSEIANVFDFPDLNRFLTRTLQVLLPDLAAKASPAASALIRTLGKQLNVNRREILINNFKYIFSHLVCSCSKDELERALHYLKNETEIELGSLLRQDFQGLHNELLLRIGEHYQQVFNGLSILASFASSDDPYQGPRDIISPELMADYLQPKLLGILAFFNMQLLSSSVGIEDKKMALNSLMSLMKLMGPKHVSSVRVKMMTTLRTGLRFKDDFPELCCRAWDCFVRCLDHACLGSLLSHVIVALLPLIHIQPKETAAIFHYLIIENRDAVQDFLHEIYFLPDHPELKKIKAVLQEYRKETSESTDLQTTLQLSMKAIQHENVDVRIHALTSLKETLYKNQEKLIKYATDSETVEPIISQLVTVLLKGCQDANSQARLLCGECLGELGAIDPGRLDFSTTETQGKDFTFVTGVEDSSFAYGLLMELTRAYLAYADNSRAQDSAAYAIQELLSIYDCREMETNGPGHQLWRRFPEHVREILEPHLNTRYKSSQKSTDWSGVKKPIYLSKLGSNFAEWSASWAGYLITKVRHDLASKIFTCCSIMMKHDFKVTIYLLPHILVYVLLGCNQEDQQEVYAEIMAVLKHDDQHTINTQDIASDLCQLSTQTVFSMLDHLTQWARHKFQALKAEKCPHSKSNRNKVDSMVSTVDYEDYQSVTRFLDLIPQDTLAVASFRSKAYTRAVMHFESFITEKKQNIQEHLGFLQKLYAAMHEPDGVAGVSAIRKAEPSLKEQILEHESLGLLRDATACYDRAIQLEPDQIIHYHGVVKSMLGLGQLSTVITQVNGVHANRSEWTDELNTYRVEAAWKLSQWDLVENYLAADGKSTTWSVRLGQLLLSAKKRDITAFYDSLKLVRAEQIVPLSAASFERGSYQRGYEYIVRLHMLCELEHSIKPLFQHSPGDSSQEDSLNWVARLEMTQNSYRAKEPILALRRALLSLNKRPDYNEMVGECWLQSARVARKAGHHQTAYNALLNAGESRLAELYVERAKWLWSKGDVHQALIVLQKGVELCFPENETPPEGKNMLIHGRAMLLVGRFMEETANFESNAIMKKYKDVTACLPEWEDGHFYLAKYYDKLMPMVTDNKMEKQGDLIRYIVLHFGRSLQYGNQFIYQSMPRMLTLWLDYGTKAYEWEKAGRSDRVQMRNDLGKINKVITEHTNYLAPYQFLTAFSQLISRICHSHDEVFVVLMEIIAKVFLAYPQQAMWMMTAVSKSSYPMRVNRCKEILNKAIHMKKSLEKFVGDATRLTDKLLELCNKPVDGSSSTLSMSTHFKMLKKLVEEATFSEILIPLQSVMIPTLPSILGTHANHASHEPFPGHWAYIAGFDDMVEILASLQKPKKISLKGSDGKFYIMMCKPKDDLRKDCRLMEFNSLINKCLRKDAESRRRELHIRTYAVIPLNDECGIIEWVNNTAGLRPILTKLYKEKGVYMTGKELRQCMLPKSAALSEKLKVFREFLLPRHPPIFHEWFLRTFPDPTSWYSSRSAYCRSTAVMSMVGYILGLGDRHGENILFDSLTGECVHVDFNCLFNKGETFEVPEIVPFRLTHNMVNGMGPMGTEGLFRRACEVTMRLMRDQREPLMSVLKTFLHDPLVEWSKPVKGHSKAPLNETGEVVNEKAKTHVLDIEQRLQGVIKTRNRVTGLPLSIEGHVHYLIQEATDENLLCQMYLGWTPYM>sp|Q13535-3|ATR_HUMAN Isoform 3 of Serine/threonine-protein kinase ATROS=Homo sapiens OX=9606 GN=ATRMGEHGLELASMIPALRELGSATPEEYNTVVQKPRQILCQFIDRILTDVNVVAVELVKKTDSQPTSVMLLDFIQHIMKSSPLMFVNVSGSHEAKGSCIEFSNWIITRLLRIAATPSCHLLHKKICEVICSLLFLFKSKSPAIFGVLTKELLQLFEDLVYLHRRNVMGHAVEWPVVMSRFLSQLDEHMGYLQSAPLQLMSMQNLEFIEVTLLMVLTRIIAIVFFRRQELLLWQIGCVLLEYGSPKIKSLAISFLTELFQLGGLPAQPASTFFSSFLELLKHLVEMDTDQLKLYEEPLSKLIKTLFPFEAEAYRNIEPVYLNMLLEKLCVMFEDGVLMRLKSDLLKAALCHLLQYFLKFVPAGYESALQVRKVYVRNICKALLDVLGIEVDAEYLLGPLYAALKMESMEIIEEIQCQTQQENLSSNSDGISPKRRRLSSSLNPSKRAPKQTEEIKHVDMNQKSILWSALKQKAESLQISLEYSGLKNPVIEMLEGIAVVLQLTALCTVHCSHQNMNCRTFKDCQHKSKKKPSVVITWMSLDFYTKVLKSCRSLLESVQKLDLEATIDKVVKIYDALIYMQVNSSFEDHILEDLCGMLSLPWIYSHSDDGCLKLTTFAANLLTLSCRISDSYSPQAQSRCVFLLTLFPRRIFLEWRTAVYNWALQSSHEVIRASCVSGFFILLQQQNSCNRVPKILIDKVKDDSDIVKKEFASILGQLVCTLHGMFYLTSSLTEPFSEHGHVDLFCRNLKATSQHECSSSQLKASVCKPFLFLLKKKIPSPVKLAFIDNLHHLCKHLDFREDETDVKAVLGTLLNLMEDPDKDVRVAFSGNIKHILESLDSEDGFIKELFVLRMKEAYTHAQISRNNELKDTLILTTGDIGRAAKGDLVPFALLHLLHCLLSKSASVSGAAYTEIRALVAAKSVKLQSFFSQYKKPICQFLVESLHSSQMTALPNTPCQNADVRKQDVAHQREMALNTLSEIANVFDFPDLNRFLTRTLQVLLPDLAAKASPAASALIRTLGKQLNVNRREILINNFKYIFSHLVCSCSKDELERALHYLKNETEIELGSLLRQDFQGLHNELLLRIGEHYQQVFNGLSILASFASSDDPYQGPRDIISPELMADYLQPKLLGILAFFNMQLLSSSVGIEDKKMALNSLMSLMKLMGPKHVSSVRVKMMTTLRTGLRFKDDFPELCCRAWDCFVRCLDHACLGSLLSHVIVALLPLIHIQPKETAAIFHYLIIENRDAVQDFLHEIYFLPDHPELKKIKAVLQEYRKETSESTDLQTTLQLSMKAIQHENVDVRIHALTSLKETLYKNQEKLIKYATDSETVEPIISQLVTVLLKGCQDANSQARLLCGECLGELGAIDPGRLDFSTTETQGKDFTFVTGVEDSSFAYGLLMELTRAYLAYADNSRAQDSAAYAIQELLSIYDCREMETNGPGHQLWRRFPEHVREILEPHLNTRYKSSQKSTDWSGVKKPIYLSKLGSNFAEWSASWAGYLITKVRHDLASKIFTCCSIMMKHDFKVTIYLLPHILVYVLLGCNQEDQQEVYAEIMAVLKHDDQHTINTQDIASDLCQLSTQTVFSMLDHLTQWARHKFQALKAEKCPHSKSNRNKVDSMVSTVDYEDYQSVTRFLDLIPQDTLAVASFRSKAYTRAVMHFESFITEKKQNIQEHLGFLQKLYAAMHEPDGVAGVSAIRKAEPSLKEQILEHESLGLLRDATACYDRAIQLEPDQIIHYHGVVKSMLGLGQLSTVITQVNGVHANRSEWTDELNTYRVEAAWKLSQWDLVENYLAADGKSTTWSVRLGQLLLSAKKRDITAFYDSLKLVRAEQIVPLSAASFERGSYQRGYEYIVRLHMLCELEHSIKPLFQHSPGDSSQEDSLNWVARLEMTQNSYRAKEPILALRRALLSLNKRPDYNEMVGECWLQSARVARKAGHHQTAYNALLNAGESRLAELYVERAKWLWSKGDVHQALIVLQKGVELCFPENETPPEGKNMLIHGRAMLLVGRFMEETANFESNAIMKKYKDVTACLPEWEDGHFYLAKYYDKLMPMVTDNKMEKQGDLIRYIVLHFGRSLQYGNQFIYQSMPRMLTLWLDYGTKAYEWEKAGRSDRVQMRNDLGKINKVITEHTNYLAPYQFLTAFSQLISRICHSHDEVFVVLMEIIAKVFLAYPQQAMWMMTAVSKSSYPMRVNRCKEILNKAIHMKKSLEKFVGDATRLTDKLLELCNKPVDGSSSTLSMSTHFKMLKKLVEEATFSEILIPLQSVMIPTLPSILGTHANHASHEPFPGHWAYIAGFDDMVEILASLQKPKKISLKGSDGKFYIMMCKPKDDLRKDCRLMEFNSLINKCLRKDAESRRRELHIRTYAVIPLNDECGIIEWVNNTAGLRPILTKLYKEKGVYMTGKELRQCMLPKSAALSEKLKVFREFLLPRHPPIFHEWFLRTFPDPTSWYSSRSAYCRSTAVMSMVGYILGLGDRHGENILFDSLTGECVHVDFNCLFNKGETFEVPEIVPFRLTHNMVNGMGPMGTEGLFRRACEVTMRLMRDQREPLMSVLKTFLHDPLVEWSKPVKGHSKAPLNETGEVVNEKVSRRYSLIWAVVLISTNELDMQL>sp|P51788|CLCN2_HUMAN Chloride channel protein 2 OS=Homo sapiens OX=9606GN=CLCN2 PE=1 SV=2MAAAAAEEGMEPRALQYEQTLMYGRYTQDLGAFAKEEAARIRLGGPEPWKGPPSSRAAPELLEYGRSRCARCRVCSVRCHKFLVSRVGEDWIFLVLLGLLMALVSWVMDYAIAACLQAQQWMSRGLNTSILLQYLAWVTYPVVLITFSAGFTQILAPQAVGSGIPEMKTILRGVVLKEYLTLKTFIAKVIGLTCALGSGMPLGKEGPFVHIASMCAALLSKFLSLFGGIYENESRNTEMLAAACAVGVGCCFAAPIGGVLFSIEVTSTFFAVRNYWRGFFAATFSAFIFRVLAVWNRDEETITALFKTRFRLDFPFDLQELPAFAVIGIASGFGGALFVYLNRKIVQVMRKQKTINRFLMRKRLLFPALVTLLISTLTFPPGFGQFMAGQLSQKETLVTLFDNRTWVRQGLVEELEPPSTSQAWNPPRANVFLTLVIFILMKFWMSALATTIPVPCGAFMPVFVIGAAFGRLVGESMAAWFPDGIHTDSSTYRIVPGGYAVVGAAALAGAVTHTVSTAVIVFELTGQIAHILPVMIAVILANAVAQSLQPSLYDSIIRIKKLPYLPELGWGRHQQYRVRVEDIMVRDVPHVALSCTFRDLRLALHRTKGRMLALVESPESMILLGSIERSQVVALLGAQLSPARRRQHMQERRATQTSPLSDQEGPPTPEASVCFQVNTEDSAFPAARGETHKPLKPALKRGPSVTRNLGESPTGSAESAGIALRSLFCGSPPPEAASEKLESCEKRKLKRVRISLASDADLEGEMSPEEILEWEEQQLDEPVNFSDCKIDPAPFQLVERTSLHKTHTIFSLLGVDHAYVTSIGRLIGIVTLKELRKAIEGSVTAQGVKVRPPLASFRDSATSSSDTETTEVHALWGPHSRHGLPREGSPSDSDDKCQ>sp|P51788-2|CLCN2_HUMAN Isoform 2 of Chloride channel protein 2 OS=Homosapiens OX=9606 GN=CLCN2MRKRLLFPALVTLLISTLTFPPGFGQFMAGQLSQKETLVTLFDNRTWVRQGLVEELEPPSTSQAWNPPRANVFLTLVIFILMKHLGVWWVKAWLPGSQMEFIRTAAPTGLCLGATLWSGQLRWQER>sp|P51788-3|CLCN2_HUMAN Isoform 3 of Chloride channel protein 2 OS=Homosapiens OX=9606 GN=CLCN2MAAAAAEEGMEPRALQYEQTLMYGRYTQDLGAFAKEEAARIRLGGPEPWKGPPSSRAAPELLEYGRSRCARCRVCSVRCHKFLVSRVGEDWIFLVLLGLLMALVSWVMDYAIAACLQAQQWMSRGLNTSILLQYLAWVTYPVVLITFSAGFTQILAPQAVGSGIPEMKTILRGVVLKEYLTLKTFIAKVIGLTCALGSGMPLGKEGPFVHIASMCAALLSKFLSLFGGIYENESRNTEMLAAACAVGVGCCFAAPIGGVLFSIEVTSTFFAVRNYWRGFFAATFSAFIFRVLAVWNRDEETITALFKTRFRLDFPFDLQELPAFAVIGIASGFGGALFVYLNRKIVQVMRKQKTINRFLMRKRLLFPALVTLLISTLTFPPGFGQFMAGQLSQKETLVTLFDNRTWVRQGLVEELEPPSTSQAWNPPRANVFLTLVIFILMKFWMSALATTIPVPCGAFMPVFVIDGIHTDSSTYRIVPGGYAVVGAAALAGAVTHTVSTAVIVFELTGQIAHILPVMIAVILANAVAQSLQPSLYDSIIRIKKLPYLPELGWGRHQQYRVRVEDIMVRDVPHVALSCTFRDLRLALHRTKGRMLALVESPESMILLGSIERSQVVALLGAQLSPARRRQHMQERRATQTSPLSDQEGPPTPEASVCFQVNTEDSAFPAARGETHKPLKPALKRGPSVTRNLGESPTGSAESAGIALRSLFCGSPPPEAASEKLESCEKRKLKRVRISLASDADLEGEMSPEEILEWEEQQLDEPVNFSDCKIDPAPFQLVERTSLHKTHTIFSLLGVDHAYVTSIGRLIGIVTLKELRKAIEGSVTAQGVKVRPPLASFRDSATSSSDTETTEVHALWGPHSRHGLPREGSPSDSDDKCQ>sp|P51788-4|CLCN2_HUMAN Isoform 4 of Chloride channel protein 2 OS=Homosapiens OX=9606 GN=CLCN2MAAAAAEEGMEPRALQYEQTLMYGRYTQDLGAFAKEEAARIRLGGPEPWKGPPSSRAAPELLEYGRSRCARCRAQQWMSRGLNTSILLQYLAWVTYPVVLITFSAGFTQILAPQAVGSGIPEMKTILRGVVLKEYLTLKTFIAKVIGLTCALGSGMPLGKEGPFVHIASMCAALLSKFLSLFGGIYENESRNTEMLAAACAVGVGCCFAAPIGGVLFSIEVTSTFFAVRNYWRGFFAATFSAFIFRVLAVWNRDEETITALFKTRFRLDFPFDLQELPAFAVIGIASGFGGALFVYLNRKIVQVMRKQKTINRFLMRKRLLFPALVTLLISTLTFPPGFGQFMAGQLSQKETLVTLFDNRTWVRQGLVEELEPPSTSQAWNPPRANVFLTLVIFILMKFWMSALATTIPVPCGAFMPVFVIGAAFGRLVGESMAAWFPDGIHTDSSTYRIVPGGYAVVGAAALAGAVTHTVSTAVIVFELTGQIAHILPVMIAVILANAVAQSLQPSLYDSIIRIKKLPYLPELGWGRHQQYRVRVEDIMVRDVPHVALSCTFRDLRLALHRTKGRMLALVESPESMILLGSIERSQVVALLGAQLSPARRRQHMQERRATQTSPLSDQEGPPTPEASVCFQVNTEDSAFPAARGETHKPLKPALKRGPSVTRNLGESPTGSAESAGIALRSLFCGSPPPEAASEKLESCEKRKLKRVRISLASDADLEGEMSPEEILEWEEQQLDEPVNFSDCKIDPAPFQLVERTSLHKTHTIFSLLGVDHAYVTSIGRLIGIVTLKELRKAIEGSVTAQGVKVRPPLASFRDSATSSSDTETTEVHALWGPHSRHGLPREGSPSDSDDKCQ>sp|P51788-5|CLCN2_HUMAN Isoform 5 of Chloride channel protein 2 OS=Homosapiens OX=9606 GN=CLCN2MAAAAAEEGMEPRALQYEQTLMYGRYTQDLGAFAKEEAARIRLGGPEPWKGPPSSRAAPELLEYGRSRCARCRVCSVRCHKFLVSRVGEDWIFLVLLGLLMALVSWVMDYAIAACLQAQQWMSRGLNTSILLQYLAWVTYPVVLITFSAGFTQILAPQAVGSGIPEMKTILRGVVLKEYLTLKTFIAKVIGLTCALGSGMPLGKEGPFVHIASMCAALLSKFLSLFGGIYENESRNTEMLAAACAVGVGCCFAAPIGGVLFSIEVTSTFFAVRNYWRGFFAATFSAFIFRVLAVWNRDEETITALFKTRFRLDFPFDLQELPAFAVIGIASGFGGALFVYLNRKIVQVMRKQKTINRFLMRKRLLFPALVTLLISTLTFPPGFGQFMAGQLSQKETLVTLFDNRTWVRQGLVEELEPPSTSQAWNPPRANVFLTLVIFILMKFWMSALATTIPVPCGAFMPVFVIGAAFGRLVGESMAAWFPDGIHTDSSTYRIVPGGYAVVGAAALAGAVTHTVSTAVIVFELTGQIAHILPVMIAVILANAVAQSLQPSLYDSIIRIKKLPYLPELGWGRHQQYRVRVEDIMVRDVPHVALSCTFRDLRLALHRTKGRMLALVESPESMILLGSIERSQVVALLGAQLSPARRRQHMQERRATQTSPLSDQEGPPTPEASVCFQVNTEDSAFPAARGETHKPLKPALKRGPSVTRNLGESPTGSAESAGIALRSLFCGSPPPEAASEKLESCEKRKLKRVRISLASDADLEGEMSPEEILEWEEQQLDEPVNFSDCKIDPAPFQLVERTSLHKLRKAIEGSVTAQGVKVRPPLASFRDSATSSSDTETTEVHALWGPHSRHGLPREGSPSDSDDKCQ>sp|Q9H324|ATS10_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 10 OS=Homo sapiens OX=9606 GN=ADAMTS10 PE=1 SV=2MAPACQILRWALALGLGLMFEVTHAFRSQDEFLSSLESYEIAFPTRVDHNGALLAFSPPPPRRQRRGTGATAESRLFYKVASPSTHFLLNLTRSSRLLAGHVSVEYWTREGLAWQRAARPHCLYAGHLQGQASTSHVAISTCGGLHGLIVADEEEYLIEPLHGGPKGSRSPEESGPHVVYKRSSLRHPHLDTACGVRDEKPWKGRPWWLRTLKPPPARPLGNETERGQPGLKRSVSRERYVETLVVADKMMVAYHGRRDVEQYVLAIMNIVAKLFQDSSLGSTVNILVTRLILLTEDQPTLEITHHAGKSLDSFCKWQKSIVNHSGHGNAIPENGVANHDTAVLITRYDICIYKNKPCGTLGLAPVGGMCERERSCSVNEDIGLATAFTIAHEIGHTFGMNHDGVGNSCGARGQDPAKLMAAHITMKTNPFVWSSCSRDYITSFLDSGLGLCLNNRPPRQDFVYPTVAPGQAYDADEQCRFQHGVKSRQCKYGEVCSELWCLSKSNRCITNSIPAAEGTLCQTHTIDKGWCYKRVCVPFGSRPEGVDGAWGPWTPWGDCSRTCGGGVSSSSRHCDSPRPTIGGKYCLGERRRHRSCNTDDCPPGSQDFREVQCSEFDSIPFRGKFYKWKTYRGGGVKACSLTCLAEGFNFYTERAAAVVDGTPCRPDTVDICVSGECKHVGCDRVLGSDLREDKCRVCGGDGSACETIEGVFSPASPGAGYEDVVWIPKGSVHIFIQDLNLSLSHLALKGDQESLLLEGLPGTPQPHRLPLAGTTFQLRQGPDQVQSLEALGPINASLIVMVLARTELPALRYRFNAPIARDSLPPYSWHYAPWTKCSAQCAGGSQVQAVECRNQLDSSAVAPHYCSAHSKLPKRQRACNTEPCPPDWVVGNWSLCSRSCDAGVRSRSVVCQRRVSAAEEKALDDSACPQPRPPVLEACHGPTCPPEWAALDWSECTPSCGPGLRHRVVLCKSADHRATLPPAHCSPAAKPPATMRCNLRRCPPARWVAGEWGECSAQCGVGQRQRSVRCTSHTGQASHECTEALRPPTTQQCEAKCDSPTPGDGPEECKDVNKVAYCPLVLKFQFCSRAYFRQMCCKTCHGH>sp|Q9H324-2|ATS10_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 10 OS=Homo sapiens OX=9606 GN=ADAMTS10MGPTSVLRAGLTPSCLPPPSGATNGSVSPLGRAQRVWTEPGGRGLHGATAAGPVAAACPLLAVTATAPGQPSGASTVWVREGGTAPATRMTVPLAPRTSEKCSVLNLTASLSVGNSTSGKRTGEACSLTCLAEGFNFYTERAAAVVDGTPCRPDTVDICVSGECKHVGCDRVLGSDLREDKCRVCGGDGSACETIEGVFSPASPGAGYEDVVWIPKGSVHIFIQDLNLSLSHLALKGDQESLLLEGLPGTPQPHRLPLAGTTFQLRQGPDQVQSLEALGPINASLIVMVLARTELPALRYRFNAPIARDSLPPYSWHYAPWTKCSAQCAGGSQVQAVECRNQLDSSAVAPHYCSAHSKLPKRQRACNTEPCPPDWVVGNWSLCSRSCDAGVRSRSVVCQRRVSAAEEKALDDSACPQPRPPVLEACHGPTCPPEWAALDWSECTPSCGPGLRHRVVLCKSADHRATLPPAHCSPAAKPPATMRCNLRRCPPARWVAGEWGECSAQCGVGQRQRSVRCTSHTGQASHECTEALRPPTTQQCEAKCDSPTPGDGPEECKDVNKVAYCPLVLKFQFCSRAYFRQMCCKTCHGH>sp|C9JDP6|CLD25_HUMAN Putative claudin-25 OS=Homo sapiens OX=9606GN=CLDN25 PE=5 SV=1MAWSFRAKVQLGGLLLSLLGWVCSCVTTILPQWKTLNLELNEMETWIMGIWEVCVDREEVATVCKAFESFLSLPQELQVARILMVASHGLGLLGLLLCSFGSECFQFHRIRWVFKRRLGLLGRTLEASASATTLLPVSWVAHATIQDFWDDSIPDIIPRWEFGGALYLGWAAGIFLALGGLLLIFSACLGKEDVPFPLMAGPTVPLSCAPVEESDGSFHLMLRPRNLVI>sp|P57739|CLD2_HUMAN Claudin-2 OS=Homo sapiens OX=9606 GN=CLDN2 PE=1SV=1MASLGLQLVGYILGLLGLLGTLVAMLLPSWKTSSYVGASIVTAVGFSKGLWMECATHSTGITQCDIYSTLLGLPADIQAAQAMMVTSSAISSLACIISVVGMRCTVFCQESRAKDRVAVAGGVFFILGGLLGFIPVAWNLHGILRDFYSPLVPDSMKFEIGEALYLGIISSLFSLIAGIILCFSCSSQRNRSNYYDAYQAQPLATRSSPRPGQPPKVKSEFNSYSLTGYV>sp|Q8TE57|ATS16_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 16 OS=Homo sapiens OX=9606 GN=ADAMTS16 PE=2 SV=3MKPRARGWRGLAALWMLLAQVAEQAPACAMGPAAAAPGSPSVPRPPPPAERPGWMEKGEYDLVSAYEVDHRGDYVSHEIMHHQRRRRAVPVSEVESLHLRLKGSRHDFHMDLRTSSSLVAPGFIVQTLGKTGTKSVQTLPPEDFCFYQGSLRSHRNSSVALSTCQGLSGMIRTEEADYFLRPLPSHLSWKLGRAAQGSSPSHVLYKRSTEPHAPGASEVLVTSRTWELAHQPLHSSDLRLGLPQKQHFCGRRKKYMPQPPKEDLFILPDEYKSCLRHKRSLLRSHRNEELNVETLVVVDKKMMQNHGHENITTYVLTILNMVSALFKDGTIGGNINIAIVGLILLEDEQPGLVISHHADHTLSSFCQWQSGLMGKDGTRHDHAILLTGLDICSWKNEPCDTLGFAPISGMCSKYRSCTINEDTGLGLAFTIAHESGHNFGMIHDGEGNMCKKSEGNIMSPTLAGRNGVFSWSPCSRQYLHKFLSTAQAICLADQPKPVKEYKYPEKLPGELYDANTQCKWQFGEKAKLCMLDFKKDICKALWCHRIGRKCETKFMPAAEGTICGHDMWCRGGQCVKYGDEGPKPTHGHWSDWSSWSPCSRTCGGGVSHRSRLCTNPKPSHGGKFCEGSTRTLKLCNSQKCPRDSVDFRAAQCAEHNSRRFRGRHYKWKPYTQVEDQDLCKLYCIAEGFDFFFSLSNKVKDGTPCSEDSRNVCIDGICERVGCDNVLGSDAVEDVCGVCNGNNSACTIHRGLYTKHHHTNQYYHMVTIPSGARSIRIYEMNVSTSYISVRNALRRYYLNGHWTVDWPGRYKFSGTTFDYRRSYNEPENLIATGPTNETLIVELLFQGRNPGVAWEYSMPRLGTEKQPPAQPSYTWAIVRSECSVSCGGGQMTVREGCYRDLKFQVNMSFCNPKTRPVTGLVPCKVSACPPSWSVGNWSACSRTCGGGAQSRPVQCTRRVHYDSEPVPASLCPQPAPSSRQACNSQSCPPAWSAGPWAECSHTCGKGWRKRAVACKSTNPSARAQLLPDAVCTSEPKPRMHEACLLQRCHKPKKLQWLVSAWSQCSVTCERGTQKRFLKCAEKYVSGKYRELASKKCSHLPKPSLELERACAPLPCPRHPPFAAAGPSRGSWFASPWSQCTASCGGGVQTRSVQCLAGGRPASGCLLHQKPSASLACNTHFCPIAEKKDAFCKDYFHWCYLVPQHGMCSHKFYGKQCCKTCSKSNL>sp|Q8TE57-2|ATS16_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 16 OS=Homo sapiens OX=9606 GN=ADAMTS16MKPRARGWRGLAALWMLLAQVAEQAPACAMGPAAAAPGSPSVPRPPPPAERPGWMEKGEYDLVSAYEVDHRGDYVSHEIMHHQRRRRAVPVSEVESLHLRLKGSRHDFHMDLRTSSSLVAPGFIVQTLGKTGTKSVQTLPPEDFCFYQGSLRSHRNSSVALSTCQGLSGMIRTEEADYFLRPLPSHLSWKLGRAAQGSSPSHVLYKRSTEPHAPGASEVLVTSRTWELAHQPLHSSDLRLGLPQKQHFCGRRKKYMPQPPKEDLFILPDEYKSCLRHKRSLLRSHRNEELNVETLVVVDKKMMQNHGHENITTYVLTILNMVSALFKDGTIGGNINIAIVGLILLEDEQPGLVISHHADHTLSSFCQWQSGLMGKDGTRHDHAILLTGLDICSWKNEPCDTLGFAPISGMCSKYRSCTINEDTGLGLAFTIAHESGHNFGMIHDGEGNMCKKSEGNIMSPTLAGRNGVFSWSPCSRQYLHKFLSTAQAICLADQPKPVKEYKYPEKLPGELYDANTQCKWQFGEKAKLCMLDFKKDICKALWCHRIGRKCETKFMPAAEGTICGHDMWCRGGQCVKYGDEGPKPTHGHWSDWSSWSPCSRTCGGGVSHRSRLCTNPKPSHGGKFCEGSTRTLKLCNSQKCPRDSVDFRAAQCAEHNSRRFRGRHYKWKPYTQVEDQDLCKLYCIAEGFDFFFSLSNKVKDGTPCSEDSRNVCIDGICERVGCDNVLGSDAVEDVCGVCNGNNSACTIHRGLYTKHHHTNQYYHMVTIPSGARSIRIYEMNVSTSYISVRNALRRYYLNGHWTVDWPGRYKFSGTTFDYRRSYNEPENLIATGPTNETLIVELLFQGRNPGVAWEYSMPRLGTEKQPPAQPSYTWAIVRSECSVSCGGGQMTVREGCYRDLKFQVNMSFCNPKTRPVTGLVPCKVSACPPSWSVGNWSACSRTCGGGAQSRPVQCTRRVHYDSEPVPASLCPQPAPSSRQACNSQSCPPAWSAGPWAECSHTCGKGWRKRAVACKSTNPSARAQLLPDAVCTSEPKPRMHEACLLQRCHKPKKLQWLVSAWSQVGALVSRERG>sp|Q8TE56|ATS17_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 17 OS=Homo sapiens OX=9606 GN=ADAMTS17 PE=2 SV=2MCDGALLPPLVLPVLLLLVWGLDPGTAVGDAAADVEVVLPWRVRPDDVHLPPLPAAPGPRRRRRPRTPPAAPRARPGERALLLHLPAFGRDLYLQLRRDLRFLSRGFEVEEAGAARRRGRPAELCFYSGRVLGHPGSLVSLSACGAAGGLVGLIQLGQEQVLIQPLNNSQGPFSGREHLIRRKWSLTPSPSAEAQRPEQLCKVLTEKKKPTWGRPSRDWRERRNAIRLTSEHTVETLVVADADMVQYHGAEAAQRFILTVMNMVYNMFQHQSLGIKINIQVTKLVLLRQRPAKLSIGHHGERSLESFCHWQNEEYGGARYLGNNQVPGGKDDPPLVDAAVFVTRTDFCVHKDEPCDTVGIAYLGGVCSAKRKCVLAEDNGLNLAFTIAHELGHNLGMNHDDDHSSCAGRSHIMSGEWVKGRNPSDLSWSSCSRDDLENFLKSKVSTCLLVTDPRSQHTVRLPHKLPGMHYSANEQCQILFGMNATFCRNMEHLMCAGLWCLVEGDTSCKTKLDPPLDGTECGADKWCRAGECVSKTPIPEHVDGDWSPWGAWSMCSRTCGTGARFRQRKCDNPPPGPGGTHCPGASVEHAVCENLPCPKGLPSFRDQQCQAHDRLSPKKKGLLTAVVVDDKPCELYCSPLGKESPLLVADRVLDGTPCGPYETDLCVHGKCQKIGCDGIIGSAAKEDRCGVCSGDGKTCHLVKGDFSHARGTALKDSGKGSINSDWKIELPGEFQIAGTTVRYVRRGLWEKISAKGPTKLPLHLMVLLFHDQDYGIHYEYTVPVNRTAENQSEPEKPQDSLFIWTHSGWEGCSVQCGGGERRTIVSCTRIVNKTTTLVNDSDCPQASRPEPQVRRCNLHPCQSRWVAGPWSPCSATCEKGFQHREVTCVYQLQNGTHVATRPLYCPGPRPAAVQSCEGQDCLSIWEASEWSQCSASCGKGVWKRTVACTNSQGKCDASTRPRAEEACEDYSGCYEWKTGDWSTCSSTCGKGLQSRVVQCMHKVTGRHGSECPALSKPAPYRQCYQEVCNDRINANTITSPRLAALTYKCTRDQWTVYCRVIREKNLCQDMRWYQRCCQTCRDFYANKMRQPPPNS>sp|Q8TE56-2|ATS17_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 17 OS=Homo sapiens OX=9606 GN=ADAMTS17MVQYHGAEAAQRFILTVMNMVYNMFQHQSLGIKINIQVTKLVLLRQRPAKLSIGHHGERSLESFCHWQNEEYGGARYLGNNQVPGGKDDPPLVDAAVFVTRTDFCVHKDEPCDTVGIAYLGGVCSAKRKCVLAEDNGLNLAFTIAHELGHNLGMNHDDDHSSCAGRSHIMSGEWVKGRNPSDLSWSSCSRDDLENFLKSKVSTCLLVTDPRSQHTVRLPHKLPGMHYSANEQCQILFGMNATFCRNMEHLMCAGLWCLVEGDTSCKTKLDPPLDGTECGADKWCRAGECVSKTPIPEHVDGDWSPWGAWSMCSRTCGTGARFRQRKCDNPPPGPGGTHCPGASVEHAVCENLPCPKGLPSFRDQQCQAHDRLSPKKKGLLTAVVVDDKPCELYCSPLGKESPLLVADRVLDGTPCGPYETDLCVHGKCQKIGCDGIIGSAAKEDRCGVCSGDGKTCHLVKGDFSHARGTGYIEAAVIPAGARRIRVVEDKPAHSFLGKTQMT>sp|Q8TE60|ATS18_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 18 OS=Homo sapiens OX=9606 GN=ADAMTS18 PE=1 SV=3MECALLLACAFPAAGSGPPRGLAGLGRVAKALQLCCLCCASVAAALASDSSSGASGLNDDYVFVTPVEVDSAGSYISHDILHNGRKKRSAQNARSSLHYRFSAFGQELHLELKPSAILSSHFIVQVLGKDGASETQKPEVQQCFYQGFIRNDSSSSVAVSTCAGLSGLIRTRKNEFLISPLPQLLAQEHNYSSPAGHHPHVLYKRTAEEKIQRYRGYPGSGRNYPGYSPSHIPHASQSRETEYHHRRLQKQHFCGRRKKYAPKPPTEDTYLRFDEYGSSGRPRRSAGKSQKGLNVETLVVADKKMVEKHGKGNVTTYILTVMNMVSGLFKDGTIGSDINVVVVSLILLEQEPGGLLINHHADQSLNSFCQWQSALIGKNGKRHDHAILLTGFDICSWKNEPCDTLGFAPISGMCSKYRSCTINEDTGLGLAFTIAHESGHNFGMIHDGEGNPCRKAEGNIMSPTLTGNNGVFSWSSCSRQYLKKFLSTPQAGCLVDEPKQAGQYKYPDKLPGQIYDADTQCKWQFGAKAKLCSLGFVKDICKSLWCHRVGHRCETKFMPAAEGTVCGLSMWCRQGQCVKFGELGPRPIHGQWSAWSKWSECSRTCGGGVKFQERHCNNPKPQYGGLFCPGSSRIYQLCNINPCNENSLDFRAQQCAEYNSKPFRGWFYQWKPYTKVEEEDRCKLYCKAENFEFFFAMSGKVKDGTPCSPNKNDVCIDGVCELVGCDHELGSKAVSDACGVCKGDNSTCKFYKGLYLNQHKANEYYPVVLIPAGARSIEIQELQVSSSYLAVRSLSQKYYLTGGWSIDWPGEFPFAGTTFEYQRSFNRPERLYAPGPTNETLVFEILMQGKNPGIAWKYALPKVMNGTPPATKRPAYTWSIVQSECSVSCGGGYINVKAICLRDQNTQVNSSFCSAKTKPVTEPKICNAFSCPAYWMPGEWSTCSKACAGGQQSRKIQCVQKKPFQKEEAVLHSLCPVSTPTQVQACNSHACPPQWSLGPWSQCSKTCGRGVRKRELLCKGSAAETLPESQCTSLPRPELQEGCVLGRCPKNSRLQWVASSWSECSATCGLGVRKREMKCSEKGFQGKLITFPERRCRNIKKPNLDLEETCNRRACPAHPVYNMVAGWYSLPWQQCTVTCGGGVQTRSVHCVQQGRPSSSCLLHQKPPVLRACNTNFCPAPEKREDPSCVDFFNWCHLVPQHGVCNHKFYGKQCCKSCTRKI>sp|Q8TE60-2|ATS18_HUMAN Isoform 2 of A disintegrin and metalloproteinasewith thrombospondin motifs 18 OS=Homo sapiens OX=9606 GN=ADAMTS18MECALLLACAFPAAGSGPPRGLAGLGRVAKALQLCCLCCASVAAALASDSSSGASGLNDDYVFVTPVEVDSAGSYISHDILHNGRKKRSAQNARSSLHYRFSAFGQELHLELKPSAILSSHFIVQVLGKDGASETQKPEVQQCFYQGFIRNDSSSSVAVSTCAGLSGLIRTRKNEFLISPLPQLLAQEHNYSSPAGHHPHVLYKRTAEEKIQRYRGYPGSGRNYPGYSPSHIPHASQSRETEYHHRRLQKQHFCGRRKKYAPKPPTEDTYLRFDEYGSSGRPRRSAGKSQKGLNVETLVVADKKMVEKHGKGNVTTYILTVMNMVSGLFKDGTIGSDINVVVVSLILLEQEPGGLLINHHADQSLNSFCQWQSALIGKNGKRHDHAILLTGFDICSWKNEPCDTLGFAPISGMCSKYRSCTINEDTGLGLAFTIAHESGHNFGMIHDGEGNPCRKAEGNIMSPTLTGNNGVFSWSSCSRQYLKKFLSTPQAGCLVDEPKQAGQYKYPDKLPGQIYDADTQCKWQFGAKAKLCSLGFVKDICKSLWCHRVGHRCETKFMPAAEGTVCGLSMWCRQGQCVKFGELGPRPIHGQWSAWSKWSECSRTCGGGVKFQERHCNNPKPQYGGLFCPGSSRIYQLCNINPCNENSLDFRAQQCAEYNSKPFRGWFYQWKPYTKVEEEDRCKLYCKAENFEFFFAMSGKVKDGTPCSPNKNDVCIDGVCELVGCDHELGSKAVSDACGVCKGDNSTCKFYKGLYLNQHKANEYYPVVLIPAGARSIEIQELQVSSSYLAVRSLSQKYYLTGGWSIDWPGEFPFAGTTFEYQRSFNRPERLYAPGPTNETLVFEILMQGKNPGIAWKYALPKVMNGTPPATKRPAYTWSIVQSECSVSCGGGYINVKAICLRDQNTQVNSSFCSAKTKPVTEPKICNAFSCPAYWMPGEWSTCSKACAGGQQSRKIQCVQKKPFQKEEAVLHSLCPVSTPTQVQACNSHACPPQWSLGPWSQCSKTCGRGVRKRELLCKGSAAETLPESQCTSLPRPELQEGCVLGRCPKNSRLQWVASSWSEVWIRSHCWVRRLRPSWLTQ>sp|P0C843|CI014_HUMAN Putative uncharacterized protein encoded byLINC00032 OS=Homo sapiens OX=9606 GN=LINC00032 PE=5 SV=1MHLHVQPLRAKGKRPKDTFNKMAHRKRHSVTSEFLSKVPDEVRQRYINLFVEKYLKVCKTEDEAVYKAKIEKKAIYERCSRRNMYVNIAVNYLKKLRDQGA>sp|P08123|CO1A2_HUMAN Collagen alpha-2(I) chain OS=Homo sapiens OX=9606GN=COL1A2 PE=1 SV=7MLSFVDTRTLLLLAVTLCLATCQSLQEETVRKGPAGDRGPRGERGPPGPPGRDGEDGPTGPPGPPGPPGPPGLGGNFAAQYDGKGVGLGPGPMGLMGPRGPPGAAGAPGPQGFQGPAGEPGEPGQTGPAGARGPAGPPGKAGEDGHPGKPGRPGERGVVGPQGARGFPGTPGLPGFKGIRGHNGLDGLKGQPGAPGVKGEPGAPGENGTPGQTGARGLPGERGRVGAPGPAGARGSDGSVGPVGPAGPIGSAGPPGFPGAPGPKGEIGAVGNAGPAGPAGPRGEVGLPGLSGPVGPPGNPGANGLTGAKGAAGLPGVAGAPGLPGPRGIPGPVGAAGATGARGLVGEPGPAGSKGESGNKGEPGSAGPQGPPGPSGEEGKRGPNGEAGSAGPPGPPGLRGSPGSRGLPGADGRAGVMGPPGSRGASGPAGVRGPNGDAGRPGEPGLMGPRGLPGSPGNIGPAGKEGPVGLPGIDGRPGPIGPAGARGEPGNIGFPGPKGPTGDPGKNGDKGHAGLAGARGAPGPDGNNGAQGPPGPQGVQGGKGEQGPPGPPGFQGLPGPSGPAGEVGKPGERGLHGEFGLPGPAGPRGERGPPGESGAAGPTGPIGSRGPSGPPGPDGNKGEPGVVGAVGTAGPSGPSGLPGERGAAGIPGGKGEKGEPGLRGEIGNPGRDGARGAPGAVGAPGPAGATGDRGEAGAAGPAGPAGPRGSPGERGEVGPAGPNGFAGPAGAAGQPGAKGERGAKGPKGENGVVGPTGPVGAAGPAGPNGPPGPAGSRGDGGPPGMTGFPGAAGRTGPPGPSGISGPPGPPGPAGKEGLRGPRGDQGPVGRTGEVGAVGPPGFAGEKGPSGEAGTAGPPGTPGPQGLLGAPGILGLPGSRGERGLPGVAGAVGEPGPLGIAGPPGARGPPGAVGSPGVNGAPGEAGRDGNPGNDGPPGRDGQPGHKGERGYPGNIGPVGAAGAPGPHGPVGPAGKHGNRGETGPSGPVGPAGAVGPRGPSGPQGIRGDKGEPGEKGPRGLPGLKGHNGLQGLPGIAGHHGDQGAPGSVGPAGPRGPAGPSGPAGKDGRTGHPGTVGPAGIRGPQGHQGPAGPPGPPGPPGPPGVSGGGYDFGYDGDFYRADQPRSAPSLRPKDYEVDATLKSLNNQIETLLTPEGSRKNPARTCRDLRLSHPEWSSGYYWIDPNQGCTMDAIKVYCDFSTGETCIRAQPENIPAKNWYRSSKDKKHVWLGETINAGSQFEYNVEGVTSKEMATQLAFMRLLANYASQNITYHCKNSIAYMDEETGNLKKAVILQGSNDVELVAEGNSRFTYTVLVDGCSKKTNEWGKTIIEYKTNKPSRLPFLDIAPLDIGGADQEFFVDIGPVCFK>sp|P56748|CLD8_HUMAN Claudin-8 OS=Homo sapiens OX=9606 GN=CLDN8 PE=1SV=1MATHALEIAGLFLGGVGMVGTVAVTVMPQWRVSAFIENNIVVFENFWEGLWMNCVRQANIRMQCKIYDSLLALSPDLQAARGLMCAASVMSFLAFMMAILGMKCTRCTGDNEKVKAHILLTAGIIFIITGMVVLIPVSWVANAIIRDFYNSIVNVAQKRELGEALYLGWTTALVLIVGGALFCCVFCCNEKSSSYRYSIPSHRTTQKSYHTGKKSPSVYSRSQYV>sp|Q8TE59|ATS19_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 19 OS=Homo sapiens OX=9606 GN=ADAMTS19 PE=2 SV=2MRLTHICCCCLLYQLGFLSNGIVSELQFAPDREEWEVVFPALWRREPVDPAGGSGGSADPGWVRGVGGGGSARAQAAGSSREVRSVAPVPLEEPVEGRSESRLRPPPPSEGEEDEELESQELPRGSSGAAALSPGAPASWQPPPPPQPPPSPPPAQHAEPDGDEVLLRIPAFSRDLYLLLRRDGRFLAPRFAVEQRPNPGPGPTGAASAPQPPAPPDAGCFYTGAVLRHPGSLASFSTCGGGLMGFIQLNEDFIFIEPLNDTMAITGHPHRVYRQKRSMEEKVTEKSALHSHYCGIISDKGRPRSRKIAESGRGKRYSYKLPQEYNIETVVVADPAMVSYHGADAARRFILTILNMVFNLFQHKSLSVQVNLRVIKLILLHETPPELYIGHHGEKMLESFCKWQHEEFGKKNDIHLEMSTNWGEDMTSVDAAILITRKDFCVHKDEPCDTVGIAYLSGMCSEKRKCIIAEDNGLNLAFTIAHEMGHNMGINHDNDHPSCADGLHIMSGEWIKGQNLGDVSWSRCSKEDLERFLRSKASNCLLQTNPQSVNSVMVPSKLPGMTYTADEQCQILFGPLASFCQEMQHVICTGLWCKVEGEKECRTKLDPPMDGTDCDLGKWCKAGECTSRTSAPEHLAGEWSLWSPCSRTCSAGISSRERKCPGLDSEARDCNGPRKQYRICENPPCPAGLPGFRDWQCQAYSVRTSSPKHILQWQAVLDEEKPCALFCSPVGKEQPILLSEKVMDGTSCGYQGLDICANGRCQKVGCDGLLGSLAREDHCGVCNGNGKSCKIIKGDFNHTRGAGYVEVLVIPAGARRIKVVEEKPAHSYLALRDAGKQSINSDWKIEHSGAFNLAGTTVHYVRRGLWEKISAKGPTTAPLHLLVLLFQDQNYGLHYEYTIPSDPLPENQSSKAPEPLFMWTHTSWEDCDATCGGGERKTTVSCTKIMSKNISIVDNEKCKYLTKPEPQIRKCNEQPCQTRWMMTEWTPCSRTCGKGMQSRQVACTQQLSNGTLIRARERDCIGPKPASAQRCEGQDCMTVWEAGVWSECSVKCGKGIRHRTVRCTNPRKKCVLSTRPREAEDCEDYSKCYVWRMGDWSKCSITCGKGMQSRVIQCMHKITGRHGNECFSSEKPAAYRPCHLQPCNEKINVNTITSPRLAALTFKCLGDQWPVYCRVIREKNLCQDMRWYQRCCETCRDFYAQKLQQKS>sp|Q9P2X8|CI027_HUMAN Putative uncharacterized protein encoded byLINC00474 OS=Homo sapiens OX=9606 GN=LINC00474 PE=5 SV=2MLCVSGFTSNLYSSKKDDKMKEISRTSNWGSSFSEKSGCMQTHPSMNLDCRDVTYVMNLLLIAHHHLLQ>sp|Q9H2J1|CI037_HUMAN Uncharacterized protein ARRDC1-AS1 OS=Homo sapiensOX=9606 GN=ARRDC1-AS1 PE=2 SV=2MEFHYVAQADLELLTSSNPPASASQSTGITGGSHRARPGPVHFIDKVTDKPSHSHPFALKENWNLNPEPSSPPSPLFLEAPSRQASQHHGASPGAGTSAGCPFEKCCSTEPCLSGLGDVGRGEAASLRARPGSGASRGQGPGSRVSCRRDLGKPLHAPAGFSAGEVHTTPLGNLGA>sp|Q9UHI8|ATS1_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 1 OS=Homo sapiens OX=9606 GN=ADAMTS1 PE=1 SV=4MQRAVPEGFGRRKLGSDMGNAERAPGSRSFGPVPTLLLLAAALLAVSDALGRPSEEDEELVVPELERAPGHGTTRLRLHAFDQQLDLELRPDSSFLAPGFTLQNVGRKSGSETPLPETDLAHCFYSGTVNGDPSSAAALSLCEGVRGAFYLLGEAYFIQPLPAASERLATAAPGEKPPAPLQFHLLRRNRQGDVGGTCGVVDDEPRPTGKAETEDEDEGTEGEDEGAQWSPQDPALQGVGQPTGTGSIRKKRFVSSHRYVETMLVADQSMAEFHGSGLKHYLLTLFSVAARLYKHPSIRNSVSLVVVKILVIHDEQKGPEVTSNAALTLRNFCNWQKQHNPPSDRDAEHYDTAILFTRQDLCGSQTCDTLGMADVGTVCDPSRSCSVIEDDGLQAAFTTAHELGHVFNMPHDDAKQCASLNGVNQDSHMMASMLSNLDHSQPWSPCSAYMITSFLDNGHGECLMDKPQNPIQLPGDLPGTSYDANRQCQFTFGEDSKHCPDAASTCSTLWCTGTSGGVLVCQTKHFPWADGTSCGEGKWCINGKCVNKTDRKHFDTPFHGSWGMWGPWGDCSRTCGGGVQYTMRECDNPVPKNGGKYCEGKRVRYRSCNLEDCPDNNGKTFREEQCEAHNEFSKASFGSGPAVEWIPKYAGVSPKDRCKLICQAKGIGYFFVLQPKVVDGTPCSPDSTSVCVQGQCVKAGCDRIIDSKKKFDKCGVCGGNGSTCKKISGSVTSAKPGYHDIITIPTGATNIEVKQRNQRGSRNNGSFLAIKAADGTYILNGDYTLSTLEQDIMYKGVVLRYSGSSAALERIRSFSPLKEPLTIQVLTVGNALRPKIKYTYFVKKKKESFNAIPTFSAWVIEEWGECSKSCELGWQRRLVECRDINGQPASECAKEVKPASTRPCADHPCPQWQLGEWSSCSKTCGKGYKKRSLKCLSHDGGVLSHESCDPLKKPKHFIDFCTMAECS>sp|Q8TAL5|CI043_HUMAN Uncharacterized protein C9orf43 OS=Homo sapiensOX=9606 GN=C9orf43 PE=1 SV=1MDLPDESQWDETTCGLAVCQHPQCWATIRRIERGHPRILGSSCKTPLDAEDKLPVLTVVDILDSGFAAHHLPECTFTKAHSLLSQSSKFYSKFHGRPPKGLPDKSLINCTNRLPKFPVLNLNETQLPCPEDVRNMVVLWIPEETEIHVSQHGKKKRKNSAVKSKSFLGLSGNQSAGTRVGTPGMIVPPPTPVQLSEQFSSDFLPLWAQSEALPQDLLKELLPGGKQTMLCPEMKIKLAMMKKNLPLEKNRPDSVISSKMFLSIHRLTLERPALRYPERLKKLHNLKTEGYRKQQQRQQQQQQQQKKVKTPIKKQEAKKKAKSDPGIQSTSHKHPVTTVHDRLYGYRTLPGQNSDMKQQQQMEKGTTSKQDSTERPKMNYYDHADFHHSVKSPELYETEPTNKDISAPVDAVPEAQAARQKKISFNFSEIMASTGWNSELKLLRILQDTDDEDEEDQSSGAE>sp|Q9NY35|CLDN1_HUMAN Claudin domain-containing protein 1 OS=Homosapiens OX=9606 GN=CLDND1 PE=1 SV=1MDNRFATAFVIACVLSLISTIYMAASIGTDFWYEYRSPVQENSSDLNKSIWDEFISDEADEKTYNDALFRYNGTVGLWRRCITIPKNMHWYSPPERTESFDVVTKCVSFTLTEQFMEKFVDPGNHNSGIDLLRTYLWRCQFLLPFVSLGLMCFGALIGLCACICRSLYPTIATGILHLLAGLCTLGSVSCYVAGIELLHQKLELPDNVSGEFGWSFCLACVSAPLQFMASALFIWAAHTNRKEYTLMKAYRVA>sp|Q9NY35-2|CLDN1_HUMAN Isoform 2 of Claudin domain-containing protein 1OS=Homo sapiens OX=9606 GN=CLDND1MDNRFATAFVIACVLSLISTIYMAASIGTDFWYEYRSPVQENSSDLNKSIWDEFISDEADEKTYNDALFRYNGTVGLWRRCITIPKNMHWYSPPERTESFDVVTKCVSFTLTEQFMEKFVDPGNHNSGIDLLRTYLWRCQFLLPFVSLGLMCFGALIGLCACICRSLYPTIATGILHLLADTML>sp|Q9NY35-3|CLDN1_HUMAN Isoform 3 of Claudin domain-containing protein 1OS=Homo sapiens OX=9606 GN=CLDND1MGESFDVVTKCVSFTLTEQFMEKFVDPGNHNSGIDLLRTYLWRCQFLLPFVSLGLMCFGALIGLCACICRSLYPTIATGILHLLAGLCTLGSVSCYVAGIELLHQKLELPDNVSGEFGWSFCLACVSAPLQFMASALFIWAAHTNRKEYTLMKAYRVA>sp|Q6ZRZ4|CI047_HUMAN Uncharacterized protein C9orf47 OS=Homo sapiensOX=9606 GN=C9orf47 PE=2 SV=1MVRIWTTIMIVLILLLRIGPNKPSLSGRQAPAQAQTSDLVPSLFPLGLWAPGFCTWSSPDEDKVWRPAWEQGPKGEPDPRGLRPRKPVPGTGNRDSGTRRRLQDATEQDPRPGNDVASAETAGPPSPSGIRAQDRAPRHRRAPPARMPVAPAPSADGEPLQEQGGGLFHRTRSVYNGLELNTWMKVERLFVEKFHQSFSLDN>sp|Q6ZRZ4-2|CI047_HUMAN Isoform 2 of Uncharacterized protein C9orf47OS=Homo sapiens OX=9606 GN=C9orf47MVRIWTTIMIVLILLLRIGPNKPSLSGRQAPAQAQTSDLVPSLFPLGLWAPGFCTWSSPDEDKRPRKPVPGTGNRDSGTRRRLQDATEQDPRPGNDVASAETAGPPSPSGIRAQDRAPRHRRAPPARMPVAPAPSADGEPLQEQGGGLFHRTRSVYNGLELNTWMKVERLFVEKFHQSFSLDN>sp|Q5SZB4|CI050_HUMAN Uncharacterized protein C9orf50 OS=Homo sapiensOX=9606 GN=C9orf50 PE=2 SV=1MFWRRLRPGAQDLAPKGLPGDGDFRRSSDPRLPKLTPPALRAALGARGSGDWRIPGGGAAWWPEGDAKPGVGVGRLPPRLPALLTATRRAVRKRGLLRSLLPPPLLSAGASRESAPRQPGPGERERPRRRVAREDPDFLGAFLGELLPSRFREFLHQLQEKCAEEPEPLTSPAPQHQRGVLEHCPGSPRCPNCSFLPDLWGQSSHLQDSLTKISLQQTPILGPLKGDHSQFTTVRKANHRPHGAQVPRLKAALTHNPSGEGSRPCRQRCPFRVRFADETLQDTTLRYWERRRSVQQSVIVNQKAALPVASERVFGSVGKRLESLPKALYPGAKEETLASSSCWDCAGLSTQKTQGYLSEDTSMNSSLPFCSWKKAAAQRPRSSLRAFLDPHRNLEQESLLPNRVLQSVLKQGCPKGYHLLLASATLQPDKR>sp|Q5W0N0|CI057_HUMAN Uncharacterized protein C9orf57 OS=Homo sapiensOX=9606 GN=C9orf57 PE=1 SV=1MKKIEISGTCLSFHLLFGLEIRMRRIVFAGVILFRLLGVILFRLLGVILFGRLGDLGTCQTKPGQYWKEEVHIQDVGGLICRACNLSLPFHGCLLDLGTCQAEPGQYCKEEVHIQGGIQWYSVKGCTKNTSECFKSTLVKRILQLHELVTTHCCNHSLCNF>sp|Q5W0N0-2|CI057_HUMAN Isoform 2 of Uncharacterized protein C9orf57OS=Homo sapiens OX=9606 GN=C9orf57MGVGFTELEYLAPWLRPPFSDLGTCQTKPGQYWKEEVHIQDVGGLICRACNLSLPFHGCLLDLGTCQAEPGQYCKEEVHIQGGIQWYSVKGCTKNTSECFKSTLVKRILQLHELVTTHCCNHSLCNF>sp|Q8NHS1|CLDN2_HUMAN Claudin domain-containing protein 2 OS=Homosapiens OX=9606 GN=CLDND2 PE=1 SV=1MGVKRSLQSGGILLSLVANVLMVLSTATNYWTRQQEGHSGLWQECNHGICSSIPCQTTLAVTVACMVLAVGVGVVGMVMGLRIRCDEGESLRGQTTSAFLFLGGLLLLTALIGYTVKNAWKNNVFFSWSYFSGWLALPFSILAGFCFLLADMIMQSTDAISGFPVCL>sp|Q8TAZ6|CKLF2_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 2 OS=Homo sapiens OX=9606 GN=CMTM2 PE=1 SV=1MAPKAAKGAKPEPAPAPPPPGAKPEEDKKDGKEPSDKPQKAVQDHKEPSDKPQKAVQPKHEVGTRRGCRRYRWELKDSNKEFWLLGHAEIKIRSLGCLIAAMILLSSLTVHPILRLIITMEISFFSFFILLYSFAIHRYIPFILWPISDLFNDLIACAFLVGAVVFAVRSRRSMNLHYLLAVILIGAAGVFAFIDVCLQRNHFRGKKAKKHMLVPPPGKEKGPQQGKGPEPAKPPEPGKPPGPAKGKK>sp|Q8TAZ6-2|CKLF2_HUMAN Isoform 2 of CKLF-like MARVEL transmembranedomain-containing protein 2 OS=Homo sapiens OX=9606 GN=CMTM2MAPKAAKGAKPEPAPAPPPPGAKPEEDKKDGKEPSDKPQKAVQDHKEPSDKPQKAVQPKHEVGTRRGCRRYRWELKDSNKEFWLLGHAEIKIRSLDLFNDLIACAFLVGAVVFAVRSRRSMNLHYLLAVILIGAAGVFAFIDVCLQRNHFRGKKAKKHMLVPPPGKEKGPQQGKGPEPAKPPEPGKPPGPAKGKK>sp|O95450|ATS2_HUMAN A disintegrin and metalloproteinase withthrombospondin motifs 2 OS=Homo sapiens OX=9606 GN=ADAMTS2 PE=2 SV=2MDPPAGAARRLLCPALLLLLLLLPPPLLPPPPPPANARLAAAADPPGGPLGHGAERILAVPVRTDAQGRLVSHVVSAATSRAGVRARRAAPVRTPSFPGGNEEEPGSHLFYNVTVFGRDLHLRLRPNARLVAPGATMEWQGEKGTTRVEPLLGSCLYVGDVAGLAEASSVALSNCDGLAGLIRMEEEEFFIEPLEKGLAAQEAEQGRVHVVYRRPPTSPPLGGPQALDTGASLDSLDSLSRALGVLEEHANSSRRRARRHAADDDYNIEVLLGVDDSVVQFHGKEHVQKYLLTLMNIVNEIYHDESLGAHINVVLVRIILLSYGKSMSLIEIGNPSQSLENVCRWAYLQQKPDTGHDEYHDHAIFLTRQDFGPSGMQGYAPVTGMCHPVRSCTLNHEDGFSSAFVVAHETGHVLGMEHDGQGNRCGDEVRLGSIMAPLVQAAFHRFHWSRCSQQELSRYLHSYDCLLDDPFAHDWPALPQLPGLHYSMNEQCRFDFGLGYMMCTAFRTFDPCKQLWCSHPDNPYFCKTKKGPPLDGTMCAPGKHCFKGHCIWLTPDILKRDGSWGAWSPFGSCSRTCGTGVKFRTRQCDNPHPANGGRTCSGLAYDFQLCSRQDCPDSLADFREEQCRQWDLYFEHGDAQHHWLPHEHRDAKERCHLYCESRETGEVVSMKRMVHDGTRCSYKDAFSLCVRGDCRKVGCDGVIGSSKQEDKCGVCGGDNSHCKVVKGTFTRSPKKHGYIKMFEIPAGARHLLIQEVDATSHHLAVKNLETGKFILNEENDVDASSKTFIAMGVEWEYRDEDGRETLQTMGPLHGTITVLVIPVGDTRVSLTYKYMIHEDSLNVDDNNVLEEDSVVYEWALKKWSPCSKPCGGGSQFTKYGCRRRLDHKMVHRGFCAALSKPKAIRRACNPQECSQPVWVTGEWEPCSQTCGRTGMQVRSVRCIQPLHDNTTRSVHAKHCNDARPESRRACSRELCPGRWRAGPWSQCSVTCGNGTQERPVLCRTADDSFGICQEERPETARTCRLGPCPRNISDPSKKSYVVQWLSRPDPDSPIRKISSKGHCQGDKSIFCRMEVLSRYCSIPGYNKLCCKSCNLYNNLTNVEGRIEPPPGKHNDIDVFMPTLPVPTVAMEVRPSPSTPLEVPLNASSTNATEDHPETNAVDEPYKIHGLEDEVQPPNLIPRRPSPYEKTRNQRIQELIDEMRKKEMLGKF>sp|O95450-2|ATS2_HUMAN Isoform SpNPI of A disintegrin andmetalloproteinase with thrombospondin motifs 2 OS=Homo sapiens OX=9606GN=ADAMTS2MDPPAGAARRLLCPALLLLLLLLPPPLLPPPPPPANARLAAAADPPGGPLGHGAERILAVPVRTDAQGRLVSHVVSAATSRAGVRARRAAPVRTPSFPGGNEEEPGSHLFYNVTVFGRDLHLRLRPNARLVAPGATMEWQGEKGTTRVEPLLGSCLYVGDVAGLAEASSVALSNCDGLAGLIRMEEEEFFIEPLEKGLAAQEAEQGRVHVVYRRPPTSPPLGGPQALDTGASLDSLDSLSRALGVLEEHANSSRRRARRHAADDDYNIEVLLGVDDSVVQFHGKEHVQKYLLTLMNIVNEIYHDESLGAHINVVLVRIILLSYGKSMSLIEIGNPSQSLENVCRWAYLQQKPDTGHDEYHDHAIFLTRQDFGPSGMQGYAPVTGMCHPVRSCTLNHEDGFSSAFVVAHETGHVLGMEHDGQGNRCGDEVRLGSIMAPLVQAAFHRFHWSRCSQQELSRYLHSYDCLLDDPFAHDWPALPQLPGLHYSMNEQCRFDFGLGYMMCTAFRTFDPCKQLWCSHPDNPYFCKTKKGPPLDGTMCAPGKFRPGAVAHACYPSTLGGQGRWIA>sp|Q8IZR5|CKLF4_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 4 OS=Homo sapiens OX=9606 GN=CMTM4 PE=1 SV=1MRSGEELDGFEGEASSTSMISGASSPYQPTTEPVSQRRGLAGLRCDPDYLRGALGRLKVAQVILALIAFICIETIMACSPCEGLYFFEFVSCSAFVVTGVLLIMFSLNLHMRIPQINWNLTDLVNTGLSAFLFFIASIVLAALNHRAGAEIAAVIFGFLATAAYAVNTFLAVQKWRVSVRQQSTNDYIRARTESRDVDSRPEIQRLDTFSYSTNVTVRKKSPTNLLSLNHWQLA>sp|Q8IZR5-2|CKLF4_HUMAN Isoform 2 of CKLF-like MARVEL transmembranedomain-containing protein 4 OS=Homo sapiens OX=9606 GN=CMTM4MRSGEELDGFEGEASSTSMISGASSPYQPTTEPVSQRRGLAGLRCDPDYLRGALGRLKVAQVILALIAFICIETIMACSPCEGLYFFEFVSCSAFVVTGVLLIMFSLNLHMRIPQINWNLTDLVNTGLSAFLFFIASIVLAALNHRAGAEIAAVIFGFLATAAYAVNTFLAVQKWRVSVRQQSTNDYIRARTESRDVDSRPEIQRLDT>sp|Q8IZR5-3|CKLF4_HUMAN Isoform 3 of CKLF-like MARVEL transmembranedomain-containing protein 4 OS=Homo sapiens OX=9606 GN=CMTM4MRSGEELDGFEGEASSTSMISGASSPYQPTTEPILALIAFICIETIMACSPCEGLYFFEFVSCSAFVVTGVLLIMFSLNLHMRIPQINWNLTDLVNTGLSAFLFFIASIVLAALNHRAGAEIAAVIFGFLATAAYAVNTFLAVQKWRVSVRQQSTNDYIRARTESRDVDSRPEIQRLDT>sp|Q96MD7|CI085_HUMAN Uncharacterized protein C9orf85 OS=Homo sapiensOX=9606 GN=C9orf85 PE=1 SV=1MSSQKGNVARSRPQKHQNTFSFKNDKFDKSVQTKKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPWSLPLLPRLECSGRILAHHNLRLPCSSDSPASASRVAGTTGAHHHAQLIFVFLVEMGFHYVGQAGLELLTS>sp|Q96MD7-1|CI085_HUMAN Isoform 2 of Uncharacterized protein C9orf85OS=Homo sapiens OX=9606 GN=C9orf85MSSQKGNVARSRPQKHQNTFSFKNDKFDKSVQTKKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPLNKETEKIEHTENNLSSNHRRSCRRNEESDDDLDFDIDLEDTGGDHQMN>sp|Q96MD7-2|CI085_HUMAN Isoform 3 of Uncharacterized protein C9orf85OS=Homo sapiens OX=9606 GN=C9orf85MSSQKGNVARSRPQKHQNTFSFKNDKFDKSVQTKC>sp|Q96DZ9|CKLF5_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 5 OS=Homo sapiens OX=9606 GN=CMTM5 PE=1 SV=2MLSARDRRDRHPEEGVVAELQGFAVDKAFLTSHKGILLETELALTLIIFICFTASISAYMAAALLEFFITLAFLFLYATQYYQRFDRINWPCLLQGHGQSGGPHPLDLLSHSAKVQPQPWPGLTPPGWHTPAAVPWVPAPAPGFWSWLLWFICFHSLGSSDFLRCVSAIIIFLVVSFAAVTSRDGAAIAAFVFGIILVSIFAYDAFKIYRTEMAPGASQGDQQ>sp|Q96DZ9-2|CKLF5_HUMAN Isoform 2 of CKLF-like MARVEL transmembranedomain-containing protein 5 OS=Homo sapiens OX=9606 GN=CMTM5MLSARDRRDRHPEEGVVAELQGFAVDKAFLTSHKGILLETELALTLIIFICFTASISAYMAAALLEFFITLAFLFLYATQYYQRFDRINWPCLDFLRCVSAIIIFLVVSFAAVTSRDGAAIAAFVFGIILVSIFAYDAFKIYRTEMAPGASQGDQQ>sp|Q96DZ9-3|CKLF5_HUMAN Isoform 3 of CKLF-like MARVEL transmembranedomain-containing protein 5 OS=Homo sapiens OX=9606 GN=CMTM5MLSARDRRDRHPEEGVVAELQGFAVDKAFLTSHKGILLETELDYQRFDRINWPCLDFLRCVSAIIIFLVVSFAAVTSRDGAAIAAFVFGIILVSIFAYDAFKIYRTEMAPGASQGDQQ>sp|Q96DZ9-4|CKLF5_HUMAN Isoform 4 of CKLF-like MARVEL transmembranedomain-containing protein 5 OS=Homo sapiens OX=9606 GN=CMTM5MLSARDRRDRHPEEGVVAELQGFAVDKAFLTSHKGILLETELVFGIILVSIFAYDAFKIYRTEMAPGASQGDQQ>sp|Q96DZ9-5|CKLF5_HUMAN Isoform 5 of CKLF-like MARVEL transmembranedomain-containing protein 5 OS=Homo sapiens OX=9606 GN=CMTM5MLSARDRRDRHPEEGVVAELQGFAVDKAFLTSHKGILLETELDFLRCVSAIIIFLVVSFAAVTSRDGAAIAAFVFGIILVSIFAYDAFKIYRTEMAPGASQGDQQ>sp|Q96DZ9-6|CKLF5_HUMAN Isoform 6 of CKLF-like MARVEL transmembranedomain-containing protein 5 OS=Homo sapiens OX=9606 GN=CMTM5MLSARDRRDRHPEEGVVAELQGFAVDKAFLTSHKGILLETELALTLIIFICFTASISAYMAAALLEFFITLAFLFLYATQYYQRFDRINWPCLVFGIILVSIFAYDAFKIYRTEMAPGASQGDQQ>sp|A6NGG3|CI092_HUMAN Putative uncharacterized protein C9orf92 OS=Homosapiens OX=9606 GN=C9orf92 PE=4 SV=1MARFQRTKEREEDRCSLNIYYVRNTTQGTAPACVGKRMQPSPTGKGGKCCTVHGLTRKIHNVQPNLQSPILSAACVD>sp|A6NGG3-2|CI092_HUMAN Isoform 2 of Putative uncharacterized proteinC9orf92 OS=Homo sapiens OX=9606 GN=C9orf92MELNTNIKSKKGLGRRNLKPMNGAWPPARREMARFQRTKEREEDRCSLNIYYVRNTTQGTAPACVGKRMQPSPTGKGGKCCTVHGLTRKIHNVQPNLQSPILSAACVD>sp|Q8NAJ2|CI106_HUMAN Putative uncharacterized protein encoded byLINC02913 OS=Homo sapiens OX=9606 GN=LINC02913 PE=5 SV=2MAYVALSDKPHLSGEVGEEACSSWNPPLFSPRPLPRLWPLPGTPFLPIRALPFSASSSGKSSLVPSPSSSAHSGFRTPCLGPDCLLCTQGCELHEGRNHMAVHSCVARAWPGDPQEVRHLNPLLCDPGSQVEPSWPWHPGLEQAAASWVGNHVSPAHRQALRGHSLGSALRALMPGGHCPLCVPCKRGCNLRGGRGKHGPRPCCPLLRKFPVLPVHPWPFPCAVWDSGWSCR>sp|B1AMM8|CI107_HUMAN Putative uncharacterized protein encoded byLINC00587 OS=Homo sapiens OX=9606 GN=LINC00587 PE=5 SV=1MQFADWLHPSGWTIEILNAYGMGDRKRTNSMSKEAFTPEQLHLEKELGEMRLRPTVLHSQTDHQGFRPIPMMQ>sp|Q9NX76|CKLF6_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 6 OS=Homo sapiens OX=9606 GN=CMTM6 PE=1 SV=1MENGAVYSPTTEEDPGPARGPRSGLAAYFFMGRLPLLRRVLKGLQLLLSLLAFICEEVVSQCTLCGGLYFFEFVSCSAFLLSLLILIVYCTPFYERVDTTKVKSSDFYITLGTGCVFLLASIIFVSTHDRTSAEIAAIVFGFIASFMFLLDFITMLYEKRQESQLRKPENTTRAEALTEPLNA>sp|Q5T280|CI114_HUMAN Putative methyltransferase C9orf114 OS=Homosapiens OX=9606 GN=SPOUT1 PE=1 SV=3MAERGRKRPCGPGEHGQRIEWRKWKQQKKEEKKKWKDLKLMKKLERQRAQEEQAKRLEEEEAAAEKEDRGRPYTLSVALPGSILDNAQSPELRTYLAGQIARACAIFCVDEIVVFDEEGQDAKTVEGEFTGVGKKGQACVQLARILQYLECPQYLRKAFFPKHQDLQFAGLLNPLDSPHHMRQDEESEFREGIVVDRPTRPGHGSFVNCGMKKEVKIDKNLEPGLRVTVRLNQQQHPDCKTYHGKVVSSQDPRTKAGLYWGYTVRLASCLSAVFAEAPFQDGYDLTIGTSERGSDVASAQLPNFRHALVVFGGLQGLEAGADADPNLEVAEPSVLFDLYVNTCPGQGSRTIRTEEAILISLAALQPGLIQAGARHT>sp|Q96FZ5|CKLF7_HUMAN CKLF-like MARVEL transmembrane domain-containingprotein 7 OS=Homo sapiens OX=9606 GN=CMTM7 PE=1 SV=1MSHGAGLVRTTCSSGSALGPGAGAAQPSASPLEGLLDLSYPRTHAALLKVAQMVTLLIAFICVRSSLWTNYSAYSYFEVVTICDLIMILAFYLVHLFRFYRVLTCISWPLSELLHYLIGTLLLLIASIVAASKSYNQSGLVAGAIFGFMATFLCMASIWLSYKISCVTQSTDAAV>sp|Q96FZ5-2|CKLF7_HUMAN Isoform 2 of CKLF-like MARVEL transmembranedomain-containing protein 7 OS=Homo sapiens OX=9606 GN=CMTM7MSHGAGLVRTTCSSGSALGPGAGAAQPSASPLEGLLDLSYPRTHAALLKVAQMVTLLIAFICVRSSLWTNYSAYSYFEVVTICDLIMILAFYLVHLFRFYRVLTCISWPLSIFGFMATFLCMASIWLSYKISCVTQSTDAAV>sp|Q5BN46|CI116_HUMAN UPF0691 protein C9orf116 OS=Homo sapiens OX=9606GN=C9orf116 PE=1 SV=1MAEECPRACAEPVAPKATAPPERTSDYYRVSADLPGRFNNPGWFRGYRTQKAVSVYRTSNQAYGSRAPTVHEMPKVFYPNSNKFSQQLAAGGMFRNNTLNVYLEKSIVTGPDNCITSCDRLNFHPSYNINRPSICD>sp|Q5BN46-2|CI116_HUMAN Isoform 2 of UPF0691 protein C9orf116 OS=Homosapiens OX=9606 GN=C9orf116MAEECPRACAEPVAPKATAPPERTSDYYRVSADLPGRFNNPGWFRGYRTQKAVSVYRTSNQAYGSRAPTVHEMPRVECSGTILSMFTWRKAS>sp|Q8WZB0|CI130_HUMAN Putative uncharacterized protein encoded byLINC00476 OS=Homo sapiens OX=9606 GN=LINC00476 PE=5 SV=1MAANATSGRPPSIALRQPEATGWRRGIPAKVATKGTQAEREGDVRSGGRARGRCVRLAKRCSPSSLGLRRRRRRTGGRQGDPQIFLGSDFRLLTPANSNPVLENPARTGSRIVIGISRERNLPFCGRSNLPDVSSL>sp|Q5VYM1|CI131_HUMAN Uncharacterized protein C9orf131 OS=Homo sapiensOX=9606 GN=C9orf131 PE=2 SV=3MEWLLEDLLGAKGDMGLLWGQLTHALACRHCGSSCFQSPGNLVTLFLFVVWQIQRWWQLGRLRQLHPWCSGNMVQGKELPLLHRVAFLDHLCKQKSEVEEEGEEEEEGEDEASLDPLKPCSPTKEAPTGEQATPAPPQPSCGSEGLLKAIGIPEQTVMQPVSPSRSFPIFQILTSFPVRHKIASGNRQQQRKSQLFWGLPSLHSESLEAIFLSSGGPSPLKWSVCSSVFFNKLAFLPRSNLLLPQYHSSAQFSTHGAHTMEDLEGMAPDPQLLPPPSSPSVSSLLLHLRPFPVDHKGVLSGAEAPTQSPGTSPLEVLPGYETHLETTGHKKMPQAFEPPMPPPCQSPASLSEPRKVSPEGGLAISKDFWGTVGYREKPQASESSMPVPCPPLDSLPELQRESSLEDPSRYKPQWECRENSGNLWAFESPVLDLNPELSGTSPECVPPASETPWKGMQSRENIWVPADPVSPPSLPSVPLLESLVMGPQGVLSESKALWETMGQKENLWASDSPDPVHSTPPTTLMEPHRINPGECLATSEATWKDTEHSRNSSASRSPSLALSPPPALAPELLRVRSMGVLSDSEARCGDIQKTKNSWASKHPACNLPQDLHGASPLGVLSDSQSIVGEMEQKENCVPVFPGRGSSPSSNSVSKSHVSEPIADQSNYKPDGEAVEQRKNHWATELPAPSSLSTPLPEPHIDLELVWRNVQQREVPQGPSPLAVDPLHPVPQPPTLAEAVKIERTHPGLPKGVTCPGVKAEAPLSQRWTVPELLTHPGIHAWQWSRELKLRLKKLRQSPASRAPGPSQSFCSSPILSSTIPDFWGLPSCPPQQIYPPNPCPHSSSCHPQEVQRTVPQPVQSSHCHHFQSSSQLQPQESGRAEQGSQRGEKMKGKMVSQVPSQGPCVHMEAGVDYLSPGPGEPSNSKVLVSGKRKDKASASSSAKKREHPRKPKAGDHRRGTARLGLSTVTGKNHPAQARSLVEAPVSTFPQRSQHRGQSSQHTALPQLLLPKASGPQDQPEAGRRASDILTPRHCKHCPWAHMEKYLSFPTLKASLTRGLQKVLAKCLDNHRPLPTKSSQ>sp|Q5VYM1-2|CI131_HUMAN Isoform 2 of Uncharacterized protein C9orf131OS=Homo sapiens OX=9606 GN=C9orf131MLRKIQRWWQLGRLRQLHPWCSGNMVQGKELPLLHRVAFLDHLCKQKSEVEEEGEEEEEGEDEASLDPLKPCSPTKEAPTGEQATPAPPQPSCGSEGLLKAIGIPEQTVMQPVSPSRSFPIFQILTSFPVRHKIASGNRQQQRKSQLFWGLPSLHSESLEAIFLSSGGPSPLKWSVCSSVFFNKLAFLPRSNLLLPQYHSSAQFSTHGAHTMEDLEGMAPDPQLLPPPSSPSVSSLLLHLRPFPVDHKGVLSGAEAPTQSPGTSPLEVLPGYETHLETTGHKKMPQAFEPPMPPPCQSPASLSEPRKVSPEGGLAISKDFWGTVGYREKPQASESSMPVPCPPLDSLPELQRESSLEDPSRYKPQWECRENSGNLWAFESPVLDLNPELSGTSPECVPPASETPWKGMQSRENIWVPADPVSPPSLPSVPLLESLVMGPQGVLSESKALWETMGQKENLWASDSPDPVHSTPPTTLMEPHRINPGECLATSEATWKDTEHSRNSSASRSPSLALSPPPALAPELLRVRSMGVLSDSEARCGDIQKTKNSWASKHPACNLPQDLHGASPLGVLSDSQSIVGEMEQKENCVPVFPGRGSSPSSNSVSKSHVSEPIADQSNYKPDGEAVEQRKNHWATELPAPSSLSTPLPEPHIDLELVWRNVQQREVPQGPSPLAVDPLHPVPQPPTLAEAVKIERTHPGLPKGVTCPGVKAEAPLSQRWTVPELLTHPGIHAWQWSRELKLRLKKLRQSPASRAPGPSQSFCSSPILSSTIPDFWGLPSCPPQQIYPPNPCPHSSSCHPQEVQRTVPQPVQSSHCHHFQSSSQLQPQESGRAEQGSQRGEKMKGKMVSQVPSQGPCVHMEAGVDYLSPGPGEPSNSKVLVSGKRKDKASASSSAKKREHPRKPKAGDHRRGTARLGLSTVTGKNHPAQARSLVEAPVSTFPQRSQHRGQSSQHTALPQLLLPKASGPQDQPEAGRRASDILTPRHCKHCPWAHMEKYLSFPTLKASLTRGLQKVLAKCLDNHRPLPTKSSQ>Claims (144)
Translated fromChineseApplications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163144895P | 2021-02-02 | 2021-02-02 | |
| US63/144895 | 2021-02-02 | ||
| US202163248516P | 2021-09-26 | 2021-09-26 | |
| US63/248516 | 2021-09-26 | ||
| PCT/US2022/014998WO2022169913A2 (en) | 2021-02-02 | 2022-02-02 | Synthetic degrader system for targeted protein degradation |
| WOPCT/US2022/014998 | 2022-02-02 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| TW202246309Atrue TW202246309A (en) | 2022-12-01 |
Family
ID=80683754
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW111104424ATW202246309A (en) | 2021-02-02 | 2022-02-07 | Synthetic degrader system for targeted protein degradation |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP4288529A2 (en) |
| TW (1) | TW202246309A (en) |
| WO (1) | WO2022169913A2 (en) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023150649A2 (en)* | 2022-02-02 | 2023-08-10 | Outpace Bio, Inc. | Synthetic degrader system for targeted protein degradation |
| WO2024124311A1 (en)* | 2022-12-16 | 2024-06-20 | Recepta Biopharma S.A. | Plp2-derived peptides, pharmaceutical compositions, methods and uses of thereof |
| TW202434618A (en)* | 2023-01-09 | 2024-09-01 | 美商奧特佩斯生化股份有限公司 | Designed cytokine compositions and methods of use |
| WO2024153211A1 (en)* | 2023-01-19 | 2024-07-25 | Nanjing Legend Biotech Co., Ltd. | Fusion polypeptides for targeted protein degradation and mehtods of use thereof |
| WO2025011459A1 (en)* | 2023-07-07 | 2025-01-16 | Nanjing Legend Biotech Co., Ltd. | Proteins and uses thereof |
| WO2025102079A1 (en)* | 2023-11-09 | 2025-05-15 | The Regents Of The University Of California | Ubiquitinating gabpa or gabpb prevents activation of the mutant tert promoter |
| WO2025105856A1 (en)* | 2023-11-15 | 2025-05-22 | 주식회사 제넥신 | Single domain antibody specifically binding to sox2, fusion protein including same, and use thereof |
| CN118252913B (en)* | 2024-02-07 | 2024-09-17 | 中国医学科学院阜外医院 | Polypeptide conjugate and application thereof in heart failure with ejection fraction reserved |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2765193B1 (en) | 2011-10-07 | 2017-08-09 | Mie University | Chimeric antigen receptor |
| CN113272317A (en)* | 2018-11-02 | 2021-08-17 | 华盛顿大学 | Orthogonal protein heterodimers |
| CA3121172A1 (en) | 2018-12-04 | 2020-06-11 | University Of Washington | Reagents and methods for controlling protein function and interaction |
- 2022
- 2022-02-02WOPCT/US2022/014998patent/WO2022169913A2/ennot_activeCeased
- 2022-02-02EPEP22710773.7Apatent/EP4288529A2/ennot_activeWithdrawn
- 2022-02-07TWTW111104424Apatent/TW202246309A/enunknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO2022169913A3 (en) | 2022-09-29 |
| EP4288529A2 (en) | 2023-12-13 |
| WO2022169913A2 (en) | 2022-08-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20250084141A1 (en) | Rna encoding a therapeutic protein | |
| US12006329B2 (en) | Protein degraders and uses thereof | |
| US20210363525A1 (en) | Sarna compositions and methods of use | |
| US11932635B2 (en) | CRBN ligands and uses thereof | |
| US11897882B2 (en) | Tricyclic crbn ligands and uses thereof | |
| US12281301B2 (en) | Sequencing-based proteomics | |
| AU2018338314B2 (en) | Protein degraders and uses thereof | |
| US20240285795A1 (en) | Targets for rna therapeutics | |
| US20230203485A1 (en) | Methods for modulating mhc-i expression and immunotherapy uses thereof | |
| TW202246309A (en) | Synthetic degrader system for targeted protein degradation | |
| US20230093080A1 (en) | Protein degraders and uses thereof | |
| US20220348556A1 (en) | Protein degraders and uses thereof | |
| US20240043934A1 (en) | Pancreatic ductal adenocarcinoma signatures and uses thereof | |
| JP2018512876A6 (en) | saRNA compositions and methods of use | |
| EP3443001A2 (en) | Regulated biocircuit systems | |
| US20240261333A1 (en) | Novel targets for enhancing anti-tumor immunity | |
| US20240398993A1 (en) | Small molecule-regulated gene expression system | |
| US20250268938A1 (en) | Small molecule-regulated cell signaling expression system |