TW202125499A - Attention concentration assisting system that comprises a sound receiving device arranged between a speaker and a listener and an earphone device wearable by the listener - Google Patents
Attention concentration assisting system that comprises a sound receiving device arranged between a speaker and a listener and an earphone device wearable by the listenerDownload PDFInfo
- Publication number
- TW202125499A TW202125499ATW108146003ATW108146003ATW202125499ATW 202125499 ATW202125499 ATW 202125499ATW 108146003 ATW108146003 ATW 108146003ATW 108146003 ATW108146003 ATW 108146003ATW 202125499 ATW202125499 ATW 202125499A
- Authority
- TW
- Taiwan
- Prior art keywords
- speaker
- voice
- image
- module
- tracking
- Prior art date
Links
- 238000000605extractionMethods0.000claimsabstractdescription42
- 238000005516engineering processMethods0.000claimsabstractdescription18
- 230000005236sound signalEffects0.000claimsabstractdescription7
- 238000004891communicationMethods0.000claimsdescription54
- 210000005069earsAnatomy0.000claimsdescription9
- 230000001960triggered effectEffects0.000claimsdescription8
- 230000000903blocking effectEffects0.000abstractdescription3
- 239000012141concentrateSubstances0.000abstractdescription3
- 230000007613environmental effectEffects0.000abstractdescription2
- 239000000284extractSubstances0.000abstractdescription2
- 208000006096Attention Deficit Disorder with HyperactivityDiseases0.000abstract1
- 208000036864Attention deficit/hyperactivity diseaseDiseases0.000abstract1
- 208000015802attention deficit-hyperactivity diseaseDiseases0.000abstract1
- 208000035231inattentive type attention deficit hyperactivity diseaseDiseases0.000abstract1
- 208000024891symptomDiseases0.000description11
- 241001310793PodiumSpecies0.000description5
- 229940079593drugDrugs0.000description5
- 239000003814drugSubstances0.000description5
- 230000000694effectsEffects0.000description5
- 230000006870functionEffects0.000description5
- 238000012545processingMethods0.000description5
- 238000010586diagramMethods0.000description4
- 238000013461designMethods0.000description3
- 238000011161developmentMethods0.000description2
- 206010019233HeadachesDiseases0.000description1
- 206010028813NauseaDiseases0.000description1
- 208000013738Sleep Initiation and Maintenance diseaseDiseases0.000description1
- 206010000059abdominal discomfortDiseases0.000description1
- 238000004458analytical methodMethods0.000description1
- 206010061428decreased appetiteDiseases0.000description1
- 230000001815facial effectEffects0.000description1
- 231100000869headacheToxicity0.000description1
- 238000010191image analysisMethods0.000description1
- 206010022437insomniaDiseases0.000description1
- 238000000034methodMethods0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 230000008693nauseaEffects0.000description1
- 230000000638stimulationEffects0.000description1
Images




Landscapes
- Circuit For Audible Band Transducer (AREA)
Abstract
Description
Translated fromChinese本發明是有關於一種輔具,特別是指一種用以輔助集中注意力的輔助系統。The present invention relates to an auxiliary device, in particular to an auxiliary system for assisting concentration.
注意力不集中是一種會影響學習與生活的症狀,有注意力不集中症狀的學童的注意力容易因周遭一點聲音刺激而被轉移,無法專心聽講與做功課,也很難集中注意力完成一件工作或遊戲。如不適時進行治療,會嚴重影響學童的學習與成長。Inattention is a symptom that affects study and life. School children with inattention symptoms are easily diverted due to a little sound stimulation around them, unable to concentrate on listening and doing homework, and it is difficult to concentrate on completing one. Piece of work or game. If treatment is not performed in time, it will seriously affect the learning and growth of school children.
目前針對注意力不集中症狀的主要治療方式為藥物治療,特別是當學童本身症狀已嚴重妨礙到學習、人際關係及人格發展時,藥物治療可以有效幫助這些學童。但因為治療藥物會引發一些副作用,例如頭痛、腸胃不適、食慾降低、噁心及失眠等,所以許多家長與老師擔心藥物治療會影響學童的成長發育與生活作息,而排斥採用藥物治療。At present, the main treatment method for the symptoms of inattention is medication, especially when the school children's own symptoms have seriously hindered learning, interpersonal relationship and personality development, medication can effectively help these school children. However, because treatment drugs can cause some side effects, such as headache, gastrointestinal discomfort, decreased appetite, nausea, and insomnia, many parents and teachers worry that drug treatment will affect the growth and development of school children and their daily routines and reject the use of drug treatment.
因此,本發明的目的,即在提供一種可用以輔助改善注意力不集中症狀的注意力集中輔助系統。Therefore, the purpose of the present invention is to provide an attention assistance system that can be used to assist in improving the symptoms of inattention.
於是,本發明注意力集中輔助系統,包含一個用以設置在一位講者與一位聽者間的收音裝置,及一個用以供該聽者配戴的耳機裝置。該收音裝置包括一個麥克風陣列、一個第一通訊模組、一個語音追蹤模組,及一個語音提取模組,該麥克風陣列具有多個用以朝該講者一側收音的麥克風,該語音追蹤模組可分析該等麥克風收音得到之聲音訊號中的語音成分,以定位得到語音訊號最強的一個語音音源方向,該語音提取模組會以波束成形技術控制該麥克風陣列朝該語音音源方向進行語音提取以得到一個語音訊號,並經由該第一通訊模組對該耳機裝置無線發送該語音訊號。該耳機裝置包括一個用以無線接收該語音訊號之第二通訊模組,及一個用以供配戴於該聽者之雙耳且用以輸出該語音訊號的耳機本體。Therefore, the attention assistance system of the present invention includes a radio device for setting between a speaker and a listener, and an earphone device for the listener to wear. The radio device includes a microphone array, a first communication module, a voice tracking module, and a voice extraction module. The microphone array has a plurality of microphones for receiving sound toward the speaker. The voice tracking module The group can analyze the voice components in the sound signals received by the microphones to locate the direction of the voice source with the strongest voice signal. The voice extraction module uses beamforming technology to control the microphone array toward the voice source direction for voice extraction To obtain a voice signal, and wirelessly send the voice signal to the earphone device through the first communication module. The earphone device includes a second communication module for wirelessly receiving the voice signal, and an earphone body for being worn on both ears of the listener and for outputting the voice signal.
於是,本發明注意力集中輔助系統,包含一個用以設置在一位講者與一位聽者間的收音裝置,及用以供該聽者攜帶的一個隨身裝置與一個耳機裝置。該收音裝置包括一個麥克風陣列、一個第一通訊模組、一個用以朝該講者一側進行影像擷取以得到一個講方影像的影像擷取模組,及一個語音提取模組,該麥克風陣列具有多個用以朝該講者一側收音的麥克風,該語音提取模組會以波束成形技術控制該麥克風陣列朝該講方影像中的一個講者方位進行語音提取以得到一個語音訊號,該第一通訊模組會透過無線通訊技術將該講方影像與該語音訊號發送給該隨身裝置。該隨身裝置包括一個用以無線接收該講方影像與該語音訊號的第三通訊模組,及一個講者追蹤模組,該講者追蹤模組可分析該講方影像中之人物以定位得到該講者方位,並經由該第三通訊模組對該第一通訊模組對應回傳該講者方位,並透過有線及/或無線通訊技術對該耳機裝置發送該語音訊號。該耳機裝置包括一個用以接收該第三通訊模組發送之該語音訊號的第二通訊模組,及一個用以供配戴於該聽者之雙耳且用以輸出該語音訊號的耳機本體。Therefore, the attention assistance system of the present invention includes a radio device for setting between a speaker and a listener, and a portable device and a headphone device for the listener to carry. The radio device includes a microphone array, a first communication module, an image capturing module for capturing images toward the speaker to obtain an image of the speaker, and a voice extracting module. The microphone The array has a plurality of microphones for receiving sound toward the speaker side, and the voice extraction module uses beamforming technology to control the microphone array to perform voice extraction toward a speaker position in the speaker image to obtain a voice signal, The first communication module sends the speaker image and the voice signal to the portable device through wireless communication technology. The portable device includes a third communication module for wirelessly receiving the speaker image and the voice signal, and a speaker tracking module, the speaker tracking module can analyze the person in the speaker image to locate The position of the speaker is returned to the first communication module through the third communication module, and the voice signal is sent to the earphone device through wired and/or wireless communication technology. The earphone device includes a second communication module for receiving the voice signal sent by the third communication module, and an earphone body for being worn on the listener's ears and for outputting the voice signal .
本發明的功效在於:透過在該講者與該聽者間設置該收音裝置,並以該收音裝置追蹤該講者的語音方向或講者方位以進行語音提取的設計,可在阻隔周遭環境聲音干擾的情況下,讓該聽者直接聆聽該講者的講話內容,而可用以協助具有注意力不集中症狀的該聽者將注意力集中向該講者。The effect of the present invention is that by setting the radio device between the speaker and the listener, and using the radio device to track the speaker's voice direction or speaker position for voice extraction, the design can block surrounding environmental sounds. In the case of interference, the listener is allowed to directly listen to the content of the speaker's speech, which can be used to assist the listener with inattention symptoms to focus on the speaker.
在本發明被詳細描述前,應當注意在以下的說明內容中,類似的元件是以相同的編號來表示。Before the present invention is described in detail, it should be noted that in the following description, similar elements are denoted by the same numbers.
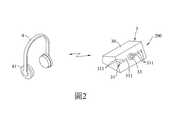
參閱圖1、2、3,本發明注意力集中輔助系統200的第一實施例,包含一個用以設置在一位講者800與一位聽者900間的收音裝置3,及一個用以供該聽者900配戴的耳機裝置4。在本第一實施例中,是以將該收音裝置3設置在一個講堂的一個講台700上為例進行說明,使該收音裝置3間隔位於一個書寫板701(黑板或白板)前方,可用以對該站在該書寫板701與該講台700間的一位講者800進行收音,並將收音內容傳送至該聽者900配戴的該耳機裝置4。所述講者800例如但不限於老師,所述聽者900例如但不限於具有注意力不集中症狀的學童。Referring to Figures 1, 2, and 3, the first embodiment of the
該收音裝置3包括一個機殼30,以及安裝在該機殼30的一個麥克風陣列31、一個第一通訊模組32、一個影像擷取模組33、一個講者追蹤模組34、一個語音追蹤模組35與一個語音提取模組36。The
該麥克風陣列31包括多個間隔設置在該機殼30且可用以朝該講者800一側收音的麥克風311。該第一通訊模組32可透過目前已知的無線通訊技術與該耳機裝置4進行通訊,所述無線通訊技術例如但不限於wifi與藍芽等。該影像擷取模組33可用以朝該機殼30面向該講者800一側進行影像擷取以得到一個講方影像。The
該講者追蹤模組34可供操作以啟動該影像擷取模組33進行影像擷取,可經由該影像擷取模組33擷取該講者800的人物影像,例如擷取該講者800的正面、左右兩側面及/或背後的人物影像。實施時,在本發明之其它實施態樣中,該講者追蹤模組34也可改為能供透過其它輸入介面來輸入該講者800的人物影像。此外,所述講者800的人物影像例如但不限於頭部,或者是半身照、全身照等。所述輸入介面例如但不限於USB介面。The
該講者追蹤模組34包括一個講者特徵建立單元341、一個講者特徵比對單元342,及一個講者追蹤單元343。該講者特徵建立單元341會分析擷取該講者800的所有人物影像的人物特徵以建立一個講者影像特徵參數。在本實施例中,是擷取每一人物影像中的頭部影像區域的人物特徵來建立該講者影像特徵參數,所述人物特徵例如但不限於臉形、臉部五官外形等特徵,但實施時,在本發明之另一實施態樣中,還可進一步分析每一人物影像的衣著的顏色、花紋與型態等來得到所述人物特徵,並彙整前述頭部影像區域的人物特徵與衣著的人物特徵以建立該講者影像特徵參數。由於透過分析人物影像之人物特徵以建立該講者影像特徵參數的方式眾多,因此實施時不以上述態樣為限。The
該講者特徵比對單元342可根據該講者影像特徵參數分析該講方影像中所存在之人物影像的影像特徵,判斷該講方影像中是否存在該講者800,藉以從該講方影像中識別出對應該講者800的一個講者影像。該講者追蹤單元343會分析定位出該講者影像於該講方影像中的位置以得到一個講者方位。The speaker
該語音追蹤模組35可分析該等麥克風311收音得到之該等聲音訊號中的語音成分,以該從等聲音訊號中定位得到語音訊號最強的一個語音音源方向。由於該等麥克風311是嵌裝外露在該機殼30面向該講者800一側,所以主要收音方向是朝向該講者800一側,對於該機殼30背向該講者800一側的收音效果極差,所以從該等麥克風311的該等聲音訊號分析得到的語音訊號最強者就可判斷是來自該講者800。The
該語音提取模組36內建有一個語音追蹤模式361與一個影像追蹤模式362,於啟動該語音追蹤模式361時,該語音提取模組36會觸發啟動該麥克風陣列31進行收音,且觸發該語音追蹤模組35定位得到該語音音源方向,然後,該語音提取模組36會以波束成形技術控制該麥克風陣列31朝該語音音源方向進行語音提取以得到一個語音訊號;於啟動該影像追蹤模式362時,該語音提取模組36會觸發該影像擷取模組33擷取得到該講方影像,且會觸發該講者追蹤模組34分析該講方影像以定位得到該講者方位,然後,該語音提取模組36會以波束成形技術控制該麥克風陣列31朝該講者方位進行語音提取以得到一個語音訊號。此外,該語音提取模組36會經由該第一通訊模組32對該耳機裝置4無線發送該語音訊號。The
該耳機裝置4包括一個用以供該聽者900配戴在雙耳的耳機本體41,及一個設置在該耳機本體41且用以和該第一通訊模組32無線通訊的第二通訊模組42。該第二通訊模組42可無線接收該語音訊號,該耳機本體41可用以輸出該語音訊號以供該聽者900聆聽。在本實施例中,該耳機本體41為耳罩式耳機型態,可用以罩蓋在該聽者900雙耳,而可阻隔外界聲音,使該聽者900可專心聆聽來自該講者800的該語音訊號內容。The
本發明注意力集中輔助系統200架設使用時,可將該收音裝置3設置在該講台700,使該影像擷取模組33的影像擷取方向與該麥克風陣列31的收音方向都朝向該書寫板701方向,並使該耳機裝置4供配戴在該聽者900頭部而罩蓋雙耳,且使該收音裝置3與該耳機裝置4訊號連接。When the attention-focusing
初始使用時,可操作該講者追蹤模組34以透過該影像擷取模組33擷取預定之講者800的人物影像,或者透過其它輸入介面將講者800的人物影像輸入該講者追蹤模組34,使該講者追蹤模組34的該講者特徵建立單元341可分析該講者800的人物影像以建立該講者影像特徵參數。In initial use, the
接著,可根據使用需求,操作該語音提取模組36以選擇啟動該語音追蹤模式361或該影像追蹤模式362。該語音提取模組36啟動該語音追蹤模式361時,會觸發該麥克風陣列31進行收音,且會觸發該語音追蹤模組35分析該麥克風陣列31收音之聲音訊號中的語音成分,藉以得到該語音音源方向,然後,該語音提取模組36會透過波束成形技術控制該麥克風陣列31朝該語音音源方向進行語音提取。該語音提取模組36啟動該影像追蹤模式362時,則會觸發該影像擷取模組33擷取該講方影像,且會觸發該講者追蹤模組34根據該講者影像特徵參數分析該講方影像以定位得到該講者方位,然後,該語音提取模組36會透過波束成形技術控制該麥克風陣列31朝該講者方位進行語音提取。最後,再經由該第一通訊模組32將所得到之該語音訊號發送至該耳機裝置4。Then, the
由於該耳機本體41是設置在該聽者900雙耳,除了可阻隔外界聲音,還可直接播放該講者800的講話內容供該聽者900聆聽,即便該聽者900轉頭看向別處,依然會清楚聽到該講者800的講話內容,所以有助於提高該聽者900對於講者800講話內容的注意力,並大幅降低周遭環境聲音對具有注意力不集中症狀的該聽者900的干擾程度。Since the
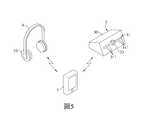
參閱圖4、5、6,本發明注意力集中輔助系統200的第二實施例與該第一實施例差異處在於:該收音裝置3設計,且該注意力集中輔助系統200還包含一個用以供該聽者900隨身攜帶,並訊號連接在該收音裝置3與該耳機裝置4間的隨身裝置5。為方便說明,以下將僅針對本第二實施例與該第一實施例差異處進行描述。Referring to Figures 4, 5, and 6, the second embodiment of the attention-focusing
在本第二實施例中,該收音裝置3包括一個機殼30,及設置在該機殼30上的一個麥克風陣列31、一個影像擷取模組33、一個語音追蹤模組35、一個語音提取模組36與一個第一通訊模組32。由於該麥克風陣列31、該影像擷取模組33與該語音追蹤模組35的功能與該第一實施例相同,所以不再詳述。In the second embodiment, the
該第一通訊模組32可透過目前已知的無線通訊技術來與該隨身裝置5進行無線通訊,可用以無線傳送該影像擷取模組33擷取之該講方影像與該講者800的人物影像至該隨身裝置5、傳送該語音提取模組36進行語音提取所得到該語音訊號至該隨身裝置5,以及接收該隨身裝置5發送的該講者方位。The
該語音提取模組36同樣內建有該語音追蹤模式361與該影像追蹤模式362,於啟動該語音追蹤模式361時,會觸發啟動該麥克風陣列31與該語音追蹤模組35,並控制該麥克風陣列31朝該語音音源方向進行語音提取;於啟動該影像追蹤模式362時,會觸發該影像擷取模組33擷取得到該講方影像,並透過該第一通訊模組32將該講方影像傳送至該隨身裝置5,以及接收該隨身裝置5對應回傳的該講者方位,並控制該麥克風陣列31朝該講者方位對應之方向進行語音提取。最後,再將所提取的該語音訊號傳送至該隨身裝置5。The
該隨身裝置5可供該聽者900隨身攜帶或配戴,包括一個第三通訊模組51與一個講者追蹤模組34。該第三通訊模組51可與該第一通訊模組32無線通訊,該講者追蹤模組34同樣具有該講者特徵建立單元341、該講者特徵比對單元342與該講者追蹤單元343,會分析該第三通訊模組51接收之該講者的人物影像以建立並儲存該講者影像特徵參數,以及分析該第三通訊模組51接收之該講方影像以得到該講者方位,並經由該第三通訊模組51回傳該講者方位至該收音裝置3。此外,該第三通訊模組51會將接收自該收音裝置3的該語音訊號傳送至該耳機裝置4。The
由於目前的手機與平板電腦等行動裝置,以及可供隨身攜帶的筆記型電腦的功能都相當強大,所以實施時,可將該講者追蹤模組34以APP(mobile application)等軟體程式的方式實施在具備與該收音裝置3及該耳機裝置4進行通訊的行動裝置或筆記型電腦上,以構成該隨身裝置5。Since current mobile devices such as mobile phones and tablets, as well as portable laptops have very powerful functions, when implemented, the
該耳機裝置4與該第一實施例相同,但該第二通訊模組42可透過有線通訊技術及/或無線通訊技術來與該第三通訊模組51訊號連接,可接收該第三通訊模組51傳送的該語音訊號,且該耳機本體41可出該語音訊號以供該聽者900聆聽,而同樣有助於提升該聽者900對於該講者800的注意力集中效果。The
藉由以該隨身裝置5之該講者追蹤模組34進行該講者影像特徵參數的建立,以及分析該講方影像以得到該講者方位的設計,可將需要耗費較多訊號處理資源的影像處理功能自該收音裝置3獨立出來,一方面可加快影像分析處理速度,另一方面可使該收音裝置3僅具備語音處理功能,而有助於該收音裝置3的小型化。By using the
必須特別說明的是,在上述兩個實施例中,使用環境是以講堂為例進行說明,但實施時不以此為限,亦可適用在其它不具有所述講台、書寫板的環境中,僅需將該收音裝置3設置在該講者800與該聽者900間,使該收音裝置3可朝該講者方向進行收音與影像擷取,並以該耳機裝置供該聽者900配戴,同樣可用以協助具有注意力不集中症狀的聽者注意聆聽該講者800的講話內容。It must be particularly noted that in the above two embodiments, the use environment is described by taking a lecture hall as an example, but it is not limited to this during implementation, and it can also be applied to other environments that do not have the podium and writing board. It is only necessary to install the
綜上所述,透過在該講者800與該聽者900間設置該收音裝置3,並以該收音裝置3追蹤該講者800的語音方向或講者方位以進行語音提取的設計,以及以該耳機裝置4供配戴在該聽者900雙耳,而直接輸出該收音裝置3接收之講者800的語音訊號的設計,除了可阻隔降低周遭環境聲音對該聽者900的干擾,不論該聽者900視線是否偏離該講者800,該聽者900都會直接聽到該講者800的講話內容,而可用以協助具有注意力不集中症狀的該聽者900專注於該講者800的講話內容,且該講者800也可更有效率地透過語音協助該聽者900將注意力往該講台700方向集中。To sum up, by setting up the
此外,可進一步配合以該隨身裝置5分析該講方影像以追蹤該講者方位的設計,將影像處理功能自該收音裝置3獨立出來,使該收音裝置3可更進一步小型化,且可將該講者追蹤模組34以APP(mobile application)等軟體程式的方式實施在具備與該收音裝置3及該耳機裝置4進行通訊,且功能強大的行動裝置或筆記型電腦上以構成該隨身裝置5,有助於加快該講者方位的追蹤速度。因此,本發明注意力集中輔助系統200確實是一種有助於改善注意力不集中症狀的創新輔具,確實能達成本發明的目的。In addition, the
惟以上所述者,僅為本發明的實施例而已,當不能以此限定本發明實施的範圍,凡是依本發明申請專利範圍及專利說明書內容所作的簡單的等效變化與修飾,皆仍屬本發明專利涵蓋的範圍內。However, the above are only examples of the present invention. When the scope of implementation of the present invention cannot be limited by this, all simple equivalent changes and modifications made in accordance with the scope of the patent application of the present invention and the content of the patent specification still belong to Within the scope covered by the patent of the present invention.
200:注意力集中輔助系統3:收音裝置30:機殼31:麥克風陣列311:麥克風32:第一通訊模組33:影像擷取模組34:講者追蹤模組341:講者特徵建立單元342:講者特徵比對單元343:講者追蹤單元35:語音追蹤模組36:語音提取模組361:語音追蹤模式362:影像追蹤模式4:耳機裝置41:耳機本體42:第二通訊模組5:隨身裝置51:第三通訊模組700:講台701:書寫板800:講者900:聽者200: Attention assist system3: Radio device30: Chassis31: Microphone array311: Microphone32: The first communication module33: Image capture module34: Speaker Tracking Module341: Speaker characteristics establishment unit342: Speaker feature comparison unit343: Speaker Tracking Unit35: Voice tracking module36: Voice extraction module361: Voice Tracking Mode362: Image Tracking Mode4: Headphone device41: Headphone body42: The second communication module5: portable device51: The third communication module700: podium701: writing board800: Speaker900: listener
本發明的其他的特徵及功效,將於參照圖式的實施方式中清楚地呈現,其中:圖1是本發明注意力集中輔助系統的一個第一實施例設置在一個講堂時的示意圖;圖2是該第一實施例的立體圖;圖3是該第一實施例的功能方塊圖;圖4是本發明注意力集中輔助系統的一個第二實施例設置在一個講堂時的示意圖;圖5是該第二實施例的立體圖;及圖6是該第二實施例的功能方塊圖。Other features and effects of the present invention will be clearly presented in the embodiments with reference to the drawings, in which:FIG. 1 is a schematic diagram of a first embodiment of the attention-concentration assisting system of the present invention when it is set in a lecture hall;Figure 2 is a perspective view of the first embodiment;Figure 3 is a functional block diagram of the first embodiment;FIG. 4 is a schematic diagram of a second embodiment of the concentration assist system of the present invention when it is set in a lecture hall;Figure 5 is a perspective view of the second embodiment; andFig. 6 is a functional block diagram of the second embodiment.
200:注意力集中輔助系統200: Attention assist system
3:收音裝置3: Radio device
31:麥克風陣列31: Microphone array
311:麥克風311: Microphone
32:第一通訊模組32: The first communication module
33:影像擷取模組33: Image capture module
34:講者追蹤模組34: Speaker Tracking Module
341:講者特徵建立單元341: Speaker characteristics establishment unit
342:講者特徵比對單元342: Speaker feature comparison unit
343:講者追蹤單元343: Speaker Tracking Unit
35:語音追蹤模組35: Voice tracking module
36:語音提取模組36: Voice extraction module
361:語音追蹤模式361: Voice Tracking Mode
362:影像追蹤模式362: Image Tracking Mode
4:耳機裝置4: Headphone device
41:耳機本體41: Headphone body
42:第二通訊模組42: The second communication module
Claims (11)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| TW108146003ATWI743624B (en) | 2019-12-16 | 2019-12-16 | Attention assist system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| TW108146003ATWI743624B (en) | 2019-12-16 | 2019-12-16 | Attention assist system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| TW202125499Atrue TW202125499A (en) | 2021-07-01 |
| TWI743624B TWI743624B (en) | 2021-10-21 |
Family
ID=77908516
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW108146003ATWI743624B (en) | 2019-12-16 | 2019-12-16 | Attention assist system |
Country Status (1)
| Country | Link |
|---|---|
| TW (1) | TWI743624B (en) |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7356473B2 (en)* | 2005-01-21 | 2008-04-08 | Lawrence Kates | Management and assistance system for the deaf |
| US8121618B2 (en)* | 2009-10-28 | 2012-02-21 | Digimarc Corporation | Intuitive computing methods and systems |
| CN113935025A (en)* | 2013-01-25 | 2022-01-14 | 高通股份有限公司 | Adaptive observation of behavioral features on mobile devices |
| US9813887B2 (en)* | 2013-03-15 | 2017-11-07 | Elwha Llc | Protocols for facilitating broader access in wireless communications responsive to charge authorization statuses |
| WO2018107489A1 (en)* | 2016-12-16 | 2018-06-21 | 深圳前海达闼云端智能科技有限公司 | Method and apparatus for assisting people who have hearing and speech impairments and electronic device |
- 2019
- 2019-12-16TWTW108146003Apatent/TWI743624B/enactive
Also Published As
| Publication number | Publication date |
|---|---|
| TWI743624B (en) | 2021-10-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11675437B2 (en) | Measurement of facial muscle EMG potentials for predictive analysis using a smart wearable system and method | |
| US20170303052A1 (en) | Wearable auditory feedback device | |
| US8254605B2 (en) | Binaural recording for smart pen computing systems | |
| US20080267433A1 (en) | Bone-Conduction Loudspeaker Set, Electronic Equipment, Electronic Translation System, Auditory Support System, Navigation Apparatus, and Cellular Phone | |
| US20220329945A1 (en) | Dynamic adjustment of earbud performance characteristics | |
| WO2020191582A1 (en) | Smart watch having embedded wireless earbud, and information broadcasting method | |
| TW201521617A (en) | Intelligent safety helmet | |
| US20230379615A1 (en) | Portable audio device | |
| CN112001189A (en) | Real-time foreign language communication system | |
| CN113709906B (en) | Wireless audio system, wireless communication method and equipment | |
| US20170195817A1 (en) | Simultaneous Binaural Presentation of Multiple Audio Streams | |
| US20250039599A1 (en) | Wearable device, sound pickup method, and apparatus | |
| JP7203775B2 (en) | Communication support system | |
| WO2018166081A1 (en) | Headset | |
| CN111428515A (en) | Simultaneous interpretation equipment and method | |
| CN109121047A (en) | The stereo implementation method of double screen terminal, terminal and computer readable storage medium | |
| KR101848458B1 (en) | sound recording method and device | |
| CN108923810A (en) | Translation method and related equipment | |
| TWI725668B (en) | Attention assist system | |
| TWI743624B (en) | Attention assist system | |
| CN203351193U (en) | Portable karaoke Bluetooth headset capable of monitoring MIC signal | |
| US20150326987A1 (en) | Portable binaural recording and playback accessory for a multimedia device | |
| US11163522B2 (en) | Fine grain haptic wearable device | |
| CN108882112A (en) | Audio playing control method and device, storage medium and terminal equipment | |
| CN114584913B (en) | FOA signal and binaural signal acquisition method, sound field acquisition device and processing device |