KR20250046799A - System and method for establishing document relationships in the form of merging triple data and location information based on a graph database - Google Patents
System and method for establishing document relationships in the form of merging triple data and location information based on a graph databaseDownload PDFInfo
- Publication number
- KR20250046799A KR20250046799AKR1020230130703AKR20230130703AKR20250046799AKR 20250046799 AKR20250046799 AKR 20250046799AKR 1020230130703 AKR1020230130703 AKR 1020230130703AKR 20230130703 AKR20230130703 AKR 20230130703AKR 20250046799 AKR20250046799 AKR 20250046799A
- Authority
- KR
- South Korea
- Prior art keywords
- document
- graph
- location
- data
- graph database
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/38—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/381—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using identifiers, e.g. barcodes, RFIDs
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/38—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/387—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using geographical or spatial information, e.g. location
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G06F16/9024—Graphs; Linked lists
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/268—Morphological analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Library & Information Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromKorean
Description
Translated fromKorean본 발명은 그래프 데이터베이스 기반 트리플 데이터와 문서 내에서 트리플 데이터의 위치 정보를 병합한 형태의 문서 관계형성 시스템 및 방법에 관한 것이다.The present invention relates to a system and method for forming document relationships in a form that combines triple data based on a graph database and location information of triple data within a document.
근래 널리 사용되고 있는 전자결제시스템의 경우, 문서가 네트워크상에서 자유롭게 소통될 수 있도록 한 시스템으로서, 종이문서가 네트워크상에 통용될 수 있도록 데이터화 되고, 도장이나 서명이 전자화된 결재시스템이다.The electronic payment system that is widely used recently is a system that allows documents to be freely communicated over a network, and is a payment system in which paper documents are digitized so that they can be used over a network, and seals and signatures are digitized.
전자결재시스템의 구조는 크게 사용자 환경과 서버로 이루어진 흐름관리 부분, 문서 정보를 관리하는 부분, 결재 경로를 관리하는 폼 네트(form net) 등 세 부분으로 구성되어 있다. 이 전자결재를 이용하면, 결재 경로를 변경한다든가 업무에 변화가 생길 경우 신속하게 대처할 수 있고, 문서의 흐름을 모니터링할 수도 있으며, 출장 계정과 같은 자료가 자동으로 입력될 뿐 아니라, 인사, 학사, 재무 등 각종 시스템과 연계할 수도 있다.The structure of the electronic approval system is largely composed of three parts: a flow management part consisting of a user environment and a server, a part that manages document information, and a form net that manages the approval path. Using this electronic approval, you can quickly respond when the approval path is changed or when there is a change in work, monitor the flow of documents, and automatically input data such as business trip accounts, and can also be linked to various systems such as personnel, academic affairs, and finance.
전자결재시스템을 사용하기 위해서는, 문서의 속성을 나타내는 메타데이터(metadata)를 활용할 수 있다.In order to use the electronic approval system, metadata that represents the properties of the document can be utilized.
메타데이터(metadata)는 문서의 속성을 나타내는 데이터로서, 회의에서 사용되는 여러 유형의 문서와 직접적이거나 간접적으로 연관된 정보를 제공하는 데이터이다.Metadata is data that represents the properties of a document and provides information directly or indirectly related to various types of documents used in meetings.
이와 같이 메타데이터를 사용하면 사용자가 원하는 데이터의 적합성 여부를 쉽게 확인할 수 있고, 또한 신속하게 원하는 데이터를 찾아낼 수 있다. 이러한 메타데이터는 XML 스키마로 표현되며 체계적으로 활용될 수 있다.By using metadata in this way, users can easily check whether the data they want is suitable and quickly find the data they want. This metadata is expressed in XML schema and can be systematically utilized.
메타데이터의 표준 모델에는 Dublin Core, GILS Core 등이 있다. 또한 이 두가지를 조합하여 인터넷 상의 과학기술 분야와 관련된 각종 논문, 보고서, 기술문서 등에 대한 메타데이터 모델로 제안된 SeriCore 모델이 있다.Standard models for metadata include Dublin Core and GILS Core. In addition, there is the SeriCore model, which is a combination of these two and proposed as a metadata model for various papers, reports, and technical documents related to science and technology on the Internet.
문서의 메타데이터를 통해 문서의 속성을 비주얼하게 표현함으로써 문서 특성을 손쉽게 인식하고 빠르게 접근할 수 있게 하려는 시도는 예전부터 있었다. University of Maryland의 HCI Lab에서 제안한 이미지 기반의 데이터 퍼블리싱 기법은 의미 있는 데이터 값을 색상과 이미지를 통하여 효과적으로 사용자에게 전달하는 방법을 제시하고 있다.There have been attempts to visually express the properties of documents through their metadata, thereby making it easier to recognize and quickly access the document characteristics. The image-based data publishing technique proposed by the HCI Lab at the University of Maryland presents a method to effectively convey meaningful data values to users through colors and images.
본 발명은 실시간 입력된 문서요소를 분석하여 트리플 데이터를 포함하는 메타데이터를 생성하는 것을 목적으로 한다.The purpose of the present invention is to analyze document elements input in real time and generate metadata including triple data.
본 발명은 클라우드 문서 플랫폼에 저장된 문서를 메타데이터로 변환하여 문서 요소들을 저장하고 특정 문서요소끼리 유사도를 비교하여 사용자에게 실시간으로 유사 문서요소를 추천하는 것을 목적으로 한다.The purpose of the present invention is to convert documents stored in a cloud document platform into metadata to store document elements, compare the similarity between specific document elements, and recommend similar document elements to users in real time.
본 발명은 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하기 위해, 데이터 시각화(data visualization)하는 것을 목적으로 한다.The purpose of the present invention is to provide data visualization to visually express data analysis results so that they can be easily understood.
본 발명은 도표(graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달하는 것을 목적으로 한다.The purpose of the present invention is to convey information clearly and effectively through a means called a graph.
본 발명은 문서 플랫폼에서 사용자가 입력한 문서요소와 데이터로 변환되어 저장된 문서요소의 유사도를 비교하여 추천하기 때문에 리소스가 많이 소요되는 기존의 문서 비교방식이 아닌 문서요소간 관계를 바탕으로 유사도를 측정하는 새로운 형태의 유사도 측정 방식을 제공하는 것을 목적으로 한다.The present invention provides a new type of similarity measurement method that measures similarity based on the relationship between document elements, rather than the existing document comparison method that consumes a lot of resources, by comparing and recommending the similarity between document elements input by a user in a document platform and document elements converted into data and stored.
일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법에 관한 것으로서, 입력된 문서요소를 분석하여 트리플 데이터인 주어(S, subject), 목적어(O, object), 및 술어(P, property)를 추출하는 단계, 추출된 주어, 목적어, 술어를 포함하는 지식그래프를 그래프 데이터베이스에 추가하는 단계, 상기 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가하는 단계, 상기 문서 위치 데이터가 추가된 메타데이터를 관계형성 모듈에 전달하는 단계, 및 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계를 포함할 수 있다.A method for forming document relationships by merging triple data and location information based on a graph database according to one embodiment of the present invention may include a step of analyzing an input document element to extract a subject (S, subject), an object (O, object), and a predicate (P, property), which are triple data, a step of adding a knowledge graph including the extracted subject, object, and predicate to a graph database, a step of adding document location data to metadata including the extracted subject, object, and predicate, a step of transmitting metadata to which the document location data has been added to a relationship formation module, and a step of recording a knowledge graph including document element information in the graph database in the relationship formation module.
일실시예에 따른 상기 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가하는 단계는, 상기 술어에 상기 문서 위치 데이터를 추가하는 단계를 포함할 수 있다.The step of adding document location data to the metadata including the extracted subject, object, and predicate according to one embodiment may include the step of adding the document location data to the predicate.
일실시예에 따른 상기 관계형성 모듈에서 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계는, 상기 트리플 데이터 그래프에 위치정보를 라벨링하여 상기 문서요소 지식그래프를 생성하고, 상기 생성된 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계를 포함할 수 있다.In the above relationship formation module according to one embodiment, the step of recording the document element knowledge graph in the graph database may include the step of labeling location information in the triple data graph to generate the document element knowledge graph, and recording the generated document element knowledge graph in the graph database.
일실시예에 따른 상기 문서 위치 데이터는, 문서 및 상기 문서 내에서 사용된 위치를 찾기 위한 정보로서, 상기 추출된 주어, 목적어, 술어가 위치하는 문서의 식별정보(ID), 문단 위치, 문장 위치를 포함할 수 있다.The document location data according to one embodiment is information for finding a document and a location used within the document, and may include identification information (ID) of the document where the extracted subject, object, and predicate are located, paragraph location, and sentence location.
일실시예에 따른 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계는, 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 기등록된 지식그래프에 업데이트 하는 단계를 포함할 수 있다.In one embodiment, the step of recording a knowledge graph including document element information in the relation formation module may include a step of updating a knowledge graph including document element information in a pre-registered knowledge graph in the relation formation module.
일실시예에 따른 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계는, 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성하는 단계를 포함할 수 있다.In one embodiment, the step of recording a knowledge graph including document element information in the graph database in the relationship formation module may include a step of generating a knowledge graph including document element information in the relationship formation module.
일실시예에 따른 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성하는 단계는, 문장요약 기술에 활용되는 문서요소 간 관계기술로써 문서에 포함된 각 문장의 단어를 나타내는 노드(node)들을 문장 내 동시 출현 관계에 대한 가중치를 가지는 엣지(edge)로 연결하여 단어 그래프(Gword)를 생성하는 단계, 및 각 문장을 나타내는 노드들을 문장간 유사도에 대한 가중치를 가지는 엣지로 연결하여 문장 그래프(Gsentence)를 생성하는 단계를 포함할 수 있다.In the above relationship formation module according to an embodiment, the step of generating a knowledge graph including document element information may include a step of generating a word graph (Gword) by connecting nodes representing words of each sentence included in a document with edges having weights for co-occurrence relationships within the sentences as a relationship technology between document elements utilized in sentence summarization technology, and a step of generating a sentence graph (Gsentence) by connecting nodes representing each sentence with edges having weights for similarity between sentences.
일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템은 입력된 문서요소를 분석하여 주어(S, subject), 목적어(O, object), 및 술어(P, property)를 추출하는 SPO 추출부, 상기 추출된 주어, 목적어, 술어를 포함하는 지식그래프를 그래프 데이터베이스에 기록하고, 상기 추출된 주어, 목적어, 술어를 문서 데이터베이스에 기록하는 데이터베이스 처리부, 상기 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가하는 문서 위치 처리부, 및 상기 문서 위치 데이터가 추가된 메타데이터를 수신하여, 문서요소 정보가 포함된 지식그래프를 생성하고, 상기 생성된 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 관계형성 처리부를 포함할 수 있다.A document relation formation system in the form of merging triple data and location information based on a graph database according to an embodiment of the present invention may include an SPO extraction unit that analyzes an input document element to extract a subject (S, subject), an object (O, object), and a predicate (P, property); a database processing unit that records a knowledge graph including the extracted subject, object, and predicate in a graph database and records the extracted subject, object, and predicate in a document database; a document position processing unit that adds document position data to metadata including the extracted subject, object, and predicate; and a relation formation processing unit that receives metadata with the document position data added thereto, generates a knowledge graph including document element information, and records the knowledge graph including the generated document element information in the graph database.
일실시예에 따른 상기 문서 위치 처리부는, 상기 술어에 상기 문서 위치 데이터를 추가할 수 있다.The document location processing unit according to one embodiment can add the document location data to the predicate.
일실시예에 따른 상기 관계형성 처리부는, 상기 트리플 데이터 그래프에 위치정보를 라벨링하여 상기 문서요소 지식그래프를 생성하고, 상기 생성된 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록할 수 있다.The relationship formation processing unit according to one embodiment can create the document element knowledge graph by labeling location information in the triple data graph, and record the created document element knowledge graph in the graph database.
일실시예에 따른 상기 문서 위치 데이터는, 문서 및 상기 문서 내에서 사용된 위치를 찾기 위한 정보로서, 상기 추출된 주어, 목적어, 술어가 위치하는 문서의 식별정보(ID), 문단 위치, 문장 위치를 포함할 수 있다.The document location data according to one embodiment is information for finding a document and a location used within the document, and may include identification information (ID) of the document where the extracted subject, object, and predicate are located, paragraph location, and sentence location.
일실시예에 따른 상기 관계형성 처리부는, 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 기등록된 지식그래프에 업데이트 할 수 있다.The relationship formation processing unit according to one embodiment can update a knowledge graph including document element information in a pre-registered knowledge graph in the relationship formation module.
일실시예에 따른 상기 관계형성 처리부는, 상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성할 수 있다.The relationship formation processing unit according to one embodiment can generate a knowledge graph including document element information in the relationship formation module.
일실시예에 따른 상기 관계형성 처리부는, 문장요약 기술에 활용되는 문서요소 간 관계기술로써 문서에 포함된 각 문장의 단어를 나타내는 노드(node)들을 문장 내 동시 출현 관계에 대한 가중치를 가지는 엣지(edge)로 연결하여 단어 그래프(Gword)를 생성하고, 각 문장을 나타내는 노드들을 문장간 유사도에 대한 가중치를 가지는 엣지로 연결하여 문장 그래프(Gsentence)를 생성할 수 있다.The above-described relation formation processing unit according to an embodiment of the present invention can create a word graph (Gword) by connecting nodes representing words of each sentence included in a document with edges having weights for co-occurrence relationships within the sentences as a relation technology between document elements utilized in sentence summary technology, and can create a sentence graph (Gsentence) by connecting nodes representing each sentence with edges having weights for similarity between sentences.
일실시예에 따르면, 실시간 입력된 문서요소를 분석하여 트리플 데이터를 포함하는 메타데이터를 생성할 수 있다.In one embodiment, metadata including triple data can be generated by analyzing real-time input document elements.
일실시예에 따르면, 클라우드 문서 플랫폼에 저장된 문서를 메타데이터로 변환하여 문서 요소들을 저장하고 특정 문서요소끼리 유사도를 비교하여 사용자에게 실시간으로 유사 문서요소를 추천할 수 있다.According to one embodiment, documents stored in a cloud document platform can be converted into metadata to store document elements, and similar document elements can be recommended to users in real time by comparing the similarity between specific document elements.
일실시예에 따르면, 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하기 위해, 데이터 시각화(data visualization)할 수 있다.In one embodiment, data visualization can be used to visually express the results of data analysis so that they can be easily understood.
일실시예에 따르면, 도표(graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달할 수 있다.In one example, information can be conveyed clearly and effectively through a means called a graph.
일실시예에 따르면, 문서 플랫폼에서 사용자가 입력한 문서요소와 데이터로 변환되어 저장된 문서요소의 유사도를 비교하여 추천하기 때문에 리소스가 많이 소요되는 기존의 문서 비교방식이 아닌 문서요소간 관계를 바탕으로 유사도를 측정하는 새로운 형태의 유사도 측정 방식을 제공할 수 있다.According to one embodiment, a new type of similarity measurement method can be provided that measures similarity based on relationships between document elements, rather than the existing document comparison method that consumes a lot of resources, by comparing the similarity between document elements input by a user in a document platform and document elements converted into data and saved, and recommending them.
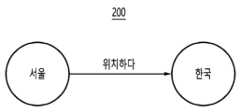
도 1은 일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터로(S,P,O)와 위치 정보를 병합한 형태의 문서 관계형성 방법을 설명하는 도면이다.
도 2는 일실시예에 따른 트리플 데이터로(S,P,O)를 설명하는 도면이다.
도 3은 트리플 데이터로(S,P,O)로 구성된 지식그래프를 설명하는 도면이다.
도 4는 위치 정보가 병합된 트리플 데이터(S,P,O)를 이용하여 기준 문서요소와 비교 문서요소 간 유사도를 판단하는 실시예를 설명하는 도면이다.
도 5는 일실시예에 따른 문서 전체구조를 시각화하는 기능을 수행하는 도면이다.
도 6은 다른 일실시예에 따른 문서 전체구조를 시각화하는 기능을 수행하는 도면이다.
도 7은 DB 기반 오피스 플랫폼을 설명하는 도면이다.
도 8은 일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터(S,P,O)와 위치 정보를 병합한 형태의 문서 관계형성 시스템을 설명하는 도면이다.Figure 1 is a drawing explaining a method for forming a document relationship by merging location information with triple data (S, P, O) based on a graph database according to one embodiment.
Figure 2 is a drawing explaining triple data (S, P, O) according to an embodiment.
Figure 3 is a diagram explaining a knowledge graph composed of triple data (S, P, O).
FIG. 4 is a diagram explaining an embodiment of determining the similarity between a reference document element and a comparison document element using triple data (S, P, O) to which location information is merged.
Figure 5 is a drawing that performs the function of visualizing the entire structure of a document according to an embodiment.
Figure 6 is a drawing that performs the function of visualizing the entire structure of a document according to another embodiment.
Figure 7 is a diagram illustrating a DB-based office platform.
FIG. 8 is a diagram illustrating a document relationship formation system that merges triple data (S, P, O) and location information based on a graph database according to one embodiment.
본 명세서에 개시되어 있는 본 발명의 개념에 따른 실시예들에 대해서 특정한 구조적 또는 기능적 설명들은 단지 본 발명의 개념에 따른 실시예들을 설명하기 위한 목적으로 예시된 것으로서, 본 발명의 개념에 따른 실시예들은 다양한 형태로 실시될 수 있으며 본 명세서에 설명된 실시예들에 한정되지 않는다.Specific structural or functional descriptions of embodiments according to the concept of the present invention disclosed in this specification are merely exemplified for the purpose of explaining embodiments according to the concept of the present invention, and embodiments according to the concept of the present invention can be implemented in various forms and are not limited to the embodiments described in this specification.
본 발명의 개념에 따른 실시예들은 다양한 변경들을 가할 수 있고 여러 가지 형태들을 가질 수 있으므로 실시예들을 도면에 예시하고 본 명세서에 상세하게 설명하고자 한다. 그러나, 이는 본 발명의 개념에 따른 실시예들을 특정한 개시형태들에 대해 한정하려는 것이 아니며, 본 발명의 사상 및 기술 범위에 포함되는 변경, 균등물, 또는 대체물을 포함한다.The embodiments according to the concept of the present invention can have various changes and can have various forms, so the embodiments are illustrated in the drawings and described in detail in this specification. However, this is not intended to limit the embodiments according to the concept of the present invention to specific disclosed forms, but includes changes, equivalents, or substitutes included in the spirit and technical scope of the present invention.
제1 또는 제2 등의 용어를 다양한 구성요소들을 설명하는데 사용될 수 있지만, 상기 구성요소들은 상기 용어들에 의해 한정되어서는 안 된다. 상기 용어들은 하나의 구성요소를 다른 구성요소로부터 구별하는 목적으로만, 예를 들어 본 발명의 개념에 따른 권리 범위로부터 이탈되지 않은 채, 제1 구성요소는 제2 구성요소로 명명될 수 있고, 유사하게 제2 구성요소는 제1 구성요소로도 명명될 수 있다.Although the terms first or second may be used to describe various components, the components should not be limited by the terms. The terms are only intended to distinguish one component from another, for example, without departing from the scope of the invention, a first component may be referred to as a second component, and similarly, a second component may also be referred to as a first component.
어떤 구성요소가 다른 구성요소에 "연결되어" 있다거나 "접속되어" 있다고 언급된 때에는, 그 다른 구성요소에 직접적으로 연결되어 있거나 또는 접속되어 있을 수도 있지만, 중간에 다른 구성요소가 존재할 수도 있다고 이해되어야 할 것이다. 반면에, 어떤 구성요소가 다른 구성요소에 "직접 연결되어" 있다거나 "직접 접속되어" 있다고 언급된 때에는, 중간에 다른 구성요소가 존재하지 않는 것으로 이해되어야 할 것이다. 구성요소들 간의 관계를 설명하는 표현들, 예를 들어 "~사이에"와 "바로~사이에" 또는 "~에 직접 이웃하는" 등도 마찬가지로 해석되어야 한다.When it is said that an element is "connected" or "connected" to another element, it should be understood that it may be directly connected or connected to that other element, but that there may be other elements in between. On the other hand, when it is said that an element is "directly connected" or "directly connected" to another element, it should be understood that there are no other elements in between. Expressions that describe the relationship between elements, such as "between" and "directly between" or "directly adjacent to", should be interpreted similarly.
본 명세서에서 사용한 용어는 단지 특정한 실시예들을 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 명세서에서, "포함하다" 또는 "가지다" 등의 용어는 설시된 특징, 숫자, 단계, 동작, 구성요소, 부분품 또는 이들을 조합한 것이 존재함으로 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부분품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.The terminology used herein is for the purpose of describing particular embodiments only and is not intended to be limiting of the present invention. The singular expression includes the plural expression unless the context clearly indicates otherwise. As used herein, the terms "comprises" or "has" and the like are intended to specify the presence of a stated feature, number, step, operation, component, part, or combination thereof, but should be understood to not preclude the possibility of the presence or addition of one or more other features, numbers, steps, operations, components, parts, or combinations thereof.
다르게 정의되지 않는 한, 기술적이거나 과학적인 용어를 포함해서 여기서 사용되는 모든 용어들은 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 의미를 가진다. 일반적으로 사용되는 사전에 정의되어 있는 것과 같은 용어들은 관련 기술의 문맥상 가지는 의미와 일치하는 의미를 갖는 것으로 해석되어야 하며, 본 명세서에서 명백하게 정의하지 않는 한, 이상적이거나 과도하게 형식적인 의미로 해석되지 않는다.Unless otherwise defined, all terms used herein, including technical or scientific terms, have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. Terms defined in commonly used dictionaries, such as those defined in common usage, should be interpreted as having a meaning consistent with the meaning they have in the context of the relevant art, and will not be interpreted in an idealized or overly formal sense unless explicitly defined herein.
이하, 실시예들을 첨부된 도면을 참조하여 상세하게 설명한다. 그러나, 특허출원의 범위가 이러한 실시예들에 의해 제한되거나 한정되는 것은 아니다. 각 도면에 제시된 동일한 참조 부호는 동일한 부재를 나타낸다.Hereinafter, embodiments will be described in detail with reference to the attached drawings. However, the scope of the patent application is not limited or restricted by these embodiments. The same reference numerals presented in each drawing represent the same components.
도 1은 일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터(S,P,O)와 위치 정보를 병합한 형태의 문서 관계형성 방법(100)을 설명하는 도면이다.FIG. 1 is a drawing explaining a document relationship formation method (100) in the form of merging location information and triple data (S, P, O) based on a graph database according to one embodiment.
그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법(100)에 따르면, 우선 DB형 오피스 플랫폼을 통해 저장되어 있는 문서로부터 입력된(101) 문서요소를 분석하여 트리플 데이터인 주어(S, subject), 목적어(O, object), 및 술어(P, property)를 추출할 수 있다.According to a document relationship formation method (100) that combines triple data and location information based on a graph database, first, a document element input (101) from a document stored through a DB-type office platform can be analyzed to extract triple data, such as a subject (S, subject), an object (O, object), and a predicate (P, property).
먼저, 문서 관계형성 방법(100)에서는 DB형 오피스 플랫폼을 통해 저장된 문서로부터 입력된 문서요소를 분석할 수 있다. 이 과정에서는 문서의 내용을 검토하고, 그 안에서 특별한 의미나 정보를 지니는 부분을 식별할 수 있다.First, in the document relationship formation method (100), document elements input from documents stored through a DB-type office platform can be analyzed. In this process, the contents of the document can be reviewed and parts with special meaning or information can be identified therein.
트리플 데이터 추출은 분석된 문서요소에서 주어(S, subject), 목적어(O, object), 및 술어(P, property)를 추출할 수 있다. 이렇게 추출된 정보는 그래프 데이터베이스에 저장될 요소들로서, 문서의 중요한 관계를 나타낼 수 있다.Triple data extraction can extract subjects (S, subject), objects (O, object), and predicates (P, property) from analyzed document elements. The information extracted in this way can be stored in a graph database as elements that represent important relationships in documents.
예를 들어, 입력된 문서가 '과일 판매 보고서'일 경우, 이 방법을 통해 '판매량(S)', '사과(O)', '증가했다(P)'와 같은 트리플 데이터가 추출될 수 있다. 이러한 정보는 나중에 그래프 데이터베이스에 저장되어 문서의 관계를 시각적으로 표현하거나 검색할 수 있다.For example, if the input document is a 'fruit sales report', triple data such as 'sales (S)', 'apple (O)', and 'increased (P)' can be extracted through this method. This information can be later stored in a graph database to visually represent or search the relationship of the document.
이와 같이, 본 발명은 그래프 데이터베이스와 위치 정보를 결합하여 문서 내의 정보를 추출하고 이를 구조화하여 관계형성을 수행할 수 있다. 이를 통해 복잡한 문서 간의 상호 연결된 정보를 효과적으로 관리하고 활용할 수 있다.In this way, the present invention can extract information within a document and structure it to form relationships by combining a graph database and location information. This allows for effective management and utilization of interconnected information between complex documents.
다음으로, 문서 관계형성 방법(100)은 추출된 주어, 목적어, 술어를 포함하는 지식그래프를 그래프 데이터베이스에 추가할 수 있다(102). 일례로, 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하기 위해서, 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성할 수 있다.Next, the document relationship formation method (100) can add a knowledge graph including the extracted subject, object, and predicate to the graph database (102). For example, in order to record a knowledge graph including document element information in the relationship formation module to the graph database, the knowledge graph including document element information can be generated in the relationship formation module.
예를 들어, 앞서 언급한 '과일 판매 보고서'에서 추출된 트리플 데이터를 기반으로, 관계형성 모듈은 '판매량(S)', '사과(O)', '증가했다(P)'와 같은 정보를 포함한 지식그래프를 생성할 수 있다. 이 지식그래프는 문서의 중요한 관계와 정보를 표현하는 그래프 구조를 가지고 있다.For example, based on the triple data extracted from the aforementioned 'fruit sales report', the relationship formation module can create a knowledge graph containing information such as 'sales (S)', 'apple (O)', and 'increased (P)'. This knowledge graph has a graph structure that expresses important relationships and information in the document.
그 다음, 이렇게 생성된 지식그래프는 그래프 데이터베이스에 기록될 수 있다. 이는 나중에 해당 정보를 쿼리하거나 시각적으로 표현하기 위해 사용될 수 있다. 그래프 데이터베이스는 관계 형성된 지식을 효율적으로 저장하고 관리할 수 있다.Then, the knowledge graph generated in this way can be recorded in a graph database. This can be used later to query or visually represent the information. Graph databases can efficiently store and manage relational knowledge.
즉, 일실시예에 따른 문서 관계형성 방법(100)은 추출된 정보를 지식그래프로 변환하고, 이를 그래프 데이터베이스에 효과적으로 저장하여 나중에 활용할 수 있다.That is, the document relationship formation method (100) according to one embodiment converts extracted information into a knowledge graph and effectively stores it in a graph database so that it can be utilized later.
특히, 문서 관계형성 방법(100)은 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성하기 위해, 문장요약 기술에 활용되는 문서요소 간 관계기술로써 문서에 포함된 각 문장의 단어를 나타내는 노드(node)들을 문장 내 동시 출현 관계에 대한 가중치를 가지는 엣지(edge)로 연결하여 단어 그래프(Gword)를 생성하고, 각 문장을 나타내는 노드들을 문장간 유사도에 대한 가중치를 가지는 엣지로 연결하여 문장 그래프(Gsentence)를 생성할 수 있다.In particular, the document relationship formation method (100) is a document element relationship technology utilized in sentence summary technology to create a knowledge graph including document element information in a relationship formation module, and creates a word graph (Gword) by connecting nodes representing words of each sentence included in a document with edges having weights for co-occurrence relationships within the sentences, and creates a sentence graph (Gsentence) by connecting nodes representing each sentence with edges having weights for similarity between sentences.
예를 들어, '과일 판매 보고서'에서 추출된 문장들로부터 단어 그래프와 문장 그래프를 생성할 때, '판매량', '사과', '증가했다'와 같은 단어를 나타내는 노드들이 생성되며, 이들 간의 관계를 나타내는 가중치가 부여된 엣지들이 형성될 수 있다. 또한, 각 문장을 나타내는 노드들이 생성되고, 이들 간의 유사도를 나타내는 가중치가 부여된 엣지들이 형성될 수 있다.For example, when generating a word graph and a sentence graph from sentences extracted from a 'fruit sales report', nodes representing words such as 'sales', 'apple', and 'increased' can be generated, and weighted edges representing the relationships between them can be formed. In addition, nodes representing each sentence can be generated, and weighted edges representing the similarity between them can be formed.
이렇게 형성된 단어 그래프(Gword)와 문장 그래프(Gsentence)는 관계형성 모듈에서 활용되어 문서의 핵심적인 내용과 관련성을 파악하고, 이를 기반으로 지식그래프를 구성할 수 있다. 이는 문서의 정보를 효과적으로 추출하고, 그래프 데이터베이스에 저장함으로써 나중에 검색하거나 활용할 수 있다.The word graph (Gword) and sentence graph (Gsentence) formed in this way can be utilized in the relationship formation module to identify the core content and relevance of the document, and construct a knowledge graph based on this. This effectively extracts information from the document and stores it in a graph database so that it can be searched or utilized later.
일실시예에 따른 문서 관계형성 방법(100)은 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가할 수 있다(103). 일실시예에 따른 문서 위치 데이터는, 문서 및 상기 문서 내에서 사용된 위치를 찾기 위한 정보로서, 추출된 주어, 목적어, 술어가 위치하는 문서의 식별정보(ID), 문단 위치, 문장 위치를 포함할 수 있다.A document relationship formation method (100) according to an embodiment can add document location data to metadata including extracted subjects, objects, and predicates (103). The document location data according to an embodiment is information for finding a document and a location used within the document, and can include identification information (ID) of a document where the extracted subjects, objects, and predicates are located, a paragraph location, and a sentence location.
문서요소를 분석하여 추출하는 주어(S, subject), 목적어(O, object), 및 술어(P, property)는 문서 내에서 중요한 정보를 식별하고 이를 지식그래프에 포함시키기 위한 핵심과정이다.Extracting subjects (S, subject), objects (O, object), and predicates (P, property) by analyzing document elements is a key process for identifying important information within a document and including it in the knowledge graph.
주어(Subject, S)는 문장이나 문서 내에서 어떤 동작이나 상태의 주체를 나타내며, 주로 누가, 무엇을 하는지에 대한 핵심 정보를 담고 있다. 예를 들어, "사과는"에서 "사과"가 주어이다.The subject (S) represents the subject of an action or state within a sentence or document, and mainly contains key information about who is doing what. For example, in "apples are," "apples" is the subject.
목적어(Object, O)는 주어의 행동이나 상태의 대상을 나타내며, 주어가 어떤 동작을 수행하는 대상이나 동작의 결과물을 나타낸다. 예를 들어, "사과를 판매했다"에서 "사과"가 목적어에 해당한다.Object (O) indicates the object of the subject's action or state, and indicates the object on which the subject performs an action or the result of the action. For example, in "sold apples," "apples" are the object.
술어(Property, P)는 주어와 목적어 사이의 관계나 상태를 나타낸다.A predicate (Property, P) expresses the relationship or state between the subject and the object.
주어가 어떤 동작을 하는지나 상태를 어떻게 변화시키는지를 나타내며, 예를 들어, "사과를 판매했다"에서 "판매했다"가 술어이다.It indicates what action the subject performs or how the state changes. For example, in "sold apples," "sold" is the predicate.
예를 들어, 문장 "사과는 시장에서 판매되었다"에서 주어(S)는 "사과", 목적어(O)는 "시장", 술어(P)는 "판매되었다"이다.For example, in the sentence "Apples were sold at the market", the subject (S) is "apples", the object (O) is "market", and the predicate (P) is "sold".
이 정보를 추출하면, 지식그래프에 "사과(S) - 판매되었다(P) - 시장(O)"와 같은 형태로 관계를 추가할 수 있다.By extracting this information, we can add relationships to the knowledge graph in the form of "Apple (S) - Sold (P) - Market (O)".
메타데이터에 병합될 수 있는 위치 정보는 문서 내의 특정한 요소나 내용의 위치를 정확히 식별하기 위한 정보를 의미한다. 일반적으로 위치 정보는 문서의 구조와 내용을 파악하고, 각 요소의 위치를 명확히 특정할 때 사용될 수 있다.Location information that can be incorporated into metadata refers to information that accurately identifies the location of a specific element or content within a document. In general, location information can be used to understand the structure and content of a document and to clearly specify the location of each element.
예를 들어, 문서 내의 특정 문장, 단락, 단어, 또는 그림 등의 위치를 정확히 파악하고자 할 때 사용될 수 있다.For example, it can be used when you want to accurately identify the location of a specific sentence, paragraph, word, or picture within a document.
예를 들어, 위치 정보는 다음과 같은 구성요소를 포함할 수 있다.For example, location information may include the following components:
문서 식별정보(ID), 문단 위치, 문장 위치, 단어 위치, 그림 위치 등을 포함할 수 있다.It may include document identification information (ID), paragraph location, sentence location, word location, image location, etc.
문서 식별정보(ID)는 문서를 고유하게 식별하는 정보로서, 일반적으로 문서 제목, 일련번호, 또은 다른 고유 식별자가 될 수 있다.A document identifier (ID) is information that uniquely identifies a document, and can typically be a document title, serial number, or other unique identifier.
문단 위치는 문서 내의 특정 문단이나 섹션의 위치를 나타내며, 예를 들어, "소개", "본문", "결론" 등이 될 수 있다.Paragraph position indicates the location of a specific paragraph or section within a document, for example, "Introduction", "Body", "Conclusion", etc.
문장 위치는 문서 내의 특정 문장의 위치를 나타내며, 이는 문장이 시작하는 지점이나 끝나는 지점을 나타낼 수 있다.Sentence position refers to the location of a particular sentence within a document, which can refer to where the sentence begins or ends.
단어 위치는 문서 내에서 특정 단어나 용어의 위치를 나타내며, 이는 단어가 나타나는 문장 내에서의 위치를 나타낼 수 있다.Word position refers to the location of a particular word or term within a document, which can refer to the position within the sentence in which the word appears.
그림 위치는 문서 내의 그림, 차트, 또는 다른 시각적 요소의 위치를 나타내며, 이는 그림이 위치한 페이지 번호나 구체적인 위치 정보를 포함할 수 있다.A figure location indicates the location of a figure, chart, or other visual element within a document, and may include the page number or specific location information where the figure is located.
일실시예에 따른 문서 관계형성 방법(100)은 문서 위치 데이터가 추가된 메타데이터를 관계형성 모듈에 전달할 수 있다(104). 일실시예에 따른 문서 관계형성 방법(100)은 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가하기 위해서, 술어에 상기 문서 위치 데이터를 추가할 수 있다.A document relationship formation method (100) according to an embodiment can transfer metadata with document location data added to a relationship formation module (104). A document relationship formation method (100) according to an embodiment can add the document location data to a predicate in order to add the document location data to metadata including extracted subjects, objects, and predicates.
일실시예에 따른 문서 관계형성 방법(100)은 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록할 수 있다(105).A document relationship formation method (100) according to an embodiment can record a knowledge graph including document element information in a relationship formation module in the graph database (105).
관계형성 모듈에서 지식그래프를 생성하기 위해, 관계형성 모듈은 앞서 언급한 주어, 목적어, 술어를 활용하여 지식그래프를 생성할 수 있다. 이 그래프는 추출된 정보의 구조화된 표현으로, 주요한 관계와 내용을 포함할 수 있다.In order to create a knowledge graph in the relationship formation module, the relationship formation module can create a knowledge graph by utilizing the aforementioned subject, object, and predicate. This graph is a structured representation of the extracted information, and can include key relationships and contents.
생성된 지식그래프를 그래프 데이터베이스에 기록될 수 있고, 이 과정에서 각 노드와 엣지는 데이터베이스 내의 특정한 테이블이나 구조에 저장될 수 있다.The generated knowledge graph can be recorded in a graph database, and in this process, each node and edge can be stored in a specific table or structure within the database.
노드는 주어, 목적어, 술어 등을 나타내는 핵심 정보를 포함하고, 엣지는 이들 간의 관계와 연결을 나타낼 수 있다.Nodes contain core information such as subjects, objects, and predicates, and edges can represent relationships and connections between them.
예를 들어, "사과(S) - 판매되었다(P) - 시장(O)"와 같은 관계가 추출되었다면, 이 정보는 지식그래프에 구조화되어 저장될 수 있다. 노드는 "사과", "시장"과 같은 주요 정보를 담고 있고, 엣지는 이들 간의 관계를 나타낼 수 있다.For example, if a relationship such as "Apple (S) - Sold (P) - Market (O)" is extracted, this information can be structured and stored in a knowledge graph. Nodes can contain key information such as "Apple" and "Market", and edges can represent the relationships between them.
다음으로, 일실시예에 따른 문서 관계형성 방법(100)은 관계형성 모듈에서 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록하기 위해, 트리플 데이터 그래프에 위치정보를 라벨링하여 상기 문서요소 지식그래프를 생성하고, 생성된 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록할 수 있다.Next, a document relationship formation method (100) according to an embodiment of the present invention can create a document element knowledge graph by labeling location information in a triple data graph to record a document element knowledge graph in the graph database in a relationship formation module, and record the created document element knowledge graph in the graph database.
일례로, 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하기 위해서는, 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 기등록된 지식그래프에 업데이트할 수 있다.For example, in order to record a knowledge graph containing document element information in a relation formation module to the graph database, the knowledge graph containing document element information in the relation formation module can be updated to a pre-registered knowledge graph.
도 2는 일실시예에 따른 트리플 데이터로(S,P,O)를 설명하는 도면이다.Figure 2 is a drawing explaining triple data (S, P, O) according to an embodiment.
도면부호 200을 살펴보면, "서울"은 주어(Subject, S)로서 특정한 역할이나 위치를 나타낼 수 있다. 또한, "위치하다"는 주어와 목적어 사이의 관계를 나타내는 술어(Predicate, P)로서 주어의 동작이나 속성을 나타낸다.Looking at the
즉, 도면부호 200에서는 "서울이 한국에 위치하다"라는 관계를 나타낼 수 있다.That is, drawing
"한국"은 술어에 의해 위치가 지정되는 대상으로서, 목적어(Object, O)에 해당하며, "서울이 한국에 위치하다"에서 "한국"이 목적어로 해석될 수 있다."Korea" is an object whose location is specified by the predicate, and corresponds to the object (O). In "Seoul is located in Korea," "Korea" can be interpreted as the object.
도 3은 트리플 데이터로(S,P,O)로 구성된 지식그래프(300)를 설명하는 도면이다.Figure 3 is a diagram explaining a knowledge graph (300) composed of triple data (S, P, O).
지식그래프(300)는 위 트리플 데이터를 기반으로 형성되며, 노드(node)와 엣지(edge)로 이루어질 수 있다. 노드는 "서울", "위치하다", "한국"과 같은 주요 정보를 담고 있고, 엣지는 노드들 간의 관계를 나타낼 수 있다.The knowledge graph (300) is formed based on the above triple data and can be composed of nodes and edges. Nodes contain key information such as “Seoul,” “located,” and “Korea,” and edges can represent relationships between nodes.
예를 들어, "서울" 노드와 "위치하다" 노드 간에 "한국" 노드로 향하는 엣지가 존재한다. 그래프 데이터베이스는, 지식그래프와 그에 대한 추가 정보를 저장하고 관리하는 시스템으로서, 예를 들어, "서울" 노드와 "위치하다" 노드, 그리고 "한국" 노드의 정보가 저장될 수 있다.For example, there is an edge between the "Seoul" node and the "located" node that points to the "Korea" node. A graph database is a system that stores and manages a knowledge graph and additional information about it, and for example, information about the "Seoul" node, the "located" node, and the "Korea" node can be stored.
도 4는 위치 정보가 병합된 트리플 데이터(S,P,O)를 이용하여 기준 문서요소와 비교 문서요소 간 유사도를 판단하는 실시예를 설명하는 도면이다.FIG. 4 is a diagram explaining an embodiment of determining the similarity between a reference document element and a comparison document element using triple data (S, P, O) to which location information is merged.
도면부호 410은 기준 문서요소이고, 도면부호 420은 기준 문서요소(410)에 대비되는 문서요소일 수 있다.Drawing symbol 410 may be a reference document element, and drawing symbol 420 may be a document element contrasting with the reference document element (410).
구체적으로는, 문서 요소를 노드와 엣지로 시각화 후 유사 노드와 엣지를 표시하여 유사 부분을 사용자가 한눈에 알아볼 수 있도록 제공할 수 있고, 문서요소간 유사도는 의미기반 문서요소 유사도 수치 기반으로 판단할 수 있다.Specifically, document elements can be visualized as nodes and edges, and similar nodes and edges can be displayed so that users can see similar parts at a glance, and the similarity between document elements can be determined based on a semantic-based document element similarity value.
기준 문서요소(410)와 비교 문서요소(420) 간 유사도를 판단하는 과정은 위치 정보가 병합된 트리플 데이터를 활용하여 두 요소 간의 유사성을 평가함으로써 수행될 수 있다.The process of determining the similarity between the reference document element (410) and the comparison document element (420) can be performed by evaluating the similarity between the two elements using triple data with merged location information.
이를 위해, 일실시예에 따른 문서 관계형성 방법에서는 우선적으로 트리플 데이터를 확보할 수 있다.To this end, in a document relationship formation method according to an embodiment, triple data can be secured first.
먼저, 일실시예에 따른 문서 관계형성 방법은 기준 문서요소(410)와 비교 문서요소(420)에 대한 위치 정보가 병합된 트리플 데이터를 확보할 수 있다.First, a document relationship formation method according to an embodiment can secure triple data in which location information for a reference document element (410) and a comparison document element (420) are merged.
이 데이터는 주어, 목적어, 술어를 포함하며, 각각의 노드와 엣지는 위치 정보가 라벨링된 지식그래프를 형성할 수 있다.This data contains subjects, objects, and predicates, and each node and edge can form a knowledge graph with location information labeled.
다음으로, 일실시예에 따른 문서 관계형성 방법은 유사도 측정 알고리즘 선택할 수 있다. 즉, 기준 문서요소(410)와 비교 문서요소(420) 간의 유사도를 판단하기 위해 사용할 적절한 유사도 측정 알고리즘을 선택할 수 있다.Next, the document relationship formation method according to one embodiment can select a similarity measurement algorithm. That is, an appropriate similarity measurement algorithm to be used to determine the similarity between the reference document element (410) and the comparison document element (420) can be selected.
유사도 측정 알고리즘은 선택한 데이터의 특성과 목적에 따라 달라질 수 있다. 예를 들어, 자연어 처리에서는 코사인 유사도, Jaccard 유사도 등이 사용될 수 있다.Similarity measurement algorithms can vary depending on the characteristics and purpose of the data selected. For example, cosine similarity and Jaccard similarity can be used in natural language processing.
일실시예에 따른 문서 관계형성 방법은 선택한 유사도 측정 알고리즘을 활용하여 기준 문서요소(410)와 비교 문서요소(420) 간의 유사도를 계산할 수 있다.A document relationship formation method according to an embodiment can calculate the similarity between a reference document element (410) and a comparison document element (420) by utilizing a selected similarity measurement algorithm.
이를 위해, 두 문서요소의 위치 정보가 병합된 트리플 데이터를 활용하여 알고리즘에 입력으로 제공할 수 있다.To this end, triple data, in which the location information of two document elements is merged, can be used as input to the algorithm.
일실시예에 따른 문서 관계형성 방법은 유사도 결과를 해석할 수 있다.The document relationship formation method according to an embodiment can interpret the similarity results.
계산된 유사도의 결과를 해석하여 두 문서요소 간의 유사성을 판단할 수 있다. 유사도 값이 높을수록 두 문서요소는 유사하다고 판단될 수 있다.The results of the calculated similarity can be interpreted to determine the similarity between two document elements. The higher the similarity value, the more similar the two document elements can be determined to be.
예를 들어, "서울(S) - 위치하다(P) - 한국(O)"와 "파리(S) - 위치하다(P) - 프랑스(O)"라는 두 문서요소가 있을 때, 위치 정보가 병합된 트리플 데이터를 활용하여 두 요소 간의 유사도를 측정할 수 있다. 이를 통해 두 도시가 위치한 국가가 유사하다는 결과를 얻을 수 있다.For example, when there are two document elements, "Seoul (S) - Location (P) - Korea (O)" and "Paris (S) - Location (P) - France (O)", the similarity between the two elements can be measured by using triple data with merged location information. This can lead to the result that the countries in which the two cities are located are similar.
동일한 주어, 술어 데이터 셋이 검색된 경우 동일한 문서요소로 판단하거나, 데이터베이스에서 동일한 술어,목적어 데이터 셋이 검색된 경우 동일한 문서요소로 판단할 수 있다.If the same subject and predicate data sets are searched, they can be judged as the same document element, or if the same predicate and object data sets are searched in the database, they can be judged as the same document element.
문서를 문단, 문장으로 분리하여 트리플 데이터를 추출한다. 최소단위를 문장 단위로 하여 한 문장에서 트리플 데이터를 상호참조복원 (CR), 개체명 인식 (NER), 관계 추출 (RE), 개체 연결 (Entity Linking) 등의 자연어 처리 기법을 이용하여 생성한다. 추출된 트리플 데이터는 트리플 데이터 형태의 관계를 형성하여 데이터베이스(130)에 저장한다.The document is divided into paragraphs and sentences to extract triple data. The minimum unit is a sentence, and triple data is generated from a sentence using natural language processing techniques such as cross-reference recovery (CR), named entity recognition (NER), relationship extraction (RE), and entity linking. The extracted triple data forms a relationship in the form of triple data and is stored in a database (130).
해당 트리플 데이터 데이터에는 문서 id, 문단 위치, 문장 위치로 구성된 문서내의 위치정보(position)를 같이 저장하여 어떤 문장에서 생성된 트리플 데이터인지 구별 할 수 있도록 하여 해당 트리플 데이터 만 사용하여 본문의 위치를 찾아갈 수 있도록 데이터를 생성한다.The triple data data stores position information (position) within the document, consisting of document ID, paragraph position, and sentence position, so that it can be distinguished from which sentence the triple data was generated, and data is generated so that the location of the text can be found using only the triple data.
표를 트리플 형태의 데이터로 변환하여 트리플 데이터 형태의 데이터를 생성한다. 표의 캡션 및 타이틀에서 트리플 데이터를 추출하고 문장과 마찬가지로 위치정보(position)를 같이 저장할 수 있다. 표의 수치 데이터는 병합된 셀과 같은 특수 케이스를 제외한 기본 2차원 표 데이터를 기준으로 추출한다.Converts tables into triple data to create triple data. Triple data can be extracted from table captions and titles, and position information can be stored together as with sentences. Numerical data in tables is extracted based on basic two-dimensional table data, excluding special cases such as merged cells.
HOP은 1칸까지의 경우만 케이스 분리, 동의어는 HOP이 떨어져있는 경우의 케이스 제외 (S` : 의미가 같은 동의어, - : 객체 사이의 hop 개수,)할 수 있다.HOP can only separate cases up to 1 space, and synonyms can exclude cases where HOPs are separated (S`: synonym with the same meaning, -: number of hops between objects).
예를 들어, "기업(S)은 재화(O)를 만든다(P)."의 문장에서 각 SOP를 확인할 수 있다.For example, you can check each SOP in the sentence, "Company (S) produces (P) goods (O)."
예를 들어, SPO`는 주어,술어 일치 목적어가 유사한 문장에 해당한다.For example, `SPO` corresponds to sentences in which the subject, predicate, and object are similar.
"기업은 상품을 만든다"의 문장의 경우, 주어, 목적어 일치 술어 유사한 SP`O의 예시로는 "기업은 재화를 생산한다."의 형태이다.For the sentence "Companies make goods", an example of a subject-object agreement predicate similar to SP`O is "Companies produce goods."
또한, 술어, 목적어 일치 주어 유사한 S`PO의 경우, "회사는 재화를 만든다"의 형태를 고려할 수 있고, 주어,술어 일치 목적어 HOP 1칸이 유사한 문장의 인 SP-O의 경우, "기업은 상품을 만든다."로서 상품은 재화와 동일한 점을 고려할 수 있다.Also, in the case of S`PO where the predicate and object match similarly to the subject, we can consider the form of "The company makes goods," and in the case of SP-O where the subject and predicate match similarly to the
이 밖에도, S-PO의 형태는 주어,목적어 일치 술어 HOP 1칸 유사한 문장으로서 "기업은 직원을 고용한다."의 형태이고, 주어,술어,목적어 일치 각각HOP1칸 유사한 문장으로는 S-P-O로서 "기업은 직원을 고용한다."의 형태일 수 있다.In addition, the form of S-PO is "The company hires employees" as a sentence similar to the subject, object agreement and predicate
SO가 일치하는 경우는, 데이터베이스에서 동일한 주어, 목적어 데이터 셋이 검색된 경우 동일한 문서요소로 판단할 수 있고, SO`가 일치하는 경우는 주어 일치 목적어가 유사가 유사한 경우로 판다할 수 있다.In the case where SO matches, it can be judged as the same document element if the same subject and object data set is searched in the database, and in the case where SO` matches, it can be judged as the case where the subject and object are similar.
S`O는 목적어 일치 주어 유사의 경우로서, "회사는 재화를 이동한다"로 해석될 수 있다.S`O is a case of similar subject and object agreement, and can be interpreted as "The company moves goods."
SP가 일치하는 경우로는, 데이터베이스에서 동일한 주어, 술어 데이터 셋이 검색된 경우 동일한 문서요소로 판단할 수 있고, SP`는 주어 일치 술어 유사한 경우를 나타낼 수 있다.In the case of SP matching, if the same subject and predicate data set is searched in the database, it can be judged as the same document element, and SP` can indicate a case where the subject matches the predicate similarly.
S`P는 술어 일치 주어가 유사한 형태로서, "회사는 일자리를 생산한다."와 같은 형태일 수 있다.S`P is a similar form of predicate agreement subject, which can take the form "The company produces jobs."
한편, PO 일치의 경우, 데이터베이스에서 동일한 술어,목적어 데이터 셋이 검색된 경우 동일한 문서요소로 판단할 수 있다.Meanwhile, in the case of PO matching, if the same predicate and object data sets are searched in the database, they can be judged as the same document elements.
동의어의 경우, 유사한 단어들을 같은 범주의 단어로 묶고 해당 단어와의 유사도를 벡터화 시켜 단어와 유사도를 저장하는 한국어 유사어 사전을 사용할 수 있다.For synonyms, you can use a Korean synonym dictionary that groups similar words into words of the same category, vectorizes the similarity with the corresponding word, and stores the similarity with the word.
도 5는 일실시예에 따른 문서 전체구조를 시각화하는 기능을 수행하는 도면(500)이다.FIG. 5 is a drawing (500) that performs the function of visualizing the entire structure of a document according to an embodiment.
도 5에 따르면, 한 문서를 구조별로 분리하여 해당 문서의 전체 구조 시각화할 수 있다.According to Figure 5, a document can be divided into structures to visualize the entire structure of the document.
또한, 분리된 각 문단의 주요 트리플 데이터를 추출하여 해당 문단의 의미를 파악할 수 있으며, 문서 내 문단 별 주제를 파악하기 쉽고 문서 전체 흐름을 보여줄 수 있다.In addition, by extracting the main triple data of each separated paragraph, the meaning of the paragraph can be understood, and it is easy to identify the topic of each paragraph within the document and show the flow of the entire document.
이는 문서 구조 분리와 구조 시각화의 과정을 통해 수행될 수 있다.This can be done through the process of document structure separation and structure visualization.
먼저, 문서 구조 분리 과정에서는 해당 문서를 구조별로 분리할 수 있다.First, in the document structure separation process, the document can be separated by structure.
예를 들어, 한 논문의 경우 제목, 초록, 서론, 본론, 결론 등의 구조로 나눌 수 있다.For example, a paper can be divided into a structure such as title, abstract, introduction, body, and conclusion.
다음으로, 구조 시각화에서는, 분리된 각 구조를 시각화하여 해당 문서의 전체 구조를 파악할 수 있다. 이를 통해 각 부분이 어떻게 연결되어 있는지, 각 구조의 역할이 무엇인지 등을 이해할 수 있다.Next, in structural visualization, you can visualize each separate structure to understand the overall structure of the document. This allows you to understand how each part is connected and what the role of each structure is.
예를 들어, 논문의 경우 초록은 논문의 간략한 개요를 제공하고, 서론은 연구 배경과 목적을 소개하며, 본론에서는 주요 연구 내용을 다루고, 결론에서는 연구 결과와 그 의의를 요약할 수 있다. 각 구조를 시각화하면 이러한 구조와 연결 관계를 명확하게 파악할 수 있다.For example, in the case of a thesis, the abstract provides a brief outline of the thesis, the introduction introduces the research background and purpose, the main body deals with the main research content, and the conclusion summarizes the research results and their significance. Visualizing each structure can help you clearly understand these structures and their relationships.
또한, 분리된 각 문단의 주요 트리플 데이터를 추출하여 해당 문단의 의미를 파악할 수 있다. 이는 각 문단에서 어떤 정보가 주어, 목적어, 술어로 나타나는지를 확인할 수 있다.In addition, the main triple data of each separated paragraph can be extracted to understand the meaning of the paragraph. This can confirm what information appears as the subject, object, and predicate in each paragraph.
이러한 과정을 통해 문서 내의 각 구조와 문단의 주요 내용을 파악할 수 있다. 이는 문서 전체의 흐름을 이해하고, 각 부분이 어떤 역할을 하는지를 파악하는 데 도움이 되며, 문서를 효과적으로 분석하고 이해하는데 활용될 수 있다.Through this process, you can understand the main content of each structure and paragraph within the document. This helps you understand the flow of the entire document, understand what role each part plays, and can be utilized to effectively analyze and understand the document.
도 6은 다른 일실시예에 따른 문서 전체구조를 시각화하는 기능을 수행하는 도면(600)이다.FIG. 6 is a drawing (600) that performs the function of visualizing the entire structure of a document according to another embodiment.
도 6을 참고하면, 특정 문서 내 문서요소를 그래프 형태로 시각화할 수 있다. 시각화 과정에서, 문서요소의 그래프를 통해 문서 전체의 내용을 간략하게 이해할 수 있고, 특정 문서의 위치, 제목, ID 등의 문서정보를 알 수 있다.Referring to Figure 6, document elements within a specific document can be visualized in the form of a graph. In the visualization process, the content of the entire document can be briefly understood through the graph of the document elements, and document information such as the location, title, and ID of a specific document can be known.
도 7은 DB 기반 오피스 플랫폼(700)을 설명하는 도면이다.Figure 7 is a drawing explaining a DB-based office platform (700).
일반적인 오피스 플랫폼 (HWP)에서는 문단, 표 등에 대한 위치정보를 따로 저장할 수 없다.In general office platforms (HWP), location information for paragraphs, tables, etc. cannot be saved separately.
그런, 도 7에서 보는 바와 같이, DB 기반의 오피스 플랫폼(700)에서는 DB 내 문단, 문장, 문서 별로 각각의 타입을 지정하는 형태의 DB 기반 오피스 플랫폼을 사용함으로써 AI 트리플 데이터 추출기에서 추출된 트리플 데이터 정보에 위치정보 병합이 가능하다.As shown in Fig. 7, in a DB-based office platform (700), location information can be merged into triple data information extracted from an AI triple data extractor by using a DB-based office platform that specifies each type for each paragraph, sentence, and document in the DB.
문단, 표, 그림 별 각각의 메타데이터 별로 DB화하여 저장할 수 있고, 위치정보 또한 도면부호 710의 테이블로써 별도 저장이 가능하다.Each metadata for each paragraph, table, and figure can be stored in a database, and location information can also be stored separately as a table with drawing
결국, 본 발명을 이용하면, 그래프 데이터베이스를 기반으로 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성이 가능하다.Ultimately, using the present invention, it is possible to form a document relationship by merging triple data and location information based on a graph database.
트리플 데이터 정보로는 질의는 할 수 있지만 해당 자료의 위치에 대해서는 알 수 없는 단점이 존재하며, 본 발명에서는 해당 단점을 극복하기 위해 위치정보를 병합하는 기술을 적용하였다.Triple data information has a disadvantage in that although queries can be made, the location of the relevant data cannot be known. In order to overcome this disadvantage, the present invention applies a technology for merging location information.
데이터 중심의 데이터베이스형 오피스 플랫폼, AI 기반의 트리플 데이터 추출 플랫폼을 이용하여 트리플 데이터와 위치정보를 병합한 형태의 문서 관계 형성이 가능하고, 해당 기술로 문서 출처 파악, 문서요소 시각화, 기존 업무시스템과의 연계 위치정보 데이터 제공 등에 활용할 수 있다.Using a data-centric database-type office platform and an AI-based triple data extraction platform, it is possible to form document relationships by merging triple data and location information. This technology can be used to identify document sources, visualize document elements, and provide location information data in connection with existing business systems.
도 8은 일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템(800)을 설명하는 도면이다.FIG. 8 is a drawing illustrating a document relationship formation system (800) that merges triple data and location information based on a graph database according to one embodiment.
일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템(800)은 실시간 입력된 문서요소를 분석하여 트리플 데이터를 포함하는 메타데이터를 생성할 수 있다. 또한, 클라우드 문서 플랫폼에 저장된 문서를 메타데이터로 변환하여 문서 요소들을 저장하고 특정 문서요소끼리 유사도를 비교하여 사용자에게 실시간으로 유사 문서요소를 추천할 수 있고, 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하기 위해, 데이터 시각화(data visualization)할 수 있다.A document relationship formation system (800) that combines triple data and location information based on a graph database according to an embodiment of the present invention can analyze document elements entered in real time to generate metadata including triple data. In addition, documents stored in a cloud document platform can be converted into metadata to store document elements, and similar document elements can be recommended to users in real time by comparing the similarity between specific document elements, and data visualization can be performed to visually express the data analysis results so that they can be easily understood.
뿐만 아니라, 도표(graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달할 수 있고, 문서 플랫폼에서 사용자가 입력한 문서요소와 데이터로 변환되어 저장된 문서요소의 유사도를 비교하여 추천하기 때문에 리소스가 많이 소요되는 기존의 문서 비교방식이 아닌 문서요소간 관계를 바탕으로 유사도를 측정하는 새로운 형태의 유사도 측정 방식을 제공할 수 있다.In addition, it can clearly and effectively convey information through a means called a graph, and it can provide a new type of similarity measurement method that measures similarity based on the relationship between document elements rather than the existing document comparison method that consumes a lot of resources by comparing and recommending the similarity between document elements input by the user in the document platform and document elements converted and saved as data.
이를 위해, 일실시예에 따른 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템(800)은To this end, a document relationship formation system (800) that merges triple data and location information based on a graph database according to an embodiment of the present invention
일실시예에 따른 SPO 추출부(810)는 입력된 문서요소를 분석하여 주어(S, subject), 목적어(O, object), 및 술어(P, property)를 추출할 수 있다.According to an embodiment, the SPO extraction unit (810) can analyze input document elements to extract a subject (S, subject), an object (O, object), and a predicate (P, property).
일실시예에 따른 데이터베이스 처리부(820)는 추출된 주어, 목적어, 술어를 포함하는 지식그래프를 그래프 데이터베이스에 기록하고, 상기 추출된 주어, 목적어, 술어를 문서 데이터베이스에 기록할 수 있다.A database processing unit (820) according to an embodiment of the present invention can record a knowledge graph including extracted subjects, objects, and predicates in a graph database, and record the extracted subjects, objects, and predicates in a document database.
일실시예에 따른 문서 위치 처리부(830)는 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가할 수 있다. 문서 위치 처리부(830)는 술어에 상기 문서 위치 데이터를 추가할 수 있다.The document location processing unit (830) according to one embodiment can add document location data to metadata including extracted subjects, objects, and predicates. The document location processing unit (830) can add the document location data to the predicate.
일례로, 문서 위치 데이터는 문서 및 상기 문서 내에서 사용된 위치를 찾기 위한 정보로서, 상기 추출된 주어, 목적어, 술어가 위치하는 문서의 식별정보(ID), 문단 위치, 문장 위치를 포함할 수 있다.For example, document location data is information for finding documents and locations used within said documents, and may include document identification information (ID), paragraph location, and sentence location of the document where the extracted subject, object, and predicate are located.
일실시예에 따른 관계형성 처리부(840)는 문서 위치 데이터가 추가된 메타데이터를 수신하여, 문서요소 정보가 포함된 지식그래프를 생성하고, 상기 생성된 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록할 수 있다.A relationship formation processing unit (840) according to an embodiment of the present invention may receive metadata with document location data added, generate a knowledge graph including document element information, and record the generated knowledge graph including the document element information in the graph database.
관계형성 처리부(840)는 트리플 데이터 그래프에 위치정보를 라벨링하여 상기 문서요소 지식그래프를 생성하고, 생성된 문서요소 지식그래프를 그래프 데이터베이스에 기록할 수 있다.The relationship formation processing unit (840) can create a document element knowledge graph by labeling location information in a triple data graph and record the created document element knowledge graph in a graph database.
일실시예에 따른 관계형성 처리부(840)는 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 기등록된 지식그래프에 업데이트할 수 있고, 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성할 수도 있다.A relationship formation processing unit (840) according to an embodiment of the present invention can update a knowledge graph including document element information in a relationship formation module to a pre-registered knowledge graph, and can also create a knowledge graph including document element information in the relationship formation module.
특히, 일실시예에 따른 관계형성 처리부(840)는 문장요약 기술에 활용되는 문서요소 간 관계기술로써 문서에 포함된 각 문장의 단어를 나타내는 노드(node)들을 문장 내 동시 출현 관계에 대한 가중치를 가지는 엣지(edge)로 연결하여 단어 그래프(Gword)를 생성할 수 있다.In particular, a relationship formation processing unit (840) according to an embodiment of the present invention can create a word graph (Gword) by connecting nodes representing words of each sentence included in a document with edges having weights for co-occurrence relationships within the sentences as a relationship technology between document elements used in sentence summary technology.
또한, 각 문장을 나타내는 노드들을 문장간 유사도에 대한 가중치를 가지는 엣지로 연결하여 문장 그래프(Gsentence)를 생성할 수 있다.Additionally, a sentence graph (Gsentence) can be created by connecting nodes representing each sentence with edges that have weights for the similarity between sentences.
일실시예에 따른 제어부(850)는 각 구성요소들로 제어명령을 전송하거나, 다른 구성요소로부터 전달된 제어신호를 특정 구성요소로 가공하여 전송하는 기능을 수행할 수 있다.A control unit (850) according to an embodiment may perform a function of transmitting a control command to each component or processing a control signal transmitted from another component and transmitting it to a specific component.
결국, 본 발명을 이용하면, 일실시예에 따르면, 실시간 입력된 문서요소를 분석하여 트리플 데이터를 포함하는 메타데이터를 생성할 수 있다.Finally, by using the present invention, according to one embodiment, it is possible to analyze document elements input in real time and generate metadata including triple data.
또한, 본 발명을 이용하면, 클라우드 문서 플랫폼에 저장된 문서를 메타데이터로 변환하여 문서 요소들을 저장하고 특정 문서요소끼리 유사도를 비교하여 사용자에게 실시간으로 유사 문서요소를 추천할 수 있고, 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하기 위해, 데이터 시각화(data visualization)할 수 있다.In addition, by utilizing the present invention, documents stored in a cloud document platform can be converted into metadata to store document elements, similarity between specific document elements can be compared to recommend similar document elements to users in real time, and data visualization can be performed to visually express data analysis results for easy understanding.
본 발명을 이용하면, 도표(graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달할 수 있고, 문서 플랫폼에서 사용자가 입력한 문서요소와 데이터로 변환되어 저장된 문서요소의 유사도를 비교하여 추천하기 때문에 리소스가 많이 소요되는 기존의 문서 비교방식이 아닌 문서요소간 관계를 바탕으로 유사도를 측정하는 새로운 형태의 유사도 측정 방식을 제공할 수 있다.By using the present invention, information can be clearly and effectively conveyed through a means called a graph, and since the similarity between document elements input by a user in a document platform and document elements converted into data and saved are compared and recommended, a new type of similarity measurement method can be provided that measures similarity based on the relationship between document elements rather than the existing document comparison method that consumes a lot of resources.
이상에서 설명된 장치는 하드웨어 구성요소, 소프트웨어 구성요소, 및/또는 하드웨어 구성요소 및 소프트웨어 구성요소의 조합으로 구현될 수 있다. 예를 들어, 실시예들에서 설명된 장치 및 구성요소는, 예를 들어, 프로세서, 콘트롤러, ALU(arithmetic logic unit), 디지털 신호 프로세서(digital signal processor), 마이크로컴퓨터, FPA(field programmable array), PLU(programmable logic unit), 마이크로프로세서, 또는 명령(instruction)을 실행하고 응답할 수 있는 다른 어떠한 장치와 같이, 하나 이상의 범용 컴퓨터 또는 특수 목적 컴퓨터를 이용하여 구현될 수 있다. 처리 장치는 운영 체제(OS) 및 상기 운영 체제 상에서 수행되는 하나 이상의 소프트웨어 애플리케이션을 수행할 수 있다. 또한, 처리 장치는 소프트웨어의 실행에 응답하여, 데이터를 접근, 저장, 조작, 처리 및 생성할 수도 있다. 이해의 편의를 위하여, 처리 장치는 하나가 사용되는 것으로 설명된 경우도 있지만, 해당 기술분야에서 통상의 지식을 가진 자는, 처리 장치가 복수 개의 처리 요소(processing element) 및/또는 복수 유형의 처리 요소를 포함할 수 있음을 알 수 있다. 예를 들어, 처리 장치는 복수 개의 프로세서 또는 하나의 프로세서 및 하나의 콘트롤러를 포함할 수 있다. 또한, 병렬 프로세서(parallel processor)와 같은, 다른 처리 구성(processing configuration)도 가능하다.The devices described above may be implemented as hardware components, software components, and/or a combination of hardware components and software components. For example, the devices and components described in the embodiments may be implemented using one or more general-purpose computers or special-purpose computers, such as, for example, a processor, a controller, an arithmetic logic unit (ALU), a digital signal processor, a microcomputer, a field programmable array (FPA), a programmable logic unit (PLU), a microprocessor, or any other device capable of executing instructions and responding to them. The processing device may execute an operating system (OS) and one or more software applications running on the operating system. In addition, the processing device may access, store, manipulate, process, and generate data in response to the execution of the software. For ease of understanding, the processing device is sometimes described as being used alone, but those skilled in the art will appreciate that the processing device may include multiple processing elements and/or multiple types of processing elements. For example, the processing device may include multiple processors, or a processor and a controller. Other processing configurations, such as parallel processors, are also possible.
소프트웨어는 컴퓨터 프로그램(computer program), 코드(code), 명령(instruction), 또는 이들 중 하나 이상의 조합을 포함할 수 있으며, 원하는 대로 동작하도록 처리 장치를 구성하거나 독립적으로 또는 결합적으로(collectively) 처리 장치를 명령할 수 있다. 소프트웨어 및/또는 데이터는, 처리 장치에 의하여 해석되거나 처리 장치에 명령 또는 데이터를 제공하기 위하여, 어떤 유형의 기계, 구성요소(component), 물리적 장치, 가상 장치(virtual equipment), 컴퓨터 저장 매체 또는 장치, 또는 전송되는 신호 파(signal wave)에 영구적으로, 또는 일시적으로 구체화(embody)될 수 있다. 소프트웨어는 네트워크로 연결된 컴퓨터 시스템 상에 분산되어서, 분산된 방법으로 저장되거나 실행될 수도 있다. 소프트웨어 및 데이터는 하나 이상의 컴퓨터 판독 가능 기록 매체에 저장될 수 있다.The software may include a computer program, code, instructions, or a combination of one or more of these, which may configure a processing device to perform a desired operation or may independently or collectively command the processing device. The software and/or data may be permanently or temporarily embodied in any type of machine, component, physical device, virtual equipment, computer storage medium or device, or transmitted signal waves, for interpretation by the processing device or for providing instructions or data to the processing device. The software may also be distributed over network-connected computer systems, and stored or executed in a distributed manner. The software and data may be stored on one or more computer-readable recording media.
실시예에 따른 방법은 다양한 컴퓨터 수단을 통하여 수행될 수 있는 프로그램 명령 형태로 구현되어 컴퓨터 판독 가능 매체에 기록될 수 있다. 상기 컴퓨터 판독 가능 매체는 프로그램 명령, 데이터 파일, 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 상기 매체에 기록되는 프로그램 명령은 실시예를 위하여 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다. 컴퓨터 판독 가능 기록 매체의 예에는 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체(magnetic media), CD-ROM, DVD와 같은 광기록 매체(optical media), 플롭티컬 디스크(floptical disk)와 같은 자기-광 매체(magneto-optical media), 및 롬(ROM), 램(RAM), 플래시 메모리 등과 같은 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 프로그램 명령의 예에는 컴파일러에 의해 만들어지는 것과 같은 기계어 코드뿐만 아니라 인터프리터 등을 사용해서 컴퓨터에 의해서 실행될 수 있는 고급 언어 코드를 포함한다. 상기된 하드웨어 장치는 실시예의 동작을 수행하기 위해 하나 이상의 소프트웨어 모듈로서 작동하도록 구성될 수 있으며, 그 역도 마찬가지이다.The method according to the embodiment may be implemented in the form of program commands that can be executed through various computer means and recorded on a computer-readable medium. The computer-readable medium may include program commands, data files, data structures, etc., alone or in combination. The program commands recorded on the medium may be those specially designed and configured for the embodiment or may be those known to and available to those skilled in the art of computer software. Examples of the computer-readable recording medium include magnetic media such as hard disks, floppy disks, and magnetic tapes, optical media such as CD-ROMs and DVDs, magneto-optical media such as floptical disks, and hardware devices specially configured to store and execute program commands such as ROMs, RAMs, flash memories, etc. Examples of the program commands include not only machine language codes generated by a compiler but also high-level language codes that can be executed by a computer using an interpreter, etc. The hardware devices described above may be configured to operate as one or more software modules to perform the operations of the embodiment, and vice versa.
이상과 같이 실시예들이 비록 한정된 도면에 의해 설명되었으나, 해당 기술분야에서 통상의 지식을 가진 자라면 상기의 기재로부터 다양한 수정 및 변형이 가능하다. 예를 들어, 설명된 기술들이 설명된 방법과 다른 순서로 수행되거나, 및/또는 설명된 시스템, 구조, 장치, 회로 등의 구성요소들이 설명된 방법과 다른 형태로 결합 또는 조합되거나, 다른 구성요소 또는 균등물에 의하여 대치되거나 치환되더라도 적절한 결과가 달성될 수 있다.Although the embodiments have been described with limited drawings as described above, those skilled in the art will appreciate that various modifications and variations may be made from the above teachings. For example, appropriate results may be achieved even if the described techniques are performed in a different order than the described method, and/or components of the described system, structure, device, circuit, etc. are combined or combined in a different form than the described method, or are replaced or substituted by other components or equivalents.
그러므로, 다른 구현들, 다른 실시예들 및 특허청구범위와 균등한 것들도 후술하는 특허청구범위의 범위에 속한다.Therefore, other implementations, other embodiments, and equivalents to the claims are also included in the scope of the claims described below.
Claims (14)
Translated fromKorean추출된 주어, 목적어, 술어를 포함하는 지식그래프를 그래프 데이터베이스에 추가하는 단계;
상기 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가하는 단계;
상기 문서 위치 데이터가 추가된 메타데이터를 관계형성 모듈에 전달하는 단계; 및
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계
를 포함하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법.A step of analyzing the input document elements to extract the subject (S, subject), object (O, object), and predicate (P, property);
A step of adding a knowledge graph including the extracted subject, object, and predicate to a graph database;
A step of adding document location data to metadata including the extracted subject, object, and predicate;
A step of transferring metadata with the above document location data added to the relationship formation module; and
Step of recording a knowledge graph containing document element information in the above relationship formation module into the above graph database
A method for forming document relationships by merging triple data and location information based on a graph database including .
상기 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가하는 단계는,
상기 술어에 상기 문서 위치 데이터를 추가하는 단계
를 포함하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법.In the first paragraph,
The step of adding document location data to the metadata including the extracted subject, object, and predicate is as follows.
Step of adding the document location data to the above predicate
A method for forming document relationships by merging triple data and location information based on a graph database including .
상기 관계형성 모듈에서 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계는,
상기 트리플 데이터 그래프에 위치정보를 라벨링하여 상기 문서요소 지식그래프를 생성하고, 상기 생성된 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계
를 포함하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법.In the first paragraph,
The step of recording the document element knowledge graph in the above relationship formation module to the above graph database is:
A step of creating a document element knowledge graph by labeling location information in the above triple data graph, and recording the created document element knowledge graph in the graph database.
A method for forming document relationships by merging triple data and location information based on a graph database including .
상기 문서 위치 데이터는,
문서 및 상기 문서 내에서 사용된 위치를 찾기 위한 정보로서, 상기 추출된 주어, 목적어, 술어가 위치하는 문서의 식별정보(ID), 문단 위치, 문장 위치를 포함하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법.In the first paragraph,
The above document location data is,
A method for forming a document relationship by merging triple data based on a graph database and location information, characterized in that it includes identification information (ID), paragraph location, and sentence location of the document in which the extracted subject, object, and predicate are located, as information for finding a document and the location used within the document.
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계는,
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 기등록된 지식그래프에 업데이트 하는 단계
를 포함하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법.In the first paragraph,
The step of recording the knowledge graph containing document element information in the above relationship formation module to the above graph database is:
Step of updating the knowledge graph containing document element information in the above relationship formation module to the pre-registered knowledge graph
A method for forming a document relationship by merging triple data and location information based on a graph database, characterized in that it includes .
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 단계는,
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성하는 단계
를 포함하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법.In the first paragraph,
The step of recording the knowledge graph containing document element information in the above relationship formation module to the above graph database is:
Step of creating a knowledge graph containing document element information in the above relationship formation module
A method for forming document relationships by merging triple data and location information based on a graph database including .
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성하는 단계는,
문장요약 기술에 활용되는 문서요소 간 관계기술로써 문서에 포함된 각 문장의 단어를 나타내는 노드(node)들을 문장 내 동시 출현 관계에 대한 가중치를 가지는 엣지(edge)로 연결하여 단어 그래프(Gword)를 생성하는 단계; 및
각 문장을 나타내는 노드들을 문장간 유사도에 대한 가중치를 가지는 엣지로 연결하여 문장 그래프(Gsentence)를 생성하는 단계
를 포함하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 방법.In Article 6,
The step of creating a knowledge graph containing document element information in the above relationship formation module is:
A step of creating a word graph (Gword) by connecting nodes representing words of each sentence included in a document with edges having weights for co-occurrence relationships within the sentence as a relationship technology between document elements used in sentence summarization technology; and
A step for creating a sentence graph (Gsentence) by connecting nodes representing each sentence with edges that have weights for the similarity between sentences.
A method for forming document relationships by merging triple data and location information based on a graph database including .
상기 추출된 주어, 목적어, 술어를 포함하는 지식그래프를 그래프 데이터베이스에 기록하고, 상기 추출된 주어, 목적어, 술어를 문서 데이터베이스에 기록하는 데이터베이스 처리부;
상기 추출된 주어, 목적어, 술어를 포함하는 메타데이터에 문서 위치 데이터를 추가하는 문서 위치 처리부; 및
상기 문서 위치 데이터가 추가된 메타데이터를 수신하여, 문서요소 정보가 포함된 지식그래프를 생성하고, 상기 생성된 문서요소 정보가 포함된 지식그래프를 상기 그래프 데이터베이스에 기록하는 관계형성 처리부
를 포함하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템.SPO extraction unit that analyzes the input document elements to extract the subject (S, subject), object (O, object), and predicate (P, property);
A database processing unit that records a knowledge graph including the extracted subject, object, and predicate in a graph database, and records the extracted subject, object, and predicate in a document database;
A document location processing unit that adds document location data to metadata including the extracted subject, object, and predicate; and
A relational processing unit that receives metadata with the document location data added thereto, generates a knowledge graph including document element information, and records the knowledge graph including the generated document element information in the graph database.
A document relational formation system that combines triple data and location information based on a graph database.
상기 문서 위치 처리부는,
상기 술어에 상기 문서 위치 데이터를 추가하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템.In Article 8,
The above document location processing unit is,
A document relation formation system that merges triple data and location information based on a graph database, characterized by adding document location data to the above predicate.
상기 관계형성 처리부는,
상기 트리플 데이터 그래프에 위치정보를 라벨링하여 상기 문서요소 지식그래프를 생성하고, 상기 생성된 문서요소 지식그래프를 상기 그래프 데이터베이스에 기록하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템.In Article 8,
The above relationship formation processing unit,
A document relationship formation system that combines triple data and location information based on a graph database, characterized in that it creates a document element knowledge graph by labeling location information in the triple data graph and records the created document element knowledge graph in the graph database.
상기 문서 위치 데이터는,
문서 및 상기 문서 내에서 사용된 위치를 찾기 위한 정보로서, 상기 추출된 주어, 목적어, 술어가 위치하는 문서의 식별정보(ID), 문단 위치, 문장 위치를 포함하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템.In Article 8,
The above document location data is,
A document relation formation system that combines triple data and location information based on a graph database, characterized in that it includes identification information (ID), paragraph location, and sentence location of the document in which the extracted subject, object, and predicate are located, as information for finding a document and the location used within the document.
상기 관계형성 처리부는,
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 기등록된 지식그래프에 업데이트 하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템.In Article 8,
The above relationship formation processing unit,
A document relationship formation system that combines triple data and location information based on a graph database, characterized in that the knowledge graph containing document element information in the above relationship formation module is updated in a pre-registered knowledge graph.
상기 관계형성 처리부는,
상기 관계형성 모듈에서 문서요소 정보가 포함된 지식그래프를 생성하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템.In Article 8,
The above relationship formation processing unit,
A document relationship formation system that combines triple data and location information based on a graph database, characterized in that it creates a knowledge graph containing document element information in the above relationship formation module.
상기 관계형성 처리부는,
문장요약 기술에 활용되는 문서요소 간 관계기술로써 문서에 포함된 각 문장의 단어를 나타내는 노드(node)들을 문장 내 동시 출현 관계에 대한 가중치를 가지는 엣지(edge)로 연결하여 단어 그래프(Gword)를 생성하고, 각 문장을 나타내는 노드들을 문장간 유사도에 대한 가중치를 가지는 엣지로 연결하여 문장 그래프(Gsentence)를 생성하는 것을 특징으로 하는 그래프 데이터베이스 기반 트리플 데이터와 위치 정보를 병합한 형태의 문서 관계형성 시스템.
In Article 13,
The above relationship formation processing unit,
A document relation formation system that combines triple data and location information based on a graph database, characterized by creating a word graph (Gword) by connecting nodes representing words of each sentence included in a document with edges having weights for co-occurrence relationships within the sentences as a relational technology between document elements utilized in sentence summarization technology, and creating a sentence graph (Gsentence) by connecting nodes representing each sentence with edges having weights for similarity between sentences.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020230130703AKR20250046799A (en) | 2023-09-27 | 2023-09-27 | System and method for establishing document relationships in the form of merging triple data and location information based on a graph database |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020230130703AKR20250046799A (en) | 2023-09-27 | 2023-09-27 | System and method for establishing document relationships in the form of merging triple data and location information based on a graph database |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20250046799Atrue KR20250046799A (en) | 2025-04-03 |
Family
ID=95478409
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020230130703APendingKR20250046799A (en) | 2023-09-27 | 2023-09-27 | System and method for establishing document relationships in the form of merging triple data and location information based on a graph database |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20250046799A (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6116247B2 (en) | 2009-10-02 | 2017-04-19 | ムスルリ, アラビンドMUSULURI, Aravind | System and method for searching for documents with block division, identification, indexing of visual elements |
| JP6629942B2 (en) | 2017-11-13 | 2020-01-15 | アクセンチュア グローバル ソリューションズ リミテッド | Hierarchical automatic document classification and metadata identification using machine learning and fuzzy matching |
| JP7289047B2 (en) | 2017-12-01 | 2023-06-09 | インターナショナル・ビジネス・マシーンズ・コーポレーション | Method, computer program and system for block-based document metadata extraction |
- 2023
- 2023-09-27KRKR1020230130703Apatent/KR20250046799A/enactivePending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6116247B2 (en) | 2009-10-02 | 2017-04-19 | ムスルリ, アラビンドMUSULURI, Aravind | System and method for searching for documents with block division, identification, indexing of visual elements |
| JP6629942B2 (en) | 2017-11-13 | 2020-01-15 | アクセンチュア グローバル ソリューションズ リミテッド | Hierarchical automatic document classification and metadata identification using machine learning and fuzzy matching |
| JP7289047B2 (en) | 2017-12-01 | 2023-06-09 | インターナショナル・ビジネス・マシーンズ・コーポレーション | Method, computer program and system for block-based document metadata extraction |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Babur et al. | Hierarchical clustering of metamodels for comparative analysis and visualization | |
| Avasthi et al. | Techniques, applications, and issues in mining large-scale text databases | |
| US11893008B1 (en) | System and method for automated data harmonization | |
| CN114254201A (en) | A recommendation method for scientific and technological project evaluation experts | |
| Lamba et al. | Text Mining for Information Professionals | |
| CN112990973B (en) | Online shop portrait construction method and system | |
| US20220358379A1 (en) | System, apparatus and method of managing knowledge generated from technical data | |
| CN116595173A (en) | Data processing method, device, equipment and storage medium for policy information management | |
| Soto et al. | Similarity-based support for text reuse in technical writing | |
| KR20240121138A (en) | Device and method for extracting semantic information from online review | |
| Ouared et al. | Capitalizing the database cost models process through a service‐based pipeline | |
| Yang et al. | User story clustering in agile development: a framework and an empirical study | |
| Siklósi | Using embedding models for lexical categorization in morphologically rich languages | |
| Wang et al. | Acemap: Knowledge discovery through academic graph | |
| Mukherjee et al. | Comparing research topics through metatags analysis: a multi-module machine algorithm approaches using real world data on digital humanities | |
| Afolabi et al. | Topic modelling for research perception: techniques, processes and a case study | |
| US20230385311A1 (en) | Semantic-Temporal Visualization of Information | |
| Alvarez-Rodriguez et al. | Enabling policy making processes by unifying and reconciling corporate names in public procurement data. The CORFU technique | |
| Graciotti et al. | Musical heritage historical entity linking | |
| Uddin et al. | Information and relation extraction for semantic annotation of ebook texts | |
| KR20250046799A (en) | System and method for establishing document relationships in the form of merging triple data and location information based on a graph database | |
| Raiyani et al. | Automated Event Extraction Model for Linked Portuguese Documents. | |
| Zhu | Financial data analysis application via multi-strategy text processing | |
| Sai et al. | Identification and visualization of legal definitions and legal term relations | |
| Charles et al. | Data Quality Assessment in Europeana: Metrics for Multilinguality. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20230927 | |
| PA0201 | Request for examination | Patent event code:PA02011R01I Patent event date:20230927 Comment text:Patent Application | |
| PG1501 | Laying open of application |