KR20230009564A - Learning data correction method and apparatus thereof using ensemble score - Google Patents
Learning data correction method and apparatus thereof using ensemble scoreDownload PDFInfo
- Publication number
- KR20230009564A KR20230009564AKR1020210090106AKR20210090106AKR20230009564AKR 20230009564 AKR20230009564 AKR 20230009564AKR 1020210090106 AKR1020210090106 AKR 1020210090106AKR 20210090106 AKR20210090106 AKR 20210090106AKR 20230009564 AKR20230009564 AKR 20230009564A
- Authority
- KR
- South Korea
- Prior art keywords
- word
- similarity
- words
- phoneme
- candidate
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/268—Morphological analysis
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromKorean본 발명은 앙상블 스코어를 이용한 학습 데이터 교정 방법 및 그 장치에 관한 것이다.The present invention relates to a learning data correction method using an ensemble score and an apparatus therefor.
최근 인공지능(AI)이 급진적으로 발전함에 따라, 다양한 AI 기술들이 진화하고 있다. 그 중 머신러닝(Machine learning)은 인공지능 기술의 여러 방법 중 중요한 방법론이며, 머신러닝 관심에 따라, 교육, 금융, 통신, 관광 등 다양한 분야로 확산되며, 다양한 형태로 발전이 되고 있다. 이러한 머신러닝은 빅데이터를 통한 학습방법으로 기본적으로 알고리즘이 탑재한 엔진을 이용해 데이터를 분석하고 분석을 통해 모델을 학습하는 기술이다. 특히, 자연어처리(Natural Language Processing, NLP)는 기계에게 인간의 언어를 이해시킨다는 점에서 인공지능의 핵심 기반 기술로 자리잡고 있다.As artificial intelligence (AI) develops rapidly in recent years, various AI technologies are evolving. Among them, machine learning is an important methodology among many methods of artificial intelligence technology, and according to interest in machine learning, it spreads to various fields such as education, finance, communication, and tourism, and is being developed in various forms. Machine learning is a learning method based on big data, which basically analyzes data using an engine equipped with an algorithm and learns a model through analysis. In particular, Natural Language Processing (NLP) is positioned as a core technology for artificial intelligence in that it enables machines to understand human language.
머신러닝 학습 과정은 도 1에서와 같이 학습 데이터(텍스트)가 입력으로 주어지면 머신러닝 엔진(Machine learning engine)에서는 데이터들의 의미를 파악하기 위한 전처리 및 분석을 수행하고 학습 데이터로 모델을 만들고 평가 세트로 그 모델의 성능을 검증하여 최종적으로 모델을 생성하는 절차를 거친다. 학습 데이터는 텍스트로, 학습 데이터는 사람이 사용하는 것이라 많은 오탈자가 발생할 수 밖에 없다. 그래서, 기계에게 인간의 언어를 이해시키기 위한 가장 기본적이면서 먼저 처리하는 수단은 오탈자를 처리하는 것이다. 오탈자는 사용자 타이핑 또는 음성인식 결과 중 잘못 쓴 텍스트(오자)와 빠진 텍스트(탈자)를 아울러 부르는 말로 해당 언어를 인식하지 못해 그 뜻이 왜곡될 수 있을 뿐더러 올바른 학습을 하지 못한다. 예를 들어, '애국가' 단어를 인식하는 기계에게 사람이 사용하는 '애국까', '애구가', '애꾹까' 등과 같은 오탈자를 입력한다면, 언어 뜻이 명확하지 않거나 의미가 변형되는 경우가 많으며, 기계는 이들 오탈자를 자연어 처리의 형태소 분석으로 진행하는 데 어려움이 있거나, 다른 의미의 언어로 인식된다면 결과치의 정확성이 떨어질 수 있다. 따라서, 이들 오탈자에 대한 정확도 문제를 해결하기 위해서는 도 2에서와 같이 단어 사전을 이용하여 오탈자를 추출하고 교정 처리하되 적은 처리 비용으로 신뢰도를 높일 수 있는 방법이 필요하다.In the machine learning learning process, when training data (text) is given as an input, as shown in FIG. 1, the machine learning engine performs preprocessing and analysis to understand the meaning of the data, creates a model with the training data, and sets the evaluation set. The performance of the log model is verified and the final model is created. Since the training data is text and the training data is used by people, many typos are bound to occur. So, the most basic and first processing means for making machines understand human language is to process typos. A typo may not only distort the meaning of a user's typing or speech recognition result, but also fail to learn correctly because he or she cannot recognize the language by calling both the incorrectly written text (misprint) and the missing text (missing character). For example, if a machine that recognizes the word 'patriotic national anthem' inputs misspellings such as 'patriotic kka', 'aeguga', and 'aegukga' that are used by humans, the meaning of the language may not be clear or the meaning may be transformed. There are many, and the machine has difficulty in proceeding with morpheme analysis of natural language processing, or if it is recognized as a language with a different meaning, the accuracy of the result may be reduced. Therefore, in order to solve the accuracy problem of these misspellings, a method of extracting and correcting the misspellings using a word dictionary as shown in FIG. 2 and increasing reliability at a low processing cost is required.
특히, 오탈자 문제를 해결하기 위해 많은 종류의 신뢰도가 개발되어 왔다. 대부분의 연구나 특허 자료에서는 음소 모델을 이용하여 오탈자 문제를 올바른 단어로 매칭하려는 시도로 진행되어 왔다. 하지만, 단어의 음소보다는 "ㄱ,ㄴ,ㄷ, .."과 같이 자소 단위로 제약적으로 사용되어 정확도를 보장할 수 없다.In particular, many types of reliability have been developed to solve the typo problem. Most studies or patent data have been carried out in an attempt to match misspelling problems with correct words using phoneme models. However, accuracy cannot be guaranteed because it is limitedly used in units of grapheme, such as "a, b, c, .." rather than phonemes of words.
또한, 종래기술에서는 음소 모델로 오탈자와 올바른 단어 간 유사도 비교로 정밀 매칭(exact matching) 방법을 적용하였다. 이 방법은 분리한 음소들을 서로 비교하여 일치하면 개수를 증가시키는 방법으로 만약, 단어의 받침이나 누락된 음소가 있다면 이 방법은 적절하지가 않다.In addition, in the prior art, an exact matching method was applied by comparing the similarity between misspellings and correct words as a phoneme model. This method compares the separated phonemes with each other and increases the number if they match. If there is a word support or missing phoneme, this method is not appropriate.
또한, 오탈자와 단어 간 편집 거리 방법의 연구들은 레벤스타인 거리(Levenshtein distance)를 활용한 한글 유사도 판단 알고리즘을 대부분 사용되었다. 레벤스타인 거리 알고리즘은 음성인식, 철자법 검사, 검색 엔진 등 다양한 분야에서 널리 사용되는 방법으로, 편집 거리 값은 0~9까지이며, 단어 간의 유사도가 높을 수록 0의 값에 가깝다. 하지만, 이 알고리즘은 단어내 음소들 간의 순서가 정해지지 않는 경우에 사용되며, 다양한 비인식 대상 단어(OOV, Out of Vocabulary)로 인하여 이들 음소 단위의 적은 유사성을 갖더라도 정확한 신뢰도를 보장할 수 없다는 문제점이 있다.In addition, most of the studies on the editing distance method between misspellings and words used the Hangul similarity judgment algorithm using the Levenshtein distance. The Levenstein distance algorithm is a method widely used in various fields such as speech recognition, spelling check, and search engines. However, this algorithm is used when the order of phonemes in a word is not determined, and due to various non-recognized target words (OOV, Out of Vocabulary), accurate reliability cannot be guaranteed even if these phoneme units have a small similarity. there is
본 발명은 전술한 필요성 및/또는 문제점을 해결하는 것을 목적으로 한다.The present invention aims to address the aforementioned needs and/or problems.
또한, 사용자 입력 채널(음성인식, 타이핑 등)로 들어온 오탈자 문제를 파악하고, 이를 낮은 비용으로도 오탈자를 올바른 결과로 개선 및 유도하여 교정하고 단어의 가장 작은 단위로 하나의 단위가 아닌 음소, 자소, 음차 단위의 신뢰도를 활용하여 정확도를 높일 수 있도록 한 앙상블 스코어를 이용한 학습 데이터 교정 방법 및 그 장치를 제공함을 목적으로 한다.In addition, it identifies typographical errors that have entered the user input channel (speech recognition, typing, etc.), corrects them by improving and inducing them to correct results at a low cost, and converts them into the smallest units of words, phonemes and graphemes, not one unit. It is an object of the present invention to provide a learning data calibration method and apparatus using an ensemble score that can increase accuracy by utilizing the reliability of a tuning fork unit.
상기한 목적을 달성하기 위한 본 발명에 따른 앙상블 스코어를 이용한 학습 데이터 교정 방법의 일측면에 따르면, 유사도 매칭 모듈이 사용자 입력채널을 통해 입력된 학습 문장을 최소 단위의 형태소 분석 및 품사 사전에 따라 단어의 품사를 태깅하는 단계; 상기 유사도 매칭 모듈이 상기 품사 태깅시 발생한 오류에 따라 학습 문장에서 오탈자 단어를 선별하는 단계; 상기 유사도 매칭 모듈이 상기 학습 문장에서 선별된 오탈자 단어에 대해 기설정된 한계값(threshold)에 기초하여 적어도 하나 이상의 후보 단어와의 단어 간 유사도를 비교하는 단계; 상기 유사도 매칭 모듈이 단어 간 유사도가 기설정된 한계값보다 작은 경우 상기 오탈자 단어를 자소, 음소 및 음차 요소로 변환하는 단계; 및 상기 유사도 매칭 모듈이 상기 변환된 오탈자 단어의 자소, 음소 및 음차 요소를 단어 요소 사전에 저장된 정단어의 자소, 음소 및 음차 요소들과 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 후보 단어를 검색하고 검색된 후보 단어가 1개이고 단어 간 유사도가 기설정된 한계값보다 큰 경우 검색된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계;를 포함할 수 있다.According to one aspect of the learning data correction method using ensemble scores according to the present invention for achieving the above object, the similarity matching module analyzes the learning sentence input through the user input channel in the smallest unit of morpheme analysis and word according to the part-of-speech dictionary. tagging parts of speech; selecting, by the similarity matching module, misspelled words from the learning sentence according to an error generated during the part-of-speech tagging; comparing, by the similarity matching module, similarities between words with at least one candidate word based on a predetermined threshold for misspelled words selected from the learning sentence; converting, by the similarity matching module, the misspelled words into grapheme, phoneme, and phoneme elements when the similarity between words is less than a predetermined threshold value; and the similarity matching module compares the phoneme, phoneme, and phoneme elements of the converted misspelled word with the phoneme, phoneme, and phoneme elements of the regular word stored in the word element dictionary, as candidates according to a similarity comparison result between words based on a Levenstein distance algorithm. Searching for a word, and generating a corrected learning sentence by replacing the misspelled word with the searched candidate word when the searched candidate word is one and the similarity between the words is greater than a predetermined threshold value.
상기 유사도 매칭 모듈이 상기 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 검색된 후보 단어가 2개 이상인 경우 2개 이상의 후보 단어 중에서 자카드 유사도 계수를 적용하여 단어 간 음소 및 자소열을 공유하는 유사도가 높은 순서에 따라 적어도 하나 이상의 후보 단어를 검색하는 단계; 및 상기 유사도 매칭 모듈이 상기 자카드 유사도 계수 적용에 의해 검색된 적어도 하나 이상의 후보 단어에서 단어 간 유사도가 기설정된 한계값보다 크고 유사도가 가장 높은 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계;를 포함할 수 있다.The similarity matching module applies a Jacquard similarity coefficient among two or more candidate words to share phonemes and grapheme sequences between words when there are two or more candidate words searched according to the similarity comparison result between words based on the Levenstein distance algorithm. Retrieving at least one or more candidate words according to a higher order of ?; and the similarity matching module generates a corrected learning sentence by replacing the misspelled word with a candidate word having a similarity greater than a preset threshold and having the highest similarity among at least one or more candidate words searched by applying the Jacquard similarity coefficient. step; may be included.
상기 유사도 매칭 모듈이 상기 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 검색된 후보 단어가 2개 이상인 경우 2개 이상의 후보 단어 중에서 자카드 유사도 계수를 적용하여 단어 간 음소 및 자소열을 공유하는 유사도가 높은 순서에 따라 적어도 하나 이상의 후보 단어를 검색하는 단계에서, 상기 유사도 매칭 모듈이 상기 자카드 유사도 계수 적용에 의해 검색된 후보 단어의 개수가 2개 이상 검색된 경우 사용자에 의해 선택된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계를 더 포함할 수 있다.The similarity matching module applies a Jacquard similarity coefficient among two or more candidate words to share phonemes and grapheme sequences between words when there are two or more candidate words searched according to the similarity comparison result between words based on the Levenstein distance algorithm. In the step of searching for at least one or more candidate words according to the order of high, the similarity matching module selects the misspelled word as a candidate word selected by the user when the number of candidate words searched by applying the Jacquard similarity coefficient is two or more. The method may further include generating a corrected learning sentence by replacing it.
상기 유사도 매칭 모듈이 단어 간 유사도가 기설정된 한계값보다 작은 경우 상기 오탈자 단어를 자소, 음소 및 음차 요소로 변환하는 단계 이후에, 단어 요소 생성모듈이 정단어를 포함하여 정단어의 자소, 음소, 음차 요소를 추출하여 저장된 단어 요소 사전으로 구성하는 단계를 더 포함할 수 있다.After the step of converting the misspelled word into grapheme, phoneme, and transliteration elements when the similarity between words is smaller than a preset threshold by the similarity matching module, the word element generation module includes the regular word and includes the phoneme, phoneme, and phoneme of the regular word. The method may further include extracting transliteration elements and constructing them into a stored word element dictionary.
상기 단어 요소 사전은 정단어를 자소 단위의 요소로 표기한 자소 사전, 자소 단위의 요소를 발음 상의 요소로 표기한 음소 사전 및 자소 단위의 요소를 발음 기호로 변환하여 표기한 음차 사전을 포함할 수 있다.The word element dictionary may include a grapheme dictionary in which positive words are expressed as elements in phoneme units, a phoneme dictionary in which elements in phoneme units are expressed as phonetic elements, and a phoneme dictionary in which elements in phoneme units are converted into phonetic symbols and displayed. there is.
상기 유사도 매칭 모듈이 상기 자카드 유사도 계수 적용에 의해 검색된 적어도 하나 이상의 후보 단어에서 단어 간 유사도가 기설정된 한계값보다 크고 유사도가 가장 높은 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계에서, 상기 유사도가 가장 높은 후보 단어는 상기 자소 사전, 음소 사전 및 음차 사전에 기초하여 상기 레벤스타인 거리 알고리즘과 상기 자카드 유사도 계수를 적용하여 계산된 유사도 앙상블 스코어에 의해 선정될 수 있다.generating a corrected learning sentence by replacing, by the similarity matching module, the misspelled word with a candidate word having the highest similarity and a similarity between words in at least one candidate word searched by applying the Jacquard similarity coefficient; In , the candidate word having the highest similarity may be selected by a similarity ensemble score calculated by applying the Levenstein distance algorithm and the Jacquard similarity coefficient based on the grapheme dictionary, the phoneme dictionary, and the transliteration dictionary.
한편, 상기한 목적을 달성하기 위한 본 발명에 따른 앙상블 스코어를 이용한 학습 데이터 교정 장치의 일측면에 따르면, 단어 요소별 자소, 음소 및 음차 요소를 생성하는 단어 요소 생성모듈; 상기 단어 요소 생성모듈에 의해 생성된 단어 요소별 자소, 음소 및 음차 요소를 각각 저장하는 단어 요소 사전; 및 사용자 입력채널을 통해 입력된 학습 문장에서 발생한 오탈자 단어를 추출하고 추출한 오탈자 단어의 자소, 음소 및 음차 요소를 상기 단어 요소 사전에 저장된 정단어의 자소, 음소 및 음차 요소들과 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 후보 단어를 검색하고, 검색된 후보 단어가 1개이고 단어 간 유사도가 기설정된 한계값보다 큰 경우 검색된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 유사도 매칭 모듈;을 포함하고, 상기 유사도 매칭 모듈은, 상기 사용자 입력채널을 통해 입력된 학습 문장을 최소 단위의 형태소 분석 및 품사 사전에 따라 단어의 품사를 태깅하고, 상기 품사 태깅시 발생한 오류에 따라 학습 문장에서 오탈자 단어를 선별하고, 상기 학습 문장에서 선별된 오탈자 단어에 대해 기설정된 한계값(threshold)에 기초하여 적어도 하나 이상의 후보 단어와의 단어 간 유사도를 비교하여 단어 간 유사도가 기설정된 한계값보다 작은 경우 상기 오탈자 단어를 자소, 음소 및 음차 요소로 변환할 수 있다.On the other hand, according to one aspect of the learning data correction device using the ensemble score according to the present invention for achieving the above object, a word element generation module for generating grapheme, phoneme and phoneme elements for each word element; a word element dictionary for storing grapheme, phoneme, and transliteration elements for each word element generated by the word element generating module; and misspelled words generated in the learning sentence input through the user input channel are extracted, and the phoneme, phoneme, and phoneme elements of the extracted misspelled word are combined with the phoneme, phoneme, and phoneme elements of the regular word stored in the word element dictionary and the Levenstein distance algorithm. A candidate word is searched according to a similarity comparison result between words based on , and when the searched candidate word is one and the similarity between words is greater than a predetermined threshold value, the misspelled word is replaced with the searched candidate word to generate a corrected learning sentence. and a matching module, wherein the similarity matching module analyzes the learning sentence input through the user input channel according to the minimum unit of morpheme analysis and parts-of-speech dictionary, tags the part-of-speech of a word, and learns according to an error generated during the part-of-speech tagging. A misspelled word is selected from the sentence, and the similarity between words is compared with at least one candidate word based on a preset threshold for the selected misspelled word in the learning sentence, so that the similarity between words is higher than the preset threshold. If it is small, the misspelled word may be converted into grapheme, phoneme, and phoneme elements.
상기 유사도 매칭 모듈은, 상기 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 검색된 후보 단어가 2개 이상인 경우 2개 이상의 후보 단어 중에서 자카드 유사도 계수를 적용하여 단어 간 음소 및 자소열을 공유하는 유사도가 높은 순서에 따라 적어도 하나 이상의 후보 단어를 검색하고, 상기 자카드 유사도 계수 적용에 의해 검색된 적어도 하나 이상의 후보 단어에서 단어 간 유사도가 기설정된 한계값보다 크고 유사도가 가장 높은 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성할 수 있다.The similarity matching module shares phonemes and grapheme sequences between words by applying a Jacquard similarity coefficient among two or more candidate words when two or more candidate words are searched according to a similarity comparison result between words based on the Levenstein distance algorithm. At least one or more candidate words are searched in order of high similarity, and among the at least one or more candidate words searched by applying the Jacquard similarity coefficient, the misspelled word is selected as a candidate word having a similarity greater than a preset threshold and having the highest similarity. The replacement can generate a corrected learning sentence.
상기 유사도 매칭 모듈은, 상기 자카드 유사도 계수를 적용하여 검색된 후보 단어의 개수가 2개 이상 검색된 경우 사용자에 의해 선택된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성할 수 있다.The similarity matching module may generate a corrected learning sentence by replacing the misspelled word with a candidate word selected by a user when the number of candidate words searched by applying the Jacquard similarity coefficient is two or more.
상기 단어 요소 생성모듈은, 정단어를 포함하여 정단어의 자소, 음소, 음차 요소를 추출하여 저장된 단어 요소 사전으로 구성할 수 있다.The word element generating module may extract the phoneme, phoneme, and phoneme elements of the regular word, including the regular word, and configure the stored word element dictionary.
상기 단어 요소 사전은 정단어를 자소 단위의 요소로 표기한 자소 사전, 자소 단위의 요소를 발음 상의 요소로 표기한 음소 사전 및 자소 단위의 요소를 발음 기호로 변환하여 표기한 음차 사전을 포함할 수 있다.The word element dictionary may include a grapheme dictionary in which positive words are expressed as elements in phoneme units, a phoneme dictionary in which elements in phoneme units are expressed as phonetic elements, and a phoneme dictionary in which elements in phoneme units are converted into phonetic symbols and displayed. there is.
상기 유사도가 가장 높은 후보 단어는 상기 자소 사전, 음소 사전 및 음차 사전에 기초하여 상기 레벤스타인 거리 알고리즘과 상기 자카드 유사도 계수를 적용하여 계산된 유사도 앙상블 스코어에 의해 선정될 수 있다.The candidate word having the highest similarity may be selected by a similarity ensemble score calculated by applying the Levenstein distance algorithm and the Jacquard similarity coefficient based on the grapheme dictionary, the phoneme dictionary, and the transliteration dictionary.
본 발명의 일 실시예에 따른 효과에 대해 설명하면 다음과 같다.Effects according to an embodiment of the present invention are described as follows.
본 발명에 의하면, 단어를 하나의 자소 및 음소 단위가 아닌 자소, 음소, 음차 등의 글자 표기상의 요소들을 사용하여 오탈자를 올바른 결과로 개선 및 유도하여 교정함으로써 오탈자 교정의 신뢰성을 향상시킬 수 있다.According to the present invention, the reliability of error correction can be improved by correcting and correcting misspellings by correcting and inducing correct results by using character representation elements such as grapheme, phoneme, and transliteration instead of single grapheme and phoneme units.
또한, 단어 간의 유사도 비교 시에 일부 사용한 종래기술의 단순한 정밀 매칭(exact matching) 방법이 아닌 단어 간의 패턴 정합을 위해 레벤스타인 거리 알고리즘을 사용하였다. 즉, 종래 기술은 유사도 비교를 위해 레벤스타인 거리 알고리즘만 사용하는 것으로 단어 내 음소 및 자소 등의 순서가 정해지지 않는 경우와 다양한 비인식 대상 단어(OOV)로 인한 신뢰성을 고려하지 않아 본 발명에서는 레벤스타인 거리 알고리즘을 통해 유사도를 계산하고 정교한 판단을 위해 두 단어에서 같은 음소 및 자소열을 더 많이 공유할수록 유사한 자카드 유사도 계수(Jaccard similarity coefficient)를 적용하여 정확도가 향상된 신뢰성을 도출할 수 있다.In addition, the Levenstein distance algorithm was used for pattern matching between words, rather than the simple exact matching method of the prior art, which was partially used when comparing the similarity between words. That is, the prior art uses only the Levenstein distance algorithm for similarity comparison, and does not consider the case where the order of phonemes and graphemes in a word is not determined and the reliability due to various unrecognized target words (OOV). Reliability with improved accuracy can be derived by calculating similarity through the Benstein distance algorithm and applying a similar Jaccard similarity coefficient as two words share the same phoneme and grapheme sequence more times for sophisticated judgment.
또한, 종래기술은 매칭되는 오탈자 교정 단어만을 제공하지만, 본 발명은 계산된 단어의 요소별로 앙상블 유사 스코어의 한계치(threshold) 기준으로 정확하게 매칭되는 단어 대치 외에도 후보 단어 목록을 선택함으로 정확도 비용을 높일 수 있다.In addition, the prior art provides only matched misspelling correction words, but the present invention selects a candidate word list in addition to word replacement that is accurately matched based on the threshold of the ensemble similarity score for each element of the calculated word, thereby increasing the accuracy cost. there is.
또한, 본 발명은 오탈자를 올바른 결과로 도출하는 과정에서 낮은 컴퓨팅 파워 비용이 발생하므로, 자연어 질의 처리를 필요로 하는 음성 대화형 에이전트, 챗봇, 기계번역, 텍스트 분석 등 다양한 응용 분야에 활용한다면 효율적일 수 있다.In addition, since the present invention requires low computing power costs in the process of deriving misspellings as correct results, it can be effective if used in various application fields such as voice interactive agents, chatbots, machine translation, and text analysis that require natural language query processing. there is.
본 발명에 관한 이해를 돕기 위해 상세한 설명의 일부로 포함되는, 첨부 도면은 본 발명에 대한 실시예를 제공하고, 상세한 설명과 함께 본 발명의 기술적 특징을 설명한다.
도 1은 일반적인 머신러닝 학습과정의 일예를 나타내는 도면이다.
도 2는 단어 사전을 이용한 오탈자 교정 후 처리하는 과정의 일예를 나타내는 도면이다.
도 3은 본 발명의 일실시예에 따른 학습 데이터 문장에 포함된 오탈자를 바르게 교정하여 올바른 학습 문장으로 생성하는 방법을 나타내는 도면이다.
도 4는 한글 글자 '한'의 자소 분리의 일예를 나타내는 도면이다.
도 5는 단어 사전에서 자소, 음소 및 음차 사전 생성 과정의 일예를 나타내는 도면이다.
도 6은 본 발명에 따른 오탈자의 유사 단어 검색 장치의 구성을 나타내는 도면이다.BRIEF DESCRIPTION OF THE DRAWINGS The accompanying drawings, which are included as part of the detailed description to aid understanding of the present invention, provide examples of the present invention and, together with the detailed description, describe the technical features of the present invention.
1 is a diagram showing an example of a general machine learning learning process.
2 is a diagram illustrating an example of a process of processing after correcting misspellings using a word dictionary.
3 is a diagram illustrating a method of generating a correct learning sentence by correctly correcting misspellings included in a learning data sentence according to an embodiment of the present invention.
4 is a diagram showing an example of character element separation of the Korean character 'Han'.
5 is a diagram illustrating an example of a process of generating a dictionary of graphemes, phonemes, and transliterations in a word dictionary.
6 is a diagram showing the configuration of a similar word search apparatus for misspelled words according to the present invention.
이하, 첨부된 도면을 참조하여 본 발명에 개시된 실시예를 상세히 설명하되, 도면 부호에 관계없이 동일하거나 유사한 구성요소는 동일한 참조 번호를 부여하고 이에 대한 중복되는 설명은 생략하기로 한다. 이하의 설명에서 사용되는 구성요소에 대한 접미사 "모듈" 및 "부"는 명세서 작성의 용이함만이 고려되어 부여되거나 혼용되는 것으로서, 그 자체로 서로 구별되는 의미 또는 역할을 갖는 것은 아니다. 또한, 본 발명에 개시된 실시예를 설명함에 있어서 관련된 공지 기술에 대한 구체적인 설명이 본 발명에 개시된 실시예의 요지를 흐릴 수 있다고 판단되는 경우 그 상세한 설명을 생략한다. 또한, 첨부된 도면은 본 발명에 개시된 실시예를 쉽게 이해할 수 있도록 하기 위한 것일 뿐, 첨부된 도면에 의해 본 발명에 개시된 기술적 사상이 제한되지 않으며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다.Hereinafter, the embodiments disclosed in the present invention will be described in detail with reference to the accompanying drawings, but the same or similar components are given the same reference numerals regardless of reference numerals, and redundant description thereof will be omitted. The suffixes "module" and "unit" for components used in the following description are given or used together in consideration of ease of writing the specification, and do not have meanings or roles that are distinct from each other by themselves. In addition, in describing the embodiments disclosed in the present invention, if it is determined that a detailed description of related known technologies may obscure the gist of the embodiments disclosed in the present invention, the detailed description will be omitted. In addition, the accompanying drawings are only for easy understanding of the embodiments disclosed in the present invention, the technical idea disclosed in the present invention is not limited by the accompanying drawings, and all changes included in the spirit and technical scope of the present invention , it should be understood to include equivalents or substitutes.
제1, 제2 등과 같이 서수를 포함하는 용어는 다양한 구성요소들을 설명하는데 사용될 수 있지만, 상기 구성요소들은 상기 용어들에 의해 한정되지는 않는다. 상기 용어들은 하나의 구성요소를 다른 구성요소로부터 구별하는 목적으로만 사용된다.Terms including ordinal numbers, such as first and second, may be used to describe various components, but the components are not limited by the terms. These terms are only used for the purpose of distinguishing one component from another.
어떤 구성요소가 다른 구성요소에 "연결되어" 있다거나 "접속되어" 있다고 언급된 때에는, 그 다른 구성요소에 직접적으로 연결되어 있거나 또는 접속되어 있을 수도 있지만, 중간에 다른 구성요소가 존재할 수도 있다고 이해되어야 할 것이다. 반면에, 어떤 구성요소가 다른 구성요소에 "직접 연결되어" 있다거나 "직접 접속되어" 있다고 언급된 때에는, 중간에 다른 구성요소가 존재하지 않는 것으로 이해되어야 할 것이다.It is understood that when an element is referred to as being "connected" or "connected" to another element, it may be directly connected or connected to the other element, but other elements may exist in the middle. It should be. On the other hand, when an element is referred to as “directly connected” or “directly connected” to another element, it should be understood that no other element exists in the middle.
단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다.Singular expressions include plural expressions unless the context clearly dictates otherwise.
본 출원에서, "포함한다" 또는 "가지다" 등의 용어는 명세서상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.In this application, terms such as "comprise" or "have" are intended to designate that there is a feature, number, step, operation, component, part, or combination thereof described in the specification, but one or more other features It should be understood that the presence or addition of numbers, steps, operations, components, parts, or combinations thereof is not precluded.
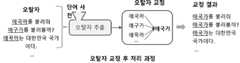
도 3은 본 발명의 일실시예에 따른 학습 데이터 문장에 포함된 오탈자를 바르게 교정하여 올바른 학습 문장으로 생성하는 방법을 나타내는 도면이다.3 is a diagram illustrating a method of generating a correct learning sentence by correctly correcting misspellings included in a learning data sentence according to an embodiment of the present invention.
도시된 바와 같이, 본 발명 방법은 학습 데이터 문장이 필요한 응용 컴퓨팅에 정상적인 결과를 얻을 수 있도록 학습 데이터 문장에 포함된 오탈자를 바르게 교정하여 올바른 학습 문장으로 생성하는 방법이며, 이를 처리하는 프로세스 다음과 같다.As shown, the method of the present invention is a method of generating correct learning sentences by correctly correcting typos included in learning data sentences so that normal results can be obtained in applied computing that requires training data sentences, and the process for processing this is as follows. .
도 3에서와 같이 입력은 학습 문장을 입력받는 것으로 본 프로세스가 동작할 수 있다. 우선, 형태소 분석과 품사 태깅 과정에서 입력 문장을 최소 단위의 형태소 분석 및 품사 사전에 따라 단어의 품사를 태깅할 수 있다.As shown in FIG. 3, this process can operate by receiving a learning sentence as an input. First, in the process of morpheme analysis and part-of-speech tagging, parts of speech of words may be tagged according to morpheme analysis of the minimum unit of an input sentence and part-of-speech dictionary.
이어서, 품사 태깅 오류 판단 과정에서는 오탈자 여부를 구별하는 것으로 태깅 오류가 발생하면 교정 단계로 진행될 수 있으며, 오류가 발생하지 않는 경우에는 정상적인 단어로 판단하여 학습 문장 생성 후 프로세스가 종료될 수 있다.Then, in the part-of-speech tagging error determination process, whether or not there is a typo is identified. If a tagging error occurs, a correction step may be performed. If no error occurs, the process may be terminated after generating a learning sentence by determining it as a normal word.
한편, 품사 태깅 오류 판단 과정에서 오류가 발생한 경우에는 단어간 유사도 분석과 단어 유사도 비교 과정이 수행될 수 있다. 단어간 유사도 분석과 단어 유사도 비교 과정에서 단어들 간 태깅 오류 확인 및 유사도를 비교하여 오탈자가 발생한 단어에 대해서는 단어 간 유사도가 기설정된 한계치(threshold) 보다 작은(threshold > sim(wi, dwj)) 경우에 단어 요소 변환 과정이 진행될 수 있다. 여기서, 단어 요소 변환은 오탈자를 단어의 요소들로 변환하는 것일 수 있다. 이때 요소들은 단어의 자소, 음소, 음차를 의미할 수 있다.Meanwhile, when an error occurs in the part-of-speech tagging error determination process, similarity analysis between words and word similarity comparison processes may be performed. In the process of analyzing the similarity between words and comparing the similarity between words, tagging errors are checked and similarity between words is compared, and for words with misspellings, if the similarity between words is less than the preset threshold (threshold > sim(wi, dwj)) A word element conversion process may be performed. Here, word element conversion may be conversion of misspelled words into word elements. In this case, the elements may mean the phonemes, phonemes, and phonemes of the word.
이어서, 요소 유사도 계산 및 비교 과정에서 이들 요소를 이용하여 단어 요소 사전의 요소들(자소, 음소, 음차)과 유사도 sim(wi, dwj)를 레벤스타인 거리(Levenshtein distance) 알고리즘을 활용하여 1차로 비교하여 후보 단어들을 찾을 수 있다. 여기서, 단어 요소 사전은 단어와 그 단어의 자소, 음소, 음차 등 사전에 변환된 요소들로 구성된 사전으로 1차로 계산 및 비교가 완료되면 설정된 한계치(threshold)에 따르게 된다. 만약, 단어 간 유사도가 한계치(threshold) 보다 크고(threshold < sim(wi, dwj)) 후보 단어 개수가 하나(count=1)인 경우에는 오탈자 발생 단어가 후보 단어로 자동 교정되어 학습 문장이 생성될 수 있다. 그러나, 그렇지 않은 경우에는 후보 단어들을 가지고 다음 단계로 진행될 수 있다.Subsequently, in the process of calculating and comparing the element similarity, these elements are used to first compare the elements (grapheme, phoneme, phoneme) and similarity sim (wi, dwj) of the word element dictionary using the Levenshtein distance algorithm Candidate words can be found by comparison. Here, the word element dictionary is a dictionary composed of words and elements converted in advance, such as grapheme, phoneme, and phoneme of the word, and follows a set threshold when the first calculation and comparison are completed. If the similarity between words is greater than the threshold (threshold < sim(wi, dwj)) and the number of candidate words is one (count=1), the misspelled word is automatically corrected as a candidate word and a learning sentence is created. can However, if not, it may proceed to the next step with candidate words.
이어서, 다음 단계인 심층 유사도 계산 및 비교 과정에서는 앞서 요소 유사도 계산 및 비교 과정에서 레벤스타인 거리(Levenshtein distance) 알고리즘을 활용하여 찾은 후보 단어들 중 좀 더 정확도가 높은 후보 단어를 찾을 수 있다. 여기서, 자카드 유사도 계수(Jaccard similarity coefficient)를 적용하여 정밀한 유사도를 계산할 수 있다.Subsequently, in the next step, the deep similarity calculation and comparison process, a candidate word with higher accuracy may be found among the candidate words found by using the Levenshtein distance algorithm in the element similarity calculation and comparison process. Here, precise similarity can be calculated by applying a Jaccard similarity coefficient.
이어서, 심층 유사도 계산 및 비교 과정에서 자카드 유사도 계수(Jaccard similarity coefficient)를 적용하여 정밀한 유사도를 계산한 결과 한계치(threshold)를 체크하여 단어 간 유사도가 한계치(threshold) 보다 낮은(threshold > sim(wi, dwj)) 경우에는 단어 후보군 추출 및 주요 단어를 결정하는 단계가 수행될 수 있다. 여기서, 학습 문장 생성 과정에서는 하나의 단어가 검색되면 자동으로 오탈자 교정이 될 수 있으며, 두 개 이상의 후보 단어들이 검색되면 선택할 수 있도록 할 수 있다. 마지막으로 오탈자로부터 유사한 최상의 단어가 찾아지면 이를 교정한 학습문장으로 생성하게 되므로 프로세스는 종료될 수 있다. 하기에서는 단어 사전 생성에 대하여 보다 상세하게 설명하기로 한다.Then, in the deep similarity calculation and comparison process, the Jaccard similarity coefficient is applied to calculate the precise similarity. In the case of dwj)), steps of extracting a word candidate group and determining a main word may be performed. Here, in the process of generating a learning sentence, a typo can be automatically corrected when one word is searched for, and can be selected when two or more candidate words are searched for. Finally, if a similar best word is found from the misspelling, it is generated as a corrected learning sentence, so the process can be ended. In the following, word dictionary generation will be described in more detail.
도 4는 한글 글자 '한'의 자소 분리의 일예를 나타내는 도면이고, 도 5는 단어 사전에서 자소, 음소 및 음차 사전 생성 과정의 일예를 나타내는 도면이다.4 is a diagram showing an example of character element separation of the Korean character 'Han', and FIG. 5 is a diagram showing an example of a process of generating a phoneme, phoneme, and transliteration dictionary in a word dictionary.
도시된 바와 같이, 본 발명에서 단어 간 유사도는 사전에 구축한 단어사전을 활용하여 유사도를 계산할 수 있다. 단어사전은 기본적으로 정단어를 포함하여 자소, 음소, 음차 등의 요소로 추출하여 저장할 수 있다. 요소들은 단어를 자소 단위의 요소로 변환한 후에 각각 음소, 음차들로 표기할 수 있다. 우선, 자소 사전은 글자의 자소를 활용하여 구축할 수 있다.As shown, the similarity between words in the present invention can be calculated using a previously constructed word dictionary. Basically, the word dictionary can extract and store elements such as grapheme, phoneme, and transliteration including regular words. Elements can be expressed as phonemes and phonemes, respectively, after converting words into elements of grapheme units. First of all, a grapheme dictionary can be constructed using grapheme of letters.
자소는 도 4에서와 같이 글자 표기상의 요소로 "한글"은 "ㅎㅏㄴㄱㅡㄹ" 로, 영단어 "text"는 "t e x t"의 요소로 나타낼 수 있다. 한글 문자는 주로 CP949 또는 EUC-KR 인코딩과 유니코드를 사용하여 조합형 형태로 초성, 중성 및 종성으로 구분하고 각각의 자소 인식을 통하여 이들의 조합에 의해 문자로 구성될 수 있다. 여기서, 조합형이란 초성, 중성, 종성에 각각 코드를 할당하는 방식이고, 완성형이란 '가', '각', '간'과 같은 완성된 문자에 코드를 할당하는 방식일 수 있다. 이에 따라, 조합형은 초성 중성, 종성에 각각 5비트씩 할당하고, 1처음 비트(MSB, Most Significant Bit)는 1로 설정하여 한글임을 표시하는 방식일 수 있다. 예를 들어, 한글 문자 '한'은 1 10100(ㅎ) 00011(ㅏ) 00101(ㄴ) (0xD1, 0xC7)로 조합형 코드로 표현될 수 있다. 이러한 자소를 바탕으로 자소 사전을 구축하고 자소를 활용하여 음소와 음차 요소들로 각각 생성할 수 있다.As shown in FIG. 4, the grapheme is an element on the character representation, and "Hangul" can be represented by "ㅎ아ㄴㄱㅡㄹ" and the English word "text" can be represented by an element of "t e x t". Hangul characters are mainly divided into initial consonants, neutral consonants, and final consonants in a combined form using CP949 or EUC-KR encoding and Unicode, and can be composed of characters by their combination through recognition of each grapheme. Here, the combination type may be a method of assigning codes to initial, middle, and final consonants, and the completion type may be a method of assigning codes to completed characters such as 'ga', 'gak', and 'gan'. Accordingly, the combination type may be a method of allocating 5 bits each to the initial consonant and the final consonant, and setting the first bit (MSB, Most Significant Bit) to 1 to indicate that it is Korean. For example, the Korean character 'Han' can be expressed as a combination code as 1 10100 (ㅎ) 00011 (A) 00101 (ㄴ) (0xD1, 0xC7). Based on these grapheme, a grapheme dictionary can be built and the grapheme can be used to create phoneme and transliteration elements respectively.
다음으로, 음소 사전은 IPA(International Phonetic Alphabet) 표기를 사용하여 사전을 구축할 수 있다. IPA(International Phonetic Alphabet)는 언어학에서 주로 사용되는 음성 기록 체계를 의미하며, 음성의 미세한 발음을 표기할 수 있다. 또한, IPA는 로마자에 바탕을 두고 있으며, 글자 발음 상의 요소로 단어 "한글"은 "h a n k u l"으로 "text"는 "t e k s u t"로 대응되는 것처럼 발음을 더 세분화하여 표기할 수 있다.Next, a phoneme dictionary may be constructed using International Phonetic Alphabet (IPA) notation. IPA (International Phonetic Alphabet) means a voice recording system mainly used in linguistics, and can mark the fine pronunciation of voice. In addition, IPA is based on the Roman alphabet, and the word “Hangeul” corresponds to “h a n k u l” and “text” to “t e k s u t” as an element of character pronunciation. It can be expressed by subdividing the pronunciation.
마지막으로, 음차 사전은 자소 음소 변환기(G2P, Grapheme to Phoneme)를 이용하여 사전을 구축할 수 있다. 자소 음소 변환기(G2P)는 문자열에서 음성학적 발음 특성을 토대로 문자의 자소를 발음열로 생성해 주는 음성 인식용 프로그램으로, 단어를 입력하면 단어의 발음 규칙에 따라 그 발음 기호로 변환할 수 있다. 예를 들어, 자소 음소 변환기(G2P)는 일정 규칙에 따라 "한글"은 "h a n g U r"로 "text"는 "t e KK s _ t"로 변환하여 사전을 구축할 수 있다. 따라서, 본 발명은 이들 단어의 자소, 음소, 음차 요소를 이용하여 단어 사전을 구축하여 단어 간 유사도 평가에 활용할 수 있다. 즉, 도 5에 예시된 바와 같이, 단어 사전에서 요소 분리기와 자소 요소 생성기, 음소 기호 사전과 음소 요소 생성기 및 자소 음소 변환기(G2P)와 음차 요소 생성기를 이용하여 각각 자소 요소 사전과 음소 요소 사전 및 음차 요소 사전을 생성할 수 있다. 하기에서는 첨부된 도 6을 참조하여 오탈자의 유사 단어 검색 장치에 대해 보다 구체적으로 설명하기로 한다.Lastly, a phoneme dictionary can be built using a grapheme to phoneme converter (G2P, Grapheme to Phoneme). The grapheme phoneme converter (G2P) is a speech recognition program that generates phonetic sequences of character elements based on phonetic pronunciation characteristics in a character string. When a word is input, it can be converted into phonetic symbols according to the pronunciation rules of the word. For example, the grapheme-phoneme converter (G2P) may construct a dictionary by converting “Hangul” into “h a n g U r” and “text” into “t e KK s _ t” according to a certain rule. Therefore, the present invention can build a word dictionary using the phoneme, phoneme, and transliteration elements of these words and use them to evaluate the similarity between words. That is, as illustrated in FIG. 5, by using the element separator and grapheme element generator, the phoneme symbol dictionary and phoneme element generator, and the grapheme-phoneme converter (G2P) and phoneme element generator in the word dictionary, respectively, A dictionary of transliteration elements can be created. In the following, a similar word search device for typos will be described in more detail with reference to FIG. 6 attached thereto.
도 6은 본 발명에 따른 오탈자의 유사 단어 검색 장치의 구성을 나타내는 도면이다.6 is a diagram showing the configuration of a similar word search apparatus for misspelled words according to the present invention.
도시된 바와 같이, 유사도 매칭 모듈(Similarity matching module)은 자소 요소 생성기와 음소 요소 생성기 및 음차 요소 생성기에 의해 각각 단어 요소별 자소, 음소, 음차 사전이 완료되면, 오탈자와 이들 요소 사전들 간의 유사도를 비교하여 유사률이 높은 단어를 선정하여 오탈자를 교정할 수 있다. 이 과정에서 유사도 검색은 레벤스타인 거리(Levenshtein distance) 알고리즘을 이용하여 후보 단어들을 선정하고 선정한 후보 단어들의 신뢰도를 높이기 위해 자카드 유사 계수(Jaccard similarity coefficient)를 활용하여 깊이 있는 유사도 계산을 수행할 수 있다.As shown, when the grapheme, phoneme, and phoneme dictionaries for each word element are completed by the grapheme element generator, the phoneme element generator, and the phoneme element generator, the similarity between misspellings and these element dictionaries is determined by the similarity matching module. It is possible to correct typos by selecting a word with a high similarity rate by comparison. In this process, the similarity search can select candidate words using the Levenshtein distance algorithm and perform in-depth similarity calculations using the Jaccard similarity coefficient to increase the reliability of the selected candidate words. there is.
학습 문장의 오탈자 단어와 자소, 음소, 음차 요소 사전을 검색하여 단어 간 유사도를 판단하여 유사 단어들을 추출하는 방법에 대해 구체적으로 설명하면 다음과 같다.A detailed description of a method of extracting similar words by determining the similarity between words by searching a misspelled word of a learning sentence and a dictionary of grapheme, phoneme, and transliteration elements is as follows.
단어 간 유사도는 오탈자 S (=S[1], S[2], ?, S[m])와 D (D[1], D[2], ... ,D[n])의 유사도가 설정한 허용치(tolerance)인 ε 이하이면, S와 D는 유사(similar)하다고 볼 수 있다. 본 발명에서 유사도 매칭 모듈은 sim(S, D)는 먼저, 레벤스타인 거리 알고리즘을 활용하여 1차로 비교하여 유사 후보 단어들을 추출한 이후에 자카드 유사도 계수(Jaccard similarity coefficient)를 활용하여 정확도가 향상된 유사 단어를 추출할 수 있다.The similarity between words is the similarity between misspellings S (=S[1], S[2], ?, S[m]) and D (D[1], D[2], ... ,D[n]). If it is less than ε, which is the set tolerance, it can be seen that S and D are similar. In the present invention, the similarity matching module first compares sim(S, D) using the Levenstein distance algorithm to extract similar candidate words, and then uses the Jaccard similarity coefficient to obtain similarities with improved accuracy. words can be extracted.
레벤스타인 거리(Levenshtein distance) 알고리즘은 두 단어간 유사도를 판단하는 알고리즘으로 두 단어를 이용하여 삽입, 삭제, 치환 연산을 기반으로 변경 연산의 횟수를 세어 유사한지를 비교하는 대표적인 방법이며, 하기의 수학식 1과 같이 나타낼 수 있다.The Levenshtein distance algorithm is an algorithm that determines the degree of similarity between two words. It is a representative method of comparing similarity by counting the number of change operations based on insertion, deletion, and substitution operations using two words. It can be expressed as in
[수학식 1][Equation 1]

상기 수학식 1을 활용한 방법은 예를 들어, "애국까"라는 단어가 오탈자일 경우,"애국까"와 요소 사전 "애국가", "애국자"의 레벤스타인 거리를 구한다면 "애국까"는 "애국가"로 바뀌기 위해서는 "애국까"의 자소 단위 "ㅇㅐㄱ ㅜ ㄱ ㄱ ㄱ ㅏ"로 "애국가"와 "애국자"는 각각 "ㅇㅐㄱ ㅜ ㄱ ㄱ ㅏ", "ㅇㅐㄱ ㅜ ㄱ ㅈ ㅏ" 요소로 변경할 수 있다. 여기서는 자소, 음소, 음차 요소가 해당되지만, 유사도 비교 방법은 동일하므로 자소 단위로만 설명하기로 한다. "애국가"의 경우에는 “까”의 "ㄱ"이 삭제되므로 계산 비용은 1이 되며, "애국자"의 경우에는 "까"의 "ㄱ"이 삭제되고 다른 "ㄱ"이 "ㅈ"으로 치환되므로 계산 비용이 2가 되므로 오탈자 "애국까"는 "애국자" 보다는 "애국가"가 더 유사성이 높아 후보 단어로 판단될 수 있다. 즉, 두 단어 간 유사도는 높을수록 계산 비용이 0에 가깝게 된다. 그러나, 레벤스타인 거리 비용이 0에 가깝더라도 단어 내 출현 가능한 요소들이 다수 존재하므로 이들 후보 단어들을 활용하여 좀 더 정교하게 계산하는 방법이 필요할 수 있다.The
본 발명은 앞서 추출한 후보 단어들의 신뢰성을 보다 높이기 위해 정교한 유사성 계수를 측정하는 방법으로 자카드 유사 계수(Jaccard similarity coefficient)을 활용할 수 있다. 이를 이용한 유사 후보 단어 추출은 두 단어 S, D의 유사도 J(S,D)는 0 ≤ J(S,D) ≤ 1 사이의 값을 가지며, 결과 값이 1인 경우에는 모든 단어의 유사도가 동일한 같은 단어이며, 0인 경우에는 일치함이 없음을 의미할 수 있다. 자캬드 유사도 계산식은 하기의 수학식 2와 같이 나타낼 수 있다.In the present invention, a Jaccard similarity coefficient may be utilized as a method of measuring an elaborate similarity coefficient in order to further increase the reliability of the previously extracted candidate words. In the case of similar candidate word extraction using this, the similarity J(S,D) of two words S and D has a value between 0 ≤ J(S,D) ≤ 1, and if the result value is 1, all words have the same similarity. It is the same word, and if it is 0, it may mean that there is no match. The Jacquard similarity calculation formula can be expressed as Equation 2 below.
[수학식 2][Equation 2]

예를 들어, 문자열 "애국까"는 사전 단어 문자열 "애국가"는 각각 "ㅇㅐㄱ ㅜ ㄱ ㄱ ㄱ ㅏ", "ㅇㅐㄱ ㅜ ㄱ ㄱㅏ" 의 유사도를 계산하는 경우, 두 단어의 합집합 개수는 | N("ㅇㅐㄱ ㅜ ㄱ ㄱ ㄱ ㅏ") | ∪ | N("ㅇㅐㄱ ㅜ ㄱ ㄱㅏ") | 는 8개이고, 두 단어의 교집합 | N("ㅇㅐㄱ ㅜ ㄱ ㄱ ㄱ ㅏ") | ∩ | N("ㅇㅐㄱ ㅜ ㄱ ㄱㅏ") | 는 7개 이므로, 자카드 유사도 값은 7/8=0.875가 될 수 있다.For example, the string “patriotic kka” is the dictionary word string “patriotic song” is “ㅇㅐㄱ ㅜ ㄱ ㄱ ㄱ ahn” and “ㅇㅐㄱ ㅜ ㄱ ㄱㄱ” respectively. If the similarity is calculated, the union of the two words | N("ㅇㅐㄱ ㅜ ㄱ ㄱ ㄱ A") | ∪ | N("ㅇㅐㄱ ㅜ ㄱ ㄱㄱ") | is 8, and the intersection of two words | N("ㅇㅐㄱ ㅜ ㄱ ㄱ ㄱ A") | ∩ | N("ㅇㅐㄱ ㅜ ㄱ ㄱㄱ") | is 7, the Jacquard similarity value can be 7/8 = 0.875.
이와 같이, 본 발명은 기계학습 등에 필요한 학습 문장의 오탈자를 올바른 정단어로 교정하여 학습 문장을 정교하게 만드는 것이 목적이다. 이 과정에서 단어 자소 및 음소 사전은 조합형 인코딩 사용으로 자소 및 음소 발음 생성하였으며, 정확도의 신뢰성을 높이기 위해 2단계로 유사 알고리즘 및 유사 계수를 활용하여 오탈자 단어를 유사 비교하여 후보 단어로 선정하도록 하였다. 이로써, 본 발명은 기계학습의 학습 문장 교정 뿐만 아니라, 검색 입력 키워드, 음성인식 분야 등 오탈자가 발생 가능한 응용 어플 탑재가 가능하며, 오탈자 발견시 즉시성으로 교정이 가능하여 다양한 자연어처리 분야에 활용할 수 있다.As described above, an object of the present invention is to elaborate a learning sentence by correcting misspellings in a learning sentence necessary for machine learning or the like into correct words. In this process, the word grapheme and phoneme dictionaries were generated using combinatorial encoding, and in order to increase the reliability of accuracy, in the second step, similar algorithms and similar coefficients were used to compare misspelled words and select them as candidate words. As a result, the present invention can not only correct machine learning learning sentences, but also install applications that can generate typos, such as search input keywords and voice recognition fields, and can be immediately corrected when a typo is found, so it can be used in various natural language processing fields. there is.
본 발명은 단어의 요소별에 따라 자소, 음소, 음차 기반을 구분하여 사전을 구축하고, 오탈자가 발견되면 각 요소별 단어 사전들을 유사도 앙상블 스코어를 2단계로 유사 알고리즘 및 유사 계수를 활용하여 계산하여 최종 올바른 정단어를 선정하여 교정할 수 있다. 여기서, 유사도 계산 알고리즘 및 유사 계수 활용은 본 발명에서 논하는 방법에만 국한되지 않으며, 이들 기반으로 단어의 요소별로 앙상블 스코어를 계산할 수 있음은 물론이다.In the present invention, dictionaries are built by dividing phoneme, phoneme, and transliteration bases according to each element of a word, and when a misspelling is found, the similarity ensemble score for each element is calculated using a similarity algorithm and a similarity coefficient in two steps. It can be corrected by selecting the final correct word. Here, the similarity calculation algorithm and utilization of the similarity coefficient are not limited to the method discussed in the present invention, and it is of course possible to calculate an ensemble score for each element of a word based on these.
즉, 본 발명에서의 제안 방법은 입력된 문장 전체를 처리하는 것이 아닌 단어 대상이며, 기존 수작업으로 이뤄지는 과정을 최대한 자동화하는 것으로 오탈자를 효율적으로 처리할 수 있다. 이를 위해 본 발명은 우선, 사용자 입력 채널에서 문장이 주어지면, 주어진 입력 문장에서 발생한 오탈자를 추출할 수 있다. 이후, 사전에 단어 사전을 구축하는 데, 단어의 특성을 추출하여 자소, 음소, 음차 단위로 변환하여 학습 사전으로 구성할 수 있으며, 이는 이들 특성들을 활용하여 단어 간의 신뢰도를 계산하기 위함이다. 이어서, 입력 문장에서 오탈자에 대하여 단어의 특성(자소, 음소, 음차)에 따라 한계치(threshold) 기반으로 올바른 단어를 대치하거나 유사한 후보 단어들을 제시할 수 있다. 여기서, 의미 유사 후보 단어들을 제시할 때, 단어의 요소별로 앙상블 스코어를 계산하는 유사도를 측정하여 편집 거리와 유사도 방법을 사용함으로써 생성된 후보 단어들을 사용자가 원하는 수준으로 선택할 수 있도록 할 수 있다. 이는 사용자가 오탈자가 발생한 단어를 직접 수정하지 않고 제공하는 후보 단어 목록에서 단어를 선택함으로써 소용되는 비용을 줄일 수 있다.That is, the proposed method in the present invention does not process the entire input sentence, but the word object, and can efficiently process typos by automating the existing manual process as much as possible. To this end, in the present invention, when a sentence is given from a user input channel, it is possible to extract typos generated in the given input sentence. Thereafter, in constructing a word dictionary in advance, the characteristics of words are extracted and converted into grapheme, phoneme, and transliteration units to form a learning dictionary. This is to calculate reliability between words by utilizing these characteristics. Subsequently, for misspellings in the input sentence, a correct word may be substituted based on a threshold according to word characteristics (grapheme, phoneme, phoneme) or similar candidate words may be presented. Here, when semantically similar candidate words are presented, the similarity of calculating an ensemble score for each element of a word is measured and the editing distance and similarity method are used, so that the user can select the generated candidate words at a desired level. This can reduce the cost required by selecting a word from the provided candidate word list without directly correcting the misspelled word.
또한, 기존 방법에서는 단어로 또는 하나의 특성으로만 유사도를 판단하므로, 단어의 특성에 부합하는 높은 정확도를 기대하기 어렵거나 유사도 비교 시 컴퓨팅 파워의 낭비도 심해진다. 이에 반해, 본 발명은 단어의 여러 특성(자소, 음소, 음차)을 활용하므로 정확도를 높이고 비교 계산 비용을 낮출 수 있는 방법으로 효율적인 차이에서 기존 방법과 차이가 있다. 이로써, 향후에는 높은 정확성을 필요로 하는 자연어 검색, 기계번역 등 다양한 응용 분야에서 효과적으로 활용될 수 있다.In addition, in the existing method, since the degree of similarity is determined by a word or only one feature, it is difficult to expect high accuracy matching the feature of a word, or computing power is severely wasted when comparing similarities. On the other hand, the present invention utilizes various characteristics (grapheme, phoneme, phoneme) of words, so it is a method that can increase accuracy and lower the cost of comparison and calculation, and is different from the existing method in terms of efficiency. As a result, it can be effectively used in various application fields such as natural language search and machine translation that require high accuracy in the future.
전술한 본 발명은, 프로그램이 기록된 매체에 컴퓨터가 읽을 수 있는 코드로서 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 매체는, 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록장치를 포함한다. 컴퓨터가 읽을 수 있는 매체의 예로는, HDD(Hard Disk Drive), SSD(Solid State Disk), SDD(Silicon Disk Drive), ROM, RAM, CD-ROM, 자기 테이프, 플로피 디스크, 광 데이터 저장 장치 등이 있으며, 또한 캐리어 웨이브(예를 들어, 인터넷을 통한 전송)의 형태로 구현되는 것도 포함한다. 따라서, 상기의 상세한 설명은 모든 면에서 제한적으로 해석되어서는 아니되고 예시적인 것으로 고려되어야 한다. 본 발명의 범위는 첨부된 청구항의 합리적 해석에 의해 결정되어야 하고, 본 발명의 등가적 범위 내에서의 모든 변경은 본 발명의 범위에 포함된다.The above-described present invention can be implemented as computer readable code on a medium on which a program is recorded. The computer-readable medium includes all types of recording devices in which data that can be read by a computer system is stored. Examples of computer-readable media include Hard Disk Drive (HDD), Solid State Disk (SSD), Silicon Disk Drive (SDD), ROM, RAM, CD-ROM, magnetic tape, floppy disk, optical data storage device, etc. , and also includes those implemented in the form of a carrier wave (eg, transmission over the Internet). Accordingly, the above detailed description should not be construed as limiting in all respects and should be considered illustrative. The scope of the present invention should be determined by reasonable interpretation of the appended claims, and all changes within the equivalent scope of the present invention are included in the scope of the present invention.
Claims (12)
Translated fromKorean상기 유사도 매칭 모듈이 상기 품사 태깅시 발생한 오류에 따라 학습 문장에서 오탈자 단어를 선별하는 단계;
상기 유사도 매칭 모듈이 상기 학습 문장에서 선별된 오탈자 단어에 대해 기설정된 한계값(threshold)에 기초하여 적어도 하나 이상의 후보 단어와의 단어 간 유사도를 비교하는 단계;
상기 유사도 매칭 모듈이 단어 간 유사도가 기설정된 한계값보다 작은 경우 상기 오탈자 단어를 자소, 음소 및 음차 요소로 변환하는 단계; 및
상기 유사도 매칭 모듈이 상기 변환된 오탈자 단어의 자소, 음소 및 음차 요소를 단어 요소 사전에 저장된 정단어의 자소, 음소 및 음차 요소들과 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 후보 단어를 검색하고 검색된 후보 단어가 1개이고 단어 간 유사도가 기설정된 한계값보다 큰 경우 검색된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계;를 포함하는 앙상블 스코어를 이용한 학습 데이터 교정 방법.
tagging the part-of-speech of words according to the morpheme analysis of the minimum unit and the part-of-speech dictionary of the learning sentence input through the user input channel by the similarity matching module;
selecting, by the similarity matching module, misspelled words from the learning sentence according to an error generated during the part-of-speech tagging;
comparing, by the similarity matching module, similarities between words with at least one candidate word based on a predetermined threshold for misspelled words selected from the learning sentence;
converting, by the similarity matching module, the misspelled words into grapheme, phoneme, and phoneme elements when the similarity between words is less than a predetermined threshold value; and
The similarity matching module compares the phoneme, phoneme, and phoneme elements of the converted misspelled word with the phoneme, phoneme, and phoneme elements of the regular word stored in the word element dictionary and the candidate word according to the result of comparing the word similarity based on the Levenstein distance algorithm. Searching for one candidate word and generating a corrected learning sentence by replacing the misspelled word with the searched candidate word when the similarity between words is greater than a preset threshold value; .
상기 유사도 매칭 모듈이 상기 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 검색된 후보 단어가 2개 이상인 경우 2개 이상의 후보 단어 중에서 자카드 유사도 계수를 적용하여 단어 간 음소 및 자소열을 공유하는 유사도가 높은 순서에 따라 적어도 하나 이상의 후보 단어를 검색하는 단계; 및
상기 유사도 매칭 모듈이 상기 자카드 유사도 계수 적용에 의해 검색된 적어도 하나 이상의 후보 단어에서 단어 간 유사도가 기설정된 한계값보다 크고 유사도가 가장 높은 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계;를 포함하는 앙상블 스코어를 이용한 학습 데이터 교정 방법.
The method of claim 1,
The similarity matching module shares phonemes and grapheme sequences between words by applying a Jacquard similarity coefficient among two or more candidate words when two or more candidate words are searched according to the similarity comparison result between words based on the Levenstein distance algorithm. Searching for at least one or more candidate words according to a higher order of ?; and
generating a corrected learning sentence by replacing, by the similarity matching module, the misspelled word with a candidate word having the highest similarity and a similarity between words in at least one candidate word searched by applying the Jacquard similarity coefficient; Learning data correction method using an ensemble score containing ;
상기 유사도 매칭 모듈이 상기 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 검색된 후보 단어가 2개 이상인 경우 2개 이상의 후보 단어 중에서 자카드 유사도 계수를 적용하여 단어 간 음소 및 자소열을 공유하는 유사도가 높은 순서에 따라 적어도 하나 이상의 후보 단어를 검색하는 단계에서,
상기 유사도 매칭 모듈이 상기 자카드 유사도 계수 적용에 의해 검색된 후보 단어의 개수가 2개 이상 검색된 경우 사용자에 의해 선택된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계를 더 포함하는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 방법.
The method of claim 2,
The similarity matching module applies a Jacquard similarity coefficient among two or more candidate words to share phonemes and grapheme sequences between words when there are two or more candidate words searched according to the similarity comparison result between words based on the Levenstein distance algorithm. In the step of searching for at least one or more candidate words according to the order of high
The similarity matching module may further include generating a corrected learning sentence by replacing the misspelled word with a candidate word selected by a user when the number of candidate words searched by applying the Jacquard similarity coefficient is two or more. Learning data correction method using ensemble score.
상기 유사도 매칭 모듈이 단어 간 유사도가 기설정된 한계값보다 작은 경우 상기 오탈자 단어를 자소, 음소 및 음차 요소로 변환하는 단계 이후에,
단어 요소 생성모듈이 정단어를 포함하여 정단어의 자소, 음소, 음차 요소를 추출하여 저장된 단어 요소 사전으로 구성하는 단계를 더 포함하는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 방법.
The method of claim 2,
After the similarity matching module converts the misspelled word into grapheme, phoneme, and phoneme elements when the similarity between words is smaller than a predetermined threshold value,
A method for correcting learning data using ensemble scores, further comprising the step of extracting, by the word element generation module, phoneme, phoneme, and transliteration elements of the regular word, including the regular word, and configuring them into a stored word element dictionary.
상기 단어 요소 사전은 정단어를 자소 단위의 요소로 표기한 자소 사전, 자소 단위의 요소를 발음 상의 요소로 표기한 음소 사전 및 자소 단위의 요소를 발음 기호로 변환하여 표기한 음차 사전을 포함하는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 방법.
The method of claim 4,
The word element dictionary includes a grapheme dictionary in which positive words are expressed as elements in phoneme units, a phoneme dictionary in which elements in phoneme units are expressed as phonetic elements, and a phoneme dictionary in which elements in phoneme units are converted into phonetic symbols and displayed. Learning data correction method using ensemble score characterized by.
상기 유사도 매칭 모듈이 상기 자카드 유사도 계수 적용에 의해 검색된 적어도 하나 이상의 후보 단어에서 단어 간 유사도가 기설정된 한계값보다 크고 유사도가 가장 높은 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 단계에서,
상기 유사도가 가장 높은 후보 단어는 상기 자소 사전, 음소 사전 및 음차 사전에 기초하여 상기 레벤스타인 거리 알고리즘과 상기 자카드 유사도 계수를 적용하여 계산된 유사도 앙상블 스코어에 의해 선정되는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 방법.
The method of claim 5,
generating a corrected learning sentence by replacing, by the similarity matching module, the misspelled word with a candidate word having the highest similarity and a similarity between words in at least one candidate word searched by applying the Jacquard similarity coefficient; at,
The candidate word having the highest similarity is selected by a similarity ensemble score calculated by applying the Levenstein distance algorithm and the Jacquard similarity coefficient based on the grapheme dictionary, the phoneme dictionary, and the transliteration dictionary. Learning data calibration method used.
상기 단어 요소 생성모듈에 의해 생성된 단어 요소별 자소, 음소 및 음차 요소를 각각 저장하는 단어 요소 사전; 및
사용자 입력채널을 통해 입력된 학습 문장에서 발생한 오탈자 단어를 추출하고 추출한 오탈자 단어의 자소, 음소 및 음차 요소를 상기 단어 요소 사전에 저장된 정단어의 자소, 음소 및 음차 요소들과 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 후보 단어를 검색하고, 검색된 후보 단어가 1개이고 단어 간 유사도가 기설정된 한계값보다 큰 경우 검색된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 유사도 매칭 모듈;을 포함하고,
상기 유사도 매칭 모듈은,
상기 사용자 입력채널을 통해 입력된 학습 문장을 최소 단위의 형태소 분석 및 품사 사전에 따라 단어의 품사를 태깅하고, 상기 품사 태깅시 발생한 오류에 따라 학습 문장에서 오탈자 단어를 선별하고, 상기 학습 문장에서 선별된 오탈자 단어에 대해 기설정된 한계값(threshold)에 기초하여 적어도 하나 이상의 후보 단어와의 단어 간 유사도를 비교하여 단어 간 유사도가 기설정된 한계값보다 작은 경우 상기 오탈자 단어를 자소, 음소 및 음차 요소로 변환하는 앙상블 스코어를 이용한 학습 데이터 교정 장치.
a word element generation module for generating grapheme, phoneme, and transliteration elements for each word element;
a word element dictionary for storing grapheme, phoneme, and transliteration elements for each word element generated by the word element generation module; and
The misspelled words generated from the learning sentence input through the user input channel are extracted, and the phoneme, phoneme, and phoneme elements of the extracted misspelled word are applied to the phoneme, phoneme, and phoneme elements of the regular word stored in the word element dictionary and the Levenstein distance algorithm. Similarity matching that searches for a candidate word according to the similarity comparison result between words based on the result, and replaces the misspelled word with the searched candidate word when the searched candidate word is one and the similarity between words is greater than a preset threshold to generate a corrected learning sentence. module; includes,
The similarity matching module,
The learning sentence input through the user input channel is analyzed in the smallest unit of morpheme analysis and parts of speech of words are tagged according to a part-of-speech dictionary, misspelled words are selected from the learning sentences according to errors generated during the part-of-speech tagging, and selected from the learning sentences. The similarity between words with at least one or more candidate words is compared based on a predetermined threshold for the misspelled word, and if the similarity between words is smaller than the predetermined threshold, the misspelled word is classified as a grapheme, phoneme, and phoneme element. Learning data correction device using ensemble score to transform.
상기 유사도 매칭 모듈은,
상기 레벤스타인 거리 알고리즘에 기초한 단어 간 유사도 비교 결과에 따라 검색된 후보 단어가 2개 이상인 경우 2개 이상의 후보 단어 중에서 자카드 유사도 계수를 적용하여 단어 간 음소 및 자소열을 공유하는 유사도가 높은 순서에 따라 적어도 하나 이상의 후보 단어를 검색하고,
상기 자카드 유사도 계수 적용에 의해 검색된 적어도 하나 이상의 후보 단어에서 단어 간 유사도가 기설정된 한계값보다 크고 유사도가 가장 높은 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 장치.
The method of claim 7,
The similarity matching module,
If there are two or more candidate words searched according to the similarity comparison result between words based on the Levenstein distance algorithm, a Jacquard similarity coefficient is applied among the two or more candidate words in order of high similarity sharing phonemes and grapheme sequences between words. Search for at least one candidate word;
Ensemble score characterized in that in at least one or more candidate words searched by applying the Jacquard similarity coefficient, a corrected learning sentence is generated by replacing the misspelled word with a candidate word having a similarity greater than a predetermined threshold and having the highest similarity between words. Learning data correction device using.
상기 유사도 매칭 모듈은,
상기 자카드 유사도 계수를 적용하여 검색된 후보 단어의 개수가 2개 이상 검색된 경우 사용자에 의해 선택된 후보 단어로 상기 오탈자 단어를 대치하여 교정된 학습 문장을 생성하는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 장치.
The method of claim 8,
The similarity matching module,
Learning data correction device using an ensemble score, characterized in that when the number of searched candidate words is two or more by applying the Jacquard similarity coefficient, the misspelled word is replaced with a candidate word selected by a user to generate a corrected learning sentence. .
상기 단어 요소 생성모듈은,
정단어를 포함하여 정단어의 자소, 음소, 음차 요소를 추출하여 저장된 단어 요소 사전으로 구성하는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 장치.
The method of claim 8,
The word element generation module,
An apparatus for correcting learning data using an ensemble score, characterized in that it extracts phonemes, phonemes, and phonetic elements of regular words, including regular words, and configures them into a dictionary of stored word elements.
상기 단어 요소 사전은 정단어를 자소 단위의 요소로 표기한 자소 사전, 자소 단위의 요소를 발음 상의 요소로 표기한 음소 사전 및 자소 단위의 요소를 발음 기호로 변환하여 표기한 음차 사전을 포함하는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 장치.
The method of claim 10,
The word element dictionary includes a grapheme dictionary in which positive words are expressed as elements in phoneme units, a phoneme dictionary in which elements in phoneme units are expressed as phonetic elements, and a phoneme dictionary in which elements in phoneme units are converted into phonetic symbols and displayed. A learning data correction device using the characterized ensemble score.
상기 유사도가 가장 높은 후보 단어는 상기 자소 사전, 음소 사전 및 음차 사전에 기초하여 상기 레벤스타인 거리 알고리즘과 상기 자카드 유사도 계수를 적용하여 계산된 유사도 앙상블 스코어에 의해 선정되는 것을 특징으로 하는 앙상블 스코어를 이용한 학습 데이터 교정 장치.The method of claim 11,
The candidate word having the highest similarity is selected by a similarity ensemble score calculated by applying the Levenstein distance algorithm and the Jacquard similarity coefficient based on the grapheme dictionary, the phoneme dictionary, and the transliteration dictionary. Learning data correction device used.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210090106AKR102794379B1 (en) | 2021-07-09 | 2021-07-09 | Learning data correction method and apparatus thereof using ensemble score |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210090106AKR102794379B1 (en) | 2021-07-09 | 2021-07-09 | Learning data correction method and apparatus thereof using ensemble score |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20230009564Atrue KR20230009564A (en) | 2023-01-17 |
| KR102794379B1 KR102794379B1 (en) | 2025-04-11 |
Family
ID=85111284
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020210090106AActiveKR102794379B1 (en) | 2021-07-09 | 2021-07-09 | Learning data correction method and apparatus thereof using ensemble score |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102794379B1 (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190045038A (en)* | 2017-10-23 | 2019-05-02 | 삼성전자주식회사 | Method and apparatus for speech recognition |
| KR102616598B1 (en)* | 2023-05-30 | 2023-12-22 | 주식회사 엘솔루 | Method for generating original subtitle parallel corpus data using translated subtitles |
| KR102632872B1 (en)* | 2023-05-22 | 2024-02-05 | 주식회사 포지큐브 | Method for correcting error of speech recognition and system thereof |
| KR102632806B1 (en)* | 2023-06-16 | 2024-02-05 | 주식회사 엘솔루 | Speech recoginition method and apparatus for early confirmation of speech-to-text results |
| WO2024226315A1 (en)* | 2023-04-28 | 2024-10-31 | Hyland Software, Inc. | Systems, methods, and devices for indexing and searching digital imaging and communications in medicine (dicom) metadata |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20010035679A (en)* | 1999-10-01 | 2001-05-07 | 윤덕용 | Phonetic distance method for similarity comparison of foreign words |
| KR20140021838A (en)* | 2012-08-10 | 2014-02-21 | 에스케이텔레콤 주식회사 | Method for detecting grammar error and apparatus thereof |
| US20200210466A1 (en)* | 2018-12-26 | 2020-07-02 | Microsoft Technology Licensing, Llc | Hybrid entity matching to drive program execution |
- 2021
- 2021-07-09KRKR1020210090106Apatent/KR102794379B1/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20010035679A (en)* | 1999-10-01 | 2001-05-07 | 윤덕용 | Phonetic distance method for similarity comparison of foreign words |
| KR20140021838A (en)* | 2012-08-10 | 2014-02-21 | 에스케이텔레콤 주식회사 | Method for detecting grammar error and apparatus thereof |
| US20200210466A1 (en)* | 2018-12-26 | 2020-07-02 | Microsoft Technology Licensing, Llc | Hybrid entity matching to drive program execution |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190045038A (en)* | 2017-10-23 | 2019-05-02 | 삼성전자주식회사 | Method and apparatus for speech recognition |
| WO2024226315A1 (en)* | 2023-04-28 | 2024-10-31 | Hyland Software, Inc. | Systems, methods, and devices for indexing and searching digital imaging and communications in medicine (dicom) metadata |
| KR102632872B1 (en)* | 2023-05-22 | 2024-02-05 | 주식회사 포지큐브 | Method for correcting error of speech recognition and system thereof |
| KR102616598B1 (en)* | 2023-05-30 | 2023-12-22 | 주식회사 엘솔루 | Method for generating original subtitle parallel corpus data using translated subtitles |
| KR102632806B1 (en)* | 2023-06-16 | 2024-02-05 | 주식회사 엘솔루 | Speech recoginition method and apparatus for early confirmation of speech-to-text results |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102794379B1 (en) | 2025-04-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102794379B1 (en) | Learning data correction method and apparatus thereof using ensemble score | |
| KR101083540B1 (en) | System and method for transforming vernacular pronunciation with respect to hanja using statistical method | |
| Alkanhal et al. | Automatic stochastic arabic spelling correction with emphasis on space insertions and deletions | |
| CN105279149A (en) | A Chinese Text Automatic Correction Method | |
| JP2013117978A (en) | Generating method for typing candidate for improvement in typing efficiency | |
| US20120179694A1 (en) | Method and system for enhancing a search request | |
| CN104239289B (en) | Syllabification method and syllabification equipment | |
| US11568150B2 (en) | Methods and apparatus to improve disambiguation and interpretation in automated text analysis using transducers applied on a structured language space | |
| CN113449514B (en) | Text error correction method and device suitable for vertical field | |
| JP6778655B2 (en) | Word concatenation discriminative model learning device, word concatenation detection device, method, and program | |
| US12437150B2 (en) | System and method of performing data training on morpheme processing rules | |
| Li et al. | Improving text normalization using character-blocks based models and system combination | |
| Kirov et al. | Context-aware transliteration of romanized South Asian languages | |
| de Silva et al. | Singlish to sinhala transliteration using rule-based approach | |
| JP6145059B2 (en) | Model learning device, morphological analysis device, and method | |
| Roy et al. | Unsupervised context-sensitive bangla spelling correction with character n-gram | |
| Nguyen et al. | OCR error correction for Vietnamese handwritten text using neural machine translation | |
| CN111429886B (en) | Voice recognition method and system | |
| CN111090720B (en) | Hot word adding method and device | |
| Núñez et al. | Phonetic normalization for machine translation of user generated content | |
| Etxeberria et al. | Weighted finite-state transducers for normalization of historical texts | |
| Lu et al. | An automatic spelling correction method for classical mongolian | |
| Hasan et al. | SweetCoat-2D: Two-Dimensional Bangla Spelling Correction and Suggestion Using Levenshtein Edit Distance and String Matching Algorithm | |
| Milon et al. | A comprehensive dialect conversion approach from chittagonian to standard bangla | |
| KR20040018008A (en) | Apparatus for tagging part of speech and method therefor |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20210709 | |
| PA0201 | Request for examination | ||
| PG1501 | Laying open of application | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20240711 Patent event code:PE09021S01D | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | Patent event code:PE07011S01D Comment text:Decision to Grant Registration Patent event date:20250326 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | Comment text:Registration of Establishment Patent event date:20250407 Patent event code:PR07011E01D | |
| PR1002 | Payment of registration fee | Payment date:20250408 End annual number:3 Start annual number:1 | |
| PG1601 | Publication of registration |