KR20210119390A - 재구성가능 데이터 프로세서의 가상화 - Google Patents
재구성가능 데이터 프로세서의 가상화Download PDFInfo
- Publication number
- KR20210119390A KR20210119390AKR1020217022207AKR20217022207AKR20210119390AKR 20210119390 AKR20210119390 AKR 20210119390AKR 1020217022207 AKR1020217022207 AKR 1020217022207AKR 20217022207 AKR20217022207 AKR 20217022207AKR 20210119390 AKR20210119390 AKR 20210119390A
- Authority
- KR
- South Korea
- Prior art keywords
- configurable
- array
- configurable units
- configuration
- units
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





















Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/78—Architectures of general purpose stored program computers comprising a single central processing unit
- G06F15/7867—Architectures of general purpose stored program computers comprising a single central processing unit with reconfigurable architecture
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/16—Handling requests for interconnection or transfer for access to memory bus
- G06F13/1668—Details of memory controller
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/38—Information transfer, e.g. on bus
- G06F13/40—Bus structure
- G06F13/4004—Coupling between buses
- G06F13/4027—Coupling between buses using bus bridges
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/78—Architectures of general purpose stored program computers comprising a single central processing unit
- G06F15/7839—Architectures of general purpose stored program computers comprising a single central processing unit with memory
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/78—Architectures of general purpose stored program computers comprising a single central processing unit
- G06F15/7867—Architectures of general purpose stored program computers comprising a single central processing unit with reconfigurable architecture
- G06F15/7871—Reconfiguration support, e.g. configuration loading, configuration switching, or hardware OS
- G06F15/7882—Reconfiguration support, e.g. configuration loading, configuration switching, or hardware OS for self reconfiguration
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/65—Details of virtual memory and virtual address translation
- G06F2212/657—Virtual address space management
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Software Systems (AREA)
- Logic Circuits (AREA)
- Multi Processors (AREA)
- Stored Programmes (AREA)
- Memory System Of A Hierarchy Structure (AREA)
- Hardware Redundancy (AREA)
Abstract
Description
우선권 적용
이 출원은 2019 년 1 월 3 일자로 출원된 미국 정규 출원 제 16/239,252 호 (대리인 문서 번호 SBNV 1001-1) 의 이익을 주장하고, 이 출원은 참조에 의해 본원에 통합된다.
기술 분야
본 기술은 재구성가능한 아키텍처들의 가상화에 관한 것이고, 코오스-그레인 재구성가능한 아키텍처들에 특히 적용될 수 있다.
관련 기술의 설명
필드 프로그래머블 게이트 어레이 (FPGA) 들을 포함하는 재구성가능한 프로세서들은 컴퓨터 프로그램을 실행하는 범용 프로세서를 사용하여 달성될 수 있는 것보다 더 효율적이거나 더 빠르게 다양한 기능들을 구현하도록 구성될 수 있다. 어레이 내의 구성가능한 유닛들이 전형적이고 더 파인-그레인의 FPGA들에서 사용되는 것보다 더 복잡하고, 다양한 클래스들의 기능들의 더 빠르거나 더 효율적인 실행을 가능하게 할 수도 있는, 소위 코오스-그레인 재구성가능한 아키텍처들 (예컨대, CGRA들) 이 개발되고 있다. 예를 들어, 머신 러닝 및 인공 지능 워크로드를 위한 에너지 효율적인 가속기들의 구현을 가능하게 할 수 있는 CGRA들이 제안되었다. Prabhakar 등의 "Plasticine: A Reconfigurable Architecture for Parallel Patterns," ISCA '17, June 24-28, 2017, Toronto, ON, Canada 참조.
재구성가능한 프로세서들의 구성은, 때때로 비트스트림 또는 비트 파일로서 지칭되는 구성 파일로 표현되는 애플리케이션 그래프를 생성하기 위한 구성 디스크립션의 컴파일, 및 구성 파일을 프로세서 상의 구성가능한 유닛들에 분배하는 것을 수반한다. 애플리케이션 그래프를 사용하여 구현되는 프로세스를 시작하기 위해, 그 프로세스에 대해 구성 파일이 로드되어야만 한다. 애플리케이션 그래프를 사용하여 구현된 프로세스를 변경하기 위해, 구성 파일을 새로운 구성 파일로 교체해야만 한다.
구성 파일을 분배하고 로드하기 위한 프로시저들 및 지원 구조들은 복잡할 수 있으며, 그 프로시저들의 실행은 시간 소비적일 수 있다.
일부 환경에서, 단일 재구성가능한 프로세서에서 다수의 애플리케이션 그래프들을 동시에 실행하는 것이 바람직할 수도 있다.
따라서, 재구성가능한 프로세서들의 가상화를 지원하는 기술들을 제공하는 것이 또한 바람직하다.
코오스-그레인 재구성 어레이 프로세서 및 구성가능한 유닛들의 어레이를 포함하는 다른 유형의 재구성가능한 프로세서들에서 다수의, 관련되지 않은 애플리케이션 그래프들의 실행을 가능하게 하는 기술이 설명된다.
본 명세서에 설명된 기술은, 구성가능한 유닛들의 어레이; 상기 구성가능한 유닛들의 어레이에 연결되어, 상기 구성가능한 유닛들의 어레이를 구성가능한 유닛들의 복수의 세트들로 파티셔닝하고 특정 세트 내의 구성가능한 유닛들과 상기 특정 세트 외부의 구성가능한 유닛들 사이의 상기 버스 시스템을 통한 통신들을 차단하도록 구성가능한 버스 시스템을 포함하는, 재구성가능한 데이터 프로세서를 제공한다. 또한, 버스 시스템에 연결된 메모리 액세스 제어기는, 특정 세트 내로부터 발생하는 대용량 DRAM, SRAM 및 다른 메모리 클래스들과 같은, 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스를, 구성가능한 유닛들의 어레이 외부의 메모리 내의 특정 세트에 할당된 메모리 공간으로 한정하도록 구성가능하다.
본 명세서에 설명된 실시형태들에서, 복수의 메모리 액세스 제어기들은, 버스 시스템 상의 어드레스가능한 노드들로서 연결되고, 구성가능한 유닛들의 대응하는 세트들 내로부터 발생하는 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스를, 대응하는 세트들에 할당된 메모리 공간으로 한정하도록 구성가능한 메모리 액세스 제어기들을 포함한다.
버스 시스템의 예는 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들에 연결된 스위치들의 그리드를 포함하고, 그리드 내의 스위치들은 버스 시스템을 파티셔닝하기 위한 회로들을 포함한다. 그리드 내의 스위치들은 포트 파라미터들에 따라 스위치들 상의 포트들을 인에이블 및 디스에이블하는, 포트 파라미터들을 사용하여 구성가능한 회로들을 포함할 수 있다.
구성가능한 유닛들의 복수의 세트들에서 구성가능한 유닛들의 세트는 가상 어드레스를 사용하여 애플리케이션 그래프를 실행하도록 구성가능할 수 있다. 메모리 액세스 제어기는 특정 세트 내에서 실행되는 애플리케이션 그래프로부터 발생하는 요청들에서의 가상 어드레스들을, 특정 세트에 할당된 메모리 공간 내의 어드레스들로 변환하기 위해 구성가능한 테이블을 포함하거나 구성가능한 테이블에 액세스한다. 본 설명의 목적들을 위한 물리적 어드레스는 외부 메모리 내의 메모리 공간 내의 위치들을 식별하는 버스 시스템 상의 메모리 인터페이스에 의해 사용되는 어드레스이고, 가상 어드레스는 메모리 액세스 제어기에 의해서와 같이 물리적 어드레스로 변환되는 특정 가상 머신 내의 애플리케이션 그래프에 의해 사용되는 어드레스이다. 본 명세서에 설명된 디바이스에서, 버스 시스템은 최상위 레벨 네트워크 및 어레이 레벨 네트워크를 포함한다. 최상위 레벨 네트워크는 물리적 어드레스들을 사용하여 어레이 외부의 메모리와 통신하기 위해 외부 데이터 인터페이스에 연결된다. 어레이 레벨 네트워크는 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들에 연결된다. 본 명세서에 설명된 것과 같은 2 레벨 버스 시스템에서, 메모리 액세스 제어기는 어레이 레벨 네트워크 및 최상위 레벨 네트워크에 연결되고, 최상위 레벨 네트워크와 어레이 레벨 네트워크 사이에서 데이터 전송들을 라우팅하기 위한 로직을 포함한다.
어레이 레벨 네트워크는 스위치들의 그리드를 포함할 수 있고, 상기 그리드 내의 스위치들, 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들 및 메모리 액세스 제어기는 어레이 레벨 네트워크 상의 어드레스가능한 노드들이다.
일부 실시형태들에서, 디바이스는 구성가능한 유닛들의 복수의 타일들을 포함하는 구성가능한 유닛들의 어레이를 포함한다. 이러한 복수의 타일들을 포함하는 디바이스는 단일 집적 회로 또는 단일 멀티칩 모듈 상에 구현될 수 있다. 버스 시스템은 타일 경계들 상에 버스 시스템을 파티셔닝하기 위한 회로들을 포함하는, 타일들 사이의 경계들 상에 스위치들을 포함할 수 있다. 보다 일반적으로, 구성가능한 유닛들의 어레이는, 파티셔닝의 목적들을 위해, 어레이 내의 파티셔닝가능한 그룹들을 포함하는 구성가능한 유닛들의 블록들을 포함할 수 있다. 일부 실시형태들에서, 파티셔닝가능한 그룹은 1 초과의 타입의 구성가능한 유닛을 포함할 수도 있다. 일부 실시형태들에서, 어레이는 가상 머신들을 구성하는데 사용가능한 구성가능한 유닛들의 최소 세트를 포함하는 원자 파티셔닝가능한 그룹들을 포함할 수 있다. 또한, 버스 시스템은 분할가능한 그룹들의 경계들 상에서 어레이 내의 구성가능한 유닛들을 분리하도록 구성될 수 있다.
구성 제어기가 버스 시스템에 연결되고, 구성가능한 유닛들의 세트에서 애플리케이션 그래프들을, 동일한 재구성가능한 프로세서 상의 구성가능한 유닛들의 다른 세트들에서 실행되는 애플리케이션 그래프들과 간섭하지 않고, 스왑하는데 사용될 수 있는, 디바이스가 설명된다. 이러한 구성 제어기를 포함하는 재구성가능한 프로세서는 단일 집적 회로 또는 단일 멀티칩 모듈 상에 구현될 수 있다. 구성 제어기는, 어레이에서 구성가능한 유닛들의 개별 세트들 내의 구성가능한 유닛들에 구성 파일들을 분배하는 것을 포함하는 구성 로드 프로세스를 실행하기 위한 로직을 포함할 수 있고, 여기서 구성가능한 유닛들의 세트들 중 일 세트에서의 애플리케이션 그래프는 구성가능한 유닛들의 다른 세트에서의 구성 로드 프로세스 동안 실행가능하다. 또한, 구성 제어기는, 개별 세트들에서의 구성가능한 유닛들로부터 상태 정보를 언로딩하는 것을 포함하는 구성 언로드 프로세스를 실행하기 위한 로직을 포함할 수 있고, 여기서 구성가능한 유닛들의 세트들 중 일 세트에서의 애플리케이션 그래프는 구성가능한 유닛들의 다른 세트에서의 구성 언로드 프로세스 동안 실행가능하다. 구성 제어기는 구성가능한 유닛들의 다른 세트들과 독립적으로 개별 구성가능한 유닛들에 대해 구성 로드 및 언로드 동작들을 실행할 수 있다.
일반적으로, 구성가능한 유닛들의 어레이 및 구성가능한 유닛들의 어레이에 연결된 버스 시스템을 포함하는 재구성가능한 데이터 프로세서를 구성하기 위한 방법을 포함하는 기술이 설명된다. 그 방법은 특정 세트 내의 구성가능한 유닛들과 특정 세트 외부의 구성가능한 유닛들 사이의 버스 시스템을 통한 통신들을 차단함으로써, 구성가능한 유닛들의 어레이를 구성가능한 유닛들의 복수의 세트들로 파티셔닝하는 단계; 및 특정 세트 내로부터 발생하는 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스를, 구성가능한 유닛들의 어레이 외부의 메모리 내의 특정 세트에 할당된 메모리 공간으로 한정하는 단계를 포함할 수도 있다.
본 명세서에 설명된 기술은 CGRA 또는 구성가능한 유닛들의 다른 타입의 어레이의 동적 재구성을 제공한다. 호스트 내의 런타임 애플리케이션 또는 서비스는 재구성가능한 프로세서 내의 리소스들의 할당 및 재할당을 위한 루틴을 포함할 수 있다. 하나의 이러한 루틴에서, 호스트는 구성가능한 유닛들의 개별 세트들 내의 애플리케이션 그래프들을 로딩하고, 복수의 애플리케이션 그래프들이 동시에 또는 병렬로 실행되게 하도록 로딩된 애플리케이션 그래프들을 시작할 수 있다. 실행중인 애플리케이션 그래프를 변경하거나 업데이트하는 것이 바람직할 때, 호스트는 구성가능한 유닛들의 세트들 중 하나에서 선택된 애플리케이션 그래프를 중지 및 언로딩할 수 있고, 세트들 중 상기 하나에서 다른 애플리케이션 그래프를 로딩할 수 있는 한편, 구성가능한 유닛들의 어레이에서 구성가능한 유닛들의 다른 세트들에서의 다른 애플리케이션 그래프들은 계속해서 실행된다.
본 명세서에 설명된 기술의 다른 양태들 및 이점들은 이하의 도면들, 상세한 설명 및 청구항들의 검토에서 알 수 있다.
도 1 은 호스트, 메모리, 및 재구성가능한 데이터 프로세서를 포함하는 시스템을 나타내는 시스템도이다.
도 2 는 CGRA ((Coarse Grain Reconfigurable Architecture) 의 최상위 레벨 네트워크 및 컴포넌트들의 간략화된 블록도이다.
도 3 은 도 2 의 구성에서 사용할 수 있는 타일 및 어레이 레벨 네트워크의 간략화된 다이어그램이고, 여기서 어레이의 구성가능한 유닛들은 어레이 레벨 네트워크의 노드들이다.
도 3a 는 어레이 레벨 네트워크에서 엘리먼트들을 연결하는 예시적인 스위치 유닛을 나타낸다.
도 4 는 가상 머신들을 구현하는 리소스들 및 구성가능한 유닛들의 어레이를 포함하는 시스템의 블록도이다.
도 5 는 도 4 와 같은 시스템에서 메모리 액세스 제어기에 의해 실행되는 절차의 흐름도이다.
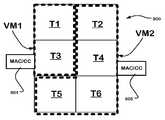
도 6 은 구성가능한 유닛들의 복수의 세트들로 파티셔닝된 구성가능한 유닛들의 어레이의 일부를 도시한다.
도 7 은 다른 실시형태에 따라 구성가능한 유닛들의 복수의 세트들로 파티셔닝된, 복수의 타일들을 포함하는 구성가능한 유닛들의 어레이의 일부를 도시한다.
도 8 은 타일 경계들 상에 구성가능한 유닛들의 복수의 세트들로 파티셔닝된 구성가능한 유닛들의 어레이의 일 예를 도시한다.
도 9 은 구성가능한 유닛들의 복수의 세트들로 파티셔닝된 구성가능한 유닛들의 어레이의 다른 예를 도시한다.
도 10 은 복수의 CGRA 디바이스들에 걸친 가상 머신들의 구현을 예시한다.
도 11 은 구성가능한 유닛들의 어레이에서 가상 머신 리소스들을 할당하기 위한 프로시저의 흐름도이다.
도 12 는 구성가능한 유닛들의 어레이에서 사용가능한 구성가능한 스위치의 일 예를 도시하는 블록도이다.
도 13 는 예시적인 구성가능한 유닛을 나타내는 블록도이다.
도 14 는 구성가능한 유닛에서 유닛 구성 로드 프로세스를 제어하기 위해 사용될 수 있는 상태 머신 다이어그램의 일 예를 나타낸다.
도 15 은 구성가능한 유닛에서의 구성 저장소의 로드를 지원하는 구조의 논리적 표현이다.
도 16 은 재구성가능한 데이터 프로세서에 커플링된 호스트의 동작들을 나타내는 흐름도이다.
도 17 은 마스터 AGCU 의 일부일 수 있거나 그 외에 타일에서의 구성가능한 유닛들의 어레이와 통신할 수 있는 구성 로드 제어기의 동작들을 나타내는 흐름도이다.
도 18 은 구성 파일의 예시적인 조직을 나타낸다.
도 19 은 도 2 및 도 3 의 것과 같은 시스템에 대한 어레이 구성 로드 프로세스를 실행하기 위한 로직의 일 예를 나타내는 상태 머신 다이어그램이다.
도 20 은 도 19 의 것과 같은 분배 시퀀스의 조기 라운드들의 타이밍을 나타내는 타이밍도이다.
도 21 는 구성가능한 유닛에서의 유닛 구성 로드 프로세스를 나타내는 흐름도이다.
도 22 은 도 2 및 도 3 의 것과 같은 시스템에 대한 어레이 구성 언로드 프로세스를 실행하기 위한 로직의 일 예를 도시하는 상태 머신 다이어그램이다.
도 23 는 구성가능한 유닛에서의 유닛 구성 언로드 프로세스를 나타내는 흐름도이다.
도 2 는 CGRA ((Coarse Grain Reconfigurable Architecture) 의 최상위 레벨 네트워크 및 컴포넌트들의 간략화된 블록도이다.
도 3 은 도 2 의 구성에서 사용할 수 있는 타일 및 어레이 레벨 네트워크의 간략화된 다이어그램이고, 여기서 어레이의 구성가능한 유닛들은 어레이 레벨 네트워크의 노드들이다.
도 3a 는 어레이 레벨 네트워크에서 엘리먼트들을 연결하는 예시적인 스위치 유닛을 나타낸다.
도 4 는 가상 머신들을 구현하는 리소스들 및 구성가능한 유닛들의 어레이를 포함하는 시스템의 블록도이다.
도 5 는 도 4 와 같은 시스템에서 메모리 액세스 제어기에 의해 실행되는 절차의 흐름도이다.
도 6 은 구성가능한 유닛들의 복수의 세트들로 파티셔닝된 구성가능한 유닛들의 어레이의 일부를 도시한다.
도 7 은 다른 실시형태에 따라 구성가능한 유닛들의 복수의 세트들로 파티셔닝된, 복수의 타일들을 포함하는 구성가능한 유닛들의 어레이의 일부를 도시한다.
도 8 은 타일 경계들 상에 구성가능한 유닛들의 복수의 세트들로 파티셔닝된 구성가능한 유닛들의 어레이의 일 예를 도시한다.
도 9 은 구성가능한 유닛들의 복수의 세트들로 파티셔닝된 구성가능한 유닛들의 어레이의 다른 예를 도시한다.
도 10 은 복수의 CGRA 디바이스들에 걸친 가상 머신들의 구현을 예시한다.
도 11 은 구성가능한 유닛들의 어레이에서 가상 머신 리소스들을 할당하기 위한 프로시저의 흐름도이다.
도 12 는 구성가능한 유닛들의 어레이에서 사용가능한 구성가능한 스위치의 일 예를 도시하는 블록도이다.
도 13 는 예시적인 구성가능한 유닛을 나타내는 블록도이다.
도 14 는 구성가능한 유닛에서 유닛 구성 로드 프로세스를 제어하기 위해 사용될 수 있는 상태 머신 다이어그램의 일 예를 나타낸다.
도 15 은 구성가능한 유닛에서의 구성 저장소의 로드를 지원하는 구조의 논리적 표현이다.
도 16 은 재구성가능한 데이터 프로세서에 커플링된 호스트의 동작들을 나타내는 흐름도이다.
도 17 은 마스터 AGCU 의 일부일 수 있거나 그 외에 타일에서의 구성가능한 유닛들의 어레이와 통신할 수 있는 구성 로드 제어기의 동작들을 나타내는 흐름도이다.
도 18 은 구성 파일의 예시적인 조직을 나타낸다.
도 19 은 도 2 및 도 3 의 것과 같은 시스템에 대한 어레이 구성 로드 프로세스를 실행하기 위한 로직의 일 예를 나타내는 상태 머신 다이어그램이다.
도 20 은 도 19 의 것과 같은 분배 시퀀스의 조기 라운드들의 타이밍을 나타내는 타이밍도이다.
도 21 는 구성가능한 유닛에서의 유닛 구성 로드 프로세스를 나타내는 흐름도이다.
도 22 은 도 2 및 도 3 의 것과 같은 시스템에 대한 어레이 구성 언로드 프로세스를 실행하기 위한 로직의 일 예를 도시하는 상태 머신 다이어그램이다.
도 23 는 구성가능한 유닛에서의 유닛 구성 언로드 프로세스를 나타내는 흐름도이다.
이하의 설명은 전형적으로 특정 구조적 실시형태들 및 방법들을 참조할 것이다. 본 기술을 구체적으로 개시된 실시형태들 및 방법들로 제한하려는 의도는 없고, 본 기술은 다른 특징들, 엘리먼트들, 방법들 및 실시형태들을 사용하여 실시될 수도 있다는 것이 이해되어야 한다. 바람직한 실시형태들은 청구항들에 의해 정의되는 그것의 범위를 제한하지 않고 본 기술을 예시하기 위해 설명된다. 당업자는 다음의 설명에 대한 다양한 등가의 변형들을 인식할 것이다.
도 1 은 호스트 (120), 메모리 (140), 및 재구성가능한 데이터 프로세서 (110) 를 포함하는 시스템을 나타내는 시스템도이다. 도 1 의 예에 도시된 바와 같이, 재구성가능한 데이터 프로세서 (110) 는 구성가능한 유닛들 (CU들) 의 어레이 (190) 및 가상화 로직 (195) 을 포함한다. 가상화 로직 (195) 은 하나의 다이 또는 하나의 멀티칩 모듈 상의 구성가능한 유닛들의 어레이에서 다수의, 관련되지 않은 애플리케이션 그래프들 (또는 관련된 그래프들) 의 동시 실행을 지원하거나 가능하게 하는 리소스들을 포함할 수 있다. 도면에서, 제 1 애플리케이션 그래프는 구성가능한 유닛들의 특정 세트 (196) 의 가상 머신 (VM1) 에서 구현되고, 제 2 애플리케이션 그래프는 구성가능한 유닛들의 다른 세트 (197) 의 가상 머신 (VM2) 에서 구현된다.
본 설명의 목적들을 위한 애플리케이션 그래프는 인공 지능 또는 머신 학습 시스템에서의 추론 또는 학습과 같이, 디바이스를 사용하여 미션 기능 프로시저 또는 프로시저들의 세트를 실행하도록 컴파일된 어레이 내의 구성가능한 유닛들에 대한 구성 파일을 포함한다. 이 설명의 목적들을 위한 가상 머신은, 물리적 머신에서 경험되는 바와 같이, 이용가능한 리소스들에 대한 물리적 제약이 있는 경우처럼 애플리케이션 그래프에 나타나는 방식으로 구성가능한 유닛들의 어레이에서 애플리케이션 그래프의 실행을 지원하도록 구성된 리소스들의 세트 (가상화 로직 (195) 및 버스 시스템 (115) 의 엘리먼트들을 포함함) 를 포함한다. 가상 머신은 가상 머신을 사용하는 미션 기능의 애플리케이션 그래프의 일부로서 확립될 수 있거나, 별도의 구성 메커니즘을 사용하여 확립될 수 있다. 본 명세서에 설명된 실시형태들에서, 가상 머신들은 애플리케이션 그래프들에서 또한 사용되는 구성가능한 유닛들의 어레이의 리소스들을 사용하여 구현되고, 따라서 애플리케이션 그래프에 대한 구성 파일은 그의 대응하는 가상 머신에 대한 구성 데이터를 포함하고, 애플리케이션 그래프를 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들의 특정 세트에 링크시킨다.
가상화 로직 (195) 은, 아래에서 더 상세히 설명되는 바와 같이, 어레이 (190) 를 파티셔닝하기 위한 회로들, 하나 또는 다수의 메모리 액세스 제어기들 및 하나 또는 다수의 구성 로드/언로드 제어기들을 포함하는 다수의 논리 엘리먼트들을 포함할 수 있다.
구문 "구성 로드/언로드 제어기" 는, 본 명세서에서 사용된 바와 같이, 구성 로드 제어기 및 구성 언로드 제어기의 조합을 지칭한다. 구성 로드 제어기 및 구성 언로드 제어기는 별개의 로직 및 데이터 경로 리소스들 (resources) 을 사용하여 구현될 수도 있거나, 특정 실시형태에 적합하게 공유 로직 및 데이터 경로 리소스들을 사용하여 구현될 수도 있다.
프로세서 (110) 는 단일 집적 회로 다이 또는 멀티칩 모듈 상에 구현될 수 있다. 집적 회로는 단일 칩 모듈 또는 멀티 칩 모듈 (MCM) 로 패키징될 수 있다. MCM 은 단일 디바이스로서 구성된, 단일 패키지로 조립된 다수의 집적 회로 다이로 구성된 전자 패키지이다. MCM 의 다양한 다이는 기판 상에 장착되고, 기판의 베어 다이는 일부 예를 들어 와이어 본딩, 테이프 본딩 또는 플립-칩 본딩을 사용하여 표면에 또는 서로 연결된다.
프로세서 (110) 는 라인들 (125) 을 통해 호스트 (120) 에 연결된 외부 I/O 인터페이스 (130) 및 메모리 (140) 에 연결된 외부 I/O 인터페이스 (150) 를 포함한다. I/O 인터페이스들 (130, 150) 은 버스 시스템 (115) 을 통해 구성가능한 유닛들의 어레이 (190) 에 그리고 가상화 로직 (195) 에 연결된다. 버스 시스템 (115) 은 데이터의 하나의 청크의 버스 폭을 가질 수도 있으며, 이는 이 예에 대해 128 비트일 수 있다 (전체적으로 128 비트에 대한 참조는 보다 일반적으로 예시적인 청크 사이즈로서 고려될 수 있다). 일반적으로, 구성 파일의 청크는 수 N 의 비트들의 데이터를 가질 수 있고, 버스 시스템은 하나의 버스 사이클에서 N 비트의 데이터를 전송하도록 구성될 수 있으며, 여기서 N 은 임의의 실제 버스 폭이다. 분배 시퀀스에서 분배된 서브-파일은 특정 실시형태에 적합한 하나의 청크, 또는 다른 양들의 데이터로 이루어질 수 있다. 프로시저들은 각각 하나의 데이터 청크로 이루어진 서브-파일들을 사용하는 것으로 본 명세서에서 설명된다. 물론, 본 기술은 예를 들어, 2 개의 버스 사이클들에서 분배된 2 개의 청크들로 이루어질 수도 있는 서브-파일들을 포함하여, 상이한 사이즈들의 서브-파일들을 분배하도록 구성될 수 있다.
구성가능한 유닛들의 어레이 (190) 에서의 구성가능한 유닛들을 애플리케이션 그래프 및 가상 머신에 대한 구성 파일로 구성하기 위해, 호스트 (120) 는 구성 파일을 재구성가능한 데이터 프로세서 (110) 내의 인터페이스 (130), 버스 시스템 (115) 및 인터페이스 (150) 를 통해 메모리 (140) 에 전송할 수 있다. 구성 파일은 구성가능한 프로세서 (110) 외부의 데이터 경로들에서를 포함하여, 특정 아키텍처에 맞는 많은 방식들로 로딩될 수 있다. 구성 파일은 메모리 인터페이스(150) 를 통해 메모리(140) 로부터 취출될 수 있다. 가상 머신 내의 애플리케이션 그래프에 대한 구성 파일의 청크들은 그 후 가상 머신에 대응하는 어레이 (190) 내의 구성가능한 유닛들의 세트 내의 구성가능한 유닛들로 본 명세서에 설명된 바와 같은 분배 시퀀스로 전송될 수 있는 한편, 구성가능한 유닛들의 다른 세트들 또는 다른 가상 머신들 내의 애플리케이션 그래프들은 계속해서 동시에 실행될 수 있다. 가상화를 지원하기 위해, 구성 파일은 어레이를 파티셔닝하기 위해 회로들에 의해 사용되는 파라미터들 및 메모리 액세스 제어기들에 의해 사용되는 파라미터들 및 특정 가상 머신들에 할당된 구성 로드 및 언로드 로직을 포함할 수 있다.
외부 클럭 생성기 (170) 또는 다른 내부 또는 외부 클럭 신호 소스들은, 구성가능한 유닛들의 어레이(190), 버스 시스템(115), 및 외부 데이터 I/O 인터페이스들을 포함하는, 재구성가능한 데이터 프로세서 (110) 내의 엘리먼트들에 클럭 신호(175) 또는 클럭 신호들을 제공할 수 있다.
도 2 는 단일 집적 회로 다이 상에 또는 멀티칩 모듈 상에 구현될 수 있는 CGRA (Coarse Grain Reconfigurable Architecture) 프로세서의 컴포넌트들의 간략화된 블록도이다. 이 예에서, CGRA 프로세서는 2 개의 타일들 (Tile1, Tile2) 을 갖는다. 타일은 이 예에서 어레이 레벨 네트워크를 포함하는, 버스 시스템에 연결된 구성가능한 유닛들의 세트를 포함한다. 버스 시스템은 타일들을 외부 I/O 인터페이스 (205)(또는 임의의 수의 인터페이스들) 에 연결하는 최상위 레벨 네트워크를 포함한다. 다른 실시형태들에서, 상이한 버스 시스템 구성들이 이용될 수도 있다. 각각의 타일에서의 구성가능한 유닛들은 본 실시형태에서 어레이 레벨 네트워크 상의 어드레스가능한 노드들이다.
4 개의 타일들의 각각은 4 개의 AGCU들 (Address Generation and Coalescing Units) (예를 들어, MAGCU1, AGCU12, AGCU13, AGCU14) 을 갖는다. AGCU들은 최상위 레벨 네트워크 상의 노드들 및 어레이 레벨 네트워크들 상의 노드들이고, 각 타일에 최상위 레벨 네트워크 상의 노드들 및 어레이 레벨 네트워크 상의 노드들 사이에 데이터를 라우팅하기 위한 리소스들을 포함한다. 다른 실시형태들에서, 상이한 수의 AGCU들이 사용될 수도 있거나, 또는 이들의 기능은 CGRA 프로세서 내의 다른 컴포넌트들 또는 타일 내의 재구성가능한 엘리먼트들과 결합될 수도 있다.
이 예에서 최상위 레벨 네트워크 상의 노드들은 인터페이스 (205) 를 포함하는 하나 이상의 외부 I/O 인터페이스들을 포함한다. 외부 디바이스들에 대한 인터페이스들은 최상위 레벨 네트워크 상의 노드들과 인터페이스들에 연결된 고용량 메모리, 호스트 프로세서들, 기타 CGRA 프로세서들, FPGA 디바이스들 등과 같은 외부 디바이스들 사이에서 데이터를 라우팅하기 위한 리소스들을 포함한다.
타일에서의 AGCU들 중 하나는 이 예에서 타일에 대한 어레이 구성 로드/언로드 제어기를 포함하는 마스터 AGCU 이도록 구성된다. 다른 실시형태들에서, 하나보다 많은 어레이 구성 로드/언로드 제어기가 구현될 수 있고, 하나의 어레이 구성 로드/언로드 제어기가 하나보다 많은 AGCU 사이에 분산된 로직에 의해 구현될 수도 있다. 타일 내의 모든 AGCU들은 이 예에서 메모리 액세스 제어기 (MAC) 를 포함한다. 다른 실시형태들에서, 메모리 액세스 제어기는 어레이 레벨 및 최상위 레벨 네트워크들 상의 별개의 노드로서 구현될 수 있고, 그래프를 실행하는 구성가능한 유닛들의 세트와의 통신들을, 최상위 레벨 네트워크를 사용하여 액세스가능한, 구성가능한 유닛들의 세트에 할당된 메모리 공간으로 그리고 옵션적으로 다른 할당된 리소스들로 한정하는, 어레이 레벨과 최상위 레벨 네트워크들 사이의 게이트웨이로서 작용하는 로직을 포함한다. 메모리 액세스 제어기는, 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스들을, 액세스들이 발생하는 구성가능한 유닛들의 세트들에 할당된 메모리 공간 또는 구성가능한 유닛들의 어레이 외부의 메모리로부터의 데이터가 지향되는 메모리 공간으로 한정하도록 구성가능한 어드레스 레지스터들 및 어드레스 변환 로직을 포함할 수 있다.
이 예에서, MAGCU1 은 Tile1 에 대한 구성 로드/언로드 제어기를 포함하고, MAGCU2 는 Tile2 에 대한 구성 로드/언로드 제어기를 포함한다. 다른 실시형태들에서, 구성 로드/언로드 제어기는 하나보다 많은 타일의 구성을 로딩 및 언로딩하도록 설계될 수 있다. 다른 실시형태들에서, 하나 초과의 구성 제어기가 단일 타일의 구성을 위해 설계될 수 있다. 또한, 구성 로드/언로드 제어기는 최상위 레벨 네트워크 및 어레이 레벨 네트워크 또는 네트워크들 상의 독립형 노드로서 포함하는, 시스템의 다른 부분들에서 구현될 수 있다.
최상위 레벨 네트워크는 AGCU들을 포함하는, 최상위 레벨 네트워크 상의 다른 노드들에 뿐만 아니라 서로 연결하는 최상위 레벨 스위치들 (211-216) 및 I/O 인터페이스(205) 를 사용하여 구성된다. 최상위 레벨 네트워크는 최상위 레벨 스위치들을 연결하는 링크들 (예를 들어, L11, L12, L21, L22) 을 포함한다. 데이터는 링크들 상의 최상위 레벨 스위치들 간에, 그리고 스위치들로부터 그 스위치들에 연결된 네트워크 상의 노드들로 패킷들에서 이동한다. 예를 들어, 최상위 레벨 스위치들 (211 및 212) 은 링크 (L11) 에 의해 연결되고, 최상위 레벨 스위치들 (214, 215) 은 링크 (L12) 에 의해 연결되고, 최상위 레벨 스위치들 (211 및 214) 은 링크 (L13) 에 의해 연결되고, 최상위 레벨 스위치들 (212 및 213) 은 링크 (L21) 에 의해 연결된다. 링크들은 하나 이상의 버스들 및 예를 들어 청크-와이드 버스 (벡터 버스) 를 포함하는 지원 제어 라인들을 포함할 수 있다. 예를 들어, 최상위 레벨 네트워크는 AXI 호환가능 프로토콜과 유사한 방식으로 데이터의 전송을 위해 협력하여 동작가능한 데이터, 요청 및 응답 채널들을 포함할 수 있다. AMBA® AXI and ACE Protocol Specification, ARM, 2017 참조.
최상위 레벨 스위치들은 AGCU들에 연결될 수 있다. 예를 들어, 최상위 레벨 스위치들 (211, 212, 214 및 215) 은 타일 (Tile1) 내의 MAGCU1, AGCU12, AGCU13 및 AGCU14에 각각 연결된다. 최상위 레벨 스위치들 (212, 213, 215 및 216) 은 타일 (Tile2) 에서의 MAGCU2, AGCU22, AGCU23 및 AGCU24 에 각각 연결된다.
최상위 레벨 스위치들은 하나 이상의 외부 I/O 인터페이스들 (예를 들어, 인터페이스 (205)) 에 연결될 수 있다.
도 3 은 도 2 의 구성에서 사용할 수 있는 타일 및 어레이 레벨 네트워크의 간략화된 다이어그램이고, 여기서 어레이의 구성가능한 유닛들은 어레이 레벨 네트워크의 노드들이다.
이 예에서, 구성가능한 유닛들의 어레이(300) 는 복수의 타입들의 구성가능한 유닛들을 포함한다. 이 예에서 구성가능한 유닛들의 타입들은 패턴 계산 유닛 (PCU), 패턴 메모리 유닛 (PMU), 스위치 유닛 (S), 및 어드레스 생성 및 병합 유닛 (각각 2개의 어드레스 생성기 (AG) 및 공유 CU를 포함) 을 포함한다. 이들 타입들의 구성가능한 유닛들의 기능들의 예에 대해, Prabhakar 등의 "Plasticine: A Reconfigurable Architecture For Parallel Patterns", ISCA '17, June 24-28, 2017, Toronto, ON, Canada 을 참조하며, 이는 본원에 완전히 설명된 바와 같이 참조로 통합된다. 이들 구성가능한 유닛들의 각각은 프로그램을 실행하기 위한 셋업 (setup) 또는 시퀀스 (sequence) 중 어느 일방을 나타내는 레지스터들 또는 플립-플롭들의 세트를 포함하는 구성 저장소를 포함하고, 네스팅된 루프들의 수, 각각의 루프 반복기의 한계들, 각각의 스테이지에 대해 실행될 명령들, 피연산자들의 소스, 및 입력 및 출력 인터페이스들에 대한 네트워크 파라미터들을 포함할 수 있다.
추가적으로, 이들 구성가능한 유닛들의 각각은 네스팅된 루프들 또는 다른 것에서 프로그레스를 추적하는데 사용가능한 상태를 저장하는 레지스터들 또는 플립-플롭들의 세트를 포함하는 구성 저장소를 포함한다. 구성 파일은 프로그램을 실행하는 컴포넌트들 각각의 초기 구성 또는 시작 상태를 나타내는 비트-스트림을 포함한다. 이러한 비트-스트림은 비트-파일로서 지칭된다. 프로그램 로드는 모든 컴포넌트들이 프로그램(즉, 머신) 을 실행하도록 허용하기 위해 비트 파일의 콘텐츠들에 기초하여 구성가능한 유닛들의 어레이에서 구성 저장소들을 셋업하는 프로세스이다. 프로그램 로드는 또한 모든 PMU 메모리들의 로드를 필요로 할 수도 있다.
어레이 레벨 네트워크는 어레이에서의 구성가능한 유닛들을 상호연결하는 링크들을 포함한다. 어레이 레벨 네트워크에서의 링크들은 하나 이상, 그리고 이 경우 3가지 종류의 물리적 버스들: 청크-레벨 벡터 버스 (예를 들어, 128 비트의 데이터), 워드-레벨 스칼라 버스 (예를 들어, 32 비트의 데이터), 및 다중 비트-레벨 제어 버스를 포함한다. 실례로, 스위치 유닛들 (311 및 312) 사이의 상호연결부 (321) 는 128 비트의 벡터 버스 폭을 갖는 벡터 버스 상호연결부, 32 비트의 스칼라 버스 폭을 갖는 스칼라 버스 상호연결부, 및 제어 버스 상호연결부를 포함한다.
세 종류의 물리적 버스들은 전송되는 데이터의 입도 (granularity) 가 다르다. 일 실시형태에서, 벡터 버스는 그 페이로드로서 16-바이트 (=128 비트) 의 데이터를 포함하는 청크를 반송할 수 있다. 스칼라 버스는 32 비트 페이로드를 가질 수 있고, 스칼라 피연산자들 또는 제어 정보를 반송할 수 있다. 제어 버스는 토큰들 및 다른 신호들과 같은 제어 핸드쉐이크들을 반송할 수 있다. 벡터 및 스칼라 버스들은 각각의 패킷의 목적지를 나타내는 헤더들, 및 패킷들이 비순차적으로 수신될 때 파일을 리어셈블링하는데 사용될 수 있는 시퀀스 넘버들과 같은 다른 정보를 포함하여, 패킷 스위칭될 수 있다. 각각의 패킷 헤더는 목적지 스위치 유닛의 지리적 좌표들 (예를 들어, 어레이에서의 행 및 열) 을 식별하는 목적지 식별자, 및 목적지 유닛에 도달하기 위해 사용되는 목적지 스위치 상의 인터페이스(예를 들어, North(북쪽), South(남쪽), East (동쪽), West (서쪽) 등) 를 식별하는 인터페이스 식별자를 포함할 수 있다. 제어 네트워크는, 예를 들어, 디바이스 내의 타이밍 회로들에 기초하여 회로 스위칭될 수 있다. 구성 로드/언로드 제어기는 128 비트의 구성 데이터의 각각의 청크에 대한 헤더를 생성할 수 있다. 헤더는 헤더 버스 상에서 구성가능한 유닛의 어레이에서의 각각의 구성가능한 유닛으로 송신된다.
일 예에서, 128 비트의 데이터의 청크는, 구성가능한 유닛에 대한 벡터 입력들로서 청크를 제공하는 벡터 버스 상에서 송신된다. 벡터 버스는 128 개의 페이로드 라인들, 및 헤더 라인들의 세트를 포함할 수 있다. 헤더는 다음을 포함할 수 있는, 각각의 청크에 대한 시퀀스 ID 를 포함할 수 있다:
● 청크가 스크래치패드 메모리 또는 구성 저장소 데이터를 포함하는지를 나타내기 위한 비트.
● 청크 넘버를 형성하는 비트들.
● 열 식별자를 나타내는 비트들.
● 행 식별자를 나타내는 비트들.
● 컴포넌트 식별자를 나타내는 비트들.
로드 동작의 경우, 구성 로드 제어기는 N-1 에서 0 의 순서로 구성가능한 유닛에 N 개의 청크들을 전송할 수 있다. 이 예에서, 6 개의 청크들은 청크 5->청크 4->청크 3->청크 2->청크 1-> 청크 0 의 최상위 비트 제 1 순서로 전송된다. (이 최상위 비트 제 1 순서는 청크 5 가 어레이 구성 로드 제어기로부터의 분배 시퀀스의 라운드 0 에 분배되는 것을 초래한다.) 언로드 동작의 경우, 구성 언로드 제어기는 역순서 (out of order) 의 언로드 데이터를 메모리에 기록할 수 있다. 로드 및 언로드 동작들 모두에 대해, 구성가능한 유닛에서의 구성 데이터 저장소에서의 구성 직렬 체인들에서의 시프팅은 LSB(최하위 비트) 로부터 MSB(최상위 비트) 로, 또는 MSB 아웃이 우선이다.
도 3a 는 어레이 레벨 네트워크에서 엘리먼트들을 연결하는 예시적인 스위치 유닛을 나타낸다. 도 3a의 예에 나타낸 바와 같이, 스위치 유닛은 8개의 인터페이스들을 가질 수 있다. 스위치 유닛의 North (북쪽), South (남쪽), East (동쪽) 및 West (서쪽) 인터페이스들은 스위치 유닛들 사이의 연결들을 위해 사용된다. 스위치 유닛의 Northeast (북동쪽), Southeast (남동쪽), Northwest (북서쪽) 및 Southwest (남서쪽) 인터페이스들은 PCU 또는 PMU 인스턴스들에 대한 연결을 만드는 데 각각 사용된다. 각 타일 사분면 내의 2개의 스위치 유닛들의 세트는, 다수의 어드레스 생성 (address generation; AG) 유닛들 및 다수의 어드레스 생성 유닛들에 연결된 병합 유닛 (coalescing unit; CU) 을 포함하는 어드레스 생성 및 병합 유닛 (Address Generation and Coalescing Unit; AGCU) 에 대한 연결들을 갖는다. 병합 유닛 (CU) 은 AG들 사이를 중재하고 메모리 요청들을 처리한다. 스위치 유닛의 8 개의 인터페이스들의 각각은 벡터 인터페이스, 스칼라 인터페이스, 및 벡터 네트워크, 스칼라 네트워크, 및 제어 네트워크와 통신하기 위한 제어 인터페이스를 포함할 수 있다.
구성가능한 스위치들의 어레이를 파티셔닝하기 위한 로직의 실시형태에서, 스위치들은 스위치 포트 디스에이블 레지스터 SPDR 및 스위치 라우팅 레지스터 SRR 와 같은 구성 데이터를 포함한다. 일 실시형태에서, 어레이 내의 각각의 스위치는 스위치 상의 스위치 포트들 중 하나 이상을 사용하여 통신들을 차단하기 위해, 구성 로드 및 언로드 프로세스들을 사용하여 구성가능하다. 이에 의해, 구성가능한 유닛들의 세트를 둘러싸는 스위치들의 세트는 타일을 상이한 애플리케이션 그래프 그래프들에 의해 사용가능한, 구성 유닛들의 복수의 세트들로 파티셔닝하도록 구성될 수 있다.
다수의 타일들이 존재하는 다른 실시형태에서, 타일들의 외부 행들 및 외부 열들 상의 스위치들만이 구성 로드 및 언로드 프로세스들을 사용하여 구성가능하여, 타일 경계들에 걸쳐 스위치 포트들 중 하나 이상을 사용하여 통신들을 허용하거나 차단하도록 한다. 예를 들어, 스위치 포트 디스에이블 레지스터는 타일 경계들에 걸친 통신을 디스에이블하도록 설정될 수 있다.
구성 후 가상 머신의 실행 동안, 데이터는 어레이 레벨 네트워크 상의 하나 이상의 스위치 유닛들의 벡터 버스 및 벡터 인터페이스(들) 를 사용하여 하나 이상의 유닛 스위치들 및 유닛 스위치들 사이의 하나 이상의 링크들을 통해 구성가능한 유닛들로 전송될 수 있다.
본 명세서에 설명된 실시형태들에서, 타일의 구성 전에, 구성 파일 또는 비트 파일은, 어레이 레벨 네트워크 상의 하나 이상의 스위치 유닛들의 벡터 버스 및 벡터 인터페이스(들) 를 사용하여 구성가능한 유닛에 대해, 유닛 스위치들 사이의 하나 이상의 링크들 및 하나 이상의 유닛 스위치들을 통해, 동일한 벡터 버스를 사용하여 구성 로드 제어기로부터 전송될 수 있다. 실례로, 구성가능한 유닛 PMU(341) 에 특정한 유닛 파일에서의 구성 데이터의 청크는 구성 로드/언로드 제어기 (301) 와 스위치 유닛 (311) 의 West (W) 벡터 인터페이스 사이의 링크 (320), 스위치 유닛 (311), 및 스위치 유닛 (311) 의 Southeast (SE) 벡터 인터페이스와 PMU(341) 사이의 링크 (331) 를 통해 구성 로드/언로드 제어기 (301) 로부터 PMU(341) 로 전송될 수 있다.
이 예에서, AGCU들 중 하나는 구성 로드/언로드 제어기 (예를 들어, 301) 를 포함하는 마스터 AGCU 이도록 구성된다. 마스터 AGCU는 호스트 (120, 도 1) 가 레지스터를 통하여, 버스 시스템을 통해 마스터 AGCU 에 커맨드들을 전송할 수 있는 그러한 레지스터를 구현한다. 마스터 AGCU 는 타일 내의 구성가능한 유닛들의 어레이 상의 동작들을 제어하고, 레지스터에 대한 기록들을 통해 호스트로부터 수신하는 커맨드들에 기초하여 타일의 상태를 추적하기 위해 프로그램 제어 상태 머신을 구현한다. 매(every) 상태 전이에 대해, 마스터 AGCU 는 데이지 체인형 커맨드 버스 (daisy chained command bus) 를 통해 타일 상의 모든 컴포넌트들에 커맨드들을 발행한다 (도 4). 그 커맨드들은 타일 내의 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들을 리셋하기 위한 프로그램 리셋 커맨드, 및 구성가능한 유닛들에 구성 파일을 로딩하기 위한 프로그램 로드 커맨드를 포함한다.
마스터 AGCU 내의 구성 로드 제어기는 메모리로부터 구성 파일을 판독하고, 구성 데이터를 타일의 매 구성가능한 유닛에 전송하는 것을 담당한다. 마스터 AGCU 는 바람직하게는 최상위 레벨 네트워크의 최대 스루풋에서 메모리로부터 구성 파일을 판독할 수 있다. 메모리로부터 판독된 데이터는 본 명세서에 설명된 분배 시퀀스에 따라 어레이 레벨 네트워크 상의 벡터 인터페이스를 통해 마스터 AGCU 에 의해 대응하는 구성가능한 유닛으로 전송된다.
일 실시형태에서, 구성가능한 유닛 내의 배선 요건들 (wiring requirements) 을 감소시킬 수 있는 방식으로, 구성 로드 프로세스에서 로딩되거나 구성 언로드 프로세스에서 언로딩될 유닛 파일들을 홀딩하는 구성 및 상태 레지스터들은 직렬 체인으로 연결되고, 그 직렬 체인을 통해 비트들을 시프팅하는 프로세스를 통해 로딩될 수 있다. 일부 실시형태들에서, 병렬로 또는 직렬로 배열된 하나 초과의 직렬 체인이 있을 수도 있다. 구성가능한 유닛이 하나의 버스 사이클에서 마스터 AGCU로부터 예를 들어 128 비트의 구성 데이터를 수신할 때, 구성가능한 유닛은 사이클 당 1 비트의 레이트로 그것의 직렬 체인을 통해 이 데이터를 시프트하고, 여기서 시프터 사이클들은 버스 사이클과 동일한 레이트로 실행될 수 있다. 구성가능한 유닛이 벡터 인터페이스를 통해 수신된 128 비트의 데이터로 128 구성 비트를 로딩하기 위해 128 시프터 사이클이 걸릴 것이다. 128 비트의 구성 데이터를 청크라고 지칭한다. 구성가능한 유닛은 모든 그것의 구성 비트들을 로딩하기 위해 다수의 데이터 청크들을 요구할 수 있다. 예시적인 시프트 레지스터 구조가 도 6 에 도시되어 있다.
구성가능한 유닛들은 다수의 메모리 인터페이스들 (150, 도 1) 을 통해 메모리와 인터페이싱한다. 메모리 인터페이스들의 각각은 여러 AGCU들을 사용하여 액세스될 수 있다. 각각의 AGCU는 오프-칩 메모리에 대한 요청들을 생성하기 위해 재구성가능한 스칼라 데이터경로를 포함한다. 각각의 AGCU 는 오프-칩 메모리로부터 발신 커맨드들, 데이터, 및 착신 응답들을 버퍼링하기 위해 데이터를 조직하기 버퍼들을 포함한다.
AGCU들에서의 어드레스 생성기들 (AG들) 은 조밀하거나 (dense) 또는 희소한 (sparse) 메모리 커맨드들을 생성할 수 있다. 조밀한 요청들은 연속적인 오프-칩 메모리 영역들을 대량 전송하는 데 사용될 수 있고, 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들로부터/로 데이터의 청크를 판독 또는 기록하는 데 사용될 수 있다. 조밀한 요청들은 AGCU들에서의 병합 유닛 (CU) 에 의해 다수의 오프-칩 메모리 버스트 요청들로 변환될 수 있다. 희소한 요청들은 어드레스들의 스트림을 병합 유닛 내로 인큐(enqueue)할 수 있다. 병합 유닛은 발행된 오프-칩 메모리 요청들에 대한 메타데이터를 유지하기 위해 병합 캐시를 사용하고, 발행된 오프-칩 메모리 요청들의 수를 최소화하기 위해 동일한 오프-칩 메모리 요청에 속하는 희소 어드레스들을 결합한다.
전술한 바와 같이, 예시된 실시형태의 AGCU들 각각은 메모리 액세스 제어기 MAC (301, 302, 303 및 304) 를 포함한다. 메모리 액세스 제어기들 각각은 타일 내의 구성가능한 유닛들 모두에 전용될 수 있다. 대안적으로, 구성 파일에 의해 설정된 상이한 그래프들은 타일에서의 구성가능한 유닛들의 상이한 파티셔닝된 세트들 상에 상주할 수도 있고, 파티셔닝된 세트들 각각은 파티셔닝된 세트 내의 스위치에 연결된 메모리 액세스 제어기들 중 하나에 구성 파일에 의해 할당될 수 있다.
도 4 는 외부 호스트 (401) 및 외부 메모리 (402) 에 커플링된 CGRA 디바이스 (400) 를 포함하는 시스템을 예시한다. 예를 들어, PCIE 타입 인터페이스들 또는 특정 구현에 적합한 다른 타입들의 인터페이스들을 포함하여, 디바이스 (400) 를 호스트 (401) 에 커플링하는 복수의 인터페이스들 (405) 이 존재할 수 있다. 인터페이스들 (405) 중 하나 이상은 인터넷 기반 네트워크 연결들을 포함하는 네트워크 연결들일 수 있다. 호스트 (401) 는 디바이스 (400) 와 협력하여 런타임 프로그램을 실행할 수 있는 클라우드 기반 시스템을 포함하는 임의의 시스템을 포함할 수 있다.
예를 들어, 고밀도 DRAM 메모리로의 연결에 적합한 고속 이중 데이터 레이트 인터페이스들, 또는 특정 구현에 적합한 다른 타입들의 인터페이스들을 포함하여, 디바이스 (400) 를 메모리 (402) 에 커플링하는 복수의 인터페이스들 (406) 이 존재할 수 있다.
CGRA 디바이스 (400) 는 어레이 레벨 네트워크 (411) 에 커플링되는 구성가능한 유닛들의 어레이 (410) 를 포함한다. 이 예시에서, 어레이는 구성가능한 유닛들 (VM1, VM2, ... VMn) 의 복수의 세트들로 파티셔닝된다. 구성가능한 유닛들의 어레이는 상이한 "형상들" 의 가상 머신들을 지원할 수 있다. 예를 들어, 일부 실시형태들에서, 리소스 요구들이 원자 그룹의 리소스들과 매칭하는 가상 머신을 지원할 수 있는, 구성가능한 유닛들 및 다른 CGRA 리소스들 (원자 그룹) 의 최소-크기 세트가 존재할 수 있다. 더 큰 VM들은 상이한 VM 형상들을 구성하기 위해 원자 그룹의 집합 세트들로 구성될 수 있다. 일 예에서, 원자 그룹은 도 3 에 예시된 바와 같은 타일이고, VM들은 여러 타일들에 걸쳐 있을 수 있다. 다른 실시형태들에서, 원자 그룹은 타일의 부분 (행들 및 열들의 서브세트) 일 수 있고, VM 통신들, 메모리, 및 원자 그룹들의 상이한 구성들로 구성된 VM들의 로드/언로드를 서로 분리하기 위한 로직을 갖는다.
어레이 레벨 네트워크 (411) 는 또한 하나 이상의 어드레스 생성 및 병합 유닛들 (AGCU들) (420) 에 커플링된다. AGCU들 (420) 은, 외부 호스트 (401) 및 외부 메모리 (402) 를 포함하는 외부 리소스들과의 통신을 위해 인터페이스들 (405, 406) 에 차례로 커플링되는 최상위 레벨 네트워크 (412) 에 커플링된다.
AGCU들 (420) 은 어레이 레벨 네트워크 (411) 와 최상위 레벨 네트워크 (412) 사이의 게이트웨이로서 동작하는 로직을 포함한다.
AGCU들의 게이트웨이 기능은 이 예에서, 어레이 (410) 내의 구성가능한 유닛들의 세트들 사이의 통신들을 구성가능한 유닛들의 대응하는 세트들에 의해 구현되는 가상 머신들에 할당된 메모리 내의 영역들로 한정하기 위해 사용되는 가상 머신들 메모리 공간을 맵핑하는 맵핑 테이블 (422) 을 활용하는 메모리 액세스 제어기를 포함한다.
일 실시형태에서, AGCU 를 통한 임의의 메모리 액세스들은 맵핑 테이블 (422) 에 의해 필터링된다. 메모리 액세스가 구성가능한 유닛들의 특정 세트에 할당된 메모리 공간 외부의 구성가능한 유닛들의 특정 세트로부터 시도되면, 메모리 액세스는 차단된다. 일부 실시형태들에서, 액세스를 차단하는 것에 부가하여, 구성가능한 유닛들의 세트에서 실행되는 특정 애플리케이션 그래프에 의한 메모리 액세스 위반을 나타내는 예외 메시지가 호스트에 전송될 수 있다.
이 예에서 AGCU들은 또한, 가상 머신들의 지원시, 어레이 내의 구성가능한 유닛들의 대응하는 세트들로부터 그래프들을 로딩 및 언로딩하는데 사용되는 구성 제어기 (421) 를 포함한다.
맵핑 테이블 (422) 은 대응하는 AGCU (420) 에 대한 구성 파일의 일부로서 구성될 수 있다.
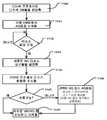
도 5 는 위에서 설명된 시스템들에서 사용될 수 있는 것과 같은, AGCU 내의 메모리 액세스 제어기에 의해 실행되는 로직을 예시하는 흐름도이다. 이 흐름에서, AGCU 를 포함하는 구성가능한 유닛들의 세트에서 애플리케이션 그래프의 실행 동안 AGCU 는 메모리 액세스에 대해 어레이 레벨 네트워크 상의 통신들을 모니터링할 수 있다 (510). 메모리 액세스가 수신되면, 그 요청에서 가상 어드레스 (즉, 특정 가상 머신에서 실행되는 애플리케이션 그래프에 의해 사용되는 어드레스) 가 파싱된다 (511). 요청의 소스는 특정 가상 머신에 매칭된다 (512). 가상 어드레스는 맵핑 테이블 (422) 을 사용하여 물리적 어드레스 (즉, 구성가능한 유닛들의 어레이 외부의 메모리에 대한 어드레스) 로 변환된다. 이는 특정 세트의 구성가능한 유닛들에 할당된 가상 머신의 식별자 (VMID) 를 사용하여 메모리 맵 (MM) 을 검색함으로써 실행될 수 있다 (513). 메모리 액세스 제어기는 액세스가 가상 머신에 할당된 메모리 공간의 경계를 벗어난 물리적 어드레스에 맵핑되는지의 여부를 결정한다 (515). 액세스가 경계를 벗어나지 않으면, 물리적 어드레스를 사용하여 최상위 레벨 네트워크 상에서 메모리 액세스 요청이 발행된다 (516). 액세스가 경계를 벗어나면 최상위 네트워크에서 예외가 발행되고 요청이 드롭된다 (517).
이 흐름도는 특정 가상 머신이 실행 중인, 구성가능한 유닛들의 특정 세트 내부로부터의 요청에 대한 로직을 설명한다. 유사한 프로세스가 구성가능한 유닛들의 특정 세트로 향하는 최상위 레벨 네트워크로부터의 데이터 전송들을 위해 실행될 수 있다.
구성가능한 유닛들의 복수의 세트들 내의 구성가능한 유닛들의 세트들은 가상 어드레스들을 사용하여 애플리케이션 그래프들을 실행하도록 구성가능하고, 메모리 액세스 제어기는 특정 세트 내에서 실행되는 애플리케이션 그래프로부터 발생하는 요청들 내의 가상 어드레스들을 특정 세트에 할당된 메모리 공간 내의 어드레스들로 변환하기 위해 구성가능한 테이블을 포함하거나 그에 대한 액세스를 갖는다. 일부 예들에서, 가상 어드레스들은 어레이 내의 다른 유닛들로부터의 통신들에 응답하여 AGCU 에서 생성된다. 이러한 가상 어드레스들은 메모리 액세스 제어기에서 물리적 어드레스들로 변환된다.
일 실시형태에서, 메모리 액세스 제어기는 각각의 애플리케이션 그래프를 다수의 메모리 영역들에 할당하도록 구성가능하다. 맵핑은 베이스/바운드 접근법을 사용하여 할당된 메모리 공간에 포함될 영역들의 최대 수에 따라 구현될 수 있다. 예를 들어, 각각의 애플리케이션 그래프에 할당된 메모리 공간이 최대 16 개의 메모리 영역들을 포함할 수 있다고 가정하면, 컴파일러는 AGCU 내의 어드레스 레지스터들의 비트들 63:60 을 사용하여 영역 ID 를 정적으로 할당할 수 있다.
하나의 접근법에서, 컴파일러는 0 의 기본 메모리 어드레스 및 크기를 각각의 영역에 할당한다. 이는 또한 할당된 각 영역의 사용을 검증하기 위한 표시기를 할당한다.
할당된 영역은 컴파일러에 의해 생성된 구성 파일 내에 포함된다. X 는 정수이고, 각각의 테이블 엔트리가 다음 필드들을 갖는 구조인 X-엔트리 영역 테이블의 형태를 취할 수 있다:
유효 - 테이블 엔트리가 할당됨;
크기 - 영역의 N 비트 크기; 영역은 크기가 2 의 거듭제곱이 아닐 수도 있음; 및
AGCU 메모리 어드레스 생성기 (카운터/ALU 출력) 를 주어진 영역에 바인딩하는 각 영역에 대한 연결들의 목록.
비트파일 로드 시간에서, 영역 테이블로부터의 엔트리들은 애플리케이션 그래프를 구현하는데 사용되는 구성가능한 유닛들의 세트에 링크된 각각의 AGCU 에서 유효, 기본, 및 경계 레지스터들을 프로그래밍하는데 사용된다. 영역 바인딩 메커니즘에 따라, 각각의 AGCU 어드레스 생성기는 또한 특정 영역에 바인딩될 수 있다. 기본 어드레스들은 일부 예들에서 런타임에 의해 할당할 수 있다.
AGCU 가 구성가능한 유닛들의 세트 내의 구성가능한 유닛들로부터 발생하는 액세스 요청에 응답하여 메모리 어드레스 및 길이를 생성할 때, 최상위 레벨 네트워크 상의 어드레스와의 트랜잭션을 전송하기 전에, 다음의 동작들이 수행된다.
이 X 영역 예에서의 Z-비트 어드레스는 2 개의 부분들을 포함할 수 있다. 다수의 상위 비트들 (Z-1:W) 은 영역 액세스 레지스터를 식별한다. 하위 비트들 (W-1:0) 은 영역에서 상대적인 가상 오프셋을 식별한다.
AGCU 는 가상 어드레스의 비트들 (Z-1:W) 을 사용하여 물리적 영역의 베이스/경계들을 검색한다. 비트 단위의 오프셋은 실제 DDR 물리적 어드레스를 생성하기 위해 그 영역에 대한 기본 레지스터에 추가된다. 기본 값이 길이만큼 증분되고, 결과적인 범위 어드레스가 제한 레지스터에 대해 체크된다. 범위 어드레스가 한계보다 작거나 같으면, 어드레스 및 요청은 프로세싱을 위해 최상위 레벨 네트워크를 통해 DDR 로 전달된다.
범위 어드레스가 한계를 초과하면, 런타임 예외가 생성되고, 최상위 레벨 네트워크 요청이 억제되고, AGCU 는 그 어드레스 생성기로부터의 추가 어드레스 요청들을 프로세싱하는 것을 중지한다.
대안적인 실시형태에서, 메모리 액세스 제어기는 다른 접근법들을 사용하여 가상 대 물리 변환을 사용하여 가상 어드레스 (VA) 대 물리 어드레스 (PA) 맵핑을 구현할 수 있다. 예를 들어, VA-PA 버퍼 변환 접근법에서, 런타임 소프트웨어는 VA-PA 변환의 프로세스를 통해 컴파일러 생성된 어드레스 영역들을 물리적 메모리 내의 이용가능한 메모리 공간에 맵핑한다. 이렇게 하면 런타임으로 큰 가상 어드레스 공간을 구성가능한 유닛들의 다수의 어레이들에 걸쳐 분산될 수 있는 다수의 물리적 어드레스 공간으로 파티셔닝할 수 있다. 물리적 어드레스 공간은 일부 경우에, 최소 크기 (예를 들어, 1MB) 및 최대 크기 (예를 들어, 1TB) 를 갖는 세그먼트들로 파티셔닝될 수 있다.
가상 어드레스를 물리적 어드레스로 효율적으로 변환하기 위해, 각각의 메모리 액세스 제어기는 16 개의 가상 세그먼트들에 대한 맵핑 정보를 보유하는 16 개의 엔트리 VA-PA 버퍼를 구현할 수 있다. 이 예에서 VA-PA 버퍼는 완전히 연관되며, 구성 로드 동안 비트 파일 (구성 파일) 에서 로드된다. 1VA-PA 버퍼의 각각의 엔트리는 또한 레지스터 기록들을 통해 기록될 수 있다. 각각의 VA-PA 버퍼 엔트리는 2 개의 서브-필드들: VSID_PA 및 V_SSIZE 로 구성될 수 있다. 이러한 서브-필드들의 각각이 아래 표에 설명된다:
VSID_PA:

V_SSIZE:

AGCU 는 구성 로드 프로세스에서 비트-파일의 VA-PA 버퍼 구조로부터 VA-PA 버퍼를 채운다.
가상 머신에서의 애플리케이션 그래프의 실행 동안, 가상 어드레스는 AGCU 에 링크된 구성가능한 유닛들의 세트에서의 애플리케이션 그래프에 기초하여 생성된다.
메모리 액세스 제어기는 매칭하는 가상 세그먼트에 대한 각각의 VA-PA 버퍼 엔트리를 검색함으로써 가상 어드레스를 변환한다.
변환 에러들은 예를 들어 다음을 포함하는 메모리 액세스 제어기에 의해 검출될 수 있다:
1. 변환 없음: 요청의 VA 가 VA-PA 버퍼 엔트리들 중 임의의 것의 VSID 비트들과 매칭하지 않는다.
2. 다수의 매칭들: 요청의 VA 는 다중 엔트리의 VSID 비트들과 매칭한다.
3. 최대치보다 큰 SSIZE : 매칭하는 엔트리들의 SSIZE 가 설정된 최대치보다 크다.
이들 에러들은 에러를 야기한 VA 와 함께 상태 레지스터에 기록될 수 있다. 또한, 변환 에러에서, 메모리 액세스 제어기는 인터럽트 또는 다른 유형의 통지를 호스트에 전송하고, 에러를 야기한 요청을 드롭하고, 임의의 새로운 요청들의 프로세싱을 중지할 수 있다.
도 6 은 PCU들, PMU들 및 스위치 유닛들을 포함하는, 도 3 을 참조하여 설명된 것들과 같은 구성가능한 유닛들의 어레이를 예시한다. 어레이 내의 (AGCU들에서와 같은) 다른 어드레스가능한 노드에 구현된 구성 로드 로직 및 메모리 액세스 제어기 로직은 도시되지 않는다. 어레이 레벨 네트워크는, 영역 내의 다른 구성가능한 유닛들에 연결하도록 구성가능한, 스위치들의 그리드를 포함한다.
구성 파일은 어레이를 구성가능한 유닛들의 분할된 세트로 파티셔닝하기 위해, 스위치의 선택된 포트로부터의 통신을 차단하도록 스위치들을 구성하는 데 사용될 수 있다. 도 6 에 도시된 예에서, 어레이는 VM1 으로 라벨링된 구성가능한 유닛들의 제 1 세트 및 VM2 로 라벨링된 구성가능한 유닛들의 제 2 세트를 포함하도록 구성된다. 구성가능한 유닛들의 세트들의 경계들 상의 스위치들은 대응하는 세트 내의 유닛들로부터 외부의 유닛들로의 통신들을 차단하도록 구성된다. 예를 들어, 스위치 (600) 는 남서쪽 포트, 서쪽 포트, 북서쪽 포트, 북쪽 포트, 및 북동쪽 포트를 차단하는 한편, 동쪽 포트, 남동쪽 포트, 및 남쪽 포트를 가능하게 하도록 구성될 수 있다. 스위치 (601) 는 남서쪽 포트, 남쪽 포트 및 남동쪽 포트를 차단하는 한편, 스위치 상의 다른 포트들을 가능하게 하도록 구성될 수 있다. 스위치 (602) 는 남동쪽 포트만을 차단하는 한편, 스위치 상의 다른 포트들을 인에이블하도록 구성될 수 있다. 이러한 방식으로, 구성가능한 유닛들의 어레이의 파티션은 구성가능한 유닛들의 분리된 세트들을 형성하도록 구성될 수 있다. 본 명세서에 설명된 실시형태들에서, 분리된 세트들 각각은 전술한 바와 같이 메모리 액세스 제어기 및 구성 제어기에 커플링된다.
보다 일반적으로, 구성가능한 유닛들의 어레이는, 파티셔닝의 목적들을 위해, 어레이 내의 파티셔닝가능한 그룹들을 포함하는 구성가능한 유닛들의 블록들을 포함할 수 있다. 일부 실시형태들에서, 파티셔닝가능한 그룹은, 도 3 에 예시된 바와 같이, PMU들, PCU들, 스위치들 및 AGCU들을 포함하는 하나 초과의 타입의 구성가능한 유닛을 포함할 수도 있다. 버스 시스템은 주어진 구현에 적합한 임의의 크기의 어레이 내의 파티션가능한 그룹들의 경계들 상의 구성가능한 유닛들의 세트들로 어레이를 파티셔닝하기 위해 제공하도록 구성될 수 있다.
도 7 은 PCU들, PMU들 및 스위치 유닛들을 포함하는, 도 3 을 참조하여 설명된 것들과 같은 구성가능한 유닛들의 어레이를 예시한다. 이 예에서, 구성가능한 유닛들의 어레이는 구성가능한 유닛들의 복수의 타일들을 포함한다. 버스 시스템은 타일 경계들 상에 버스 시스템을 파티셔닝하기 위한 회로들을 포함하는 타일들 사이의 경계들 상에 스위치들을 포함한다. 이 예에서, 대응하는 세트들에서 실행되는 특정 가상 머신들 또는 그래프들에 할당될 수 있는 구성가능한 유닛들의 세트들은 타일 경계들 상에서 파티셔닝되고, 하나 이상의 타일들을 포함할 수 있다.
따라서, 도시된 바와 같이, 제 1 가상 머신 (VM1) 은 타일들 (T1 및 T3) 의 적어도 부분들을 포함하는 구성가능한 유닛들의 세트 내에서 분리된다. 제 2 가상 머신 (VM2) 은 타일들 (T2, T4, T5 및 T6) 의 적어도 부분들을 포함하는 구성가능한 유닛들의 세트 내에서 분리된다.
어레이 내의 (AGCU들에서와 같은) 다른 어드레스가능한 노드에 구현된 구성 로드 로직 및 메모리 액세스 제어기 로직은 도시되지 않고, 각각의 타일의 적어도 하나를 포함한다.
타일 경계들 상의 스위치들은 앞서 논의된 바와 같이 구성 파일을 사용하여 선택된 포트들 상의 통신들을 차단하도록 구성가능한 경계 스위치들로 지칭될 수 있다. 그리드의 다른 스위치들은 포트들을 비활성화하는 능력을 가질 수도 있거나 그렇지 않을 수도 있다. 예를 들어, 스위치 (700) 는 타일 T5 내의 구성가능한 유닛들의 세트로부터 타일 T3 내의 구성가능한 유닛들의 세트로 이어지는 모든 포트들을 차단하도록 구성될 수 있다. 마찬가지로, 스위치 (701) 는 타일들 T5 로부터 T3 로 경계를 가로지르는 포트들을 차단하도록 구성될 수 있다. 이 예시된 실시형태에서, 각각의 타일은 행들 및 열들로 배열된 스위치들의 그리드를 포함한다. 경계 스위치는 각 행의 끝에 배치된다. 각 타일의 상부 및 하부 행에 있는 모든 스위치들은 경계 스위치들일 수 있다. 경계 스위치들은 다음과 같이 서로 라우팅하도록 구성될 수 있다. 각 타일의 최내측 칩 열에서의 스위치는 좌측/우측 이웃에 연결되어 그 이웃하는 타일에 대한 양방향 동쪽/서쪽 링크를 생성하고, 그에 의해 단일 논리 타일로 연합할 수 있다. 유사하게, 각각의 타일에서 최내측 칩 행들을 따른 스위치들은 그들의 북쪽/남쪽 이웃에 결합하여, 북쪽/남쪽 타일 쌍을 단일 타일로 연합할 수 있다. 일부 실시형태들에서, 경계 스위치들의 오직 하나의 행 또는 열만이 예시된 바와 같이 각각의 타일에서 하나의 행 및 하나의 열보다는 타일 경계들 상에 구현될 수 있다.
구성가능한 유닛들의 어레이로 파티셔닝된 구성가능한 유닛들의 세트들은 다양한 구성들을 가질 수 있다. 도 8 은 구성가능한 유닛들의 어레이 (800) 가 복수의 타일들 (T1 내지 T6) 을 포함하고, 경계 스위치들이 타일 경계들 상의 통신을 가능하게 하거나 차단하도록 구성가능한 시스템에서의 예시적인 구성을 도시한다. 이 예에서, 제 1 가상 머신 (VM1) 은 타일들 (T1 및 T3) 내에 구성되고, 제 2 가상 머신 (VM2) 은 타일들 (T2, T4, T5 및 T6) 내에 구성된다. 가상 머신들 (VM1 및 VM2) 로서 구성된 구성가능한 유닛들의 세트들 각각은 구성가능한 유닛들의 세트 내로부터 액세스가능한 어레이 레벨 네트워크 상의 어드레스가능한 노드 상의 메모리 액세스 제어기 (MAC) 및 구성 제어기 (CC) (804, 805) 를 포함한다.
도 9 는 구성가능한 유닛들의 어레이가 타일들을 포함하지 않을 수도 있거나, 구성가능한 유닛들의 어레이의 단일 타일 내에 있을 수도 있는 시스템에서의 예시적인 구성을 도시하며, 여기서 어레이 레벨 네트워크 상의 스위치들은 어레이를 더 유연한 경계들을 갖는 복수의 세트들로 파티셔닝하도록 구성된다. 이 예시에서, 가상 머신 (VM1) 은 좌측 상단의 예시된 영역에서 구성가능한 유닛들의 세트로 구현되고, 가상 머신 (VM2) 은 어레이 (900) 의 하단 부분의 예시된 영역에서 구성가능한 유닛들의 세트로 구현된다. 가상 머신들 (VM1 및 VM2) 로서 구성된 구성가능한 유닛들의 세트들 각각은 구성가능한 유닛들의 세트 내로부터 액세스가능한 어레이 레벨 네트워크 상의 어드레스가능한 노드 상의 메모리 액세스 제어기 (MAC) 및 구성 제어기 (CC) (904, 905) 를 포함한다.
도 10 은 CGRA1 과 CGRA2 에 걸쳐 가상 머신들이 구성될 수 있는, 복수의 CGRA들을 포함하는 시스템을 도시한다. CGRA들은 각각 단일 집적 회로 상에 구현될 수 있다. CGRA들은 도 3 및 다른 도면들과 관련하여 위에서 논의된 것과 같은 구성가능한 유닛들의 어레이, 또는 가상화 로직을 지원하는 구성가능한 유닛들의 세트들로 파티션가능한 구성가능한 유닛들의 임의의 다른 타입의 어레이를 가질 수 있다.
도 10 의 시스템은 런타임 프로그램을 실행하는 호스트 (1000) 를 포함한다. 또한, CGRA1 상에 구현된 구성가능한 유닛들 (1010) 의 제 1 어레이 및 구성가능한 유닛들 (1020) 의 제 2 어레이는 CGRA2 상에 구현된다. CGRA들 각각은 대응하는 메모리 (1110, 1120) 에 커플링된다. 호스트 시스템 버스 (1005) 는 호스트 (1000) 를 2 개의 CGRA들 상의 구성가능한 유닛 (1010, 1020) 의 어레이와 상호연결시킨다. 고속 메모리 인터페이스들 (1015, 1025) 은 CGRA들을 대응하는 메모리 (1110, 1120) 에 커플링한다.
일부 실시형태들에서, 호스트 (1000) 는 CGRA 에서 최상위 레벨 네트워크를 통해 메모리 (1110) 및 메모리 (1120) 와 통신할 수 있다.
도 10 에서, 제 1 가상 머신 (VM1) 은 CGRA1 상의 어레이 (1010) 에 한정된 구성가능한 유닛들의 세트로 구성된다. 또한, 제 2 가상 머신 (VM2) 은 CGRA1 상의 어레이 (1010) 내의 구성가능한 유닛들 및 CGRA2 상의 어레이 (1020) 상의 구성가능한 유닛들을 포함하는 구성가능한 유닛들의 세트로 구성된다.
도 11 은 시스템 내의 구성가능한 유닛들의 어레이들의 최적의 사용을 위해 리소스 할당 루틴들을 수행하기 위해 본 명세서에 설명된 바와 같은 가상 머신들을 지원하는 시스템의 능력을 예시하는 흐름도이다. 단순화된 흐름도에서, 런타임으로 호스트 상에서 실행되는 애플리케이션 또는 다른 모니터링 서비스는 재구성가능한 프로세서의 구성가능한 유닛들의 어레이에 다수의 VM들 및 대응하는 애플리케이션 그래프들 (AG들) 을 로딩할 수 있다 (1140). 호스트 애플리케이션은 다수의 AG들이 그들 각각의 VM들 내에서 동시에 실행되도록, 로딩된 AG들의 실행을 개시하기 위한 커맨드들을 전송할 수 있다 (1141). AG들이 실행되는 동안, 호스트 애플리케이션은, 예를 들어, 실행중인 AG 가 새로운 AG 로 업데이트될 필요가 있거나 또는 더 높은 우선순위 AG 가 개시될 필요가 있을 때와 같이, 특정 애플리케이션 그래프에 대한 가상 머신을 구현하기 위해 리소스들을 할당하라는 요청을 모니터링할 수 있다 (1142). 그 후에, 서비스는 새로운 AG 를 구현할 수 있는 새로운 가상 머신의 요구들을 결정한다 (1143). 또한, 서비스는 재구성가능한 프로세서 내의 구성가능한 유닛들의 어레이에서의, 더 일반적으로는 시스템 내의 모든 이용가능한 재구성가능한 프로세서들에서의 리소스 활용을 조사할 수 있다 (1144). 새로운 AG 의 요구와 실행중인 AG들에 의한 리소스들의 활용을 비교하여, 요청에 응답하여 할당될 사용가능한 리소스들이 있는지 여부를 결정한다 (1145). 리소스들이 사용가능하지 않으면, 서비스는 더 낮은 우선순위를 갖는 애플리케이션 그래프를 선택하고, 선택된 AG를 (이용가능한 경우 체크포인트를 사용하여) 중지하고, AG 를 언로딩하여 리소스를 해제할 수 있다 (1154). 일부 실시형태들에서, 서비스는 리소스들이 다른 이유들로 이용가능하게 될 때까지 대기할 수 있다. AG들을 실행하기 위한 VM들을 구현하는 시스템들에서, 선택된 AG 가 중지되고 언로딩되는 동안 다른 AG들은 계속 실행될 수 있다. 리소스가 이용가능한 경우, VM 은 구성가능한 유닛들의 새롭게 이용가능한 세트를 사용하여 프로비저닝될 수 있고, 새로운 AG 구성 파일이 로딩되고 시작될 수 있다 (1155).
일반적으로, 가상화는 애플리케이션 그래프를 실행하는 동안 변경될 수 있는 방식으로 리소스들의 할당 및 재할당을 가능하게 한다. 애플리케이션 그래프를 완전히 체크하기 위해, 애플리케이션 그래프는, 미해결 메모리 또는 호스트 트랜잭션들을 갖지 않고, 타일들 및 칩들 전체에 걸쳐 일관된 방식으로 중지될 수 있는 대기 포인트들로 컴파일될 수 있다. 일 접근법에서, 컴파일러는 그래프 실행시 특정 포인트들에 체크포인트 동작들을 삽입할 수 있다. 이들은 특정 수의 최외측 루프 또는 기타 실행 관련 이벤트들의 완료에 대응할 수도 있다.
체크포인트에서, 애플리케이션 그래프가 중지되고, 정지된 (paused) 애플리케이션 그래프를 재시작하는데 사용가능한 구성가능한 유닛들의 상태 정보를 포함하는 구성 언로드가 실행될 수 있다. 따라서, 구성 언로드 프로세스는 스크래치패드 메모리 (예를 들어, 플라스티신 (Plastine) 예에서의 PMU 메모리), 파이프라인 및 제어 레지스터 상태, 및 스위치 및 메모리 액세스 제어기 또는 AGCU 상태를 덤핑하는 것을 포함할 수 있다.
도 12 는 본 명세서에서 사용된 것과 같이 구성가능한 유닛들의 어레이에서 사용가능한 예시적인 구성가능한 스위치를 도시하는 블록도이다. 구성가능한 스위치는 어레이 레벨 네트워크에서 벡터, 스칼라 및 제어 버스들 중에서의 통신들을 중재하기 위한 회로 (1205) 를 포함한다. 이 실시형태에서, 각각의 스위치는 스위치들의 그리드에서 인접한 스위치들로의 연결을 위해 구성된 북쪽, 남쪽, 동쪽 및 서쪽 포트들을 포함하는 8 개의 포트들을 갖는 회로 (1205) 를 포함한다. 또한, 8 개의 포트들은 PCU들, PMU들, 및 AGCU들 (본 명세서에 설명된 바와 같은 메모리 액세스 제어기들 및 구성 제어기들을 포함할 수 있음) 과 같은 다른 타입들의 구성가능한 유닛들로의 연결을 위해 구성된 북동쪽, 남동쪽, 남서쪽 및 북서쪽 포트들을 포함한다.
어레이를 구성가능한 유닛들의 세트들로 파티셔닝하기 위해, 구성가능한 스위치들은 스위치 포트 디스에이블 레지스터 SPDR[0:7] 를 포함한다. 일 구현에서, SPDR 레지스터는 각각의 방향으로 각각의 북/남/동/서 포트에 대해 1 비트를 포함하고; 비트 할당은 다음과 같다.
[0]: '1' 로 설정하는 경우, 북쪽 포트에서 아웃바운드 트랜잭션을 비활성화한다. 임의의 발신 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 북쪽 포트의 아웃바운드 트랜잭션이 인에이블된다.
[1]: '1' 로 설정하는 경우, 북쪽 포트에서 인바운드 트랜잭션들을 디스에이블한다. 임의의 인바운드 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 북쪽 포트의 인바운드 트랜잭션이 인에이블된다.
[2]: '1' 로 설정하는 경우, 남쪽 포트에서 아웃바운드 트랜잭션을 디스에이블한다. 임의의 발신 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 남쪽 포트의 아웃바운드 트랜잭션이 인에이블된다.
[3]: '1' 로 설정하는 경우, 남쪽 포트에서 인바운드 트랜잭션을 디스에이블한다. 임의의 인바운드 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 남쪽 포트의 인바운드 트랜잭션이 인에이블된다.
[4]: '1' 로 설정하는 경우, 동쪽 포트에서 아웃바운드 트랜잭션을 디스에이블한다. 임의의 발신 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 동쪽 포트의 아웃바운드 트랜잭션이 인에이블된다.
[5]: '1' 로 설정하는 경우, 동쪽 포트에서 인바운드 트랜잭션을 디스에이블한다. 임의의 인바운드 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 동쪽 포트의 인바운드 트랜잭션이 인에이블된다.
[6]: '1' 로 설정하는 경우, 서쪽 포트에서 아웃바운드 트랜잭션을 디스에이블한다. 임의의 발신 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 서쪽 포트의 아웃바운드 트랜잭션이 인에이블된다.
[7]: '1' 로 설정하는 경우, 서쪽 포트에서 인바운드 트랜잭션을 디스에이블한다. 임의의 인바운드 트랜잭션들은 조용히 드롭될 것이다. 그렇지 않으면, 서쪽 포트의 인바운드 트랜잭션이 인에이블된다.
개별 인바운드 및 아웃바운드 포트 제어가 불필요한 경우, 포트 방향당 단일 비트를 가짐으로써 이 설계를 단순화할 수 있다. 또한, 더 적은 수의 미리 정의된 구성들이 훨씬 더 적은 비트들을 사용하여 구성 레지스터에 표시될 수 있다.
그리드 내의 구성가능한 스위치들은 대응하는 스위치에 특정한 구성 데이터의 복수의 청크들 (또는 다른 사이즈의 서브-파일들) 을 포함하는 유닛 파일들을 저장하기 위한 구성 데이터 저장소들 (1220) (예를 들어, 포트 디스에이블 레지스터를 포함할 수 있는 직렬 체인들) 을 포함한다. 구성 데이터 저장소 (1220) 는 라인 (1221) 을 통해 회로 (1205) 에 연결된다. 또한, 그리드 내의 구성가능한 스위치들은 각각 라인 (1222) 을 통해 구성 데이터 저장소 (1220) 에 연결된 유닛 구성 로드 로직 (1240) 을 포함한다. 유닛 구성 로드 로직 (1240) 은 유닛 구성 로드 프로세스를 실행한다. 유닛 구성 로드 프로세스는 버스 시스템 (예를 들어, 벡터 입력들) 을 통해, 구성가능한 스위치에 특정한 통일된 청크들을 수신하는 것, 및 수신된 청크들을 구성가능한 스위치의 구성 데이터 저장소 (1220) 에 로딩하는 것을 포함한다. 유닛 구성 로드 프로세스에 대해서는 도 15 를 참조하여 추가로 설명된다.
이 예에서 그리드 내의 구성가능한 스위치들에서의 구성 데이터 저장소들은 래치들의 직렬 체인들을 포함하고, 여기서 래치들은 스위치에서의 리소스들의 구성을 제어하는 비트들을 저장한다. 구성 데이터 저장소에서의 직렬 체인은 구성 데이터에 대한 제 1 시프트 레지스터 체인, 예컨대 포트 인에이블 및 디스에이블 파라미터들, 및 직렬로 연결된 상태 정보 및 카운터 값들에 대한 제 2 시프트 레지스터 체인을 포함할 수 있다.
구성가능한 스위치의 각각의 포트는 입력 및 출력의 3 개의 대응하는 세트들을 사용하여 스칼라, 벡터 및 제어 버스와 인터페이싱할 수 있다. 또한, 구성가능한 스위치는, 예를 들어, 구성 로드 및 언로드 프로세스들과 연관된 통신들을 포함하는, 스위치로 지향된 통신들을 위해 스칼라, 벡터 및 제어 버스들과 인터페이싱할 수 있다.
도시되지 않았지만, 포트들 각각은 스위치들의 그리드에서 패킷-기반 및/또는 루트 기반 통신을 지원하기 위해 FIFO 버퍼들 및 다른 리소스들을 포함할 수 있다.
이 실시형태에서, 구성 로드 및 언로드 프로세스는, 그리드 내의 구성가능한 스위치들을 구성하기 위한 로드/언로드 커맨드가 완료되는 시기를 표시하기 위해 데이지 체인형 완료 버스를 사용한다. 도 12 의 예에 도시된 바와 같이, 데이지 체인형 완료 버스 (1291) 및 데이지 체인형 명령 버스 (1292) 는 데이지 체인형 로직 (1293) 에 연결된다. 데이지 체인형 로직 (1293) 은 유닛 구성 로드 로직 (1240) 과 통신한다. 데이지 체인형 로직 (1293) 은 아래에서 설명되는 바와 같이 로드 완료 상태 로직을 포함할 수 있다. 데이지 체인형 완료 버스는 아래에서 추가로 설명된다. 제어 입력들은 제어 블록 (1270) 에 의해 수신되고, 제어 출력들은 제어 블록 (1270) 에 의해 제공된다. 커맨드 및 완료 버스들에 대한 다른 토폴로지들이 가능하지만 여기서는 설명되지 않는다.
도 13 은 패턴 계산 유닛 (PCU) 과 같은 예시적인 구성가능한 유닛 (1300) 을 나타내는 블록도이다. 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들은 대응하는 구성가능한 유닛들에 특정한 구성 데이터의 복수의 청크들 (또는 다른 사이즈들의 서브-파일들) 을 포함하는 유닛 파일들을 저장하기 위한 구성 데이터 저장소들 (1320) (예를 들어, 직렬 체인들) 을 포함한다. 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들 각각은 유닛 구성 로드 프로세스를 실행하기 위해 라인 (1322) 을 통해 구성 데이터 저장소 (1320) 에 연결된 유닛 구성 로드 로직(1340) 을 포함한다. 유닛 구성 로드 프로세스는 버스 시스템 (예를 들어, 벡터 입력들) 을 통해, 구성가능한 유닛에 특정한 유닛 파일의 청크들을 수신하는 것, 및 수신된 청크들을 구성가능한 유닛의 구성 데이터 저장소 (1320) 에 로딩하는 것을 포함한다. 유닛 구성 로드 프로세스에 대해서는 도 14 를 참조하여 보다 상세히 설명된다.
복수의 구성가능한 유닛들에서의 구성가능한 유닛들에서의 구성 데이터 저장소들은 이 예에서 래치들의 직렬 체인들을 포함하고, 여기서 래치들은 구성가능한 유닛에서의 리소스들의 구성을 제어하는 비트들을 저장한다. 구성 데이터 저장소에서의 직렬 체인은 구성 데이터에 대한 제 1 시프트 레지스터 체인, 및 직렬로 연결된 상태 정보 및 카운터 값들에 대한 제 2 시프트 레지스터 체인을 포함할 수 있다. 구성 저장소에 대해서는 도 15 을 참조하여 추가로 설명된다.
구성가능한 유닛은 입력들 및 출력들 (IO) 의 3개의 대응하는 세트들: 스칼라 입력들/출력들, 벡터 입력들/출력들, 및 제어 입력들/출력들을 사용하여 스칼라, 벡터, 및 제어 버스들과 인터페이싱할 수 있다. 스칼라 IO들은 데이터의 단일 워드들 (예를 들어, 32 비트) 을 통신하기 위해 사용될 수 있다. 벡터 IO들은, 유닛 구성 로드 프로세스에서 구성 데이터를 수신하는 것, 및 다수의 PCU들 사이의 긴 파이프라인에 걸쳐 구성 후에 동작 동안 데이터를 송신 및 수신하는 것과 같은 경우들에서, 데이터의 청크들 (예를 들어, 128 비트들) 을 통신하기 위해 사용될 수 있다. 제어 IO들은 구성가능한 유닛의 실행의 시작 또는 종료와 같은 제어 신호들을 통신하기 위해 사용될 수 있다. 제어 입력들은 제어 블록 (1370) 에 의해 수신되고, 제어 출력들은 제어 블록 (1370) 에 의해 제공된다.
각각의 벡터 입력은 하나 이상의 벡터 FIFO들을 포함할 수 있는 벡터 FIFO 블록 (1360) 에서의 벡터 FIFO를 사용하여 버퍼링된다. 각각의 스칼라 입력은 스칼라 FIFO (1350) 를 사용하여 버퍼링된다. 입력 FIFO들을 사용하는 것은 데이터 생산자들과 소비자들 사이의 타이밍을 디커플링하고, 입력 지연 불일치들에 대해 강건하게 함으로써 구성가능한 유닛 간 제어 로직을 단순화한다.
입력 구성 데이터 (1310) 는 벡터 입력들로서 벡터 FIFO에 제공될 수 있고, 그 후, 구성 데이터 저장소 (1320) 에 전송될 수 있다. 출력 구성 데이터 (1330) 는 벡터 출력들을 사용하여 구성 데이터 저장소 (1320) 로부터 언로딩될 수 있다.
CGRA 는 로드/언로드 커맨드가 완료된 때를 나타내기 위해 데이지 체인형 완료 버스를 사용한다. 마스터 AGCU 는 데이지 체인형 커맨드 버스를 통해 (S0 에서 S1으로 전이하기 위해, 도 14) 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들에 프로그램 로드 및 언로드 커맨드들을 송신한다. 도 13의 예에 도시된 바와 같이, 데이지 체인형 완료 버스(1391) 및 데이지 체인형 커맨드 버스 (1392) 는 유닛 구성 로드 로직(1340) 과 통신하는 데이지 체인 로직 (1393) 에 연결된다. 데이지 체인 로직 (1393) 은 아래에서 설명되는 바와 같이 로드 완료 상태 로직을 포함할 수 있다. 데이지 체인형 완료 버스는 아래에서 추가로 설명된다. 커맨드 및 완료 버스들에 대한 다른 토폴로지들은 분명히 가능하지만 여기서는 설명되지 않는다.
구성가능한 유닛은 블록 (1380) 에서 다수의 재구성가능한 데이터경로들을 포함한다. 구성가능한 유닛에서의 데이터 경로는 다중-스테이지(스테이지 1 ... 스테이지 N), 재구성가능한 SIMD (Single Instruction, Multiple Data) 파이프 라인으로서 구성될 수 있다. 구성가능한 유닛에서의 구성 직렬 체인 내로 푸시된 데이터의 청크들은 구성가능한 유닛에서의 각각의 데이터 경로의 각각의 스테이지에 대한 구성 데이터를 포함한다. 구성 데이터 저장소 (1320) 의 구성 직렬 체인은 라인들 (1321) 을 통해 블록 (1380) 의 다수의 데이터 경로들에 연결된다.
패턴 메모리 유닛 (예를 들어, PMU) 은 PCU 에서 사용되는 버스 인터페이스들과 함께, 어드레스 계산을 위해 의도된 재구성가능한 스칼라 데이터 경로와 커플링된 스크래치패드 메모리를 포함할 수 있다. PMU들은 재구성가능한 유닛들의 어레이 전체에 걸쳐 온-칩 메모리를 분배하는데 사용될 수 있다. 일 실시형태에서, PMU들에서의 메모리 내의 어드레스 계산은 PMU 데이터 경로에 대해 수행되는 한편, 코어 계산은 PCU 내에서 수행된다.
도 14 는 구성가능한 유닛에서 유닛 구성 로드 프로세스를 제어하는 데 사용될 수 있는 상태 머신의 일 예를 나타낸다. 일반적으로, 유닛 구성 로드 프로세스는 하나의 버스 사이클에서 버스 시스템으로부터 구성가능한 유닛에 특정한 유닛 파일의 제 1 청크 (또는 서브-파일) 를 수신하고, 유닛 파일의 제 2 청크가 수신되기 전에, 버스 사이클들과 동일한 레이트로 발생하는 후속 시프터 사이클들 동안, 수신된 제 1 청크를 직렬 체인 내로 푸시하기 시작한다. 나중의 버스 사이클에서 버스 시스템으로부터 구성가능한 유닛에 특정한 유닛 파일의 제 2 청크를 수신 시, 프로세스는 이전에 수신된 청크를 직렬 체인 내로 푸시한 후에 사이클들 동안, 수신된 제 2 청크를 직렬 체인 내로 푸시하기 시작한다. 구성 로드 프로세스의 일부 또는 모든 라운드들에서, 복수의 순서화된 청크들에서의 (단위 파일의 청크들의 순서에서 다음인) 제 2 청크가 구성가능한 유닛에 의해 수신되기 전에, 제 1 청크가 구성가능한 유닛에서의 유닛 구성 로드 프로세스에 의해 소비될 수 있다.
도 14 의 상태 머신은 6 개의 상태들 (S0 내지 S5) 을 포함한다. 상태 S0 (유휴) 에서, 유닛 구성 로드 프로세스는 마스터 AGCU의 구성 로드/언로드 제어기로부터 구성 로드/언로드 커맨드를 기다린다. 구성 로드/언로드 제어기는 구성가능한 유닛들의 오프-칩 메모리 (140, 도 1) 로부터/로 및 어레이 (190, 도 1) 로부터/로 구성 데이터의 로딩 및 언로딩을 담당한다. 구성 로드/언로드 제어기에서 로드 커맨드가 수신될 때, 유닛 구성 로드 프로세스는 상태 S1 로 진입한다.
상태 S1 (정지상태 대기) 에서, 다수의 데이터 경로들에서의 기능적 플롭들은 디스에이블되어 그 기능적 플롭들은 사이클링하지 않고, 스칼라 출력들, 벡터 출력들 및 제어 출력들이 턴 오프되어 출력들이 임의의 로드들을 구동하지 않는다. 로드 커맨드가 수신되는 경우에는, 유닛 구성 로드 프로세스는 상태 S2로 진입한다. 언로드 커맨드가 수신될 때, 유닛 구성 로드 프로세스는 상태 S4로 진입한다.
상태 S2 (입력이 유효할 때까지 대기함) 에서, 유닛 구성 로드 프로세스는 입력 FIFO (1510, 도 15) 가 유효하게 될 때까지 대기한다. 입력 FIFO 가 유효하게 될 때, 입력 FIFO 는 버스 시스템을 통해 구성 파일의 구성 데이터의 청크를 수신하였다. 실례로, 구성 데이터의 청크는 128 비트의 로드 데이터를 포함할 수 있고, 이는 버스 시스템의 벡터 네트워크 상에서 수신되고, 벡터 네트워크는 128 비트의 벡터 버스 폭을 갖는다. 입력 FIFO가 유효하게 될 때, 유닛 구성 로드 프로세스는 상태 S3로 진입한다.
상태 S3 (로드 시프트) 에서, 128 비트의 구성 데이터의 청크는 입력 FIFO 로부터 하나의 클럭 사이클에서 먼저 디큐잉되고, 그 다음에, 128 비트의 구성 데이터의 청크는 128 클럭 사이클에서 입력 시프트 레지스터 (1520, 도 15) 내로 시프트된다. 입력 시프트 레지스터는 구성 데이터의 청크와 동일한 길이 (예컨대, 128 비트) 를 가질 수 있고, 구성 데이터의 청크를 구성 데이터의 청크의 길이로서 입력 시프트 레지스터로 시프트하기 위해 동일한 수의 시프터 클럭 사이클들 (예컨대, 128) 을 취한다. 전술한 바와 같이, 시프터 클럭 및 버스 클럭 (또는 버스 사이클들) 은 일부 실시형태들에서 동일한 레이트로 실행될 수 있다.
구성가능한 유닛에서의 구성 데이터 저장소는 구성가능한 유닛에 특정한 구성 데이터의 복수의 청크들을 포함하는 유닛 파일을 저장하기 위해 FIFO 체인으로서 구성될 수 있는 구성 직렬 체인 (1530, 1540, 도 15) 을 포함한다. 구성 데이터의 복수의 청크들은 구성 데이터의 제 1 청크 및 구성 데이터의 마지막 청크를 포함한다. 입력 시프트 레지스터에서의 구성 데이터의 청크는 후속 클럭 사이클들에서 구성 데이터 저장소로 추가로 직렬로 시프트된다. 구성 데이터 저장소는 도 15 을 참조하여 추가로 설명된다.
구성가능한 유닛에 특정한 유닛 파일의 제 1 청크가 상태 S3에서 입력 시프트 레지스터로 시프트된 후에, 유닛 구성 로드 프로세스는 구성 데이터의 제 1 청크가 구성가능한 유닛에 특정한 구성 데이터의 마지막 청크인지 여부를 결정한다. 만약 그렇다면, 구성가능한 유닛에 대한 유닛 파일의 로딩이 완료되고, 유닛 구성 로드 프로세스는 상태 S0로 진입한다. 그렇지 않다면, 유닛 구성 로드 프로세스는 상태 S2로 진입하고, 구성가능한 유닛에 특정한 구성 데이터의 제 2 청크에 대해 입력 FIFO가 유효해지기를 기다린다.
상태 S1 에서 언로드 커맨드가 수신될 때, 유닛 구성 로드 프로세스는 상태 S4로 진입한다.
상태 S4 (언로드 시프트) 에서, 구성 데이터 저장소로부터의 구성 데이터의 청크는 출력 시프트 레지스터 (1550, 도 15) 내로 시프트된다. 구성 데이터의 청크는 128 비트의 언로드 데이터를 포함할 수 있다. 출력 시프트 레지스터는 구성 데이터의 청크와 동일한 길이 (예를 들어, 128) 를 가질 수 있고, 구성 데이터의 청크의 길이로서 구성 데이터의 청크를 구성 데이터 저장소로부터 출력 FIFO로 시프트하기 위해 동일한 수의 시프터 클럭 사이클 (예를 들어, 128) 이 걸린다. 구성 데이터의 청크가 출력 시프트 레지스터 내로 시프트될 때, 유닛 구성 로드 프로세스는 상태 S5 (출력 유효 대기) 에 진입한다.
상태 S5 (축력이 유효할 때까지 대기) 에서, 유닛 구성 로드 프로세스는 출력 FIFO (1560, 도 15) 가 유효해질 때까지 대기한다. 출력 FIFO가 유효하게 될 때, 출력 시프트 레지스터로부터 128 비트를 갖는 구성 데이터의 청크는 하나의 클럭 사이클에서 출력 FIFO 내로 삽입된다. 출력 FIFO에서의 구성 데이터 청크는 그 다음에 버스 시스템으로 전송될 수 있다 (도 3).
상태 S5에서 구성 데이터의 제 1 청크가 출력 FIFO로 시프트된 후에, 유닛 구성 로드 프로세스는 구성 데이터의 제 1 청크가 구성 데이터 저장소에서의 구성 데이터의 마지막 청크인지 여부를 결정한다. 만약 그렇다면, 구성가능한 유닛에 대한 구성 데이터의 언로딩이 완료되고, 유닛 구성 로드 프로세스는 상태 S0으로 진입한다. 그렇지 않다면, 유닛 구성 로드 프로세스는 상태 S4로 진입하고, 구성 데이터 저장소로부터의 구성 데이터의 제 2 청크는 출력 시프트 레지스터로 직렬로 시프트된다.
도 15 는 구성가능한 유닛에서의 구성 저장소의 논리적 표현이다. 구성가능한 유닛에서의 구성 데이터 저장소 (420, 도 4) 는 제 1 시프트 레지스터 체인 (1530) 및 제 2 시프트 레지스터 체인 (1540) 을 포함하는, 본 실시형태에서의 구성 직렬 체인을 포함한다. 제 1 시프트 레지스터 체인 (1530) 은 레지스터들 또는 래치들의 세트를 포함한다. 제 2 시프트 레지스터 체인 (1540) 은 레지스터들 또는 래치들 (플립-플롭들) 의 다른 세트를 포함한다. 이 실시형태에서 제 1 시프트 레지스터 체인과 제 2 시프트 레지스터 체인은 직렬로 연결되어 단일의 체인을 형성한다.
구성 파일은 구성가능한 유닛들의 어레이에서의 복수의 구성가능한 유닛들에서의 각각의 구성가능한 유닛에 대한 구성 데이터의 복수의 청크들을 포함한다. 구성 데이터의 청크들은 각각의 구성가능한 유닛들의 초기 구성 또는 시작 상태를 나타낸다. 이 시스템에서의 구성 로드 동작은 모든 구성가능한 유닛들이 프로그램을 실행할 수 있도록 구성가능한 유닛들의 어레이에서 구성 데이터의 유닛 파일들을 셋업하는 프로세스이다.
제 1 시프트 레지스터 체인 (1530) 내의 레지스터들의 세트는, 레지스터들을 포함하는 구성가능한 유닛들의 동작의 정의를 포함하는, 프로그램을 실행하기 위한 셋업 또는 시퀀스 중 어느 일방을 나타낼 수 있다. 이들 레지스터들은 네스팅된 루프들의 수, 각각의 루프 반복기의 제한들, 각각의 스테이지에 대해 실행될 명령들, 피연산자들의 소스, 및 입력 및 출력 인터페이스들에 대한 네트워크 파라미터들을 등록할 수 있다. 제 2 시프트 레지스터 체인에서의 레지스터들의 세트는 구성가능한 유닛에서 로딩된 프로그램의 사이클-바이-사이클 실행 상태에 관한 데이터를 포함할 수 있다.
도 15 의 예에서 나타낸 바와 같이, 제 1 시프트 레지스터 체인 (1530) 및 제 2 시프트 레지스터 체인 (1540) 은 직렬로 연결되어, 제 1 시프트 레지스터 체인의 MSB (최상위 비트) 는 제 2 시프트 레지스터 체인의 LSB(최하위 비트) 에 연결된다. 로드 신호 또는 언로드 신호는 제 1 시프트 레지스터 체인과 제 2 시프트 레지스터 체인에 대한 로드/언로드 동작을 제어하기 위해 제 1 시프트 레지스터 체인의 LSB와 제 2 시프트 레지스터 체인의 LSB 에 커플링된 시프트 인에이블 신호로서 작용할 수 있다. 입력 FIFO (1510) 는 선택기 (1570) 를 통해 입력 시프트 레지스터 (1520) 에 커플링된다. 선택기 (1570) 는, 로드 신호가 활성일 때, 입력 시프트 레지스터 (1520) 를 구성 데이터 저장소 (제 1 시프트 레지스터 체인 (1530) 의 LSB) 의 입력에 연결한다.
로드 신호가 활성일 때, 입력 시프트 레지스터 (1520) 내의 구성 데이터는 구성 직렬 체인에서의 제 1 시프트 레지스터 체인 (1530) 및 제 2 시프트 레지스터 체인 (1540) 내로 시프트될 수 있다. 여기서, 로드 신호는 입력 시프트 레지스터, 제 1 시프트 레지스터 체인, 및 제 2 시프트 레지스터 체인에 대해 인에이블 신호로서 작용할 수 있다. 로드 동작은 구성가능한 유닛에 대한 구성 데이터의 모든 청크들이 구성가능한 유닛에서의 구성 데이터 저장소 내로 로딩될 때까지 반복될 수 있다. 직렬 체인의 길이가 정수 개수의 청크들 (또는 서브-파일들) 의 길이와 상이할 때, 직렬의 제 1 청크는 그 차이로 패딩될 수 있고, 마지막 청크가 시프트인될 때 패드 비트들은 체인의 끝까지 시프트아웃될 것이다. 예를 들어, 구성가능한 유닛에서의 구성 데이터 저장소는 760 비트의 사이즈를 갖는 단위 파일을 저장할 수 있다. 유닛 구성 로드 프로세스는 정수 N개의 청크들을 로딩할 수 있다. 이 예에서, N=6 이고, N 개의 청크들은 청크 5, 청크 4, 청크 3, 청크 2, 청크 1 및 청크 0 을 포함한다. 벡터 버스는 128 비트의 벡터 폭을 가지며, 구성 데이터의 청크는 128 비트를 가지며, 청크는 하나의 버스 클럭 사이클에서 구성가능한 유닛으로 전송될 수 있다. N 개의 청크들은 N x 128 = 6 * 128 = 768 비트의 사이즈를 가지며, 이는 760 비트의 유닛 파일 사이즈에 매칭하는 8 패드 비트를 포함한다.
오류를 복구하기 위해, 언로드 동작은 각각의 구성가능한 유닛의 상태를 체크할 수 있다. 언로드 동작은 재시작을 위해 필요한 각각의 구성가능한 유닛의 실행 상태를 저장하고, 에러가 발생할 경우 애플리케이션 그래프가 재시작되도록 할 수 있다. 그것은 또한 구성가능한 유닛들의 상태가 저장되거나 디버그 목적들을 위해 전송되도록 허용한다. 저장될 필요가 있는 상태는 적어도 제 1 또는 제 2 시프트 레지스터들의 일부의 콘텐츠, 및 선택적으로 PMU 메모리들의 콘텐츠를 포함한다. 프로그램 언로드는 또한 제 1 및 제 2 시프트 레지스터들의 전부의 상태를 언로딩하는 것을 필요로 할 수도 있다.
출력 FIFO (1560) 는 출력 시프트 레지스터 (1550) 에 커플링되고, 이는 차례로 구성 데이터 저장소 (제 2 시프트 레지스터 체인 (1540) 의 MSB) 의 출력에 커플링된다. 언로드 동작을 위해, 언로드 신호가 활성일 때, 제 2 시프트 레지스터 체인 (1540) 및 제 1 시프트 레지스터 체인 (1530) 에서의 구성 데이터는 출력 시프트 레지스터 (1550) 로 시프트될 수 있다. 출력 FIFO (1560) 가 유효할 때, 출력 시프트 레지스터 (1550) 에서의 구성 데이터 (예를 들어, 128 비트) 는 하나의 클럭 사이클에서 출력 FIFO (1560) 에 삽입될 수 있다. 구성가능한 유닛에서의 구성 데이터 저장소 내의 구성 데이터의 모든 청크들이 출력 FIFO로 언로딩될 때까지 언로드 동작은 반복될 수 있다.
MAGCU 에서 구성 로드 제어기에 의해 발행된 구성 로드 커맨드들의 완료를 동기화하고 통신하기 위해, 단일 와이어 데이지 체인형 방식이 일 예에서 구현되고, 체인의 각각의 컴포넌트에서 데이지 체인 로직(예컨대, 도 13 에서의 데이지 체인 로직 (1393)) 에 포함된 로직에 의해 지원된다. 이 방식은 매 컴포넌트가 다음의 2 포트들을 가질 필요가 있다:
1. PROGRAM_LOAD_DONE_IN 이라고 불리는 입력 포트
2. PROGRAM_LOAD_DONE_OUT 이라고 불리는 출력 포트
컴포넌트는, 그것이 MAGCU 에 의해 발행된 커맨드의 실행을 완료하고 그것의 PROGRAM_LOAD_DONE_IN 입력이 하이로 구동될 때, 그것의 PROGRAM_LOAD_DONE_OUT 신호를 구동할 것이다. MAGCU는, 그것이 커맨드를 실행하기 위한 모든 필요한 단계들을 완료했을 때, 그것의 PROGRAM_LOAD_DONE_OUT 을 구동함으로써 데이지 체인을 개시할 것이다. 체인에서의 마지막 컴포넌트는 MAGCU의 PROGRAM_LOAD_DONE_IN 에 연결될 그것의 PROGRAM_LOAD_DONE_OUT 을 구동할 것이다. MAGCU 의 PROGRAM_LOAD_DONE_IN 이 하이인 것은 커맨드의 완료를 나타낸다. 모든 컴포넌트들의 모든 청크들에 대응하는 데이터를 전달한 후에, MAGCU 는 그것의 PROGRAM_LOAD_DONE_OUT 포트를 하이로 구동한다. 모든 컴포넌트들은, 그것들이 모든 그들의 구성 비트들의 로딩을 완료했을 때, 그들의 각각의 PROGRAM_LOAD_DONE_OUT 포트들을 하이로 구동할 것이다.
MAGCUs 입력 포트 PROGRAM_LOAD_DONE_IN이 활성화될 때, 구성 파일 로드가 완료된다.
도 16 은 재구성가능한 데이터 프로세서에 커플링된 호스트의 동작들을 나타내는 흐름도이다. 단계 (1611) 에서, 호스트 (120, 도 1) 는 PCIE 인터페이스 (130, 도 1) 및 최상위 레벨 네트워크 (115, 도 1) 를 통해 구성가능한 유닛의 어레이에 대한 구성 파일을 오프-칩 메모리 (140, 도 1) 에 전송하거나, 그렇지 않으면, 구성가능한 프로세서에 액세스가능한 메모리에 그 구성 파일을 저장한다.
단계 (1612) 에서, 메모리에 구성 파일을 로딩하는 것이 완료되면, 호스트 (120) 는 프로세서 내의 구성 로드 제어기 (이 예에서 마스터 AGCU의 일부) 에 구성 로드 커맨드를 전송한다. 마스터 AGCU는, 레지스터를 통해 호스트가 구성 로드 커맨드를 구성 로드 제어기에 전송할 수 있는 그러한 레지스터를 구현할 수 있다. 구성 로드 커맨드는 구성 파일의 위치를 특정하는 구성가능한 프로세서 상의 메모리 인터페이스를 통해 액세스가능한 메모리 내의 위치를 식별할 수 있다. 그 후, 구성 로드 제어기는 구성 파일을 취출하기 위한 커맨드에 응답하여 최상위 레벨 네트워크를 통해 하나 이상의 메모리 액세스 요청들을 생성할 수 있다. 그 다음에, 호스트는 구성 파일이 완전히 로딩되었다는 신호에 대해 구성가능한 프로세서를 모니터링할 수 있다 (1614). 파일 로딩이 완료되면, 호스트는 머신에 의해 실행될 기능을 개시할 수 있다 (1616).
도 17 은 MAGCU의 일부일 수 있거나 그 외에 타일에서의 구성가능한 유닛들의 어레이와 통신할 수 있는 구성 로드 제어기의 동작들을 나타내는 흐름도이다. 구성 로드 제어기는 오프-칩 메모리 (140, 도 1) 로부터 구성 파일을 판독하고 구성가능한 유닛들의 어레이에서의 매 구성가능한 유닛에 구성 데이터를 전송하는 것을 담당한다. 이 흐름도는 구성 로드 제어기가 구성 로드 커맨드를 기다리는 것으로 시작한다 (1710). 전술한 바와 같이, 구성 로드 커맨드는 구성 파일, 및 프로세서에 액세스가능한 메모리에서의 그것의 로케이션을 식별한다.
로드 커맨드를 수신 시, 단계 (1711) 에서, 구성 로드 제어기는 재구성가능한 데이터 프로세서 (110, 도 1) 에 연결된 메모리 (140, 도 1) 에 로드 요청들을 발행한다. 단계 (1712) 에서, 구성 로드 제어기는 메모리 인터페이스를 통해 최상위 레벨 네트워크 상에서 구성 파일의 청크들을 취출한다. 단계 (1713) 에서, 구성 로드 제어기는 어레이 레벨 네트워크 상에서 정렬된 라운드들에서의 구성 파일의 청크들을 어레이 내의 구성가능한 유닛들로 분배한다. 구성 파일의 모든 청크들이 수신되고 분배되었을 때, 구성 로드 제어기는 단계 (1714) 에서 분배 완료 신호 (예를 들어, 그것의 PROGRAM_LOAD_DONE_OUT) 를 생성한다. 그 후, 구성 로드 제어기는, 예를 들어, 단계 (1715) 에서 그것의 PROGRAM_LOAD_DONE_IN의 활성화에 의해 표시된, 그들의 각각의 유닛 파일들이 로드되었다는, 구성가능한 유닛들로부터의 확인을 대기한다. 성공적인 구성 로드의 확인시, 구성 로드 제어기는 호스트에 통지할 수 있다 (1716).
도 18 은 구성 파일의 하나의 예시적인 조직을 나타낸다. 구성 파일을 로드 및 언로드하기 위한 특정 프로토콜에 맞게 다른 조직들이 역시 배열될 수 있다. 도 9 를 참조하여 설명된 예에서, 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들은 스위치, PCU, PMU, 및 AGCU 를 포함한다. 이들 구성가능한 유닛 각각은 프로그램을 실행하기 위한 셋업 또는 시퀀스를 나타내는 레지스터들의 세트를 포함한다. 이들 레지스터들은 네스팅된 루프들의 수, 각각의 루프 반복기의 제한들, 각각의 스테이지에 대해 실행될 명령들, 피연산자들의 소스, 및 입력 및 출력 인터페이스들에 대한 네트워크 파라미터들과 같은, 그것을 포함하는 구성가능한 유닛의 동작을 정의하기 위한 데이터를 포함한다. 추가적으로, 각 구성 파일들은 각각의 네스팅된 루프에서 진행을 추적하는 카운터들의 세트에서 컨텍스트를 설정하기 위한 데이터를 포함할 수 있다.
프로그램 실행가능물은 프로그램을 실행하는 구성가능한 유닛들 각각의 초기 구성, 또는 시작 상태를 나타내는 비트-스트림을 포함한다. 이 비트-스트림은 비트-파일로서 지칭되거나, 또는 본 명세서에서 구성 파일로서 지칭된다. 프로그램 로드는 구성 파일의 콘텐츠에 기초하여 구성가능한 유닛들에서 구성 저장소들을 셋업하여 모든 구성가능한 유닛들이 프로그램을 실행할 수 있도록 하는 프로세스이다. 프로그램 언로드는 구성가능한 유닛들로부터 구성 저장소들을 언로딩하고, 본 명세서에서 언로드 구성 파일이라고 불리는 비트-스트림을 어셈블링(assembling)하는 프로세스이다. 언로드 구성 파일은, 본 명세서에 설명된 예들에서, 동일한 배열 청크들 또는 서브-파일들 및 프로그램 로드를 위해 사용되는 구성 파일을 갖는다.
구성 파일은 구성가능한 유닛들의 어레이에서 각각의 구성가능한 유닛에 대한 구성 데이터의 복수의 청크들을 포함하고, 그 청크들은 그들이 분배될 시퀀스와 매칭하는 방식으로 구성 파일에 배열된다. 이러한 구성 파일의 조직은 어레이 구성 로드 프로세스가 구성 파일에서의 청크의 로케이션들에 기초하여 청크를 구성가능한 유닛들로 라우팅하는 것을 가능하게 한다.
도 18 에서 예시된 바와 같이, 구성 파일 (및 동일한 방식으로 배열된 언로드 구성 파일) 은 복수의 구성가능한 유닛들에서의 각각의 구성가능한 유닛에 대한 유닛 파일들의 복수의 청크들을 포함하고, 유닛 파일들은 유닛 파일에서 순서 (i) 를 갖는 M 개 (이 예에서 Z4 = 6) 까지의 서브-파일들을 갖는다. 도 9 에서 M은 6이고, 청크들은 첫 번째부터 여섯 번째까지 순서화된다 (즉, 제 1 내지 제 6 청크들은 이 인덱싱에서 청크들 (0) 내지 (5) 와 대응한다). 청크들은, 로드 또는 언로드 구성 파일에서의 모든 유닛 파일들에 대해, 0 에서 M-1 로 진행하는 (i) 에 대한 순서 (i) 의 모든 서브-파일들이, 0 에서 M-1 로 진행하는 (i) 에 대해, 메모리에서의 어드레스 공간의 대응하는 블록 (i) 에 저장되도록 배열된다. 순서 (0) 의 청크들은 어드레스들 (A0 내지 A1-1) 을 포함하는 블록 (0) 에 저장된다. 이 예에서 스위치 유닛들에 대한 순서 (0) 의 청크들은 블록 (0) 내의 연속적인 어드레스들의 그룹에 있다. PCU들에 대한 순서 (0) 의 청크들은 블록 (0) 내의 연속적인 어드레스들의 그룹에 있다. PMU들에 대한 순서 (0) 의 청크들은 블록 (0) 내의 연속적인 어드레스들의 그룹에 있다. AGCU들에 대한 순서 (0) 의 청크들은 연속적인 어드레스들의 그룹에 있다. 순서 (1) 의 청크들은 어드레스들 (A1 내지 A2-1) 을 포함하는 블록 (1) 에 저장된다. 이 예에서 스위치 유닛들에 대한 순서 (1) 의 청크들은 블록 (1) 내의 연속적인 어드레스들의 그룹에 있다. PCU들에 대한 순서 (1) 의 청크들은 블록 (1) 내의 연속적인 어드레스들의 그룹에 있다. PMU들에 대한 순서 (1) 의 청크들은 블록 (1) 내의 연속적인 어드레스들의 그룹에 있다. AGCU들에 대한 순서 (1) 의 청크들은 블록 (1) 내의 연속적인 어드레스들의 그룹에 있다. 3 내지 5 번 순서들의 청크들은 블록들 (2) 내지 (5) 의 패턴에 따라, 도 9 에 도시된 바와 같이 배열된다.
도시된 바와 같이, 선형 어드레스 공간은 이 예에서 라인 경계들 상의 구성 파일에 대해 블록들 내에 할당된다. 다른 실시형태들에서, 선형 어드레스 공간은 워드 경계들 또는 청크 경계들 상에 할당될 수 있다. 경계들은 사용될 메모리의 효율 특성들에 매칭하도록 선택될 수 있다. 따라서, 이 예에서의 구성 파일은 순차적인 라인 어드레스들을 갖는 메모리의 라인들을 포함한다.
또한, 어레이는 하나 초과의 타입의 구성가능한 유닛을 포함하고, 상이한 타입들의 구성가능한 유닛들에 대한 유닛 파일들은 구성 데이터의 상이한 수들의 서브-파일들을 포함하고, 어드레스 공간의 블록 (i) 내에서, 구성가능한 유닛의 각각의 타입에 대한 서브-파일들은 어드레스 공간의 블록 (i) 내의 연속적인 어드레스들의 대응하는 그룹에 저장된다.
어레이는 하나 초과의 타입의 구성가능한 유닛을 포함할 수 있고, 상이한 타입들의 구성가능한 유닛들에 대한 유닛 파일들은 구성 데이터의 상이한 수들의 청크들을 포함할 수 있다. 실례로, 도 3 에 도시된 바와 같이, 어레이에서의 구성가능한 유닛들의 타입들은 스위치 유닛들, PCU(패턴 계산 유닛), PMU(패턴 메모리 유닛) 및 AGCU(어드레스 생성 및 병합 유닛) 를 포함할 수 있다.
예시적인 구성 파일 조직은 다음을 포함한다:
W (예컨대, 도 3 에서 28) 스위치 유닛들, 각 유닛은 구성 비트들의 Z1 청크들을 필요로 함;
X (예컨대, 9) PCU 유닛들, 각 유닛은 구성 비트들의 Z2 청크들을 필요로 함;
Y (예컨대, 9) PMU 유닛들, 각 유닛은 구성 비트들의 Z3 청크들을 필요로 함;
Z (예컨대, 4) AGCU 유닛들, 각 유닛은 구성 비트들의 Z4 청크들을 필요로 함.
따라서, 제 1 타입의 구성가능한 유닛에 대한 유닛 파일들은 Z1 청크들을 포함할 수 있고, 제 2 타입의 구성가능한 유닛에 대한 유닛 파일들은 Z2 청크들을 포함하고, 여기서 Z1 은 Z2 보다 적다. 어레이 구성 로드 프로세스는, 0 에서 Z1-1 로 진행하는 (i) 에 대한 Z1 라운드들에서 제 1 타입 및 제 2 타입의 구성가능한 유닛들의 모두에 대해 유닛 파일들의 청크 (i) 를 포함하는 구성 파일의 세그먼트들을 취출하고, 그 다음에, Z1 에서 Z2-1 로 진행하는 (i) 에 대한 Z2 라운드들에서 제 2 타입의 상기 구성가능한 유닛들의 모두에 대해 유닛 파일들의 청크 (i) 를 포함하는 구성 파일의 세그먼트들을 취출하는 것을 포함할 수 있다. 제 3 타입의 구성가능한 유닛에 대한 유닛 파일들은 Z3 청크들을 포함할 수 있고, 제 4 타입의 구성가능한 유닛에 대한 유닛 파일들은 Z4 청크들을 포함하며, 여기서 Z1은 Z2 보다 적고, Z2 는 Z3 보다 적으며, Z3 은 Z4 보다 적다. (i+1) 초과의 청크들을 필요로 하는 모든 상이한 타입들의 구성가능한 유닛들에 대해 각 청크 (i) 에 대해 하나의 라운드로 분배 시퀀스가 이 모드에서 계속될 수 있다.
예시적인 구성 파일 조직에서 도시된 바와 같이, 구성 파일에서의 구성 데이터의 청크들은 인터리빙된 방식으로 배열된다:
라운드 R(i = 0) 에 대한 스위치 유닛들의 각각에 대한 구성 비트들의 2 개의 청크들의 첫 번째;
라운드 R(i = 0) 에 대한 PCU 유닛들의 각각에 대한 구성 비트들의 3 개의 청크들의 첫 번째;
라운드 R(i = 0) 에 대한 PMU 유닛들의 각각에 대한 구성 비트들의 5 개의 청크들의 첫 번째;
라운드 R(i = 0) 에 대한 AGCU 유닛들의 각각에 대한 구성 비트들의 6 개의 청크들의 첫 번째;
라운드 R(i = 1) 에 대한 스위치 유닛들의 각각에 대한 구성 비트들의 2 개의 청크들의 두 번째;
라운드 R(i = 1) 에 대한 PCU 유닛들의 각각에 대한 구성 비트들의 3 개의 청크들의 두 번째;
라운드 R(i = 1) 에 대한 PMU 유닛들의 각각에 대한 구성 비트들의 5 개의 청크들의 두 번째;
라운드 R(i = 1) 에 대한 AGCU 유닛들의 각각에 대한 구성 비트들의 6 개의 청크들의 두 번째;
라운드 R(i = 2) 에 대한 PCU 유닛들의 각각에 대한 구성 비트들의 3 개의 청크들의 세 번째;
라운드 R(i = 2) 에 대한 PMU 유닛들의 각각에 대한 구성 비트들의 5 개의 청크들의 세 번째;
라운드 R(i = 2) 에 대한 AGCU 유닛들의 각각에 대한 구성 비트들의 6 개의 청크들의 세 번째;
라운드 R(i = 3) 에 대한 PMU 유닛들의 각각에 대한 구성 비트들의 5 개의 청크들의 네 번째;
라운드 R(i = 3) 에 대한 AGCU 유닛들의 각각에 대한 구성 비트들의 6 개의 청크들의 네 번째;
라운드 R(i = 3) 에 대한 PMU 유닛들의 각각에 대한 구성 비트들의 5 개의 청크들의 다섯 번째;
라운드 R(i = 4) 에 대한 AGCU 유닛들의 각각에 대한 구성 비트들의 6 개의 청크들의 다섯 번째;
라운드 R(i = 5) 에 대한 4 개의 AGCU 유닛들의 각각에 대한 구성 비트들의 6 개의 청크들의 여섯 번째.
유닛 파일들은 복수의 순서화된 청크들 (또는 다른 사이즈의 서브-파일들) 을 포함하도록 조직될 수 있다. 상이한 구성가능한 유닛들에 특정한 유닛 파일들은 일부 실시형태들에서 상이한 수들의 순서화된 청크들을 가질 수도 있다. 구성가능한 유닛들의 어레이에 대한 구성 파일은 유닛 파일들의 청크들이 다른 유닛 파일들에 대해 동일한 순서의 청크들로 그룹화되도록 배열된다. 또한, 구성 파일은 구성 파일에서의 청크의 로케이션이 청크의 어레이에서의 구성가능한 유닛 및 구성가능한 유닛에 특정한 유닛 파일에서의 그것의 순서를 의미하도록 배열된다.
어레이 구성 로드 프로세스는, 0 에서 Z1-1 (=1) 로 진행하는 (i) 에 대해, 제 1 타입 (스위치 타입), 제 2 타입 (PCU 타입), 제 3 타입 (PMU 타입) 및 제 4 타입 (AGCU 타입) 의 구성가능한 유닛들의 모두에 대한 유닛 파일들의 청크 (i) 를 포함하는 구성 파일의 세그먼트들을 취출할 수 있다. 4 가지 타입들의 구성가능한 유닛들의 모두에 대한 유닛 파일들의 청크들 (0) 은 제 1 라운드에서 취출되고, 4 가지 타입들의 구성가능한 유닛들의 모두에 대한 유닛 파일들의 청크들 (1) 은 제 2 라운드에서 취출된다. 제 1 및 제 2 라운드 후에, 제 1 타입 (스위치 타입) 의 구성가능한 유닛들의 모두에 대한 유닛 파일들의 모든 (2) 청크들이 취출되었다. 제 1, 제 2, 제 3 및 제 4 타입들의 구성가능한 유닛들의 모두에 대한 유닛 파일들은 각각 0, 1, 3 및 4 개의 청크들이 취출되도록 남아 있다.
그 후, 어레이 구성 로드 프로세스는 제 3 라운드에서 제 2, 제 3 및 제 4 타입들의 구성가능한 유닛들 모두에 대한 유닛 파일들의 청크 (i) 를 포함하는 구성 파일의 세그먼트들을 취출할 수 있다. 제 3 라운드 후에, 제 2 타입 (PCU 타입) 의 구성가능한 유닛들의 모두에 대한 단위 파일들의 모두 (3) 청크들이 취출되었다. 제 0, 제 2, 제 2 및 제 3 타입들의 구성가능한 유닛들의 모두에 대한 유닛 파일들은 각각 0, 0, 2 및 3 개의 청크들이 취출되도록 남아 있다.
그 후, 어레이 구성 로드 프로세스는 제 4 라운드에서 제 3 및 제 4 타입들의 구성가능한 유닛들 모두에 대한 유닛 파일들의 청크 (i) 를 포함하는 구성 파일의 세그먼트들을 취출할 수 있다. 제 4 라운드 후에, 제 3 타입 (PMU 타입) 의 구성가능한 유닛들의 모두에 대한 유닛 파일들의 모두 (4) 청크들이 취출되었다. 제 1, 제 2, 제 3 및 제 4 타입들의 구성가능한 유닛들의 모두에 대한 유닛 파일들은 각각 0, 0, 1 및 2 개의 청크들이 취출되도록 남아 있다.
그 후, 어레이 구성 로드 프로세스는 제 5 및 제 6 라운드들에서, Z3 (=4) 에서 Z4-1 (5) 로 진행하는 (i) 에 대해, 제 3 및 제 4 타입들의 구성가능한 유닛들의 모두에 대한 유닛 파일들의 청크 (i) 를 포함하는 구성 파일의 세그먼트들을 취출할 수 있다. 제 6 라운드 후에, 제 4 타입 (AGCU 타입) 의 구성가능한 유닛들의 모두에 대한 유닛 파일들의 모두 (6) 청크들이 취출되었다. 제 1, 제 2, 제 3 및 제 4 타입들의 구성가능한 유닛들의 모두에 대한 유닛 파일들은 각각 0, 0, 0 및 0 청크들이 취출되도록 남아 있다.
전술한 방식으로, 어레이 구성 로드 프로세스는, 제 1, 제 2, 제 3 및 제 4 타입들의 구성가능한 유닛들 모두에 대한 유닛 파일들이 취출될 남아있는 청크들을 갖지 않을 때까지 계속될 수 있다.
어레이 구성 로드 프로세스는 구성 파일에서의 청크들의 로케이션에 의해 암시되는 (implied) 어드레스들을 사용하여 어레이 레벨 네트워크를 통해 구성가능한 유닛들로 구성 데이터의 청크들을 라우팅한다. 실례로, 198개의 스위치 유닛들의 각각에 대한 구성 데이터의 2개의 청크들 중 제 1 청크는 선형 메모리 어드레스들 012288 을 갖고, 198개의 스위치 유닛들의 각각에 대한 구성 데이터의 2개의 청크들 중 제 2 청크는 선형 메모리 어드레스들 33792-46080을 갖는다.
일부 실시형태들에서, 구성 파일의 청크들은 메모리로부터 구성 로드 제어기로 비순차적으로 리턴될 수 있다. 구성 파일에서의 청크들의 로케이션은 청크를 정확한 구성가능한 유닛으로 라우팅하는 데 사용될 수 있다. 배포 시퀀스에서의 라운드들의 조직 때문에, 구성가능한 유닛들은 그것들의 유닛 파일들의 청크들을 순서대로 수신하도록 보장된다.
도 19 는 도 2 및 도 3의 것과 같은 시스템에 대한 어레이 구성 로드 프로세스를 실행하기 위한 로직의 일 예를 나타내는 상태 머신 다이어그램이며, 구성 파일에서의 유닛 파일들이 복수의 구성가능한 유닛들에서의 구성가능한 유닛들로 분배될 때까지, N 라운드들 (i = 0 내지 N-1 에 대해 R(i)) 의 시퀀스로 순서 (i) 의 하나의 유닛 청크를 버스 시스템을 통해 복수의 구성가능한 유닛들에서 최대 N개의 서브-파일들을 포함하는 구성가능한 유닛들의 모두에 전송함으로써, 어레이에서의 복수의 구성가능한 유닛들에 대한 유닛 파일들을 포함하는 구성 파일을 분배하는 것을 포함하고, 유닛 파일들 각각은 복수의 순서화된 청크들 (또는 서브-파일들) 을 포함한다.
이 예에서, 상태 머신은 6 개의 상태들 (S1~S6) 을 포함한다. 상태 S1 (유휴) 에서, 구성 로드 제어기는 호스트로부터의 구성 로드 커맨드를 대기한다. 구성 로드 커맨드가 수신될 때, 로드 프로세스는 분배 시퀀스의 제 1 라운드 R(0) 의 실행을 시작하기 위해 상태 S2 로 진입한다. 각각의 라운드는 상태들 S2 내지 S6을 가로지른다. 본 명세서에 설명된 예에서, 어레이에서의 구성가능한 유닛에 분배될 청크들의 최대 수가 6 개이기 때문에 6 라운드들이 존재한다.
상태 S2 (스위치 요청) 에서, 구성 로드 제어기는 각각의 스위치 유닛들에 대한 구성 유닛 파일들의 라운드 R(i) 의 상태 S2에 대한 청크들을 취출하기 위해 최상위 레벨 네트워크를 통해 메모리 액세스 요청들을 생성하고, 취출된 청크들을 각각의 스위치 유닛들에 분배한다. i=0 에 대해, 라운드 R(0) 에서, 구성 로드 제어기는 개별 스위치 유닛들에 대한 다수의 청크들에서 청크 (0) 에 대한 메모리 액세스 요청들을 생성하고, 청크들 (0) 을 개별 스위치 유닛들에 전송한다. i=1 에 대해, 라운드 R(1) 에서, 구성 로드 제어기는 각각의 스위치 유닛들에 대한 다수의 청크들에서 청크 (1) 에 대한 메모리 액세스 요청들을 생성하고, 청크들을 각각의 스위치 유닛들에 전송한다. 라운드 R(i) 에서, 구성 로드 제어기가 각각의 스위치 유닛들에 대한 다수의 청크들에서의 청크들 (i) 에 대한 메모리 액세스 요청들을 생성하고, 모든 스위치 유닛들에 대한 청크들을 분배했을 때, 로드 프로세스는 상태 S3 으로 진입한다.
상태 S3 (PCU 요청) 에서, 구성 로드 제어기는 각각의 PCU 유닛들 (패턴 계산 유닛들) 에 대한 구성 유닛 파일들의 라운드 R(i) 에 대한 청크들을 취출하기 위해 최상위 레벨 네트워크를 통해 메모리 액세스 요청들을 생성하고, 취출된 청크들을 각각의 PCU 유닛들에 분배한다. 라운드 R(i) 의 상태 S3에서, 구성 로드 제어기는 각각의 PCU 유닛들에 대한 다수의 청크들에서의 청크들 (i) 에 대한 메모리 액세스 요청들을 생성하고, 그 청크들 (i) 을 각각의 PCU 유닛에 전송한다. 라운드 R(i) 에서, 구성 로드 제어기가 각각의 PCU 유닛들에 대한 다수의 청크들에서의 청크 (i) 에 대한 메모리 액세스 요청들을 생성하고 청크들을 분배했을 때, 로드 프로세스는 상태 S4로 진입한다.
상태 S4 (PMU 요청) 에서, 구성 로드 제어기는 구성가능한 유닛들의 어레이에서의 각각의 PMU 유닛들 (패턴 메모리 유닛들) 에 대한 구성 유닛 파일들의 청크들을 취출하기 위해 최상위 레벨 네트워크를 통해 메모리 액세스 요청들을 생성하고, 취출된 청크들을 각각의 PMU 유닛들에 전송한다. 라운드 R(i) 의 상태 S4에서, 구성 로드 제어기는 각각의 PMU 유닛들에 대한 다수의 청크들에서의 청크들 (i) 에 대한 메모리 액세스 요청들을 생성하고, 그 청크들 (i) 을 각각의 PMU 유닛들에 전송한다. 실례로, i=0 에 대해, 라운드 R(0) 에서, 구성 로드 제어기는 각각의 PMU 유닛들에 대한 다수의 청크들에서의 청크들 (0) 에 대한 메모리 액세스 요청들을 생성하고, 청크들 (0) 을 각각의 PMU 유닛들에 전송한다. i=1 에 대해, 라운드 R(1) 에서, 구성 로드 제어기는 각각의 PMU 유닛들에 대한 다수의 청크들에서의 청크들 (1) 에 대한 메모리 액세스 요청들을 생성하고, 청크들 (1) 을 각각의 PMU 유닛들에 전송한다. 라운드 R(i) 에서, 구성 로드 제어기가 각각의 PMU 유닛들에 대한 다수의 청크들에서의 청크들 (i) 에 대한 메모리 액세스 요청들을 생성하고 청크들을 분배했을 때, 로드 프로세스는 상태 S5로 진입한다.
상태 S5 (AGCU 요청) 에서, 구성 로드 제어기는 구성가능한 유닛들의 어레이에서의 각각의 AGCU들 (어드레스 생성 및 병합 유닛들) 에 대한 구성 유닛 파일들의 청크들을 취출하기 위해 최상위 레벨 네트워크를 통해 메모리 액세스 요청들을 생성하고, 취출된 청크들을 각각의 AGCU 유닛들로 전송한다. 라운드 R(i) 의 상태 S5에서, 구성 로드 제어기는 각각의AGCU 유닛들에 대한 다수의 청크들에서의 청크들 (i) 에 대한 메모리 액세스 요청들을 생성하고, 그 청크들 (i) 을 각각의 AGCU 유닛들에 전송한다. 라운드 R(i) 의 상태 S5 에서, 구성 로드 제어기가 각각의 AGCU 유닛들에 대한 다수의 청크들에서의 청크들 (i) 에 대한 메모리 액세스 요청들을 생성하고 청크들을 분배했을 때, 로드 프로세스는 라운드 R(i) 의 상태 S6로 진입한다.
상태 S6(응답 대기) 에서, 구성 로드 제어기는 어레이에서의 구성가능한 유닛들 (스위치, PCU, PMU, AGCU 유닛들) 이 다음 라운드에서 구성 데이터의 더 많은 청크들을 수신할 준비가 되는 것을 보장하기 위해 대기한다. 스위치 유닛들에 대한 모든 청크들이 전송되지 않으면, 로드 프로세스는 증분(i)하고, 상태 S2로 진행하여 다음 라운드 R(i+1) 을 시작한다. 스위치 유닛들에 대한 모든 청크들이 전송되지만 PCU 청크들에 대한 모든 청크들이 전송되지 않으면, 로드 프로세스는 증분(i)하고, 다음 라운드 R(i+1) 를 시작하기 위해 상태 S3 으로 진행한다. 스위치 유닛들 및 PCU 유닛들에 대한 모든 청크들이 전송되지만 PMU 청크들에 대한 모든 청크들이 전송되지 않으면, 로드 프로세스는 증분(i)하고, 다음 라운드 R(i+1) 를 시작하기 위해 상태 S4 로 진행한다. 스위치 유닛들, PCU 유닛들, 및 PMU 유닛들에 대한 모든 청크들이 전송되지만 AGCU 청크들에 대한 모든 청크들이 전송되지 않는 경우, 로드 프로세스는 증분(i)하고 상태 S5 로 진행하여 다음 라운드 R(i+1) 를 시작한다. 모든 구성가능한 유닛들 (스위치, PCU, PMU, AGCU 유닛들) 에 대한 모든 청크들이 전송되면 (즉, 모든 라운드들이 완료되면), 로드 프로세스는 상태 S1 으로 진행한다.
도 20 은 도 10 의 것과 같은 분배 시퀀스의 조기 라운드들의 타이밍을 나타내는 타이밍도이다. 이 예에서, 구성 유닛 파일의 청크는 데이터의 비트 수 B (예를 들어, B = 128) 를 갖고, 분배 시퀀스에서의 라운드는 구성가능한 유닛들의 수 X를 포함할 수 있고, 구성가능한 유닛들의 어레이는 구성가능한 유닛들의 수 Y (예컨대, Y = 148) 를 포함할 수 있다. 라운드 R(0) 에 대해, X는 Y와 동일할 수 있다. 후속 라운드들에서, X는 Y 이하일 수 있다.
이 예에서, 라운드 R(0) 은 Y = 148 개의 구성가능한 유닛들을 포함한다. 라운드들 R(0) 및 R(1) 의 경우, X=Y 이다. 처음 두 라운드들 R(0) 및 R(1) 후에, 스위치 유닛들은 모두 (2) 의 그것들의 청크들을 수신하였고, 따라서 제 3 라운드 R(2) 는 128 개 보다 적은 구성가능한 유닛들을 포함한다.
도 20의 예에서 도시된 바와 같이, 라운드 R(0), 구성 유닛 파일의 제 1 청크 (P11) 는 제 1 버스 사이클(C0) 에서 버스 시스템을 통해 구성가능한 유닛에서 수신된다. 그 후, 제 1 청크는, 라운드의 다른 청크들이 구성 로드 제어기에 의해 다른 구성가능한 유닛들로 분배되는 동안 구성가능한 유닛에서 병렬 태스크 (parallel task) 로 직렬로 시프팅함으로써, 제 1 구성가능한 유닛 "유닛 1"의 구성 저장소에 로딩되고, 제 1 청크 (P11) 내의 데이터의 B 비트들은 B 클럭 사이클들 (버스 클럭과 동일한 레이트로 실행될 수 있음) 로 시프팅된다. 구성 파일의 제 2 청크 (P21) 는 제 2 버스 사이클 (C1) 에서 버스 시스템을 통해 수신된다. 제 2 청크 (P21) 의 데이터의 B 비트를 B 클럭 사이클들로 직렬로 시프팅함으로써, 제 2 청크는 병렬 태스크로 제 2 구성가능한 유닛 "유닛 2" 의 구성 저장소에 로딩된다. 구성 파일의 제 3 청크 (P31) 는 제 3 버스 사이클 (C2) 에서 버스 시스템을 통해 수신된다. 그 후, 제 3 청크 (P31) 는 제 3 청크 (P31) 에서의 B 비트의 데이터를 B 클럭 사이클로 직렬로 시프팅함으로써 제 3 구성가능한 유닛 "유닛 3" 의 구성 저장소에 로딩된다. 이 라운드는 모든 구성가능한 유닛들이 그것들에 특정적인 유닛 파일의 제 1 청크를 수신할 때까지 진행된다.
라운드 R(0) 은 어레이에서의 Y개의 각각의 구성가능한 유닛들 (유닛 1 ... 유닛 Y) 에서 구성 파일 (P11, P21, P31 ... PY1) 의 Y개의 청크들의 제 1 세트를 분배하는 것을 포함한다. 구성 파일의 청크는 데이터의 비트 수 B를 갖고, 구성가능한 유닛들의 어레이는 구성가능한 유닛들의 수 Y를 갖는다. 라운드 R(0) 가 완료되면, 제 1 세트에서의 구성 파일 (P11, P21, P31 ... PY1) 의 Y개의 청크들은 Y개의 버스 사이클들 (C0 내지 CY-1) 에서 어레이에서의 Y개의 구성가능한 유닛들로 수신되었고, 제 1 청크 (P11) 는 B개의 클럭 사이클들에서 제 1 구성가능한 유닛 "유닛 1"의 구성 저장소로 로딩되거나 직렬로 시프트되었다. B 클럭 사이클들은 제 1 청크 (P11) 가 수신되는 제 1 클럭 사이클(C0) 에 후속한다.
다음 라운드 R(1) 은 어레이에서의 Y개의 각각의 구성가능한 유닛들 (유닛 1... 유닛 Y) 에서 구성 파일 (P12, P22, P32... Py2) 의 Y개의 청크들의 제 2 세트를 수신하는 것을 포함한다. 라운드 R(1) 이 완료되면, 제 2 세트에서의 구성 파일 (P12, P22, P32 ... Py2) 의 Y 청크들은 Y 클럭 사이클(Cy 내지 C2y-1) 에서 어레이에서의 Y 개의 각각의 구성가능한 유닛들로 수신되었다. 라운드 R(1) 이 완료되면, 라운드 R(1) 에서 제 1 클럭 사이클(Cy) 에 후속하는 B 클럭 사이클들에서 제 1 구성 유닛 "유닛 1" 에 대한 제 2 청크 (P12) 가 제 1 구성가능한 유닛 "유닛 1" 의 구성 저장소에 로딩되거나 직렬로 시프트되었다. 또한, 제 2 라운드가 완료되면, 라운드 R(0) 에서 수신된 구성 파일의 Y 청크들의 제 1 세트 내의 마지막 청크 PY1 은 마지막 구성가능한 유닛 "유닛 Y" 의 구성 저장소로 로딩되거나 직렬로 시프트된다.
청크 내의 비트 수 B(128) 가 라운드에서의 구성가능한 유닛들의 수 X보다 적은 한, 구성가능한 유닛은 이전 청크가 로딩된 후에 유닛 구성 파일의 다음 청크를 수신할 것이어서, 구성가능한 유닛들은 시퀀스를 스톨할 필요 없이 준비되어야 한다. 이 예에서, 청크 내의 비트의 수 B는 128이고, 라운드 R(0) 에서의 구성가능한 유닛들의 수 X는 X=Y=148이다. 청크 내의 128 비트를 구성가능한 유닛의 구성 데이터 저장소로 직렬로 시프트하는 데 128 클럭 사이클들이 필요하기 때문에, 시프팅이 수행된 후에 효과적으로 20 (Y-B = 148-128) 버퍼 사이클들이 있을 수 있고, 이는 제 1 구성가능한 유닛 "유닛 1"이 다음 라운드 R(1) 에서 다음 청크 (P12) 를 수용할 준비가 됨을 보장한다. 청크의 비트 수 B가 라운드에서의 구성가능한 유닛들의 수 X보다 큰 경우, 이전 청크가 소비되는 동안 다음 청크가 수신될 수 있다. 여기서 소모된다는 것은 청크 내의 비트들을 구성가능한 유닛의 구성 데이터 저장소 내로 직렬로 시프트하는 것을 지칭한다.
일반적으로, 유닛 구성 로드 프로세스는, 하나의 버스 사이클에서 버스 시스템으로부터 구성가능한 유닛에 특정한 유닛 파일의 제 1 청크 (또는 서브-파일) 를 수신하고, 다음 라운드에 대한 유닛 파일의 제 2 청크가 수신되기 전에 후속 버스 사이클들 동안, 수신된 제 1 청크를 직렬 체인 내로 푸시하기 시작하고, 나중의 버스 사이클에서 시퀀스의 다음 라운드에 대해 버스 시스템으로부터 구성가능한 유닛에 특정한 유닛 파일의 제 2 청크를 수신하고, 이전에 수신된 청크를 직렬 체인 내로 푸시한 후에 시퀀스의 사이클들 동안, 수신된 제 2 청크를 직렬 체인 내로 푸시하기 시작한다. 일부 라운드들에서, 수신된 모든 청크는 다음 청크가 수신되기 전에 소비될 수 있다.
상이한 타입들의 구성가능한 유닛들은 상이한 수의 구성 비트들을 가질 수도 있기 때문에, 구성가능한 유닛들은 다양한 수의 청크들을 필요로 할 수도 있다. 더 적은 수의 청크들을 필요로 하는 구성가능한 유닛들이 그것들의 구성 비트들의 모두를 일단 로드했으면, 구성 로드 제어기는 그것들에 데이터를 전송하는 것을 중지한다. 이렇게 하면 더 적은 구성가능한 유닛들 (X개) 이 인터리빙되는 것을 초래할 수 있고, 구성가능한 유닛들이 이전 청크를 프로세싱하기 전에 새로운 청크를 수신하는 것을 초래할 수 있다. 이는 어레이 레벨 네트워크에 대한 배압(back-pressure)으로 이어질 수 있다.
배압은 어레이 레벨 네트워크 상의 크레딧 메커니즘을 통해 핸들링될 수 있다. 실례로, 각각의 입력 FIFO는 홉-투-홉 크레딧(hop-to-hop credit) 을 가질 수 있어서, PCU의 입력 FIFO가 채워지면, 그 PCU의 입력 FIFO에 구성 데이터를 전송하려고 시도하는 어레이 레벨 네트워크의 어떤 스위치도 입력 FIFO가 하나의 엔트리를 비우고 전송 스위치에 크레딧을 리턴할 때까지 데이터를 전송할 수 없다. 결국, 배압은 링크들이 분주함에 따라 AGCU가 데이터를 전송하는 것을 정지시킬 수 있다. 그러나, 일단 구성가능한 유닛이 청크의 128 비트 모두를 소비하면, 그것은 하나의 입력 FIFO 엔트리를 비우고, 크레딧이 해제되고, 그 후 전송기는 이용가능한 경우 새로운 청크를 전송할 수 있다.
도 21 는 구성가능한 유닛에서의 유닛 구성 로드 프로세스를 나타내는 흐름도이다. 단계 (2121) 에서, 유닛 구성 로드 프로세스는 입력 FIFO (610, 도 6) 가 유효해질 때까지 대기한다. 유효할 때, 입력 FIFO 는 구성가능한 유닛을 구성하기 위해 버스 시스템을 통해 구성 파일의 구성 데이터의 청크를 수신했다. 입력 FIFO 가 유효한 경우, 플로우는 단계 (2122) 로 진행한다.
단계 (2122) 에서, 입력 FIFO 는 디큐잉된다. 단계 (2123) 에서, 입력 FIFO로부터의 구성 데이터의 청크는 입력 시프트 레지스터 (620, 도 6) 에 병렬로 로딩된다. 단계 (2124) 에서, 입력 시프트 레지스터 내의 구성 데이터의 청크는 구성가능한 유닛의 구성 데이터 저장소에서의 구성 직렬 체인으로 시프트된다.
단계 (2125) 에서, 유닛 구성 로드 프로세스는 구성 데이터의 로딩된 청크가 구성가능한 유닛에 대한 구성 데이터의 마지막 청크인지 여부를 결정한다. 그러한 경우, 구성가능한 유닛에 대한 구성 데이터 로드가 완료된다. 그렇지 않다면, 플로우는 단계 (2121) 로 진행하고, 유닛 구성 로드 프로세스는 구성 데이터의 다음 청크에 대해 입력 FIFO 가 유효해질 때까지 대기한다. 구성가능한 유닛에서의 유닛 구성 로드 프로세스는 도 14 및 도 15을 참조하여 추가로 설명된다.
도 22 는 어레이 구성 언로드 프로세스를 실행하는 로직의 일 예에 대한 상태 시스템 다이어그램이다.
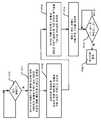
이 예에서, 상태 머신은 3개의 상태들 (S1 내지 S3) 을 포함한다. 상태 S1 (유휴) 에서, 구성 언로드 제어기는 호스트로부터 구성 언로드 커맨드를 기다린다. 구성 언로드 제어기는 어레이 구성 언로드 프로세스를 위해 2 개의 카운트들 "next_unld_req_count" 및 "next_unld_resp_count" 을 구현한다. "next_unld_req_count" 는 다음 언로드 요청 카운트를 추적하는 것을 유지한다. "next_unld_resp_count" 는 다음 언로드 응답 카운트의 추적을 유지한다. 상태 S1 에서, 양 카운트들은 0 과 같은 초기 값으로 리셋된다. 구성 언로드 커맨드가 수신되면, 언로드 프로세스는 상태 S2로 진입한다.
상태 S2 (요청 생성) 에서, 구성 언로드 제어기는, 어레이에서의 스위치 유닛들, PCU들, PMU들 및 AGCU들을 포함하는 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들의 각각에 대해 언로드 요청들을 생성한다. 카운트 "next_unld_req_count" 는 생성된 각 언로드 요청에 대해 증분된다. 카운트 "next_unld_req_count" 는 구성가능한 유닛들의 어레이에서의 구성가능한 유닛들의 총 수를 나타내는 미리 결정된 수 PROGRAM_UNLOAD_REQ_COUNT 에 대해 비교된다. 카운트 "next_unld_req_count" 가 PROGRAM_UNLOAD_REQ_COUNT 보다 적은 한, 언로드 프로세스는 상태 S2에 머무른다. 카운트 "next_unld_req_count" 가 PROGRAM_UNLOAD_REQ_COUNT 와 동일할 때, 언로드 요청들은 어레이에서의 구성가능한 유닛들 각각에 대해 생성되었고, 언로드 프로세스는 상태 S3로 진입한다.
상태 S3 (응답 대기) 에서, 구성 언로드 제어기는 어레이에서의 구성가능한 유닛들로부터 수신된 각각의 응답에 대한 카운트 "next_unld_resp_count" 를 증분시킨다. 응답은 구성가능한 유닛에 대한 구성 데이터의 유닛 파일에 청크 (서브 파일) 를 포함한다. 응답은 또한 일부 예들에서 PMU 스크래치패드 데이터를 포함할 수 있다. 언로드 프로세스 동안, 응답은 구성가능한 유닛의 벡터 출력에 제공되고, 벡터 버스 상에서 구성 로드 제어기에 전송된다. 카운트 "next_unld_resp_count" 가 PROGRAM_UNLOAD_REQ_COUNT 보다 적은 한, 언로드 프로세스는 상태 S3 에 머무른다.
상태 S3 에서, 언로드 프로세스는 수신된 각각의 응답에 대한 메모리 어드레스를 생성하고, 최상위 레벨 네트워크 상에서 생성된 메모리 어드레스와 함께 수신된 각각의 응답을 삽입한다. 각 응답은 언로드 청크 및 시퀀스 ID 를 포함한다. 메모리 어드레스는, 시퀀스 ID에서의 청크 넘버, 열 식별자, 행 식별자, 및 컴포넌트 식별자를 포함하는, 어레이 레벨 네트워크에서 청크들을 반송하는 패킷들을 수반하는 헤더들로부터 생성된다. 컴포넌트 식별자는 구성가능한 유닛이 스위치 유닛, PCU 유닛, PMU 유닛 또는 AGCU 유닛인지 여부를 나타낼 수 있다.
카운트 "next_unld_resp_count"가 PROGRAM_UNLOAD_REQ_COUNT와 동일할 때, 응답들은 어레이에서의 구성가능한 유닛들 각각으로부터 수신되고 최상위 레벨 네트워크 상에 삽입되었고, 언로드 프로세스는 상태 S1 로 다시 천이한다.
일 실시형태에서, 스위치 유닛들에서의 구성 데이터에 대한 선형 메모리 어드레스에 대한 순서는, 스위치 유닛들의 제 1 열 내의 각각의 행의 제 1 청크들, 이어서 스위치 유닛들의 제 2 열 내의 각각의 행의 제 1 청크들, 이어서 스위치 유닛들의 제 3 열 내의 각각의 행의 제 1 청크들, ... 마지막 열 내의 각각의 행의 제 1 청크들까지이다. 이것은 선형 어드레스 공간 내의 모든 스위치 유닛들의 제 1 청크를 그룹화한다. 다른 타입들의 구성가능한 유닛들에 대한 제 1 청크들은 인접한 어드레스 공간의 그룹들에 로딩된다. 그 다음, 순서는, 구성가능한 유닛들의 모든 타입들의 제 2 청크들에 대해, 그 다음에 스위치 유닛들의 제 1 열 내의 각 행의 제 2 청크들, 그 다음에 스위치 유닛들의 제 2 열 내의 각 행의 제 2 청크들, 그 다음에 제 3 열 내의 각 행의 제 2 청크들, 그 다음에 스위치 유닛들의 마지막 열 내의 마지막 행에서의 마지막 청크까지 등이 이어진다.
전술한 바와 같이 스위치 유닛들에서의 구성 데이터에 대한 메모리 어드레스에 대한 순서를 사용하여, 아래의 의사 코드는 스위치 유닛에 대한 선형 메모리 어드레스(comp_switch) 를 생성하는 방법을 예시한다. 의사 코드는 4 개의 입력들을 사용한다:
comp_id: 컴포넌트 식별자;
comp_col:열 식별자;
comp_row:행 식별자;
comp_chunk:청크 넘버;
그리고 다음과 같이 출력을 생성한다:
linear_address:언로드 청크에 대한 선형 메모리 어드레스;
스위치 유닛의 특정 언로드 청크에 대한 선형 메모리 어드레스를 생성하기 위한 의사 코드는 다음과 같다:

여기서,
●comp_switch 는 스위치 유닛을 나타낸다;
●NUM_ROW_SW 는 모든 스위치 유닛들의 행들의 수이다;
●COMP_COUNT_ALL 은 모든 구성가능한 단위들의 합이다.
PCU, PMU, 또는 AGCU 유닛의 특정 언로드 청크에 대한 선형 메모리 어드레스를 생성하기 위해, 유사한 코드가 사용될 수 있다. 한 가지 차이점은 모든 스위치 유닛들의 행들의 수가 모든 PCU들의 행들의 수, 모든 PMU들의 행들의 수, 및 모든 AGCU들의 행들의 수와 다르다는 것이다. 또 다른 차이점은 스위치 유닛들에 대한 선형 메모리 어드레스들이 베이스 어드레스(예를 들어, 0) 에서 시작할 수 있는 반면, PCU들, PMU들 및 AGCU들에 대한 선형 메모리 어드레스들은 각각 스위치 유닛들, PCU들 및 PMU들에 대한 마지막 청크 후의 어드레스에서 시작할 수 있다는 것이다.
도 23 는 구성가능한 유닛에서의 유닛 구성 언로드 프로세스를 나타내는 흐름도이다. 단계 (2331) 에서, 구성 데이터 저장소에서의 구성 직렬 체인으로부터의 구성 데이터의 청크는 출력 시프트 레지스터 (1550, 도 15) 로 직렬로 시프트된다. 플로우는 단계 2332 로 진입한다.
단계 (2332) 에서, 유닛 구성 언로드 프로세스는 출력 FIFO (1560, 도 15) 또는 다른 타입의 출력 버퍼 회로가 유효해지기를 기다린다. 단계 (2333) 에서, 출력 FIFO 가 유효해질 때, 출력 시프트 레지스터로부터의 구성 데이터의 청크가 출력 FIFO 내로 삽입된다. 단계 (2334) 에서, 출력 FIFO 에서의 구성 데이터의 청크는 버스 시스템에 기입된다.
단계 (2335) 에서, 유닛 구성 언로드 프로세스는 구성 데이터의 제 1 청크가 구성 데이터 저장소 내의 구성 데이터의 마지막 청크인지 여부를 결정한다. 그러한 경우, 구성가능한 유닛에 대한 구성 데이터의 언로드가 완료된다. 그렇지 않은 경우, 플로우는 단계 (2331) 로 다시 천이하고, 구성 데이터 저장소로부터의 구성 데이터의 제 2 청크는 출력 시프트 레지스터로 직렬로 시프트된다. 실행 애플리케이션 그래프들을 일시정지 및 언로딩하는 것을 지원함에 있어서, 유닛 내의 직렬 체인 또는 다른 메모리의 일부와 같은 구성 저장소는, 애플리케이션 그래프가 재로딩되고 재시작되어 실행이 일시 정지되었던 지점에서 또는 그 일시 정지된 지점에 가까운 체크포인트들에서 실행을 픽업할 때, 사용가능한 상태 정보를 저장하는 레지스터들을 포함할 수 있다.
하나의 다이 상의 구성가능한 유닛들의 어레이에서 다수의, 관련되지 않은 애플리케이션 그래프들의 동시 실행을 가능하게 하는 기술이 본 명세서에서 제공된다. 이는 머신 러닝 기반 인공 지능 시스템에서 사용되는 추론 또는 트레이닝 애플리케이션 그래프와 같은 작은 애플리케이션 그래프의 세트 중에서 다이의 계산 능력을 공유하는 것을 가능하게 하기 위해 특히 매력적이다.
여기에 설명된 실시형태들은 타일 레벨로 가상화를 지원한다. 다른 실시형태들에서, 가상화는 서브-타일 레벨로 지원된다. 가상화를 지원하는 기술은 다음 메커니즘 중 하나 이상을 포함한다.
a) 인바운드 트래픽을 무시하고, 대응하는 타일들 또는 서브타일들에 대해 아웃바운드 트래픽을 드롭하기 위해, 스위치들 그리고 실시형태들에서 타일 경계 스위치들을 프로그래밍 하는 것. 이것은 구성가능한 유닛들의 임의의 에러있거나 악의적으로 프로그래밍된 세트들이 다른 세트들을 프로빙하거나 간섭하는 것을 방지한다.
b) 허용된 영역들 내의 주어진 타일 또는 서브-타일 세트 (가상 타일 당 어드레스들임) 로부터의 메모리 바운드 요청들의 메모리 어드레스들을 체크하기 위해, 예를 들어 AGCU 에 구현된 메모리 액세스 제어기를 프로그래밍하는 것, 및 이들 영역들을 프로세서를 공유하는 임의의 다른 프로세스들과 구별되는 물리적 어드레스들에 맵핑하는 것. 이는 타일이 액세스하도록 허용되는 영역들의 세트에 대한 베이스/바운드 레지스터들에 의해, 그리고 가상 어드레스를 그 어드레스 공간에 적합한 물리적 어드레스로 재배치/맵핑하기 위해 각각의 아웃바운드 어드레스에 오프셋을 부가함으로써 달성될 수 있다.
c) 다른 타일이 동작하는 동안 구성 비트파일을 로딩함으로써 각 타일을 독립적으로 프로그래밍하는 능력. 예시적인 실시형태에서, 비트파일은 로컬 또는 원격 메모리로부터 또는 적절한 링크를 통해 호스트로부터 로딩될 수 있다.
d) 다른 타일 또는 서브-타일과 독립적으로 타일 또는 서브-타일을 언로딩하는 능력.
본 발명이 위에서 설명된 바람직한 실시형태들 및 예들을 참조하여 개시되지만, 이러한 예들은 제한적인 의미보다는 예시적인 것으로 의도되는 것으로 이해되어야 한다. 변형들 및 조합들은 당업자에게 용이하게 일어날 것이며, 이러한 변형들 및 조합들은 본 발명의 사상 및 다음의 청구항들의 범위 내에 있을 것이다.
Claims (22)
- 재구성가능한 데이터 프로세서로서,
구성가능한 유닛들의 어레이;
상기 구성가능한 유닛들의 어레이에 연결된 버스 시스템으로서, 상기 구성가능한 유닛들의 어레이를 구성가능한 유닛들의 복수의 세트들로 파티셔닝하고 특정 세트 내의 구성가능한 유닛들과 상기 특정 세트 외부의 구성가능한 유닛들 사이의 상기 버스 시스템을 통한 통신들을 차단하도록 구성가능한, 상기 버스 시스템; 및
상기 버스 시스템에 연결되고, 상기 특정 세트 내로부터 발생하는 상기 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스를, 상기 구성가능한 유닛들의 어레이 외부의 상기 메모리 내의 상기 특정 세트에 할당된 메모리 공간으로 한정하도록 구성가능한 메모리 액세스 제어기를 포함하는, 재구성가능한 데이터 프로세서. - 제 1 항에 있어서,
제 1 의 상기 메모리 액세스 제어기를 포함하는 복수의 메모리 액세스 제어기들을 포함하며, 상기 복수의 메모리 액세스 제어기들 내의 메모리 액세스 제어기들은 상기 버스 시스템 상의 어드레스가능한 노드들이고, 상기 메모리 액세스 제어기들은 상기 구성가능한 유닛들의 복수의 세트들에서 구성가능한 유닛들의 대응하는 세트들 내로부터 발생하는 상기 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스를, 상기 대응하는 세트들에 할당된 상기 구성가능한 유닛들의 어레이 외부의 상기 메모리 내의 메모리 공간으로 한정하도록 구성가능한, 재구성가능한 데이터 프로세서. - 제 1 항에 있어서,
상기 구성가능한 유닛들의 복수의 세트들 내의 구성가능한 유닛들의 세트들은 가상 어드레스들을 사용하여 애플리케이션 그래프들을 실행하도록 구성가능하고, 상기 메모리 액세스 제어기는 상기 특정 세트 내에서 실행되는 애플리케이션 그래프로부터 발생하는 요청들 내의 가상 어드레스들을 상기 특정 세트에 할당된 상기 메모리 공간 내의 어드레스들로 변환하기 위해 구성가능한 테이블을 포함하거나 또는 구성가능한 테이블에 대한 액세스를 가지는, 재구성가능한 데이터 프로세서. - 제 1 항에 있어서,
상기 버스 시스템은 상기 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들에 연결된 스위치들의 그리드를 포함하고, 상기 그리드 내의 스위치들은 상기 버스 시스템을 파티셔닝하기 위한 회로들을 포함하는, 재구성가능한 데이터 프로세서. - 제 1 항에 있어서,
상기 버스 시스템은 상기 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들에 연결된 스위치들의 그리드를 포함하고, 상기 그리드 내의 스위치들은 포트 파라미터들에 따라 상기 스위치들 상의 포트들을 인에이블 및 디스에이블하는, 상기 포트 파라미터들을 사용하여 구성가능한 회로들을 포함하는, 재구성가능한 데이터 프로세서. - 제 1 항에 있어서,
상기 버스 시스템은 최상위 레벨 네트워크 및 어레이 레벨 네트워크를 포함하고,
상기 최상위 레벨 네트워크는 상기 어레이 외부의 메모리와 통신하기 위해 외부 데이터 인터페이스에 연결되고,
상기 어레이 레벨 네트워크는 상기 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들에 연결되며,
상기 메모리 액세스 제어기는 상기 어레이 레벨 네트워크 및 상기 최상위 레벨 네트워크에 연결되고, 상기 최상위 레벨 네트워크와 상기 어레이 레벨 네트워크 사이의 데이터 전송들을 라우팅하기 위한 로직을 포함하는, 재구성가능한 데이터 프로세서. - 제 6 항에 있어서,
상기 어레이 레벨 네트워크는 스위치들의 그리드를 포함하고, 상기 그리드 내의 스위치들, 상기 구성가능한 유닛들의 어레이 내의 상기 구성가능한 유닛들 및 상기 메모리 액세스 제어기는 상기 어레이 레벨 네트워크 상의 어드레스가능한 노드들인, 재구성가능한 데이터 프로세서. - 제 6 항에 있어서,
제 1 의 상기 메모리 액세스 제어기를 포함하는 복수의 메모리 액세스 제어기들을 포함하며, 상기 복수의 메모리 액세스 제어기들 내의 메모리 액세스 제어기들은 상기 어레이 레벨 네트워크 내의 어드레스가능한 노드들인, 재구성가능한 데이터 프로세서. - 제 8 항에 있어서,
상기 어레이 레벨 네트워크는 스위치들의 그리드를 포함하고, 상기 그리드 내의 스위치들, 상기 구성가능한 유닛들의 어레이 내의 상기 구성가능한 유닛들 및 상기 복수의 메모리 액세스 제어기들 내의 상기 메모리 액세스 제어기들은 상기 어레이 레벨 네트워크 상의 어드레스가능한 노드들인, 재구성가능한 데이터 프로세서. - 제 1 항에 있어서,
상기 구성가능한 유닛들의 어레이는 구성가능한 유닛들의 복수의 타일들을 포함하고, 상기 버스 시스템은 타일 경계들 상에 상기 버스 시스템을 파티셔닝하기 위한 회로들을 포함하는, 상기 타일들 사이의 경계들 상에 스위치들을 포함하는, 재구성가능한 데이터 프로세서. - 제 10 항에 있어서,
제 1 의 상기 메모리 액세스 제어기를 포함하는 복수의 메모리 액세스 제어기들을 포함하며, 상기 복수의 메모리 액세스 제어기들 내의 적어도 하나의 메모리 액세스 제어기는 상기 복수의 타일들 내의 각각의 타일에 동작가능하게 커플링되는, 재구성가능한 데이터 프로세서. - 제 1 항, 제 4 항, 제 5 항, 제 6 항 또는 제 10 항 중 어느 한 항에 있어서,
상기 버스 시스템에 연결되어, 상기 어레이에서 상기 구성가능한 유닛들의 개별 세트들 내의 구성가능한 유닛들에 구성 파일들을 분배하는 것을 포함하는 구성 로드 프로세스를 실행하기 위한 로직을 포함하는 구성 제어기를 포함하며,
상기 구성가능한 유닛들의 세트들 중 일 세트에서의 애플리케이션 그래프는 구성가능한 유닛들의 다른 세트에서의 상기 구성 로드 프로세스 동안 실행가능한, 재구성가능한 데이터 프로세서. - 제 1 항, 제 4 항, 제 5 항, 제 6 항 또는 제 10 항 중 어느 한 항에 있어서,
상기 버스 시스템에 연결되어, 개별 세트들 내의 구성가능한 유닛들로부터 상태 정보를 언로딩하는 것을 포함하는 구성 언로드 프로세스를 실행하기 위한 로직을 포함하는 구성 제어기를 포함하며,
상기 구성가능한 유닛들의 세트들 중 일 세트에서의 애플리케이션 그래프는 구성가능한 유닛들의 다른 세트에서의 상기 구성 언로드 프로세스 동안 실행가능한, 재구성가능한 데이터 프로세서. - 재구성가능한 데이터 프로세서로서,
구성가능한 유닛들의 복수의 타일들을 포함하는 구성가능한 유닛들의 어레이;
상기 구성가능한 유닛들의 어레이에 연결된 버스 시스템으로서, 상기 버스 시스템을 타일 경계들 상에 파티셔닝하고, 특정 타일 내의 구성가능한 유닛들과 상기 특정 타일 외부의 구성가능한 유닛들 사이의 상기 버스 시스템을 통한 통신들을 차단하도록 구성가능한 회로들을 포함하는, 상기 타일들 사이의 타일 경계들 상의 경계 스위치들을 포함하는, 상기 버스 시스템; 및
상기 버스 시스템에 연결된 복수의 메모리 액세스 제어기들로서, 상기 복수의 메모리 액세스 제어기들 내의 메모리 액세스 제어기들은 대응하는 타일들 내로부터 발생하는 상기 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스를, 상기 구성가능한 유닛들의 어레이 외부의 상기 메모리 내의 상기 대응하는 타일에 할당된 메모리 공간으로 한정하도록 구성가능하며, 상기 복수의 메모리 액세스 제어기들 내의 적어도 하나의 메모리 액세스 제어기는 상기 복수의 타일들 내의 각각의 타일에 동작가능하게 커플링되는, 상기 복수의 메모리 액세스 제어기들을 포함하는, 재구성가능한 데이터 프로세서. - 제 14 항에 있어서,
상기 버스 시스템은 최상위 레벨 네트워크 및 어레이 레벨 네트워크를 포함하고,
상기 최상위 레벨 네트워크는 상기 어레이 외부의 메모리와 통신하기 위해 외부 데이터 인터페이스에 연결되고,
상기 어레이 레벨 네트워크는 상기 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들에 연결되며,
상기 복수의 메모리 액세스 제어기들 내의 상기 메모리 액세스 제어기들은 상기 어레이 레벨 네트워크 및 상기 최상위 레벨 네트워크에 연결되고, 상기 최상위 레벨 네트워크와 상기 어레이 레벨 네트워크 사이의 데이터 전송들을 라우팅하기 위한 로직을 포함하는, 재구성가능한 데이터 프로세서. - 제 15 항에 있어서,
상기 어레이 레벨 네트워크는 상기 경계 스위치들을 포함하는 스위치들의 그리드를 포함하고, 상기 그리드 내의 상기 스위치들, 상기 구성가능한 유닛들의 어레이 내의 상기 구성가능한 유닛들 및 상기 메모리 액세스 제어기들은 상기 어레이 레벨 네트워크 상의 어드레스가능한 노드들인, 재구성가능한 데이터 프로세서. - 제 14 항 또는 제 15 항에 있어서,
상기 버스 시스템에 연결된 구성 제어기를 포함하며,
상기 구성 제어기는,
상기 어레이에서 상기 구성가능한 유닛들의 개별 세트들 내의 구성가능한 유닛들에 구성 파일들을 분배하는 것을 포함하는 구성 로드 프로세스를 실행하기 위한 로직으로서, 상기 구성가능한 유닛들의 세트들 중 일 세트에서의 애플리케이션 그래프는 구성가능한 유닛들의 다른 세트에서의 상기 구성 로드 프로세스 동안 실행가능한, 상기 구성 로드 프로세스를 실행하기 위한 로직; 및
개별 세트들 내의 구성가능한 유닛들로부터 상태 정보를 언로딩하는 것을 포함하는 구성 언로드 프로세스를 실행하기 위한 로직으로서, 상기 구성가능한 유닛들의 세트들 중 일 세트에서의 애플리케이션 그래프는 구성가능한 유닛들의 다른 세트에서의 상기 구성 언로드 프로세스 동안 실행가능한, 상기 구성 언로드 프로세스를 실행하기 위한 로직을 포함하는, 재구성가능한 데이터 프로세서. - 구성가능한 유닛들의 어레이 및 상기 구성가능한 유닛들의 어레이에 연결된 버스 시스템을 포함하는 재구성가능한 데이터 프로세서를 구성하는 방법으로서,
특정 세트 내의 구성가능한 유닛들과 상기 특정 세트 외부의 구성가능한 유닛들 사이의 상기 버스 시스템을 통한 통신들을 차단함으로써, 상기 구성가능한 유닛들의 어레이를 구성가능한 유닛들의 복수의 세트들로 파티셔닝하는 단계; 및
상기 특정 세트 내로부터 발생하는 상기 구성가능한 유닛들의 어레이 외부의 메모리에 대한 액세스를, 상기 구성가능한 유닛들의 어레이 외부의 상기 메모리 내의 상기 특정 세트에 할당된 메모리 공간으로 한정하는 단계를 포함하는, 재구성가능한 데이터 프로세서를 구성하는 방법. - 제 18 항에 있어서,
경계들에 걸친 통신들을 차단하기 위해 상기 구성가능한 유닛들의 세트들의 경계들 상의 스위치들에 구성 데이터를 로딩함으로써 상기 구성가능한 유닛들의 어레이를 파티셔닝하는 단계를 포함하는, 재구성가능한 데이터 프로세서를 구성하는 방법. - 제 18 항에 있어서,
상기 구성가능한 유닛들의 복수의 세트들 내의 구성가능한 유닛들의 세트들은 가상 어드레스들을 사용하여 애플리케이션 그래프들을 실행하도록 구성가능하고,
상기 특정 세트 내에서 실행되는 애플리케이션 그래프로부터 발생하는 요청들 내의 가상 어드레스들을 상기 특정 세트에 할당된 상기 메모리 공간 내의 어드레스들로 변환함으로써 상기 어레이 외부의 메모리에 대한 액세스를 한정하는 단계를 포함하는, 재구성가능한 데이터 프로세서를 구성하는 방법. - 제 18 항에 있어서,
구성가능한 유닛들의 개별 세트들에 애플리케이션 그래프들을 로딩하고, 로딩된 상기 애플리케이션 그래프들을 시작하는 단계; 및
상기 구성가능한 유닛들의 세트들 중 일 세트에서 선택된 애플리케이션 그래프를 중지하고 언로딩하고, 상기 세트들 중 상기 일 세트에 다른 애플리케이션 그래프를 로딩하는 동안 상기 구성가능한 유닛들의 어레이 내의 구성가능한 유닛들의 다른 세트들에서의 다른 애플리케이션 그래프들이 계속해서 실행되는 단계를 포함하는, 재구성가능한 데이터 프로세서를 구성하는 방법. - 제 21 항에 있어서,
상기 선택된 애플리케이션 그래프는 체크포인트를 포함하고, 상기 선택된 애플리케이션 그래프를 중지하는 것은 상기 체크포인트에 도달할 때까지 대기하는 것을 포함하는, 재구성가능한 데이터 프로세서를 구성하는 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/239,252 | 2019-01-03 | ||
| US16/239,252US10698853B1 (en) | 2019-01-03 | 2019-01-03 | Virtualization of a reconfigurable data processor |
| PCT/US2020/012079WO2020142623A1 (en) | 2019-01-03 | 2020-01-02 | Virtualization of a reconfigurable data processor |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210119390Atrue KR20210119390A (ko) | 2021-10-05 |
Family
ID=69400643
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217022207ACeasedKR20210119390A (ko) | 2019-01-03 | 2020-01-02 | 재구성가능 데이터 프로세서의 가상화 |
Country Status (8)
| Country | Link |
|---|---|
| US (4) | US10698853B1 (ko) |
| EP (1) | EP3906476A1 (ko) |
| JP (1) | JP2022516739A (ko) |
| KR (1) | KR20210119390A (ko) |
| CN (1) | CN113424168A (ko) |
| CA (1) | CA3125707C (ko) |
| TW (2) | TWI719788B (ko) |
| WO (1) | WO2020142623A1 (ko) |
Families Citing this family (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230134744A1 (en)* | 2021-11-01 | 2023-05-04 | SambaNova Systems, Inc. | Execution State Management |
| US10832753B2 (en)* | 2017-07-31 | 2020-11-10 | General Electric Company | Components including structures having decoupled load paths |
| US10831507B2 (en) | 2018-11-21 | 2020-11-10 | SambaNova Systems, Inc. | Configuration load of a reconfigurable data processor |
| US11188497B2 (en) | 2018-11-21 | 2021-11-30 | SambaNova Systems, Inc. | Configuration unload of a reconfigurable data processor |
| US10698853B1 (en) | 2019-01-03 | 2020-06-30 | SambaNova Systems, Inc. | Virtualization of a reconfigurable data processor |
| US11386038B2 (en) | 2019-05-09 | 2022-07-12 | SambaNova Systems, Inc. | Control flow barrier and reconfigurable data processor |
| US11055141B2 (en) | 2019-07-08 | 2021-07-06 | SambaNova Systems, Inc. | Quiesce reconfigurable data processor |
| US11327923B2 (en) | 2019-09-04 | 2022-05-10 | SambaNova Systems, Inc. | Sigmoid function in hardware and a reconfigurable data processor including same |
| US11327713B2 (en) | 2019-10-01 | 2022-05-10 | SambaNova Systems, Inc. | Computation units for functions based on lookup tables |
| US11327717B2 (en) | 2019-11-19 | 2022-05-10 | SambaNova Systems, Inc. | Look-up table with input offsetting |
| US11328038B2 (en) | 2019-11-25 | 2022-05-10 | SambaNova Systems, Inc. | Computational units for batch normalization |
| US11150872B2 (en) | 2019-12-17 | 2021-10-19 | SambaNova Systems, Inc. | Computational units for element approximation |
| US11836629B2 (en) | 2020-01-15 | 2023-12-05 | SambaNova Systems, Inc. | Computationally efficient softmax loss gradient backpropagation |
| US12052370B2 (en)* | 2020-05-04 | 2024-07-30 | Intel Corporation | Managing state in accelerators |
| US11809908B2 (en) | 2020-07-07 | 2023-11-07 | SambaNova Systems, Inc. | Runtime virtualization of reconfigurable data flow resources |
| US11782729B2 (en)* | 2020-08-18 | 2023-10-10 | SambaNova Systems, Inc. | Runtime patching of configuration files |
| US11200096B1 (en) | 2021-03-26 | 2021-12-14 | SambaNova Systems, Inc. | Resource allocation for reconfigurable processors |
| US11556494B1 (en) | 2021-07-16 | 2023-01-17 | SambaNova Systems, Inc. | Defect repair for a reconfigurable data processor for homogeneous subarrays |
| US11327771B1 (en) | 2021-07-16 | 2022-05-10 | SambaNova Systems, Inc. | Defect repair circuits for a reconfigurable data processor |
| US11409540B1 (en)* | 2021-07-16 | 2022-08-09 | SambaNova Systems, Inc. | Routing circuits for defect repair for a reconfigurable data processor |
| US11841823B2 (en)* | 2021-08-16 | 2023-12-12 | Micron Technology, Inc. | Connectivity in coarse grained reconfigurable architecture |
| US11709611B2 (en) | 2021-10-26 | 2023-07-25 | SambaNova Systems, Inc. | Determining and using memory unit partitioning solutions for reconfigurable dataflow computing systems |
| US11892966B2 (en)* | 2021-11-10 | 2024-02-06 | Xilinx, Inc. | Multi-use chip-to-chip interface |
| US11487694B1 (en) | 2021-12-17 | 2022-11-01 | SambaNova Systems, Inc. | Hot-plug events in a pool of reconfigurable data flow resources |
| US12056085B2 (en) | 2022-01-20 | 2024-08-06 | SambaNova Systems, Inc. | Determining internodal processor interconnections in a data-parallel computing system |
| US11983141B2 (en)* | 2022-01-27 | 2024-05-14 | SambaNova Systems, Inc. | System for executing an application on heterogeneous reconfigurable processors |
| US12072836B2 (en)* | 2022-02-09 | 2024-08-27 | SambaNova Systems, Inc. | Fast argument load in a reconfigurable data processor |
| WO2023154411A1 (en) | 2022-02-10 | 2023-08-17 | SambaNova Systems, Inc. | Aribitration for a network in a reconfigurable data processor |
| US12210857B2 (en) | 2022-02-10 | 2025-01-28 | SambaNova Systems, Inc. | Head of line blocking mitigation in a reconfigurable data processor |
| US12242403B2 (en) | 2022-03-18 | 2025-03-04 | SambaNova Systems, Inc. | Direct access to reconfigurable processor memory |
| US12189570B2 (en) | 2022-05-25 | 2025-01-07 | SambaNova Systems, Inc. | Low latency nodes fusion in a reconfigurable data processor |
| US12271333B2 (en) | 2022-07-15 | 2025-04-08 | SambaNova Systems, Inc. | Peer-to-peer route through in a reconfigurable computing system |
| US12143298B2 (en) | 2022-07-15 | 2024-11-12 | SambaNova Systems, Inc. | Peer-to-peer communication between reconfigurable dataflow units |
| US12206579B2 (en) | 2022-07-15 | 2025-01-21 | SambaNova Systems, Inc. | Reconfigurable dataflow unit with remote read/write functionality |
| US12306788B2 (en) | 2022-07-15 | 2025-05-20 | SambaNova Systems, Inc. | Reconfigurable dataflow unit with streaming write functionality |
| US20240069770A1 (en)* | 2022-08-23 | 2024-02-29 | SambaNova Systems, Inc. | Multiple contexts for a memory unit in a reconfigurable data processor |
| CN116257320B (zh)* | 2022-12-23 | 2024-03-08 | 中科驭数(北京)科技有限公司 | 一种基于dpu虚拟化配置管理方法、装置、设备及介质 |
Family Cites Families (127)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS6238075A (ja) | 1985-08-13 | 1987-02-19 | Fuji Xerox Co Ltd | 行列デ−タの転置処理装置 |
| US5963746A (en)* | 1990-11-13 | 1999-10-05 | International Business Machines Corporation | Fully distributed processing memory element |
| US5430850A (en) | 1991-07-22 | 1995-07-04 | Massachusetts Institute Of Technology | Data processing system with synchronization coprocessor for multiple threads |
| US5684980A (en)* | 1992-07-29 | 1997-11-04 | Virtual Computer Corporation | FPGA virtual computer for executing a sequence of program instructions by successively reconfiguring a group of FPGA in response to those instructions |
| US5434995A (en) | 1993-12-10 | 1995-07-18 | Cray Research, Inc. | Barrier synchronization for distributed memory massively parallel processing systems |
| CN1076838C (zh) | 1994-08-19 | 2001-12-26 | 财团法人工业技术研究院 | 离散余弦转换/反离散余弦转换电路的转置存储器 |
| US5794033A (en) | 1995-10-24 | 1998-08-11 | International Business Machines Corporation | Method and system for in-site and on-line reprogramming of hardware logics with remote loading in a network device |
| DE19651075A1 (de)* | 1996-12-09 | 1998-06-10 | Pact Inf Tech Gmbh | Einheit zur Verarbeitung von numerischen und logischen Operationen, zum Einsatz in Prozessoren (CPU's), Mehrrechnersystemen, Datenflußprozessoren (DFP's), digitalen Signal Prozessoren (DSP's) oder dergleichen |
| DE19654595A1 (de) | 1996-12-20 | 1998-07-02 | Pact Inf Tech Gmbh | I0- und Speicherbussystem für DFPs sowie Bausteinen mit zwei- oder mehrdimensionaler programmierbaren Zellstrukturen |
| US6105119A (en)* | 1997-04-04 | 2000-08-15 | Texas Instruments Incorporated | Data transfer circuitry, DSP wrapper circuitry and improved processor devices, methods and systems |
| US6327634B1 (en)* | 1998-08-25 | 2001-12-04 | Xilinx, Inc. | System and method for compressing and decompressing configuration data for an FPGA |
| US6467009B1 (en)* | 1998-10-14 | 2002-10-15 | Triscend Corporation | Configurable processor system unit |
| US7073069B1 (en)* | 1999-05-07 | 2006-07-04 | Infineon Technologies Ag | Apparatus and method for a programmable security processor |
| WO2000077652A2 (de) | 1999-06-10 | 2000-12-21 | Pact Informationstechnologie Gmbh | Sequenz-partitionierung auf zellstrukturen |
| US6845445B2 (en) | 2000-05-12 | 2005-01-18 | Pts Corporation | Methods and apparatus for power control in a scalable array of processor elements |
| US6817005B2 (en) | 2000-05-25 | 2004-11-09 | Xilinx, Inc. | Modular design method and system for programmable logic devices |
| US8058899B2 (en) | 2000-10-06 | 2011-11-15 | Martin Vorbach | Logic cell array and bus system |
| US6990555B2 (en) | 2001-01-09 | 2006-01-24 | Pact Xpp Technologies Ag | Method of hierarchical caching of configuration data having dataflow processors and modules having two- or multidimensional programmable cell structure (FPGAs, DPGAs, etc.) |
| JP2004524617A (ja) | 2001-02-14 | 2004-08-12 | クリアスピード・テクノロジー・リミテッド | クロック分配システム |
| US20090300262A1 (en) | 2001-03-05 | 2009-12-03 | Martin Vorbach | Methods and devices for treating and/or processing data |
| US9411532B2 (en) | 2001-09-07 | 2016-08-09 | Pact Xpp Technologies Ag | Methods and systems for transferring data between a processing device and external devices |
| US9170812B2 (en) | 2002-03-21 | 2015-10-27 | Pact Xpp Technologies Ag | Data processing system having integrated pipelined array data processor |
| GB0304628D0 (en)* | 2003-02-28 | 2003-04-02 | Imec Inter Uni Micro Electr | Method for hardware-software multitasking on a reconfigurable computing platform |
| EP1372084A3 (en) | 2002-05-31 | 2011-09-07 | Imec | Method for hardware-software multitasking on a reconfigurable computing platform |
| US7412581B2 (en)* | 2003-10-28 | 2008-08-12 | Renesas Technology America, Inc. | Processor for virtual machines and method therefor |
| US7386703B2 (en) | 2003-11-18 | 2008-06-10 | International Business Machines Corporation | Two dimensional addressing of a matrix-vector register array |
| US7373467B2 (en) | 2004-05-17 | 2008-05-13 | Hewlett-Packard Development Company, L.P. | Storage device flow control |
| JP4547198B2 (ja)* | 2004-06-30 | 2010-09-22 | 富士通株式会社 | 演算装置、演算装置の制御方法、プログラム及びコンピュータ読取り可能記録媒体 |
| JP4594666B2 (ja) | 2004-07-12 | 2010-12-08 | 富士通株式会社 | 再構成可能な演算装置 |
| US7224184B1 (en)* | 2004-11-05 | 2007-05-29 | Xilinx, Inc. | High bandwidth reconfigurable on-chip network for reconfigurable systems |
| US8155113B1 (en) | 2004-12-13 | 2012-04-10 | Massachusetts Institute Of Technology | Processing data in a parallel processing environment |
| US20060190517A1 (en) | 2005-02-02 | 2006-08-24 | Guerrero Miguel A | Techniques for transposition of a matrix arranged in a memory as multiple items per word |
| JP6059413B2 (ja) | 2005-04-28 | 2017-01-11 | クアルコム,インコーポレイテッド | 再構成可能命令セル・アレイ |
| JP4804829B2 (ja) | 2005-08-24 | 2011-11-02 | 富士通株式会社 | 回路 |
| US7571269B2 (en) | 2005-08-25 | 2009-08-04 | Silicon Image, Inc. | Covert channel for conveying supplemental messages in a protocol-defined link for a system of storage devices |
| GB0605349D0 (en) | 2006-03-17 | 2006-04-26 | Imec Inter Uni Micro Electr | Reconfigurable multi-processing coarse-grain array |
| US8456191B2 (en)* | 2006-06-21 | 2013-06-04 | Element Cxi, Llc | Data-driven integrated circuit architecture |
| US8407429B2 (en)* | 2006-06-21 | 2013-03-26 | Element Cxi, Llc | Multi-context configurable memory controller |
| US7797258B1 (en) | 2006-11-02 | 2010-09-14 | Nvidia Corporation | Graphics system transposer read scheduler |
| US8026739B2 (en)* | 2007-04-17 | 2011-09-27 | Cypress Semiconductor Corporation | System level interconnect with programmable switching |
| US7669014B2 (en) | 2007-07-23 | 2010-02-23 | Nokia Corporation | Transpose memory and method thereof |
| JP5089776B2 (ja)* | 2007-09-11 | 2012-12-05 | コア ロジック,インコーポレイテッド | 浮動小数点演算のための再構成アレイプロセッサ |
| US8156313B2 (en)* | 2007-09-22 | 2012-04-10 | Navosha Corporation | Chained operation of functional units in integrated circuit by writing DONE/complete value and by reading as GO/start value from same memory location |
| US8526422B2 (en)* | 2007-11-27 | 2013-09-03 | International Business Machines Corporation | Network on chip with partitions |
| US7873701B2 (en)* | 2007-11-27 | 2011-01-18 | International Business Machines Corporation | Network on chip with partitions |
| US8001316B2 (en)* | 2007-12-27 | 2011-08-16 | Sandisk Il Ltd. | Controller for one type of NAND flash memory for emulating another type of NAND flash memory |
| US8006021B1 (en)* | 2008-03-27 | 2011-08-23 | Xilinx, Inc. | Processor local bus bridge for an embedded processor block core in an integrated circuit |
| CN101593169A (zh) | 2008-05-30 | 2009-12-02 | 国际商业机器公司 | 可配置逻辑阵列的配置管理器和配置方法 |
| US8045546B1 (en)* | 2008-07-08 | 2011-10-25 | Tilera Corporation | Configuring routing in mesh networks |
| US7952387B1 (en) | 2008-08-13 | 2011-05-31 | Altera Corporation | Securing memory based IP in FPGAs |
| US9152427B2 (en) | 2008-10-15 | 2015-10-06 | Hyperion Core, Inc. | Instruction issue to array of arithmetic cells coupled to load/store cells with associated registers as extended register file |
| US20100191814A1 (en) | 2008-12-23 | 2010-07-29 | Marco Heddes | System-On-A-Chip Employing A Network Of Nodes That Utilize Receive Side Flow Control Over Channels For Messages Communicated Therebetween |
| US20100161309A1 (en) | 2008-12-23 | 2010-06-24 | Scaleo Chip | Apparatus and Methods Thereof for Configuration and Control of a System-On-Chip Emulation Platform |
| CN101485576A (zh) | 2008-12-30 | 2009-07-22 | 深圳市蓝韵实业有限公司 | 一种对设备内fpga芯片统一配置和管理的系统 |
| KR101581882B1 (ko) | 2009-04-20 | 2015-12-31 | 삼성전자주식회사 | 재구성 가능한 프로세서 및 그 재구성 방법 |
| US8095700B2 (en) | 2009-05-15 | 2012-01-10 | Lsi Corporation | Controller and method for statistical allocation of multichannel direct memory access bandwidth |
| GB2471067B (en) | 2009-06-12 | 2011-11-30 | Graeme Roy Smith | Shared resource multi-thread array processor |
| US8321618B1 (en) | 2009-07-28 | 2012-11-27 | Nvidia Corporation | Managing conflicts on shared L2 bus |
| US8886899B1 (en)* | 2009-09-21 | 2014-11-11 | Tilera Corporation | Managing memory requests based on priority |
| KR101076869B1 (ko) | 2010-03-16 | 2011-10-25 | 광운대학교 산학협력단 | 코어스 그레인 재구성 어레이에서의 메모리 중심 통신 장치 |
| US20110264723A1 (en) | 2010-04-21 | 2011-10-27 | Samsung Electronics Co., Ltd. | System and method for successive matrix transposes |
| US9015436B2 (en) | 2011-08-22 | 2015-04-21 | Intel Corporation | Performing an atomic operation without quiescing an interconnect structure |
| KR101869749B1 (ko) | 2011-10-05 | 2018-06-22 | 삼성전자 주식회사 | 정적 라우터 기반의 코어스 그레인 재구성가능 어레이 |
| CN103168289B (zh) | 2011-10-14 | 2016-07-06 | 松下知识产权经营株式会社 | 转置运算装置及其集成电路、以及转置处理方法 |
| WO2013100782A1 (en) | 2011-12-29 | 2013-07-04 | Intel Corporation | Method and system for controlling execution of an instruction sequence in a accelerator. |
| KR101978409B1 (ko) | 2012-02-28 | 2019-05-14 | 삼성전자 주식회사 | 재구성가능 프로세서, 이를 위한 코드 변환 장치 및 방법 |
| US9875105B2 (en) | 2012-05-03 | 2018-01-23 | Nvidia Corporation | Checkpointed buffer for re-entry from runahead |
| US9348792B2 (en) | 2012-05-11 | 2016-05-24 | Samsung Electronics Co., Ltd. | Coarse-grained reconfigurable processor and code decompression method thereof |
| CN104813238B (zh) | 2012-11-13 | 2017-07-14 | 惠普深蓝有限责任公司 | 在介质上形成压痕和图像 |
| US20140149480A1 (en) | 2012-11-28 | 2014-05-29 | Nvidia Corporation | System, method, and computer program product for transposing a matrix |
| US9411715B2 (en)* | 2012-12-12 | 2016-08-09 | Nvidia Corporation | System, method, and computer program product for optimizing the management of thread stack memory |
| CN103906068B (zh)* | 2012-12-26 | 2017-07-21 | 华为技术有限公司 | 虚拟基站创建方法及装置 |
| US9569214B2 (en) | 2012-12-27 | 2017-02-14 | Nvidia Corporation | Execution pipeline data forwarding |
| JP6092649B2 (ja) | 2013-02-15 | 2017-03-08 | キヤノン株式会社 | 演算装置、アレイ型演算装置およびその制御方法、情報処理システム |
| US10628578B2 (en)* | 2013-03-15 | 2020-04-21 | Imagine Communications Corp. | Systems and methods for determining trust levels for computing components using blockchain |
| KR20140126190A (ko) | 2013-04-22 | 2014-10-30 | 삼성전자주식회사 | 프로세서의 긴 라우팅 처리를 지원하는 메모리 장치, 그 메모리 장치를 이용한 스케줄링 장치 및 방법 |
| KR20140131472A (ko) | 2013-05-03 | 2014-11-13 | 삼성전자주식회사 | 상수 저장 레지스터를 구비하는 재구성 가능 프로세서 |
| US9588774B2 (en) | 2014-03-18 | 2017-03-07 | International Business Machines Corporation | Common boot sequence for control utility able to be initialized in multiple architectures |
| US9785576B2 (en)* | 2014-03-27 | 2017-10-10 | Intel Corporation | Hardware-assisted virtualization for implementing secure video output path |
| US10140157B2 (en) | 2014-05-29 | 2018-11-27 | Apple Inc. | Multiple process scheduling of threads using process queues |
| TWI570573B (zh) | 2014-07-08 | 2017-02-11 | 財團法人工業技術研究院 | 矩陣轉置電路 |
| US20170249282A1 (en)* | 2014-10-08 | 2017-08-31 | Analog Devices, Inc. | Configurable pre-processing array |
| US10025608B2 (en) | 2014-11-17 | 2018-07-17 | International Business Machines Corporation | Quiesce handling in multithreaded environments |
| US10133670B2 (en) | 2014-12-27 | 2018-11-20 | Intel Corporation | Low overhead hierarchical connectivity of cache coherent agents to a coherent fabric |
| US10180908B2 (en)* | 2015-05-13 | 2019-01-15 | Qualcomm Incorporated | Method and apparatus for virtualized control of a shared system cache |
| US10116557B2 (en)* | 2015-05-22 | 2018-10-30 | Gray Research LLC | Directional two-dimensional router and interconnection network for field programmable gate arrays, and other circuits and applications of the router and network |
| US9698790B2 (en)* | 2015-06-26 | 2017-07-04 | Advanced Micro Devices, Inc. | Computer architecture using rapidly reconfigurable circuits and high-bandwidth memory interfaces |
| US20170083313A1 (en) | 2015-09-22 | 2017-03-23 | Qualcomm Incorporated | CONFIGURING COARSE-GRAINED RECONFIGURABLE ARRAYS (CGRAs) FOR DATAFLOW INSTRUCTION BLOCK EXECUTION IN BLOCK-BASED DATAFLOW INSTRUCTION SET ARCHITECTURES (ISAs) |
| US10019234B2 (en) | 2015-10-05 | 2018-07-10 | Altera Corporation | Methods and apparatus for sequencing multiply-accumulate operations |
| US9697318B2 (en) | 2015-10-08 | 2017-07-04 | Altera Corporation | State visibility and manipulation in integrated circuits |
| EP3157172B1 (en) | 2015-10-15 | 2018-11-28 | Menta | System and method for testing and configuration of an fpga |
| US10528356B2 (en) | 2015-11-04 | 2020-01-07 | International Business Machines Corporation | Tightly coupled processor arrays using coarse grained reconfigurable architecture with iteration level commits |
| GB2545170B (en)* | 2015-12-02 | 2020-01-08 | Imagination Tech Ltd | GPU virtualisation |
| US10037227B2 (en) | 2015-12-17 | 2018-07-31 | Intel Corporation | Systems, methods and devices for work placement on processor cores |
| US10230817B2 (en) | 2015-12-21 | 2019-03-12 | Intel Corporation | Scheduling highly parallel applications |
| JP6669961B2 (ja) | 2015-12-24 | 2020-03-18 | 富士通株式会社 | プロセッサ、再構成可能回路の制御方法及びプログラム |
| US10516396B2 (en) | 2016-04-29 | 2019-12-24 | University Of Florida Research Foundation, Incorporated | Overlay architecture for programming FPGAs |
| US10067911B2 (en) | 2016-07-26 | 2018-09-04 | Advanced Micro Devices, Inc. | High performance inplace transpose operations |
| DE102016216944A1 (de) | 2016-09-07 | 2018-03-08 | Robert Bosch Gmbh | Verfahren zur Berechnung einer Neuronenschicht eines mehrschichtigen Perzeptronenmodells mit vereinfachter Aktivierungsfunktion |
| US20180089117A1 (en) | 2016-09-26 | 2018-03-29 | Wave Computing, Inc. | Reconfigurable fabric accessing external memory |
| US10223317B2 (en) | 2016-09-28 | 2019-03-05 | Amazon Technologies, Inc. | Configurable logic platform |
| US10459644B2 (en)* | 2016-10-28 | 2019-10-29 | Western Digital Techologies, Inc. | Non-volatile storage system with integrated compute engine and optimized use of local fast memory |
| CN112217746B (zh) | 2016-11-09 | 2024-06-18 | 华为技术有限公司 | 云计算系统中报文处理的方法、主机和系统 |
| US11487445B2 (en) | 2016-11-22 | 2022-11-01 | Intel Corporation | Programmable integrated circuit with stacked memory die for storing configuration data |
| US10558575B2 (en) | 2016-12-30 | 2020-02-11 | Intel Corporation | Processors, methods, and systems with a configurable spatial accelerator |
| US9952831B1 (en) | 2017-02-16 | 2018-04-24 | Google Llc | Transposing in a matrix-vector processor |
| US10261786B2 (en) | 2017-03-09 | 2019-04-16 | Google Llc | Vector processing unit |
| WO2019005093A1 (en) | 2017-06-30 | 2019-01-03 | Intel Corporation | MODIFYING THE PROCESSOR FREQUENCY BASED ON AN INTERRUPTION FREQUENCY |
| US11256978B2 (en) | 2017-07-14 | 2022-02-22 | Intel Corporation | Hyperbolic functions for machine learning acceleration |
| US11055126B2 (en)* | 2017-08-16 | 2021-07-06 | Royal Bank Of Canada | Machine learning computing model for virtual machine underutilization detection |
| WO2019089816A2 (en)* | 2017-10-31 | 2019-05-09 | Micron Technology, Inc. | System having a hybrid threading processor, a hybrid threading fabric having configurable computing elements, and a hybrid interconnection network |
| GB2568087B (en) | 2017-11-03 | 2022-07-20 | Imagination Tech Ltd | Activation functions for deep neural networks |
| US10599596B2 (en) | 2018-01-08 | 2020-03-24 | Intel Corporation | Management of processor performance based on user interrupts |
| US20190303297A1 (en)* | 2018-04-02 | 2019-10-03 | Intel Corporation | Apparatus, methods, and systems for remote memory access in a configurable spatial accelerator |
| US11048661B2 (en) | 2018-04-16 | 2021-06-29 | Simple Machines Inc. | Systems and methods for stream-dataflow acceleration wherein a delay is implemented so as to equalize arrival times of data packets at a destination functional unit |
| US11200186B2 (en) | 2018-06-30 | 2021-12-14 | Intel Corporation | Apparatuses, methods, and systems for operations in a configurable spatial accelerator |
| GB2575293B (en) | 2018-07-04 | 2020-09-16 | Graphcore Ltd | Data Through Gateway |
| US11188497B2 (en)* | 2018-11-21 | 2021-11-30 | SambaNova Systems, Inc. | Configuration unload of a reconfigurable data processor |
| US10831507B2 (en) | 2018-11-21 | 2020-11-10 | SambaNova Systems, Inc. | Configuration load of a reconfigurable data processor |
| US10698853B1 (en) | 2019-01-03 | 2020-06-30 | SambaNova Systems, Inc. | Virtualization of a reconfigurable data processor |
| US10768899B2 (en) | 2019-01-29 | 2020-09-08 | SambaNova Systems, Inc. | Matrix normal/transpose read and a reconfigurable data processor including same |
| US11055141B2 (en) | 2019-07-08 | 2021-07-06 | SambaNova Systems, Inc. | Quiesce reconfigurable data processor |
| US10886921B1 (en) | 2020-03-20 | 2021-01-05 | Xilinx, Inc. | Multi-chip stacked devices |
| US11741025B2 (en) | 2020-12-01 | 2023-08-29 | Western Digital Technologies, Inc. | Storage system and method for providing a dual-priority credit system |
| US11824791B2 (en) | 2021-09-08 | 2023-11-21 | Nvidia Corporation | Virtual channel starvation-free arbitration for switches |
| US20230244748A1 (en) | 2022-02-01 | 2023-08-03 | SambaNova Systems, Inc. | Matrix Multiplication on Coarse-grained Computing Grids |
| US12271333B2 (en) | 2022-07-15 | 2025-04-08 | SambaNova Systems, Inc. | Peer-to-peer route through in a reconfigurable computing system |
- 2019
- 2019-01-03USUS16/239,252patent/US10698853B1/enactiveActive
- 2019-12-30TWTW108148376Apatent/TWI719788B/zhactive
- 2019-12-30TWTW110101760Apatent/TWI789687B/zhactive
- 2020
- 2020-01-02CACA3125707Apatent/CA3125707C/enactiveActive
- 2020-01-02KRKR1020217022207Apatent/KR20210119390A/konot_activeCeased
- 2020-01-02CNCN202080013580.1Apatent/CN113424168A/zhactivePending
- 2020-01-02WOPCT/US2020/012079patent/WO2020142623A1/ennot_activeCeased
- 2020-01-02JPJP2021538966Apatent/JP2022516739A/jaactivePending
- 2020-01-02EPEP20702939.8Apatent/EP3906476A1/enactivePending
- 2020-04-29USUS16/862,445patent/US11237996B2/enactiveActive
- 2022
- 2022-01-31USUS17/589,467patent/US11681645B2/enactiveActive
- 2023
- 2023-05-18USUS18/199,361patent/US12306783B2/enactiveActive
Also Published As
| Publication number | Publication date |
|---|---|
| EP3906476A1 (en) | 2021-11-10 |
| CN113424168A (zh) | 2021-09-21 |
| TWI789687B (zh) | 2023-01-11 |
| TW202117547A (zh) | 2021-05-01 |
| WO2020142623A1 (en) | 2020-07-09 |
| US12306783B2 (en) | 2025-05-20 |
| US10698853B1 (en) | 2020-06-30 |
| CA3125707C (en) | 2023-07-04 |
| TWI719788B (zh) | 2021-02-21 |
| CA3125707A1 (en) | 2020-07-09 |
| US20200218683A1 (en) | 2020-07-09 |
| US11237996B2 (en) | 2022-02-01 |
| US20200257643A1 (en) | 2020-08-13 |
| US20220156213A1 (en) | 2022-05-19 |
| US11681645B2 (en) | 2023-06-20 |
| JP2022516739A (ja) | 2022-03-02 |
| US20230289310A1 (en) | 2023-09-14 |
| TW202040368A (zh) | 2020-11-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11681645B2 (en) | Independent control of multiple concurrent application graphs in a reconfigurable data processor | |
| US11609769B2 (en) | Configuration of a reconfigurable data processor using sub-files | |
| US11983140B2 (en) | Efficient deconfiguration of a reconfigurable data processor | |
| US20220309029A1 (en) | Tensor Partitioning and Partition Access Order | |
| TWI825853B (zh) | 可重組態資料處理器的缺陷修復電路 | |
| US11366783B1 (en) | Multi-headed multi-buffer for buffering data for processing | |
| TWI766211B (zh) | 可重組態資料處理器的組態加載和卸載 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application | Patent event date:20210714 Patent event code:PA01051R01D Comment text:International Patent Application | |
| PG1501 | Laying open of application | ||
| PA0201 | Request for examination | Patent event code:PA02012R01D Patent event date:20221026 Comment text:Request for Examination of Application | |
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20241117 Patent event code:PE09021S01D | |
| E601 | Decision to refuse application | ||
| PE0601 | Decision on rejection of patent | Patent event date:20250212 Comment text:Decision to Refuse Application Patent event code:PE06012S01D |