KR20160087730A - Method and apparatus of parallelization of motion compensation on general purpose graphics - Google Patents
Method and apparatus of parallelization of motion compensation on general purpose graphicsDownload PDFInfo
- Publication number
- KR20160087730A KR20160087730AKR1020150064901AKR20150064901AKR20160087730AKR 20160087730 AKR20160087730 AKR 20160087730AKR 1020150064901 AKR1020150064901 AKR 1020150064901AKR 20150064901 AKR20150064901 AKR 20150064901AKR 20160087730 AKR20160087730 AKR 20160087730A
- Authority
- KR
- South Korea
- Prior art keywords
- macroblock
- macroblocks
- motion compensation
- type
- spatially
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription39
- 239000013598vectorSubstances0.000claimsabstractdescription20
- 238000010586diagramMethods0.000description16
- 238000005192partitionMethods0.000description4
- 230000006835compressionEffects0.000description2
- 238000007906compressionMethods0.000description2
- 230000006870functionEffects0.000description2
- 230000000295complement effectEffects0.000description1
- 229910044991metal oxideInorganic materials0.000description1
- 150000004706metal oxidesChemical class0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 238000011084recoveryMethods0.000description1
- 239000004065semiconductorSubstances0.000description1
Images











Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
- H04N19/436—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation using parallelised computational arrangements
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computing Systems (AREA)
- Theoretical Computer Science (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
Translated fromKorean본 발명의 실시예는 H.264 비디오 디코더의 그래픽 프로세서(graphics processing unit; GPU)에서의 고성능 컴퓨팅에 관한 것으로, 보다 상세하게는 범용 그래픽 프로세서(general purpose graphics processing unit; GPGPU)에서의 모션 보상의 병렬화 방법에 관한 것이다.An embodiment of the present invention relates to high performance computing in a graphics processing unit (GPU) of an H.264 video decoder, and more particularly to a high performance computing in a general purpose graphics processing unit (GPGPU) To a parallelization method.
H.264는 가장 인기 있는 비디오 압축 표준이다. 그러나 계산 복잡도가 이전의 표준들과 비교할 때 매우 높다. 이것이 다중 채널 H.264 스트림들을 디코딩하기 위한 서버 클래스의 PC에 대한 수요를 야기하며, 이는 전체 다중채널 비디오 디코더 시스템의 비용을 증가시킨다. 이러한 비용을 감소시키기 위해서는, 서버 클래스 시스템이 데스크탑 클래스 시스템으로 교체되어야 하고 스트림을 디코딩하기 위하여 모든 가용의 컴퓨팅 리소스들(CPU + GPU)을 사용해야 한다. GPU와 같은 고병렬적 아키텍처를 효율적으로 활용하기 위하여, H.264 디코더는 병렬화될 필요가 있다(parallelized). 본 발명의 실시예는 H.264 디코더의 계산 집중적 모션 보상 모듈의 병렬화에 관련된다.H.264 is the most popular video compression standard. However, computational complexity is very high when compared to previous standards. This causes a demand for a server class PC for decoding multi-channel H.264 streams, which increases the cost of the entire multi-channel video decoder system. To reduce these costs, the server class system must be replaced with a desktop class system and all available computing resources (CPU + GPU) must be used to decode the stream. In order to efficiently utilize a highly parallel architecture such as a GPU, the H.264 decoder needs to be parallelized. Embodiments of the present invention relate to parallelization of a computationally intensive motion compensation module of an H.264 decoder.
병렬 컴퓨팅 플랫폼 및 프로그래밍 모델인 CUDA(Compute Unified Device Architecture)는 병렬 처리를 위한 그래픽 프로세서에 의하여 구현된다. CUDA를 사용하면, GPU는 범용 처리를 위하여 설계될 수 있고, 이러한 접근법은 GPGPU라고 알려진다. CUDA는 'C' 언어를 확장시키고 호출 되면 'N' 개의 상이한 CUDA 쓰레드들에 의하여 'N'번 병렬적으로 실행되는 "커널"이라고 불리는 특수 C 함수를 프로그래머가 정의하도록 허용하는데, 이것은 정규의 C 함수들과 같이 오직 한번만 실행되는 것과 반대이다.Compute Unified Device Architecture (CUDA), a parallel computing platform and programming model, is implemented by a graphics processor for parallel processing. With CUDA, the GPU can be designed for general purpose processing, and this approach is known as GPGPU. CUDA extends the 'C' language and allows programmers to define special C functions called 'kernels' that are executed 'N' times in parallel by 'N' different CUDA threads, It is the opposite of running only once, like functions.
H.264 비디오 압축 표준의 P-프레임/슬라이스는 인터 매크로블록 및 인트라 매크로블록을 지원한다. 모든 인터 매크로블록들은 독립적으로 디코딩될 수 있고, 이것은 GPU 상에서의 병렬 디코딩을 위한 이상적인 선택이 된다. GPU는 P-프레임의 모든 인터 매크로블록(MB)을 디코딩하기 위하여 모션 보상(motion compensation; MC)이라고 불리는 기법을 사용한다.P-frames / slices of the H.264 video compression standard support inter macroblocks and intra macroblocks. All inter-macroblocks can be decoded independently, which is an ideal choice for parallel decoding on GPUs. The GPU uses a technique called motion compensation (MC) to decode all inter macroblocks (MB) of a P-frame.
블록의 모션 보상 및 복원을 병렬화하는 기존 방법은 N 개의 채널들을 포함할 수 있고, 각 채널이 독립적이기 때문에, 모션 보상(MC)과 함께 복원이 병렬적으로 발생하며, 따라서 각각의 채널 커널이 상이한 CUDA 스트림들 내에 론칭된다. 현재의 GPU들은 최대 32 개의 커널의 병렬 실행을 지원할 수 있다. P 프레임/슬라이스의 인터 MB들이 독립적이기 때문에, 이들은 MB당 1개의 쓰레드를 사용하여 병렬적으로 디코딩될 수 있다. 결과적으로, 한 워프(warp)의 32개의 쓰레드가 상이한 MB 타입들을 디코딩할 수 있다. 상이한 MB 타입 모션 보상은 상이한 실행 경로들을 요구한다. 이것은 결과적으로 GPU의 다중프로세서 내에 채용된 SIMT 아키텍처 때문에 제어 다이버전스(control divergence)를 초래하고, 커널 실행의 속도를 늦추는 결과를 가져온다. 이러한 접근법에서는, 단일 커널이 모든 인터 MB 타입들을 디코딩하기 위하여 사용되며, 그 결과로서 이러한 커널은 더 많은 하드웨어 리소스들, 특히 레지스터들을 소모한다(통상적으로 GTX 780에서는 92개를 소모함). 더 많은 하드웨어 리소스가 커널 당 소모되기 때문에, 다중 채널 커널 실행은 직렬화된다. 따라서 다중채널 디코더의 전체 성능이 열화된다. 커널 당 레지스터의 개수를 제한하면, 결과적으로 레지스터 스필링(spilling)을 초래할 것이고 성능을 더욱 열화시킬 것이다.An existing method of parallelizing the motion compensation and restoration of blocks may include N channels, and since each channel is independent, restoration occurs in parallel with motion compensation (MC), so that each channel kernel is different CUDA streams. Current GPUs can support parallel execution of up to 32 kernels. Since the inter-MBs of the P frame / slice are independent, they can be decoded in parallel using one thread per MB. As a result, 32 threads of a single warp can decode different MB types. Different MB type motion compensation requires different execution paths. This results in control divergence due to the SIMT architecture employed within the multiple processors of the GPU, resulting in slower kernel execution. In this approach, a single kernel is used to decode all inter-MB types, and as a result, these kernels consume more hardware resources, especially registers (typically consuming 92 on the GTX 780). Because more hardware resources are consumed per kernel, multichannel kernel execution is serialized. Therefore, the overall performance of the multi-channel decoder is deteriorated. Limiting the number of registers per kernel will result in register spilling and even worse performance.
제어 다이버전스를 회피하는 솔루션은 단일 MB를 디코딩하기 위하여 32 개의 쓰레드 또는 1개의 워프를 사용하고 있다. 이러한 솔루션은 척도변경이 가능한 솔루션이 아니고, 하드웨어 리소스를 낭비하고 있는 셈이며, 최종적으로 병렬적으로 매우 적은 개수의 MB들만을 디코딩할 수 있게 될 것이다.The solution avoiding control divergence uses 32 threads or one warp to decode a single MB. This solution is not a scalable solution, it is wasting hardware resources and will eventually be able to decode only a very small number of MBs in parallel.
본 발명의 실시예들은 최소의 하드웨어 리소스를 가지고 모션 보상 및 복원을 병렬화할 수 있고 제어 다이버전스를 제거할 수 있는 장치 및 방법을 제공하는 것이다.Embodiments of the present invention provide an apparatus and method that can parallelize motion compensation and recovery with minimal hardware resources and eliminate control divergence.
본 발명의 다양한 실시예들은 범용 그래픽 프로세서에서의 모션 보상의 병렬화 방법을 개시한다. 상기 방법은 P/B 프레임 또는 슬라이스의 하나 이상의 인터 매크로블록들(MBs)을 파싱하는 단계를 포함한다. 파싱 단계는 잔차 데이터와 관련된 정보, 각 매크로블록과 연관된 모션 벡터, 매크로블록의 타입 및 매크로블록을 디코딩하기 위한 정보를 획득하기 위하여 수행된다. 상기 방법은 매크로블록의 타입에 기초하여 하나 이상의 파싱된 인터 매크로블록들을 클러스터링하는 단계, 상기 클러스터링된 매크로블록들을 참조 픽쳐 인덱스 및 모션 벡터에 기초하여 공간적으로 그룹화하는 단계, GPU에 의하여, 공간적으로 그룹화된 매크로블록들 각각에 대하여 다중 커널들을 실행하는 단계, 및 매크로블록들의 모션 보상 및 복원을 수행하는 단계를 포함한다.Various embodiments of the present invention disclose a method of parallelizing motion compensation in a general purpose graphics processor. The method includes parsing one or more inter macroblocks (MBs) of a P / B frame or slice. The parsing step is performed to obtain information related to the residual data, the motion vector associated with each macroblock, the type of macroblock, and information for decoding the macroblock. The method includes clustering one or more parsed inter macroblocks based on a type of macroblock, spatially grouping the clustered macroblocks based on reference picture indexes and motion vectors, spatially grouping Executing multiple kernels for each of the macroblocks, and performing motion compensation and reconstruction of the macroblocks.
본 발명의 일 실시예에 따르면, 하나 이상의 파싱된 매크로블록들을 매크로블록의 타입에 기초하여 파싱하는 단계는, 현재 매크로블록과 연관된 매크로블록 번호가 상기 P/B 프레임 또는 슬라이스의 매크로블록들의 총 개수보다 작은지를 검사하는 단계, 그렇다면, 각 매크로블록을 상기 매크로블록의 타입에 기초하여 분류하는 단계, 및 매크로블록 정보를 상기 매크로블록의 각각의 타입과 연관된 버퍼에 저장하는 단계를 포함한다.According to one embodiment of the present invention, parsing the one or more parsed macroblocks based on the type of macroblocks comprises: determining whether the macroblock number associated with the current macroblock is greater than the total number of macroblocks of the P / B frame or slice And if so, classifying each macroblock based on the type of the macroblock, and storing macroblock information in a buffer associated with each type of macroblock.
본 발명의 일 실시예에 따르면, 각 매크로블록을 매크로블록의 타입에 기초하여 분류하는 단계는, 상기 매크로블록의 타입이 16x16 매크로블록인지를 검사하는 단계, 그렇다면, 매크로블록 정보를 16x16 매크로블록 버퍼에 저장하는 단계, 및 그렇지 않다면, 매크로블록의 타입이 16x8 매크로블록인지를 검사하는 단계를 포함한다.According to an embodiment of the present invention, the step of classifying each macroblock based on a type of a macroblock includes the steps of checking whether the type of the macroblock is a 16x16 macroblock, , And if not, checking whether the type of the macroblock is a 16x8 macroblock.
본 발명의 일 실시예에 따르면, 매크로블록의 타입이 16x8 매크로블록인지 검사하는 단계는, 매크로블록의 타입이 16x8 매크로블록인지 검사하는 단계, 그렇다면, 상기 매크로블록 정보를 16x8 매크로블록 버퍼에 저장하는 단계, 및 그렇지 않다면, 매크로블록의 타입이 8x16 매크로블록인지 검사하는 단계를 포함한다.According to an embodiment of the present invention, the step of checking whether a type of a macroblock is a 16x8 macroblock includes checking whether a type of the macroblock is a 16x8 macroblock, and if so, storing the macroblock information in a 16x8 macroblock buffer Step, and if not, checking whether the type of the macroblock is an 8x16 macroblock.
본 발명의 일 실시예에 따르면, 매크로블록의 타입이 8x16 매크로블록인지 검사하는 단계는, 매크로블록의 타입이 8x16 매크로블록인지 검사하는 단계, 그렇다면, 상기 매크로블록 정보를 8x16 매크로블록 버퍼에 저장하는 단계, 및 그렇지 않다면, 매크로블록의 타입이 8x8 매크로블록인지 검사하는 단계를 포함한다.According to an embodiment of the present invention, the step of checking whether a type of a macroblock is an 8x16 macroblock includes the steps of checking whether the type of the macroblock is an 8x16 macroblock, and if so, storing the macroblock information in an 8x16 macroblock buffer Step, and if not, checking whether the type of the macroblock is an 8x8 macroblock.
본 발명의 일 실시예에 따르면, 매크로블록의 타입이 8x8 매크로블록인지 검사하는 단계는, 매크로블록의 타입이 8x8 매크로블록인지 검사하는 단계, 그렇다면, 상기 매크로블록 정보를 8x8 매크로블록 버퍼에 저장하는 단계, 및 그렇지 않다면, 상기 매크로블록 정보를 스킵 매크로블록 버퍼에 저장하는 단계를 포함한다.According to an embodiment of the present invention, the step of checking whether a type of the macroblock is an 8x8 macroblock includes the steps of checking whether the type of the macroblock is an 8x8 macroblock, and if so, storing the macroblock information in an 8x8 macroblock buffer And, if not, storing the macroblock information in a skip macroblock buffer.
본 발명의 일 실시예에 따르면, 상기 매크로블록을 참조 픽쳐 인덱스에 기초하여 공간적으로 그룹화하는 단계는, 효율적 메모리 액세스를 위하여 동일한 참조 픽쳐를 참조하는 특정 그룹의 매크로블록들을 정렬함으로써 정렬된 매크로블록들이 GPU 상의 워프(warp) 내의 연속 쓰레드에 의하여 처리되게 하는 단계 및 예측된 위치에 기초하여 동일한 참조 픽쳐를 참조하는 매크로블록들을 버퍼에 재정렬하는 단계를 포함한다.According to one embodiment of the present invention, the step of spatially grouping the macroblocks based on the reference picture indexes comprises arranging the macroblocks of a particular group referring to the same reference picture for efficient memory access, Causing it to be processed by a continuous thread in a warp on the GPU and reordering the macroblocks referencing the same reference picture in the buffer based on the predicted position.
본 발명의 실시예들로서 범용 그래픽 프로세서에서의 모션 보상의 병렬화 방법을 추가 기술한다. 상기 방법은, P/B 프레임 또는 슬라이스의 하나 이상의 인터 매크로블록들을 파싱하는 단계, 보간의 타입에 기초하여 하나 이상의 마이크로블록들을 클러스터링하는 단계, 상기 클러스터링된 마이크로블록들을 상기 마이크로블록의 참조 픽쳐 인덱스 및 모션 벡터에 기초하여 공간적으로 그룹화하는 단계, GPU에 의하여, 상기 공간적으로 그룹화된 마이크로블록들 각각에 대하여 다중 커널들을 실행하는 단계, 및 블록들의 모션 보상 및 복원을 수행하는 단계를 포함한다.As an embodiment of the present invention, a method of parallelizing motion compensation in a general-purpose graphics processor is further described. The method includes parsing one or more inter macroblocks of a P / B frame or slice, clustering one or more micro blocks based on the type of interpolation, comparing the clustered micro blocks to a reference picture index of the micro block, Spatially grouping based on motion vectors, executing multiple kernels for each of the spatially grouped microblocks by the GPU, and performing motion compensation and reconstruction of the blocks.
본 발명의 일 실시예에 따르면, 하나 이상의 마이크로블록들을 보간의 타입에 기초하여 클러스터링하는 단계는, 4x4 현재 마이크로블록과 연관된 마이크로블록 번호가 마이크로블록들의 총 개수보다 작은지를 검사하는 단계, 그렇다면, 각 마이크로블록을 상기 보간의 타입에 기초하여 분류하는 단계, 및 상기 마이크로블록 정보를 상기 보간의 각 타입과 연관된 버퍼에 저장하는 단계를 포함한다.According to one embodiment of the present invention, clustering one or more micro blocks based on the type of interpolation comprises: checking whether the micro block number associated with the 4x4 current micro block is less than the total number of micro blocks, Classifying the micro blocks based on the type of the interpolation, and storing the micro block information in a buffer associated with each type of interpolation.
본 발명의 일 실시예에 따르면, 상기 방법은 마이크로블록의 픽셀들의 서브 픽셀 위치에서 블록의 모션 보상 및 복원을 수행하는 단계를 더 포함한다.According to one embodiment of the present invention, the method further comprises performing motion compensation and reconstruction of the block at sub-pixel locations of the pixels of the micro-block.
본 발명의 실시예들은 범용 그래픽 프로세서에서의 모션 보상의 병렬화를 위한 장치를 또한 개시한다. 상기 장치는 호스트를 포함하는 중앙 프로세서(CPU)와, 본 명세서에서 개시되는 바와 같은 본 발명의 방법을 수행하는 디바이스를 포함하는 그래픽 프로세서(GPU)를 포함한다.Embodiments of the present invention also disclose an apparatus for parallelizing motion compensation in a general purpose graphics processor. The apparatus includes a central processor (CPU) including a host and a graphics processor (GPU) including a device that performs the method of the present invention as disclosed herein.
개략적으로 전술된 본 발명의 다양한 양태들은 후술될 더 완전한 상세한 설명을 더욱 잘 이해하는 것을 돕는 역할을 수행하기 위한 것이다. 따라서, 본 발명이 본 명세서에서 기술되고 도시되는 방법 또는 적용 용도로 한정되지 않는다는 것이 명백하게 이해될 것이다. 상세한 설명 또는 본 명세서에 포함된 예시들로부터 명백해지거나 분명해지는 본 발명의 다른 장점들 및 목적들이 본 발명의 범위 내에 속한다.Various aspects of the invention outlined above are intended to serve aiding in a better understanding of the more complete detailed description that is presented later. Thus, it will be clearly understood that the invention is not limited to the methods or applications described and illustrated herein. Other advantages and objects of the invention that are apparent from and elucidated from the detailed description or examples contained herein are within the scope of the invention.
본 발명의 실시예에 의한 모션 보상 및 복원의 병렬화 방법은 최소의 하드웨어 리소스를 가지고 병렬화할 수 있다.The motion compensation and restoration parallelization method according to the embodiment of the present invention can parallelize with minimum hardware resources.
본 발명의 앞서 언급된 양태들 및 다른 특징들은 첨부 도면과 함께 후술하는 상세한 설명에서 설명될 것이다.
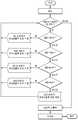
도 1a는 본 발명의 일 실시예에 따르는 그래픽 프로세서를 사용한 블록의 모션 보상 및 복원의 병렬화의 예시적인 방법을 도시하는 흐름도이다.
도 1b는 본 발명의 다른 실시예에 따르는, 그래픽 프로세서를 사용한 블록의 모션 보상 및 복원의 병렬화의 예시적인 방법을 도시하는 흐름도이다.
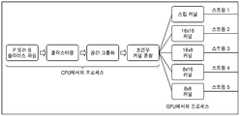
도 2는 본 발명의 일 실시예에 따르는, CPU 및 GPU를 포함하는 예시적인 CUDA 기반 비디오 디코딩 시스템을 도시하는 블록도이다.
도 3a는 본 발명의 일 실시예에 따르는, 매크로블록의 타입에 기초하여 모션 보상의 병렬화를 수행하는 예시적인 프로세스를 도시하는 개략도이다.
도 3b는 본 발명의 일 실시예에 따르는, 매크로블록의 타입에 기초하여 하나 이상의 인터 매크로블록들을 클러스터링하는 예시적인 방법을 도시하는 흐름도이다.
도 3c는 본 발명의 일 실시예에 따르는, 매크로블록의 타입에 기초하여 하나 이상의 인터 매크로블록들을 클러스터링하는 예를 도시한다.
도 4a 내지 도 4e는 본 발명의 일 실시예에 따르는, 블록의 모션 보상 및 복원을 수행하기 위한 4x4 마이크로블록의 처리를 예시한다.
도 5는 본 발명의 일 실시예에 따르는, 참조 픽쳐 인덱스 및 모션 벡터에 기초하여 마이크로블록/매크로블록을 공간적으로 그룹화하는 예시적인 프로세스를 도시하는 흐름도이다.
도 6은 본 발명의 일 실시예에 따르는, 블록의 예측된 위치에 기초한 MiB/MB의 그룹화 및 모션 보상을 수행하는 예시도이다.
본 명세서에서 설명되는 도면들은 오직 예시적인 목적을 위하여 제공되었으며 어떠한 경우에도 청구된 본 발명의 범위를 한정하는 것으로 의도되지 않는다.BRIEF DESCRIPTION OF THE DRAWINGS The foregoing aspects and other features of the present invention will become apparent from the following detailed description taken in conjunction with the accompanying drawings.
1A is a flow diagram illustrating an exemplary method of parallelization of motion compensation and reconstruction of a block using a graphics processor in accordance with an embodiment of the present invention.
1B is a flow diagram illustrating an exemplary method of parallelization of motion compensation and reconstruction of a block using a graphics processor, in accordance with another embodiment of the present invention.
2 is a block diagram illustrating an exemplary CUDA-based video decoding system including a CPU and a GPU, in accordance with an embodiment of the present invention.
3A is a schematic diagram illustrating an exemplary process for performing parallelization of motion compensation based on a type of macroblock, in accordance with an embodiment of the present invention.
Figure 3B is a flow diagram illustrating an exemplary method of clustering one or more inter macroblocks based on a type of macroblock, in accordance with an embodiment of the invention.
3C illustrates an example of clustering one or more inter-macroblocks based on the type of macroblock, in accordance with an embodiment of the present invention.
Figures 4A-4E illustrate the processing of a 4x4 microblock for performing motion compensation and reconstruction of a block, in accordance with an embodiment of the present invention.
5 is a flow diagram illustrating an exemplary process for spatially grouping microblocks / macroblocks based on a reference picture index and a motion vector, in accordance with an embodiment of the present invention.
6 is an exemplary diagram for performing grouping and motion compensation of MiB / MBs based on predicted locations of blocks, in accordance with an embodiment of the present invention.
The drawings described herein are provided for illustrative purposes only and are not intended in any way to limit the scope of the claimed invention.
본 발명은 아래에서 특정한 예시적인 실시예들 및 특정한 도면들을 참조하여 본 명세서에서 설명되지만 본 발명은 이에 한정되지 않고 청구항에 의해서 설명된다. 설명된 도면들은 예시적인 것이며 비한정적이다. 도면에서, 예시적인 목적을 위하여, 구성 요소들 중 일부의 크기는 과장될 수도 있으며 특정한 척도에 맞춰서 도시되지 않는다. "포함한다"라는 용어가 제시된 설명 및 청구항에서 사용되는 경우, 상기 용어는 다른 구성 요소 또는 단계를 배제하지 않는다. 부정관사 또는 정관사, 예를 들어 "하나(a)" "하나의(an)" 또는 "그(the)"가 단수 명사를 지칭하는 경우 사용되면, 이것은 그렇지 않다고 구체적으로 진술되지 않으면 그 명사의 복수형을 포함한다. 그러므로, "포함한다"라는 용어는 그 이후에 열거된 아이템들로 한정되는 것으로 해석되어서는 안 된다; 이것은 다른 구성 요소 또는 단계들을 제외시키지 않으며, 그러므로 "아이템 A 및 B를 포함하는 디바이스"라는 표현의 범위는 오직 컴포넌트 A 및 B만으로 이루어진 디바이스들로 한정되어서는 안 된다. 이러한 표현은 본 발명에 대해서 그 디바이스의 관련된 컴포넌트들이 A 및 B라는 것을 의미한다.BRIEF DESCRIPTION OF THE DRAWINGS The invention will be described herein below with reference to specific exemplary embodiments and specific drawings, but the invention is not so limited and is described by the claims. The described illustrations are illustrative and non-limiting. In the drawings, for purposes of example, the size of some of the elements may be exaggerated and not drawn to scale. Where the term "comprises" is used in the description and claims, the term does not exclude other elements or steps. If an indefinite article or a definite article, for example, "a", "an" or "the" is used to refer to a singular noun, . Therefore, the term "comprising" should not be construed as limited to the items listed thereafter; This does not exclude other components or steps, and therefore the scope of the expression "device comprising items A and B" should not be limited to devices consisting solely of components A and B. This expression means for the present invention that the associated components of the device are A and B.
명세서 전체에 걸쳐서, "MB" 및 "매크로블록(Macroblock)"이라는 용어는 상호 교환가능하게 혼용되고, 이와 유사하게 "MiB" 및 "마이크로블록(Microblock)"이라는 용어가 상호 교환가능하게 혼용될 수 있다.Throughout the description, the terms "MB" and "Macroblock" are interchangeably used interchangeably and, similarly, the terms "MiB" and "Microblock" have.
본 발명의 일 실시예에 따르면, 용어 "스트림"은 GPU에서 이슈 순서(issue order)로 실행하는 동작들의 시퀀스를 지칭한다.According to one embodiment of the present invention, the term "stream" refers to a sequence of operations that execute in an issue order in a GPU.
본 발명은 범용 그래픽 프로세서에서의 모션 보상의 병렬화 방법을 기술한다. 본 발명의 예시적인 실시예들의 후속하는 상세한 설명에서, 본 명세서의 일부를 형성하는 첨부 도면에 대한 참조가 이루어지고, 그 안에서 본 발명이 실시될 수도 있는 특정한 실시예가 예시를 통하여 도시된다. 이러한 실시예들은 당업자들이 본 발명을 실시하도록 하기에 충분히 세부적으로 설명되며, 본 발명의 사상 및 첨부된 청구항의 범위에서 벗어나지 않으면서 다른 실시예들이 활용될 수도 있고 변경을 가할 수도 있음이 이해되어야 한다. 그러므로, 후술하는 발명을 실시하기 위한 구체적인 내용은 한정하는 의미로 이해되어서는 안 되고, 본 발명의 범위는 첨부된 청구항에 의해서만 정의된다.The present invention describes a method of parallelizing motion compensation in a general purpose graphics processor. In the following detailed description of exemplary embodiments of the invention, reference is made to the accompanying drawings which form a part hereof, and in which is shown by way of illustration specific embodiments in which the invention may be practiced. It is to be understood that these embodiments are described in sufficient detail to enable those skilled in the art to practice the invention and that other embodiments may be utilized and made without departing from the scope of the invention and the scope of the appended claims . Therefore, the specific contents for carrying out the invention described below are not to be understood in a limiting sense, and the scope of the present invention is defined only by the appended claims.
도 1a는 본 발명의 일 실시예에 따르는, 그래픽 프로세서(GPU)를 이용한 블록의 모션 보상 및 복원의 병렬화의 예시적인 방법의 흐름도이다.1A is a flow diagram of an exemplary method of parallelization of motion compensation and reconstruction of a block using a graphics processor (GPU), in accordance with an embodiment of the invention.
P/B 슬라이스 또는 프레임의 하나 이상의(one or more) 인터 매크로블록들이 파싱된다(단계 102). 여기에서, 고려되는 매크로블록의 사이즈는 16x16 매크로블록이다. 매크로블록의 사이즈는 픽쳐의 해상도에 기초하여 변경될 수 있다. 파싱 이후에, 각 매크로블록과 연관된 모션 벡터에 대한 정보, 매크로블록의 타입 및 매크로블록을 디코딩하기 위한 정보가 획득된다.One or more inter macroblocks of the P / B slice or frame are parsed (step 102). Here, the size of the considered macroblock is a 16x16 macroblock. The size of the macroblock can be changed based on the resolution of the picture. After parsing, information about the motion vector associated with each macroblock, the type of macroblock, and information for decoding the macroblock are obtained.
하나 이상의 파싱된 인터 매크로블록들은 매크로블록의 타입에 기초하여 클러스터링된다(단계 104). 매크로블록의 타입은 16x16, 16x8, 8x16, 8x8 및 스킵 중 적어도 하나이다. 그러므로, 매크로블록들은 매크로블록의 타입에 기초하여 5개의 그룹들로 클러스터링된다. 클러스터링된 그룹의 각 매크로블록은 참조 픽쳐 인덱스 및 매크로블록의 모션 벡터에 기초하여 공간적으로 다시 그룹화된다(단계 106).The one or more parsed inter macroblocks are clustered based on the type of macroblock (step 104). The type of the macroblock is at least one of 16x16, 16x8, 8x16, 8x8, and skip. Thus, macroblocks are clustered into five groups based on the type of macroblock. Each macroblock in the clustered group is spatially re-grouped based on the reference picture index and the motion vector of the macroblock (step 106).
다음으로, 공간적으로 그룹화된 매크로블록들 각각의 다중 커널들이 GPU에 의하여 병렬적으로 실행되고(단계 108), 이에 기초하여 매크로블록의 모션 보상 및 복원이 수행된다(단계 110).Next, multiple kernels of each of the spatially grouped macroblocks are executed in parallel by the GPU (step 108), and based on this, motion compensation and restoration of the macroblock is performed (step 110).
도 1b는 본 발명의 다른 실시예에 따르는, 그래픽 프로세서를 사용한 블록의 모션 보상 및 복원의 병렬화의 예시적인 방법의 흐름도를 도시한다.Figure 1B shows a flow diagram of an exemplary method of parallelization of motion compensation and reconstruction of a block using a graphics processor, in accordance with another embodiment of the present invention.
매크로블록의 하나 이상의 마이크로블록들이 파싱되는데(단계 152), 여기에서 마이크로블록은 모션 벡터가 정의되는 대상이 되는 16x16 매크로블록의 작은 블록 파티션이다. 마이크로블록의 사이즈는 4x4 픽셀이다. 파싱 이후에, 각 마이크로블록과 연관된 모션 벡터에 대한 정보, 및 그 마이크로블록을 디코딩하기 위한 정보가 획득된다.One or more micro blocks of a macroblock are parsed (step 152), wherein the micro blocks are small block partitions of the 16x16 macroblock to which the motion vectors are defined. The size of the micro block is 4x4 pixels. After parsing, information about the motion vector associated with each microblock, and information for decoding the microblock, is obtained.
하나 이상의 마이크로블록들이 보간 타입에 기초하여 클러스터링된다(단계 154). 마이크로블록의 모션 벡터의 해상도가 Q-pel(quarter pixel)이기 때문에 서브-픽셀 예측 블록을 생성하기 위한 16개의 보간 타입들이 존재한다.One or more micro blocks are clustered based on the interpolation type (step 154). Since the resolution of the motion vector of the micro block is Q-pel (quarter pixel), there are 16 interpolation types for generating the sub-pixel prediction block.
클러스터링된 그룹으로부터의 각 마이크로블록은 각 마이크로블록의 모션 벡터 및 참조 픽쳐 인덱스에 기초하여 공간적으로 다시 그룹화된다(단계 156).Each micro-block from the clustered group is spatially re-grouped based on the motion vector and reference picture index of each micro-block (step 156).
다음으로, 공간적으로 그룹화된 마이크로블록들 각각에 대한 다중 커널들이 병렬적으로 실행되고(단계 158), 이에 기초하여 마이크로블록의 모션 보상 및 복원이 수행된다(단계 160).Next, multiple kernels for each of the spatially grouped micro blocks are executed in parallel (step 158), based on which motion compensation and restoration of the micro blocks is performed (step 160).
도 2는 본 발명의 일 실시예에 따르는, CPU 및 GPU를 포함하는 예시적인 CUDA 기반 비디오 디코딩 시스템을 도시하는 블록도이다.2 is a block diagram illustrating an exemplary CUDA-based video decoding system including a CPU and a GPU, in accordance with an embodiment of the present invention.
CUDA 기반 비디오 디코딩 시스템(200)은 개인용 컴퓨터, 비디오 게임 콘솔, 또는 비디오 데이터를 수신, 디코딩 및 렌더링하도록 구성되는 다른 디바이스 내에 구현될 수 있다. CUDA 기반 비디오 디코딩 시스템(200)은 중앙 프로세서(CPU; 202), CUDA-가능 그래픽 프로세서(GPU; 206), CPU용 프로그램 및 데이터를 저장하기 위한 호스트(203), 및 GPU용 프로그램 및 데이터를 저장하기 위한 디바이스(209)를 포함한다. 호스트(203) 및 CPU(202)는 하나의 디바이스(예를 들어 칩, 보드 등)에 함께 집적될 수도 있고, 디바이스(209) 및 GPU(206)도 역시 함께 집적될 수 있으며, 이 경우가 통상적이다.The CUDA-based
호스트(203)는 파싱 모듈(204), 클러스터링 모듈(205), 공간적 그룹화 모듈(206), 및 커널 론칭 모듈(kernel launch module; 207)로 구성된다.The
파싱 모듈(204)은 각 인터 매크로블록과 연관된 필요한 정보를 획득하고, 상기 정보를 클러스터링 모듈(205)로 전송한다.The
클러스터링 모듈(205)은 일 실시예에 따라서, 하나 이상의 파싱된 매크로블록들을 매크로블록의 타입에 기초하여 그룹화한다. 다른 실시예에서, 클러스터링 모듈은 보간의 타입에 기초하여 하나 이상의 마이크로블록을 그룹화한다. MB들 및 MiB들의 그룹화는 후술하겠다. 클러스터링 이후에, 그룹화된 MB들/MiB들은 공간적 그룹화를 위하여 처리된다.
공간적 그룹화 모듈(206)은 예측된 위치를 기초로 클러스터링된 MB들/MiB들을 추가로 그룹화한다.The
마지막으로, 커널 론칭 모듈(207)은 공간적으로 그룹화된 MB들/MiB들에 대한 다중 커널들을 실행한다.Finally, the
그 이후에, 디바이스(209)에 상주하는 모션 보상 및 복원 모듈(210)이 GPU(208)의 상이한 스트림들을 사용하여 블록의 모션 보상 및 복원을 수행한다.Thereafter, the motion compensation and
도 3a는 본 발명의 일 실시예에 따르는, 매크로블록의 타입에 기초하여 모션 보상의 병렬화를 수행하는 예시적인 프로세스를 도시하는 개략도이다.3A is a schematic diagram illustrating an exemplary process for performing parallelization of motion compensation based on a type of macroblock, in accordance with an embodiment of the present invention.
상기 실시예에서, 16x16 매크로블록에 대하여 고려되는 매크로블록의 타입은 16x16, 16x8, 8x16, 8x8 및 스킵이다. 이러한 타입에 기초하여 하나 이상의 파싱된 매크로블록들이 CPU에 의하여 클러스터링되고 공간적으로 그룹화되고, 다음으로 매크로블록들은 GPU에 의하여 추가 프로세싱된다. 여기서 매크로블록의 각 타입에 대한 커널들은 GPU의 하드웨어 리소스들을 사용하여 개별적으로 그리고 효율적으로 론칭되어 블록들을 복원한다. 5개 타입의 매크로블록들이 사용되기 때문에, GPU는 스트림1 내지 스트림5인 5개의 스트림을 사용하여 블록의 복원을 수행한다. 이러한 구성이 도 3a에 도시되어 있다.In this embodiment, the types of macroblocks considered for a 16x16 macroblock are 16x16, 16x8, 8x16, 8x8 and skip. Based on this type, one or more parsed macroblocks are clustered and spatially grouped by the CPU, and then the macroblocks are further processed by the GPU. Here, the kernels for each type of macroblock are individually and efficiently launched using the hardware resources of the GPU to recover the blocks. Since five types of macroblocks are used, the GPU performs restoration of blocks using five streams, stream 1 through stream 5. Such a configuration is shown in Fig.
도 3b는 본 발명의 일 실시예에 따르는, 매크로블록의 타입에 기초하여 하나 이상의 인터 매크로블록들을 클러스터링하는 예시적인 방법을 도시하는 흐름도이다.Figure 3B is a flow diagram illustrating an exemplary method of clustering one or more inter macroblocks based on a type of macroblock, in accordance with an embodiment of the invention.
우선, 하나 이상의 파싱된 인터 매크로블록이 획득된다. 파싱된 매크로블록들은 잔차 데이터와 관련된 정보, 각각의 매크로블록과 연관된 모션 벡터, 매크로블록의 타입 및 매크로블록을 디코딩하기 위한 정보를 제공한다. 또한, 각 매크로블록은 스스로를 표시하기 위한 매크로블록 번호(MBno)를 포함한다. 매크로블록들은 프레임의 상단-좌측에서 시작하여 좌측에서 우측으로 그리고 상단으로부터 하단으로 증가하는 순서로 번호가 매겨진다.First, one or more parsed inter macroblocks are obtained. The parsed macroblocks provide information related to the residual data, the motion vector associated with each macroblock, the type of macroblock, and information for decoding the macroblock. Each macroblock includes a macroblock number MBno for displaying itself. Macroblocks are numbered starting from the top-left of the frame and increasing in order from left to right and from top to bottom.
파싱의 종료 이후에, 현재 매크로블록과 연관된 매크로블록 번호가 P프레임의 매크로블록들의 총 개수보다 작은지가 검사된다. 만일 현재 매크로블록과 연관된 매크로블록 번호가 매크로블록들의 총 개수보다 작으면, 현재 매크로블록의 타입이 16x16 매크로블록인지가 검사된다. 만일 그렇다면, 이제 16x16 매크로블록과 관련된 정보가 16x16 매크로블록과 연관된 버퍼에 저장된다. 만일 그렇지 않다면, 현재 매크로블록의 타입이 16x8 매크로블록에 속하는지가 검사된다. 만일 그렇다면, 16x8 매크로블록에 관련된 정보가 16x8 매크로블록과 연관된 버퍼에 저장된다. 만일 그렇지 않다면, 현재 매크로블록의 타입이 8x16 매크로블록에 속하는지가 검사된다. 만일 그렇다면, 8x16 매크로블록에 관련된 정보가 8x16 매크로블록과 연관된 버퍼에 저장된다. 만일 그렇지 않다면, 현재 매크로블록의 타입이 8x8 매크로블록에 속하는지가 검사된다. 만일 그렇다면, 8x8 매크로블록에 관련된 정보가 8x8 매크로블록과 연관된 버퍼에 저장된다. 만일 그렇지 않다면, 정보는 스킵 매크로블록과 연관된 버퍼에 저장된다. 따라서, 매크로블록들은 그들의 타입에 기초하여 그룹화된다.After the end of parsing, it is checked whether the macroblock number associated with the current macroblock is less than the total number of macroblocks in the P frame. If the number of macroblocks associated with the current macroblock is less than the total number of macroblocks, it is checked whether the type of the current macroblock is a 16x16 macroblock. If so, the information associated with the 16x16 macroblock is now stored in the buffer associated with the 16x16 macroblock. If not, it is checked whether the type of the current macroblock belongs to a 16x8 macroblock. If so, the information associated with the 16x8 macroblock is stored in a buffer associated with the 16x8 macroblock. If not, it is checked whether the type of the current macroblock belongs to the 8x16 macroblock. If so, the information associated with the 8x16 macroblock is stored in a buffer associated with the 8x16 macroblock. If not, it is checked whether the type of the current macroblock belongs to an 8x8 macroblock. If so, the information associated with the 8x8 macroblock is stored in a buffer associated with the 8x8 macroblock. If not, the information is stored in a buffer associated with the skip macroblock. Thus, the macroblocks are grouped based on their type.
도 3c는 매크로블록의 타입에 기초하여 매크로블록들을 클러스터링하는 예시도이다. 이제, 매크로블록의 각 그룹은 공간적 그룹화 및 이에 후속하는 블록의 디코딩을 위하여 처리된다. 여기에서, 디코딩이란 커널 론칭, 블록 모션 보상 및 블록의 복원을 포함하는 프로세스를 지칭한다.3C is an example of clustering macroblocks based on types of macroblocks. Now, each group of macroblocks is processed for spatial grouping and subsequent decoding of the blocks. Here, decoding refers to a process including kernel launching, block motion compensation, and restoration of blocks.
도 4a는 본 발명의 일 실시예에 따라서 16x16 매크로블록으로부터 4x4 마이크로블록을 유도하는 방법을 개략적으로 도시한다.4A schematically illustrates a method for deriving 4x4 micro blocks from 16x16 macroblocks in accordance with an embodiment of the present invention.
16x16 매크로블록에서 4x4 픽셀로 구성된 영역을 갖는 최소 파티션이 취해지고 상기 최소 파티션에 대한 모션 벡터가 정의된다. 상기 최소 파티션은 마이크로블록(microblock; MiB)이라고 칭한다.A minimum partition having an area consisting of 4x4 pixels in a 16x16 macroblock is taken and a motion vector for the minimum partition is defined. The minimum partition is referred to as a microblock (MiB).
도 4b는 본 발명의 일 실시예에 따르는, 보간의 타입에 기초하여 모션 보상의 병렬화를 수행하는 예시적인 방법을 도시하는 개략도이다.4B is a schematic diagram illustrating an exemplary method of performing parallelization of motion compensation based on the type of interpolation, in accordance with an embodiment of the invention.
파싱 이후에 하나 이상의 마이크로블록들이 보간의 타입에 기초하여 클러스터링된다. 마이크로블록에 대한 모션 벡터의 해상도가 Q-pel이기 때문에, 서브-픽셀 예측 블록을 생성하기 위하여 사용가능한 16개의 보간들이 존재한다. 16개의 보간의 타입은 'G', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'n', 'p', 'q', 및 'r'이다.After parsing, one or more micro blocks are clustered based on the type of interpolation. Since the resolution of the motion vector for the micro-block is Q-pel, there are 16 possible interpolations to generate the sub-pixel prediction block. The sixteen types of interpolation are 'G', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i' 'k', 'n', 'p', 'q', and 'r'.
도 4c는 서브-픽셀 레벨에서 블록들을 생성하기 위하여 사용되는 상이한 보간의 타입들을 설명하는 예시도이다. 상기 타입들에 기초하여, 하나 이상의 마이크로블록들은 도 4d에 도시된 바와 같이 클러스터링된다.4C is an exemplary diagram illustrating the types of different interpolation used to generate blocks at the sub-pixel level. Based on these types, the one or more microblocks are clustered as shown in FIG. 4D.
도 4d는 본 발명의 일 실시예에 따르는, 보간의 타입에 기초하여 하나 이상의 마이크로블록들을 클러스터링하는 흐름도이다.4D is a flow chart for clustering one or more micro blocks based on the type of interpolation, in accordance with an embodiment of the present invention.
클러스터링 단계 동안에, 마이크로블록 번호(MiBno)가 마이크로블록의 총 개수보다 작은지가 검사된다. 만일 그렇다면, 상기 마이크로블록이 결과적 방식으로 16개의 보간의 타입 중 임의의 하나에 속하는지가 검사되고, 만일 그렇다면, 각 마이크로블록과 연관되는 마이크로블록 정보가 대응하는 버퍼에 저장된다. 이러한 프로세스는 모든 마이크로블록들이 그룹화될 때까지 반복된다.During the clustering step, it is checked whether the microblock number (MiBno) is less than the total number of microblocks. If so, it is checked whether the micro block belongs to any one of the 16 interpolation types in a resultant manner, and if so, the micro block information associated with each micro block is stored in the corresponding buffer. This process is repeated until all micro blocks are grouped.
도 4e는 보간의 타입에 기초한 마이크로블록의 클러스터링을 설명하는 예시도이다.Figure 4E is an exemplary diagram illustrating clustering of microblocks based on the type of interpolation.
클러스터링된 마이크로블록들은 참조 픽쳐 인덱스 및 그 마이크로블록의 모션 벡터에 기초하여 공간적으로 그룹화된다. 공간적으로 그룹화된 마이크로블록들은 GPU에 의하여 추가적으로 처리되는데, 여기에서 마이크로블록의 각 그룹에 대한 커널들이 효율적으로 GPU의 하드웨어 리소스를 사용하여 개별적으로 그리고 병렬적으로 론칭되어 블록들을 복원한다. 16개의 보간 타입들이 사용되기 때문에, GPU는 스트림1 내지 스트림16인 16개의 스트림을 사용하여 블록의 복원을 수행한다.The clustered micro blocks are spatially grouped based on the reference picture index and the motion vectors of the micro blocks. Spatially grouped microblocks are additionally handled by the GPU where the kernels for each group of microblocks are efficiently and individually launched in parallel using the hardware resources of the GPU to recover the blocks. Since 16 interpolation types are used, the GPU performs the restoration of the block using 16 streams, stream 1 through
도 5는 본 발명의 일 실시예에 따르는, 참조 픽쳐 인덱스 및 모션 벡터에 기초하여 마이크로블록/매크로블록을 공간적으로 그룹화하는 예시적인 프로세스를 도시하는 흐름도이다.5 is a flow diagram illustrating an exemplary process for spatially grouping microblocks / macroblocks based on a reference picture index and a motion vector, in accordance with an embodiment of the present invention.
클러스터링에 의하여 형성된 상이한 그룹들이 공간적 그룹화를 수행하기 위한 입력으로서 주어진다. 동일한 참조 픽쳐를 참조하는 특정 그룹 내의 MB들/MiB들은 메모리 내에서 인접하도록 정렬됨으로써 그러한 MB들/MiB들이 GPU 상의 워프 내의 연속 쓰레드에 의하여 처리되게 한다. H.264 표준에 따라서 이용가능한 전체 16개의 참조 프레임들이 존재한다. 그 이후에, 동일한 참조 픽쳐 MB들/MiB들은 예측된 위치에 기초하여 버퍼에 다시 재정렬된다. 이는 예측된 위치에 의해 인접한 MB들/MiB들이 버퍼에서 더 근접하게 배치됨으로써 한 워프 내의 쓰레드에 의하여 처리되기 때문이다. 따라서, 전체적인 광역 메모리 병합(coalescing)이 공간적 그룹화에 의하여 개선된다. 공간적 그룹화 이후에 디코딩이 수행된다. 여기서, 디코딩이란 커널 론칭, 블록 예측 및 블록의 복원을 포함하는 프로세스를 지칭한다.Different groups formed by clustering are given as input to perform spatial grouping. MBs / MiBs in a particular group that refer to the same reference picture are aligned to be contiguous in memory so that such MBs / MiBs are processed by a contiguous thread in the warp on the GPU. There are a total of 16 reference frames available according to the H.264 standard. Thereafter, the same reference picture MBs / MiBs are re-ordered into the buffer based on the predicted location. This is because the neighboring MBs / MiBs are processed by a thread in one warp by being placed closer in the buffer by the predicted position. Thus, global wide memory coalescing is improved by spatial grouping. Decoding is performed after spatial grouping. Here, decoding refers to a process including kernel launching, block prediction, and restoration of a block.
도 6은 블록의 예측된 위치에 기초한 마이크로블록/MB들의 그룹화 및 모션 보상과 복원을 수행하는 방법의 예시도이다.6 is an illustration of a method of performing grouping and motion compensation and restoration of microblocks / MBs based on predicted locations of blocks.
공간적 그룹화 이후에, CPU는 조건부 커널 론칭을 수행한다. 한 프레임 내에서 모든 MB 타입들이 존재하지 않을 수도 있고 또는 모든 보간 방법이 필요하지 않을 수도 있다. MC 및 복원을 수행하는 단일 커널 대신에, 다중 커널들은 MB 타입 또는 상이한 보간 방식에 기초하여 상이한 스트림 상에 론칭된다. 상기 접근법은 하드웨어 리소스, 특히 레지스터를 최소화하고, 커널들이 조건부로 론칭되기 때문에 전체 성능이 고성능이다. 커널 실행 구성은 GPU에 기초하고, 또한 런 타임 시에 구성될 수 있다. 커널들이 실행되면, 워프의 각 쓰레드가 각 블록에 대해 MC 및 복원 완료를 수행한다. 블록의 개수가 더 많기 때문에 병렬도(parallelism)가 매우 높다. 그러나 하드웨어의 제한 사항에 기인하여 쓰레드의 총 개수는 한 프레임 내의 블록들의 개수와 동일할 수 없다. 따라서, 커널 실행 구성은 일부의 "N" 개의 쓰레드들이 론칭되는 방식일 수 있다. 이러한 "N" 개의 쓰레드들은 N 개의 블록들이 디코딩된 이후에 재사용되는데, 여기에서 "N"의 값은 GPU에 기초하여 결정된다.After spatial grouping, the CPU performs a conditional kernel launch. Not all MB types within a frame may be present or not all interpolation methods may be necessary. Instead of a single kernel performing MC and restoration, multiple kernels are launched on different streams based on the MB type or different interpolation schemes. This approach minimizes hardware resources, particularly registers, and overall performance is high performance because the kernels are conditionally launched. The kernel run configuration is based on the GPU and can also be configured at runtime. When the kernels are executed, each thread in the warp performs MC and restore completion for each block. Since there are more blocks, the parallelism is very high. However, due to hardware limitations, the total number of threads can not equal the number of blocks in a frame. Thus, the kernel execution configuration may be such that some "N" threads are launched. These "N" threads are reused after N blocks are decoded, where the value of "N" is determined based on the GPU.
본 발명의 실시예들이 특정한 예시적인 실시예들을 참조하여 설명되어 왔지만, 다양한 실시예들의 더 넓은 사상 및 범위로부터 벗어나지 않으면서 이러한 실시예에 다양한 수정 및 변경이 가해질 수도 있다는 것이 명백할 것이다. 더욱이, 본 명세서에서 설명되는 다양한 디바이스, 모듈 등은 하드웨어 회로부, 예를 들어, 상보적 금속 산화물 반도체 기반 로직 회로부, 펌웨어, 소프트웨어 및/또는 머신 판독가능 매체 내에 구현된 하드웨어, 펌웨어, 및/또는 소프트웨어의 임의의 조합을 사용하여 이네이블되고 동작될 수도 있다. 예를 들어, 다양한 전기적 구조 및 방법들이 트랜지스터, 로직 게이트, 및 주문형 집적회로와 같은 전기 회로를 사용하여 구현될 수도 있다.While the embodiments of the present invention have been described with reference to specific exemplary embodiments, it will be apparent that various modifications and changes may be made to these embodiments without departing from the broader spirit and scope of the various embodiments. Moreover, the various devices, modules, and the like described herein may be implemented within hardware circuitry, e.g., complementary metal oxide semiconductor based logic circuitry, firmware, software, and / or hardware, firmware, and / Lt; / RTI > may be enabled and operated using any combination of < RTI ID = 0.0 > For example, various electrical structures and methods may be implemented using electrical circuits such as transistors, logic gates, and custom integrated circuits.
Claims (4)
Translated fromKoreanP/B 슬라이스 또는 프레임의 하나 이상의 인터 매크로블록(macroblock; MB)을 파싱하는 단계;
매크로블록의 타입에 기초하여 상기 하나 이상의 파싱된 인터 매크로블록을 클러스터링하는 단계;
상기 클러스터링된 매크로블록을 참조 픽쳐 인덱스 및 모션 벡터에 기초하여 공간적으로 그룹화하는 단계;
상기 그래픽 프로세서(GPU)에 의하여, 상기 공간적으로 그룹화된 매크로블록들 각각에 대하여 다중 커널들을 실행하는 단계; 및
매크로블록의 모션 보상 및 복원을 수행하는 단계;를 포함하는 모션 보상 병렬화 방법.A motion compensation parallelization method in a general purpose graphics processing unit (GPGPU) of an H.264 decoder,
Parsing one or more inter macroblocks (MB) of a P / B slice or frame;
Clustering the one or more parsed inter macroblocks based on the type of macroblock;
Spatially grouping the clustered macroblocks based on a reference picture index and a motion vector;
Executing multiple kernels for each of the spatially grouped macroblocks by the graphics processor (GPU); And
And performing motion compensation and reconstruction of the macroblock.
P/B 슬라이스 또는 프레임의 하나 이상의 인터 매크로블록을 파싱하는 단계;
보간의 타입에 기초하여 하나 이상의 마이크로블록을 클러스터링하는 단계;
상기 클러스터링된 마이크로블록들을 참조 픽쳐 인덱스 및 모션 벡터에 기초하여 공간적으로 그룹화하는 단계;
상기 GPU에 의하여, 상기 공간적으로 그룹화된 마이크로블록들 각각에 대하여 다중 커널들을 실행하는 단계; 및
마이크로블록의 모션 보상 및 복원을 수행하는 단계;를 포함하는 모션 보상 병렬화 방법.A motion compensated parallelization method using a graphics processor (GPU) of an H.264 decoder,
Parsing one or more inter macroblocks of the P / B slice or frame;
Clustering one or more micro blocks based on the type of interpolation;
Spatially grouping the clustered micro blocks based on a reference picture index and a motion vector;
Executing, by the GPU, multiple kernels for each of the spatially grouped micro blocks; And
And performing motion compensation and restoration of the micro blocks.
상기 공간적으로 그룹화된 매크로블록들 각각에 대하여 다중 커널들을 실행하고, 매크로블록의 모션 보상 및 복원을 수행하는 디바이스를 포함하는, 그래픽 프로세서(graphics processing unit; GPU);를 포함하는 장치.Parsing the one or more inter macroblocks of the P / B slice or frame, clustering the one or more parsed inter macroblocks based on the type of macroblock, and comparing the clustered macroblocks based on the reference picture indexes and motion vectors A central processing unit (CPU), including a host spatially grouping; And
And a device for executing multiple kernels for each of the spatially grouped macroblocks and performing motion compensation and reconstruction of the macroblocks.
상기 공간적으로 그룹화된 마이크로블록들 각각에 대하여 다중 커널들을 실행하고, 마이크로블록의 모션 보상 및 복원을 수행하는 디바이스를 포함하는, 그래픽 프로세서(graphics processing unit; GPU);를 포함하는 장치.Parsing one or more inter macroblocks of a P / B slice or frame, clustering one or more parsed microblocks based on the type of interpolation, and comparing the clustered microblocks based on the reference picture indexes and motion vectors of the microblocks A central processing unit (CPU), including a host that spatially groups the devices; And
A graphics processing unit (GPU) comprising a device for executing multiple kernels for each of the spatially grouped micro blocks and performing motion compensation and reconstruction of the micro blocks.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| IN229/CHE/2015 | 2015-01-14 | ||
| IN229CH2015 | 2015-01-14 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20160087730Atrue KR20160087730A (en) | 2016-07-22 |
| KR102366519B1 KR102366519B1 (en) | 2022-02-23 |
Family
ID=80495836
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020150064901AActiveKR102366519B1 (en) | 2015-01-14 | 2015-05-08 | Method and apparatus of parallelization of motion compensation on general purpose graphics |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102366519B1 (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100359821B1 (en) | 2000-01-20 | 2002-11-07 | 엘지전자 주식회사 | Method, Apparatus And Decoder For Motion Compensation Adaptive Image Re-compression |
| JP2009522650A (en)* | 2005-12-30 | 2009-06-11 | インテル コーポレイション | Hardware motion compensation in video recording |
| US8396122B1 (en)* | 2009-10-14 | 2013-03-12 | Otoy, Inc. | Video codec facilitating writing an output stream in parallel |
| KR20130140066A (en)* | 2010-11-09 | 2013-12-23 | 소니 컴퓨터 엔터테인먼트 인코포레이티드 | Video coding methods and apparatus |
- 2015
- 2015-05-08KRKR1020150064901Apatent/KR102366519B1/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100359821B1 (en) | 2000-01-20 | 2002-11-07 | 엘지전자 주식회사 | Method, Apparatus And Decoder For Motion Compensation Adaptive Image Re-compression |
| JP2009522650A (en)* | 2005-12-30 | 2009-06-11 | インテル コーポレイション | Hardware motion compensation in video recording |
| US8396122B1 (en)* | 2009-10-14 | 2013-03-12 | Otoy, Inc. | Video codec facilitating writing an output stream in parallel |
| KR20130140066A (en)* | 2010-11-09 | 2013-12-23 | 소니 컴퓨터 엔터테인먼트 인코포레이티드 | Video coding methods and apparatus |
Non-Patent Citations (2)
| Title |
|---|
| B.Pieters et al., "Performance evaluation of H.264/AVC decoding and visualization using the GPU," Proceedings Vol. 6696, Applications of Digital Image Processing XXX; (2007.09.24.)** |
| T.Wiegand et al., "Overview of the H.264/AVC Video Coding Standard," IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 13, NO. (2003.08.04.)* |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102366519B1 (en) | 2022-02-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8218640B2 (en) | Picture decoding using same-picture reference for pixel reconstruction | |
| US20160080766A1 (en) | Encoding system using motion estimation and encoding method using motion estimation | |
| WO2016055484A1 (en) | Method and apparatus for vector encoding in video coding and decoding | |
| US9020286B2 (en) | Apparatus for dividing image data and encoding and decoding image data in parallel, and operating method of the same | |
| US10924753B2 (en) | Modular motion estimation and mode decision engine | |
| US20100122044A1 (en) | Data dependency scoreboarding | |
| De Souza et al. | GHEVC: An efficient HEVC decoder for graphics processing units | |
| De Souza et al. | HEVC in-loop filters GPU parallelization in embedded systems | |
| US10237561B2 (en) | Video coding apparatus and video coding method | |
| Lee et al. | Fast motion estimation for HEVC on graphics processing unit (GPU) | |
| Cho et al. | Efficient in-loop filtering across tile boundaries for multi-core HEVC hardware decoders with 4 K/8 K-UHD video applications | |
| Ko et al. | An efficient parallelization technique for x264 encoder on heterogeneous platforms consisting of CPUs and GPUs | |
| KR102366519B1 (en) | Method and apparatus of parallelization of motion compensation on general purpose graphics | |
| US9241142B2 (en) | Descriptor-based stream processor for image processing and method associated therewith | |
| Ko et al. | An efficient parallel motion estimation algorithm and X264 parallelization in CUDA | |
| Han et al. | HEVC decoder acceleration on multi-core X86 platform | |
| US20080059546A1 (en) | Methods and Apparatus For Providing A Scalable Motion Estimation/Compensation Assist Function Within An Array Processor | |
| Agha et al. | Efficient motion estimation and discrete cosine transform implementation using the graphics processing units | |
| US9787880B2 (en) | Video pre-processing method and apparatus for motion estimation | |
| Migallón et al. | Synchronous and asynchronous HEVC parallel encoder versions based on a GOP approach | |
| Jeong et al. | Parallelization and performance prediction for HEVC UHD real-time software decoding | |
| Zhang et al. | Highly parallel acceleration of hevc encoding on arm platform | |
| Szwoch | Parallel background subtraction in video streams using OpenCL on GPU platforms | |
| US20130094586A1 (en) | Direct Memory Access With On-The-Fly Generation of Frame Information For Unrestricted Motion Vectors | |
| Al-kadi et al. | Meandering based parallel 3DRS algorithm for the multicore era |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20150508 | |
| PG1501 | Laying open of application | ||
| PN2301 | Change of applicant | Patent event date:20180919 Comment text:Notification of Change of Applicant Patent event code:PN23011R01D | |
| A201 | Request for examination | ||
| PA0201 | Request for examination | Patent event code:PA02012R01D Patent event date:20200318 Comment text:Request for Examination of Application Patent event code:PA02011R01I Patent event date:20150508 Comment text:Patent Application | |
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20210714 Patent event code:PE09021S01D | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | Patent event code:PE07011S01D Comment text:Decision to Grant Registration Patent event date:20211124 | |
| PR0701 | Registration of establishment | Comment text:Registration of Establishment Patent event date:20220218 Patent event code:PR07011E01D | |
| PR1002 | Payment of registration fee | Payment date:20220221 End annual number:3 Start annual number:1 | |
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee | Payment date:20250122 Start annual number:4 End annual number:4 |