KR20150048028A - Managing Data Transfer - Google Patents
Managing Data TransferDownload PDFInfo
- Publication number
- KR20150048028A KR20150048028AKR1020140115135AKR20140115135AKR20150048028AKR 20150048028 AKR20150048028 AKR 20150048028AKR 1020140115135 AKR1020140115135 AKR 1020140115135AKR 20140115135 AKR20140115135 AKR 20140115135AKR 20150048028 AKR20150048028 AKR 20150048028A
- Authority
- KR
- South Korea
- Prior art keywords
- payload data
- virtual machine
- threshold
- shared heap
- ring buffer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45583—Memory management, e.g. access or allocation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45595—Network integration; Enabling network access in virtual machine instances
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer And Data Communications (AREA)
Abstract
Description
Translated fromKorean본 발명은 데이터 전송 관리, 특히 가상 머신 사이의 페이로드(payload) 데이터 전송을 관리하는 방법과 관련된다.The present invention relates to data transfer management, and in particular, to a method for managing payload data transfer between virtual machines.
하드웨어 가상화(hardware virtualization)는 잘 알려진 기술이지만, 매우 복잡한 하드웨어 서브시스템(일반적으로 그 상태를 캡쳐/복구하기 위해 많은 양의 정보를 요구하는 서브시스템)에 대한 그 적용은 굉장히 노동 집약적이고, 각 서브시스템에 대한 특정한 작업(effort)으로 인해, 새로운 세대의 하드웨어가 개발되면 일반적으로 재사용될 수 없다.Hardware virtualization is a well-known technology, but its application to very complex hardware subsystems (subsystems that typically require a large amount of information to capture / recover the state) is very labor intensive, Due to the specific effort on the system, a new generation of hardware can not normally be reused once it is developed.
여러 가상 머신(VM, virtual machine)들이 동일한 물리 디바이스(physical device) 상에 위치한 경우 이 가상 머신들 상호간에 (API 요청(application programming interface requests)과 같은) 메시지를 보내서 통신하기 위해서는 필수조건(a necessity)이 간혹 존재한다.When multiple virtual machines (VM) are located on the same physical device, it is necessary to send a message (such as application programming interface requests) ) Sometimes exists.
이를 위한 여러 솔루션들이 현존하지만, 분산 컴퓨팅(distributed computing)(서버 팜(server farms) 및 클라우드 시스템)) 또는 상위 자원 데스크톱 머신(higher resource desktop machines)에서 그 본질(origins)은 그것들이 가상 머신들 사이에서 API 요청을 전송하기 위한 가장 효율적인 메커니즘을 사용하지 못한다는 것을 의미한다.There are many solutions for this, but the origins in distributed computing (server farms and cloud systems) or higher resource desktop machines are that they are between virtual machines Which means that it does not use the most efficient mechanism for sending API requests in the network.
일반적으로, 전송 메커니즘은 그 전송을 위해 TCP/IP 네트워크 연결을, 또는 그 통신을 위해 대용량 FIFP 버퍼(a large first-in-first-out buffer)를 이용한다. 이와 같은 FIFO 버퍼들은 대용량 데이터 페이로드들을 운송하는 API 요청들을 전송하기 위해 종종 매우 큰 용량을 가질 수 있다.In general, the transport mechanism uses a large first-in-first-out buffer (FIFP buffer) for its transmission or a TCP / IP network connection for its transmission. Such FIFO buffers can often have very large capacities to transmit API requests to transport large data payloads.
매우 큰 용량의 FIFO 버퍼를 사용하는 것은, 자원 제약 임베디드 시스템(resource constrained embedded system)에서 사용될 때, 상기 버퍼가 가용 시스템 리소스(자원)의 상당한 양을 소비하는 경우, FIFO 버퍼 사이즈의 관점에서 리소스로 인해 문제점을 유발한다.The use of a very large capacity FIFO buffer, when used in a resource constrained embedded system, allows the resource to be used as a resource in terms of FIFO buffer size when the buffer consumes a significant amount of available system resources Causing problems.
(서버 기반 시스템들로부터 유래된) 네트워크 기반 실행들은 가상 머신 환경에서의 고대역 통신용 네트워크 계층의 이용에 내재된 잘 기록된 성능 이슈들(well documented performance issues)로 인해 문제점을 유발한다.Network-based implementations (derived from server-based systems) cause problems due to well documented performance issues inherent in the use of network layers for high-bandwidth communications in a virtual machine environment.
본 발명의 제1 실시 형태는 제1 가상 머신과 제2 가상 머신 사이에서 페이로드 데이터 전송을 관리하는 방법을 제공하는데, 상기 제1 가상 머신과 상기 제2 가상 머신은 복수의 가상 머신들을 포함하는 호스트 환경에 의해 지원되고, 상기 방법은, 상기 제1 가상 머신에서 상기 제2 가상 머신으로 전송될 상기 페이로드 데이터가 제1 임계 값을 초과하는 페이로드 데이터 사이즈를 포함하는지 여부를 판단하는 동작; 및 상기 판단에 기반한 상기 페이로드 데이터 용 전송 매체(transfer medium)를 선택하는 동작을 포함한다.A first aspect of the present invention provides a method of managing payload data transfer between a first virtual machine and a second virtual machine, the first virtual machine and the second virtual machine including a plurality of virtual machines The method comprising: determining whether the payload data to be transferred from the first virtual machine to the second virtual machine includes a payload data size that exceeds a first threshold; And selecting a transfer medium for the payload data based on the determination.
상기 방법은 만약 상기 페이로드 데이터 사이즈가 상기 제1 임계 값을 초과하지 않으면 상기 페이로드 데이터를 링 버퍼(ring buffer)를 통해 전송되는 전송 패킷에 커밋하는 동작(committing)을 더 포함할 수 있다.The method may further include committing the payload data to a transport packet transmitted through a ring buffer if the payload data size does not exceed the first threshold value.
만약 상기 페이로드 데이터 사이즈가 상기 제1 임계 값을 초과하면, 상기 방법은, 상기 페이로드 데이터 사이즈를 제2 임계 값(상기 제2 임계 값은 상기 제1 임계 값보다 큼)과 비교하는 동작, 및 만약 상기 페이로드 데이터 사이즈가 상기 제2 임계 값을 초과하면 상기 페이로드 데이터의 적어도 일부를 벌크 전송 채널(bulk transfer channel)에 할당하거나, 만약 상기 페이로드 데이터 사이즈가 상기 제2 임계 값을 초과하지 않으면 상기 페이로드 데이터의 적어도 일부를 공유 힙(shared heap)에 할당하는 동작을 더 포함할 수 있다.If the payload data size exceeds the first threshold, the method further comprises: comparing the payload data size to a second threshold (the second threshold is greater than the first threshold) And if the payload data size exceeds the second threshold, assign at least a portion of the payload data to a bulk transfer channel, or if the payload data size exceeds the second threshold And if not, allocating at least a portion of the payload data to a shared heap.
상기 방법은, 메타데이터(metadata) 및 상기 벌크 전송 채널 또는 공유 힙에 할당되지 않은 임의의 페이로드 데이터를 링 버퍼를 통해 전송되는 전송 패킷에 커밋하는 동작을 더 포함할 수 있다.The method may further include committing metadata and any payload data not allocated to the bulk transport channel or the shared heap to transport packets transmitted through the ring buffer.
상기 메타데이터는 상기 공유 힙 또는 상기 벌크 전송 채널에 할당된 상기 페이로드 데이터의 적어도 일부를 각각 참조하는 공유 힙 레퍼런스 태그(reference tag) 또는 벌크 전송 채널 레퍼런스 태그를 포함할 수 있다.The metadata may include a shared heap reference tag or a bulk transport channel reference tag that respectively references at least a portion of the payload data allocated to the shared heap or the bulk transport channel.
상기 방법은 공유 힙으로의 할당이 성공하지 못했다는 판단에 응답하여 상기 공유 힙에 할당된 상기 페이로드 데이터의 상기 적어도 일부를 상기 벌크 전송 채널에 커밋하는 동작을 더 포함할 수 있다.The method may further comprise committing the at least a portion of the payload data allocated to the shared heap to the bulk transport channel in response to determining that allocation to the shared heap was unsuccessful.
상기 판단에 기반한 상기 페이로드 데이터 용 전송 매체(transfer medium)를 선택하는 동작은, 만약 상기 페이로드 데이터 사이즈가 상기 제1 임계 값을 초과하면 상기 페이로드 데이터의 적어도 일부를 벌크 전송 채널에 할당하는 동작을 포함할 수 있다.Wherein the act of selecting a transfer medium for the payload data based on the determination comprises assigning at least a portion of the payload data to a bulk transport channel if the payload data size exceeds the first threshold Operation.
상기 제1 임계 값은 링 버퍼를 통한 전송 패킷에서 전송 가능한 페이로드 데이터의 최대 양에 대응할 수 있다.The first threshold may correspond to a maximum amount of payload data that can be transmitted in a transmission packet through the ring buffer.
상기 링 버퍼를 통한 전송은 비동기(asynchronous) 방식일 수 있다.The transmission through the ring buffer may be asynchronous.
상기 공유 힙을 통한 전송은 비동기 방식일 수 있다.Transmission through the shared heap may be asynchronous.
상기 제1 가상 머신은 어플리케이션을 포함할 수 있고 상기 제2 가상 머신은 API 서버를 포함할 수 있다.The first virtual machine may include an application and the second virtual machine may include an API server.
상기 페이로드 데이터는 API 요청(API request)을 포함할 수 있다.The payload data may include an API request.
상기 방법은 상기 선택된 전송 매체를 이용하여 상기 페이로드 데이터를 전송하는 동작을 더 포함할 수 있다.The method may further include transmitting the payload data using the selected transmission medium.
상기 호스트 환경은 그 환경에 저장된(stored thereon) 복수의 가상 머신들을 포함하는 물리 디바이스를 포함할 수 있다.The host environment may comprise a physical device comprising a plurality of virtual machines stored thereon.
일 실시 예에 따른 비 일시적인 컴퓨터-판독 가능한 기록 매체는 컴퓨팅 장치에 의해 실행될 때 상기 컴퓨팅 장치로 하여금 상기 방법을 수행하도록 하는 컴퓨터-판독가능한 코드를 저장하고 있을 수 있다.A non-temporary computer-readable medium according to one embodiment may store computer-readable code that, when executed by a computing device, causes the computing device to perform the method.
복수의 데이터 전송 메커니즘이 상기 컴퓨팅 장치 상에서 동작 가능할 수 있다.A plurality of data transfer mechanisms may be operable on the computing device.
본 발명의 실시 예들은 비교적 낮은 사용량(low footprint)을 갖는 고성능 전송을 제공한다.Embodiments of the present invention provide high performance transmission with relatively low footprint.
이제 본 발명의 실시예들이, 오직 예시적으로, 첨부된 도면을 참조하여 기술될 것이다.
도 1은 본 발명의 일 실시 예에 따른 시스템의 도식적인 예시;
도 2는 인터도메인 통신 채널(interdomain communication channel)의 도식적인 예시;
도 3은 패킷의 도식적인 예시;
도 4는 본 발명의 일 실시예를 나타내는 흐름도;
도 5는 공유 힙 구조의 도식적인 예시; 및
도 6-9는 본 발명의 실시 예들의 도식적인 예시를 나타낸다.Embodiments of the present invention will now be described, by way of example only, with reference to the accompanying drawings.
Figure 1 is a schematic illustration of a system according to one embodiment of the present invention;
Figure 2 is a schematic illustration of an interdomain communication channel;
Figure 3 is a schematic illustration of a packet;
4 is a flow chart illustrating an embodiment of the present invention;
Figure 5 is a schematic illustration of a shared heap structure; And
Figures 6-9 illustrate diagrammatic illustrations of embodiments of the present invention.
본 발명의 실시 예들은 디바이스들, 예를 들어 스마트 폰이나 태블릿과 같은 모바일 디바이스 상에서 동작할 수 있다. 확실하게, 이하에서 기술되는 실시 예들은 자원 제약 환경(resource constrained environments)에서 그래픽 집중적인 애플리케이션을 실행하는 임의의 디바이스에 특히 유용하다.Embodiments of the present invention may operate on devices, for example mobile devices such as smart phones or tablets. Obviously, the embodiments described below are particularly useful for any device that executes graphics-intensive applications in resource constrained environments.
설명의 편의를 위해, 실시 예들이 수행되는 물리 디바이스는 모바일 디바이스로 참조될 수 있다. 상기 모바일 디바이스는 모바일 디바이스에서 전형적으로 발견되는 프로세서, 메모리, (터치스크린일 수 있는) 디스플레이, 오디오 입/출력과 같은 하드웨어 컴퍼넌트를 포함하는 것으로 이해되어야 한다. 이와 같은 디바이스는 알려진 전화 네트워크(예: 3G 또는 4G) 및 기존의 인터페이스를 이용하여 인터넷에 접속할 수 있도록 하는 (WiFi와 같은) 다른 네트워크에 연결할 수 있다.For convenience of description, the physical device on which embodiments are performed may be referred to as a mobile device. The mobile device should be understood to include hardware components such as a processor, memory, display (which may be a touch screen), audio input / output, and the like typically found in mobile devices. Such devices can connect to other networks (such as WiFi) that allow access to the Internet using known telephone networks (such as 3G or 4G) and existing interfaces.
상기 프로세서는 임의의 타입의 처리 회로(processing circuitary)일 수 있다. 예를 들어, 상기 처리 회로는 컴퓨터 프로그램 명령어를 해석하고 데이터를 처리하는 프로그램 작동 가능한(programmable) 프로세서일 수 있다. 상기 처리 회로는 복수의 프로그램 작동 가능한 프로세서들을 포함할 수 있다. 그 대신에, 상기 처리 회로는, 예를 들어, 임베디드 펌웨어(embedded firmware)를 탑재한 프로그램 작동 가능한 하드웨어일 수 있다. 상기 처리 회로 또는 프로세서는 처리 수단(processing means)으로 표현될 수 있다.The processor may be any type of processing circuitry. For example, the processing circuitry may be a programmable processor that interprets computer program instructions and processes the data. The processing circuitry may include a plurality of programmable processors. Alternatively, the processing circuitry may be programmable hardware, for example, with embedded firmware. The processing circuit or processor may be represented by processing means.
용어 “메모리(memory)”는 본 명세서에서 사용될 때, 상기 용어가 하나 이상의 휘발성(volatile) 메모리만, 하나 이상의 비-휘발성(non-volatile) 메모리만, 또는 하나 이상의 휘발성 및 하나 이상의 비-휘발성 메모리를 포함할 수 있음에도 불구하고, 문맥상 다른 의미가 없다면 주로 비-휘발성 메모리와 휘발성 메모리 모두를 포함하는 메모리와 주로 관련되는 것을 의도한다. 휘발성 메모리의 예시들은 RAM, DRAM, SDRAM 등을 포함한다. 비-휘발성 메모리의 예시들은 ROM, PROM, EEPROM, 플래시 메모리, 광학 스토리지, 자기 스토리지(magnetic storage) 등을 포함한다.The term " memory, " as used herein, is intended to encompass all types of memory, including, but not limited to, one or more volatile memory, one or more non-volatile memory only, or one or more volatile and one or more non- It is intended primarily to relate primarily to memory including both non-volatile memory and volatile memory, unless context otherwise indicates. Examples of volatile memory include RAM, DRAM, SDRAM, and the like. Examples of non-volatile memory include ROM, PROM, EEPROM, flash memory, optical storage, magnetic storage, and the like.
상기 물리 디바이스는 상기 디바이스의 메모리에 저장될 수 있는 운영체제(OS, operation system) 및 소프트웨어 어플리케이션을 실행할 수 있는 하나 이상의 가상 머신(VM)을 지원할 수 있다. 물리 디바이스 상에서 상기 가상 머신의 운영은 하이퍼바이저(hypervisor)에 의해 제어될 수 있다.
The physical device may support one or more virtual machines (VM) capable of executing software applications and an operating system (OS) that may be stored in the memory of the device. The operation of the virtual machine on the physical device can be controlled by a hypervisor.
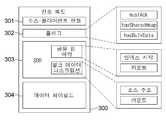
도 1은 프론트엔드(frontend)와 백엔드(backend)에 위치한 가상 머신들의 관계가 도시된 시스템 100의 도식적인 표현이다.Figure 1 is a schematic representation of a system 100 illustrating the relationship of virtual machines located on the frontend and backend.
프론트엔드에(예: 클라이언트 단(client end)에) 위치한 가상 머신은 거기에서 실행되는 하나 이상의 어플리케이션 160을 포함한다. 각 프론트엔드 가상 머신 상에서 동작하는 어플리케이션 160의 수는 실행 중인 상기 어플리케이션의 보안 또는 격리(isolation) 요구에 의존한다. 동일한 가상 머신 상에서 동작하는 어플리케이션들은 기존의 API를 이용하여 그들 사이에서 통신한다.A virtual machine located at the front end (e.g., at the client end) includes one or
백엔드 가상 머신은 거기에 위치한 API 서버 140을 포함할 수 있다. 백엔드 가상 머신은 하나 이상의 프론트엔드(또는 클라이언트) 가상 머신 상에서 실행중인 어플리케이션들에 의존하는 다수의 다른 가상 백엔드 API를 호스팅할 수 있다.The back-end virtual machine may include an
프론트엔드 어플리케이션 160 및 상기 백엔드에 위치한 API 서버 140은 서로 통신할 수 있다. API와 같은 메시지는 프론트엔드 전송 드라이브 170 및 백엔드 전송 드라이버 180 사이에서 보내질 수 있다.The front-
이 메시지들은 3-계층 전송 메커니즘을 통해 보내질 수 있다. 패킷은 링 버퍼(ring buffer) 110을 통해 보내질 수 있다. 상기 링 버퍼 110을 통해 전송될 수 없는 페이로드 데이터는 공유 힙(shared heap) 120 또는 벌크 전송(bulk transfer) 130을 통해 전송될 수 있다. 상기 전송 매체가 선택되는 것에 의한 상기 전송 메커니즘이 이하에서 서술된다.These messages can be sent via a three-layer transport mechanism. The packet may be sent via a
바람직하게, 이 메시지들은 어떤 응답 메시지도 요구되지 않도록 비동기식으로(asynchronously) 보내질 수 있다. 메시지를 비동기식으로 전송하는 것은 시스템상에서 처리 및 잠재적 사용량(latency footprint)을 감소시킨다. 가상 머신들 사이에서 호출(call)을 형성할 때 1차 오버헤드(primary overhead)는 “도메인 스왑(domain swaps)”의 수(물리 CPU가 가상 CPU들 사이에서 교환해야 하는 횟수)이기 때문에, 이는 시스템에 대한 중요한 요구이다. 이는 매우 자원 집약적인 3D 렌더링에 있어서 특히 중요하다.Preferably, these messages may be sent asynchronously so that no response message is required. Asynchronously sending messages reduces processing and latency footprints on the system. Because the primary overhead is the number of "domain swaps" (the number of times the physical CPU must exchange between virtual CPUs) when making calls between virtual machines, It is an important requirement for the system. This is especially important for very resource-intensive 3D rendering.
그러나 특정 상황에서 API 메시지는 가상 머신들 사이에서 동기식으로, 예를 들어, 응답 메시지가 보내지는, 동기식으로 전송될 수 있다.However, in certain circumstances, the API message may be transmitted synchronously between virtual machines, e.g., synchronously, with a response message being sent.
절대 다수의 API 호출(또는 메시지)는 상대적으로 적은 페이로드 데이터를 수반하지만, 높은 빈도수로 발생한다. 이 작은 페이로드 데이터 호출은 높은 빈도수로 발생한다. 그러나 상대적으로 드문 API 콜은 매우 높은 양의 데이터를 수반한다. 높은 페이로드 데이터 API 호출에 대한 낮은 페이로드 데이터의 비율은 숫자상으로 4000:1을 초과할 수 있다.An absolute number of API calls (or messages) involve relatively little payload data, but occur at a high frequency. This small payload data call occurs with a high frequency. However, relatively rare API calls involve very high amounts of data. High Payload Data The ratio of low payload data to API calls can exceed 4000: 1 numerically.
따라서 전송될 페이로드 데이터의 사이즈에 기반하여 페이로드 데이터 용 전송 매체를 선택하는 것이 유리할 수 있다.Therefore, it may be advantageous to select the transmission medium for the payload data based on the size of the payload data to be transmitted.
상기 전송 메커니즘은 하나 이상의 메시지(예를 들어, API 메시지)를 하나의 가상 머신 상에 위치한 프론트엔드 어플리케이션 160에서 다른 가상 머신 상에 위치한 백엔드 API 서버 140으로 도 2에 도시된 인터도메인 통신 채널을 통해 이동시키는 것에 기반한다.The transport mechanism may communicate one or more messages (e.g., API messages) from a front-
바람직한 실시 예에서, 상기 인터도메인 통신 채널 200은 링 버퍼 계층 210, 공유 힙 계층 220, 및 벌크 전송 채널(BTC, bulk transfer channel) 계층 230을 포함한다. 상기 전송 메커니즘은 폴-백 접근법(fall-back approach)에 기반한다.
In a preferred embodiment, the
도 3은 링 버퍼 210을 통해 전송될 수 있는 전송 패킷 300을 나타낸다.3 shows a
전송 패킷 300은 상기 전송 메커니즘을 이용하는 각 프론트엔드 클라이언트와 연관된 고유 식별자인 소스 클라이언트 핸들(source client handle) 301을 포함한다.The
전송 패킷 300은 또한 상기 적절한 전송 계층(들)을 이용하도록 패킷 300의 핸들링을 위한 제어(control)를 수신 단(receiving end)으로 제공하는 하나 이상의 플래그 320를 포함할 수 있다. 예시적인 플래그들은, 수신 측에 반드시 애크(acknowledgement)(예: 동기 메시지(synchronous message))를 보내야 한다는 것을 말해주는 플래그 또는 수신 측에 페이로드 데이터가 공유 힙 또는 BTC에 커밋 되었음을 말해주는 플래그를 포함할 수 있다.The
전송 패킷 300은 또한 (공유 힙 또는 벌크 전송 채널을 통한) 대용량 데이터 전송을 위해 요구되는 정보를 제공하는 SDD(Sideband Data Description) 303을 포함할 수 있다.The
전송 패킷 300은 또한 적은 양의 페이로드 데이터에 대한 인-패킷 전송(in-packet transport)을 제공하는 적은(small) 데이터 페이로드 304를 포함할 수 있다.The
바람직한 실시 예에서, 만약 메시지가 전체적으로 링 버퍼 계층 210 내에서 전송될 수 없다면, 역시 비동기식이지만 제한된 이용성(limited availability)을 갖는 링 계층 패킷을 보충하기 위해 공유 힙 220 내의 블록을 이용하는 시도를 할 수 있다. 적합한 사이즈의 공유 힙 블록이 이용 가능하지 않다면, 전송 메커니즘은 동기식 벌크 전송 채널 230을 이용하기 위해 폴백(falls back)한다.
In a preferred embodiment, if a message can not be transmitted entirely in the
도 4는 바람직한 실시 예에 따라 전송 매체를 선택하기 위한 전송 메커니즘에 따른 프로세스를 나타내는 흐름도를 나타낸다.4 shows a flow diagram illustrating a process according to a transmission mechanism for selecting a transmission medium according to a preferred embodiment.
단계 401에서 프로세스가 시작한다.The process begins at
단계 402에서, 전송 패킷은 링 버퍼를 통한 전송을 위해 예약될 수 있다.At
단계 403에서, API 메시지 발신 측(sender)은 프론트엔드 애플리케이션 160에서 백엔드 API 서버 140으로 보내지는 페이로드 데이터의 사이즈가 링 버퍼 계층에서만 전송하기 위한 링 버퍼 임계 값(ring buffer threshold)을 초과하는지 여부를 판단한다.In
단계 404에서, 만약 상기 페이로드 데이터 사이즈가 상기 링 버퍼 계층에서만 전송하기 위한 상기 임계 값을 초과하지 않은 것으로 판단되면, 상기 페이로드 데이터를 담고 있는 전송 패킷 300은 상기 링 버퍼에 커밋된다.In
단계 405에서, 만약 상기 페이로드 데이터 사이즈가 상기 링 버퍼 계층에서만 전송하기 위한 상기 임계 값을 초과하는 것으로 판단되면, 상기 페이로드 데이터 사이즈는 공유 힙 임계 값과 비교될 수 있다.In
상기 공유 힙 임계 값은 상기 링 버퍼를 통해 전송되지 않은 임의의 페이로드 데이터가 상기 공유 힙 계층을 통해 전송될 수 있는 데이터 사이즈 임계 값으로 이해될 수 있다. 상기 공유 힙 임계 값은 상기 공유 힙 내의 메모리 이용성에 의존할 것이고 상기 공유 힙의 여유 용량(spare capacity)이 변경되면 변동될 수 있다.The shared heap threshold may be understood as a data size threshold at which any payload data not transmitted via the ring buffer can be transmitted through the shared heap layer. The shared heap threshold may depend on memory availability in the shared heap and may change if the spare capacity of the shared heap changes.
만약 상기 페이로드 데이터 사이즈가 상기 공유 힙 임계 값을 초과하지 않는 다면, 예를 들어, 상기 공유 힙 계층이 이용될 수 있고, 상기 공유 힙 내의 블록이 (단계 406에서) 상기 링 버퍼를 통해 전송되지 못한 상기 페이로드 데이터를 위해 할당되고, 이 페이로드 데이터는 상기 공유 힙에 커밋된다.If the payload data size does not exceed the shared heap threshold, for example, the shared heap layer may be used, and if a block in the shared heap is not sent (at step 406) via the ring buffer And the payload data is committed to the shared heap.
단계 407은 단계 406에서 공유 힙에 대한 할당이 성공적이었는지 여부가 판단되는 옵셔널(optional) 단계이다. 만약 상기 할당이 성공적이지 않았다면 상기 공유 힙을 통해 전송될 것으로 의도되었던 상기 페이로드 데이터는 대신에 BTC에 할당된다.Step 407 is an optional step in which it is determined in
단계 408에서 상기 페이로드 데이터가 커밋된 상기 공유 힙 블록이 전송 패킷 300이 상기 백엔드에서 수신된 후에 접속될 수 있도록 (예를 들어 공유 힙 예약(shared heap reservation)으로서) 공유 힙 레퍼런스 태그(shard heap reference tag)가 전송 패킷 300에 부가될 수 있다. 전송 패킷 300은 이제 전술한 단계 404와 유사한 방식으로 상기 링 버퍼에 커밋될 수 있다.In
만약 페이로드 데이터 사이즈가 상기 공유 힙 임계 값을 초과한다면 벌크 전송 채널(BTC)이 상기 공유 힙 대신에 사용될 수 있다.A bulk transport channel (BTC) may be used instead of the shared heap if the payload data size exceeds the shared heap threshold.
상기 페이로드 데이터가 커밋된 상기 BTC 블록이 전송 패킷 300이 수신된 후에 접속될 수 있도록 (예를 들어 BTC 예약으로서) BTC 레퍼런스 태그가 전송 패킷 300에 부가될 수 있다(단계 409). 전송 패킷 300은 이제 전술한 단계 404와 유사한 방식으로 상기 링 버퍼에 커밋될 수 있다(단계 410).A BTC reference tag may be added to the transport packet 300 (e.g., as a BTC reservation) (step 409) so that the BTC block with the payload data is accessed after the
단계 411에서, 상기 BTC 내의 블록이 상기 링버퍼 또는 상기 공유 힙을 통해 전송되지 못한 상기 페이로드 데이터를 위해 할당되고 이 페이로드 데이터는 상기 BTC에 커밋된다.In
상기 공유 힙 계층 또는 BTC 계층이 상기 페이로드 데이터의 적어도 일부를 전송하기 위해 사용되는 상황에서, 전송 패킷 300은 상기 공유 힙 또는 BTC 채널을 통해 전송되지 않은 임의의 페이로드 데이터뿐만 아니라 메타데이터 301-303을 포함하는 상기 링 버퍼를 통해서 여전히 전송되는 것이 이해될 수 있다.In the situation where the shared heap layer or the BTC layer is used to transmit at least a portion of the payload data, the
예를 들어, 만약 메시지가 (적은 데이터 사이즈를 갖는) 텍스트 및 (훨씬 큰 데이터 사이즈를 갖는) 이미지 모듀를 포함하는 페이로드를 갖는 경우, 상기 페이로드 데이터 사이즈는 상기 링 버퍼 임계 값을 초과하기 쉽다. 상기 이미지는 (전술한 프로세스에 따라 상기 이미지 데이터의 크기에 의존하는) 공유 힙 또는 상기 벌크 채널에 커밋될 수 있다. 상기 패킷은 상기 링 버퍼를 통해 보내지고 상기 텍스트 파트를 적은 데이터 페이로드 304에 포함한다.For example, if a message has a payload that includes text (with a small data size) and imageModew (with a much larger data size), then the payload data size is likely to exceed the ring buffer threshold . The image may be committed to the shared heap (depending on the size of the image data according to the process described above) or to the bulk channel. The packet is sent through the ring buffer and includes the text part in a
대안적인 실시 예에서, 상기 공유 힙은 생략될 수 있다. 다시 말해서, 2-계층 전송 메커니즘이 제공될 수 있다. 이 실시 예에서, 페이로드 데이터는 상기 링 버퍼를 통해 전송되고, 폴백으로서(as a fallback), 벌크 전송 채널이 상기 링 버퍼를 통해 전송되지 못하는 임의의 페이로드 데이터를 운송하기 위해 제공된다.
In an alternative embodiment, the shared heap may be omitted. In other words, a two-layer transport mechanism can be provided. In this embodiment, the payload data is transmitted through the ring buffer and is provided to transport any payload data that the bulk transport channel can not transmit through the ring buffer as a fallback.
링 버퍼 계층(Ring Buffer Layer)Ring buffer layer < RTI ID = 0.0 >
링 버퍼 계층, 공유 힙 계층, 및 벌크 전송 채널 계층의 구조가 기술된다.The structures of the ring buffer layer, the shared heap layer, and the bulk transport channel layer are described.
도 2를 다시 참조하면, 링 버퍼 계층은 2개의 단방향(unidirectional) 링 버퍼를 포함한다. 클라이언트-to-서버 링 210a는 클라이언트(프론트엔드 가상 머신)에서 서버(백엔드 가상 머신)로의 메시지 전송을 제공한다. 서버-to-클라이언트 링 210b는 백엔드 가상 머신에서 프론트엔드 가상 머신으로의 경로(path)를 제공한다. 각 링 버퍼는 인덱스 링(index ring) 및 전송 패킷 어레이(transport packet array)를 포함하도록 구조화될 수 있다.Referring back to FIG. 2, the ring buffer layer includes two unidirectional ring buffers. The client-to-
전송 패킷은 자유맵(freemap) 또는 할당 맵(allocation map)을 통해 할당되고, 할당된 전송 패킷의 인덱스 N은 도 5에 도시된 인덱스 링에 기록된 값이다.The transport packet is allocated through a freemap or an allocation map, and the index N of the transport packet allocated is a value recorded in the index ring shown in FIG.
상기 링 버퍼 및 상기 인덱스 링((및 그 리저브(reserve)/커밋(commit)/릴리즈(release) 프로토콜)을 통한 전송 패킷의 디커플링(decoupling)은 메시지 패킷의 제로-카피 처리(zero-copy processing)를 고려한다. 상기 패킷은 상기 수신 단에서 사용 상태로 남아 있을 수 있고 레퍼런스로 전달될 수 있고, 처리가 완료되었을 때 한 번만 릴리즈 될 수 있다.Decoupling of the transport packets through the ring buffer and the index ring (and its reserve / commit / release protocol) may result in zero-copy processing of the message packets, The packet may remain in use state at the receiving end and may be passed to the reference and may be released only once when processing is complete.
전술한 바와 같이, 링 버퍼에서 개별 메시지는 상대적으로 적은 데이터 사이즈를 갖는다. 개별 메시지의 사이즈는 각 API 메시지의 페이로드가 다수의 API 메시지 용 단일 메시지에 적합해질 수 있도록 선택될 수 있다. 다시 말해서, 다수의 API 메시지들은 공유 힙 또는 BTC를 이용하지 않고 링 버퍼 계층으로 통해서 전송된다.As described above, individual messages in the ring buffer have a relatively small data size. The size of the individual messages can be selected such that the payload of each API message can be adapted to a single message for multiple API messages. In other words, multiple API messages are sent to the ring buffer layer without using the shared heap or BTC.
API 메시지의 예시적인 사이즈는 92 바이트가 될 수 있다. 이 상대적으로 적은 사이즈는 매우 다수의 메시지들이 많은 양의 메모리를 요구하지 않고, 메시지 채널을 통해 전송되도록 한다(예를 들어, 매우 다수의 메시지들은 임의의 시간에 링 버퍼에서 취급될 수 있다). 이 특징은 인터페이스에 대한 API 메시지 빈도 요구조건(API message frequency requirement)을 충족하는데 일조한다.An exemplary size of an API message may be 92 bytes. This relatively small size allows very large numbers of messages to be transmitted over the message channel (e.g., a very large number of messages can be handled in the ring buffer at any time) without requiring a large amount of memory. This feature helps to meet the API message frequency requirement for the interface.
안드로이드 젤리빈(Android Jellybean)이 실행되는 가상 환경의 일 예시에서, 92 바이트의 패킷 사이즈는 98%의 OpenGLES API 메시지들이 공유 힙 또는 BTC의 이용 없이 링 버퍼를통해 전송되는 것을 가능하게 한다.In one example of a virtual environment in which Android Jellybean is running, a packet size of 92 bytes enables 98% of OpenGLES API messages to be transmitted through the ring buffer without using a shared heap or BTC.
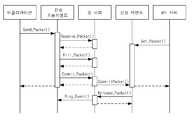
링 버퍼만을 이용한 비동기식 전송에 요구되는 동작 시퀀스가 도 6에 도시된다. API가 클라이언트로 값을 반환할 것이 요구(예를 들어 동기식 호출을 수행)되는 경우에, 링 버퍼만을 이용한 동기식 전송에 요구되는 동작 시퀀스가 도 7에 도시된다. 개별 API 실행에 있어서 상기 전송 메커니즘을 이용은 언제 상기 동기식 통신 변형(synchronous communication variant)을 이용하는지 또는 이용할 것인지의 문제이다(It is a matter for the individual API implementation making use of the transport mechanism as to when and if to employ the synchronous communication variant.)
The operation sequence required for asynchronous transmission using only the ring buffer is shown in Fig. The operation sequence required for synchronous transmission using only the ring buffer is shown in FIG. 7 when the API is required to return a value to the client (e.g., performs a synchronous call). It is a matter of when to use or use the above synchronous communication variant in the implementation of the individual APIs (It is a matter of how to use the transport mechanism as to when if to employ the synchronous communication variant.
공유 힙 계층(Shared Heap Layer)Shared Heap Layer
공유 힙 계층은 메시지 페이로드가 개별 전송 패킷보다 크고 수용 가능한 경우 비동기 방식(asynchronous behavior)을 유지하기 위해 제공된다.The shared heap layer is provided to maintain asynchronous behavior when the message payload is larger than an individual transport packet and is acceptable.
공유 힙은 하나의 가상 머신으로 하여금 전송용 메모리 블록을 할당하도록 하고 다른 가상 머신으로 하여금 수신 상의 메모리를 릴리즈(release that memory on reception) 하도록 하는 구조이다.The shared heap is a structure that allows one virtual machine to allocate a block of memory for transmission and cause the other virtual machine to release the memory on reception.
공유 힙은 큰 데이터 블록들이 전송 도메인(sending domain)에 의해 할당되고 링 버퍼를 통해 전송되는 메시지 패킷에 첨부되도록 한다. 통신 채널용 단일 공유 힙이 있는데, 이는 고대역 프론트엔드-to-백엔드 통신 및 저대역 백엔드-투-프론트엔드 통신 모두를 위해 사용된다.The shared heap allows large blocks of data to be allocated by the sending domain and appended to message packets sent through the ring buffer. There is a single shared heap for the communication channel, which is used for both high-bandwidth front-end-to-backend communication and low-bandwidth backend-to-front end communication.
도 5는 공유 힙의 구조를 나타낸다. 공유 힙은 프론트엔드 도메인 및 백엔드 도메인 사이에서 공유되는 메모리(힙)의 인접 페이지의 블록(a block of contiguous pages)이다. 공유 힙은 부가적은 할당 비트맵(allocation bitmap)을 포함하는 관리 페이지(또는 페이지 들)을 포함하고, 각 비트는 상기 공유 힙 내의 상기 할당된/자유 상태의 소정의 페이지를 나타낸다. 원자 비트 조작(atomic bit manipulation) 오퍼레이션이 비트를 설정하거나 초기화하기 위해(페이지를 할당하거나 릴리즈 하기 위해)사용된다. 페이지 블록은 항상 전송 가상 머신에 의해 할당되고, 수신 가상 머신에 의해 해제(freed)된다.Figure 5 shows the structure of the shared heap. A shared heap is a block of contiguous pages of memory (heap) shared between the front-end domain and the back-end domain. The shared heap includes a management page (or pages) that contains an additional allocation bitmap, and each bit represents a predetermined page of the allocated / free state in the shared heap. Atomic bit manipulation operations are used to set or initialize bits (to allocate or release pages). The page block is always allocated by the transport virtual machine and freed by the receiving virtual machine.
공유 힙 계층을 통한 전송을 나타내는 동작 시퀀스가 도 8에 도시된다.An operational sequence representing transmission over the shared heap layer is shown in FIG.
공유 힙을 사용하는 실시 예의 이점은 상대적으로 적은 메모리 사용량(low memory footprint)을 유지하는 동안 비동기식으로 지원될 수 있는 페이로드 사이즈의 범위를 확장하는 것이다.An advantage of the embodiment using the shared heap is to extend the range of payload sizes that can be supported asynchronously while maintaining a relatively low memory footprint.
GPU 가상화의 적용에 있어서, 거의 모든 API 메시지는 비동기식으로 전송된다. 대용량 데이터 전송 시 비동기성(asynchronicity)의 유지는 그것이 그래픽 시스템에서 높은 처리량(throughput)에 기여하기 때문에 중요하다.In the application of GPU virtualization, almost all API messages are transmitted asynchronously. Maintaining asynchronicity in large data transfers is important because it contributes to high throughput in graphics systems.
본 발명의 다른 실시 예에서 링 버퍼의 재순환(recirculating)은 상기 할당 맵/자유맵을 대신해서 공유 힙 할당기(shared heap allocator)로 제공된다. 이는 개별 디바이스 및 데이터 페이로드에서의 비-선형성(non-linearity)을 해소하기 위한 가상 CPU의 메모리 관리 유닛(Memory Management Unit)의 사용을 가능하게 한다. 공유 힙 할당 맵이 소정의 시스템에 적합하지 않다면, 이 대안은 3개의 계층 아키텍처가 지속되도록 허용한다.
In another embodiment of the present invention, recirculating the ring buffer is provided to the shared heap allocator on behalf of the allocation map / free map. This enables the use of a memory management unit (Memory Management Unit) of the virtual CPU to resolve the non-linearity in the individual device and data payloads. If the shared heap allocation map is not suitable for a given system, this alternative allows the three tier architectures to persist.
벌크 전송 채널(bluk transfer channel)A bulk transfer channel (BLU)
벌크 전송 채널은 상기 전송 메커니즘의 추가적인 폴백 계층이다. 벌크 전송 채널은 도메인들 사이에서 공유되는 하나의 큰 메모리 블록을 제공한다. 데이터는 단순한 반복적인 충전/배출(fill/drain) 프로세스에 의해 가상 머신들 사이에서 이동한다.The bulk transport channel is an additional fallback layer of the transport mechanism. The bulk transport channel provides one large block of memory that is shared between domains. The data is moved between virtual machines by a simple repetitive fill / drain process.
벌크 전송 채널은 다음의 속성을 갖는다:The bulk transport channel has the following attributes:
다수의 클라이언트(예: 프론트엔드 가상 머신들)는 계류 중인(pending) 벌크 채널 전송을 포함할 수 있다. 한번에 하나의 클라이언트만이 벌크 채널을 통해 데이터를 유효하게(actively) 전송할 수 있다. 벌크 채널을 통해 전송된 메시지들은 항상 동기식이다.A number of clients (e.g., front end virtual machines) may include pending bulk channel transmissions. Only one client at a time can actively transmit data over the bulk channel. Messages sent over the bulk channel are always synchronous.
백엔드 가상 머신은 어느 프론트엔드 클라이언트와 벌크 채널 전송을 수행할 것인지 선택한다.The back-end virtual machine chooses which of the front-end clients to perform the bulk-channel transmission.
공유 힙과 유사하게 벌크 전송 채널은 또 다른 인접한 페이지들의 블록이다. 하지만 이는, 단일 전송은 전체 페이지 블록(전체 벌크 채널)에 대한 총체적인 소유권(ownership)이 주어지고, 전체 전송은 데이터를 소스(source) 가상 머신의 벌크 채널 페이지로 및 공유 페이지로부터 수신 가상 머신의 요청된 타겟 메모리로 반복적으로 카피함으로써 완료될 때까지 수행되는, 다른 제어 구조(control structure)를 갖는다.Similar to the shared heap, the bulk transport channel is another block of contiguous pages. However, this is because a single transfer is given overall ownership of the entire page block (the entire bulk channel), and the entire transfer takes data from the virtual machine's request to the bulk channel page of the source virtual machine and from the shared page Lt; RTI ID = 0.0 > by < / RTI > repeatedly copying to the target memory.
벌크 채널을 통한 전송을 나타내는 동작 시퀀스가 도 9에 도시된다.An operational sequence representing transmission over a bulk channel is shown in Fig.
전술한 바와 같이, 여기에 기술되는 본 발명의 실시 예들은 다수의 가상 머신들이 동일한 물리 디바이스에서 실행될 때 API(application programming interface) 가상화 영역에 적용될 수 있다.As described above, the embodiments of the present invention described herein can be applied to an application programming interface (API) virtualization area when a plurality of virtual machines are executed in the same physical device.
본 발명의 실시 예들은 비교적 낮은 사용량(low footprint)을 갖는 고성능 전송을 제공한다.Embodiments of the present invention provide high performance transmission with relatively low footprint.
본 기술의 하나의 특정 적용은 GPU(graphics processing unit) 가상화에 대한 것이다. 프론트엔드에서 백엔드로 전송 메커니즘을 통해 보내진 각 패킷은 GPU 벤더(vendor)들의 고유한 API에 대한 단일 호출의 세부 사항을 포함한다. 백엔드 API 서버는 GPU에 대한 호출을 그 제조업체(예를 들어, Nvidia, ARM, Imagination 등)에 의해 제공되는 GPU 인터페이스 라이브러리를 통해 구성할 수 있다. 어플리케이션 프로그램들이 GPU를 구동하고 요청(requests)을 전송한다는 것이 이해될 수 있다. GPU는 어플리케이션으로부터 아이템(items)을 요청할 필요가 없다.One particular application of the technology is for graphics processing unit (GPU) virtualization. Each packet sent through the transport mechanism from the front-end to the back-end contains details of a single call to the proprietary APIs of the GPU vendors. The backend API server can configure calls to the GPU through the GPU interface library provided by the manufacturer (e.g., Nvidia, ARM, Imagination, etc.). It can be appreciated that application programs run the GPU and send requests. The GPU does not need to request items from the application.
3 계층 폴백 방법(3 layer fallback method)을 이용하는 실시 예들은, 낮은 빈도 높은 페이로드 메시지를 지원하는 동시에 높은 빈도, 낮은 페이로드 사이즈 메시지의 비동기적인 지원의 유연성을 유지하면서, 기본적인 크로스 도메인, 큰 공유 FIFO 버퍼를 사용하는 것에 비하여 낮은 메모리 오버헤드를 제공한다.Embodiments that utilize a three-layer fallback method can be used to support a low frequency high payload message while maintaining the flexibility of asynchronous support of high frequency, low payload size messages, Which provides lower memory overhead than using FIFO buffers.
전송 메커니즘의 다수의 예시들은 다수의 프론트엔드 가상 머신들과 백엔드 사이의 통신을 지원하기 위해 백엔드에 병렬적으로 위치할 수 있다.Multiple examples of transport mechanisms may be located in parallel on the backend to support communication between the plurality of front end virtual machines and the back end.
전술한 예시들은 단순히 예시적인 것이며, 본 발명의 범위를 한정하는 것이 아님이 이해될 것이다. 다른 변형 및 수정은 본 출원을 읽는 당업자에게 명백할 것이다. 나아가, 본 출원에 개시된 내용은 여기에 명시적으로 또는 묵시적으로 개시된 임의의 신규한 특징 또는 임의의 신규한 특징의 조합 또는 임의의 그 일반화를 포함하는 것으로 이해되어야 하며, 본 출원 또는 그로부터 파생된 임의의 출원 절차에서 임의의 특징 및/또는 그와 같은 특징의 조합을 커버하는 새로운 청구항들이 생성될 수 있다.
It is to be understood that the foregoing examples are merely illustrative and are not intended to limit the scope of the invention. Other variations and modifications will be apparent to those skilled in the art having read the present disclosure. Further, the disclosure of the present application is to be understood as embracing any novel feature or combination of any novel features disclosed herein, either explicitly or impliedly, or any generalization thereof, New claims may be generated that cover any feature and / or combination of features in the filing procedure of FIG.
Claims (16)
Translated fromKorean상기 제1 가상 머신에서 상기 제2 가상 머신으로 전송될 상기 페이로드 데이터가 제1 임계 값을 초과하는 페이로드 데이터 사이즈를 포함하는지 여부를 판단하는 동작; 및
상기 판단에 기반한 상기 페이로드 데이터 용 전송 매체(transfer medium)를 선택하는 동작을 포함하는 방법.A method for managing payload data transfer between a first virtual machine and a second virtual machine, the first virtual machine and the second virtual machine being supported by a host environment comprising a plurality of virtual machines, silver,
Determining whether the payload data to be transferred from the first virtual machine to the second virtual machine includes a payload data size exceeding a first threshold; And
And selecting a transfer medium for the payload data based on the determination.
만약 상기 페이로드 데이터 사이즈가 상기 제1 임계 값을 초과하지 않으면 상기 페이로드 데이터를 링 버퍼(ring buffer)를 통해 전송되는 전송 패킷에 커밋하는 동작(committing)을 더 포함하는 방법.The method according to claim 1,
And committing the payload data to a transport packet transmitted through a ring buffer if the payload data size does not exceed the first threshold value.
상기 페이로드 데이터 사이즈를 제2 임계 값과 비교하는 동작, 상기 제2 임계 값은 상기 제1 임계 값보다 큼; 및
만약 상기 페이로드 데이터 사이즈가 상기 제2 임계 값을 초과하면, 상기 페이로드 데이터의 적어도 일부를 벌크 전송 채널(bulk transfer channel)에 할당하거나,
만약 상기 페이로드 데이터 사이즈가 상기 제2 임계 값을 초과하지 않으면, 상기 페이로드 데이터의 적어도 일부를 공유 힙(shared heap)에 할당하는 동작을 포함하는 방법.The method of claim 1, wherein if the payload data size exceeds the first threshold,
Comparing the payload data size to a second threshold, the second threshold being greater than the first threshold; And
Allocating at least a portion of the payload data to a bulk transfer channel if the payload data size exceeds the second threshold,
And allocating at least a portion of the payload data to a shared heap if the payload data size does not exceed the second threshold.
메타데이터(metadata) 및 상기 벌크 전송 채널 또는 공유 힙에 할당되지 않은 임의의 페이로드 데이터를 링 버퍼를 통해 전송되는 전송 패킷에 커밋하는 동작을 더 포함하는 방법.The method of claim 3,
Further comprising committing metadata and any payload data not allocated to the bulk transport channel or the shared heap to transport packets transmitted through the ring buffer.
상기 메타데이터는 상기 공유 힙 또는 상기 벌크 전송 채널에 할당된 상기 페이로드 데이터의 적어도 일부를 각각 참조하는 공유 힙 레퍼런스 태그(reference tag) 또는 벌크 전송 채널 레퍼런스 태그를 포함하는 방법.The method of claim 4,
Wherein the metadata includes a shared heap reference tag or a bulk transport channel reference tag that respectively references at least a portion of the payload data allocated to the shared heap or the bulk transport channel.
공유 힙으로의 할당이 성공하지 못했다는 판단에 응답하여 상기 공유 힙에 할당된 상기 페이로드 데이터의 상기 적어도 일부를 상기 벌크 전송 채널에 커밋하는 동작을 더 포함하는 방법.The method of claim 3,
Committing the at least a portion of the payload data allocated to the shared heap to the bulk transport channel in response to determining that allocation to the shared heap was not successful.
상기 판단에 기반한 상기 페이로드 데이터 용 전송 매체(transfer medium)를 선택하는 동작은, 만약 상기 페이로드 데이터 사이즈가 상기 제1 임계 값을 초과하면 상기 페이로드 데이터의 적어도 일부를 벌크 전송 채널에 할당하는 동작을 포함하는 방법.The method according to claim 1,
Wherein the act of selecting a transfer medium for the payload data based on the determination comprises assigning at least a portion of the payload data to a bulk transport channel if the payload data size exceeds the first threshold ≪ / RTI >
상기 제1 임계 값은 링 버퍼를 통한 전송 패킷에서 전송 가능한 페이로드 데이터의 최대 양에 대응하는 방법.The method according to claim 1,
Wherein the first threshold corresponds to a maximum amount of payload data that can be transmitted in a transport packet through the ring buffer.
상기 링 버퍼를 통한 전송은 비동기(asynchronous) 방식인 방법.The method of claim 8,
Wherein transmission through the ring buffer is asynchronous.
상기 공유 힙을 통한 전송은 비동기 방식인 방법.The method of claim 3,
Wherein transmission over the shared heap is asynchronous.
상기 제1 가상 머신은 어플리케이션을 포함하고 상기 제2 가상 머신은 API 서버를 포함하는 방법.The method according to claim 1,
Wherein the first virtual machine comprises an application and the second virtual machine comprises an API server.
상기 페이로드 데이터는 API 요청(API request)을 포함하는 방법.The method according to claim 1,
Wherein the payload data comprises an API request.
상기 선택된 전송 매체를 이용하여 상기 페이로드 데이터를 전송하는 동작을 더 포함하는 방법.The method according to claim 1,
And transmitting the payload data using the selected transmission medium.
상기 호스트 환경은 그 환경에 저장된 복수의 가상 머신들을 포함하는 물리 디바이스를 포함하는 방법.The method according to claim 1,
Wherein the host environment comprises a physical device comprising a plurality of virtual machines stored in the environment.
복수의 데이터 전송 메커니즘이 상기 컴퓨팅 장치 상에서 동작 가능한 기록 매체.
16. The method of claim 15,
Wherein a plurality of data transfer mechanisms are operable on the computing device.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/524,952US20150121376A1 (en) | 2013-10-25 | 2014-10-27 | Managing data transfer |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB1318913.9AGB2519578B (en) | 2013-10-25 | 2013-10-25 | Managing data transfer |
| GB1318913.9 | 2013-10-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150048028Atrue KR20150048028A (en) | 2015-05-06 |
Family
ID=49767184
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020140115135AWithdrawnKR20150048028A (en) | 2013-10-25 | 2014-09-01 | Managing Data Transfer |
Country Status (2)
| Country | Link |
|---|---|
| KR (1) | KR20150048028A (en) |
| GB (1) | GB2519578B (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10768964B2 (en) | 2016-01-05 | 2020-09-08 | Hewlett Packard Enterprise Development Lp | Virtual machine messaging |
| US10956240B2 (en) | 2018-10-30 | 2021-03-23 | Blackberry Limited | Sharing data by a virtual machine |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7689800B2 (en)* | 2005-05-12 | 2010-03-30 | Microsoft Corporation | Partition bus |
| CN102334112B (en)* | 2009-02-27 | 2014-06-11 | 美国博通公司 | Method and system for virtual machine networking |
- 2013
- 2013-10-25GBGB1318913.9Apatent/GB2519578B/ennot_activeExpired - Fee Related
- 2014
- 2014-09-01KRKR1020140115135Apatent/KR20150048028A/ennot_activeWithdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| GB201318913D0 (en) | 2013-12-11 |
| GB2519578B (en) | 2016-02-17 |
| GB2519578A (en) | 2015-04-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3900308B1 (en) | Input/output processing in a distributed storage node with rdma | |
| US10897428B2 (en) | Method, server system and computer program product for managing resources | |
| EP3796168A1 (en) | Information processing apparatus, information processing method, and virtual machine connection management program | |
| US20160314008A1 (en) | Method for implementing gpu virtualization and related apparatus, and system | |
| US20050144402A1 (en) | Method, system, and program for managing virtual memory | |
| CN103440202B (en) | A kind of communication means based on RDMA, system and communication equipment | |
| US11201836B2 (en) | Method and device for managing stateful application on server | |
| US20180219797A1 (en) | Technologies for pooling accelerator over fabric | |
| JP6763984B2 (en) | Systems and methods for managing and supporting virtual host bus adapters (vHBAs) on InfiniBand (IB), and systems and methods for supporting efficient use of buffers with a single external memory interface. | |
| CN111970213B (en) | A method for writing data into a memory and a network element | |
| CN113886019A (en) | Virtual machine creation method, device, system, medium and equipment | |
| US9697047B2 (en) | Cooperation of hoarding memory allocators in a multi-process system | |
| US20150121376A1 (en) | Managing data transfer | |
| CN114911411A (en) | Data storage method and device and network equipment | |
| US9990303B2 (en) | Sharing data structures between processes by semi-invasive hybrid approach | |
| US7788463B2 (en) | Cyclic buffer management | |
| KR20150048028A (en) | Managing Data Transfer | |
| US8898353B1 (en) | System and method for supporting virtual host bus adaptor (VHBA) over infiniband (IB) using a single external memory interface | |
| CN116737413A (en) | Cross-system data sharing method based on hardware isolation, electronic equipment and medium | |
| CN114489465A (en) | Method, network device and computer system for data processing using network card | |
| CN120010792B (en) | Data writing method and system, storage medium, electronic device and computer program product | |
| US9104637B2 (en) | System and method for managing host bus adaptor (HBA) over infiniband (IB) using a single external memory interface | |
| US11755496B1 (en) | Memory de-duplication using physical memory aliases | |
| CN102447725B (en) | Method, device and system for virtualizing network equipment | |
| US20160321118A1 (en) | Communication system, methods and apparatus for inter-partition communication |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20140901 | |
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |